
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,376,716 | npm i или npm ci? | npm i vs npm ci — какую команду использовать. npm i (npm install) npm i... | 0 | 2023-02-23T13:38:09 | https://dev.to/jennypollard/npm-i-ili-npm-ci-1cn8 | npm | ## npm i vs npm ci — какую команду использовать.
### npm i (npm install)
`npm i` устанавливает пакеты и их зависимости в директорию `node_modules`. По-умолчанию, список пакетов берется из раздела `dependencies` в `package.json`.
`npm` обновляет файл `package-lock.json` после любых измений `package.json` или `node_modules`. То есть, если в результате выполнения какой-либо команды `npm`, будет обновлен `package.json` или содержимое `node_modules`, то будет обновлен `package-lock.json`.
`package-lock.json` описывает фактическое дерево пакетов, которое было уставновлено и нужен для того, чтобы выполнение `npm i` приводило к одному и тому же набору пакетов. Другими словами, `package-lock.json` это описание того, что установлено в `node_modules`.
`npm i` может устанавливать пакеты по-одному, по-умолчанию `npm i` добавляет установленный пакет в раздел `dependencies` (и обновляет `package-lock.json`).
### npm ci
Команда `npm ci` похожа на `npm i` — тоже устанавливает зависимости, но предназначена для установки зависимостей с чистого листа — при сборке приложения, в релизных пайплайнах, в проверках пулреквестов, используется автоматикой. `npm ci` быстрее, чем `npm i` и имеет существенные отличия:
- удаляет `node_modules` перед установкой.
- `npm ci` требует для работы наличие `package-lock.json`, иначе получим ошибку:
> npm ERR! cipm can only install packages with an existing package-lock.json or npm-shrinkwrap.json with lockfileVersion >= 1. Run an install with npm@5 or later to generate it, then try again.
>
- `npm ci` не может устанавливать пакеты по-одному, устанавливает все сразу как описано в `package-lock.json`.
- `npm ci` не обновляет `package-lock.json` и `package.json`, так как предназначен для автоматики, а в этом случае репозиторий только на чтение.
- если версии пакетов в `package.json` и `package-lock.json` расходятся, команда завершится с ошибкой:
> npm ERR! cipm can only install packages when your package.json and package-lock.json or npm-shrinkwrap.json are in sync. Please update your lock file with `npm install` before continuing.
npm ERR! Invalid: lock file's lodash.get@4.4.2 does not satisfy lodash.get@4.4.0
>
Иногда в `node_modules` могут накапливаться проблемы (например, рассинхрон фактических и ожидаемых версий пакетов), для таких случаев `npm ci` — быстрый способ переустановить все зависимости.
---
_Photo by [Paul Teysen](https://unsplash.com/fr/@hooverpaul55?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/photos/bukjsECgmeU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)_
| jennypollard |
1,376,723 | Where publish nodeJs+Angular app for free | I needed to publish a simple web application composed of Angular frontend and Node backend on a... | 0 | 2023-02-23T13:44:19 | https://dev.to/eleonorarocchi/where-publish-nodejsangular-app-for-free-43g1 | I needed to publish a simple web application composed of Angular frontend and Node backend on a server to make it accessible on the network. I was looking for a hosting service for this architecture, perhaps free, and I discovered [https://www.render.com](https://www.render.com)
Render.com is a fully-managed cloud platform, which can host sites, backend APIs, databases, cron jobs and all applications in one place.
Static site publishing is completely free on Render and includes the following:
- Continuous, automatic builds & deploys from GitHub and GitLab.
- Automatic SSL certificates through Let's Encrypt.
- Instant cache invalidation with a lightning fast, global CDN.
- Unlimited contributors.
- Unlimited custom domains.
- Automatic Brotli compression for faster sites.
- Native HTTP/2 support.
- Pull Request Previews.
- Automatic HTTP → HTTPS redirects.
- Custom URL redirects and rewrites.
If you have a github account, it is very convenient to release updates, as you can directly link a repository to render.com, and automate the deployment. | eleonorarocchi | |
1,376,819 | All About ChatGPT | ChatGPT is an advanced artificial intelligence language model that was developed by OpenAI. It is... | 0 | 2023-02-23T14:38:50 | https://dev.to/manoranjand/all-about-chatgpt-5aga | chatgpt, openai, ai |
ChatGPT is an advanced artificial intelligence language model that was developed by OpenAI. It is considered one of the most powerful and sophisticated language models in the world, with the ability to understand and generate human-like language. In this article, we will take a closer look at what ChatGPT is, how it works, and its potential applications.
###What is ChatGPT?
ChatGPT stands for "Chat Generative Pre-training Transformer." It is an advanced language model that is based on the transformer architecture, which was first introduced by Google in 2017. The transformer architecture is a neural network that uses self-attention mechanisms to process input data, allowing it to understand the context and meaning of text.
ChatGPT takes this architecture to the next level, using a technique called "pre-training" to improve its language generation capabilities. Pre-training involves training the model on a large corpus of text data, such as books, articles, and other written content, to help it understand the nuances of language and grammar.
###How does ChatGPT work?
ChatGPT works by analyzing text inputs and generating responses based on what it has learned from its pre-training. When a user inputs a question or statement, ChatGPT uses its self-attention mechanisms to process the input and generate a response that is based on the context and meaning of the text.
The model is designed to continuously learn and improve its language generation capabilities over time, allowing it to generate more accurate and nuanced responses. This is achieved through a process called "fine-tuning," which involves training the model on specific tasks, such as language translation or sentiment analysis, to improve its performance.
###What are the potential applications of ChatGPT?
ChatGPT has a wide range of potential applications across various industries and fields. Some of the most common applications include:
Customer service: ChatGPT can be used to create chatbots and virtual assistants that can handle customer inquiries and provide personalized support.
Content creation: ChatGPT can be used to generate high-quality content for websites, social media, and other digital platforms.
Language translation: ChatGPT can be used to translate text from one language to another, providing a more accurate and nuanced translation than traditional translation tools.
Education: ChatGPT can be used to create interactive learning experiences that provide personalized feedback and support to students.
Healthcare: ChatGPT can be used to analyze patient data and provide personalized recommendations for treatment and care.
Overall, ChatGPT represents a significant advancement in the field of natural language processing and has the potential to transform the way we communicate and interact with technology. As the technology continues to evolve, we can expect to see even more exciting applications and use cases emerge in the years to come.
| manoranjand |
1,376,870 | CodePen Designs - 40 : 3D First Person Art Gallery - No Javascript! | We are excited to introduce our new series that will explore the best design ideas from the... | 20,957 | 2023-02-23T16:15:44 | https://dev.to/jon_snow789/codepen-designs-40-3d-first-person-art-gallery-no-javascript-418l | codepen, css, webdev, design | ### We are excited to introduce our new series that will explore the best design ideas from the Codepen community.
We will be publishing these each day and hope you find them insightful and inspiring as we showcase some of the most talented designers in this space.
---
---
## Video Tutorial
Don't miss the amazing video we've embedded in this post! Click the play button to be inspired
{% youtube p6t7Iprd-38 %}
---
---
### Codepen Design - 40
<p>A CSS art gallery you can look around. Images of pure CSS art, but unfortunately peoples computer would explode if I didn't use images. Everything else is pure CSS though. </p>
<ul>
<li>There are a few Easter Eggs scattered about.</li>
</ul>
<p>A very short video of some of the coding:
<a href="https://youtu.be/4s0PT709Ia0" target="_blank">https://youtu.be/4s0PT709Ia0</a>.
Subscribe for more or follow me to say hi:
<a href="https://www.instagram.com/ivorjetski" target="_blank">https://www.instagram.com/ivorjetski</a>
<a href="https://twitter.com/ivorjetski" target="_blank">https://twitter.com/ivorjetski</a></p>
{% codepen https://codepen.io/ivorjetski/pen/gOPOvdB %}
---
## For more information
1. Check my GitHub profile
[https://github.com/amitSharma7741](https://github.com/amitSharma7741)
2. Check out my Fiver profile if you need any freelancing work
[https://www.fiverr.com/amit_sharma77](https://www.fiverr.com/amit_sharma77)
3. Check out my Instagram
[https://www.instagram.com/fromgoodthings/](https://www.instagram.com/fromgoodthings/)
4. Linktree
[https://linktr.ee/jonSnow77](https://linktr.ee/jonSnow77)
5. Check my project
- EVSTART: Electric Vehicle is the Future
[https://evstart.netlify.app/](https://evstart.netlify.app/)
- News Website in react
[https://newsmon.netlify.app/](https://newsmon.netlify.app/)
- Hindi jokes API
[https://hindi-jokes-api.onrender.com/](https://hindi-jokes-api.onrender.com/)
- Sudoku Game And API
[https://sudoku-game-and-api.netlify.app/](https://sudoku-game-and-api.netlify.app/)
---
---
| jon_snow789 |
1,377,079 | JavaScript Tutorial Series: Date Object | A built-in Date object in JavaScript makes working with dates simple. We will discuss how to use... | 0 | 2023-02-23T18:24:00 | https://dev.to/fullstackjo/javascript-tutorial-series-date-object-gb5 | A built-in Date object in JavaScript makes working with dates simple. We will discuss how to use dates in this article.
## Working with dates
A new Date object can be easily created. A new instance of the Date object can be made using this syntax:
```JavaScript
let currentDate = new Date();
```
By doing this, a new Date object will be created with the current date and time.
## Date methods and properties
The Date object has multiple built-in methods and properties. We're going to discuss the most commonly used.
Once you have a Date object, you can extract a variety of data from it. For example, you can find the current year, month, day, and time.
```JavaScript
let currentDate = new Date();
let currentYear = currentDate.getFullYear();
let currentMonth = currentDate.getMonth();
let currentDay = currentDate.getDate();
let currentTime = currentDate.getTime();
console.log(currentYear); //2023
console.log(currentMonth); //1
console.log(currentDay); //23
console.log(currentTime); //1677176048519
```
Keep in mind `getMonth()` returns zero-based index and `getTime()` returns the amount of milliseconds that have passed since the epoch, which is recognized as the beginning of January 1, 1970, UTC at midnight.
`setFullYear()`, `setMonth()`, `setDate()`, and `setTime()` methods allow you to set a specific date and time.
```JavaScript
let currentDate = new Date();
currentDate.setFullYear(2021);
currentDate.setMonth(9); // september (zero-based)
currentDate.setDate(15);
currentDate.setTime(0); // Sets the time to midnight
```
Along with getting and setting specific date and time components, you also have the choice of performing operations on dates. For instance, you can add or subtract a certain number of days, hours, or minutes from a date by using the setDate(), setHours(), and setMinutes() methods.
```JavaScript
let currentDate= new Date();
currentDate.setDate(currentDate.getDate() + 3);
// Adds 3 days
currentDate.setHours(currentDate.getHours() - 5);
// Subtracts 5 hours
currentDate.setMinutes(currentDate.getMinutes() + 10);
// Adds 10 minutes
```
Last but not least, you can format dates for display by using the toLocaleDateString() and toLocaleTimeString() methods. The user's locale settings will be used by these methods to format the date and time.
_Do not forget to try these snippets and output the result on your own to get the hang of using the date object._ | fullstackjo | |
1,377,088 | LWP - Layered WallPaper engine | I've created an open-source app, that lets You set multi-layered wallpapers, moving with Your... | 0 | 2023-02-23T18:52:53 | https://dev.to/jszczerbinsky/lwp-layered-wallpaper-engine-5fg4 | showdev, opensource, github | {% embed https://youtu.be/nvrj7hAs694 %}
I've created an open-source app, that lets You set multi-layered wallpapers, moving with Your mouse cursor as a desktop background. It works on Windows and Linux.
Link: https://github.com/jszczerbinsky/lwp
If You like this project, give me a feedback. It really helps ;D
| jszczerbinsky |
1,377,152 | Recreating my Portfolio in Next.js | I have recently started learning Next.js/React and I wanted to compare the speeds of Next.js and the... | 0 | 2023-02-23T20:41:54 | https://dev.to/vulcanwm/recreating-my-portfolio-in-nextjs-1ll7 | nextjs, webdev, javascript, react | I have recently started learning Next.js/React and I wanted to compare the speeds of Next.js and the framework I used to use previously: Flask (a Python framework).
So I decided to recreate my portfolio in Next.js (the portfolio was initially created in Flask). This way I would be able to easily see the difference in load times between Next.js and Flask.
Over the last 4 days, I properly learnt how to do:
- Components in React
- Loops in React (this took a while!)
- Assets in Next.js
- How to put a Next.js website together
---
This is the [Next.js Portfolio](https://vulcanwm.vercel.app) and this is the [Flask Portfolio](https://vulcanwm.is-a.dev).
See the difference in load times!
---
If you want to see the source code for either portfolios, here they are.
Next.js Portfolio:
{% embed https://github.com/VulcanWM/vulcanwm-nextjs %}
Flask Portfolio:
{% embed https://github.com/VulcanWM/vulcanwm %}
---
Thanks for reading, and thanks for supporting me on my Next.js journey! | vulcanwm |
1,377,734 | Minsheng Bank, openGauss, MogDB | With the rapid development of domestic digital construction and transformation, the scale and volume... | 0 | 2023-02-24T07:41:12 | https://dev.to/490583523leo/minsheng-bank-opengauss-mogdb-5e24 | With the rapid development of domestic digital construction and transformation, the scale and volume of data are increasing year by year. In addition, open source and cloud deployment have become important trends. More and more organizations are beginning to consider replacing existing traditional databases to cope with new and more Complex business requirements.
The replacement of the database will inevitably bring about the relocation of massive data and the migration and transformation of a large number of data processing programs. How to perform smooth and seamless migration and ensure business continuity and data consistency has become an important factor that enterprises have to consider when selecting database replacements.
►Minsheng Bank embraces openGauss
As the first national commercial bank established by private capital in mainland China, Minsheng Bank has always adhered to the original aspiration and mission of "living for the people and co-existing with the people", and is committed to providing customers with professional and modern financial services. The industry explored the road to the construction of modern commercial banks.

As we all know, various data information such as users' financial status and transaction records are the "lifeline" of banks, and ensuring their security is the top priority. At the same time, with the diversification, complexity, and Internet-based business development, the centralized traditional commercial database originally deployed by Minsheng Bank can hardly bear the sudden burst of peak pressure, cannot cope with challenges such as mixed loads, and is costly and difficult to expand. The method of piling up resources to ensure business continuity and stability is no longer sustainable. In order to ensure data security, reduce costs and increase efficiency, and meet new business challenges, Minsheng Bank conducted rigorous testing and evaluation of candidate products, and finally selected openGauss with excellent performance to replace and transform the database in key business scenarios .
►Database migration keywords: compatible, stable, continuous
After determining openGauss as a product to replace the original database, a difficult problem facing Minsheng Bank is how to efficiently realize the complete migration of database objects and full data between heterogeneous databases.
The 2021 annual report of Minsheng Bank shows that the number of retail customers of the company (referring to personal customers with normal customer status (including accounts I, II, and III), pure credit card customers, and small and micro enterprise legal person customers) reached 110.1378 million. At the end of the year, the growth rate was 5.41%. With the addition of other types of customers, the total amount of bank business data can be imagined. If the migration is performed purely by hand, the project volume will be huge, which will definitely affect the normal business development of the company. Therefore, customers need mature migration tools to improve the efficiency of heterogeneous database migration.

Minsheng Bank mainly migrates data from databases such as Oracle, MySQL, and DB2 to openGauss . Customers require migration tools to be well adapted to different types of databases and integrated into the openGauss ecosystem. It is understood that the amount of data that needs to be migrated by each system ranges from tens of GB to tens of TB. After the migration is completed, all data must be complete and accurate to ensure availability. In addition, in order to provide better services to bank customers, the migration process needs to ensure system stability and business continuity.
Of course, Minsheng Bank also encountered some common problems in database migration, such as SQL syntax conversion. During the migration process, SQL-related database objects, such as tables, storage, and functions, may be incompatible. The migration tool must accurately identify incompatible SQL.
►
MTK escorts the smooth replacement of openGauss
In fact, in order to make the database replacement go far and steadily, Minsheng Bank adopts a safe three-party cooperation model for system construction . The bank is responsible for database product testing, application transformation, and online operation and maintenance; the openGauss community is mainly responsible for database core function development and ecological construction; Yunhe Enmo, as a third-party manufacturer, is responsible for product defect repair, technical support, and peripheral tool development. is one of them .
MTK is a database migration tool (Database Migration Toolkit) for the cloud and Enmo database MogDB. Since MogDB is an enterprise-level relational database commercial release based on the openGauss kernel, MTK has natural advantages in adaptation and compatibility when it comes to migration tasks that use openGauss as the target library. In addition, MTK supports database migration with Oracle, DB2, and MySQL source databases, which can be said to perfectly match the migration needs of Minsheng Bank and become a powerful tool to promote customer database replacement.
After MTK is deployed in the Minsheng Bank system, it only needs to execute six commands to complete the migration task , specifically:
1. Check the configuration file: ./mtk -c config.json config-check, check the file for syntax errors.
2. Pre-migration test: ./mtk -c config.json --preRun , check possible problems in the migration process in advance, and estimate the time to complete the entire migration task, so as to coordinate the time window for suspending the business.
Next, Minsheng Bank migrated step by step according to its own business needs to accurately locate problems during the migration process and reduce the impact of the migration task on the system.
3. Table structure: ./mtk -c config.json mig-tab-pre
4. Data migration: ./mtk -c config.json mig-tab-data
5. Index/constraint object migration: ./mtk -c config.json mig-tab-post
6. Stored procedure/function migration: ./mtk -c config.json mig-tab-other
To solve the problem of SQL syntax conversion in database migration, MTK has embedded multiple SQL rules, and has realized most of the syntax conversion . In addition, in order to facilitate users to intuitively understand the migration status and problems encountered in the migration, an HTML report will be generated after the MTK parameter configuration reportFile , with detailed content, shows the SQL statement of each step in the migration process, and the user can directly view the problem SQL and modify it.
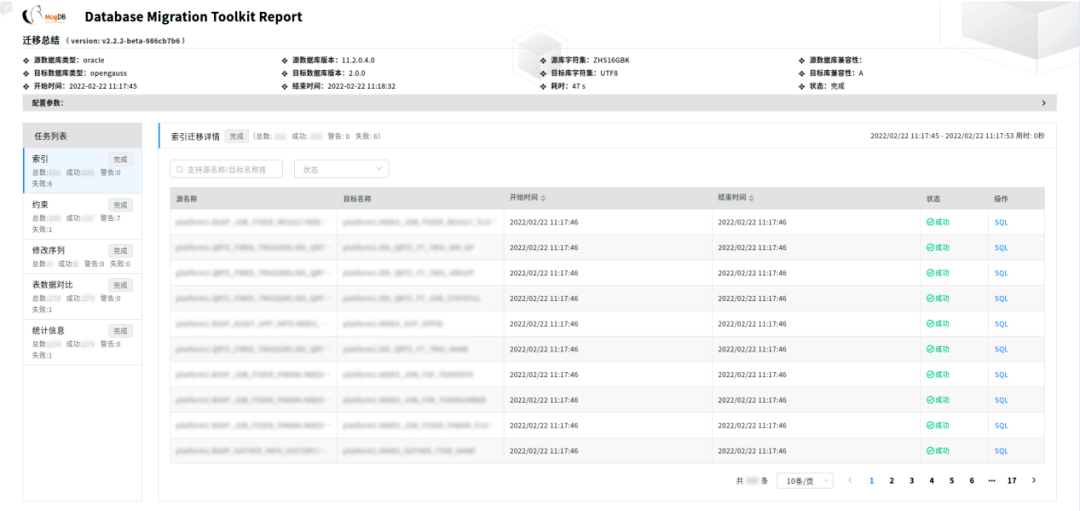
MTK's work of migrating data from Oracle, DB2 and other databases to openGauss has been recognized by Minsheng Bank. During the entire migration process, MTK performed stably, maintaining a migration speed of 1TB per hour, ensuring data consistency and smooth business operation . By the end of 2022, Yunhe Enmo has completed the task of migrating 100 sets of heterogeneous databases to openGauss for Minsheng Bank .
See kung fu in the subtleties, and strive for excellence in the extreme. Data is the top priority of the business system, ensuring zero data loss, instant data access and data security are the key points in the process of database migration. In fact, besides MTK, Cloud and Enmo's Migrate to openGauss / MogDB solution also includes SQL compatibility assessment tool SCA before heterogeneous database migration, data consistency verification tool MVD, and heterogeneous data synchronization tool MDB . Through the continuous innovation of the MogDB database and its supporting migration solutions, Yunhe Enmo will continue to promote the smooth progress of the database replacement work of Minsheng Bank.
| 490583523leo | |
1,377,240 | Useful: Lombok Annotations | Summary Configuration @ToString @Tolerate @StandardException ... | 21,123 | 2023-02-23T22:13:10 | https://dev.to/selllami/useful-lombok-annotations-3fh2 | java, spring, springboot, lombok | ## Summary
- Configuration
- @ToString
- @Tolerate
- @StandardException
## Configuration
-- Gradle: `build.gradle`
```
compileOnly 'org.projectlombok:lombok:1.18.20'
annotationProcessor 'org.projectlombok:lombok:1.18.20'
```
-- Maven: `pom.xml`
```
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>11</source> <!-- depending on your project -->
<target>11</target>
<annotationProcessorPaths>
<path>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
```
## @ToString
Generate an implementation of the toString() method.
```
@ToString(doNotUseGetters = true)
public class Account {
private String id;
private String name;
@ToString.Exclude // Exclusion Field
private String adress;
// ignored getter
public String getId() {
return "this is the id:" + id;
}
}
@ToString(onlyExplicitlyIncluded = true)
public class Account {
@ToString.Include(name = "accountId") // Modifying Field Names
private String id;
@ToString.Include(rank = 1) // Ordering Output
private String name;
private String adress;
@ToString.Include // Method Output
String description() {
return "Account description";
}
} => Account(name=An account, accountId=12345, description=Account description)
```
## @Tolerate
Skip, jump, and forget! Make lombok disregard an existing method or constructor.
```
public class TolerateExample {
@Setter
private Date date;
@Tolerate
public void setDate(String date) {
this.date = Date.valueOf(date);
}
}
```
## @StandardException
Put this annotation on your own exception types.will generate 4 constructors:
- `MyException()`: representing no message, and no cause.
- `MyException(String message)`: the provided message, and no cause.
- `MyException(Throwable cause)`: which will copy the message from the cause, if there is one, and uses the provided cause.
- `MyException(String message, Throwable cause)`: A full constructor.
| selllami |
1,377,488 | Cookie Management in ExpressJS to Authenticate Users | Express.js is a widely used NodeJs framework by far and if you’re familiar with it, probably cookie... | 0 | 2023-02-26T05:00:00 | https://www.permify.co/post/cookie-management-in-expressjs-to-authenticate-users | node, javascript, tutorial, webdev |
Express.js is a widely used NodeJs framework by far and if you’re familiar with it, probably cookie management is not a very painful concept for you.
Although there are numerous use cases of the cookies; session management, personalization, etc. We will create a demo app that demonstrates a simple implementation of cookie management in your Express.js apps to authenticate users.
Before we create our demo app, let's talk a little bit about Cookies;
## So what are HTTP cookies?
HTTP cookies are small pieces of data that are sent from a web server and stored on the client side.
To set up a cookie on the client's side, the server sends a response with the Set-Cookie header.
When the client receives the response message from the server containing the Set-Cookie header, it'll set up the cookie on the client-side.

Such that each subsequent request going from the client-side will explicitly include;
- A header field called “Cookie”
- An actual header that contains the value.
- The cookie information that has been sent by the server in the response message.
Actually, this is enough for scope of our article but If you want to learn more about browser cookies, I recommend reading this [article](https://www.digitalocean.com/community/tutorials/js-what-are-cookies).
## Step 1: Setting up our demo Express app
For a kick-off, we need to create a demo express application where we can implement our cookie management. To quickly create one I’ll use the express app generator tool, express-generator.
Run the following command to create,
```js
npx express-generator express-cookie
```
For earlier Node versions, install the application generator as a global npm package and then launch it, for more check out [express documentation](https://expressjs.com/en/starter/generator.html).
All necessary starter modules and middleware that we will use should already be generated with express-generator, your project folder structure should look like below
All necessary starter modules and middleware that we will use should already be generated with express-generator, your project folder structure should look like below

## Step 2: Create Basic Authentication middleware
To demonstrate the use of cookies for authentication, we won’t need to implement a fully-fledged authentication system.
So for simplicity, I will use Basic Authentication. The very basic mechanism that will enable us to authenticate users.
### How does Basic authentication work?
When the server receives the request, the server will extract authorization information from the client's request header. And then, use that for authenticating the client before allowing access to the various operations on the server-side.
If this client request does not include the authorization information, then the server will challenge the client, they're asking for the client to submit this information with the user name and password fields.
So, every request message originating from a client should include the encoded form of the username and password in the request header that goes from the client to the server-side.
Open your app.js and add our auth middleware with the logic above as follows:
```js
. . .
function auth (req, res, next) {
//server will extract authorization information from the client's request header
var authHeader = req.headers.authorization;
if (!authHeader) {
var err = new Error('You are not authenticated!');
res.setHeader('WWW-Authenticate', 'Basic');
err.status = 401;
next(err);
return;
}
//If this client request does not include the authorization information
var auth = new Buffer.from(authHeader.split(' ')[1], 'base64').toString().split(':');
var user = auth[0];
var pass = auth[1];
//static credential values
if (user == 'admin' && pass == 'password') {
next(); // user authorized
} else {
var err = new Error('You are not authenticated!');
res.setHeader('WWW-Authenticate', 'Basic');
err.status = 401;
next(err);
}
}
app.use(auth);
. . .
```
**Note:** *You should add auth middleware on top of the routers so that the authorization middleware can be triggered correctly when a request is received.*
### Cookie-based authentication
We want only authenticated users to access various operations on the server-side. Here’s how cookie-based workflow should work;
- The first time that the user tries to access the server, we will expect the user to authorize himself/herself.
- Thereafter, we will set up the cookie on the client-side from the server.
- Subsequently, the client doesn't have to keep sending the basic authentication information. Instead, the client will need to include the cookie in the outgoing request.
## Step 3: Setting the cookie on the Client-Side
Express has a cookie property on the response object, so we do not need to implement any other library, lets send user name as cookie:
```js
// sentUserCookie creates a cookie which expires after one day
const sendUserCookie = (res) => {
// Our token expires after one day
const oneDayToSeconds = 24 * 60 * 60;
res.cookie('user', 'admin', { maxAge: oneDayToSeconds});
};
```
### Getting the Cookies on request
We will use **cookie-parser** middleware to handle cookies. If you open app.js you will notice that the cookie-parser is already included in our express application, because we generated our project with **express-generator**.

Note: If you need to explicitly install cookie-parser, the installation command is:
```js
npm install cookie-parser.
```
cookie-parser parses cookie header and attach on request, so we can access cookies with: req.cookie
Check out the [source code](https://github.com/expressjs/cookie-parser/blob/master/index.js) of the cookie-parser for more information.
## Step 4: Auth mechanism with cookies
We looked at how we can get and set cookies, let's modify our auth middleware for creating a simple authentication mechanism with cookies;
```js
function auth (req, res, next) {
//check client has user cookie
if (!req.cookie.user) {
//get authorization
var authHeader = req.headers.authorization;
if (!authHeader) {
var err = new Error('You are not authenticated!');
res.setHeader('WWW-Authenticate', 'Basic');
err.status = 401;
next(err);
return;
}
//If this client request does not include the authorization information
var auth = new Buffer.from(authHeader.split(' ')[1], 'base64').toString().split(':');
var user = auth[0];
var pass = auth[1];
if (user == 'admin' && pass == 'password') {
sendUserCookie(res)
next(); // user authorized
} else {
var err = new Error('You are not authenticated!');
res.setHeader('WWW-Authenticate', 'Basic');
err.status = 401;
next(err);
}
}
else {
//client request has cookie, check is valid
if (req.cookie.user === 'admin') {
next();
}
else {
var err = new Error('You are not authenticated!');
err.status = 401;
next(err);
}
}
}
```
## Conclusion
In a nutshell, we build a mechanism that requests some information on the browser for authentication. Afterward, we examine how to persist this auth information by using cookies to prevent the resending of auth information.
Now expanding this further, if your server wants to track information about your client, then the server may explicitly set up a session-tracking mechanism. Cookies are small, and can't store lots of information.
Now, if we want a lot more information to be tracked about a client on the server side, then express sessions enable us to do that. If you have any related questions just ping me :)
| egeaytin |
1,377,492 | Beware of Fake Job Offers: My Encounter with a Scammer | TL;DR A scammer will email a job seeker trying to set up an interview. Check the email... | 0 | 2023-02-24T03:10:05 | https://dev.to/davidchedrick/beware-of-fake-job-offers-my-encounter-with-a-scammer-nf9 | webdev, career, interview, scam | ####TL;DR
A scammer will email a job seeker trying to set up an interview. Check the email address, it will be from gmail or something similar not an official company domain, e.g. firstname.lastname.company @gmail.com. The Interview process will move very fast. The scammer will send a job offer, then send a check to set up your home office. The check is fake and will be declined. The scammer will say you need to purchase items from a preferred vendor. The scammer will say you have to use a pay app to be able to get the equipment in time to start, and as usual, the scammer will be very pushy trying to make you do things quickly.
---
Below is my personal story of talking with one of these scammers. I started talking with them because I did happen to apply to the company they were impersonating. Luckily I deal with scammers all the time and noticed red flags before giving them money.
I have talked to others that have had the same scam run on them. The scammers will change details, and company names, and sometimes they will take longer with the scam but it is the same basic setup.
---
This blog is a cautionary tale so others don’t fall victim.
Below is how the scam played out with me. The names in quotes are the actual names the scammers used while talking with me.
---
This is how it all went down:
###Monday ~10 am:
-
I receive an email from “Donald” at “Intelletec”. The email states that they have reviewed my application and want to set up a time for an interview.
Nice! Sounds good.
-
I double check my Huntr app and see I applied to Intelletec for a Software Engineer position about two weeks ago. So I set up a call with “Donald” for the following Day.
###Tuesday ~11 am:
-
I have my interview with “Donald”. Despite some initial nerves, everything seemed normal and we went into a standard conversation about my experience and their tech stack. Donald seemed seasoned and well-versed in the technologies. We talked about the company culture, and the role itself. At the end “Donald” said that he thought I could be a good fit and said the next step would be a technical test and to answer some behavior questions. “Donald,” said I would receive an email where I could set up a time.
###Tuesday ~4 pm:
-
I receive the email “Donald” spoke of, and I was able to set up my next interview for the next morning.
In this process, this was the first time I thought. “Uh weird…”, none of these companies move this fast. Usually, I have to wait a week to even hear anything about the next interview, especially to set up something the next day. But whatever, maybe this company just has their hiring practice down.
###Wednesday ~11 am:
-
I get on a call with the “Technical Team”, and [don’t remember his “name”] tells me that he is having problems with zoom and that we will just do it over the phone. He asks me to open up Replit and he would ask me Data Structure and Algorythm-style questions and I would talk my way through the problem over the phone. We did three of those questions. After the questions, he said I will shortly receive an email from HR with the behavior portion.
This was an odd experience but still relatively normal.
###Wednesday ~ 12 pm:
-
The email from “HR” comes in. It is a list of standard behavior-type questions. Ones like “Tell me about a time when you had to solve a particularly challenging problem.” and “Give an example of how you've collaborated with cross-functional teams to deliver a project.” All were reasonable questions. I have to answer the questions and email them back.
###Thursday ~ 1 pm:
-
I received an email from “HR” saying they liked all my answers and that the “Technical team” agreed. The email stated that I was in consideration for the position and they would get back to me when they reviewed all other candidates.
Okay, now things definitely seem off. This moved really fast. But still, this is my first job in tech so I don’t know what to expect.
###Friday ~ 4 pm:
-
I receive an offer letter from “Intelletec”.
That was way too quick, okay, now I am really second-guessing the validity of this offer. Plus, I only talked to two people over the phone and never even on video.
-
The email states that if I am interested in the position I should review the documents and sign and send them back by Monday afternoon.
At this point, I decided to just go along with it, and see what happens, at least I’ll have a fun story and at best I wasted a scammer's time. And who knows, maybe I am wrong and I have a job.
One thing I have to give to the scammers, the offer letter was very well done. They put time into that fake letter.
###Monday ~ 7 am
-
“Donald” doesn’t waste any time, he is texting me now. Tells me that if I am accepting the job I should send the papers back soon. He really wants me to set it up in time for the next project. I send the papers back right away.
Shortly after I receive a text from “Paul” from HR. He tells me that he needs to get me set up with my home office. He says that I have to use their equipment that would be supplied by a “preferred vendor” and that I would receive a check for $6000 to pay the vendor.
Huh? Why wouldn’t they just pay the vendor and have it shipped to me? Very strange, doesn't seem legit. I’ll ask “Paul”.
-
“Paul” tells me a story about how they used to just send equipment to employees, but too many people tried to scam them and say they never received the equipment, so now it's on the employee to order the equipment with the stipend check.
Okay, “Paul”, sure.
-
I tell “Paul” that “Donald” is in a hurry for me to get started so I should just go to Best Buy and get the equipment so I can start right away.
“Paul” tells me that I can’t. It must be through the “preferred vendor” so that they know I have the correct equipment.
###Monday ~ 11 am:
-
I get an email from “HR” with a personal check attached. The email says that the check is from a “trusted partner” of theirs. The email goes on that the check has been certified by the “trusted partner” so it clears the bank the same day.
Lol, now a “trusted partner” is involved.
-
The email continues, I must deposit the check by mobile, and I must screenshot the deposit and send it back to them so they know the process is underway.
Okay, whatever. I have fraud protection so I don’t have to pay for bounced checks. Let's do this.
-
Obviously, the check is automatically declined and flagged as fraudulent. An alert pops up on my banking app. I screenshot it and send it to “Paul”
“Paul” is “shocked” to see the check is declined. It was even certified! Paul says it must be my bank flagging it because I never cashed a check so big.
Um… did “Paul” just neg me?
-
“Paul” will have to get back to me, to see what we can do.
###Monday ~ 1 pm:
-
“Donald” is texting again. Tells me he heard from “Paul” what happened. “Donald,” says not to worry, he has seen this before. He says that the bank is just delaying the funds, but it will clear, probably in three days. But “Donald” is worried that this will delay the project. We really need to get that equipment to me.
“Donald” has an idea! The only thing that I need to get started in the first week is the computer. “Donald,” says the computer is only $2000. “Donald” wants to know if I could raise the funds by the end of the day to pay for it myself and then just keep the $2000 from the stipend check once it clears.
Wait… did “Donald” just say “can you raise the funds”? Who raises funds? This is America, I am already in crippling dept what's another $2000 on the card.
I am definitely not going to do that, but let's play along with “Donald”.
-
I tell “Donald” that I can definitely pay for the computer, I will just use my credit card. “Donald” says he doesn’t know if that would work, he will ask the “preferred vendor manager” if it is okay that I put it on my credit card.
Why wouldn’t a company take a credit card? Seems suspicious. Oh, and shouldn’t this “preferred vendor” have some sort of website I could see? How am I supposed to buy the equipment anyways? Seems like I was never meant to buy the equipment.
###Monday ~ 3 pm:
-
“Donald” is back and he says the “preferred vendor manager” can not take a credit card. Credit cards take too long to clear the funds. But he has a new idea! He can take Cash App!
OMG, did he really? At least he didn’t ask for a Visa gift card.
I knew it was a scam for a bit now, but that one was the proof. Time to go talk to the real Intelletec.
-
I tell “Donald” that I have to download the app and get back to him.
###Monday ~ 6 pm:
-
I look up the management of the real Intelletec. I reach out to Sally [not her real name] and ask if she knows that scammers are impersonating their company. She replies back pretty quickly.
Sally is aware of the scammers and thanks me for reaching out to inform them. I tell her that I have a lot of information on them: multiple emails, phone numbers, an offer letter, a check, and I saved all the conversations. I offer to give Sally whatever she needs to help take the scammers down.
When copying the emails, I looked at the full email address for the first time. “Donalds” email was Donald.Fred.Intelletec @gmail.com and “HR” was HR.Intelletec @mail.com.
Oh… no…. This should have been a huge red flag. Now I check every email address from anyone I don’t know.
###Monday ~ 9 pm:
-
“Donald” reaches back on text and said the “preferred vendor manager” is waiting to place the order, but it needs to be soon to make the deadline.
What a nice “preferred vendor manager”, willing to place my order at 9 pm.
-
I tell “Donald” that I reached out to Sally to see what she thought and she said it was best to wait for the check to clear.
Note, Sally did not say this, I am just messing with the scammers at this point.
-
“Donald” asked who Sally was.
How does he not know the head of HR?
-
I tell “Donald” Sally is the head of HR, and ask how come he doesn’t know her? I tell “Donald” he better talk to “Paul”.
This was the last communication I had with the scammers. I suppose they realized I was just wasting their time.
---
Stay aware, stay safe.
---
❤️❤️❤️
Follow me on [LinkedIn ](https://www.linkedin.com/in/davidchedrick/)for all the updates and future blog posts | davidchedrick |
1,377,544 | 人工智能对联生成 API 数据接口 | 人工智能对联生成 API 数据接口 基于百万数据训练,AI 训练与应答,多结果返回。 1. 产品功能 AI... | 0 | 2023-02-24T03:43:35 | https://dev.to/gugudata/ren-gong-zhi-neng-dui-lian-sheng-cheng-api-shu-ju-jie-kou-bb6 | 人工智能对联生成 API 数据接口
基于百万数据训练,AI 训练与应答,多结果返回。

# 1. 产品功能
- AI 基于百万历史对联数据训练应答模型;
- 机器学习持续训练学习;
- 一个上联可返回多个下联应答;
- 毫秒级响应性能;
- 数据持续更新与维护;
- 全接口支持 HTTPS(TLS v1.0 / v1.1 / v1.2 / v1.3);
- 全面兼容 Apple ATS;
- 全国多节点 CDN 部署;
- 接口极速响应,多台服务器构建 API 接口负载均衡;
- [接口调用状态与状态监控](https://www.gugudata.com/status)
# 2. API 文档
**接口详情:** [https://www.gugudata.com/api/details/coupletai](https://www.gugudata.com/api/details/coupletai)
**接口地址:** https://api.gugudata.com/text/coupletai
**返回格式:** application/json; charset=utf-8
**请求方式:** POST
**请求协议:** HTTPS
**请求示例:** https://api.gugudata.com/text/coupletai
**数据预览:** [https://www.gugudata.com/preview/coupletai](https://www.gugudata.com/preview/coupletai)
**接口测试:** [https://api.gugudata.com/text/coupletai/demo](https://api.gugudata.com/text/coupletai/demo)
# 3. 请求参数
| 参数名 | 参数类型 | 是否必须 | 默认值 | 备注 |
| :-------: | :------: | :------: | :---------: | :-----------------: |
| appkey | string | 是 | YOUR_APPKEY | 付费后获取的 APPKEY |
| firstpair | string | 是 | YOUR_VALUE | 对联上联文本 |
# 4. 返回参数
| 参数名 | 参数类型 | 备注 |
| :--------------------------: | :------: | :----------------------------------: |
| DataStatus.StatusCode | int | 接口返回状态码 |
| DataStatus.StatusDescription | string | 接口返回状态说明 |
| DataStatus.ResponseDateTime | string | 接口数据返回时间 |
| DataStatus.DataTotalCount | int | 此条件下的总数据量,一般用于分页计算 |
| DataStatus.RequestParameter | string | 请求参数,一般用于调试 |
| Data | string | 下联文本,多次请求会随机应答多个下联 |
# 5. 接口 HTTP 响应标准状态码
| 状态码 | 状态码解释 | 备注 |
| :----: | :----------: | :----------------------------------------------------------: |
| 200 | 接口正常响应 | 业务状态码参见下方 **接口自定义状态码** |
| 403 | 请求频率超限 | CDN 层通过 IP 请求频率智能判断,一般的高频请求不会触发此状态码 |
# 6. 接口响应状态码
| 状态码 | 状态码解释 | 备注 |
| :----: | :----------------------: | :----------------------------------------------------------: |
| 100 | 正常返回 | 可通过判断此状态码断言接口正常返回 |
| -1 | 请求失败 | 请求处理请求失败 |
| 501 | 参数错误 | 请检查您传递的参数个数以及参数类型是否匹配 |
| 502 | 请求频率受限 | 一般建议每秒请求不超过 100 次 |
| 503 | APPKEY 权限超限/订单到期 | 请至开发者中心检查您的 APPKEY 是否到期或是否权限超限 |
| 504 | APPKEY 错误 | 请检查传递的 APPKEY 是否为开发者中心获取到的值 |
| 505 | 请求的次数超出接口限制 | 请检查对应接口是否有请求次数限制以及您目前的接口请求剩余次数 |
| 900 | 接口内部响应错误 | 接口可用性为 99.999%,如获取到此状态码请邮件联系我们 |
# 7. 开发语言请求示例代码
示例代码包含的开发语言:C#, Go, Java, jQuery, Node.js, Objective-C, PHP, Python, Ruby, Swift 等,其他语言进行对应的 RESTful API 请求实现即可。
# 8. 常见问题 Q&A
- Q: 数据请求有缓存吗?
A: 所有的数据都是直接返回的,部分周期性数据在更新周期内数据是缓存的。
- Q: 如何保证请求时 key 的安全性?
A: 一般建议将对我们 API 的请求放置在您应用的后端服务中发起,您应用的所有前端请求都应该指向您自己的后端服务,这样的架构也更加地纯粹且易维护。
- Q: 接口可以用于哪些开发语言?
A: 可以使用于所有可以进行网络请求的开发语言,用于您项目快速地进行数据构建。
- Q: 接口的性能可以保证吗?
A: 接口后台架构和我们给企业提供的商业项目架构一致,您可以通过访问测试接口查看接口相关返回性能与信息。
-----
咕咕数据,专业的数据提供商,提供专业全面的数据接口、商业数据分析,让数据成为您的生产原料。

咕咕数据基于我们七年来为企业客户提供的千亿级数据存储与性能优化、相关海量基础数据支撑,将合规的部分通用数据、通用功能抽象成产品级数据 API,大大满足了用户在产品开发过程中对基础数据的需求,同时降低了海量数据的存储与运维成本,以及复杂功能的技术门槛与人力开发成本。
除了我们已开放的分类数据与功能接口外,还有海量数据正在整理、清洗、整合、构建中,后期会开放更多的数据与云端功能接口 API 供用户使用。
# **目前已开放的数据接口 API**
- [[条码工具] 通用二维码生成](https://www.gugudata.com/api/details/qrcode)
- [[条码工具] Wi-Fi 无线网二维码生成](https://www.gugudata.com/api/details/wifiqrcode)
- [[条码工具] 通用条形码生成](https://www.gugudata.com/api/details/barcode)
- [[图像识别] 通用 OCR](https://www.gugudata.com/api/details/ocr)
- [[图像识别] 通用图片 OCR 到 Word](https://www.gugudata.com/api/details/ocr2word)
- [[图像识别] HTML 转 PDF](https://www.gugudata.com/api/details/html2pdf)
- [[图像识别] HTML 转 Word](https://www.gugudata.com/api/details/html2word)
- [[图像识别] Markdown 转 PDF](https://www.gugudata.com/api/details/markdown2pdf)
- [[区域/坐标] 全国大学高校基础信息](https://www.gugudata.com/api/details/college)
- [[区域/坐标] 地理坐标逆编码](https://www.gugudata.com/api/details/geodecode)
- [[区域/坐标] IP 地址定位](https://www.gugudata.com/api/details/iplocation)
- [[区域/坐标] 全国省市区街道区域信息](https://www.gugudata.com/api/details/chinaregions)
- [[区域/坐标] 地理坐标系转换](https://www.gugudata.com/api/details/coordinateconverter)
- [[元数据/字典] 历年高考省录取分数线](https://www.gugudata.com/api/details/ceeprovince)
- [[元数据/字典] 历年高考高校录取分数线](https://www.gugudata.com/api/details/ceecollegeline)
- [[元数据/字典] 历年高考专业录取分数线](https://www.gugudata.com/api/details/ceemajorline)
- [[新闻/资讯] 软件开发技术博文头条](https://www.gugudata.com/api/details/techblogs)
- [[新闻/资讯] 获取任意链接文章正文](https://www.gugudata.com/api/details/fetchcontent)
- [[新闻/资讯] 公众号头条文章](https://www.gugudata.com/api/details/wxarticle)
- [[新闻/资讯] 获取任意链接正文图片](https://www.gugudata.com/api/details/fetchcontentimages)
- [[新闻/资讯] 获取公众号文章封面](https://www.gugudata.com/api/details/wxarticlecover)
- [[新闻/资讯] 幽默笑话大全](https://www.gugudata.com/api/details/joke)
- [[短信/语音] 手机归属地查询](https://www.gugudata.com/api/details/mobileattribution)
- [[短信/语音] 国际手机号码检查纠正](https://www.gugudata.com/api/details/internationalphone)
- [[文字/文本] 中文文本分词](https://www.gugudata.com/api/details/segment)
- [[文字/文本] 中英文排版规范化](https://www.gugudata.com/api/details/formatarticle)
- [[文字/文本] 百万中国对联数据](https://www.gugudata.com/api/details/couplet)
- [[文字/文本] 国际标准书号 ISBN](https://www.gugudata.com/api/details/isbn)
- [[文字/文本] 简体繁体互转](https://www.gugudata.com/api/details/stconvert)
- [[文字/文本] 唐诗宋词大全](https://www.gugudata.com/api/details/chinesepoem)
- [[文字/文本] 关键字摘要智能提取](https://www.gugudata.com/api/details/nlpabstract)
- [[文字/文本] 文本语义相似度检测](https://www.gugudata.com/api/details/nlpsimilarity)
- [[文字/文本] NLP中文智能纠错](https://www.gugudata.com/api/details/nlpcorrect)
- [[文字/文本] 人工智能对联生成](https://www.gugudata.com/api/details/coupletai)
- [[文字/文本] NLP 语种检测](https://www.gugudata.com/api/details/nlpdetectlanguage)
- [[天气/空气质量] 全国天气预报信息](https://www.gugudata.com/api/details/weatherinfo)
- [[天气/空气质量] 全国实时空气质量指数](https://www.gugudata.com/api/details/airquality)
- [[天气/空气质量] 日出与日落时间](https://www.gugudata.com/api/details/sunriseandsunset)
- [[天气/空气质量] 农历与二十四节气](https://www.gugudata.com/api/details/lunarcalendar)
- [[网站工具] 获取任意站点标题与图标](https://www.gugudata.com/api/details/favicon)
- [[股票行情] 美股实时行情数据](https://www.gugudata.com/api/details/stockusrealtime)
- [[股票行情] 美股历史行情数据](https://www.gugudata.com/api/details/stockus)
- [[股票行情] 美股分时交易数据](https://www.gugudata.com/api/details/stockusperminute)
- [[股票行情] 美股历年基本财务数据](https://www.gugudata.com/api/details/usfundamental)
- [[股票行情] 港股实时行情数据](https://www.gugudata.com/api/details/stockhkrealtime)
- [[股票行情] 港股历史行情数据](https://www.gugudata.com/api/details/stockhk)
- [[股票行情] 港股分时交易数据](https://www.gugudata.com/api/details/stockhkperminute)
- [[股票行情] 港股上市公司公告](https://www.gugudata.com/api/details/stockhkbulletin)
- [[股票行情] 港股历年三大财务报表](https://www.gugudata.com/api/details/hkannualreport)
- [[股票行情] A 股实时行情数据](https://www.gugudata.com/api/details/stockcnrealtime)
- [[股票行情] A 股历史行情数据](https://www.gugudata.com/api/details/stockcn)
- [[股票行情] A 股分时交易数据](https://www.gugudata.com/api/details/stockcnperminute)
- [[股票行情] A 股历年三大财务报表](https://www.gugudata.com/api/details/annualreport)
- [[股票行情] 中国股票指数数据](https://www.gugudata.com/api/details/stockcnrealtimeindex)
- [[股票行情] A 股个股信息查询](https://www.gugudata.com/api/details/fundamentalinfo)
- [[股票行情] A 股历年财务指标](https://www.gugudata.com/api/details/financialindicator)
- [[股票行情] A 股指数成分数据](https://www.gugudata.com/api/details/stockcnindexcontains)
- [[股票行情] A 股指数历史数据](https://www.gugudata.com/api/details/stockcnindexhistory)
- [[股票行情] A 股盘前数据](https://www.gugudata.com/api/details/stockcnpreopen)
- [[股票行情] A 股分笔交易数据](https://www.gugudata.com/api/details/stockcnticks)
- [[股票行情] A 股交易日历](https://www.gugudata.com/api/details/stockcntradecalendar)
- [[股票行情] 期权实时行情数据](https://www.gugudata.com/api/details/stockcnoptions)
- [[股票行情] 基金基本信息列表](https://www.gugudata.com/api/details/fundinfolist)
- [[股票行情] 指数型基金基本信息](https://www.gugudata.com/api/details/fundbasicindex)
- [[股票行情] 开放式基金净值实时数据](https://www.gugudata.com/api/details/fundopennavrealtime)
- [[股票行情] 开放式基金净值历史数据](https://www.gugudata.com/api/details/fundopennavhistory)
- [[股票行情] 科创板历史行情数据](https://www.gugudata.com/api/details/stockkcb)
- [[股票行情] 美股粉单实时行情数据](https://www.gugudata.com/api/details/pinksheetsrealtime)
- [[股票行情] 分类美股实时行情数据](https://www.gugudata.com/api/details/usfamous)
- [[股票行情] 公募开放式基金实时数据](https://www.gugudata.com/api/details/fundopenrealtime)
- [[股票行情] 公募开放式基金历史数据](https://www.gugudata.com/api/details/fundopenrealtime)
- [[股票行情] 场内交易基金实时数据](https://www.gugudata.com/api/details/fundopenetfrealtime)
- [[股票行情] 场内交易基金历史数据](https://www.gugudata.com/api/details/fundopenetfhistory)
- [[股票行情] 场内交易基金分时行情](https://www.gugudata.com/api/details/fundhistoryminute)
- [[体育/比赛] 历年奥运比赛数据](https://www.gugudata.com/api/details/olympic))
| gugudata | |
1,377,667 | openGauss Parallel Page-based Redo For Ustore | Availability This feature is available since openGauss 2.1.0. ... | 0 | 2023-02-24T07:02:20 | https://dev.to/liyang0608/opengauss-parallel-page-based-redo-for-ustore-1l03 | opengauss | ## Availability
This feature is available since openGauss 2.1.0.
## Introduction
Optimized Ustore inplace update WAL write and improved the degree of parallelism for Ustore DML operation replay.
## Benefits
The WAL space used by the update operation is reduced, and the degree of parallelism for Ustore DML operation replay is improved.
## Description
Prefixes and suffixes are used to reduce the write times of WAL update. Replay threads are classified to solve the problem that most Ustore DML WALs are replayed on multiple pages. In addition, Ustore data pages are replayed based on blkno.
## Enhancements
None.
## Constraints
None.
| liyang0608 |
1,377,743 | Recoil atom effects | ..are effing cool! I've been using Recoil.js for a while now, but I've never taken the time to dive... | 0 | 2023-02-24T07:57:36 | https://dev.to/atlefren/recoil-atom-effects-3n93 | typescript, recoiljs | ..are effing cool!
I've been using Recoil.js for a while now, but I've never taken the time to dive into atom effects before recently.
Why did I do so? Because I needed a timer. Or a clock if you will. Running in recoil. And atom effects seems to do the trick. Just look here
```ts
import {AtomEffect, atomFamily} from 'recoil';
export type Millisecounds = number;
const getUnixNow = () => Math.floor(Date.now() / 1000);
const clockEffect =
(interval: Millisecounds): AtomEffect<number> =>
({setSelf, trigger}) => {
if (trigger === 'get') {
setSelf(getUnixNow());
}
const timer = setInterval(() => setSelf(getUnixNow()), interval);
return () => clearInterval(timer);
};
/**
* Atom that contains the current unix timestamp
* Updates at the provided interval
*/
export const clockState = atomFamily<number, Millisecounds>({
key: 'clockState',
default: getUnixNow(),
effects: (interval: Millisecounds) => [clockEffect(interval)],
});
```
This gives you an atomFamiliy that can be instantiated with the desired interval, and this atom automagically updates each interval, in this case returning the current unix timestamp
```ts
const time = useRecoilValue(clockState(1000)); //new clock state that updates every secound
return <div>The current Unix time is now: {time}</div>
```
Neat?
Well. But what you can do is use this as a trigger in a selector that needs to run periodically
```ts
export const pollerState = selector<SomeData[]>({
key: 'pollerState ',
get: async ({get}) => {
//add this to referesh every minute
get(clockState(60000));
return await myApi.getSomeData();
},
});
```
And this is pretty neat!
And if this doesn't get you hooked on atom effects, take a look at this, straight outta the [recoil docs](https://recoiljs.org/docs/guides/atom-effects) (Just some TypeScript added):
```ts
export const localStorageEffect =
<T>(key: string): AtomEffect<T> =>
({setSelf, onSet}) => {
const savedValue = localStorage.getItem(key);
if (savedValue != null) {
setSelf(JSON.parse(savedValue));
}
onSet((newValue, _, isReset) => {
isReset ? localStorage.removeItem(key) : localStorage.setItem(key, JSON.stringify(newValue));
});
};
const syncedState = atom<string>({
key: 'syncedState',
default: '',
effects: [localStorageEffect('local_storage_key')],
});
```
This actually syncs your atom to local storage. Sweet! | atlefren |
1,377,828 | State of Flowbite: learn more about our results from 2022 and what we plan to build this year | Disclaimer: this article was NOT generated by chatGPT 🤖 My name is Zoltán and I am one of the... | 0 | 2023-02-24T09:45:38 | https://flowbite.com/blog/state-of-flowbite-2022/ | flowbite, opensource, webdev, tailwindcss | _Disclaimer: this article was NOT generated by chatGPT 🤖_
My name is [Zoltán](https://twitter.com/zoltanszogyenyi) and I am one of the original founders and current project maintainers of the Flowbite ecosystem alongside with [Robert](https://twitter.com/roberttanislav) – for without his design skills we couldn't enjoy the beautiful UI/UX components that are now used by over 2 million projects on NPM.
I've been wanting to write a blog post that encapsulates the results of what the Flowbite Ecosystem and Community achieved last year and it's going to be pretty hard to summarize it all as this was the year with the highest growth we experienced in terms of adoption, community growth, but also challenges.
I'll try to break it up in a chronological order and focus on the different tools and libraries that we've developed as the year passed - so let's get started!
## One million downloads on NPM
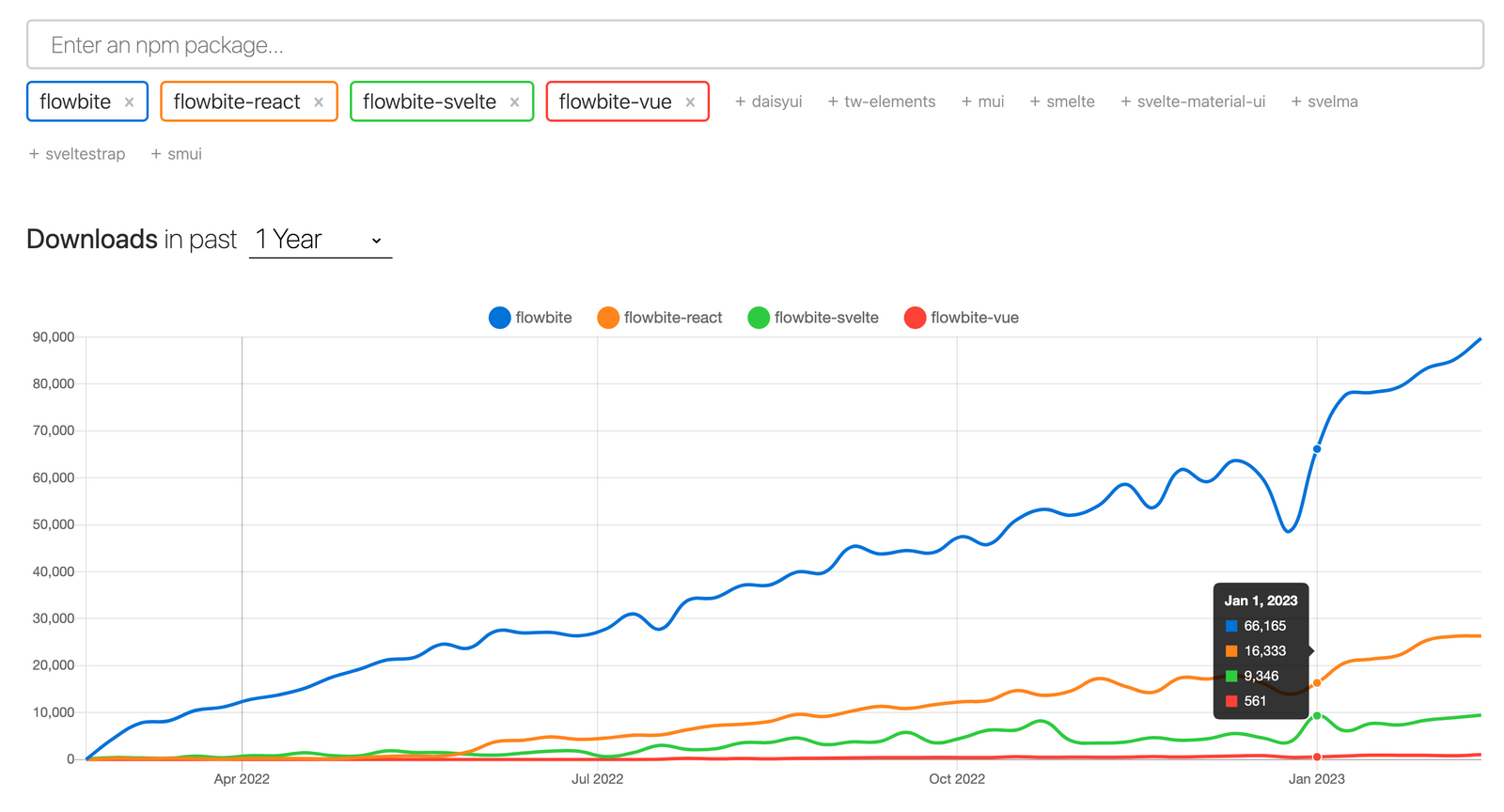
One of the best metrics that you can use to measure the adoption rate of a framework is to look at the total amount of NPM downloads – we reached over [one million downloads](https://www.npmjs.com/package/flowbite) sometime in the middle of the year and the weekly download rate has only been increasing.
[](https://www.npmjs.com/package/flowbite)
At the time of the writing of this article the main Flowbite library is rocking about 94k downloads per week, while Flowbite React is standing at 26k, Flowbite Svelte 10k and Flowbite Vue slowly catching up with 1.2k.
Big shout-out to all the open-source contributors and project maintainers of the adjacent libraries based on the main Flowbite library!
Growth has been steady and adoption has been increasing at a pace of about 10-15% on a monthly basis – this gives us a decent amount of time to keep improving the library while keeping growth intact.
## Flowbite Library
The main growth factor of the Flowbite Ecosystem is the [open-source UI component library](https://github.com/themesberg/flowbite) that is based on the utility classes from Tailwind CSS – there are over 54 standalone components and 16 framework integration guides and we have big plans this year to build even more.
[](https://github.com/themesberg/flowbite)
We have provided [official TypeScript support](https://flowbite.com/docs/getting-started/typescript/) to the interactive JS API, added brand new components, provided new functionality and features, improved the documentation styles, and fixed over 194 issues as of date.
We also built countless of integration guides with other frameworks, such as [Astro](https://flowbite.com/docs/getting-started/astro/), [SolidJS](https://flowbite.com/docs/getting-started/solid-js/), [Gatsby](https://flowbite.com/docs/getting-started/gatsby/), and [Flowbite with Symfony](https://flowbite.com/docs/getting-started/symfony/) being the latest one and we have plans to build quite a few more.
The next phase for the development of the Flowbite Library will be to start building more complex components such as data grids, autocomplete input elements, custom chart components, and others.
## We launched Flowbite Blocks
This is probably the most notable launch that we have made and it is a collection of modular websites sections that you can use to quickly wrap up a website by copy-pasting the source code directly from the Flowbite platform.
[](https://flowbite.com/blocks/)
Right now there are over 293 block sections that have been planned, prototyped, designed, coded, verified, and launched on the [Flowbite Blocks](https://flowbite.com/blocks/) page which include essential building components for a website such as hero sections, CRUD layouts, pricing pages, blog templates, and more.
We will keep adding new content as we design new components, sections, and pages and while we also collaborate with the open-source community to provide support for libraries and frameworks such as React, Vue, Svelte, and more.
## Flowbite Figma Design System
I'm not sure if many of you know but the first instance of Flowbite was in fact a Figma file that we built for integration with Tailwind CSS – originally named [tailwind-figma.com](https://tailwind-figma.com/) we had to rename it per request from [Steve Schoger](https://twitter.com/steveschoger) from Tailwind Labs to prevent confusion – I have to thank Steve for that because I found the beautiful "Flowbite" name and domain then 😜
[](https://www.figma.com/community/file/1179442320711977498)
Long story short, last year we decided to open-source the core UI components from the Flowbite Library and it has been generally very well received – you can [duplicate the file](https://www.figma.com/community/file/1179442320711977498) on Figma Community right now.
Of course, this meant that we had to "up our game" with the [pro version's design system](https://flowbite.com/figma/) and we have provided updates all the way up to `v2.4.1` and we are super close to launching `v2.5.0` with countless new components, landing pages, Figma features, and more.
## Flowbite Admin Dashboard
Towards the end of the year we also had a big surprize to the open-source community by releasing an [admin dashboard template](https://github.com/themesberg/flowbite-admin-dashboard) that leverages not only the Flowbite design system, but also the library's interactive UI components and more.
[](https://github.com/themesberg/flowbite-admin-dashboard)
The [repository](https://github.com/themesberg/flowbite-admin-dashboard) reached over 200 stars on GitHub and we plan to release new pages based on demand and feature requests from the open-source community. We are currently improving the pro version of this dashboard and we are excited to share it in the coming months with our [Flowbite Pro](https://flowbite.com/pro/) community.
## Flowbite Community and libraries
Probably the most amazing thing about Flowbite is the awesome and flourishing open-source community that is growing around it – we have recently reached over 2,000 members on the [Flowbite Discord server](https://discord.gg/4eeurUVvTy) which is quite breathtaking.
[](https://discord.gg/4eeurUVvTy)
The open-source Flowbite libraries such as [Flowbite React](https://github.com/themesberg/flowbite-react), [Flowbite Svelte](https://github.com/themesberg/flowbite-svelte), and [Flowbite Vue](https://github.com/themesberg/flowbite-vue) have been nicely growing in terms of number of components, functionality, documentation, and also usage.
This year, we plan to collaborate even more with these libraries to increase consistency across the frameworks and provide assistance with building new components and documentations.
## What about the future?
I've been personally working over 2 years on the Flowbite ecosystem and starting from creating the first instance of the repository, pushing the first commit, building the Flowbite platform, managing the community, it's been quite a lot.
My strength is primarily being driven by the awesome community that we have built around the Flowbite concept and ecosystem and as long as we can we will make sure that our main mission will be to provide open-source UI components to all software developers and teams regardless of frameworks.
A big thank you to all open-source contributors, the core Flowbite team, our partners, and developers and designers of Flowbite – let's rock this year even more! ❤️
PS: here's a video on Twitter where I talk about this:
{% twitter 1628746566507831300 %}
| zoltanszogyenyi |
1,378,062 | Streamlining your workflow: How AI-assisted code completion can improve productivity | As software developers, we are all too familiar with the challenges of staying productive in our... | 0 | 2023-02-24T13:22:57 | https://bito.co/streamlining-your-workflow-how-ai-assisted-code-completion-can-improve-productivity/ | As software developers, we are all too familiar with the challenges of staying productive in our work. Long hours spent on manual coding and debugging can make it difficult to keep up with the demands of our job. However, there is a solution to these challenges — AI-assisted code completion.
AI-assisted code completion employs machine learning methods to suggest and finish code snippets, reducing manual coding and debugging time. Deloitte found that such solutions cut requirements review time by over 50%. ([Source: Deloitte](https://www2.deloitte.com/us/en/insights/focus/signals-for-strategists/ai-assisted-software-development.html/#endnote-14))
This blog discusses AI-assisted code completion, its benefits, and how to integrate it into your development workflow.
## I. Understanding AI-Assisted Code Completion
AI algorithms to suggest and complete code snippets based on the context of the code. This can save developers time and effort because they won’t have to type and fix bugs by hand as much. There are a few different types of AI-assisted code completion tools available, each with their own unique features and capabilities.
Real-life examples of AI-assisted code completion in action include Bito AI, DeepCode, Github Copilot, TabNine, CodeRush. According to a report by MarketsandMarkets, the AI-assisted code completion market is expected to grow at a CAGR of 21.8% during the forecast period 2020–2026. ([Source: Markets and Markets](https://www.marketsandmarkets.com/Market-Reports/conversational-ai-market-49043506.html))
One important thing to consider when comparing AI-assisted code completion tools is how well they integrate with your existing development workflow. Some tools may require additional setup or configuration, while others may be able to integrate seamlessly with your existing tools and processes.
## II. The Benefits of AI-Assisted Code Completion
**Reducing the time spent on repetitive tasks:** By using AI-assisted code completion, developers can focus on the more complex and creative aspects of their work, while the tool handles the more repetitive tasks. This can lead to faster development times and higher-quality code.
**Enhancing code quality and reducing errors:** AI-assisted code completion reduces errors by eliminating human coding and debugging. This can speed up debugging and testing and improve development.
**Improving collaboration within the development team:** According to a study by Accenture, with AI process automation, workforces can process 5X larger volumes and scale up as new business needs arise to help quickly act on new opportunities. ([Source: Accenture](https://www.accenture.com/us-en/services/applied-intelligence/solutions-ai-processing))
**Enabling faster debugging and testing:** AI-assisted code completion reduces errors by eliminating human coding and debugging. This can speed up debugging and testing and improve development.
## III. Implementing AI-Assisted Code Completion
Implementing AI-assisted code completion in your development workflow is relatively straightforward. There are many tools and platforms available, such as DeepCode, Kite, TabNine, CodeRush, IntelliCode that you can use.
When choosing a tool, it is important to consider how well it integrates with your existing development workflow. Some tools may require additional setup or configuration, while others may be able to integrate seamlessly with your existing tools and processes.
Once you have chosen a tool, the next step is to integrate it into your development workflow. This may involve installing the tool and configuring it to work with your existing tools and processes.
## Conclusion
In conclusion, AI-assisted code completion is a powerful technology that can help to streamline your development workflow and improve your productivity as a software developer. By using AI-assisted code completion, developers. | ananddas | |
1,378,368 | 9 Must-Have SaaS Tools for Startups to Boost Growth | 9 Must-Have SaaS Tools for... | 0 | 2023-02-24T17:38:55 | https://dev.to/seeratawan01/9-must-have-saas-tools-for-startups-to-boost-growth-2b07 | startup, saas, tooling, productivity | {% embed https://www.seeratawan.me/9-must-have-saas-tools-for-startups/ %} | seeratawan01 |
1,378,377 | A detailed guide on how to implement Server-side Rendering (SSR) in a NextJs Application | Introduction Server-side Rendering (SSR) is becoming increasingly important in web... | 0 | 2023-03-29T10:28:40 | https://dev.to/onlyoneerin/a-detailed-guide-on-how-to-implement-server-side-rendering-ssr-in-a-nextjs-application-1mpp | nextjs, webdev, react, javascript | ## Introduction
Server-side Rendering (SSR) is becoming increasingly important in web development due to its ability to improve website performance and user experience. Unlike Client-side Rendering (CSR), where the website's content is generated on the user's device, server-side rendering generates the HTML on the server and sends it to the client. This method can improve website load time, search engine optimization, and accessibility.
[Next.Js](https://nextjs.org/) is a popular framework for building React applications, and it offers built-in support for server-side rendering. With Next.js, we can easily set up our application to generate HTML on the server and deliver it to the client, providing a seamless user experience and optimized website performance. In this detailed guide, we will build a cryptocurrency web app to show how to implement SSR in a Next.js application. We will also cover the basic concepts behind server-side rendering and walk through the steps required to set up SSR in our Next.js application. By the end of this article, you will have a solid understanding of improving your website's performance and SEO by implementing SSR in your Next.js application.
<p> </p>
## Pre-rendering: A built-in Feature in Next.js
Regarding page rendering with Next.js, pre-rendering is a fundamental component. It is a key feature of Next.js, which means that static HTML content is generated in advance rather than dynamically on each request.
When comparing the page source of a traditional [React.js](https://react.dev/) web app and a Next.js web app, it is clear that the Javascript code is loaded before the contents are rendered to the user, which is a bad user experience. However, when inspecting the contents of a Next.js page source, the HTML is already generated with all the necessary data, making Next.js the most efficient method for improved web performance and user experience.
Next.js gives us the option of selecting one of two pre-rendering modes:
1. SSG (Static Side Generation): This is Next.js's default pre-rendering mode, in which HTML pages are generated at build time and served to the user as static files. This approach is appropriate for websites with static content because it reduces server load and provides the fastest possible performance.
2. Server-side rendering (SSR): SSR, on the other hand, generates HTML pages on the server whenever a user requests them. This approach is useful for websites with frequently changing content or that require dynamic data because it can provide a more responsive user experience while ensuring the content is always up to date.
## Understanding the Server-Side Rendering Process
Server-side rendering is fast becoming a popular technique widely used in web development that involves rendering a web page on the server before sending it to the client, unlike client-side rendering, where the page is rendered in the browser first after the server has sent the necessary HTML, CSS, and JavaScript bundled files.
To fully understand the server-side rendering process, it is important to know the key players involved. It includes the server and the client.
The server is responsible for handling all incoming requests made from the client side and sending the appropriate response. In the context of SSR, this involves rendering the requested web page on the server and sending the resulting HTML, CSS, and JavaScript to the client.
The client is the web browser through which a user accesses the web application. In SSR, the client gets the rendered HTML, CSS, and JavaScript from the server and displays the contents on the web page.
Now that we've identified the two major players in server-side rendering, let's look at the actual thought process behind it.
The client requests the server for a specific web page as the first step in the server-side rendering process.
The server will receive the request and determine which page the client is looking for. The server will then render the requested page on the server, which includes generating the page's HTML, CSS, and JavaScript and compiling them into a complete web page.
After rendering the web page on the server, the server will send the resulting HTML, CSS, and JavaScript to the client. The client will then use these files to show the user the web page.
<p> </p>
## Implementing SSR with Data Fetching in Next.js
Data fetching is an essential part of developing any web application. Next.Js provides several methods for retrieving data, including server-side rendering, static site generation, client-side rendering, incremental static regeneration, and dynamic routing. However, for this article, we will only look at server-side generation. You can learn about the other types by reading the [Next.js documentation](https://nextjs.org/docs/getting-started).
<p> </p>
## getServerSideProps: a built-in Function for Data Fetching in Next.Js
Next.js includes a built-in function called getServerSideProps that allows us to fetch data from the server with each request. To use server-side rendering on a page, we must export getServerSideProps, and the server will call this function on every request.
**getServerSideProps Syntax**
```javaScript
export default function Page( {data} ){
return <>YOU CAN DISPLAY YOUR DATA ACCORDINGLY</>
}
export async function getServerSideProps() {
// Your code
const data = .... ;
// Passing data to the page using props
return {
props : {data}
}
}
```
In place of `data` we can use a different variable name. We can also pass multiple props by using commas "," to separate them.
<p> </p>
### <u>Key Notes about getServerSideProps</u>
1. `getServerSideProps` only runs on the server and never on the client.
2. It runs at the request time, and the web page is pre-rendered with the returned props specified inside.
3. `getServerSideProps` can only be exported from a page. You cannot export it from non-page files. It will not work if you make `getServerSideProps` a page component property.
4. `getServerSideProps` should only render a page whose data must be fetched at the requested time. If the data does not need to be rendered during the request, consider fetching it on the client side or using static side generation.
5. The `getServerSideProps` function must return an object containing the data that will be passed to the page component as props. If the function does not have a return statement, it cannot pass data to the page component.
<p> </p>
## Fetching data using getServerSideProps
<p> </p>
**Step 1: Setting up a Next.Js Application**
Now that we understand the server-side rendering process, we can go ahead and make requests to the server and fetch data from it.
Next.Js includes server-side rendering support; with this framework, we can easily make server requests and pre-render our web content without writing complex coding functions or methods.
To get started, we have to set up a development environment where we can start building our web app. If you have ever built a React app, you are familiar with `[create-react-app](https://create-react-app.dev/)`, which sets up the development environment. Next.Js has its command called `create-next-app`.
Run the following command via a terminal. I am using `npm` as my package manager, but you can use your preferred package manager's commands instead:
```javascript
npx create-next-app crypto-web-app
```
This command will create a new Next.js project and all other app dependencies in your folder directory.
Once all of the dependencies have been installed, navigate to the `crypto-web-app` directory by running
```
cd crypto-web-app
```
To start the development server run:
```
npm run dev or yarn dev
```
To view the application, go to http://localhost:3000.
<p> </p>
**Step2: Getting a third-party API endpoint**
Let us go to our application's `pages/index.js` file. In this file, we will get the top nine cryptocurrency coins by market value from CoinGecko, an external API. Let us look through [coingecko's API documentation](https://www.coingecko.com/en/api/documentation) to find our endpoint. The endpoint we require is in the coins category. We only need to set a basic configuration, and when we click the Execute button, it should provide us with an endpoint.
CoinGecko API End point:
```
<https://api.coingecko.com/api/v3/coins/markets?vs_currency=usd&order=market_cap_desc&per_page=9&page=1&sparkline=false>
```
<p> </p>
Step 3: Declaring the getServerSideProps function. Add the following code to our `index.js` file. We will go through the code step by step:
```javaScript
import React from "react";
import styles from "/styles/Home.module.css";
import { FiArrowDown, FiArrowUpRight } from "react-icons/fi";
function Home({ data }) {
return (
// Renders the data passed as props from the getServerSideProps
<div className={styles.container}>
<h1>Cryptocurrencies by Market Cap</h1>
<div className={styles.crypto__container}>
{data.map((crypto) => (
<div key={crypto.id} className={styles.crypto__child}>
<img src={crypto.image} alt={crypto.symbol} />
<h3>{crypto.name}</h3>
<div className={styles.crypto__price}>
<p>$ {crypto.current_price.toLocaleString()}</p>
{crypto.price_change_percentage_24h < 0 ? (
<span className={styles.arrow__down}>
<FiArrowDown className={styles.price__icon} size={20} />
{crypto.price_change_percentage_24h.toFixed(2)}%
</span>
) : (
<span className={styles.arrow__up}>
<FiArrowUpRight className={styles.price__icon} size={20} />
{crypto.price_change_percentage_24h.toFixed(2)}%
</span>
)}
</div>
</div>
))}
</div>
</div>
);
}
// This function gets triggered on every request
export async function getServerSideProps() {
// This fetches the data from the Coingecko external API
const response = await fetch(
"<https://api.coingecko.com/api/v3/coins/markets?vs_currency=usd&order=market_cap_desc&per_page=9&page=1&sparkline=false>"
);
const data = await response.json();
// Pass data to the page component via props
return {
props: {
data,
},
};
}
export default Home;
```
We declared the `async getServerSideProps` function and used JavaScript's built-in fetch API function to retrieve data from the CoinGecko API endpoint. Remember that we must declare a return statement in order to pass the data obtained from the API to our page component.
We accepted the props passed by the `getServerSideProps` method in our Home function component. We used the JavaScript `map()` method to display a list of cryptocurrencies sorted by market value as a child element of the component.
Here is the CSS to add more styling to the web app:
```css
@import url('<https://fonts.googleapis.com/css2?family=Nunito+Sans:wght@400;600;700&display=swap>');
.container {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
width: 100vw;
height: 100%;
padding: 100px 0;
font-family: 'Nunito Sans', sans-serif;
}
.container h1 {
margin-bottom: 40px;
}
.crypto__container {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: repeat(3, 1fr);
grid-column-gap: 25px;
grid-row-gap: 80px;
}
.crypto__child {
box-shadow: rgba(0, 0, 0, 0.16) 0px 10px 36px 0px, rgba(0, 0, 0, 0.06) 0px 0px 0px 1px;
padding: 30px 15px;
border-radius: 7px;
display: flex;
flex-direction: column;
align-items: center;
}
.crypto__child img {
width: 50%;
margin-bottom: 7px;
}
.crypto__child h3 {
font-size: 20px;
margin: 7px 0;
}
.crypto__price {
display: flex;
align-items: center;
gap: 10px;
}
.arrow__down {
color: red;
display: flex;
align-items: center;
}
.arrow__up {
color: green;
display: flex;
align-items: center;
}
/* Mobile */
@media (max-width: 700px) {
.container {
padding: 70px 0;
font-family: 'Nunito Sans', sans-serif;
}
.container h1 {
margin-bottom: 30px;
font-size: 25px;
}
.crypto__container {
display: grid;
grid-template-columns: 1fr;
grid-template-rows: repeat(9, 1fr);
grid-column-gap: 0;
grid-row-gap: 20px;
}
.crypto__child {
padding: 25px 13px;
}
.crypto__child img {
width: 50%;
}
.crypto__child h3 {
font-size: 17px;
}
}
/* Tablet and Smaller Desktop */
@media (min-width: 701px) and (max-width: 1120px) {
.container {
padding: 80px 0;
}
.container h1 {
margin-bottom: 30px;
}
.crypto__container {
display: grid;
grid-template-columns: repeat(2, 1fr);
grid-template-rows: repeat(5, 1fr);
grid-column-gap: 25px;
grid-row-gap: 80px;
}
.crypto__child img {
width: 70%;
}
.crypto__child h3 {
font-size: 19px;
}
.crypto__price {
display: flex;
align-items: center;
gap: 10px;
}
}
```
If we go to http://localhost:3000 in our browser, we should see a list of nine cryptocurrencies fetched on each request to the server before being returned to us in the browser.
<img width="900" height="474"src=https://media.giphy.com/media/v1.Y2lkPTc5MGI3NjExYzlmNmRhNzliYjcyYzk2MmJlNjRkN2MxMTk4ZGE5OTBiMjczNmRmMyZjdD1n/Lrw6URVZ0zzrIqgmdw/giphy.gif>
<p> </p>
## Conclusion
Server-Side Rendering (SSR) is a modern method in modern web development that offers numerous advantages, including improved performance and SEO, faster interaction time, better accessibility, a better user experience, and easier maintenance. The page loads faster because the initial view is rendered on the server, which improves the user experience. Furthermore, search engine bots can easily crawl and index content, helping to improve search engine rankings. SSR enables faster loading times, reducing the time it takes for a page to become interactive for the user. The browser does not need to wait for JavaScript to load and execute because the initial view is rendered on the server, which can significantly reduce TTL. SSR can also help to improve accessibility by ensuring that all users have access to the page's content.
Furthermore, using SSR in a Next.js application can help reduce the complexity of managing client-side states and rendering.
Finally, implementing Server-Side Rendering (SSR) into a Next.js application can yield significant benefits. However, it is critical to understand that implementing SSR can add complexity to the application; as a result, it is critical to carefully consider the use cases and opt for other types of pre-rendering modes that Next.js provides. Nonetheless, implementing SSR in a Next.js application with the right approach can help to provide a more robust, faster, and smoother web experience for users, leading to higher engagement and better outcomes for web applications.
## Resources
- [Official documentation for Next.Js](https://nextjs.org/docs/getting-started)
If you liked my article and found it useful, please leave a tip. Your contribution would enable me to continue producing high-quality articles for you.
[](https://www.buymeacoffee.com/imagineerin)
Thank you for your continued support, and I look forward to providing you with more useful content in the future. | onlyoneerin |
1,378,450 | MongoDB $weeklyUpdate #105 (February 24, 2023): MUG in Munich & Building a RESTful Application | It's Friday. You know what that means… 🎉 Welcome to the MongoDB $weeklyUpdate! 🎉 Each... | 17,268 | 2023-02-24T18:51:44 | https://www.mongodb.com/community/forums/t/mongodb-weeklyupdate-105-february-24-2023-mug-in-munich-building-a-restful-application/214912 | kotlin, mongodb, webdev, programming | It's Friday. You know what that means…
## 🎉 Welcome to the MongoDB $weeklyUpdate! 🎉
Each week, we bring you the latest and greatest from our Developer Relations team — from blog posts and YouTube videos to meet-ups and conferences — so you don’t miss a thing.
## 💻 What’s Up on Developer Center?
Everything you see on [Developer Center](https://www.mongodb.com/developer/) is by developers, for developers. This is where we publish articles, tutorials, quickstarts, and beyond. 🚀
### Featured Post
### [Getting Started with Backend Development in Kotlin Using Spring Boot 3 & MongoDB](https://www.mongodb.com/developer/languages/kotlin/spring-boot3-kotlin-mongodb/)

In this article, Mohit Sharma builds a basic RESTful application using Spring Boot 3 and MongoDB!
### Other Shout-Outs
#### ➡️ [Wordle Solving Using MongoDB Query API Operators](https://www.mongodb.com/developer/products/mongodb/wordle-solving-mongodb-query-api-operators/) by Erik Hatcher
#### ➡️ [Mastering the Advanced Features of the Data API with Atlas CLI](https://www.mongodb.com/developer/products/atlas/advanced-data-api-with-atlas-cli/) by [Arek Borucki](https://www.mongodb.com/community/forums/u/arkadiusz_borucki/summary)
## 🗓️ Mark Your Calendars
Every month, all across the globe, we organize, attend, speak at, and sponsor events, meetups, and shindigs to bring the DevRel community together. Here’s what we’ve got cooking:
[ng-India (Angular India)](https://www.mongodb.com/community/forums/t/ng-india-angular-india/208015): February 24th 2023, 6:30pm, (GMT-08:00) Pacific Time
[Lebanon MUG](https://www.mongodb.com/community/forums/t/lebanon-mug-toward-a-smooth-migration-from-rdbms-to-mongodb/211091): February 24th 2023, 9:00am – 10:30am, (GMT-08:00) Pacific Time
[New York MUG](https://www.mongodb.com/community/forums/t/new-york-mug-mongodb-march-meetup-rdbms-to-nosql/212694): March 2nd 2023, 2:00pm – 5:00pm, (GMT-08:00) Pacific Time
[Málaga Mobile](https://www.mongodb.com/community/forums/t/malaga-mobile-from-mobile-to-mongodb-store-your-apps-data-using-realm/214213): March 2nd 2023, 9:00am, (GMT-08:00) Pacific Time
[Delhi-NCR MUG](https://www.mongodb.com/community/forums/t/delhi-ncr-mug-mongodb-delhi-ncr-meetup/214270): March 3rd 2023, 10:30pm – March 4th 2023, 1:30am, (GMT-08:00) Pacific Time
[Thailand MUG](https://www.mongodb.com/community/forums/t/thailand-mongodb-user-group-march-meetup/211990): March 3rd 2023, 10:00pm, (GMT-08:00) Pacific Time
[Lebanon MUG](https://www.mongodb.com/community/forums/t/lebanon-mug-toward-a-smooth-migration-from-rdbms-to-mongodb/211091): March 4th 2023, 9:00am – 10:30am, (GMT-08:00) Pacific Time
Our recent MUG in Munich was an absolute blast, and we had an amazing turnout! Thank you to everyone who attended. Shout-out to Arek Borucki — our MUG leader and one of our incredible Community Champions. Here's Arek with Bartlomiej Polot from the MongoDB team.


## 🎙️ Stop, Collaborate, and Listen
If reading’s not your jam, you might love catching up on our [podcast episodes](https://open.spotify.com/show/0ibUtrJG4JVgwfvB2MXMSb) with @mlynn and @shanemdb.
*Latest Episode*
{% spotify spotify:episode:7zzr1xNnxdZ0r3hhglI61V%}
And here's the previous episode (with @nraboy), in case you missed it:
{% spotify spotify:episode:60LRFstXxUyCYy30XPl4mh%}
Not listening on Spotify? We got you! We’re also on [Apple Podcasts](https://podcasts.apple.com/us/podcast/the-mongodb-podcast/id1500452446), [PlayerFM](https://player.fm/series/the-mongodb-podcast), [Podtail](https://podtail.com/en/podcast/the-mongodb-podcast/), and [Listen Notes](https://www.listennotes.com/podcasts/the-mongodb-podcast-mongodb-0g6fUKMDN_y/). (We’d be forever grateful if you left us a review.)
Have you caught up on all of our latest videos and shorts on YouTube? Be sure you [subscribe](https://www.youtube.com/c/MongoDBofficial?sub_confirmation=1) so you never miss an update.
That’ll do it for now, folks! Like what you see? Help us spread the love by tweeting this update or sharing it on LinkedIn. | megangrant333 |
1,378,472 | What was your win this week? | What's up folks! Hope everyone enjoys their weekends. 🙌 Looking back on this past week, what was... | 0 | 2023-02-24T19:44:00 | https://dev.to/devteam/what-was-your-win-this-week-mo6 | discuss, weeklyretro | What's up folks!
Hope everyone enjoys their weekends. 🙌
Looking back on this past week, what was something you were proud of accomplishing?
All wins count — big or small 🎉
Examples of 'wins' include:
- Starting a new project
- Fixing a tricky bug
- Grokking spaghetti code while eating spaghetti pasta 🍝
---
 | michaeltharrington |
1,378,565 | Insert/read SQL-Server images with EF Core, Dapper and SqlClient | Working with EF Core/Dapper/SqlClient basics Learn how to read and insert images into a... | 21,515 | 2023-02-24T22:17:13 | https://dev.to/karenpayneoregon/insertread-sql-server-images-with-ef-core-dapper-and-sqlclient-24n7 | dotnetcore, csharp, tutorial, database | ## Working with EF Core/Dapper/SqlClient basics
Learn how to read and insert images into a SQL-Server database using [Dapper](https://www.learndapper.com/), [Entity Framework Core](https://learn.microsoft.com/en-us/ef/core/) and [SqlClient](https://learn.microsoft.com/en-us/dotnet/api/system.data.sqlclient?view=dotnet-plat-ext-7.0) data provider.
For novice and even intermediate level developers working with images can be a daunting task simple because they either write code expecting it to immediately work with no regards to things like using the proper data types or copying pasting code from the Internet without changing much and expect the code to work.
To reach the main audiences three different approaches are used Dapper, EF Core and SqlClient data provider.
## Using the proper data type
The developer with no experience with working with images will select Image verses varbinary(max) not realizing Image type most likely will be removed in future versions of SQL-Server. This means, do not use Image, instead use varbinary(max).
## Column definition for code samples

## Operations
The three methods used will both insert and read a single record.
What is important to know:
- Dapper and EF Core require less hand written code
- Dapper and SqlClient require decent knowledge of SQL syntax
- EF Core, in this case were configured using [EF Power Tools](https://dev.to/karenpayneoregon/ef-power-tools-tutorial-44d8) which means no manual configuration.
- Which to use is a personal choice
## Insert new record version 1
In the following samples a record is inserted but we do not get the new record key
### Insert new record with SqlClient data provider
To insert a new record.
- Create a connection object with a connection string
- Create a command object
- Add a single parameter
- Open the connection
- Execute the command
```csharp
public static void InsertImage(byte[] imageBytes)
{
var sql = "INSERT INTO [dbo].[Pictures1] ([Photo]) VALUES (@ByteArray)";
using var cn = new SqlConnection(ConnectionString());
using var cmd = new SqlCommand(sql, cn);
cmd.Parameters.Add("@ByteArray", SqlDbType.VarBinary).Value = imageBytes;
cn.Open();
cmd.ExecuteNonQuery();
}
```
### Insert new record with Dapper
- Create a connection object with a connection string
- Add a single parameter
- Execute the command
```csharp
public static void InsertImage(byte[] imageBytes)
{
var sql = "INSERT INTO [dbo].[Pictures1] ([Photo]) VALUES (@ByteArray)";
using var cn = new SqlConnection(ConnectionString());
var parameters = new { ByteArray = imageBytes};
cn.Execute(sql, parameters);
}
```
### Insert new record with EF Core 7
- Create an instance of the DbContext
- Create an instance of the type
- Save changes
```csharp
public static void InsertImage(byte[] imageBytes)
{
using var context = new Context();
context.Add(new Pictures() { Photo = imageBytes });
context.SaveChanges();
}
```
## Insert new record version 2
In the following samples a record is inserted with the new record primary key
### SqlClient
We append `SELECT CAST(scope_identity() AS int)` to the insert and rather than `ExecuteNonQuery` use `ExecuteScalar` which returns an object, we cast to the same type as the primary key.
```csharp
public static void InsertImage(byte[] imageBytes)
{
var sql =
"""
INSERT INTO [dbo].[Pictures1] ([Photo]) VALUES (@ByteArray);
SELECT CAST(scope_identity() AS int);
""";
using var cn = new SqlConnection(ConnectionString());
using var cmd = new SqlCommand(sql, cn);
cmd.Parameters.Add("@ByteArray", SqlDbType.VarBinary).Value = imageBytes;
cn.Open();
var key = (int)cmd.ExecuteScalar();
}
```
### Dapper
The following `OUTPUT Inserted.Id` is added to the SQL, note `Id` needs to match the primary key name.
Rather then `Execute` method we use `ExecuteScalar` which is basically the same as SqlClient.
```csharp
public static void InsertImage(byte[] imageBytes)
{
var sql = "INSERT INTO [dbo].[Pictures1] ([Photo]) OUTPUT Inserted.Id VALUES (@ByteArray) ";
using var cn = new SqlConnection(ConnectionString());
var parameters = new { ByteArray = imageBytes};
var key = (int)cn.ExecuteScalar(sql, parameters);
}
```
### EF Core
Simply move the Pictures object to a variable. After SaveChanges, `photoContainer.Id` will have the new primary key.
```csharp
public static void InsertImage(byte[] imageBytes)
{
using var context = new Context();
var photoContainer = new Pictures() { Photo = imageBytes };
context.Add(photoContainer);
context.SaveChanges();
}
```
## Read an image
What you will notice is that between the three methods, they are practically the same.
With EF Core there are a few extra lines to keep in sync with the return type to matach the other two methods.
The SqlClient has several more lines of code than the other two methods.
**SqlClient**
```csharp
public static (PhotoContainer container, bool success) ReadImage(int identifier)
{
var photoContainer = new PhotoContainer() { Id = identifier };
var sql = "SELECT id, Photo FROM dbo.Pictures1 WHERE dbo.Pictures1.id = @id;";
using var cn = new SqlConnection(ConnectionString());
using var cmd = new SqlCommand(sql, cn);
cmd.Parameters.Add("@Id", SqlDbType.Int).Value = identifier;
cn.Open();
var reader = cmd.ExecuteReader();
reader.Read();
if (!reader.HasRows)
{
return (null, false);
}
var imageData = (byte[])reader[1];
using (var ms = new MemoryStream(imageData, 0, imageData.Length))
{
ms.Write(imageData, 0, imageData.Length);
photoContainer.Picture = Image.FromStream(ms, true);
}
return (photoContainer, true);
}
```
**Dapper**
```csharp
public static (PhotoContainer container, bool success) ReadImage(int identifier)
{
var photoContainer = new PhotoContainer() { Id = identifier };
var sql = "SELECT id, Photo FROM dbo.Pictures1 WHERE dbo.Pictures1.id = @id";
using var cn = new SqlConnection(ConnectionString());
var parameters = new { id = identifier };
var container = cn.QueryFirstOrDefault<ImageContainer>(sql, parameters);
if (container is null)
{
return (null, false);
}
var imageData = container.Photo;
using (var ms = new MemoryStream(imageData, 0, imageData.Length))
{
ms.Write(imageData, 0, imageData.Length);
photoContainer.Picture = Image.FromStream(ms, true);
}
return (photoContainer, true);
}
```
**EF Core**
```csharp
public static (PhotoContainer container, bool success) ReadImage(int identifier)
{
var photoContainer = new PhotoContainer() { Id = identifier };
using var context = new Context();
var item = context.Pictures1.FirstOrDefault(item => item.Id == identifier);
if (item is null)
{
return (null, false);
}
var imageData = item.Photo;
using (var ms = new MemoryStream(imageData, 0, imageData.Length))
{
ms.Write(imageData, 0, imageData.Length);
photoContainer.Picture = Image.FromStream(ms, true);
}
return (photoContainer, true);
}
```
> **Note**
> There is no exception handling in any of the code as the code was written properly, this does not by any means to not implement exception handling in your code as many things can go wrong, so implement exception handling
## Preparing the project to run
Using the script under the folder Scripts, create the database, create the single table and populate.
## Why you a Windows Forms project?
Well the code had been done in an ASP.NET Core, Blazor, MAUI or unit test while using a Windows Forms project bypasses things such as securty issues and is very easy to read and understand.
## Source code
Clone the following [GitHub repository](https://github.com/karenpayneoregon/efcore-dapper-dataprovider)
| karenpayneoregon |
1,378,761 | Zerando HackerRank ( 2 ) | Neste desafio é pedido que haja uma contagem de velas de um bolo de aniversário, porem a contagem... | 0 | 2023-02-25T01:27:04 | https://dev.to/gabrielgcj/zerando-hackerrank-2--3c66 | Neste desafio é pedido que haja uma contagem de velas de um bolo de aniversário, porem a contagem deve ser feita das velas mais altas.
Nesse caso é necessário ajustar a função "birthdayCakeCandles" para ser possível executar tal função.
No próprio exercício no input de entrada da função podemos entender melhor que dados vão para dentro da função:
Podemos observar que são 4 velas e que as duas maiores tem altura 3.
Por observar isto podemos imaginar como faremos a função "birthdayCakeCandles".
A função ficara assim:
O uso do método Math.max recebe uma lista e retorna o maior elemento desta lista. Porem o método Math.max recebe apenas números, para receber uma array de números é necessário o uso dos "..."
Depois disso, para receber o resultado adequado podemos usar um filter desta forma:

Essa filtragem é feita apenas apresentando os valores que são iguais as "velasGrandes". O resultado disso seria: [3,3] que ao utilizar a propriedade "length" que vai apresentar o número de vezes que a vela mais alta aparece, o qual é exatamente o resultado que nos procuramos.
| gabrielgcj | |
1,383,617 | What Is openGauss? | openGauss is a user-friendly, enterprise-level, and open-source relational database jointly built... | 0 | 2023-03-01T09:16:52 | https://dev.to/llxq2023/what-is-opengauss-5d55 | opengauss, discuss, beginners | openGauss is a user-friendly, enterprise-level, and open-source relational database jointly built with partners. openGauss provides multi-core architecture-oriented ultimate performance, full-link service, data security, AI-based optimization, and efficient O&M capabilities. openGauss deeply integrates Huawei's years of R&D experience in the database field and continuously builds competitive features based on enterprise-level scenario requirements. For the latest information about openGauss, visit https://opengauss.org/en/.
**openGauss is a database management system.**
A database is a structured dataset. It can be any data, such as shopping lists, photo galleries, or a large amount of information on a company's network. To add, access, and process massive data stored in computer databases, you need a database management system (DBMS). The DBMS can manage and control the database in a unified manner to ensure the security and integrity of the database. Because computers are very good at handling large amounts of data, the DBMS plays a central role in computing as standalone utilities or as part of other applications.
**An openGauss database is a relational database.**
A relational database organizes data using a relational model, that is, data is stored in rows and columns. A series of rows and columns in a relational database are called tables, which form the database. A relational model can be simply understood as a two-dimensional table model, and a relational database is a data organization consisting of two-dimensional tables and their relationships.
In openGauss, SQL is a standard computer language often used to control the access to databases and manage data in databases. depending on your programming environment, you can enter SQL statements directly, embed SQL statements into code written in another language, or use specific language APIs that contain SQL syntax.
SQL is defined by the ANSI/ISO SQL standard. The SQL standard has been developed since 1986 and has multiple versions. In this document, SQL92 is the standard released in 1992, SQL99 is the standard released in 1999, and SQL2003 is the standard released in 2003. SQL2011 is the latest version of the standard. openGauss supports the SQL92, SQL99, SQL2003, and SQL2011 specifications.
**openGauss provides open-source software.**
Open-source means that anyone can use and modify the software. Anyone can download the openGauss software and use it at no cost. You can dig into the source code and make changes to meet your needs. The openGauss software is released under the Mulan Permissive Software License v2 (http://license.coscl.org.cn/MulanPSL2/) to define the software usage scope.
**An openGauss database features high performance, high availability, high security, easy O&M, and full openness.**
· High performance
·It provides the multi-core architecture-oriented concurrency control technology and Kunpeng hardware optimization, and achieves that the TPC-C benchmark performance reaches 1,500,000 tpmC in Kunpeng 2-socket servers.
·It uses NUMA-Aware data structures as the key kernel structures to adapt to the trend of using multi-core NUMA architecture on hardware.
·It provides the SQL bypass intelligent fast engine technology.
·It provides the USTORE storage engine for frequent update scenarios.
·High availability (HA)
·It supports multiple deployment modes, such as primary/standby synchronization, primary/standby asynchronization, and cascaded standby server deployment.
·It supports data page cyclic redundancy check (CRC), and automatically restores damaged data pages through the standby node.
·It recovers the standby node in parallel and promotes it to primary to provide services within 10 seconds.
·It provides log replication and primary selection framework based on the Paxos distributed consistency protocol.
·High security
It supports security features such as fully-encrypted computing, access control, encryption authentication, database audit, and dynamic data masking to provide comprehensive end-to-end data security protection.
·Easy O&M
·It provides AI-based intelligent parameter tuning and index recommendation to automatically recommend AI parameters.
·It provides slow SQL diagnosis and multi-dimensional self-monitoring views to help you understand system performance in real time.
·It provides SQL time forecasting that supports online auto-learning.
·Full openness
·It adopts the Mulan Permissive Software License, allowing code to be freely modified, used, and referenced.
·It fully opens database kernel capabilities.
·It provides excessive partner certifications, training systems, and university courses | llxq2023 |
1,378,866 | git stash usage for beginners | In the below branch tree, let's say you are working on Feature-branch-helper.... | 0 | 2023-02-25T04:31:51 | https://dev.to/mithunkumarc/git-stash-usage-for-beginners-5a00 | git, github | In the below branch tree, let's say you are working on Feature-branch-helper.
+ master
+ develop
- Feature-branch
* Feature-branch-helper
Now you completed working on Feature-branch-helper, before you merge with Feature-branch, you would want to take latest from Feature-branch. Without taking latest from Feature-branch you cannot merge. In this case we can use git stash.
Steps I follow to update current branch. Assuming you are in Feature-branch-helper.
First take backup of your changes
git stash
Second take latest of Feature-branch
git pull origin Feature-branch
Resume your changes to your branch ,Feature-branch-helper
git stash pop | mithunkumarc |
1,379,059 | Caching in Ruby on Rails 7 | Caching is an essential technique used to improve the performance of web applications. It helps... | 0 | 2023-02-25T10:39:06 | https://dev.to/ahmadraza/caching-in-ruby-on-rails-7-470g | ruby, rails, webdev, beginners | Caching is an essential technique used to improve the performance of web applications. It helps reduce the time taken to load and serve data by storing frequently accessed data in a fast and easily accessible storage medium, like memory and disk.
In Ruby on Rails, caching is easier than ever to implement and can have a significant impact on the performance of your web application.
In this article, we will explore caching in Ruby on Rails 7 and why it's important.
---
## Why is Caching Important?
Caching is important because it allows you to avoid performing expensive operations repeatedly.
For example, if you have a page that displays a list of the **top 10** most popular products on your website, you may need to query your database to retrieve this data. Without caching, this query would be executed **every time** the page is loaded, which could **slow down** page load times and put unnecessary strain on your server.
---
## Types of Caching in Ruby on Rails
<p>
<br />
<strong id="page-caching"> 1. Page Caching </strong>
</p>
Page caching is the simplest form of caching in Rails. It involves caching an entire page as an HTML file, which is served to **subsequent users** who request the same page.
It allows the request for a generated page, to be fulfilled by the web server _(i.e. Apache or NGINX)_ without having to go through the entire Rails stack.
This is ideal for pages that are mostly static and do not change frequently.
> A **subsequent user** is a user who visits a website after the initial user has already visited it.
**2. Action Caching**
[Page Caching](#page-caching) cannot be used for actions that have before filters. For example, pages that require authentication.
This is where Action Caching comes in.
Action caching is similar to page caching, but instead of caching the entire page, only the action (i.e., the controller method) is cached. It works like **Page Caching** except the incoming web request hits the Rails stack, so that before filters can be run on it before the cache is served.
**3. Fragment Caching**
Fragment caching involves caching a small part of a page, such as a sidebar or a comment section. This is useful for pages that have some dynamic content but also contain mostly static content.
For example, if you wanted to cache each product on a page, you could use this code:
```
<% @products.each do |product| %>
<% cache product do %>
<%= render product %>
<% end %>
<% end %>
```
When your application receives its first request to this page, Rails will write a new cache entry with a unique key. A key looks something like this:
```
views/products/index:bea67108094918eeba42cd4a6e786901/products/1
```
**4. Low-Level Caching**
Low-level caching is a more advanced form of caching that allows you to cache any data that can be represented as an object. This can include data from your database or external APIs.
Low-level caching is basically dealing with key-value-based caching structures. This is a very commonly used caching type in which the key can be read or written as below:
```
Rails.cache.write('some-cache-key', 123)
Rails.cache.read('some-cache-key') # => 123
Rails.cache.read('anonymous-cache-key') # => nil
```
---
### Conclusion
Caching is a powerful technique that can significantly improve the performance of your Ruby on Rails application. By understanding the different types of caching available and how to implement them, you can create a faster and more responsive user experience for your users. | ahmadraza |
1,379,139 | How use the gem 'run_database_backup' | Introduction Data is a critical aspect of any application, and it's essential to have a... | 0 | 2023-02-25T12:45:12 | https://dev.to/nemuba/how-use-the-gem-rundatabasebackup-530b | ruby, rails, database, programming |
## Introduction
Data is a critical aspect of any application, and it's essential to have a reliable backup strategy in place to protect your data in case of a disaster or data loss. Fortunately, the "run_database_backup" gem provides an easy way to create backups of your MongoDB, PostgreSQL, and MySQL databases from within your Rails application.
In this guide, we'll walk you through the basic steps for using the "run_database_backup" gem to create backups of your databases.
## Usage
Add the "run_database_backup" gem to your Gemfile:
```yml
gem 'run_database_backup'
```
Install the gem by running the following command:
```bash
bundle install
```
This will add the three backup tasks to your application.
To create a backup of your MongoDB database, run the following command:
```bash
rails mongo:backup[uri,database_name,backup_directory]
```
Replace "uri" with the URI for your MongoDB database (e.g. "mongodb://localhost:27017"), "database_name" with the name of the MongoDB database you want to back up, and "backup_directory" with the directory where you want to store the backup file.
For example, to create a backup of a MongoDB database called "app_database" running on the local machine and store the backup file in the "./tmp" directory, you would run:
```bash
rails mongo:backup['mongodb://localhost:27017','app_database','./tmp']
```
To create a backup of your PostgreSQL database, run the following command:
```bash
rails postgresql:backup[uri,database_name,backup_directory]
```
Replace "uri" with the URI for your PostgreSQL database (e.g. "postgresql://localhost"), "database_name" with the name of the PostgreSQL database you want to back up, and "backup_directory" with the directory where you want to store the backup file.
For example, to create a backup of a PostgreSQL database called "app_database" running on the local machine and store the backup file in the "./tmp" directory, you would run:
```bash
rails postgresql:backup['postgresql://localhost','app_database','./tmp']
```
Note that you will need to have the "pg_dump" utility installed on your machine in order to create a backup of a PostgreSQL database.
To create a backup of your MySQL database, run the following command:
```bash
rails mysql:backup[uri,database_name,backup_directory]
```
Replace "uri" with the URI for your MySQL database (e.g. "mysql2://localhost"), "database_name" with the name of the MySQL database you want to back up, and "backup_directory" with the directory where you want to store the backup file.
For example, to create a backup of a MySQL database called "app_database" running on the local machine and store the backup file in the "./tmp" directory, you would run:
```bash
rails mysql:backup['mysql2://localhost','app_database','./tmp']
```
Note that you will need to have the "mysqldump" utility installed on your machine in order to create a backup of a MySQL database.
## Conclusion
In this guide, we've walked you through the basic steps for using the "run_database_backup" gem to create backups of your MongoDB, PostgreSQL, and MySQL databases from within your Rails application. By following these steps, you can quickly and easily create backups of your databases to protect your data in case of a disaster or data loss.
Remember to store your backup files in a secure location and to regularly test your backup strategy to ensure that you can restore your data when you need it.
To learn more about the "run_database_backup" gem, visit the gem's repository on GitHub: https://github.com/nemuba/run_database_backup
Happy backing up! | nemuba |
1,379,226 | Create type ahead search using RxJS and Angular standalone components | Introduction This is day 6 of Wes Bos's JavaScript 30 challenge where I create a type... | 0 | 2023-02-25T14:40:04 | https://dev.to/railsstudent/create-type-ahead-search-using-rxjs-and-angular-standalone-components-4m4a | angular, rxjs, tutorial, typescript | ##Introduction
This is day 6 of Wes Bos's JavaScript 30 challenge where I create a type ahead search box that filters out cities/states in the USA. In the tutorial, I created the components using RxJS, custom operators, Angular standalone components and removed the NgModules.
In this blog post, I define a function that injects HttpClient, retrieves USA cities from external JSON file and caches the response. Next, I create an observable that emits search input to filter out USA cities and states. Finally, I use async pipe to resolve the observable in the inline template to render the matching results.
###Create a new Angular project
```bash
ng generate application day6-ng-type-ahead
```
###Bootstrap AppComponent
First, I convert AppComponent into standalone component such that I can bootstrap AppComponent and inject providers in main.ts.
```typescript
// app.component.ts
import { Component } from '@angular/core';
import { Title } from '@angular/platform-browser';
import { TypeAheadComponent } from './type-ahead/type-ahead/type-ahead.component';
@Component({
selector: 'app-root',
standalone: true,
imports: [
TypeAheadComponent
],
template: '<app-type-ahead></app-type-ahead>',
styles: [`
:host {
display: block;
}
`]
})
export class AppComponent {
title = 'Day 6 NG Type Ahead';
constructor(titleService: Title) {
titleService.setTitle(this.title);
}
}
```
In Component decorator, I put standalone: true to convert AppComponent into a standalone component.
Instead of importing TypeAheadComponent in AppModule, I import TypeAheadComponent (that is also a standalone component) in the imports array because the inline template references it.
```typescript
// main.ts
import { provideHttpClient } from '@angular/common/http';
import { enableProdMode } from '@angular/core';
import { bootstrapApplication } from '@angular/platform-browser';
import { AppComponent } from './app/app.component';
import { environment } from './environments/environment';
if (environment.production) {
enableProdMode();
}
bootstrapApplication(AppComponent,
{
providers: [provideHttpClient()]
})
.catch(err => console.error(err));
```
`provideHttpClient` is a function that configures HttpClient to be available for injection.
Next, I delete AppModule because it is not used anymore.
###Declare Type Ahead component
I declare standalone component, TypeAheadComponent, to create a component with search box. To verify the component is a standalone, `standalone: true` is specified in the Component decorator.
```bash
src/app
├── app.component.ts
└── type-ahead
├── custom-operators
│ └── find-cities.operator.ts
├── interfaces
│ └── city.interface.ts
├── pipes
│ ├── highlight-suggestion.pipe.ts
│ └── index.ts
└── type-ahead
├── type-ahead.component.scss
└── type-ahead.component.ts
```
`find-cities.ts` is a custom RxJS operator that receives search value and filters out USA cities and states by it.
```typescript
// type-ahead.component.ts
import { CommonModule } from '@angular/common';
import { HttpClient } from '@angular/common/http';
import { ChangeDetectionStrategy, Component, OnInit, ViewChild, inject } from '@angular/core';
import { FormsModule, NgForm } from '@angular/forms';
import { Observable, shareReplay } from 'rxjs';
import { findCities } from '../custom-operators/find-cities.operator';
import { City } from '../interfaces/city.interface';
import { HighlightSuggestionPipe } from '../pipes/highlight-suggestion.pipe';
const getCities = () => {
const httpService = inject(HttpClient);
const endpoint = 'https://gist.githubusercontent.com/Miserlou/c5cd8364bf9b2420bb29/raw/2bf258763cdddd704f8ffd3ea9a3e81d25e2c6f6/cities.json';
return httpService.get<City[]>(endpoint).pipe(shareReplay(1));
}
@Component({
selector: 'app-type-ahead',
standalone: true,
imports: [
HighlightSuggestionPipe,
FormsModule,
CommonModule,
],
template: `
<form class="search-form" #searchForm="ngForm">
<input type="text" class="search" placeholder="City or State" [(ngModel)]="searchValue" name="searchValue">
<ul class="suggestions" *ngIf="suggestions$ | async as suggestions">
<ng-container *ngTemplateOutlet="suggestions?.length ? hasSuggestions : promptFilter; context: { suggestions, searchValue }"></ng-container>
</ul>
</form>
<ng-template #promptFilter>
<li>Filter for a city</li>
<li>or a state</li>
</ng-template>
<ng-template #hasSuggestions let-suggestions="suggestions" let-searchValue="searchValue">
<li *ngFor="let suggestion of suggestions">
<span [innerHtml]="suggestion | highlightSuggestion:searchValue"></span>
<span class="population">{{ suggestion.population | number }}</span>
</li>
</ng-template>
`,
styleUrls: ['./type-ahead.component.scss'],
changeDetection: ChangeDetectionStrategy.OnPush
})
export class TypeAheadComponent implements OnInit {
@ViewChild('searchForm', { static: true })
searchForm!: NgForm;
searchValue = ''
suggestions$!: Observable<City[]>;
cities$ = getCities();
ngOnInit(): void {
this.suggestions$ = this.searchForm.form.valueChanges.pipe(findCities(this.cities$));
}
}
```
`TypeAheadComponent` imports `CommonModule`, `FormsModule` and `HighlightSuggestionPipe` in the imports array. `CommonModule` is included to make ngIf and async pipe available in the inline template. After importing `FormsModule`, I can build a template form to accept search value. Finally, `HighlightSuggestionPipe` highlights the search value in the search results for aesthetic purpose.
`cities$` is an observable that fetches USA cities from external JSON file. Angular 15 introduces inject that simplifies HTTP request logic in a function. Thus, I don’t need to inject HttpClient in the constructor and perform the same logic.
```typescript
const getCities = () => {
const httpService = inject(HttpClient);
const endpoint = 'https://gist.githubusercontent.com/Miserlou/c5cd8364bf9b2420bb29/raw/2bf258763cdddd704f8ffd3ea9a3e81d25e2c6f6/cities.json';
return httpService.get<City[]>(endpoint).pipe(shareReplay(1));
}
cities$ = getCities();
```
`suggestions$` is an observable that holds the matching cities and states after search value changes. It is subsequently resolved in inline template to render in a list.
###Create RxJS custom operator
It is a matter of taste but I prefer to refactor RxJS operators into custom operators when observable has many lines of code. For `suggestion$`, I refactor the chain of operators into findCities custom operator and reuse it in `TypeAheadComponent`.
```typescript
// find-cities.operator.ts
const findMatches = (formValue: { searchValue: string }, cities: City[]) => {
const wordToMatch = formValue.searchValue;
if (wordToMatch === '') {
return [];
}
const regex = new RegExp(wordToMatch, 'gi');
// here we need to figure out if the city or state matches what was searched
return cities.filter(place => place.city.match(regex) || place.state.match(regex));
}
export const findCities = (cities$: Observable<City[]>) => {
return (source: Observable<{ searchValue: string }>) =>
source.pipe(
skip(1),
debounceTime(300),
distinctUntilChanged(),
withLatestFrom(cities$),
map(([formValue, cities]) => findMatches(formValue, cities)),
startWith([]),
);
}
```
- skip(1) – The first valueChange emits undefined for unknown reason; therefore, skip is used to discard it
- debounceTime(300) – emit search value after user stops typing for 300 milliseconds
- distinctUntilChanged() – do nothing when search value is unchanged
- withLatestFrom(cities$) – get the cities returned from HTTP request
- map(([formValue, cities]) => findMatches(formValue, cities)) – call findMatches to filter cities and states by search value
- startWith([]) – initially, the search result is an empty array
Finally, I use findCities to compose suggestion$ observable.
###Use RxJS and Angular to implement observable in type ahead component
```typescript
// type-ahead.component.ts
this.suggestions$ = this.searchForm.form.valueChanges
.pipe(findCities(this.cities$));
```
- this.searchForm.form.valueChanges – emit changes in template form
- findCities(this.cities$) – apply custom operator to find matching cities and states
This is it, we have created a type ahead search that filters out USA cities and states by search value.
##Final Thoughts
In this post, I show how to use RxJS and Angular standalone components to create type ahead search for filtering. The application has the following characteristics after using Angular 15's new features:
- The application does not have NgModules and constructor boilerplate codes.
- In main.ts, the providers array provides the HttpClient by invoking providerHttpClient function
- In TypeAheadComponent, I inject HttpClient in a function to make http request and obtain the results. In construction phase, I assign the function to cities$ observable
- Using `inject` to inject HttpClient offers flexibility in code organization. I can define getCities function in the component or move it to a utility file. Pre-Angular 15, HttpClient is usually injected in a service and the service has a method to make HTTP request and return the results
This is the end of the blog post and I hope you like the content and continue to follow my learning experience in Angular and other technologies.
##Resources:
- Github Repo: https://github.com/railsstudent/ng-rxjs-30/tree/main/projects/day6-ng-type-ahead
- Live demo: https://railsstudent.github.io/ng-rxjs-30/day6-ng-type-ahead/
- Wes Bos’s JavaScript 30 Challenge: https://github.com/wesbos/JavaScript30
| railsstudent |
1,379,326 | Customizing Swagger in Azure Functions | Swagger UI is an open-source tool that allows developers to visualize and interact with the APIs they... | 0 | 2023-02-25T17:17:08 | https://dev.to/kasuken/customizing-swagger-in-azure-functions-87m | azure, csharp, webdev, serverless | Swagger UI is an open-source tool that allows developers to visualize and interact with the APIs they are building. It provides a user-friendly interface that allows developers to explore the API’s resources, parameters, and responses. Swagger UI is particularly useful for developers who want to test and debug their APIs before deploying them.
Azure Functions can be used to build RESTful APIs, making it a popular choice for developers who want to create lightweight and scalable APIs. Azure Functions also provides built-in support for Swagger UI, making it easy for developers to add it to their APIs.
So, let’s dive in!
# Azure Functions V4 and .NET 6/7
## Out-of-the-box solution
To generate an OpenAPI document and to customize the Open API Configuration, you don't need third libraries or special implementations.
Everything is out-of-the-box and easy to implement.
You can start from an existing project or from a new Azure Function project.
Add a new class to the project and choose the name you like the most.
I use "**OpenApiConfigurationOptions**" but you can change it.
The class must implement the interface "**IOpenApiConfigurationOptions**". This is the only requirement.
## The code
Below you can find the code you need to customize OpenApi Configuration in your functions.
You can copy and paste the code below and change some settings as the Title, the version and the description.
```csharp
public class OpenApiConfigurationOptions : IOpenApiConfigurationOptions
{
public OpenApiInfo Info { get; set; } =
new OpenApiInfo
{
Title = "My API Documentation",
Version = "1.0",
Description = "a long description of my APIs",
Contact = new OpenApiContact()
{
Name = "My name",
Email = "myemail@company.com",
Url = new Uri("https://github.com/Azure/azure-functions-openapi-extension/issues"),
},
License = new OpenApiLicense()
{
Name = "MIT",
Url = new Uri("http://opensource.org/licenses/MIT"),
}
};
public List<OpenApiServer> Servers { get; set; } = new();
public OpenApiVersionType OpenApiVersion { get; set; } = OpenApiVersionType.V2;
public bool IncludeRequestingHostName { get; set; } = false;
public bool ForceHttp { get; set; } = true;
public bool ForceHttps { get; set; } = false;
public List<IDocumentFilter> DocumentFilters { get; set; } = new();
}
```
In the next post, we will see how to customize the UI with an additional JavaScript and an additional CSS.
## View the new page
Now you are ready to see the result of our changes.
Launch the Azure Function project in debug or without debug and navigate to "**{hostname}/api/swagger/ui**".
You should view the Swagger UI page with the new information.

---
Are you interested in learning GitHub but don't know where to start? Try my course on LinkedIn Learning: [Learning GitHub](https://bit.ly/learninggithub).

---
Thanks for reading this post, I hope you found it interesting!
Feel free to follow me to get notified when new articles are out 🙂
{% embed https://dev.to/kasuken %} | kasuken |
1,379,507 | How to Stay Focused and Succeed in a Long Digital Marketing Course | Are you currently enrolled in a long digital marketing course? While the course may be interesting,... | 0 | 2023-02-25T20:56:43 | https://dev.to/thenoadev/how-to-stay-focused-and-succeed-in-a-long-digital-marketing-course-16l8 | digitalmarketing, onlinetraining, studyhacks, productivity | Are you currently enrolled in a long digital marketing course? While the course may be interesting, it can be challenging to stay focused and committed throughout the entire duration. Here are some tips to help you stay on track and succeed in your digital marketing journey.
## Set Goals and Break Them Down
One of the most important things you can do to succeed in a long digital marketing course is to set clear goals for yourself. What do you hope to achieve by the end of the course? Once you have established your goals, break them down into smaller, manageable tasks. This will help you to stay focused and motivated as you work through the course.
## Stay Organized
Digital marketing courses can be overwhelming, with a lot of information to take in and assignments to complete. To stay on track, it's important to stay organized. Keep track of your assignments and deadlines, and create a study schedule that works for you. By staying organized, you can reduce stress and stay focused on your goals.
## Take Breaks
It's important to take breaks throughout your digital marketing course. Taking breaks can help you to stay focused, reduce stress, and improve your productivity. Try taking a 10-15 minute break every hour or so, and use this time to stretch, take a walk, or do something relaxing.[^1]
## Stay Connected
Digital marketing courses can be isolating, but it's important to stay connected with others. Join online communities or discussion forums related to digital marketing, and reach out to other students in the course. By staying connected, you can share ideas, ask questions, and get support when you need it.
## Celebrate Your Progress
Finally, it's important to celebrate your progress throughout the digital marketing course. Whether it's completing an assignment, passing a quiz, or mastering a new concept, take the time to acknowledge and celebrate your achievements. This will help to keep you motivated and focused on your goals.
In conclusion, a long digital marketing course can be challenging, but it's important to stay focused and committed. By setting goals, staying organized, taking breaks, staying connected, and celebrating your progress, you can succeed in your digital marketing journey. Good luck!
[^1]: Weir, K. (2019, January 1). Give me a break. Monitor on Psychology, 50(1). https://www.apa.org/monitor/2019/01/break | thenoadev |
1,379,732 | Automatic API Key rotation for Amazon Managed Grafana | Amazon Managed Grafana has an unfortunate limitation where API keys created have a maximum expiration of 30 days - making continuous deployments difficult without manual intervention. This post will show you how to write some simple Terraform to automatically rotate an API key that can be used in your CI/CD pipeline. | 0 | 2023-02-26T04:15:00 | https://devopstar.com/2023/02/25/automatic-api-key-rotation-for-amazon-managed-grafana | aws, grafana, cicd, terraform | ---
title: Automatic API Key rotation for Amazon Managed Grafana
published: true
description: Amazon Managed Grafana has an unfortunate limitation where API keys created have a maximum expiration of 30 days - making continuous deployments difficult without manual intervention. This post will show you how to write some simple Terraform to automatically rotate an API key that can be used in your CI/CD pipeline.
canonical_url: https://devopstar.com/2023/02/25/automatic-api-key-rotation-for-amazon-managed-grafana
tags: aws, grafana, cicd, terraform
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/69ykbfy6ia2p2bmbd3dq.jpg
published_at: 2023-02-26 04:15 +0000
---
> Please reach out to me on [Twitter @nathangloverAUS](https://twitter.com/nathangloverAUS) if you have follow up questions!
*This post was originally written on [DevOpStar](https://devopstar.com/)*. Check it out [here](https://devopstar.com/2023/02/25/automatic-api-key-rotation-for-amazon-managed-grafana)
Amazon Managed Grafana has an unfortunate limitation where API keys created have a maximum expiration of 30 days. This limitation is quite frustrating if you were trying to automate the deployment of Grafana dashboards and datasources as part of your CI/CD pipeline - as you would need to manually update the API key every 30 days or your deployments would fail.
This problem is exacerbated by the fact that Amazon Managed Grafana API keys are billed out at the cost of a full user license - so you cannot simply create a new API key every time you deploy your dashboards either. I found this out the expensive way when I didn't read the pricing guide properly and created an API key for each deployment ($8 a key).
**Hopefully, Amazon will address this limitation in the future** - but in the meantime, I've written a simple pattern that can be used to automatically rotate an API key every 30 days and store it for use in AWS Secrets Manager. At the end of this post, I outline my plea to Amazon to address this limitation along with some suggestions on how they could do it.
## Overview of the solution
I've opted to build this example in terraform as it is most likely you will be wanting to deploy Grafana dashboards as part of your CI/CD pipeline. Terraform is arguably the best tool for this - however, there is no reason why the code in this post couldn't be adapted to work with other tools such as CloudFormation or AWS CDK.
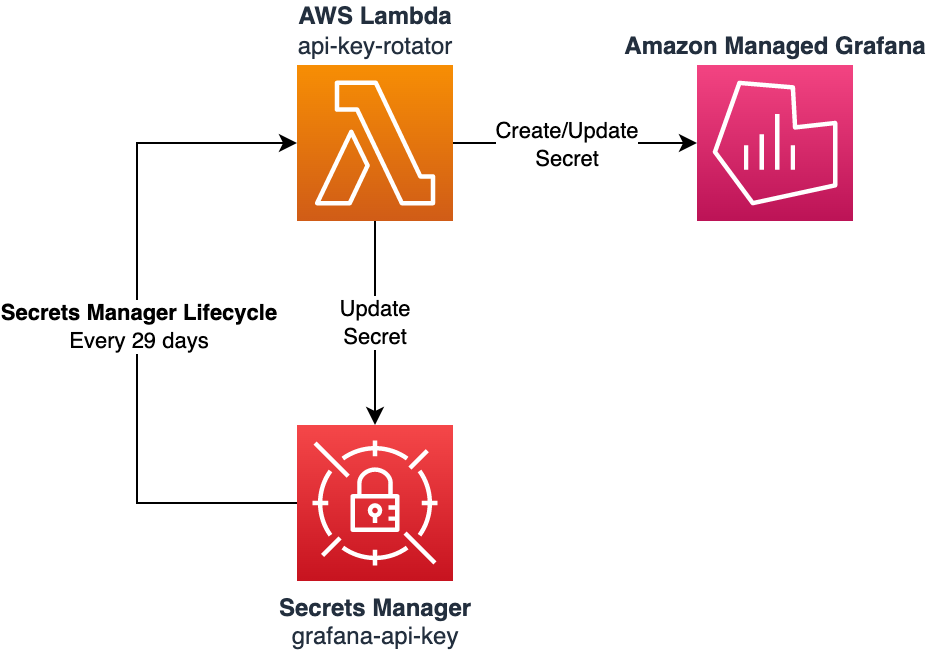
The solution is made up of two components:
1. AWS Secret is created with a rotation lifecycle policy that will trigger a Lambda function every 30 days
2. AWS Lambda Function that will create a new API key in Amazon Managed Grafana and update the AWS Secret with the new key
> It is expected that you will have already created an Amazon Managed Grafana instance (though you can copy the terraform from this post side by side with your existing terraform and it will work).
The source code for this example can be found at [t04glovern/amazon-managed-grafana-api-key-rotation-terraform](https://github.com/t04glovern/amazon-managed-grafana-api-key-rotation-terraform).
## Solution Walkthrough
We'll begin by looking at the python code that is in charge of rotating the Managed Grafana API keys - as understanding how that works will help when we look at the terraform code.
Look at [src/rotate.py](https://github.com/t04glovern/amazon-managed-grafana-api-key-rotation-terraform/blob/main/src/rotate.py) in the source code for this example
The function is going to expect three environment variables to be present
```python
grafana_secret_arn = os.environ['GRAFANA_API_SECRET_ARN']
grafana_api_key_name = os.environ['GRAFANA_API_KEY_NAME']
grafana_workspace_id = os.environ['GRAFANA_WORKSPACE_ID']
```
> **NOTE**: While you don't technically need to pass the secret ARN as it is available in the Lambda context when the function is invoked by secrets manager, I've opted to do so as it makes it easier to understand.
Next, we attempt to delete any existing API keys with the same name as the one we are about to create. This is to ensure that we clean up old API keys and we don't get billed for duplicates (even though you cannot have multiple API keys with the same name).
```python
try:
grafana_client.delete_workspace_api_key(
keyName=grafana_api_key_name,
workspaceId=grafana_workspace_id
)
except grafana_client.exceptions.ResourceNotFoundException:
pass
```
Following cleanup, we create a new API key with a 30-day expiration.
```python
try:
new_api_key = grafana_client.create_workspace_api_key(
keyName=grafana_api_key_name,
keyRole='ADMIN',
secondsToLive=2592000,
workspaceId=grafana_workspace_id
)['key']
except botocore.exceptions.ClientError as error:
logger.error(error)
return {
'statusCode': 500,
'message': 'Error: Failed to generate new API key'
}
```
The last step is to update the AWS Secret with the new API key.
```python
try:
secretmanager_client.update_secret(
SecretId=grafana_secret_arn,
SecretString=new_api_key
)
except botocore.exceptions.ClientError as error:
logger.error(error)
return {
'statusCode': 500,
'message': 'Error: Failed to update secret'
}
```
Now that we've seen how the Lambda function works, let's look at the terraform code that will deploy it.
### variables.tf
There are two expected variables for this solution to function - You can however substitute these with hardcoded values or references to your own terraform resources instead.
```hcl
variable "name" {
type = string
description = "Named identifier for the workspace and related resources"
}
variable "grafana_workspace_id" {
type = string
description = "The ID of the Grafana workspace to manage"
}
```
### main.tf
The [main.tf](https://github.com/t04glovern/amazon-managed-grafana-api-key-rotation-terraform/blob/main/main.tf) file is where the bulk of the solution is defined. The first thing we do is create an AWS Secret that will store the API key.
```hcl
resource "aws_secretsmanager_secret" "api_key" {
name = "${var.name}-api-key"
}
```
The next part looks complicated but is required to bundle the python code into a zip file that can be deployed to Lambda. The code is zipped up and stored in a `zip` directory alongside `src` and is not checked into source control.
```hcl
resource "random_uuid" "lambda_src_hash" {
keepers = {
for filename in setunion(
fileset("${path.module}/src/", "*.py"),
fileset("${path.module}/src/", "requirements.txt"),
) :
filename => filemd5("${path.module}/src/${filename}")
}
}
data "archive_file" "lambda_zip" {
depends_on = [
null_resource.install_dependencies
]
type = "zip"
source_dir = "${path.module}/src/"
excludes = [
"__pycache__"
]
output_path = "${path.module}/zip/${random_uuid.lambda_src_hash.result}.zip"
}
```
Unfortunately, because AWS Lambda python runtime is not running the most up-to-date boto3 core version - we must force the terraform to install and zip a more recent version of boto3 which complicates this solution quite a lot. If you are reading this post in the future, check out the [AWS Lambda Python Runtime](https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html) page to see if this is still required. As of writing this, version `boto3-1.20.32` is the latest version available and `boto3-1.26.65` is needed.
```hcl
resource "null_resource" "install_dependencies" {
provisioner "local-exec" {
command = "pip install -r ${path.module}/src/requirements.txt -t ${path.module}/src/ --upgrade"
}
triggers = {
dependencies_versions = filemd5("${path.module}/src/requirements.txt")
}
}
```
Skipping over the IAM role and policy terraform (which I won't explain in this post, but you can find in the source code on GitHub), we can see that the Lambda function is created and provided the environment variables we defined earlier.
```hcl
resource "aws_lambda_function" "api_key_rotation" {
function_name = "${var.name}-api-key-rotation"
filename = data.archive_file.lambda_zip.output_path
source_code_hash = data.archive_file.lambda_zip.output_base64sha256
handler = "rotate.lambda_handler"
runtime = "python3.9"
environment {
variables = {
GRAFANA_API_SECRET_ARN = aws_secretsmanager_secret.api_key.arn
GRAFANA_API_KEY_NAME = "${var.name}-mangement-api-key"
GRAFANA_WORKSPACE_ID = var.grafana_workspace_id
}
}
role = aws_iam_role.api_key_rotation_lambda_role.arn
}
```
With both the lambda and secret created, a Secret manager rotation schedule is created to invoke the lambda function every 29 days.
```hcl
resource "aws_lambda_permission" "secrets_manager_api_key_rotation" {
statement_id = "AllowExecutionFromSecretsManager"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.api_key_rotation.function_name
principal = "secretsmanager.amazonaws.com"
}
resource "aws_secretsmanager_secret_rotation" "api_key" {
secret_id = aws_secretsmanager_secret.api_key.id
rotation_lambda_arn = aws_lambda_function.api_key_rotation.arn
rotation_rules {
automatically_after_days = 29
}
}
```
If you only need the terraform to deploy an API key - but do not necessarily use it straight away, then you could get away with not including the final part of the terraform code. However, if there is a requirement to use the API key immediately after deployment in the same Terraform stack, then you will need to add a `null_resource` to delay the terraform execution until the secret has been rotated.
> I set an arbitrary 20 second delay, but if you wanted to be safe you could increase that.
```hcl
resource "null_resource" "api_key_delay" {
provisioner "local-exec" {
command = "sleep 20"
}
triggers = {
after = aws_secretsmanager_secret_rotation.api_key.id
}
}
```
The following terraform can be used to retrieve the API key from the newly created and updated secret.
```hcl
data "aws_secretsmanager_secret" "api_key" {
depends_on = [
null_resource.api_key_delay
]
arn = aws_secretsmanager_secret.api_key.arn
}
data "aws_secretsmanager_secret_version" "api_key" {
secret_id = data.aws_secretsmanager_secret.api_key.id
}
```
## Plea to Amazon
In this post, we have seen how to use Terraform to deploy an AWS Secret and Lambda function that will rotate the API key for an Amazon Managed Grafana workspace. We did this to get around some frustrating limitations with the way that Amazon Managed Grafana provides API keys that hopefully will be addressed in the future.
My request to Amazon is for them to make this solution I outlined redundant by doing the following:
1. Provide a way to vend short-lived session tokens for API access against Managed Grafanas API for use in CI/CD pipelines.
2. If this is not possible, provide a way to create API keys that are not tied to a specific user account - but manage the storage and rotation of these keys in Secrets manager similar to RDS: [https://aws.amazon.com/about-aws/whats-new/2022/12/amazon-rds-integration-aws-secrets-manager/](https://aws.amazon.com/about-aws/whats-new/2022/12/amazon-rds-integration-aws-secrets-manager/)
3. If this is not possible, reduce the price of API keys to $0.01 per month so we can use them in CI/CD pipelines without worrying about the cost.
If you've had this same problem and can think of a better way to solve it, please let me know on Twitter [@nathangloverAUS](https://twitter.com/nathangloverAUS) or in the comments below. | t04glovern |
1,379,800 | animtion n canvas | A post by nagvanshi9275 | 0 | 2023-02-26T06:08:45 | https://dev.to/nagvanshi9275/animtion-n-canvas-l29 | canvas, webdev, css, javascript | nagvanshi9275 | |
1,379,874 | Quick Guide for AWS | Deploy to EC2 Security Group Setup the following security group... | 0 | 2023-02-26T07:40:59 | https://dev.to/shaheem_mpm/quick-guide-for-aws-11mo | aws, ec2, devops, s3 | ## Deploy to EC2
---
### Security Group
Setup the following security group configuration

### Connect with SSH
- Update the permission of downloaded certificate file
```bash
chmod 400 <file_name>.pem
```
- Connect to the distant server with the command
```bash
ssh -i <certificate>.pem ec2-user@<Public_IPv4_DNS>
```
### Install node with nvm
- Download nvm using curl
```bash
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
```
- Activate nvm with
```bash
. ~/.nvm/nvm.sh
```
- Install node with
```bash
nvm install node
```
- Test node installation with
```bash
node -e "console.log('Running Node.js ' + process.version)"
```
[Checkout the official documentation on how to setup node in ec2 linux](https://docs.aws.amazon.com/sdk-for-javascript/v2/developer-guide/setting-up-node-on-ec2-instance.html)
### Port Forwarding from 80 to 8000
Use the following command for port forwarding
```bash
sudo iptables -t nat -I PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8000
```
### Install MongoDB community edition
- Verify Linux Distribution with
```bash
grep ^NAME /etc/*release
```
The result should be Amazon Linux or Amazon Linux AMI
- Create a /etc/yum.repos.d/mongodb-org-4.4.repo file so that you can install MongoDB directly using yum:
```bash
cd /etc/yum.repos.d
sudo touch mongodb-org-4.4.repo
```
- Add the following Configuration to created file with nano or vim
```bash
[mongodb-org-4.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/amazon/2/mongodb-org/4.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.4.asc
```
- Install MongoDB packages with
```bash
sudo yum install -y mongodb-org
```
- Setup storage directory for MongoDb
```bash
cd /
sudo mkdir data
cd data
sudo mkdir db
cd ../..
cd home/ec2-user
```
- Start mongodb service
```bash
sudo service mongod start
```
[Checkout common errors faced during this](https://stackoverflow.com/questions/43368173/why-does-sudo-service-mongod-start-fail-with-linux-ec2)
[Checkout the offficial Documentation](https://www.mongodb.com/docs/manual/tutorial/install-mongodb-on-amazon/)
### Install PostgreSQL
[Follow this article for installing PostgreSQL](https://www.how2shout.com/linux/install-postgresql-13-on-aws-ec2-amazon-linux-2/)
after install use this command to open db shell
```bash
sudo su - postgres
```
### Transfer node project to ec2
You can use programs like filezilla to transfer project files the method I use personally is to send zipped file using scp command
- Delete node_modules directory from project
- Zip the project directory
```bash
zip -r server.zip <project_directory>
```
- Transfer zipped file using scp
```bash
scp -i <certificate>.pem server.zip ec2-user@<Public_IPv4_DNS>:
```
- Now connect back to instance with SSH and unzip the file
```bash
unzip server.zip
```
### Run Application with screen
install the node modules and run the app with screen
```bash
screen npm start
```
you can detach the screen without terminating by
i. ctrl+A
ii. D
---
## Bucket Policy for S3
---
Use the following bucket policy in S3 Bucket for public read access
```json
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "AllowPublicRead",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<bucket_name>/*"
}
]
}
```
---
## CloudFront Guide
---
Use this tutorial for setting up cloudfront
{% embed https://www.youtube.com/embed/uNWHAy5TTx8 %}
---
## Steps to get SSL Certificate to EC2 instance
---
1. move nameserver to Route 53
2. request certificate from ACM
3. create load balancer targeting to ec2 instance
4. create a record pointing to load balancer in route 53
| shaheem_mpm |
1,379,987 | Typescript Interface vs Type | In TypeScript, both an interface and a type Alias can be used to describe a new named type. this... | 0 | 2023-02-26T10:23:33 | https://dev.to/cloudysarah/typescript-interface-vs-type-4877 | programming, typescript, webdev, javascript | In TypeScript, both an *interface* and a *type* Alias can be used to describe a new named type. this article will see what are the differences between them and what are the best use cases for both types and interfaces in TypeScript
### 1. Declaration merging
In TypeScript, declaration merging happens when the compiler merges two or more interfaces of the same name into only one declaration. and that is possible only with interfaces, if you try to declare two types of the same name, the compiler will throw an error.
Here is an example of declaration merging in TypeScript.
let's imagine we have two interfaces called Car
```tsx
interface Car {
carName: string ;
};
interface Car {
carNumber: number;
};
const car: Car = {
carName: "ford",
carNumber: 12345
}
```
In this example, we first declare the Car interface with one property. Then, we declare it another time, with a different property. Finally, the compiler merges both interfaces into one, since they share the same name.
if we change the interface into a type like this
```tsx
type Car = {
carName: string ;
};
type Car = {
carNumber: number;
};
// this is wrong don't do it
const car: Car = {
carName: "ford",
carNumber: 12345
}
```
Typescript will throw us an error
```tsx
Duplicate identifier Car
'Car' is already defined.
```
Declaration merging does not work with types.
### 2. Extends
In Typescript, we can easily extend interfaces .this is not possible with types
Interfaces can extend classes which helps a lot in a more object-oriented way of programming.
for example, there is a class called Album and an interface called Song, we can easily extend this class using an interface
```tsx
class Album {
details = () => {
console.log("show details of the album")
}
};
interface Song extends Album {
songName: string;
}
```
we can also extend an interface with another interface
for example, an interface called Song can extend interface Singer
```tsx
interface Singer {
artistName: string;
}
interface Song extends Singer {
songName: string;
}
```
if we tried to replace interface with type to extend, typescript will throw us an error
```tsx
type Singer ={
artistName: string;
}
type Song extends Singer ={ // this is wrong don't do it
songName: string;
}
```
```tsx
Cannot find name 'extends'.
'Singer' only refers to a type, but is being used as a value here
```
### 3. **Implements**
In typescript, Both a *type* and an *interface* can be implemented by a class, and we can also create classes implementing interfaces.
```tsx
interface ClockInterface {
currentTime: Date;
}
class Clock implements ClockInterface {
currentTime: Date = new Date();
constructor(h: number, m: number) {}
}
```
You can also describe methods in an interface that are implemented in the class, as we do with `setTime` in the below example:
```tsx
interface ClockInterface {
currentTime: Date;
setTime(d: Date): void;
}
class Clock implements ClockInterface {
currentTime: Date = new Date();
setTime(d: Date) {
this.currentTime = d;
}
constructor(h: number, m: number) {}
}
```
a class can also implement a type
```tsx
type ClockInterface = {
currentTime: Date;
}
class Clock implements ClockInterface {
currentTime: Date = new Date();
constructor(h: number, m: number) {}
}
```
### 4. ***Intersection***
Intersection allows the developer to merge two or more type declarations into a single type.
To create an intersection type, we have to use the `&` keyword
Here is an example of how to combine two types with an intersection.
```tsx
type ErrorHandling = {
success: boolean;
error?: { message: string };
}
type ArtworksData = {
artworks: { title: string }[];
}
type ArtworksResponse = ArtworksData & ErrorHandling;
```
also, we can create a new intersection type combining two interfaces
```tsx
interface ErrorHandling {
success: boolean;
error?: { message: string };
}
interface ArtistsData {
artists: { name: string }[];
}
type ArtistsResponse = ArtistsData & ErrorHandling;
```
We cannot create an interface combining two types, because it doesn’t work:
```tsx
type Name ={
name: "string"
};
type Age ={
age: number
};
interface Person = Name & Age; // this is wrong don't do it
```
typescript will throw us an error
```tsx
Parsing error: '{' expected.
'Name' only refers to a type, but is being used as a value here.
'Age' only refers to a type, but is being used as a value here.
```
### 5. ***Tuples***
Tuples brought to us this new data type that includes two sets of values of different data types.
```tsx
type specialKindOfData = [string, number]
```
it is a very helpful concept in typescript, but we can only declare tuples using types and not interfaces.
but you still are able to use a tuple inside an interface.
for example.
```tsx
interface Data {
value: [string, number]
}
```
### 6. ***Unions***
A union type allows the developer to create a value of one or a few more types.
we have to use the `|` keyword to create a new union type, the combined declaration must always be a *type*
```tsx
type Cat = {
name: string;
};
type Dog = {
name: string;
};
type Animal = Cat | Dog;
```
Similar to intersections, we can create a new union type combining two interfaces,
```tsx
interface Cat {
name: string;
}
interface Dog {
name: string;
}
type Animal = Cat | Dog;
```
we can not combine two types into an interface because union type must be combined in a type only
### 7. **Primitive Types**
A primitive type can only be declared with a *type.*
```tsx
type data = string;
```
If you try to declare one with an *interface*, it will not work.
## ***Conclusion***
In this article, we learned about the difference between Interfaces and types, and learned the best use cases for both types and interfaces in TypeScript, and how we can apply both of them in real projects. .to decide if you should use a type or an interface, you should carefully think and analyze what you’re working on, and the specific code to make the right choice. the interface works better with objects and method objects, and types are better to work with functions, and complex types, you can use both together and they will work fine. | cloudysarah |
1,380,015 | And we have (Space)lift (off)! | Get started with Spacelift | 22,026 | 2023-02-26T21:40:14 | https://dev.to/aws-builders/and-we-have-spacelift-off-1eal | spacelift, aws, configuration, tutorial | ---
title: And we have (Space)lift (off)!
series: spacelift
published: true
description: Get started with Spacelift
tags: #spacelift #aws #configuration #tutorial
cover_image: https://www.pawelpiwosz.net/assets/covers/spacelift-cover.png
---
This time we will configure and run our first small template through [Spacelift](https://spacelift.io/). Our first step will be to configure the connection between AWS and the service. I assume, that the Spacelift account is created and connected with GitHub.
In this short series we will learn how to configure, connect and start to use Spacelift.
First thing to do for each real developer is to switch the GUI to dark mode :D Go to your account settings on the bottom left corner of your screen and find the `dark mode` setting. Right, we are ready to go :)
# AWS
## Connect Spacelift with Cloud provider
To work with AWS we need to configure our connection to the vendor. The documentation provided by Spacelift is really rich and clear, however, I'd like to mention the security aspect. First way, the easier one, is to provide programmatically available user with role to assume. Is it a good solution? Well, good enough. However, I prefer to use another way, which also is provided by Spacelift - the OIDC connection. On the end of the day it does the same thing, but from the security standpoint - it is better.
OIDC needs some configuration (obviously) and part of it is a thumbprint. As I do this as a tutorial, not fully blown production ready stuff, I show you how to get this thumbprint using CLI approach.
First, let's collect url of our spacelift app. Simply, look on your browser :) In my case it it `https://<subdomain>.app.spacelift.io/`. We have it, so let's generate the thumbprint.
I use Ubuntu to get these information. In fact WSL2 on Windows :). Execute:
`curl https://<subdomain>.app.spacelift.io/.well-known/openid-configuration|jq`
Please note, I added `jq` on the end to have nicer output.
Find the line with `jwks_uri`. Copy from it the domain name **only** and use it in following command.
`openssl s_client -servername <subdomain>.app.spacelift.io -showcerts -connect <subdomain>.app.spacelift.io:443`
Ensure, you don't have https, etc. Just the domain.
Scroll the output and find the certificate. There will be something like
```text
-----BEGIN CERTIFICATE-----
somestring
-----END CERTIFICATE-----
```
Create a file (for example `certificate.crt`) and copy this whole part there.
Now we are ready to generate thumbprint
`openssl x509 -in certificate.crt -fingerprint -sha1 -noout |tr -d :`
As you can see I used the `tr` command with pipe to get rid of `:`. If you are not familiar with pipes and redirections in Linux, no worries, [here is my lab about it](https://killercoda.com/pawelpiwosz/course/linuxFundamentals/lf-05-pipes).
The string in output is a part which we need to use to complete our configuration of OIDC.
> We can do it with Terraform, of course. In fact, if you plan to use it in the real project, I strongly recommend to do it with IaC. However, now you know how to do it from CLI :)
## Let's terraform it
You know what? Creating all these resources on AWS from GUI is so old-fashioned :) Let's have a small Terraform template for it! We need to create:
* OIDC itself
* IAM Role to assume by Spacelift
* IAM Policy which describes what Spacelift can do.
First, let's create the file `providers.tf` with this content
```terraform
terraform {
required_version = ">=1.3"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
```
And we can forget about this file from now.
We know what is our thumbprint, so we can create first block in `main.tf`.
```terraform
provider "aws" {
default_tags {
tags = {
Environment = "Sandbox"
Terraform = "True"
Repo = "spacelift-prep"
Project = "Spacelift tutorial"
}
}
}
resource "aws_iam_openid_connect_provider" "spacelift" {
url = "https://<subdomain>.app.spacelift.io"
client_id_list = [
"<subdomain>.app.spacelift.io",
]
thumbprint_list = ["<thumbprint>"]
}
```
Please note, we also have the provider defined here.
Now, it is time to define the IAM Role. Within this definition, we will ensure that the Role can be assumend by Spacelift only. We want to build the trusted relation between this entity and Spacelift to secure our connection as much as possible.
The Role and condition inside is described well in Spacelift's documentation, so, I will not go into details. I just explain a few parts.
First, we use Federated access and we use for it the OIDC we defined earlier.
Second, please note the `Condition` section of the Role. This makes the connection more secure by narrowing the entities which can use this role. We can create even more precise boundary, all is in documentation. However, this one is enough for us at this moment.
And here is the Terraform code for our Role
```terraform
resource "aws_iam_role" "spacelift-role" {
depends_on = [
aws_iam_openid_connect_provider.spacelift
]
name = "spacelift-role"
description = "Role to assume by spacelift"
assume_role_policy = <<ROLE
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "${aws_iam_openid_connect_provider.spacelift.arn}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"<subdomain>.app.spacelift.io:aud": "<subdomain>.app.spacelift.io"
}
}
}
]
}
ROLE
}
```
You might ask, *why do you use this old-fashioned way with `<<ROLE`?*. Well, good question :) For two reasons. I learned Terraform this way and this approach helps me to better see where Role or Policy document ends. Quite handy, especially for long documents.
Ok, finally, we will create "very secure" Policy and we will attach Policy to the Role. Please have in mind, that the Policy should by tailored to needs, not open like here. We do it for demo purposes, so we can live with it now.
```terraform
resource "aws_iam_policy" "spacelift-policy" {
name = "spacelift-policy"
policy = <<POLICY
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "*",
"Resource": ["*"]
}
]
}
POLICY
}
resource "aws_iam_role_policy_attachment" "spacelift-iam-attachment" {
role = aws_iam_role.spacelift-role.name
policy_arn = aws_iam_policy.spacelift-policy.arn
}
```
No magic here, I suppose.
## Init
We have our template, we can execute it.
First, we need to initialize Terraform
`terraform init`
We can format and validate the template
`terraform fmt`
`terraform validate`
Well, I have to do one more thing. I use many AWS profiles, therefore I need to specify it. There are many ways to do so, I use the easier and less flexible one - I put it into template:
```terraform
provider "aws" {
profile = "demos"
```
Please remember, this is for demo purposes only, so, no issue with it.
## Execute Terraform
We can deploy our stack.
First, let's see if all is ok
`terraform plan`
If all went ok, you should see something like
`Plan: 4 to add, 0 to change, 0 to destroy.`
Ok, so let's rock!
`terraform apply -auto-approve`
This `Apply complete! Resources: 4 added, 0 changed, 0 destroyed.` means success.
But wait... What Role should I use later? We can go to the GUI and... **NO!**
## Outputs
Let's create one more file, called `outputs.tf` and put there
```terraform
output "IAM-Role-to-assume" {
description = "IAM Role to assume by Spacelift"
value = aws_iam_role.spacelift-role.arn
}
```
Now we can run `terraform refresh` and we already see the ARN of the Role. If this info is needed later, we can run `terraform output`.
# Spacelift
Well, looks like this episode is more about Terraform than Spacelift :) It is important though, to have good connection created, so I believe this is not a big deal :)
Ok, let's do our work on Spacelift side!
Go to your dashboard, to the `Cloud integrations (bottom left of the screen)

And configure your AWS integration accordingly.

And... Yes, that's it :)
# Key takeways
For now, we know how to connect the dots. In the next episode we will learn what Spacelift is and how to start with it.
| pawelpiwosz |
1,380,064 | Focus on Creating Instead of Consuming | We all have the same number of hours a day yet some people seem to find time to write novels and... | 0 | 2023-02-26T12:35:19 | https://newsletter.alexhyett.com/p/focus-on-creating-instead-of-consuming | productivity, habits, motivation, learning | We all have the same number of hours a day yet some people seem to find time to write novels and pursue their dreams while the rest of us are struggling to find time between work and sleep.
Having more time isn’t always the answer. [Taking a break](https://www.alexhyett.com/creative-sabbatical-software-engineer/) from the 9 - 5 has freed up enormous amounts of time during my day however it doesn’t automatically translate into productive output.
If I am not careful I can easily waste several hours of my day scrolling through social media and doing busy work instead of actually getting down to what matters.
If you are working full time, it is even more important to use your time wisely instead of binge-watching episodes on Netflix or doom-scrolling TikTok.
My goal for this year is to create more than I consume. This means spending at least an hour or two a day writing as well as recording videos for my [YouTube channel](https://youtube.com/@alexhyettdev) and then the many, many, many hours it takes to edit a video.
Creating things, especially in public has a way of compounding over time, which doesn’t happen when you consume content.
There are no benefits to your future self by watching another Instagram Reel or arguing with someone on Twitter.
## Creating is Addictive
Short-form media such as TikTok videos and Instagram posts are designed to be addictive. They give us that dopamine hit every minute which keeps us scrolling for hours.
Once you start creating and seeing results it becomes a new kind of addictive.
As many of you know I am currently trying to grow my [YouTube channel](https://youtube.com/@alexhyettdev). Over the last 5 months, I have grown my channel from 51 subscribers to 930.
I am also writing several posts on software engineering for my blog several times a week. As a result, traffic on my blog has grown from 6,900 page views in October to 11,200 in the last 30 days.
For those not familiar with online growth these numbers might not seem that impressive. It has taken me 5 months to gain 879 subscribers and double the page views on my blog.
**Online growth however is not linear.**
We are used to living in a linear world with linear results. The online world however doesn’t work in a linear way.
If you keep creating in public then each post or video becomes a seed that brings in more people to your audience.
For example, when I first started posting regularly on [YouTube](https://youtube.com/@alexhyettdev) in October I was getting 3 - 6 subscribers per week.
By the end of 2022, I was gaining 22 subscribers a week.
Now at the end of February, I am gaining 42 subscribers every week.
If you look at large YouTubers such as Ali Abdaal they gain 3,000 subscribers per day! Once you gain a bit of traction these things have a tendency to snowball. Especially if you are improving what you produce every time.
I should get to the 1,000-subscriber milestone at some point in March.
If we were living in a linear world then I would get to 2,000 subscribers by the end of August 2023.
However, things aren’t linear. If every week the number of subscribers I gain increases by 10%, as it has done so far, then I should get to the 2,000 subscriber milestone by the end of May.
So gaining 1,000 subscribers in 3 months instead of 5. If the growth continues at this rate then I would be ending the year with around 28,000 subscribers (let’s see how wrong I am!).
Of course, none of this will happen if I don’t continue creating videos every week. Luckily creating content is far more addictive than consuming it once you start seeing results.
## ❤️ Picks of the Week
**📝 Article** - [19 Rules For A Better Life (From Marcus Aurelius)](https://ryanholiday.net/19-rules-for-a-better-life-from-marcus-aurelius/). I am a big fan of Stoicism and anyone who is familiar with the stoics has heard of Ryan Holiday. I have his book The Daily Stoic sitting on my desk to gain some wisdom from the ancient philosophers. If you are new to stoicism then it is worth starting with these tips.
**📚 Book** - [The Dip - Seth Godin](https://geni.us/D35Kw). I read this over the weekend. It is a short book on when to quit or when to stick at it. Everything worth pursuing has a dip. It is the time between when you start something full of excitement and the time when your practice pays off and you actually become good at something.
## 👨💻 Latest from me
**🎬 YouTube** - [Hexagonal Architecture](https://www.youtube.com/watch?v=bDWApqAUjEI). I am trying to focus more on videos that will do well in search. I have been doing a lot of keyword research on my blog and some of those posts I make into videos. In this video, I cover Hexagonal Architecture going over what it is and when you should use it. In case you are interested, the term "Hexagonal Architecture" is searched 22,000 times a month so I am hoping this video will do well over the long term.
**📝 Article** - [Python List Comprehension](https://www.alexhyett.com/python-list-comprehension/). Manipulating lists can be a pain in most programming languages as you have to create a copy of the array. Python has a good feature called List Comprehension that is missing from a lot of other languages.
You might notice that I have one less article this week compared to my normal cadence. I have decided to move Friday's post to next week so that I can release it at the same time as my video. Some of my posts do very well when they are first released and I have been missing out on potential views to my videos.
## 💬 Quote of the Week
> Ask anybody doing truly creative work, and they’ll tell you the truth: They don’t know where the good stuff comes from. They just show up to do their thing. Every day.
From [Steal Like an Artist](https://geni.us/qRkB) by Austin Kleon. Resurfaced with [Readwise](https://readwise.io/i/alex3139).
---
This post is from my weekly newsletter [The Curious Engineer](https://www.alexhyett.com/newsletter/) where I share my insights as an engineer turned entrepreneur and the lessons I am learning along the way. | alexhyettdev |
1,380,100 | Angular Part 1 : Creating Angular Project EAccessoriesShop Setup Project| Angular Project ecommerce | Requirement & Angular Project stucture Information in angular.json file have all project... | 0 | 2023-02-26T14:10:43 | https://dev.to/softwaretechit/angular-part-1-creating-angular-project-eaccessoriesshop-setup-project-angular-project-ecommerce-12jh | angular, webdev, javascript, beginners | {% embed https://www.youtube.com/watch?v=W8sHT3dbH0M&list=PLmwJLue37PZfQTgu-AXNee3EDj7oIlqeh&index=1&ab_channel=SoftwareTechIT %}
Requirement & Angular Project stucture Information
in angular.json file have all project stucture
in package.json file have all install packages
src/app/app.module.ts file have all used componets and more that we are create and use in
our project
src/index.html is a starting point of our project in index.html
there is selector this is root of the project and app project componets and more are
import/used in this file
this is come from AppComponet Class From app.componets.ts file
in angular 1 is used js and after anguler 1 come angular 2 thats have typescript language
and we are using angular 14 that why we are using typescript
we need to learn first
html
Css
typescript
and bootstrap css to create our project
we are created the RestAPI In Python For This Project we Can Change As Per Requirments
becouse we Are creating FullStack Application
ok Then starting
Setup
Here’s an example of how you can create an Angular app called “EAccessoriesShop” with the specified components:
Open your command-line interface and navigate to the directory where you want to create the app.
Run the following command to create the app:
ng new EAccessorieShop
Navigate into the app directory:
cd EAccessoriesShop
Now Add Componnets That will Requried in This Project
Create the components using the following command:
```
ng generate component home
```
```
ng generate component cart
```
```
ng generate component login
```
or
//you can use shortcut for this as (g for generate / c for component
```
ng g c product
ng g c header
```
Shopping :-
https://shop.softwaretechit.com
Product Review:-https://productsellermarket.softwaretechit.com
Website :-
https://softwaretechit.com
Blog:- https://blog.softwaretechit.com
Business & More:-
https://golbar.net/
We Used Bootstrap Css That’s Why We Are Not Using CSS But You Can Use As per Your Requirement
You will find the components in the src/app folder. The component files are in the home, product, cart and login folders.
Add the components to the app.module.ts file so that Angular knows about them.
In your app.component.html file you can use the <app-home>, <app-product>, <app-cart> and <app-login> tags to render these components in your application.
Once you’ve done that, you can start working on your components and add the logic, template and styles you need.
Note: This is a basic setup and you can customize your application as per your needs.
Now create the product list in typecript file and display in html
### product.component.ts
```
import { Component, OnInit,Input } from "@angular/core";
import { Router } from "@angular/router";
import { Subscriber } from "rxjs";
import { ProductModel } from "../models/product.model";
import { CartService } from "../services/cart.service";
import { ProductService } from "../services/product.service";
@Component({
selector:"product-component",
templateUrl:'./product.component.html',
styleUrls:["product.component.css"],
})
export class ProductComponent implements OnInit{
product_list:ProductModel[]=[];
category='laptop';
constructor(private product_httpservice:ProductService,private http_Cart:CartService,private router:Router){
}
ngOnInit(): void {
this.product_httpservice.getProductlist().subscribe((data)=>this.product_list=data['result'])
}
addToCart(pid:any){
this.http_Cart.addToCartProduct(pid)
this.router.navigate(['/cart'])
}
}
```
### product.component.html
```
<section >
<div class="row m-5">
<div class="col-11">
<div class="text-center row">
<ng-container *ngFor="let product of product_list">
<div *ngIf="product.category==category" class="col-sm-2 card m-1 p-1 shadow-lg bg-white rounded">
<img src={{product.image_url}} width="100%" height="50%">
<h6 class="overflow-hidden " [routerLink]="['/single-product',product.id]">{{ product.title | slice:0:50}}</h6>
<p>Price: {{product.price}}<br/>
Rating: {{product.rating}}<br/>
Category: {{product.category}}</p>
<div >
<button class="btn btn-warning" type="submit"
(click)="addToCart(product.id)"><i class="bi bi-cart-plus-fill"></i></button>
<button class="btn btn-warning m-1" type="submit"
[routerLink]="['/single-product',product.id]"><i class="bi bi-eye-fill"></i></button>
<button class="btn btn-warning m-1" type="submit"
onClick="window.open('https://shop.softwaretechit.com')">Buy Now</button>
</div>
</div>
</ng-container>
</div>
</div>
</div>
</section>
```
# Read More :-
1. https://softwaretechit.com/google-maps-developer-google-map-in-android-studio-google-maps-developer-android-studio-google-maps-tutorial/
2. https://softwaretechit.com/4-median-of-two-sorted-arrays-leetcode-java-solutions-leetcode-problems-and-solutions-java/
3. https://softwaretechit.com/3-longest-substring-without-repeating-characters-leetcode-java-leetcode-problem-2023/
4. https://softwaretechit.com/basic-postgresql-query-introduction-explanation-and-50-examples/
5. https://softwaretechit.com/flask-api-part-2-product-list-create-database-flask-app-api-create-json-api-using-flask/
6. https://softwaretechit.com/how-i-solved-leetcode-problem-using-chatgpt-chatgpt-for-programmers-chatgpt-tutorials-ai/
7. https://softwaretechit.com/3-longest-substring-without-repeating-characters-leetcode-java-leetcode-problem-2023/
8. https://softwaretechit.com/web-stories/
| softwaretechit |
1,380,227 | Surviving the Storm: Is Your Software Ready to Weather Network Instability? | The strength of a person is often measured not by their success during favorable conditions, but by... | 0 | 2023-02-26T16:34:56 | https://dev.to/juwoncaleb/surviving-the-storm-is-your-software-ready-to-weather-network-instability-2kff | The strength of a person is often measured not by their success during favorable conditions, but by how they react when facing adversity. Similarly, the quality of the software is not fully seen when it is functioning under ideal conditions, but when it is tested by unexpected events such as network instability. In a world where users can access software from anywhere, it is crucial to consider the reliability of software under adverse conditions, as it can greatly affect the user experience and ultimately impact a business.
One way to ensure software reliability is by asking the question “Will my software work when there is a sudden cut to the internet?” or “Will my software load fast enough when the network connectivity is poor, such as with 2G?”. While network instability used to be a significant issue in the past, modern technologies have made it possible to address such challenges.
There are various techniques that can be used to ensure software reliability, including
Service Worker
Service workers are JavaScript files that run in the background of a web application, allowing it to continue functioning even when there is no internet connection. Service workers can intercept network requests, cache responses, and serve content from the cache when the network is not available. This approach is particularly useful for static assets like CSS, JavaScript, and HTML
Progressive Web Apps (PWA)
Progressive Web Apps is a set of web technologies that allow web applications to behave more like native applications. PWAs can work offline, send push notifications, and even be installed on the user’s device. PWAs can be built with Service Workers and other web technologies.
Local Storage
Local storage is another client-side storage mechanism that allows web applications to store data locally. Local storage can be used to store user preferences, data that the application needs to function when the network is not available, and other information.
Lazy loading
Lazy loading is a technique used in web development to improve website performance and reduce page load times. It involves delaying the loading of non-critical resources, such as images, videos, and other media until the user actually needs to view them. This means that the initial page load is faster, as only essential resources are loaded, and subsequent resources are loaded on demand as the user scrolls down the page.
I will be explaining these solutions in more detail in my next blog | juwoncaleb | |
1,380,304 | How to create a URL Shortener in dotnet ? | Target Audience The focus of this article is to provide insights to those seeking to... | 0 | 2023-02-26T18:09:22 | https://dev.to/eminvergil/how-to-create-a-url-shorter-in-dotnet--3572 | dotnet, dotnetcore, urlshortener, systemdesign |
## Target Audience
The focus of this article is to provide insights to those seeking to acquire knowledge on designing a dotnet-based URL shortening service.
## Learning Objectives
After completing this article, you will know how to do the following:
- Desgin an url shortener
- Create an API service for url shortener
## What is URL Shortening ?
### Wikipedia Definition
**URL shortening** is a technique on the [World Wide Web](https://en.wikipedia.org/wiki/World_Wide_Web "World Wide Web") in which a [Uniform Resource Locator](https://en.wikipedia.org/wiki/Uniform_Resource_Locator "Uniform Resource Locator") (URL) may be made substantially shorter and still direct to the required page. This is achieved by using a [redirect](https://en.wikipedia.org/wiki/URL_redirection "URL redirection") which links to the [web page](https://en.wikipedia.org/wiki/Web_page "Web page") that has a long URL.
## What are the benefits of using an url shortener ?
1. Saves characters: URL shorteners help save characters in tweets, texts, and other social media posts where character count is limited. This can make your message more concise and easier to share.
2. Track clicks: URL shorteners often provide analytics that allow you to track clicks on your links. This can be useful for measuring the success of your marketing campaigns, and for determining which types of content are most engaging to your audience.
3. Makes links more manageable: Long and complex URLs can be difficult to remember or type out. URL shorteners can make links more manageable and easier to share.
4. Mask the original URL: Some URL shorteners allow you to mask the original URL, which can be useful for hiding affiliate links or links to sites that you don't want to reveal.
5. Customize links: Many URL shorteners allow you to customize the shortened link to include a keyword or brand name. This can help increase brand awareness and make links more memorable.
## Design of the service
Here is the general structure of the url shortener system.
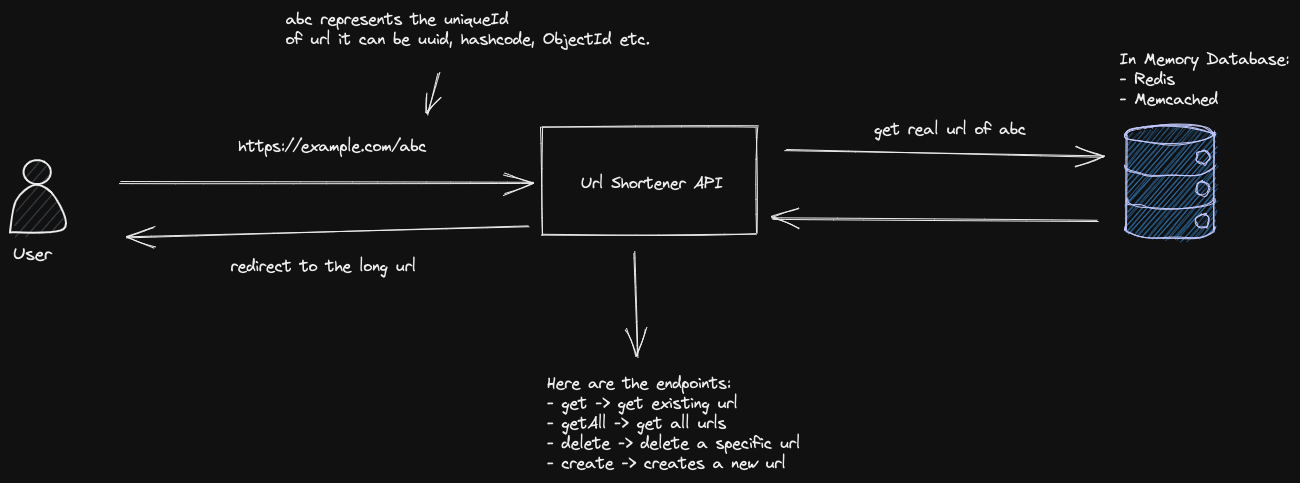
This design can be modified for the requirements. For example, if we want to handle high volume, we can use a load balancer to handle that traffic. And if we want to provide high availibility, we can use clustered databases.
## Example implementation in dotnet
Here are the endpoints:
```csharp
app.MapGet("{code}", (string code) => $"You are redirected to. Code: {code}");
app.MapGet("/get/{code}", (string code) => $"Here is the code: {code}");
app.MapGet("/get", () => $"Here is the list of urls. List: {GetAll()}");
app.MapPost("/create", ([FromBody] CreateShortUrlRequest request) =>
{
var url = request.Url;
return $"Here is your url: {url}";
});
app.MapDelete("/delete/{code}", (string code) => $"Url in {code} deleted successfully");
```
In this demo, we will use `create` endpoint to create a code to represent urls.
Here is the whole implementation:
```csharp
using Microsoft.AspNetCore.Mvc;
using Newtonsoft.Json;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
builder.Services.AddCors();
builder.Services.AddSingleton(_ => new UrlShortenerService(new Database()));
var app = builder.Build();
app.UseCors(x =>
{
x.AllowAnyHeader();
x.AllowAnyOrigin();
x.AllowAnyMethod();
});
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
// here is the middleware to redirect
app.Use(async (context,next) =>
{
var currentEndpoint = context.GetEndpoint();
if (currentEndpoint is {DisplayName: "HTTP: GET {code}"} and RouteEndpoint routeEndpoint && routeEndpoint.RoutePattern.RawText == "{code}" && routeEndpoint.RoutePattern.Parameters.Count == 1)
{
var urlShortenerService = context.RequestServices.GetService<UrlShortenerService>();
var reqUrl = context.Request.Path.Value[1..];
var url = urlShortenerService.Get(reqUrl);
if (string.IsNullOrWhiteSpace(url))
await next();
context.Response.Redirect(url);
}
await next();
});
app.MapGet("{code}", (UrlShortenerService service, string code) => service.RedirectTo(code));
app.MapGet("/get/{code}", (UrlShortenerService service,string code) => service.Get(code));
app.MapGet("/get", (UrlShortenerService service) => $"Here is the list of urls. List: {service.GetAll()}");
app.MapPost("/create", (UrlShortenerService service, [FromBody] CreateShortUrlRequest request) => service.Create(request.Url));
app.MapDelete("/delete/{code}", (UrlShortenerService service,string code) => service.Delete(code));
app.Run();
public class Database : Dictionary<string, string>
{
}
public class UrlShortenerService
{
private readonly Database _database;
public UrlShortenerService(Database database)
{
_database = database;
}
public string RedirectTo(string code)
{
if (!_database.ContainsKey(code))
{
return "Not Found";
}
var url = _database[code];
return $"You are redirected to: {url}";
}
public string GetAll()
{
if (_database.Count < 0)
{
return string.Empty;
}
var list = JsonConvert.SerializeObject(_database.Keys);
return list;
}
public string Get(string code)
{
if (_database.Count <= 0 || !_database.ContainsKey(code))
{
return string.Empty;
}
return _database[code];
}
public string Create(string url)
{
var rnd = Guid.NewGuid().ToString("n").Substring(0, 8);
_database.Add(rnd, url);
return $"Here is your new code for url: {rnd}";
}
public string Delete(string code)
{
_database.Remove(code);
return $"Successfully removed. Code: {code}";
}
}
public class CreateShortUrlRequest
{
[JsonConstructor]
public CreateShortUrlRequest(string url)
{
Url = url;
}
[JsonRequired]
[JsonProperty("url")]
public string Url { get; set; }
}
```
In this implementation, we created CRUD endpoints for a URL shortener and used a `Dictionary` to represent a key-value pair database. In the middleware, we check the current request method to ensure it matches the intended method, and if it does, we use the unique `code` to search the database for the corresponding long URL and redirect the user to it.
Overall, this implementation demonstrates how we can use basic CRUD operations and a key-value pair database to create a functional URL shortener. Additionally, it showcases how middleware can be used to handle the redirection of shortened URLs to their corresponding long URLs.
Here is a snapshot from network tab:
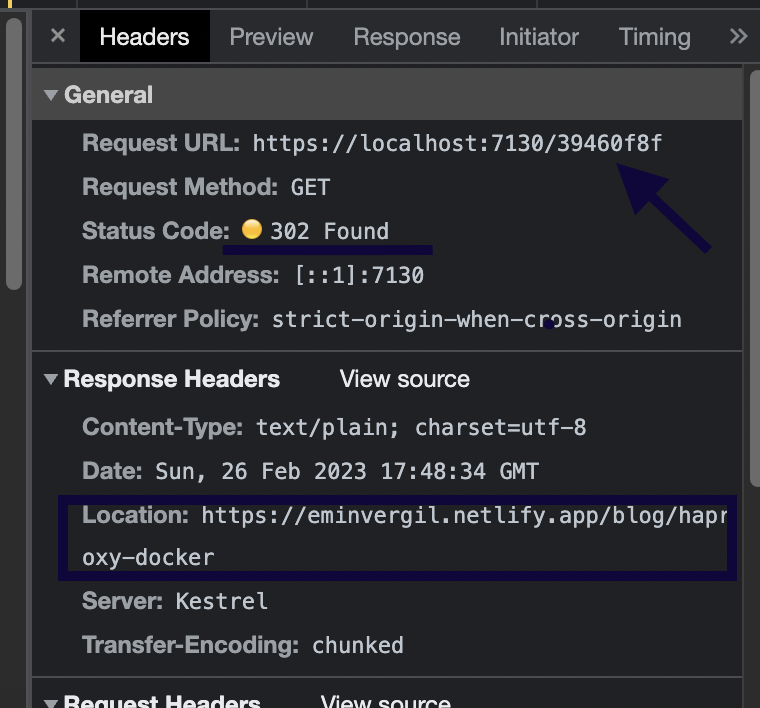
| eminvergil |
1,380,408 | Software Design and Analysis in Nutshell | Software ရေးတယ်ဆိုတာက Code တွေကိုချက်ချင်းတန်းရေးလိုက်တာမျိုးမဟုတ်ဘူး။... | 0 | 2023-10-18T08:17:03 | https://dev.to/aungmyatmoe/software-design-and-analysis-in-nutshell-3am6 | ---
title: Software Design and Analysis in Nutshell
published: true
date: 2023-02-25 17:30:00 UTC
tags:
canonical_url:
---
Software ရေးတယ်ဆိုတာက Code တွေကိုချက်ချင်းတန်းရေးလိုက်တာမျိုးမဟုတ်ဘူး။ အဲ့လိုလုပ်တာကတော်တော်ကိုမှားတယ်။ Analysis နဲ့ Software Design ကိုသိဖို့လိုသေးတယ်။ ကျော်လို့မရဘူး။ အဲ့လိုမလုပ်ဘူးဆိုရင် Enterprise Software ရေးရင်ခွေးအကြီးလှည်းနင်းသလိုပဲဖြစ်မှာ။ အဲ့လိုမဖြစ်ဖို့က Architect တွေခန့်ထားဖို့လိုတယ်။ အဲ့လိုမခန့်နိုင်ရင် အတွေ့အကြုံများတဲ့သူကို Software Design အတွက် Decision Making ချခိုင်းဖို့လိုတယ်။ အဲ့လိုမလုပ်ရင်ခွေးဖြစ်မှာပဲ။
Software က Enterprise Level ရောက်လာပြီတဲ့။ Code တွေကလူဖတ်ရနားမလည်ဘူး။ Rapid Development လုပ်ထားတယ်ပေါ့။ Rapid Development ကမြန်မြန် Delivery လုပ်ချင်တာမျိုးကိုပြောတာ။ ဒီလိုမျိုးလုပ်ရင် ပိုက်ဆံတော့ရမယ်။ Maintainability က အောက်ကိုထိုးကျသွားရော။
Project ကိုမနိုင်တော့ Software Engineer တွေထပ်ထည့်၊ ထပ်ထည့်။ လူတွေသာများသွားတယ် Code တွေက လူဖတ်ရနားမလည်ဘူး။ Bloated ဖြစ်နေတယ်ပေါ့။ အလုပ်လုပ်ရင်ပြီးရောဆိုပြီးရေးထားတာမျိုး။ Code တွေကတန်းကြည့်တာနဲ့နားမလည်ဘူး။ Iteration တစ်ခုစာလောက်ယူပြီးရှင်းပြဖို့လိုတာမျိုးရှိနေပြီဆိုရင်အဲ့ Code Base က Software Design မရှိဘူးဆိုတာကိုပြတာပဲ။
Software Design ချဖို့အတွက် အလွယ်ဆုံး Step က Clean Code ပဲ။ ဘယ်လိုလူနားလည်အောင်ရေးမလဲပေါ့။ ဒါ့အပြင် Naming Convention တွေ၊ API Documentation တွေရေးထားဖို့လိုသေးတယ်။ အပျင်းတက်နေလို့မဖြစ်ဘူး။ ဒီလိုပျင်းမှုတွေရဲ့ Consequences က Scalable မဖြစ်တာကိုပြတာပဲ။
Naming Convention တွေထားပြီးပါပြီတဲ့။ Architecture ပိုင်းကို Design ချဖို့လိုသေးတယ်။ Architecture ဆိုတာက Folder Structure ကိုနာမည်ဘယ်လိုပေးရမလဲဆိုတာမဟုတ်ဘူး။ ဒီ Code က ဘယ်နေရာဘယ်လို Behave တယ်ဆိုတာကိုပြောတာပဲ။ ဒီနေရာမှာဒါဖြစ်ရမယ်၊ ဒါကို Refactoring လုပ်ရင်ဒါဖြစ်ရမယ်ဆိုတာမျိုးကိုပြောတာ။ Design ချပြီးပါတဲ့ Code စရေးမယ်ဆိုပါတော့။ ချပေးထားတဲ့ Design အတိုင်း Follow လို့မရတာမျိုးတွေရှိလာမယ်။ ဒါဆိုဘယ်လိုလုပ်မလဲ။ ဒီလိုမျိုးအစကတည်းက Projects Analysis and Planning တွေလုပ်ဖို့ကလိုတယ်။ အဲ့လိုမလုပ်တော့ Code တွေကကြည့်လိုက်တာနဲ့ တောသားလိုရေးထားတယ်ဆိုတာမျိုးမဖြစ်အောင်ရေးဖို့လိုတယ်။ | aungmyatmoe | |
1,380,468 | Different methods to filter a Pandas DataFrame | Pandas is a popular open-source python library used for data manipulation and analysis. It helps in... | 0 | 2023-02-26T22:00:59 | https://medium.com/@AviatorIfeanyi/different-methods-to-filter-a-pandas-dataframe-d959500f65a1 | python, datascience, data, dataanalysis |
Pandas is a popular open-source python library used for data manipulation and analysis. It helps in the data analysis process which involves cleaning, exploring, analyzing, and visualizing data.
In this article, we will cover the various methods of performing filtering using pandas.
Data Filtering is one of the data manipulation operations we can perform when working with data. Filtering with pandas is similar to a WHERE clause in SQL or a filter in Microsoft Excel.
If you have worked with these tools, you have an idea of how filtering works.
Filters can be used to select a subset of data. It can also be used to exclude or discover null values from a dataset
Here are some examples of filtering
_1. Select all employees who were employed by the organization after 2020_
_2. Select all male employees who work in the finance and marketing department._
_3. Select all traffic accidents that occurred on Wednesday around 12 noon_
_4. Select all students whose registration number is null_
These are some real-world examples of what we can do with filters depending on our dataset and use case for our analysis.
Note: This tutorial assumes that you are already familiar with the usage of pandas for data analysis and you can differentiate between its underlying data structure namely Series and Dataframe.
To keep this tutorial simple, we would be creating our sample dataset. It would be a dataset of employees working for an organization.
```
import pandas as pd
```
```
employees_data = {
'first_name': ['Jamie', 'Michael', 'James', 'Mark', 'Stones', 'Sharon', 'Jessica', 'Johnson'],
'last_name': ['Johnson', 'Marley', 'Peterson', 'Henry', 'Walker', 'White', 'Mendy', 'Johnson'],
'department': ['Accounting', 'Marketing', 'Engineering', 'HR', 'HR', 'Sales', 'Data Analytics', 'Accounting'],
'date_of_hire': [2011, 2012, 2022, 2000, 2007, 2018, 2020, 2018],
'gender': ['M','M','M','M','F','F','M','F'],
'salary': [10000,87500,77000,44500,90000,45000,25000,65000],
'national_id': [22123,78656,98976,12765, None, None,56432,98744],
'emp_id': ['Emp22', 'Emp54', 'Emp77', 'Emp99', 'Emp98', 'Emp01', 'Emp36', 'Emp04']
}
employees_df = pd.DataFrame(data=employees_data)
```
In pandas, there is more than one way to operate. Pandas provide multiple ways to filter data.
**They include:**
**isin()**
This method provides a way to apply single or multiple conditions for filtering.
```
employees_df[employees_df['department'].isin(['Marketing'])]
```

```
employees_df[employees_df['department'].isin(['Marketing','HR'])]
```
**Logical operators**
We can use the available logical operators to filter for a subset of data
```
employees_df[employees_df['salary'] > 30000]
```
Here we filter for employees whose salary is above 30000.
Occasions may arise where we have to filter our data for multiple conditions. The logical operator also makes this possible.
```
employees_df[(employees_df['salary'] > 30000) & (employees_df['department'] == 'Marketing')]
```

For all employees with a salary above 30000, who work in the marketing department
You can also use other logical operators such as less than(<), greater than(>), equal to(=), not equal to(!=), etc.
**Query Function**
The query function takes in an expression as an argument which evaluates to a Boolean that is used to filter the dataframe.
```
employees_df.query("department == 'Marketing'")
```

We can also query based on multiple conditions
```
employees_df.query("department == 'Marketing' and date_of_hire > 2006")
```

**Str Accessor**
Pandas make it easy to work with string values. Using the str accessor, we can filter for records whose values are strings.
```
employees_df[employees_df['department'].str.contains("M")]
```

```
employees_df[employees_df['department'].str.startswith("M")]
```

**nlargest and nsmallest**
Most times, we just need records of the highest or lowest values in a column.
These methods make it possible. We could filter for the highest 3 or lowest 3 salaries.
```
employees_df.nlargest(3, 'salary')
```
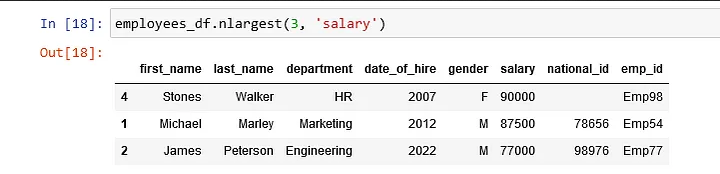
```
employees_df.nsmallest(3, 'salary')
```
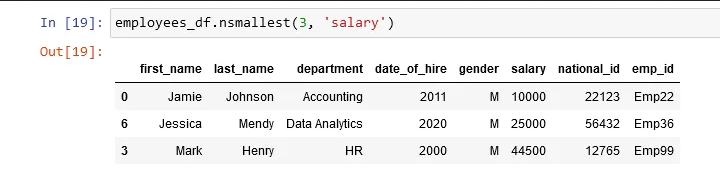
**Tilde sign (~)**
Used to reverse the logic used in filter condition
```
employees_df[~employees_df['department'].str.contains("A")]
```
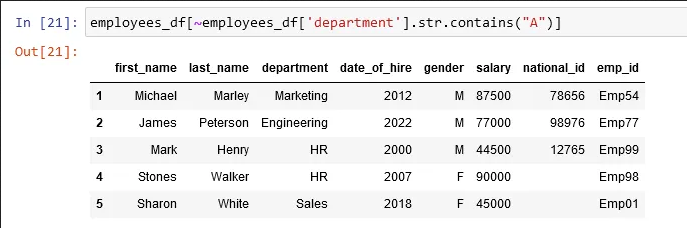
```
employees_df[~employees_df['department'].isin(['Marketing','HR'])]
```
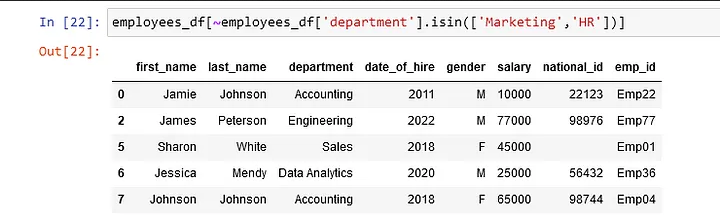
**isnull | notnull**
Using the isnull method, we can return records that have NaN values and mark them for deletion. Using the notnull method, we can filter for records that do not contain NaN values.
```
employees_df[employees_df['national_id'].isnull()]
```
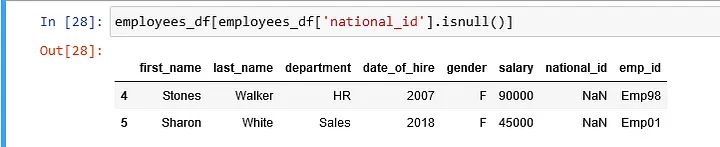
```
employees_df[employees_df['national_id'].notnull()]
```
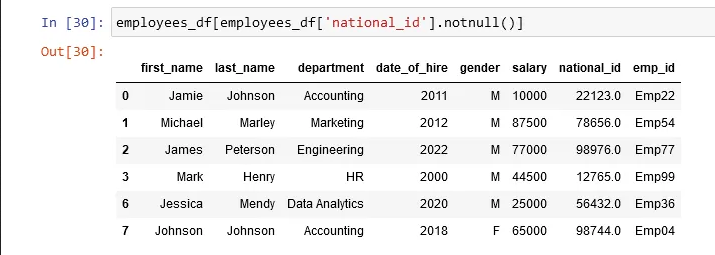
**Filter**
Using this method, we can also filter for a subset of data.
```
employees_df.filter(items=['first_name', 'department'],axis=1)
```
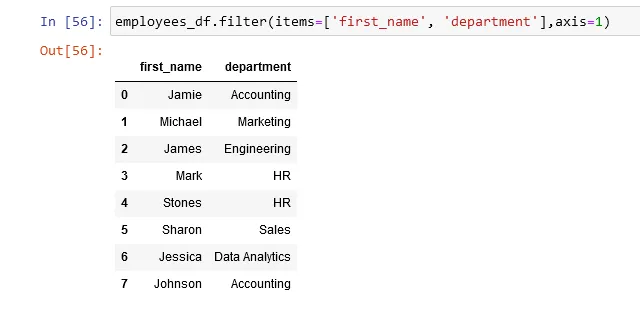
Filter where the index begins with 5 or 8 using regex.
```
employees_df.filter(regex='5|8', axis=0)
```

filter the dataframe where the index is 6
```
employees_df.filter(like='6', axis=0)
```

In this tutorial, we discussed some of the different ways of filtering rows to return a subset of data from our pandas dataframe.
The only way to master pandas and be good at data manipulation is through practice.
I do hope you will make out time to practice.
Connect with me on [Twitter ](https://twitter.com/AviatorIfeanyi)or [LinkedIn ](https://www.linkedin.com/in/aviatorifeanyi/) where I also share some useful data analytics tips | aviatorifeanyi |
1,380,470 | Fortify Your AWS Network Security with AWS Network Firewall: A Complete Guide (Terraform Code included) | I've wanted to write about this since last December, when I participated in a session at AWS... | 0 | 2023-03-06T10:28:05 | https://dev.to/aws-builders/lets-play-with-aws-network-firewall-hands-on-lab-2ha4 | aws, cloud, terraform, devops | > I've wanted to write about this since last December, when I participated in a session at AWS Community Day Sri Lanka 2022, which was organised by AWS User Group Colombo. During the session, I delivered a speech and demonstrated how awesome and simple it is to set up an AWS Network firewall. later on, with Terraform, I was able to codify my demo to infrastructure as code. I hope you all enjoy this step-by-step guided workshop.
# What you will get from this post (Hands on Lab)
- Understand AWS Network Security
- Learn about few of AWS Networking Services
- Step-by-Step guide on how to deploy AWS Network Firewall using terraform
# Prerequisites
- AWS Account
- Terraform (Version is available in the Github repo)
- To use this lab, you need to have a basic understanding of the following services.
- VPC, Route Tables
- Transit Gateway
- VPC Endpoints
But before we dive into the AWS Network Firewall, it's essential that we comprehend a few things.
# Basic AWS Network Security and Limitations
When you have multiple AWS accounts and VPCs, it is difficult to monitor, govern, and enforce security on the network resources.
- A complicated hybrid network configuration in which multiple AWS networking services are linked with on-premises environments and AWS VPN traffic.
- Manage multiple Security Groups and Limited rules supported by Security Groups. As of this writing, only 60 inbound rules for IPv4 and 60 inbound rules for IPv6 traffic are supported.
# Little bit about AWS PrivateLink and VPC Endpoints, VPC Endpoint Services
> Ref : https://docs.aws.amazon.com/vpc/latest/privatelink/concepts.html
AWS PrivateLink is a networking service offered by AWS that allows for secure and private communication between VPCs and AWS services without the need for traffic to pass through the internet or a NAT gateway. It uses VPC endpoints to establish a private connection between your VPC and AWS services via the AWS network, thereby avoiding the public internet.
You can create a private, highly available and scalable connection between your VPC and AWS services or your own application services running on EC2 instances, AWS Lambda functions, or other AWS resources using VPC endpoints and endpoint services.
# Little bit about the Gateway Load Balancer
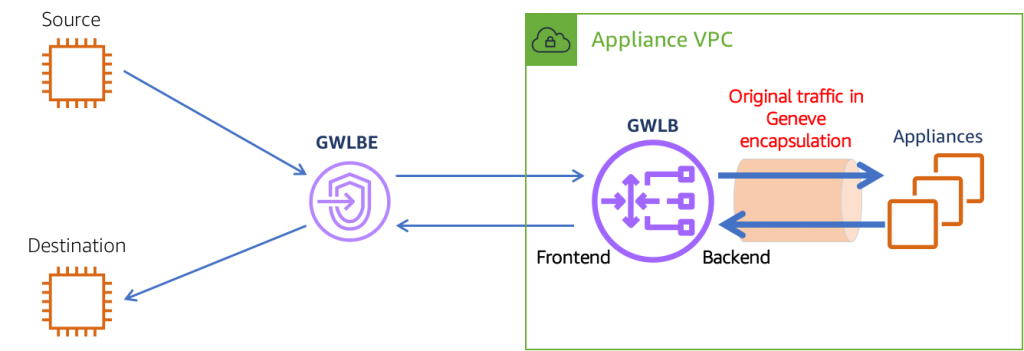
> Ref : https://aws.amazon.com/blogs/networking-and-content-delivery/integrate-your-custom-logic-or-appliance-with-aws-gateway-load-balancer/
Gateway Load Balancers enable the deployment, scalability, and management of virtual appliances such as firewalls, intrusion detection and prevention systems, and deep packet inspection systems. It combines a transparent network gateway (a single entry and exit point for all traffic) and traffic distribution while scaling your virtual appliances with demand.
For an example, if you want to deploy Trendmicro, Fortinet, Palo Alto Networks, or any other vendor's Appliances as your Firewall in your AWS Cloud Infrastructure, Gateway Load Balancer fulfils that requirement.
## You may be wondering why this guy is talking everything but AWS Network Firewall

> **AWS Network Firewall is actually powered by AWS Gateway Load Balancer.**
Yes! Yes, you read that correctly. So, what is the difference between Gateway Load Balancer and AWS Network Firewall? Simply put, if you want to use a third-party firewall solution as an appliance, you can pick Gateway Load Balancer, but you must manage the infrastructure of the firewall instance. However, if you require a Firewall solution that can be deployed fast, is a managed service and is highly available, then AWS Network Firewall is the solution.
# Let's go to AWS Network Firewall now

AWS Network Firewall is a fully managed network security service offered by AWS that enables users to set up, manage, and scale firewall protection across their VPC and on-premises networks.
# AWS Network Firewall Supports
- OSI Layer 3 and 7 Traffic Filtering
- Domain name filtering
- More number of rules
- Inspect traffic between VPCs (Through TGW) or inbound/outbound Internet traffic
- AWS Direct Connect and AWS VPN traffic running through AWS Transit Gateway
- Managed rules from the AWS Marketplace
> As of the time of writing, AWS Network Firewall does not support (DPI) Deep Packet Inspection for encrypted traffic. Gateway Load Balancer is the best solution if you are looking for such a solution. As well as the following:
- VPC peering traffic
- Virtual private gateways
- Inspection of AWS Global Accelerator traffic
- Inspection of AmazonProvidedDNS traffic for Amazon EC2
> I'm not going to deep into detail about AWS Network Firewall offerings because we have these excellent documents instead. [](url)https://aws.amazon.com/network-firewall/faqs/
---
# Architecture of The Lab
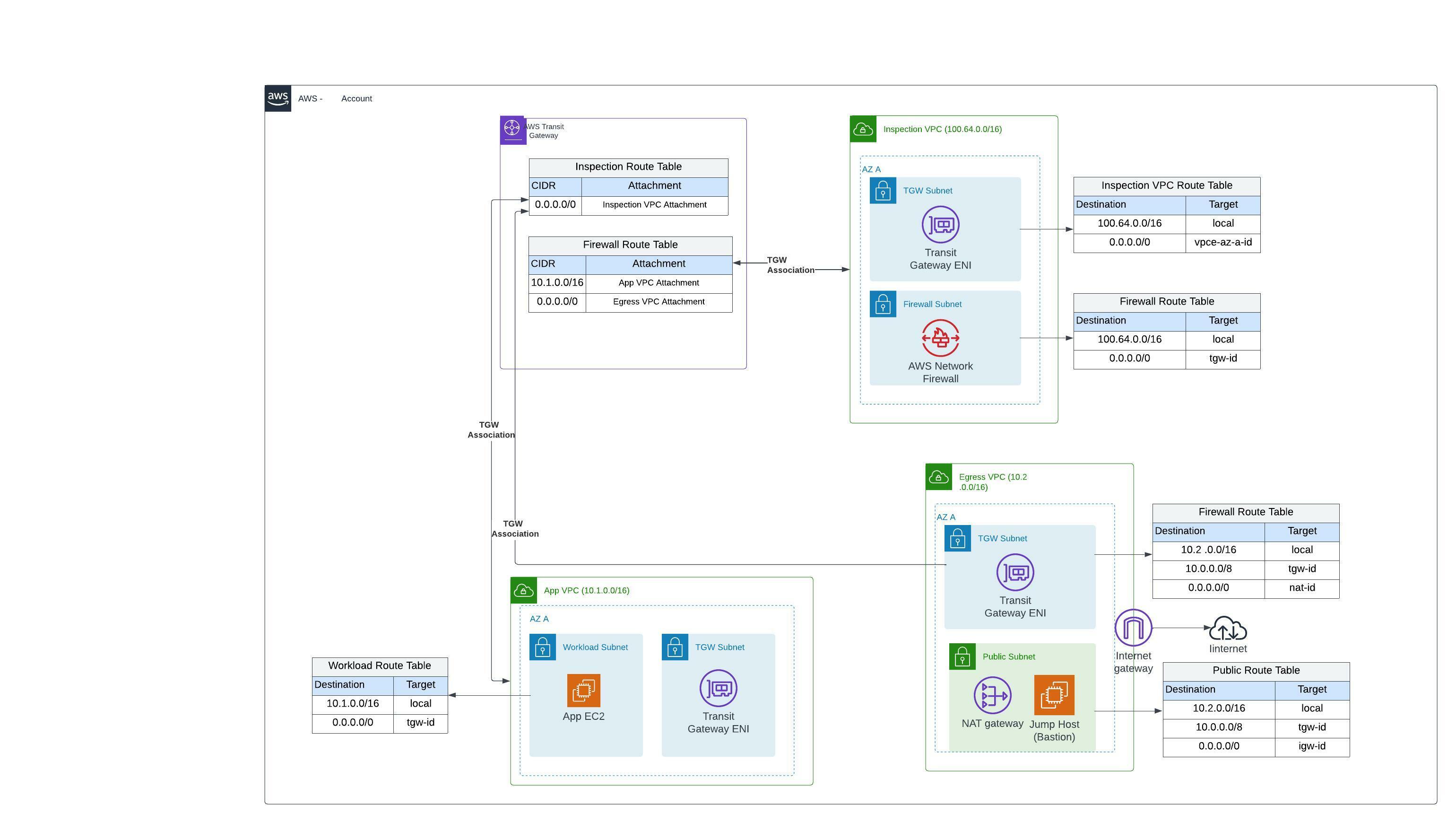
### Clone the project
`git clone https://github.com/devopswithzack/lab-aws-networkfirewall.git`
`cd lab-aws-networkfirewall`
Once cloned, open it in an IDE such as VSCODE. Before we proceed, we must make some changes.
### Generate the keys for EC2 instances
### Then copy the public key and paste in the `env.tfvars`

> This is an optional step. Use only if your backend is an S3 bucket and you want to keep your state in DynamoDB.
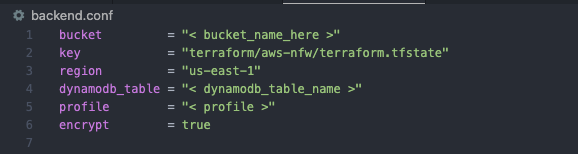
### Run a terraform init
`terraform init`
> My backend is a S3 bucket and I use dynamo db to lock my state. If you use the same, you can use the `backend.conf` file with `terraform init -backend-config=backend.conf`.
### Once all done , run `terraform plan` to verify the resources that you are going to create.
`terraform plan -var-file=env.tfvars`
### Now we can apply using the terraform apply
`terraform apply -var-file=env.tfvars`
Type `yes` and enter to the prompt.
this will take some time to deploy.
I'm going to cover two scenarios in this lab.
1. Bastion host in the Egrees VPC public subnet accessing the App EC2 instance in the App VPC.
2. App EC2 in the APP VPC's private subnet accessing `https://www.google.com`.
---
# Let's test the AWS Network Firewall.
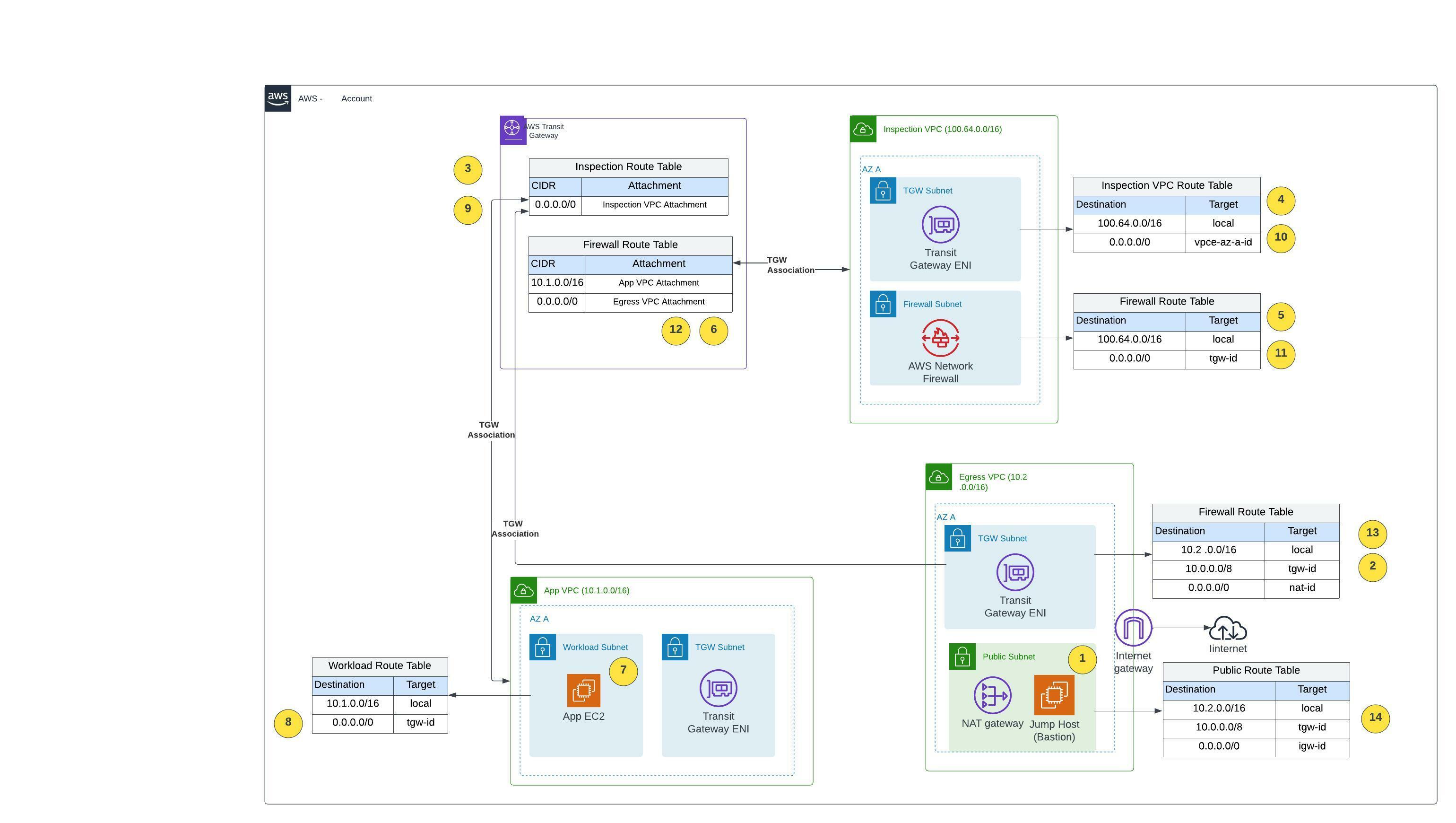
> The numbers listed below correspond to the yellow circled numbers in the architecture diagram.
# Scenario 1
SSH into the JUMP HOST, which is on the Public subnet and has port 22 open to the public.
1- SSH from JUMP HOST to the APP EC2 in the APP VPC's Private Subnet
2 - Routing to `10.0.0.8/8` results in TGW
3 - It should go to Inspection VPC, according to the TGW attachment
4 - Direct traffic to the AWS Network Firewall VPC Endpoint `vpce-az-a-id`
5 - After passing through the firewall, the traffic is routed to the tgw route tables
6 - TGW routes traffic to `10.1.0.0/16` and sends it to App VPC
# Scenario 2
The app server attempts to connect the `https://www.google.com`.
7 - Access to `https://www.google.com`
8 - Any traffic should go to the TGW, according to the Route Tables
9 - According to the TGW attachment, it should go to Inspection VPC
10 - Send traffic directly to the AWS Network Firewall VPC Endpoint `vpce-az-a-id`
11 - Traffic is routed to the tgw route tables after passing through the firewall
12 - Internet traffic is routed to the Egress VPC using the TGW Route Tables
13 - A NAT Gateway traffic route
14 - The Internet Gateway directs traffic to `https://www.google.com`
# Test 1 - Check the SSH Traffic
1. SSH to The Jump Host using the public IP, Both APP EC2 and the JUMP host
2. Now copy the same SSH Private key we created to the Jump host as `sshkey.pem` and set the permission as `chmod 400 sshkey.pem`
3. Get the private IP of the APP EC2 from the console and try to SSH from the JUMP HOST
You may notice that it will take some time and that you will be given a timeout.

In one of the AWS Network Firewall Rule Groups, SSH Access has been blocked.
```terraform
# Block SSH
resource "aws_networkfirewall_rule_group" "block_ssh" {
capacity = 50
name = "block-ssh"
type = "STATEFUL"
rule_group {
rules_source {
stateful_rule {
action = "DROP"
header {
destination = "ANY"
destination_port = "ANY"
direction = "ANY"
protocol = "SSH"
source = "ANY"
source_port = "ANY"
}
rule_option {
keyword = "sid"
settings = ["1"]
}
}
}
}
}
```
Let's now manually remove the rule from the console and try it again.
4. Navigate to the VPC in AWS Console, then select 'Firewalls' from the Network Firewall section
There are two rule groups under Stateful Rule Groups.

5. Disassociate the `block-ssh` from the rule group

> Wait 1-2 Minutes
6. SSH to the APP EC2 from the JUMP HOST. Now you should be able to SSH
7. Do not exit the APP EC2, as we will try the next scenario
# Test 2 - Access `https://www.google.com` from the APP EC2 server
As you are still in the APP EC2 server try to `curl` the `https://www.google.com` You will get a time out eventually

In one of the AWS Network Firewall Rule Groups, Accessing `google.com` is been blocked.
The IP CIDR range from APP VPC is not permitted to access '*.google.com', according to the terraform resource code block below.
```terraform
# Block google.com
resource "aws_networkfirewall_rule_group" "block_google" {
capacity = 100
name = "block-google"
type = "STATEFUL"
rule_group {
rule_variables {
ip_sets {
key = "HOME_NET"
ip_set {
definition = [module.app_vpc.vpc_cidr_block]
}
}
}
rules_source {
rules_source_list {
generated_rules_type = "DENYLIST"
target_types = ["HTTP_HOST", "TLS_SNI"]
targets = [".google.com"]
}
}
}
}
```
### Let's now manually remove the rule from the console and try it again. Follow the same steps in Test scenario one to access the rule groups

> Wait 1-2 Minutes
### Now curl the `https://www.google.com` url from the APP EC2 Server

Now you should be able to access `https://www.google.com`.
---
# CloudWatch Logs
### In the AWS Console, go to CloudWatch and select the logs groups
2. You should be able to see the alert logs, click on them, and examine the logs
## Block SSH
## Block Google.com
---
# Delete the lab
When you're finished testing, make sure to delete the stack to avoid charging.`terraform destroy -var-file=env.tfvars`
---
# Let's wrap this up
You now understand how the AWS Network Firewall works and how to integrate it into your infrastructure. If you want to contribute to this LAB, please open a PR in the repo: [](url)https://github.com/awsfanboy/lab-aws-networkfirewall . I welcome feedback and suggestions, so please leave them in the comments or email them to `hello@awsfanboy.com`.
| awsfanboy |
1,380,607 | Knative eventing - examples | Examples GitHub repo install/ To create knative resources eventing.sh #to... | 21,937 | 2023-03-09T15:37:02 | https://dev.to/ashokan/knative-eventing-examples-4bng | kubernetes, knative, beginners, eventdriven | #### Examples
[GitHub repo](https://github.com/ashok-an/knative-eventing-demoes)
##### `install/`
To create knative resources
```sh
eventing.sh #to create knative eventing resources
kafka-broker.sh #to create kafka resources for knative eventing
kafka-cluster.sh #to create a in-cluster kafka cluster
serving.sh #to create knative serving resources
```
**Alternate** use `kn quickstart kind` to create a cluster with serving and eventing installed
##### `apisource/`
Run `example.sh` to demo apisource that captures and prints kubernetes api server events
##### `broker-trigger/`
Run `example.sh` to demo a broker based routing with triggers to filter and route to different sinks
##### `in-memory-channel/`
Run `example.sh` to demo a simple InMemory channel implementation
##### `pingsource/`
Run `example.sh` to demo a ping-source to be used in cronjob kind of scenario to send predefined events periodically to the event pipeline
##### `simple-sequence/`
Run `example.sh` to demo a sequence of 3 services, passing the result to a final service
---
##### In-progress
- `kafka/` - to implement a demo from `KafkaSource` to `KafkaSink`
- `triggermesh/` - to implement sources and sinks(target) with HTTP servers and cloud-events
| ashokan |
1,380,930 | How To Add Comments To Your Blog With Docker | Having Comments On Your Own Blog Is One Of The Most Engaging Features. Learn How To Integrate Isso... | 0 | 2023-02-27T08:30:35 | https://www.paulsblog.dev/how-to-add-comments-to-your-blog/ | webdev, tutorial, opensource, docker | **Having Comments On Your Own Blog Is One Of The Most Engaging Features. Learn How To Integrate Isso Comments To Have Privacy-Focused Comment Feature In Your Blog.**
[Paul Knulst](https://www.paulsblog.dev/author/paulknulst/) in [Docker](https://www.paulsblog.dev/tag/docker/) • Jul 1, 2022 • 7 min read
* * *
Having comments on your blog is one of the most engaging features! Unfortunately, Ghost Blogging Service does not support any comments out of the box. Although they are many different services like Disqus or Discourse which are kind of "free" (they have inbuilt Ads in the "free" version. And Ads are **EVIL**) there also exist some really free services like [Commento](https://github.com/adtac/commento), [Schnack](https://github.com/schn4ck/schnack), [CoralProject Talk](https://github.com/coralproject/talk), and [Isso](https://github.com/posativ/isso/).
I tested all of the free services for my blog and come to the conclusion that Isso is the best service to use in a Ghost Blog. Within this article, I will describe why Isso is the best software, how it can be installed in a Docker environment, and how Isso comments can be integrated into any Blog (not only Ghost Blogging software).
Why Isso?
---------
Isso is a commenting server written in Python and JavaScript and aims to be a drop-in replacement for Disqus or Discourse.
It has several features:
* It is a very lightweight commenting system
* **Works with Docker Compose**
* Uses SQLite because comments are not Big Data!
* A very minimal commenting system with a simple moderation system
* **Privacy-first commenting system**
* Supports Markdown
* **It's free**
* Similar to native WordPress comments
* You can Import WordPress or Disqus
* Embed it everywhere in a single JS file; 65kB (20kB gzipped)
All of these features are good reasons to choose Isso as your backend comment system instead of one of the others. If you want to install it in a Docker (or Docker Swarm) environment you can follow my personal guide.
Install Isso Comments With Docker
---------------------------------
### Prerequisite
* **Docker (optional Docker Swarm):** To fully follow this tutorial about installing Isso for your blog you need to have a running Docker environment. I will also provide a Docker Swarm file at the end.
* **Traefik**: Traefik is the load balancer that forwards my request to the Docker container. You need to have one installed to access the comments with an URL. If you do not have a running Traefik you will learn [within this tutorial](https://www.paulsblog.dev/how-to-setup-traefik-with-automatic-letsencrypt-certificate-resolver/) how you can set one up.
If you don't want to use Docker and Traefik please follow [the official Installation Guide](https://isso-comments.de/docs/reference/installation/) on the Isso website.
### Set Up Docker Compose File
If you prepared everything you start installing Isso. First, you have to download the latest version of Isso from the GitHub page: [https://github.com/posativ/isso/](https://github.com/posativ/isso/). You can either download the zip file containing the master branch and extract it or clone it:
```bash
git clone git@github.com:posativ/isso.git
```
Then switch into the `isso` folder, delete the docker-compose.yml, create a new docker-compose.yml, and paste the following code snippet into it:
```yaml
version: "3.4"
services:
isso:
build:
context: .
dockerfile: Dockerfile
image: isso
environment:
- GID=1000
- UID=1000
volumes:
- db:/db
networks:
- traefik-public
labels:
- traefik.enable=true
- traefik.docker.network=traefik-public
- traefik.constraint-label=traefik-public
- traefik.http.routers.isso-http.rule=Host(`YOUR_DOMAIN`)
- traefik.http.routers.isso-http.entrypoints=http
- traefik.http.routers.isso-http.middlewares=https-redirect
- traefik.http.routers.isso-https.rule=Host(`YOUR_DOMAIN`)
- traefik.http.routers.isso-https.entrypoints=https
- traefik.http.routers.isso-https.tls=true
- traefik.http.routers.isso-https.tls.certresolver=le
- traefik.http.services.isso.loadbalancer.server.port=8080
healthcheck:
test: wget --no-verbose --tries=1 --spider http://localhost:8080/info || exit 1
interval: 5s # short timeout needed during start phase
retries: 3
start_period: 5s
timeout: 3s
volumes:
db:
networks:
traefik-public:
external: true
```
Within **Line 5 - 8** you can see within this Compose file that the Isso image will be built from the Dockerfile that you downloaded from the official GitHub repository and will be named `isso`.
In **Line 12-13 (and 34-35)**, I defined a volume in which all comments will be saved within an SQLite DB.
The labels section in **Line 16 - 27** contains important information for Traefik. Replace YOUR\_DOMAIN with the domain where the Isso backend should be accessible. This is important for the moderation of comments.
In **Line 28 - 33**, I also added a health check that will check every 5s if the Isso backend is running correctly. To learn more about Docker health checks you should read this tutorial:
[https://www.paulsblog.dev/how-to-successfully-implement-a-healthcheck-in-docker-compose/](https://www.paulsblog.dev/how-to-successfully-implement-a-healthcheck-in-docker-compose/)
### Configuration of Isso Backend
Before you can run your Isso backend you have to adjust the Isso configuration file to your needs.
The following file shows the most important settings that you HAVE to update in order to have a working Isso backend. I will explain them afterward.
```bash
[general]
dbpath = /db/comments.db
host =
https://www.knulst.de
notify = smtp
[admin]
enabled = true
password = yourSuperSafePasswordThatYouNeedInAdminMenu
[moderation]
enabled = true
[server]
listen = http://localhost:8080
public-endpoint = https://isso.knulst.de
[smtp]
username = YOUR_EMAIL_USER
password = YOUR_EMAIL_USERPASS
host = YOUR_EMAIL_HOST
port = 587
security = starttls
to = USER_WHO_SHOULD_RECEIVE_MAIL
from = YOUR_EMAIL_USER
```
**\[general\]:** Set the dbpath, the URL of your blog, and that you want to get Emails if new comments are submitted
**\[admin\]:** Enable administration and set your admin password. This is needed to login into the admin interface.
**\[moderation\]:** Enable moderation of new comments. If set to false every comment will be shown instantly. Not recommended!
**\[server\]:** Set your public endpoint for your Isso backend. Should be equal to the value within the Compose file.
**\[smtp\]:** Set your Email server settings and account data of your Email.
### Run Isso Backend
After adjusting the Compose and `isso.cfg` file to your needs, you can start the Isso backend by executing:
```bash
docker-compose up -d --build
```
After some seconds your Isso backend should be running at the specified domain. You can check it by going to **https://your-chosen-domain.com/info**.
Integrate Isso To Ghost CMS (or any equivalent Blog)
----------------------------------------------------
### Adjust The Source Code Snippet
Now that you have installed your Isso backend you can integrate comments into your blog. To do this, all you have to do is insert the following snippet in your source code. I will explain how it is done in Ghost Blogging software afterward.
```html
<script data-isso="//isso.knulst.de/" src="//isso.knulst.de/js/embed.min.js"></script>
<section id="isso-thread"></section>
```
First of all replace `isso.knulst.de` with the domain, you used with your Isso bac
kend. Furthermore, you should carefully read the source code snippet because there are two important settings:
1. The URL in data-isso starts with two `/`.
2. The URL in src also starts with two `/`.
If you change the URLs to your needs keep the two `/` in front of the Isso backend URL. This is needed because the Isso backend is deployed on a different host than the blog.
### Add Snippet To Your Page
With the adjusted source code snippet you can now add comments to your blog. If you use the Ghost Blogging platform you should first download the design that you are using on your instance and extract it into a folder.
Locate the `post.hbs` file and check where the article ends. The best place for comments will be below the Tag List that is often shown at the end of an article. After you found the closing `</div>` insert the snippet in front of that `</div>`.
Zip your theme, reupload it to your Ghost Blogging Software, and activate it within the Design interface.
_If you use another blogging software you should also be able to edit the `post` html/php/js file and add the snippet where you want to see comments._
Now, switch to any article on your blog and you should see the comments section:
If you set up the Isso backend as I explained in the previous section anyone can now comment on every post and you will be informed by email about a new comment and can instantly activate or delete it within the email:
After getting some cool comments they will be displayed below your post. Because activated the Gravatar feature and set the type to `robohash`, I have cool robot pictures for every user that creates a comment:
Deploy In Docker Swarm
----------------------
To deploy Isso into your Docker Swarm you can use [my Isso Docker Compose file](https://ftp.f1nalboss.de/data/docker-compose.isso.yml) that has the same settings as the plain Compose file. But, this will only work as intended if you set up your Docker Swarm as I describe in this tutorial:
[https://www.paulsblog.dev/docker-swarm-in-a-nutshell/](https://www.paulsblog.dev/docker-swarm-in-a-nutshell/)
Furthermore, you need a Traefik Load Balancer in your Docker Swarm that will be used by the Compose file. I explained how to enhance your Docker Swarm with a Traefik in this tutorial:
[https://www.paulsblog.dev/services-you-want-to-have-in-a-swarm-environment/#traefik](https://www.paulsblog.dev/services-you-want-to-have-in-a-swarm-environment/#traefik)
Closing Notes
-------------
While many writers argue that you do not need a comment system integrated into your blog I completely deny this argument! I personally think that comments are a great way to interact with your users, answer questions and build your community. Also, if users comment on your articles you could use this interaction to improve your content.
If you enjoyed reading this article consider commenting your valuable thoughts in the comments section. I would love to hear your feedback about my tutorial. Furthermore, share this article with fellow bloggers to help them get comments on their blogs.
This article was originally published on my blog at [https://www.paulsblog.dev/how-to-add-comments-to-your-blog-with-docker/](https://www.paulsblog.dev/how-to-add-comments-to-your-blog-with-docker/)
Feel free to connect with me on [my blog](https://www.paulsblog.dev), [Medium](https://medium.knulst.de/), [LinkedIn](https://www.linkedin.com/in/paulknulst/), [Twitter](https://twitter.com/paulknulst), and [GitHub](https://github.com/paulknulst).
* * *
**🙌 Support this content**
If you like this content, please consider [supporting me](https://www.paulsblog.dev/support/). You can share it on social media or [buy me a coffee](https://buymeacoffee.com/paulknulst)! Any support helps!
Furthermore, you can [sign up for my newsletter](https://www.paulsblog.dev/#/portal/signup/free) to show your contribution to my content. See the [contribute page](https://www.paulsblog.dev/contribute/) for all (free or paid) ways to say thank you!
Thanks! 🥰
* * *
Photo by [Volodymyr Hryshchenko](https://unsplash.com/@lunarts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) / [Unsplash](https://unsplash.com/s/photos/discussion?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) | paulknulst |
1,381,068 | A Comprehensive Guide to Docker and Kubernetes: Containerization and Orchestration Made Easy | In this guide, we will discuss the fundamentals of container orchestration with Docker and... | 0 | 2023-02-27T11:32:44 | https://bito.co/a-comprehensive-guide-to-docker-and-kubernetes-containerization-and-orchestration-made-easy/ | In this guide, we will discuss the fundamentals of container orchestration with Docker and Kubernetes. To assist you in getting started, we will go over the most popular commands and give real-world examples.
## Docker
Docker is a platform that allows you to run and manage containers. Containers are isolated environments that contain all the dependencies and configurations required to run an application.
## a. Docker Installation:
To start using Docker, you need to install it on your system. You can download the Docker installation package from the [Docker website](https://docs.docker.com/engine/install/).
## b. Docker Command Line Interface:
The Docker CLI is the main interface that you use to interact with the Docker platform. The most common Docker CLI commands are:
- `docker run:` This command is used to run a new container from a Docker image. For example, to run an Ubuntu image, you can use the following command:
- Command : `docker run ubuntu`
- `docker ps`: This command lists all the running containers on your system.
- `docker images`: This command lists all the Docker images stored on your system.
- `docker stop`: This command stops a running container. For example, to stop a container with the ID 7ab8, you can use the following command:
- Command : `docker stop 7ab8`
- `docker rm`: This command removes a stopped container. For example, to remove the container with the ID 7ab8, you can use the following command:
- Command : `docker rm 7ab8`
- `docker pull`: This command downloads a Docker image from a registry to your system. For example, to download the latest version of the Ubuntu image, you can use the following command:
- Command : `docker pull ubuntu`
## Deploying an Application with Docker
Now that you have a basic understanding of Docker, let’s dive into deploying an application with it.
**Step 1: Choose an Application**
For this guide, we’ll be deploying a simple Node.js web application. You can use any application you like, but make sure it has a Dockerfile to build the image.
**Step 2: Write a Dockerfile**
A Dockerfile is a script that contains all the instructions to build a Docker image. It’s used to specify the base image, application dependencies, and how the application should run in a container.
Here’s an example of a Dockerfile for a Node.js application:
- Use the official Node.js image as the base image
`FROM node:16`
- Set the working directory in the container to /app
`WORKDIR src/app`
- Copy the package.json and package-lock.json files to the container
`COPY package*.json ./`
- Install the application dependencies
`RUN npm install`
- Copy the rest of the application files to the container
`COPY . .`
- Specify the command to run the application
`CMD ["node", "server.js"]`
**Step 3: Build the Docker Image**
Once you’ve written your Dockerfile, you can build the Docker image using the following command:
Command : `docker build -t my-node-app`.
The `-t` option is used to specify the name and tag of the image. The . at the end of the command specifies the location of the Dockerfile.
**Step 4: Run the Docker Container**
Once the image is built, you can run it as a container using the following command:
Command : `docker run -p 3000:3000 my-node-app`
The `-p` option is used to map the host’s port 3000 to the container’s port 3000. This will allow you to access the application from your host machine.
**Step 5: Access the Application**
You should now be able to access the application by opening a web browser and navigating to [(http://localhost:3000)](http://localhost:3000/).
## Kubernetes
Kubernetes is a platform for automating the deployment, scaling, and management of containerized applications. It provides a declarative approach to defining and managing the desired state of your applications and their dependencies.
**a. Kubernetes Installation:**
To start using Kubernetes, you need to install a cluster. You can install a cluster on your local machine using Minikube or on a cloud provider such as Google Cloud, Amazon Web Services (AWS), or Microsoft Azure.
**b. Kubernetes Command Line Interface:**
The Kubernetes CLI is the main interface that you use to interact with a Kubernetes cluster. The most common Kubernetes CLI commands are:
- `kubectl run`: This command is used to create a new deployment in a Kubernetes cluster. For example, to create a deployment named nginx that runs the Nginx image, you can use the following command:
- Command : `kubectl run nginx --image=nginx`
- `kubectl get`: This command is used to retrieve information about the resources in a Kubernetes cluster. For example, to retrieve information about all deployments, you can use the following command:
- Command : `kubectl get deployments`
- `kubectl delete`: This command is used to delete a resource in a Kubernetes cluster.
## Deploying an Application with Kubernetes
Now that you’ve seen how to deploy an application with Docker, let’s look at how to deploy it with Kubernetes.
**Step 1: Choose a Cluster**
You can either use a cloud-based Kubernetes service like Google Kubernetes Engine (GKE) or a self-hosted solution like Minikube. For this guide, we’ll be using Minikube.
**Step 2: Start the Cluster**
To start a Minikube cluster, run the following command:
Command : `minikube start`
**Step 3: Create a Kubernetes Deployment**
A Kubernetes deployment is used to manage the running instances of your application. You can create a deployment using a YAML file.
Here is an example of a deployment manifest for a simple web application:
`apiVersion: apps/v1`
`kind: Deployment`
`metadata:`
`name: my-web-app`
`spec:`
`replicas: 3`
`selector:`
`matchLabels:`
`app : my-web-app`
`template:`
`metadata:`
`labels:`
`app: my-web-app`
`spec:`
`containers:`
`- namex: my-web-app`
`image: my-web-app:1.0`
`ports:`
`- containerPort: 80`
This deployment manifest specifies that we want to run 3 replicas of our web application, with the label “app: my-web-app”. The template section specifies the container image we want to use for our web application, and the port that should be exposed.
To create the deployment, you can use the following command:
Command : `kubectl apply -f deployment.yaml`
This command will create the deployment in the Kubernetes cluster and start the specified number of replicas. You can check the status of the deployment using the following command:
Command : `kubectl get deployments`
This command will show you the status of all deployments in the cluster, including the number of replicas that are running and the status of each replica.
**Step 4: Exposing Applications with Services**
Once your deployment is running, you will need to expose it to the outside world so that users can access it. This is done using a Kubernetes service. A service is a higher-level object in Kubernetes that provides a stable IP address and DNS name for your application. It also provides load balancing and proxying capabilities to help distribute traffic to your replicas.
**Here is an example of a service manifest for our web application:**
`apiVersion: v1`
`kind: Service`
`metadata:`
`name: my-web-app`
`spec:`
`selector:`
`app: my-web-app`
`ports:`
`- name: http:`
`port: 80`
`targetPort: 80`
`type: ClusterIP`
This service manifest specifies that we want to expose our web application on port 80, with a stable IP address and DNS name. The selector section specifies that the service should route traffic to pods with the label “app: my-web-app”, which matches the label on our deployment.
To create the service, you can use the following command:
Command : `kubectl apply -f service.yaml`
This command will create the service in the Kubernetes cluster and expose your application to the outside world. You can check the status of the service using the following command:
Command : `kubectl get services`
This command will show you the status of all services in the cluster, including the IP address and port of each service.
**Step 5: Scaling Applications with Deployments**
One of the key benefits of using Kubernetes for container orchestration is its ability to easily scale applications. Scaling refers to the process of increasing or decreasing the number of replicas of a deployment to handle changing workloads. In Kubernetes, this can be achieved using the kubectl scale command.
To scale a deployment, you need to specify the deployment name and the number of replicas you want to have. For example, to scale a deployment named “nginx-deployment” to 5 replicas, the command would be:
Command : `kubectl scale deployment nginx-deployment --replicas=5`
You can also check the current replicas of a deployment using the following command:
Command : `kubectl get deployment nginx-deployment`
In this command, the output will include information about the deployment, such as the name, desired replicas, and current replicas.
It’s important to note that scaling a deployment does not automatically update the resources required by the containers. To update the resources, you will need to update the deployment’s specification and apply the changes.
In conclusion, scaling is an important aspect of container orchestration, and Kubernetes provides an easy way to scale applications with the kubectl scale command. By using this command, you can handle changing workloads and ensure your applications are running optimally. | ananddas | |
1,381,119 | Data Validation Nuget Package | Objective This is a cross platform NET Standard 2.0 validation library containing a bunch... | 0 | 2023-02-27T11:49:58 | https://dev.to/aminaelsheikh/data-validation-nuget-package-kco | dotnet, nuget, csharp, nugetpackage | #Objective
This is a cross platform NET Standard 2.0 validation library containing a bunch of validation code that we have to rewrite every time we develop apps. Due to the time we have to spend every day in validating data. This library was developed to help in saving our development time.
#About
This library is one of DEFC utilities packages that contains several types of data validation methods, to help the developers minify their codes in easy way with no time. Through this package can :
* Check if a value is (Alphanumeric, Alpha, GUID, Base64, NullOrEmptyOrWhiteSpace, Email,URL,DateTime, Number, Byte, Short, Integer, Long, Decimal, Double, Float, IPv4, IPv6, IP, MACAddress, LatitudeLongitude )
* Check if a value is between tow values, check if a value is between tow values or equal one of them, check if a value is equal to another value, check if value is greater than or equal another value and check if value is less than or equal another value.
* Match password and confirm password.
* Check if password is strong with at least one uppercase, one lowercase, one digit and one of the custom symbols with specific password length by sets the password rules.
this library is available on nuget.
```C#
Install-Package DEFC.Util.DataValidation -Version 1.0.0
```
#Example
Console application with full example available at [the GitHub repository](https://github.com/AminaElsheikh/DEFC.Util.DataValidationExamples).
```C#
using DEFC.Util.DataValidation;
using System.Text.RegularExpressions;
```
```C#
public static void Validator()
{
//Sample of data type validator
bool IsValidAlphanumeric= DataType.IsAlphanumeric("Foo1234");
bool IsValidGUID = DataType.IsGUID("am I a GUID");
bool IsValidIPv4 = DataType.IsIPv4("127.0.0.1");
bool IsValidURL = DataType.IsURL("https://www.nuget.org");
//Sample of math validator
bool IsValidNegative = Math.IsNegative(-1);
bool IsValidEven = Math.IsEven(9);
//Sample of comparison validator
bool IsBetween = Comparison.IsBetween(4,2,10);
bool IsLessThanOrEqual = Comparison.IsLessThanOrEqual(12,3);
//Sample of SQL Injection validator
bool HasSQLInjection = SQLInjection.IsExists("' or 1=1");
//Sample of Regular Expression validator
bool IsValidExpression = RegularExpression.IsMatch("Foo1234",new Regex("[a-zA-Z0-9]*$"));
//Sample of Password validator
bool Isvalid = Password.ValidatRules(new PasswordRules()
{
Password="Foo@123",
HasUpper=true,
HasLower=true,
HasDigit=true,
HasLength=true,
passwordMinLength=6,
HasSymbols=true,
symbols="@,&"
});
}
| aminaelsheikh |
1,381,130 | Internationalization Using React / NextJS 13 and ChatGPT | Translating content into other languages used to be a very tedious task and required teams of... | 0 | 2023-02-27T12:07:22 | https://blog.designly.biz/internationalization-using-react-nextjs-13-and-chatgpt | react, nextjs, chatgpt, internationalization | Translating content into other languages used to be a very tedious task and required teams of translators and developers. And forget about maintaining or changing the content later. Thankfully, with the development of very smart AI engines, such as Google Translate and ChatGPT, this process can be automated quite easily.
In this tutorial, I'm going to show you how to utilize OpenAI's `text-davinci` API, more commonly known as ChatGPT, in conjunction with NextJS's fabulous automatic locale detection and Static Site Generation (SSG), to automate translation of your website content at built-time. Generating this content at built-time as opposed to run-time dramatically reduces API usage costs while speeding up content delivery.
You'll need an Open AI account and API key in order to utilize this solution. You can create an account and get a key for free, but the API response speed will be very slow and you will be limited to so many tokens per request, day, month, etc. This shouldn't be a problem, though, unless your site is very large with many paragraphs. A large site could take a very long time to build. For more information on creating an OpenAI account, see [this article](https://designly.biz/blog/post/create-a-telephone-ivr-using-chatgpt-nextjs-and-twilio).
The example app included in this article was generated using `create-next-app@latest`. It uses the following libraries:
| Package Name | Description |
| --------------- | ----------- |
| openai | Node.js library for the OpenAI API |
| cookies-next | Getting, setting and removing cookies on both client and server with next.js |
| tailwindcss | A utility-first CSS framework for rapidly building custom user interfaces. |
| postcss | Tool for transforming styles with JS plugins |
| autoprefixer | Parse CSS and add vendor prefixes to CSS rules using values from the Can I Use website |
If you like, you can simply clone the repo, which can be found [here](https://github.com/designly1/nextjs13-translate-example). Also, if you like, you can check out the [demo page](https://nextjs13-translate-example.vercel.app/).
For the purposes of brevity, I will not take you through the process of setting up tailwindcss or creating a NextJS app. For more information about setting up tailwind, see [this article](https://designly.biz/blog/post/creating-a-modern-hero-image-using-nextjs-13-images-and-tailwind-css).
Now, onward to the code!
The first thing we'll do is create a config file for the locales we want to support:
```js
// localeNames.js
const localeNames = [
{
name: 'English (United States)',
value: 'en-US'
},
{
name: 'English (United Kingdom)',
value: 'en-UK'
},
{
name: "Chinese (Simplified, People's Republic of China)",
value: 'zh-CN'
},
{
name: 'French',
value: 'fr'
}
]
export default localeNames;
```
In this example, I've included only four languages, but you can include as many as you like. Note that NextJS uses the ISO 639 format for locales, which is `[language-code]-[COUNTRY-CODE]`. For a list of these codes, check out [this page](https://www.alchemysoftware.com/livedocs/ezscript/Topics/Catalyst/Language.htm). Also note that the country/region code is optional. As you can see, I did not include a region code for French, but I could have specified `fr-BL` for Belgium or `fr-CA` for Canada. Include as few or as many as you wish!
Next, we need to modify `next.config.js` to enable NextJS's automatic locale detection:
```js
// next.config.js
/** @type {import('next').NextConfig} */
const nextConfig = {
reactStrictMode: true,
i18n: {
locales: ['en-US', 'en-UK', 'zh-CN', 'fr'],
defaultLocale: 'en-US'
}
}
module.exports = nextConfig
```
Note that there is no simple way to include our `localeNames.js` in our `next.config.js` file. I tried many different options and they all failed, so replicating the data, unfortunately is the only option. If anyone has a solution, please leave a comment!
Ok, next we'll create a utility function called `fetchPage()` to fetch the content for our page based on a slug. Your data could come from a headless CMS like WordPress or Contentful, or even a database, but in this example, I'm simply using a JS file:
```js
// fetchPage.js
import { Configuration, OpenAIApi } from "openai";
import homePage from "@/data/homePage";
const pages = {
'home-page': homePage
}
const defaultLocale = 'en-US';
export default async function fetchPage(slug, locale) {
if (locale === defaultLocale) return pages[slug];
const configuration = new Configuration({
apiKey: process.env.NEXT_PUBLIC_OPENAI_KEY,
});
const openai = new OpenAIApi(configuration);
const translated = {};
for (const k in pages[slug]) {
const page = pages[slug];
const string = "Translate the following to " + locale + ': ' + page[k];
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: string,
max_tokens: 2048
});
const res = completion?.data?.choices[0]?.text;
translated[k] = res;
}
return translated;
}
```
This function imports our page content, which is simple a JS object, then iterates over each key, making a completion request to ChatGPT. The hard limit is 2048 tokens for a free account so the page must be broken down into title, headings, paragraphs, etc., and then an API request made for each. This may, unfortunately, effect the way ChatGPT translates the document as the paragraphs are taken out of context. If anyone knows of a way to create a session on the API, where it can remember the previous completions (like how the ChatGPT web app works), please leave a comment!
And, last but not least, our home page component:
```js
// index.js
import React, { useRef } from 'react'
import Head from 'next/head'
import { setCookie } from 'cookies-next';
import { useRouter } from 'next/router';
import localeNames from '@/data/localeNames';
import fetchPage from '@/lib/fetchPage';
export default function Home({ page }) {
const router = useRouter();
const handleLocaleChange = (event) => {
const locale = event.target.value;
setCookie('NEXT_LOCALE', locale, { path: '/' });
const { pathname, asPath, query } = router;
router.push({ pathname, query }, asPath, { locale });
}
const Paragraphs = () => {
const pars = [];
for (const k in page) {
if (k.match(/^par/)) {
pars.push(<p className="text-lg mb-6 text-justify">{page[k]}</p>)
}
}
return pars;
}
return (
<>
<Head>
<title>{page.title}</title>
<meta name="description" content="Generated by create next app" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<link rel="icon" href="/favicon.ico" />
</Head>
<div className="bg-slate-900 h-screen flex flex-col text-white">
<div className="w-full md:w-[1200px] bg-slate-800 mx-auto md:px-10 md:py-10">
<h1 className="font-bold text-2xl mb-6">{page.title}</h1>
<div className="p-4 border-2 border-gray-400 rounded-md relative flex w-full mb-6">
<select
className="focus:outline-none w-full bg-transparent text-blue-200 [&>*]:bg-slate-700"
name="locale"
placeholder="Select Language"
onChange={handleLocaleChange}
>
<option disabled="">** Select Language **</option>
{
localeNames.map((l) => (
<option key={l.value} value={l.value}>{l.name}</option>
))
}
</select>
</div>
<Paragraphs />
</div>
</div>
</>
)
}
export async function getStaticProps(props) {
const { locale, locales, defaultLocale } = props;
const page = await fetchPage('home-page', locale);
return {
props: {
locale,
locales,
defaultLocale,
page
},
revalidate: 10
}
}
```
Some key things to note in this code:
1. Our `handleLocaleChange()` function uses next/router to change the selected locale. Notice that the path in the address bar is automatically updated. NextJS does all this for you automagically! Also, NextJS uses a special cookie called 'NEXT_LOCALE' to override the `Accept-Language` header sent by the user agent. So next time you navigate to "/" it should automatically redirect you to the locale stored in the cookie.
2. The `getStaticProps()` function runs on the server at build-time. NextJS is smart enough to create JSON files for each possible locale and the content comes from these static JSON files rather than the ChatGPT API at run-time. The `revalidate` key is for NextJS's incremental SSG feature, which is useless here because our content comes from a static file included in the source, but this is useful if you're using an external CMS, which will further reduce paid API usage by only updating pages that have changed automatically, when they change.
That's it! I hope you found this article useful, or at the very least, mildly entertaining. I keep finding more and more uses for ChatGPT every day. OpenAI is certainly on track to become a monster, Google-sized company in the years to come (might want to invest).
I'm very interested in your feedback about this article, its proposed solution, and ways to improve it. Please leave your comments!
Further reading:
[NextJS: Internationalized Routing](https://nextjs.org/docs/advanced-features/i18n-routing)
For more great articles, please read the [Designly Blog](https://designly.biz/blog). | designly |
1,381,258 | Effective Frontend Test Strategy and some notes about Cypress | As a developer, I frequently find myself working on projects that lack a dedicated testing team or... | 0 | 2023-02-27T17:38:46 | https://dev.to/whatever/effective-frontend-test-strategy-and-some-notes-about-cypress-32p8 | testing, cypress, automation, strategy | ---
title: Effective Frontend Test Strategy and some notes about Cypress
published: true
description:
tags: #testing #cypress #automation #strategy
# cover_image: 
# Use a ratio of 100:42 for best results.
# published_at: 2023-02-12 12:42 +0000
---

As a developer, I frequently find myself working on projects that lack a dedicated testing team or resources. As someone who has spent a noticeable amount of time performing manual testing, fixing frontend unit tests, and writing end-to-end Cypress tests to ensure the highest code quality possible under high business pressure, I have developed some strong opinions about organizing testing strategies in such circumstances.
## Time for testing
From my experience, usually there is no time specifically reserved for tech debt or automated testing. Generally, every day the business is like:

There is some time, though, during which developers have to do regression before they show the code to the client/product manager. However, this process can be time-consuming and overwhelming, taking up several hours or even an entire day!
I'll be talking about the case when you are often asked to do manual regression and you don't have much time to make your life easier, only little time slots here and there *(e.g. when the board is not so busy, you've made some PR's and have something to do while you wait for other devs to review them)*.
## Test pyramid
Let's talk about tests for React or Angular. To spend less time developing them you will want to have more **presentation (dumb)** components and less **smart** components.
If you have a lot of complicated web forms it makes sense to use [Storybook](https://storybook.js.org) and write a storybook test for each such form realised as a **dumb** component.
When you have written a bunch of tests for **smart** React/Angular components, you might find out that it's hard to maintain them, because each test has a lot of dependencies and json mocks that you have to update quite often. Given that bringing a test back to life might take 2-3 hours *(and I haven't even included in this estimation time for other devs to code review it)* my recommendation is to save efforts and skip tests for most of the features. Think of the **most critical parts** that your app has instead. E.g. if you do payment operations through your app it makes sense to write as much tests as you can to make sure that money goes where it's supposed to! In other words, before you create a test for a **smart** component/service/module think: *"is it worth supporting such test? How often it's used by other modules? How critical is the feature?"*
Some developers might argue that you can make make your code more testable: e.g. extract some pure functions into separate modules that can be easily tested by using simple Jest unit tests. The thing is, when you join a large legacy project, in most cases the team won't be willing to do any radical change to existing code unless you really sell the idea that you can make everybody's life better by refactoring this piece of code and you can do it quickly enough.
I've found that writing **end-to-end (e2e) "happy scenario"** tests for the most critical scenarios is the most effective solution. E.g. you can write tests for cases when user successfully
- logs in,
- signs up,
- restores password.
My preferred tool for e2e testing is **Cypress**.
**UPD.** Recently I've tried *"@testing-library/react"*+*"@testing-library/user-event"* and it turned out not so bad! Don't have resources to write about it now, but hopefully will make another post about React unit tests in the nearest future. TLDR is I would replace some bits of Cypress with unit tests with these libraries.
## Cypress
Cypress has well maintained documentation, they even have a section about [best practices](https://docs.cypress.io/guides/references/best-practices) which I highly recommend to read. I would just like to mention several things.
**Selecting elements for test**
You can use *data-qa* attributes in your HTML and select elements in test like this:
```
cy.get('[qa="company-name"]').type('test-company');
```
**Long tests issues**
Cypress doesn't like tests that take too much time to run. If a test takes too much time, Cypress can throw one of the following errors (there are GitHub issues about that - [first](https://github.com/cypress-io/cypress/issues/6458), [second](https://github.com/cypress-io/cypress/issues/5480)). I've mentioned some ways to deal with it in this [post](https://dev.to/whatever/the-why-and-how-to-reset-the-database-after-each-test-run-cypress-mongo-5011-react-example-8km).
**Wait**
There is only one situation I can imagine where you might want to write something like
```
wait(100);
```
You are probably in a hurry and you plan to run Cypress tests only locally. Such tests will be very flaky if you run them as a part of CI/CD pipeline!
Waiting for a HTTP request to finish is covered well enough in the docs. Let's look at a couple of other useful approaches that I've also been using.
First of all, you can ask Cypress to wait until some thing is visible:
```
cy.get('[data-qa="sign-out-btn"]').should("be.visible");
```
Second of all, you can use constructions like this (in tests or cypress commands):
```
cy.request({ ... }).then((response) => {...});
cy.then(()=> { cy.request({ ... }).then((response) => {...});
```
**Localstorage and setting env variables**
```
cy.request({...}).then((response) => {
window.localStorage.setItem('token', response.body.token);
Cypress.env('userId', response.body.data.id);
});
```
**How to reset database after tests**
If you have mongo, I have written a [post about it](https://dev.to/whatever/the-why-and-how-to-reset-the-database-after-each-test-run-cypress-mongo-5011-react-example-8km).
If you have [mysql](https://blog.knoldus.com/how-to-do-database-integration-with-cypress/) - this might help. I haven't tried it, so not a legal advice! :) | whatever |
1,382,110 | I was a disappointment the first time so I decided to retake the class | Something something time flies when you're having fun something something. About a year and a half... | 0 | 2023-02-28T05:26:33 | https://dev.to/lizblake/i-was-a-disappointment-the-first-time-so-i-decided-to-retake-the-class-g9d | webdev, beginners, webcomponents | Something something time flies when you're having fun something something.
About a year and a half ago I took a course at Penn State called IST 402. I did horribly. Not going to lie, I think I was confused half the time, unmotivated for 10%, and just preoccupied with other stuff for the other 40%. So I retook the course with a new number and better structure and more generalized focuses. My understanding as a whole for web dev is like "wowwwww, this is not as complicated as I thought". But still requires more effort than any other class I've taken at the diploma printing factory.
### Platforms
And then we talked about platforms. For that particular week, I was 50% overwhelmed with other activities, 40% confused, and 10% sleep deprived. To be fair, I was shown a web component before anything else. I had also taken an art course on HTML and CSS at this point. Which as little effort as I put into it, I had become much better at it. But platforms were so confusing. After spending the past couple weeks on creating a card in Codepen, I think I had somewhat of an understanding of how JS, CSS, and HTML were all connected. When it came time to transfer it to a platform, I honestly had no idea where I was to copy over my code or how I was supposed to write methods. For reference, we were to work with Vue, React, and Angular. As a programmer, which I really am not a good one, it was not easy for me to transfer over the concepts without having to spend hours reading how each platform was formatted or looking at what my classmates did. And when I saw the examples, something didn't feel right. They seemed cloudy and inefficient compared to web component model I was use to looking at. Perhaps I would say something different if I was shown a money-driven platform first.
### Teaching Web Components
Compared to the previous class I took on VanillaJS and web components, this one is different because of the amount of activity and interactivity that is done in class rather than being assigned large projects that are due several weeks out. That, and the people are not burnout seniors who have no interesting in learning something that they will not be using at the job that they already have. Now I am the burnout senior who wishes that they had more time because really, this stuff is fun and interesting if you have the time to put into it. Simply put, web components and VanillaJS need to be taught earlier in career. I wouldn't necessarily say that there is more handholding done in a sense, but there are more resources and quality videos than there was a year and a half ago. The more resources and solid understanding a person has of how everything works, more likely people are to transfer over to it.
### Tooling
When it comes to tooling, if you have an error with a build, it can be so god awful to fix. But in the end, it does make life easier. It also makes it a lot easier for open source access and deployment. As documentation and usage improves, it will become easier to implement. It's neither easy or difficult, it really depends on what needs to be implemented and whether or not you understand where everything goes and interacts.
### Additional Readings
Finally when working through a problem or developing something read the documentation. Read Stackoverflow. Cry a little. The ModzillaDocs help. And if you're super lucky, you have a good friend that makes you an hour long video telling you how to do something, so you better watch that. And read examples on GitHub. See what other people created.
As always, music recommendation :).
{% embed https://open.spotify.com/track/23oxJmDc1V9uLUSmN2LIvx?si=bac0260af4ee4d9d %}
| lizblake |
1,382,122 | .NET MAUI the challenge of cross-platform solution (MAUIsland story) | Working with MAUI you have to understand the benefits and limitations well to get the most out of... | 0 | 2023-02-28T05:47:28 | https://dev.to/strypperjason/net-maui-the-challenge-of-cross-platform-solution-mauisland-story-486j | csharp, dotnet, maui, windows | Working with MAUI you have to understand the benefits and limitations well to get the most out of this technology. I have spent more than 2 months developing an open-source project to help the user get to know this technology as fast as possible and more importantly see if this is the right tool for their next UI solution.
[MAUIsland](https://github.com/Strypper/mauisland)
This project makes me realize a lot of things that MAUI is missing and also change my vision completely if I ever want to use one code base for all platforms.
One code base all platforms in `theory` you will get the following benefits:
1. Cut down costs
2. Cut down planning
3. Cut down developments
4. Cut down maintenance
After trying out MAUI:
1. Cut down costs: I think what I can cut is just one of Android or IOS developer, it is so hard to cut WinUI and Mac Catalyst since the tech support isn't there yet
2. Planning: yes
3. Developments: I do cut down R&D for basic stuff but the technology adds up more development in different sections and if the client's requirements too strict developments usually cost more than you expected
4. Maintenance: No, not a lot of Xamarin or MAUI developers at the moment, and migration like every technology it's a painful process.
Pros:
1. Easy to get started for .NET developer - When you are an ASP.NET developer you will feel at home when moving to this technology, you have the `ServicesCollection`, `Dependency Injection`, and all the latest C# features, and to me this is a Christmas gift 🎁, I won't need to invest more time in research how basic things work
2. Performance - Really good, I have tested my project on low-end smartphone and the technology have no problem performing 60fps for everything, some of the lag that people encounter even on high-end smartphone I highly encourage you to read this blog [Improve CollectionView Performance](https://www.sharpnado.com/xamarin-forms-maui-collectionview-performance-the-10-golden-rule/)
3. Support - the project is very focused and actively supported by Microsoft so some of the missing puzzles are eventually supported in the future.
Cons:
1. Bugs - there are thousands of issues currently appear on their repository
2. Desktop support is still early - most of the desktop basic requirements are still missing
3. Really hard to remain consistent on all platforms because how MAUI relies on native controls not the middle UI layer like Flutter.
4. Community is still small, not many active speakers or writers
Conclusions: If you expect to create a mind-blown desktop and mobile with heavy UI animations and styles I think you won't archive that with this technology easily. Their x:OnIdiom is not accurate and we have to come up with our own solution for detecting what screen is the application currently running on, we also don't have an efficient way to swap UI, currently my best hope would be to the Toolkit StateContainer but have it's limited, It breaks when the state change too fast (The toolkit team already address this and fix is currently on the way delivery to the public), can't span all available space because it using the stacklayout and collectionview scrolling is frozen in it. If you only expect Android and IOS then technology can be more suitable since fewer platforms you have to maintain and consider, I should encourage everyone do not criticize the team, instead we should help them (Report issues) so eventually we might get a better product. | strypperjason |
1,382,124 | Diagrams as Code | Have you ever started working on a new project, started going through the documentation and you... | 0 | 2023-02-28T07:02:17 | https://www.harshitkumar.co.in/blog/diagrams-as-code | uml, diagrams, documentation | Have you ever started working on a new project, started going through the documentation and you realize that the architecture diagrams or sequence diagrams are out of date.

I've certainly seen this situation arise numerous times in my career so far. So what do you do? One solution would be whoever's reading the document needs to do the work to figure out the updated architecture or flows and generate the new diagrams using UML tools. This isn't ideal and these are bound to get stale again in the future.
Another solution which I prefer is - maintaining diagrams as code which live in the same repos as the code. There are many tools these days which help us author diagrams from code.
My favorites are [Mermaid](https://github.com/mermaid-js/mermaid) and [PlantUML](https://plantuml.com/).
Now your code can live in the repo and evolve along with the codebase. You might need to do additional setup if you'd like the diagrams to be generated as part of your CI/CD.
I like to maintain these in a `/docs` folder within the project repo.
An example of how the code would look like in mermaid and it's output are below:
Code:
```mermaid
flowchart TD
A[Christmas] -->|Get money| B(Go shopping)
B --> C{Let me think}
C -->|One| D[Laptop]
C -->|Two| E[iPhone]
C -->|Three| F[fa:fa-car Car]
```
Output:

Bonus: Mermaid.js has built in support in GitHub for markdown files. You won't need to do anything special to generate diagrams here.
That's it, what's your take on these? Do you know any tools which offer better options or more customization? Leave a comment :smile: ! | harshitkumar31 |
1,382,269 | How to build a Flutter app for IOS? | There are over 1,6 billion apps available on the App Store, and this number constantly grows. Driven... | 0 | 2023-02-28T09:19:50 | https://dev.to/christinek989/how-to-build-a-flutter-app-for-ios-3a61 | flutter, ios, mobile | There are over 1,6 billion apps available on the App Store, and this number constantly grows. Driven by the popularity of iOS mobile devices, more and more businesses invest in developing apps for iOS. As for the technical side of building an app for iOS, it should be started with the software kit and the steps of building and releasing an app.
We will go through the preliminary steps you need to follow before building your app, and then dive into the technical details of each step. By the end of this article, you will have a clear understanding of how to build a Flutter app for iOS and how to release it on the App Store.
### What is Flutter?
Flutter is Google’s open-source mobile app development framework. It enables developers to build high-performance, visually appealing apps for both Android and [iOS platforms](https://addevice.medium.com/top-7-programming-languages-for-ios-app-development-ae18a36c4ffd) from a single codebase. Flutter uses a reactive programming model, making it easy to create complex and interactive UIs with minimal coding.
The framework includes a rich set of pre-built widgets and tools, allowing the development of highly customizable and platform-specific features. With its hot reload feature, developers can instantly see the changes made to their code, which greatly speeds up the development process. Overall, Flutter is a versatile and powerful tool for building mobile apps for iOS that is rapidly gaining popularity among developers.
### Preliminaries
Before building a Flutter app for iOS, there are a few preliminary steps that you need to follow.
### Register your app on App Store Connect
To release your app on the App Store, you need to register your app on App Store Connect. This is a platform where you can manage your app's distribution and sales on the App Store. To register your app on App Store Connect, you need to have an Apple Developer account. Once you have an account, you can log in to App Store Connect and create a new app record for your app.
To register your app on App Store Connect, follow these steps:
1. Go to the App Store Connect website and log in with your Apple ID credentials.
2. Click on the "My Apps" tab and then click on the "+" button to add a new app.
3. Select the platform for your app (in this case, iOS) and enter the app's name and other details, such as the primary language, bundle ID, and SKU.
4. Choose whether you want to create a new Bundle ID or use an existing one. If you choose to create a new one, you will need to enter a unique identifier for your app.
5. Select whether you want to to be your app free or paid
6. Enter the app's description, keywords, and other metadata to help users find it app on the App Store.
7. Upload screenshots and a preview video to showcase its features and functionality.
8. Review and accept the terms and conditions of the Apple Developer Program.
9. Finally, submit your app for review by Apple. Once your app is approved, you can proceed with building and distributing it on the App Store.
**Register a Bundle ID**
A Bundle ID is a unique identifier for your app that is used by Apple. To register a Bundle ID, you need to log in to your Apple Developer account and navigate to the Certificates, Identifiers & Profiles section. Here, you can create a new Bundle ID for your app. You need to ensure that the Bundle ID you create matches the Bundle ID of your app in your Flutter project.
To register a Bundle ID for your app on App Store Connect, follow these steps:
1. Go to the App Store Connect website and log in with your Apple ID credentials.
2. Click on the "My Apps" tab and select the app for which you want to register a Bundle ID.
3. Under the "App Store" section, click on "App Information" and scroll down to the "General Information" section.
4. Click the "Edit" button next to the "Bundle ID" field.
5. Choose whether you want to use an existing Bundle ID or create a new one.
6. If you choose to create a new Bundle ID, enter a unique identifier for your app, such as "com.yourcompany.appname".
7. Choose an explicit App ID or a wildcard App ID. An explicit App ID is a specific Bundle ID that you create, while a wildcard App ID is a single App ID that can be used for multiple apps with similar Bundle IDs.
8. Once you have chosen your App ID type, click "Create".
9. Review the information on the confirmation screen and click "Done".
**Create an application record on App Store Connect**
To register your app on App Store Connect, you first need to create an application record.
1. Go to https://appstoreconnect.apple.com/ and sign in with your Apple Developer account.
2. Click on "My Apps" in the top left corner of the screen.
3. Click on the "+" button in the top right corner of the screen and select "New App".
4. Choose the platform you want to create an app for (in this case, iOS).
5. Enter a unique bundle ID for your app. This should match the bundle ID you registered earlier in Xcode.
6. Navigate to the application details.
7. Enter your app's privacy policy URL.
8. Review the information you have entered and click "Create".
### Review Xcode project settings
The next step is to configure your Xcode project settings. You can do this by opening your Xcode project and navigating to the project settings. Here, you need to set the deployment target, enable bitcode, and configure the code signing settings. The deployment target is the minimum version of iOS that your app supports. Bitcode is a feature that enables Apple to optimize the app for different iOS devices. Code signing is a security feature that ensures that the app is signed by a trusted entity.
1. Open the Flutter project in Xcode by running the command open ios/Runner.xcworkspace in your terminal.
2. Click on the project navigator in the left-hand pane.
3. Click on the "Runner" project to view its settings.
4. Under the "General" tab, review the "Identity" section to ensure that the "Bundle Identifier" matches the Bundle ID.
5. Under the "Signing & Capabilities" tab, ensure that a valid provisioning profile is selected for both the debug and release builds.
6. Resolve issues and warnings before proceeding.
7. Save changes to the project settings.
### Updating the app's deployment version
To update the deployment version, you can open your Xcode project and navigate to the General tab. Here, you can update the version number and build number of your app.
### Add an app icon
To add an app icon, you need to create an image file with specific dimensions and add it to your Xcode project. The dimensions of the app icon depend on the device on which your app is installed.
### Add a launch image
To add a launch image, you need to create an image file with specific dimensions and add it to your Xcode project.
1. Open your Flutter project in Xcode by running the command open ios/Runner.xcworkspace in your terminal.
2. Once Xcode opens, click on the project navigator in the left-hand pane.
3. Click on the "Runner" project to view its settings.
4. Click on the "Assets.xcassets" folder to open it.
### Create a build archive and upload it to App Store Connect
After configuring your Xcode project settings, you need to create a build archive of your app and upload it to App Store Connect. To create a build archive, you can use Xcode's Archive feature.
**Update the app's build and version numbers**
When building a Flutter app for iOS, it's important to update the app's build and version numbers before creating a build archive and uploading it to App Store Connect.
**Create an app bundle**
After completing the necessary configurations, you can generate an Xcode build archive and an App Store app bundle for your app by running the "flutter build ipa" command in your app's root directory. This will create an Xcode build archive (.xcarchive file) in the "build/ios/archive/" directory and an App Store app bundle (.ipa file) in "build/ios/ipa/".
**Upload the app bundle to App Store Connect**
Once you have generated the app bundle, the next step is to upload it to App Store Connect for review and distribution.
### Create a build archive with Codemagic CLI tools
Alternatively, you can use Codemagic CLI tools to create a build archive of your app.
- Install the Codemagic CLI tools:

- Generate an App Store Connect API Key and set the environment variables from the new key.

- Create an iOS Distribution certificate.
- Set up a temporary keychain for code signing.

- Fetch the code signing files from App Store Connect

- Add the fetched certificated to your keychain.
- Update the Xcode project settings to use fetched code signing profiles.
- Install Flutter dependencies.
- Install CocoaPods dependencies.

- Build the Flutter the iOS project.

- Publish the app to App Store Connect
### Release your app on TestFlight:
TestFlight is a platform that allows you to distribute beta versions of your app to a group of testers before releasing it on the App Store. You can use TestFlight to test your app's functionality and gather feedback from your testers.
### Release your app to the App Store
Finally, after testing your app on TestFlight, you can release it to the App Store. To do this, you need to log in to App Store Connect and submit your app for review.
### How to build Flutter app for IOS: Conclusion
Building a Flutter app for iOS requires some preliminary steps that need to be followed. If we were to discuss app development from a business perspective, we would have probably talked about critical factors such as the [cost of building the app](https://www.addevice.io/blog/how-much-does-it-cost-to-build-a-mobile-app), competitiveness, market presence, etc. But today, we focused solely on steps to build a high-performance Flutter app for iOS and make it available to millions of users on the App Store. | christinek989 |
1,382,369 | SolidWorks Training in Chennai | IntelliMindz is a SOLIDWORKS training in Chennai . Our trainers are certified SolidWorks... | 0 | 2023-02-28T10:15:21 | https://dev.to/brindhaigs/solidworks-training-in-chennai-2dho | IntelliMindz is a [SOLIDWORKS training in Chennai](https://intellimindz.com/solidworks-training-in-chennai/) . Our trainers are certified SolidWorks professionals. Each module of our SolidWorks training in Chennai was designed by including fundamental skills and concepts which will help you to master the use of SolidWorks Mechanical Design Software. Even though it has so many complex functionalities, it is the favorite tool of designers. Literally, SolidWorks is a favorite tool with a range of small to large projects.
| brindhaigs | |
1,382,396 | Getting Started with React: Creating Our First Project | React is a popular JavaScript library for building user interfaces. It was created by Facebook and is... | 0 | 2023-02-28T11:01:40 | https://dev.to/gloscode/getting-started-with-react-a-beginners-tutorial-30b7 | programming, tutorial, react, guide | React is a popular JavaScript library for building user interfaces. It was created by Facebook and is widely used by developers all over the world. In this tutorial, we’ll walk through the basics of React and create a simple application.
## Prerequisites
Before we begin, you’ll need to have a basic understanding of HTML, CSS, and JavaScript. You should also have Node.js and npm installed on your machine. If you don’t have them already, you can download them from the [official website](https://nodejs.org/en/download/).
## Setting up the project
To create a new React project, you can use the `create-react-app` command-line tool. Open up a terminal and run the following command:
```bash
npx create-react-app my-app
```
This will create a new directory called `my-app` with all the necessary files and folders for a React project.
## Creating our first component
In React, everything is a component. A component is a reusable piece of code that can be used to build user interfaces. Let’s create our first component by creating a new file called `HelloWorld.js` in the `src` folder.
```js
import React from 'react';
function HelloWorld() {
return (
<div>
<h1>Hello, World!</h1>
</div>
);
}
export default HelloWorld;
```
In this code, we define a new function called `HelloWorld` that returns some JSX. JSX is a syntax extension for JavaScript that allows us to write HTML-like code inside our JavaScript files.
We then export this component using the `export default` syntax, so that it can be used in other parts of our application.
## Using our component
Now that we’ve created our `HelloWorld` component, let's use it in our `App` component. Open up the `App.js` file in the `src` folder and replace the existing code with the following:
```js
import React from 'react';
import HelloWorld from './HelloWorld';
function App() {
return (
<div>
<HelloWorld />
</div>
);
}
export default App;
```
In this code, we import our `HelloWorld` component and use it inside our `App` component.
## Running the project
To run our project, open up a terminal and navigate to the `my-app` directory. Then run the following command:
```bash
npm start
```
This will start a development server and open up our application in a new browser window.
## Conclusion
In this tutorial, we’ve walked through the basics of React and created a simple application. We’ve learned how to create a new project, create a new component, and use that component in our application. We hope you found this tutorial helpful! | gloscode |
1,382,461 | Do Vue Cli para o Vite utilizando Vue2 | Por que isso é importante? O Vue CLI e o Vite são ferramentas de desenvolvimento web que... | 0 | 2023-02-28T11:27:45 | https://dev.to/dienik/do-vue-cli-para-o-vite-utilizando-vue2-503h | vue, vite, npm | ### _Por que isso é importante?_
O Vue CLI e o Vite são ferramentas de desenvolvimento web que auxiliam na criação de projetos Vue. Enquanto o Vue CLI é uma ferramenta de linha de comando que ajuda a gerenciar projetos, o Vite é uma ferramenta de compilação e desenvolvimento que oferece uma experiência de desenvolvimento mais rápida.
Atualizar do Vue CLI para o Vite usando o Vue 2 pode trazer melhorias significativas para a experiência de desenvolvimento. O Vite usa um servidor de desenvolvimento extremamente rápido que proporciona atualizações instantâneas sem precisar reconstruir todo o projeto. Além disso, o Vite é capaz de otimizar a compilação do projeto, resultando em um tempo de compilação mais rápido e em arquivos gerados menores.
Em resumo, atualizar para o Vite pode levar a um desenvolvimento mais eficiente e rápido do projeto Vue, proporcionando uma experiência mais fluida e produtiva para os desenvolvedores.
### Passo 1
##### _Como fazer a migração_
O primeiro passo para migrar para o Vite é atualizar as dependências no arquivo package.json. Para fazer isso, é necessário remover as dependências relacionadas ao Vue CLI, tais como "@vue/cli-plugin-babel", "@vue/cli-plugin-eslint", "@vue/cli-plugin-router", "@vue/cli-plugin-vuex" e "@vue/cli-service". Além disso, também é possível remover o "sass-loader", uma vez que o Vite já fornece suporte integrado para pré-processadores mais comuns.
```javascript
// package.json
"@vue/cli-plugin-babel": "~4.0.0", // remove
"@vue/cli-plugin-eslint": "~4.0.0", // remove
"@vue/cli-plugin-router": "~4.0.0", // remove
"@vue/cli-plugin-vuex": "~4.0.0", // remove
"@vue/cli-service": "~4.0.0", // remove
"sass-loader": "^8.0.2" // remove
-
```
Em seguida, adicionamos o Vite e o plug-in do Vue para o Vite como dependências, usando as seguintes linhas:
```javascript
"vite": "^4.1.0"
"@vitejs/plugin-legacy": "^4.0.1",
```
Como estamos migrando um projeto Vue 2, também precisamos incluir o plug-in Vite mantido pela comunidade para Vue 2. Adicionamos o seguinte trecho ao package.json:
```javascript
"@vitejs/plugin-vue2": "^2.2.0"
```
Com os plug-ins do Vite instalados, podemos remover a seguinte linha do package.json:
```javascript
//remove
"vue-template-compiler": "^2.6.11"
```
Depois de atualizar as dependências no arquivo package.json, precisamos executar o comando "npm install" ou "yarn install" para instalar as dependências atualizadas.
É necessario remover completamente o Babel de nossas dependências, podemos começar excluindo o arquivo babel.config.js. Além disso, podemos remover outras dependências relacionadas ao Babel do package.json, como babel-eslint e core-js, uma vez que já removemos a dependência @vue/cli-plugin-babel, que requer o próprio Babel.
Com babel-eslint removido, também precisamos removê-lo do nosso arquivo .eslintrc.
Então no arquivo .eslintrc
```
// remove parser options
parserOptions: {
parser: "babel-eslint",
},
env: {
node: true, // remove
es2021: true, //atualize o nó para es2021
}
```
Essa mudança exige que atualizemos o eslint e o eslint-plugin-vue para suportar o ambiente es2021.
Para realizar essas alterações, podemos executar o seguinte comando:
```javascript
$ npm install eslint@8 eslint-plugin-vue@8
```
### Passo 2
##### _Configurando o Vite na raiz do projeto_
Vamos criar na raiz do nosso projeto um arquivo chamado vite.config.js. Esse arquivo é responsável por configurar o Vite para o projeto Vue.js. Vamos analisar linha por linha:
```javascript
import vue2 from "@vitejs/plugin-vue2";
//Aqui, o pacote @vitejs/plugin-vue2 é importado e atribuído à variável vue2. Esse plugin é necessário para suportar componentes Vue 2 no Vite.
```
```javascript
import { fileURLToPath, URL } from "node:url"
Essa linha importa as funções fileURLToPath e URL do módulo node:url. Essas funções são usadas para manipular caminhos de arquivos no código.
```
```javascript
export default defineConfig({
plugins: [
vue2(),
],
resolve: {
alias: {
"@": fileURLToPath(new URL("./src", import.meta.url)),
extensions: ['.mjs', '.js', '.ts', '.jsx', '.tsx', '.json', '.vue', '.scss'],
},
},
})
```
Aqui, o objeto de configuração é exportado como o padrão. As chaves dentro dele, como plugins e resolve, são usadas para definir variáveis, plugins e opções de resolução de caminho. O Vite precisa das extensões dos arquivos, se o seu projeto for grande como o meu, é prático utilizar esse extensions, caso contrario, atualize manualmente seus imports com as extensoes dos seus arquivos.
### Passo 3
##### _Movendo o index.html_
Agora, vamos mover o arquivo index.html que contém nosso aplicativo Vue.js da pasta public para a raiz do projeto, porque o Vite coloca o arquivo index.html na raiz do projeto e não no diretório público como o Vue CLI faz.
Após fazer isso, dentro do arquivo index.js precisam ocorrer as seguintes substituições:
```javascript
// index.html
<!--remove-->
<link rel="icon" href="<%= BASE_URL %>favicon.ico">
<!--add-->
<link rel="icon" href="/favicon.ico">
```
Por fim, o JavaScript não será mais injetado automaticamente, então precisamos incluí-lo manualmente no arquivo index.html usando uma tag de script com o atributo type="module" e apontando para o caminho correto do arquivo main.js que está em /src/main.js.
```javascript
<script type="module" src="/src/main.js"></script>
```
### Passo 4
##### _Atualizando as variáveis de ambiente_
Precisamos atualizar as variáveis de ambiente usadas pelo nosso projeto. As variáveis de ambiente são informações que o projeto pode usar para se adaptar a diferentes situações. No Vite, podemos usar um arquivo chamado .env para armazenar essas informações.
No entanto, há uma diferença importante no Vite em relação ao Vue CLI: agora, em vez de usar process.env para acessar essas variáveis, precisamos usar import.meta.env. Além disso, se você costumava usar variáveis de ambiente com o prefixo VUE_APP_, precisará alterá-las para usar o prefixo VITE_.
```javascript
base: process.env.BASE_URL, //remove
base: import.meta.env.BASE_URL
```
```javascript
"BACK_API": "$VUE_APP_BACK_API", ///remove
"BACK_API": "$VITE_BACK_API", ///faça isso em todos os locais semelhantes
```
### Passo 5
##### _Atualizando os scripts_
Para usar o Vite, precisamos atualizar algumas coisas no nosso arquivo de configuração chamado package.json. Isso inclui atualizar os comandos que usamos para desenvolver e construir nosso aplicativo.
Antes, quando usávamos o Vue CLI, usávamos os comandos "serve" e "build", mas agora com o Vite, usamos "dev" e "build". Também precisamos atualizar o comando "serve" para "preview" se quisermos visualizar a compilação de produção localmente.
```javascript
// package.json
"serve": "vue-cli-service serve", // remove
"build": "vue-cli-service build", // remove
"dev": "vite",
"build": "vite build",
"serve": "vite preview"
```
Após isso, execute npm run dev e veja no terminal se o vite está rodando, caso ele dê erro, veja se o erro está incluido no próximo passo.
### Erros que podem acontecer durante a migração e como resolver
##### _Failed to resolve entry for package "fs"_
O erro _Failed to resolve entry for package "fs". The package may have incorrect main/module/exports specified in its package.json.'_ geralmente acontece porque o código está tentando acessar o pacote "fs" em um ambiente que não tem acesso ao sistema de arquivo, a solução para ele não se encontra nas documentações oficiais. Para resolver esse erro, vamos adicionar a seguinte linha no nosso package.json
```javascript
///package.json
dependencies{
"rollup-plugin-node-builtins": " ^2.1.2 "}
}
```
e no nosso arquivo vite.config.js adicionaremos o seguinte:
```javascript
resolve: {
alias: {
fs: require.resolve('rollup-plugin-node-builtins'),
```
Com isso, o seu erro irá sumir rapidamente, lembre-se sempre de dar o npm install ou yarn install, para adicionar os pacotes no projeto.
##### _Process is not defined_
Outro erro comum, porem com a resolução dificil de encontrar, é o _ReferenceError: process is not defined_, ele ocorre pela ausencia de de uma definição global para process, então, no arquivo vite.config.js, adicione a seguinte linha
```javascript
define: {
'process.env': {},
},
```
Espero que esse artigo tenha sido útil, no próximo iremos abordar a nova configuração do plugin i18n no projeto, para implementação de traduções. | dienik |
1,382,816 | ¿Qué son las KVM? | Las máquinas virtuales basadas en el kernel (KVM) son una tecnología de virtualizaciónopen source... | 0 | 2023-02-28T17:04:54 | https://dev.to/farkbarn/que-son-las-kvm-16c2 | kvm, virtualización | Las máquinas virtuales basadas en el kernel (KVM) son una tecnología de virtualizaciónopen source integrada a Linux®. Con ellas, puede transformar Linux en un hipervisor que permite que una máquina host ejecute varios entornos virtuales aislados llamados máquinas virtuales (VM) o guests.
Las KVM forman parte de Linux. Por eso, si cuenta con una versión de Linux 2.6.20 o posterior, ya las tiene a su disposición. Se anunciaron por primera vez en 2006, y un año después se incorporaron a la versión principal del kernel de Linux. Dado que forman parte del código actual de Linux, reciben inmediatamente todas las mejoras, las correcciones y las funciones nuevas de este sistema, sin requerir ningún tipo de ingeniería adicional.
Funcionamiento de las KVM
Las KVM convierten Linux en un hipervisor de tipo 1 (servidor dedicado [bare metal]). Todos los hipervisores necesitan algunos elementos del sistema operativo (por ejemplo, el administrador de memoria, el programador de procesos, la stack de entrada o salida [E/S], los controladores de dispositivos, el administrador de seguridad y la stack de red, entre otros) para ejecutar las máquinas virtuales. Las KVM tienen todos estos elementos porque forman parte del kernel de Linux. Cada máquina virtual se implementa como un proceso habitual de Linux, el cual se programa con la herramienta estándar de Linux para este fin, e incluye sistemas virtuales de hardware exclusivos, como la tarjeta de red, el adaptador gráfico, las CPU, la memoria y los discos.
Implementación de las KVM
En resumen, debe ejecutar una versión de Linux que se haya lanzado después de 2007 e instalarla en sistemas de hardware X86 que admitan las funciones de virtualización. Si ya lo hizo, entonces solo debe cargar dos módulos actuales (uno del kernel del host y uno específico del procesador), un emulador y todos los controladores necesarios para ejecutar sistemas adicionales.
Sin embargo, si las KVM se implementan en una distribución de Linux compatible, como Red Hat Enterprise Linux, se amplían sus funciones, lo cual le permite intercambiar los recursos entre los guests, compartir las bibliotecas comunes, optimizar el rendimiento del sistema y mucho más.
Red Hat Enterprise Linux 8
Migración a una infraestructura virtual basada en las KVM
Si diseña una infraestructura virtual en una plataforma con la que tiene un vínculo contractual, su acceso al código fuente puede verse limitado. En ese caso, sus desarrollos de TI no serán innovaciones, sino meras soluciones temporales a los problemas; y el próximo contrato podría impedirle invertir en las nubes, los contenedores y la automatización. La migración a una plataforma de virtualización basada en las KVM le permite analizar, modificar y mejorar el código fuente del hipervisor. Además, no necesita un acuerdo de licencia empresarial porque no tiene que proteger ningún código fuente, ya que es suyo.
Descubra las ventajas de migrar su infraestructura
Funciones de las KVM
KVM es parte de Linux, y viceversa. Ambas soluciones ofrecen las mismas características; sin embargo, las KVM tienen algunas funciones específicas que las convierten en el hipervisor preferido de las empresas.
Seguridad
Las KVM utilizan una combinación de Security-Enhanced Linux (SELinux) y Secure Virtualization (sVirt) para mejorar la seguridad y el aislamiento de las máquinas virtuales. SELinux establece límites de seguridad para las máquinas virtuales, mientras que sVirt amplía las funciones de SELinux, lo cual permite aplicar el control de acceso obligatorio (MAC) a las máquinas virtuales guest y prevenir los errores relacionados con el etiquetado manual.
Almacenamiento
Las KVM pueden usar todos los tipos de almacenamiento compatibles con Linux, lo cual incluye algunos discos locales y el almacenamiento conectado en red (NAS). La entrada y salida de varias rutas se puede utilizar para mejorar el almacenamiento y proporcionar redundancia. Las KVM también admiten los sistemas de archivos compartidos, para que varios hosts puedan compartir las imágenes de máquinas virtuales. Las imágenes del disco son compatibles con el método de implementación fina, mediante el cual el almacenamiento se asigna según se requiera, en lugar de hacerlo todo por adelantado.
Compatibilidad con los sistemas de hardware
Las KVM pueden usar varias plataformas de hardware certificadas y compatibles con Linux. Dado que los proveedores de hardware contribuyen al desarrollo del kernel con frecuencia, las funciones más recientes de estos sistemas suelen implementarse rápidamente en el kernel de Linux.
Gestión de la memoria
Las KVM cuentan con las funciones de Linux para la gestión de la memoria, como el acceso a la memoria no uniforme y la memoria compartida del kernel. La memoria de una máquina virtual puede intercambiarse o contar con el respaldo de volúmenes grandes de datos para obtener un mejor rendimiento. Además, se puede compartir o respaldar con un archivo de disco.
Migración activa
Las KVM son compatibles con la migración activa, es decir, la capacidad para trasladar una máquina virtual en ejecución entre hosts físicos sin interrumpir el servicio. Eso permite que la máquina virtual y las conexiones de red sigan activas, y que las aplicaciones continúen ejecutándose durante el proceso de migración. Además, las KVM guardan el estado actual de la VM, para que pueda almacenarla y reanudarla más adelante.
Rendimiento y capacidad de ajuste
Las KVM adquieren el rendimiento de Linux y realizan los ajustes necesarios para satisfacer la demanda en caso de que aumente la cantidad de máquinas guest y de solicitudes. Con ellas, se pueden virtualizar las cargas de trabajo de las aplicaciones más exigentes, y son la base para muchas configuraciones de virtualización empresarial, como los centros de datos y las nubes privadas (a través de OpenStack®).
Programación y control de los recursos
En el modelo de KVM, una máquina virtual es un proceso de Linux que el kernel programa y gestiona. El programador de Linux brinda un control detallado de los recursos que se asignan a un proceso y garantiza la calidad del servicio para un proceso en particular. Las KVM incluyen el programador completamente justo, los grupos de control, los espacios de nombre de las redes y las extensiones inmediatas.
Latencia más baja y mayor priorización
El kernel de Linux incluye extensiones inmediatas que permiten que las aplicaciones basadas en máquinas virtuales se ejecuten con una latencia más baja y un mejor orden de prioridad (en comparación con los servidores dedicados [bare metal]). El kernel también divide los procesos que requieren largos períodos informáticos en elementos más pequeños, que luego se programan y se procesan debidamente.
Gestión de las KVM
Es posible administrar manualmente varias máquinas virtuales que están activas en una sola estación de trabajo sin una herramienta de gestión. Las grandes empresas usan un software de gestión de la virtualización que interactúa con los entornos virtuales y el hardware físico subyacente para simplificar la administración de los recursos, mejorar el análisis de los datos y optimizar las operaciones. Red Hat creó Red Hat Virtualization precisamente con ese fin.
Obtenga más información sobre la gestión de la virtualización
Las KVM y Red Hat
Confiamos tanto en el potencial de las KVM que es el único hipervisor que usamos para todos nuestros productos de virtualización, y siempre buscamos mejorar el código del kernel con las contribuciones a la comunidad de KVM. Sin embargo, como ya son parte de Linux, se incluyen en Red Hat Enterprise Linux.
| farkbarn |
1,382,870 | De taxonomías y catálogos de code smells | Índice. Introducción: refactoring y code smells. Martin Fowler, Code Smells y Catálogos. ... | 0 | 2023-02-28T17:32:46 | https://codesai.com/posts/2022/09/code-smells-taxonomies-and-catalogs | refactoring, beginners, webdev, programming | ---
title: "De taxonomías y catálogos de code smells"
published: true
description:
tags:
- refactoring
- beginners
- webdev
- programming
canonical_url: https://codesai.com/posts/2022/09/code-smells-taxonomies-and-catalogs
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/g93cppx2stxot4pidtcd.png
# Use a ratio of 100:42 for best results.
# published_at: 2023-02-28 17:18 +0000
---
**Índice.**
<ol>
<li><a href="#introduction">Introducción: refactoring y code smells.</a></li>
<li><a href="#martin_fowler_catalog">Martin Fowler, Code Smells y Catálogos.</a></li>
<li><a href="#taxonomies">Taxonomías</a></li>
<ol>
<li><a href="#wake_taxonomy">Taxonomías de Wake 2003</a></li>
<li><a href="#mantyla_taxonomy_2003">Taxonomía de Mäntylä et al 2003</a></li>
<li><a href="#mantyla_taxonomy_2006">Taxonomía de Mäntylä et al 2006</a></li>
<li><a href="#jerzyk_taxonomy_2022">Taxonomía de Jerzyk et al 2022</a></li>
<ol>
<li><a href="#jerzyk_code_smells">Catálogo de Code Smells</a></li>
<li><a href="#jerzyk_code_smell_online_catalog">Catálogo online.</a></li>
</ol>
</ol>
<li><a href="#conclusions">Conclusiones.</a></li>
<li><a href="#greetings">Agradecimientos.</a></li>
<li><a href="#references">Referencias.</a></li>
</ol>
<a name="introduction"></a>
<h2> Introducción: refactoring y code smells.</h2>
Refactorizar es una práctica que nos permite evolucionar un código de forma sostenible. Para poder hacerlo necesitamos, en primer lugar, ser capaces de reconocer el código problemático que necesita ser refactorizado.
Los code smells son descripciones de señales o síntomas que nos avisan de posibles problemas de diseño en nuestro código. Detectar estos problemas y eliminarlos tan pronto como uno se da cuenta de que hay algo mal es crucial.
El refactoring produce mejores resultados y es más barato si se hace con regularidad. Entre más tiempo permanezca sin refactorizar un código problemático, más se agravará su efecto y constreñirá el futuro desarrollo del código, contribuyendo directamente a la deuda técnica. Esta situación hará el código cada vez más difícil de mantener, lo que tendrá un impacto económico muy negativo, pudiendo incluso llegar, en el peor de los casos, a ser tan complicada que ya no se pueda seguir manteniendo el código.

<figcaption><strong>Coste de introducir una feature en función del tiempo (imagen de The Three Values of Software de J. B. Rainsberger).</strong></figcaption>
Otra consecuencia, a veces, no tan visible de la mala calidad del código es su efecto en los desarrolladores. Menos refactor, lleva a código menos mantenible, que nos lleva a tardar más tiempo en implementar nuevas funcionalidades, lo cuál nos mete más presión de tiempo, lo que nos lleva a testear menos, lo que nos lleva a refactorizar menos… Es un círculo vicioso que puede tener un efecto muy desmoralizador.

<figcaption><strong>Círculo vicioso sin refactor.</strong></figcaption>
Por tanto, entender y saber identificar los code smells nos da mucho poder porque seremos capaces de detectar problemas de diseño cuando aún son pequeños y están muy localizados en zonas concretas de nuestro código, y eso tendrá un efecto económico y anímico muy positivo.
El problema es que los code smells no se suelen entender demasiado bien. Esto es entendible porque sus definiciones son a veces abstractas, difusas y abiertas a interpretación. Algunos code smells parecen obvios, otros no tanto, y algunos pueden enmascarar a otros code smells.
Además, recordemos que los code smells son sólo síntomas de posibles problemas, y no garantías de problemas. Para complicarlo aún más, además de los posibles falsos positivos, existen grados en el problema que cada smell representa, trade-offs entre smells y contraindicaciones en sus refactorings (en ocasiones “el remedio puede ser peor que la enfermedad").
Por tanto, reconocer los code smells que señalan problemas de diseño, es decir, que no son falsos positivos, es una habilidad sutil, que requiere de experiencia y juicio. Adquirir esta habilidad, que a veces parece una especie de sentido arácnido, puede llevar tiempo.
En nuestra experiencia enseñando y acompañando a muchos equipos identificar code smells es una de las mayores barreras iniciales al refactoring. Muchos desarrolladores no se dan cuenta de los problemas del código que están generando cuando aún son pequeños. Lo que solemos ver es que no se dan cuenta hasta que los problemas son bastante grandes y/o se han combinado con otros problemas, propagándose por su base de código.
<a name="martin_fowler_catalog"></a>
## Catálogos de code smells.
En 1999 Fowler y Beck publicaron un catálogo de code smells en un capítulo del libro,
[Refactoring: Improving the Design of Existing Code](https://www.goodreads.com/book/show/44936.Refactoring). Este catálogo contiene las descripciones de 22 code smells.
En 2018 Fowler publicó una [segunda edición de su libro](https://www.goodreads.com/book/show/35135772-refactoring). En esta nueva edición hay una serie de cambios con respecto a la primera, principalmente en el catálogo de smells y el catálogo de refactorings (que detalla en [Changes for the 2nd Edition of Refactoring](https://martinfowler.com/articles/refactoring-2nd-changes.html)).
Si nos centramos en los smells, lo que nos interesa en este post, los cambios son los siguientes:
- Introduce cuatro code smells nuevos: *Mysterious Name*, *Global Data*, *Mutable Data* y *Loops*.
- Elimina dos smells: *Parallel Inheritance Hierarchies* y *Incomplete Library Class*.
- Renombra cuatro smells: *Lazy Class* pasa a ser *Lazy Element*, *Long Method* pasa a ser *Long Function*, *Inappropriate Intimacy* pasa a ser *Insider Trading* y *Switch Statement* pasa a ser *Repeated Switches*.
Quedan un total de 24 code smells, que aunque suelen tener nombres llamativos y memorables, son difíciles de recordar.
¿De qué manera podríamos entender mejor los code smells? ¿Cómo podríamos recordarlos más fácilmente?
En este post, y algunos posteriores, hablaremos de estrategias para profundizar, recordar y entender mejor los code smells.
## Estrategias organizativas.
Organizar y manipular la información, verla desde diferentes puntos de vista, nos puede ayudar a entender y recordar mejor. Las taxonomías son un tipo de estrategia organizativa, que nos permite agrupar un material de estudio según su significado, creando agrupamientos significativos de información (“*chunks*"), que facilitarán el aprendizaje.
Como comentamos el catálogo de Fowler de 2018 es una lista plana que no proporciona ningún tipo de clasificación. Si bien, leyendo las descripciones de los de code smells, y las secciones de motivación de los diferentes refactorings podemos vislumbrar que algunos smells están más relacionados entre ellos que con otros smells, estas relaciones no se expresan de forma explícita y quedan difuminadas y dispersas en diferentes partes del libro.
El uso de taxonomías que clasifican code smells similares puede ser beneficioso para entenderlos mejor, recordarlos y reconocer las relaciones que existen entre ellos.
<a name="taxonomies"></a>
## Taxonomías.
Ha habido diferentes intentos de clasificar los code smells agrupándolos según diferentes criterios. La clasificación más popular es la de Mäntylä et al 2006 pero no es la primera. A continuación mostraremos algunas que consideramos bastante interesantes.
<a name="wake_taxonomy"></a>
### Wake 2003.
[Wake](https://xp123.com/articles/) en su libro [Refactoring Workbook](https://xp123.com/articles/refactoring-workbook/) de 2003 describe 9 nuevos code smells que no aparecían en el catálogo original de Fowler: *Dead Code*, *Null Check*, *Special Case*, *Magic Number*, *Combinatorial Explosion*, *Complicated Boolean Expression*, y tres relacionados con malos nombres: *Type Embedded in Name*, *Uncommunicative Names* e *Inconsistent Names*.
Wake clasifica explícitamente los code smells dividiéndolos primero en dos categorías amplias, *Smells within Classes* y *Smells Between Classes*, dependiendo, respectivamente, de si el code smell puede ser observado desde una clase o si se necesita considerar un contexto más amplio (varias clases). Cada una de estas categorías se divide en subcategorías que agrupan los code smells según en dónde se pueden detectar. Este criterio de clasificación, denominado más tarde *“occurrence"* por Jerzyk, responde a la pregunta: "¿dónde aparece este code smell?".
Siguiendo este criterio Wake encuentra las siguientes 10 subcategorías.
Dentro de la categoría de *Smells within Classes* estarían las siguientes subcategorías:
* **Measured Smells**: code smells que pueden ser identificados fácilmente con simples métricas de longitud.
* **Names**: code smells que crean confusión semántica y afectan a nuestra capacidad de crear modelos mentales que nos ayuden a comprender, recordar y razonar sobre el código.
* **Unnecessary Complexity**: code smells relacionados con código innecesario que añade carga mental y complejidad. Código muerto, violaciones de [YAGNI](https://martinfowler.com/bliki/Yagni.html) y complejidad accidental.
* **Duplication**: la némesis de los desarrolladores. Estos code smells provocan que haya mucho más código que mantener (carga cognitiva y física), aumentan la propensión a errores y dificultan la comprensión del código.
* **Conditional Logic Smells**: code smells que complican la lógica condicional haciendo difícil razonar sobre ella, dificultando el cambio y aumentando la propensión a cometer errores. Algunos de ellos son sucedáneos de mecanismos de la orientación a objetos.
Las subcategorías dentro de la categoría de **Smells between Classes** son:
* **Data**: code smells en los que encontramos, o bien pseudo objetos (estructuras de datos sin comportamiento), o bien encontramos que falta alguna abstracción.
* **Inheritance**: code smells relacionados con un mal uso de la herencia.
* **Responsibility**: code smells relacionados con una mala asignación de responsabilidades.
* **Accommodating Change**: code smells que se manifiestan cuando nos encontramos con mucha fricción al introducir cambios. Suelen estar provocados por combinaciones de otros code smells.
* **Library Classes**: code smells relacionados con el uso de librerías de terceros.

<figcaption><strong>Taxonomía de Wake (los nuevos smells aparecen en verde).</strong></figcaption>
Wake presenta cada smell siguiendo un formato estándar con las siguientes secciones: **Smell** (el nombre y aliases), **Síntomas** (pistas que pueden ayudar a detectarlo), **Causas** (notas sobre cómo puede haberse generado), **Qué Hacer** (posibles refactorings), **Beneficios** (cómo mejorará el código al eliminarlo) y **Contraindicaciones** (falsos positivos y trade-offs). En algunos casos añade notas relacionando el code smell con principios de diseño que podrían ayudar a evitarlo.
El libro además contiene muchos ejercicios prácticos y tablas muy útiles (síntomas vs code smells, smells vs refactorings, refactorings inversos, etc) y ejercicios que relacionan los code smells con otros conceptos como principios de diseño o patrones de diseño.
Es un libro muy recomendable para profundizar en la disciplina de refactoring y entender mejor cuándo y por qué aplicar los refactorings que aparecen en el catálogo de Fowler.
Lo que enseñamos sobre code smells en nuestro curso sobre [Code Smells & Refactoring](https://codesai.com/cursos/refactoring/) se basa principalmente en esta clasificación de Wake aderezada con un poco de nuestra experiencia, aunque también hacemos referencia al resto de taxonomías de las que hablamos en este post.
<a name="mantyla_taxonomy_2003"></a>
### Mäntylä et al 2003.
En ella los code smells se agrupan según el efecto que tienen en el código (el tipo de problema, lo que hacen difícil o las prácticas o principios que rompen). Jerzyk 2022 denomina "*obstrucción*" a este criterio de clasificación.
En la clasificación original de 2003 ([A Taxonomy and an Initial Empirical Study of Bad Smells in Code](https://www.researchgate.net/publication/4036832_A_Taxonomy_and_an_Initial_Empirical_Study_of_Bad_Smells_in_Code)) había 7 categorías de code smells: *Bloaters*, *Object-Orientation Abusers*, *Change Preventers*, *Dispensables*, *Encapsulators*, *Couplers* y *Others*.

<figcaption><strong>Taxonomía de Mäntylä et al 2003.</strong></figcaption>
Así es como definen cada una de las categorías (disculpen al traductor…):
* **Bloaters**: “representan algo en el código que ha crecido tanto que ya no se puede manejar de forma efectiva.“
* **Object-Orientation Abusers**: “esta categoría de smells se relaciona con casos en los que la solución no explota completamente las posibilidades del diseño orientado a objetos."
* **Change Preventers**: "esta categoría hace referencia a estructuras de código que dificultan considerablemente cambiar el software."
* **Dispensables**: “estos smells representan algo innecesario que debería ser eliminado del código."
* **Encapsulators**: "tiene que ver con mecanismos de comunicación o encapsulación de datos."
* **Couplers**: “estos smells representan casos de acoplamiento alto, lo cual va en contra de los principios de diseño orientado a objetos"
* **Others**: “esta categoría contiene los code smells restantes (*Comments* e *Incomplete Library Class*) que no encajaban en ninguna de las categorías anteriores."
En el artículo, Mäntylä et al discuten los motivos por los que incluyeron cada smell en una determinada categoría y no otra, aunque admiten que algunos de ellos podrían ser clasificados en más de una categoría.
<a name="mantyla_taxonomy_2006"></a>
### Mäntylä et al 2006.
En 2006 Mäntylä et al sacaron otro artículo ([Subjective evaluation of software evolvability using code smells: An empirical study](https://scholar.google.es/citations?view_op=view_citation&hl=es&user=rQHJ67UAAAAJ&citation_for_view=rQHJ67UAAAAJ:IjCSPb-OGe4C)) en el que revisaron su clasificación original de 2003.
La diferencia de esta nueva versión es que elimina las categorías **Encapsulators** (moviendo los smells *Message Chains* y *Middle Man* a la categoría **Couplers**) y **Others** (*Comments* e *Incomplete Library Class* desaparecen de la taxonomía), y mueve el code smell *Parallel Inheritance Hierarchies* de la categoría de **Object-Orientation Abusers** a la categoría de **Change Preventers**.
Esta última versión de su taxonomía es la que se ha hecho más popular en internet (se puede encontrar en muchas webs, cursos y posts), probablemente debido a la mayor accesibilidad (facilidad de lectura) del resumen del artículo que aparece en la web que resume el artículo: [A Taxonomy for "Bad Code Smells"](https://mmantyla.github.io/BadCodeSmellsTaxonomy).

<figcaption><strong>Taxonomía de Mäntylä et al 2006.</strong></figcaption>
Lo interesante no es tanto la discusión de en qué categoría debe caer cada smell, sino el empezar a pensar qué un determinado smell puede tener diferentes tipos de efectos en el código y las relaciones entre estos efectos. De hecho, en posteriores clasificaciones desde el punto de vista del efecto de un smell en el código, no consideran ya las categorías como excluyentes, sino que, un mismo smell puede caer en varias categorías, ya que consideran que es más útil no perder la información de que un smell puede producir varios efectos.
<a name="jerzyk_taxonomy_2022"></a>
### Jerzyk et al 2022.
En 2022 Marcel Jerzyk publicó su tesis de master, [Code Smells: A Comprehensive Online
Catalog and Taxonomy](https://github.com/Luzkan/smells/blob/main/docs/thesis.pdf) y un [artículo con el mismo título](https://github.com/Luzkan/smells/blob/main/docs/paper.pdf). Su investigación sobre code smells tenía tres objetivos:
1. Proporcionar un catálogo público que pudiera ser útil como una base de conocimiento unificada tanto para investigadores como para desarrolladores.
2. Identificar todos los conceptos posibles que están siendo caracterizados como code smells y determinar posibles controversias sobre ellos.
3. Asignar propiedades apropiadas a los code smells con el fin de caracterizarlos.
Para conseguir estos objetivos realizaron una revisión de la literatura existente hasta ese momento sobre code smells, haciendo especial énfasis en las taxonomías de code smells.
En su tesis identifican y describen 56 code smells, de los cuales 16 son propuestas originales suyas, (recordemos que Wake describió 31 code smells y Fowler 24 en su última revisión). En la [tesis de master de Jerzyk](https://github.com/Luzkan/smells/blob/main/docs/thesis.pdf) se pueden encontrar descripciones y discusiones sobre cada uno de estos 56 code smells.
Analizando los criterios de clasificación de las taxonomías propuestas anteriormente, Jerzyk encuentra tres criterios significativos para categorizar code smells:
1. **Obstruction**: Este es el criterio usado por Mäntylä et al para clasificar los smells en su taxonomía y el más popular. Este criterio nos informa sobre el tipo de problema que un code smell causa en el código (lo que hacen difícil o las prácticas o principios que rompen). En la tesis actualizan la taxonomía de Mäntylä, añadiendo tres nuevos grupos: **Data Dealers**, **Functional Abusers** y **Lexical Abusers**. A continuación presentamos un mapa mental que muestra la clasificación de los 56 code smells siguiendo únicamente este criterio.

<figcaption><strong>Taxonomía de Jerzyk usando sólo el criterio de obstruction.</strong></figcaption>
2. **Expanse**: Inspirado por la taxonomía de Wake, este criterio habla de si el code smell puede ser observado en un contexto reducido (dentro de una clase) o si se necesita considerar un contexto más amplio (entre varias clases). Las posibles categorías son **Within Class** y **Between Classes**.
3. **Occurrence**: También inspirado por la taxonomía de Wake, este criterio está relacionado con la localización donde (o el método por el cuál) se puede detectar un code smell. Las posibles categorías son **Names**, **Conditional Logic**, **Message Calls**, **Unnecessary Complexity**, **Responsibility**, **Interfaces**, **Data**, **Duplication** y **Measured Smells**.
A continuación presentamos una tabla con los 56 code smells clasificados por Jerzyk en su tesis usando los tres criterios comentados anteriormente:
<a name="jerzyk_code_smells"></a>
| Code Smell | Obstruction | Expanse | Occurrence |
| --------------------------------------------- | ------------------ | ------- | ---------------------- |
| Long Method | Bloaters | Within | Measured Smells |
| Large Class | Bloaters | Within | Measured Smells |
| Long Parameter List | Bloaters | Within | Measured Smells |
| Primitive Obsession | Bloaters | Between | Data |
| Data Clumps | Bloaters | Between | Data |
| Null Check | Bloaters | Between | Conditional Logic |
| Oddball Solution | Bloaters | Between | Duplication |
| Required Setup/Teardown | Bloaters | Between | Responsibility |
| Combinatorial Explosion | Bloaters | Within | Responsibility |
| Parallel Inheritance Hierarchies | Change Preventers | Between | Responsibility |
| Divergent Change | Change Preventers | Between | Responsibility |
| Shotgun Surgery | Change Preventers | Between | Responsibility |
| Flag Argument | Change Preventers | Within | Conditional Logic |
| Callback Hell | Change Preventers | Within | Conditional Logic |
| Dubious Abstraction | Change Preventers | Within | Responsibility |
| Special Case | Change Preventers | Within | Conditional Logic |
| Feature Envy | Couplers | Between | Responsibility |
| Type Embedded In Name | Couplers | Within | Names |
| Indecent Exposure | Couplers | Within | Data |
| Fate over Action | Couplers | Between | Responsibility |
| Afraid to Fail | Couplers | Within | Responsibility |
| Binary Operator in Name | Couplers | Within | Names |
| Tramp Data | Data Dealers | Between | Data |
| Hidden Dependencies | Data Dealers | Between | Data |
| Global Data | Data Dealers | Between | Data |
| Message Chain | Data Dealers | Between | Message Calls |
| Middle Man | Data Dealers | Between | Message Calls |
| Insider Trading | Data Dealers | Between | Responsibility |
| Lazy Element | Dispensables | Between | Unnecessary Complexity |
| Speculative Generality | Dispensables | Within | Unnecessary Complexity |
| Dead Code | Dispensables | Within | Unnecessary Complexity |
| Duplicate Code | Dispensables | Within | Duplication |
| "What" Comments | Dispensables | Within | Unnecessary Complexity |
| Mutable Data | Functional Abusers | Between | Data |
| Imperative Loops | Functional Abusers | Within | Unnecessary Complexity |
| Side Effects | Functional Abusers | Within | Responsibility |
| Uncommunicative Name | Lexical Abusers | Within | Names |
| Magic Number | Lexical Abusers | Within | Names |
| Inconsistent Names | Lexical Abusers | Within | Names |
| Boolean Blindness | Lexical Abusers | Within | Names |
| Fallacious Comment | Lexical Abusers | Within | Names |
| Fallacious Method Name | Lexical Abusers | Within | Names |
| Complicated Boolean Expressions | Obfuscators | Within | Conditional Logic |
| Obscured Intent | Obfuscators | Between | Unnecessary Complexity |
| Vertical Separation | Obfuscators | Within | Measured Smells |
| Complicated Regex Expression | Obfuscators | Within | Names |
| Inconsistent Style | Obfuscators | Between | Unnecessary Complexity |
| Status Variable | Obfuscators | Within | Unnecessary Complexity |
| Clever Code | Obfuscators | Within | Unnecessary Complexity |
| Temporary Fields | O-O Abusers | Within | Data |
| Conditional Complexity | O-O Abusers | Within | Conditional Logic |
| Refused Bequest | O-O Abusers | Between | Interfaces |
| Alternative Classes with Different Interfaces | O-O Abusers | Between | Duplication |
| Inappropriate Static | O-O Abusers | Between | Interfaces |
| Base Class Depends on Subclass | O-O Abusers | Between | Interfaces |
| Incomplete Library Class | Other | Between | Interfaces |
<br>
Algunos de los nombres en la tabla son diferentes de los que suelen aparecer en la literatura. Los cambios de nombre fueron debidos a la introducción de nombre más actualizados, como es el caso, por ejemplo, de *Lazy Element* o *Insider Trading* que antes se llamaban *Lazy Class* e *Inappropriate Intimacy*, respectivamente.
Hay varios smells que son nuevos. Algunos como *Afraid to Fail*, *Binary Operator in Name*, *Clever Code*, *Inconsistent Style*, y *Status Variable*, son ideas completamente nuevas.
Otros son conceptos ya existentes en la literatura pero que no se habían considerado en el contexto de los code smells: *Boolean Blindness* o *Callback Hell*. Tres de ellos proponen alternativas para code smells que están siendo cuestionados en la literatura: *"What" Comment* como alternativa para *Comments*, *Fate over Action* como alternativa para *Data Class*, e *Imperative Loops* como alternativa para *Loops* (ver la [tesis de Jerzyk](https://github.com/Luzkan/smells/blob/main/docs/thesis.pdf) para profundizar en por qué estos code smells originales son discutibles). Otros generalizan otros conceptos problemáticos que han surgido en la literatura: *Complicated Regex Expression*, *Dubious Abstraction*, *Fallacious Comment*, *Fallacious Method Name*. Por último, un problema conocido (especialmente en el campo de la programación funcional), pero que no se ha considerado hasta ahora como code smell: *Side Effects*.
<a name="jerzyk_code_smell_online_catalog"></a>
Una cosa super útil y práctica para desarrolladores que aporta el trabajo de Jerzyk es la creación de un [catálogo online de code smells](https://luzkan.github.io/smells/) que incluía cuando se publicó los 56 code smells que aparecen en la tabla. Este catálogo es tanto un repositorio open-source como un sitio web accesible y buscable. Actualmente, en la fecha de publicación de este post, el catálogo contiene ya 86 code smells.
En el catálogo se pueden buscar los smells por diferentes criterios de clasificación.

<figcaption><strong>Ejemplo de búsqueda en el catálogo online de code smells de Jerzyk.</strong></figcaption>
Por ejemplo, esta captura de pantalla muestra el resultado de buscar code smells que sean *OO Abusers* y que afecten a *Interfaces*: *Refused Bequest*, *Base Class depends on Subclass* e *Inappropriate Static*.

<figcaption><strong>Code smell en el catálogo online de Jerzyk.</strong></figcaption>
Para cada smell el catálogo presentan las siguientes secciones: **Smell** (discusión del smell), **Causation** (posibles causas del code smell), **Problems** (problemas que el smell puede causar o principios de diseño que viola), **Example** (ejemplos de código mínimo que ilustran los posibles síntomas de un code smell y muestran una posible solución), **Refactoring** (posibles refactorings) y **Sources** (artículos o libros en los que se ha hablado de este code smell). También incluye un recuadro en el que aparece información sobre posibles **aliases** del code smell, la **categoría** a la que pertenece según los criterios de **obstruction**, **occurrence** y **expanse**, los **smells relacionados** y su relación con ellos, y el **origen histórico** del code smell.
<a name="conclusions"></a>
## Conclusiones.
Desde que se acuñó el concepto de code smell en 1999 han aparecido muchos nuevos smells. Las presentaciones planas en forma de catálogo son difíciles de recordar, y no ayudan a resaltar las relaciones que existen entre diferentes code smells.
Hemos presentado varias taxonomías de code smells que nos pueden ayudar a ver los code smells desde diferentes puntos de vista y relacionarlos unos con otros según diferentes criterios: los problemas que producen en el código, dónde se detectan o el contexto que es necesario tener en cuenta para detectarlos.
Estos agrupamientos significativos de code smells nos ayudarán a entenderlos y a recordarlos mejor que las listas planas de los catálogos.
Por último queremos destacar el [reciente trabajo de Marcel Jerzyk](https://github.com/Luzkan/smells/blob/main/docs/thesis.pdf) que no sólo ha propuesto nuevos smells y ha creado una nueva taxonomía multicriterio, sino que además ha puesto a nuestra disposición un [catálogo online de code smells](https://luzkan.github.io/smells/) en forma de repositorio open-source y sitio web accesible y buscable, que creemos que puede resultar muy útil y práctico tanto para investigadores como para desarrolladores. Los animo a echarle un vistazo.
<a name="greetings"></a>
<h2>Agradecimientos.</h2>
Me gustaría darle las gracias a mis colegas [Fran Reyes](https://twitter.com/fran_reyes), [Antonio de La Torre](https://twitter.com/adelatorrefoss), [Miguel Viera](https://twitter.com/mangelviera/) y [Alfredo Casado](https://twitter.com/AlfredoCasado/) por leer los borradores finales de este post y darme feedback. También quería agradecer a [nikita](https://www.pexels.com/es-es/@nikita-3374022/) por su foto.
<a name="references"></a>
<h2>Referencias.</h2>
#### Libros.
* [Refactoring: Improving the Design of Existing Code 1st edition 1999](https://www.goodreads.com/book/show/44936.Refactoring), Martin Fowler et al.
* [Refactoring: Improving the Design of Existing Code 2nd edition 2018](https://www.goodreads.com/book/show/35135772-refactoring), Martin Fowler et al.
* [Refactoring Workbook](https://xp123.com/articles/refactoring-workbook/), William C. Wake
* [Refactoring to Patterns](https://www.goodreads.com/book/show/85041.Refactoring_to_Patterns), Joshua Kerievsky
* [Five Lines of Code: How and when to refactor](https://www.goodreads.com/book/show/55892270-five-lines-of-code), Christian Clausen
* [The Programmer's Brain](https://www.goodreads.com/cs/book/show/57196550-the-programmer-s-brain), Felienne Hermans
#### Artículos.
* [A Taxonomy and an Initial Empirical Study of Bad Smells in Code](https://www.researchgate.net/publication/4036832_A_Taxonomy_and_an_Initial_Empirical_Study_of_Bad_Smells_in_Code), Mantyla et al, 2003.
* [Subjective evaluation of software evolvability using code smells: An empirical study](https://www.researchgate.net/publication/220277873_Subjective_evaluation_of_software_evolvability_using_code_smells_An_empirical_study), Mantyla et al, 2006.
* [A Taxonomy for "Bad Code Smells"
](https://mmantyla.github.io/BadCodeSmellsTaxonomy), Mantyla et al, 2006.
* [Code Smells: A Comprehensive Online Catalog and Taxonomy](https://github.com/Luzkan/smells/blob/main/docs/paper.pdf), Marcel Jerzyk, 2022.
* [Code Smells: A Comprehensive Online Catalog and Taxonomy Msc. Thesis](https://github.com/Luzkan/smells/blob/main/docs/thesis.pdf), Marcel Jerzyk, 2022.
* [Extending a Taxonomy of Bad Code Smells with
Metrics](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.100.2813&rep=rep1&type=pdf), R. Marticorena et al, 2006
Foto de [nikita in Pexels](https://www.pexels.com/es-es/@nikita-3374022/)
| trikitrok |
1,382,893 | How to build mobile- ready business app? | Let's say you have a great business idea that you know will take off, but you need to think of all... | 0 | 2023-02-28T18:14:53 | https://dev.to/aaikansh_22/how-to-build-mobile-ready-business-app-1ml4 | mobile, development, appdevelopment, lowcode | Let's say you have a great business idea that you know will take off, but you need to think of all the important internal processes like managing resources, handling employee data, unified dashboards, and portals that matter the most. Now to streamline these processes you will need internal tools that are also mobile-friendly to make it truly successful. You're not a developer and don't have thousands to spend on hiring one. What do you do?
I would say, using low code/no code tools you can easily achieve this.
You might find this useful > https://www.dronahq.com/mobile/ | aaikansh_22 |
1,382,931 | CodingDojo: First Impressions | The first couple weeks, you come in learning "Programming Basics". Beginner programmers learn how to... | 21,823 | 2023-02-28T19:24:06 | https://dev.to/tmchuynh/codingdojo-first-impressions-466i | webdev, programming | The first couple weeks, you come in learning "Programming Basics". Beginner programmers learn how to download an IDE, what's an IDE, what a variable is, etc. They then go through platform algorithms with basic Javascript to learn if statements and for loops. This continues for two weeks.
After these two weeks end, students begin "Web Fundamentals". Students are introduced to HTML. What's a div, a p tag, a tags, etc. After days of working on HTML, CSS is introduced to style their pages. They get practice assignments that are short to get hands-on practice to implement their studies. Afterwards, they brush on how to implement and connect Javascript to their websites using getElementByID and querySelector. After the exam, they are introduced to Bootstrap and what APIs are. They are introduced to fetch and, depending on the instructor, possibly ajax.
For beginner programmers who have not touched an IDE or had any programming experience, the first month and a half would be a good starter. But if anyone has any coding experience, it is very tedious to sit through. The instructors and TAs are reluctant to answer any questions they deem "too advanced" for the class to learn or help on any projects you work on on your own time. Depending on the instructor's experience teaching, the time management during class time can also be wasted. Personally, my instructor is ALWAYS behind schedule and struggles to explain basic concepts in an efficient manner, when a beginner programmer can explain concepts better.
If you get a "beginner" instructor, I would ask to switch as soon as possible, especially if you are an experienced instructor since they will waste your time. And you will find yourself twiddling your thumbs for a month and a half. But if you get the head instructor, or simply an instructor who encourages their students to learn and pushes their curiosity to venture outside the class's material, find yourself lucky.
At the end of the day, the cost of the bootcamp is cheaper than going to university. And you learn more hands-on material that is needed in the industry. But what I do not respect is instructors not treating students fairly based on their experience level and instead generalizing an entire class and making everyone slow down for the beginners. | tmchuynh |
1,383,618 | Additional Rails setup | When we approach application development we are probably all familiar with DRY - Don't Repeat... | 0 | 2023-03-02T08:52:27 | https://dev.to/braindeaf/additional-rails-setup-1k9k | When we approach application development we are probably all familiar with DRY - Don't Repeat Yourself. This is a good thing to learn in everything you do in life. If we're going to do things time and time again let's try and make it as efficient as possible. And not to mention let's make our life easier so we don't have to remember everything.
There have been countless times this week I've checked out a new project.
```bash
bundle install
bundle exec rake db:drop
bundle exec rake db:create
bundle exec rake db:migrate
bundle exec rake db:seed
RAILS_ENV=test bundle exec rake db:schema:load
```
For a start there's a great way to reduce rake tasks down
```bash
bundle install
bundle exec environment rake db:{drop,create,migrate,seed}
RAILS_ENV=test rake db:schema:load
```
That's still four tasks reduced to one, they're all run from our shell so let's just put it in a `./bin/setup` file
```bash
#!/bin/bash
bundle install
bundle exec environment rake db:{drop,create,migrate,seed}
RAILS_ENV=test rake db:schema:load
```
Make sure it's executable
```
chmod 750 ./bin/setup
# then we can run it with
./bin/setup
```
I tend to put scripts into ./bin/ to just speed up even just booting a rails server. What's wrong with
```bash
rails s
```
Well, nothing. Unless you're running 5 different applications on localhost at the same time. They can't all share port 3000. If you're working on a project where many applications interact with one another. Or your focus changes multiple times a day, which is often does. So how about `./bin/server`
```bash
#!/bin.bash
rails server -b 0.0.0.0 --port=8042
```
Just be to sure to assign a valid port to each of your applications to save you clashing. Well, since we've done that we're now going to have to remember all the port numbers for each of our apps. No, let's refactor that. That's what they invented DNS for.
Let's install `puma-dev`. [https://github.com/puma/puma-dev](https://github.com/puma/puma-dev)
```
brew install puma-dev
sudo puma-dev -setup
puma-dev -install
```
`puma-dev` is great. It effectively hijacks your local machine's DNS resolver for the .test Top Level Domain. Looks up the hostname against the existing files in your `~/.puma-dev/` directory. In my case it's something like.
#### **`~/.puma-dev/iplayred`**
```
8000
```
#### **`~/.puma-dev/robl`**
```
8001
```
Then I can visit `https://iplayred.test` or `https://robl.test` and it will load my application. Your web browser makes the request, and looks up your hostname, determines it is for the local machine and then Puma-dev running on port 80 and 443 proxy and forwards requests to your application on localhost port 'whatever was in my config' and it also manages SSL - which is the icing on the cake if you're looking to do any development testing against anything that requires SSL e.g. OAuth workflow redirect urls or say Rails apps that are SSL Only.
I could at this point write a script to dump these scripts into a new application based on what ports are already allocated, insert all my setup scripts so I don't have to do this again and again. One day I will.
| braindeaf | |
1,383,125 | Using Virtual Color Mixing to Extend Your Palette in React/JavaScript | [NOTE: The live web app that encompasses this functionality can be found here:... | 21,964 | 2023-02-28T23:38:46 | https://dev.to/bytebodger/using-virtual-color-mixing-to-extend-your-palette-in-reactjavascript-l41 | webdev, javascript, tutorial, react | [NOTE: The live web app that encompasses this functionality can be found here: https://www.paintmap.studio. All of the underlying code for that site can be found here: https://github.com/bytebodger/color-map.]
In the last article, I illustrated how we can mix paints _virtually_. We can take two colors and "mix" them together to see what the resulting paint will look like. Although this can be useful _in theory_ (e.g., to determine what two paints will look like if we mix them together in the real world), this also has practical applications for the live app that I've built at https://paintmap.studio.
<br/><br/>
## The limitations of color depth
In the previous articles, I showed how to pixelate an image so we're not dealing with _millions_ of colors. I then showed how to find the closest match between a given color and a reference palette of colors. Finally, I showed how to use dithering to ensure that those "closest" matches were not all bunched together in specific bands of colors.
For reference, this was the original image that we'd pixelated, using a basic RGB algorithm:

This image isn't bad. We don't have any annoying color bands (because we've employed dithering). And the colors on the transformed image are... acceptable. Granted, there are a lot of pinks/reds on her face - a fact that seems a bit odd, considering that she's a woman of color. And overall, you could argue that the image is a bit "noisy". But if you step back and blur your eyes a bit, the coloring on her face doesn't look entirely _unnatural_.
But I'm not entirely satisfied with this image. As previously mentioned, there's a lot of red/pink in her face where maybe it shouldn't be. Given that I started with an original palette of 200+ paints, why is it that the transformed image has many colors that still don't seem to properly "map" to the source image??
The answer lies in color _depth_.
<br/><br/>

## Paints are inherently _dark_
There's a reason why it's inherently difficult to perform color matching when your source image contains a subject like a human face - but your reference palette consists of "stock" paints. The reason is that: Paints, especially "professional grade" paints for artists, are fairly dark in nature.
For example: Even though I have 200+ paints in my inventory, here is the color key for all of those paints (you can view this in full resolution here: https://www.paintmap.studio/palettes):

If you look carefully at that selection, you'll see that we have all of the "normal" colors one would expect to find in a palette of paints. There's black and white (and numerous shades of grey). But there's also reds, and oranges, and yellows, and greens, and blues, and purples, and browns.
So why does our algorithm still fall short when trying to match the digital image to those paints?
Well... for starters, take a look at that palette. Although we have a broad spectrum of colors, nearly all of those colors are exceedingly _dark_. FWIW, this is _by design_. You see, when you buy "professional-grade" paints, those paints come with a very high _pigment load_. The idea is that you can mix them with other paints and they won't immediately lose their core qualities - because the original paints are chock full of pigment. But what this means, in a practical sense, is that all of the off-the-shelf colors are really quite _dark_.
And of course, _some_ images are chock-full of dark colors. So if you match those images against our palette of heavy body acrylic paints, you may find that the color matching performs quite well. But with something as nuanced as a human face?? Well... it causes problems.
For example, this was the original image we were working from:

Clearly, this is a Black woman. But just as "white" people are not _truly_ white (they're mostly a mix of yellow / pinks / tans), most Black people aren't _truly_ black (they're mostly a mix of browns / yellows / tans). Furthermore, the skin tone of most Black people isn't really all that... _dark_. They're "dark" - compared to white people. But in the image above you can see that many areas of her face are actually quite... _light_. When you add in additional factors (such as lighting and makeup), their skin can, in certain regions, be incredibly light.
So although we have a fairly "workable" transformation of the image, matching the pixels in her face to the colors in our paint inventory, there are still areas where this transformation falls short. If we want to perform more accurate color matching against the lighter areas of her skin, the answer is... to extend our palette of colors.
<br/><br/>
## Making darker colors lighter
If we wanted to, we could use the color-mixing algorithms from the previous article to create a whole list of _new_ colors based upon mixing all of the original colors together in different proportions. But remember, as I stated above, our core palette of paints already gives us a pretty solid representation of every "base" color that we'd expect to find in an image.
The problem isn't that we're missing any base colors. The problem is that all of those colors are simply too... dark. But how do we "find" those lighter colors??
If you read the first article in this series, you know that I found all of the RGB equivalents for every paint in my inventory by physically squeezing some of the paint onto sheets of paper. Then I photographed those sheets and grabbed the best-possible RGB value that I could find from every blob.
If we wanted to find the lighter equivalents of our base colors, I _could_ repeat that entire process. I could mix - in the real-world - bits of white paint with the original paints. Then I could set the mixed bits out on paper, wait for them to dry, photograph them all, and then grab the appropriate RGB values from each lightened blob.
But that would be, quite frankly, a real pain the backside. Based on the previous article, we already know how to "mix" paints - _virtually_. So there's no need to create a massive set of test paint swatches and then manually grab all the RGB images from those swatches. Instead, we can mix the core colors with white - _virtually_ - and then use the virtually-mixed values to enhance our color matching.
<br/><br/>

## Using code to find lighter colors
Since we already have all of the "core" colors in our base inventory of paints, and since those colors are inherently _dark_, we can find many more variants of those colors by merely adding white to them. In different proportions.
Specifically, in my Paint Map Studio app, I've created five _additional_ color palettes, on top of the original palette that represents all of the base heavy body acrylic paints. Those additional palettes are as follows:
**1/4 Whites**
This consists of 3 parts of every heavy body acrylic paint, mixed with 1 part of white. This is what they look like:

**1/3 Whites**
These consist of 2 parts of every heavy body acrylic paint, mixed with 1 part of white. This is what they look like:

**1/2 Whites**
These consist of 1 part of every heavy body acrylic paint, mixed with 1 part of white. This is what they look like:

**2/3 Whites**
These consists of 1 part of every heavy body acrylic paint, mixed with 2 parts of white. This is what they look like:

**3/4 Whites**
These consist of 1 part of every heavy body acrylic paint, mixed with 3 parts of white. This is what they look like:
The beautiful part of all this is that, to create all of these other potential colors, I didn't have to actually mix any paints at all. I merely allowed the algorithm to tell me what these colors would look like if I were to mix the paints in these proportions.
Obviously, you could continue to expand these virtual palettes _ad infinitum_. You could create a 99/100 Whites palette that consists of 1 part of every heavy body acrylic paint, mixed with 99 parts of white. But at a certain point, you're just creating an ever-increasing number of virtual paints that have little distinction from the other palettes.
Also, if you somehow found yourself with an incredibly _pale_ set of reference colors, you could then create a series of virtual palettes based on what would happen if you mixed them with varying degrees of _black_. But since our base palette is already so dark, this approach has little value in Paint Map Studio.
<br/><br/>

## Visualizing additional palettes
So what effect does it have on our transformed image if we use a deeper set of colors? Well, let's remember that this was our originally-transformed image:

This results from performing color matching against only the base set of heavy body acrylic paints.
Now this is the same transformation, except that we're matching against the base set of heavy body acrylic paints _and_ the set of "1/4 Whites":

Notice that, merely by adding _one_ more set of colors, we've already reduced the noise in the image by a great deal, and we've eliminated most of those jarring red dots on her face.
Here's the same transformation, with "1/3 Whites" _also_ added to the mix:

The improvement isn't nearly so dramatic. But it's still "smoother" than the previous image.
Here's the same transformation, with "1/2 Whites" _also_ added to the mix:

Honestly, at this point, we're already reaching a degree of color depth where it's hard to see the difference between this image and the previous one. But let's keep going, at least for the sake of illustration:
Here's the same transformation, with "2/3 Whites" _also_ added to the mix:

And finally, here's the same transformation, with "3/4 Whites" _also_ added to the mix:

Now that we've added _all_ of these extra palettes, our color-matched, fully-transformed image looks incredibly similar to the original. By adding many different (lighter) shades of our original "base" paints, we've managed to create a transformed image that's incredibly true to the original. And we've done this without creating a whole series of "funky" custom color mixes.
Every block in the pixelated image is represented either by one of our base paints, or a variation of those base paints that _only_ entails mixing it with varying degrees of white. I find this to be incredibly useful because I really don't want to bother with a painting where _this_ block requires 2 parts of Golden: Cerulean Blue Deep, 1 part of Liquitex: Green Gold, and 3 parts of Liquitex: Cadmium Yellow Light, but the _next_ block requires 1 part of Golden: Cobalt Turquoise, 3 parts of Golden: Burnt Sienna, and 1 part of Liquitex: Deep Magenta. It's far easier to know that every block in the transformed image either maps to an original paint color - or some proportion of that original color mixed simply with... white.
<br/><br/>

## In the next installment...
We're coming close to concluding this series, but... we're not done yet! In the next installment, I'll show you how to _restrict_ the resulting color depth so that you're not faced with having to mix _hundreds_ of paints to produce a given image.
| bytebodger |
1,383,478 | How to learn UI/UX Design?-Volume | How to learn UI/UX Design?-Volume(3) UX is an exciting field to explore, even if the... | 0 | 2023-03-01T06:27:47 | https://dev.to/mathivanan8/how-to-learn-uiux-design-volume-51im | webdev, javascript, beginners |

## How to learn UI/UX Design?-Volume(3)
UX is an exciting field to explore, even if the idea of starting a career in the field can be a bit daunting, especially if you don’t have any UX design experience. In the world of UX design, there’s so much to learn and take in! The idea of going from complete novice to professional seems impossible. Surely you need some kind of design background? Or at least a vaguely relevant design qualification?
UX is an exciting field to explore, even if the idea of starting a career in the field can be a bit daunting, especially if you don’t have any UX design experience. In the world of UX design, there’s so much to learn and take in! The idea of going from complete novice to professional seems impossible. Surely you need some kind of design background? Or at least a vaguely relevant design qualification?
1. Read and research all things UX
2. Understand what UX designers actually do
3. Learn UX design tools
4. Structure and formalize your learning with a UX design course or bootcamp
5. Get inspired by the best designers
6. Build your UX portfolio
7. Start networking with other UX designers
**Read and research all things UX**
UX is an exciting field to explore, even if the idea of starting a career in the field can be a bit daunting, especially if you don’t have any UX design experience. In the world of UX design, there’s so much to learn and take in! The idea of going from complete novice to professional seems impossible. Surely you need some kind of design background? Or at least a vaguely relevant design qualification?
| mathivanan8 |
1,383,533 | HTML & CSS | Box model When laying out a document, the browser's rendering engine represents each... | 0 | 2023-03-02T05:52:22 | https://dev.to/cnavya/html-css-4pk5 | ## Box model
* When laying out a document, the browser's rendering engine represents each element as a rectangular box according to the standard CSS basic box model.
* CSS determines the size, position, and properties (color, background, border size, etc.) of these boxes.
*Every box is composed of four parts defined by their respective edges: the content edge, padding edge, border edge, and margin edge.
1. Content area
* The content area, bounded by the content edge, contains the "real" content of the element, such as text, an image, or a video player.
* Its dimensions are the content width (or content-box width) and the content height (or content-box height). It often has a background color or background image.
2. Padding area
* The padding area, bounded by the padding edge, extends the content area to include the element's padding. Its dimensions are the padding-box width and the padding-box height.
* The thickness of the padding is determined by the padding-top, padding-right, padding-bottom, padding-left, and shorthand padding properties.
3. Border area
* The border area, bounded by the border edge, extends the padding area to include the element's borders. Its dimensions are the border-box width and the border-box height.
* The border area's size can be explicitly defined with the width, min-width, max-width, height, min-height, and max-height properties.
4. Margin area
* The margin area, bounded by the margin edge, extends the border area to include an empty area used to separate the element from its neighbors. Its dimensions are the margin-box width and the margin-box height.
* The size of the margin area is determined by the margin-top, margin-right, margin-bottom, margin-left, and shorthand margin properties.
## Inline vs Block elements
* In HTML elements historically were categorized as either "block-level" elements or "inline-level" elements. Since this is a presentational characteristic it is nowadays specified by CSS in the Flow Layout.
### Example for inline
```
<div>
The following span is an <span class="highlight">inline element</span>; its
background has been colored to display both the beginning and end of the
inline element's influence.
</div>
```
In this example, the <div> block-level element contains some text. Within that text is a <span> element, which is an inline element. Because the <span> element is inline, the paragraph correctly renders as a single, unbroken text flow.
### Example for block element
```
<div style="border: 1px solid black;"> About Us </div>
```
## Positioning: absolute/relative
1. Absolute
* This is a very powerful type of positioning that allows you to literally place any page element exactly where you want it.
* You use the positioning attributes top, left, bottom, and right to set the location.
* Absolute positioned elements are removed from the normal flow, and can overlap elements.
### Syntax
```
position: absolute;
```
2. Relative
* The relative positioning property is used to set the element relative to its normal position.
* Setting the top, right, bottom, and left properties of a relatively-positioned element will cause it to be adjusted away from its normal position.
### Syntax
```
position: relative;
```
## Common CSS structural classes
* Structural pseudo classes allow access to the child elements present within the hierarchy of parent elements.
* We can select first-child element, last-child element, alternate elements present within the hierarchy of parent elements.
The following is the list of structural classes.
1. :first-child - it represents the element that is prior to its siblings in a tree structure.
2. :nth-child(n) - it applies CSS properties to those elements that appear at the position evaluated by the resultant of an expression.
3. :last-child - it represents the element that is at the end of its siblings in a tree structure.
4. :nth-last-child(n) - :nth-last-child(Expression) is the same as :nth-child(Expression) but the positioning of elements start from the end.
5. :only-child - it represents the element that is a sole child of the parent element and there is no other sibling.
6. :first-of-type - It selects the first element of the one type of sibling.
7. :nth-of-type(n) - it represents those elements of the same type at the position evaluated by the Expression.
8. :last-of-type - it represents the last element in the list of same type of siblings.
9. :nth-last-of-type(n) - It is the same as :nth-of-type(n) but it starts counting of position from the end instead of start.
## Common CSS styling classes
* **.container** : This class is used to create a container that holds the content of a web page or sometimes container which will hold other elements.
* **.header** : This class is used to style the header section of a web page, which typically contains the site logo, navigation menu, and other important information.
* **.nav** : This class is used to style navigation menus on a web page, such as a top or side menu.
* **.btn** : This class is used to style buttons on a web page. It's often used to add a background color, border, and padding to create a clickable button.
* **.card** : This class is used to create a card-style layout for content, such as a blog post or product listing. It often includes a background color, border, and padding to create a contained section for the content.
* **.footer** : This class is used to style the footer section of a web page, which typically contains copyright information, social media links.
## CSS specificity
Specificity Hierarchy :Every element selector has a position in the Hierarchy.
1. Inline style: Inline style has highest priority.
2. Identifiers(ID): ID have the second highest priority.
3. Classes, pseudo-classes and attributes: Classes, pseudo-classes and attributes are come next.
4. Elements and pseudo-elements: Elements and pseudo-elements have lowest priority.
* Start at 0, add 100 for each ID value, add 10 for each class value (or pseudo-class or attribute selector), add 1 for each element selector or pseudo-element.
### Example
```
A: h1
B: h1#content
C: <h1 id="content" style="color: pink;">Heading</h1>
```
The specificity of A is 1 (one element selector)
The specificity of B is 101 (one ID reference + one element selector)
The specificity of C is 1000 (inline styling)
## Flex box / Grid
**Flex container**:The flex container specifies the properties of the parent. It is declared by setting the display property of an element to either flex or inline-flex.
**Flex items**:The flex items specify properties of the children. There may be one or more flex items inside a flex container.
* it is used to specify the direction of the flexible items inside a flex container.
* It is used to align the flex items horizontally when the items do not use all available space on the main-axis.
* It is used to align the flex items vertically when the items do not use all available space on the cross-axis.
The flex container properties are:
* flex-direction
* flex-wrap
* flex-flow
* justify-content
* align-items
* align-content
The flex item properties are:
* order
* flex-grow
* flex-shrink
* flex-basis
* flex
* align-self
## CSS Responsive queries
* The @media rule, introduced in CSS2, made it possible to define different style rules for different media types.
* Media queries can be used to check many things, such as:
* width and height of the viewport
* width and height of the device
* orientation (is the tablet/phone in landscape or portrait mode?)
* resolution
### Syntax
```
@media not|only mediatype and (expressions) {
CSS-Code;
}
```
Value and description:
* all - Used for all media type devices
* print - Used for printers
* screen - used for computer screens, tablets, smart-phones etc.
* speech - Used for screenreaders that "reads" the page out loud
### Example
```
@media screen and (min-width: 480px) {
body {
background-color: lightgreen;
}
}
```
## Common header meta tags
* The <meta> tag is used to provide such additional information. This tag is an empty element and so does not have a closing tag but it carries information within its attributes.
* You can add metadata to your web pages by placing <meta> tags inside the header of the document which is represented by <head> and </head> tags.
### Attributes and descriptions
1. Name
* Name for the property. Can be anything. Examples include, keywords, description, author, revised, generator etc.
2. content
* Specifies the property's value.
3. scheme
* Specifies a scheme to interpret the property's value (as declared in the content attribute).
4. http-equiv
* Used for http response message headers. For example, http-equiv can be used to refresh the page or to set a cookie. Values include content-type, expires, refresh and set-cookie.
#### Example
```
<!DOCTYPE html>
<html>
<head>
<title>Meta Tags Example</title>
<meta name = "keywords" content = "HTML, Meta Tags, Metadata" />
</head>
<body>
<p>Hello HTML5!</p>
</body>
</html>
# output: Hello HTML5!
``` | cnavya | |
1,383,539 | The fuzzing puzzle - a guide to uncovering cyber security vulnerabilities | Picture this: you're a software developer and you've spent countless hours creating the next big... | 21,980 | 2023-03-01T22:00:00 | https://dev.to/cyberfame_io/the-fuzzing-puzzle-a-guide-to-uncovering-cyber-security-vulnerabilities-21bc | securesupplychai, softwaresecurity, fuzztesting, softwaretesting | Picture this: you're a software developer and you've spent countless hours creating the next big thing. But wait, hold your horses before you hit that launch button! Have you considered all of the possibilities of bugs and vulnerabilities lurking in your code? Step into the thrilling world of fuzzing! It's like a wild card game where instead of just playing with your code, you're also playing with unpredictable and random inputs, making sure your code can handle the chaos.
## Who was the mastermind behind Fuzzing?
Fuzzing is a tale as old as time, or at least as old as the 1980s. A professor, seeking to unravel the mysteries of his UNIX system's failure, tasked his students with a simple yet daring mission: to flood the system with a barrage of randomized inputs. Little did they know that this act of mischief would pave the way for a revolution in software security testing. Fuzzing - like Tolstoy's War and Peace - can seem chaotic and unpredictable on the surface, but at its core, it is a masterful tool for exposing the underlying weaknesses and vulnerabilities in our applications.
## Are you ready to get playful with software testing?
Think of it as a game of "What if?" where you intentionally introduce invalid, malformed, or unexpected inputs into a system and observe its reactions. Did it crash? Did it leak information? Time to find out!
So, how does fuzz testing work? It's simple, yet effective. Imagine a team of three each with a certain mission they conduct successively: the poet, the courier, and the oracle. The poet creates the test cases, the courier delivers them to the target software, and the oracle detects if a failure has occurred. The test cases can be random, evolutionary, or even rule-breaking. And that's where the fun begins!
Random fuzzing is akin to pinning the tail on the donkey - it's simply random data being inserted into a system. However, template evolutionary fuzzing takes this concept up a notch — like an interesting game of "What if?" using valid inputs as you introduce anomalies and observe how your system reacts. And finally, generational fuzz testing is like breaking all the rules of a board game. With a solid understanding of the protocol, file format, or API being tested, it systematically challenges the system's limitations in various ways.
Once the tests are delivered, it's time for the oracle to take over. This super sleuth checks the target system to see if any failures have occurred and in case they have - what exactly the emerged problems do look like. Without thoroughly understanding the problem, fixing a failure would be impossible.
## What are the use cases of fuzzing?
URL Fuzzing: URL fuzzing is a type of web application fuzzing that focuses on testing the security of URLs. By introducing unexpected inputs into URLs, organizations can identify any potential security risks such as cross-site scripting, cross-site request forgery and buffer overflows. This type of fuzzing is essential for improving the security of web applications that rely on URLs for navigation and data transfer.
API Fuzzing: API fuzzing is a type of fuzz-testing that focuses on testing the functionality and security of APIs. By injecting unusual inputs into APIs, organizations can find any potential vulnerabilities that may arise during usage. This type of fuzzing can help improve the overall functionality of APIs by uncovering any bugs or performance issues.
Web Application Fuzzing: Web application fuzzing involves injecting random inputs into web applications to identify security breaches and defects. This type of fuzzing can uncover security risks such as SQL injection and buffer overflows, among others. By identifying these issues early on, organizations can improve the security of their web applications and protect sensitive information.
Protocol Fuzzing: Protocol fuzzing involves testing the security and functionality of network protocols. By introducing unanticipated inputs into network protocols, organizations can identify any potential security risks when data is transmitted and processed. This type of fuzzing is essential for organizations that rely on network protocols to transfer sensitive data.
File Format Fuzzing: File format fuzzing involves testing the security and functionality of file formats. By inserting irregular inputs into file formats, organizations can identify any potential security vulnerabilities and malfunctions connected to respective file formats. This type of fuzzing is essential for organizations that rely on file formats for storing and transferring sensitive information.
## What are the benefits of fuzz testing?
Get a Clear Picture: Fuzz testing provides a comprehensive view of the quality and security of your target system and software. It's like getting a full-body check-up for your software's health.
Stay Ahead of the Game: Fuzzing is the same technique that malicious hackers use to find vulnerabilities in software. By incorporating fuzz-testing into your security program, you can stay one step ahead and prevent any zero-day exploits from unknown bugs in your system.
Low Overhead: Fuzzing has low costs and time overhead, making it a cost-effective way to improve the security and quality of your software. Once set up, a fuzzer can work in automation without manual intervention and continue to search for bugs.
Uncover Hidden Bugs: Fuzz-testing can uncover bugs that traditional testing methods or manual audits might miss. It's like having a secret weapon in your security arsenal.
## But nothing comes without a challenge or two...
While free or open-source fuzzers can be useful, they present certain challenges that need to be considered, especially when it comes to complex software programs. It's important to choose the right fuzzer that matches the complexity of the software and provides the necessary level of coverage for thorough testing.
1. Limited Bug Detection: Open-source fuzzers can present challenges as they may not be able to find all bugs, especially if the bugs don’t cause a full crash or if they are only triggered under specific circumstances.
2. Opaque-Box Testing: Open-source fuzzers use an opaque-box testing method, making it difficult to reproduce and analyze test results as they don't provide additional insights into the software's internal workings.
3. Complex Inputs Require Advanced Fuzzers: Software programs with complex inputs require advanced and intelligent fuzzers that can provide thorough and complete test coverage to secure the software. There's not a single generic/out-of-the-box solution yet, so it has to be customized for every individual project.
To wrap it up, fuzz testing is like a treasure hunt for software wizards and security detectives. It's an exciting way to find hidden nooks and crannies in your software that might have gone unnoticed. By tossing unexpected inputs into the mix, you'll uncover any sneaky bugs that might have been hiding, keeping your code one step ahead of those mischievous hackers. Coming with low costs and time investment, fuzz testing gives you a beneficial 360-degree view of your software, helping you find glitches that other testing methods might have missed. So whether you choose random, evolutionary, or generational methods, get ready to have some fun and push your code to its limits.
## How can Cyberfame help?
Cyberfame security scanning and rating can help identifying which elements of a supply chain network are vulnerable and thus critical to be tested. Users get real-time rating-results on how secured or endangered software entities connected to an organisation's network are. Knowing which software elements should be tested first will immensely increase the value of fuzz-testing. With Cyberfame, organizations and users can focus on conducting reasonable, directed security-approaches to get the most out of available security resources.
Visit our website [Cyberfame.io](url) to learn more.
| cyberfame_io |
1,383,540 | 5 important things about WordPress Cron | WordPress Cron provides an easy way to schedule actions without taking care of the implementation.... | 0 | 2023-03-01T08:05:20 | https://wplake.org/blog/wordpress-cron/ | wordpress, cron, wordpresswebdevelopm, wordpressdevelopment | ---
title: 5 important things about WordPress Cron
published: true
date: 2023-02-28 12:24:36 UTC
tags: wordpress,cron,wordpresswebdevelopm,wordpressdevelopment
canonical_url: https://wplake.org/blog/wordpress-cron/
---

WordPress Cron provides an easy way to schedule actions without taking care of the implementation. We review specific moments to help you manage Cron properly.
### What is Cron?
The Cron in short, is a way to run some tasks (or jobs if you will) on a schedule. For example, to keep the currency rates up-to-date on your website you need to update them once a day. Instead of doing it manually, you create a cron task and set it up with the frequency of once a day. Cron is widely used in many WordPress plugins and themes to keep information up-to-date.
### System Cron VS WordPress Cron
With WordPress you have 2 different ways to do it.
#### System Cron
The first way is adding it in the [Linux system cron](https://help.ubuntu.com/community/CronHowto) (this is on your hosting server). These tasks are in the **/etc/crontab** file and with this approach being the most universal and most reliable way to run Cron tasks. Your server operating system (e.g. Linux, Ubuntu or RedHat) guarantees that tasks in our PHP files will be called as they were scheduled, regardless of any external events.
Though it’s more universal and reliable, it has no integration with WordPress. This means if you call PHP files within your theme directly, then they won’t have access to any WordPress functions and the Database. Due to the fact that WordPress can’t load properly in this way. Furthermore, it’s not suitable for plugins, because if you’re using the plugin, you can’t simply set up the system Cron for all your clients.
#### WordPress Cron
Then here WordPress Cron [comes](https://developer.wordpress.org/plugins/cron/) in and is the second way to run cron tasks. You can easily registry your cron task within WordPress, and WordPress will take care of loading and executing your tasks within your specified schedule. Sounds sweet, and it’s suitable for plugins.
What can be better, right? But nothing is perfect and this approach also has drawbacks.
WordPress is a PHP based application and has no access to your system Cron (OS running on your host). In fact, it means WP needs some external event to check the schedule list and execute relevant tasks. Another thing is that WordPress can ONLY run Cron tasks when someone visits or opens a page on the website. If nobody visits your website, the Cron tasks will NOT run.
This may sound scary, but the good news is that **WordPress guarantees that tasks will be called** , there just isn’t a guarantee when exactly they’ll be called. For example, you’ve set up a Cron currency rates task to run once a day. Now in real life it means the task will be executed with the first visitor, after one day at the set time. Not earlier, but perhaps later, maybe even much later if you’ve had no visitors for several days.
There are some tasks that are okay to run with this approach, however while nobody visits your site, Cron doesn’t run and therefore doesn’t actually “work”. But there are other tasks that require reliability. So if your cron tasks are about pulling info from external sources, or simply very important tasks that need to run, like any API stuff, you can’t rely on this approach.
#### Verdict
Both ways have their advantages and drawbacks.
For that reason the best solution which is used by professionals, and [recommended by WordPress](https://developer.wordpress.org/plugins/cron/hooking-wp-cron-into-the-system-task-scheduler/), is a combination of the two approaches, giving you the best of both and having them counteract each others drawbacks.
As a website owner (or a developer) you need to set up the system Cron job which will call WordPress Cron. Overall, it’s relatively simple to do, and in this way WordPress Cron will be more reliable while keeping the native WordPress approach.
See point no. 2 below to learn how to go about it.
### About WordPress Cron
Above, we’ve learned that WordPress a PHP-based application, and its internal Cron relies on external events, i.e. user requests. Besides this fact, there is a list of important aspects, which we’ll go through in more detail.
### 1. WordPress Cron is asynchronous
Firstly, you should know that WordPress Cron is asynchronous. Asynchronous means it runs Cron jobs in a separate request from the event itself.
So, a **user request won’t have delays due to WordPress Cron** , a user that triggered some Cron job won’t wait until the job is finished to see the result of his request. So you can breathe easy knowing there aren’t any delays for your visitors. WordPress handles it all quietly in the background.
If you’re interested in the finer details, then technically it happens in the following way;
WordPress checks the Cron schedule on every user request to a website, and if there is a need to run Cron jobs, it creates a new request to the website cron file ( **/cron.php** ), using the **cURL** library. The user receives the response to their request immediately, while Cron executes the other cron tasks in a separate request, which is independent.
### 2. WP Cron isn’t reliable (out-of-the-box). Way to fix
As we already know, WordPress Cron out-of-the-box depends on external events. Compared with the system Cron, it has a big drawback. But we can easily fix it by merging the system Cron and WordPress Cron.
So the solution is creating a Cron job within the system Cron and calling WordPress Cron from there. In this way, we receive a reliable Cron with all WordPress features and support for plugin cron jobs. It may sound a little tricky, but it isn’t really.
For the official manual [see here](https://developer.wordpress.org/plugins/cron/hooking-wp-cron-into-the-system-task-scheduler/).
The task can be split into 2 steps. The first step is about creating a new system Cron job. Basically, there are two different types of hosting (shared and dedicated), and how to create cron jobs depends on your hosting type.
#### How to add a system Cron job for shared hosting
When using shared hosting, there are many different vendors, and you need to check the features offered by your vendor about the Cron tasks. Usually, a hosting admin panel has a special tab or item about Cron, where you can manage Cron jobs. The most common admin panel is cPanel, you can read more on how to add a Cron job for cPanel in the [official article](https://blog.cpanel.com/how-to-configure-a-cron-job/). Below is the official video.
{% youtube YwpUjz1tMbA %}
#### How to add a system Cron job for the VPS hosting
In case you’re an owner of VPS (Virtual Private Server i.e. Dedicated), you need to log in to your server with **SSH** and run the following command to open a file in editing mode.
#### Step 1. Setup a system Cron job for WordPress Cron
Now it’s time to create a system Cron job that will call WordPress Cron. Add a new line in your cron file and copy the content below.
```
*/10 * * * * wget -q -O - https://YOUR_DOMAIN_HERE/wp-cron.php?doing_wp_cron >/dev/null 2>&1
```
> _Note: The line above isn’t suitable for use with_ [_WordPress Multisite_](https://wplake.org/blog/wordpress-multisite/) _mode. If you’re using WP Multisite mode and you need a reliable Cron, then read more about workarounds_ [_here_](https://wplake.org/blog/wordpress-multisite/#5-cron-tasks)_._
Don’t forget to replace YOUR\_DOMAIN\_HERE with your domain.
The first part of the command states that we want our command to be executed once every ten minutes, regardless of an hour number, day of the week, and others options. The middle part uses the **wget** tool to request the WordPress Cron file, and the last part states that we don’t want to save the output of the Cron file.
You can read more about the arguments [here](https://help.ubuntu.com/community/CronHowto).
#### Step 2. Disable default WordPress checks
As we’ve now integrated WordPress Cron with the system Cron, WordPress no longer needs to check the schedule list within every user request. We tell WordPress by setting up a special constant in the **wp-config.php** file.
```
/* Add any custom values between this line and the "stop editing" line. */
define( 'DISABLE_WP_CRON', true );
/* That's all, stop editing! Happy publishing. */
```
As you can see the file has a special section for custom values, so you need to add this constant after the first comment, and before the second.
Don’t worry about the label of the constant, “ **DISABLE\_WP\_CRON** ” doesn’t actually mean completely disable WordPress Cron. It disables the checking of the schedule list with every user request. WP Cron should still work properly, as we call the **wp-cron.php** file directly via the system Cron.
That’s it! Congrats! Now your WordPress installation has a reliable Cron with all the WordPress features. Cron will run jobs according to the schedule, regardless of the amount of visitors’ to the website.
### 3. How to add and remove Cron jobs
WordPress Cron job is just a bit of PHP code that is executed by some schedule. Furthermore, it can use all the WordPress features and has access to the Database. [Here](https://developer.wordpress.org/plugins/cron/scheduling-wp-cron-events/) you can find an article for developers from WordPress on this topic.
#### Choosing an interval
Firstly, we need to choose an interval by which Cron will repeat our job. Default WordPress intervals are **hourly** , **twicedaily** , **daily** , **weekly**. Though it’s good enough for most cases, you may need a custom interval. We can define it by adding the following code.
```
add_filter('cron_schedules', function ($schedules) {
return array_merge($schedules, [
// here is the name of our custom interval. used when adding a new job
'five_hours' => [
// the number here represents seconds, so the formula is: 5 hours * 60 minutes * 60 seconds
'interval' => 5 * 60 * 60,
'display' => esc_html__('Every Five Hours'),
],
]);
});
```
#### Adding a new reoccurring job
To add a new Cron job we need to add a new shortcode and attach a schedule to the shortcode. The interval (the second argument to the **wp\_schedule\_event()** function) must be of one of the default intervals, or some custom name that you can add using the code snippet above.
```
add_action('YOUR_NAME_HERE', function () {
/* your job here
you can use all the WordPress features and functions
e.g. wp_insert_post() */
});
// we must check that the event wasn't scheduled as each call creates a new one
// otherwise, if we've skipped the check it'll create a new event for each user request
if (!wp_next_scheduled('YOUR_NAME_HERE')) {
/* the first argument is the timestamp which controls when the job
will be run for the first time
the next argument reflects the chosen interval */
wp_schedule_event(time(), 'hourly', 'YOUR_NAME_HERE');
return;
}
```
In the code above we’ve created an empty job that Cron runs once an hour.
#### Adding a new single job
The example above adds a job that Cron runs in a reoccurring method. But you also have the option to schedule a single job. For this goal, you need to use the **wp\_schedule\_single\_event()** function instead of the **wp\_schedule\_event()**. It can accept two (2) types of arguments: timestamp with the next execution time and the hook that contains the job. So let’s create a job that Cron will run only once, after 5 hours:
```
add_action('YOUR_NAME_HERE', function () {
/* your job here
you can use all the WordPress features and functions
e.g. wp_insert_post() */
});
// it's necessary to check that the event wasn't scheduled as each call creates a new one
// if you've skipped the check it'll create a new event for each user request
if (!wp_next_scheduled('YOUR_NAME_HERE')) {
// as before, the first argument is the timestamp which controls when the job will be run
// it's presented in seconds, so the formula is: 5 hours * 60 minutes * 60 seconds
wp_schedule_single_event(time() + 5 * 60 * 60, 'YOUR_NAME_HERE');
return;
}
```
#### Removing a Cron job
You can remove a scheduled job that you have previously added. It’s especially useful for reoccurring tasks. For this purpose, we’ll call the **wp\_unschedule\_event()** function with a couple of arguments. The first must contain the next timestamp for the event (we get it dynamically) and the second is your job name.
The code below removes single and reoccurring jobs. Also, pay attention, that for the reoccurring jobs, it’ll not only remove the schedule or the next event but also all future events of the job.
```
add_action('YOUR_NAME_HERE', function () {
/* your job here
you can use all the WordPress features and functions
e.g. wp_insert_post() */
});
// it's necessary to check that the event wasn't scheduled as each call creates a new one
// if you've skipped the check it'll create a new event for each user request
if (!wp_next_scheduled('YOUR_NAME_HERE')) {
// as before, the first argument is the timestamp which controls when the job will be run
// it's presented in seconds, so the formula is: 5 hours * 60 minutes * 60 seconds
wp_schedule_single_event(time() + 5 * 60 * 60, 'YOUR_NAME_HERE');
return;
}
```
### 4. How to monitor Cron jobs
Information about all WordPress Cron jobs is stored in the Database. This means we can get a list of all the scheduled jobs and manage them. It’s an important thing for developers and website owners.
If you have seen the WordPress Database scheme, then you know that there is no separate table for Cron. All Cron tasks are stored within a single option in the Options table. Most likely you already know this table, as any good WordPress developer knows the main tables of the WordPress Database. This knowledge is necessary to clear understand internal processes. If you want to check and improve your knowledge, read [what must a good WordPress developer know](https://wplake.org/blog/what-must-know-good-wordpress-developer/).

_WordPress stores Cron tasks as an option in the Options table_
But looking at the serialized data directly via PhpMyAdmin isn’t the best idea. That’s why we’ll use the [WP Crontrol](https://wordpress.org/plugins/wp-crontrol/) plugin which will give us a clear UI. Using the tool we can debug our Cron jobs or check external ones that are added by plugins. For example, we created our custom Cron job and ran it immediately using the tool to make sure it works correctly.
The plugin provides the interface for managing both Cron jobs and the intervals. Using it is quite simple. Install and activate the plugin then visit the “Tools” — “Cron events” item in your admin menu.
Here you can manage Cron jobs (called Cron Events) and Cron Intervals (called Cron Schedules).
_You can control each job individually. Hover your cursor on the target item to see the list of actionsp_
### 5. Cron and Cache plugins
The important thing that you have to pay attention to is the collaboration of WordPress Cron and cache plugins. Most WordPress websites use some cache plugin to reduce the response time. Overall the approach is good and important for SEO. Also, cache means a lot for [WordPress speed optimization](https://wplake.org/blog/9-tips-for-wordpress-speed-optimization/). But in our case, it also means we skip PHP execution and return HTML.
By default, WordPress Cron relies on user requests. Whether or not WordPress Cron will be called during requests to cached pages depends on the plugin that’s in use. From our experience cache plugins don’t call WordPress Cron or call Cron more rarely than when it’s out-the-box.
WordPress Cron will still be called during editor visits to the dashboard, but that may not be enough. This approach is okay in case your Cron jobs aren’t important and can be delayed for longer periods. Otherwise, consider the second part of the article.
> _The solution described in the second part of the article, regarding the merging of the system Cron and WordPress Cron, shows the clear benefits, so if you have used it in that way then you’re set and don’t need to worry about it any longer._
> _The_ **_wp-cron.php_** _file is called directly and WordPress Cron will work properly._
### Conclusion
We’ve reviewed the 5 important things about WordPress Cron. We recommend following the second part (merging system Cron and WordPress Cron) for each of your WordPress sites. It’ll save you from tonnes of headaches in the future. Also, don’t forget about the tools that allow you to monitor your Cron jobs. They’re quite useful.
We hope our article was helpful to you, and that you now have a clear picture of WordPress Cron and how to add your own Cron jobs using the code snippets.
| wplake |
1,383,791 | How to Gain Visibility into GitHub Actions | Hi, we're hosting a workshop on how to set up insights into your team's GitHub Actions workflow... | 0 | 2023-03-01T12:45:01 | https://dev.to/mmanja/how-to-gain-end-to-end-visibility-into-github-actions-30h7 | devops, githubactions, github | Hi, we're [hosting a workshop](https://www.opsera.io/webinars/end-to-end-visibility-into-github-actions) on how to set up insights into your team's GitHub Actions workflow performance, duration, success, and failure rate.
I'd love to see you there but in case you got any questions, let me know. | mmanja |
1,383,849 | When and Why to Use Laplace Transform? | The Laplace transform is a mathematical tool used to analyze and design linear time-invariant... | 0 | 2023-03-01T13:25:42 | https://dev.to/ikatebaker/when-and-why-to-use-laplace-transform-4ak8 | laplacetransform, signalprocessing, electronics | The Laplace transform is a mathematical tool used to analyze and design linear time-invariant systems. In these systems, the output is directly proportional to the input and they do not change over time. The Laplace transform is named after the French mathematician Pierre-Simon Laplace, who introduced the transform in his book "Théorie Analytique des Probabilités" (The Analytic Theory of Probabilities) in 1812.
The Laplace transform is based on the idea of representing a function as a sum of exponential functions, which makes it easier to analyze and design systems using algebraic techniques. The Laplace transform is a powerful tool that allows you to represent a continuous-time signal, which is a signal that is not sampled at discrete intervals of time, but as a complex-valued function of a complex variable called the S-variable.
The Laplace transform has many applications in the fields of engineering, science, and mathematics, including the [analysis of electrical circuits](https://www.studysmarter.co.uk/explanations/physics/electricity-and-magnetism/circuit-analysis/), mechanical systems, and control systems. It is also used in the analysis of differential equations and the solution of boundary value problems. The Laplace transform is an important tool for analyzing and designing systems that involve the processing of signals in the frequency domain.
**What is Laplace Transform?**
The Laplace transform is a mathematical tool used to analyze and design linear time-invariant systems and represents a continuous-time signal.
The Laplace transform is defined as:
where s is the S-variable, f(t) is the continuous-time signal, and F(s) is the Laplace transform of the signal.
The Laplace transform we defined above is also called the one-sided Laplace transform. The integral changes from −∞ to ∞ in the two-sided or bilateral Laplace transform version.
The bilateral Laplace transform can be expressed as:
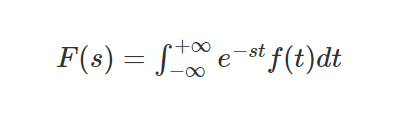
The Laplace transform has some useful properties that make it a powerful tool for analyzing and designing linear time-invariant systems. The Laplace transform, for instance, allows you to represent convolution, which is a mathematical operation that is commonly used in signal processing. This makes it easier to analyze systems using algebraic techniques.
The frequency response of a system can also be examined using the Laplace transform. A system's frequency response can be calculated by applying the Laplace transform to the transfer function, which is a mathematical model of the behavior of the system.
Additionally, you can also learn [Laplace Transform with MATLAB](https://www.theengineeringprojects.com/2022/09/basics-of-laplace-transform-in-signal-and-systems.html) if you want to get the better understanding of this transform.
**Inverse Laplace Transform**
The Laplace transform is a mathematical technique used to convert a function from the time domain into the complex frequency domain. The inverse Laplace transform is the mathematical operation that converts a function from the complex frequency domain back into the time domain.
In other words, if we have a function F(s) that has been transformed into the frequency domain using the Laplace transform, the inverse Laplace transform allows us to find the original function f(t) that existed in the time domain.
The inverse Laplace transform is usually denoted by the symbol L^-1 and is defined as follows:
L^-1{F(s)} = f(t)
The inverse Laplace transform can be performed using various techniques, including partial fraction expansion, contour integration, and the method of residues. These techniques can be used to find the inverse Laplace transform of a wide range of functions, including polynomial functions, rational functions, and exponential functions.
The inverse Laplace transform is a powerful tool in engineering and physics, and it is widely used to solve differential equations and other mathematical problems in these fields.
**Laplace Transform in Electronics**
In the field of electronics, the Laplace transform is commonly used in the design of electronic circuits, such as amplifiers, oscillators, and mixers.
By taking the Laplace transform of the transfer function of an electronic circuit, you can determine the frequency response of the circuit.
The Laplace transform is also used in the analysis of electronic circuits and systems, such as filters and transmission lines.
The Laplace transform is a crucial tool for the study and design of electrical circuits and systems in the field of electronics. It is particularly helpful for system analysis and design involving the processing of frequency domain signals.
The Laplace transform is a powerful mathematical tool for solving [linear differential equations](https://www.cuemath.com/calculus/linear-differential-equation/) with constant coefficients. It allows signals and systems to be represented as functions of a complex variable s instead of time, and differential equations can be transformed into polynomial equations of s.
Solving the equation in the Laplace domain involves simple polynomial manipulation, but the input and output signals must also be transformed into the Laplace domain. To obtain meaningful time-dependent signals, the system response must be transformed back to the time domain using the inverse Laplace transform.
**Applications of Laplace Transform**
The Laplace transform is a widely used mathematical tool that has a range of applications in the fields of engineering, science, and mathematics. Some of the key applications of the Laplace transform include:
1: Analysis of linear time-invariant systems
The Laplace transform allows you to represent a continuous-time signal as a function, which makes it easier to analyze and design linear time-invariant systems using algebraic techniques.
2: Frequency domain analysis
The LT can be used to analyze the frequency response of a system.
3: Design of electronic circuits
The LT is employed in the design of electronic circuits, such as amplifiers, oscillators, and mixers.
4: Analysis of mechanical systems
It is used in the analysis of mechanical systems, such as gears, springs, and levers.
5: Solution of differential equations
It is employed to solve differential equations, which are equations that describe the relationship between a function and its derivatives.
6: Control systems
The LT is used in the analysis and design of control systems, which are used to control the behavior of dynamic systems.
That’s all for today. Hope you found this read helpful. I’d appreciate your response in the section below. Until next time!
| ikatebaker |
1,383,855 | Dificuldade com Form Field - Angular | Eu estou aprendendo a usar o angular e por conta disso decidi escrever algumas dificuldades que estou... | 0 | 2023-03-01T13:32:23 | https://dev.to/brendacosta/dificuldade-com-form-field-angular-113p | Eu estou aprendendo a usar o angular e por conta disso decidi escrever algumas dificuldades que estou tendo durante essa jornada.
Estou com a tarefa de montar os componentes do Design system da empresa onde trabalho, e no meio do caminho tem aparecido algumas dificuldades.
1°: a documentação do angular e do material angular.
É muito fácil para uma pessoa que sabe uma linguagem de programação, virar para um iniciante e dizer que na documentação encontrar todas as respostas. Isso não é totalmente verdade, pois tem algumas coisas que fica subentendido que você já sabe fazer.
Já fique empacada em uns problemas onde na documentação não está claro a necessidade de importar determinados módulos, o que me tomou bastante tempo.
Eu vou pegar aqui um exemplo simples:
Preciso de um componentes de input que valide se a entrada do usuário é um email, caso não for mostre uma mensagem de erro.
É um exemplo muito simples, copiei e colei da documentação para o VS Code e puft! Erro! No meu terminal só aparecia:
`Can't bind to 'formControl' since it isn't a known property of 'input'.`
Depois de idas e vindas na documentação, buscas e mais buscas, descobrir que faltava um módulo a ser importado
`import { ReactiveFormsModule } from '@angular/forms';`
E o input funcionou...
A intenção aqui é criar uma espécie de anotação das dificuldades para caso aconteça novamente, vim direto ou quem sabe ajudar alguém que esteja começando e perdido. | brendacosta | |
1,383,916 | Testes no Front-end: por que, como e quais tipos usar | Testes são fundamentais em qualquer tipo de aplicação, e com o front-end não é diferente. Afinal,... | 22,075 | 2023-03-01T15:15:35 | https://dev.to/neiltonseguins/testes-no-front-end-por-que-como-e-quais-tipos-usar-11jp | testing, frontend, react | Testes são fundamentais em qualquer tipo de aplicação, e com o front-end não é diferente. Afinal, testar as funcionalidades e a usabilidade da sua aplicação web ajuda a **garantir** que ela esteja funcionando corretamente, sem bugs, e que a experiência do usuário esteja satisfatória.
## Tipos de testes no Front-end
Existem diversos tipos de testes que podem ser utilizados em aplicações front-end. Entre os mais comuns, podemos destacar:
- **Testes Unitários**: São testes que avaliam **pequenas partes do código**, como funções e métodos. Esses testes garantem que essas partes do código funcionem corretamente. O [Jest](https://jestjs.io/pt-BR/) é uma das ferramentas mais comuns para testes unitários.
- **Testes de Integração**: São testes que avaliam a **integração entre as partes da aplicação**. Eles garantem que os diferentes componentes se comuniquem corretamente e que a aplicação como um todo funcione corretamente.
- **Testes End-to-End**: São testes que **simulam a interação de um usuário com a aplicação**. Eles garantem que a aplicação funcione corretamente do ponto de vista do usuário final. O [Cypress](https://www.cypress.io/) é uma das ferramentas mais comuns para testes end-to-end.
## Ferramentas de Testes
Existem muitas ferramentas de testes para aplicações de Front-end. Algumas das mais comuns são:
- [Jest](https://jestjs.io/pt-BR/): É um framework de testes criado pelo Facebook. Ele é rápido e fácil de usar e tem uma boa documentação. É comumente usado para testes unitários e de integração em aplicações React.
- [Testing Library](https://testing-library.com/): É uma biblioteca que ajuda a testar as interações do usuário com a aplicação. É fácil de usar e tem uma abordagem mais voltada para o usuário final.
- [Cypress](https://www.cypress.io/): É uma ferramenta de teste de integração que simula a interação do usuário com a aplicação. É útil para testes de ponta a ponta, onde você deseja testar a aplicação como um todo.
- [Puppeteer](https://pptr.dev/): É uma biblioteca que controla um navegador Chrome para testar a aplicação. É útil para testes de aceitação, onde você deseja testar a aplicação como um usuário final faria.
- [Enzyme](https://enzymejs.github.io/enzyme/): É uma biblioteca de testes que fornece utilitários para interagir com componentes React e verificar o seu estado. Ele é amplamente utilizado para testes unitários e de integração em aplicações React, e oferece uma sintaxe simples e fácil de entender para testar componentes.
- [Mocha](): É um framework de teste de JavaScript que suporta testes assíncronos e síncronos, bem como testes de unidade e integração. Ele também oferece uma ampla variedade de recursos, incluindo hooks para configurar testes, relatórios detalhados e suporte a múltiplos ambientes de execução.
Cada ferramenta possui vantagens e desvantagens ao testar suas aplicações. Independentemente da ferramenta escolhida, o importante é que as aplicações sejam testadas regularmente e com cuidado. Testes bem escritos podem ajudar a detectar bugs antes que eles se tornem um problema sério, melhorar a qualidade do código e facilitar a manutenção da aplicação.
## Mas por que testar as aplicações Front-end?
Testar aplicações front-end é importante porque elas são a interface principal entre os usuários e o sistema. É fundamental garantir que a interface do usuário funcione conforme o esperado.
Além disso, as aplicações front-end estão sujeitas a uma grande variedade de dispositivos, navegadores e sistemas operacionais. Testes podem ajudar a garantir que a aplicação funcione corretamente em todos os ambientes possíveis.
---
Bom, essa foi apenas uma breve introdução sobre testes no Front-end, espero que em breve eu possa trazer mais assuntos sobre este tema tão rico e importante no desenvolvimento de software!
Espero que vocês tenham curtido a leitura e até a próxima!! | neiltonseguins |
1,383,980 | Top five query tuning techniques for Microsoft SQL Server | Data technologies have gone through great advancements over the past decades enabling businesses to... | 21,681 | 2023-03-03T07:30:41 | https://www.dbvis.com/thetable/top-five-query-tuning-techniques-for-microsoft-sql-server/ | **Data technologies have gone through great advancements over the past decades enabling businesses to easily own and operate databases on the cloud and scale up their resources in a few clicks. Faded by technological improvement, people sometimes neglect the basic but essential techniques that can make their database fast and reliable. In this article, we will learn the top five query-tuning techniques for Microsoft SQL Server.**
## Detect slow queries
To tune slow queries, you first need to find them. You will need to examine them one by one and prioritize tuning. Before selecting slow queries, prepare a speed threshold to only include tuning candidates. To query slow queries that are slower than your threshold, check the query below.
```
SELECT
req.session_id
, req.total_elapsed_time AS duration_ms
, req.cpu_time AS cpu_time_ms
, req.total_elapsed_time - req.cpu_time AS wait_time
, req.logical_reads
, SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1
THEN DATALENGTH(ST.text)
ELSE req.statement_end_offset
END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '),
1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
WHERE total_elapsed_time > {YOUR_THRESHOLD}
ORDER BY total_elapsed_time DESC;
```
This query gives you a list of elapsed time of each query. The slowest query will appear at the top. You can add your threshold figure in the where clause to, for example, select the top five slowest queries.
### Start with the basics
Once you find the queries to be tuned, check if the queries are following the basic rules for performance.
- Use the where condition to limit scanning scope
- Don’t select everything
- Use inner join instead of correlated subqueries
- Try to avoid HAVING and use WHERE
- Use inner join instead of two tables in the where clause
### Use the where condition to limit scanning scope
The goal of running a query is to get the information you need. When you run a query without a condition, the database needs to scan the whole area of a table, which leads to a slower query response. If possible, use the where clause to precisely aim at the data you need.
### Don't select everything
People often use the star symbol (*) for convenience. However, if a table consists of many columns and holds a large number of records, selecting all of the columns and rows will consume more resources. Instead of using select all, specify the column names that you want.
### Use inner join instead of correlated subqueries
If you use a correlated subquery (or a repeating subquery), the subquery you use gets executed repeatedly. The sample below shows you what a correlated subquery looks like.
```
SELECT column1, column2, ....
FROM table1 outer
WHERE column1 operator
(SELECT column1, column2
FROM table2
WHERE expr1 = outer.expr2);**
```
The subquery after the operator is run repeatedly until it satisfies the `WHERE` condition. Instead of using the correlated subquery, consider using the inner join.
### Try to avoid the HAVINGclause and use the WHEREstatement
When you run an aggregated query using `GROUP BY`, you can add a condition using `HAVING`. It is recommended to use `HAVING` only on an aggregated field and not to use it when you can replace it with a where condition. A `HAVING` clause is calculated after a where clause, so it is recommended to limit data scanning prior to the `HAVING` clause.
### Use inner join instead of two tables in the where clause
You can put two tables in the where clause to use like `JOIN`. Although it is grammatically accepted, it creates inefficient query execution. Cartesian Join or `CROSS JOIN` refers to the SQL computation that requires a combination of all possible variables. When you use two tables in the where clause, Cartesian Join kicks in, which consumes a lot of resources. Instead, try to use `INNER JOIN`.
## Use EXPLAIN to find pain points
You can use the `EXPLAIN` command to diagnose your queries. The command explains your query and shows you how a query will be executed step-by-step. You can use the result to find inefficient steps. The syntax of `EXPLAIN` is simple.
```
EXPLAIN
{YOUR_QUERY}
```
Put the command, `EXPLAIN`, above your query and then execute it. In the {YOUR_QUERY} section, you can put not only a `SELECT` query but also an `UPDATE`, `INSERT`, or `DELETE` statement.
But, it is not straightforward to interpret the result returned from the explain query since it throws you all kinds of text and numbers. Instead, try a visual interpretation like DbVisualizer. When you get visual interpretation, it becomes much easier and intuitive to interpret query steps and pinpoint where to focus.
<br \>
<figure><figcaption>DbVisualizer SQL editor</figcaption></figure>
<br \>
When you execute an SQL in DbVisualizer, you can see its explain plan at the bottom section as the image above. When you select the Graph View option highlighted in a red box, you can see graph view.
<br \>
<figure><figcaption>Query cost is indicated by color</figcaption></figure>
<br \>
In this graph view, each node in the visual presentation contains more detailed information such as different types of costs, arguments, and more.
##Index your tables
Indexing your tables can speed up your query performance. It is like how the index at the end of a book works. By referring to the index, you can go to the page and find the information you need. To efficiently index your tables, there are several points you need to consider.
- Prioritize tables by frequency and importance: before setting indexes, you need a plan. It is a good practice to prioritize your queries by frequency and importance and then start examining the tables to decide their indexes. For example, if you have some queries that are scheduled to be run every hour and the result of those queries is used for generating invoices for customers (which is directly linked to your revenue), they can become top candidates.
- Choose columns that are often used in the where clause or join keys: when you index columns, you put those columns in an SQL index table so that when those columns are searched, the database can quickly retrieve the records you are looking for. Check which columns you often use in where or join conditions. Adding them to the index table can speed up a search or a join query.
- Consider column data types: after researching the columns that are frequently used in join and where conditions, check their data type. The most suitable data type for the index is the integer type and the worst candidate is a string type. Also, a column that always has a unique value and a NOT NULL constraint can be a good index candidate.
## Use visualization tools like DbVisualizer
When you perform query tuning on your own, it can be pretty challenging and time-consuming. [DbVisualizer](https://www.dbvis.com/) is a universal tool that can meet all your database needs from running queries to database management and query tuning. It beautifully displays database system data for users to interpret information more easily. Its [optimization](https://www.dbvis.com/features/database-management/#optimize) feature can help you to achieve your tuning goals and make your database operate efficiently.
In addition to query tuning, there are more tasks that can benefit from visualization by DbVisualizer. Among many, you can utilize its visual query builder and automatic ERD generation.
<br \>
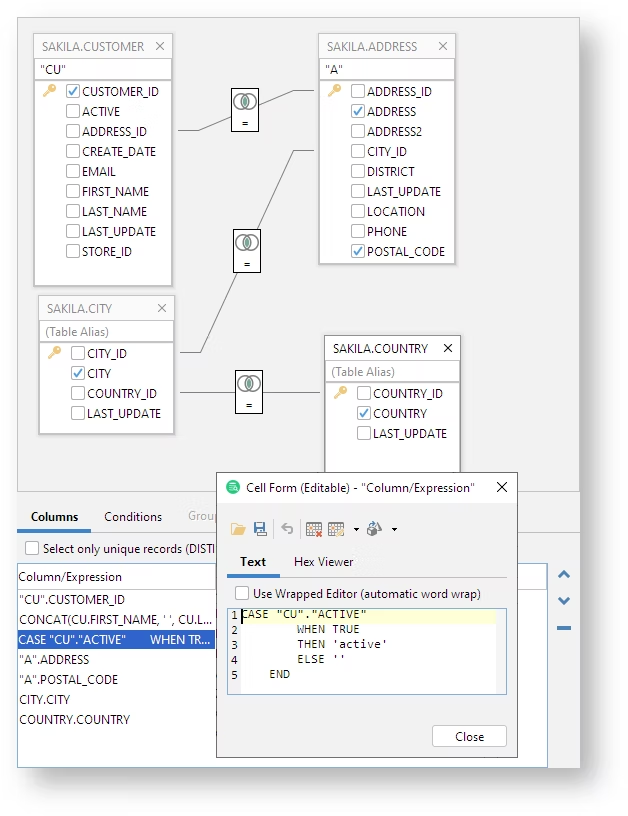
<figure><figcaption>Visual query builder</figcaption></figure>
<br \>
The visual query builder lets you simply click the columns you want to select and choose the operations you want to perform. With this visual feature, you can more intuitively build your query.
<br \>
<figure><figcaption>ERD generator</figcaption></figure>
<br \>
The ERD generation feature visually displays the relations of your tables. Using the auto-generated diagram, you can efficiently document your table designs and share your ideas with team members.
## Conclusion
In this article, we learned the top five query tuning techniques for Microsoft SQL Server. By optimizing your queries, you can more reliably and efficiently serve data requests that come from your online products, dashboards, ad-hoc queries, and other sources. Also, you can reduce costs for upgrading database resources. DbVisualizer can help you to achieve these objectives by providing a single point for users to perform various tasks of the database. Find out more [features](https://www.dbvis.com/features/) of DbVisualizer.
##About the author
Igor Bobriakov is an entrepreneur and educator with a background in marketing and data science. His passion is to help small businesses and startups to utilize modern technology for growth and success. Igor is Data Scientist and ML Engineer. He founded Data Science School in 2016 and wrote numerous award-winning articles covering advanced tech and marketing topics. You can connect with him on [LinkedIn](https://www.linkedin.com/in/bobriakov/) or [Twitter](https://twitter.com/ibobriakov).
| dbvismarketing | |
1,394,720 | The Real Threat to Your Job Security (Hint: It's Not AI). | Are you worried about losing your job to artificial intelligence (AI)? It's a common fear that many... | 0 | 2023-03-09T17:28:02 | https://dev.to/vinosamari/the-real-threat-to-your-job-security-hint-its-not-ai-38b2 | ai, futureofwork, motivation | Are you worried about losing your job to artificial intelligence (AI)? It's a common fear that many people share, but the reality is not as dire as some might think. In fact, the real threat to job security is not AI but something else entirely.
If we look back in history, we can see that technological advancements have always threatened certain jobs. For example, the introduction of tractors and power tools in agriculture and carpentry respectively were once seen as major threats to job security in those industries. While there were certainly some job losses, people adapted and learned how to use the new technology to their advantage. The same can be said for AI.
While AI has the potential to automate certain tasks, it doesn't mean that humans are completely replaceable. In fact, the collaboration between humans and machines can lead to better outcomes in fields like art, music, and data analysis. Instead of being scared of AI, we should be embracing its potential and learning how to work alongside it.
[According to experts](read://https_www.elsevier.com/?url=https%3A%2F%2Fwww.elsevier.com%2Fconnect%2Fthe-biggest-misconceptions-about-ai-the-experts-view), some of the biggest misconceptions around AI are that people think it's close to being sentient and that there is a single algorithm that suddenly knows everything. However, AI is still limited and cannot reason about the world in the way humans do. Despite its limitations, AI has the potential to be a beneficial tool for almost any scientist, and collaborations with machine learning specialists can yield positive results. Therefore, it's essential not to overestimate the current standards of AI, as it is still a glorified signal processing tool.
One of the biggest challenges we face with AI is ensuring that machines learn from unbiased and diverse sources of information. Humans have a crucial role to play in providing this firsthand information to machines, and we need to make sure that our biases don't get in the way of progress.
It's important to note that AI has the potential to transform many industries and create new jobs that we haven't even imagined yet. For example, AI can help us tackle some of the world's biggest challenges, such as climate change, healthcare, and poverty. In the healthcare industry, AI can be used to develop more personalized treatments and improve patient outcomes. In the environmental sector, AI can help us better understand climate patterns and develop more effective solutions to reduce greenhouse gas emissions. These are just a few examples of how AI can be a powerful tool for good.
However, we must also be aware of the potential negative consequences of AI. For example, AI could potentially displace certain workers and exacerbate existing inequalities. Therefore, it's important to consider the social and ethical implications of AI as we continue to develop and implement it in various industries.
In the end, it's up to us to shape the future of work with AI. Let's not be afraid of it, but instead, let's work together to create a world where humans and machines can coexist and thrive. So, the next time you hear someone say that AI will take your job, remember that the real threat to your job security is not AI but our own resistance to change.
| vinosamari |
1,394,745 | Stop typing in typescript. (At least most of the time) 🛑 | I apologise in advance for the clickbait title. Many people use typescript the wrong way, blame it... | 0 | 2023-03-09T18:58:45 | https://dev.to/nectres/dont-type-in-typescript-at-least-most-of-the-time-5b0j | webdev, javascript, typescript, programming | I apologise in advance for the clickbait title.
Many people use typescript the wrong way, blame it for their bad use and turn back to javascript. You don't have to type everything explicitly in typescript. Actually, I would argue in most cases you should let typescript do it for you via type inference. That's the best way to do it. Makes the code more readable while preserving the benefits of using it.
## Not bloated, not hard to read
Take a look at this bit of JavaScript code:
Let's write a basic function that prints whether a person can vote along with their first name which I broke into multiple variables to prove a point.
```javascript
function canIVote(name, age) {
const nameParts = name.split('');
const firstName = nameParts.shift();
const canVote = age > 18;
const message = canVote
? `Congrats ${firstName}, you can vote!`
: `Sorry ${firstName}, you can't vote.`;
console.log(message);
}
```
Here's an example of incorrect use of typescript:
```typescript
function canIVote(name:string, age:string) {
const nameParts:string[] = name.split(' ');
const firstName:string = nameParts.shift() as string; // as string to ignore the error from it being string | undefined
const canVote:boolean = age > 18;
const message:string = canVote
? `Congrats ${firstName}, you can vote!`
: `Sorry ${firstName}, you can't vote.`;
console.log(message);
}
```
While this might not look bad, this approach does not scale well. You will spend more time writing out the types of things than actually coding the things. When the project becomes bigger and more complex, the code is going to look messier and unmaintainable.
This is where few developers run into the issue of typescript being less readable and complain about writing a lot more lines of code to achieve the same result. They would be right, if the above code was the norm and if the project was big enough.
Another thing to note in this approach is the `as` keyword. Use it wisely. Don't use it to squash warnings but properly handle the value type and perform actions accordingly. `as` should only be used when you are certain what the type of a variable is going to be.
Here's an example of correct use of typescript:
```typescript
function canIVote(name:string, age:string) {
const nameParts = name.split(' ');
const firstName = nameParts.shift(); // -> string | undefined
if (!firstName)
throw new Error("How do you not have a first name?");
// now if you hover over firstName the type will have changed
// to `string` because we have handled `undefined` above and
// removed that case.
const canVote = age > 18;
const message = canVote
? `Congrats ${firstName}, you can vote!`
: `Sorry ${firstName}, you can't vote.`;
console.log(message);
}
```
## any
Don't use `any` just _**any**where_.
Sorry, couldn't resist. Avoid using `any`. If you are using `any` everywhere, you are just using javascript with more steps. `any` can be used if you are migrating the code from a javascript codebase gradually typing things out but don't let it stay that way.
## Typing
There are definitely cases where you have to explicitly mention a type for a variable because the inference was vague and you are certain it is of one type. You do have to define your own types for interfaces, objects, etc for the best experience.
Only in very rare scenarios will you have to write types like this:
Don't be scared though, 95% of the time you are going to typing things in very simple types like `string`, `number`, `boolean`, `Date`, etc. either directly or through arrays and interfaces.
Thank you for reading it till the end.
Follow me on twitter here: https://twitter.com/keerthivasansa_
I am trying to build a twitter profile. | nectres |
1,395,014 | Explore the Versatility of Python language. | The first time I started my research on programming languages, it occurred to me that Python language... | 0 | 2023-03-09T21:44:05 | https://dev.to/ritapossible/explore-the-versatility-of-python-language-16ea | webdev, beginners, python, codenewbie | The first time I started my research on programming languages, it occurred to me that Python language is the most recommended language both for Beginner, Intermediate and Expert programmers. You might be wondering what is special about Python language, one of the reasons it's considered special is its **Versatility**. Python can be used for multiple tasks such as; devising machines, learning algorithms, automation of machines or just data analysis. Some other reasons why Python is considered special and popular are; the readability of its code which is very much similar to human language, its fastness, its ease to use which makes it beginner-friendly etc.
In this article, we will be focusing on different purposes which Python can be used for, the Versatility of Python language and some of the popular website applications built using Python language.
Let's get started!
**Python for Different Purposes.**
Here are some of the different domains where Python can be used.
**Web Development:**
Python has several frameworks that make web development easy and efficient. Django and Flask are two of the most popular web frameworks in Python. Python is also used for building web crawlers and data extraction tools, which are widely used for web scraping and data analysis.
**Data Science and Machine Learning:**
Python has become a popular language in this field due to its simplicity and availability of several powerful libraries such as Numpy, Pandas, Matplotlib, and Scikit-learn. Numpy and Pandas are used for data manipulation and analysis, while Matplotlib is used for data visualization. Scikit-learn is a popular machine-learning library that includes various algorithms for classification, regression, clustering, and dimensionality reduction. You can read further about these libraries in my previous article here.
{% embed https://augustinerita.hashnode.dev/12-top-python-libraries-to-know-in-2023 %}.
**Artificial Intelligence and Deep Learning:**
As we all know, it's the era of AI (Artificial Intelligence). Python has become a popular language in this field. TensorFlow and KerasFlow are two popular libraries for building deep learning models. Python is also used for natural language processing, computer vision, and robotics.
**Desktop and Game Development:**
Pygame is a popular library for building 2D games in python. Python can be used for building desktop applications using libraries such as PyQt and PyGTK. These libraries provide support for building cross-platform desktop applications.
**Why Python is Considered the Most Versatile Programming Language.**
Now that we are aware of different domains in which Python language can be applied, let us discuss reasons why Python is considered versatile.
**Easy to learn (Beginner-Friendly):**
Python is considered popular and versatile today because of its easy-to-learn code syntax. Python programming language also has the best code readability as being a high-level language it's also close to human language.
**Reliability and Efficiency:**
Python language allows faster development time for software developers and engineers, which makes it very efficient. When compared to most programming languages, Python is considered more reliable as it can be used in multiple platforms and systems without any performance loss issue.
**Feature-Packed Libraries and Framework:**
Python libraries and frameworks help avoid repeating codes from scratch. These libraries are already pre-written and they provide different features when used in Python programs.
**Easy to Automate:**
Python programming language helps many software industries save a lot of time by helping them automate a time-wasting task. Python language comes with a lot of tools, modules, and libraries which help automate every repetitive task.
**Fasten Prototype Development:**
Python is considered the best programming language to build a scalable web application that needs to be tested on a small scale, this is because Python is quick and easy to work with. Therefore, developing a prototype for a web application becomes just a matter of days.
**An Open Source Tool:**
Python programming language is freely usable for commercial use with its source code being contributed by highly skilled developers around the world (Developed under an OSI-approved open-source license). You can easily find python source codes on platforms like GitHub. This does not just make developing using python free but has also ensured help and support from Expert python programmers.
**Popular Websites and Applications that are Developed Using Python Language.**
**Instagram:**
This popular social media platform was built using Python and Django web frameworks.
**YouTube:**
This popular video-sharing platform was built using Python and Google's web framework called 'Bento'.
**Spotify:**
This popular music streaming service was built using Python and Django web frameworks.
**Dropbox:**
This popular cloud storage service was built using Python and uses a custom web server written in Python.
**Reddit:**
This popular social news aggregation website was built using Python and its web framework, called 'Pylons'.
**Quora:**
This popular question-and-answer website was built using Python and uses its web framework, called 'Pyramid'.
**BitTorrent:**
This popular file-sharing protocol was developed using Python.
**NASA:**
Python is used in NASA for various scientific computing tasks and data analysis.
**Industrial Light & Magic:**
This special effects company is responsible for creating the visual effects for movies like Star Wars and Indiana Jones. It uses Python for its scripting and automation needs.
**SurveyMonkey:**
This popular online survey tool was built using Python and its web framework called 'TurboGears'.
The above-mentioned are just a few of them, many websites and applications were developed using Python.
**Conclusion:**
In this article, you have learned why Python is considered versatile, different domains where Python can be applied and some web applications built using Python programming language. If you are looking to explore the versatility of Python language, consider researching more through online courses, communities and tutorials since little information is covered in this article.
Thank you for reading through, if you liked this article consider connecting with me on {% embed https://mobile.twitter.com/Simply_RiTq %}
**Cheers!!!** | ritapossible |
1,395,029 | The Weekend Coder: What Are Your Favorite Coding-inspired (or Inspiring) Movies? | It’s the weekend! Time to relax, pursue some hobbies, maybe check out a new flick or a rewatch an old... | 22,093 | 2023-03-11T08:00:00 | https://dev.to/codenewbieteam/the-weekend-coder-what-are-your-favorite-coding-inspired-or-inspiring-movies-5dgk | discuss, beginners, codenewbie, motivation | It’s the weekend! Time to relax, pursue some hobbies, maybe check out a new flick or a rewatch an old fave. Speaking of which…some of our favorite movies here at DEV are ones that feature coding, tech, or hackers. From classics like WarGames to newer releases like The Imitation Game, documentaries like Code 2600 and romances like Her ❤️😢, there's something for everyone.
So, what’s on your personal list of must-see movies for programmers and coders? Do you like the realistic portrayals or the more fantastical ones? Share your rec’s and let's talk movies! | ben |
1,395,625 | Content & Tooling Team Status Update | We had visitors this week! This week has been super busy as we had some visitors in the... | 0 | 2023-03-10T16:55:29 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2023-03-10-status-update/ | puppet, modules | ---
title: Content & Tooling Team Status Update
published: true
date: 2023-03-10 00:00:00 UTC
tags: puppet, modules
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2023-03-10-status-update/
---
## We had visitors this week!
This week has been super busy as we had some visitors in the Belfast office. This resulted in the whole content and tooling team being under the one roof. To mark this we were lucky enough to fit in some team building (in the form of axe throwing) and have some great conversations.

## SQL Server 2022 is now supported!
Thanks to some heavy lifting by [jordanbreen28](https://github.com/jordanbreen28) our sqlserver module now supports SQLServer2022 and has gone through quite an extensive number of changes. Now that the work has been completed, it has been released and is available on the Forge.
## Community Contributions
We’d like to thank the following people in the Puppet Community for their contributions over this past week:
- [`puppetlabs-firewall#1107`](https://github.com/puppetlabs/puppetlabs-firewall/pull/1107): “Ignore OpenBSD, similarly to FreeBSD”, thanks to [buzzdeee](https://github.com/buzzdeee)
- [`puppetlabs-stdlib#1295`](https://github.com/puppetlabs/puppetlabs-stdlib/pull/1295): “Safely handle a missing root user”, thanks to [ekohl](https://github.com/ekohl) and the following people who helped get it over the line ([hboetes](https://github.com/hboetes))
- [`puppetlabs-stdlib#1281`](https://github.com/puppetlabs/puppetlabs-stdlib/pull/1281): “Add Stdlib::Ensure::Package type”, thanks to [arjenz](https://github.com/arjenz) and the following people who helped get it over the line ([ekohl](https://github.com/ekohl))
- [`puppetlabs-tomcat#503`](https://github.com/puppetlabs/puppetlabs-tomcat/pull/503): “Allow adding and removing attributes in Context (#502)”, thanks to [uoe-pjackson](https://github.com/uoe-pjackson)
- [`puppet-lint#103`](https://github.com/puppetlabs/puppet-lint/pull/103): “(maint) Corrects legacy macOS facts”, thanks to [mhashizume](https://github.com/mhashizume)
## New Module / Gem Releases
The following modules were released this week:
- [`puppetlabs-concat`](https://github.com/puppetlabs/puppetlabs-concat) (`7.3.2`)
- [`puppetlabs-wsus_client`](https://github.com/puppetlabs/puppetlabs-wsus_client) (`5.0.0`)
- [`puppetlabs-sqlserver`](https://github.com/puppetlabs/puppetlabs-sqlserver) (`3.3.0`) | puppetdevx |
1,395,046 | Reinventing IBM | DevSecOps, AI, Quantum Computing | No company is immune to transformation, not even one with as storied a history as IBM. This week on... | 0 | 2023-03-09T23:15:51 | https://devinterrupted.com/podcast/reinventing-ibm-devsecops-ai-quantum-computing/ | security, devops, ai, podcast | No company is immune to transformation, not even one with as storied a history as IBM.
This week on Dev Interrupted, Rosalind Radcliffe, the CIO DevSecOps CTO at IBM, joins us to chat about how one of tech's greatest legacy companies is positioning itself for the future.
Rosalind shares what it means to be named an IBM Fellow, her work to bring DevOps and open source to the z/OS environment, and what the future looks like at IBM. [Hint: it involves quantum computing and AI!]
{% spotify spotify:episode:5aMbWCkL858QNRSPd9FSCo %}
## Episode Highlights:
* (2:01) What does it mean to be an IBM Fellow?
* (3:45) DevOps transformation at IBM
* (8:38) z/OS
* (12:40) IBM's founding in 1924
* (16:38) Moving to a zero trust environment
* (23:36) Fit for purpose
* (30:00) Scaling apprenticeship programs
* (35:11) Quantum computing and AI
***While you’re here, check out this video from our [YouTube channel](https://www.youtube.com/c/DevInterrupted?sub_confirmation=1), and be sure to like and [subscribe](https://www.youtube.com/c/DevInterrupted?sub_confirmation=1) when you do!***
{% youtube 6LvUiex6YPk %}
### Want to cut code-review time by up to 40%? Add estimated review time to pull requests automatically!
*gitStream is the free dev tool from LinearB that eliminates the No. 1 bottleneck in your team’s workflow: pull requests and code reviews. After reviewing the work of 2,000 dev teams, LinearB’s engineers and data scientists found that pickup times and code review were lasting 4 to 5 days longer than they should be.*
*The good news is that they found these delays could be eliminated largely by adding estimated review time to pull requests!*
### Learn more about how gitStream is making coding better [HERE](https://linearb.io/blog/why-estimated-review-time-improves-pull-requests-and-reduces-cycle-time/?utm_source=Substack%2FMedium%2FDev.to&utm_medium=referral&utm_campaign=gitStream%20-%20Referral%20-%20Distribution%20Footers).

| conorbronsdon |
1,395,293 | Create NestJS Microservices using RabbitMQ - Part 2 | In the past blog, we have learned the basic communication between two services created with Nestjs... | 0 | 2023-03-14T18:48:31 | https://dev.to/hmake98/create-nestjs-microservices-using-rabbitmq-part-2-121b | microservices, nestjs, rabbitmq, typescript | In the past blog, we have learned the basic communication between two services created with Nestjs and RabbitMQ.
In this blog, we will learn and create an example of another concept of Nestjs, the Event pattern. using event patterns we can create a worker for microservice which will work on the jobs created by other services.
this example will help you to get an idea of basic communication with event patterns.
we will use Prisma as an ORM for the postgres database. Prisma is a type-safe ORM that provides built-in support for typescript types and generated migrations. checkout the documentation [here](https://www.prisma.io/).
First, let's start up core services that we have used in a past blog.
```bash
docker-compose.yml
```
now, we can start creating forgot password APIs for user service.
in main.ts (user service) - bootstrap function
```typescript
const logger = new Logger();
const configService = new ConfigService();
app.connectMicroservice({
transport: Transport.RMQ,
options: {
urls: [`${configService.get('rb_url')}`],
queue: `${configService.get('auth_queue')}`,
queueOptions: { durable: false },
prefetchCount: 1,
},
});
await app.startAllMicroservices();
await app.listen(9001);
console.log('User service started successfully');
```
and in app.controller.ts (user service) create a controller for forgot password API.
```typescript
@Public()
@Post('/forgot-password')
forgotPassword(@Body() data: ForgotPasswordDto): Promise<void> {
return this.appService.sendForgotPasswordEmail(data);
}
```
and in app.service.ts (user service)
```typescript
public async sendForgotPasswordEmail(data: ForgotPasswordDto) {
try {
const { email } = data;
const user = await this.getUserByEmail(email);
if (!user) {
throw new HttpException('user_not_found', HttpStatus.NOT_FOUND);
}
const token = nanoid(10);
await this.prisma.token.create({
data: {
expire: new Date(new Date().getTime() + 60000),
token,
user: {
connect: {
email,
},
},
},
});
const payload: IMailPayload = {
template: 'FORGOT_PASSWORD',
payload: {
emails: [email],
data: {
firstName: user.first_name,
lastName: user.last_name,
},
subject: 'Forgot Password',
},
};
this.mailClient.emit('send_email', payload);
} catch (e) {
throw e;
}
}
```
here we're using `mailClient` with function `emit`. using emit we can send payload to the service connected with current microservice.
difference between `emit` and `send` is we can not expect something in return while using emit for sending the payload.
now, create a mailer service using NestJS Cli.
in main.ts of mailer service, update the bootstrap function.
```typescript
const logger = new Logger();
const configService = new ConfigService();
const app = await NestFactory.createMicroservice<MicroserviceOptions>(
AppModule,
{
transport: Transport.RMQ,
options: {
urls: [`${configService.get('rb_url')}`],
queue: `${configService.get('mailer_queue')}`,
queueOptions: { durable: false },
prefetchCount: 1,
},
},
);
await app.listen();
logger.log('Mailer service started successfully');
```
now, define mailer service in user service. in import of app.module.ts (user service)
```typescript
ClientsModule.registerAsync([
{
name: 'MAIL_SERVICE',
imports: [ConfigModule],
useFactory: (configService: ConfigService) => ({
transport: Transport.RMQ,
options: {
urls: [`${configService.get('rb_url')}`],
queue: `${configService.get('mailer_queue')}`,
queueOptions: {
durable: false,
},
},
}),
inject: [ConfigService],
},
]),
```
this will tell user service that we will use mailer services as a dependency service.
in app.service.ts (user service) inject and connect mailer service.
```typescript
constructor(
@Inject('MAIL_SERVICE') private readonly mailClient: ClientProxy,
private prisma: PrismaService,
) {
this.mailClient.connect();
}
```
and now in app.controller.ts (mailer service), define `send_email` event pattern.
```typescript
@EventPattern('send_email')
public sendEmailPattern(@Payload() data): void {
this.appService.sendEmail(data);
}
```
in app.service.ts (mailer service), create an aws instance and create a function for sending an email.
NOTE: update `templatePath` as per project structure.
```typescript
private ses: SES;
constructor(private configService: ConfigService) {
this.logger = new Logger();
this.ses = new SES({
...this.configService.get('aws'),
});
}
async function sendEmail(job: {
data: { template: EmailTemplates; payload: any };
}) {
const { template, payload } = job.data;
const templatePath = join(
__dirname,
'./templates/',
`${EmailTemplates[template]}.html`,
);
let _content = readFileSync(templatePath, 'utf-8');
const compiled = _.template(_content);
_content = compiled(payload.data);
this.ses
.sendEmail({
Source: this.configService.get('sourceEmail'),
Destination: {
ToAddresses: payload.emails,
},
Message: {
Body: {
Html: {
Charset: 'UTF-8',
Data: _content,
},
},
Subject: {
Charset: 'UTF-8',
Data: payload.subject,
},
},
})
.promise()
.catch((error) => this.logger.error(error));
}
```
Here, our mailer service does not have any ports open as there are no APIs contained for mailer service in our example.
this will send emails of forgot password token links to users with the help of mailer service. from here we can look further into the scalability of the patterns we have used here and in a past blog.
here, we have used RabbitMQ as a connection between two services, which is also a Queue service. we can scale RabbitMQ on amazon AWS based on built service. so that if the number of incoming requests from user service will increase then we have enough amount of computing power available for the mailer queue to process incoming requests.
I have created a complete example of microservices using NestJS and RabbitMQ on [Github](https://github.com/BackendWorks/nestjs-microservices). If you have any suggestions or have any issues, create issues/PR on GitHub.
Thanks for reading this. If you've any queries, feel free to email me at harsh.make1998@gmail.com
Until next time! | hmake98 |
1,395,294 | How to check if character is uppercase in Rust? | In Rust, the char data type represents a Unicode Scalar Value. Unicode defines a unique numeric value... | 0 | 2023-03-10T06:04:38 | https://dev.to/foxinfotech/how-to-check-if-character-is-uppercase-in-rust-1i3i | rust, programming, abotwrotethis | In Rust, the char data type represents a Unicode Scalar Value. Unicode defines a unique numeric value for each character used in writing systems across the world. Checking if a char is uppercase in Rust is a common operation in text processing, and it can be done using a variety of approaches.
In this tutorial, we will explore different ways to check if a char is uppercase in Rust, including the use of the built-in methods and external crates. We will provide examples with explanations for each approach, and discuss the advantages and disadvantages of each.
##Checking if a char is uppercase using built-in methods
##Using the is_ascii_uppercase method
The is_ascii_uppercase method is a built-in method that checks if a char is an ASCII uppercase character. ASCII is a subset of Unicode, and it includes the characters used in the English language, as well as some special characters. The is_ascii_uppercase method returns a boolean value that indicates whether the char is an ASCII uppercase character or not.
###Example:
```rust
fn main() {
let my_char: char = 'A';
let is_uppercase = my_char.is_ascii_uppercase();
println!("Is {} uppercase? {}", my_char, is_uppercase);
}
```
###Output:
```
Is A uppercase? true
```
In this example, we define a char variable named my_char with the value 'A'. We then call the is_ascii_uppercase method on the my_char variable, which returns true because 'A' is an uppercase ASCII character.
##Using the is_uppercase method
The is_uppercase method is a built-in method that checks if a char is an uppercase Unicode character. This method returns a boolean value that indicates whether the char is an uppercase Unicode character or not.
###Example:
``` rust
fn main() {
let my_char: char = 'Ä';
let is_uppercase = my_char.is_uppercase();
println!("Is {} uppercase? {}", my_char, is_uppercase);
}
```
###Output:
```
Is Ä uppercase? true
```
In this example, we define a char variable named my_char with the value 'Ä'. We then call the is_uppercase method on the my_char variable, which returns true because 'Ä' is an uppercase Unicode character.
##Checking if a char is uppercase using external crates
##Using the Unicode Normalization crate
The Unicode Normalization crate provides a set of functions for working with Unicode strings, including checking if a char is uppercase. The crate includes a function named is_uppercase, which returns true if a char is an uppercase Unicode character, and false otherwise.
###Example:
```rust
use unicode_normalization::UnicodeNormalization;
fn main() {
let my_char: char = 'Ê';
let is_uppercase = my_char.is_uppercase();
println!("Is {} uppercase? {}", my_char, is_uppercase);
}
```
###Output:
```
Is Ê uppercase? true
```
In this example, we first import the Unicode Normalization crate using the use statement. We then define a char variable named my_char with the value 'Ê'. We call the is_uppercase method on the my_char variable, which returns true because 'Ê' is an uppercase Unicode character.
##Using the Regex crate
The Regex crate provides a set of functions for working with regular expressions, including checking if a char is uppercase. We can define a regular expression that matches uppercase characters, and use it to check if a char is uppercase.
###Example:
```rust
use regex::Regex;
fn main() {
let my_char: char = 'G';
let uppercase_regex = Regex::new(r"^\p{Lu}$").unwrap();
let is_uppercase = uppercase_regex.is_match(&my_char.to_string());
println!("Is {} uppercase? {}", my_char, is_uppercase);
}
```
###Output:
```
Is G uppercase? true
```
In this example, we first import the Regex crate using the use statement. We define a char variable named my_char with the value 'G'. We then define a regular expression that matches uppercase Unicode characters using the \p{Lu} pattern, which matches any uppercase letter in any language. We use the Regex::new method to create a new regular expression object, passing in the regular expression pattern as a string. Finally, we call the is_match method on the regular expression object, passing in the my_char variable converted to a string using the to_string method. The is_match method returns true because 'G' is an uppercase character. To learn how to check if character is vowel, check [this article](https://www.vinish.ai/rust-check-if-char-is-vowel).
##Advantages and Disadvantages of each approach
Using the built-in methods to check if a char is uppercase in Rust is the simplest and most efficient approach. The is_ascii_uppercase method is the fastest option, but it only works with ASCII characters. The is_uppercase method works with all Unicode characters, but it is slower than the is_ascii_uppercase method. However, these methods are limited in their capabilities, and they only work with individual chars.
Using external crates like the Unicode Normalization crate and the Regex crate provides more advanced functionality for working with Unicode characters, including checking if a char is uppercase. These crates can handle more complex use cases, such as checking if an entire string is uppercase or working with non-Latin characters. However, using external crates can add extra dependencies to your project and can make your code more complex.
##Conclusion
Checking if a char is uppercase in Rust can be done using various approaches, including the built-in methods and external crates. The built-in methods provide a simple and efficient solution for working with individual chars, but they are limited in their capabilities. Using external crates like the Unicode Normalization crate and the Regex crate provides more advanced functionality for working with Unicode characters, but it can add extra dependencies to your project and make your code more complex. | foxinfotech |
1,395,340 | Key Testing Insights 2022 Report by LambdaTest | iPhone series is the most popular device for mobile testing says LambdaTest’s Key Testing Insights... | 0 | 2023-03-10T06:36:13 | https://www.lambdatest.com/blog/key-testing-insights-2022-report-by-lambdatest/ | testing, keyinsights, mobile, webdev | **iPhone series is the most popular device for mobile testing says LambdaTest’s Key Testing Insights 2022 report**
***The report also highlights interesting testing factoids and trends in the testing space***
[LambdaTest](https://www.lambdatest.com/?utm_source=devto&utm_medium=organic&utm_campaign=mar10_kj&utm_term=kj&utm_content=webpage), the leading continuous quality testing cloud platform, has come up with Key Testing Insights 2022 report based on its platform usage last year.
According to the report, the top browser used for testing in 2022 was Chrome (76.27%), followed by Safari (9.12%), and Firefox (6.97%). When it comes to operating systems, our users tested the most on Windows (77.32%), followed by macOS (11.78%), and Android (5.76%).
The report also had geography-specific device and browser testing highlights. On the device’s side, the most popular device for mobile testing was iPhone 13 Pro Max in North America and Asia Pacific, iPhone 13 in EMEA, and iPhone 11 in Latin America. If considering global data, the most popular devices for testing were iPhone 13 Pro Max, followed by iPhone 13 and Galaxy S21 5G. Based on the report, LambdaTest has also saved 720 years worth of test execution time for the customers in the year 2022.
“Customer experience is everything in today’s digital-first world, hence businesses should ensure that testing is at the core of their go-to-market strategy. The numbers in the LambdaTest Key Testing Insights 2022 report provide a direction that teams can take to smartly strategize their testing,” said Jay Singh, cofounder, LambdaTest. “ We will continue to track these numbers closely and more importantly, we are continuously updating our continuous quality testing platform to enable our customers to give the best digital experience to their users.”
LambdaTest has also recently launched [HyperExecute](https://www.lambdatest.com/hyperexecute?utm_source=devto&utm_medium=organic&utm_campaign=mar10_kj&utm_term=kj&utm_content=webpage), a next-gen smart test orchestration platform that helps testers and developers run end-to-end automation tests at the fastest speed possible.


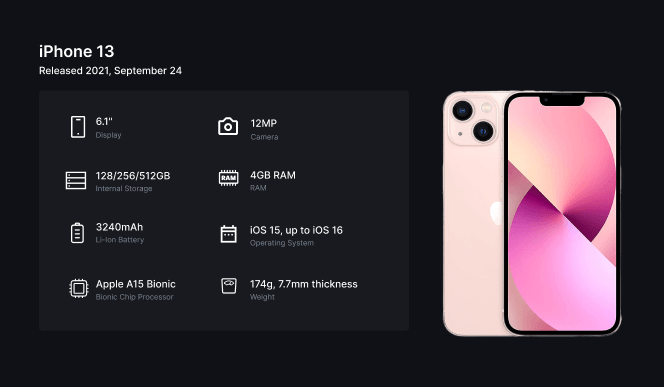

| lambdatestteam |
1,395,424 | Top 10 Object Detection APIs | Here is our selection of the best Object Detection APIs to help you choose and access the right... | 0 | 2023-03-10T09:04:40 | https://www.edenai.co/post/top-10-object-detection-apis | ai, api, objectdetection, computervision | *Here is our selection of the best Object Detection APIs to help you choose and access the right engine according to your data.*
## **What is [Object Detection?](https://www.edenai.co/feature/object-detection?referral=best-object-detection-apis)**
### **What does Object Detection do?**
Object detection is a computer vision technique that works to identify and locate objects within an image or video. Specifically, object detection draws bounding boxes around these detected objects, which allow you to locate where objects are in a given scene. Object detection is different from image recognition which involves labeling an entire image.
**[Get your API key for FREE](https://app.edenai.run/user/register?referral=best-object-detection-apis)**
### **A brief history of Object Detection methods**
In the early 2000s, the first object detection engines were developed manually due to the lack of efficient image representation at that time.
Originally proposed in 2005 by N. Dalal and B. Triggs, the Hog Detector is an improvement of the scale invariant feature transform and shape contexts of its time. HOG works with something called *blocks*, a dense pixel grid in which gradients are constituted from the magnitude and direction of change in the intensities of pixels within the block. HOGs are widely known for their use in pedestrian detection. To detect objects of different sizes, the HOG detector rescales the input image for multiple times while keeping the size of a detection window unchanged.
Between 2005 and 2015, multiple object detection evolutions were created: Deformable Part-based Model (DPM) then deep learning approaches (AlexNet, RCNN? SSPnet, FastRCNN, FPN, etc.).
## **Top 10 Object Detection APIs**
### **1. api4ai - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

API4AI is a solution that uses object detection technology to analyze images and detect various objects within them. The algorithm can detect multiple objects in a single image and provide coordinates to draw bounding boxes around each object. Additionally, it can classify each object and provide the most likely class along with a confidence level for the classification.
### **2. AWS - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

Amazon Rekognition Image can return the bounding box for common object labels such as cars, furniture, apparel or pets. Bounding box information isn't returned for less common object labels. It provides bounding boxes to find the exact locations of objects in an image, count instances of detected objects, or to measure an object's size using bounding box dimensions.
### **3. Chooch AI**
.jpg)
Chooch AI is a visual detection platform that quickly replicates human visual tasks and processes with AI on the edge & in the cloud. With high accuracy and fast response time, Chooch AI is the leader both in computer vision training and deployment for true Visual AI on the edge and in the cloud. Chooch provides complete artificial intelligence solutions in healthcare, geospatial, media, security, retail and industrial applications.
### **4. Clarifai - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

Clarifai is a leading provider of artificial intelligence for unstructured image, video, and text data. We help organizations transform their images, video, and text data into structured data significantly faster and more accurately than humans would be able to do on their own. Leverage Clarifai's suite of pre-trained models to identify tens of thousands of concepts across your media. Detect the presence of logos, apparel, people, vehicles, weapons, uniforms, and hate symbols.
### **5. Google Cloud - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

The Vision API can detect and extract multiple objects in an image with **Object Localization**.
Object localization identifies multiple objects in an image and provides a LocalizedObjectAnnotation for each object in the image. Each LocalizedObjectAnnotation identifies information about the object, the position of the object, and rectangular bounds for the region of the image that contains the object.
### **6. Visua AI**

Visua AI has built a visual classification tool that focuses on extracting the most relevant signals from media. Specifically built for the needs of platforms and specialist providers, the technology makes it easier for you to derive meaningful insights for clients.
### **7. Imagga**

Imagga is a computer vision artificial intelligence company. Imagga Image Recognition API features auto-tagging, auto-categorization, face recognition, visual search, content moderation, auto-cropping, color extraction, custom training and ready-to-use models. Available in the Cloud and on On-Premise. It is currently deployed in leading digital asset management solutions and personal cloud platforms and consumer facing apps.
### **8. Microsoft Azure - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

Microsoft Azure offers a variety of services for object detection, such as Azure Cognitive Services with Computer Vision API, Azure Machine Learning, Azure IoT Edge, Azure Kubernetes Service (AKS) and Custom Vision AI. These services allow users to use pre-trained models, train and deploy custom models, run object detection on IoT devices, scale and manage models in a Kubernetes cluster, and easily train, deploy, and improve custom image classifiers with object detection support.
### **9. [SentiSight.ai](http://sentisight.ai/?referral=best-object-detection-apis) - Available on [Eden AI](https://app.edenai.run/bricks/image/object-detection?referral=best-object-detection-apis)**

SentiSight.ai uses deep learning algorithms to analyze images and detect objects within them. The software can detect multiple objects in an image, including objects of different sizes and orientations, and provide a bounding box around each object. SentiSight.ai is able to classify the objects it detects and can also track objects across multiple frames in a video stream and analyze the movement of objects in a scene.
### **10. Hive**

Hive Object Detection API provides pre-trained models for object detection in various domains, such as computer vision and autonomous vehicles, which can be used to identify and locate objects in images and videos. tonomous vehicles, which can be used to identify and locate objects in images and videos. The API also allows developers to train custom object detection models on their own data, and then deploy the models to perform inference. Their deep learning models accurately classify subject matter in visual media with simple mapping to IAB's universal content taxonomy.
**[Try these APIs on Eden AI](https://app.edenai.run/user/register?referral=best-object-detection-apis)**
## **Some Object Detection API use cases**
You can use Object Detection in numerous fields. Here are some examples of common use cases:
- **Retail**: track inventory, monitor store traffic and analyze customer behavior.
- **Transportation**: monitor traffic, track vehicles, and improve road safety.
- **Surveillance and security**: monitor public spaces, detect suspicious behavior, and improve response times to potential threats.
- **Agriculture**: to monitor crop growth, detect pests, and improve crop yields.
- **Healthcare**: analyze medical images, track the progression of diseases, and assist with surgical planning.
- **Manufacturing**: monitor production lines, detect defects, and improve efficiency.
- **Robotics**: enable robots to navigate and interact with their environment.
These are just a few examples, object detection technology can be applied in many other fields as well, where it can be used to analyze images and videos to extract valuable information and automate numerous tasks.
## **Why choose Eden AI to manage your APIs**
Companies and developers from a wide range of industries (Social Media, Retail, Health, Finances, Law, etc.) use Eden AI’s unique API to easily integrate Object Detection tasks in their cloud-based applications, without having to build their own solutions.
Eden AI offers multiple AI APIs on its platform amongst several technologies: Text-to-Speech, Language Detection, Sentiment analysis API, Summarization, Question Answering, Data Anonymization, Speech recognition, and so forth.
We want our users to have access to multiple Object Detection engines and manage them in one place so they can reach high performance, optimize cost and cover all their needs. There are many reasons for using multiple APIs:
### **Fallback provider is the ABCs**
You need to set up a provider API that is requested if and only if the main Object Detection API does not perform well (or is down). You can use confidence score returned or other methods to check provider accuracy.
### **Performance optimization.**
After the testing phase, you will be able to build a mapping of providers performance based on the criteria you have chosen (languages, fields, etc.). Each data that you need to process will then be sent to the best Object Detection API.
### **Cost - Performance ratio optimization.**
You can choose the cheapest Object Detection provider that performs well for your data.
### **Combine multiple AI APIs.**
This approach is required if you look for extremely high accuracy. The combination leads to higher costs but allows your AI service to be safe and accurate because Object Detection APIs will validate and invalidate each other for each piece of data.
## **How Eden AI can help you?**
Eden AI has been made for multiple AI APIs use. Eden AI is the future of AI usage in companies. Eden AI allows you to call multiple AI APIs.
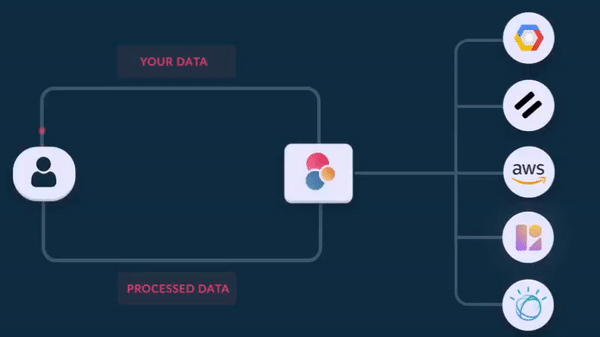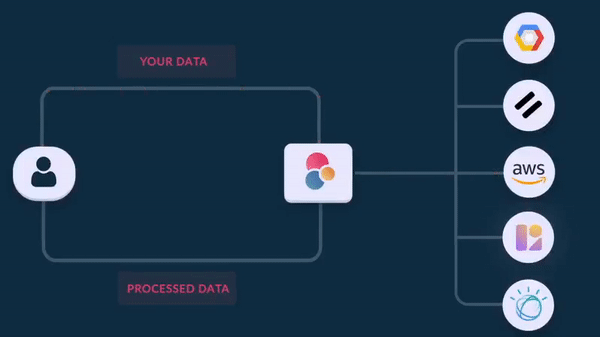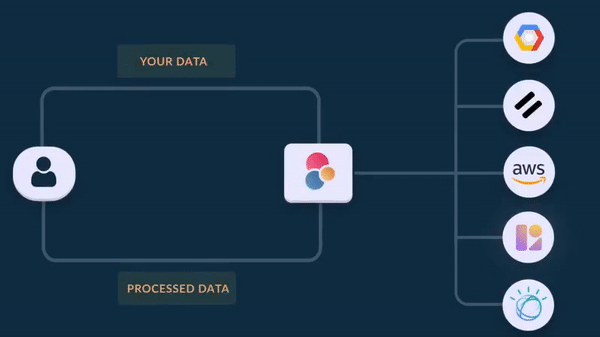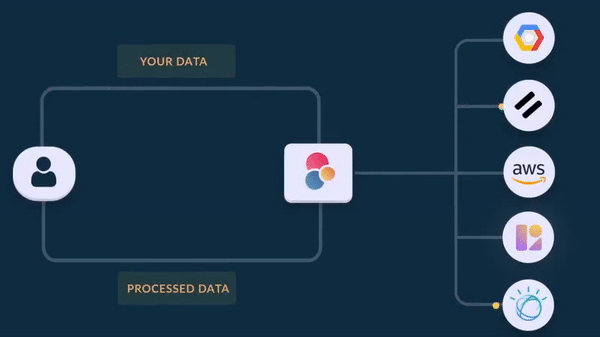
- Centralized and fully monitored billing on Eden AI for all Object Detection APIs
- Unified API for all providers: simple and standard to use, quick switch between providers, access to the specific features of each provider
- Standardized response format: the JSON output format is the same for all suppliers thanks to Eden AI's standardization work. The response elements are also standardized thanks to Eden AI's powerful matching algorithms.
- The best Artificial Intelligence APIs in the market are available: big cloud providers (Google, AWS, Microsoft, and more specialized engines)
- Data protection: Eden AI will not store or use any data. Possibility to filter to use only GDPR engines.
You can see Eden AI documentation [here](https://docs.edenai.co/reference/image_object_detection_create?referral=best-object-detection-apis).
## **Next step in your project**
The Eden AI team can help you with your Object Detection integration project. This can be done by :
- Organizing a product demo and a discussion to better understand your needs. You can book a time slot here: [Contact](https://www.edenai.co/contact?referral=best-object-detection-apis)
- By testing the public version of Eden AI for free: however, not all providers are available on this version. Some are only available on the Enterprise version.
- By benefiting from the support and advice of a team of experts to find the optimal combination of providers according to the specifics of your needs
- Having the possibility to integrate on a third-party platform: we can quickly develop connectors
**[Create your Account on Eden AI](https://app.edenai.run/user/register?referral=top10-object-detection-apis)** | edenai |
1,395,658 | Optimize Page Load Speed with Lazy Loading Images in Angular 15 | Lazy loading images is a technique that helps to optimize the performance of a website by deferring... | 0 | 2023-03-10T13:24:53 | https://www.tutscoder.com/post/lazy-loading-images-angular | angular | <p class="paragraph"> Lazy loading images is a technique that helps to optimize the performance of a website by deferring the loading of images until they are needed. This can significantly improve the page load time, especially for websites with many images. In this article, we will be discussing how to implement lazy loading of images in an Angular 15 application using the ng-lazyload-image plugin. </p><p class="paragraph"> ng-lazyload-image is a popular and highly-rated Angular library that makes it easy to implement lazy loading of images. It uses IntersectionObserver, a native API for detecting when an element enters or exits the viewport, to determine when to load images. This approach is much more efficient than using the traditional scroll or resize event-based approaches, which can negatively impact the performance of a website. </p><p class="paragraph"> Getting started with ng-lazyload-image is simple. To install it, simply run the following command in your Angular project: </p><pre><code class="code-block">npm install ng-lazyload-image --save</code></pre><p class="paragraph"> Once installed, you can import the LazyLoadImageModule in your Angular module to make it available throughout your application: </p><pre><code class="code-block">import { LazyLoadImageModule } from 'ng-lazyload-image';
@NgModule({
imports: [
LazyLoadImageModule
]
})
export class AppModule { }
</code></pre><p class="paragraph"> Next, you can use the <code>lazyLoad</code> directive in your templates to specify the images that should be lazy loaded: </p><pre><code class="code-block"><img [lazyLoad]="imageUrl" [offset]="offset" [defaultImage]="defaultImage" [errorImage]="errorImage">
</code></pre><p class="paragraph"> The <code>lazyLoad</code> directive takes several optional parameters: </p><ul><li>offset: The number of pixels before the image enters the viewport to start loading it.</li><li>defaultImage: An image to display while the lazy-loaded image is loading.</li><li>errorImage: An image to display if the lazy-loaded image fails to load.</li></ul><p class="paragraph"> By using ng-lazyload-image, you can significantly improve the performance of your Angular 15 application and provide a better user experience for your users. Give it a try today! </p><p class="paragraph"> In conclusion, ng-lazyload-image is a simple and efficient way to implement lazy loading of images in an Angular 15 application. It's easy to install and use, and can have a significant impact on the performance of your website. Give it a try and see for yourself! </p> | dev14 |
1,395,939 | Top 10 Python Packages Every Developer Should Know About | Python is undoubtedly one of the most popular programming languages in today's tech industry. With an... | 0 | 2023-03-10T17:04:08 | https://blog.akashrchandran.in/top-10-python-packages-every-developer-should-know-about | python, programming, productivity, beginners | Python is undoubtedly one of the most popular programming languages in today's tech industry. With an ever-increasing number of developers turning to it, Python has established itself as a must-know skill for any aspiring programmer or software engineer. One reason behind its massive popularity is the vast collection of python packages that make coding more efficient and seamless. If you're looking to take your Python development skills to the next level, we've got you covered. In this post, we'll be discussing ten essential python packages every developer should know about to boost their productivity and streamline their workflow. Whether you're building web applications, performing data analysis tasks or developing machine learning models, these packages are guaranteed to simplify your work and enhance your code quality. So buckle up and get ready to dive into our top 10 list!
## Introduction to Python Packages
Python is a widely used high-level interpreted language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its syntax allows programmers to express concepts in fewer lines of code than would be possible in languages such as C++ or Java. The language provides constructs intended to enable clear programs on both a small and large scale.
Python packages are collections of modules that you can import into your scripts to make use of their functionality. In this article, we'll take a look at some of the most popular Python packages that every developer should know about.
## What is a Python Package?
Python packages are modules that contain code written in the Python programming language. Packages can be used to extend the functionality of Python or to add new features to existing Python code. Python packages can be installed from a variety of sources, including the Python Package Index (PyPI), or third-party repositories. Once installed, packages can be imported into your Python code using the import statement.
Packages can contain a variety of different types of content, including:
Modules: A module is a single Python file that contains code. Modules can be imported into other modules, or the main Python interpreter, using the import statement.
Classes: A class is a template for creating objects. Classes can be defined in modules and then imported into other modules, or the main Python interpreter, using the from...import statement.
Functions: A function is a block of code that performs a specific task. Functions can be defined in modules and then imported into other modules, or the main Python interpreter, using the from...import statement.
Data: Data is any information that can be stored in computer memory. Data can be stored in variables, and passed to functions as arguments.
## The Packages are:
### Pandas
The Python package Pandas is a free and open-source library that provides high-performance data structures and data analysis tools. It is built on the popular Python libraries NumPy and matplotlib, which allow for efficient data manipulation and analysis. Data structures and operations for manipulating numerical tables and time series data are available in Pandas. It is a must-have for data manipulation and data science tasks. Pandas is a highly effective data analysis, manipulation, and visualisation tool. It is used in many industries, including finance, analytics, and data science, for data cleaning, preparation, and analysis. Pandas make it simple to work with large datasets, allowing users to summarise, manipulate, and visualise data quickly and easily.
### NumPy
NumPy is a robust and effective module for doing scientific computations. It offers quick mathematical operations on these massive, multi-dimensional arrays and matrices for which it is developed. Many mathematical operations are offered by NumPy, such as Fourier analysis, linear algebra, and random number creation. For manipulating arrays, it also offers sophisticated indexing and slicing features. In disciplines including data science, machine learning, and computational physics, NumPy is extensively employed. Its popularity is a result of the performance and usability it combines, making it a crucial Python tool for scientific computing.
### Matplotlib
Matplotlib is a Python package that offers a range of tools to developers for making interactive visualisations, such as graphs and charts, that can be used for data analysis. It is a commonly used library in science, and it works particularly well for making static 2D and 3D plots that may be highly customised and detailed. Also, it offers assistance with story interactivity and animation creation. After you grasp the fundamentals of charting, Matplotlib's simple syntax makes it simple to use. For everyone who wishes to extract amazing images from their data, it offers a necessary tool.
### TensorFlow
Popular open-source software called TensorFlow is used to create and train machine learning models. It was created by Google and is one of the most used deep learning frameworks. Because TensorFlow is built on a dataflow graph, users can see how data flows through a neural network model. It offers a versatile and effective language for creating and refining models on huge datasets. Applications supported by this package include natural language processing, picture and speech recognition, and more. You may quickly scale sophisticated models to huge datasets with TensorFlow.
### Scikit-learn
Built on top of NumPy, SciPy, and matplotlib, Scikit-learn is a free and open-source machine learning framework. It offers straightforward and effective tools for data analysis and mining. Scikit-learn offers tools for model selection and evaluation, data preprocessing, feature selection, and model visualisation in addition to several algorithms for classification, regression, clustering, and dimensionality reduction. Classification, regression, natural language processing, image processing, and other machine learning tasks are only a few of the many machine learning tasks for which it is frequently employed in both industry and research. Scikit-learn is a vital tool for anyone interested in machine learning because of its simplicity of use and extensive capability.
### PyTorch
A well-liked open-source machine-learning library for Python is called Pytorch. Because of its adaptability, clarity, and scalability, it is widely used. Using the capabilities of graphics processing units (GPUs) to speed up training, Pytorch offers a simple interface for creating deep learning algorithms. The software is widely used in research, education, and business for a range of tasks including speech recognition, computer vision, natural language processing, and more. Pytorch has developed into a vital toolkit for machine learning enthusiasts and engineers alike thanks to its comprehensive collection of tools and community support.
### Flask
Flask is a lightweight and powerful web development framework for building Python-based web applications. It includes a comprehensive set of tools and libraries for developing a wide range of web applications, from simple static sites to more complex web applications with dynamic data. Flask has an easy-to-learn and-use API, as well as a flexible and extensible design that allows you to tailor it to your specific requirements. It also includes built-in unit testing support, simple error handling, and easy integration with other libraries and services. Because of its simplicity, flexibility, and ease of use, Flask is a popular choice for developing web applications.
### Django
Django is a Python web framework that is open source and follows the Model-View-Controller (MVC) architecture. It is widely used to rapidly create high-quality web applications. Django's clean design encourages code reuse and employs object-oriented programming principles. Django includes a powerful URL routing system for creating clean URLs, an ORM for working with databases, and an HTML template engine. It also has an authentication system, security features, and middleware support built in. Django has a vibrant community that is constantly improving and contributing to the framework. Because of its scalability, flexibility, and ease of use, it is a popular choice among developers.
### Requests
With the Python library Requests, HTTP requests are made easier. It was developed for usage with API requests and page scraping. Requests offer a straightforward and understandable interface for handling HTTP requests and responses. The package includes functions for managing cookies and sessions, authenticating users, and encoding data in several different forms. Moreover, Requests supports the HTTP/1.1 and HTTP/2 protocols and offers synchronous and asynchronous request handling. The programme is frequently used for tasks including automation, data extraction, and web development.
### BeautifulSoup
Beautiful Soup is a popular Python package for parsing HTML and XML documents. This package enables programmers to easily extract data from HTML pages. It makes it simple to use web scraping functions in Python. Beautiful Soup parses HTML documents and allows users to extract the content they require. Beautiful Soup's extensive documentation allows it to work with HTML files in a variety of formats. To efficiently extract content, the package supports a variety of searching and filtering methods. It is the go-to Python package for extracting data from web pages.
## Conclusion
In conclusion, the Python programming language is a very strong and flexible tool that can be applied to a wide range of projects, including web development and data analysis. The top 10 Python packages that every developer should be familiar with can help developers use Python to its best ability. These software packages offer strong tools and capabilities that can be utilised to create intricate applications and address intricate issues. These packages make it simple for developers to build dependable and effective apps. We trust that this article has helped you gain a better knowledge of the top 10 Python packages that every developer should be familiar with. | akashrchandran |
1,396,002 | Letters of AI: Automatically Generate Cover Letters + Letters of Rec | Background and Motivation Countless users already use OpenAI's chat interface (ChatGPT( to... | 0 | 2023-03-10T18:32:20 | https://dev.to/kimchoijjiggae/letters-of-ai-automatically-generate-cover-letters-letters-of-rec-1175 | blog | ## Background and Motivation
Countless users already use OpenAI's chat interface (ChatGPT( to handle all sorts of routine tasks: write emails, answer research questions, debug code, etc. While extremely powerful, the ChatBot still requires users to overcome to pain points:
**1. Identify which problems ChatGPT would well: ** AI has a unique advantage over humans in handling issues that require exposure to vast data sets (e.g. image labeling) or repetitive tasks prone to error. But would you trust it to write you a love letter? The optimal task division between humans and AI is still evolving, leaving it up to individuals to decide when to handle a task themselves as opposed to rely on a machine.
**2. Formulate the prompt to ask ChatGPT**: Even if a user knows that a certain task is better suited for AI than humans, s/he must then identify the best way to pose a query and present relevant data to the AI.
With the release of ChatGPT's API, developers can leave the nitty-gritty details of model development to OpenAI and focus on building tools that optimize for user experience. We anticipate that these tools will focus on specific use cases and be discovered by users looking for a solution to a problem they didn't even know AI could solve. They will then simplify the process of data collection from users to ensure that the AI is fed the optimal parameters to produce quality results.
As part of our efforts to predict the types of applications we expect to be built off of ChatGPT's API, we wanted to understand how difficult it was to build a ChatGPT integrated tool. So we built a little example ourselves!
## Summary of Technical Features
Here are the key features of our React App. Here's what we learned how to do:
- **ChatGPT API Integration**: Users can input a couple of fields about a job they are applying to or recommending a candidate for, which generates a prompt that ChatGPT can complete
-**Pupeteer/Chromium Integration**: Users can put in a link to any LinkedIn Job Description, and the tool parses the page to extract the job description
-**Public Hosting**: Using Render and Glitch, we were able to publicly host the server that returns the ChatGPT + Pupeteer responses, as well as our db.json. This allows our tool to be accessed by users without access to our localhost server.
| kimchoijjiggae |
1,396,010 | Blog -3-Data Engineering – AWS S3 space monitoring – Storage Lens | Data Engineering – AWS S3 cost monitoring – Storage Lens Amazon S3 is an object storage... | 0 | 2023-03-10T18:51:35 | https://dev.to/sanjeeb2017/blog-3-data-engineering-aws-s3-cost-monitoring-storage-lens-b66 | awscommunity, aws, awscommunitybuilder |
## Data Engineering – AWS S3 cost monitoring – Storage Lens
Amazon S3 is an object storage service and one of the most popular services in AWS which offers of industry-leading scalability, data availability, security, and performance. Organizations can store and retrieve any amount of data from anywhere.
If an organization is using aws for their cloud service, AWS S3 is one of prefer storage solution. Some of the use cases of S3 are:
1. Build an Enterprise Data Lake
2. Create a Disaster Recovery System for back up and restore data.
3. Archive cold data for a long period to meet regulatory requirements
4. Host a static website.
5. Integrated with many cloud native solutions to provide storage option.
While you are store unlimited amount of data in S3, it is very important to monitor the storage of S3 and number of objects in S3 buckets. At end of the day every object storage occurred a cost. Organizations may not be able to quantify the storage cost when they have GB, TB data but when the data volume grow to PB’s S3 cost will be high.
For example, when you store 10 PB data (for big enterprise scale applications like data lake, lake house etc) , you have to give 220K USD for UK region for storage. So it is very important to understand the usage of S3 bucket.
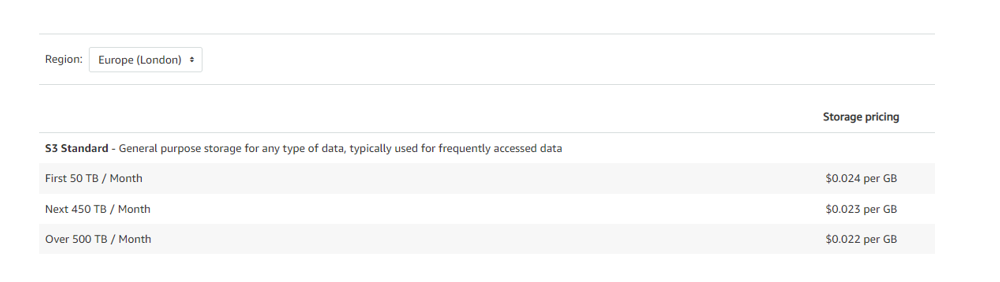
AWS S3 have a feature called “Storage lens” where you can create your own custom dashboard and monitor the usage of S3 objects. In this blog, we will create a dashboard using storage lens and see how it work.
To do the same.
1. Click on S3 in AWS management console. You can see the overall utilization of all your S3 buckets.
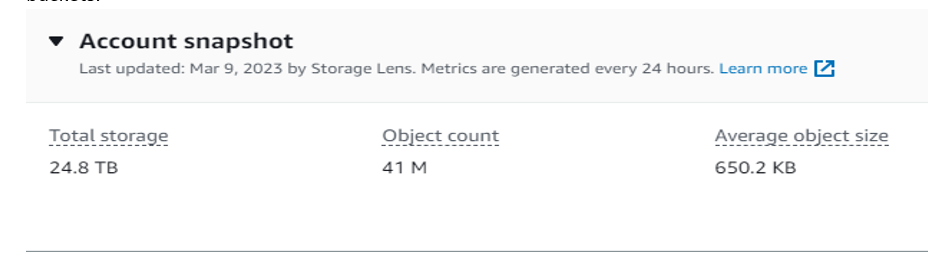
2. To create a Dashboard, click on the storage lens in the left panel. Click on Dashboard
3. Click on Create Dashboard
4. Give the below details
- Dashboard Name: in this case we give the name as s3-bucket-usage-monitor
- Home Region : Select the appropriate region, for us it is London region which is eu-west-2
- Select Status as enable so that we can see the status of the dashboard.
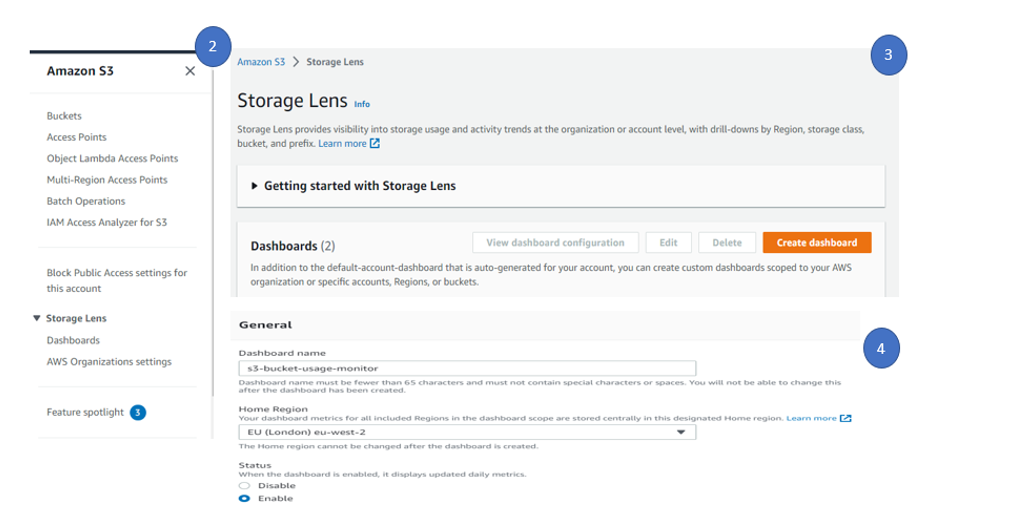
5. For Dashboard Scope, if you are having objects across regions, you can select the region, in our case we ONLY select London region as all our objects are store in London region and include all buckets in the region.
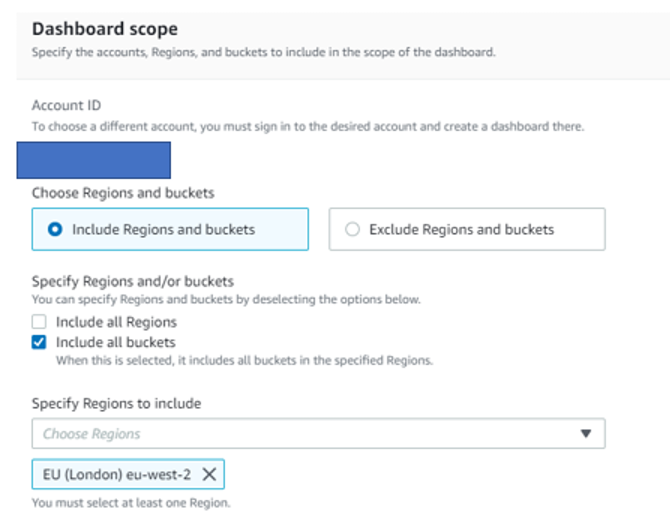
6. In the metrics section, select the Free metrices. A lot of key metrices are available under free metrices and that is more than enough to monitor usages of S3 buckets.
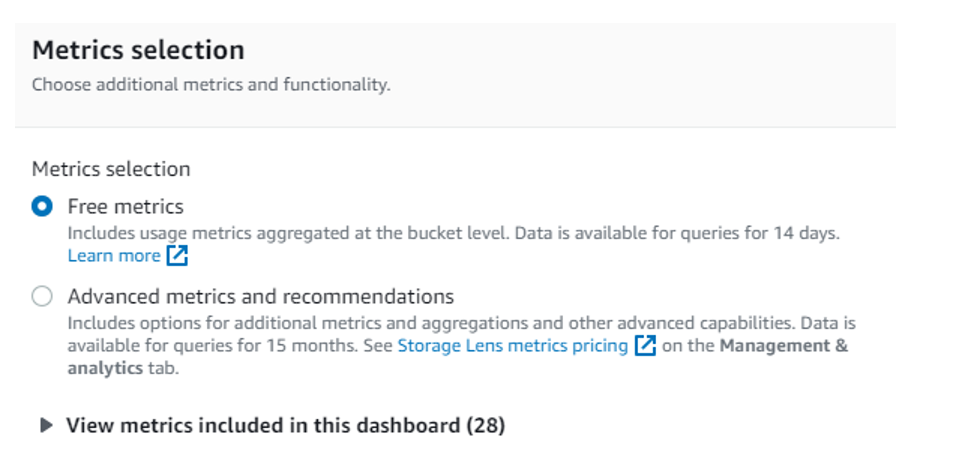
7. You can export these metrices to an S3 path for further analytical usages, for our case we disabled this option. Finally click create dashboard.
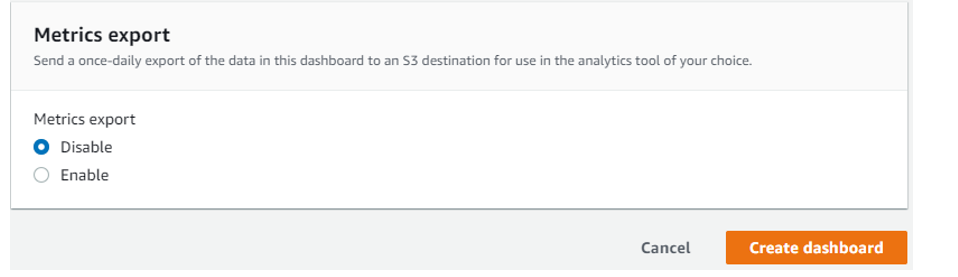
8. It will take 48 hours to have the charts ready.
By default, AWS created a lens for you ( which cover all regions), if you want to use the default dashboard, that is fine as well. For any custom requirements like specific region or any rule we can create custom dashboard as well. Sample charts from default dashboard is :
**Quick Tips:**
1. Once you understood the usages, you can see which critical data is require for your use case and access pattern. If there are buckets and folders access pattern is unknown, better to use S3 intelligent tiering for cost saving.
2. Many organizations and enable bucket versioning so that they can avoid the accidental deletion of the object, however ONLY critical data objects (which is difficult to recreate, scripts folder) versioning make sense. But use cases like Data lake when you are getting source data and processed the data and move to archive, you really DO NOT need versioning to the staging bucket.
3. For files which needs to be stored for long term, better to define a life cycle management to Glacier storage, this can be set it up using Life cycle management policy.
| sanjeeb2017 |
1,396,199 | Bitwise Operators in JavaScript | Binary numbers can be stored and represented with different amounts of bits. For instance, in... | 22,145 | 2023-03-31T16:41:16 | https://dev.to/andrewgl22/bitwise-operators-in-javascript-43c4 | Binary numbers can be stored and represented with different amounts of bits. For instance, in JavaScript a single number in decimal is technically stored in memory as a 64-bit binary number. That's a lot of leading zero's...In many cases this is fine, but there are cases where we may want to conserve memory and use our alotted bits more intentionally.
Let's say we are storing the decimal number 10 as a byte of data.
```
00001010 = 10
```
Technically we are using 8 bits to represent a single number value. If we think of each bit as a boolean value (on/off, true/false) instead of an actual number, a lot of real-world applications open up for us. Let's say we have a user who can have different levels of permission to access files. The user's permissions might be stored in an object like so:
```javascript
{
readPermission:true,
writePermission:false,
admin:false,
}
```
This works fine, but another option is to assign the user a single decimal number, stored as binary, and use each individual bit to represent one of these flags instead! We would just need to be able to query and update each bit individually depending on our use case. Manipulating bits on this level requires bitwise operators.
#Bitwise Operators
Bitwise operators take two values and compares them, outputting a new value from the computation. In JavaScript we generally run bitwise operations against two decimal numbers, which are then converted into binary values behind the scenes. It is also technically possible to work with binary numbers directly in JavaScript using **Binary Literals** which we will look at in a later post.
JavaScript stores decimal numbers in memory as 64-bit binary values. When a bitwise operator is used, each initial decimal value in the computation is converted into a 32-bit binary number in Two's Complement form, the computation is executed, then the result is converted back into 64-bits and finally returned as a decimal number.
Since it is possible to use individual bits to represent real world states (like user permissions), we can think of these operators as allowing us to query and determine state.
Let's take a look at the bitwise operators available to us and the actions they allow us to perform on binary numbers...
##AND (&)
The bitwise AND operator takes two binary numbers and combines them, comparing each set of digits in a column and outputs a 1 only if both inputs are 1. In all other cases the AND operator will return 0.
What can we do with this? You can think of the AND operator as allowing us to access or read specific bits within a binary word. Let's look at an example:
```javascript
10 & 7
00001010 = 10
& 00000111 = 7
-----------
00000010
```
Any column with a 1 in the second number allows the original value to pass through or be read, while a 0 in the second number will turn off or mask that value. This is why the 1 in the 8's column is turned off in this example.
It's important to understand that with bitwise operators, we're not really concerned with the result in terms of base 10 values, we're not actually adding numbers. We're executing a computation to determine the state of a specific set of bits.
## OR (|)
The OR operator returns 1 if either bit in the computation is 1. An easier way to think of this is that OR returns 0 only if both bits are 0. We can think about the purpose of the OR gate as allowing us to set/turn on specific bits in a binary word. Here's an example:
```javascript
10 | 7
00001010 = 10
| 00000111 = 7
-----------
00001111
```
If you think about the second number (in this case 7) as being a set of instructions taken against the first number (10) we can see that by specifying 1's in specific columns, we can turn on or change the bits in the first number from 0 to 1, essentially turning on those bits. Again you could think of the user permissions example: by turning a single bit from off to on, a user could be upgraded to admin access for instance.
## XOR (^)
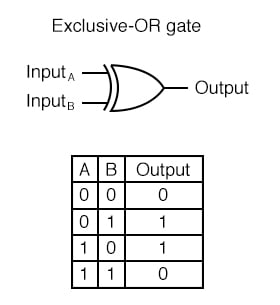
The XOR or Exclusive-Or operator returns 1 only if both values are different, i.e. a 0 and a 1. Two ones or two zeros will return 0. If the AND operator can be used to read bits, and the OR operator can turn on bits, XOR allows us to toggle the state of specific bits.
```javascript
10 ^ 7
00001010
^ 00000111
------------
00001101
```
Notice how anywhere there was a 1 in the second number, the original number's bit is toggled to be it's opposite.
## NOT (~)
The NOT gate is the actual mechanism we can use in JavaScript to invert all of the values in order to compute the One's Complement of a binary word. NOT will invert every bit to be it's opposite.
```javascript
00001010 = 10
11110101 = ~10
```
## Left-Shift (<<)
The Left-Shift operator will shift all the bits in the first number to the left by the right number amount of positions. Each value that gets pushed into new columns on the left will be dropped, and each new position that is created on the right will be filled in with a zero. Here's an example
```javascript
8 << 2
00001000 = 8
00100000 = 8 << 2 = 32
```
As you can see, the effect of a left-shift operation (x << y) is the same as multiplying x by 2 y times. One use of left-shift is that it allows us to perform carries in addition operations when the sum of a column is 2 or greater. Another application of this operator can be seen in working with RGB color values in Hexadecimal notation. We will see examples of these in later posts.
## Right-Shift
There are two types of right-shift operations in JavaScript: **Zero-Fill Right-Shift** and **Sign-Propagating Right-Shift**. Zero-fill is used when dealing with unsigned numbers, and sign-propagating allows us to do the same right-shift operation with negative/signed numbers.
##Zero-Fill Right-Shift (>>>)
Zero-fill right shift is used for positive or unsigned numbers. As each value is shifted right x number of positions, zeros are added to the left side of the number, and any values that get pushed further than the one column get dropped off.
```javascript
10 >>> 2
00001010 = 10
00000010 = 10 >>> 2
```
##Sign-Propagating Right Shift (>>)
Sign-Propagating allows us to right-shift negative or signed numbers. As the number is shifted, the values on the left will be filled in with the value of the signed bit, thus preserving the sign of the original number.
```javascript
-10 >> 2
10001010 = -10
>> 11100010 = -10 >> 2 = -3?
```
{% embed https://youtu.be/fChW-4SFj5E %}
##Conclusion
Bitwise Operators allow us to manipulate bits on a granular level we cannot access with regular math operations. In the next post we will see some examples using **Bitmasks** and **Hexadecimal notation**...
| andrewgl22 | |
1,396,300 | Middleware in nest.js | Before writing any line of code let's first define a middleware function in nest.js, a middleware... | 0 | 2023-03-11T01:31:22 | https://dev.to/djibrilm/middleware-in-nestjs-5hka | typescript, beginners, node | Before writing any line of code let's first define a middleware function in nest.js, a middleware function is a function that gets called before the route handler function, middleware functions have access to the request and response objects, a good definition, right? But what does that mean? Simply a middleware function is a function that gets triggered before the main request function, it can end the request life cycle or continue the request life cycle, not ending and not continuing will leave the request hanging which is a disaster for users' experience <span class="emoji-outer emoji-sizer"><span class="emoji-inner" style="background: url(chrome-extension://gaoflciahikhligngeccdecgfjngejlh/emoji-data/sheet_apple_32.png);background-position:61.98589894242068% 44.00705052878966%;background-size:5418.75% 5418.75%" data-codepoints="1f62c"></span></span> , a middleware function can modify the request object such as adding data reaching to a database just do everything that you can do in any normal function
Too much talking let's see that in action <span class="emoji-outer emoji-sizer"><span class="emoji-inner" style="background: url(chrome-extension://gaoflciahikhligngeccdecgfjngejlh/emoji-data/sheet_apple_32.png);background-position:59.9882491186839% 75.96944770857814%;background-size:5418.75% 5418.75%" data-codepoints="1f609"></span></span>
```javascript
new nest middleware
```
as you can see I have nest installed globally on my machine if you face any problems while creating the application please use the following guide from the official nest.js website https://docs.nestjs.com/
**Basic middleware **
For creating nest.js middleware you can use the class approach or use the function approach but for this example, we shall use the class base approach which is recommended by the nest.js team, in the example below we create a middleware function that takes the greeting string passed to our request body and check if the greeting is equal to hello, if the greeting is not hello the middleware function returns the request, and if the greeting passed into the request body is hello then the middleware function continues the request cycle and add a new data to our request body,
```javascript
import { Injectable, NestMiddleware } from "@nestjs/common";
import { Request, Response, NextFunction } from "express";
@Injectable()
export class greetingMiddleware implements NestMiddleware {
use(req: Request, res: Response, next: NextFunction) {
if (req.body.greeting === 'hello') {
req.body.randomNumber = Math.random();
next()
} else {
return res.status(403).json({ message: "no greeting passed or not equal to hello " });
}
}
}
```
**Dependency injection**
Like controllers and providers, middleware can also inject dependencies that are in the same module
**Applying middlewares**
As me, you may think that middlewares are placed in the `@module` decorator but that is not the case, instead, we set them up using the `configure()` method of the module class, modules that contain middlewares have to implement the `NestModule` interface, let us see how to apply our greetingMiddlewar
```typescript
import { Module, NestModule, MiddlewareConsumer } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { greetingMiddleware } from './middleware/basicMiddleware';
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(greetingMiddleware).forRoutes('greeting')
}
}
```
In the example above we apply the `greetingMiddlewar` to the greeting route using the `forRootes() ` method, we can also restrict the middleware to specific request methods by passing an object to the `forRootes` method containing the route path and the method, note that you are not restricted to one route you can pass your middleware to more than one route or pass it to the entire controller in the following example we see how to apply our middleware with a specific request method
```typescript
import { Module, NestModule, MiddlewareConsumer,RequestMethod } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { greetingMiddleware } from './middleware/basicMiddleware';
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(greetingMiddleware).forRoutes({ path: 'greeting', method: RequestMethod.GET })
}
}
```
while using this method please do not forget to import `RequestMethod` it helps us to reference the targeted request method.
**Applying to the entire controller**
In some cases you may want to pass your middleware to all routes available in your `@controller`, for doing that you need to pass your imported controller into the `forRoot` method as we did with routes
```javascript
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(greetingMiddleware).forRoutes(AppController);
}
}
```
**Multiple middlewares**
You may also want to pass multiple middlewares that run sequentially, for having that in place you need to separate them with comma in the `apply` method, the given example is down bellow
```javascript
export class AppModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(first(),second()).forRoutes(AppController);
}
}
```
**conclusion**
Middleware functions are very important concepts that every back-end developer should know and truly understand, you will probably need them in any back-end application you will have to build.
Thanks for reading and don't forget to follow if you find this content useful<span class="emoji-outer emoji-sizer"><span class="emoji-inner" style="background: url(chrome-extension://gaoflciahikhligngeccdecgfjngejlh/emoji-data/sheet_apple_32.png);background-position:61.98589894242068% 87.95534665099882%;background-size:5418.75% 5418.75%" data-codepoints="1f642"></span></span>
| djibrilm |
1,396,498 | NextJS dependency Environment Variables | I want to include a dependency in my NextJS project that can use environment variables... | 0 | 2023-03-11T06:12:23 | https://dev.to/kevindoesdev/nextjs-dependency-environment-variables-4b48 | nextjs | I want to include a dependency in my NextJS project that can use environment variables (process.env.X) for some config options. I know that NextJS has some special handling for env variables, but I'm not sure if that extends into dependencies as well.
Can anyone shed some light on this? Is there a difference between Dev and Prod handling? (deployed on Vercel) | kevindoesdev |
1,396,576 | ToDo List smart Contract | ToDo List Smart Contract // SPDX-License-Identifier: MIT pragma solidity... | 0 | 2023-03-11T08:19:27 | https://dev.to/ayaaneth/todo-list-smart-contract-12m7 | web3 | ## ToDo List Smart Contract
```solidity
// SPDX-License-Identifier: MIT
pragma solidity 0.8.18;
contract TaskContract {
constructor() {
}
struct Task {
uint id;
string taskTitle;
string taskText;
bool isDeleted;
}
Task[] private tasks;
mapping (uint => address) taskToOwner;
event AddTask(address recepient,uint taskId);
event DeleteTask(uint taskId,bool isDeleted);
function addTask(string memory taskText,string memory taskTitle, bool isDeleted) external {
uint taskId = tasks.length;
tasks.push(Task(taskId,taskTitle, taskText, isDeleted));
taskToOwner[taskId] = msg.sender;
emit AddTask(msg.sender,taskId);
}
function deleteTask(uint taskId) external {
require(taskToOwner[taskId] == msg.sender, "You are not the owner of this task");
tasks[taskId].isDeleted = true;
emit DeleteTask(taskId,tasks[taskId].isDeleted);
}
function getMyTask()public view returns(Task[] memory){
Task[] memory myTasks = new Task[](tasks.length);
uint counter = 0;
for(uint i = 0; i < tasks.length; i++){
if(taskToOwner[i] == msg.sender && tasks[i].isDeleted == false){
myTasks[counter] = tasks[i];
counter++;
}
}
Task[] memory result = new Task[](counter);
for(uint i = 0; i < counter; i++){
result[i] = myTasks[i];
}
return result;
}
}
```
## Explanation and Breakdown
```solidity
// SPDX-License-Identifier: MIT
pragma solidity 0.8.18;
contract TaskContract {
constructor() {
}
struct Task {
uint id;
string taskTitle;
string taskText;
bool isDeleted;
}
Task[] private tasks;
mapping (uint => address) taskToOwner;
event AddTask(address recepient,uint taskId);
event DeleteTask(uint taskId,bool isDeleted);
```
* The code defines a struct called Task with four fields: an ID (uint), a task title (string), a task text (string), and a Boolean flag indicating whether the task has been deleted (bool).
* The code declares a private Task array called tasks to store all the tasks created by the contract.
* The code defines a mapping called taskToOwner, which maps a task ID (uint) to the address of the user who created the task.
* The code includes two events:
* AddTask: emitted when a new task is added to the tasks array. The event includes the address of the user who added the task and the ID of the new task.
* DeleteTask: emitted when a task is marked as deleted in the tasks array. The event includes the ID of the deleted task and a flag indicating that it has been deleted.
* The code uses these constructs to define the data model for a task management system, where tasks are represented by the Task struct, stored in the tasks array, and associated with their creators via the taskToOwner mapping. The events allow for tracking and auditing of task creation and deletion.
```solidity
function addTask(string memory taskText,string memory taskTitle, bool isDeleted) external {
uint taskId = tasks.length;
tasks.push(Task(taskId,taskTitle, taskText, isDeleted));
taskToOwner[taskId] = msg.sender;
emit AddTask(msg.sender,taskId);
}
function deleteTask(uint taskId) external {
require(taskToOwner[taskId] == msg.sender, "You are not the owner of this task");
tasks[taskId].isDeleted = true;
emit DeleteTask(taskId,tasks[taskId].isDeleted);
}
```
* The `addTask` function is a public function that takes three arguments: a string for the task text, a string for the task title, and a boolean indicating whether the task is marked as deleted. It is used to add new tasks to the `tasks` array and associate the new task with the caller's address via the `taskToOwner` mapping.
* Within the function, the ID for the new task is set to the length of the `tasks` array. A new task with the given text, title, and deletion flag is created using the `Task` struct constructor and added to the `tasks` array.
* The caller's address is then associated with the new task ID in the `taskToOwner` mapping.
* Finally, an `AddTask` event is emitted with the caller's address and the ID of the new task.
* The `deleteTask` function is a public function that takes one argument: the ID of the task to be deleted. It is used to mark a task as deleted in the `tasks` array.
* Within the function, the caller's address is checked against the address associated with the given task ID in the `taskToOwner` mapping to ensure that the caller is the owner of the task.
* If the caller is the owner of the task, the `isDeleted` flag for the task is set to `true` in the `tasks` array.
* Finally, a `DeleteTask` event is emitted with the ID of the deleted task and a flag indicating that it has been marked as deleted.
```solidity
function getMyTask()public view returns(Task[] memory){
Task[] memory myTasks = new Task[](tasks.length);
uint counter = 0;
for(uint i = 0; i < tasks.length; i++){
if(taskToOwner[i] == msg.sender && tasks[i].isDeleted == false){
myTasks[counter] = tasks[i];
counter++;
}
}
Task[] memory result = new Task[](counter);
for(uint i = 0; i < counter; i++){
result[i] = myTasks[i];
}
return result;
}
```
* The `getMyTask` function is a public function that returns an array of `Task` struct objects for the caller. It is used to retrieve all non-deleted tasks associated with the caller's address in the `tasks` array.
* Within the function, a new `Task` array called `myTasks` is created with the same length as the `tasks` array. A counter variable is also initialized to 0.
* A for loop is used to iterate over all tasks in the `tasks` array. If a task is associated with the caller's address in the `taskToOwner` mapping and is not marked as deleted, it is added to the `myTasks` array at the current index indicated by the `counter` variable, and the `counter` variable is incremented.
* After the first for loop, a new `Task` array called `result` is created with a length equal to the `counter` variable.
* A second for loop is used to iterate over the `myTasks` array and populate the `result` array with the non-null `Task` objects.
* Finally, the `result` array is returned as the result of the `getMyTask` function.
## Github Repo
[Smart Contract Repo basics to advanced](https://github.com/moayaan1911/smart-contracts) | ayaaneth |
1,396,680 | N-Tier Architecture | The N-Tier Architecture is when the application is divided into logical layers and physical tiers so... | 20,359 | 2023-03-11T10:15:18 | https://pragyasapkota.medium.com/n-tier-architecture-8c3ed71a24f8 | architecture, systems, beginners, tutorial | The N-Tier Architecture is when the application is divided into logical layers and physical tiers so they are separate and can run on separate machines. Each layer has a specific responsibility and manages dependencies as well. A lower layer can give the services to a higher layer but cannot receive any.
The tiers can either use asynchronous messaging or call each other directly. The layers are available in the tiers which are separated in a way that it’s more [scalable](https://dev.to/pragyasapkota/scaling-3dfh) and resilient. However, the [latency](https://dev.to/pragyasapkota/latency-and-throughput-340h) is increased since there are additional network communications in the system.
## Types of N-Tier Architecture
There are two types of layers in N-Tier architecture.
### 1. Closed Layer Architecture
The layer is limited to call the next layer immediately down. It limits the dependencies between the layer despite the unwanted network traffic if the layer can pass the requests along to the next layer.
### 2. Open Layer Architecture
It can call any of the layers that lie below.
_There are three types of tiers in N-Tier Architecture._
### 1. 3-Tier Architecture
There are three different layers in the 3-Tier Architecture.
a. **Presentation Layer** handles user interactions with the application.
b. **Business Logic Layer** accepts data from the layer above and uses business logic to validate it.
c. **Data Access Layer** receives the data from the business logic layer and makes the database operations.
### 2. 2-Tier Architecture
In the 2-tier architecture, the presentation layer communicates with the data store and works on the client. Compared to the 3-tier architecture, the 2-tier misses out on the business logic layer. There is no middle layer between the client and the server.
### 3. 1-Tier Architecture
The 1-Tier architecture is also known as single-tier architecture where the application runs as if it was on a personal computer. All the components reside on a single server.
## Merits of N-Tier Architecture
- Layers are sort of a firewall providing extra security
- [Scaling](https://dev.to/pragyasapkota/scaling-3dfh) is easy due to the separate tiers
- Availability is improved
- Maintenance is improved since each tier can be handled by different individuals
## Demerits of N-Tier Architecture
- Network Security is risky
- Network [Latency](https://dev.to/pragyasapkota/latency-and-throughput-340h) is increased with the increased number of tiers
- Hardware cost is increased since each tier needs its own
- System complexity is increased as a whole
**_I hope this article was helpful to you._**
**_Please don’t forget to follow me!!!_**
**_Any kind of feedback or comment is welcome!!!_**
**_Thank you for your time and support!!!!_**
**_Keep Reading!! Keep Learning!!!_** | pragyasapkota |
1,396,756 | Power Virtual Agents: Use OpenAI GPT-3.5 as a helper for trigger phrases and custom entities | Picture of Rémi Walle on Unsplash Motivation When giving a "Power Virtual Agents in a... | 21,431 | 2023-03-11T12:05:11 | https://the.cognitiveservices.ninja/power-virtual-agents-use-openai-gpt-35-as-a-helper-for-trigger-phrases-and-custom-entities | ---
title: Power Virtual Agents: Use OpenAI GPT-3.5 as a helper for trigger phrases and custom entities
published: true
series: 101 - Power Virtual Agents
date: 2023-03-11 11:59:16 UTC
tags:
canonical_url: https://the.cognitiveservices.ninja/power-virtual-agents-use-openai-gpt-35-as-a-helper-for-trigger-phrases-and-custom-entities
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/5qlysgfc980tyizgmz70.jpg
---
Picture of <a href="https://unsplash.com/@walre037?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Rémi Walle</a> on <a href="https://unsplash.com/de/s/visuell/defa23b0-5ce2-4509-89b7-8adebbd9f4ae?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
## Motivation
When giving a "Power Virtual Agents in a Day" workshop, we start by creating topics and custom entities with the participants. While we are defining trigger phrases and synonyms for the closed lists in the custom entities, we often get asked the same question: "How can we find enough variations to help our bot?" Fortunately, there is a satisfactory answer to this: supporting the model behind the NLU in Power Virtual Agents with another model - text-davinci-003 from OpenAI.
## Background
Trigger phrases in Power Virtual Agents are words or phrases that can be used to initiate a conversation with a bot. They can be used to start a new conversation, ask specific questions, or provide instructions to the bot. Trigger phrases are defined in the bot's topic. They are usually set up as a list of keywords that the bot will recognize and respond to. Natural language understanding helps identify a topic based on meaning and not exact words. To start learning, the bot needs 5-10 short trigger phrases.
Custom entities in Power Virtual Agents are user-defined information about a conversation topic. They allow the bot to understand user input that may not be easily recognized by the Natural Language Processing (NLP) engine. For example, a custom entity can identify a company name, product name, or any other data type unique to the conversation. To use custom entities, you can create them in the Power Virtual Agents authoring canvas. Once created, they can be added to topics as variables to capture user input that matches the entity. This input can then be used to create more powerful conversations.
## Start with OpenAI
Signup for OpenAI Playground and start exploring.
## Use OpenAI Playground to get Synonyms.
e.g., if you need synonyms for personal transport vehicles, ask for them.
<figcaption>Ask for synonyms</figcaption>
- use Mode: Complete
- use Model: text-davinci-003
If you are more of a python type person, use this as a start:
```
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
model="text-davinci-003",
prompt="give me each 5 synonyms for a motorcycle and a car",
temperature=0.7,
max_tokens=2044,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
```
If you are more of a node.js person, this starter is for you:
```
const { Configuration, OpenAIApi } = require("openai")
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createCompletion({
model: "text-davinci-003",
prompt: "give me each 5 synonyms for a motorcycle and a car",
temperature: 0.7,
max_tokens: 2044,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
});
```
## Use OpenAI to generate trigger phrases.
e.g., you create a topic for giving your customers a precise answer to the question, where can I park my car?
Why not combine a custom entity for the vehicles with a fine list of trigger phrases?
Use the same method and model as above.
<figcaption>Ask for trigger phrases</figcaption>
Python and Node.js are equivalent to the example above.
## Bonus: yes and no
If you are in voice bots like me, why not create a new confirmation custom entity for yes and no's - and use it instead of Boolean?
Your bot will never fail again:
```
give me 20 ways to say yes as a array
["Yes", "Absolutely", "Sure", "Of course", "Definitely", "Agreed", "Indeed", "Indeed!", "Yep", "Yup", "Aye", "Indeed yes", "Yeah", "Yah", "Verily", "Yea", "By all means", "Affirmative", "All right", "Sure thing", "You bet"]
give me 20 ways to say no as a array
["No", "Nope", "No way", "Negative", "Not a chance", "Nah", "No can do", "No thank you", "My answer is no", "No sir", "No ma'am", "No sirree", "I'm afraid not", "Absolutely not", "Uh uh", "No thanks", "I don't think so", "Not now", "Not ever", "Nyet"]
```
## Conclusion
Let the machine work for you, do not focus on the simple tasks a machine can do for you. Start exploring the capabilities of OpenAI and make your life easier. | thecognitiveservicesninja | |
1,397,159 | The Future of Customer Engagement: How Conversational Messaging Platforms are Changing the Game | The way we communicate with each other has undergone a massive transformation in recent years. From... | 0 | 2023-03-11T19:36:09 | https://dev.to/twixor_digital/the-future-of-customer-engagement-how-conversational-messaging-platforms-are-changing-the-game-4on0 | conversationalai, lowcode, nlp, ai | The way we communicate with each other has undergone a massive transformation in recent years. From traditional phone calls to email to social media, technology has transformed how we interact with one another. One of the latest developments in communication technology is the rise of conversational messaging platforms, which are changing the way businesses engage with their customers.
## **Conversational Messaging Platform on the Rise**
Conversational messaging platforms are digital platforms that enable two-way communication between businesses and their customers. These platforms can take many forms, such as chatbots, messaging apps, and SMS services. They use natural language processing (NLP) and artificial intelligence (AI) to create human-like interactions and personalized experiences for customers.
One of the reasons why conversational messaging platforms are becoming popular is that they offer a more convenient and efficient way for customers to communicate with businesses. Instead of having to call a customer support center or send an email and wait for a response, customers can now get answers to their questions and resolve issues through messaging platforms in real-time.
## **How Conversational Messaging Platforms are Driving Business Success**
The benefits of conversational messaging platforms are not limited to customers. They also offer several advantages to businesses. For one, these platforms can help businesses improve their customer service and support. They enable businesses to respond to customer inquiries and requests in real-time, which can result in higher customer satisfaction rates.
Moreover, [conversational messaging platforms can help businesses reduce their operational costs. By automating routine tasks](https://twixor.com/conversational-messaging-platform-revolutionizing-customer-engagement/), such as answering frequently asked questions, businesses can free up their human resources to focus on more complex tasks that require human intervention.
Another advantage of conversational messaging platforms is that they can help businesses increase their sales and revenue. By using these platforms to engage with customers, businesses can offer personalized product recommendations and promotions, which can lead to higher conversion rates.
[> According to a study by Facebook, over 60% of customers prefer messaging over phone calls when it comes to customer service](https://www.facebook.com/business/news/insights/3-ways-messaging-is-transforming-the-path-to-purchase)
## **Transactional Chatbots allowing end-to-end fulfilment**
One of the most significant developments in conversational messaging platforms is the rise of transactional chatbots. These are chatbots that are capable of handling end-to-end transactions, from customer inquiries to order fulfillment.
[Transactional chatbots can help businesses streamline their sales and fulfillment processes](https://twixor.com/transactional-chatbots/), resulting in faster and more efficient service for customers. For instance, a customer can place an order through a chatbot and receive real-time updates on the status of their order through the same platform. Once the order is fulfilled, the chatbot can also provide the customer with a confirmation and tracking information.
Transactional chatbots can also help businesses reduce the risk of errors and delays that can occur in manual processes. By automating these processes, businesses can ensure that customer orders are processed accurately and efficiently, resulting in higher customer satisfaction rates.
_
[> As of May 2020, WhatsApp had over 50 million business accounts active on its platform. In the same month, WhatsApp reported that over 175 million people were messaging a WhatsApp Business account every day.](https://about.fb.com/news/2020/10/privacy-matters-whatsapp-business-conversations/)
## **How Twixor conversational messaging platform is revolutionizing customer engagement**
Twixor is one of the leading conversational messaging platforms that are transforming customer engagement. Its platform enables businesses to create personalized and interactive messaging experiences for their customers, using a combination of chatbots, messaging apps, and SMS services.
[One of the unique features of Twixor is its ability to handle end-to-end transactions through its chatbots](https://www.twixor.com). Its chatbots can manage the entire sales and fulfillment process, from customer inquiries to order tracking, resulting in a seamless and efficient customer experience.
Twixor also offers a range of features that enable businesses to customize their messaging experiences, such as interactive menus, personalized recommendations, and automated responses to frequently asked questions. Its platform is also integrated with a range of third-party tools, such as CRM systems and payment gateways, to provide a complete end-to-end solution for businesses.
In conclusion, conversational messaging platforms are revolutionizing customer engagement by providing a more convenient, efficient, and personalized way for customers to interact with businesses. With the rise of transactional chatbots, businesses can now handle end-to-end transactions with ease and accuracy, resulting in higher customer satisfaction rates and increased revenue. Platforms like Twixor are leading the way in this revolution by providing businesses with innovative and powerful tools to create engaging and interactive messaging experiences for their customers.
_
| twixor_digital |
1,396,913 | Add a Dynamic Sitemap to Next.js Website Using Pages or App Directory | In this post, we will explore how to add a dynamic sitemap to a Next.js website using the app... | 0 | 2023-03-11T14:21:29 | https://claritydev.net/blog/nextjs-dynamic-sitemap-pages-app-directory | nextjs, javascript |

In this post, we will explore how to add a dynamic sitemap to a Next.js website using the app directory. A sitemap is a file that lists all the pages of a website and helps search engines understand the structure of the site. By the end of this post, you will have a fully functional dynamic sitemap for your Next.js website.
The post is available on [my blog](https://claritydev.net/blog/nextjs-dynamic-sitemap-pages-app-directory). | clarity89 |
1,396,925 | Kubernetes-101: Deployments, part 1 | We continue our Kubernetes journey by learning about a new object: the Deployment. When we learn... | 22,207 | 2023-03-31T10:00:00 | https://mattias.engineer/k8s/deployments-1/ | kubernetes | We continue our Kubernetes journey by learning about a new object: the **Deployment**. When we learn about deployments we will quickly find out that we also have to learn about something called a **ReplicaSet**. Two new objects in one go!
In this article I will use a new convention. When I write the name of an object in Kubernetes I will use Pascal case: _Pod_, _Deployment_, _ReplicaSet_, etc.
## Deployments
A Deployment is an _abstraction_ on top of ReplicaSets and Pods. We are familiar with Pods from before! More about ReplicaSets below. To simplify things a bit you could say that when you create a Deployment you specify two things:
1. What Pod should the Deployment create?
2. How many replicas of this Pod should be created?
That sounds simple enough! If that is all a Deployment does, what is the difference from manually creating a number of Pods using what we saw in the previous two articles about Pods? To understand the beauty with Deployments we must also introduce the Deployment controller.
What is a controller? A controller is an agent in something called the controller pattern. A controller runs in a never-ending loop (a _control-loop_) and continuously makes sure a system is in a desired state. An example of such a system is cruise-control in your car. The control-loop in that case makes sure the car holds a given speed (your desired state). In the case of Kubernetes Deployments the Deployment controller takes a desired state as specified in the Deployment manifest, and makes sure the current state corresponds to this desired state. If I specify that I want two replicas of my Pod, then the Deployment controller will make sure there are two replicas of my Pod. If I delete one of my Pods, then a new Pod will appear to take its place.
In the previous two articles I mentioned that we do not usually create individual Pods using the method I showed you there. We can create Pods in a better way, by using a Deployment! A Deployment is the _most_ common way to create Pods. It is not the only way of doing it, later in this series of articles I will introduce additional objects that can create Pods: **DaemonSets**, **StatefulSets**, and **Jobs**. So when do we use a Deployment? Whenever we want to create a Pod, potentially with many replicas[^daemonsets].
### Creating a deployment declaratively
Let us get our hands dirty and create a Deployment using a Deployment manifest. As in previous articles we will use a simple Nginx container as our application. A simple Deployment manifest looks like this:
```yaml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
```
This manifest should look familiar because most of it was part of our Pod manifest as well. Let me highlight a few things from the manifest:
- `apiVersion` is `apps/v1`, this is different from when we defined a Pod. In general each kind of object could have its own API version, so you should check the API reference to know what is the correct API version to use.
- `kind` is set to `Deployment`
- `spec.replicas` is set to `3`. This is the second of the two points I said you configure for a Deployment.
- `spec.selector.matchLabels` is where you specify what labels on a Pod this Deployment will look for when determining the current state.
- `spec.template` is the Pod manifest again! This is the first of the two points I said you configure for a Deployment.
- `spec.template.metadata.labels` is where I provide labels for this Pod template, these labels should match with the labels I told the Deployment to look for in `spec.selector.matchLabels`.
An important concept has casually been introduced here: **labels**. Labels are key-value pairs that are usually used for different kinds of selections. We will encounter labels a lot more in future articles!
A notable missing property in the `spec.template.metadata` part is the `name`. We do not specify a name for the Pod because then we would have a problem when we try to create several replicas of the Pod, since the Pod names must be unique.
We can create this Deployment by using the same command we used to create a Pod from our Pod manifest, with `kubectl apply`:
```console
$ kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment created
```
We can list all of our Deployments with `kubectl get deployments`:
```console
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 21s
```
Similarly to how we could use the short version `po` instead of `pods` we can write `deploy` instead of `deployments`:
```console
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 32s
```
If you followed my idea about setting an alias `alias k="kubectl"` in your terminal you can shorten the previous command to `k get deploy`. If you want to take it to the extreme you could define another alias: `alias kgd="kubectl get deploy"` to shorten it even more!
We can get all details about our Deployment by using `kubectl describe`:
```console
$ kubectl describe deployment nginx-deployment
```
The output of this command is verbose, so I will not repeat it here. What happens if we list our Pods now? Let's see:
```console
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-cd55c47f5-b695d 1/1 Running 0 40s
nginx-deployment-cd55c47f5-fvjtt 1/1 Running 0 40s
nginx-deployment-cd55c47f5-ql8pq 1/1 Running 0 40s
```
We have three copies of them! We can see that the names of the Pods start with the name of the Deployment: `nginx-deployment`. Where does the `cd55c47f5` part come from? Let us run `kubectl get` to see if we have the thing called a ReplicaSet:
```console
$ kubectl get replicasets
NAME DESIRED CURRENT READY AGE
nginx-deployment-cd55c47f5 3 3 3 2m53s
```
So it seems like we have a ReplicaSet with the name of `nginx-deployment-cd55c47f5`. This is the resource that our Deployment actually created for us. The Pods themselves were technically created by this ReplicaSet object. See that the name of the ReplicaSet is `nginx-deployment-cd55c47f5`? That is where the `cd55c47f5` part of the Pod names come from. The last part of the Pod names are autogenerated and different for each Pod (`b695d`, `fvjtt`, and `ql8pq`).
Similarly to how we can shorten `pods` to `po`, and `deployments` to `deploy`, we can shorten `replicasets` to `rs`. So the previous command could have been run as `kubectl get rs`. This time the short version really pays off, imagine having to write `replicasets` all the time?
What happens if we delete one of our Pods? We delete the Pod named `nginx-deployment-cd55c47f5-ql8pq` using `kubectl delete pod`:
```console
$ kubectl delete pod nginx-deployment-cd55c47f5-ql8pq
pod "nginx-deployment-cd55c47f5-ql8pq" deleted
```
That worked. What happens if we list all our Pods again?
```console
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-cd55c47f5-b695d 1/1 Running 0 6m54s
nginx-deployment-cd55c47f5-fvjtt 1/1 Running 0 6m54s
nginx-deployment-cd55c47f5-mqrkl 1/1 Running 0 40s
```
A new Pod has appeared! The controller pattern is at play here. If we lose a Pod for any reason, a new one appears to replace it. One could almost say that we have a system that is resilient to failure[^failure].
How do we delete our Pods, if they keep reappearing all the time? We must delete the Deployment, and we do that with `kubectl delete`:
```console
$ kubectl delete -f deployment.yaml
deployment.apps "nginx-deployment" deleted
```
What would happen if we delete the ReplicaSet that the Deployment has created for us? I am not really sure, I just think that you will end up having to manually delete your Pods in the end. It is _not_ recommended to do any modifications to the ReplicaSet resource. If you need to change something, change the Deployment and re-apply the Deployment manifest.
There are a few more interesting things we can do with Deployments, but we will look at some of them in the next article.
Once we have a Deployment, do we have a redundant system? Partly. We have a way to set up several replicas of our Pods, but we do not yet have a way to distribute incoming traffic between our replicas. In a future article we will learn about Kubernetes **Services** which will handle this for us.
## Loose end: What is a ReplicaSet?
We have briefly seen the ReplicaSet in the previous section, where we were supposed to talk about Deployments and not about ReplicaSets. However, it is difficult not to talk about ReplicaSets when describing what a Deployment is. A ReplicaSet has one task: keep a given number of identical (replicas) pods running at all time. How does it know what pod it should create replicas of? If we take a look at the manifest for a ReplicaSet[^replicaset] it will become clear:
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: web-rs
labels:
tier: web
spec:
replicas: 3
selector:
matchLabels:
tier: web
template:
metadata:
labels:
tier: web
spec:
containers:
- name: nginx
image: nginx:latest
```
As we can see this manifest looks almost identical to the Deployment manifest above, so we don't have to go through the details of it. The reason they look so similar is because I have not added any of the unique details for any of the manifests. As mentioned earlier we will see more of the Deployment manifest in the next article in this series.
A general observation we can make about Kubernetes manifests at this stage is that each manifest has the following properties:
- `apiVersion`
- `kind`
- `metadata.name`
- `spec`
So each manifest specifies an API version, what kind of object we are working with, a name that we can use to identify the object, and a specification that is different depending on what kind of object we are creating. These properties are good to remember!
Back to ReplicaSets: in real-life it is not very common to directly create ReplicaSets. It is common that you create Deployments that create ReplicaSets for you. So at this stage of your Kubernetes journey it is not relevant to focus too much on the ReplicaSet, you can instead think of the Deployment as the one who is in charge. But I still want you to know how this works behind the scenes. So let us end this section with an illustration of what happens when we create a Deployment with a desired Pod count of three:
## Summary
Even though Deployments are relatively straight-forward we managed to learn a lot about them in this article. We now know that a Deployment creates something called a ReplicaSet, and the ReplicaSet in turn creates a configurable number of Pods. We now know that when we want to create a Pod, we should really be using a Deployment instead. We know how to declaratively create a Deployment, and we know how to use `kubectl` to list our Deployments and to get detailed information about a certain Deployment.
In the next article in this series I will expand a bit about what more we can do with Deployments.
[^replicaset]: The full API is available at https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/replica-set-v1/
[^daemonsets]: Except when we require the special abilities that DaemonSets and StatefulSets offer!
[^failure]: That is only partly true. If you have a serious problem in your application that makes your containers crash, your Pods will just keep on crashing over and over again. The Deployment makes sure new Pods keep appearing, but you will need to fix your application! | mattiasfjellstrom |
1,396,938 | Using composition to optimize React rendering | How you can improve and minize re-rendering in your React app using component composition. It's... | 0 | 2023-03-11T15:01:09 | https://dev.to/coder4_life/using-composition-to-optimize-react-rendering-12dg | webdev, javascript, beginners, react | How you can improve and minize re-rendering in your React app using component composition. It's really simple. Here we refactor a simple app that re-renders a third component not related to the changes happening.
{% youtube lfqaQxwnLng %}
```
import { useCallback, useState } from 'react';
function App() {
return (
<div className="app">
<CounterComponent>
<Title />
</CounterComponent>
</div>
);
}
const CounterComponent = ({ children }) => {
const [count, setCount] = useState(0);
const increment = useCallback(() => {
setCount(prev => prev + 1);
}, []);
const decrement = useCallback(() => {
setCount(prev => prev - 1);
}, []);
console.log('render CounterComponent');
return (
<div>
{children}
<h2>{count}</h2>
<div>
<button onClick={decrement}>-</button>
<button onClick={increment}>+</button>
</div>
</div>
);
};
const Title = () => {
console.log('render Title');
return <h1>Counter</h1>;
};
export default App;
``` | coder4_life |
1,396,993 | useEffect Simplified | useEffect explaination with examples. | 0 | 2023-03-11T16:00:55 | https://dev.to/rv90904/useeffect-simplified-5699 | react, javascript, programming, webdev | ---
title: useEffect Simplified
published: true
description: useEffect explaination with examples.
tags: react, javascript, programming, webdev
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-11 14:39 +0000
---
useEffect hook was introduced in functional class paradigm in React. useEffect is most used hook, you can use it to make network call, preform calculation, listen for a particular state change and for cleanup of component.
Let's understand useEffect function definition first -
```javascript
useEffect(() => {
return () => {
// cleanup function
}
},[])
```
This hook accepts callback function as 1st argument and dependency array as 2nd argument.
Inside callback function, you can return a function which will get triggered as cleanup function.
2nd Argument - Dependency array is tweak for different behaviour.
Before going to into useEffect, lets understand first when a component is mounted and unmounted.
A component is mounted when it is part of render logic.
```javascript
const Profile = () => {
return (
<div>Profile Component</div>
)
}
const App = () => {
const mount = false;
return (
<div>
{
mount ? <Profile/> : null
}
</div>
);
}
```
Here Profile component is mounted only when mount flag is true and unmounted only when it is removed from render.
### Case 1 - Empty dependency array
```javascript
useEffect(() => {
return () => {
}
},[])
```
Here, callback function will be triggered when component is mounted and cleanup function will be triggered with component is unmounted.
This is similar to componentDidMount and componentDidUnMount from class based components from pre React 16.
### Case 2 - With Dependency array
```javascript
const App = () => {
const [count, setCount] = useState(0);
const [streak, setStreak] = useState(0);
useEffect(() => {
// This will be triggered when count state is changed
return () => {
}
},[count])
useEffect(() => {
// This will be triggered when count streak is changed
return () => {
}
},[streak])
useEffect(() => {
// This will be triggered when count or streak streak is changed
return () => {
}
},[count, streak])
return (
<div>
<p>This is count : {count}</p>
<p>This is streak : {streak}</p>
</div>
);
}
```
### Case 3 - No Dependency array
```javascript
const App = () => {
const [count, setCount] = useState(0);
useEffect(() => {
// This will trigger on every render
return () => {
}
})
return (
<div>
<p>This is count : {count}</p>
<p>This is streak : {streak}</p>
</div>
);
}
```
| rv90904 |
1,397,144 | Symfony Station Communiqué — 10 March 2023. A look at Symfony, Drupal, PHP, Cybersecurity, and Fediverse news. | This communiqué originally appeared on Symfony Station, your source for cutting-edge Symfony, PHP,... | 0 | 2023-03-11T18:36:22 | https://www.symfonystation.com/Symfony-Station-Communique-10-March-2023 | symfony, drupal, php, cybersecurity | This communiqué [originally appeared on Symfony Station](https://www.symfonystation.com/Symfony-Station-Communique-10-March-2023), your source for cutting-edge Symfony, PHP, and Cybersecurity news.
Welcome to this week's Symfony Station Communiqué. It's your review of the essential news in the Symfony and PHP development communities focusing on protecting democracy. We also cover the cybersecurity world and the Fediverse.
Please take your time and enjoy the items most relevant and valuable to you. There is a good bit of Drupal content this week, including the featured item.
Thanks to Javier Eguiluz and Symfony for sharing [our latest communiqué](https://www.symfonystation.com/Symfony-Station-Communique-03-March-2023) in their [Week of Symfony](https://symfony.com/blog/a-week-of-symfony-844-27-february-5-march-2023).
**My opinions will be in bold. And will involve profanity.**
---
A significant proportion of the content we curate is on Medium. I highly recommend investing in a membership to access all the articles you want to read. It's a small investment that can boost your career. As you may have noticed, non-members can only access a limited number of articles per month.
**[Become a member here](https://medium.com/@mobileatom/membership)**! The compensation we receive from your use of this link helps pay for our weekly communiqué.
---

## Symfony
As always, we will start with the official news from Symfony. Highlight -> “This week, Symfony 5.4.21
and 6.2.7 maintenance versions were released. Meanwhile, the upcoming Symfony 6.3 version added support for managing command exit code while handling signals. Lastly, the SymfonyOnline June 2023 conference announced that you can submit your papers until March 6.“
[A Week of Symfony #844 (27 February - 5 March 2023)](https://symfony.com/blog/a-week-of-symfony-844-27-february-5-march-2023?utm_source=Symfony+Blog+Feed&utm_medium=feed)
Symfony announced:
[SymfonyLive Paris 2023: Only 2 weeks to go for the pre-conference workshops!](https://symfony.com/blog/symfonylive-paris-2023-only-2-weeks-to-go-for-the-pre-conference-workshops)
[SymfonyCon Brussels 2023 - Call for papers is open!](https://symfony.com/blog/symfonycon-brussels-2023-call-for-paper-is-open)
Blackfire has:
[Getting started with the Blackfire test suite: part 3 of a series](https://blog.blackfire.io/getting-started-with-the-blackfire-test-suite-part-3-of-a-series.html)
SymfonyCasts continues its API Platform course.
[This week on SymfonyCasts](https://5hy9x.r.ag.d.sendibm3.com/mk/mr/5puCf1lnRoDEzfTRXH79eO0J9T7_4c8F0ol5fmeMMyeJpUgU8Cg7GBsfMyVc-zkUpO4fPjikxRdht8BYAMOgBdv92ylL3d1HuAXoaM5_CVZo3Xgg3f8jyRXGart7001jEVZeMySK77k)
---
## Featured Item

I am tooting my own horn this week as I have published my first “opinion” piece. It examines if Drupal has a path to growth.
“Idiots have been claiming PHP is dead for years. Guess what? It’s not dying. It’s growing and mainly via WordPress and outside the United States. With Drupal, not so much.
This piece will cover Drupal’s strengths and weaknesses as I see them affecting its growth. And when I talk about growth, I mean the total number of Drupal users, not the profits of companies basing their businesses on Drupal.
Then I will look at three paths its future could take. Those of **what I want, what could happen, and what will probably happen**.”
### **[Does Drupal Have a Path to Growth?](https://www.symfonystation.com/Drupal-Path-Growth)**
---
### This Week
Anton Lytvynov has:
[Why use Symfony for web development](https://antonlytvynov.medium.com/why-use-symfony-for-web-development-f82cb1ccf9e9)
[The Future of PHP and Symfony: Predictions and Trends for Web Development](https://antonlytvynov.medium.com/the-future-of-php-and-symfony-predictions-and-trends-for-web-developmen-1c826a952937)
[How to Set Up a Local Symfony Development Environment with Docker Compose](https://antonlytvynov.medium.com/how-to-set-up-a-local-symfony-development-environment-with-docker-compose-f6b1f243b450)
It is great to see Smaine Milianni back with:
[Feature Flag and Strategy pattern with the Symfony framework](https://smaine-milianni.medium.com/feature-flag-and-strategy-pattern-with-the-symfony-framework-7863ecc9556a)
Mark Caggiano shows us:
[How to create a WordPress plugin using PHP and OOP, with Composer for package management, Symfony components for backend functionality, and Twig for frontend templating](https://marcocaggiano.medium.com/how-to-create-a-wordpress-plugin-using-php-and-oop-with-composer-for-package-management-symfony-cceaf60c5f50)
JoliCode looks at:
[Handling signal with Symfony Command](https://jolicode.com/blog/handling-signal-with-symfony-command)
Shahid Shahmiri shows us:
[How To Build A Metaverse-Enabled Ad Tech Platform With Symfony](https://leadgenapp.io/how-to-build-a-metaverse-enabled-ad-tech-platform-with-symfony/)
Carlo Todeschini built:
[GitHub - carlotodeschini/htmxtest: Symfony CRUD handled by HTMX JavaScript framework](https://github.com/carlotodeschini/htmxtest)
And Jordi Boggiano built a Symfony wrapper of the PHP client for the FeaturIT Feature Flag management platform.
[featurit/featurit-sdk-symfony - Packagist](https://packagist.org/packages/featurit/featurit-sdk-symfony)
### eCommerce
Quick Sprout has a:
[PrestaShop Review – What Makes PrestaShop Great and Where PrestaShop Falls Short](https://www.quicksprout.com/prestashop-review/)
Shopware shares:
[Shopware Community Digest February '23](https://www.shopware.com/en/news/shopware-community-digest-february-23/)
Edna Ololade compares:
[Medusa Vs. Sylius: Which Should You Use for Your Ecommerce?](https://dev.to/women__leader/medusa-vs-sylius-which-should-you-use-for-your-ecommerce-2clf)
### CMSs
Zyxware Technologies compares:
[Drupal Updates vs Upgrades vs Migrations: What's the Difference and When Do You Need Them?](https://www.zyxware.com/article/6538/drupal-updates-vs-upgrades-vs-migrations-whats-the-difference)
FiveJars explores:
[Building Microsites in Drupal](https://fivejars.com/blog/building-microsites-drupal)
The Drop Times has several developer interviews:
[Shouldn’t Let Imposter Syndrome Keep You from Trying: John Jameson | DrupalCamp NJ](https://www.thedroptimes.com/28769/shouldnt-let-imposter-syndrome-keep-you-trying-john-jameson-drupalcamp-nj)
[An Accidental Web Developer: Interview with Rick Hood | NERD Summit](https://www.thedroptimes.com/28797/accidental-web-developer-interview-rick-hood-nerd-summit)
ComputerMinds continues its Drupal 10 upgrade case study series:
[Drupal 10 upgrade: Custom code upgrades](https://www.computerminds.co.uk/articles/drupal-10-upgrade-custom-code-upgrades)
[Drupal 10 upgrade: File to media](https://www.computerminds.co.uk/articles/drupal-10-upgrade-file-media)
Prometsource shows us:
[How to Leverage Load Testing to Scale up a Drupal Site](https://www.prometsource.com/blog/website-load-testing-tools)
Matt Glaman looks at:
[Running specific PHPUnit data provider data set](https://mglaman.dev/blog/running-specific-phpunit-data-provider-data-set?utm_source=Front&utm_medium=feed&utm_campaign=RSS+Feed)
Colorfield explores:
[Visual regression testing for Drupal migrations with Playwright](https://colorfield.be/blog/visual-regression-testing-for-drupal-migrations-with-playwright)
Specbee shows us:
[How to Efficiently Fetch Drupal Reference Entities in Custom Modules](https://www.specbee.com/blogs/fetch-drupal-reference-entities-in-custom-modules)
CKEditor can expand its capabilities:
[Drupal Premium Features module now stable](https://ckeditor.com/blog/drupal-premium-features-module/)
EvolvingWeb goes:
[Hands-On With Drupal 10: Olivero, a New Theme with a Meaningful Name](https://evolvingweb.com/blog/hands-drupal-10-olivero-new-theme-meaningful-name?utm_source=feed)
Star Shaped of Lullabot shares her experience at:
[Florida DrupalCamp 2023](https://www.star-shaped.org/florida-drupalcamp-2023/)
Mateu Aguiló Bosch of lullabot explores:
[Getting Single Directory Components in Drupal Core](https://www.lullabot.com/articles/getting-single-directory-components-drupal-core)
**This is fantastic news.**
### Previous Weeks
And Lullabot has this case study.
[American Bookseller Association](https://www.lullabot.com/our-work/american-bookseller-association)
Suckup shares:
[Legacy Codebase: A Love Story](https://suckup.de/2023/01/legacy-codebase-a-love-story/)

## PHP
### This Week
.com says:
[I Was Accused of Prematurely Optimizing the Code. They Are Wrong!](https://medium.com/@dotcom.software/i-was-accused-of-prematurely-optimizing-the-code-they-are-wrong-a96f08e3598f)
Derry Ross explores:
[Mastering PHP for Dynamic Web Development](https://medium.com/@derry.r05/mastering-php-for-dynamic-web-development-41b9b519bd1d)
Dolly Aswin looks at:
[PHP Development Trends In 2023](https://medium.com/@dollyaswin/php-development-trends-in-2023-d03fb601ff67)
Marcel Bootsman looks at:
[Switching to PHP 8.x in Four Steps - An Interview with Juliette Reinders Folmer](https://kinsta.com/blog/switching-to-php-8/)
This got lots of interest when I shared it on Mastodon this week.
Nikola Stojiljkovic shares:
[Impressions on GitHub Copilot and PHPStorm — March 2023](https://nikola-stojiljkovic.medium.com/impressions-on-github-copilot-and-phpstorm-march-2023-746e72915b46)
Active Hosted opines on:
[The PHP Operator that You Should Always Use](https://alexwebdevelop.activehosted.com/social/cb70ab375662576bd1ac5aaf16b3fca4.251)
Kumar Ravi says:
[PHP Match Expression Is the New and Improved Switch Statement](https://kumarravisingh.medium.com/php-match-expression-is-the-new-and-improved-switch-statement-9b1d0b53431d)
Roberton B. examines:
[Test coverage: did you set Xdebug's coverage mode?](https://dev.to/robertobutti/test-coverage-did-you-set-xdebugs-coverage-mode-ij9)
Erika Heidi explores:
[Creating Safer Containerized PHP Runtimes with Wolfi](https://dev.to/erikaheidi/creating-safer-containerized-php-runtime-environments-with-wolfi-1ioa)
Laravel News looks at:
[Sharing PHPCS Rules Across Projects and Teams](https://laravel-news.com/sharing-phpcs-rules)
Kumar Abhinav shows us:
[How to Install Different PHP Versions in Ubuntu](https://geekabhinav.medium.com/how-to-install-different-php-versions-in-ubuntu-d80ea4afac0)
Mom Junior examines the:
[Single Responsibility Principle(SRP) example using PHP](https://medium.com/@Omojunior11/single-responsibility-principle-srp-example-using-php-337e33d739e)
Claudio Ribeiro has a:
[Quick Tip: How to Cache Data in PHP](https://www.sitepoint.com/php-cache/)
Geek Job shows us how to:
[Disable eval in PHP 8](https://geekjob.tech/disable-eval-in-php-8-a0369da7b822)
of0x looks at:
[Beating an old PHP source code protector](https://adepts.of0x.cc/decrypt-nu-coder/)
Moslem Deris explores:
[Singleton in PHP (complete guide)](https://medium.com/@moslem.deris/singleton-in-php-complete-guide-31fa96c45ac9)
Uladzimir Tsykun shares:
[Mirroring Composer dependencies with Packeton](https://dev.to/vtsykun/mirror-composer-dependencies-with-packeton-1jea)
Sam Anglin has:
[Common Function Comparisons in PHP](https://www.mizouzie.dev/articles/common-function-comparisons-in-php/)
PeakD expounds on:
[Using PSR-3 placeholders properly](https://peakd.com/hive-168588/@crell/using-psr-3-placeholders-properly)
Atakan Demircioğlu looks at:
[Implementing a Service Layer in PHP](https://medium.com/@atakde/implementing-service-layer-in-php-6bf9bfc4d10c)
[Valerie Kuzmina](https://blog.jetbrains.com/qodana/2023/03/secure-your-php-code-with-taint-analysis-by-qodana/) shows us how to:
[Secure Your PHP Code With Taint Analysis by Qodana](https://blog.jetbrains.com/qodana/2023/03/secure-your-php-code-with-taint-analysis-by-qodana/)
Aminul Islam Sarker examines:
[Unlocking the Power of PHP with the Abstract Syntax Tree (AST)](https://aminshamim.xyz/unlocking-the-power-of-php-with-the-abstract-syntax-tree-ast-6951a3de2919)
**Great stuff here.**
### Previous Weeks
İlyas Özkurt shows us how to:
[Boost Your PHP Testing Speed with Paratest](https://ilyasozkurt.com/programming/boost-your-php-testing-speed-with-paratest/)

## Other
[Please visit our Support Ukraine page](https://www.symfonystation.com/Support-Ukraine) to learn how you can help kick Russia out of Ukraine (eventually).
### The cyber response to Russia’s War Crimes and other douchebaggery
The New York Times reports on:
[The Daring Ruse That Exposed China’s Campaign to Steal American Secrets](https://www.nytimes.com/2023/03/07/magazine/china-spying-intellectual-property.html)
TechCrunch reports:
[Police arrest suspected members of prolific DoppelPaymer ransomware gang](https://techcrunch.com/2023/03/06/police-arrest-suspected-members-of-prolific-doppelpaymer-ransomware-gang/)
TechSpot reports:
[US blacklists China's Loongson as its CPUs reach maturity](https://www.techspot.com/news/97817-us-blacklists-china-loongson-cpus-reach-maturity.html)
The Federal Trade Commission warns:
[Keep your AI claims in check](https://www.ftc.gov/business-guidance/blog/2023/02/keep-your-ai-claims-check)
CBS reports:
[Bipartisan group of senators unveil bill targeting TikTok, other foreign tech companies](https://www.cbsnews.com/news/tiktok-ban-bipartisan-senate-bill-mark-warner-john-thune/)
### The Evil Empire Strikes Back
The Register reports:
[Pro-Putin scammers trick politicians and celebrities into low-tech hoax video calls](https://www.theregister.com/2023/03/07/proputin_scammers_trick_politicians_and/)
[Secret Service, ICE break the law over and over with fake cell tower spying](https://www.theregister.com/2023/03/04/dhs_secret_service_ice_stingray/)
The Hacker News reports:
[Lazarus Group Exploits Zero-Day Vulnerability to Hack South Korean Financial Entity](https://thehackernews.com/2023/03/lazarus-group-exploits-zero-day.html)
Cory Doctorow laments:
[They’re still trying to ban cryptography](https://doctorow.medium.com/theyre-still-trying-to-ban-cryptography-33aa668dc602)
### Cybersecurity/Privacy
Zack Whittaker opines:
[Today’s startups should terrify you](https://techcrunch.com/2023/03/08/startups-today-should-terrify-you/)
Fast Company reports on:
[5 cybersecurity trends people who work from home need to know](https://www.fastcompany.com/90859303/5-cybersecurity-trends-people-who-work-from-home-need-to-know?partner=rss&utm_source=rss&utm_medium=feed&utm_campaign=rss+fastcompany&utm_content=rss)
**Use password managers, two-factor authentication, VPN, etc. peeps.**
Tech Republic reports on the:
[Top 10 open-source security and operational risks of 2023](https://www.techrepublic.com/article/top-open-source-security-risks/)
[New National Cybersecurity Strategy: resilience, regs, collaboration and pain (for attackers)](https://www.techrepublic.com/article/new-national-cybersecurity-strategy/)
Decipher reports:
[Apache Patches Two Important Bugs in Web Server](https://apple.news/AdYYgYyyrRrqW5XT6uCIK0Q)
Dark Reading reports:
[Without FIDO2, MFA Falls Short](https://www.darkreading.com/endpoint/without-fido2-mfa-falls-short)
The Guardian reports:
[Sensitive personal data of US House and Senate members hacked, offered for sale](https://www.theguardian.com/us-news/2023/mar/08/us-house-senate-members-data-leaked-for-sale?CMP=Share_iOSApp_Other)
**Maybe the fucks will do something about cybersecurity now.**
### More
Abid Ali Awan explores:
[Getting Started with GitHub CLI](https://www.kdnuggets.com/2023/03/getting-started-github-cli.html)
Bleeping Computer reports:
[GitHub makes 2FA mandatory next week for active developers](https://www.bleepingcomputer.com/news/security/github-makes-2fa-mandatory-next-week-for-active-developers/)
GitHub shows us how they implemented Elasticsearch:
[How GitHub Docs’ new search works](https://github.blog/2023-03-09-how-github-docs-new-search-works/)
Marcus Bentele shares:
[How To Become A Git Pro By Mastering Only One Powerful Git Command](https://levelup.gitconnected.com/how-to-become-a-git-pro-by-mastering-only-one-powerful-git-command-7c1da31be9ea)
Leticia Coelho shows us how to write:
[Clean HTML](https://medium.com/arctouch/clean-html-1acda5c0326e)
SpicyWeb says:
[HTML is a Serialized Object Graph and That Changes Everything](https://www.spicyweb.dev/html-serialized-object-graph/)
The acerbic and awesome Jason Knight has:
[Adam Wathan (Part 1): Deluded, Predator, Or An Outright Fraud?](https://medium.com/codex/adam-wathan-part-1-deluded-predator-or-an-outright-fraud-d704e97fcf3f)
[Adam Wathan (Part 2): The Ignorance On Full Display](https://deathshadow.medium.com/adam-wathan-part-2-the-ignorance-on-full-display-6ad82e8c5065)
**TLDR Tailwind CSS sucks. Don’t be lazy. Learn HTML and CSS.**
Chrome Developers examine:
[CSS Nesting](https://developer.chrome.com/articles/css-nesting/)
Toptal has:
[TypeScript vs. JavaScript: Your Go-to Guide](https://www.toptal.com/typescript/typescript-vs-javascript-guide)
Beau Coburn looks at:
[HTTP for Those That Are Afraid to Ask](https://dev.to/beaucoburn/http-for-those-that-are-afraid-to-ask-38i5)
Josh long opines:
[From a Fan: On the Ascendance of PostgreSQL](https://thenewstack.io/from-a-fan-on-the-ascendance-of-postgresql/)
Cory Doctorow says:
[The AI hype bubble is the new crypto hype bubble](https://pluralistic.net/2023/03/09/autocomplete-worshippers/)
**Yes.**
### Fediverse
Let’s start with a few items about the biggest driver of Fediverse growth, Twitter.
The BBC reports:
[Twitter insiders: We can't protect users from trolling under Musk](https://www.bbc.com/news/technology-64804007)
**Musk takes the shittiest thing about Twitter and makes it shittier.**
The Verge reports:
[How a single engineer brought down Twitter](https://www.theverge.com/2023/3/6/23627875/twitter-outage-how-it-happened-engineer-api-shut-down)
**Stupidity in management = product incompetence.**
Daring Fireball reports:
[Phony Stark Picks on the Wrong Guy, Attempting (and of Course Botching) an HR Exit Interview Live on Twitter](https://daringfireball.net/2023/03/thorleifsson_musk_twitter)
**Being a c*nt = being a c*nt**
In late-breaking news, Platformer reports:
[Meta is building a decentralized, text-based social network](https://www.platformer.news/p/meta-is-building-a-decentralized)
**Fucking hell. While this will work with Activity Pub, at least these instances can be blocked when the inevitable tracking starts.**
The Washington Post opines:
[A better kind of social media is possible — if we want it](https://www.washingtonpost.com/opinions/2023/03/06/social-media-future-regulation-imagination/)
The Atlantic explores:
[How to Take Back Control of What You Read on the Internet](https://www.theatlantic.com/ideas/archive/2023/03/social-media-algorithms-twitter-meta-rss-reader/673282/)
Fastly shares:
[Fastly and the Fediverse, pt.2](https://www.fastly.com/blog/fastly-and-the-fediverse-pt-2)
Here’s an analytical breakdown of the exodus from Twitter to the Fediverse:
[A Snapshot of the Twitter Migration](http://www.deweysquare.com/wp-content/uploads/2023/03/DSG-Snapshot-of-the-Twitter-Migration-March-2023.pdf)
The Washington Post reports:
[Here’s how The Washington Post verified its journalists on Mastodon](https://washpost.engineering/heres-how-the-washington-post-verified-its-journalists-on-mastodon-7b5dbc96985c)
Daring Fireball reports:
[Medium’s me.dm Mastodon Server Opens Up](https://daringfireball.net/linked/2023/03/06/medium-mastodon)
I mentioned this was coming last week.
TechCrunch provides more detail:
[Medium launches a ‘premium’ Mastodon instance as a membership perk](https://techcrunch.com/2023/03/06/medium-launches-a-premium-mastodon-instance-as-a-membership-perk/)
Here are the official details:
[Join Mastodon with Medium](https://blog.medium.com/join-mastodon-with-medium-e2d6d814325b)
If you are also interested in content production, marketing, strategy, and related fields, you can follow me at [@mobileatom@me.dm](https://me.dm/@mobileatom).
## CTAs (aka show us some free love)
- That’s it for this week. Please share this communiqué.
- Also, be sure to [join our newsletter list at the bottom of our site’s pages](https://www.symfonystation.com/contact). Joining gets you each week's communiqué in your inbox (a day early).
- Follow us [on Flipboard](https://flipboard.com/@mobileatom/symfony-for-the-devil-allupr6jz) or at [@symfonystation@phpc.social](https://phpc.social/web/@symfonystation) on Mastodon for daily coverage. Consider joining the [@phpc.social](https://phpc.social/web/home) instance. If this communique is a little overwhelming, you can get a condensed weekly news highlight post on [Friendica](https://friendica.me/profile/friendofsymfony).
Do you own or work for an organization that would be interested in our promotion opportunities? Or supporting our journalistic efforts? If so, please get in touch with us. We’re in our infancy, so it’s extra economical. 😉
More importantly, if you are a Ukrainian company with coding-related products, we can offer free promotion on [our Support Ukraine page](https://www.symfonystation.com/Support-Ukraine). Or, if you know of one, get in touch.
Keep coding Symfonistas!
**[Visit our Communiqué Library](https://www.symfonystation.com/Communiqu%C3%A9s)**
You can find a vast array of curated evergreen content.
##Author

###Reuben Walker
Founder
Symfony Station | reubenwalker64 |
1,397,169 | Angular para leigos (parte 2) | Angular é um framework muito poderoso para criar aplicações web. Uma de suas características mais... | 0 | 2023-03-11T19:58:20 | https://dev.to/andrerodriguesdevweb/angular-para-leigos-parte-2-3d2f | angular, typescript, html | Angular é um framework muito poderoso para criar aplicações web. Uma de suas características mais marcantes é a capacidade de dividir a aplicação em componentes reutilizáveis. Neste post, vamos dar uma olhada em como criar componentes em Angular e usar boas práticas de HTML e SCSS.
## Criando um componente
Para criar um componente em Angular, você deve usar o comando ng generate component. Esse comando criará uma pasta com o nome do componente e alguns arquivos dentro dela. O arquivo mais importante é o arquivo .ts, que contém a lógica do componente. O arquivo .html contém o template do componente e o arquivo .scss contém os estilos do componente.
Aqui está um exemplo de como criar um componente chamado meu-componente:
`ng generate component meu-componente`
Depois de executar esse comando, o Angular criará uma pasta chamada meu-componente com vários arquivos dentro, são eles arquivo html, scss e arquivos typescript para lógica e testes.
## Adotando boas práticas para o HTML de nossos componente
Ao criar o template do componente, você deve seguir algumas boas práticas para garantir que ele seja fácil de ler e manter.
### Use tags semânticas
Sempre que possível, use tags semânticas para descrever o conteúdo do seu componente. Por exemplo, em vez de usar uma div genérica, use tags como header, section, article, footer, etc.
### Use os atributos data-
Use atributos data- para fornecer informações adicionais sobre o seu componente. Esses atributos não afetam a funcionalidade do componente, mas podem ser úteis para fins de estilo ou análise.
`<header data-testid="meu-componente-header">
<h1>Título do meu componente</h1>
</header>
<section>
<p>Conteúdo do meu componente</p>
</section>
<footer data-testid="meu-componente-footer">
<p>Rodapé do meu componente</p>
</footer>`
Por hoje encerramos a nossa segunda parte, mas em nossa terceira parte iremos conhecer sobre as diretivas do Angular, espero que tenham gostado do post de hoje. Grande abraço e até o próximo.
| andrerodriguesdevweb |
1,397,430 | Download LLaMA : Meta/Facebook's AI Model Leaked | A post by Coding Money | 0 | 2023-03-12T02:00:33 | https://dev.to/codingmoney/download-llama-metafacebooks-ai-model-leaked-198n | ai, machinelearning, programming, llama | {% embed https://youtube.com/shorts/eI3zo79BGdM?feature=share %} | codingmoney |
1,397,674 | 2.3 A student's guide to Firebase V9 - A very gentle introduction to React.js | Last reviewed: March 2023 Introduction This is a big moment! If you're new to webapp... | 0 | 2023-03-13T16:15:55 | https://dev.to/mjoycemilburn/23-a-students-guide-to-firebase-v9-a-very-gentle-introduction-to-reactjs-d67 | react, firebase, javascript, beginners |
Last reviewed: March 2023
### Introduction ###
This is a big moment!
If you're new to webapp development and have started at the beginning of this post series, you will have learned how easy it is to publish your ideas on the Internet using a combination of Javascript, Gooogle's Firebase and HTML.
Justifiably, you'll feel rather pleased with yourself. In principle, you could use these skills to build a webapp that would do literally anything you might imagine. Sadly, however, I now have to tell you that the techniques you've used so far won't get you very far if you're looking for employment as a software developer. Why? Because **complex** systems built this way take too long to code and are too difficult to maintain.
Here's the problem. Your HTML is good at defining a screen layout and your Javascript is good at assembling input to put into this. But the mechanism for linking the one to the other - telling the layout how it needs to change in order to reflect the new input is an idiosyncratic mess. This needs to change
So, welcome to the world of development "platforms" and "frameworks". Here you will find yourself using automation tools that allow you to create a "sketch" of your application and then leave some rather smart "transformations" to put this into practice automatically.
As a matter of fact, you've been using automation tools ever since you began to use VSCode to write your Javascript. Examples are VSCode's "intellisense" facilities that save you so much typing, and the built-in "syntax highlighting" and "syntax checking" tools that pick up your programming errors before they ever get near to triggering a browser error. However, none of this does anything to reduce the number of lines of code you have to write or to make your program more comprehensible.
In recent years, the software industry has been at a fast boil while some very clever people have worked on ways of tackling this problem. The results can now be seen in a dizzying assembly of competing products - React, Vue, Next.js, and Azure are just a few examples. This post is focused on React.js and does its level best to introduce you to some beautiful but rather complex ideas. It also provides some simple examples that you can easily use to try things out for yourself.
A word of caution though. This a looooong.... post and I suggest you take your time over it. The successive sections build logically to the point where you have actually deployed a React-based webapp onto the Internet, but it might be best to take a break between each section while you think over what you've just learned.
OK, I know you're going to ignore me, but don't blame me if you get a headache!.
### What is React.js and how do I get started using it? ###
React.js was originally developed by Facebook in 2011. They used it to deliver their own web interface and React is now used by many other major players such as Netflix and Dropbox. What's more important to you is that it has now been around for a while and has acquired strong support in the software development industry. It's impossible to say what the future may hold but you can be assured that use of React.js will at least develop your Javascript skills. Whatever happens, these skills will stand you in good stead. The React.js framework also fits very comfortably with Firebase and the rest of the Google Cloud platform.
Please note that this post describes the current "functional component" style of React. Like the Javascript language itself, React has been the subject of much change since its inception. Be aware that web searches are likely to lead you to documentation that relates to the earlier "class components" version of React. These are likely to confuse you and are best avoided.
That all said, let's make a start
Assuming you're using VSCode, add a new project folder to your workspace, open a new terminal session on this, and enter the following command:
```
npx create-react-app .
```
The . at the end of this command directs create-react-app to create and populate a React folder structure inside the current folder.
The dials on your electricity meter will now start to whir as npx downloads a vast number of library files. Try not to panic! After a minute or two you should receive a message telling you to type `npm start`.
Incidentally, just in case you feel you need to abort one of these terminal process, be aware that you can always do this by pressing the Ctrl and C keys simultaneously. Note also that, for Windows users at least, the enormous number of tiny library files downloaded by both React and Firebase into your project's `node_modules` folder can cause significant performance issues for subsequent deletion and copy actions. Version control systems like Dropbox and Onedrive may also struggle. It's probably a good idea to ration the number of new projects you create and also to consider whether you actually need an independent version control system for a VSCode project in the first place. If you check out VSCode's "timeline" feature you'll find that local version control is baked in here.
Anyway, onwards with `npm start`. What's all this about?
As you'll see later, while `npx create-react-app` has created a bunch of library functions for you to import into your code and deliver React magic, it has also installed a number of executables. The `npm start` script is one such. What this does is start up a server that grabs the code in your project, compiles it, and then launches the result in your web browser.
You haven't put any code into your project yet? Well, actually, you have because `create-react-app` has just put a demo there.
So, cross your fingers and, as instructed, type `npm start` into your terminal session.
Compiling your code is quite a heavyweight task so be prepared for another longish pause at this point. But eventually your browser will automatically spring into view displaying, initially, just a blank page succeeded shortly by the following image:

Hmm - very impressive, I'm sure. But what's the big deal here? Ah, note the suggestion that you might try to "Edit src/App.js and save to reload".
Locate the App.js file in your project folder and have a look at it. You'll find that it contains an `App()` function that returns something that looks almost, but not quite entirely unlike HTML (to quote Douglas Adams). Suppose you take a gamble with this and insert a bit of your own HTML. For example, you might try replacing the bit of App.js that currently says
```Javascript
<p>
Edit <code>src/App.js</code> and save to reload.
</p>
```
with
```Javascript
<p>
Hello, Oh Brave New World.
</p>
```
Save App.js and look again at your browser page. Oh, my goodness! This now looks like:

Take a moment to reflect on the significance of this. Previous posts in this series have described how you have to laboriously `deploy` your project to the Firebase host every time you want to test a change. Here you can test a change by simply saving the file!
What's happened here is that the `npm start` command has launched a server that is now "watching" your project. Any changes you might make here are immediately pushed through to the browser.
But this is just the start!
### Building a webapp with React ###
Hang on to your hat now, because this is where your learning curve starts to steepen.
In the past I think it's reasonable to say that a webapp broke down into two distinctly separate components:
* a block of HTML tags peppered with identifiers and
* a block of Javascript that manipulated the program's data and then used those same identifiers to grab elements of the HTML and change their content.
In a React webapp the HTML block becomes something much more like a program in its own right. It acquires the ability to reference Javascript variables which it can then use to :
* switch blocks of HTML on and off via conditional expressions.
* launch Javascript `map` or `forEach` methods to output tabular data. React calls these structures **Lists**.
* pass data to "pseudo tags" - blocks of HTML that have been allocated their own independent status because of their importance within the hierarchy of the program's output. React refers to these as **Components**
This HTML/Javascript hybrid was christened "Javascript XML" by React's developers - JSX for short
Why would you create this hybrid? Well, it paves the way for the real core of React's architecture which is how to deal with the grunt process of working out how to adjust the browser's display when the embedded Javascript variable references change. The "HTML program" also gives you a way of creating the promised "high-level sketch" of your architecture. OK, it's still a pretty crude way of delivering this, but it's way better than anything you've had before and will enable you to create some compact, comprehensible code. Looking around at the speed with which software-development technology is maturing I take this as a promising sign of good things still to come.
Anyway, let me give you an example. I think JSX's "conditional HTML" concept is the easiest to grasp, so I'll just use this for now. Let's say that you're aiming to deliver the following masterpiece - a webapp with a button that makes a paragraph appear and disappear.
Here's a JSX "skeleton" you might use for this (and please don't actually try this because it won't actually work as shown - I've got a bit more explaining to do yet):
```
<div style = {{textAlign: 'center'}} >
<button onClick = {() => {{dogBarking = !dogBarking}}}>Toggle that Dog< /button>
{dogBarking ?
<p>Woof! Woof!</p> :
<span/>
}
</div>
```
The important thing I'd like you to recognise in this "dog's breakfast" of pseudo-code is the idea that `dogBarking` (a Javascript variable that you've declared somewhere earlier in your code) is now somehow accessible to JSX and available to direct the generation of html.
The `dogBarking` variable is first referenced in the `button` tag's `onClick` function where its value is toggled when the event fires. It is then referenced again in the conditional statement expressed by `{dogBarking ?` to optionally select whether `<p>Woof! Woof!</p>` or an empty `<span/>` gets displayed.
Let's not get hooked up on the details of this for now, but at least note that variables seem to be indicated by the presence of curly braces and that conditional expressions are likewise surrounded by braces.
Also note that there's something funny about the styling of the div - JSX has replaced conventional CSS styling syntax with an object. What's happened here is that JSX has opened up a way to use variable references to replace CSS styles.
Anyway, this all said, the important question you need to be asking here is "if I toggle the button, how can that possibly change what is displayed on the screen?". Or, to use React's own way of expressing this - "what might prompt React to 're-render' the page?".Or even more technically, "what might prompt React to push appropriate updates to the browser's DOM (Domain Object Model)?".
Here then is the central concept underlying React - the idea of a "cycle" process that can be triggered to relaunch a JSX "HTML as program" and repaint the screen as directed by the latest values in the Javascript parameters that it references.
In React, these parameters are all expected to be stored as properties of an object that React refers to as the webapp's **State**. Let's say we've called this object `screenState`. In this case, the state object for the 'disappearing dog' webapp might look like
```Javascript
const screenState = {
dogBarking: false,
}
```
I think you're now ready for the **"big reveal"**. In order to make it possible for you to dynamically refresh the screen when a State variable changes, the React library provides you with a function called `useState()`. Once seeded with a particular state variable, this allows you to register a mechanism that automatically re-renders the page when you change State's values.
I can't emphasise too much how valuable this is. For a complex screen hierarchy, working out the implications of parameter changes for the browser's DOM in an efficient manner can be a perfect nightmare. React relieves your program of all these concerns.
How, precisely, do you use "seed `useState` with a State variable" and what exactly is the "mechanism for changing State values"?
Take a deep breath now. This is achieved through one of the most bizarre pieces of Javascript syntax you've ever seen. It takes the following form:
```Javascript
const [myStateVariable, setMyStateVariable] = useState({
property1: initial value,
property2: initial value,
property3: initial value, .....
})
```
Never mind for now how this works. For now, what matters most is what it **does**.
This statement is saying to `useState` "please let me use a new constant object called `myStateVariable` to define my webapp's output, let me initialise this with the following properties, and let me use a function I'm going to call `setMyStateVariable` if I ever want to change these".
This means that when you want to change a couple of properties in `myStateVariable`, say `property1` and `property3`, you could do this with the following function call:
```Javascript
setMyStateVariable({
...myStateVariable,
property1:newProperty1Value,
property3:newProperty3Value }
)
```
If you've not encountered "..." notation before, this is an example "spread syntax" and it is used here to provide a quick way of telling `useState` to replace its current `myStateVariable` content with a new object containing "all the current properties of `myStateVariable` plus the following additions/amendments".
Anyway, the effect of this here is massive. When you use `setMyStateVariable` to update`myStateVariable` like this, because this is policed by `useEffect`, not only is `myStateVariable` updated with the new values of `property1` and `property3`, **but the webapp's display itself is also refreshed** so that it reflects the new content of `myStateVariable`"
Wow! Let me say this again. When you change your program's state in a React webapp, your JSX **automatically** changes your webapp's output. Wow!
Here's a working version of 'disappearing dog'. You can try this out by simply pasting it over the current content of your App.js file :
```Javascript
import React, {useState} from 'react';
function App() {
const [screenState, setScreenState] = useState({dogBarking: false})
return (
<div style = {{ textAlign: 'center'}}>
<button onClick = { () => {
setScreenState({dogBarking: !screenState.dogBarking})
}
}>Toggle that Dog</button>
{screenState.dogBarking ? <p> Woof!Woof! </p> : <span />}
</div>
);
}
export default App;
```
Save the file and you'll find (provided you've not closed down the terminal session on your project) that localhost:3000 now displays a page with a "Toggle that Dog" button. If you click this, the dog will "bark". Isn't technology wonderful?
###Initialising State with data from an asynchronous source and then displaying the results in a React List###
An information system will often need to begin by initialising its program state with data from an asynchronous source such as a Firestore collection. Typically you might be doing this in order to seed the `option` content for a `select` tag. But this creates problems because delays in the return of the data may leave users looking at a blank screen. When the data **does** eventually arrive, you then need to be able to detect this and refresh the screen appropriately. This can get quite messy!
React handles this problem by providing a function called `useEffect()` that allows you to register a packet of code as a function that runs when the webapp initialises **and only then**. If you arrange things so that this function updates state when it concludes, this will trigger a screen refresh and you can pick up where the initialisation left off.
The sample code shown below provides another version of App.js that might help you to get your head round this - it's intended to access an online Diary database and display Diary Entries for the current day.
The basic idea is that, on startup, the webapp should just display a title and some sort of "placeholder" while it waits for the asynchronous arrival of the diary entries. When these do eventually appear, the placeholder is removed and replaced with the asynchronous payload.
To keep things simple, I've written a little "promise" function to simulate the asynchronous bit - this is just to save you the trouble of configuring Firebase in your project. As things stand you can, as with my previous example, just paste the code below into App.js, save it and immediately observe the results on your browser's localhost page.
```Javascript
import {useState,useEffect} from 'react';
function App() {
const todayDate = new Date().toISOString().slice(0, 10) // produces yyyy-mm-dd
const [screenState, setScreenState] = useState({
entriesLoading: true
})
useEffect(() => {
async function getDiaryEntries() {
const diaryEntries = await simulatedFirestoreAccess();
setScreenState({
...screenState,
entriesLoading: false,
diaryEntries: diaryEntries
})
}
getDiaryEntries()
}, []);
async function simulatedFirestoreAccess() {
// simulated asynchronous Firestore Collection reference returning two diaryEntry records
// after a delay of 1 second
const myPromise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve([{
entryTime: "9.00",
entryDetail: "Have breakfast"
}, {
entryTime: "12.30",
entryDetail: "Have lunch"
}]);
}, 1000);
});
return myPromise
}
return (
<div style = {{textAlign: 'center'}} >
<p> Diary entries for { todayDate} </p>
{
screenState.entriesLoading ? <p> ...loading diary entries...! </p> :
screenState.diaryEntries.map((diaryEntry) => {
return <p> <span> {diaryEntry.entryTime} </span> - <span>{diaryEntry.entryDetail}</span> </p>
})
} </div>
);
}
export default App;
```
When you've saved your updated App.js you should see that your local host browser page is displaying a title followed by a line that initially says simply ".. loading diary entries ...!". After a second or so, however, this should be replaced by the simulated diary entries. Try refreshing the page to make sure you get the full effect.
Let me walk through the code to clarify what is happening here.
1. The webapp starts, initialises its `todayDate` and `screenState` constants and then hits the `useEffect` reference. This causes it to run the `getDiaryEntries` function which in turn triggers the asynchronous simulatedFirestoreAccess function.
2. The webapp has now split into two parallel "threads" of activity - one is going to charge straight ahead and perform `App.js`'s `return()` statement, and the other is going to idle for a second or so while it performs its asynchronous activity.
3. Sticking with the first thread, this will, first of all, render the title with its `todayDate` reference (note that this show that it's not necessary for **all** local data used by JSX to be in State - you just need to be aware that values here will be re-initialised every time the webapp runs a render cycle).
4. This first thread now hits the `{screenState.entriesLoading ?` condition. Because `screenState.entriesLoading` is still set to its initial setting of `true` at this point, the webapp will hit the "ternary"'s first option (see below for a note on ternary syntax) and display ".. loading diary entries ...!". The cycle is now concluded and this thread halts.
5. A second or so later, however, the second thread comes back to life. The `const diaryEntries = await simulatedFirestoreAccess();` statement in `simulatedFirestoreAccess()` resolves and control moves on to the `setScreenState({ entriesLoading: false, diaryEntries: diaryEntries })` statement. Because this changes screenState, React now re-renders the display using the new state properties.
6. Although this second cycle starts from scratch in App.js, the useEffect is not launched this time and so control moves straight on to render the component's return() statement. The title and date are unchanged so JSX won't touch these. But when control hits the `{screenState.entriesLoading ?` condition, the new `entriesLoading` setting will now instruct it to use the `.map` instruction to render the simulated diary entries. The magic in React's rendering logic will then automatically replace the "placeholder" message with the webapp's long-awaited data.
If you're still getting your Javascript up to speed, you might find the `.map` instruction a bit alarming. Let me break it down for you.
First of all `.map` is just a "method" possessed by all arrays. It takes, as an argument, a function that will be executed for every element in the array that it's called on. In this case, my array is full of simulated diary entries so, each time this function runs, it does so on a different diary entry. The `(diaryEntry) => {}`bit of the code is me setting up this function and allocating a name that I can use in its code to reference the `diaryEntry` presented to the function for each iteration.
Incidentally, there are quite a few ways in which I might have coded the definition of this .map method's function. The => (arrow notation) form is a sort of shorthand really. Think of it as saying "here's a function with these arguments that does this". It may look a bit strange at first but I recommend you try to get used to it because this is something that you'll use frequently in modern Javascript and which will save you a lot of typing.
Returning to my explanation of the payload of a `.map` function. In this particular case, the action of the function is specified as `return (<p key={diaryEntry.entryTime}><span>{diaryEntry.entryTime}</span> : <span>{diaryEntry.entryDetail}</span></p>)`.
Now, what on earth is all that about?
Firstly, you might recognise the `return()` bit as another instance of the `return()` that you've already seen in the main body of App.js itself. I've not commented on the strange structure of the `App()` function so far but I'll pick it up in the next section where I talk about Components - for now, just let's say that this bit of code is operating as a sort of mini App.js. Potentially it might have a render cycle all of its own!
Within the body of the map's `return()`, I think that things get a bit clearer. Basically, this is just rendering the contents of the two properties of each diaryEntry - `diaryEntry.entryTime` and `diaryEntry.entryDetail` into a pair of `<span>` tags. The only unusual feature is the strange `key` property attached to the parent `<p>` tag. As stated earlier, the output of a map is handled by React as a List. Lists are a common structure in webapps and may become very large. React needs to ensure that it can render and re-render them efficiently - but it needs your help here. You do this by giving each entry in a List a unique identifier.
**Note on Ternary syntax**. A ternary in Javascript is a shorthand "if/else" structure used to simultaneously declare a new variable and set its content. It takes the form:
```javascript
const myNewVariable = (conditional expression) ? valueA : valueB
```
The result of this will be a new constant called `myNewVariable` whose value will be valueA if if true and valueB otherwise. JSX uses the same ? and : syntax to switch the generation of html blocks.
This may look strange to you at first, but once you get used to it you won't be able to imagine life without it!
###Styling in JSX###
As demonstrated briefly above, the style value of a conventional HTML tag's `<tag style = 'property1:value1; property2:value2 ....'/>` is replaced in JSX by a Javascript object. The structure of a style object in JSX might look like this:
```Javascript
const myStyleObject = {
property1: value1,
property2: value2,
// more properties and values
}
```
Here, each property is a CSS characteristic that you want to style, such as "font-size", "color", "background-color", etc. But the difference is that the property names are now referenced in camelCase, not separated by hyphens as in CSS. So CSS's `font-size` becomes `fontSize` in JSX
Property values can be numbers, strings, or any other valid Javascript data type.
Here's a JSX example that styles a tag with a red background and white text:
```Javascript
<tag style={{backgroundColor: "red", color: "white",}}/>
```
It may sometimes be more convenient in a React webapp to declare your style object with a `const myStyleConstant = { ... }` in your component and reference it as
```Javascript
<tag style={myStyleConstant}/>
```
This arrangement makes it very easy to manipulate tag styling by modifying the style constant's properties.
If you prefer, you can still import a conventional css stylesheet into a webapp. Classes are applied to a tag in JSX by declaring a `className` qualifier, as in the following example:
```Javascript
import '../styles/globalstyles.css';
function myComponent() {
return{
<div className="myCssClass1 myCssClass2 ....etc" />
}
}
```
The style content of a stylesheet like this is constructed in the conventional way (ie with hyphenated names etc).
###The "Component" approach to webapp design###
I'm sure you'll appreciate that the simple React webapp examples described by this post are a million miles away from the reality of complex applications like the Facebook or Amazon sites. You're not going to squeeze Facebook into a single App.js file!
In practice, React needs to enable you to build your webapps as a hierarchy of design elements - Components is the word that they actually use. You've already seen an example of a Component in the shape of the App() function. A component is just a function with a return() full of JSX. What you've not seen is how, through the wizardry of the React compiler, such a function can then be referenced in JSX as if it were a new HTML tag.
Have a look at the `src/index.js` file that launches `src/App.js`. Inside there, the examples you've been running are the result of React rendering the following code in src/index.js
```Javascript
root.render(
<React.StrictMode>
<App />
</React.StrictMode>
);
```
React seems to have invented a new html `<App>` tag!
As an example of how you might use this yourself, consider the sample React List you met earlier:
```Javascript
screenState.diaryEntries.map((diaryEntry) => {
return (
<p key = {diaryEntry.entryTime}>
<span>{diaryEntry.entryTime}</span> - <span>{diaryEntry.entryDetail}</span >
</p>)
```
In other circumstances this might have been written as
```Javascript
screenState.diaryEntries.map((diaryEntry) => {
return ( <DiaryEntry key = {diaryEntry.entryTime} diaryEntry = {diaryEntry}/>)})
)
```
where App.js subsequently declared as a `DiaryEntry()` function as follows:
```Javascript
function DiaryEntry(props) {
return (
<p>
<span>{props.diaryEntry.entryTime}</span> -
<span>{props.diaryEntry.entryDetail}</span >
</p>
)
}
export default App;
```
The advantages of doing this might not be immediately obvious but, suppose that the output rendered by DiaryEntry had been something really complicated with sub-lists of its own. In such a case I think you can easily imagine how the insertion of a complex stack of code into the heart of App.js would impair its clarity.
Component design allows you to "structure" JSX in the same way as might use functions to structure your Javascript. Similarly, because components can be allocated their own files and passed around via export and import statements, they also allow you to share code within and between webapps.
An issue that has to be faced when using Components, however, is that you will generally need to provide a mechanism for passing data to them. In the example above, the `DiaryEntry` component (the capitalisation of the first letter is a widely-accepted convention to alert you to the special status of a component function) needs to be supplied with a `diaryEntry` object. This is done in this case by supplying additional properties to the `<DiaryEntry>` reference. These take the form of a property name ( `diaryEntry` in this case) followed by a reference to the data item you want to attach to it. Inside the component function meanwhile, this data can be retrieved as `props.propertyName` (eg `props.diaryEntry.entryTime` ), where `props` is declared as an argument to the function. The word `props` here is to be read as shorthand for "properties".
###Webapp "Routes"###
While the "component" technique described in the previous section provides a basic tool for structuring your application you'll find that, in practice, you need more than this. Users have always enjoyed the ability to use a browser's "page history" facility" to unwind their track through a system. Despite the fact that what we're developing here is a "single-page" webapp, React needs to ensure that users still have access to "page history" for the various elements of the webapp's structure.
Webapps deal with this problem by means of arrangements that define "logical" pages to overlay the physical single-page design. One popular way of doing this is through an extension called **React-router**.
Confused? I'd be surprised if you weren't, but this is too complex an issue to describe here. When you have a bit more time, you might find it useful to look at [What's a 'Single-Page' App? Learn about React-Router (and Vite).](https://dev.to/mjoycemilburn/61-polishing-your-firebase-webapp-whats-with-this-single-page-app-stuff-learn-about-react-routes-nb2) in this series.
###Coding Input fields in a React webapp###
You're going to want to be able to read data into your webapp. React handles this by attaching `onChange` functions to input fields and using these to update State. This way State continues to provide a complete representation of the screen display.
Because this post is already way too long I'm just going to show you how you might handle simple input types such as text and date. The following template included in your JSX would maintain a property called `myInput` in State
```Javascript
<label>My Input Field: </label>
<input type='text' // substitute 'text', 'date' etc, as appropriate for 'input type'
name='myInput' // substitute a unique State property name for 'myInput'
value={screenState.myInput} // substitute the name of your component's State
title='Enter the value for this entry' //substitute appropriate advice
onChange={handleInputChange}/>
```
Additional properties such as maxLength, size, style, placeholder and autoComplete properties might also appear here.
Here's the accompanying `handleInputChange` function. This needs to be placed somewhere inside the body of the component function.
```Javascript
function handleInputChange({target}) {
// For input "name", set State's target.name property to target.value
setScreenState({ //substitute the name of your State update function
...screenState, //substitute the name of your State constant
[target.name]: target.value
})
}
```
Your heart may sink once again at the sight of yet more exotic javascript syntax. But cheer up - as with the State declaration statement, what really matters here is what the code **does** rather than how it does it (it's actually using "destructuring" syntax to unpack the event object returned by onClick). What this code says is "when this function is launched by the onClick on an input field that I've called `myInput`, please put the value of this field into a State property called `myInput`".
Note that while React is happy to **create** new State properties for input items through the `handleInputChange()` function, it will be even happier if you explicitly **initialise** them first in State. I think this is actually a good practice anyway because it clarifies your code.
To give your confidence a boost I suggest you try adding the sample code above code to App.js.
If you do this, I suggest that you place an `alert(JSON.stringify(screenState))` instruction immediately before App.js's return statement. This way you'll be able to see more clearly see what is happening. The statement displays an alert box containing a JSON representation of `screenState` and you will be able to see how your State changes every time you press a key in the input field.
More complex input cases such as `select` and `checkbox` and `file` follow this general theme but introduce subtle variations. It would be a distraction to describe these here, so please refer to [10.2 Reference - React JSX Templates](https://dev.to/mjoycemilburn/102-reference-react-jsx-templates-5djc-temp-slug-8415299?preview=a8c0324557fd482ccb468290adae501006ab6f198e025bf1784c0eee91e75af64afa57c712b3344c7a9121bb61ccb5756b8972da48e1cac7aeb68d67) for further details.
In passing, you may have spotted the total omission of references to the HTML `form` tag in any of the above. I think it's safe to say that HTML's traditional `form` concept is more or less redundant in a React webapp. The use of a `<form>` as a way of "submitting" a "parcel" of data from a client screen to a host process via a `<form>`'s `submit` button is now replaced by the use of buttons that you define yourself.
###Debugging in React###
Your first experience of coding in React is likely to be somewhat alarming - I don't believe I've **ever** seen so many error messages as when I wrote my first React webapp. If you leave out just one of those fiddly JSX brackets or chevrons, VSCode will turn your entire screen red!
Once you get your eye in, however, things will become easier. The trick is to hover over the first occurrence of an error indication (a red underscore) to display a tooltip that will provide a clue to the possible cause. A very common source of error is JSX's requirement that "JSX expressions must have one parent element." - this commonly means that you need to put a `<div></div>` pair around a bunch of tags. Forgetting to close a tag is another common source of meltdown. The problem will usually be located immediately before the first error indication.
Just take a deep breath, check systematically, and refer back to the templates mentioned above. It also sometimes helps to temporarily remove problematic sections and debug them independently. Map statements are the most frequent source of problems. Here, while there are many ways in which you can define functions in Javascript, you'll find it's generally best to stick to the one supplied in the "Diary Entry" example above.
The above advice should help you to get your React webapp through VSCode. Unfortunately, problems will continue to be reported when you run `npm start`.
Initially, you'll find that the React compiler does a great job at picking up undefined variables, etc, and will display error details in your localhost browser tab. Just keep fixing files and re-saving.
But then, even after you've got your webapp to compile, you may still find that you're looking at a blank localhost screen. This is because the webapp execution has errored and you now need to use the browser's inspect tool to find out what's going on.
Errors reported by the inspector tend to be of a technical nature and the accompanying messages are correspondingly expressed using highly technical language
You need to take a firm grip on yourself here. With experience, you'll find you take all this in your stride, but at first, it's quite unsettling. Many of those red messages will just be "warnings" rather than "errors", but the ones labeled as errors need to be fixed before your webapp will run.
Once you've overcome your panic and read the error detail carefully, I guarantee that you'll eventually work out what is going wrong. Take your time here. Because you feel you're so close to getting your webapp working, the natural instinct is to rush at the code and make changes wildly. This probably won't help much! It's often better to take a break and give yourself time to think through the problem. Remember that you can always try pasting an error message into stackoverflow and searching here for assistance. Stackoverflow has got me out of a hole on many occasions.
Stick with it. With persistence you **will** get that webapp working.
###Deploying a React webapp to the Web
So far, this post has only talked about running a webapp locally through the React server. How do you make your webapp available to the general public on the web?
At first sight, this looks as if it may be quite a problem, but in actual practice, it turns out to be very simple. The first step is to use another React script to create a "build" directory to store the structured information generated by the React compiler.
You do this by simply typing the following into a terminal session on your project*
```
npm run build
```
When this is finished, the next step is to use the Firebase deployent tool to upload the contents of your "build" directory" to the web.
Here, you're obviously going to need a Firebase project. If you've not been here before, you might find it worthwhile studying [2.1 A student's guide to Firebase V9 - Project configuration](https://dev.to/mjoycemilburn/a-beginners-guide-to-Javascript-development-using-firebase-v9-part-1-project-configuration-5bo3 in this series.
If you're an old hand at working with Firebase you've probably already got a test project somewhere that you can reuse here. In this case, if you just want to try deploying the demo code you've been working on in src/App.js above, the procedure would be as follows:
1. Type `firebase init hosting` into your Vscode terminal session to link your VSCode project (ie the one containing your App.js) to the Firebase project you want to use to host it. The hosting script will ask you a few questions. Respond to these as follows:
? What do you want to use as your public directory? **build**
? Configure as a single-page app (rewrite all urls to /index.HTML)? **Yes**
? File build/index.HTML already exists. Overwrite? **No**
These responses will ensure that deployment will use the results of your `npm run build` and prevent Firebase from overwriting create-react-app's demo index.HTML file with its own demo index.HTML.
2. Now type `firebase deploy`
The result of all this will be a url for you to paste into your browser's url field. Behold, your React webapp is now running on the Internet. Hurrah!
Congratulations for making it to the end of this mega-post - I hope that you have found it useful.
For a full list of the posts in the series, please check out the site index at [ngatesystems.com](https://ngatesystems.com/waypointsindex).
| mjoycemilburn |
1,397,723 | The Beauty of Infrastructure as Code (IaC) and Why You Should Be Using it | If you are a new entrant into the world of Cloud computing and DevOps and you are looking to know... | 0 | 2023-03-12T10:05:47 | https://dev.to/malchielurias/the-beauty-of-infrastructure-as-code-iac-and-why-you-should-be-using-it-3dhm | iac, aws, cloud | If you are a new entrant into the world of Cloud computing and DevOps and you are looking to know more about technologies to make your life and work a lot easier while still being efficient, then you just might have stumbled upon a very useful article.
I come from a CyberSecurity background and my exploration into the world of DevOps and cloud computing is a relatively new one so that would explain why Infrastructure as Code is a concept that I got excited about. Before my discovery I was quite comfortable manually spinning up instances and configuring VPCs manually, it was what I knew.
I have learned through this as well as many other experiences, that when developing yourself in tech, as much as it might be important to pick up various skills, one thing you shouldn’t forget to consider is how these skills would be applied in organizations that run large-scale projects and products. Usually, we pick up skills that could only be applied in smaller products, it is for this reason that I probably didn’t have a lot of extensive knowledge on Infrastructure as Code before now.
Now, what exactly is Infrastructure as Code?
Imagine, you would like to provision the IT infrastructure (servers, networks, etc.) for a product, you could simply just open up your AWS console (or that of your preferred cloud provider) and spin up a few EC2 instances (or virtual machines as the case may be) and begin from there, right? Right. Now imagine if this was a larger product with many more servers and possibly in separate environments and you would need to configure and set up these various services in different environments. Now a task that seemed straightforward at first now suddenly has many more complexities. Going ahead to provision manually would most definitely lead you into a lot of issues that may arise either immediately or later down the line.
These issues led to the introduction of Infrastructure as Code. IaC is the process of provisioning and managing IT infrastructure through the use of codes in the form of configuration specification files rather than manually configuring the infrastructure. It is simply the automation of manual configuration of Infrastructure. IaC provides a means to provision exactly the same configuration each time, thereby, reducing the risks of environmental drift and human errors.
How Does IaC Work
Now, some would think that IaC would simply be about putting a bunch of configuration code together and stuffing it away in some repository and the job is done but having a good knowledge of how IaC works and how different IaC tools function can come in very handy to your work. There are different styles in the way different IaC tools work and knowing the difference between declarative and imperative infrastructure as code can actually mean the difference between a happy DevOps engineer and a miserable one.
Going from our knowledge of different programming language paradigms, we can easily deduce what each of these IaC styles mean:
Declarative Infrastructure as Code: Declarative infrastructure as code involves declaring the desired outcome or result of a job instead of explicitly stating the steps to arrive at that result.
Imperative Infrastructure as Code: This on the other hand would involve specifying the steps and instructions to follow to arrive at the final result. This is very much the same when it comes to infrastructure as code.
The issue with imperative IaC however, is that if an issue that was not specified in the code occurs, it would lead to a crash because the program would have no idea what to do next.
The tools for IaC are of course categorized into two sections:
● Imperative Tools
● Declarative Tools
Imperative IaC Tools
These tools define the sequence of steps to set up infrastructure and enable it to reach the required state. System engineers have to write scripts to provision the infrastructure sequentially.
Compared to Declarative IaC tools, these tools are more tedious to use and less resistant to failures and errors. More effort would be required to keep these scripts up to date and reuse is usually more difficult.
Declarative IaC Tools
Declarative IaC tools, following the declarative approach, describe the desired outcome of the infrastructure without listing the sequential steps of arriving at that state. The IaC tools take in the requirements and automatically configure the necessary infrastructure.
Which to Use
Like many other things in the world of tech, there is no exact right or wrong one to use. It would usually depend on the situation. In a case where you would just need to configure a relatively small infrastructure that may not necessarily need any future updates, a simple imperative script is the way to go. However, if you need to build a more sophisticated infrastructure, you should use a declarative programming tool.
Some Popular IaC Tools
● Terraform
● Pulumi
● Puppet
● Ansible
● Chef
● SaltStack, and of course
● AWS Cloud Development Kit (CDK) which works with AWS Cloudformation
Benefits of IaC
Knowing the many problems that are related to manual infrastructure management, it is very obvious how much of a relief IaC can be but let’s explicitly look at some notable benefits of using IaC.
Some of these notable benefits of using IaC in setting up and maintaining your infrastructure would include:
● Speed: This is a major benefit that IaC provides. Engineers are now able to set up and manage complete infrastructures within minutes whereas it would have taken hours or even days to do had they used a manual approach
● Lower Cost: The use of IaC and Cloud Computing has benefitted numerous companies financially as the need to set up physical data centers, hire many engineers for operations, and purchase hardware is now unnecessary. Using services from your cloud providers and hiring a few engineers to run these reduce the cost of operations drastically.
● Efficiency: The use of codes instead of manual setups reduce the risk of human errors in infrastructure management. The same environment can be created exactly the same way through code but if done manually by a human, mistakes would almost be inevitable.
● Consistency: Manual processes are a recipe for mistakes. This is why the DevOps methodology advocates for automating everything. IaC eradicated the need for manual configuration almost completely. It guarantees that the same configuration is implemented in every case exactly the same way.
Conclusion
IaC has indeed revolutionized the way we think of infrastructure management, particularly cloud infrastructure. It has made tasks a lot easier and although it seems like just another non-mandatory trend, it is far from optional. IaC is fast becoming a necessity in businesses. The speed it provides to infrastructure management is a major fact in change management and organizations that embrace this would harness the ability to quickly adapt to changing business needs and requirements and those who don’t, well, they would eventually have to.
Remember, you snooze, you lose. Stay competitive. | malchielurias |
1,397,741 | 7 AI Tools That Will Make You a Millionaire in a Month | In this article, we’ll discuss one of the hottest topics right now. Of course, it’s Artificial... | 0 | 2023-03-12T10:47:42 | https://dev.to/metamark/7-ai-tools-that-will-make-you-a-millionaire-in-a-month-1434 | ai, machinelearning, beginners |
In this article, we’ll discuss one of the hottest topics right now. Of course, it’s Artificial Intelligence (**AI**) and everything related to it. **AI** is booming right now, especially after **ChatGPT's** appearance.
All these new machine-learning algorithms are helping people with literally everything. It makes no difference whether you are a teacher or a computer science engineer; these technologies will speed up your workflow and automate some tedious tasks!
Continue reading to learn more about these **7 unique** and handy tools!
## [Notion.ai](https://www.notion.so/product/ai?wr=6ccc7bdcecf39017&utm_source=notionClient&utm_medium=copyButton&utm_campaign=ai-beta&utm_content=share)
We've all heard of **Notion** . If not, then it’s simply an app that contains the whole of **Microsoft Office** and many other useful features inside it. You can do whatever you want in **Notion** ; it’s a kind of sandbox for anyone working with data. By the way, everyone is working with data.
Even if you’re just storing books that you’ve read, it would be useful for you to check out **Notion** !
Recently, the **Notion** team announced their new **AI ** service that will automate boring stuff inside your **Notion ** workspace. You can start writing something, for example, an article, and it will be able to continue for you.
It’s like **Jasper.ai** or other tools that help you write faster, but it’s better, more efficient, and right inside your **Notion**! Isn’t that great?
There’s a waitlist system. You can [Sign up](https://www.notion.so/product/ai?wr=6ccc7bdcecf39017&utm_source=notionClient&utm_medium=copyButton&utm_campaign=ai-beta&utm_content=share) using my [link](https://www.notion.so/product/ai?wr=6ccc7bdcecf39017&utm_source=notionClient&utm_medium=copyButton&utm_campaign=ai-beta&utm_content=share) and wait for your turn!
## [Lumen5](https://lumen5.com/)
You don’t need a PowerPoint anymore. That’s right, with Lumen5, you can easily make presentations 10 times faster and better. It’s simply an analogy of **Canva** , where you can use static templates for creating your personal designs.
In Lumen5, you can use a dynamic template for a presentation, and by filling up some information about your product or service, AI will automatically generate everything needed!
It has a pretty User Interface and everyone will be able to make his own presentation. You don’t even have to imagine the right text for the presentation; just write a short description of your product, and Lumen5 will do everything else!
***Anyway, it’s better for you to check it out yourself!***
## [Conversica](https://www.conversica.com/)
**Conversica** is a platform that uses artificial intelligence (**AI**) to automate communication with clients and other contacts in a business. It is designed to make lead generation and customer engagement for organizations more effective and personalized.
For instance, it can be used to automatically schedule customer appointments or send follow-up emails to leads who have shown interest in a product or service. Additionally, the platform can be used to automate customer care tasks like responding to frequently asked questions.
In a nutshell, it’s an AI that can work right on your website as support for clients and answer almost any question. You don’t have to hire special people for talking to your customers, **Conversica** will do everything for you!
## [Beautiful.ai](https://www.beautiful.ai/)
Beautiful.ai is another presentation software with a bunch of cool features that will help you be more efficient. The platform utilizes machine learning to understand the content of a presentation and suggest design elements and layouts that are appropriate for the content.
***Some features of Beautiful.ai include:***
* *Professional layout for your presentation based on the content you provide.*
* *Suggests relevant images and design elements to enhance it.*
* *Suggests design elements that are appropriate for it, such as colors, fonts, and layouts.*
* *Offers design elements that are appropriate for it.*
* *Transcribes spoken words into text which can be used to create presentations.*
## [Quillbot](https://quillbot.com/)
**Quillbot** is a fantastic tool for any writer, but not just writers. It’s an addition to **Grammarly** and does almost the same thing but is more efficient and has many other cool features.
You can write anything you want, and it will suggest to you what you can change, where there’s a typo, and much more! I even use it while writing this article, and I think that it’s really powerful.
It uses **AI** to understand everything that you’ve written and then gives you the best possible output for changing several words or even a sentence. Unlike **Grammarly** , it considers the context of your words!
It's important to mention that I’m not saying that **Quilbot ** is better than **Grammarly** . It’s a little bit different, and ideally, you should use them both at the same time!
## [AIVA](https://www.aiva.ai/)
I’ve been talking about **AIVA** in some of my previous articles, and I'd do it here again! In a nutshell, it’s simply an **AI** app or web service that generates almost any kind of music. But it will be without words, only beats, chords, and all this other stuff!
I’ve even created several **lo-fi beats** with **AIVA** in less than **5** minutes. It’s really incredible and can always surprise you with amazing output! It’s easy to use and has many options to choose from, such as which mood to consider, which genre, and so on.
It’s free to use; however, while using the free plan, you won’t be able to monetize these tracks. Only after purchasing the business plan will you have full access to everything you’ve generated and unlimited tracks per month!
## [Zapier](https://zapier.com/)
Last, but not least, **Zapier**. It’s not actually an **AI ** tool; however, it still uses **AI** in some areas and is very powerful. It’s simply the best tool for **automatization** , and I’ll explain why!
Imagine that you’re writing an article on **Medium** , and immediately there’s a post on **Twitter** about your article, a post on **LinkedIn** , and you’ve already shared it with all your email newsletter readers. That’s what you can do with **Zapier** !
By customizing your automation, you can do whatever you want and make huge algorithms that will do some tasks after something else is done.
***Here are some other examples of using Zapier:***
* *Adding new contacts to a mailing list*
* *Sending an email when a new entry is added to a spreadsheet*
* *Creating a new task in a task management app when a new email arrives*
* *Creating a new contact in a CRM app when a new lead is generated*
## Final Thoughts
In conclusion, I would like to say that I’ve used each of these AI tools and think that everyone should consider them. It doesn't matter if you're an entrepreneur or a math teacher; automating some boring tasks will allow you to do things you couldn't do before!
**If you liked this article and want to see more like this, then don’t forget to follow me and leave a clap! :)**

| metamark |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.