
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,330,000 | Understanding gRPC Concepts, Use Cases & Best Practices | Original blog post As we progress with application development, among various things, there is one... | 0 | 2023-01-15T17:03:40 | https://dev.to/hiteshrepo/understanding-grpc-concepts-use-cases-best-practices-2npk | grpc, go, communication, framework | [Original blog post](https://www.infracloud.io/blogs/understanding-grpc-concepts-best-practices/)
As we progress with application development, among various things, there is one primary thing we are less worried about i.e. computing power. With the advent of cloud providers, we are less worried about managing data centers. Everything is available within seconds, and that too on-demand. This leads
With the increase in the size of data, we have activities like serializing, deserializing and transportation costs added to it. Though we are not worried about computing resources, the latency becomes an overhead. We need to cut down on transportation. A lot of messaging protocols have been developed in the past to address this. SOAP was bulky, and REST is a trimmed-down version, but we need an even more efficient framework. That’s where Remote Procedure Calls (RPC) comes in.
In this blog post, we will understand what RPC is and the various implementations of RPC with a focus on gRPC, which is Google's implementation of RPC. We'll also compare REST with RPC and understand various aspects of gRPC, including security, tooling, and much more. So, let's get started!
## What is RPC?
RPC stands for ‘Remote Procedure Calls’. The definition is in the name itself. Procedure calls simply mean function/method calls; it's the ‘Remote’ word that makes all the difference. What if we can make a function call remotely?
Simply put, if a function resides on a ‘server’ and in order to be invoked from the ‘client’ side, could we make it as simple as a method/function call? Essentially what an RPC does is it gives the ‘illusion’ to the client that it is invoking a local method, but in reality, it invokes a method in a remote machine that abstracts the network layer tasks. The beauty of this is that the contract is kept very strict and transparent (we will discuss this later in the article).
Steps involved in an RPC call:
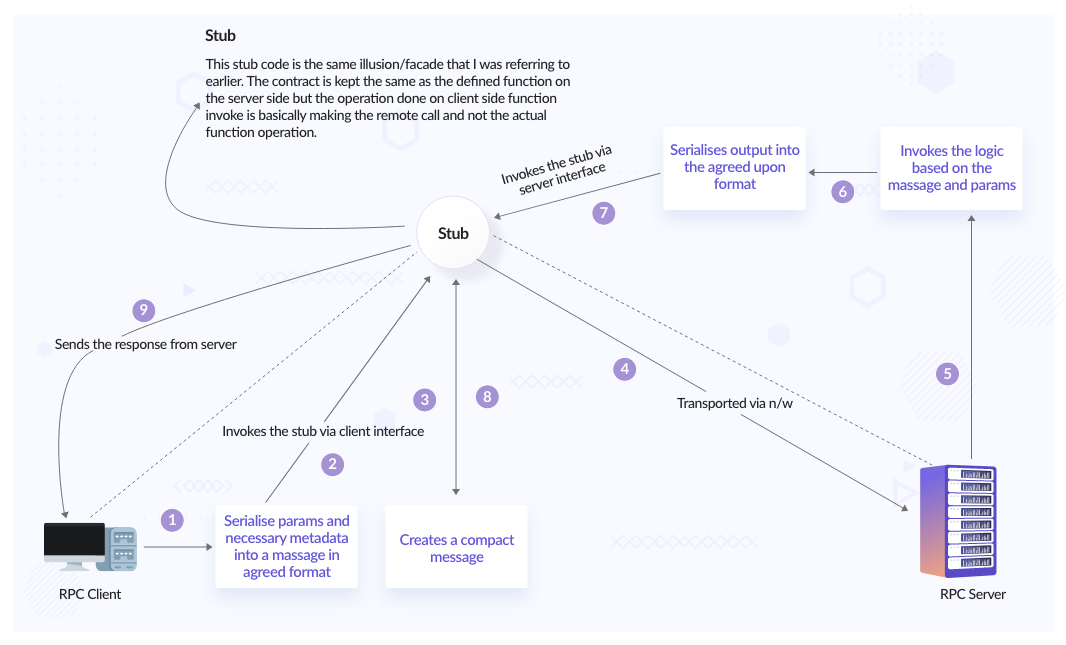
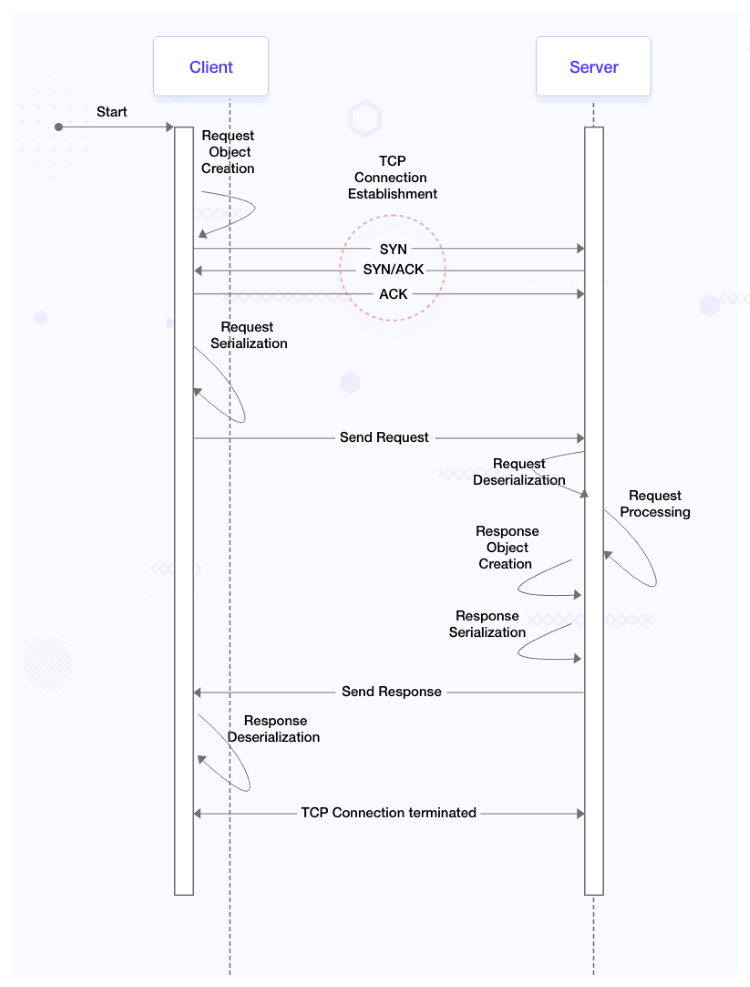
This is how a typical REST process looks like:
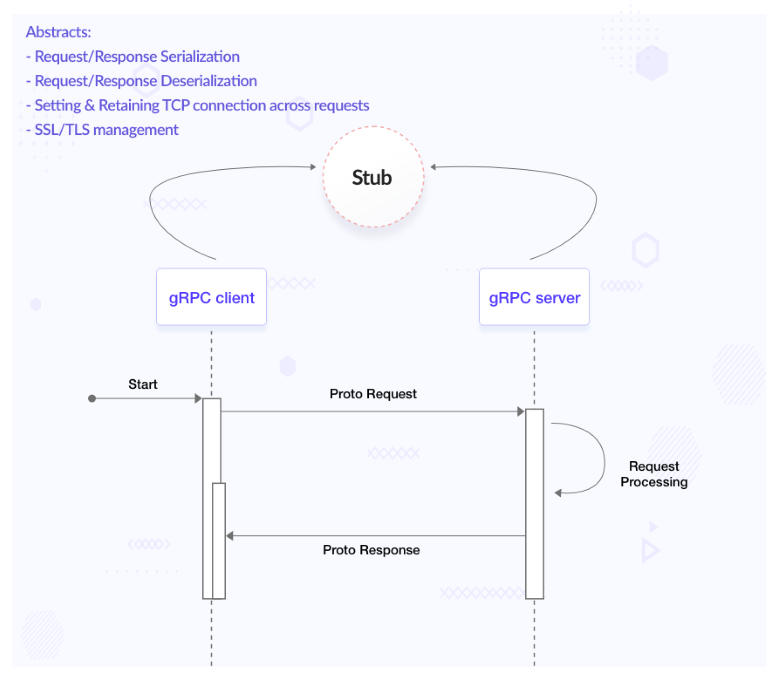
RPCs boil down the process to below:
This is because all the complications associated with making a request are now abstracted from us (we will discuss this in code-generation). All we need to worry about is the data and logic.
## gRPC - what, why, and how of it
So far, we discussed RPC, which essentially means making function/method calls remotely. Thereby giving us the benefits like ‘[strict contract definition](#clean-contract)’, ‘abstracting transmission and conversion of data’, ‘reducing latency’, etc. Which we will be discussing as we proceed with this post. What we would really like to dive deep into is one of the implementations of RPC. RPC is a concept, and gRPC is a framework based on it.
There are various implementations of RPCs. They are:
- gRPC (Google)
- Thrift (Facebook)
- Finagle (Twitter)
Google’s version of RPC is referred to as gRPC which was introduced in 2015 and has been gaining traction since. It is one of the most chosen communication mechanisms in a microservice architecture.
gRPC uses [protocol buffers](https://developers.google.com/protocol-buffers) (it is an open source message format) as the default method of communication between client and server. Also, gRPC uses HTTP/ 2 as the default protocol.
There are again four types of communication that gRPC supports:
- [Unary](https://grpc.io/docs/what-is-grpc/core-concepts/#unary-rpc) (typical client and server communication)
- [Client side streaming](https://grpc.io/docs/what-is-grpc/core-concepts/#client-streaming-rpc)
- [Server side streaming](https://grpc.io/docs/what-is-grpc/core-concepts/#server-streaming-rpc)
- [Bidirectional streaming](https://grpc.io/docs/what-is-grpc/core-concepts/#bidirectional-streaming-rpc)
Coming on to the message format that is being used widely in gRPC - protocol buffers a.k.a protobufs. A protobuf message looks something like below:
```protobuf
message Person {
string name = 1;
string id = 2;
string email = 3;
}
```
Here, `Person` is the message we would like to transfer (as a part of request/response), which has fields `name` (string type), `id` (string type) and `email` (string type). The numbers 1, 2, 3 represent the position of the data (as in `name`, `id`, and `has_ponycopter`) when it is serialized to binary format.
Once the developer has created the Protocol Buffer file(s) with all messages, we can use a ‘protocol buffer compiler’ (a binary) to compile the written protocol buffer file, which will generate all the utility classes and methods which are needed to work with the message. For example, as shown in the above `Person` message, depending on the chosen language, the [generated code will look like this](https://github.com/infracloudio/grpc-blog/blob/master/proto/example/person.pb.go).
### How do we define services?
We need to define services that use the above messages to be sent/received.
After writing the necessary request and response message types, the next step is to write the service itself.
gRPC services are also defined in Protocol Buffers and they use the ‘service’ and ‘rpc’ keywords to define a service.
Take a look at the content of the below proto file:
```protobuf
message HelloRequest {
string name = 1;
string description = 2;
int32 id = 3;
}
message HelloResponse {
string processedMessage = 1;
}
service HelloService {
rpc SayHello (HelloRequest) returns (HelloResponse);
}
```
Here, `HelloRequest` and `HelloResponse` are the messages and `HelloService` is exposing one unary RPC called `SayHello` which takes `HelloRequest` as input and gives `HelloResponse` as output.
As mentioned, `HelloService` at the moment contains a single unary RPC. But it could contain more than one RPC. Also, it can contain a variety of RPCs (unary/client-side streaming/server-side streaming/Bidirectional).
In order to define a streaming RPC, all you have to do is prefix ‘stream’ before the request/response argument, [Streaming RPCs proto definitions, and generated code](https://github.com/infracloudio/grpc-blog/tree/master/proto/streaming).
In the above code-base link:
- [streaming.proto](https://github.com/infracloudio/grpc-blog/blob/master/proto/streaming/streaming.proto): this file is user defined
- [streaming.pb.go](https://github.com/infracloudio/grpc-blog/blob/master/proto/streaming/streaming.pb.go) & [streaming_grpc.pb.go](https://github.com/infracloudio/grpc-blog/blob/master/proto/streaming/streaming_grpc.pb.go): these files are auto-generated on running [proto compiler command](https://github.com/infracloudio/grpc-blog/blob/883e25e207b8e7d3fdf8384b98fb0828a982d5b3/proto/Taskfile.yaml#L18) command.
## gRPC vs REST
We did talk about gRPC a fair bit. Also, there was a mention of REST. What we missed was discussing the difference. I mean when we have a well-established, lightweight communication framework in the form of REST, why was there a need to look for another communication framework? Let us understand more about gRPC with respect to REST along with the pros and cons of each of it.
In order to compare what we require are parameters. So let’s break down the comparison into the below parameters:
- **Message format: protocol buffers vs JSON**
- Serialization and deserialization speed is way better in the case of protocol buffers across all data sizes (small/medium/large). [Benchmark-Test-Results](https://github.com/infracloudio/grpc-blog/blob/master/proto/test.out).
- Post serialization JSON is human readable while protobufs (in binary format) are not. Not sure if this is a disadvantage or not because sometimes you would like to see the request details in the Google developers tool or Kafka topics and in the case of protobufs you can't make out anything.
- **Communication protocol: HTTP 1.1 vs HTTP/2**
- REST is based on HTTP 1.1; communication between a REST client and server would require an established TCP connection which in turn has a 3-way handshake involved. When we get a response from the server upon sending a request from the client, the TCP connection does not exist after that. A new TCP connection needs to be spun up in order to process another request. This establishment of a TCP connection on each and every request adds up to the latency.
- So gRPC which is based on HTTP 2 has encountered this challenge by having a persistent connection. We must remember that persistent connections in HTTP 2 are different from that in web sockets where a TCP connection is hijacked and the data transfer is unmonitored. In a gRPC connection, once a TCP connection is established, it is reused for several requests. All requests from the same client and server pair are multiplexed onto the same TCP connection.
- **Just worrying about data and logic: Code generation being a first-class citizen**
- Code generation features are native to gRPC via its in-built protoc compiler. With REST APIs, it’s necessary to use a third-party tool such as Swagger to auto-generate the code for API calls in various languages.
- In the case of gRPC, it abstracts the process of marshaling/unmarshalling, setting up a connection, and sending/receiving messages; what we all need to worry about is the data that we want to send or receive and the logic.
- **Transmission speed**
- Since the binary format is much lighter than JSON format, the transmission speed in the case of gRPC is 7 to 10 times faster than that of REST.
|**Feature**|**REST**|**gRPC**|
|:---:|:---:|:---:|
|Communication Protocol|Follows request-response model. It can work with either HTTP version but is typically used with HTTP 1.1|Follows client-response model and is based on HTTP 2. Some servers have workarounds to make it work with HTTP 1.1 (via rest gateways)|
|Browser support|Works everywhere|Limited support. Need to use [gRPC-Web](https://github.com/grpc/grpc-web), which is an extension for the web and is based on HTTP 1.1|
|Payload data structure|Mostly uses JSON and XML-based payloads to transmit data|Uses protocol buffers by default to transmit payloads|
|Code generation|Need to use third-party tools like Swagger to generate client code|gRPC has native support for code generation for various [languages](https://grpc.io/docs/languages/)|
|Request caching|Easy to cache requests on the client and server sides. Most clients/servers natively support it (for example via cookies)|Does not support request/response caching by default|
Again for the time being gRPC does not have browser support since most of the UI frameworks still have limited or no support for gRPC. Although gRPC is an automatic choice in most cases when it comes to internal microservices communication, it is not the same for external communication that requires UI integration.
Now that we have done a comparison of both the frameworks: gRPC and REST. Which one to use and when?
- In a microservice architecture with multiple lightweight microservices, where the efficiency of data transmission is paramount, gRPC would be an ideal choice.
- If code generation with multiple language support is a requirement, gRPC should be the go-to framework.
- With gRPC’s streaming capabilities, real-time apps like trading or OTT would benefit from it rather than polling using REST.
- If bandwidth is a constraint, gRPC would provide much lower latency and throughput.
- If quicker development and high-speed iteration is a requirement, REST should be a go-to option.
## gRPC Concepts
### Load balancing
Even though the persistent connection solves the latency issue, it props up another challenge in the form of load balancing. Since gRPC (or HTTP2) creates persistent connections, even with the presence of a load balancer, the client forms a persistent connection with the server which is behind the load balancer. This is analogous to a sticky session.
We can understand the challenge via a demo & the code and deployment files for the same are present [in this repository](https://github.com/infracloudio/grpc-blog/tree/master/grpc-loadbalancing).
From the above demo code base, we can find out that the onus of load balancing falls on the client. This leads to the fact that the advantage of gRPC i.e. persistent connection does not exist with this change. But gRPC can still be used for its other benefits.
Read more about [load balancing in gRPC](https://grpc.io/blog/grpc-load-balancing/).
In the above demo code-base, only a ‘round-robin’ load balancing strategy is used/showcased. But gRPC does support another client-based load balancing strategy OOB called ‘pick-first’.
Furthermore, [custom client-side](https://learn.microsoft.com/en-us/aspnet/core/grpc/loadbalancing?view=aspnetcore-6.0) load balancing is also supported.
### Clean contract
In REST, the contract between the client and server is documented but not strict. If we go back even further to SOAP, contracts were exposed via wsdl files. In REST we expose contracts via Swagger and other provisions. But the strictness is lacking, we cannot for sure know if the contract has changed on the server's side while the client code is being developed.
With gRPC, the contract is shared with both the client and server either directly via proto files or generated stub from proto files. This is like making a function call but remotely. And since we are making a function call we exactly know what we need to send and what we are expecting as a response. The complexity of making connections with the client, taking care of security, serialization-deserialization, etc are abstracted. All we care about is the data.
Lets consider the code base for [Greet App](https://github.com/infracloudio/grpc-blog/tree/master/greet_app).
The client uses the [stub](https://github.com/infracloudio/grpc-blog/blob/883e25e207b8e7d3fdf8384b98fb0828a982d5b3/greet_app/internal/app/client/client.go#L6) (generated code from proto file) to create a client object and invoke remote function call:
```go
import greetpb "github.com/infracloudio/grpc-blog/greet_app/internal/pkg/proto"
cc, err := grpc.Dial("<server-address>", opts)
if err != nil {
log.Fatalf("could not connect: %v", err)
}
c := greetpb.NewGreetServiceClient(cc)
res, err := c.Greet(context.Background(), req)
if err != nil {
log.Fatalf("error while calling greet rpc : %v", err)
}
```
Similarly, the server too uses the same [stub](https://github.com/infracloudio/grpc-blog/blob/883e25e207b8e7d3fdf8384b98fb0828a982d5b3/greet_app/internal/app/server/server.go#L6) (generated code from proto file) to receive request object and create response object:
```go
import greetpb "github.com/infracloudio/grpc-blog/greet_app/internal/pkg/proto"
func (*server) Greet(_ context.Context, req *greetpb.GreetingRequest) (*greetpb.GreetingResponse, error) {
// do something with 'req'
return &greetpb.GreetingResponse{
Result: result,
}, nil
}
```
Both of them are using the same stub generated from the proto file [greet.proto](https://github.com/infracloudio/grpc-blog/blob/master/greet_app/internal/pkg/proto/greet.proto).
And the stub was generated using ‘proto’ compiler and the command to generate is [this](https://github.com/infracloudio/grpc-blog/blob/883e25e207b8e7d3fdf8384b98fb0828a982d5b3/greet_app/Taskfile.yaml#L10).
```bash
protoc --go_out=. --go_opt=paths=source_relative --go-grpc_out=. --go-grpc_opt=paths=source_relative internal/pkg/proto/*.proto
```
### Security
gRPC authentication and authorization works on two levels:
- Call-level authentication/authorization is usually handled through tokens that are applied in metadata when the call is made. [Token based authentication example](https://github.com/infracloudio/grpc-blog/compare/master...secure_token).
- Channel-level authentication uses a client certificate that's applied at the connection level. It can also include call-level authentication/authorization credentials to be applied to every call on the channel automatically. [Certificate based authentication example](https://github.com/infracloudio/grpc-blog/compare/secure_grpc).
Either or both of these mechanisms can be used to help secure services.
### Middlewares
In REST, we use middlewares for various purposes like:
- Rate limiting
- Pre/Post request/response validation
- Address security threats
We can achieve the same with gRPC as well. The verbiage is different in gRPC, they are referred as ‘interceptors’ but they do similar activities.
In [the middlewares branch](https://github.com/infracloudio/grpc-blog/tree/middlewares/greet_app/internal/app) of the `greet_app` code base, we have integrated logger and Prometheus interceptors.
Look how the interceptors are configured to use Prometheus and logging packages in [middleware.go](https://github.com/infracloudio/grpc-blog/blob/7700323e1e488eb8777a06ca762e4d29602d2424/greet_app/internal/pkg/middleware/middleware.go#L29).
```go
// add middleware
AddLogging(&zap.Logger{}, &uInterceptors, &sInterceptors)
AddPrometheus(&uInterceptors, &sInterceptors)
```
But we can integrate other packages to interceptors for purposes like preventing panic and recovery (to handle exceptions), tracing, even authentication, etc.
[Supported middlewares by gRPC framework](https://github.com/grpc-ecosystem/go-grpc-middleware).
### Packaging, versioning and code practices of proto files
#### Packaging
Let's follow [the packaging branch](https://github.com/infracloudio/grpc-blog/blob/packaging/proto/packaging/processor.proto).
First start with `Taskfile.yaml`, the task `gen-pkg` says `protoc --proto_path=packaging packaging/*.proto --go_out=packaging`. This means `protoc` (the compiler) will convert all files in `packaging/*.proto` into its equivalent Go files as denoted by flag `--go_out=packaging` in the `packaging` directory itself.
Secondly in the ‘processor.proto’ file, 2 messages have been defined namely ‘CPU’ and ‘GPU’. While CPU is a simple message with 3 fields of in-built data types, GPU message on the other hand has an additional custom data type called ‘Memory’ along with in-built data types same as CPU message. ‘Memory’ is a separate message and is defined in a different file altogether.
So how do you use the ‘Memory’ message in the ‘processor.proto’ file? By using [import](https://github.com/infracloudio/grpc-blog/blob/436d84358868f463ea7929eb14120eb80801fde1/proto/packaging/processor.proto#L6).
```protobuf
syntax = "proto3";
package laptop_pkg;
option go_package = "/pb";
import "memory.proto";
message CPU {
string brand = 1;
string name = 2;
uint32 cores = 3;
}
message GPU {
string brand = 1;
string name = 2;
uint32 cores = 3;
Memory memory = 4;
}
```
```protobuf
syntax = "proto3";
package laptop_pkg;
option go_package = "/pb";
message Memory {
enum Unit {
UNKNOWN = 0;
BIT = 1;
BYTE = 2;
KILOBYTE = 3;
MEGABYTE = 4;
GIGABYTE = 5;
}
uint64 value = 1;
Unit unit = 2;
}
```
Even if you try to generate a proto file by running task `gen-pkg` after mentioning import, it will throw an error. As by default `protoc` assumes both files `memory.proto` and `processor.proto` to be in different packages. So you need to mention the same package name in both files.
The optional `go_package` indicates the compiler to create a package name as `pb` for Go files. If any other language-d proto files were to be created, the package name would be `laptop_pkg`.
#### Versioning
There can be two kinds of changes in gRPC breaking and non-breaking changes:
- Non-breaking changes include adding a new service, adding a new method to a service, adding a field to request or response proto, and adding a value to enum
- Breaking changes like renaming a field, changing field data type, field number, renaming or removing a package, service or methods require versioning of services
- In order to distinguish between same name messages or services across proto files, [optional packaging](https://developers.google.com/protocol-buffers/docs/proto#packages) can be implemented.
#### Code practices
- Request message must suffix with request `CreateUserRequest`.
- Response message must suffix with request `CreateUserResponse`.
- In case the response message is empty, you can either use an empty object `CreateUserResponse` or use the `google.protobuf.Empty`.
- Package name must make sense and must be versioned, for example: package `com.ic.internal_api.service1.v1`.
### Tooling
gRPC ecosystem supports an array of tools to make life easier in non-developmental tasks like documentation, rest gateway for a gRPC server, integrating custom validators, linting, etc. Here are some tools that can help us achieve the same:
- [protoc-gen-grpc-gateway](https://github.com/grpc-ecosystem/grpc-gateway) — plugin for creating a gRPC REST API gateway. It allows gRPC endpoints as REST API endpoints and performs the translation from JSON to proto. Basically, you define a gRPC service with some custom annotations and it makes those gRPC methods accessible via REST using JSON requests.
- [protoc-gen-swagger](https://github.com/grpc-ecosystem/grpc-gateway) — a companion plugin for grpc-gateway. It is able to generate swagger.json based on the custom annotations required for gRPC gateway. You can then import that file into your REST client of choice (such as [Postman](https://www.postman.com/)) and perform REST API calls to the methods you exposed.
- [protoc-gen-grpc-web](https://github.com/grpc/grpc-web) — a plugin that allows our front end to communicate with the backend using gRPC calls. A separate blog post on this coming up in the future.
- [protoc-gen-go-validators](https://github.com/mwitkow/go-proto-validators) — a plugin that allows to define validation rules for proto message fields. It generates a `Validate() error` method for proto messages you can call in Go to validate if the message matches your predefined expectations.
- [protolint](https://github.com/yoheimuta/protolint) - a plugin to add lint rules to proto files.
## Testing using Postman
Unlike testing REST APIs with Postman or any equivalent tools like Insomnia, it is not quite comfortable to test gRPC services.
**Note:** gRPC services can also be tested from CLI using tools like [evans-cli](https://github.com/ktr0731/evans). But for that reflection needs (if not enabled the path to the proto file is [required](https://github.com/infracloudio/grpc-blog/blob/ed390485e12ce6b63fd9fd53f867cf6e818a5407/greet_app/Taskfile.yaml#L82)) to be enabled in gRPC servers. This [compare link](https://github.com/infracloudio/grpc-blog/compare/evans) shows the way to enable reflection and how to enter into evans-cli repl mode. Post entering repl mode of evans-cli, gRPC services can be tested from CLI itself and the process is described in [evans-cli GitHub page](https://github.com/ktr0731/evans).
Postman has a [beta version](https://blog.postman.com/postman-now-supports-grpc/) of testing gRPC services.
Here are the steps of how you can do it:
1. Open Postman, goto ‘APIs’ in the left sidebar and click on ‘+’ sign to create new api. In the popup window, enter ‘Name’, ‘Version’, and ‘Schema Details’ and click on create [unless you need to import from some sources like GitHub, Bitbucket].
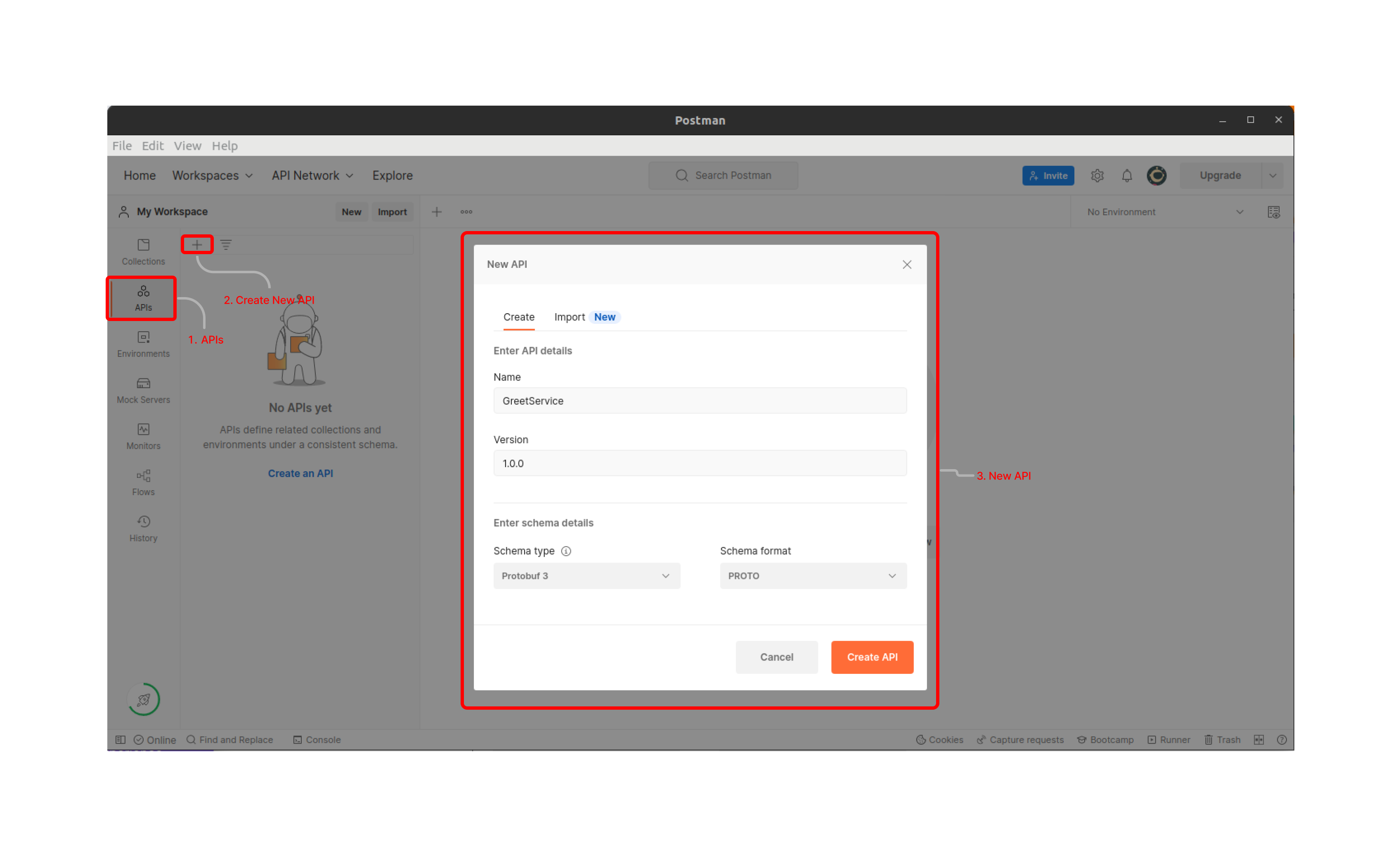
2. Once Your API gets created then go to definition and enter your proto contract.
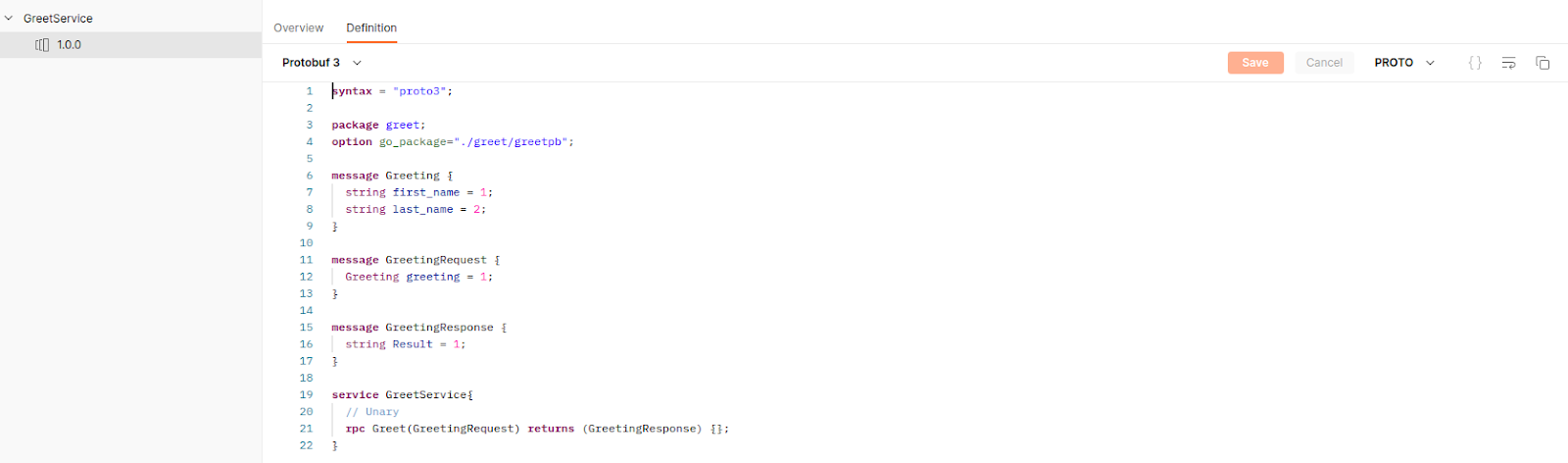
3. Remember importing does not work here, so it would be better to keep all dependent protos at one place.
4. The above steps will help to retain contracts for future use.
5. Then click on ‘New’ and select ‘gRPC request', enter the URI and choose the proto from the list of saved ‘APIs’ and finally enter your request message and hit ‘Invoke’
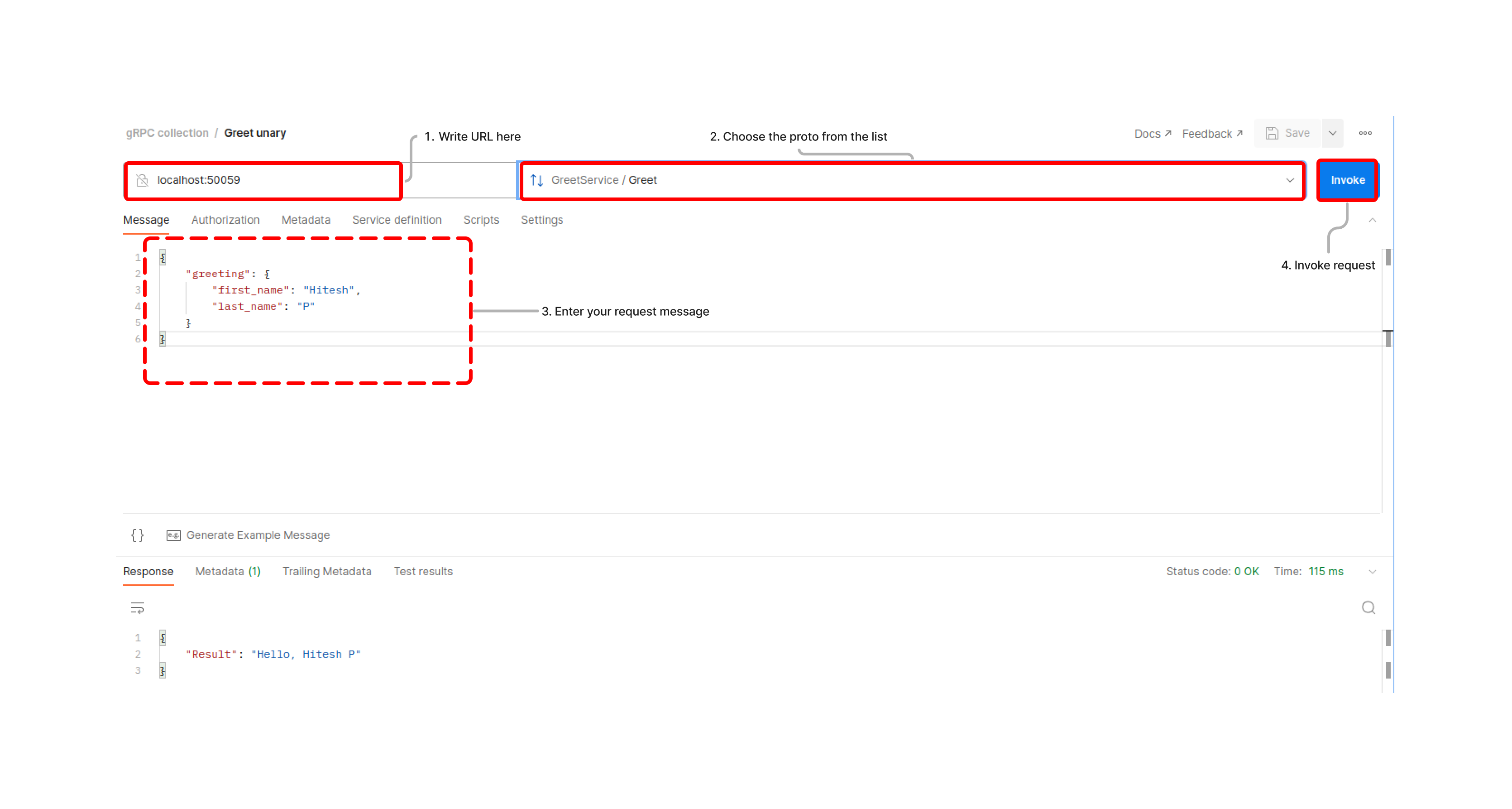
In the above steps we figured out the process to test our gRPC APIs via Postman. The process to test gRPC endpoints is different from that of REST endpoints using Postman. One thing to remember is that while creating and saving proto contract as in 5, all proto message and service definitions need to be in the same place. As there is no provision to access proto messages across versions in Postman.
## Conclusion
In this post, we developed an idea about RPC, drew parallels with REST as well as discussed their differences, then we went on to discuss an implementation of RPC i.e. gRPC developed by Google.
gRPC as a framework can be crucial, especially for microservice-based architecture for internal communication. It can be used for external communication as well but will require a REST gateway. gRPC is a must for streaming and real-time apps.
The way Go is proving itself as a server-side scripting language, gRPC is proving itself as a de-facto communication framework.
That's it folks! Feel free to reach out to [Hitesh](https://www.linkedin.com/in/hitesh-pattanayak-52290b160/)/[Pranoy](https://www.linkedin.com/in/pranoy-kundu-74b179167) for any feedback and thoughts on this topic.
Looking for help with building your DevOps strategy or want to outsource DevOps to the experts? Learn why so many startups & enterprises consider us as one of the [best DevOps consulting & services companies](https://www.infracloud.io/devops-consulting-services/).
**Further reads**
- [gRPC official documentation](https://grpc.io/docs/)
- [Protobuff golang documentation](https://developers.google.com/protocol-buffers/docs/gotutorial)
- [gRPC ecosystem](https://github.com/grpc-ecosystem)
- [REST vs gRPC](https://www.baeldung.com/rest-vs-grpc)
- [RPC concepts](https://www.ibm.com/docs/en/aix/7.1?topic=concepts-remote-procedure-call) | hiteshrepo |
1,330,079 | Redux Vs Redux Toolkit | Difference Between Redux & Redux Toolkit. First of all, before knowing the difference... | 0 | 2023-01-15T19:16:03 | https://dev.to/azadulkabir455/redux-vs-redux-toolkit-472b | react, redux, javascript, webdev | ## Difference Between Redux & Redux Toolkit.
First of all, before knowing the difference between redux and redux toolkit we must know what definition two of this is.
**Redux:** Redux is an open-source JavaScript library for managing and centralizing application states.
That means if you have a state(like a variable) or many states that need to many components or modules. So you need to make globalize those states to easily access them. Redux does this work for us.
**Redux Toolkit:** Redux Toolkit is a set of tools that helps simplify Redux development.
In other words, if I configure something through redux, as hard as it will be, but the same task we can perform it easily with the redux toolkit.
## Redux VS Redux Toolkit
Some of the differences are highlighted below
1. In Redux you must configure Devtools but in the Redux toolkit, you don't have to configure. Because it already has.
2. In Redux for asynchronous performance you need to add Redux Thunk, But in the Redux toolkit, it's already built-in.
3. Redux requires too much boilerplate code but the Redux toolkit doesn't.
## What Should I learn?
In my preference, you should learn the Redux toolkit. It also depends on other requirements.
But before learning the Redux toolkit you must learn Redux basics. Because, you have to crystal clear concept about **Action**, **Reducer**, and **Store **and their work procedure. After that, you can jump to the Redux toolkit.
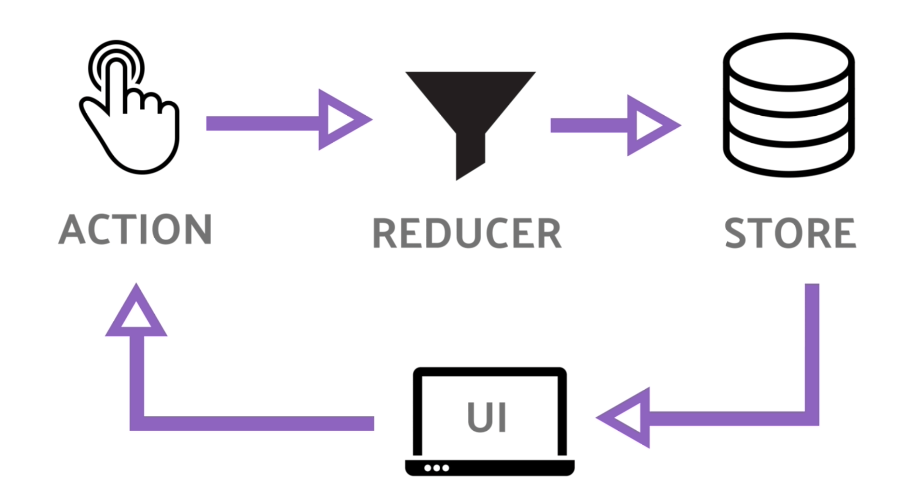
## React Redux Toolkit Roadmap.
Their three things that you have to learn to use redux in your react app and the learning sequence is below. (Top to bottom)
1. Redux (Basic must).
2. React Redux. After that
3. Redux Toolkit.
If you are a beginner you can follow this tutorial playlist. I hope it helps you a lot.
[Tutorial Link](https://www.youtube.com/watch?v=0awA5Uw6SJE&list=PLC3y8-rFHvwiaOAuTtVXittwybYIorRB3) | azadulkabir455 |
1,330,209 | Building a Resilient Static Website on AWS | Do you remember the AWS outage in December 2021? I do. My client at work had a P1 incident. Many of... | 0 | 2023-01-15T23:58:29 | https://jasonbutz.info/2023/01/website-cdn/?utm_source=dev.to | aws, cloudfront, s3, resiliency |
Do you remember the [AWS outage in December 2021](https://aws.amazon.com/message/12721/)? I do. My client at work had a P1 incident. Many of their applications were unresponsive or returned errors that weren't user-friendly. It drove home the importance of fault-tolerant redundant architectures when using a cloud provider. If my client's application had been built to be redundant across regions and not just availability zones the application could have survived the outage with limited impact.
At the time of the outage this website was hosted on Netlify, so I wasn't affected by the outage, but it got me thinking about what it would take to deploy the site to AWS in a fault-tolerant and redundant configuration. "How difficult was it to host a static site on AWS with a multi-region configuration?" Turns out, it isn't that difficult. The tricky part was deploying everything with the [AWS CDK].
I knew I needed to use Amazon CloudFront for a CDN to deliver the content. Exposing an S3 bucket website can be more expensive, and caching is a beneficial feature. If you're interested in the price difference, I've put together an [estimate]. I hadn't used the feature before, but CloudFront's [Origin Groups] turned out to be a key part of creating the redundancy I wanted. To have two origins, I knew I would need two S3 buckets in different regions. To save on trying to upload to both placed, I knew I could replicate objects from one bucket to the other.
<figure style="text-align: center">
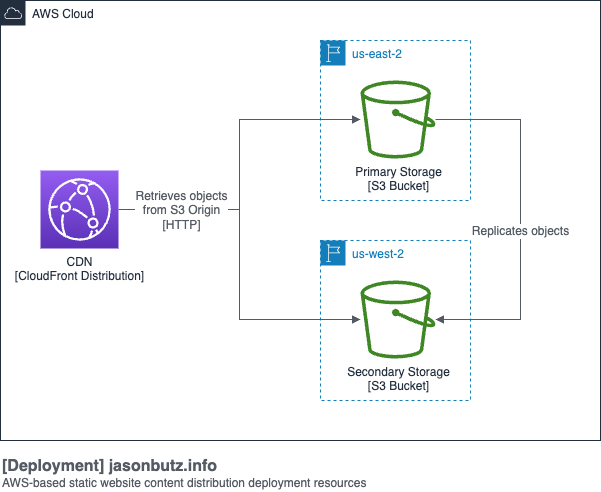
</figure>
Figuring out how to deploy this architecture using the CDK took some experimentation, the architecture builds on itself which means you need to consider the dependencies. In the end, I have one stack for the CloudFront distribution, one stack for the primary S3 bucket, and one stack for the secondary S3 bucket. The trick is they are deployed in the opposite of that order. First, the secondary bucket gets deployed, fulfilling a dependency for the primary bucket and enabling replication to be configured. Those two buckets being deployed allows the distribution to be created and to point to both buckets.
To reduce duplication I was able to use inheritance for the primary bucket's stack. It inherits from the secondary bucket's stack and layers on the bucket replication.
Here is an example of what my stack looks like to create the S3 bucket and prepare it for replication and use with CloudFront. Versioning is required for replication, but I don't want to have useless object versions building up, so I provide a lifecycle rule for cleanup.
```typescript
import { Duration, RemovalPolicy, Stack, StackProps } from 'aws-cdk-lib';
import {
AccountRootPrincipal,
Effect,
PolicyStatement,
} from 'aws-cdk-lib/aws-iam';
import { Bucket, IBucket } from 'aws-cdk-lib/aws-s3';
import { Construct } from 'constructs';
export type CommonStackProps = StackProps & {
resourceKey: string;
};
export class CommonBucketStack extends Stack {
public readonly bucket: IBucket;
constructor(scope: Construct, id: string, props: CommonStackProps) {
super(scope, id, props);
this.bucket = new Bucket(this, 'bucket', {
bucketName: `YOUR-BUCKET-NAME-${this.region}`,
removalPolicy: RemovalPolicy.RETAIN,
versioned: true,
lifecycleRules: [
{
enabled: true,
noncurrentVersionExpiration: Duration.days(1),
expiredObjectDeleteMarker: true,
abortIncompleteMultipartUploadAfter: Duration.days(1),
},
],
websiteIndexDocument: 'index.html',
websiteErrorDocument: '404.html',
});
this.bucket.addToResourcePolicy(
new PolicyStatement({
effect: Effect.ALLOW,
principals: [new AccountRootPrincipal()],
actions: ['s3:*'],
resources: [this.bucket.bucketArn, this.bucket.arnForObjects('*')],
})
);
this.bucket.grantPublicAccess();
}
}
```
There surprisingly isn't a CDK L2 Construct to help with replication, so you have to make do with the L1 constructs, below is an example of how I accomplished it.
```typescript
import {
Effect,
Policy,
PolicyStatement,
Role,
ServicePrincipal,
} from 'aws-cdk-lib/aws-iam';
import { Bucket, CfnBucket } from 'aws-cdk-lib/aws-s3';
import { Construct } from 'constructs';
import {
CommonBucketStack,
CommonBucketStackProps,
} from './common-bucket-stack';
export type PrimaryStackProps = CommonBucketStackProps & {
secondaryBucketArn: string;
};
export class PrimaryStack extends CommonBucketStack {
constructor(scope: Construct, id: string, props: PrimaryStackProps) {
super(scope, id, props);
const sourceBucket = this.bucket;
const destinationBucket = Bucket.fromBucketArn(
this,
'destination-bucket',
props.secondaryBucketArn
);
const replicationRole = new Role(this, 'bucket-replication-role', {
assumedBy: new ServicePrincipal('s3.amazonaws.com'),
});
replicationRole.attachInlinePolicy(
new Policy(this, 'replication-policy', {
statements: [
new PolicyStatement({
effect: Effect.ALLOW,
actions: [
's3:GetObjectVersionForReplication',
's3:GetObjectVersionAcl',
's3:GetObjectVersionTagging',
],
resources: [sourceBucket.arnForObjects('*')],
}),
new PolicyStatement({
effect: Effect.ALLOW,
actions: ['s3:ListBucket', 's3:GetReplicationConfiguration'],
resources: [sourceBucket.bucketArn],
}),
new PolicyStatement({
effect: Effect.ALLOW,
actions: [
's3:ReplicateObject',
's3:ReplicateDelete',
's3:ReplicateTags',
],
resources: [destinationBucket.arnForObjects('*')],
}),
],
})
);
const cfnBucket = sourceBucket.node.defaultChild as CfnBucket;
cfnBucket.replicationConfiguration = {
role: replicationRole.roleArn,
rules: [
{
destination: {
bucket: destinationBucket.bucketArn,
},
priority: 1,
deleteMarkerReplication: {
status: 'Enabled',
},
filter: {
prefix: '',
},
status: 'Enabled',
},
],
};
}
}
```
Once you have all that sorted out, defining a stack for the CloudFront distribution takes a little trial and error to get the origins and behaviors properly configured but is much easier than everything else.
```typescript
import { Stack, StackProps } from 'aws-cdk-lib';
import {
Certificate,
CertificateValidation,
} from 'aws-cdk-lib/aws-certificatemanager';
import {
AllowedMethods,
Distribution,
OriginProtocolPolicy,
PriceClass,
ViewerProtocolPolicy,
} from 'aws-cdk-lib/aws-cloudfront';
import { HttpOrigin, OriginGroup } from 'aws-cdk-lib/aws-cloudfront-origins';
import { Construct } from 'constructs';
export type CdnStackProps = StackProps & {
primaryBucketWebsite: string;
secondaryBucketWebsite: string;
cnames: string[];
};
export class CdnStack extends Stack {
readonly distribution: Distribution;
constructor(scope: Construct, id: string, props: CdnStackProps) {
super(scope, id, props);
const primaryBucketOrigin = new HttpOrigin(props.primaryBucketWebsite, {
protocolPolicy: OriginProtocolPolicy.HTTP_ONLY,
});
const secondaryBucketOrigin = new HttpOrigin(props.secondaryBucketWebsite, {
protocolPolicy: OriginProtocolPolicy.HTTP_ONLY,
});
const originGroup = new OriginGroup({
primaryOrigin: primaryBucketOrigin,
fallbackOrigin: secondaryBucketOrigin,
fallbackStatusCodes: [400, 403, 416, 500, 502, 503, 504],
});
this.distribution = new Distribution(this, 'cdn', {
enabled: true,
priceClass: PriceClass.PRICE_CLASS_100,
defaultBehavior: {
allowedMethods: AllowedMethods.ALLOW_GET_HEAD,
origin: originGroup,
viewerProtocolPolicy: ViewerProtocolPolicy.REDIRECT_TO_HTTPS,
compress: true,
cachedMethods: AllowedMethods.ALLOW_GET_HEAD,
},
domainNames: props.cnames,
certificate: new Certificate(this, 'Certificate', {
domainName: props.cnames[0],
subjectAlternativeNames: props.cnames.slice(1) || [],
validation: CertificateValidation.fromDns(), // Records must be added manually
}),
defaultRootObject: 'index.html',
errorResponses: [
{
httpStatus: 404,
responseHttpStatus: 404,
responsePagePath: '/404.html',
},
],
});
}
}
```
All of these code snippets are a bit different than what I have in use, where possible I broke things out into their own constructs to help with composing the architecture but they are enough to help give you an idea.
Overall this architecture should be able to withstand regional outages for either bucket. I already have ideas on how to make the architecture even more resilient, but I don't need for them yet. I expect I'll write more about that idea later. I think it has significant potential for improving user experience in some situations.
[AWS CDK]: https://docs.aws.amazon.com/cdk/v2/guide/home.html
[estimate]: https://calculator.aws/#/estimate?id=60863c4c1ab49cb3654f5df861674d16d14a63e7
[Origin Groups]: https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/DownloadDistS3AndCustomOrigins.html#concept_origin_groups
| jbutz |
1,330,391 | Write Clear and Meaningful Git Commit Messages | There are no strict rules for writing commit messages but When working on a project on GitHub, it's... | 0 | 2023-01-16T05:37:16 | https://dev.to/ashishxcode/mastering-the-art-of-writing-effective-github-commit-messages-5d2p | webdev, productivity, github, git | There are no strict rules for writing commit messages but When working on a project on GitHub, it's important to communicate clearly and concisely about the changes you've made. One way to do this is through the use of keywords in your commit messages.
These keywords, or labels, help to indicate the nature of the changes and make it easier for others to understand the context of your contributions.
Here are some common keywords and what they indicate:
FEAT: Use this keyword to indicate that you are committing to a new feature.
`"FEAT: Add new login functionality."`
FIX: Use this keyword to indicate that you are committing a fix for a specific problem or issue.
`"FIX: Fix bug causing crashes on certain devices."`
STYLE: Use this keyword to indicate that you are making changes to the style or formatting of the code, but not its functionality.
`"STYLE: Update indentation in main.js."`
REFACTOR: Use this keyword to indicate that you are making changes to the code that improve its structure or organisation, but do not add new features or fix bugs.
`"REFACTOR: Refactor the code to improve readability."`
TEST: Use this keyword to indicate that you are adding or updating tests for the code.
`"TEST: Add new unit tests for login functionality."`
CHORE: Use this keyword to indicate that you are making changes to the build process or other tasks that are not directly related to the code itself.
`"CHORE: Update dependencies in package.json."`
PERF: Use this keyword to indicate that you are making changes to improve the performance of the code.
`"PERF: Optimize image loading for faster performance."`
CI: Use this keyword to indicate that you are making changes to the continuous integration process.
`"CI: Fix issue with test pipeline on Dashboard CI."`
BUILD: Use this keyword to indicate that you are making changes to the build process.
`"BUILD: Add new script for building the production version of the app."
`
By using these keywords in your commit messages, you can help to make your contributions more clear and more understandable to others. However, it is important to note that these are just suggestions and not all projects use them, it's important to check the project's documentation to see if there are any specific guidelines you should follow.
In summary, clear and concise commit messages are a key aspect of good development practices. Using keywords in your commit messages can help to indicate the nature of the changes you've made, making it easier for others to understand and review your contributions.
My Other Blogs
**[BEM Methodology for CSS - A Guide for Developers](https://dev.to/ashishxcode/bem-methodology-for-css-a-guide-for-developers-34jl)** | ashishxcode |
1,330,396 | QR Code Generator + Download QR as Image | 🙋♂️Hello Friends! 👨💻So I tried building QR code Generator from input link with simple API And... | 0 | 2023-01-18T07:27:20 | https://dev.to/developedbyjk/qr-code-generator-download-qr-as-image-15gg | javascript, qrcodegenerator, api, webdev |
🙋♂️Hello Friends!
👨💻So I tried building QR code Generator from input link with simple [API](https://goqr.me/api/doc/) And added the feature to Download That QR Code & Yeah🥵 faced a lot of bugs dealing with two different APIs but finally Made it🤩
Let me show you how simple it is!😉
(full code below the article)
---
📌**Step 1**
👉 We will need an input to paste our URL and a button to do work with that input
```
<input type="text" id="input"/>
<button onclick="generate()">Generate</button>
```
👉we added generate function that will trigger JavaScript
🤾♂️But we need to show out output so we will create an an image
---
📌***Step 2***
```
\\create image element
let img = document.createElement("img");
\\select the div from html
let qr = document.querySelector(".qr-code");
\\ stick the generated image to html div
qr.appendChild(img);
```
👉Okay so now 🏖
Input and button - Ready ✅
div to get output - Ready ✅
---
📌***Step 3***
👉The Third and main step is to add JavaScript code to generate QR
🚦Let get the input value from input tab
```
function generate(){
let input = document.getElementById("input");
}
```
👉Next we will check if the value is inserted or not before clicking the generate button 🎯
The code will only run if there is value in input 😉
if yes!🤩
then we will search the qr img by API:🤓
👉we will use [template literal](https://www.w3schools.com/js/js_string_templates.asp) to Pass Value of input that we got
`
https://api.qrserver.com/v1/create-qr-code/?size=180x180&data=${input.value}
`
👉And Boom💥 The API will do its work😎
```
if(input.value){
img.src = `https://api.qrserver.com/v1/
create-qr-code/?size=180x180&data=${input.value}`
};
```
---
## Now Let's Download Our QR 😍
👉To download our image we will use Another API [FileSaver.js](https://github.com/eligrey/FileSaver.js/)
📌**Step 1**
👉Adding the Cdn in Head of Html:
```
<script src="https://cdnjs.cloudflare.com/ajax/libs/FileSaver.js/2.0.0/FileSaver.min.js" integrity="sha512-csNcFYJniKjJxRWRV1R7fvnXrycHP6qDR21mgz1ZP55xY5d+aHLfo9/FcGDQLfn2IfngbAHd8LdfsagcCqgTcQ==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
```
👉Now Lets Create Download Button :🎨
```
<button id="mybutton" >Download</button>
```
And👀
```
//get the html button
let btnDownload = document.querySelector('#mybutton');
//get the html image
let imgdwn = document.querySelector('img');
```
---
📌**Step 2**
👉Now Add a Event Listener that work when we click download button
So when we click it:🧐
-🐠first get the img src and set in imagePath ✅
```
btnDownload.addEventListener('click', () => {
//getting the src of image
let imagePath = imgdwn.getAttribute('src');
});
```
-🦐second get the img name from the url✅
eg : https://httpbin.org/image get the >>image and add + '.jpg' at end
```
btnDownload.addEventListener('click', () => {
//getting the src of image
let imagePath = imgdwn.getAttribute('src');
//image format
let fileName = getFileName(imagePath);
//eg :saveAs("https://httpbin.org/image", "image.jpg");
saveAs(imagePath, fileName);
});
```
🧐so it will be image.jpg from the url to do that we will create `getFileName(imagePath)` Function
👉after getting the name of image (eg: image.jpg) from function
we will pass into `saveAs(imagePath, fileName)`; 😀
```
function getFileName(str) {
//search '=' from url starting from end and give the output
let gotstr = str.substring(str.lastIndexOf('=') + 1 );
let format = ".jpg";
// return the format ie image.jpg
return gotstr.concat(format);
}
```
**Congratulation**🎉✨
You Successfully🏆 Created a QR code Generator 🎀 and with Download Button😍
## Full Code Below 👇
**📌 HTML 📙 **
```
<!DOCTYPE html>
<html>
<head>
<script src="https://cdnjs.cloudflare.com/ajax/libs/FileSaver.js/2.0.0/FileSaver.min.js" integrity="sha512-csNcFYJniKjJxRWRV1R7fvnXrycHP6qDR21mgz1ZP55xY5d+aHLfo9/FcGDQLfn2IfngbAHd8LdfsagcCqgTcQ==" crossorigin="anonymous" referrerpolicy="no-referrer"></script>
</head>
<body>
<div class="container">
<div class="input-container">
<input type="text" id="input" placeholder="Enter
Url" autocomplete="off"/>
<button onclick="generate()">Generate</button>
</div>
<div class="qr-code"></div>
<button id="maindwnbtn" ><a href="#" id="mybutton"
download="qr">Download</a></button>
</div>
<a href="linktr.ee/developedbyjk">@developedbyjk</a>
</body>
</html>
```
**📌 CSS - if you want 😉 📗 **
```
@import url('https://fonts.googleapis.com/css2?family=Space+Mono&display=swap');
body{
font-family: 'Space Mono', monospace;
background-color: aliceblue;
}
.container{
max-width: 400px;
margin: 10%;
max-height: 500px;
padding: .2rem;
display: flex;
flex-direction: column;
justify-content: space-evenly;
background-color:aliceblue;
}
.input-container{
display: flex;
flex-direction: column;
}
.input-container input{
padding: 12px;
outline: none;
border-radius: 5px;
border: 2px dashed #c7c7c7;
font-family: 'Space Mono', monospace;
}
.qr-code{
margin-top: 100px;
height: 200px;
width: 200px;
border: 2px dashed #c7c7c7;
}
.input-container button{
padding: 0.5rem;
height: 40px;
color: #fff;
font-size: 1rem;
margin-top: .5rem;
outline: none;
border-radius: 90px;
border: none;
background-color: #332fd0;
cursor: pointer;
font-family: 'Space Mono', monospace;
}
#maindwnbtn{
padding: 0.5rem;
height: 40px;
font-size: 1rem;
margin-top: 80%;
outline: none;
border-radius: 90px;
border: none;
background-color: #332fd0;
cursor: pointer;
}
#maindwnbtn a{
color: #fff;
text-decoration:none;
font-family: 'Space Mono', monospace;
}
.qr-code{
width: 100%;
height: 180px;
text-align: center;
}
```
**📌 JavaScript 📗 **
```
let img = document.createElement("img");
let qr = document.querySelector(".qr-code");
qr.appendChild(img);
function generate(){
let input = document.getElementById("input");
if(input.value){
input.style.borderColor = "#c7c7c7";
img.src = `https://api.qrserver.com/v1/create-qr-code/?size=180x180&data=${input.value}`;
}
else{
input.style.borderColor="red";
return false;
}
input.value = "";
}
let btnDownload = document.querySelector('#mybutton');
let imgdwn = document.querySelector('img');
btnDownload.addEventListener('click', () => {
let imagePath = imgdwn.getAttribute('src');
let fileName = getFileName(imagePath);
saveAs(imagePath, fileName);
});
function getFileName(str) {
let gotstr = str.substring(str.lastIndexOf('=') + 1 );
let format = ".jpg";
return gotstr.concat(format);
}
```
Wait 😳
You reached so Below 🤯 I can't Believe it
You seem great Diver 😍😉
So Hi👋 My diver Friend👨
Myself JK 👨💻
I share Stuff Related to Web Design & Development
If you like this😄
I'm Sure you'll Love My [Instagram Page](https://www.instagram.com/developedbyjk) Where I share the same,but with Visual Taste.🤝😎👀
Hope we meet There😉🎀🏝
Happy Coding 💪✨🎉
My All Links [linktr.ee/developedbyjk](linktr.ee/developedbyjk)
| developedbyjk |
1,330,694 | How to use PHP native enum? | PHP 8.1 offers natively the new enum structure. Let's see how we can use them in an advanced way! 🚀... | 0 | 2023-01-16T11:35:45 | https://dev.to/pierre/php-enum-2ac7 | php, programming, cleancode, php8 | [PHP 8.1](https://www.php.net/manual/en/language.types.enumerations.php) offers natively the new `enum` structure. Let's see how we can use them in an advanced way! 🚀 And how it can make your code cleaner, more consistent, and easier to understand! 💡
{% youtube https://youtu.be/c080A4Lrnps %} | pierre |
1,330,774 | Becoming a Cloud Engineer in 2023 (A Roadmap) | Here is Simon Holdorf’s recommendation for becoming a Cloud Engineer in 2023. Step 1: The Role On a... | 0 | 2023-01-16T13:38:44 | https://dev.to/ileriayo/becoming-a-cloud-engineer-in-2023-a-roadmap-1f6k | cloud, aws, devops, beginners |
Here is Simon Holdorf’s recommendation for becoming a Cloud Engineer in 2023.
**Step 1: The Role**
On a high level, a cloud engineer is responsible for designing, building, and maintaining an organization's cloud computing infrastructure and systems.
**Step 2: The Fundamentals**
Don't skip the Fundamentals!
Learn:
- General Cloud Computing
- Networking
- Operating systems
- Virtualization
- Security
**Step 3: Selecting a Cloud Provider**
It is beneficial to have experience with multiple cloud providers as a cloud engineer.
If you are starting, I would highly recommend concentrating on one cloud provider first: AWS, Azure, or GCP.
**Step 4: Acquiring programming knowledge**
As a cloud engineer, it is important to understand at least one programming or scripting language, especially for automating tasks and provision resources in the cloud.
Know your way around Git and a product like GitHub or Gitlab.
**Step 5: Learning DevOps principles & tools**
DevOps is a set of practices that aims to improve collaboration between development and operations teams and increase software delivery speed and reliability.
Know:
- CI/CD
- IaC
- Monitoring & Logging
- Collaboration & Communication
**Step 6: Gaining Hands-On experience**
Seeking opportunities to gain practical, hands-on experience with cloud technologies is essential to becoming a successful cloud engineer.
The first step is to create an account with one of the big cloud providers, AWS, Azure, or GCP.
**Step: 7 Earning Certifications**
Obtaining a certification can be beneficial for several reasons:
- Validation of skills
- Improved job prospects
- Professional development
- Increased earning potential
- Fun challenge
To become a successful Cloud Engineer, you need to have a mindset focused on delivering scalable, reliable, and secure solutions.
Check out Simon's video https://www.youtube.com/watch?v=6Yi3c259RE0
Follow Ileriayo Adebiyi on LinkedIn & Twitter for more on Cloud & DevOps.
LinkedIn: https://www.linkedin.com/in/ileriayoadebiyi
Twitter: https://twitter.com/ileriayooo | ileriayo |
1,330,952 | What are your Goals for the week of January 16? | What are your goals for this week? What are you building? What will be a good result by week's... | 19,128 | 2023-01-16T15:58:03 | https://dev.to/jarvisscript/what-are-your-goals-for-the-week-of-january-16-38o1 | discuss, watercooler, motivation | What are your goals for this week?
- What are you building?
- What will be a good result by week's end?
- Did you meet your goals last week?
**Last Week's Goals**
- [:white_check_mark:] Update resume/linkedIN/portfolio.
- [:white_check_mark:] Job Search. Spending my mornings hitting LinkedIn and sending DMs. Applying to open roles.
- [:white_check_mark:] Hit milestone in blog views.
**Last Week's Wins**
- I received my HacktoberFest 9 (2022) Tee-shirt and my Trusted User badge for DEV.
### Still working on:
- Update resume/linkedIN/portfolio.
- I'm taking a course starting later this month, course hasn't dropped yet.
**This Week's Goals**
- Update resume/linkedIn/portfolio.
- Continue Job Search.
- Learn something. Planning a project out.
- Encourage Virtual Coffee members in our Month of Learning Challenge.
- Blog.
**This Month's Goals**
- Gain more followers here. I would like to have more followers on DEV than I had on the bird site. Need about 100 more here.
- Gain more followers on Mastodon. @jarvisscript@hachyderm.io I'm nowhere near my DEV or bird numbers but that's ok.
You've read my goals so I'll throw that question back to you.
What are your goals for the week?
```
-$JarvisScript git push
``` | jarvisscript |
1,330,955 | Java 101 for software testing (Using fruits and vehicle as example) | I think many of you might have similar experience like me where I found myself struggle to... | 0 | 2023-01-16T16:03:42 | https://dev.to/alanliew88/java-101-for-software-testing-12bg | testing, bugs, automationtest, java |

I think many of you might have similar experience like me where I found myself struggle to understand of Java language.
There was a time I try to avoid myself from writing selenium testing script in Java, instead, I'm using Python to code.
And when I decided to learn and write selenium testing script using java but I'm devastated because of the endless of error seem to appear.. I can't understand the error log, the console log and etc. And I knew that was because lack of basic understanding of Java language.
Hence, I strongly recommend you to read this article before you write any selenium test scripts because you must build your foundation right before you write any scripts.
**
## First, we ask WHY ? Why Java ?
**
✅ Java is a programming language that is commonly used in combination with the Selenium web automation tool.
✅ Selenium is a powerful tool for automating web browsers, and it can be used to automate a wide variety of web-based tasks.
✅ When used with Java, Selenium allows developers to write automated tests for web applications using the Java programming language.
✅ This can be useful for a variety of purposes, including functional testing, performance testing, and regression testing. Not only that, selenium has a number of libraries that can be used to extend its functionality or make it easier to use in certain situations.
**
## Next, what is Java ?
**
✅ Java is an object-oriented programming (OOP) language.
You may wonder what is OOP means ? Don't freak out.
Let me make this simple for you. For example:
Fruits.

There are bananas, cherries, oranges, kiwis, grapes and apples in the picture.
✅ These are called Objects.
✅ And what are they categories as ? Fruits
Hence, Fruits is the **Class** and bananas, cherries, oranges, kiwis, grapes and apples is the **Objects**.
Is this sound simple ?
What about this picture ?
We can see trucks , ambulance, bus and car.
And what are they ? **Vehicles**
So we know **Vehicles** is **Class** and trucks , ambulance , bus and car is an **Object**.
Now, what is the color of the car ? **Blue**
Blue is the **attribute** of the Car.
How do we operate the vehicles ? **Drive**
Drive is the **method**
We can conclude 4 things from this , we know the class (vehicles), the object (car, bus, trucks, ambulance), attributes (blue, 4 tires , etc) and method (drive).
***
public class Vehicle { **<- this is class = vehicles**
String carBrand = honda; **<- this is objects and attributes**
Int numOfTires = 4; **<- this is objects and attributes**
void Drive(){ **<- this is drive method**
System.out.print("Car is driving");
}
public static void main(String[]args){
Car myCar = new Car();
myCar.drive();
***
This is just a simple java program to show you how the java structure it is. It's OK not to understand everything in the first place. Just get along with me , and I can assure you will have sufficient java knowledge to write your first selenium script with Java.
❤️
Related Articles:
[1. Cloud Computing , let’s talk about it [Part 2]](https://dev.to/alanliew88/cloud-computing-lets-talk-about-it-part-2-2mgj)
[2. AWS ! the terms you must know 🤫](https://dev.to/alanliew88/aws-the-terms-you-must-know-2k8p)
[3. ISTQB 🧙🏻♀️The software testing Myth, do you need that?](https://dev.to/alanliew88/istqb-the-software-testing-myth-do-you-need-that-1ajj)
[4. Why Software Testing is necessary in the first place?👀 ](https://dev.to/alanliew88/why-software-testing-is-necessary-in-the-first-place-181)
❤️
Connect with me in [Linkedin](https://www.linkedin.com/in/alan-liew/) !
| alanliew88 |
1,331,362 | Interfaces and Polymorphism in PHP - Practical Guide | Polymorphism Polymorphism in OOP's is a concept that allows you to create classes with... | 0 | 2023-01-21T03:58:38 | https://dev.to/saravanasai/interfaces-and-polymorphism-in-php-practical-guide-pfc | php, webdev, explanation, cleancode | ## Polymorphism
Polymorphism in OOP's is a concept that allows you to create classes with different functionalities in a single interface generally, it is of two types:
1. compile-time (overloading)
2. run time (overriding)
But polymorphism in PHP does not support overloading, or in other words, compile-time polymorphism.
! Let don’t have to worry about the technicalities & jargon's. Let see a example with a explanation.
## Scenario:
Let consider that we have to write a code for payment gateway integration & they may be more than one payment gateway (stripe & pay-pal) . The different users may choose different payment method & also in future there may be a some other payment methods also.
Just take a min & roll up you heads for a solution . There are different ways to approach this with simple if-else condition but by using a PHP interface we can get a clean implementation.
let's create an interface
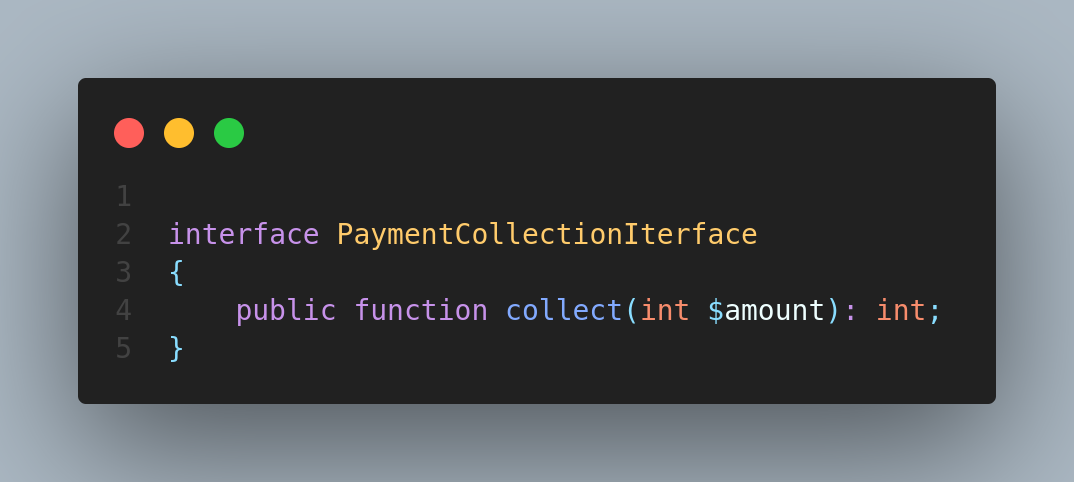
The class which uses or implements PaymentCollectionIterface en-forces the class to implement the collect method.
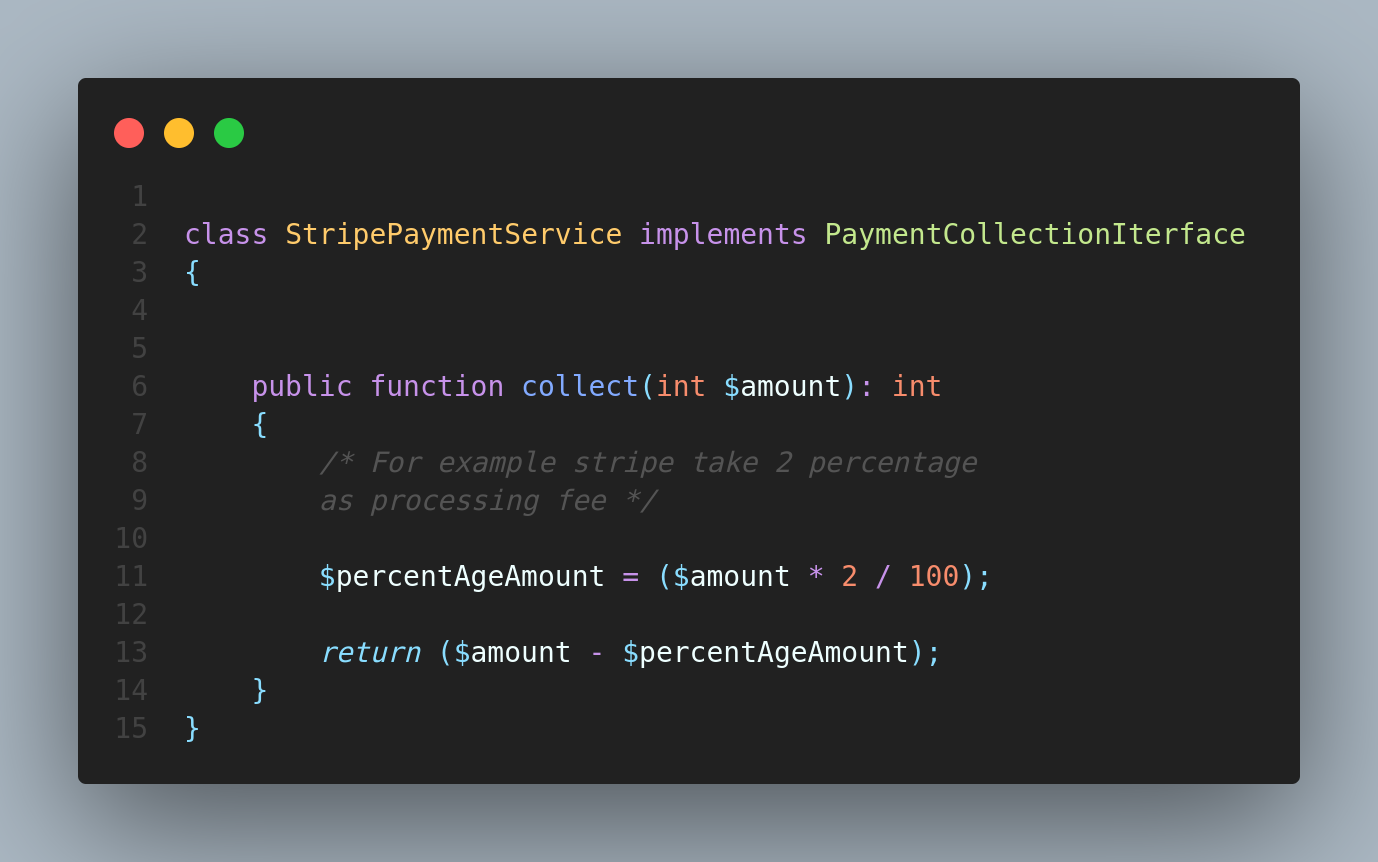
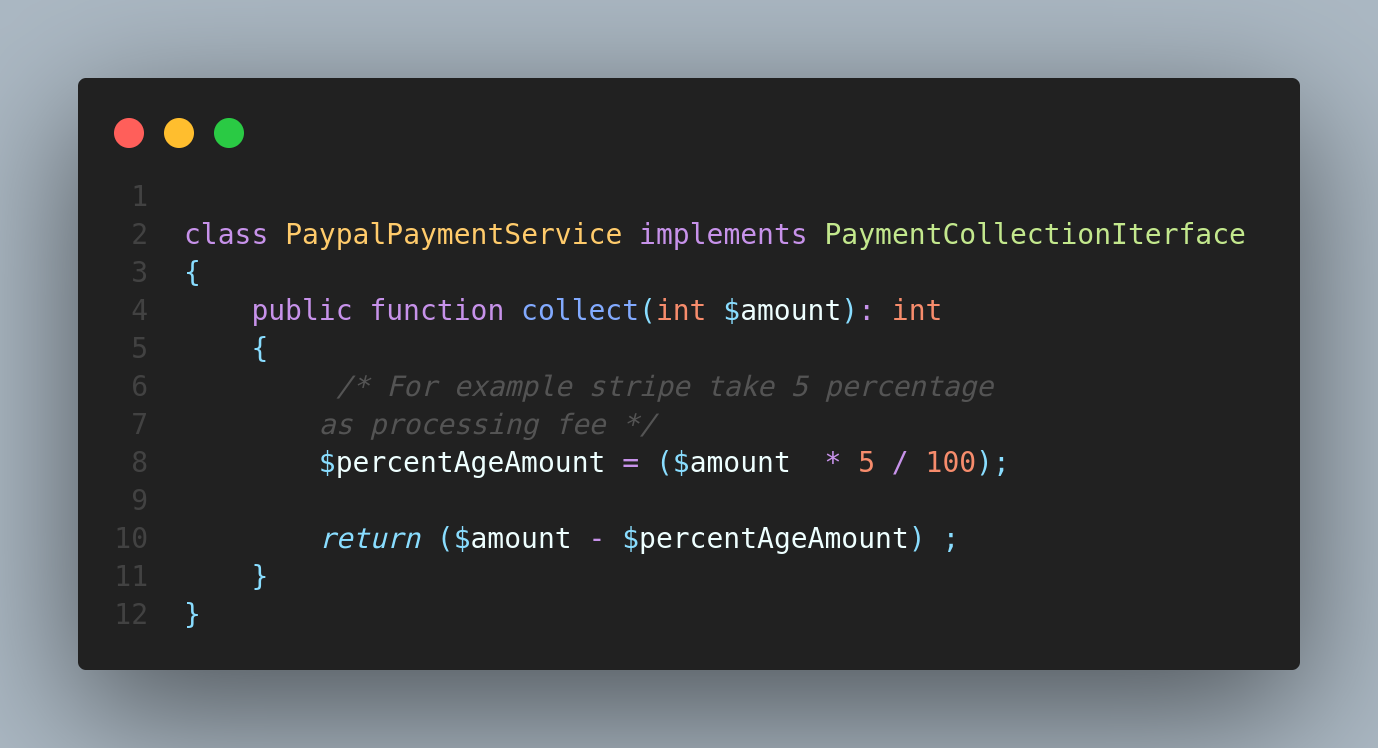
StripePaymentService implements PaymentCollectionIterface
as well as for PaypalPaymentService.
Don't take the implementation part of collect method so seriously that is just an example. Let's focus on a problem. Till now we have a two separate class for each payment method.
Now let's create a PaymentService class which handle the payment detection logic.
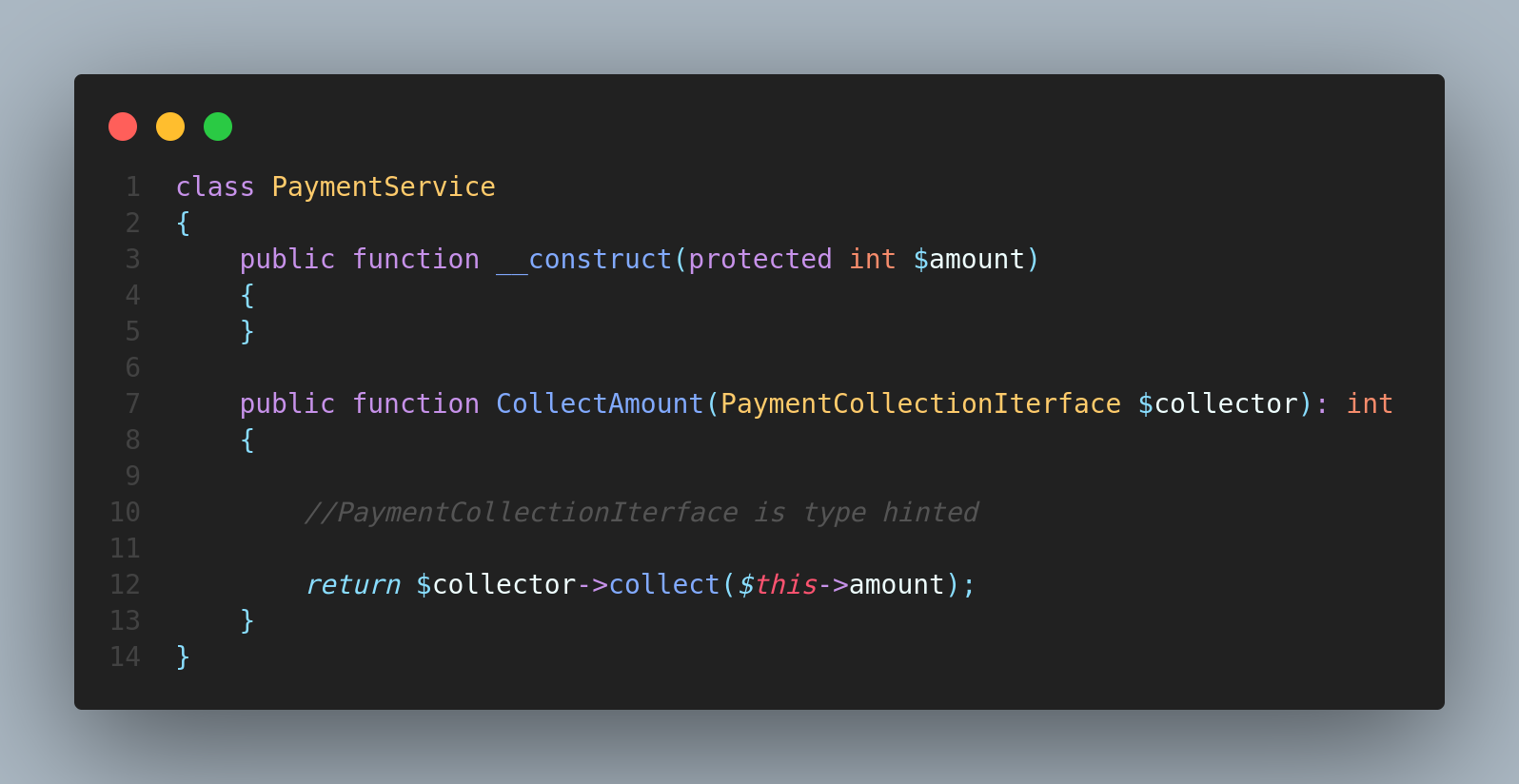
In above code we have type hinted the
`CollectAmount(PaymentCollectionIterface $collector)` method with PaymentCollectionIterface.This is where the polymorphism come in to play.The argument passed to the `CollectAmount()` method should the the instance of a class which implements the `PaymentCollectionIterface` else it will throw an error.
As we know that both **StripePaymentService & PaypalPaymentService** implements PaymentCollectionIterface. So , PHP is smart enough to resolve that collect method on the class which the instance is passed.
It resolves the payment method on run time.Now if user want to pay with paypal.you can invoke a paymentService class like below.

if user want to pay with stripe then you can do like this below.
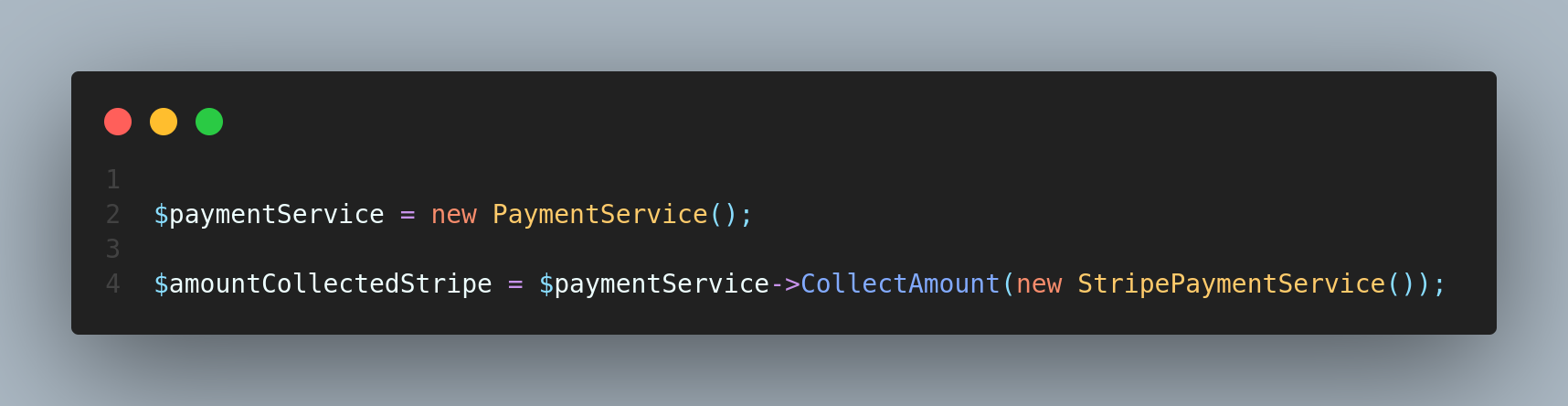
**Conclusion**
... So that's it a Interfaces and Polymorphism in PHP using in a more practical way
Hopefully this will be useful to some of you :)
I'd love to hear what you're comments & more example let me know in the comments below!
Follow for more content like this & share
| saravanasai |
1,331,392 | Day 12 #100DaysofCode | What I Learned Today Difference between CSS Grid and CSS Flexbox Creating a... | 21,279 | 2023-01-17T03:38:42 | https://dev.to/developing-vic/day-12-100daysofcode-2k5p | webdev, beginners, 100daysofcode | ## What I Learned Today
* Difference between CSS Grid and CSS Flexbox
* Creating a Grid
* Positioning Grid Elements
* Advanced Grid Properties
I am 91% completed with the TOP Intermediate HTML and CSS Course. The last project in this section is an Admin Dashboard. | developing-vic |
1,331,404 | Prometheus: How is the Remote Write API code Path different from the Scrape Code Path | In my last post, I wanted to dig into the remote write code to learn more about how it worked and see... | 0 | 2023-01-17T03:59:23 | https://dev.to/mikkergimenez/prometheus-how-is-the-remote-write-api-code-path-different-from-the-scrape-code-path-579c | prometheus, observability | In my last post, I wanted to dig into the remote write code to learn more about how it worked and see if you could use it to simulate a push based agent. This is all just experimental to learn how Prometheus works. I think you can, and I'm working on testing it out, but before I get there, I wanted to explore the other side: that is the prometheus remote-write receiver.
I came up with a few questions I want to answer while exploring the remote write API:
1. Where does the code path between scraping a prometheus endpoint and remote write differ?
2. In what format does Prometheus write data to disk?
3. What exactly in the code makes Prometheus pull based over push based. Can I identify the specific code blocks where algorithms are implemented that will optimize for one over the other?
## Web API write endpoint
[main/web/api/v1/api.go](https://github.com/prometheus/prometheus/blob/main/web/api/v1/api.go#L364)
```go
// Line 364
r.Post("/write", api.ready(api.remoteWrite))
```
The remote write handler (api.remoteWrite) is created by the following code block.
[storage/remote/write_handler.go](https://github.com/prometheus/prometheus/blob/main/storage/remote/write_handler.go#L37)
```go
// NewWriteHandler creates a http.Handler that accepts remote write requests and
// writes them to the provided appendable.
func NewWriteHandler(logger log.Logger, appendable storage.Appendable) http.Handler {
return &writeHandler{
logger: logger,
appendable: appendable
}
}
```
I guess I'm surprised how quickly we get from remote write endpoint to the appender, it seems like there's no real special buffering on remote write to make it different from the scraper? In the previous article, we traced remote write back to an appender, so write is writing to an appender which may then re-write to another upstream pretty directly. I don't know why Prometheus writing would be more complicated than this, but as an SRE who doesn't write low level code, I'm curious to go back to the question "What makes us say that Prometheus isn't push based" Seems like you could write a push agent pretty easily.
I traced this back quite a bit, but this appendable is injected from the prometheus command code [here](https://github.com/prometheus/prometheus/blob/main/cmd/prometheus/main.go#L566) (cfg.web.storage is passed) fanout has primary and secondary storages. The local storage configured below is the 'primary' storage and remote storage is the 'secondary' storage. Ready Storage is a struct.
```go
var (
localStorage = &readyStorage{stats: tsdb.NewDBStats()}
scraper = &readyScrapeManager{}
remoteStorage = remote.NewStorage(log.With(logger, "component", "remote"), prometheus.DefaultRegisterer, localStorage.StartTime, localStoragePath, time.Duration(cfg.RemoteFlushDeadline), scraper)
fanoutStorage = storage.NewFanout(logger, localStorage, remoteStorage)
)
// Line 1287
type readyStorage struct {
mtx sync.RWMutex
db storage.Storage
startTimeMargin int64
stats *tsdb.DBStats
}
```
https://github.com/prometheus/prometheus/blob/main/cmd/prometheus/main.go#L566
[storage/interface.go](https://github.com/prometheus/prometheus/blob/136956cca40b7bf29dc303ad497d01c30534e373/storage/interface.go#L57)
```go
type Appendable interface {
// Appender returns a new appender for the storage. The implementation
// can choose whether or not to use the context, for deadlines or to check
// for errors.
Appender(ctx context.Context) Appender
}
```
https://github.com/prometheus/prometheus/blob/main/storage/remote/write_handler.go#L86
https://github.com/prometheus/prometheus/blob/136956cca40b7bf29dc303ad497d01c30534e373/storage/interface.go#L219
```go
type Appender interface {
// Append adds a sample pair for the given series.
// An optional series reference can be provided to accelerate calls.
// A series reference number is returned which can be used to add further
// samples to the given series in the same or later transactions.
// Returned reference numbers are ephemeral and may be rejected in calls
// to Append() at any point. Adding the sample via Append() returns a new
// reference number.
// If the reference is 0 it must not be used for caching.
Append(ref SeriesRef, l labels.Labels, t int64, v float64) (SeriesRef, error)
// Commit submits the collected samples and purges the batch. If Commit
// returns a non-nil error, it also rolls back all modifications made in
// the appender so far, as Rollback would do. In any case, an Appender
// must not be used anymore after Commit has been called.
Commit() error
// Rollback rolls back all modifications made in the appender so far.
// Appender has to be discarded after rollback.
Rollback() error
ExemplarAppender
HistogramAppender
MetadataUpdater
}
```
## Scrape Code Path:
Prometheus works by scraping endpoints periodically according to a scrape interval. This process is a loop, defined very clearly by the process entitied "mainLoop":
[scrape/scrape.go](https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L1235)
```go
mainLoop:
for {
...
}
```
Alot of these are really long functions so I'm going to pull out the key pieces.
Calls "Scrape and Report":
https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L1264
```last = sl.scrapeAndReport(last, scrapeTime, errc)```
Calls "Scrape":
https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L1340
```
scrapeCtx, cancel := context.WithTimeout(sl.parentCtx, sl.timeout)
contentType, scrapeErr = sl.scraper.scrape(scrapeCtx, buf)
#... Line 1364
total, added, seriesAdded, appErr = sl.append(app, b, contentType, appendTime)
```
This function is what actually makes the HTTP request to Scrape a Destination:
https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L792
```
func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) {
if s.req == nil {
req, err := http.NewRequest("GET", s.URL().String(), nil)
if err != nil {
return "", err
}
req.Header.Add("Accept", s.acceptHeader)
req.Header.Add("Accept-Encoding", "gzip")
req.Header.Set("User-Agent", UserAgent)
req.Header.Set("X-Prometheus-Scrape-Timeout-Seconds", strconv.FormatFloat(s.timeout.Seconds(), 'f', -1, 64))
s.req = req
}
resp, err := s.client.Do(s.req.WithContext(ctx))
if err != nil {
return "", err
}
defer func() {
io.Copy(io.Discard, resp.Body)
resp.Body.Close()
}()
if resp.StatusCode != http.StatusOK {
return "", errors.Errorf("server returned HTTP status %s", resp.Status)
}
if s.bodySizeLimit <= 0 {
s.bodySizeLimit = math.MaxInt64
}
if resp.Header.Get("Content-Encoding") != "gzip" {
n, err := io.Copy(w, io.LimitReader(resp.Body, s.bodySizeLimit))
if err != nil {
return "", err
}
if n >= s.bodySizeLimit {
targetScrapeExceededBodySizeLimit.Inc()
return "", errBodySizeLimit
}
return resp.Header.Get("Content-Type"), nil
}
if s.gzipr == nil {
s.buf = bufio.NewReader(resp.Body)
s.gzipr, err = gzip.NewReader(s.buf)
if err != nil {
return "", err
}
} else {
s.buf.Reset(resp.Body)
if err = s.gzipr.Reset(s.buf); err != nil {
return "", err
}
}
n, err := io.Copy(w, io.LimitReader(s.gzipr, s.bodySizeLimit))
s.gzipr.Close()
if err != nil {
return "", err
}
if n >= s.bodySizeLimit {
targetScrapeExceededBodySizeLimit.Inc()
return "", errBodySizeLimit
}
return resp.Header.Get("Content-Type"), nil
}
```
Sets s.buf and s.gzipr:
https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L835
Loop through and switch based on datatype:
https://github.com/prometheus/prometheus/blob/6fc5305ce904a75f56ca762281c7a1b052f19092/scrape/scrape.go#L1535
```
### For example, this switches on whether or not to append a histogram or just append:
if isHistogram {
if h != nil {
ref, err = app.AppendHistogram(ref, lset, t, h)
}
} else {
ref, err = app.Append(ref, lset, t, val)
}
```
This is where it gets back to the same 'Append' function as before, there are a few different types of Appenders, the one mentioned above seems to be a base struct. The appender is assigned by the following function in scrape.go.
```
// appender returns an appender for ingested samples from the target.
func appender(app storage.Appender, limit int) storage.Appender {
app = &timeLimitAppender{
Appender: app,
maxTime: timestamp.FromTime(time.Now().Add(maxAheadTime)),
}
// The limit is applied after metrics are potentially dropped via relabeling.
if limit > 0 {
app = &limitAppender{
Appender: app,
limit: limit,
}
}
return app
}
```
So, where does it go from here?
The /tsdb folder contains the code that we use to write Prometheus data to disk. Specifically blockwriter.go has a method called flush
[tsdb/blockwriter.go](https://github.com/prometheus/prometheus/blob/main/tsdb/blockwriter.go#L92)
```go
// Flush implements the Writer interface. This is where actual block writing
// happens. After flush completes, no writes can be done.
func (w *BlockWriter) Flush(ctx context.Context) (ulid.ULID, error) {
mint := w.head.MinTime()
// Add +1 millisecond to block maxt because block intervals are half-open: [b.MinTime, b.MaxTime).
// Because of this block intervals are always +1 than the total samples it includes.
maxt := w.head.MaxTime() + 1
level.Info(w.logger).Log("msg", "flushing", "series_count", w.head.NumSeries(), "mint", timestamp.Time(mint), "maxt", timestamp.Time(maxt))
compactor, err := NewLeveledCompactor(ctx, nil, w.logger []int64{w.blockSize}, chunkenc.NewPool(), nil)
if err != nil {
return ulid.ULID{}, errors.Wrap(err, "create leveled compactor")
}
id, err := compactor.Write(w.destinationDir, w.head, mint, maxt, nil)
if err != nil {
return ulid.ULID{}, errors.Wrap(err, "compactor write")
}
return id, nil
}
```
This process takes us to the 'LeveledCompactor` which has a write method:
[tsdb/compact.go](https://github.com/prometheus/prometheus/blob/b768247df877ce244eabf66cee30e36a743dba30/tsdb/compact.go#L549)
```
I think I'm close now but oddly can't find the specific method that writes the data files. [This block here](https://github.com/prometheus/prometheus/blob/b768247df877ce244eabf66cee30e36a743dba30/tsdb/compact.go#L625
) writes the metadata file, the tombstones and I assume the samples as well:
```go
### The above block is very long, but for example, ehre is where it writes metadata and tombesones
if _, err = writeMetaFile(c.logger, tmp, meta); err != nil {
return errors.Wrap(err, "write merged meta")
}
// Create an empty tombstones file.
if _, err := tombstones.WriteFile(c.logger, tmp, tombstones.NewMemTombstones()); err != nil {
return errors.Wrap(err, "write new tombstones file")
}
```
And that's about it for our overview of the different scrape types. Let's look back at the questions we had before exploring this API:
**Where does the code path between scraping a prometheus endpoint and remote write differ?
**
**In what format does Prometheus write data to disk?**
* According to [this](https://prometheus.io/docs/prometheus/latest/storage/#local-storage), it's the 'tsdb' format: https://github.com/prometheus/prometheus/blob/release-2.41/tsdb/docs/format/README.md
* **What exactly in the code makes Prometheus pull based over push based. Can I identify the specific code blocks where algorithms are implemented that will optimize for one over the other?**
* I'm going to save the details of this for the next post, but I think the answer might be... Nothing.
In the next blog post, I'll show my demo of a push-based agent, and summarize my findings from all the posts.
| mikkergimenez |
1,331,641 | Books for System Design | "Designing Data-Intensive Applications" by Martin Kleppmann is a comprehensive guide to designing,... | 0 | 2023-01-17T09:31:27 | https://dev.to/ridhisingla001/books-for-system-design-2l3l | books, systems, design, beginners |
1. "Designing Data-Intensive Applications" by Martin Kleppmann is a comprehensive guide to designing, implementing, and maintaining data-intensive applications.
2. "Building Microservices" by Sam Newman is a book that discusses the principles and practices of building microservices-based systems.
3. "Systems Performance: Enterprise and the Cloud" by Brendan Gregg is a book that covers performance analysis and optimization for systems running in the cloud.
4. "Site Reliability Engineering" by Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy is a book that discusses the principles and practices of site reliability engineering, which is a discipline that combines software engineering and systems engineering to build and run large-scale, fault-tolerant systems.
5. "Designing Distributed Systems" by Brendan Burns is a book that covers the fundamental patterns and practices for designing distributed systems.
I hope these recommendations are helpful! | ridhisingla001 |
1,331,698 | Six Agile Team Behaviors to Consider | Are members of agile teams different from members of other teams? Both yes and no. Yes, because some... | 0 | 2023-01-17T10:56:06 | https://www.lambdatest.com/blog/agile-team-behaviors-to-consider/ | agile, testing, devlopment, webdev | Are members of agile teams different from members of other teams? Both yes and no. Yes, because some of the behaviors we observe in agile teams are more distinct than in non-agile teams. And no, because we are talking about individuals!
However, effective agile team members exhibit certain traits more often than non-agile project team members because agile requires these behaviors to create a successful team and product. What traits should you look for in an agile team? Below are six essential habits that members of a successful agile team exhibit. I have also included interview questions to help determine if a candidate for an agile team has what it takes to join a strong agile team.
## People Willing to Work Outside of Their Expertise
A person’s willingness to work beyond his or her area of expertise is an indicator of adaptability. I do not recommend anyone to do things they do not know anything about — a programmer should not become a salesman, for example. I believe that someone good with the database should try to work a little on the user interface as well. If she knows middleware, she might want to do some work on the platform or a higher level of the application. If she’s always been an inquisitive tester, she might be willing to try some scripting.
We see this desire to work outside of one’s area of expertise in agile teams, when individuals work together to rally around a product. People are willing to work beyond their area of expertise, but not far from it. To learn more about this talent, ask, “Tell me about a time when you took on additional work to support the team. What was that like?” A candidate may not be able to answer this question. Therefore, you may need to provide context by saying something like, “In order to complete a feature, we work on things that we may not like. Have you ever been in a similar situation?” If the candidate does not answer positively, you need to rephrase the question. For example, I have had success with the following, “Tell me about a time when you did something that you did not think was part of the requirements of your job. What exactly did you do?”
***The most simple online utility that generates random strings. Free, quick, and powerful [Random String Generator](https://www.lambdatest.com/free-online-tools/random-string-generator?utm_source=devto&utm_medium=organic&utm_campaign=jan17_kj&utm_term=kj&utm_content=free_tools) that allows you to flexibly create random strings ranging from minimum 8 to maximum 25 character length.***
## Adaptable Individuals
As with all projects, things are not always ideal in agile initiatives. Even if we do not have a team room, do not have acceptance criteria for all functions, or are not even able to remove obstacles, we still need to get the work done. We are not looking for heroes, we are looking for adaptable people. People who continue to get the job done despite adverse circumstances. If you get one of these adaptable people in response to the following question, “Tell me about a time when the circumstances for your endeavor were not as ideal as you had hoped. How did you handle it?”
## Individuals Who Are Willing to Take Small Steps and Receive Feedback
Agile is all about getting feedback. We use iterations to do things and get feedback. We build in small increments so that our customers can give us feedback on what we are doing. One of the qualities you should look for in a candidate is a willingness to take small steps and receive feedback on their work. People who give the impression that they need to finish a feature (whether they are a developer, tester, or whatever) before anyone else sees it are unsuitable for an agile team.
One of the questions you might ask is, “Tell me about your work style. Think about the last project you worked on. Did you try to get everything done before asking for feedback?” Wait for the answer. Now ask yourself, “Why?” The candidate might tell you that he or she only had one chance to solicit feedback. Or the candidate may claim that he or she was expected to complete everything.
***Here’s Free online tool [random sentence generator](https://www.lambdatest.com/free-online-tools/random-sentence-generator?utm_source=devto&utm_medium=organic&utm_campaign=jan17_kj&utm_term=kj&utm_content=free_tools) that can help you create senetnces effortlessly.***
## People that Work Together
People who can work together are far more effective than those who have to work individually. But what exactly does it mean to truly build a team? The first thing you notice about an agile team is that individuals work together on functions. It’s typical for employees on a non-agile team to work alone on features or requirements. However, this is unusual in a well-managed agile team, where multiple developers and one or two testers work together to ensure that — as a team -they have completed a story. It is possible to see a group of testers creating tests, or developers and testers working together to create a framework for system testing for the entire project.
The entire team contributes to the definition, initiation, and completion of features. Because they work together to complete features, effective agile teams avoid the problem of having many features started but none completed by the end of the sprint. You might ask a potential candidate, “Think about a recent project you undertook. Give me an example of a moment when you had to work with others to make sure you got a task done. What happened during that time?”
## Those Who Seek Assistance
Many of us find it difficult to ask for help. However, people who can ask for help are the kind of people we want on an agile team. Why is it so necessary to ask for help? We all know a little about the project, but none of us know everything. We need to be able to ask for help from a position of strength, not weakness. Asking for help is not a problem for an agile team. In an agile team, it’s more important to deliver all the agreed-upon features at the end of the sprint than for one individual to become a rock star. We do not want delays because individuals are waiting to ask for help when they are blocked.
Here is an example of a question you might ask a candidate regarding their ability to ask for help: “Think about your last project. Tell me about a moment when you were confused by something. What exactly did you do?”
***This free online UUID v4 generator ([random UUID generator](https://www.lambdatest.com/free-online-tools/random-sentence-generator?utm_source=devto&utm_medium=organic&utm_campaign=jan17_kj&utm_term=kj&utm_content=free_tools)) instantly creates version-4 universally unique identifiers according to RFC 4122. Version-4 UUIDs are 128-bit encryption keys that are random and dynamically generated.***
## People who are willing to do whatever is enough at the time being
People who can take small steps and get feedback may be willing to achieve something that is sufficient for now. One of the problems with agile is that we do not have enough time to get everything done at once. That’s why we use both soft and hard timelines. We do what is needed in the moment, and then decide whether or not to come back to it later, depending on feedback. It’s unusual to be able to do something well enough just for now, and then come back to it later when it has greater business value. That may be the case with testers who want the best possible test system at the start of a project. It may be the case with architects who want to thoroughly describe the architecture from the beginning of a project.
One of the challenges of the agile approach is that we cannot predict what will be ideal at the beginning of the project. Even in the middle, we can not always tell! So we need to do something appropriate first and come back to it later when we can get more business value from working on it. To find out if a candidate can execute something well enough for now without doing it flawlessly, ask, “Tell me about a situation where you did not know everything at the beginning of a project. What exactly did you do?”
## Closing
These may not be the only qualities your agile team needs. Make sure you do a job analysis to see how your agile team is different, and then you’ll understand what kind of candidates you should pursue.
| davidtz40 |
1,331,825 | Build an Effective Junior Developer Portfolio That Will Get You Hired 👨💻🔥 | How to build an Effective Junior Developer Portfolio That Will Get You Hired In 2023 👨💻🔥 Some... | 0 | 2023-01-17T12:22:40 | https://dev.to/rammcodes/build-an-effective-junior-developer-portfolio-that-will-get-you-hired-4m8c | beginners, webdev, html, portfolio | How to build an Effective Junior Developer Portfolio That Will Get You Hired In 2023 👨💻🔥
Some important points that you can follow while building your Developer Portfolio ✨
1️⃣
Showcase your best work: Include only your most impressive and relevant projects in your portfolio. Use screenshots and explain the technologies and techniques used.
2️⃣
Make it easy to navigate: Organize your portfolio in a logical and easy-to-use manner. Make sure it's clear what each project is about and how to view it.
3️⃣
Include a brief bio and contact information: Give potential employers or clients an idea of who you are, what you can do, and how to contact you.
4️⃣
Use a clean and modern design: Keep the design of your portfolio simple and clean, using a modern design aesthetic. This will help your work stand out and make a good impression.
5️⃣
Keep it up-to-date: Make sure to keep your portfolio up-to-date with your latest work and skills. This will help demonstrate your growth as a developer and your ability to stay current with industry trends.
6️⃣
Optimize for mobile and web: Your portfolio should be optimized for different devices and web browsers so that it looks good and works well on any device.
Hope this will help you to build an effective portfolio to make yourself stand out from the crowd and land your dream opportunity 🗽
Do Like ❤️ & Save 🔖
𝗙𝗼𝗹𝗹𝗼𝘄 me on **[Linkedin](https://Linkedin.com/in/rammcodes)** for more:
Tips💡+ Guides📜 + Resources ⚡ related to programming and Web Development 👨💻
Feel free to connect with me 👍🔖 | rammcodes |
1,331,894 | Auto Sliding Carousel with Javascript | Hello everyone, in this tutorial, I'll show you how to use HTML, CSS, and Javascript to make a basic... | 0 | 2023-01-17T14:17:23 | https://dev.to/shubhamtiwari909/auto-sliding-carousel-with-javascript-5h47 | html, css, javascript, webdev | Hello everyone, in this tutorial, I'll show you how to use HTML, CSS, and Javascript to make a basic auto-sliding carousel. I'll outline all the logics and provide the complete code for the Codepen example.
Let's get started...
# Overview
{% codepen https://codepen.io/shubhamtiwari909/pen/xxJrXwZ %}
# HTML -
```html
<div class="carousel-container">
<div class="carousel_items">
<div class="carousel_item item1">
<p class="carousel_text">Image 1</p>
</div>
<div class="carousel_item item2">
<p class="carousel_text">Image 2</p>
</div>
<div class="carousel_item item3">
<p class="carousel_text">Image 3</p>
</div>
<div class="carousel_item item4">
<p class="carousel_text">Image 4</p>
</div>
<div class="carousel_item item5">
<p class="carousel_text">Image 5</p>
</div>
</div>
</div>
```
* I've placed the carousel pieces with some text inside the main container, which will be shown at the bottom centre.
# CSS - The CSS is compiled from SASS.
```css
* {
margin: 0;
padding: 0;
}
.carousel_items {
display: flex;
wrap: nowrap;
overflow: hidden;
}
.carousel_item {
position: relative;
min-width: 100%;
height: 100vh;
transition: all 0.5s linear;
background-repeat: no-repeat;
background-size: cover;
background-attachment: fixed;
}
.carousel_text {
position: absolute;
bottom: 10%;
left: 50%;
transform: translate(-50%);
padding: 0.5rem 1rem;
border-radius: 3px;
background-color: rgba(0, 0, 0, 0.8);
color: white;
text-shadow: 1px 1px black;
font-size: calc(1.5rem + 0.3vw);
font-weight: bolder;
}
.item1 {
background-image: url("https://images.unsplash.com/photo-1426604966848-d7adac402bff?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=870&q=80");
}
.item2 {
background-image: url("https://images.unsplash.com/photo-1501862700950-18382cd41497?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=519&q=80");
}
.item3 {
background-image: url("https://images.unsplash.com/photo-1536697246787-1f7ae568d89a?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MzR8fHNwYWNlfGVufDB8fDB8fA%3D%3D&auto=format&fit=crop&w=500&q=60");
}
.item4 {
background-image: url("https://images.unsplash.com/photo-1620712943543-bcc4688e7485?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8OHx8QUl8ZW58MHx8MHx8&auto=format&fit=crop&w=500&q=60");
}
.item5 {
background-image: url("https://images.unsplash.com/photo-1673901736622-c3f06b08511f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&auto=format&fit=crop&w=874&q=80");
}
```
* We created a flexible container, then we set the container's wrap value to nowrap to arrange the carousel items in a single row, with overflow hidden hiding the remaining items in the row. * When the carousel item's min-width is set to 100%, the other items will be hidden and will occupy the entire width. In order to position the carousel text at the bottom center, I adjusted its position to absolute with relative to carousel items.
* Set a different background picture for each carousel item by using the item-* class name for each item independently.
# Javascript -
```js
const carouselItems = document.querySelectorAll(".carousel_item");
let i = 1;
setInterval(() => {
// Accessing All the carousel Items
Array.from(carouselItems).forEach((item,index) => {
if(i < carouselItems.length){
item.style.transform = `translateX(-${i*100}%)`
}
})
if(i < carouselItems.length){
i++;
}
else{
i=0;
}
},2000)
```
* Using setInterval, the condition is run every two seconds. If the value of i is fewer than the number of carousel items, then all of the carousel items should be moved 100% to the left.
* Increase the value of i by one if it is less than the number of items on the carousel. In the event that it exceeds the number of carousel elements, set the value of i to 0.
THANK YOU FOR CHECKING THIS POST
You can contact me on -
Instagram - https://www.instagram.com/supremacism__shubh/
LinkedIn - https://www.linkedin.com/in/shubham-tiwari-b7544b193/
Email - shubhmtiwri00@gmail.com
^^You can help me with some donation at the link below Thank you👇👇 ^^
☕ --> https://www.buymeacoffee.com/waaduheck <--
Also check these posts as well
https://dev.to/shubhamtiwari909/css-iswherehas-and-not-2afd
https://dev.to/shubhamtiwari909/theme-changer-with-html-and-css-only-4144
https://dev.to/shubhamtiwari909/swiperjs-3802
https://dev.to/shubhamtiwari909/going-deep-in-array-sort-js-2n90
| shubhamtiwari909 |
1,332,339 | Build a Node.js Payment Gateway with Rapyd | By James Olaogun With the increase of digital payment transactions across the globe, payment... | 0 | 2023-01-17T18:14:40 | https://community.rapyd.net/t/build-a-node-js-payment-gateway-with-rapyd | paymentapi, node, tutorial | *By James Olaogun*
With the increase of digital payment transactions across the globe, *payment gateways* are becoming a familiar feature of every online shop. Used by clients to accept digital payment methods, payment gateways can usually accommodate local and international credit or debit cards, eWallets, bank transfers, and even sometimes cash.
In this article, I’ll walk you through a step-by-step tutorial for integrating a payment gateway called [Rapyd Collect](https://www.rapyd.net/products/payments/api/) into any of your Node.js applications.
But before I go into the tutorial, let me tell you a bit about Rapyd Collect.
## What is Rapyd Collect?
Rapyd Collect is a payment gateway platform that enables businesses and individuals (clients) to accept payment fast, easily, securely, globally, and via multiple channels. Its security while managing sensitive information is assured with a [Level 1 service provider certification](https://docs.rapyd.net/en/information-security.html).
While Rapyd supports a variety of payment options, including checkout, invoicing, and subscription, the main emphasis of this tutorial will be Rapyd checkout. It’s the easiest way to accept payments via your website or mobile app, and you can incorporate it as hosted or as a toolkit.
The toolkit integration is embedded in your website as an iframe, and the hosted integration sends your clients to a page hosted on Rapyd servers. I'll be using the hosted technique in this tutorial.
## What You Need to Start
Before we dive into the process of building a Node.js payment gateway, there are a few requirements you must meet:
- Basic knowledge of Node.js
- Node installed on your local machine
- Basic knowledge of Express.js
- Basic knowledge of a database (this tutorial uses PostgreSQL, but feel free to use any database of your choice. Just make sure it’s installed on your local machine)
- Knowledge of HTML/CSS/JS
- A [Rapyd Collect Account](https://dashboard.rapyd.net/sign-up)
## How to Set Up Node.js
Having met all these requirements, let’s get started.
Set up Node.js by creating a new directory called `rapyd-nodejs` in your desired folder.
### 1. Initialize a New Node Application
Open your terminal or CLI and run the following command to create and enter the new directory:
```
mkdir rapyd-nodejs && cd rapyd-nodejs
```
Initialize a new node application from the `rapyd-nodejs` directory.
> Note that for the purpose of this tutorial, I’m using node version 16.13.0 and npm version 8.1.0. You can make use of [Node Version Manager (NVM)](https://github.com/nvm-sh/nvm) to manage and use this exact version of node and npm. Follow this [guide](https://www.freecodecamp.org/news/node-version-manager-nvm-install-guide) for a step-by-step tutorial on how to use NVM.
Run the following command to initialize a new node application:
```
npm init
```
The command will also walk you through creating a `package.json` file. It will ask you for the package name, version, description, entry point, test command, git repository, keywords, author, and license.
Some of these requests come with a default adoption in brackets. Click **Enter** to go with the default option; the others are blank, but you can add a value or just press **Enter** to leave it blank. You can always edit the `package.json` file.
### 2. Install Required Node Packages
The required dependencies for this tutorial include `express`, `dotenv`, `pg`, `body-parser`, and `ejs`. Run the following command from the root directory of the application to install the modules:
```
npm install express dotenv pg body-parser ejs
```
Set up the application directory structure. Create the following directories and files in the root the `rapyd-nodejs` directory:
- `/Model`
- `/Controller`
- `/Config`
- `/Views`
- `/Routes/index.js`
- `Public/css`
- `Public/js`
- `/Helpers`
Also, create `.env` and `index.js` files (the `index.js` file will be the entry point of the application; it can also be named `app.js` or `main.js`) in the root folder of the application from which the application would be served. Your application directories should now look like the following screenshot:

Add the application `PORT` and `NODE_ENV` variable to your `.env` file, as in this example:
```
NODE_ENV=development
PORT={{Any_port_number _of_your_choice}}
```
Go to `/Config` and create a `server.js` file. Add the block of code below to the `server.js` file:
```
const express = require('express');
const app = express();
module.exports = app;
```
Add the following block of code to the `index.js` file (at the root of your project):
```
const app = require('./Config/server');
const dotEnv = require('dotenv')
dotEnv.config()
const port = process.env.PORT || {{YOUR_PORT_NUMBER}}; // replace `{{YOUR_PORT_NUMBER}}` with the port number you used in the `.env` file.
app.listen(port, () => {console.log(`App listening on port ${port}`)})
```
### 3. Set Up the Development Server
Next, install [nodemon](https://www.npmjs.com/package/nodemon) to help monitor, reload, and serve the application when it notices any changes. Run the following command to install nodemon as a dev dependency into the application:
```
npm install --save-dev nodemon
```
To run the application, open the `package.json` file and add the code block below to the `"scripts": {}` section (that should be line number 6):
```
"start": "node index.js",
"dev": "nodemon index.js",
```
Open your CLI or terminal, change directory to the root folder of the application, and run `npm run dev` to start the application in dev mode. You should see something like the following screenshot:

## How to Set Up the Database
Now it’s time to set up the database connection. As stated in the introduction, I’ll be making use of PostgreSQL. Follow this [guide](https://www.postgresql.org/download/) to install PostgreSQL if you plan to use it, too.
### 1. Create the Database Config File
To connect the database to the application, create a new file called `db-config.js` in the `/Config` folder. Then add the following code to the `db-config.js` file:
```
const dotEnv = require('dotenv');
const postgres = require('pg');
const { Pool } = postgres;
dotEnv.config()
const dbConfig = {
user: process.env.DB_USER,
host: process.env.DB_HOST,
database: process.env.DB_NAME,
password: process.env.DB_PASSWORD,
port: process.env.DB_PORT
}
const pool = new Pool(dbConfig)
module.exports = pool;
```
### 2. Create a New Database in PostgreSQL
Create a new database called `rapyd_node`, set its user and password, and create a table named `checkout_details` with the following column and constraints:
```
CREATE TABLE checkout_details(
id SERIAL PRIMARY KEY,
full_name varchar(255) NOT NULL,
email varchar(255) NOT NULL,
full_address TEXT NOT NULL,
amount DOUBLE PRECISION NOT NULL,
reference varchar(255) NOT NULL,
product_details varchar(225) NOT NULL,
meta_data TEXT NULL,
status varchar(11) NOT NULL,
created_at TIMESTAMP NOT NULL
);
```
Head back to the `.env` and add the database variable. See the following code:
```
DB_USER='postgres'
DB_HOST='localhost'
DB_NAME={{database_name}}
DB_PASSWORD={{db_password}}
DB_PORT={{postgres_db_port}}
```
Where `{{database_name}}` is `rapyd_node`, `{{db_password}}` is the password set for the database user (the default password is most often an empty string), and `{{postgres_db_port}}` is the database port (the default port number is 5432).
### 3. Test the Database Connection
To test the database connection, add the following code to the `index.js`:
```
const pool = require('./Config/db-config');
var sql = `SELECT * FROM checkout_details`
pool.query(sql, (error, response) => {
if (error) return console.log(error);
console.log(response.rows);
}
)
```
Save the file, and if you’ve deactivated the nodemon server, run `npm run dev`. It should output an empty array to the terminal.
## How to Develop the Application Interface
Congrats! By now, you’ve set up the node application and database. Next up, add the application interface.
### 1. Create the Interface File
Go to the `/Views` folder and create a new file called `checkout.ejs`. Add the following code to the file:
```
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Product Checkout</title>
<link rel="stylesheet" href="https://codepen.io/gymratpacks/pen/VKzBEp#0">
<link href='https://fonts.googleapis.com/css?family=Nunito:400,300' rel='stylesheet' type='text/css'>
<link rel="stylesheet" href="public/css/style.css">
</head>
<body>
<div class="row">
<div class="col-md-12">
<form id="checkoutForm">
<h1> Product Checkout </h1>
<h3>
Item: <%= product_name %>
<br>
<span class="price"> Price: <%= price %> </span>
</h3>
<fieldset>
<label for="name">Full Name:</label>
<input type="text" required id="u_full_name" name="user_full_name">
<label for="email">Email:</label>
<input type="email" required id="user_email" name="user_email">
<label for="name">Full Address:</label>
<textarea id="user_full_address" required name="user_full_address"></textarea>
</fieldset>
<button type="submit" id="notloading">Checkout</button>
<button type="button" style="display: none;" id="loading">Loading......</button>
</form>
</div>
</div>
</body>
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.3.1/jquery.min.js"></script>
<script src="public/js/ajax-script.js"></script>
</html>
```
Create a `/Public` folder in the root directory of the application. In the `/Public` folder, create `/css` and `/js` folders.
Go to `/Config/server.js` and add `app.use('/Public', express.static('public'));` above the `module.exports = app;`.
In the `/Public/css` folder, create a new stylesheet called `style.css`. Paste the following code into the file:
```
*, *:before, *:after {
-moz-box-sizing: border-box;
-webkit-box-sizing: border-box;
box-sizing: border-box;
}
body {
font-family: 'Nunito', sans-serif;
color: #384047;
}
form {
max-width: 300px;
margin: 30px auto;
padding: 10px 20px;
background: #f4f7f8;
border-radius: 8px;
}
h1, h2, h3 {
margin: 0 0 30px 0;
text-align: center;
}
input[type="text"],
input[type="email"],
input[type="number"],
textarea,
select {
background: rgba(255,255,255,0.1);
border: none;
font-size: 16px;
height: auto;
margin: 0;
outline: 0;
padding: 15px;
width: 100%;
background-color: #e8eeef;
color: #8a97a0;
box-shadow: 0 1px 0 rgba(0,0,0,0.03) inset;
margin-bottom: 30px;
}
input[type="radio"],
input[type="checkbox"] {
margin: 0 4px 8px 0;
}
select {
padding: 6px;
height: 32px;
border-radius: 2px;
}
.price{
color: #4bc970;
}
button {
padding: 19px 39px 18px 39px;
color: #FFF;
background-color: #4bc970;
font-size: 18px;
text-align: center;
font-style: normal;
border-radius: 5px;
width: 100%;
border: 1px solid #3ac162;
border-width: 1px 1px 3px;
box-shadow: 0 -1px 0 rgba(255,255,255,0.1) inset;
margin-bottom: 10px;
cursor: pointer;
}
fieldset {
margin-bottom: 30px;
border: none;
}
legend {
font-size: 1.4em;
margin-bottom: 10px;
}
label {
display: block;
margin-bottom: 8px;
}
label.light {
font-weight: 300;
display: inline;
}
@media screen and (min-width: 480px) {
form {
max-width: 480px;
}
}
```
In the `/Public/js` folder, create a new JavaScript file called `ajax-script.js`. Paste the following code into the file:
```
$(document).ready(function() {
$("#checkoutForm").submit(function(e){
e.preventDefault()
$("#notloading").hide()
$("#loading").show()
$.ajax('/create-checkout', {
type: 'POST',
data: {
'u_full_name': $("#u_full_name").val(),
'user_email': $("#user_email").val(),
'user_full_address': $("#user_full_address").val(),
},
success: function (data, status, xhr) {
window.location.href = data.data.redirect_url;
},
error: function (jqXhr, textStatus, errorMessage) {
$("#notloading").show()
$("#loading").hide()
console.log('Error' + errorMessage);
}
});
});
})
```
### 2. Set Up the Route
First, import the route script into the `index.js` file by adding `require('./Routes/index')` to the `index.file`.
Add the following code to the `/Routes/index.js` file:
```
const app = require('../Config/server')
const path = require('path');
const dotEnv = require('dotenv');
dotEnv.config()
app.set('views', path.join(__dirname, '../Views'))
app.set('view engine', 'ejs')
app.get('/', function(req, res){
var price = 3000 / 100
res.render('Checkout', {
product_name: 'Gold Digger',
price: '$'+price.toFixed(2)
})
})
```
Save all files, and if you’ve deactivated the nodemon server, run `npm run dev`. Proceed to your browser and load the application via `http://127.0.0.1:{{your_port_number}}`. It should look like this:

Kudos to you if you’ve gotten to this stage! I’d recommend that you initiate git and commit your changes so far. Ensure that you git ignore the `.env` file and the `/node_modules` folder.
## How to Develop the Payment Module
This is the final and most important process of the development of the application. We’ll integrate the Rapyd Collect API into the application, enabling it to accept payment from all over the world.
### 1. Set Up a Rapyd Account
Log in to your Rapyd account.
There are two environments in Rapyd, namely *production* and *sandbox*. The sandbox environment is not used to process real transactions; it’s mainly for testing purposes. Go to the top right of your Rapyd dashboard to activate the sandbox environment.

### 2. Customize the Checkout Page
Go to the sidebar and click **Settings > Branding**. Here, customize your hosted Rapyd checkout page to fit your requirements.
You can change the logo, color, and text to reflect your brand. Specify the redirect URL that the checkout page directs your user to after a successful transaction is completed. Decide which payment method to utilize.
> In this tutorial, we’ll only use and test the card payment method.

Please note that Rapyd will not allow you to use a fallback URL containing or similar to `localhost`. You’ll have to create a new test domain and attach the port number. In my case, I used `http://rapyd-demo.test:3153/`.
> Visit this [guide](https://www.basezap.com/setting-up-virtual-hosts-on-windows-linux-and-macos/) to learn how to add a new test domain to the virtual host on your local computer.
### 4. Grab Your API Keys
Go to the sidebar and click **Developers > Credentials Details** to see your access and secret key.

### 5. Connect Your Node Application to the Rapyd Server
To connect the Rapyd server to your application, install `https` by running `npm install https` in the root directory of your application.
Go to the `/Model` folder and create a new file called `DBQueries.js`. Paste the code below into the file. The code block exports a class that has a generic function for the creation of new checkout records in the database.
```
const pool = require('../Config/db-config');
const DEFAULT_PROPERTIES = {
status: 'In Progress',
created_at: new Date(Date.now()),
}
class DBQueries {
constructor(){
}
static create(entry){
const {full_name, email, full_address, amount, reference, product_details, meta_data} = entry;
return new Promise((resolve, reject) => {
pool.query(
`INSERT INTO checkout_details(full_name, email, full_address, amount, reference, product_details, meta_data, status, created_at)
VALUES($1, $2, $3, $4, $5, $6, $7, $8, $9)`,
[full_name, email, full_address, amount, reference, product_details, meta_data, DEFAULT_PROPERTIES.status, DEFAULT_PROPERTIES.created_at],
(error, response) => {
if (error) return reject(error);
resolve(response)
});
})
}
}
module.exports = DBQueries;
```
Go to the `/Controller` folder and create a new file called `checkoutController.js`. Paste the code block below into the file; it receives the checkout form request from the route and sends a payment request to the Rapyd API using the `makeRequest` function from `rapydUtilities.js`. It also uses the generic function from `DBQueries.js` to create a record in the database. Finally, it sends the response from Rapyd API back to the frontend interface.
```
const {makeRequest} = require('../Helpers/rapydUtilities')
const DBQueries = require('../Model/DBQueries')
class checkoutController{
constructor(){
}
static createCheckout(request, response, next){
const {u_full_name, user_email, user_full_address} = request.body
var price = 3000 / 100
price = price.toFixed(2)
const body = {
amount: 30.00,
country: 'US',
currency: 'USD',
language: 'en',
metadata: {
u_full_name: u_full_name,
user_email: user_email,
user_full_address: user_full_address,
},
};
makeRequest('POST', '/v1/checkout', body).then((data)=>{
const entry = {
full_name: u_full_name,
email: user_email,
full_address: user_full_address,
amount: price * 100,
reference: data.body.data.id,
product_details: 'Gold Digger',
meta_data: data.body.data
};
DBQueries.create(entry)
.then((entry) => {
return response.json({status: 200, message: 'checkout created', data: data.body.data});
}).catch((error)=>{
console.log('error: ',error);
});
})
.catch((error)=>{
console.log('error: ',error);
});
}
}
module.exports = checkoutController;
```
Go to the `/Helpers` folder and create a new file called `rapydUtilities.js`. Paste the following code into the file; it contains all the core functions used to integrate (make requests to) the Rapyd Collect API:
```
const https = require('https');
const crypto = require('crypto');
const dotEnv = require('dotenv');
dotEnv.config()
const secretKey = process.env.SECRETE_KEY;
const accessKey = process.env.ACCESS_KEY;
const log = false;
async function makeRequest(method, urlPath, body = null) {
try {
httpMethod = method;
httpBaseURL = "sandboxapi.rapyd.net";
httpURLPath = urlPath;
salt = generateRandomString(8);
idempotency = new Date().getTime().toString();
timestamp = Math.round(new Date().getTime() / 1000);
signature = sign(httpMethod, httpURLPath, salt, timestamp, body)
const options = {
hostname: httpBaseURL,
port: 443,
path: httpURLPath,
method: httpMethod,
headers: {
'Content-Type': 'application/json',
salt: salt,
timestamp: timestamp,
signature: signature,
access_key: accessKey,
idempotency: idempotency
}
}
return await httpRequest(options, body, log);
}
catch (error) {
console.error("Error generating request options");
throw error;
}
}
function sign(method, urlPath, salt, timestamp, body) {
try {
let bodyString = "";
if (body) {
bodyString = JSON.stringify(body);
bodyString = bodyString == "{}" ? "" : bodyString;
}
let toSign = method.toLowerCase() + urlPath + salt + timestamp + accessKey + secretKey + bodyString;
log && console.log(`toSign: ${toSign}`);
let hash = crypto.createHmac('sha256', secretKey);
hash.update(toSign);
const signature = Buffer.from(hash.digest("hex")).toString("base64")
log && console.log(`signature: ${signature}`);
return signature;
}
catch (error) {
console.error("Error generating signature");
throw error;
}
}
function generateRandomString(size) {
try {
return crypto.randomBytes(size).toString('hex');
}
catch (error) {
console.error("Error generating salt");
throw error;
}
}
async function httpRequest(options, body) {
return new Promise((resolve, reject) => {
try {
let bodyString = "";
if (body) {
bodyString = JSON.stringify(body);
bodyString = bodyString == "{}" ? "" : bodyString;
}
log && console.log(`httpRequest options: ${JSON.stringify(options)}`);
const req = https.request(options, (res) => {
let response = {
statusCode: res.statusCode,
headers: res.headers,
body: ''
};
res.on('data', (data) => {
response.body += data;
});
res.on('end', () => {
response.body = response.body ? JSON.parse(response.body) : {}
log && console.log(`httpRequest response: ${JSON.stringify(response)}`);
if (response.statusCode !== 200) {
return reject(response);
}
return resolve(response);
});
})
req.on('error', (error) => {
return reject(error);
})
req.write(bodyString)
req.end();
}
catch(err) {
return reject(err);
}
})
}
exports.makeRequest = makeRequest;
```
After adding all these files, import the Body parser and the checkoutController to the route file (`/Routes/index.js`) and also configure express to use `body-parser`.
```
const bodyParser = require('body-parser');
const checkoutController = require('../Controller/checkoutController')
app.use(bodyParser.urlencoded({extended: true}));
app.use(bodyParser.json());
```
Create a new post route to accept the form request. The post route will send the form data to the checkoutController.
```
app.post('/create-checkout', (req, res, next) => {checkoutController.createCheckout(req, res, next)})
```
Finally, go back to your `.env` file and add your Rapyd secret and access key, like so:
```
SECRETE_KEY={{YOUR_SECRET_KEY}}
ACCESS_KEY={{YOUR_ACCESS_KEY}}
```
Save all the files and run the `npm run dev` to start the nodemon server.
## How to Demonstrate the Application
Congratulations for getting to this stage! Now go to your browser and load the application via `http://127.0.0.1:{{YOUR_PORT_NUMBER}}`.
Fill out the checkout form.

Click **Checkout**. It should send the request to Rapyd and redirect you to the payment page.

Use the following test card info to make a payment:
- Card number: 4111 1111 1111 1111 (Mastercard)
- Expiration date: Any date in the future.
- CVV: Any three-digit number. (e.g. 123)
- Cardholder name: Any name
Click **Place your Order**. You should see a success page like this:

Click **Finish**. You should be redirected to the `{{redirection_url}}` you added when you were customizing the checkout page.
To see the payment you just made and other previous payments, navigate back to your Raypd Client Portal. Go to the sidebar and click **Collect > Payments**, as shown in the screenshot below.
> Remember to toggle to the sandbox environment.

To get back the details about the accepted payment, you have to set up a webhook that will receive all the notifications about payment status from Rapyd and update your record accordingly. Learn more about webhook and payment status in the [official documentation](https://docs.rapyd.net/en/payment-succeeded-webhook.html).
## Get Support
This article provided a quick overview of Rapyd and its capabilities, as well as a step-by-step tutorial for implementing the Rapyd Collect API checkout page in a Node.js application. You can see payment history, edit the checkout page, and switch between production and sandbox environments. You can access the [complete code](https://github.com/Rapyd-Samples/nodejs-payment-gateway-integration-with-rapyd) for this tutorial on GitHub.
Rapyd provides a fast, secure, and reliable payment gateway solution that can power both local and international business transactions. It supports more than 900 payment methods, and more than 65 currencies in hundreds of countries. If you’re looking to start your integration, you can get started by signing up the [Client Portal](https://dashboard.rapyd.net/sign-up), and follow the [get started guide](https://docs.rapyd.net/en/get-started.html). | kylepollock |
1,332,394 | Refatorando Ifs Aninhados com Chain of Responsibility | Funções ideais Num mundo ideal funções são pequenas, muito bem definidas, possuem uma... | 21,459 | 2023-01-22T16:00:00 | https://dev.to/abelsouzacosta/refatorando-ifs-aninhados-com-chain-of-responsibility-4l7p | designpatterns, typescript, tutorial, javascript | ## Funções ideais
Num mundo ideal funções são pequenas, muito bem definidas, possuem uma única responsabilidade e não crescem, mas no mundo real isso não é uma realidade, funções tendem a crescer, mesmo que tenham uma única função de fato.
Imagine uma função de uma aplicação veterinária que deve dizer ao usuário qual comida é adequada para um determinado animal, de forma simples a função seria mais ou menos dessa forma:
```ts
function properFoodForAnimal(anAnimal: string): string {
let food;
if ("dog" === anAnimal.toLowerCase()) food = "beef meat";
if ("cat" === anAnimal.toLowerCase()) food = "fish meat";
if ("owl" === anAnimal.toLowerCase()) food = "rat meat";
if ("monkey" === anAnimal.toLowerCase()) food = "banana";
if ("horse" === anAnimal.toLowerCase()) food = "corn";
return `Animal ${anAnimal} will eat ${food}`;
}
```
Note que a medida em que a veterinária "expandir o seu mercado" e novos animais forem atendidos essa função tende a crescer ganhando novos `ifs`.
Para evitar que isso aconteça podemos aplicar o design pattern _chain of responsibility_.
## Chain of Responsibility
É um padrão de projeto comportamental muito utilizado quando temos uma cadeia (_chain_) de situações que lidam com o mesmo escopo como a escolha de uma comida, calculo de um preço, filtragem de campos dentre outras.
Esse padrão permite que vários objetos manipulem a solicitação sem que haja acoplamento entre o trecho de código que envia a requisição e seus receptores. Podemos facilmente identificar esse padrão no nosso código através da interface a qual a solução é implementada.
```ts
interface Handler {
setNext(handler: Handler): Handler;
handle(request: string): string;
}
```
## Procedimento
Sempre que vamos começar a refatorar um trecho de código temos de nos certificar que aquele trecho possui uma suite de testes robusta que vai nos assegurar de não causar nenhum bug, então a primeira coisa que vamos fazer é justamente escrever os testes para a função.
```ts
describe("Proper food for animal", () => {
it("should return the correct phrase containing the proper for a dog", () => {
let phrase = properFoodForAnimal("dog");
expect(phrase).toBe("Animal dog will eat beef meat");
});
it("should return the correct phrase containing the proper for a cat", () => {
let phrase = properFoodForAnimal("cat");
expect(phrase).toBe("Animal cat will eat fish meat");
});
it("should return the correct phrase containing the proper for a owl", () => {
let phrase = properFoodForAnimal("owl");
expect(phrase).toBe("Animal owl will eat rat meat");
});
it("should return the correct phrase containing the proper for a monkey", () => {
let phrase = properFoodForAnimal("monkey");
expect(phrase).toBe("Animal monkey will eat banana");
});
it("should return the correct phrase containing the proper for a horse", () => {
let phrase = properFoodForAnimal("horse");
expect(phrase).toBe("Animal horse will eat corn");
});
});
```
Escritos os testes iniciamos a refatoração, primeiramente criando a interface `AnimalFoodHandler` que é nada além da interface genérica do pattern apresentada anteriormente.
```ts
interface ProperFoodHandler {
setNext(handler: ProperFoodHandler): ProperFoodHandler;
handle(anAnimal: string): string;
}
```
Pode parecer desnecessário a primeira vista nomear essa interface de forma tão específica uma vez que a proposta é que ela seja genérica, mas isso impede outros programadores de aplicar handlers não adequados para aquela situação já que o intellisense do ts avisará que os objetos não são do mesmo tipo.
O próximo passo então é criarmos as classes handlers para cada animal que temos no código hoje, como todo handler possui a mesma estrutura e lida com o mesmo domínio podemos fazer o uso de herança e polimorfismo para deixar o nosso código ainda mais claro. Vamos criar uma classe abstrata de handler da qual se derivarão as classes filhas.
```ts
export class AbstractFoodHandler implements IFoodHandler {
private nextHandler: IFoodHandler | undefined;
next(handler: IFoodHandler): IFoodHandler {
this.nextHandler = handler;
return handler;
}
handle(anAnimal: string): string | null {
if (this.nextHandler) {
return this.nextHandler.handle(anAnimal);
}
return null;
}
}
```
Agora podemos ter handlers concretos derivado da classe abstrata de forma com que haja um handler para cada situação, assim sendo temos
`DogFoodHandler.ts`
```ts
export class DogFoodHandler extends AbstractFoodHandler {
handle(anAnimal: string): string | null {
if ("dog" === anAnimal.toLowerCase())
return `Animal dog will eat beef meat`;
return super.handle(anAnimal);
}
}
```
`CatFoodHandler.ts`
```ts
export class CatFoodHandler extends AbstractFoodHandler {
handle(anAnimal: string): string | null {
if ("cat" === anAnimal.toLowerCase())
return `Animal cat will eat fish meat`;
return super.handle(anAnimal);
}
}
```
`OwlFoodHandler.ts`
```ts
export class OwlFoodHandler extends AbstractFoodHandler {
handle(anAnimal: string): string | null {
if ("owl" === anAnimal) return `Animal owl will eat rat meat`;
return super.handle(anAnimal);
}
}
```
`MonkeyFoodHandler.ts`
```ts
export class MonkeyFoodHandler extends AbstractFoodHandler {
handle(anAnimal: string): string | null {
if ("monkey" === anAnimal.toLowerCase())
return `Animal monkey will eat banana`;
return super.handle(anAnimal);
}
}
```
`HorseFoodHandler.ts`
```ts
export class HorseFoodHandler extends AbstractFoodHandler {
handle(anAnimal: string): string | null {
if ("horse" === anAnimal.toLowerCase()) return `Animal horse will eat corn`;
return super.handle(anAnimal);
}
}
```
Ainda podemos criar um arquivo `index.ts` para facilitar a exportação de arquivos.
```ts
import { CatFoodHandler } from "./CatFoodHandler";
import { DogFoodHandler } from "./DogFoodHandler";
import { MonkeyFoodHandler } from "./MonkeyFoodHandler";
import { OwlFoodHandler } from "./OwlFoodHandler";
import { HorseFoodHandler } from "./HorseFoodHandler";
const catHandler = new CatFoodHandler();
const monkeyHandler = new MonkeyFoodHandler();
const owlHandler = new OwlFoodHandler();
const horseHandler = new HorseFoodHandler();
const handler = new DogFoodHandler();
handler
.next(catHandler)
.next(owlHandler)
.next(monkeyHandler)
.next(horseHandler);
export { handler };
```
O código final da nosssa aplicação ficará assim:
```ts
export function properFoodForAnimal(anAnimal: string): string | null {
return handler.handle(anAnimal);
}
```
Assim, se quisermos adicionar uma nova condição dentro desse fluxo de código basta criarmos uma nova classe concreta de Handler, inicializá-la e colocá-la na cadeia dentro do arquivo `index.ts`.
[Código fonte](https://github.com/abelsouzacosta/chain-of-responsibility-example) | abelsouzacosta |
1,332,627 | Go Memory Allocation | What is memory allocation Memory allocation is the process of how programming languages... | 0 | 2023-01-18T01:43:19 | https://dev.to/zaf07/go-memory-allocation-2n4m | ## What is memory allocation
Memory allocation is the process of how programming languages store or keep track of in-memory data like variables, arguments or any other data in your program’s runtime.
There are two places where the runtime keeps track of memory; `Heap` & `Stack`
## Heap
A `Heap` *(same name as the data structure but not related at all)* is a portion of physical memory on your machine where global variables, arguments or any data used by the runtime is stored. `Heaps` are generally shared by the entire program meaning that all `stacks` have access to data stored in the `heap`.
Data in the `heap` stays in the `heap` until it is freed or your program terminates.
Go has a`Garbage Collector` and it is responsible for freeing up unused data in the `heap` automatically for us *(we can manipulate this behaviour with the `runtime` package)*
## Stack
`Stack` is a short lived memory space to store data that is local to a function or a thread (`goroutine`).
Memory in the stack are removed once the function or `goroutine` returns/terminates.
Any new memory that is created inside of a `stack` that is passed and used outside of the stack (********************passed up the stack********************) is said to have `escaped to the heap`. This is when the memory is “transferred” over to the `heap` from the stack.
## Passing down the stack
`Passing down the stack` refers to passing an `address of a variable` instead of the value of the variable itself down to a function.
Example of Passing down the stack
```go
package main
func main() {
num := 2
add(&num)
}
func add(i int) {
result := *i + 10
return result
}
```
## Passing up the stack
`Passing up the stack` refers to passing an `address of a variable` instead of the value of the variable itself up/outside the function.
Example of passing up the stack:
```go
package main
func main() {
num := getNum()
}
func getNum() int {
number := 7
// This causes the variable number to be moved to the heap
return &number
}
``` | zaf07 | |
1,332,692 | Use the network tab a lot when Ajaxifying to understand what is happening in the code | A post by bomoniyi | 0 | 2023-01-18T02:45:49 | https://dev.to/bomoniyi/use-the-network-tab-a-lot-when-ajaxifying-to-understand-what-is-happening-in-the-code-44m9 | bomoniyi | ||
1,332,713 | Does MERN Stack Make Sense in 2023? | When thinking about building a web application, the MERN stack is often the first choice for many... | 0 | 2023-01-18T04:08:37 | https://www.locofy.ai/blog/mern-stack-in-2023 | webdev, javascript, programming, beginners | When thinking about building a web application, the MERN stack is often the first choice for many developers.
With this technology stack, a developer may create a full-stack web application with JavaScript as the fundamental language, which makes it easier to use, and has a broad range of uses.
All the technologies present in the MERN stack complement each other and dominate the market in their respective domains — making this stack a popular option among developers.
But will it still make sense in 2023? Let’s explore.
## MERN Stack: A Powerful Tech Stack for Web Development
MERN Stack is built with four main technologies i.e. [MongoDB](https://www.mongodb.com/), [Express](https://expressjs.com/), [React](https://reactjs.org/), and [Node.js](https://nodejs.org/en/).
### MongoDB
The web application’s data is kept in a NoSQL database called MongoDB. Here, the data is kept in a semi-structured BSON (Binary JSON) format since it is a document-based database, as opposed to a fixed-column format like a conventional relational database.
Due to its increased flexibility, MongoDB is better able to handle massive volumes of unstructured data. Additionally, it is capable of horizontal scalability, which enables it to accommodate growing demands by introducing additional servers.
### Express.js
Running on top of Node.js is the back-end web application framework known as Express.js. It offers a set of powerful tools for managing routing, middleware, and other typical back-end activities — streamlining the process of developing and delivering online applications. Moreover, it provides a simple method for managing CORS, cookies, and other web-related functionality needed by web applications.
### React.js
A JavaScript library called React is used to create user interfaces. It is a game changer in the frontend space as it enables programmers to design reusable, dynamic user interface (UI) components that may be quickly combined to produce complex user interfaces.
React also employs a virtual DOM (Document Object Model) to streamline updates and reduce the amount of work required by the browser to update the user interface. Because of this, it is very effective and simple to use, even for complicated applications.
### Node.js
A JavaScript runtime called Node.js enables programmers to execute JavaScript on the server side. Employing the enormous ecosystem of npm modules and the strength of JavaScript, it allows developers to create quick, scalable, and high-performance web applications. Real-time data communication is another benefit of Node.js that is required by most web applications.
These four components of the MERN Stack are simple to master, and it is even simpler to create web apps using them. When combined, they complement each other and create a robust full-stack app with support for APIs, caching, real-time events, and also client-side rendering.
## The Key Factors That Make MERN Stand Out
MERN stack is popular for a variety of reasons, including:
- **JavaScript for both front-end and back-end:** Developers may create a web application using only one programming language, JavaScript, for both the front-end and back-end.
- **Shallow learning curve:** Because there is just one programming language to learn, it is easy to learn and implement.
- **Community support:** Every technology in this stack is popular and loved by developers, hence you will find a massive number of communities centered around them. This makes debugging issues easier and more resources to get started with.
- **A large number of packages, and libraries:** The MERN stack provides an extensive collection of library and package support that allows developers to construct applications in less time.
- **Flexibility and Scalability:** This technology combination provides a high level of flexibility and scalability, making it suitable for a wide range of use cases, from tiny startups to major companies.
All of these factors contribute to MERN’s popularity and widespread use in the development of web applications.
## How does MERN Stack Perform in 2023?
MERN Stack is essentially a tech stack that enables developers to build & connect front-end and backend. However, frameworks like Next.js and Gatsby have also spun up lately that do the same, and even offer a much more elegant way to connect server-side functions to the front end.
With these frameworks, you can easily build a serverless architecture, and API endpoints, and even manage how the individual pages are rendered with Next.js. Likewise, it becomes simple to utilize and create front-end applications with Gatsby or Svelte.
What’s more, is that Express.js is also facing stiff competition from the likes of Fastify which [performs twice as fast as Express.js](https://www.educative.io/answers/fastify-vs-express). MongoDB is also competing with other NoSQL databases like Cassandra and Couchbase.
Even though all these points may make MERN sound obsolete but it’s far from the truth. To be more precise, the MERN tech stack’s future is promising since the underlying technologies will keep developing and gaining popularity.
One of the biggest advantages of MERN over other frameworks is the easier integration of a database and also the fact that you get a full-fledged Express.js and Node.js server which makes backend operations such as WebSockets and authentication seamless. Moreover, since React renders on the client side, you get fewer server calls and the performance is high when compared to other server-side rendering frameworks.
However, even if you use Next.js, Gatsby, or any other framework over MERN, you will still be dealing with creating aesthetically pleasing websites that are also responsive. This process is tedious and the designer-developer handoff is not always seamless.
This is where [Locofy.ai](https://www.locofy.ai/) can come in handy. The Locofy.ai plugin for Figma and Adobe XD can accelerate the frontend development process and convert your designs file directly into production-ready React, React Native, Gatsby, Next.js, and HTML-CSS code.
The code is not only highly extensible but you can also customize it to include TypeScript, TailwindCSS, UI libraries, and much more.
[Build pixel-perfect frontend code using Locofy.ai for free!](https://www.locofy.ai/signup)
Hope you like it.
That’s it — thanks.
| nitinfab |
1,332,926 | Creating Singleton Classes with Typescript and Proxies | In general, it is my opinion that the best way to implement a singleton in Javascript is to just use... | 0 | 2023-01-18T09:13:04 | https://dev.to/bradennapier/creating-singleton-classes-with-typescript-and-proxies-1om1 | typescript, node, tutorial | > In general, it is my opinion that the best way to implement a **singleton** in Javascript is to just use plain objects. They can easily and precisely provide all the functionality of classes without all the mess. However, this isn't always an option and classes are everywhere in the Typescript world, so lets play.
> Consider this a fun experimental way to play with the powerful `Proxy` object in Javascript/Typescript.
I have seen a few articles discussing how one might implement the [Singleton Pattern](https://en.wikipedia.org/wiki/Singleton_pattern) with Typescript.
In most cases, they have involved adding certain static fields to any class you wish to use as a singleton which becomes tedious.
I will not be able to explain the benefits of using Singletons better than the many articles out there already available, here is one that uses the "standard" method that describes all the benefits clearly:
- [Design Patterns: Singleton in Typescript](https://levelup.gitconnected.com/design-patterns-singleton-pattern-in-typescript-e98ec08a9c14)
> Kudos to him for at least pointing out that in the end, the best option is usually to just use plain objects. This is almost always cleaner!
## Standard Methods
### Construct / Export on Startup
```typescript
class MyClassCtor {
}
export const myInstance = new MyClassStor()
```
But this means that just by importing the file this class will get created (including any initialization built into the constructor).
We may not even want to use the instance at all so we would be potentially creating instances all over our app as we use this method more and more that become essentially useless.
### Static Methods
This is what I generally see being used. It isn't terrible but requires that each class have its own code to handle getting instances lazily.
To use the example from the linked article above by @bytefer :
```typescript
class Singleton {
private static singleton: Singleton; // ①
private constructor() {} // ②
public static getInstance(): Singleton { // ③
if (!Singleton.singleton) {
Singleton.singleton = new Singleton();
}
return Singleton.singleton;
}
}
```
- This requires that every class we may want to act as a singleton must have at the very least, the code above (which is why he points out later in his article that often plain objects are the way to go).
### Proxies
[Proxies](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) are very powerful and allow us to handle how a user interacts with any Javascript object that we pass into the Proxy!
> There are more handlers to consider with Proxies, so be sure to read about the various handlers.
> We also have [Proxy.revocable](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy/revocable) which could be used for more advanced cases.
Say we have a simple class we want to be a singleton:
```typescript
class Test {
private singletonArgs: ConstructorParameters<typeof Test>;
public check = 'this.check value';
constructor(...args: number[]) {
this.singletonArgs = args;
console.log('Creating Instance with Args: ', this.singletonArgs);
}
public sayHello() {
console.log('Hi! My Args are: ', this.singletonArgs);
}
}
```
Lets see what a Proxy might provide us to make our singleton classes reusable throughout our code:
```typescript
// A simple type to represent our class, taken from
// https://www.typescriptlang.org/docs/handbook/mixins.html#how-does-a-mixin-work
type Constructor = new <A extends any[]>(...args: A) => {}; // ①
function singleton<C extends Constructor>(
Ctor: C,
...args: ConstructorParameters<C> // ②
) {
let instance: InstanceType<C>;
const ProxyClass = new Proxy(Ctor, {
get(_target, prop, receiver) {
instance = instance ?? (new Ctor(...args) as typeof instance);
return Reflect.get(instance, prop, receiver);
},
});
return ProxyClass as typeof instance; // ③
}
```
1. We build a `Constructor` type that will infer the class we pass into the `singleton` function.
- Since it will only be constructed once, we must pass the args that we want to use when it is used for the first time when we first create the singleton.
- The class will not be initialized until it is actually used by runtime code, but it will never be initialized more than once.
2. We use `ConstructorParameters` utility type to infer the args from the classes constructor and allow passing them in at startup.
- In most cases a singleton should probably not have any args, but I included it to show it is possible.
3. We do a cast here, which I generally frown upon, but for utility and higher-order concepts like Proxies, they allow us to tell Typescript how the returned value **actually** behaves at runtime.
```typescript
console.log(`
1. Create Singleton of Test Class
`);
// Generate the singleton version of the Test class
// and pass it its expected args of `number[]`
// (It will not instantiate the class until it is actually used in the codebase)
const myInstance = singleton(Test, 1, 2, 3);
console.log(`
2. The class wont be constructed until it is used
`);
myInstance.sayHello();
// Creating Instance with Args: [ 1, 2, 3 ]
// Hi! My Args are: [ 1, 2, 3 ]
console.log(`
3. And it wont be constructed again if we continue using it
`);
myInstance.sayHello();
// Hi! My Args are: [ 1, 2, 3 ]
console.log(myInstance.check);
// this.check value
```
### Taking it Further
If we really wanted that pesky `new` option we could utilize the `construct` handler and simply refuse to construct our class if `instance` already exists.
I would not recommend adding the pointless complexity, but it illustrates just how flexible `Proxy` can be:
```typescript
function Singleton<C extends Constructor>(
Ctor: C,
...args: ConstructorParameters<C>
) {
let instance: InstanceType<C>;
const ProxyClass: C = new Proxy(Ctor, {
get(_target, prop, receiver) {
const cls = instance ?? new ProxyClass(...args);
return Reflect.get(cls, prop, receiver);
},
construct(_target) {
if (instance) {
return instance;
}
instance = new Ctor(...args) as InstanceType<C>;
return instance;
},
});
return ProxyClass as typeof instance & (new () => typeof instance);
}
const MySingleton = Singleton(Test)
const one = new MySingleton()
const two = new MySingleton();
console.log(one === two); // true
```
> This example has issues as the way it is typed it would think it can access static properties that we have not implemented (more reason not to use this in the real-world ;-))
| bradennapier |
1,332,932 | JSTools Weekly - 2023#2 | The latest issues of our weekly newsletter called JSTools Weekly just released. ⭐TOP new javascript... | 0 | 2023-01-18T17:10:00 | https://jstools.substack.com/p/2023-hotjstools-2 | javascript, typescript, node, news | The latest issues of our weekly newsletter called [JSTools Weekly](https://jstools.substack.com/) just released.
⭐TOP new javascript releases in this issue:

[See more new javascript releases](https://jstools.substack.com/p/2023-topjstools-2
)
🔥HOT javascript tools in this issue:

[See more hot javascript tools](https://jstools.substack.com/p/2023-hotjstools-2
)
✨NEW javascript tools in this issue:

[See more new javascript tools](https://jstools.substack.com/p/2023-newjstools-2
) | jstoolsweekly |
1,332,995 | Proxies Misconceptions: Speed | Because of the proxies’ complex nature that depends on many variables. Whether you are a newbie or a... | 0 | 2023-01-18T11:27:12 | https://blog.soax.com/proxies-misconceptions-speed?utm_source=devto&utm_medium=social&utm_term=post | proxy, connectionspeed | Because of the proxies’ complex nature that depends on many variables. Whether you are a newbie or a seasoned proxy user, there are always some technical details that might need additional clarification. In this article, we will try to unpack the mystery of proxies’ speed – how providers achieve high connection response times, and what might influence it.
Speed is one of the crucial proxies’ features because you need to get your data quickly (nobody has time to wait more than several seconds for a connection to happen, it’s 2022, after all). For example, [SOAX residential proxies](https://soax.com/residential-proxies?utm_source=devto&utm_medium=social&utm_term=post)’ response time is an impressive 2.34s (according to [Proxy Market Research 2022](https://proxyway.com/research/proxy-market-research-2022?utm_source=devto&utm_medium=social&utm_term=post)). They describe the details of the experiment how the test proxy speed was achieved. But would you be able to replicate the exact conditions?
However, some knowledge of the behind the scene of proxy life can help you understand why your connection time might be slower at times or explain some peculiar speed-related cases in your practice. By peculiar cases, I mean something like:
A big range during proxy speed testing, as it is not uncommon to be connected to a considerably fast proxy server (with a speed up to 50 MB per second) and then, after rotation, get connected to a slower one.
A slow proxy server becoming faster over time.
Let’s start with the basics – how do proxies actually work? Essentially, web browsing through proxy happens in 5 steps:
1. Your device connects to a proxy server
2. A proxy server connects to IP in a chosen location
3. A proxy server via a new IP sends the request to a requested site
4. Requested data from a site is sent to a server
5. A server sends data back to you
The full proxy speed during all of these steps depends on different things and can be manipulated.
To paint a better picture, let’s use Jack’s case of using proxies as an example.
_Jack is an entrepreneur building a platform that aggregates real-time rental offers for office buildings in Brazil. He is based in France and uses SOAX proxies to scrape the Brazilian real estate market. To deliver on his business goals, he is using Brazilian IPs with city targeting and requires not only good speed but also steady rotation._

Now let’s see what might influence Jack’s proxy speed on each of the aforementioned steps.
## Step 1: Connecting to a proxy server
At this point, several things can influence the user’s connection:
Internet speed of a local provider
If the provider’s speed is not satisfactory, other than changing ISP, there is little that can be done.
Distance between the user and a proxy server
Basically, the further the user is from it, the longer it takes for a signal to reach the server. Ideally, processing a request should take milliseconds.
_So how is Jack doing at this point?
Before starting his web scraping activities, Jack did some research and purchased a plan from a local ISP that has the best offer when it comes to the speed and reliability of internet connection.
As for his proxy provider, Jack chose SOAX, which was very wise of him because one of SOAX’s proxy servers is located in Europe. Being in France, Jack is very close to the server, and his server connection time should be instantaneous._
> NB: SOAX has multiple servers worldwide to provide users from different continents with consistently high connection speeds.
How to affect speed on this step?
- Change an ISP provider.
- Choose a proxy provider with a proxy server close to your location/ has servers in multiple locations.
## Step 2: The proxy server connects to an IP in a targeted location
This step is the one that influences speed the most. A provider can only have a certain number of servers, while targeted locations can be virtually anywhere, resulting in distances between the server and the IP location still being quite long.
Another factor is an ISP provider of an IP that the user gets connected to. If the ISP signal transmission quality is subpar, unfortunately, you just have to deal with it (or rotate your proxy in hopes of connecting to an IP of a different provider).
And finally, an excessive number of people simultaneously connected to the same IP can slow down their speed. Some providers do not control this moment; however, reliable companies with large proxy pools have smart systems behind IP rotation to avoid such conundrums.
_As for Jack, his request from the fast proxy server in France is now travelling to an IP in Brazil. This is quite a trip, considering there is an ocean between these two countries, so the speed might slow down here a bit.
Then Jack gets connected to an IP that is working just fine. However, after rotation happens, he notices that the speed goes down. Here, Jack can check what ISPs provide both of these proxies and then filter further IP connections by the provider with faster IPs.
If the connection time is still unsatisfactory, Jack can contact support@soax.com (he loves working with Kate, a proxy fairy who manages to always solve any possible issue) to consult if his signal could be transferred to a different proxy server. Sometimes it might help with the speed._

> NB: Overall time between the user sending a signal and connecting to an IP in the requested location is usually about 3 seconds. So when I say that speed slows down or is unsatisfactory, I mean that it takes ~2 more seconds to connect. If your current proxy provider’s connection speed is more than 10 seconds (especially if it is counted in minutes rather than seconds), please, do yourself a favour – change your provider.
How to affect speed on this step?
- switch the port number to get a faster IP
- Filter IPs by ISP (if you know which one has a faster connection)
- Consult support for transferring your signal to a different, quick proxy server
## Step 3: The signal goes back to a proxy server
After the user’s request has been fulfilled (i.e. all necessary data has been collected from targeted sites through someone’s IP), this data needs to be transferred to the user. But first, it needs to get back to the proxy server. It usually happens in milliseconds, but sometimes due to the same issues as in the 2nd step, it might take a bit longer.
_After Jack noticed that the Brazilian IP he received wasn’t fast enough. He switched the port number to receive a new IP address and improved speed._
How to affect speed on this step?
- switch the port number to get a faster IP
- Filter IPs by ISP (if you know which one has a faster connection)
- Consult support for transferring your signal to a different proxy server
## Step 4: The signal goes from a proxy server to you (finally)
The distance, network workload, user’s local Internet speed, and used IP’s ISP speed play a huge role here.
_Since Jack was already using the fastest local internet and changed his assigned IP, he did not experience any speed-related issues here and got his data just the way he wanted._
How to affect speed on this step?
- increase your local download speed by switching your Internet provider
- switch the port number to get a faster IP
- contact _support@soax.com_ to get a consultation on other available proxy servers
## To Wrap-Up
The main things that can affect proxy speed are:
- User’s local Internet speed
- Distance of the user from the proxy server
- Distance of a targeted IP from the proxy server
- Speed and quality of ISP signal transmission the IP has at the moment
- IP load
Depending on the reason, the speed of proxy can be improved by:
- upgrading your local Internet speed by reaching out to your Internet provider
- connecting to a closer proxy server (usually through support)
- switching your port number to get a new IP that could be faster
- filter IPs in the region by an ISP with faster internet
- contact support@soax.com if all else fails 🙂

## Proxy speed FAQ:
**What is a good proxy speed?**
Proxy speed is individual for each IP you have and it is safe to say that good proxy speed is the one that allows comfortable work for your particular use case. Proxy speed above 2 Mbs per second is considered to be a high proxy speed.
**Does proxy increase internet speed?**
It does not. Proxies are not designed to enhance your internet speed and do not directly influence it either.
**Do proxy servers slow down internet?**
Proxies do not slow down your internet connection per se. You might notice that when using proxies sites are loading a bit slower than usual BUT it is not because proxies have an effect on the speed of your Internet. There are multiple things that are engaged in the work of proxies and influence their speed, like distance between you and a server, internet speed of your ISP or ISP of an IP that you are connecting to. All these together are responsible for the speed you are getting which might be slower than usual.
**How to check proxy speed?**
You can test proxy speed by visiting fast.com or any other speedtest website. Please be aware that for testing you are downloading a file, so your package traffic can be used very quickly.
**How to increase internet speed using proxy?**
Depending on the reason, the speed of proxy can be improved by:
- upgrading your local Internet speed by reaching out to your Internet provider
- Switching from free to paid proxies or changing your proxy provider
- connecting to a closer proxy server (usually through support)
- switching your port number to get a new IP that could be faster
- filter IPs in the region by an ISP with faster internet
- if all else fails, contact support@soax.com
**Is proxy faster than VPN?**
Neither is faster. Speed is not something inherent and fixed neither for proxy nor VPN. Their speed is a sum of factors, such as distance between you and a server, internet speed of your ISP or ISP of an IP that you are connecting to. Instead, it is more accurate to compare service quality of [proxy VS VPN ](https://blog.soax.com/vpn-vs.-proxy-whats-the-difference?utm_source=devto&utm_medium=social&utm_term=post)providers, because it is their job to come up with solutions that provide users with high speed while using their products.
_This post was originally published on [SOAX blog](https://blog.soax.com/proxies-misconceptions-speed?utm_source=devto&utm_medium=social&utm_term=post)._ | dnasedkina |
1,333,258 | Default to Deny for More Secure Apps | Every product we build deals with user authorization. Users may only access certain features or data... | 0 | 2023-01-18T15:32:18 | https://twinsunsolutions.com/blog/default-to-deny-more-secure-apps/ | security, rails, authorization, ruby | Every product we build deals with user authorization.
Users may only access certain features or data based on their permissions within the app.
While we want to ensure users can access everything they should, we also want to ensure they can't access anything they shouldn't.
This is why we default to deny all user privileges when starting a new app.
## What is Default to Deny?
Network security practitioners are familiar with a similar concept.
The National Institute of Standards and Technology (NIST) issued security guidance that describes a ["deny by default / allow by exception"](https://csf.tools/reference/nist-sp-800-53/r4/sc/sc-7/sc-7-5/) security control.
The idea is simple: deny all network traffic by default and only allow traffic that is explicitly authorized.
This concept is more broadly known as the [principle of least privilege](https://csrc.nist.gov/glossary/term/least_privilege).
"Default to deny" is our application of this principle to mobile and web apps.
When we start a new app, users are initially denied access to all features and data.
We then explicitly grant access to the things the user is permitted to access.
## Why is Default to Deny Important?
Defaulting to deny is an important safeguard for user data.
Let's say we have an app that lets users purchase books.
Users save their credit card information in the app so they don't have to re-enter it every time they make a purchase.
If we let every user access everything by default, what might happen?
We could miss all of the ways that credit card data could be accessed.
A malicious user could probably find a way to steal credit card numbers from other user accounts.
We certainly don't want that!
So why don't we start with the complete opposite position?
If we deny all access by default, no one can steal credit card information.
Users also wouldn't be able to access their own credit card details.
That isn't _great_, but it's much better than letting anyone see all credit card numbers.
And opening up user permissions just a little bit is much easier than trying to find all the ways sensitive data might be accessed.
By defaulting to deny, we can be confident that no one is doing anything unless it is explicitly allowed.
Our users' data is protected from accidental exposure and malicious attacks.
## How to Implement Default to Deny
As an example of how to default to deny, consider a Ruby on Rails app ([as we tend to do](https://twinsunsolutions.com/blog/why-we-use-ruby-on-rails-for-web-apps)).
The primary way a user interacts with the app is through API endpoints powered by controllers.
We use [Pundit](https://github.com/varvet/pundit), a popular authorization library for Rails, to manage user permissions.
Using a `BaseController` class, we can define an `after_action` that ensures an authorization check is performed on all requests by default.
```ruby
class BaseController < ActionController::Base
include Pundit::Authorization
after_action :verify_authorized
end
```
Then we can define a base Pundit policy that denies all access by default.
Note that we don't need to define any actions in the policy.
Pundit will automatically check for a policy method that matches the controller action.
However, actions are defined in our example to make it clear that we are denying access by default.
```ruby
class BasePolicy
def index?
false
end
def show?
false
end
def create?
false
end
def update?
false
end
def destroy?
false
end
end
```
Now, we can have any controller inherit from `BaseController` and Pundit will deny all access to all actions.
For each model class we define, we can add a new Pundit policy that inherits from `BasePolicy`.
Then we can explicitly allow access to the actions we want to allow.
Consider the following policy example for a `Book` model.
All users can use the `index` or `show` actions, but only administrators can use the `create`, `update`, or `destroy` actions.
```ruby
class BookPolicy < BasePolicy
def index?
true
end
def show?
true
end
def create?
user.admin?
end
def update?
user.admin?
end
def destroy?
user.admin?
end
end
```
## Starting With Security
Default to deny is a simple concept that can have a big impact on the security of your app.
By denying all access by default, you can be confident that no one is doing anything unless it is explicitly allowed.
This is especially important for apps that deal with sensitive user data.
Consider defaulting to deny when starting your next app and see how much more confident you feel about your authorization rules.
| twinsun |
1,333,461 | Accessibility Statement | Templates for Websites | Websites need an accessibility statement to communicate the steps you’ve taken to make the site... | 0 | 2023-01-18T17:25:02 | https://mirelaprifti.medium.com/accessibility-statement-templates-for-websites-a3dd60e01388 | accessibilitystateme, a11y, webaccessibility | ---
title: Accessibility Statement | Templates for Websites
published: true
date: 2023-01-18 14:00:08 UTC
tags: accessibilitystateme,a11y,accessibility,webaccessibility
canonical_url: https://mirelaprifti.medium.com/accessibility-statement-templates-for-websites-a3dd60e01388
---

Websites need an accessibility statement to **communicate the steps you’ve taken** to make the site accessible and what people can do if they encounter any accessibility barriers.
In addition, by providing an accessibility statement, website owners can **demonstrate their commitment** to web accessibility and inclusivity.
Note that these are examples, and [**accessibility statements**](https://mirelaprifti.gumroad.com/l/website-accessibility-statement) can be more detailed and will depend on the website’s design, features, and audience.
It’s also worth noting that the accessibility statement is not a one-time task, and it should be reviewed and updated regularly to ensure that the website remains accessible and conformant to the latest guidelines and regulations.
Accessibility Statement Templates for Websites
**→ Partially conformant**
**→ Non-conformant**
**→ Not assessed**
👉 [**Get your templates**](https://mirelaprifti.gumroad.com/l/website-accessibility-statement) 👈
---
#### Check out my other product on Gumroad:
[UX Heuristics (Usability) Evaluation Report Template](https://mirelaprifti.gumroad.com/l/ux-heuristics-report)
[Accessibility Statement | Templates for Websites](https://mirelaprifti.gumroad.com/l/website-accessibility-statement)
[Accessibility Design Guidelines (Webflow)](https://mirelaprifti.gumroad.com/l/accessibility-design-guidelines)
---
✅ Follow me on [Twitter](https://twitter.com/mirepri4) or [LinkedIn](https://www.linkedin.com/in/mirelaprifti/) | mirelaprifti |
1,333,818 | Watchit - What the @# is it? | Welcome to Watchit! Welcome to the world of decentralized streaming! Welcome to the revolutionary... | 0 | 2023-01-19T03:16:56 | https://dev.to/geolffreym/watchit-what-the-is-it-4ce6 | watchit, ipfs, blockchain, streaming | Welcome to Watchit!
Welcome to the world of decentralized streaming!
Welcome to the revolutionary decentralized streaming platform that connects filmmakers, investors, and fans. The film industry is constantly evolving, and with the rise of streaming platforms like Netflix and YouTube, it's clear that the future of cinema lies in the digital realm. However, traditional streaming platforms often suffer from privacy and censorship issues, and content creators aren't always fairly compensated for their work.
Decentralized streaming addresses these issues by using a combination of blockchain technologies, IPFS for decentralized storage, smart contracts, and OrbitDB to create a secure, transparent, and cyber-attack-resistant content network.
With blockchain technology, content is distributed among multiple nodes in a decentralized network, eliminating the risk of a single point of failure. Additionally, content creators can receive payments directly from viewers through cryptocurrency, eliminating intermediaries and ensuring fair compensation. Furthermore, decentralized streaming is not subject to censorship. Since there is no central entity controlling the network, content creators can post without fear of censorship.
Watchit also utilizes a token called WVC, which serves as a utility and governance tool within the platform's ecosystem. WVC holders receive platform revenues and have the power to vote on changes to the project's parameters, giving them real control over the future of the content network.
We also offer developer tools such as SDK, API and CLI, allowing developers to create additional applications and services that seamlessly integrate with the platform. Our goal as well is to provide an agnostic architecture that allows developers to work with many different types of media. This allows for the creation of multiple different clients that can provide and consume data to and from the network to build parallel teams and products.
In terms of streaming consumption statistics, according to recent studies, streaming consumption has significantly increased worldwide, with over 70% of households in the United States and Europe using at least one streaming service. This trend is expected to continue to grow in the future, creating a great opportunity for platforms like Watchit that offer a decentralized streaming experience and a collaborative community.
To further support the benefits of Watchit, let's take a look at some concrete evidence and data. A study conducted by the Motion Picture Association of America found that in 2019, streaming made up for 75% of the total home video market, with digital purchases and rentals reaching $7.2 billion and streaming reaching $11.5 billion. Additionally, a study by Deloitte found that in 2020, streaming video services had an average of 42 million subscribers in the US alone, a 29% increase from 2019.
These statistics demonstrate the growing demand and need for a platform like Watchit in the film industry, as it offers a decentralized and fair solution for content creators to monetize their work and for audiences to access and enjoy a wide range of films.
The growing popularity of streaming and the increasing demand for fairer and more transparent compensation for content creators are trends that Watchit is well-positioned to capitalize on. Additionally, as more and more consumers become interested in decentralized technology, Watchit has the potential to attract a dedicated and engaged community of users.
Overall, while there are certainly challenges that Watchit must overcome, there are also many opportunities for the platform to succeed and make a real impact in the film industry. With its unique combination of cutting-edge technology, collaborative community, and transparent governance, Watchit has the potential to revolutionize the way films are created, distributed, and consumed.
Good, now let's answer some questions:
**What is Watchit trying to solve?**
Watchit, as a decentralized streaming platform, could offer several solutions to current issues in the film industry. Some of them could be:
1. Transparency and fairness in content creators compensation: By using blockchain, smart contracts and cryptocurrency, Watchit could ensure that filmmakers receive payments directly from viewers and avoid traditional intermediaries, which would ensure fair and transparent compensation for content creators.
2. Accessibility for small studios and independent filmmakers: Being decentralized, Watchit could welcome enthusiasts and small studios who want a platform with less bureaucracy in the middle to promote or distribute their films.
3. Collaborative community: By using a token-based voting system, Watchit could give users control over the content network and build a collaborative community where filmmakers, investors, and fans can work together to improve and develop the platform.
4. Increased security and resistance to cyber attacks: By using technologies such as IPFS as decentralized storage and OrbitDB, Watchit could provide a more secure and resistant network to cyber attacks.
**How can NFTs help the movie industry?**
NFTs, or non-fungible tokens, can help the movie industry in a number of ways. Here are a few examples:
1. Monetizing content: NFTs allow movie studios and filmmakers to monetize their content in new ways by creating unique, digital collectibles that can be bought and sold. This could include limited-edition movie posters, behind-the-scenes footage, or even virtual experiences.
2. Providing ownership: NFTs can provide movie studios and filmmakers with a way to prove ownership and authenticity of their content, which can be especially useful in the digital age where content is often shared and copied without permission.
3. Building fan engagement: NFTs can be used to create a more immersive and engaging experience for fans by giving them access to unique digital assets related to their favorite movies. This could include virtual meet-and-greets with cast members, virtual tours of movie sets, or even virtual reality experiences.
4. Providing transparency: NFTs can provide transparency in the secondary market and the provenance of the content, it can help to fight piracy and the distribution of counterfeit items.
5. New revenue streams: NFTs provide a new way for movie studios and filmmakers to generate revenue from their content beyond traditional channels, such as box office and streaming services.
Overall, NFTs have the potential to revolutionize the way the movie industry operates by providing new ways for studios and filmmakers to monetize their content, build fan engagement, and promote transparency.
In conclusion, Watchit is an exciting option for those seeking a more secure, decentralized, and fair streaming experience. With its combination of cutting-edge technologies, collaborative community, and transparent governance, Watchit is well-positioned to revolutionize the film industry and provide a new level of control and transparency for content creators and consumers alike. Stay tuned as this technology continues to evolve and grow!
### More info:
* Crowdfunding has [begun](https://opencollective.com/watchit-app).
* Visit our site [watchit.movie](https://watchit.movie).
* Check out the [roadmap](orgs/ZorrillosDev/projects) to future features.
* Get in touch with us in [gitter](https://gitter.im/watchit-app/community) | #watchit:matrix.org.
* See our [FAQ](https://github.com/ZorrillosDev/watchit-desktop/blob/v0.1.0/FAQ.md) for frequently asked questions.
* For help or bugs please [create an issue](https://github.com/ZorrillosDev/watchit-desktop/issues).
| geolffreym |
1,334,108 | Playwright - CI | Hi there, Today I want to speak about integrating Playwright in your GitHub action CI. So don't waste... | 20,832 | 2023-01-19T09:46:28 | https://blog.delpuppo.net/playwright-ci | playwright, testing, github, githubaction | ---
title: Playwright - CI
published: true
date: 2023-01-19 09:00:45 UTC
tags: Playwright, testing, GitHub, GitHubAction
canonical_url: https://blog.delpuppo.net/playwright-ci
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/q11ysdmfrkl6hah0vrt3.png
series: Playwright
---
Hi there,
Today I want to speak about integrating Playwright in your GitHub action CI.
So don't waste time and let's start.
To start, you have to create a file called `playwright.yml` in this path `.github/workflows`.
> The `.github/workflows`' path is used to save the files for your GitHub Actions, and the name of the file is not important for GitHub because the value for it is inside of your files.
Let's start to copy and paste this code into the playwright.yml
```yaml
name: Playwright Tests
on: [push]
```
These two info are used to give a name to the CI and to define what triggers this CI.
These are standard fields that you can find in every GitHub Action in the world.
In this case, the CI will trigger every push in the project.
Now it's time to add the first job to run your e2e tests in CI.
To do that, add this to your file.
```yaml
jobs:
test-e2e:
timeout-minutes: 60
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: 16
- name: Install dependencies
run: npm ci
- name: Install Playwright Browsers
run: npx playwright install --with-deps
- name: Run Playwright tests
run: npx playwright test
- uses: actions/upload-artifact@v3
if: always()
with:
name: playwright-e2e-report
path: playwright-report/
retention-days: 30
```
Jobs are used in GitHub Action to run different stuff, like build, test, deploy etc. etc.
In this example, the `test-e2e`'s job creates a list of steps to run the test in the CI.
But what this job does:
1. `runs-on` is used to indicate on which platform the job has to run
2. `actions/checkout@v3` checkouts the code
3. `actions/setup-node@v3` setups the node version for the job
4. `Install dependencies` installs all the dependencies in the `node_modules`
5. `Install Playwright Browsers` installs the browsers for Playwright
6. `Run Playwright tests` runs the e2e tests
7. `actions/upload-artifact@v3` uploads the test's results in the GitHub Artifact
Ok, this is the job for the e2e tests; now it's time to add the job for the component tests.
To do that, copy and paste the following code
```yaml
test-ct:
timeout-minutes: 60
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: 16
- name: Install dependencies
run: npm ci
- name: Install Playwright Browsers
run: npx playwright install --with-deps
- name: Run Playwright tests
run: npx playwright test -c playwright-ct.config.ts
- uses: actions/upload-artifact@v3
if: always()
with:
name: playwright-ct-report
path: playwright-report/
retention-days: 30
```
As you can see, it's similar to the previous job but has different configurations, so I don't dive into it.
Now with these two jobs, you have a CI ready to run.
To do that, `git add` + `git commit` + `git push`, and go into your online GitHub repository. In the tab Actions, you can find your CI in action, and If you click on it, you can see the two jobs running. (It's important to understand that these two jobs run in parallel, you can find more info about job execution [here](https://docs.github.com/en/actions/using-jobs/using-jobs-in-a-workflow))
When the CI is ended, you are sure that your tests are ok as expected. And the result will be like this.
Perfect, now you have your first GitHub action configured to run your tests with Playwright.
Good, that's all folk, I think you have all the info to integrate Playwright in your CI without any problem.
Thank you and see you soon.
Bye Bye 👋
_The code of this post is available_ [_here_](https://github.com/Puppo/playwright-series/tree/07-ci)_._
{% embed https://dev.to/puppo %} | puppo |
1,334,123 | What Types of Services are Offered in Web Development? | The internet is the center for anyone seeking entertainment, news, shopping, and information. various... | 0 | 2023-01-19T10:13:07 | https://dev.to/ferry/what-types-of-services-are-offered-in-web-development-2m1e | startup, news, webdev, web3 | The internet is the center for anyone seeking entertainment, news, shopping, and information. various utility of the internet makes it the best investment to leverage your business, by utilizing the internet you can create a web application that can generate leads, sell products, or even build an online presence that can serve as a brochure and information center about your company.
But developing a website is not a simple walk in the park, more so if you are not the person who dives into the specific skill of developing a website. As of January 2021, over 1.7 billion live websites are on the internet. This is the number of competitions you will face when you create a website.
But do not be intimidated by this number. You just need to find suitable web development services for your business and build a website that can stand out from the crowd.
## Web Development Services
You might need help building the most suitable website for your business and the service for creating it is called a web development service. The service involves everything related to building a web-based solution. Whether it is a simple text page to a complex web application.
Many people think of “web development” as just using a variety of programming languages to create the web app code and put everything together. But web developers can help with various tasks, and we will discuss the types of web development services.
## Service Types for Web Development
Web development companies typically offer a vast array of services, so each client could find the one that best suits their needs. Depending on the project’s requirements, a development team can create a fully custom website, help with regular maintenance, develop a web app or optimize your existing one. Here are a few of the most common web development services available today.
## Custom Web Applications
The first is a custom web application. These services create custom web-based solutions for considering business needs. Unlike a website, the web application is a software element that runs on a web server. They are web-based, but function like a traditional desktop application. You probably use a web application every day without even knowing it.
Some popular web applications you may already be familiar with include:
- [GoPlay](https://www.emveep.com/work/goplay/)
- [KoinWorks](https://www.emveep.com/work/koinworks/)
- [Julo](https://www.emveep.com/work/julo/)
## Content Management Systems
Content Management Systems are web applications that allow users to update website content through a web browser. CMS services are often used by companies to update web pages quickly without the need for hiring web developers. Besides that, we have also completed a CMS project with a client.
The most common CMS platforms include:
- WordPress
- Drupal
- Joomla
- HubSpot
## E-commerce Applications
E-commerce web development is a subset of full-stack web development. The UX & UI considers both the front and back-end web technologies needed to run an online store. These services are often geared toward businesses looking to sell products online.
These types of projects will require experienced E-commerce UX designers and website designers to get the most excellent type of results. E-commerce application goes beyond simply having a shopping cart, it handles inventory, payment processing, and product listings for you. Apart from that, we are also experienced in completing e-commerce platform projects with clients, which you can see here.
The familiar eCommerce platforms are:
- Shopify
- Alibaba
- Amazon
- eBay
- Flipkart
- WooCommerce
- QA & Testing
Now you have your website. But how could you evaluate how well your website performance? That is when QA & Testing will come into play. While quality assurance and testing are sometimes the most overlooked web development service. Quality assurance helps web developers ensure the application they are building works properly.
Testing your web applications and websites is a crucial step in web development to make sure your website meets the performance, quality, and usability requirements for your business need before moving forward with any project.
## Web Support and Maintenance
When you have finished building your website or web application, web maintenance will help to keep it running smoothly. This service includes the tasks to help your employees to use your web application correctly, monitoring system performance, reviewing logs for errors or security vulnerabilities, etc.
Web Maintenance ensures a website runs as expected after launch by fixing web issues, making web improvements, updating web content, and more. Website support and maintenance usually come in three different types:
- Monitoring: web monitoring means you have dedicated professionals monitoring your infrastructure 24/7. Web monitoring is also web security – so your website can detect potential threats and escalate them quickly.
- Remediation: monitoring service on issue resolution with trusted and experienced developers.
- Management: web management includes web support and maintenance services that help maintain a healthy, bug-free environment for all of your web applications. it might include tasks like updating software libraries or plugins and patching servers against known vulnerabilities.
## End note
Hiring an experienced web development company will ensure you get the web presence your business needs to succeed. It is a great idea to start digitalizing your business, although it may cost more budget, creating an online presence can make your business more relevant.
Read more about our discussion about the development of a website:
- [Emveep Recognized as Top RoR Development in 2021
](https://www.emveep.com/blog/emveep-recognized-as-top-ror-development-in-2021/)
- [How to Scale Up Your Website Applications](https://www.emveep.com/blog/how-to-scale-up-your-website-applications/)
- [Understanding the Fixed-Price Software Development](https://www.emveep.com/blog/understanding-the-fixed-price-software-development/)
| ferry |
1,334,215 | Docker Overlayfs: How filesystems work in Docker | This is a brief follow up to my article on Docker networking: Network Namespaces, Docker Bridge and... | 0 | 2023-01-19T12:53:51 | https://dev.to/pemcconnell/docker-overlayfs-network-namespaces-docker-bridge-and-dns-52jo | docker, overlayfs, filesystems, devops | This is a brief follow up to my article on [Docker networking: Network Namespaces, Docker Bridge and DNS](https://www.petermcconnell.com/posts/linux_networking/)
Docker uses the OverlayFS file system to manage the file system of its containers. When a container is run, Docker creates a new layer for the container's file system on top of the base image. This allows the container to have its own file system that is isolated from the host system and other containers.
Running the `ubuntu:22.04` image we can see the root file system differs from the host where I'm running it. Below you can see there is a file in root called `/.dockerenv`:
```sh
$ docker run --rm -ti ubuntu:22.04 bash
root@541cc3b62543:/# ls -al /
total 56
drwxr-xr-x 1 root root 4096 Jan 19 11:51 .
drwxr-xr-x 1 root root 4096 Jan 19 11:51 ..
-rwxr-xr-x 1 root root 0 Jan 19 11:51 .dockerenv
lrwxrwxrwx 1 root root 7 Nov 30 02:04 bin -> usr/bin
drwxr-xr-x 2 root root 4096 Apr 18 2022 boot
drwxr-xr-x 5 root root 360 Jan 19 11:51 dev
drwxr-xr-x 1 root root 4096 Jan 19 11:51 etc
drwxr-xr-x 2 root root 4096 Apr 18 2022 home
lrwxrwxrwx 1 root root 7 Nov 30 02:04 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Nov 30 02:04 lib32 -> usr/lib32
lrwxrwxrwx 1 root root 9 Nov 30 02:04 lib64 -> usr/lib64
lrwxrwxrwx 1 root root 10 Nov 30 02:04 libx32 -> usr/libx32
drwxr-xr-x 2 root root 4096 Nov 30 02:04 media
drwxr-xr-x 2 root root 4096 Nov 30 02:04 mnt
drwxr-xr-x 2 root root 4096 Nov 30 02:04 opt
dr-xr-xr-x 491 root root 0 Jan 19 11:51 proc
drwx------ 2 root root 4096 Nov 30 02:07 root
drwxr-xr-x 5 root root 4096 Nov 30 02:07 run
lrwxrwxrwx 1 root root 8 Nov 30 02:04 sbin -> usr/sbin
drwxr-xr-x 2 root root 4096 Nov 30 02:04 srv
dr-xr-xr-x 13 root root 0 Jan 19 11:51 sys
drwxrwxrwt 2 root root 4096 Nov 30 02:07 tmp
drwxr-xr-x 14 root root 4096 Nov 30 02:04 usr
drwxr-xr-x 11 root root 4096 Nov 30 02:07 var
```
Which does not exist at root on the host running the container:
```sh
root@541cc3b62543:/#
root@541cc3b62543:/# exit
exit
$ stat /.dockerenv
stat: cannot statx '/.dockerenv': No such file or directory
```
So ... _where_ does it exist? To inspect the layers of a running container, you can use the "docker inspect" command followed by the container ID or name. This will return a JSON object containing information about the container, including its layers. To view this we'll re-run our `ubuntu:22.04` container, grab the ID and inspect it:
```sh
$ docker run --rm -d -ti ubuntu:22.04 bash
6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb
# lower directory
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.LowerDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a-init/diff:/dockerstore/overlay2/bb9057b4f1980fe004301f181c3313c15c2a75b7c7b7c5a6fe80159d2275f0d3/diff
# upper directory
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.UpperDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/diff
# merged directory
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.MergedDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/merged
```
I'll keep this container running and we'll dig into these contents shortly.
When a container is run, its layers are stored in the host system's file system, typically in the `/var/lib/docker/overlay2` directory. You can see mine is in `/dockerstore/` as I have manually set `data-root` in `/etc/docker/daemon.json` for the host that I'm testing this on. Each layer is represented by a directory that contains the files and directories that make up that layer. The topmost layer is the one that the container is currently using, and the lower layers are the ones that are inherited from the base image.
The advantages of using layers in Docker include:
- Smaller image size, since multiple containers can share a common base image
- Faster container startup time, since only the changes made to the container are stored in new layers
- Easier to manage and update containers, since changes can be made to a container's layer without affecting the base image
- Greater security, since each container's file system is isolated from other containers and the host system.
Please keep in mind that the information is general and may vary depending on specific scenarios.
Now lets take a deeper look at the filesystem for our running container.
LowerDir
--------
This value is unique in the outputs above in that it's actually two paths, separated by a colon:
```sh
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.LowerDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a-init/diff:/dockerstore/overlay2/bb9057b4f1980fe004301f181c3313c15c2a75b7c7b7c5a6fe80159d2275f0d3/diff
```
The first part (left side of `:`) is the path to the init layer of the container. this is the layer that contains the initial filesystem of the container, which is based on the base image. We can take a look at the contents of that layer with `ls`:
```sh
sudo ls /dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a-init/diff
dev etc
```
The second part (right side of `:`) is the path to the layer of the container that includes changes from the rest of the Dockerfile. Again we can take a look:
```sh
sudo ls /dockerstore/overlay2/bb9057b4f1980fe004301f181c3313c15c2a75b7c7b7c5a6fe80159d2275f0d3/diff
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
```
To better visualise this, lets create our own Dockerfile:
```dockerfile
FROM ubuntu:22.04
RUN mkdir -p /testinglowerdir/ && echo -n "hellothere" > /testinglowerdir/foo
```
Now, given what we learned above, when we run this container the first part of `LowerDir` should contain _all_ the contents for `ubuntu:22.04` and the second part of `LowerDir` should contain only `/testinglowerdir/`:
```sh
$ docker build -t=test .
Sending build context to Docker daemon 2.048kB
Step 1/2 : FROM ubuntu:22.04
---> 6b7dfa7e8fdb
Step 2/2 : RUN mkdir -p /testinglowerdir/ && echo -n "hellothere" > /testinglowerdir/foo
---> Running in e71a7cd5541c
Removing intermediate container e71a7cd5541c
---> df924945a2b0
Successfully built df924945a2b0
Successfully tagged test:latest
$ docker run --rm -d -ti test bash
9c9fe0bcd283bc0c9649b77246115e3a09e8885efd53f0e9de09de537bea9188
$ docker inspect 9c9fe0bcd283bc0c9649b77246115e3a09e8885efd53f0e9de09de537bea9188 -f '{{.GraphDriver.Data.LowerDir}}'
/dockerstore/overlay2/5501fd185b14a60317f3e0db485bb8f8c5cf41b7cb1ed0688526ba918938b7bf-init/diff:/dockerstore/overlay2/4d49e9a62bad55c3761ab08ded87f56010b28a40f264896c01e5c1c653b826a8/diff:/dockerstore/overlay2/bb9057b4f1980fe004301f181c3313c15c2a75b7c7b7c5a6fe80159d2275f0d3/diff
$ # show directory contents for second part of LowerDir
$ sudo ls /dockerstore/overlay2/4d49e9a62bad55c3761ab08ded87f56010b28a40f264896c01e5c1c653b826a8/diff
testinglowerdir
```
UpperDir
--------
```sh
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.UpperDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/diff
```
The UpperDir contains changes that we've made at runtime. To see this in action we can exec into our container and create a simple directory with a file in the root directory:
```sh
docker exec -ti 6a9 bash
root@6a9014d7ebfd:/# mkdir /tutorial
root@6a9014d7ebfd:/# echo 'iseeyou' > /tutorial/ohai
```
We can now see this in our UpperDir directory:
```sh
$ sudo ls /dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/diff/
root tutorial
$ sudo cat /dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/diff/tutorial/ohai
iseeyou
```
Want to quickly see what files are being created by a running container? This is something the `UpperDir` can tell you.
MergedDir
---------
```sh
$ docker inspect 6a9014d7ebfddb3a107b29aca3764f24e51f64fda1e8b8cec135c18923daefeb -f '{{.GraphDriver.Data.MergedDir}}'
/dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/merged
```
I'm sure you've guessed what this one is... This is the merged structure:
```sh
$ sudo ls /dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/merged
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp tutorial usr var
```
Here you can see all of the directories from the LowerDir and UpperDir together. We can chroot into this directory to "see what docker sees":
```sh
sudo chroot /dockerstore/overlay2/268eb11c54948d6293aa3947b7a2c83b1395b18509518e26487f0e79997f787a/merged /bin/bash
root@pete:/# ls -al
total 72
drwxr-xr-x 1 root root 4096 Jan 19 12:21 .
drwxr-xr-x 1 root root 4096 Jan 19 12:21 ..
-rwxr-xr-x 1 root root 0 Jan 19 11:56 .dockerenv
lrwxrwxrwx 1 root root 7 Nov 30 02:04 bin -> usr/bin
drwxr-xr-x 2 root root 4096 Apr 18 2022 boot
drwxr-xr-x 1 root root 4096 Jan 19 11:56 dev
drwxr-xr-x 1 root root 4096 Jan 19 11:56 etc
drwxr-xr-x 2 root root 4096 Apr 18 2022 home
lrwxrwxrwx 1 root root 7 Nov 30 02:04 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Nov 30 02:04 lib32 -> usr/lib32
lrwxrwxrwx 1 root root 9 Nov 30 02:04 lib64 -> usr/lib64
lrwxrwxrwx 1 root root 10 Nov 30 02:04 libx32 -> usr/libx32
drwxr-xr-x 2 root root 4096 Nov 30 02:04 media
drwxr-xr-x 2 root root 4096 Nov 30 02:04 mnt
drwxr-xr-x 2 root root 4096 Nov 30 02:04 opt
drwxr-xr-x 2 root root 4096 Apr 18 2022 proc
drwx------ 1 root root 4096 Jan 19 12:16 root
drwxr-xr-x 5 root root 4096 Nov 30 02:07 run
lrwxrwxrwx 1 root root 8 Nov 30 02:04 sbin -> usr/sbin
drwxr-xr-x 2 root root 4096 Nov 30 02:04 srv
drwxr-xr-x 2 root root 4096 Apr 18 2022 sys
drwxrwxrwt 2 root root 4096 Nov 30 02:07 tmp
drwxr-xr-x 2 root root 4096 Jan 19 12:20 tutorial
drwxr-xr-x 14 root root 4096 Nov 30 02:04 usr
drwxr-xr-x 11 root root 4096 Nov 30 02:07 var
root@pete:/# cat /tutorial/ohai
iseeyou
root@pete:/#
```
Pretty sweet! Another way / a "better" way that we can get this view is with `nsenter`:
```sh
$ sudo nsenter --target $(docker inspect --format {{.State.Pid}} 6a9) --mount --uts --ipc --net --pid
root@6a9014d7ebfd:/# cat /tutorial/ohai
iseeyou
root@6a9014d7ebfd:/#
```
Do it yourself
--------------
This has been a quick look into how Docker avails of OverlayFS, but you can of course do this yourself. The basic syntax is:
```sh
mount -t overlay overlay -o lowerdir=lower,upperdir=upper,workdir=workdir target
```
- `lowerdir` is the lower filesystem
- `upperdir` is the upper filesystem
- `workdir` is a directory where the OverlayFS stores metadata about the overlay
- `target` is the mount point where the overlay will be mounted
For example, if you have two directories, /mnt/lower and /mnt/upper, you can create an OverlayFS file system that combines them at /mnt/overlay with the following command:
```sh
mount -t overlay overlay -o lowerdir=/mnt/lower,upperdir=/mnt/upper,workdir=/mnt/workdir /mnt/overlay
```
To view the contents of the overlay, you can simply navigate to the mount point (in this example, /mnt/overlay) and use standard Linux commands to view the files and directories.
You can also use `lsblk` command to view the mounted overlays in your system and also you can unmount the overlays using umount command.
Please keep in mind that this is a basic example and there are many other options and settings that can be used when creating an OverlayFS file system. | pemcconnell |
1,334,329 | Debug Angular with Intellij | Does anyone know if it is possible to debug an angular application that opens several Tabs when... | 0 | 2023-01-19T13:38:23 | https://dev.to/waldmeye/debug-angular-with-intellij-3bkp | Does anyone know if it is possible to debug an angular application that opens several Tabs when "routed" ?
localhost:4200/app --> I can debug with Intellij
localhost:4200/app/myTask --> opens in a separate tab in chrome and my breakpoints in typescript code are not considered.
Does anyone know if it is possible to debug multiple tabs within Intellij ? | waldmeye | |
1,334,345 | The Application of GIS (Cesium) in Smart City | Click to see more demonstrations including Digital Twins, GIS, VR, BIM, etc. An Integrated Command... | 0 | 2023-01-19T14:07:46 | https://dev.to/hightopo/leveraging-gis-for-smart-city-am5 | webdev, javascript, programming, html | [Click to see more demonstrations including Digital Twins, GIS, VR, BIM, etc.](https://www.hightopo.com/demos/en-index.html)
An Integrated Command and Control Centre (ICCC), as the name suggests, works as a brain for all smart solutions implemented across a city — be it a surveillance system, smart traffic management, waste management, utility management, environmental sensors, public information system, etc.
Responsible development requires robust spatial information that is refined and constantly updated. In addition, foresight and problem-solving skills are required to put data to good use. This challenge has made Geographic Information System (GIS) invaluable to the city ecosystem to integrate every aspect of a city from conceptualization and planning to development and maintenance. Combine GIS with Cloud Computing, Big Data, IoT, Data Visualization and other kinds of technologies, to help different stakeholders prepare for exigencies, coordinate and manage response efforts, and enhance the ongoing efficiency of city operations.
Hightopo’s "HT for Web" visualization platform integrated with GIS, supports loading geographic data from various kinds, such as 3D Tiles, Map Tiles, etc. Visualizing massive data such as POI (Point of Interest) Data, Traffic Data, Urban Infrastructure Data, etc.
The Smart City concept aims at developing a comprehensive system that uses geospatial data to enhance the understanding of complex urban systems and to improve the efficiency and security of these systems. This geospatial data concerns (i) the urban built environment such as infrastructure, buildings and public spaces, (ii) the natural environment such as biodiversity, green spaces, air quality, soil and water, and (iii) urban services such as transport, municipal waste, water, energy, health and education.
**Environment**
Smart city planners can model potential buildings and predict short and long-term impacts on the environment. Conservationists can choose where best to incorporate green spaces or plan conservation projects, as well as analyze air quality and spot its causes in different areas of the city.
**Governance**
City agencies often use location technology to share data across silos and operate more efficiently. Smart city operation platform centralizes the city’s open data and communicates with citizens about smart city initiatives.
**Human Capital**
Strategists and business leaders can analyze the demographics of a city’s population and use that insight to plan improvements that attract specific talent.
**Mobility and Transportation**
GIS empowers the assets management and long-term plans improvements of the country’s traffic. Meanwhile, IoT-based applications can be used to optimize the flow of traffic in the city.
Combined GIS with building information modelling (BIM) technology, underground infrastructures can be undertaken by knowing the precise locations of them and, to safely weave new tunnels through the built environment.
**Urban Planning**
City leaders, businesses, and architecture, engineering, and construction (AEC) firms can see how a structure will look before they decide to build it, measuring views from a virtual apartment window or the shadow of a skyscraper on a local park. And Digital Twin and location data is come to help. Utilizing 3D models of their physical infrastructure and location data as a connective thread to experiment with virtual plans.
Click to see the video on YouTube:
[Intelligent Operations Centre for Smart City](https://youtu.be/Bz0VIM4LsWE)
**The Business Value of Smart Cities**
The "HT for Web" GIS is intended to helping users integrated location information (GIS related) into their own projects, and reduce users’ learning and investment costs for GIS. Combined with the powerful visualization engine, enable superimposed display of different map tile data, oblique photography, 3D model, POI and other data; Combined with "HT for Web" BIM, enable the combination of BIM model and GIS Visual display; Combined with "HT for Web" 3D video fusion, to achieve real-time video fusion display in GIS scenes. The "HT for Web" GIS makes the visual display of GIS data richer, clearer and more intuitive, empowers users with data-driven insight.
**Conclusion**
Hightopo "HT for Web" GIS provides local government with tools to develop smarter cities and deliver better services to the community. As a collaborative platform, it enables government agencies to share spatial data to break through traditional data silos and build a more transparent organization. Furthermore, the platform can be scaled to provide the tools for enterprise-wide data-driven decision making that improves management efficiency. Its mobility capabilities allow staff to access data any time, on any device, from anywhere to ensure enterprise data is always accurate and up to date.
| hightopo |
1,334,482 | Create Real State Hero Section Using HTML CSS for Beginners Step By Step From Scratch in 20 Minutes | Support us and GET 10% OFF of your next order in my shop using the code: EARLYBIRD... | 0 | 2023-01-19T17:13:13 | https://dev.to/hojjatbandani/create-real-state-hero-section-using-html-css-for-beginners-step-by-step-from-scratch-in-20-minutes-mna | html, css, tutorial, beginners | {% youtube xLrk619vZj0 %}
Support us and GET 10% OFF of your next order in my shop using the code: EARLYBIRD 🙏❤️
https://my-store-d97fa0.creator-spring.com/listing/soudemy
Hi Guys, today we want to show How To Create Real State Hero Section Using HTML CSS for Beginners Step By Step From Scratch.
Please, if you love it, Support us with Like & Subscribe.🙏🙏❤️❤️
Subscribe Link :
https://shorturl.at/gKWY9
In the comments, you can say what design you want so that we can prepare the video for you.
If you want to know how the design was done, check here :
https://youtu.be/DpYMz0XN64s | hojjatbandani |
1,334,521 | Get Started with Strapi Using Azure ARM templates | Author: Sangram Rath All components, i.e., Strapi & MySQL, run on a single VM; hence it is ideal... | 0 | 2023-01-19T17:30:47 | https://strapi.io/blog/how-to-quickly-get-started-with-strapi-using-azure-arm-templates?utm_campaign=Strapi%20Blog&utm_source=devto&utm_medium=blog | strapi, azure, webdev, headlesscms | Author: Sangram Rath
All components, i.e., Strapi & MySQL, run on a single VM; hence it is ideal for getting started, exploring Strapi, or a sandbox scenario.
## What are Azure ARM templates?
[Azure ARM](https://learn.microsoft.com/es-es/azure/azure-resource-manager/management/overview) templates are a way to implement infrastructure as code in Azure. Infrastructure as code's benefits includes deployment automation, consistent and repeatable infrastructure, and agility.
## Deployment Specifications & Important Details
This guide uses an ARM (Azure Resource Manager) template to deploy the required Azure resources and a bash script to configure and install Strapi in it. You can do this with minimal user intervention.
The template creates the following required resources in its own new Resource Group:
- Azure Virtual Machine & a disk
- VNET & a Subnet
- vNIC, Network Security Group
Strapi installation steps run using a bash script after the VM provisioning. The script is part of the repository that contains the ARM template.
The ARM template (JSON file) and the bash script are available on the [GitHub repo](https://github.com/sangramrath/strapi-community-content/tree/master/tutorials/code/strapi-quickstart-azure-arm).
### Default Values
**Azure Defaults**
| Parameter | Value | Description |
| ------------------ | ------------ | --------------------------------------------- |
| adminUsername | strapiadmin | Username for connecting (SSH) to the Azure VM |
| adminPasswordOrKey | $tr@p!@12345 | Default password for the user |
**Strapi Defaults**
A Strapi app called *blog* is created with the following defaults.
| Parameter | Value |
| ---------- | ---------------- |
| NODE_ENV | development |
| DB_HOST | localhost |
| DB_PORT | 3306 |
| DB_NAME | strapi_dev |
| DB_USER | strapi |
| DB_PASS | mysecurepassword |
| JWT_SECRET | aSecretKey |
>**NOTE**: This template has been deliberately created so that it requires the least possible inputs to get a working Strapi installation. Hence, many variables have been pre-defined as per minimum requirements. You can edit the ARM template if you wish to modify any variables, such as Azure VM size or password(s).
Running this Azure deployment as it is in Production is not recommended.
## Pre-requisites
- An Azure account with an active Subscription
While it is not mandatory but a basic understanding of the following will help if you wish to customize this template or the script
- Basic knowledge of Microsoft Azure
- Basic knowledge of JSON
- Bash
- Git
## Deploying the ARM template
1. Click the **Deploy to Azure** button below to load the template in Azure Portal. You may be prompted to sign in to Azure.

2. In the custom deployment page, click **Create new** and create a new Resource Group for this deployment.

3. Next, select your preferred **Region** and then click **Review + create**.

4. Ensure *Validation passes* , click **Create** to start the Azure resource deployment.

5. The deployment process will begin and take around 5-10 minutes.
**NOTE:** If the deployment fails, delete the resource group completely and restart the deployment. Do not use the *Redeploy* feature.
6. Once the deployment is complete, click **Outputs** to retrieve the randomly generated Public DNS of the Azure VM.

You can also retrieve this & the Public IP address from the **Overview** section of the Azure VM.
7. You can now access the Strapi administration page at **[DNS]:1337** or **[PublicIP]:1337** and create the first administrator.
## Modifying the default values
### Azure infrastructure
You can modify the default values of the Azure infrastructure to your need. The following values could be changed (avoid changing other values, such as for networking and DNS, unless you are sure of the expected outcome):
- *virtualMachineName*
- *adminUsername*
- *adminPasswordOrKey* (we are using a password based login approach)
- *vmSize* (you will need to know the VM size SKUs)
After clicking *Deploy to Azure*, click **Edit template**.

Modify values as needed.

Click **Save**.
Continue with deployment.
### Strapi installation
The installation uses some default values for database username, password, port, database name, etc. As mentioned earlier in the article, one can modify them after the installation if needed.
Refer to [the documentation](https://docs.strapi.io/developer-docs/latest/setup-deployment-guides/configurations/required/databases.html#configuration-structure) for instructions.
## Security
- The installation does not expose the MySQL database running locally from outside.
- The installation does not use SSL/TLS by default.
## Conclusion
This article demonstrates how to quickly bring up an Azure VM running Strapi using an ARM template or Infrastructure as Code approach.
| strapijs |
1,334,537 | Smart Contract Upgrade | Smart contracts are self-executing programs that run on the Ethereum Virtual Machine (EVM). These... | 0 | 2023-03-18T08:54:03 | https://dev.to/joshuajee/smart-contract-upgrade-1ec2 | solidity, web3, evm, smartcontractupgrade | Smart contracts are self-executing programs that run on the Ethereum Virtual Machine (EVM). These programs are immutable by design, which means no update to the business logic after deployment. While this is good for user trust, decentralization, and security of smart contracts, it may be a drawback as vulnerabilities in smart contracts cannot be fixed after deployment.
Smart Contracts are upgraded for various reasons, which include:
- Fixing Bugs
- Fixing Security issues
- Adding new features to the Smart Contract
## What is a Smart contract upgrade?
A smart contract upgrade is a process of updating the business logic of an already deployed smart contract while preserving the states (data) of the smart contract.
There are different ways of upgrading smart contracts, and we will talk about a few of them in this article.
- Contract Migration
- Data separation
- Proxy Pattern
- Diamond Pattern (EIP-2535)
## Contract Migration
This is one of the oldest and crudest way of upgrading smart contracts, it is very tedious and expensive in terms of gas fees and may be impractical in large applications. It is implemented by deploying a new smart contract with the updated business logic, and then copying the states from the old smart contract to the new one, then changing the smart contract address to the new one in your DApp.
This method is used when the smart contract was developed without the intention to upgrade it.
## Data separation
This method uses two smart contracts; one smart contract contains the business logic, and the other smart contract contains the contract's data, users interact directly with the logic contract, and the logic contract calls the data contract as the name implies all state variables are stored here.

Upgrades are done by changing ownership of the data contract to that of the new business logic contract and using the address of the new business contract in your DApp. This method is better than Contract Migration as it is cheaper, but you have to change the contract address with each upgrade you make which is not ideal as other software may depend on your Smart contract.
## Proxy Pattern
This method makes use of an immutable proxy contract that stores the data and an upgradable logic contract, the user interacts directly with the immutable proxy contract, and this contract delegate calls the logic contract.
To upgrade in this pattern, you need to deploy a new logic contract, then update the address on the proxy contract to that of the new one, subsequent calls to the proxy contract will be implemented by the new logic contract.
## Diamond Pattern (EIP-2535)
This method is an extension of the Proxy Pattern. This pattern uses a contract called the Diamond. The Diamond contract delegate call multiple logic contracts called facets. These facets execute the logic, and the diamond contract stores the state (data). The most important feature of the Diamond pattern is that it is not constrained by the 24kb maximum contract size in solidity, as larger contracts can be splited into smaller facets, also with this pattern you don't need to update the whole contract during upgrades, you only need to deal with the facet that contains that function or add a new facet.
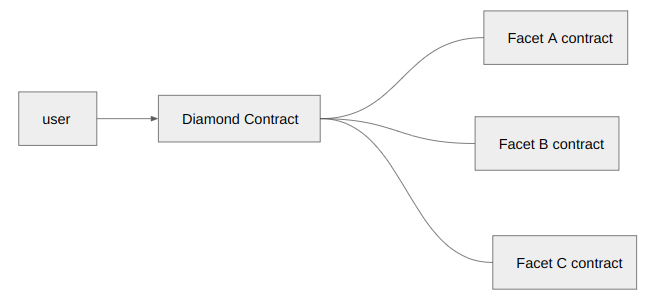
In the Diamond pattern, upgrades are handled by a facet called the DiamondCutFacet with this facet, you can add, remove or replace functionalities. If this facet is removed the contract can't be upgraded anymore.
## Conclusion
In this article we have talked about four popular methods of upgrading smart contracts, the Contract Migration pattern should only be used when you deployed the contract without intention of upgrading it, it is not advisable to use Separation of Logic method as it brings the inconvience of changing the contract address with each deployment the Proxy Pattern is currently the most used pattern so more people in the EVM community understands it, but the Diamond pattern is a game changer, it makes it possible for developers to exceed the 24kb size limit of smart contracts, so you smart contract can grow to any size.
| joshuajee |
1,335,116 | Embracing the journey as a freelancer | You probably dreamed about becoming a freelancer after taking your first sip of office coffee on a... | 0 | 2023-01-19T20:47:29 | https://livecodestream.dev/post/embracing-the-journey-as-a-freelancer/ | careeradvice, freelancing | ---
title: Embracing the journey as a freelancer
published: true
date: 2023-01-11 22:35:34 UTC
tags: CareerAdvice,Freelancing
canonical_url: https://livecodestream.dev/post/embracing-the-journey-as-a-freelancer/
---

You probably dreamed about becoming a freelancer after taking your first sip of office coffee on a Monday morning or after staying late working on a project that wasn’t supposed to be your responsibility on a Friday. Freelancing seemed like the perfect escape.
> Many freelancers start their freelancing journey with starry-eyed dreams of having a flexible work schedule, working from exotic locations, and building a satisfying career.
And, while all of that is possible, what they don’t count on is that the life of a freelancer is both easier and harder than the life of a salaried programmer.
It is both simpler and more complicated.
It is both more rewarding and more frustrating.
It is both more freeing and more constraining.
Eventually, you’re due for a wake-up call.
Don’t misunderstand me. I love freelancing, as do many people.
In fact, in the United States, freelancers now make up nearly 35% of the workforce.
But, here’s the thing, freelancing isn’t like a traditional salaried career. You don’t put in the work for an annual raise, slowly climbing the corporate ladder.
Freelancing is a journey, and at least in the beginning, you only have a foggy idea of where or what the destination is.
Often, the short term objectives are clear and involve finishing projects, getting new clients, or meeting some goals you’ve set for yourself. But, the longer term questions of where you want to be in five years, what you want to be doing, and where you ultimately want your career to lead are covered by thickly obscuring fog.
Today, I want to talk about embracing the journey as a freelancer because this is the number one rule that you must learn. You MUST embrace this long, sometimes confusing, and somewhat opaque journey that you signed up for when you became a freelancer.
But, what exactly does “embracing the journey” mean? It’s a nice cliche, but how exactly are you supposed to do that?
Let me explain.
* * *
## Embracing the Journey Means Taking the Long View of Things. [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#embracing-the-journey-means-taking-the-long-view-of-things)
This could mean making long term plans. But, conversely, it could mean making a short term sacrifice for a long term gain, like refunding a client to maintain a relationship that will be profitable in the long term.
_Generally though, taking the long view means keeping a clear eye on the urgent and the important._
In the day-to-day, it is easy to get these two confused, but they are not the same.
If you are like many freelancers, you will get many different types of clients. Some are central pillars of your business; others exist on the periphery.
Because you only have so many hours in the day, there is only so much you can do. And, while the peripheral client might be demanding early delivery of a project (the urgent), you know you have to take care of the client you’ve been working with for years (the important) first.
Taking the long view also involves maintaining a clear sense of where you are going. You don’t need to know your exact destination. But, if you know that you want to be working with a certain type of client three years from now, you need to do certain things to set yourself up today.
Sometimes, taking the long view means saying no to a client because you don’t think it is in your best interest for one reason or another. Maybe they’ll take too much time, robbing you of time with your family. Or, they could be asking for something that you are not proficient in and therefore, can’t guarantee results.
Either way, if you are clear about your long-term goals and the difference between urgent and important, you’ll consistently put yourself into situations where you can succeed.
> [Embracing the journey of freelancing also means recognizing that there will be ups and downs.](http://twitter.com/share?url=https%3a%2f%2flivecodestream.dev%2fpost%2fembracing-the-journey-as-a-freelancer%2f&text=%22Embracing%20the%20journey%20of%20freelancing%20also%20means%20recognizing%20that%20there%20will%20be%20ups%20and%20downs.=%22&via=livecodestream)[Tweet this](http://twitter.com/share?url=https%3a%2f%2flivecodestream.dev%2fpost%2fembracing-the-journey-as-a-freelancer%2f&text=%22Embracing%20the%20journey%20of%20freelancing%20also%20means%20recognizing%20that%20there%20will%20be%20ups%20and%20downs.%22&via=livecodestream)
In the daily grind, it is hard to keep perspective as a freelancer.
Maybe you’ve mastered how to [plan your day effectively as a freelancer](/post/freelancer-daily-plan/) and [project management](/post/how-to-manage-projects-as-a-freelancer/), so you feel like things are going well.
You feel invincible. The clients keep coming, your business keeps growing, and you are tempted to say yes to everything (and count the money as it rolls in.)
But, what happens when you get to the top of the mountain?
You have to head back down.
Good times will inevitably give way to bad ones.
_Your success as a freelancer depends more on how you handle the bad times than how you handle the good ones._
This is radically different from a traditional company.
As a software engineer for a traditional company, the general success or health of the company isn’t really your daily concern and only becomes your concern if the company starts talking about restructuring, layoffs, or other ways to shed unwanted salary.
As a freelancer, though, the success of your career is always your concern, which makes everything so much more personal.
When a client doesn’t like your work, they don’t like YOUR WORK. That hurts.
When a client decides to leave you, they are leaving YOU. That hurts.
There are times when you feel invincible. Then, there are times when you feel worthless, asking yourself why anyone would be stupid enough to pay you for anything.
Which leads me to my next point.
* * *
## Imposter Syndrome Is Real. [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#imposter-syndrome-is-real)
If you look around, you’ll always find someone better than you at what you do.
They’ll be smarter, faster, more efficient, more well-spoken, or more attractive (which has nothing to do with programming, but we notice it anyway).
When you are pitching your services to a client, inside you’ll feel like a fool.
Over time, this feeling diminishes as you get more and more success beneath your belt.
But, it never really goes away.
Imposter syndrome is a constant companion, like a chronic disease you have to learn to live with.
You can’t let it paralyze you, because it will if you let it.
> [The antidote to imposter syndrome is action.](http://twitter.com/share?url=https%3a%2f%2flivecodestream.dev%2fpost%2fembracing-the-journey-as-a-freelancer%2f&text=%22The%20antidote%20to%20imposter%20syndrome%20is%20action.=%22&via=livecodestream)[Tweet this](http://twitter.com/share?url=https%3a%2f%2flivecodestream.dev%2fpost%2fembracing-the-journey-as-a-freelancer%2f&text=%22The%20antidote%20to%20imposter%20syndrome%20is%20action.%22&via=livecodestream)
Relentless, constant, regular action.
If you are moving, working, meeting with clients, growing, and getting better, imposter syndrome doesn’t have the oxygen it needs to thrive.
The life of a freelancer is a life of action. You are getting stuff done for clients, for yourself, for your family. You are [building habits that will help you be successful as a freelancer](/post/freelancer-habits/).
Every successful freelancer is an action-oriented person. And, every action-oriented person is capable of being a successful freelancer.
This can be an exceptional thing because if you are looking for a career that actually grows based on what you put into it, freelancing is for you.
> Lastly, realize that there is only one constant in freelancing. Change.
Everything is always changing.
From the programs you use, to the technology you are developing, to the things your clients demand from you.
It is always changing.
While there are [many tools that help you manage your business](/post/freelancer-tools/), ultimately your business is you.
This means that you need to read, study, and learn. If you don’t, you’ll soon fall behind the curve, and clients will look for someone else who can deliver what they want.
It also means **you must be ready to adapt, change, and grow throughout your career**. To do so, you can take advantage of industry conferences, local business organizations, and networking with other freelancers and online groups.
The more you put yourself out there and invest in your personal and professional growth, the better your business will become. You’ll be able to offer more to your clients, and your business will grow and become all you’ve dreamed it could be.
* * *
## Conclusion [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#conclusion)
> Each freelancer’s journey is unique, but there are some common denominators that all freelancers must embrace, sooner or later.
In order to realize your dreams, you’ll need to take the long view of things and determine what is important so as not to succumb to the urgent.
You’ll need to recognize that there will be ups and downs, and that how you handle the bad times will really determine your success as a freelancer.
You’ll need to face imposter syndrome and not let it paralyze you, but instead, be determined to take action.
Lastly, you’ll need to embrace and prepare for change - both in yourself and in your business.
If you’re able to do these things, your journey as a freelancer will become the flexible, rewarding, satisfying career that you’ve always wanted.
Thanks for reading!
[Subscribe to my weekly newsletter](https://livecodestream.dev/newsletter/) for developers and builders and get a weekly email with relevant content. | bajcmartinez |
1,335,290 | What Is a Higher Order Function? | Learn what higher-order functions are and why they are important in functional programming, and code some examples in Python and JavaScript. | 0 | 2023-01-22T22:11:14 | https://livecodestream.dev/post/what-is-a-higher-order-function/ | programming, python, javascript, typescript | ---
title: What Is a Higher Order Function?
published: true
date: 2023-01-22 08:51:01 UTC
description: Learn what higher-order functions are and why they are important in functional programming, and code some examples in Python and JavaScript.
tags: Programming,Python,Javascript,Typescript
canonical_url: https://livecodestream.dev/post/what-is-a-higher-order-function/
---

When we think of functions in any programming language, we think of reusable code abstracted into a separate block that performs specific tasks. Such functions can take inputs, process them and provide output according to the instructions coded in the function.
Functions normally receive values as inputs, such as numbers, strings, and references or copies of objects and lists, and would optionally return values in those types.
But hold on, what if, for example, we are implementing a `timer` function that, after X seconds passed, will execute a given piece of code? Could such a `timer` function have another function as its input?
----
## What are higher-order functions?
In computer science, higher-order functions (a key element of functional programming) are functions that can take other functions as inputs or return them as outputs. They, therefore, allow us to create abstractions over existing functionality and compose new functionality out of existing ones.
As a big fan of functional programming, I love higher-order functions. They are useful for writing more readable and easier-to-maintain code. And its a paradigm I often use when working with JavaScript/TypeScript, especially when working with React. Though I gotta admit, I haven't used that much of it when working with Python.
Higher-order functions are great, but...
-----
## Why would I use higher-order functions?
Higher-order functions are useful for writing code that is more general, extensible, and reusable. You can use them to create abstractions over existing functionality and compose new functionality out of existing ones. Additionally, they let you control scope, simplify callbacks (like promises), eliminate unnecessary code duplication, and write cleaner code by separating the logical flow from the implementation details.
Ever worked with `filter`, `map`, `forEach` methods in JavaScript? Those are excellent examples of higher-order JavaScript functions.
-----
## Writing your first higher-order functions
Let's start simply by building two different higher-order functions. The first one would take a function as input, while the second example would return a function. Next, we'll write our own definitions for some of the most popular higher-order functions, some of which we have already named before.
All code samples are provided in Python and JavaScript as those are the language I'm most familiar with, but if you want to help, you can send me these same functions in other programming languages, and I'll gladly add them here.
### Taking a function as an argument
To start, let’s build a very simple function, `doOperation` which takes 3 arguments:
- The function operation
- number1
- number2
Additionally, we will create an operation called sumBothNumbers which will simply return the sum of 2 numbers.
The idea is that `doOperation` would run the given operation function to both numbers and return the final result. The `operation` input can by any function that takes two numbers and performs a calculation, such as calculating the sum of both numbers.
*Python:*
```python
def doOperation(operation, number1, number2):
return operation(number1, number2)
def sumBothNumbers(number1, number2):
return number1 + number2
doOperation(sumBothNumbers, 3, 5)
------------
Output
------------
8
```
*Javascript:*
```javascript
function doOperation(operation, number1, number2) {
return operation(number1, number2)
}
function sumBothNumbers(number1, number2) {
return number1 + number2
}
doOperation(sumBothNumbers, 3, 5)
------------
Output
------------
8
```
### Returning a function
Next, we will build a higher-order function that returns a function. Our function will be called multiplyBy and it will take a number as an argument and return a function that will multiply its input by that number.
*Python:*
```python
def multiplyBy(multiplier):
def result(num):
return num * multiplier
return result
multiplyByThree = multiplyBy(3)
multiplyByThree(4)
------------
Output
------------
12
```
*JavaScript:*
```javascript
function multiplyBy(multiplier) {
return function result(num) {
return num * multiplier
}
}
multiplyByThree = multiplyBy(3)
multiplyByThree(4)
------------
Output
------------
12
```
-----
## Building Filter(), Map() and Reduce()
We are getting pros at working with higher-order functions, and though it may still take some practice to find out good opportunities to use them, you are in great shape to work on some more complex implementations.
To level up our higher-order functions skills, we will write the code for some of the most popular array methods in the functional programming paradigm.
### filter() aka filtering()
The `filtering` function will have 2 parameters, an `array` and a `test` function. It will return a new array with all the elements that pass the test.
*Python:*
```python
def filtering(arr, test):
passed = []
for element in arr:
if (test(element)):
passed.append(element)
return passed
def isSuperNumber(num):
return num >= 10
filtering([1, 5, 11, 3, 22], isSuperNumber)
------------
Output
------------
[11, 22]
```
*JavaScript:*
```javascript
function filtering(arr, test) {
const passed = []
for (let element of arr) {
if (test(element)) {
passed.push(element)
}
}
return passed
}
function isSuperNumber(num) {
return num >= 10
}
filtering([1, 5, 11, 3, 22], isSuperNumber)
------------
Output
------------
> (2) [11, 22]
```
### map() aka mapping()
The function `mapping` will take 2 parameters: an `array` and a `transform` function, and it will return a new transformed array where each item is the result of the `transform` function called over each element of the original array.
*Python:*
```python
def mapping(arr, transform):
mapped = []
for element in arr:
mapped.append(transform(element))
return mapped
def addTwo(num):
return num+2
mapping([1, 2, 3], addTwo)
------------
Output
------------
[3, 4, 5]
```
*JavaScript:*
```javascript
function mapping(arr, transform) {
const mapped = []
for (let element of arr) {
mapped.push(transform(element))
}
return mapped
}
function addTwo(num) {
return num + 2
}
mapping([1, 2, 3], addTwo)
------------
Output
------------
> (3) [3, 4, 5]
```
### reduce() aka reducing()
The function reducing will take 3 parameters: a reducer function, an initial value for the accumulator and an array. For each item in the array, the reducer function is called, passing it to the accumulator and the current array element. The return value is assigned to the accumulator. After reducing all the items in the list, the accumulated value is returned.
*Python:*
```python
def reducing(reducer, initial, arr):
acc = initial
for element in arr:
acc = reducer(acc, element)
return acc
def accum(acc, curr):
return acc + curr
reducing(accum, 0, [1, 2, 3])
------------
Output
------------
6
```
*JavaScript:*
```javascript
function reducing(reducer, initial, arr) {
let acc = initial
for (element of arr) {
acc = reducer(acc, element)
}
return acc
}
function accum(acc, curr) {
return acc + curr
}
reducing(accum, 0, [1, 2, 3])
------------
Output
------------
6
```
----
## FAQs
### Why are they called higher-order functions?
A higher-order function takes its name because they typically act on or return functions from a higher order (or level) of abstraction.
### What is functional programming?
Functional programming is a programming paradigm focusing on writing programs as a series of functions rather than code with a mutable state. It emphasizes using higher-order functions and immutable data structures to create modular, maintainable code.
### Are higher-order functions a common topic in interviews?
Yes, higher-order functions are a common topic in software engineering interviews, it depends on the programming role and language, but generally speaking, it is good to know it. They are an important aspect of functional programming and writing code with scalability and reusability in mind. Knowing how to write and use higher-order functions is essential for software engineers who want to work on modern web or mobile applications.
-----
## Conclusion
Next time when you get to that interview, or simply you see a pattern where a function is either returned or taken as a parameter, you will know we are dealing with higher-order functions.
Today for the first time, I’ve introduced an article covering more than one language. If you find it a great way to showcase and compare them, or if you think it was a terrible idea, please let me know in the comments or by [Twitter](https://twitter.com/bajcmartinez). I’d love to hear your ideas.
Thanks so much for reading!
---
## Newsletter
[Subscribe to my weekly newsletter](https://livecodestream.dev/newsletter/) for developers and builders and get a weekly email with relevant content. | bajcmartinez |
1,335,414 | Backend Portfolio Projects for Developers Who Dread CSS | This article was originally published at... | 0 | 2023-01-20T06:01:19 | https://maximorlov.com/backend-portfolio-projects-no-css/ | beginners, javascript, webdev, node | *This article was originally published at https://maximorlov.com/backend-portfolio-projects-no-css/*
Having a portfolio is *essential* to landing a web development job. As a back-end developer, how do you *showcase* your skills when most of it happens, well, in the back end?!
You might use Postman to send requests to your server, but you can't expect recruiters to do that. They need an easy and quick way to *see* what you've built. You need a *front end* to accompany your back end.
You need **HTML** and **CSS**.
But writing CSS isn't your forte. In fact, you could easily spend *hours* fiddling with CSS only to end up with a page that looks like it was built in the 90s.
Imagine showing one of your projects to a recruiter while trying to convince them the back end is really well done and they should **ignore the design..**
That's awkward.
Despite having the design skills of a 5-year-old, your projects *don't have to* reflect that.
What if you had a portfolio you were *truly* proud of? A portfolio of beautifully designed projects that are worthy of your intelligently written back ends.
**A portfolio worthy of YOU.**
This portfolio would make you **stand out** from all other candidates. It would get you past the screening stage and sitting at a table in front of your future employer.
Best of all, what if you accomplished all of that without writing even *a single line* of CSS? Wouldn't it be great if you spent your time writing back-end logic instead — the type of coding you're *actually* good at.
Well, now you can!
## Introducing back-end projects packaged with a front-end application
I'm releasing a collection of portfolio projects that come with an already **built front-end application** so you can focus *entirely* on the back end.
These projects will cover a wide range of back-end topics such as authentication, caching, sockets and security, making them an ideal choice for **learning and practicing Node.js**.
By the time you complete several of these projects, you'll have a *strong* portfolio showcasing your web development skills.
Want to use Express, Fastify, Nest.js, or any other back-end framework? Not a problem! SQL or NoSQL? Up to you! There are absolutely *no restrictions* on how you should build these projects.
You're free to choose *any* frameworks and libraries you want. This is an excellent opportunity to try out a new library or learn a technology that will give you an edge on the job market.
## URL Shortener project
The first project in the series is a **URL Shortener** service.
Your task is to implement a back-end that enables users to shorten a long URL. The short URL should redirect visitors to the original URL when visited. Additionally, users should be able to view the number of times an URL has been visited.
> I'm giving the first project away for FREE. [**Learn more →**](https://maximorlov.com/backend-portfolio-projects-no-css/)
## What's inside
### Front-end application
<figcaption>Screenshots of the Home, Short URL and Analytics mobile pages</figcaption>
Each project comes with a fully designed and implemented front-end application. It's a plug-and-play application ready to connect to a back end. Just give it a URL and you're good to go.
### API Documentation
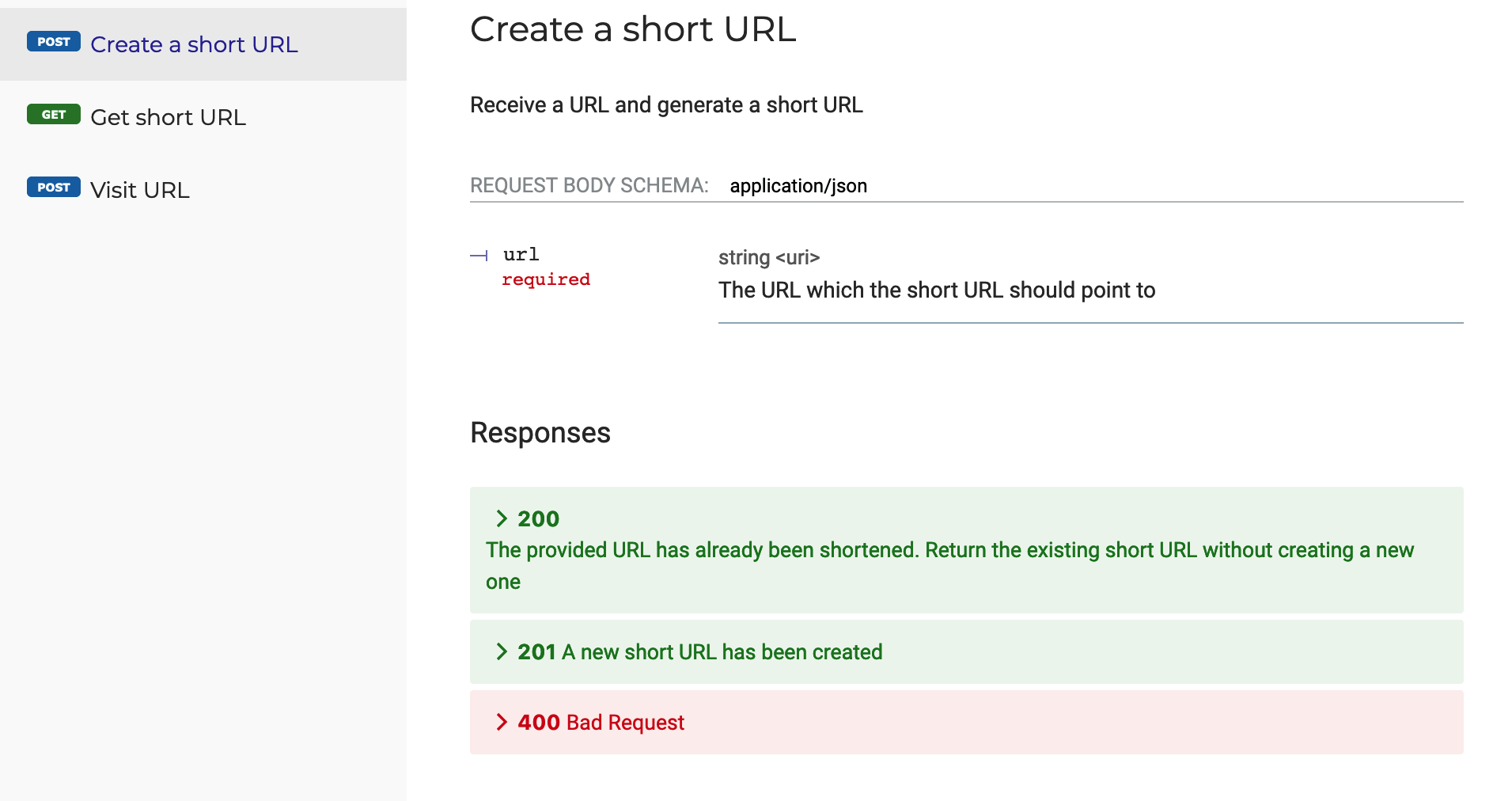
<figcaption>API documentation for the endpoint to create a short URL</figcaption>
Back-end developers often use the API documentation to coordinate with front-end developers. API documentation is a formalized document of how the client and server will communicate.
Typical API documentation will describe how the client should authenticate with the server, what the available endpoints are, and what the data returned by the back end looks like.
As a back-end developer, you should be comfortable with implementing a back end that closely matches the documentation. API documentation is to back-end developers, what design files are to front-end developers.
### User stories

<figcaption>Essential features of the URL Shortener project</figcaption>
User stories provide an overview of the features you will be implementing. They give you a good idea of what the project is about.
These are a collection of essential features written from the user's perspective. User stories encourage backward planning by starting with the end result first. Use them to work your way backward and decompose the project into many small tasks.
Together with the API documentation, user stories are a great starting point for integration tests.
### Bonus tasks

<figcaption>Bonus tasks add an extra level of difficulty</figcaption>
For ambitious developers who like an extra challenge, each project comes with additional bonus tasks. These tasks go beyond the initial scope of the project and challenge your problem-solving skills.
If the user stories are the Minimum Viable Product (MVP), bonus tasks are the polished version of a product. Completing the bonus tasks shows you're capable of analyzing, researching, and solving real-world problems.
Don't feel the pressure to finish all, or any, bonus tasks. If you implement just the essential features that's already a big accomplishment.
### Resources
Resources are various links to tutorials, Stack Overflow questions, Wikipedia pages, or blog posts that can help you with the project. If you get stuck building the project, these resources can help you get unstuck and learn a different problem-solving approach.
These resources work best when used as inspiration. Try not to copy-paste code from them and if you absolutely have to, make sure you fully understand what each line of code does.
### Additional support
**A workflow for building the project.** This is a step-by-step workflow on how I would build the project. From initializing a GitHub repository to implementing a mock server to connecting a database. These are a sequence of steps. Feel free to adapt it to your liking or use your own workflow.
**Deployment tips.** How you deploy the back end will largely depend on whether you want to host it on a server (VPS) or a managed server (PaaS). With the plethora of cloud providers today, I lay out the options available to you along with some recommendations that have free tiers.
> For a limited time only, I'm offering FREE **professional code reviews** for anyone who completes a project! Don't miss this unique opportunity to get actionable personalized feedback on your code.
## Go build something awesome!
[**Visit the original article**](https://maximorlov.com/backend-portfolio-projects-no-css/) and download the project files to get started.
I'm super excited to see the awesome stuff you'll make and I'm curious to see what approach you'll take to solve these projects.
I'd love to have a look at your solution. [Shoot me an email](mailto:hello@maximorlov.com) with a link or [mention me on Twitter](https://twitter.com/_maximization). I'll help spread the word!
**Have fun building! ⚒️** | maximization |
1,335,428 | Understanding How Web 3.0 Will Affect Business In The Future | Krishna Jadhav Understanding How Web 3.0 Will Affect Business in the Future Krishna Jadhav has... | 0 | 2023-01-20T06:28:11 | https://dev.to/krishna1412/understanding-how-web-30-will-affect-business-in-the-future-4ok0 | Krishna Jadhav
Understanding How Web 3.0 Will Affect Business in the Future
Krishna Jadhav has observed over the previous three decades, the Web has undergone a significant transformation. Since Web 1.0's early years, when the internet primarily served as a channel for transmitting text-based information, a lot has changed (Boudlaie, Nargesian and Keshavarz Nik, 2019). Rich media content has now arrived due to the shifting tides of fast-increasing consumer requirements and the arrival of Web 3.0. Web 3.0 is the next significant advancement in how we access and exchange information online. Soon-to-be-released AI-enabled search engines are already having an impact on user behaviour. The user's experience will be personalised in this next Web generation to meet their wants and tastes (Figure 1). Data that any organisation, such as governments, cannot suppress will be accessible to users.
Figure 1: SEMIoTICS interoperability framework
(Source: Hatzivasilis et al., 2018)
Since it is on their own devices, Suffice it to say that will be the next stage of corporate development. Before delving more into Web 3.0, it is vital to clarify that Web 3.0 and Web3 are not synonymous (Bergquist Mcneil, 2022). Although Web 3.0 and Web 3 cannot be seen theoretically or practically in isolation, they should not be used interchangeably. Web3 is a more advanced decentralised blockchain-based Web (Figure 1). Semantic Online is a new type of web content in which data is arranged so that machines rather than humans can decipher it. According to the official W3C website, "Semantic Web technologies enable anyone to develop web-based data repositories, define vocabularies, and write rules."
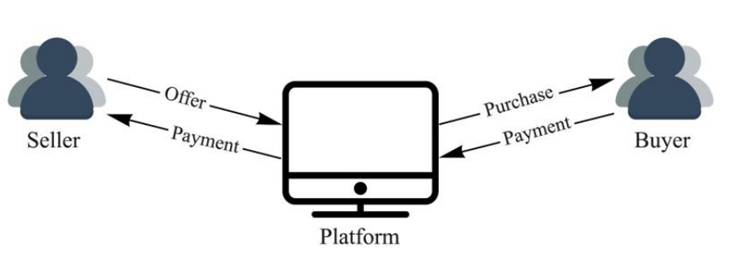
Figure 2: Interaction between two users on a platform (Web 3.0 Decentralised Application)
(Source: Lundberg and Petrén, 2022)
Personalisation: Web 3.0 pushes personalisation to new heights. Real-time data integration can help to make online interactions and interests more relevant (Figure 2). Adopting the proper business model may help firms give a considerably enhanced client experience while providing numerous advertising and promotion opportunities.
Mobile-First Experiences: If you want to capitalise on Web 3.0 and better engage and reach your target audience, you must provide end users with a mobile-first experience. Businesses that do not react to this trend risk falling behind. Consumers today want not just an integrated omnichannel experience but also easier and faster access to information (Hatzivasilis et al., 2018).
Conclusion
In Krishna Jadhav’s conclusion, Web3 may be thought of as the progression of Web 3.0. This concept is built around the idea of a decentralised Web, focusing on blockchain technology, encryption, and cryptocurrencies. It also includes the application of virtual reality (VR), augmented reality (AR), and, most recently, the metaverse.
With that being said, what are the Essential Web 3.0 trends and their current benefits? Want to know? The next article is meant for you.
Reference List
Bergquist Mcneil, L. (2022). Blockchains, smart contracts, and stablecoins as a global payment system: The rise of web 3.0. https://www.diva-portal.org/smash/record.jsf?pid=diva2:1671071
Boudlaie, H., Nargesian, A., and Keshavarz Nik, B. E. H. R. O. O. Z. (2019). Digital footprint in web 3.0: social media usage in recruitment. AD-minister, (34), 139-156. http://www.scielo.org.co/scielo.php?pid=S1692-02792019000100139&script=sci_arttext&tlng=en
Hatzivasilis, G., Askoxylakis, I., Alexandris, G., Anicic, D., Bröring, A., Kulkarni, V., ... and Spanoudakis, G. (2018, September). The Interoperability of Things: Interoperable solutions as an enabler for IoT and Web 3.0. In 2018 IEEE 23rd International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD) (pp. 1-7). IEEE. https://ieeexplore.ieee.org/abstract/document/8514952/
Lundberg, L., and Petrén, M. (2022). DApp Revolution: An Investigation into the Nature and Business Models of Web 3.0 Decentralized Applications. https://odr.chalmers.se/handle/20.500.12380/305006 | krishna1412 | |
1,335,479 | How To Setup Redux Slices with Redux Toolkit | You must always maintain the application's state when working on a React project. The best way to do... | 0 | 2023-01-20T07:51:18 | https://dev.to/quokkalabs/how-to-setup-redux-slices-with-redux-toolkit-337o | redux, javascript, react, webdev | You must always maintain the application's state when working on a React project. The best way to do this is to use a tool like Redux to store the state in one place. However, if you are building a large application, its state can become very complex and hard to maintain.
This blog will look at how you can use Redux Slices with the react-redux toolkit to manage the complexity of your application.
But before proceeding, let’s discuss Redux and Redux Toolkit!!
## What is Redux?
Redux is a JavaScript library for managing app state. It is often used with React, a popular JavaScript library for building user interfaces, but it can also be used with other frameworks or on its own.
Redux is based on the idea of a global, immutable state tree, which means that the entire application's state is stored in a single, immutable data structure. This data structure can only be modified by dispatching an action, an object describing a state change. When an action is dispatched, it is passed through a series of functions called reducers, which update the state tree according to the action.
One of the main benefits of using Redux is that it makes it easy to manage and debug the state of a complex application. Because the state is stored in a single, immutable data structure, it is easy to track changes over time and understand how the application's state evolved. In addition, because actions and reducers are pure functions, they are easy to test and debug.
### What is Redux Toolkit?
**[Redux Toolkit](https://www.softkraft.co/how-to-setup-slices-with-redux-toolkit/)** is a set of libraries and utilities designed to make it easier to work with Redux and write Redux-based applications. It provides a streamlined, opinionated approach to defining actions and reducers. It includes a set of utility functions for common Redux tasks, such as store setup, immutable update logic, and serialization.
One of the main benefits of using Redux Toolkit is that it helps reduce the boilerplate code typically required when working with Redux. For example, the **createSlice** function allows you to define a reducer and associated actions in a single place and automatically generates the action types and creators for you. This can make it much easier to work with Redux, especially in larger applications where there may be many actions and reducers.
In addition to providing utility functions, React-Redux Toolkit includes a set of recommended best practices for working with Redux. These best practices are designed to help developers write clean, maintainable code that is easy to test and debug.
Overall, Redux Toolkit react is a powerful tool for working with Redux that can help developers build complex, scalable applications easily.
**Read More:** {% embed https://quokkalabs.hashnode.dev/complete-guide-to-redux-toolkit-rtk-query-with-react %}
### What is CreateSlice?
CreateSlice is a utility function provided by Redux Toolkit that makes it easier to define a reducer and associated actions for a particular application state. It is designed to reduce the boilerplate code typically required when working with Redux. And to make it easier to organize and structure your code.
To use CreateSlice, you pass in an object that defines the initial state of the slice, as well as any reducer functions that you want to create. CreateSlice will then generate the action types & action creators based reducer function name you provided.
Here's an illustration of how you can use CreateSlice to define a reducer for a slice of state called "counter":
```
import { createSlice } from '@reduxjs/toolkit';
const counterSlice = createSlice({
name: 'counter',
initialState: {
value: 0
},
reducers: {
increment: state => {
state.value += 1;
},
decrement: state => {
state.value -= 1;
}
}
});
export const { increment, decrement } = counterSlice.actions;
export default counterSlice.reducer;
```
This code defines a reducer with two actions: increment and decrement. CreateSlice will automatically generate action types and action creators for these actions based on the names of the reducer functions.
You can then use the generated action creators to dispatch actions and the generated reducer to update the state in response to those actions. For example-
`import store from './store';
import { increment, decrement } from './counterSlice';
store.dispatch(increment());
store.dispatch(decrement());`
In a nutshell, CreateSlice is a powerful and convenient tool for defining reducers and actions in Redux applications, and it can help you write clean, maintainable code with less boilerplate.
## How To Setup Redux Slices with Redux Toolkit?
Let's build a quick application to dynamically add a place name to the existing list. This will aid in the implementation of CreateSlice, dispatch action, and store configuration.
### Step 1: Process to Implement createSilce and Export Actions and Reducer
Creating the file containing the slice is a part of this phase. Here, the file name is maintained as "locationSlice.js."
- Initially, import the redux-toolkit library's createSlice method.
- Use the createSlice method to generate your slice.
- All the values needed to build a reducer are present in the locationSlice that was created earlier. We now need to export the reducer and the actions.
```
import { createSlice } from '@reduxjs/toolkit';
const locationSlice = createSlice({
name: "location",
initialState: {
location: ['Noida', 'Banglore', 'Delhi'],
},
reducers: {
save: (state, param) => {
const { payload } = param;
state.location = [...state.location, payload];
},
}
});
const { actions, reducer } = locationSlice
export const { save } = actions;
export default reducer;
```
In each scenario, createSlice generates an action creator using the reducer name as the action type itself after examining all the functions declared in the reducers field.
In the code mentioned above, the save reducer created above evolved an action type of location/save, and the save() action creator will produce an action with that type.
Here, we also define the slice and export its action creators and reducers using the advised ES6 de-structuring. However, if favored, we can export the slice object directly instead of de-structuring and exporting.
### Step 2: Here, Dispatch Action by Using React Hooks in Functional Component
We must now use the React Hooks. Use the useSelector to read the state and the useDispatcher to send the slice-created action. We'll implement it now and check out the app's functionality.
`import { useDispatch, useSelector } from "react-redux";
import { save } from "./locationSlice";`
We can destruct the redux-store object provided by the useSelector hook to obtain the state values.
The dispatcher must be configured by calling useDispatch hook.
`const { location } = useSelector(state=>state)
const dispatch = useDispatch();`
Here is the final code for integrating the above logic to have an app that dynamically reads and updates the state value.
```
import React, { useState } from "react";
import { save } from "./locationSlice";
import { useDispatch, useSelector } from "react-redux";
import { Box, TextField, Button } from "@material-ui/core";
export default function App() {
const [locationName, setLocationName] = useState('');
const dispatch = useDispatch();
const { location } = useSelector(state=>state)
const handleData = (e) => {
setLocationName(e.target.value);
}
const handleSave = () => {
const ifPrestent = location.includes(locationName);
if(locationName !== undefined && !ifPrestent) {
dispatch(save(locationName));
setLocationName('')
} else {
setLocationName('')
}
}
return (
<Box>
<Box>
<TextField
onChange={handleData}
value={locationName}
label="Enter location name"
/>
<Button
style={{margin: '10px'}}
variant="contained"
color="primary"
onClick={handleSave}
>
add
</Button>
</Box>
<Box>
<h3> List of locations </h3>
</Box>
<Box>
{location.map((item) => <li>{item}</li>) }
</Box>
</Box>
);
}
```
### Step 3: Store Configuration
We now require to link our store with the application. CreateStore() is wrapped by configureStore({}) in this case to make configuration easier for us. The complete state tree of your app is stored in the redux store created by createStore().
```
import React from "react";
import ReactDOM from "react-dom";
import App from "./App";
import { configureStore } from "@reduxjs/toolkit";
import { Provider } from "react-redux";
import rootReducer from "./locationSlice";
const store = configureStore({
reducer: rootReducer
});
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
);
```
Here is how the app appears in the browser after its use. Try adding a new location name to see if the list of locations is dynamically updated.

### Final TakeAway
You now know how to create and use the redux toolkit's createSlice method. This allows you to write all the actions and reducers for your redux store in a single file and to do it in a much more readable style.
| labsquokka |
1,335,501 | A "Shallow" Dive into Memory Leaks in Ruby | Intro A memory leak is a type of software bug where a program or application continuously... | 0 | 2023-01-20T08:50:49 | https://dev.to/daviducolo/memory-leak-and-ruby-a1m | ruby, tutorial, performance, programming | ## Intro
A memory leak is a type of software bug where a program or application continuously allocates memory but fails to properly deallocate it, causing the memory usage to increase over time. This can lead to the program crashing or freezing if it exhausts the available memory resources. Memory leaks can occur in any programming language, but are particularly common in C and C++ programs due to the manual memory management. Common causes of memory leaks include failing to free memory that is no longer needed, or creating circular references where two objects refer to each other and prevent the memory manager from freeing their memory. Memory leaks can be difficult to detect and fix, but tools such as memory profilers and leak detectors can help.
Memory leaks can also occur in systems that use automatic memory management, such as those that use garbage collection. In these systems, a memory leak can occur when the garbage collector is unable to determine that a piece of memory is no longer in use and therefore cannot free it.
Memory leaks can have serious consequences, such as causing a program to slow down or crash, or causing a system to become unstable or unresponsive. In some cases, a memory leak can even lead to a security vulnerability, as it can cause a program to allocate so much memory that it exhausts the available resources and causes other programs to fail.
To detect and fix memory leaks, developers can use tools such as memory profilers and leak detectors. These tools can provide information on memory usage and can help identify the source of a leak. Additionally, good programming practices such as proper memory management, and using smart pointers, RAII, and garbage collection can also help to prevent memory leaks.
It's important to note that memory leaks are not always easy to detect and fix, and can require a significant amount of time and effort to resolve. However, identifying and addressing memory leaks is crucial for the stability and performance of any program or application.
In a garbage collected language like **Ruby**, memory leaks can occur when objects are not properly cleaned up by the garbage collector.
There are several ways in which memory leaks can occur in Ruby, including:
1. Circular references: A circular reference occurs when two or more objects hold references to each other. This can prevent the garbage collector from being able to clean up the objects, leading to a memory leak.
2. Long-lived objects: Objects that are no longer needed, but are not properly cleaned up by the garbage collector, can lead to a memory leak.
3. Event handlers: Event handlers that are not properly unregistered can lead to a memory leak.
4. Singletons: Singleton objects, if not properly managed, can lead to a memory leak.
## Techniques
To avoid memory leaks in Ruby, it is important to understand the ways in which memory leaks can occur and to use best practices to prevent them.
One way to avoid circular references is to use weak references. A weak reference is a reference that does not prevent the garbage collector from cleaning up the object. In Ruby, the **WeakRef** class provides a way to create weak references.
```ruby
require 'weakref'
class Foo
def initialize
@bar = "Hello, World!"
end
end
foo = Foo.new
weak_foo = WeakRef.new(foo)
```
Another way to avoid memory leaks is to use the **ObjectSpace** module to manually mark objects as eligible for garbage collection. This can be useful in situations where the garbage collector is not able to properly clean up objects.
```ruby
require 'objspace'
class Foo
def initialize
@bar = "Hello, World!"
end
end
foo = Foo.new
ObjectSpace.define_finalizer(foo, proc {|id| puts "Object #{id} has been GCed"})
```
To avoid memory leaks due to event handlers, it's important to unregister event handlers when they are no longer needed. A common pattern is to use a block and pass self to the block. This way the block will have access to the instance and can unregister the event handler.
```ruby
class Foo
def initialize
@listener = EventHandler.new
@listener.register(self) do |event|
puts "event received: #{event}"
end
end
def unregister_listener
@listener.unregister(self)
end
end
```
Finally, it's important to properly manage singletons in Ruby. One way to do this is to use the **singleton** module and the instance method to create a singleton object.
```ruby
require 'singleton'
class Foo
include Singleton
def initialize
@bar = "Hello, World!"
end
end
foo = Foo.instance
```
## Simulation
Simulating a memory leak in a program can be done by creating a program that continuously allocates memory without releasing it. Here is an example of a simple Ruby script that simulates a memory leak:
```ruby
# Simulating a memory leak
leak_array = []
while true do
leak_array << "a" * 1024 * 1024 # Allocate 1MB of memory
sleep 1 # Wait for 1 second before allocating more memory
end
```
This script creates an array, leak_array, and continuously appends a string of 1MB to it. This will cause the program's memory usage to continuously grow, simulating a memory leak.
To correct this memory leak, we need to ensure that the memory is properly released when it is no longer needed. One way to do this is to periodically empty the **leak_array**:
```ruby
# Correcting a memory leak
leak_array = []
while true do
leak_array << "a" * 1024 * 1024
sleep 1
leak_array.clear # Release the memory
end
```
Another way to correct the memory leak is to use a different data structure, such as a queue, where old elements are automatically removed as new elements are added.
```ruby
# Correcting a memory leak
require 'queue'
leak_queue = Queue.new
while true do
leak_queue << "a" * 1024 * 1024
sleep 1
end
```
The Queue class in Ruby is a commonly used data structure that can lead to memory leaks if not used correctly. Here are a few examples of how memory leaks can occur with the Queue class:
1. Forgetting to remove items from the queue: If items are continuously pushed onto a Queue instance without removing them, the queue can grow larger and larger over time, eventually exhausting the available memory. To prevent this, developers should make sure to call the pop method on the queue after processing each item.
2. Holding onto references of items within the queue: If objects that are added to the queue are referenced elsewhere in the application and those references are not cleared, the objects will not be garbage collected even after they are removed from the queue. This can cause the memory usage to grow indefinitely, as the objects accumulate in the queue. To prevent this, developers should make sure to remove any references to objects after they are no longer needed.
3. Using threads and not terminating them: If a Queue instance is used with multiple threads, and the threads are not properly terminated, the Queue instance can become a source of memory leaks. When threads are not properly terminated, they can keep references to the objects they were processing in the queue, preventing them from being garbage collected. To prevent this, developers should ensure that all threads are properly terminated after they have finished their work.
4. Using Queue#clear: If a Queue instance is cleared using the clear method, but the objects within the queue are not explicitly removed from memory, the memory allocated to those objects will not be reclaimed by the garbage collector. This can lead to memory leaks as the number of objects that have been added to the queue grows. To prevent this, developers should ensure that any objects added to the queue are removed from memory once they are no longer needed, even if the queue is cleared.
Overall, it is crucial to be aware of how the Queue class is being used and to adopt best practices to prevent memory leaks. By properly managing the queue and the objects within it, developers can avoid memory leaks and ensure that their applications run efficiently and reliably.
You can also use **GC.start** to force a garbage collection and release the unused memory.
```ruby
# Correcting a memory leak
leak_array = []
while true do
leak_array << "a" * 1024 * 1024
sleep 1
GC.start
end
```
## Conclusion
In conclusion, understanding the causes of memory leaks and using best practices to prevent them is essential for maintaining the performance and stability of Ruby applications. By using techniques such as weak references, manual garbage collection, unregistering event handlers, and properly managing singletons, developers can prevent memory leaks and ensure that their applications run smoothly.
It's important to note that memory leaks can be difficult to detect and diagnose, and the correct solution will depend on the specific cause of the leak. It is always a good practice to monitor the memory usage of an application and to use tools such as **ObjectSpace** to inspect objects and track down memory leaks.
Developers must pay close attention to memory management and monitor the memory usage of their applications to detect and diagnose leaks. Memory leaks can lead to poor performance and instability, which can have a significant impact on user experience. Therefore, it is essential to take proactive steps to prevent them, and it is a good practice to incorporate memory management into the development process from the start. By doing so, developers can ensure that their applications run smoothly and deliver a great user experience.
| daviducolo |
1,335,512 | What is the use of histogram in image processing? | A histogram is a graphical representation of the distribution of pixel values in an image. It is a... | 0 | 2023-01-20T09:25:42 | https://dev.to/aback/what-is-the-use-of-histogram-in-image-processing-3i0e | A histogram is a graphical representation of the distribution of pixel values in an image. It is a powerful tool used in image processing to analyze and understand the characteristics of an image. Histograms can be used to perform a variety of tasks such as image enhancement, color correction, and object recognition.
One of the main uses of histograms in image processing is image enhancement. Histograms can be used to adjust the brightness and contrast of an image to improve its overall appearance. By analyzing the distribution of pixel values in the image, the histogram can reveal if the image is under or over-exposed. If the majority of the pixels are located at the extremes of the histogram, it means that the image is either too dark or too bright. By adjusting the brightness and contrast of the image, the histogram can be made to look more balanced, resulting in a more visually pleasing image.
Histograms can also be used to perform color correction on an image. By analyzing the distribution of pixel values for each color channel, the histogram can reveal if an image has color cast. A color cast is an overall color bias that affects the entire image. By adjusting the color balance of the image, the histogram can be made to look more balanced, resulting in a more natural-looking image. Make histograms with one click on [histogram maker](https://histogrammaker.co/).
Another use of histograms in image processing is object recognition. Histograms can be used to extract features from an image that can be used to identify objects or patterns in the image. By analyzing the distribution of pixel values in the image, the histogram can reveal the shape, size, and texture of an object. This information can then be used to train a machine learning algorithm to recognize the object in future images.
Histograms can also be used to segment an image. Image segmentation is the process of partitioning an image into multiple segments or regions, each of which corresponds to a different object or part of the image. By analyzing the distribution of pixel values in the image, the histogram can reveal the boundaries between different objects or regions in the image. This information can then be used to segment the image into multiple regions, each of which corresponds to a different object or part of the image.
Histograms can also be used for image compression. By analyzing the distribution of pixel values in the image, the histogram can reveal the most common pixel values in the image. These common pixel values can then be used to create a color map, which can be used to compress the image. This is known as color quantization.
In conclusion, histograms are a powerful tool used in image processing to analyze and understand the characteristics of an image. They can be used to perform a variety of tasks such as image enhancement, color correction, object recognition, image segmentation and image compression. By analyzing the distribution of pixel values in an image, the histogram can reveal important information about the image that can be used to improve its overall appearance and make it more useful for a specific task.
| aback | |
1,431,719 | Building a Microfrontend... | Article 3 In this continuation article of the "Building a Mircofrontend" series, we will... | 0 | 2023-04-10T15:46:29 | https://dev.to/danialamo/building-a-microfrontend-29af | ### Article 3
In this continuation article of the "Building a Mircofrontend" series, we will dive into the progression we have made on our project. The main portion of this article will be talking about how we got the searching and rendering connectivity to work for our badges.
### Next Step : Render and Search
Now that we are satisfied with our badge "card" and have carved out a portion of the backend API, we started the process of developing how the cards will be rendered and searched. For this we have created "badge-list" which will hold the place for the user to search for badges, and a place where the badges will be displayed.
### Step one: Scope out properties
The main property of the badge-list will be the array of badges that data coming from the backend will be loaded into in order to display the badges searched.
This is how we started to develop badge-list:
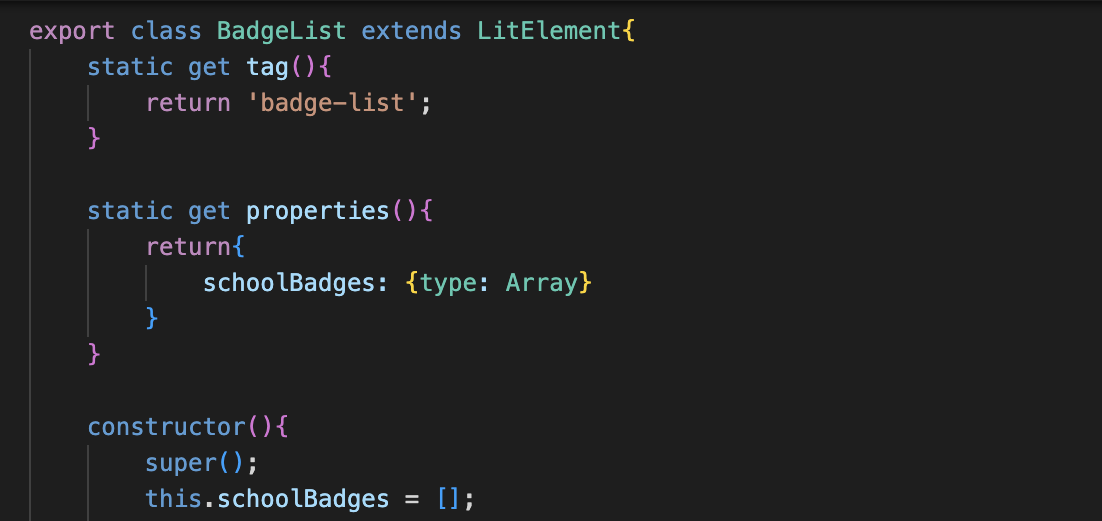
### Step two: Some Frontend Dev
In this step, we started to build out some of the visuals that will be seen on the frontend. We built two containers. The first container (Box1), will hold the search component. The section container (Box2), will render the badges from the user search.
Code:
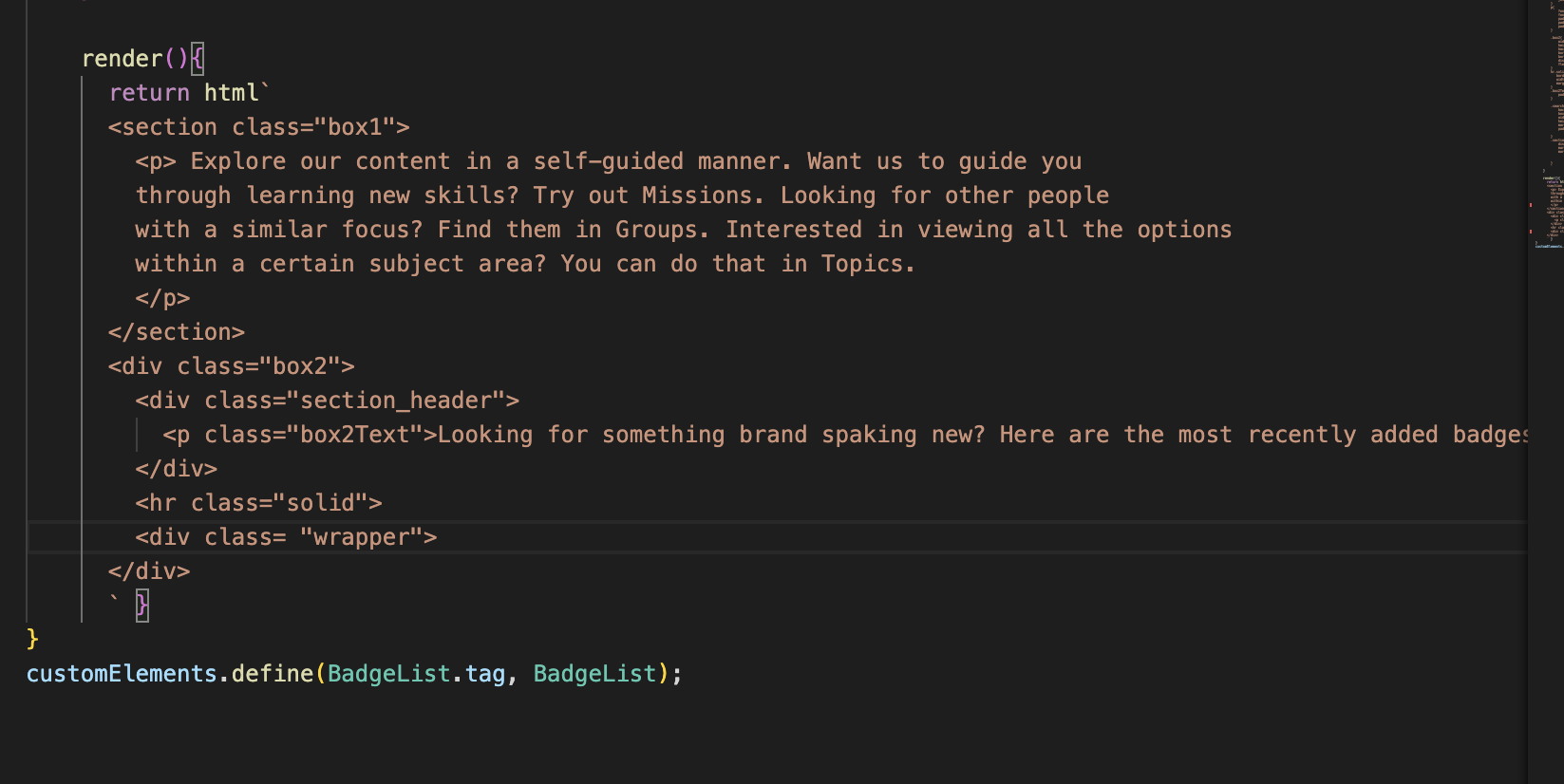
How it looked after CSS styling:
### Step three: Creating the search widget
The next step was to create the search implementation to render some badges from the backend to be displayed on the frontend. We tried to attack this problem with three big steps:
#### Step 1: Create search-widget.js
* Return property of value that will hold the value of what the user is searching.
* Renders a search symbol and input field for user search.
* Creates a method handleInput, that creates a CustomEvent for when the value is changed to respond accordingly.
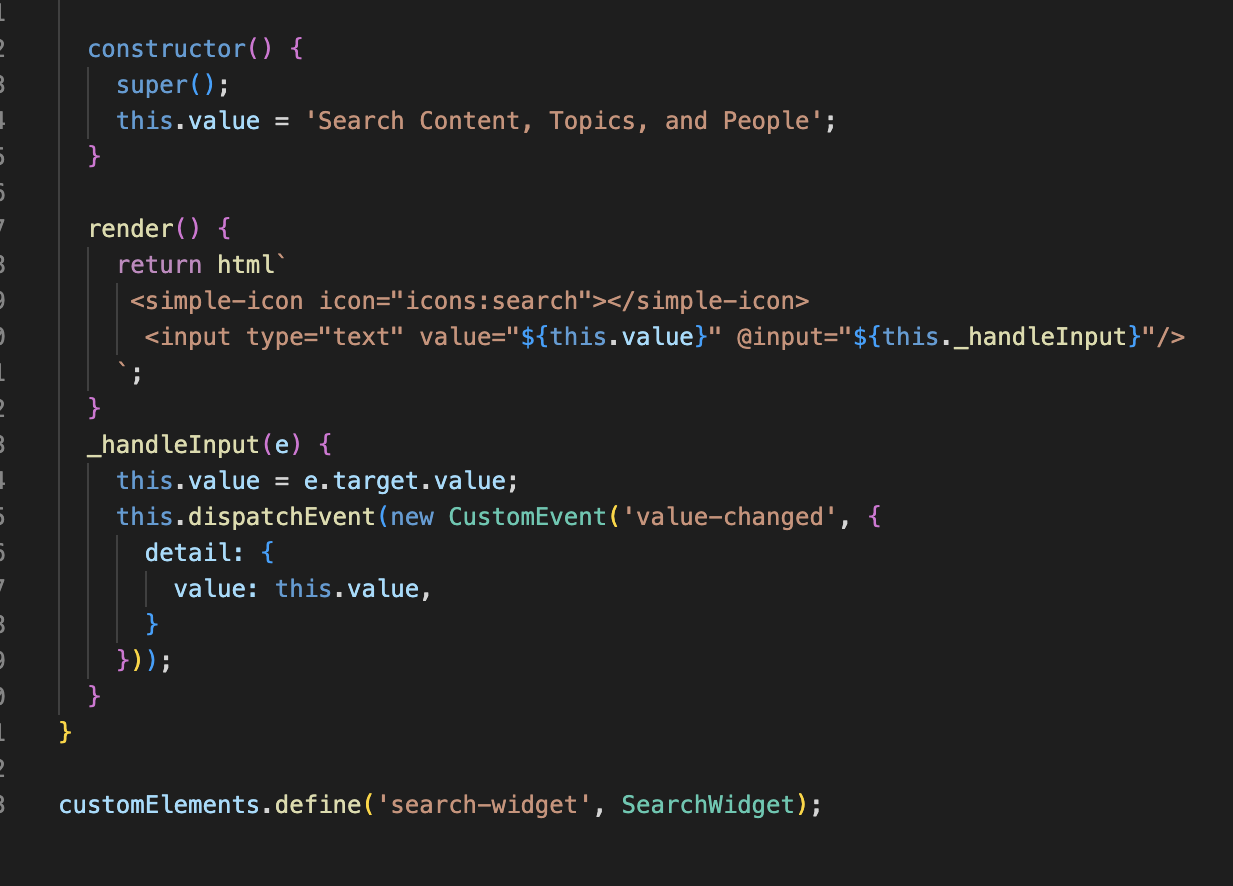
#### Step 2: Add search-widget to badge-list and add search functionality
* Add search-widget to the html portion badge-list.
* Add methods to get the value from the input of the search widget and fetch data from the backend API to search and render badges based on the search.
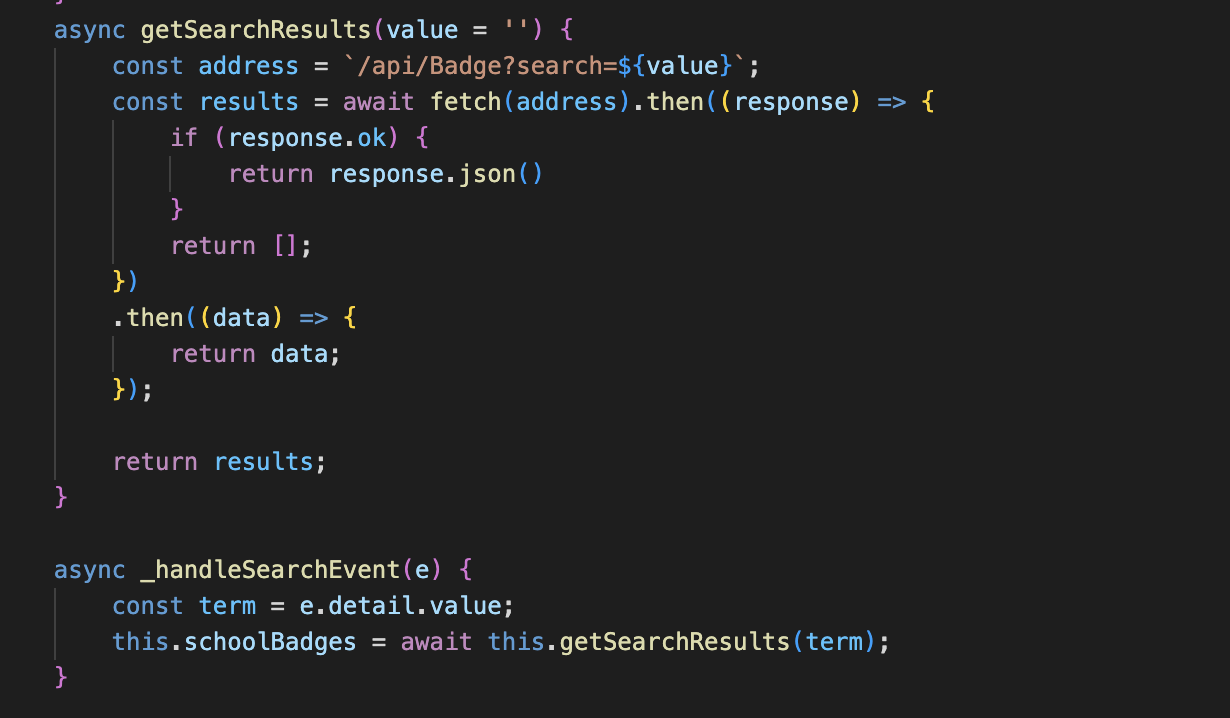
* Style the search widget using CSS styling

#### Step 3: Add .map functionality to the backend to display or "map" out the badges to the badge-list based on the search value.
* This will map out the badge data needed to be sent to badge-list to display the badges based the user search value.
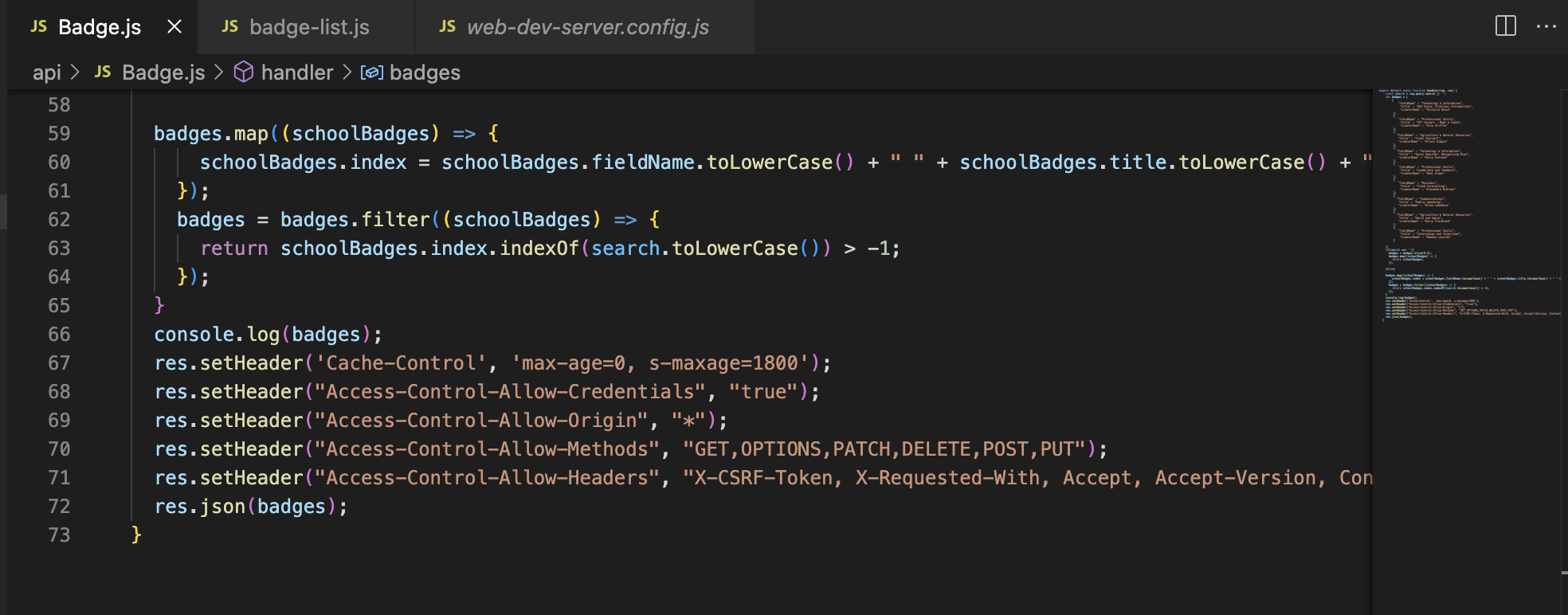
#### Issues
* The main issue that we were having is that all the badges in the backend were rendering on the frontend so it was causing on overflow of badges displaying on the frontend and messing up the structure of the second container
The mircofrontend is starting to come together. We will continue to work on and fix bugs that are currently present to deliver a complete mircofrontend with a nice user experience.
To Be Continued... | danialamo | |
1,335,625 | What's your guess? | Link to source: https://www.linkedin.com/feed/update/urn:li:activity:7022113050010808320 | 0 | 2023-01-20T10:26:40 | https://dev.to/abhisheknellikkalaya/whats-your-guess-3mlm | discuss, books |
Link to source: https://www.linkedin.com/feed/update/urn:li:activity:7022113050010808320 | abhisheknellikkalaya |
1,335,635 | Why choose Jetpack Compose? | Jetpack Compose is a newer way to create the look and feel of an app on an Android device. It can... | 0 | 2023-01-20T10:37:56 | https://dev.to/teka/why-choose-jetpack-compose-3ic2 | [Jetpack Compose](https://developer.android.com/jetpack/compose/why-adopt) is a newer way to create the look and feel of an app on an Android device. It can make the process of building the user interface easier and more efficient for developers. Some reasons why someone might choose to use Jetpack Compose are:
1. It uses the latest features and technology of the Android platform to create a better performance and more beautiful user interface.
2. It's designed to quickly respond and adapt to the user's interactions and changes in the data.
3. It uses a language that is simpler and faster for developers to use when creating and modifying the layout and design of the app.
4. It's easier to understand and keep track of the code which helps with maintaining the app.
5. Overall, Jetpack Compose can make building the user interface faster, simpler and with better performance.
| teka | |
1,335,849 | Authentication vs. Authorization – What's the Difference? | Authentication and authorization terms are often used interchangeably by many, but they are two... | 0 | 2024-06-22T08:45:09 | https://mojoauth.com/blog/authentication-vs-authorization | ---
title: Authentication vs. Authorization – What's the Difference?
published: true
date: 2023-01-20 08:03:58 UTC
tags:
canonical_url: https://mojoauth.com/blog/authentication-vs-authorization
---
Authentication and authorization terms are often used interchangeably by many, but they are two completely different concepts. Both are crucial in ensuring the security of resources in any application or system. Businesses should efficiently configure both authentication and authorization in their application to ensure the utmost security. This article details the concepts of both authorization and authorization along with the following: How authentication and authorization work Types of authentication and authorization Difference between authentication and authorization or authentication vs. | auth-mojoauth | |
1,336,039 | KL Animation | A post by kelismor | 0 | 2023-01-20T18:33:25 | https://github.com/kelismor/KL-Animation |
[](https://github.com/kelismor/KL-Animationurl) | kelismor | |
1,338,863 | Corda 4.10 is here! | Corda 4.10 comes with new exciting features and enhancements plus bug fixes. Learn more: Corda 4.10 | 0 | 2023-01-23T18:22:19 | https://dev.to/r3developers/corda-410-is-here-59d2 | Corda 4.10 comes with new exciting features and enhancements plus bug fixes. Learn more: [Corda 4.10](https://developer.r3.com/blog/corda-4-10-is-here/) | r3developers | |
1,336,215 | Software Architecture Patterns: Layered Architecture | Join Me Follow me on Twitter and Linkedin for more Career, Leadership and Growth advice.... | 21,504 | 2023-01-20T20:55:23 | https://dev.to/alexr/5-common-software-architecture-patterns-28a7 | architecture, programming, computerscience, performance | ### Join Me
Follow me on [Twitter](https://twitter.com/alexrashkov) and [Linkedin](https://www.linkedin.com/in/alexrashkov) for more Career, Leadership and Growth advice.
<a href="https://engineeringbolt.substack.com/embed" target="_blank" title="Subscribe to Engineering Bolt ⚡ Newsletter"></a>
### Intro
Layered architecture, also known as the n-tier architecture pattern, is a software design approach that separates an application into distinct layers, each with a specific purpose and set of responsibilities. This pattern is widely used in enterprise-level software development, and it has proven to be a powerful tool for creating large, complex systems that are easy to maintain and evolve over time.
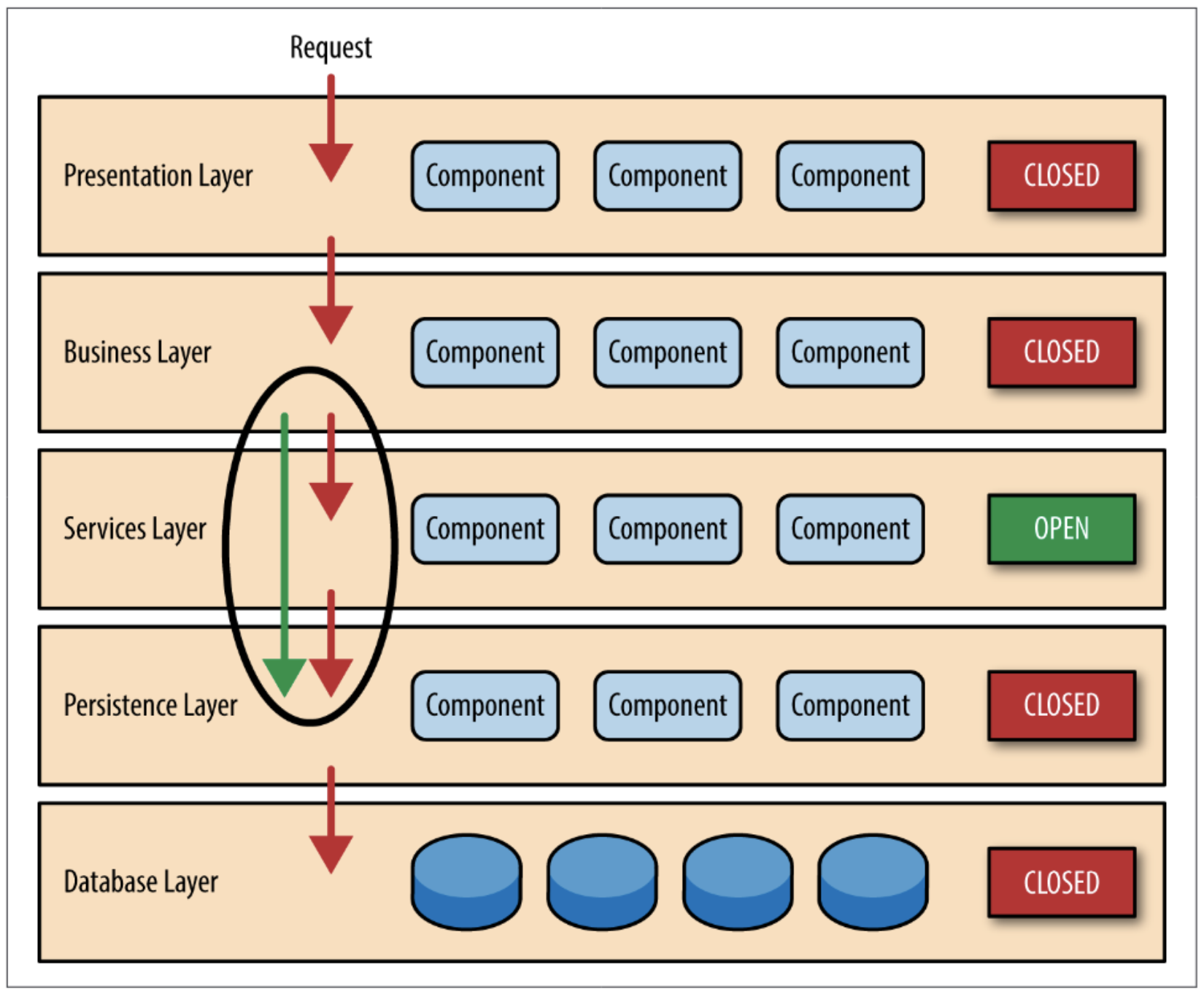*Software Architecture Patterns (Mark Richards)*
### Advantages
The main advantage of using a layered architecture is that it promotes separation of concerns and modularity in the code. By separating the application into distinct layers, developers can focus on specific areas of the system without worrying about the implementation details of other layers. This makes the code more reusable and easier to understand, and it also facilitates testing and maintenance.
Another advantage of layered architecture is that it allows for flexibility and scalability in the system. Because the different layers are decoupled from each other, it is easy to make changes or add new functionality to one layer without affecting the others. Additionally, different layers can be scaled independently, allowing the system to handle a high volume of traffic or data without performance issues.
### Disadvantages
The main disadvantage of using a layered architecture is that it can add complexity to the system. Because the different layers are decoupled, communication between them can be challenging, and it requires careful planning and coordination. Additionally, it can be difficult to design the layers in a way that ensures that they are loosely coupled and don't end up creating dependencies between them.
### Wrap up
In conclusion, the Layered architecture pattern is a powerful tool for building large, complex software systems. It promotes separation of concerns, modularity, flexibility, and scalability. However, it also requires careful planning and coordination and can add complexity to the system. Layered architecture is suitable for enterprise-level software development, and it's good to use in systems that require high scalability and maintainability.
### Join Me
Follow me on [Twitter](https://twitter.com/alexrashkov) and [Linkedin](https://www.linkedin.com/in/alexrashkov) for more Career, Leadership and Growth advice.
<a href="https://engineeringbolt.substack.com/embed" target="_blank" title="Subscribe to Engineering Bolt ⚡ Newsletter"></a> | alexr |
1,336,221 | How to Turn Increased Resource Usage into an Advantage For You | A Service Mesh is a fantastic solution for a variety of problems. Critics, however, might bring up a... | 0 | 2023-01-20T21:52:44 | https://dev.to/ciscoemerge/how-to-turn-increased-resource-usage-into-an-advantage-for-you-1p4f | servicemesh, istio, saas, microservices | A Service Mesh is a fantastic solution for a variety of problems.
Critics, however, might bring up a considerable disadvantage: **The
increased need for computing resources.** If you're considering
deploying a Service Mesh but are hesitant because of the increased
resource usage, keep reading. In this blog post, you will learn why a
Service Mesh is worth its spending.
## Increased Resource Usage in Exchange for What?
Let's be clear, installing a Service Mesh increases your infrastructure
bill. Istio, for instance, installs proxies with every pod to intercept
network traffic. These proxies can consume quite a bit of memory. To
give you an example, let's say we run a pod with
[httpbin](https://httpbin.org/). The total memory usage might be in the
neighborhood of \~300 MB. Broken down, httpbin consumes 70-80 MB at
most, while over 200+mb goes towards the Istio proxy.
That's a substantial increase. Looking at these numbers without
additional context, it is not worth our while to run Istio.
## Gain Insight into your Cluster
If you had to find out right now what services within your Kubernetes
cluster handle a lot of traffic or are close to failing because they
reach resource limits, could you find out without too much effort?
Without any additional tooling, it's a challenging and time-consuming
task. It's like standing at the observation deck at a larger airport and
looking in the sky for approaching airplanes. You know they're there,
but you can only see them a minute before the touchdown. Up in the
tower, on the other hand, with radar available, monitoring air traffic
became much more manageable. With the right equipment at your disposal,
keeping track of incoming airplanes is more than manageable, whether
sunny or foggy.
The same is true for a Service Mesh. Once installed, you see which
services are healthy or need more attention. You also learn about all
"traffic patterns" within your Kubernetes Cluster. With that data
available, it might turn out there are services that shouldn't be
talking to each other.
## Planning for the Future
When was the last time your business faced a **"scaling event"**, such
as Black Friday or onboarding a large new Customer? Whatever the event
might be, it results in a (significant) increase in traffic. Is your
cluster ready for that?
Without doing anything, and the new customer just onboarded, things will
likely break, like too many new users and too much traffic to handle. To
mitigate such outages, what services would you need to scale? The good
news is: It doesn't have to come that far. With Istio, you can
investigate in advance to find out: Are all services healthy right now?
What happens when we add some more traffic? Do we see any red bubbles
pop up?
Nothing feels better than coming in to work on the day when a massive
number of new users start using the system, and everything **just**
works. Events like Black Friday or new Enterprise customers became a lot
less intimidating.
## Rapid Response During Outages
It's everybody's worst nightmare: Receiving an emergency ticket because
a critical feature stopped working. Users can't check out their products
or can't complete that one important transaction. In either case, time
is of the essence to fix it.
Every minute the application is completely offline or only partially
functional costs the company money. Figures quickly go up to Thousands
of Dollars per Minute.
How long does it usually take for the team to resolve a critical user
issue and find the faulty service(s)? With a Service Mesh, you can
identify these faults almost in real time. What would it mean for you if
you could reduce your MTTR from several hours to one hour or less?
In such scenarios, it becomes easier to offset the increased hardware
usage with a significantly reduced MTTR.
## Conclusion
A Service Mesh requires additional resources, which increases your
infrastructure spending. This increase, on the other hand, buys you
Insight into the following:
- What services are causing an outage?
- Current resource utilization
- Potential Bottlenecks
If you're interested in getting started with a Service Mesh, but you're
not feeling comfortable reading Istio documentation for hours at a time,
check out [Calisti.app](https://calisti.app). Calisti is a managed Service Mesh
using Istio under the hood. You get all features Istio offers already
configured so that you can get started right away. To get started, visit https://calisti.app.
| schultyy |
1,336,438 | Why I selected Elixir and Phoenix as my main stack | This is just a personal journey documentation on how I decided to use my current tech stack. Over... | 0 | 2023-01-21T16:16:04 | https://dev.to/clsource/why-i-selected-elixir-and-phoenix-as-my-main-stack-3i4a | elixir, webdev, beginners, programming | This is just a personal journey documentation on how I decided to use my current tech stack.
Over the years I have tried different frameworks, mostly in PHP, like [Code Igniter](https://codeigniter.com/) (2010), [ProcessWire](https://processwire.com/) (2014) and [Laravel](https://laravel.com/) (2015).
They helped me complete different projects with diverse complexity. They are wonderful tools. But sadly most of the jobs I managed to land were using legacy versions of PHP and the codebase and developer experience was spartan to say the least. As an example in one project (2020) I had to connect to a remote Windows machine, edit the code in Notepad++ and then upload it using FTP. Odd workflows aside, I wanted to land more modern projects. So I embarked in a quest to find a new tech stack.
First I wanted to update my tools, maybe I just needed a small patch instead of changing them. So I made a project for a client using Laravel, [Inertia.js](https://inertiajs.com/) [Svelte](https://svelte.dev/), and then other project using Laravel, Inertia and [React](https://reactjs.org/). I liked *Svelte* over *React*, so if future frontend projects appear, my main tool would be *Svelte*.
Both projects resulted in a superb improved developer experience and were finished in record time. A single monolith with backend and frontend did wonders because I did not need to create REST apis or GraphQL endpoints to make a fullstack system. Now I can have all the power of an SPA with all the good parts of a Backend, like direct access to a database.
I explored using *Inertia.js* as my main tool and made some adapters for ProcessWire, to understand better how it worked.
{% embed https://dev.to/clsource/inertia-adapter-for-processwire-3l6i %}
## Vapor (Swift)
My first option other than PHP was using [Swift](https://developer.apple.com/swift/) and [Vapor](https://vapor.codes/). I have made some projects with iOS and Objective-C, maybe I could also learn *Swift* and create both native iOS apps and backends with the same language.
But I discovered that it lacked the *Inertia.js* adapter, so I found this project
{% embed https://github.com/lloople/vapor-inertia-adapter %}
and created an example
{% embed https://dev.to/clsource/vapor4-inertia-svelte-laravel-mix-3dh1 %}
### Pros
- Using *Xcode* to program a backend application was super nice, It was awesome to have an IDE with all the bells and whistles for the *Swift* language.
- Coming from *Objective-C* was helpful to understand the Apple ecosystem and workflows.
### Cons
- I often have to resort to other editors such as *VSCode* to edit non well supported files such as *JS*, *CSS* or *HTML* files.
- If you want to use *XCode* you need to use an updated operating system, if you have an older not supported Mac computer you will need to use *Docker* and use the *Linux* version of the *Vapor* framework, with poorer perfomance and developer experience due to using containers instead of *Xcode*.
## Masonite (Python)
[Masonite](https://docs.masoniteproject.com/) is a wonderful [Python](https://www.python.org/) framework, much similar to *Laravel* I found in 2018. I even chatted with Joseph about it in the old Slack channels, before the community moved to Discord.
{% embed https://dev.to/masonite/the-history-of-the-masonite-framework-2n2b %}
And there were some *Masonite* Inertia adapter too
{% embed https://github.com/girardinsamuel/masonite-inertia/ %}
### Pros
- I liked the way is well organized and the maintainer is super friendly.
- You can leverage all the wonderful tools that *Python* has like [PyCharm](https://www.jetbrains.com/pycharm/).
### Cons
- I did not like the way *Python* manage it dependencies, having so many options like [Poetry](https://python-poetry.org/) or [Pipenv](https://pipenv.pypa.io/en/latest/), it feels non standarized as other languages.
- Many of the available jobs for *Python* that I could find were either for [*Django*](https://www.djangoproject.com/) based projects or Machine Learning stuff I didn't like too much. So using *Masonite* would only be for green field type projects.
## Springboot (Java)
In university I learned a bit of [Java](https://www.java.com/), so maybe I could use it professionally I guess?. There were many options to choose from. [DropWizard](https://www.dropwizard.io/en/latest/), [Spark](https://sparkjava.com/), [Play Framework](https://www.playframework.com/). But the more documented one in the internet I found was [Springboot](https://spring.io/projects/spring-boot), besides there were some courses in spanish and some friends that knew something about *Springboot*, so I give it a chance.
I created some experiments like a simple Discord bot
{% embed https://github.com/NinjasCL/wrenbot %}
But I could not find an adapter to Inertia, just some *POC*, and I did not want to invest too much time in creating an adapter for it.
{% embed https://github.com/jrodalo/inertia %}
### Pros
- Highly robust framework, lots of documentation, courses and examples.
- Super mature libraries and dependencies.
### Cons
- Most of the jobs I could find were for Banks and other "older" institutions. That have requirements such as going to the office (before C19) and even dress codes. I prefer to work remotely.
## JavaScript
I already use some [*Javascript*](https://www.javascript.com/) at the frontend, why not use it at the backend?. I tried [Adonis.js](https://adonisjs.com/) because it was similar to Laravel, but felt odd to me. Also a client once required some bridge and I used [Fastify](https://www.fastify.io/).
{% embed https://github.com/NinjasCL/airnotifier-moodle-bridge %}
## Pros
- I already knew *Javascript* and made some small apis and scripts.
## Cons
- There are lot of different frameworks out there. If you learn one, there is no guarantee that the next job you find will use the same. For example if you learn [*Express*](https://expressjs.com/) and the next one used [*Koa*](https://koajs.com/) or [*Nest*](https://nestjs.com/).
- Already felt like a there were something wrong in *Javascript*, because there is always some breaking change that needs to rewrite the codebase or update the dependencies. I did not like that *npm* throws a lot warnings in the bootstrap of the project or installing deps.
## Elixir and Phoenix
Ok so I previously toyed around with [Elixir](https://elixir-lang.org/) in [Exercism](https://exercism.org/tracks/elixir) and liked a lot the language. I found [Phoenix framework](https://www.phoenixframework.org/) but I did not understand it quite well.
A functional language took time for me to understand the conventions and workflows. It was like a whole new world.
Nevertheless I just waited some time before going fulltime as an Elixir dev. Accepting small freelance jobs in PHP and other small projects. But I decided to write in my *CV*:
> "Would love to participate in Elixir based projects"
I really loved the idea of *LiveView* and how it wasn't needed a separate frontend framework to achieve a SPA like experience. So Inertia.js wasn't needed in the first place.
Although an adapter is available, before *LiveView* was created.
{% embed https://github.com/devato/inertia_phoenix %}
In February 2022 I received my first offer as a fulltime Elixir developer, just because I said I liked to work with Elixir, no previous experience with it required!.
There I learned more deeply about *LiveView* and [Surface UI](https://surface-ui.org/).
Even took a course with [Grox.io](https://grox.io/)'s awesome teacher [Bruce Tate](https://twitter.com/redrapids), It was an awesome experience. Highly recommended.
### Pros
- Elixir is a fun language. **fun**ctional and **fun** to work with.
- Is easier to find good jobs and be selected, comparing it to other markets such as Javascript were there are more job opportunities, but also more people to compete with.
- The [Erlang](https://www.erlang-solutions.com/) (1986) ecosystem is older than Java (1995). So is filled with lots of robust solutions to real world problems, like concurrency.
### Cons
- In my country there are few companies that uses Elixir (I hope that changes soon), but if you know english you can easily access international remote positions.
## Conclusions
Why I selected Elixir?. Because I found it fun, functional and robust. And I landed a dream like job just because I liked the language, compared to other technologies that I have to create a "doctoral thesis" just to be interviewed. Elixir's job seeking experience was smooth.
That first Elixir job finished in October 2022 and after some small vacations I landed another dream like job soon after.
Elixir is a powerhouse both in the Technology side of things and the Job market side of things.
For me is the technology of the 2020's decade and much more!.
| clsource |
1,336,673 | Using Amplitude in a VueJS A/B testing scenario | When it comes to releasing new features or changes in software, we can rely on A/B testing for making... | 0 | 2023-01-21T09:25:16 | https://configcat.com/blog/2022/12/23/measuring-the-impact-of-a-test-variation-in-vuejs/ | vue, amplitude, testing, howto | When it comes to releasing new features or changes in software, we can rely on A/B testing for making informed decisions. In this type of testing, we can measure the impact of the new change or feature on users before deciding to deploy it. By doing so, we can carefully roll out updates without negatively impacting user experience.
## Introduction
A/B testing can be applied to many software applications, including Vue. Let's use it to determine if the "Get a loan immediately!" call to action text can influence more loan sign-ups compared to the previous "Need a loan?" CTA text.
Feel free to reference the [sample app](https://github.com/configcat-labs/measuring-the-impact-of-a-test-variation-in-vuejs) for the full solution.
Here's a look at what the app looks like so far:
## Setting up Amplitude
Without a tool for collecting and comparing test results, it is almost impossible to make an informed decision. For this, we're going to use [Amplitude](https://amplitude.com/), but you can also use similar tools like [Datadog](https://www.datadoghq.com/).
**1.** [Sign up](https://analytics.amplitude.com/signup) for a free Amplitude account.
**2.** Switch to the **Data** section by clicking the dropdown at the top left.
**3**. Click the **Sources** link under **Connections** in the left sidebar, then click the **+ Add Source** button on the top right to create a source.
**4**. Select the **Browser SDK** from the SDK sources list and enter the following details to create a source.
**5**. You should be automatically redirected to the implementation page as shown below. We'll follow these instructions after adding an event.
### Adding an event
**1**. Click the **Events** link in the left sidebar under **Tracking Plan** to access the events page.
**2.** Click the **+ Add Event** button at the top right to create an event and fill in the following details:
**3**. Click the **Save changes** button on the left sidebar.
Let's integrate Amplitude into our Vue application to log the event we created above.
## Integrating Amplitude with Vue
Click the **Implementation** link in the left sidebar to see the integration instructions page.
**1**. Install the [Ampli CLI](https://www.docs.developers.amplitude.com/data/ampli/cli/#npm) with the following command:
```bash
npm install -g @amplitude/ampli
```
**2**. Install the amplitude JavaScript SDK dependencies:
```bash
npm install amplitude-js
```
**3**. Run the following command to pull the SDK into Vue:
```bash
ampli pull
```
Using this command, Amplitude will download all the necessary settings and configurations into our Vue application, including those added in the previous steps.
## Sending an event
When it comes to Amplitude, there are two terms to be aware of. **Source** (where the data comes from) and **destination** (where the data goes). We are using Vue as the source and Amplitude as the destination in this example. The user can trigger the event we created earlier when they click the button under the CTA text:
**1.** Import and initialize amplitude in the **banner component**:
```js
<script>
// Import the amplitude configuration in this component.
import { ampli } from '../../ampli';
export default {
setup() {
// Initialize amplitude with the production environment as stated on the integration page.
ampli.load({ environment: 'production' });
},
}
</script>
```
**2.** Create a method that triggers and sends the event when the button under the CTA text is clicked.
```js
export default {
// ... code omitted for clarity
methods: {
handleLoanSignupClick() {
// Log the event to amplitude when the loan signup button is clicked
ampli.loanSignupClick();
},
},
};
```
## Checking for successful requests
**1.** Under **Connections** in the left sidebar, click on **Sources**.
**2.** Clicking on the **Claim my offer now!** button under the CTA text in the banner
will log the event to amplitude as shown in the **Successful Requests** graph on the left:
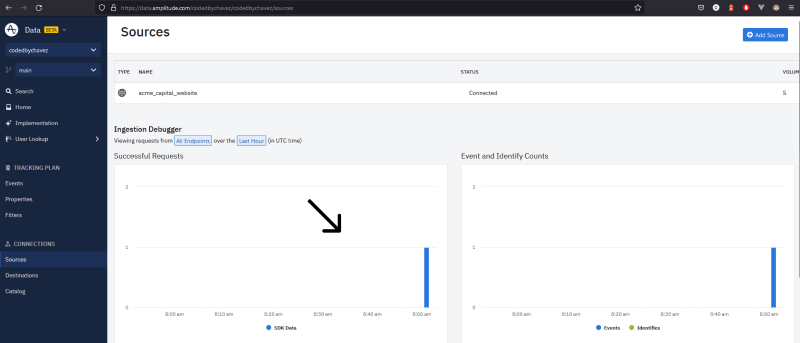
## Tracking the event on an analysis chart
Tracking successful requests is useful for debugging purposes only.
To analyze the events, we want them to be displayed as a chart. Let's do that.
**1.** Switch to the **Analytics** dashboard, by clicking the dropdown arrow on the top left next to **Data**.
**2.** In the analytics dashboard, click the **New** button in the left sidebar.
**3**. Select **Chart** then select the event we created earlier:

## Analyzing test results
You can compare which CTA text influenced the most loan sign-up clicks by clicking the **Compare to past** dropdown at the top of the analysis chart. As shown below, you can compare the results to a previous period:
Based on the results here, you can make an informed decision moving forward on whether to keep or revert the new change or feature.
## Final words

Most often, A/B tests are complemented by feature flags since they can be used to manage new changes or features.
A 10-minute trainable feature flag management interface, such as ConfigCat's, simplifies the process even further. In the dashboard, we can turn features on or off for different user segments without changing code or redeploying the application when performing tests. As a bonus tip, you can also keep track of how often your feature flags are changed during testing by connecting your ConfigCat account to Amplitude. I highly recommend you give this a try with a [free account](https://app.configcat.com/signup).
There are also many other frameworks and languages that ConfigCat supports. The full list of supported SDKs is available [here](https://configcat.com/docs/sdk-reference/overview/).
Get the latest updates from ConfigCat on [Twitter](https://twitter.com/configcat), [Facebook](https://www.facebook.com/configcat), [LinkedIn](https://www.linkedin.com/company/configcat/), and [GitHub](https://github.com/configcat).
| codedbychavez |
1,336,841 | Trunk-based Development: Simplifying Software Development | This post has been published in my personal website too:... | 0 | 2023-01-21T14:10:55 | https://dev.to/hitonomi_0/trunk-based-development-simplifying-software-development-np9 | webdev, productivity, git, beginners | This post has been published in my [personal website](https://devsdepot.com) too: https://www.devsdepot.com/blog/trunk-based-development
## Introduction
[Trunk-based development](https://trunkbaseddevelopment.com/#one-line-summary) is a method of software development that is centered on a single, central code repository known as the "trunk." Developers in this paradigm work on the trunk at the same time, committing changes and collaborating in real time. This differs from other branching methods, such as [Gitflow](https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow), in which developers work on distinct branches before merging their modifications into the main branch.
Trunk-based development has a number of advantages over typical branching approaches. One of the primary advantages is speedier deployment. Because all development work is done on the trunk, code updates may be sent to production more quickly because no code from other branches must be merged. Furthermore, because developers are working on the same codebase at the same time, trunk-based development facilitates collaboration. This can result in fewer disputes and a more efficient process.
Despite its advantages, trunk-based development can be difficult to execute, especially for teams used to working with traditional branching models. Trunk-based development, with the correct tactics in place, such as [continuous integration](https://semaphoreci.com/continuous-integration) and [testing](https://www.globalapptesting.com/blog/what-is-automation-testing), can be a strong tool for boosting software development productivity and cooperation.
## Background
Trunk-based development dates back to the early days of [version control systems](https://hackernoon.com/top-10-version-control-systems-4d314cf7adea), when developers would work on a single codebase and commit changes to the trunk directly. For many years, this was common practice; but, as software development became more complicated and teams became larger, the need for more robust branching models arose.
[Gitflow](https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow), which was established in 2010, was one of the most popular branching models to emerge. Gitflow is built around the concept of a central "main" branch and many "feature" branches. Developers work on their own feature branches and merge their modifications into the main branch when they are finished.
Trunk-based development, on the other hand, is a relatively contemporary strategy that has gained favor in recent years; it is built on the concept of having a single, central code repository on which all developers work concurrently. There are no feature branches in this model, and all code changes are committed directly to the trunk. This method is more efficient since it avoids the need to merge code from various branches.
## Implementation
Implementing trunk-based development needs some discipline and forethought. The following are some measures that can assist teams in successfully using this development model:
1. Implement a clear [code review](https://about.gitlab.com/topics/version-control/what-is-code-review/) process: With all developers working on the same codebase, a clear code review procedure is important. This can aid in ensuring that code changes are thoroughly examined before being submitted to the trunk.
2. Implement [continuous integration](https://flexagon.com/blog/5-best-practices-for-implementing-continuous-integration/) and testing: Continuous integration and testing are critical to trunk-based development because they can detect conflicts and problems before they reach the trunk.
3. Use [feature flags](https://www.flagship.io/feature-flags/): Feature flags enable teams to deliver code to production while keeping it hidden from end users. This can assist teams in properly deploying code changes to the trunk without interfering with users.
4. Establish a [hotfix procedure](https://t2informatik.de/en/smartpedia/hotfix/): In the event of a critical bug, teams should have a process in place to quickly resolve the issue without interfering with ongoing development work. This procedure may include the usage of feature flags to distribute the hotfix to a subset of users.
5. Train the team: For trunk-based development to be successful, you must have a team that understands the approach and is willing to work in this manner. It is critical to train the team on best practices, methods, and the process of resolving problems.
Overall, implementing trunk-based development requires some discipline and planning, but when done correctly, it can be a powerful tool for boosting software development efficiency and collaboration.
## Best practices
To ensure the success of trunk-based development, teams should adhere to the following best practices:
1. [Continuous Integration](https://aws.amazon.com/devops/continuous-integration/) (CI): Continuous integration is a methodology that enables teams to recognize and handle integration issues as soon as they arise. Teams may catch and repair bugs before they reach the trunk by automating the build and test procedures.
2. [Continuous Testing](https://www.synopsys.com/glossary/what-is-continuous-testing.html) (CT): Continuous testing is a strategy that enables teams to notice and resolve problems as soon as possible. Teams can catch and repair bugs before they reach the trunk by automating the test processes.
3. [Code Review](https://www.devsdepot.com/blog/the-code-review-guide): In trunk-based development, code review is a fundamental activity. Teams may discover and address bugs early and ensure high-quality code by having other developers review code changes before they are pushed to the trunk.
4. [Test-Driven Development](https://testdriven.io/test-driven-development/) (TDD): TDD is a practice in which teams must write tests before producing code. This ensures that code updates are adequately tested and that errors are discovered early.
5. [Feature Flags](https://www.flagship.io/feature-flags/): Using feature flags, teams can deliver code to production while keeping it hidden from end users. This can assist teams in properly deploying code changes to the trunk without interfering with users.
6. [Continuous Deployment](https://www.ibm.com/topics/continuous-deployment): The process of automatically deploying code changes to production as soon as they are committed to the trunk is known as continuous deployment. This enables teams to deliver code updates more quickly and with fewer errors.
7. Embrace [Pair Programming](https://www.codementor.io/pair-programming): Pair programming is a practice in which two developers collaborate at a single workstation, with one typing and the other examining the code. This can be a useful method for detecting and resolving issues early on.
By adhering to these best practices, teams may assure the success of trunk-based development and the full testing, review, and deployment of code changes in a timely and efficient manner.
## Conclusion
Finally, trunk-based development is a software development methodology that is built on a single, central code repository known as the "trunk." This architecture has various advantages over typical branching models, including faster deployment and simpler cooperation. Implementing trunk-based development, on the other hand, can be difficult, especially for teams used to working with traditional branching models. Teams should build a clear code review process, implement continuous integration and testing, apply feature flags, be prepared for conflicts, have a hotfix procedure, and train the team on best practices to be successful with trunk-based development. Teams and organizations can reap the benefits of trunk-based development by adopting the tactics mentioned in this article.
| hitonomi_0 |
1,336,848 | Mac Mini M2 Pro - Should you upgrade as a software developer? | With the arrival of the new wave of Macs announced by Apple a few days ago, one wonders how powerful... | 22,194 | 2023-01-21T14:13:26 | https://davidserrano.io/mac-mini-m2-pro-should-you-upgrade-as-a-software-developer | apple, mac | With the arrival of the [new wave of Macs announced by Apple](https://www.youtube.com/watch?v=6Ij9PiehENA) a few days ago, one wonders how powerful they will be and if it is worth spending the money to buy a Mac Mini with the M2 chip or even if it would be better to buy the new top range with the new M2 Pro chip.
A few months ago I published [an article](https://davidserrano.io/this-is-why-i-bought-the-m1-mac-mini-in-late-2022) explaining why I bought a Mac Mini with the old M1 chip late last year. In that article, I made some arguments based on my specific requirements at the time and on the future forecasts that were being considered about when the new Macs would arrive and what price they would have. At that time it was rumored that the new machines would arrive around March and that they could also arrive with a price increase of up to 30%... well, in the end, they arrived much earlier, and not only have they not had a price increase, but just the opposite: the price of the new Mac Minis, even though they are more powerful machines, **has gone down**.
> 📽 Video version available on [YouTube](https://youtu.be/mIPE2Y185f0) and [Odysee](https://odysee.com/@svprdga:d/mac-mini-m2-pro-should-you-upgrade-as-a-software-developer)
{% embed https://youtu.be/mIPE2Y185f0 %}
### What to do now?
At this point, you may be wondering if you should upgrade if you already have a Mac Mini M1, or if you don't have one you may be wondering if now is a good time to get these powerful mini-machines. Also, if you want to upgrade or are buying one for the first time, is it worth spending more money to get the new higher-end Mac Mini with an M2 chip?
In this regard, it is interesting to observe a [series of leaks](https://www.macrumors.com/2023/01/19/mac-mini-m2-pro-geekbench-scores/) circulating on the internet recently about the performance of the M2 chip mounted in the Mac Mini. Let's first recall the scores that the current Mac Mini with an M1 chip gives in the well-known benchmark software Geekbench 5:
* Single Core: **1765**
* Multi-Core: **7764**
These are the results that I have obtained myself by running the test on my machine, which has 16GB of RAM.
According to the information contained in the aforementioned leak, the scores of the new Mac Mini with M2 Pro would be:
* Single-Core: **1952**
* Multi-Core: **15013**
These values would indicate an approximate increase of **10% in single-core and 93%** in multi-core.
Regarding the performance result at the single-core level, it is quite probable that the observed value ends up being the value that the leak indicates; and we know this because all the cores of the M series chips are the same, the only thing that changes between the different ranges (base, Pro, Max...etc) is, among other things, the number of cores. So, it is quite likely that we will be able to observe this 10% improvement in tasks related to single-core operations.
However, the most interesting result is undoubtedly the multi-core score, where we see that the performance almost doubles. This would be aligned with what Apple exposes precisely about the performance of its new machine:
> Note: this image is taken from the [official Apple website](https://www.apple.com/mac-mini/).
So if all this information is confirmed, we would undoubtedly be facing a qualitative leap of impact in terms of performance with this new Mac Mini with an M2 Pro chip, something that can improve the workflow of many people who use their computers professionally with intensive tasks.
In any case, **I've already ordered a Mac Mini with an M2 Pro** chip and I intend to put it to the test to see how it performs and to suggest to you whether or not it's worth upgrading. Follow closely the content I publish in this blog because I intend to check how it performs compiling iOS projects, both from the command line and from XCode itself; I'll also check its performance with Android development, run build tests for Flutter as well, even try building the Godot game engine to see how it performs building C++ projects. And these are just some of the examples of what I am going to benchmark and that of course I will bring you this coming week so that you have all the information you need to make a firm decision.
This is all for today, see you next week with the promised material. Happy coding! | svprdga |
1,337,061 | Building Real-Time Recommendation System | In the first part of the series on building a personalised music recommendation system, we discussed... | 0 | 2023-01-23T11:25:51 | https://dev.to/vhutov/building-personalised-recommendation-system-p2-53gk | node, showdev, tutorial, javascript |
In the [first part](https://dev.to/vhutov/building-personalised-music-recommendation-system-24lc) of the series on building a personalised music recommendation system, we discussed the use of machine learning algorithms such as Collaborative Filtering and Co-occurrence Counting to create an items similarity matrix. This resulted in a set of files, each representing the similarities between various artists and tracks.
As an example, one of these files may look like this:
```
00FQb4jTyendYWaN8pK0wa 0C8ZW7ezQVs4URX5aX7Kqx ... 66CXWjxzNUsdJxJ2JdwvnR
02kJSzxNuaWGqwubyUba0Z 137W8MRPWKqSmrBGDBFSop ... 3nFkdlSjzX9mRTtwJOzDYB
04gDigrS5kc9YWfZHwBETP 0du5cEVh5yTK9QJze8zA0C ... 1Xyo4u8uXC1ZmMpatF05PJ
06HL4z0CvFAxyc27GXpf02 4AK6F7OLvEQ5QYCBNiQWHq ... 26VFTg2z8YR0cCuwLzESi2
07YZf4WDAMNwqr4jfgOZ8y 23zg3TcAtWQy7J6upgbUnj ... 6LuN9FCkKOj5PcnpouEgny
```
Here, the first entry is the key entity, followed by N entities that are similar to it.
In this second part of the series, we will delve into the process of building a Node.js application that utilises this data and other information to provide real-time music recommendations to users, based on their individual tastes. We will explore the use of different database paradigms to ensure our solution is both scalable and performant.
If you're just joining and want to follow along as we build this system, but don't want to dive into the world of machine learning, you'll need the following data:
- The original raw playlist dataset, which can be found at [Kaggle](https://www.kaggle.com/datasets/vladyslavhutov/spotify-playlists-csv).
- The similarity matrices, which can be found at [GitHub](https://gist.github.com/vhutov/5e5f49906cd4924b1e2ecfcc85c5d914), and contain artist similarities (matrix factorization, MLP, and co-occurrence) and track similarities (matrix factorization).
With that out of the way, let's get started!
## System Architecture
The Node.js application we are building will consist of three peripheral services and a high-level recommendation service with a fluent API, a request handler, and an express route to handle requests.
The following diagram gives a high-level overview of the application architecture:
To build this app, we will start by implementing the lower-level services before moving on to the higher-level ones. This approach is known as building bottom-up, and I hope it will help understand the process better.
## Services
### TracksService
To store and retrieve the track and artist data, we will use a relational database paradigm. This requires us to create two tables: one for storing artists, and another for storing the tracks of each artist.
Here is the SQL code needed to create these tables:
```sql
CREATE TABLE artists (
uri varchar(32) NOT NULL,
name varchar(100) NOT NULL,
PRIMARY KEY (uri)
);
CREATE TABLE tracks (
uri varchar(32) NOT NULL,
name varchar(100) NOT NULL,
artist_uri varchar(32) NOT NULL,
PRIMARY KEY (uri),
KEY artist_uri (artist_uri),
CONSTRAINT tracks_fk_1 FOREIGN KEY (artist_uri) REFERENCES artists (uri)
);
```
To run all the services we need, we will use Docker containers. One option is to use `docker-compose` with the `mysql` image to create these tables and store the data persistently.
Here is an example of a `docker-compose.yml` file that can be used to create a MySQL container and set up the necessary environment variables, volumes, and ports:
```yml
services:
mysql-server:
image: mysql:8.0.31
command: --default-authentication-plugin=mysql_native_password
environment:
MYSQL_ROOT_PASSWORD: admin123
MYSQL_DATABASE: music
MYSQL_USER: user
MYSQL_PASSWORD: user123
volumes:
- db:/var/lib/mysql
ports:
- 3306:3306
volumes:
db:
```
> You need to have a `docker-compose` installed on your machine.
Using the above `docker-compose.yml` file, we can easily start a MySQL server and connect to it from our Node.js application.
To populate the data from the raw playlist dataset into the database, we will need to write a script. I used Python for this task as it is simple to use, but since the main focus of this article is the Node.js application for recommendations, I will not go into the details of how the script works. You can find the script in the [GitHub repo](https://github.com/vhutov/personalised-recommender/blob/main/scripts/populate-db-data.py).
You can run this script to import the data from the raw dataset into the database. Once the data is imported, our application can then use this data to query tracks and artists.
Now, let's implement the `TracksService` class. This service will be responsible for handling various queries related to track data, this is the service interface:
```js
class TrackService {
/** @type {knex.Knex} */
#db
constructor(db) {
this.#db = db
}
asyncTrackData = async (trackIds) => { ... }
asyncGetTracksByArtist = async (artistIds, {fanOut, randomize}) => { ... }
}
```
The first function is a simple query for track data. It selects tracks by their URI and renames the `uri` column to `id`, which we will need later on.
```js
/**
* Gets track data from db
*
* @param {string[]} trackIds
*
* @returns {Promise<Object.<string, any>[]>} tracks data
*/
asyncTrackData = async (trackIds) => {
const rows = await this.#db
.select()
.from('tracks')
.whereIn('uri', trackIds)
return rows.map(({ uri: id, ...rest }) => ({ id, ...rest }))
}
```
This function accepts an array of track IDs as an input and returns a promise that resolves to an array of track data. It uses the `knex.js` library to connect and query the MySQL database.
The second function of the `TracksService` class allows us to query track IDs by their authors. It may appear complex at first glance, but the complexity arises from the fact that we want to limit the maximum number of tracks per author.
```js
/**
* Get list of tracks per artist.
*
* @param {string[]} artistIds list of artist ids
* @param {Object} options configuration:
* @param {number} [options.fanOut] max number tracks per artist
* @param {boolean} [options.randomize = false] when fan_out specified - if true, will randomly shuffle tracks before limiting
*
* @returns {Promise<Object.<string, string[]>>} map where key is artist_id and value is a list of artist track_ids
*/
asyncGetTracksByArtist = async (artistIds, { fanOut = null, randomize = false } = {}) => {
const rows = await this.#db
.select({
track_id: 'uri',
artist_id: 'artist_uri'
})
.from('tracks')
.whereIn('artist_uri', artistIds)
const fanOutFun =
randomize ?
(v) => _.sampleSize(v, fanOut) :
(v) => _.slice(v, 0, fanOut)
const applyLimitToArtist = R.map(([k, v]) => [k, fanOutFun(v)])
const groupByArtist = R.groupBy(R.prop('artist_id'))
const limitPerArtist = fanOut
? R.pipe(
R.toPairs, // split object to a list of tuples
applyLimitToArtist, // per tupple apply the limit function
R.fromPairs // construct the object back
)
: R.identity // if fanout is false, do nothing
/*
For each value within parent object, take field track_id
Convert
{
artist_id1: [{ track_id: a, artist_id: artist_id1}],
artist_id2: [{ track_id: b, artist_id: artist_id2}]
}
to
{
artist_id1: [a],
artist_id2: [b]
}
*/
const projectTrackId = R.mapObjIndexed(R.pluck('track_id'))
return R.pipe(groupByArtist, limitPerArtist, projectTrackId)(rows)
}
```
It starts by querying an unlimited number of tracks per artist, and then, depending on the input arguments, randomly or deterministically limits the number of tracks. We make use of two additional libraries here: `Ramda` and `Lodash` for object and array manipulations.
It's important to note that `artist_uri` column in the `tracks` table is a foreign key, which means that MySQL creates a secondary index on this field. Having a secondary index ensures that our query will run quickly even when we have a large amount of data in the database, as we do not need to perform a full scan of the table.
### SimilarityService
Our next service helps us to find similar entities. As you may recall, we previously created similarity matrices, which hold the similarity relations.
The service API is straightforward: given a list of entity IDs and an index (which serves as an identifier for the ML model used to build a similarity matrix), the function returns a list of similar entities.
```js
class SimilarityService {
/** @type {redis.RedisClientType} */
#redis
constructor(redis) {
this.#redis = redis
}
asyncGetSimilar = async (ids, { indexName, fan_out }) => { ... }
}
```
While it would be possible to use SQL to model this functionality, I propose using a key-value based NoSQL solution. We can use an in-memory database, such as Redis, to store our similarity matrices, as they can fit in RAM. For example, the artist files use less than 500 KB and the track files need 2 MB. Even if we had 1,000 or 10,000 more artists (and tracks), it would still fit within memory. Additionally, we can also shard if more memory is needed.
Using RAM based storage type we ensure that request is fulfilled with the least possible delay. Redis also has persistence mode, which we will use for durability of the data.
To use our similarity service, we will need to update our `docker-compose` file to start a Redis server as well. Here is an example of how we can do that:
```yml
services:
redis:
image: redis
ports:
- 6379:6379
volumes:
- redis:/data
command: redis-server --save 60 1 --loglevel warning
volumes:
redis:
```
The schema we will use for storing the similarity data in Redis is as follows:
- key: list[entity_id]
The key consists of two parts: `<index_name>:<entity_id>`.
We will also need a script that populates Redis with similarity data. This script can be found [here](https://github.com/vhutov/personalised-recommender/blob/main/scripts/populate-redis-data.py). Once the script is run, it will create four different similarity indices.
With the setup in place, we can now write the implementation for the similarity service:
```js
/**
* For provided entity ids fetches similar entities
*
* @param {string[]} ids
* @param {Object} options
* @param {string} options.indexName redis index name
* @param {number} [options.fanOut = 10] limit number of similar entities per entity
*
* @returns {Promise<Object.<string, string[]>>} map of similar entities, where key is input entity_id and values are similar entity_ids
*/
asyncGetSimilar = async (ids, { indexName, fanOut = 10 }) => {
const key = (id) => `${indexName}:${id}`
// creates array of promises
const pendingSimilarities = ids.map(async (id) => {
const similarIds = await this.#redis.lRange(key(id), 0, fanOut)
if (similarIds.length == 0) return null
return [id, similarIds]
})
// when promises are awaited, we get a list of tuples [id, similarIds]
// ideally we want to have some error handling here
const similarities = (await Promise.allSettled(pendingSimilarities)).filter((r) => r.value).map((r) => r.value)
return Object.fromEntries(similarities)
}
```
The implementation is simple - it executes N concurrent requests to Redis to get array slices for the provided entity keys. It returns an object, where the key is the original entity ID and the value is an array of similar entity IDs.
Ideally we should have error handling for the promises here to handle any errors that might occur when querying Redis.
### FuzzySearch
Our recommendation system is not based on user activities, and we do not have access to internal track IDs. Instead, we will be relying on arbitrary strings of text entered by the user to specify track or artist names. In order to provide accurate recommendations, we will need to implement a fuzzy search mechanism for tracks and artists.
Fuzzy search is an approach that can help us build a robust system for finding actual tracks based on user input. It allows for a degree of flexibility in the user's search queries, making it less prone to errors. A standard example of a system which supports such queries is ElasticSearch.
To begin, let's take a look at our `docker-compose` configuration for setting up ElasticSearch:
```yml
services:
elastic:
image: elasticsearch:8.6.0
ports:
- 9200:9200
- 9300:9300
environment:
- xpack.security.enabled=false
- discovery.type=single-node
volumes:
- elastic:/usr/share/elasticsearch/data
volumes:
elastic:
```
In our implementation, we will be using two types of indices in ElasticSearch: one for indexing tracks with artists, and another for indexing just artists. This is similar to a reverse representation of the original SQL model.
The diagram below illustrates how we are storing and querying data in SQL:
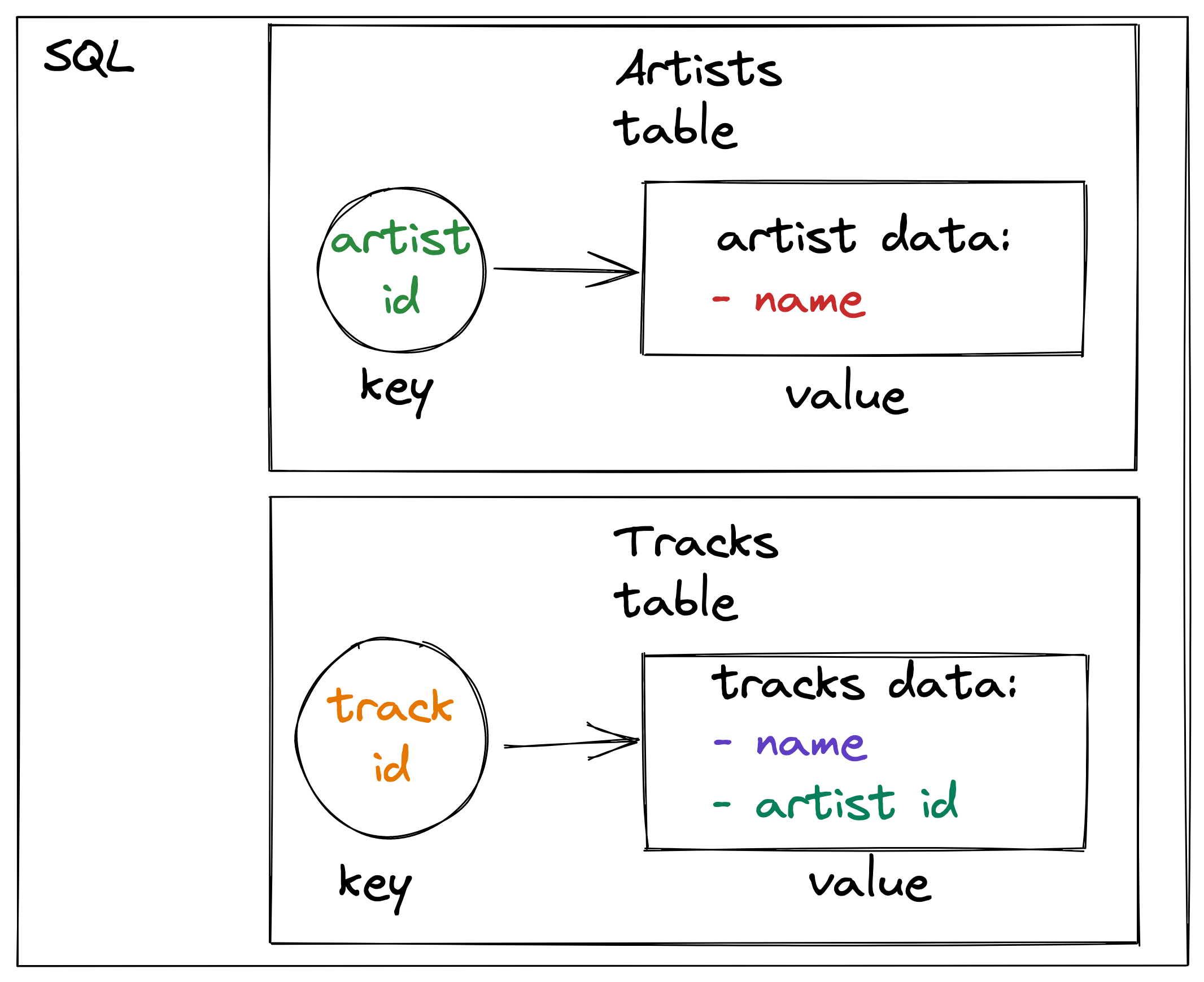
And this is how we are storing them in ElasticSearch:
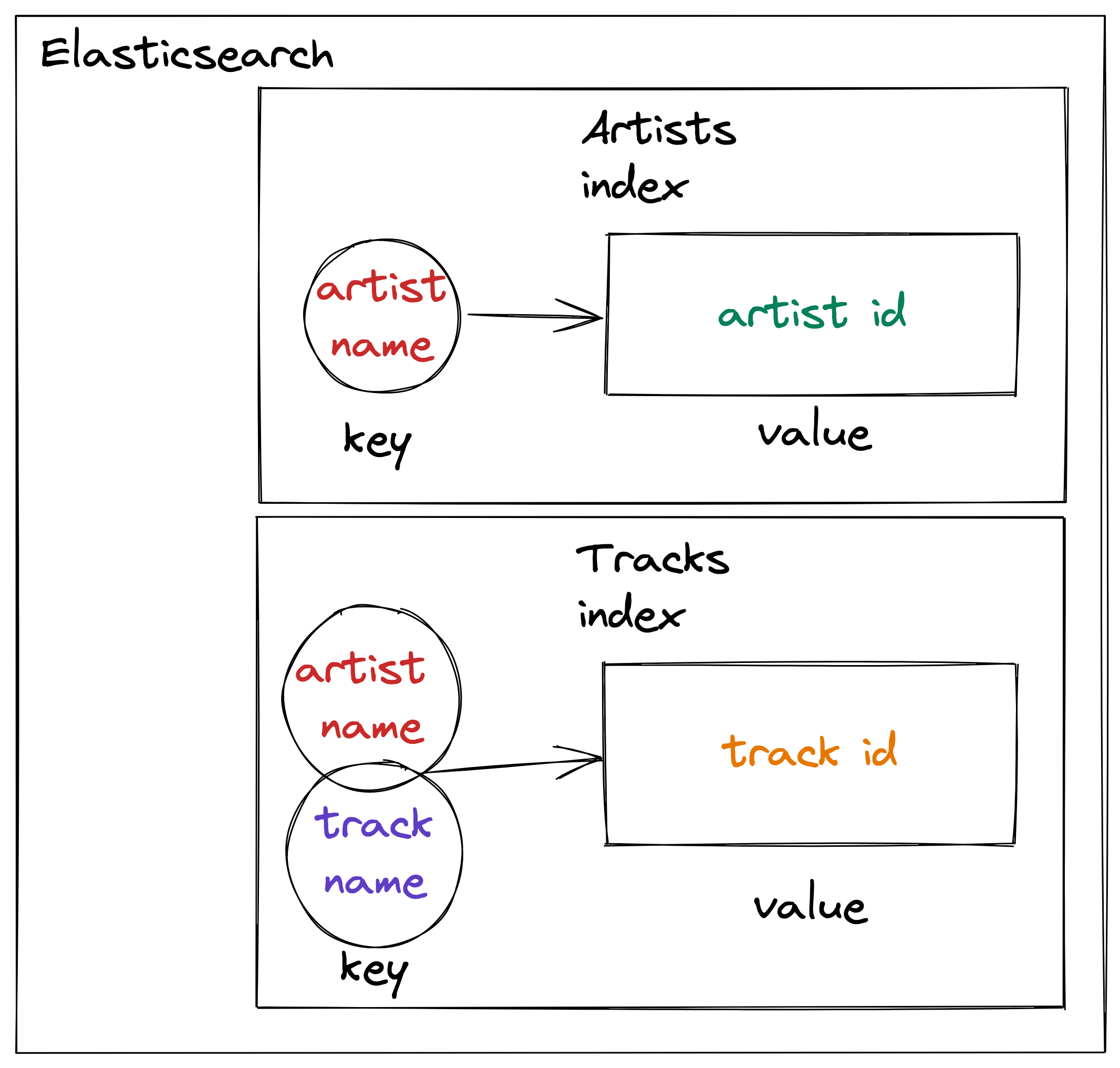
The ElasticSearch indices allow us to query the required track and artist IDs by their names very quickly, providing a fast and efficient search process. This improves the overall user experience, as the system is able to provide recommendations in a timely manner.
The built-in fuzzy search mechanism enables us to handle variations in the user's input, such as misspellings or slight variations in the search query. This ensures that our system can still provide accurate recommendations even if the user's input is not perfect.
The `FuzzySearch` class is responsible for handling the search functionality in our recommendation system:
```js
class FuzzySearch {
/**
* @type {Client}
*/
#es
constructor(es) {
this.#es = es
}
asyncSearchArtist = async (artists) => { ... }
asyncSearchTrack = async (tracks) => { ... }
}
```
The `asyncSearchArtists` method is responsible for searching for artists in the "artists" index using the provided name(s) as the search query. The method uses a helper method called `matchField` to compose the "SELECT" part of the ElasticSearch query.
```js
/**
* @param {string} fieldName field name which need to match
* @param {string} value matching value
* @returns elasticsearch query for matching <fieldName> field
*/
const matchField = (fieldName, value) => ({
match: {
[fieldName]: {
query: value,
operator: 'AND'
}
}
})
```
The `asyncSearchArtists` method then constructs the full request, specifying the "artists" index and the query for each artist. It uses the ElasticSearch client's `msearch` (multiple search) method to perform the search:
```js
/**
* @param {{artist: string}[]} artists
* array of query strings for matching artists
* each object must contain artist name
* @returns {Promise<SearchResult[]>} track and artist ids
*/
asyncSearchArtists = async (artists) => {
const { responses } = await this.#es.msearch({
searches: artists.flatMap(({ artist }) => [
{ index: 'artists' },
{
query: matchField('name', artist)
}
])
})
return maybeGetFirstFrom(responses)
}
```
The search results returned by ElasticSearch may contain zero to many matched objects, so we need to flatten the result set. For simplicity, let’s select the first result from the result set if it exists.
```js
const maybeGetFirstFrom = (responses) =>
responses.flatMap((r) => {
if (!r.hits.hits) return []
const { _id } = r.hits.hits[0]
return [
{
id: _id
}
]
})
```
When searching for tracks, we have two cases: when artist name search clause is present or is missing, so let’s create a helper function for constructing the query:
```js
/**
* @param {{track: string, artist: ?string}} value matching value
* @returns {{match: Object}[]} array of matching clauses in elastic query dsl
*/
const searchTrackTerms = ({ track, artist = null }) => {
const trackTerm = matchField('name', track)
if (!artist) {
return [trackTerm]
}
const artistTerm = matchField('artist', artist)
return [trackTerm, artistTerm]
}
```
The `asyncSearchTracks` method makes use of this helper function to construct the query for searching for tracks in the "tracks" index.
```js
/**
* @param {{track: string, artist: ?string}[]} tracks
* array of query strings for matching tracks
* each object must contain either track name or track and artist names
* having artist name present increases likelyhood of finding the right track
* @returns {Promise<{id: string}[]>} track ids for matched queries
*/
asyncSearchTracks = async (tracks) => {
const { responses } = await this.#es.msearch({
searches: tracks.flatMap((track) => [
{ index: 'tracks' },
{
query: {
bool: {
must: searchTrackTerms(track)
}
}
}
])
})
return maybeGetFirstFrom(responses)
}
```
This concludes the implementation of peripheral services. In summary, we have implemented three services which we’ll use to build our recommendation system:
- Data retrieval using an SQL model: This service allows us to quickly lookup data by its ID, providing fast access to the required information.
- Similarity retrieval using an in-memory key-value model: This service provides a blazing fast access to the similarity matrix, which is crucial for generating recommendations based on similar items.
- Fuzzy search using a text index: This service allows us to quickly find relevant entity IDs, even when the user's input is not perfect. The built-in search mechanism in the text index provides a degree of flexibility in the search process, handling variations in the user's input.
Each of these services targets to decrease latency time in their respective zones of responsibility. Together, they provide a robust and efficient ground for the recommendation system that can handle variations in user input, while providing accurate and timely recommendations.
### Fluent API
In the remaining sections, we will look at how we can integrate the services we have built to create a functional recommendation system. While we could start using the services as-is, building a real-world recommendation flow would become tedious and cumbersome.
To improve the development process, we need to build a data model and a service that provides a fluent API for construction recommendation flows.
The core concepts in this data model will be a dynamic entity and a pipe. A dynamic entity represents a piece of data that can change over time, such as a user's query or a track's artist. A pipe represents a flow of data through the system, allowing us to apply different operations on the data as it moves through the system.
The data model and service will provide a simple and intuitive way to build recommendation systems, making it easy to experiment with different approaches and fine-tune the system to achieve the desired performance.
#### Entity
As mentioned previously, a dynamic entity is just a container of properties. It is a plain JavaScript object that can hold any properties that are relevant to the recommendation system.
We won't enforce any specific structure for this entity, and the responsibility of type checking will be on the client of this API. This allows for maximum flexibility in the data model, and makes it easy to add or remove properties as needed.
#### Pipe
A pipe is an asynchronous function that receives an array of entities and returns a modified array of entities. It can perform various operations on them, such as filtering, sorting, or transforming the data. For example, a pipe can filter out entities that do not meet certain criteria, sort based on a specific property, or transform the entities by adding or removing properties.
If a pipe creates a new entity, it copies over properties from the parent entity. This allows for the preservation of relevant information from the original entity, while also allowing for the addition of new properties.
### RecommendationService
With the concepts of dynamic entities and pipes, we can now introduce the `RecommendationService` API.
```js
type Config = Object
type Entity = { [string]: any }
type OneOrMany<A> = A | A[]
type Pipe = (OneOrMany<Entity> => Promise<Entity[]>)
class RecommendationService {
/* Peripheral API */
fuzzySearchTracks: Pipe
fuzzySearchArtists: Pipe
enrichTrack: Pipe
similar: (options: Config) => Pipe
artistTracks: (options: Config) => Pipe
/* Util API */
dedupe: (by: string | string[]) => Pipe
diversify: (by: string | string[]) => Pipe
sort: (by: string | string[]) => Pipe
take: (limit: int) => Pipe
set: (from: string, to: string) => Pipe
setVal: (key: string, value: any) => Pipe
/* Composition API */
merge: (...pipes: Pipe[]) => Pipe
compose: (...pipes: Pipe[]) => Pipe
/* internals */
#similarityService: SimilarityService
#trackService: TrackService
#fuzzyService: FuzzySearch
}
```
The API is split into three main sections: peripheral API, util API and composition API.
Peripheral API provides the core services that are necessary to build a recommendation system, such as the `fuzzySearchTracks`, `fuzzySearchArtists`, `enrichTrack`, `similar` and `artistTracks` methods. These methods provide access to the services that were previously created and make it easy to retrieve data from the system.
Util API provides utility methods for manipulating the data as it moves through the system, such as the `dedupe`, `diversify`, `sort`, `take`, `set`, and `setVal` methods.
Composition API provides methods for composing and merging pipes. These methods allow for the creation of complex data manipulation flows by combining multiple individual pipe functions.
The full implementation of the `RecommendationService` service is not included in the article, but it can be found in the [GitHub repository](https://github.com/vhutov/personalised-recommender/blob/main/app/recommendation.js).
Let’s take a look at the `fuzzySearchTracks` method as an example of how we can implement one of the peripheral API methods in the `RecommendationService`. The method takes an input of user search requests, which are represented as dynamic entities. Each entity must contain a track name and optionally an artist name:
```js
/**
* @typedef {Object.<string, any>} Entities
* @param {Entity|Entity[]} input user search requests. Each entity must contain track name and optionally artist name
* @returns {Promise.<Entity[]>} found track ids
*/
fuzzySearchTracks = async (input) => {
input = toArray(input)
const trackInputs = input.filter((v) => v.track)
const searchResults = await this.#fuzzyService.asyncSearchTracks(trackInputs)
return searchResults
}
```
The `fuzzySearchTracks` method does not preserve any of the parent properties of the input entities, as they have no use in the recommendation flow. The method serves as an entry point and its primary function is to retrieve the relevant track ids.
The `similar` method is another example of how we can implement one of the peripheral API methods. It takes an input of entities and an options object, and finds similar entities.
```js
/**
* Finds similar entities. Copies properties from parent to children.
* @typedef {Object.<string, any>} Entities
* @param {Object|Function} options see SimilarityService#asyncGetSimilar options
* @param {Entity|Entity[]} input
* @returns {Promise<Entity[]>} similar entities for every entity from input
*/
similar = (options) => async (input) => {
input = toArray(input)
options = _.isFunction(options) ? options() : options
const ids = input.map(R.prop('id'))
const similarMap = await this.#similarityService.asyncGetSimilar(ids, options)
return input.flatMap((entity) => {
const similar = similarMap[entity.id] || []
return similar.map((id) => ({
...entity,
id
}))
})
}
```
The method then maps over the input entities and for each entity, it flattens an array of similar entities by copying over the properties from the parent entity to the child entities, which get new ids. This allows for the preservation of relevant information from the original entity.
Let’s also overview how composition functions work. We have two of those: `merge` and `compose`.
The `merge` takes a list of pipes and runs them in parallel, creating a higher-level pipe. The high-level pipe internally feeds input to the composed parts, runs them concurrently, and then merges their output.
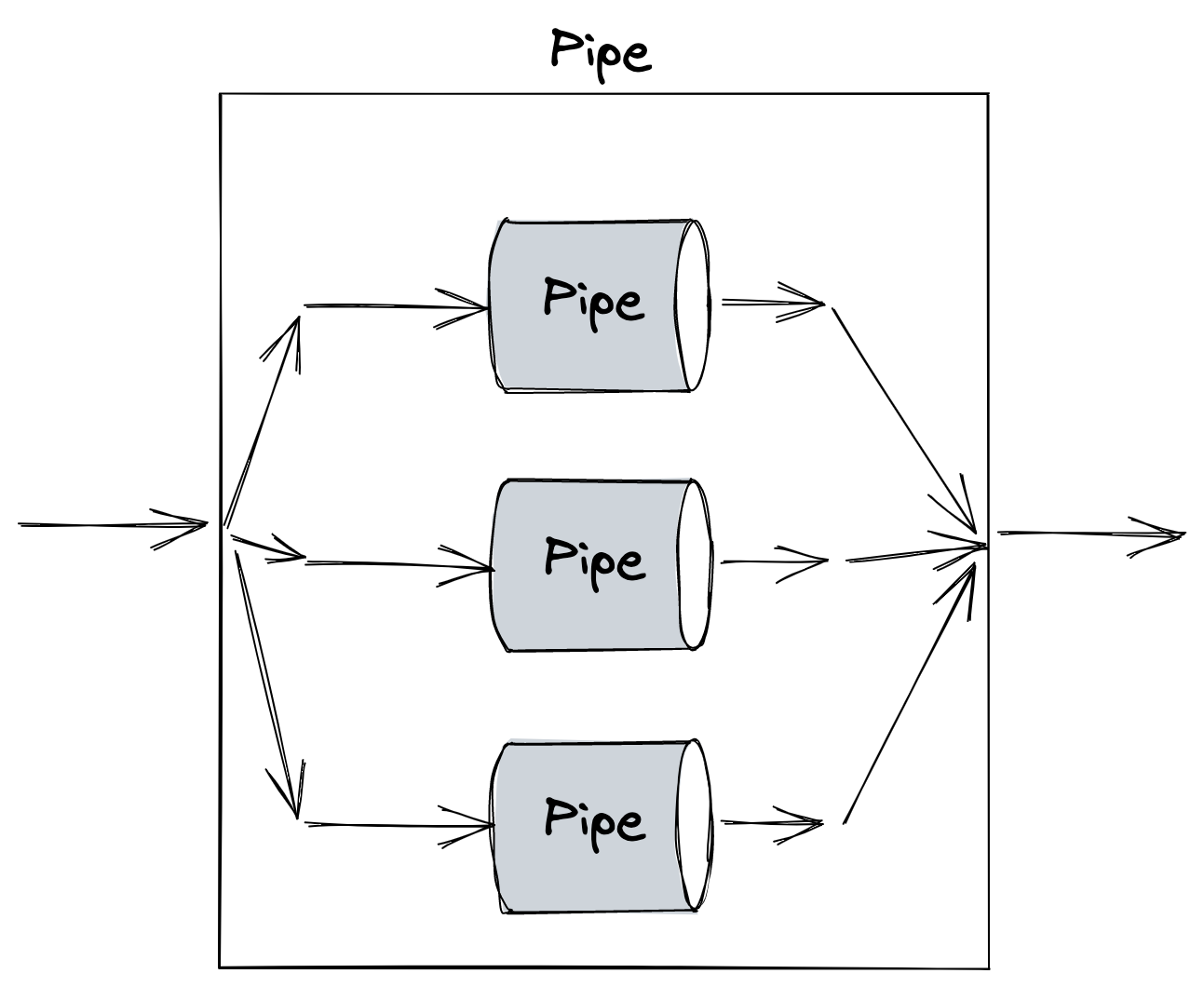
```js
/**
* Merges few pipes into single pipe
* @typedef {Object.<string, any>} Entities
* @param {...(Entity[] => Promise<Entity[]>)} pipes
* @returns high level pipe
*/
merge = (...pipes) => async (input) => {
// converging function receives an array of triggered promisses
// and awaits all of them concurrently
const convergingF = async (...flows) =>
(await Promise.allSettled(flows))
.filter((v) => v.value) // missing error handling
.map((v) => v.value)
.flat()
return R.converge(convergingF, pipes)(input)
}
```
The `merge` function is a powerful tool that allows us to run multiple pipes concurrently, which can greatly speed up the process of generating recommendations.
The `compose` function is another composition function in the `RecommendationService`. It creates a sequential execution of pipes, where the output of one pipe is fed as input to the next pipe:
```js
/**
* Creates sequential composition of pipes
* @typedef {Object.<string, any>} Entities
* @param {...(Entity[] => Promise<Entity[]>)} pipes
* @returns high level pipe
*/
compose = (...pipes) => async (input) => {
return R.pipeWith(R.andThen, pipes)(input)
}
```
Using the `compose` function we can create complex recommendation flows.
### FlowBuilder
We can now utilise this API to construct a recommendation flow. The flow will be split into two branches: we will be recommending tracks based on the user's track preferences and also based on their artist preferences, as seen in the flow diagram.
The following is the interface for the flow builder:
```js
const buildFuzzySearchFlow = (config, recs: RecommendationService) => {
// Importing the fluent API interface
const {
fuzzySearchTracks,
fuzzySearchArtists,
similar,
enrichTrack,
artistTracks,
dedupe,
diversify,
take,
set,
setVal,
merge,
compose
} = recs
// Flow implementation
...
}
```
And this is how we can implement the flow based on user search input:
```js
const artistFlow = compose(
dedupe('artist'),
fuzzySearchArtists,
dedupe('id'),
set('id', 'recommender'),
setVal('flow', 'artist-flow'),
similar(config.recs.artist.mlp),
dedupe('id'),
artistTracks(config.artistTracks),
diversify(['recommender', 'artist_id']),
take(50)
)
const trackFlow = compose(
fuzzySearchTracks,
dedupe('id'),
set('id', 'recommender'),
setVal('flow', 'track-flow'),
similar(config.recs.track),
dedupe('id'),
diversify('recommender'),
take(50)
)
return compose(
merge(artistFlow, trackFlow),
dedupe('id'),
diversify('flow'),
take(config.limit),
enrichTrack
)
```
Let’s dive into the specifics of the artist recommendations branch.
To begin, we use the `compose` function to build a sequential chain of underlying pipes. This allows us to perform a series of operations in a specific order.
First, we use the `dedupe` function to take unique artist names (based on the user's search input) and then query ElasticSearch to retrieve artist IDs. Then, we use the `dedupe` function again to ensure that the results from ElasticSearch are also unique.
```js
dedupe('artist')
fuzzySearchArtists
dedupe('id')
```
Next, we use the `set` and `setVal` functions to create new properties on each entity.
```js
set('id', 'recommender')
setVal('flow', 'artist-flow')
```
The `set` function creates a new property called "recommender" by copying the value of the entity's "id" property. The `setVal` function creates a new property called "flow" with a constant value of "artist-flow". These two functions will allow us to trace the origin of recommendations later on when needed.
We then move on to finding similar artists to the ones provided by the user.
```js
similar(config.recs.artist.mlp)
dedupe('id')
```
This is done by querying the `similar` index with values specified in the config file. We then use the `dedupe` function again to remove any duplicate results.
Finally, the last step in the artist flow is to retrieve the songs for the recommended artists and limit the number of results.
```js
artistTracks(config.artistTracks)
diversify(['recommender', 'artist_id'])
take(50)
```
To ensure a more natural shuffle of the results, the `diversify` function is used, which uses a Round-Robin shuffling mechanism:
When we call the full flow, we will receive results similar to the example shown below.
```js
[
{
id: '1VpSH1BPdKa7KYVjH1O892',
recommender: '711MCceyCBcFnzjGY4Q7Un',
flow: 'artist-flow',
artist_id: '4F84IBURUo98rz4r61KF70',
name: 'The Air Near My Fingers',
artist_uri: '4F84IBURUo98rz4r61KF70'
},
{
id: '32lm3769IRfcnrQV11LO4E',
flow: 'track-flow',
recommender: '08mG3Y1vljYA6bvDt4Wqkj',
name: 'Bailando - Spanish Version',
artist_uri: '7qG3b048QCHVRO5Pv1T5lw'
},
{
id: '76wJIkA63AgwA92hUhpE2V',
recommender: '711MCceyCBcFnzjGY4Q7Un',
flow: 'artist-flow',
artist_id: '1ZwdS5xdxEREPySFridCfh',
name: 'Me Against The World',
artist_uri: '1ZwdS5xdxEREPySFridCfh'
},
...
]
```
Each result will have properties such as "id", "recommender", "flow", "artist_id", "name", and "artist_uri". These properties provide information about the recommended track, as well as where it came from in the recommendation flow.
The full code, that includes a request handler and express app, can be found in the [GitHub repository](https://github.com/vhutov/personalised-recommender).
That's it. I hope you have enjoyed building the recommendation systems and learned something new! | vhutov |
1,337,062 | Interface Segregation Principle in React | What is the Single Responsibility Principle? The Interface Segregation Principle (ISP) is an oop... | 0 | 2023-01-21T18:25:11 | https://dev.to/zahidhasan24/interface-segregation-principle-in-react-2k8c | **What is the Single Responsibility Principle?**
The Interface Segregation Principle (ISP) is an oop principle that states that clients (objects or classes) should not be required to implement interfaces (or methods) that they do not utilize. In other words, it is a philosophy that favors smaller, more particular interfaces over larger, more broad ones. This contributes to reducing system complexity by making it more modular and easier to comprehend and maintain.
Consider the Toy interface, which offers numerous methods such as play(), stop(), and break() (). Assume we have two kinds of toys: a vehicle toy and a doll toy. The play() and stop() methods are sufficient for the vehicle toy, while the play() and break() methods are required for the doll toy.
If we do not adhere to the ISP, the Toy interface would have all three methods (play(), stop(), and break()), and both the vehicle toy and the doll toy would be required to implement all three methods, even though the doll toy will never utilize the stop() method.
We would construct two new interfaces, VeichleToy and DollToy, in accordance with the ISP. The VeichleToy interface would only have the play() and stop() methods, whereas the DollToy interface would only have the break() and play() methods. In this manner, the vehicle toy can implement the VeichleToy interface and the doll toy can implement the DollToy interface without implementing extra methods.
We have thereby decreased the system’s complexity while increasing its maintainability.
**How can you implement ISP in React?**
In React, you can implement the Interface Segregation Principle using hooks or Higher-Order Components (HOC), or Render Props.
In this article, we will use hooks to learn about this.
Here’s an example of how the ISP can be violated when using React hooks:
Assume you have a `UserProfile` component that displays a user’s information such as their name, email, and profile image. The component utilizes the `useEffect` hook to contact an API and set the user’s data in the component’s state in order to retrieve the user’s data.
Suppose you have a component named `UserSettings` that similarly needs to get the user’s data, but this time it needs to update the user’s data by accessing another API.
You might be tempted to reuse the `UserProfile` component’s code to retrieve the user’s data in this scenario. However, you are breaking the ISP by doing so because the `UserProfile` component simply needs to fetch data, whereas the `UserSettings` component needs to fetch and alter data.
Here’s the code that violates the ISP:
```javascript
import { useEffect, useState } from 'react';
const UserProfile = () => {
const [userData, setUserData] = useState({});
useEffect(() => {
const fetchUserData = async () => {
const response = await fetch('/api/user');
const data = await response.json();
setUserData(data);
}
fetchUserData();
}, []);
return <div>{userData.name}</div>;
}
const UserSettings = () => {
const [userData, setUserData] = useState({});
useEffect(() => {
const fetchUserData = async () => {
const response = await fetch('/api/user');
const data = await response.json();
setUserData(data);
}
fetchUserData();
}, []);
const updateUserData = async () => {
await fetch('/api/user', {
method: 'PATCH',
body: JSON.stringify(userData),
});
}
return (
<div>
<input
value={userData.name}
onChange={(e) => setUserData({ ...userData, name: e.target.value })}
/>
<button onClick={updateUserData}>Save</button>
</div>
);
}
```
You may solve this issue by creating two different hooks: one for getting data and one for changing data. Then, in each component, you may use the relevant hook.
For example, you might construct a hook named `useFetchUserData` that just deals with getting the user’s data and another called `useUpdateUserData` that only deals with updating the user’s data. The `useFetchUserData` hook may be used by the `UserProfile` component, while the `useUpdateUserData` hook can be used by the `UserSettings` component.
Because each component only implements the methods it requires, and the hooks are short and have particular interfaces, you are complying with the ISP.
Here’s the refactored code:
```javascript
import { useEffect, useState } from 'react';
const useFetchUserData = () => {
const [userData, setUserData] = useState({});
useEffect(() => {
const fetchData = async () => {
const response = await fetch('/api/user');
const data = await response.json();
setUserData(data);
}
fetchData();
}, []);
return userData;
}
const useUpdateUserData = () => {
const [userData, setUserData] = useState({});
const updateData = async () => {
await fetch('/api/user', {
method: 'PATCH',
body: JSON.stringify(userData),
});
}
return { userData, setUserData, updateData };
}
const UserProfile = () => {
const userData = useFetchUserData();
return <div>{userData.name}</div>;
}
const UserSettings = () => {
const { userData, setUserData, updateData } = useUpdateUserData();
return (
<div>
<input
value={userData.name}
onChange={(e) => setUserData({ ...userData, name: e.target.value })}
/>
<button onClick={updateData}>Save</button>
</div>
);
}
```
| zahidhasan24 | |
1,337,298 | Pastes.io - API DOCS | We have a New API! You can find Docs here https://docs.pastes.io | 0 | 2023-01-22T02:10:57 | https://dev.to/pastebin/pastesio-api-docs-19km | update, webdev, api | _We have a New API! You can find Docs here_ [https://docs.pastes.io](https://docs.pastes.io)
 | pastebin |
1,337,457 | Basics of Minkowski Distance | Classification problem involving Minkowski distance at p=2 in Iris dataset Distance metrics are... | 0 | 2023-02-08T04:20:40 | https://dev.to/ralphgutz/basics-of-minkowski-distance-pab | machinelearning, datascience, statistics, optimization | <figure>
<img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/u2oqbdvygayf00yoyjkg.png" alt="Classification problem involving Minkowski distance at p=2 in Iris dataset" style="width:100%">
<figcaption align="center"><p>Classification problem involving Minkowski distance at p=2 in Iris dataset</p></figcaption>
</figure>
<br />
Distance metrics are used by proximity-based models to find certain paths between two points.
One of the best applications of distance metrics is in the [travelling salesman problem](https://en.wikipedia.org/wiki/Travelling_salesman_problem) where nearest neighbour, an approximation algorithm, is usually utilized. Aside from combinatorial optimization, distance metrics are also widely used in classification, clustering, and special relativity problems.
In this article, we will tackle one of the basic distance metrics, named after the German mathematician Hermann Minkowski—the Minkowski distance.
## By definition
Minkowski distance is a distance metric, or a similarity measurement, between two points in a [normed vector space](https://en.wikipedia.org/wiki/Normed_vector_space). It uses a parameter {% katex inline %} p {% endkatex %} which represents the order of the norm.
Let’s say we have {% katex inline %} X_n {% endkatex %} and {% katex inline %} Y_n {% endkatex %} denoted as:
{% katex %} X = (x_1,x_2,...,x_n), {% endkatex %}{% katex %} Y = (y_1,y_2,...,y_n) {% endkatex %}
The distance of two points can be measured by getting the absolute value of the difference of {% katex inline %} X_i {% endkatex %} and {% katex inline %} Y_i {% endkatex %} ({% katex inline %} |X_i - Y_i| {% endkatex %}). Hence, to get the distances of all {% katex inline %} X,Y {% endkatex %} points ({% katex inline %} D(X,Y) {% endkatex %}), the formula will be in the form of:
{% katex %} D(X,Y) = \displaystyle\sum_{i=1}^n{|x_i - y_i|}^p {% endkatex %}
To satisfy the Minkowski distance, adding {% katex inline %} \frac{1}{p} {% endkatex %} (which, again, represents the order of the norm) completes the equation:
{% katex %} D(X,Y) = \bigg(\displaystyle\sum_{i=1}^n {|x_i - y_i|}^p\bigg)^{\frac{1}{p}} {% endkatex %}
Minkowski distance can also be derived as:
{% katex %} { D(X,Y) = \sqrt[p]{|x_{1}-y_{1}|^p + |x_{2}-y_{2}|^p + ... + |x_{n}-y_{n}|^p} } , {% endkatex %}
{% katex %} D(i,j) = \sqrt[p]{|x_{i1}-x_{j1}|^p + |x_{i2}-x_{j2}|^p + ... + |x_{in}-x_{jn}|^p} {% endkatex %}
## Orders of the norm
<figure>
<img src="https://dev-to-uploads.s3.amazonaws.com/uploads/articles/0us1d5q4gs5y2g65gv1o.png" alt="Unit circles with various values of p" style="width:100%">
<figcaption align="center"><p>Unit circles with various values of p</p></figcaption>
</figure>
<br />
The order of the norm (denoted by the parameter {% katex inline %} p{% endkatex %}) varies the distance norm of the points.
The case where {% katex inline %} p=1 {% endkatex %} is equivalent to the **Manhattan distance**—named after the rectilinear street layout of Manhattan since it measures the distance between two points in a city if we can only travel along orthogonal city blocks.
Manhattan distance can be calculated using:
{% katex %} { D(X,Y) = \bigg(\displaystyle\sum_{i=1}^n {|x_i - y_i|}\bigg) } , {% endkatex %}
{% katex %} D(i,j) = {|x_{i1}-x_{j1}| + |x_{i2}-x_{j2}| + ... + |x_{in}-x_{jn}|} {% endkatex %}
The case where {% katex inline %} p=2 {% endkatex %} is equivalent to the **Euclidean distance** (or the Pythagorean distance, since it can be calculated from the Cartesian coordinates of the points using the Pythagorean theorem).
Euclidean distance can be calculated using:
{% katex %} { D(X,Y) = \bigg(\displaystyle\sum_{i=1}^n {|x_i - y_i|}^2\bigg)^{\frac{1}{2}} } , {% endkatex %}
{% katex %} D(i,j) = \sqrt{|x_{i1}-x_{j1}|^2 + |x_{i2}-x_{j2}|^2 + ... + |x_{in}-x_{jn}|^2} {% endkatex %}
Therefore, Minkowski distance can also be considered as a generalization of both the Euclidean distance and the Manhattan distance.
The parameter {% katex inline %} p {% endkatex %} can extend to more than the value of {% katex inline %} 2 {% endkatex %} to {% katex inline %} \infty {% endkatex %} that is equal to the [Chebyshev distance](https://en.wikipedia.org/wiki/Chebyshev_distance). Having {% katex inline %} p<1 {% endkatex %} violates the [triangle inequality](https://en.wikipedia.org/wiki/Triangle_inequality)—an advanced topic that is out of the scope of this article.
## Applications of Minkowski distance
Minkowski distance is widely used in machine learning (classification, clustering, and feature extraction) and special relativity ([Minkowski space](https://en.wikipedia.org/wiki/Minkowski_space)) problems.
One example is in Chess programming. The Minkowski distance at {% katex inline %} p=1 {% endkatex %} can be used in the static evaluation of the late endgame, where for instance races of the two king to certain squares is often an issue—or in so called Mop-up evaluation, which considers the Manhattan-Distance between winning and losing king.<sup>[[1]](https://www.chessprogramming.org/Manhattan-Distance)</sup>
{% katex inline %} p=2 {% endkatex %} has its best usage in calculating the length of a line segment between the two points. It is widely used in geocoding/reverse geocoding applications, such as finding the distance between the geocoded point and the true address location is computed to evaluate the positional accuracy of a geocoding procedure.<sup>[[2]](https://www.sciencedirect.com/science/article/pii/B9780124095489095932)</sup>
<sup>[1]</sup> https://www.chessprogramming.org/Manhattan-Distance
<sup>[2]</sup> https://www.sciencedirect.com/science/article/pii/B9780124095489095932
| ralphgutz |
1,337,533 | 131. Leetcode Solution in Javascript | /** * @param {string} s * @return {string[][]} */ var partition = function(s) { var result =... | 0 | 2023-01-22T10:44:47 | https://dev.to/chiki1601/131-leetcode-solution-in-javascript-4d7p | javascript, chiki1601, misspoojaanilkumarpatel | ```javascript
/**
* @param {string} s
* @return {string[][]}
*/
var partition = function(s) {
var result = [];
var results = [];
if (!s) return results;
helper(s, 0, result, results);
return results;
};
var helper = function(s, start, result, results) {
if (start >= s.length) {
results.push(result.slice());
result = [];
}
for (var i = start; i < s.length; i++) {
var newStr = s.substring(start, i + 1);
if (isPalindrome(newStr)) {
result.push(newStr);
helper(s, i + 1, result, results);
result.pop();
}
}
};
var isPalindrome = function(s) {
if (!s || s.length === 1) return true;
var length = s.length;
for (var i = 0; i < length; i++) {
if (s[i] !== s[length - i - 1]) return false;
}
return true;
};
```
#leetcode
#challenge
Here is the link for the problem:
https://leetcode.com/problems/palindrome-partitioning | chiki1601 |
1,337,615 | How to install Spring Tool Suite | Installing the Spring Tool Suite (STS) is easy. This article shows how to do this in three sequential... | 21,533 | 2023-01-22T15:31:43 | https://dev.to/eugenioca/how-to-install-spring-cloud-suite-49k8 | java, spring, springboot, springcloudsuite | Installing the Spring Tool Suite (STS) is easy. This article shows how to do this in three sequential steps. The example is based on Windows OS, but similar procedures work for other operating systems.
## Step 1 - Download the installer
To download the installer, go to [spring.io/tools](https://spring.io/tools) and select the installer that you need. In our case, we will select the Windows option.
## Step 2 - Extract the files
Once you have downloaded the jar file, move it to the directory were you want to install the STS and extract the files by opening the jar file
or extract them using an application such as WinRar.
## Step 3 - Open the application
Go to the extracted directory and run the application.
If everything went right, this screen will welcome you:
| eugenioca |
1,337,649 | Become a Full-stack | Become a Full-stack dev for FREE 👇👇 HTML ➡️ learn-html.org CSS ➡️ web.dev/learn/css JavaScript ➡️... | 0 | 2023-01-22T14:49:37 | https://dev.to/naoufel/become-a-full-stack-507e | webdev, programming, beginners, career | Become a Full-stack dev for FREE 👇👇
HTML ➡️ learn-html.org
CSS ➡️ web.dev/learn/css
JavaScript ➡️ javascript.info
Git ➡️ atlassian.com/git
React ➡️ beta.reactjs.org
Node ➡️ nodejs.dev/en/learn
Postgres ➡️ postgresqltutorial.com
API ➡️ rapidapi.com/learn | naoufel |
1,338,098 | Quick way to combine io.Reader and io.Closer | There are many interesting tools in Golang's standard library to wrap io.Reader instance such as... | 0 | 2023-01-23T11:15:09 | https://blog.bswiecki.dev/post/2023-01-22-combining-reader-closer/ | go, todayilearned, code | ---
title: Quick way to combine io.Reader and io.Closer
published: true
date: 2023-01-22 00:00:00 UTC
tags: ["go", "til", "code"]
canonical_url: https://blog.bswiecki.dev/post/2023-01-22-combining-reader-closer/
---
There are many interesting tools in Golang's standard library to wrap [`io.Reader`][io.Reader] instance such as [`io.LimitedReader`][io.LimitedReader] or [`cipher.StreamReader`][cipher.StreamReader]. But when wrapping a [`io.ReadCloser`][io.ReadCloser] instance, the `Close` method is hidden.
Here's a quick code snippet to combine wrapped [`io.Reader`][io.Reader] and the original [`io.Closer`][io.Closer] through an inline `struct` to rebuild the [`io.Closer`][io.Closer] interface.
## Code
```go
var rc io.ReadCloser = struct {
io.Reader
io.Closer
}{
Reader: r,
Closer: c,
}
```
## What it is about?
The [`io.Reader`][io.Reader] interface in Golang is a very powerful abstraction when streaming data. It can be used to read files, http responses, even raw byte arrays using a generic code:
```go
func sumAllBytes(r io.Reader) (uint64, error) {
var buff [512]byte
var sum uint64
for {
n, err := r.Read(buff[:])
for i := 0; i < n; i++ {
sum += uint64(buff[i])
}
if errors.Is(err, io.EOF) {
return sum, nil
}
if err != nil {
return sum, err
}
}
}
```
That method can be used to process files, http responses, even memory buffers:
```go
func main() {
// Process a buffer
buff := bytes.NewReader([]byte{0x01, 0x02, 0x03, 0x04})
sum, err := sumAllBytes(buff)
if err != nil {
log.Fatal(err)
}
log.Println("Sum from buffer:", sum)
// Process a http response
resp, err := http.Get("https://www.google.com")
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
sum, err = sumAllBytes(resp.Body)
if err != nil {
log.Fatal(err)
}
log.Println("Sum from http:", sum)
// Process a file
fl, err := os.Open("/some/file/path")
if err != nil {
log.Fatal(err)
}
defer fl.Close()
sum, err = sumAllBytes(fl)
if err != nil {
log.Fatal(err)
}
log.Println("Sum from file:", sum)
}
```
## Cleaning up
In many cases (like the http and file instances above), the reader has to be explicitly closed to avoid resource leaks. For that reason, many resources are using the [`io.ReadCloser`][io.ReadCloser] interface and cleaning up can easily be achieved with a `defer rc.Close()` statement. But there are some cases where the close method is not called at the same function but somewhere at the caller site. At that construct, the caller is responsible for cleanup:
```go
func getDataStream(name string) (io.ReadCloser, error) {
switch name {
case "file":
return os.Open("/some/file")
case "http":
resp, err := http.Get("https://www.google.com/")
if err != nil {
return nil, err
}
return resp.Body, nil
case "buffer":
return io.NopCloser(
bytes.NewReader([]byte{0x01, 0x02, 0x03, 0x04}),
), nil
default:
return nil, errors.New("Invalid data stream name")
}
}
func printSum(streamName string) {
stream, err := getDataStream(streamName)
if err != nil {
log.Fatal(err)
}
defer stream.Close()
sum, err := sumAllBytes(stream)
if err != nil {
log.Fatal(err)
}
log.Printf("Sum of bytes in stream '%s' is '%d\n", streamName, sum)
}
```
So far so good, nothing to worry about. But let's extend this example with some stream wrapping:
```go
func getDataStream(name string) (io.ReadCloser, error) {
switch name {
case name == "file":
return os.Open("/some/file")
case name == "http":
resp, err := http.Get("https://www.google.com/")
if err != nil {
return nil, err
}
return resp.Body, nil
case name == "buffer":
return io.NopCloser(
bytes.NewReader([]byte{0x01, 0x02, 0x03, 0x04}),
), nil
// v--- Create a truncated stream by applying limit over the base one ---v
case strings.HasPrefix(name, "limit:"):
r, err := getDataStream(name[6:])
if err != nil {
return nil, err
}
return io.LimitReader(r, 3)
default:
return nil, errors.New("Invalid data stream name")
}
}
```
Unfortunately this code does not compile and ends up with this error:
```plain
cannot use io.LimitReader(r, 100) (value of type io.Reader) as type io.ReadCloser in return statement:
io.Reader does not implement io.ReadCloser (missing Close method)
```
Wrapping the [`io.ReadCloser`][io.ReadCloser] with [`io.LimitedReader`][io.LimitedReader] does hide the [`io.Closer`][io.Closer] functionality of the original instance. And it turns out that there are many places in golang standard lib where such wrapping takes place.
## Inline struct to the rescue
There's an easy trick to bring back the `Close` method from the original reader back to the wrapped one:
```go
func getDataStream(name string) (io.ReadCloser, error) {
switch name {
case name == "file":
return os.Open("/some/file")
case name == "http":
resp, err := http.Get("https://www.google.com/")
if err != nil {
return nil, err
}
return resp.Body, nil
case name == "buffer":
return io.NopCloser(
bytes.NewReader([]byte{0x01, 0x02, 0x03, 0x04}),
), nil
// v--- Create a truncated stream by applying limit over the base one ---v
case strings.HasPrefix(name, "limit:"):
r, err := getDataStream(name[6:])
if err != nil {
return nil, err
}
limitReader := io.LimitReader(r, 3)
return struct {
io.Reader
io.Closer
}{
Reader: limitReader, // Read method will come from the wrapped reader
Closer: r, // Close method will come from the original reader
}, nil
default:
return nil, errors.New("Invalid data stream name")
}
}
```
## How does it work?
The inline `struct` contains two [embedded fields][embedded_fields], one for the reader and the other for the closer.
Since those fields are anonymous, the struct itself *inherits* methods from those fields as if those were declared on the struct. By doing so, whenever the compiler tries to cast the struct to some interface, it can *promote* those methods to fulfil the requirements of the interface.
In the code above we return an instance of [`io.ReadCloser`][io.ReadCloser] interface that requires both `Read` and `Close` methods - and those are *borrowed* from embedded fields respectively.
Interestingly, if we would use whole [`io.ReadCloser`][io.ReadCloser] as the second embedded field instead of [`io.Reader`][io.Reader], the compiler (go 1.19 as of writing) throws an error which is caused by ambiguity between promoted field members (the `Read` method is not promoted due to ambiguity):
```plain
cannot use struct{io.Reader; io.ReadCloser}{…} (value of type struct{io.Reader; io.ReadCloser}) as type io.ReadCloser in return statement:
struct{io.Reader; io.ReadCloser} does not implement io.ReadCloser (missing Read method)
```
[io.Reader]: https://pkg.go.dev/io#Reader
[io.Closer]: https://pkg.go.dev/io#Closer
[io.ReadCloser]: https://pkg.go.dev/io#ReadCloser
[io.LimitedReader]: https://pkg.go.dev/io#LimitedReader
[cipher.StreamReader]: https://pkg.go.dev/crypto/cipher#StreamReader
[embedded_fields]: https://go.dev/ref/spec#EmbeddedField
| byo |
1,338,835 | Different ways to implement LRU (Least Recently Used) Cache | Different ways to implement LRU (Least Recently Used) Cache | 0 | 2023-01-23T18:05:24 | https://dev.to/rahulraj/different-ways-to-implement-lru-least-recently-used-cache-9o6 | [Different ways to implement LRU (Least Recently Used) Cache](https://rahulraj.io/different-ways-to-implement-lru-least-recently-used-cache) | rahulraj | |
1,338,951 | Episode 23/03: Service Patterns, tRPC in Angular, and much more... | Manfred Steyer took a deep dive into Angular Services. A bunch of excellent articles from Enea... | 0 | 2023-01-23T21:05:27 | https://dev.to/ng_news/episode-2303-service-patterns-trpc-in-angular-and-much-more-4b8g | angular, webdev, javascript, programming | Manfred Steyer took a deep dive into Angular Services.
A bunch of excellent articles from Enea Jahollari (pure pipes), Thomas Laforge (functional router guards), and Robin Götz (structural directives series) were released.
And Kevin Kreuzer shows tRPC for Angular.
{% embed https://youtu.be/lWqFFv_vnTE %}
## Patterns for Custom Standalone APIs in Angular
Manfred Steyer, known for his work on Micro Frontends, wrote a deep-dive article about providing services and design patterns. The focus lies on library developers.
He showcases how to make sure developers can only provide services on the root scope. Also, how services provided in lazy-loaded scopes can interact with their root-scoped services or even delegate to them.
Although application developers will need them rarely, it is still good to know what is possible.
{% embed https://www.angulararchitects.io/aktuelles/patterns-for-custom-standalone-apis-in-angular/ %}
## Advanced Articles
### Async pipe is not pure
Enea Jahollair explained the inner workings of the async pipe by implementing a prototype.
{% embed https://dev.to/this-is-angular/async-pipe-is-not-pure-5h6p %}
### Everything you need to know about route Guard in Angular
Thomas Laforge wrote about the different router guards and that you should start to move to the functional types because the services will be deprecated in 15.2.
{% embed https://dev.to/this-is-angular/everything-you-need-to-know-about-route-guard-in-angular-2hkn %}
### Mastering Angular Structural Directives - It’s all about the context
Robin Götz published his second article in his series about structural directives.
{% embed https://dev.to/this-is-angular/mastering-angular-structural-directives-its-all-about-the-context-5hai %}
## Kevin Kreuzer: tRPC & Angular
If your stack runs entirely on TypeScript, you should definitely take a look into tRPC. It gives you type safety for your backend calls. Very similar to OpenAPI or GraphQL but without a code generator.
Kevin Kreutzer showed on Twitch how to integrate tRPC in Angular. A summarized version is available on YouTube.
{% embed https://youtu.be/gp1db5xKqck %}
## Miscellaneous
The Angular Developer Survey is open. So please provide feedback.
{% embed https://google.qualtrics.com/jfe/form/SV_czN8BZO9GHXnJJ4 %}
The CfP for the Angular Tiny is also open. That's a free, remote conference lasting one day. You can apply until the 5th of February.
{% embed https://twitter.com/adyngom/status/1617145182993924096 %}
## New Releases
Ionic had a minor version upgrade to 6.5.
[Release Notes](https://github.com/ionic-team/ionic-framework/releases/tag/v6.5.0)
---
Spectator, a testing library, had a major upgrade to 14.
[Release Notes](https://github.com/ngneat/spectator/blob/master/CHANGELOG.md)
| ng_news |
1,339,085 | Imperative vs Declarative Programming in DevOps | Some teams might adopt several tools to automate DevOps with Infrastructure as Code, depending on the... | 0 | 2023-04-13T22:18:22 | https://dev.to/ctoai/imperative-vs-declarative-programming-in-devops-2jo6 | productivity, automation, tooling, devops | Some teams might adopt several tools to automate DevOps with Infrastructure as Code, depending on the team's maturity level, which implies knowledge about declarative and imperative programming. These approaches are easy to find in many IaC tools.
Still, for an efficient implementation of an IaC in your project, see the difference between these approaches:
- Imperative: The code written is very explicit in every single line, which will help the computer understand **how** the algorithm should be executed. The developer will put on the "machine's hat" and think like a machine to understand how the computer operates so it can understand the given instructions. It's a more detailed programming style, which requires deep knowledge of code skills.
- Declarative: For the declarative approach, there's more abstraction when writing the IaC to tell **what** you want to be executed. It is more focused on the outcome without explicitly defining every step or condition the code will perform in the machine.
As an example of an imperative code, this one below creates explicitly the function that will track the events that will be sent to CTO.ai's Platform in order to measure the deployment metrics with DORA:
```
export async function track(
tags: string[] | string,
metadata: object,
): Promise<void> {
try {
await request.track({
tags: Array.isArray(tags) ? tags : [tags],
...metadata,
})
} catch (e) {
throw new CTOAI_Error(100, 'sdk.track')
}
}
```
And for the Declarative code type, we can demonstrate it by importing the SDK to declare the event that will be traced.
```
sdk.track([], {
event_name: 'deployment',
event_action: 'failed',
environment: STACK_ENV,
repo: STACK_REPO,
branch: STACK_TAG,
commit: STACK_TAG,
image: `${STACK_REPO}:${STACK_TAG}`
})
```
Both approaches may be used when defining the Infrastructure as Code to automate Workflow processes for software deliveries. However, declarative programming is the most common approach used in DevOps tools, such as Terraform and CloudFormation from AWS, because it's more efficient for replicating the code throughout the CI/CD definition.
With the CTO.ai Developer Control Plane, the way of defining infrastructure is mostly in the declarative approach, although the usage of imperative programming can be applicable in some cases, depending on how are the developer workflows of an organization.
You can see the [source code of the SDKs provided by CTO.ai](https://github.com/cto-ai/sdk-js) mentioned in this article, which allow teams to write customizable workflows and enable dev teams to interact with deployment and builds from Slack or GitHub.
Therefore, you can see some templates of workflows, which [you can see in this GitHub repository](https://github.com/workflows-sh/aws-ecs-fargate), in order to measure your deployment performance with DORA metrics by sending deployment data to the Platform.
I hope this helped you understand Imperative and Declarative concepts and their applicability in DevOps within IaC for Workflows definition.
See you soon! | biagotaski |
1,339,180 | Final Project walkthrough P.1 | At the end of the bootcamp we are to create an app as our capstone project. With the ability to pick... | 0 | 2023-01-24T19:58:25 | https://dev.to/truetallman/final-project-walkthrough-p1-3lme | react, ruby, javascript | At the end of the bootcamp we are to create an app as our capstone project. With the ability to pick whatever topic you want to work on, it gives the students a chance to really explore coding with a something they have a connection to. This has a similar feel to our previous group project but this time working solo. However no matter how much time you are given it will never feel like enough.
Armed with the knowledge of a ruby backend and react as the face, it is a challenge nonetheless. Working with visible milestones helped pace out the completion of the project. This blog will talk about the set up of the backend of ruby and the implementation of a log-in function.
The backend was fairly simple as the vision for this application is a blog with the flair of Instagram/Pinterest. The app is to be centered around interior design and decor and allowing users to post and share photos they found on the internet or of their own design/curation. The unique feature is to be that users are encourage to highlight pieces in the photo so that others who are curious can identify and look for the piece if they want to it.
So the app will have Users, Posts, Likes, Comments, and Descriptions on the back end. Utilizing a template to set up the app made it fairly simple. While an error did occur early on with no resolution requiring a hard restart, it did lead to a learning that while copy and pasting of code is not bad, it can easily lead to a domino effect of issues down the line.
Another learning was understanding how your tables talk to each other. How does an user interact with a post via their likes or their comments. how does it look in the back end. what belongs to what or what only has one of? understanding this concept will lead to a strong foundation that will not need to be modified, leading to potential issues.
After triple or quadruple checking your tables, you can then finally run the following commands:
`rails db:create
rails db:migrate
rails db:seed`
Seeing no errors means that you have a working database and now is onto connecting the tables together and giving them functionality. This will be for the next part of the final project walkthrough. | truetallman |
1,339,393 | How to submit your iOS application on App Store | Prerequisites You should have at least one .ipa file, which is a generated build for iOS... | 21,577 | 2023-01-25T09:35:23 | https://dev.to/alexcoding42/how-to-submit-your-mobile-application-on-app-store-408i | appstore, mobile, application, submission | ## Prerequisites
You should have at least one *.ipa file*, which is a generated build for iOS ready for production.
You can take a look at [this article](https://dev.to/alexcoding42/how-to-create-production-builds-for-app-store-and-play-store-with-easexpo-and-react-native-491d) if you want to learn how to generate a production ready build with React Native and EAS/Expo
Besides you should have an [Apple Developer Account](
Apple Developerhttps://developer.apple.com)
## Create an app
When you are connected to your developer account, you can click on My Apps from the dashboard

Then create a new app by clicking on the + icon
Choose `New app`
Configure your new app like this
**Bundle ID** should be the one you use in Xcode, you can create a new one or choose an existing one
**SKU** is a unique ID for your app, I recommend using the same as the bundle ID
**User Access** by default should be `Full Access` to make your app available to everyone. But if it is an admin app for example you can choose `Limited Access`
## Fill in the details
The most important section appears first where you have to upload screenshots. You should fill in all the required fields.
For the **Support URL** I recommend using the one from a privacy policies generator where your privacy policies are stored, or the url of your website
For **Marketing URL** you can put the name of your website/portfolio
### Build section
Under the **Build** section should appear the binary that you uploaded from Xcode or another tool. For example in React Native with EAS you just have to configure the `eas.json` file like this
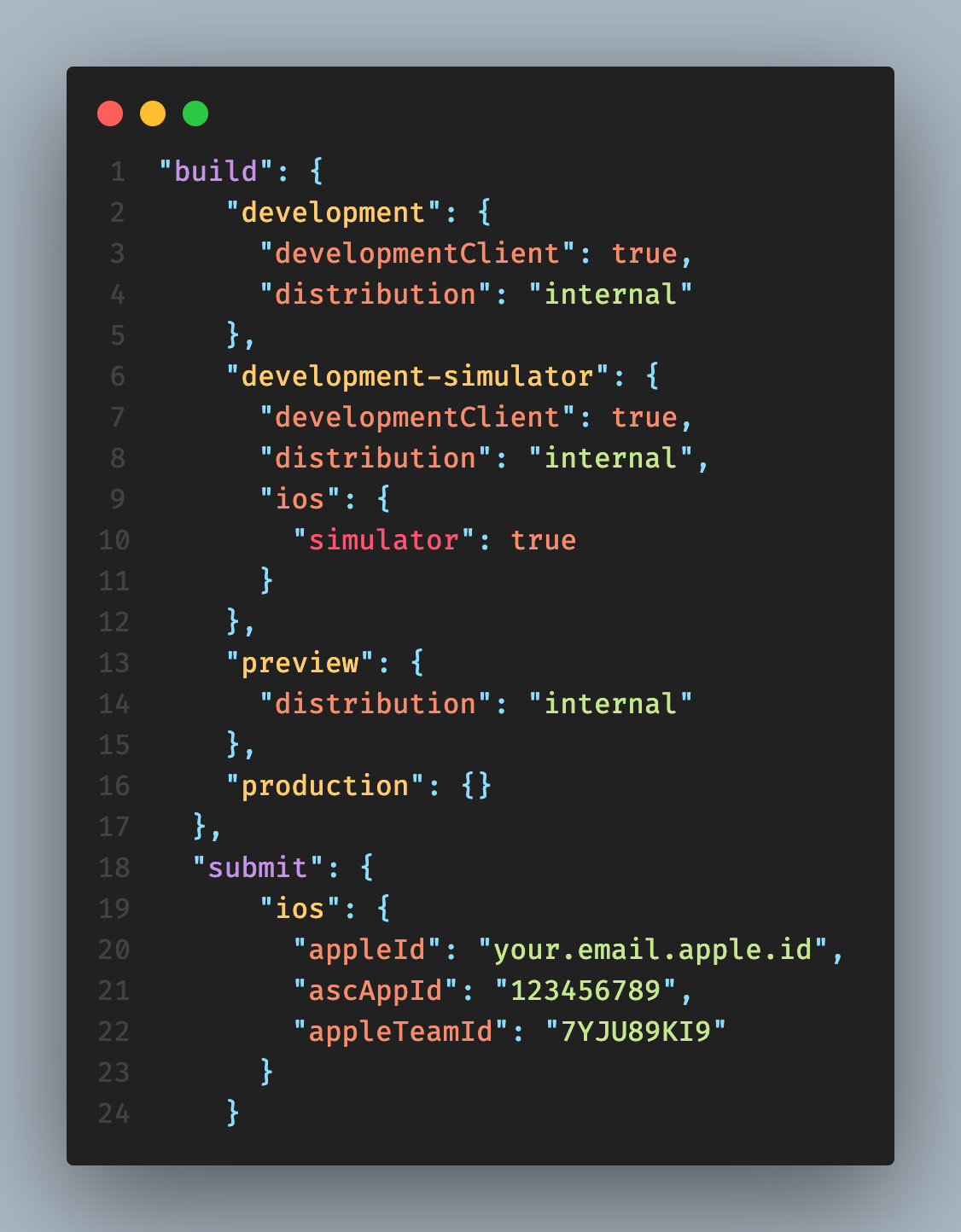
You can find the **ascAppId** from the App Store connect dashboard under App Information section
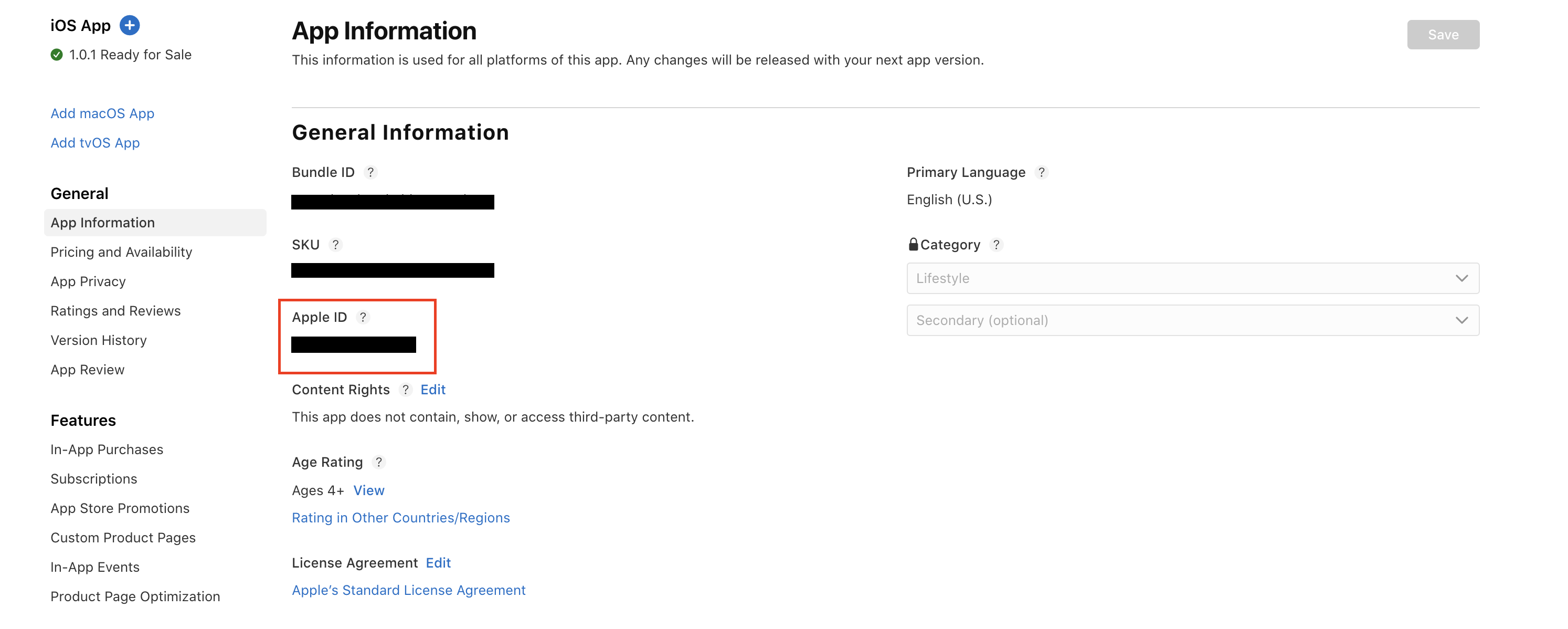
The **appleTeamId** can be found in your App Store settings profile
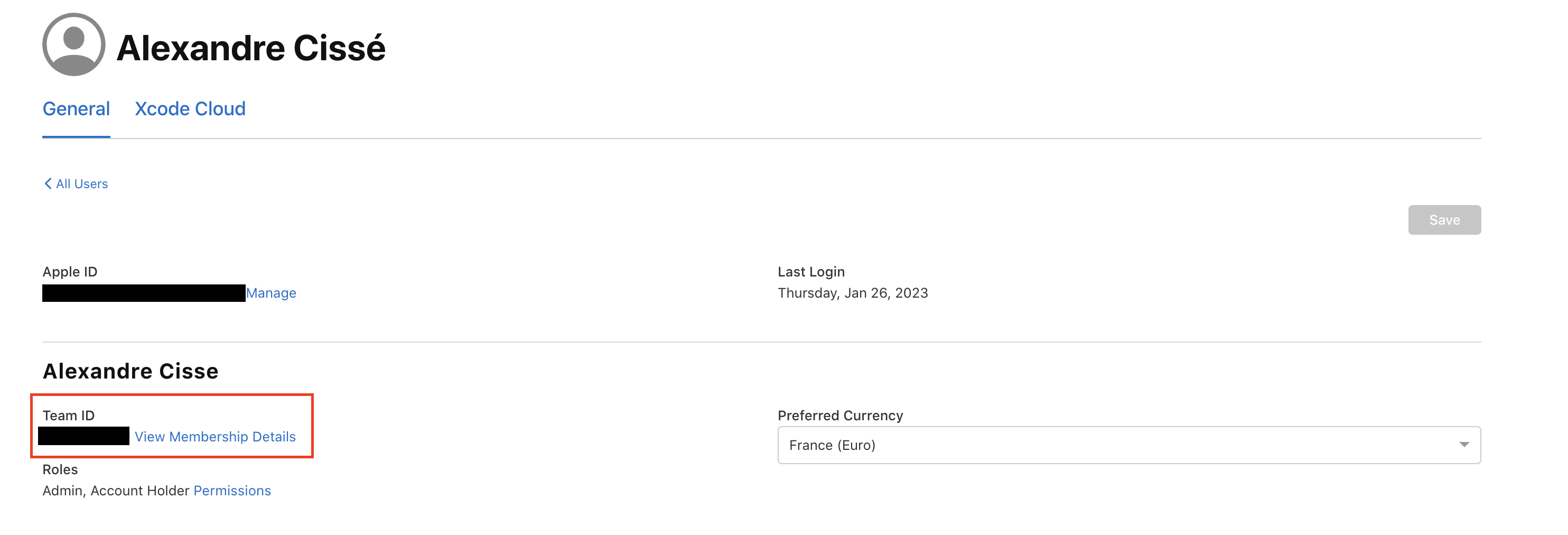
Then, to upload your iOS app to the Apple App Store, run `eas submit --platform ios` from a terminal
### App Review Information
The **App Review Information** must be checked and filled **only if** your app contains any authentication. You should provide an account that an Apple support member can use to authenticate through your app, and describe the steps in *Notes*. You can also provide a video in *Attachment*
## App Information
You must fill in the details according to your needs in this section
## Pricing and Availability
You must fill in the details according to your needs in this section
## App Privacy
A very important section. You should fill in the details of your privacy policies according to your app features. This is important to tell the truth as your app will be review by a member of Apple team, and rejection of your app can delay your production deployment.
I recommend strongly to use this [privacy policies generator](https://app.privacypolicies.com/) to ease the process, and you can get a free URL storing your privacy policies
## Submit your app for review
Other sections are not mandatory you can fill in if you want.
When everything is filled you can go back to the dashboard or your app and click on `Add for Review`

## Ready for sale
When your app is available on App Store, the status should change to `Ready for Sale` from your app dashboard. Please note that the review process can take few days according to the complexity of your app and the detailed information that you have filled. It is important to give clear and accurate information to speed the process.
| alexcoding42 |
1,339,500 | Flutter(IOS) app concern in the External Link Account API | 0 I've submitted my app for review on App Store. It got rejected and they replied me with this... | 0 | 2023-01-24T12:06:34 | https://dev.to/ayubkidvento/flutterios-app-concern-in-the-external-link-account-api-n6k | flutter, ios, xcode | 0
I've submitted my app for review on App Store. It got rejected and they replied me with this explanation.
Your "reader" app uses the External Link Account entitlement to link out for account creation and management but does not meet all requirements for using this entitlement.
Specifically, we found that your app does not meet the following requirement(s):
Your app does not use the External Link Account API to populate the modal sheet before every instance of linking out for account creation and management.
These requirements help protect user privacy and security, prevent scams and fraudulent activity, and maintain the overall quality of the experience when leaving the app to create or manage accounts.
Next Steps
It would be appropriate to revise your app to address the issues identified above. Make sure it meets all other requirements for apps using the External Link Account entitlement before resubmitting for review.
Resources
Learn more about the StoreKit External Link Account entitlement on Apple Developer.
Learn more about requirements for "reader" apps in App Store Review Guideline 3.1.3(a).
Requesting help in understanding and resolving this.
I tried every solution and configuration which they have recommended, I resubmitted the app and again got rejected.
On their official website there are two methods: canOpen(popup model for confirmation that you're about leave the app) and open(to open the link in the browser). What they are saying that if your app is redirecting to some link, it should open a confirmation popup model and then on confirmation, it should move forward.
But I didn't understand where these methods are defined or where can I get any sample or demo app. | ayubkidvento |
1,339,633 | Compreendendo o papel do mecanismo de renderização em navegadores | O navegador é fundamental no funcional de qualquer site. Desde como a aplicação renderiza até como... | 0 | 2023-01-24T13:29:17 | https://dev.to/trinitypath/compreendendo-o-papel-do-mecanismo-de-renderizacao-em-navegadores-3j24 | webdev, braziliandevs, web | O navegador é fundamental no funcional de qualquer site. Desde como a aplicação renderiza até como ele funciona, tudo depende do navegador e seu funcionando. Para oferecer uma experiência de usuário perfeita com testes de compatibilidade entre navegadores, é essencial entender a função dos mecanismos de renderização nos navegadores.
Também é importante que os desenvolvedores front-end entendam como os navegadores funcionam, porque isso os ajuda a criar aplicações e sites web que funcionam de maneira consistente em vários navegadores e plataformas.
O que abordaremos nesse artigo:
- Compreendendo a arquitetura dos navegadores da Web
- Componentes do navegador da Web
- Interface de usuário
- Motor do navegador
- Rede
- Intérprete JavaScript
- Back-end UI
- Armazenamento/Persistência de dados
- Função do mecanismo de renderização
## Compreendendo a arquitetura dos navegadores da Web
Os navegadores são construídos de Front-end e Back-end. Enquanto o Front-end garante como as páginas Web apareçam no navegador, o Back-end trata das solicitações e é o portador da informação. Seus diferentes componentes funcionam em coordenação para oferecer uma experiência Web perfeita.
## Componentes do navegador Web
Os navegadores Web consistem em 7 componentes diferentes listados abaixo:
### Interface de usuário
Esse componente permite que os usuários finais interajam com todos os elementos visuais disponíveis na página web. Os elementos visuais incluem a barra de endereço, o botão home, o botão próximo, etc, e todos os outros elementos que buscam e exibem a página Web solicitada pelo usuário final.
### Motor do navegador
É um componente central de todos os navegadores web. O mecanismo do navegador funciona como um intermediário ou uma ponte entre a interface do usuário e o mecanismo de renderização. Ele consulta e manipula o mecanismo de renderização de acordo com as entradas recebidas da interface de usuário.
### Motor de Renderização
Como o nome sugere, este componente é responsável por renderizar uma página web específica solicitada pelo usuário em sua tela. Ele interpreta documentos HTML e XML junto com imagens que são estilizadas ou formatadas usando CSS, e um layout final é gerado, que é exibido na interface do usuário.
usando CSS, e um layout final é gerado, que é exibido na interface do usuário.
Nota: Cada navegador tem seu próprio mecanismo de renderização exclusivo. Os mecanismos de renderização também podem diferir para diferentes versões de navegador. A lista abaixo menciona os mecanismos de navegador usados por alguns navegadores comuns:
1. Google Chrome e Opera v.15+: **Blink**
2. Internet Explorer: **Trident**
3. Mozilla Firefox: **Gecko**
4. Chrome para iOS e Safari: **WebKit**
### Rede
Esse componente é responsável por gerenciar chamadas de rede usando protocolos padrão como HTTP ou FTP. Ele também cuida de questões de segurança associadas à comunicação na Internet.
### Intérprete JavaScript
Como o nome sugere, é responsável por analisar e executar o código JavaScript incorporado em um site. Depois que os resultados interpretados são gerados, eles são encaminhados ao mecanismo de renderização para exibição na interface do usuário.
### Back-end UI
Esse componente usa os métodos de interface do usuário do sistema operacional subjacente. É usado principalmente para desenhar widgets básicos (janelas e caixas de combinação).
### Armazenamento/Persistência de Dados
É uma camada persistente. Um navegador web precisa armazenar vários tipos de dados localmente, por exemplo, cookies. Como resultado, os navegadores devem ser compatíveis com mecanismos de armazenamento de dados como WebSQL, IndexedDB, FileSystem, etc.
Agora que estamos cientes dos principais componentes envolvidos na construção de um navegador Web, vamos nos aprofundar no papel do mecanismo de renderização.
## Função do mecanismo de renderização
Depois que um usuário solicita um determinado documento, o mecanismo de renderização começa a buscar o conteúdo do documento solicitado. Isso é feito através da camada de rede. O mecanismo de renderização começa a receber o conteúdo desse documento específico em blocos de 8 KB da camada de rede. Depois disso, o fluxo básico do mecanismo de renderização começa.

As quatro etapas básicas incluem:
1. A página HTML solicitada é analisada em blocos, incluindo os arquivos CSS externos e elementos de estilo, pelo mecanismo de renderização. Os elementos HTML são então convertidos em nós DOM para formar uma **“árvore de conteúdo”** ou **“árvore DOM”**.
2. Simultaneamente, o navegador também cria uma **árvore de renderização**. Essa árvore inclui tanto as informações de estilo quanto as instruções visuais que definem a ordem em que os elementos serão exibidos. A árvore de renderização garante que o conteúdo seja exibido na ordem desejada.
3. Além disso, a árvore de renderização passa pelo **processo de layout**. Quando uma árvore de renderização é criada, os valores de posição ou tamanho não são atribuídos. Todo o processo de cálculo de valores para avaliar a posição desejada é chamado de **processo de layout**. Neste processo, cada nó recebe as coordenadas exatas. Isso garante que cada nó apareça em uma posição precisa na tela.
4. A etapa final é pintar a tela, onde a árvore de renderização é percorrida e o método `paint()` do renderizador é invocado, que pinta cada nó na tela usando a camada de back-end UI.
Conforme discutido anteriormente, cada navegador tem seu próprio mecanismo de renderização exclusivo. Então, naturalmente, cada navegador tem sua própria maneira de interpretar as páginas Web na tela do usuário. É aqui que surge um desafio para os desenvolvedores Web em relação à compatibilidade entre navegadores de seu site.
É aqui que o teste entre navegadores entra em cena.
O teste entre navegadores é um método de garantia de qualidade usado para verificar a consistência de aplicações Web em termos de funcionalidade e design em vários navegadores. Esses testes permitem que as equipes de controle de qualidade explorem quaisquer problemas realizando um teste responsivo, que pode ocorrer quando o site é acessado por meio de diferentes navegadores ou versões de navegadores.
Ao entender como um mecanismo de renderização funciona, os desenvolvedores Web podem obter uma visão mais ampla sobre como os sites funcionam. Consequentemente, eles podem desenvolver, projetar e fazer deploy do conteúdo com mais eficiência. Se alguém compreender as nuances de como o conteúdo da Web é exibido na tela de um usuário por vários navegadores, estará simplesmente mais equipado para criar conteúdo compatível com vários navegadores.
Espero que tenha gostado do artigo, obrigado por ler! | trinitypath |
1,340,465 | Optimizing Angular Unit Tests for Faster Execution ⏳⏰ | In this Medium article, I share my experience and tips on how to optimize Angular unit tests for... | 0 | 2023-01-25T05:41:22 | https://dev.to/rebaiahmed/optimizing-angular-unit-tests-for-faster-execution-1pg7 | angular, jasmine, testing, karma | In this Medium article, I share my experience and tips on how to optimize Angular unit tests for faster execution. I present different strategies for optimizing unit tests, such as reducing the number of dependencies, mocking services and using the TestBed utility.
This article is a must-read for developers working with Angular and looking to improve the performance of their unit tests.
Medium link: https://levelup.gitconnected.com/optimizing-angular-unit-tests-for-faster-execution-70c7adda6b21
| rebaiahmed |
1,340,634 | State management thoughts... | Every now and then when I'm thinking about managing state in react applications I end up, asking... | 0 | 2023-01-25T09:57:31 | https://dev.to/metafoo/state-management-thoughts-kbf | react, discuss | Every now and then when I'm thinking about managing state in react applications I end up, asking myself the same questions over and over again:
- Is there missing something or am I just using it wrong?
- How do I reuse reducer-logic?
- Is there a way to apply a reducer on the fly to new objects?
- How do I manage relationships (1:n) between objects without putting all of them into the same bucket/reducer ending up with crazy, unreadable update logic?
- How to deal with objects, associated with more than one object (n:m)?
To be more precise let's assume the following data-model:
> task-lists → tasks → comments → quick-reactions
> threads → comments → quick-reactions
> activities → (task-list|task|thread|comment)
A naive approach would end up having three deeply nested objects with a different reducer managing updates each.
The reducers will operate on the data in an immutable way of course, so when I add a task the task-list can properly re-render. With a new comment, a task or thread is able to reflect the changes immediately an so on. So everything is fine here!
Drawbacks:
1. Update logic is ugly as hell: Just adding a quick-reaction to a comment would lead to apply updates all the way up to task-lists. **→ breaks readable/maintainable code (to me)**
2. Due to this "update-issue" it's difficult to extract and reuse reducer logic like the quick-reaction, or even the comments-logic at all. **→ breaks DRY**
3. Assuming to have a (totally decoupled) list of activities rendered besides the tasks: It's nearly impossible to for example a change on a task made here, being reflected in the "original" task-list (in a nice way without "hacking" it...). **→ breaks single-source-of-truth**
On the other hand: When thinking about having a reducer for every single entity each and somehow managing their relationships by hand this feels very much like reinventing the wheel and implementing a lightweight client-side RDBMS.
Always thinking of a way to somehow apply different reducers to several parts of an object. Combined with the option to just subscribe to specific parts. This would solve 1. + 2. at least...
How do you cope with these problems? Am I missing something? Do I over-complicate things?
✌🏻 | metafoo |
1,340,669 | What NOT to do as a developer | The following views were expressed by a member of our Codacy Community Before I came to the industry... | 0 | 2023-01-25T10:40:00 | https://dev.to/codacy/what-not-to-do-as-a-developer-1mp9 | programming, discuss, community, motivation | _The following views were expressed by a member of our [Codacy Community](https://community.codacy.com/)_
Before I came to the industry side of the world, I was an academic. I was focused on computer science research (with a special love for software quality) and on teaching students at the university.
From my years in academia, I was able to determine patterns in students when they were writing code. I saw the same patterns from junior to senior developers at different companies. Some of those patterns might be hindering your performance, so let’s take a look at what not to do as a developer:
-
**Jumping into programming right away.** Before writing your first lines of code, think about the problem and the proper solution. It might help brainstorm on a piece of paper!
-
**Not updating your knowledge.** Programming languages, frameworks, technologies, and techniques change every day. So you need to keep yourself updated and never stop learning.
-
**Forgetting edge cases.** Even if your code seems to be working and you added some tests, don’t forget to check for edge cases. It depends on the solution you are working on, but it might be negative numbers, empty strings, different input types, and everything else in between.
-
**Not checking performance and complexity.** Most of the time, there are better and simpler ways to go about a particular solution and piece of code. So always check the complexity of your code and if you can improve it. I discussed the Big-O notation in a previous post, so give it a read.
-
**Not reviewing your code.** Always review your code, both manually and automatically. With code reviews, your team can find issues early on, share knowledge, distribute ownership, and standardize development practices, among many other benefits. Plus, static code analysis tools like Codacy Quality can effectively reduce heavy lifting and tedious parts of the code review process.
Free to share other things developers should not do 👇 | heloisamoraes |
1,341,008 | What Is ChatGPT: How It Work And It's Limitations? | Introduction OpenAI unveiled ChatGPT, a long-form question-answering AI that successfully answers... | 0 | 2023-01-25T16:13:18 | https://dev.to/centdam/what-is-chatgpt-how-it-work-and-its-limitations-3g86 | chatgpt, ai | Introduction
OpenAI unveiled ChatGPT, a long-form question-answering AI that successfully answers difficult inquiries. It is a revolutionary piece of technology because it can be trained to comprehend what users mean when they ask questions.
Many users are astounded by its capacity for human-quality responses, which has led them to speculate that it may one day be able to transform how people interact with computers and how information is found. It comes with a ChatGPT conversational interaction model.
ChatGPT can answer follow-up questions, confess to errors, disprove unproven hypotheses, and decline inappropriate requests. InstructGPT, a sibling model of ChatGPT, which is trained to follow a prompt's instruction and provide a thorough response.
ChatGPT was developed by San Francisco-based artificial intelligence company OpenAI, a nonprofit organization. OpenAI is renowned for its well-known DALLE deep learning model, which creates images from text prompts. Sam Altman, who formerly served as the president of Y Combinator, is the CEO. Microsoft has invested $1 billion as a partner and investor. They worked together to create the Azure AI Platform.
What is ChatGPT?
ChatGPT is a chatbot launched by OpenAI in November 2022. It is built on top of OpenAI's GPT-3 family of large language models and is fine-tuned with both supervised and reinforcement learning techniques.
How does ChatGPT work?
ChatGPT has a remarkable ability to interact in conversational dialogue form and provide responses that can appear surprisingly human. It performs the task of predicting the next word in a series of words. Reinforcement Learning with Human Feedback (RLHF) is an additional layer of training that uses human feedback to help ChatGPT learn to follow directions and generate responses that are satisfactory to humans.
How was ChatGPT trained?
chatgpt diagram
In order to help ChatGPT learn dialogue and develop a human-like style of responding, GPT-3.5 was trained on enormous amounts of code-related data and information from the internet, including sources like Reddit discussions. In order for ChatGPT to understand what people expect when they ask a question, reinforcement learning with human feedback was also used during training. This new method of training the LLM goes beyond simply teaching it to predict the next word, making it revolutionary.
Training language models to follow instructions with human feedback
What are the limitations of ChatGPT?
An important limitation of ChatGPT is that the quality of the output depends on the quality of the input. In other words, expert directions (prompts) generate better answers.
ChatGPT is specifically programmed not to provide toxic or harmful responses. So it will avoid answering those kinds of questions.
Another limitation is that because it is trained to provide answers that feel right to humans, the answers can trick humans that the output is correct.
Many users discovered that ChatGPT can provide incorrect answers, including some that are wildly incorrect.
OpenAI explains ChatGPT's limitations as follows:
"
ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers. Fixing this issue is challenging, as: (1) during RL training, there’s currently no source of truth; (2) training the model to be more cautious causes it to decline questions that it can answer correctly; and (3) supervised training misleads the model because the ideal answer depends on what the model knows, rather than what the human demonstrator knows.
ChatGPT is sensitive to tweaks to the input phrasing or attempting the same prompt multiple times. For example, given one phrasing of a question, the model can claim to not know the answer, but given a slight rephrase, can answer correctly.
The model is often excessively verbose and overuses certain phrases, such as restating that it’s a language model trained by OpenAI. These issues arise from biases in the training data (trainers prefer longer answers that look more comprehensive) and well-known over-optimization issues.12
Ideally, the model would ask clarifying questions when the user provided an ambiguous query. Instead, our current models usually guess what the user intended.
While we’ve made efforts to make the model refuse inappropriate requests, it will sometimes respond to harmful instructions or exhibit biased behavior. We’re using the Moderation API to warn or block certain types of unsafe content, but we expect it to have some false negatives and positives for now. We’re eager to collect user feedback to aid our ongoing work to improve this system.
"
How to use ChatGPT
The ChatGPT webpage is simple and includes an area for the results to populate and a text box at the bottom of the page for users to type inquiries.
You also have the option of more specifically inputting requests for an essay with a specific number of paragraphs or a Wikipedia page. If there is enough information available, the generator will fulfill the commands with accurate details. Otherwise, there is potential for ChatGPT to begin filling in gaps with incorrect data. You also have the option to use ChatGPT in dark mode or light mode.
Do you need to download ChatGPT?
ChatGPT is available via a webpage, so no downloading is needed. OpenAI has yet to release an official app, despite the fact that app stores are full of fake versions. These should be installed and used with caution, as they are not official ChatGPT apps.
You can, apparently, download ChatGPT locally through Github, though it’s not necessary to use it.
visit https://www.centdam.com.ng/ for more... | centdam |
1,341,555 | How to toonify yourself | Artificial intelligence is rapidly advancing, and it is now possible to utilize it to create a... | 0 | 2023-01-25T21:58:41 | https://dev.to/wimdenherder/how-to-toonify-yourself-3756 |

Artificial intelligence is rapidly advancing, and it is now possible to utilize it to create a cartoon version of oneself. One can visit the website https://huggingface.co/spaces/PKUWilliamYang/VToonify to experiment with this technology. However, it should be noted that the server may be overwhelmed, leading to difficulties in accessing the video feature.
To overcome this issue, one can use the colab link and should first convert the video to the .mov format using the following command, which requires the installation of ffmpeg on one's computer:
`ffmpeg -i <YOURVIDEO> -c:v libx264 -profile:v main -pix_fmt yuv420p -s 1280x720 -b:v 9710k -r 30 -g 30 -keyint_min 30 -c:a aac -ac 1 -ar 48000 -b:a 242k -strict -2 <OUTPUTNAME>.mov`
Here is the link to the google colab page: https://colab.research.google.com/github/williamyang1991/VToonify/blob/master/notebooks/inference_playground.ipynb
You should execute the necessary steps, including uploading the video and rescaling it.
To download the resulting video, the traditional right-click method may not work. Instead, one must use the Chrome Developer Console by pressing cmd+shift+c and clicking on the video element to find the path, which will be in the format of "temp/output9f832f8huh".
Go to sidebar on the left with files
click .. to go to parent folder, and then open folder temp and the output file, click the dots to open menu to download it
Now mix it with original audio
`ffmpeg -i <originalvideo>.mov -i <toonify-video>.mov -c:a copy -c:v copy -map 0:a -map 1:v -y <outputfile>.mov` | wimdenherder | |
1,341,717 | Fun With Flags | Here's a link to my solution:... | 0 | 2023-01-26T01:11:55 | https://dev.to/jansellopez/fun-with-flags-42io | react, css, api, javascript | Here's a link to my solution: https://www.frontendmentor.io/solutions/rest-countries-api-with-color-theme-switcher-b9kxBNvj22Any feedback and suggestions on how I can improve are very welcome!
| jansellopez |
1,341,967 | Routing with Rails | Routing: When you go out to a restaurant you place an order with your waiter, your waiter then puts... | 0 | 2023-01-26T07:02:00 | https://dev.to/juliannehuynh/routing-with-rails-18fg | ruby, rails, codenewbie, webdev | **Routing:**
When you go out to a restaurant you place an order with your waiter, your waiter then puts that order in, and the kitchen prepares your order. Once the kitchen is done preparing your order, the waiter brings your order to you. This concept applies similarly when a client utilizes the internet. A client makes a request to the server(backend) and the server returns data back to the client(frontend).
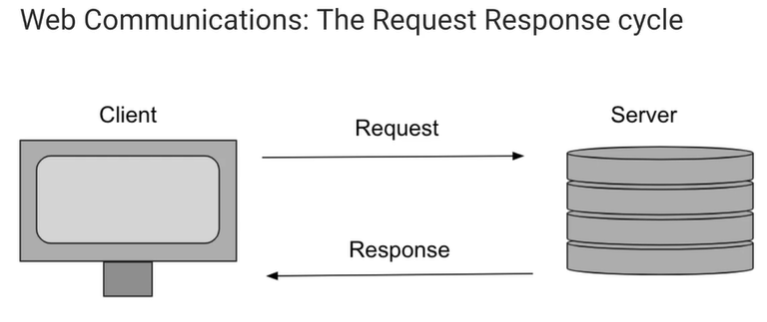
**Routing with Rails:**
Ruby on rails allows programmers to use the 7 different routes to execute the different action methods mapped to the object within the app>controllers.rb. Custom routing are created in config>routes.rb where resources also are used.
- 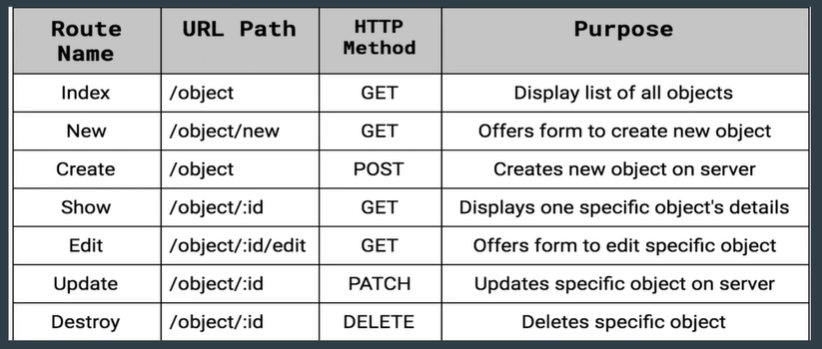
- Custom Routing:
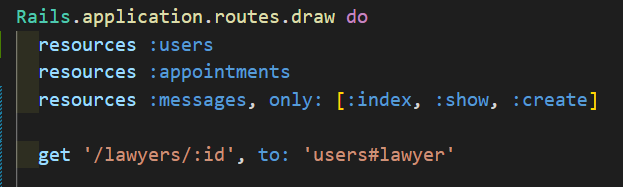
When a client puts a request into the application for '/lawyers/:id', the request fetches the custom method of lawyer in the app>controller>users_controller.rb.
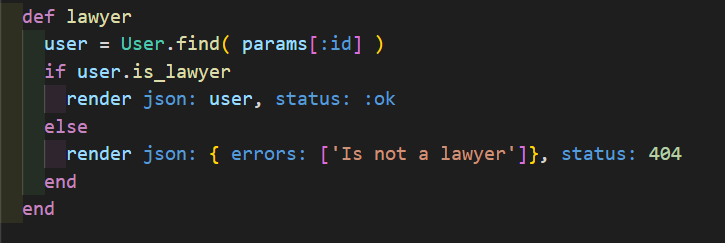
Here, user is set to a variable and active record rescue_from is used as our error handling when .find is used. To check if the routing was successfully created use Postman to test route:
Custom Route Works!!!
| juliannehuynh |
1,342,208 | Developer productivity for fun and profit - Parte 1 | Seja em cenários de crescimento acelerado ou mesmo no infeliz momento de layoffs que estamos... | 0 | 2023-01-26T11:53:00 | https://dev.to/eminetto/developer-productivity-for-fun-and-profit-parte-1-15bc | productivity | ---
title: Developer productivity for fun and profit - Parte 1
published: true
description:
tags: productivity
cover_image: https://miro.medium.com/v2/resize:fit:1400/0*uv_P7DqUZy_-tNIe
# Use a ratio of 100:42 for best results.
published_at: 2023-01-26 11:53 +0000
---
Seja em cenários de crescimento acelerado ou mesmo no infeliz momento de *layoffs* que estamos passando, horas de desenvolvimento são um dos recursos mais caros e valiosos para as empresas. Desta forma, a produtividade e eficiência tornam-se diferenciais importantes para profissionais e times.
Mas qual é a diferença entre produtividade e eficiência? Gostei bastante da definição que encontrei [neste post](https://medium.com/wise-engineering/platform-engineering-kpis-6a3215f0ee14):
> Enquanto a produtividade visa mais resultados com o mesmo esforço, a eficiência visa menos esforço, mantendo o mesmo resultado.
Nesta série de posts vou apresentar formas como Devs e empresas podem melhorar a sua produtividade e eficiência em tarefas e projetos, garantindo seus empregos, lucros e satisfação no trabalho.
Vou começar com a parte 1, falando **o que a pessoa desenvolvedora pode fazer para melhorar sua produtividade e eficiência.**
A parte 2, sobre **o que o time e a empresa podem fazer** vai ser assunto de outro post.
Antes de tudo, esse conteúdo é fruto de minhas experiências como desenvolvedor, líder técnico e tech manager, assim como resultado de leituras no decorrer dos anos.
[](https://eltonminetto.dev/images/posts/joao-kleber-para_905.jpg)
> E você não vai falar nada sobre como medir a produtividade???
Realmente, um dos assuntos que sempre nos vem na mente quando falamos sobre isso é "e como vamos medir se estamos melhorando?". Esse é um assunto complexo e vou deixar de fora destes posts, mas recomendo muito a leitura de dois materiais importante sobre isso:
- [What are DORA Metrics and Why Do They Matter?](https://codeclimate.com/blog/dora-metrics/)
- [The SPACE of Developer Productivity](https://queue.acm.org/detail.cfm?id=3454124)
Dito isso, vamos aos tópicos.
## Domine suas ferramentas
Sou muito fã da cultura e mitologia nórdicas, e alguns anos atrás encontrei um texto que gosto muito de citar de tempos em tempos. Trata-se das [leis Vikings](https://eltonminetto.dev/2012/06/21/as-leis-vikings/) e uma delas se encaixa perfeitamente neste contexto. É a "Mantenha suas armas em boas condições", e ela se refere ao fato de que um guerreiro viking poderia entrar em combate a qualquer momento, então ter suas armas sempre em boas condições poderia ser uma diferença de vida ou morte.
Menos dramático no nosso dia a dia, as ferramentas (armas) que usamos podem ser cruciais para aumentar nossa produtividade. Dedique tempo para estudar a linguagem que você usa, a IDE, o seu [sistema operacional](https://eltonminetto.dev/post/2018-09-06-windows-linux-mac/). Crie e faça uso de atalhos, crie *snippets de código*, faça scripts para tarefas repetitivas como [build da aplicação](https://eltonminetto.dev/post/2022-08-31-improve-local-development-tilt/). Aprenda a usar o Terminal do sistema operacional, bem como criar scripts em *shell* ou usando ferramentas como o *make*.
Quanto a automação de tarefas, gosto de usar como referência este [post](https://medium.com/@miere/regra-da-exce%C3%A7%C3%A3o-coincid%C3%AAncia-ou-tend%C3%AAncia-b0e8be7c0a01), de um amigo meu. Quando eu preciso executar uma tarefa a primeira vez, eu faço ela o mais rápido possível, geralmente de forma manual. Se a mesma tarefa aparecer uma segunda vez eu ainda executo manualmente, mas começo a dedicar mais atenção a ela, pois deixou de ser uma exceção e passa a se tornar uma coincidência. Se ela aparecer novamente ela se torna uma tendência, e neste momento eu crio um script para não precisar realizar o processo manualmente daí em diante. Com isso evito de automatizar coisas desnecessariamente.
## Documente
Se tem uma coisa que eu aprendi com o passar dos anos é que o cérebro humano é feito para criar coisas e não guardá-las para sempre. Pelo menos o meu cérebro é assim :) Parei de confiar na minha memória e passei a anotar tudo que eu aprendo e faço. Com isso minha cabeça fica mais livre para criar coisas novas.
Eu sugiro que você crie um registro dos seus aprendizados. Este meu site surgiu para esse fim, e venho fazendo isso nos últimos 20 anos. Mas você não precisa fazer isso em público, pode anotar em um documento de texto, em um Google Docs ou Notion. O importante é que seja algo fácil de você encontrar quando precisar. Eu tenho várias anotações armazenadas, de coisas que uso no dia a dia:
[](https://eltonminetto.dev/images/posts/notes_productivity_1.png)
[](https://eltonminetto.dev/images/posts/notes_productivity_2.png)
Aliás, para adicionar estas imagens no texto eu procurei na minha anotação como fazer, pois não lembrava qual era o diretório correto para salvá-las ;)
Outra coisa que eu tenho feito e tem me ajudado bastante é, ao ler um post complexo ou livro, fazer anotações em um documento. Pontos importantes do texto, anotações, etc. Isso tem me ajudado a absorver melhor o conhecimento e ajuda a encontrar a informação quando eu preciso:
[](https://eltonminetto.dev/images/posts/notes_productivity_3.png)
E um último item que eu posso incluir nessa categoria é o Brag Document, mas eu já dediquei um [post inteiro](https://eltonminetto.dev/post/2022-04-14-brag-document/) sobre ele. Recomendo a leitura devido a sua importância.
## Simplifique
A complexidade é um dos maiores males da tecnologia e é algo que geralmente está sob nosso controle, pelo menos parcialmente. Falei bastante sobre isso em outro [post](https://eltonminetto.dev/post/2022-11-25-dicas-livros-complexidade/).
Com certeza eu não consegui esgotar esse assunto, e nem acredito ser possível fazer isso em alguns posts, mas espero que estes tópicos façam sentido para você como tem feito para a minha experiência. E estou aberto para discutirmos mais sugestões nas redes sociais, e talvez adicionar novos posts a essa série com dicas de outras pessoas.
Publicado originalmente em [https://eltonminetto.dev](https://eltonminetto.dev/post/2023-01-25-developer-productivity-fun-profit-p1/) no dia 25/01/2023. | eminetto |
1,342,689 | Understanding Garbage Collection and Hunting Memory Leaks in Node.js | https://www.cloudbees.com/blog/understanding-garbage-collection-in-node-js | 0 | 2023-01-26T20:45:44 | https://dev.to/dingzhanjun/understanding-garbage-collection-and-hunting-memory-leaks-in-nodejs-18kb | node, memory, leak, garbage | https://www.cloudbees.com/blog/understanding-garbage-collection-in-node-js | dingzhanjun |
1,355,503 | tailwindCSS's classes order pattern "best practice" 🍃 | Using patterns 📊 in your codes is always a pretty great thing👍 because your code looks much better 👀,... | 0 | 2023-02-06T19:43:50 | https://dev.to/vitomohagheghian/tailwindcsss-classes-order-pattern-best-practice-1g1 | webdev, tailwindcss, react, javascript | Using patterns 📊 in your codes is always a pretty great thing👍 because your code looks much better 👀, in the future, you won't be confuse 🧠, and other developers 🧑💻 that contribute to your project will understand it better, especially in open source projects 📖.
Some patterns are confusing 🧠, and hard to remember 😡 since one of the goals of the tailwindCSS is not to be complicated 🦾, I try a lot to make as much as easy, and easy to customize 🖌️.
> I also made a [GitHub repository](https://github.com/vito-mohagheghian/tailwindcss-classes-pattern/tree/main) for you guys to be able to contribute and make it better. 😉
# Basics
Let's take a look at it.
You may say what is special about this piece of code 🤔💭, the answer is that during coding we have no pattern and methodology we just type class names that we thinking of, and this will make our code dirty 💩.
# Logic
the logic behind orders and patterns is we go from outside to inside 📥. It means first we define positions, after that margin, padding, outline, and border, and then we define element inner styles like display, align-items, background-color, text-color, font properties, etc. 🚌 Next we define class names like transitions, animations, and external CSS classes.
# Responsive
Some developers prefer to use media queries at the end of the string which is not perfect 🔔 because it's easier to have all media queries of one element in one look 👁️. like below.
------
# Orders
The most important thing in this pattern is orders but how do we categorize them in groups, and what are the categories? 👆
-----
## 1. position, inset, top, bottom...
Including position, inset, top, left, bottom, and right.
1️⃣ position => absolute, relative, static...
2️⃣ inset => inset-2, inset-4...
3️⃣ top => top-6, top-10...
4️⃣ right => right-6, right-10...
5️⃣ bottom => bottom-6, bottom-10...
6️⃣ left => left-6, left-10...
```jsx
<div className="absolute top-10 right-10">
<h1>Position</h1>
</div>
```
-----
## 2. Margin, Padding, outline, and border
the Order of the directions are clockwise 🔃, like: mt-0 => mr-0 => mb-0 => ml-0
1️⃣ Margin
2️⃣ Padding
3️⃣ Outline
4️⃣ Border
```jsx
<div className="my-10 p-24 outline-none border-2">
<h1>Margin, Padding, Outline, and Border</h1>
</div>
```
-----
## 3. Height, width, min and max-width, and min and max-height
1️⃣ width => w-10
2️⃣ height => h-10
3️⃣ min-width => h-5
4️⃣ min-height => h-5
5️⃣ max-width => h-16
6️⃣ max-height => h-16
```jsx
<div className="w-10 h-4 min-h-2 max-w-36 max-h-10">
<h1>Width, Height, min-..., and max-...</h1>
</div>
```
-----
## 4. Display (grid or flexbox items in addition)
The order in this category does not matter 🫠, because it may be different. 🛫
```jsx
<div className="flex items-center justify-content flex-col">
<h1>Flex, and Grid</h1>
</div>
```
-----
## 5. Background-color, and box-shadow
1️⃣ background color
2️⃣ box shadow
3️⃣ drop-shadow
```jsx
<div className="bg-red-900 shadow-xl drop-shadow-lg">
<h1>background-color, and box-shadow, and drop-shadow</h1>
</div>
```
------
## 6. Text, and font
First, we define text color, then text font-size, and last but not least font-weight.
1️⃣ color => text-red-600, text-white...
2️⃣ font-size => text-lg, text-3xl...
3️⃣ font-height => leading-9, leading-5...
4️⃣ font-weight => font-semibold, font-medium...
```jsx
<div className="text-red-600 text-sm leading-4 font-semibold">
<h1>Color, font-size, font-height, and font-weight</h1>
</div>
```
these most common classes, so for more classes you can add them at the end of the category.
-------
## 7. Transitions, and animations
1️⃣ transition => transition-all duration-750...
2️⃣ animation => animate-spin
```jsx
<div className="transition-all duration-1000 animation-ping">
<h1>Transition, and Animation</h1>
</div>
```
-----
## 8. Filters
Due to a large number of cases, it's not great.
```jsx
<div className="backdrop-blur-lg">
<h1>Filters</h1>
</div>
```
------
# Conclusion
I developing a react project with this method, and after finishing it I will share the link here. So be sure to save it 😉😈.
[back to top](#basics)
[keep in touch](https://vito-dev.ir)
Keep Coding Y'All 👨🏻💻 | vitomohagheghian |
1,355,610 | TheBrag CLI: Save your brags from terminal | What I built If you're anything like me, you believe in getting things done as quickly as... | 0 | 2023-02-19T16:08:46 | https://dev.to/khushboo/thebrag-cli-save-your-brags-from-terminal-2b6o | linodehackathon, go, cli, api | ## What I built
If you're anything like me, you believe in getting things done as quickly as possible, but when the time comes for a performance review or job interview, you're stuck with a bad memory and a blank page, frantically combing through JIRA tickets, emails, and closed PRs from multiple projects.
Now, you don't have to think about what you did in the last six months or a year with **TheBrag**!
> Brag now, remember later.
**TheBrag** is a CLI-based application that lets you save your brags (things you want to show off) directly from your terminal.
**TheBrag has the following features:**
- You can add, view, update, or delete brags directly from the CLI.
- Create custom categories to sort out your accomplishments like work tasks, personal tasks, blogs, etc.
- Use the "export to file" functionality to recieve a copy of your accomplishments via email.
- You can export all your data or by selected categories within a date range.
### Category Submission:
- Wacky Wildcard
- Integration Innovators
- SaaS Superstars
### App Link
Download the CLI application from this [link](https://thebrags.ap-south-1.linodeobjects.com/thebrag).
**Installation Steps:**
1. Download the application from the link above.
2. Run `chmod a+x thebrag` from the directory where the file was downloaded. This will make the file executable for all groups on your system.
3. From the same directory you can run `./thebrag` on your terminal to start using it.
OR
4. If you want to access `thebrag` command from anywhere in your system, you need to add the application path to your $PATH environment variable.
- Navigate to your home directory by typing `cd` in the terminal.
- Type `nano .profile` or `nano .zshrc`.
- Inside this file, add the following line:
`export PATH=$PATH:/foo/bar`
(Replace /foo/bar with the location of the downloaded file)
- Save and quit.
- Exit Terminal.app (or whichever term program you're using) and restart it.
You should now be able to run `thebrag` from anywhere.
### Screenshots
- `thebrag` command: Gives the basic information about the app along with a list of commands that can be used.
- `thebrag login` command
- Add a new category: `thebrag category -c "<category_name>"`
- List all existing categories: `thebrag category`

- Add a brag: `thebrag add -c "<category_name>" -t "<brag title>" -d "<brag details>"`
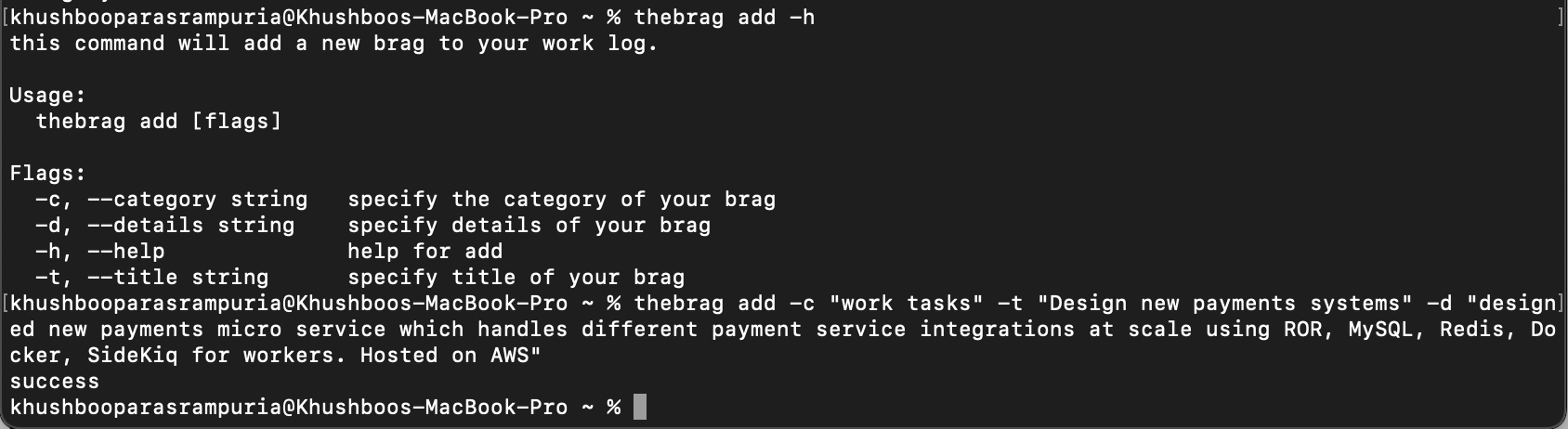
- List brags: `thebrag get -n <no. of brags>`
`thebrag get -n <no. of brags> -s <skip_from_start> `
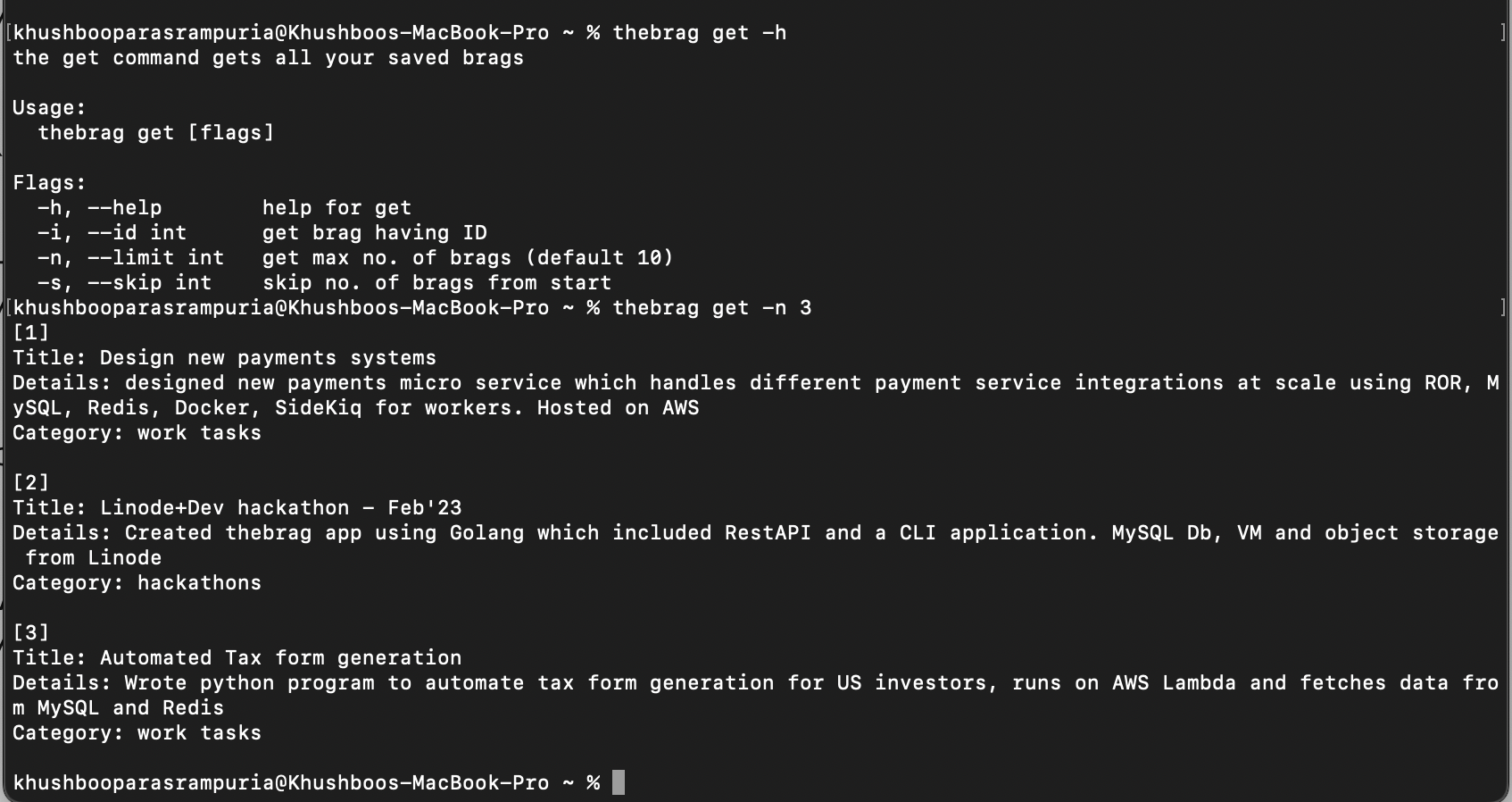
- Get a specific brag: `thebrag get -i <brag_id>`

- Update a brag: `thebrag update -i <brag_id> -d "new details content" -t "new title content" -c "new category name"`
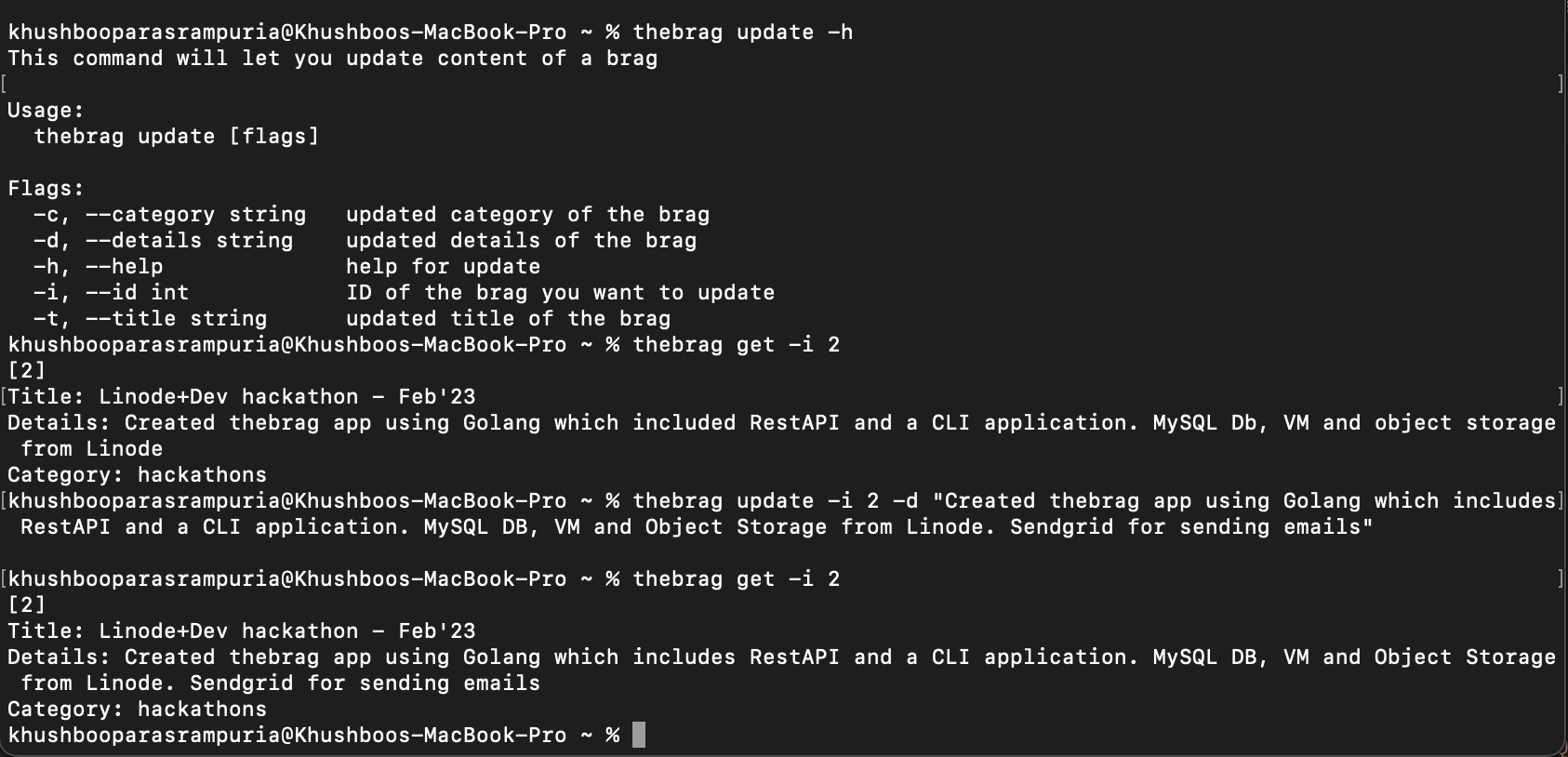
- Delete a brag: `thebrag delete -i <brag_id>`

- Export brags: `thebrag export -d "<from_date>,<to_date>" -c "<category_name>"`
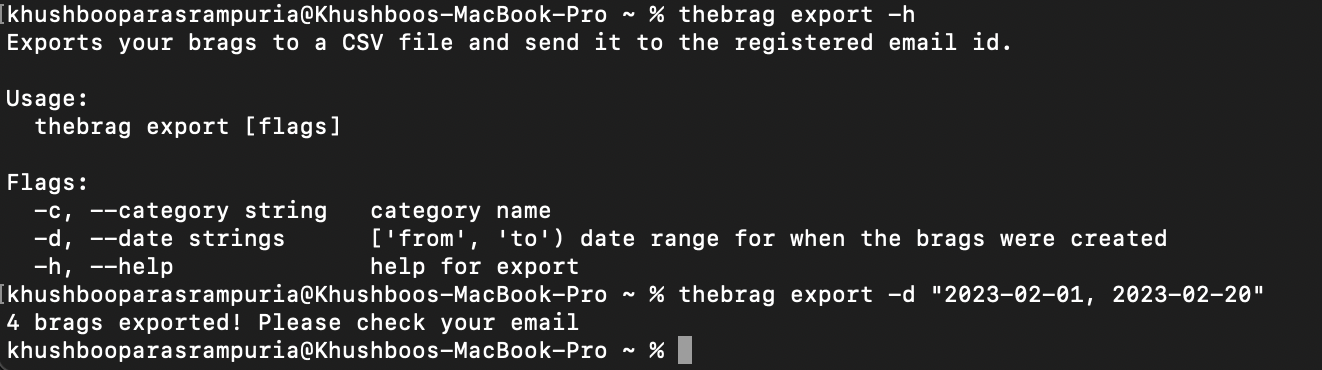
- Received Email:
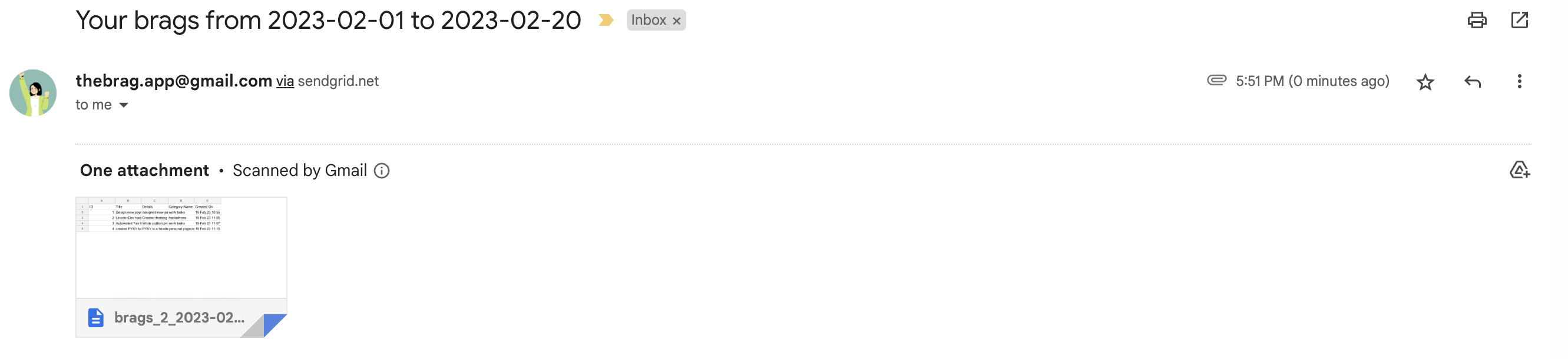
- Exported Brags CSV:
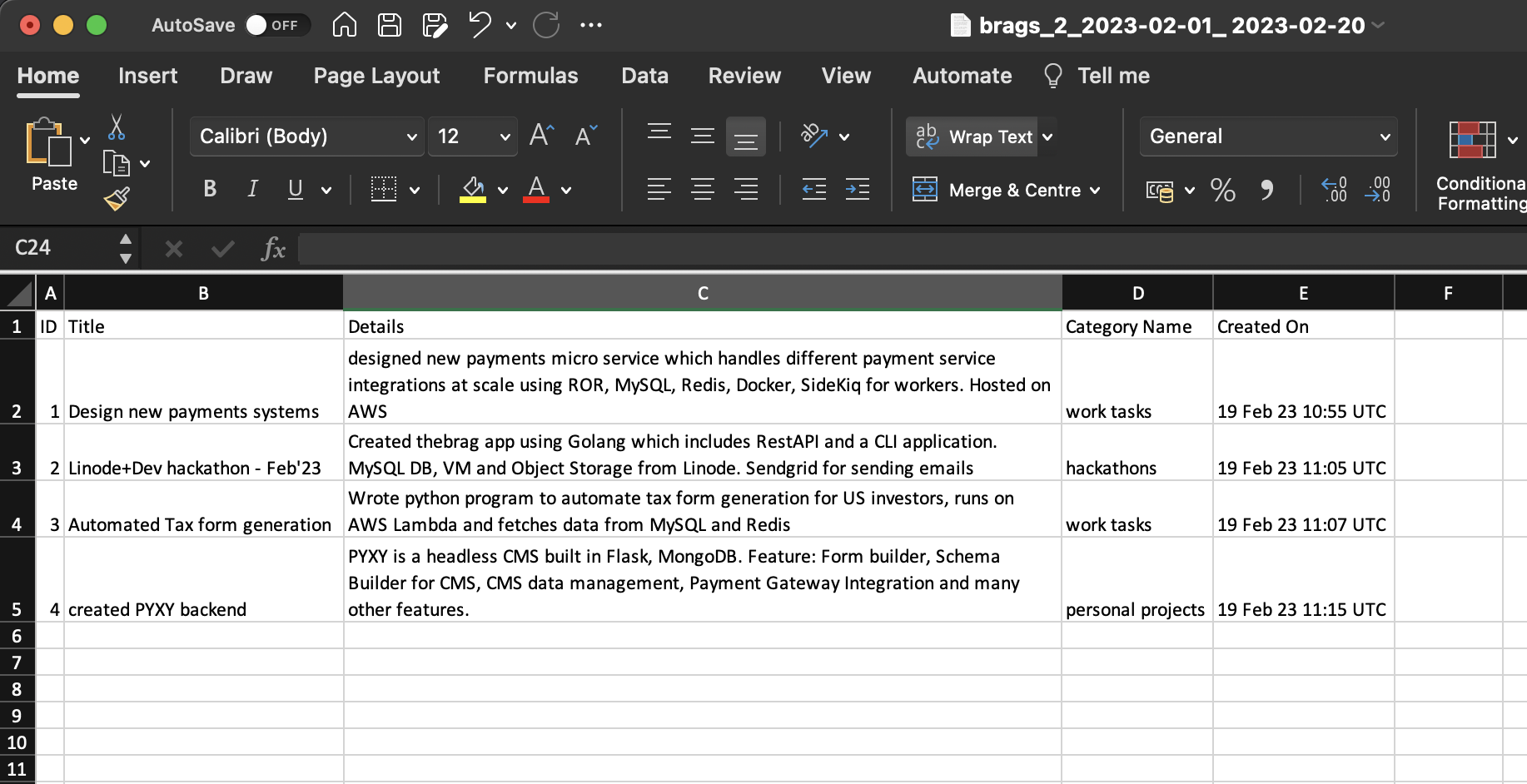
### Description
A high level view of the system:
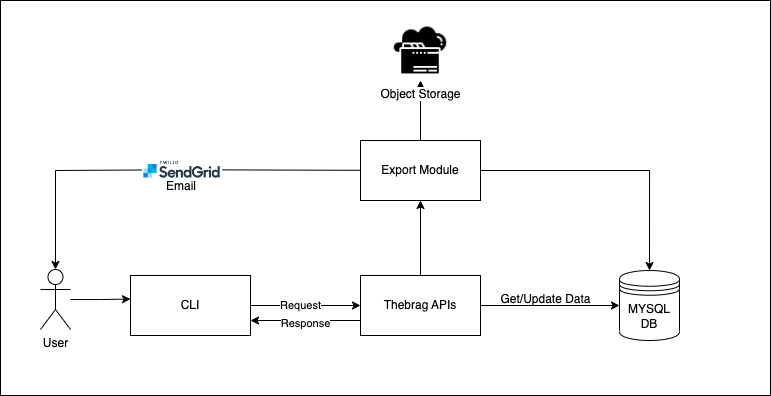
1. The `user` interacts with the application via the `CLI` to manage their brags.
2. The request is sent to the `thebrag APIs`, hosted on Linode servers, for processing .
3. The API interacts with the `MySQL` database to get/update the data.
4. The `Export Module` will let you export brags into a CSV file.
5. After generating the file, it is uploaded an Object Storage bucket on Linode and sent to the registered email id using SendGrid Emails.
### Link to Source Code
1. APIs: [thebrag-api](https://github.com/khushboop09/thebrag-api)
2. CLI: [thebrag-cli](https://github.com/khushboop09/thebrag-cli)
### Permissive License
MIT License
## Background
From trying to come up with things to write about in the year end review for appraisals and giving talking points to help my manager for award nomination at work, made me think that I should start logging the things I've worked on in one place.
Inspired by this [post](https://jvns.ca/blog/brag-documents/) by Julia Evans and practically spending all day in the terminal, I decided to just a write CLI application which will let me log my work directly from the terminal.
The skeleton is me 😵💫.

### How I built it
**Language, Framework and Libraries:**
TheBrag-CLI uses the Golang's **Cobra library** which provides a simple interface to create powerful CLI applications.
TheBrag-API is built using Golang's **Gin framework** for easy implementation of REST-APIs and **Gorm** for MySQL integration.
This is my first GoLang Application 🤩
**Infrastructure:**
- APIs are deployed on Linux virtual machines called **Compute Instances** provided by Linode. For demo purpose this is setup on a shared CPU nanode 1GB.
- **MySQL** is also provisioned on Linode using their **high performing managed database clusters**. Also on shared CPU nanode 1GB.
- Exported brag files are uploaded in a private bucket on **Object Storage** offering by Linode to save the exported data files on cloud.
- **SendGrid** is used to send the **email** containing the exported data file.
- Thebrag CLI app is hosted in a bucket on **Object Storage** by Linode with **public read access** to allow anyone to download the app and start using it.
### Future Scope/Roadmap
This is not the end for this project, I'm going to continue adding features to this.
- Filter brags by category, date range etc.
- Setup Github Actions for deployment.
- Convert your brags into a resume.
- Performance optimisation: Move export functionality to a worker.
- Dashboard for people who prefer a GUI.
PS: Feel free to share suggestions or feature requests.
### Additional Resources/Info
[1] [Opening a port on linux](https://www.digitalocean.com/community/tutorials/opening-a-port-on-linux) or this one [linux-how-to-open-a-port](https://phoenixnap.com/kb/linux-how-to-open-a-port)
[2] [Copy files from local to remote server](https://phoenixnap.com/kb/linux-scp-command)
[3] All go tutorials use localhost for API to listen to, remember to change the IP for production deployment. After 2 days of confusion I found this: [port-seems-to-be-open-but-connection-refused](https://askubuntu.com/questions/166068/port-seems-to-be-open-but-connection-refused)
[4] [SendGrid for emails](https://sendgrid.com/solutions/email-api/) | khushboo |
1,355,611 | Mastodon for Developers: Everything You Need to Know | Learn how to use Mastodon effectively as a developer. | 0 | 2023-02-06T13:34:14 | https://auth0.com/blog/mastdon-for-developers/ | social, mastodon | ---
title: "Mastodon for Developers: Everything You Need to Know"
published: true
description: "Learn how to use Mastodon effectively as a developer."
tags:
- "social"
- "mastodon"
cover_image: "https://images.ctfassets.net/23aumh6u8s0i/48DMcrjsrTyczgB2Im8ii7/8b8e3050f1c04e797181500c44da05ee/mastodon-color.png"
canonical_url: "https://auth0.com/blog/mastdon-for-developers/"
devto_id: 1355611
devto_url: "https://dev.to/deepu105/mastodon-for-developers-everything-you-need-to-know-2hhf"
---
_Originally published at [auth0.com](https://auth0.com/blog/mastdon-for-developers/)_
## What Is Mastodon?
Mastodon is an open-source, distributed micro-blogging platform that can host social networking sites. It was created by [Eugen Rochko](https://en.wikipedia.org/wiki/Eugen_Rochko) and was first released in 2016. It is similar to Twitter regarding features, target audience, and user experience. But unlike Twitter, it is run on a decentralized network of servers, each of which is called an **instance**. This does not mean that you have fragmented silos; instances are federated, which means you can talk to other instances, follow people, and see content from other instances, making Mastodon the ideal decentralized social network.
Any single company does not own the Mastodon network, and users can join any instance they wish. The federation allows people to connect and interact with each other across different instances, making Mastodon more open, secure, and free than something like Twitter. This means no single entity has absolute control over Mastodon, which is a big advantage over traditional social networks like Twitter, which is owned by a single company and is not open source.
After the recent [Twitter saga](https://twitterisgoinggreat.com), it's clear why this is a major benefit. However, this does not mean there is no moderation. Quite the contrary, actually. Each instance can have its own rules and can moderate content as they see fit. This means you can join an instance that is more aligned with your values and beliefs or even hosts your own if you have the necessary resources.
## Why Should You Care about Mastodon?
Platforms like Twitter, Facebook, Instagram, and TikTok make most of their revenue from advertisements. This means they are selling our attention to advertisers.
How do you keep someones attention? Our brains are naturally wired to seek dopamine reward pathways and [algorithms](https://www.iomcworld.org/open-access/neurotransmitter-dopamine-da-and-its-role-in-the-development-of-social-media-addiction-59222.html) used by these social media often target dopamine pathways to create a feeling of reward and reinforcement that encourages people to keep using their services. This is done by providing users with a steady stream of new content and positive feedback, such as likes and comments, which stimulates dopamine production in the brain. This can lead to people becoming addicted to social media, as they constantly seek out the reward of dopamine that comes with using the platform.
In addition, many platforms use algorithms to personalize content and increase the chance of a positive outcome, further encouraging people to use the service. But that's not all; these algorithms also use tactics like amplifying content that is reactionary, sensational, or [frightening](https://en.wikipedia.org/wiki/Mean_world_syndrome), which grabs our attention.
Platforms like Mastodon, which [does not operate for profit](https://arstechnica.com/tech-policy/2022/12/twitter-rival-mastodon-rejects-funding-to-preserve-nonprofit-status/), do not have any incentives to follow similar tactics. This does not mean that it is not possible as a Mastodon instance can choose to serve advertisements. But since you have control as a user, you can choose to join an instance that does not serve advertisements. This means that algorithms are not manipulating you to keep you hooked on the platform. This is a big advantage over platforms like Twitter which are designed to keep you hooked on the platform, making it easier to sow division and hatred by nefarious actors.
Mastodon is an important platform for anyone who values their freedom, security, mental health, and privacy online. It is a great alternative to Twitter for those who are looking for a more open and secure platform to connect with others without having to worry about being harassed or bullied. It is quite customizable and provides greater control over your data. With its growing user base, Mastodon is quickly becoming the go-to platform for many people looking for a better way to connect with others and get out of the grasp of BigTech.
## What Is Fediverse, and How Does It Work?
Fediverse is the term used to describe a network of interconnected servers that can communicate with each other using decentralized networking protocols. Fediverse is bigger than Mastodon and can include, among others:
- Mastodon servers (social networking and microblogging)
- [Friendica](https://friendi.ca/) servers (social networking and microblogging)
- [PeerTube](https://joinpeertube.org/) servers (video hosting)
- [Pleroma](https://pleroma.social/) servers (social networking and microblogging)
Fediverse networks can be used for social networks, file hosting services, and so on.
Fediverse works using several different communication protocols. The most important ones are [ActivityPub](https://activitypub.rocks/), [OStatus](https://www.w3.org/community/ostatus/wiki/Main_Page), and [diaspora](https://diaspora.github.io/diaspora_federation/).
ActivityPub is a protocol that allows servers to communicate with each other. It is a decentralized protocol based on the [ActivityStreams](https://www.w3.org/TR/activitystreams-core/) standard. Mastodon, PeerTube, and Pleroma use ActivityPub.
OStatus is a decentralized protocol based on the [Atom Syndication Format](https://www.rfc-editor.org/rfc/rfc4287). OStatus is a predecessor to ActivityPub and is used by older instances of Mastodon and Pleroma.
Diaspora is a decentralized protocol. Mastodon, Friendica, and Pleroma use it.
Any server that supports one of these protocols can communicate with other servers that support the same protocol.
It is difficult to estimate the number of users in Fediverse due to the distributed nature, but [rough third-party estimates](https://fediverse.observer/stats) put it at around 8 million users. This is a small fraction of the number of users on Twitter, but it is growing rapidly, as well as the number of instances.
## Choosing Servers
One of the biggest strengths of Mastodon, decentralization, is also its biggest hurdle when it comes to adoption. This means that there is no single place to sign up for Mastodon. Instead, you have to choose an instance to join. Choosing a server could be a daunting task, especially if you are new to Mastodon. There are some factors to consider when choosing a server. These include:
- Quality and reliability of the server
- Community and moderation
- Rules and Policies
- Non-profit status
Choosing a server based on this is important, but it's not as critical as it seems. This is because you can follow people from other servers and see their content in your timeline. This means you can join a server that is more aligned with your values and beliefs and still follow people from other servers. This is one of the biggest advantages of Mastodon over Twitter, where you are forced to follow people from the same server. Not just that, Mastodon lets you move from one server to another in case you choose a server that turns out to be unreliable, or you realize that you disagree with the server's policies. You can also easily import your data, like your followers and people you follow, to the new server. So choose a server you feel comfortable with and stick around to see how it goes. You can always move to another server if you don't like it.
As of this writing, there are over 17,000 instances of Mastodon, which is growing daily. This means that there is a Mastodon instance for everyone. You can find a list of Mastodon instances on [instances.social](https://instances.social/).
### Recommended servers
For technical folks like developers, you could consider joining one of these servers:
- [fosstodon.org](https://fosstodon.org/): Ideal for developers, especially if you are an open-source enthusiast
- [mstdn.social](https://mstdn.social/): It's a general-purpose server with a good community and is quite reliable
- [mastodon.social](https://mastodon.social/): The official Mastodon server with a good community and is quite reliable
- [hachyderm.io](https://hachyderm.io/): A server for tech industry professionals
- [techhub.social](https://techhub.social/): A server for technology enthusiasts
## Building a Timeline Based on Hashtags and Follows
Unlike Twitter, when you join a Mastodon server, you will not be greeted by a timeline with interesting posts and recommendations for people to follow. Instead, you are going to be greeted by an empty timeline. This is by design, as Mastodon does not have any algorithm or recommendation system, and you will not be following people from the same server. This means that you have to build your timeline by following people and hashtags. This is a good thing as it gives you more control over your timeline, and you will not be bombarded with content you are not interested in. You can find and follow people from other instances by searching for their usernames. For example, if you want to follow me, you can search for my username `@deepu105` or `@deepu105@mastodon.social`
Similarly, you can also follow hashtags; look for the **+** button on the top right corner of the screen when you are on the hashtag page. This works on the web version and some mobile clients.
It is important to follow people and hashtags you are interested in to have interesting content on your timeline. You can mute people you are not interested in.
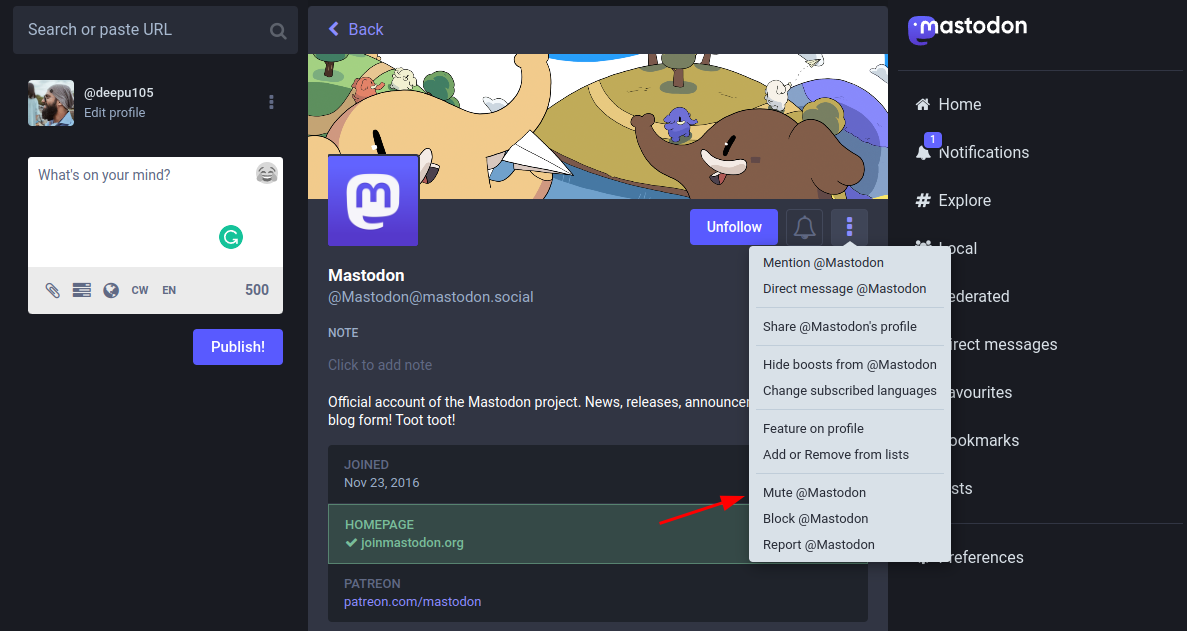
You can also filter hashtags or words you don't want to see on your timeline.
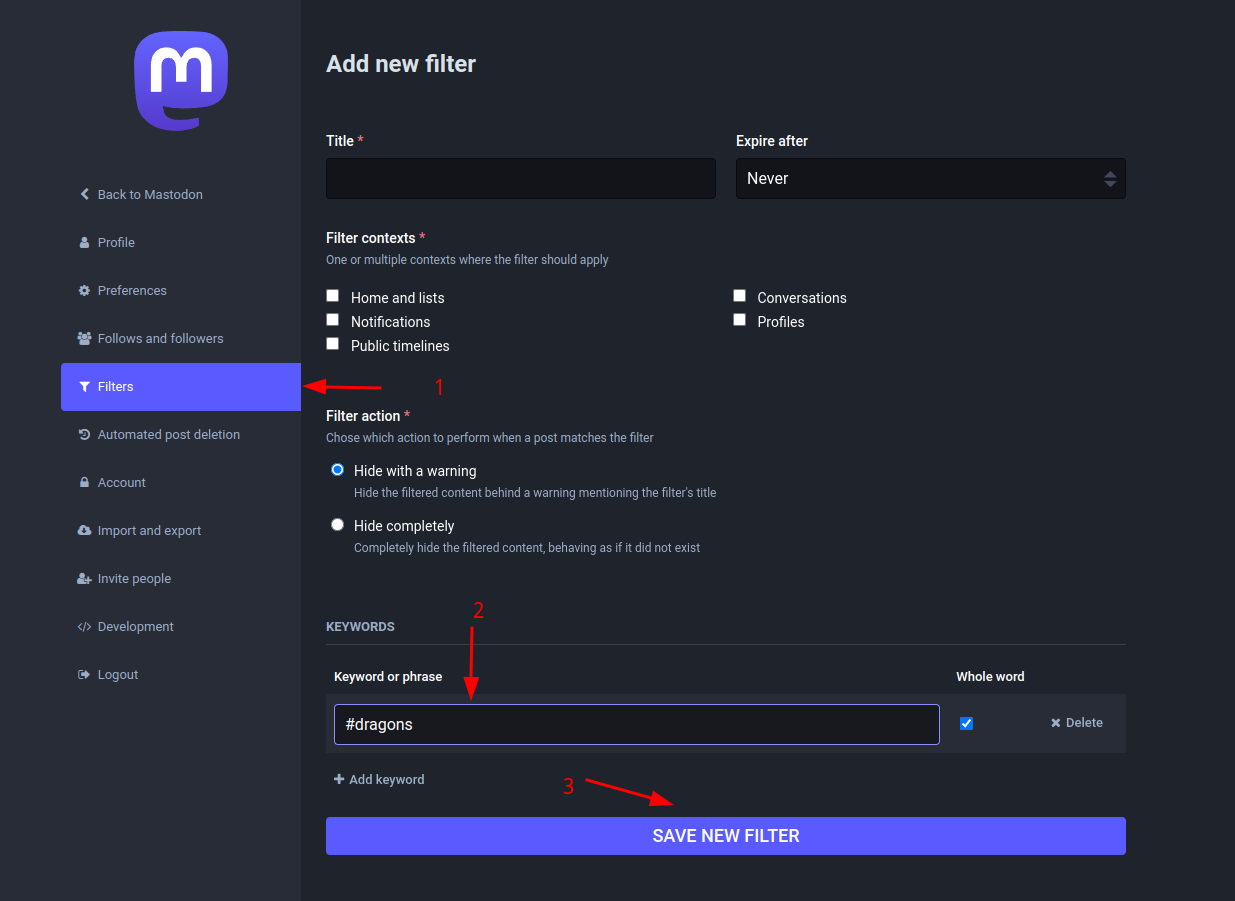
This is a great way to keep your timeline clean and free of unwanted content.
If you are migrating from Twitter, [Movetodon.org](https://www.movetodon.org/) is a great tool to help you find and follow people from Twitter on Mastodon.
## Cross-Posting
If you prefer to keep your Twitter account and cross-post to Mastodon and vice versa, you can use some tools to do so, including writing your own scripts using Twitter and Mastodon APIs. My personal favorite is [moa.party](https://moa.party/). It supports cross-posting to and from Twitter and Mastodon and is simple to setup and use. It can also post from Instagram to Mastodon. It is [open-source](https://gitlab.com/fedstoa/moa), and you can host it yourself if you don't want to give the service access to your Twitter/Mastodon accounts [using OAuth](https://moaparty.com/oauth/).
## Securing the Account
As usual, it is important to keep your Mastodon account secure. This includes using a strong password, using a password manager, and enabling two-factor authentication (2FA). Mastodon supports 2FA using TOTP (Time-based One-time Password Algorithm) authenticator apps like Google Authenticator and FIDO security keys like Yubikey.
You can also verify your Mastodon account by linking your official website, GitHub profile, and so on. This is a great way to prove that you are the owner of the account and prevent impersonation.
To do this, go to **Preferences** -> **Appearance** -> **Profile metadata** and copy the verification URL and add it to your website as instructed. For the GitHub profile, add your Mastodon profile URL in the GitHub profile's website field. For example, my Mastodon profile URL is `https://mastodon.social/@deepu105`. Now add your website or GitHub profile URL to your Mastodon profile metadata and save.
## Moving between Servers
If you decide to move from one Mastodon server to another, here are a few tips to make the process smooth.
1. First, create a profile on the new server you want to use. Note that this will be a new username, as Mastodon usernames include the server name, and you need to choose a username that is available on the new server.
2. Export your data from the old server by going to **Preferences** -> **Import and export** -> **Data export**. You will get CSV files for each item you export, like Follows, mutes, and so on.
3. Create an account alias in your new account by going to **Preferences** -> **Account** -> **Account settings** -> **Moving from a different account**. This will allow you to redirect your old account and move followers from your old account to the new account.
4. Now, from your old account, redirect to the new account by going to **Preferences** -> **Account** -> **Account settings** -> **Moving to a different account**. This will redirect your old account to the new account, and all your followers will be moved to the new account.
5. Now, from your new account, go to **Preferences** -> **Import and export** -> **Import** and import the CSV files that you exported from your old account. This will import all your follows, mutes, lists, and so on to the new account.
## Conclusion
Mastodon is a great alternative to Twitter and is a great way to connect with people from around the world without worrying about a single entity dictating what you can and cannot do with your social media. It is a great way to build a community around your projects and share your thoughts and ideas. It is also a great way to connect with people from the open-source community. I hope this guide will help you get started with Mastodon.
---
If you like this article, please leave a like or a comment.
You can follow me on [Mastodon](https://mastodon.social/@deepu105) and [LinkedIn](https://www.linkedin.com/in/deepu05/).
| deepu105 |
1,355,631 | The Dark Side of ChatGPT: How Scammers are Abusing AI Technology | ChatGPT is an impressive language model developed by OpenAI with many potential uses, from chatbots... | 0 | 2023-02-06T14:18:01 | https://blog.learnhub.africa/2023/02/06/the-dark-side-of-chatgpt-how-scammers-are-abusing-ai-technology/ | ai, machinelearning, cybersecurity, business |
ChatGPT is an impressive language model developed by OpenAI with many potential uses, from chatbots and content creation to answering questions. However, its popularity has also made it a target for scammers looking to gain people's trust in AI technology.
In this article, we'll look at how scammers use ChatGPT, the dangers posed by these scams, and what you can do to protect yourself.
<h4 data-usually-unique-id="576818177910981768393180">How Scammers Are Using ChatGPT</h4>
Scammers are using ChatGPT to automate their fraudulent activities in several ways, and we have compiled 10 top scams with the help of ChatGPT.
<b>Phishing scams</b>: ChatGPT can generate mass phishing emails that trick people into giving up sensitive information, such as passwords or credit card numbers.
<b>How does it work?
</b>In a phishing scam with ChatGPT, the scammer would use the language model to generate emails that appear to be from a legitimate source, such as a bank or government agency.The emails would contain a request for the recipient to provide sensitive information or a link to a fake website designed to steal information.
The emails may also contain an urgent message, such as a warning that the recipient's account will be closed unless they provide the requested information.
The sophisticated nature of ChatGPT makes it possible for scammers to create compelling phishing emails that are difficult to distinguish from legitimate ones.
This increases the risk of people falling for the scam and giving up sensitive information, which can lead to financial and personal harm.
To protect yourself from phishing scams with ChatGPT, it's essential to be cautious when receiving emails from unknown sources.
<b style="font-style: inherit;">Don't provide sensitive information or click on links in emails that you're not sure are legitimate. Instead, check the sender's email address; if unsure, contact the sender through a known channel, such as their official website or a verified customer service number.</b>
<b>Fake customer service scams</b>: Scammers can use ChatGPT to create fake customer service accounts on social media or messaging platforms to trick people into giving up sensitive information.
<b>How does it work?
</b>In a fake customer service scam with ChatGPT, the scammer would create a fake customer service account on a social media or messaging platform, such as Facebook or WhatsApp.They would then use the language model to generate messages that appear to be from the customer service representative of a legitimate company.
The messages would contain requests for sensitive information, such as login credentials or credit card numbers, or links to fake websites designed to steal information.
Using ChatGPT in fake customer service scams makes it possible for scammers to create persuasive messages that are difficult to distinguish from legitimate ones.
This increases the risk of people falling for the scam and giving up sensitive information, which can lead to financial and personal harm.
To protect yourself from fake customer service scams with ChatGPT, it's essential to be cautious when receiving messages from customer service representatives on social media or platforms.
<b style="font-style: inherit;">Only provide sensitive information through secure channels, such as the company's official website or a verified customer service number. Additionally, you can check the account's authenticity by looking at the account's creation date, the number of followers, and the presence of legitimate information.</b>
<b>Fake reviews and advertisements</b>: ChatGPT can generate fake reviews or advertisements for products or services to deceive potential customers.
<b>Investment scams</b>: Scammers can use ChatGPT to create fake investment opportunities that promise high returns with little risk of stealing money from unsuspecting investors.
<b style="font-style: inherit;">How does it work?
</b>In a fake investment scam with ChatGPT, the scammer would create a fake investment website using the language model.The website would contain false information about high-return, low-risk investments supposedly backed by a reputable company or government agency.
The scammer would also use ChatGPT to generate messages that appear to be from satisfied customers who have made large profits from the investment.
Using ChatGPT in fake investment scams makes it possible for scammers to create persuasive websites and messages that are difficult to distinguish from legitimate ones. This increases the risk that people will fall for the scam and invest their money, only to discover later that the investment was a scam and they have lost their money.
<b>To protect yourself from fake investment scams with ChatGPT, it's essential to be cautious when considering investments that promise high returns with low risk. Always thoroughly research the investment opportunity, including the company behind it and its track record, before investing any money. Additionally, be wary of testimonials and reviews, as these can be easily generated by scammers using tools like ChatGPT.</b>
<b>Technical support scams</b>: ChatGPT can be used to impersonate technical support personnel to trick people into giving up sensitive information or sending money.
<b style="font-style: inherit;">How does it work
</b>In a technical support scam with ChatGPT, the scammer would create a script for the language model to follow.The script would contain false information about a technical issue with the victim's device or software.
The scammer would then use ChatGPT to generate phone calls or messages that appear to be from a technical support representative and request access to the victim's device or sensitive information, such as passwords or credit card numbers.
Using ChatGPT in technical support scams makes it easier for scammers to carry out this type of fraud, as the language model can generate compelling messages and phone calls.
This increases the risk that people will fall for the scam and provide the requested information, which can then be used to steal money or commit identity theft.
<b>To protect yourself from technical support scams carried out with ChatGPT, it's essential to be cautious when you receive phone calls or messages claiming to be from a technical support representative. Always verify the identity of the person contacting you, and never provide sensitive information or access to your device without verifying that they are a legitimate representative of a trusted company. If you have any doubts, hang up the phone or close the message, and seek advice from a trusted professional or the appropriate government agency.</b>
<b>Loan scams:</b> ChatGPT can be used to offer fake loans to people to steal money or sensitive information.
<b>How does it work?
</b>Scammers can use ChatGPT to automate the creation of fake loan websites that seem trustworthy and believable.These websites often have false information about loans with low-interest rates and great repayment terms. And to make things even trickier, the scammers can use ChatGPT to write messages from "happy customers" who have supposedly received loans through the site.
The problem is these fake loan websites and messages can be so convincing that it's hard to tell the difference between them and the real thing. That's why it's essential to be careful when looking for a loan online.
The user is asked to pay upfront money to expedite their loan, which ChatGPT generates, and when the users do, they are deleted.
So, how can you protect yourself from loan scams that use ChatGPT? The best thing you can do is to do your research before you apply for any loan.
Look into the lender's reputation and history, and make sure the loan offer seems legitimate. Additionally, be wary of loans that require you to pay money upfront or to provide sensitive information.
<b>If something seems too good to be true, it probably is. If you're ever in doubt, don't hesitate to get a second opinion from a financial expert or the proper government agency. They'll be able to help you sort out the real loan opportunities from the fake ones.</b>
<strong>Charity scams</strong>: ChatGPT can be used to impersonate charitable organizations to trick people into giving money to fake causes.
<b style="font-style: inherit;">How does it work
</b>With ChatGPT, scammers can easily create fake websites, social media posts, and emails that look like they're from an actual charity.They might promise that your donation will go towards helping people in need, but in reality, the money will go into the scammer's pocket.
It's essential to be careful when you're thinking about donating to a charity. Do your research and ensure the charity is legitimate before you give any money.
If unsure, check with a trusted source, like the Better Business Bureau or a charity watchdog organization.
A charity using ChatGPT to communicate with you is one red flag to look out for<b>.</b>
<b></b><b style="font-style: inherit;">Automated messages can be convincing, but they're not the same as a real human being who can answer your questions and provide more information. If you're getting messages from a charity that seem too good to be true, it might be a scam.</b>
<b style="font-style: inherit;"> </b><b style="font-style: inherit;"></b>So, how can you avoid being scammed by a fake charity using ChatGPT? The best way to protect yourself is to be informed and cautious. Do your research and make sure the charity you're considering is legitimate.
If you're ever in doubt, don't hesitate to get a second opinion from a trusted source. Your generosity can make a real difference, but it's essential to ensure your donation goes where it's supposed to.
<strong>Romance scams:</strong> ChatGPT can be used to impersonate romantic partners to trick people into sending money or sensitive information.
<b>How does it work
</b>ChatGPT can aid scammers in generating believable profiles and messages as if they are genuinely interested in you. They may offer false promises and seem like the perfect partner, but their only intention is to scam you.When seeking love online, it's crucial to be vigilant. Be wary of individuals who seem too perfect, and never give out personal information or money without verifying their identity.
If someone is urging you for money or information, that's a warning sign. ChatGPT can automate messages, keep track of previous messages, and build a socially engineered scam to collect private details over a long period if used by a scammer.
So, how can you avoid falling victim to a fake romance scam using ChatGPT? The key is to be informed and cautious.
Take your time getting to know the person before trusting them with personal information or money. If someone appears too good to be true, they probably are.
Don't let a scam artist shatter your hope of finding true love. Stay informed and be mindful.
A genuine romantic interest will be understanding and won't push you to provide personal information or money. If you have any doubts, contact a trusted friend or family member for advice. Your heart is valuable and deserves protection!
<strong>Employment scams</strong>: ChatGPT can be used to offer fake job opportunities to steal sensitive information or money from job seekers.
<b style="font-style: inherit;">How does it work
</b>Have you ever applied for a job and thought you hit the jackpot, only to find out it was a scam? Unfortunately, employment scams are all too common these days, and scammers are using ChatGPT to make these fake job offers seem even more legitimate.
I remember being fresh out of college and eager to start my career. I was scrolling through job postings online when I came across the perfect opportunity. It was for a well-paying marketing position at a top company, and I was thrilled to have been selected for an interview.
But after the interview, I was asked to wire a small fee for a background check. That's when I started to get suspicious.
I discovered this was a common tactic used by scammers in employment scams. They offer you a great job but then ask for money or personal information before you can start.
It's a cruel trick, and it's happening more often as scammers use ChatGPT to create fake job postings and emails that look legitimate. But there are ways to protect yourself.
Always be wary of job postings that seem too good to be true, and never give out personal information or money without thoroughly verifying the company and the job offer.
And if you're unsure, don't hesitate to contact someone you trust for advice. Remember, a genuine job offer will never require you to pay a fee or provide personal information upfront.
<strong>Lottery and prize scams</strong>: ChatGPT can offer fake lottery or prize opportunities to trick people into sending money or sensitive information.
<b>
How does it work
</b>You have won a jackpot, excited and thrilled; your next step is how you collect your winnings; this is where it gets strange.ChatGPT can easily pull off this kind of scam with more dexterity, as it can formulate convincing and believable lottery-winning stories.
<strong> Here is one </strong>
<b><s>Subject: You've Won the International Lottery Jackpot!
</s></b><b><s></s></b><b><s>Dear</s></b><b><s> </s></b><b><s>[Your</s></b><b><s> Name],</s></b><b><s> </s></b>
<b><s></s></b><b><s>We are delighted to inform you that you have been selected as the lucky winner of the International Lottery Jackpot worth $5,000,000!</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>Congratulations! This is a once-in-a-lifetime opportunity, and we are sure you must be ecstatic.</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>To claim your prize, you need to follow a few simple steps. Firstly, you need to confirm your winnings by responding to this email. Secondly, you will be required to pay a small processing fee of $200 to cover the taxes and administrative costs.</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>Please note that this fee must be paid within 24 hours, or your winnings will be forfeited. We understand that you must be eager to claim your prize, and we assure you that this is a standard procedure for all lottery winners.</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>To make the payment, you can use Western Union or MoneyGram. Our payment agent will provide you with all the necessary details once you respond to this email.</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>Don't miss out on this fantastic opportunity. Respond to this email immediately to claim your prize.</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>Best regards,</s></b>
<b><s> </s></b>
<b><s></s></b><b><s>The International Lottery Team.</s></b>
<h4 data-usually-unique-id="474804456367256382398550">The Dangers of AI-Assisted Scams</h4>
AI-assisted scams are particularly dangerous because they can be highly sophisticated and convincing.
Scammers can use ChatGPT to mimic the writing style and language of a legitimate business or individual, making it more difficult for people to tell the difference.
This can make it easier for scammers to trick people into giving up their personal information or sending money.
AI, like ChatGPT, has opened new frontiers for cyber security experts, mostly social engineers, to up their game and try to learn as quickly newer and more advanced modes of scams as possible.
With the ease of training such AI to become more devious in their algorithms, how effective would it be to know what is scam anymore?
<h4 data-usually-unique-id="765430697791990790535924">What You Can Do to Protect Yourself</h4>
The best way to protect yourself from ChatGPT scams is to be cautious when interacting with unknown entities online. Here are some steps you can take to minimize your risk:
<ul>
<li>Don't give out personal information or send money to anyone you don't know.</li>
<li>Be wary of offers that seem too good, or ask for personal information upfront.</li>
<li>Verify the identity of anyone who contacts you by checking their website, email address, or other information.</li>
<li>Report any suspicious activity to the relevant authorities.</li>
</ul>
<h4 data-usually-unique-id="873053265973396345193212">Conclusion</h4>
Using ChatGPT by scammers is a growing concern and highlights the need for increased awareness and protection.
The future is unclear, but the rise of AI has shown it can be used for good and evil. However, we must be careful and vigilant.
To learn more about protecting your business and yourself from scams, <a href="https://blog.learnhub.africa/category/security/">subscribe</a> and <a href="http://linkedin.com/company/learnhub-africa/?viewAsMember=true">follow us</a>. | scofieldidehen |
1,355,953 | Claim 2 AWS Certifications for free | Only for women in tech, AWS offers 2 vouchers each year. One is for the AWS Solution Architect... | 0 | 2023-02-06T18:49:24 | https://dev.to/mitul3737/claim-2-aws-certifications-for-free-4e2o | aws | Only for women in tech, AWS offers 2 vouchers each year.
One is for the AWS Solution Architect Associate certification exam and the other is for the Cloud Practitioner one.
Feel free to apply sisters and claim these vouchers.
AWS Solution Architect Associate: https://awscloudupforher-saa.splashthat.com/
AWS Cloud Practitioner: https://awsshebuildscloudupcpe.splashthat.com/
Feel free to share this with your peers too.
-Mitul
(AWS Community Builder in Machine learning) | mitul3737 |
1,355,981 | Shrink your Rails 7 application.js files | I discovered that my rails app was bundling a few too many stimulus controllers. Whoa! Slow down... | 0 | 2023-02-06T19:30:15 | https://dev.to/mrnagoo/shrink-your-rails-7-applicationjs-files-lop | rails, stimulus, esbuild | I discovered that my rails app was bundling a few too many stimulus controllers. Whoa! Slow down there buddy, save some of those controllers for individual pages! Here's my browser trying to download the deferred file...
<img width="100%" style="width:100%" src="https://media4.giphy.com/media/kaZdqgKC2Dg0XoRzgD/giphy.gif">
Maybe you're like me and you thought... "you can choose which stimulus controllers to import?"
Yes. Obvs.
I followed the upgrade tutorials and my application.js using `esbuild` and `js-bundling_rails` loaded my new stimulus controllers like this:
```ruby
import '@hotwired/turbo-rails';
import './controllers';
```
I added a few more controllers and then BAM! I had a massive 4.5MB application.js file!
Turns out I had a couple pages that used a third party UI component and for reasons I couldn't stop using those components. So I loaded them into my controllers.
<img width="100%" style="width:100%" src="https://media2.giphy.com/media/Td2ohS6FcoSGjyyyf3/giphy.gif">
I didn't want to stop using the controllers in the same way, but I wanted to use them when I needed them. So I load my controllers dynamically now. But I still register them to the `{ Application }`
Here is my current setup:

Anything in my `controllers` directory goes to application.js. I use active admin...(I know, I know, zip it.)
So I load `jquery` to the window when I'm on active admin pages.
I then bring in my other controllers individually and use `<%= javascript_include_tag 'preview(or upload)' %> where needed.
Here's what the preview directory looks like:
Here is what the index.js file looks like.
```javascript
import { application } from "../controllers/application"
import PreviewController from "./preview_controller"
application.register("preview", PreviewController)
```
So now my application.js file is 13x smaller. Maybe there is a better way to do it. I'm not entirely sure. But here I am putting out a way where it works for me. Lighthouse Performance score went from 33 to 93. I really don't need that much javascript globally so I'll be trying to deliver almost 0 javascript to the page over time. I'll have ChatGPT research the best admin, or roll my own for me 😂. | mrnagoo |
1,356,435 | Question for Angular DEVs | Is there any package/library to scan credit /debit card & barcodes in angular ? angular... | 0 | 2023-02-07T05:44:03 | https://dev.to/akhilshaji86/question-for-angular-devs-533c | angular, cardscan, creditcard | Is there any package/library to scan credit /debit card & barcodes in angular ?
#angular #cardscan #barcodescanner | akhilshaji86 |
1,356,520 | How JavaScript Can Enhance Your Web Development Skills | JavaScript is a high-level, dynamic and interpreted programming language used to create interactive... | 0 | 2023-02-07T07:07:01 | https://dev.to/indtechverse/how-javascript-can-enhance-your-web-development-skills-56m8 | javascript, webdev, career, indtechverse | **JavaScript** is a high-level, dynamic and interpreted programming language used to create interactive and dynamic web pages. It's a fundamental tool for web developers to bring life to websites and provide users with an engaging and interactive experience.
Here are a few ways that JavaScript can help you enhance your web development skills:
1. Dynamic Content: JavaScript allows you to add dynamic elements to your website, such as animations, real-time data updates, and user interaction.
2. Cross-Platform Development: With JavaScript, you can develop applications for multiple platforms, including web, desktop, and mobile, making it a versatile tool for developers.
3. Interactivity: JavaScript enables you to create interactive forms, quizzes, and games that engage users and keep them coming back to your site.
4. Improved User Experience: By using JavaScript, you can improve the overall user experience of your website, such as making it more responsive, easy to navigate, and visually appealing.
5. Faster Loading Times: JavaScript is often used to create asynchronous loading, allowing you to load elements of a web page faster, improving the overall load time of the site.
In conclusion, if you're looking to enhance your web development skills, JavaScript is a tool you definitely want to master. Whether you're looking to create dynamic content, cross-platform applications, or improve the user experience, JavaScript can help you achieve your goals. | indtechverse |
1,356,644 | 10 AI APIs to make your projects magical🪄 | Artificial intelligence has revolutionized the way we approach software development, and the use of... | 0 | 2023-02-07T09:58:04 | https://bito.co/10-ai-apis-to-make-your-projects-magical/ | softwaredevelopment, ai, api, coding | Artificial intelligence has revolutionized the way we approach software development, and the use of AI APIs is making it easier than ever to integrate cutting-edge technology into your projects. Whether you're looking to improve efficiency, automate repetitive tasks, or enhance the user experience, there's an AI API that can help. In this blog, we'll be exploring 10 of the most magical AI APIs available to help you take your projects to the next level.
## **1. Google Cloud Natural Language API**
Google Cloud Natural Language API is a powerful tool for analyzing and understanding text data. With the ability to detect sentiment, entities, syntax, and more, it makes it easier to extract meaningful insights from large amounts of text-based data.
Whether you're looking to analyze customer reviews or social media posts, this API is an essential tool for any data-driven project.
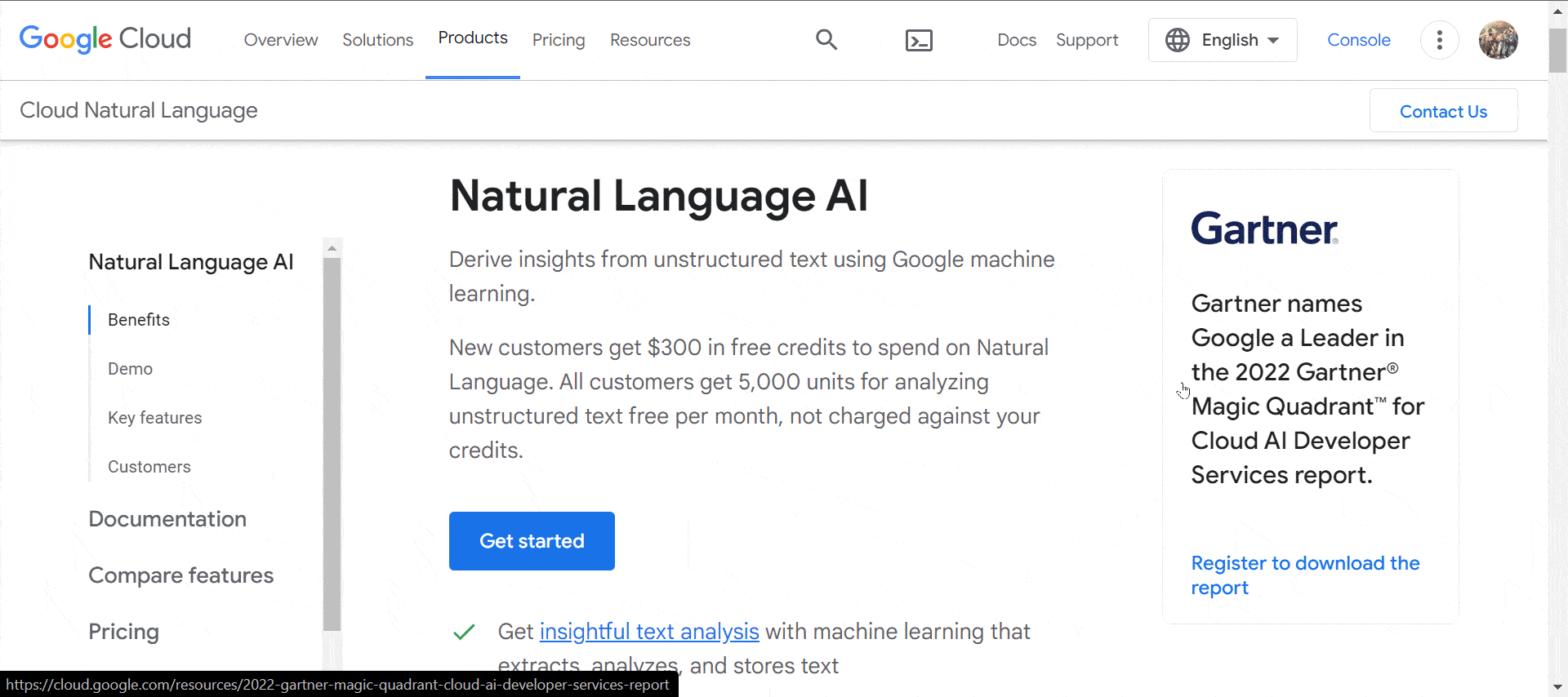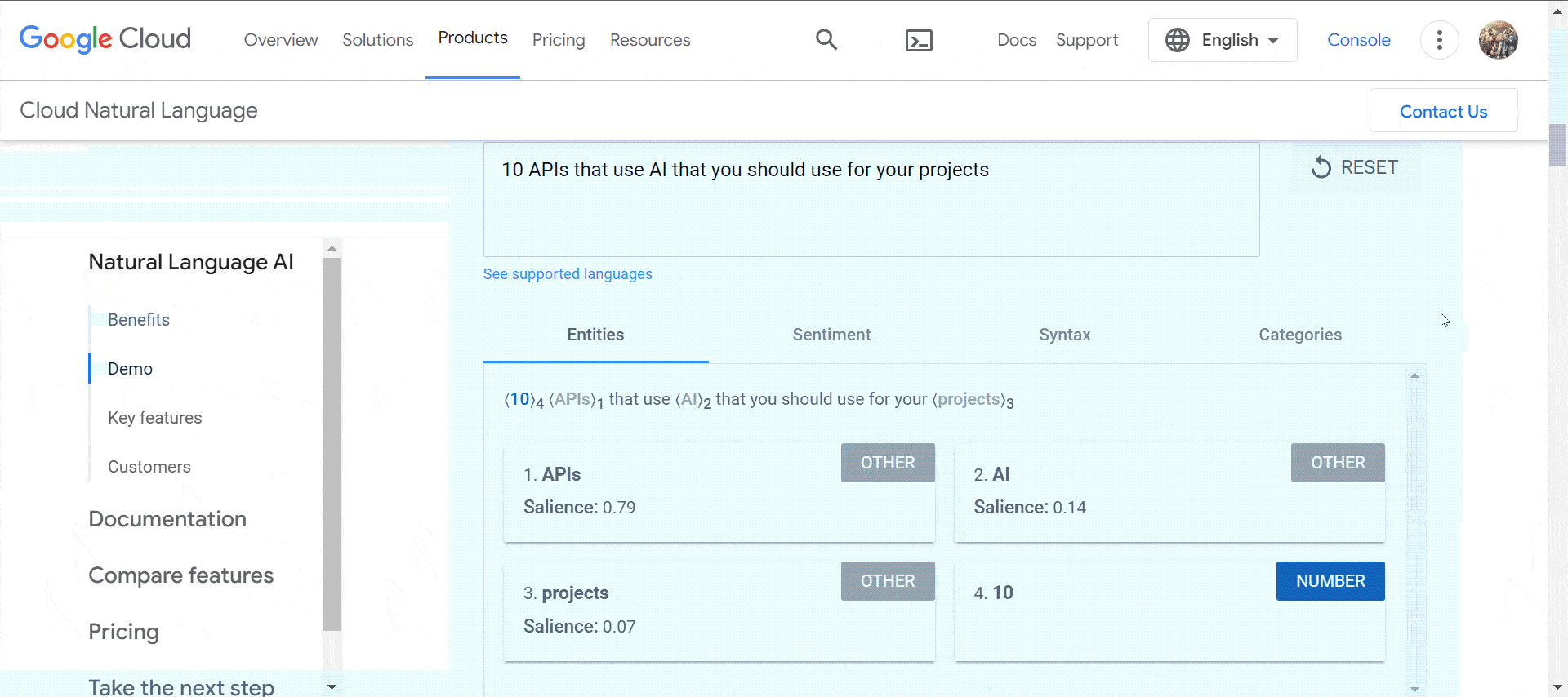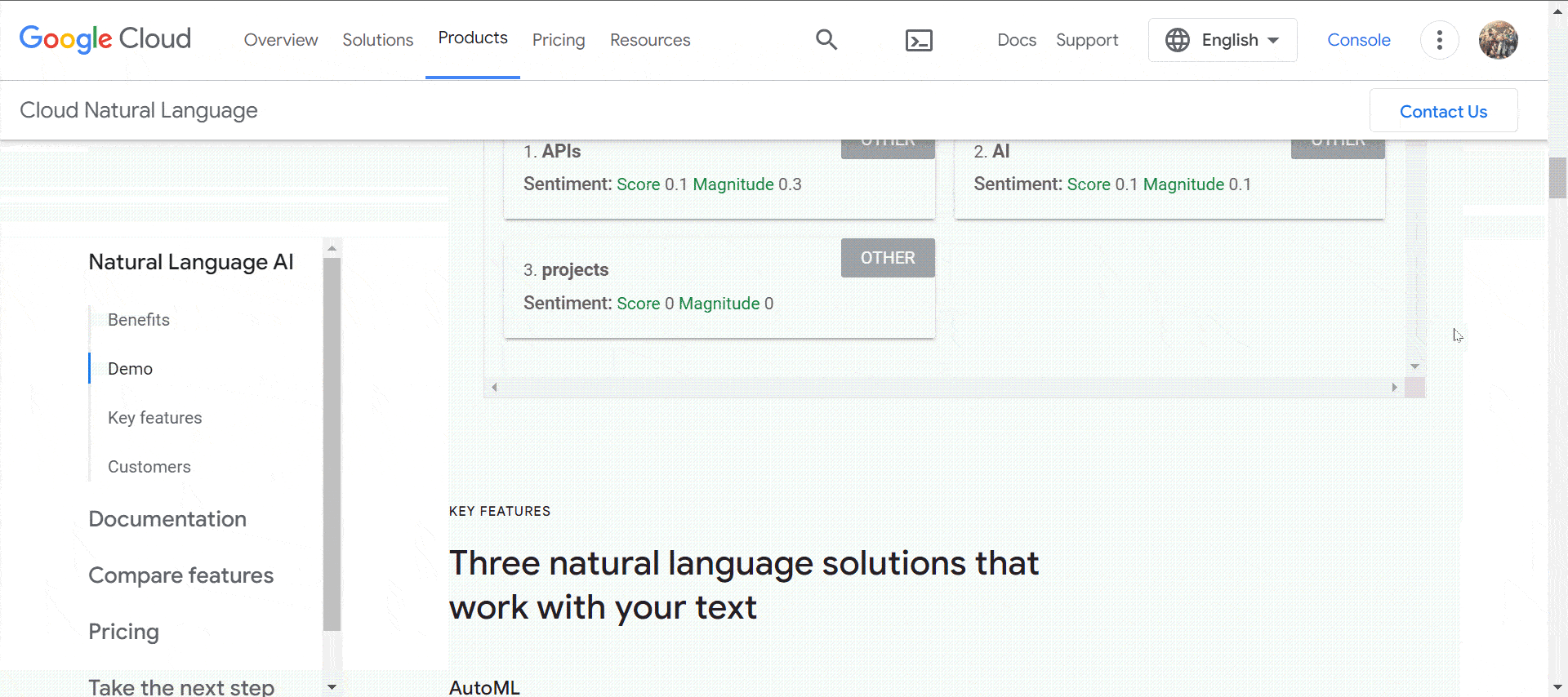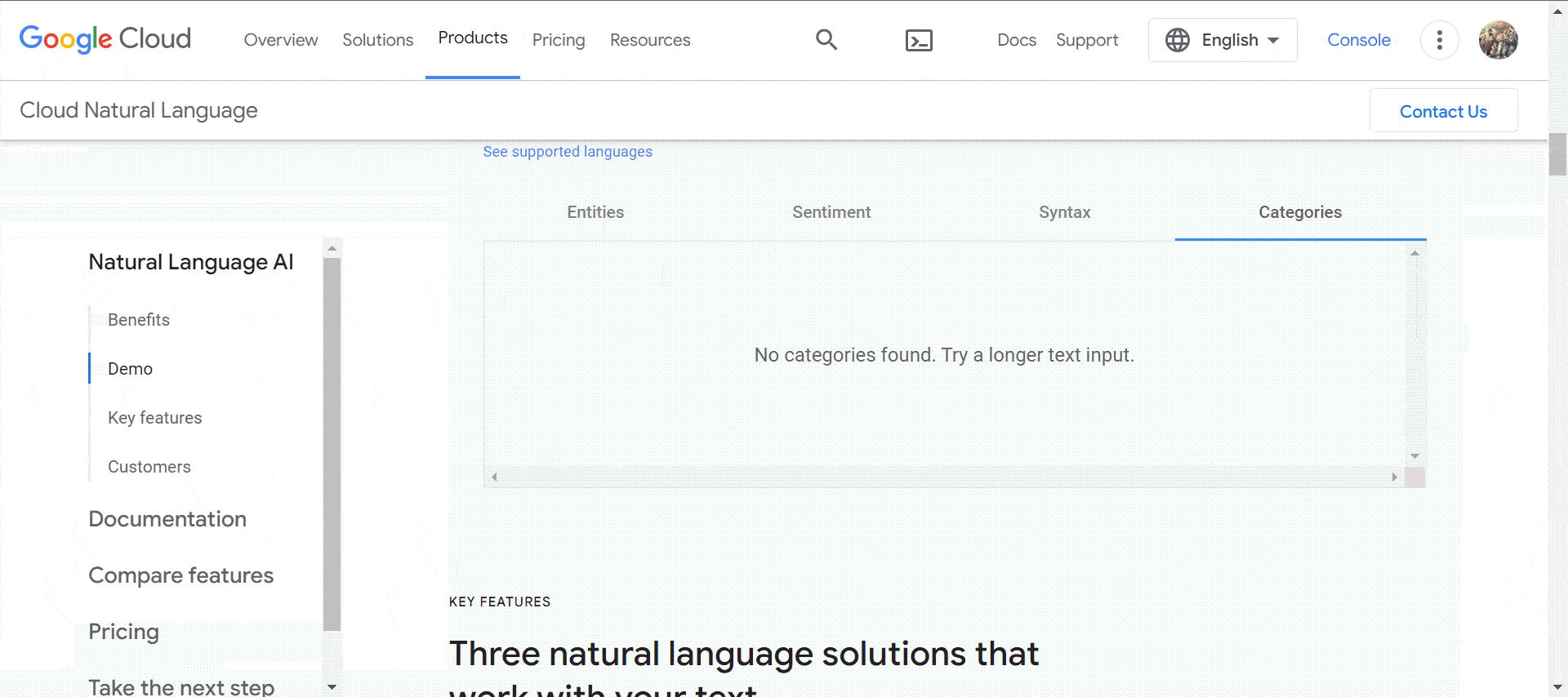
## **2. IBM Watson Text to Speech API**
The IBM Watson Text to Speech API is an innovative technology that converts written text into spoken words. With a natural and human-like voice, this API is perfect for creating audio content for your applications, such as virtual assistants, educational tools, and more.
## **3. Amazon Rekognition**
Amazon Rekognition is an image and video analysis API offered by Amazon Web Services. It utilizes deep learning algorithms to identify objects, people, text, and activities within images and videos.
With the ability to analyze thousands of images in real-time, Amazon Rekognition is perfect for applications in various industries, including security, retail, and media.
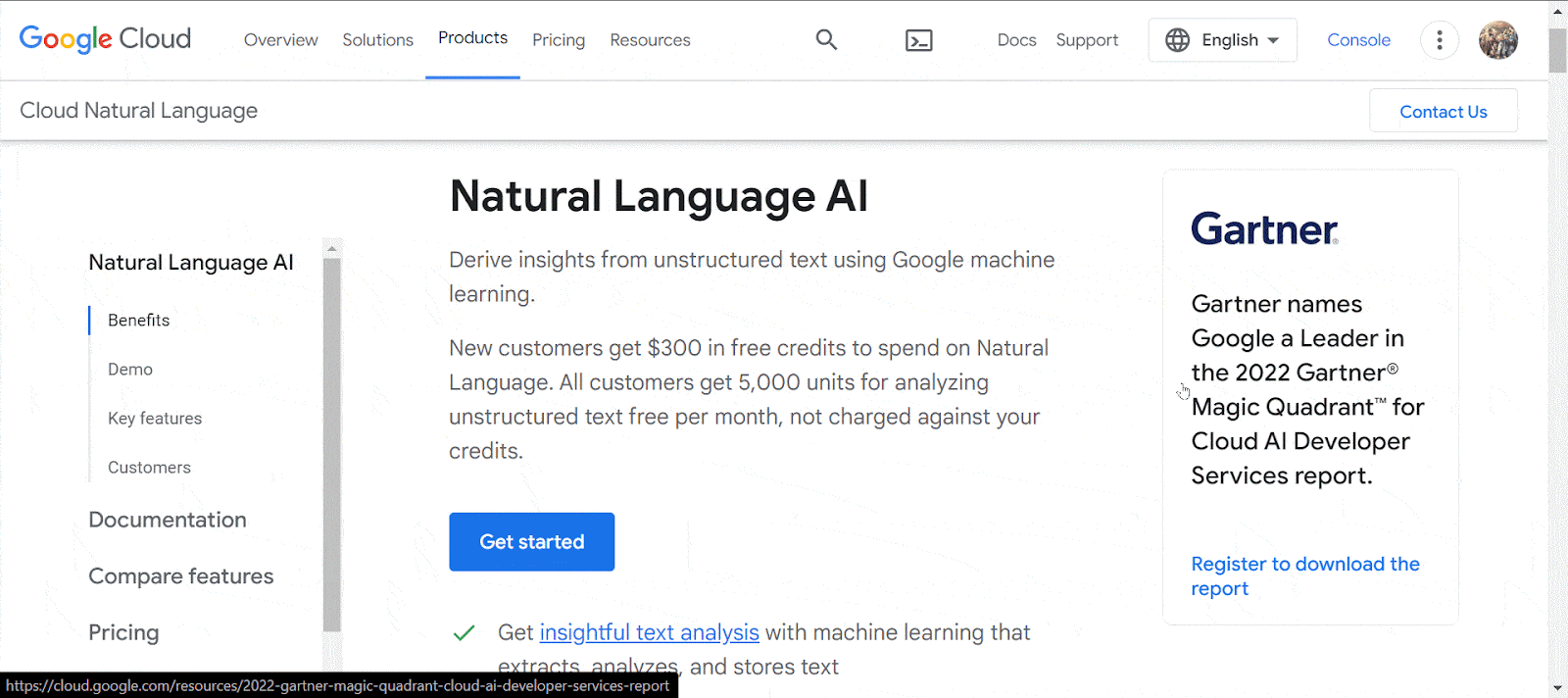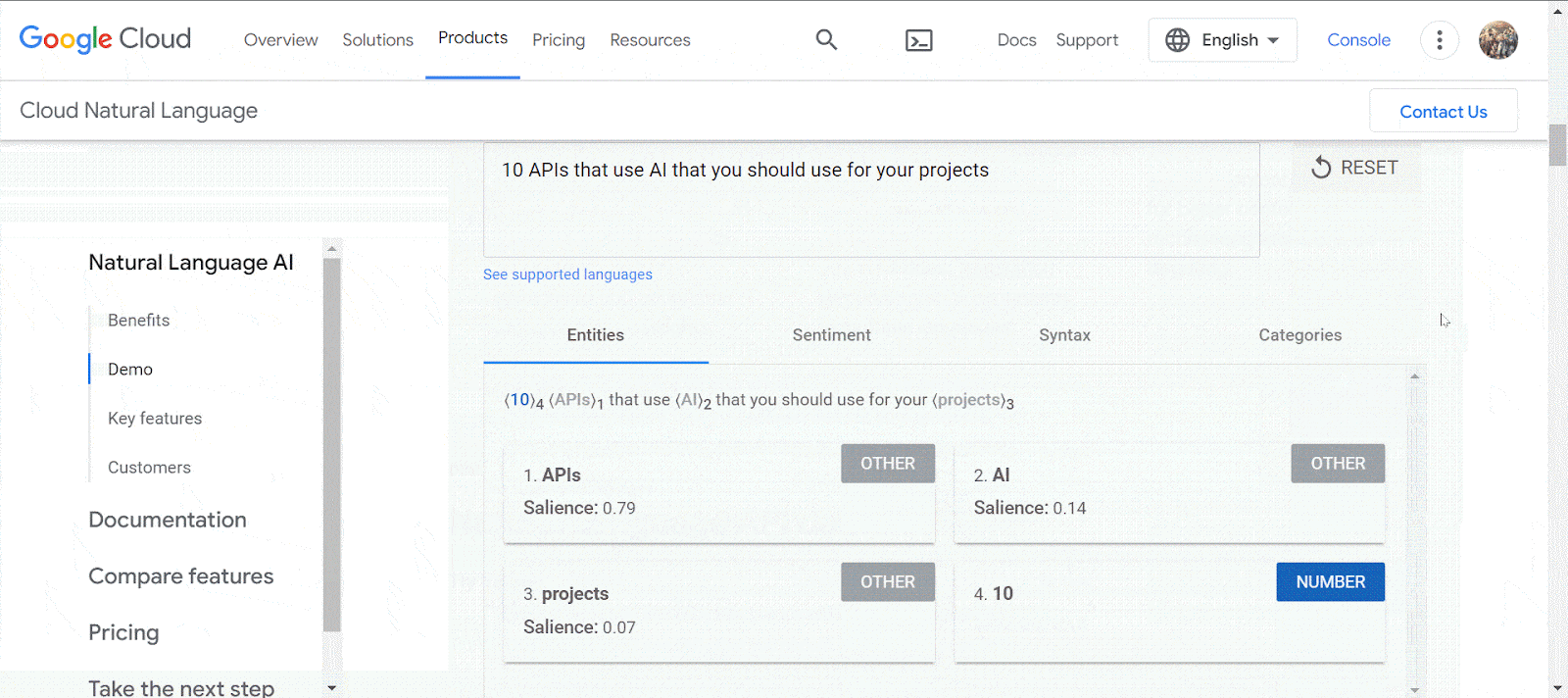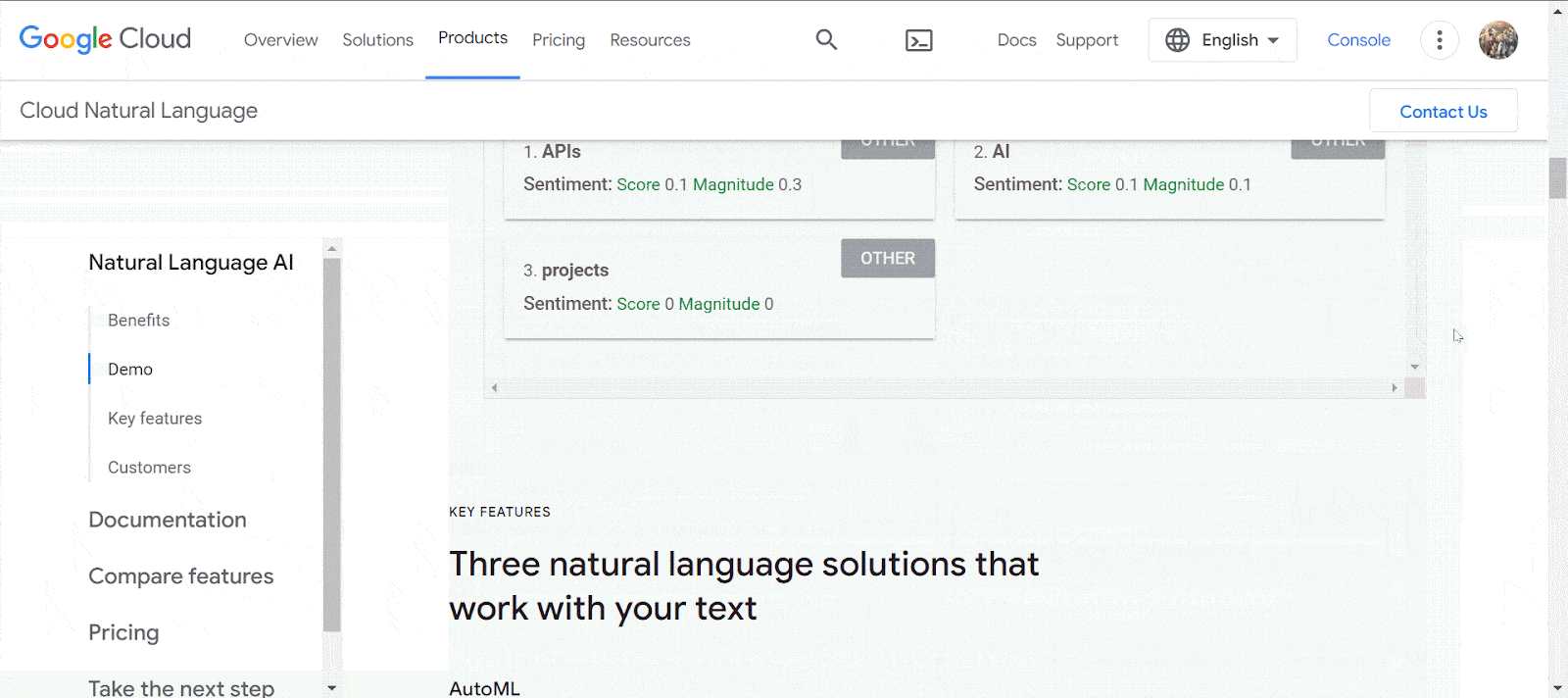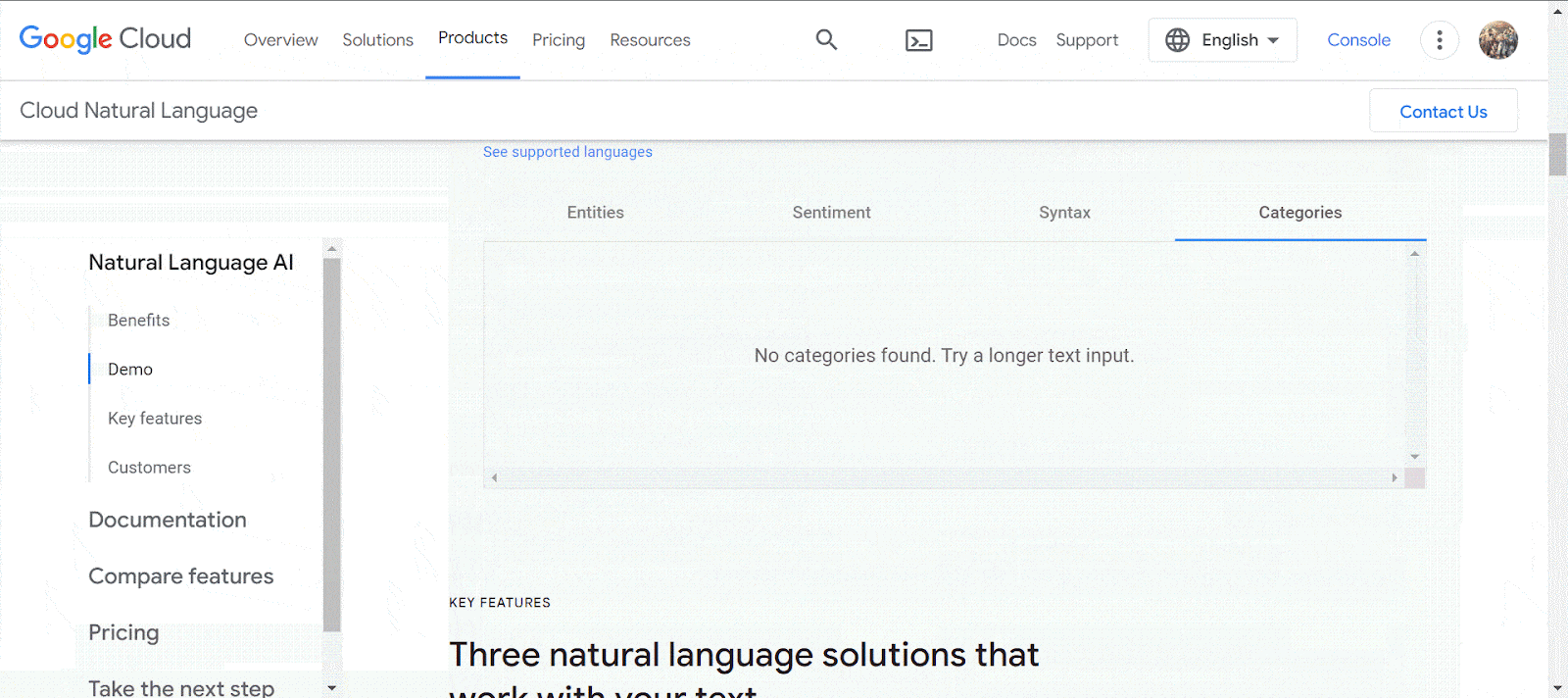
## **4. Microsoft Azure Cognitive Services**
Microsoft Azure Cognitive Services is a collection of APIs that enable developers to add intelligent features to their applications. With services ranging from speech recognition to language analysis and computer vision, Azure Cognitive Services makes it easy to integrate advanced artificial intelligence capabilities into your projects.
Whether you're looking to improve customer experiences or streamline operations, Azure Cognitive Services has the tools you need to get the job done.
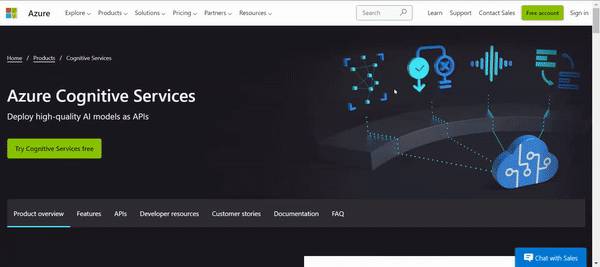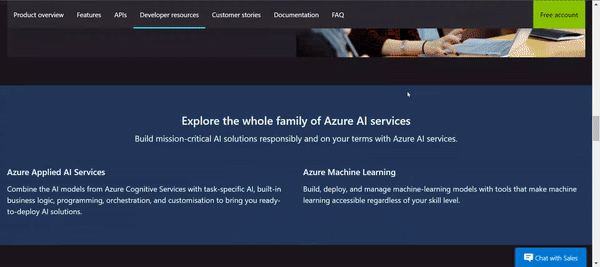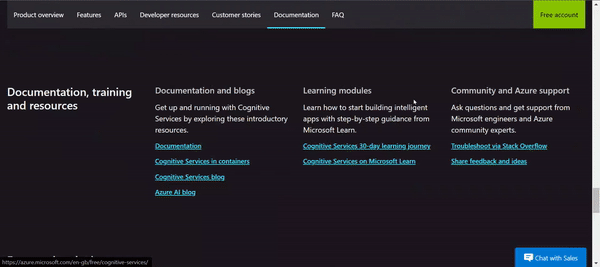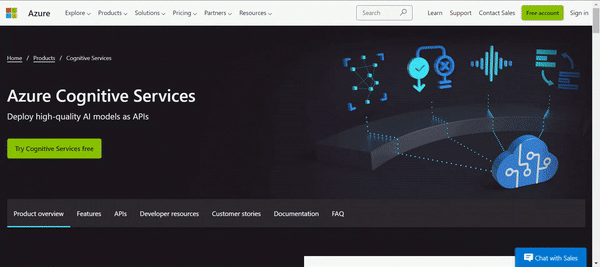
## **5. Google Cloud Speech-to-Text API**
Google Cloud Speech-to-Text API is a powerful tool for converting speech into text. With support for multiple languages and the ability to transcribe speech in real-time, this API is perfect for a range of applications, including voice-controlled devices, voice search, and call centers.
Google Cloud Speech-to-Text API makes it easy to turn spoken words into actionable data, helping to streamline operations and improve customer experiences.
## **6. IBM Watson Tone Analyzer**
IBM Watson Tone Analyzer is an AI-powered tool for analyzing the tone of written text. Whether you're looking to understand customer feedback, analyze social media posts, or evaluate your own writing, this API makes it easy to extract meaningful insights from large amounts of text data.
With the ability to detect emotions, writing styles, and social tones, IBM Watson Tone Analyzer is an essential tool for any data-driven project.
## **7. Amazon Lex**
Amazon Lex is an AI-powered conversational interface that makes it easy to build chatbots and virtual assistants. With the ability to understand natural language and respond with real-time, human-like responses, Amazon Lex is perfect for creating conversational experiences across a wide range of applications, including customer service, entertainment, and more.
Whether you're looking to improve user engagement or streamline operations, Amazon Lex is a powerful tool for making your projects magical.
## **8. Google Cloud Vision API**
Google Cloud Vision API is a powerful tool for analyzing images and videos. With the ability to detect objects, faces, logos, and more, this API makes it easy to extract meaningful insights from visual data. Whether you're looking to analyze customer photos or automate image-based tasks, Google Cloud Vision API is an essential tool for any data-driven project. With real-time analysis and support for multiple file types, this API is the perfect solution for bringing your image-based projects to life.
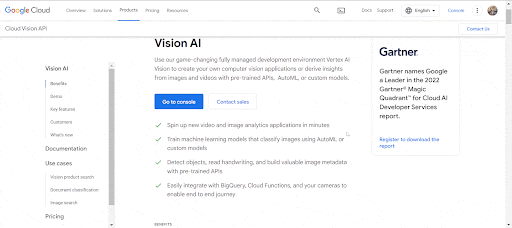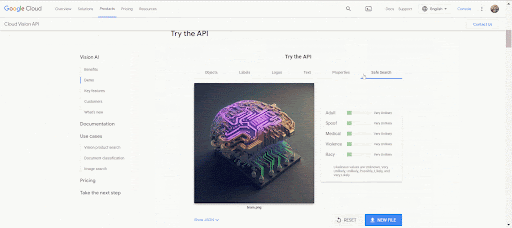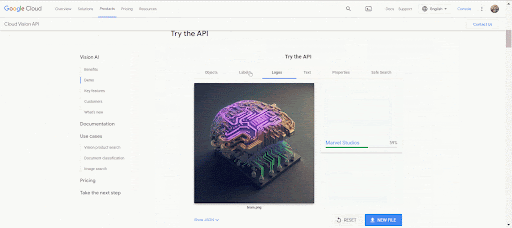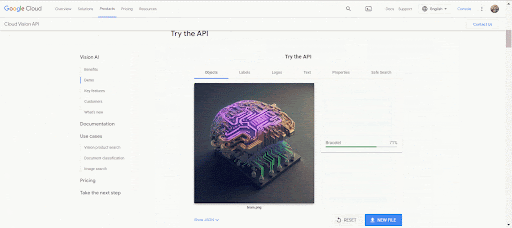
## **9. IBM Watson Assistant**
IBM Watson Assistant is an AI-powered virtual assistant tool that makes it easy to build conversational experiences. Whether you're looking to create chatbots, voice assistants, or text-based interfaces, Watson Assistant makes it simple to add natural language processing and machine learning capabilities to your projects.
With pre-built templates, customizable skills, and a powerful development platform, IBM Watson Assistant is the perfect solution for creating engaging and intelligent conversational experiences.
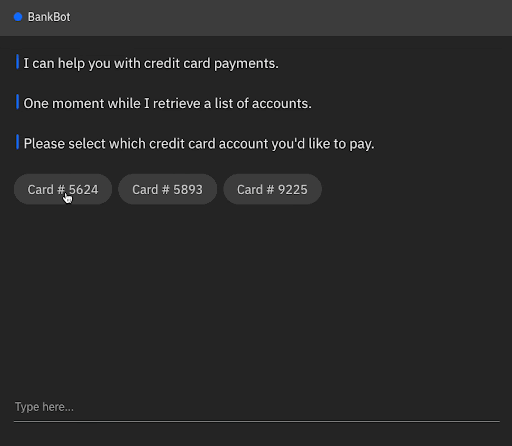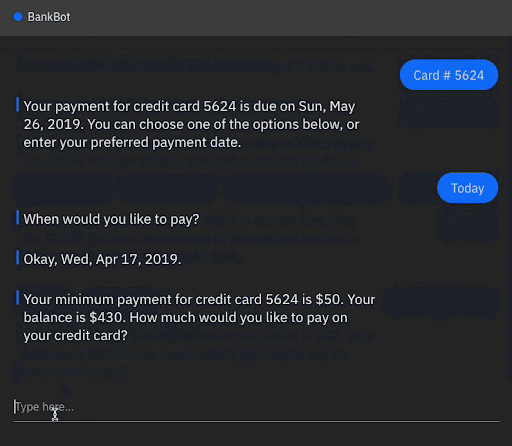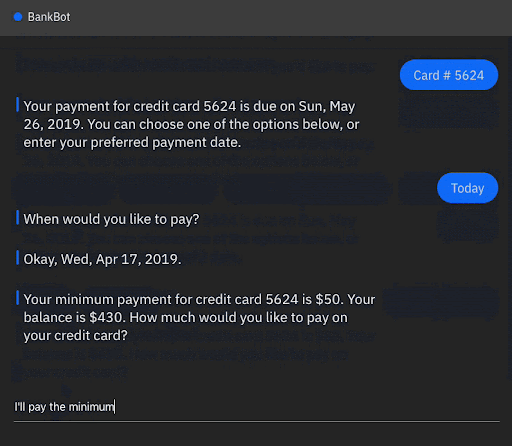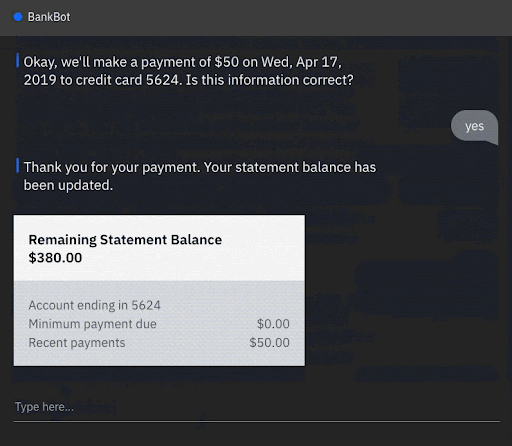
## **10. Amazon SageMaker**
Amazon SageMaker is a fully managed platform for developing, training, and deploying machine learning models. With built-in algorithms, pre-built workflows, and a powerful development environment, SageMaker makes it easy to add machine learning capabilities to your applications.
Whether you're looking to create predictive models, improve customer experiences, or automate tasks, Amazon SageMaker provides the tools and resources you need to bring your projects to life.
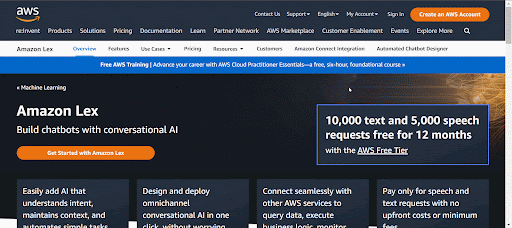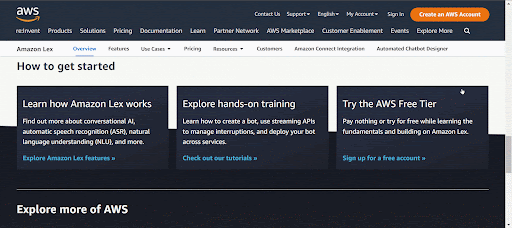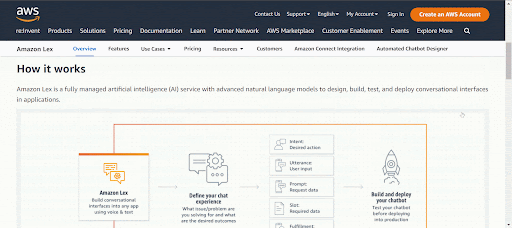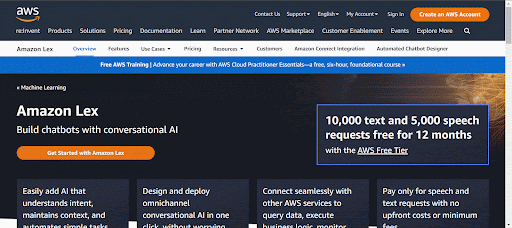
These are just a few examples of the many AI-powered APIs that are available. You may want to consider which one is the best fit for your specific project needs. | ananddas |
1,356,659 | Generate requirements.txt file using pipreqs | In this article, I will explain how to Generate a requirements.txt file for any project based on... | 0 | 2023-02-07T10:21:28 | https://dev.to/aws-builders/generate-requirementstxt-file-using-pipreqs-31db | git, cloud, opensource, programming | In this article, I will explain how to Generate a `requirements.txt` file for any project based on imports libraries using pipreqs
First, install pipreqs : `pip install pipreqs`
after that you can use any of these commands :
```
Usage:
pipreqs [options] [<path>]
Arguments:
<path> The path to the directory containing the application files for which a requirements file
should be generated (defaults to the current working directory)
Options:
--use-local Use ONLY local package info instead of querying PyPI
--pypi-server <url> Use custom PyPi server
--proxy <url> Use Proxy, parameter will be passed to requests library. You can also just set the
environments parameter in your terminal:
$ export HTTP_PROXY="http://10.10.1.10:3128"
$ export HTTPS_PROXY="https://10.10.1.10:1080"
--debug Print debug information
--ignore <dirs>... Ignore extra directories, each separated by a comma
--no-follow-links Do not follow symbolic links in the project
--encoding <charset> Use encoding parameter for file open
--savepath <file> Save the list of requirements in the given file
--print Output the list of requirements in the standard output
--force Overwrite existing requirements.txt
--diff <file> Compare modules in requirements.txt to project imports
--clean <file> Clean up requirements.txt by removing modules that are not imported in project
--mode <scheme> Enables dynamic versioning with <compat>, <gt> or <non-pin> schemes
<compat> | e.g. Flask~=1.1.2
<gt> | e.g. Flask>=1.1.2
<no-pin> | e.g. Flask
```
Example
`$ pipreqs /home/project/location
Successfully saved requirements file in /home/project/location/requirements.txt`
after that, you will find the requirement.txt was added to the folder path
**Note: I copied this post from my classmate @kareemnegm who passed away this year. So please, pray to him. God’s mercy for you, Kareem❤💚🤍💔💔**
<br>
[GitHub](https://github.com/a00ayad00)
[LinkedIn](https://www.linkedin.com/in/a00ayad00)
[Facebook](https://m.facebook.com/a00ayad00)
[Medium](https://a00ayad00.medium.com/) | ayad |
1,356,807 | Web Security | What are these texts? I was studing and for me to have some real study done I need to write it down,... | 0 | 2023-02-07T12:23:58 | https://dev.to/shinspiegel/web-security-c9h | webdev, security, websecurity | ---
title: Web Security
published: true
description:
tags: webdev, security, websecurity
cover_image: https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTzEZGP6gE8LAnZ6NlSZUG-jat5bkkrZebqQA&usqp=CAU
---
> **What are these texts?**
> I was studing and for me to have some real study done I need to write it down, this is a small collection of topics that I studied in the last few weeks.
> Other links from the same study-pool:
> - [Branching Strategies](https://dev.to/shinspiegel/branching-strategies-535m/edit) > > - [CI / CD](https://dev.to/shinspiegel/ci-cd-nb7)
> - [Critical Rendering Path](https://dev.to/shinspiegel/critical-rendering-path-1acm)
> - [Requirements](https://dev.to/shinspiegel/requirements-7d4)
> - [Release Strategy](https://dev.to/shinspiegel/release-strategy-51be)
> - [REST](https://dev.to/shinspiegel/rest-3877)
> - [Static Analysis](https://dev.to/shinspiegel/static-analysis-2650)
> - [Web Security](https://dev.to/shinspiegel/web-security-c9h)
## Web Security
Web apps have become essential business enablers as more organizations use them for a variety of purposes, including e-commerce, customer engagement, and employee empowerment. These apps continue to be the target of serious cyber attacks despite the fact that they generate enormous amounts of user and organizational data. Web security fundamentals, common vulnerabilities, and resources to keep up with the shifting threat landscape are covered in this article.
## Online Web Applications Security Project (OWASP)
The Open Web Application Security Project, or OWASP, is an international non-profit organization dedicated to web application security. One of OWASP’s core principles is that all of their materials be freely available and easily accessible on their website, making it possible for anyone to improve their own web application security. The materials they offer include documentation, tools, videos, and forums. Perhaps their best-known project is the OWASP Top 10.
### Top ten list
1. **Injection.**
Before understanding user input, web apps that take it must correctly validate it. Attackers may inject code or commands that are then executed if this is not done correctly. A successful injection can lead to a number of detrimental effects, ranging from attackers gaining access to sensitive information to losing administrative control of the server.
1. **Broken Authentication.**
Many web applications depend on authentication and session management. Attackers may be able to steal user identities and accounts thanks to security weaknesses in these procedures.
1. **Sensitive Data Exposure.**
To keep it from being accessed by outside parties, web applications must secure the data they process, both while it is in transit and while it is at rest. This is crucial for PII that relates to financial data, healthcare data, and other types of PII (Personally Identifiable Information). Credit card fraud, identity theft, account takeover, and other attacks are included in the risk category of sensitive data exposure.
1. **XML External Entities (XXE).**
A common format for storing and sharing data is XML and JSON. It features the capability to dereference local or external URIs using the parser. An attacker may use a poorly-configured parser in a number of different ways. Malicious XML/JSON can attempt remote code execution, refer to confidential local data (such a file containing user credentials), or conduct a DoS (Denial of Service) assault by accessing local resources, among other things.
1. **Broken Access Control.**
This refers to inadequately-enforced restrictions on what authenticated users are allowed to do. A system with this flaw can allow attackers to gain unauthorized access to data, and even to interfere with the access that legitimate users have.
1. **Security Misconfiguration.**
This group of dangers is highly diverse. It covers a wide range of topics, such as unpatched vulnerabilities in services, libraries, frameworks, and applications, incorrectly configured HTTP headers, sensitive information contained in verbose error messages that can be used to strengthen an attack, and open cloud storage (data stored in the cloud with unrestricted access privileges).
1. **Cross-Site Scripting (XSS).**
Numerous online apps include user inputs into their sites. In XSS, an attacker provides inputs that contain scripts, the attacker wants the scripts to be included in the pages delivered to other users. (Common examples include comments, product reviews, user profiles for membership sites, etc.) An attacker can do a number of things if a web application does not correctly validate its inputs, including hijacking user sessions, changing the pages that are served to other users, and rerouting other users to malicious websites.
1. **Insecure Deserialization.**
XML and JSON are often used to serialize data. Web applications are vulnerable to malware payloads if they receive serialized data from unreliable sources. Numerous exploits, such as privilege escalation and remote code execution, may emerge from this.
1. **Using Components with Known Vulnerabilities.**
If a library or framework that an application utilizes has a known exploit, the attacker may be able to access the same internal resources as the program if they are successful. Depending on the application's access, this might lead to anything from server espionage and remote code execution to data theft.
1. **Insufficient Logging & Monitoring.**
Web applications must accurately record events so that administrators may determine if potentially malicious activity is taking place. Organizational regulations should also mandate that administrators keep a close eye on the logs to see what's happening. Failure to do so will significantly increase the harm done by successful attacks and frequently enable attackers to switch targets and broaden the scope of their operations. This risk might appear the simplest to manage out of the top 10, yet it still poses a serious threat to business.
## Some Specifics
OWASP is a gives the general idea on how to manage and work with the security for web applications. Still there is some common know vector for attacks.
### SQL Injection
An attacker can take advantage of weaknesses in a database's search process by using SQL injection. SQL injection allows an attacker to get access to sensitive data, create or modify user rights, or carry out data change, manipulation, or destruction schemes. A hacker can thus seize important data or change it to prevent or manage the operation of a vital system. An easy way to accomplish this though non-validate user input, or query params.
### Cross-site Scripting
Cross-site scripting (XSS) is the name of a flaw that allows attackers to place client-side scripts inside of a page. This is then utilized to have immediate access to crucial info. A hacker may employ XSS to impersonate another user or trick a user into exposing important information. Some examples could be unintentional ability for the user to add custom details on their profile non-validating this user input.
### Remote File Inclusion
With remote file inclusion, an attacker makes use of flaws in a web application to reference external scripts. The attacker can then try to upload malware using an application's referencing feature. These malware varieties are also known as backdoor shells. The entire process is carried out from a different Uniform Resource Locator (URL) on a different domain.
### Password Breach
Password hacking is a frequent method used to access online resources. Frequently, a hacker will use a password that a user or administrator had previously used to sign in to a different website for which the hacker has a list of login information.
In other instances, hackers employ a method known as "password spraying," in which they utilize well-known passwords like "12345678" or "password123" and attempt each one individually until they succeed in gaining access. Other methods include employing keyloggers or just looking for your password on paper and utilizing it.
### Data Breach
An information breach occurs when private or delicate data is made public. Data breaches can occasionally occur by mistake, but they are frequently the work of hackers who want to use or sell the data.
### Malware Installation
Malware can do a great deal of harm once it has been installed on a local network, including data exfiltration, ransomware encryption, and extortion.
### Phishing
Since the majority of attacks begin with phishing emails, online security must have a method to prevent fraudulent emails from getting to an employee's inbox.
### Distributed denial-of-service (DDoS)
The distributed denial-of-service (DDoS) assault allows attackers to disrupt services for days at a time, harming revenue and operational continuity.
## Tool of trade when dealing with web security
These are some ways to protect the web application against some attack vectors.
### Web Application Firewall (WAF)
A good WAF can potentially reduce or stop DDoS attacks and reduce or block malicious code injection when users submit information using online forms. It can substantially boost your techniques and reduce attacks, but it shouldn't be the only way to counter web-based attacks.
### Vulnerability scanners
Before it is put into use, any software should be penetration tested, but even in production, it should be regularly checked for security flaws. Scanners carry out simple hacker behaviors to discover weaknesses in your software. You can address problems before they lead to a serious data breach if you identify vulnerabilities before attackers do. Good scanning tools also look for corporate infrastructure configuration errors.
### Fuzzing tools
Similar to scanners, fuzzing tools can evaluate code as it is being produced in real time. A fuzzer checks the code before it is deployed to staging, throughout testing, and lastly before it is deployed to production. A fuzzer, as opposed to a straightforward scanner, offers information on the potential issue to assist developers and operational staff in resolving it.
### Black box testing tools
Black box testing techniques simulate real-world attacks to detect flaws in software, which attackers utilize in a variety of ways. These tools carry out harmful operations against installed software to find potential security holes and make use of widely available exploits to assist developers in fixing problems.
### White box testing tools
Coding errors cause widespread vulnerabilities to be introduced as developers create their programs. A white box testing tool evaluates code as it is written and gives developers knowledge to assist them avoid frequent errors. Consider white box testing as a means to monitor the creation of software in order to identify vulnerabilities before the code is compiled and released to testing and production settings.
| shinspiegel |
1,356,826 | API de patentes de autos en Chile | Autente.io | Hace unos días me encontraba buscando un API que me permitiera obtener datos de un auto por la... | 0 | 2023-02-07T12:51:59 | https://dev.to/ocarmora/buscador-de-patentes-de-autos-en-chile-autenteio-5aen | spanish, webdev, api, node | Hace unos días me encontraba buscando un API que me permitiera obtener datos de un auto por la patente (con información pública, claro) para poderlo integrar a la página web del emprendimiento que tenemos con mi hermano. Mala suerte la mía, no encontré nada.
Demás que debe haber algo, pensé. Busqué APIs, NPM, proyectos en github y nada. Así que me puse manos a la obra y estuve trabajando un par de días en desarrollar algo (básico pero funcional).
Servía, pero, demoraba algo así como 9 segundos en traerme los datos que necesitaba. Seguí con las manos en el código y logré hacer que se demorara entre 800ms a 2s. Como verás, en algunos casos, seguía demorando mucho pero, de momento, me sirve.
Ahora bien. Si me sirve a mí, ¿le servirá a alguien más?. Me puse a probar distintos servicios cloud para subir el proyecto. Así que, en una suerte de **beta**, liberé https://autente.io. Autente es una API que te permite obtener datos (públicos y no relacionados al dueño) de un auto o motocicleta por la patente. Trabajé algo así como 1 semana así que la estaré probando, pero, para probarla, necesito de vuestra ayuda.
Si bien el API como tal está funcionando, aún me falta hacer la documentación de los endpoints (sí, lo más importante jeje) pero en https://autente.io les dejo una sección con una demo de los datos que obtienen a ver si a alguien que tenga un emprendimiento automotriz, de seguros o quien necesite este tipo de datos le pueda servir y podamos colaborar.
FAQ:
1. ¿Tendrá costo? - De momento no, pero creo que sí. Algo mínimo, para poder costear los servicios Cloud.
2. ¿Tendrá soporte? - Pues sí. Imagino que si se paga por un servicio, el soporte es prácticamente obligatorio.
3. ¿Tendrá soporte para otros países? - Es algo a ver con el tiempo. Imagino que sí, creo que los procesos internos pueden ser similares. No lo tengo claro.
¡Gracias por leer! Responderé cualquier duda respecto a Autente.io en los comentarios :) | ocarmora |
1,356,904 | Web Scraping in Golang | Introduction Every developer uses web scraping as a necessary tool at some time in their... | 21,222 | 2023-02-07T13:23:47 | https://dev.to/siddheshk02/web-scraping-in-golang-4hcl | go, scraping, colly, gofiber | ## Introduction
Every developer uses web scraping as a necessary tool at some time in their career. Therefore, developers must understand web scrapers and how to create them.
In this blog, we will be covering the basics of web scraping in Go using the [Fiber](https://docs.gofiber.io/) and [Colly](http://go-colly.org/) frameworks. Colly is an open-source web scraping framework written in Go. It provides a simple and flexible API for performing web scraping tasks, making it a popular choice among Go developers. Colly uses Go's concurrency features to efficiently handle multiple requests and extract data from websites. It offers a wide range of customization options, including the ability to set request headers, handle cookies, follow redirects, and more
We'll start with a simple example of extracting data from a website and then move on to more advanced topics like customizing the scraping process and setting request headers. By the end of this blog, you'll have a solid understanding of how to build a web scraper using Go and be able to extract data from any website.
## Prerequisites
To continue with the tutorial, firstly you need to have Golang and Fiber installed.
### Installations :
- [Golang](https://go.dev/doc/install)
- [Fiber](https://docs.gofiber.io/): We'll see this ahead in the tutorial.
- [Colly](http://go-colly.org/): We'll see this ahead in the tutorial.
## Getting Started
Let's get started by creating the main project directory `Go-Scraper` by using the following command.
(🟥Be careful, sometimes I've done the explanation by commenting in the code)
```
mkdir Go-Scraper //Creates a 'Go-Scraper' directory
cd Go-Scraper //Change directory to 'Go-Scraper'
```
Now initialize a mod file. (If you publish a module, this must be a path from which your module can be downloaded by Go tools. That would be your code's repository.)
```
go mod init github.com/<username>/Go-Scraper
```
To install the Fiber Framework run the following command :
```
go get -u github.com/gofiber/fiber/v2
```
To install the Colly Framework run the following command :
```
go get -u github.com/gocolly/colly/...
```
Now, let's make the `main.go` in which we are going to implement the scraping process.
In the `main.go` file, the first step is to initialize a new Fiber app using the `fiber.New()` method. This creates a new instance of the Fiber framework that will handle the HTTP requests and responses.
Next, we define a new endpoint for the web scraper by calling the `app.Get("/scrape", ...)` method. This creates a new GET endpoint at the `/scrape` route, which will be used to trigger the web scraping process.
```
package main
import (
"fmt"
"github.com/gofiber/fiber/v2"
)
func main() {
app := fiber.New() // Creating a new instance of Fiber.
app.Get("/scrape", func(c *fiber.Ctx) error {
return c.SendString("Go Web Scraper")
})
app.Listen(":8080")
}
```
After running the go run main.go command the terminal will look like this,
Let's create a new instance of the Colly collector using the `colly.NewCollector()` method. The collector is responsible for visiting the website, extracting data, and storing the results.
```
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
```
The `colly.AllowedDomains` property in the Colly framework is used to restrict the domains that the web scraper is allowed to visit. This property is used to prevent the scraper from visiting unwanted websites. For this blog, we are going to use [this](http://j2store.net/demo/index.php/shop) site which contains sample data and the domain is `j2store.net` .
The Colly collector can be configured in a variety of ways to customize the web scraping process. In this case, we define a request handler using the `collector.OnRequest(...)` method. This handler is called each time a request is made to the website, and it simply logs the URL being visited.
Now, to extract data from the website, we are going to use the `collector.OnHTML(...)` method to define a handler for a specific HTML element.
This is how the sample data on the site looks,
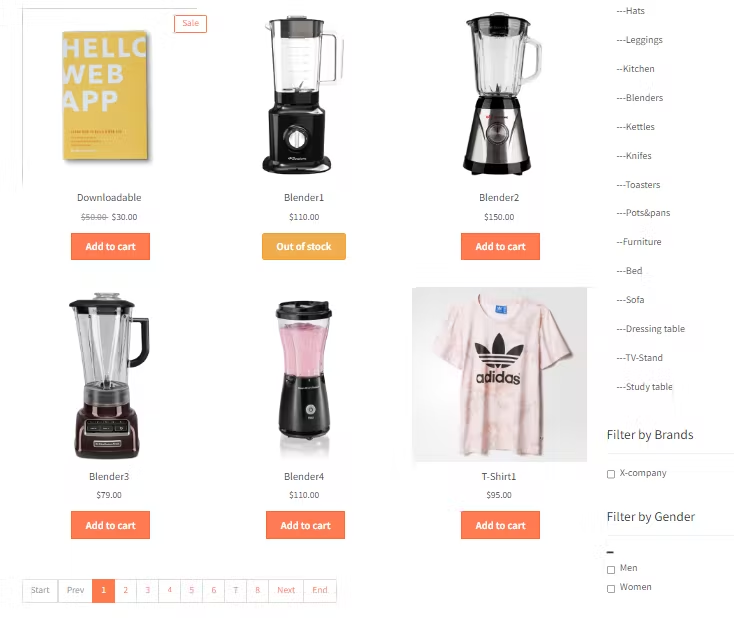
Here are some product images, their names and their price. We are just going the extract their names, image URL and prices.
So, let's create a struct item containing these three fields i.e. Name, Price, Image URL. The data type is defined as a string. JSON field is added as we are going to return all the data in JSON.
```
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
```
Now, Let's work on the `OnHTML()` callback.
```
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
```
Here, inside the OnHTML() function firstly, we added something inside quotes that is the parent element it's a CSS selector, inside this div tags all the products are added. You can see it on the page by Inspect Element and hovering over the product just like the way I did in the image below. This means that whenever this parent element comes then this OnHTML callback must be called.
We've used the child element to get only the required data i.e the Name, Price and the ImgUrl. You can see these Child elements just the way we did for the parent element.
Finally, add the product details one by one into `items` .
Now, the `main.go` will look like,
```
package main
import (
"fmt"
"github.com/gocolly/colly"
"github.com/gofiber/fiber/v2"
)
type item struct {
Name string `json:"name"`
Price string `json:"price"`
ImgUrl string `json:"imgurl"`
}
func main() {
app := fiber.New()
app.Get("/scrape", func(c *fiber.Ctx) error {
var items []item
collector := colly.NewCollector(
colly.AllowedDomains("j2store.net"),
)
collector.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
collector.OnHTML("div.col-sm-9 div[itemprop=itemListElement] ", func(h *colly.HTMLElement) {
item := item{
Name: h.ChildText("h2.product-title"),
Price: h.ChildText("div.sale-price"),
ImgUrl: h.ChildAttr("img", "src"),
}
items = append(items, item)
})
collector.Visit("http://j2store.net/demo/index.php/shop") // initiate a request to the specified URL.
return c.JSON(items) //we return the extracted data to the client by calling the c.JSON(...) method.
})
app.Listen(":8080")
}
```
Now, run the command `go run main.go` and head to `http://127.0.0.1:8080/scrape` on your browser.
You'll see the data like the following,
Now, this data is from the first page but there are multiple pages on the site so we've to deal with all the pages. Colly Framework works very well with this. We need to add one more OnHTML callback for moving to the next page.
```
collector.OnHTML("[title=Next]", func(e *colly.HTMLElement) {
next_page := e.Request.AbsoluteURL(e.Attr("href"))
collector.Visit(next_page)
})
```
[title=Next] is the CSS selector for the Next button. You can see this by following the same way as did earlier. Now the URL added in the href tag is not an absolute URL, so we've used the AbsoluteUrl() function to convert the relative URL to an absolute URL.
Now, run the command `go run main.go` and head to `http://127.0.0.1:8080/scrape` on your browser.
You'll see all product details from all the pages.
This is the basic implementation of a web scraper using the Fiber and Colly frameworks in Go.
## Conclusion
You can find the complete code repository for this tutorial here 👉[Github](https://github.com/Siddheshk02/Go-Scraper).
Now, I hope you must have a solid foundation to build more complex and sophisticated web scraping projects. Now, you can try Scraping dynamic websites along with Data storage(SQL or NoSQL), Image and file download, Distributed scraping and so on.
To get more information about Golang concepts, projects, etc. and to stay updated on the Tutorials do follow [Siddhesh on Twitter](https://twitter.com/siddhesh1102) and [GitHub](https://github.com/Siddheshk02).
Until then Keep Learning, Keep Building 🚀🚀
| siddheshk02 |
1,357,294 | Create a New Jekyll Post with a Simple Shell Command | Let's build a shell command to automate the creation of a new post in Jekyll. This will be a short... | 0 | 2023-02-07T18:36:38 | https://codegazerants.com/2023/01/01/create-new-jekyll-post-with-a-command/ | jekyll, bash, shell, automation | ---
title: Create a New Jekyll Post with a Simple Shell Command
published: true
description:
tags: jekyll, bash, shell, automation
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-02-07 18:32 +0000
canonical_url: https://codegazerants.com/2023/01/01/create-new-jekyll-post-with-a-command/
---
Let's build a shell command to automate the creation of a new post in Jekyll.
This will be a short one.
Jekyll has its quirks, and I always wondered why they don't have a simple command to create a new post. I used to copy/paste the previous one, but you know how things are... If you can automate something boring in a few minutes, just do it.
## Creating the Script
We first need to create a simple bash script to do the job for us.
So, create a new file. I call mine `newjekyllpost.sh` and add the following parts to it:
```bash
#!/bin/bash
filename=`date +%Y-%m-%d-new-post.md`
cat > $filename <<EOF
---
layout: post
title: A title
description: A description
categories: ["tag"]
social_image: add here
---
EOF
```
Let's rubberduck this.
The second line is a variable called `filename`. This will be used for our file name with today's date and the following format:
```
YYYY-MM-DD-new-post.md #
```
The third line will create the file with the contents we like. I chose to add the YAML front matter with the most used content for my posts. If I don't want something, I remove it.
And that's it. Our script is that simple. Let's now try to execute it.
## Making the Script Executable
If you try to run it, you will get an error about permissions. There is one more step, which is to change the file's permissions.
```
chmod u+x ./newjekyllpost.sh
```
After that, running `./newjekyllpost.sh` will create a file in the specific folder with our contents.
## Adding an Alias
Let's do one more last thing to make our lives easier.
Right now, we have our script in a specific folder, so we need to write the path each time, which is also boring. Adding an alias for the script will work like magic.
Move the script to any path you want. I keep a `scripts` folder inside my `Users` folder.
Open the profile your shell is using. I'm using ZSH, so I have this line in my `.zshrc` file:
```
alias njp="~/scripts/newjekyllpost.sh"
```
Every time I run `njp` in a folder, the script creates a new file. You can choose any alias you want, of course.
Run `source pathoftheprofilefile` to reload the new changes, and we are done.
## Improving the Script
As I was writing this, I though there is one more thing we could do to improve the script. If there are argguments to the script use them to postfix the filename.
So our first part of the script becomes:
```
if [ $# -gt 0 ]
then
filename=`date +%Y-%m-%d-`
filename+=`echo "$@" | sed -e 's/ /-/g'`.md
else
filename=`date +%Y-%m-%d-new-post.md`
fi
```
In the "bash" language what that means is:
If I have arguments add the date in the filename. Then join with a space all the arguments as string with `"$@"` and then replace the spaces with `-` which is done by the `sed` part.
If I have no arguments, business as usual.
If we run `njp this is my new post` at 2022-12-30 the file will be create will have the following name:
```
2022-12-30-this-is-my-new-post.md
```
Just remember, all of this can be achieved with any language. The logic is the same. I just chose to do it in a bash script because, why not?
_Originally posted on https://codegazerants.com/2023/01/01/create-new-jekyll-post-with-a-command/_ | codegaze |
1,357,365 | How to Deploy to AWS from Fargate backed Gitlab Runners | Introduction I love AWS CodePipeline. It integrates with GitHub and Bitbucket, you can add... | 0 | 2023-02-18T14:27:02 | https://dev.to/aws-builders/how-to-deploy-to-aws-from-fargate-backed-gitlab-runners-184n | aws, community, devops, containers | ## Introduction
I love [AWS CodePipeline](https://aws.amazon.com/codepipeline/). It integrates with GitHub and Bitbucket, you can add as many stages for your pipeline as you want, be it for Approval, Build, Invoking, Testing, and efficiently deploying to multiple AWS Services. One thing it does not to integrate with, unfortunately (at the time of my writing this article), is Gitlab.

This article will cover the steps required to deploy to AWS from a GitLab runner backed by the Amazon Fargate service. I will not talk about how to set everything up, Gitlab covers it in detail on their documentation https://docs.gitlab.com/runner/configuration/runner_autoscale_aws_fargate/
## Prerequisites
Before we get started, there are a few things you need to have set up:
1. [A GitLab account with a repository that will run CI jobs with Fargate.](https://gitlab.com/)
2. [An AWS account.](https://aws.amazon.com/)
3. [GitLab runner set up and running in your AWS account.](https://docs.gitlab.com/runner/configuration/runner_autoscale_aws_fargate/)
4. Fargate task definition that Gitlab runner will use to run your CI jobs.
[A modified version of the example debian image](https://gitlab.com/femilawal76/fargate-driver-debian) in the instructions from Gitlab will be used for the Fargate task Gitlab runner invokes, the only addition is the AWS CLI
```Dockerfile
FROM debian:buster
# ---------------------------------------------------------------------
# Install https://github.com/krallin/tini - a very small 'init' process
# that helps processing signalls sent to the container properly.
# ---------------------------------------------------------------------
ARG TINI_VERSION=v0.19.0
RUN apt-get update && \
apt-get install -y curl && \
curl -Lo /usr/local/bin/tini https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini-amd64 && \
chmod +x /usr/local/bin/tini
# --------------------------------------------------------------------------
# Install and configure sshd.
# https://docs.docker.com/engine/examples/running_ssh_service for reference.
# --------------------------------------------------------------------------
RUN apt-get install -y openssh-server && \
# Creating /run/sshd instead of /var/run/sshd, because in the Debian
# image /var/run is a symlink to /run. Creating /var/run/sshd directory
# as proposed in the Docker documentation linked above just doesn't
# work.
mkdir -p /run/sshd
EXPOSE 22
# ----------------------------------------
# Install GitLab CI required dependencies.
# ----------------------------------------
ARG GITLAB_RUNNER_VERSION=v12.9.0
RUN curl -Lo /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/${GITLAB_RUNNER_VERSION}/binaries/gitlab-runner-linux-amd64 && \
chmod +x /usr/local/bin/gitlab-runner && \
# Test if the downloaded file was indeed a binary and not, for example,
# an HTML page representing S3's internal server error message or something
# like that.
gitlab-runner --version
RUN apt-get install -y bash ca-certificates git git-lfs && \
git lfs install --skip-repo
# ----------------------------------------
# Install AWS CLI.
# ----------------------------------------
RUN apt-get install -y awscli
# -------------------------------------------------------------------------------------
# Execute a startup script.
# https://success.docker.com/article/use-a-script-to-initialize-stateful-container-data
# for reference.
# -------------------------------------------------------------------------------------
COPY docker-entrypoint.sh /usr/local/bin/docker-entrypoint.sh
RUN chmod +x /usr/local/bin/docker-entrypoint.sh
ENTRYPOINT ["tini", "--", "/usr/local/bin/docker-entrypoint.sh"]
```
You will have to [create an ECR repository for the image, build your image and push it ECR](https://aws.amazon.com/ecr/), then create the task definition that uses the image.
## Setting Up The Deployment
The scenario is you have a Gitlab repository that holds a CloudFormation template for creating ECR Repositories, merges to the main branch should update the template in your AWS account. Our pipeline requires two key components
1. Creating a `ecr.yaml` CloudFormation template.
```yaml
AWSTemplateFormatVersion: "2010-09-09"
Description: >
This template creates ECR resources
Parameters:
IAMUserName:
Type: String
Description: IAM User Name
Default: "YOUR_USER_NAME"
AllowedPattern: "[a-zA-Z0-9-_]+"
ConstraintDescription: must be a valid IAM user name
Resources:
ECRRepository:
Type: AWS::ECR::Repository
Properties:
RepositoryName: !Ref AWS::StackName
RepositoryPolicyText:
Version: "2012-10-17"
Statement:
- Sid: "AllowPushPull"
Effect: Allow
Principal:
AWS:
!Join [
"",
[
"arn:aws:iam::",
!Ref AWS::AccountId,
":user/",
!Ref IAMUserName
],
]
Action:
- "ecr:GetDownloadUrlForLayer"
- "ecr:BatchGetImage"
- "ecr:BatchCheckLayerAvailability"
- "ecr:PutImage"
- "ecr:InitiateLayerUpload"
- "ecr:UploadLayerPart"
- "ecr:CompleteLayerUpload"
Outputs:
ECRRepository:
Description: ECR repository
Value: !Ref ECRRepository
```
2. Modifying the `.gitlab-ci.yml` file to include a deployment stage that will deploy your changes to AWS.
```yaml
variables:
STACK_NAME: ecr-stack
TEMPLATE_PATH: /templates/ecr.yaml
stages:
- deploy
cloudformation_deploy:
stage: deploy
script:
- aws cloudformation deploy --template-file $TEMPLATE_PATH --stack-name $STACK_NAME --capabilities CAPABILITY_NAMED_IAM
```
## The Problem
The pipeline is not actually going to work, the AWS CLI will be unable to locate the credentials and will ask you to run `aws configure`. You might be thinking the simple solution is to just create credentials for Gitlab then set the AWS_SECRET_ACCESS_KEY and AWS_ACCESS_KEY_ID environment variables, but that's completely unnecessary (and not very secure).
The pipeline is running in a Fargate container within your AWS account and has proper permissions, so why doesn't it work?
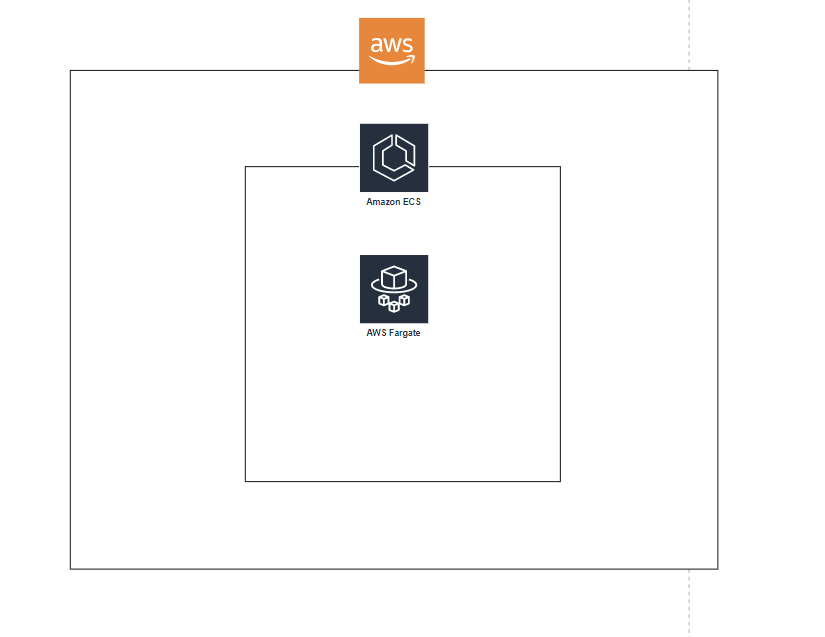
Ordinarily, the container makes a request to the task metadata endpoint to get temporary AWS credentials, but unfortunately, the environment variable it uses for that is only available to the init container process (PID 1). So to fix this issue, we have to set that environment variable.
How do we get an environment variable from an entirely different process? PID 1 environment variables are stored in the environ file of the process, so we can retrieve it from there by running:
```bash
export $(strings /proc/1/environ | grep AWS_CONTAINER_CREDENTIALS_RELATIVE_URI)
```
This will make the variable avaialable to the CI process and enable to container to retrieve temporary AWS credentials, the final `.gitlab.ci.yaml` file will look like this:
```yaml
variables:
STACK_NAME: ecr-stack
TEMPLATE_PATH: /templates/ecr.yaml
stages:
- deploy
deploy:
stage: deploy
script:
- export $(strings /proc/1/environ | grep AWS_CONTAINER_CREDENTIALS_RELATIVE_URI)
- aws cloudformation deploy --template-file $TEMPLATE_PATH --stack-name $STACK_NAME --capabilities CAPABILITY_NAMED_IAM
```
## Conclusion
In this article, we covered the steps required to use the AWS CLI for deployments from a GitLab runner backed by the Amazon Fargate service. With these steps in place, you can automate the deployment of your resources to AWS.
| femilawal |
1,357,525 | 10 Questions to ask your unified API provider | Integrations will form a core part of your product offering and its customer-facing. It's paramount... | 0 | 2023-02-16T14:47:36 | https://truto.one/blog/questions-to-ask-your-unified-api-provider/ | saas, api, productivity |

Integrations will form a core part of your product offering and its customer-facing. It's paramount that it just works 100% of the time. Use the questions below to make sure you don't end up firefighting one day.
## Questions to ask your Unified API provider
- What is your plan for the next 1,2 and 3 years?
Look for stability and clarity in thinking.
- What is your product roadmap?
Look for features that will add value as time goes by. You don't want to use many SaaS products to get integrations done.
- What's their plan for adding to their integrations catalogue?
Look for steady building activity on integrations. Make sure they will continue to support newer integrations. Better yet, ask them for custom integrations.
- Who are your current customers?
Look for big well-known names here.
- What is your tech stack?
Identify any gaps and make sure the tech stack is built for scale.
- What happens if you choose to shut down the company?
Look for open-source solutions or solutions which have open-source elements in them. There are other solutions to alleviate this fear as well such as sharing the code base and self-hosted solutions.
- Is a price increase on the horizon?
Since will be a fundamental part of your product offering, you want to make sure it doesn't become a burden later on. Make sure you have a long-term contract or a commitment to pricing caps.
- Do you do multi-year contracts?
Any vendor will appreciate it when you ask them this question. The benefit you want to look for here for your team is a good price and/or services geared for you.
- Will there be any issues when we scale?
This will bring out any gaps in the tech stack that may have been missed earlier.
- How can we switch to another vendor?
If you are speaking with the right vendor, they will love this question and happily suggest how best to prepare for this event. Solutions you want to look for - help with migration, architecture design, and switching timelines.
>Build +200 native integrations
>Using Truto's Unified API for CRM, Unified API for ATS, Unified API for HRIS, Unified API for Accounting, and 26 other categories
[Get started free](https://truto.one/?ref=devto) | gettruto |
1,358,042 | Use Maps more and Objects less | Objects in JavaScript are awesome. They can do anything! Literally…anything. But, like all things,... | 0 | 2023-02-08T11:05:15 | https://www.builder.io/blog/maps | javascript, performance, typescript | Objects in JavaScript are awesome. They can do anything! Literally…anything.
But, like all things, just because you *can* do something, doesn’t (necessarily) mean you *should.*
```tsx
// 🚩
const mapOfThings = {}
mapOfThings[myThing.id] = myThing
delete mapOfThings[myThing.id]
```
For instance, if you're using objects in JavaScript to store arbitrary key value pairs where you'll be adding and removing keys frequently, you should really consider using a `map` instead of a plain object.
```tsx
// ✅
const mapOfThings = new Map()
mapOfThings.set(myThing.id, myThing)
mapOfThings.delete(myThing.id)
```
### Performance issues with objects
Whereas with objects, where the delete operator is notorious for poor performance, maps are optimized for this exact use case and in some cases can be seriously faster.

Note of course this is just one [example benchmark](https://perf.builder.io/?q=eyJpZCI6IndkbG1kbG94cm5nIiwidGl0bGUiOiJNYXAgdnMgT2JqZWN0IFBlcmZvcm1hbmNlIiwiYmVmb3JlIjoiY29uc3QgcmFuZG9tS2V5ID0gKCkgPT4gTWF0aC5mbG9vcihNYXRoLnJhbmRvbSgpICogMTAwMDAwMDApXG5jb25zdCBkYXRhID0gWy4uLkFycmF5KDEwMDAwKV0ubWFwKHJhbmRvbUtleSlcbmNvbnN0IG9iaiA9IE9iamVjdC5mcm9tRW50cmllcyhkYXRhLm1hcCh4ID0%2BIFt4LCB4XSkpXG5jb25zdCBtYXAgPSBuZXcgTWFwKE9iamVjdC5lbnRyaWVzKG9iaikpIiwidGVzdHMiOlt7Im5hbWUiOiJNYXAiLCJjb2RlIjoiLy8gRnJlZXplIHRoZSBrZXlzIGxpc3QgKHdlIGRvbid0IHdhbnQgdG8gbXV0YXRlIHdoaWxlIGl0ZXJhdGluZylcbmNvbnN0IGtleXMgPSBBcnJheS5mcm9tKG1hcC5rZXlzKCkpXG5mb3IgKGNvbnN0IGtleSBvZiBrZXlzKSB7XG4gIC8vIERlbGV0ZSBrZXlcbiAgbWFwLmRlbGV0ZShrZXkpXG4gIC8vIENyZWF0ZSBhIHJhbmRvbSBuZXcga2V5XG4gIGNvbnN0IG5ld0tleSA9IHJhbmRvbUtleSgpXG4gIG1hcC5zZXQobmV3S2V5LCBuZXdLZXkpXG59IiwicnVucyI6W10sIm9wcyI6OTAxfSx7Im5hbWUiOiJPYmplY3QiLCJjb2RlIjoiY29uc3Qga2V5cyA9IE9iamVjdC5rZXlzKG9iailcbmZvciAoY29uc3Qga2V5IG9mIGtleXMpIHtcbiAgLy8gRGVsZXRlIGtleVxuICBkZWxldGUgb2JqW2tleV1cbiAgLy8gQ3JlYXRlIGEgcmFuZG9tIG5ldyBrZXlcbiAgY29uc3QgbmV3S2V5ID0gcmFuZG9tS2V5KClcbiAgb2JqW25ld0tleV0gPSBuZXdLZXlcbn0iLCJydW5zIjpbXSwib3BzIjoxODN9XSwidXBkYXRlZCI6IjIwMjMtMDItMDlUMDc6MDk6MzQuMjY2WiJ9) (run with Chrome v109 on a Core i7 MBP). You can also compare [another benchmark](https://www.notion.so/Use-Maps-more-and-Objects-less-Outline-6f3e4c17e18543908ddde250ad9d2315) created by [Zhenghao He](https://www.zhenghao.io/posts/object-vs-map#performance-extravaganza). Just keep in mind — micro benchmarks like this are [notoriously imperfect](https://mrale.ph/blog/2012/12/15/microbenchmarks-fairy-tale.html) so take them with a grain of salt.
That said, you don’t need to trust my or anyone else’s benchmarks, as [MDN itself clarifies that maps are specifically optimized for this use case](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map#objects_vs._maps) of frequently adding and removing keys, as compared with an object that is not as optimized for this use case:
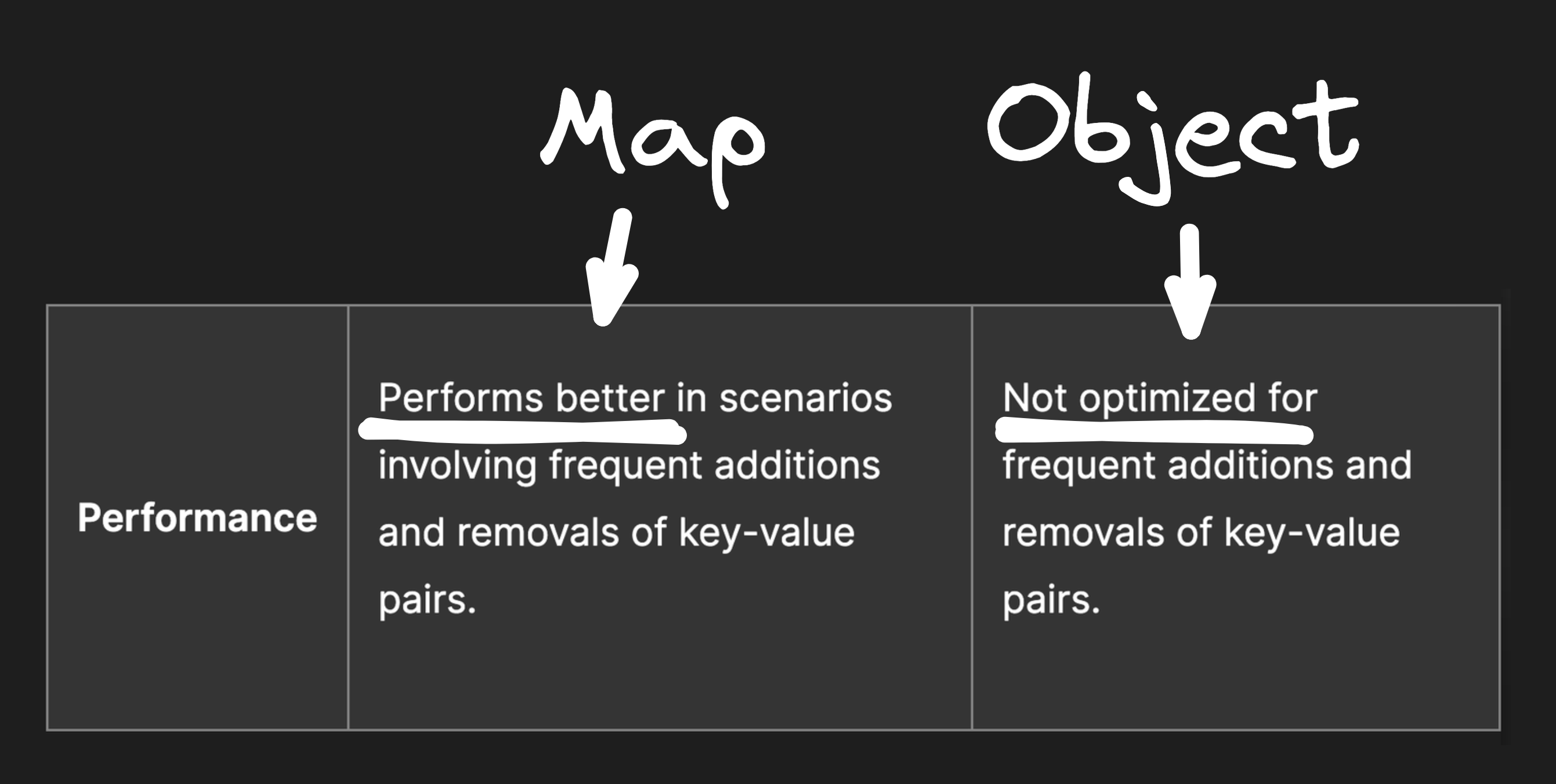
If you are curious why, it has to do with how JavaScript VMs optimize JS objects by assuming their [shape](https://mathiasbynens.be/notes/shapes-ics), whereas a map is purpose-built for the use case of a hashmap where keys are dynamic and ever-changing.
Read more about how VMs assume shapes in this thread by Miško (CTO of [Builder.io](https://www.builder.io/), and creator of Angular and [Qwik](https://qwik.builder.io/)):
{% embed https://twitter.com/Steve8708/status/1622499500739932160 %}
Another great article is [What’s up with monomorphism](https://mrale.ph/blog/2015/01/11/whats-up-with-monomorphism.html), which explains the performance characteristics of objects in JavaScript, and why they are not as optimized for hashmap-like use cases of frequently adding and removing keys.
But beyond performance, maps also solve for several issues that exist with objects.
### Built-in keys problem
One major issue of objects for hashmap-like use cases is that objects are polluted with tons of keys built into them already. *WHAT?*
```tsx
const myMap = {}
myMap.valueOf // => [Function: valueOf]
myMap.toString // => [Function: toString]
myMap.hasOwnProperty // => [Function: hasOwnProperty]
myMap.isPrototypeOf // => [Function: isPrototypeOf]
myMap.propertyIsEnumerable // => [Function: propertyIsEnumerable]
myMap.toLocaleString // => [Function: toLocaleString]
myMap.constructor // => [Function: Object]
```
So if you try and access any of these properties, each of them has values already even though this object is supposed to be empty.
This alone should be a clear reason not to use an object for an arbitrary-keyed hashmap, as it can lead to some really hairy bugs you’ll only discover later.
### Iteration awkwardness
Speaking of strange ways that JavaScript objects treat keys, iterating through objects is riddled with gotchas.
For instance, you may already know not to do this:
```tsx
for (const key in myObject) {
// 🚩 You may stumble upon some inherited keys you didn't mean to
}
```
And you may have been told instead to do this:
```tsx
for (const key in myObject) {
if (myObject.hasOwnProperty(key)) {
// 🚩
}
}
```
But this is still problematic, as `myObject.hasOwnProperty` can easily be overridden with any other value. Nothing is preventing anyone from doing `myObject.hasOwnProperty = () => explode()`.
So instead you should really do this funky mess:
```tsx
for (const key in myObject) {
if (Object.prototype.hasOwnProperty.call(myObject, key) {
// 😕
}
}
```
Or if you prefer your code to not look like a mess, you can give up on a `for` loop entirely and just use `Object.keys` with `forEach`.
```tsx
Object.keys(myObject).forEach(key => {
// 😬
})
```
However, with maps, there are no such issues at all. You can use a standard `for` loop, with a standard iterator, and a really nice destructuring pattern to get both the `key` and `value` at once:
```tsx
for (const [key, value] of myMap) {
// 😍
}
```
*Me gusta.*
### Key ordering
One additional perk of maps is they preserve the order of their keys. This has been a long asked for quality of objects, and now exists for maps.
This gives us another very cool feature, which is that we can destructure keys directly from a map, in their exact order:
```tsx
const [[firstKey, firstValue]] = myMap
```
This can also open up some interesting use cases, like trivially implementing an O(1) LRU Cache:
{% embed https://twitter.com/Steve8708/status/1623906230841536515 %}
### Copying
Now you might say, *oh, well, objects have some advantages, like they're very easy to copy*, for instance, using an object spread or assign.
```tsx
const copied = {...myObject}
const copied = Object.assign({}, myObject)
```
But it turns out that maps are just as easy to copy:
```tsx
const copied = new Map(myMap)
```
The reason this works is because the constructor of `Map` takes an iterable of `[key, value]` tuples. And conveniently, maps are iterable, producing tuples of their keys and values. Nice.
Similarly, you can also do deep copies of maps, just like you can with objects, using [structuredClone](https://developer.mozilla.org/en-US/docs/Web/API/structuredClone):
```tsx
const deepCopy = structuredClone(myMap)
```
### Converting maps to objects and objects to maps
Converting maps to objects is readily done using [Object.fromEntries](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/fromEntries):
```tsx
const myObj = Object.fromEntries(myMap)
```
And going the other way is straightforward as well, using [Object.entries](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/entries):
```tsx
const myMap = new Map(Object.entries(myObj))
```
Easy!
And, now that we know this, we no longer have to construct maps using tuples:
```tsx
const myMap = new Map([['key', 'value'], ['keyTwo', 'valueTwo']])
```
You can instead construct them like objects, which to me is a bit nicer on the eyes:
```tsx
const myMap = new Map(Object.entries({
key: 'value',
keyTwo: 'valueTwo',
}))
```
Or you could make a handy little helper too:
```tsx
const makeMap = (obj) => new Map(Object.entries(obj))
const myMap = makeMap({ key: 'value' })
```
Or with TypeScript:
```tsx
const makeMap = <V = unknown>(obj: Record<string, V>) =>
new Map<string, V>(Object.entries(obj))
const myMap = makeMap({ key: 'value' })
// => Map<string, string>
```
I’m a fan of that.
### Key types
Maps are not just a more ergonomic and better-performing way to handle key value maps in JavaScript. They can even do things that you just cannot accomplish at all with plain objects.
For instance, maps are not limited to only having strings as keys — you can use any type of object as a key for a map. And I mean, like, anything.
```tsx
myMap.set({}, value)
myMap.set([], value)
myMap.set(document.body, value)
myMap.set(function() {}, value)
myMap.set(myDog, value)
```
But, why?
One helpful use case for this is associating metadata with an object without having to modify that object directly.
```tsx
const metadata = new Map()
metadata.set(myDomNode, {
internalId: '...'
})
metadata.get(myDomNode)
// => { internalId: '...' }
```
This can be useful, for instance, when you want to associate temporary state to objects you read and write from a database. You can add as much temporary data associated directly with the object reference, without risk.
```tsx
const metadata = new Map()
metadata.set(myTodo, {
focused: true
})
metadata.get(myTodo)
// => { focused: true }
```
Now when we save `myTodo` back to the database, only the values we want saved are there, and our temporary state (which is in a separate map) does not get included accidentally.
This does have one issue though.
Normally, the garbage collector would collect this object and remove it from memory. However, because our map is holding a reference, it'll never be garbage collected, causing a memory leak.
### WeakMaps
Here’s where we can use the `WeakMap` type. Weak maps perfectly solve for the above memory leak as they hold a weak reference to the object.
So if all other references are removed, the object will automatically be garbage collected and removed from this weak map.
```tsx
const metadata = new WeakMap()
// ✅ No memory leak, myTodo will be removed from the map
// automatically when there are no other references
metadata.set(myTodo, {
focused: true
})
```
### Moar map stuff
A few remaining useful things to know about Maps before we continue on:
```tsx
map.clear() // Clear a map entirely
map.size // Get the size of the map
map.keys() // Iterator of all map keys
map.values() // Iterator of all map values
```
Ok, you get it, maps have nice methods. Moving on.
### Sets
If we are talking about maps, we should also mention their cousin, Sets, which give us a better-performing way to create a *unique* list of elements where we can easily add, remove, and look up if a set contains an item:
```tsx
const set = new Set([1, 2, 3])
set.add(3)
set.delete(4)
set.has(5)
```
In some cases, sets can [yield significantly better performance](https://perf.builder.io/?q=eyJpZCI6IjZtaDFsdjJscm56IiwidGl0bGUiOiJBcnJheSB2cyBTZXQgcGVyZm9ybWFuY2UiLCJiZWZvcmUiOiJjb25zdCBsZW5ndGggPSAxMF8wMDBcbmNvbnN0IGFyciA9IFsuLi5BcnJheShsZW5ndGgpLmtleXMoKV0ubWFwKHggPT4gKHggKiAxNikudG9TdHJpbmcoMzYpKVxuY29uc3Qgc2V0ID0gbmV3IFNldChhcnIpIiwidGVzdHMiOlt7Im5hbWUiOiJBcnJheSIsImNvZGUiOiJjb25zdCByYW5kb21WYWx1ZSA9IChNYXRoLmZsb29yKE1hdGgucmFuZG9tKCkgKiBsZW5ndGgpICogMTYpLnRvU3RyaW5nKDM2KVxuXG4vLyBGaW5kIHRoZSB2YWx1ZVxuYXJyLmluY2x1ZGVzKHJhbmRvbVZhbHVlKVxuXG4vLyBSZW1vdmUgdGhlIHZhbHVlXG5hcnIuc3BsaWNlKGFyci5pbmRleE9mKHJhbmRvbVZhbHVlKSwgMSlcblxuLy8gQWRkIGl0IGJhY2tcbmFyci5wdXNoKHJhbmRvbVZhbHVlKSIsInJ1bnMiOltdLCJvcHMiOjEwNDQwfSx7Im5hbWUiOiJTZXQiLCJjb2RlIjoiY29uc3QgcmFuZG9tVmFsdWUgPSAoTWF0aC5mbG9vcihNYXRoLnJhbmRvbSgpICogbGVuZ3RoKSAqIDE2KS50b1N0cmluZygzNilcblxuLy8gRmluZCB0aGUgdmFsdWVcbnNldC5oYXMocmFuZG9tVmFsdWUpXG5cbi8vIFJlbW92ZSB0aGUgdmFsdWVcbnNldC5kZWxldGUocmFuZG9tVmFsdWUpXG5cbi8vIEFkZCBpdCBiYWNrXG5zZXQuYWRkKHJhbmRvbVZhbHVlKSIsInJ1bnMiOltdLCJvcHMiOjc4MTMxNn1dLCJ1cGRhdGVkIjoiMjAyMy0wMi0wN1QxMDoxOTozMi4wNjVaIn0%3D) than the equivalent operations with an array.

*Blah blah microbenchmarks are not perfect, test your own code under real-world conditions to verify you get a benefit, or don’t just take [my word for it](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Set#performance)*.
Similarly, we get a `WeakSet` class in JavaScript that will help us avoid memory leaks as well.
```tsx
// No memory leaks here, captain 🫡
const checkedTodos = new WeakSet([todo1, todo2, todo3])
```
### Serialization
Now you might say there's one last advantage that plain objects and arrays have over maps and sets — serialization.
*Ha! You thought you got me on that one. But I’ve got answers for you, friend.*
So, yes, `JSON.stringify()`/ `JSON.parse()` support for objects and maps is extremely handy.
But, have you ever noticed that when you want to pretty print JSON you always have to add a `null` as the second argument? Do you know what that parameter even does?
```tsx
JSON.stringify(obj, null, 2)
// ^^^^ what dis do
```
As it turns out, that parameter can be very helpful to us. It is called a *replacer* and it allows us to define how any custom type should be serialized.
We can use this to easily convert maps and sets to objects and arrays for serialization:
```tsx
JSON.stringify(obj, (key, value) => {
// Convert maps to plain objects
if (value instanceof Map) {
return Object.fromEntries(value)
}
// Convert sets to arrays
if (value instanceof Set) {
return Array.from(value)
}
return value
})
```
> *Why did the JavaScript developer quit? They didn’t get arrays. Ha ha ho ho. Ok.*
Now we can just abstract this into a basic reusable function, and serialize away.
```tsx
const test = { set: new Set([1, 2, 3]), map: new Map([["key", "value"]]) }
JSON.stringify(test, replacer)
// => { set: [1, 2, 3], map: { key: value } }
```
For converting back, we can use the same trick with `JSON.parse()`, but doing the opposite, by using its *reviver* parameter, to convert arrays back to Sets and objects back to maps when parsing:
```tsx
JSON.parse(string, (key, value) => {
if (Array.isArray(value)) {
return new Set(value)
}
if (value && typeof value === 'object') {
return new Map(Object.entries(value))
}
return value
})
```
Also note that both *replacers* and *revivers* work recursively, so they are able to serialize and deserialize maps and sets *anywhere* in our JSON tree.
But, there is just one small problem with our above serialization implementation.
We currently don’t differentiate a plain object or array versus a map or a set at parse time, so we cannot intermix plain objects and maps in our JSON or we will end up with this:
```tsx
const obj = { hello: 'world' }
const str = JSON.stringify(obj, replacer)
const parsed = JSON.parse(obj, reviver)
// Map<string, string>
```
We can solve this by creating a special property; for example, called `__type`, to denote when something should be a map or a set as opposed to a plain object or array, like so:
```tsx
function replacer(key, value) {
if (value instanceof Map) {
return { __type: 'Map', value: Object.fromEntries(value) }
}
if (value instanceof Set) {
return { __type: 'Set', value: Array.from(value) }
}
return value
}
function reviver(key, value) {
if (value?.__type === 'Set') {
return new Set(value.value)
}
if (value?.__type === 'Map') {
return new Map(Object.entries(value.value))
}
return value
}
const obj = { set: new Set([1, 2]), map: new Map([['key', 'value']]) }
const str = JSON.stringify(obj, replacer)
const newObj = JSON.parse(str, reviver)
// { set: new Set([1, 2]), map: new Map([['key', 'value']]) }
```
Now we have full JSON serialization and deserialization support for sets and maps. Neat.
### When you should use what
For structured objects that have a well-defined set of keys — such as if every `event` should have a title and a date — you generally want an object.
```tsx
// For structured objects, use Object
const event = {
title: 'Builder.io Conf',
date: new Date()
}
```
They're very optimized for fast reads and writes when you have a fixed set of keys.
When you can have any number of keys, and you may need to add and remove keys frequently, consider using `map` for better performance and ergonomics.
```tsx
// For dynamic hashmaps, use Map
const eventsMap = new Map()
eventsMap.set(event.id, event)
eventsMap.delete(event.id)
```
When creating an array where the order of elements matter and you may intentionally want duplicates in the array, then a plain array is generally a great idea.
```tsx
// For ordered lists, or those that may need duplicate items, use Array
const myArray = [1, 2, 3, 2, 1]
```
But when you know you never want duplicates and the order of items doesn't matter, consider using a set.
```tsx
// For unordered unique lists, use Set
const set = new Set([1, 2, 3])
```
## About me
Hi! I'm [Steve](https://twitter.com/Steve8708?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor), CEO of [Builder.io](https://www.builder.io/).
We make a way to drag + drop with your components to create pages and other CMS content on your site or app, [visually](https://www.builder.io/blog/headless-cms-workflow).
So this:
```tsx
import { BuilderComponent, registerComponent } from '@builder.io/react'
import { Hero, Products } from './my-components'
// Dynamically render compositions of your components
export function MyPage({ json }) {
return <BuilderComponent content={json} />
}
// Use your components in the drag and drop editor
registerComponent(Hero)
registerComponent(Products)
```
Gives you this:
 | steve8708 |
1,358,061 | Cyclope - connect your bike for the ultimate cycling information and experience. | Cyclope is a comprehensive bike application designed to provide cyclists with maximum information and... | 0 | 2023-02-08T11:24:18 | https://dev.to/asgarde/cyclope-connect-your-bike-for-the-ultimate-cycling-information-and-experience-3jb0 | bike, app, sport, cycling |
[Cyclope](https://www.cyclope.dev/) is a comprehensive bike application designed to provide cyclists with maximum information and connect their bikes.
It features GPS navigation, 3D map display, live communication with other cyclists through a built-in walkie-talkie and messaging system, weather information, performance recording, 3D video replay of rides, social sharing, and various competition modes such as the World Cycling Championship.
It also includes bike tracking, fall detector, compass, customizable horn, and other classic and advanced functions such as speedometer, distance traveled, altitude measurement, inclinometer...
Android app on Play Store.
https://play.google.com/store/apps/details?id=com.Illusion.Cyclope
https://play-lh.googleusercontent.com/R3JdebhuEHux0LrIzApQ-Vih8VO9MZ7JAKvZs7UK5PgBoTAjrYEjdxDZBvgbXK7DPmdB=w2560-h1440-rw
https://play-lh.googleusercontent.com/SBLMjsDHGkPVJ7Qb66nljh1V7lHkeQQRePe9hf3ncYO7tqC4SCmEWwiHlIfZ7-o_bA=w2560-h1440-rw
https://play-lh.googleusercontent.com/_L4jvdbOhShRGOOCVnYjJgJYPQYIP4W0ns3QzIYzdl84yDnU4NsSKTHwu9T6USIMe9s=w2560-h1440-rw | asgarde |
1,358,197 | Improve Your Dev Productivity with Bookmarks, Snippets and Notes Management | As a software developer, having quick access to relevant information and resources is essential to... | 0 | 2023-02-08T12:27:47 | https://www.linkedin.com/feed/update/urn:li:activity:7028664734967046144 | productivity, tooling, bookmarking, codever | As a software developer, having quick access to relevant information and resources is essential to your productivity and success. Bookmarks, snippets and notes are an important tool in achieving this, allowing you to save links to websites, articles, documentation, as well as code snippets and notes. However, with so many bookmarks and snippets, it can be challenging to find what you need quickly.
Here are some tips for using bookmark and snippet management to improve your productivity as a software developer:
1. **Use tags to categorize your bookmarks and snippets** instead of organizing your bookmarks and snippets into folders, consider using tags to categorize them. This way, you can quickly filter and search for bookmarks and snippets based on their tag, making it easier to find what you're looking for. For example, you could use tags such as "javascript," "api", "tutorial" or "your-company-name".
2. **Keep your bookmarks and snippets up-to-date** In the world of software development, information can become outdated quickly. Regularly review your bookmarks and snippets and delete any that are no longer relevant or useful. This will ensure that you have quick access to only the most accurate and up-to-date information.
3. **Use browser & IDE extensions for better bookmark and snippet management**. There are several browser extensions available that can help you manage your bookmarks and snippets more efficiently. These extensions often come with features such as tag-based organization, search functionality, and the ability to find bookmarks and snippets across devices. Consider using one of these extensions to improve your bookmark and snippet management.
4. **Take advantage of the cloud**. Storing your bookmarks and snippets in the cloud can allow you to access them from any device, regardless of where you are. This is particularly useful for developers who work on multiple devices, as it ensures that they always have access to their most important information and resources.
5. **Use markdown for notes and snippets.** Using markdown to write your notes and snippets can provide a more organized and readable format. Markdown allows you to format your text using simple syntax, making it easier to quickly read and understand your notes and snippets.
In conclusion, by using tags to categorize your bookmarks and snippets, keeping them up-to-date, utilizing browser extensions, taking advantage of the cloud, and using **markdown** for notes and snippets, you can improve your productivity as a software developer. Quick access to relevant information and resources, as well as organized and easily readable notes and snippets, can help you make the most of your time and stay ahead of the game.
[Codever](https://www.codever.dev) offers all this and more, plus it's free and open source at [github.com/CodeverDotDev](https://github.com/CodeverDotDev) | ama |
1,358,312 | File Share Website [Updated Version] | Django Project | | Hello Friends, I am Madhuban Khatri - A Self Taught Python Developer. I was working on another new... | 0 | 2023-02-08T14:38:11 | https://dev.to/madhubankhatri/file-share-website-updated-version-django-project--1akp | django, python, webdev, javascript |
Hello Friends, I am Madhuban Khatri - A Self Taught Python Developer. I was working on another new project that is **File Share Website**. It is an _updated version_ of [previos projectd](https://dev.to/madhubankhatri/file-sharing-website-using-django-2ko7).
You can add more functionality to my project to improve working process. Now I am sharing my source code of **File Share Website**.
{% embed https://youtu.be/8I6-b_v94pg %}
First , We have to create a Django project and an App in this project.
```
# To create a project
django-admin startproject <your_project_name>
```
```
# To create an App
python manage.py startapp <your_app_name>
```
Code Files are below:-
### Views.py
```python
from django.shortcuts import render, redirect
from .models import User, File_Upload
from django.contrib import messages
# Create your views here.
def index(request):
if 'user' in request.session:
all_files = File_Upload.objects.all()
data = {'files': all_files}
return render(request, 'index.html', data)
else:
return redirect('login')
def login(request):
if 'user' not in request.session:
if request.method == 'POST':
email = request.POST['email']
pwd = request.POST['pwd']
userExists = User.objects.filter(email=email, pwd=pwd)
if userExists.exists():
request.session["user"] = email
return redirect('index')
else:
messages.warning(request, "Wrong user or details.")
return render(request, 'login.html')
else:
return redirect('index')
def logout(request):
del request.session['user']
return redirect('login')
def signup(request):
if request.method == 'POST':
name = request.POST['name']
email = request.POST['email']
pwd = request.POST['pwd']
gender = request.POST['gender']
if not User.objects.filter(email=email).exists():
create_user = User.objects.create(name=name, email=email, pwd=pwd, gender=gender)
create_user.save()
messages.success(request, "Your account is created successfully!")
return redirect('login')
else:
messages.warning(request, "Email is already registered!")
return render(request, 'signup.html')
def settings(request):
if 'user' in request.session:
user_obj = User.objects.get(email = request.session['user'])
user_files = File_Upload.objects.filter(user = user_obj)
img_list = []
audio_list = []
videos_list = []
pdfs_list = []
for file in user_files:
if str(file.file_field)[-3:] == 'mp3':
audio_list.append(file)
elif str(file.file_field)[-3:] == 'mp4' or str(file.file_field)[-3:] == 'mkv':
videos_list.append(file)
elif str(file.file_field)[-3:] == 'jpg' or str(file.file_field)[-3:] == 'png' or str(file.file_field)[-3:] == 'jpeg':
img_list.append(file)
elif str(file.file_field)[-3:] == 'pdf':
pdfs_list.append(file)
data = {'user_files': user_files, 'videos': len(videos_list), 'audios': len(audio_list), 'images': len(img_list), 'pdf': len(pdfs_list), 'img_list': img_list, 'audio_list': audio_list, 'videos_list': videos_list, 'pdfs_list': pdfs_list}
return render(request, 'settings.html', data)
def file_upload(request):
if request.method == 'POST':
title_name = request.POST['title']
description_name = request.POST['description']
file_name = request.FILES['file_to_upload']
user_obj = User.objects.get(email=request.session['user'])
new_file = File_Upload.objects.create(user = user_obj, title=title_name, description=description_name, file_field = file_name)
messages.success(request, "File is uploaded successfully!")
new_file.save()
return render(request, 'file_upload.html')
def delete_file(request, id):
if 'user' in request.session:
file_obj = File_Upload.objects.get(id = id)
file_obj.delete()
return redirect('settings')
else:
return redirect('login')
```
### Urls.py (App)
```python
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name="index"),
path('login/', views.login, name="login"),
path('logout/', views.logout, name="logout"),
path('signup/', views.signup, name="signup"),
path('settings/', views.settings, name="settings"),
path("file_upload/", views.file_upload, name="file_upload"),
path('delete/<str:id>/', views.delete_file, name="delete_file")
]
```
### Urls.py(Project)
```python
from django.contrib import admin
from django.urls import path, include
from django.conf import settings
from django.conf.urls.static import static
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('main.urls'))
]
urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
```
### Models.py
```python
from django.db import models
# Create your models here.
class User(models.Model):
name = models.CharField(max_length=50)
email = models.EmailField()
pwd = models.CharField(max_length=100)
gender = models.CharField(max_length=20)
def __str__(self):
return self.name
class File_Upload(models.Model):
user = models.ForeignKey(User, models.CASCADE)
title = models.CharField(max_length=50)
description = models.TextField()
file_field = models.FileField(upload_to="")
def __str__(self):
return self.title
```
### Admin.py
```python
from django.contrib import admin
from .models import User, File_Upload
# Register your models here.
admin.site.register(User)
admin.site.register(File_Upload)
```
### Settings.py
```
# Add some lines of Code in Settings.py
STATIC_URL = 'static/'
STATICFILES_DIRS = [BASE_DIR/'static']
MEDIA_URL = '/media/'
MEDIA_ROOT = BASE_DIR/'static'/'media'
```
## Templates Folder contains Html Files
## Base.html
```html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>{% block title %}{% endblock %}</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
<style>
::selection
{
background-color: rgb(5, 220, 5);
color: white;
}
</style>
</head>
<body class="bg-primary text-light">
<nav class="navbar navbar-expand-lg bg-body-tertiary bg-primary" data-bs-theme="dark">
<div class="container-fluid">
<a class="navbar-brand" href="{% url 'index' %}">File Sharing</a>
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent">
<ul class="navbar-nav me-auto mb-2 mb-lg-0">
<li class="nav-item">
<a class="nav-link" aria-current="page" href="{% url 'index' %}">Home</a>
</li>
{% if not request.session.user %}
<li class="nav-item">
<a class="nav-link" href="{% url 'login' %}">Login</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'signup' %}">Signup</a>
</li>
{% else %}
<li class="nav-item">
<a class="nav-link" href="{% url 'file_upload' %}">Upload a file</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'settings' %}">Settings</a>
</li>
<li class="nav-item">
<a class="nav-link" href="{% url 'logout' %}">Logout</a>
</li>
{% endif %}
</ul>
<form class="d-flex" role="search">
<input class="form-control me-3" type="search" placeholder="Search" aria-label="Search">
<button class="btn btn-outline-success" type="submit">Search</button>
</form>
</div>
</div>
</nav>
{% block body %}
{% endblock %}
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/js/bootstrap.bundle.min.js" integrity="sha384-w76AqPfDkMBDXo30jS1Sgez6pr3x5MlQ1ZAGC+nuZB+EYdgRZgiwxhTBTkF7CXvN" crossorigin="anonymous"></script>
</body>
</html>
```
## Index.html
```html
{% extends 'base.html' %}
{% block title %}
Home
{% endblock %}
{% block body %}
{% for file in files reversed %}
<div class="container border border-success my-5 py-4 form-control">
<h1 class="mx-5">
{{file.title}}
</h1>
<small><p class="mx-5 text-primary">uploaded by <i>{{file.user.name}}</i></p></small>
<p class="mx-5">
{{file.description}}
</p>
<div class="mx-5">
<a class="btn btn-outline-success btn-sm" href="media/{{file.file_field}}/" target="_blank">View</a>
<a class="btn btn-outline-success btn-sm" href="media/{{file.file_field}}/" download>Download</a>
</div>
</div>
{% endfor %}
{% endblock %}
```
## Login.html
```html
{% extends 'base.html' %}
{% block title %}
Login
{% endblock %}
{% block body %}
<div class="container w-25 my-5">
<h2 class="my-5">Login</h2>
<hr>
{% if messages %}
{% for message in messages %}
<div class="alert alert-{{message.tags}} alert-dismissible fade show" role="alert">
{{message}}
<button type="button" class="btn-close" data-bs-dismiss="alert" aria-label="Close"></button>
</div>
{% endfor %}
{% endif %}
<form action="{% url 'login' %}" method="post">
{% csrf_token %}
<div class="mb-3">
<input type="email" class="form-control" name="email" id="exampleFormControlInput1" placeholder="Email" required>
</div>
<div class="mb-3">
<input type="password" class="form-control" name="pwd" id="exampleFormControlInput1" placeholder="Password" required>
</div>
<div class="mb-3">
<input type="submit" class="btn btn-danger w-100" value="Login">
</div>
<center>
Don't have an account? <a href="{% url 'signup' %}" class="text-light">Signup</a>
</center>
</form>
</div>
{% endblock %}
```
## Signup.html
```html
{% extends 'base.html' %}
{% block title %}
Create an Account
{% endblock %}
{% block body %}
<div class="container w-25 my-5">
<h2 class="my-5">Create your account</h2>
<hr>
{% if messages %}
{% for message in messages %}
<div class="alert alert-{{message.tags}} alert-dismissible fade show" role="alert">
{{message}}
<button type="button" class="btn-close" data-bs-dismiss="alert" aria-label="Close"></button>
</div>
{% endfor %}
{% endif %}
<form action="{% url 'signup' %}" method="post">
{% csrf_token %}
<div class="mb-3">
<input type="text" class="form-control" name="name" id="exampleFormControlInput1" placeholder="Name" required>
</div>
<div class="mb-3">
<input type="email" class="form-control" name="email" id="exampleFormControlInput1" placeholder="Email" required>
</div>
<div class="mb-3">
<input type="password" class="form-control" name="pwd" id="exampleFormControlInput1" placeholder="Password" required>
</div>
<div class="mb-3">
<select class="form-select" name="gender" aria-label="Default select example" required>
<option value="1">Male</option>
<option value="2">Female</option>
</select>
</div>
<div class="mb-3">
<input type="submit" class="btn btn-danger w-100" value="Signup">
</div>
</form>
<center>
Already have an account? <a href="{% url 'login' %}" class="text-light">Login</a>
</center>
</div>
{% endblock %}
```
## Settings.html
```html
{% extends 'base.html' %}
{% block title %}
Settings
{% endblock %}
{% block body %}
<div class="container form-control my-4">
<h3>Welcome! {{request.session.user}}</h3>
</div>
<div class="container">
<table class="table">
<tbody>
<tr>
<td>
<div class="card w-50 py-3 px-4">
<h4 class="card-text">Videos: {{videos}}</h4>
</div>
</td>
<td>
<div class="card w-50 py-3 px-4">
<h4 class="card-text">Audios: {{audios}}</h4>
</div>
</td>
<td>
<div class="card w-50 py-3 px-4">
<h4 class="card-text">Images: {{images}}</h4>
</div>
</td>
<td>
<div class="card w-50 py-3 px-4">
<h4 class="card-text">Pdfs: {{pdf}}</h4>
</div>
</td>
</tr>
</tbody>
</table>
</div>
<div class="container form-control">
<nav>
<div class="nav nav-tabs" id="nav-tab" role="tablist">
<button class="nav-link" id="nav-images-tab" data-bs-toggle="tab" data-bs-target="#nav-images" type="button" role="tab" aria-controls="nav-images" aria-selected="true">Images</button>
<button class="nav-link" id="nav-audios-tab" data-bs-toggle="tab" data-bs-target="#nav-audios" type="button" role="tab" aria-controls="nav-audios" aria-selected="false">Audios</button>
<button class="nav-link" id="nav-videos-tab" data-bs-toggle="tab" data-bs-target="#nav-videos" type="button" role="tab" aria-controls="nav-videos" aria-selected="false">Videos</button>
<button class="nav-link" id="nav-pdfs-tab" data-bs-toggle="tab" data-bs-target="#nav-pdfs" type="button" role="tab" aria-controls="nav-pdfs" aria-selected="false">Pdfs</button>
</div>
<div class="tab-content" id="nav-tabContent">
<div class="tab-pane fade show active" id="nav-images" role="tabpanel" aria-labelledby="nav-images-tab" tabindex="0">
{% if img_list %}
{% for img in img_list%}
<div class="container my-3">
<h3>{{img.title}}</h3>
<p>{{img.description}}</p>
<a class="btn btn-outline-success btn-sm" href="../media/{{img.file_field}}/" target="_blank">View</a>
<a class="btn btn-outline-success btn-sm" href="../media/{{img.file_field}}/" download>Download</a>
<a href="{% url 'delete_file' img.id %}" class="btn btn-outline-danger btn-sm">Delete</a>
</div>
<hr>
{% endfor %}
{% else %}
No images
{% endif %}
</div>
<div class="tab-pane fade" id="nav-audios" role="tabpanel" aria-labelledby="nav-audios-tab" tabindex="0">
{% if audio_list %}
{% for aud in audio_list %}
<div class="container my-3">
<h3>{{aud.title}}</h3>
<p>{{aud.description}}</p>
<a class="btn btn-outline-success btn-sm" href="../media/{{aud.file_field}}/" target="_blank">View</a>
<a class="btn btn-outline-success btn-sm" href="../media/{{aud.file_field}}/" download>Download</a>
<a href="{% url 'delete_file' aud.id %}" class="btn btn-outline-danger btn-sm">Delete</a>
</div>
<hr>
{% endfor %}
{% else %}
No audios
{% endif %}
</div>
<div class="tab-pane fade" id="nav-videos" role="tabpanel" aria-labelledby="nav-videos-tab" tabindex="0">
{% if videos_list %}
{% for vid in videos_list %}
<div class="container my-3">
<h3>{{vid.title}}</h3>
<p>{{vid.description}}</p>
<a class="btn btn-outline-success btn-sm" href="../media/{{vid.file_field}}/" target="_blank">View</a>
<a class="btn btn-outline-success btn-sm" href="../media/{{vid.file_field}}/" download>Download</a>
<a href="{% url 'delete_file' vid.id %}" class="btn btn-outline-danger btn-sm">Delete</a>
</div>
<hr>
{% endfor %}
{% else %}
No videos
{% endif %}
</div>
<div class="tab-pane fade" id="nav-pdfs" role="tabpanel" aria-labelledby="nav-pdfs-tab" tabindex="0">
{% if pdfs_list %}
{% for pdf in pdfs_list %}
<div class="container my-3">
<h3>{{pdf.title}}</h3>
<p>{{pdf.description}}</p>
<a class="btn btn-outline-success btn-sm" href="../media/{{pdf.file_field}}/" target="_blank">View</a>
<a class="btn btn-outline-success btn-sm" href="../media/{{pdf.file_field}}/" download>Download</a>
<a href="{% url 'delete_file' pdf.id %}" class="btn btn-outline-danger btn-sm">Delete</a>
</div>
<hr>
{% endfor %}
{% else %}
No pdfs
{% endif %}
</div>
</div>
</nav>
</div>
{% endblock %}
```
## File_upload.html
```html
{% extends 'base.html' %}
{% block title %}
File Upload
{% endblock %}
{% block body %}
<div class="container w-50">
<h2 class="my-3">Upload a File</h2>
<hr>
<form class="form-control" action="{% url 'file_upload' %}" method="post" enctype="multipart/form-data">
{% csrf_token %}
{% if messages %}
{% for message in messages %}
<div class="alert alert-{{message.tags}} alert-dismissible fade show" role="alert">
{{message}}
<button type="button" class="btn-close" data-bs-dismiss="alert" aria-label="Close"></button>
</div>
{% endfor %}
{% endif %}
<input type="text" name="title" placeholder="Title" class="form-control my-3">
<textarea placeholder="Description" name="description" class="form-control my-3"></textarea>
<input type="file" class="form-control my-3" name="file_to_upload">
<input type="submit" value="Upload" class="btn btn-outline-primary my-3">
</form>
</div>
{% endblock %}
```
Thank for reading file blog.
You can check my other posts to get knowledgeable stuff. These projects are useful for College students or others who want to get idea for their projects. | madhubankhatri |
1,358,315 | TypeScript: Interface or Type? Hint: it's in the name | It's called TypeScript not InterfaceScript If you're a purist like I am, you know the debate... | 0 | 2023-02-08T15:03:07 | https://dev.to/manuartero/my-take-on-interface-vs-type-hc8 | typescript, node, react, webdev | > It's called **Type**Script not _InterfaceScript_
If you're a purist like I am, you know the debate between 'interface vs. type' can be frustrating. Why is there no official stance on this issue?
I've been using Ts since 2015 and I've been through different phases.
First, I encouraged using interfaces instead of types (unless an [Union/Intersection](https://www.typescriptlang.org/docs/handbook/unions-and-intersections.html?ref=hackernoon.com) was needed);
...then I reached the stable plateau of _"whichever you prefer, it doesn't matter"_ 😄.
**Till now.**
For some time I've been using the type **"Any key-value object"** a.k.a `Record<string, unknown>`
If you type something as any key-value object;
```ts
function foo(data: Record<string, unknown>) {
for (const [key, value] of Object.entries(data)) {
// ...
}
}
```
You might reach a dead end if you use `interface`:
```ts
interface Profile {
name: string;
}
function getProfile(): Profile {
/* fetch data */
return Promise.resolve({ name: 'jane' });
}
...
const profile = await getProfile()
foo(profile); // ERROR ❌
// Argument of type 'Profile' is not assignable to parameter of type
// 'Record<string, unknown>'.
// Index signature for type 'string' is missing in type
// 'Profile'.ts(2345)
```
Our interface `{ name: string }` does NOT fulfill `Record<string, unknown>`.
I _respectful disagree?_ with typescript here 🤓
***
Now, let's change the thing to `type` instead:
```ts
function foo(data: Record<string, unknown>) {
for (const [key, value] of Object.entries(data)) {
// ...
}
}
type Profile = {
name: string;
};
function getProfile(): Profile {
/* fetch data */
return Promise.resolve({ name: 'jane' });
}
...
const profile = await getProfile()
foo(profile); // ✅ nice
```
👉 The type `{ name: string }` **does** fulfill `Record<string, unknown>`
***
This type of situation isn't specific to `Record<string, unknown>`' but I don't want to research which [Advanced types](https://www.typescriptlang.org/docs/handbook/advanced-types.html) will work and which won't. So, **I've turned to using types -almost- exclusively**."
***
I was shocked to find out that [Matt Pocock](https://twitter.com/mattpocockuk) also **went through the same three phases!**.
If you haven't heard of Matt, I highly recommend checking him out. He creates high-quality TypeScript content on Youtube (and is a nice guy on Twitter 🦜).
{% embed https://www.youtube.com/watch?v=zM9UPcIyyhQ %}
***
**TL;DR**: prefer types to interfaces, people on the internet defend types.
| manuartero |
1,358,359 | JavaScript Fundamentos - Tipos Objetos | Nesse post vamos conhecer um pouco sobre o tipo objeto da linguagem, sendo esse mais um fundamento... | 0 | 2023-02-08T15:44:10 | https://dev.to/nascimento_/javascript-fundamentos-tipos-objetos-183p | beginners, javascript, webdev | Nesse post vamos conhecer um pouco sobre o tipo objeto da linguagem, sendo esse mais um fundamento importante para fortalecer nossa base em JavaScript.
Os **Tipos Objetos** são valores que representam uma referência em memória que pode ser alterada, os principais objetos globais utilizados são: **Object** | **Regex** |**Function** | **Arrays** | **Math** | **Date** entre outros.
Em **JS** tudo é objetos, mesmo os tipos primitivos se comportam como objetos quando precisamos utilizar métodos para sua manipulação.
```js
typeof function sum(a, b) {
return a + b;
}; // => 'function'
typeof { name: "Linus Torvald" }; // => 'object'
typeof [1, 2, 3, 4, 5]; // => 'object'
typeof /[a-zA-Z_$]/; // => 'object'
typeof new Date(); // => 'object'
```
- Vamos conhecer os principais tipos de objetos e algumas das API's fornecidas.
#### Objetos
Um objeto é uma coleção dinâmica de propriedades definidas por chaves, que podem ser do tipo string ou symbol, e valores que podem ser de qualquer tipo de dados.
> É possível criar objetos de várias formas : pela notação literal, por meio de uma função construtura ou do método create da Object API
```js
{} // literal
new Object(); // Construtora
Object.create(null); // API
```
- Atribuindo um objeto a uma constante.
```js
const book = {
title: "Clean Code",
author: "Robert C Martin",
pages: 464,
language: "English",
available: true,
};
```
- **Shorthand notation**, quando o nome de uma variável é utilizado com o mesmo nome da chave, utiliza se apenas o nome da variável.
```js
const book = { title, author, pages, language, available };
```
- É possível computar chaves em tempo de execução.
```js
const key1 = "title";
book[key1] = "other title";
```
- Na criação de chaves com nomes composto é necessário utilizar aspas.
```js
const person = {
//name-sobrenome: "Jorge Nascimento", -> gera erro na chave
"nome-sobrenome": "Jorge Nascimento",
};
```
- Além do notação literal , é possível atribuir propriedades aos objetos por meio da usa referência.
```js
const car = {};
car.marca = "Ferrari";
car.ano = "2020";
car.modelo = "Spider";
```
- Propriedades consultadas por meio de sua referência.
```js
car.modelo; // => "Spider"
```
- É possível consultar uma determinada chave por meio do operador **in**.
```js
"modelo" in car; // => true
```
- As propriedades de um objeto podem ser apagadas por meio do operador **delete**;
```js
delete car.ano;
```
- Iterando objeto com o **for in**
```js
for (let key in car) {
console.log(car[key]); // iterando sobre as chaves do objeto
}
```
- Criando um cópia do objeto **car**.
```js
const car2 = {};
for (let key in car) {
car2[key] = car[key];
}
```
- A comparação dos objetos é feita por meio de sua referência , assim, ainda que dois objetos tenham exatamente as mesmas propriedades eles serão considerados diferentes.
```js
const book = {
title: "JavaScript",
author: "Nascimento",
};
const book2 = {
title: "JavaScript",
author: "Nascimento",
};
book === book2; // => false
```
- Um das formas para comparar os objetos é analisando cada uma das propriedades por meio da comparação das **chaves** e **valores**.
```js
let equal = true;
for (let key in book) {
if (book[key] !== book2[key]) equal = false;
}
for (let key in book2) {
if (book[key] !== book2[key]) equal = false;
}
```
> Para garantir que um objeto é igual ao outro é necessário verificar seus **protótipos**.
- **Herança** - O principal objetivo de herança é permitir o reuso de código por meio do compartilhamento de propriedades entre objetos, evitando duplicação.
- - Na linguagem Javascript a herança é realizada entre objetos e não classes.
- - A propriedade **proto** é uma referência para o prototipo do objeto.
```js
const functionalLanguage = {
paradigm: "Functional",
};
const scheme = {
name: "Scheme",
year: 1975,
// paradigm: "Functional" , - propriedade que se repete.
__proto__: functionalLanguage,
};
const javascript = {
name: "Javascript",
year: 1995,
// paradigm: "Functional"
__proto__: functionalLanguage,
};
javascript.paradigm; // => Functional
```
- Quando a propriedade não é encontrada no objeto atual esse sera buscada na sua cadeia de protótipos, chegando até **object** que tem **proto** null.
> O método **hasOwnProperty** pode ser utilizado para determinar se uma propriedade pertence ao objeto.
```js
for (let key in scheme) {
console.log(key, scheme.hasOwnProperty(key));
}
```
- Os métodos **Object.setPrototypeOf** e **Object.getPrototypeOf** permite setar ou retornar prototipo de um objeto.
```js
// seta prototipo através da API do Object
Object.setPrototypeOf(objeto, prototipo);
// Retorna o seu prototipo
Object.getPrototypeOf(objeto);
```
- Com o método **Object.create** é possível criar um objeto passando seu protótipo como parâmetro.
```js
const scheme = Object.create(functionalLanguage);
scheme.name = "Scheme";
scheme.year = 1975;
```
> Sem prototipo o objeto perde algumas operações importantes ( método como **hasOwnProperty**)
- Vamos conhecer os métodos da **Object API**.
- - O método **Object.assign** faz a cópia das propriedades dos objetos passados por parâmetro para o objeto alvo, que é retornado.
```js
const javascript = Object.create({});
Object.assign(
javascript,
{
name: "JavaScript",
year: 1995,
paradigm: "OO and Functional",
},
{
author: "Brendan Eich",
influenceBy: "Java, Scheme and Self",
}
);
```
- - O método **Object.keys** retorna um array com as chaves do objeto informado.
```js
Object.keys(javascript); // ==> [ 'name', 'year', 'paradigm', 'author', 'influenceBy' ]
```
- - O método **Object.value** retorna um array os valores das propriedades.
```js
Object.values(javascript); // => [ 'JavaScript', 1995,'OO and Functional', 'Brendan Eich','Java, Scheme and Self' ]
```
- - O método **Object.entries** retorna um array de arrays onde cada posição do array retornado possui o par chave e valor do objeto passado.
```js
Object.entries(javascript); // ==> [ [ 'name', 'JavaScript' ], [ 'year', 1995 ], [ 'paradigm', 'OO and Functional' ],[ 'author', 'Brendan Eich' ],[ 'influenceBy', 'Java, Scheme and Self' ] ]
```
- - O método **Object.is** compara dois objetos, considerando os tipos de dados, de forma similar ao operador **===** ( comparação de referência )
```js
Object.is(javascript, javascript); // ==> true
```
- - O método **Object.defineProperty** define uma nova propriedade diretamente em um objeto, ou modifica uma propriedade já existente em um objeto, e retorna o objeto.
_Na definição dessa propriedade essa pode ter configurações conforme abaixo:_
> **configurable** - Permite que uma determinada propriedade seja apagada.
> **enumerable** - permite que uma determinada propriedade seja enumerada ( exibida ).
> **value** - Define o valor de uma determinada propriedade.
> **writable** - Permite que uma determinada propriedade tenha seu valor modificado
```js
const JavaScript = {};
Object.defineProperty(JavaScript, "name", {
value: "JavaScript",
enumerable: true,
writable: true,
configurable: true,
});
```
> Caso apenas o **value** seja especificada as demais são consideradas falsa (enumerable | writable | configurable)
- - O método **Object.preventExtensions** impede que o objeto tenha novas propriedades, mas permite modificar ou remover as propriedades existentes.
```js
Object.preventExtensions(JavaScript);
Object.isExtensible(JavaScript); // => false
```
- - O método **Object.seal** impede que o objeto tenha novas propriedades ou apague propriedades existentes, mas permite modificar propriedades existentes.
```js
Object.seal(JavaScript);
Object.isSealed(JavaScript); // => true
```
- - O método **Object.freeze** impede que o objeto tenha novas propriedades apague ou modifique propriedades existentes.
```js
Object.freeze(JavaScript);
Object.isFrozen(JavaScript); // => true
```
### RegExp
As expressões regulares são estruturas formadas por uma sequência de caracteres que especificam um padrão formal que servem para validar, extrair ou mesmo substituir caracteres dentro de um string.
```js
let regExp = /john@gmail.com/ || new RegExp(/john@gmail.com/);
```
- O método **test** verifica se a string passada por parâmetro possui o padrão da regexp, retornando um booleano.
```js
let result = regExp.test("john@gmail.com"); // => true - padrão identificado
```
- O método **exec** possui um retorno com mais informações ele retorna um array com index onde foi encontrado o padrão e input analisado, grupos.
```js
regExp.exec("john@gmail.com");
/*[ 'john@gmail.com',
index: 0,
input: 'john@gmail.com',
groups: undefined ] */
```
> Documentação: [RegExp](https://developer.mozilla.org/pt-BR/docs/Web/JavaScript/Reference/Global_Objects/RegExp)
### Function
Uma função é um objeto que contém código executável. Assim como o programa em si, uma função é composta por uma sequência de instruções chamada _corpo da função_. Valores podem ser passados para uma função e ela vai retornar um valor.
> Na linguagem JavaScript, as funções são de **primeira classe**, ou seja, podem ser atribuída a uma variável, passadas por parâmetro ou serem retornada de uma outra função.
- **function declaration** forma padrão de declara com a palavra reservado _function_.
```js
function sum(a, b) {
return a + b;
}
```
> Na _function declaration_ a mesma é içada para o inicio do contexto de execução sendo assim ela pode ser chamada antes de declarada.
- **function expression** declaração de função atribuída a uma variável.
```js
const sum = function (a, b) {
return a + b;
};
```
- Função que retorna outra função - para ter acesso a a função interna é necessário realizar uma dupla invocação calculator()()
```js
const calculator = function (fn) {
return function (a, b) {
return fn(a, b);
};
};
calculator(sum)(2, 2); // => 4
```
- Definindo valores padrão para o parâmetro, no caso desse parâmetro não for passado ele irá assumir o default.
```js
const subtract = function (a = 0, b = 2) {
return a - b;
};
subtract(5); // => 3
```
- **arguments** é uma variável implícita que é possível acessar os parâmetros da função invocada, essa retorna um objeto com índice e valor passado.
```js
const argsFunction = function () {
return arguments;
};
argsFunction(1, 2, 3, 4, 5); // => { '0': 1, '1': 2, '2': 3, '3': 4, '4': 5 }
```
- Também é possível acessar os parâmetros da função invocada por meio do **_rest paramenter_**, esse retorna um array com os parâmetros passados, deve ser usado como último da lista de parâmetros.
```js
const restFunction = function (...numbers) {
return numbers;
};
restFunction(1, 2, 3, 4, 5); // => [ 1, 2, 3, 4, 5 ]
```
- **constructor functions** ( Funções Construtoras ) servem como molde para a criação de objetos, essas precisam ser instanciadas pelo operador **new**. O _this_ dentro delas se referencia ao objeto criado a partir delas.
> **New** permite que crie objetos tanto das funções construtoras quanto das classes.
```js
const Person = function (name, city, year) {
this.name = name;
this.city = city;
this.year = year;
};
```
- Toda função tem uma propriedade chamada prototype, que é vinculada ao **\_\_proto\_\_** do objeto criado pelo operador **new**.
```js
Person.prototype.getAge = function () {
return new Date().getFullYear() - this.year;
};
const newPerson = new Person("Bill Gates", "Seattle", 1955);
```
- **factory function** ( Funções Fábricas ) são semelhantes às funções construtoras / funções de classe, mas em vez de usar _new_ para criar um objeto, as funções de fábrica simplesmente criam um objeto e o retorna.
```js
// Reaproveitando propriedades em comuns.
const personPrototype = {
getAge() {
return new Date().getFullYear() - this.year;
},
};
const createPerson = function (name, city, year) {
const person = {
name,
city,
year,
};
Object.setPrototypeOf(person, personPrototype);
return person;
};
const createPerson = createPerson("Linus Torvalds", "Helsinki", 1965);
```
- **Call** e **Apply** - Essas funções são capaz de alterar o valor _this_. Por padrão, o primeiro parâmetro que recebe é o valor do _this_ e o demais parâmetros são da função que invoca o método.
```js
const circle = {
radius: 10,
};
function calculateArea(fn) {
return fn(Math.PI * Math.pow(this.radius, 2));
}
calculateArea.call(circle, Math.round); // => 315
calculateArea.apply(circle, [Math.ceil]); // => 315
```
> A diferença entre call e apply é que no apply os parâmetros são passando como um array.
- **Bind** funciona de uma maneira diferente do **call** e do **apply**, ao invés de executar uma função, este retorna uma nova função. O seu primeiro parâmetro continua recebendo o valor que será atribuído ao _this_ e os demais argumentos serão os parâmetros que definirão os valores atribuídos da primeira função.
```js
const calculateAreaForCircle = calculateArea.bind(circle);
calculateAreaForCircle(Math.round); // => 315
```
### Arrow Function
As Arrow Functions tem uma abordagem mais simples e direta para escrever uma função e podem melhorar a legibilidade do código em diversas situações.
- Com a arrow function retiramos a palavra **function** e apos os parêntese se utiliza o **=>**, podendo também retirar as chaves **{ }** que nesse caso será realizado um retorno implícito sem o uso da palavra **return** .
```js
const sum = (a, b) => a + b;
// {
// return a + b;
// };
const subtract = (a, b) => a - b;
// {
// return a - b;
// }
```
- Um exemplo com função que retorna outra função.
```js
const calculate = (fn) => (a, b) => fn(a, b);
// (fn) =>{
// return (a, b) =>{
// return fn(a, b);
// };
// };
calculate(sum)(2, 3); // ==> 5
```
> **Cuidado** com a legibilidade do código.
> A Arrow functions nos permite também abrir mão dos parênteses nos casos onde é utilizado apenas um parâmetro.
- Arrow functions não possuem as suas próprias variáveis _this_ e _arguments_.
```js
// this
const person = {
name: "James Gosling",
city: "Alberta",
year: 1955,
getAge: () => {
return new Date().getFullYear - this.year; // => NaN
},
};
```
```js
// arguments
const sum = () => {
let total = 0;
for (let argument in arguments) {
total += arguments[argument];
}
return total;
};
sum(2, 3, 4, 5); // error
```
### Arrays
Um Array é um objeto similar a uma lista que armazena diferentes tipos de dados e oferece operações para acessar e manipular suas propriedades.
- Podemos criar um array através da função construtora ou iniciando com **[ ]**
```js
const languages = new Array("Python", "C", "Java");
const languages = ["Python", "C", "Java"];
```
- É possível iniciar um array passando apenas um Number para a função construtora.
```js
const numbers = new Array(10);
console.log(numbers); // => [ <10 empty items> ]
```
- A propriedade **length** indica a quantidade de elementos que existem dentro do array. Os elementos vazios sao considerados no length, caso o array tenha elementos com indices com espaços com elementos vazios esses são contabilizados no length)
```js
console.log(numbers.length); // => 10
```
#### AccessorAPI
Os accessor methods quando invocados retornam informações especificas sobre o array.
- **indexOf**: Retorna a posição do primeiro elemento encontrado, caso não exista o elemento no array é retornado -1.
```js
const languages = ["Python", "C", "Java"];
console.log(languages.indexOf("Python")); // => 0
```
- **lastIndexOf**: Retorna a posição do último elemento encontrado, caso tenha mais de um elemento igual no array.
```js
console.log(languages.lastIndexOf("Python")); // => 0
```
- **includes**: Retorna true se o elemento existir no array.
```js
console.log(languages.includes("JavaScript")); // => false
```
- **concat**: Retorna um novo array resultante da concatenação de um ou mais array.
> Arrays não são alterados, apenas é retornado um novo array com a concatenação.
```js
const veiculos = ["HB20", "Opalla", "Agile"];
const motocicletas = ["Honda CB", "Kawasaki Ninja"];
console.log(veiculos.concat(motocicletas)); // => [ 'HB20', 'Opalla', 'Agile', 'Honda CB', 'Kawasaki Ninja' ]
```
- **slice**: Retorna partes de um determinado array de acordo com a posição **inicio** e **fim**, posição fim é o valor -1, caso passe apenas o valor inicial irá retornar desse ponto até o final.
```js
console.log(veiculos.slice(1, 3)); // => ['Opalla,'Agile']
```
- **join**: Converte o array para uma String, juntando os elementos com base em um separador.
```js
const joinArray = veiculos.join("-");
console.log(joinArray); // => HB20-Opalla-Agile
```
#### MutatorAPI
Os mutator methods quando invocados modificam o array.
- **push**: Adiciona um elemento no final e retorna o novo length do array.
```js
const languages = ["Python", "C", "Java"];
languages.push("C#");
console.log(languages); // ==> [ 'Python', 'C', 'Java', 'C#' ]
```
- **pop**: Remove um elemento do final e o retorna.
```js
console.log(languages); // ==> [ 'Python', 'C', 'Java' ]
```
- **unshift**: Adiciona um elemento no inicio e retorna o novo length.
```js
languages.unshift("JavaScript");
console.log(languages); // ==> [ 'JavaScript', 'Python', 'C', 'Java' ]
```
- **shift**: Remove um elemento no inicio e o retorna.
```js
languages.shift();
console.log(languages); // ==> ["Python", "C", "Java"]
```
- **splice**: Remove, Substitui ou Adiciona um ou mais elementos em uma determinada posição e retorna um novo array com os elementos removidos.
- - splice(**posição do elemento a ser removido**, **quantidade de elementos a serem removido a parti daquele ponto**)
```js
languages.splice(1, 1); // Remove C e retorna ["C"];
console.log(languages); // ==> [ 'Python', 'Java' ]
```
- Inserindo elementos com **splice**, quando não for remover no segundo parâmetro utiliza se 0.
```js
languages.splice(1, 0, "C++", "C#"); // Partindo da posição 1 é inserido os elementos C++ e C#
console.log(languages); // ==> [ 'Python', 'C++', 'C#', 'Java' ]
```
- Removendo os 2 elementos inseridos e colocando novamente o **C**.
```js
languages.splice(1, 2, "C"); // Retorna ["C++", C#]
console.log(languages); // ==> ["Python", "C", "Java"]
```
- **sort**: Ordena os elementos de acordo com a função de ordenação.
- - **Sort** recebe uma função com parâmetros **a** e **b**, sendo seu retorno **a - b** pra ordenação crescente, **b - a** inverte a ordem.
```js
const languagesObj = [
{
name: "Python",
year: 1991,
},
{
name: "C",
year: 1972,
},
{
name: "Java",
year: 1995,
},
];
languagesObj.sort(function (a, b) {
return a.year - b.year;
// return (a.name <= b.name) ? -1 : 1; // Para ordenação por ordem alfabética
// return a.name.localeCompare(b.name);
});
console.log(languagesObj);
/*[ { name: 'C', year: 1972 },
{ name: 'Python', year: 1991 },
{ name: 'Java', year: 1995 } ] */
```
- **reverse**: Inverte a ordem dos elementos.
```js
languages.reverse();
console.log(languages); // => ["Java", "C", "Python"]
```
- **fill**: Preenche os elementos de acordo com a posição de inicio e fim.
- - fill(**value**, **pos. inicial**,**pos. final**) - preenche com o value o intervalo passado no parâmetro.
```js
languages.fill("JavaScript", 0, 2);
console.log(languages); // ==> [ 'JavaScript', 'JavaScript', 'Python' ]
```
#### IterationAPI
Os iteration methods quando invocados iteram sobre os elementos do array.
- **forEach**: Executa a função passada por parâmetro para cada elemento.
```js
const frameworks = ["VueJS", "NextJS", "AngularJS"];
frameworks.forEach((framework) => console.log(framework)); // ==> "VueJS", "NextJS", "AngularJS"
```
- **filter**: Retorna um novo array contendo somente os elementos que retornaram **true** na condição da função passada por parâmetro.
```js
const frameworks = [
{
name: "AngularJS",
contributors: 1548,
},
{
name: "EmberJS",
contributors: 746,
},
{
name: "VueJS",
contributors: 240,
},
];
const resultFilter = frameworks.filter(
(framework) => framework.contributors < 1000
);
console.log(resultFilter);
// =>
/* [ { name: 'EmberJS', contributors: 746 },
{ name: 'VueJS', contributors: 240 } ] */
```
- **find**: Retorna o primeiro elemento que retornou **true** na condição da função passada por parâmetro.
```js
const resultFind = frameworks.find((framework) => framework.name === "VueJS");
console.log(resultFind); // ==> { name: 'VueJS', contributors: 240 }
```
- **some**: Retorna **true** se um ou mais elementos retornaram **true** na condição da função passada por parâmetro.
```js
const resultSome = frameworks.some(
(framework) => framework.name === "AngularJS"
);
console.log(resultSome); // ==> true
```
- **every**: Retorna **true** se todos elementos retornaram **true** na condição da função passada por parâmetro.
```js
const resultEvery = frameworks.every(
(framework) => framework.contributors > 1000
);
console.log(resultEvery); // ==> false
```
- **map**: Retorna um novo array com base no retorno da função passada por parâmetro.
```js
const resultMap = frameworks.map((framework) => framework.name);
console.log(resultMap); // ==> ["AngulaJS", "EmberJS", "VueJS"]
```
- **reduce**: Recebe uma função de callback que possui 2 parâmetros principais o **acc** ( accumulator ) e o **currentItem** ( item atual do array iterado), o segundo parâmetro é o tipo de dado que será retornado do reduce.
```js
const resultReduce = frameworks.reduce(function (total, framework) {
return total + framework.contributors;
}, 0);
console.log(resultReduce); // ==> 2534 ( soma do total de contribuidores )
```
#### Math API
Math é um objeto global que contém constantes matemática e métodos para realização de operações envolvendo números.
- **Constantes Matemáticas**
```js
Math.E; // => 2.718281828459045
Math.LN10; // => 2.302585092994046
Math.LN2; // => 0.6931471805599453
Math.LOG10E; // => 1.4426950408889634
Math.PI; // => 3.141592653589793
Math.SQRT2; // => 1.4142135623730951
Math.SQRT1_2; // => 0.7071067811865476
```
- **Operações de arredondamentos**
- - **abs** - converte o sinal de um número para positivo
```js
Math.abs(10); // =>10
Math.abs(-10); // => 10
```
- - **ceil** - Arredonda o número para cima.
```js
Math.ceil(1.1); // => 2
Math.ceil(-1.1); // => -1
```
- - **floor** - Arrendonda o número para baixo.
```js
Math.floor(9.9); // => 9
Math.floor(-9.9); // => 10
```
- - **round** - Arredonda o número para cima se a parte decimal for de 5 a 9 e para baixo se for de 0 a 4;
```js
Math.round(4.5); // => 5
Math.round(-4.5); // => -4
```
- - **sign** - Retorna 1 se o número for positivo e -1 se for negativo.
```js
Math.sign(5); // => 1
Math.sign(-5); // => -1
```
- - **trunc** - Elimine a parte decimal do número ,tornando-o um inteiro.
```js
Math.trunc(2.3); // => 2
Math.trunc(-2.3); // => -2
```
- **Operações aritméticas / Trigonometria**
- - **cbrt** - Retorna a raiz cúbica do número.
```js
Math.cbrt(8); // => 2
```
- - **cos** - Retorna o cosseno de um ângulo
```js
Math.cos(Math.PI / 3); // => 0.5000000000000001
```
- - **exp** - Retorna **ex**, onde **x** é o argumento, e **e** é a Constante de Euler, a base dos logaritmos naturais
```js
Math.exp(1); // => 2.718281828459045
```
- - **hypot** - Retorna a raiz quadrada dos quadrado dos números.
```js
Math.hypot(3, 4); // => 5
```
- - **log** - Retorna o logaritmo do número em base natural.
```js
Math.log(1); // => 0
```
- - **pow** - Retorna o número elevado a um determinado expoente.
```js
Math.pow(2, 10); // => 1024
```
- - **sin** - Retorna o seno de um ângulo.
```js
Math.sin(Math.PI / 2); // => 1
```
- - **sqrt** - Retorna a raiz quadrada do número.
```js
Math.sqrt(4); // => 2
```
- - **tan** - Retorna a tangente de um ângulo.
```js
Math.tan(Math.PI / 4); // => 0.9
```
- Mínimo, Máximo e Random.
- - **min** - Retorna o menor número passado por parâmentro.
```js
Math.min(1, 2, 3, 4, 5, 6); // => 1
```
- - **max** - Retorna o maior número passado por parâmetro.
```js
Math.max(1, 2, 3, 4, 5, 6); // => 6
```
- - **random** - Retorna um número randômico entre 0 e 1, não incluindo o 1;
```js
Math.floor(Math.random() * 1000);
```
Por hoje é isso pessoal, conseguimos ter uma boa noção dos principais tipos objetos e como manipula-los, nos próximo posts iremos conhecer conceitos como **closures** e **assíncronismo** ( **Promises )**.
Obrigado por ler.
** <small>Exemplos são baseado no curso JavaScript - MasterClass do Rodrigo Branas. </small>
---
- Links de **referências** e **saiba mais**.
- - [Objetos Globais](https://developer.mozilla.org/pt-BR/docs/Web/JavaScript/Reference/Global_Objects)
---
<p align="center"> Me paga um ☕ ? | pix: <strong>nascimento.dev.io@gmail.com</strong> </p>
---
> <sub> _Este post tem como objetivo ajudar quem esta começando no aprendizado das tecnologias web, além de servir como incentivo no meus estudos e a criar outros posts pra fixação do aprendizado._ </sub>
---
<h4> <em> Me Sigam :) </em> </h4>
[Linkedin](https://www.linkedin.com/in/nascimento-dev-io/) | [Github](https://github.com/nascimento-dev-io)
| nascimento_ |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.