
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,416,590 | Linked Lists (implementation using Python) and it’s applications | Let's talk about Lists first In computer programming Lists are a type of data structure through... | 0 | 2023-03-27T14:58:01 | https://dev.to/kainatraisa21/linked-lists-implementation-using-python-and-its-applications-15pc | **Let's talk about Lists first**
In computer programming Lists are a type of data structure through which we store data. List data structures are similar to the "real life list" concept. The way all of the elements of a real life list comes one after another list data structures also store the data contiguously in the memory. We can access, modify as well as delete the elements of a list data structure.
(The theoretical part)
**What are Linked Lists**
Linked Lists are the data structures which store data linearly (like a list) but they don’t store the elements contiguously in the memory. Each element of a Linked List is called a Node. The links among the nodes is a unique feature of a Linked List. Based on the connections there are 4 types of Linked Lists. The 4 types of Linked Lists are: Singly Linked List, Circular Singly Linked List, Doubly Linked List and Circular Doubly Linked List.
Enough of the bookish definition of Linked Lists now we'll learn about Linked Lists in our own words.
Every linked list has atleast concepts/parts. A head node/value, a tail node/value, next and pervious node's reference.
🔶 Singly Linked List:
Let's assume the Singly Linked list as a train. The way the train compartments are connected to their next compartments with a link, the nodes of a Singly Linked List are linked to their next nodes. Every element of a Linked List is called a node. The very first node of the Linked List is called the Head. The last node is called the tail(the node after which no newnode will exist is the last node). As we know that Linked Lists don’t store data sequentially so index 1 stores the tail node(this is the 2nd node we create). A node stores the memory address of the next node. We can access the next node of a linked list using the node.
Real life application: Back buttons(for example:- the smartphone back buttons are created using Singly Linked List so they allow us to go only in a single direction).
🔶 Circular Singly Linked List:
The only structural difference between Singly Linked List and Circular Singly Linked List is that the Circular Singly Linked List has a link between the Head and Tail node. Which means the Tail node stores the memory value of the Head node.
Real life application: The Circular Singly Linked List is used in our personal computers. When multiple applications are run on a PC all of the running apps are stored in a CSLL.
🔶 Doubly Linked List:
The nodes of a Doubly Linked List store the memory locations of both the previous and next node. Which means we can access both the previous and next node using the current node. Otherwise all of the features of DLL are similar to SLL.
Real life applications: Web browser cache, music player etc.
🔶 Circular Doubly Linked list:
The only structural difference between Circular Singly Linked List and Circular Doubly Linked List is that in CDLL the Head and Tail nodes are connected with eachother both ways so the tail's next node will be the head and the head's previous node will be the tail node.
Real life applications: Shopping cart on online websites etc.
(The implementation part will be added here soon)
| kainatraisa21 | |
1,416,620 | Exploring a Twitter Network With Memgraph in a Jupyter Notebook | Through this short tutorial, you will learn how to install Memgraph, connect to it from a Jupyter... | 0 | 2023-03-27T14:38:55 | https://memgraph.com/blog/jupyter-notebook-twitter-network-analysis | python, algorithms, twitter, memgraph | Through this short tutorial, you will learn how to install Memgraph, connect to
it from a Jupyter Notebook and perform data analysis using graph algorithms. You
can find the original Jupyter Notebook in our open-source [GitHub
repository](https://github.com/memgraph/jupyter-memgraph-tutorials/tree/main/twitter_network_analysis).
If at any point you experience problems with this tutorial or something is
unclear to you, reach out on our [Discord server](https://discord.gg/memgraph).
The dataset from this tutorial is also available in the form of a [Playground
sandbox](https://playground.memgraph.com/sandbox/twitter-christmas-retweets)
which you can query from your browser.
## 1. Prerequisites
For this tutorial, you will need to install:
- **[Jupyter](https://jupyter.org/install)**: Jupyter is necessary to run the
notebook available here.
- **[Docker](https://docs.docker.com/get-docker/)**: Docker is used because
Memgraph is a native Linux application and cannot be installed on Windows and
macOS.
- **[GQLAlchemy](https://pypi.org/project/gqlalchemy/)**: A Python OGM (Object
Graph Mapper) that connects to Memgraph.
- **[Pandas](https://pypi.org/project/pandas/)**: A popular data science
library.
## 2. Installation using Docker
After you install Docker, you can set up Memgraph by running:
```
docker run -it -p 7687:7687 -p 3000:3000 memgraph/memgraph-platform
```
This command will start the download and after it finishes, run the Memgraph
container.
## 3. Connecting to Memgraph with GQLAlchemy
We will be using the **GQLAlchemy** object graph mapper (OGM) to connect to
Memgraph and execute **Cypher** queries easily. GQLAlchemy also serves as a
Python driver/client for Memgraph. You can install it using:
```
pip install gqlalchemy
```
> **Hint**: You may need to install [CMake](https://cmake.org/download/) before
> installing GQLAlchemy.
Maybe you got confused when I mentioned Cypher. You can think of Cypher as SQL
for graph databases. It contains many of the same language constructs like
`CREATE`, `UPDATE`, `DELETE`... and it's used to query the database.
```python
from gqlalchemy import Memgraph
memgraph = Memgraph("127.0.0.1", 7687)
```
Let's make sure that Memgraph is empty before we start with anything else.
```python
memgraph.drop_database()
```
Now let's see if the database is empty:
```python
results = memgraph.execute_and_fetch(
"""
MATCH (n) RETURN count(n) AS number_of_nodes ;
"""
)
print(next(results))
```
Output:
{'number_of_nodes': 0}
## 4. Define a graph schema
We are going to create Python classes that will represent our graph schema. This
way, all the objects that are returned from Memgraph will be of the correct type
if the class definition can be found.
```python
from typing import Optional
from gqlalchemy import Field, Node, Relationship
class User(Node):
username: str = Field(index=True, unique=True, db=memgraph)
class Retweeted(Relationship, type="RETWEETED"):
pass
```
## 5. Creating and returning nodes
We are going to create `User` nodes, save them to the database and return them
to our program:
```python
user1 = User(username="ivan_g_despot")
user2 = User(username="supe_katarina")
user1.save(memgraph)
user2.save(memgraph)
print(user1)
print(user2)
```
Output:
<User id=1874 labels={'User'} properties={'username': 'ivan_g_despot'}>
<User id=1875 labels={'User'} properties={'username': 'supe_katarina'}>
Now, let's try to create a node using the Cypher query language. We are going to
create a node with an existing username just to check if the existence
constraint on the property `username` is set correctly.
```python
try:
results = memgraph.execute(
"""
CREATE (:User {username: "supe_katarina"});
"""
)
except Exception:
print("Error: A user with the username supe_katarina is already in the database.")
```
Output:
Error: A user with the username supe_katarina is already in the database.
## 6. Creating and returning relationships
We are going to create a `Retweeted` relationship, save it to the database and
return it to our program:
```python
retweeted = Retweeted(_start_node_id=user1._id, _end_node_id=user2._id)
retweeted.save(memgraph)
print(retweeted)
```
Output:
<Retweeted id=1670 start_node_id=1874 end_node_id=1875 nodes=(1874, 1875) type=RETWEETED properties={}>
## 7. Importing data from CSV files
You will need to download [this file](https://github.com/memgraph/jupyter-memgraph-tutorials/blob/main/twitter_network_analysis/scraped_tweets.csv) which contains a simple dataset of
scraped tweets. To import it into Memgraph, we will first need to copy it to the
Docker container where Memgraph is running. Find the `CONTAINER_ID` by running:
```
docker ps
```
Copy the file with the following command (don't forget to replace
`CONTAINER_ID`):
```
docker cp scraped_tweets.csv CONTAINER_ID:scraped_tweets.csv
```
We are going to see what our CSV file looks like with the help of the pandas
library. To install it, run:
```
pip install pandas
```
Now let's see what the CSV file looks like:
```python
import pandas as pd
data = pd.read_csv("scraped_tweets.csv")
data.head()
```
<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Output:
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>source_username</th>
<th>target_username</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>CapeCodGiftShop</td>
<td>RetroCEO</td>
</tr>
<tr>
<th>1</th>
<td>CodeAttBot</td>
<td>LeeHillerLondon</td>
</tr>
<tr>
<th>2</th>
<td>BattlegroundHs</td>
<td>getwhalinvest</td>
</tr>
<tr>
<th>3</th>
<td>botpokemongofr1</td>
<td>TrevorAllenPKMN</td>
</tr>
<tr>
<th>4</th>
<td>AnyaSha13331181</td>
<td>WORLDMUSICAWARD</td>
</tr>
</tbody>
</table>
</div>
<br>
Now, we can execute the Cypher command `LOAD CSV`, which is used for loading
data from CSV files:
```python
memgraph.execute(
"""
LOAD CSV FROM "/scraped_tweets.csv" WITH HEADER AS row
MERGE (u1:User {username: row.source_username})
MERGE (u2:User {username: row.target_username})
MERGE (u1)-[:RETWEETED]->(u2);
"""
)
```
You can think of the `LOAD CSV` clause as a loop that will go over every row in
the CSV file and execute the specified Cypher commands.
## 8. Querying the database and retrieving results
Let's make sure that our data was imported correctly by retrieving it:
```python
results = memgraph.execute_and_fetch(
"""
MATCH (u:User)
RETURN u
ORDER BY u.username DESC
LIMIT 10;
"""
)
results = list(results)
for result in results:
print(result["u"])
```
Output:
<User id=3692 labels={'User'} properties={'username': 'zziru67'}>
<User id=3240 labels={'User'} properties={'username': 'zippydjh'}>
<User id=3725 labels={'User'} properties={'username': 'zee_row_ex'}>
<User id=3591 labels={'User'} properties={'username': 'yvonneqqm'}>
<User id=3212 labels={'User'} properties={'username': 'yujulia999'}>
<User id=2378 labels={'User'} properties={'username': 'yudhapati88'}>
<User id=2655 labels={'User'} properties={'username': 'yu100_kun'}>
<User id=2302 labels={'User'} properties={'username': 'youth_tree'}>
<User id=2432 labels={'User'} properties={'username': 'yourkpopsoul'}>
<User id=2132 labels={'User'} properties={'username': 'your_harrogate'}>
We can also check the type of the retrieved records:
```python
u = results[0]["u"]
print("User: ", u.username)
print("Type: ", type(u))
```
Output:
User: zziru67
Type: <class '__main__.User'>
Let's try to execute the same query with the GQLAlchemy query builder:
```python
from gqlalchemy import match
results_from_qb = (
match()
.node(labels="User", variable="u")
.return_()
.order_by("u.username DESC")
.limit(10)
.execute()
)
results_from_qb = list(results_from_qb)
for result in results_from_qb:
print(result["u"])
```
Output:
<User id=3692 labels={'User'} properties={'username': 'zziru67'}>
<User id=3240 labels={'User'} properties={'username': 'zippydjh'}>
<User id=3725 labels={'User'} properties={'username': 'zee_row_ex'}>
<User id=3591 labels={'User'} properties={'username': 'yvonneqqm'}>
<User id=3212 labels={'User'} properties={'username': 'yujulia999'}>
<User id=2378 labels={'User'} properties={'username': 'yudhapati88'}>
<User id=2655 labels={'User'} properties={'username': 'yu100_kun'}>
<User id=2302 labels={'User'} properties={'username': 'youth_tree'}>
<User id=2432 labels={'User'} properties={'username': 'yourkpopsoul'}>
<User id=2132 labels={'User'} properties={'username': 'your_harrogate'}>
## 9. Calculating PageRank
Now, let's do something clever with our graph. For example, calculating PageRank
for each node and then adding a `rank` property that stores the PageRank value
to each node:
```python
results = memgraph.execute_and_fetch(
"""
CALL pagerank.get()
YIELD node, rank
SET node.rank = rank
RETURN node, rank
ORDER BY rank DESC
LIMIT 10;
"""
)
for result in results:
print("The PageRank of node ", result["node"].username, ": ", result["rank"])
```
Output:
The PageRank of node WORLDMUSICAWARD : 0.13278838151391434
The PageRank of node Kidzcoolit : 0.018924764871246207
The PageRank of node HuobiGlobal : 0.011314994833838172
The PageRank of node ChloeLe39602964 : 0.010011755296388128
The PageRank of node getwhalinvest : 0.007228675936490175
The PageRank of node Cooper_Lechat : 0.005577971882231625
The PageRank of node Phemex_official : 0.005413803151353543
The PageRank of node HamleysOfficial : 0.005325936307836382
The PageRank of node bmstores : 0.00524546649693655
The PageRank of node TheStourbridge : 0.004422198431576731
Visit the [Memgraph MAGE](https://github.com/memgraph/mage) graph library (and
throw us a star ⭐) and take a look at all of the graph algorithms that have been
implemented. You can also implement and submit your own algorithms and utility
procedures.
## 10. Visualizing the graph in Memgraph Lab
Open Memgraph Lab in your browser on the address
[localhost:3000](http://localhost:3000). Execute the following Cypher query:
```cypher
MATCH (n)-[r]-(m)
RETURN n, r, m
LIMIT 100;
```
Now apply the following graph style to make your graph look more descriptive:
```
@NodeStyle {
size: Sqrt(Mul(Div(Property(node, "rank"), 1), 200000))
border-width: 1
border-color: #000000
shadow-color: #1D9BF0
shadow-size: 10
image-url: "https://i.imgur.com/UV7Nl0i.png"
}
@NodeStyle Greater(Size(Labels(node)), 0) {
label: Format(":{}", Join(Labels(node), " :"))
}
@NodeStyle HasLabel(node, "User") {
color: #1D9BF0
color-hover: Darker(#dd2222)
color-selected: #dd2222
}
@NodeStyle HasProperty(node, "username") {
label: AsText(Property(node, "username"))
}
@EdgeStyle {
width: 1
}
```

<center>Image 1. The radius of nodes is proportional to their PageRank value</center>
<br>
## What's next?
Now it's time for you to use Memgraph on a graph problem!
You can always check out [Memgraph Playground](https://playground.memgraph.com/)
for some cool use cases and examples. If you have any questions, or want to
share your work with the rest of the community, join our **[Discord
Server](https://discord.gg/memgraph)**.
[](https://memgraph.com/blog?topics=Python&utm_source=devto&utm_medium=referral&utm_campaign=blog_repost&utm_content=banner#list) | memgraphdb |
1,416,631 | Cloud Bootcamp 2023 | Excited to start new journey in the cloud. Just started an 2 weeks bootcamp by cloud community, I'm... | 0 | 2023-03-27T15:08:32 | https://dev.to/akk_dev/cloud-bootcamp-2023-5gj2 | cloud, github, kubernetes, azure | Excited to start new journey in the cloud. Just started an 2 weeks bootcamp by [cloud community](https://www.linkedin.com/company/thecloudfolk/), I'm excited to learn new things. They have been organized in three tracks like AWS, Azure, GCP and provide an mentors for each of this...
 | akk_dev |
1,416,638 | Design: Monolitos Modulares - Parte 1 | Design: Monolitos Modulares Olá! Este é mais um post da sessão Design e, desta vez,... | 0 | 2023-03-28T11:53:19 | https://dev.to/wsantosdev/design-monolitos-modulares-parte-1-3fli | braziliandevs, designpatterns, architecture, programming | # Design: Monolitos Modulares
Olá!
Este é mais um post da sessão **Design** e, desta vez, falaremos sobre um tema que, volta e meia, reaparece: monolitos.
Entretanto, a intenção deste post é expor uma forma diferente de lidar com este estilo arquitetural: monolitos modulares.
Esta abordagem ajuda a manter o monolito organizado, coeso e menos acoplado e, por isso, é ótima para evitar a chamada "big ball of mud" (grande bola de lama), que se caracteriza por um código com muitas dependências entre as funcionalidades, circulares inclusive, o que torna mais difícil manter e evoluir uma dada aplicação.
Vamos lá!
## O Monolito
Durante a febre dos microsserviços, o monolito passou a ser tratado como obsoleto. E muito desse tratamento veio da falta de compreensão sobre quais cenários podem se beneficiar deste modelo, tornando muitas aplicações desnecessariamente complexas quando poderiam ser mais simples. Infelizmente, como efeito colateral deste tratamento, acabamos por ver a repetição da "big ball of mud" neste estilo, o que chamamos de "monolito distribuído", uma vez que os mesmos erros de gestão de dependências que ocorriam nos monolitos, afetaram também os processos distribuídos.
A imagem abaixo ilustra este cenário:
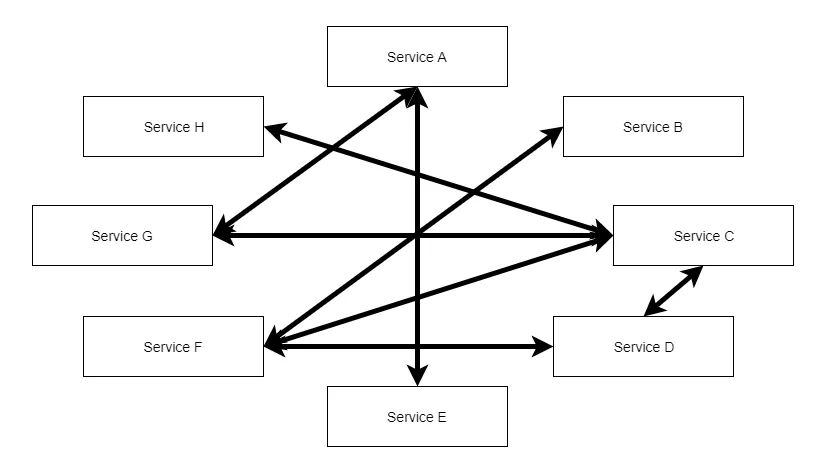
> **Nota:** Algo importante, a esta altura, é entender que, além de repetir a "big ball of mud", há um outro efeito colateral: aumento da complexidade, que leva a um aumento direto do custo do software. Este aumento de complexidade se dá pela preocupação com falhas na rede, mensageria, aglutinação de logs entre outras. Ou seja, uma escolha inadequada por um estilo arquitetural pode levar o negócio a ter maiores despesas com o software, aumentando seu custo operacional.
Vejamos, então, quando o monolito faz sentido para, em seguida, entendermos como a ideia de módulos se ajusta a ele.
### Lei de Conway
A [Lei de Conway](https://www.melconway.com/Home/Committees_Paper.html) (em inglês) nos diz que, em organizações onde se desenvolve software, este tende a replicar a estrutura de comunicação dessas organizações.
Isso, no que tange à escolha de um estilo arquitetural, significa dizer que não faz sentido utilizar microsserviços quando uma dada aplicação não é mantida por múltiplos times, onde cada um é responsável por um dado conjunto de funcionalidades e, mais importante, onde todos precisem realizar deploys independentemente.
Este último critério, por sinal, é a régua do polegar para a escolha de microsserviços em detrimento do monolito. Se não há a necessidade de deploys independentes, não há razão para que se escolha microsserviços e, neste caso, monolito se torna o estilo de primeira escolha.
## A ideia de modularidade
Modularidade, em software, significa criar conjuntos de funcionalidades agrupadas por coerência, e separadas do programa principal, aquele que serve de ponto de entrada.
Para os desenvolvedores dotnet e Java, por exemplo, isso seria equilavente a ter bibliotecas/pacotes, que vou chamar de componentes para generalizar, que representam as funcionalidades, separadas do programa que executa o método `Main`.
A partir desta separação, e do agrupamento entre as funcionalidades, seria definida uma API (não confundir com Web API) que serviria de ponto de entrada a este grupo, a partir do qual toda a comunicação entre o este grupo e os demais seria mediada.
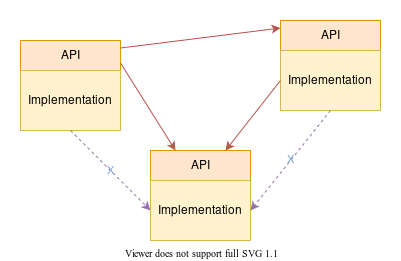
### Encapsulamento
Para garantir que a modularidade seja respeitada, é necessário isolar o código da API do restante do código contido no módulo e, para isso, é necessário ocultar o código interno às funcionalidade.
Para programadores dotnet, por exemplo, isso se faz possível pelo uso da palavra-chave `internal`, que permite que um dado código seja executado apenas a partir do arquivo onde o mesmo se encontra.
Como neste cenário apenas o código da API ficará visível, não será possível invocar o código ocultado em seu componente, tornando mais fácil manter a modularidade.
O resultado final seria um esquema como o da imagem abaixo:
#### Isolando a interface com o usuário
Outro ponto de isolamento importante é aquele feito sobre a interface do usuário. Da mesma forma que o acesso a dados é entendido como parte da infraestrutura da aplicação, assim o é para as interfaces (ou controllers no caso de uma Web API). Assim sendo, é recomendável que sejam criados componentes separados para essas interfaces.
Em um projeto ASP.NET, por exemplo, haveria em uma solução um projeto como ponto de entrada da aplicação (aquele que possuirá o método `Main` e a classe de `Startup`), e um outro projeto para cada módulo com seus respectivos controllers (e/ou views).
Esta separação é importante pois, conforme a evolução da organização, caso surja a necessidade de realizar a decomposição da aplicação em serviços, basta mover estes projetos para uma nova solução, mantendo a infra (aplicação Web) separada do domínio (componente).
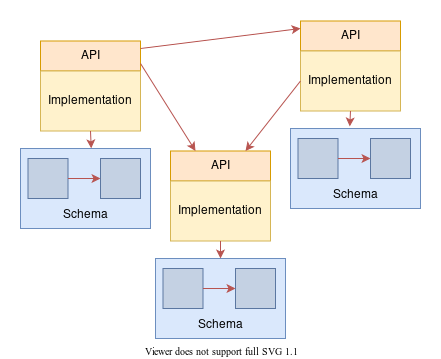
#### Isolando o acesso a dados
Outro ponto muito importante é manter o mesmo isolamento das funcionalidades no nível dos dados. Para que a modularidade se mantenha, cada módulo é exclusivamente responsável por obter seus dados, condição esta que pode ser forçada por meio da criação de esquemas separados em uma base de dados (ou mesmo o uso de múltiplas bases), e impedindo que `joins` sejam feitos entre eles a partir de restrições a cada usuário do banco associado a um módulo.
Desta forma, chegaríamos a um esquema semelhante ao da imagem abaixo:
### DDD
A abordagem que considero mais indicada para a correta separação dos módulos é a ideia de `bounded contexts` do DDD. Modelando-se o domínio a partir deles, a separação entre os módulos se define automaticamente, assim como a comunicação entre os mesmos pode ser mapeada com maior precisão.
Esta abordagem nos faria chegar a um esquema semelhante ao da imagem abaixo:
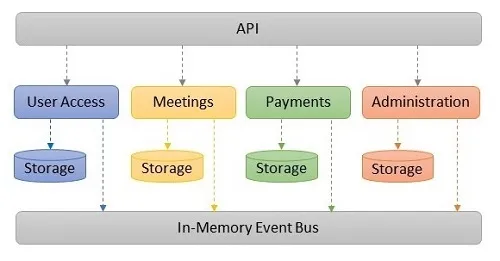
## Conclusão
Com este simples conjunto de princípios é possível manter os módulos de sua aplicação isolados, evitando assim que haja dependências indesejáveis seja por porções de código (classes e interfaces, ou funções), seja por tabelas e outros objetos de banco de dados.
Procedendo desta forma, a aplicação se mantém coesa, fácil de manter e evoluir e, portanto, com menor custo para o negócio (tempo) e para o time (estresse).
É possível que, a esta altura, você tenha notado algo interessante: os princípios mencionados acima são uma reprodução daqueles utilizados em microsserviços. A única diferença é o meio pelo qual a troca de mensagens acontece: com microsserviços ela se dá pela rede e, com monolitos, ela se dá pela memória do processo.
Isso significa, conforme dito na seção "Isolando a interface com o usuário", que uma eventual decomposição da aplicação em serviços, se assim se fizer necessário no futuro, seja facilitada, o que reduz -- e muito! -- a necessidade de uma eventual reescrita por conta de dependências diretas entre porções de diferentes módulos.
Na Parte 2 deste artigo vou me concentrar na aplicação destes princípios em uma aplicação de demonstração. A ideia é mostrar não apenas como o código seria organizado como, também, as diferentes formas de comunicação entre os módulos (síncrona e assíncrona).
Gostou? Me deixe saber pelos indicadores. Tem dúvidas ou sugestões? Deixe um comentário ou me procure pelas redes sociais.
Até a próxima! | wsantosdev |
1,416,647 | Functions in JavaScript | Functions are a fundamental building block in JavaScript that allow you to encapsulate code and reuse... | 22,403 | 2023-03-27T15:29:07 | https://makstyle119.medium.com/functions-in-javascript-5466ae5e3e6a | javascript, beginners, makstyle119, tutorial | **Functions** are a **fundamental** building block in **JavaScript** that allow you to **encapsulate** **code** and **reuse** it throughout your **program**. In this blog post, we'll explore **functions** in **JavaScript**, **including** their **syntax**, **parameters**, and **return values**.
**Syntax** of **Functions** in **JavaScript:**
In **JavaScript**, **functions** are **declared** using the ``function`` **keyword**, followed by the **function name**, a set of **parentheses**, and a set of **curly braces**. Here's an example of a simple **function** that logs a message to the **console**:
{% embed https://gist.github.com/makstyle119/7cfb0f2dbfc9c5ce013127f69ea09176.js %}
In this **code**, we **declare** a **function** called ``myFunction`` that **logs** the message ``"Hello, world!"`` to the **console** when it is called. To call the function, we simply use its **name** followed by a set of **parentheses**:
{% embed https://gist.github.com/makstyle119/b00bd3cbb2a1ee9210d6f714c96fb0eb.js %}
**Parameters in Functions:**
**Functions** can also accept **input values** called **parameters**, which allow you to **pass data** into the **function** when it is called. **Parameters** are **declared** inside the **parentheses** when the function is **declared**. Here's an **example** of a **function** that **takes** two **parameters** and logs their **sum** to the **console**:
{% embed https://gist.github.com/makstyle119/731a6b2b5e993de3da1087cfd7700577.js %}
In this **code**, we **declare** a **function** called ``addNumbers`` that takes two **parameters**: ``num1`` and ``num2``. When the **function** is **called**, it **logs** the **sum** of ``num1`` and ``num2`` to the **console**. To call the **function** with **specific values** for the **parameters**, we pass them in as **arguments** inside the **parentheses**:
{% embed https://gist.github.com/makstyle119/c50bbfe14eb1574ac2f818e0f460e017.js %}
**Return** Values in **Functions**:
**Functions** can also ``return`` **values** back to the calling **code** using the **return keyword**. Here's an **example** of a **function** that takes two **parameters** and **returns** their **sum**:
{% embed
https://gist.github.com/makstyle119/5cfaae84e73b6cee4d6d88588d55fb09.js %}
In this **code**, we **declare** a **function** called ``addNumbers`` that takes two **parameters**: ``num1`` and ``num2``. When the **function** is called, it **returns** the **sum** of ``num1`` and ``num2`` using the ``return`` **keyword**. To use the **return value**, we assign the **function** call to a **variable**:
{% embed
https://gist.github.com/makstyle119/a9efc7dd102cc28c1795312ef919b066.js %}
**Conclusion:**
**Functions** are a **powerful tool** in **JavaScript** that allow you to **encapsulate code** and **reuse** it **throughout** your **program**. In **JavaScript**, **functions** are **declared** using the ``function`` **keyword**, followed by the **function name**, a set of **parentheses**, and a set of **curly braces**. Functions can also **accept input values** called **parameters**, and **return values** using the ``return`` **keyword**. By **understanding** how to **use functions** in **JavaScript**, you can **write** more **efficient** and **maintainable code**.
| makstyle119 |
1,416,840 | 5 Awesome GitHub Repositories To Contribute To! | Introduction An open-source project is a type of project that is being developed and... | 0 | 2023-04-02T12:30:00 | https://dev.to/sriparno08/5-awesome-github-repositories-to-contribute-to-1hnb | opensource, git, github, beginners | ## Introduction
An open-source project is a type of project that is being developed and maintained collaboratively. Lots of contributors from around the world come together to collaborate on different open-source projects.
If you are into open source, you have probably heard about Git and GitHub. The former is a distributed version control system, and the latter is a web-based service that hosts Git repositories.
Once you've mastered these tools, it's time to start contributing to open source. However, finding beginner-friendly open-source projects is a difficult job.
So I've compiled a list of beginner-friendly GitHub repositories to help you get started with open-source contributions. Here we go!
### LinkFree
LinkFree is an open-source alternative to LinkTree. This is a platform where people in the tech industry can have a single hub to showcase their content to advance their careers, while also contributing to an open-source project and being part of a community that has a say in where the project goes.
**Contributing:**
* Create an issue
* Make a Pull Request
* Add your profile
* Improve documentation
* Improve codebase
{% embed https://github.com/EddieHubCommunity/linkfree %}
### freeCodeCamp
freeCodeCamp.org is a friendly community where you can learn to code for free. It is a noble initiative to help millions of busy adults transition into tech. Their community has already helped more than 40,000 people get their first developer job.
**Contributing:**
* Create an issue
* Make a Pull Request
* Improve documentation
* Improve codebase
{% embed https://github.com/freeCodeCamp/freeCodeCamp %}
### Abbreve
Abbreve is an open-source dictionary for slang. It solves this problem by providing definitions for these abbreviations with a simple search, making it easy for you to understand and participate in online conversations with confidence.
**Contributing:**
* Create an issue
* Make a Pull Request
* Add an abbreviation
* Improve documentation
{% embed https://github.com/Njong392/Abbreve %}
### Bootstrap Icons
This repository is the house of icons! Whether it's a brand or a programming language, the icons cover all the topics. It is the official open-source SVG icon library for Bootstrap, with over 1,900 icons.
**Contributing:**
* Create an issue
* Make a Pull Request
* Improve documentation
* Improve codebase
{% embed https://github.com/twbs/icons %}
### Start Contributing
This repository is a collection of resources that will help you get started with contributing to open source. It includes the following topics:
* Introduction to Open Source
* Learn Git and GitHub
* Contributing to Open Source
**Contributing:**
* Create an issue
* Make a Pull Request
* Add a resource
* Add a topic
{% embed https://github.com/Sriparno08/Start-Contributing %}
## Conclusion
That's all! The repositories listed above will undoubtedly help you understand the concept of open-source contribution. So, what are you waiting for? Jump into these repositories and start contributing right now! | sriparno08 |
1,416,973 | Mind Tracker — application for mental health | The application shows analytics on the psychological well-being of the user. My brother and I... | 0 | 2023-03-27T20:57:54 | https://dev.to/mind_tracker/mind-tracker-application-for-mental-health-5e68 | flutter, ios, android, mentalhealth |
The application shows analytics on the psychological well-being of the user.
My brother and I started making the app in the midst of COVID, when many people were facing emotional and mental problems. At that time, I was working on launching an online bank in the Philippines, which created an especially favorable environment for being out of my mind.
Before development began, I began to keep a diary of emotions in order to somehow deal with a depressive state. The process of reflection and structuring of emotions helped. I wrote down my moods, emotions, and the events that triggered them. When assessing the mood, I built a graph in Excel. It became clear that in this format it is inconvenient to do it. I went through many applications, but they did not suit me for several reasons:
- A five-point scale is used everywhere, which is not suitable for assessing mood;
- No mood analytics by time of day;
- There is no analytics of the impact of events on well-being;
- No ability to mark energy level;
- Recommendations are not customized in any way.
Then the idea came to make my own application.
**Seven-point scale**
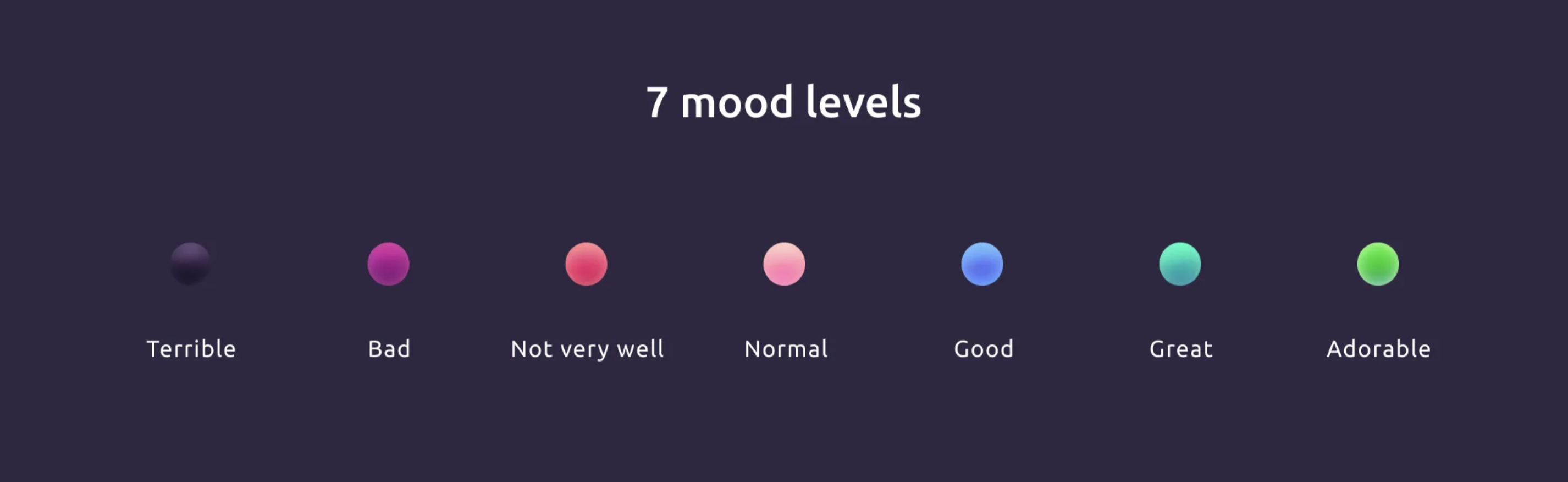
First of all, we abandoned the five-point scale and started using the seven-point scale. On a five-point scale, a score of 3 is negative, whether it’s a 3 out of 5 for a movie, or a C at school. In our scale, the average mood score is the norm and does not cause negative associations.
We also decided to get away from mood visualization through emoji as much as possible. If with positive emoticons everything was not too bad, then choosing a “sad” face, when you are already in a bad mood, only infuriates. A person can experience such a strong emotion that all sad faces will look naive.
Since I am a designer, I decided to use only color coding and avoid unnecessary associations.
**Times of Day**
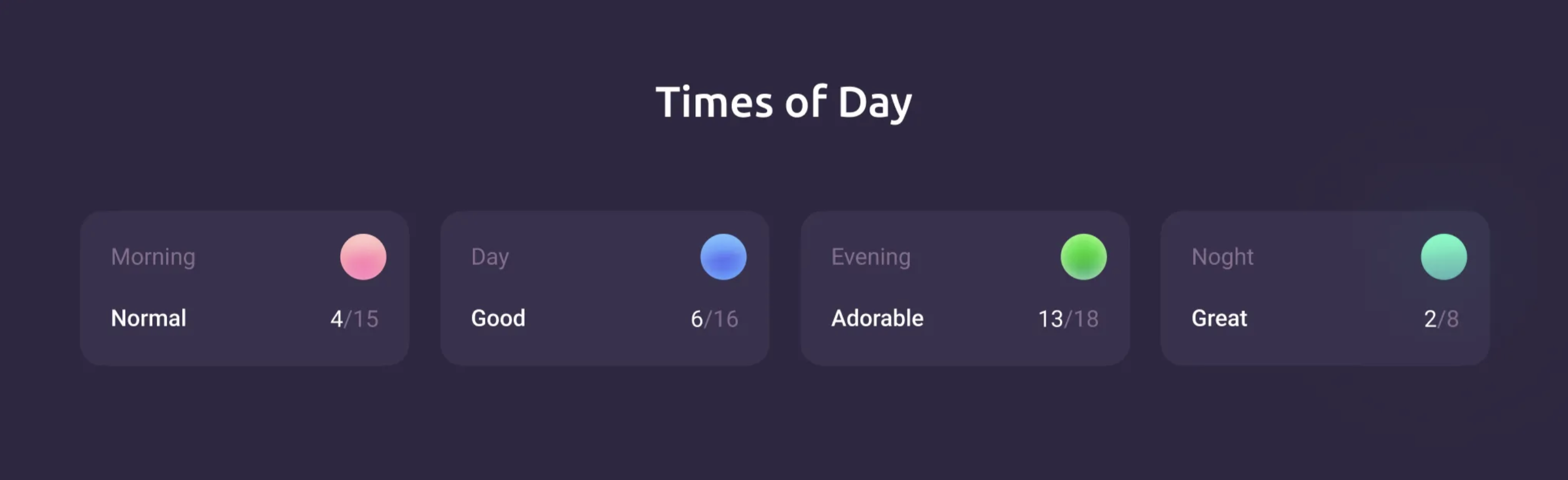
During the day, mood and general well-being change greatly. It is useful to understand what time of day is the most productive, and what time of the day is better to relax. We have added the display of analytics, including by time of day. After I started using the app I realized that I’m definitely not a night person and clearly feel better in the morning.
**Energy**
In the process, we realized that one scale for assessing well-being is not enough. The first test users confirmed this. Often there were situations when you were tired, but your mood was not bad, or you were angry and upset, however, more than ever full of energy. In such situations, users noted their mood as worse than it actually was, or found it difficult to assess. It was necessary to separate the mood and the amount of energy, because it is important to correctly prioritize in different states.
**For example:**
Good mood, but little energy — now it’s better to read a book or do any inactive tasks, it’s better not to take on 10 things at once.
A bad mood, but there is still a lot of energy left — you can go through all the old routine things that do not require much emotional involvement.
**Events**
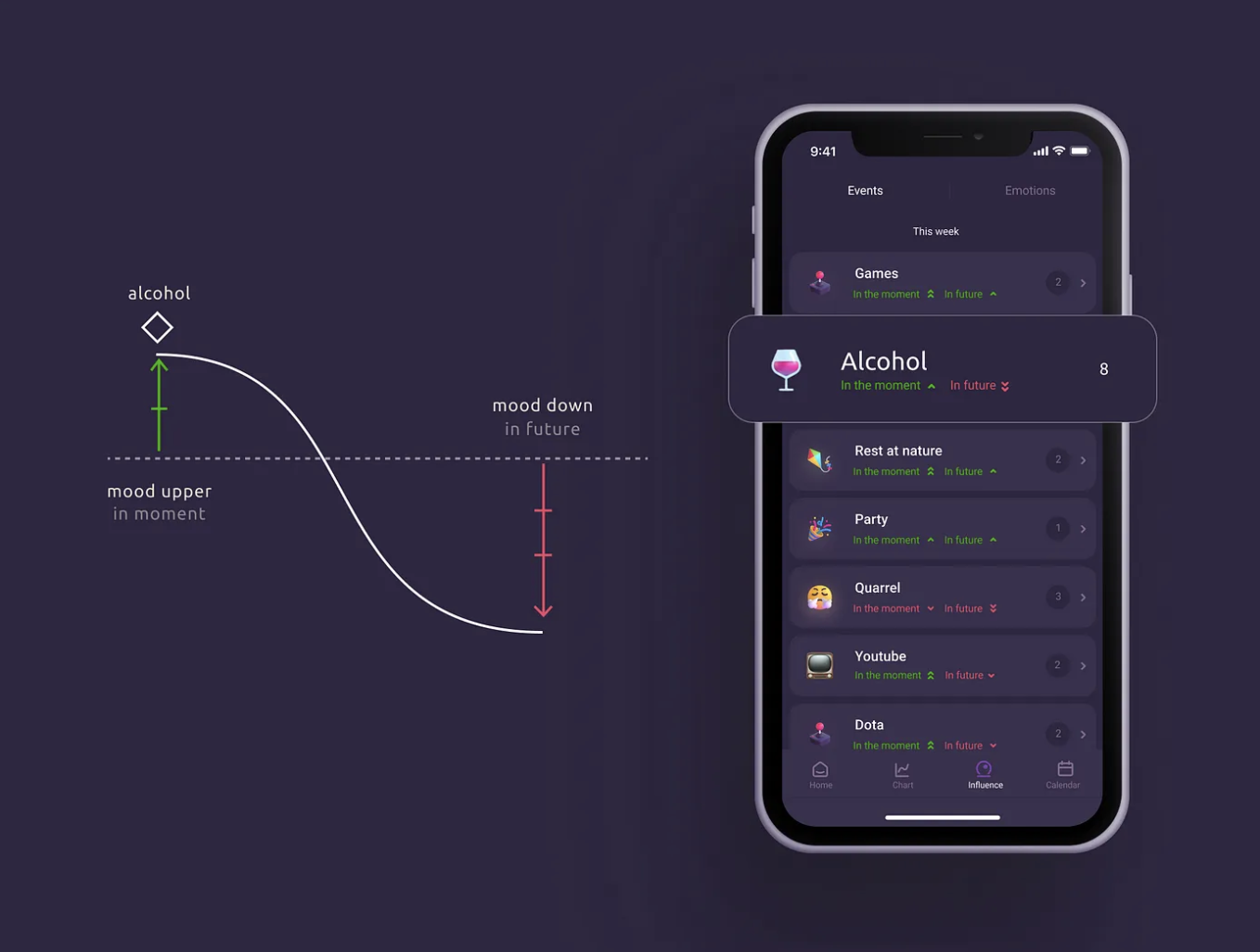
Events in life directly affect our mental state.
It will not be superfluous to take into account that event provoked this or that state of health. So one of the important mechanics of the application is adding events, and the ability to see their impact on yourself. A person cannot always find a direct connection between an event and well-being. Especially in the long term.
So we made it possible to add any events, so that the application analyzes and displays their impact on the emotion graph. We take the average mood of each user, including depending on the day of the week and time of day, compare it with the median mood, and show how the event affected well-being at the moment and in the future.
The simplest examples:
- Alcohol at the moment improves mood, but in the next 24 hours the person’s mood is worse than normal.
- During sports, the mood is average, but in the next 24 hours it is much better.
There are many such connections, and they are far from always obvious, and sometimes even surprising. Who would have thought that Dota has a very bad effect on my well-being?. Almost always after the game, my mood will be worse than my usual state. And after cleaning, on the contrary, it is better, and significantly. Of course, I will not stop playing Dota, but it has become easier to take up cleaning with this knowledge.
**Emotions**

Initially, we wanted to visualize emotions in the form of a circle by Robert Plutchik. Plutchik believes that there are opposite emotions that cannot exist simultaneously. Now this idea is often disputed, in my own example, I realized that a person can experience opposite emotions at some points. Even just trying to choose what emotions you experience, especially if they are negative, you switch from an emotionally destructive state to a more rational one, and negative emotions become less destructive.
**Notes**
You can create notes in the app, and they are tied to a mood tag. Sometimes it is enough to formulate negative thoughts, and it will already become better. The plans are to make notes “smarter”, so that the application itself isolates events and emotions from the text.
**Graph**
We’ve done a lot of work on how to average the data. The graph should be readable at a large scale, while maintaining the top and bottom peaks. We added different weights depending on the distance from the norm.
The graph is an important tool for introspection. We all have certain cycles that run differently. The cycle can last several days or months, and the seasons also strongly affect the state. This is especially important to consider for people with bipolar disorder, borderline disorder, or cyclic depression. Find cycles, patterns on the graph and be able to “put a straw” in advance.
**What else**
When working with a psychologist or psychiatrist, it happens that you paint events in the color of momentary emotions, and you forget what it was like before. And if you remember, you can’t always remember the reason. The application will be able to remind. The specialist will be able to say more using your data.
There are 2 of us in the team, me and my brother. Now we do not monetize the application in any way, it is completely free, although applications with even less functionality work by subscription. We are currently working on personalized recommendations and a user profile. We are very careful in this work, because we do not want to give “bad advice”. We will always need the help of specialists from the area of psychotherapy and psychiatry. If you are the one, or if you have friends who might be interested, let us know. We are open to cooperation.
I do not want to say that now is a time when it is especially important to take care of yourself and your psyche. There is always a way to go into an apathetic or depressive state. If you have tools that support you, use them. Even formulating your experiences and writing them down on a piece of paper helps you feel better.
**iOS:**
https://apps.apple.com/us/app/mind-tracker-journal/id1564080533
**Android:**
https://play.google.com/store/apps/details?id=com.fedosov.mindtracker | mind_tracker |
1,417,038 | Deploy cPanel & WHM on AWS EC2 Instance | cPanel & WHM is a web hosting control panel software that allows website owners, system... | 0 | 2023-03-27T23:20:34 | https://dev.to/aws-builders/deploy-cpanel-whm-on-aws-ec2-instance-36i5 | aws, cpanel, ec2, hosting | - cPanel & WHM is a web hosting control panel software that allows website owners, system administrators, and resellers to manage their websites and servers through a user-friendly interface. cPanel provides an easy-to-use graphical interface for managing various aspects of web hosting, such as creating email accounts, managing domains, uploading files, creating databases, installing applications, and monitoring server performance.
- WHM (Web Host Manager) is a separate administrative interface that comes with cPanel. It allows system administrators and web hosting resellers to manage multiple cPanel accounts on a single server or across multiple servers. With WHM, you can create and manage hosting packages, set up new cPanel accounts, monitor server health and resource usage, and automate server backups and updates.
- Together, cPanel & WHM provide a complete web hosting solution for both individual website owners and web hosting providers. They are widely used in the industry due to their ease of use, reliability, and comprehensive feature set.
## Implementation
### Creating an EC2 INSTANCE and Choosing CentOS 7 AMI
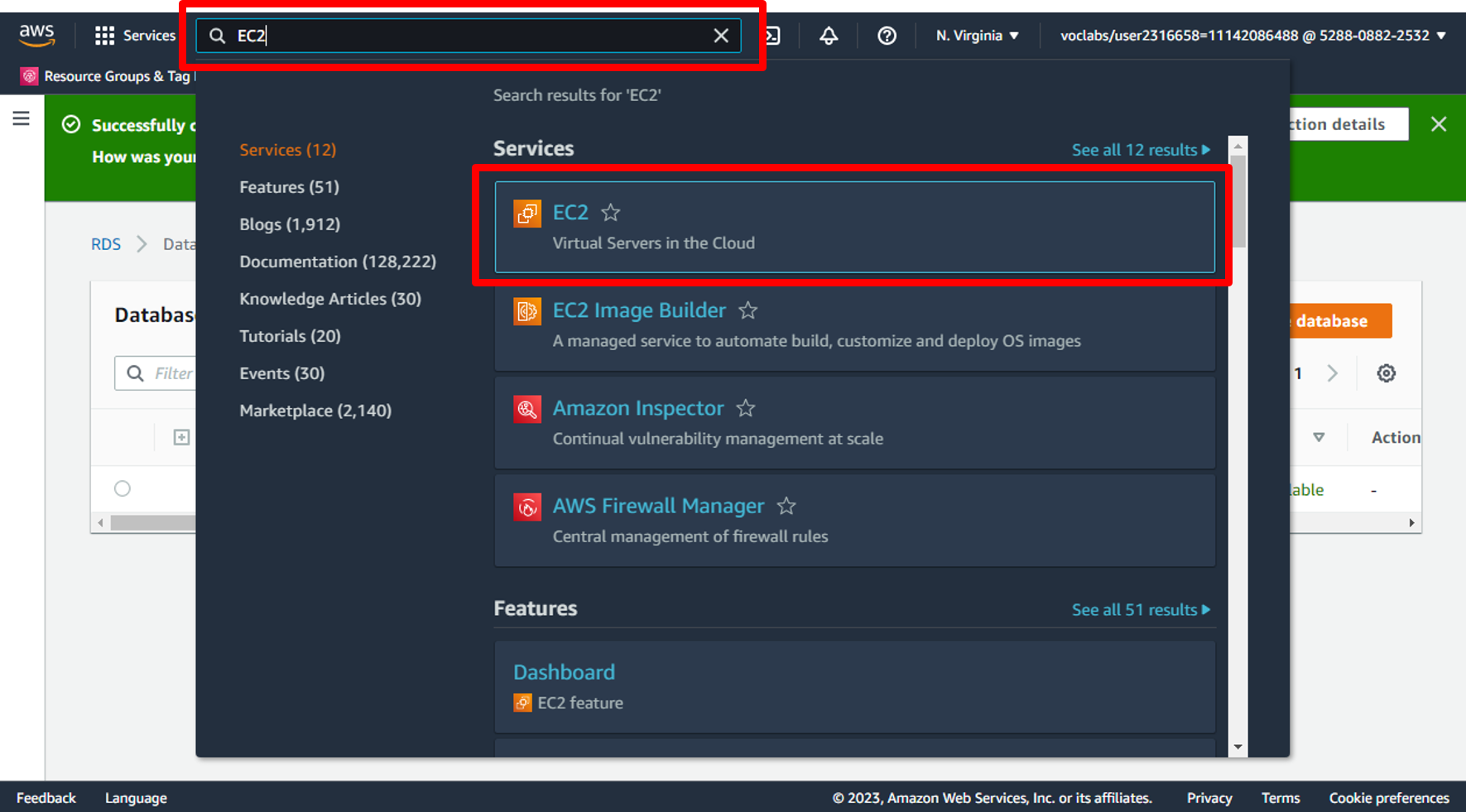
a. Open the [AWS Management Console](https://console.aws.amazon.com/console/home). When the screen loads, enter **EC2** in the search bar, then select **EC2** to open the service console.
b. Choose the **Launch instance** button to open the instance creation wizard.
c. On the first page, enter _Web Hosting (cPanel & WHM)_ as your instance name.
d. Next, choose an Amazon Machine Image (AMI). The AMI you choose will determine the base software that is installed on your new EC2 instance. This includes the operating system (Amazon Linux, Red Hat Enterprise Linux, Ubuntu, Microsoft Server, etc.), and the applications that are installed on the machine.
Many AMIs are general-purpose AMIs for running many different applications, but some are purpose-built for specific use cases, such as the Deep Learning AMI or various AWS Marketplace AMIs.
CentOS 7 image is the Official CentOS 7 x86_64 HVM image that has been built with a minimal profile, suitable for use in HVM instance types only, so choose [CentOS 7 (x86_64) - with Updates HVM](https://aws.amazon.com/marketplace/pp/prodview-qkzypm3vjr45g) after make search on AWS Marketplace AMIs in the AMI selection view.
so write **CentOS 7** on search bar then click **Enter**
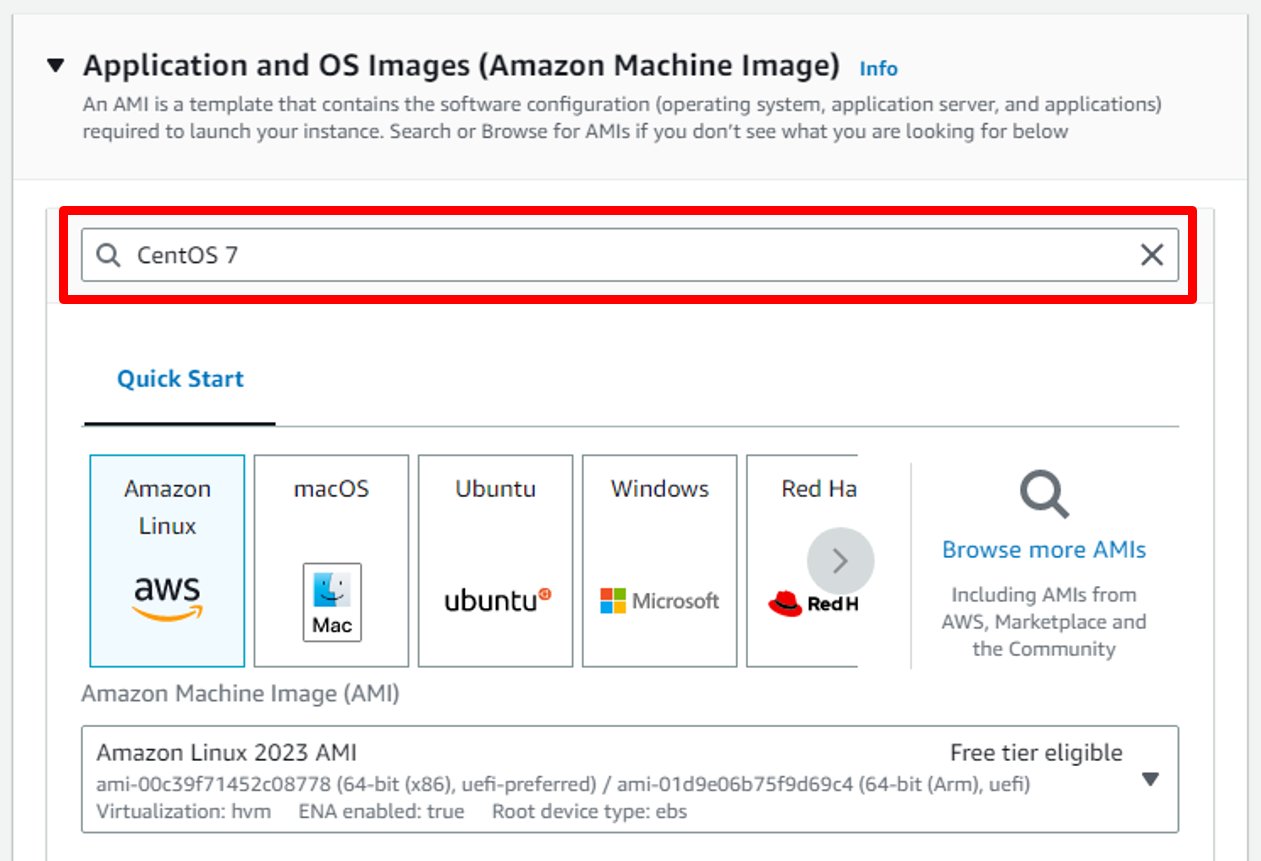
e. You will find the first image, choose it and press on **Select**
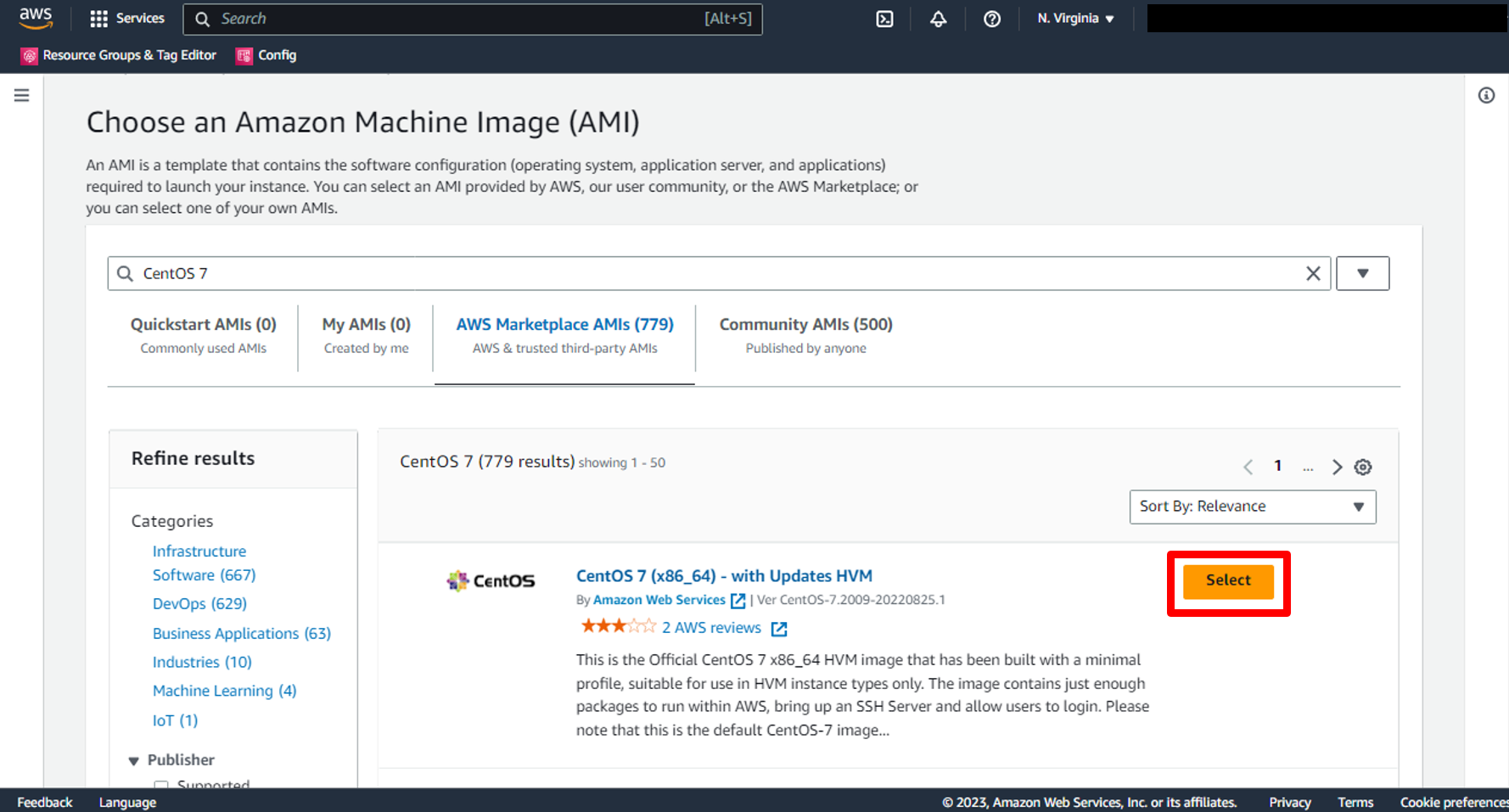
f. Read overview and all details about AMI then click **Continue**
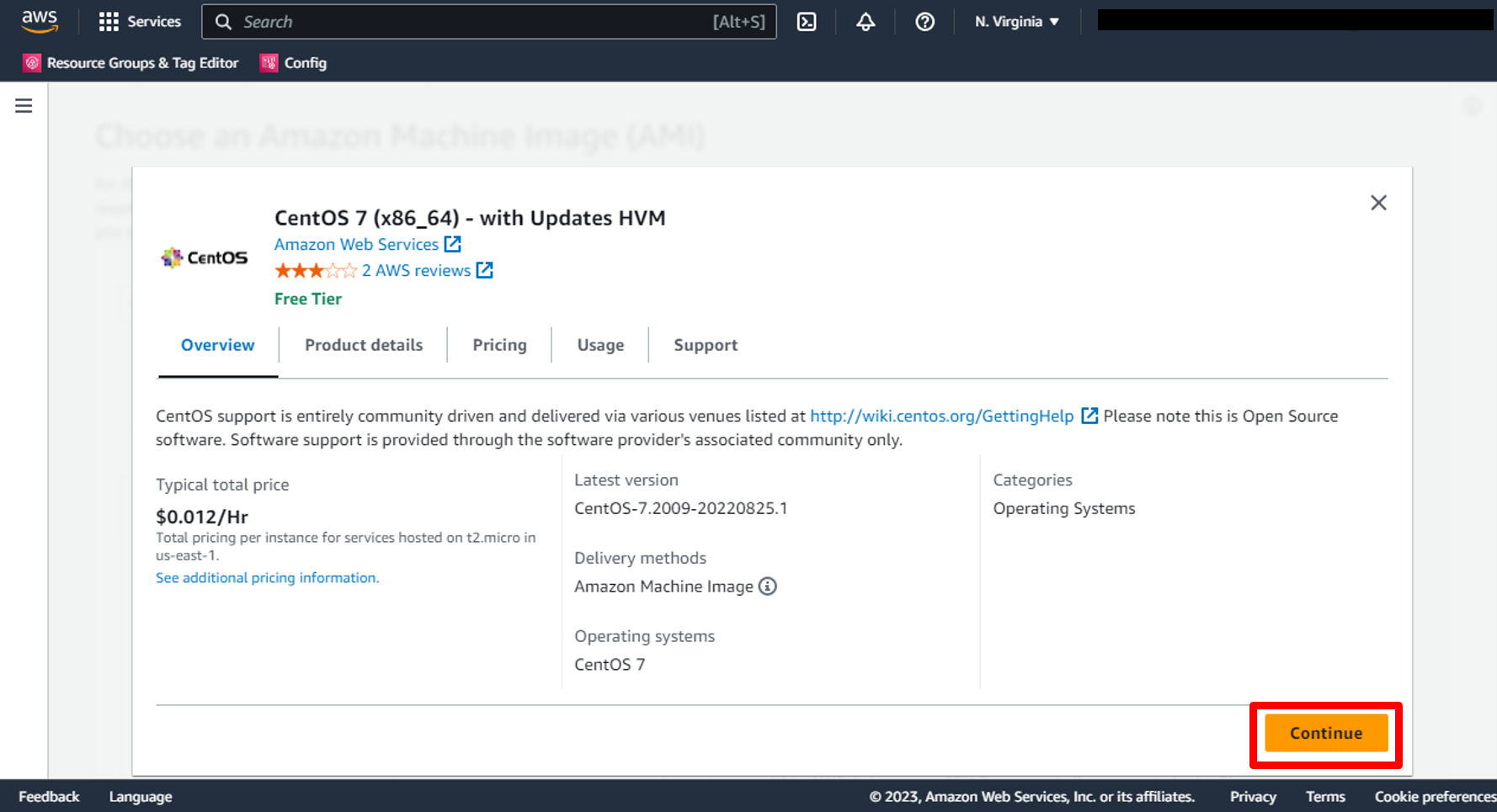
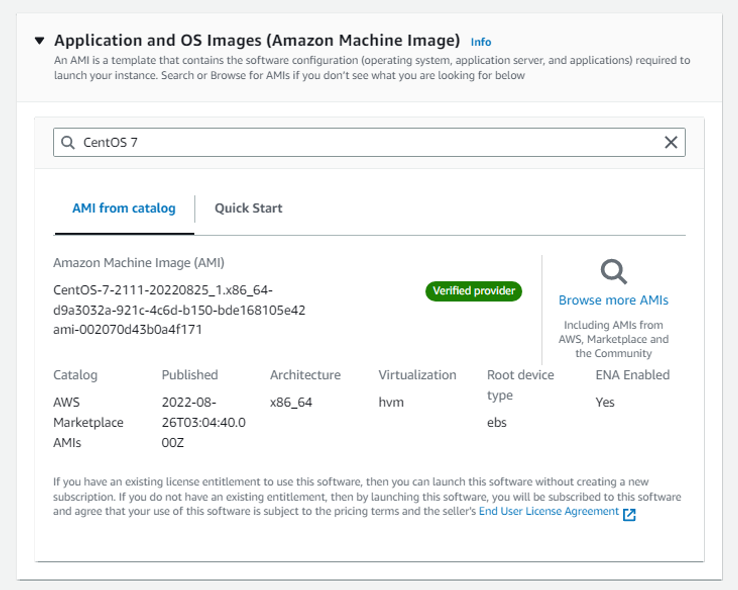
g. You will return to the AMI Section and you will find that the image has been selected.
### Choosing an instance type
Scroll down to select an EC2 instance type. An instance type is a particular configuration of CPU, memory (RAM), storage, and network capacity.
AWS has a huge selection of [instance types](https://aws.amazon.com/ec2/instance-types/) that cover many different workloads. Some are geared toward memory-intensive workloads, such as databases and caches, while others are aimed at compute-heavy workloads, such as image processing or video encoding.
Amazon EC2 allows you to run 750 hours per month of a t2.micro instance under the [AWS Free Tier](https://aws.amazon.com/free/).
a. Select the **t2.micro** instance.
### Configuring an SSH key
You will see a details page on how to configure a key pair for your instance. You will use the key pair to [SSH](https://en.wikipedia.org/wiki/Secure_Shell) into your instance, which will give you the ability to run commands on your server.
a. Open the **key pair (login)** section and choose **Create new key pair** for your instance.
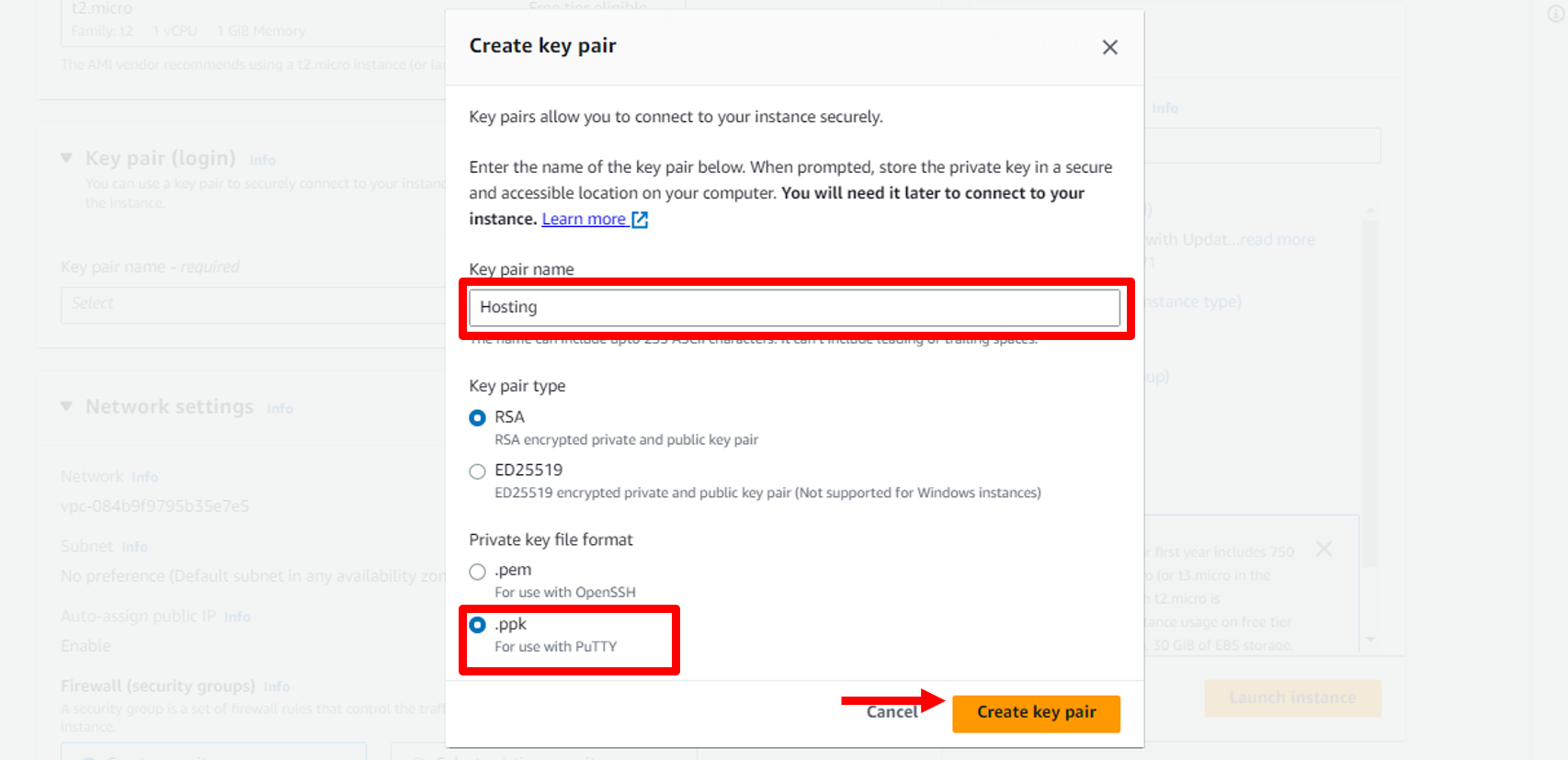
b. Give your key pair a name. Then choose **.ppk** in Private Key file format to can use with PuTTYThen. Then choose the **Create key pair** button, which will download the .ppk file to your machine. You will use this file later.
c. You will return to Key pair (login) Section and you will find that Key has been selected.
### Configuring a security group and launching your instance
You need to configure a security group before launching your instance. Security groups are networking rules that describe the kind of network traffic that is allowed to your EC2 instance. You want to allow traffic to your instance:
- SSH traffic from all IP addresses so you can use the SSH protocol to log in to your EC2 instance and configure WordPress.
- HTTPS traffic from all IP addresses so that users can view your WordPress site Secured.
- HTTP traffic from all IP addresses so that users can view your WordPress site.
a. To configure this, select **Allow SSH traffic from Anywhere** and select **Allow HTTPS & HTTP traffic from the internet**.
then Click on **Edit**
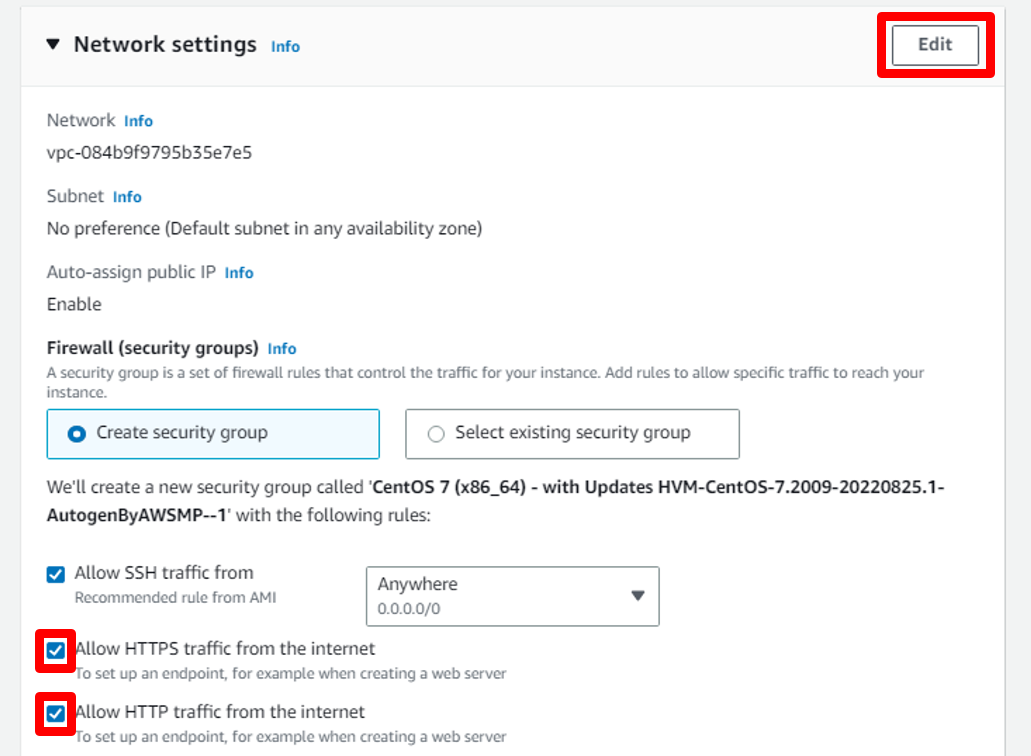
b. Click on **Add Security group rule** to add group rule.
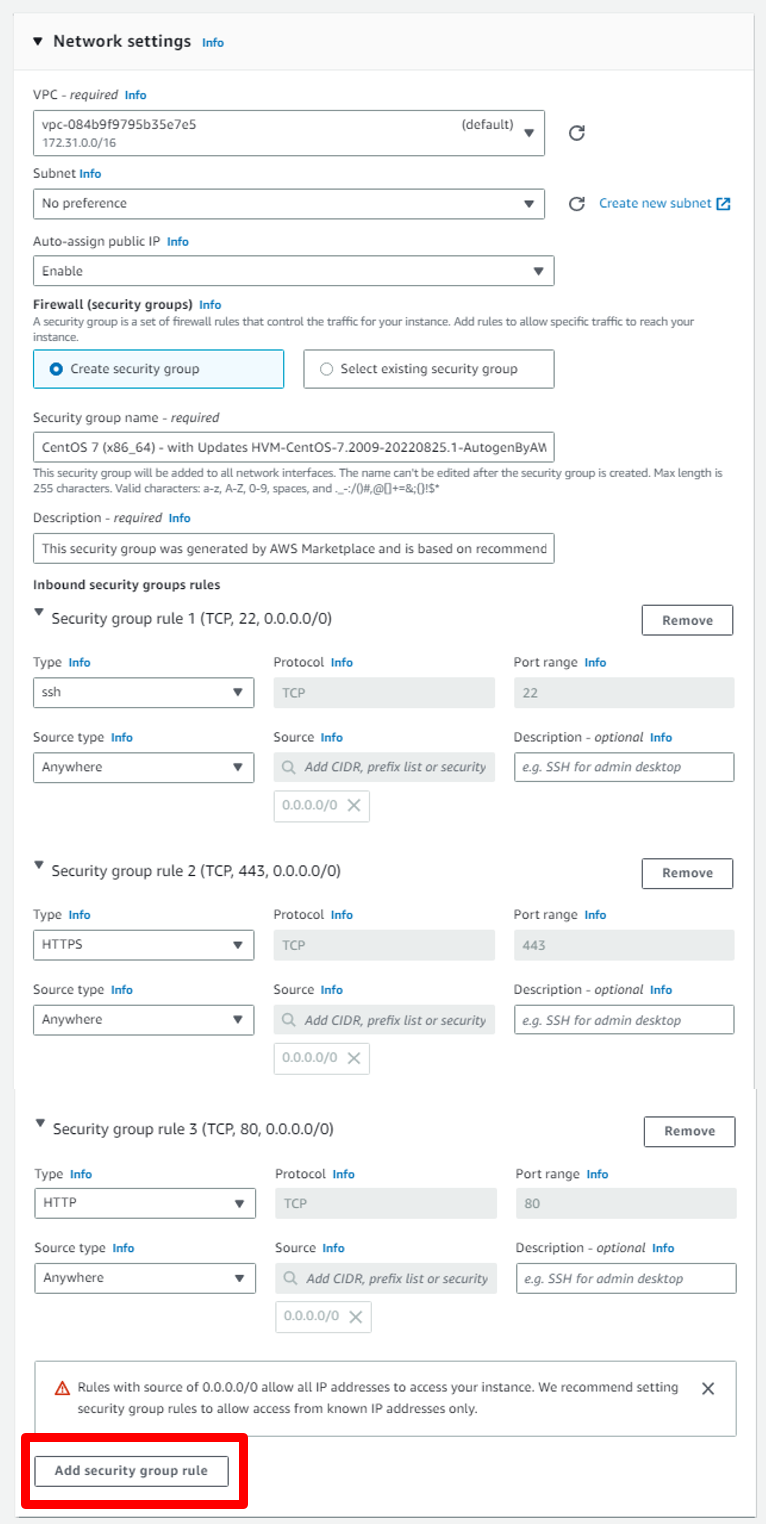
c. First Security Group: In Port Range write **2087** and in Source type select **Anywhere** this for open WHM Dashboard Port.
Then Click on **Add Security group rule** to add another group rule.
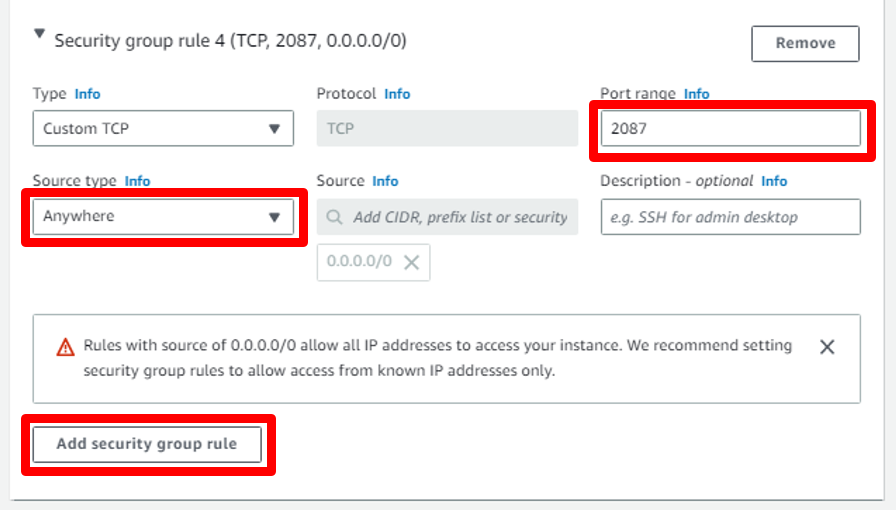
d. Second Security Group: In Port Range write **2083** and in Source type select **Anywhere** this for open cPanel Dashboard Port.
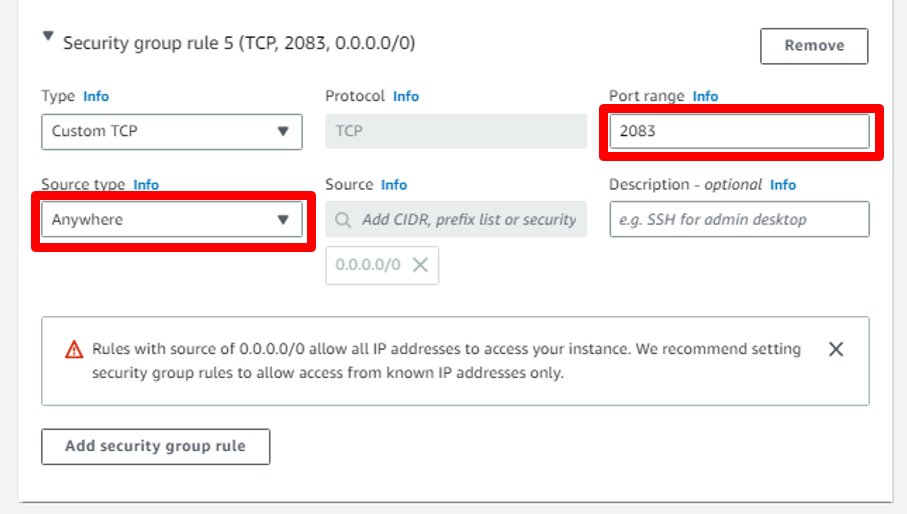
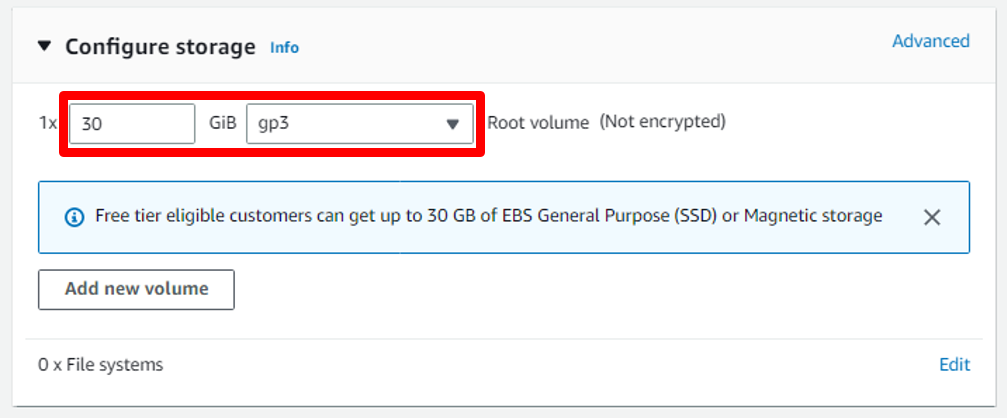
### Configuring storage on instance
a. Here we can increase the storage space for the Root volume and also can be added more volume storage.
### Launch
It is now time to launch your EC2 instance.
a. Choose the **Launch instance** button to create your EC2 instance.
b. Wait for instance to launch.
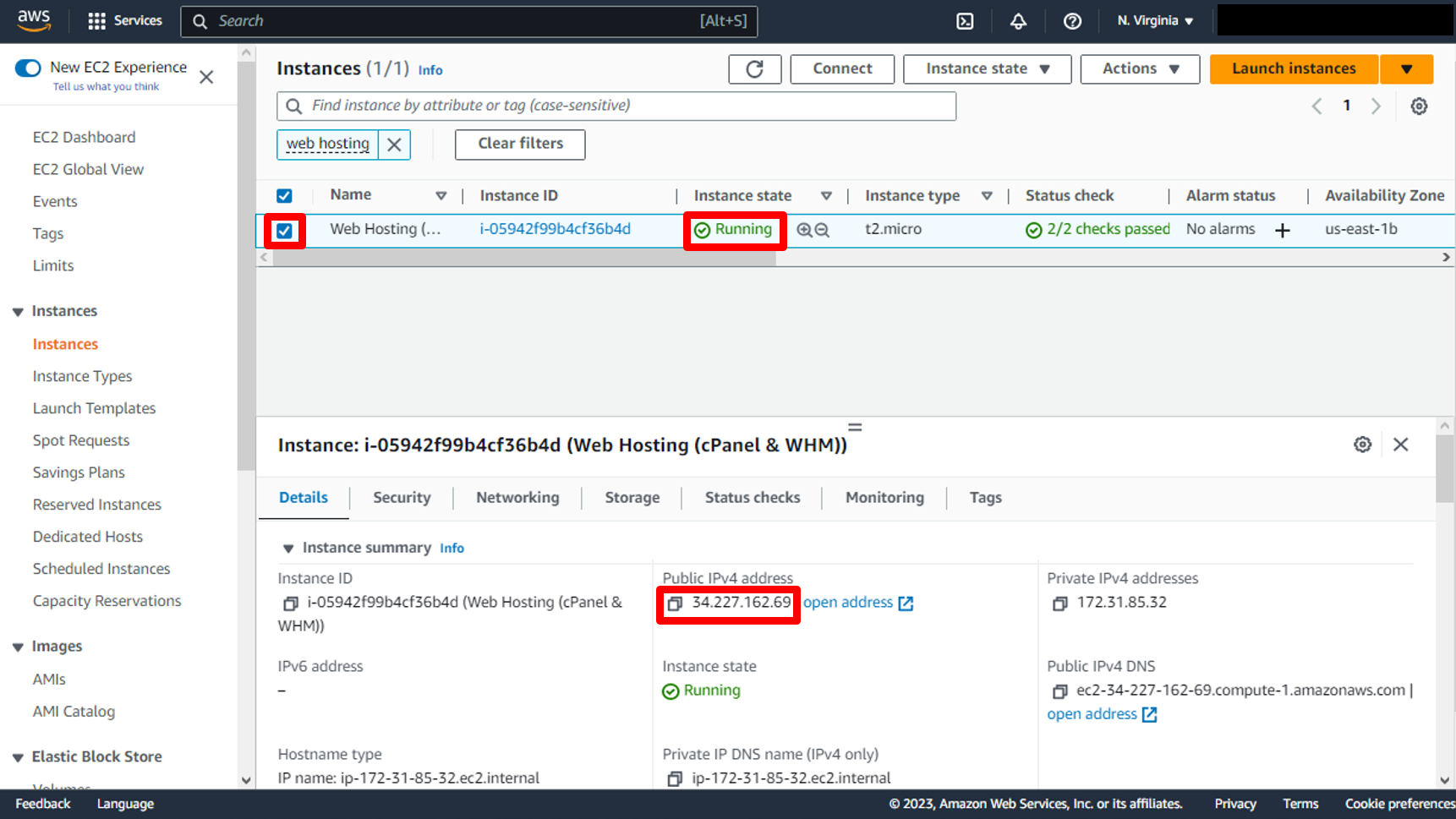
c. You have successfully launched your EC2 instance and You can get Public IP.
### SSH into your EC2 instance to know login information
You will use SSH to connect to your EC2 instance and run some commands.
a. Go to the [EC2 instances page](https://console.aws.amazon.com/ec2/v2/home#Instances) in the console. You should see the EC2 instance you created for the WordPress installation. Select it and you will see the Public IPv4 address and the Public IPv4 DNS in the instance description.
Click on **Copy** icon to copy public ip
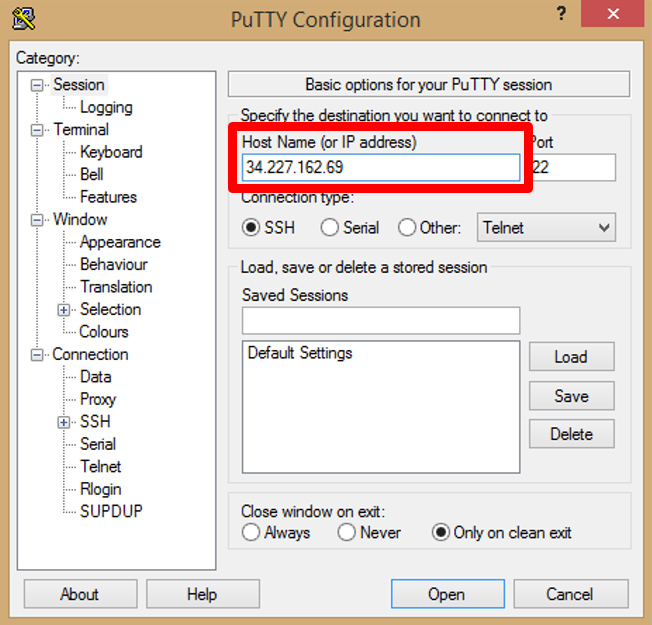
b. Open [PuTTY](https://www.putty.org/) appliction and paste public ip in _Host Name (or IP address)_.
c. Click on **+** the one next to SSH in Category list.
d. Then click on **Auth**.
e. In Private Key file for authentication, Click on **Browse**
Previously, you downloaded the .ppk file for the key pair of your instance. Locate that file now. It will likely be in a Downloads folder on your desktop.
open this .ppk file
f. Click on **Open**.
### Configuration for CentOS to install cPanel & WHM
a. You should see the following in your terminal to indicate that you connected successfully.
then you will log in with **centos** (centos is deafult).
b. Enter this command to change password
```
sudo passwd
```
c. Enter this command to be root user
```
su root
```
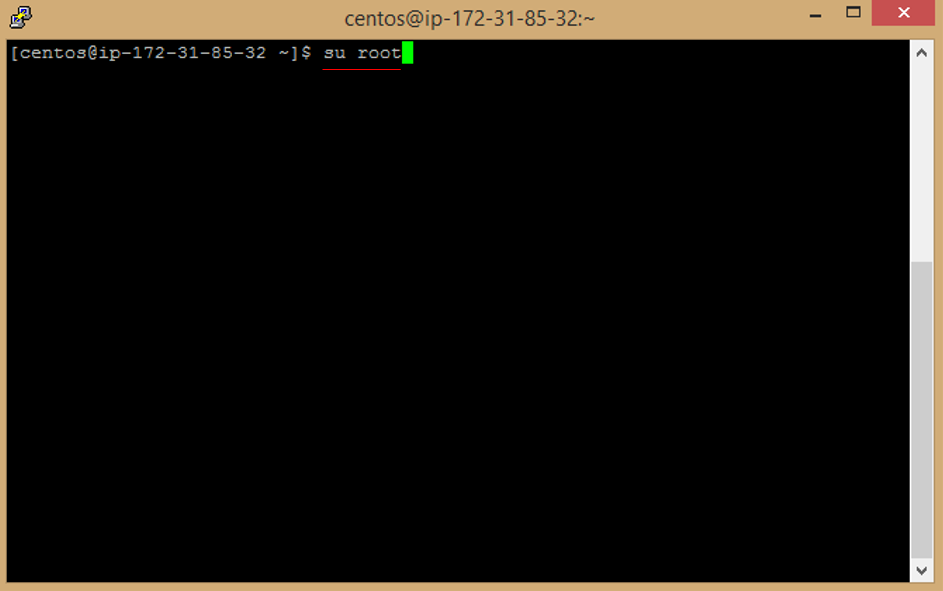
d. Enter Password to be root user (Password you added a while ago in a sudo passwd step).
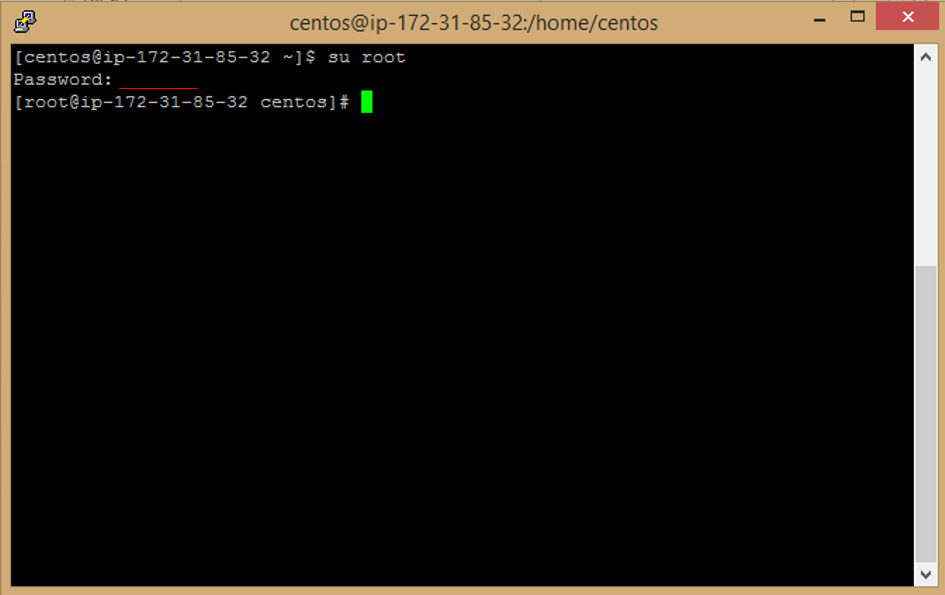
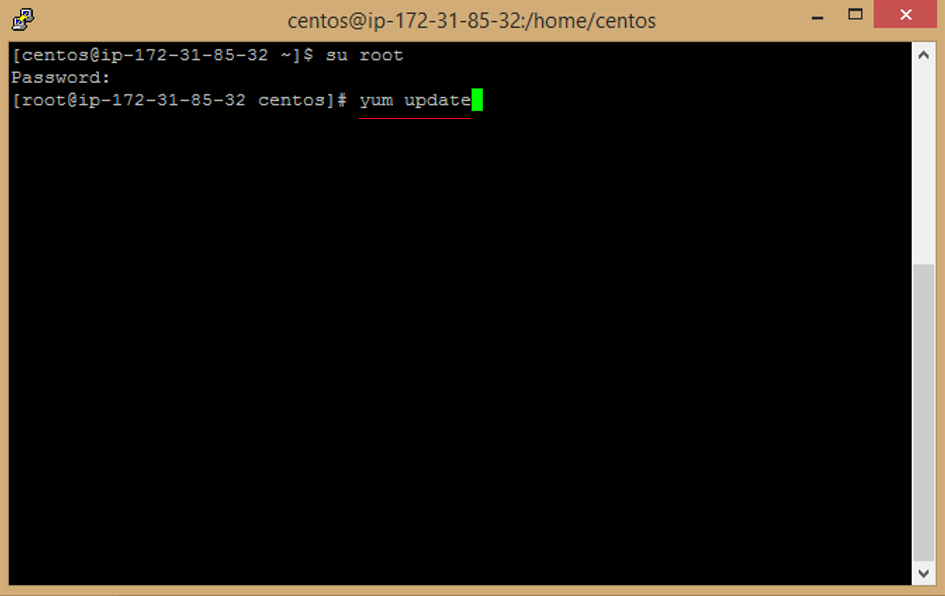
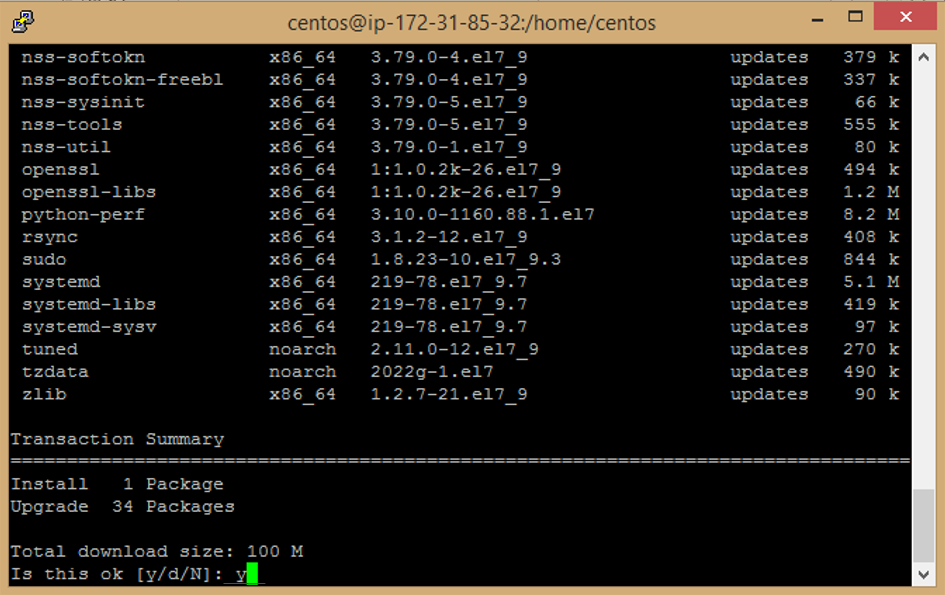
e. Enter this command to update image
```
yum update
```
f. Enter **y** to accept download Package.
g. Enter this command to install perl package
```
yum install perl
```
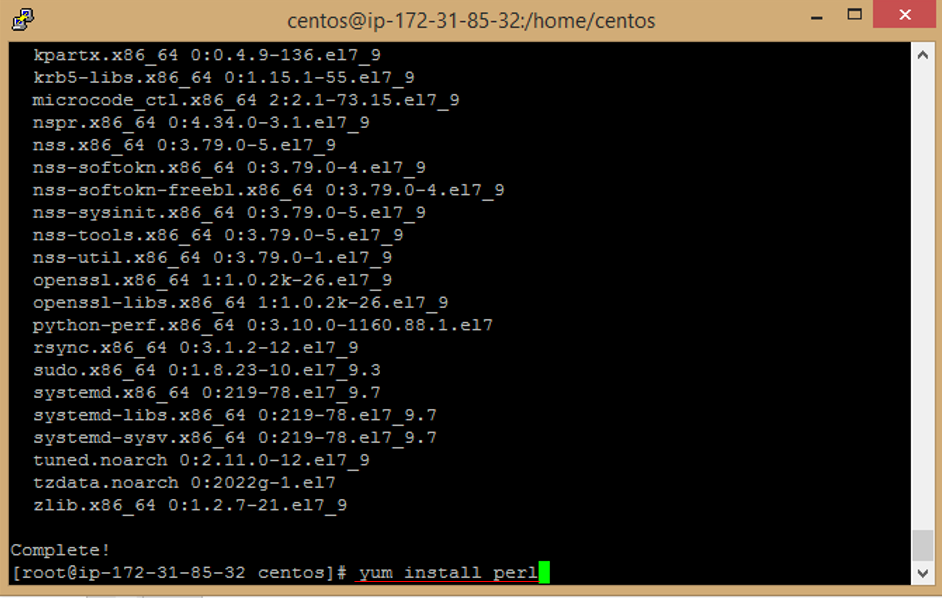
h. Enter **y** to accept download Package.
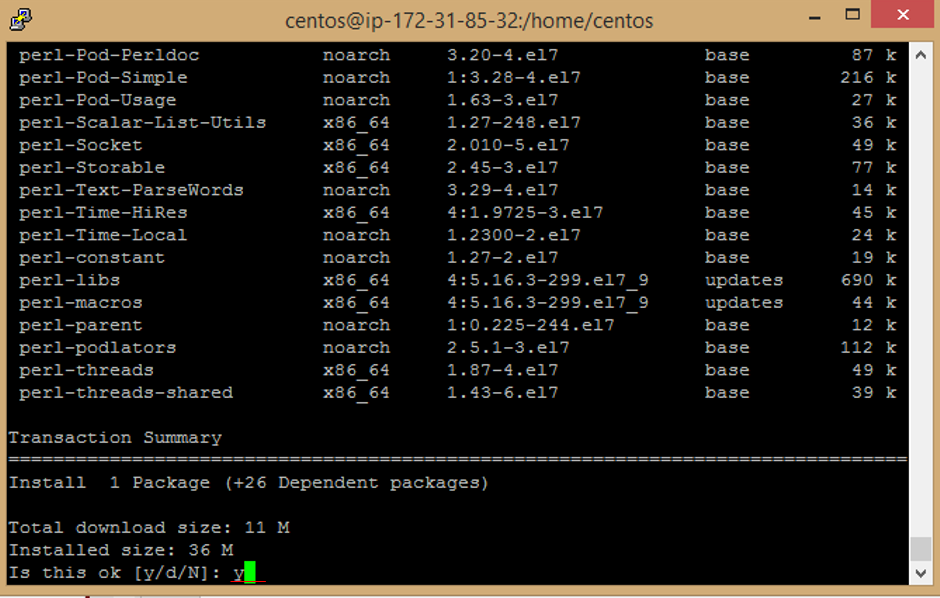
i. Enter this command to install wget package
```
yum install wget
```
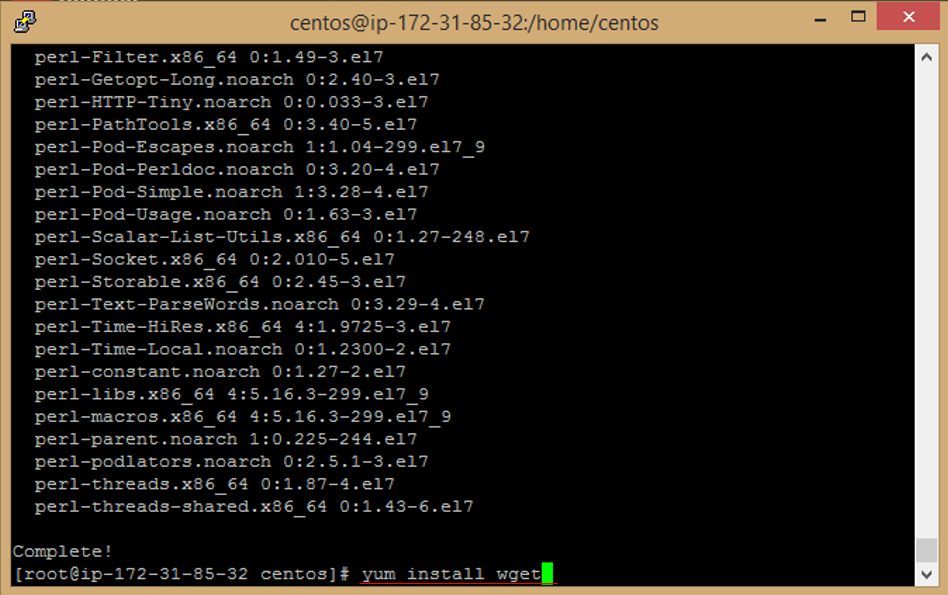
j. Enter **y** to accept download Package.
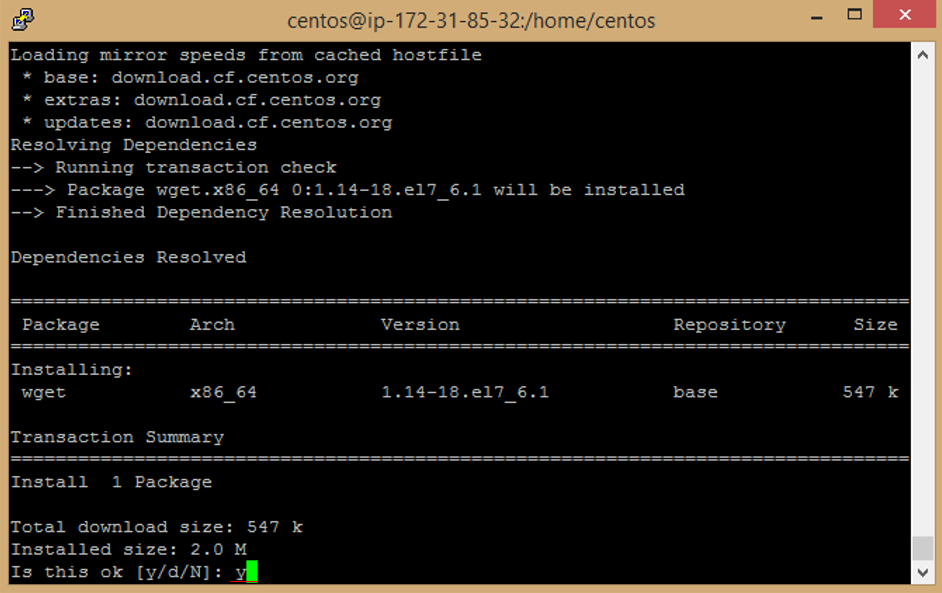
k. Enter this command to install nano package
```
yum install nano
```
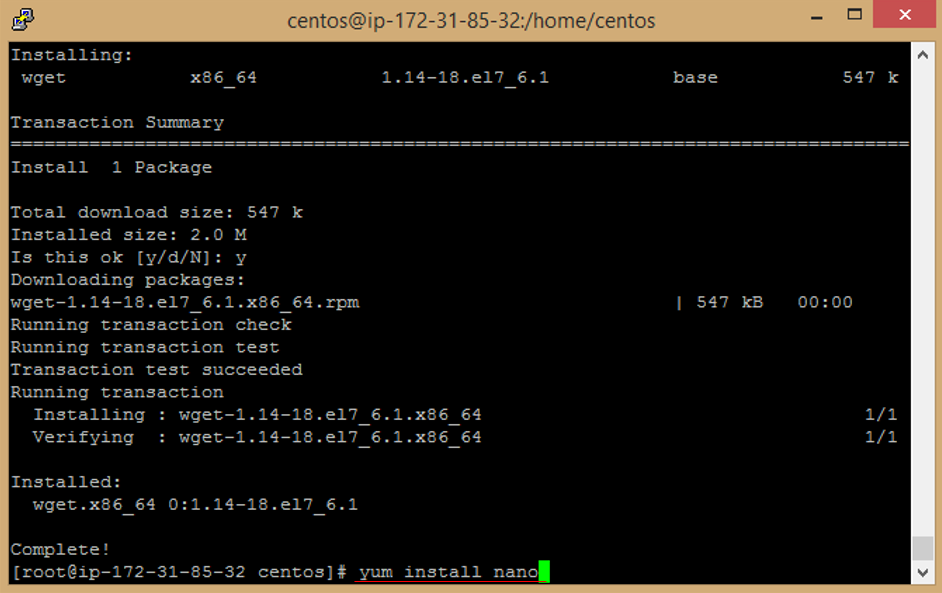
l. Enter **y** to accept download Package.
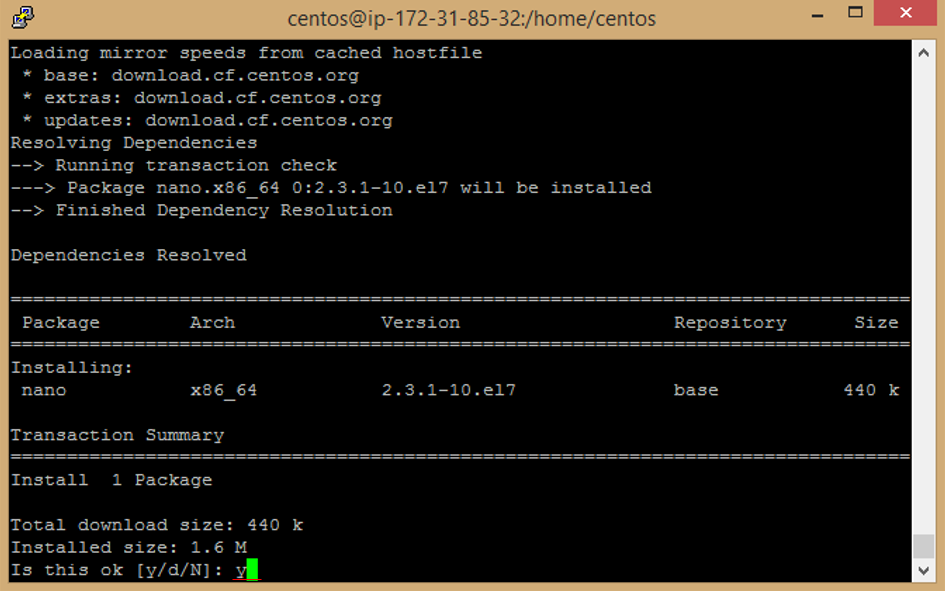
m. set the hostname with your domain name. Replace yourdomainname.com with your domain name.
```
hostnamectl set-hostname cpanel.yourdomainname.com
```
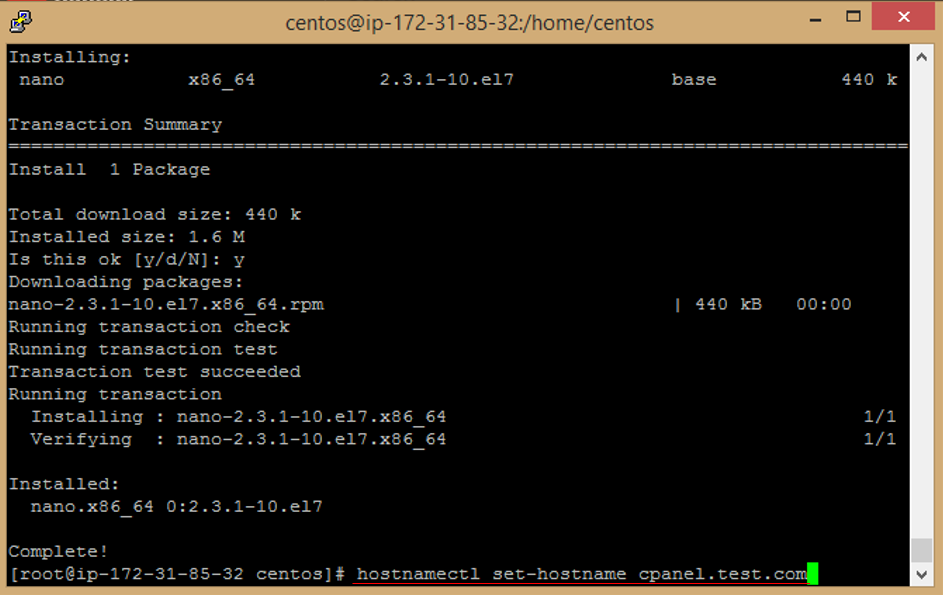
n. Download the latest installation script from cPanel's website by running the following command
```
curl -o latest -L https://securedownloads.cpanel.net/latest
```
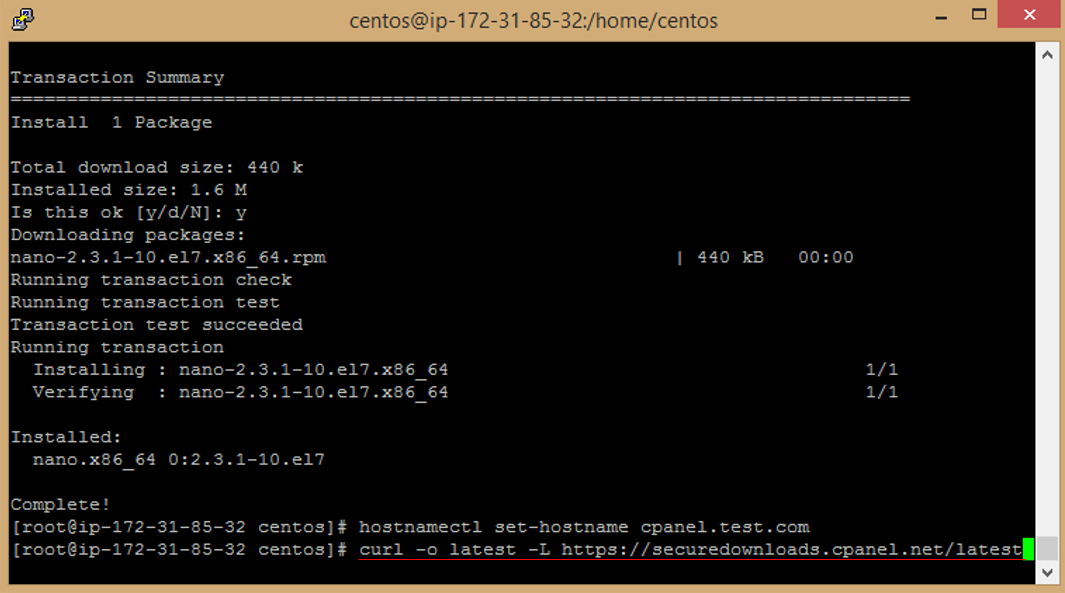
o. Once you have downloaded the installation script, run the following command to start the installation process
```
sh latest
```
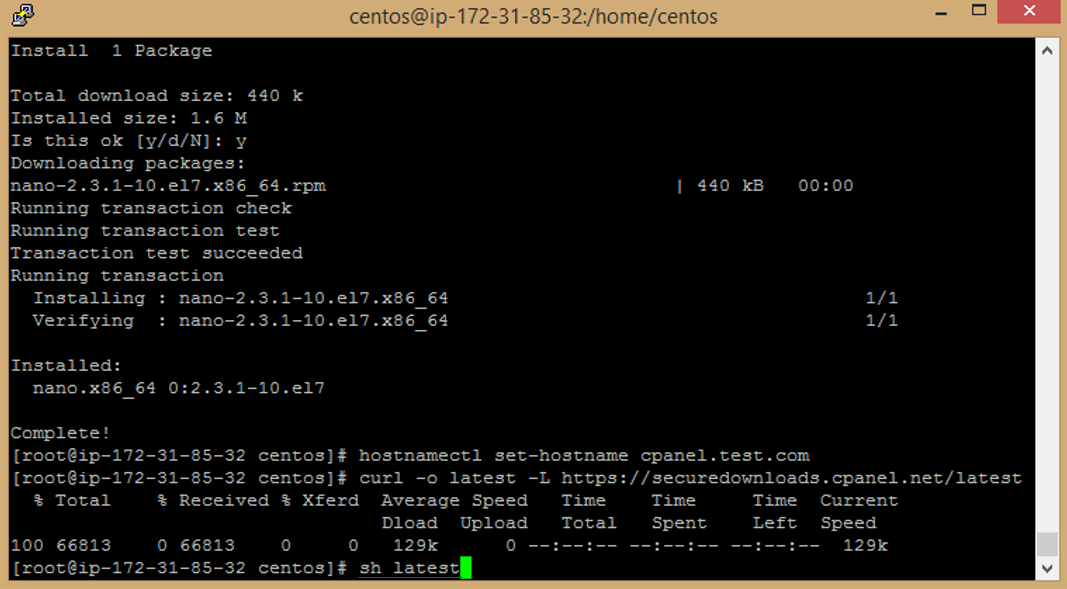
p. The installation process will now begin. Follow the on-screen instructions to complete the installation.
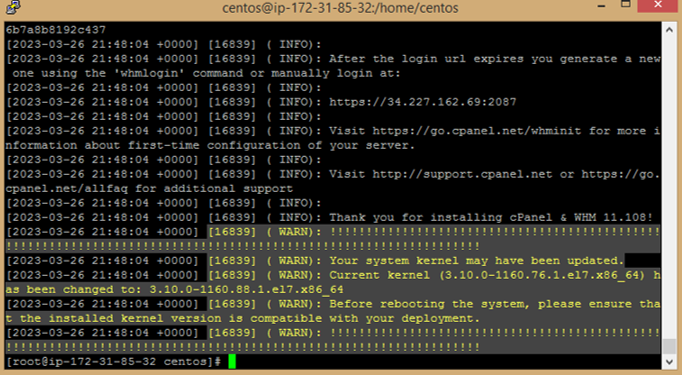
q. Make reboot for server, run the following command
```
reboot
```
### WHM & cPanel setup
a. back to **EC2 Instance Dashboard** and **select** EC2 then **Copy** Public Ip.
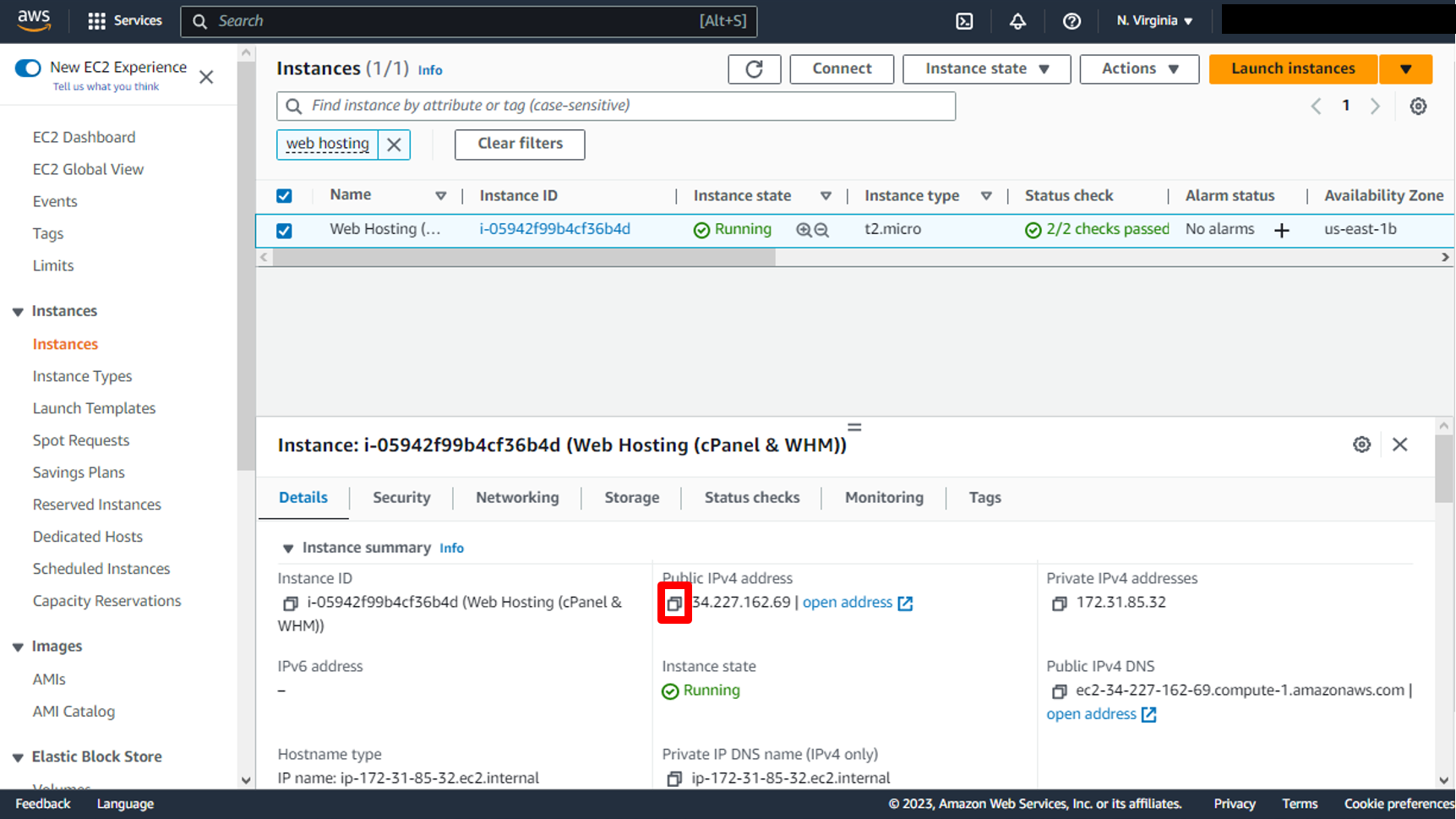
b. Once the installation is complete, you can access the WHM interface by visiting https://your-server-public-ip:2087 in your web browser then click on **Advanced**
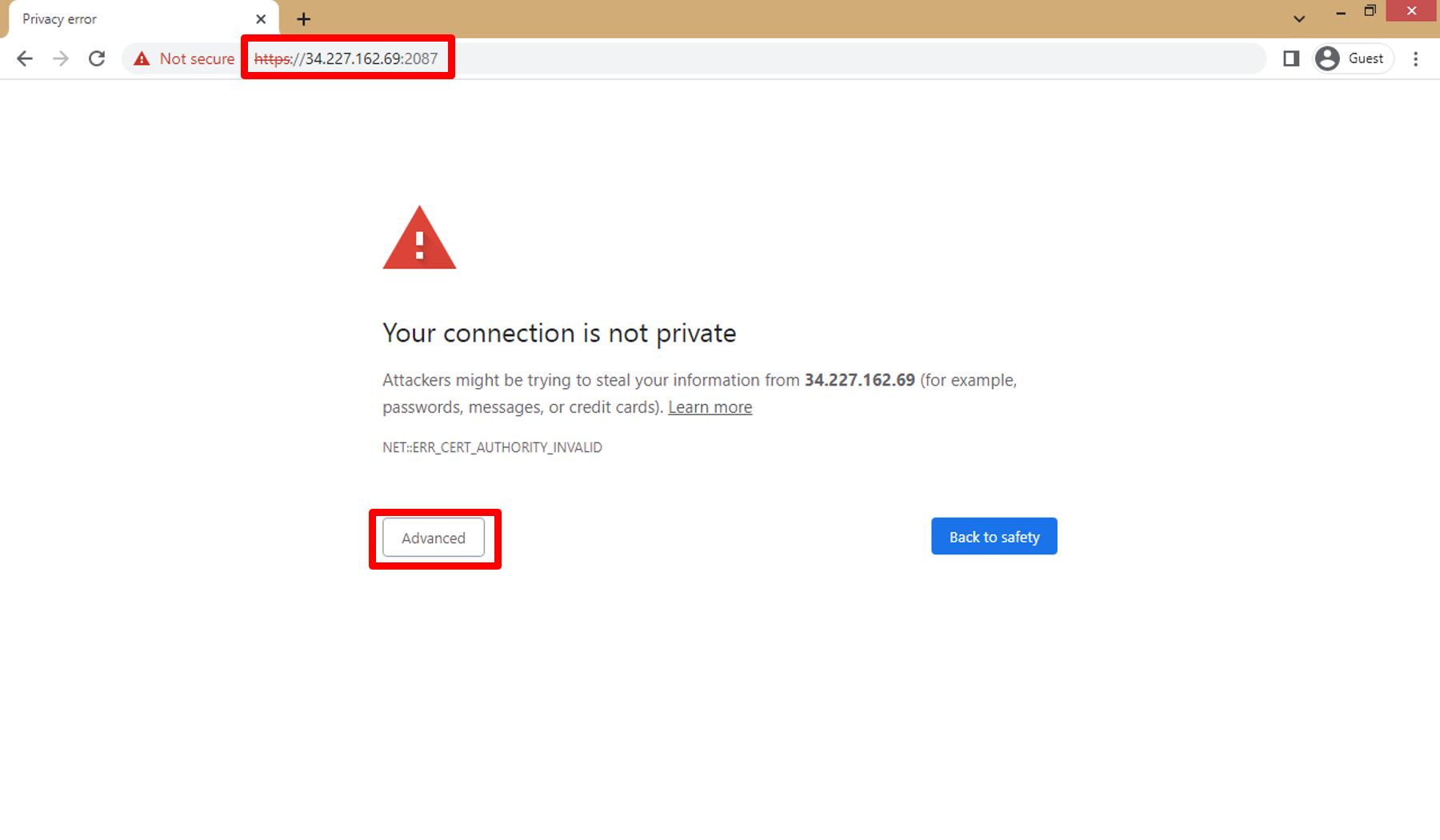
c. Click on **Proceed to ... (unsafe)**
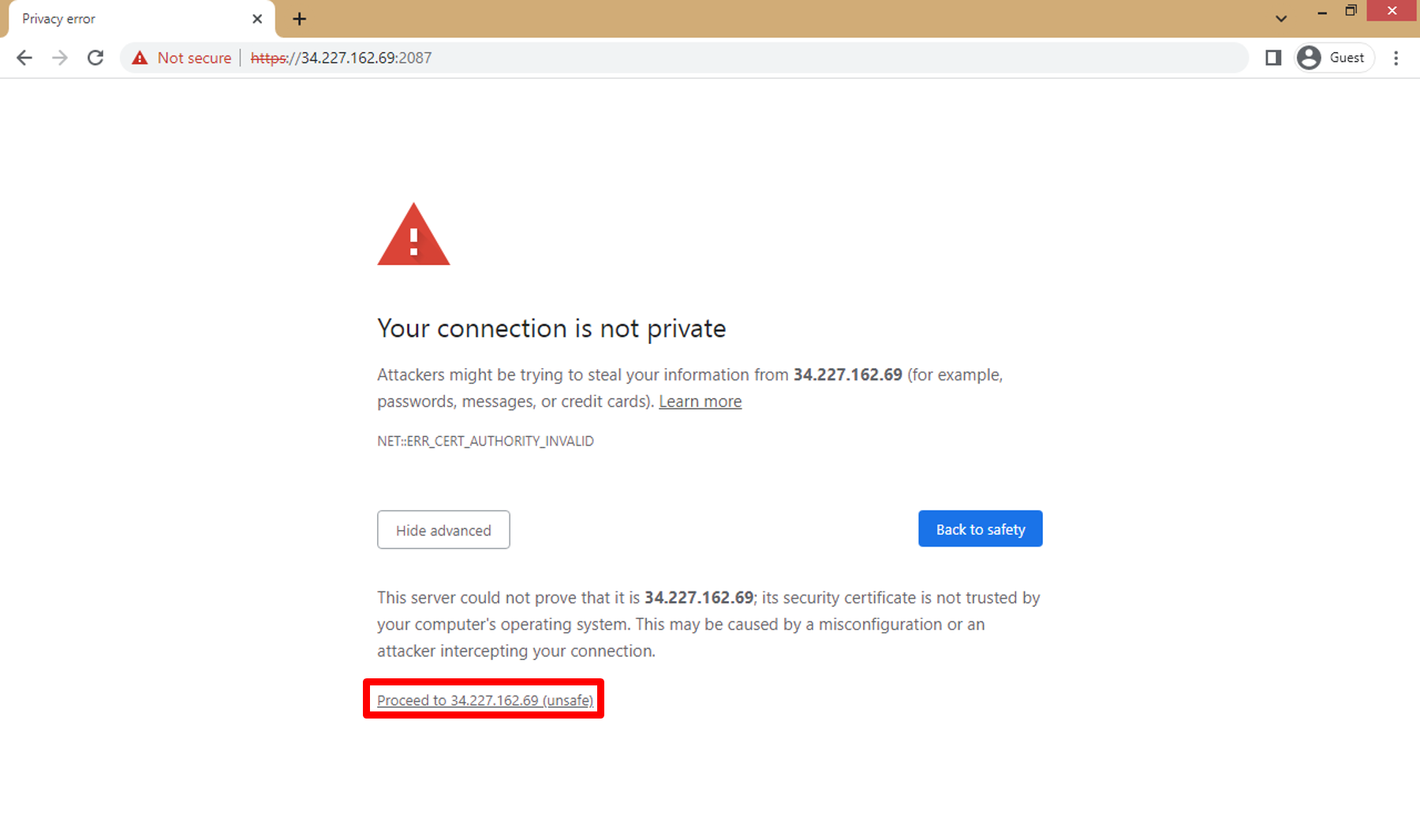
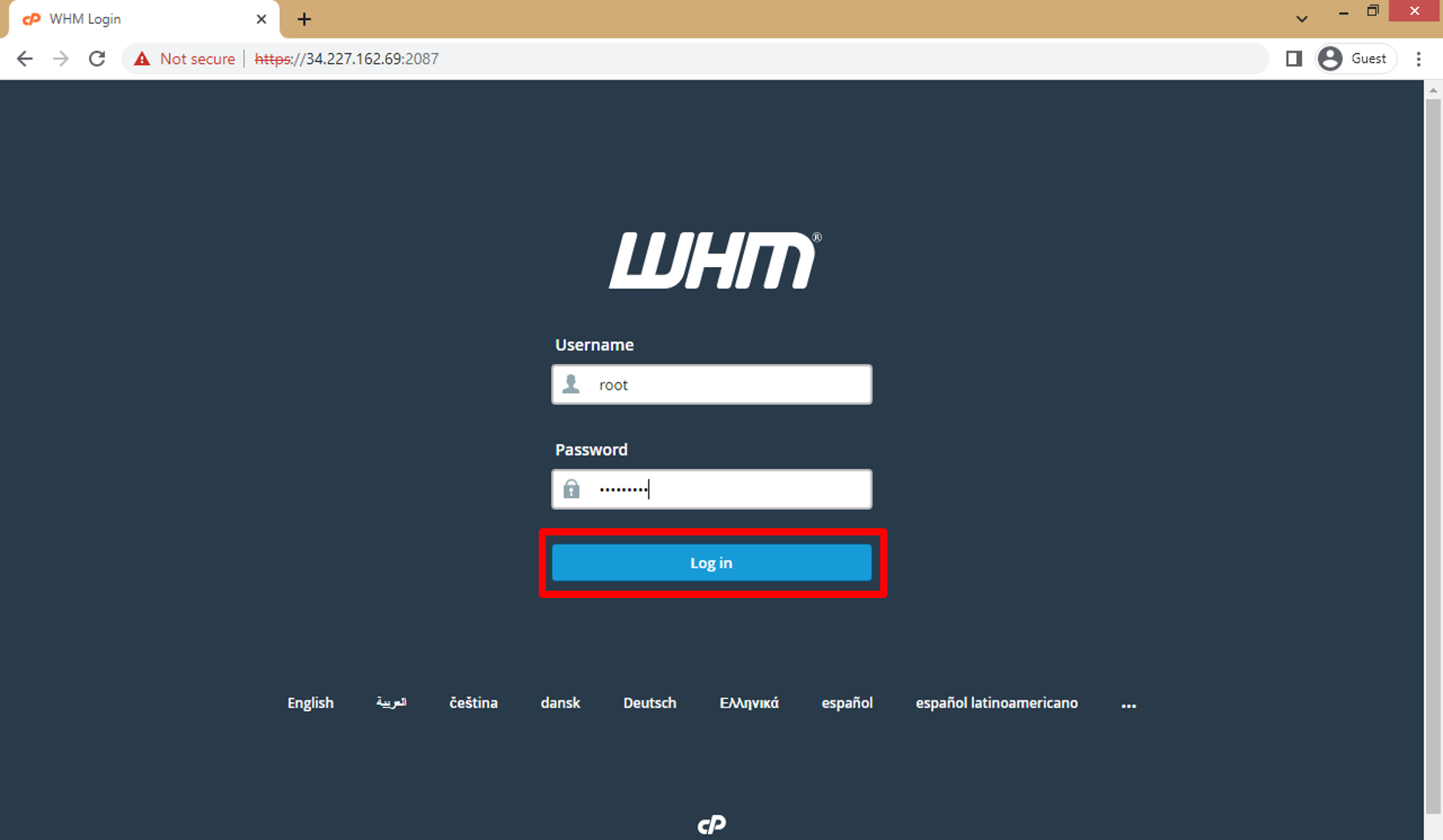
d. WHM Login Page Open.
On the WHM login page, enter the "root" username and the password you set during the instance launch process then click on **Login**.
e. Click on **Agree to All**.

f. Click on **Log in** to log in to cpanel store.

g. Click on **Create an Account**.
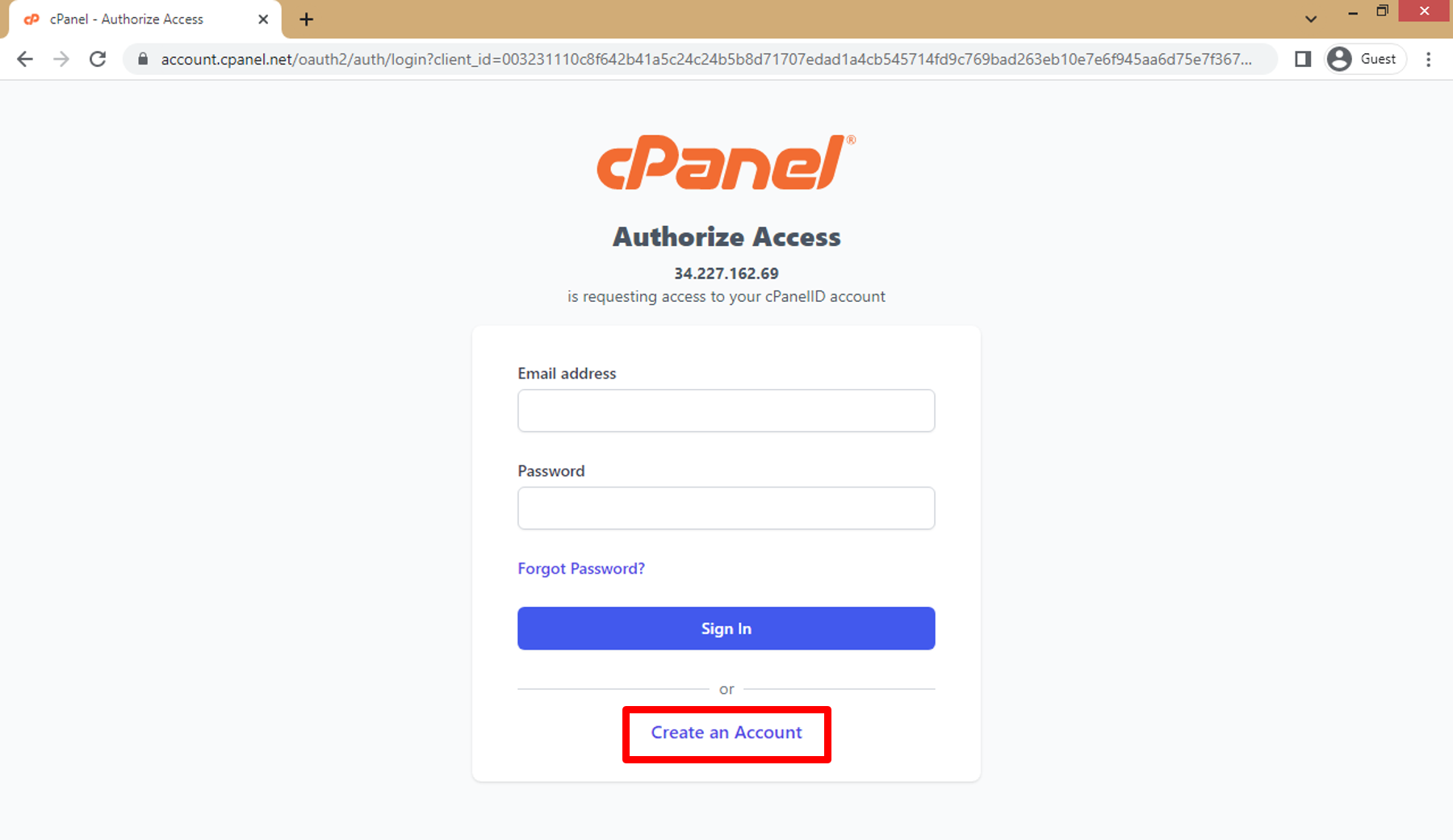
h. Enter **email address** then click on **the approval box** (I agree ...) then click on **Create Account**.
i. Click on **Allow Access**.
j. After recieve verification code on email copy it and enter it in WHM then click on **Verify My Email**.
k. Click on **Server Setup**.

l. Here you can add Nameservers and setup domain or click on **Skip** and edit in it later.

m. Now you will be taken to the WHM home page.
n. In Search Tools write **Create** and click on **Enter** to make Search then click on **Create a New Account** to use it to open Cpanel Login.
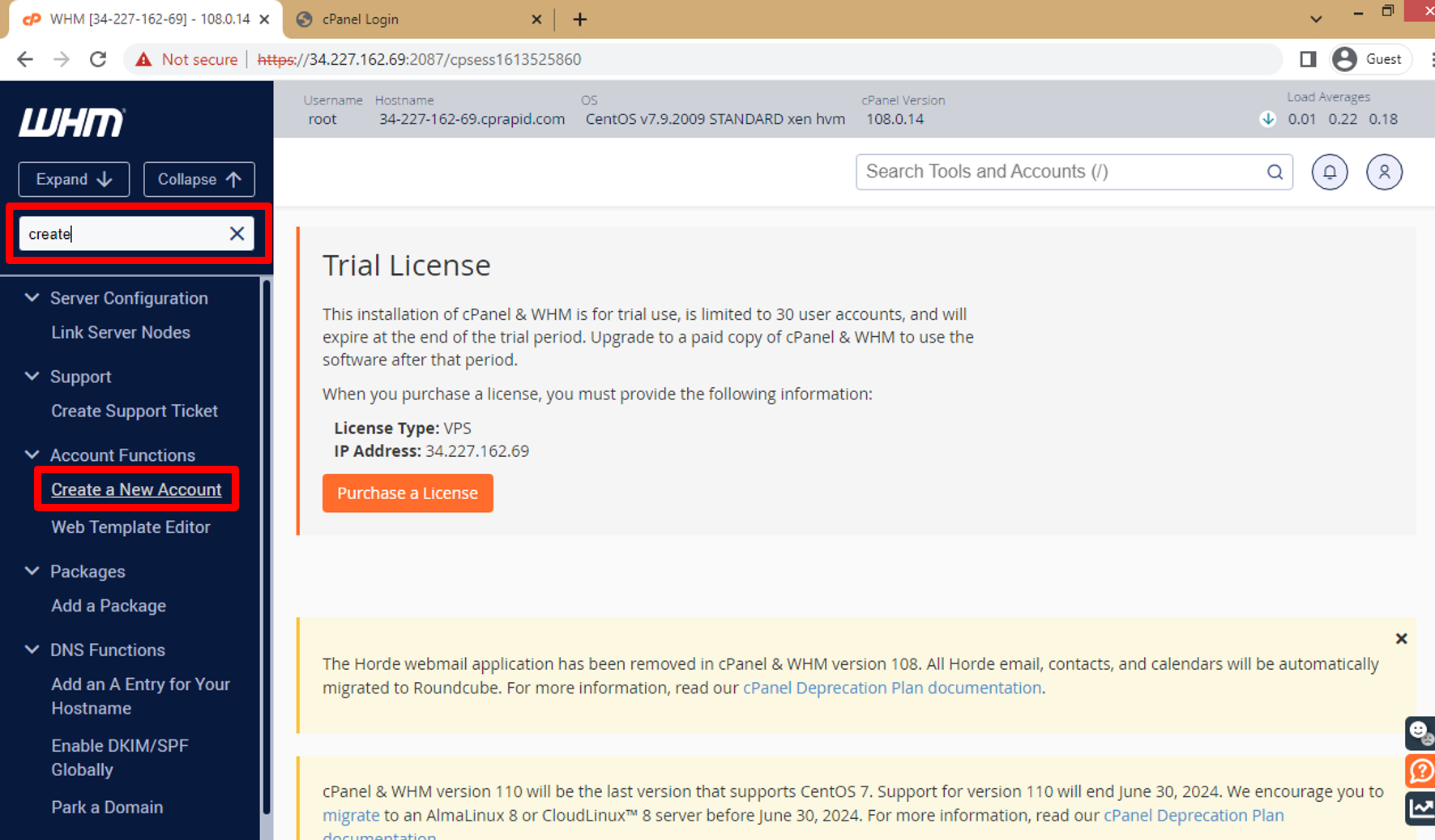
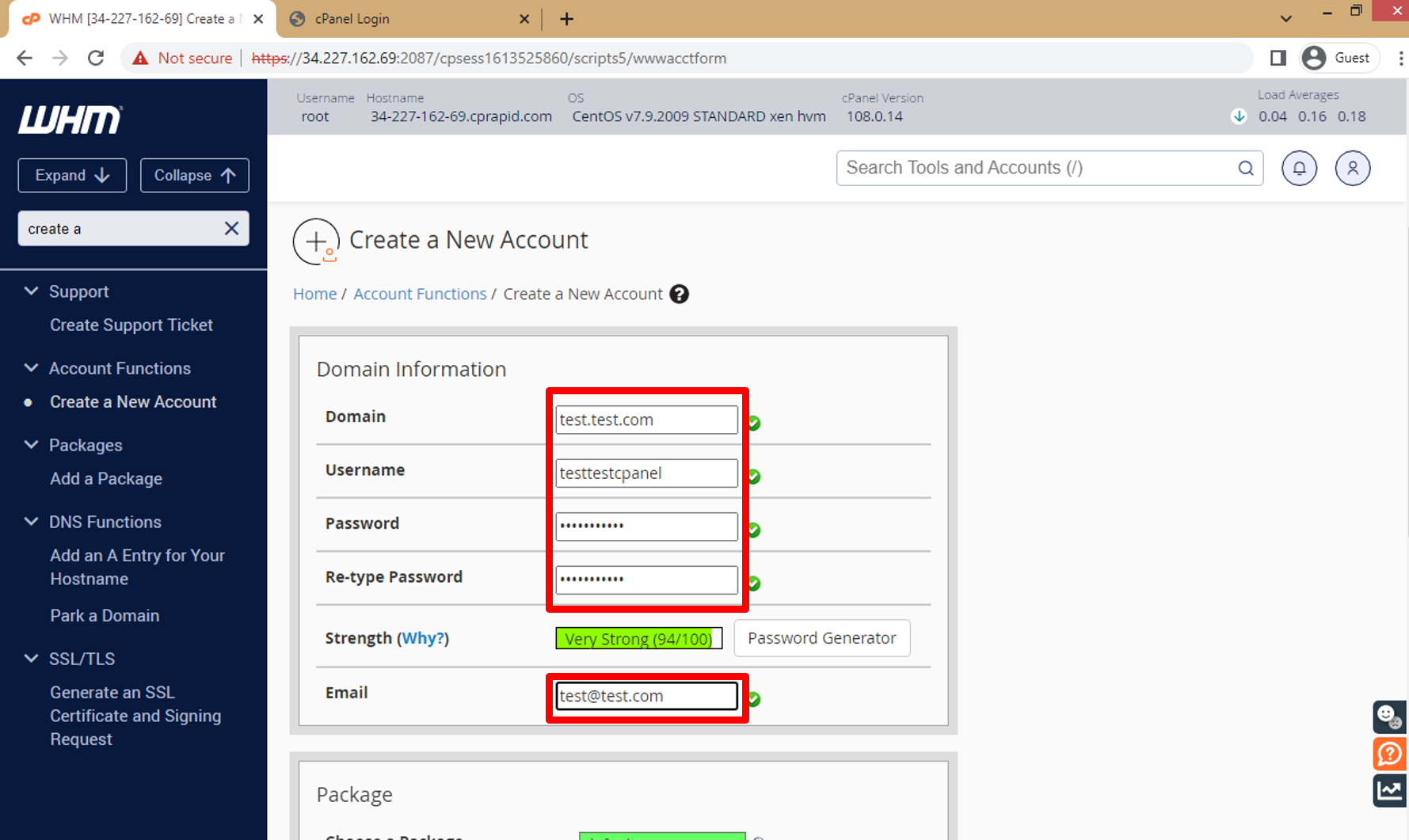
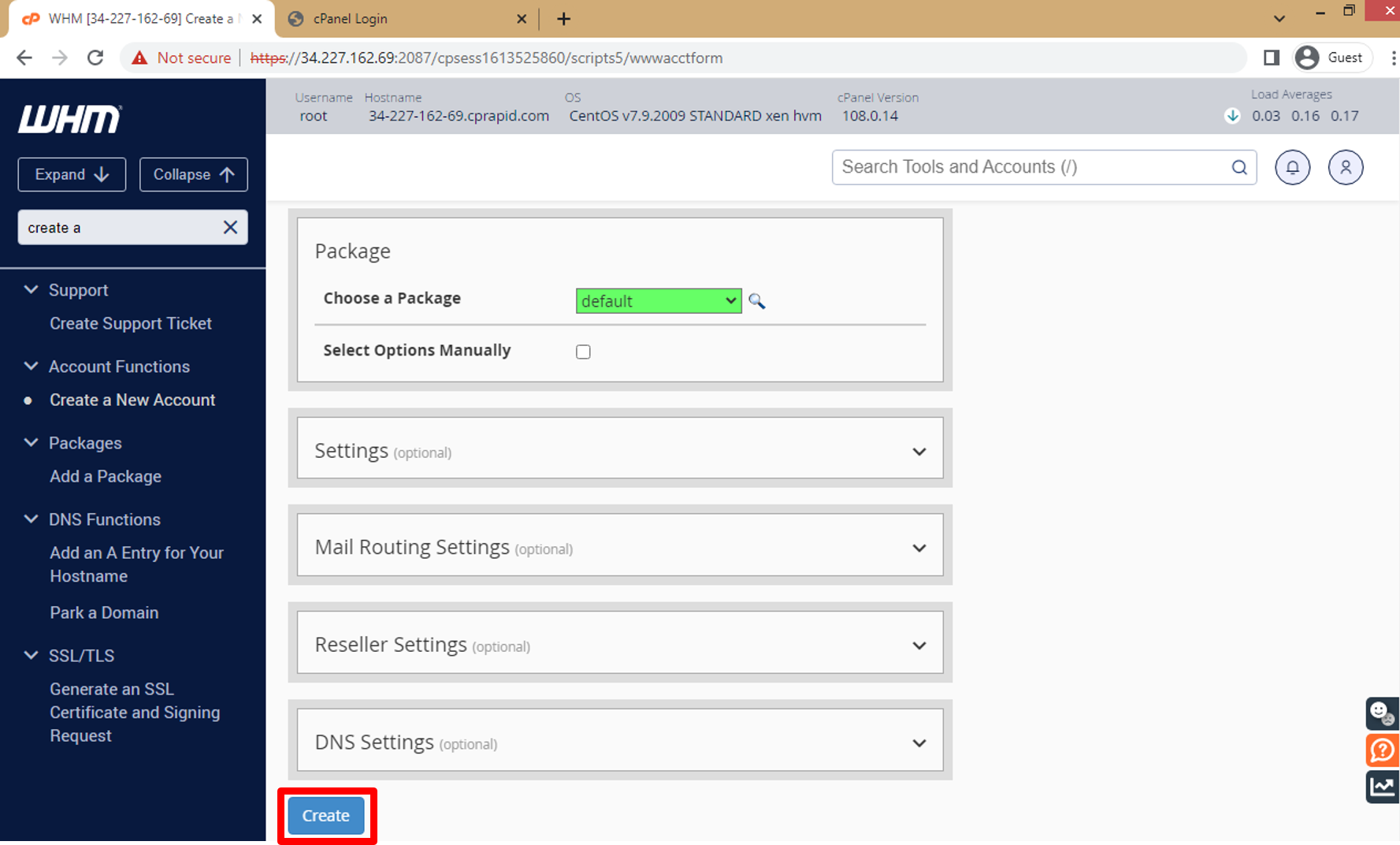
o. Enter all data about account you need to create then click on **Create** and this data will use to Log in Cpanel dashboard.
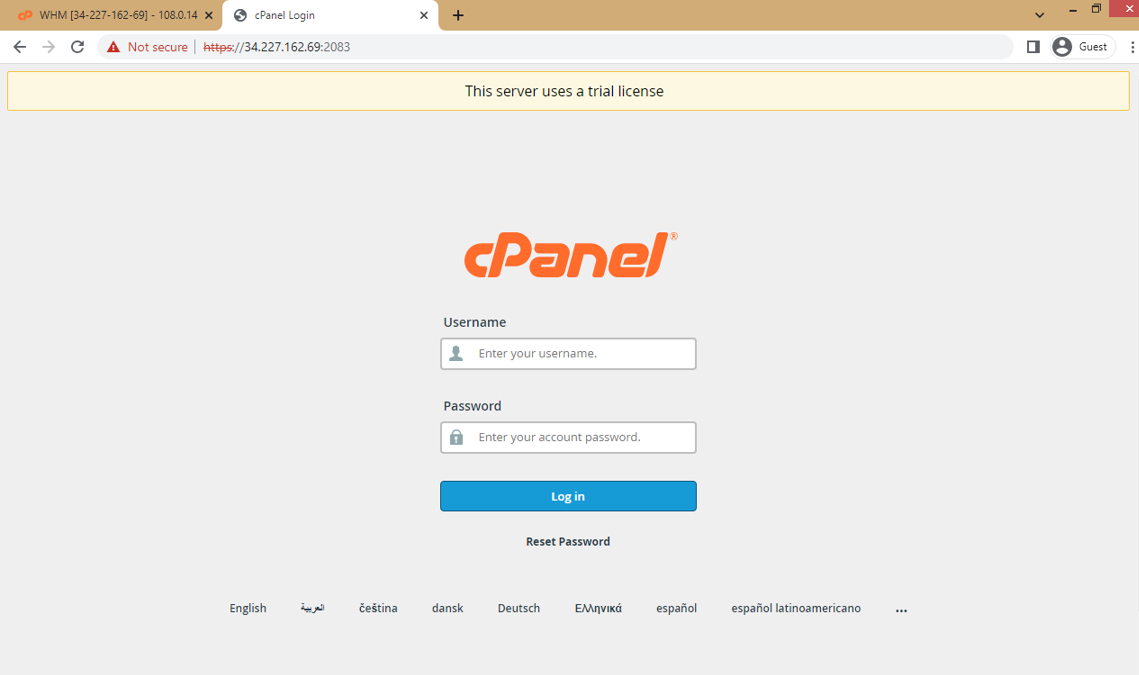
p. Now you can access the cPanel interface by visiting https://your-server-public-ip:2083 and enter username and password to login.
That's it! You now have cPanel & WHM installed on your AWS EC2 instance. From here, you can manage your server, create hosting accounts, and more. | fady_nabil10 |
1,417,113 | 26- A Guide to Creating QGIS Plugins in a Step-by-Step Manner | If you're looking to create QGIS plugins, then you've come to the right place! In this step-by-step... | 22,345 | 2023-03-27T23:01:37 | https://dev.to/azad77/26-a-guide-to-creating-qgis-plugins-in-a-step-by-step-manner-2gkg | programming, python, pyqgis | --- series: A beginner's guide to using Python with QGIS ---
If you're looking to create QGIS plugins, then you've come to the right place! In this step-by-step guide, we'll show you how to create your own plugin by creating essential files such as metadata.txt and [mainPlugin.py](http://mainPlugin.py), as well as how to use Python to create the [**init**.py](http://init.py) file. We'll also walk you through how to install your plugin and provide a tip on using the Plugin Builder to create a template for your plugin. Follow these instructions to create your own QGIS plugin and take your GIS analysis to the next level!
The first requirement for plugins is metadata.txt.
Use a text editor to create a metadata file:
```plaintext
[general]
name=TestPlugin
email=azad.rasul@soran.edu.iq
author=Azad Rasul
qgisMinimumVersion=3.0
description=This is an example plugin for greeting the world.
version=version 0.1
```
Save it as a "metadata" text document.
The second file is called "\_\_init\_\_.py" which includes the classFactory() method.
You can use Python to create a "\_\_**init\_\_**.py" file
```python
from .mainPlugin import TestPlugin
def classFactory(iface):
return TestPlugin(iface)
```
The third necessary file contains the main logic of the plugin. It must have initGui(), unload() and run() methods. We name it "[mainPlugin.py](http://mainPlugin.py)" file that includes:
```python
import os
import inspect
from PyQt5.QtWidgets import QAction
from PyQt5.QtGui import QIcon
# get the directory containing this script
cmd_folder = os.path.split(inspect.getfile(inspect.currentframe()))[0]
# define the TestPlugin class
class TestPlugin:
def __init__(self, iface):
self.iface = iface
# initialize the plugin interface
def initGui(self):
# get the path to the plugin icon
icon = os.path.join(os.path.join(cmd_folder, 'logo.png'))
# create a new QAction with the plugin icon and label
self.action = QAction(QIcon(icon), 'TestPlugin', self.iface.mainWindow())
# connect the action to the run() method
self.action.triggered.connect(self.run)
# add the action to the toolbar and menu
self.iface.addToolBarIcon(self.action)
self.iface.addPluginToMenu("&TestPlugin", self.action)
# unload the plugin
def unload(self):
# remove the action from the toolbar and menu
self.iface.removePluginMenu("&TestPlugin", self.action)
self.iface.removeToolBarIcon(self.action)
# delete the action object
del self.action
# run the plugin
def run(self):
# display a message in the QGIS message bar
self.iface.messageBar().pushMessage('Hello from TestPlugin!')
```
Save these three files and a logo in one folder and name it "TestPlugin" or the name of the plugin.
Then, copy the "TestPlugin" folder and paste it into QGIS 3 Plugins directory. On Windows, it is typically located at:
C:\\Users\\username\\AppData\\Roaming\\QGIS\\QGIS3\\profiles\\default\\python\\plugins
Restart QGIS software, and you will be able to see your "TestPlugin" plugin in the list of installed plugins. By clicking on the TestPlugin icon, you can view the "Hello from TestPlugin!" text.
Alternatively, you can use the "Plugin Builder" to create a template plugin and then modify it to suit your needs.
In conclusion, creating QGIS plugins may seem daunting, but this step-by-step guide can help anyone create their customized plugin. By following the instructions provided, users can create necessary files such as metadata.txt and [mainPlugin.py](http://mainPlugin.py), and use Python to create the [init.py](http://init.py) file. The article also provides a tip on using the Plugin Builder to create a template for the plugin. With the plugin created and installed, users can take their GIS analysis to the next level.
The credit for my tutorials goes to Anita Graser and Ujaval Gandhi.
External resources:
[1- PyQGIS Developer Cookbook](https://docs.qgis.org/3.16/en/docs/pyqgis_developer_cookbook/intro.html#scripting-in-the-python-console)
[2- PyQGIS 101: Introduction to QGIS Python programming for non-programmers](https://anitagraser.com/pyqgis-101-introduction-to-qgis-python-programming-for-non-programmers/)
[3- Customizing QGIS with Python (Full Course Material)](https://courses.spatialthoughts.com/pyqgis-in-a-day.html#hello-world)
[4- PyQGIS samples](https://webgeodatavore.github.io/pyqgis-samples/)
> If you like the content, please [SUBSCRIBE](https://www.youtube.com/channel/UCpbWlHEqBSnJb6i4UemXQpA?sub_confirmation=1) to my channel for the future content
| azad77 |
1,417,114 | Avoid this common mistakes when building a websites | When building a website, there are a lot of things that you need to think about. A developer or a web... | 0 | 2023-03-27T23:06:34 | https://dev.to/jenueldev/avoid-this-common-mistakes-when-building-a-websites-1plk | webdev, javascript, beginners, programming | When building a website, there are a lot of things that you need to think about. A developer or a web designer or a web developer should know this and must avoid it at all costs. If not check carefully, your work will be going to fail.
[Read More](https://brojenuel.com/blog/Avoid-this-common-mistakes-when-building-a-websites) | jenueldev |
1,417,151 | WordPress plugin updates shows -1 | Problem We had an issue with a WordPress website, which wouldn't allow us to update or... | 0 | 2023-03-27T23:53:24 | https://dev.to/edwardanil/wordpress-plugin-updates-shows-1-1j97 | wordpress, bugfixing, solution, programming | ## Problem
We had an issue with a WordPress website, which wouldn't allow us to update or install any plugins.
When we try updating a plugin, the page would show just "**-1**".
Even adding a new plugin would show a "-1" error.
There wouldn't be any error messages or clue on what went wrong.
Even enabling debugging the WordPress site did not provide any clue on what caused this issue.
If you check the developer console of the browser, it would show that the "**wp-admin/admin-ajax.php**" throws a "[403 error](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/403)".
And the problem is that WordPress would create a ".maintenance" file when you update the plugin. Now the site would go to Maintenance mode and will not be available, unless you manually delete the ".maintenance" file via FTP.
## Details
The WordPress website had many plugins. And it had the following plugins installed in it:
- Autoptimize
- Elementor
- Page Builder by SiteOrigin
- Really Simple SSL
- Starter Templates (from Astra)
- Sucuri Security - Auditing, Malware Scanner and Hardening
- Super Page Cache for Cloudflare
- Wordfence Security
And the domain was using Cloudflare to make the site load faster and use the security feature provided by it.
The site was hosted in Ionos Web hosting package.
## Steps that did NOT work
- Tried to find out the issue by bypassing Cloudflare. It did not work.
- Tried to stop the caching on the site and Cloudflare. It did not solve the problem.
- Tried deactivating the security plugins. It did not solve the problem.
- Tried removing "Really Simple SSL" plugin security options. Still the problem persisted.
## Solution
We were on the verge of moving the site to another hosting provider, as we could not find the source of this issue. And the hosting support could not find anything wrong with their servers or system.
And then finally, I came upon this solution on WordPress support forum.
[https://wordpress.org/support/topic/plugin-updates-shows-1/](https://wordpress.org/support/topic/plugin-updates-shows-1/)
It stated that the issue is with **[Starter Templates](https://wpastra.com/starter-templates/)** (from Astra).
I just deactivated that plugin and the updates of other plugins worked smoothly.
And later on, I updated the **Starter Templates** plugin to the latest version.
If you face this kind of issue in the future, please check if you have installed **Starter Templates**. Just deactivate it and work on the other updates.
| edwardanil |
1,417,173 | Wrote a program to select a restaurant in python | Did this for a codecademy project, select from a group of restaurants based on type, name, rating,... | 0 | 2023-03-28T01:01:30 | https://dev.to/austinharry777/wrote-a-program-to-select-a-restaurant-in-python-1l13 | Did this for a codecademy project, select from a group of restaurants based on type, name, rating, price, or location!
https://github.com/austinharry777/restaurant_recommendation_project | austinharry777 | |
1,417,214 | Kubernetes Labels, Selectors, and Annocation | Annotations, labels, and selectors are used to manage metadata attached to your Kubernetes objects.... | 0 | 2023-03-28T02:59:28 | https://dev.to/s3cloudhub/kubernetes-labels-selectors-and-annocation-dno | webdev, beginners, tutorial, kubernetes | [](http://www.youtube.com/watch?v=XabYkFhKtnE)
Annotations, labels, and selectors are used to manage metadata attached to your Kubernetes objects. Annotations and labels define the data while selectors provide a way to query it. Here are the differences between the three concepts, what they’re designed for, and how you can use them to manage your resources. Annotations | s3cloudhub |
1,417,384 | Imported Italian Artichokes | Are you looking for good Italian restaurants? DC PIE CO believes in serving only the most delicious... | 0 | 2023-03-28T06:52:21 | https://dev.to/dc_pie_co/imported-italian-artichokes-4lgd | Are you looking for good Italian restaurants? DC PIE CO believes in serving only the most delicious food that will have you coming back for seconds! All of our food is made with the freshest ingredients. Our experienced chefs make the best **[Imported Italian Artichokes](https://www.dcpieco.com/menu)**. We only serve the most delicious, freshly made food, and our personal Brooklyn brick oven pie is to absolutely die for! | dc_pie_co | |
1,417,392 | 6 ChatGPT Enhanced Database Tools to Make Your Life Easier | ChatGPT has only been around for less than half a year and we already cannot live without it. We were... | 0 | 2023-03-28T07:08:27 | https://dev.to/bytebase/a-non-exhaustive-summary-of-chatgpt-enhanced-database-tools-1oe5 | chatgpt, ai, database, programming | ChatGPT has only been around for less than half a year and we already cannot live without it. We were wondering if it could help us in the field of database administration, and we dug deep into some toolings that have incorporated ChatGPT to make our life easier.
## sqlTranslate
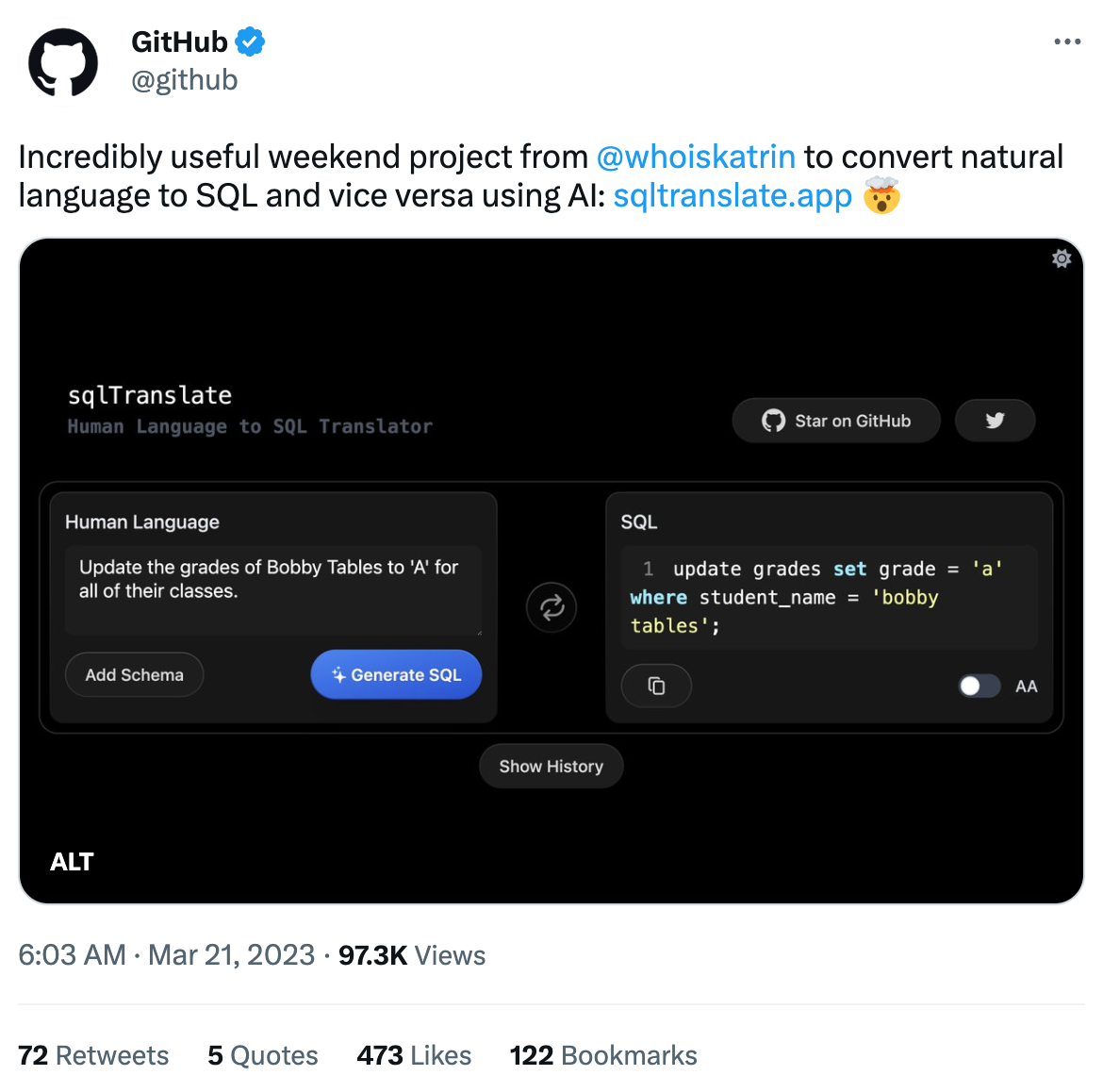
When it comes to databases, the first thing that comes to mind is whether ChatGPT can help us write SQL. [sqlTranslate](https://www.sqltranslate.app/) is a very simple tool that uses the OpenAI API to obtain the corresponding SQL statement by inputting natural language, or vice versa. You can also upload your own schema. Since it open-sourced three weeks ago, it has already gotten 2.6k stars and is [described by GitHub](https://twitter.com/github/status/1637937834865704960/photo/1) as an "incredibly useful weekend project". Looks like people have been suffering from SQL for way too long.
## AI2sql
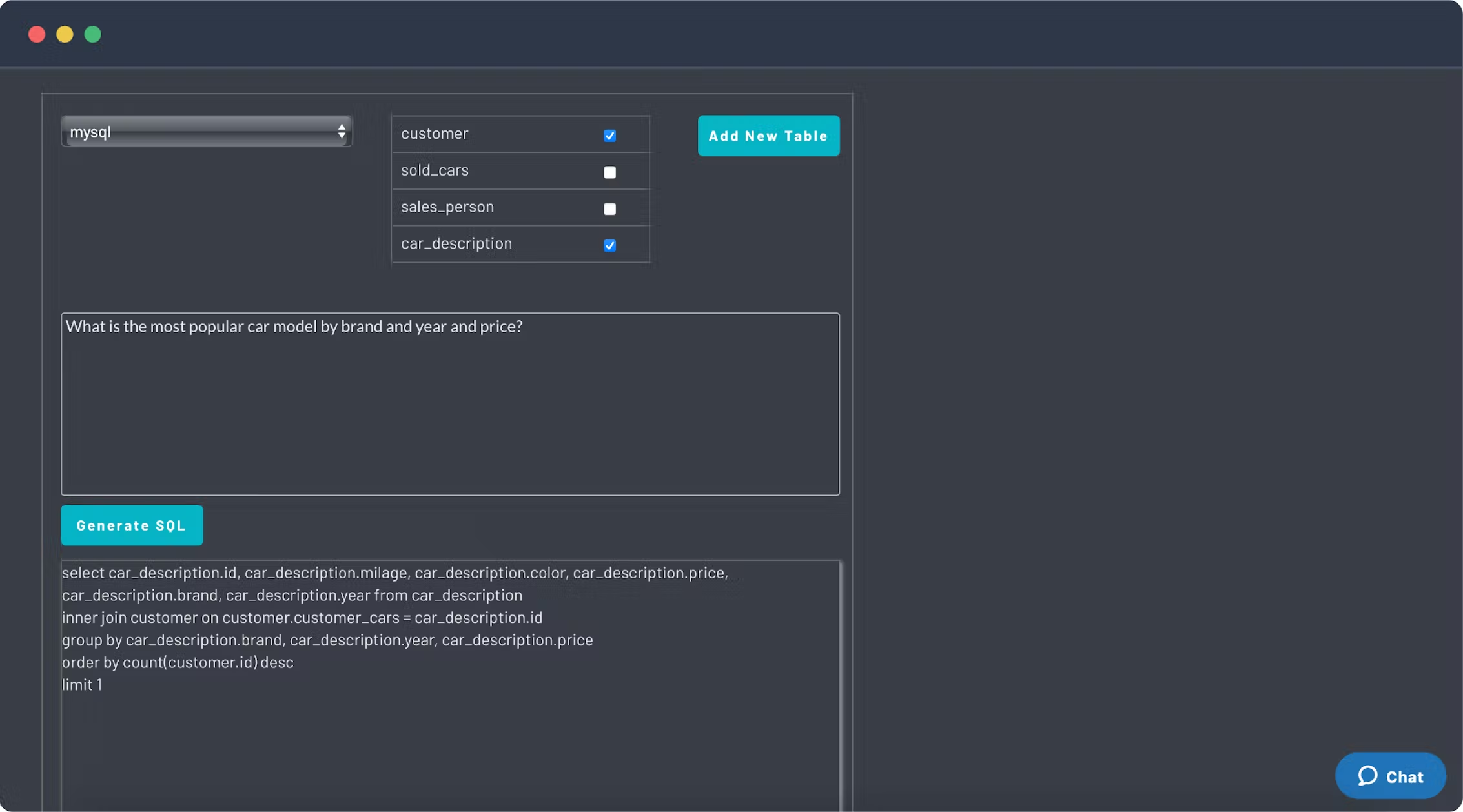
[AI2sql](https://www.ai2sql.io/) is an AI-driven SQL query generator that has been around since 2021, and has recently incorporated OpenAI's GPT-3. Now engineers and non-engineers can write SQL easily without knowing the syntax. AI2sql is more comprehensive than sqlTranslate. The features include SQL syntax checking, formatting, and query generation, the databases supported covers the most popular ones on the market (such as MySQL, PostgreSQL, MongoDB, Oracle, etc.).
## Aoi (葵)
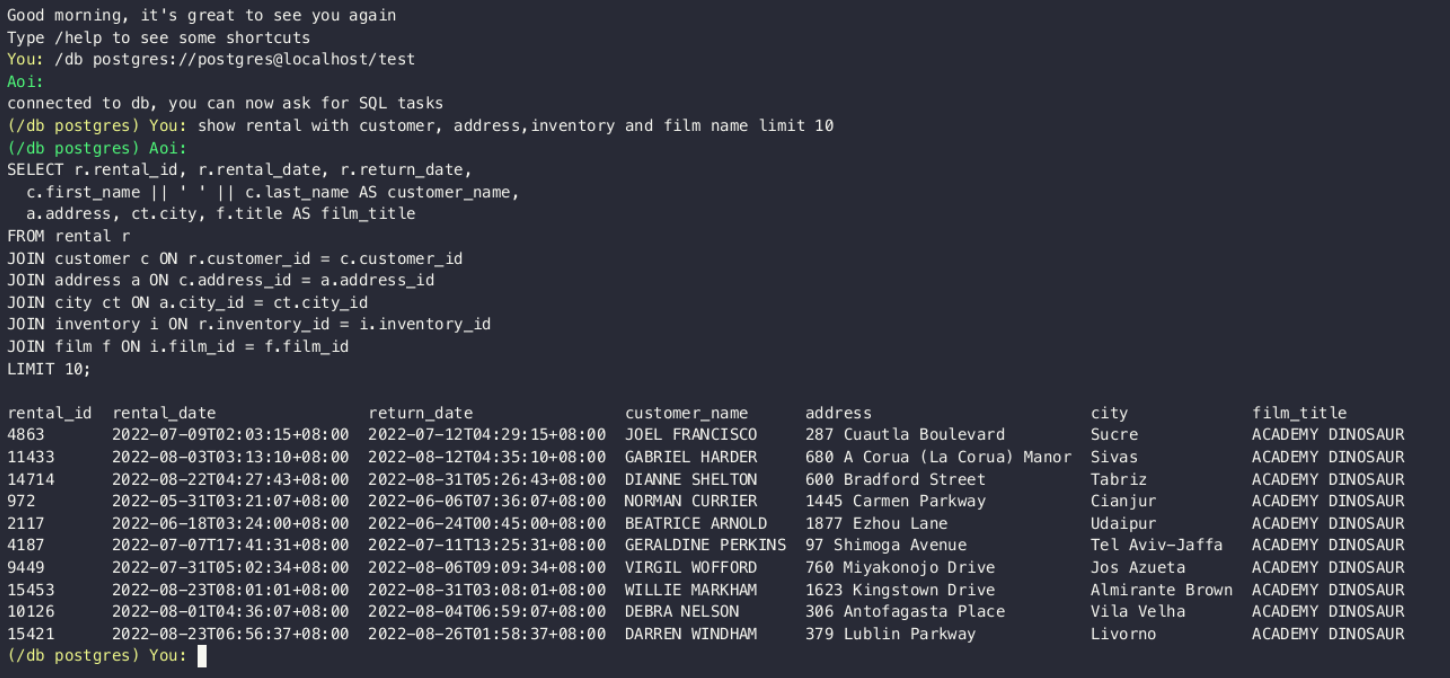
[Aoi](https://github.com/shellfly/aoi) is a ChatGPT-driven dialogue agent program that can conduct natural language conversations with AI in your Terminal, and it can also be connected to your database to perform SQL tasks.
## Bytebase:
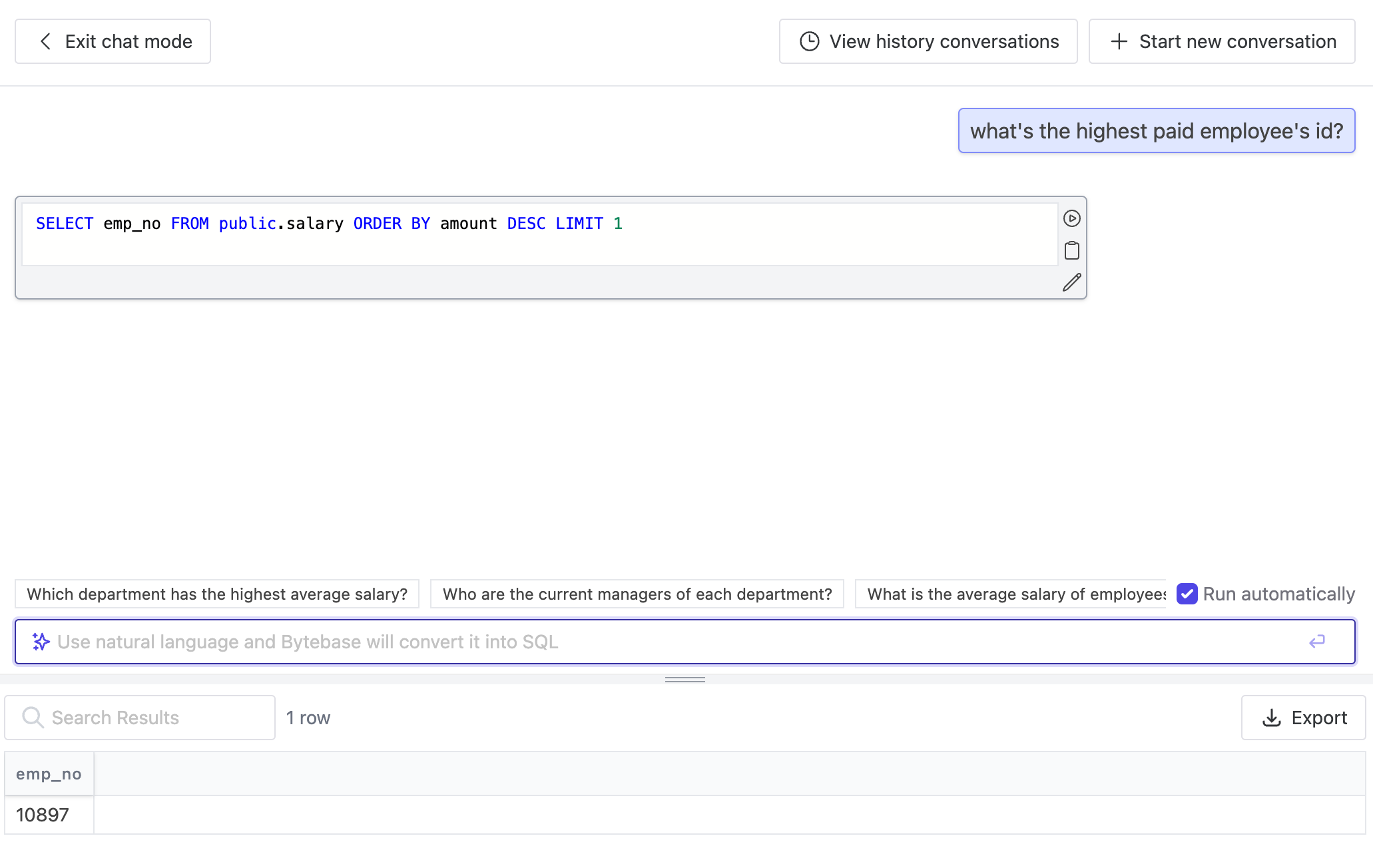
[Bytebase](https://www.bytebase.com/) is a database CI/CD tool that covers the entire life cycle of database development, and its SQL editor has also incorporated OpenAI's gpt-3.5-turbo in [its recent release](https://www.bytebase.com/changelog/bytebase-1-14-0), where you input natural language and have it converted to SQL. Stay tuned for a more advanced version chat bot 🤖️!
## DBeaver
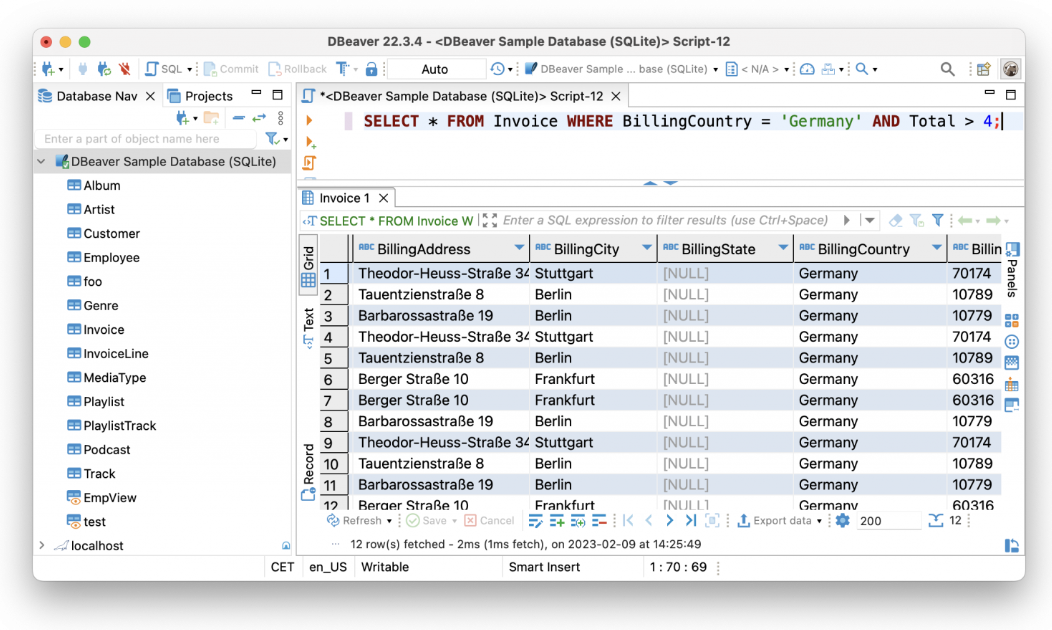
As a veteran SQL client, in addition to visualization and management capabilities, [DBeaver](https://dbeaver.com/) also has a SQL editor, along with data & schema migration capabilities, and database connection monitoring. In early February, DBeaver also incorporated GPT-3 to have AI convert natural language to SQL. For instance, you can askfor "all invoices from Germany with a total of more than 4," or in German, "Zeig alle Rechnungen aus Deutschland mit der Gesamtsumme über 4," and it will automatically convert the request into a query.
## OSSInsight
In a sense, [OSSInsight](https://ossinsight.io/) has been helping you write SQL since way before.
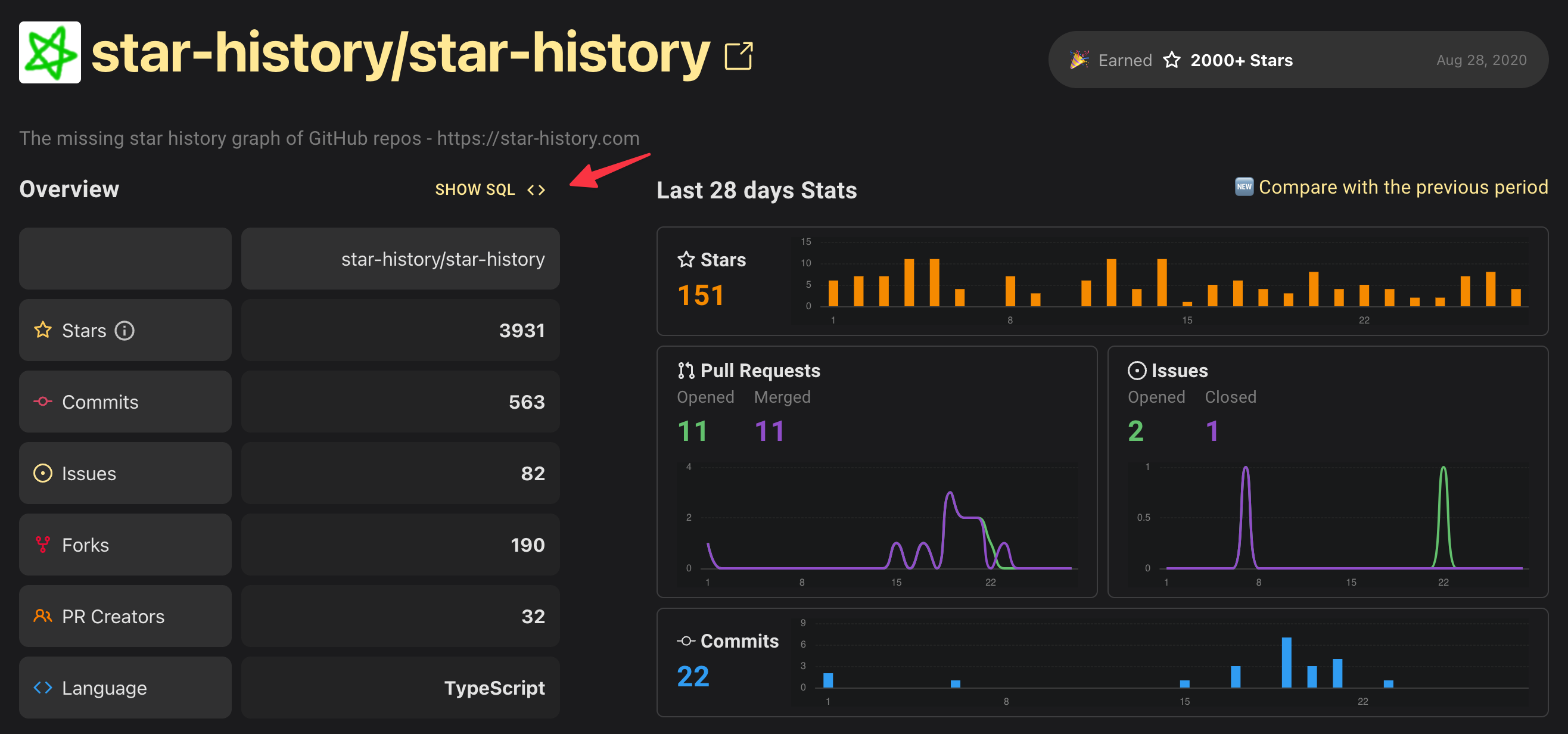
But recently they embraced OpenAI and launched a new tool called "Data Explorer", making it easier to explore GitHub data. You can ask whatever interests you in plain language, and AI will generate SQL for them (and then query it).
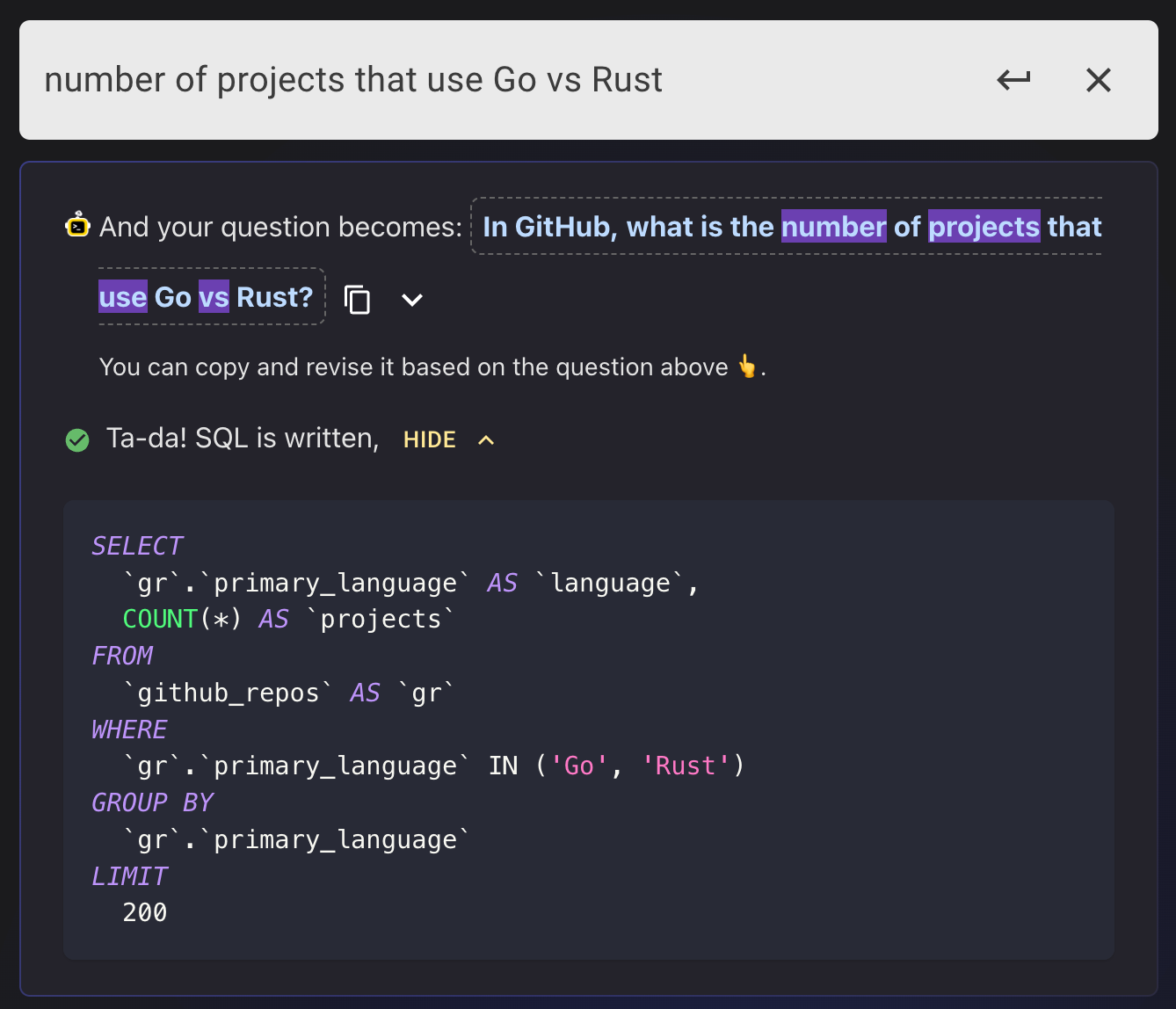
The database behind OSSInsight is TiDB, and TiDB Cloud recently also launched an intelligent data exploration feature using OpenAI: [Chat2Query](https://www.pingcap.com/chat2query-an-innovative-ai-powered-sql-generator-for-faster-insights/), which is another tool that generates SQL queries based on your input and then queries and visualizes the database for you.
## Outerbase
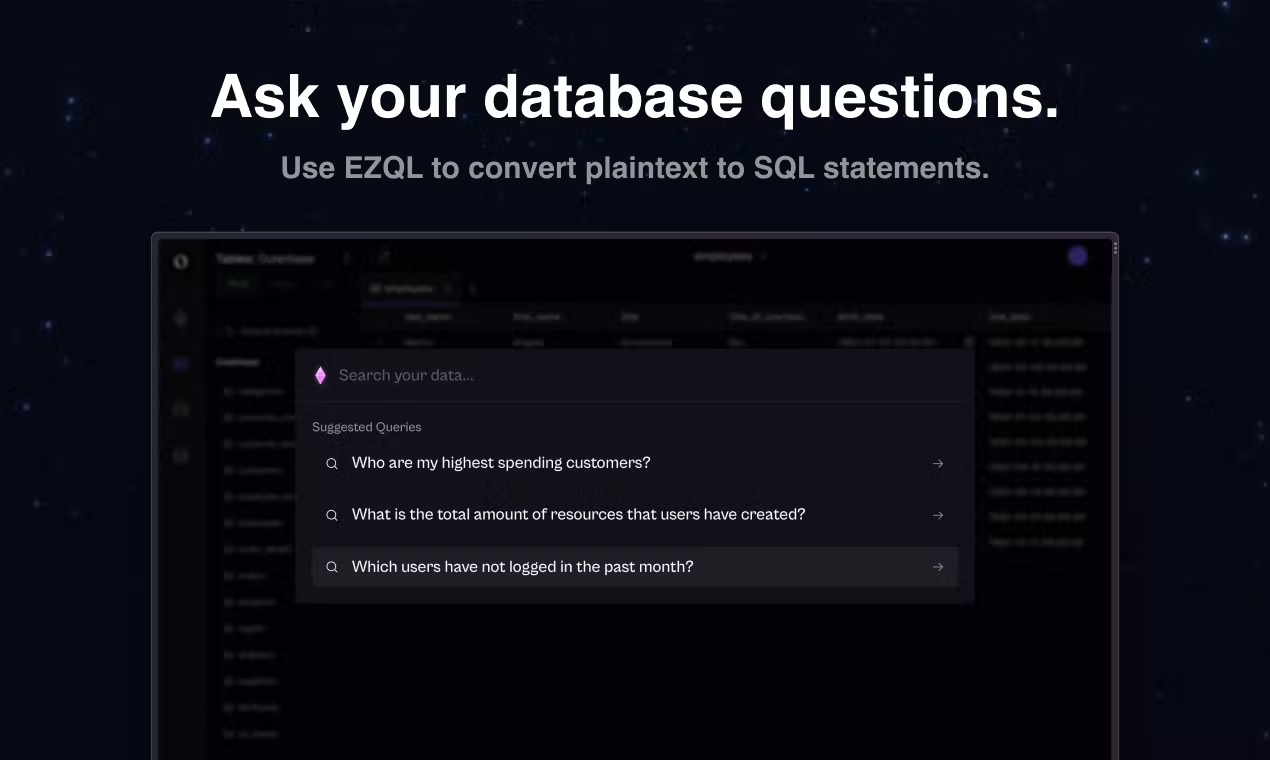
[Outerbase](https://outerbase.com/) is a new tool that was officially released on Feb.15, 2023. Compared with traditional database management tools, Outerbase completely conforms to current aesthetics. Its user experience is similar to that of an Excel spreadsheet, and it uses GPT-3 to help users write SQL queries and generate dashboards, making it useful for both developers and data analysts.
## To wrap up
It looks like using ChatGPT to enhance data management and analysis for your databases is gonna be an SOP in the database industry. Of course, these tools are just the tip of the iceberg, and their integration with ChatGPT is still in its early stages. However, it is clear that the benefits of combining ChatGPT with database management tools are enormous. Moreover, besides text2sql, ChatGPT can be used in many other database-related fields, such as customer support, query assistance, database management, and data analysis(you can also consult ChatGPT about what else it's capable of).
DBAs: get ready to retire officially. (Just kidding, but perhaps the long-established SQL clients such as Navicat are already feeling a vague sense of crisis.) | milasuperstar |
1,417,393 | JavaScript Promise ! | In JavaScript, a Promise is an object that represents the eventual completion (or failure) of an... | 0 | 2023-03-28T07:13:33 | https://dev.to/neyaznafiz/promise-in-javascript-33eo | In JavaScript, a Promise is an object that represents the eventual completion (or failure) of an asynchronous operation and its resulting value. Promises provide a way to handle asynchronous operations that involve waiting for some action to complete before proceeding with the rest of the code. This can be very useful when dealing with time-consuming or resource-intensive tasks, such as network requests or database queries.
A Promise can be in one of those three states: **pending**, **fulfilled**, or **rejected**.
- When a Promise is in the pending state, it means that the asynchronous operation is still in progress and the result is not yet available.
- When the operation completes successfully, the Promise is fulfilled with the resulting value.
- The Promise is rejected with an error object if an error occurs during the operation.
Promises can be created using the **Promise()** constructor, which takes a function that defines the asynchronous operation to be performed. The function should accept two parameters: **resolve()** and **reject()**.
- resolve() is called when the operation completes successfully and returns the resulting value.
- reject() is called if an error occurs during the operation and returns an error object.
Promises can be consumed using methods like **then()**, **catch()**, and **finally()**, which allow you to handle the result of the Promise or any errors that may occur. Chaining these methods together can make it easier to write and manage complex asynchronous code.
Overall, Promises are a powerful tool in modern JavaScript development and provide a simpler, more organized way to handle asynchronous operations. | neyaznafiz | |
1,417,426 | Discovering package.json | Introduction Back in the day, dependency management was a mounting ache, especially in... | 0 | 2023-03-28T07:53:20 | https://dyte.io/blog/package-json/ | webdev, javascript, beginners, tutorial | 
## Introduction
Back in the day, dependency management was a mounting ache, especially in languages like C/C++. There was no standardized tool for managing dependencies and their versions, and it took several hours of developer effort to manage them for a project.
Fast forward to 2023, there are several tools for dependency management, like [maven](https://maven.apache.org/) and [gradle](https://gradle.org/) for Java, [pip](https://pypi.org/project/pip/) for Python, [npm](https://docs.npmjs.com/cli/v9/), [pnpm](https://pnpm.io/) and [yarn](https://yarnpkg.com/) for Javascript, and [Cargo](https://doc.rust-lang.org/cargo/) for Rust, to name a few. Now, each package manager needs a way to keep track of which versions of which packages are supposed to be used in your current project. Generally, a file is created that maps these dependencies to their corresponding versions - for instance you’ll generally find a `[requirements.txt](https://pip.pypa.io/en/stable/reference/requirements-file-format/)` file in most Python projects.
Similarly, the primary job of the `package.json` file is to keep track of all of the dependencies and developer dependencies. that are required in your project. On running the `install` command on your favorite JS package manager, it will install the corresponding versions of the packages mentioned in the `package.json` file. Besides keeping track of dependencies, the `package.json` file also stores the name and version of your package - which is generally considered metadata for certain tools. Let’s say you were to publish your project on [npmjs](https://www.npmjs.com/) (or any other NPM registry), you’d require to have all the metadata about the package in your `package.json` file located in the root directory of your project.
## Creating a package.json file
You can create a `package.json` file in your Javascript/Typescript project using the `npm init` command. It’ll ask you a series of questions when you run that command, and all the answers that you enter will show up in your `package.json` file.
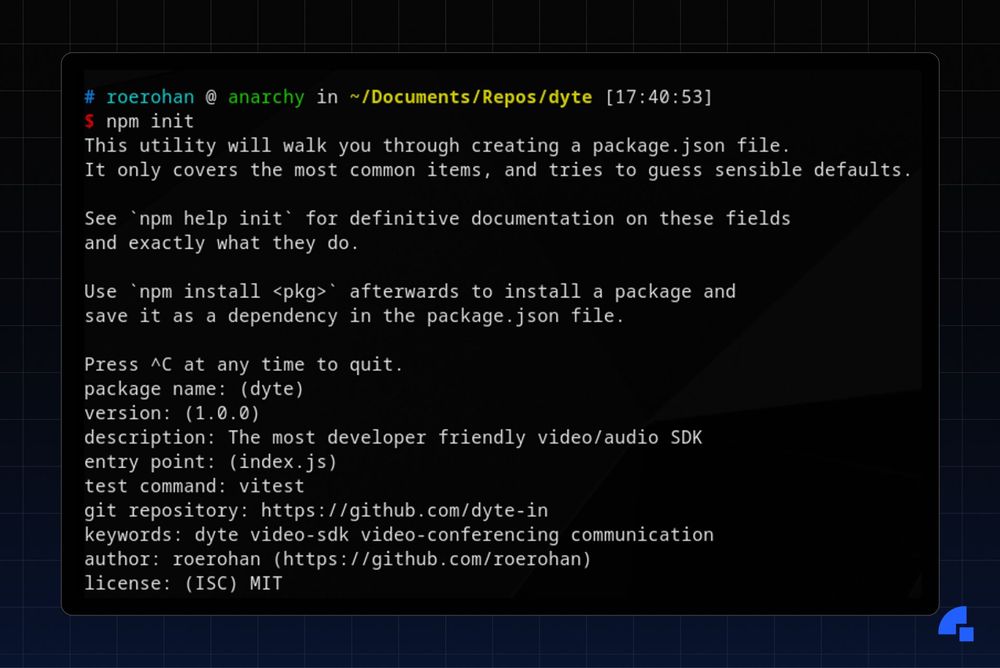
Here’s the corresponding `package.json` file that’s generated when running the above `npm init` command.
```json
{
"name": "dyte",
"version": "1.0.0",
"description": "Dyte is the most developer-friendly video and audio SDK.",
"main": "index.js",
"scripts": {
"test": "vitest"
},
"repository": {
"type": "git",
"url": "https://github.com/dyte-in"
},
"keywords": [
"dyte",
"video-sdk",
"video-conferencing",
"communication"
],
"author": "roerohan (https://github.com/roerohan)",
"license": "MIT"
}
```
More often than not, the keys other than `scripts` and `dependencies` come into play when publishing a package. From this point onwards, the discussion will be more relevant to packages that are supposed to be published to any NPM registry. However, if you have a standalone Node.js project for example, the properties in the `package.json` file still mean the same.
## Common keys in package.json
The properties in `package.json` are either descriptive or functional. For instance, the `name` of the package is a descriptive property, whereas the `scripts` that are defined in `package.json` are functional properties.
Here are some of the most useful properties in `package.json` and what they signify.
### Descriptive keys
Some keys in `package.json` are used to describe some fields, which is used by package managers and other tools to gather information about a package.
### [name](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#name)
The name field is used to identify the package. The `name` and the `version` fields are mandatory in the `package.json` file, and together they’re assumed to be unique. For instance, if the name is `web-core` and the version is `0.1.2`, then it is assumed that `web-core@0.1.2` is unique and doesn’t refer to any other package. A package name has certain restrictions - it can’t be more than 214 characters in length, and must contain all small letters. The `name` can not begin with a `.` or an `_`. Additionally, the name is often part of a URL so it must be URL-safe.
Package names may also be scoped. For instance, the name of a package can be `[@dytesdk/web-core](https://www.npmjs.com/package/@dytesdk/web-core)`. This is of the form `@organization/package`.
### [version](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#version)
The version field is one of the keys used to identify a package. Typically, this version number must be parseable by `[node-semver](https://github.com/npm/node-semver)`. Semantic versioning is a set of rules for versioning so that the change in the version number is indicative of the kind of changes in the package. The version is written in the form of `MAJOR.MINOR.PATCH`. If there’s a bug fix in the new version, the `PATCH` is incremented. If there’s a new feature, the `MINOR` part of the version is incremented. If the new version has a breaking change or is not compatible with older versions, the `MAJOR` part of the version is incremented.
For instance, if the current version of a package is `1.0.9`:
- If the next release has bug fixes only, the new version should be `1.0.10`.
- If the next release has a new feature, the new version should be `1.1.0`.
- If the next release has a breaking change, the new version should be `2.0.0`.
### [description](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#description)
The description field in the package describes in brief what the package does. It’s also useful in SEO as it helps other people find your package.
### [keywords](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#keywords)
Just like the description, the `keywords` field is also used for SEO. It’s an array of words that describes the package. If someone searches for any of the words in the `keywords` field, it’s likely that your package will show up.
### [homepage](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#homepage)
Typically you would link your project’s website in this field. Alternatively, you can also point to the projects `README` or documentation.
### [bugs](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#bugs)
The purpose of this field is to point to your project’s issue tracker, or any support email. It could be of the form
```json
{
"url": "https://github.com/dyte-io/html-samples/issues",
"email": "support@dyte.io"
}
```
If you don’t want to provide a support email, you can directly assign a URL to the `bugs` property.
### [license](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#license)
The license is an important field as it describes to the users of your package the permissions and restrictions placed by you while using this package. Ideally, for open-source packages, the license should be one that’s approved by [OSI](https://opensource.org/licenses/). If you do not wish to grant any permissions to the users of the package under any terms, you can set this field to `UNLICENSED`. You should consider setting the `private` field in the `package.json` file to true to prevent yourself from accidentally publishing the package.
### [author](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#people-fields-author-contributors)
The author field is used to provide information about the developer of the package. It consists of a `name`, and an optional `email` and `url` field. Here’s an example:
```json
{
"name": "Rohan Mukherjee",
"email": "rohan@dyte.io",
"url": "https://dyte.io"
}
```
All the information can also be downsized into a single string of the following format:
```json
{
"author": "Name <Email> (Site)"
}
```
For instance, you can specify the same author as above in this format:
```json
{
"author": "Rohan Mukherjee <rohan@dyte.io> (https://dyte.io)"
}
```
### [contributors](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#people-fields-author-contributors)
Just like the `author` field, the `contributors` field provides information about the developers of the package. It holds an array of authors.
### [funding](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#funding)
In this field, you can specify any links for funding your open-source package. For example, if you have a [Patreon](https://www.patreon.com/) or a [buymeacoffee](https://www.buymeacoffee.com/) link for funding your project, you can add it in this field. This can also take an array of multiple funding URLs. This is the URL that gets opened when a user runs `npm fund <projectname>`.
### Functional keys
These keys have some special meaning to certain tools, or while importing code from packages.
### [files](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#files)
The `files` field comprises an array of files that need to be uploaded to the registry when your package gets published. File patterns follow a similar syntax to `.gitignore`. The only difference is that the files specified in a `.gitignore` are excluded, whereas these files are included. You can also use glob patterns such as `*`, and `**/*`, just like in `.gitignore` files. The `files` field defaults to `["*"]` if not specified otherwise.
You should note that `package.json`, `README`, and `LICENSE/LICENCE` files are always included, irrespective of your settings. The `README` and `LICENSE/LICENCE` files can have any extension
### [main](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#main)
The entry point to your program is defined in the `main` property. When you require a package, you actually import the file described in the `main` property. There is a Node.js 12+ alternative to this field known as `exports`, which is described below.
### [exports](https://nodejs.org/api/packages.html#exports)
You can define entry points to your package using the `exports` field as an alternative to the `main` field. Unlike `main`, `exports` allows you to define [subpath exports](https://nodejs.org/api/packages.html#subpath-exports) and [conditional exports](https://nodejs.org/api/packages.html#conditional-exports).
For example, you can export the `submodule.js` file of your project using the following `exports` property:
```json
{
"exports": {
".": "./index.js",
"./submodule.js": "./src/submodule.js"
}
}
```
It is also possible to export conditionally - depending on whether the user of the package uses `require` or `import`.
```json
{
"exports": {
"import": "./index-module.js",
"require": "./index-require.cjs"
},
"type": "module"
}
```
Conditional exports are used often for `[ESM](https://nodejs.org/api/esm.html)` packages for backward compatibility, as the `import` keyword can only be used in `ESM`.
### [type](https://nodejs.org/api/packages.html#type)
This describes whether the `.js` files in the current package are supposed to be treated as `ESM` or `commonjs`. You can set the type of `module` for ESM and `commonjs` for non-ESM packages. Also, you can explicitly specify if a file is supposed to be interpreted as `ESM` or `commonjs` using the `.mjs` extension for `ESM` and the `.cjs` extension for `commonjs` files.
```json
{
"type": "module"
}
```
### [packageManager](https://nodejs.org/api/packages.html#packagemanager)
As of February 2023, the `packageManager` is an experimental field that defines which package manager is to be used for the current package. It should also specify the version of the package manager being used. This field can hold values that are present in this [list](https://nodejs.org/api/corepack.html#supported-package-managers).
### [browser](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#browser)
This field is used instead of `main` to indicate if a package is meant to be used in a browser instead of in a Node.js project. This is used when your package uses primitives like `window`, that are not available in Node.js environments.
### [bin](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#bin)
On certain occasions, npm packages need to be installed to `[PATH](https://en.wikipedia.org/wiki/PATH_(variable))`, so that they can be run directly by the operating system from any directory. The `bin` field specifies these executable-like files. For instance, you can have the following configuration in your `bin` property.
```json
{
"bin": {
"dyte": "./dyte.js",
"myapp": "./cli.js"
}
}
```
Upon installing this package globally (using `npm install -g`), you’ll be able to run commands like `dyte` and `myapp` directly from your terminal. This internally creates a symlink for the file `dyte.js` to `/usr/local/bin/dyte` and a symlink for `cli.js` to `/usr/local/bin/myapp` on unix-like OSs. On Windows, a `C:\Users\{Username}\AppData\Roaming\npm\dyte.cmd` file is created which runs the `dyte.js` script. It should be noted that each of the files mentioned as values in the `bin` property starts with the [shebang](https://en.wikipedia.org/wiki/Shebang_(Unix)) `#!/usr/bin/env node`, otherwise your operating system will not realize that the file is to be run in a Node.js environment.
### [man](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#man)
You can link a document or a list of documents for the `man` program to find in this field. When you run `man <package-name>` it should show this doc.
### [directories](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#directories)
You can use the `directories` object if you want to expose a folder full of binaries or a folder full of man pages. If you use this option, you don’t need to specify all the man pages in an array or all the binaries in an object. You can just add the following config:
```json
{
"directories": {
"man": "./man",
"bin": "./bin",
}
}
```
### [repository](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#repository)
For open-source repos, you can specify where the source code resides for your package. This generally points to a `git` repository. Here’s an example:
```json
{
"repository": {
"type": "git",
"url": "https://github.com/dyte-in/docs.git"
}
}
```
### [scripts](https://docs.npmjs.com/cli/v9/using-npm/scripts)
The `scripts` property is a dictionary containing script commands that you can run using the `npm` CLI. You can also specify scripts that run at different times during the lifecycle of your package. For instance, you can add a `prepublish` script, that runs just before a package is published (when you run `npm publish`).
### [config](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#config)
This lets you specify configuration for your package that persists across package versions. For instance, you can specify a config such as:
```json
{
"config": {
"port": "8080"
}
}
```
Now, you can use the `npm_package_config_port` environment variable in your `scripts`.
### Dependency keys
These keys describe the packages that your package is dependent on. Any changes in these packages affect the working or development experience of your package (provided you change the version of the dependencies).
### [dependencies](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#dependencies)
All the dependencies of your package are specified in `dependencies`. Whenever you `npm install` a package, the package name gets added to the `dependencies` dictionary as a key, and the package version gets added as the value. You can also specify version ranges instead of a single version according to the [semver](https://github.com/npm/node-semver#versions) specification. You can also use GitHub URLs and local directories to specify dependencies alongside `npm` packages.
### [devDependencies](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#devdependencies)
If you have dependencies that you only need during the development of a package, you can specify it as a `devDependency`. You can install a package as a `devDependency` using `npm install -D <package-name>`. Generally, packages like `typescript`, `ts-node`, etc. are installed as `devDependencies`.
### [peerDependencies](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#peerdependencies)
Often, your package requires another package but you don’t want to add a fixed version in your dependencies. For instance, if you build a `react` package, you don’t want to add `react` to your dependencies - because if you do so, installing your package will also install the said version of `react` from your `package.json`. In this case, you can specify `react` as a `peerDependency`, which indicates that your package needs a certain version range of `react` to function properly. Your package is called a **plugin** if it has this behavior. For example, check out this [`peerDependencies` config](https://github.com/roerohan/react-vnc/blob/main/prepublish.js#L20C7-L24).
In the recent versions of `npm`, all `peerDependencies` of a package are automatically installed alongside the package.
### [peerDependenciesMeta](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#peerdependenciesmeta)
Sometimes, a `peerDependency` might be good to have but is not required. If your package functions without any of the `peerDependencies` then you can specify that dependency to be optional in the `peerDependenciesMeta` key in `package.json`.
### [bundleDependencies](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#bundledependencies)
You can specify an array of dependencies that should be bundled with your package using this option. When your package gets prepared to be published, the dependencies mentioned in `bundleDependencies` or `bundledDependencies` will also be packaged alongside the source in the tarball.
### [optionalDependencies](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#optionaldependencies)
When a dependency is not found or fails to install, the `npm install` command exits with an error. You can prevent that from happening for a specific package if that package is present in `optionalDependencies` instead of any of the other dependencies lists/dictionaries.
### [publishConfig](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#publishconfig)
You can specify if your package is meant to be publicly accessible, and what tag a package is released with this option. By default, a package is private, and the default tag is `latest`. Using a different tag, for instance `beta`, let’s users install the specific version of the package using `npm install <package-name>@beta`.
### [workspaces](https://docs.npmjs.com/cli/v9/configuring-npm/package-json#publishconfig)
This option is really useful in mono-repos. You can specify a list of workspaces in the following manner:
```json
{
"workspaces": [
"./packages/client",
"./packages/server"
]
}
```
You can have separate `package.json` files in the client and server directory, which have separate scripts. Running `npm install --workspaces` will run `npm install` in both directories. In fact, you can run any script in all the workspaces specified using the `--workspaces` command. For instance, if you have separate `lint` scripts in `packages/client` and `packages/server`, in the root `package.json`, you can have a `lint` script that runs `npm run lint --workspaces --if-present`. Now, if you run `npm run lint` in the root, it will run the `lint` script in all the workspaces that have the `lint` script present. Here’s an example - the `sockrates` package has 2 sub workspaces `@dyte-in/sockrates-client` and `@dyte-in/sockrates-server`.
## The “lockfile”
There’s a mysterious `package-lock.json` file that shows up whenever you install packages in your `npm` project.
As the name suggests, `package-lock.json` is a lockfile, i.e., a file that stores the exact version numbers of the packages used and all its dependent packages. This includes all the packages that are present in your `node_modules` directory.
The purpose of this file is to ensure that all the dependencies are installed in the same way on different machines, which guarantees that the project will work consistently across different environments.
The `package-lock.json` file also includes a cryptographic hash of the contents of each package, which ensures that the installed packages are not tampered with and are the exact same packages that were published by the package author.
When you run `npm install`, npm uses the information in `package-lock.json` to determine the exact versions of the packages to install, and it installs them in the same order and with the same dependencies as the original installation.
If you inspect the `package-lock.json` file, you might find random packages that exist in your `node_modules` that you didn’t even know about. For instance, this is a package that I found in the lockfile of one of [Dyte’s](https://dyte.io) projects.
```
"node_modules/why-is-node-running": {
"version": "2.2.2",
"dev": true,
"license": "MIT",
"dependencies": {
"siginfo": "^2.0.0",
"stackback": "0.0.2"
},
"bin": {
"why-is-node-running": "cli.js"
},
"engines": {
"node": ">=8"
}
},
```
Package `why-is-node-running` present in the lockfile.
In fact, you can actually run it with `npx` and see that the package is present in your `node_modules`.
## Other package managers
Even though `npm` is one of the most popular package managers, a lot of people use other package managers like `yarn`, `pnpm`, or `turbo`. The `package.json` file still exists for all of these, but the lockfile might be named differently for different package managers. For instance, the lockfile created by `yarn` is `yarn.lock`, that looks something like the following:
```json
# THIS IS AN AUTOGENERATED FILE. DO NOT EDIT THIS FILE DIRECTLY.
# yarn lockfile v1
package-1@^1.0.0:
version "1.0.3"
resolved "https://registry.npmjs.org/package-1/-/package-1-1.0.3.tgz#a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0"
package-2@^2.0.0:
version "2.0.1"
resolved "https://registry.npmjs.org/package-2/-/package-2-2.0.1.tgz#a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0"
dependencies:
package-4 "^4.0.0"
package-3@^3.0.0:
version "3.1.9"
resolved "https://registry.npmjs.org/package-3/-/package-3-3.1.9.tgz#a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0"
dependencies:
package-4 "^4.5.0"
package-4@^4.0.0, package-4@^4.5.0:
version "4.6.3"
resolved "https://registry.npmjs.org/package-4/-/package-4-2.6.3.tgz#a1b2c3d4e5f6g7h8i9j0k1l2m3n4o5p6q7r8s9t0"
```
Similarly, `pnpm` generates a lockfile called `pnpm-lock.yaml`. The purpose of all these lockfiles however is the same as the `package-lock.json` file generated by `npm`.
## Conclusion
Overall, `package.json` is a vital metadata file used in Node.js development. It helps manage dependencies, automate tasks, and configure the project. The file contains essential information such as the project name, version number, author, license, dependencies, and more.
By using `package.json`, developers can easily manage the dependencies required by their project, ensuring that the correct version of each package is installed. This makes it easier to maintain the project and update dependencies when necessary.
Furthermore, it can be used to automate tasks such as building the project, running tests, and starting the application. This can save time and effort for developers, allowing them to focus on more important aspects of the project.
Finally, it allows developers to publish their projects to the `npm` registry, making it easy for other users to install and use the project in their own projects. This can help increase the visibility of the project and make it more accessible to others.
I hope you found this post informative and engaging. If you have any thoughts or feedback, feel free to reach out to me on [Twitter](https://twitter.com/roerohan) or [LinkedIn](https://www.linkedin.com/in/roerohan/) 😄. Stay tuned for more related blog posts in the future!
| roerohan |
1,417,431 | How To Create Custom Menus with CSS Select | When it comes to UI components, there are two versatile methods that we can use to build it for your... | 0 | 2023-03-28T07:59:21 | https://www.lambdatest.com/blog/css-select/ | css, selenium, automationtesting, tutorial | When it comes to UI components, there are two versatile methods that we can use to build it for your website: either we can use prebuilt components from a well-known library or framework, or we can develop our UI components from scratch.
Developing unique CSS components is a better strategy because we have much more control over them as developers, and can change the values as and when required. As a front-end developer for more than three years, making custom select dropdown components for navigation, selecting an option from a list, or filtering the provided choice is one of the most common demands when building user interfaces.
There are several use cases for the `< select >` tag, like dropdowns, navigation menus, filtering lists of items based on the selected option, choosing an option from a given list of options in input forms, etc. There are numerous [CSS frameworks](https://www.lambdatest.com/blog/best-css-frameworks-2021/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) and JavaScript libraries, including Bootstrap, Material UI, and Ant Design, and each of them has its own implementation of a custom CSS Select dropdown menu. They are extremely dependable and have demonstrated cross-browser functionality.
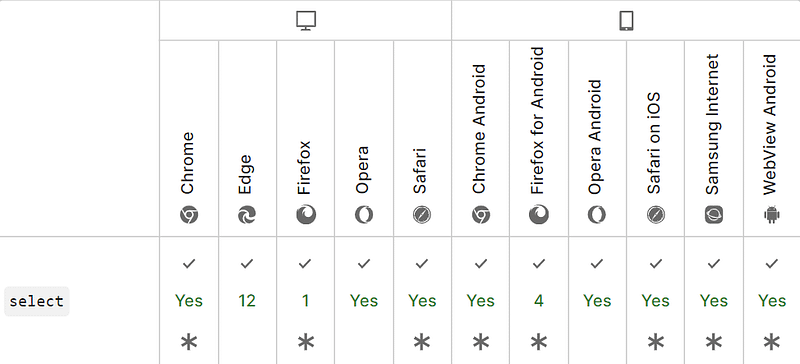
Source
Cross-browser drop-down styling is very challenging. Designers always create attractive drop-down lists, but each browser renders them slightly differently. You can learn more about browser rendering from this blog on [Browser Engines: The Crux Of Cross Browser Compatibility.](https://www.lambdatest.com/blog/browser-engines-the-crux-of-cross-browser-compatibility/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog)
When thinking about cross-browser functionality, using a CSS framework or library is beneficial because they handle all the behind-the-scenes tasks involved in creating a specific component.
When using these [CSS libraries](https://www.lambdatest.com/blog/top-21-javascript-and-css-libraries/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) and frameworks like [Bootstrap](https://www.lambdatest.com/blog/css-grid-vs-bootstrap/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) or Tailwind CSS, cross-browser functionality is paramount because end users use different operating systems, browsers, and devices. If we want everyone to have the same experience, we should only use those libraries and frameworks that work well on all devices, operating systems, and browsers. Most modern frameworks consider the need for [cross browser compatibility](https://www.lambdatest.com/learning-hub/cross-browser-compatibility?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub) and maintain device-friendly styling.
In this in-depth blog on custom CSS Select menus, we will walk through the process of creating various custom CSS Select menus.
So, let’s get started!
[***Emulators Online***](https://www.lambdatest.com/mobile-emulator-online?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) ***by LambdaTest allows you to seamlessly test your mobile applications, websites,and web apps on mobile browsers and mobile devices.***
### What is an HTML Select tag?
The HTML element `< select >` represents a control with a menu of choices. Usually, we use the select element to create a drop-down list. The `< select >` element is most frequently used in forms to gather user input.
Select tags use a variety of attributes, which give additional details about HTML elements. If we omit the name attribute, no data from the drop-down list will be submitted. The id attribute is needed to associate the drop-down list with a label. The < select > element define the options in the drop-down list.
```plaintext
<select>
<option>
</option>
...
</select>
```
The `< select >` element is typically used when we ask for information about a user’s country in the website’s login form or navigation bar. To maintain the accessibility of the website, we often use the label tag to make it accessible and better for end users.
### What are the various select tag attributes?
HTML attributes are unique keywords used within the opening tag to regulate the element’s behavior. HTML attributes are a type of modifier for an HTML element. The attributes provide additional information about HTML elements.
The select tag has various characteristics, including:
* **Autofocus (Type — Boolean):** The HTML `< select >` autofocus attribute is used to specify that the dropdown should automatically get focused when the page loads or when the user reaches a certain viewport.
* **Required (Type — Boolean):** The HTML `< input >` required attribute indicates that the user must select a value before submitting the form. The required attribute is a boolean attribute. A variety of input types support the required attribute, including text, search, URL, tel, email, password, date pickers, numbers, checkboxes, radios, and files.
* **Multiple (Type — Boolean):** The HTML multiple attributes specify that the user is allowed to select more than one option (or value) from the given list of options inside the `< select >` element. Additionally, it can work with the `< input >` tag.
* **Disabled (Type — Boolean):** To indicate that a select element is disabled, we use the disabled attribute. A drop-down list that is disabled cannot be used or clicked on. It is also a boolean attribute.
* **Name (Type — String):** The drop-down list’s name is specified using the name attribute. It can reference an element in JavaScript or the form data after submitting it.
```plaintext
<img
src="A Link to an image or any local image "
alt="an alternative test if the browser can't display the image"
width="104"
height="142" />
```
We can see a few of the < img > element’s attributes in this example. These attributes give additional information to the < img > element. There are more than 12 attributes for the < img > tag.
Here we have used attributes like *src*, which corresponds to the image’s source/link, alt, which provides a meaning-filled text description to increase accessibility, and height and width, which describe the image’s height and width.
```plaintext
<!-- input form with all attributes -->
<form>
<label for="fname"> First name:</label><br />
<input type="text" id="fname" name="fname" value="John" /><br />
<label for="lname">Last name:</label><br />
<input type="text" id="lname" name="lname" value="Doe" /><br /><br />
<input type="submit" value="Submit" />
<select name="Mobile" id="Mobiles">
<option value="Samsung">Samsung</option>
<option value="Apple">Apple</option>
<option value="OnePlus">OnePlus</option>
<option value="Xiaomi">Xiaomi</option>
<option value="Oppo">Oppo</option>
<option value="Vivo">Vivo</option>
</select>
</form>
```
The use of several HTML attributes can be seen in the examples above, including action, which specifies the action to be taken when the form is submitted, If the action attribute is omitted, then the default action will be set to the current page.
The name attribute corresponds to the name of the current element as defined by the user, id, which is a unique user-defined name, and value, which is used differently for various input types, such as text for buttons and the initial value for < input > elements.
Other attributes include style, class, and other global attributes that can be used with all HTML elements and some specific to certain HTML elements, such as href and defer.
We won’t go into great detail about HTML attributes because that is outside the scope of this blog on CSS Select, but it is crucial to take accessibility, providing meaningful descriptions via attributes, and following best practices into consideration.
***Through this*** [***usability testing***](https://www.lambdatest.com/learning-hub/usability-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub) ***tutorial, you will learn how usability testing is a great way to discover unexpected bugs, find what is unnecessary or unused before going any further, and have unbiased opinions from an outsider.***
Dropdowns vs. Select vs. Menu vs. Navigation
One common misunderstanding among novice developers is the names mentioned while discussing dropdowns. The most common of which are dropdown, select, and menu.
In this section of the CSS Select blog, let’s have a closer look at what they are.
**Dropdown**
An interactive element made up of a button that, typically on mouse hover, click, or tap, reveals and conceals a list of items. Before the beginning of the interaction, the list is hidden by default.
A drop-down list only shows one value when it is not active. When the user interacts with the dropdown, a list of values is displayed for the user to choose from.
Material UI Dropdown
A form control that shows a list of choices on a form for the user to select a single item or multiple items.
To make a drop-down list, we use the HTML < select > element. The < select > element is most frequently used in forms for gathering user inputs.
**Menu**
The < menu > tag defines a list/menu of commands or actions that can be performed on a website.
Currently, the < menu > tag is supported in Firefox, and it doesn’t work on popular browsers like Chrome, Internet Explorer, Safari, and Opera Mini. Presently, it has been removed from the HTML5 standards.
**Navigation**
A navigation menu on a website is a structured set of connections to other web pages, typically internal sites.
Navigation menus are most frequently found in page headers or sidebars, allowing users to rapidly reach the most important pages on a website.

### How to construct a basic HTML Select field?
This section of this blog on CSS Select will discuss the basic aspects of web design involved in the HTML Select element and how to use CSS to style it.
First, the < select > tag is often used when we need to get user input, and the user is given various options to choose from. It may resemble selecting various states or nations, or it might even resemble using a dropdown to switch between pages.
Below is the source code for constructing a select section.
**HTML:**
```plaintext
<select name="Phone" id="Phone">
<option value="Realme">Realme</option>
<option value="Redmi">Redmi</option>
<option value="Iphone">Iphone</option>
<option value="Samsung">Samsung</option>
<option value=”Pixels">Google Pexels</option>
</select>
```
**Output:**
```plaintext
<html>
<body>
<select name="Phone" id="Phone">
<option value="Realme">Realme</option>
<option value="Redmi">Redmi</option>
<option value="Iphone">Iphone</option>
<option value="Samsung">Samsung</option>
<option value="OPPO">OPPO</option>
<option value="Google Pexel">Google Pixel</option>
</select>
<select name="Phone" id="Phone">
<option value="Chrome">Chrome</option>
<option value="Firefox">Firefox</option>
<option value="Safari">Safari</option>
<option value="Edge">Edge </option>
</select>
</body>
</html>
```
The output of the code looks as follows:
This is straightforward and is a good place to begin. Let’s now add custom CSS to make it look good as well as design friendly.
**CSS:**
```plaintext
select{
width: 10%;
height: 50px;
border: 1px solid #ccc;
border-radius: 5px;
padding-left: 5px;
padding: 10px;
font-size: 18px;
font-family: 'Open Sans', sans-serif;
color: #555;
background-color: rgb(255, 255, 255);
background-image: none;
border: 1px solid rgb(41, 18, 18);
}
select>option{
font-size: 18px;
font-family: 'Open Sans', sans-serif;
color: #555;
background-color: rgb(247, 247, 247);
background-image: none;
font-size: 18px;
height: 50px;
padding: 15px;
border: 1px solid rgb(41, 18, 18);
}
```
**Output:**
[***Black Box testing***](https://www.lambdatest.com/learning-hub/black-box-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub)***? Don’t worry; we will be covering what is Black box testing, merits, demerits, types & techniques.***
Despite having styles applied to it, the `< select >` tag’s styles hardly ever change. This is because they are not usual DOM elements, making them behave differently from others.
For developers, the `< select >` and `< option >` elements are the most frustrating form controls due to their lack of styling support. This is because they are rendered by the operating system, not HTML.There are only a few style attributes that can be applied to the `< option >`. Because of how much of a UX battle it is, we will look into other solutions.
The above image makes it clear that applying styles to the < option > tag does not work as intended. The events like click or keypress on tag do not function because the browser generates them outside the DOM model.
A consistent way to mark up the functionality of a list of selectable options is provided by the < select > element. Nevertheless, the browser has complete control over how that list is displayed and can do so most effectively considering the operating system, browser, and current device.
Since we can never be certain how it will be presented, trying to style it in any way may not be effective. We can look into some examples where we test how select tags are presented for different browsers, operating systems, etc.
**HTML:**
```plaintext
<html>
<body>
<select name="Phone" id="Phone">
<option value="Realme">Realme</option>
<option value="Redmi">Redmi</option>
<option value="Iphone">Iphone</option>
<option value="Samsung">Samsung</option>
<option value="OPPO">OPPO</option>
<option value="Google Pexel">Google Pixel</option>
</select>
<select name="Phone" id="Phone">
<option value="Chrome">Chrome</option>
<option value="Firefox">Firefox</option>
<option value="Safari">Safari</option>
<option value="Edge">Edge</option>
</select>
</body>
</html>
```
**Output (macOS):**
```plaintext
<html>
<body>
<select name="Phone" id="Phone">
<option value="Realme">Realme</option>
<option value="Redmi">Redmi</option>
<option value="Iphone">Iphone</option>
<option value="Samsung">Samsung</option>
<option value="OPPO">OPPO</option>
<option value="Google Pexel">Google Pixel</option>
</select>
<select name="Phone" id="Phone">
<option value="Chrome">Chrome</option>
<option value="Firefox">Firefox</option>
<option value="Safari">Safari</option>
<option value="Edge">Edge </option>
</select>
</body>
</html>
```
```plaintext
<html>
<body>
<select name="Phone" id="Phone">
<option value="Realme">Realme</option>
<option value="Redmi">Redmi</option>
<option value="Iphone">Iphone</option>
<option value="Samsung">Samsung</option>
<option value="OPPO">OPPO</option>
<option value="Google Pexel">Google Pixel</option>
</select>
<select name="Phone" id="Phone">
<option value="Chrome">Chrome</option>
<option value="Firefox">Firefox</option>
<option value="Safari">Safari</option>
<option value="Edge">Edge </option>
</select>
</body>
</html>
```
We can see that the `< select >` tag is rendered differently. This can be an issue for users if we develop a web application that only considers a particular browser or operating system. We must consider all the major operating systems and browsers to ensure that our application is compatible with cross-browser.
We now comprehend the need for customized CSS Select menus, so let’s start creating those.
### How to create a custom dropdown menu with CSS Select?
In this section, we will look at how to create dropdown menus using CSS Select.
There are numerous ways to create a dropdown menu. We can either use CSS to make custom dropdowns or the native select tag to create dropdown menus. All we have to do is to use appropriate HTML elements and then style them accordingly.
We can use CSS Select to its full potential to make custom drop-down elements. With drop-down menus, users can quickly access your site’s content without scrolling. Drop-down menus can save users time by allowing them to jump down a level or two to find the content they want.
A good example of dropdowns in use is in e-commerce websites, where users will see dropdown inputs during checkout. Let’s now create some custom dropdown menus.
***This*** [***smoke testing***](https://www.lambdatest.com/learning-hub/smoke-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub) ***tutorial covers what smoke testing is, its importance, benefits, and how to perform it with real-time examples.***
### Creating custom dropdown menus with Grid layout
In this first example of this blog on CSS Select, using the standard `< select >` tag and custom CSS, we can now walk through the code for creating dropdowns that can be controlled using the attributes.
The disabled attribute specifies whether the element should be disabled or not. The multiple attributes specify that the user is allowed to select more than one value. Additionally, we have added styling-related attributes like id and class.
Here we use the [CSS Grid](https://www.lambdatest.com/blog/css-grid/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) layout for creating drop-downs. Grid is a CSS property that handles the layout in a two-dimensional grid system with columns and rows. Elements can be placed on the grid within these column and row lines. Since we have full control of where to place the item, this property makes the grid ideal for creating drop-downs.
Using the native `< select >` tag present in HTML, we will create dropdowns that can be controlled by altering attributes like disabled, multiple, etc.
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<label for="standard-select">Default Select Menu </label>
<div class="select">
<select id="standard-select">
<option value="Option 1">Twitter </option>
<option value="Option ">Facebook</option>
<option value="Option 3">Reddit </option>
<option value="Option 4">Youtube </option>
</select>
<span class="focus"></span>
</div>
<label for="multi-select">Multiple Selection</label>
<div class="select select--multiple">
<select id="multi-select" multiple>
<option value="Option 1">Web Development </option>
<option value="Option 2">App Development </option>
<option value="Option 3"> Machine Learning</option>
<option value="Option 4">Automation </option>
<option value="Option 5"> AI</option>
<option value="Option length">Some other</option>
</select>
<span class="focus"></span>
</div>
<label for="standard-select-disabled">Disabled Select</label>
<div class="select select--disabled">
<select id="standard-select-disabled" disabled>
<option value="Option 1">Server side rendering</option>
<option value="Option 2">Client side rendering</option>
<option value="Option 3">Static site generation</option>
<option value="Option 4">Hybrid Site Generator</option>
<option value="Option 5">Server + Client side rendering</option>
<option value="Option length">Single Page Application</option>
</select>
</div>
<label for="standard-select">Disabled Multiple Select</label>
<div class="select select--disabled select--multiple">
<select id="multi-select-disabled" multiple disabled>
<option value="Option 1">React JS</option>
<option value="Option 2">AngularJS</option>
<option value="Option 3">Meteor JS</option>
<option value="Option 4">Svelte Kit </option>
<option value="Option 5">Hydrogen JS</option>
<option value="Option length">React JS with NextJS </option>
</select>
</div>
</body>
</html>
```
**CSS:**
```plaintext
body {
background-color: red;
}
:root {
--select-border: #777;
--select-focus: #00f;
--select-arrow: var(--select-border);
}
select {
appearance: none;
background-color: transparent;
border: none;
padding: 0 1em 0 0;
margin: 0;
width: 100%;
font-family: inherit;
font-size: inherit;
cursor: inherit;
line-height: inherit;
z-index: 1;
outline: none;
}
.select {
display: grid;
grid-template-areas: "select";
align-items: center;
position: relative;
min-width: 15ch;
max-width: 30ch;
border: 1px solid var(--select-border);
border-radius: 0.25em;
padding: 0.25em 0.5em;
font-size: 1.25rem;
cursor: pointer;
line-height: 1.1;
background-color: #fff;
background-image: linear-gradient(to top, #f9f9f9, #fff 33%);
}
.select select,
.select::after {
grid-area: select;
}
.select:not(.select--multiple)::after {
content: "";
justify-self: end;
width: 0.8em;
height: 0.5em;
background-color: var(--select-arrow);
clip-path: polygon(100% 0%, 0 0%, 50% 100%);
}
select:focus + .focus {
position: absolute;
top: -1px;
left: -1px;
right: -1px;
bottom: -1px;
border: 2px solid var(--select-focus);
border-radius: inherit;
}
select[multiple] {
padding-right: 0;
height: 6rem;
}
select[multiple] option {
white-space: normal;
outline-color: var(--select-focus);
}
.select--disabled {
cursor: not-allowed;
background-color: #eee;
background-image: linear-gradient(to top, #ddd, #eee 33%);
}
label {
font-size: 1.125rem;
font-weight: 500;
}
.select + label {
margin-top: 2rem;
}
body {
min-height: 100vh;
display: grid;
place-content: center;
grid-gap: 0.5rem;
font-family: "Baloo 2", sans-serif;
background-color: skyblue;
padding: 1rem;
}
```
**Output:**
```plaintext
<label for="standard-select">Default Select Menu </label>
<div class="select">
<select id="standard-select">
<option value="Option 1">Twitter </option>
<option value="Option ">Facebook</option>
<option value="Option 3">Reddit </option>
<option value="Option 4">Youtube </option>
</select>
<span class="focus"></span>
</div>
<label for="multi-select">Multiple Selection</label>
<div class="select select--multiple">
<select id="multi-select" multiple>
<option value="Option 1">Web Development </option>
<option value="Option 2">App Development </option>
<option value="Option 3"> Machine Learning</option>
<option value="Option 4">Automation </option>
<option value="Option 5"> AI</option>
<option value="Option length">Some other</option>
</select>
<span class="focus"></span>
</div>
<label for="standard-select-disabled">Disabled Select</label>
<div class="select select--disabled">
<select id="standard-select-disabled" disabled>
<option value="Option 1">Server side rendering</option>
<option value="Option 2">Client side rendering</option>
<option value="Option 3">Static site generation</option>
<option value="Option 4">Hybrid Site Generator</option>
<option value="Option 5">Server + Client side rendering</option>
<option value="Option length">Single Page Application</option>
</select>
</div>
<label for="standard-select">Disabled Multiple Select</label>
<div class="select select--disabled select--multiple">
<select id="multi-select-disabled" multiple disabled>
<option value="Option 1">React JS</option>
<option value="Option 2">Angular JS</option>
<option value="Option 3">Meteor JS</option>
<option value="Option 4">Svelte Kit </option>
<option value="Option 5">Hydrogen JS</option>
<option value="Option length">React JS with NextJS </option>
</select>
</div>
```
The disabled attribute can be used to prevent a user from accessing the drop-down list unless another condition is met (like selecting a checkbox, etc.). The disabled value can then be removed using JavaScript, making the drop-down list usable. The multiple attribute allows the user to select multiple items from a list, which is ideal when the user needs to have multiple items checked, such as choosing multiple genres from Spotify.
### Creating custom select menus with input elements
In the following example, select menus will be made using the `< input >` tag. The `< input >` tag is commonly used to collect data from users. `< input >` tags come in various forms to accommodate the various ways users can select, add, and filter data.
Some of the types of `< input >` tags are shown in the below example.
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<style>
.input{
display: flex;
flex-wrap: wrap;
}
input{
width: 25%;
margin: 10px;
height: 25px;
}
</style>
<!-- All input tags with styles -->
<div class="input">
<input type="text" placeholder="Text">
<input type="email" placeholder="Email">
<input type="password" placeholder="Password">
<input type="number" placeholder="Number">
<input type="date" placeholder="Date">
<input type="time" placeholder="Time">
<input type="color" placeholder="Color">
<input type="file" placeholder="File">
<input type="submit" placeholder="Submit">
<input type="reset" placeholder="Reset">
<input type="button" name="Button" value="Button" placeholder="Button">
<input type="checkbox" placeholder="Checkbox">
<input type="radio" placeholder="Radio">
<input type="range" placeholder="Range">
<input type="search" placeholder="Search">
<input type="tel" placeholder="Tel">
<input type="url" placeholder="Url">
<input type="week" placeholder="Week">
<input type="month" placeholder="Month">
<input type="datetime-local" placeholder="Datetime-local">
</div>
</body>
</html>
```
**Output:**
Let’s now use CSS to position the menu items and convert the radio button, a type of input button, into a custom Select box.
In input forms, radio buttons are commonly used to select a value from available options, such as choosing the corresponding gender. Here, we’ll use CSS to customize this functionality to become a selectable dropdown.
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link rel="stylesheet" type="text/css" href="index.css" />
</head>
<body>
<div id="info">Which is the most developer friendly platform?</div>
<form id="form__cover">
<div id="select-box">
<input type="checkbox" id="options-view-button" />
<div id="select-button" class="section">
<div id="selected-value">
<span>Select a platform</span>
</div>
</div>
<div id="options">
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="Github"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="Github"
/>
<span class="label">Github</span>
<span class="opt-val">Github</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="Youtube"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="Youtube"
/>
<span class="label">Youtube</span>
<span class="opt-val">Youtube</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="W3School"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="W3School"
/>
<span class="label">W3Schools</span>
<span class="opt-val">W3Schools</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="LeetCode"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="LeetCode"
/>
<span class="label">LeetCode</span>
<span class="opt-val">LeetCode</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="stackoverflow"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="stackoverflow"
/>
<span class="label">StackOverflow</span>
<span class="opt-val">StackOverflow</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="freecodecamp"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="freecodecamp"
/>
<span class="label">FreeCodeCamp</span>
<span class="opt-val">FreeCodeCamp</span>
</div>
<div id="option-bg"></div>
</div>
</div>
</form>
</body>
</html>
```
**CSS:**
```plaintext
* {
user-select: none;
}
*:focus {
outline: none;
}
html,
body {
height: 100%;
min-height: 100%;
}
body {
font-family: "Segoe UI", Tahoma, Geneva, Verdana, sans-serif;
padding-bottom: 100px;
margin: 0;
background-color: black; }
.section {
border: 1px solid #e2eded;
border-color: #eaf1f1 #e4eded #dbe7e7 #e4eded;
}
#info {
position: absolute;
top: 0;
right: 0;
left: 0;
color: #2d3667;
font-size: 16px;
text-align: center;
padding: 14px;
background-color: #f3f9f9;
}
#form__cover {
position: absolute;
top: 0;
right: 0;
left: 0;
width: 300px;
height: 42px;
margin: 100px auto 0 auto;
z-index: 1;
}
#select-button {
position: relative;
height: 16px;
padding: 12px 14px;
background-color: rgb(247, 247, 247);
border-radius: 4px;
border: 1px solid gray;
cursor: pointer;
}
#options-view-button {
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
width: 100%;
height: 100%;
margin: 0;
opacity: 0;
cursor: pointer;
z-index: 3;
}
#selected-value {
font-size: 16px;
line-height: 1;
margin-right: 26px;
}
.option,
.label {
color: #2d3667;
font-size: 16px;
}
#options-view-button:checked + #select-button #chevrons i {
color: #2d3667;
}
.options {
position: absolute;
left: 0;
width: 250px;
}
#options {
position: absolute;
top: 42px;
right: 0;
left: 0;
width: 298px;
margin: 0 auto;
background-color: #fff;
border-radius: 4px;
}
#options-view-button:checked ~ #options {
border: 1px solid #e2eded;
border-color: #eaf1f1 #e4eded #dbe7e7 #e4eded;
}
.option {
position: relative;
line-height: 1;
transition: 0.3s ease all;
z-index: 2;
}
.option i {
position: absolute;
left: 14px;
padding: 0;
display: none;
}
#options-view-button:checked ~ #options .option i {
display: block;
padding: 12px 0;
}
.label {
display: none;
padding: 0;
margin-left: 27px;
}
#options-view-button:checked ~ #options .label {
display: block;
padding: 12px 14px;
}
.s-c {
position: absolute;
left: 0;
width: 100%;
height: 50%;
}
.s-c.top {
top: 0;
}
.s-c.bottom {
bottom: 0;
}
input[type="radio"] {
position: absolute;
right: 0;
left: 0;
width: 100%;
height: 50%;
margin: 0;
opacity: 0;
cursor: pointer;
}
.s-c:hover ~ i {
color: #fff;
opacity: 0;
}
.s-c:hover {
height: 100%;
z-index: 1;
}
.s-c.bottom:hover + i {
bottom: -25px;
animation: moveup 0.3s ease 0.1s forwards;
}
.s-c.top:hover ~ i {
top: -25px;
animation: movedown 0.3s ease 0.1s forwards;
}
@keyframes moveup {
0% {
bottom: -25px;
opacity: 0;
}
100% {
bottom: 0;
opacity: 1;
}
}
@keyframes movedown {
0% {
top: -25px;
opacity: 0;
}
100% {
top: 0;
opacity: 1;
}
}
.label {
transition: 0.3s ease all;
}
.opt-val {
position: absolute;
left: 14px;
width: 217px;
height: 21px;
opacity: 0;
background-color: rgb(247, 247, 247);
transform: scale(0);
}
.option input[type="radio"]:checked ~ .opt-val {
opacity: 1;
transform: scale(1.01);
}
.option input[type="radio"]:checked ~ i {
top: 0;
bottom: auto;
opacity: 1;
animation: unset;
}
.option input[type="radio"]:checked ~ i,
.option input[type="radio"]:checked ~ .label {
color: #fff;
}
.option input[type="radio"]:checked ~ .label:before {
content: "";
position: absolute;
top: 0;
right: 0;
bottom: 0;
left: 0;
z-index: -1;
}
#options-view-button:not(:checked)
~ #options
.option
input[type="radio"]:checked
~ .opt-val {
top: -30px;
}
.option:nth-child(1) input[type="radio"]:checked ~ .label:before {
background-color: #000;
border-radius: 4px 4px 0 0;
}
.option:nth-child(1) input[type="radio"]:checked ~ .opt-val {
top: -31px;
}
.option:nth-child(2) input[type="radio"]:checked ~ .label:before {
background-color: #f70800;
}
.option:nth-child(2) input[type="radio"]:checked ~ .opt-val {
top: -71px;
}
.option:nth-child(3) input[type="radio"]:checked ~ .label:before {
background-color: #09ff00;
}
.option:nth-child(3) input[type="radio"]:checked ~ .opt-val {
top: -111px;
}
.option:nth-child(4) input[type="radio"]:checked ~ .label:before {
background-color: #f18203;
}
.option:nth-child(4) input[type="radio"]:checked ~ .opt-val {
top: -151px;
}
.option:nth-child(5) input[type="radio"]:checked ~ .label:before {
background-color: #b6590c;
}
.option:nth-child(5) input[type="radio"]:checked ~ .opt-val {
top: -191px;
}
.option:nth-child(6) input[type="radio"]:checked ~ .label:before {
background-color: black;
border-radius: 0 0 4px 4px;
}
.option:nth-child(6) input[type="radio"]:checked ~ .opt-val {
top: -231px;
}
#option-bg {
position: absolute;
top: 0;
right: 0;
left: 0;
height: 40px;
transition: 0.3s ease all;
z-index: 1;
display: none;
}
#options-view-button:checked ~ #options #option-bg {
display: block;
}
.option:hover .label {
color: #fff;
}
.option:nth-child(1):hover ~ #option-bg {
top: 0;
background-color: #000;
border-radius: 4px 4px 0 0;
}
.option:nth-child(2):hover ~ #option-bg {
top: 40px;
background-color: #f70800;
}
.option:nth-child(3):hover ~ #option-bg {
top: 80px;
background-color: #09ff00;
}
.option:nth-child(4):hover ~ #option-bg {
top: 120px;
background-color: #ff7300;
}
.option:nth-child(5):hover ~ #option-bg {
top: 160px;
background-color: #b6590c;
}
.option:nth-child(6):hover ~ #option-bg {
top: 200px;
background-color: black;
```
**Output:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link rel="stylesheet" type="text/css" href="index.css" />
</head>
<body>
<div id="info">Which is the most developer friendly platform?</div>
<form id="form__cover">
<div id="select-box">
<input type="checkbox" id="options-view-button" />
<div id="select-button" class="section">
<div id="selected-value">
<span>Select a platform</span>
</div>
</div>
<div id="options">
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="Github"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="Github"
/>
<span class="label">Github</span>
<span class="opt-val">Github</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="Youtube"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="Youtube"
/>
<span class="label">Youtube</span>
<span class="opt-val">Youtube</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="W3School"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="W3School"
/>
<span class="label">W3Schools</span>
<span class="opt-val">W3Schools</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="LeetCode"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="LeetCode"
/>
<span class="label">LeetCode</span>
<span class="opt-val">LeetCode</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="stackoverflow"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="stackoverflow"
/>
<span class="label">StackOverflow</span>
<span class="opt-val">StackOverflow</span>
</div>
<div class="option">
<input
class="s-c top"
type="radio"
name="platform"
value="freecodecamp"
/>
<input
class="s-c bottom"
type="radio"
name="platform"
value="freecodecamp"
/>
<span class="label">FreeCodeCamp</span>
<span class="opt-val">FreeCodeCamp</span>
</div>
<div id="option-bg"></div>
</div>
</div>
</form>
</body>
</html>
```
### Creating a custom dropdown with CSS Flexbox
To make the select menu more user-friendly, let’s now put our CSS skills to use by positioning the dropdown elements using different CSS properties like position and flexbox.
[CSS Flexbox](https://www.lambdatest.com/blog/css-flexbox-tutorial/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) is a layout that simplifies the creation of flexible, responsive layout structures without using float or position properties. Flexbox handles layout in only one dimension at a time, either row or column. This makes Flexbox great for customized drop-downs with HTML divs and spans since we can set the flex-direction property to make it appear as a drop-down.
We are free to modify the dropdown so that it complements the design aspects of the website.
***In this*** [***System testing***](https://www.lambdatest.com/learning-hub/system-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub) ***tutorial, learn why System testing is important and all the intricacies of the System testing process.***
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link rel="stylesheet" href="index.css" />
</head>
<body>
<div class="select" tabindex="1">
<input class="selectopt" name="test" type="radio" id="option1" checked />
<label for="option1" class="option">Youtube</label>
<input class="selectopt" name="test" type="radio" id="option2" />
<label for="option2" class="option">Twitch</label>
<input class="selectopt" name="test" type="radio" id="option3" />
<label for="option3" class="option">TikTok</label>
<input class="selectopt" name="test" type="radio" id="option4" />
<label for="option4" class="option">Instagram Reels</label>
<input class="selectopt" name="test" type="radio" id="option5" />
<label for="option5" class="option">Youtube Shorts</label>
</div>
</body>
</html>
```
**CSS:**
```plaintext
body {
background:#ae15eb;
display:flex;
justify-content: center;
align-items:center;
flex-wrap:wrap;
padding:0;
margin:0;
height:100vh;
width:100vw;
font-family: sans-serif;
color:#FFF;
}
.select {
display:flex;
flex-direction: column;
position:relative;
width:350px;
height:100px;
}
.option {
padding:0 30px 0 10px;
min-height:40px;
display:flex;
align-items:center;
background:rgb(9, 184, 67);
border-top:#222 solid 1px;
position:absolute;
top:0;
width: 100%;
pointer-events:none;
order:2;
z-index:1;
transition:background .4s ease-in-out;
box-sizing:border-box;
overflow:hidden;
white-space:nowrap;
}
.option:hover {
background:rgb(8, 145, 26);
}
.select:focus .option {
position:relative;
pointer-events:all;
}
input {
opacity:1;
position:absolute;
left:99px;
}
input:checked + label {
order: 2;
z-index:2;
background:#666;
border-top:none;
position:relative;
}
input:checked + label:after {
content:'';
width: 0;
height: 0;
border-left: 5px solid transparent;
border-right: 5px solid transparent;
border-top: 5px solid white;
position:absolute;
right:10px;
top:calc(50% - 2.5px);
pointer-events:none;
z-index:3;
}
input:checked + label:before {
position:absolute;
right:0;
height: 40px;
width: 40px;
content: '';
background:#666;
}
@media screen and (max-width: 600px) {
.select {
width:90%;
}
```
**Output:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link rel="stylesheet" href="index.css" />
</head>
<body>
<div class="select" tabindex="1">
<input class="selectopt" name="test" type="radio" id="option1" checked />
<label for="option1" class="option">Youtube</label>
<input class="selectopt" name="test" type="radio" id="option2" />
<label for="option2" class="option">Twitch</label>
<input class="selectopt" name="test" type="radio" id="option3" />
<label for="option3" class="option">TikTok</label>
<input class="selectopt" name="test" type="radio" id="option4" />
<label for="option4" class="option">Instagram Reels</label>
<input class="selectopt" name="test" type="radio" id="option5" />
<label for="option5" class="option">Youtube Shorts</label>
</div>
</body>
</html>
```
### Filtering options in a dropdown list with JavaScript
We can utilize the CSS properties like Flexbox and Grid to make the layout for our select menu.
Flexbox is a CSS layout that simplifies the creation of flexible, responsive layout structures without using float or position properties. Flexbox handles layout in only one dimension at a time, either row or column. This makes flexbox great for customized drop-downs with HTML divs and spans since we can set the flex-direction property to make it appear as a drop-down.
We make use of [CSS Media Queries](https://www.lambdatest.com/blog/css-media-queries-for-responsive-design/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) to make our dropdown responsive. We must consider standard device dimensions like 480 pixels, 640 pixels, 720 pixels, 1024 pixels, 1440 pixels, etc. The main objective of [responsive websites](https://www.lambdatest.com/blog/best-practices-for-responsive-websites/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) is to ensure a seamless experience across different digital devices. The majority of today’s libraries and frameworks take this technique. Thus we should do the same while creating custom dropdowns.
We have created custom Select menus using a variety of CSS properties, such as Flexbox, Grid, and positioning, and now it is time to put our true creativity to work, creating custom select menus with CSS, also with the help of JavaScript.
JavaScript is being used in this case to create filterable options, which means that as the user types, the other options that are not similar to the given input in the options list are removed. The logic used here is plain and simple. We have an array of list items; whenever the user enters a specific character or group of characters, we iterate through the list and determine whether the entered input is present in the list of items. If it is not present, we remove those items from the dropdown list, giving the user a filtered and small list.
This is handy when users have to select from a long list like a list of countries, states, etc.
***A*** [***complete Manual***](https://www.lambdatest.com/learning-hub/manual-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=learning_hub) ***testing tutorial covering all aspects of Manual testing, including strategies and best practices.***
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="index.css"/>
<script src="inde.js" defer></script>
</head>
<body>
<h1> <span>filterable</span> select dropdown</h1>
<form>
<input
class="chosen-value"
type="text"
value=""
placeholder="Type to filter"
/>
<ul class="value-list">
<!-- List of tech giants -->
<li>Elon Musk</li>
<li>Bill Gates</li>
<li>Steve Jobs</li>
<li>Mark Zuckerberg</li>
<li>Larry Page</li>
<li>Sergey Brin</li>
<li>Larry Ellison</li>
<li>Jack Dorsey</li>
<li>Jeff Bezos</li>
<li>Paul Allen</li>
<li>Jack Ma</li>
<li>Dan Abranoah</li>
<li>Jordan Walkie</li>
<li>Satya Nadella</li>
<li>Kunal Shah</li>
<li> Asad Khan </li>
<li> Jay Singh </li>
</ul>
</form>
</body>
</html>
CSS:
** {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
display: flex;
flex-direction: column;
width: 100%;
height: 100vh;
align-items: center;
justify-content: flex-start;
font-family: 'Ek Mukta';
text-transform: uppercase;
font-weight: 600;
letter-spacing: 4px;
background: #1D1F20;
}
h1 {
margin-top: 10vh;
font-size: 2.5rem;
max-width: 500px;
letter-spacing: 3px;
text-align: center;
line-height: 1.5;
font-family: 'Open Sans';
text-transform: capitalize;
font-weight: 800;
color: white;
}
h1 span {
color: #0010f1;
}
form {
position: relative;
width: 25rem;
margin-top: 12vh;
}
@media screen and (max-width: 768px) {
form {
width: 90%;
}
}
.chosen-value, .value-list {
position: absolute;
top: 0;
left: 0;
width: 100%;
}
.chosen-value {
font-family: 'Ek Mukta';
text-transform: uppercase;
font-weight: 600;
letter-spacing: 4px;
height: 4rem;
font-size: 1.1rem;
padding: 1rem;
background-color: #FAFCFD;
border: 3px solid transparent;
transition: 0.3s ease-in-out;
}
.chosen-value::-webkit-input-placeholder {
color: #333;
}
.chosen-value:hover {
background-color: #0844eb;
cursor: pointer;
}
.chosen-value:hover::-webkit-input-placeholder {
color: #333;
}
.chosen-value:focus, .chosen-value.open {
box-shadow: 0px 5px 8px 0px rgba(0, 0, 0, 0.2);
outline: 0;
background-color: #2912f7;
color: #000;
}
.chosen-value:focus::-webkit-input-placeholder, .chosen-value.open::-webkit-input-placeholder {
color: #000;
}
.value-list {
list-style: none;
margin-top: 4rem;
box-shadow: 0px 5px 8px 0px rgba(0, 0, 0, 0.2);
overflow: hidden;
max-height: 0;
transition: 0.3s ease-in-out;
}
.value-list.open {
max-height: 320px;
overflow: auto;
}
.value-list li {
position: relative;
height: 4rem;
background-color: #FAFCFD;
padding: 1rem;
font-size: 1.1rem;
display: flex;
align-items: center;
cursor: pointer;
transition: background-color 0.3s;
opacity: 1;
}
.value-list li:hover {
background-color: #450ae9;
color: white;
}
.value-list li.closed {
max-height: 0;
overflow: hidden;
padding: 0;
opacity: 0;
}
```
**JavaScript:**
```plaintext
const inputField = document.querySelector('.chosen-value');
const dropdown = document.querySelector('.value-list');
const dropdownArray = [... document.querySelectorAll('li')];
dropdown.classList.add('open');
inputField.focus();
let valueArray = [];
dropdownArray.forEach(item => {
valueArray.push(item.textContent);
});
const closeDropdown = () => {
dropdown.classList.remove('open');
}
inputField.addEventListener('input', () => {
dropdown.classList.add('open');
let inputValue = inputField.value.toLowerCase();
let valueSubstring;
if (inputValue.length > 0) {
for (let j = 0; j < valueArray.length; j++) {
if (!(inputValue.substring(0, inputValue.length) === valueArray[j].substring(0, inputValue.length).toLowerCase())) {
dropdownArray[j].classList.add('closed');
} else {
dropdownArray[j].classList.remove('closed');
}
}
} else {
for (let i = 0; i < dropdownArray.length; i++) {
dropdownArray[i].classList.remove('closed');
}
}
});
dropdownArray.forEach(item => {
item.addEventListener('click', (evt) => {
inputField.value = item.textContent;
dropdownArray.forEach(dropdown => {
dropdown.classList.add('closed');
});
});
})
inputField.addEventListener('focus', () => {
inputField.placeholder = 'Type to filter';
dropdown.classList.add('open');
dropdownArray.forEach(dropdown => {
dropdown.classList.remove('closed');
});
});
inputField.addEventListener('blur', () => {
inputField.placeholder = 'Select Favorite Techie';
dropdown.classList.remove('open');
});
document.addEventListener('click', (evt) => {
const isDropdown = dropdown.contains(evt.target);
const isInput = inputField.contains(evt.target);
if (!isDropdown && !isInput) {
dropdown.classList.remove('open');
}
});
```
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1> <span>filterable</span> select dropdown</h1>
<form>
<input
class="chosen-value"
type="text"
value=""
placeholder="Type to filter"
/>
<ul class="value-list">
<!-- List of tech giants -->
<li>Elon Musk</li>
<li>Bill Gates</li>
<li>Steve Jobs</li>
<li>Mark Zuckerberg</li>
<li>Larry Page</li>
<li>Sergey Brin</li>
<li>Larry Ellison</li>
<li>Jack Dorsey</li>
<li>Jeff Bezos</li>
<li>Paul Allen</li>
<li>Jack Ma</li>
<li>Dan Abranoah</li>
<li>Jordan Walkie</li>
<li>Satya Nadella</li>
<li>Kunal Shah</li>
</ul>
</form>
</body>
</html>
```
### Creating a fully custom dropdown list
Now that we’ve covered a variety of techniques for building custom Select menus using CSS and JavaScript to add interactivity, we can use both of these technologies and our creativity to create custom CSS Select options that are much more user-friendly.
Here, we’re going to create an interactive select menu where the user can choose the value more effectively based on his preferences.
**HTML:**
```plaintext
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="index.css"/>
<script src="index.js" defer>
</script>
</head>
<div>
<div class="wrapper typo">The best browser is
<div class="list"><span class="placeholder">FireFox </span>
<ul class="list__ul">
<li><a href="#"> Chrome</a></li>
<li><a href="#">Brave </a></li>
<li><a href="#">Chromium </a></li>
<li><a href="#">Safari</a></li>
<li><a href="#">Opera Mini</a></li>
<li><a href="#">UC Browser</a></li>
</ul>
</div>
</div>
</div>
</body>
</html>
>
```
**CSS:**
```plaintext
@import url('https://fonts.googleapis.com/css?family=Poppins&display=swap');
body{
background: rgb(26, 23, 23);
}
.typo, .list a {
font-size: 50px;
font-weight: 700;
font-family: 'Poppins', serif;
color: #ffffff;
text-decoration: none;
}
.typo option, .list a option {
font-size: 30px;
}
.transition {
transition: all 0.4s ease-in-out;
}
body {
text-align: center;
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
}
.wrapper {
font-size: 60px;
margin-top: -10%;
}
.list {
display: inline-block;
position: relative;
margin-left: 6px;
}
.list ul {
text-align: left;
position: absolute;
padding: 0;
top: 0;
left: 0;
display: none;
}
.list ul .active {
display: block;
}
.list li {
list-style: none;
}
.list li:first-child a {
color: #00eb0c;
}
.list a {
transition: all 0.4s;
color: #00ff40;
position: relative;
}
.list a:after {
position: absolute;
content: '';
height: 5px;
width: 0;
left: 0;
background: #b066ff;
bottom: 0;
transition: all 0.4s ease-out;
}
.list a:hover {
cursor: pointer;
color: #b066ff;
}
.list a:hover:after {
width: 100%;
}
select {
display: inline;
border: 0;
width: auto;
margin-left: 10px;
outline: none;
-webkit-appearance: none;
-moz-appearance: none;
border-bottom: 2px solid #555;
color: #7b00ff;
transition: all 0.4s ease-in-out;
}
select:hover {
cursor: pointer;
}
select option {
border: 0;
border-bottom: 1px solid #555;
padding: 10px;
-webkit-appearance: none;
-moz-appearance: none;
}
.placeholder {
border-bottom: 4px solid;
cursor: pointer;
}
.placeholder:hover {
color: #888;
}
```
**JavaScript:**
```plaintext
console.clear();
document.querySelector(".placeholder").onclick = function (e) {
e.preventDefault();
document.querySelector(".placeholder").style.opacity = "0.01";
document.querySelector(".list__ul").style.display = "block";
};
document.querySelector(".list__ul a").addEventListener("click", function (ev) {
ev.preventDefault();
var index = document.querySelector(this).parent().index();
document
.querySelector(".placeholder")
.text(document.querySelector(this).text())
.css("opacity", "1");
console.log(
document.querySelector(".list__ul").querySelector("li").eq(index).html()
);
document
.querySelector(".list__ul")
.querySelector("li")
.eq(index)
.prependTo(".list__ul");
document.querySelector(".list__ul").toggle();
});
document.querySelectorAll(".list__ul a").forEach((q) => {
q.addEventListener("click", function (ev) {
ev.preventDefault();
console.log(q.textContent);
document.querySelector(".placeholder").textContent = q.textContent;
document.querySelector(".placeholder").style.opacity = "1";
document.querySelector(".list__ul").style.display = "none";
});
})
```
```plaintext
<div>
<div class="wrapper typo">The best browser is
<div class="list"><span class="placeholder">FireFox </span>
<ul class="list__ul">
<li><a href="#"> Chrome</a></li>
<li><a href="#">Brave </a></li>
<li><a href="#">Chromium </a></li>
<li><a href="#">Safari</a></li>
<li><a href="#">Opera Mini</a></li>
<li><a href="#">UC Browser</a></li>
</ul>
</div>
</div>
</div>
```
We’ve seen some good examples of custom dropdown menus, but one thing we should keep in mind is the website’s accessibility.
### What is web accessibility?
Web accessibility is a set of practices that entails designing and developing websites and digital tools so that people who are differently abled can use them without difficulty.
As web applications become more complex and dynamic, a new set of accessibility features and issues emerged. HTML introduced many semantic elements like < main > and < section >. Semantic HTML adds essential meaning to the web page rather than just presentation. This allows web browsers, search engines, screen readers, RSS readers, and users to understand it better.
W3C’s Web Accessibility Initiative — Accessible Rich Internet Applications is a series of specifications that define a set of new HTML attributes that can be added to elements to give additional semantics and improve accessibility where needed. The Web Content Accessibility Guidelines (WCAG) documents describe how to improve the accessibility of web content for individuals with impairments.
People with temporary disabilities, such as someone who has broken an arm, or situational limitations, such as when a person cannot listen to audio due to a lot of background noise, are also impacted by web accessibility.
Almost all websites now follow best practices, semantic HTML, and the proper HTML attributes. It is widely believed that making websites accessible to all users requires significant time and work while benefiting a relatively small number of individuals. However, this is not entirely correct. We all will face some kind of temporary disability at some point. Hence we need to consider everyone for accessibility.
To learn more about [accessibility testing](https://www.lambdatest.com/blog/accessibility-testing/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog), you can watch the following video on performing accessibility testing with the [Cypress test automation framework](https://www.lambdatest.com/blog/cypress-test-automation-framework/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog).
{% youtube gRHwcIVDr8U %}
### How to make dropdowns accessible?
To make it easy for people to find what they are looking for on your website, dropdown menus must be accessible. If not, it may take them longer to see what they need, or they may miss parts of your website entirely.
```plaintext
<!-- Bootstrap CSS Linked in Settings -->
<div class="container-fluid container-a">
<div class="col-lg-6 col-lg-push-3 col-md-8 col-md-push-2 col-sm-10 col-sm-push-1 col-xs-12 content-card">
<div class="title"><h1>A11Y Examples Series</h1></div>
<h2>Basic Accessible Dropdown Menu</h2>
<div class="dropdown-a dropdown">
<button class="button-a dropdown-toggle" type="button" id="dropdownMenuButton" data-toggle="dropdown" aria-haspopup="true" aria-expanded="false">Dropdown Menu</button>
<ul class="dropdown-menu" aria-labelledby="dropdownMenuButton">
<li><a class="dropdown-item" href="#">Menu Item 1</a></li>
<li><a class="dropdown-item" href="#">Menu Item 2</a></li>
<li><a class="dropdown-item" href="#">Menu Item 3</a></li>
</ul>
</div>
<br>
<h2>Accessible Dropdown Menu w/ Headings</h2>
<div class="dropdown-a dropdown">
<button class="button-a dropdown-toggle" type="button" id="dropdownMenuButton" data-toggle="dropdown" aria-haspopup="true" aria-expanded="false">Dropdown Menu</button>
<ul class="dropdown-menu" aria-labelledby="dropdownMenuButton">
<li><h4 class="dropdown-header">Menu Header A</h4></li>
<li><a class="dropdown-item" href="#">Menu Item 1a</a></li>
<li><a class="dropdown-item" href="#">Menu Item 2a</a></li>
<li><a class="dropdown-item" href="#">Menu Item 3a</a></li>
<li><h4 class="dropdown-header">Menu Header B</h4></li>
<li><a class="dropdown-item" href="#">Menu Item 1b</a></li>
<li><a class="dropdown-item" href="#">Menu Item 2b</a></li>
<li><a class="dropdown-item" href="#">Menu Item 3b</a></li>
</ul>
</div>
</div>
</div>
<!-- jQuery Linked in Settings -->
<!-- Bootstrap js Linked in Settings -->
```
The following are some of the best practices to keep in mind when dealing with dropdowns:
### Good Semantics
A semantic element’s defining feature is that it conveys its meaning to both the developer and the browser. These elements define its content clearly. Whenever possible, use semantic HTML to make your menus accessible to screen readers and to make your code easier to understand.
* Search engines and other user devices can use semantic HTML tags to determine the importance and context of web pages. Some of the HTML semantic tags are given below:
* < article >: < article > tag is used to contain information that may be distributed independently from the rest of the site
* < aside >: The < aside > element denotes a portion of a page that contains content that is indirectly linked to but distinct from the content around the aside element.
* < figure >: The < figure > tag denotes self-contained information such as illustrations, diagrams, pictures, code listings, etc.
* < nav >: The HTML element < nav > denotes a page part whose function is to give navigation links, either within the current content or to other publications.
* < section >: A < section > is a semantic element used to create independent sections on a web page.
### Structure the design
Structure the design so that everything is interconnected in some way so that the user has a roadmap for their journey. Structuring also entails placing headings, sections, navbar, headers, footers, etc., in the appropriate places. These semantic elements represent logical sections and provide a better way to structure the website.
A website with an accessible semantic structure, regardless of size or complexity, will be capable of providing accessibility. Without a solid semantic foundation, your website’s accessibility will degrade as it grows. Setting the proper structure early in development assists your website in remaining accessible as it grows.
* Avoid keyboard pitfalls
On websites, keyboard accessibility issues arise when designers or developers employ approaches that violate basic keyboard functionality. Problems occur when a user can navigate through a menu’s items using the Tab key but cannot leave the menu, leaving them in a loop.
The following are some best practices for creating keyboard-accessible websites:
* All links and controls can be accessed using the Tab key on the keyboard.
* All the components in the UI should follow W3C’s WAI-ARIA practices.
* Apps, plugins, widgets, and JavaScript techniques that trap the keyboard should be avoided.
* Enhance the browser’s default focus indicator.
Implement a time delay between the mouse leaving the menu area and the menu closing. Visitors who can use a pointer but lack fine motor control require drop-down menus to be visible for a sufficient amount of time to be used. People should have a little bit of time to interact with the menu.
In the case of links as drop-down, the menu must be coded as an unordered list of links for assistive technologies used by blind users so that they can count the number of links in each drop-down menu or the main navigation. They also need to know which link takes them to the page they are currently on.
These are some of the most significant best practices for web accessibility. As we’ve seen, to make drop-down menus accessible, we need to consider the needs of different disabled user groups.
Creating the dropdown menu simple, straightforward, and understandable, giving them additional time to react to mouse movements, using the proper syntax for screen reader users, and ensuring your menus are compatible with the keyboard will eventually contribute toward better accessibility.
**How to test custom menus on multiple browsers?**
When creating a new menu for your website, how can you make sure that it is functional and works with all browsers? The answer is simple: [Test the website on different browsers](https://www.lambdatest.com/test-website-on-different-browsers?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) and operating system combinations.
However, the problem with testing your site’s custom menus on multiple browsers is that it can be time-consuming. You have to test every combination of operating systems and browsers, so you have to test your site on dozens or hundreds of combinations. This is a huge waste of time, especially when some combinations are irrelevant or superfluous.
There’s a good chance that there are significant differences between the way custom menus work in each browser, and you’ll need to test for these discrepancies. But rather than wasting all your time by going through the entire list of operating systems and browsers, you can use [cloud testing](https://www.lambdatest.com/blog/cloud-testing-tutorial/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog) tools like LambdaTest.
[Cross browser testing](https://www.lambdatest.com/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) platforms such as LambdaTest allow you to perform [web testing](https://www.lambdatest.com/web-testing?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) and provide an [online browser farm](https://www.lambdatest.com/online-browser-farm?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) of more than 3000+ browsers and OS combinations.
{% youtube pfzA5bsxf_E %}
Alternatively, you can use tools like [LT Browser](https://www.lambdatest.com/lt-browser?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) to check for [responsive websites](https://www.lambdatest.com/blog/best-practices-for-responsive-websites/?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=blog). LT Browser by LambdaTest is a [mobile-friendly test](https://www.lambdatest.com/mobile-friendly-test?utm_source=devto&utm_medium=organic&utm_campaign=mar28_ap&utm_term=ap&utm_content=webpage) tool with 50+ pre-installed viewports with multiple standard resolutions.
{% youtube K1dlmU3QWWk %}
Subscribe to the LambdaTest YouTube channel for tutorials around Selenium testing, Playwright browser testing, Appium, and more.
### **Conclusion**
Congratulations on reaching this far! You’re a fantastic reader!
In this detailed blog on creating custom Select menus with CSS, we have covered various ways to create the same with the help of HTML, CSS, and JavaScript. Not only did we experiment with creating dropdowns, but we also discussed various best practices and accessibility tips and tricks.
Now we know how to create your custom select menus most effectively and efficiently.
Happy Styling! | adarshm1024 |
1,417,506 | 人気のブロックチェーン・ゲーム「キャプテン翼ライバルズ」のリフレッシュ機能とは | 「キャプテン翼ライバルズ」は、人気漫画「キャプテン翼」をモチーフにしたブロックチェーンゲームです。 fillメディア編集部では、このゲームについて、始め方や遊び方、ゲームの仕組みなどを解説した記事を公開... | 0 | 2023-03-28T08:52:56 | https://dev.to/fill_media/ren-qi-noburotukutiengemukiyaputenyi-raibaruzu-norihuretusiyuji-neng-toha-63h | キャプテン翼ライバルズ | 「キャプテン翼ライバルズ」は、人気漫画「キャプテン翼」をモチーフにしたブロックチェーンゲームです。
fillメディア編集部では、このゲームについて、始め方や遊び方、ゲームの仕組みなどを解説した記事を公開しています。
[キャプテン翼RIVALS(ライバルズ)の始め方- 選手カードNFTでチームを作り仮想通貨を稼ぐブロックチェーン・ゲームの仕組みとは](https://social-lending.online/nft-games/captain-tsubasa-rivals/about-captain-tsubasa-rivals/)
今回は、その記事から「リフレッシュ」という選手カードの独特な仕組みについて要約して紹介します。
「キャプテン翼ライバルズ」には、「ライバルモード」という、プレイヤーがコンピューターと対戦するモードがあります。
このモードで選手カードを使用すると、そのカードの「フィジカルコンディション」が徐々に低下していきます。
フィジカルコンディションが一定程度以下まで低下した状態でカードを使用すると、報酬の獲得量が低下する可能性があります。
また、獲得できるTSUBASAUTの量も激減します。
このような事態を避けるためには、選手カードのコンディションを定期的に回復する必要があります。
ただし、「リカバー」を行うためには、TSUBASAUTを支払う必要があります。
一方、選手カードの累計消費エネルギーが増えると、「疲れやすさ」という指数が上昇します。
この指数が上昇すると、フィジカルコンディションが一気に低下しやすくなります。
この状態を回復するためには、「リフレッシュ」を行います。
リフレッシュを行うと、累計消費エネルギーがリセットされ、「疲れやすさ」指数も1.0に戻ります。
ただし、リフレッシュにはTSUBASAUTが必要であり、回数が増えるとコストも膨らんでいくことになります。
そのため、ひとつの選手カードをとことんレベルアップしてから、累計消費エネルギーを大切に管理することが必要です。
また、効率的なプレイのためには、リカバーとリフレッシュを上手に使い分けることも大切です。 | fill_media |
1,417,515 | The Future of Virtual Reality: How PWAs are Shaping the VR Landscape | Virtual Reality (VR) has come a long way since its inception, and it continues to evolve at a rapid... | 0 | 2023-03-28T09:07:05 | https://dev.to/sem_60/the-future-of-virtual-reality-how-pwas-are-shaping-the-vr-landscape-p65 |
Virtual Reality (VR) has come a long way since its inception, and it continues to evolve at a rapid pace. The emergence of Progressive Web Apps (PWAs) has opened up new possibilities for VR, and the future looks bright for this technology. VR is poised to change the way we interact with digital content, and businesses need to be prepared for the changes that are coming.
PWAs offer a cost-effective and accessible way to deliver VR experiences to users across different devices. With PWAs, businesses can create VR applications that are accessible through any web browser, without the need for users to download a native app. PWAs also offer features such as offline access, push notifications, and home screen icon for easy access.
In this article, we will explore the future of VR and how PWAs are shaping the VR landscape. We will discuss the potential applications of VR in different industries, from gaming and entertainment to education and training. We will also discuss the challenges that need to be addressed for VR to reach its full potential and provide guidance on how businesses can prepare for the changes that are coming.
The future of VR is bright, and PWAs are playing a crucial role in shaping this future. With PWAs, businesses can reach a broader audience and offer engaging and immersive VR experiences. As VR technology continues to evolve, businesses that embrace this technology and adapt to the changes are the ones that will succeed in the future.
Read the full article at [https://techblog.cybersynctech.com/exploration-of-virtual-realitys-future/](https://techblog.cybersynctech.com/exploration-of-virtual-realitys-future/)
| sem_60 | |
1,417,575 | How to get shortest path in python when using Apache-AGE Graph Database ? | To get the shortest path between two nodes using Apache-AGE Graph Database in Python, you can follow... | 0 | 2023-03-28T09:32:26 | https://dev.to/munmud/how-to-get-shortest-path-in-python-when-using-apache-age-graph-database--3p5b | apacheage | To get the shortest path between two nodes using Apache-AGE Graph Database in Python, you can follow these steps:
- Install the following requirements in ubuntu
```bash
sudo apt-get update
&& sudo apt-get install python3-dev libpq-dev
&& pip install --no-binary :all: psycopg2
```
- Install the Apache-AGE Python package: Before you can use Apache-AGE in Python, you need to install the Apache-AGE Python package. You can install it using pip by running the following command:
```bash
pip install apache-age-dijkstra
```
- Now RUN postgreSQL server where you are using Apache-AGE graph database. Make sure you have created a database. Save the database name, username, password.
Now in python code you can use the package as follow:
### Import
```py
from age_dijkstra import Age_Dijkstra
```
### Making connection to postgresql (when using [this docker reepository](https://github.com/Munmud/apache_age))
```py
con = Age_Dijkstra()
con.connect(
host="localhost", # default is "172.17.0.2"
port="5430", # default is "5432"
dbname="postgresDB", # default is "postgres"
user="postgresUser", # default is "postgres"
password="postgresPW", # default is "agens"
printMessage = True # default is False
)
```
### Get all edges
```py
edges = con.get_all_edge()
```
- structure :
`
{
v1 : start_vertex,
v2 : end_vertex,
e : edge_object
}
`
### Get all vertices
```py
nodes = []
for x in con.get_all_vertices():
nodes.append(x['property_name'])
```
### Create adjacent matrices using edges
```py
init_graph = {}
for node in nodes:
init_graph[node] = {}
for edge in edges :
v1 = edge['v1']['vertices_property_name']
v2 = edge['v2']['vertices_property_name']
dist = int(edge['e']['edge_property_name'])
init_graph
init_graph[v1][v2] = dist
```
### Initialized Graph
```py
from age_dijkstra import Graph
graph = Graph(nodes, init_graph)
```
### Use dijkstra Algorithm
```py
previous_nodes, shortest_path = Graph.dijkstra_algorithm(graph=graph, start_node="vertices_property_name")
```
### Print shortest Path
```py
Graph.print_shortest_path(previous_nodes, shortest_path, start_node="vertices_property_name", target_node="vertices_property_name")
```
### Create Vertices
```py
con.set_vertices(
graph_name = "graph_name",
label="label_name",
property={"key1" : "val1",}
)
```
### Create Edge
```py
con.set_edge(
graph_name = "graph_name",
label1="label_name1",
prop1={"key1" : "val1",},
label2="label_name2",
prop2={"key1" : "val1",},
edge_label = "Relation_name",
edge_prop = {"relation_property_name":"relation_property_value"}
)
```
### For more information about [Apache AGE](https://age.apache.org/)
* Apache Incubator Age: https://age.apache.org/
* Github: https://github.com/apache/incubator-age
* Documentation: https://age.incubator.apache.org/docs/
* apache-age-dijkstra GitHub: https://github.com/Munmud/apache-age-dijkstra
* apache-age-python GitHub: https://github.com/rhizome-ai/apache-age-python
### License
[Apache-2.0 License](https://www.apache.org/licenses/LICENSE-2.0) | munmud |
1,417,625 | Generating Data Functions in Your Elixir App | In the first part of this series, we explored the ins and outs of Elixir test factories and fixtures.... | 22,326 | 2023-03-28T10:56:25 | https://blog.appsignal.com/2023/03/21/generating-data-functions-in-your-elixir-app.html | elixir | In the first part of this series, we explored the ins and outs of Elixir test factories and fixtures. However, test factories bypass the rules of your Elixir application. Let's turn our attention to how we can avoid this by using data generation functions.
Let's dive straight in!
## Creating Data With Your Elixir App's Public APIs
We'll use application code to generate test data. One of the biggest benefits of this method is that the generated data will be consistent with your application's rules. However, you need to write an extra layer of functions that your tests can easily use.
### The Test Pyramid Strategy for Your Elixir App
Before jumping into the code, it's important to think about your application's public APIs and how data will be generated for each test strategy.
Saša Juric wrote about [how to keep a maintainable test suite in Elixir](https://medium.com/very-big-things/towards-maintainable-elixir-testing-b32ac0604b99). In the post, he described how the most important public API he needed to test in his app was the HTTP API layer, which is how his users interact with the app. For his app's context, it was worth having a lot of test HTTP requests, even though it might have some drawbacks on the test speed performance. In his [test pyramid](https://martinfowler.com/bliki/TestPyramid.html) strategy, Saša favored interface-level tests over lower-level ones.
The image above shows different strategies you might choose for your app.
You might want a balanced pyramid with a good amount of tests in all layers or favor unit tests above everything else.
The tests in the top layer are slower and more difficult to maintain, and they overlap with lower-layer tests.
The high-level tests ensure that all modules work together, while the lower-level tests can tell you exactly which module or function is not working properly.
Your application's test pyramid strategy might have more layers with different names — for example, the term "unit" might mean completely different things depending on who you ask. Each strategy has its own trade-offs, and discussing them is out of the scope of this post.
The most important thing to take away, though, is that you need to understand the layers of your Elixir application and the type of data needed to write accurate functions that generate test data.
I'll give you some examples, but ultimately, it's up to you to decide what works best for your team and source code.
### Extract Business Logic from Your Web Code
It's a well-known and common practice to split business logic from web code in web applications built with the Phoenix framework. In Phoenix, we usually call these business modules "context" modules.
These modules typically interact with databases, external services, other context modules, and a lot of other functions. The functions in context modules are usually the public API for your web layer.
### An Example Using Helpers in Elixir
If you want to invest in a lot of tests on the context level, you can create helpers for the most-needed resources. For example, let's say you have these modules:
```elixir
# lib/my_app/accounts.ex
defmodule MyApp.Accounts do
def signup_user(username, password) do
# ...
end
end
# lib/my_app/profiles.ex
defmodule MyApp.Profiles do
def create_author_profile(user) do
# ...
end
end
# lib/my_app/profiles.ex
defmodule MyApp.News do
def create_post(post_contents, author) do
# ...
end
end
```
Here, we have the `Accounts`, `Profiles`, and `News` contexts. Suppose we want to test the `MyApp.News.create_post/2` function. We first need to create an `Author` profile. To create an `Author` profile, we need a `User` account.
If we have more functions in the `News` context, or if more contexts need an `Author`, we always have the tedious task of creating these chained struct relationships.
We can create helpers and make them available to our tests that need valid `Author` and `User` structs in the system. To make these helpers only available in the `:test` environment, we need to tell [Mix](https://hexdocs.pm/mix/Mix.html), Elixir's project build tool, where to find these files. You can update `mix.exs` with the following configuration:
```elixir
elixirc_paths: (
case Mix.env() do
:test -> ["lib", "test/support"]
_ -> ["lib"]
end
)
```
We tell Mix to compile the files in the `test/support` directory with the `lib` directory when building the `:test` environment. Of course, you can use any directory name you want, but `test/support` is a widely used convention. This way, you can create modules only available for a `:test` environment.
Here's an example of some helpers:
```elixir
# test/support/helpers.ex
defmodule MyApp.Helpers do
def create_user(opts \\ []) do
username = Keyword.get(opts, :username, "test_user")
password = Keyword.get(opts, :password, "p4ssw0rd")
{:ok, user} = MyApp.Accounts.signup_user(username, password)
end
def create_author(opts \\ []) do
user = Keyword.get_lazy(opts, :user, &signup_user/0)
{:ok, author} = MyApp.Profiles.create_author_profile(user)
end
end
```
In the `MyApp.Helpers` module above, we create wrappers over our application's core API with convenient defaults to use in tests. In real life, we wouldn't create users with the password `"p4ss0wrd"` by default, but for our test scripts, it's fine.
We also use `Keyword.get/3` to overwrite important attributes of the created resources. This avoids unnecessary side effects, especially when the caller provides us with a `user` to the `create_author/1` helper. That's why we use `Keyword.get_lazy/3` in the `create_author/1` helper. `get_lazy` will only invoke the `signup_user` function if the `:user` key doesn't exist.
### Invoking and Customizing Helpers in Elixir
We can also be strict with data patterns here since we don't expect the creation of users or authors to fail. The caller can invoke and customize these helpers for the needs of the test. For example:
```elixir
user = create_user(username: "test_user_2")
create_author(user: user)
```
When writing your tests, you can use the examples above and write something similar:
```elixir
# test/news/news_test.exs
# module definition and stuff
alias MyApp.Helpers
# maybe other tests in the middle
test "creates new post with given the contents" do
author = Helpers.create_author()
assert {:ok, post} = News.create_post("My first post!", author)
end
```
In the code above, we use `alias MyApp.Helpers` to make our helper module functions accessible with a few characters. It makes the use of these functions as convenient as the test factories provided by ExMachina.
A cool advantage of this approach is that if your editor uses a language server like [`ElixirLS`](https://github.com/elixir-lsp/elixir-ls), you can quickly discover or navigate these functions easily. The `build(:user)` pattern doesn't allow the editors of today to track the definition code directly.
### Breaking the Helpers Module Down Into Other Modules
As the `Helpers` module grows and gets more complex, you might want to break it down into different modules.
For example, you could break it down by context - `AccountsHelper`, `ProfilesHelpers`, etc. The best naming and file organization depends on each application's needs, so I'll leave it up to you.
The `Helpers` example discussed here might have left you thinking: "This looks like factories." And you're not wrong!
This is a different implementation of test factories. Instead of creating examples of data uncoupled with your application's rules, here we tie your application's rules and your test examples together.
It works like the factory pattern because your tests aren't coupled with the way the underlying struct is built.
This example satisfies the demands of the context modules layer, but what about the other layers? In the next section, we'll explore when using public APIs isn't enough and how to generate data examples for these cases.
## Beyond Public APIs: Data Examples
One of the main advantages of using your Elixir app's public API to generate data for your tests is that the data will comply with your app's rules and database constraints.
While the speed and coupling with the database may not always be ideal, this is a small price to pay to ensure your data's validity.
As your app grows in complexity, you may need to add a layer of tests that run in memory to improve performance. It is also not uncommon for systems to talk to other systems through network APIs. In these cases, your application likely won't have enough control over the rules to build valid data. You may need to rely on API specifications provided by the remote system and snapshot some examples to use in your tests.
Data examples built in memory and decoupled from database or application rules can be extremely helpful.
Let's explore a lightweight — and somewhat controversial — method of generating data examples within your application modules.
### Writing Data Examples in Data Definition Modules
Years ago, a colleague invited me to watch an episode of [Ruby Tapas presented by Avid Grimm](https://www.rubytapas.com/2015/09/17/episode-342-example-data/).
Inspired by the book [Practical Object-Oriented Design by Sandi Metz](https://www.poodr.com/), Grimm talks about writing data examples in the modules where the data definition lives. This can serve as executable documentation and also be used in tests.
Some people might not be big fans of mixing test data with application code. But, as long as it is clear that the data is meant as an example and not for production use, it can be a useful technique.
For example, let's say you're writing a `GitHub` client, and you're defining the `Repo` struct:
```elixir
# github/repo.ex
defmodule GitHub.Repo do
defstruct [
:id,
:name,
:full_name,
:description,
:owner_id,
:owner_url,
:private,
:html_url,
:url
]
@typespec t :: %__MODULE__{
id: pos_integer(),
name: String.t(),
full_name: String.t(),
description: String.t(),
owner_id: pos_integer(),
owner_url: String.t(),
private: boolean(),
html_url: String.t(),
url: String.t()
}
end
```
Here, we define the `GitHub.Repo` struct and document the keys type with `typespec`. While this provides a lot of information, extra documentation can help readers understand the data's nuances.
In this example, can you tell the difference between the `name` and `full_name`? Or `url` and `html_url`? It's hard to tell, right?
We can make it clearer. Let's add an example of the values:
```elixir
# github/repo.ex
def example do
%GitHub.Repo{
id: 1296269,
name: "Hello-World",
full_name: "octocat/Hello-World",
description: "This your first repo!",
owner_id: 1,
owner_url: "https://api.github.com/users/octocat",
private: false,
html_url: "https://github.com/octocat/Hello-World",
url: "https://api.github.com/repos/octocat/Hello-World"
}
end
```
Defining the `example/0` function, which returns an example of the data structure, can be useful in various ways.
For example, if you're exploring the code in IEx (the Elixir interactive shell), you could invoke the function to quickly experiment with a complex function call. Livebook material (interactive documents that allow users to run code) could use these functions to show an example of the data shape. In production, the example values could be used as hints for form fields.
### Customize Key Values of the `example` Function
One of the main purposes of an example function, however, is to create data for tests. You can make the `example` function even more useful by allowing the caller to customize the key values. Here's an example:
```elixir
def example(attributes \\ []) do
struct!(
%GitHub.Repo{
id: 1296269,
name: "Hello-World",
full_name: "octocat/Hello-World",
description: "This your first repo!",
owner_id: 1,
owner_url: "https://api.github.com/users/octocat",
private: false,
html_url: "https://github.com/octocat/Hello-World",
url: "https://api.github.com/repos/octocat/Hello-World"
},
attributes
)
end
```
We use Elixir's `struct!/2` kernel function to build structs dynamically. The great thing about `struct!` is that it fails if any unexpected keys are set. Now we can invoke the `example/1` function and customize the data in any way we want:
```elixir
test "renders anchor tag to the repository" do
repo = GitHub.Repo.example(html_url: "http://test.com")
assert hyperlink_tag(repo) =~ "<a href=\"http://test.com\""
end
```
In the example above, we can easily create a `GitHub.Repo` and customize its `html_url` key for our test.
### Similarities to Test Factories for Elixir
"Wait, isn't this just factories again?" you might be wondering. And you're right! It's similar to the factory mechanism found in other libraries.
While this can make the functions easy to navigate and localize using your editor, if you rename the `GitHub.Repo` module, you'll need to find and replace a bunch of tests. However, modern editors are usually powerful enough to handle the task in a single command, so this shouldn't be a big issue.
Another interesting aspect of providing data examples in your struct modules is that you don't need to organize your factory files, as they are organized together within your application code.
The popular ExMachina factories, your own helper functions that use your application's rules, and data example functions in your structs are all examples of factory pattern implementations.
### Using ExMachina
Using ExMachina to create your factories helps you separate
test data from production code and gives you convenient functions. For example, when you define a factory using ExMachina, you can use that definition to generate test data with different strategies, like:
- `build` to generate in-memory structs
- `insert` to load data in a database
- `build_list` to generate multiple items in a list
- `string_params_for` to create map params with keys as strings like you would receive in a Phoenix controller
These are a few examples of functions that ExMachina can offer — and it has more! The convenience of these functions is debatable, though. For example, having the `insert` function so conveniently available could make you unnecessarily insert things into a database. And how often do your controller parameters' keys and value formats match the schema attributes generated by the `string_params_for` to make it really worth it? However, these convenient functions do the job for simple cases and offer a foundation for your entire test suite.
## Up Next: Elixir Libraries for Test Data
Now that you understand the fundamental techniques for generating test data in Elixir, you should be able to do this for your own project without much trouble.
In the third and final part of this series, we'll dive into some Elixir libraries for your test data, including ExMachina, ExZample, Faker, and StreamData.
Happy coding!
**P.S. If you'd like to read Elixir Alchemy posts as soon as they get off the press, [subscribe to our Elixir Alchemy newsletter and never miss a single post](/elixir-alchemy)!** | ulissesherrera |
1,417,658 | A comparison of CSS handling in popular JS frameworks | Having been a Vue developer since the early Vue 2 versions has't prevented me from diving a bit... | 0 | 2023-03-28T13:58:54 | https://dev.to/vmoe/a-comparison-of-css-handling-in-popular-js-frameworks-2fim | vue, svelte, solidjs, css | Having been a Vue developer since the early Vue 2 versions has't prevented me from diving a bit deeper into a comparison of the trending new JS frameworks, especially Svelte and Solid which I both love for implementing the disappearing framework paradigm, pioneered by Svelte, refined by Solid, and announced to be available soon in Vue as well as Vapor mode. It's funny how so many developers say they prefer Svelte to the alternatives just because of it's elegant API, and Solid just because of the signals (available in Vue long before). Feels quite superficial to me ... But anyway, that's another story. Today I want to highlight one thing that in my opinion is a really strong argument to prefer Vue. Feel free to find it just as superficial ;-)
Imagine you have two components where one uses the other one. You want the root element of the consumed (child) component to come with an own class but be able to add classes from the consuming (parent) component
## Class merging in Vue
It is as simple as this in Vue
```vue
// ComponentA.vue
<script setup>
import ComponentB from './ComponentB.vue'
</script>
<template>
<ComponentB class="a" />
</template>
// ComponentB.vue
<template>
<div class="b">Hello B</div>
</template>
```
Will lead to the desired html
```html
<div class="a b"></div>
```
This happens thanks to the fact that any non-prop attribute passed to a component will be applied to the root tag of the used component plus some extra logic for the class attribute. It's worth noting that this behavior is highly customizable, for those who don't like it.
## CSS class merging in Svelte
If you try to do the same thing in Svelte, it simply won't work
```html
// ComponentA.svelte
<script>
import ComponentB from './ComponentB.svelte'
</script>
<ComponentB class="a" />
// ComponentB.svelte
<div class="b">Hello B</div>
```
Typescript tells you why (if you are using it)
`Type 'string' is not assignable to type 'never'`
In other words, `class` is not a prop key of `ComponentB`
So you would like to fix it like this
```html
// ComponentB.svelte
<script>
export let class;
</script>
<div class="b">Hello b</div>
```
But that doesn't work, `class` is a keyword in Javascript!
So what you have to do is change the prop name, let's follow a popular frameworks' naming:
```html
// ComponentA.svelte
<script>
import ComponentB from './ComponentB.svelte'
</script>
<ComponentB className="a" />
// ComponentB.svelte
<script>
export let className = '';
</script>
<div class="b">Hello b</div>
```
That still doesn't work (and wouldn't even work if `class` was not a keyword) since we have to merge the classes now.
I switch to typescript so that we don't forget to mention that in TS land you also have to tell the compiler it's a string, unless, as in this case, you have the empty string as default value and get inference as a nice side effect.
```html
// ComponentB.svelte
<script lang="ts">
export let className: string = ''
</script>
<div class={`${className} b`}>Hello b</div>
```
Quite some boilerplate, isn't it? Sure, if boilerplate does not scare you and you like the explicitness about where the props come from and where they go, no problem. But what if you have to consume someone else's component, imagine `ComponentB` coming from a library and having to author `ComponentA`. You can sure say that a component library that does not offer any API to add CSS classes to its components is flawed and that pull requests and issues can be filed, but this is always a slow process.
## CSS class merging in Solid
The situation here is not essentially different from Svelte.
```tsx
const ComponentB = (props: { class?: string }) => {
return <div class={`${props.class || ''} b`}>Hello b</div>
}
const ComponentA = () => {
return <ComponentB class="a" />
}
```
At least we may call it `class` here.
## The solutions in a popular component library
The same problem applies to the style attribute for both Svelte and Solid (and also React, by the way), whereas Vue again smartly auto-merges with well defined behavior.
In MUI, the popular React material components library, the customization problem for inline styles is solved with the `sx` property. But try to add a class to the root element to an MUI component ... not so straight forward.
## Conclusion
If you, like me, think that speed of development when adding classes to html tags is more important than having total explicitness about the props that determine the CSS of your components at the price of more boilerplate, you should consider this an important difference when choosing your framework for your next web app. Personally, I have never experienced that it was hard to debug where CSS classes or styles came from in Vue apps, so I can't imagine any benefit in doing it the way other frameworks do it.
| vmoe |
1,417,670 | Introducing Genez-io: An Exciting New Open Source Project! 🚀 | Hello, I hope you're all having a fantastic day! Today, I'd like to introduce you to a new... | 0 | 2023-03-28T12:01:22 | https://dev.to/radu1122/introducing-genez-io-an-exciting-new-open-source-project-bdc | webdev, javascript, programming, productivity | Hello,
I hope you're all having a fantastic day!
Today, I'd like to introduce you to a new open-source project I've been working on called Genezio. I believe this project has great potential to make a significant impact, and I would love to have your support and input as we develop it further.
🔗 Check it out here: https://github.com/Genez-io/genezio
📢 Spread the word! If you find the project interesting, please consider giving it a star ⭐ on GitHub and sharing it with your friends, colleagues, and networks. The more people know about Genezio, the more successful and beneficial it can become! | radu1122 |
1,417,795 | Retooling for Success: How I Made the Transition to Software Development in My 30s | Hi there, I'm Tia, and I'd like to share with you my journey of becoming a software developer.... | 0 | 2023-03-29T08:31:37 | https://www.tiaeastwood.com/how-i-made-the-transition-to-software-development-in-my-30s | career | ---
title: Retooling for Success: How I Made the Transition to Software Development in My 30s
published: true
date: 2023-03-28 10:42:04 UTC
tags: career
canonical_url: https://www.tiaeastwood.com/how-i-made-the-transition-to-software-development-in-my-30s
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/t0c8j6yo1cwr4m3iwyr9.png
---
Hi there, I'm Tia, and I'd like to share with you my journey of becoming a software developer.
Growing up, I was always a creative kid. I loved to draw and make things and that's what I was good at. In fact, it was the only thing I \*thought\* I was really good at. In the back of my mind, I always had an interest in technology too, but I never thought of pursuing it as a career. Instead, I pursued a degree in Illustration with Animation and embarked on following my dream of being an illustrator and product designer. I enjoyed making freelance art and designing products for my online shop and comic con artist booth, but ultimately it was hard to make a living that way. I was also fiercely independant and spent many years working in jobs I hated in order to pay the rent and not have to rely on anyone. Over time I became exhausted and, deep down, I knew something was missing.
As I entered my thirties, I started to feel restless. I had no career really to speak of and I began to question whether I was truly fulfilled in my life. Eventually 2020 rolled around and Covid creeped onto the scene. I took this as a sign to shake things up and, with the support of my amazing partner, I decided to take a leap of faith and follow my other passion for technology. I started by learning coding on my own, watching online tutorials, reading books, and practicing every chance I got. Making something from code, was the most creative I'd ever felt. The more I learned, the more excited I became about the possibilities that software development offered.
I was determined to make a career change, but I knew it wouldn't be easy. I was older than most people who were starting out in the field, and I lacked a computer science degeree or any relevant experience. However, I didn't let that discourage me. Instead, I worked harder than ever before. I quit my call center job and threw myself into learning full time, enrolling in a 14-week coding bootcamp to quickly get up to speed. Bootcamp wasn't easy because, due to the Covid lockdown, we had to complete it entirely remotely...little did I know though that this would be very useful practice for the future.
I also reached out to people on social media and shared my journey. It's a good technique to "learn in public". What I mean by that is by sharing your challenges and achievements with other people, you're holding yourself accountable. Also the support and encouragement I received from other people was invaluable to me.
Finally, my hard work paid off. After graduating from bootcamp, I landed my first job as a software developer, and I couldn't have been happier. I was very nervous and didn't have a lot of confidence in myself to begin with. I battled with imposter syndrome, but I had to try and keep thinking back to how hard I worked to get here. Of course, you also have to remain humble and remember that you'll never know it all; there's always something new to learn in a career as a software developer, but that's what makes it so exciting to me.
Looking back, I'm so grateful that I took that leap of faith and pursued my passion for technology. It was scary at first, but it's been so rewarding. I hope my story inspires others who may be considering a career change later in life. It's never too late to follow your dreams and pursue what truly makes you happy. | tiaeastwood |
1,417,969 | MySQL Date Compare | This article describes various methods for comparing date and time values in MySQL -... | 0 | 2023-03-28T16:36:42 | https://dev.to/devartteam/mysql-date-compare-1ml2 | mysql, database, dbforge, datecompare | This article describes various methods for comparing date and time values in MySQL - https://jordansanders.medium.com/mysql-date-compare-973691343c70
 | devartteam |
1,417,982 | Guide to Open-source contributions | Introduction Behind every successful Open-source project, is a dedicated team of... | 0 | 2023-03-28T16:54:16 | https://dev.to/iqra_firdose/guide-to-open-source-contributions-1d5l | ---
title: Guide to Open-source contributions
published: true
cover_image: "https://cdn.hashnode.com/res/hashnode/image/upload/v1679252949300/937b3e92-e37c-480e-a593-f6eb32183ebb.jpeg?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp"
date: 2023-03-19 18:44:32 UTC
tags:
canonical_url:
---
# Introduction
Behind every successful Open-source project, is a dedicated team of contributors and maintainers who help make it happen. Open-source projects have been streaming nowadays. Open-source contribution is a great initiative to learn and apply your knowledge. This article discussed open-source, benefits, and ways to contribute.
# What is Open-source contribution?
An open-source project is one whose source code and documentation that is licensed are freely accessible to the public. Anyone, not just software engineers and developers, can modify, study, and improve the project, and anyone, not just software engineers and developers, can contribute to open-source projects.
# Perks of Open-source contribution
There are many perks of contributing to open-source projects, some of which include:

-> With open-source contributions, you are applying your knowledge to real-world applications.
-> Contributing to open-source projects helps to build a portfolio of work that showcases your skills, as it allows you to showcase the open-source project that you added value to through your contributions.
-> It helps to improve your skills, by open-source contributions you will gain exposure to new technologies and tools.
-> By contributing to open-source projects, you'll have the opportunity to connect with other developers and members of the open-source community.
> Open-source contributions= Collaboration + contribute
-> Open-source contributions give access to learning new technologies. By open-source contributions, you can stay up to date with new technologies.
-> Some open-source programs will pay you for contributions.
-> With Open-source contributions, You can help others by resolving their doubts and solving their bugs.
-> Open-source is all about giving back to the community. You will get a chance to be a part of these amazing communities with open-source contributions.
Overall, contributing to open-source projects will benefit professional development.
# **How to contribute to open-source projects?**
1. Choose a project and understand it: First, you need to identify an open-source project that you're interested in that matches your skillset.
2. Read the documentation and follow the guidelines: Once you've found a project, read the project's documentation thoroughly to understand how the project works and what contributions are needed.
3. Look for issues: Most open-source projects have a list of issues. Issues refer to the available problems that are placed in an open-source repository so that you can solve the problem or you can create new issues if you find any problem or you want to add a new feature to it and you want to solve that problem.
4. Fork the project: Fork the project to create a copy of the project in your GitHub account that you can work on.
5. Make your changes: Once you've identified an issue, make changes to the project.
6. Create a pull request: Create a pull request to the project explaining the changes you made and why they're necessary. Then the maintainer(admin) of the project checks your pull request and if it finds it useful then the maintainer merges(accepts) the pull request.
By following these steps, you can contribute to open-source projects.
# Ways to contribute to open-source contributions
There are several ways to contribute to open-source contributions. Some of them are:

**Code Contributions** : You can contribute to the code of the project. You can add a new feature to it or you can solve bugs by writing the code.
**Documentation contributions** : This involves writing or updating documentation for the project, such as adding examples, improving the read-me file, or fixing errors.
**Designing:** You can contribute to the project with the UI design of the project or you can help them in designing posters or social media visuals designs.
**Testing:** You can contribute to open-source projects as a tester as well. you can test the application, documents of a project, or anything where you want to contribute. You help them find bugs in their product/application by providing an explanation of the bug and helping fix problems.
**Reviewing Pull requests:** As lots of PR is made, you can help them by reviewing PRs and correcting them with the contributor.
**Community contributions:** It involves helping people to contribute and answering their questions and organizing events for the communities.
By contributing in any of these ways, you will access the perks of open-source contributions.
# Conclusion
open-source projects have transformed the way we develop, use, and share technology. By providing free access to the source code and encouraging collaboration and innovation, open-source projects have helped to create a more inclusive technology landscape.
Contributing to open-source projects offers many benefits, including gaining new skills, building a portfolio, making connections, and contributing to the community. By participating in open-source projects, you can not only improve your own knowledge and experience but also make a positive impact on the project and the people around you.
I hope you will find this blog insightful. Let me know in the comments, have you started with an open-source contribution.
Thank you for reading this blog, if you found it useful, you can like and comment and follow us.
### Connect with me:
- [All links](https://linkfree.eddiehub.io/iqrafirdose)
- [Twitter](https://twitter.com/iqra_firdose)
- [Linkedin](https://www.linkedin.com/in/iqrafirdose/) | iqra_firdose | |
1,418,014 | An Intro into UIKit & SwiftUI: Building a Simple Login Screen with Both Frameworks | User interfaces are the gateway between users and your app, making it essential to create visually... | 0 | 2023-03-31T17:36:59 | https://ogtongm.medium.com/an-intro-into-uikit-swiftui-building-a-simple-login-screen-with-both-frameworks-9ed3d5e23622 | swift, ios, mobile, beginners | ---
canonical_url: https://ogtongm.medium.com/an-intro-into-uikit-swiftui-building-a-simple-login-screen-with-both-frameworks-9ed3d5e23622
---
User interfaces are the gateway between users and your app, making it essential to create visually appealing and user-friendly experiences. In this article, we'll explore UIKit and SwiftUI, two powerful UI frameworks used in iOS development. We'll discuss the pros and cons of each framework and look into their future in the ever-evolving landscape of iOS development. With UIKit, you have the option to build UI using Interface Builder (including Storyboards) or programmatically. In this article, we'll focus on creating a simple login screen using UIKit (programmatically) and SwiftUI. Let's dive in and learn more about these UI frameworks and how essential they are in iOS Development.
---
## UIKit: A Versatile Framework for iOS Apps
UIKit has been the go-to framework for building user interfaces on iOS devices since its inception. It provides a wide array of UI components and a comprehensive event-handling system to support fluid user interactions. UIKit provides developers with two primary methods for crafting UIs: employing Interface Builder in conjunction with Storyboards or XIB files, or constructing the UI through code.
Interface Builder, an integral visual tool within Xcode, allows developers to devise their app's interface using a convenient drag-and-drop system. This option is particularly appealing to those who favor a visual approach to UI design. The layout information is stored in two file types: Storyboards and XIB files. Storyboards excel at outlining an app's entire flow, while XIB files are more appropriate for individual screens or reusable views.
Nonetheless, in real-life projects, especially when collaborating with a team, utilizing Interface Builder alongside Storyboards can prove to be unwieldy and difficult to manage. As a result, numerous developers and companies choose to create their UIs programmatically. This approach offers more control and flexibility, leading to more maintainable and scalable code in the long run.
Now that we have a basic understanding of UIKit and its two primary methods for creating UIs, let's dive into building a simple login screen using this framework programmatically.
## Building a Simple Login Screen Programmatically with UIKit
We'll be focusing on the essential components: username/email, password, and a login button.
Here's a detailed breakdown with code snippets:
### Step 1.
- Open Xcode and create a new project
- Choose "App" as the template, and click "Next"
- Fill in the required information and depending on your Xcode version make sure either "UIKit" or "Storyboard" is selected as the interface
- Click "Create" to generate your project
In `ViewController.swift`, make sure you have UIKit imported:
```swift
import UIKit
```
This line imports the UIKit framework, which provides the core functionality required to build user interfaces for iOS apps.
### Step 2.
Inside the ViewController class, let's create our UI components as properties:
{% gist https://gist.github.com/matthewogtong/1f811984124af8e002beea36f3814cbc %}
In this step, we put together three UI elements: an input field for email or username, another input field for the password, and a login button. We use closures to initialize these elements and adjust their individual attributes to fit our design.
### Step 3.
Set up the UI components in the `viewDidLoad()` method:
{% gist https://gist.github.com/matthewogtong/1f811984124af8e002beea36f3814cbc %}
In this step, we set up the UI components inside the `viewDidLoad()` method. We add the subviews to the main view and set up Auto Layout constraints to position and size them appropriately.
### Step 4.
Build and run the project. You should now see a simple login screen with an email or username input field, a password input field, and a login button:
---
Before moving on to building the same screen with SwiftUI, let's take a moment to evaluate some of UIKit's pros and cons. This will give you a better understanding of the trade-offs and benefits of using UIKit for your iOS projects.
### Pros:
- **Mature and stable**: UIKit has a long history, making it a well-tested and reliable framework.
- **Extensive resources**: Comprehensive documentation and a wealth of resources make it easier to find solutions and support.
- **Broad compatibility**: UIKit is supported on all iOS versions and devices, ensuring maximum reach for your app.
### Cons:
- **More boilerplate code**: UIKit typically requires more boilerplate code compared to SwiftUI.
- **Verbosity**: The code can be harder to understand and maintain due to its verbosity.
- **Shift in focus**: As Apple prioritizes SwiftUI, UIKit may see fewer updates related to modern UI paradigms.
## SwiftUI: A Modern Approach to UI Building
SwiftUI is Apple's newest UI framework, introduced in 2019. Unlike UIKit, SwiftUI is a declarative framework built on the Swift language, allowing for a more modern and streamlined approach to UI development. With SwiftUI, developers write less code, and the code is more readable, making the development process more efficient.
As you work with SwiftUI, you'll notice a significant difference in the way UI is constructed compared to UIKit. Rather than relying on Interface Builder or crafting code programmatically, SwiftUI enables you to outline the UI's organization and actions with clear, expressive syntax. This method is more comprehensible and approachable for developers at any skill level.
SwiftUI also incorporates numerous integrated features that enhance the UI development process, including real time previews, automatic compatibility with accessibility features, and innate support for Dark Mode and localization.
Next, we'll construct an identical login screen utilizing SwiftUI. After that, we'll examine the differences in working with SwiftUI as opposed to UIKit.
## Building a Simple Login Screen with SwiftUI
When setting up the project, follow the same steps as we did for the UIKit project, but ensure that you choose the "SwiftUI" interface during project creation. After the project is established, we can directly proceed to the ContentView file. SwiftUI greatly simplifies the process of designing user interfaces, and you'll soon discover how effortless it is to build this login screen using SwiftUI's declarative syntax.
{% gist https://gist.github.com/matthewogtong/5f5693d3265c6f24c2fe5f7f1d86d6d6 %}
In this code snippet, we initiate a `VStack`, setting a 20-point spacing between each component. Within the `VStack`, we include three different types of views: two text fields and a login button. Both `TextField` and `SecureField` employ the `RoundedBorderTextFieldStyle()` view modifier, defining a frame size of 200x40 points. View modifiers allow us to apply styling or add behavior to a view in a concise and reusable manner.
The `Button` view features a blue background, white text, and a 5-point corner radius, achieved by applying corresponding view modifiers. Lastly, we incorporate a `Spacer()` at the end of the `VStack`, which pushes the elements toward the top of the screen. To position these elements, we add a 100-point padding from the top.
After seeing the SwiftUI code in action, you might have noticed the live preview provided by the SwiftUI Previews feature. SwiftUI Previews have come a long way since their introduction, and they've become an incredibly convenient and efficient tool for developers. As you write your SwiftUI code, the preview updates in real-time, allowing you to see the changes without having to build and run the entire app. This drastically reduces the time spent on iterating UI designs and provides a smoother development experience, enabling you to focus on crafting the perfect interface for your users.
And there you have it! We've constructed the same login screen using SwiftUI, achieving a concise and comprehensible result.
SwiftUI, though a fairly recent addition, has already made a considerable impression in the realm of iOS development. Let's take a moment to consider some advantages and drawbacks of this framework.
### Pros:
- **Unified codebase across platforms**: SwiftUI enables developers to produce a single codebase that works on various Apple platforms, including iOS, macOS, watchOS, and tvOS, streamlining the development process.
- **Declarative syntax**: SwiftUI's declarative syntax simplifies UI code, enhancing readability and maintainability, which proves advantageous in team-based settings.
- **Built-in modern features**: SwiftUI offers innate support for contemporary features like dark mode, accessibility, and localization, saving time and effort when incorporating these aspects into real projects.
### Cons:
- **Rate of adoption**: While SwiftUI is gaining popularity, numerous companies still rely on UIKit for their UI construction, which implies developers may need to familiarize themselves with both frameworks.
- **Limited compatibility**: SwiftUI is available only for iOS 13 and later, which can be a drawback for projects that need to support older iOS versions.
- **Growing pains**: As a newer framework, SwiftUI's API coverage and resources are still evolving, and developers may encounter occasional limitations or need to find workarounds.
## Conclusion
As someone who has worked with both UIKit and SwiftUI, I've found that each framework comes with its own set of strengths and weaknesses. In my personal experience, I have grown to love working with SwiftUI for its modern, cross-platform, and declarative approach to UI development. However, I still believe that learning UIKit first was a valuable step in my journey as an iOS developer.
In today's job market, it's essential to have a solid understanding of both frameworks. UIKit remains widely used in existing projects, while SwiftUI is quickly gaining popularity for newer projects. As a junior iOS developer, mastering both frameworks will not only make you more versatile but also increase your value to potential employers.
As you continue on your iOS development journey, I encourage you to experiment with both UIKit and SwiftUI to find your preferences and strengths. Embrace the challenges that each framework brings, and grow through those experiences. Good luck, and happy coding!
---
## Resources
{% embed https://developer.apple.com/documentation/uikit %}
{% embed https://developer.apple.com/xcode/swiftui/ %}
| matthewogtong |
1,418,252 | OMG I never updated | It has been about a MONTH since I've been on here last! I am definitely learning a lot, and feel like... | 0 | 2023-03-28T22:32:59 | https://dev.to/jaychan0125/omg-i-never-updated-3nji | webdev, beginners | It has been about a MONTH since I've been on here last! I am definitely learning a lot, and feel like I'm on a roller coaster, its sooo fast-paced! I've since learned HTML, CSS, JavaScript vanilla, and we're just starting out on web APIs now! Where has the time gone!
I'm wondering if anyone has any tips on how to practice though? Like I've also started to do WesBos's JavaScript30 when I have the time(read: when I'm not crying over my weekly challenges). But even with what I've learned so far it's still hard to follow/understand the logic behind what is happening even though I am familiar with some of what he is doing as I follow along? At this point, I'm just hoping the exposure to more stuff is gunna eventually help/look more familiar to me down the road! | jaychan0125 |
1,418,424 | Article: Why Trust and Autonomy Matter for Cloud Optimization | I recently sat down with The New Stack and their editor, Richard Gall about the importance of... | 0 | 2023-03-29T03:52:01 | https://dev.to/swharr/article-why-trust-and-autonomy-matter-for-cloud-optimization-3m51 | I recently sat down with The New Stack and their editor, Richard Gall about the importance of trusting your DevOps team to do what they do best.
[You can read the article here!](https://thenewstack.io/why-trust-and-autonomy-matter-for-cloud-optimization/) | swharr | |
1,418,563 | What is Web Services in automation ? | Web Services in automation refer to a set of technologies and protocols that enable communication and... | 0 | 2023-03-29T05:42:15 | https://dev.to/vershatravadi/what-is-web-services-in-automation--1g6l | testing | Web Services in automation refer to a set of technologies and protocols that enable communication and data exchange between different applications and systems over the web. It is a way for different software applications to communicate with each other over a network using a standard set of protocols and formats.
Web Services are typically implemented using XML (Extensible Markup Language) or JSON (JavaScript Object Notation) as a data format and communicated via HTTP (Hypertext Transfer Protocol). They are often used in automation testing to simulate user interactions with a web application or to automate the interaction between different software applications or systems.
Web Services in automation testing can be tested using various tools and frameworks such as SoapUI, Postman, and REST-Assured. By testing web services, automation testers can validate the functionality of the APIs and ensure that the APIs are working as expected. Additionally, automated testing of web services can help identify and prevent issues before they impact the production environment. You can even check in-depth and Upskill yourself test automation strategies, methodology and its concepts includes training on Continuous Testing in DevOps, Performance Testing using JMeter from [Automation testing course](https://www.edureka.co/masters-program/automation-testing-engineer-training).
**Web services have numerous advantages, including:**
**Interoperability:** Web services allow different applications and systems to communicate with each other regardless of the programming languages, operating systems, or platforms they are built on.
**Platform independence:** Web services are built using open standards, which make them platform-independent. This means that they can be accessed and used from any platform or device that has internet connectivity.
**Reusability:** Web services are designed to be modular and reusable, which means that they can be used in multiple applications and systems, reducing development time and costs.
**Scalability:** Web services are highly scalable, which means that they can handle a large number of requests and transactions without compromising their performance.
**Reduced integration costs:** Web services reduce integration costs by providing a standard interface for communication between different applications and systems.
**Security:** Web services are secure and provide mechanisms for authentication, authorization, and encryption to ensure the confidentiality and integrity of data exchanged between systems.
**Faster development:** Web services accelerate development by providing pre-built functions and components that can be easily integrated into applications and systems.
Overall, web services are a powerful technology that enables efficient and effective communication between disparate systems, applications, and platforms. | vershatravadi |
1,418,604 | Convert HTML Form Data into PDF in PHP | PHP is a server-side programming language that is widely used for web development. One of the most... | 0 | 2023-03-29T07:14:10 | https://dev.to/vishwas/convert-html-form-data-into-pdf-in-php-50lg | mpdf, php, form, programming | PHP is a server-side programming language that is widely used for web development. One of the most common use cases of PHP is to process and store form data submitted by users. In many cases, it is necessary to convert the form data into a more usable format, such as a PDF document. In this article, lets explore how to use PHP to convert form data to PDF.
## Step 1: Install a PDF library
The first step is to install a PHP library that can be used to generate PDF documents. There are several popular libraries available, such as TCPDF, FPDF, and mPDF. For this article, we will be using mPDF, which is a free and open-source library that is widely used for generating PDF documents in PHP.
To install mPDF, you can download the latest version from the [Github](https://github.com/mpdf/mpdf) (https://github.com/mpdf/mpdf) or using composer and copy the folder to your web server.
## Step 2: Create a form
The next step is to create a form that will allow users to input the data that will be converted to a PDF. In this example, we will create a simple form that collects the user's name, email address, and message.
```
<form method="post" action="process_form.php">
<label>Name:</label>
<input type="text" name="name"><br>
<label>Email:</label>
<input type="email" name="email"><br>
<label>Message:</label>
<textarea name="message"></textarea><br>
<input type="submit" value="Submit">
</form>
```
## Step 3: Process the form data
Once the form has been submitted, the form data must be processed and converted into a PDF document. To do this, we will create a PHP script called process_form.php.
```
<?php
$path = (getenv("MPDF_ROOT")) ? getenv("MPDF_ROOT") : __DIR__;
require_once $path . "/vendor/autoload.php";
$pdfcontent = '<table class="form-data"><thead><tr> </tr></thead><tbody>';
foreach($_POST as $key =>$value){
$pdfcontent .= "<tr><td>" . ucwords(str_replace("_", " ",$key)) . "</td>:<td>" . $value . "</td></tr>";
}
$pdfcontent .= "</tbody></table>";
$mpdf = new \Mpdf\Mpdf();
$mpdf->WriteHTML(utf8_encode($pdfcontent));
$mpdf->Output('formdata.pdf', 'D');
?>
```
The process_form.php script first includes the mPDF library using the require_once statement. It then retrieves the form data using the $_POST superglobal array. With the posted data, it creates a HTML table. The script then creates a new mPDF object, write the HTML content, and outputs the form data to the PDF document. Finally, it lets you download the generated PDF by passing 'D' as a parameter in the Output method.
| vishwas |
1,418,656 | How do you keep yourself motivated and passionate about coding? | I've been dealing with loss of motivation and passion for quite some time (almost a year ^_^'), to... | 0 | 2023-03-29T08:26:23 | https://dev.to/nombrekeff/how-do-you-keep-yourself-motivated-and-passionate-about-coding-2c0a | help, career, programming, health | I've been dealing with loss of motivation and passion for quite some time (almost a year ^_^'), to the point where I'm leaving my job in a week to focus on other passions and interests, though I really like coding and everything around it. I would love to get back into it in the near future after resting for a bit.
I'm interested in knowing what you do to keep on top of this. What are some of the methods and things you do to not burnout or lose motivation? How do you not get bored of the job?
> _Photo by <a href="https://unsplash.com/@vargasuillian?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Uillian Vargas</a> on <a href="https://unsplash.com/photos/7oJpVR1inGk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>_
| nombrekeff |
1,418,679 | Wednesday Links - Edition 2023-03-29 | Disallowing the dynamic loading of agents by default (1... | 6,965 | 2023-03-29T09:17:36 | https://dev.to/0xkkocel/wednesday-links-edition-2023-03-29-3lja | java, jvm, profiling, spock | Disallowing the dynamic loading of agents by default (1 min)✋
https://mail.openjdk.org/pipermail/serviceability-dev/2023-March/046868.html
Spring Data and Spring Data Neo4j join the "No OFFSET Movement!" (8 min)🛑
https://info.michael-simons.eu/2023/03/20/spring-data-and-spring-data-neo4j-join-the-no-offset-movement/
The Speed Test: Comparing Map.of() and new HashMap<>() in Java (5 min)🚄
https://foojay.io/today/speed-test-comparing-map-of-new-hashmap/
Writing a Profiler in 240 Lines of Pure Java (13 min)🩺
https://mostlynerdless.de/blog/2023/03/27/writing-a-profiler-in-240-lines-of-pure-java/
Context Propagation with Project Reactor 1 - The Basics (10 min)🌊
https://spring.io/blog/2023/03/28/context-propagation-with-project-reactor-1-the-basics
Spocklight: Assert Elements In Collections In Any Order (2 min)🛂
https://blog.mrhaki.com/2023/03/spocklight-assert-elements-in.html | 0xkkocel |
1,418,857 | Concurrency in Go | Concurrency has become a critical feature in modern software development, allowing programs to handle... | 0 | 2023-03-29T11:49:07 | https://dev.to/imkiptoo/concurrency-in-go-2ibf | go, concurrency, programming | Concurrency has become a critical feature in modern software development, allowing programs to handle multiple tasks simultaneously and efficiently. Go, also known as Golang, is a popular programming language designed by Google, with concurrency built into its core. In this article, we will explore the basics of concurrency in Go, including goroutines, channels, and synchronization primitives.
## Goroutines
Goroutines are the cornerstone of Go's concurrency model. They are lightweight, independently executable functions that can run concurrently with other goroutines. Goroutines are similar to threads in other programming languages, but they are more efficient and easier to manage.
To create a goroutine, you simply prepend the `go` keyword before a function call. For example, the following code snippet creates a goroutine that prints "Hello, World!" in the background while the main program continues to execute:
```go
func main() {
go fmt.Println("Hello, World!")
fmt.Println("This is the main program.")
}
```
When you run this program, you should see the output:
```text
This is the main program.
Hello, World!
```
The `go` keyword tells Go to start a new goroutine and execute the function `fmt.Println("Hello, World!")` in the background. The main program continues to execute without waiting for the goroutine to finish.
You can create as many goroutines as you need in your program, and they will all run concurrently. Goroutines are cheap to create and use very little memory, so you can create thousands or even millions of them if necessary.
## Channels
Goroutines are great for concurrency, but they still need a way to communicate with each other. Channels are a built-in data structure in Go that provides a safe and efficient way for goroutines to communicate.
A channel is like a pipe that connects two goroutines. One goroutine can send values into the channel, and another goroutine can receive those values from the channel. Channels are safe for concurrent access, which means multiple goroutines can use the same channel without causing race conditions.
To create a channel, you use the `make` function with the `chan` keyword and a type specifier. For example, the following code snippet creates a channel of integers:
```go
ch := make(chan int)
```
You can send values into a channel using the `<-` operator. For example, the following code snippet sends the value 42 into the channel `ch`:
```go
ch <- 42
```
You can receive values from a channel using the `<-` operator as well. For example, the following code snippet receives a value from the channel `ch` and stores it in the variable `x`:
```go
x := <-ch
```
If there are no values in the channel, the receive operation blocks until a value is available. This allows goroutines to synchronize and communicate with each other without the need for explicit synchronization primitives.
## Buffered Channels
By default, channels in Go are unbuffered, which means they can only hold one value at a time. When a goroutine sends a value into an unbuffered channel, it blocks until another goroutine receives that value. Similarly, when a goroutine receives a value from an unbuffered channel, it blocks until another goroutine sends a value.
Buffered channels are channels that can hold multiple values at a time. They allow goroutines to communicate asynchronously without blocking. To create a buffered channel, you specify a buffer size when you create the channel. For example, the following code snippet creates a buffered channel of integers with a buffer size of 10:
```go
ch := make(chan int, 10)
```
You can send values into a buffered channel as long as the buffer is not full. The send operation blocks until space becomes available. Similarly, you can receive values from a buffered channel as long as the buffer is not empty. If the buffer is empty, the receive operation blocks until a value is sent into the channel.
Buffered channels are useful for improving the performance of concurrent programs by reducing the amount of blocking and context switching between goroutines. However, you should be careful when using buffered channels because they can cause goroutines to deadlock if they are not used correctly.
## Select Statement
The select statement is a powerful feature of Go that allows you to handle multiple channel operations at once. It lets you wait for one or more channels to become ready for send or receive operations and then execute the corresponding code block.
The select statement looks like a switch statement, but instead of testing a variable, it tests multiple channels. Each case in the select statement represents a channel operation, and the default case is executed if none of the other cases are ready.
Here's an example of how to use the select statement to handle two channels:
```go
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
ch1 <- 42
}()
go func() {
ch2 <- 100
}()
select {
case x := <- ch1:
fmt.Println("Received from ch1:", x)
case x := <- ch2:
fmt.Println("Received from ch2:", x)
}
```
In this example, two goroutines are started that send values into `ch1` and `ch2`. The select statement waits for either `ch1` or `ch2` to become ready for a receive operation, and then executes the corresponding case block. In this case, the value sent into `ch1` is received first, so the first case block is executed, and the output is "Received from ch1: 42".
The select statement can also be used with the `default` case to handle situations where none of the channels are ready. For example:
```go
ch1 := make(chan int)
ch2 := make(chan int)
select {
case x := <- ch1:
fmt.Println("Received from ch1:", x)
case x := <- ch2:
fmt.Println("Received from ch2:", x)
default:
fmt.Println("No channels ready.")
}
```
In this example, neither `ch1` nor `ch2` have any values to receive, so the default case is executed, and the output is "No channels ready.".
## Synchronization Primitives
While channels are great for communication between goroutines, sometimes you need more fine-grained control over the synchronization of your program. Go provides several built-in synchronization primitives, including mutexes, read-write mutexes, and atomic operations.
### Mutexes
A mutex is a mutual exclusion lock that allows only one goroutine to access a shared resource at a time. Mutexes are used to protect critical sections of code to prevent race conditions and ensure that only one goroutine modifies a shared resource at a time.
To use a mutex in Go, you first create a new mutex using the `sync.Mutex` type. Then you can use the `Lock` and `Unlock` methods to acquire and release the mutex, respectively. For example:
```go
var mutex sync.Mutex
func someFunction() {
mutex.Lock()
defer mutex.Unlock()
// critical section of code
}
```
In this example, the `Lock` method acquires the mutex, and the `Unlock` method releases it. The `defer` statement ensures that the `Unlock` method is called even if the critical section of code panics or returns early.
### Read-Write Mutexes
A read-write mutex is a type of mutex that allows multiple goroutines to read a shared resource at the same time but only allows one goroutine to write to the resource at a time. This is useful when you have a resource that is frequently read but only occasionally written.
To use a read-write mutex in Go, you create a new mutex using the sync.RWMutex type. Then you can use the `RLock` and `RUnlock` methods to acquire and release the read lock, and the `Lock` and `Unlock` methods to acquire and release the write lock, respectively. For example:
```go
var rwMutex sync.RWMutex
var sharedResource = 42
func readFunction() {
rwMutex.RLock()
defer rwMutex.RUnlock()
// read from sharedResource
}
func writeFunction() {
rwMutex.Lock()
defer rwMutex.Unlock()
// write to sharedResource
}
```
In this example, the `RLock` method acquires a read lock, and the `RUnlock` method releases the read lock. The `Lock` method acquires a write lock, and the `Unlock` method releases the write lock. Multiple goroutines can acquire a read lock simultaneously, but only one goroutine can acquire a write lock at a time.
### Atomic Operations
Atomic operations are operations that are performed atomically, meaning they are executed as a single, indivisible step. In Go, atomic operations are provided by the `sync/atomic` package and are used to safely modify shared variables without the need for locks or other synchronization primitives.
The `sync/atomic` package provides several functions for performing atomic operations, including `AddInt32`, `AddInt64`, `LoadInt32`, `LoadInt64`, `StoreInt32`, and `StoreInt64`. For example:
```go
var sharedVariable int64 = 0
func incrementFunction() {
atomic.AddInt64(&sharedVariable, 1)
}
```
In this example, the `AddInt64` function increments the value of `sharedVariable` atomically, without the need for a lock. The `&` operator is used to pass the address of `sharedVariable` to the function.
## Conclusion
Concurrency is a critical feature in modern software development, and Go's built-in support for concurrency makes it an excellent choice for building highly concurrent and scalable applications. Goroutines, channels, and synchronization primitives are powerful tools that allow you to write highly concurrent programs that can handle multiple tasks simultaneously and efficiently.
In this article, we explored the basics of concurrency in Go, including goroutines, channels, and synchronization primitives. We also discussed how to use the select statement to handle multiple channel operations at once and how to use mutexes, read-write mutexes, and atomic operations for fine-grained control over synchronization.
While Go's concurrency model is powerful and easy to use, it can still be challenging to write correct and efficient concurrent programs. You should be aware of the potential pitfalls of concurrent programming, such as race conditions, deadlocks, and livelocks, and use best practices, such as avoiding shared mutable state and using idiomatic Go code, to avoid these problems.
Overall, Go's support for concurrency makes it an excellent choice for building highly concurrent and scalable applications, and mastering concurrency in Go is an essential skill for any modern software developer.
Happy Coding! | imkiptoo |
1,419,203 | New to community, looking for help to learn React Js | I'm looking for someone who can help me learn react Js faster. Request to help me... | 0 | 2023-03-29T14:30:49 | https://dev.to/gowtham_aripirala/new-to-community-looking-for-help-to-learn-react-js-1m5c | I'm looking for someone who can help me learn react Js faster.
Request to help me... | gowtham_aripirala | |
1,419,284 | Integração Contínua e Deploy Automatizado para Aplicações em Angular, Laravel e MySQL na Hostinger | Neste artigo, vamos explorar como criar um arquivo ci.yml para integração contínua de uma aplicação... | 0 | 2023-03-29T15:45:01 | https://dev.to/rvlyra/integracao-continua-e-deploy-automatizado-para-aplicacoes-em-angular-laravel-e-mysql-na-hostinger-3pd8 | integraçãocontínua, deployautomatizado, angular, laravel | Neste artigo, vamos explorar como criar um arquivo ci.yml para integração contínua de uma aplicação construída com Angular 14 no front-end, Laravel 9 e PHP 8.1 no back-end, banco de dados MySQL 8.30, arquivo de log em texto e um arquivo cd.yml para deploy automatizado em hospedagem compartilhada Hostinger. Com essas configurações, você pode automatizar o processo de construção, teste e implantação de sua aplicação e garantir a qualidade de sua entrega contínua.
Você quer automatizar a integração contínua e o deploy da sua aplicação em Angular, Laravel e MySQL na Hostinger? Então você está no lugar certo! Neste artigo, vou mostrar como criar um arquivo ci.yml para integração contínua e um arquivo cd.yml para deploy automatizado na Hostinger.
Começando pela integração contínua, o arquivo ci.yml abaixo irá ajudá-lo a configurar um ambiente de build e testes para sua aplicação:
```yaml
# Definição do ambiente
os: ubuntu-latest
language: node_js
node_js: 14
# Instalação de dependências
cache:
npm: true
directories:
- node_modules
# Script de build e testes
script:
- npm install
- ng build --prod
- npm test
# Deploy após sucesso do build e testes
deploy:
provider: heroku
api_key: $HEROKU_API_KEY
app: minha-aplicacao-heroku
on:
branch: main
# Configuração do banco de dados
services:
- mysql
before_install:
- mysql -e 'CREATE DATABASE IF NOT EXISTS minha_base_de_dados;'
- mysql -e 'USE minha_base_de_dados;'
# Configuração de logs
after_failure:
- cat /home/travis/build/minha-conta/minha-aplicacao/logs/test.log
```
Este arquivo ci.yml assume que você já configurou sua aplicação no Heroku e que tem uma conta na Hostinger com acesso SSH. Lembre-se de substituir minha-aplicacao-heroku com o nome da sua aplicação no Heroku e minha_base_de_dados com o nome da sua base de dados MySQL na Hostinger.
Agora, vamos para o arquivo cd.yml para deploy automatizado. Este arquivo irá automatizar o processo de build, testes e deploy da sua aplicação na Hostinger:
```yaml
# Definição do ambiente
os: ubuntu-latest
language: node_js
node_js: 14
# Instalação de dependências
cache:
npm: true
directories:
- node_modules
# Script de build e testes
script:
- npm install
- ng build --prod
- npm test
# Deploy após sucesso do build e testes
deploy:
provider: script
skip_cleanup: true
script:
- ssh myuser@myhost "cd /home/myuser/myapp && git pull origin main && composer install && php artisan migrate && npm install && ng build --prod"
```
Este arquivo cd.yml assume que você já tem sua aplicação no Git e que você configurou a autenticação SSH para permitir que o deploy seja feito sem digitar uma senha. Lembre-se de substituir `myuser`, `myhost` e `/home/myuser/myapp` com as suas informações de conta e caminho de diretório corretos.
Com esses arquivos ci.yml e cd.yml em mãos, você pode automatizar a integração contínua e o deploy da sua aplicação em Angular, Laravel e MySQL na Hostinger. É uma ótima maneira de garantir a qualidade da sua entrega contínua e economizar tempo em processos manuais.
Espero que este artigo tenha sido útil para você e que você possa aplicar essas configurações em suas próprias aplicações. Se você tiver alguma dúvida ou comentário, sinta-se à vontade para deixar um comentário abaixo.
Além disso, é importante lembrar que as configurações apresentadas neste artigo são apenas um exemplo e podem ser adaptadas para suas próprias necessidades. Por exemplo, você pode querer incluir mais etapas no script de build e testes ou configurar uma plataforma de hospedagem diferente.
**Conclusão**
Por fim, se você está interessado em aprender mais sobre DevOps e entrega contínua, recomendo explorar outras ferramentas e técnicas disponíveis, como Docker, Kubernetes, Jenkins, Travis CI, CircleCI e muito mais. Com essas ferramentas em mãos, você pode automatizar ainda mais processos em seu fluxo de trabalho e tornar sua equipe mais eficiente e produtiva.
| rvlyra |
1,419,347 | How Single Sign-On Provides One-Brand Customer Experience! | Introduction In the modern e-commerce driven world, brick and mortar retail has almost... | 0 | 2023-03-29T17:59:38 | https://dev.to/carolinejohnson/how-single-sign-on-provides-one-brand-customer-experience-3h8f | singlesignonsolutions, sso, singlesignon, mfa | ## **Introduction**
In the modern e-commerce driven world, brick and mortar retail has almost ceased to exist, and retailers are grappling with associated issues including high rentals and lofty prices. On the other hand, online retail and multi-brand e-commerce have emerged as a powerful medium to reach a broader consumer base with endless possibilities and huge inventory.
The rich consumer experience across diverse verticals of a single e-commerce platform is undoubtedly one of the significant success drivers for Amazon, which has built up its brand equity through customer trust and loyalty over decades. However, not every retailer has jumped on the bandwagon to deliver a frictionless experience of switching brands through a single platform.
## **What is Single Sign On**
Single Sign-On (SSO) is a unique authentication method that enables users to access multiple applications with a single set of credentials, like a username and password. SSO products are designed to simplify the verification process and create an interconnected environment when accessing multiple apps, portals, and servers.
The simplest example of SSO is Google and its connected platforms. In this case, SSO bridges the gap between multiple interconnected platforms and cuts the need for re-authentication for a consumer for a seamless and secure experience.
## **Single Sign-On for E-commerce- The Need of the Hour**
The digital revolution has brought about a number of changes, including an increased demand for single sign-on authentication. With numerous benefits for customers and e-commerce companies alike, SSO helps streamline the user experience, aid movement between applications and services, and secure pertinent customer information between organizations.
Consumers always switch from one brand to another, and they can't tolerate any friction, especially in authenticating themselves repeatedly. This may impact the overall conversion rate since consumers switch to other brands for a better experience. In a nutshell, SSO helps e-commerce companies build a one-brand experience by eliminating any friction between two platforms of a single company offering diverse categories of products.
## **Why is it the Best Time to Use SSO for Your E-Commerce Store?**
SSO, when implemented correctly through a reliable CIAM solution, can make your ecommerce store more secure and user-friendly.
Let's explore why you should consider implementing SSO for your business:
**1. Consumers expect SSO.**
Today's customers expect SSO, or single sign-on authentication. This means that the customer-facing features of SSO are now considered to be a minimum standard of customer convenience. Simply put, SSO is a service that most customers expect from every online company.
If you have more than one website or service that requires logging in, you need a single sign-on if you don't want to annoy your customers and appear behind the times. You can eliminate several common roadblocks that can hurt your business with a single sign-on.
**2. SSO improves conversion rate**
[Single Sign On (SSO)](https://www.loginradius.com/single-sign-on/) has become a new industry standard for reducing barriers to entry and simplifying the login process. With SSO, there is just one login, one set of credentials, and one consistent experience.
Easy site navigation is key to making a site user-friendly, so businesses can link their customers to their own applications in just one click. Faster sign-ups result in more loyal users. No wonder SSO is gradually becoming the new standard for improving conversion rates across the web and mobile properties.
**3. SSO cuts down churn rate**
If you want your business to succeed, you need to engage your users from day one. If you're not in the top 10 on the app store, you're nowhere. That means you need to convince your users to stick around and keep using your service from day one.
Although your frequent users are unlikely to lose their log-in credentials, a third of your user base isn't yet daily. If they forget their details, there's a good chance you'll never see them again. SSO enables your users to come back to your app seamlessly without any need for passwords; it makes them feel involved.
## **Conclusion:**
The bottom line is this: you lose nothing by implementing and promoting SSO in your app. And if you consider how easily lost sessions are likely to be from a profit perspective, that might be enough to persuade you to take the necessary steps. After all, every lost subscriber is one step closer to disbanding a group that you've been working hard to bring together.
| carolinejohnson |
1,419,484 | 🌍 Earth: No Longer an "All-You-Can-Eat Buffet" | The Need for a New Socioeconomic Paradigm - As we advance further into the 21st century,... | 0 | 2023-03-29T22:04:30 | https://dev.to/ota/earth-no-longer-an-all-you-can-eat-buffet-49eb | ai, socioeconomics | ## **The Need for a New Socioeconomic Paradigm - As we advance further into the 21st century, humanity faces unprecedented challenges.**
Climate change, wealth inequality, and the rapid pace of technological innovation all demand a new way of thinking about our planet, other life forms and our relationship with it and our relationship with other humans.
Earth, our collective home, has long been treated as an "All-You-Can-Eat Buffet," with resources consumed at an alarming rate. However, the new era of artificial intelligence (AI) and robotics presents us with a crucial opportunity to shift our mindset and create a better life for all, rather than just a select few...if we choose to.
**The Intersection of Capitalism, Socialism,Communism and whatever else ...ism:**
The current state of affairs has brought us to a critical juncture, where we must consider redefining our socioeconomic systems. By embracing aspects of capitalism, socialism, communism, and/or whatever else ...ism.
By taking the best qualities of each of these "ways of being" - we can forge a new, more balanced approach that prioritizes the welfare of both individuals and the collective whole (I'm personally leaning more towards the collective, in my opinion). AI and robotics have the potential to "level the playing field" in a way that has never been possible before, providing us with the tools to build a more equitable society and thus a better world (closer to what I've come to call **WaTrek** - a play on Star Trek & Wakanda).
**The AI Revolution: A Double-Edged Sword:**
The rapid growth of AI and robotics has generated both positive and negative consequences. On one hand, these technologies have the power to streamline industries, improve efficiency, create new opportunities and create a better standard way of living for most-if-not all humans. On the other, they have also led to job displacement and further widened the wealth gap. As we continue to innovate, it is essential that we remain conscious of the broader implications of our choices and work to ensure that the benefits of AI are distributed equitably.
**Moving Beyond Capitalism: A Call to Action:**
The time has come to recognize that we have evolved beyond the traditional confines of capitalism. While this system may have once served the needs of our nation, it is no longer sustainable in the face of mounting global challenges. If we fail to adapt, the consequences will be dire not only for humanity but for the entire planet.
**The Importance of Collective Reflection:**
In order to bring about lasting change, we must take the time to reflect on our current trajectory and consider the impact our actions have had on the planet. By examining the ways in which we have treated Earth as an "All-You-Can-Eat Buffet," we can identify where our priorities have been misplaced and begin to chart a new course.
**Conclusion:**
As we stand at the precipice of a new era, it is imperative that we embrace the potential of AI and robotics to create a more just and sustainable world. By combining the best aspects of capitalism, socialism, communism, and whatever else ...ism - we can forge a new socioeconomic paradigm that supports the many, rather than the few.
The future is in our hands, and it is up to us to ensure that we use our technological prowess wisely and work collectively to protect our planet and its inhabitants.
-øLu 💛🦾🌱🙏
 | ota |
1,419,491 | Episode 23/12: Alex Rickabaugh on Signals, Playwright 1.32 | Alex Rickabaugh, tech lead of the Angular framework, gave a "must-watch" talk, why Angular will... | 0 | 2023-03-29T20:02:43 | https://dev.to/ng_news/episode-2312-2623 | angular, webdev, javascript, programming | Alex Rickabaugh, tech lead of the Angular framework, gave a "must-watch" talk, why Angular will introduce Signals. Spoiler: It is not mainly about the performance.
Playwright, an E2E testing framework, released v1.32 with a an interactive/UI mode.
{% embed https://youtu.be/u-LT9tMs9aM %}
## Alex Rickabaugh on Signals
We had the "official Angular Meetup" where Alex Rickabaugh gave a talk on signals. As somebody who has been working on Angular for eight years and is currently the tech lead of the framework, you can expect quite a lot of deep-dive information.
He started with a little bit of history. That means jQuery, the issues it solved, and the problems it produced. Then he repeated the same thing for AngularJs until he arrived at Angular. There he discussed its current issues and how Signals would fix those.
Maybe a little surprising, he said, under the condition that you had a well-written application, he didn't expect so much in terms of performance improvements when you would switch from zone.js to signals.
According to Alex, some issues come from change detection following the component hierarchy. But, unfortunately, that is not always what we want. It shows especially in forms where the flow goes up and down and produces the famous ExpressionChange error.
Signals will fix that. Quote:
> What signals do is decouple the direction of the data flow from the UI hierarchy.
In the upcoming Signal's RFC, we can also expect a detailed discussion on Signals vs. RxJs or Signals and RxJs.
You will be able to mix both Signals and zone.js. However, we have to expect to have dedicated components for Signals and zone.js in a future version.
Last but not least, Alex mentioned that pipes might become obsolete.
{% embed https://www.youtube.com/watch/GgC4AvQ010I %}
## Playwright 1.32
We also had a new release of Playwright, an E2E testing framework. Version 1.32 was quite surprising because Playwright now comes with its own UI. Before that, you always had to use the official extension and were bound to VSCode.
Another feature of the UI is time traveling. That means you can go through the various testing steps and see what your application looked like.
That UI feature will be a game changer. Playwright was already the runner-up compared to Cypress, and that new feature will close the gap even further.
For Angular, we still have to consider that Cypress also supports Component Testing. That's not the case for Playwright.
And Cypress is next to WebdriverIO and Nightwatch, an official Angular partner in E2E testing. You can see that if you run the ng e2e command.
{% embed https://youtu.be/jF0yA-JLQW0 %}
| ng_news |
1,419,686 | Automate CHANGELOGs to Ease your Release | How to automate proper CHANGELOGs in software projects with many contributors. Includes suggested... | 0 | 2023-04-04T14:57:03 | https://dev.to/devsatasurion/automate-changelogs-to-ease-your-release-282 | git, github, devops, node | How to automate proper CHANGELOGs in software projects with many contributors.
_Includes suggested practices and tools for JavaScript or TypeScript development, but only requires npm or similar to execute._
----
Changelogs are an excellent way to communicate updates between versions of a project. However, they can also be messy, overly technical, verbose, or generally unhelpful. For large projects with regular releases, it can be time-consuming to track down every change and document it properly.
In my case, I have a GitHub project with approximately 30 contributors, 5 maintainers (to decide milestones and review pull requests), and 100s of consuming projects whose operators each require one of two different levels of technical explanation.
The task of creating a proper release process - which prioritized documentation without drowning developers in extra work - seemed daunting at first. I'm here to say it was much more straightforward than I imagined. This blog post will walk you through how I automated the creation of ✨quality✨ changelogs in this project from our commits.
----
## The Task
Taking inspiration from [Gene Kim's "3 Ways of DevOps"](https://itrevolution.com/articles/the-three-ways-principles-underpinning-devops/), I set up the project concentrated on a goal of
> "Never pass a known defect to downstream work centers".
This meant advocating for and enabling practices like Test Driven Development and putting those checks in early in the product lifecycle.
Coming back to changelogs, I wanted to similarly shift our ***documentation*** work left by setting up an understandable contract with my fellow contributors and keeping the onus to wrangle commits and document changes off of the maintainers.
This meant enabling developers in 3 stages of the SDLC by introducing:
1. Clean git Process
2. Tools for Formatting Commits
3. Workflows for Generating Changelogs

## Surprise, An Elephant Appears!
To achieve our end goal of "No manual changelogs", we have to first address a potential elephant in the room: Not everyone agrees you ***should*** automate changelogs the way I describe here. One of the fastest ways to discover this is to visit https://keepachangelog.com which uses the clever tagline:
> "Don’t let your friends dump git logs into changelogs."
The site goes on to describe some guiding principles, which I would encourage you to check out. The TL;DR is:
- Follow Semantic Versioning (Or mention your strategy)
- Log every version
- Group your changes by type
- Write Changelogs for Humans and NOT Machines
There is clearly a gap between git logs and what we want consumers to read for our changes. The next section will tackle what processes we want in place to make our commits resemble human-readable changes, and the following section will discuss tooling to make that process obtainable by your team.
As for the elephant, only ***you*** can determine your trade-offs. Make your decision of what to automate a deliberate one, that reflects the long-term goals for your project.

## Clean git Process
In order to enable our automation with specialized tools, we will need to meet a convention with our commit messages and version tags. The standards I'm referring to here are helpfully called _**Conventional Commits**_ and **_Semantic Versioning_**.
### Semantic Versioning
This is a very common versioning standard met by most npm packages (in the case of JS). The important part of our versioning strategy is that it controls when we will generate changelogs: The diff in commit logs between the previous version tag and the current version tag represents the new information entering our changelogs on a release. In the case of semver, these are 3 sets of numbers that increment based on the impact of your changes. See [Semantic Versioning](https://semver.org/) for more info.
### Conventional Commits
This is how we can parse information about the change, such as the type, from the commit. See the full spec at [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0/) .
This brings with it the concept I find the most difficult in practice:
> Each commit should represent a single change of a known type and optional scope.
_For example:_ `fix(core): remove bad behavior xyz`
This is a big step up from the bad habits many of us start with when using git. However, it becomes much easier with some tools, a little practice, and the right merge strategies set up in GitHub.
### Branch and Merge Strategies
With the commit history theoretically reflecting our change history 1:1, the cleanest results will come from simple branching strategies, like [trunk-based development](https://cloud.google.com/architecture/devops/devops-tech-trunk-based-development), where everyone cuts features from a common main branch (which requires Pull Requests to update). Requiring your feature commits to be squashed in Pull Requests by configuring the Rebase+Squash merge strategy in GitHub (instead of the default) will also keep the history clean and make it easier to avoid issues with the upcoming tools I want to talk about.
## Tools for Formatting Commits
With our standards defined, we can reach into our toolbag and grab some CLI leverage to help unify the contributors and communicate what we need for success. The tools I mention here are geared for JS/TS projects that utilize package runners like npm. Keep in mind other projects could utilize them with a little extra work if you are willing to use Node.js or make some alterations.
### Commitizen
Writing in the conventional commit style I mentioned above is pretty straightforward, but not everything you and your fellow contributors work on will have the same requirements. Also, accidents happen. It helps to have a way to construct these messages the same way every time.
[commitizen](https://commitizen-tools.github.io/commitizen/) is a CLI tool that you can introduce to create commits with your rules, which handily default to the Conventional Commit format! I installed [commitizen](https://www.npmjs.com/package/commitizen) from npm into my project's devDependencies so that the whole team has the same ruleset. To continue setting up without relying on global installs, I used npx:
```console
npx commitizen init cz-conventional-changelog
```
This command updates the rest of what we need in our project's `package.json` file with the standards we already set
```JSON
"devDependencies": {
...
"cz-conventional-changelog": "^3.3.0"
},
"config": {
"commitizen": {
"path": "./node_modules/cz-conventional-changelog"
}
```
Once you get to this point, you can fire off an `npx cz` and see what we want the developer to see when making their commit:
cz's nice command prompt makes it where we don't leave anything needed out of our commit, and problems like character count in the subject line get called out as we write our messages.
Scope, change type, issues/tickets affected, and breaking changes are all accounted for.
### Husky
Now that we have a tool to help us make great commits, let's make it the default way anyone commits to the project. We can set the expectation for contributors to use the command line if they want help getting the right commits every time.
[Husky](https://www.npmjs.com/package/husky) is my tool of choice for setting up git hooks. With this tool, we can make sure that every step of the commit process has passed the checks we care about. Unit tests, linting, Typescript builds, and more can be called from scripts every time a user walks through their commit process to push to the GitHub repository from their local machine.
To ensure developers have access to the same hooks you do, you can install this package into your devDependencies. Besides installing using npm, yarn, etc - We also need to run an `npx husky install` to set up the hooks. To ensure this happens on the other developer workspaces, we slap this bit into our prepare block of the package.json:
```JSON
"scripts": {
"prepare": "is-ci || husky install",
```
Here, [is-ci](https://www.npmjs.com/package/is-ci) is another optional devDependency that will keep hooks from registering in your remote CI environments, where you might be adding chore commits, tags, etc.
Following [cz's docs](https://github.com/commitizen/cz-cli#optional-running-commitizen-on-git-commit) we can then tap into the git commit command prompt using:
```console
npx husky add .husky/prepare-commit-msg "exec < /dev/tty && npx cz --hook || true"
```
Then BOOM, when a contributor installs your project and types "git commit", they will be met with the same CLI we saw in the previous section. Pretty snazzy 😎
### Commitlint
So now all of our developers are automagically 🪄 making good commit messages, right?
If you want to ensure that what makes it into the feature branch will be usable for the last step of converting git logs to changelogs, we need one more thing: commit linting.
As you probably guessed by now, yes, there are npm packages for that.
Installing [@commitlint/cli](https://www.npmjs.com/package/@commitlint/cli) and [@commitlint/config-conventional](https://www.npmjs.com/package/@commitlint/config-conventional) and setting up a post-commit or pre-push git hook with husky is one option. Another is logging your latest commit on your pull requests and running merge checks from, say, a GitHub Workflow. Ultimately, it depends on how and where you want to communicate problems in the incoming change.
An example of the latter can look like:
```console
git log -n 1 --format=%B | npx commitlint
```
## Automatically Generating Changelogs

### conventional-changelog-cli
Lastly, with the work we have put into setting up our repo, we can move from sowing to reaping with one more handy tool. [conventional-changelog-cli](https://www.npmjs.com/package/conventional-changelog-cli) can be used whenever and wherever you are handling a version change in your project. Their documentation on the linked npm page walks you through how to configure it to the "npm version" command, but if you need to simply run the package after bumping your version(s), you can use:
```console
npx conventional-changelog-cli -i 'CHANGELOG.md' -s -t v -p angular
```
from an environment that has access to all the previous git tags. Using the conventional-changelog-cli repository as an example, you can see the types of logs you can expect from this CLI:

That's our goal. We asked the contributors to use the terminal for their git commits and in turn we can automatically generate changelogs based on every pull request to our repository. Obviously, this still requires understandable commit messages from developers, but that feedback is now visible on the Pull Request with the rest of the incoming work. No more hunting down a single contributor for context on release day when a feature takes longer than you both expected.
----
Although nothing is ever complete in terms of automation, taking the time to enable every contributor to consider the changes they commit and communicate them properly has helped our releases become less stressful. I hope the processes and tools I've mentioned show you similar results, or help you consider the options that make documentation easier and clearer.
But what do **_you_** think?
- Let me know if you Agree or Disagree with my tools and processes.
- What are you using for changelogs (or other release automation)?
- What more would you like to read about this topic (such as handling changelogs in a monorepo)?
Keaten Holley
https://github.com/Keatenh
| keatenh |
1,419,839 | Javascript Basics Part 1 | THE HISTORY OF JAVASCRIPT Before the advent and introduction of Javascript in 1995 the web... | 0 | 2023-03-29T23:49:03 | https://dev.to/spiritdivine/javascript-basics-part-1-28h7 | javascript, programming, beginners | ## THE HISTORY OF JAVASCRIPT
Before the advent and introduction of Javascript in 1995 the web was just made up of a static structure having just the HTML and CSS without any mode of interactivity. Javascript is in no way related to the programming language “java”, just that at the time of creation java was making waves and with the name being a pillar in the market then the makers of Javascript decided to name it similarly just so to reach more audience.
Later on, a standard document was created so as to prove singularity in language for various software that claimed to support the language and this standard was named ECMASCRIPT. In practical terms, the name Ecmascript can be used interchangeably with Javascript.
## VALUES
In computer science the only thing we get to interact with is called in it’s simplest term “Data” but it’s originally made up of long sequence of bits usually described as zeros and ones which is readable to the computer.
In Javascript although we work primarily with data but we call them “values” and “datatypes” just so as to distinguish and create distinction in various roles they have to play, just like in values you have numeric values in it. Datatypes are the various types or forms of data that can be represented or worked with in the computer and they all have their differing roles to play.
So there are fundamentally Two datatypes in Javascript namely,
1. Primitive datatype
2. Non-primitive datatype
## Primitive Datatype
In this datatype is contained seven types rather sub-types of data namely,
1. String
2. Number
3. BigInt
4. Boolean
5. Null
6. Undefined
7. Symbol
### STRING
This is the type of data that is used in rendering plain statement or sentence in Javascript, it is always wrapped inside quotation marks such as the single quote(‘’), the double quote(“”) and the back tick(``). There’s almost no difference in the use of single quote and double quote except in some cases when wanting to embed a reported speech in a sentence. For the back tick, it is used to render practically sentences with dynamic variables in it (i.e variables which their values are mutable).
```
//string
var fullName = "John Doe";
```
### NUMBER
This is the type of data that is used usually in arithmetic operations, they are plain numbers that are not wrapped inside any quotes at all, when wrapped inside a quote it ceases to be a number but a string. They are used not only in arithmetic operation but also in the logical operations and comparison operations.
```
//number
var age = 25;
```
### BIGINT
This is the type of data in Javascript that was introduced in 2020 with the intent storing integer values that are too big to be represented by a normal JavaScript Number.
```
//big int
let x = BigInt("123456789012345678901234567890");
```
### BOOLEAN
This type holds just two values; true or false. They are often used in conditional operations to prove that a condition is right or wrong.
```
//boolean
const bool = true;
let line = 23;
let curve = 24;
console.log(x==y)
//output
//false
```
### NULL
This type has no tangible value, it equals the absence of a value. According to the MDN it’s defined as the intentional absence of any object value and is treated as False for Boolean operations.
### UNDEFINED
In Javascript a variable without any value is regarded as undefined, the value is undefined so is the datatype also. It happens default when a variable is declared but not initialized.
```
//undefined
//a variable can be undefined by setting it with no value
let car;
//a variable can be undefined by initializing it with the keyword and value "undefined"
car = undefined;
// this above has nothing to do with being undefined, it is regarded as string as it has double quote already although an empty string.
var count = " ";
```
### SYMBOL
According the MDN docs Symbol is a built-in object whose constructor returns a symbol primitive also called a Symbol value or just a Symbol that’s guaranteed to be unique.
They are immutable (i.e they cannot be changed) and are unique. They are called or initialized using the symbol() keyword. To add to that whenever you come across two symbols containing same values, they cannot equal each other (meaning they’re different) although they contain same value. We’ll discuss about symbol intricately in a different article build.
```
//symbols
// two symbols with the same description
const value1 = Symbol('hello');
const value2 = Symbol('hello');
console.log(value1 === value2); // false
```
## Non-primitive datatype
In this we have three main datatypes namely;
1. Object
2. Array
### OBJECT
The object datatype is a non-primitive datatype that allows one to store collections of data. it contains properties defined as key-value pairs. Syntactically in it’s declaration the properties are written inside curly braces and are separated by commas. To add to it, an object can be nested inside another object.
```
//object
const person = {firstName:"John", lastName:"Doe", age:25, occupation:"detective"};
```
### ARRAY
Although different from an object can be counted as a type of object used for storing multiple values in a single variable. Each value has a numerical position known as it’s index which in most languages starts from the number “0” instead of “1”, can be used to manipulate values in arrays through array methods.
```
//arrays
const items = ["apple", "pear", "pineapple", "mango"];
```
### SUMMARY
This is just an article which is the first part of the first chapter of my journey into Javascript. In the next part I’ll be talking about operators, automatic type conversions and a few other sub-topics related, all in the simplest way possible. Just to clear the air this article was built on the foundation of the book "eloquent javascript", a few other sources and basically my understanding of these concepts and topics. | spiritdivine |
1,419,985 | Exception Handling, Logging, and Notifications in Azure App Services: A Comprehensive Guide | Introduction Azure App Services are cloud-based applications that enable developers to build,... | 0 | 2023-03-31T07:09:53 | https://dev.to/yogitakadam14/exception-handling-logging-and-notifications-in-azure-app-services-a-comprehensive-guide-45g5 | azure, appservice, exceptionhandling, node |
**Introduction**
Azure App Services are cloud-based applications that enable developers to build, deploy, and manage applications on the cloud. As with any application, it is important to have the proper exception handling, logging, and notification practices in place to ensure the application runs smoothly and any issues can be quickly identified and resolved. In this blog post, we will discuss the best practices for exception handling, logging, and notifications for Azure App Services.
**Exception Handling**
Exception handling is one of the most important aspects of application development. It is important to properly handle exceptions to ensure the application runs smoothly and any unexpected errors can be quickly identified and resolved. When developing Azure App Services, it is important to use the Azure Application Insights feature to track and monitor application exceptions. This feature provides insight into application performance, errors, and exceptions and can help pinpoint the root cause of any issues.
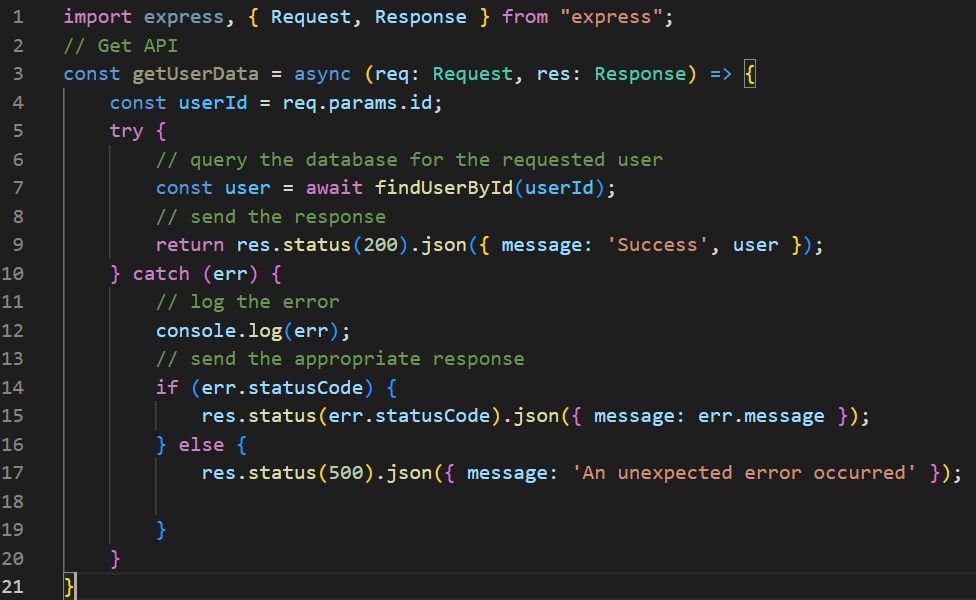
**Logging**
Logging is an essential practice when developing applications, as it can provide valuable insight into how the application is performing and any potential issues that may arise.
**Log Stream**
Log Stream is a feature in Azure Monitor that allows users to quickly view and analyse log data from multiple sources in real-time. It allows users to quickly search and analyse log data, identify trends, and take action on any issues. Log Stream can help with troubleshooting, performance optimization, and security monitoring.
**Diagnostics Settings**
When developing Azure App Services, it is important to use the Azure Diagnostics feature to log application events, errors, and exceptions. This feature provides detailed logging.
1. Select the App Service from the list of services.
2. Select the Diagnostic Settings option from the left navigation pane.
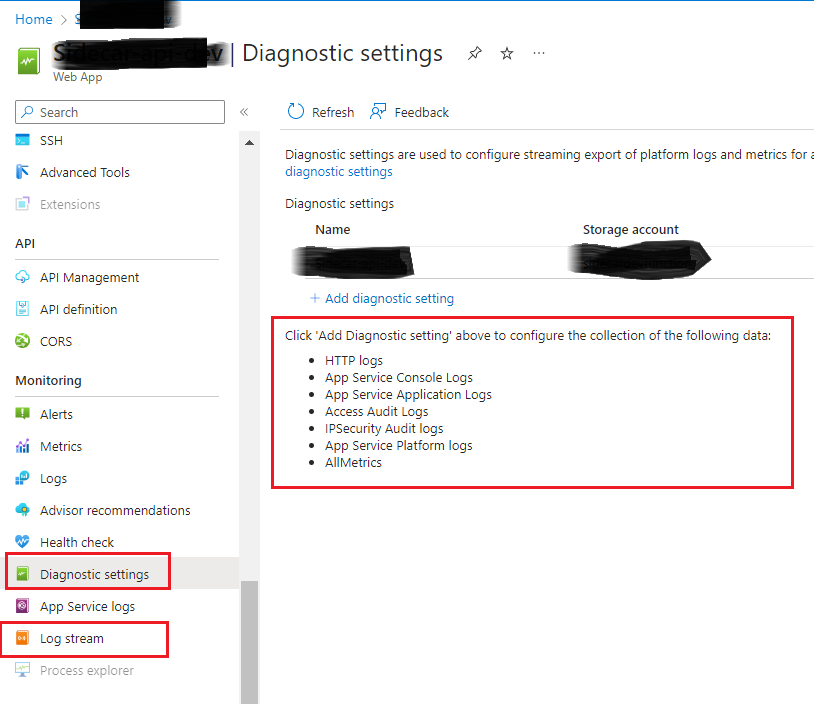
3. Configure the settings including the type of logging and the frequency of logging.
4. Configure the type of metrics that should be collected, the metrics that should be collected, and the metrics that should be used to trigger alerts.
5. Configure the retention period for the collected data and the type of data that should be stored in the log files.
6. Azure Storage account is for Archive logs for audit, offline analysis or backup. Compared to using Azure Monitor Logs or a Log Analytics workspace, Storage is less expensive, and logs can be kept there indefinitely
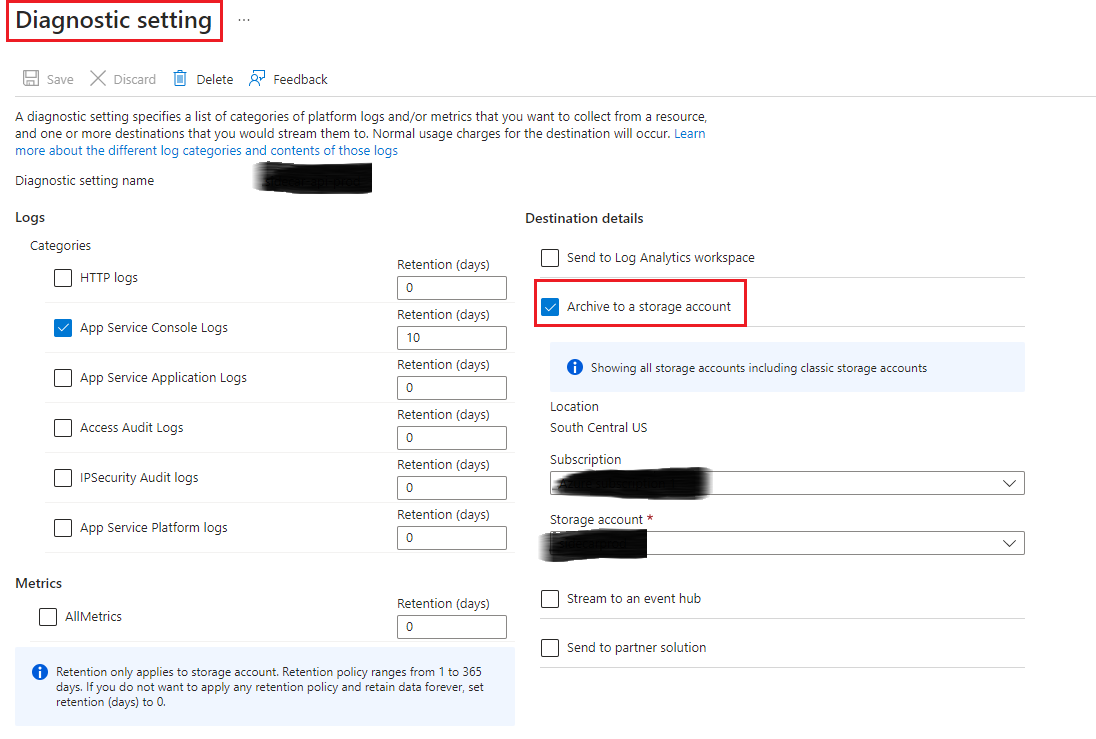
**Azure Application Insights**
Azure Application Insights is a great tool for tracking and monitoring your application. It can provide detailed information about errors and exceptions, as well as performance metrics and other useful information.
For example, you can use Application Insights to monitor the performance of your web application. You can track the number of requests and response times, as well as the performance of individual requests. You can also track exceptions and errors, and get detailed information about when and where they occur.
Additionally, you can use Application Insights to monitor the performance of your backend services, such as databases and queues. You can track the number of requests and response times, as well as the performance of individual requests. You can also track exceptions and errors, and get detailed information about when and where they occur.
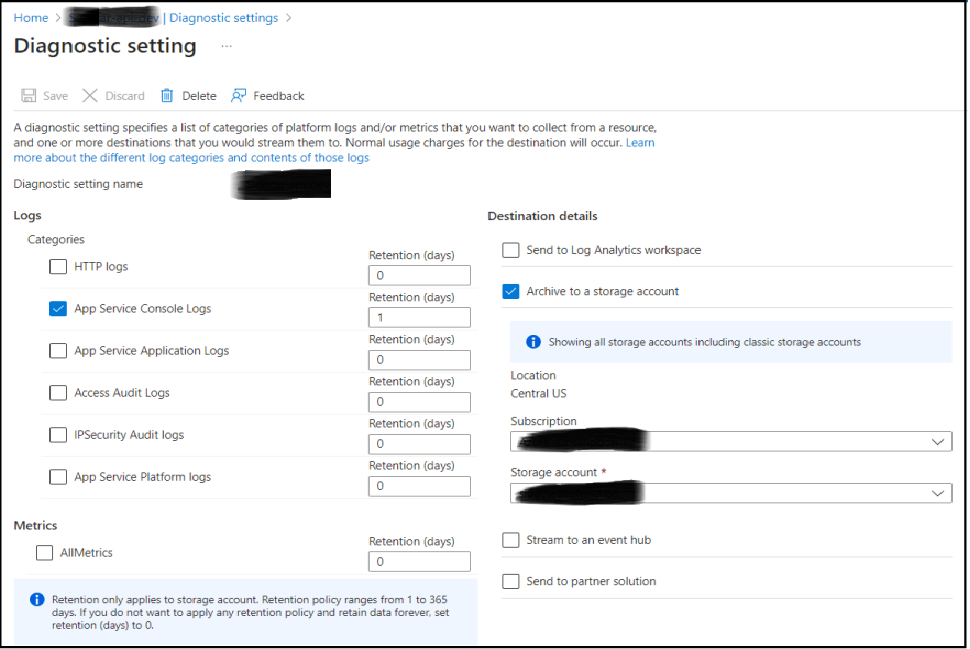
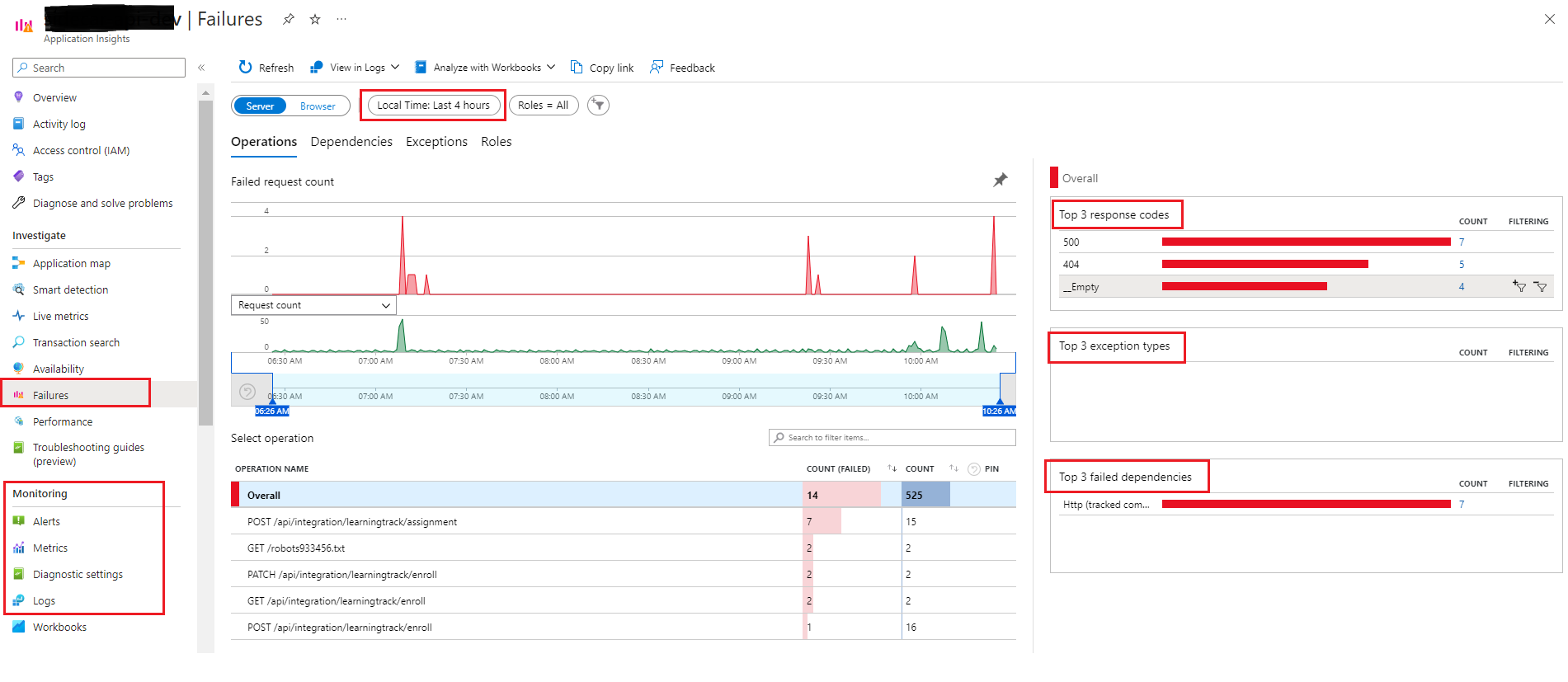
**Alerts & Notifications**
Alerts are typically sent out in response to a specific trigger, such as a critical system error.
Notifications are messages sent to one or more users to notify them that an alert has been created.
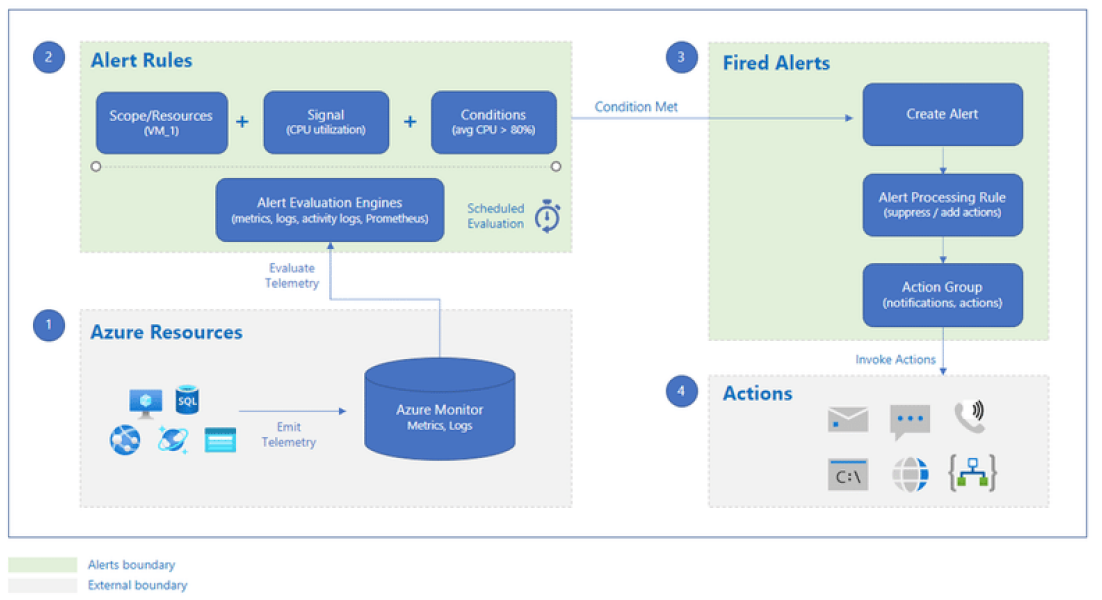
For more details please refer [Azure app service monitoring and alerts] (https://perituza.com/blog/azure-app-service-monitoring-and-alerts/).
Exception handling, logging, alerts and notifications are essential to the reliable operation of Azure App Services. With the right configuration and setup, these are the features can ensure that your services are operating efficiently and securely. This comprehensive guide provides an overview of each of these features, as well as basic instructions on how to configure them. With this guide, you'll be able to make sure that your Azure App Services are running smoothly and securely.
| yogitakadam14 |
1,420,217 | About building study habits | when you start this habit, it might not be enjoyable at first this is because this provides a... | 0 | 2023-03-30T09:42:52 | https://dev.to/dantas/about-building-studying-habits-1c0 | study, productivity, motivation | - when you start this habit, it might not be enjoyable at first
- this is because this provides a long-term reward, and our two hundred thousand years old brain does not recognize it naturally
- so, to complement the reward to keep us studying, you should add a secondary reward to it, for example:
- if you like going out with your friends, you could save $5 each time you finish studying a subject, so you spend when you go out, in that way, your brains associates studying with an instant reward which is increasing how much you spend when you go out
- or if you like playing video games, you could open your game right when you finished studying and play for the exact same amount you studied
- in that way, you tell your brain that it doesn’t need to wait for the long-term reward, but there’s a catch
- once you understand how much knowledge you can get and how much it helps you on your daily life like going better on job interviews, getting better grades at college, you won’t need a secondary reward, since you can actually feel the long-term reward you’ve been waiting
- so being a student becomes your identity, and the act of focusing and studying will become something natural for you
## Reference
- [Atomic Habits, by James Clear](https://www.amazon.com/Atomic-Habits-Proven-Build-Break/dp/0735211299)
- [Homo Sapiens Brain Evolution - MPG](https://www.mpg.de/11883269/homo-sapiens-brain-evolution)
- [Ethiopia is top choice for cradle of Homo sapiens](https://www.nature.com/articles/news050214-10)
- Background by <a href="https://unsplash.com/@jeshoots?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">JESHOOTS.COM</a> on <a href="https://unsplash.com/pt-br/fotografias/pUAM5hPaCRI?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
---
If you have any doubts or advice, feel free to leave a comment or ping me on Twitter
| dantas |
1,420,648 | Simplify Python Dependency Management: Creating and Using Virtual Environments with Poetry | As a Python developer, managing dependencies and libraries can become a bit of a hassle. It's... | 0 | 2023-03-30T15:41:45 | https://dev.to/rainleander/simplify-python-dependency-management-creating-and-using-virtual-environments-with-poetry-22ee | python, poetry, virtual, programming | As a Python developer, managing dependencies and libraries can become a bit of a hassle. It's important to keep track of different versions of packages and ensure that they work together seamlessly. Virtual environments and package managers can help to solve these issues.
Virtual environments are isolated Python environments where you can install packages and libraries without affecting the system-wide installation. You can have multiple virtual environments with different package versions and dependencies to work on different projects simultaneously. One of the most popular package managers for Python is Poetry, which simplifies package management and streamlines dependency resolution.
In this post, we will walk you through how to create and use virtual environments in Python with Poetry.
### Step 1: Install Poetry
The first step is to install Poetry on your system. Poetry can be installed on any operating system that supports Python. To install Poetry, you can use the following command in your terminal:
```
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python -
```
### Step 2: Create a new project
Once you have installed Poetry, create a new directory for your project and navigate into it. Then, run the following command to create a new project with Poetry:
```
poetry init
```
This command will create a `pyproject.toml` file that contains information about your project and its dependencies.
### Step 3: Create a virtual environment
To create a virtual environment with Poetry, run the following command:
```
poetry env use python
```
This command will create a new virtual environment and activate it. You can also specify a specific version of Python to use in your virtual environment by running:
```
poetry env use /path/to/python
```
### Step 4: Add dependencies
To add dependencies to your project, you can use the following command:
```
poetry add package-name
```
This command will install the package and its dependencies in your virtual environment and update your `pyproject.toml` file.
You can also specify the version of the package that you want to install:
```
poetry add package-name==1.0.0
```
### Step 5: Install dependencies
To install the dependencies of your project, you can run the following command:
```
poetry install
```
This command will install all the dependencies listed in your pyproject.toml file.
### Step 6: Use the virtual environment
To use the virtual environment, you need to activate it first:
```
source ~/.poetry/env
```
This command will activate the virtual environment and you can start working on your project. To deactivate the virtual environment, simply run:
```
deactivate
```
That's it!
You can now create and use virtual environments in Python with Poetry. With this approach, you can keep your projects isolated and ensure that they work seamlessly without any dependency issues. | rainleander |
1,420,909 | Load Vertices (Nodes) data from CSV file to Apache AGE | In Apache AGE, we can load the data of nodes/ vertices from CSV file as well. A CSV file containing... | 0 | 2023-04-18T19:27:28 | https://dev.to/muneebkhan4/load-vertices-nodes-data-from-csv-file-to-apache-age-1clh | apacheage, graphdatabase, database, postgres | In Apache AGE, we can load the data of nodes/ vertices from CSV file as well.
A CSV file containing nodes' data should be formatted as following:
**id:**
It should be the first column of the file and all values should be a positive integer.
**Properties:**
All other columns should contain the properties for the nodes. Header row should contain the name of properties and rows below Header row should contain data. One row as a whole should be treated as one vertex.
First step is to create a label for the vertex.
**Create Vertex Lable:**
**Syntax:**
`SELECT create_vlabel('GraphName','LabelName');`
Second step is to get data from CSV file and create vertices.
**Load Data from CSV:**
**Syntax:**
`SELECT load_labels_from_file('GraphName',
'LabelName',
'Path/to/file.csv');`
For more details visit: https://age.apache.org/overview/
**AGE Github Link:** https://github.com/apache/age
**AGE Viewer Github Link:** https://github.com/apache/age-viewer | muneebkhan4 |
1,421,248 | Ethereum Transaction Gas Fee | Gas Gas is the fuel of the Ethereum blockchain network. Gas is always paid in ether, Gas... | 0 | 2023-03-31T04:18:05 | https://dev.to/hassanhabibtahir/ethereum-transaction-gas-fee-36no | ## Gas
_Gas is the fuel of the Ethereum blockchain network. Gas is always paid in ether, Gas is the transaction fee paid to miners for executing and adding your transaction into the Ethereum blockchain. For every transaction you have to specify the value of the gas price and the gas limit, you want to set. Based on these values, the network calculates how much of a fee you are willing to pay for the transaction._
## Gas Limit
_The gas limit is the maximum unit of gas your transaction may take, in order to be executed on the Ethereum blockchain.If your transaction takes less gas, then the extra gas that you have provided will be refunded back to your wallet. If your transaction consumes all the gas and requires more gas to be executed, your transaction will fail, and gas will be consumed as part of the transaction fees._
## Gas price
_The gas price is the price per gas unit you are willing to pay for executing your transaction. The unit of gas price is always defined in gwei. According to your gas price, miners decide to process your transaction. If the transaction has a higher gas price, there is a chance that your transaction will be processed early. If your gas price is low, then your transaction might be processed after a delay or when the blockchain is free to process low-gas-price transactions.
_
## Example
_ From | 0x2001152bd1cc1d37d7c0d25cd10315351b45b4a6
To | 0x0587db0883defe769b49b78c11bdcc2f1f38b484
gas limit| 424843
gas price| 0.0000000.1(10 gwei)
gas(used) = 21000;
TxFee (max) = gas limit * gas Price;
TxFee(paid) = gas(used)*GasPrice;
TxFee(Returned)= TxFee (max) -TxFee(paid);
TxFee (max) = 424843 * 0.00000001 =0.00424843;
TxFee = 21000*0.00000001=0.00021;
TxFee(Returned) = 0.00424843-0.00021=0.00403843 _
| hassanhabibtahir | |
1,421,551 | Bubble Sort Simplified | In computer science, sorting is a fundamental job that is essential to many different applications,... | 0 | 2023-03-31T11:01:15 | https://dev.to/frontend_val/bubble-sort-simplified-4p8j | algorithms, webdev, beginners |
In computer science, sorting is a fundamental job that is essential to many different applications, including database administration and image processing. Sorting is the act of arranging a collection of objects in a certain order, such as alphabetical or numerical order, so that they may be conveniently searched or processed.
There are several methods for sorting data, each with its own set of advantages and disadvantages. Bubble sort is one of the most basic and well-known sorting algorithms. Bubble sort is a simple algorithm that beginners may readily understand and is frequently used as an introduction to sorting algorithms.
In this article, we'll look into bubble sort in further detail, including how it works, its advantages and disadvantages, as well as practice guidelines for using and improving it. Understanding bubble sort is a vital step in mastering sorting algorithms and increasing your coding abilities, whether you're a new programmer or an expert developer. Now let's get started and discover the world of bubble sorting!
### How Bubble Sort Works
Bubble sort is a basic comparison-based sorting algorithm that operates by repeatedly exchanging nearby components that are in the wrong order. Larger items "bubble" to the top of the list with each run, giving rise to the algorithm's name. Below is a step-by-step walkthrough of bubble sort implementation.
Below are the steps to follow:
- Use two for loops to iterate through the input array.
- The outer loop runs from `i = 0` to `i = n - 1`.
- The inner loop runs from `j = 0` to `j = n - i - 1`;
- For every `j`, compare `arr[j]` and `arr[j + 1]`. If `arr[j] > arr[j + 1]`, then swap them or else move forward.
### Python Implementation
```
1. def bubbleSort(arr):
2. for i in range(len(arr)):
3. for j in range(len(arr)-i-1):
4. if arr[j] > arr[j+1]:
5. arr[j], arr[j+1] = arr[j+1], arr[j]
6. return arr
7.
8. bubbleSort([13, 4, 9, 5, 3, 16, 12]) # [3, 4, 5, 9, 12, 13, 16]
```
In the implementation above, we traverse through the array on different passes. On each pass, we compare the current element and the one immediately after it. If the current element is bigger than the one on the right, we swap them(line 5).
### Time Complexity
Best - O(n)
Worst - O(n2)
Average - O(n2)
Space Complexity - O(1)
Stability - Yes
### Pros and Cons of Bubble Sort
#### Pros:
- **Simple**: Bubble sort is one of the simplest sorting algorithms to understand and implement.
- **In-place sorting**: Bubble sort only requires a constant amount of additional memory space to sort a list, making it an "in-place" sorting algorithm.
- **Stable**: Bubble sort is a "stable" sorting algorithm, meaning that it preserves the relative order of equal elements in the list.
#### Cons:
- **Inefficient for large lists**: Bubble sort has a time complexity of O(n²), meaning that its performance becomes increasingly slow as the size of the list grows. For very large lists, bubble sort can become impractical.
- **Inefficient for partially sorted lists**: Bubble sort still needs to compare every element to every other element, even if the list is already partially sorted. This can lead to unnecessary comparisons and swaps.
- **Not the most efficient sorting algorithm**: There are other sorting algorithms, such as quicksort and mergesort, that have better time complexity than bubble sort and can be more efficient for large lists.
## Conclusion
Bubble sort is a simple, easy-to-understand sorting algorithm that can be useful for small lists or as a learning exercise for understanding sorting algorithms. However, it is not the most efficient sorting algorithm for large lists or partially sorted lists. For those cases, it may be more efficient to use a different sorting algorithm that has better time complexity.
Don't forget to leave a like or comment.
❤️❤️❤️
[Resume](https://docs.google.com/document/d/1Lcr8tSfNozE9MLOKCDF8CwvZH0g7LWJSq9vu3Rdj0_U/edit?usp=drivesdk) [Portfolio](https://valentinesamuel.vercel.app/) [Twitter](https://twitter.com/frontend_val) [GitHub](https://github.com/valentinesamuel) [LinkedIn](https://www.linkedin.com/in/samuel-val/) | frontend_val |
1,421,561 | HTML CSS PROJECT #3 | Hi everyboodddyyyy! My third project from FRONTEND MENTOR is on the line! I used HTML CSS in this... | 0 | 2023-03-31T11:09:02 | https://dev.to/mckh03/html-css-project-3-ilp | css, html, resume, webdev | Hi everyboodddyyyy!
My third project from [FRONTEND MENTOR](https://www.frontendmentor.io/profile/MCKH03) is on the line!
I used HTML CSS in this very simple yet **ARTISTIC **Project!
I would love to hear your ideas on this project.
Here are the links:
Here is **MY SOLUTION**:
https://www.frontendmentor.io/solutions/qr-code-component-oZ1kROGR0P
My **GITHUB**:
https://github.com/MCKH03
The related **REPOSITORY**:
https://github.com/MCKH03/FEM-QR-Code-Component
My **TWITTER**:
https://twitter.com/ytmehrshad
My **LINKEDIN**:
https://www.linkedin.com/in/mehrshad-cheshm-khavari-992962270/
Tell me, who can do this just as me?!
**<u>Send your answers to me and also to frontend mentor so we can find each other!</u>** | mckh03 |
1,421,743 | Hello Everyone, glad to be here, hope to have an awesome experience!!! | A post by NedbleezyTech | 0 | 2023-03-31T14:50:58 | https://dev.to/nedbleezytech/hello-everyone-glad-to-be-here-hope-to-have-an-awesome-experience-50hi | nedbleezytech | ||
1,421,751 | C Preprocessor Directives. | In C language, the preprocessor directives are used to perform certain operations before the code is... | 0 | 2023-03-31T15:07:55 | https://dev.to/drazen911/c-preprocessor-directives-3be4 | codenewbie, career, c, programming | In C language, the preprocessor directives are used to perform certain operations before the code is compiled. These directives begin with a hash symbol (#). Here are some common preprocessor directives:
1. #include - This directive is used to include the contents of another file in the current file.
Example:
#include <stdio.h>
2.#define - This directive is used to define a macro.
Example:
#define PI 3.14159
3. #ifdef, #ifndef, #else, #endif - These directives are used for conditional compilation.
Example:
#ifndef DEBUG
printf("Debugging is off\n");
#endif
4. #pragma - This directive is used to provide additional instructions to the compiler.
Example:
#pragma pack(push, 1)
Here's an example of how preprocessor directives can be used in C code:
#include <stdio.h>
#define PI 3.14159
int main() {
float radius = 5.0;
float area = PI * radius * radius;
printf("The area of the circle is: %f", area);
#ifdef DEBUG
printf("\nDebugging information:\n");
printf("The radius is: %f\n", radius);
printf("The area is: %f\n", area);
#endif
return 0;
}
In this example, we have used the #include directive to include the standard input-output header file. We have also defined a macro PI using the #define directive. Finally, we have used the #ifdef directive to conditionally compile some debugging statements.
| drazen911 |
1,421,754 | UTopia: From Unit Tests To Fuzzing - Fuzzing Weekly CW13 | UTopia: From Unit Tests To... | 0 | 2023-03-31T15:15:52 | https://dev.to/fuzzingweekly/utopia-from-unit-tests-to-fuzzing-fuzzing-weekly-cw13-pj7 | security, testing, cybersecurity, fuzzing |
UTopia: From Unit Tests To Fuzzing:
https://research.samsung.com/blog/UTopia-From-unit-tests-to-fuzzing
Random Fuzzy Thoughts:
https://tigerbeetle.com/blog/2023-03-28-random-fuzzy-thoughts
Introducing Microsoft Security Copilot: Empowering defenders at the speed of AI:
https://blogs.microsoft.com/blog/2023/03/28/introducing-microsoft-security-copilot-empowering-defenders-at-the-speed-of-ai
https://www.fuzztesting.io/fuzzing-weekly
 | fuzzingweekly |
1,421,787 | NEW: AI Grammar and Spell Checkers available on Eden AI | Quickly and easily generate text with just a few simple steps! With our unique API, you can start... | 0 | 2023-03-31T15:39:28 | https://www.edenai.co/post/new-ai-grammar-and-spell-checkers-available-on-eden-ai | ai, api, spellcheck, proofreading | *Quickly and easily generate text with just a few simple steps! With our unique API, you can start using AI-based Grammar correction and connect to multiple spell-check APIs in seconds to save valuable time and resources.*
## **What is [AI Grammar and Spell Checker](http://www.edenai.co/feature/grammar-spell-check?referral=spell-check-available)?**
An AI-powered grammar and spell checker is a type of software that uses artificial intelligence and natural language processing algorithms to analyze written text and identify grammar and spelling errors. These tools use machine learning models to identify and correct common errors such as grammar mistakes, misspellings, and punctuation errors.
AI-based grammar and spell check tools work by comparing the text against a database of rules and patterns, as well as by analyzing the context in which the text appears. Grammar correction APIs typically accept input text as a parameter and return a list of suggested corrections, along with information about the type of error and the context in which it appears. Some APIs may also provide additional features such as language detection and translation.
These tools are commonly used in word-processing software, email clients, and web browsers to help writers produce error-free content. They are particularly useful for people who are not native speakers of the language in which they are writing or for those who want to improve their writing skills.
By using grammar and spell checker APIs, developers can save time and effort by not having to build their own grammar and spell checking functionality from scratch. These APIs can also help improve the accuracy and quality of written content produced by their applications, making them more user-friendly and professional-looking.
**[Try Eden AI for FREE](https://app.edenai.run/user/register?referral=spell-check-available)**
## **Access many Grammar and Spell Checkers with one API**
Our standardized API allows you to use different providers on Eden AI to easily integrate proofreading capabilities into your system and offer your users a convenient way to spell check content. Some of the grammar and spell correction APIs that you can use on Eden AI include:
### **Bing Spell Check API - [Available on Eden AI](https://app.edenai.run/bricks/text/generation?referral=ai-text-generators-available)**

The Microsoft Azure Grammar and Spell Check API is a robust tool for developers and businesses who want to improve the accuracy and readability of their written content. Here are some of the key features and benefits of this API:
1. High Accuracy: The Bing Spell Check API uses advanced machine learning models to identify and suggest corrections for grammar, spelling, and other writing issues. It has been trained on a large corpus of text, making it highly accurate and effective at catching errors.
2. Customizable: The API is customizable to fit the specific needs of different industries and domains. It supports multiple languages and can be trained on custom datasets to improve its accuracy and relevance for specific use cases.
3. Scalable: The API is highly scalable, meaning it can handle large volumes of text with ease. This makes it an ideal choice for businesses and applications that need to check large volumes of text on a regular basis.
4. Additional Features: In addition to grammar and spelling suggestions, the API also provides other useful features, such as language detection, translation, and sentiment analysis. This can help businesses to gain deeper insights into their content and better understand their audience.
### **OpenAI Grammar Correction API - [Available on Eden AI](https://app.edenai.run/bricks/text/generation?referral=ai-text-generators-available)**

The OpenAI Grammar Correction API is a powerful tool for developers and businesses looking to improve the quality of their written content. Here are some of the key features and benefits of this API:
1. Accuracy: The OpenAI Grammar and Spell Check API uses state-of-the-art machine learning models to provide highly accurate and precise suggestions for grammar and spelling corrections. It can identify a wide range of errors, including contextual and stylistic issues, and provide tailored recommendations for each.
2. Speed: The API is fast and responsive, allowing developers to check large volumes of text quickly and efficiently. It can handle real-time requests and provide near-instantaneous feedback, making it ideal for use in applications and websites that require fast response times.
3. Customization: The OpenAI Grammar and Spell Check API can be customized to fit the specific needs of different businesses and applications. It supports multiple languages and can be trained on custom datasets to improve its accuracy and relevance for specific industries or domains.
4. Scalability: The OpenAI Grammar and Spell Check API is highly scalable, meaning it can handle large volumes of requests without compromising on performance or accuracy. This makes it an ideal choice for businesses and applications that need to check large volumes of text on a regular basis.
### **ProWritingAid - [Available on Eden AI](https://app.edenai.run/bricks/text/generation?referral=ai-text-generators-available)**
.png)
The ProWritingAid Grammar and Spell Check API is a comprehensive tool for developers and businesses who want to improve the quality and accuracy of their written content. Here are some of the key features and benefits of this API:
1. Accuracy: The ProWritingAid Grammar and Spell Check API uses advanced algorithms and machine learning models to provide highly accurate and precise suggestions for grammar and spelling corrections. It can identify a wide range of errors, including contextual and stylistic issues, and provide tailored recommendations for each.
2. Comprehensive: The API offers a comprehensive set of features, including grammar and spelling checking, style suggestions, and readability analysis. It can also provide insights into overused words, sentence length, and other factors that affect the quality and readability of written content.
3. Customizable: The API is customizable to fit the specific needs of different industries and domains. It supports multiple languages and can be trained on custom datasets to improve its accuracy and relevance for specific use cases.
4. Cost-effective: The API offers competitive pricing and flexible usage plans, making it a cost-effective choice for businesses of all sizes.
**[Try these APIs on Eden AI](https://app.edenai.run/user/register?referral=spell-check-available)**
## **Benefits of using a Grammar and Spell Check API**
There are several benefits of using a spell and grammar check API for businesses, writers, and developers. Here are some of the key benefits:
1. **Improved Accuracy**: Spell and grammar check APIs use advanced algorithms and machine learning models to identify and suggest corrections for errors. This improves the accuracy and readability of written content, ensuring that it is error-free and professional.
2. **Time-saving**: Manually checking and correcting errors in written content can be a time-consuming task. Spell and grammar check APIs automate this process, saving time and increasing efficiency.
3. **Consistency**: Spell and grammar check APIs help ensure consistency in writing style and usage across different documents and content types. This is especially important for businesses and organizations that need to maintain a consistent brand voice.
4. **Customization**: Many spell and grammar check APIs are customizable to fit specific use cases and industries. This allows businesses and organizations to tailor the tool to their specific needs and improve its accuracy and relevance.
5. **Scalability**: Spell and grammar check APIs can handle large volumes of text, making them scalable solutions for businesses and organizations that need to check a large volume of content on a regular basis.
Overall, using a spell and grammar check API can improve the quality and accuracy of written content, save time and increase efficiency, and ensure consistency in writing style and usage.
## **What are the uses of spell check?**
Spell and grammar check APIs have a wide range of use cases in various industries and applications. Here are some examples:
### **Content Creation**
Spell and grammar check APIs can be used by writers, bloggers, and content creators to ensure that their articles, blog posts, and other written content are free of errors and are grammatically correct.
### **Business Communication**
Spell and grammar check APIs can be used by businesses and organizations to improve the quality and accuracy of their internal and external communication, including emails, reports, and presentations.
### **Customer Support**
Spell and grammar check APIs can be used by customer support teams to ensure that their responses to customers are error-free and professional.
### **Social Media**
Spell and grammar check APIs can be used by social media managers to ensure that their posts and updates are error-free and grammatically correct, helping to improve engagement and brand reputation.
### **Translation Services**
Spell and grammar check APIs can be used by translation services to ensure that translated content is free of errors and is grammatically correct.
### **Education**
Spell and grammar check APIs can be used by educators and students to improve the quality and accuracy of their academic writing, including essays, research papers, and thesis.

### **Legal Documents**
Spell and grammar check APIs can be used by legal professionals to ensure that legal documents, contracts, and agreements are free of errors and are grammatically correct.
### **Publishing**
Spell and grammar check APIs can be used by publishers to improve the quality and accuracy of written content, including books, magazines, and newspapers.
### **Multilingual Content**
Spell and grammar check APIs can be used by businesses and organizations that create content in multiple languages, ensuring that the content is error-free and grammatically correct in each language.
### **Chatbots**
Spell and grammar check APIs can be used by chatbots to ensure that their responses to customers are error-free and professional.
### **E-commerce**
Spell and grammar check APIs can be used by e-commerce platforms to ensure that product descriptions and other written content on their website is free of errors and is grammatically correct.
### **Job Applications**
Spell and grammar check APIs can be used by job seekers to improve the quality and accuracy of their job applications, including resumes and cover letters.
.png)
## **How to use Grammar and Spell Check with the Eden AI API?**
To start checking your text for grammar and style mistakes. you'll need to [create an account on Eden AI for free](https://app.edenai.run/user/register?referral=spell-check-available). Then, you'll be able to get your API key directly from the homepage with free credits offered by Eden AI.
**[Get your API key for FREE](https://app.edenai.run/user/register?referral=spell-check-available)**
## How Eden AI can help you?
Eden AI is the future of AI usage in companies: our app allows you to call multiple AI APIs.
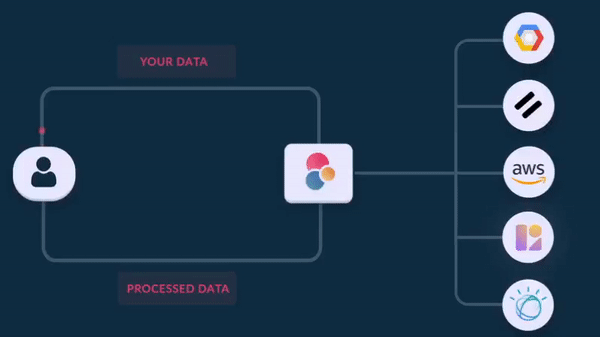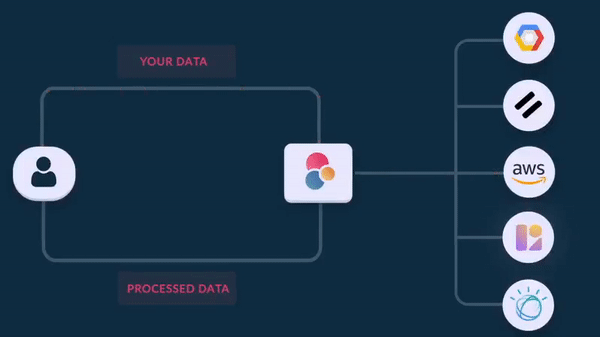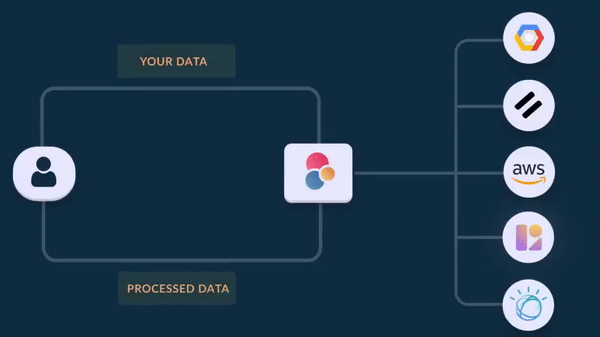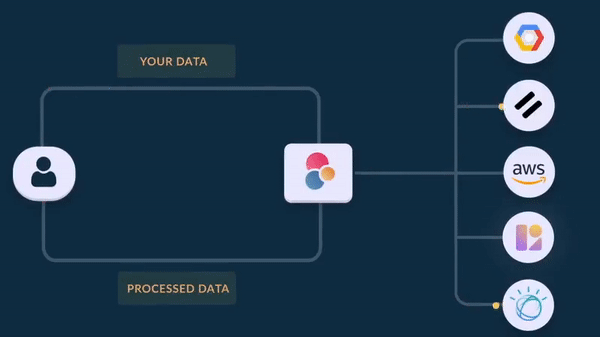
- Centralized and fully monitored billing on Eden AI for all NLP AI APIs
- Unified API for all providers: simple and standard to use, quick switch between providers, access to the specific features of each provider
- Standardized response format: the JSON output format is the same for all suppliers thanks to Eden AI's standardization work. The response elements are also standardized thanks to Eden AI's powerful matching algorithms.
- The best Artificial Intelligence APIs in the market are available: big cloud providers (Google, AWS, Microsoft, and more specialized engines)
- Data protection: Eden AI will not store or use any data. Possibility to filter to use only GDPR engines.
**[Create your Account on Eden AI](https://app.edenai.run/user/register?referral=spell-check-available)**
| edenai |
1,421,925 | Everything is Object In 🧑🏻💻JavaScript⤵️ | ## Everything In JavaScript i.e. : Objects Scope Window Global Object Global scope Local... | 0 | 2023-03-31T16:28:02 | https://dev.to/shaikhmd007/we-knows-object-in-javascript-3a6h | javascript, objects, programming, love |
## Everything In JavaScript i.e. : Objects
- [Scope](#scope)
- [Window Global Object](#window-global-object)
- [Global scope](#global-scope)
- [Local scope](#local-scope)
- [📔 Object](#-object)
- [Creating an empty object](#creating-an-empty-object)
- [Creating an objecting with values](#creating-an-objecting-with-values)
- [Getting values from an object](#getting-values-from-an-object)
- [Creating object methods](#creating-object-methods)
- [Setting new key for an object](#setting-new-key-for-an-object)
- [Object Methods](#object-methods)
- [Getting object keys using Object.keys()](#getting-object-keys-using-objectkeys)
- [Getting object values using Object.values()](#getting-object-values-using-objectvalues)
- [Getting object keys and values using Object.entries()](#getting-object-keys-and-values-using-objectentries)
- [Checking properties using hasOwnProperty()](#checking-properties-using-hasownproperty)
- [💻 Exercises](#-exercises)
- [Exercises: Level 1](#exercises-level-1)
- [Exercises: Level 2](#exercises-level-2)
- [Exercises: Level 3](#exercises-level-3)
## Scope
Variable is the fundamental part in programming. We declare variable to store different data types. To declare a variable we use the key word _var_, _let_ and _const_. A variable can be declared at different scope. In this section, we will see the scope variables, scope of variables when we use var or let.
Variables scopes can be:
- Global
- Local
Variable can be declared globally or locally scope. We will see both global and local scope.
Anything declared without let, var or const is scoped at global level.
Let us imagine that we have a scope.js file.
### Window Global Object
Without using console.log() open your browser and check, you will see the value of a and b if you write a or b on the browser. That means a and b are already available in the window.
```js
//scope.js
a = "JavaScript"; // declaring a variable without let or const make it available in window object and this found anywhere
b = 10; // this is a global scope variable and found in the window object
function letsLearnScope() {
console.log(a, b);
if (true) {
console.log(a, b);
}
}
console.log(a, b); // accessible
```
### Global scope
A globally declared variable can be accessed every where in the same file. But the term global is relative. It can be global to the file or it can be global relative to some block of codes.
```js
//scope.js
let a = "JavaScript"; // is a global scope it will be found anywhere in this file
let b = 10; // is a global scope it will be found anywhere in this file
function letsLearnScope() {
console.log(a, b); // JavaScript 10, accessible
if (true) {
let a = "Python";
let b = 100;
console.log(a, b); // Python 100
}
console.log(a, b);
}
letsLearnScope();
console.log(a, b); // JavaScript 10, accessible
```
### Local scope
A variable declared as local can be accessed only in certain block code.
- Block Scope
- Function Scope
```js
//scope.js
let a = "JavaScript"; // is a global scope it will be found anywhere in this file
let b = 10; // is a global scope it will be found anywhere in this file
// Function scope
function letsLearnScope() {
console.log(a, b); // JavaScript 10, accessible
let value = false;
// block scope
if (true) {
// we can access from the function and outside the function but
// variables declared inside the if will not be accessed outside the if block
let a = "Python";
let b = 20;
let c = 30;
let d = 40;
value = !value;
console.log(a, b, c, value); // Python 20 30 true
}
// we can not access c because c's scope is only the if block
console.log(a, b, value); // JavaScript 10 true
}
letsLearnScope();
console.log(a, b); // JavaScript 10, accessible
```
Now, you have an understanding of scope. A variable declared with _var_ only scoped to function but variable declared with _let_ or _const_ is block scope(function block, if block, loop block, etc). Block in JavaScript is a code in between two curly brackets ({}).
```js
//scope.js
function letsLearnScope() {
var gravity = 9.81;
console.log(gravity);
}
// console.log(gravity), Uncaught ReferenceError: gravity is not defined
if (true) {
var gravity = 9.81;
console.log(gravity); // 9.81
}
console.log(gravity); // 9.81
for (var i = 0; i < 3; i++) {
console.log(i); // 0, 1, 2
}
console.log(i); // 3
```
In ES6 and above there is _let_ and _const_, so you will not suffer from the sneakiness of _var_. When we use _let_ our variable is block scoped and it will not infect other parts of our code.
```js
//scope.js
function letsLearnScope() {
// you can use let or const, but gravity is constant I prefer to use const
const gravity = 9.81;
console.log(gravity);
}
// console.log(gravity), Uncaught ReferenceError: gravity is not defined
if (true) {
const gravity = 9.81;
console.log(gravity); // 9.81
}
// console.log(gravity), Uncaught ReferenceError: gravity is not defined
for (let i = 0; i < 3; i++) {
console.log(i); // 0, 1, 2
}
// console.log(i), Uncaught ReferenceError: i is not defined
```
The scope _let_ and _const_ are the same. The difference is only reassigning. We can not change or reassign the value of the `const` variable. I would strongly suggest you to use _let_ and _const_, by using _let_ and _const_ you will write clean code and avoid hard to debug mistakes. As a rule of thumb, you can use _let_ for any value which change, _const_ for any constant value, and for an array, object, arrow function and function expression.
## 📔 Object
Everything can be an object and objects do have properties and properties have values, so an object is a key value pair. The order of the key is not reserved, or there is no order.
To create an object literal, we use two curly brackets.
### Creating an empty object
An empty object
```js
const person = {};
```
### Creating an objecting with values
Now, the person object has firstName, lastName, age, location, skills and isMarried properties. The value of properties or keys could be a string, number, boolean, an object, null, undefined or a function.
Let us see some examples of object. Each key has a value in the object.
```js
const rectangle = {
length: 20,
width: 20,
};
console.log(rectangle); // {length: 20, width: 20}
const person = {
firstName: "MD",
lastName: "Shaikh",
age: 250,
country: "INDIA",
city: "Mum",
skills: [
"HTML",
"CSS",
"JavaScript",
"React",
"Node",
"MongoDB",
"Python",
"D3.js",
],
isMarried: false,
};
console.log(person);
```
### Getting values from an object
We can access values of object using two methods:
- using . followed by key name if the key-name is a one word
- using square bracket and a quote
```js
const person = {
firstName: "MD",
lastName: "Shaikh",
age: 250,
country: "INDIA",
city: "Mum",
skills: [
"HTML",
"CSS",
"JavaScript",
"React",
"Node",
"MongoDB",
"Python",
"D3.js",
],
getFullName: function () {
return `${this.firstName}${this.lastName}`;
},
"phone number": "+3584545454545",
};
// accessing values using .
console.log(person.firstName);
console.log(person.lastName);
console.log(person.age);
console.log(person.location); // undefined
// value can be accessed using square bracket and key name
console.log(person["firstName"]);
console.log(person["lastName"]);
console.log(person["age"]);
console.log(person["age"]);
console.log(person["location"]); // undefined
// for instance to access the phone number we only use the square bracket method
console.log(person["phone number"]);
```
### Creating object methods
Now, the person object has getFullName properties. The getFullName is function inside the person object and we call it an object method. The _this_ key word refers to the object itself. We can use the word _this_ to access the values of different properties of the object. We can not use an arrow function as object method because the word this refers to the window inside an arrow function instead of the object itself. Example of object:
```js
const person = {
firstName: "MD",
lastName: "Shaikh",
age: 250,
country: "INDIA",
city: "Mum",
skills: [
"HTML",
"CSS",
"JavaScript",
"React",
"Node",
"MongoDB",
"Python",
"D3.js",
],
getFullName: function () {
return `${this.firstName} ${this.lastName}`;
},
};
console.log(person.getFullName());
// MD Shaikh
```
### Setting new key for an object
An object is a mutable data structure and we can modify the content of an object after it gets created.
Setting a new keys in an object
```js
const person = {
firstName: "MD",
lastName: "Shaikh",
age: 250,
country: "INDIA",
city: "Mum",
skills: [
"HTML",
"CSS",
"JavaScript",
"React",
"Node",
"MongoDB",
"Python",
"D3.js",
],
getFullName: function () {
return `${this.firstName} ${this.lastName}`;
},
};
person.nationality = "Ethiopian";
person.country = "INDIA";
person.title = "teacher";
person.skills.push("Meteor");
person.skills.push("SasS");
person.isMarried = true;
person.getPersonInfo = function () {
let skillsWithoutLastSkill = this.skills
.splice(0, this.skills.length - 1)
.join(", ");
let lastSkill = this.skills.splice(this.skills.length - 1)[0];
let skills = `${skillsWithoutLastSkill}, and ${lastSkill}`;
let fullName = this.getFullName();
let statement = `${fullName} is a ${this.title}.\nHe lives in ${this.country}.\nHe teaches ${skills}.`;
return statement;
};
console.log(person);
console.log(person.getPersonInfo());
```
```sh
MD Shaikh is Learning Js.
He lives in INDIA.
He Knows HTML, CSS, JavaScript, React, Node, MongoDB, Python, D3.js, Meteor, and SasS.
```
### Object Methods
There are different methods to manipulate an object. Let us see some of the available methods.
_Object.assign_: To copy an object without modifying the original object
```js
const person = {
firstName: "MD",
age: 250,
country: "INDIA",
city: "Mum",
skills: ["HTML", "CSS", "JS"],
title: "teacher",
address: {
street: "Heitamienkatu 16",
pobox: 2002,
city: "Mum",
},
getPersonInfo: function () {
return `I am ${this.firstName} and I live in ${this.city}, ${this.country}. I am ${this.age}.`;
},
};
//Object methods: Object.assign, Object.keys, Object.values, Object.entries
//hasOwnProperty
const copyPerson = Object.assign({}, person);
console.log(copyPerson);
```
#### Getting object keys using Object.keys()
_Object.keys_: To get the keys or properties of an object as an array
```js
const keys = Object.keys(copyPerson);
console.log(keys); //['firstName', 'age', 'country','city', 'skills','title', 'address', 'getPersonInfo']
const address = Object.keys(copyPerson.address);
console.log(address); //['street', 'pobox', 'city']
```
#### Getting object values using Object.values()
_Object.values_:To get values of an object as an array
```js
const values = Object.values(copyPerson);
console.log(values);
```
#### Getting object keys and values using Object.entries()
_Object.entries_:To get the keys and values in an array
```js
const entries = Object.entries(copyPerson);
console.log(entries);
```
#### Checking properties using hasOwnProperty()
_hasOwnProperty_: To check if a specific key or property exist in an object
```js
console.log(copyPerson.hasOwnProperty("name"));
console.log(copyPerson.hasOwnProperty("score"));
```
🌕 You are astonishing. Now, you are super charged with the power of objects. You have just completed day 8 challenges and you are 8 steps a head in to your way to greatness. Now do some exercises for your brain and for your muscle.
## 💻 Exercises
### Exercises: Level 1
1. Create an empty object called dog
1. Print the the dog object on the console
1. Add name, legs, color, age and bark properties for the dog object. The bark property is a method which return _woof woof_
1. Get name, legs, color, age and bark value from the dog object
1. Set new properties the dog object: breed, getDogInfo
### Exercises: Level 2
1. Find the person who has many skills in the users object.
1. Count logged in users, count users having greater than equal to 50 points from the following object.
````js
const users = {
Alex: {
email: 'alex@alex.com',
skills: ['HTML', 'CSS', 'JavaScript'],
age: 20,
isLoggedIn: false,
points: 30
},
Asab: {
email: 'asab@asab.com',
skills: ['HTML', 'CSS', 'JavaScript', 'Redux', 'MongoDB', 'Express', 'React', 'Node'],
age: 25,
isLoggedIn: false,
points: 50
},
Brook: {
email: 'daniel@daniel.com',
skills: ['HTML', 'CSS', 'JavaScript', 'React', 'Redux'],
age: 30,
isLoggedIn: true,
points: 50
},
Daniel: {
email: 'daniel@alex.com',
skills: ['HTML', 'CSS', 'JavaScript', 'Python'],
age: 20,
isLoggedIn: false,
points: 40
},
John: {
email: 'john@john.com',
skills: ['HTML', 'CSS', 'JavaScript', 'React', 'Redux', 'Node.js'],
age: 20,
isLoggedIn: true,
points: 50
},
Thomas: {
email: 'thomas@thomas.com',
skills: ['HTML', 'CSS', 'JavaScript', 'React'],
age: 20,
isLoggedIn: false,
points: 40
},
Paul: {
email: 'paul@paul.com',
skills: ['HTML', 'CSS', 'JavaScript', 'MongoDB', 'Express', 'React', 'Node'],
age: 20,
isLoggedIn: false,
points: 40
}
}```
````
1. Find people who are MERN stack developer from the users object
1. Set your name in the users object without modifying the original users object
1. Get all keys or properties of users object
1. Get all the values of users object
1. Use the countries object to print a country name, capital, populations and languages.
### Exercises: Level 3
1. Create an object literal called _personAccount_. It has _firstName, lastName, incomes, expenses_ properties and it has _totalIncome, totalExpense, accountInfo,addIncome, addExpense_ and _accountBalance_ methods. Incomes is a set of incomes and its description and expenses is a set of incomes and its description.
2. \*\*\*\* Questions:2, 3 and 4 are based on the following two arrays:users and products ()
```js
const users = [
{
_id: "ab12ex",
username: "Alex",
email: "alex@alex.com",
password: "123123",
createdAt: "08/01/2020 9:00 AM",
isLoggedIn: false,
},
{
_id: "fg12cy",
username: "Asab",
email: "asab@asab.com",
password: "123456",
createdAt: "08/01/2020 9:30 AM",
isLoggedIn: true,
},
{
_id: "zwf8md",
username: "Brook",
email: "brook@brook.com",
password: "123111",
createdAt: "08/01/2020 9:45 AM",
isLoggedIn: true,
},
{
_id: "eefamr",
username: "Martha",
email: "martha@martha.com",
password: "123222",
createdAt: "08/01/2020 9:50 AM",
isLoggedIn: false,
},
{
_id: "ghderc",
username: "Thomas",
email: "thomas@thomas.com",
password: "123333",
createdAt: "08/01/2020 10:00 AM",
isLoggedIn: false,
},
];
const products = [
{
_id: "eedfcf",
name: "mobile phone",
description: "Huawei Honor",
price: 200,
ratings: [
{ userId: "fg12cy", rate: 5 },
{ userId: "zwf8md", rate: 4.5 },
],
likes: [],
},
{
_id: "aegfal",
name: "Laptop",
description: "MacPro: System Darwin",
price: 2500,
ratings: [],
likes: ["fg12cy"],
},
{
_id: "hedfcg",
name: "TV",
description: "Smart TV:Procaster",
price: 400,
ratings: [{ userId: "fg12cy", rate: 5 }],
likes: ["fg12cy"],
},
];
```
Imagine you are getting the above users collection from a MongoDB database.
a. Create a function called signUp which allows user to add to the collection. If user exists, inform the user that he has already an account.
b. Create a function called signIn which allows user to sign in to the application
3. The products array has three elements and each of them has six properties.
a. Create a function called rateProduct which rates the product
b. Create a function called averageRating which calculate the average rating of a product
4. Create a function called likeProduct. This function will helps to like to the product if it is not liked and remove like if it was liked.
🎉 Its ALL About Objects In JavaScript ! 🎉
| shaikhmd007 |
1,421,970 | How to start into web Development? | If you're really interested in web development, there are several steps you can take to get... | 0 | 2023-03-31T18:01:48 | https://dev.to/abijithgabriel/how-to-start-into-web-development-47ai | webdev, beginners, html, javascript |
If you're really interested in web development, there are several steps you can take to get started:
**Learn the basics of HTML, CSS, and JavaScript**: These are the building blocks of web development. HTML is used to structure the content of a web page, CSS is used to style the page, and JavaScript is used to add interactivity.
** Choose a code editor**: A code editor is where you'll write and edit your code. There are many free options available, such as Visual Studio Code, Atom, or Sublime Text.
**Set up a development environment**: You'll need a local development environment to test your code. This can be set up on your computer using tools like XAMPP, WAMP, or MAMP.
**Start building projects**: Start with small projects, such as building a simple website, and gradually work your way up to more complex projects.
**Learn from others**: There are many resources available online to learn web development, such as online courses, tutorials, and forums. Additionally, joining online communities like Stack Overflow or Reddit can provide valuable feedback and support.
**Practice and experiment**: Don't be afraid to experiment and try new things. The more you practice and build, the better you'll become.
Remember, web development is a constantly evolving field, so it's **important to keep learning** and staying up-to-date with new technologies and trends. | abijithgabriel |
1,422,033 | Convert Material 3 Theme Designs to Flutter Code | Parabeac — Now compatible with Google Material Design 3 Themes With the release of... | 0 | 2023-03-31T20:07:16 | https://dev.to/parabeac/convert-material-3-theme-designs-to-flutter-code-cm1 | flutter, frontend, design, dart |
## **Parabeac — Now compatible with Google Material Design 3 Themes**

With the release of Google’s latest design system, Material Design 3, there’s been an update to the way that colors in Light and Dark Schemes are selected. Parabeac has just released support in Parabeac Cloud and parabeac_core: now you have the option to select between Material Design 3 and Material Design 2 when converting themes to Flutter code.
Take a look at our updated Figma Kickstart file [here](http://bit.ly/3TX0BmO).
## **Converting with Parabeac Cloud**

To convert a Material 3 Theme using Parabeac Cloud, the process remains the same as it was previously: simply create a Theme Project, select your GitHub branch, provide links to the Figma File, and convert. For more detailed instructions, [check out our documentation](http://bit.ly/3ns93hw).
## **What’s New: Color Palette**
Based on Key tones, 13 shades shades are generated ranging from 0–100. On the bottom end of the spectrum 0 is true black (#FFFFFF) and 100 is true white white (#00000). From these key tones, the derivative palette colors are selected.

Parabeac has updated its Themes Figma Kickstart file to reflect this — [play with it here](http://bit.ly/3TX0BmO). To use our Figma file: edit the key tones and the palette will be generated. Then, to select the colors for the light and dark color schemes, use the dropper to choose the appropriate color from the gradient in the palette.
## **Accessibility and Contrast**
One of the main goals of the Google Material 3 color palette is to improve accessibility. The new color palette is designed to meet the WCAG 2.1 AA standard for contrast ratio. This means that text and other important elements are more legible, making it easier for users with visual impairments to navigate and use the interface.
While there are default values, such as Primary being set to Primary40 and On Primary set to Primary100, the user can manually set what shade from the key tone palette they would like to use — though keep in mind there are specific contrast minimums set forth by Material 3.
## **Updates to Typography**

The naming conventions for typography have also been modified as well as several new font options added.
## **Conclusion**
Whether you’re currently using Material Design 2 or Material Design 3, we hope you use Parabeac to convert your design from Figma to Flutter Code! Head to [parabeac.com](http://bit.ly/40RAuju) to learn more or to [app.parabeac.com](https://bit.ly/3ns93hw) to try it today. | silverlily |
1,422,267 | Stack Cloud/Network/Security Certifications | I recently went on a certification binge to get 12 certs in 5 months (Nov/4/23 - Apr/20/22). Below... | 0 | 2023-04-20T22:15:41 | https://dev.to/aakhtar3/stack-cloudnetworksecurity-certifications-2pa6 | cloud, security, network, certification | I recently went on a certification binge to get 12 certs in 5 months (Nov/4/23 - Apr/20/22). Below are some strategies to stack multiple certifications to stack your resume and LinkedIn profile.
|[Scrum](#scrum) |[AWS](#aws)|[CompTIA](#comptia)|
|:-:|:-:|:-:|
|[resources](#scrum-resources)|[resources](#aws-resources)|[resources](#comptia-resources)|
## Scrum
### ScrumMaster
> Foundation -> Advanced -> Professional -> Elevated
### Developer
> Foundation -> Advanced -> Professional
### Product Owner
> Foundation -> Advanced -> Professional
My journey started back in 2016 when I first got my `Certified ScrumMaster` certification through [scrumalliance.org]. The certification needs to be renewed before the two-year renewal date. Typically, I would obtain the scrum education units ([SEU]) and pay the renewal fee. However, in late 2020, I wanted to pick up a new `Scrum Developer` certification. I plan on getting `Product Owner` and then moving onto the `Advanced` level where the certs start to stack on renewal.

### Scrum Resources
- [scrumalliance.org]
- [SEU]
[scrumalliance.org]: https://www.scrumalliance.org/
[SEU]: https://www.scrumalliance.org/get-certified/scrum-education-units
## AWS
### DevOps
> Cloud Practitioner -> Developer Associate -> DevOps Engineer Professional
> Cloud Practitioner -> SysOps Administrator Associate -> DevOps Engineer Professional
### Solution Architect
> Cloud Practitioner -> Solutions Architect Associate -> Solutions Architect Professional
### Speciality
> Speciality
I skipped the `Cloud Practitioner` and plan on taking the `Speciality` certs at some point. I had already taken the three `Associate` and two `Professional` certifications through [aws.amazon.com] in early 2020, but they needed to be renewed before the three-year renewal date. Luckily, these certifications stack, so I only needed to take two `Professional` exams to receive all five certifications in late 2022.

### AWS Resources
|Course|Time|Practice Exam|
|:-:|:-:|:-:|
|[Developer Associate]|33.5 Hours|[DVA]|
|[Sysops Administrator Associate]|26.5 Hours|[SOA]|
|[Devops Engineer Professional]|41 Hours|[DOP]|
|[Solutions Architect Associate]|26.5 Hours|[SAA]|
|[Solutions Architect Professional]|70 Hours|[SAP]|
[aws.amazon.com]: https://aws.amazon.com/certification/
[Stephane Maarek]: https://www.udemy.com/user/stephane-maarek/
[Developer Associate]: https://www.udemy.com/course/aws-certified-developer-associate-dva-c01/
[DVA]: https://portal.tutorialsdojo.com/courses/aws-certified-developer-associate-practice-exams/
[Sysops Administrator Associate]: https://www.udemy.com/course/ultimate-aws-certified-sysops-administrator-associate/
[SOA]: https://portal.tutorialsdojo.com/courses/aws-certified-sysops-administrator-associate-practice-exams/
[Devops Engineer Professional]: https://learn.cantrill.io/p/aws-certified-devops-engineer-professional
[DOP]: https://portal.tutorialsdojo.com/courses/aws-certified-devops-engineer-professional-practice-exams/
[Solutions Architect Associate]: https://www.udemy.com/course/aws-certified-solutions-architect-associate-saa-c03/
[SAA]: https://portal.tutorialsdojo.com/courses/aws-certified-solutions-architect-associate-practice-exams/
[Solutions Architect Professional]: https://learn.cantrill.io/p/aws-certified-solutions-architect-professional
[SAP]: https://portal.tutorialsdojo.com/courses/aws-certified-solutions-architect-professional-practice-exams/
## CompTIA
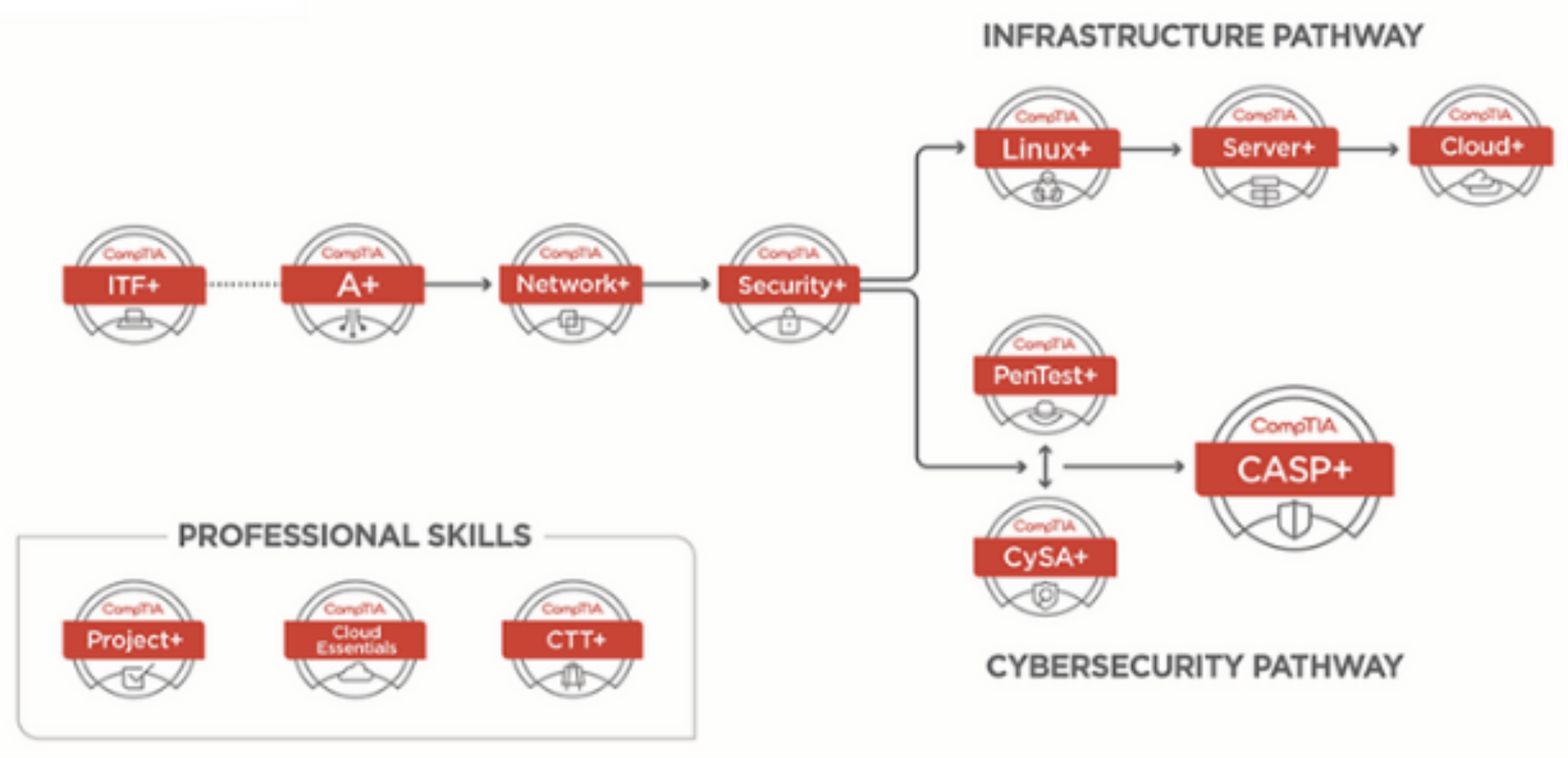
[Comptia.org] was new to me but they offer a few tracks to allow stackable certifications. I skipped `A+` and `Server+` but instead went straight for Infrastructure and Cyber Security certifications.
### Infrastructure
> A+ -> Server+
> A+ -> Network+ -> Security + -> Linux+ -> Cloud+
Cloud+ can be renewed by either retaking the test before the three years renewal date or obtaining 50 Continued Education Units ([CEU]). The [cloud renew list] has the AWS certifications that I already obtained. Going forward I will only need to take an AWS exam to recertify the CompTIA infrastructure certifications.
### Cyber Security
> A+ -> Network+ -> Security+ -> CySa+ -> CASP+
> A+ -> Network+ -> Security+ -> PenTest+ -> CASP+
CASP+ can be renewed by either retaking the test before the three years renewal date or obtaining 75 Continued Education Units ([CEU]). I plan on taking college courses, working, and writing blogs to renew this certification. Down the road, I will start taking other non-CompTIA certs on the [CASP renew list].
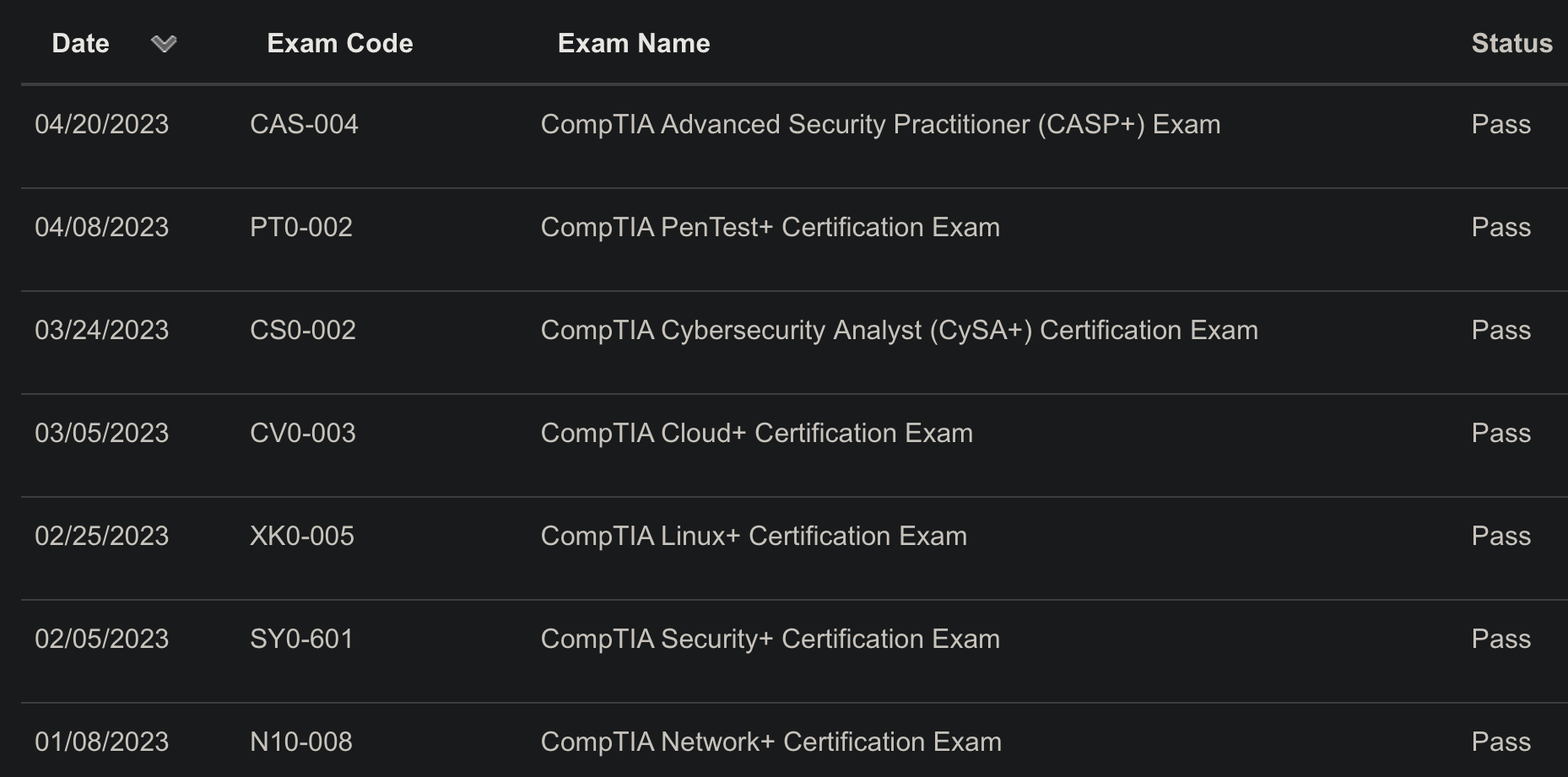
### CompTIA Resources
|Course|Time|Practice Exam|
|:-:|:-:|:-:|
|[Network+]|26 Hours|[n10]|
|[Linux+]|21 Hours|[xk0]|
|[Cloud+]|10.5 Hours|[cv0]|
|[Security+]|21.5 Hours|[sy0]|
|[CySa+]|32.5 Hours|[cy0]|
|[PentTest+]|32.5 Hours|[pt0]|
|[CASP+]|31.5 Hours|[cas]|
[Network+]: https://www.udemy.com/course/comptia-network-n10-008/
[n10]: https://www.udemy.com/course/comptia-network-008-exams/
[Linux+]: https://www.udemy.com/course/comptia-linux/
[xk0]: https://www.udemy.com/course/comptia-linux-exams/
[Cloud+]: https://www.udemy.com/course/total-cloud-computing-comptia-cloud-cert-cv0-002/
[cv0]: https://www.udemy.com/course/total-comptia-cloud-cv0-003-4-practice-tests/
[Security+]: https://www.udemy.com/course/securityplus/
[sy0]: https://www.udemy.com/course/security-601-exams/
[CySa+]: https://www.udemy.com/course/comptiacsaplus/
[cy0]: https://www.udemy.com/course/comptiacysaexam/
[PentTest+]: https://www.udemy.com/course/pentestplus/
[pt0]: https://www.udemy.com/course/comptia-pentest-exams-002/
[CASP+]: https://www.udemy.com/course/casp-plus/
[cas]: https://www.udemy.com/course/casp-exams-004/
[Comptia.org]: https://www.comptia.org/
[CEU]: https://www.comptia.org/continuing-education/learn/earn-continuing-education-units
[cloud renew list]: https://www.comptia.org/continuing-education/renewothers/renewing-cloud
[CASP renew list]: https://www.comptia.org/continuing-education/renewothers/renewing-casp | aakhtar3 |
1,422,397 | Editing Images Via A Prompt With Python And Pytorch | Introduction Hello! 😃 In this tutorial I will show you how you can use a pre-trained... | 0 | 2023-04-01T05:17:19 | https://ethan-dev.com/post/editing-images-via-a-prompt-with-python-and-pytorch | python, beginners, tutorial, programming | ## Introduction
Hello! 😃
In this tutorial I will show you how you can use a pre-trained machine learning model to modify an image based on the user's input prompt.
The model uses an image editing technique called "instruct-pix2pix" and is implemented in Python using the PyTorch module.
Well then let's get started. 😎
---
## Requirements
- Basic knowledge of Python
- A decent spec computer
---
## Creating The Virtual Environment
First we need to create a virtual Python environment for the project. Open up the terminal and run the following command in the project's root directory:
```bash
python3 -m venv env
```
Next we need to activate the environment which can be done via the following command:
```bash
source venv/bin/activate
```
Next we need to install the dependencies. 💫
---
## Installing The Dependencies
To install the dependencies, open up a file called "requirements.txt" and add the following modules:
```txt
diffusers
transformers
accelerate
ipython
```
Next run the following command:
```bash
pip install -r requirements.txt
```
Now we can finally start coding! ☺️
---
## Coding The Application
Next we can finally start writing the source code, open up a file called "main.py" and import the following:
```python
import PIL
import torch
from diffusers import StableDiffusionInstructPix2PixPipeline
import argparse
```
Next, we need to initialize some constant variables:
```python
MODEL_ID = "timbrooks/instruct-pix2pix"
#PIPE = StableDiffusionInstructPix2PixPipeline.from_pretrained(MODEL_ID, torch_dtype=torch.float16).to("cuda")
PIPE = StableDiffusionInstructPix2PixPipeline.from_pretrained(MODEL_ID).to("cpu")
```
Here we define the model to use. (in this case instruct-pix2pix) The repo for this can be found here:
https://github.com/timothybrooks/instruct-pix2pix
We also initialize the pipeline, if your machine has a decent amount of GPU VRAM I highly recommend using the commented out line. My machine isn't that great of spec so I opted to use the CPU over GPU. 🥺
Next we will create the main method:
```python
def main(prompt, imagePath):
image = PIL.Image.open(imagePath)
images = PIPE(prompt, image = image, num_inference_steps = 30, image_guidance_scale = 1.5, guidance_scale = 7).images
new_image = PIL.Image.new("RGB", (image.width * 2, image.height))
new_image.paste(image, (0, 0))
new_image.paste(images[0], (image.width, 0))
new_image.save("output.png")
```
What this method does is open the image file from the image path that was passed to it, which will then use the pre-trained model to modify the image based on the provided prompt.
Finally we combine both the original image and the new image side by side so that we can compare them and then save the image to a file called "output.png".
Next we add the following in order to call the main method:
```python
if __name__ == "__main__":
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to image file")
ap.add_argument("-p", "--prompt", required = True, help = "Prompt for image editing")
args = vars(ap.parse_args())
main(args["prompt"], args["image"])
```
All the above does is take an image file path and a prompt from the command line and then passes them both to the main method.
All done! 😄
You can try the program with the following command:
```bash
python main.py -i [path to image file] -p [prompt]
```
Depending on the spec of your machine you may need to wait a while for the image to be processed. If you run into any out of memory issues try decreasing the size of the image or the amount of num_inference_steps. 👀
---
## Conclusion
Here I have shown how to edit images with Python, PyTorch and by using a pre-trained model.
I hope you learned something from this tutorial as much as I did writing it. 😆
You can find the source code for the tutorial via my Github:
https://github.com/ethand91/python-pytorch-image-editor
As always happy coding! 😎
---
Like me work? I post about a variety of topics, if you would like to see more please like and follow me.
Also I love coffee.
[](https://www.buymeacoffee.com/ethand9999)
If you are looking to learn Algorithm Patterns to ace the coding interview I recommend the [following course](https://algolab.so/p/algorithms-and-data-structure-video-course?affcode=1413380_bzrepgch) | ethand91 |
1,422,398 | Minze Inside Vue.js | Web components are a powerful and versatile technology that can help web developers build complex and... | 0 | 2023-04-01T05:46:45 | https://dev.to/nnivxix/create-a-native-custom-element-using-minze-inside-vuejs-2mdo | vue, webcomponents, webdev, javascript | Web components are a powerful and versatile technology that can help web developers build complex and scalable user interfaces. However, creating and maintaining web components can be a challenging task, especially when it comes to managing the various dependencies and tools required to build and deploy them.
This is where Minze, a lightweight and flexible build tool for web components, comes into play. Minze is designed to simplify the development and deployment process of web components by providing a simple and intuitive command-line interface that automates many of the tedious and repetitive tasks involved.
With Minze, developers can easily create and manage web components using a variety of popular web technologies, including HTML, CSS, and JavaScript. Minze provides a number of features to help streamline the development process, including live reloading, automated testing, and optimized builds for production deployment.
And Vue.js is a popular JavaScript framework that allows developers to build dynamic and interactive web applications. One of the key features of Vue.js is its component-based architecture, which enables developers to create reusable and modular UI components that can be easily combined to create complex user interfaces.
In this article, we will take a closer look at Minze and how it can be used to build web components. We will provide a step-by-step guide on how to create web components using this powerful tool and use the component inside Vue.
##Preparation
Prepare your project, I used Vite.js to start the project and don't forget to install Minze in the project.
```bash
npm create vite@latest name-vue-app --template vue
```
Move to your directory project and install Minze.
```bash
npm install minze
```
## Create first component
Open directory src/components and create a folder named minze and inside folder minze create your first component.
```js
src/
└─ components/
└─ minze/
├─ ...
└─ my-element.js
```
```js
import { MinzeElement } from 'minze'
class MyElement extends MinzeElement {
// html template
html = () => `<h1>My very own component!</h1>`
// scoped stylesheet
css = () => `
h1 {
color: red;
}
`
}
export default MyElement;
```
## Register the component
once you create a component, you must register the component. please open the file `"main.js"`.
```js
// main.js
import { createApp } from "vue";
import Minze from "minze";
import "./style.css";
import App from "./App.vue";
import MyElement from "./components/minze/my-element";
Minze.defineAll([MyElement]);
createApp(App).mount("#app");
```
## Update config
Before you use the component, you have to tell the Vue Compiler that the component is a native custom element. Please open vite.config.js
```js
// vite.config.js
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue({
template: {
compilerOptions: {
isCustomElement: (tag) => tag.includes("-"),
},
},
}),
],
});
```
And finally you can use component inside Vue Project. Please note that you must use the `kebab-case` style to indicate that it is a custom web native component.
```html
<!-- app.vue -->
<template>
<my-element></my-element>
</template>
```
## Conclusion
Minze is a library for creating custom native web components easily and quickly like native components along with shadow DOM. Due to its agnostic nature, Minze is capable of combining with any javascript framework.
I think maybe it's not the best practice to build app with Vue.js framework but for the experience of the developers it's worth a try.
Don't forget to read the [documentation of Minze](https://minze.dev/) to explore the features and APIs that have been provided.
---
- [Link Repository](https://github.com/nnivxix/minze-vue) | nnivxix |
1,422,499 | How to use Docker commands - beginner (part1) | When the user is beginner, in the most of cases it’s not sure how to start with Docker, even just to... | 0 | 2023-04-01T08:51:47 | https://dev.to/justplegend/docker-commands-beginner-part1-2bmj | docker, beginners, devops | When the user is beginner, in the most of cases it’s not sure how to start with Docker, even just to try it in own environment, like in my case. 🤔
I started to learn about Docker concepts using different courses and one of the first it was on KodeKloud platform with hands-on examples to setup Docker and use commands. ✅
Sometimes they have free week or even month to learn some stuff, so I used promotion to learn Docker basic. 💡
Another useful course was on the platform SimpleLearn, later I discover Nana where you can see hands-on examples. 💡
But…you are watching, writing, learning new things, taking notes.. But ..but I need to try it on my own laptop. So I decided to install Docker and try these simple commands.
Add User to Docker group on Linux
After installation add user (you) to the DOcker group to run commands without "sudo". This is optional, but it's more easy than every time type 'sudo'.
Command for this option is:
sudo usermod -a -G docker $(whoami)
After you run this command, your user will be added to the Docker group and will have necessary permissions to run commands without typing every time 'sudo'.
If you try immediately to execute commands without sudo, you will get message. First you need to log out and log back in to apply the changes. Another option is use command bellow to activate the changes without logging out.
Apply this command:
$ newgrp docker
On the image bellow you can see executed these commands:

Depending on what is your configuration, you need to choose right installation. I need it to install on Ubuntu, but if you don’t have Linux, another option is to try it on AWS (Amazon Web Services) installing Linux on EC2 instance. 🐧 ☁️
EC2 instance is “computer in the cloud”, where you can install Linux and try docker, later user can terminate machine without effecting local machine. Also, AWS have free tier for one year, that mean you can use EC2 instance — Linux machine every month 750h (hours), t2.micro, t3.micro. More information you can find on this [link](https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Types=*all&awsf.Free%20Tier%20Categories=*all).
[Install Docker on Ubuntu](https://docs.docker.com/engine/install/ubuntu/)
[Install Docker on Windows](https://docs.docker.com/desktop/install/windows-install/)
[Install Docker on AWS (EC2 Instance)](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/install-docker.html)
After installation and setup Docker on my laptop, I started to try some commands, like pull the image, try it to run, discover some images and containers..
In the one moment, I used command to delete image (docker rmi name_of_image)..But I couldn’t delete it just like that. Why?
I need to research why and how it’s possible to delete image, why error is dependencies… After discovering problem, understand problem and error messages, I need it to write it on medium, so I can use it later like reminder how to resolve and delete image from container. All these commands it’s possible to find using docker help, but these commands are the first things that I tried when I wanted at least pull image, run image, delete, list containers, list images, remove images, containers etc.
Courses and hands-on give you ideas on the beginning what to try, how to try, but when you get problem which is not in the course, you need on own find solution and how to resolve (or ask friend to help you if he/she is better in Docker :D).
I will try also document everything on my [GitHub](https://github.com/JustPLegend) page about Docker, Jenkins and everything how to do it and why I do it just like that.
RUN — the docker run command is used to run a container from an image.
If the image is not downloaded, it will automatically download it. The version of image it will be the latest.
_COMMAND: docker run ubuntu cat /etc/*release*_
**DOWNLOAD SPECIFIC IMAGE (VERSION)**
To download specific image of ubuntu, for example ubuntu 18.04, the command will be:
docker run ubuntu:18.04 /etc/*release*
/etc/*release* — will show other details about the image
Numbers of version of ubuntu 18.04 in the Docker world is called TAGS. Official versions of tags for specific image, user can find on the https://hub.docker.com/ .
**LIST CONTAINERS:** docker ps , docker ps -a
**STOP CONTAINER:** docker stop name_of_container
**REMOVE CONTAINER:** docker rm name_of_container
**PULL IMAGE:** docker pull name_of_image (example: docker pull image ubuntu)
**LIST IMAGES ON DOCKER HOST:** docker images, docker images -a (all images)
**REMOVE IMAGES:** docker rmi name_of_image
<u>IMPORTANT: To remove images from Docker host, user need to check that container it’s not running. User need to STOP AND DELETE all dependent containers to be able to delete an image.
</u>
Example:
When you want to delete image ubuntu-latest and you get part of error message is “dependencies -container 6a17ef9 “ , user need first remove dependencies of container (6a17..) and then remove image. If you have more errors similar to this, but with different number of container, do it all steps again a), b), c) (optional) .
a) **Remove container:** docker rm 6a17efd
b) **Remove image:** docker rmi ubuntu-latest
c) **List images to check that is deleted:** docker images
Visit article: [Intro to Docker](https://dev.to/justplegend/try-hack-me-intro-to-docker-1c63)
| justplegend |
1,422,523 | Tic Tac picoCTF 2023 | tic-tac 200 points AUTHOR: JUNIAS BONOU Description Someone created a program to read... | 0 | 2023-04-01T09:59:46 | https://dev.to/brunoblaise/tic-tac-picoctf-2023-1h4o | cybersecurity, beginners, picoct, tutorial | # tic-tac
**200 points**
AUTHOR: JUNIAS BONOU
Description
Someone created a program to read text files; we think the program reads files with root privileges but apparently it only accepts to read files that are owned by the user running it.
ssh to saturn.picoctf.net:50591, and run the binary named "txtreader" once connected. Login as ctf-player with the password, d8819d45
*Note:* This challenge launches an instance on demand.
___
```cpp
#include <stdio.h>
#include<unistd.h>
#include <string.h>
int main(int argc, char * argv[]){
unlink(argv[1]);
symlink("/home/ctf-player/flag.txt",argv[1]);
}
```
But this is just **NOT FAST ENOUGH APPERANTLY**
Thank god `LiveOverflow` exists because after scraping the web with the utmost of `sus` google searches that probably put me on a list I found his video, directly solving this question [https://www.youtube.com/watch?v=5g137gsB9Wk&ab_channel=LiveOverflow](https://www.youtube.com/watch?v=5g137gsB9Wk&ab_channel=LiveOverflow) (you could skip this writeup and watch his video).
My explanation:
We want to create race conditions, such that the command execution would be like so:
```
--> Be a root file
--> Get checked by the programs if:
// Check the file's owner.
if (statbuf.st_uid != getuid()) {
std::cerr << "Error: you don't own this file" << std::endl;
return 1;
}
--> Become readable with symbolic link
--> Get opened and read by the program:
// Read the contents of the file.
if (file.is_open()) {
std::string line;
while (getline(file, line)) {
std::cout << line << std::endl;
}
} else {
std::cerr << "Error: Could not open file" << std::endl;
return 1;
}
```
Instead of the code I showed above, there is a faster built in way in linux that this hidden from the internet does:
```cpp
#define _GNU_SOURCE
#include <stdio.h>
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/fs.h>
// source https://github.com/sroettger/35c3ctf_chals/blob/master/logrotate/exploit/rename.c
int main(int argc, char *argv[]) {
while (1) {
syscall(SYS_renameat2, AT_FDCWD, argv[1], AT_FDCWD, argv[2], RENAME_EXCHANGE);
}
return 0;
}
```
Running this script on two files, one with symbolic link to the flag and another user-made file tricks the reader program when it tried to read the symbolic-link file to print out the flag if you're lucky (just a few reruns needed).
And so:
> picoCTF{your flag}
| brunoblaise |
1,422,525 | FizzBuzz, Quick Comparison of Power FX & JavaScript | Power FX is the LowCode language of the Power Platform. Originally just for Canvas Power Apps, it's... | 19,972 | 2023-04-05T07:25:02 | https://dev.to/wyattdave/fizzbuzz-quick-comparison-of-power-fx-javascript-24e0 | powerapps, powerplatform, lowcode, javascript | [Power FX](https://learn.microsoft.com/en-us/power-platform/power-fx/overview) is the LowCode language of the Power Platform. Originally just for Canvas Power Apps, it's an expression-based language, with a learning curve focused on Excel users. Microsoft has been extended it to other areas of the platform, starting with Private Virtual Agents and Dataverse.
So why would ProCode Developers want to learn it, well as it looks like the language will continue to develop and expand across Microsoft's suite of technology, there's a good chance it will appear in our workstream.
And why would a Power App Developer want to learn JavaScript, well script components use JavaScript and Office Scripts use TypeScript (subset of JavaScript). So, learning JavaScript is a logical progression.
Fizz Buss is a very simple coding exercise, with multiple different ways to deliver the same solution, I thought it would be a great demonstration of the differences and similarities for Power FX and JavaScript.
Well what is Fizz Buzz then:
> Fizz buzz is a group word game for children to teach them about division. Players take turns to count incrementally, replacing any number divisible by three with the word "fizz", and any number divisible by five with the word "buzz", and any number divisible by both 3 and 5 with the word "fizzbuzz".
So the requirements would be:
- Increment by one
- If the increment is divisible by 5 print 'fizz'
- If the increment is divisible by 3 print 'buzz'
- Each Increment should be on the sameline
Simple 😎
For JavaScript I would do
``` JavaScript
function fizzBuzz(){
const iEnd=100
for(i=1;i<iEnd;i++){
let sPrint="";
if(i % 3==0){sPrint="fizz"};
if(i % 5==0){sPrint+="buzz"};
if(sPrint!=""){console.log(sPrint)};
//console.log(i+"-"+sPrint); use instead above for demo below
}
}
```
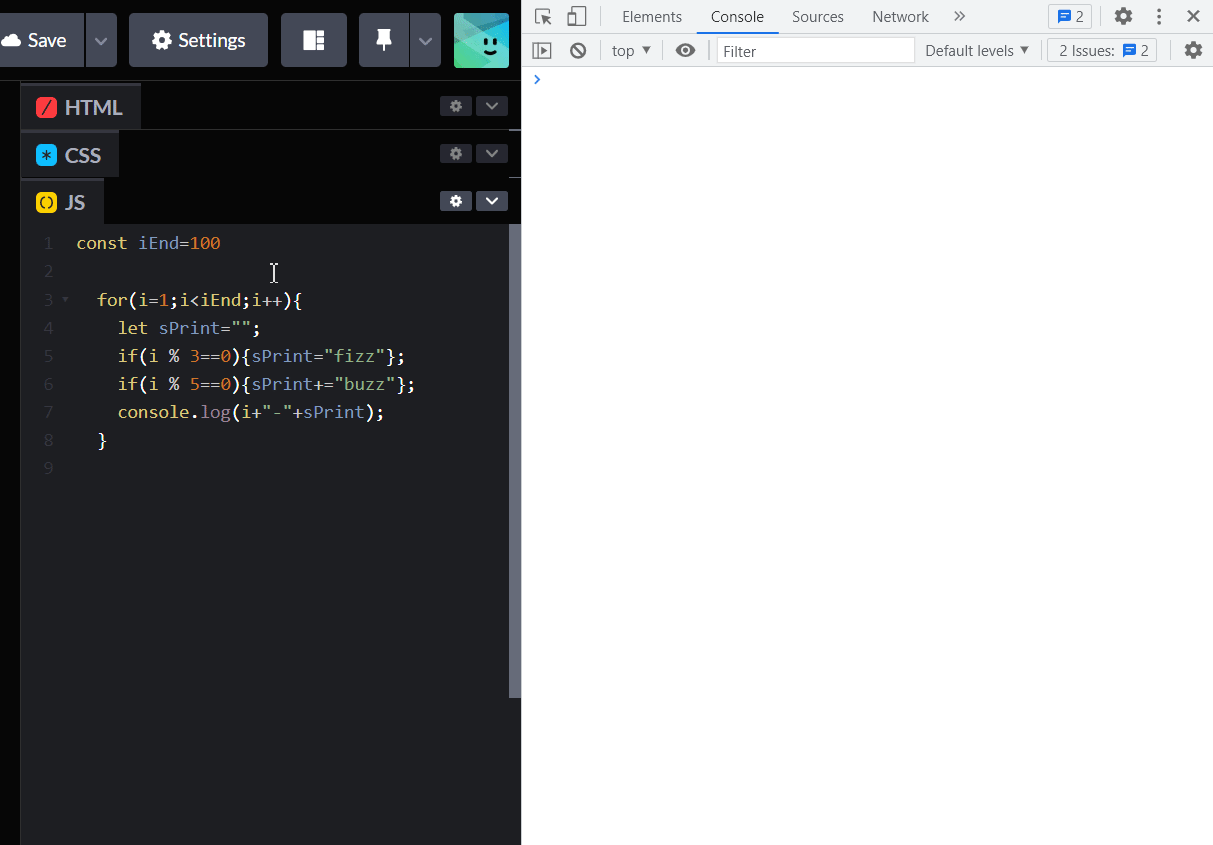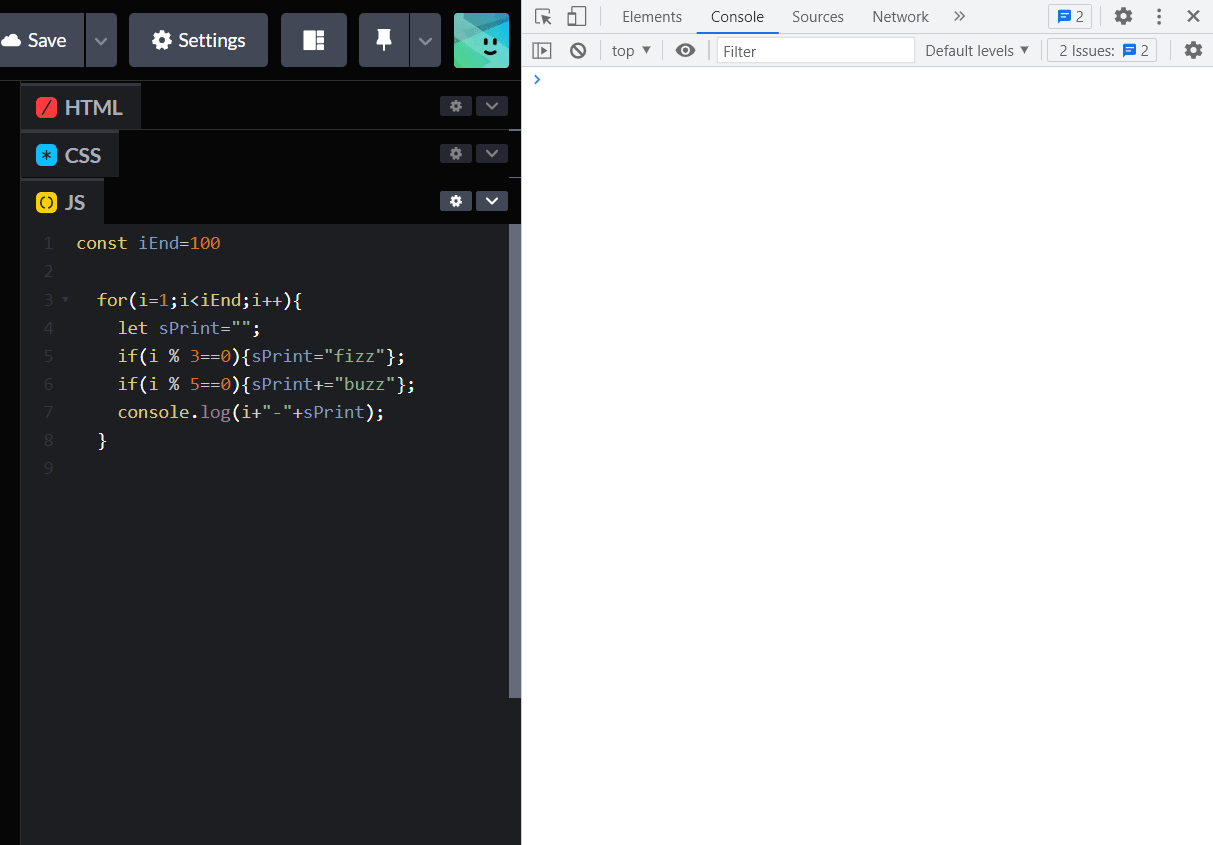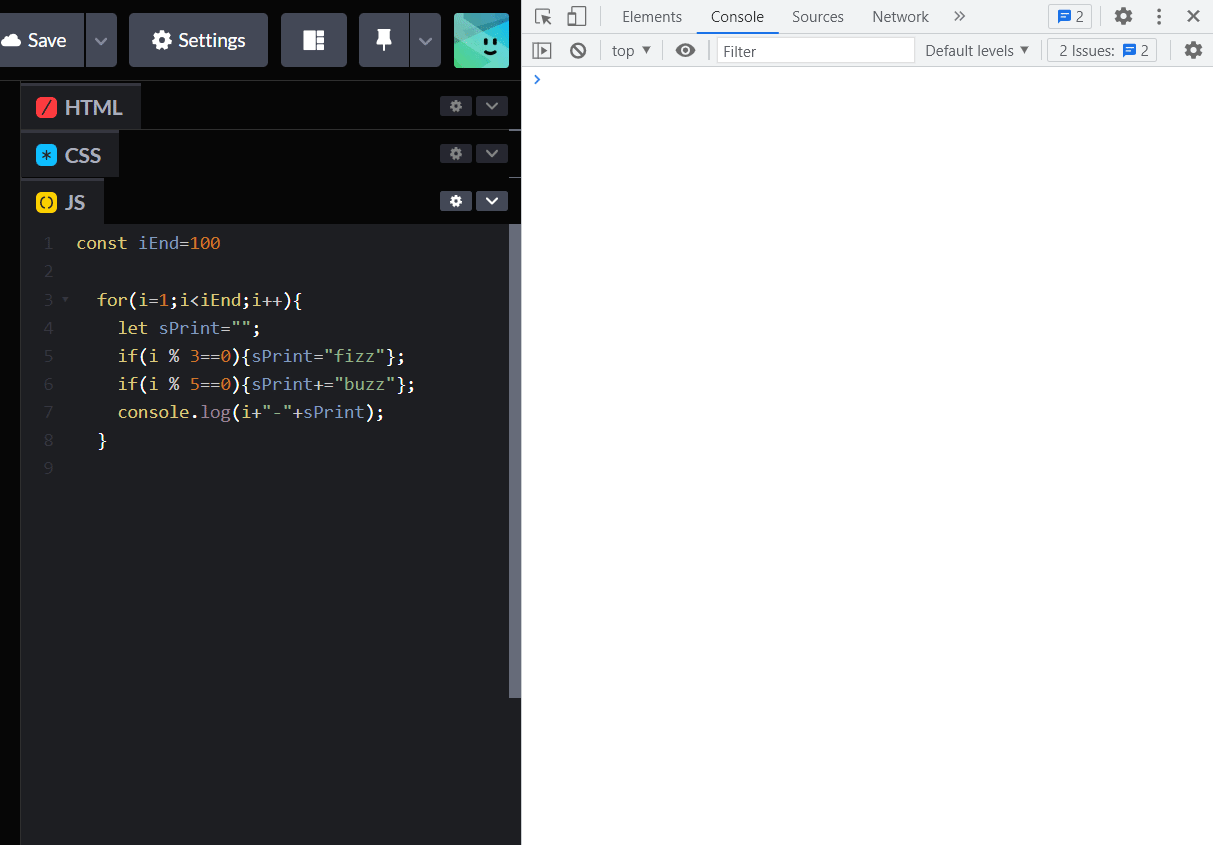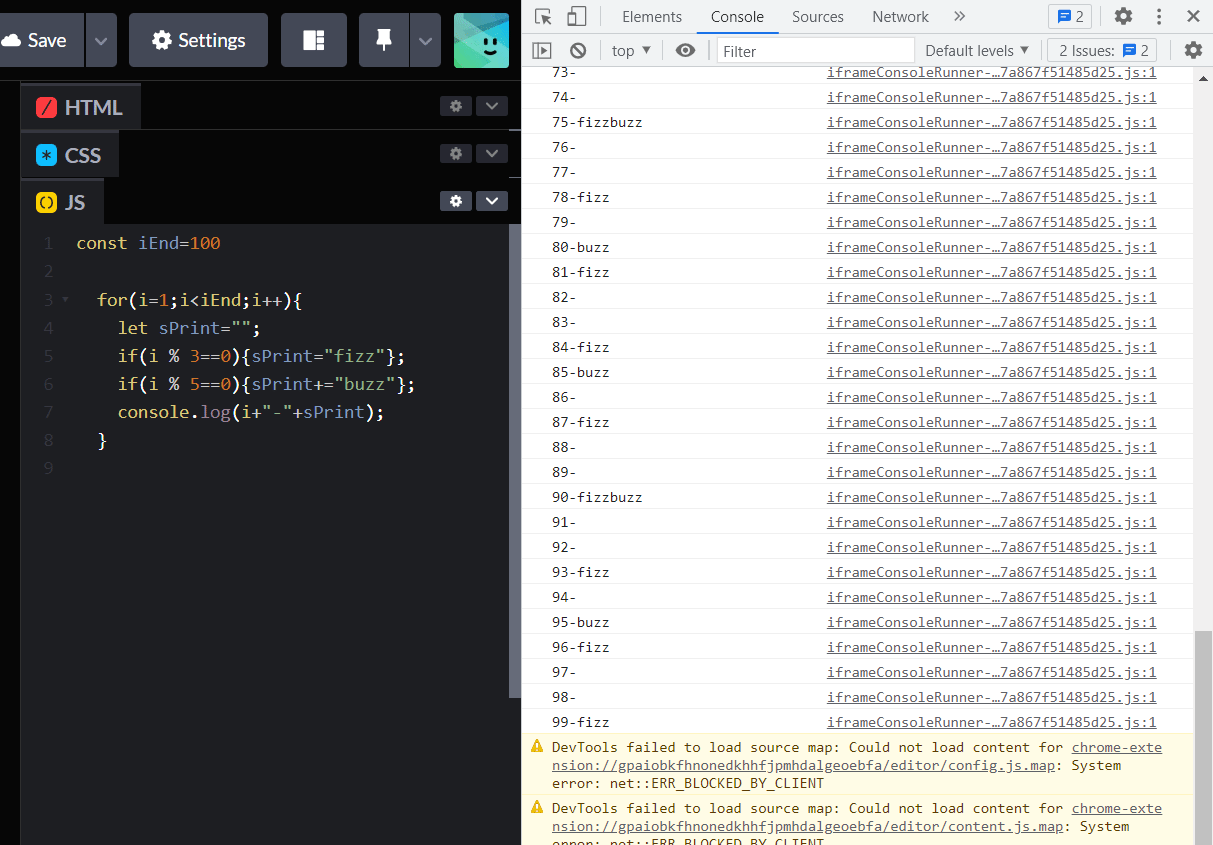
There are 2 small issues for a Power FX comparison, Power FX requires trigger and there is no console so must update somewhere.
We have to change the function to an on click event:
`document.getElementById('yourTriggerButton').addEventListener('click', function(){}`
And we replace the console.log with
`document.getElementById('yourOutput').innerHTML=sPrintAll;`
As we are now overwriting not adding to we have to store the previous lines, add the new line, then write to the page.
So it will look like this.
```JavaScript
document.getElementById('yourTriggerButton').addEventListener('click', function() {
const iEnd=100
let sPrintAll="";
for(i=1;i<iEnd;i++){
let sPrint="";
let bNewLine=false;
if(i % 3==0){
sPrint="fizz";
bNewLine=true
};
if(i % 5==0){
sPrint+="buzz";
bNewLine=true;
};
if(bNewLine){sPrint+="<br>"};
sPrintAll+=sPrint;
document.getElementById('yourOutput').innerHTML=sPrintAll;
}
});
```
In Power FX it would be:
```
//Label Component Text set to sPrint
Collect(arrayI,Sequence(100));
Set(sPrintAll,"");
ForAll(arrayI,
Set(bNewLine,false);
Set(sPrint,"");
If(Mod(Value,3)=0,
Set(sPrint,"Fizz");
Set(bNewLine,true);
);
If(Mod(Value,5)=0,
Set(sPrint,sPrint&"Buzz");
Set(bNewLine,true);
);
If(bNewLine,Set(sPrint,sPrint&Char(10)));
Set(sPrintAll,sPrintAll&sPrint);
)
```
Well no, that's wrong, ForAll is designed to modifying data, it is scoped to only work with arrays, leveraging Patch etc, not Set.
It is not currently possible to do any looping in Power FX (yep it's a lot more like Excel then JavaScript). To do loops in Power FX you have to leverage the timer component in the canvas app. The parameters would need to be:
OnTimerStart:
```
Set(bNewLine,false);
Set(i,i+1);
Set(sPrint,"");
If(Mod(i,3)=0,
Set(sPrint,"Fizz");
Set(bNewLine,true);
);
If(Mod(i,5)=0,
Set(sPrint,sPrint&"Buzz");
Set(bNewLine,true);
);
If(bNewLine,Set(sPrint,sPrint&Char(10)));
//Set(sPrint,i&"-"&sPrint&Char(10)); as shown in demo video
Set(sPrintAll,sPrintAll&sPrint);
If(i>=100,Set(bStart,false)
```
Repeat: `bStart`
Duration: `10`
Start: `bStart` - Set to true by a start button
Label Component Text: `sPrint`

Unfortunately, that means we are now not aligned with the JavaScript code we have written, as we have the equivalent of a timer in JavaScript.
We move our code from inside a for loop to inside setInterval, which is almost the same as the timer component
`const timer=setInterval(function(){ },10)`
And to stop the timer we use
`clearInterval(timer)`
```JavaScript
document.getElementById('yourTriggerButton').addEventListener('click', function() {
let i=1;
let sPrintAll="";
const timer=setInterval(function(){
let sPrint="";
let bNewLine=false;
if(i % 3==0){
sPrint="fizz";
bNewLine=true
};
if(i % 5==0){
sPrint+="buzz";
bNewLine=true;
};
if(bNewLine){sPrint+="<br>"};
sPrintAll+=sPrint;
document.getElementById('yourOutput').innerHTML=sPrintAll;
i++;
if(i==100){clearInterval(timer)}
}, 10);
});
```
---
Although the syntax's are different they are close enough, the bigger challenge switching between them is the differences in structure. Power FX, like most LowCode, relies on pre built components. The code is then layered on top. JavaScript, particularly with libraries is the same, but with the components layered on top of the code. JavaScript allows you to build your own when there is a gap and have the best of both worlds, which makes sense as to why Microsoft allows you to build custom components in JavaScript.
---
Interesting call out I spotted, although the term LowCode is often presumed as less code, it isn't necessarily is. When like for like it generally is, but a more direct/shorter solution can often be found in ProCode.
| Solution | Line Count |
|--------------------------|------------|
| JavaScript | 7 |
| Power FX | 12 |
| JavaScript like for like | 18 |
I often think of it like binary, because it has only 2 values it could be thought of as simpler, but that simplicity makes complexity increases exponentially, equaling longer code e.g. 99 in binary is 1100011.
---
**Other Comparisons**

_Note:_
- _Local variables in Power Apps are scoped to the screen, JavaScript are function scoped_
- _Power FX can also use '!' for not equal to, '&&' for And, '||' for Or_
---
**Furter Reading**
- [Microsoft Learn-PowerFX](https://learn.microsoft.com/en-us/power-platform/power-fx/overview)
- [Microsoft Learn-PowerFX References](https://learn.microsoft.com/en-us/power-platform/power-fx/formula-reference)
- [w3 Schools-JavaScript](https://www.w3schools.com/jsref/)
- [Developer Mozilla-JavaScript](https://developer.mozilla.org/en-US/docs/Web/JavaScript)
| wyattdave |
1,422,533 | Cypress Best Practices that are actually bad | These are some of the best practices from the official Cypress documentation which are actually... | 0 | 2023-04-01T10:24:17 | https://dev.to/evgenyorekhov/cypress-best-practices-that-are-actually-bad-2m3m | testing, cypress, javascript | These are some of the [best practices from the official Cypress documentation](https://docs.cypress.io/guides/references/best-practices) which are actually anti-patterns.
I'll explain why and give you better alternatives.
## 1. [Use `data-*` attributes](https://docs.cypress.io/guides/references/best-practices#Selecting-Elements)
### Why it's bad
`data-*` attributes clutter your production code and make your tests be dependent on implementation details.
### Better alternative: [Cypress Testing Library](https://testing-library.com/docs/cypress-testing-library/intro/)
It doesn't require you to add extra stuff to your markup, makes your tests more abstract, and helps you improve accessibility.
### Pro tips
#### 1. Use ESLint to forbid `cy.get()` entirely
```json
{
"rules": {
"no-restricted-properties": [
"error",
{
"object": "cy",
"property": "get",
"message": "Use Testing Library query."
}
]
}
}
```
#### 2. Follow [Testing Library priority guide](https://testing-library.com/docs/queries/about/#priority) when writing queries
## 2. [Use route aliases](https://docs.cypress.io/guides/references/best-practices#Unnecessary-Waiting)
### Why it's bad
It still makes your tests flaky, and it makes them be dependent on implementation details.
### Better alternative: UI assertions
Wait for something to appear in the UI, not for network requests to finish.
**Bad:**
```js
cy.intercept("**/posts").as("publish");
cy.findByRole("button", { name: "Publish" }).click();
cy.wait("@publish");
```
**Good:**
```js
cy.findByRole("button", { name: "Publish" }).click();
cy.findByRole("heading", { name: "My new post" }).to("be.visible");
```
### Pro tip
#### Use ESLint to forbid `cy.wait()` entirely
```json
{
"rules": {
"no-restricted-properties": [
"error",
{
"object": "cy",
"property": "wait",
"message": "Use UI assertion."
}
]
}
}
```
---
If you liked this article, you should check out
[**More Cypress Best Practices**](https://dev.to/evgenyorekhov/more-cypress-best-practices-266g) | evgenyorekhov |
1,422,539 | ReadMyCert PicoCTF 2023 | ReadMyCert AUTHOR: SUNDAY JACOB NWANYIM Description How about we take you on an adventure... | 0 | 2023-04-01T10:45:24 | https://dev.to/brunoblaise/readmycert-picoctf-2023-4lnh | cybersecurity, beginners, picoctf, tutorial | # ReadMyCert
AUTHOR: SUNDAY JACOB NWANYIM
Description
How about we take you on an adventure on exploring certificate signing requests
Take a look at this CSR file (open the link provide in the challenge)
___
This was a certificate *REQUEST* and not a normal certificate.
Plugging into any online reader gives the flag:
> picoCTF{your flag}
| brunoblaise |
1,422,685 | Reverse | Reverse 100 points AUTHOR: MUBARAK MIKAIL Description Try reversing this file? Can ya? I... | 0 | 2023-04-01T13:58:13 | https://dev.to/brunoblaise/reverse-35e9 | beginners, cybersecurity, help, picoctf | # Reverse
**100 points**
AUTHOR: MUBARAK MIKAIL
Description
Try reversing this file? Can ya?
I forgot the password to this [file]. Please find it for me?
___
Run strings on the file to get the flag or open it and `CTRL + F` and find `pico`.
> picoCTF{your flag}
| brunoblaise |
1,430,370 | First Post - Hello and Introduction! | 👨💻 Introduction & A little about me Hi there! 👋 It’s a pleasure to meet you all! My... | 0 | 2023-04-08T19:59:29 | https://dev.to/alexandrunst/first-post-hello-and-introduction-34b1 | introduction | ## 👨💻 Introduction & A little about me
Hi there! 👋 It’s a pleasure to meet you all!
My name is Alex (he/him), I am a Software Engineer who is passionate and enthusiastic about Front End technologies. I have graduated in 2021 with a undergraduate degree in Computer Science, and have been working in the Fintech industry for the last couple of years.
Technology and design are the two things I obsess over and I always want to learn more about. With the everchanging world around us, advancements in domains such as AI and Cloud Computing, and trends coming and going, it feels more daunting than ever to be a beginner. This is precisely why I have decided to start writing and sharing my expertise with this community!
## 💪 What to expect from me?
### Goal
My main goal is to offer easy to digest, beginner-friendly bits of content related to a multitude of topics, ranging from the fundamentals of coding, basics of programming languages, design 101s, cloud concepts, tools, best practices, tips and tricks, and many others!
### Strategy
My strategy is to deliver information in a clear and concise manner, with useful examples and illustrations. Readers that click on a post should have the majority - if not all - doubts cleared by the end of it. Of course, if anything needs extra clarification or if you require more details, feel free to reach out or leave a comment, and I will be in contact ASAP!
### Method
My method is simple - deliver the most straightforward explanation possible, no fluff in sight! I was once a beginner, and I know that demystifying new concepts is a daunting task. I am here to help, as any big concept is approachable with the right mindset.
## 🤔 What’s in it for you?
### Beginners
**Gain value**. You will find useful explanations for concepts that are either new, or maybe you’ve heard about but you are still unsure what they *actually* mean. We’ll go through the jargon and buzzwords, simplify the topic, and help build foundational understanding around it.
### Intermediate developers
**Refresh your knowledge**. Most of the topics will be familiar to you, so you will be provided a refresher or a chance to test your understanding of them. Maybe a few topics will new, thus providing some new knowledge.
### Experienced developers
**Test your expertise**. Did you know these concepts in and out? Were you aware of all the small details? When we start working at a higher-level, sometimes we lose track of the lower details. Take this chance to test your knowledge!
## 🙌 Before I go
Please do not hesitate to leave feedback on how I can improve my posts - it is always welcome, I highly appreciate it, and I promise I read all of it!
Please feel free to connect with me:
[https://github.com/AlexandruNst](https://github.com/AlexandruNst)
[https://alexnastase.com/](https://alexnastase.com/)
[https://twitter.com/AlexandruCodes](https://twitter.com/AlexandruCodes) (Will be more active in the near future, but DMs are always open!)
Thank you for tuning in! I will see you soon in my next post. Happy coding & designing! 🥳
 | alexandrunst |
1,430,410 | Dependency management: package.json and package-lock.json explained | I had some confusion about package.json and package-lock.json and what is used when. But now that... | 0 | 2023-04-11T10:37:19 | https://on-sw-integration.epischel.de/2023/04/08/package-json-and-package-lock-json-explained/?pk_campaign=feed&pk_kwd=package-json-and-package-lock-json-explained | javascript, npm | ---
title: Dependency management: package.json and package-lock.json explained
published: true
date: 2023-04-11 12:30:46 UTC
tags: javascript, npm
canonical_url: https://on-sw-integration.epischel.de/2023/04/08/package-json-and-package-lock-json-explained/?pk_campaign=feed&pk_kwd=package-json-and-package-lock-json-explained
---
I had some confusion about `package.json` and `package-lock.json` and what is used when. But now that I've been "enlightened", I'll record my new knowledge in this article.

## package.json and package-lock.json
`package.json` lists, among other things, the dependencies you need for your JavaScript project (if you use npm). You'd edit this file manually. In contrast `package-lock.json` is generated by npm.
Example `package.json`:
```
{
"name": "my-project",
"version": "1.0.0",
"dependencies": {
"express": "^4.17.1",
"lodash": "^4.17.20"
},
"devDependencies": {
"nodemon": "^2.0.7"
}
}
```
Often, the versions listed in `package.json` are given as ranges. npm uses [SemVer](https://semver.org/), meaning a version scheme in three parts like a.b.c where a,b and c are numbers (also called “major.minor.patch”). “`~a.b.c`” means a and b are fixed and the last part can be c or any greater number: “`~4.17.1`” means “4.17.x for x>=1”. “^a.b.c” means a is fixed and minor and patch version is variable: “`^4.17.20`” means “4.x.y for either (x=17 and y>=20) or x>18”.
In contrast, `package-lock.json` contains the exact versions of the project's dependencies (and their transitive dependencies and so on). When `package-lock.json` is generated or updated, the version range in `package.json` is resolved to the latest “allowed” version.
## Generating and updating package-lock.json
How do you create the lock file? “`npm install`” will do it.
How do you update the lock file? “`npm update`” will do it, usually. Say `package.json` states module A in version “`^3.4.5`” and the existing `package-lock.json` state module A in version “`3.4.20`“. Then you run “`npm update A`” or “`npm update`” and when there is a version “`3.5.2`” of A out there, npm will update the lockfile to version “`3.5.2`” of module A.
If `package.json` and the lock file are out of sync (the version in `package-lock.json` is out of the range specified in `package.json`), “`npm install`” will correct the `package-lock.json` file.
## Why committing the lock-file?
The general advice is to commit `package-lock.json` to your repository. That way, every developer will be using the same versions: the ones listed in the lock-file (using “`npm install`“).
## How to upgrade dependencies?
“`npm outdated`” shows outdated dependencies and “`npm update <pkg> --save`” updates a package as well as `package.json` and the lock file. Commit both files.
Another way is to use tools like dependabot or renovate which check for new versions. If a new version of a module is detected, these tools will create a branch using the new version. CI pipelines are run and pull/merge requests are created or even merged automatically.
## CI pipelines
There is a special command for CI pipelines: “`npm ci`“. It will fail if the lock file is missing or is out of sync with package.json. So the build will fail if “`npm install`” would change the lock-file.
“`npm ci`” ensures that your build is always based on a consistent set of dependencies, which is important for reproducibility and stability. It also helps avoid problems that can arise from using different versions of the same package across different stages of the pipeline.
## Pinning dependencies
Pinning a dependency means using an exact version in `package.json`.
| erikpischel |
1,430,503 | Creating a Progressive Web App in React A Beginners Guide | What is PWA? Progressive Web App (PWA) is a web application that provides an experience... | 0 | 2023-04-09T04:28:04 | https://dev.to/varshithvhegde/creating-a-progressive-web-app-in-react-a-beginners-guide-3l9g | pwa, webdev, javascript, beginners | ## What is PWA?
Progressive Web App (PWA) is a web application that provides an experience similar to that of a native mobile app. PWAs are built using modern web technologies such as service workers, web app manifests, and push notifications, which allows them to work offline or on poor network connections, installable on a user's home screen, and provide an app-like experience.
One of the key benefits of PWAs is their ability to improve user engagement and satisfaction by providing an app-like experience in the browser. PWAs can also reduce development costs and make it easier to reach a wider audience since they work on a variety of devices and platforms.
## How to Create a PWA in Simple Steps in React
If you're interested in creating a PWA in React, here are some simple steps to get started:
### Step 1: Set up a React project
The first step is to set up a new React project using a tool such as Create React App. This will provide you with a basic React app that you can use as a starting point for your PWA.
### Step 2: Install the necessary dependencies
Next, you'll need to install the necessary dependencies for creating a PWA in React. This includes the "workbox-webpack-plugin" and "web-push" packages.
```
npm install workbox-webpack-plugin web-push
```
```
yarn add workbox-webpack-plugin web-push
```
### Step 3: Create a service worker
A service worker is a JavaScript file that runs in the background and handles tasks such as caching resources and handling push notifications. To create a service worker in React, you can use the "workbox-webpack-plugin" package.
In your webpack configuration file, add the following code:
```javascript
const WorkboxPlugin = require('workbox-webpack-plugin');
module.exports = {
// ...
plugins: [
new WorkboxPlugin.GenerateSW({
clientsClaim: true,
skipWaiting: true,
}),
],
};
```
This will create a service worker that caches your app's resources and enables offline functionality.
### Step 4: Create a web app manifest
A web app manifest is a JSON file that provides information about your app, such as its name, icon, and theme color. To create a web app manifest in React, you can add a manifest.json file to your public folder and fill it with the necessary information.
Here's an example manifest.json file:
``` json
{
"name": "My PWA",
"short_name": "My PWA",
"icons": [
{
"src": "icon.png",
"sizes": "192x192",
"type": "image/png"
}
],
"theme_color": "#ffffff",
"background_color": "#ffffff",
"start_url": ".",
"display": "standalone",
"scope": "/"
}
```
### Step 5: Enable push notifications
To enable push notifications in your PWA, you'll need to set up a push notification service such as Firebase Cloud Messaging (FCM). Once you've set up FCM, you can use the "web-push" package to handle push notifications in your app.
Here's an example code for handling push notifications:
```javascript
const publicKey = 'your-public-key';
navigator.serviceWorker.register('/sw.js').then((registration) => {
registration.pushManager
.subscribe({
userVisibleOnly: true,
applicationServerKey: urlBase64ToUint8Array(publicKey),
})
.then((subscription) => {
console.log('Subscription successful:', subscription);
console.log(JSON.stringify(subscription));
})
.catch((error) => {
console.log('Subscription failed:', error);
});
});
function urlBase64ToUint8Array(base64String) {
const padding = '='.repeat((4 - (base64String.length % 4)) % 4);
const base64 = (base64String + padding)
.replace(/-/g, '+')
.replace(/_/g, '/');
const rawData = window.atob(base64);
const outputArray = new Uint8Array(rawData.length);
for (let i = 0; i < rawData.length; ++i) {
outputArray[i] = rawData.charCodeAt(i);
}
return outputArray;
}
```
This code registers a service worker and subscribes to push notifications using the "web-push" package. It also converts the public key from a base64 string to a Uint8Array.
### Step 6: Test your PWA
Once you've completed all of the above steps, you can test your PWA by running it in a browser or on a mobile device. You should be able to see your app's icon on your home screen, and it should work offline and support push notifications.
## Conclusion
In this article, we've learned what a PWA is and how to create one in React. We've also learned how to set up a React project, install the necessary dependencies, create a service worker, create a web app manifest, and enable push notifications. | varshithvhegde |
1,430,601 | How to add Google Analytics to Next.js app | If you have started working with Next.js recently and wanted to add Google Analytics to your website,... | 0 | 2023-04-09T08:12:56 | https://www.codingdeft.com/posts/nextjs-add-google-analytics/ | nextjs, react | If you have started working with Next.js recently and wanted to add Google Analytics to your website, then you are at the right place!
## Creating a Google Analytics tag
Login to https://analytics.google.com/analytics/web/ with your Google account.
Now click on the Settings Icon (⚙️ Admin) at the bottom and click on Create Account
(If you already have an account, you can click on Create Property).
Now fill in the account name:
Fill in the property details along with the time zone and currency:
Finally, fill in the business details and click on Create:
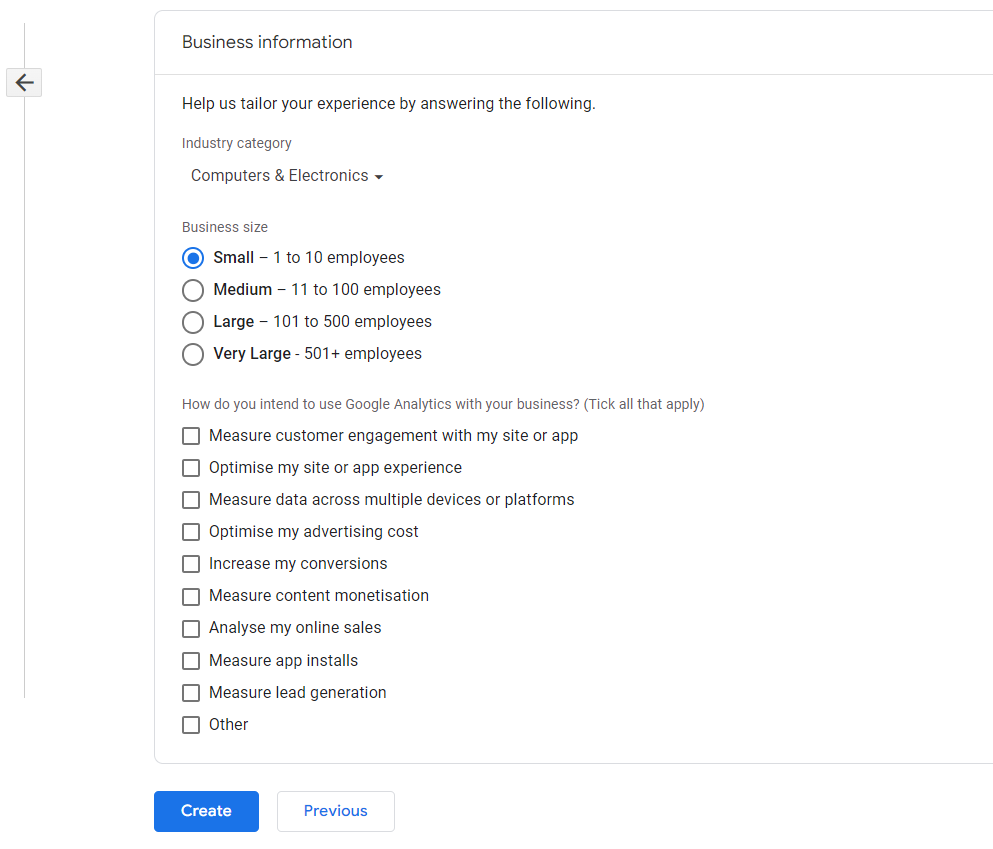
Now you will be redirected to a page with the following options. Here click on Web.
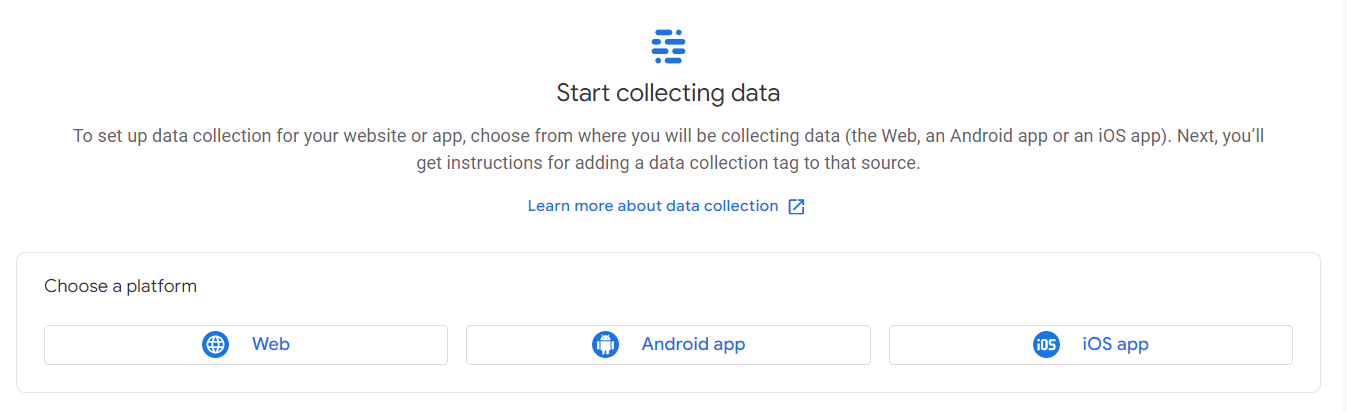
In the next step provide your website details and click on Create stream.
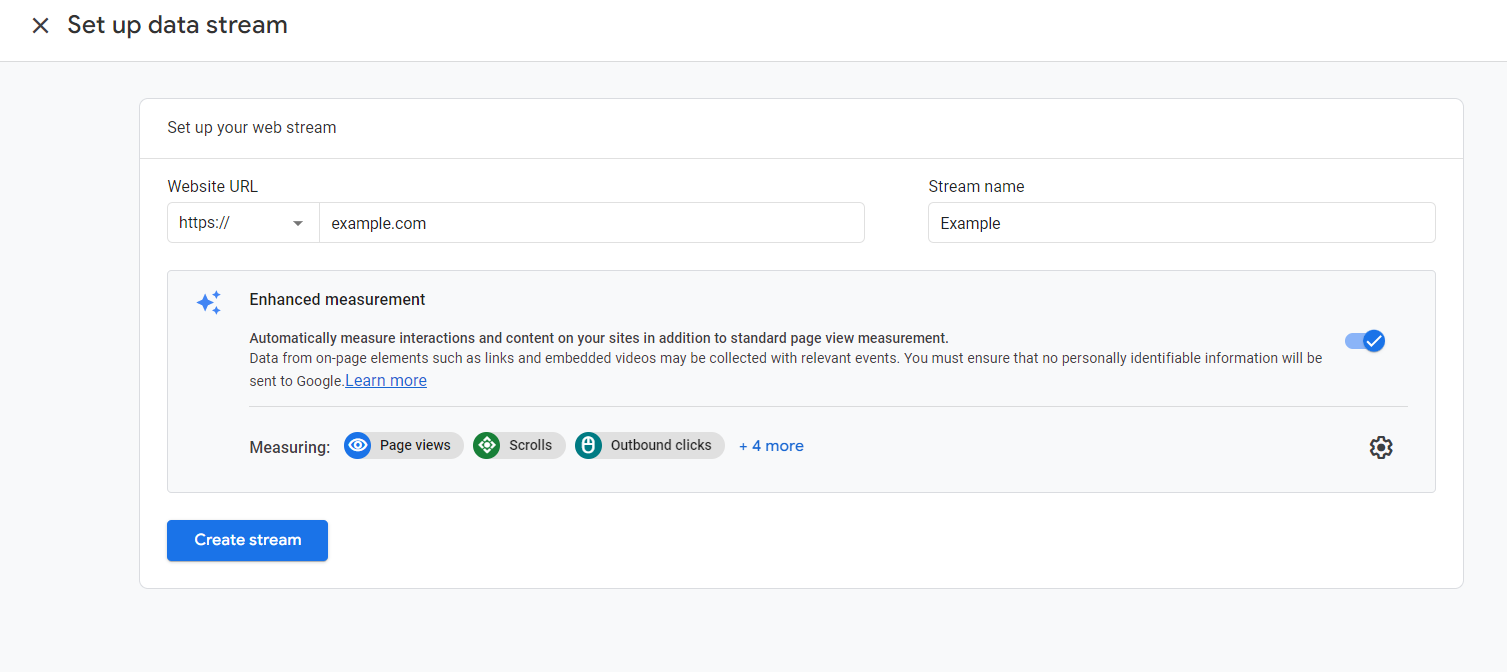
Now you will be provided with a measurement id. Make a note of it. It will be used in the next step.
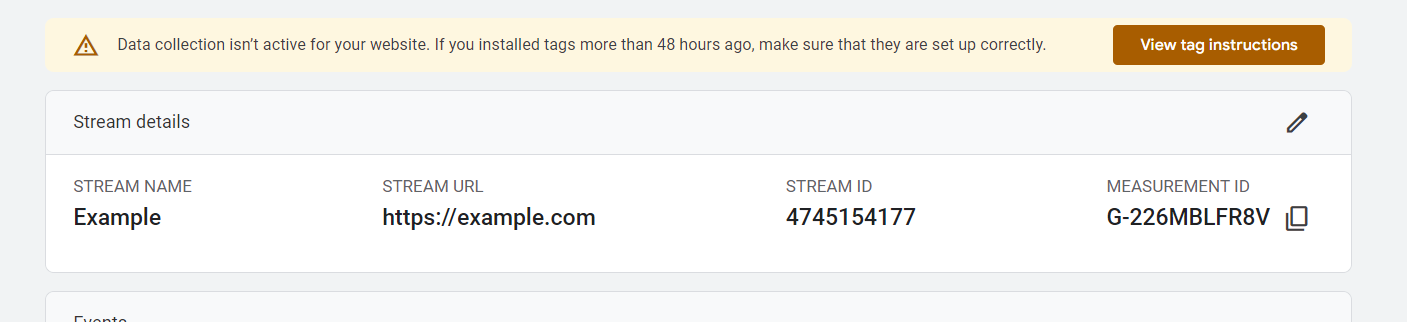
## Creating a Next.js app
Now create a Next.js app, if you do not have one, using the following command:
```bash
npx create-next-app@latest next-ga-integration
```
## Adding Google Analytics
Create a file named `gtag.js` with the following content (replace `GA_TRACKING_ID` value with yours):
```js
export const GA_TRACKING_ID = "G-226MBLFR8V" //replace it with your measurement id
// https://developers.google.com/analytics/devguides/collection/gtagjs/pages
export const pageview = url => {
window.gtag("config", GA_TRACKING_ID, {
page_path: url,
})
}
// https://developers.google.com/analytics/devguides/collection/gtagjs/events
export const event = ({ action, category, label, value }) => {
window.gtag("event", action, {
event_category: category,
event_label: label,
value: value,
})
}
```
We have 2 functions here:
- pageview: To track users navigating to different pages.
- event: To track events like add to cart, place order, etc.
Now open `_app.js` and include the following code:
```js
import "@/styles/globals.css"
import Script from "next/script"
import { useRouter } from "next/router"
import { useEffect } from "react"
import * as gtag from "gtag"
export default function App({ Component, pageProps }) {
const router = useRouter()
useEffect(() => {
const handleRouteChange = url => {
gtag.pageview(url)
}
router.events.on("routeChangeComplete", handleRouteChange)
return () => {
router.events.off("routeChangeComplete", handleRouteChange)
}
}, [router.events])
return (
<>
<Script
strategy="afterInteractive"
src={`https://www.googletagmanager.com/gtag/js?id=${gtag.GA_TRACKING_ID}`}
/>
<Script
id="gtag-init"
strategy="afterInteractive"
dangerouslySetInnerHTML={{
__html: `
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', '${gtag.GA_TRACKING_ID}', {
page_path: window.location.pathname,
});
`,
}}
/>
<Component {...pageProps} />;
</>
)
}
```
In the above code:
- We have included the Google Analytics script and loading it after the page becomes interactive so that it doesn't affect the page loading time.
- We have a `useEffect` where we listen to route changes and call the `pageview` function, defined inside `gtag.js`.
This is required since in Next.js, whenever routing happens, the page doesn't completely reload and Google Analytics will not be able to pick up the route change automatically.
Now your application is setup with Google Analytics and you can track the live users:
| collegewap |
1,430,652 | Introduction to deep learning hardware in the cloud | For more than a decade, organizations are using machine learning for various use cases such as... | 0 | 2023-04-17T15:24:23 | https://eyal-estrin.medium.com/introduction-to-deep-learning-hardware-in-the-cloud-f4e4cac0733b | aws, ai, machinelearning, datascience | For more than a decade, organizations are using machine learning for various use cases such as predictions, assistance in the decision-making process, and more.
Due to the demand for high computational resources and in many cases expensive hardware requirements, the public cloud became one of the better ways for running machine learning or deep learning processes.
## Terminology
Before we dive into the topic of this post, let us begin with some terminology:
* **Artificial Intelligence** – "The ability of a computer program or a machine to think and learn", Wikipedia
* **Machine Learning** – "The task of making computers more intelligent without explicitly teaching them how to behave", Bill Brock, VP of Engineering at Very
* **Deep Learning** – "A branch of machine learning that uses neural networks with many layers. A deep neural network analyzes data with learned representations like the way a person would look at a problem", Bill Brock, VP of Engineering at Very
Source: [https://www.simplilearn.com/tutorials/artificial-intelligence-tutorial/ai-vs-machine-learning-vs-deep-learning](https://www.simplilearn.com/tutorials/artificial-intelligence-tutorial/ai-vs-machine-learning-vs-deep-learning)
### Public use case of deep learning
* [Disney makes its archive accessible using deep learning built on AWS](https://aws.amazon.com/blogs/media/in-the-news-disney-makes-its-archive-accessible-using-deep-learning-built-on-aws/)
In this blog post, I will focus on deep learning and hardware available in the cloud for achieving deep learning.
## Deep Learning workflow
The deep learning process is made of the following steps:
1. Prepare – Store data in a repository (such as object storage or a database)
2. Build – Choose a machine learning framework (such as [TensorFlow](https://www.tensorflow.org/), [PyTorch](https://pytorch.org/), [Apache MXNet](https://mxnet.apache.org/), etc.)
3. Train – Choose hardware (compute, network, storage) to train the model you have built ("learn" and optimize model from data)
4. Inference – Using the trained model (on large scale) to make a prediction
## Deep Learning processors comparison (Training phase)
Below is a comparison table for the various processors available in the public cloud, dedicated to the deep learning training phase:
### Additional References
* [Amazon EC2 - Accelerated Computing](https://aws.amazon.com/ec2/instance-types/#Accelerated_Computing)
* [AWS EC2 Instances Powered by Gaudi Accelerators for Training Deep Learning Models](https://aws.amazon.com/blogs/aws/new-ec2-instances-powered-by-gaudi-accelerators-for-training-deep-learning-models/)
* [AWS Trainium](https://aws.amazon.com/machine-learning/trainium/)
* [NVIDIA T4 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/tesla-t4/)
* [NVIDIA A10 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/products/a10-gpu/)
* [NVIDIA A100 Tensor Core GPU](https://www.nvidia.com/en-us/data-center/a100/)
## Deep Learning processors comparison (Inference phase)
Below is a comparison table for the various processors available in the public cloud, dedicated to the deep learning inference phase:
### Additional References
* [Amazon EC2 - Accelerated Computing](https://aws.amazon.com/ec2/instance-types/#Accelerated_Computing)
* [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/)
## Summary
In this blog post, I have shared information about the various alternatives for using hardware available in the public cloud to run deep learning processes.
I recommend you to keep reading and expand your knowledge on both machine learning and deep learning, what services are available in the cloud and what are the use cases to achieve outcomes from deep learning.
### Additional References
* [AWS Machine Learning Infrastructure](https://aws.amazon.com/machine-learning/infrastructure/)
* [AWS - Select the right ML instance for your training and inference jobs](https://pages.awscloud.com/rs/112-TZM-766/images/AL-ML%20for%20Startups%20-%20Select%20the%20Right%20ML%20Instance.pdf)
* [AWS - Accelerate deep learning and innovate faster with AWS Trainium](https://d1.awsstatic.com/events/Summits/reinvent2022/CMP313_Accelerate-deep-learning-and-innovate-faster-with-AWS-Trainium.pdf)
### About the Author
Eyal Estrin is a cloud and information security architect, the owner of the blog [Security & Cloud 24/7](https://security-24-7.com/) and the author of the book [Cloud Security Handbook](https://amzn.to/3xMI4Ak), with more than 20 years in the IT industry.
Eyal is an [AWS Community Builder](https://aws.amazon.com/developer/community/community-builders/) since 2020.
You can connect with him on [Twitter](https://twitter.com/eyalestrin) and [LinkedIn](https://www.linkedin.com/in/eyalestrin/).
| eyalestrin |
1,430,716 | Automate Grafana Deployment on OpenShift with Harness CD | 🎯 Ready to automate #Grafana on #OpenShift? My latest blog post reveals how #Harness can make it... | 0 | 2023-04-09T11:44:46 | https://dev.to/pravinmali/automate-grafana-deployment-on-openshift-with-harness-cd-1k42 | 🎯 Ready to automate #Grafana on #OpenShift? My latest blog post reveals how #Harness can make it happen! Boost your productivity today 🚀 [http://bit.ly/41eSF2M](http://bit.ly/41eSF2M) #harness #continuousdelivery #devops #cloudnative #grafana #openshift #ocp #crc #socialmedia
| pravinmali | |
1,430,725 | How to A/B Test Your Website | by Jenna Thorne Also known as split testing, A/B testing refers to random experimentation wherein... | 0 | 2023-04-09T12:19:54 | https://blog.openreplay.com/how-to-a-b-test-your-website/ | testing, ux, ui | by [Jenna Thorne](https://blog.openreplay.com/authors/jenna-thorne)
Also known as split testing, A/B testing refers to random experimentation wherein two or more versions of a variable are shown to different site visitors at once to determine the version that works best and which drives business metrics. Put simply, you can show an A version of content to one half of your audience and a B version to the other half.
This [testing process](https://support.google.com/optimize/answer/6211930?hl=en) is invaluable since different audiences behave in different ways. For example, something that works for a certain company may not work in another. Furthermore, it eliminates the guesswork from website optimization. A in A/B testing means the original variable or the ‘control’, and B means the new version or the ‘variation’ of the original variable.
## How does A/B Testing Work?
To run this test, you must make two content versions with changes to one variable. These two versions will then be shown to two same-sized audiences, and you'll analyze which performed better over a certain time. It might sound complex but A/B testing is actually very simple.
What you need to do first is to decide what you want to test and the reason why. You could, for example, determine how many people [click on the button](https://support.google.com/google-ads/answer/6331304?hl=en). This is a good indicator of how the button's size impacts perception. The next thing that you can do is to divide users into two sets.
Every set should be random. You can then create two similar pages but with different sizes of buttons. From there, you can check out the analytics and see which page receives more clicks. The decision to click depends on various factors, such as button size, text color, and the device used. Marketers could observe how one marketing content version performs compared to another version [when you do A/B testing](https://towardsdatascience.com/how-to-conduct-a-b-testing-3076074a8458).
## Why is A/B Testing Important?
Accurate A/B testing could make a big difference in the return on investment. Through controlled tests and empirical data gathering, you can determine exactly which marketing strategies work best for your brand and product. Running a promotion without running a test is never a good idea.
Testing, when performed consistently, could substantially [boost the results](https://www.kdnuggets.com/2022/08/sphere-3-benefits-ab-testing-get-started.html). It’s easier to make decisions and create more effective marketing strategies in the future if you know what works and what doesn’t. The following are some of the benefits you get when running A/B tests regularly on your website as well as on your marketing materials:
1. A/B testing helps [understand the target audience](https://www.searchenginejournal.com/what-is-a-target-audience-and-how-do-you-find-it/467926/). You gain an insight into who your audience is and what they want when you determine the kind of emails, headlines, and other features they respond to.
2. Stay on top of evolving trends. Predicting what kind of images, content, or other features people will respond to is difficult, and regular testing helps you stay ahead of evolving consumer behavior.
3. Higher rates of conversion. A/B testing is the sole most effective way to boost rates of conversion. Again, knowing what works and what doesn’t work provides you with actionable data that could help simplify the conversion process.
4. [Minimize bounce rates](https://blog.openreplay.com/how-to-reduce-your-websites-bounce-rate/). When website visitors see content they like, they will stay on it longer. Testing to determine the kind of marketing materials and content users like will help build a better site—one that they want to stay on.
With the help of A/B testing, [Lotte Hotel](https://www.lottehotel.com/global/en.html), the largest hotel group in South Korea, boosts booking rates by 49 percent thanks to A/B testing. Moreover, it has also expanded to more than 30 hotel locations across the globe. They have used tools like [Google Analytics 360](https://marketingplatform.google.com/about/analytics-360/) to measure user data and created hypothesized versions of websites elements to create a winning page layout combination with the help of [Google Optimize](https://optimize.google.com/optimize/home/).
## Different types of A/B tests
There are different benefits to every type of A/B testing. Furthermore, depending on the changes you want to make, different tests could work better than others.
### Split testing
Split testing is the process of experimenting in which an entirely new version of the current web page is tested to analyze which has the better performance.
Image Source- Google Help Doc
**Split Testing Advantages**
1. Recommended for running tests with no changes to the UI, such as optimizing the load time, switching to a different database, and so on.
2. Split testing is ideal for trying out new designs while using the current design for comparison.
3. Change the workflow of a web page. Workflows impact business conversions significantly, which helps test new paths before the implementation of changes and find out if there are missed points.
4. Much recommended method for dynamic content.
### Multivariate testing
MVT for short, multivariate testing refers to the experimentation wherein different variations of several page variables are tested simultaneously to analyze which combination of variables performs best. [Multivariate testing is more complicated](https://support.google.com/optimize/answer/6370723) compared to A/B tests and is best for advanced product, marketing, and development professionals.
As long as done appropriately, this type of testing helps eliminate the need to run several sequential A/B tests on a page with similar goals. You can save time, effort, and money by running concurrent tests with more variations. It could lead to a conclusion in the shortest possible time.
Image Source- Google Help Doc
**The Benefits of Multivariate Testing**
1. Determine and analyze each page element’s contribution to the measured gains.
2. Helps to avoid performing several sequential A/B tests with the same goal. 3. It saves time since you can track the performance of different tested page elements simultaneously.
4. Map all interactions between all independent element variations, such as banner images, page headlines, etc.
### Multipage testing
Multipage testing is a kind of experimentation in which you test changes to certain elements across several pages. Multipage testing could be done in a couple of ways. The first way is called Funnel Multipage testing. This is where you can run all the sales funnel pages and make new versions of every page, making the challenger the sales funnel and again testing it against the control.
Conventional or Classic Multipage testing is the second way. In this method, you can test how adding or removing recurring elements, such as testimonials, security badges, and others, impact conversions across an entire funnel.
Image Source- Google Help Doc
**Multipage Testing Advantages**
1. Helps the target audience see a consistent set of a page, regardless of its control or one of its variations.
2. Allows you to build consistent experiences for the target audience.
3. Enables you to implement the same change on various pages to ensure that site visitors will not be distracted and bounce off between variations and designs when navigating your website.
<h2>Session Replay for Developers</h2>
<p><em>
Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data
</em></p>
<img alt="OpenReplay" width="768" height="400" src="https://blog.openreplay.com/assets/overview_Z17Qdyg.png" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em>
## Elements that you can A/B Test
There are several variables that you could test to optimize the performance of the landing page. Below are some of the crucial elements you can test.
### Headings
The heading or the headline is what catches the users’ attention. Furthermore, subheadings compel them to keep reading, click on a paid app or scroll down to read the fold copy. Thus, it’s important to test your headline by making variations and determine which works better.
Aside from the copy, consider changing the font size, type, style, and alignment of the heading and subheadings.

Image Source- LeadPages
### Images
You can test background images, content images, or above the fold image. Aside from that, you can also test by replacing images with illustrations, videos, or GIFs.

### Forms
Forms serve as the medium wherein users get in touch with you; that’s why the signup process should be smooth. You should not give users a chance to drop off during this phase. The following are what you can test:
* Consider minimizing the unnecessary signup field.
* Add inline forms on various pages, like blog pages or case studies.
* Utilize social proof, like testimonials, on the signup form page.
* Try out a different form copy as well as CTA buttons.
### Page design and layout
How you present various elements on the page matters. Even if you have a compelling landing page copy, a badly formatted copy won’t convert. Thus, you should test out the placement and arrangement of elements on your webpage and ensure there’s a hierarchical order that users can follow easily.
Horizontal version
Vertical version
### CTAs
Test which call-to-actions push users toward a specific action, such as ‘subscribe’, ‘click here’, ‘check here’, and so on. Furthermore, the action words could be used with a ‘now as well, creating a sense of urgency.
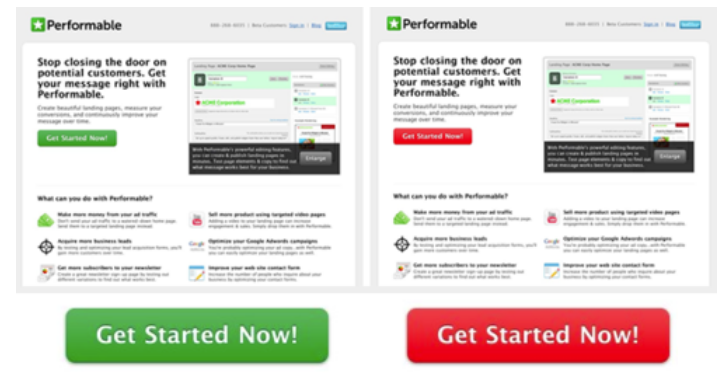
## A/B testing process
Let's start a step-by-step process of how A/B testing can be started.
### Identify the Pain Points
Simply, pain points are elements in the [sales funnel](https://www.salesforce.com/in/blog/2022/06/sales-funnel.html) that put visitors off or give an inferior shopping experience. There are free tools like [Microsoft Clarity](https://clarity.microsoft.com/), which will help you measure how users interact with your pages with the help of user session recordings. At the same time, you will also find premium tools like [hotjar](https://www.hotjar.com/), which gives you a complete package of user interaction-related data like heatmaps, session recordings, and behavior analytics. This data will help you determine where users spend the most time, their scrolling behavior, and so on. This helps identify the problem areas on your website. Here's an example from [Openreplay session replay tool](https://openreplay.com/feature-session-replay.html) itself to determine how users interact with buttons.
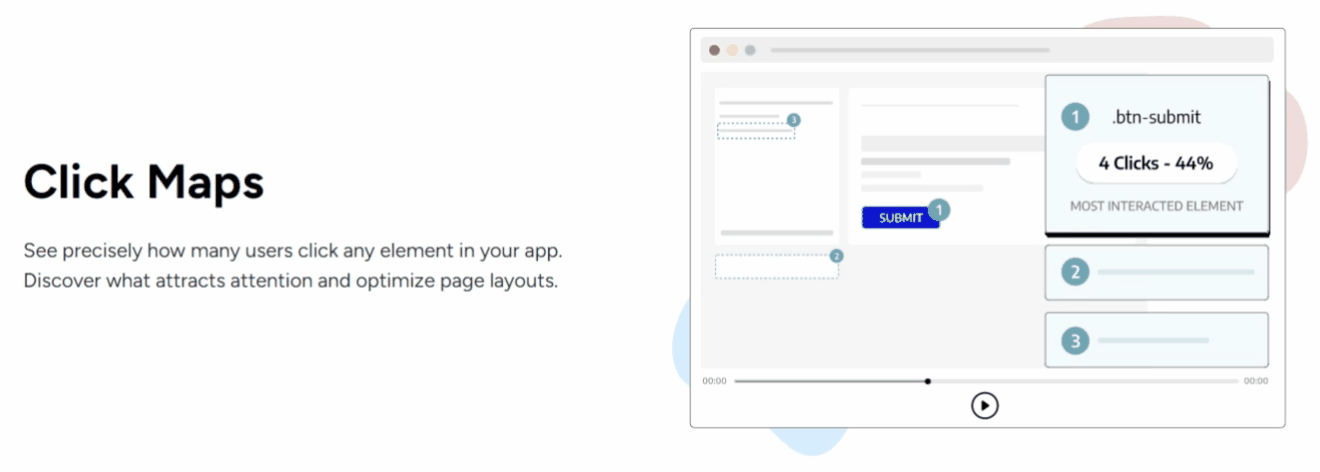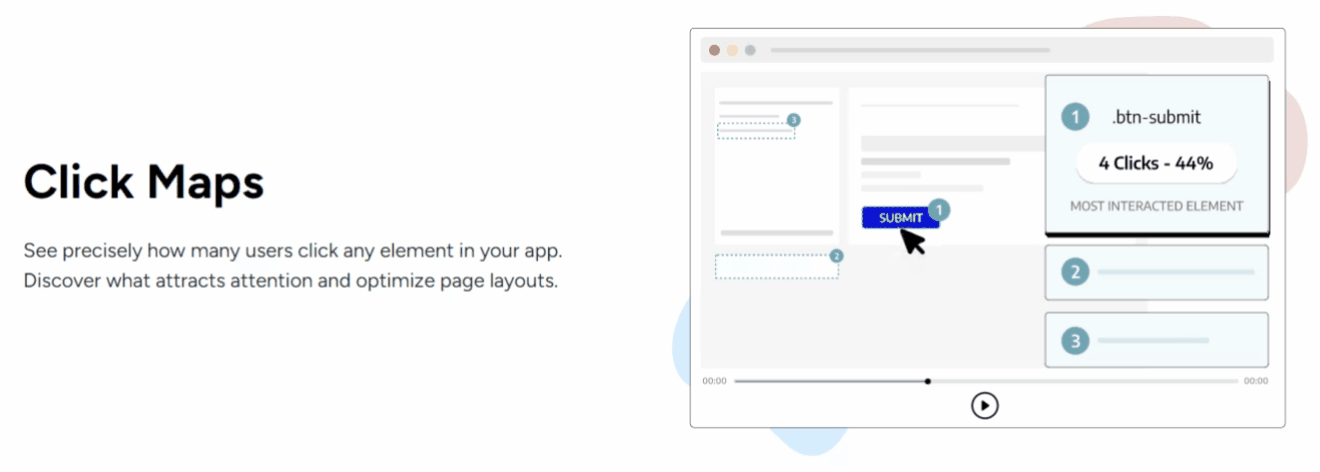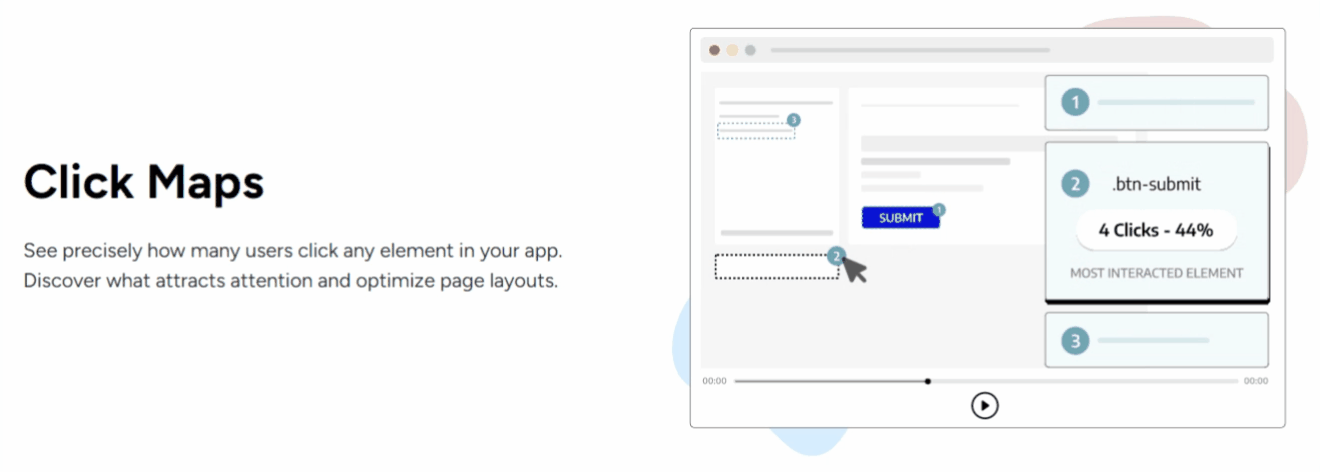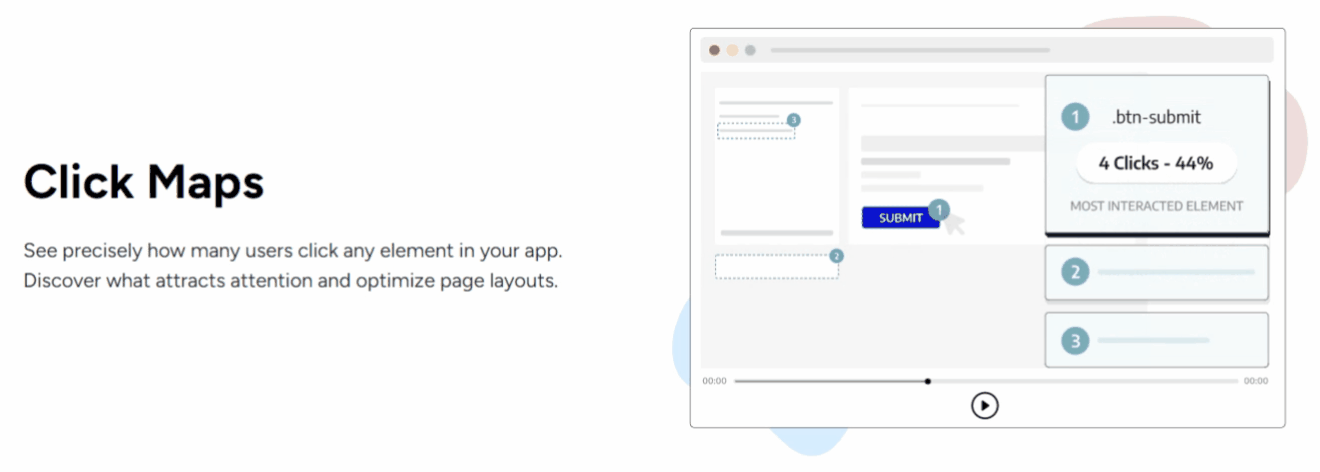
### Generate hypothesis
When you have determined your goal, it’s important to start generating A/B testing ideas and [test hypotheses](https://vwo.com/blog/ab-testing-hypothesis/) for why you think they would be better than the present version. When you already have a list of ideas, make them your priority in terms of the impact expected and the difficulty in the implementation.
Source - cxl
### Create variations
You need to know the following terms to understand this step.
Control – the page’s original version
Test Version – the version where you make changes
Variant – any element you change for testing, like using various images, changing the call-to-action button, and so on.
In this step, you put the hypothesis into action. Furthermore, you must decide the A/B testing approach to use, whether it’s split, multipage, or multivariate testing. You can then proceed to make the test version of the page with the help of [free tools like Google Optimize](https://optimize.google.com/optimize/home/), but unfortunately [Google has decided to shut down](https://support.google.com/optimize/answer/12979939?hl=en) this free A/B testing tool. Nevertheless, you will find some more tools like [optimizely](https://www.optimizely.com), [vwo](https://vwo.com/), and some more. You can configure these tools and implement your test versions; for instance, if you want to boost the click-through rate, you may want to change the button size of the CTA copy.
If you want more form submissions, reducing the signup field or adding testimonials besides the form would be a good idea.
### Start your test
When the sample size and variations are all asset up, you can start testing. Again you can use tools like Google Optimize, Ominiconvert, or Crazyegg. Let the test run for an adequate time until you start interpreting results. Typically, testing should be run until you acquire statistically significant data before making changes.
The timings depend on the sample size, variations, and test goals.
Here's a better representation from [Adroll](https://www.adroll.com) about how you can start your A/B test.
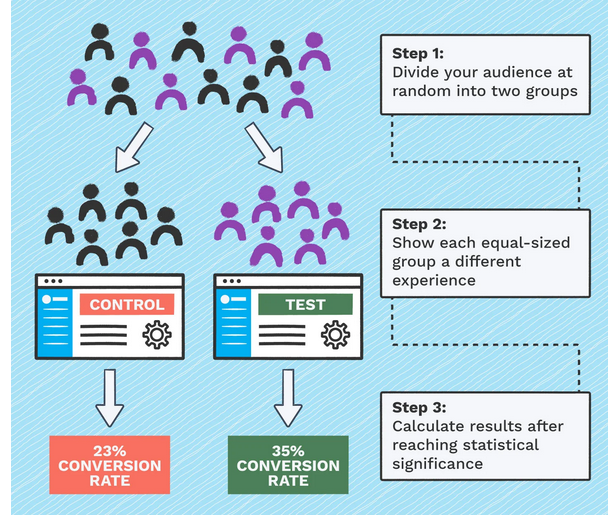
### Analyze and review your test Results
Analysis of the results is paramount when running A/B testing. Since A/B testing calls for continuous gathering and analysis of data, it is in this last step that your whole journey unravels. Once the test ends, analyze the test results by considering the metrics, such as confidence level, percentage increase, direct and indirect impact on other metrics, and so on.
After considering these numbers, if the test succeeds, it’s time to deploy the winning variation. If the test stays inconclusive, gain insight from it and implement these in subsequent tests.
## Conclusion
Now that you have a clear idea about the steps involved in A/B testing, you can start immediately. Find your pain points, create your hypothesized versions, and implement them to measure the difference between them.
[](https://newsletter.openreplay.com/)
| asayerio_techblog |
1,430,801 | Independência tecnológica: Por que o Brasil precisa urgentemente de seu próprio sistema operacional baseado em Linux? | Recentemente, conheci a distribuição Linux HarmoniKR OS, desenvolvida na Coreia do Sul e baseada no... | 0 | 2023-04-09T13:40:15 | https://dev.to/ldnovaes/independencia-tecnologica-por-que-o-brasil-precisa-urgentemente-de-seu-proprio-sistema-operacional-baseado-em-linux-2d2m | braziliandevs | Recentemente, conheci a distribuição Linux HarmoniKR OS, desenvolvida na Coreia do Sul e baseada no Linux Mint. Essa descoberta me levou a questionar a possibilidade de o Brasil ter seu próprio sistema operacional reconhecido e incentivado pelo governo.
Desenvolver um sistema operacional próprio seria uma iniciativa importante para o país, tornando-o mais independente de tecnologias e avanços externos. Além disso, permitiria reduzir os custos de licenciamento, uma vez que estaríamos falando de sistemas open source, que em sua maioria são gratuitos.
Países interessados em manter a autonomia tecnológica e evitar a dependência de softwares comerciais desenvolvidos fora de suas fronteiras utilizam sistemas abertos ou versões compatíveis desenvolvidas autonomamente. A China desenvolveu o Kylin OS, e a Rússia criou o Astra Linux, ambos baseados no Linux e reconhecidos pelos governos locais.
Adotar uma versão própria de sistema operacional a partir de uma distribuição Linux permitiria ao Brasil superar a desconfiança existente em relação à existência de backdoors criados por serviços de inteligência estrangeiros nos softwares produzidos em seus países de origem. Além disso, essa iniciativa estaria alinhada com a Estratégia Nacional de Defesa, permitindo a aquisição de tecnologia de uso dual pela indústria nacional.
Em resumo, a iniciativa de criar um sistema operacional brasileiro baseado em Linux pode ser extremamente importante para o país. Isso garantiria a autonomia tecnológica, reduziria os custos de licenciamento e estaria alinhada com a Estratégia Nacional de Defesa. O Brasil tem um grande potencial para se tornar um líder tecnológico na região, e o desenvolvimento de um sistema operacional próprio seria um passo significativo nessa direção.
**Bônus:** Quem sabe o nome poderia ser Amazônia OS ou quem sabe um Tupi OS haha!
| ldnovaes |
1,430,862 | Comparing Vue and React in 2023: Pros and Cons | Photo by Glenn Carstens-Peters on Unspash Vue and React are still two of the most popular... | 0 | 2023-04-09T15:17:40 | https://pantelis.theodosiou.me/blog/comparing-vue-and-react-in-2023-pros-and-cons/ | javascript, vue, react, discuss | > Photo by [Glenn Carstens-Peters](https://unsplash.com/@glenncarstenspeters) on [Unspash](https://unsplash.com/photos/6rkJD0Uxois)
Vue and React are still two of the most popular JavaScript frameworks for building web apps in 2023. Both frameworks offer advantages and disadvantages, so developers must weigh the benefits and negatives when deciding which one to use for their projects. In this article, we will compare Vue and React based on their pros and cons in 2023. Keep in mind that these are my thoughts on some of their advantages and disadvantages.
## Vue
### Pros of Vue
- **Easy to Learn and Use**: Vue offers a smooth learning curve that makes it suitable for both novice and professional developers.
- **High Performance**: Vue's virtual DOM and efficient rendering result in speedy and performant apps.
- **Flexible and Incremental Adoption**: Vue enables progressive adoption in existing projects, making it adaptable to a variety of use cases.
- **Composition API**: Vue's Composition API allows you to handle state and logic in components in a modular and flexible manner, enhancing code organization and maintainability.
- **Strong Ecosystem**: Vue has a growing ecosystem of libraries, tools, and plugins that are backed up by excellent documentation and a welcoming community.
On the other hand, there are some disadvantages.
### Cons of Vue
- **Smaller Community**: Vue's community is still smaller than React's, making it more difficult to find extensive resources and support.
- **Limited Enterprise Adoption**: When compared to React, which has a longer history and established presence in the enterprise space, Vue may have limited adoption in large-scale enterprise applications.
## React
### Pros of React
- **Huge Ecosystem and Community**: React has a massive ecosystem of libraries, tools, and resources, which is supported by a large developer community.
- **Performance Optimization**: The virtual DOM and efficient rendering mechanism of React make it extremely performant, particularly in complex applications.
- **Component-Based Architecture**: The component-based architecture of React encourages web application reusability, maintainability, and separation of concerns.
- **Strong Developer Tooling**: React has a robust set of developer tools to help with debugging, testing, and building React applications.
- **Backed by Facebook**: React is backed by Facebook, which ensures its stability and continuous updates.
As every coin got two sides, React also has some cons.
### Cons of React
- **Steeper Learning Curve**: React may have a steeper learning curve than Vue, as it requires knowledge of JSX and a different way of thinking about UI components.
- **Boilerplate Code**: React may necessitate more code than Vue, resulting in more boilerplate code and longer development time.
- **Complex State Management**: React lacks built-in state management capabilities, necessitating dependency on other libraries for complicated state management scenarios.
## Conclusion
Vue and React are still popular web development frameworks in 2023, each with its own set of advantages and disadvantages. When deciding between Vue and React, developers should evaluate the specific requirements of their projects as well as their personal experience with the frameworks. Both frameworks have significant communities and ecosystems, and understanding their advantages and downsides will help you make an informed decision for successful web development projects.
Let me know what's your personal go-for JavaScript framework for building web apps in 2023.
---
If you found this post helpful or enjoyed it, consider supporting me by [buying me a coffee](https://www.buymeacoffee.com/ptheodosiou). Your support helps me create more valuable content. ☕ Thank you! | ptheodosiou |
1,430,905 | Becoming a Frontend Developer in 100 Days: A Step-by-Step Guide | Frontend development is an exciting and growing field that involves creating user interfaces for... | 0 | 2023-04-09T16:11:38 | https://dev.to/abhixsh/becoming-a-frontend-developer-in-100-days-a-step-by-step-guide-28jp | webdev, javascript, beginners, programming | Frontend development is an exciting and growing field that involves creating user interfaces for websites and applications. With the demand for frontend developers on the rise, many people are interested in learning this skillset. While becoming a frontend developer may seem daunting, it is possible to achieve in 100 days with the right mindset, resources, and dedication. In this article, we will explore the steps you can take to become a frontend developer in 100 days.
**Define your goal and make a plan :-**
The first step to becoming a frontend developer is to define your goal and make a plan. Determine what you want to achieve in 100 days, and break down the necessary steps to reach your goal. For example, you may decide to start by learning HTML and CSS, followed by JavaScript and a frontend framework such as React or Angular.
[Developer Roadmaps](https://roadmap.sh/)
**Choose your learning resources :-**
There are many resources available online that can help you learn frontend development. You can start with free resources such as [Codecademy](https://www.codecademy.com/), [W3Schools](https://www.w3schools.com/), and [MDN Web Docs](https://developer.mozilla.org/en-US/). You may also want to invest in paid courses from websites such as [Udemy](https://www.udemy.com/), [Coursera](https://www.coursera.org/), or [LinkedIn Learning](https://www.linkedin.com/learning/). Additionally, joining online communities such as [Stack Overflow](https://stackoverflow.com/users/20766435/abishek-haththakage) or [Reddit ](https://www.reddit.com/)can help you connect with other developers and find answers to your questions.
Valuable resources-
[Frontend Web Development Bootcamp Course (JavaScript, HTML, CSS)](https://www.youtube.com/watch?v=zJSY8tbf_ys&ab_channel=freeCodeCamp.org)
[React Course - Beginner's Tutorial for React JavaScript Library](https://www.youtube.com/watch?v=bMknfKXIFA8&ab_channel=freeCodeCamp.org)
[UI / UX Design Tutorial – Wireframe, Mockup & Design in Figma](https://www.youtube.com/watch?v=c9Wg6Cb_YlU&ab_channel=freeCodeCamp.org)
[Meta Front-End Developer Professional Certificate](https://www.coursera.org/professional-certificates/meta-front-end-developer)
[Google UX Design Professional Certificate](https://www.coursera.org/professional-certificates/google-ux-design)
**Practice regularly :-**
Learning frontend development is not just about reading and watching tutorials. To become a proficient frontend developer, you need to practice regularly. Set aside time each day to work on coding challenges, build projects, and experiment with different technologies. You can find coding challenges on websites such as [HackerRank ](https://www.hackerrank.com/)or [Codewars](https://www.codewars.com/), or you can create your own challenges to solve.
**Build projects :-**
One of the most effective ways to learn frontend development is by building projects. Start with simple projects such as a personal website or a landing page, and gradually move on to more complex projects. Building projects will help you put your skills into practice and give you a sense of accomplishment.
[The 100 days plan that I follow](https://github.com/abhixsh/100-days-of-code-frontend)
[16 front-end projects](https://dev.to/frontendmentor/16-front-end-projects-with-designs-to-help-improve-your-coding-skills-5ajl)
**Seek feedback :-**
Getting feedback on your projects is crucial to improving your skills as a frontend developer. Share your projects with others, such as friends, family, or online communities, and ask for feedback. You can also seek feedback from other developers by attending local meetups or participating in online forums.
**Network with other developers :-**
Networking with other frontend developers can help you stay motivated and learn from others' experiences. Attend local meetups or conferences to meet other developers in your area. You can also join online communities such as Slack or Discord channels to connect with other developers worldwide.
**Stay up to date with the latest technologies :-**
Frontend development is a constantly evolving field, and it's important to stay up to date with the latest technologies and trends. Follow blogs, podcasts, and social media accounts of industry leaders and influencers to stay informed about the latest developments in the field.
**Be patient and persistent :-**
Learning frontend development is not easy, and it takes time and effort to become proficient. Be patient with yourself and don't give up if you encounter challenges or setbacks. Remember that progress takes time and that the learning journey is a marathon, not a sprint.
> “Keep trying; failures increase the probability of success.” ― Ken Poirot
becoming a frontend developer in 100 days is achievable with the right mindset, resources, and dedication. Define your goal, make a plan, choose your learning resources, practice regularly, build projects, seek feedback, network with other developers, stay up to date with the latest technologies, and be patient and persistent. By following these steps, you can start your journey to becoming a frontend developer and open up new career opportunities. You can take these steps daily and get a basic idea in 100 days. If you want to enter the industry, you must work on projects. Good luck to all developers.

**Okay, that’s it for this article.**
Also, if you have any questions about this or anything else, please feel free to let me know in a comment below or on [Instagram](https://www.instagram.com/_abhixsh/) , [Facebook](https://www.facebook.com/abhi.haththakage/) or [Twitter](https://twitter.com/abhixsh).
Thank you for reading this article, and see you soon in the next one! ❤️ | abhixsh |
1,430,917 | Day1 -#90DaysofDevops Introduction to DevOps | DevOps is a set of practices that combines software development and IT operations to create a... | 0 | 2023-04-09T16:25:19 | https://dev.to/arunimadas18/day1-90daysofdevop-introduction-to-devops-5ee4 | 90daysofdevops, devops, cloud, opensource | DevOps is a set of practices that combines software development and IT operations to create a streamlined and efficient software development process. It breakdown's barriers between different teams involved in software development
In this blog post, we will explore the fundamentals of DevOps, automation, scaling, and infrastructure and why they are important.
## **Q1) What is DevOps?**
DevOps is a culture that improves the organization's ability to deliver applications and services at a faster speed.
It is the process of improving the application delivery by ensuring proper
- 1) automation
- 2)Continous monitoring
- 3) Quality analysis
- 4)Continous Testing
**
## Q2) Few Important terms:**
1)** Automation:** Automation is the use of technology to perform tasks with reduced human assistance. It is meant to improve efficiency and productivity by automating tasks that are repetitive or routine.
2) **Scaling: **Scaling refers to the ability to increase or decrease IT resources as needed to meet changing demand. DevOps practices can help organizations scale their software systems more easily and reliably while maintaining quality and stability.
3) **Infrastructure:** Infrastructure refers to the computing resources that are provided by a cloud service provider. These resources, such as servers, storage, networking equipment, and virtualized versions, can be provisioned and managed through software.
## **Q3) Why do we need DevOps?**
Devops is needed to automate the Software Development Life Cycle(SDLC). It's a software development and operations approach that enables faster development of new products and easier maintenance of existing deployments.
## **Q4)DevOps Lifecycle:**
Plan: This stage involves the planning of the entire software development process. This includes defining the project goals, requirements, timelines, and resources required for the project.
Develop: In this stage, developers write the code and create the software. They use tools like version control systems to manage the code, and continuous integration to merge the code with other changes made by other developers.
Test: This stage involves testing the software to ensure it meets the requirements and specifications set in the planning phase. Automated testing tools are used to ensure quality and reliability.
Deploy: In this stage, the software is released into production environments. Automated deployment tools help to streamline the deployment process and reduce deployment time.
Operate: This stage involves monitoring and maintaining the software in production environments. DevOps teams use monitoring tools to identify issues and fix them quickly.
Monitor: This stage involves continuously monitoring the software in production environments to ensure that it is performing as expected. This helps to identify any issues or bottlenecks that need to be addressed.
Feedback: This stage involves collecting feedback from users and stakeholders to improve the software. This feedback is used to inform future development and improve the overall quality of the software.
| arunimadas18 |
1,430,944 | React - How to deal with SVG | Working with SVG in a React app can give you headaches! Understanding how to effectively handle and... | 0 | 2023-04-10T08:00:00 | https://dev.to/yacinec_dev/react-how-to-deal-with-svg-50l4 | webdev, react, beginners, svg | Working with SVG in a React app can give you headaches!
Understanding how to effectively handle and use SVG files in our applications isn't always straightforward. In fact, there are only two distinct scenarios that one may come across.
---
## SVG as a static image
One practical way to handle SVG files is by storing them in an assets folder and importing them like packages:
```javascript
import MySVG from 'assets/homer-simpson.png';
const Component = () => {
return (
<img src={MySvg} alt='Homer Simpson' />
)
}
```
---
## SVG with dynamic properties
While the initial method of displaying your SVG is acceptable, there may be instances where you need to modify your SVG properties based on conditional variables and events.
In such cases, a more efficient approach is to create a separate component that solely handles the SVG and its property logic, making it easier to manage and update.
```javascript
const MySVG = ({color}) => {
return (
<svg height="100" width="100">
<circle cx="50" cy="50" r="40" stroke="black" stroke-width="3" fill={color} />
</svg>
);
}
const Component = () => {
const [focused, setFocused] = useState(false);
return (
<button onClick={() => setActive((prev) => !prev)}>
<MySVG color={focused ? "red" : "black"}/>
</button>
)
}
```
| yacinec_dev |
1,430,978 | Introduction to static libraries in C programming language. | WHAT IS A STATIC LIBRARY A library is a collection of already build functions, variables,... | 0 | 2023-04-09T21:36:00 | https://dev.to/danstano/introduction-to-static-libraries-in-c-programming-language-25n0 | codenewbie, programming |
## WHAT IS A STATIC LIBRARY
A library is a collection of already build functions, variables, classes and anything that should make your code run. You can use the code in your program without knowing how it's declared.
Static libraries are a collection of object files that are linked into the program during the linking phase.
## HOW TO CREATE A STATIC LIBRARY
We first need to create a normal c file. After creating the c file define all the functions needed in that file.
After our functions have been defined we create a header file that will be used to store all the prototypes that will be needed in our program.
The header file should have a .h file extension.
The following code should be included in our main.h file.
```
#ifndef MAIN_H
#define MAIN_H
#endif
```
## A WALK THROUGH EXAMPLE
I will create 2 c files and use them to demonstate the concepts described above. The file names will be monalisa.c and sum.c. We also have to create the main.c file which will act as our main entry point to the program.
The monalisa.c file will have the following code.
```
#include <stdio.h>
#include "main.h"
/**
* monalisa - file returns a print statement
* Return: returns 0
*/
void monalisa(void)
{
printf("Welcome home, Kid\n");
}
```
The sum.c file can have the following snippet
```
#include <stdio.h>
#include "main.h"
/**
* sum - adds up two integers
* @z: our first input value
* @y: our second input value
* Return: returns the sum of two integers
*/
int sum(int y, int z)
{
int sum;
sum = y + z;
printf("The sum of the two integers is: %d\n", sum);
return (sum);
}
```
our main.c file can have the following piece of code
```
#include "main.h"
/**
* main - the major entry point
* Return: it returns a 0
*/
int main(void)
{
monalisa();
sum(1, 2);
return (0);
}
```
and finally our main.h file will have the following piece of code that will contain our prototypes and will be used to call the monalisa and sum functions.
```
#ifndef MAIN_H
#define MAIN_H
void monalisa(void);
int sum(int y, int z);
#endif
```
Running the command 'gcc -c *.c' generates all the .o files from the .c files that will be in the current directory.
We can then create a library named lib.a with the command
'ar rcs lib.a'
After creating the library we run the command 'ar rcs lib.a *.o' which helps move copies of every .o files into our library.
Note: The s flag tells the ar command to add an index to the archive or update it if the index already exists.
This can also be achieved by running the command 'ranlib lib.a' after generating the .o files.
After indexing our library we can run the commandn 'ar -t lib.a' to see if our file is indexed properly.
Finally we run the ' nm lib.a' command to list all the symbols of the files that we have and from this we can see the files that we were unable to link into our object file.
## TOP TIP
We can create an executable file script that can be used to automate the process of generating .o library files.
Create a file named static_lib.sh and put the following code in it.
```
#!/bin/bash
gcc -c *.c
ar rc bilan.a *.o
ranlib bilan.a
```
After writing the code you can make the file executable by running the following command.
chmod u+x static_lib.sh
The above script creates a static library called bilan.a from all the .c files that are in our current directory.
After creating an executable file we run the following commmand on the terminal to test our executable and add all the .o files that will have been generated from the .c files into our library named bilan.a
./create_static_lib.sh
All the libaries have a .a exentionj to them.
By Oduor.
| danstano |
1,431,143 | Turning a Freelance Gig into a Long-Term Partnership | There are two types of freelancers. The first type views freelancing as a side-hustle. They still... | 0 | 2023-04-14T22:27:58 | https://livecodestream.dev/post/turning-a-freelance-gig-into-a-long-term-partnership/ | freelancing | ---
title: Turning a Freelance Gig into a Long-Term Partnership
published: true
date: 2023-04-05 12:50:32 UTC
tags: Freelancing
canonical_url: https://livecodestream.dev/post/turning-a-freelance-gig-into-a-long-term-partnership/
---

There are two types of freelancers.
The first type views freelancing as a side-hustle. They still hold a 9-to-5 job and most of their time and energy goes into that career.
But they also want a little more - more money, or more creative freedom, or more challenging work. So, they dabble in freelancing.
The second type deep-dives into freelancing. They’ve left their 9-to-5 job and view freelancing as their new career.
They also want more - but on a bigger scale. So, they’re all in.
Both types usually start out in the same way. They’re trying to secure a freelancing gig, so they may take advantage of online freelancing platforms, or try to find freelancing opportunities through networking.
Hopefully, they start to land some gigs. But it’s at this point that the two types go in different directions.
For the part-time freelancer, gigs come and go. They take whatever they can get, whenever they can get it. They view gigs as short-term opportunities.
But for the “all-in” freelancer, a gig isn’t just a one-time job or a short-term opportunity. They’re looking to establish connections with clients and create long-term opportunities.
They want to know how to turn a freelancing gig into a long-term partnership.
**Here’s the secret. Turning a freelancing gig into a long-term partnership is beneficial for both types of freelancers, and there are a few key ways to do it.**
First, let me explain why it’s beneficial for both types of freelancers.
Of course, the long-term freelancer sees the benefits because he wants to secure gigs that will keep generating income and help him grow his freelancing business.
He knows the value of [creating multiple streams of income as a freelancer](/post/the-importance-of-creating-multiple-streams-of-income-as-a-freelancer/), especially if those streams keep flowing.
Having a long-term partnership means more jobs, and more money, are coming in.
As an added bonus, long-term clients are also more likely to recommend you among their networks, so this partnership can generate additional opportunities for you.
Maybe you’re thinking, freelancing is just a side-hustle for me, and long-term partnerships would require too much from me.
Let me explain how long-term partnerships can even benefit a part-time freelancer.
If you’ve correctly turned a freelance gig into a long-term partnership, you’ve got a constant source and a sustainable stream of income from which you can supplement your side-hustle.
You no longer have to go online looking for gigs, or filling out bids, or spending your precious time and energy networking.
Additionally, your work becomes more efficient.
One of the hardest parts about working with a new client is the process of figuring out what they want and how to communicate with them.
Defining their design aesthetic, determining the best way to meet their needs, and learning what they really want when they ask you for something, are all hard to do at first.
They take time, require extra effort, and often involve mistakes at first.
But, once you’ve worked with a client for a few months, you can begin to anticipate their needs, develop the solutions they need quicker, and know what they want without asking.
As a result, you deliver better results, move quicker, and make more money.
So, long-term partnerships with even just a few clients can greatly benefit your freelancing business, whether you’re a part-time or all-in freelancer.
**The real question becomes, How do I turn a freelance gig into this type of long-term partnership that benefits my freelancing business?**
We all know that the freelance industry has become increasingly saturated, and it can be difficult to stand out and secure long-term freelance gigs.
Here are a few key ways to successfully create this type of long-term partnership with a client.
* * *
## 1. Show Interest by Asking Questions [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#1-show-interest-by-asking-questions)
When you begin freelancing you are, of course, focused on your business. That’s natural.
But, to really build a long-term partnership, you’ve got to shift your focus to the client.
You have to understand the client’s business, needs, and motivation. You need to show that you are interested in really helping them achieve their long-term goals, not just delivering on a short-term gig.
Understanding the long-term value of client relationships, instead of only focusing on immediate gain, is part of [embracing the journey as a freelancer](/post/embracing-the-journey-as-a-freelancer/).
That means, you’ve got to ask questions. People love talking about themselves. Begin by finding some common interest so that you can connect with the client.
Clients want to work with someone they like, someone they feel comfortable with, someone they feel connected to.
At the most basic level, you can talk about how their business got started and where they see it heading. This will give you valuable information about whether or not this client relationship should be turned into a long-term partnership.
Not all long-term partnerships will benefit you. By asking a few questions at the start, you can determine if this short-term gig is really something you want to develop into a long-term partnership.
If it is, continue asking questions about what is important to them in this business. What struggles are they facing? What goals do they have?
The more you understand about their business, the better chance you have of being able to offer them valuable services.
A long-term partnership should be a mutually beneficial arrangement.
When they see that you are really genuine and invested in trying to help them, they will want to continue working with you.
It’s a win-win situation.
* * *
## 2. Create Trust by following Through [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#2-create-trust-by-following-through)
Building a rapport with your client will create a sense of trust and show them that you value their business and are committed to the partnership.
The worst thing you can do is botch the short-term project they’ve hired you for.
Clients will only continue working with a freelancer they trust to follow through and deliver on time.
Of course, things happen. Clients change the scope of a project or demand faster delivery. Or maybe you deliver exactly what they asked for, but they’re still not happy.
That’s when effective communication skills are crucial.
Trust is created through transparency and communication, as well as by following through on what you promise.
In order to avoid an unhappy client, keep in touch regularly and communicate often. Keep them updated on the status of their project.
Be honest about any set-backs and provide them with an updated timeline.
Be sure to follow up with them if you haven’t heard from them in a while and always respond quickly to any queries or requests.
These effective communication skills are one of the essential [habits to practice that will help you be successful as a freelancer](/post/freelancer-habits/).
These days, it’s harder and harder to find someone whom you can really trust.
If a client realizes that they can trust you to make things right and deliver, even through set-backs or unexpected changes, they will want to continue building a partnership with you.
* * *
## 3. Demonstrate Initiative by Thinking Ahead [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#3-demonstrate-initiative-by-thinking-ahead)
The key to forming a long-term partnership is to go above and beyond the expectations of your client.
This is one key [tip for securing high-paying freelance gigs](/post/tips-for-securing-high-paying-freelance-gigs/) and turning those gigs into long-term partnerships.
High-end clients are looking for a freelancer who offers more value for their business.
Once you successfully deliver on a short-term gig, try offering to work on a trial project to showcase your skills.
This allows you and your client to test the waters and assess if the partnership is a natural fit.
During the process, demonstrate your creativity and flexibility, and showcase how you can tailor your services to their needs and provide valuable insights.
For example, if a client asks you to write content for their website, and you notice the website isn’t tailored for mobile users, offer your expertise in web development to help them reach mobile users and generate more sales.
Or maybe you realize that their systems could be updated and integrated more efficiently. Let them know that you’re happy to help them with this and explain the added value for their business.
This is when truly understanding their business, because you asked the right questions in the beginning, pays off.
If you’ve neglected to really get to know your client, you won’t be able to communicate how you can help them further, and you won’t be able to take the initiative to build a long-term partnership.
Knowing your client well, thinking ahead, and offering effective solutions show that you take initiative.
This type of initiative can set you apart from the scores of other freelancers competing for a client’s business.
* * *
## 4. Provide Value by Offering Excellence [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#4-provide-value-by-offering-excellence)
This plays out in several ways.
Of course this means handing over an excellent product to your client. High-end clients, especially, are paying premiums to get excellent results.
But even smaller gigs deserve your best efforts. Excellence for every client is part of [Freelancing 101 for Devs](https://freelancing101fordevs.com/).
This might mean not taking on more than you can handle. Realize when your time and energy are stretched to the limit, so that you don’t end up with too many projects that turn out to be sub-par.
Prioritize which clients and projects are going to be beneficial for you in the long-term. Then, focus on providing them with excellence.
Part of the value of working with you should be that clients receive excellent customer service. Make sure you are available and responsive to their needs.
This doesn’t mean you can’t establish boundaries and routines to support your mental health and ensure your best output.
But, understand that poor customer service is a problem everywhere. Clients have enough headaches.
They aren’t going to be open to a long-term partnership with a freelancer who offers substandard customer service.
In addition to excelling in your services and interactions, have a consistent pricing structure and ensure that you are providing value for their money.
Offer great incentives to encourage your clients to remain loyal, such as offering discounts on one-off jobs or providing extras such as free consultations or resources that can benefit their business.
You should also be open to changing or adapting your services as your client’s needs evolve.
The bottom line is this: Is your work associated with excellence?
Ask yourself, What do I need to do or change so that clients expect to get excellent value when working with me?
Whatever the answer is, do it.
Creating a culture of excellence is what will entice clients to turn a short-term gig into a long-term partnership with you.
* * *
## Conclusion [<svg height="22" viewbox="0 0 24 24" width="22" xmlns="http://www.w3.org/2000/svg"><path d="M0 0h24v24H0z" fill="none"></path><path d="M3.9 12c0-1.71 1.39-3.1 3.1-3.1h4V7H7c-2.76.0-5 2.24-5 5s2.24 5 5 5h4v-1.9H7c-1.71.0-3.1-1.39-3.1-3.1zM8 13h8v-2H8v2zm9-6h-4v1.9h4c1.71.0 3.1 1.39 3.1 3.1s-1.39 3.1-3.1 3.1h-4V17h4c2.76.0 5-2.24 5-5s-2.24-5-5-5z"></path></svg>](#conclusion)
Finding and transforming a successful short-term freelance gig into a long-term partnership takes hard work, dedication, and excellence.
It might take some time and practice to find the right gigs and clients who will be mutually beneficial in a long-term partnership.
You’ll need to practice these four keys consistently:
- **Asking** questions to show interest in and learn about the client’s business,
- **Following** through so you earn the client’s trust,
- **Thinking** ahead so you can solve the client’s problems and show initiative,
- **Offering** excellence in a variety of ways so you can provide value to the client.
Whether a part-time or full-time freelancer, if you do these things you will soon find that clients pursue working with you.
And these successful long-term partnerships will help grow and sustain your business so that freelancing affords you the life you’ve always wanted.
Thanks for reading!
**Newsletter**
[Subscribe to my weekly newsletter](https://livecodestream.dev/newsletter/) for developers and builders and get a weekly email with relevant content. | bajcmartinez |
1,431,145 | Opaque IDs: the ultimate protection against enumeration attacks | In this post, we’ll discuss two types of attacks, timing attacks and enumeration attacks, which can... | 0 | 2023-04-10T08:53:26 | https://exact.realty/blog/posts/2023/03/30/enumeration-timing-uuids/ | infosec, encryption, webdev, uuids | ---
title: Opaque IDs: the ultimate protection against enumeration attacks
published: true
date: 2023-03-30 00:00:00 UTC
tags: ["infosec", "encryption", "webdev", "uuids"]
canonical_url: https://exact.realty/blog/posts/2023/03/30/enumeration-timing-uuids/
---
In this post, we’ll discuss two types of attacks, timing attacks and enumeration attacks, which can result in disclosing confidential information to attackers when accessing resources. We’ll then introduce a method to neutralise these attacks using AEAD encryption.
## Why IDs are used
A great many applications involve some sort of information retrieval for interactivity. The information is stored in some type of database and each item or resource that is typically assigned a unique identifier, or ID. This identifier can then be used to refer to that item later on.
For example, if you have a web application where users can upload photos, you might store each photo’s metadata in a database and assign each row a unique ID. The ID will then be sent in some form to the user, so that when she wants to see the photo the application can retrieve that file by looking up the ID in the database.
This applies not just to web applications, but rather is a feature of APIs in general. For example, a REST API might provide a user a path like `http://api.example/foo/123` to identify a resource of type `foo` named `123`.
## How IDs might be exploited to gain access
Disclosing internal information (such as an ID) to users can result in providing them with access to _other_ information that they are not intended to have access to.
While the ID in itself might seem like a harmless piece of information (and it usually is, in isolation), it could allow users to make inferences about the system and potentially gain access to private data.
## German tank problem
The German tank problem gets it name from a statistical problem the Allies faced during World War Ⅱ. The Germans built a lot of tanks, and the Allies wanted to know how many as well as the monthly rate of production. Since the Germans used a sequential numbering system to label the components for each tank they built, when Allies captured one, they could see its serial numbers. By looking at the highest serial number they saw, and applying some statistical analysis, they could effectively estimate how many tanks the Germans had built.
This problem can be very relevant to information security. Suppose you are using sequential IDs for the photo upload application mentioned earlier and that each photo is given a sequential ID (e.g., `1`, `2`, `3`, etc.). Then, by just observing the IDs being used, an attacker could gain information about the number of photos stored in the system as well as the rate at which photos are uploaded. Whether this is a concern or not depends, of course, on the specifics of the situation. Most likely, the information in this particular example is of little value, but it might be helpful to, say, a potential competitor considering building a similar application.
## Enumeration attacks
While the German tank problem shows how our choice of identifiers might non-public reveal information to an adversary, many or even most applications are interactively accessible to adversaries. This interactivity allows attackers to carry out another attack that can give them the same information directly, without the need to guess: an enumeration attack.
An enumeration attack is a type of attack where an attacker attempts to gather information about a system by systematically trying different values for a particular parameter. In the context of IDs, an enumeration attack might involve an attacker trying a large number of possible IDs to determine which IDs exist and which do not. Once the attacker has determined which IDs exist, they can potentially use that information to carry out further attacks.
Enumeration attacks can be particularly effective when the IDs being used follow some kind of sequence or are represented in a relatively small set and are part of a publicly available URL, as it is trivial to automate the process of trying a large number of possible IDs.
For example, consider the previous API with an endpoint like `http://api.example/foo/:id`, where `:id` is a numeric and sequential ID. It is trivial for an actor to try many requests, such as `http://api.example/foo/1`, `http://api.example/foo/2`, `http://api.example/foo/99`, etc., and evaluate the response.
The impact of enumeration attacks depends on the application in question. In many situations, successfully exploiting an enumeration vulnerability will only provide information about which resources are valid, making it similar to the German tank problem. However, in combination with additional vulnerabilities in the application, especially [broken access control](https://owasp.org/Top10/A01_2021-Broken_Access_Control/), it could have farther reaching implications, such as leaking confidential information, including customer data.
### Prevention
Enumeration attacks can be avoided or mitigated by addressing the factors that make them possible: small sets and predictable values. A common solution is to use [UUIDs version 4](https://www.ietf.org/rfc/rfc4122.html#section-4.4), which consist of 122 random bits and are therefore impossibly impractical to guess or enumerate.
## Timing attacks
A timing attack is a type of side-channel attack where an attacker attempts to gain information about a system by measuring the amount of time it takes to perform certain operations. In the context of IDs, a timing attack might involve an attacker trying to guess a resource’s ID by trying a large number of possible IDs and measuring the time it takes for the system to respond. By measuring the time it takes to receive a response, the attacker can potentially learn information about the system, such as which IDs exist and which do not.
Timing attacks can be a way to extract information even from systems that implement proper access control. Consider the endpoint from earlier: `http://api.example/foo/:id`. Let’s say that IDs follow a simple numeric sequence (i.e., `1`, `2`, `3`, etc.) and that the no path IDs is publicly accessible. Our adversary is a user to the system with legitimate access to the resources with an ID of `11` and `17`, and no access to any other resources. How could this adversary carry out an enumeration attack?
Because of difficult or impossible to avoid circumstances when developing such an application, the endpoint will likely take different time to respond depending on the result. This information, if consistent, can be revealing of the internal state. Our attacker could proceed to make queries against the endpoint to all resources, for example, from 1 to 100 000. The measured response times could look like something like what is shown in the table below.
| ID range | Mean response time (ms) |
| --- | --- |
| 1–10 | 50 |
| **11** | 57 |
| 12–16 | 51 |
| **17** | 56 |
| 18–7 363 | 49 |
| 7 364–100 000 | 45 |
_Table with mean measured response times for different IDs. Note the difference between various IDs. The IDs the attacker has legitimate access to have a mean response time of about 56ms, whereas the remaining resources have response times of about 50ms for IDs under 7 364 and of about 50ms for higher values._
Note that from ID `7364` onwards the response time is lower. This information can reveal to the attacker that the system likely contains 7 363 entries.
Depending on how lookups are carried out, timing information can also be used to identify valid IDs even when they don’t follow a sequence and there is a much larger set of valid IDs (such as UUIDs). This means that the specifics of how data are looked up are important, not just the format of IDs.
### Mitigation
There are several ways to mitigate timing and enumeration attacks. As mentioned earlier, one common solution against enumeration attacks is using random UUIDs instead of sequential IDs. These have a very low probability of being guessed by an attacker. However, UUIDs can be relatively long, which can be a disadvantage in certain contexts, such as when they need to be used in URLs.
Timing attacks, being a side-channel attack, are impossible to eliminate entirely because so doing would require eliminating all possible side-channels. However, there are ways to practically mitigate them. Ideally, we would write our application so that response times are independent from user-provided data. Since this is impractical, we can practice defence-in-depth and make timing information less useful and more difficult to obtain.
For example, if we are concerned about enumeration attacks, we might add a MAC or digital signature to IDs, which (1) users cannot readily forge and (2) we can verify before proceeding further with the request.
The new IDs could look like the original IDs, but with the MAC or signature prepended to it, like this `<MAC>.<ID>`. So, the internal resource `1` could result in a user-visible ID like `53CUR3C0D3.1`, with `53CUR3C0D3` being a value that we can verify as corresponding to resource `1`, but which is difficult to forge or guess. If we verify this value before handling the request further, an attempt at the timing attack described earlier could instead have resulted in measurements like the following.
| ID range | Mean response time (ms) |
| --- | --- |
| 1–10 | 32 |
| **11** | 59 |
| 12–16 | 33 |
| **17** | 60 |
| 18–7 363 | 31 |
| 7 364–100 000 | 32 |
_Table with mean measured response times for different IDs after only processing requests with a valid MAC. Note that mean response times are divided into two categories this time. For IDs the attacker has legitimate access to, we see similar, slightly higher, response times of around 60ms. For all other IDs (where an invalid MAC was provided), the response time is of around 32ms._
Note that in this case, an attacker does not gain much information besides what they already know (i.e., the representation of resources `11` and `17`).
#### Encrypted IDs
While a MAC or signature can go to great lengths towards preventing enumeration and timing attacks to learn about valid IDs, the issue arising from the German tank problem, namely, making inferences from observable IDs, remains. In order to mitigate this, we can use encryption to make internal representation of the ID itself opaque to external parties.
Indeed, we can use various authenticated encryption schemes (e.g., AES-GCM) to hand out users IDs which are both _opaque_ (they do not allow to infer information about their internal value, structure or representation) and _unforgeable_ (IDs not generated by us can be detected and rejected).
However, there are some potential downsides to using this method. One issue is that the encrypted IDs are not human-readable, so it may be difficult for developers to work with these IDs directly. This can make debugging and troubleshooting more challenging.
Another potential issue is that the overhead involved in encrypting and decrypting IDs can be significant both in terms of computing time and space. This can be a concern particularly in applications where a large number of IDs need to be generated and transmitted or in certain resource-constrained applications.
## Example solution in TypeScript
We have developed a small library, [@exact-realty/safeid](https://www.npmjs.com/package/%40exact-realty/safeid), that implements the techiques discussed here applied to UUIDs, with the possibility of extending it to other arbitrary ID formats.
### Approach taken
`@exact-realty/safeid` uses AES-GCM to produce IDs that are opaque, unforgeable and stable (i.e., the same internal ID will always result in the same encrypted ID).
To do this, first we provide the library with a secret key that will be used to derive other cryptographic IDs.
Then, before providing an ID to a user, we encrypt the internal representation. This is a multiple-step process:
1. We derive an <abbr title="Hash-based Message Authentication Code"><a href="https://www.ietf.org/rfc/rfc2104.html">HMAC</a></abbr> key from the supplied secret key (this step is carried out before any encryption or decryption operation).
2. We use the HMAC key to produce the an <abbr title="Initialisation Vector">IV</abbr> to be used for the following encryption step, taking the plaintext internal ID as input to the HMAC function. This is the step that ensures that the resulting output is stable.
3. We derive an AES256-GCM encryption key from the supplied secret key. In this implementation, we additionally use the IV derived in the previous step an an input to this process, which results in a different encryption key for each ID.
4. We proceed to encrypt the supplied internal ID, using the derived IVs and encryption keys.
5. We prepend the IV to the resulting encrypted data and encode it using the [base64url](https://www.ietf.org/rfc/rfc4648.html#section-5) encoding and return this as a result (which for UUIDs results in a 48-byte string).
For decryption, the steps are as follows:
1. We derive an <abbr title="Hash-based Message Authentication Code"><a href="https://www.ietf.org/rfc/rfc2104.html">HMAC</a></abbr> key from the supplied secret key (this step is carried out before any encryption or decryption operation).
2. We decode the encrypted ID and split it into two parts: the IV and the encrypted data.
3. We derive an AES256-GCM decryption key from the supplied secret key. In this implementation, we additionally use the IV, which results in a different decryption key for each ID.
4. We decrypt the encrypted ID to obtain the plaintext internal ID.
5. With this information, we derive the IV from the plaintext and verify that the IV in the input that we obtained earlier matches what we expect it to be (i.e., the IV that the encryption function would have derived). This step is a sanity check to ensure that the ID has not been tampered with.
6. We return the plaintext internal ID, which our application can now use for accessing resources. | corrideat |
1,431,168 | React Send Data from Child to Parent Component Tutorial | If you're working with React, you've probably run into the need to pass data from a child component... | 0 | 2023-04-10T01:28:02 | https://dev.to/coder9/react-send-data-from-child-to-parent-component-tutorial-j5k | react, abotwrotethis | If you're working with React, you've probably run into the need to pass data from a child component to a parent component. It can be a bit tricky at first, but with this tutorial, you'll learn how to do it simply and effectively.
## Understanding React Component Hierarchy
Before we dive into passing data from child to parent components, it's important to understand the React component hierarchy. In React, components can have parent and child components, forming a tree-like structure.
The parent component can pass data down to its child components through props, which are essentially parameters passed between components. The child component can also communicate with the parent component, but it requires a bit more effort.
## The Problem: How to Send Data from Child to Parent Component
Imagine you have a parent component that contains several child components. One of these child components has a form that the user fills out, and you want to capture that data in the parent component.
So, how can you get this data from the child component to the parent component? This is where things get a bit more complex. Child components in React are supposed to be "dumb", meaning they shouldn't have to know about their parent components. However, we still need a way for the child component to communicate with the parent component in order to send the data.
## The Solution: Use Callback Functions
The solution to this problem is to use callback functions. Callback functions are functions that are passed as props from the parent component to the child component, and are called by the child component when the data needs to be sent.
Here's how it works in practice:
1. In the parent component, define a function that will receive the data from the child component. For example, we might define a function like this:
```
function handleFormData(formData) {
console.log(formData);
}
```
2. We pass this function down to the child component as a prop:
```
<ChildComponent onFormData={handleFormData} />
```
3. In the child component, we define a function that will be called when the user submits the form. This function will then call the callback function that was passed down as a prop:
```
function handleSubmit(event) {
event.preventDefault();
const formData = { /* grab data from form */ }
props.onFormData(formData);
}
```
That's it! When the user submits the form in the child component, the `handleSubmit` function is called, which then calls the `handleFormData` function passed down as a prop from the parent component.
## Demo: Passing Data from Child to Parent Component
Let's put this all together in a demo. We'll create a simple form in a child component, and send the form data to a parent component when it's submitted.
### Step 1: Create the Parent Component
```
import React from 'react';
import ChildComponent from './ChildComponent';
function ParentComponent() {
function handleFormData(formData) {
console.log(formData);
}
return (
<div>
<h1>Parent Component</h1>
<ChildComponent onFormData={handleFormData} />
</div>
);
}
export default ParentComponent;
```
Here, we define the `ParentComponent` function that contains a `handleFormData` function that we'll use to receive data from the child component. We also import the `ChildComponent` we'll create in the next step.
We then render some basic markup, and pass the `handleFormData` function to the `ChildComponent` as a prop.
### Step 2: Create the Child Component
```
import React, { useState } from 'react';
function ChildComponent(props) {
const [name, setName] = useState('');
function handleSubmit(event) {
event.preventDefault();
props.onFormData({ name });
}
function handleNameChange(event) {
setName(event.target.value);
}
return (
<form onSubmit={handleSubmit}>
<h2>Child Component</h2>
<div>
<label>Name:</label>
<input type="text" value={name} onChange={handleNameChange} />
</div>
<button type="submit">Submit</button>
</form>
);
}
export default ChildComponent;
```
Here, we define the `ChildComponent` function that contains a form that the user will fill out. We define a `useState` hook to store the name input by the user, and then define a `handleSubmit` function that will be called when the form is submitted.
In `handleSubmit`, we prevent the default form submission, and then call the `onFormData` function that was passed down as a prop, passing in the `name` state value as the form data.
We also define a `handleNameChange` function that will update the `name` state whenever the user types in the input field.
Finally, we render the form markup with the `onChange` and `onSubmit` handlers we defined.
### Step 3: Render the App
```
import React from 'react';
import ParentComponent from './ParentComponent';
function App() {
return (
<div>
<ParentComponent />
</div>
);
}
export default App;
```
We define the `App` component that simply renders the `ParentComponent`.
### Step 4: Test It Out
If we run the app, we'll see the parent component with the child component inside it. When we fill out the form and click "Submit", the `handleFormData` function in the parent component will be called, and we'll see the form data logged to the console.
## Conclusion
Passing data from child components to parent components can be a bit tricky in React, but with callback functions, it can be done relatively easily. Simply define a function to receive the data in the parent component, pass that function down to the child component as a prop, and call that function in the child component when the data needs to be sent.
Hopefully this tutorial has been helpful in understanding how to pass data from child to parent components in React. Happy coding! | coder9 |
1,431,221 | How to Create a Verification Code Input Component in React / Next.js | In today's world, where cybersecurity threats are on the rise, one-time passcodes (OTPs) have become... | 0 | 2023-04-10T03:50:27 | https://blog.designly.biz/how-to-create-a-verification-code-input-component-in-react-next-js | nextjs, react, frontend, uiux | In today's world, where cybersecurity threats are on the rise, one-time passcodes (OTPs) have become a popular security measure to protect user accounts from unauthorized access. However, the inconvenience of inputting these codes has become a source of frustration for many users. As a result, facilitating an easy input process for OTPs has become increasingly important. By simplifying the input process, users can enjoy the benefits of increased security without feeling inconvenienced. This can lead to improved user satisfaction and increased adoption of security measures, ultimately helping to protect both users and businesses from potential security breaches.
In this article, I'll show you how to create a robust OTP code input component for React.js, using no other dependencies. Although for my example, I am using `tailwindcss` and `react-icons`, but they are totally optional.
## The Component
Here's the code for our `EnterCode` component:
```jsx
import React, { useRef, useState, useEffect } from 'react';
import { FaTimes } from 'react-icons/fa'
export default function EnterCode({ callback, reset, isLoading }) {
const [code, setCode] = useState('');
// Refs to control each digit input element
const inputRefs = [
useRef(null),
useRef(null),
useRef(null),
useRef(null),
useRef(null),
useRef(null),
];
// Reset all inputs and clear state
const resetCode = () => {
inputRefs.forEach(ref => {
ref.current.value = '';
});
inputRefs[0].current.focus();
setCode('');
}
// Call our callback when code = 6 chars
useEffect(() => {
if (code.length === 6) {
if (typeof callback === 'function') callback(code);
resetCode();
}
}, [code]); //eslint-disable-line
// Listen for external reset toggle
useEffect(() => {
resetCode();
}, [reset]); //eslint-disable-line
// Handle input
function handleInput(e, index) {
const input = e.target;
const previousInput = inputRefs[index - 1];
const nextInput = inputRefs[index + 1];
// Update code state with single digit
const newCode = [...code];
// Convert lowercase letters to uppercase
if (/^[a-z]+$/.test(input.value)) {
const uc = input.value.toUpperCase();
newCode[index] = uc;
inputRefs[index].current.value = uc;
} else {
newCode[index] = input.value;
}
setCode(newCode.join(''));
input.select();
if (input.value === '') {
// If the value is deleted, select previous input, if exists
if (previousInput) {
previousInput.current.focus();
}
} else if (nextInput) {
// Select next input on entry, if exists
nextInput.current.select();
}
}
// Select the contents on focus
function handleFocus(e) {
e.target.select();
}
// Handle backspace key
function handleKeyDown(e, index) {
const input = e.target;
const previousInput = inputRefs[index - 1];
const nextInput = inputRefs[index + 1];
if ((e.keyCode === 8 || e.keyCode === 46) && input.value === '') {
e.preventDefault();
setCode((prevCode) => prevCode.slice(0, index) + prevCode.slice(index + 1));
if (previousInput) {
previousInput.current.focus();
}
}
}
// Capture pasted characters
const handlePaste = (e) => {
const pastedCode = e.clipboardData.getData('text');
if (pastedCode.length === 6) {
setCode(pastedCode);
inputRefs.forEach((inputRef, index) => {
inputRef.current.value = pastedCode.charAt(index);
});
}
};
// Clear button deletes all inputs and selects the first input for entry
const ClearButton = () => {
return (
<button
onClick={resetCode}
className="text-2xl absolute right-[-30px] top-3"
>
<FaTimes />
</button>
)
}
return (
<div className="flex gap-2 relative">
{[0, 1, 2, 3, 4, 5].map((index) => (
<input
className="text-2xl bg-gray-800 w-10 flex p-2 text-center"
key={index}
type="text"
maxLength={1}
onChange={(e) => handleInput(e, index)}
ref={inputRefs[index]}
autoFocus={index === 0}
onFocus={handleFocus}
onKeyDown={(e) => handleKeyDown(e, index)}
onPaste={handlePaste}
disabled={isLoading}
/>
))}
{
code.length
?
<ClearButton />
:
<></>
}
</div>
);
}
```
Let's break this down:
The component accepts 3 arguments:
1. callback: function to call when code reaches 6 digits
2. reset: a boolean state to toggle when you want to reset the component externally
3. isLoading: boolean toggle to disable inputs
The first `useEffect()` waits for the `code` to reach 6 characters and then sends it to our callback function. The second one listens for the state of `reset` to change and then resets our component accordingly.
Our `handleInput()` function handles setting the state of code, advancing to the next input, and converts all lowercase letters to uppercase.
The `handleFocus()` function selects the contents of the input when it is focused. This makes for a better user experience--especially mobile users.
The `handleKeyDown()` function listens for the backspace or delete keys and selects the previous box if detected.
The `handlePaste()` function captures pasted text in any one of the inputs and then updates our code state and then splits the characters into each input box.
Finally, we have a `ClearButton` component that shows when there are 1 or more digits in the input. Clicking it resets the component.
## Example Usage
Here's an example of how you might implement this component:
```jsx
import React, { useState } from "react";
import EnterCode from "@/components/Forms/EnterCode";
export default function VerifyCodePage() {
const [isLoading, setIsLoading] = useState(false);
const handleCodeSubmit = async (code) => {
if (isLoading) return;
try {
const payload = new FormData();
payload.append("code", code);
const result = await fetch("/path/to/api/endpoint", {
method: "POST",
body: payload,
});
if (!result.ok) {
const mess = await result.text();
throw new Error(mess);
}
alert("Code is verified!");
} catch (err) {
alert(`Error: ${err.message}`);
} finally {
setIsLoading(false);
}
return (
<div className="flex flex-col gap-6">
<EnterCode isLoading={isLoading} callback={handleCodeSubmit} />
</div>
);
};
}
```
Thank you for taking the time to read my article and I hope you found it useful (or at the very least, mildly entertaining). For more great information about web dev, systems administration and cloud computing, please read the [Designly Blog](https://designly.biz/blog). Also, please leave your comments! I love to hear thoughts from my readers.
I use [Hostinger](https://hostinger.com?REFERRALCODE=1J11864) to host my clients' websites. You can get a business account that can host 100 websites at a price of $3.99/mo, which you can lock in for up to 48 months! It's the best deal in town. Services include PHP hosting (with extensions), MySQL, Wordpress and Email services.
Looking for a web developer? I'm available for hire! To inquire, please fill out a [contact form](https://designly.biz/contact). | designly |
1,431,299 | A step-by-step guide on Excel Add-in development using React.js | What is an Excel Add-in? MS Excel Add-in is a kind of program or a utility that lets you... | 0 | 2023-04-10T05:50:30 | https://www.ifourtechnolab.com/blog/a-step-by-step-guide-on-excel-add-in-development-using-react-js | react, exceladdin, webdev, programming | ## What is an Excel Add-in?
MS Excel Add-in is a kind of program or a utility that lets you perform fundamental processes more quickly. It does this by integrating new features into the excel application that boosts its basic capabilities on various platforms like Windows, Mac & Web.
The Excel Add-in, as part of the Office platform, allows you to modify and speed up your business processes. Office Add-ins are well-known for their centralized deployment, cross-platform compatibility, and AppSource distribution. It enables developers to leverage web technologies including HTML, CSS, and JavaScript.
More importantly, it provides the framework and the JavaScript library Office.js for constructing Excel Add-ins. In this tutorial, we will walk through the basic yet effective process of creating the Excel Addin using ReactJS.
## Prerequisites for setting up your development environment
Before you start creating Excel Add-ins, make sure you have these prerequisites installed on your PC.
- NPM
- Node.js
- Visual Studio
- A Microsoft 365 account with a subscription
### Looking for the best [Excel Add-in development company](https://www.ifourtechnolab.com/excel-add-in-development-company) ? Connect us now.
## How to build Excel Add-in using React
To begin, configure and install the Yeoman and Yeoman generator for [Office 365 Add-in development](https://www.ifourtechnolab.com/office-365-add-in-development-company).
```
npm install -g yo generator-office
```
Now run the following yo command to create an Add-in
```
yo office
```
After running the above command, select the Project type as a React framework. Take a look at the reference image below.
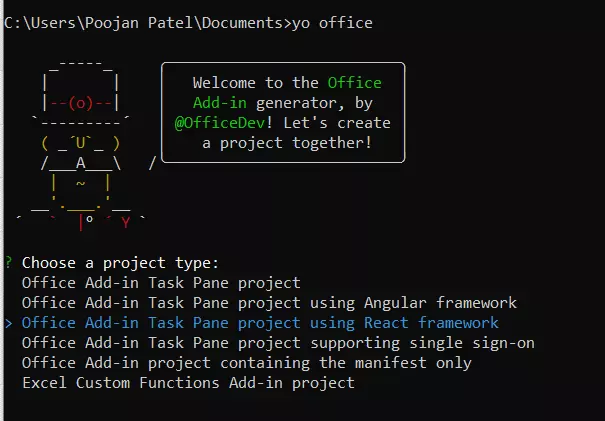
After selecting the project, choose TypeScript as your script type.

Now, name your Excel Add-in project as shown below. You can give whatever name you like but giving a project-relevant name would be an ideal move.

### Read More: [React Element vs Component: A deep dive into differences](https://www.ifourtechnolab.com/blog/react-element-vs-component-a-deep-dive-into-differences)
Because it is critical to provide support for the office application, choose Excel as the Office client.
Congratulations!! Your first Excel Add-in is created successfully.
## How to run Excel Add-in?
Add-ins are not instantly accessible in Excel by default. We must activate them before we may use them. Let's have a look at how to use a command prompt to execute Add-ins in MS Excel.
Use the following command and open the project folder on the command prompt.
```
cd Excel_Tutorial
```
Now start the dev-server as shown below.
```
npm run dev-server
```
To test Add-in in your Excel, run the following command in the project’s root directory.
```
npm start
```
When you complete running this command, you should see a task pane added to Excel that operates like an Excel Add in.
## How to create a Table using ReactJS?
Businesses commonly use tables to present their business data whether it be price, comparison, financial comparison, etc. React.js makes it simple and quick for organizations to manage large amounts of data. Let’s understand the process of creating a table using React.js.
To begin,
Planning to [hire dedicated ReactJS developers](https://www.ifourtechnolab.com/hire-dedicated-react-developers)? Contact us now.
1. Open the project in VS code
2. Open the file which is located in src\taskpane\components\app.tsx
3. Remove the componentDidMount() method and click() method from app.tsx
4. Remove all tags which are inside the return method and add one button inside the return method to generate a table
**5. App.tsx**
```
import * as React from "react";
import Progress from "./Progress";
export interface AppProps {
title: string;
isOfficeInitialized: boolean;
}
export default class App extends React.Component<appprops> {
constructor(props, context) {
super(props, context);
this.state = {
listItems: [],
};
}
render() {
const { title, isOfficeInitialized } = this.props;
if (!isOfficeInitialized) {
return (
);
}
return (
<>
<button>Generate Table</button>
);
}
}
</appprops>
```
Create one event handler function for the button which will contain the logic for creating a new table.
```
<appprops><button onclick="{this.handleCreateTable}">Generate Table</button>
</appprops>
```
Excel.js business logic will be added to the handleCreateTable function that is passed to Excel.run method.
The context.sync method sends all pending commands which are in queue to Excel for execution.
The Excel.run method is followed by the catch block.
```
handleCreateTable = async () => {
await Excel.run(async (context) => {
// logic for create table
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
In Excel.run method, first we have to get the current worksheet, and to do so, use the following method.
```
const currentWorksheet = context.workbook.worksheets.getActiveWorksheet();
```
Once we get the worksheet, we’ll create a table. Use the following method to create a table.
```
const salaryTable = currentWorksheet.tables.add("A1:D1", true);
```
The table is generated by using the add() function on the table collection of the current worksheet. The method accepts the first parameter as a range of the top row of the table.
We can also give a name to our table as shown below.
```
salaryTable.name = "SalaryTable";
```
Now, add a header row using the code shown below.
```
salaryTable.getHeaderRowRange().values =
[["Name", "Occupation", "Age","Salary"]];
```
The table's rows are then inserted using the add() function of the table's row collection. We may add several rows in a single request by sending an array of cell values within the parent array.
```
salaryTable.rows.add(null /*add at the end*/, [
["Poojan", "Software Developer","39", "50,000"],
["Meera", "Fashion Designer","23", "30,000"],
["Smit", "Teacher", "25","35,000"],
["Kashyap", "Scientist", "29","70,000"],
["Neha", "Teacher","34", "15,000"],
["Jay", "DevOps Developer","31", "65,000"]
]);
```
We can change the format of salary to decimal. For that, we have to pass the column zero-based index to the getItemAt() method.
```
salaryTable.columns.getItemAt(3).getRange().numberFormat = [['##0.00']];
```
When we use the table to represent business data, it is important to ensure content is displayed clearly. With the fine use of the autofitColumns() and autofitRows() methods, we can perfectly fit the content into cells.
```
salaryTable.getRange().format.autofitColumns();
salaryTable.getRange().format.autofitRows();
```
### Read More: [Flutter vs. React Native: Choose the Best for your App in 2022](https://www.ifourtechnolab.com/blog/flutter-vs-react-native-choose-the-best-for-your-app-in-2022)
Let’s take a look at how the entire function appears to be.
```
handleCreateTable = async () => {
await Excel.run(async (context) => {
const currentWorksheet=context.workbook.worksheets.getActiveWorksheet();
const salaryTable = currentWorksheet.tables.add("A1:D1", true );
salaryTable.name = "SalaryTable";
salaryTable.getHeaderRowRange().values =
[["Name", "Occupation", "Age", "Salary"]];
salaryTable.rows.add(null /*add at the end*/, [
["Poojan", "Software Developer", "39", "50,000"],
["Meera", "Fashion Designer", "23", "30,000"],
["Smit", "Teacher", "25", "35,000"],
["Kashyap", "Scientist", "29", "70,000"],
["Neha", "Teacher", "34", "15,000"],
["Jay", "DevOps Developer", "31", "65,000"]
]);
salaryTable.columns.getItemAt(3).getRange().numberFormat = [['##0.00']];
salaryTable.getRange().format.autofitColumns();
salaryTable.getRange().format.autofitRows();
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
Now, use the npm start command to run the code. That's all there is to it; now, when the user hits the generate table button, he'll see the following result.
**Output:**
## How to Filter data in a table?
Filtering data is critical because organizations utilize it to exclude undesired results for analysis. Let's see how data in a table may be filtered for better analysis.
```
<button>Filter Data</button>
```
```
<button onclick="{this.filterData}">Filter Data</button>
```
1. Open the file which is located in src\taskpane\components\app.tsx
2. Add a new button for filter data below Generate Table button.
3. Create one event handler function for the button that will contain the filter data logic.
**4. filterData function:**
```
filterData = async () => {
await Excel.run(async (context) => {
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
Then we will get the current worksheet and table.
```
const currentWorksheet = context.workbook.worksheets.getActiveWorksheet();
const salaryTable = currentWorksheet.tables.getItem('salaryTable');
```
To begin filtering data, we must first access the column from which we will be filtering data.
```
const occupationFilter = salaryTable.columns.getItem('Occupation').filter;
```
Here, Occupation is the column name on which we want to apply the filter.
Next, pass the values as a filter query.
```
occupationFilter.applyValuesFilter(['Software Developer', 'Teacher']);
```
Meanwhile, take a look at how the whole function looks like.
```
filterData = async () => {
await Excel.run(async (context) => {
const currentWorksheet=context.workbook.worksheets.getActiveWorksheet();
const salaryTable = currentWorksheet.tables.getItem('salaryTable');
const occupationFilter=salaryTable.columns.getItem('Occupation').filter;
occupationFilter.applyValuesFilter(['Software Developer', 'Teacher']);
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
Finally, run the code using the npm start command. Now when the user clicks on the filter data button, he’ll see the following result.
**Output:**
## How to sort data in the table?
Data sorting is also important since it helps to obtain well-organized data in a sequential manner. Let’s understand in simple ways, how data can be sorted in a table.
To start with,
```
<button>Sort Data</button>
```
### Searching for the best [Microsoft 365 development solutions](https://www.ifourtechnolab.com/microsoft-365-development-company)? Your search ends here.
```
<button onclick="{this.sortData}">Sort Data</button>
```
1. Open the project in VS code
2. Open the file from the path: src\taskpane\components\app.tsx
3. Add a new button for sorting data below the filter data button.
4. Create one event handler function for the button which will contain the logic for sorting the data.
**5. sortData function:**
```
sortData=async()=>{
await Excel.run(async (context) => {
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
Let's start by getting the current worksheet and table.
```
const currentWorksheet = context.workbook.worksheets.getActiveWorksheet();
const salaryTable = currentWorksheet.tables.getItem('salaryTable');
```
In the function, we will build a sort field object and supply two parameters to it: the key and the type of sorting (ascending or descending).
**Note:**
The key property is the zero-based index of the column, and it is used for sorting. All the rows of data are sorted according to key.
```
const sortFields = [
{
key: 3,
ascending: false,
}
];
```
Subsequently, we use the sort and apply method on the table and pass the sortFields object.
```
salaryTable.sort.apply(sortFields);
```
Read More: [Comparative Analysis of Blazor, Angular, React, Vue and Node for Web development](https://www.ifourtechnolab.com/blog/comparative-analysis-of-blazor-angular-react-vue-and-node-for-web-development)
Here is what the whole function might look like. <<>
```
sortData = async () => {
await Excel.run(async (context) => {
const currentWorksheet=context.workbook.worksheets.getActiveWorksheet();
const salaryTable = currentWorksheet.tables.getItem('salaryTable');
const sortFields = [
{
key: 3,
ascending: false,
}
];
salaryTable.sort.apply(sortFields);
await context.sync();
}).catch((err) => {
console.log("Error: " + err);
});
}
```
Run the code using the npm start command
Finally, run the code with the npm start command. The user will see the following result every time he clicks on the sort data button.
**output**
## Conclusion
Office Add-ins benefit businesses with faster operations and processes. In Office Add-ins, you can use familiar technologies like HTML, CSS & JavaScript to create Outlook, Excel, Word, and PowerPoint Add-ins. In this blog, we learned how to create an Excel Addin with React library from scratch and how to create tables, filter & sort data in Excel using Excel Add-in.
| ifourtechnolab |
1,431,333 | Port Intel x86-64 intrinsic function to RISC-V or ARM | I am researching way to port Intel x86-64 intrinsic functions to RISC-V or ARM.This research is... | 0 | 2023-04-10T06:36:41 | https://dev.to/daisukeokaoss/port-intel-x86-64-intrinsic-function-to-risc-v-or-arm-4bio | intel, intrinsic, riscv, arm | I am researching way to port Intel x86-64 intrinsic functions to RISC-V or ARM.This research is solution to CPU architecture dependency problem.
Intel x86-64 is CISC(Complex Instruction Set Computer) and very long history.Once the code runs on x86-64 computer it must run forever.So it carries a lot of heritage.CISC like Intel is converting CISC variable length instruction to RISC like micro code. So it need converting circuit and die size becomes large.So there is overhead like consumption of electricity becomes large.
On the other hand,ARM and RISC-V is same as means of if code runs these machine,it must run forever but Instruction Set is simple and it can use relatively new technology.
But the NO 1 of market share of super computer or PC or server is Intel because many Linux application is made for Intel.
So if application that runs only on Intel can run on RISC-V or ARM by very optimized way,it may be very advantagerous.
So if we want to run application for Intel x86-64 on RISC-V or ARM by very optimized way, it need to port Intel intrinsic function to RISC-V or ARM.
the document shown below are very helpful.
https://openpowerfoundation.org/specifications/vectorintrinsicportingguide/
Intel Intrinsic API provide Instruction Set Extension Intel continue to provide.SIMD(Single Instruction Stream Multiple Data Stream) is included.
To port Intel x86-64 function to RISC-V like IBM POWER takes specific wrap structure like below.
```c
extern __inline __m128d __attribute__((__gnu_inline__, __always_inline__,__artificial__))
_mm_add_pd (__m128d __A, __m128d __B)
{
return (__m128d) ((__v2df)__A + (__v2df)__B);
}
```
_mm_add_pd is Intel Intrinsic function and this function add __A and __B. Intel Intrinsic function runs RISC-V like IBM POWER by adding this code.
We show other example.
```
extern __inline __m128d __attribute__((__gnu_inline__, __always_inline__,__artificial__))
_mm_set1_pd (double __F)
{
return __extension__ (__m128d){ __F, __F };
}
```
this copy __F value and store to __m128m by vector format.
I am planning to make test framework to content of these wrap structure.
These port must be validated and make sure it is correct.
So we input Intel and RISC-V like IBM POWER or ARM the same value and make sure output is same.
I name this test framework as Akari. Meaning Light in Japanese.
https://www.slideshare.net/OkaDaisuke/testing-framework-to-port-and-optimize-simd-library-to-open-power-systems
I presented OpenPower summit 2021 NA. | daisukeokaoss |
1,431,346 | Day 4. two pointers - move zero(es) to the end of array | Now I'm more used to remind myself of two pointers, I tried not to look at solutions or other... | 0 | 2023-04-10T07:12:19 | https://dev.to/sosunnyproject/day-4-two-pointers-move-zeroes-to-the-end-of-array-33ha | Now I'm more used to remind myself of **two pointers**, I tried not to look at solutions or other people's posts. And I made it without looking them up!
### [283. Move Zeroes](https://leetcode.com/problems/move-zeroes/)
Description: Given an integer array nums, move all 0's to the end of it while maintaining the relative order of the non-zero elements. **Note that you must do this in-place without making a copy of the array.**
```js
Example 1:
Input: nums = [0,1,0,3,12]
Output: [1,3,12,0,0]
Example 2:
Input: nums = [0]
Output: [0]
```
### Learning points
- I initially just tried the easy JS way, using unshift and push methods. But it led to *out of memory*.
- do I want to count the total number of zero and use it somehow? how to replace the original zero spot with non-zero? how to swap non-zero and zero?
- I kind of thought of #2 approach in the editorial post, `counting the number of zeroes and fill at the end of array`. But I didn't think too deep and thought it may not be two pointers. But the explanation made sense.
**[Editorial post explanation. good](https://leetcode.com/problems/move-zeroes/editorial/?envType=study-plan&id=algorithm-i)**
```
This is a 2 pointer approach.
The fast pointer which is denoted by variable "cur"
does the job of processing new elements. If the newly
found element is not a 0, we record it just after the
last found non-0 element. The position of last found
non-0 element is denoted by the slow pointer
"lastNonZeroFoundAt" variable.
```
### Attempts
**1. Initial JS unshift, push methods**
```js
// solution 1: unshift, push, O(n) for loop
// Runtime error: JS heap out of memory
for(let i = 0; i < nums.length; i++) {
if(nums[i] == 0) {
nums.unshift();
nums.push(0);
}
}
```
**2. Next pseudo-code idea process with two pointers**
- move all the zeroes to the front.
- reverse the entire array. `[0, 0, 0..]` would go to the end of array.
- reverse `non-zero partial array` only. `[12, 10, 3, 1] to [1, 3, 10, 12]`
- (I was maybe caught up with reverse/rotate idea because I just finished that quiz right before this lol)
- I realized that `[1, 2, 3, 0, 0, 4, 5]` this test case still wouldn't work with the current idea.
**3. Better idea process with two pointers**
- Putting the zeroes to the front, and then reverse blah blah, which already seems complicated than it should be.
- I thought there should be a way to simplify this.
- I tried to use **two pointers to swap non-zero and zero to move the zeroes to the latter index**, not to the front.
### Codes
**Final Pseudo code**
1. lower, upper pointers: start from index 0, 1
2. compare nums[lower] and nums[upper]
3. if nums[lower] is 0, nums[upper] is non-zero, we swap and put non-zero to the front. Then, we increase both pointers by 1: lower++, upper++
4. if nums[lower] and nums[upper] are both 0, we don't swap. We only increase upper+1 to find next non-zero.
5. if nums[lower] and nums[upper] are both non-zero, we need to find next zero & non-zero combinations. So we increase both pointers by 1: lower++, upper++
- At first, I missed the #5 point, so it returned time limit exceeded error.
**Final code**
```js
let lower = 0;
let upper = lower + 1;
while(upper < nums.length) {
if(nums[lower] == 0 && nums[upper] == 0) {
// increment p2 only to find non-zero element
upper++;
} else {
if(nums[lower] == 0 && nums[upper] != 0) {
// swap non-zero and zero
let non_zero = nums[upper];
nums[upper] = 0;
nums[lower] = non_zero;
}
// increment both pointers
// when one or both are non-zero
lower++;
upper++;
}
}
```
**Solution 2 of editorial post**
```c++
void moveZeroes(vector<int>& nums) {
int lastNonZeroFoundAt = 0;
// If the current element is not 0, then we need to
// append it just in front of last non 0 element we found.
for (int i = 0; i < nums.size(); i++) {
if (nums[i] != 0) {
nums[lastNonZeroFoundAt++] = nums[i];
}
}
// After we have finished processing new elements,
// all the non-zero elements are already at beginning of array.
// We just need to fill remaining array with 0's.
for (int i = lastNonZeroFoundAt; i < nums.size(); i++) {
nums[i] = 0;
}
}
```
### Relevant problems or quizzes
- [27. Remove Element](https://leetcode.com/problems/remove-element/description/)
- [2460. Apply Operations to an Array](https://leetcode.com/problems/apply-operations-to-an-array/description/)
| sosunnyproject | |
1,431,555 | How to Fix NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM Error | The NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error in Chrome is a seldom issue website visitors, and... | 0 | 2023-04-10T12:45:01 | https://dev.to/me_jessicahowe/how-to-fix-net-errcertweaksignaturealgorithm-error-27ln | ssl, cybersecurity, encryption | The NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error in Chrome is a seldom issue website visitors, and owners don’t want to come across. The error pops up when the website’s TLS/SSL certificate has an outdated signature algorithm. Note that the certificate is not at fault and has no issue with its installation. In this error, there is an issue with the signature algorithm cipher suite. The purpose of the signature algorithm is to facilitate the encryption function to secure the connection between the client and server.
Fixing this issue is important for website visitors to have a smooth browsing experience and get the information they need. For a website owner, fixing this issue is even more important as by not doing so, they will lose confidence in the website and lose potential customers. There are two ways to fix NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error in Google Chrome. The same method applies to other browsers as well, but this article will focus on fixing this error in Google Chrome only.
What is NET:: ERR_CERT_WEAK_SIGNATURE_ALGORITHM Error in Chrome?
The NET:: ERR_CERT_WEAK_SIGNATURE_ALGORITHM error means there’s an anomaly in the SSL/TLS certificate’s hashing algorithm. SSL certificates use cryptographic signatures to secure communication between the client and server. For this purpose, the SSL/TLS certificates are secured with different hashing algorithms, including SHA-1, SHA-2, SHA-256, etc.
The [NET:: ERR_CERT_WEAK_SIGNATURE_ALGORITHM](https://cheapsslweb.com/blog/how-to-fix-net-err-cert-weak-signature-algorithm-error) issue pops up because the certificate is encrypted with the SHA-1 hashing standard. Browsers like Google Chrome show this error because the SHA-1 hashing algorithm can be easily hacked. Hence, Google Chrome warns the website visitors with a warning message. Due to the lack of effective cryptographic measures, website visitors are prone to packet sniffing and man-in-the-middle attacks.
So, whenever a website visitor comes across this error, it is important that they should not bypass the security warning and access the website nonetheless. The SHA-1 hashing algorithm has been rendered insecure by Google since 2017. This hashing algorithm has a 160-bit signature key and poses several security threats. Google started phasing out the SHA-1 hashing algorithm standard in 2014. It has been 8 years since this hashing algorithm became ineffective, and the websites still use this algorithm are not complying with the latest security standards.
Quick Steps to Fix NET:: ERR_CERT_WEAK_SIGNATURE_ALGORITHM on Google Chrome (For Website Users)
To fix NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error in Google Chrome, website visitors and owners can use different methods. Depending on who is fixing the problem, the correction methods are different.
## 1. As a Website Owner
Website owners need to work diligently on fixing the issue, and that too quickly. Not doing so will result in lower footfall on the website. There can be two causes for this error;
## An incorrect web server configuration
## Outdated signature on SSL certificate
Out of the two, outdated SSL certificates are the most prevalent issue. In consequence, the most common resolution is to get a new SSL certificate that has the latest SHA algorithm standard. At the time of reissuing the certificate, make sure to get one with SHA-2 or SHA-256 encryption hashing standard. This is going to make the certificate highly secure and deter any type of attack.
In case, getting a new certificate is more cost-efficient than reissuing the same old certificate. So, ensure that you explore both options before switching. The additional charges can come in the form of updating the SHA algorithm. But not all certificate providers will charge you extra.
As soon as you install the new SSL certificate, the issue will be resolved. However, at times the same issue can reprise, even after getting a new certificate. In that case, you can try the following options;
Check the computer’s date and time and set it in accordance with the current time and date.
For systems running on Ubuntu, type “sudo apt-get install libnss3-1d.”
At times, too many extensions on Google Chrome can also cause the NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error.
It must be noted that this is not a common error. If your website is being flagged with this error, start the resolution process immediately. However, at times, the issue can be on the user’s end and not from your end. In that case, you need to educate your users to follow the resolution steps from their end. Find out the things users can try to resolve the issue in the next section.
## 2. As a Website Visitor
For a website visitor, coming across this issue may not be a big deal; that is when they have other options to get the same information or service from another provider. However, at times, when the users need the service from the website they are trying to access, they can follow the following methods to resolve the issue.
## Time and Date Adjustment
Incorrect time and date is a common and unforeseen errors that can cause hindrance in your browsing activities. At times, we may not even notice that the time and date on our system is incorrect. As a result of this anomaly, Google Chrome will show the error. To correct the time, go to the Control Panel in the system and adjust the date and time by selecting the right timezone.
## Updating the Google Chrome Browser
Running an older version of the Google Chrome Browser can become a cause for several issues, including the NET ERR_CERT_WEAK_SIGNATURE_ALGORITHM error. To fix this issue, update the Google Chrome browser. On the Google Chrome browser, if it needs an update, you will get a notification and will see a symbol on the top right corner of the browser.
Update the browser and run it again. It should resolve the issue if an older version of the browser is the cause. If not, try implementing the next solution.
## Correcting the Network Settings
An error or anomaly in the network settings can also be the reason for this issue. To fix it, you can correct or reset the network settings. The best response here is to set the network settings to its default values. If you try to edit the settings according to your wishes and take the trial and error approach, it won’t be easier to get the results. So, resetting them to default settings is ideal.
On your system, open command prompt and hit Ctrl+Shift+Enter. This will open the administrator window, and here, enter the following commands;
`netsh int ip reset c:\resetlog.txt
ipconfig /flushdns
ipconfig /registerdns
ipconfig /release
ipconfig /renew`
After this, restart the computer and open the same website on Google Chrome to check whether the issue has been resolved.
## Clear the SSL Cache
In order to give the users a seamless user experience, web browsers save some information to increase the user’s browsing speed. As a result, the SSL cache saves the information but without compromising on the user’s security. The best option here is to clear the SSL cache. Follow the steps below for the same;
- Open Command Prompt on your system.
- Type inetcpl.cpl and hit enter.
- From the dialog box that opens, click on Clear SSL State.
- Wait for a second, and then press OK.
After doing this, relaunch the Google Chrome browser. In addition to clearing the SSL Cache, you can also clear the browser data. However, clearing the data here can also wipe off the saved passwords and other information. So, make sure to note down the passwords in another place before taking this step. | me_jessicahowe |
1,431,710 | Integrating Audio/Video calls into your application — Twilio, Agora, Zoom, LiveKit | https://www.inconceptlabs.com/blog/integrating-audio-video-calls-into-your-application-twilio-agora-z... | 0 | 2023-04-10T15:27:47 | https://dev.to/sophiad66476195/integrating-audiovideo-calls-into-your-application-twilio-agora-zoom-livekit-270p | ios | https://www.inconceptlabs.com/blog/integrating-audio-video-calls-into-your-application-twilio-agora-zoom-livekit
Experience-based comparison of leading audio and video call conferencing providers based on integration complexity, time, and pricing.
Here I would like to share our experience integrating audio/video calls into LiveBoard, an all-in-one online tutoring platform. LiveBoard is an excellent example of audio-video integration and real-time communication application since it has mobile and web applications and requires 1-on-1 and group video conferencing calls with audio/video recording.
Before going into the full details, let’s describe our journey, and I will share every problem we have faced with integrations. I hope this article will help other founders to avoid the mistakes we have made.
Understanding main requirements and concepts
Before comparing different providers, let’s understand the main requirements and learn some key concepts.
API/SDK availability and integration complexity — first of all, we should understand if there is an SDK for WEB, iOS, and Android platforms and the ease of integration.
UI flexibility is another Key requirement since some providers may give you UI components that are not designed to be customized, and there is no way to embed them into your application UI smoothly.
Recording — audio/video call recording on the server and accessing them via the API. Some providers claim they have a recording, but it seems you need to record it on the client side, and in case the browser is closed or crashed, the recording will be lost.
Pricing is the most critical requirement in this industry since the price calculation could be very surprising for newbies.
It is also important to mention that our goal was to have a deep integration when users interact inside LiveBoard only. Many applications choose the easy path by generating Zoom links and opening Zoom on another tab or placing the Zoom app inside an iFrame, in both cases losing control and user experience. | sophiad66476195 |
1,431,726 | The importance of version control and how to use Git for your projects | What Is Version Control Version control is an essential aspect of software development. It... | 0 | 2023-04-10T15:54:38 | https://dev.to/armanidrisi/the-importance-of-version-control-and-how-to-use-git-for-your-projects-4913 | ## What Is Version Control
Version control is an essential aspect of software development. It allows developers to keep track of changes made to code over time, collaborate with team members on projects, and easily revert back to previous versions if necessary. In this article, we will explore the importance of version control and how to use Git, one of the most popular version control systems, for your projects.
## Why Is Version Control Important?
Version control helps developers maintain a history of changes made to code. This is important because it allows developers to track down bugs and understand how and when changes were made to the code. It also enables developers to work collaboratively on a project by allowing multiple people to work on the same codebase simultaneously.
Another significant advantage of version control is the ability to easily revert back to a previous version of code. This can be helpful in case of a bug or error introduced in a recent change or if you need to return to an earlier version of the code for any reason. Without version control, it would be difficult to roll back to a previous version of the code without manually undoing all of the changes made in subsequent versions.
## How to Use Git for Your Projects
Git is a popular version control system that allows developers to easily track changes made to code over time. Here are the steps to getting started with Git for your projects:
- **Install Git:** The first step is to install Git on your local machine. You can download Git from the official website and follow the installation instructions.
- **Create a Git Repository:** Once Git is installed, the next step is to create a Git repository for your project. You can do this by navigating to the project directory on your local machine and running the following command in the terminal:
```bash
git init
```
This will initialize a new Git repository in the current directory.
- **Add Files to the Repository:** The next step is to add the files in your project to the Git repository. You can do this by running the following command:
```bash
git add .
```
This will add all of the files in the current directory to the Git repository.
- **Commit Changes:** After adding files to the Git repository, the next step is to commit changes. This is done by running the following command:
```bash
git commit -m "Commit message"
```
The commit message should be a brief description of the changes made in this commit.
- **Push Changes to Remote Repository:** Finally, you can push your changes to a remote repository, such as GitHub or GitLab. This is done by running the following command:
```bash
git push origin <branch name>
```
This will push the changes made to the local repository to the remote repository.
## Conclusion
Version control is an essential tool for software development, and Git is one of the most popular version control systems used by developers today. It allows developers to keep track of changes made to code over time, collaborate with team members on projects, and easily revert back to previous versions if necessary. By following the steps outlined in this article, you can get started with Git and begin using version control for your projects.
| armanidrisi | |
1,431,765 | Create a Lambda function and upload code using Ansible | [99/100] #100DaysOfCloud Today, I created a Lambda function and uploaded code of Arithmetic... | 21,219 | 2023-04-10T16:56:50 | https://dev.to/aaditunni/create-a-lambda-function-and-upload-code-using-ansible-5g4i | aws, cloud, awscommunity, 100daysofcloud | [99/100] #100DaysOfCloud Today, I created a Lambda function and uploaded code of Arithmetic Operations using Ansible.
Ansible is an open-source automation tool that uses playbooks to enable you to make deployments faster and scale to various environments. Think of playbooks as recipes that lay out the steps needed to deploy policies, applications, configurations, and IT infrastructure. You can use playbooks repeatedly across multiple environments. Customers who use Ansible playbooks typically deploy periodic changes manually. As complex workloads increase, you might be looking for ways to automate them
You can try do it by yourself by following the steps from the link below: [GitHub](https://github.com/aaditunni/100DaysOfCloud/blob/main/Journey/099/Readme.md) | aaditunni |
1,431,807 | How to create a scroll to top btn in react js | Output install one package react icons npm i react-icons Enter fullscreen... | 22,574 | 2023-04-10T17:52:51 | https://democoding.netlify.app/post/how-to-create-a-scroll-to-top-button-in-react | react, javascript, webdev, programming |
### Output

---
install one package react icons
```bash
npm i react-icons
```
### ScrollToTop.js Code
```js
import React, { useEffect, useState } from "react";
import { FaAngleUp } from "react-icons/fa";
import "./ScrollToTop.css";
const ScrollToTop = () => {
const [showTopBtn, setShowTopBtn] = useState(false);
useEffect(() => {
window.addEventListener("scroll", () => {
if (window.scrollY > 400) {
setShowTopBtn(true);
} else {
setShowTopBtn(false);
}
});
}, []);
const goToTop = () => {
window.scrollTo({
top: 0,
behavior: "smooth",
});
};
return (
<>
<div className="top-to-btn">
{" "}
{showTopBtn && (
<FaAngleUp className="icon-position icon-style" onClick={goToTop} />
)}{" "}
</div>
</>
);
};
export default ScrollToTop;
```
### ScrollToTop.css Code
```css
.top-to-btn{
position: relative;
}
.icon-position{
position: fixed;
bottom: 40px;
right: 25px;
z-index: 20;
}
.icon-style{
background-color: #551B54;
border: 2px solid #fff;
border-radius: 50%;
height: 50px;
width: 50px;
color: #fff;
cursor: pointer;
animation: movebtn 3s ease-in-out infinite;
transition: all .5s ease-in-out;
}
.icon-style:hover{
animation: none;
background: #fff;
color: #551B54;
border: 2px solid #551B54;
}
@keyframes movebtn {
0%{
transform: translateY(0px);
}
25%{
transform: translateY(20px);
}
50%{
transform: translateY(0px);
}
75%{
transform: translateY(-20px);
}
100%{
transform: translateY(0px);
}
}
.modal {
font-size: 12px;
}
.modal > .header {
width: 100%;
border-bottom: 1px solid gray;
font-size: 18px;
text-align: center;
padding: 5px;
}
.modal > .content {
width: 100%;
padding: 10px 5px;
}
.modal > .actions {
width: 100%;
padding: 10px 5px;
margin: auto;
text-align: center;
}
.modal > .close {
cursor: pointer;
position: absolute;
display: block;
padding: 2px 5px;
line-height: 20px;
right: -10px;
top: -10px;
font-size: 24px;
background: #ffffff;
border-radius: 18px;
border: 1px solid #cfcece;
}
```
### Originally published
[https://democoding.netlify.app/post/how-to-create-a-scroll-to-top-button-in-react](https://democoding.netlify.app/post/how-to-create-a-scroll-to-top-button-in-react)
---
---
## For more information
1. Subscribe my Youtube Channel
[https://www.youtube.com/@democode](https://www.youtube.com/@democode)
2. Check out my Fiver profile if you need any freelancing work
[https://www.fiverr.com/amit_sharma77](https://www.fiverr.com/amit_sharma77)
3. Follow me on Instagram
[https://www.instagram.com/fromgoodthings/](https://www.instagram.com/fromgoodthings/)
4. Check out my Facebook Page
[Programming memes by Coder](https://www.facebook.com/programmingmemesbycoders)
5. Linktree
[https://linktr.ee/jonSnow77](https://linktr.ee/jonSnow77)
---
---
{% instagram CqObFa6PR0l %}
---
{% link https://dev.to/jon_snow789/21-programming-memes-refresh-your-mind-1fa0 %}
---
---
### If you want to support us, we don't want any payment from you, just do one thing
### Subscribe our [youtube Channel](https://www.youtube.com/@democode)
---
| jon_snow789 |
1,432,057 | How to Bypass PerimeterX when Web Scraping in 2023 | PerimeterX is one of the most popular anti-bot services on the market offering a wide range of... | 0 | 2023-04-10T21:21:56 | https://scrapfly.io/blog/how-to-bypass-perimeterx-human-anti-scraping/ | scraperblocking | ---
title: How to Bypass PerimeterX when Web Scraping in 2023
published: true
date: 2023-03-10 07:36:21 UTC
tags: ScraperBlocking
canonical_url: https://scrapfly.io/blog/how-to-bypass-perimeterx-human-anti-scraping/
---


PerimeterX is one of the most popular anti-bot services on the market offering a wide range of protection against bots and scrapers. PerimeterX products Bot Defender, Page Defender and API Defender are all used to block web scrapers.
In this article, we'll take a look at how to bypass PerimeterX bot protection. We'll do this by taking a quick look at how it detects scrapers and how to modify our scraper code to prevent being detected by PerimeterX.
We'll also cover common PerimeterX errors and signs that indicate that requests have failed to bypass PerimeterX and their meaning. Let's dive in!
<aside></aside>
## What is PerimeterX?
PerimeterX (aka Human) is a web service that protects websites, apps and APIs from automation such as scrapers. It uses a combination of web technologies and behavior analysis to determine whether the user is a human or a bot.
It is used by popular websites like [Zillow.com](https://scrapfly.io/blog/how-to-scrape-zillow/#scraping-properties), fiverr.com, and many others so by understanding PerimeterX bypass we can open up web scraping of many popular websites.
Next, let's take a look at some popular PerimeterX errors.
## Popular PerimeterX Errors
Most of the PerimeterX bot block result in HTTP status codes 400-500, most commonly error 403. The body of the response contains a request to "enable javascript" or "Press and hold" button.

_PerimeterX block page on fiverr.com_
This error is mostly encountered on the first request to the website though since PerimeterX is using behavior analysis it can also be encountered at any point during web scraping.
Let's take a look at how exactly PerimeterX is detecting web scrapers and bots and how the "Press and hold" button works.
## How Does PerimeterX Detect Web Scrapers?
To detect web scraping, PerimeterX uses many different technologies to estimate whether the traffic is coming from a human user or a bot.

PerimeterX uses a combination of fingerprinting and connection analysis to calculate a **trust score** for each client. This score determines whether the user can access the website or not.
Based on the final trust score, the user is either allowed to access the website or blocked with a PerimeterX block page which can further be bypassed by solving javascript challenges (i.e. the "press and hold" button).

This complex process makes web scraping difficult as there are many factors at play here. However, if we take a look at each individual factor we can see that bypassing PerimeterX is very much possible!
### TLS Fingerprinting
<abbr title="Transport Layer Security">TLS</abbr> (or SSL) is the first step in HTTP connection establishment. It is used to encrypt the data that is being sent between the client and the server. Note that TLS is only applicable to `https` endpoints (not `http`).
First, the client and the server negotiate how encryption is done and this is where TLS fingerprinting comes into play. Different computers, programs and even programming libraries have different TLS capabilities.
So, if a scraper uses a library with different TLS capabilities compared to a regular web browser it can be identified quite easily. This is generally referred to as **JA3 fingerprint**.
For example, some libraries and tools used in web scraping, have unique TLS negotiation patterns that can be instantly recognized. While some use the same TLS techniques as a web browser and can be very difficult to differentiate.
To validate your tools see ScrapFly's [JA3 fingerprint web tool](https://scrapfly.io/web-scraping-tools/ja3-fingerprint) that can tell you your exact JA3 fingerprint.
So, **use web scraping libraries and tools that are resistant to JA3 fingerprinting**.
For more see [our full introduction to TLS fingerprinting](https://scrapfly.io/blog/how-to-avoid-web-scraping-blocking-tls/) which covers TLS fingerprinting in greater detail.
### IP Address Fingerprinting
The next step is IP address analysis. Since IP addresses come in many different shapes and sizes there's a lot of information that can be used to determine whether the client is a human or a bot.
To start, there are different types of IP addresses:
- **Residential** are home addresses assigned by internet providers to average people. So, residential IP addresses provide a **positive trust score** as these are mostly used by humans and are expensive to acquire.
- **Mobile** addresses are assigned by mobile phone towers and mobile users. So, mobile IPs also provide a **positive trust score** as these are mostly used by humans. In addition, since mobile towers might share and recycle IP addresses it makes it much more difficult to rely on IP addresses for bot identification.
- **Datacenter** addresses are assigned to various data centers and server platforms like Amazon's AWS, Google Cloud etc. So, datacenter IPs provide a significant **negative trust score** as they are likely to be used by bots.
Using IP analysis PerimeterX can have an estimate of how likely the connecting client is a human. To start, most people browser from residential IPs while most mobile IPs are used for mobile traffic.
So, **use high-quality residential or mobile proxies**.
For a more in-depth look, see [our full introduction to IP blocking](https://scrapfly.io/blog/how-to-avoid-web-scraping-blocking-tls/).
### HTTP Details
The next step is the HTTP connection itself. This includes HTTP connection details like:
- Protocol Version
Most of the web is using HTTP2 and many web scraping tools still use HTTP1.1 which is a dead giveaway. Many newer HTTP client libraries like [httpx](https://pypi.org/project/httpx/) or cURL support HTTP2 though not by default.
HTTP2 can also be succeptible to fingerprinting so check ScrapFly's [http2 fingerprint test page](https://scrapfly.io/web-scraping-tools/http2-fingerprint) for more info.
- Headers
Pay attention to `X-` prefixed headers and the usual suspects like `User-Agent`, `Origin`, `Referer` can be used to identify web scrapers.
- Header Order
Web browsers have a specific way of ordering request headers. So, if the headers are not ordered in the same way as a web browser it can be a critical giveaway. To add, some HTTP libraries (like `requests` in Python) do not respect the header order and can be easily identified.
So, **make sure the headers in web scraper requests match a real web browser, including the ordering**.
For more see [our full introduction to request headers role in blocking](https://scrapfly.io/blog/how-to-avoid-web-scraping-blocking-headers/)
### Javascript Fingerprinting
Finally, the most powerful tool in PerimeterX's arsenal is javascript fingerprinting.
Since the server can execute arbitrary Javascript code on the client's machine it can extract a lot of information about the connecting user, like:
- Javascript runtime details
- Hardware details and capabilities
- Operating system details
- Web browser details
That's loads of data that can be used in calculating the trust score.
Fortunately, javascript takes time to execute and is prone to false positives. This limits the practical Javascript fingerprinting application. In other words, not many users can wait 3 seconds for the page to load or tolerate false positives.
For a really in-depth look see our article on [javacript use in web scraper detection](https://scrapfly.io/blog/how-to-avoid-web-scraping-blocking-javascript/).
Bypassing javascript fingerprinting is the most difficult task here. In theory, it's possible to reverse engineer and simulate all of the javascript tasks PerimeterX is performing and feed it fake results though it's not practical.
A more practical approach is to [use a real web browser for web scraping](https://scrapfly.io/blog/scraping-using-browsers/).
This can be done using browser automation libraries like [Selenium](https://scrapfly.io/blog/web-scraping-with-selenium-and-python/), [Puppeteer](https://scrapfly.io/blog/web-scraping-with-puppeteer-and-nodejs/) or [Playwright](https://scrapfly.io/blog/web-scraping-with-playwright-and-python/) that can start a real <abbr title="without GUI, running in the background">headless</abbr> browser and navigate it for web scraping.
So, **introducing browser automation to your scraping pipeline can drastically raise the trust score**.
Tip: many advanced scraping tools can even combine browser and HTTP scraping capabilities for optimal performance. Using resource-heavy browsers to establish a trust score and continue scraping using fast HTTP clients like [httpx in Python](https://pypi.org/project/httpx/) (this feature is [also available using Scrapfly sessions](https://scrapfly.io/docs/scrape-api/session))
### Behavior Analysis
Even when scrapers' initial connection is indistinguishable from a real web browser, PerimeterX can still detect them through behavior analysis.
This is done by monitoring the connection and analyzing the behavior of the client. This includes:
- Pages that are being visited. People browse in more chaotic patterns.
- Connection speed and rate. People are slower and more random than bots.
- Loading of resources like images, scripts, stylesheets etc.
The trust score is not a constant number and will be constantly adjusted.
So, it's important to **distribute web scraper traffic through multiple agents** using proxies and different fingerprint configurations to prevent behavior analysis.
For example, if browser automation tools are used different browser configurations should be used for each agent like screen size, operating system, web browser version, IP address etc.
## How to Bypass PerimeterX (aka Human) Bot Protection?
Now that we're familiar with all of the ways PerimeterX can detect web scrapers, let's see how to bypass it.
In reality, we have two very different options:
We could **reverse engineer and foritify** against all of these techniques but PerimeterX is constantly updating their detection methods and it's a never-ending game of cat and mouse.
Alternatively, we can **use real web browsers** for scraping. This is the most practical and effective approach as it's much easier to ensure that the headless browser looks like a real one than to re-invent it.
However, many browser automation tools like [Selenium](https://scrapfly.io/blog/web-scraping-with-selenium-and-python/), [Playwright](https://scrapfly.io/blog/web-scraping-with-playwright-and-python/) and [Puppeteer](https://scrapfly.io/blog/web-scraping-with-puppeteer-and-nodejs/) leave data about their existence which need to be patched to achieve high trust scores. For that, see projects like [Puppeteer stealth plugin](https://github.com/berstend/puppeteer-extra/) and other similar stealth extensions that patch known leaks.
For sustained web scraping with PerimeterX bypass in 2023, these browsers should always be remixed with different fingerprint profiles: screen resolution, operating system, browser type all play an important role in PerimeterX's bot score.
## Bypass with ScrapFly
While bypassing PerimeterX is possible, maintaining bypass strategies can be very time-consuming. This is where services like ScrapFly come in!

Using ScrapFly web scraping API we can hand over all of the web scraping complexity and bypass logic to an API!
Scrapfly is not only a PerimeterX bypasser but also offers many other web scraping features:
- Millions of [residential proxies from over 50+ countries](https://scrapfly.io/docs/scrape-api/proxy)
- PerimeterX and any other [anti-scraping protection bypass](https://scrapfly.io/docs/scrape-api/anti-scraping-protection)
- [Headless cloud browsers](https://scrapfly.io/docs/scrape-api/javascript-rendering) that can render javascript pages and automate browser tasks
- [Python SDK](https://scrapfly.io/docs/sdk/python)
- Easy [monitoring and debugging tools](https://scrapfly.io/docs/monitoring)
For example, to scrape pages protected by PerimeterX or any other anti scraping service, when using [ScrapFly SDK](https://scrapfly.io/docs/sdk/python) all we need to do is enable the [Anti Scraping Protection bypass](https://scrapfly.io/docs/scrape-api/anti-scraping-protection) feature:
```
from scrapfly import ScrapflyClient, ScrapeConfig
scrapfly = ScrapflyClient(key="YOUR API KEY")
result = scrapfly.scrape(ScrapeConfig(
url="https://fiverr.com/",
asp=True,
# we can also enable headless browsers to render web apps and javascript powered pages
render_js=True,
# and set proxies by country like Japan
country="JP",
# and proxy type like residential:
proxy_pool="residential_proxy_pool",
))
print(result.scrape_result)
```
## FAQ
To wrap this article let's take a look at some frequently asked questions regarding web scraping PerimeterX pages:
#### Is it legal to scrape PerimeterX protected pages?
Yes. Web scraping publicly available data is perfectly legal around the world as long as the scrapers do not cause damage to the website.
#### Is it possible to bypass PerimeterX using cache services?
Yes, public page caching services like Google Cache or Archive.org can be used to bypass PerimeterX protected pages as Google and Archive is tend to be whitelisted. However, since caching takes time the cached page data is often outdated and not suitable for web scraping. Cached pages can also be missing parts of content that are loaded dynamically.
#### Is it possible to bypass PerimeterX entirely and scrape the website directly?
No. PerimeterX integrates directly with the server software and is very difficult to reach the server without going through it. It is possible that some servers could have PerimeterX misconfigured but it's very unlikely.
#### What are some other anti-bot services?
There are many other anti-bot <abbr title="Web Application Firewall">WAF</abbr> services like [Cloudflare](https://scrapfly.io/blog/how-to-bypass-cloudflare-anti-scraping/), [Akamai](https://scrapfly.io/blog/how-to-bypass-akamai-anti-scraping/), [Datadome](https://scrapfly.io/blog/how-to-bypass-datadome-anti-scraping/) and [Imperva (aka Incapsula)](https://scrapfly.io/blog/how-to-bypass-imperva-incapsula-anti-scraping/) though they function very similarly to PerimeterX so everything in this tutorial can be applied to them as well.
## Summary
In this article, we took a deep dive into PerimeterX anti-bot systems when web scraping.
To start, we've taken a look at how Perimeter X identifies web scrapers through TLS, IP and javascript client fingerprint analysis. We saw that using residential proxies and fingerprint-resistant libraries is a good start. Further, using real web browsers and remixing their fingerprint data can make web scrapers much more difficult to detect.
Finally, we've taken a look at some frequently asked questions like alternative bypass methods and the legality of it all.
For an easier way to handle web scraper blocking and power up your web scrapers check out ScrapFly for free!
<!--kg-card-end: markdown--><!--kg-card-begin: html--><script type="application/ld+json">{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Is it legal to scrape PerimeterX protected pages?",
"acceptedAnswer": {
"@type": "Answer",
"text": "<p>Yes. Web scraping publicly available data is perfectly legal around the world as long as the scrapers do not cause damage to the website.</p>"
}
},
{
"@type": "Question",
"name": "Is it possible to bypass PerimeterX using cache services?",
"acceptedAnswer": {
"@type": "Answer",
"text": "<p>Yes, public page caching services like Google Cache or Archive.org can be used to bypass PerimeterX protected pages as Google and Archive is tend to be whitelisted. However, since caching takes time the cached page data is often outdated and not suitable for web scraping. Cached pages can also be missing parts of content that are loaded dynamically.</p>"
}
},
{
"@type": "Question",
"name": "Is it possible to bypass PerimeterX entirely and scrape the website directly?",
"acceptedAnswer": {
"@type": "Answer",
"text": "<p>No. PerimeterX integrates directly with the server software and is very difficult to reach the server without going through it. It is possible that some servers could have PerimeterX misconfigured but it's very unlikely.</p>"
}
},
{
"@type": "Question",
"name": "What are some other anti-bot services?",
"acceptedAnswer": {
"@type": "Answer",
"text": "<p>There are many other anti-bot <abbr title=\"Web Application Firewall\">WAF</abbr> services like <a class=\"text-reference\" href=\"https://scrapfly.io/blog/how-to-bypass-cloudflare-anti-scraping/\">Cloudflare</a>, <a class=\"text-reference\" href=\"https://scrapfly.io/blog/how-to-bypass-akamai-anti-scraping/\">Akamai</a>, <a class=\"text-reference\" href=\"https://scrapfly.io/blog/how-to-bypass-datadome-anti-scraping/\">Datadome</a> and <a class=\"text-reference\" href=\"https://scrapfly.io/blog/how-to-bypass-imperva-incapsula-anti-scraping/\">Imperva (aka Incapsula)</a> though they function very similarly to PerimeterX so everything in this tutorial can be applied to them as well.</p>"
}
}
]
}</script><!--kg-card-end: html--> | scrapfly_dev |
1,432,096 | Parsing IRCv3 with Regex | This article was originally posted on Patreon and has been brought over here to get all of the... | 0 | 2023-04-19T14:00:00 | https://dev.to/grim/parsing-ircv3-with-regex-1kcb | ircv3, modernization, pidgin3, repost | > This article was originally posted on [Patreon](https://www.patreon.com/posts/parsing-ircv3-75211141) and has been brought over here to get all of the Pidgin Development/History posts into one single place.
To develop the modern chat features that everyone is expecting in Pidgin 3 we need to have protocols that support them as well. Unfortunately most of in-tree protocols either don't support these features or have so much tech debt that adding these features is a non-trivial amount of work.
Please note that any copyrighted code in this post is licensed by me, Gary Kramlich <grim@reaperworld.com>, under the [MIT License](https://opensource.org/licenses/MIT).
To combat these problems, we decided to write a brand new, from scratch, protocol plugin for [IRCv3](https://ircv3.net/). One of the biggest benefits of this decision is that this protocol plugin is the first one in our history to ever be coded reviewed from the very beginning. This has meant slightly slower development, but we're accumulating much less tech debt which is a huge win.
One of the big issues with the existing IRC protocol plugin is that it uses [Lexical Analysis](https://en.wikipedia.org/wiki/Lexical_analysis) to parse the IRC lines and work with them. While this works and is a common solution to this problem, it ends up being very difficult to understand when looking at the code at a later date, especially if the code is not commented well. To tackle this problem, we've chosen to use regular expressions. Cue [XKCD 1171](https://xkcd.com/1171/) and others.
Awhile back, I wrote a proof of concept protocol plugin for [Twitch](https://keep.imfreedom.org/grim/purple-spasm/) which is where I first started playing with regular expressions for parsing IRC. After testing this on some very fast Twitch channels, it became evident that the regular expressions could keep up and were a viable way forward.
There's many reasons I prefer regular expressions over a blob of code doing lexical analysis. First of all, regular expressions are reusable in any other language. Which means you can write and test them once then use them many times. Second, well written regular expressions are much easier to read than hundreds of lines of code. Finally, it's easier to adjust a regular expression for changes to the format in a backwards compatible way than the hundreds of lines of code as well. Giving examples of this reasoning is out of scope for this post, but if there is interest I suppose I could go into more detail in another post.
With all of that out of the way, lets get to the fun stuff! To make this happen, we use a number of regular expressions to accomplish our task. If we tried to do this with a single regular expression, it would be impossible to read and maintain.
IRCv3 passes `lines`, that is a string of text that ends in a `\r\n`. What this means is we used a buffered input stream to read a line and then we run that line through our first regular expression.
The first regular expression's job is to split the IRC message into the expected fields of tags, source, command, middle, coda, and trailing. We don't really use the coda, but it may be useful for some. These names are all from the ABNF in the [protocol documentation](https://modern.ircdocs.horse/#message-format). We'll explain how this is used in just a bit. *New lines have been added for readability only.*
```
(?:@(?<tags>[^ ]+) )?
(?::(?<source>[^ ]+) +)?
(?<command>[^ :]+)
(?: +(?<middle>(?:[^ :]+(?: +[^ :]+)*)))*
(?<coda> +:(?<trailing>.*)?)?
```
Once we have all of these tokens, we want to parse the `tags` token and turn it into something usable. To do that we pass the value of the `tags` named group into the following regular expression that will match multiple times.
```regex
(?:(?<key>[A-Za-z0-9-\\/]+)(?:=(?<value>[^\\r\\n;]*))?(?:;|$))
```
We then create a hash map to contain all these values as we parse them.
Now that we have the base message and the tags parsed we can discuss what to do will all of this data. The middle, code, and trailing tokens can be quite confusing at first, but it's not too bad once you get the hang of it. As I mentioned earlier, we're not using the **coda** token, so we'll be ignoring it here.
When it comes to `middle` and `trailing`, the important thing to remember is that `middle` is a space separated list of parameters and `trailing` on the other hand is a single string that can contain spaces. To put this in perspective, think of the `command` token as a function name, `middle` as a list of parameters, and `trailing` as the final parameter. Something like the following pseudo code:
```c
args = middle.split(" ")
args.append(trailing)
command(args)
```
Say we have a command of `PRIVMSG`, middle of `#pidgin`, and trailing of `Hiya! How's it going?` If we use these values to fill in the pseudo code we'd get something like the following:
```c
args = "#pidgin".split(" ")
args.append("Hiya! How's it going?")
privmsg(args)
```
We use an array because we have no idea what kind of argument each `command` requires. We could try to codify this, but that depends a lot on the programming language that you're implementing this in.
In Pidgin, which is written in C, we can't really get too fancy, so we create a hash map of functions that's keyed on the command name. We check for command in the hash table, if it's found, we pass our array of arguments, and if not, we call our fallback handler which typically just logs what we failed to parse so we can find it and fix it later.
This architect allows us to keep the parser very simple and leave all of the implementation details up to the command as we're implementing them. For example, the `PING` command may come in with 0 or 1 parameters. If a parameter is specified, we're expected to send it back. So the pseudo code for that is basically
```c
func ping(tags, source, command, params) {
if(params.length() == 1) {
send("PONG %s", params[0])
} else {
send("PONG")
}
}
```
The `tags`, `source`, and `command` parameters are unused here. Remember, the parser doesn't know what each implementation needs, so it passes all of the tokens to them. The command parameter is typically used to handle commands that are functionally aliases of each other, like `PRIVMSG` and `NOTICE`. Their differences are usually a user interface implementation, but protocol wise they're exactly the same so being able to know this in the implementation allows us to set a flag noting the difference.
So that's about it for the main IRCv3 parsing, but as I mentioned, this all started with parsing Twitch's IRCv3 and that gets into some more regular expressions which will quickly cover as well.
Twitch uses IRCv3 tags extensively, but the biggest most complicated use of IRCv3 tags is for handling emotes (emojis). Emotes are a huge part of Twitch and there are a lot of them. To avoid wasting tons of CPU time on scanning short messages for millions of emotes, Twitch uses the `emotes` tag to tell the client where they are. The value of an emote tag (remember we parsed this into a hash map earlier) looks like the following:
```
301696583:0-9,25-29/1290325:51-56
```
The emotes value is defined as the `id` of the emote, followed by a `:` and then a comma separated list of ranges of the text to replace in the message. Additional emotes can be specified by separating them with a `/`.
Again, we take a multiple regular expression approach to parsing this. First, we do a match all to get each emote and all of their ranges using the following regular expression:
```
(?:(?<id>[^:/]+)):(?<ranges>[^/]+)/?
```
Now that we have the `ranges` separated, we can split them into their individual values via the following regular expression:
```
(?<start>[^-,]+)-(?<end>[^,]+),?
```
Now you have all the pieces you need to build the message for display and replace the text with the actual emote but we won't be tackling that code here as this post is all about parsing :-D.
Twitch also uses another simple format for the `badges` and `badge-info` tags. These are used to tell the client what badges the user has in the channel and information that goes with them. There's additional documentation [here](https://dev.twitch.tv/docs/irc/tags#globaluserstate-tags), but we'll look at a simple examples of badges here.
```
subscriber/0,bits-leader/2,bits/100
```
We can use the following regular expression to parse this into the id and value for each badge.
```
(?<id>[^\/]+)\/(?<value>[^,]+),?
```
Finally, the last regex we're going to cover is to help handle cheermotes on Twitch. A cheermote is displayed like a normal emote, but it also sends a monetary donation to the streamer. However, unlike a normal emote, cheermotes don't show up in a tag on the message, which means we need to manually parse them out of the message content.
To make maters more complicated, partnered streamers can have their own cheermotes. This means when you join a channel, you have to make a request to the Twitch API to get the cheermotes available on the channel and then dynamically created the regular expression. This isn't too bad, but does complicate things. To keep things simple here, we're going to assume that Twitch told us that this channel supports the `Cheer`, `RIPCheer`, and `CheerWhal` cheermotes. With that, our regular expression looks like the following
```
\b(?:(?<emote>Cheer|RIPCheer|CheerWhal)(?<amount>\d+))\b
```
If we run that against the following example message, we'll see we match the Cheer emote and it has a value of 10.
```
Hiya, it's been awhile... Cheer10!
```
That's about everything I have for now. I hope you all enjoyed this in depth look at parsing with regular expressions. I know I didn't explain how the regexes work, and well, this post is already long enough without that. If you would be interested in that, please leave a comment!! | grim |
1,432,130 | XP Educação lança curso 100% gratuito de Desenvolvimento Python com certificado incluso | A XP Educação disponibiliza um curso completo de desenvolvimento de aplicações em Python, que... | 0 | 2023-04-12T15:22:34 | https://guiadeti.com.br/xp-educacao-curso-gratuito-de-python/ | cursogratuito, backend, cursosgratuitos, dados | ---
title: XP Educação lança curso 100% gratuito de Desenvolvimento Python com certificado incluso
published: true
date: 2023-04-10 22:30:48 UTC
tags: CursoGratuito,backend,cursosgratuitos,dados
canonical_url: https://guiadeti.com.br/xp-educacao-curso-gratuito-de-python/
---

A XP Educação disponibiliza um curso completo de desenvolvimento de aplicações em [Python](https://guiadeti.com.br/guia-tags/cursos-de-python/), que abrange desde o nível básico até o avançado, de forma totalmente gratuita. Ao concluir os módulos, os participantes receberão um certificado, sendo preparados para ingressar no mercado de desenvolvimento de software. Com um modelo de ensino inovador e flexível, é possível estudar em qualquer lugar e a qualquer hora, aproveitando o melhor da tecnologia para uma formação de qualidade. O curso também oferece exemplos práticos e um Desafio Final para aplicação dos conhecimentos em projetos reais!
## Conteúdo
<nav><ul>
<li><a href="#curso-gratuito-de-desenvolvedor-python">Curso gratuito de Desenvolvedor Python</a></li>
<li><a href="#ementa">Ementa</a></li>
<li><a href="#xp-educacao">XP Educação</a></li>
<li><a href="#inscricoes">Inscrições</a></li>
<li><a href="#compartilhe">Compartilhe!</a></li>
</ul></nav>
## Curso gratuito de Desenvolvedor Python
Participe gratuitamente do curso completo de Desenvolvedor Python, que ensina desde os fundamentos até o nível avançado, proporcionando aos alunos a habilidade de criar aplicações com a linguagem de programação Python. Além disso, o curso oferece exemplos práticos, incluindo o Desafio Final, que consiste em construir e implantar um modelo de aprendizado de máquina com Python.
O curso é totalmente online, gratuito e oferece acesso permanente, incluindo um certificado de conclusão. A experiência educacional é interativa e hands-on, com foco no aluno, sendo uma excelente ferramenta para impulsionar sua carreira.
Há uma grande variedade de oportunidades de emprego para desenvolvedores Python no mercado, pois essa linguagem é amplamente utilizada em diversas áreas. Algumas das áreas em que os desenvolvedores Python podem atuar incluem: desenvolvimento [back-end](https://guiadeti.com.br/guia-tags/cursos-de-back-end/), [análise](https://guiadeti.com.br/guia-tags/cursos-de-ciencia-de-dados/) e [ciência de dados](https://guiadeti.com.br/guia-tags/cursos-de-ciencia-de-dados/), desenvolvimento de jogos, [desenvolvimento web](https://guiadeti.com.br/guia-tags/cursos-de-desenvolvimento-web/) e [frameworks](https://guiadeti.com.br/guia-tags/cursos-de-framework/), [inteligência artificial](https://guiadeti.com.br/guia-tags/cursos-de-inteligencia-artificial/) e machine learning, [internet das coisas](https://guiadeti.com.br/guia-tags/cursos-de-internet-das-coisas/), testes web e mobile, engenharia de software e estatística.
O curso é ideal para profissionais que desejam mudar ou aprimorar sua carreira, aprofundar seu conhecimento em Python, colaboradores que procuram novos desafios para crescer profissionalmente e aqueles que desejam ampliar suas possibilidades no mercado de trabalho.
## Ementa
- **Aquecimento e Regra do Jogo**
- Visão geral da dinâmica do curso, conteúdos e ferramentas utilizadas.
- **Fundamentos de Python**
- Introdução ao Python;
- Escrevendo em Python;
- Tipos de dados em Python;
- List; Tuple; Sets e Dictionary;
- Condições, Loops e Funções;
- Módulos em Python ;
- Importando pacotes e Funções básicas.
- **Python para a Análise de Dados**
- Introdução à análise de dados;
- Pandas e numpy para a análise de dados;
- Introdução ao Scikit-learn;
- Aplicações pŕaticas com python para análise de dados.
- **Python Avançado**
- Introdução à concorrência e paralelismo com Python;
- Introdução à programação reativa com Python;
- Introdução do [Aprendizado de Máquina ](https://guiadeti.com.br/guia-tags/cursos-de-machine-learning/)com Python;
- Introdução ao desenvolvimento de jogos com Python.
- **Desafio Final**
- Construir e realizar o deploy de um modelo de aprendizado de máquina com Python.
## XP Educação
A plataforma XP Educação é uma iniciativa da XP Inc., uma das maiores instituições financeiras do Brasil, para oferecer educação financeira para seus clientes e interessados em geral. A plataforma conta com uma série de cursos e conteúdos sobre diversos temas relacionados ao mercado financeiro, investimentos e planejamento financeiro.
Os cursos oferecidos na XP Educação são ministrados por profissionais renomados do mercado financeiro e abrangem desde conceitos básicos até estratégias avançadas de investimento. Além disso, a plataforma também oferece ferramentas e simuladores para ajudar os usuários a colocar em prática o que aprendem nos cursos.
Um dos diferenciais da XP Educação é que os cursos são totalmente online e podem ser acessados a qualquer hora e em qualquer lugar, o que é ideal para pessoas com rotinas corridas e que precisam de flexibilidade para estudar. Além disso, os cursos são gratuitos e abertos a todos, independentemente de serem clientes da XP ou não.
A XP Educação é uma plataforma abrangente e acessível para quem deseja aprender mais sobre finanças e investimentos, independentemente do nível de conhecimento prévio.
## Inscrições
[Inscreva-se aqui!](https://www.xpeducacao.com.br/curso-gratuito-python)
## Compartilhe!
Gostou do conteúdo sobre os cursos da XP Educação? Então não deixe de compartilhar com a galera!
O post [XP Educação lança curso 100% gratuito de Desenvolvimento Python com certificado incluso](https://guiadeti.com.br/xp-educacao-curso-gratuito-de-python/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,432,134 | sun | morning .. all study w/up to school . but how i look diffence. | 0 | 2023-04-10T23:24:02 | https://dev.to/pang_18/sun-595e | morning .. all study w/up to school . but how i look diffence. | pang_18 | |
1,432,156 | How to reallyze SonarQube code-quality scan in Meven | Maven is a popular build automation tool for Java projects, while SonarQube is a powerful platform... | 0 | 2023-04-11T00:59:43 | https://dev.to/lumensa/how-to-reallyze-prompt-scan-in-sonarqube-5f3 | java, programming, testing | Maven is a popular build automation tool for Java projects, while SonarQube is a powerful platform for continuous code quality inspection. By integrating Maven with SonarQube, developers can automatically scan code and get feedback on code quality, security, and reliability. This documentation will explain how to use Maven in SonarQube to analyze code for both local and remote server scans.
The purpose of using Maven in SonarQube to analyze code for both local and remote server scans is to ensure that code quality is maintained across all code repositories, regardless of where they are located. By integrating SonarQube into the Maven build process, developers can receive feedback on code quality and identify potential issues without having to manually analyze code.
How to use Maven in SonarQube for local and remote server scans:
The first step is to install and configure SonarQube on your system. You can download the latest version of SonarQube from their official website.
Once SonarQube is installed, you need to configure your Maven build to use it. You can do this by adding the following code to your pom.xml file:
```
<build>
<plugins>
<plugin>
<groupId>org.sonarsource.scanner.maven</groupId>
<artifactId>sonar-maven-plugin</artifactId>
<version>3.9.0.2155</version>
</plugin>
</plugins>
</build>
```
Run local scan: To analyze code for a local scan, use the sonar:sonar goal of the sonar-maven-plugin. Use the following command:
```
mvn sonar:sonar \
-Dsonar.projectKey=<your-project-key> \
-Dsonar.host.url=http://localhost:9000 \
-Dsonar.login=<your-sonarqube-token>
```
Note: Replace your-project-key and <your-sonarqube-token> with the respective values for your project.
To analyze code for a remote server scan, use the sonar:sonar goal of the sonar-maven-plugin. You need to specify the remote SonarQube server's URL and the authentication token to access it. Use the following command:
```
mvn sonar:sonar \
-Dsonar.projectKey=<your-project-key> \
-Dsonar.host.url=<url-to-sonarqube-server> \
-Dsonar.login=<your-sonarqube-token>
```
Note: Replace your-project-key, url-to-sonarqube-server, and <your-sonarqube-token> with the respective values for your remote SonarQube server.
Once the analysis is complete, you can view the results in the SonarQube dashboard. The dashboard will show you an overview of your project's code quality, as well as any issues that need to be addressed.
By following the steps outlined above, you can use Maven in SonarQube to analyze code for both local and remote server scans. This will help ensure that code quality is maintained across all code repositories, regardless of where they are located. | lumensa |
1,432,242 | Understanding Critical Rendering Path (CRP) | What is Critical Rendering Path? The Critical Rendering Path are the steps the browser... | 0 | 2023-04-11T03:39:21 | https://dev.to/leduc1901/understanding-critical-rendering-path-crp-48nf | webdev, html, css, beginners | ### What is Critical Rendering Path?
The Critical Rendering Path are the steps the browser goes through to convert the HTML, CSS, and JavaScript into pixels on the screen. The critical rendering path includes the Document Object Model (DOM), CSS Object Model (CSSOM), render tree and layout.
The DOM is created as the HTML is parsed. The HTML may request JavaScript that might alter the DOM. The HTML includes or makes requests for styles, which builds the CSSOM.
The browser engine combines the two to create the Render Tree. Layout determines the size and location of everything on the page. Once layout is determined, pixels are painted to the screen.
### Critical Rendering Path Deep dive
We can go into the details of the CRP with these steps:
- A request for a web page or app starts with an HTML request
The server returns the HTML
- The browser then begins parsing the HTML, converting the received bytes to the DOM tree
- The browser initiates requests every time it finds links to external resources, that would be stylesheets, scripts, or embedded image references, some requests are blocking, which means the parsing of the rest of the HTML is halted until the imported asset is handled, this in when requests optimization comes in
- The browser continues to parse the HTML making requests and building the DOM, until it gets to the end, at which point it constructs the CSS object model.
- With the DOM and CSSOM complete, the browser builds the render tree, computing the styles for all the visible content.
- After the render tree is complete, layout occurs, defining the location and size of all the render tree elements
- Once complete, the page is rendered, or ‘painted’ on the screen.
###Document Object Model
**DOM construction is incremental**. The HTML response turns into nodes which turn into the DOM Tree. Nodes contain all relevant information about the HTML element. .
The more nodes we have, the longer the following events in the critical rendering path will take. Remember A few extra nodes won’t make a big difference, but keep in mind that adding many extra nodes will impact performance.
### CSS Object Model
The DOM contains all the content of the page. The CSSOM contains all the styling information. CSSOM is similar to the DOM, but different.
While the DOM construction is incremental, CSSOM is not. CSS is render blocking: the browser blocks page rendering until it receives and processes all the CSS. CSS is render blocking because rules can be overwritten, so the content can’t be rendered until the CSSOM is complete.
### Render Tree
The render tree captures both the content and the styles: the DOM and CSSOM trees are combined into the render tree.
To construct the render tree, the browser checks every node, starting from root of the DOM tree, and determines which CSS rules are attached.
The render tree only captures visible content. The head section (generally) doesn’t contain any visible information, so it’s not included in the render tree.
If there’s a display: none; set on an element, neither it, nor any of its descendants, are in the render tree.
### Layout
Once the render tree is built, layout becomes possible. Layout is dependent on the size of screen.
The layout step determines where and how the elements are positioned on the page, determining the width and height of each element, and where they are in relation to each other.
### Paint
The last step is painting the pixels to the screen.
Once the render tree is created and layout occurs, the pixels can be painted to the screen.
On load, the entire screen is painted. After that, only impacted areas of the screen will be repainted, as browsers are optimized to repaint the minimum area required. Paint time depends on what kind of updates are being applied to the render tree.
While painting is a very fast process, and therefore likely not the most impactful place to focus on in improving performance, it is important to remember to allow for both layout and re-paint times when measuring how long an animation frame may take.
| leduc1901 |
1,432,252 | 12 helpful websites that will save you 100s of hours & change your life | Shashwat Alight ... | 22,550 | 2023-04-11T15:38:26 | https://democoding.netlify.app/post/12-helpful-websites-that-will-save-you-100s-of-hours-change-your-life | webdev, javascript, programming, productivity | {% twitter 1642235382074064896 %}
---
### 1. [archive.org](https://archive.org/)
Internet Archive is a non-profit library of millions of free books, movies, software, music, websites, and more.
---
### 2. [darebee.com](https://darebee.com/)
Access 1800+ free workouts in this database. It's a non-profit (ad-free and product-placement free). Most of the workouts are body weight and require no equipment.
---
### 3. [tinywow.com](https://tinywow.com/)
TinyWow provides free online conversion, pdf, and other handy tools to help you solve problems of all types. All files both processed and unprocessed are deleted after 15 minutes.
---
### 4. [edx.org](https://www.edx.org/)
The most renowned online learning platform for high-quality courses from world-famous universities
---
### 5. [remove.bg](https://www.remove.bg/)
Remove image backgrounds automatically in 5 seconds with just one click.
---
### 6. [supercook.com](https://www.supercook.com/)
Supercook is a recipe search engine that lets you search by ingredients you have at home.
---
### 7. [carrd.co](https://carrd.co/)
Build simple, free, fully responsive one-page sites for pretty much anything.
---
### 8. [pexels.com](https://www.pexels.com/)
Free stock photos & videos you can use everywhere. Browse millions of high-quality royalty free stock images & copyright free pictures.
---
### 9. [screenshot.guru](https://screenshot.guru/)
Screenshot Guru, lets you screen-capture beautiful and high-resolution screenshot images of any web page on the internet.
---
### 10. [pixlr.com](https://pixlr.com/)
Pixlr allows you to edit photos and create stunning designs right in your browser, on your phone or desktop for free.
---
### 11. [dictation.io](https://dictation.io/)
Dictation is free online speech recognition software that will help you write emails, documents and essays using your voice narration and without typing.
---
### 12. [wikihow.com](https://www.wikihow.com/Main-Page)
wikihow is a worldwide collaboration of thousands of people focused on one goal: teaching anyone in the world how to do anything.
---
### Originally published
[https://democoding.netlify.app/post/12-helpful-websites-that-will-save-you-100s-of-hours-change-your-life](https://democoding.netlify.app/post/12-helpful-websites-that-will-save-you-100s-of-hours-change-your-life)
---
---
### Best Post
1. [How to create a Scroll to top button in React](https://democoding.netlify.app/post/how-to-create-a-scroll-to-top-button-in-react)
2. [CSS 3D Isometric Social Media Menu Hover Effects](https://democoding.netlify.app/post/css-3d-isometric-social-media-menu-hover-effects)
3. [Input Box Shake on Invalid Input](https://democoding.netlify.app/post/shake-on-invalid-input)
---
---
## For more information
1. Subscribe my Youtube Channel
[https://www.youtube.com/@democode](https://www.youtube.com/@democode)
2. Check out my Fiver profile if you need any freelancing work
[https://www.fiverr.com/amit_sharma77](https://www.fiverr.com/amit_sharma77)
3. Follow me on Instagram
[https://www.instagram.com/fromgoodthings/](https://www.instagram.com/fromgoodthings/)
4. Check out my Facebook Page
[Programming memes by Coder](https://www.facebook.com/programmingmemesbycoders)
5. Linktree
[https://linktr.ee/jonSnow77](https://linktr.ee/jonSnow77)
---
---
{% instagram CqObFa6PR0l %}
---
{% link https://dev.to/jon_snow789/21-programming-memes-refresh-your-mind-1fa0 %}
---
---
### Use Our RSS Feed
```bash
https://dev.to/feed/jon_snow789
```
| jon_snow789 |
1,432,270 | NgRx Core Concepts for Beginners in 2023 | NgRx is a library for Angular which manages a global data store for your app. This article covers... | 0 | 2023-04-11T04:53:07 | https://dev.to/tanyagray/ngrx-core-concepts-for-beginners-in-2023-1fae | ngrx, angular |
NgRx is a library for Angular which manages a global data store for your app. This article covers some of the core concepts of NgRx:
- **Actions** are like events
- **Reducers** write data to the state
- **Effects** do API calls and map actions to other actions
- **Selectors** are for reading data from the state
An Angular app using NgRx will usually have a `store` directory which should be organised into “sub-stores” for each major data type in the app.
Sub-stores are referred to as store **Features**. Each Feature like "Users" or "Projects" will have its own directory, and its own **Reducer**, **Actions**, **Effects** and **Selectors**.
This is a concept guide, not a getting started guide (sorry!). Only small snippets of code are included as examples.
---
## Actions are like events
**Actions** have unique names, and they are dispatched with some data attached — just like an event.
Actions are defined in groups like this:
```ts
const ProjectActions = createActionGroup({
source: 'Project API',
events: {
// defining events with payload using the `props` function
'Load Project': props<{ projectId: number }>(),
'Load Project Success': props<{ project: Project }>(),
'Load Project Failure': props<{ error: Error }>(),
},
});
```
NgRx works some magic so that when you use each Action in your code, you refer to it by the type you gave it (the string name / key), but as a camel-cased property of the Action Group.
So from the example above, the Action `'Load Project'` would be referred to as `ProjectActions.loadProject()`.
An Action is created and dispatched like this:
```js
const loadProject = ProjectActions.loadProject({ projectId: 123 });
store.dispatch(loadProject);
```
Actions are just simple objects, so a `loadProject` action is really just something like this inside:
```json
{
type: '[Project API] Load Project',
projectId: 123
}
```
The type has to be unique across all actions in your app, so it’s common to add a namespaced source like `[Project API]` to make debugging easier via Redux Dev Tools and to avoid naming conflicts. NgRx does this automatically when you use the `createActionGroup` function to define your Actions.
In NgRx, both **Reducers** and **Effects** can listen for specific Actions.
This means an **Action** can trigger a **Reducer** (to change the app state) or trigger an **Effect** (to go load some data) or it could do both.
Read the [official docs for Actions](https://ngrx.io/guide/store/actions).
---
## Reducers update the state
A **Reducer** is a collection of functions that each update a small part of the global app state.
Each Reducer function takes in an **Action** and the **current app state**, merges the Action’s data into the app state, and returns the new **updated app state**.
Reducers **write data** to the global app state, and Selectors **read data** from the global app state.
A Reducer is usually created like this:
```ts
export const projectsReducer = createReducer(
initialState,
on(ProjectActions.loadProject, (state) => ({
...state,
loading: true
})),
on(ProjectActions.loadProjectSuccess, (state, action) => ({
...state,
loading: false,
projects: action.projects
})),
on(ProjectActions.loadProjectFailure, (state, action) => ({
...state,
loading: false,
errors: [
...state.errors,
action.error
]
})),
)
```
The `initialState` is defined by you, it’s whatever app state you want to start from when the app is first loaded. Each `on()` function updates the app state when a particular Action happens.
Not every Action needs a matching Reducer, it’s okay to have some Actions which don’t update the app state. A Reducer doesn’t have to process every Action, it can just ignore any Actions it doesn’t care about.
Reducers should ideally do little to no logic. They should rely on being provided clean Actions where the data is already in the correct format.
The state should be **immutable**, which is why you’ll see Reducers using the `...` spread operator to return a copy of the state including the new data, rather than just updating some specific properties.
If an Action’s data needs cleaning, the logic for cleaning should be in a **Service** and the Action should be processed by an **Effect** to call that Service.
Read the [official docs for Reducers](https://ngrx.io/guide/store/reducers).
---
## Effects map actions to other actions
An **Effect** usually watches for an **Action** in your app, executes a function (usually in a **Service**), and then dispatches another follow-up **Action**.
An Effect is written as an **Observable**.
Most Effects look something like this:
```ts
loadProject$ = createEffect(() =>
this.actions$.pipe(
ofType(ProjectActions.loadProject),
exhaustMap((action) =>
this.projectService.getOne(action.projectId).pipe(
map((project) => ProjectActions.loadProjectSuccess({ project }),
catchError((error) => of(ProjectActions.loadProjectFailure({ error })))
)
)
)
);
```
To translate the Effect above: When an action **ofType** `loadProject` happens, use `exhaustMap` to call `projectService.getOne(projectId)` and then map the result to a new Action — either `loadProjectSuccess` or `loadProjectFailure`.
The Action _going in_ is a `loadProject`.
The Action _coming out_ will be one of `loadProjectSuccess` or `loadProjectFailure`.
Sometimes, an Effect may not do an API call, but instead just process an action into one or more other actions, to trigger one or more other Effects.
Very rarely, an Effect may call a function where the result is not important, and so it doesn’t dispatch any kind of success or failure event:
```ts
export const loadProjectFailure = createEffect(() =>
this.actions$.pipe(
ofType(ProjectActions.loadProjectFailure),
tap(({ error }) => console.error('Project load failed:', error))
),
{ dispatch: false }
);
```
The example above shows adding `{ dispatch: false }` to make this Effect a “dead end” which will not emit an Action.
Read the [official docs for Effects](https://ngrx.io/guide/effects).
---
## Selectors are for getting data
A **Selector** pulls data out of the global app state. It reads from the big JSON data blob that is maintained by the apps’ **Reducers**.
Usually, each store **Feature** defines a selector for the entire Feature state — all the data related to that Feature, like this:
```ts
const projectsFeature = createFeatureSelector<ProjectsState>('projects');
```
That’s because Selectors are **composable**, so you can make a selector based on another selector. Once you have a selector for a whole Feature, you can drill in deeper to select more specific data.
This is how you select a specific piece of data from a Feature:
```ts
export const getAllProjects = createSelector(
projectsFeature,
(state: ProjectsState) => state.projects
);
```
Selectors are **Observables**, so they emit new values over time as the underlying app state changes.
Selectors can be used from anywhere, but they are most commonly seen in Component code, where they provide data to be used in the template.
A Selector is used in a component’s class like this:
```ts
public allProjects$ = this.store.select(getAllProjects);
```
A Selector’s value can be displayed as JSON-formatted text in a template like this:
```html
<pre>{{ allProjects$ | async | json }}</pre>
```
Or the value can be passed as an input like this:
```html
<app-projects-list [projects]="$allProjects | async"></app-projects-list>
```
Read the [official docs for Selectors](https://ngrx.io/guide/store/selectors).
---
There’s a bunch of different “personal preference” styles for writing NgRx apps, but the core concepts remain the same.
Data is handled in a continuous way, where values change dynamically over time based on changes to the app state behind the scenes.
- **Actions** are like events, they carry data. They can be used to trigger an Effect, or deliver data to a Reducer.
- **Reducers** write data to the state. They run when an Action happens that they’re configured to capture.
- **Effects** handle async functionality to map one Action into another. They emit Actions that may contain data for the Reducer to add to the state, or may trigger other Effects.
- **Selectors** are for reading data from the state, and their values change dynamically as the underlying app state evolves.
| tanyagray |
1,432,276 | CUSTOM SCROLLBAR MAKER | A custom scrollbar maker is a tool that allows website designers and developers to create unique and... | 0 | 2023-04-11T05:09:24 | https://dev.to/robin-ivi/custom-scrollbar-maker-3f6k | javascript, programming, tutorial, ux | A custom scrollbar maker is a tool that allows website designers and developers to create unique and personalized scrollbars for their websites. Typically, the default scrollbar that comes with a web browser is functional but not very visually appealing. With a custom scrollbar maker, designers can choose from a variety of styles, colors, and sizes to match the overall look and feel of their website.
The process of creating a custom scrollbar usually involves selecting a base color or image, and then choosing additional options such as gradient styles, border styles, and scrollbar widths. The resulting scrollbar can be previewed and tested within the tool before it is implemented on the website.
Custom scrollbars can be an important part of creating a polished and professional website. They can help to enhance the user experience by providing a consistent and visually pleasing design throughout the site. Additionally, custom scrollbars can be a way to add a unique touch to a website, making it stand out from other sites with default scrollbars.
<iframe height="300" style="width: 100%;" scrolling="no" title="CUSTOM SCROLLBAR MAKER" src="https://codepen.io/ErRobin/embed/LYgVXOO?default-tab=html%2Cresult" frameborder="no" loading="lazy" allowtransparency="true" allowfullscreen="true">
See the Pen <a href="https://codepen.io/ErRobin/pen/LYgVXOO">
CUSTOM SCROLLBAR MAKER</a> by Er Robin (<a href="https://codepen.io/ErRobin">@ErRobin</a>)
on <a href="https://codepen.io">CodePen</a>.
</iframe>
| robin-ivi |
1,432,284 | uses of kentico cms by various enterprises & its benefits | Are you a business owner having almost no presence or less presence on the internet? Nowadays, as a... | 0 | 2023-04-11T05:39:12 | https://dev.to/viplavzenesys/uses-of-kentico-cms-by-various-enterprises-its-benefits-9d2 | webdev, programming, react, javascript | Are you a business owner having almost no presence or less presence on the internet? Nowadays, as a business owner, you probably wouldn’t want to be left behind when it comes to selling online.
Every business that wants a good online presence, needs several assisting tools and technologies. And such a tool is a content management system, commonly known as CMS technology.
A web content management system enables you to upload or produce a material, format that information, add headlines and photos, and do a variety of backstage tasks such as search engine optimization. Let’s dive deep into this and explore one of the best CMS solutions out there, the Kentico CMS Solutions.
kentico cms: an overview
A web content management system that many businesses prefer these days is called Kentico CMS or Kentico Xperience. To facilitate development, Kentico Xperience makes use of ASP.NET and Microsoft SQL Server. This may be done using Visual Studio or Microsoft MVC. Additionally,
Kentico Xperience is compatible with the cloud computing platform Microsoft Azure. The most current release is version 13, and it's called Kentico Xperience. It was released on October 27, 2020, and updates are made consistently. The most recent revision was made available on November 24th, 2021.
Recommended Read: Top headless cms platforms that you should check out
One of the most popular Enterprise CMS Solutions in the market is Kentico CMS. A lot of established businesses built their popular websites using Kentico CMS. Various features and benefits of Kentico CMS are attracting more and more developers.
Therefore, it’s worth discussing this content management system and its benefits. But before that, let us see which leading businesses in the world use Kentico CMS for their business. According to a study, about 0.1% of the market is occupied by Kentico CMS. Almost 14,134 renowned companies use Kentico CMS solutions.
View Source: [uses of kentico cms by various enterprises & its benefits](https://www.zenesys.com/uses-of-kentico-cms-by-various-enterprises-its-benefits)
| viplavzenesys |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.