
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,306,454 | The Four Horsemen of Software Complexity — Architecture Decision Records to the Rescue | When we try to reduce complexity in software development — we always address accidental... | 0 | 2022-12-22T22:39:23 | https://dev.to/karvozavr/the-four-horsemen-of-software-complexity-architecture-decision-records-to-the-rescue-1211 | architecture, productivity, softwaredesign, methodology | When we try to reduce complexity in software development — we always address accidental complexity.
Accidental complexity refers to the complexity that arises from the way a system is designed or implemented, rather than from the inherent nature of the problem being solved. This type of complexity can often be avoided by making design decisions that are simpler and more straightforward.
Essential complexity, on the other hand, is inherent in the problem being solved. It cannot be avoided and is a necessary part of the solution.

Let’s take a look at several potential sources of accidental complexity in software development:
1. Over-engineering: when a system is designed with more features or functionality than are actually needed, it can introduce unnecessary complexity.
2. Poorly chosen abstractions: abstractions, such as design patterns or software architectures, can help simplify complex systems. However, choosing the wrong abstractions can actually add complexity, rather than reducing it.
3. Unnecessary dependencies: adding code dependencies, such as external libraries or frameworks, can provide useful functionality, but it can also introduce complexity. When dependencies are not carefully managed, they can become a source of accidental complexity.
4. Inconsistent or conflicting design choices: when different parts of a system are designed in incompatible or inconsistent ways, it can introduce complexity. For example, using different programming languages or frameworks in different parts of the same system can make it more difficult to understand and maintain.
By understanding the sources of accidental complexity and taking steps to minimize it, it is possible to build software systems that are more maintainable, more prepared for the changes, and easier to work on.
---
Let’s first take a closer look at these sources of the problem and then get familiar with the practices that might help to mitigate accidental complexity caused by these reasons.
## Over-engineering
When a system is over-engineered, it may include features that are not needed or are only used in rare or edge cases. This can make the system more difficult to understand and maintain, as developers must spend time and effort understanding and working with unnecessary features. In addition, over-engineering can lead to code bloat, where the size of the system grows unnecessarily, which can make it more difficult to navigate and debug.
## Poorly chosen abstractions
Abstractions, such as design patterns or software architectures, can be a useful tool for simplifying complex systems by providing a common language and framework for understanding and organizing the various parts of a system. However, choosing the wrong abstractions or using them in an inappropriate way can actually add complexity to a system, rather than reducing it.
For example, using an overly complicated or poorly understood design pattern can make it more difficult for developers to understand and work with the system, as they must spend time and effort learning and working with the abstractions. Similarly, using an architecture that is not well suited to the needs of the system can introduce unnecessary complexity and make it more difficult to maintain and scale the system.
## Unnecessary dependencies
Code dependencies, such as external libraries or frameworks, can be a valuable resource in software development, as they can provide useful functionality and streamline the development process. However, when dependencies are not carefully managed, they can also introduce complexity to a system. This is considered accidental complexity, as it arises from the way the system is designed or implemented, rather than from the inherent nature of the problem being solved.
Unnecessary dependencies can contribute to complexity in a number of ways. For example:
1. Size and complexity: adding unnecessary dependencies can increase the size and complexity of the system, as developers must include and manage additional code in the project.
2. Compatibility issues: dependencies that are not needed may not be compatible with the rest of the system, which can introduce complexity when integrating them into the project.
3. Maintenance and updates: unnecessary dependencies may require regular updates and maintenance, which can add additional overhead to the project.
4. Risk of security vulnerabilities: unnecessary dependencies may introduce security vulnerabilities to the system, which can increase the risk of a data breach or other security incident.
## Inconsistent design choices
Inconsistent or conflicting design choices can contribute to complexity in software development by making it more difficult to understand and work with the system. When different parts of a system are designed in incompatible or inconsistent ways, it can make it more challenging for developers to understand how the system fits together and how to make changes to it.
For example, using different programming languages or frameworks in different parts of the same system can introduce complexity, as developers must switch between different languages and frameworks and adapt to different conventions and APIs. Similarly, using different design patterns or architectures in different parts of the system can make it more difficult to understand and work with the system as a whole.
> So how do we fight these four horsemen of software complexity?
All these problems have one thing in common — they are the result of chaotic, ungoverned decisions and "accidental" software architecture process.
## Architecture Decision Records
One tool that I found really useful in my experience to help with it is Architecture Decision Records.
Architecture Decision Records (ADRs) are a way to document important design decisions made during the development of a software system. They are used to capture the reasoning behind these decisions and the trade-offs that were considered, as well as the consequences of the decisions. This documentation can be useful for a number of purposes, including:
1. Providing context: ADRs can provide context for developers working on the system, helping them to understand the reasoning behind certain design choices and the constraints that were considered.
2. Facilitating communication: ADRs can help to facilitate communication between team members and stakeholders by providing a clear and concise record of the decisions that have been made.
3. Facilitating future decision-making: ADRs can serve as a reference for future decision-making, helping to ensure that new design decisions are aligned with the overall architecture of the system.
4. Improving transparency: by documenting design decisions, ADRs can increase transparency and help to ensure that all relevant parties are aware of the decisions that have been made.
To create an ADR, it is important to include a clear and concise description of the decision that was made, the context in which the decision was made, the alternatives that were considered, and the consequences of the decision. It is also important to include any relevant supporting documentation, such as diagrams or code examples, to help provide context and clarify the decision.
## Summary
A huge advantage of Architecture Decision Records is that one ADR document can be really small, and doesn’t take much time to write down or review. Yet it gives you a whole versioned history of how your project architecture developed over time and gives an insight into all places where accidental complexity was introduced and what was the reasoning behind doing this. It helps you to keep consistency with your decisions and critically revisit them in face of new requirements emerging.
There are several interesting links on the topic of ADR:
- [https://adr.github.io/](https://adr.github.io/) — homepage of a community popularising ADR technique, improving and introducing tooling for it and sharing knowledge and experience.
- [AWS](https://docs.aws.amazon.com/prescriptive-guidance/latest/architectural-decision-records/adr-process.html), [Google](https://cloud.google.com/architecture/architecture-decision-records), [RedHat](https://www.redhat.com/architect/architecture-decision-records) — articles where the companies share their experience and tips in ADRs.
- [A very interesting serverless cloud architecture example project](https://github.com/GoogleCloudPlatform/emblem/tree/main/docs/decisions) where Google Cloud team shows not only the tech, but the development process as well, and a part of it are some really good real-world Architecture Decision Records examples. | karvozavr |
1,306,602 | Django Object Level Permission In APIView Class | Is Owner? | How to check if requested user is owner of a object in django. video: https://youtu.be/nQeOJl8uEp0 | 0 | 2022-12-23T02:54:03 | https://dev.to/veewebcode/django-object-level-permission-in-apiview-class-is-owner-5216 | django, python, coding, permission | How to check if requested user is owner of a object in django.
video: https://youtu.be/nQeOJl8uEp0 | veewebcode |
1,306,606 | How to Use Jasypt or Jce to Encrypt Passwords in Spring Config | Jasypt and JCE are two encryption protocols that we can use in our Spring config to secure passwords.... | 0 | 2022-12-23T02:59:08 | https://www.czetsuyatech.com/2021/06/spring-config-jasypt-jce.html | jasypt, jce, spring, encryption | Jasypt and JCE are two encryption protocols that we can use in our Spring config to secure passwords. For example, if you wanted to encrypt the API token of your Github repository. Or encrypting the Spring config server's security.user.password value.
## Jasypt Example
Instruction on how we can use Jasypt in our Spring Boot application security.
1. Create a new Spring project, we will use it to encrypt our password.
2. Include jasypt dependency.
```
<dependency>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-spring-boot-starter</artifactId>
<version>3.0.3</version>
</dependency>
```
3. Use this code block to encrypt a string.
```
private static void encryptString() {
StandardPBEStringEncryptor encryptor = new StandardPBEStringEncryptor();
encryptor.setPassword("password");
encryptor.setAlgorithm("PBEWITHSHA1ANDDESEDE");
encryptor.setIvGenerator(new RandomIvGenerator());
String result = encryptor.encrypt("Hello World!");
System.out.println("encrypted=" + result); // prints differently on each run
result = encryptor.decrypt(result);
System.out.println("decrypted=" + result);
}
```
4. To use it in Spring security, we must set add these security lines in Spring config's bootstrap.xml file
```
security:
user:
name: czetsuya
password: ENC(3E31QZ4Ih8kbEYl141+Hd8zG1N/Pt9c60nHkGX9lnG4=)
```
5. And on the service side Spring application, we need to configure the Spring cloud config location and jasypt encryptor password.
```
spring:
cloud:
config:
uri: http://localhost:8888
username: czetsuya
password: ENC(T9aWpcoGGXGV6x+D/oiJGWkvJSBjwEmpLaBy7utknQo=)
jasypt:
encryptor:
password: password # or you can replace this with an environment variable ${JASYPT_ENCRYPTOR_PASSWORD}
```
JCE Example
Instruction on how we can use JCE in our Spring Boot application security.
To make this exercise easier on Windows, I'll be using WSL2 to run Ubuntu and install sdkman.
You must also take note of the latest spring-boot-cli version from https://mvnrepository.com/artifact/org.springframework.cloud/spring-cloud-cli
Follow this guide https://sdkman.io/install. Check if it succeeded by running the command `sdkman version` in a terminal.
Execute the following commands:
```
# install spring
sdk install springboot
# install spring-cloud-cli
spring install org.springframework.cloud:spring-cloud-cli:3.0.2
# encrypt your text
spring encrypt 'Hello World!' --key 'password'
# results in 5f8aaa3be65f159b439008faf1d4efb5eb6c6d3d8ccd9ddfe5028decb5c3b2c1
# should be different on each run
# decrypt the text
spring decrypt 5f8aaa3be65f159b439008faf1d4efb5eb6c6d3d8ccd9ddfe5028decb5c3b2c1 --key 'password'
```
As before we need to set the encrypted password both in the Spring cloud config server and client. This time instead of using 'ENC', we will use 'cipher'.
Server
```
security:
user:
name: czetsuya
password: 'cipher{5f8aaa3be65f159b439008faf1d4efb5eb6c6d3d8ccd9ddfe5028decb5c3b2c1}'
```
Client
```
spring:
cloud:
config:
uri: http://localhost:8888
username: czetsuya
password: 'cipher{3079cb49646bf1a11dc15e3563c16cb3fb614aebdb5fe389f75d48d3ac43ae6f}'
encrypt:
key: password # or you can replace this with an environment variable ${ENCRYPT_KEY}
```
And there you go folks, stop committing your password in plaintext on public repositories :-)
| czetsuya |
1,306,611 | Raku on asdf | I've created a plugin for installing Raku using the asdf version manager 🎉 Check it out here:... | 0 | 2022-12-23T03:35:43 | https://dev.to/dango/raku-on-asdf-l19 | asdf, languages, opensource, raku | I've created a plugin for installing Raku using the asdf version manager 🎉
Check it out here: https://github.com/m-dango/asdf-raku | dango |
1,306,785 | Upload a file from AWS S3 bucket to another S3 bucket using AWS Lambda (Nodejs) | By using Aws lambda (Nodejs) we can upload a file to from source s3 bucket to the s3 bucket we want... | 0 | 2022-12-23T11:45:32 | https://dev.to/kprasannamahesh/upload-a-file-from-aws-s3-bucket-from-another-s3-bucket-using-aws-lambda-nodejs-299g | node, aws | By using Aws lambda (Nodejs) we can upload a file to from source s3 bucket to the s3 bucket we want to upload.
```
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
exports.handler = async (event) => {
console.log('event',event);
//Reading Source file from source bucket
const sourceFile = await s3.getObject({ Bucket: event.sourceBucket, Key : event.sourceFilePath}, (err,data) =>{
if(err) throw err;
else{
return data.Body.toString('utf-8');
});
//uploading to destination bucket
const param = {
Bucket : event.destination,
Key : event.destinationFilePath,
Body : sourceFile,
ContentType : 'csv'
};
await s3.putObject(params).promise().then((data) =>{console.log('uploaded');
return data}).catch((err) =>{console.log('err',err)
return err;});
```
| kprasannamahesh |
1,306,827 | How to import or use js file configuration into any vue page in your nuxt app | hello i have a nuxtjs project of listing booking I have done all my API calls and configurations... | 0 | 2022-12-23T10:37:43 | https://dev.to/nonciok89/how-to-import-or-use-js-file-configuration-into-any-vue-page-in-your-nuxt-app-2he3 | javascript, vue, api, nuxt | ```
hello
i have a nuxtjs project of listing booking
I have done all my API calls and configurations on " index.js in the store folder " and would like to display the listing data gotten from the API call on my "listing.vue page " please how do I call do to print my data gotten or make my index.js accessable all over the app
app setup
{
"name": "lisngbook,,
"version": "1.0.0",
"scripts": {
"dev": "nuxt",
"build": "nuxt build",
"start": "nuxt start",
"generate": "nuxt generate"
},
"dependencies": {
"@nuxtjs/axios": "^5.13.6",
"core-js": "^3.9.1",
"nuxt": "^2.15.3",
},
"devDependencies": {
"@nuxtjs/moment": "^1.6.1"
},
```
```
| nonciok89 |
1,306,991 | My Journey in Open Source - rate-limiter-fn | Link to the repo What is this? A higher-order function to provide a Rate Limiting... | 20,983 | 2023-01-24T14:00:00 | https://dev.to/cadienvan/my-journey-in-open-source-rate-limiter-fn-735 | javascript, typescript, opensource, github | [Link to the repo](https://github.com/Cadienvan/rate-limiter-fn)
## What is this?
A higher-order function to provide a Rate Limiting mechanism to the given function.
## How do I install it?
```bash
npm install rate-limiter-fn
```
## How can I use it?
```javascript
const rateLimiter = require('rate-limiter-fn');
const rateLimitedFn = rateLimiter(fn, {
limit: 10,
interval: 1000,
});
rateLimitedFn();
```
## API
The module exports a single function (`rateLimit`) that takes two arguments:
- `fn` - The function to be rate limited.
- `options` - An object with the following properties:
- `limit` - The number of times the function can be called within the given interval.
- `interval` - The interval in milliseconds.
- `onLimitReached` - A function that will be called when the limit is reached. It will be called with the following arguments:
- `limit` - The limit that was reached.
- `interval` - The interval that was reached.
- `fn` - The function that was rate limited.
- `args` - The arguments that were passed to the function.
- `identifierFn` - A function that will be called to get the identifier for the rate limit. It will be called with the following arguments:
- `fn` - The function that was rate limited.
- `args` - The arguments that were passed to the function.
## Tests
You can run the tests by using the following command:
```bash
npm test
``` | cadienvan |
1,307,262 | 100 APIs for Indian devs to integrate different financial services in your apps | In my early 10 yrs of my developer career, only FinTech APIs I knew were Stripe and CCAvenue. My... | 0 | 2023-01-11T14:06:14 | https://dev.to/ekodevs/100-apis-for-indian-devs-to-integrate-different-financial-services-in-your-apps-72k | fintech, api | In my early 10 yrs of my developer career, only FinTech APIs I knew were Stripe and CCAvenue. My ideas to build something cool in FinTech were limited to usage of these APIs only. I had little hopes from Indian FinTech ecosystem. Only when I started to look around, I was surprised to find plethora of FinTech services that are accessible with APIs and this exploded the use cases I could build with these APIs. It's been almost a month since I started collecting these APIs down and here I present them to you, the only thing I expect in return from you is - share your ideas what do you wish to build with these APIs or share what's missing here. Deal? Let's go.
> Brought to you by [Eko team](http://developers.eko.in)
First, let's understand different categories of FinTech APIs
## Categories of FinTech APIs
1. Payment processing APIs: These APIs enable online and mobile payments, including payment gateway APIs, digital wallet APIs, and online invoicing APIs.
2. Credit and lending APIs: These APIs provide access to credit scoring, loan origination, and other lending-related services.
3. Insurance APIs: These APIs provide access to insurance products and services, including APIs for health insurance, life insurance, car insurance, and other types of insurance.
4. Wealth management APIs: These APIs provide access to investment products and services, including mutual fund APIs, stock trading APIs, and wealth management platform APIs.
5. Personal finance APIs: These APIs provide access to personal finance management tools, including budgeting and expense tracking APIs, credit card management APIs, and more.
6. Business finance APIs: These APIs provide access to business finance management tools, including invoicing and accounting APIs, financial reporting APIs, and more.
7. Financial comparison APIs: These APIs provide access to financial product comparison tools, including APIs for banking products, insurance products, and mutual funds.
8. Financial market data APIs: These APIs provide access to real-time or historical financial market data, including stock prices, currency exchange rates, and more.
9. Foreign exchange APIs: These APIs provide access to foreign exchange rates and currency conversion services.
10. Cryptocurrency APIs: These APIs provide access to cryptocurrency market data and trading services.
11. Real estate APIs: These APIs provide access to real estate market data and property listings.
12. Financial planning and advice APIs: These APIs provide access to financial planning and investment advice tools.
Banking APIs: These APIs provide access to banking products and services, including APIs for account management, money transfers, and more.
13. Credit card APIs: These APIs provide access to credit card products and services, including APIs for credit card application and management.
14. Lending and borrowing APIs: These APIs provide access to peer-to-peer lending and borrowing platforms.
15. Payment gateway APIs: These APIs enable merchants to accept payments from customers through a variety of payment methods.
16. E-commerce APIs: These APIs provide access to e-commerce platforms and tools, including APIs for product listings, inventory management, and more.
17. Personal identification and verification APIs: These APIs enable identity verification and authentication services.
18. Customer relationship management (CRM) APIs: These APIs provide access to customer relationship management tools, including APIs for customer data management,
19. Data analysis and visualization APIs: These APIs provide access to tools for analyzing and visualizing financial data.
20. Fraud detection and prevention APIs: These APIs provide access to tools for detecting and preventing financial fraud.
21. Financial reporting APIs: These APIs provide access to financial reporting and analysis tools.
22. Financial modeling and simulation APIs: These APIs provide access to tools for creating financial models and simulations.
Financial risk management APIs: These APIs provide access to tools for managing financial risks, such as credit risk, market risk, and more.
23. Supply chain finance APIs: These APIs provide access to tools for managing supply chain financing, including APIs for invoice financing and trade finance.
24. Financial messaging APIs: These APIs provide access to financial messaging and communication platforms, such as SWIFT.
25. Financial education and training APIs: These APIs provide access to financial education and training resources.
There are so many of them, let's apply 80-20 rule and list down the APIs in the most useful categories
## Top Payment Processing APIs in India
- [Paytm API](https://developer.paytm.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Google Pay API](https://developers.google.com/pay/api) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Eko](https://developers.eko.in) - Domestic Money Transfer, Bill Payment, AePS and distribution of multiple financial services via 150k retail shops in India
- [PhonePe API](https://www.phonepe.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Amazon Pay API](https://www.amazon.in/b?ie=UTF8&node=14343320031) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [MobiKwik API](https://www.mobikwik.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Ola Money API](https://www.olamoney.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [PayU API](https://www.payu.in/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Razorpay API](https://razorpay.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [Instamojo API](https://www.instamojo.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
- [PayPal API](https://www.paypal.com/) - Payment processing API that offers a range of payment and financial services, including mobile payments, e-commerce, and more.
## Top Banking APIs in India
- [HDFC Bank API](https://www.hdfcbank.com/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [ICICI Bank API](https://www.icicibank.com/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Eko](https://developers.eko.in) - Domestic Money Transfer, Bill Payment, AePS and distribution of multiple financial services via 150k retail shops in India
- [Axis Bank API](https://www.axisbank.com/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Kotak Mahindra Bank API](https://www.kotak.com/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [SBI Bank API](https://www.sbi.co.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [PNB Bank API](https://www.pnb.co.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Bank of Baroda API](https://www.bankofbaroda.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Canara Bank API](https://www.canarabank.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Union Bank of India API](https://www.unionbankofindia.co.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
- [Bank of India API](https://www.bankofindia.co.in/) - Banking API that offers a range of banking products and services, including checking and savings accounts, loans, and more.
## Top Investment and Wealth Management APIs in India
- [Zerodha API](https://kite.trade/docs/) - Investment API that offers low-cost brokerage services for trading in multiple asset classes.
- [Upstox API](https://developer.upstox.com/docs/) - Investment API that offers a high-speed trading platform for multiple asset classes.
- [5paisa API](https://developer.5paisa.com/docs/) - Investment API that offers a user-friendly trading platform with advanced charting tools.
- [TradeJini API](https://www.tradejini.com/) - Investment API that offers brokerage services with a focus on customer service and support.
- [Edelweiss API](https://www.edelweiss.in/) - Investment API that offers a range of financial products and services, including brokerage, mutual funds, and more.
- [Angel Broking API](https://developer.angelbroking.com/) - Investment API that offers a range of brokerage services for multiple asset classes, including equities, derivatives, and more.
- [ICICI Direct API](https://www.icicidirect.com/) - Investment API that offers brokerage and financial services, including equity trading, mutual funds, and more.
- [HDFC Securities API](https://www.hdfcsec.com/) - Investment API that offers brokerage services for multiple asset classes, including equities, derivatives, and more.
- [Kotak Securities API](https://www.kotaksecurities.com/) - Investment API that offers brokerage services for multiple asset classes, including equities, derivatives, and more.
- [Motilal Oswal API](https://www.motilaloswal.com/) - Investment API that offers brokerage and financial services, including equity trading, mutual funds, and more.
## Top Insurance APIs in India
- [PolicyBazaar API](https://www.policybazaar.com/) - Insurance API that offers a comparison platform for insurance products, including life, health, and car insurance.
- [Tata AIA API](https://www.tataaia.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [HDFC ERGO API](https://www.hdfcergo.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [Bajaj Allianz API](https://www.bajajallianz.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [Max Life Insurance API](https://www.maxlifeinsurance.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [SBI Life Insurance API](https://www.sbilife.co.in/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [ICICI Prudential API](https://www.iciciprulife.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [LIC API](https://www.licindia.in/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [Birla Sun Life Insurance API](https://www.birlasunlife.com/) - Insurance API that offers a range of insurance products, including life, health, and car insurance.
- [Reliance Nippon Life Insurance API](https://www.reliancenipponlife.com/) - Insurance API that offers a range of insurance products, including
## Top Credit and Lending APIs in India
- [Lendingkart API](https://www.lendingkart.com/) - Credit and lending API that offers working capital loans to small businesses.
- [Capital Float API](https://www.capitalfloat.com/) - Credit and lending API that offers a range of financial products, including loans and credit lines, to small businesses.
- [Indifi API](https://www.indifi.com/) - Credit and lending API that offers working capital loans to small businesses.
- [Loanzen API](https://www.loanzen.in/) - Credit and lending API that offers working capital loans to small businesses.
- [InCred API](https://www.incred.com/) - Credit and lending API that offers a range of financial products, including loans, to individuals and small businesses.
- [KreditBee API](https://www.kreditbee.in/) - Credit and lending API that offers short-term personal loans to individuals.
- [EarlySalary API](https://www.earlysalary.com/) - Credit and lending API that offers short-term personal loans to individuals.
- [Credy API](https://www.credy.in/) - Credit and lending API that offers short-term personal loans to individuals.
- [StashFin API](https://www.stashfin.com/) - Credit and lending API that offers short-term personal loans to individuals.
- [MoneyTap API](https://www.moneytap.com/) - Credit and lending API that offers personal credit lines to individuals.
## Top Identity verification APIs in India
- [Authy API](https://www.authy.com/) - Identity verification API that offers two-factor authentication and phone verification services.
- [Truemail API](https://truemail.io/) - Identity verification API that offers email verification services.
- [Jumio API](https://www.jumio.com/) - Identity verification API that offers identity verification services using artificial intelligence and machine learning.
- [Onfido API](https://www.onfido.com/) - Identity verification API that offers identity verification services using artificial intelligence and machine learning.
- [SumSub API](https://www.sumsub.com/) - Identity verification API that offers identity verification and compliance services for financial institutions and e-commerce companies.
- [Shufti Pro API](https://www.shuftipro.com/) - Identity verification API that offers identity verification services using artificial intelligence and machine learning.
- [IDology API](https://www.idology.com/) - Identity verification API that offers identity verification and fraud prevention services.
- [IDnow API](https://www.idnow.de/) - Identity verification API that offers identity verification services using video identification technology.
- [IdentityMind API](https://www.identitymind.com/) - Identity verification API that offers identity verification and risk assessment services.
- [Veratad API](https://www.veratad.com/) - Identity verification API that offers identity verification and age verification services.
## FinTech API Aggregators in India
- [Eko Node SDK](https://github.com/ekoindia/eko-sdk-node) - Aggregator of all financial services APIs into one SDK
If you want me to create such useful content on regular basis without getting fired from my job :) , do check out the [FinTech APIs for Money Transfer and Bill Payments](http://developers.eko.in) that my team is building. And do check out a new [Open-Source Node.js SDK](https://github.com/ekoindia/eko-sdk-node) we recently started building to make it easy to integrate any FinTech service in your app. | ekodevelopers |
1,307,412 | Merry Christmas Codepen ! | Little experiment with parallax effect thanks to 3D perspective | 0 | 2022-12-23T22:56:28 | https://dev.to/one_div/merry-christmas-codepen--53jk | codepen | <p>Little experiment with parallax effect thanks to 3D perspective</p>
{% codepen https://codepen.io/onediv/pen/zYLGeQw %} | one_div |
1,307,460 | Runtime check on borrowing rule with RefCell | Rust does compile time check on borrowing rule. But there are some scenarios we need to defer it to... | 0 | 2022-12-24T02:39:54 | https://dev.to/franzwong/runtime-check-on-borrowing-rule-with-refcell-5b13 | rust, refcell | Rust does compile time check on borrowing rule. But there are some scenarios we need to defer it to runtime. Let me show a simplified version from one of the examples in [the book](https://doc.rust-lang.org/book/ch15-05-interior-mutability.html)
We have a trait with one method. No change on internal states is allowed inside this method. (`&self` is used instead of `&mut self`)
```rust
pub trait Messenger {
fn send(&self, msg: &str);
}
```
What if we want to store the messages sent? (e.g. it's common when we create a mock object for testing) It means we need to change the internal states. For some reasons (e.g. it is from 3rd party), we can't modify this trait, so we can't change to `&mut self`. Anyway, let's do it first and see what will happen.
```rust
struct MyMessenger {
messages: Vec<String>
}
impl MyMessenger {
fn new() -> MyMessenger {
MyMessenger { messages: vec![] }
}
}
impl Messenger for MyMessenger {
fn send(&self, msg: &str) {
self.messages.push(String::from(msg));
}
}
```
On the line `push` method is called, the compiler complains.
```
cannot borrow `self.messages` as mutable, as it is behind a `&` reference
`self` is a `&` reference, so the data it refers to cannot be borrowed as mutablerustcClick for full compiler diagnostic
main.rs(2, 13): consider changing that to be a mutable reference: `&mut self`
```
We want to make it passes the compilation. Let's rewrite it with `RefCell`.
```rust
use std::cell::RefCell;
struct MyMessenger {
messages: RefCell<Vec<String>>
}
impl MyMessenger {
fn new() -> MyMessenger {
MyMessenger { messages: RefCell::new(vec![]) }
}
}
impl Messenger for MyMessenger {
fn send(&self, msg: &str) {
self.messages.borrow_mut().push(String::from(msg));
}
}
```
We use `borrow_mut` to borrow a mutable value. Compilation passes this time.
The borrowing rule is still checked in runtime. Runtime error will occur if we do this.
(This violates the rule "At any given time, we can have either one mutable reference or any number of immutable references".)
```rust
let x = RefCell::new(String::from("Hello World"));
let y = x.borrow_mut();
let z = x.borrow(); // Error occurs here in runtime
``` | franzwong |
1,307,587 | Day 24: CI for perl5-MIME-Types | Sometimes it is very easy. | 20,737 | 2022-12-24T07:47:00 | https://code-maven.com/ci-for-perl5-mime-types | perl, ci, programming, devops | ---
title: Day 24: CI for perl5-MIME-Types
published: true
description: Sometimes it is very easy.
tags: perl, ci, programming, devops
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
published_at: 2022-12-24 07:47 +0000
canonical_url: https://code-maven.com/ci-for-perl5-mime-types
series: ci-2022-12
---
After the heavy-lifting of the previous entry in the Daily CI series this was a very easy task. Looking at [CPAN Digger](https://cpan-digger.perlmaven.com/) I saw [MIME-Types](https://metacpan.org/dist/MIME-Types). That sounded like a simple Perl module and indeed adding CI was straight forward.
[Pull-request](https://github.com/markov2/perl5-MIME-Types/pull/14) It was already accepted.
## Conclusion
There are many projects that are low-hanging fruits where you can add GitHub Actions in a matter of minutes and get the benefits immediately.
| szabgab |
1,307,818 | Free Developer T-Shirt Design | Download My Free T-Shirt Design and follow me for more. The Link if you want any custom... | 0 | 2022-12-24T14:08:04 | https://dev.to/ahmed_onour/free-developer-t-shirt-design-5dpg | free, freedesign | Download My Free T-Shirt Design and follow me for more.
[The Link](https://ahmedonour.gumroad.com/l/Developer-t-shirt-design)
## if you want any custom design i am available free of charge just DM me in [twitter](https://twitter.com/ahmed_onour) | ahmed_onour |
1,307,910 | New Joiner of Dev platform | Hi All, Firstly I would like to introduce myself I'm Shivani Goyal(25F) from India. I'm working in... | 0 | 2022-12-24T18:02:52 | https://dev.to/shivanigoyal/new-joiner-of-dev-platform-4498 | python, aws, beginners, knowledge | Hi All,
Firstly I would like to introduce myself I'm Shivani Goyal(25F) from India. I'm working in IT field as a System Engineer. I have completed MCA degree in 2021. I'm new joiner on this Dev platform. I would be very thankful to all of you if you'll give my some guidelines, tips and tricks, guidance, knowledge etc. Anything which will be helpful to enhance my knowledge. **If someone wanna connect with me please lemme know in terms of knowledge sharing, guidance only.** I hope we all are here to help each other and enhance the knowledge and programming skills as well.
## > I wish you Merry Christmas and Happy New Year to you and your family. Spread good thoughts, knowledge and happiness.
| shivanigoyal |
1,308,203 | My new portfolio which is built on top of next 13 app directory | I have been working around with my portfolio website in last two week ago. I forgot to grab review... | 0 | 2022-12-25T06:21:39 | https://dev.to/aungmyatmoe/my-new-portfolio-which-is-build-on-top-of-next-13-app-directory-1o6i | nextjs, portfolio, webdev, javascript | I have been working around with my portfolio website in last two week ago. I forgot to grab review from dev community.
I am warmly welcome to grab your review and feedback.
**My website is alive here.**
[https://www.aungmyatmoe.me/](https://www.aungmyatmoe.me/)
## Project can be found here
https://github.com/amm834/aungmyatmoe.me
## See review
I inspired tailwind's portfolio template. It is so cool and elegant to me. So, u don't need to invent a new wheel with figma 👻.
Figma is a bit hard for small screen.
I use,
- Next
- Tailwind
to accomplish my app's domain and then I inspired tailwind's open source documentation website to config my tailwind config.
It's open source by default. I love open source projects. They give me an opportunity to learn their code and how should I improve well in future.
## Lighthouse Result

| aungmyatmoe |
1,308,310 | Microservice architecture for software development | Microservice architecture is a software design pattern that decomposes a large, complex system into a... | 0 | 2022-12-25T10:08:10 | https://dev.to/giasuddin90/microservice-architecture-for-software-development-58kd | webdev, programming, architecture | Microservice architecture is a software design pattern that decomposes a large, complex system into a set of independent, self-contained services that communicate with each other over well-defined interfaces. This approach is becoming increasingly popular in the software industry due to its many benefits, including:
**1.Modularity:** Microservices are designed to be self-contained, with each service responsible for a specific set of functionality. This makes it easier to develop and maintain the system, as changes to one service are less likely to affect the rest of the system.
**2.Scalability:** Microservices can be scaled independently of each other, allowing the system to handle increased workloads without having to scale the entire system. This makes it easier to manage resource utilization and cost.
**3.Flexibility:** Microservices can be developed and deployed independently, allowing the system to be more flexible and adaptable to change. This makes it easier to add new features and capabilities to the system.
**4.Reliability:** Microservices are designed to be fault-tolerant, with each service able to operate independently of the others. This makes the system more resilient to failures, as the rest of the system can continue to operate even if one service goes down.
**5.Reusability:** Microservices can be reused in multiple applications, allowing developers to build new systems faster and more efficiently.
However, microservice architecture also has its challenges, including:
**1.Complexity:** Microservice architecture can be more complex to design and implement than traditional monolithic architecture, as it requires more coordination between the different services.
**2.Testing:** Testing microservices can be more difficult, as each service must be tested independently and in combination with the other services.
**3.Deployment:** Deploying microservices can be more challenging, as each service must be deployed and managed separately.
**4.Monitoring:** Monitoring microservices can be more difficult, as there are more components to keep track of.
Despite these challenges, microservice architecture is becoming increasingly popular in the software industry due to its many benefits. It allows developers to build scalable, flexible, and reliable software systems that can adapt to changing requirements and workloads. If you are considering using microservice architecture for your next software project, it is important to carefully evaluate the benefits and challenges to determine if it is the right fit for your needs.
Thank you for reading my article! If you enjoyed it and would like to support my work, please consider buying me a coffee at **[Buy Me a Coffee](https://www.buymeacoffee.com/giasuddin)**. You can also learn more about me and my work by visiting my **[Giasuddin Bio ](https://bio.link/giasuddi)**and following me on LinkedIn and Twitter. Thank you for your support!
| giasuddin90 |
1,308,356 | Managing React State Like A Superhero 🦸 | The state is an important concept in React, as it allows components to store and manage data that can... | 0 | 2022-12-25T13:17:22 | https://dev.to/majdsufian/managing-react-state-like-a-superhero-5gnp | react, javascript, typescript, webdev | The state is an important concept in React, as it allows components to store and manage data that can change over time. Properly managing state can help make your React application more efficient and easier to maintain. In this article, we will explore different ways to manage state in React and provide code examples for each method.
**1- Using the useState Hook:**
One of the most common ways to manage state in React is by using the `useState` hook. This hook allows you to add state to functional components, which were previously unable to have state. Here is an example of how to use the `useState` hook:
```ts
import React, { useState } from 'react';
function Example() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
```
In this example, we are using the `useState` hook to create a piece of state called `count`, which is initially set to 0. The `useState` hook returns an array with two elements: the current value of the state (in this case, `count`) and a function to update the state (in this case, `setCount`). We can use the `setCount` function to update the value of `count` by passing a new value as an argument.
**2- Using the useReducer Hook:**
Another way to manage state in React is by using the `useReducer` hook. This hook is similar to the `useState` hook, but it allows you to manage complex state logic with reducers, which are functions that take in the current state and an action, and return a new state. Here is an example of how to use the `useReducer` hook:
```ts
import React, { useReducer } from 'react';
const initialState = { count: 0 };
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
case 'decrement':
return { count: state.count - 1 };
default:
throw new Error();
}
}
function Example() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div>
<p>You clicked {state.count} times</p>
<button onClick={() => dispatch({ type: 'increment' })}>
Increment
</button>
<button onClick={() => dispatch({ type: 'decrement' })}>
Decrement
</button>
</div>
);
}
```
**3- Using the useContext Hook:**
Another way to manage the state in React is by using the `useContext` hook in combination with the `createContext` function. The `createContext` the function allows you to create a context object, which can be used to pass data down the component tree without the need for props drilling. The `useContext` hook allows you to access the context object from a functional component. Here is an example of how to use them `createContext` && `useContext` hooks:
```ts
import React, { createContext, useContext } from 'react';
const CountContext = createContext();
function Example() {
const count = useContext(CountContext);
return (
<div>
<p>You clicked {count} times</p>
</div>
);
}
function App() {
const [count, setCount] = useState(0);
return (
<CountContext.Provider value={count}>
<Example />
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</CountContext.Provider>
);
}
```
**4- Using a Higher-Order Component:**
Another way to manage the state in React is by using a higher-order component (HOC). A HOC is a function that takes a component as an argument and returns a new component with additional functionality. Here is an example of how to use a HOC to manage the state:
```ts
import React from 'react';
function withState(WrappedComponent) {
return class extends React.Component {
state = { count: 0 };
increment = () => {
this.setState({ count: this.state.count + 1 });
}
render() {
return (
<WrappedComponent
count={this.state.count}
increment={this.increment}
{...this.props}
/>
);
}
};
}
function Example(props) {
return (
<div>
<p>You clicked {props.count} times</p>
<button onClick={props.increment}>
Click me
</button>
</div>
);
}
const EnhancedExample = withState(Example);
function App() {
return (
<EnhancedExample />
);
}
```
In this example, we are using a HOC called withState to add state management functionality to the `Example` component. The `withState` HOC returns a new component that has a `count` state and an `increment` function, which updates the `count` state. The `Example` component receives the `count` and `increment` props from the HOC and uses them to render the component.
**5- Using a State Management Library:**
Finally, another way to manage the state in React is by using a state management library.
Using a state management library is a popular approach to managing the state in larger React applications. A state management library is a separate package that provides additional functionality for managing the state, such as support for handling asynchronous actions and managing a global state.
One popular state management library for React is Redux. Redux is a predictable state container for JavaScript applications that helps you write applications that behave consistently. It works by creating a store that holds the application's state and provides functions for updating the state in a predictable way.
Here is an example of how to use Redux to manage the state in a React application:
```ts
import React from 'react';
import { createStore } from 'redux';
import { Provider, connect } from 'react-redux';
const initialState = { count: 0 };
function reducer(state = initialState, action) {
switch (action.type) {
case 'INCREMENT':
return { count: state.count + 1 };
case 'DECREMENT':
return { count: state.count - 1 };
default:
return state;
}
}
const store = createStore(reducer);
function Example(props) {
return (
<div>
<p>You clicked {props.count} times</p>
<button onClick={props.increment}>
Increment
</button>
<button onClick={props.decrement}>
Decrement
</button>
</div>
);
}
function mapStateToProps(state) {
return {
count: state.count
};
}
function mapDispatchToProps(dispatch) {
return {
increment: () => dispatch({ type: 'INCREMENT' }),
decrement: () => dispatch({ type: 'DECREMENT' })
};
}
const EnhancedExample = connect(
mapStateToProps,
mapDispatchToProps
)(Example);
function App() {
return (
<Provider store={store}>
<EnhancedExample />
</Provider>
);
}
```
In this example, we are using Redux to create a store that holds the application's state and a reducer function that updates the state in a predictable way. We are then using the `connect` function from the `react-redux` library to connect the `Example` component to the Redux store. The `connect` function returns a new component that receives the state and dispatch functions as props. The `Example` component uses the count prop to render the component and the `increment` and `decrement` props to update the state.
------------------------------------------------
In conclusion, there are several different ways to manage the state in React, each with its own advantages and disadvantages. It is important to choose the right approach for your specific use case and to consider factors such as the complexity of your state, the size of your application, and the needs of your team.
| majdsufian |
1,308,378 | Multiple Checkbox Form in React Js | Multiple Checkbox list is very often seen on the websites like Amazon, Flipkart etc. So today we... | 0 | 2022-12-25T14:15:44 | https://dev.to/mayankkashyap681/multiple-checkbox-form-in-react-js-3elb | javascript, webdev, react, tutorial | Multiple Checkbox list is very often seen on the websites like Amazon, Flipkart etc.
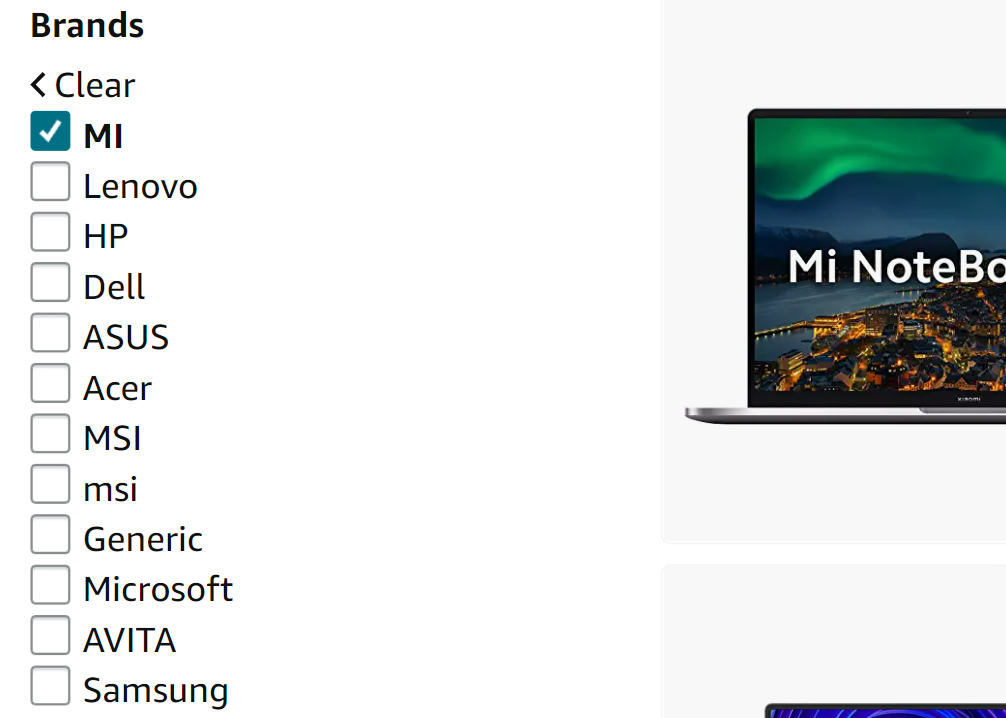
So today we are going to build multiple checkbox list from scratch using React.
So, our final result will look like the gif below
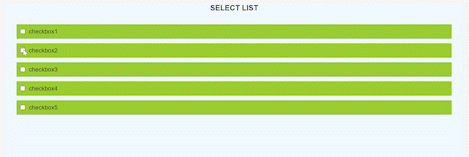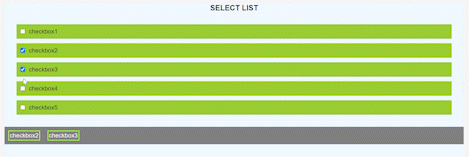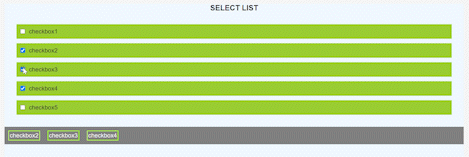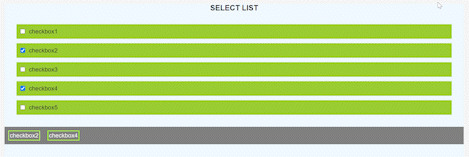
This is **App.js**, make a React project and you will find it over there.
You can create a separate file for the Checkbox list or simple write your code in the App.js but I prefer to create a new file for Checkbox list. Import the Checkbox from the File Checkbox.js and make it a component. Styling is up to you. You can style it anyway you want.
```
import "./styles.css";
import Checkbox from "./Checkbox";
export default function App() {
return (
<div className="App">
<Checkbox />
</div>
);
}
```
This is our Checkbox.js
```
import React from "react";
const Checkbox = () => {
const list = [
"checkbox1",
"checkbox2",
"checkbox3",
"checkbox4",
"checkbox5"
];
return (
<div
className="selector-bg"
style={{ background: "aliceblue", height: "100vh", margin: "20px" }}
>
<div>
<h1
style={{
textAlign: "center",
fontWeight: "bold",
textTransform: "uppercase",
fontSize: "20px"
}}
>
Select List
</h1>
<form>
<div style={{ padding: "20px" }}>
{list.map((val) => (
<div
style={{
display: "flex",
backgroundColor: "yellowgreen",
padding: "10px",
margin: "12px"
}}
key={val}
>
<input
type="checkbox"
id={val}
value={val}
name={val}
style={{ marginRight: "10px" }}
/>
<label for={val}>{val}</label>
</div>
))}
</div>
</form>
</div>
</div>
);
};
export default Checkbox;
```
So in the Checkbox.js we have firstly made the list of all the tags which we want to display and to keep everything simple I have named them checkbox1, checkbox2, checkbox3 and so on you can also replace them with some real tags like brand names, color names or whatever you like.
> const list = [ "checkbox1", "checkbox2", "checkbox3", "checkbox4", "checkbox5"];
we are making this list so that we don't need to hardcode tags and write repetitive code, instead of that we can simply use map on the list of the tags and display them by writing code once.
`<div
className="selector-bg"
style={{ background: "aliceblue", height: "100vh", margin: "20px" }}
>
<div>
<h1
style={{
textAlign: "center",
fontWeight: "bold",
textTransform: "uppercase",
fontSize: "20px"
}}
>
Select List
</h1>
<form>
<div style={{ padding: "20px" }}>
{list.map((val) => (
<div
style={{
display: "flex",
backgroundColor: "yellowgreen",
padding: "10px",
margin: "12px"
}}
key={val}
>
<input
type="checkbox"
id={val}
value={val}
name={val}
style={{ marginRight: "10px" }}
/>
<label for={val}>{val}</label>
</div>
))}
</div>
</form>
</div>`
In the code written above we have only done some styling and created a form, iterated over the list of tags and displayed them. After all this we will get the output something like the image below.
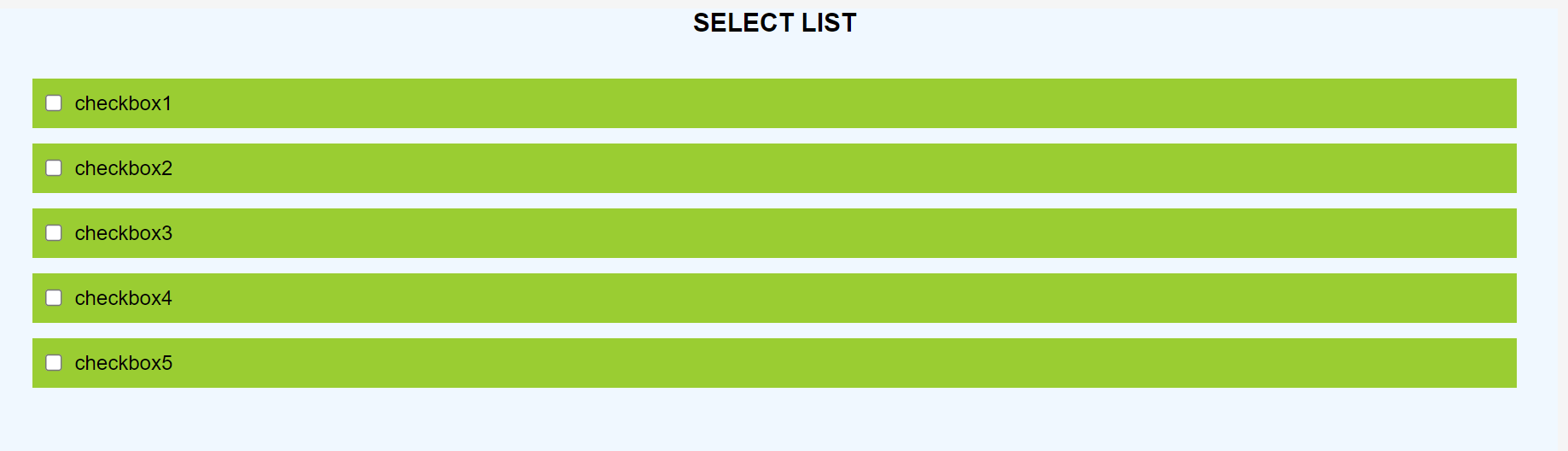
**Now, lets add state and add logic to make things work**
Import useState() from React
> import {useState} from 'react'
A). Add a state checked to keep track of all the tags which are checked.
_const [checked, setChecked] = useState([]);_
B). Add onChange Event handler on the input field
_onChange={() => handleToggle(val)}_
C). Write the logic for the handleToggle function, so that whenever a box is checked or unchecked the handleToggle function get triggered.
```
const handleToggle = (val) => {
var currentIndex = checked.indexOf(val);
var newArr = [...checked];
if (currentIndex === -1) {
newArr.push(val);
} else {
newArr.splice(currentIndex, 1);
}
setChecked(newArr);
};
```
Handle Toggle function doing following things
1). It is finding the index of the tag in the checked array,
if the tag is present then we will get the index, otherwise we will get -1
2). we are creating another array newArray and initializing it with all the tags which are currently in the checked array, in simple words we are making copy.
3). If the currentIndex is -1, it means the tag is not present in the array so we are pushing it in the newArr by using push() method.
4). If the currentIndex is not equal to -1 it means the tag is already checked thus present in the checked array, so we are removing it using splice() method.
5). At last we are setting the checked array using setChecked(newArr);
**To display all the checked tags we are adding another div which get diplayed only when the size of checked array is greater than 0 means the checked array is having atleast one element**
```
<div style={{ display: "flex", backgroundColor: "gray" }}>
{checked.map((item) => (
<p
key={item}
style={{
margin: "10px",
color: "whitesmoke",
border: "2px solid greenyellow",
padding: "2px"
}}
>
{item}
</p>
))}
</div>
```
**_The link for the final code of Checkbox.js_**
https://github.com/MaYaNkKashyap681/React-Native-Features-Implementation/blob/main/Selection%20Checkbox%20in%20React.js
| mayankkashyap681 |
1,308,438 | Justify-content in Flex Box | Simply we can say that justify contet set items horizontal. but with it has also few... | 0 | 2022-12-25T14:44:35 | https://dev.to/sutharrahul/justify-content-in-flex-box-pi3 | Simply we can say that justify contet set items horizontal.
but with it has also few property.
`.flxbox{
justify-content: flex-start | flex-end | center | space-between | space-around | space-evenly | start | end | left | right;
}`
## Flex-star (default) :
Item are set on star (left side of page). If we use `row-revers` but we want that item should be start from left side. so we use `justify-content: flex-start`.
`justify-content: flex-start;`

## flex-end:
Item are set on end (right side of page)
`justify-content: flex-end;`

## flex-center:
This property set out item on center of the page
`justify-content: center;`

## space-between:
Items are evenly distributed in the line; first item is on the start line, last item on the end line.
`justify-content: space-between;`

## space-around:
To create evenly space around items
`justify-content: space-around;`

## space-evenly:
Items are distributed so that the spacing between any two items (and the space to the edges) is equal.
| sutharrahul | |
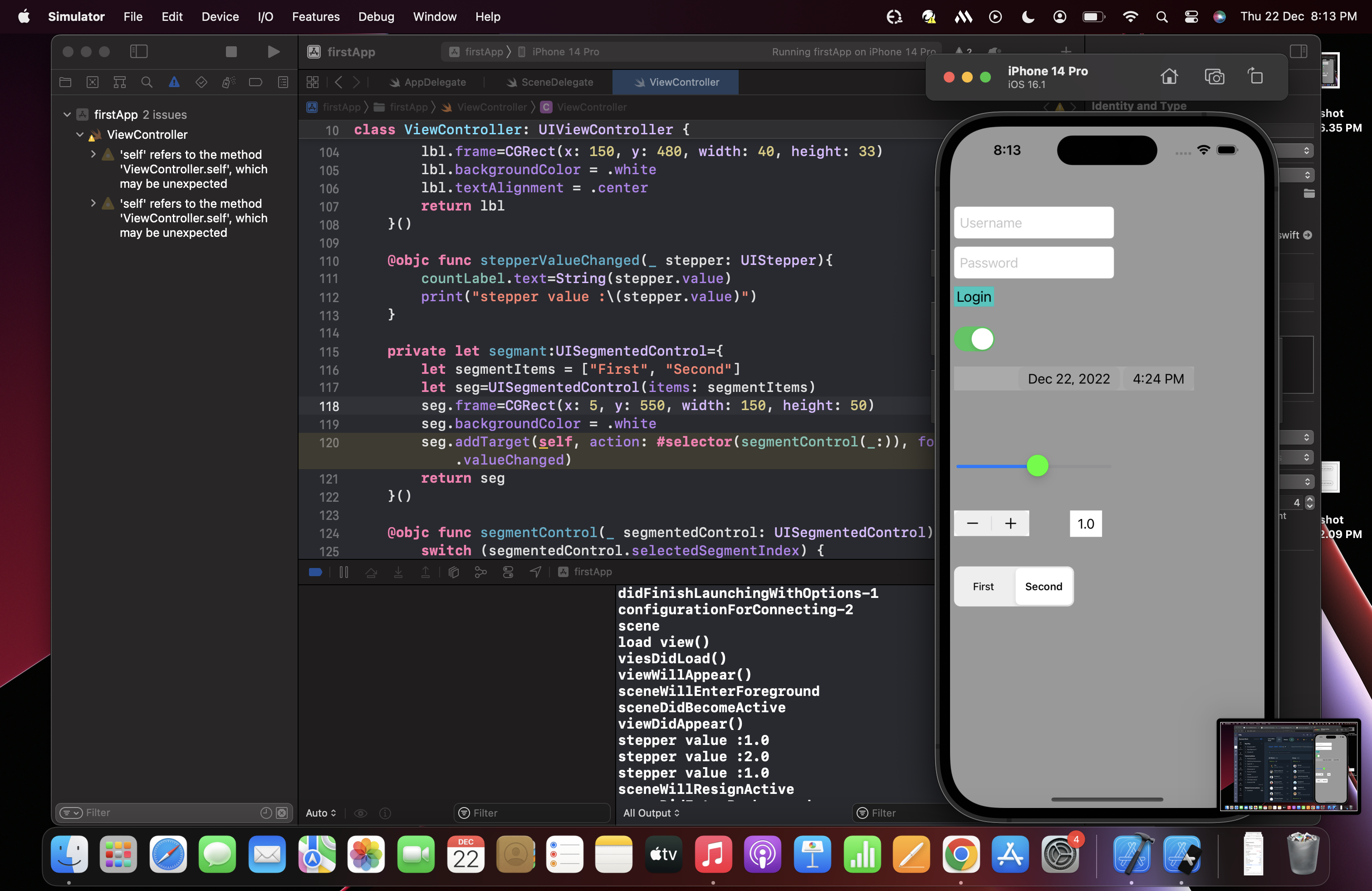
1,308,922 | UI Controls | Label a label is a visual element that displays text. It is an instance of the UILabel... | 21,130 | 2022-12-26T10:02:03 | https://dev.to/ajith_karuna/ui-controls-4122 | ## Label
a label is a visual element that displays text. It is an instance of the UILabel class, which is a subclass of UIView. Labels are commonly used to display static text, such as labels for form fields or titles for sections of content.
A label has a number of properties that you can use to customise its appearance, such as its font, text colour, and alignment and more.
```
let label=UILabel()
label.text="Welcome to zoho!"
label.textAlignment = .center
label.textColor = .blue
label.frame=CGRect(x: 5, y: 60, width: 150, height: 20)
view.addSubview(label)
```
## Button
It is a control that enables the user to interact with the application. It is used to trigger the events performed by the user. It executes the custom code in response to user interactions.
The buttons are one of the most important parts of iOS applications. Buttons are associated with the actions that are performed when the user interacts with the button. We can add the button to the iOS application programmatically or by using interface builder.
```
private let Button:UIButton={
let btn=UIButton()
btn.setTitle("Login", for: .normal)
btn.setTitleColor(UIColor.black, for: .normal)
btn.frame = CGRect(x: 5, y: 200, width: 50, height: 25)
btn.backgroundColor = .systemMint
btn.addTarget(target, action: #selector(call),for: .touchUpInside)
return btn
}()
@objc func call(){
print("button clicked")
Button.backgroundColor = .red
}
```
## TextField
It can be defined as an object which is used to display an editable text area in the interface. Textfields are used to get the text-based input from the user.
```
private let userNameText:UITextField={
let text=UITextField()
text.placeholder="Username"
text.borderStyle = .roundedRect
text.textColor = .black
text.frame = CGRect(x: 5, y:100 , width: 200, height: 40)
return text
}()
```
## DatePicker
DatePicker is a control used in IOS applications to get the date and time values from the user. We can allow the user to either enter the time in point or time interval.
```
private let DatePicker:UIDatePicker={
let picker=UIDatePicker()
picker.frame=CGRect(x: 5, y: 300, width: 300, height: 30)
picker.backgroundColor = .lightGray
return picker
}()
```
## Slider
A slider can be defined as a UIControl, which provides the contiguous range of values on a single scale to the user, out of which the user is prompted to select a single value.
The slider is connected with the action method, which is notified every time the user moves the thumb onto a slider. The value of the slider can be retrieved each time the action method is called.
```
private let Slider:UISlider={
let slider=UISlider()
slider.frame=CGRect(x: 5, y: 400, width: 200, height: 50)
slider.minimumValue=0
slider.maximumValue=100
slider.thumbTintColor = .green
return slider
}()
```
## Stepper
It is a type of UIControl which is used to increase and decrease value. The stepper consists of two buttons. It is associated with a value which gets repeatedly increased or decreased on holding down two of the buttons once at a time. The rate of the change depends on the duration the user presses the control.
```
private let Stepper={
var steper=UIStepper()
steper.frame=CGRect(x: 5, y: 480, width: 30, height: 60)
steper.backgroundColor = .white
steper.value=0
steper.minimumValue = -10
steper.maximumValue = 10
steper.addTarget(self, action: #selector(stepperValueChanged(_:)), for: .valueChanged)
return steper
}()
```
## Switch
The switch can be defined as the UIControl, which provides binary choices to the user either on or off. The state of a switch is managed by properties and methods defined in the UISwitch class, which is the subclass of UIControl.
```
private let Switch:UISwitch={
let Switch=UISwitch()
Switch.frame=CGRect(x: 5, y: 250, width: 50, height: 30)
Switch.isOn=true
Switch.setOn(true, animated: false)
return Switch
}()
```
## Segment
Segment control can be defined as the horizontal control, which controls multiple segments where a discrete button controls each segment. A segment control can be used to display multiple views within a single view controller, where each view can be displayed by using a discrete button.
```
private let segmant:UISegmentedControl={
let segmentItems = ["First", "Second"]
let seg=UISegmentedControl(items: segmentItems)
seg.frame=CGRect(x: 5, y: 550, width: 150, height: 50)
seg.backgroundColor = .white
seg.addTarget(self, action: #selector(segmentControl(_:)), for: .valueChanged)
seg.selectedSegmentIndex=0
seg.selectedSegmentTintColor = .lightGray
seg.tintColor = .blue
return seg
}()
```
**Sample App**
| ajith_karuna | |
1,418,643 | Membuat Simple Bank App Menggunakan Strapi v4 | Hi, selamat datang di artikel kami. Untuk kali ini kita akan sharing dan belajar bareng terkait... | 0 | 2023-04-02T07:47:52 | https://dev.to/wildananugrah/membuat-simple-bank-app-menggunakan-strapi-v4-386h | Hi, selamat datang di artikel kami. Untuk kali ini kita akan sharing dan belajar bareng terkait [Strapi](https://strapi.io). Namun, sebelum kita mulai, ada beberapa hal yang mesti temen-temen pahami.
Pertama, [Strapi](https://strapi.io) adalah *Headless Content Management System* atau *Headless CMS* yang dimana sangat membantu untuk mempercepet waktu _developer_ untuk membuat sebuah aplikasi.
Lalu apa itu *Headless Content Management System* atau *Headless CMS*? *Headless CMS* adalah sebuah CMS tanpa [Frontend](https://en.wikipedia.org/wiki/Front-end_web_development) yang dimana *content*-nya dapat diakses melalui [API](https://en.wikipedia.org/wiki/API). Sehingga dengan sebuah *Headless CMS* membantu temen-temen *developer* membuat backend aplikasi lebih cepat dan mudah.
[API](https://en.wikipedia.org/wiki/API) memungkinan dua aplikasi untuk saling berkomunikasi melalui sebuah *protocol* dengan *message contract* tertentu. Untuk pembahasan kali ini, kita akan menggunakan [HTTP](https://en.wikipedia.org/wiki/HTTP) dan [JSON](https://en.wikipedia.org/wiki/JSON)
[Strapi](https://strapi.io) biasanya digunakan para developer untuk mengembangkan *Static Websites*, *Mobile Apps*, *e-Commerce*, *Editorial*, dan *Corporate websites*. Namun, tidak menutup kemungkinan untuk mengembangankan aplikasi lebih dari itu. Untuk di artikel kami kali ini, kami akan coba membuat aplikasi bank yang sederhana atau **API Simple Bank App**.
Kami merasa dengan mempelajari **API Simple Bank App**, dapat membantu kita untuk mempelajari sistem perbankan dalam scope kecil dan manfaat dari API terutama di era digital saat ini. Adapun yang akan kita pelajari di artikel ini antara lain:
1. Business Requirements
2. Design System
3. Development
## Business Requirements
**API Simple Bank App** melayani user dalam beberapa hal antara lain:
1. User dapat mendaftarkan diri menjadi nasabah baru dan mendapatkan nomor *Customer Identification File* (CIF) dengan meng-input data antara lain:
1. Nomor ID atau KTP
2. Nama lengkap
2. Nasabah dapat membuat nomor rekening baru dengan menginput data CIF
3. Dapat melihat daftar nomor rekening dengan menginput data CIF
4. Nasabah dapat men-topup uang ke nomor rekeningnya sendiri
1. Nomor Rekening
2. *Amount*
5. Nasabah dapat menarik uang dari nomor rekeningnya sendiri dengan data antara lain:
1. Nomor ID atau KTP
2. Nomor Rekening
3. *Amount*
## Design system
Berdasarkan Business Requirement di sebelumnya, kami melihat bahwa ada beberapa *service* yang perlu kita bangun di dalam sistem kita antara lain:
1. Customer service: service yang melayani nasabah dalam [CRUD](https://www.codecademy.com/article/what-is-crud) customer.
2. Account service: service yang melayani nasabah dalam [CRUD](https://www.codecademy.com/article/what-is-crud) account.
3. Transaction service: service yang melayani nasabah dalam [CRUD](https://www.codecademy.com/article/what-is-crud) transaction.
## Development
- Buka Terminal lalu jalankan perintah dibawah
```sh
npx create-strapi-app@latest app-simple-bank
```
- Masuk ke folder _app-simple-bank_ dengan menjalankan code di bawah
```sh
cd app-simple-bank
```
- Buat dua file yaitu _app.Dockerfile_, _docker-compose.yml_, dan _Makefile_
- Untuk _app.Dockerfile_, ketik kode di bawah ini
```dockerfile
FROM node:16-alpine
# Installing libvips-dev for sharp Compatibility
RUN apk update && apk add --no-cache build-base gcc autoconf automake zlib-dev libpng-dev nasm bash vips-dev
ARG NODE_ENV=development
ENV NODE_ENV=${NODE_ENV}
WORKDIR /opt/
COPY ./package.json ./yarn.lock ./
ENV PATH /opt/node_modules/.bin:$PATH
RUN yarn config set network-timeout 600000 -g && yarn install
WORKDIR /opt/app
COPY ./ .
RUN yarn build
EXPOSE 1337
CMD ["yarn", "develop"]
```
- Untuk compose-docker.yml. ketik kode di bawah ini
```yaml
version: "3.7"
services:
app-simple-bank:
build:
context: .
dockerfile: ./app.Dockerfile
container_name: app-simple-bank
environment:
- DATABASE_HOST=db-simple-bank
- DATABASE_PORT=5432
- DATABASE_NAME=postgres
- DATABASE_USERNAME=postgres
- DATABASE_PASSWORD=password
- HOST=0.0.0.0
- PORT=1337
- APP_KEYS=mc68ZV26OzOPQ0A1ESUvNA==,b4sM7ksQE3eqfteYmqWzwA==,UUWwjcxNoDrGvSwnDDhwxA==,j7T57Bls1mSggOLIrsljkg==
- API_TOKEN_SALT=nagThNX7aJINn6oaOpMOyg==
- ADMIN_JWT_SECRET=9VrfUyP40Cqxy+6qNvucQQ==
- TRANSFER_TOKEN_SALT=ar4K31sLK7NONBhHQ6t2zw==
ports:
- "8000:1337"
depends_on:
- db-simple-bank
volumes:
- ./src:/opt/app/src
- ./config:/opt/app/config
- ./package.json:/opt/app/package.json
- ./public/uploads:/opt/app/public/uploads
networks:
app-net: {}
db-simple-bank:
image: postgres:alpine
container_name: db-simple-bank
environment:
- POSTGRES_PASSWORD=password
volumes:
- ./data/pg-data:/var/lib/postgresql/data
networks:
app-net: {}
networks:
app-net:
external: true
name: 'dev-to-network'
```
- Terakhir untuk _Makefile_, ketik kode di bawah ini
```Makefile
compose-up:
docker compose up -d --build
compose-down:
docker compose down
```
- Buka terminal di bawah, buat network baru di docker dengan menjalankan kode di bawah ini
```sh
docker network create dev-to-network
```
- Untuk menjalankan aplikasi nya, ketik kode di bawah ini di terminal
```sh
make compose-up
```
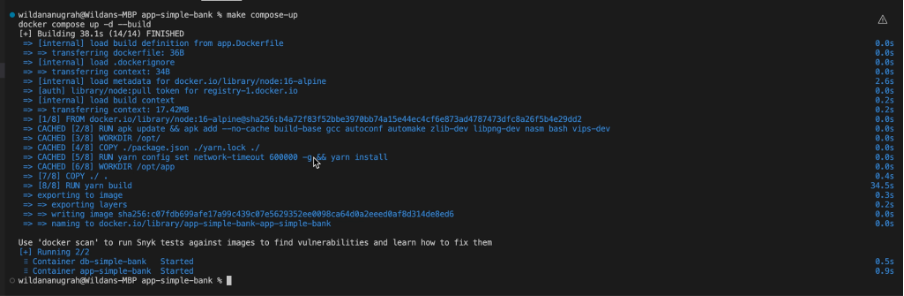
- Buka browser, ketik di address bar http://localhost:8000/admin, maka tampilan akan seperti di bawah ini
- Masukan data sesuai dengan yang diminta
- Setelah masuk ke halaman dashboard admin, pilih menu _Content-Type builder_
- Klik _Create new collection type_, lalu create _Customer_
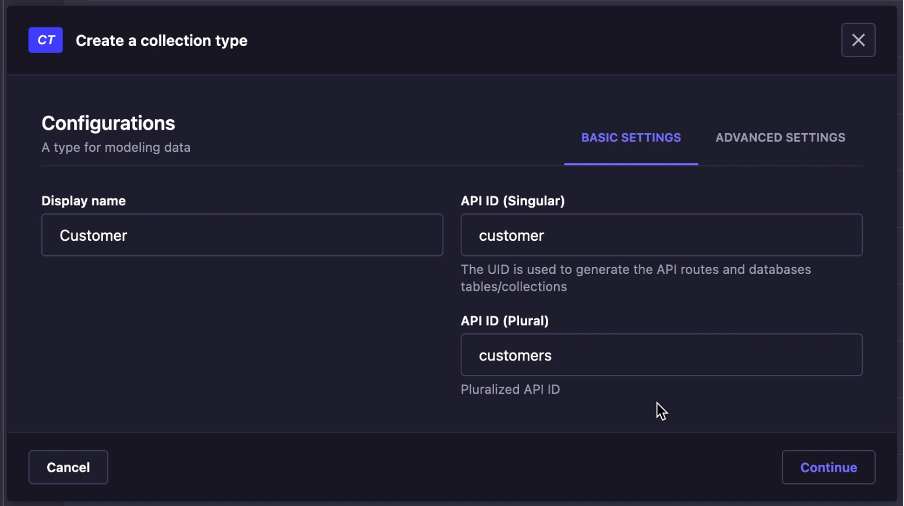
- Create beberapa field seperti dibawah
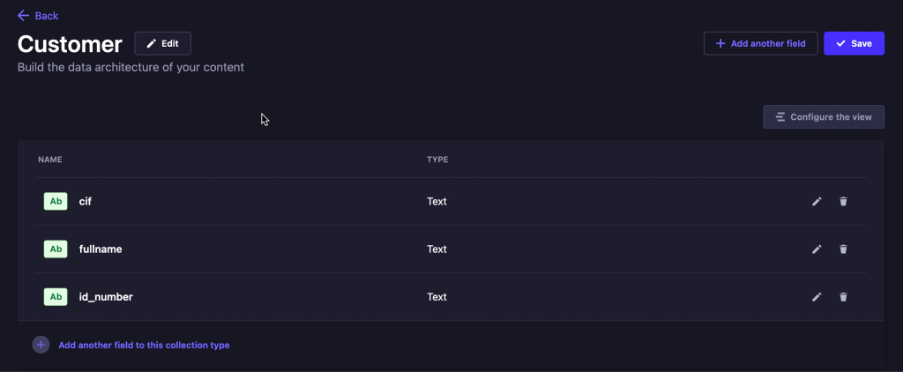
- Klik _Create new collection type_, lalu create _Account_
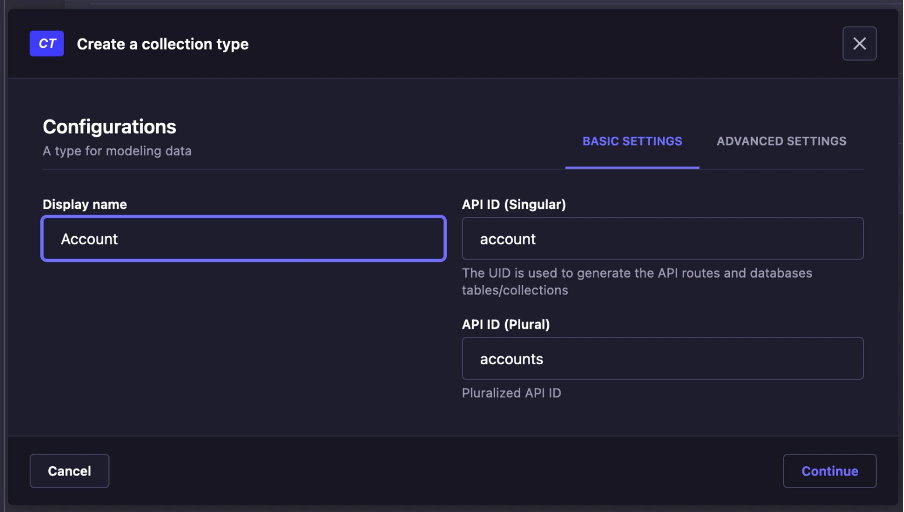
- Create beberapa field seperti dibawah
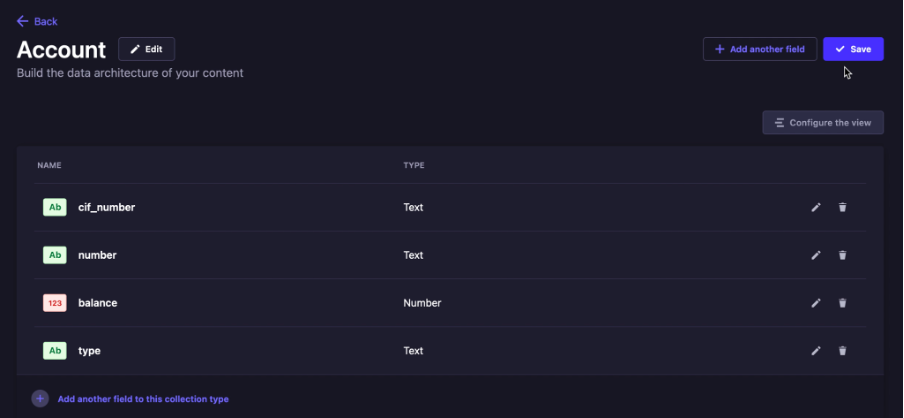
- Klik Create new collection type, lalu create Transaction
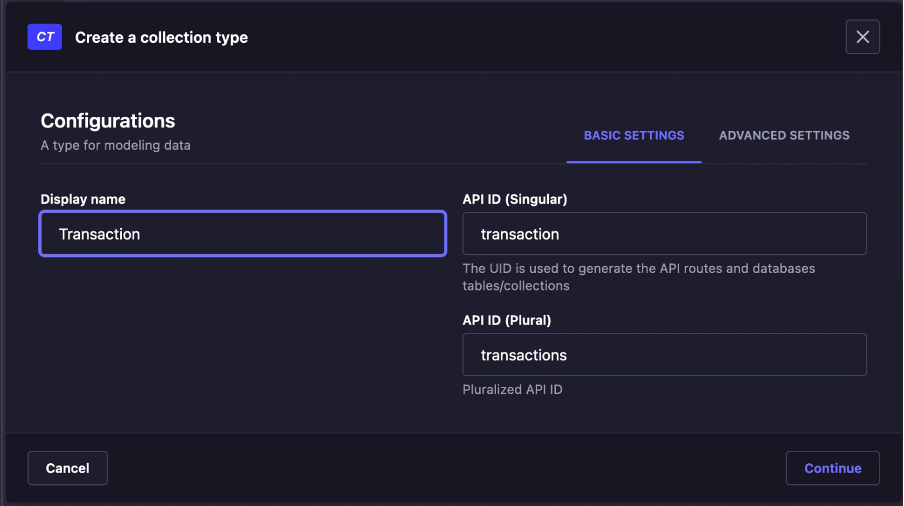
- Create beberapa field seperti dibawah
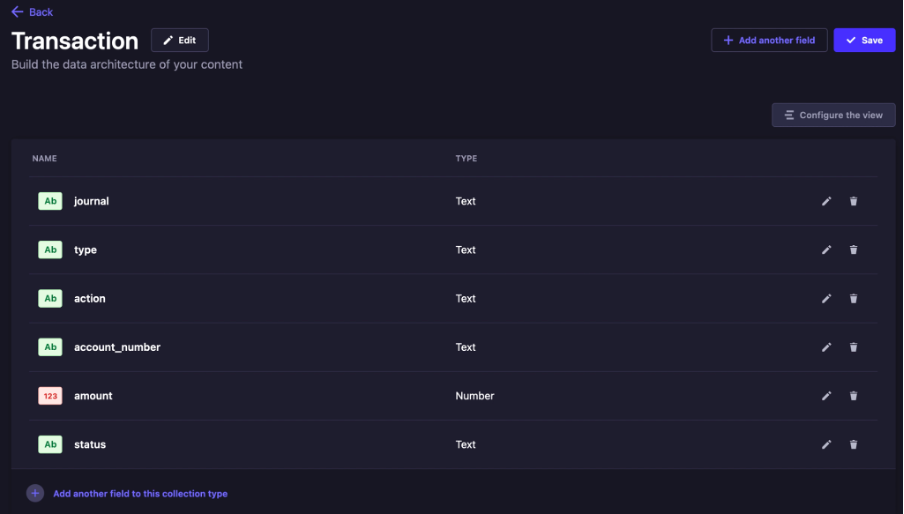
- Create _lifecycles.js_ file di _src/api/content-types/customer/lifecycles.js_, lalu ketikan kode di bawah ini
```javascript
// src/api/content-types/customer/lifecycles.js
module.exports = {
beforeCreate: async (event) => {
const generate_cif = async (length) => {
let result = '';
const characters = '0123456789';
const charactersLength = characters.length;
let counter = 0;
while (counter < length) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
counter += 1;
}
return result;
}
const get_cif = async () => {
let cif = ""
let customer = []
do {
cif = await generate_cif(10)
customer = await strapi.entityService.findMany("api::customer.customer", {
filters: {
cif: cif
}
})
console.log(`customer: ${customer}`)
console.log(`cif: ${cif}`)
} while (customer.length != 0)
return cif
}
const { data } = event.params;
data.cif = await get_cif()
},
};
```
- Create _lifecycles.js_ file di _src/api/content-types/account/lifecycles.js_, lalu ketikan kode di bawah ini
```javascript
// src/api/content-types/account/lifecycles.js
const utils = require('@strapi/utils');
const { ApplicationError } = utils.errors;
module.exports = {
beforeCreate: async (event) => {
const generate_account_number = async (length) => {
let result = '';
const characters = '0123456789';
const charactersLength = characters.length;
let counter = 0;
while (counter < length) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
counter += 1;
}
return result;
}
const get_account_number = async () => {
let account_number = ""
let account = []
do {
account_number = await generate_account_number(10)
account = await strapi.entityService.findMany("api::account.account", {
filters: {
number: account_number
}
})
console.log(`account: ${account}`)
console.log(`account_number: ${account_number}`)
} while (account.length != 0)
return account_number
}
const { data } = event.params;
const customer = await strapi.entityService.findMany("api::customer.customer", {
filters: {
cif: data.cif_number
}
})
if(customer.length == 0)
{
throw new ApplicationError('Invalid cif number', { message: `can not find '${data.cif_number}' cif number` });
}
else
{
data.number = await get_account_number()
data.balance = 0
}
},
};
```
- Create file _custom-transaction.js_ di _src/api/transaction/controllers/custom-transaction.js_, lalu ketikan kode di bawah ini
```javascript
// src/api/transaction/controllers/custom-transaction.js
const utils = require('@strapi/utils');
const { ApplicationError } = utils.errors;
const get_account = async (account_number) => {
const accountResponse = await strapi.entityService.findMany("api::account.account",
{
filters: {
number: account_number
}
}
)
return accountResponse[0]
}
const generate_journal = async (length) => {
let result = '';
const characters = '0123456789';
const charactersLength = characters.length;
let counter = 0;
while (counter < length) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
counter += 1;
}
return result;
}
const get_journal = async () => {
let journal = ""
let transaction = []
do {
journal = await generate_journal(10)
transaction = await strapi.entityService.findMany("api::transaction.transaction", {
filters: {
journal: journal
}
})
console.log(`journal: ${journal}`)
} while (transaction.length != 0)
return journal
}
module.exports = {
async debit(ctx, next) {
const requestBody = ctx.request.body.data
const account = await get_account(requestBody.account_number)
if (account.length == 0) {
throw new ApplicationError('Invalid account number', { message: `Can not find ${requestBody.account_number} account number` });
}
else {
const new_balance = account.balance - requestBody.amount
const transaction = {
data: {
journal: await get_journal(),
account_number: requestBody.account_number,
type: requestBody.type,
status: "SUCCEED",
action: "DEBIT",
amount: requestBody.amount,
publishedAt: new Date()
}
}
await strapi.entityService.create("api::transaction.transaction", transaction)
await strapi.entityService.update("api::account.account", account.id, {
data: {
balance: new_balance
}
})
return transaction
}
},
async credit(ctx, next) {
const requestBody = ctx.request.body.data
const account = await get_account(requestBody.account_number)
console.log(account)
if (account.length == 0) {
throw new ApplicationError('Invalid account number', { message: `Can not find ${requestBody.account_number} account number` });
}
else {
const new_balance = account.balance + requestBody.amount
const transaction = {
data: {
journal: await get_journal(),
account_number: requestBody.account_number,
type: requestBody.type,
status: "SUCCEED",
action: "CREDIT",
amount: requestBody.amount,
publishedAt: new Date()
}
}
await strapi.entityService.create("api::transaction.transaction", transaction)
await strapi.entityService.update("api::account.account", account.id, {
data: {
balance: new_balance
}
})
return transaction
}
}
}
```
- Ubah nama file _transaction.js_ menjadi _01-transaction.js_ di folder _src/api/transaction/routes/_
- Create file 02-transactions.js di folder src/api/transaction/routes/, lalu ketikan kode di bawah ini
```javascript
module.exports = {
routes: [
{ // Path defined with an URL parameter
method: 'POST',
path: '/transactions/debit',
handler: 'custom-transaction.debit',
},
{ // Path defined with an URL parameter
method: 'POST',
path: '/transactions/credit',
handler: 'custom-transaction.credit',
},
]
}
```
- Re-run kembali aplikasi dengan menjalankan command ini di terminal
```sh
make compose-down; make compose-up
```
- Buka browser, lalu kembali ke http://localhost:8000/admin dan masuk ke menu _Settings > Roles_ lalu pilih _Authenticated_
- Buka _Permissions_ untuk _Account_ dan _Select All_ semua
- Buka _Permissions_ untuk _Customer_ dan _Select All_ semua
- Buka _Permissions_ untuk _Transaction_ dan _Select All_ semua
- Lalu masuk ke menu _Content-Manager > User_ lalu klik _Create new entry_
- Input data sesuai form dan pastikan untuk mengingat _username, email,_ dan _password_. Jangan lupa pilih _confirmed_-nya _true_ dan _role_-nya _Authenticated_
- Pengembangan aplikasi sudah selesai, teman-teman bisa menjalankan test dengan _Postman_ atau semacamnya. Disini kami menggunakan _Rest Client VSCode extension_ dengan create file _normal.http_ dan menjalankan kode di bawah ini
```http
@host=http://localhost:8000
POST {{host}}/api/auth/local
Content-Type: application/json
{
"identifier" : "developer",
"password" : "password"
}
### create customer
POST {{host}}/api/customers
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MSwiaWF0IjoxNjgwNDE1MzI1LCJleHAiOjE2ODMwMDczMjV9.HaZpvrouMAjkvm51w0DkRwXjKOdVrInkYvcKfUE_teY
{
"data" : {
"id_number" : "3175023005912345",
"fullname" : "Wildan Anugrah"
}
}
### create account
POST {{host}}/api/accounts
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MSwiaWF0IjoxNjgwNDE1MzI1LCJleHAiOjE2ODMwMDczMjV9.HaZpvrouMAjkvm51w0DkRwXjKOdVrInkYvcKfUE_teY
{
"data" : {
"cif_number" : "5685265072",
"type" : "DEPOSIT"
}
}
### accounts
GET {{host}}/api/accounts
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MSwiaWF0IjoxNjgwNDE1MzI1LCJleHAiOjE2ODMwMDczMjV9.HaZpvrouMAjkvm51w0DkRwXjKOdVrInkYvcKfUE_teY
### credit
POST {{host}}/api/transactions/credit
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MSwiaWF0IjoxNjgwNDE1MzI1LCJleHAiOjE2ODMwMDczMjV9.HaZpvrouMAjkvm51w0DkRwXjKOdVrInkYvcKfUE_teY
{
"data" : {
"account_number" : "1473367796",
"payment_type" : "CREDIT",
"amount" : 10000
}
}
### debit
POST {{host}}/api/transactions/debit
Content-Type: application/json
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6MSwiaWF0IjoxNjgwNDE1MzI1LCJleHAiOjE2ODMwMDczMjV9.HaZpvrouMAjkvm51w0DkRwXjKOdVrInkYvcKfUE_teY
{
"data" : {
"account_number" : "1473367796",
"payment_type" : "DEBIT",
"amount" : 2000
}
}
```
Cheers :)
Github: https://github.com/wildananugrah/simple-bank-with-strapi-v4 | wildananugrah | |
1,309,233 | How to use knowledge of OOP in Go | Using the Simple Knowledge of OOP to Build simple classes for the following “objects” in Go ... | 0 | 2022-12-26T16:06:23 | https://dev.to/sunday4me/how-to-use-knowledge-of-oop-in-go-1e28 | Using the Simple Knowledge of OOP to Build simple classes for the following “objects” in Go
## The following Objects are use
1. Car
2. Product
3. Store
> The Car class can have any car attributes you can think of.
The Product class should have attributes of a product i.e (the product, quantity of the product in stock, price of the product). A car is a product of the store, but there can be other products so the attribute of the car can be promoted to the Product. The Product class should have methods to display a product, and a method to display the status of a product if it is still in stock or not.
> The Store class should have attributes like
Number of products in the store that are still up for sale
Adding an Item to the store
Listing all product items in the store
Sell an item
Show a list of sold items and the total price
Kindly [Click Here](https://github.com/sunday4me/Backend_Golang_S_S_E_Project) to view the complete Project and how to Implement the simple OOP in Golang | sunday4me | |
1,309,444 | An Introduction to the Fomantic UI Framework | by Gabriel Delight An HTML development framework called Fomantic-UI makes it easier to produce... | 0 | 2022-12-26T23:35:34 | https://blog.openreplay.com/an-introduction-to-the-fomantic-ui-framework/ | css, webdev | by [Gabriel Delight](https://blog.openreplay.com/authors/gabriel-delight)
An HTML development framework called Fomantic-UI makes it easier to produce stunning, responsive layouts. Fomantic UI sees words and classes as interchangeable ideas.
Fomantic-UI creates amazing and gorgeous layouts and designs for web pages, including sliders, cards, custom buttons, calendars, dropdown menus, etc., in contrast to existing CSS front-end frameworks. The majority of the topics we specified will be covered by the tutorial's conclusion. The Fomantic-UI is simple to use and learn. Fomantic-UI has consistently been a preferred choice for developers worldwide since it allows faster and more responsive delivery of websites.
If you are familiar with CSS Frameworks from a different perspective, you will notice that CSS Frameworks are not tough to use because all of the layouts and designs are already available for you to use. It is always a good idea to work with anything that is not difficult.
A front-end framework called Fomantic-UI improves the design of online interfaces. It is lightweight and flexible. It is a framework for developing websites that makes it easier to create stunning responsive layouts with user-friendly HTML.
I'll show you how to get started with Fomantic-UI in this tutorial. And by the time the article is over, you will be among the top developers working with Fomantic-UI. However, let's first examine the benefits and drawbacks of the Fomantic-UI before we begin developing Fomantic Codes.
## Benefits of Fomantic-UI
- Fomantic-UI creates quick and adaptable user interfaces.
- Controls how your app communicates with the system and provides classes that allow you to manage the resources and data.
- Improves follow-up and accelerates learning via documentation and content accessibility
- Produced by Fomantic-UI are Mobile Friendly Views.
- The load time is fast
- Code maintenance is always simple and easy.
## Drawbacks of Fomantic-UI
- Utilizing Fomantic-UI could result in styling conflicts.
Recent developer reviews of Fomantic-UI have not received many unfavorable comments. However, stylistic conflicts are common among developers. In this article, we'll discuss how to handle stylistic conflicts while using the Fomantic-UI application.
All modern web browsers support Fomantic-UI:
- Internet Explorer by Microsoft (beginning with version 3.0)
- Firefox
- Safari
- Opera
- Chrome
## Fomantic-UI Extensions for Auto Complete
VS-Code now supports the most used Fomantic-UI plugin. And the Auto-Complete, which accelerates development, makes it a top choice. The VS-Code addon is available on GitHub and is listed below.
- [Snippets for Visual Studio Code](https://github.com/fomantic/Fomantic-UI-vscode-snippets)
The simplest method to obtain this extension is to use VS-Code to perform a search for Fomantic-UI Extension. From there, you can locate and download the extension by installing it.
A screenshot of the auto-complete VS-Code extensions may be found below.
## Installation
Let's begin the installation now that we are familiar with the fundamentals of Fomantic-UI. It's way too simple to install Fomantic-UI; in this section, we'll cover how to do it utilizing CDN setup and node.js setup. It's simple to complete all this installation and setup, so we'll also go over how to distribute LESS & SASS in Fomantic-UI. Please read on to get the installation instructions.
### Method 1: Installation via npm
You must have node.js installed and running to install Fomantic-UI using npm or yarn. If you don't already have node.js installed, please [click here](https://nodejs.org/en/download/) to get the most recent version. You don't have to click the link to install node.js on your computer if you are already using or running it. Run the code below in a terminal window (CMD) to see if node.js is already installed and running on your computer:
```
node -v
// Output: 18.12.1
```
Let's use npm to install Fomantic-UI now that node.js is operational.
Please run "npm init" in your project folder and respond to the prompted questions. To disable the prompting questions, please run "npm init -y"; this bypasses the questions and produces the lovely package.json file.
Run the code listed below to install Fomantic-UI next in your terminal.
```
npm i fomantic-ui
```
You will find a node modules folder containing all the downloaded files after installing Fomantic-UI. Open it, navigate to a folder named "Fomantic UI," and click on it. Inside, you will find a folder called "dist." copy the "dist" folder from the node module folder, then paste it outside the node module folder where your files are.
As you can see from the example above, we are only linking the files in the dist folder to our HTML file. If you have reached this stage, I will encourage you to take your time and carefully study the instructions for setting this up again if you are having trouble. Although I am certain you will figure this out correctly, if you find this step more challenging, you shouldn't have any problems because we'll be configuring Fomantic UI utilizing a CDN below.
### Method 2: Using a CDN provider
There are versions of Fomantic-UI for cdnjs, jsDelivr, and unpkg. However, we'll be using the CNDJS-based Fomantic-UI CDN. To find Fomantic-UI, we shouldn't use [cdnjs.com](https://cdnjs.com/) as a search engine. Please use the code below as a starting point.
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Fomantic-UI</title>
</head>
<body>
</body>
<!-- You MUST include jQuery before Fomantic -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.6.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="https://cdnjs.cloudflare.com/ajax/libs/fomantic-ui/2.9.0/semantic.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/fomantic-ui/2.9.0/semantic.min.js"></script>
</html>
```
The javascript and css from Fomantic-UI are included in the code above, which will help us get started using Fomantic UI.
### Adding LESS or SASS
Run the following command if you're using the SASS or LESS packages through NPM.
```
CSS
$ npm update fomantic-ui-css
LESS
$ npm update fomantic-ui-less
```
If the files are already downloaded locally, you must download the most recent version and replace your local files. For this article, the coding will be done utilizing CDN. You're now prepared to go on to the coding portion, where we'll be utilizing visual components and modules from Fomantic-UI.
<h2>Open Source Session Replay</h2>
_<a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a> is an open-source, session replay suite that lets you see what users do on your web app, helping you troubleshoot issues faster. OpenReplay is self-hosted for full control over your data._

_Start enjoying your debugging experience - <a href="https://github.com/openreplay/openreplay" >start using OpenReplay for free</a>._
## Getting Started
Our emphasis here will be on code because we discussed the concept of Fomantic-UI at the beginning of this article. We'll work with HTML properties like classes and ids during the coding portion. The custom style of an element from Fomantic-UI will be applied using the class name in CSS. We'll use any Fomantic-UI component's Id attributes for the JavaScript implementation. However, there isn't just one complexity. Since everything you need to know is available to you, you must pick the code that best fits your needs.
The class names are self-explanatory, and we'll discuss this as we work through the code. We'll be looking at some stunning patterns and layouts because we'll deal with code in this segment, so I would like you to have your hands ready.
In this section, we will study and discuss the customizable elements that Fomantic-UI offers us to use on our web pages. Let's examine the key fundamental elements of Fomantic-UI by focusing on just six of them.
### Buttons
We'll use some cool, readymade buttons; some even describe what they do, so let's take a closer look.
Code:
```html
<button class= "ui button">
Follow
</button>
```
Output:

You can see that the class attribute for a basic button has the class name "ui button" if you closely examine the code. As I explained to you earlier in the getting started section, class names are used for styling purposes, while id attributes integrate any element containing JavaScript.
The following are some stunning buttons from the Fomantic-UI buttons collection, along with their source code:
Code:
```html
<div class="ui labeled button" tabindex="0">
<div class=" ui red button">
<i class="heart icon"></i> Like
</div>
<a class= "ui basic red left pointing label">
1,048
</a>
</div>
<div class="ui labeled button" tabindex="0">
<div class=" ui basic blue button">
<i class="fork icon"></i> Forks
</div>
<a class= "ui basic left pointing blue label">
1,048
</a>
</div>
```
Output:
### Inverted buttons

Code:
```html
<div class= "ui inverted segment">
<button class="ui inverted button">Standard</button>
<button class="ui inverted primary button">Primary</button>
<button class="ui inverted secondary button">Secondary</button>
<button class="ui inverted red button">Red</button>
<button class="ui inverted orange button">Orange</button>
<button class="ui inverted yellow button">Yellow</button>
<button class="ui inverted olive button">Olive</button>
<button class="ui inverted green button">Green</button>
<button class="ui inverted teal button">Teal</button>
<button class="ui inverted blue button">Blue</button>
<button class="ui inverted violet button">Violet</button>
<button class="ui inverted purple button">Purple</button>
<button class="ui inverted pink button">Pink</button>
<button class="ui inverted brown button">Brown</button>
<button class="ui inverted grey button">Grey</button>
<button class="ui inverted black button">Black</button>
</div>
```
According to the code above, the buttons have the class names inverted, color, and button. This is from the Fomantic semantic.min.css file in the dist folder, and you can also find it in the CDN we put into our HTML. [Click here](https://fomantic-ui.com/elements/button.html) to view some of the buttons in the Fomantic-UI.
### Images
A quick way to improve user experience on your website is to include photos. 90% of the information ingested and transmitted to our brains is visual. Images can help direct users' eyes and draw attention to your website. Before discussing Fomantic-image Ui's layouts, let's look at the table below.
There are certain class names in the table you can see above that are used in Fomantic, and you can also see their sizes. Before we move on to the real image-related scripts we will create later in this tutorial, I'd like to demonstrate this to you. You may locate most of the class names from the previous list in some programs.
Rounded images:
Without writing any CSS code, like the border-radius property we do in conventional CSS, we can easily create a rounded picture in Fomantic-UI.

Code:
```html
<img class= "ui medium circular image"
src="https://cdn.pixabay.com/photo/2018/04/26/12/14/travel-3351825_960_720.jpg">
```
You can see how simple and cool this is by looking at the image class name, which has the phrase "ui medium circle picture." The circular shape has a rounded radius added to it. It's really simple to use. Simply [click here](https://fomantic-ui.com/elements/image.html) to discover more about Fomantic-UI pictures.
### Icons
Awesome icons from the Fomantic-UI library are available for use. Please remember that you use the `<i>` tag, which is also prevalent in ordinary HTML when using these icons.
We'll use a selection of animal icons from Fomantic-UI in the section below.

Code:
```html
<i class="cat large blue icon" style="visibility: visible;"></i>
<i class="crow icon" style="visibility: visible;"></i>
<i class="dog icon" style="visibility: visible;"></i>
<i class="dove icon" style="visibility: visible;"></i>
<i class="dragon gold icon" style="visibility: visible;"></i>
<i class="feather icon" style="visibility: visible;"></i>
<i class="feather alternate icon" style="visibility: visible;"></i>
<i class="fish icon" style="visibility: visible;"></i>
<i class="frog yellow icon" style="visibility: visible;"></i>
<i class="hippo icon" style="visibility: visible;"></i>
<i class="horse red icon" style="visibility: visible;"></i>
<i class="horse head icon" style="visibility: visible;"></i>
<i class="kiwi bird icon" style="visibility: visible;"></i>
<i class="otter icon" style="visibility: visible;"></i>
<i class="paw icon" style="visibility: visible;"></i>
<i class="spider icon" style="visibility: visible;"></i>
```
You may have noticed that we added a color name, and it reflected to give some of the icons new colors. To find out how to use more of these cool icons from Fomangtic-UI, just click this [link](https://fomantic-ui.com/elements/icon.html).
### Inputs
Inputs are utilized to obtain user information or details, so Fomantic-UI offers fantastic designs and a quick and simple method of employing inputs.
The Fomantic-UI file upload input is shown below.
```html
<div class=" ui file input">
<input type="file">
</div>
<hr>
<input type="file" id="invisibleupload1" class="ui invisible file input">
<label for="invisibleupload1" class="ui red icon button">
<i class="file icon"></i>
Open any file
</label>
<input type="file" id="invisibleupload2" class="ui invisible file input">
<label for="invisibleupload2" class="ui placeholder segment">
<div class="ui icon header" style="width: 500px">
<i class="upload icon"></i>
Click here to upload
</div>
</label>
```
Output:
Please be aware that you can also customize the designs by adding your own class name, but you have to be aware of styling conflicts. Styling conflicts come when your own added class name has the same class name as a CSS library or framework., but we'll talk more about resolving styling conflicts in this article. To learn more about input, [click here](https://fomantic-ui.com/elements/input.html).
### Dividers
A divider is a tool used in web development to visually separate content into categories. Text is frequently used in situations like this. Let's use Fomantic-UI to create a divider so you can understand how it functions. I'm not entirely sure what they used for theirs, but I can confidently say that it has to do with CSS flex-direction. Please inspect the output preview and the code below.
Code:
```html
<div class= "ui placeholder segment">
<div class= "ui two column very relaxed stackable grid">
<div class="column">
<div class= "ui form">
<div class="field">
<label>Username</label>
<div class=" ui left icon input">
<input type="text" placeholder="Username">
<i class="user icon"></i>
</div>
</div>
<div class="field">
<label>Password</label>
<div class=" ui left icon input">
<input type="password">
<i class="lock icon"></i>
</div>
</div>
<div class="ui blue submit button">Login</div>
</div>
</div>
<div class= "middle aligned column">
<div class=" ui big button">
<i class="signup icon"></i>
Sign Up
</div>
</div>
</div>
<div class= "ui vertical divider">
Or
</div>
</div>
```
I hope you now have a better understanding of how Dividers work in Fomantic-IU. You can view further Driver's samples by [clicking here](https://fomantic-ui.com/elements/divider.html).
### Loaders
We'll be utilizing Loaders in Fomantic-UI element collections in this part. Spinners warn a user to hold off until an activity is finished.

Code:
```html
<div class="ui segment " style="padding: 20px">
<div class= "ui active dimmer">
<div class="ui loader "></div>
</div>
</div>
```
This one should be your first choice when using loaders because it won't require writing a lot of CSS code. Everything is ready for you to use on your website, thanks to Fomantic-UI. [Click here](https://fomantic-ui.com/elements/loader.html) for additional information on loaders.
### Breadcrumbs
A website's breadcrumb navigation system gives links to each previous page the user has visited while also displaying the user's current location within the website. It is simple for users to understand how their position on a page (such as a product page) relates to higher-level pages thanks to breadcrumbs, a secondary navigation tool (a category page, for instance)
A standard breadcrumb:

Code:
```html
<div class= "ui breadcrumb">
<a class="section">Home</a>
<div class="divider"> / </div>
<a class="section">Store</a>
<div class="divider"> / </div>
<div class="active section">T-Shirt</div>
</div>
```
### Tables
Table layouts will automatically stack for mobile devices. Use the tablet stackable variant to enable responsive modifications or the unsackable variant to stop this behavior.
Code:
```html
<table class=" ui celled padded table">
<thead>
<tr>
<th class="single line">Evidence Rating</th>
<th>Effect</th>
<th>Efficacy</th>
<th>Consensus</th>
<th>Comments</th>
</tr>
</thead>
<tbody>
<tr>
<td>
<h2 class="ui center aligned header">A</h2>
</td>
<td class=" single line">
Power Output
</td>
<td>
<div class="ui yellow rating" data-rating="3" data-max-rating="3"></div>
</td>
<td class=" right aligned">
80% <br>
<a href="#">18 studies</a>
</td>
<td>Creatine supplementation is the reference compound for increasing muscular creatine levels; there is
variability in this increase, however, with some nonresponders.</td>
</tr>
<tr>
<td>
<h2 class="ui center aligned header">A</h2>
</td>
<td class=" single line">
Weight
</td>
<td>
<div class="ui yellow rating" data-rating="3" data-max-rating="3"></div>
</td>
<td class=" right aligned">
100% <br>
<a href="#">65 studies</a>
</td>
<td>Creatine is the reference compound for power improvement, with numbers from one meta-analysis to
assess potency</td>
</tr>
</tbody>
<tfoot>
<tr>
<th colspan="5">
<div class=" ui right floated pagination menu">
<a class=" icon item">
<i class="left chevron icon"></i>
</a>
<a class="item">1</a>
<a class="item">2</a>
<a class="item">3</a>
<a class="item">4</a>
<a class=" icon item">
<i class="right chevron icon"></i>
</a>
</div>
</th>
</tr>
</tfoot>
</table>
```
### Statistics
Web statistics are log files that keep track of specifics about your website and track visitor behavior. This tool is useful for businesses as it evaluates and rates website elements contributing to organizational goals.
CodeL
```html
<div class= "ui inverted segment">
<div class=" ui inverted statistic">
<div class="value">
54
</div>
<div class="label">
Inverted
</div>
</div>
<div class= "ui red inverted statistic">
<div class="value">
27
</div>
<div class="label">
Red
</div>
</div>
<div class= "ui orange inverted statistic">
<div class="value">
8
</div>
<div class="label">
Orange
</div>
</div>
<div class= "ui yellow inverted statistic">
<div class="value">
28
</div>
<div class="label">
Yellow
</div>
</div>
<div class=" ui olive inverted statistic">
<div class="value">
7
</div>
<div class="label">
Olive
</div>
</div>
<div class=" ui green inverted statistic">
<div class="value">
14
</div>
<div class="label">
Green
</div>
</div>
<div class= "ui teal inverted statistic">
<div class="value">
82
</div>
<div class="label">
Teal
</div>
</div>
<div class= "ui blue inverted statistic">
<div class="value">
1
</div>
<div class="label">
Blue
</div>
</div>
<div class= "ui violet inverted statistic">
<div class="value">
22
</div>
<div class="label">
Violet
</div>
</div>
<div class= "ui purple inverted statistic">
<div class="value">
23
</div>
<div class="label">
Purple
</div>
</div>
<div class= "ui pink inverted statistic">
<div class="value">
15
</div>
<div class="label">
Pink
</div>
</div>
<div class= "ui brown inverted statistic">
<div class="value">
36
</div>
<div class="label">
Brown
</div>
</div>
<div class= "ui grey inverted statistic">
<div class="value">
49
</div>
<div class="label">
Grey
</div>
</div>
</div>
```
### Cards
Website content is shown on a playing card-like card. A card is a container for a handful of relevant, brief facts. Its size and shape are similar to playing cards, and its function is to represent a mental unit in a linked, condensed manner. [Click here](https://fomantic-ui.com/views/card.html) to learn more about cards and how to use more card examples.
Code:
```html
<div class= "ui link cards">
<div class="card">
<div class="image">
<img
src="https://images.unsplash.com/photo-1554151228-14d9def656e4?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8OXx8aHVtYW58ZW58MHx8MHx8&auto=format&fit=crop&w=500&q=60">
</div>
<div class="content">
<div class="header">Amelia John</div>
<div class="meta">
<a>Friends</a>
</div>
<div class="description">
Matthew is an interior designer living in New York.
</div>
</div>
<div class=" extra content">
<span class=" right floated">
Joined in 2013
</span>
<span>
<i class="user icon"></i>
75 Friends
</span>
</div>
</div>
<div class="card">
<div class="image">
<img
src="https://images.unsplash.com/photo-1571816119607-57e48af1caa9?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MjB8fGh1bWFufGVufDB8fDB8fA%3D%3D&auto=format&fit=crop&w=500&q=60">
</div>
<div class="content">
<div class="header">Sophia</div>
<div class="meta">
<span class="date">Coworker</span>
</div>
<div class="description">
Molly is a personal assistant living in Paris.
</div>
</div>
<div class=" extra content">
<span class=" right floated">
Joined in 2011
</span>
<span>
<i class="user icon"></i>
35 Friends
</span>
</div>
</div>
<div class="card">
<div class="image">
<img
src="https://plus.unsplash.com/premium_photo-1664368832363-9f9c97e40aed?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MTl8fGh1bWFufGVufDB8fDB8fA%3D%3D&auto=format&fit=crop&w=500&q=60">
</div>
<div class="content">
<div class="header">Elyse</div>
<div class="meta">
<a>Coworker</a>
</div>
<div class="description">
Elyse is a copywriter working in New York.
</div>
</div>
<div class=" extra content">
<span class=" right floated">
Joined in 2014
</span>
<span>
<i class="user icon"></i>
151 Friends
</span>
</div>
</div>
</div>
```
### Accordions
A web design technique for a menu called an accordion displays a group of headers stacked on top of one another. If you click on these headers, associated content will either appear or disappear (or when a keyboard click or screen reader click is made). For your use, Fomantic-UI offers a ton of awesome accordions; [click here](https://fomantic-ui.com/modules/accordion.html) to see more accordions.
HTML Code:
```html
<div class= "ui basic styled accordion">
<div class="title">
<i class="dropdown icon"></i>
What is a dog?
</div>
<div class="content">
<p class=" transition hidden">A dog is a type of domesticated animal. Known for its loyalty and faithfulness, it can be found as a welcome guest in many households across the world.</p>
</div>
<div class=" title active">
<i class="dropdown icon"></i>
What kinds of dogs are there?
</div>
<div class=" content active">
<p style="display: block !important;" class="visible">There are many breeds of dogs. Each breed varies in size and temperament. Owners often select a breed of dog that they find to be compatible with their own lifestyle and desires from a companion.</p>
</div>
<div class="title">
<i class="dropdown icon"></i>
How do you acquire a dog?
</div>
<div class="content">
<p>Three common ways for a prospective owner to acquire a dog is from pet shops, private owners, or shelters.</p>
<p>A pet shop may be the most convenient way to buy a dog. Buying a dog from a private owner allows you to assess the pedigree and upbringing of your dog before choosing to take it home. Lastly, finding your dog from a shelter, helps give a good home to a dog who may not find one so readily.</p>
</div>
</div>
```
JavaScript:
```javascript
$('.ui.accordion')
.accordion()
;
```
### Dropdowns
The purpose of a dropdown menu, sometimes called a pull-down menu or list, is to make it simpler for website visitors to find specific pages or features. The input pick type currently uses a dropdown. However, we'll be making a prettier dropdown for Fomantic-UI. To view more dropdowns, click on this link.
We must understand how to use a dropdown before we leap to initializing one. For Fomantic-U Dropdowns to function, the dropdown must be initialized with JavaScript; otherwise, it will simply be displayed on the browser without any functionality. The Jquery code for initializing the javaScript is located underneath the HTML code. But to save time for this article, I ask that you click on this [link](https://fomantic-ui.com/modules/dropdown.html#/usage) to take advantage of the dropdown's full functionality. The official page covers everything you need to know to get started using the dropdown.
HTML:
```html
<div class= "ui search selection dropdown">
<input name="states" type="hidden">
<i class="dropdown icon"></i>
<div class="default text">States</div>
<div class="menu">
<div class="unfilterable item" data-value="AL">Alabama (unfilterable)</div>
<div class="item" data-value="AK">Alaska</div>
<div class="unfilterable item" data-value="AZ">Arizona (unfilterable)</div>
<div class="unfilterable item" data-value="AR">Arkansas (unfilterable)</div>
<div class="item" data-value="CA">California</div>
<div class="item" data-value="OH">Ohio</div>
<div class="item" data-value="OK">Oklahoma</div>
</div>
</div>
```
JavaScript:
```javascript
<script>
$('.ui.dropdown')
.dropdown()
;
</script>
```
Output:
### Progress Bars
Using a progress bar, a graphical control element, one can see an extended computer process, such as a download, file transfer, or installation. There are several reasons why a webpage might employ progress indicators, such as The user can get a general sense of how long it takes to complete the task. By showing the level of completion, progress indicators can estimate the performance rate of a certain activity, such as upload speed.
We'll be using some Progress Bar from the official Fomantic-UI websites in this progress bar area. There are several lovely progress bars, and most of these will be put to the test, but first, let's look at how the Progress Bar is used and protected in the Fomantic-Ui. You must execute a javascript code before using the Progress Bar in Fomantic-UI, but the javascript code you are about to do will match with the precise Progress Bar HTML code you are collecting from the Fomantic-UI Progress Bar page. [Click here](https://fomantic-ui.com/modules/progress.html#/usage) to read more about the Progress Bar.
Sample Progress Bar:
HTML code:
```html
<div class="ui teal progress" data-percent="74" id="example1">
<div class="bar"></div>
<div class="label">74% Funded</div>
</div>
```
JavaScript:
```javascript
$('#example1').progress();
```
### Calendars
A web calendar is a tool to keep track of upcoming events, dates, appointments, deadlines or special occasions for you or other people.
HTML code:
```html
<div class="ui calendar" id="inline_calendar">
</div>
```
JavaScript:
```javascript
$('#inline_calendar')
.calendar();
```
You can see from the code that everything appears to be quite simple. Fomantic-UI is a preferred choice for developers because of this. [Read more here](https://fomantic-ui.com/modules/calendar.html) about Calendar.
### Checkboxes
A user can select a value from a handful of binary alternatives that are used frequently by checking a box.

HTML:
```html
<div class= "ui form">
<div class=" grouped fields">
<label>Outbound Throughput</label>
<div class="field">
<div class= "ui slider checkbox">
<input type="radio" name="throughput" checked="checked">
<label>20 mbps max</label>
</div>
</div>
<div class="field">
<div class= "ui slider checkbox">
<input type="radio" name="throughput">
<label>10mbps max</label>
</div>
</div>
<div class="field">
<div class= "ui slider checkbox">
<input type="radio" name="throughput">
<label>5mbps max</label>
</div>
</div>
<div class="field">
<div class= "ui slider checkbox checked">
<input type="radio" name="throughput">
<label>Unmetered</label>
</div>
</div>
</div>
</div>
```
## How to prevent styling conflicts in Fomantic-UI
You must be very careful when adding any extra class names to your elements when using Fomantic-UI; this caution helps you avoid stylistic conflicts. CSS doesn't generally have conflicts, but developers are to blame for those that do. The notion is that you can specify several rules that apply to the same elements, and the order in which you list the styles indicates importance; for example, if a style is listed last, it will take precedence over earlier rules in situations where you've identified a conflict. Giving a unique class name that does not correspond to any other general class names while using Fomantic-UI is the best solution to avoid this general styling conflict.
## Conclusion
I hope it was enjoyable for you to finish this tutorial. In this article, we learned how to set up Fomantic-UI and developed a few sample projects to understand the fundamental concepts of the tool. To create a portfolio website, you can customize this example to your preferences or put what you've learned into action by creating more stunning websites.
[](https://newsletter.openreplay.com/)
| asayerio_techblog |
1,309,740 | REST API vs GraphQL : The Battle for API Supremacy 🥷 | REST (Representational State Transfer) APIs and GraphQL are two different approaches to building APIs... | 0 | 2022-12-27T07:28:36 | https://dev.to/kyar/rest-apis-vs-graphql-the-battle-for-api-supremacy-1o55 | javascript, api, graphql, programming | REST (Representational State Transfer) APIs and GraphQL are two different approaches to building APIs (Application Programming Interfaces) that allow clients to request data from a server.
## REST APIs
REST (Representational State Transfer) APIs are a standardized way to request and retrieve data from a server using HTTP methods, such as `GET`, `POST`,` PUT`, and `DELETE`. REST APIs are designed to be stateless, meaning that the server does not store any information about the client's session or state.
To use a REST API, a client sends an HTTP request to a specific endpoint (a URL) on the server, along with any necessary parameters or data. The server then processes the request and sends back an HTTP response, which may include the requested data or an error message.
Lets consider a simple REST API for a blog website that allows clients to retrieve a list of blog posts, as well as individual blog posts. The API might have the following endpoints:
`GET /posts`: Retrieve a list of all blog posts.
`GET /posts/:id`: Retrieve a specific blog post by its ID.
To retrieve a list of all blog posts, the client would send a GET request to the `/posts `endpoint. The server would then respond with a list of all blog posts in the form of a JSON object. To retrieve a specific blog post, the client would send a GET request to the `/posts/:id` endpoint, where :id is the ID of the specific blog post.
Here is an example of a simple REST API that allows a client to retrieve a list of users from a server:
Endpoint: GET /users
Request:
```http
GET /users HTTP/1.1
Host: example.com
Accept: application/json
```
Response:
```http
HTTP/1.1 200 OK
Content-Type: application/json
[
{ "id": 1, "name": "Alice" },
{ "id": 2, "name": "Bob" },
{ "id": 3, "name": "Charlie" }
]
```
In this example, the client sends a GET request to the /users endpoint on the server, and the server responds with a list of user objects in JSON format. The server also includes an HTTP status code of 200, indicating that the request was successful.
1. REST APIs are often used to create web services, which are APIs that are accessible over the internet and can be used by a wide range of clients, such as web browsers, mobile apps, and other servers. REST APIs are also commonly used to integrate different systems and applications, allowing them to exchange data and perform actions on each other's behalf.
2. REST APIs typically use HTTP status codes to indicate the success or failure of a request, and may also use HTTP headers and response codes to provide additional information about the request and the response.
## GraphQL
GraphQL is a query language for APIs that was developed by Facebook. It allows clients to request specific data from the server, rather than receiving a fixed set of data from a specific endpoint. This allows clients to request exactly the data they need, and nothing more.
To use a GraphQL API, a client sends a GraphQL query to the server, which specifies the data that the client wants to retrieve. The server then processes the query and returns the requested data to the client in the form of a JSON object.
One of the key benefits of GraphQL is its flexibility. Unlike REST APIs, which have a fixed set of endpoints for each type of request, GraphQL allows the client to request any data that is available on the server, as long as the server's GraphQL schema defines it. This means that the client can request exactly the data it needs, and can easily change the data it retrieves by modifying the GraphQL query.
For example, consider the same blog API as above, but this time implemented using GraphQL. The client could send a GraphQL query to the server that looks like this:
Request:
```js
{
users {
id
name
}
}
```
Response:
```js
{
"data": {
"users": [
{ "id": 1, "name": "Alice" },
{ "id": 2, "name": "Bob" },
{ "id": 3, "name": "Charlie" }
]
}
}
```
This query would retrieve a list of users, including their IDs, name. The client can also request specific data for a single user by including an id field in the query:
```js
{
users(id : 007) {
id
name
}
}
```
This query would retrieve a single user with the ID "123", including its ID, Name.
GraphQL also includes support for mutations, which allow clients to send data to the server and modify server-side resources. For example, a client might use a GraphQL mutation to create a new user or update an existing user's data.
Overall, GraphQL is a powerful tool for building APIs that allow clients to request exactly the data they need, and is particularly well-suited for modern, data-driven applications.
**In summary, REST APIs are a standardized way to request and retrieve data from a server using specific endpoints, while GraphQL allows clients to request specific data from the server using a flexible query language query language.** | kyar |
1,309,779 | useReducer for dummies(kid friendly) | Imagine that you are in charge of keeping track of the snacks in your house. You have a bunch of... | 0 | 2022-12-27T08:17:52 | https://dev.to/csituma/usereducer-for-dummieskid-friendly-26c2 | javascript, beginners, react, webdev | Imagine that you are in charge of keeping track of the snacks in your house. You have a bunch of different snacks that you like to eat, and you want to be able to **keep track of how many of each snack you have left.**
To do this, you could use a react reducer. Here's how it might work:
The react reducer is a special function that helps you keep track of your snacks. It takes in two things: **the current state of your snacks** (i.e. the number of each snack you have left), and **an action** (e.g. "eat a snack" or "buy more snacks").
1. When you want to **eat a snack**, you dispatch an action to the reducer that tells it what snack you want to eat. The reducer then **checks to see if you have any of that snack left**. If you do, it returns a new state that has one fewer of that snack (so you now have one fewer of that snack). **If you don't have any of that snack left, it returns the current state without any changes.**
2. When you want to **buy more snacks**, you dispatch an action to the reducer that tells it what snack you want to buy more of. **The reducer then adds more of that snack to your supply and returns a new state that includes the additional snacks.**
This way, **you can use the react reducer to keep track of your snacks and make sure you always have enough to eat**. You can use the actions to tell the reducer what to do (e.g. eat a snack, buy more snacks, etc.), and the reducer will take care of updating your snack supply and returning a new state based on the actions you dispatch to it.
**QUICK CATCHUP SUMMARY**
--**_WHEN WE EAT A SNACK, THE SNACK COUNT WILL REDUCE, WHEN WE BUY A SNACK, THE SNACK COUNT WILL INCREASE_**
Code example:
```javascript
const snackReducer = (state, action) => {
switch (action.type) {
case 'EAT_SNACK':
const newState = { ...state }; // create a copy of the current state
newState[action.snack]--; // decrease the count of the specified snack by 1
return newState;
case 'BUY_SNACKS':
const newState = { ...state }; // create a copy of the current state
newState[action.snack] += action.count; // increase the count of the specified snack by the specified count
return newState;
default:
return state;
}
}
```
To use this reducer, you would need to initialize the state with the initial counts of each snack that you have. For example:
```javascript
const initialState = {
chips: 10,
cookies: 5,
crackers: 20
}
```
Then, you can dispatch actions to the reducer using the dispatch function, like this:
```javascript
dispatch({ type: 'EAT_SNACK', snack: 'chips' });
dispatch({ type: 'BUY_SNACKS', snack: 'cookies', count: 10 });
```
This should give you a basic understanding of how you can use a react reducer to keep track of your snack supply! | csituma |
1,309,787 | What are some rules to follow for good app architecture in Flutter App? | RULE: Avoid singletons If you want your code to be testable, there are various alternatives to... | 21,140 | 2022-12-27T08:29:39 | https://dev.to/borisgauty/what-are-some-rules-to-follow-for-good-app-architecture-in-flutter-app-1cla | app, flutter, architecture, rule |
**RULE: Avoid singletons**
If you want your code to be testable, there are various alternatives to singletons:
- constructor arguments (doesn't scale well with deep widget hierarchies)
- InheritedWidget or Provider
- Service locators
**RULE: Zero (or very little) business logic in the widgets.**
Widgets should be as dumb as possible and only be used to map the state to the UI.
Small exceptions: sometimes I include some simple currency, date, or number formatting code in my widgets if it makes life easier.
**RULE: No Flutter code (including BuildContext) in the business logic.**
Your view models/blocs/controllers are used to update the widget state in response to events.
By ensuring that these classes don't have any UI code in them, they can be easily unit tested.
**RULE: Navigation code belongs to the widgets**
If you try to put your navigation code in the business logic, you'll have a hard time because you need a BuildContext to do so.
Solution:
- emit a new widget state
- listen to the state in the widget and perform the navigation there
**RULE: Show dialogs and snackbars in the widgets**
Same as above. When we need to show an alert dialog because something went wrong, this is what we should do:
- emit a new error state
- listen to the state in the widget and use the context to show the alert dialog
**RULE: Do UI validation in the widgets***
*This may be a controversial one.
FormState and TextEditingController depend on the widget lifecycle, so they shouldn't go in the view models/blocs etc.
Keep them in your widgets and offload everything else to the business logic. | borisgauty |
1,309,963 | Настройка ssh на linux для GitHub. | Всем привет. Чтобы клонировать свои репозитории на удаленные сервера нужно выполнить всего несколько... | 0 | 2023-03-06T06:11:23 | https://dev.to/kesio/nastroika-ssh-na-linux-dlia-github-3p9n | github, ubuntu, ssh | Всем привет. Чтобы клонировать свои репозитории на удаленные сервера нужно выполнить всего несколько шагов. Приятного чтения.
## 1 - Создание ключ пары
Для начала вам нужно сгенерировать два ключа для ssh, один публичный и один приватный.
```
ssh-keygen -t ed25519
```
Нажимаем enter несколько раз.
После этого в вашей домашней директории появится папка **.ssh**, переходим в нее
## 2 - Создание конфигурации
Создаем в папке **.ssh** файл **config**
```
nano config
```
В нее вставляем вот такой конфиг:
```
Host github.com
HostName github.com
IdentityFile ~/.ssh/id_ed25519
IdentitiesOnly yes
```
А теперь сохраняем файл. Если вы никогда не пользовались nano то вам сюда [*тык*](https://losst.pro/kak-sohranit-fajl-v-nano-linux)
после копируем данные с id_ed25519.pub с помощью cat
```
cat id_ed25519.pub
```
после получаем вот такой текст
```
ssh-ed25519 AAAAC3N...LpPG kesio@pc
```
копируем его и идем в github, заходим в настройки, ищем пункт
`SSH and GPG keys`
далее нажимаем на `New SSH key` в поле title пишите для вас удобное название подключения и в нижнее поле тот самый ключ.
Готово! теперь у вас подключен ваш github аккаунт к пк/серверу. | kesio |
1,309,970 | Multiprocessing basic concepts | Multiprocessing basic... | 0 | 2022-12-27T12:11:45 | https://dev.to/skonik/multiprocessing-basic-concepts-1hke | python | {% embed https://skonik.me/multiprocessing-basic-concepts/ %} | skonik |
1,310,002 | api test | A post by najib2050 | 0 | 2022-12-27T13:04:32 | https://dev.to/najib2050/api-test-45ik | najib2050 | ||
1,310,457 | Deixando seu 'Olá, mundo' com o Python | O que faremos aqui? Vamos instalar o Python, a IDE, corrigir variáveis de ambiente e... | 21,157 | 2022-12-28T02:37:40 | https://dev.to/feministech/deixando-seu-ola-mundo-com-o-python-1dga | python, beginners, braziliandevs | ## O que faremos aqui?
Vamos instalar o Python, a IDE, corrigir variáveis de ambiente e escrever nosso primeiro comando no Python no sistema operacional Windows.
## Por que Python?
Para novas aventuras no mundo DevRel, precisei iniciar meus estudos - de verdade, dessa vez - para aprender Python. E, nada mais justo, que dar os primeiros passos fazendo o famoso "Hello, World". Ou, "Olá, mundo".
Sendo assim, fui diretamente na [playlist](https://www.youtube.com/watch?v=S9uPNppGsGo&list=PLHz_AreHm4dlKP6QQCekuIPky1CiwmdI6) de Python do Professor Gustavo Guanabara, do canal [Curso em Vídeo](https://www.youtube.com/@CursoemVideo) no YouTube. E seguindo os primeiros passos, já vi que eu estava fazendo coisa errada logo na instalação.
Por isso, resolvi deixar registrado como fazer o primeiro Hello World em Python, considerando instalação e uso da IDE ou terminal do sistema operacional. No meu caso, eu utilizo Windows. Então é para ele que esse pequeno tutorial e demais artigos serão direcionados, tudo bem?
## Fazendo o download
Você deverá entrar no site oficial do Python (https://www.python.org/) e identificar a opção "Downloads" no menu. Assim que você passa o cursor por cima dessa opção, uma nova janela se abrirá, conforme imagem abaixo.
É possível ir até a opção do sistema operacional que você usa (Windows, MacOS, entre outros) ou pelas releases. Mas o próprio site já ajuda a identificar qual a versão mais recente e estável para você baixar a instalar no seu computador.
No momento em que este artigo está sendo escrito, a versão é a 3.11.1. Pode acontecer de você ver este artigo em um momento em que há novas opções para baixar. Para seus estudos, considere sempre baixar a mais recente e estável. E eu aconselho que baixe a opção que ele deixa como sugestão no site.
OBS: Pode ser que dependendo do projeto que você vai mexer, é necessário baixar outras versões. Explore o menu de downloads que você encontrará aquela que precisa.
## Instalando o Python no Windows
Sei que no Windows estamos sempre seguindo o padrão "next, next, finish". Mas foi aí que eu errei. Então vamos por partes. Ao clicar duas vezes no ícone executável da instalação, abrirá a janela com as primeiras opções.
É extremamente recomendável que você escolha a opção "install now" ao invés da opção da instalação recomendada. E também é importante, para facilitar a configuração, que você deixe selecionada a opção "add python.exe to PATH". E então, basta prosseguir com a instalação normalmente.
## Ajustando variáveis de ambiente
Caso você tenha esquecido de selecionar a opção para adicionar o python no PATH das variáveis de ambiente, é possível fazer isso manualmente. Basta seguir o passo a passo.
**Passo 1.** No Python que foi instalado, que você pode identificar dentro do menu iniciar do seu Windows, clique com o botão direito e escolha a opção "abrir local do arquivo". Isso vai facilitar para você encontrar onde o Python ficou instalado.
**Passo 2.** No atalho do arquivo executável do Python, que no meu caso se chama "Python 3.11 (64-bit)". Copie o caminho de onde está esse arquivo, por exemplo: "`C:\Users\[teu_usuário]\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.11`". Em seguida clique com o botão direito e escolha a opção "abrir local do arquivo".
**Passo 3.** Dentro desse novo diretório, você deverá identificar a pasta chamada "scripts". Copie também o caminho de onde está essa pasta, por exemplo: "`C:\Users\teu_usuário\AppData\Local\Programs\Python\Python311\Scripts`".
**Passo 4.** Em "Propriedades do Sistema" (dependendo da versão do seu Windows, ele poderá ser encontrado de maneiras diferentes no computador"). Entre na opção "Avançado" e depois clique no botão "Variáveis de Ambiente".
**Passo 5.** Após abrir a nova janela, você irá até a parte onde está identificada como "Variáveis do sistema" e clicará em "novo". Em "nome da variável" escreva "Path" (e deve ser escrito exatamente desta forma). Em "valor da variável", cole o primeiro caminho que você copiou, que leva até o arquivo executável do Python, digite ponto e vírgula e, em seguida, cole o segundo caminho da pasta scripts. Ficará parecido com isso:
`C:\Users\[teu_usuário]\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.11;C:\Users\[teu_usuário]\AppData\Local\Programs\Python\Python311\Scripts`
**Passo 6.** Clique em Ok em todas as janelas para adicionar, de fato, essa variável.
## Testando a instalação
Por que essa questão da variável de ambiente é importante? Para o que vamos fazer agora: validar a instalação e utilizar comandos python no terminal.
Abra o terminal do seu computador e digite `python --version`. Caso ele retorne a versão instalada, estará correto:

Você também pode digitar apenas "python" e será aberto um terminal para que possa digitar comandos da linguagem, logo após os símbolos ">>>".

Para sair, basta você digitar "exit()".
## Escrevendo o "Olá, mundo"
Para isso, você pode usar o mesmo terminal no prompt de comando no Windows, ou já podemos usar a IDE que vem na instalação do Python, a "**IDLE**".
Ao abrir essa IDE, logo teremos já a liberação aguardando para que os comandos python sejam digitados. Para seguir a tradição, vamos escrever o primeiro comando que toda pessoa programadora deve escrever quando vai aprender qualquer linguagem nova: Hello World, ou Olá Mundo.
Então digite `print('Olá, mundo')` e, logo depois, aperte a tecla "enter" do seu teclado. O resultado retornará com a mensagem que você escreveu.
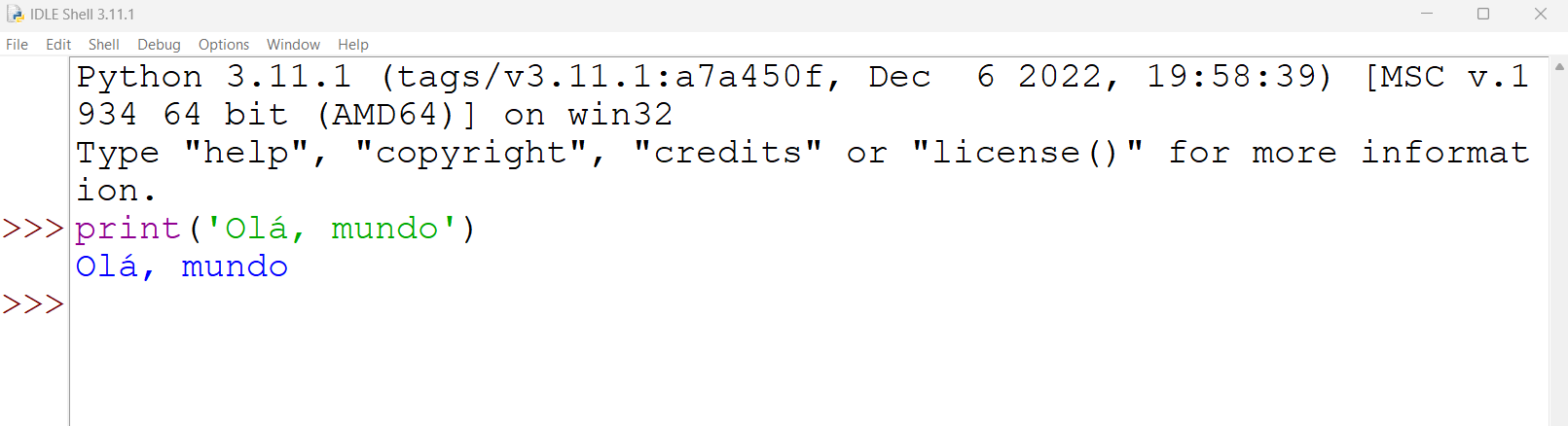
E aí, bora para os próximos comandos?
---
Espero que tenha gostado das dicas, principalmente considerando os problemas que podem acontecer no meio do caminho. De qualquer forma, também aproveitei esse artigo para registrar um aprendizado que eu tive. E pretendo escrever sobre a minha evolução nessa linguagem.
Fique a vontade para deixar dúvidas e problemas que tenha enfrentado para nos ajudarmos, assim como seu feedback também.
Até a próxima!
| morgannadev |
1,310,604 | Why Use Flutter Embedded Systems? | The Flutter framework has undergone a revolution with Flutter for Embedded Systems. With... | 0 | 2022-12-28T06:27:59 | https://dev.to/rachgrey/why-use-flutter-embedded-systems-4p36 | flutter, embedded, appdevelopment, webdev | The Flutter framework has undergone a revolution with Flutter for Embedded Systems. With characteristics like layered architecture, portable code, and the flexibility to use a single Dart interface across multiple platforms, the Embedded Systems market and Flutter have a bright future.
In this blog post, I have explored the broad facets of Flutter Embedded systems and a few Case Studies of how some well-known brands are converting their Embedded Flutter development to the Flutter Infrastructure.
Additionally, I discussed Flutter's potential for Embedded Systems and how it would transform the creation of infotainment, the Internet of Things, and other Embedded Systems of a like nature.
## How do embedded Systems Work?
As the name implies, embedded systems are groups of hardware and software that work together to complete a particular purpose. They can function independently or as a component of a more extensive system that uses a microprocessor or a microcontroller. An integrated circuit created to calculate real-time processes is also a feature of embedded systems.
## The Benefits of Flutter Embedded Systems
When it comes to embedded systems, Flutter has seen a substantial increase in demand. If Flutter is the best option for commercial needs and requirements, the market is still at a loss. Well! Cross-platform development, which enables using a single codebase on different platforms while saving time and money, is the feature that puts Flutter in the front row and provides the solution to this problem.
### AGL's Easy Embedder API
By incorporating an API, any infotainment system running Automotive Grade Linux can use the technology. The Flutter engine's architecture makes it comparatively easy to allow embedding in a variety of target settings. It only requires wrapping the machine in an embedder and cross-compiling it. Embedder API, available to many engineers, makes it simple to combine Flutter apps with in-vehicle technologies.
### Support from the Community for Current Development
Without the help of a large and open ecosystem, no one could improve Flutter to meet their embedded scenarios. Because developers see working with open-source software as a wise investment in their embedded user experiences at any firm, they are eager to participate in the open-source Flutter community.
## The Reason Toyota Selected Flutter Embedded
Toyota is a business that appreciates its customers, as we all know. By the time the on-screen infotainment systems are installed on the dash, they have worked hard to enhance their driving experience. Toyota develops it's in car technology, which is more of a reason why they were intrigued by Flutter and thrilled about how Flutter may improve the User Experience for their consumers.
When Flutter began supporting embedded devices, Toyota's interest level increased, and the company proposed cooperation with Flutter. Toyota's clients share a similar bond with the business. They anticipate the same level of performance from their car systems, an improved driving experience, and an interface that matches Toyota's style and feel.
### Toyota's dependability and consistency, combined with outstanding performance
Toyota customers desire a dependable and high-performance in-vehicle user experience to match the general quality of Toyota cars. The graphics engine in Flutter works well in a constrained environment, and features like AOT compilation provide us with the consistency we require in in-vehicle technology.
### Similar Touch Mechanics to Smartphones
in the vehicle's technology. Thanks to Flutter, the Toyota team can provide an in-car user experience on par with what customers have grown to expect from their smartphones. Everyone may recall a bad touchscreen app experience that has nothing to do with their smartphone.
These apps typically have the impression that they could be cozier. What Toyota is using Flutter for immediately addresses that problem using its cross-platform mechanics. Touch mechanics always appear natural, thanks to the excellent job Flutter has done packaging them.
### More rapid iteration in response to customer feedback
The ultimate objective of the Toyota team's use of Flutter is to hasten the creation of in-vehicle software and enhance customer experience. They can create a more tightly-knit overall feedback loop in their design and engineering processes because of technology that has a high productivity rate and a low barrier to entry.
## Flutter Embedded Systems' Future
Flutter was initially only accessible on the app store. The Flutter development team subsequently added support for desktop OSs like macOS, Windows, and Linux. There was even support for building web apps. This shows that they will support a variety of streams in the future. With the impending release of Flutter 4.0, Google will formally declare its commitment to the Flutter platform for many years.
At the same rate as the advancements in productivity and capability of the technology, there are an increasing number of target platforms available for Flutter development. No matter the venue, the app you are creating, or the market you want to target, Flutter will continue to be a technology to employ when designing apps.
I had all of this in mind for Flutter Embedded Systems and the potential it offers for the future if you're a product owner who needs to decide whether using [Flutter for Embedded](https://www.bacancytechnology.com/blog/flutter-for-embedded) Systems in the development of your infotainment project is a viable alternative.
| rachgrey |
1,310,614 | Top 10 Django Tips for Working with Databases | Django is a popular web framework that makes it easy to work with databases in your web applications.... | 0 | 2022-12-28T06:47:54 | https://dev.to/giasuddin90/top-10-django-tips-for-working-with-databases-573j | webdev, python, productivity | Django is a popular web framework that makes it easy to work with databases in your web applications. Whether you are building a simple database-driven website or a complex web application, Django provides a variety of tools and features to help you efficiently manage and interact with your database. In this article, we will provide some tips and best practices for working with databases in Django.
Use Django's ORM for database interactions: Django's ORM (Object-Relational Mapper) allows you to interact with your database through Python code, rather than writing raw SQL queries. This is not only more efficient, but it also allows for easier maintenance and better readability of your code.
Define your models carefully: Your Django models should accurately reflect the structure of your database tables, so take the time to plan out your models and relationships before implementing them.
Use Django's migrations feature: Django's migrations feature allows you to easily make changes to your models and apply them to your database, without having to manually modify the database schema. This is especially useful when working in a team, as it allows for easier collaboration and avoids the risk of breaking the database.
Use Django's built-in database management tools: Django provides several useful tools for managing your database, such as the dumpdata and loaddata commands for exporting and importing data, and the sqlflush and sqlmigrate commands for viewing and executing SQL commands.
Use Django's bulk_create method for efficient data insertion: If you need to insert a large number of records into your database, the bulk_create method can greatly improve performance compared to inserting each record individually.
Use the select_related and prefetch_related methods to improve query performance: When working with foreign keys, the select_related method allows you to include related objects in a single database query, while prefetch_related allows you to efficiently retrieve related objects for multiple instances at once.
Use F objects for atomic updates: Django's F objects allow you to perform atomic updates on your database, ensuring that multiple updates are made in a single transaction and avoiding the risk of data inconsistency.
Use the transaction.atomic decorator for complex transactions: The transaction.atomic decorator allows you to wrap a block of code in a database transaction, ensuring that all changes are either applied or rolled back in the event of an error.
Use Django's caching framework to improve performance: Django's caching framework allows you to store frequently-accessed data in memory, reducing the number of database queries and improving performance.
Use Django's inspectdb command to generate models from an existing database: If you are working with an existing database and want to use Django's ORM, the inspectdb command can generate models based on the structure of your database tables, saving you the time and effort of defining your models manually.
By following these tips and best practices, you can optimize your database interactions and improve the performance of your Django web application. Whether you are new to Django or an experienced developer, these tips will help you get the most out of Django's powerful database management features.
| giasuddin90 |
1,310,703 | 5 Ways to make money as a frontend developer | As a frontend developer, you have a range of options when it comes to making money. Here are some... | 0 | 2022-12-28T08:17:40 | https://dev.to/yogeshtewari/5-ways-to-make-money-as-a-frontend-developer-1kg4 | webdev, javascript, react, programming | As a frontend developer, you have a range of options when it comes to making money. Here are some strategies you can consider:
**Freelance or contract work**: One way to make money as a frontend developer is to offer your services on a freelance or contract basis. This can be a good option if you want the freedom to work on a variety of projects and to set your own rates. To find freelance work, you can search online job boards, reach out to companies directly, or join a freelance platform like Upwork or Fiverr.
**Full-time employment**: Another option is to work as a full-time frontend developer for a company. This can be a good option if you want the stability and benefits that come with a regular job. To find full-time employment, you can search job listings online, network with industry professionals, or apply directly to companies that interest you.
**Start your own business**: If you want to be your own boss, you can consider starting your own business as a frontend developer. This could involve offering web design or development services to clients, or creating your own products or tools that you can sell. To get started, you'll need to create a business plan, build a portfolio, and market yourself to potential clients.
**Sell your skills online**: Another option is to sell your skills online through platforms like Udemy or Skillshare. This can involve creating courses or tutorials that teach others how to code or use specific technologies. To be successful, you'll need to create high-quality content and market your courses effectively.
**Contribute to open-source projects**: If you enjoy working on open-source projects, you can contribute to these projects and make money through donations or sponsorships. This can be a good way to build your skills and reputation as a developer, as well as to make some extra money.
Overall, the key to making money as a frontend developer is to build a strong skillset, market yourself effectively, and be open to a variety of opportunities. By staying up to date with the latest technologies and continuously learning and improving your skills, you'll be well-positioned to succeed in this field.
| yogeshtewari |
1,310,887 | What Is Password Salting & How It Improves Security? | What if I tell you Password Hashing is not that secure, and attackers have workarounds to attack... | 0 | 2024-06-22T09:01:36 | https://mojoauth.com/blog/what-is-password-salting | ---
title: What Is Password Salting & How It Improves Security?
published: true
date: 2022-12-26 18:30:00 UTC
tags:
canonical_url: https://mojoauth.com/blog/what-is-password-salting
---
What if I tell you Password Hashing is not that secure, and attackers have workarounds to attack hashed passwords as well? Harsh but true, however, the real question is what to do to make password-based authentication more secure if hashing passwords is not enough. The answer is Password Salting, to make it much more difficult for attackers to crack the passwords, even if they manage to get access of the hashed passwords. | auth-mojoauth | |
1,310,909 | Fuzzy query for CipherColumn | ShardingSphere 5.3.0 Deep Dive | 1. Background Apache ShardingSphere supports data encryption. By parsing users’ SQL input... | 0 | 2022-12-29T02:30:01 | https://dev.to/apache_shardingsphere/fuzzy-query-for-ciphercolumn-shardingsphere-530-deep-dive-55ja | database, java, opensource, cloudnative | ## 1. Background
[Apache ShardingSphere](https://shardingsphere.apache.org/) supports data encryption. By parsing users’ SQL input and rewriting the SQL according to the users’ encryption rules, the original data is encrypted and stored with ciphertext data in the underlying database at the same time.
When a user queries the data, it only fetches the ciphertext data from the database, decrypts it, and finally returns the decrypted original data to the user. However, because the encryption algorithm encrypts the whole string, fuzzy queries cannot be achieved.
Nevertheless, many businesses still need fuzzy queries after the data is encrypted. [In version 5.3.0](https://medium.com/faun/shardingsphere-5-3-0-is-released-new-features-and-improvements-bf4d1c43b09b?source=your_stories_page-------------------------------------), Apache ShardingSphere provides users with a default fuzzy query algorithm, supporting the fuzzy query for encrypted fields. The algorithm also supports hot plugging, which can be customized by users, and the fuzzy query can be achieved through configuration.
## 2. How to achieve fuzzy query in encrypted scenarios?
### 2.1 Load data to the in-memory database (IMDB)
Load all the data into the IMDB to decrypt it; then it’ll be like querying the original data. This method can achieve fuzzy queries. If the amount of data is small, this method will prove to be simple and cost-effective, while on the other hand, if the amount of data is large, it’ll turn out to be a disaster.
### 2.2 Implement encryption & decryption functions consistent with database programs
The second method is to modify fuzzy query conditions and use the database decryption function to decrypt data first and then implement fuzzy query. This method’s advantage is the low implementation & development cost, as well as use cost.
Users only need to slightly modify the previous fuzzy query conditions. However, the ciphertext and encryption functions are stored together in the database, which cannot cope with the problem of account data leaks.
```
Native SQL: select * from user where name like "%xxx%"
After implementing the decryption function: ѕеlесt * frоm uѕеr whеrе dесоdе(namе) lіkе "%ххх%"
```
### 2.3 Store after data masking
Implement data masking on ciphertext and then store it in a fuzzy query column. This method could lack in terms of precision.
```
For example, mobile number 13012345678 becomes 130****5678 after the masking algorithm is performed.
```
### 2.4 Perform encrypted storage after tokenization and combination
This method performs tokenization and combination on ciphertext data and then encrypts the resultset by grouping characters with fixed length and splitting a field into multiple ones. For example, we take four English characters and two Chinese characters as a query condition:
`ningyu1` uses the 4-character as a group to encrypt, so the first group is `ning`, the second group `ingy`, the third group `ngyu`, the fourth group `gyu1`, and so on. All the characters are encrypted and stored in the fuzzy query column. If you want to retrieve all data that contains four characters, such as `ingy`, encrypt the characters and use a key `like"%partial%"` to query.
**Shortcomings:**
- Increased storage costs: free grouping will increase the amount of data and the data length will increase after being encrypted.
- Limited length in fuzzy query: due to security issues, the length of free grouping cannot be too short, otherwise it will be easily cracked by the [rainbow table](https://www.techtarget.com/whatis/definition/rainbow-table). Like the example I mentioned above, the length of fuzzy query characters must be greater than or equal to 4 letters/digits, or 2 Chinese characters.
### 2.5 Single-character digest algorithm (default fuzzy query algorithm provided in ShardingSphere [version 5.3.0](https://medium.com/faun/shardingsphere-5-3-0-is-released-new-features-and-improvements-bf4d1c43b09b?source=your_stories_page-------------------------------------))
Although the above methods are all viable, it’s only natural to wonder if there’s a better alternative out there. In our community, we find that single-character encryption and storage can balance both performance and query, but fails to meet security requirements.
Then what’s the ideal solution? Inspired by masking algorithms and cryptographic hash functions, we find that data loss and one-way functions can be used.
The cryptographic hash function should have the following four features:
1. For any given message, it should be easy to calculate the hash value.
2. It should be difficult to infer the original message from a known hash value.
3. It should not be feasible to modify the message without changing the hash value.
4. There should only be a very low chance that two different messages produce the same hash value.
**Security:** because of the one-way function, it’s not possible to infer the original message. In order to improve the accuracy of the fuzzy query, we want to encrypt a single character, but it will be cracked by the rainbow table.
So we take a one-way function (to make sure every character is the same after encryption) and increase the frequency of collisions (to make sure every string is 1: N backward), which greatly enhances security.
## 3. Fuzzy query algorithm
Apache ShardingSphere implements a universal fuzzy query algorithm by using the below single-character digest algorithm `org.apache.shardingsphere.encrypt.algorithm.like.CharDigestLikeEncryptAlgorithm`.
```
public final class CharDigestLikeEncryptAlgorithm implements LikeEncryptAlgorithm<Object, String> {
private static final String DELTA = "delta";
private static final String MASK = "mask";
private static final String START = "start";
private static final String DICT = "dict";
private static final int DEFAULT_DELTA = 1;
private static final int DEFAULT_MASK = 0b1111_0111_1101;
private static final int DEFAULT_START = 0x4e00;
private static final int MAX_NUMERIC_LETTER_CHAR = 255;
@Getter
private Properties props;
private int delta;
private int mask;
private int start;
private Map<Character, Integer> charIndexes;
@Override
public void init(final Properties props) {
this.props = props;
delta = createDelta(props);
mask = createMask(props);
start = createStart(props);
charIndexes = createCharIndexes(props);
}
private int createDelta(final Properties props) {
if (props.containsKey(DELTA)) {
String delta = props.getProperty(DELTA);
try {
return Integer.parseInt(delta);
} catch (NumberFormatException ex) {
throw new EncryptAlgorithmInitializationException("CHAR_DIGEST_LIKE", "delta can only be a decimal number");
}
}
return DEFAULT_DELTA;
}
private int createMask(final Properties props) {
if (props.containsKey(MASK)) {
String mask = props.getProperty(MASK);
try {
return Integer.parseInt(mask);
} catch (NumberFormatException ex) {
throw new EncryptAlgorithmInitializationException("CHAR_DIGEST_LIKE", "mask can only be a decimal number");
}
}
return DEFAULT_MASK;
}
private int createStart(final Properties props) {
if (props.containsKey(START)) {
String start = props.getProperty(START);
try {
return Integer.parseInt(start);
} catch (NumberFormatException ex) {
throw new EncryptAlgorithmInitializationException("CHAR_DIGEST_LIKE", "start can only be a decimal number");
}
}
return DEFAULT_START;
}
private Map<Character, Integer> createCharIndexes(final Properties props) {
String dictContent = props.containsKey(DICT) && !Strings.isNullOrEmpty(props.getProperty(DICT)) ? props.getProperty(DICT) : initDefaultDict();
Map<Character, Integer> result = new HashMap<>(dictContent.length(), 1);
for (int index = 0; index < dictContent.length(); index++) {
result.put(dictContent.charAt(index), index);
}
return result;
}
@SneakyThrows
private String initDefaultDict() {
InputStream inputStream = CharDigestLikeEncryptAlgorithm.class.getClassLoader().getResourceAsStream("algorithm/like/common_chinese_character.dict");
LineProcessor<String> lineProcessor = new LineProcessor<String>() {
private final StringBuilder builder = new StringBuilder();
@Override
public boolean processLine(final String line) {
if (line.startsWith("#") || 0 == line.length()) {
return true;
} else {
builder.append(line);
return false;
}
}
@Override
public String getResult() {
return builder.toString();
}
};
return CharStreams.readLines(new InputStreamReader(inputStream, Charsets.UTF_8), lineProcessor);
}
@Override
public String encrypt(final Object plainValue, final EncryptContext encryptContext) {
return null == plainValue ? null : digest(String.valueOf(plainValue));
}
private String digest(final String plainValue) {
StringBuilder result = new StringBuilder(plainValue.length());
for (char each : plainValue.toCharArray()) {
char maskedChar = getMaskedChar(each);
if ('%' == maskedChar) {
result.append(each);
} else {
result.append(maskedChar);
}
}
return result.toString();
}
private char getMaskedChar(final char originalChar) {
if ('%' == originalChar) {
return originalChar;
}
if (originalChar <= MAX_NUMERIC_LETTER_CHAR) {
return (char) ((originalChar + delta) & mask);
}
if (charIndexes.containsKey(originalChar)) {
return (char) (((charIndexes.get(originalChar) + delta) & mask) + start);
}
return (char) (((originalChar + delta) & mask) + start);
}
@Override
public String getType() {
return "CHAR_DIGEST_LIKE";
}
}
```
- Define the binary `mask` code to lose precision `0b1111_0111_1101` (mask).
- Save common Chinese characters with disrupted order like a `map` dictionary.
- Obtain a single string of `Unicode` for digits, English, and Latin.
- Obtain `index` for a Chinese character belonging to a dictionary.
- Other characters fetch the `Unicode` of a single string.
- Add `1 (delta)` to the digits obtained by different types above to prevent any original text from appearing in the database.
- Then convert the offset `Unicode` into binary and perform the `AND` operation with `mask`, and carry out a 2-bit digit loss.
- Directly output digits, English, and Latin after the loss of precision.
- The remaining characters are converted to decimal and output with the common character `start` code after the loss of precision.
## 4. The fuzzy algorithm development progress
### 4.1 The first edition
Simply use `Unicode` and `mask` code of common characters to perform the `AND` operation.
```
Mask: 0b11111111111001111101
The original character: 0b1000101110101111讯
After encryption: 0b1000101000101101設
```
```
Assuming we know the key and encryption algorithm, the original string after a backward pass is:
1.0b1000101100101101 謭
2.0b1000101100101111 謯
3.0b1000101110101101 训
4.0b1000101110101111 讯
5.0b1000101010101101 読
6.0b1000101010101111 誯
7.0b1000101000101111 訯
8.0b1000101000101101 設
```
We find that based on the missing bits, each string can be derived `2^n` Chinese characters backward. When the `Unicode` of common Chinese characters is decimal, their intervals are very large. Notice that the Chinese characters inferred backward are not common characters, and it's more likely to infer the original characters.

### 4.2 The second edition
Since the interval of common Chinese characters `Unicode` is irregular, we planned to leave the last few bits of Chinese characters `Unicode` and convert them into decimal as `index` to fetch some common Chinese characters. This way, when the algorithm is known, uncommon characters won't appear after a backward pass, and distractors are no longer easy to eliminate.
If we leave the last few bits of Chinese characters `Unicode`, it has something to do with the relationship between the accuracy of fuzzy query and anti-decryption complexity. The higher the accuracy, the lower the decryption difficulty.
Let’s take a look at the collision degree of common Chinese characters under our algorithm:
1. When `mask`=0b0011_1111_1111:
2. When `mask`=0b0001_1111_1111:

For the mantissa of Chinese characters, leave 10 and 9 digits. The 10-digit query is more accurate because its collision is much weaker. Nevertheless, if the algorithm and the key are known, the original text of the 1:1 character can be derived backward.
The 9-digit query is less accurate because 9-digit collisions are relatively stronger, but there are fewer 1:1 characters. We find that although we change the collisions regardless of whether we leave 10 or 9 digits, the distribution is very unbalanced due to the irregular Unicode of Chinese characters, and the overall collision probability cannot be controlled.
### 4.3 The third edition
In response to the unevenly distributed problem found in the second edition, we take common characters with disrupted order as the dictionary table.
1. The encrypted text first looks up the `index` in the out-of-order dictionary table. We use the `index` and subscript to replace the `Unicode` without rules.
Use `Unicode` in case of uncommon characters. (Note: evenly distribute the code to be calculated as far as possible.)
2. The next step is to perform the `AND` operation with `mask` and lose 2-bit precision to increase the frequency of collisions.
Let’s take a look at the collision degree of common Chinese characters under our algorithm:
1. When `mask`=0b1111_1011_1101:

2. When `mask`=0b0111_1011_1101:

When the `mask` leaves 11 bits, you can see that the collision distribution is concentrated at 1:4. When `mask` leaves 10 bits, the number becomes 1:8. At this time, we only need to adjust the number of precision losses to control whether the collision is 1:2, 1:4 or 1:8.
If `mask` is selected as 1, and the algorithm and key are known, there will be a 1:1 Chinese character, because what we calculate at this time is the collision degree of common characters. If we add the missing 4 bits before the 16-bit binary of Chinese characters, the situation becomes `2^5=32` cases.
Since we encrypted the whole text, even if the individual character is inferred backwards, there will be little impact on overall security, and it will not cause mass data leaks. At the same time, the premise of backward pass is to know the algorithm, key, `delta` and dictionary, so it's impossible to achieve from the data in the database.
## 5. How to use fuzzy query
Fuzzy query requires the configuration of `encryptors`(encryption algorithm configuration), `likeQueryColumn` (fuzzy query column name), and `likeQueryEncryptorName`(encryption algorithm name of fuzzy query column ) in the encryption configuration.
Please refer to the following configuration. Add your own sharding algorithm and data source.
```
dataSources:
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/test?allowPublicKeyRetrieval=true
username: root
password: root
rules:
- !ENCRYPT
encryptors:
like_encryptor:
type: CHAR_DIGEST_LIKE
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
user:
columns:
name:
cipherColumn: name
encryptorName: aes_encryptor
assistedQueryColumn: name_ext
assistedQueryEncryptorName: aes_encryptor
likeQueryColumn: name_like
likeQueryEncryptorName: like_encryptor
phone:
cipherColumn: phone
encryptorName: aes_encryptor
likeQueryColumn: phone_like
likeQueryEncryptorName: like_encryptor
queryWithCipherColumn: true
props:
sql-show: true
```
Insert
```
Logic SQL: insert into user ( id, name, phone, sex) values ( 1, '熊高祥', '13012345678', '男')
Actual SQL: ds_0 ::: insert into user ( id, name, name_ext, name_like, phone, phone_like, sex) values (1, 'gyVPLyhIzDIZaWDwTl3n4g==', 'gyVPLyhIzDIZaWDwTl3n4g==', '佹堝偀', 'qEmE7xRzW0d7EotlOAt6ww==', '04101454589', '男')
```
Update
```
Logic SQL: update user set name = '熊高祥123', sex = '男1' where sex ='男' and phone like '130%'
Actual SQL: ds_0 ::: update user set name = 'K22HjufsPPy4rrf4PD046A==', name_ext = 'K22HjufsPPy4rrf4PD046A==', name_like = '佹堝偀014', sex = '男1' where sex ='男' and phone_like like '041%'
```
Select
```
Logic SQL: select * from user where (id = 1 or phone = '13012345678') and name like '熊%'
Actual SQL: ds_0 ::: select `user`.`id`, `user`.`name` AS `name`, `user`.`sex`, `user`.`phone` AS `phone`, `user`.`create_time` from user where (id = 1 or phone = 'qEmE7xRzW0d7EotlOAt6ww==') and name_like like '佹%'
```
Select: federated table sub-query
```
Logic SQL: select * from user LEFT JOIN user_ext on user.id=user_ext.id where user.id in (select id from user where sex = '男' and name like '熊%')
Actual SQL: ds_0 ::: select `user`.`id`, `user`.`name` AS `name`, `user`.`sex`, `user`.`phone` AS `phone`, `user`.`create_time`, `user_ext`.`id`, `user_ext`.`address` from user LEFT JOIN user_ext on user.id=user_ext.id where user.id in (select id from user where sex = '男' and name_like like '佹%')
```
Delete
```
Logic SQL: delete from user where sex = '男' and name like '熊%'
Actual SQL: ds_0 ::: delete from user where sex = '男' and name_like like '佹%'
```
The above example demonstrates how fuzzy query columns rewrite SQL in different SQL syntaxes to support fuzzy queries.
This blog post introduced you to the working principles of fuzzy query and used specific examples to demonstrate how to use it. We hope that through this article, you will have gained a basic understanding of fuzzy queries.
## Links
🔗 [Download Link](https://shardingsphere.apache.org/document/current/en/downloads/)
🔗 [Project Address](https://shardingsphere.apache.org/)
🔗 [ShardingSphere-on-Cloud](https://github.com/apache/shardingsphere-on-cloud)
## Author
Xiong Gaoxiang, an engineer at [Iflytek](https://global.iflytek.com/) and a ShardingSphere Contributor, is responsible for the data encryption and data masking R&D. | apache_shardingsphere |
1,311,297 | WordPress Cookie Plugin: which one to choose? | ...which cookie-plugin would you use in WordPress for a new project i am trying to find out which... | 0 | 2022-12-28T22:10:55 | https://dev.to/digital_hub/wordpress-cookie-plugin-which-one-to-choose-djg |
...which cookie-plugin would you use in WordPress
for a new project i am trying to find out which plugin is appropiate:
which one would you choose?
**Cookie Notice & Compliance for GDPR / CCPA
**https://wordpress.org/plugins/cookie-notice/
By Hu-manity.co : https://hu-manity.co/
**Info**: Version:2.4.4 Last updated:4 days ago Active installations:1+ million WordPress Version:4.7 or higher Tested up to:6.1.1 PHP Version:5.4 or higher Languages:See all 30 Tags:CCPAcomplianceconsentcookiesGDPR
**Ratings** 2800 x Fünf Sterne
Description
Cookie Notice provides a simple, customizable website banner that can be used to help your website comply with certain cookie consent requirements under the EU GDPR cookie law and CCPA regulations and includes seamless integration with Cookie Compliance to help your site comply with the latest updates to existing consent laws.
**CookieYes | GDPR Cookie Consent & Compliance Notice (CCPA Ready)**
https://wordpress.org/plugins/cookie-law-info/
https://www.cookieyes.com/
**info:** Version:3.0.7 Last updated:6 days ago Active installations:1+ million WordPress Version:5.0.0 or higher Tested up to:6.1.1 PHP Version:5.6 or higher Languages:See all 40 Tags:CCPAcookie noticedsgvoGDPRrgpd
**Ratings**: 2000 x Fünf-Sterne
Description
The CookieYes GDPR Cookie Consent plugin will assist you in making your website GDPR (RGPD, DSVGO) compliant by adding a cookie banner to your site. Additionally, this GDPR WordPress plugin also supports cookie compliance with the LGPD of Brazil, CNIL of France, and the California Consumer Privacy Act (CCPA) which is a state statute intended to enhance privacy rights and consumer protection for residents of California.
The plugin is one of the best WordPress GDPR cookie compliance plugins as it comes with a host of features some of which are listed below.
**Complianz – GDPR/CCPA Cookie Consent**
https://wordpress.org/plugins/complianz-gdpr/
by: https://www.complianz.io/
info: Version:6.3.6.1 Last updated:5 days ago Active installations:500,000+ WordPress Version:4.9 or higher Tested up to:6.1.1 PHP Version:7.2 or highe
**Ratings:** 900 x Fünf-Sterne
Description: Complianz is a GDPR/CCPA Cookie Consent plugin that supports GDPR, ePrivacy, DSGVO, TTDSG, LGPD, POPIA, APA, RGPD, CCPA/CPRA and PIPEDA with a conditional Cookie Notice and customized Cookie Policy based on the results of the built-in Cookie Scan.
FEATURES
COOKIE CONSENT NOTICE
Configure a Cookie Notice for your specific region: European Union, United Kingdom, United States, Australia, South Africa, Brazil or Canada. Or use one Cookie Notice worldwide.
Configure specific cookie consent per subregion, for example: European Union + TTDSG/DSGVO/CNIL or USA + specific states for CCPA/CPRA/CTDPA etc
Cookie Consent and Conditional Cookie Notice with Custom CSS and Customizable Templates. WCAG Level AA and ADA Compliant.
Banner Templates include: GDPR-friendly Cookie Wall – Accept/Dismiss – Consent per Category – Consent per Service: Banner Templates also include; Dismiss on scroll, time on page or both based on legislation
Cookie Banners and Legal Documents conform to WCAG 2.1 AA Accessibility Guidelines and ADA Compliance.
**Real Cookie Banner: GDPR (DSGVO) & ePrivacy Cookie Consent**
https://wordpress.org/plugins/real-cookie-banner/
www.devowl.io
info: version:3.4.9 Last updated:6 days ago Active installations:100,000+ WordPress Version:5.2 or higher Tested up to:6.1.1 PHP Version:7.2.0 or higher Languages:See all 4 Tags:cookie bannercookie consentcookie pluginCookie ScannerGDPR
**Ratings:** 270 5 Sterne
Cookie Banner and Consent Management for your WordPress website – easy to be legally compliant
Obtain GDPR and ePrivacy Directive compliant consents. Find services, cookies etc. and fill all legal information in your cookie banner. More than just a cookie notice! Cookie plugin designed specifically for WordPress websites to simplify setup.
Real Cookie Banner is an cookie and consent management plugin. Obtain consent to load services and set cookies for your visitors in accordance with the GDPR and ePrivacy Directive. In addition, content blockers help you to be compliant even if your theme, plugin or content loads styles, scripts or iframes that would transfer personal data. Start now with our guided-configuration and avoid legal risks!
**GDPR Cookie Compliance (CCPA, DSGVO, Cookie Consent)**
https://wordpress.org/plugins/gdpr-cookie-compliance/
By Moove Agency: https://www.mooveagency.com/
**Ratings:** 100 5 Sterne
info: Version:4.9.6 Last updated:2 weeks ago Active installations:200,000+ WordPress Version:4.5 or higher Tested up to:6.1.1 Languages:See all 17 Tags:CCPAcookie bannercookie noticedsgvoGDPR
Description
Prepare your website for cookie consent requirements related to GDPR, CCPA, DSGVO, EU cookie law and notice requirements with this incredibly powerful, easy-to-use, well supported and 100% free WordPress plugin.
KEY FEATURES
Local Data Storage – all user data is stored locally on your website only – we do not collect or store any of your user data on our servers
Simple to use — install & setup in seconds
Give your users full control over cookies stored on their computer, including the ability for users to revoke their consent.
Fully customisable – upload your own logo, colours, fonts
**iubenda | All-in-one Compliance for GDPR / CCPA Cookie Consent + more**
https://wordpress.org/plugins/iubend...-law-solution/
By iubenda :: https://www.iubenda.com/
info: Version:3.3.3 Last updated:2 weeks ago Active installations:100,000+ WordPress Version:5.0 or higher Tested up to:6.1.1 PHP Version:7.0.0 or higher Languages:See all 5 Tags:cookie bannercookie lawePrivacyGDPR
**Ratings:** 270 x 5 Sterne
Description
The iubenda plugin is an all-in-one, extremely easy to use 360° compliance solution, with text crafted by actual lawyers, that quickly scans your site and auto-configures to match your specific setup. It supports the GDPR (DSGVO, RGPD), UK-GDPR, ePrivacy, LGPD, CCPA, CalOPPA, PECR and more.
**Cookiebot CMP by Usercentrics | The reliable, flexible and easy to use consent solution**
https://wordpress.org/plugins/cookiebot/
By Usercentrics A/S: http://cookiebot.com/
info: Version:4.2.2 Last updated:2 weeks ago Active installations:100,000+ WordPress Version:4.4 or higher Tested up to:6.1.1 PHP Version:5.6 or higher Languages:See all 5 Tags:CCPAcookie bannercookie noticecookiesGDPR
Ratings: 190 x 5 Sterne:
Description
RELIABLE, FLEXIBLE AND EASY TO USE COOKIE CONSENT SOLUTION FOR GDPR/EPR, CCPA/CPRA AND IAB TCF COMPLIANCE.
Cookiebot consent management platform (CMP) provides a plug-and-play cookie consent solution that enables compliance with the GDPR, LGPD, CCPA and other international regulations. It deploys industry-leading scanning technology and seamless integration with Google Consent Mode to help you balance data privacy with data-driven business on your domain.
which one would you choose? | digital_hub | |
1,311,371 | Learning Kafka Part One: What is Kafka? | Welcome to the first installment of Learning Kafka series. It’s time to meet Kafka proper. ... | 21,137 | 2022-12-29T00:07:53 | https://dev.to/ibrahim_anis/learning-kafka-part-one-what-is-kafka-2da6 | apache, kafka, streaming, datapipeline | Welcome to the first installment of Learning Kafka series. It’s time to meet Kafka proper.
## What Exactly is Kafka?
According to Kafka’s documentation, Kafka is described _“as an open-source Distributed Event Streaming Platform used by thousands of companies for high-performance data pipelines, data integration and mission critical-applications”._
But Kafka can be captured the three words really; distributed, event and streaming-platform.
Let’s take a closer look at each of these words.
### Distributed
A distributed system is nothing but a group (two or more) of systems or computers working together in parallel as a single, logical unit. They appear as a single unit to the end user. A system in this context can be anything from a laptop, a desktop, a server to a compute instance on the cloud.
For example, traditional databases are run on a single instance, whenever we want to query the database, we send request to that single instance directly.
A distributed version of this system will have the same database running on multiple instances at the same time. We would be able to talk to any of these instances and not be able to tell the difference. For example, if we inserted a record into instance 1, then instance 3 must be able to return the record.
A group of these instances is collectively known as a cluster while a single instance in the cluster is called a node or server.
Apache Kafka works in a distributed fashion, although it’s possible to run Kafka on a single node, this means losing out on all the things that makes Kafka……… Kafka.
### Event
An event is…… just an event. Okay, that’s not helpful, but an event is really just an event. Sometimes (most-times?) traditional English words can mean a totally different thing in computer, but that’s not the case here. According to Oxford dictionary _“An event is a thing that happens, especially something important”._ An event in Kafka means just that. A user clicks on a particular link? An event. A traffic light changed from red to green? An event. An administrator logs into a computer? And event. Someone tweets a tweet? (Okay, don’t know if that is correct) An event. We now hopefully get the idea of what an event is. An event is an event. Moving on.
### Streaming platform
Before discussing streaming platform, lets first understand what streaming is. Streaming is the unending, continuous generation of data. These data can be from different sources, be of diverse types and comes in different formats. They are also generated by both humans and machines.
A streaming platform is a platform or a system that helps in the gathering and movement of streaming data.
From the above explanations, we can say that Kafka is a group of systems (working together as one) that facilitates the movement of streaming data (called events) from source systems to target systems.
## Origin
Developed at LinkedIn in 2010, by team that included Jay Kreps, Jun Rao, and Neha Narkhede, Kafka was used originally for the purpose of tracking LinkedIn users’ activities in real time. It was open-sourced and released to the Apache Software Foundation in 2011, and was graduated to a full Apache Project in 2012.
Kafka is written in Java and Scala and was named after the author Franz Kafka.
## Features
Kafka is known for being durable, scalable and fault tolerant. Coupled with its high-throughput and high availability, Kafka has become the most popular choice for event driven systems. A quick refresher;
- Durability is the ability of a system to retain and not lose data permanently.
- Scalability is the ability of a system to grow and manage increased demands.
- Fault tolerance is the ability of a system to continue operating without interruption when one or more of its components fail.
- Throughput is the measure of how many units of work, information or request a system can handle in a given amount of time.
- Availability is the percentage of time that a system remains operational under normal circumstances.
## Use cases
Kafka’s original use case was to track users’ activities like page views, searches and other actions users may take, but its success has seen it evolved to other uses, for example;
**Streaming Data Pipelines**
One of the most popular use cases for Kafka is building streaming data pipelines. Where data is continuously being moved from source to destination in real time.
**Messaging system**
Messaging system is a system that enables applications to share data between each other.
Because of its design architecture (which we will cover in part three), Kafka can also be used as a replacement for traditional messaging systems like ActiveMQ and RabbitMQ.
**Stream Processing**
Instead of just storing and moving streams of data, Kafka can also be used to process, transform and enrich these data in real time with Kafka streams.
And that’s the end of this section, we have discussed what Kafka is, its origin and use cases, we also touched, briefly, on distributed systems, streaming, and events. And a quick explanation on words like throughput, availability, fault tolerance, durability, and scalability. Now that we are better equipped, lets dive even deeper into Kafka.
Up next, the core components of Kafka.
| ibrahim_anis |
1,311,802 | Decentralized Storages | A team’s success is a recipe that has to be enjoyed once the dish is served. But what is that recipe?... | 0 | 2022-12-29T12:40:11 | https://dev.to/aptacore/decentralized-storages-32kc | cloud, security, storybytes |
A team’s success is a recipe that has to be enjoyed once the dish is served. But what is that recipe? What are the ingredients? How about the quantity and the preparation time? Well, if that were easy, we would have only high-performing teams. One ingredient that we in Web and App Studio believe in to create a high-performing team is the need for Psychological Safety. Paul Santagata from HBR reveals, “There’s no team without trust”, and he couldn’t be more correct. But what is psychological safety, and why is it important? Psychological safety is the conviction that you won't suffer the consequences of the mistakes that have occurred. If we get to our unsafe zone, our thinking brains shut off, and our primal instincts take over, leading to nothing productive. And that's why psychological safety is so important. Psychological safety empowers employees to take risks and speak their minds. Team members who are quick to point the finger at one another when something goes wrong, team members who have different values or beliefs than others, and teams with a conflict-ridden culture are all signs of poor psychological safety. So rather than developing a compete-with-each-other mindset, we must never forget that it’s the team vs the problem. Blame can become a curiosity. Ask for feedback to improve on your own. When people feel connected to each other, they know that they're safe to step outside of their comfort zone. And yes, Feeling safe is a fundamental human need. Once this is covered, any performance will scale higher. | aptacore |
1,311,811 | O que é runtime javascript ? | O que é o ambiente de execução(runtime environment) ? No contexto do browser esse ambiente... | 0 | 2023-01-02T12:18:06 | https://dev.to/h1bertobarbosa/o-que-e-runtime-javascript--55bd | javascript, beginners, programming, webdev | ## O que é o ambiente de execução(runtime environment) ?
No contexto do browser esse ambiente de execução é composto por:
- Javascript Engine
- Web API
- Fila de callbacks(The callback queue)
- Loop de eventos(Event Loop)
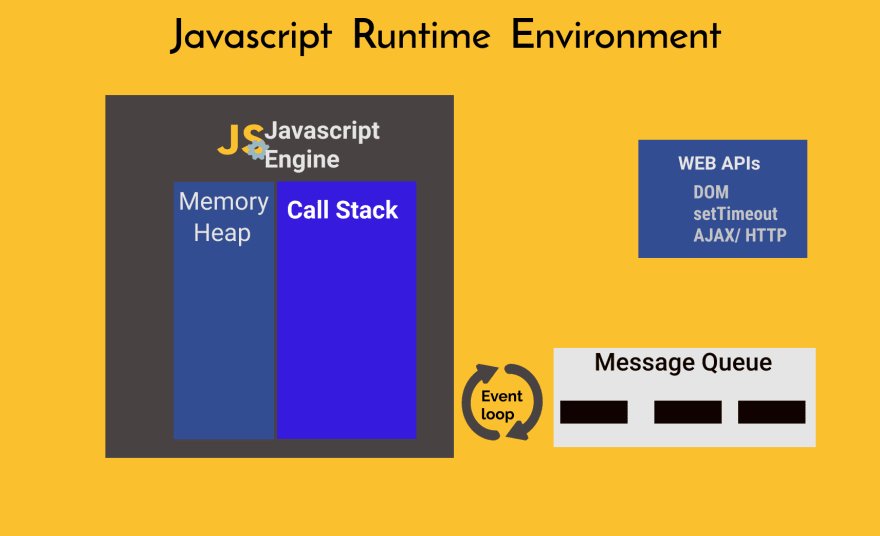
## Javascript Engine
Javascript Engine é um programa que executa código JavaScript. É o que torna possível a execução de código JavaScript em um navegador web ou em um ambiente de servidor, como o Node.js e agora mais recentemente o Deno.
Cada navegador web tem sua própria implementação de uma engine JavaScript, como o JavaScript V8 da Google, que é usado no Chrome e no Chromium, ou o Spider Monkey da Mozilla, que é usado no Firefox.
As engines JavaScript são otimizadas para interpretar e executar o código JavaScript de maneira rápida e eficiente. Elas fazem isso através de diversas técnicas, como pré-compilação de código e otimização de memória. As engines também implementam APIs JavaScript, como a API do Document Object Model (DOM), que permite que o código JavaScript acesse e manipule elementos HTML na página da web.
**Call Stack**: Dentro dessa engine nos temos a call stack e memory heap, toda vez que agente executa um código javascript as funções vão para a call stack que é o local onde as funções são empilhadas para serem executadas, essa estrutura é formada ultimo a entrar é primeiro a sair e só passa para a próxima execução quando concluir a atual.
Caso existe uma função da web api na call stack essa função é enviada para lá, apos o termino da execução o callback é enviado para a fila de callback(callback queue) para retornar pra call stack pra concluir a execução do código
**Memory Heap**: é um "pedaço" da memória do computador que é usada para alocar novos objetos. Quando um novo objeto é criado no código JavaScript, ele é alocado na memory heap.
A memory heap é dividida em duas partes: new space e old space. O new space é usada para alocar novos objetos e é otimizada para alocação rápida. O old space é usado para objetos que são mantidos por mais tempo e é otimizada para acesso rápido.
Quando new space está cheia, o V8 realiza uma operação chamada garbage collection, durante a qual ele examina os objetos no new space e remove aqueles que não são mais usados pelo código. Os objetos que ainda são usados são movidos para o old space. Isso libera espaço no new space para novos objetos.
O V8 também faz o garbage collection no old space, mas elas são menos frequentes e mais lentas do que as coletas no new space, pois envolvem a verificação de todos os objetos no old space.
Espero que isso tenha esclarecido um pouco sobre como a memory heap funciona no JavaScript V8.
## Web API
JavaScript Web APIs são conjuntos de interfaces de programação de aplicativos (APIs) que fornecem acesso a recursos do navegador e do sistema operacional. Eles permitem a criação de aplicativos web que possam fazer coisas como acessar a câmera e o microfone do usuário, enviar solicitações HTTP, manipular o DOM e muito mais. Alguns exemplos de JavaScript Web APIs incluem:
**Geolocation API**: permite que os aplicativos web acessem as informações de localização do usuário.
**Web Audio API**: permite que os aplicativos web reproduzam áudio e criem efeitos de áudio complexos.
**Web Storage API**: permite que os aplicativos web armazenem dados no navegador do usuário, como informações de login ou preferências de usuário.
Essas são apenas algumas das muitas APIs disponíveis para os desenvolvedores de aplicativos web. Elas fornecem uma ampla gama de recursos que podem ser usados para criar aplicativos web poderosos e interativos.
O famoso setTimeout, ajax(xmlhttprequest) fazem parte da web api
## Callback queue e Event Loop
A fila de callbacks, também conhecida como a "fila de eventos", é uma fila de funções que são chamadas quando um evento específico ocorre. No JavaScript, esses eventos podem incluir coisas como o carregamento de uma página web, o clique em um botão ou o recebimento de uma resposta de uma solicitação HTTP.
Quando um evento ocorre, a função de callback associada a ele é adicionada à fila de callbacks. O JavaScript possui um loop de eventos que executa continuamente e verifica a fila de callbacks para ver se há funções para serem chamadas. Quando uma função está disponível na fila, ela é removida da fila e chamada. Isso permite que o código JavaScript responda a eventos de maneira assíncrona.
Por exemplo, quando um usuário clica em um botão em uma página web, é adicionada uma função de callback à fila de callbacks. Quando o loop de eventos verifica a fila, essa função é chamada e o código associado ao clique no botão é executado. Isso permite que o código continue a ser executado enquanto o navegador está ocupado processando o clique do botão, sem bloquear a interface do usuário.
## Node.js
O node.js é uma runtime para executar o javascript no backend a diferença do browser é que em vez de ter a Web Api ele tem a libuv que é onde ocorre a execuçaõ de funções assincronas.
Se você quer visualizar essas coisas acontecendo tem esse site http://latentflip.com/loupe onde é possivel ver o código passando pelos mecanismos da runtime, ao entrar no site já existe um código de exemplo mas você pode colocar esse abaixo ou inventar algum:
`
console.log("Hi!");
setTimeout(function timeout() {
console.log("5 segundos depois");
}, 5000);
console.log("executei antes do setTimeout");
`
**Links pesquisados:**
https://medium.com/@gemma.croad/understanding-the-javascript-runtime-environment-4dd8f52f6fca
https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Client-side_web_APIs/Introduction
https://nodejs.org/en/docs/guides/diagnostics/memory/using-gc-traces/ | h1bertobarbosa |
1,311,886 | How to Keep Sync ElasticSearch with MySQL Relational Data | Before starting to deep dive into the subject, I want to say that I'm not an expert on ElasticSearch... | 0 | 2022-12-29T14:01:36 | https://dev.to/batuhannarci/how-to-keep-sync-elasticsearch-with-mysql-relational-data-47if | Before starting to deep dive into the subject, I want to say that I'm not an expert on ElasticSearch (ES) 😃. My motivation for writing this is that it is difficult to find comprehensive guides about parent/child relationships on ES.
On ES, we can find hundreds of posts and guides about indexing data. However, I want to concentrate on indexing relational data in this story.
## Content
- What is the problem with indexing relational data?
- How we can solve this problem?
- Proof of concept of my proposition
- Resources
---
## What is the problem with indexing relational data?
Our apps now retrieve data from many tables or even databases. All those data must be combined to be displayed on a panel or dashboard. Using an RDBMS database for this is becoming slower as the data grows larger.
We want to filter or search this data in addition to showing it. If we have multiple text fields from different tables, joining those tables and performing a search can put a significant strain on our database.
There ES comes to the stage. It's a distributed, free, and open search and analytics engine for all types of data. And, this is how we can solve this issue.
## How we can solve this problem?
ES can be used for searching, logging, analytics, and several useful stuff 😃. We focus on searching capability in this story.
To make a search on our data, we need to index it first on ES and we can use several patterns to index data.
Denormalizing, nested or parent/child patterns are the most used ways to index relational data.
Let's say we have two tables: product and tag. A product can have zero or more tags and a tag can belong to one or more products. The entity relation looks like the one below.
We can write a query like that to get a product and its tags.
```sql
SELECT p.id, p.name, t.id, t.name
FROM product p
LEFT JOIN tag t ON t.product_id = p.id
WHERE p.id = 98452;
```
And the result can be like this

The **denormalized** version of this relationship is;
```json
{
"product" : {
"id" : 214673,
"name" : "AliExpress Fitness Trackers - mint green",
"tags" : "tag1, tag22"
}
}
```
To achieve this we can modify the query above like the following.
```sql
SELECT p.id as product_id, p.name as product_name, t.id as tag_id, group_concat(t.name) as tags
FROM product p
LEFT JOIN tag t ON t.product_id = p.id
WHERE p.id = 2141673
GROUP BY t.product_id;
```
This pattern is the easiest way to index relational data but has some caveats. If you have several tables to join with many columns, it's not practical and performant.
So there comes another approach: **nested** structure.
For the same example, the **nested** structure of this relationship is;
```json
{
"product" : {
"id" : 214673,
"name" : "AliExpress Fitness Trackers - mint green",
"tags" : {
{
"id" : 1,
"name" : "tag1"
},
{
"id" : 2,
"name" : "tag22"
}
}
}
}
```
This appears to be very promising, but with the caveat that we must proceed to choose a parent/child structure. If a nested entity is updated in a nested structure, the entire index must be updated. If you have nested entities that are frequently updated, you should use the next structure.
For the same example, the **parent/child** structure of this relationship is;
```json
{
"product" : {
"id" : 214673,
"name" : "AliExpress Fitness Trackers - mint green"
}
}
{
"tag" : {
"id" : 1,
"name" : "tag1",
"product_id" : 214673
}
}
{
"tag" : {
"id" : 2,
"name" : "tag22",
"product_id" : 214673
}
}
```
We can use any programming language to index data on ES.
In this story, I'll use Logstash and multiple pipelines to create the initial index and keep synced with our database.
After all of this summarized info, I'm going to proof of the parent/child concept.
## Proof of concept of my proposition
My technical stack is;
- MySQL 8
- ElasticSearch 8.5.3
- Logstash 8.5.3 with JDBC plugin enabled
- Kibana 8.5.3
- Docker
You can find the complete code in the [es_relations_example](https://github.com/batuhannarci/es_relations_example) repo.
First, we are going to create a database and fill it with sample data. Then, we will add ES, Kibana, and Logstash step by step. At last, we will look into pipelines one by one to understand better how it works.
**Step 1**: Create MySQL and fill it with data.
After you create your project directory, Create a directory with the name **data** and put [this](https://raw.githubusercontent.com/batuhannarci/es_relations_example/main/data/es_relations_example.sql) SQL file in it. Then, create a file with the name **docker-compose.yml**. Put the following lines in it.
```yaml
version: "3"
services:
mysql:
image: mysql:8
ports:
- 3306:3306
environment:
MYSQL_RANDOM_ROOT_PASSWORD: "yes"
MYSQL_DATABASE: "es_relations_example"
MYSQL_USER: "test"
MYSQL_PASSWORD: "test"
volumes:
- ./data/:/docker-entrypoint-initdb.d/
```
That piece of code says that create a MySQL 8 server and use given queries in the **data** directory to fill it.
> If you want to set the root password, you can delete **MYSQL_RANDOM_ROOT_PASSWORD** config and add **MYSQL_RANDOM_ROOT** with a root password as your wish.
Then, run the following commands to see that the database is set up correctly.
```bash
docker-compose up -d mysql
# Once the container is ready, run the following to find container ID
docker ps -l # -l for latest container
docker exec -it 136faa620a82 bash # Use the container ID that you get above
mysql -utest -ptest es_relations_example # Username, password and database name given in docker-compose.yml
show tables;
```
You need to see an output like below.
Yaay! 🎊 Our database is running.
**Step 2**: Set up ElasticSearch and Kibana. First, create a directory with the name **volumes** and another one in it with the name **elasticsearch**. This directory will keep our indexed data. Then, add the following lines to the **docker-compose.yml**.
```yaml
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.5.3
environment:
discovery.type: "single-node"
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
xpack.security.enrollment.enabled: "false"
xpack.monitoring.collection.enabled: "true"
ES_JAVA_OPTS: "-Xms1g -Xmx1g"
volumes:
- ./volumes/elasticsearch/data:/usr/share/elasticsearch/data
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:8.5.3
environment:
ELASTICSEARCH_HOSTS: "http://elasticsearch:9200"
ports:
- 5601:5601
depends_on:
- elasticsearch
```
You can run the following command to build our new containers.
```bash
docker-compose up -d elasticsearch kibana
# You can check if everything is fine after build is done
docker ps
```

You should see something like the above. Everything is fine till now.
**Step 3**: Now, we can set up Logstash to send data from the database to ES.
We can connect Logstash to MySQL using the JDBC plugin.
So, create a file named **Dockerfile-logstash** at the root of your project and put the following in it.
```bash
FROM docker.elastic.co/logstash/logstash:8.5.3
# Download JDBC MySQL connector
RUN curl -L --output "mysql-connector-j-8.0.31.tar.gz" "https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-j-8.0.31.tar.gz" \
&& tar -xf "mysql-connector-j-8.0.31.tar.gz" "mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar" \
&& mv "mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar" "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar" \
&& rm -r "mysql-connector-j-8.0.31" "mysql-connector-j-8.0.31.tar.gz"
ENTRYPOINT ["/usr/local/bin/docker-entrypoint"]
```
And, add the following lines to the **docker-compose.yml**.
```yaml
logstash:
build:
context: .
dockerfile: ./Dockerfile-logstash
environment:
LS_JAVA_OPTS: "-Xmx1g -Xms1g"
depends_on:
- mysql
- elasticsearch
```
Now, we have everything that we need but need to configure Logstash to get data from the database and index it on ES.
Logstash is using pipelines to retrieve data from the source and process it and lastly sent it to the output which we choose.
We'll use three pipelines to create the index at first, keep updates synced and keep deletions synced.
Let's create a directory named **logstash** under **volumes**. Create another three directories under **logstash** with the name **config**, **pipeline**, and **templates**.
Create a file named **products.json** under **volumes/logstash/templates** and put the following in it.
> This will be our index mapping template. You can find details about the mapping [here](https://www.elastic.co/guide/en/elasticsearch/reference/current/explicit-mapping.html).
```json
{
"index_patterns": "products",
"template": {
"settings" : {
"index" : {
"number_of_shards" : "1",
"number_of_replicas" : "1"
}
},
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"barcode": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"brand_name": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"category_name": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"product_id": {
"type": "long"
},
"tag_name": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"join_field": {
"type": "join",
"relations": {
"product": "tag"
}
},
"type": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
```
Now, we will create our first pipeline to index data from scratch. Create a file named **initial_index.conf** under **volumes/logstash/pipeline**.
The content of this will be as below.
```perl
# This part contains database information with a query to get data.
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es_relations_example"
jdbc_user => "test"
jdbc_password => "test"
clean_run => true
record_last_run => false
statement => "SELECT product.id as id, product.name, category.name as category_name, brand.name as brand_name, barcode FROM product LEFT JOIN category ON product.category_id = category.id LEFT JOIN brand ON product.brand_id = brand.id"
type => "product"
}
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es_relations_example"
jdbc_user => "test"
jdbc_password => "test"
clean_run => true
record_last_run => false
statement => "SELECT id, product_id, name as tag_name FROM tag"
type => "tag"
}
}
# We are adding some fields to create parent/child structure and remove unnecessary field
filter {
if [type] == "product" {
mutate {
add_field => {"join_field" => "product"}
remove_field => ["@version"]
}
} else if [type] == "tag" {
mutate {
add_field => {
"[join_field][name]" => "tag"
"[join_field][parent]" => "%{product_id}"
}
remove_field => ["@version"]
}
}
}
# Send the data to the ElasticSearch with our mapping schema.
# stdout's are for debug purpose. You can delete them
output {
if [type] == "product" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "index"
document_id => "%{id}"
routing => "%{id}"
manage_template => true
template => "/usr/share/logstash/templates/products.json"
template_name => "products"
template_overwrite => true
}
stdout {}
} else if [type] == "tag" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "index"
document_id => "%{id}"
routing => "%{product_id}"
manage_template => true
template => "/usr/share/logstash/templates/products.json"
template_name => "products"
template_overwrite => true
}
stdout {}
}
}
```
We have to tell Logstash that we have a pipeline to execute.
Create a file named **pipelines.yml** in **volumes/logstash/config**.
Put the lines below in it.
```yaml
- pipeline.id: initial_index-pipeline
path.config: "/usr/share/logstash/pipeline/initial_index.conf"
```
And finally, update docker-compose.yml as the following.
```yaml
logstash:
build:
context: .
dockerfile: ./Dockerfile-logstash
environment:
LS_JAVA_OPTS: "-Xmx1g -Xms1g"
depends_on:
- mysql
- elasticsearch
volumes:
- ./volumes/logstash/pipeline/:/usr/share/logstash/pipeline/
- ./volumes/logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml
- ./volumes/logstash/templates/products.json:/usr/share/logstash/templates/products.json
```
Run the following command and Logstash will index our data into ES.
```bash
docker-compose up -d logstash
docker ps -l # Get the container ID of logstash
docker logs -f 7e22a14208fa # This will print out the logs of the Logstash container
```
In the end, you need to see a line like that
`[2022-12-28T14:30:16,972][INFO ][logstash.runner] Logstash shut down.`
At this point, our data has to be indexed 😃
Let's check if it's there.
Go to http://localhost:5601/app/dev_tools
This will open a query console to make a search in our index.
We can get all indexed data using the query below.
```json
GET products/_search
{
"query": {
"match_all": {}
}
}
```
The result looks like this.
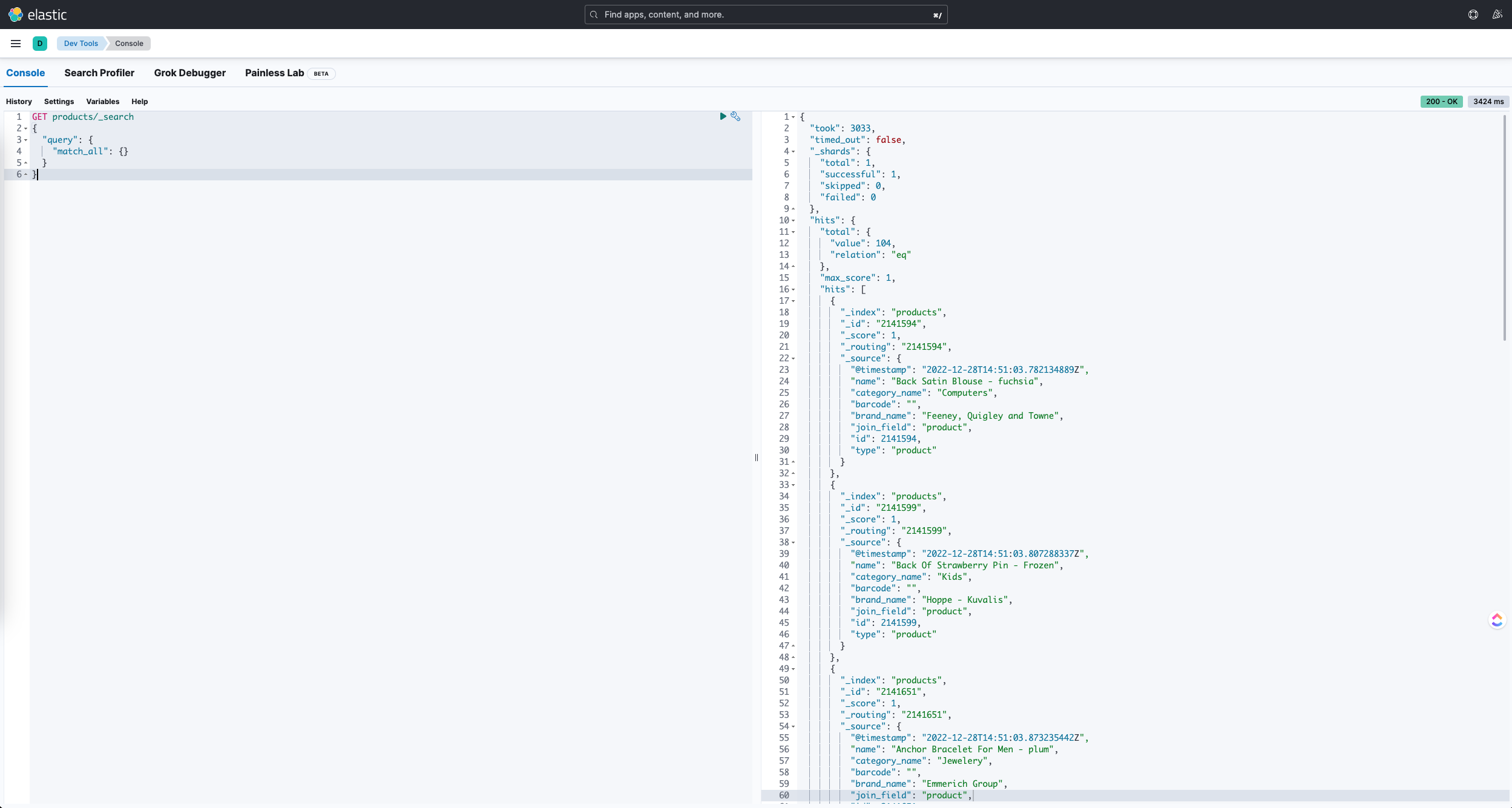
As you can see in the response, hits->total->value:104, we have 100 products and 4 tags in our database.
I actually use two patterns at the same time in this project.
Denormalized data to put category/brand names in the product object and parent/child pattern to get product tags.
Use the query below to see products with tags.
```json
GET products/_search
{
"query": {
"has_child": {
"type": "tag",
"query": {
"match_all": {}
},
"inner_hits": {}
}
}
}
```
This will return products and their tags.
The key points of this project so far are how we create the parent/child relationship.
1. Check the **products.json** to see the **join_field**. This is how we define the relationship between product and tag.
2. Check the **initial_index.conf** filter section to see how we add necessary fields to the related type of document. We just add the **join_field** field to the product and **join_fields** **name** and **parent** fields to the tag.
> You can find out detailed information about join at this [link](https://www.elastic.co/guide/en/elasticsearch/reference/current/parent-join.html).
We indexed our data already. But, what will happen when something is updated or deleted from the database?
I have a solution for you 😃 We need two more pipelines to keep updates/deletes synced with our database.
Let's create another pipeline with the name **keep_sync.conf** under **volumes/logstash/pipeline** and put the followings in it.
```perl
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es_relations_example"
jdbc_user => "test"
jdbc_password => "test"
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT product.id as id, product.name, category.name as category_name, brand.name as brand_name, barcode, UNIX_TIMESTAMP(GREATEST(product.date_updated, brand.date_updated, category.date_updated)) as unix_ts_in_secs FROM product LEFT JOIN category ON product.category_id = category.id LEFT JOIN brand ON product.brand_id = brand.id WHERE UNIX_TIMESTAMP(GREATEST(product.date_updated, brand.date_updated, category.date_updated)) > :sql_last_value AND GREATEST(product.date_updated, brand.date_updated, category.date_updated) < NOW()"
type => "product"
}
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es_relations_example"
jdbc_user => "test"
jdbc_password => "test"
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT id, product_id, name as tag_name, date_created as unix_ts_in_secs FROM tag WHERE UNIX_TIMESTAMP(date_created) > :sql_last_value AND date_created < NOW()"
type => "tag"
}
}
filter {
if [type] == "product" {
mutate {
add_field => {"join_field" => "product"}
remove_field => ["@version", "unix_ts_in_secs"]
}
} else if [type] == "tag" {
mutate {
add_field => {
"[join_field][name]" => "tag"
"[join_field][parent]" => "%{product_id}"
}
remove_field => ["@version", "unix_ts_in_secs"]
}
}
}
output {
if [type] == "product" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "index"
document_id => "%{id}"
routing => "%{id}"
}
} else if [type] == "tag" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "index"
document_id => "%{id}"
routing => "%{product_id}"
}
}
}
```
Did you notice the changes in the **jdbc** section?
We modified the SQL statement to get updated rows a bit and put a cron scheduler to run it automatically. This will run the statement every 5 seconds and retrieve the updates if there are any.
And, we'll say Logstash to run this pipeline too by adding the following lines to the **pipeline.yml**
```yaml
- pipeline.id: keep_sync-pipeline
path.config: "/usr/share/logstash/pipeline/keep_sync.conf"
```
Now, build and run the Logstash container again.
```bash
docker-compose up -d logstash
```
When you check the Logstash logs, you will see that it won't shut down anymore. Instead, it will periodically run the statement.
Let's check if it is working.
Firstly, I'm going to check the indexed data for the product with ID 2141673.
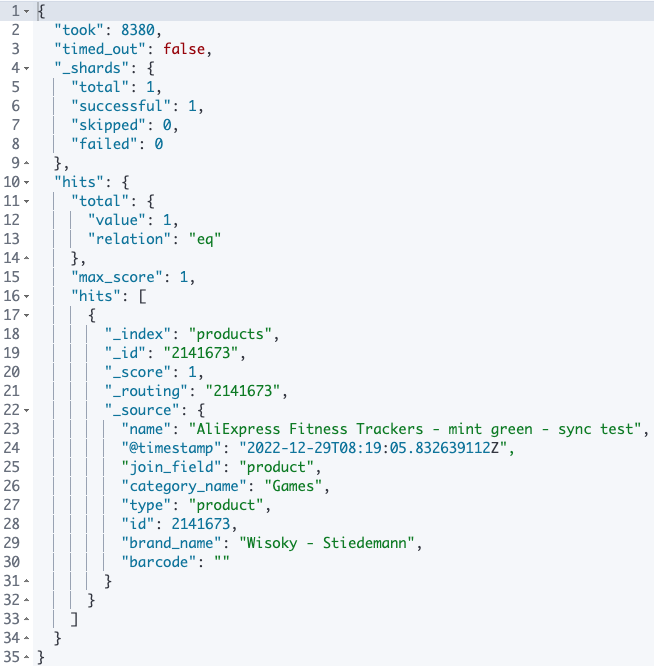
Now, I'll update the name of it from the database.
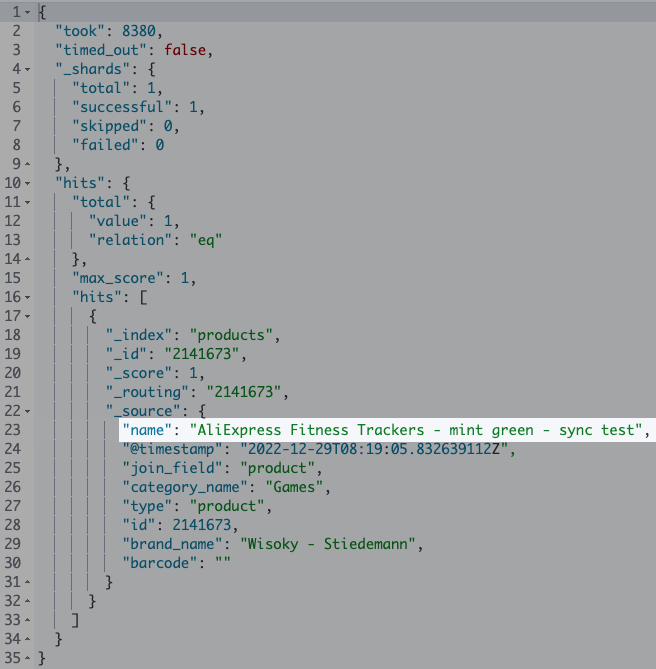
A few seconds later, it was already synced.
We indexed our data and can keep synced updates. Lastly, we will keep synced deletions.
To keep deletions synced, there are two ways.
The first one is to add a soft delete column to the related tables and modify your queries to keep them away from your results and delete those rows later with a script.
The second one is to create a log book for your deletions and read this table using Logstash and delete related indexes.
The latter one is better suited for our case and we implemented it. When you check the example database, you will see a table with named **sync_log**. When rows are deleted from other tables, their triggers create a row on this.
We'll be going to add a new pipeline to read this table and delete related indexes from ES.
Now, create a new pipeline named **keep_sync_deletions.conf**.
```perl
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-j.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://mysql:3306/es_relations_example"
jdbc_user => "test"
jdbc_password => "test"
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT model_id, model_type, parent_id, UNIX_TIMESTAMP(action_time) as unix_ts_in_secs FROM sync_log WHERE UNIX_TIMESTAMP(action_time) > :sql_last_value AND action_time < NOW()"
type => "tag"
}
}
filter {
mutate {
remove_field => ["@version", "unix_ts_in_secs"]
}
}
output {
if [type] == "product" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "delete"
document_id => "%{model_id}"
routing => "%{model_id}"
}
} else if [type] == "tag" {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "products"
action => "delete"
document_id => "%{model_id}"
routing => "%{parent_id}"
}
}
}
```
The main difference of this pipeline is we changed the action in the **output** section. The **action** was **index** for the other ones but now it's **delete**.
Update the **pipeline.yml** to say Logstash we have a new pipeline. Then, restart the Logstash container.
```yaml
- pipeline.id: keep_sync_deletions-pipeline
path.config: "/usr/share/logstash/pipeline/keep_sync_deletions.conf"
```
```bash
docker-compose up -d logstash
```
You can delete something from your database and try to reach it in the index. You can find it anymore, hopefully. 😃
## Last Words
I try to give a brief explanation about how we can keep our relational data in ES and sync it after. I hope you find this story useful. Keep in mind this story assumes that you already know about the tech stack which we used. So, I try not to deep dive into how they are working or set up.
This is my first story by the way. Please let me know anything about the story.
Feel free to ask questions about the ES, Logstash, or something.
Thank you for your time.
## Resources
- [ElasticSearch Documentation](https://www.elastic.co/guide/index.html)
- [How to keep Elasticsearch synchronized with a relational database using Logstash and JDBC](https://www.elastic.co/blog/how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash)
- https://towardsdatascience.com/how-to-synchronize-elasticsearch-with-mysql-ed32fc57b339 This story helps me a lot. Thanks to [Redouane Achouri](https://medium.com/@redouane.achouri) | batuhannarci | |
1,311,918 | Eventos em Node.js: a magia por trás da comunicação entre módulos | Os eventos são uma parte fundamental da programação em Node.js, e são usados para permitir que... | 0 | 2022-12-31T23:09:37 | https://dev.to/leeodev/eventos-em-nodejs-a-magia-por-tras-da-comunicacao-entre-modulos-6mk | javascript, node, beginners, events | Os eventos são uma parte fundamental da programação em Node.js, e são usados para permitir que diferentes partes de um aplicativo se comuniquem entre si de maneira assíncrona. Mas o que exatamente isso significa e por que é importante?
Imagine que você tem um aplicativo que precisa realizar uma série de tarefas. Por exemplo, você pode ter um módulo que lê um arquivo do disco, outro módulo que processa os dados lidos e um terceiro módulo que escreve os dados processados em outro arquivo. Cada um desses módulos é responsável por realizar uma tarefa específica, e eles precisam trabalhar juntos para concluir o processo.
Sem eventos, esses módulos teriam que se comunicar de alguma forma para coordenar suas ações. Isso poderia ser feito de várias maneiras, como chamadas de função ou variáveis compartilhadas. No entanto, essas abordagens podem ser problemáticas, pois requerem que os módulos estejam sincronizados em relação ao tempo e às threads. Isso pode tornar o código mais complexo e difícil de manter e depurar.
Ao invés disso, os eventos permitem que os módulos se comuniquem de forma assíncrona, o que significa que eles não precisam esperar uns pelos outros. Um módulo pode emitir um evento quando ele terminar de realizar sua tarefa, e outro módulo pode ouvir esse evento e agir em resposta. Isso permite que os módulos trabalhem de forma independente, mas ainda assim se comuniquem para coordenar suas ações.
Existem muitos benefícios em usar eventos em seu aplicativo Node.js.
- **Comunicação assíncrona**: como mencionado anteriormente, os eventos permitem que diferentes partes de um aplicativo se comuniquem entre si de maneira assíncrona. Isso significa que um módulo pode emitir um evento e outro módulo pode ouvir esse evento e agir em resposta, sem que haja necessidade de sincronização ou bloqueio de threads. Isso pode tornar o seu código mais fácil de escrever e manter, pois cada módulo pode trabalhar de forma independente.
- **Modularidade**: os eventos também podem ajudar a tornar o seu código mais modular, pois permitem que diferentes módulos do aplicativo trabalhem de forma independente, mas ainda assim se comuniquem entre si para coordenar suas ações. Isso pode tornar o seu aplicativo mais fácil de manter e escalar, pois cada módulo pode ser testado e modificado independentemente dos outros.
- **Performância**: os eventos também podem ajudar a tornar o seu código mais performático, pois permitem que você execute várias tarefas de maneira assíncrona, em vez de precisar esperar por cada tarefa ser concluída antes de iniciar a próxima. Isso pode ser especialmente útil em aplicativos que realizam muitas tarefas de entrada e saída de dados, como acesso a banco de dados ou chamadas de rede, pois essas tarefas podem ser bastante lentas e consumir muitos recursos do sistema.
Para usar eventos em Node.js, você pode usar a classe _EventEmitter_, que é fornecida pelo módulo _events_ padrão do Node.js. Você pode criar um novo objeto _EventEmitter_ e usá-lo para emitir e ouvir eventos. Por exemplo:
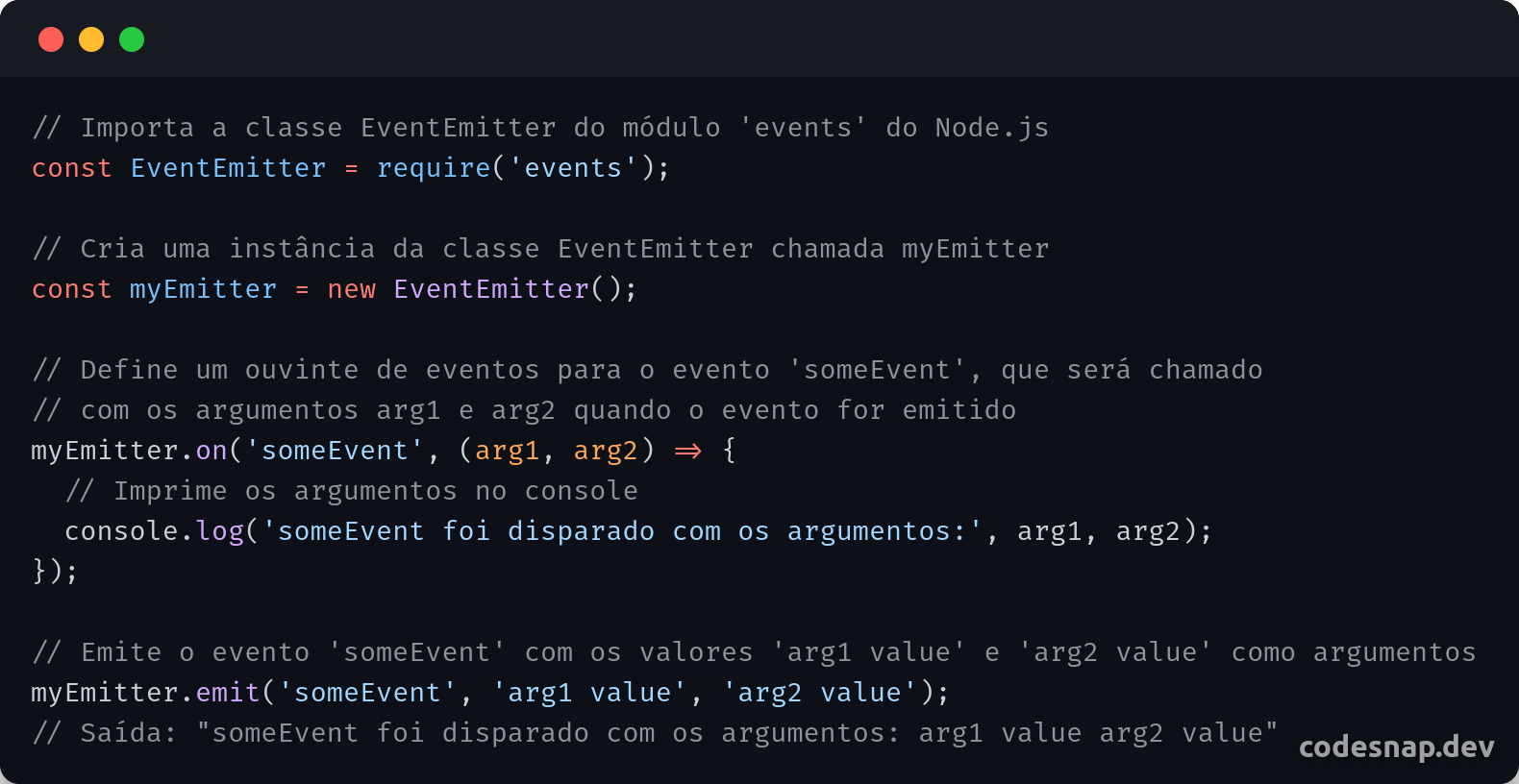
Neste exemplo, estamos criando um novo objeto _EventEmitter_ e usando o método on para adicionar um callback para o evento _someEvent_. O callback é uma função que será chamada toda vez que o evento for emitido. Em seguida, estamos usando o método emit para emitir o evento someEvent, passando dois argumentos para ele: 'arg1 value' e 'arg2 value'. Quando o evento é emitido, o callback é chamado e os argumentos são passados para ele, imprimindo a mensagem "someEvent triggered with args: arg1 value arg2 value" no console.
Como qualquer ferramenta, é importante usar eventos de maneira responsável e considerar os possíveis riscos e cuidados que devemos tomar ao trabalhar com eles. Aqui estão alguns dos principais cuidados a serem tomados ao usar eventos em Node.js:
- **Evite usar eventos para comunicação síncrona**: como mencionado anteriormente, os eventos são projetados para permitir comunicação assíncrona entre módulos. Se você tentar usar eventos para comunicação síncrona, pode encontrar problemas de sincronização e bloqueio de threads, o que pode afetar negativamente o desempenho do seu aplicativo.
- **Seja cuidadoso ao adicionar e remover callbacks**: é importante ter cuidado ao adicionar e remover callbacks de eventos, pois se você adicionar um callback mas esquecer de removê-lo, isso pode levar a problemas de memória e pode ser difícil de depurar. Certifique-se de remover callbacks quando eles não são mais necessários para liberar recursos.
- **Evite dependências circulares**: os eventos podem ser uma ótima maneira de permitir que diferentes módulos se comuniquem, mas é importante tomar cuidado para evitar dependências circulares. Isso ocorre quando um módulo precisa do outro, mas o outro módulo também precisa do primeiro. Isso pode levar a problemas de inicialização e deve ser evitado.
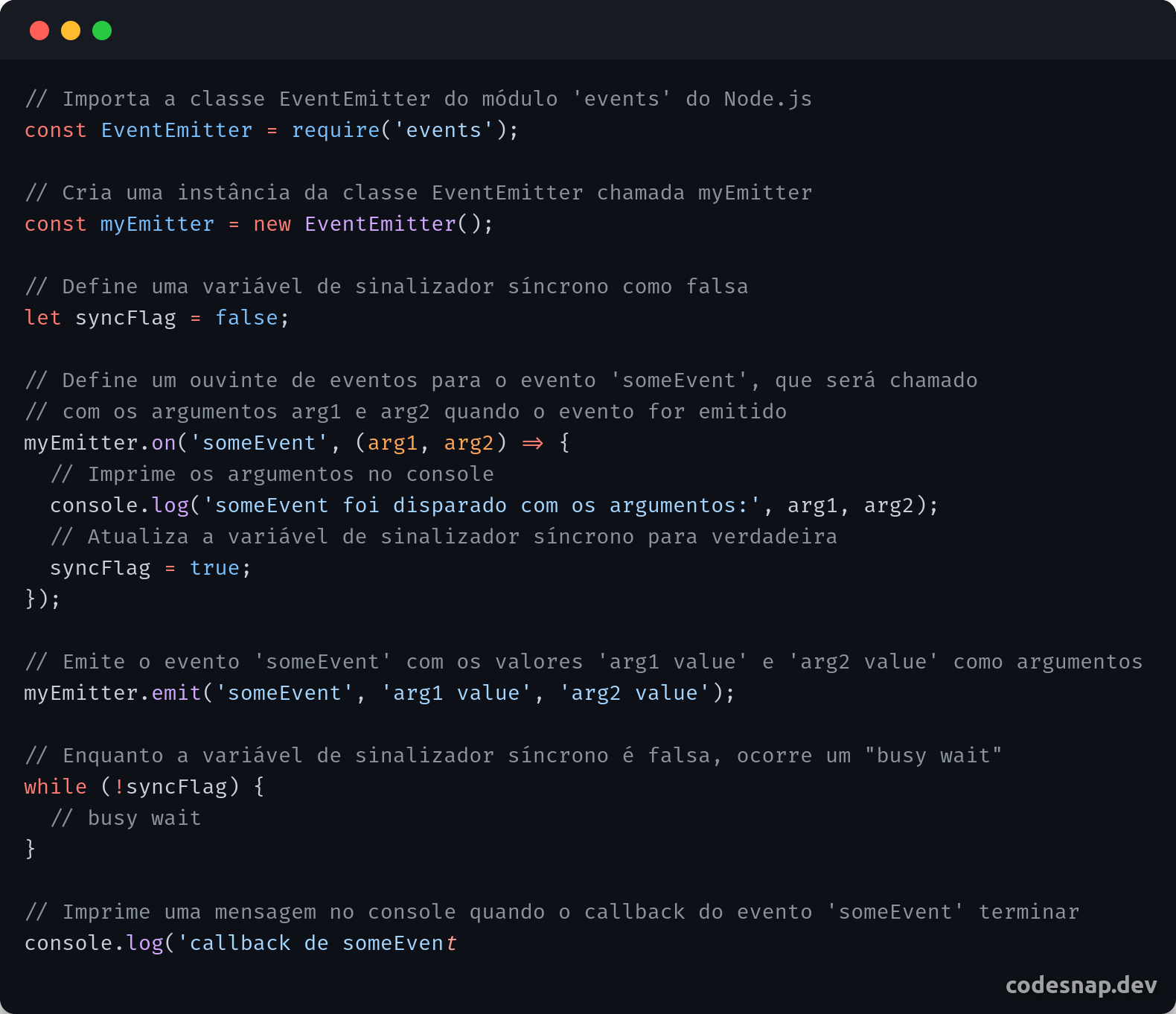
Neste exemplo, estamos usando uma variável de sincronização para fazer o código aguardar até que o callback do evento seja chamado. Isso transforma os eventos em uma forma de comunicação síncrona, mas é importante lembrar que isso pode levar a problemas de sincronização e bloqueio de threads se usado de maneira inadequada.
Em conclusão, os eventos são um mecanismo fundamental em Node.js que permitem que diferentes partes de um aplicativo se comuniquem entre si de maneira assíncrona. Eles têm muitos benefícios, como comunicação assíncrona, modularidade e performância, e são usados em muitos aplicativos diferentes.
Se você estiver interessado em aprender mais sobre eventos em Node.js, aqui estão alguns próximos passos que você pode considerar:
- **Lea a documentação do módulo events**: essa é a fonte principal de informação sobre como usar eventos em Node.js. Você pode encontrar a documentação completa aqui: [Events](https://nodejs.org/api/events.html)
- **Experimente usando eventos em seus próprios aplicativos**: a melhor maneira de aprender sobre eventos é experimentando por conta própria. Crie um novo projeto em Node.js e experimente emitir e ouvir eventos em diferentes partes do seu aplicativo.
- **Explore outros recursos e tutoriais online**: há muitos tutoriais e exemplos de código disponíveis online que podem ajudá-lo a aprender mais sobre eventos em Node.js. Você pode começar a procurar por alguns desses recursos usando a sua ferramenta de pesquisa favorita. | leeodev |
1,311,961 | Test-Driven Development isn't about Unit Tests | I've met quite a number of people excitedly talking about how they wanted to adopt TDD (test-driven... | 0 | 2022-12-29T16:24:45 | https://dev.to/gervg/test-driven-development-isnt-about-unit-tests-48e3 | tdd, productivity, testing, programming | I've met quite a number of people excitedly talking about how they wanted to adopt TDD (test-driven development), citing its ability to “catch bugs before you make them” or something about improving the code quality. While that is not entirely wrong, I think it's a bit misguided and overlooks TDD’s foremost benefit.
Worse, some of them seemingly take TDD as if it's an interchangeable term with unit testing. I am not being pedantic - unit testing is an art of its own and you can write effective tests without doing TDD. Unit test's responsibility is to ensure that your code works as intended; TDD's job is to help you get your code working as intended. See the difference, no? Okay, let's first talk about unit tests.
## Everyone loves unit tests
Devs hate meetings. But what do devs love? Writing code, of course! So much so that we're also writing code to test code. The most common of which are unit tests.

Unit tests help us slice our programs into smaller individual pieces (units) and test them independently. They're cheaper to write (relative to integration/end-to-end testing) and they provide very quick feedback to the developer. With just a quick run on the CLI or IDE, a dev can easily find out if something broke. Unit tests are your first line of defence against defects. Martin Fowler describes how it serves as the foundation of your [testing pyramid](https://martinfowler.com/bliki/TestPyramid.html).
When you write unit tests, your objective is to _test_ and ensure that your production code works as expected. Now let's move to TDD…
## Driven by Tests
There are A LOT of other *X-driven Development*: BDD, DDD, FDD, etc.
I'm starting to think the industry sometimes just loves to formalize processes and slap them with _-driven development_ on its name. Kidding aside, let's take our focus back on TDD.
I believe there's a subtle problem with the name “test-driven”. Not that I think I can do a better job than Kent Beck, but it seems that the name led people to conflate testing with TDD.
But the operative word here is “driven”. TDD is a development technique driven by tests. **Tests are the means not the goal**. The goal is still to write functioning production code and you're just leveraging the power of tests while doing so.
### F*ck around and Find out
Have you seen this meme?
It's a funny, perhaps oversimplified, overview of the scientific method. But I think it's a very good analogy to what TDD is meant for in software development.
Writing unit tests in TDD is similar to coming up with a hypothesis and preparing the workbench in a lab. You have an idea in your head, and you verify it with an experiment. Oh, the idea didn't work - tweak some variables and run the test again. Did it work this time? See if it can still be improved… the cycle repeats. [Red-Green-Refactor](https://blog.cleancoder.com/uncle-bob/2014/12/17/TheCyclesOfTDD.html) is exactly that!
TDD is for times when you don't have a clear path ahead yet. It's for discovering the solution and refinement. It is a [design activity](https://www.developerdotstar.com/mag/articles/reeves_design_main.html). Take for example, a method signature. When writing tests, you think about the signature first but not yet the implementation details. How do you want it to look like? Inputs? Outputs? Is it easy to wield? And so forth.
**TDD is a technique meant to help you iteratively reach your objective: a working software**. So maybe, we can call it _experiment-driven_. But after a quick Google search, that name is already taken. Gosh darn, naming is indeed hard.
## Quality is a by-product
Let's talk about quality on two fronts: correctness and maintainability.
When you do TDD, you write tests (duh). These in turn cover a huge chunk of your code base. While code coverage is not necessarily indicative of good quality, the tests created through TDD gives some confidence that your production code works based on the assumptions you've established. These tests also create a safety net, guaranteeing that existing behaviours will not be accidentally changed when modifying the production code.
TDD also levels up maintainability by producing testable code. Sometimes when writing tests after production code, you might find yourself having to deal with a lot of coupling between different parts. This makes it hard to test them independently. TDD inverts that process hence you end up with code that is surely testable.
So yes, TDD helps improve quality. But **it is not the quality gate**, tests are, regardless if you write them before or after. | gervg |
1,312,106 | You should be using HTTP Strict Transport Security (HSTS) headers in your Node.js server | For most websites and apps, employing security-related HTTP headers has become standard practice.... | 0 | 2023-01-09T10:18:27 | https://snyk.io/blog/http-strict-transport-security-hsts-headers-node-js/ | applicationsecurity, ecosystems, engineering | ---
title: You should be using HTTP Strict Transport Security (HSTS) headers in your Node.js server
published: true
date: 2022-12-29 15:35:59 UTC
tags: ApplicationSecurity,Ecosystems,Engineering
canonical_url: https://snyk.io/blog/http-strict-transport-security-hsts-headers-node-js/
---
For most websites and apps, employing security-related [HTTP headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers) has become standard practice. Websites use headers as part of HTTP requests and replies to convey information about a page or data sent via the HTTP protocol. They might include a [Content-Encoding](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Encoding) header to indicate that the content is a compressed zip file or a [Location](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Location) header to specify a redirect URL.
Among the many available [security headers](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers#security) that modern web browsers use to protect users, one crucial type is the HTTP Strict Transport Security ([HSTS](https://developer.mozilla.org/en-US/docs/Glossary/HSTS)) header. The HSTS header that a website provides tells the browser to use the HTTPS protocol on each subsequent visit.
However, despite their utility, ease of implementation, and support from virtually every browser, only [about 25% of mobile and 28% of desktop HTTP responses](https://almanac.httparchive.org/en/2022/security#http-strict-transport-security) include HSTS headers.
Let’s take an in-depth look at HSTS headers to discover how they affect web security and why we should use them on Node.js. Then, we’ll learn how to enable HSTS inside a Node.js server.
## Why enable HSTS?
HTTPS connections are secure because they encrypt and decrypt transmitted data packets using SSL/TLS certificates, which well-known certificate authorities (CAs) can verify. As a result, only the user’s computer and the server can read the transmitted data packets, regardless of who intercepts the network traffic.
Typical HTTP connections are unencrypted, meaning that anyone who accesses the data can read it. These unintended recipients might include servers routing and forwarding the user’s data to its destination server or a hacker who accesses the network traffic on a public WiFi router.
Consider these findings from the Web Almanac 2022 report, which Snyk also co-authored.

Currently, just 34% of mobile and 37% of desktop request responses include the `includeSubdomain` directive.
The remaining majority remains more susceptible to [man-in-the-middle](https://snyk.io/learn/man-in-the-middle-attack/) (MITM) attacks, which might result in anything from credit or identity theft to compromised web credentials for our Node.js web application. Notably, malicious actors don’t need to intercept data at the moment we enter our login credentials. Browser cookies often store and send our session/access tokens, enabling these malicious actors to obtain them via session hijacking.
### How does HSTS work?
When the HTTP response header contains an HSTS, web browsers know to always use an HTTPS connection with the server and automatically redirect users who first connected via HTTP. From then on, connections to the web application or site remain encrypted and secure, enabling the app to use secure cookies and helping prevent MITM security attacks.
There are three different parameters available in the HSTS header. Let’s check them out.
### max-age=<expire-time>
This required parameter specifies the amount of time in seconds that the browser should remember to connect to the site via HTTPS. Once this time expires, the browser will load the site normally on the next visit. The expiration time is updated in the user’s browser every time it sees the HSTS header. As a result, the parameter can remain active indefinitely. Alternatively, certain sites may immediately disable HSTS by setting this value to 0.
When testing your HSTS configuration, you can set the time to a short duration, such as 300 seconds (five minutes). Then, once you’ve verified that your site functions properly, you can set it to a longer-term duration, like 31,536,000 seconds (one year).
### includeSubDomains
The `includeSubDomains` parameter is an optional flag that tells the browser to enable HSTS for the website and all its subdomains. Because this setting applies broadly, you should ensure that all of your subdomains can support HTTPS before implementing the parameter.
### preload
An initial connection could potentially use a compromised HTTP connection. In response, Google has maintained the unofficial `preload` parameter. Most major browsers support this security header, which significantly mitigates the risk. A website can add the `preload` parameter to the HSTS header and then register the domain to the [preload service](https://hstspreload.org/). Browsers can then check this reference list to determine whether their initial connections can use HTTPS. Note that you need to set the `max-age` parameter to at least 31,536,000 seconds and enable the `includeSubDomains` parameter for the `preload` parameter to work.
Note that once the preload service adds your domain, a removal request can take several months to process. If you would like to register your domain for preloading, you should familiarize yourself with the [submission requirements](https://hstspreload.org/#submission-requirements) and [deployment recommendations](https://hstspreload.org/#deployment-recommendations).
## Enhancing security with HSTS
Let’s dive into an example Node.js server code and respond with an HSTS header.
### Prerequisites
This project will need the following to run:
- A registered domain name
- A server with [Node.js](https://nodejs.org/) and network ports 80 and 433 available
- A usable DNS record for the domain pointing to the server
### Get an SSL/TLS certificate
The first thing we will need before enabling HTTPS is a certificate and private key for the domain. If you don’t have one already, you can get one via [Let’s Encrypt](https://letsencrypt.org/) using the following steps:
First, install `certbot` by following these [instructions](https://certbot.eff.org/instructions). Select **other** from the **Software** dropdown and choose your server’s operating system from the **System** dropdown. Then, follow the instructions that appear.

Next, ensure that ports 80 and 443 are open on the server and run the following command with your domain for the server:
```
certbot certonly --standalone -d your.domain.url
```
You may need to prefix the command with sudo and run as a privileged user.

Now, run `certbot certificates` (with sudo if needed) to obtain the file paths for the certificate and the private key.

### Set up the server code
Start by creating a project folder on the server by running the command: `mkdir snyk-demo`.
Next, enter the folder using: `cd snyk-demo`.
Then, initialize the folder as a Node.js project using: `npm init -y`.

Now, let’s install some project dependencies for the server. Ensure you follow the relevant Express or Fastify instructions.
**Express:**
```
npm install express helmet
```
**Fastify:**
```
npm install fastify @fastify/helmet
```
Now, we can create a basic Express Node.js server running HTTP and HTTPS.
Create an `index.js` file in this folder and add the following Node modules at the top of the code.
**Express:**
```
const fs = require( "fs" );
const http = require( "http" );
const https = require( "https" );
const express = require( "express" );
const helmet = require( "helmet" );
```
**Fastify:**
```
const fs = require( "fs" );
const helmet = require( "@fastify/helmet" );
```
Add the following code to load the certificate files and replace the `certificatePath` value with your domain certificate’s path. If you used the LetsEncrypt’s certbot, you can run `certbot certificates` to retrieve the file paths.
**Express:**
```
// Replace the following with your domain certificate path
const certificatePath = `/etc/letsencrypt/live/snykdemo.instafluff.tv/;
const privateKey = fs.readFileSync( `${certificatePath}/privkey.pem, "utf8" );
const certificate = fs.readFileSync( `${certificatePath}/fullchain.pem, "utf8" );
// Add the following if your certificate includes a certificate chain
// const ca = fs.readFileSync( `${certificatePath}/chain.pem, "utf8" );
const credentials = {
key: privateKey,
cert: certificate,
// ca: ca, // Add the ca if there is a certificate chain
};
```
**Fastify:**
```
// Replace the following with your own domain certificate path
const certificatePath = `/etc/letsencrypt/live/snykdemo.instafluff.tv/`;
const fastify = require( "fastify" )({
https: {
key: fs.readFileSync( `${certificatePath}/privkey.pem, "utf8" ),
cert: fs.readFileSync( `${certificatePath}/fullchain.pem, "utf8" ),
// // Add the following if your certificate includes a certificate chain
// ca: fs.readFileSync( `${certificatePath}/chain.pem, "utf8" ),
},
});
const fastifyHttp = require( "fastify" )();
```
Now it’s time to initialize the Express/Fastify app and create a basic route.
The following code demonstrates all three HSTS parameters, but you may wish to only use the `max-age` parameter to start.
### Option 1: Use Helmet middleware
The first way we can set HSTS is via [Helmet](https://helmetjs.github.io/) middleware with the app initialization:
**Express:**
```
const app = express();
app.use( helmet() );
app.use( helmet.hsts( { maxAge: 300, includeSubDomains: true, preload: true } ) );
app.use( ( req, res ) => {
res.send( "Hello secure web!" );
});
```
**Fastify:**
```
const hsts = { maxAge: 300, includeSubDomains: true, preload: true };
fastify.register( helmet, { hsts } );
fastifyHttp.register( helmet, { hsts } );
```
### Option 2: Manually set the header
Alternatively, we can manually set the HSTS header through a middleware that applies it to every reply:
**Express:**
```
const app = express();
app.use( ( req, res ) => {
if( req.secure ) {
res.setHeader( "Strict-Transport-Security", "max-age=300; includeSubDomains; preload" );
}
res.send( "Hello secure web!" );
});
```
**Fastify:**
```
fastify.get( "/", ( req, res ) => {
res.header( "Strict-Transport-Security", "max-age=300; includeSubDomains; preload" );
res.send( "Hello secure web!" );
});
fastifyHttp.get( "/", ( req, res ) => {
res.header( "Strict-Transport-Security", "max-age=300; includeSubDomains; preload" );
res.send( "Redirect to HTTPS" );
});
```
We can finish the code by creating the HTTP and HTTPS servers with the following code:
**Express:**
```
const httpServer = http.createServer( app );
httpServer.listen( 80, () => {
console.log( "HTTP server started." );
});
const httpsServer = https.createServer( credentials, app );
httpsServer.listen( 443, () => {
console.log( "HTTPS server started" );
});
```
**Fastify:**
```
fastifyHttp.listen( { port: 80, host: "0.0.0.0" }, ( err, address ) => {
console.log( "HTTP server started" );
});
fastify.listen( { port: 443, host: "0.0.0.0" }, ( err, address ) => {
console.log( "HTTPS server started" );
});
```
Finally, run the server code with `node index.js` and then open your domain in a web browser.
```
bitnami@ip-172-26-14-29:~/snyk-demo$ sudo node index.js
HTTP server started.
HTTPS server started
```
Open DevTools in your browser and inspect the response headers in the **Network** tab. We can see that the HSTS header is specified.

## What’s next?
Now that you’ve learned why HTTP Strict Transport Security headers are important for the security of Node.js applications, how they help prevent MITM attacks, and how to implement them in your Node.js code, you have the tools to secure your web applications for your users.
There is one more critical point to remember. When you’re working in a production environment, you should not set HSTS or serve SSL via the Node.js app. Instead, you should offload these processes to static file HTTP servers like NGINX or Apache.
## Free developer security education
Learn about the biggest developers face and how to avoid them.
[Start learning](https://learn.snyk.io)
<!-- /.block --> | snyk_sec |
1,312,143 | Transfer a domain between AWS accounts | It is easy to transfer a domain from one AWS account to another AWS account with the help of AWS... | 0 | 2022-12-29T19:29:27 | https://dev.to/stefanalfbo/transfer-a-domain-between-aws-accounts-5gfj | aws, route53 | It is easy to transfer a domain from one AWS account to another AWS account with the help of AWS CLI.
These commands are done with AWS CLI in bash.
```bash
# Make sure that you have the AWS CLI installed
aws --version
```
We will use the command [route53domains](https://awscli.amazonaws.com/v2/documentation/api/latest/reference/route53domains/index.html) and its sub commands to do the transfer.
Three things are needed for the first step, the __domain name__ to transfer, the __account id__ that should have the domain name and the __credentials__ (perhaps as an AWS CLI profile) of the owner of the domain.
```bash
aws route53domains transfer-domain-to-another-aws-account \
--domain-name example.com \
--account-id 111122223333 \
--region us-east-1 \
--profile DomainOwner
```
Note that it's important that this is done in the __us-east-1__ region since the route53 service is global. The error message would look like this otherwise.
```bash
Could not connect to the endpoint URL: "https://route53domains.eu-west-3.amazonaws.com/"
```
If the transfer was successful, then there would be a response with an __operation id__ and a __password__.
```bash
# the response depending on you output preference
984188c3-1238-457c-a4ab-c6cc064f043d =xfdf%/fj/5nr=
```
Command for checking the status of the transfer.
```bash
aws route53domains get-operation-detail \
--operation-id 984188c3-1238-457c-a4ab-c6cc064f043d \
--profile DomainOwner
--region us-east-1
```
The last step is to accept the transfer with the account that should receive the domain, which means that we need the credentials for that account when running the AWS CLI commands. The __domain name__ and the __password__ from the first command will also be needed here.
```bash
aws route53domains accept-domain-transfer-from-another-aws-account \
--domain-name example.com \
--password =xfdf%/fj/5nr= \
--profile DomainReceiver
--region us-east-1
```
All done, the last command will also get an __operation id__ in the response that could be used to check the status with the sub command __get-operation-detail__ as described above, remember to use the correct profile.
Resources:
- [route53domains](https://awscli.amazonaws.com/v2/documentation/api/latest/reference/route53domains/index.html)
- [Route53 Developer guide](https://docs.aws.amazon.com/Route53/latest/DeveloperGuide/domain-transfer-between-aws-accounts.html)
| stefanalfbo |
1,312,392 | Customize the deployment of AWS Lambda Layer anyhow you like | Separate NPM Dependencies into layers One way to improve deployment time when developing... | 0 | 2022-12-29T23:56:23 | https://dev.to/asinkxcoswt/customize-the-deployment-of-aws-lambda-layer-anyhow-you-like-5a02 | aws, serverless, devops | ## Separate NPM Dependencies into layers
One way to improve deployment time when developing AWS Lambda functions is to separate your function's dependencies into layers. You can save time by deploying the layers once so that the subsequent deployments of your main functions code are as lightweight as possible.
Serverless Framework has built-in support for deploying layers by creating your desired dependencies in a separated `package.json` file and putting the file in the `nodejs` directory under the layer path.
```cmd
# directory structure
layers/
stablelibs/
nodejs/
package.json
otherLibs/
nodejs/
package.json
serverless.yml
package.json
```
```yml
# serverless.yml
layers:
commonlibs:
path: layers/commonlibs
functions:
...
```
## The problems
However, this method has some problems.
1. You have to maintain multiple `package.json` files. It will be very difficult to keep the dependencies version in sync in every file, especially if you are using Github's `dependabot` to keep updating the dependencies version.
2. It will involve multiple manual steps for each deployment. For example, you have to go into each layer and run `yarn install` to populate `node_modules` before running the actual deploy command.
3. The deployment time can be even worst because it now has to take time to install dependencies and package each layer for every deployment.
For the second and third points, the existing plugin such as [serverless-layer](https://www.npmjs.com/package/serverless-layers) is a good solution, but in exchange, you will lose some built-in features such as the ability to exclude unnecessary files inside `node_modules` for some packages.
Different projects have different requirements for the workflow. It would be unfortunate to let the framework or plugins limit what you want to do.
I have been researching this problem, and It turns out that Serverless Framework is more flexible and powerful than I thought. It is very easy to customise the deployment workflow anyhow I like. And what follows is an example of what I have done with my current project.
## 1. Separate layers deployment from functions
In my project, I already have multiple `serverless.yml` for each of my API gateways. For example, I have `serverless.internal-api.yml` and `serverless.external-api.yml` for my internal and external API gateways.
The functions in both files share the same dependencies. So I create another file dedicated to the layers only.
```cmd
serverless.internal-api.yml
serverless.external-api.yml
serverless.layers.yml <-- this
package.json
```
Let's start with the simple version of `serverless.layers.yml`
```yml
service: dependency-layers
layers:
awslibs:
path: layers/awslibs
name: ${self:service}-${sls:stage}-awslibs
platformlibs:
path: layers/platformlibs
name: ${self:service}-${sls:stage}-platformlibs
stablelibs:
path: layers/stablelibs
name: ${self:service}-${sls:stage}-stablelibs
otherlibs:
path: layers/otherlibs
name: ${self:service}-${sls:stage}-otherlibs
```
And then use these layers with the functions in `serverless.internal-api.yml` and `serverless.external-api.yml`
```yml
package:
individually: true
# include only the functions code in the dist folder
patterns:
- "!**"
- "dist/**"
providers:
layers:
- arn:aws:lambda:${aws:region}:${aws:accountId}:layer:dependency-layers-${sls:stage}-awslibs:latest
- arn:aws:lambda:${aws:region}:${aws:accountId}:layer:dependency-layers-${sls:stage}-platformlibs:latest
- arn:aws:lambda:${aws:region}:${aws:accountId}:layer:dependency-layers-${sls:stage}-stablelibs:latest
- arn:aws:lambda:${aws:region}:${aws:accountId}:layer:dependency-layers-${sls:stage}-otherlibs:latest
plugins:
# This plugin will replace the 'latest' after the ARNs to the actual version number
- serverless-latest-layer-version
```
Now I can deploy the layers independently from the functions. I have this npm script in `package.json`
```json
scripts: {
"deploy:layer": "serverless deploy -c serverless.layers.yml",
"deploy:internal-api": "serverless deploy -c serverless.internal-api.yml",
"deploy:external-api": "serverless deploy -c serverless.external-api.yml"
}
```
## 2. Use hooks to populate layer's files at built-time
Notice that we will need the following folder structure for the layer files.
```cmd
# directory structure
layers/
awslibs/
nodejs/
node_modules
package.json
platformlibs/
nodejs/
node_modules
package.json
stablelibs/
nodejs/
node_modules
package.json
otherlibs/
nodejs/
node_modules
package.json
serverless.internal-api.yml
serverless.external-api.yml
serverless.layers.yml
package.json
```
We will populate these files dynamically when running the `deploy:layers` script. To do that, I insert `dependencyIncludeRegexPatterns` for each layer configuration to tell which dependencies to be copied from the main `package.json` to the layer's `package.json`.
```yml
service: dependency-layers
layers:
awslibs:
path: layers/awslibs
name: ${self:service}-${sls:stage}-awslibs
installCommand: yarn install
dependencyIncludeRegexPatterns:
- "^@aws-sdk"
- "^aws"
platformlibs:
path: layers/platformlibs
name: ${self:service}-${sls:stage}-platformlibs
installCommand: yarn install
dependencyIncludeRegexPatterns:
- "^@opentelemetry"
- "^@nestjs"
stablelibs:
path: layers/stablelibs
name: ${self:service}-${sls:stage}-stablelibs
dependencyIncludeRegexPatterns:
- "^date-fns$"
- "^rxjs$"
otherlibs:
path: layers/otherlibs
name: ${self:service}-${sls:stage}-otherlibs
dependencyIncludeRegexPatterns:
- "."
```
Then I use [serverless-plugin-scripts](https://www.serverless.com/plugins/serverless-plugin-scripts) to define a hook script that will run right after we kick off the script `deploy:layer`.
```yml
plugins:
- serverless-plugin-scripts
custom:
scripts:
commands:
hooks:
"before:package:initialize": ts-node tools/initializeLayerDependencies.ts serverless.layers.yml
```
Basically, we can do anything in `tools/initializeLayerDependencies.ts`, but here I populate the `package.json` for each layer and run the `installCommand`
```typescript
import { mkdirSync, readFileSync, rmSync, writeFileSync } from "fs";
import * as yaml from "js-yaml";
import packageJson from "../package.json";
import { run } from "./libs/process-utils";
const configFile = process.argv[2];
initializeLayerDependencies(configFile);
// ################################################################
interface LayerConfig {
path: string;
installCommand: string;
yarnCacheFolder: string;
dependencyIncludeRegexPatterns: string[];
dependencyExcludeRegexPatterns?: string[];
}
async function initializeLayerDependencies(configFile: string) {
const config = yaml.load(readFileSync(configFile, "utf8")) as {
layers: { [layerName: string]: LayerConfig };
};
const remainingDependencies = packageJson.dependencies;
for (const [_layerName, layerConfig] of Object.entries(config.layers)) {
console.log({ _layerName, layerConfig });
if (!validConfig(layerConfig)) {
console.warn("Invalid layerConfig!");
continue;
}
const dependencyPath = `${layerConfig.path}/nodejs`;
rmSync(dependencyPath, { recursive: true, force: true });
console.log(`Initializing dependencies for ${layerConfig.path} ...`);
const layerDependencies = Object.keys(remainingDependencies).reduce(
(filteredDeps, key) => {
if (
shouldInclude(
key,
layerConfig.dependencyIncludeRegexPatterns,
layerConfig.dependencyExcludeRegexPatterns,
)
) {
filteredDeps[key] = remainingDependencies[key];
delete remainingDependencies[key];
}
return filteredDeps;
},
{},
);
mkdirSync(dependencyPath, { recursive: true });
writeFileSync(
`${dependencyPath}/package.json`,
JSON.stringify({ dependencies: layerDependencies }, null, 4),
);
writeFileSync(`${dependencyPath}/yarn.lock`, "");
await run(layerConfig.installCommand, dependencyPath, {
YARN_CACHE_FOLDER: layerConfig.yarnCacheFolder,
});
}
}
function shouldInclude(
packageName: string,
includePatterns?: string[],
excludePatterns?: string[],
) {
if (
excludePatterns &&
excludePatterns.some((regex) => packageName.match(regex))
) {
return false;
}
if (
includePatterns &&
includePatterns.some((regex) => packageName.match(regex))
) {
return true;
}
return false;
}
function validConfig({
path,
yarnCacheFolder,
installCommand,
dependencyIncludeRegexPatterns,
}: LayerConfig) {
return (
path &&
yarnCacheFolder &&
installCommand &&
dependencyIncludeRegexPatterns &&
true
);
}
export async function run(
cmd: string,
cwd: string,
env: Record<string, string> = {},
) {
try {
execSync(cmd, {
cwd,
env: {
...process.env,
...env,
},
maxBuffer: 1024 * 1024 * 500,
stdio: "inherit",
});
} catch (error) {
console.log(error.stdout?.toString());
throw error;
}
}
```
## 3. Improve installment time with yarn cache
We can further speed up the `yarn install` by utilizing `yarnCacheFolder`
```yml
service: dependency-layers
layers:
awslibs:
path: layers/awslibs
name: ${self:service}-${sls:stage}-awslibs
installCommand: yarn install
yarnCacheFolder: ../../../.yarn/cache <-- here
dependencyIncludeRegexPatterns:
- "^@aws-sdk"
- "^aws"
```
## 4. Save the dependencies and skip deployment
Imagine the sequence to run in our CI/CD would be like
```
- yarn install
- yarn deploy:layer # serverless deploy -c serverless.layers.yml
- yarn deploy:internal-api # serverless deploy -c serverless.internal-api.yml
- yarn deploy:external-api # serverless deploy -c serverless.external-api.yml
```
So far so good, but it still takes non-trivial time to build the layers. Serverless Framework can check the deployment hash and skip the deployment, but it does not know when to skip the build (packaging) step.
This is easy. First, we will cache the `dependencies` from the main `package.json` in the SSM parameter store together with the deployment package.
```yml
# serverless.layers.yml
resources:
Resources:
LayerDependencies:
Type: AWS::SSM::Parameter
Properties:
Type: String
Name: /${self:service}/${sls:stage}/dependencies
Value: ${file(./tools/getDependenciesAsString.js):value}
```
```typescript
# tools/getDependenciesAsString.js
module.exports = async () => {
const fs = require("fs");
const packageJson = JSON.parse(fs.readFileSync("package.json", "utf-8"));
return {
value: JSON.stringify(packageJson.dependencies),
};
};
```
Next, we can create a command to compare the cached dependencies with the current dependencies in the main `package.json` and run `yarn deploy:layer` when we detect the diff.
```yml
# serverless.layers.yml
custom:
scripts:
commands:
update: ts-node tools/updateDependencyLayers.ts "/${self:service}/${sls:stage}/dependencies" ap-southeast-1 "yarn deploy:lambda:layer"
hooks:
"before:package:initialize": ts-node tools/initializeLayerDependencies.ts serverless.layers.yml
```
```typescript
# tools/updateDependencyLayers.ts
import packageJson from "../package.json";
import _ from "lodash";
import { GetParameterCommand, SSMClient } from "@aws-sdk/client-ssm";
import { run } from "./libs/process-utils";
main(process.argv[2], process.argv[3], process.argv[4]);
async function main(ssmPath: string, region: string, deployCommand: string) {
const ssm = new SSMClient({ region });
const response = await ssm.send(
new GetParameterCommand({
Name: ssmPath,
}),
);
const cachedDependenciesString = response.Parameter.Value;
if (!cachedDependenciesString) {
console.log("Not found dependencies in cache, should deploy layers");
await run(deployCommand, ".");
return;
}
const cachedDependencies = JSON.parse(cachedDependenciesString);
if (!_.isEqual(cachedDependencies, packageJson.dependencies)) {
console.log(
"Found dependencies in cache and is not equal to dependencies in package.json, should deploy layers",
);
await run(deployCommand, ".");
return;
}
console.log("The dependencies are up-to-date, should skip deploy layers");
}
```
Now we can run `npx serverless update -c serverless.layers.yml` to invoke this script.
## Conclusion
It will be much faster for developers to edit the function code and deploy it because the function code is lightweight.
Only when adding new libraries or updating their versions should we then deploy the layers.
The CI/CD pipeline can always run the update, which will skip the deployment if the dependencies are up-to-date. | asinkxcoswt |
1,312,471 | Introduction to AWS AppSync - Fully managed GraphQL Service | Build, deploy, and manage mobile and web apps that need real-time or offline data are simple with AWS... | 0 | 2023-02-02T02:44:54 | https://medium.com/gitconnected/an-introduction-to-aws-appsync-the-fully-managed-graphql-service-9f429a664e2f | aws, graphql, datascience, python | Build, deploy, and manage mobile and web apps that need real-time or offline data are simple with AWS AppSync, a fully managed serverless GraphQL service. Your apps may securely access and work with data stored in AWS services like Amazon DynamoDB, Amazon Elasticsearch Service, and AWS Lambda by building GraphQL APIs using AppSync.
One of the key benefits of using AppSync is that it allows you to build scalable, responsive applications without the need to manage complex server infrastructure. AppSync handles all of the underlying network and security protocols for you, allowing you to focus on building great user experiences.
In addition to providing real-time and offline data access, AppSync also offers a number of other features that make it a powerful tool for building modern applications. These features include:
⦿ GraphQL Transform: This is a tool that helps you build GraphQL APIs quickly and easily by providing a set of pre-built, customizable GraphQL resolvers.
⦿ Subscriptions: AppSync allows you to create real-time subscriptions that allow your clients to receive updates in real-time when certain events occur, such as when data is updated or deleted.
⦿ Data manipulation: AppSync provides a number of powerful data manipulation capabilities, including the ability to create, update, and delete data, as well as the ability to perform complex queries and mutations on data.
⦿ Security: AppSync integrates with AWS Identity and Access Management (IAM), AWS Cognito, and API Keys to provide fine-grained access controls and protect your data from unauthorized access.
Some other key security features of AWS AppSync include:
1. Data encryption: All data is encrypted in transit and at rest using industry-standard encryption algorithms.
2. Identity and access management (IAM): You can use IAM to control access to your AWS AppSync resources and data.
3. VPC Endpoints: You can use VPC Endpoints to securely access your AppSync APIs from within your Amazon VPC, without exposing your APIs to the public internet.
4. Resource-level permissions: You can use resource-level permissions to control access to specific GraphQL operations and fields.
5. Amazon Cognito authentication: You can use Amazon Cognito to authenticate users and authorize access to your AppSync APIs.
6. OAuth 2.0 support: You can use OAuth 2.0 to authenticate users and authorize access to your AppSync APIs.
7. Identity federation: You can use identity federation to authenticate users with third-party identity providers, such as Google or Facebook.
## 1️⃣️ Schema
In AppSync, the schema defines the shape of your data and the operations that can be performed on it. The schema is written in GraphQL, which is a language for querying and mutating data. The schema consists of types, fields, and relationships between those types.
## 2️⃣ Resolvers
Resolvers are functions that resolve a GraphQL query to a specific data source. When a client issues a query to the GraphQL API, the query is forwarded to the appropriate resolver for handling. The resolver retrieves the requested data from the data source and returns it to the client.
## 3️⃣️ Mutations
AppSync also allows you to define mutations, which are operations that modify data. Mutations work similarly to queries, but they require a resolver to handle the data modification and return the updated data to the client.
The schema defines the structure of the data and the operations that can be performed on it, while the resolvers handle the actual retrieval and modification of data from the data sources.
For example, consider a schema that has a type called "Post" and fields called "title" and "content". To retrieve the data for a specific Post, you might define a resolver that queries a DynamoDB table for the Post with a specific ID. The resolver would return the Post's title and content to the client as a response to the query. Mutations helps to make any update to the title or post.

## 🎥 Demo
First, let’s create a GraphQL endpoint to retrieve the title and content from post DynamoDB.
Step 1: Login to the console and go to AppSync

Step 2: Choose Create with wizard and Create a model. The `model` should contains the list of fields you want to store and retrieve from DynamoDB Table.

Step 3: Click **Create**, and on the next screen name your API "**My AppSync App API**". Click **Create**.
The AppSync console will deploy your DynamoDB table and create your AppSync schema. The schema includes autogenerated queries, mutations, and subscriptions.

Step 4: On the left, you can see the list of tabs such as **Schema, Data Sources, Functions, Queries, Caching, Setting and Monitoring.**

- Schema: The schema defines the types, fields, and operations (queries, mutations, and subscriptions) that clients can execute on the API. The schema is written in the GraphQL schema definition language (SDL) and is used to validate client requests and generate a client-side code generation.
- **Data Sources**: AppSync allows you to connect to various data sources, such as DynamoDB tables, Lambda functions, and Elasticsearch domains, to retrieve and manipulate data in your API. You can also use AppSync's built-in data sources for authentication and authorization.
- **Functions**: AppSync allows you to write custom Lambda functions to perform additional logic or data manipulation before or after data is retrieved from a data source. These functions can be triggered by specific events, such as a client query or mutation.
- **Queries**: Clients can use the GraphQL query operation to retrieve data from the API. AppSync automatically maps the client query to the appropriate data source and resolves any fields in the query that are defined in the schema.
- **Caching**: AppSync allows you to enable caching for specific queries to improve the performance of your API. Cached data is stored in an in-memory cache and is automatically invalidated when the data in the data source is updated.
- **Setting and Monitoring**: AppSync provides a variety of settings and monitoring options that allows you to customize the behavior of your API and monitor its usage. You can set up logging and tracing for debugging and troubleshooting, configure caching and connection pooling, and use CloudWatch for monitoring metrics and log streams.
Let’s go to schema and look for the schema, resolvers and query to be able to fetch the title and content from the DynamoDB.
```json
type MyModelType {
id: ID!
title: String
content: String
}
type Query {
getMyModelType(id: ID!): MyModelType
}
```
On the right, you can see the Resolvers are set to the Dynamo table.
Now to query the table by Id, we can go to the `queries` tab and run this below snippet to fetch the information
```json
query DemoQuery {
getMyModelType(id: "123") {
id
content
title
}
}
```

The endpoint uses the API Key to authenticate the requests. With this API Key and the URL we can also use the Postman to try running the query.
### Go to Settings tab to get the credentials

## Now in the Postman..
Enter the copied URL and API key, and the query in the Body.


Now in this demo, we have seen how GraphQL fetches the data from DynamoDB. Similarly you can have a different Resolver such as Lambda Function to handle the request.
## Securing your AppSync Endpoint..
AWS Web Application Firewall (WAF) is a web security service that helps protect web applications from common web exploits that could affect availability, compromise security, or consume excessive resources.
To secure an AppSync endpoint with WAF, you can create a WAF rule and associate it with the AppSync endpoint. The rule can be configured to block or allow traffic based on certain criteria, such as IP address or request headers. This can help protect against common web attacks such as SQL injection, cross-site scripting, and others. Additionally, you can also use WAF to rate-limit requests to the AppSync endpoint to prevent denial-of-service attacks.
## Conclusion
AWS AppSync is a powerful tool that makes it easy to build, deploy, and manage real-time and offline applications that require data access and manipulation. It supports various use cases from Data Ingestion to pub/sub services.
---
### **✍️ About the Author**:
**Mohamed Fayaz** is a Data & AI Consultant, and a technical blogger who writes and speaks about the topics such as **Software Engineering**, **Big Data Analytics**, and **Cloud Engineering**. Connect with him on [LinkedIn](https://www.linkedin.com/in/mohamedfayazz/) or follow him on [Twitter](https://twitter.com/0xfayaz) for updates.
---
| mohamedfayaz |
1,313,637 | Permanently Change CMD Font Color Using (.reg) Files. | We all have gone through the trouble of manually changing the CMD font color using the color... | 0 | 2022-12-31T14:39:58 | https://dev.to/tabbysl/permanently-change-cmd-font-color-using-reg-files-5hh6 | windowscmd, technology, cmdtipsandtricks, changecmdfontcolor | ---
title: Permanently Change CMD Font Color Using (.reg) Files.
published: true
date: 2022-12-30 04:01:35 UTC
tags: windowscmd,technology,cmdtipsandtricks,changecmdfontcolor
canonical_url:
---
> We all have gone through the trouble of manually changing the CMD font color using the **color** command. And even then, when you restart CMD; it all resets to default white. But, no worries! There’s a fix to this!
With This guide, I’ll be teaching you how you can change your CMD font color permanently; without any effort. And, it turns out that its not that hard!

_Image Credits: TechRepublic_
### **Step 1**
Firstly, we have to head over to this [**GitHub Page**](https://github.com/TabbySL/Permanent-CMD-Font-Color-Change) and fetch the necessary files. All you have to do, is click the Green color **_“Code”_** button, and then select **_‘Download ZIP’._**
Use the image below as reference;
_Downloading the Repository As a ZIP file._
### **Step 2**
Now that you have downloaded the Repository, it should appear in your **‘Downloads’** folder, or whichever folder you have selected for downloads to appear.
Now, double-click on the _.zip_ file that you downloaded, and there will be a folder in it. Clicking on that folder will lead you to a list of registry(_.reg_) files, which you can select one color that you like from the list.

_Selecting a color that you like For your CMD to be._
### **Step 3**
Alright! Now that you have a color selected, you can Double click on the file with your chosen color. You will be prompted with 2 messeges; click yes for both of them.
Finally, you will get a popup, saying **‘Key values were sucessfully added to the Registry’** This means, that the color was sucessfully changed, and now you can open your CMD prompt, and Enjoy your new font color!

_CMD Font color has been Sucessfully changed!_
And now, you dont have to bother about changing the color manually — ever again! Just click on the color you want, and it will last forever! (unless you reset your computer or something… lol)
Also, you might have noticed the ‘Bright-White’ (.reg) registry file too. Well, as you know; the CMD has a bit of a dull white font color by default. Its not complete white, but kinda like a shaded grey. So, when you click that (.reg) file, it will change the font color to complete White — which, I personally prefer. ; )
I hope the guide explained ‘ **How to change the CMD font color permanently’** very well. If you are stuck somewhere, you can also watch this Video, in which I explain it in a Screen-Recording;
[https://youtu.be/aiV7ezXJLvI](https://youtu.be/aiV7ezXJLvI) | tabbysl |
1,313,710 | React+Node Projects for Resume Building and Learning Suggestions | I was looking for some React + Node projects to learn from and fill my resume with. Came across this... | 0 | 2022-12-31T16:06:09 | https://dev.to/shadduu/reactnode-projects-for-resume-building-and-learning-suggestions-43m2 | fullstack, react, node, discuss | I was looking for some React + Node projects to learn from and fill my resume with.
Came across this https://www.youtube.com/watch?v=BCkWFblNLKU and his channel has many other common projects with similar stack.
The initial 2 minutes of the video will give an idea about the project and tech used in the project.
Is it a good idea to do this way in order to learn and have good projects on your resume? Thank you in advance for any suggestions/recommendations.
Note: I have less than one year experience in web dev looking for full stack roles in Canada. I do have some basic knowledge of MERN stack as I have build simpler apps with it, but trying to look for something a bit advance here. | shadduu |
1,313,750 | Deep linking with Azure Static Web Apps and Easy Auth | Azure Static Web Apps doesn't support deep linking with authentication. The post login redirect... | 0 | 2022-12-31T17:53:28 | https://johnnyreilly.com/2022/12/04/azure-static-web-apps-easyauth-deeplink | authorization, easyauth, deeplink, staticwebapps | ---
title: Deep linking with Azure Static Web Apps and Easy Auth
published: true
tags: Authorization,EasyAuth,deeplink,StaticWebApps
canonical_url: https://johnnyreilly.com/2022/12/04/azure-static-web-apps-easyauth-deeplink
---
Azure Static Web Apps doesn't support deep linking with authentication. The [post login redirect](https://learn.microsoft.com/en-us/azure/static-web-apps/authentication-authorization?tabs=invitations#post-login-redirect) parameter of `post_login_redirect_uri` does not support query string parameters. This post describes how to work around this limitation.

## Deep linking
Imagine the situation: your colleague sends you `https://our-app.com/pages/important-page?someId=theId`. You click the link and you're presented with a login screen. You login and you're presented with a page, but not the one your colleague meant you to see. What do you do now? If you realise what's happened, you'll likely paste the URL into the address bar again so you end up where you hope to. But what if you don't realise what's happened? Answer: confusion and frustration.
If you're using Azure Static Web Apps, you're likely to have this problem. [Azure Static Web Apps doesn't support deep linking with authentication](https://github.com/Azure/static-web-apps/issues/435). When you get redirected you'll find you are (at best) missing the query parameters. If you take a look at the link here you'll see a suggested workaround. We're going to develop that idea in this post.
## The workaround
The idea of the workaround is this:
- at the start of the authentication process, store the URL you're trying to get to in local storage
- when the authentication process completes, redirect to the URL you stored in local storage
The post suggested a React specific approach. We'd like something that is framework agnostic. So if you're running with Svelte, Vue, Angular or something else, you can use this approach too.
## The implementation
We're going to need to make sure our [`staticwebapp.config.json`](https://learn.microsoft.com/en-us/azure/static-web-apps/configuration) is set up to support our goal:
```json
{
"auth": {
"identityProviders": {
"azureActiveDirectory": {
"registration": {
"openIdIssuer": "https://login.microsoftonline.com/AAD_TENANT_ID/v2.0",
"clientIdSettingName": "AAD_CLIENT_ID",
"clientSecretSettingName": "AAD_CLIENT_SECRET"
}
}
}
},
"navigationFallback": {
"rewrite": "index.html"
},
"routes": [
{
"route": "/login",
"rewrite": "/.auth/login/aad",
"allowedRoles": ["anonymous", "authenticated"]
},
{
"route": "/.auth/login/github",
"statusCode": 404
},
{
"route": "/.auth/login/twitter",
"statusCode": 404
},
{
"route": "/logout",
"redirect": "/.auth/logout",
"allowedRoles": ["anonymous", "authenticated"]
},
{
"route": "/*.json",
"allowedRoles": ["authenticated"]
}
],
"responseOverrides": {
"401": {
"redirect": "/login",
"statusCode": 302
}
},
"globalHeaders": {
"content-security-policy": "default-src https: 'unsafe-eval' 'unsafe-inline'; object-src 'none'"
},
"mimeTypes": {
".json": "text/json",
".md": "text/markdown",
".xml": "application/xml"
}
}
```
There's a number of things to note here:
- we're using Azure Active Directory as our identity provider (and disabling others) - the approach in this post will work with any identity provider; this is just the one I'm using. Easy Auth supports [a number of identity providers](https://learn.microsoft.com/en-us/azure/app-service/overview-authentication-authorization#identity-providers)
- we're creating a `/login` route to redirect to the Azure AD login page - you don't have to do this, but it's a nice touch.
- we're protecting the `*.json` files with authentication - this is because our JSON files actually contain secure information. If we were using say an API instead, we'd protect that with authentication instead. Crucially, access to HTML / JS / CSS is _not_ protected. This is important, because we need to be able to access our `index.html` file and associated JavaScript to store the URL we're trying to get to in local storage.
With this in place, we can implement our workaround. Let's create a file called `deeplink.ts`:
```ts
const deeplinkPathAndQueryKey = 'deeplink:pathAndQuery';
/**
* If authenticated, redirect to the path and query string stored in local storage.
* If not authenticated, store the current path and query string in local storage and redirect to the login page.
*
* @param loginUrl The URL to redirect to if the user is not authenticated
*/
export async function deeplink(loginUrl: string) {
if (!loginUrl) {
throw new Error('loginUrl is required');
}
const pathAndQuery = location.pathname + location.search;
console.log(`deeplink: URL before: ${pathAndQuery}`);
const deeplinkPathAndQuery = localStorage.getItem(deeplinkPathAndQueryKey);
const isAuth = await isAuthenticated();
if (isAuth) {
if (deeplinkPathAndQuery && pathAndQuery === '/') {
console.log(`deeplink: Redirecting to ${deeplinkPathAndQuery}`);
localStorage.removeItem(deeplinkPathAndQueryKey);
history.replaceState(null, '', deeplinkPathAndQuery);
}
} else if (!deeplinkPathAndQuery) {
if (pathAndQuery !== '/' && pathAndQuery !== loginUrl) {
console.log(
`deeplink: Storing redirect URL of ${pathAndQuery} and redirecting to ${loginUrl}`
);
localStorage.setItem(deeplinkPathAndQueryKey, pathAndQuery);
location.href = loginUrl;
} else {
console.log(`deeplink: Redirecting to ${loginUrl}`);
location.href = loginUrl;
}
}
}
async function isAuthenticated() {
try {
const response = await fetch('/.auth/me');
const authMe = (await response.json()) as AuthMe;
const isAuth = authMe.clientPrincipal !== null;
return isAuth;
} catch (error) {
console.error('Failed to fetch /.auth/me', error);
return false;
}
}
interface AuthMe {
clientPrincipal: null | {
claims: {
typ: string;
val: string;
}[];
identityProvider: string;
userDetails: string;
userId: string;
userRoles: string[];
};
}
```
The code above implements our workaround. It does the following:
- it checks whether a user is authenticated by hitting the `/.auth/me` endpoint that is provided by the Easy Auth / Static Web Apps authentication system
- if users are not authenticated, it:
- stores the path and query string in localStorage and
- redirects them to the login page
- when they return post-authentication it retrieves the path and query string from localStorage and sets the URL to that
What does usage look like? Well let's take the root of a simple React app:
```tsx
import { StrictMode } from 'react';
import { BrowserRouter } from 'react-router-dom';
import { createRoot } from 'react-dom/client';
import App from './App';
import { deeplink } from 'easyauth-deeplink';
function main() {
const container = document.getElementById('root');
if (container) {
const root = createRoot(container);
root.render(
<StrictMode>
<BrowserRouter>
<App />
</BrowserRouter>
</StrictMode>
);
}
}
deeplink('/login').then(main);
// or
deeplink('/.auth/login/aad').then(main);
// or
deeplink('/.auth/login/github').then(main);
// or
deeplink('/.auth/login/twitter').then(main);
// or
deeplink('/.auth/login/google').then(main);
// etc
```
You can see here that the first thing we do is call `deeplink` with the URL of the login page (you can see I've provided a number of options). This will redirect the user to the login page if they're not authenticated, and will redirect them to the URL they were trying to access if they are authenticated. Once that's done, we render our app.
You should be able to apply this regardless of your framework. The important thing is that you call `deeplink` before you render your app.
## Announcing `easyauth-deeplink`
I've created a package called [`easyauth-deeplink`](https://github.com/johnnyreilly/easyauth-deeplink) that implements the workaround above. You can install it with `npm install easyauth-deeplink` or `yarn add easyauth-deeplink`. It's a single file, so you can just copy and paste it into your project if you prefer.
## Conclusion
It would be tremendous if this became a feature that was built into Azure Static Web Apps. Maybe one day it will be. In the meantime, I hope this workaround helps you.
It should be said that whilst we've described usage in this post with Static Web Apps, the same approach should work with any Azure Service that has Easy Auth enabled; App Service / Function Apps etc. I've not tried it, but I'd be surprised if it didn't work. | johnnyreilly |
1,313,759 | Advent of Code 2022 Day 17 | Advent of Code 2022 Day 17: Pyroclastic Flow | 20,760 | 2022-12-17T00:51:00 | https://nickymeuleman.netlify.app/garden/aoc2022-day17 | adventofcode, rust | ---
title: "Advent of Code 2022 Day 17"
published: true
description: "Advent of Code 2022 Day 17: Pyroclastic Flow"
tags:
- "adventofcode"
- "rust"
series: "Advent of Code 2022"
canonical_url: "https://nickymeuleman.netlify.app/garden/aoc2022-day17"
published_at: 2022-12-17 00:51 +0000
---
## Day 17: Pyroclastic Flow
https://adventofcode.com/2022/day/17
> TL;DR: [my solution in Rust](https://github.com/NickyMeuleman/scrapyard/blob/main/advent_of_code/2022/src/day_17.rs)
You enter a tall, narrow chamber.
Rocks start falling.
For some reason, there's a loud [song playing](https://www.youtube.com/watch?v=NmCCQxVBfyM) in this room.
Very mysterious stuff!
I don't mind, it's a bop.
The falling rocks have these shapes, where `#` is rock and `.` is air:
```txt
####
.#.
###
.#.
..#
..#
###
#
#
#
#
##
##
```
The "pieces" fall in that order, wrapping when the end of that list of 5 pieces is reached.
Jets of steam push around the rocks as they fall.
Today's puzzle input is the sequence of directions the pieces will be pushed in.
An example input looks like this:
```txt
>>><<><>><<<>><>>><<<>>><<<><<<>><>><<>>
```
- `<` means a jet of air that blows a piece left
- `>` means a jet of air that blows a piece right
As with the pieces, if the end of the list is reached, it repeats.
The chamber is exactly seven units wide.
Each piece appears so that its left edge is two units away from the left wall and its bottom edge is three units above the highest rock in the room (or the floor, if there isn't one).
After a piece appears, it alternates between being pushed by a jet of hot gas one unit and falling down one unit.
If a movement would cause the piece to move into the walls, the floor, or an other piece, that movement doesn't happen.
When a piece is prevented from falling, a new piece immediately begins falling.
## Parsing
The jets are an instance of a `Jet` enum that's `Left` or `Right`.
The input is a list of them.
```rust
enum Jet {
Left,
Right,
}
fn parse(input: &str) -> Vec<Jet> {
input
.trim()
.chars()
.map(|c| match c {
'<' => Jet::Left,
'>' => Jet::Right,
_ => panic!("invalid input, {}", c),
})
.collect()
}
```
I'm also counting getting those pieces into useful data structure as parsing today.
Oh, and I'm also storing the width of the chamber in a constant.
I chose to represent the pieces as a series of point offsets to a point.
Point? You know what that means, `Coord` is back for an other appearance!
Each `Coord` offset represents a rock in the piece.
```rust
#[derive(Debug, PartialEq, Default)]
struct Coord {
x: usize,
// positive y goes up.
// happy mathematicians, sad game programmers
y: usize,
}
const WIDTH: usize = 7;
const PIECES: [&[Coord]; 5] = [
// horizontal line
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 2, y: 0 },
Coord { x: 3, y: 0 },
],
// plus
&[
Coord { x: 0, y: 1 },
Coord { x: 1, y: 0 },
Coord { x: 1, y: 1 },
Coord { x: 1, y: 2 },
Coord { x: 2, y: 1 },
],
// J (or backwards L)
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 2, y: 0 },
Coord { x: 2, y: 1 },
Coord { x: 2, y: 2 },
],
// vertical line
&[
Coord { x: 0, y: 0 },
Coord { x: 0, y: 1 },
Coord { x: 0, y: 2 },
Coord { x: 0, y: 3 },
],
// square
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 0, y: 1 },
Coord { x: 1, y: 1 },
],
];
```
## Part 1
The question asks how tall the tower of rocks will be when 2022 pieces stopped falling.
The instructions in pseudocode:
```rust
let jets = parse(input);
let mut pieces_count = 0;
let mut top = 0;
while pieces_count != 2022 {
// choose new piece to start dropping
// set current coordinate all offsets in a piece are related to as x: 2, y: top + 3
loop {
// get new jet direction
// apply jet (update current coordinate if successful)
// try to fall (update current coordinate if successful)
// if not successful: break out of loop
}
// settle the current piece, add all offsets to the map of settled pieces
// update the highest rock coordinate and store it in "top"
pieces_count += 1;
}
top
```
I grouped a couple of variables to keep track of the state of the chamber in a struct:
```rust
#[derive(Default)]
struct State {
jet_count: usize,
piece_count: usize,
top: usize,
map: Vec<[bool; WIDTH]>,
curr: Coord,
}
```
At the start of the simulation, every number starts at 0, and the map is empty.
- `jet_count` is a number to keep track of how many jets in total have blown.
- `piece_count` is a number to keep track of how many pieces in total have started falling.
- `top` is a number to keep track of how tall the tower currently is
- `map` is a list of 7 wide boolean arrays, each keeping track of where settled rocks are at that height.
- `curr` is the coordinate pair where the offsets of a piece will apply to in order to figure out where the rocks of a piece are.
When a piece stops falling, it is added to the `map` list.
### Helpers
A helper to determine given a new `curr` coordinate, if the state using that as `curr` would be valid.
```rust
impl State {
fn is_valid(&mut self, new_curr: &Coord, piece: &[Coord]) -> bool {
piece.iter().all(|offset| {
let x = new_curr.x + offset.x;
let y = new_curr.y + offset.y;
while self.map.len() <= y {
self.map.push([false; WIDTH]);
}
x < WIDTH && !self.map[y][x]
})
}
}
```
The only wall collision that is checked is the one with the right wall.
This is because a `Coord` has fields that can only ever be 0 or greater
Collisions with other pieces are checked by indexing into `map` and seeing if a rock is there.
`piece` is passed into this method as a convenience.
It could have been derived from the current `State` like so:
`let piece = PIECES[self.piece_count % PIECES.len()];`
That `while` loop exists to make sure we never index the `map` at an index that doesn't exist yet.
If it doesn't exist, that means there are no rocks at that location.
Because this was a finnicky problem to get right, I implemented `Display` so I could print out the state of the chamber.
This takes the list of booleans in `map` and turns them into:
- `#` for `true`
- `.` for `false`
It then creates empty rows to fit the current piece if necessary.
For every offset in the current piece, it adds a `@` to that map.
That map is then printed to the screen with `|` on the sides or each row.
And at the bottom, a `+-----+`, just like the examples in the question!
That way, in the solution code I can pop in a `println!("{}", state);` and see the same output as in the question text.
This was an awesome tool for finding off by one errors (and there were a lot of those)
```rust
impl Display for State {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
let piece = PIECES[self.piece_count % PIECES.len()];
let mut print: Vec<Vec<_>> = self
.map
.iter()
.map(|row| {
row.iter()
.map(|rock| if *rock { '#' } else { '.' })
.collect()
})
.collect();
let mut local_top = self.top;
for offset in piece {
let x = self.curr.x + offset.x;
let y = self.curr.y + offset.y;
while print.len() <= y {
print.push(vec!['.'; WIDTH]);
}
print[y][x] = '@';
local_top = local_top.max(y + 1);
}
for row in (0..local_top).rev() {
let mut row_str = String::from('|');
for col in 0..7 {
row_str.push(print[row][col]);
}
row_str.push('|');
row_str.push('\n');
write!(f, "{}", row_str)?;
}
writeln!(f, "+{}+", "-".repeat(WIDTH))
}
}
```
The code for part1 has the locations where that printing of the state is used commented out.
### Final code
```rust
pub fn part_1(input: &str) -> usize {
let target = 2022;
let jets = parse(input);
let mut state = State::default();
while state.piece_count != target {
// new piece starts falling
let piece = PIECES[state.piece_count % PIECES.len()];
state.curr.x = 2;
state.curr.y = state.top + 3;
// println!("== Piece {} begins falling ==", state.piece_count + 1);
// println!("{}", state);
loop {
// jet
let jet = &jets[state.jet_count % jets.len()];
let new_curr = match jet {
Jet::Left => Coord {
x: state.curr.x.saturating_sub(1),
y: state.curr.y,
},
Jet::Right => Coord {
x: state.curr.x + 1,
y: state.curr.y,
},
};
if state.is_valid(&new_curr, piece) {
state.curr = new_curr;
}
state.jet_count += 1;
// println!(
// "Jet of gas pushes piece {}:",
// match jet {
// Jet::Left => "left",
// Jet::Right => "right",
// }
// );
// println!("{}", state);
// fall
let new_curr = Coord {
x: state.curr.x,
y: state.curr.y.saturating_sub(1),
};
if state.curr.y == 0 || !state.is_valid(&new_curr, piece) {
break;
}
state.curr = new_curr;
// println!("Piece falls 1 unit:");
// println!("{}", state);
}
// settle
for offset in piece {
let x = state.curr.x + offset.x;
let y = state.curr.y + offset.y;
while state.map.len() <= y {
state.map.push([false; WIDTH]);
}
state.map[y][x] = true;
// y is 0 indexed.
state.top = state.top.max(y + 1);
}
// prepare for next iteration of while loop
state.piece_count += 1;
}
state.top
}
```
## Part 2
The elephants with you are not impressed.
They would like to know how tall the tower will be after `1000000000000` pieces have stopped.
That's a lot of zeros.
A trillion rocks! Must be quite a high chamber, eh?
The question asks how tall the tower of rocks will be when `1000000000000` pieces stopped falling.
Changing the `2022` to a trillion in the code above would provide a correct answer.
The only question is, am I willing to wait the time it takes to complete?
The answer is no.
Luckily, there is a pattern in the dropped rocks that repeats.
Part 2 is about finding that repetition and fast forwarding as close to that trillion as possible.
To help with that, a few extra fields for the `State` struct:
```rust
#[derive(Default)]
struct State {
jet_count: usize,
piece_count: usize,
top: usize,
map: Vec<[bool; WIDTH]>,
curr: Coord,
seen: HashMap<(usize, usize), (usize, usize, usize)>,
added_by_repeats: usize,
}
```
A `seen` key is a combination of the index into `PIECES` and the index into `jets`.
A cycle can only be detected the third time we encounter such a pair though.
This is because some of the first pieces will have hit the floor.
By the time a combination of `pieces_idx, jets_idx` comes around again, the fallen blocks only interact with other blocks when falling.
That is the first repeatable cycle.
The `seen` values are:
1. A counter of how many times a key was seen
2. The `pieces_count` at that time
3. The `top` at that time
Using those 2 last pieces of information, the difference in `top` between now and the previous time we encountered a `(pieces_idx, jet_idx)` pair can be calculated.
We fast forward as much times as we can without hitting the trillion.
The increase in `top` that would have caused is stored in `amount_added`.
The remaining amount to the trillion is simulated as before.
### Final code
```rust
pub fn part_2(input: &str) -> usize {
let target = 1_000_000_000_000;
let jets = parse(input);
let mut state = State::default();
while state.piece_count != target {
// new piece starts falling
let piece = PIECES[state.piece_count % PIECES.len()];
state.curr.x = 2;
state.curr.y = state.top + 3;
loop {
// jet
let jet = &jets[state.jet_count % jets.len()];
let new_curr = match jet {
Jet::Left => Coord {
x: state.curr.x.saturating_sub(1),
y: state.curr.y,
},
Jet::Right => Coord {
x: state.curr.x + 1,
y: state.curr.y,
},
};
if state.is_valid(&new_curr, piece) {
state.curr = new_curr;
}
state.jet_count += 1;
// fall
let new_curr = Coord {
x: state.curr.x,
y: state.curr.y.saturating_sub(1),
};
if state.curr.y == 0 || !state.is_valid(&new_curr, piece) {
break;
}
state.curr = new_curr;
}
// settle
for offset in piece {
let x = state.curr.x + offset.x;
let y = state.curr.y + offset.y;
while state.map.len() <= y {
state.map.push([false; WIDTH]);
}
state.map[y][x] = true;
// y is 0 indexed
state.top = state.top.max(y + 1);
}
// look for cycle
if state.added_by_repeats == 0 {
let key = (
state.piece_count % PIECES.len(),
state.jet_count % jets.len(),
);
// at third occurrence of key, the values in the seen map repeat
// add as many of them as possible without hitting the goal piece_count
if let Some((2, old_piece_count, old_top)) = state.seen.get(&key) {
let delta_top = state.top - old_top;
let delta_piece_count = state.piece_count - old_piece_count;
let repeats = (target - state.piece_count) / delta_piece_count;
state.added_by_repeats += repeats * delta_top;
state.piece_count += repeats * delta_piece_count;
}
// update seen map
// key: (piece_count % PIECES.len(), jet_count % jets.len())
// value: (amount_of_times_key_was_seen, piece_count, top)
state
.seen
.entry(key)
.and_modify(|(amnt, old_piece_count, old_top)| {
*amnt += 1;
*old_piece_count = state.piece_count;
*old_top = state.top;
})
.or_insert((1, state.piece_count, state.top));
}
// prepare for next iteration of while loop
state.piece_count += 1;
}
state.top + state.added_by_repeats
}
```
I then made a method with that logic to reuse it between part 1 and part 2.
## Final code
```rust
use std::{collections::HashMap, fmt::Display};
const WIDTH: usize = 7;
const PIECES: [&[Coord]; 5] = [
// horizontal line
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 2, y: 0 },
Coord { x: 3, y: 0 },
],
// plus
&[
Coord { x: 0, y: 1 },
Coord { x: 1, y: 0 },
Coord { x: 1, y: 1 },
Coord { x: 1, y: 2 },
Coord { x: 2, y: 1 },
],
// J (or backwards L)
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 2, y: 0 },
Coord { x: 2, y: 1 },
Coord { x: 2, y: 2 },
],
// vertical line
&[
Coord { x: 0, y: 0 },
Coord { x: 0, y: 1 },
Coord { x: 0, y: 2 },
Coord { x: 0, y: 3 },
],
// square
&[
Coord { x: 0, y: 0 },
Coord { x: 1, y: 0 },
Coord { x: 0, y: 1 },
Coord { x: 1, y: 1 },
],
];
enum Jet {
Left,
Right,
}
#[derive(Debug, PartialEq, Default)]
struct Coord {
x: usize,
// positive y goes up.
// happy mathematicians, sad game programmers
y: usize,
}
#[derive(Default)]
struct State {
jet_count: usize,
piece_count: usize,
top: usize,
map: Vec<[bool; WIDTH]>,
curr: Coord,
added_by_repeats: usize,
seen: HashMap<(usize, usize), (usize, usize, usize)>,
}
impl State {
fn is_valid(&mut self, new_curr: &Coord, piece: &[Coord]) -> bool {
piece.iter().all(|offset| {
let x = new_curr.x + offset.x;
let y = new_curr.y + offset.y;
while self.map.len() <= y {
self.map.push([false; WIDTH]);
}
x < WIDTH && !self.map[y][x]
})
}
fn simulate(&mut self, target: usize, jets: Vec<Jet>) {
while self.piece_count != target {
// new piece starts falling
let piece = PIECES[self.piece_count % PIECES.len()];
self.curr.x = 2;
self.curr.y = self.top + 3;
// println!("== Piece {} begins falling ==", state.piece_count + 1);
// println!("{}", state);
loop {
// jet
let jet = &jets[self.jet_count % jets.len()];
let new_curr = match jet {
Jet::Left => Coord {
x: self.curr.x.saturating_sub(1),
y: self.curr.y,
},
Jet::Right => Coord {
x: self.curr.x + 1,
y: self.curr.y,
},
};
if self.is_valid(&new_curr, piece) {
self.curr = new_curr;
}
self.jet_count += 1;
// println!(
// "Jet of gas pushes piece {}:",
// match jet {
// Jet::Left => "left",
// Jet::Right => "right",
// }
// );
// println!("{}", state);
// fall
let new_curr = Coord {
x: self.curr.x,
y: self.curr.y.saturating_sub(1),
};
if self.curr.y == 0 || !self.is_valid(&new_curr, piece) {
break;
}
self.curr = new_curr;
// println!("Piece falls 1 unit:");
// println!("{}", state);
}
// settle
for offset in piece {
let x = self.curr.x + offset.x;
let y = self.curr.y + offset.y;
while self.map.len() <= y {
self.map.push([false; WIDTH]);
}
self.map[y][x] = true;
// y is 0 indexed
self.top = self.top.max(y + 1);
}
// look for cycle
if self.added_by_repeats == 0 {
let key = (self.piece_count % PIECES.len(), self.jet_count % jets.len());
// at third occurrence of key, the values in the seen map repeat
// add as many of them as possible without hitting the goal piece_count
if let Some((2, old_piece_count, old_top)) = self.seen.get(&key) {
let delta_top = self.top - old_top;
let delta_piece_count = self.piece_count - old_piece_count;
let repeats = (target - self.piece_count) / delta_piece_count;
self.added_by_repeats += repeats * delta_top;
self.piece_count += repeats * delta_piece_count;
}
// update seen map
// key: (piece_count % PIECES.len(), jet_count % jets.len())
// value: (amount_of_times_key_was_seen, piece_count, top)
self.seen
.entry(key)
.and_modify(|(amnt, old_piece_count, old_top)| {
*amnt += 1;
*old_piece_count = self.piece_count;
*old_top = self.top;
})
.or_insert((1, self.piece_count, self.top));
}
// prepare for next iteration of while loop
self.piece_count += 1;
}
}
}
impl Display for State {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
let piece = PIECES[self.piece_count % PIECES.len()];
let mut print: Vec<Vec<_>> = self
.map
.iter()
.map(|row| {
row.iter()
.map(|rock| if *rock { '#' } else { '.' })
.collect()
})
.collect();
let mut local_top = self.top;
for offset in piece {
let x = self.curr.x + offset.x;
let y = self.curr.y + offset.y;
while print.len() <= y {
print.push(vec!['.'; WIDTH]);
}
print[y][x] = '@';
local_top = local_top.max(y + 1);
}
for row in (0..local_top).rev() {
let mut row_str = String::from('|');
for col in 0..7 {
row_str.push(print[row][col]);
}
row_str.push('|');
row_str.push('\n');
write!(f, "{}", row_str)?;
}
writeln!(f, "+{}+", "-".repeat(WIDTH))
}
}
fn parse(input: &str) -> Vec<Jet> {
input
.trim()
.chars()
.map(|c| match c {
'<' => Jet::Left,
'>' => Jet::Right,
_ => panic!("invalid input, {}", c),
})
.collect()
}
pub fn part_1(input: &str) -> usize {
let target = 2022;
let jets = parse(input);
let mut state = State::default();
state.simulate(target, jets);
state.top + state.added_by_repeats
}
pub fn part_2(input: &str) -> usize {
let target = 1_000_000_000_000;
let jets = parse(input);
let mut state = State::default();
state.simulate(target, jets);
state.top + state.added_by_repeats
}
``` | nickymeuleman |
1,313,890 | Modern Software Development Tools and oneAPI Part 1 | This will be the last blog post for this year (unless, I manage to get a second one in by the stroke... | 0 | 2022-12-31T23:50:26 | https://dev.to/oneapi/modern-software-development-tools-and-oneapi-part-1-40km | sycl, oneapi, opensource, tips |
This will be the last blog post for this year (unless, I manage to get a second one in by the stroke of midnight tomorrow!).
I wanted to end 2022 with a departure from the last two blog posts. In this one, we're going to be looking at oneAPI toolchain from a different perspective.
I wanted to build a pure oneAPI environment that uses two things:
* A different build system than your usual CMake _and_
* an opportunity to use a Linux based IDE to write code.
Most HPC code runs on Linux in Data center. Linux is known for using arcane tools like VIM or Emacs and a build system. Sure, you can use VScode on Linux and that can be a viable option. However, I am an open-source person; I live and breathe the ideology and I am a true believer. oneAPI is an open platform, and we should use it on an open platform.
The two pieces of software I want to introduce you all is GNOME Builder and Meson.
## GNOME Builder
GNOME Builder is an IDE that is primarily targeted at building GNOME-based applications. Unlike your typical IDE, GNOME Builder uses containers for building software internally. Containers in these case are flatpak SDKs - containers that contain everything you need to build an application. With GNOME Builder, you can get started writing code without the tedium of installing the entire software development toolchain you'd need to build said applications. That means, you aren't going to need to install a compiler, linker, libraries and anything else. Everything is all-inclusive - much like a vacation resort in Cancun, say! :-)
Back to Builder! oneAPI is not one of the options for building software inside GNOME Builder. GNOME Builder includes containers to build against GNOME software.
GNOME Builder is the brainchild of Christian Hergert, a long time Free Software programmer who was frustrated with the current state of tools to build software within the application community and started the Builder project about 7 years ago and was initially funded by a kickstarter. Through some great luck, Christian is now paid by Red Hat to help build GNOME Builder as well as improving the application building story on Linux and other platforms.
There is something wonderfully intriguing about Builder which is why I'm highlighting it here and why I picked it as the IDE of choice to write oneAPI-related code.
### This one special trick
Builder will allow you to use a podman or docker container to run everything. So in this case, we're going to create that all-inclusive experience! Once you've done the work of building a container with all the oneAPI tools into it, others can then re-use the container as a fixed environment and other folx can clone the project you are working on and then easily collaborate.
## Meson
The next piece of software I wanted to highlight is Meson. Meson is a build system that is written in python and _tries_ to be an intuitive system that _tries_ to do the right thing through easily understandable syntax. For those of you who have ever used autoconf - this was the application community's response to autoconf.
Autoconf during its heyday was a massive boon to those who were writing code that could work on many different UNIX and Linux distributions. However, autoconf was difficult to figure out and most folx simply copy from another project and then move on. Writing anything sophisticated required extensive, expended effort.
In my personal opinion, build systems are really hard to get right and there are so many oddities in how we build software that a build system has to get right, in order to be effective.
Meson is written by Finnish programmer, Jussi Pakkanen, who was frustrated with the current state of build systems and their arcane configuration syntax and sometimes rather unexpected behaviors!
Meson can be better described as a system that generates the configurations for build systems to use. It isn't a full-fledged build system like Make or CMake. In fact, you could easily re-use CMake configuration files in Meson. It has a concept of a backend and can generate config for Xcode on MacOS, VScode on Windows and Ninja on Linux systems. Meson easily integrates with profilers and debuggers and is designed not to build within source tree but in a designed build area.
For those not familiar with ninja, it is an extremely fast build system that has been shown to be effective in building software very quickly!!
## Build an oneAPI Container
In this first part, we will focus on building an oneAPI container based on the Ubuntu 20.04 LTS release since that is what oneAPI works optimally on.
I will be using Fedora 37 SilverBlue edition. I like SilverBlue as it is built with containerized environments in mind. It allows you to build different container environments that you can enter and exit from on the command line and still easily integrate with the desktop.
Let's start then with building our oneAPI environment so that it will be able to run a simple oneAPI sample program.
Staying true to the spirit of open-source, I will build this environment from source and only use what's available on GitHub.
To start, find and install the 'distrobox' tool on your distro.
`dnf install distrobox -y`
Distrobox allows you to create containerized environments from the command line.
I use podman as I live in the Fedora world. Podman is a command line compatible version of Docker. It's reasonable that the following could be done through a Dockerfile but the oneAPI libraries changes often enough that this blog post would become stale in short order.
`$ distrobox create oneapi -i docker.io/library/ubuntu:20.04 `
This will create a container called oneapi with an Ubuntu 20.04 setup.
`$ distrobox enter oneapi `
Will let you enter the container.
The beauty of distrobox is that you are in this container, it has mounted your home directory and you have essentially inherited your desktop system but the container is Ubuntu - and so you can use the Ubuntu distro tools to install software. Pretty neat, huh?
The first step is to build the DPC++ oneAPI compiler from source.
`$ mkdir -p ~/src/sycl_workspace `
You can use whatever area you want. I'm following this [guide](https://intel.github.io/llvm-docs/GetStartedGuide.html#create-dpc-workspace) to build the compiler.
### Prequisites
Let's first grab our pre-requisites for building.
``` $ apt install git python3 gcc c++ libstdc++ libstdc++-9-dev python3-pip python3-distutils python-distutils-extra python3-psutil -y
$ pip3 install meson
$ pip3 install ninja ```
Now that we have our build environment.
### Build DPC++ Compiler
``` $ cd ~/src/sycl_workspace
$ export DPCPP_HOME=`pwd`
$ git clone https://github.com/intel/llvm -b sycl```
We can start the actual build:
``` $ python $DPCPP_HOME/llvm/buildbot/configure.py
$ python $DPCPP_HOME/llvm/buildbot/compile.py ```
At the end of this exercise, you should have a working oneAPI DPC++ compiler.
But we aren't done yet - we still need to add some of the oneAPI libraries and runtimes to make our simple oneAPI example work.
We first need to install our low level runtimes: the things that recognizes accelerators. For now, we'll use the ones that recognize the x86 Intel processors as that is what is on my laptop right now.
We will first need to identify the latest versions of the runtimes we need to download. You need to look this up in the [dependency.conf](https://github.com/intel/llvm/blob/sycl/buildbot/dependency.conf).
```bash
$ sudo mkdir -p /opt/intel
$ sudo mkdir -p /etc/OpenCL/vendors/intel_fpgaemu.icd
$ cd /tmp
$ wget https://github.com/intel/llvm/releases/download/2022-WW50/oclcpuexp-2022.15.12.0.01_rel.tar.gz
$ wget https://github.com/intel/llvm/releases/download/2022-WW50/fpgaemu-2022.15.12.0.01_rel.tar.gz
$ sudo bash
# cd /opt/intel
# mkdir oclfpgaemu-<fpga_version>
# cd oclfpgaemu-<fpga_version>
# tar xvfpz /tmp/fpgaemu-2022.15.12.0.01_rel.tar.gz
# cd ..
# mkdir oclcpuexp_<cpu_version>
# cd oclcpuexp-<cpu_version>
# tar xvfpz /tmp/oclcpuexp-<cpu_version>
# cd ..
```
Now to create some configuration files.
```bash
# pwd
/opt/intel
# echo /opt/intel/oclfpgaemu_<fpga_version>/x64/libintelocl_emu.so >
/etc/OpenCL/vendors/intel_fpgaemu.icd
# echo /opt/intel/oclcpuexp_<cpu_version>/x64/libintelocl.so >
/etc/OpenCL/vendors/intel_expcpu.icd
```
We'll need to grab a release of oneTBB from [github](https://github.com/oneapi-src/oneTBB/releases)
```bash
$ cd /tmp
$ wget https://github.com/oneapi-src/oneTBB/releases/download/v2021.7.0/oneapi-tbb-2021.7.0-lin.tgz
```
and now extract it.
```bash
$ cd /opt/intel
$ sudo bash
# tar xvfpz /tmp/oneapi-tbb-2021.7.0-lin.tgz
```
We'll need to reference some of the libraries in the oneTBB directory in our build.
```bash
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbb.so /opt/intel/oclfpgaemu_<fpga_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbbmalloc.so /opt/intel/oclfpgaemu_<fpga_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbb.so.12 /opt/intel/oclfpgaemu_<fpga_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbbmalloc.so.2 /opt/intel/oclfpgaemu_<fpga_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbb.so /opt/intel/oclcpuexp_<cpu_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbbmalloc.so /opt/intel/oclcpuexp_<cpu_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbb.so.12 /opt/intel/oclcpuexp_<cpu_version>/x64
# ln -s /opt/intel/oneapi-tbb-<tbb_version>/lib/intel64/gcc4.8/libtbbmalloc.so.2 /opt/intel/oclcpuexp_<cpu_version>/x64
```
Now we need to configure the library paths:
```bash
# echo /opt/intel/oclfpgaemu_<fpga_version>/x64 > /etc/ld.so.conf.d/libintelopenclexp.conf
# echo /opt/intel/oclcpuexp_<cpu_version>/x64 >> /etc/ld.so.conf.d/libintelopenclexp.conf
# ldconfig -f /etc/ld.so.conf.d/libintelopenclexp.conf
```
and we're done! Now we need to make sure that this toolchain actually works. So run this test.
**Make sure you are not root.**
```bash
$ python $DPCPP_HOME/llvm/buildbot/check.py
```
If you come back with no failure then, congratulations, you're in good shape!! Sometimes, there might be a few missing dependencies, especially when it comes to python.
We are now ready to create a simple SYCL application and test. I'm going to re-use the one that is located on [Github](https://intel.github.io/llvm-docs/GetStartedGuide.html#run-simple-dpc-application).
Let's create our workspace and build this sample project.
```bash
$ mkdir -p ~/src/simple-oneapi/
$ cd ~/src/simple-oneapi
$ export PATH=$DPCPP_HOME/llvm/build/bin:$PATH
$ export LD_LIBRARY_PATH=$DPCPP_HOME/llvm/build/lib:$LD_LIBRARY_PATH
$ cat > simple-oneapi.cpp
#include <sycl/sycl.hpp>
int main() {
// Creating buffer of 4 ints to be used inside the kernel code
sycl::buffer<sycl::cl_int, 1> Buffer(4);
// Creating SYCL queue
sycl::queue Queue;
// Size of index space for kernel
sycl::range<1> NumOfWorkItems{Buffer.size()};
// Submitting command group(work) to queue
Queue.submit([&](sycl::handler &cgh) {
// Getting write only access to the buffer on a device
auto Accessor = Buffer.get_access<sycl::access::mode::write>(cgh);
// Executing kernel
cgh.parallel_for<class FillBuffer>(
NumOfWorkItems, [=](sycl::id<1> WIid) {
// Fill buffer with indexes
Accessor[WIid] = (sycl::cl_int)WIid.get(0);
});
});
// Getting read only access to the buffer on the host.
// Implicit barrier waiting for queue to complete the work.
const auto HostAccessor = Buffer.get_access<sycl::access::mode::read>();
// Check the results
bool MismatchFound = false;
for (size_t I = 0; I < Buffer.size(); ++I) {
if (HostAccessor[I] != I) {
std::cout << "The result is incorrect for element: " << I
<< " , expected: " << I << " , got: " << HostAccessor[I]
<< std::endl;
MismatchFound = true;
}
}
if (!MismatchFound) {
std::cout << "The results are correct!" << std::endl;
}
return MismatchFound;
}
```
Let's build our simple oneapi source code!
```bash
$ clang++ -fsycl simple-sycl-app.cpp -o simple-sycl-app
```
It should compile and run without any errors.
If all works as anticipated, you should have a working setup.
### Setting up the container to code SYCL when you enter
Now, the next step is to make this container useful when you enter and have it always ready to build a sycl app.
Exit out of the container using the 'exit' command and you should be back on the host operating system.
Type:
` $ uname -a `
On my system, I get:
`Linux fedora 6.0.13-300.fc37.x86_64 #1 SMP PREEMPT_DYNAMIC Wed Dec 14 16:15:19 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux`
Re-enter the container:
```bash
$ distrobox enter oneapi
$ uname -a
Linux oneapi.fedora 6.0.13-300.fc37.x86_64 #1 SMP PREEMPT_DYNAMIC Wed Dec 14 16:15:19 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
```
You will notice that after "Linux" when you are in the container, there is a "oneapi" prefix to fedora.
We can take advantage of that. Let's make sure that when we enter the container that we can set things up from the shell perspective to be ready to write SYCL code.
Add this bit to your .bashrc:
```bash
oneapi=``uname -a | grep -c oneapi``
if [ $oneapi -gt 0 ]; then
echo "Initializing oneAPI"
export DPCPP_HOME="/var/home/sri/src/dpcplusplus"
export PATH="$PATH:/var/home/sri/.local/bin:$DPCPP_HOME/llvm/build/bin"
export LD_LIBRARY_PATH="$DPCPP_HOME/llvm/build/lib"
fi
```
**Make sure you replace 'sri' with your your login details**
Now when we enter the 'oneapi' container our environment will be properly initialized.
Let's stop here, and we'll pick it up in the next post. The next post will focus on creating a meson setup around this simple oneapi code. Part 3 will focus on taking our meson configured source code and using GNOME Builder to build it. Stay tuned!
Photo by <a href="https://unsplash.com/@imattsmart?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">iMattSmart</a> on <a href="https://unsplash.com/photos/sm0Bkoj5bnA?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
| sramkrishna |
1,313,999 | Performance Testing Concepts & Terms | This article describes key concepts in building an approach to Performance Testing. Performance... | 0 | 2023-04-23T03:46:42 | https://dev.to/gallau/performance-testing-concepts-terms-3c6f | This article describes key concepts in building an approach to Performance Testing. Performance testing involves evaluating how a system performs under a specific workload. This can help determine if the system is able to handle the expected number of transactions and if its configuration is suitable.
Key Concepts
**Load testing** involves putting a system or application through a defined transaction model, either through scripts or by simulating a large number of users. The model typically consists of various functions, such as common transactions or transactions that require a high amount of system resources, such as searches and report retrieval.
---
**Stress testing** involves putting a system under abnormal or extreme workload in order to observe its behaviour. This can help identify if the system will crash or experience timeouts when subjected to high levels of transactions. For example, stress testing might involve seeing if a database connection times out before the application crashes when subjected to a high volume of transactions.
---
Response Times
These are the duration it takes to complete a transaction. There are different levels of transactions For user-facing transactions
```
<pre class="mermaid">
graph LR
A[Start] --> B[Step 1]
B --> C[Step 2]
C --> D[Step 3]
D --> E[End]
</pre>
```
`<pre class="mermaid">
graph LR
A[Start] --> B[Step 1]
B --> C[Step 2]
C --> D[Step 3]
D --> E[End]
</pre>`
| gallau | |
1,314,725 | Learning blog-93 | A post by HONGJU KIM | 0 | 2023-01-02T06:54:47 | https://dev.to/hongju_kim_821dc285a52c96/learning-blog-93-cho |

| hongju_kim_821dc285a52c96 | |
1,314,044 | What is the difference between ‘for’ loop and other iterations in JavaScript | There are several ways to iterate over items in JavaScript. One of the most used is for loop. It’s an... | 0 | 2023-01-01T07:03:14 | https://dev.to/limjinda/what-is-the-difference-between-for-loop-and-other-iterations-in-javascript-1nkb | javascript, iteration, programming, tutorial | There are several ways to iterate over items in JavaScript. One of the most used is `for` loop. It’s an essential method, and most teach in the university if you are a computer science student.
The concept of `for` loop is easy to understand. It iterates item through item, and we can control when to stop(with break), or continue(with continue), or how many times the loop should run, and get index easily, Which means you can manipulate some data or set a special condition as you need. For example, you get a bunch of news and want to render ads after the third.
`for` loop is faster than other iteration methods because they are implemented using a lower-level approach, as you see the result in this image below.
source: https://jsben.ch/wY5fo
Compared with other iteration methods like `forEach` or `map` function, They are higher-order functions that are implemented for easy access to the item when iterating, which means this should make a slight overhead and affect the performance.
However, If you have a small number in the array, The performance of for loop or other iteration methods does not matter. The `map` function or `forEach` would be preferred because it easy to access the object and easy to read more than for loop method. Here, take the example:
```
const arr = [1, 2, 3, 4, 5];
arr.forEach(function(element) {
console.log(element);
});
```
```
arr.map(function(element){
console.log(element)
});
```
Compare to for loop. You have to define which item or index you want to access, which should cause a problem `for` the newbie programmer.
```
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]);
}
```
It is generally best to choose the iteration method that is most appropriate for your task rather than trying to optimize for performance. In most cases, the performance difference between the different iteration methods will not be significant. | limjinda |
1,314,461 | Source code structure checklist | This is my checklist for a source code structure. Of course, there is no silver bullet and different... | 0 | 2023-01-02T18:50:02 | https://dev.to/0x808080/source-code-structure-checklist-a8f | codequality, programming, microservices | This is my checklist for a source code structure. Of course, there is no silver bullet and different domains/technologies/languages have their specific requirements and limitations. So, here is the language-agnostic and domain-agnostic set of questions I usually ask myself while assessing the existing code base and before creating a new one. I do not try to get all of those boxes checked altogether, but I should understand why any of them is unchecked and determine whether it is a “red flag” for the particular project.
## 1. Does the source code tell you “what does the service do” instead of “which framework or library it is based on”?
This will check how easy it is to open the code and quickly find a place for a new feature, make a bug fix or check how the particular part of the business logic works.
We are used to read the code much more often than to write it. So we need to squeeze the maximum out of our programming language’s expressiveness. I’m talking not only about the proper names for variables, classes etc., but about the structure of files and directories as well. We often build our projects on top of a certain framework which imposes a structure to the entire project. Switching to the new framework often leads to re-writing the whole code base. Steve McConnell in his book [“Code Complete”](https://www.oreilly.com/library/view/code-complete-2nd/0735619670/) describes this effect as “writing in programming language” opposed to “writing with help of the programming language”. In that book, you may find a very profound explanation of how to write a program for people, not for computers.
Try to make the file tree self-explanatory, and try to extend generic terms, like `utils`, `models`, `validators`, and so on. As for me, is better to see the `utils` directory with a single file per each helper-object instead of the single `utils` file with all helpers inside and with dozens of lines of code. I am also not a big fan of shortened entity names. I’d rather spend yet another microsecond reading a complex name and catching the concept, rather than reading a shortened but ambiguous one. All of those points sound obvious, but save hours of time in the long run.
## 2. Can you easily run the project or its test suite locally with a simple command?
This will check how easy it is to pick up the project by a team members (especially newcomers).
We usually do not want to spend an hour in order to find all possible startup options and distract our colleagues by asking corresponding questions. Some kind of command automation utility may help.
I use good old [Makefile](https://en.wikipedia.org/wiki/Make_(software)#Makefile) where I keep all needed complex commands associated with shortcuts like: `image`, `deploy`, `bootstrap`, `test`, `clean`, etc. I also add a “help section” to it, which prints a brief explanation of all commands and a couple of examples so that any team member can just type `make help` in the command line and recall all details. It is much easier to run `make image test clean` or something like that instead of typing long docker or docker-compose related commands and try to remember commands specific to each project. I am also happy when the CI/CD config may run those Makefile commands. That helps to keep all possible ways to run and manage application in a single place.
## 3. Can you add support for the "--dry-run" flag without a significant redesign of the project itself and its tests?
This will check whether your business logic is tightly coupled with the database and external services.
By this “dry run” mode I mean the ability to run the service with isolated or mocked external dependencies. We need this not only to perform manual testing and debugging but also to increase testability and extensibility of the project. This topic is described in details in the [“Architecture Patterns with Python”](https://www.oreilly.com/library/view/architecture-patterns-with/9781492052197/) book by Harry Percival and Bob Gregory. As written in the book - "patching out the dependency you’re using makes it possible to unit test the code, but it does nothing to improve the design. For that, you’ll need to introduce abstractions". As for unit testing, there is two most popular approaches for testing external calls: London-school TDD using Mocks (patching the call in place) and the Classic Style using Fakes (Fakes are working implementations of the thing they’re replacing). Dynamic languages such as Python allow you to simplify the structure and just monkey-patch all needed calls. But, strictly speaking, mocking is a code smell and may lead to complicated tests.
My choice is - Mocks for small or short-term solutions and Fakes for the medium/big and long-lasting ones.
## 4. Can you add support for the new version of the API/Model without a significant redesign of the project itself and its tests?
This check is like the previous one but examines extensibility of the business logic-related parts of the application.
Not the severe point, but it is better to think about the place for different versions of the same entities ahead of time and about how they may live together within the particular code base.
In my personal experience, the initial version of the API or business logic entities seems the most proper one and stable, but the stable requirements are a myth. The task to add a new API version usually comes when the service is already deployed to the production and making such a change involves lots of steps with further refactoring. As proposed in the famous [tweet](https://twitter.com/kentbeck/status/250733358307500032): “Make the change easy (warning: this may be hard), then make the easy change.”
## 5. Can you add support for the new interface, e.g. CLI without a significant redesign of the project itself and its tests?
This will check whether your business logic is tightly coupled with the representation layer.
If so, it would be much harder to add a new external interface or to build a healthy testing-pyramid. Loose coupling of the business logic with the representation layers (actual HTTP endpoints in case of a web application) helps us to simplify unit tests and to prepare to switching to another framework. That switch might look like an impossible case, but in my opinion, it is often almost impossible to painlessly switch to a better framework just because of the tightly coupled code. Not because we do not want to switch to the better framework. It is usually not just a major refactoring, it means rewriting the major portion of the code (and tests), which is not desirable at all.
I’m going to suggest here any kind of approach based on the inversion of control. The [Hexagonal architecture](https://en.wikipedia.org/wiki/Hexagonal_architecture_(software)) or any of its [variants](https://en.wikipedia.org/wiki/Hexagonal_architecture_(software)#Variants) should work. Such kind of code structure makes it easy to separate business logic from representation and persistence layers or to add new layers as the Web interface besides existing CLI Interface and vice versa. Although using such approaches for small or short-term solutions may be an overkill.
## 6. Are there any unused/unnecessary dependencies in the source code?
This will check whether the code base depends on things it doesn't use.
Although we mostly use open-sourced dependencies, the risk of having related security issues is still there. Also, each added dependency does not decrease the compile time/startup time/binary size (depending on the particular programming language) of the service. For the same reasons, it is better not to keep testing-related dependencies in a production image/binary. There are also cases when we add dependency on the whole package if we actually need one or two helper functions from it. In most cases, it is better to copy-paste those helper functions into your code base and get rid of the extra dependency.
## 7. Does the source code have a “gentleman set” of root-level helper files?
This will check, I'd say, the general "maturity" of the repository.
There is a set of commonly used files, which doesn't influence the functionality itself but helps us to maintain the codebase in a unified manner.
Such files are: `.gitignore`, `.dockerignore`, `.editorconfig`, `CHANGELOG.md`, `CONTRIBUTING.md`, explicit configs for static code analyzers? And by the way... the actual version of the `Readme` file. No joke. Let’s end the practice when the main contributors to the readme file are newcomers, who found that steps described in the `Readme` file do not work anymore...
## Afterword
**Note that I deliberately skipped any checks for unit-tests as they deserve a separate checklist.**
One of the main goals of such a strict inspection is to increase the readability and maintainability of the project. This is extremely important for long-lasting projects. In most cases, we shouldn’t bother a lot about how easy it will be for a processor to parse our code base and create a nice abstract syntax tree from it. But we should bother about how much time it will take for a newcomer/your colleague/yourself to find the right place for a new feature or a bug fix. Let’s be honest, human beings are not so good at keeping a lot of objects and abstractions in memory simultaneously. We shouldn’t neglect our natural peculiarities and help ourselves in any ways possible.
## Bibliography:
[McConnell, Steve. 2004. Code Complete, 2nd Edition](https://www.oreilly.com/library/view/code-complete-2nd/0735619670/)
[Percival, Harry and Gregory, Bob. 2020. Architecture Patterns with Python](https://www.oreilly.com/library/view/architecture-patterns-with/9781492052197/)
| 0x808080 |
1,314,471 | A 30-Day challenge in backend web development | As you begin your journey into web development, you will often encounter the terms front end and back... | 0 | 2023-01-01T23:23:29 | https://dev.to/efkumah/a-30-day-challenge-in-backend-web-development-3g1f | webdev, javascript, beginners, programming | As you begin your journey into web development, you will often encounter the terms front end and back end. When it comes down to it, what does it really mean?
A typical web app can be segmented into two: Frontend and backend.
The front-end focuses on the visual aspect of the web app, the part the user sees and interacts with.
The back end is the part of the web app the user does not see and interact with. It is the server, application, and databases working behind the scenes to deliver the information requested by the user.
It is an exciting challenge for me to learn and share knowledge, insights, and thoughts about backend development for the next 30 days.
Let's walk this journey together, and at the end of the month, we'll be able to build robust web apps with the ExpressJS framework.
 | efkumah |
1,314,659 | 😅 スクロールで動かなくなります! をどうやってchrome dev tool使用してfrontの問題を解決したのか | Solve frontend performance problem by chrome dev tool in real... | 0 | 2023-01-02T05:45:22 | https://dev.to/kaziusan/sukurorudedong-kanakunarimasu-wodouyatutechrome-dev-toolshi-yong-sitefrontnowen-ti-wojie-jue-sitanoka-53a2 | javascript | {% link https://dev.to/kaziusan/analyse-ag-grid-performance-problem-in-real-project-318m %}
↑ これの日本語版です (Japanese version of this article)
---
業務で[ag-grid](https://www.ag-grid.com/)というテーブルのライブラリを使っていました
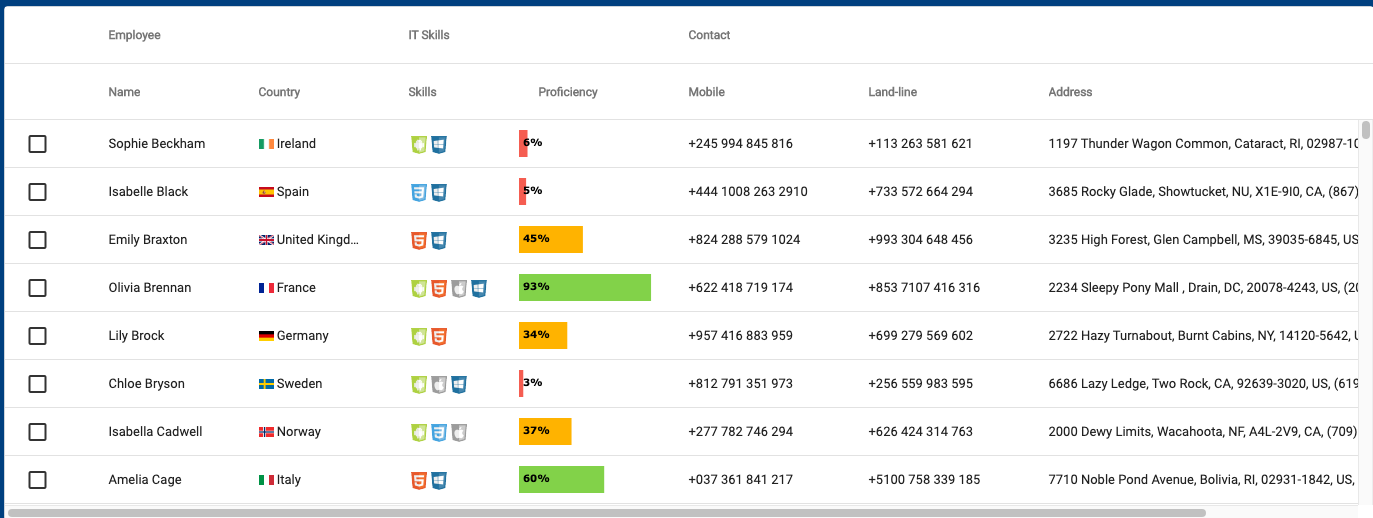
ある日同僚のQAの方からこんなタスクが作成されました
> テーブルにデータが500ぐらいあると、スクロールがスムーズに動かないです。またたまに動かなくなります
▼ 調査開始ですが、まずこのprojetでは **tree data grid** と呼ばれるものを使用していました。
[tree-data](https://www.ag-grid.com/javascript-data-grid/tree-data/)
しかし他のタスクで既に、Javascriptを使用し画像のような縦線を入れておりました
なので直感的に「あ、DOM operationしてるこの線が原因だろうなぁ」と思ってました。
しかしそれは厳禁、前[ここ](https://dev.to/kaziusan/rail-important-way-of-thinking-about-frontend-performance-97i)で書いたように、パフォーマンスに関しては「予測するな、測れ」が基本原則なので、測ることにしました。
**google chrome > Inspect > Performance**
ジャーン

2箇所重い部分が見つかりました(オレンジと青の線)
- オレンジ -> JS scripting
- 青 -> styleの再計算
### 1.オレンジ部分
`userComponentFactory.newCellRenderer`というag-gridの関数を見つけました、これはtableのcellをcustomizeするときの関数です
[cell renderer (string以外をcellで使用したい時など)](https://www.ag-grid.com/javascript-data-grid/component-cell-renderer/)

これを削除できたらよかったですが、プロジェクトではリンクやhoverでのtooltip表示があり、できませんでした。
### 2.青い部分
↑ これが私が直感で思った「Javascriptで縦の線を入れる」部分です。
しかし思っていたよりもかなり軽い。。。
そしてもっと重い処理を見つけました

> redrawAfterScroll()
👨💻 スクロール後の何か関数。。
> removeRowCompos()
> RowContainerComponent.removeRowElement()
👨💻 remove row ...??
最初は意味がわかりませんでしたが、後に`rowBuffer: 100`というag-gridの設定をコード内で見つけました。
[RowBuffer](https://www.ag-grid.com/javascript-data-grid/dom-virtualisation/#row-buffer)
**RowBufferってなに??**
例えばサーバーから1万データがきたとします、するとDOM作成に時間がかかりすぎてブラウザがcrashするかもしれません。
なのでag-gridはデフォルトで表示以外に上下10列DOMを作成する設定になってます(Row buffer: 10の状態)
この数値がプロジェクトでは100になっていました、するとこうなります
> 1, 500データをサーバーから取得
> 2, 100列DOMを作成
> 3, スクロールします
> 4, 新しいDOMを作成し、前のDOMを削除...この繰り返し
この見えない位置の上下100列を保つための関数`RowContainerComponent.removeRowElement()`が重かったのです。
😮 ではどう`RowBuffer`を設定したのか?
[max-rendered-rows](https://www.ag-grid.com/javascript-data-grid/dom-virtualisation/#max-rendered-rows)
ag-gridでは設定をmax 500だと記載があり、450に設定しました。(500だと重すぎた)
もちろん最初のダウンロードで時間はかかりますが、スクロール中のラグやクラッシュよりかは良いので、こうしました。
| kaziusan |
1,314,719 | Events in Solidity. | Events in Solidity. **Events are the way Solidity **and the EVM provides developers with logging... | 0 | 2023-01-02T06:43:10 | https://dev.to/abhaypatel/events-in-solidity-4d5d | blockchain, beginners, webdev, solidit | Events in Solidity.
**Events are the way Solidity **and the EVM provides developers with logging functionality used to write information to a data structure on the blockchain that lives outside of smart contracts’ storage variables.
Events are an abstraction on top of the EVM’s low-level logging functionality, opcodes LOG0 to LOG4. The specific opcode used will depend on the number of topics the event declares using the indexed keyword. A topic is just a variable that we want to be included in the event and tells Solidity we want to be able to filter on the variable as well.
The low-level logs are stored in the transaction receipt of the transaction under the transaction receipts trie. Logs are written by the smart contract when the contract emits events, but these logs cannot be ready by the smart contract. The inaccessibility of the logs allows developers to store data on-chain that is more searchable and gas efficient than saving data to the smart contract’s storage variables.
Events are defined in smart contracts using the event keyword. Here is the transfer event from the ERC20 smart contract. It is emitted whenever tokens are transferred from 1 account to another.
**Here we can see the different components of an event:**
**the event's name Transfer**
the event's topics from (sender's address), to (the receiver's address), value (the amount transferred).
if a variable in the event is not marked as indexed it will be included when the event is emitted, but code listening on the event will not be ablel to filter on non-indexed varables (aka topics).
Whenever a Transfer event is emitted, the from, to and value data will be contained in the event.
**Emiting Events**

Once an event has been defined we can emit the event from the smart contract. Continuing on from the ERC20 smart contract let's see where the Transfer event is emitted.
**Listening to Events**
If you remember the definition of an Event from above, smart contracts can write events, but not read events. So how do we listen/read to data that smart contracts cannot read?
We listen to and read events from code connected to a provider. From what we've learned so far in this course we could do this in JS code using an ethers provider to connect to a contract and listen to transfer events and do something with the event data. | abhaypatel |
1,314,869 | The Role of Automation in Replacing Human Jobs: A Detailed Examination | Introduction Automation has been a hot topic in the field of data science for some time now, and it's... | 0 | 2023-01-02T10:14:08 | https://dev.to/1stepgrow/the-role-of-automation-in-replacing-human-jobs-a-detailed-examination-4n07 | javascript, programming, career, database | **Introduction**
Automation has been a hot topic in the field of data science for some time now, and it's not hard to see why. With the rapid advancement of technology and the increasing availability of data, it's becoming easier and more cost-effective for companies to automate certain tasks and processes. While automation has the potential to bring many benefits, including increased efficiency and accuracy, it also raises concerns about the potential for replacing human jobs. In this article, we'll delve into the role of automation in replacing human jobs, as well as the ethical implications of this trend.

**To start, let's define automation and understand how it works.**
At its most basic level, automation refers to the use of technology to perform tasks or processes without human intervention. This can take many forms, from simple algorithms that perform basic calculations to more complex systems that use artificial intelligence (AI) to learn and adapt over time. Automation can be applied to a wide range of industries and processes, from manufacturing and logistics to customer service and data analysis.
**Now, let's examine the role of automation in replacing human jobs.**
One of the main concerns about automation is that it has the potential to replace human labor, leading to widespread unemployment and economic disruption. This is especially true in industries where automation can perform tasks more efficiently and accurately than humans, such as manufacturing and data entry. In these cases, companies may be more likely to invest in automation as a cost-saving measure, leading to job losses for human workers.
However, it's important to note that automation is not always a replacement for human labor. In many cases, automation can augment human work, allowing workers to focus on more complex and higher-value tasks while the automation handles the more routine or repetitive tasks. This can lead to increased productivity and job satisfaction for human workers. For example, a customer service representative may use automation to handle basic inquiries and freeing up their time to handle more complex customer issues.
**So, how do we balance the benefits of automation with the potential for job loss?**
One solution is to consider the impact on affected workers and take steps to support them during the transition. This could include providing training and support for workers who may need to transition to new roles, or offering severance packages and other forms of compensation for those who may lose their jobs. It's also important to consider the broader economic and social impacts of automation. For example, automation may lead to increased efficiency and productivity, but it may also lead to income inequality if certain groups of workers are more likely to be replaced by automation.
In addition to the impact on human jobs, there are also ethical implications to consider when it comes to automation. One key issue is the potential for biased algorithms or systems. For example, if a company develops an AI system to screen job applicants, there is a risk that the system may be biased against certain groups of people, leading to discrimination. This is a complex issue, and it's important for companies to be transparent about their use of automation and to take steps to ensure that their systems are fair and unbiased.
Another ethical consideration is the potential for automation to be used for nefarious purposes. For example, an automated system could be programmed to manipulate public opinion or to spread misinformation. It's important for companies to be aware of these potential risks and to take steps to prevent their systems from being used in unethical ways. So, what can be done to address these concerns? One solution is to prioritize responsible data practices and ethical AI development. This includes ensuring that data is collected, stored, and used in a transparent and responsible manner, as well as developing and implementing ethical guidelines for AI development.
**Conclusion:**
Automation has the potential to bring many benefits, but it's important to carefully consider the potential impacts on human jobs and the ethical implications of this trend. If you're interested in learning more about data science and how it can be applied to real-world problems, consider enrolling in a **[data science course in Bangalore](https://1stepgrow.com/course/advance-data-science-and-artificial-intelligence-course/)**. With a strong foundation in data science principles and techniques, you'll be well-equipped to tackle the challenges and opportunities presented by automation and other emerging technologies. Upon completing a data science course in Bangalore, you'll be well-equipped to pursue a career in data science or related fields. Also, you'll be able to extract insights and knowledge from data and use it to inform decision-making and solve complex problems. Whether you're interested in pursuing a career in data science or simply want to learn more about this exciting and rapidly growing field, a data science course in Bangalore is a great place to start.
| 1stepgrow |
1,314,873 | Auto Clicker Installation on Ubuntu Linux | In this tutorial I will be explaining the installation of Max Auto Clicker on Ubuntu, Linux Mint, and... | 0 | 2023-01-02T10:43:13 | https://dev.to/flaxalex57/auto-clicker-ubuntu-1mkn | ubuntu, linux, autoclicker, mouse | In this tutorial I will be explaining the installation of Max Auto Clicker on Ubuntu, Linux Mint, and all Debian-based Linux distributions.
## Installation Guide
### Step #1
Install the required libraries (dependencies) with this command line:
```
sudo apt update
```
Then:
```
sudo apt install libc6 libgtk2.0-0 libx11-6 libgdk-pixbuf2.0-0 libglib2.0-0 libglib2.0-dev libpango-1.0-0 libcairo2 libatk1.0-0 libxtst6
```
### Step #2
Download the deb package with this command line:
```
wget https://sourceforge.net/projects/maxautoclicker/files/maxautoclicker_1.5_amd64.deb/download -O maxautoclicker_1.5_amd64.deb
```
### Step #3
Install the Max Auto Clicker software with this command line:
```
sudo dpkg -i maxautoclicker_1.5_amd64.deb
```
For **Ubuntu 22 Gnome users** only, execute these lines to disable Wayland.
```
sudo nano /etc/gdm3/custom.conf
```
And add this option after **[daemon]** section line or remove the **#** character from the line that contain it:
```
WaylandEnable=false
```
Press **CTRL+S** (to save changes) and **CTRL+X** (to exit).
Then restart your Gnome Display Manager (GDM) with this command:
```
sudo systemctl restart gdm3
```
{% embed https://www.youtube.com/watch?v=qePXGa0GplA %} | flaxalex57 |
1,314,940 | Programmer: The Silent Loner's Dream Job | facebook.com/Trinwhocode Programmers are often seen as introverts, but why is this the case? The... | 0 | 2023-01-02T11:43:40 | https://dev.to/trinly01/programmer-the-silent-loners-dream-job-3n7g | career, productivity, beginners, programming | [facebook.com/Trinwhocode](https://www.facebook.com/Trinwhocode)
Programmers are often seen as introverts, but why is this the case? The answer may surprise you.
First and foremost, it is important to understand the characteristics of an introvert. An introvert is someone who prefers to work alone, is more comfortable in small groups, and is more introspective than an extrovert. They are often labeled as shy, but this is not necessarily true.
So why are almost all programmers considered introverts? Part of the reason is that coding is a solitary activity. Programmers spend most of their time writing code and debugging. This requires a lot of concentration and focus and can be difficult to do in a loud or crowded environment.
Another reason is that programming requires a lot of problem solving and critical thinking. Programmers must be able to think logically and come up with creative solutions to problems. This requires a great deal of introspection and can be difficult to do in a group setting.
Programming also requires a great deal of patience. Programmers must be able to work through complex problems and be willing to adjust their code as needed. This requires a great deal of patience and discipline, both of which are traits of an introvert.
It is not surprising that almost all programmers are introverts. Coding is a solitary activity that requires problem solving, critical thinking, and patience, all of which are traits of introversion. So the next time someone labels you as an introvert because you are a programmer, you can confidently explain why.
[linkedin.com/in/trinmar](https://www.linkedin.com/in/trinmar) | trinly01 |
1,314,978 | How does Claims Management Software help in the Healthcare Sector? | The Claims management softwares aids in handling the insurance claims of those in high-level... | 0 | 2023-01-02T12:33:30 | https://dev.to/rosefox90/how-does-claims-management-software-help-in-the-healthcare-sector-1h33 |
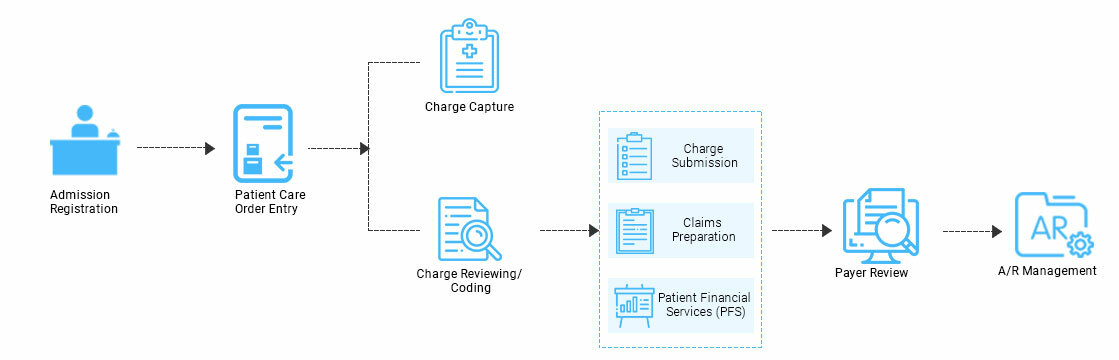
The Claims management softwares aids in handling the insurance claims of those in high-level management, which reduces manual labour and advances automation. In the business sector, claim management systems assist in managing insurance claims, removing the complexity of healthcare legacy concerns, lowering maintenance and training expenses, and streamlining the customer experience. This makes sure that everything goes very smoothly in the healthcare sector. Claims software aids in the deployment, construction, and claiming of efficient, agile, and ROI-maintaining end-to-end business processes.
Automation in claims software management promotes openness, ensures that you don't encounter victims, uncover fraud claims, or run across people who aren't paying their bills on time in a timely manner. This promotes secure claim processing and fosters solid relationships with market-leading insurance providers.
How does Claim management software help to take steps in the future?
This medical claims software is the internet security measure that guarantees its data is secured on the cloud. Its entire data set is encrypted, thus there is no possibility that it might be stolen by unauthorised users. One advantage of this approach is that it has low effective costs and is lawful. This solution enhances effective healthcare solutions and analyzes data analysis more completely while guaranteeing claims processing effectiveness and efficiency of operations.
Every company will need this data right now, and it won't be permitted to be taken for granted because it will be secure and more accurate. Even if the business doesn't pay the consumers, research indicates that 80% of expenses go toward handling claims. This kind of data guarantees transparency and clarity for a more modern and efficient solution to concerns that are on the rise.
Future for Insurance Companies:-
In the near future, insurance firms will wish to see more claimed sales. This is due to the many efforts made to get insurance and assure efficient procedures. They do not wish to have to pay more in the end as a result of fraud cases. They are going to work on a dependable server that is routinely reviewed in order to foster positive customer interactions since they want to secure the privacy of user data.
The introduction of cloud-based technologies by healthcare claim management firms will assist them in increasing automation and focus more on what matters. Insurance providers ought to assist customers make fair claims for insurance and balance the motives why they do so.
Source : https://www.osplabs.com/healthcare-payer-software-solutions/medical-claims-management/
| rosefox90 | |
1,314,984 | The Ethics of AI Generators: are They exchange Human Creativity? | Introduction AI generators, conjointly referred to as AI generators or AI content generators, are... | 0 | 2023-01-02T12:50:10 | https://dev.to/bel775/the-ethics-of-ai-generators-are-they-exchange-human-creativity-6fg | ai, art, community |

**Introduction**
[AI generators](https://www.digistore24.com/redir/456090/Bahar7/), conjointly referred to as AI generators or AI content generators, are laptop programs that use tongue process and machine learning techniques to mechanically generate written or spoken content. they're changing into more and more fashionable and wide employed in a spread of industries, as well as selling, education, and client service.
One of the most advantages of victimisation AI generators is their ability to supply massive amounts of content quickly and with efficiency. this could be particularly helpful for businesses that require to supply a high volume of content on a daily basis, like social media posts or web site content. AI generators can even doubtless save time and cash for businesses by automating bound tasks that may ordinarily be done by human employees.
However, the increasing quality and usage of AI generators raises moral issues concerning their impact on the task market and therefore the potential loss of human power. during this diary post, we'll explore each the professionals and cons of victimisation AI generators and contemplate the moral implications of their use.
**The professionals of victimisation AI Generators**
One of the most advantages of victimisation AI generators is their ability to extend potency and productivity. as a result of they will mechanically manufacture massive amounts of content quickly, they will facilitate businesses save time and resources that may ordinarily be spent on manual content creation. this could permit businesses to target alternative tasks and doubtless increase their overall productivity.
In addition to increasing potency, AI generators even have the flexibility to come up with content quicker and in larger quantities than humans. this could be particularly helpful for businesses that require to supply a high volume of content on a daily basis, like social media posts or [web site content](https://www.digistore24.com/redir/456090/Bahar7/). By victimisation associate degree AI generator, businesses will quickly and simply generate an oversized quantity of content while not the requirement for multiple human writers.
Another potential good thing about victimisation AI generators is their ability to avoid wasting time and cash for businesses. as a result of they will change bound tasks, businesses are also able to scale back their reliance on human labor and doubtless save cash on labor prices. additionally, the employment of AI generators will facilitate businesses save time by automating tasks that may ordinarily be done manually, like making selling materials or generating reports. Overall, the exaggerated potency and productivity provided by AI generators will facilitate businesses save each time and cash.
**The Cons of victimisation AI Generators**
While there are actually advantages to victimisation AI generators, there also are many potential drawbacks to think about. one amongst the most moral issues concerning AI generators is that the potential for exchange human jobs with machines. As AI technology becomes additional advanced, there's a risk that bound jobs could become automatic, doubtless resulting in state for a few employees. This raises moral questions about the responsibility of firms to their workers and therefore the impact of AI on the task market.
[Another potential](https://www.digistore24.com/redir/456090/Bahar7/) downside of victimisation AI generators is that the potential loss of human power and originality. as a result of AI generators are supported algorithms and pre-programmed rules, they'll not be able to manufacture content that's actually original or innovative. this might result in a scarcity of diversity and power within the content that's created, as AI generators could merely replicate concepts and ideas that have already been explored.
In addition to those moral issues, there also are issues concerning the standard and accuracy of AI-generated content. whereas AI generators have created nice strides in tongue process and might manufacture content that's coherent and clear, there's still a risk that the content could contain errors or be of lower quality than content created by human writers. this might doubtless impact the quality and name of the business victimisation the AI generator.
**The Future of AI Generators **
As [AI technology](https://www.digistore24.com/redir/456090/Bahar7/) continues to advance, it's probably that AI generators can become even additional rife and integrated into varied industries. whereas they need already found success in fields like selling and client service, there's potential for additional integration into industries like education, translation, and even the humanities.
As AI generators become additional rife, it'll be vital to ascertain moral tips and laws to make sure their accountable use. this might embody making certain that the employment of AI generators doesn't result in job loss or discrimination, which the content created by AI generators is of prime quality and accuracy.
Ultimately, the long run of AI generators can rely upon finding a balance between their advantages and downsides. whereas they need the potential to extend potency and productivity, it's vital to think about the moral implications of their use and to make sure that they're not exchange human power and jobs. By finding a balanced approach to the mixing of AI generators, it's potential to reap the advantages of this technology whereas minimizing any negative impacts.
**Conclusion**
[In conclusion](https://www.digistore24.com/redir/456090/Bahar7/), AI generators have the potential to revolutionize the approach businesses and organizations manufacture and consume content. they provide exaggerated potency and productivity, the flexibility to come up with massive amounts of content quickly, and therefore the potential to avoid wasting time and cash. However, there also are many moral issues to think about, as well as the potential for exchange human jobs with machines, the loss of human power and originality, and issues concerning the standard and accuracy of AI-generated content.
It is vital to think about these professionals and cons once deciding whether or not or to not use AI generators. whereas they will actually be a useful gizmo, it's essential to approach their integration with caution and to ascertain moral tips to make sure their accountable use. By finding a balanced approach to the mixing of AI generators, it's potential to reap the advantages of this technology whereas minimizing any negative impacts.
| bel775 |
1,331,940 | URL Decoder/Encoder | Using JavaScript, let's create a URL decoder Code HTML <textarea... | 0 | 2023-01-18T05:00:00 | https://dev.to/walternascimentobarroso/url-decoderencoder-5203 | javascript, html, tutorial, beginners | Using JavaScript, let's create a URL decoder
## Code
### HTML
```html
<textarea id="data"></textarea><br />
<button id="encode">Encode</button>
<button id="decode">Decode</button>
```
HTML code is used to create the basic structure of the page, including elements such as text areas and buttons.
In the given example, a text area with the ID "data" and two buttons with the IDs "encode" and "decode" were created.
The text area with the ID "data" is where the user can type or paste the text they want to encode or decode, while the "encode" and "decode" buttons are used to indicate the action the user wants to perform.
### JS
```js
const data = document.querySelector("#data");
const encode = document.querySelector("#encode");
const decode = document.querySelector("#decode");
encode.addEventListener('click', encodeURL);
decode.addEventListener('click', decodeURL);
function encodeURL() {
data.value = encodeURIComponent(data.value);
}
function decodeURL() {
data.value = decodeURIComponent(data.value);
}
```
JavaScript is used to add functionality to previously created HTML elements. In the given example, the lines of JavaScript code are responsible for selecting the HTML elements, adding event listeners for the "encode" and "decode" buttons and the "encodeURL" and "decodeURL" functions that respectively encode and decode the text contained in the area "date" text icon.
When the user clicks the "encode" button, the "encodeURL" function is called, using the JavaScript "encodeURIComponent" function to encode the text contained in the "data" text area and assigning the result back to the "value" property of the "date" text area. Likewise, when the user clicks the "decode" button, the "decodeURL" function is called, using the JavaScript "decodeURIComponent" function to decode the text contained in the "data" text area and assigning the result back to the property "value" from the "data" text area.
## Demo
See below for the complete working project.
{% codepen https://codepen.io/WalterNascimento/pen/vYJaqzw %}
_if you can't see it [click here](https://codepen.io/WalterNascimento/pen/vYJaqzw) and see the final result_
***
## Thanks for reading!
If you have any questions, complaints or tips, you can leave them here in the comments. I will be happy to answer!
😊😊 See you later! 😊😊
***
## Support Me
[Youtube - WalterNascimentoBarroso](https://www.youtube.com/channel/UCXm0xRtDRrdnvkW24WmkBqA)
[Github - WalterNascimentoBarroso](https://github.com/walternascimentobarroso)
[Codepen - WalterNascimentoBarroso](https://codepen.io)
| walternascimentobarroso |
1,315,040 | What are some must-use things for new Angular projects in 2023? | So I'm switching jobs soon and will be setting up a few new Angular projects, new libraries and... | 0 | 2023-01-02T13:34:36 | https://dev.to/martinspire/what-are-some-must-use-things-for-new-angular-projects-in-2023-5bc | angular, typescript, testing, tooling | So I'm switching jobs soon and will be setting up a few new Angular projects, new libraries and whatnot and am wondering what I might be missing out on and should be implementing in new projects.
The past months I've been working on weird architectures and overly complex systems that made me realize that I might be used to outdated concepts and not been using the latest tools that would make me a happy dev.
I am aware of NX and how things change because of it. Not sure if its usable for every use case I will have but I will keep that in mind. So for folks that have been finding new stuff to use the past 2 years, let me know as I have a few questions:
1. What SCSS framework is currently the most recommended (like Tailwind, Material or something else? Of course "it depends" but whats your favorite right now?)
2. What ESLint rules and extentions would you recommend (over the default ones)
3. What mocking and testing extensions are now recommended? I know of NGMocks and NGSpectator but perhaps there is something else new for speeding up building tests
4. Should I switch Cypress with something else? Or get something to speed up writing E2E tests?
5. Should I switch to Jest and if so what helper libraries are recommended?
6. What other tools have you been using?
7. What other code quality things have you started using?
8. Whats something you didn't use one year ago that you think people should try?
Basically pretend I've been under a rock for 2 years and tell me what you've been using that has improved your Angular project code and made your projects more fun to work on. Aside the blatantly obvious things like migrating to Angular 15 and so on... | martinspire |
1,315,362 | Log Forwarding To Linux | In this video: - Configure Syslog Monitoring via Palo Alto Firewall Syslog is a standard log... | 0 | 2023-01-02T19:25:29 | https://dev.to/hackh3rgr1fl0/log-forwarding-to-linux-5117 | cybersecurity, socananlyst, tech |
{% embed https://youtu.be/XDs6NCLH6yM %}
In this video:
**- Configure Syslog Monitoring via Palo Alto Firewall**
Syslog is a standard log transport mechanism that enables the aggregation of log data from different network devices - such as routers, firewalls, printers - from different vendors into a central repository for archiving, analysis, and reporting.
Palo Alto Firewalls can forward every type of log they generate to an external Syslog server. Using TCP or SSL for reliable and secure log forwarding, or UDP for non-secure forwarding.
**- Verify Syslog Forwarding**
able to connect to the DMZ server and verify that the syslogs are being forwarded. Using Xfce Terminal, I was able to ping the DMZ server address by typing **ping -c4 192.168.50.10.**
Also using **tail -f /var/log/messages** can connect the current file for any changes that are occurring. Which should show the date, source of the syslog data, and information about the traffic. | hackh3rgr1fl0 |
1,315,579 | How to create a toggling menu button | A post by yemyemco | 0 | 2023-01-02T23:27:20 | https://dev.to/yemyemco/how-to-create-a-toggling-menu-button-3fi2 | codepen | {% codepen https://codepen.io/yemyemco/pen/GRBqQRJ %} | yemyemco |
1,315,677 | MySql CheatSheet | SQL Commands Create Database Create new database or schema Command - CREATE... | 0 | 2023-03-05T14:29:20 | https://dev.to/ishanshre/mysql-cheatsheet-ol6 | # SQL Commands
## Create Database
- Create new database or schema
- Command - `CREATE DATABASE <DATABASE NAME>;`
- Eg:- `CREATE DATABASE myDB;`
## Drop Database
- Delete the database
- Command - `DROP DATABASE <DATABASE NAME>;`
- Eg:- `DROP DATABASE myDB;`
## Use Database
-Set the database default
- Command- `USE <DATABASE NAME>;`
- Eg:- `USE myDB;`
## Alter Database
- We can change the database to read only and vice versa. When the database is read only we can only view its data. We cannot do any operations in database except reading and altering the read only to false or 0
- Command- `ALTER <DATABASE NAME> READ ONLY=1;`
- Command- `ALTER <DATABASE NAME> READ ONLY=0;`
# Table
## Create Table
- Use CREATE to create new table in the database
- Command:-
```
CREATE TABLE <TABLE NAME> (
column 1 DATATYPE,
column 2 DATATYPE,
column 3 DATATYPE,
…
);
```
- Eg:
```
CREATE TABLE user (
user_id INT,
username VARCHAR(50),
password VARCHAR(50),
joined_date DATE,
last_login DATE
);
```
```
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(100),
created DATE DEFAULT (CURRENT_DATE())
);
```
## Rename Table
- Command:- `RENAME TABLE <TABLE NAME> TO <NEW TABLE NAME>;`
- Eg:- `RENAME TABLE user TO account;`
## Alter Table
- Alters the table details
- Commands:-
- Add column
```
ALTER TABLE account
ADD phone_number VARCHAR(10);
```
- Rename column
```
ALTER TABLE account
RENAME phone_number to email;
```
- Change column datatype
```
ALTER TABLE account
MODIFY COLUMN email VARCHAR(255);
```
- Change the column order
```
ALTER TABLE account
MODIFY email VARCHAR(255)
AFTER password;
```
- Drop Column
```
ALTER TABLE account
DROP COLUMN email
```
# Insert Rows
## Insert single data or single row
```
INSERT INTO account
VALUES (1,"user1","userPassword1","2021-01-23","2022-12-01");
```
## Insert multiple rows or multiple data
```
INSERT INTO user
VALUES (3, "admin1","admin1pass","2021-01-02","2022-01-09"),
(3, "admin2","admin2@pass","2021-01-02","2022-01-09"),
(4, "admin3","admin3@pass","2021-01-02","2022-01-09"),
(5, "admin4","admin4@pass","2021-01-02","2022-01-09");
```
## Insert data into selected columns of the row
```
INSERT INTO user (user_id, username, password)
VALUES (6, "admin5","admin6pass");
```
## Update columns data with where clause
```
UPDATE accounts
SET password = "hello@123"
WHERE user_id = 2;
```
## Delete row data(where clause is important in DELETE command other wise our whole data will be deleted
```
DELETE FROM accounts
WHERE user_id = 2;
```
## Enable/Disable safe mode in MySql
```
SET SQL_SAFE_UPDATES = 0
SET SQL_SAFE_UPDATES = 1
```
## Disable autocommit
```
SET AUTOCOMMIT = OFF;
```
## Manually create a save point and make changes
```
COMMIT;
```
## Roll Back Changes(only possible if commit changes
```
ROLLBACK;
```
## Add UNIQUE Constraints to column when creating a table
```
CREATE TABLE profile (
profile_id INT,
name VARCHAR(50) UNIQUE,
age INT
);
```
## Add UNIQUE to a column of a table
```
ALTER TABLE profile
ADD CONSTRAINT
UNIQUE (profile_id);
```
## Set Column NOT NULL when creating a table
```
CREATE TABLE student (
student_id INT NOT NULL,
class INT
);
```
## Set column NOT NULL for existing tables
```
ALTER TABLE student
MODIFY class INT NOT NULL;
```
## Set a default value new table
```
CREATE TABLE employees (
id INT,
name VARCHAR(255),
salary DECIMAL(10,2) DEFAULT 0
);
```
## Set a default value for existing table
```
ALTER TABLE employees
ALTER salary SET DEFAULT 10;
```
## Set Primary key for new table
```
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50)
);
```
## Set Primary key for existing table
```
ALTER TABLE employees
ADD CONSTRAINT
PRIMARY KEY(id);
```
## Set Primary key for new table with auto increment
```
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50)
);
```
## Set auto_increment value starts from
```
ALTER TABLE employee
AUTO_INCREMENT = 1000;
```
## Creating a foriegn key(one to many relationship)
```
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(5),
);
INSERT INTO customers (name)
VALUES ("ishan"),("binod"),("anil");
SELECT * FROM customers;
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
amount DECIMAL(10,2),
customer_id INT,
FOREIGN KEY(customer_id) REFERENCES customers(customer_id)
);
SELECT * FROM orders;
```
## Drop the foreign key
```
ALTER TABLE orders
DROP FOREIGN KEY orders_ibfk_1
```
## Add foriegn key to existing table with custom name
```
ALTER TABLE orders
ADD CONSTRAINT fk_customer_id
FOREIGN KEY(customer_id) REFERENCES customers(customer_id);
```
## Inner Join
- Select records from two tables having matching values in both table
```
SELECT customers.customer_id, customers.name, orders.amount
FROM customers INNER JOIN orders
ON customers.customer_id = orders.customer_id;
```
## Left join
- Selects all records from left table
- Right side table records are not displayed if record does not matches from the left
```
SELECT *
FROM customers LEFT JOIN orders
ON customers.customer_id = orders.customer_id;
```
## Right join
- Selects all the records from the right table
- Selects all the records from the left table that matches with the right table
```
SELECT *
FROM customers RIGHT JOIN orders
ON customers.customer_id = orders.customer_id;
```
## COUNT function
- Counts the records in that column
```
SELECT COUNT(amount) AS no_of_amounts
FROM orders;
```
## MAX Function
- Max returns the highest order of the record in the column
```
SELECT MAX(amount) as maximum_amount
FROM orders;
```
```
SELECT MAX(name) AS large_name
FROM customers;
```
## MIN function
- MIN returns the lowest order of the record in the column
```
SELECT MIN(amount) as minimum_amount
FROM orders;
```
```
SELECT MIN(name) AS small_name
FROM customers;
```
## AVG function
- AVG returns the average of the records in the columns
```
SELECT AVG(amount) AS average_amount
FROM orders;
```
## SUM function
- SUM returns the sum of the records in the columns
```
SELECT SUM(amount) AS sum_of_amount
FROM orders;
```
## CONCAT function
- returns a records concatinating two or more columns
```
SELECT CONCAT(first_name, " ", last_name) AS "Full Name"
FROM employees;
```
## AND, OR, NOT, BETWEEN AND IN
- They are logical keywords for logical operations
```
SELECT *
FROM employees
WHERE hire_date < "2015-01-15 AND job = "Teacher";
```
```
SELECT *
FROM employees
WHERE job = "Manager" OR job = "Boxer";
```
```
SELECT *
FROM employees
WHERE NOT age = 20;
```
```
SELECT *
FROM employees
WHERE NOT age = 23 AND NOT age = 40;
```
```
SELECT *
FROM employees
WHERE hire_date BETWEEN "2022-5-20" AND "2023-1-2";
```
```
SELECT *
FROM employees
WHERE jobs IN ("Cook","Teacher","Doctor","Manager");
```
## Wildcards (%, _)
- % represents number of characters
- _ represents only one characters
```
SELECT *
FROM employees
WHERE first_name LIKE "I%";
```
```
SELECT *
FROM employees
WHERE last_name LIKE "%t";
```
```
SELECT *
FROM employees
WHERE jobs LIKE "_OO_";
```
```
SELECT *
FROM employees
WHERE jobs LIKE "_e_ach_r";
```
```
SELECT *
FROM employees
WHERE hire_date LIKE "____-01-__";
```
```
SELECT *
FROM employees
WHERE last_name LIKE "_a%";
```
## ORDER BY
- Default order : Ascending (ASC keyword)
- To order in reverse, add DESC keyword
```
SELECT * FROM employees
ORDER BY last_name;
```
```
SELECT * FROM employees
ORDER BY first_name DESC;
```
```
SELECT * FROM employees
ORDER BY hire_date DESC;
```
## LIMIT and OFFSET
- LIMIT is used for returning limited records, especially usefull for large datasets
- OFFSET is used to display next records to limit. Especially used in pagination
```
-- Displays next 10 records i.e. record from 11 to 20
SELECT * FROM employees
LIMIT 10
OFFSET 1;
```
## UNION and UNION ALL
- Combines the result of two or more tables
- Must have same number of columns in the tables
- UNION remove the duplicates
- UNION ALL allows duplicates
```
SELECT first_name, last_name FROM employees
UNION
SELECT first_name, last_name FROM customers
```
```
SELECT * FROM incomes
UNION
SELECT * FROM expences
```
```
SELECT first_name, last_name FROM employees
UNION ALL
SELECT first_name, last_name FROM customers
```
## Self Join
- Join a table to itself
- Comparing rows with other rows in same table
```
SELECT a.first_name, a.last_name,
CONCAT(b.first_name,b.last_name) as "Referred by"
FROM customers as a
INNER JOIN customers as b
ON a.referred_id = b.customer_id;
```
```
SELECT a.first_name, a.last_name
CONCAT(b.first_name, b.last_name) as "Supervised by"
FROM employees as a
LEFT JOIN employees as b
ON a.supervisor_id = b.employee_id;
```
## VIEW
- VIEW is a virtual table of a result of a query
- Can perform operations of table in view as well
- VIEW get updated as corresponding table updates
```
CREATE VIEW employeee_attendances AS
SELECT first_name, last_name
FROM employees;
```
```
CREATE VIEW email_employees_list AS
SELECT email
FROM employees;
```
## INDEX
- INDEX is applied to the column
- INDEX is a BTree data structure
- It is used for increasing the speed of searching
- Disadvantage of Index is that it slows down the update
- Longer the column, longer the operations takes
```
SHOW INDEX FROM customers;
```
```
CREATE INDEX last_name_idx
ON customers(last_name);
```
```
CREATE INDEX last_name_first_name_idx
ON customers(last_name, first_name);
```
```
ALTER TABLE customers
DROP INDEX last_name_idx;
```
## SUBQUERIES
- A query within a query
- Syntax:- query(subquery)
- Result of the subquery is used in the outer query.
```
SELECT * FROM employees
WHERE hourly_pay > (SELECT AVG(hourly_pay) FROM employees);
```
```
SELECT first_name, last_name
FROM customers
WHERE customer_id IN
(SELECT DISTINCT customer_id
FROM orders
WHERE customer_id IS NOT NULL);
```
## GROUP BY clause
- Allows to group rows based upon one or more column
- Most often used with aggregate function such as max, avg, etc.
- Use HAVING instead of WHERE keyword when using GROUP BY
- Using WHERE results an error with GROUP BY
```
SELECT COUNT(amount), ordered_date
FROM orders
GROUP BY ordered_date;
```
```
SELECT SUM(amount), customer_id
FROM orders
GROUP BY customer_id;
```
```
SELECT MAX(amount), customer_id,
FROM orders
GROUP BY customer_id;
```
```
SELECT COUNT(amount) AS total_orders, customer_id
FORM orders
GROUP BY customer_id
HAVING total_orders > 1;
```
## ROLLUP clause
- Extension of GROUP BY clause
- Super aggregate value or grand total in new row
```
SELECT SUM(amount), ordered_date
FROM orders
GROUP BY ordered_date WITH ROLLUP;
```
```
SELECT COUNT(order_id), ordered_date
FROM orders
GROUP BY ordered_date WITH ROLLUP;
```
```
SELECT SUM(hourly_pay) AS "Hourly Pay", employee_id
FROM employees
GROUP_BY employee_id WITH ROLLUP;
```
## ON DELETE
- Important for tables with relations
```
-- ON DELETE SET NULL = SET NULL when FK is deleted
-- ON DELETE CASCADE = DELETE record when FK is deleted
```
```
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(100),
created DATE DEFAULT (CURRENT_DATE())
);
CREATE TABLE posts (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(100),
body VARCHAR(1000),
user_id INT,
FOREIGN KEY (user_id) REFERENCES users(id)
ON DELETE CASCADE
);
CREATE TABLE comments (
id INT PRIMARY KEY AUTO_INCREMENT,
body VARCHAR(100),
post_id INT,
user_id INT,
FOREIGN KEY (post_id) REFERENCES posts(id) ON DELETE CASCADE,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE SET NULL
);
```
```
-- adding FK and ON DELETE CASCADE to existing table
ALTER TABLE orders
ADD CONSTRAINT fk_customer_id
FOREIGN KEY(customer_id) REFERENCES customers(customer_id)
ON DELETE CASCADE
```
```
-- adding FK and ON DELETE SET NULL to exisiting table
ALTER TABLE orders
ADD CONSTRAINT fk_customer_id
FOREIGN KEY(customer_id) REFERENCES customers(customer_id)
ON DELETE SET NULL
```
## Stored Procedure
- It is same as function or methods in programming.
- It is a prepared SQL code that can be used again and again.
- Some advantages are reduces network traffic, increase performance, secure and admin can grant permission to use.
- The only disadvantage is it increases the memory usuage of every connection.
- We also change the delimiter from ; to $$ for the procedure.
```
DELIMITER $$
CREATE PROCEDURE get_users()
BEGIN
SELECT * FROM users;
END $$
DELIMITER ;
```
- To call a procedure
```
CALL get_users();
```
- To drop a procedure
```
DROP PROCEDURE get_users();
```
- Passing a argument
```
DELIMITER $$
CREATE PROCEDURE get_user_by_id(IN id INT)
BEGIN
SELECT * FROM user
WHERE user_id = id;
END $$
DELIMITER ;
```
```
CALL get_user_by_id(1);
```
## Trigger
- A special type stored procedure that automatically runs when an event occurs.
```
CREATE TRIGGER before_hourly_pay_update
BEFORE UPDATE ON employees
FOR EACH ROW
SET NEW.salary = (NEW.hourly_pay * 2080);
```
```
CREATE TRIGGER before_hourly_pay_insert
BEFORE INSERT ON employees
FOR EACH ROW
SET NEW.salary = (NEW.hourly_pay * 2080);
``` | ishanshre | |
1,315,794 | SABONG INTERNATIONAL ME | Sabong International is regulated by PAGCOR, and we are dedicated to providing you with the most... | 0 | 2023-01-03T06:09:10 | https://dev.to/jeromestevenson265/sabong-international-me-hj0 |
Sabong International is regulated by PAGCOR, and we are dedicated to providing you with the most legitimate and reputable online Sabong in the Philippines. Watch Premium Live Online Sabong for FREE and take advantage of the plethora of promos that Sabong International Me has to offer, ranging from 1st Time Deposit to rebates and a great deal more.
| jeromestevenson265 | |
1,315,926 | Hello | A post by Imnul Haque Ruman | 0 | 2023-01-03T08:45:41 | https://dev.to/imnulhaqueruman/hello-325g | imnulhaqueruman | ||
1,315,939 | FADFAF | A post by zawa | 0 | 2023-01-03T09:42:58 | https://dev.to/zawa_nisar/fadfaf-22i1 |
 | zawa_nisar | |
1,316,008 | Strings Formatting in Python | String formatting is the process of infusing things in the string dynamically and presenting the... | 0 | 2023-01-03T11:54:49 | https://dev.to/rahulgtst/strings-formatting-in-python-h00 | python, programming, beginners | String formatting is the process of infusing things in the string dynamically and presenting the string.
There are 3 different methods to format a string in string
- Old style formatting
- String Format method
- F-string / String interpolation
## Old style formatting technique
In this technique we need percent symbol `%` followed by some characters inside the string as placeholder for the values that will be embedded in string.
There are four placeholder or special symbols:
- `%s` → string
- `%d` → integer
- `%f` → float
- `%.(n)f` → for floating value with n digit precision (n is a positive integer)
These symbols are similar that use in c programming language.
Example 1:
```
a=5
b=3
print(‘%d + %d = %d’%(a,b,a+b))
# 5+ 3 = 8
```
Example 2:
```
name= ‘Anuj’
like=’Bikes’
print(‘My name is %s. I like %s’%(name,like))
# My name is Anuj. I like Bikes.
```
## String format Method
In this technique we use string format method. To use format method we need to use pair of empty curly bracket `{}` for each variable we need to embed in the string at place of brackets
Example 1:
```
a=5
b=3
print(‘{} + {} = {}’.format(a,b,a+b))
# 5+ 3 = 8
```
Example 2:
```
name= ‘Anuj’
like=’Bikes’
print(‘My name is {}. I like {}.’.format(name,like))
# My name is Anuj. I like Bikes.
```
## F-string / Literal string interpolation
To create an f-string, prefix the string with the letter “ f ”. The string itself can be formatted in much the same way that you would with str.format().
Example 1:
```
a=5
b=3
print(f.‘{a} + {b} = {a+b}’)
# 5+ 3 = 8
```
Example 2:
```
name= ‘Anuj’
like=’Bikes’
print(f.‘My name is {name}. I like {like}’)
# My name is Anuj. I like Bikes.
```
If you like my post consider following me I am sharing content on programming and development. Please comment any improvement on this post.
You can contact me on-
`Linkedin: https://www.linkedin.com/in/rhlgt/
Twitter: https://twitter.com/rahulgtst` | rahulgtst |
1,316,129 | The Future of Technology: What's Next for Our World? | Finally, biotechnology is also making amazing advances. Biotechnology can be used to create new... | 0 | 2023-01-03T13:53:10 | https://dev.to/javaoneworld/the-future-of-technology-whats-next-for-our-world-2jjd | news, future, technology, artificialintelligency | Finally, biotechnology is also making amazing advances. Biotechnology can be used to create new medicines and treatments, as well as modify existing organisms to create new products. In the future, biotechnology could be used to create new cures for diseases and even modify the human body itself.
Nanotechnology is also becoming increasingly powerful and widespread. Nanotechnology can be used to create incredibly small machines that can perform complex tasks with incredible precision. In the future, nanotechnology could be used to create new materials and medicines that could revolutionize our world.
These are just a few of the amazing advances in technology that we are seeing today. As technology continues to evolve and become more powerful, the possibilities are endless. In the future, we could see robots that can think and act like humans, new types of materials that could revolutionize our world, and technologies that could help us explore space. The future of technology is truly exciting, and only time will tell what amazing advances are in store for us.
[Visit To Read Full Article Originally Published On:-3/01/2023](https://www.javaoneworld.com/2023/01/the-future-of-technology-whats-next-for.html) | javaoneworld |
1,316,192 | JavaScript to Java - A Comprehensive Comparison | Comparing 2 weirdly different languages to get a better understanding. Some may like this approach... | 0 | 2023-01-03T14:38:03 | https://dev.to/shaheerk/javascript-to-java-a-comprehensive-comparison-4cin | javascript, java, core, oop | Comparing 2 weirdly different languages to get a better understanding. Some may like this approach and some won't. But no other ways to find out. And this is not like that one place that you find everything that you need to know about these languages. this will more like be an article on where it is and where might these be heading to.
I'm a bit hesitant on recommending this to absolute beginners as some of the words can be confusing. But still I'll try to use as mush as simple words to explain these concepts.
As the Programming industry has been constantly improving with no slow downs, we have ended up with a load of technologies and languages to learn. And when you look at it from a beginner perspective it can be so confusing. So, I'll to give a little bit of overall on what has changed on these two languages and how they work. Because java is one of the oldest and a most solid language and JavaScript on the other hand is mentioned as some kind of a modern language and so I think it'll be interesting to compare them and see what has changed.
Before we go deep down let me give a little overview on..
**Where we use these languages.**
Java is a general-purpose programming language that is widely used in a variety of contexts, including desktop app development, web development, mobile development, and enterprise applications.
Java is known for its portability, scalability, and performance, and it is commonly used to build large-scale applications that need to run on a variety of platforms.
And JavaScript is also a general-purpose programming language, but it is primarily used for web development. JavaScript is used to add interactivity and dynamic behavior to web pages, and it is supported by all modern web browsers. JavaScript is also used to build server-side applications using runtime environments like Node.js, and it is increasingly being used for mobile development using frameworks like React Native.
So, generally we can use both languages to build Desktop apps, Mobile apps and Server side apps with their own pros and cons.
And that is also a main reason for choosing this topic as both of them are competitive with their abilities.
And now go a bit deep and look at a core attribute of these languages.
**How these languages talks with the processor.**
Even though they mostly serve similar purposes the way that they talk to the processor (central processing unit or CPU) can be quite different.
In Java, the code is compiled into bytecode, which is a low-level machine-readable format that can be executed by the Java Virtual Machine (JVM). The JVM is a runtime environment that is responsible for executing the bytecode and managing the memory and resources of the program. When the JVM runs the bytecode, it translates the instructions into machine code that can be understood by the CPU.
In JavaScript, the code is typically interpreted by a JavaScript engine, which is a software program that executes JavaScript code. The JavaScript engine reads the code and translates it into machine code that can be understood by the CPU. Unlike Java, JavaScript is not compiled into a standalone executable file (You can find a ton of tutorials on how to compile java code on YouTube), but is instead executed directly by the JavaScript engine as it is encountered in a web page or other context.
JavaScript engine may differ from the browser you use.
**Data types**
In both Java and JavaScript, variables are used to store values in memory. However, the way that these values are stored and accessed in memory can be quite different between the two languages.
In Java, variables are stored in a specific location in memory, and the location is determined at runtime by the Java Virtual Machine (JVM). The JVM also manages the lifetime of variables, allocating and deallocating memory as needed. Java has a number of different data types, including primitive types (such as int, double, and char) and reference types (such as objects and arrays). Primitive types are stored directly in memory, while reference types are stored as pointers to the memory location where the object is stored.
In JavaScript, variables are also stored in memory, but the way that they are stored and accessed is quite different from Java. JavaScript is a dynamically-typed language, which means that the type of a variable is determined at runtime and can change during the lifetime of the variable. JavaScript variables are not bound to a specific location in memory and are instead stored in a variable object associated with the current execution context. JavaScript has a number of different data types, including primitive types (such as number, string, and boolean) and reference types (such as objects and arrays). Primitive types are stored directly in memory, while reference types are stored as references to the objects they represent.
Also something we often hear is that Java is a statically typed language and JavaScript is a dynamically typed language. And recently TypeScript was introduced and it works like JavaScript with types and more. And java also recently introduced the `var` keyword in Java 10 which acts like a dynamic datatype. Still it is not a dynamic data type it just allows you to declare variables without specifying an explicit type, and the type is inferred from the initializer expression. So, here also we can see these languages are having some similar moves.
Understanding these can be an advantage when working with either language.
**Object Orientation**
Object oriented programming is not specific to any languages. It is a concept used in programming and can be achieved with their own ways with different languages.
_Java_
Java can be one of the first languages that comes to our mind when we hear OOP. And below I'll add the key areas of how these two languages handle this technique.
- Java is a class-based OOP language, which means that objects are created based on a class definition.
Example for class-based OOP -
```
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void greet() {
System.out.println("Hello, my name is " + this.name + " and I am " + this.age + " years old.");
}
}
```
To create a new Person object in Java, you would use the new operator like this:
```
Person p = new Person("John", 30);
p.greet(); // Output: "Hello, my name is John and I am 30 years old."
```
- Java has four access modifiers (public, protected, private, and default) that determine the visibility and accessibility of class members (fields, methods, etc.).
- In Java, it is possible to define multiple methods with the same name but different parameter lists, a technique known as method overloading.
- Java has a concept of static members, which are associated with a class rather than a specific instance of the class.
- Java has a feature called interfaces, which allow a class to specify a set of methods that it must implement.
_JavaScript_
- JavaScript is a prototype-based OOP language, which means that objects can inherit properties and methods from other objects (called prototypes). (Also note that JavaScript introduced Classes in ES6 which can be used as a syntax to create objects and defining their behaviors).
Example for prototype-based OOP
```
let person = {
name: 'John',
age: 30,
greet: function() {
console.log('Hello, my name is ' + this.name);
}
};
```
To create a new object that inherits from the person object in JavaScript, you would use the Object.create method like this:
```
let student = Object.create(person);
student.study = function() {
console.log(this.name + ' is studying.');
};
student.greet(); // Output: "Hello, my name is John"
student.study(); // Output: "John is studying."
```
class-based OOP languages use classes to define objects, while prototype-based OOP languages use prototypes to create new objects that inherit from existing objects. Both approaches have their own benefits and trade-offs, and the best approach to use depends on the specific needs of the application.
- JavaScript does not have access modifiers, and all object properties and methods are public by default.
- JavaScript does not support method overloading, but it does allow functions to be defined with optional parameters.
- JavaScript does not have a direct equivalent to static members, but it is possible to achieve a similar effect using the static keyword in a class definition.
- JavaScript does not have interfaces, but still we can use a regular object with no special behavior or enforcement if we want.
These are just a few of the differences between Java and JavaScript. There are many other differences between the two languages, and it is important to understand the specific features and capabilities of each language when working with them.
I didn't go in-depth about all the features. But I hope someone would find this helpful. And your corrections or suggestions are always welcome as they helps me to improve.
And If you loved it, please don't hesitate to leave a reaction Your support will be very much appreciated. | shaheerk |
1,316,208 | 4 ways ChatGPT can boost your programming | Pretty much everyone is talking about how ChatGPT could replace programmers. While I am not that... | 0 | 2023-01-03T15:15:59 | https://dev.to/dadyasasha/4-ways-chatgpt-can-boost-your-programming-4dm8 | chatgpt, ai, programming, beginners | Pretty much everyone is talking about how ChatGPT could replace programmers.
While I am not that worried about ChatGPT replacing me as a programmer any time soon, it would be a huge mistake to ignore this tool.
## 1) ChatGPT programming usecase 1: Explain complicated code
With its natural language processing capabilities, chatGPT can take a code snippet and break it down into easily understandable chunks.
I often use chatGPT when I am working in TypeScript - a language I am not yet very proficient with.
## 2) ChatGPT programming usecase 2: StackOverflow replacement
Hate browsing or searching StackOverflow? Asking questions on StackOverflow may be even more intimidating.
What if you need to find an answer to some stupid question fast? Ask chatGPT! In many cases, it will be able to find the right explanation for you. What is more important is that chatGPT seems to take a bit of extra effort to write a response which is easy to understand.
## 3) ChatGPT programming usecase 3: Find errors in code
Another great use of chatGPT is its ability to quickly find errors in code. Just copy the code that you can't find an error in, and give chatGPT a try.
## 4) ChatGPT programming usecase 4: Copyediting
Very often non-native speakers get really worried about making grammar or spelling mistakes.
Let's say you need to write an important memo which will be read by the entire organization... Well - write the memo and ask chatGPT for copy editing.
Feel free to watch this video for more details
{% embed https://www.youtube.com/watch?v=AHNlCo69W0s %}
#ai #chatgpt #ML #programming | dadyasasha |
1,316,578 | Skills you need to become a successful Software Engineer | As a software engineer, you need to have a combination of hard and soft skills. Your job involves... | 0 | 2023-01-03T21:09:57 | https://dev.to/nuraddeenmisah1/skills-you-need-to-become-a-successful-software-engineer-4fg4 | programming, webdev, javascript, productivity | As a software engineer, you need to have a combination of hard and soft skills.
Your job involves writing code, reviewing code, and working with product developers and the project manager.
**"But this is not the case!"**
As any software Engineer can do, what do you need to do to stand out from the crowd?
I have broken things down so that you know how to succeed and stand out from the crowd.
let us take a look at the Hard skills you need to be a successful engineer.
Hard skills are technical abilities learned through education or professional development. These are skills for proficiency and competency.
A need to be successful software engineer needs to be familiar with:
1. Programming language
2. Data structure and algorithms
3. Testing and Debugging
4. containers
These are hard skills you need to be more familiar with if you want to be a successful software engineer who stands out from the crowd and drives more successfully.
We shall take a first seat on soft skills in our next post.
Don't forget to leave a comment or add value to the above-mentioned.
| nuraddeenmisah1 |
1,316,730 | Day 3/ 100DaysOfCode | Day 3 of 100DaysOfCode Today was a long day - I started CS50 on edX and learned a lot in just the... | 0 | 2023-01-04T00:50:21 | https://dev.to/tinkersdev/day-3-100daysofcode-128n | beginners, programming, 100daysofcode | **<u>Day 3 of 100DaysOfCode</u>**
Today was a long day - I started CS50 on edX and learned a lot in just the one lecture and also I played with the Scratch problem set.
Once again on my solo project I played with the CSS Grid some more to get it looking the way I want, it looks good, will put it up later today on my github.
Other things I did that had me writing code were:
Helped in a community chat, which was good, it was a moment for recall on information and I liked that.
<3 onward to day 4. | tinkersdev |
1,316,900 | NFT Interview Questions | Here are top 10 potential interview questions on NFTs (non-fungible tokens): Can you explain what... | 0 | 2023-01-04T06:39:16 | https://dev.to/satyam_prg/nft-interview-questions-549k | nft, nftinterview, interviewquestions, onlineinterveiwquestions | Here are top 10 potential [interview questions on NFTs](https://www.onlineinterviewquestions.com/nft-interview-questions/) (non-fungible tokens):

1. Can you explain what an NFT is and how it differs from other types of cryptocurrency tokens?
2. How are NFTs used in the art world?
3. Can you give an example of a project or platform that utilizes NFTs?
4. What are some considerations to keep in mind when buying or selling NFTs?
5. How do NFTs ensure authenticity and ownership of digital assets?
6. What are some potential drawbacks or limitations of using NFTs?
7. In your opinion, what impact do you think NFTs will have on the art industry or other industries in the future?
8. How do you think the market for NFTs will evolve in the coming years?
9. Are there any legal or regulatory issues to be aware of when it comes to NFTs?
10. Can you discuss any notable projects or developments in the NFT space that you find interesting or important?
Finally, learn more [NFT Interview Questions and Answers](https://www.onlineinterviewquestions.com/nft-interview-questions/).
| satyam_prg |
1,317,035 | Microservices | Introduction Microservices are a relatively new type of software architecture that has... | 0 | 2023-01-04T09:20:42 | https://dev.to/pandiyancool/microservices-2den |
## Introduction
Microservices are a relatively new type of software architecture that has become increasingly popular in the development world. In this blog post, we will discuss what microservices are, their benefits and drawbacks, and how they fit into a larger software architecture.
## What are Microservices?
Microservices are a type of software architecture in which applications are built as a suite of independently deployable, loosely coupled services. Each service handles a specific business function and is implemented as a separate application. This approach allows developers to build applications faster and more efficiently by focusing on individual services and decoupling them from the entire system.
Microservices are typically deployed in a cloud-based environment and are designed to be resilient and self-healing. This allows applications to scale quickly and easily when the demand for services increases.
## Benefits of Microservices
The main benefit of microservices is that they allow developers to quickly develop and deploy applications. This is because each service is decoupled from the rest of the system, meaning that changes and updates to one service will not affect the other services. This makes it easier to develop and deploy new features without having to worry about the entire system.
The use of microservices also makes applications more resilient and fault-tolerant. This is because each service is independently deployable and can be updated or changed without affecting the entire system.
Finally, microservices allow applications to scale more quickly and easily because each service is independent and can be deployed independently. This reduces the amount of time and effort required to scale an application.
Microservices also make it easier to maintain applications over the long term. By decoupling services, developers can more easily update and maintain individual services without having to worry about the entire system. This reduces the amount of time and effort needed to maintain applications. Additionally, microservices also make it easier to deploy applications in different environments, such as on-premises or in a cloud environment. This flexibility makes it easier to adjust applications to changes in technology and user needs.
## Drawbacks of Microservices
Although microservices provide many benefits, there are also some drawbacks to consider. For example, microservices can be more complex to develop and maintain because each service is independent and needs to be managed separately. This can increase the overall cost of development and maintenance.
In addition, microservices can be slower than monolithic applications because each service needs to communicate with the other services before it can be deployed. This can lead to performance issues and slow down the development process.
Finally, microservices can be more challenging to debug because each service needs to be tested individually. This can be time-consuming and difficult for developers.
## Conclusion
Microservices are a powerful and efficient way to develop and deploy applications. They allow developers to quickly develop and deploy applications, scale applications quickly and easily, and make applications more resilient and fault-tolerant. However, microservices can be more complex to develop and maintain, slower than monolithic applications, and more difficult to debug. Careful planning is needed to decide whether microservices are the right choice for a project. | pandiyancool | |
1,317,064 | So, why Server Components? | Let's talk components .. but on the server. But .. why would you want something like that? Are good... | 0 | 2023-01-04T10:11:22 | https://dev.to/jankoritak/so-why-server-components-2nk3 | webdev, javascript, nextjs, react | Let's talk components .. but on the server.
But .. why would you want something like that? Are good old (client) components not good enough?
Of course, they are! Client components are a perfect match for **rich, interactive UIs that implement immediate feedback loops**. However, as it usually goes, each concept implies a certain set of advantages, as well as a certain set of limitations.
[Till late 2020](https://reactjs.org/blog/2020/12/21/data-fetching-with-react-server-components.html), the only option to render a component was doing it client-side, in the browser. Let's discuss some of the major disadvantages of this approach and explore how the concept of React Server Components helps us push the entire ecosystem forwards by addressing these limitations.
## Client Components limitations
### 1\. Long [TTI (Time to Interactive)](https://github.com/WICG/time-to-interactive)
Let's recap how client-side rendering with the help of SSR works.
1. The client requests a page from the server.
2. The server builds the JS bundle and hopefully also some basic HTML to give the user a fast, static response.
3. The server returns the JS assets to the client.
4. The client renders the HTML.
5. The client loads, parses, and executes the JS.
6. The client hydrates the JS into HTML to achieve the desired interactive page.
The red horizontal line in the image indicates where TTI would sit. The heavier the JS bundle, the longer loading, parsing, executing, and hydrating the JS take.
### 2\. Dependencies bloat the JS bundle
The logic is somewhat linear. The heavier the bundle, the longer will it take to transfer it over the network barrier to the browser and the longer will it take to render it. However, an example speakrs a thousand words, so let's bring in some code.
I borrowed this piece of code from the [React Server Components demo Notes application](https://github.com/reactjs/server-components-demo/).
```typescript
import {format, isToday} from 'date-fns';
import excerpts from 'excerpts';
import marked from 'marked';
import ClientSidebarNote from './SidebarNote.client';
export default function SidebarNote({note}) {
const updatedAt = new Date(note.updated_at);
const lastUpdatedAt = isToday(updatedAt)
? format(updatedAt, 'h:mm bb')
: format(updatedAt, 'M/d/yy');
const summary = excerpts(marked(note.body), {words: 20});
return (
<ClientSidebarNote
id={note.id}
title={note.title}
expandedChildren={
<p className="sidebar-note-excerpt">{summary || <i>(No content)</i>}</p>
}>
<header className="sidebar-note-header">
<strong>{note.title}</strong>
<small>{lastUpdatedAt}</small>
</header>
</ClientSidebarNote>
);
}
```
The code above describes quite a straightforward component. Most notably the component formats and renders a date-time value and formats and renders a piece of markdown that is a summary of a note.
To achieve this, the component uses 3 dependencies `date-fns`, `excerpts`, and `marked`. When we examine the dependencies closer, we can immediately see, they sum to ~80KB gZipped. Keep in mind this is only one client component and consider yourself, how large can the entire application get?

### 3\. Susceptible to request waterfalls
Let's start with a quote:
> Rendered JS **does not guarantee** an useful UI.
If we do all the work we discussed in [Long time-to-interactive](#heading-1-long-tti-time-to-interactive), to only present the user with something like this. We probably can agree we didn't do the best job in the initial user experience.

Now imagine, the spinner is rendered by a component tree similar to this.
```typescript
import React from 'react';
import Spinner from 'components/Spinner';
import Something from 'components/Something';
const ChildComponentA = () => <Something />
const ChildComponentB = () => {
const dataC = useDataC();
return dataC
? <Something />
: <Spinner />
}
const Root = () => {
const dataA = useDataA();
const dataB = useDataB({ skip: !dataA });
if (!dataA || !dataB) {
return <Spinner />
}
return (
<>
<ChildComponentA data={dataB} />
<Something />
<ChildComponentB data={dataB} />
</>
)
}
```
From the code above, we can derive the fact, that to present the user with a full user experience, we'll need to fire and wait for three sequential queries. All this, in sequence, after we fetched the JS bundle from the server and rendered the initial UI on the client.

It should be pretty obvious that the diagram is far from optimal. With the current set-up, we're firing three requests to the same server, for each request have to wait for the server to resolve the request by e.g. talking to DB, a close (micro) service, or maybe an FS and then returning the result. Three requests equal three [round-trips](https://www.cloudflare.com/learning/cdn/glossary/round-trip-time-rtt/) from client to server and back.
### 4\. The browser has only one thread
The browser still has only one thread reserved for JS runtime. This means, all the operations we've mentioned so far have to run with a single call stack.
### 5\. The browser can't access server APIs
Quite obviously, the browser can access browser APIs like DOM manipulation APIs, fetch API, or Canvas/WebGL, while the server can work with e.g. environment variables, access local file-system, and can directly reach out to databases or services, which the client can only reach out via a controlled proxy.
This is all for the better, as it allows us to securely work only with exposed REST/GraphQL API to talk to the BE resources. However, there are use cases where a little more control would result in a more comfortable development experience. For E.g. developers tend to struggle to realize they only can access environment variables in Next.js in server-side code, as `process.env` differs on the client. You can definitely work around this by making the variable of the choice public by prepending its name with the `PUBLIC_` prefix, but you always need to pay attention not to leak a private variable this way.
It would be great, if we could access `process.env` directly in a component, without limitations though, right?
## Server components to the rescue
We managed to explore the intrinsic limitations of React's client components. These limitations are implied by the concept of rendering the component in the browser environment, or on the client if you will.
Let's now turn the list around and look into each of the limitations, one by one again, and discuss how Server Component help us counter the limitations by unlocking a completely new set of possibilities, by rendering them in the server environment.
### 1\. <s>Long</s> Shorter [TTI (Time to Interactive)](https://github.com/WICG/time-to-interactive)
One of the amazing benefits of rendering components on the server is that we don't have to transfer as large JS bundles to the client anymore. If our application tree consists of 1000 components and we manage to (pre)render 500 of them server-side, we can be certain, that the JS bundle will be dramatically thinner. The less JS we need to transfer and then load, parse and execute on the client, the quicker will the initial experience be.
The rendered Server Components are not included in the JS bundle, they are rendered on the server and serialized into a special notation designed by the React.js team. This notation not only helps React@18/Next.js@13 transfer the code over the network barrier but also helps client-side React reconcile the component tree update without losing the application state.
To expand the context, let's pull up an example of a batch component update coming from the server to update the UI.
The data are again taken from the [React Server Components demo Notes application](https://github.com/reactjs/server-components-demo/).
```json
M1:{"id":"./src/SearchField.client.js","chunks":["client5"],"name":""}
M2:{"id":"./src/EditButton.client.js","chunks":["client1"],"name":""}
S3:"react.suspense"
J0:["$","div",null,{"className":"main","children":[["$","section",null,{"className":"col sidebar","children":[["$","section",null,{"className":"sidebar-header","children":[["$","img",null,{"className":"logo","src":"logo.svg","width":"22px","height":"20px","alt":"","role":"presentation"}],["$","strong",null,{"children":"React Notes"}]]}],["$","section",null,{"className":"sidebar-menu","role":"menubar","children":[["$","@1",null,{}],["$","@2",null,{"noteId":null,"children":"New"}]]}],["$","nav",null,{"children":["$","$3",null,{"fallback":["$","div",null,{"children":["$","ul",null,{"className":"notes-list skeleton-container","children":[["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}],["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}],["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}]]}]}],"children":"@4"}]}]]}],["$","section","null",{"className":"col note-viewer","children":["$","$3",null,{"fallback":["$","div",null,{"className":"note skeleton-container","role":"progressbar","aria-busy":"true","children":[["$","div",null,{"className":"note-header","children":[["$","div",null,{"className":"note-title skeleton","style":{"height":"3rem","width":"65%","marginInline":"12px 1em"}}],["$","div",null,{"className":"skeleton skeleton--button","style":{"width":"8em","height":"2.5em"}}]]}],["$","div",null,{"className":"note-preview","children":[["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}]]}]]}],"children":["$","div",null,{"className":"note--empty-state","children":["$","span",null,{"className":"note-text--empty-state","children":"Click a note on the left to view something! 🥺"}]}]}]}]]}]
M5:{"id":"./src/SidebarNote.client.js","chunks":["client6"],"name":""}
J4:["$","ul",null,{"className":"notes-list","children":[["$","li","1",{"children":["$","@5",null,{"id":1,"title":"Meeting Notes","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"This is an example note. It contains Markdown!"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Meeting Notes"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","2",{"children":["$","@5",null,{"id":2,"title":"A note with a very long title because sometimes you need more words","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"You can write all kinds of amazing notes in this app! These note live on the server in the notes..."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"A note with a very long title because sometimes you need more words"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","3",{"children":["$","@5",null,{"id":3,"title":"I wrote this note today","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"It was an excellent note."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"I wrote this note today"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","4",{"children":["$","@5",null,{"id":4,"title":"Make a thing","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"It's very easy to make some words bold and other words italic with Markdown. You can even link to React's..."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Make a thing"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","6",{"children":["$","@5",null,{"id":6,"title":"Test Noteeeeeeeasd","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"Test note's text"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Test Noteeeeeeeasd"}],["$","small",null,{"children":"11/29/22"}]]}]}]}],["$","li","7",{"children":["$","@5",null,{"id":7,"title":"asdasdasd","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"asdasdasd"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"asdasdasd"}],["$","small",null,{"children":"11/29/22"}]]}]}]}]]}]
```
That's a JSON-y-looking mess! At least it sure feels like that to the human eye. After all, it's a set of instructions for React runtime on how to update the application as a result of e.g. a user's action. These instructions are likely therefore not designed with human readability in mind. However, it's still pretty close to a JSON, so on a second glance, we can see some patterns there, right?
We can identify a bunch of shorter lines, e.g.:
```json
M1:{"id":"./src/SearchField.client.js","chunks":["client5"],"name":""}
M2:{"id":"./src/EditButton.client.js","chunks":["client1"],"name":""}
M5:{"id":"./src/SidebarNote.client.js","chunks":["client6"],"name":""}
```
The first line is actually instructing React runtime to render a `SearchField` component, that is located in a file called `client5`. In other words, it's a pointer to the Client Component, which is located in a JS bundle chunk, called `client5`. Since it's a Client Component, it's yet to be rendered.
We can also clearly identify a line marking a suspense boundary, which is not that interesting.
```plaintext
S3:"react.suspense"
```
But there are also two more lines starting with `J0` and `J4`, that look pretty expressive.
```plaintext
J0:["$","div",null,{"className":"main","children":[["$","section",null,{"className":"col sidebar","children":[["$","section",null,{"className":"sidebar-header","children":[["$","img",null,{"className":"logo","src":"logo.svg","width":"22px","height":"20px","alt":"","role":"presentation"}],["$","strong",null,{"children":"React Notes"}]]}],["$","section",null,{"className":"sidebar-menu","role":"menubar","children":[["$","@1",null,{}],["$","@2",null,{"noteId":null,"children":"New"}]]}],["$","nav",null,{"children":["$","$3",null,{"fallback":["$","div",null,{"children":["$","ul",null,{"className":"notes-list skeleton-container","children":[["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}],["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}],["$","li",null,{"className":"v-stack","children":["$","div",null,{"className":"sidebar-note-list-item skeleton","style":{"height":"5em"}}]}]]}]}],"children":"@4"}]}]]}],["$","section","null",{"className":"col note-viewer","children":["$","$3",null,{"fallback":["$","div",null,{"className":"note skeleton-container","role":"progressbar","aria-busy":"true","children":[["$","div",null,{"className":"note-header","children":[["$","div",null,{"className":"note-title skeleton","style":{"height":"3rem","width":"65%","marginInline":"12px 1em"}}],["$","div",null,{"className":"skeleton skeleton--button","style":{"width":"8em","height":"2.5em"}}]]}],["$","div",null,{"className":"note-preview","children":[["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}],["$","div",null,{"className":"skeleton v-stack","style":{"height":"1.5em"}}]]}]]}],"children":["$","div",null,{"className":"note--empty-state","children":["$","span",null,{"className":"note-text--empty-state","children":"Click a note on the left to view something! 🥺"}]}]}]}]]}]
J4:["$","ul",null,{"className":"notes-list","children":[["$","li","1",{"children":["$","@5",null,{"id":1,"title":"Meeting Notes","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"This is an example note. It contains Markdown!"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Meeting Notes"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","2",{"children":["$","@5",null,{"id":2,"title":"A note with a very long title because sometimes you need more words","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"You can write all kinds of amazing notes in this app! These note live on the server in the notes..."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"A note with a very long title because sometimes you need more words"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","3",{"children":["$","@5",null,{"id":3,"title":"I wrote this note today","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"It was an excellent note."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"I wrote this note today"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","4",{"children":["$","@5",null,{"id":4,"title":"Make a thing","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"It's very easy to make some words bold and other words italic with Markdown. You can even link to React's..."}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Make a thing"}],["$","small",null,{"children":"12/30/20"}]]}]}]}],["$","li","6",{"children":["$","@5",null,{"id":6,"title":"Test Noteeeeeeeasd","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"Test note's text"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"Test Noteeeeeeeasd"}],["$","small",null,{"children":"11/29/22"}]]}]}]}],["$","li","7",{"children":["$","@5",null,{"id":7,"title":"asdasdasd","expandedChildren":["$","p",null,{"className":"sidebar-note-excerpt","children":"asdasdasd"}],"children":["$","header",null,{"className":"sidebar-note-header","children":[["$","strong",null,{"children":"asdasdasd"}],["$","small",null,{"children":"11/29/22"}]]}]}]}]]}]
```
The lines `J0` and `J4` are in fact two atomic components - `div` and `unordered list` - that were rendered on the server and completely serialized to be dumped into the view on the client. The browser does not have to perform any work to render these. Of course apart from the reconciliation and the update itself. Very cool, right?
From the client-server communication point of view, the diagram would now look something like this.
The green rectangles mark differences from the pre-React@18/Next.js@13 we mentioned in [Long TTI](#heading-1-long-tti-time-to-interactive). To sum it up, notable facts are:
* Server bundles only the Client Component to the JS bundle
* Server renders Server Component into instructions for React runtime, not HTML
* The updates are streamed to the client
* The client can reconcile the changes while keeping the client's state
The bottom line is - less JS, shorter TTI!
### 2\. Dependencies *no longer* bloat the bundle
0-bundle size components are another great argument for Server Components. Since the components are compiled on the server. There is no need for us to include the component dependencies inside of the JS bundle.
From the implementation point of view, when server-side React@18 encounters a Server Component in the component tree, it compiles the component into atoms. For E.g. in case your component uses `date-fns/format` to format a date, it'll happen on the server and the result of the operation will be transferred to the client, without the dependency itself.
Say farewell to bundling heavy dependencies to execute on the client.
To update the image we used above, we can just scratch the ~80 gZipped KBs and replace it with straight 0.

### 3\. Request waterfalls with zero round-trips
A Server Component is always closer to the hardware than a Client Component. Every request that would go from client to server and back now lives fully on the server side. To put this thought into a diagram, let's update the request waterfall we discussed in to reflect that.
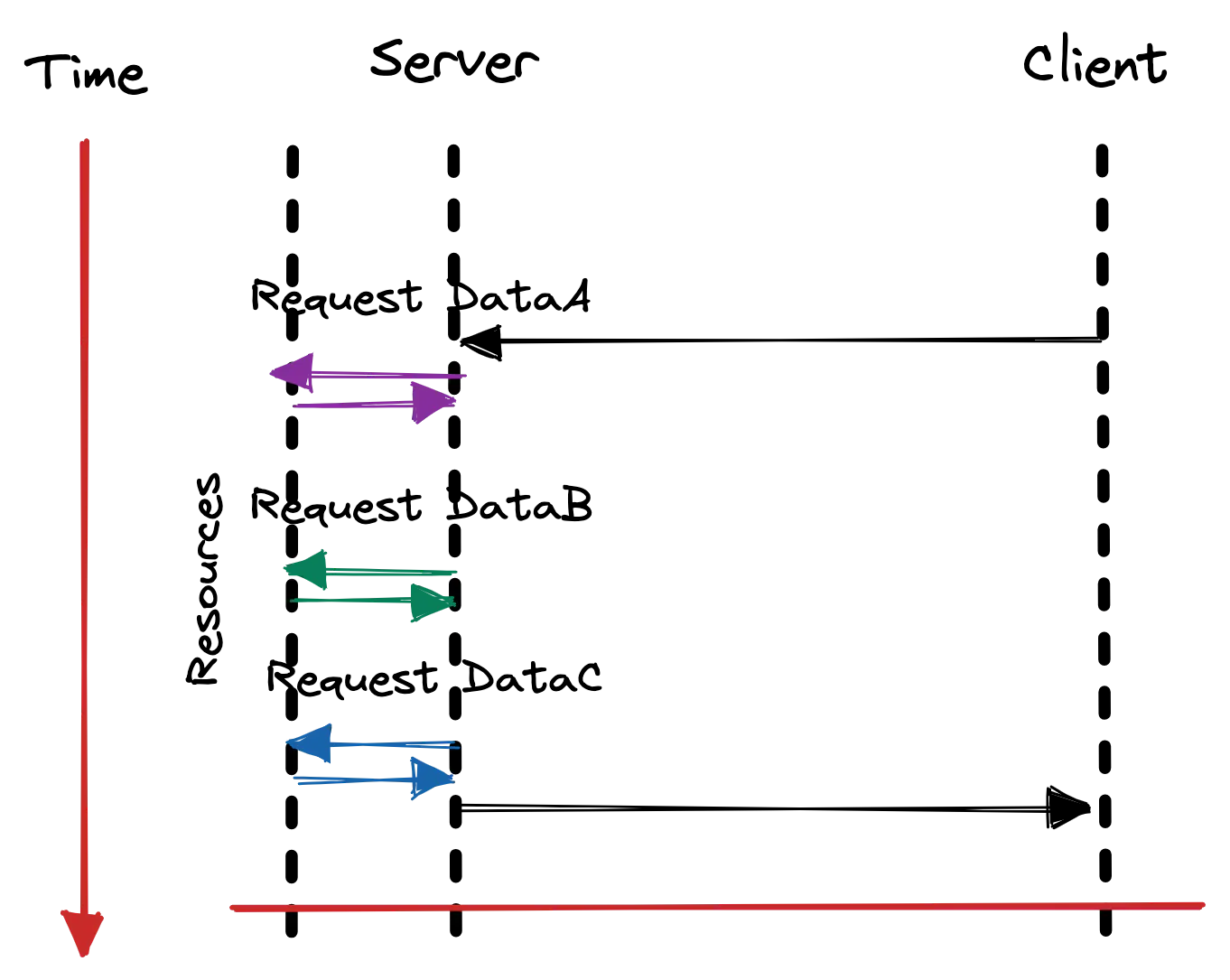
The clear difference to the Client Components architecture is that we only need to really do one round-trip. Notice the colorful arrows, that denote the actual requests on the component level that stay server-side. If the waterfall exists, it's way faster.
### 4\. The server has more than one thread
This one is pretty obvious. While browsers still reserve only one thread for JS runtime, servers usually feature more than a single thread for Node.js. More bandwidth for Server Components!
### 5\. The server (obviously) can access the server APIs
When rendering components on the server, we can directly access e.g. `process.env` variables, therefore we can seamlessly integrate corresponding logic directly into our components. That's quite slick, right?
Moreover, we can directly access local databases, file systems, or (micro)services. I'm not implying accessing a DB directly from a component is the best idea, but you get the point. However, there is a great use case for accessing an FS directly in the component e.g. when implementing a static blog by just mapping the fs into blog pages, which would not be possible on the component level before React@18.
## Summary
We explored 5 pre-React@18 pain points that Client Components do suffer from. Server Components allow us to view components in a different light (meaning environment), which turns out to provide implicit solutions for all of the pain points we explored.
Hopefully, the article gave you a better idea of why React@18 pivoted towards Server Components, why Next.js@13 treats a component as a server one by default, unless told not to, and overall, how will the ecosystem look in the near future. | jankoritak |
1,337,486 | Gradient descent - why the partial derivative? | Derivatives are an important tool in machine learning, and they are used in gradient descent... | 0 | 2023-01-22T09:45:35 | https://dev.to/thisissouray/gradient-descent-why-the-partial-derivative-1dal |
Derivatives are an important tool in machine learning, and they are used in gradient descent algorithms to optimize the performance of a model. Gradient descent is an iterative optimization algorithm that is used to find the minimum of a given function. It works by taking small steps in the direction of the negative gradient of the function at each iteration. The size of these steps is determined by the derivative of the function at each point.
The derivative tells us how quickly a function is changing with respect to its input variables. This information can be used to determine which direction we should take our next step in order to minimize our cost function. By taking smaller steps in the direction of the negative gradient, we can ensure that we reach our minimum faster and more accurately than if we took larger steps.
**What will happen when we take larger steps ?**
When we take larger steps in Gradient Descent, it can cause the algorithm to overshoot the minimum point. This means that instead of converging to the minimum point, it will go past it and then oscillate around it. This can lead to slower convergence and longer training times.
In addition, taking larger steps can also lead to instability in the model. If the step size is too large, then the model may not converge at all or may diverge instead of converging. This can lead to inaccurate results or even complete failure of the model.
Finally, taking larger steps can also lead to local minima traps. If the step size is too large, then it may cause the algorithm to get stuck in a local minima instead of finding the global minima. This means that even though there may be a better solution available, the algorithm will not be able to find it due to getting stuck in a local minima trap.
So in conclusion , derivatives are an essential tool for optimizing models using gradient descent algorithms in machine learning. They provide us with valuable information about how quickly a function is changing with respect to its input variables, which allows us to take smaller steps towards our desired solution more accurately and efficiently than if we took larger steps without considering derivatives. | thisissouray | |
1,317,106 | 💾 Comandos de Git que podem te ajudar na hora de publicar um repositório | ⑆ Entender sobre Git e um dos pré-requisito caso busque concorrer para uma vaga de emprego, entender... | 0 | 2023-01-04T11:21:47 | https://dev.to/diogox451/comandos-de-git-que-pode-te-ajudar-na-hora-de-publicar-um-repositorio-21gf | ⑆ Entender sobre Git e um dos pré-requisito caso busque concorrer para uma vaga de emprego, entender seus comandos e fundamental no seu dia a dia. Seguindo assim, segue alguns comandos git que será interessante usar nos seus projetos e no trabalho:
---
⑆ Comandos base: Alguns comandos bases que sempre faz uma diferença:
* git init: inicializar um repositorio novo, se caso não tenha dado o “git clone”;
* git clone: clonar um repositório que já existe no Github ou Gitlab;
* git add: adicionar as modificações ou novos arquivos no repositório;
* git config — global user.name “Diogo” : Nisso você mostrar na hora do commit quem foi o autor que fez o commit;
* git config — global user.email “diogosgn@gmail.com”: Aqui você mostra o email de quem fez o commit;
* git config — list : Mostra as configurações realizadas;
* git status: Mostra como está o status dos arquivos localmente (Removido, Modificado, Novo);
* git diff : Mostra o que foi modificado;
* git rm — cached: Remove o arquivo do repositório;
* git mv : Move um arquivo do repositório;
* git log: Mostra os logs do commit;
* git log — oneline: Mostra os logs de forma resumida;
Para mais prefixos do git log :[link](https://git-scm.com/book/en/v2/Git-Basics-Viewing-the-Commit-History)
* git remote -v: Mostra a origem dos repositórios se vem do Github ou Gitlab;
* git remote add name url: Adiciona um novo repositórios;
---
⑆ Branch: Possuir uma branch no seu repositório, divide o que realmente cada desenvolvedor irá construir:
* git branch: Mostra quais branch existe;
* git push origin nome_branch: Publicar a branch no repositório;
* git branch -D nome_branch: Deleta a branch;
* git checkout nome_branch: Navega entre as branches;
* git checkout -b nome_branch: Cria uma nova branch e direcionado até ela;
* git merge nome_branch: Mescla a branch principal com a criada;
* git merge — abort: Reverte a mesclagem;
⑆ Commit: Nesta hora que preparamos o arquivo para ser publicado e salvamos:
> Observação: Para realizar um commit precisa ter dado um git add antes
* git commit -m “Escrever alguma coisa aqui”: Escrever uma mensagem no commit, ajuda indentificar o que foi feito;
* git commit -a -m “Escreve Algo”: Adiciona e faz o commit;
---
⑆ Push e Pull: São dois que se complementa, sendo um para publicar no Github ou Gitlab, em vista o git pull atualizaria o código para quem tiver utilizando aquele repositório:
* git push: enviar os arquivos para o Github ou Gitlab;
* git push origin nome_branch: Publicar a branch no repositorio;
* git pull: Se caso houver modificações no repositorio, pode enviar git pull para atualizar os arquivos localmente;
⑆ Tag: As tag são fundamentais para mostra a evolução de versão que está seu codigo e nisso fazer commit e publicar elas:
* git tag: Mostra as tag que já existem;
* git tag -a v0.1 -m “Coloque uma mensagem da versão”: Cria uma tag;
* git push origin v0.1: Envia a tag para o repositório;
* git show nome_tag: Mostra que foi feito naquela tag;
---
⑆ Se curtiu um pouco do conteúdo, segue nas minhas redes sociais para ficar ligado para as novas publicações:
[Linkedin](https://www.linkedin.com/in/diogo-dos-reis-almeida-3973541b1/)
[Github](https://github.com/diogoX451)
[Instagram](https://www.instagram.com/diogoreisalmeida07/) | diogox451 | |
1,317,142 | Digital transformation – part 3 – My view | Recap: What is digital transformation? Digital transformation is using technology to... | 0 | 2023-01-04T12:32:17 | https://www.lambdatest.com/blog/digital-transformation-part-3-my-view/ | tutorial, typescript, beginners | Recap:
## What is digital transformation?
Digital transformation is using technology to create new or modify existing business processes, culture and customer experience to meet changing business and market requirements.
It can be summarized as the reimaging of business in the digital age.
***Test your native, hybrid, and web apps across all legacy and latest mobile operating systems on the most powerful [online emulator Android](https://www.lambdatest.com/android-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=jan04_pk&utm_term=pk&utm_content=webpage).***
## Why should companies consider digital transformation?
Personally, I have seen the power of digital transformation and it really sets you up for working in an agile, cross-collaborative way that pushes a company towards the journey of growth.
It also allows value add to every customer interaction and can give a better customer experience. In most cases, companies push towards digital transformation as it helps to stand out against competitors.
The big add for me is the fact that data collected via digital transformation means that companies can make more informed decisions, and at the same time they can understand more about their customers. One brand that comes to mind is Tesco and their use of the Clubcard — this allowed them to recommend offers to customers based on what they buy generally and it enticed customers to come back when they had previously left for competitors.
## My view
Digital transformations work where leaders want to go back to the fundamentals, they focus on changing the mindset of its members as well as the culture and processes before they decide what digital tools to use and how to use them.
When in an enterprise environment I found that it was essential to retrain employees around digital, cloud, CI/CD, devops and other modern technology.
Whether in an enterprise or a startup environment I found that DevOps was a big tool in the digital transformation toolbox. Devops leaders galvanize software development, by merging development with operations, enabling companies to continuously iterate software to speed up delivery.
Devops was key to our digital transformation in a start-up environment and I have seen exactly the same in an enterprise setting.
I have recently also seen the value of data scientists and data architects. The key reason is that companies seek to glean insights out of vast data, and transformations lean increasingly on machine learning and artificial intelligence (AI).
Digital transformations generally succeed where they are led from the top and are accepted bottom up. In our startup setting, I found that when the whole team is invested it means that there is more chance of success. What was great was that we had a clear vision to add/improve our digital products, and this went a large way in attracting new talent. With the right culture and mindset, we found that the innovation just kept growing.
It was important to reflect weekly, this allowed us to change our path and thus focus on another change to add more value. For example if we focused on the mobile app and adding new options, if users found a defect which halted them reading articles we would shift our priorities.
The key tip I would give leaders is to really focus on the cultural aspects, with the right culture it will mean that you have a higher chance of success. What was important was that the team feel valued, respected, listened to, and are in the best environment to do their best work. I liken this to a plant where if it is in the right environment, with the right soil and right nourishment, it will surely flourish.
***Test your web and mobile apps on [online Android emulator](https://www.lambdatest.com/android-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=jan04_pk&utm_term=pk&utm_content=webpage). Ensure your apps are compatible across latest and legacy Android operating systems, devices, and browsers. Start Testing Now !!***
## Applying this to Quality Assurance
Digital transformation in a startup and enterprise environment can be different.
For instance, when I worked in a startup it was pushing more towards agile processes and what was key was that we really accelerated on automation, also ensuring that engineering and QA understood the automation and they could run it together. The automation framework selection was a group decision rather than just QA, this led to group acceptance and it pushed us to digitally transform as a team in an agile environment.
In contrast, in an enterprise environment, it was key that the assurance aspect was first, that there was buy-in for stakeholders first to prove that we knew what we were testing, whether it was prioritized with product and we were ensuring that we had no escaped defects first. Once the basics were in place they wanted to see a clear framework selection, with a proof of concept and key success criteria for the selection of the framework.
In a startup, I would say there was more appetite for experimentation and if one framework failed it was fine to try something else, though with data we could make this decision quickly.
In an enterprise environment, there was less appetite for risk and it meant that the framework selection had to be well thought out as the impact of getting this wrong was more wide facing.
## Why can digital transformations fail?
Some of the key reasons why I have seen failure are due to:
1. Resistance — where the team is not invested in the change. The team must be taken on a journey to ensure they are committed, and this ensures more chance of success.
2. Ensure there are change leaders — it is essential that there are vocal supporters of your digital transformation.
3. There is a lack of a review process. We must review where we are and whether we are on the right path to success and if we are not on the right path then make a change.
***Test On [Android online emulator](https://www.lambdatest.com/android-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=jan04_pk&utm_term=pk&utm_content=webpage) now!***
## Closing
Thanks for sticking with me on this digital transformation journey. Digital transformation is never easy and it is difficult to put a time frame on this.
What is most important is that there are checkpoints and measures in place so that you have a greater chance of success! | dileepms12 |
1,328,351 | Technical books | In this post, we will be building a Technical Book class that inherits from the Book class from one... | 21,789 | 2023-02-05T07:42:38 | https://dev.to/zuzexx/6-js-challenge-technical-books-4485 | webdev, javascript, beginners, tutorial | In this post, we will be building a Technical Book class that inherits from the Book class from one of the previous challenges. The Technical Book class will have an additional element, edition. We will also provide a function that returns a string that includes the book's edition.
```
/**
* Goal is to create a Technical Book class that inherits from
* the Book class from one of the previous challenges.
* It also has a fifth element, an edition.
* Provide a function that returns a string that includes the book's edition
*/
```
First, let's start by creating the Book class and an instance of the TechnicalBook class.
```js
class Book {
constructor(title, author, ISBN, currentCopies) {
this.title = title;
this.author = author;
this.ISBN = ISBN;
this.currentCopies = currentCopies;
}
}
class TechnicalBook extends Book {
constructor(title, author, ISBN, currentCopies, edition) {
super(title, author, ISBN, currentCopies);
this.edition = edition;
}
}
```
To test the function we will write shortly it is important to create a few books, that we can use.
```js
const firstBook = new TechnicalBook(
"The best technical Book",
"mrs. Author",
123456567,
0,
"first"
);
const secondBook = new TechnicalBook(
"The mostest technical Book",
"mr. Author",
9876543,
4,
"third"
);
const thirdBook = new TechnicalBook(
"The best Book of technicalities",
"mrs. Author Jr.",
1212345121,
5,
"fifth"
);
```
To get the information about the book, we can create a function that returns a string that includes the book's information.
```js
TechnicalBook.prototype.bookEdition = function () {
return console.log(
`The book ${this.title} was written by ${this.author} with ISBN: ${this.ISBN} and is the ${this.edition} edition. We have ${this.currentCopies} in stock`
);
};
firstBook.bookEdition();
secondBook.bookEdition();
thirdBook.bookEdition();
/*Result:
The book The best technical Book was written by mrs. Author with ISBN: 123456567 and is the first edition. We have 0 in stock
The book The mostest technical Book was written by mr. Author with ISBN: 9876543 and is the third edition. We have 4 in stock
The book The best Book of technicalities was written by mrs. Author Jr. with ISBN: 1212345121 and is the fifth edition. We have 5 in stock
*/
```
And that's it! With this solution, we were able to create a TechnicalBook class that inherits from the Book class and also has an additional element, edition. We also provided a function that returns a string that includes the book's edition. This can be further customized and expanded upon to suit your needs.
| zuzexx |
1,328,360 | How I'm trying to build my portfolio with three.js and AI | You can also watch this as a video: https://www.youtube.com/watch?v=QDoiD5vst9o Some nice, juicy... | 0 | 2023-01-13T18:18:48 | https://dev.to/nevoo/how-i-try-to-build-my-portfolio-with-threejs-and-the-help-of-ai-4cgf | webdev, javascript, ai, design | You can also watch this as a video:
https://www.youtube.com/watch?v=QDoiD5vst9o
_Some nice, juicy spinning piles of melons..
were one of my first attempts to build something with three.js._
A library to create interactive 3D Websites, which could be games, eye catching product showcases or anything else you can imagine and i tried to use it, to create my personal portfolio website.

## Why I’m using three.js
Why you ask? I always found it very intriguing and wanted to create something similar myself. I’ve actually been intrested in 3D Design/ Modeling for a long time and played around with Blender and other Software. So I really wanted to start creating something with three.js.
## Challenges I Faced
The biggest challenge i had was that i kind of overkilled my tech stack. I didn’t use react for almost 2 years and already wanted to jump in with next.js and many other libraries and everything kind of fell apart. I got errors upon errors and nothing worked and with that, my motivation was gone.
BUT, my desire to restart this project got reignited and now I want to approach this differently.
## My Vision and Idea
First of all, I want to share my journey of creating this portfolio. I want to share what I learn and what challenges I face along the way, in the hope that it will keep my motivation up. When this website is finally done, I surely want to keep this channel going and finish all my abandoned side projects I have gathered in the past years, and even start new ones!
So… what was my idea in the first place? What did I want to use three.js for? Well, I had and still have a pretty clear picture in my mind: I’m a developer and a hobby photographer and I wanted to display both of these respectively. And since we now have all these fancy AI tools, I tried to let them paint this picture for me I had in my head for the past year. My idea was to display a laptop and a camera as 3D models which the user could interact with. The AI got me some pretty interesting results I can use for inspiration, when I create my actual design later on. And I’ll probably come back to the AI again and again as this turned out to be a really useful tool already!

## Creating 3D Models
I need to create these 3D models, which means I have to dive deep back into Blender, which already brings up donut flashbacks again. So for now, all I want to achieve is to create a donut and display it on the website which might be hard enough already, since I also don’t have much experience in three.js and gonna learn this as I go.
Therefore the next logical step is TO DELETE EVERYTHING I had before, to really start this project from scratch again… And fix my git config because it somehow got broken on this pc. Great, already wasting time on the most important stuff again.
Before I really started with Blender i tried to use ChatGPT to help me create some 3D models, because I saw some people using it to create svgs and some crazy python scripts so I thought, why not?
Well it was completely lost with my prompts. Maybe I could get more useful results if I tried to fine tune them, but I think the models were just to complex because look what weird creatures it created:

After this little adventure I decided to model some delicious donuts by myself. And after about 7 hours I had created this beauty:
## Exporting from Blender
With my donut finished and my repository fixed I successfully created a new react project, installed all the three.js libraries I needed and now I only had to figure out how to export my model from Blender so I could use them in the project but this already lead to some problems.
After a quick research, I read through this documentation which recommended to use this tool to convert your model to a react component which seemed to good to be true. Turns out, half of the stuff that I had in the render didn’t work in three.js
Either it was so bright, you couldn’t see anything or random planes that got imported because I forgot to turn them off in the render. But after some trial and error I got something working in the preview.
As I already said, some stuff of the render didn’t work and as you can see the sprinkles on the donut and in the background are not being displayed. This is because I used geometry nodes in blender to create them and I couldn’t really figure out how to get them working with the model export. If this is even possible. So I shifted my focus and just tried to get something to show up for now, since the donut wouldn’t be my final render, and more like a proof of concept. But it was good to know I really had to look out for a lot of things when I create my real models later on.
Funny enough, my biggest problem was to figure out why the donut was always displayed in such a small part of the screen. And as I dug deep into the 20 lines of CSS that came with the default react app I found the issue.. I mindlessly used min-width and min-height which for some reason didn’t cover the full height of the screen. My washed CSS knowledge can’t explain why this happens but after some digging around I changed it to width and height and everything worked as expected. I love CSS.
The next thing i want to figure out is how i could display animations I created in blender, because that would open up some possibilities for later, but i don’t wanna spend too much time on it for now.
Thanks for reading! | nevoo |
1,328,451 | Half-baked knowledge | This video is (I think) targeted towards new language learners. If feels applicable with coding as... | 0 | 2023-01-13T19:30:04 | https://dev.to/caseyeee/half-baked-knowledge-10cn | beginners, programming | This video is (I think) targeted towards new language learners. If feels applicable with coding as well.
{% embed https://www.youtube.com/watch?v=i8oDLO7GPsk %}
It further supports my initiative to make multiple passes on difficult / new material and to move on without fully understanding.
The word **the** is hard to define or understand. If I had put all my effort into defining **the** before learning to speak any other word then my growth would have been stunted. By moving on and partially understanding thousands of words I've been able to put **the** in the necessary context to give it meaning.
Likewise, **downcasting** means little to me at the moment. I made an honest attempt to understand it, and now my strategy is to cover enough ground where I find myself needing to **downcast**. Then I can revisit a concept that is already slightly familiar.
96 | caseyeee |
1,328,492 | Part 2: Catching Bugs Early | One of the main benefits of unit testing is that it allows developers to catch bugs early in the... | 21,437 | 2023-01-13T21:09:59 | https://dev.to/svenherr/part-2-catching-bugs-early-b3f | testing, beginners, programming, writing | One of the main benefits of unit testing is that it allows developers to catch bugs early in the development process. By testing individual units or components of the software application, developers can identify and fix issues before they make their way into the final product. This can save a lot of time and resources compared to catching and fixing bugs later on in the development cycle or after the product has been released.
It’s important to write tests for edge cases as well as the most common scenarios. Edge cases are the less likely scenarios, but they are also the ones that can cause the most problems. By testing for edge cases, developers can identify and fix issues that would otherwise go unnoticed. For example, in a function that takes two integers as input and returns their sum, an edge case would be when one or both of the input integers are the maximum or minimum value that an integer can hold.
It’s also important to write tests for all the important functionalities of the software. This way, it ensures that all the features are working as intended. Writing test for the core functionality of the software is crucial, as it can help prevent regressions and ensure that the software performs as expected.
Unit testing also provides a way to ensure that new changes don’t break existing functionality. Every time a change is made, the unit tests are run to check if the code still works as expected. If a test fails, it means that something is wrong and needs to be fixed. This helps to catch and fix issues early on, before they cause more serious problems down the line.
---
Example Use Case:
Consider a software application that manages financial transactions for a bank. As part of the development process, the team writes unit tests for the code that handles the processing of transactions. These tests cover different scenarios, such as the deposit of funds, the withdrawal of funds, and the transfer of funds between accounts.
During development, the team runs these tests frequently to ensure that the code is working as intended. One day, a developer makes a change to the code that handles the withdrawal of funds. They run the unit tests, and one of the tests fails. The test is designed to check that the withdrawal of funds is processed correctly, and it fails because the change that the developer made introduced a bug.
Thanks to the unit tests, the bug is caught early in the development process, and it can be fixed quickly. If the bug had not been caught, it could have gone unnoticed and caused issues in the production environment, resulting in incorrect transactions and unhappy customers.
---
In summary, unit testing helps to catch bugs early in the development process by testing individual units or components of the software application. Writing tests for edge cases and important functionalities can also help to identify and prevent bugs. Additionally, unit testing provides a way to ensure that new changes don’t break existing functionality, by running the tests every time a change is made. This helps to catch and fix issues early on, before they cause more serious problems down the line.
Series: Why unit testing is important ? All about unit testing
[Part 1: Introduction to Unit Testing](https://dev.to/svenherr/part-1-introduction-to-unit-testing-with-examples-21k2)
[Part 2: Catching Bugs Early](https://dev.to/svenherr/part-2-catching-bugs-early-b3f)
[Part 3: Ensuring Code Quality](https://dev.to/svenherr/part-3-ensuring-code-quality-with-examples-3p3n)
[Part 4: Living Documentation](https://dev.to/svenherr/part-4-living-documentation-with-examples-chk)
[Part 5: Continuous Integration and Deployment](https://dev.to/svenherr/part-5-continuous-integration-and-deployment-with-examples-2hkg) | svenherr |
1,328,515 | Monitoramento completo com EC2 + Grafana + Prometheus e Loki | Em um post passado fiz a criação do servidor do Grafana e instalação do plugin do Loki. Também montei... | 0 | 2023-03-02T21:52:38 | https://dev.to/pcb737/monitoramento-completo-com-ec2-grafana-prometheus-e-loki-385 | Em um post [passado](https://dev.to/pcb737/ec2-com-logs-centralizados-utilizando-loki-fluentbit-grafana-8jp) fiz a criação do servidor do Grafana e instalação do plugin do Loki. Também montei um servidor com nginx padrão para se utilizado no envio dos logs.
Neste post quero trazer o monitoramento full de uma instância EC2, monitoramento de disco, cpu, rede, swap, processos que estão rodando na máquina e logs.
Não vou contemplar a criação do servidor do Grafana e nem o servidor que será monitorado. Já vou direto para o ponto onde vou subir o contêiner com o Prometheus, na máquina do server do Grafana e a configuração do dashboard para análise da saúde do ambiente.
Neste ponto já temos o docker instalado na instância do Grafana, com o contêiner do Grafana e Loki rondando. Agora vou subir o contêiner do Prometheus, mas antes vou baixar o arquivo de configuração e fazer a criação de um diretório onde ficará o arquivo de configuração para ser mapeado no contêiner do Prometheus. Segue abaixo os comandos:
```
sudo mkdir /docker && \
cd /docker && \
git clone https://gitlab.com/snippets/2484803.git && \
sudo mv 2484803 prometheus
```
Neste ponto já temos os arquivos de configuração, agora podemos subir o contêiner do Prometheus com esse arquivo de configuração.
```
docker run -d --name=prometheus \
--network monitoring \
-p 9090:9090 \
-v /docker/prometheus/prometheus.yml:/opt/bitnami/prometheus/conf/prometheus.yml bitnami/prometheus:latest
```
Se tudo estiver ok, deverá estar desta forma:

Com o contêiner do Prometheus up, vou iniciar a configuração do Datasource. Para isso vá em **configurações > Plugins** na busca digite Prometheus. Deve estar assim:
Selecionando o plugin do Prometheus irá para tela onde irei configurar o Datasource.
Selecione **Create a Prometheus data source** e faça o preenchimento das seguintes informações:
Feito isso clique em **Salve & test**
Neste ponto já temos o Datasource do Prometheus configurado com o Grafana.
Agora vou fazer as configurações na instância que será monitorada. Na instância que será monitorada eu irei configurar o **node exporter**, que é responsável por enviar as métricas para o Prometheus.
## Instalando Node Exporter
Acesse via ssh a instância a ser monitorada. Esse servidor que será monitorado, eu estou utilizando Amazon Linux2. Com isso vou baixar o executável do **node_exporter** no diretório home do usuário **ec2-user** utilizando o comando abaixo:
```
wget https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz
```
Você pode verificar [aqui](https://prometheus.io/download/) versões mais atualizadas do node_exporter.
Agora vou descompactar e renomear o diretório do pacote baixado:
```
tar xf node_exporter-1.5.0.linux-amd64.tar.gz && \
mv node_exporter-1.5.0.linux-amd64 node_exporter
```
Feito isso, vou acessar o diretório node_exporter e inciar o executável. Vou executar com **nohup**, para que minha sessão não fica presa ao executável. O comando fica assim:
```
nohup ./node_exporter &
```
Pressionando 2x o enter para liberar a console, deverá ficar desta forma:
Para certificar que está tudo ok, podemos acessar via browser:
```
http://ip_do_server_node_exporter:9100
```
Você deve ver uma tela igual a essa:
Agora vou voltar ao servidor onde está instalado o Prometheus para que posso adicionar o ip interno da instância a ser monitorada, para que possa fechar a comunicação entre eles.
No servidor do Prometheus vá no diretório **docker/prometheus** e edite o arquivo **prometheus.yml**. Se você estiver com o arquivo que eu disponibilizei, deverá editar somente a **linha 28**.

Basta salvar o arquivo, o servidor já irá começar a se comunicar com o agente. Você pode validar, acessando o Prometheus via browser.
```
http://ip_do_servidor_grafana:9090
```
Acessando no menu superior **status > Service Discovery**. Você será direcionado para essa tela:
Agora clicando em **show more**, terá no próprio servidor do Prometheus e o servidor que vou monitorar.
Configurações ok, vou para criação do dashboard de monitoramento de recursos e recebimento dos logs. A parte de config de recebimento de logs contemplei neste [post](url)
Para facilitar vou pegar um dashboard pronto e apenas importa-lo para o ambiente de teste. Selecione a opção **Dashboard > + Import**.
Nessa tela você vai adicionar o **ID 1860 > load**
A tela seguinte deverá estar desta forma:
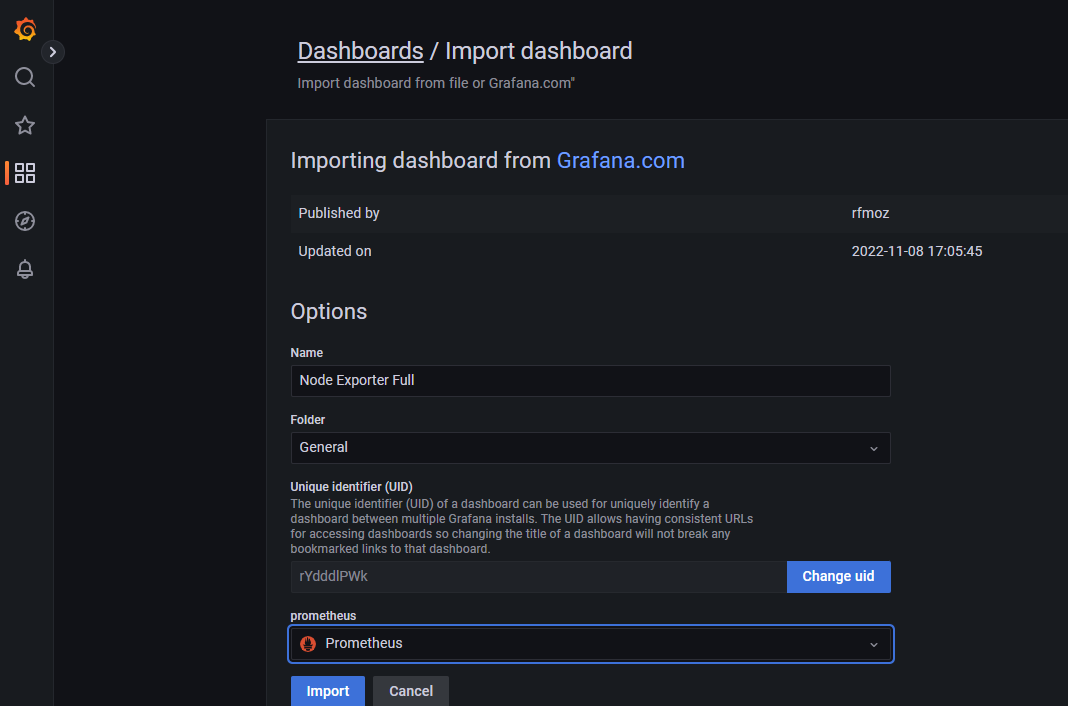
Agora é clicar em **import**
Se estiver tudo ok, você deve visualizar algo:
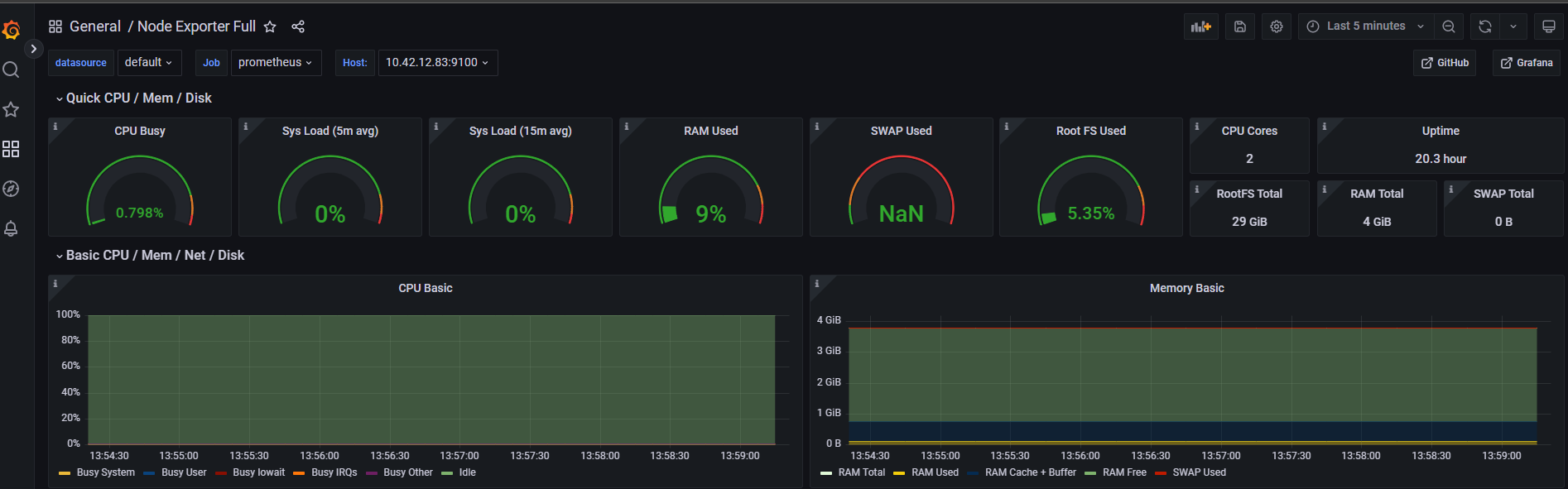
**Não esqueça de salvar o dash para não peder as configs..**
Agora vou inserir a visualização dos logs, as configs para deixar o Loki funcional estão [aqui](url).
Selecione add painel > add new panel
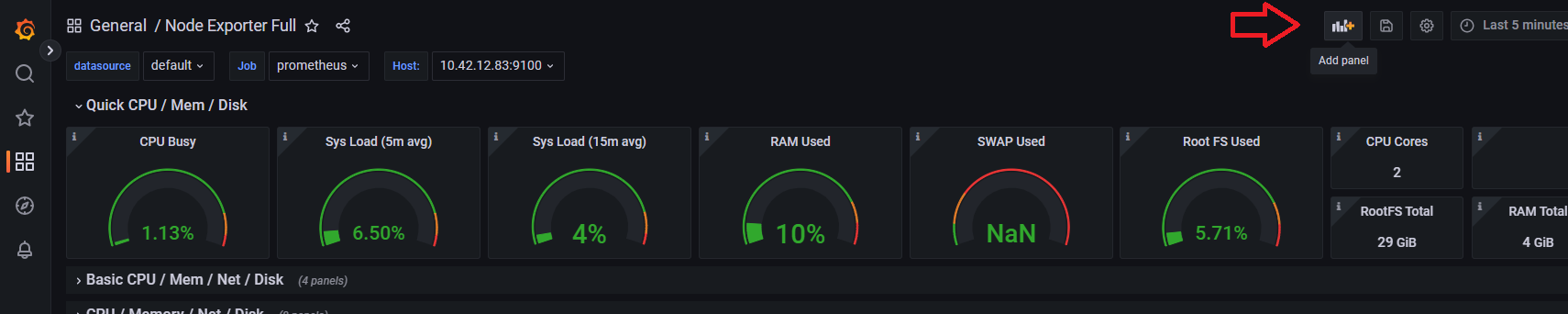
Add new panel, vamos selecionar o Datasource Loki
Agora vamos filtrar por labels:
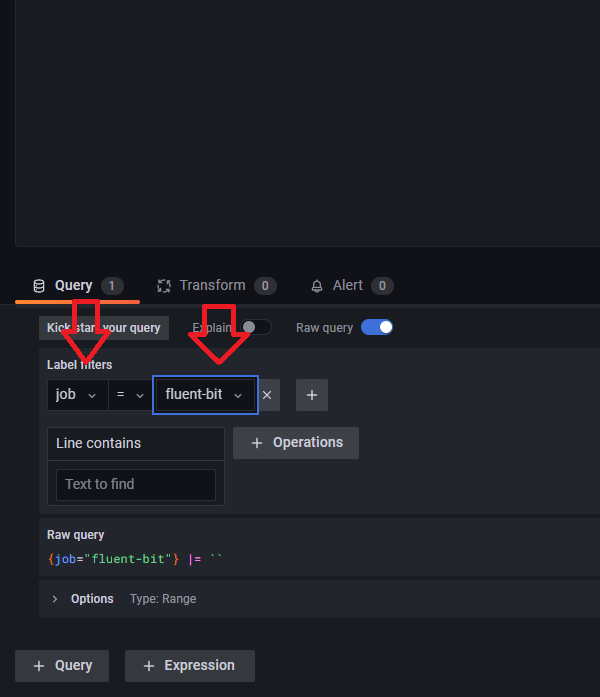
Pode dar um **Run queries** para validar que está trazendo os logs do ambiente correto. Se o retorno estiver desta forma:
Basta dar um apply.
Para que você veja os logs sendo exibidos é necessário acessar o Nginx no servidor que está enviando os logs via browser, e ficar dando f5 na página para gerar conteúdo dentro do access.log.
Ambiente finalizado! Espero ter ajudo e nos vemos no próximo post
E ai vamos se conectar? Entre em contato comigo:
https://www.linkedin.com/in/pcmalves/
| pcb737 | |
1,328,871 | Type of data in hadoop | First developed by Doug Cutting and Mike Cafarella in 2005, Licence umder forApache License... | 21,403 | 2023-01-14T05:17:00 | https://www.developerindian.com/developer/hadoop-tutorial-for-beginners | bigdata, hadoop, datascience | First developed by Doug Cutting and Mike Cafarella in 2005, Licence umder forApache License 2.0
Apache Hadoopis an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. The Hadoop Distributed File System (HDFS) is Hadoop's storage layer. Housed on multiple servers, data is divided into blocks based on file size. These blocks are then randomly distributed and stored across slave machines. HDFS in Hadoop Architecture divides large data into different blocks
Cloudera HadoopCloudera's open source platform, is the most popular distribution of Hadoop and related projects in the world .
** What is big data ?
**
Big Data is a collection of data that is huge in volume, yet growing exponentially with time. It is a data with so large size and complexity that none of traditional data management tools can store it or process it efficiently. Big data is also a data but with huge size. For this we can useApache Hadoopandcloudera hadoop
## Type of data used in big data(Apache Hadoop / Spark)?
**Structured –
**that which can be stored in rows and columns like relational data sets
Unstructured – data that cannot be stored in rows and columns like video, images, etc.
Semi-structured – data in XML that can be read by machines and human
Unstructured
Structured –that which can be stored in rows and columns like relational data sets
**Semi-structured
**Unstructured – data that cannot be stored in rows and columns like video, images, etc.
Lights
Semi-structured – data in XML that can be read by machines and human
## About Apache Hadoop
Hadoop is the most important framework for working with Big Data. The biggest strength of Hadoop is scalability. It can upgrade from working on a single node to thousands of nodes without any issue in a seamless manner.
Advantages of hadoop
Apache hadoopstores data in a distributed fashion, which allows data to be processed distributedly on a cluster of nodes
In short, we can say thatApache hadoopis an open-source framework. Hadoop is best known for its fault tolerance and high availability feature
Apache hadoopclusters are scalable.
TheApache hadoopframework is easy to use.
In HDFS, the fault tolerance signifies the robustness of the system in the event of failure. The HDFS is highly fault-tolerant that if any machine fails, the other machine containing the copy of that data automatically become active. | mishraoct786 |
1,328,898 | Getting Started With React Query(@tanstack/react-query) | When a React application has many effects, it can soon become chaotic as to which effect is happening... | 0 | 2023-01-14T06:37:03 | https://dev.to/coxmd/getting-started-with-react-querytanstackreact-query-10bp | react, webdev, javascript | When a React application has many effects, it can soon become chaotic as to which effect is happening at what time, and performance may start to suffer if effects start occurring quickly one after the other. It is manageable, but it can be challenging to comprehend.
Here I am going to teach you a library called **@tanstack/react-query.** It is the same people who do react-query. This is just the newer version. They now support than just React.
npm install @tanstack/react-query@4.10.1. This will install the package in your project directory.
React is built on the premise that you should cache the majority of the data you retrieve from a database. If a user visits that page again after you have already fetched the information for pet ID 1, you normally want to cache it instead of fetching it again. React-query will help you with this because it has an **integrated caching layer for async data stores** that performs admirably inside the confines of React. Let’s look at how to apply it on our React application.
First thing, we need to **wrap our app in a query client.**More concretely though is that it’s using React context to pass our app’s cache around. So let’s go handle that.
Below is my App.jsx file which is a simple react application that fetches a list of pets from an API and renders them to the user. The user can then click on each individual pet and he/she will be redirected to the details page where more details about the pet will be displayed.
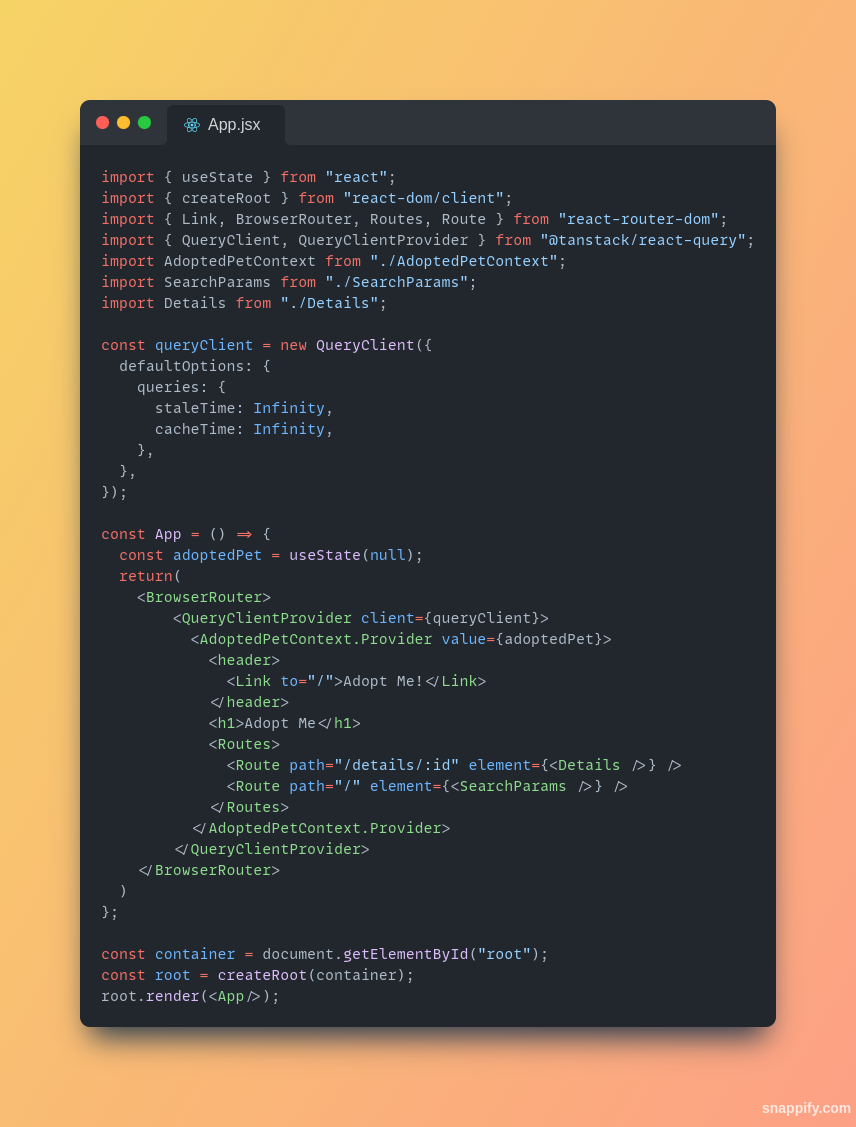
This will wrap our app with the provider necessary to power react-query. We have to give it **cache and stale times** so that it will actually use its caching layer. Otherwise it’ll fetch each time. Here we’re saying “never invalidate” but in many apps you’d probably want to still fetch every few minutes or so.
Next I have created a file called fetchPet.jsx that will actually make a request to the API.
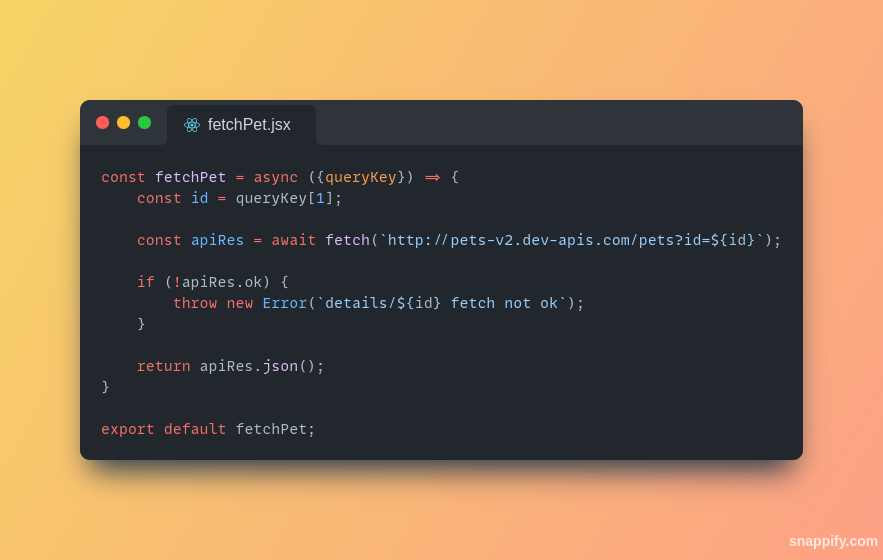
By splitting it, it can be tested independently and used repeatedly throughout our app.Notice the if conditional. We need it to throw if there’s an error and fetch wouldn’t throw here if there’s a 400 or a 500 error. We need it to.
Observe that we don’t wait for the json response. We don’t need to await it in the function body because any async function will always return a promise. You might. The outcome would still be the same.
Below is My Details.jsx file.
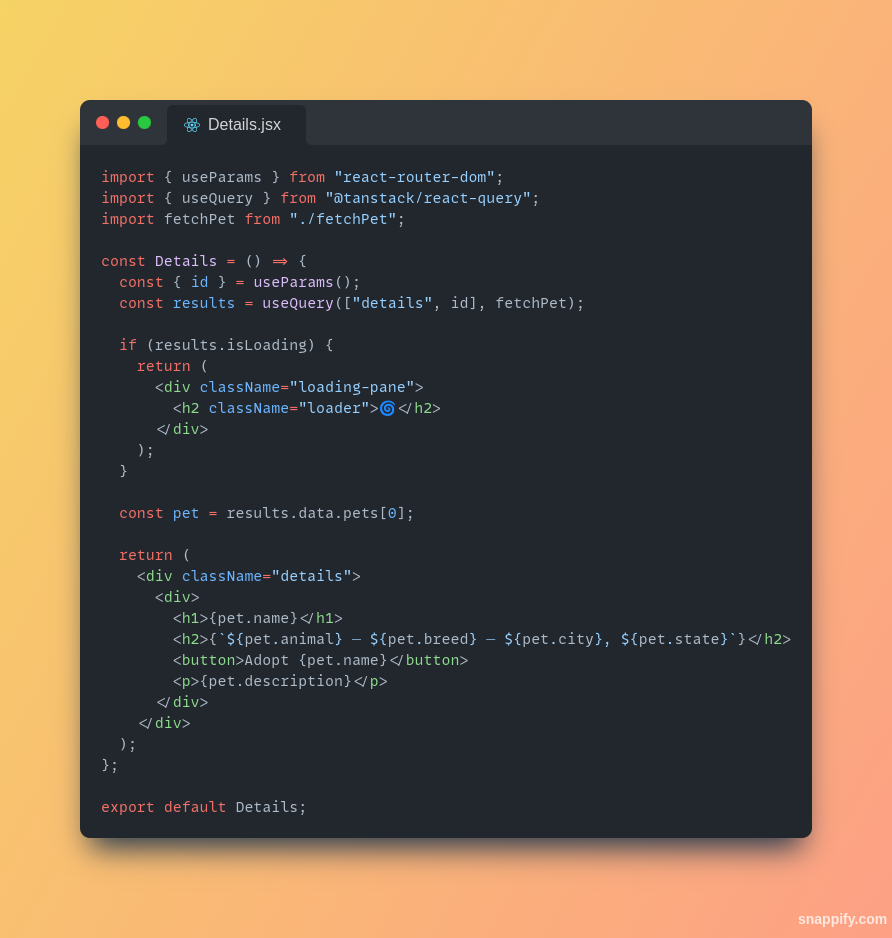
useQuery will actually use the queryClient that we instantiated above via context.
**The query key** is the first thing you provide to useQuery. It could be a string; for instance, details:1 could have been used as the key for details 1. However, I appreciate the array approach. You can supply it with a variety of keys. Therefore, it must match both the first key, details, and its subkey, 1, which are both keys.
In this case react-query will make it start its first fetch (but not finish) and then continue rendering.This should all work now! Notice if we navigate back and forth from a page, the first time it will load it and the second time it won’t; it’ll just **pull it from the cache!** Perfect! Exactly what we wanted.
This got a lot simpler, didn’t it? It’s because **react-query handles all the caching for us instead of us having to.** I hope that this brief article will enable you to easily get started with React query.
| coxmd |
1,328,917 | AWS AI Services: Unleashing the Power of Artificial Intelligence | Introduction: AWS offers a wide range of AI services that can help organizations of all sizes to... | 0 | 2023-01-14T06:59:13 | https://dev.to/keentechs/aws-ai-services-unleashing-the-power-of-artificial-intelligence-2bdj | ai, aws, machinelearning, automation | **Introduction:**
AWS offers a wide range of AI services that can help organizations of all sizes to leverage the power of artificial intelligence.
From image and text analysis to natural language processing and machine learning, AWS has something for everyone.
**Amazon SageMaker:**
Amazon SageMaker is a fully-managed service that enables developers and data scientists to build, train, and deploy machine learning models at scale.
It includes built-in algorithms, pre-built environments for popular machine learning frameworks, and integration with other AWS services.
**Amazon Rekognition:**
Amazon Rekognition is an image and video analysis service that can be used for tasks such as object and scene detection, facial analysis, and moderation of image and video content.
It can be easily integrated into applications such as security systems, media platforms, and customer service chatbots.
**Amazon Transcribe:**
Amazon Transcribe is a real-time speech-to-text service that can be used to transcribe audio and video files in multiple languages.
It can also be used for tasks such as speaker identification, language identification, and transcription of multiple speakers in a single audio file.
**Amazon Translate:**
Amazon Translate is a neural machine translation service that can be used to translate text from one language to another.
It supports a wide range of languages and can be integrated into applications such as chatbots, e-commerce platforms, and customer service systems.
**Amazon Comprehend:**
Amazon Comprehend is a natural language processing service that can be used for tasks such as sentiment analysis, language detection, and named entity recognition.
It can also be used to extract insights from unstructured text data such as customer reviews and social media posts.
**Conclusion:**
AWS AI services provide a powerful and easy-to-use platform for organisations of all sizes to leverage the power of artificial intelligence.
Whether you're a developer, data scientist, or business leader, there's something for everyone in the AWS AI portfolio. | keentechs |
1,357,787 | A Guide to Oracle Testing and Its Benefits | Any utility will tell you that keeping its operations operating successfully depends on managing its... | 0 | 2023-02-08T05:41:55 | https://www.interpages.org/a-guide-to-oracle-testing-and-its-benefits/ | oracle, testing | 
Any utility will tell you that keeping its operations operating successfully depends on managing its customers and assets. That business is responsible for billing clients, caring for property, and collecting user fees for their major resource, which might be gas, water, or any other service they oversee. They set the three pillars of stability, accuracy, and efficiency as what they demand of their solutions and the businesses that use them. So, when a shift of any size occurs, they want to shield their business from its effects.
Making sure the solution satisfies your needs both now and in the future is the key to achieving corporate goals. The method that most people choose is testing, notably using the Opkey test automation platform. Testing is a costly process regardless of the technology or methods used. It comprises planning, designing, and building or carrying out tests. The risk level varies based on the technique, and it requires time and money. In order to reduce testing expenses and risks, the Oracle testing platform Accelerator employs a novel strategy:
● Since the tool is only available for test automation procedures, all test materials must be created, sometimes from scratch. As part of the licencing for the supported versions and products of Oracle Utilities.
● The Oracle Utilities Testing Accelerator is a comprehensive collection of prebuilt assets offered by Oracle. Additionally, with the aid of the Oracle migration to cloud, prebuilt, ready-to-use assets based on the Oracle Utilities Reference Model, the business process modelling approach may be greatly accelerated. As a result, adoption and ongoing maintenance expenses are significantly decreased.
● Solutions are a group of utility-focused techniques that may be employed in original ways to complete business tasks. These operating procedures explain how a certain utility uses the solution to accomplish its objectives. A fundamental strategy for making testing efficient and immediately helpful to a company is to model your tests to fit your business operations. Using Oracle Utilities Testing Accelerator, tests may be appropriately modelled against business operations.
● The only constant in life is change. The Oracle Utility Testing Accelerator aims to cut down on the costs related to change. The Oracle Utilities Testing Accelerator enables updates to test assets without the requirement for redesign as part of every upgrade. This reduces the cost and risk associated with upgrading between versions, regardless of which ones are updated. One of the primary reasons for the presence of this type of capability is the ability to enable users to benefit from the platform much more quickly.
The cost of testing is significant when adopting a solution. There are several methods that may be utilised to lower the cost and risk of installing and maintaining, but each has advantages and disadvantages. By efficiently ensuring that your business operations continue to work smoothly even after updates, you can make the most of your investment by using the Oracle Utility Testing Accelerator. One of the top platforms when it comes to testing is Opkey. It is a no code, easy to use test automation platform for Oracle where application testing can be automated in hours.
| rohitbhandari102 |
1,329,067 | Key notes for Frontend Web development and Steps for deploying app on AWS | I. Introduction Explanation of front-end web development and its importance II. User Experience... | 0 | 2023-01-14T09:44:50 | https://dev.to/keentechs/key-notes-for-frontend-web-development-and-steps-for-deploying-app-on-aws-185a | frontend, webdev, aws, cloud | I. Introduction
Explanation of front-end web development and its importance
II. User Experience (UX)
Importance of user-centered design
Techniques for improving UX, such as user research and prototyping
III. Web Design
The role of visual design in front-end development
Best practices for layout, typography, and color
IV. HTML and CSS
Basic structure and layout of a web page using HTML
Styling and presentation of a web page using CSS
V. JavaScript
How JavaScript can add interactivity and dynamic behavior to a web page
Popular JavaScript libraries and frameworks
VI. Responsive Design
Techniques for creating websites that adapt to different screen sizes and devices
Best practices for mobile web development
VII. Accessibility
The importance of making web pages accessible to users with disabilities
Techniques for improving accessibility, such as proper use of HTML and CSS.
**Step by Step Guide for Creating and Hosting application**
I. Plan and design the web application: The first step is to plan and design the web application, taking into account the user experience, layout, and overall functionality. This should include creating wireframes and mockups to visualize the final product.
II. Build the web application: Next, the frontend developer will use HTML, CSS, and JavaScript to build the web application. This will involve creating the user interface and implementing any necessary interactivity and dynamic behavior.
IIII. Deploy the web application: After the web application is built, it needs to be deployed to a hosting platform. For an AWS web application, this would typically involve using Amazon S3 to host the application's static files and Amazon Elastic Beanstalk or Amazon Lightsail to host the application's backend.
IV. Configure the web application: The frontend developer will need to configure the web application to work properly on the hosting platform. This may include setting up routing, configuring security settings, and connecting to any necessary services or databases.
V. Test the web application: Before launching the web application, it's important to thoroughly test it to ensure that it functions as intended. This may include both manual and automated testing, and should include testing for both functionality and performance.
VI. Monitor and maintain the web application: Once the web application is live, it will need to be regularly monitored and maintained. This may include fixing bugs, adding new features, and updating the application to keep it secure and up-to-date.
| keentechs |
1,329,089 | AWS Certified Cloud Practitioner Exam Preparation and Key Tips | AWS Certified Cloud Practitioner Exam Preparation and Key Tips The AWS Certified Cloud... | 0 | 2023-01-14T10:23:15 | https://dev.to/aymanmetwally2020/aws-certified-cloud-practitioner-exam-preparation-and-key-tips-2051 | aws, cloud, serverless, tutorial |
## AWS Certified Cloud Practitioner Exam Preparation and Key Tips

The AWS Certified Cloud Practitioner exam is a great way to demonstrate your knowledge of the AWS cloud platform. It is designed to validate your understanding of the core services, fundamentals, and best practices of the AWS cloud. To help you prepare for this exam, here are some key tips and strategies:
1. Understand the Exam Structure: The AWS Certified Cloud Practitioner exam consists of multiple-choice questions that cover a variety of topics related to the AWS cloud platform. It is important to understand the structure of the exam so that you can focus your preparation on the issues that are most likely to be tested.
2. Familiarize Yourself with AWS Services: The AWS Certified Cloud Practitioner exam covers a wide range of services offered by AWS. It is essential to familiarize yourself with each service and its features so that you can answer questions related to them accurately.
3. Practice with Sample Questions: One of the best ways to prepare for any certification exam is by practising with sample questions. This will help you get familiar with the types of questions that may be asked on the exam and give you an idea of how long it will take you to answer them correctly.
4. Utilize Online Resources: There are many online resources available that can help you prepare for the AWS Certified Cloud Practitioner exam, such as practice tests, study guides, and tutorials. Utilizing these resources can help ensure that you have a thorough understanding of all topics covered in the exam before taking it.
5. Take Practice Tests: Taking practice tests is one of the best ways to prepare for any certification exam, including the AWS Certified Cloud Practitioner exam. Practice tests provide an opportunity for you to test your knowledge and identify any areas where additional study may be needed before taking the actual test.
By following these tips and strategies, you should be well prepared for success on your AWS Certified Cloud Practitioner Exam! Good luck!

| aymanmetwally2020 |
1,329,113 | The Chitchat of the other kind - ChatGPT in Power Virtual Agents | Picture of Christina @ wocintechchat.com on Unsplash Note: a lot has changed since the release of... | 21,431 | 2023-01-14T11:35:15 | https://the.cognitiveservices.ninja/the-chitchat-of-the-other-kind-chatgpt-in-power-virtual-agents | ---
title: The Chitchat of the other kind - ChatGPT in Power Virtual Agents
series: 101 - Power Virtual Agents
published: true
date: 2023-01-14 11:11:21 UTC
tags:
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/qas8lhz3u5kt26loxzth.jpg
canonical_url: https://the.cognitiveservices.ninja/the-chitchat-of-the-other-kind-chatgpt-in-power-virtual-agents
---
Picture of <a href="https://unsplash.com/@wocintechchat?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Christina @ wocintechchat.com</a> on <a href="https://unsplash.com/de/fotos/OW5KP_Pj85Q?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
> Note: a lot has changed since the release of the article in Jan 2023
> Everything described below is still working (2023.05.22), but I would suggest using [OpenAI Services on Azure](https://the.cognitiveservices.ninja/series/openai-on-azure) instead of OpenAI directly. as with Azure OpenAI Services you have control regarding your Data.
## Motivation
While working with bots, you must consider two points,
_how to present the answer_ and
_where does the answer come from?_
With all articles you might have read in the last few days about openais ChatGPT, you could think - why not integrate this in my installation as a last line of defense to answer when my system is incapable of doing so - at least for chitchat.
This article demonstrates the "how". But do not forget to read the entire article and find some thoughts about the "why" in the conclusions.
## OpenAi
To use openai, you need to create an account with them at [www.openai.com](https://www.openai.com) and generate an API token.
After creating an account and adding some funds as pocket money,
Click top right on your account and the on "View API Keys"

<figcaption>Figure 1: Account Settings</figcaption>
Generate a new API Key
---

<figcaption>Figure 2: Create new secret key</figcaption>
## Power Virtual Agent
### Activate the Fallback topic in Power Virtual Agent
Power Virtual Agent has a built-in topic that can be a hook to the outside world, the Fallback system topic.
To activate the Fallback system topic, go to Settings within the editing canvas (click on the cog symbol), then System fallback, and then +Add.

<figcaption>Figure 3: activated fallback topic</figcaption>
### Edit the fallback topic
Create a message box with a meaningful message and a new action.

<figcaption>Figure 4: Fallback topic with message and action node</figcaption>
In Power Automate, create a new text-based variable, "UnrecognizedUserInput"

<figcaption>Figure 5: text variable as input</figcaption>
and an HTTP Node.
> The syntax for openai is straightforward. We need to authenticate ourselves within the header and give the model, the question, the temperature, and max\_tokens as the body. [[documentation](https://beta.openai.com/docs/api-reference/completions/create)].
> temperature: Higher values mean the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.

<figcaption>Figure 6: syntax sample</figcaption>
I translated this to Power Automate; it will look like the following in the HTTP node.
The token you created above goes directly behind Bearer in the header.

<figcaption>Figure 7: complete HTTP Request</figcaption>
As a next step, we create a String variable.

<figcaption>Figure 8: Initialize a Variable</figcaption>
Create a "Parse JSON node" to analyze the Body of the answer we get from openai.

<figcaption>Figure 9: Parse JSON</figcaption>
You can use the following as a schema or generate it with the Body of the outcome of the previous step.
```
{
"type": "object",
"properties": {
"id": {
"type": "string"
},
"object": {
"type": "string"
},
"created": {
"type": "integer"
},
"model": {
"type": "string"
},
"choices": {
"type": "array",
"items": {
"type": "object",
"properties": {
"text": {
"type": "string"
},
"index": {
"type": "integer"
},
"logprobs": {},
"finish_reason": {
"type": "string"
}
},
"required": [
"text",
"index",
"logprobs",
"finish_reason"
]
}
}
}
}
```
After this, we create an "Apply to each" node with a "Set variable"
and we close by creating an output value.

<figcaption>Figure 10: Last step</figcaption>
Back to Power Virtual Agent, we adjust the created action to the correct input and output values and create a new message box to speak/display the answer on openai.

<figcaption>Figure 11: Completing Action Node</figcaption>
## Test the result
Lets test the result within our configured channels as text chat or voice with Dynamics Customer Service 365 or AudioCodes VoiceAI.

<figcaption>Figure 12: Output</figcaption>
## Conclusion
ChatGPT gives us answers, most of the time correct answers, and the models are getting better and better.
Is there a downside? Why should we integrate it or why should we not to do so?
Do the user or us will "like" the answer or is it appropriate? Here we have no control; we do not own the model.
**If you check the logs of your bots, you will see questions asked by users you would not even expect in your darkest dreams.**
There are situations where a technically correct answer is not the answer you will give to your users when they are, e.g., in highly emotional situations. | thecognitiveservicesninja | |
1,329,145 | Testing the Performance of User Authentication Flow | Testing the performance of the backend API on high traffic is a must-have step before deploying it to... | 0 | 2023-01-14T12:56:06 | https://dev.to/kursataktas/testing-the-performance-of-user-authentication-flow-41p3 | testing, performance, devops, api | Testing the performance of the backend API on high traffic is a must-have step before deploying it to production. We have to simulate the traffic as realistically as possible. This includes testing the endpoints that require authentication. In this article, we explained how to simulate hundreds of users that first get their JWT token from the Login endpoint and hits the private endpoints. We have used [Ddosify Open Source Load Engine](https://github.com/ddosify/ddosify), so we didn't need to write any line of code.
Happy reading
[Testing the Performance of User Authentication Flow](https://ddosify.com/blog/testing-the-performance-of-user-authentication-flow) | kursataktas |
1,329,461 | Making Smart Choices: An Introduction to Decision Trees and Random Forests | Decision Trees and Random Forests are popular algorithms in the field of Artificial Intelligence and... | 21,370 | 2023-02-12T10:00:00 | https://dev.to/msmello_/making-smart-choices-an-introduction-to-decision-trees-and-random-forests-g4 | machinelearning, computerscience | Decision Trees and Random Forests are popular algorithms in the field of Artificial Intelligence and Machine Learning. They are used for tasks such as classification and regression, and are known for their ease of interpretability and ability to handle large datasets. In this article, we'll explore the basics of decision trees and random forests, how they work, and their potential applications in the future.
---
## **What are Decision Trees?**
A decision tree is a tree-like model of decisions and their possible consequences. Each internal node represents a "test" on an attribute (e.g. whether a coin flip comes up heads), each branch represents the outcome of the test, and each leaf node represents a class label (decision taken after computing all attributes). The paths from root to leaf represent classification rules.
## **How do Decision Trees work?**
Decision Trees work by recursively partitioning the data into subsets based on the values of the input features. Each internal node of the tree represents a test on the value of a particular input feature, each branch represents the outcome of the test, and each leaf node represents a predicted output value. The algorithm works by recursively selecting the feature that results in the purest subsets, until a stopping criterion is met.
## **What are Random Forests?**
A Random Forest is an ensemble of Decision Trees. The basic idea behind ensemble methods is to combine the predictions of several models in order to improve the overall performance. The random forest algorithm combines multiple decision trees in determining the final output rather than relying on individual decision tree.
## **How do Random Forests work?**
Random Forests work by training multiple decision trees on random subsets of the data, and then averaging the predictions of all the trees. This has the effect of reducing overfitting and improving the overall performance of the model.
## **Applications of Decision Trees and Random Forests**
Decision Trees and Random Forests have a wide range of applications in various industries, including:
- **Finance**: Decision Trees and Random Forests are used for tasks such as credit scoring and fraud detection.
- **Healthcare**: Decision Trees and Random Forests are used for tasks such as medical diagnosis and treatment prediction.
- **Marketing**: Decision Trees and Random Forests are used for tasks such as customer segmentation and targeting.
- **Natural Resources**: Decision Trees and Random Forests are used for tasks such as oil and gas exploration and soil analysis.
- **Manufacturing**: Decision Trees and Random Forests are used for tasks such as quality control and predictive maintenance.
---
Decision Trees and Random Forests are powerful algorithms that are widely used in the field of Artificial Intelligence and Machine Learning. They are known for their ease of interpretability and ability to handle large datasets, making them a valuable tool for tasks such as classification and regression. With continued research and development, we can expect to see even more exciting applications of Decision Trees and Random Forests in the future. | msmello_ |
1,329,476 | How to use Chart.js to create a Chart for Your Project | Data visualization is a powerful tool for interpreting large and complex data sets. It involves... | 0 | 2023-01-14T22:37:44 | https://dev.to/ijay/how-to-use-chartjs-to-create-a-chart-for-your-project-3kk2 | react, webdev, javascript, tutorial | Data visualization is a powerful tool for interpreting large and complex data sets. It involves creating graphical representations that give detailed information and can be used to generate insights into a given topic. It can be as simple as a graph or chart or as complex as an interactive dashboard with a variety of widgets and interactive elements.
The ability to see data in a visual format can aid in the identification of patterns and issues, as well as the discovery of correlations and relationships that are not immediately apparent when looking at raw data alone.
In this tutorial, I will be walking you through the process of building a chart utilizing chart.js within a React.js application.
## prerequisite
1. Have a basic understanding of the React.js framework.
2. Install node.js on your system.
3. Install Chart.js library and react-chartjs-2.
4. Install Tailwindcss or any other CSS framework for styling your project.
## What is Chart.js
Chart.js is a JavaScript library for creating charts and graphs on a web page. It allows developers to create charts such as bar charts, line charts, and pie charts.
The library uses the HTML5 canvas element to draw the charts, and it is designed to be highly customizable and easy to use. It also supports animation and interactive features. It's widely used and widely supported by many developers.
## Why Should You Use Chart.js for Your Project?
**Responsiveness:** Chart.js is designed to be responsive and will automatically adjust the chart size to fit the available space.
**Cross-browser compatibility:** Chart.js is compatible with most modern web browsers, including recent versions of Chrome, Firefox, Safari, and Edge.
**Animation:** Chart.js also allows you to add some nice animations to the chart which makes them more engaging and interactive.
**Open-source:** Chart.js is an open-source library, which means that it is free to use and can be easily integrated into any project.
**Customization:** Chart.js offers a wide range of customization options, including different chart types, colors, and data labels.
## Getting Started with Chart.js in React project
React-chartjs-2 provides various chart types for selection, such as Bar, Pie, and Line charts. Its React components have attributes, that are passed in as props to what is rendered.
To integrate Chart.js in a React project, you'll need to install the **chart.js and react-chartjs-2** packages, which provide a React-friendly wrapper for the Chart.js library.
Here's an example of how you can get started:
```
npm install react-chartjs-2 chart.js --save
```
### Creating a Bar chart using chart.js
A bar chart is a graphical representation of data using rectangles, usually with heights or lengths proportional to the values they represent. They are commonly used to compare changes over time or differences between groups.
- Import Bar from the react-chartjs-2 library into your React component.
```
import { Bar } from 'react-chartjs-2'
```
- Next, Import labels from Chart.js
```
import {
Chart as ChartJS,
CategoryScale,
LinearScale,
Title,
BarElement,
Tooltip,
} from 'chart.js';
```
- Activate the labels by registering them such as tooltips. This will ensure that the labels are displayed when the user hovers over the chart data.
```
ChartJS.register(CategoryScale, LinearScale, Title, BarElement, Tooltip);
```
- Then, create a state object in your React component to store the data for the chart.
```
const state = {
labels: [
'JUNE',
'JULY',
'AUGUST',
'SEPTEMBER',
'OCTOBER',
'NOVEMBER',
'DECEMBER',
],
// datasets stored in an array of objects
datasets: [
{
// you can set individual colors for each bar
backgroundColor: ['red', 'green', 'pink', 'orange', 'yellow', 'lime'],
hoverBackgroundColor: 'lightblue',
borderRadius: 8,
data: [40, 40, 50, 60, 80, 90, 70],
},
],
};
export default BarChart
```
- Lastly, create a function that returns the JSX of the React component with the data you have made.
```
const BarChart = () => {
return (
<div>
<h1 className="font-extrabold">sales for the month of JUNE-DECEMBER</h1>
<Bar data={state} />
</div>
);
}
export default BarChart
```
**The result**
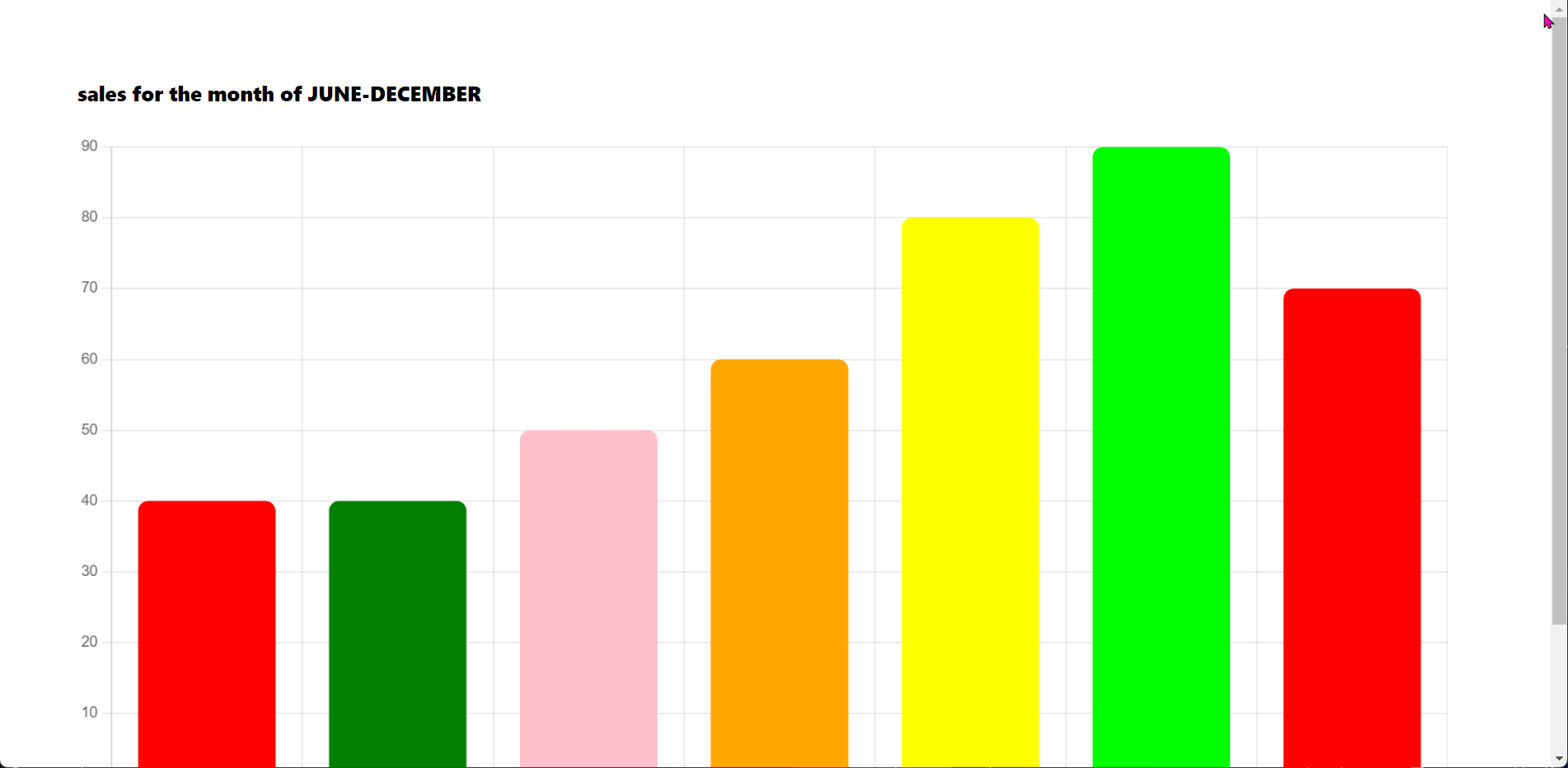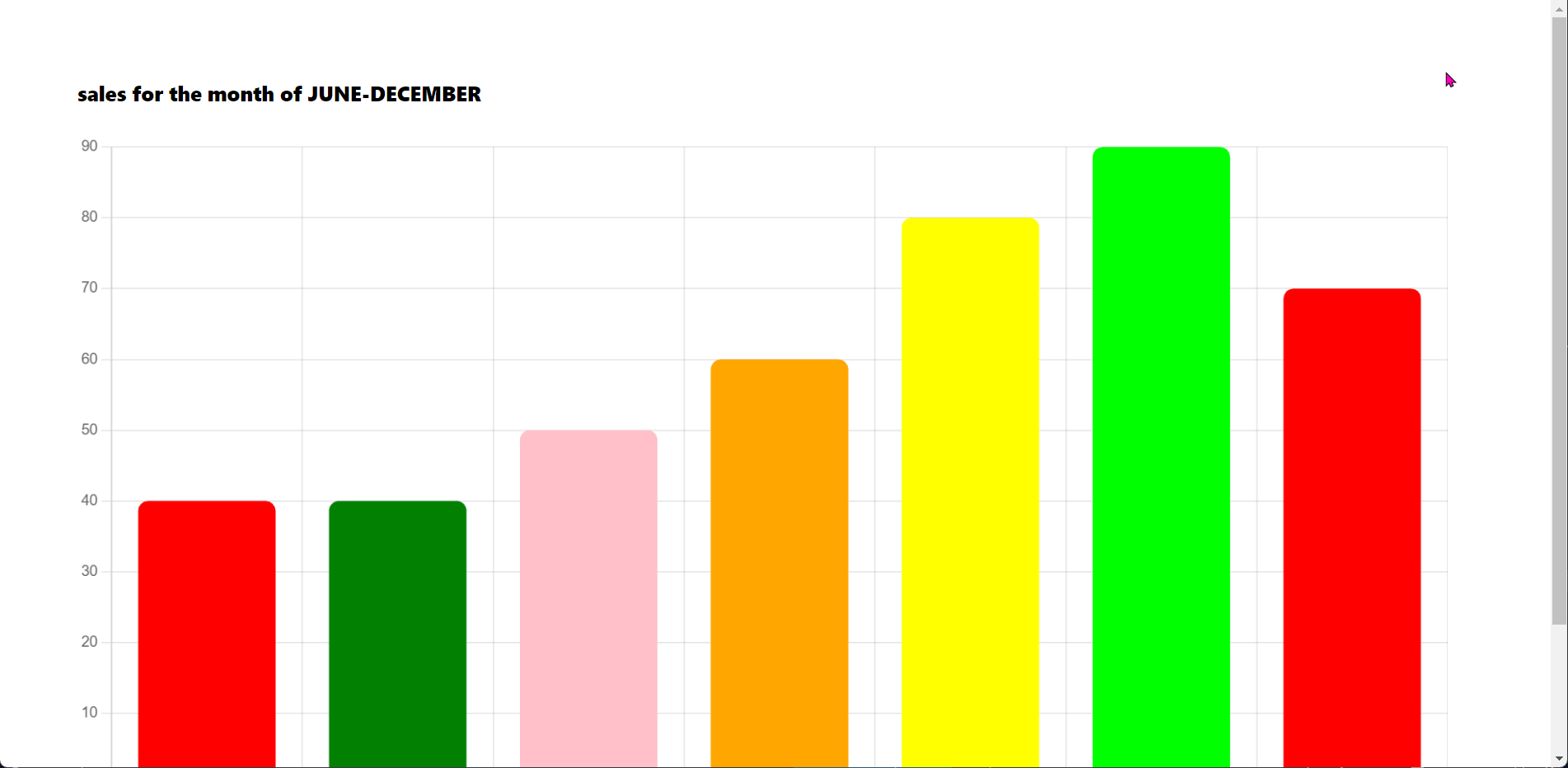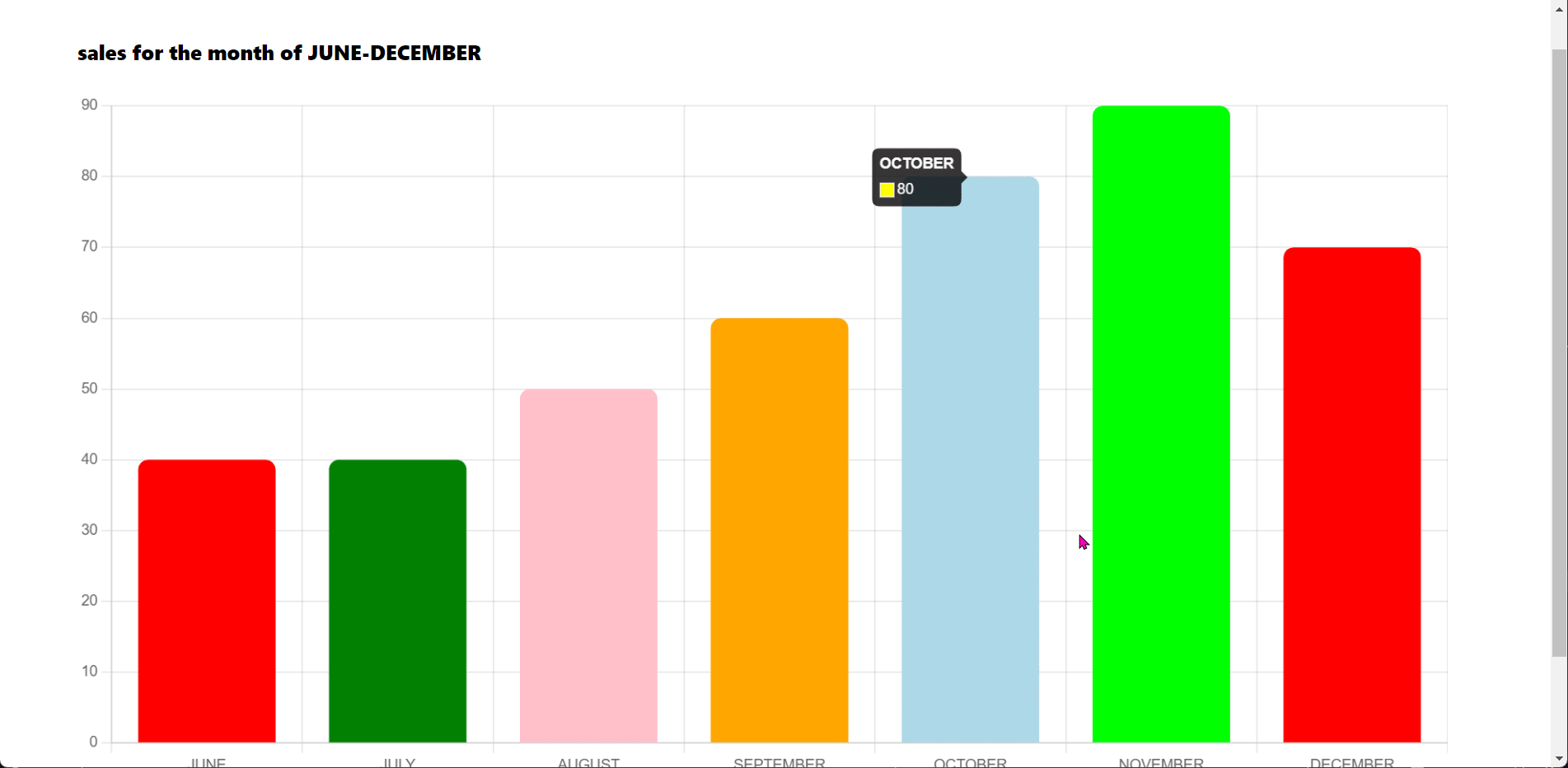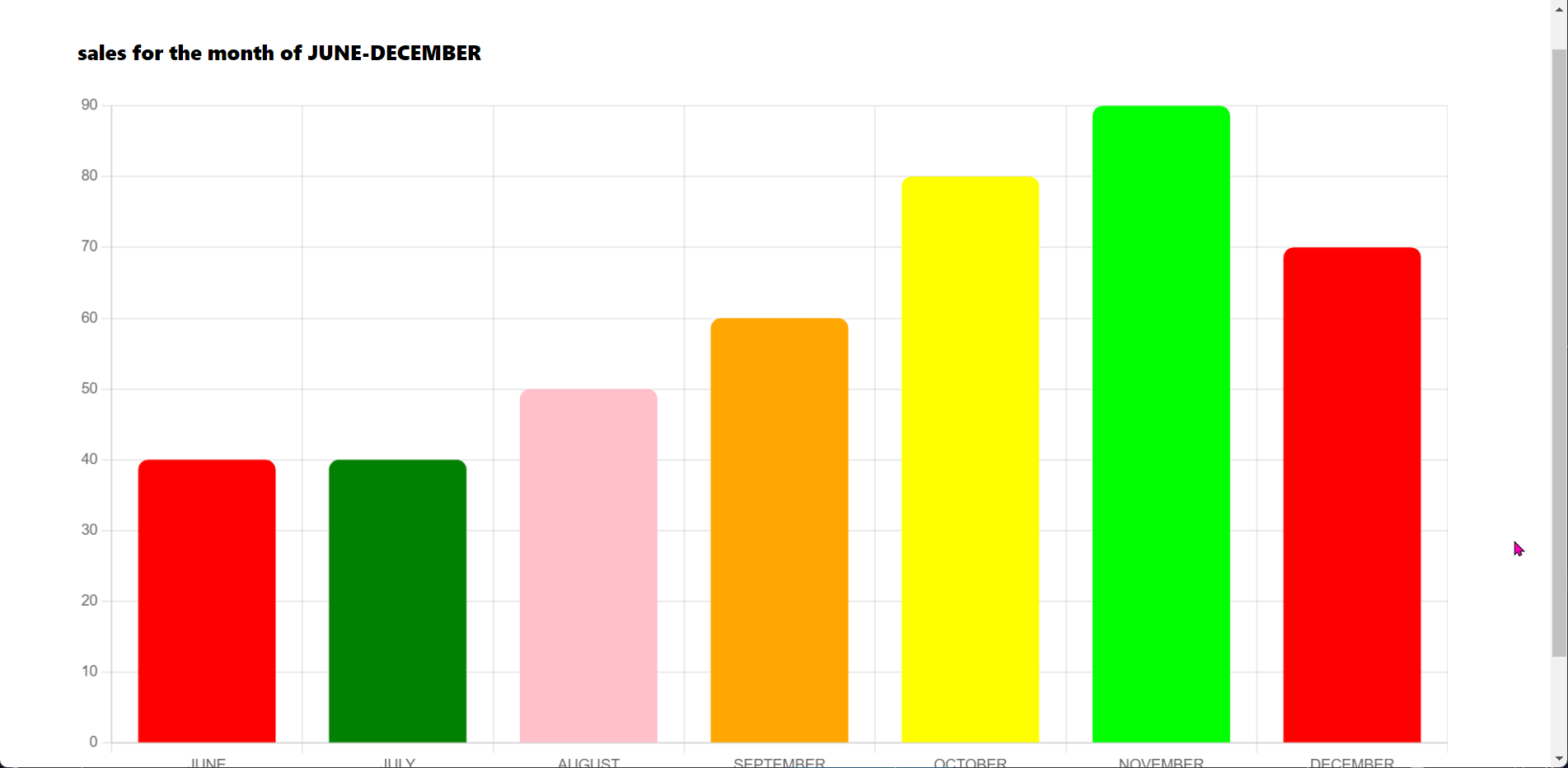
In addition to creating bar charts, the chart.js library also offers the ability to create other types of charts, such as pie charts and line charts.
### Creating a Pie chart using chart.js
A pie chart is a circular chart that is divided into segments, or "slices," that display the proportion of different data values. Each segment represents a category of data, and the size of the segment corresponds to the magnitude of the data value for that category.
In comparison to a bar chart, a pie chart provides better visualization for showing the proportion of different data categories within the whole dataset.
- Import the Pie from thereact-chartjs-2 library into your React component.
```
import { Pie } from 'react-chartjs-2'
```
- Import the pie chart labels from Chart.js
```
import { Chart as ChartJS, ArcElement, Tooltip, Legend } from 'chart.js'
```
Activate the labels by registering them such as tooltips. This will ensure that the labels are displayed when the user hovers over the chart data.
```
ChartJS.register(ArcElement, Tooltip, Legend);
```
Create a state object in your React component to store the data for the chart.
```
const state = {
labels: [
'JUNE',
'JULY',
'AUGUST',
'SEPTEMBER',
],
// datasets is an array of objects
datasets: [
{
// you can set individual colors for each pie
backgroundColor: ['purple', 'green', 'yellow', 'orange'],
hoverBackgroundColor: 'lightblue',
data: [40, 40, 50, 60],
},
],
};
```
- Lastly, create a function that returns the JSX of the React component with the data you have made.
```
const Piechart = () => {
return (
<div>
<h1 className='font-extrabold'>Pie chart representation of Sales from June-September</h1>
<div style={{ width: '40%' }}>
<Pie data={state} />
</div>
</div>
);
}
```
From the above code, the returned JSX is wrapped in another div; this is just for styling purposes to reduce the width.
**The result**

### Creating a Line chart using chart.js
A line chart is a graph made up of points connected by straight lines. It can be used to visualize changes in data over time and other types of data relationships.
- Import Line from thereact-chartjs-2 library into your React component.
```
import { Line } from 'react-chartjs-2'
```
- Import Line chart labels from Chart.js
```
import {
Chart as ChartJS,
LineElement,
CategoryScale, //x-axis
LinearScale, //y-axis
PointElement,
Tooltip,
} from 'chart.js';
```
- Activate the labels by registering them such as tooltips. This will ensure that the labels are displayed when the user hovers over the chart data.
```
ChartJS.register(
LineElement,
CategoryScale,
LinearScale,
PointElement,
Tooltip
);
```
- Create a state object in your React component to store the data for the chart.
```
const state = {
labels: ['Lagos', 'Usa', 'Canada', 'Australia'],
datasets: [
{
backgroundColor: ['blue', 'green', 'yellow', 'red'],
data: [30, 4, -5, 37],
borderColor: 'black',
},
],
};
```
- Lastly, create a function that returns the JSX of the React component with the data you have made.
```
const Linechart = () => {
return (
<div>
<div>
<h1 className="font-extrabold">Temperature line chart</h1>
<div style={{width: '50%' }}>
<Line data={state} />
</div>
</div>
</div>
);
}
export default Linechart
```
From the above code, the returned JSX is wrapped in another div; this is just for styling purposes to reduce the width.
**The result**
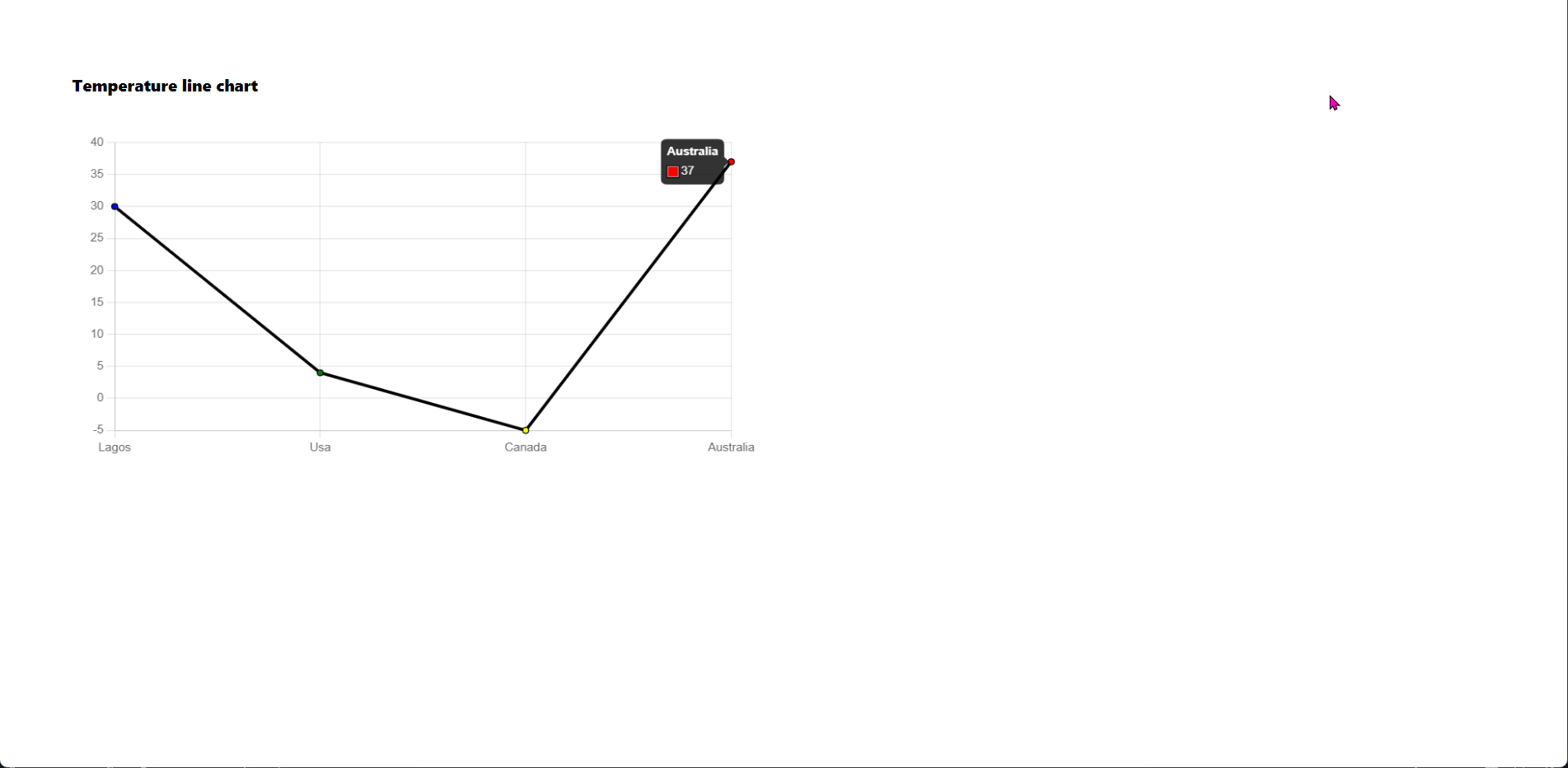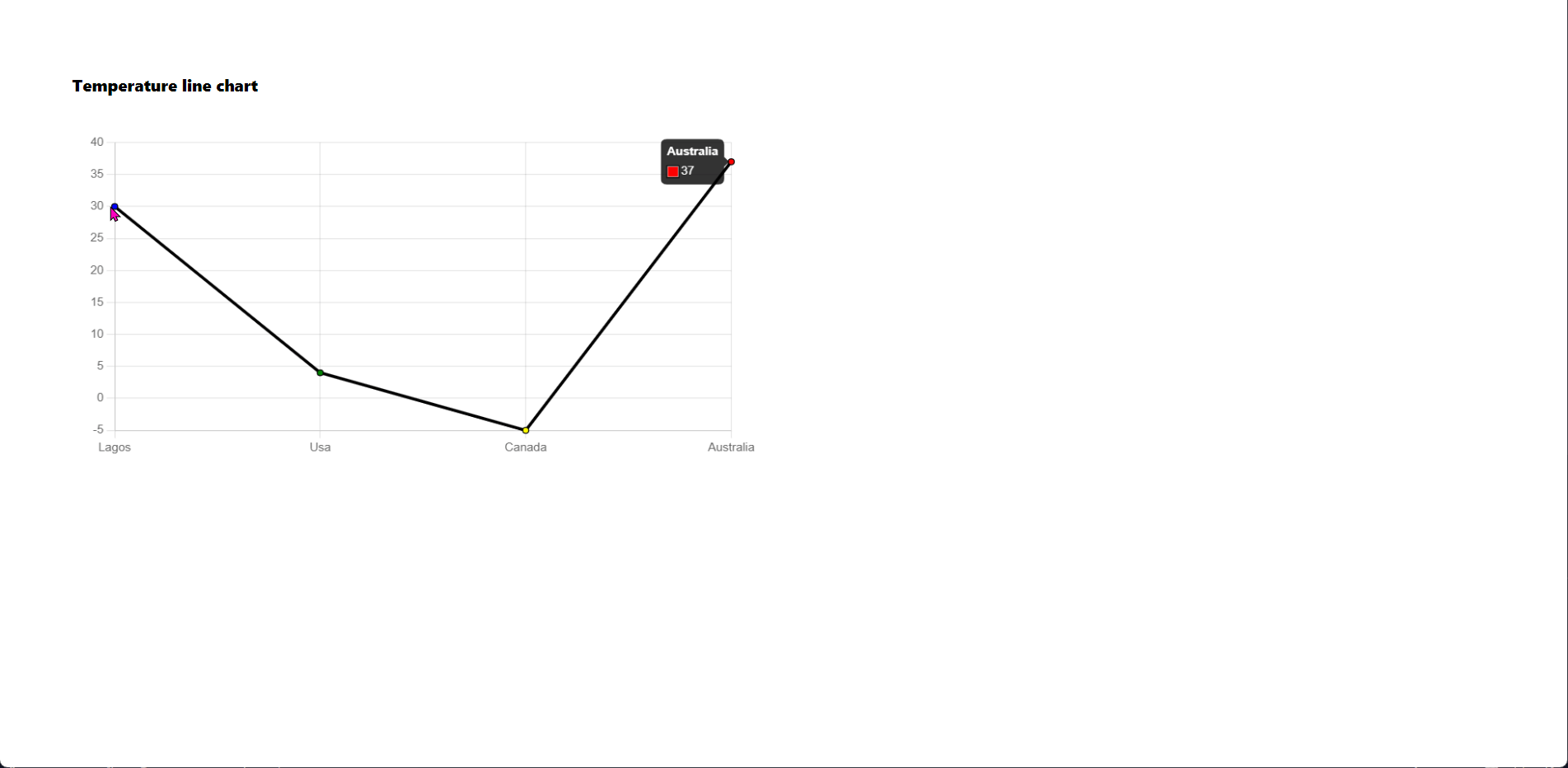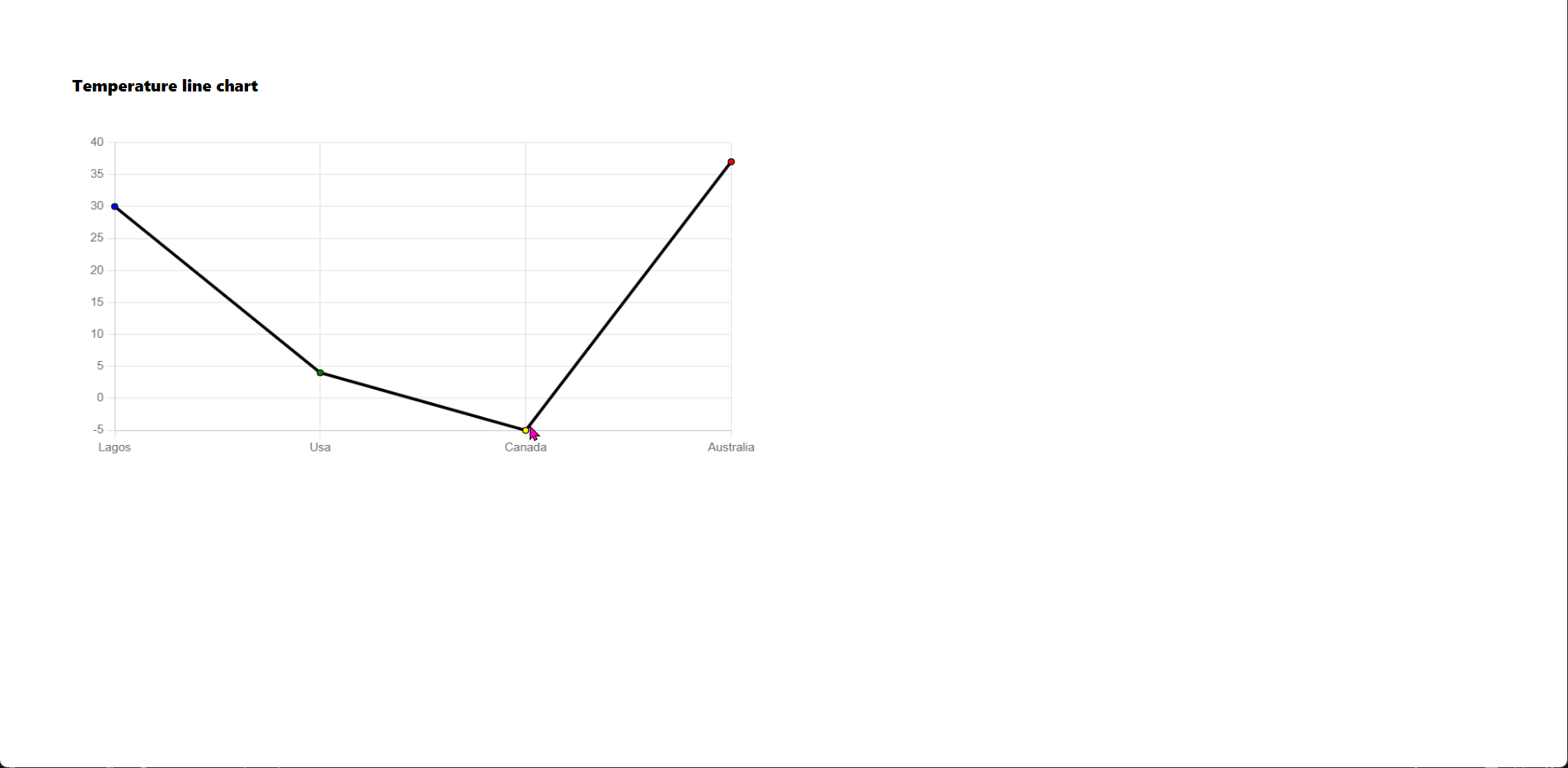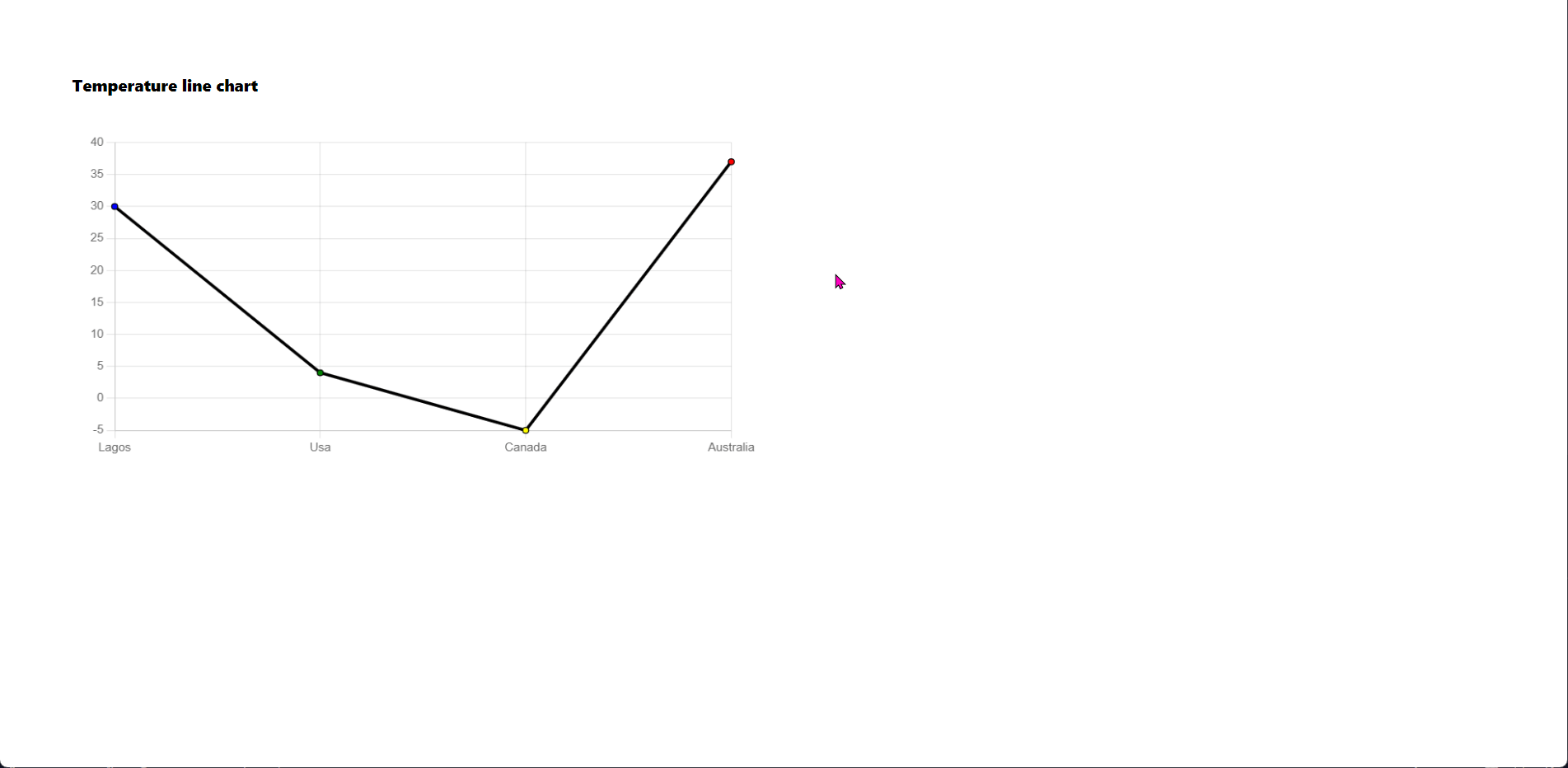
## Conclusion
Chart.js is an effective tool for creating various charts in React applications. However, we were only able to cover the most commonly used ones in this article.
The react-chartjs-2 package makes it easy to implement Chart.js charts in React applications by providing a set of React components that can be used to compose charts with just a few lines of code, making the process of creating charts in React applications very simple and easy.
Check out a[ project ](https://react-barchart-dashboard.netlify.app)I created using char.js
## Resource
You can find more information about Chart.js by reading through its [official documentation](https://www.chartjs.org/docs/latest/). It covers the library's features, usage, and more.
Thanks for reading💖 | ijay |
1,329,739 | A story about a site created with Blazor to add a Discord bot for AI image generation (Stable Diffusion, etc.) | TL;DR Created a website with Blazor Server. Created a Bot for Discord that uses AI to... | 0 | 2023-01-17T11:18:20 | https://dev.to/kawa0x0a/a-story-about-a-site-created-with-blazor-to-add-a-discord-bot-for-ai-image-generation-stable-diffusion-etc-b1g | c, blazor, ai, stablediffusion | ---
title: A story about a site created with Blazor to add a Discord bot for AI image generation (Stable Diffusion, etc.)
published: true
description:
tags: C#,Blazor,AI,StableDiffusion
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-01-15 08:48 +0000
---
## TL;DR
* Created a website with Blazor Server.
* Created a Bot for Discord that uses AI to generate images.
* Created website : https://stablediffusiondiscordbot.azurewebsites.net/
* Repository : https://github.com/kawa0x0A/StableDiffusionDiscordBot
## Websites created with Blazor
* Made by Blazor Server
* Hosting is Azure and payment service is Stripe
* What I learned : How to write authentication process for login, Website design, How to use Bootstrap
* Impressions : It's great to be able to create websites in C#. And I found that I can't live without Visual Studio's completion.
* Issues : It takes a little bit of time to load the site for the first time.
## Discord Bot
* Made in Python
* The way to make it is probably the same as the way to make a general bot.
* AI models available are Stable Diffusion, Stable Diffusion 2, Waifu Diffusion, and Anything models.
* I personally don't like programming languages other than C#, so I'll spare you the code.
* Problem : Bot sometimes doesn't work because of Gradient Paperspace (I considered GCP, but it's too expensive to keep it running 24/7 ......)
## Technical notes (list of setbacks)
* I started with Blazor WebAssembly, but changed to Blazor Server in the middle of the project.
* Reason : Because the information that I want to keep secret such as API key of Stripe cannot be kept secret, I changed from Blazor WebAssembly to Blazor Server.
Translated with www.DeepL.com/Translator (free version) | kawa0x0a |
1,329,953 | Navigating the internet using only the screen reader | I recently tried doing tasks on the internet without using the mouse (or trackpad). Now I'm going to... | 21,432 | 2023-01-15T15:08:15 | https://blog.nicm42.co.uk/navigating-the-internet-using-only-the-screen-reader | a11y | ---
title: Navigating the internet using only the screen reader
published: true
date: 2023-01-15 15:06:54 UTC
tags: a11y
canonical_url: https://blog.nicm42.co.uk/navigating-the-internet-using-only-the-screen-reader
series: a11y navigation
---
I recently tried doing tasks on the internet without using the mouse (or trackpad). Now I'm going to do the same using a screen reader (the one on my computer is Orca).
To stop me peeking, I'm sticking a piece of paper to the top of my screen.
## Task 1: Gmail
**Find a starred email in Gmail, go to the link within it, read the article in the link, then unstar the email and return to the inbox**
This was made easier by already having done this using only the keyboard and remembering the shortcuts. I just used the shortcut to get the starred emails, pressed j until I found the one I wanted, then tab until I found the link within it I wanted. Although of course this was made slower by waiting for Orca to read things out.
I did press ? to get the keyboard shortcuts, to test that out. Waiting for Orca to read everything rather than just scanning it and picking out what I needed is a lot slower. And I was a bit confused about what it was saying - possibly because I have it set to read things a bit too fast.
But on the whole it was pretty painless.
## Task 2: YouTube
**Find my watch later list, watch a video on it that's not last on the list, look at the comments, then remove it from the watch later list**
This was hard work. I'm not as familiar with the site and I usually have my watch later list bookmarked, so I just go to that.
I initially skipped navigation and after a lot of tabbing realised the navigation was the bit I needed... I ended up refreshing the page, tabbing some more and eventually getting to my watch later list. And then it got weird because it told me it had pressed enter and I thought "does that mean I'm now on the watch later page?". I ended up looking to find that I was. But I was really expecting it to tell me that.
And eventually made my way to the videos. It read out the title of the video and who did it, but it would have been nice if it had read out the time.
It also keeps talking as the video auto-plays...
I took the paper down and turned Orca off while I watched the video. Once it got to the end I put it all back and pressed a tab a lot to read the comments. Although they were weird - I had to look and see what was going on. It was reading out a lot of "parens", which I guessed meant brackets. It was a coding video, so it's understandable that people might have them in their comments. But it turned out that some of them were smilies! It's really not as obvious that "colon right parens" is a smiley face.
Removing the video from the watch list was fine, although it wasn't entirely obvious that's what had happened.
## **Task 3: BBC iPlayer**
**Go to the BBC iPlayer, search for Click and play the most recent episode.**
There was a lot of tabbing here - but looking back when I last did this task I said the same thing. I had just forgotten how bad it was. However, I noticed that this site read a lot of things out every time a page loaded, which the other two didn't. And it told me about whether every link had been visited.
When I got the video listing it read out the description, told me how long it was and that I'd already watched it. Which is really useful information. I don't know if it was just coincidence, but the video didn't make a whole lot of noise while Orca was still speaking.
## **Conclusion**
I expecting Gmail to be easy since I was already familiar with it, and it was. But what surprised me was the BBC website. I hated it last time due to all the tabbing. There was still a lot of tabbing, but I felt like I knew more about what was going on than with YouTube (which also had quite a lot of tabbing). The BBC website just had the best experience and I wasn't trying to picture the site in my head as I tabbed. | nicm42 |
1,329,969 | Hi! I'm new here... | System.out.printnl("Hello, World!"); Hey, I'm new here and I would like to know what this social... | 0 | 2023-01-15T16:05:55 | https://dev.to/devsantiag/hi-im-new-here-1i7 | System.out.printnl("Hello, World!");
Hey, I'm new here and I would like to know what this social network is (laughs)I'm new here and I would like to know what this social network is (laughs) | devsantiag |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.