
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,398,041 | Java str into obj data func | <!DOCTYPE html> Converting a string into a date object. const... | 0 | 2023-03-12T15:27:35 | https://dev.to/yourdadaf/java-str-into-obj-data-func-3p98 | <!DOCTYPE html>
<html>
<body>
<h2>Converting a string into a date object.</h2>
<p id="demo"></p>
<script>
const text='{"name":"Munira","birth":"1986-1-11","city":"Vadodara"}';
const obj=JSON.parse(text);
obj.birth= new Date(obj.birth);
document.getElementById("demo").innerHTML=obj.name+","+obj.birth;
</script>
</body>
</html>
| yourdadaf | |
1,398,117 | TypeScript: Generic Types | TypeScript is a statically typed superset of JavaScript that allows developers to write code with... | 0 | 2023-03-12T16:47:12 | https://dev.to/donstefani/typescript-generic-types-4h80 | typescript, javascript, webdev, programming | TypeScript is a statically typed superset of JavaScript that allows developers to write code with more safety and accuracy. Generic types in TypeScript make it possible to write reusable and flexible code by creating generic types that can be used with different data types.
You can use generic types to write functions, classes, and interfaces that can work with any data type. The syntax for creating a generic type in TypeScript is to use angle brackets `<>` to define the generic type parameter. For example:
```
function identity<T>(arg: T): T {
return arg;
}
```
Here, `identity` is a generic function that takes a type parameter `T` and returns a value of type `T`. The `arg` parameter is of type `T`, and the return value is also of type `T`. This means that the function can work with any data type.
We can call the `identity` function with different data types as follows:
```
let output1 = identity<string>("hello");
let output2 = identity<number>(10);
```
In this example, we called the `identity` function with a string and a number as the type argument.
Another way of using generic types in TypeScript is with interfaces. We can create a generic interface that can work with any data type, as follows:
```
interface List<T> {
data: T[];
add(item: T): void;
remove(item: T): void;
}
```
In this example, `List` is a generic interface that has a `data` property of type `T[]` and two methods `add` and `remove` that take a parameter of type `T`. This means that we can create a `List` of any data type.
We can create a `List` of strings as follows:
```
let list = { data: ["apple", "banana"], add: function(item) { this.data.push(item); }, remove: function(item) { this.data.splice(this.data.indexOf(item), 1); } };
```
In this example, we created a `List` of strings and added two items to it. We used anonymous object syntax to define the `data`, `add`, and remove properties.
In conclusion, generic types in TypeScript allow you to write flexible and reusable code that can work with any data type. It's possible to create generic functions, classes, and interfaces that can be used with different data types by defining a generic type parameter.
A good question is, "when should I use generic types, and are there any drawbacks to using them?".
More to come... | donstefani |
1,398,136 | What is the difference between null and undefined? | The convention in TypeScript is that undefined values have not been defined yet, whereas null values... | 0 | 2023-03-12T17:28:15 | https://dev.to/typescripttv/what-is-the-difference-between-null-and-undefined-5h76 | javascript, typescript, webdev, programming | The convention in TypeScript is that `undefined` values have not been defined yet, whereas `null` values indicate intentional absence of a value.
<!--more-->
## Example with `null`
The below function shows how `null` can be used by returning an object that always has the same structure, but with **intentionally assigned** `null` values when the function does not return an `error` or `result`:
```ts
function divide(a: number, b: number) {
if (b === 0) {
return {
error: 'Division by zero',
result: null
};
} else {
return {
error: null,
result: a / b
};
}
}
```
## Example with `undefined`
On the other hand, `undefined` represents the absence of any value. It is a value that is **automatically assigned** to a variable when no other value is assigned. It often indicates that a variable has been declared but not initialized. It can also signify a programming mistake, such as when a property or function parameter was not provided:
```ts
let ratio: number | undefined;
if (ratio === undefined) {
console.log('Someone forgot to assign a value.');
} else if (ratio === null) {
console.log('Someone chose not to assign a value.');
}
```
## Best Practice
The **TypeScript Coding guidelines** recommend using only `undefined` and discouraging the use of `null` values (see [here](https://github.com/Microsoft/TypeScript/wiki/Coding-guidelines#null-and-undefined)). It is important to note, however, that these guidelines are tailored towards the TypeScript project's codebase and may not necessarily be applicable to your own projects.
## Want more?
If you found this short explainer helpful, hit that **subscribe button** on my [YouTube channel](https://www.youtube.com/typescripttv?sub_confirmation=1) or give me a [follow on Twitter](https://twitter.com/bennycode) to level up your TypeScript game. | bennycode |
1,398,150 | TIL 03/12/23 | Today I learned about loops in Ruby. *Simple Loops* loop do print "Do you want to continue? (y/n)... | 0 | 2023-03-12T18:06:56 | https://dev.to/jazmineubanks/til-031223-52l3 | Today I learned about loops in Ruby.
****Simple Loops****
loop do
print "Do you want to continue? (y/n) "
answer = gets.chomp.downcase
end
**While loops:**
answer = ""
while answer != "n"
print "Do you want me to repeat this pointless loop again? (y/n) "
answer = gets.chomp.downcase
end
**Until Loops****
answer = ""
until answer == "no" do
print "Do you want this loop to continue? (y/n) "
answer = gets.chomp
end | jazmineubanks | |
1,398,630 | Yet Another Functions of Functions Python Tutorial | The Topic Are you confused by Python functions that return functions and the places and... | 0 | 2023-03-13T06:31:00 | https://dev.to/techocodger/yet-another-functions-of-functions-python-tutorial-3809 | python, tutorial | ## The Topic
Are you confused by Python functions that return functions and the places and ways that Python requires you to understand that? If so, perhaps this description of one example use case may help you.
## Rationale
This article was written this as a note-to-self - and if anyone finds it helpful then that's good too. Some opinions will be expressed that hopefully are relevant to the code that's being discussed.
## The Example
This example comes from a very small part of the process of writing the Python program Foldatry. However, that program is merely incidental for this article. It is however, a real example, from a real application that is being written and used.
## Dictionary of Single Value Items
There is a part of Foldatry where it traverses a folder tree and noting the file extensions - the dot-something at the end of the name - as it goes.
To store those, it created a dictionary, where each new extension became a new key, and the value at the key was the count of files it had seen with that extension.
Thus, after the traversal was done, and the dictionary built, it was desired to output the findings, in order from the extension with the most files found, to the least found.
- Something to note about Python and dictionaries, is that its idea of how the keys _are_ has changed. In earlier Python the .keys() list was either considered unsorted or would be in the order that the keys were added. Perhaps to remove the ambiguity and/or to match the under-the-hood implementation of Python, that list is now defined as being tp preserve their order of insertion.
So, with the dictionary collected and held as the variable `i_dct_counts` - if we didn't care at all about the order to print them, we could do:
``` Python
for k_ext in i_dct_counts.keys() :
print( i_dct_counts[ k_ext ] )
```
- for the Python pedants, yes, this is overlooking that iterating over the dictionary inherently goes through the keys - without explictly calling on `.keys()`
Most likely though, what a user wants to see, is which extension accounts for the most files, so to do that we will want to re-sort the list of keys - to be in descending order by the discovered counts.
To do that, we can use a generic `sorted` function that Python offers. The code will then look like:
``` Python
lst_keys_sorted = sorted( i_dct_counts, key=i_dct_counts.get)
for k_ext in lst_keys_sorted :
print( i_dct_counts[ k_ext ] )
```
Frankly that kind of thing - the use of `sorted` is easy to look up online and plug into place - and indeed that's what was done here. In doing so, note that the `sorted` function needed to be passed the slighlty non-obvious thing: `i_dct_counts.get` but it clearly worked so all was good.
## Dictionary of Tuples
For a revision of the program, it was decided to have the dictionary also hold information about the sizes of the files it found. To that end a "named tuple" was made to be used as the new data item.
Here's the definition for it:
``` Python
tpl_Extn_Info = namedtuple('tpl_Extn_Info', 'ei_Count ei_SizeSum ei_SizeMin ei_SizeMax')
```
for which you can ignore the Pythonist mechanics and just see it as a non-simple data type to hold named elements of:
- `ei_Count` - to hold the counts of files
- `ei_SizeSum` - to hold the total size of files encountered
- `ei_SizeMin` - to hold the largest size of file encountered
- `ei_SizeMax` - to hold the smallest size of file encountered
where these are all things that could just be updated as files are encountered during the traversal, and are meaningful at the end of the traversal.
This change required some other bits of code to handle creating and updating these tuples during the folder tree travervals - but those don't matter for this tutorial, where we will merely assume it resuls in a suitably created dictionary of tuples.
But what this did change is what happens where this line executes:
``` Python
lst_keys_sorted = sorted( i_dct_counts, key=i_dct_counts.get)
```
Because unlike before, the part `key=i_dct_counts.get` no longer tells the `sorted` function how to get a simple value that can control the sorting - and instead that will now deliver a tuple. This causes an error at run time, from inside the `sorted` function - because it "gets" something that has no defined comparison operation.
This means needing to have to done one of two things:
- have our dictionary item be a kind of thing that is inherently sortable ;
- provide a better function to `sorted` than the `.get`
Here we will ignore the first of those options - partly because it just wasn't the implemented resolution, but also because requires tackling a different aspect of how Python operates - and would thus be a tutorial about something else.
So the question then, became: what kind of function needs to be provided to `sorted` ? And how do we make such a thing?
## Function that returns a Function
It is very tempting to show the blundering steps that was taken to work this out. It didn't take long - maybe 20 or 30 minutes - but those steps are harder to write about.
- And to be very clear, this is certainly **not** claiming this is the best way to do this.
So let's jump to the code, and then talk it through.
``` Python
tpl_Extn_Info = namedtuple('tpl_Extn_Info', 'ei_Count ei_SizeSum ei_SizeMin ei_SizeMax')
def ei_Count_of( p_tpl_Extn_Info ):
return p_tpl_Extn_Info.ei_Count
def ei_Count_at_key( p_dct_tpl_Extn_Info, p_key ):
return ei_Count_of( p_dct_tpl_Extn_Info[ p_key ] )
def fn_ei_Count_at_key( p_dct_tpl_Extn_Info ):
def fn_ei_Count_of_dct_at_key( p_key ):
return ei_Count_at_key( p_dct_tpl_Extn_Info, p_key )
return fn_ei_Count_of_dct_at_key
```
The first function is simple - `ei_Count_of` when passed a tuple, will return its `ei_Count` value. Of course, when you have a particular tuple item the code for this is so trivial as to not be worth writing a function - but we know our goal here is to have a function we can quote. At first glance, this can seem to be the function required by `sorted` but cannot work because there is no way to tell `sorted` about this function as operating on the specific dictionary that it is dealing with.
The next function `ei_Count_at_key` is one that can be passed *two* things, the *dictionary* and the *key*, and will then return the count for that key. At first glance, this can seem to be the function required by `sorted` but cannot work because `sorted` needs to given a function that only takes the key as a parameter.
Finally we have the tricky bit. This is a function with a nested function. While that idea is not itself obscure, the reason for doing this is different to the reason we often do this kind of nesting - because here the reason for the inner function is so that **it** rather than what it does at execution time, is what the outer function returns.
Because, yes, when we call `fn_ei_Count_at_key` - passing it the dictionary we have in mind - what we get back is a *function* - and notably is a function that is customised for just that dictionary.
The reason this works is perhaps subtle - it is because the inner function makes use of the parameter passed to the outer function, so that it (the inner function) does not need the dictionary as a parameter. This makes the inner function - customised by the outer call - to be the kind of function that `sorted` needs to be told to use.
And here is how that new function gets used for supplying to the `sorted` function.
``` Python
lst_keys_sorted = sorted( i_dct_counts, key=fn_ei_Count_at_key( i_dct_counts), reverse=True )
for k_ext in lst_keys_sorted :
print( i_dct_counts[ k_ext ] )
```
A major part of understanding what happens at run-time is that when the above line is executed, the `key=` calling clause derives a function for the specific dictionary and then passed that in to the `sorted` function for it to use as it iterates through the dictionary.
A lesser part to be clear about there, is that when it does that iteration, it will iterate through the keys of the dictionary but operate on the items of the dictionary. Depending on your viewpoint, that is either obvious, or a subtle thing about handling dictionaries. It is worth noting that `sorted` is quite generic, and operates on anything (or almost anything?) that is iterable.
## Process of Discovery and Aftermath Options
A reality of those functions, is that they represent the steps of building a way to having a *function* to pass to the `sorted` function. What is needed is a function, not to execute immediately in the `sorted` call, but for it to use as it iterates through the dictionary. Hence started by writing *functions* - rather than object de-references.
Indeed the meta-function approach arrived from realising that `sorted` was not happy to be given the function `ei_Count_at_key` or even a use of `ei_Count_of` combined with the `get` from the simpler non-tuple method.
Having solved the problem - of how to get a suitably sorted list of keys - the functions have been left in place. But should they now be revised to be more Pythonic, perhaps even to use a `lambda` in the `sorted` line?
Perhaps as written makes it quite clear what is going on. In terms of performance, there isn't much concern because the set of extensions is generally small - often finding between 5 and 100 discovered extension in typical usage.
Also, consider that maybe:
- code that is more brief can be problematic by depending on deeper understanding of Python at run-time;
- there isn't a problem with functions that are constructed but only used *once* - i.e. that this is not a good enough reason to use *nameless* methods, such as `lambda` | techocodger |
1,398,210 | The Power of JavaScript: Tips and Tricks for Writing Clean, Efficient Code | JavaScript is a powerful programming language that has become an essential tool for web developers.... | 21,805 | 2023-03-12T18:46:37 | https://dev.to/zuzexx/the-power-of-javascript-tips-and-tricks-for-writing-clean-efficient-code-20p | webdev, javascript, beginners, programming | JavaScript is a powerful programming language that has become an essential tool for web developers. With its dynamic and versatile nature, JavaScript is ideal for creating interactive web applications that can run on a variety of platforms. However, as with any programming language, writing clean and efficient code in JavaScript can be a challenge.
Here are some tips and tricks that can help you write clean and efficient JavaScript code:
### Use Variables Properly
One of the most important things you can do to write clean and efficient code in JavaScript is to use variables properly. Variables allow you to store data and manipulate it as needed throughout your code. However, if you're not careful, you can end up creating too many variables or using them in ways that slow down your code.
To use variables properly, you should aim to:
- Use descriptive variable names that make it clear what the variable represents.
- Avoid global variables whenever possible, as they can cause naming conflicts and memory leaks.
- Use `let` and `const` instead of `var` to define variables, as they have better scoping rules and prevent unwanted changes to your code.
- Use destructuring to extract values from objects and arrays, as it makes your code more concise and easier to read.
Here's an example of how to use destructuring to extract values from an array:
```js
const numbers = [1, 2, 3, 4, 5];
const [first, second, ...rest] = numbers;
console.log(first); // Output: 1
console.log(second); // Output: 2
console.log(rest); // Output: [3, 4, 5]
```
### Use Functions Wisely
Functions are a fundamental building block of JavaScript code. They allow you to break down complex tasks into smaller, more manageable pieces. However, if you're not careful, you can end up creating functions that are too large or that do too many things at once.
To use functions wisely, you should aim to:
- Use descriptive function names that make it clear what the function does.
- Aim for functions that do one thing and do it well. This makes your code more modular and easier to read.
- Avoid nested functions whenever possible, as they can make your code more complex and harder to debug.
- Use arrow functions instead of traditional function expressions, as they have a more concise syntax and don't change the value of this.
Here's an example of how to use arrow functions to write more concise code:
```js
const numbers = [1, 2, 3, 4, 5];
const evenNumbers = numbers.filter(number => number % 2 === 0);
console.log(evenNumbers); // Output: [2, 4]
```
### Optimize Loops
Loops are an essential tool for processing data in JavaScript. They allow you to iterate over arrays and objects and perform operations on each item. However, if you're not careful, you can end up creating loops that are slow and inefficient.
To optimize loops, you should aim to:
- Use the right type of loop for the task at hand. For example, use a `for` loop when you need to iterate over an array with a known length, and use a `for...in` loop when you need to iterate over an object's properties.
- Avoid creating unnecessary variables or doing unnecessary calculations inside a loop.
Use the `Array.prototype` methods like `map()`, `filter()` and `reduce()` to transform and extract data from arrays.
- Use the break statement to exit a loop early if the condition has already been met.
Here's an example of how to use the `map()` method to transform data in an array:
```js
const numbers = [1, 2, 3, 4, 5];
const doubledNumbers = numbers.map(number => number * 2);
console.log(doubledNumbers); // Output: [2, 4, 6, 8, 10]
```
### Avoid Callback Hell
Callback hell is a common problem in JavaScript code, especially when dealing with asynchronous operations. It happens when you have nested callbacks that become difficult to read and maintain. To avoid callback hell, you should use `Promises` or `async/await` functions.
Here's an example of how to use `Promises` to handle asynchronous code:
```js
function getUser(userId) {
return new Promise((resolve, reject) => {
// Code to fetch user data
// ...
if (user) {
resolve(user);
} else {
reject("User not found");
}
});
}
getUser(123)
.then(user => {
// Code to handle user data
// ...
})
.catch(error => {
console.log(error);
});
```
### Use Debugging Tools
Debugging is an essential part of writing clean and efficient JavaScript code. It helps you identify and fix errors in your code, and improve its overall performance. There are several tools and techniques you can use to debug your JavaScript code, such as `console.log()`, breakpoints, and browser dev tools.
Here's an example of how to use console.log() to debug your code:
```js
function calculateSum(numbers) {
let sum = 0;
for (let i = 0; i < numbers.length; i++) {
sum += numbers[i];
console.log(sum); // Output the sum at each iteration
}
return sum;
}
const numbers = [1, 2, 3, 4, 5];
const total = calculateSum(numbers);
console.log(total); // Output: 15
```
In conclusion, JavaScript is a powerful language that can be used to create complex and dynamic web applications. By following these tips and tricks, you can write clean and efficient code that is easy to read, maintain, and debug. Remember to use variables properly, functions wisely, optimize loops, avoid callback hell, and use debugging tools to improve your code's performance. | zuzexx |
1,398,246 | Rustling Up Cross-Platform Development | My experience with cross-platform mobile development lacks some important elements, such as Flutter... | 0 | 2023-03-12T21:26:11 | https://dev.to/complexityclass/rustling-up-cross-platform-development-5en | rust, ios, crossplatform | _My experience with cross-platform mobile development lacks some important elements, such as Flutter or Xamarin. Therefore, this article is not a comprehensive analysis of tools in this space._
Over the years, I've tried a few different tools for cross-platform development, including PhoneGap (which, in hindsight, I probably should have avoided), React Native, Qt, and a bit of Kotlin Native. Generally speaking, I firmly believe that the UI should be native, and that tools like PhoneGap just don't cut it for anything more than a simple app. While React Native has its pros and cons, it hasn't won me over as a developer. Instead, I prefer the idea of having a cross-platform core and native UI. As someone who switched from Android to iOS around the time of KitKat (4.4? 🤔), As I'm naturally more inclined towards llvm based languages, C++ was my first choice for a cross-platform code. On iOS it's relatively easy to bridge C++ and Objective-C through a mix of both called Objective-C++. I've worked on some big projects that were heavily based on this idea, and I can attest that it's a working solution. However, Objective-C is becoming less popular every day, and Objective-C++ is an even scarier beast to work with. I can't say that I found writing it enjoyable. Furthermore, I can't see any compelling reason to write application-level code in C++. Perhaps for OS-level code, but that's a topic for another discussion. After a few attempts with C++, I tried Kotlin Native (KN), which had much better tooling and IDE support, even in the earliest versions. Kotlin is a fun language to read and write, and with the "Native" part, we can even rid ourselves of the JVM. So if you're already immersed in the Android ecosystem, love Kotlin, and enjoy working in Android Studio, then KN should be a good choice for you. However, in this article, I'd like to explore a more "rusty" perspective. Let's dive in.
I've dabbled with Rust on iOS a few times, and it seemed a lot like C++. You build a static library, use C headers as glue, and end up struggling with debugging. This approach is straightforward when you're only extracting a small piece of logic into a shared library and interacting with it through a thin interface. But what if you want to put most of the app logic into the shared lib? That's when things get tricky.
Recently, I stumbled upon a project at the Rust London conference that caught my eye. It's called [Crux](https://github.com/redbadger/crux), and it's a library that helps you implement a functional core and imperative shell paradigm. In other words, it allows you to separate your app logic from your UI code, and share it between platforms.
Although the idea of a functional core and imperative shell might sound straightforward, the actual implementation can be tricky. As you start working on it, you'll inevitably run into obstacles and challenges, especially when it comes to separating the core logic from the user interface.
Second biggest challenges after "variable naming" is finding the appropriate architecture to use. Traditional MVC/MVP architectures may not always be the best fit, and I found it difficult to keep track of all the data flows in applications I used to work with. Additionally, real-world user interfaces can be complex and dynamic, which adds even more states and interactions to the UI layer.
This is where functional concept of free from side-effects Core comes in. Crux helps to build foundation. For me, it's been really helpful in figuring out how to structure my code and how to isolate the core logic in a way that's both ergonomic and easy to read. In a few hours I created a small app that interacts with the DALL-E APIs (pretty obvious, right?) and works on 3 platforms (actually 2.5 as I haven't finished web 😅). In the following section, I'll share my initial impressions.
### Setup
Since the project is in its very early stages, setting it up isn't quite as seamless as with React Native. However, it's not a big deal to contribute to the tooling in-house if you decide to go with this stack for a real project. In fact, most big projects, even single-platform ones, contain a zoo of different bash scripts and make files anyway. The [book](https://redbadger.github.io/crux/overview.html) has a really good explanation of how it works and even provides example apps.
Personally, I found it better to set up the project from scratch using the book. That way, I was able to see all the places to look if something went wrong. It took me less than an hour to set up the core and iOS project, and the process was straightforward. Luckily, the core configuration is in .rs and toml files, which are very easy to follow.
For iOS, you need some bash scripts (oh, I hate writing bash). But in my case, copy-pasting was enough, and ChatGPT made life bearable even if some customisation in bash is needed. Long story short, you need to compile the core as a static library, generate UI languages bindings using the [uniffi](https://crates.io/crates/uniffi) crate, and add these steps to the Xcode project so you don't need to rebuild and relink the core manually. The uniffi requires to write an IDL Interface Definition Language file describing the methods and data structures available to the targeted languages. I generated Swift/ Kotlin and TS for iOS/Android and Web respectively.
UDL looks like this:
```
namespace core {
sequence<u8> handle_event([ByRef] sequence<u8> msg);
sequence<u8> view();
};
```
At the end, the project structure looks like this (no Android and web on the screenshot):
### Development
When it comes to development, you'll probably be splitting your time between Xcode/Android Studio and whatever you prefer for Rust and web development. I've seen some brave souls trying to do mobile development in Emacs, but at the end of the day, they were significantly slower than their teammates.
The good news is that it's quite convenient to work on the core first, crafting the interface and writing tests, and then switching to Xcode/Studio to polish bits of the Core in parallel. Personally, I use CLion for Rust and I don't dare to open more than 2 out of the 3 (CLion/Xcode/Android Studio) at once. Rust compiles quite slowly, which isn't a problem for me since my Swift/ObjC project at work took around 50 minutes for a clean build on a top configuration MacPro(not a MacBook 🐌). However, for web developers, this might be a bit of a drag. But proper project modularization can help with this.
Writing code in Rust can be a bit challenging at first, but I found that a lot of the ideas are similar to Swift, so it's not like a completely different experience. Enums like in Swift, isn't it? 😁
```
#[derive(Serialize, Deserialize)]
pub enum Event {
Reset,
Ask(String),
Gen(String),
#[serde(skip)]
Set(Result<Response<gpt::ChatCompletion>>),
#[serde(skip)]
SetImage(Result<Response<gpt::PictureMetadata>>),
}
```
When it comes to debugging, you can use breakpoints through the **lldb "breakpoint set"** command to debug both the Swift and Rust code in your linked static library. It's not as convenient as debugging a pure Kotlin project in Android Studio, but it still gets the job done.
E.g missing .env variable error easily identifiable even from within Xcode.

Exact line in the logs:
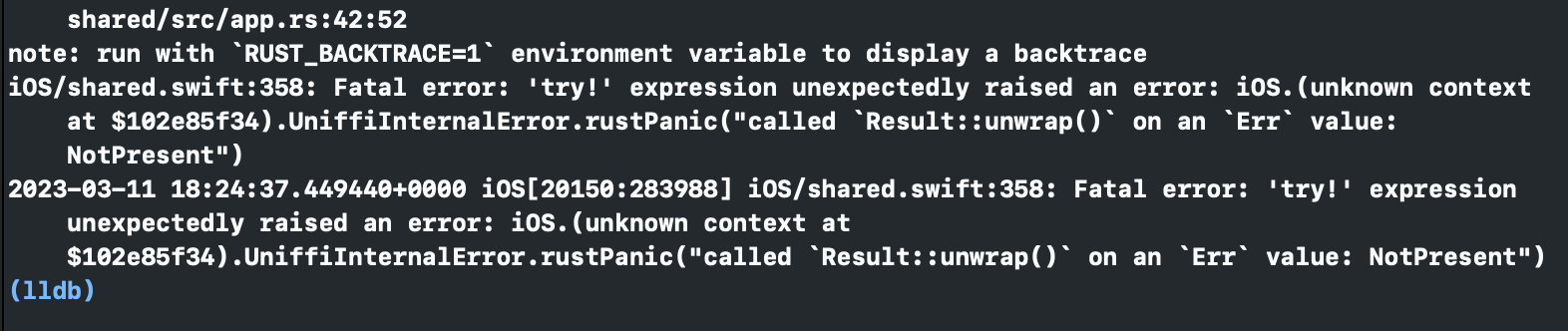
However, I couldn't see any issues with debugging the core and shell separately. In fact, it can be quite helpful to be able to debug each component independently, as it can make it easier to pinpoint the source of any bugs or issues.
What about interop... I'm not going to lie, it's not ideal. In particular, interop between Rust and Swift isn't as seamless as it is between Swift/Objective-C and Kotlin/Java. For example, **f64** can't be passed as is through the boundary ( _which is logical, but still_). However, there are some cheat sheets available to help make sense of the interop rules. For Swift, the following rules apply:
- Primitives map to their obvious Swift counterpart (e.g. **`u32`** becomes **`UInt32`**, **`string`** becomes **`String`**, etc.).
- An object interface declared as **`interface T`** is represented as a Swift protocol **`TProtocol`** and a concrete Swift class **`T`** that conforms to it.
- An enum declared **`enum T`** or **`[Enum] interface T`** is represented as a Swift enum **`T`** with appropriate variants.
- Optional types are represented using Swift's built-in optional type syntax **`T?`**.
- Sequences are represented as Swift arrays, and maps as Swift dictionaries.
- Errors are represented as Swift enums that conform to the **`Error`** protocol.
- Function calls that have an associated error type are marked with **`throws`** in Swift.
I remember similar rules for Kotlin Native. Actually, the interface between the core and shell should be laconic. I don't think these limitations are good, but they don't hurt too much either.
### Architecture
Talking about architectural patterns. _Have you seen mobile Eng who are not talking about patterns?_ Crux is inspired by Elm, there is quite good page in the [book](https://redbadger.github.io/crux/guide/elm_architecture.html) and also [Elm docs](https://guide.elm-lang.org/architecture/) worth reading, so let’s skip the description. In general I see movement to unidirectional and message passing architectures. They are clean and quite strict, which makes it easier to update code and not introduce inconsistency when one text field has three different states across layers. True that UIKit or Vanila android libraries are not the best fit (though still possible to reuse some ideas), but SwiftUI and Jetpack Compose fit quite nice. If you write gesture interaction and animation heavy UIs - this would be challenging. Like if you do some gesture driven transition, should you keep current state in UI or pass it to the core? Or UITableView (iOS) and RecyclerView (Android) have a bit different lifecycle for cells, hence for cell models, how core will be dealing with it. A bit challenging, but still possible, no silver bullets as always.
The part that I liked the most, though, was the capabilities feature. Capabilities provide a nice and clear way to deal with side effects, such as networking, databases, and system frameworks. Sure, you could write a single HTTP library in C and use it everywhere, and maybe you could even standardize persistence to use only SQLite. But there are so many different things to consider, such as audio/video, file systems, notifications, biometrics, or even peripherals like the Apple Pencil. And your system already has good libraries to deal with these things, which might even be optimized ( quality of service or URLSession configuration on iOS) to be more effective. That's where capabilities come in - they allow you to declare what you need, while keeping the implementation specifics for the platform code. It's a great way to keep your code modular and maintainable.
When core handles event that need to make an HTTP call, it's actually instructing Shell to do the call.
```
fn update(&self, event: Self::Event, model: &mut Self::Model, caps: &Self::Capabilities) {
match event {
Event::Ask(question) => {
model.questions_number += 1;
gpt::API::new().make_request(&question, &caps.http).send(Event::Set);
},
...
```
And shell is sending request
```
switch req.effect {
...
case .http(let hr):
// create and start URLSession task
}
```
The same logic can be applied to databases (just separate KV-storages and relational), biometric, whatever else.
### Final Thoughts
Despite the fact that I'm new to Crux and not yet fluent in Rust, I was able to build a simple app that works on iOS, Android, and Web (almost) in less time than it would have taken to build all three from scratch.
Crux is still in its early stages, e.g. at the time of my note, the HTTP capability didn't support headers and body. But I have high hopes that this project will continue to grow and attract more contributors, as the idea behind it is really cool.
Even if you don't want to use Rust for cross platform development, I think it's worth taking a look at this project to see how you might be able to reuse some of the ideas in your favourite stack. At the end of the day, anything that helps us write better, more modular, and more maintainable code is a win. | complexityclass |
1,398,343 | Multilingual sites in React | by Suprabhat Kumar Our chances of converting visitors into clients considerably rise if our website... | 0 | 2023-03-12T21:56:11 | https://blog.openreplay.com/multilingual-sites-in-react/ | webdev, react | by [Suprabhat Kumar](https://blog.openreplay.com/authors/suprabhat-kumar)
Our chances of converting visitors into clients considerably rise if our website is translated into the user's native language. This article will explain implementing the multilingual feature in a website using React. Hopefully, by the end of this article, we will be able to translate any website into any language we want. The multilingual functionality makes navigating sites in different languages easier for our readers.
## Getting Started
At first, we create a React app using the following:
```
npx create-react-app app-name
```
This command lets us create a basic react app.
After that, we change the working directory using the following command -
```
cd app-name
```
Then we start the React application using -
```
npm start
```
Next, we follow mentioned steps below -
1. Create an `i18n` file.
2. Create a `LanguageSelector` file enabling us to select the website's language.
3. Create a `locales` folder where we store the translations in different languages used by our site.
4. Map `contents` with languages.
Following are the npm packages used in translation -
> * i18next
> * react-i18next
Command to install the packages -
```
npm install react-i18next i18next
```
Let’s dive deeper now.
Following is the project structure -
### 1. Creating i18n file
src > i18n > index.js
```javascript
import i18n from "i18next";
import { initReactI18next } from "react-i18next";
import translationsInEng from '../locales/en/translation.json';
import translationsInGerman from '../locales/de/translation.json';
import translationsInItalian from '../locales/it/translation.json';
// the translations
const resources = {
en: {
translation: translationsInEng
},
de: {
translation: translationsInGerman
},
it: {
translation: translationsInItalian
},
};
i18n
.use(initReactI18next) // passes i18n down to react-i18next
.init({
resources, // resources are important to load translations for the languages.
lng: "it", // It acts as default language. When the site loads, content is shown in this language.
debug: true,
fallbackLng: "de", // use de if selected language is not available
interpolation: {
escapeValue: false
},
ns: "translation", // namespaces help to divide huge translations into multiple small files.
defaultNS: "translation"
});
export default i18n;
```
In this file, we described
a. resources (for translating in different languages): It contains the files helping map the translations with the selected languages. If we interchange `translationsInEng` and `translationsInGerman`, then the content available in the `translation.json` file of the `en` and `de` folders will be shown in `German` and `English`, respectively. The translations in the `en` and `de` folders get mapped in German and English.
b. lng: The `default` language is responsible for showing the translations when the site loads. If we change it to `de`, the website will be translated to `de` on loading the site.
c. debug: It is `boolean` and gives detailed information on the console if assigned `true`. It also helps in analyzing the issues(if any occurred). Below is the screenshot attached for more information -
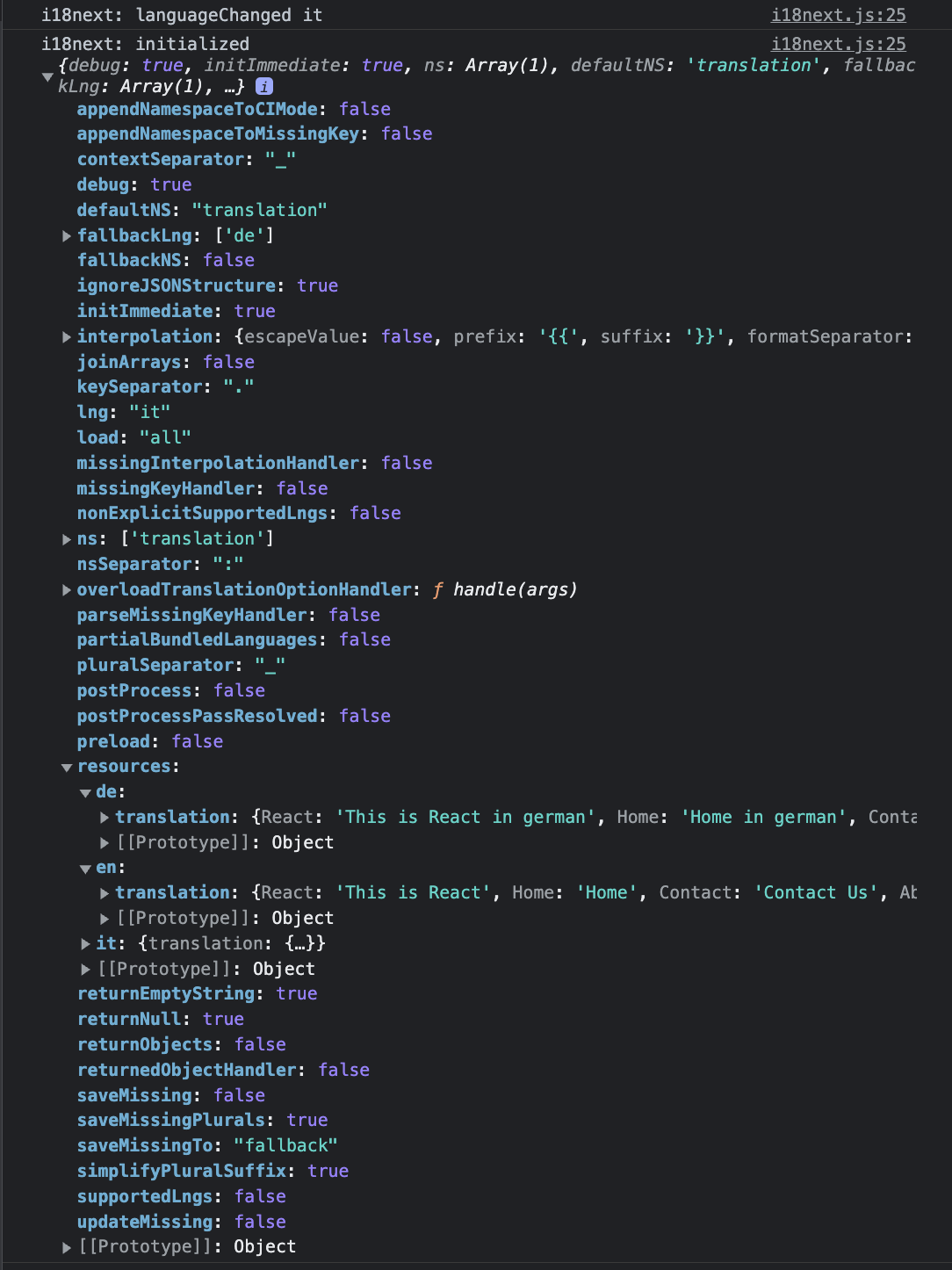
d. fallbackLng: This language is used when the selected language(`lng`) is unavailable. Acts as default language in the absence of `lng`.
e. ns (Namespaces): It allows us to break huge translations into multiple small files instead of writing in a single large file.
### 2. Create a LanguageSelector file enabling us to select the language of the website
The language can be changed by using i18n imported from the i18n.js file.
src > components > LanguageSelector.js
```javascript
import React, {useState} from "react";
import i18n from '../i18n';
const LanguageSelector = () => {
const [selectedLanguage, setSelectedLanguage] = useState(i18n.language); // i18n.language contains the language assigned to lng in i18n.js file.
const chooseLanguage = (e) => {
e.preventDefault();
i18n.changeLanguage(e.target.value); // i18n.changeLanguage() is used to change the language assigned to lng in i18n.js file.
setSelectedLanguage(e.target.value);
}
return (
<select defaultValue={selectedLanguage} onChange={chooseLanguage}>
<option value="de">German</option>
<option value="en">English</option>
<option value="it">Italian</option>
</select>
);
};
export default LanguageSelector;
```
### 3. Create a locales folder to store the translations in our site's different languages.
1. de
src > locales > de > translation.json
```json
{
"React" : "Das ist React",
"Home": "Daheim",
"Contact": "Kontaktiere uns",
"About": "Über uns",
"username": {
"label": "Nutzername",
"placeholder": "Platzhalter..."
},
"password": {
"label": "Kennwort",
"placeholder": "passwort platzhalter..."
},
"location": "Geben Sie den Standort ein",
"Address": "Gib die Adresse ein"
}
```
2. en
src > locales > en > translation.json
```json
{
"React" : "This is React",
"Home": "Home",
"Contact": "Contact Us",
"About": "About Us",
"username": {
"label": "username",
"placeholder": "placeholder..."
},
"password": {
"label": "password",
"placeholder": "password placeholder..."
},
"location": "Enter the location",
"Address": "Enter the address"
}
```
3. it
src > locales > it > translation.json
```json
{
"React" : "Questo è React",
"Home": "Casa",
"Contact": "Contattaci",
"About": "Riguardo a noi",
"username": {
"label": "nome utente",
"placeholder": "segnaposto..."
},
"password": {
"label": "parola d'ordine",
"placeholder": "segnaposto password..."
},
"location": "Inserisci la posizione",
"Address": "Inserisci l'indirizzo"
}
```
### 4. Map contents with the languages.
Following is the App.js -
src > App.js
```javascript
import './App.css';
import LanguageSelector from './components/LanguageSelector';
import Content from './components/Content';
import Sidebar from './components/Sidebar';
function App() {
return (
<div className="App">
<LanguageSelector />
<Content />
<Sidebar />
</div>
);
}
export default App;
```
In Sidebar.js, we import `useTranslation()` hook to implement the translation of the words. We get the `t` function and `i18n` instance from `useTranslation()`.
The `t` function is used to translate our contents while `i18n` changes the language.
But, we will only use `t` here.
The following code will translate words like Home, Contact, and About.
src > components > Sidebar.js
```javascript
import { useTranslation } from 'react-i18next'
import React from 'react'
const Sidebar = () => {
const { t } = useTranslation();
return (
<div style={{marginTop: "10px"}}>
<button>{t("Home")}</button>
<button>{t("Contact")}</button>
<button>{t("About")}</button>
</div>
)
}
export default Sidebar
```
`Content.js` shows how to translate the content.
src > components > Content.js
```javascript
import React from 'react'
import { useTranslation } from 'react-i18next'
const Content = () => {
const { t } = useTranslation();
return (
<div>
<p>{t("React")}</p>
<hr/>
<p>{t("username.label")}</p>
<p>{t("username.placeholder")}</p>
<hr/>
<p>{t("password.label")}</p>
<p>{t("password.placeholder")}</p>
<hr/>
<p>{t("location")}</p>
<p>{t("Address")}</p>
</div>
)
}
export default Content;
```
Translation of contents takes time. As a result, we wrap the `<App/>` component within `Suspense` with `fallback`.
`Loading...` will be shown on the screen until the translation is done.
src > index.js
```javascript
import React, { Suspense } from 'react';
import ReactDOM from 'react-dom/client';
import App from './App';
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(
<React.StrictMode>
<Suspense fallback={<div>Loading....</div>}>
<App />
</Suspense>
</React.StrictMode>
);
```
<h2>Session Replay for Developers</h2>
<p><em>
Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data
</em></p>
<img alt="OpenReplay" width="768" height="400" src="https://blog.openreplay.com/assets/overview_Z17Qdyg.png" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em>
## Common Mistake
Till this point, everything seems OK, but it’s not.
Once you select a particular language from the dropdown, the contents of the website change accordingly, but on `refreshing` the webpage, the selected language changes back to that language which is mentioned in `lng` in the `i18n.js` file because we assigned `i18n.language` to `selectedLanguage` (check 6th line in `LanguageSelector.js`).
### Fun Activity
Change the `lng` (in i18n.js file) to `en` and now change the language from the dropdown on the webpage; you’ll see contents change as per the selected language but do refresh the page. This time you’ll notice the content is in `English` as the `selectedLanguage`; this time is `en`.
The problem, as of now, is refreshing the webpage changes the selected language of the website. So, what to do now?
### Solution
The solution is to use the `localStorage` object. This object stores the data in the browser's `key:value pair` with no expiration date.
* Let’s see what changes we must introduce in the already available code.
1. In `chooseLanguage() in LanguageSelector.js`, we set the key as lang and its value equal to the language selected by the user.
src > components > LanguageSelector.js
```javascript
import React, {useState} from "react";
import i18n from '../i18n';
const LanguageSelector = () => {
const [selectedLanguage, setSelectedLanguage] = useState(i18n.language); // i18n.language contains the language assigned to lng in i18n.js file.
const chooseLanguage = (e) => {
e.preventDefault();
i18n.changeLanguage(e.target.value); // i18n.changeLanguage() is used to change the language assigned to lng in i18n.js file.
setSelectedLanguage(e.target.value);
localStorage.setItem("lang", e.target.value);
}
return (
<select defaultValue={selectedLanguage} onChange={chooseLanguage}>
<option value="de">German</option>
<option value="en">English</option>
<option value="it">Italian</option>
</select>
);
};
export default LanguageSelector;
```
2. In `i18n.js`, `lng` gets the value available in the `lang` key (in our case, it’s `it`) because of `lng: localStorage.getItem("lang").`
src > i18n > index.js
```javascript
import i18n from "i18next";
import { initReactI18next } from "react-i18next";
import translationsInEng from '../locales/en/translation.json';
import translationsInGerman from '../locales/de/translation.json';
import translationsInItalian from '../locales/it/translation.json';
// the translations
const resources = {
en: {
translation: translationsInEng
},
de: {
translation: translationsInGerman
},
it: {
translation: translationsInItalian
},
};
i18n
.use(initReactI18next) // passes i18n down to react-i18next
.init({
resources, // resources are important to load translations for the languages.
lng: localStorage.getItem("lang"), // It acts as default language. When the site loads, content is shown in this language.
debug: true,
fallbackLng: "de", // use de if selected language is not available
interpolation: {
escapeValue: false
},
ns: "translation", // namespaces help to divide huge translations into multiple small files.
defaultNS: "translation"
});
export default i18n;
```
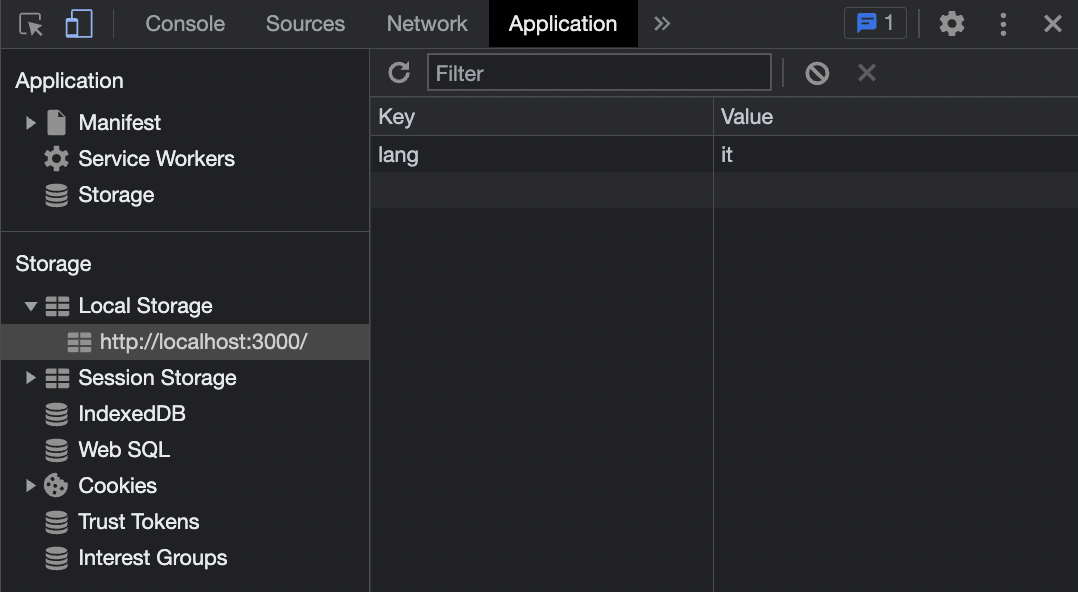
Check the `Local Storage` section under the `Application` tab in the developer console. The selected language is `it`. Now if you refresh the browser, the selected language will still be `it`.
## Output
We are focusing on translating, so there is no styling in it. The final output looks like this -
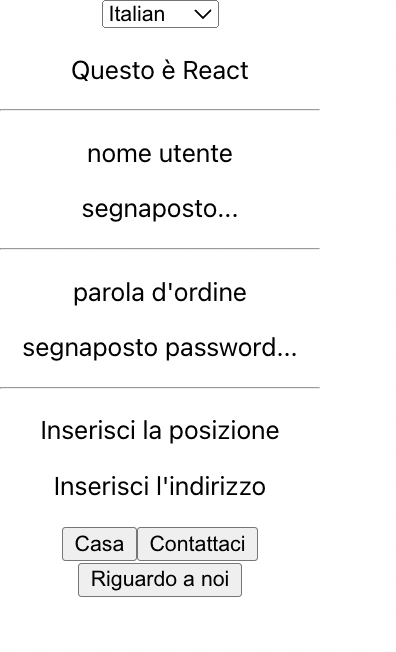
Selected Language is `it(Italian)`
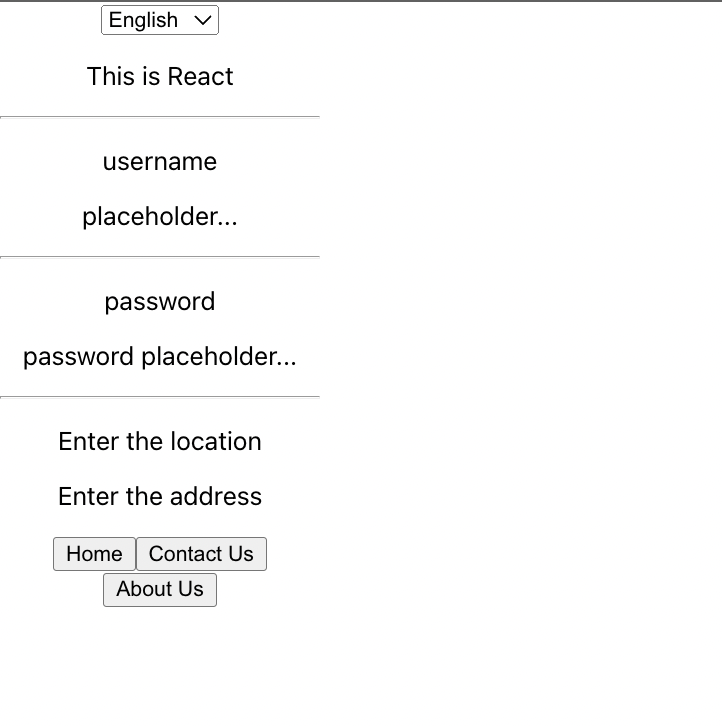
Selected Language is `en(English)`
Selected Language is `de(German)`

## Conclusion
With this, we come to the end of this article. I believe you have learned how to implement the multilingual feature in a website.
## References
https://react.i18next.com/
[](https://newsletter.openreplay.com/)
| asayerio_techblog |
1,398,576 | Animation -3 : CSS push pop loaders | Are you looking for animations to enhance your website? We've got you covered with our wide selection... | 22,215 | 2023-03-13T14:30:00 | https://dev.to/jon_snow789/animation-3-css-push-pop-loaders-4o23 | css, webdev, animation, design | Are you looking for animations to enhance your website? We've got you covered with our wide selection of creative and engaging #animations. Say goodbye to endless searching and hello to seamless integration on your website!
#### We're excited to introduce our latest YouTube series, which features diverse creative and inspiring website animations.
---
In our short videos, you'll find a variety of #animations that can be easily implemented on your website to enhance user experience.
---
### CSS push pop loaders
---
{% youtube CZcEDsdrkI4 %}
---
### [Source code](https://codepen.io/jh3y/pen/ZEEEGWr)
---
## For more information
1. Check my GitHub profile
[https://github.com/amitSharma7741](https://github.com/amitSharma7741)
2. Check out my Fiver profile if you need any freelancing work
[https://www.fiverr.com/amit_sharma77](https://www.fiverr.com/amit_sharma77)
3. Check out my Instagram
[https://www.instagram.com/fromgoodthings/](https://www.instagram.com/fromgoodthings/)
4. Linktree
[https://linktr.ee/jonSnow77](https://linktr.ee/jonSnow77)
5. Check my project
- EVSTART: Electric Vehicle is the Future
[https://evstart.netlify.app/](https://evstart.netlify.app/)
- News Website in react
[https://newsmon.netlify.app/](https://newsmon.netlify.app/)
- Hindi jokes API
[https://hindi-jokes-api.onrender.com/](https://hindi-jokes-api.onrender.com/)
- Sudoku Game And API
[https://sudoku-game-and-api.netlify.app/](https://sudoku-game-and-api.netlify.app/)
---
--- | jon_snow789 |
1,398,603 | The 10 Best Task Management Software In 2023 (For The Developer Team) | Achieving business goals is impossible without effective task management. Reaching your business... | 0 | 2023-07-07T04:04:24 | https://medium.com/@smartONES/the-10-best-task-management-software-in-2023-for-the-developer-team-749e7d27420a | webdev, developertools, productivity, agile | ---
title: The 10 Best Task Management Software In 2023 (For The Developer Team)
published: true
date: 2023-01-04 14:00:10 UTC
tags: webdev,developertools,productivity,agile
canonical_url: https://medium.com/@smartONES/the-10-best-task-management-software-in-2023-for-the-developer-team-749e7d27420a
---
Achieving business goals is impossible without effective task management. Reaching your business goals requires you and your team to perform various tasks. For this, you need to manage them effectively. Holistic task management brings you closer to your goals and lets you achieve them efficiently.
Over time, modern task management tools and practices have replaced traditional methodologies. Several task management software solutions are available for businesses of all scales and operating in all industries.
So, what is task management software?
### What Is Task Management Software?
**Task management software** is a software solution that helps you organize, prioritize, and streamline your business tasks to achieve your goals. It enables you to fulfill your goals or execute your projects effectively. Modern task management software provides automated tools that prevent your team from performing repetitive processes manually.
The essence and purpose of task management are similar to **project management**. The two services’ software solutions often overlap and provide similar business tools. However, it is essential to understand the subtle difference between task management and [project management](https://blog.ones.com/enterprise-project-management?hsLang=en).
Project management has a broader scope than task management. It includes identifying a core goal to be achieved and several aspects involved in reaching that goal. On the other hand, task management involves handling each project element simultaneously. Instead of worrying about the project timeline, task management is concerned with the team’s specific task(s) deadline.
### The 10 Best Task Management Software In 2023 For Your Developer Team
Software development involves multiple team members performing different tasks. Especially if you follow the [Agile development methodology](https://blog.ones.com/how-does-agile-product-development-work?hsLang=en), it is crucial to ensure seamless coordination between your team members as they perform different tasks. Task management software helps your developer team track their processes and work towards a common goal.
Here are 10 of the best task management software in 2023 for your developer team:
#### 1. ONES.com
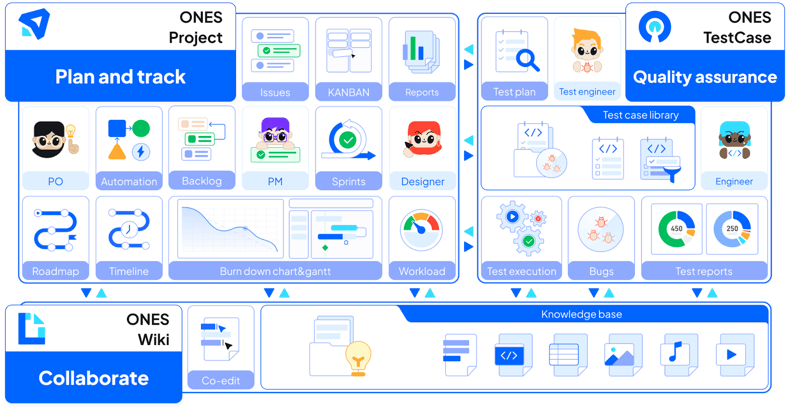
[ONES.com](https://ones.com/)is a powerful project and task management software that helps you organize your performance and achieve your goals in the best way possible. Designed especially for managing software development projects, [ONES.com](https://ones.com/) allows you to identify, define, and track all developer tasks you need for your software development project.
[ONES.com](https://ones.com/) provides your developer team with manageable milestones, roadmaps, sprints, and more to align them with your objectives. Depending on your business requirements, you can create, track, and perform tasks using a centralized platform. The task management software also allows all users to view their teams’ workload and the status of the ongoing tasks while highlighting the most productive aspects.
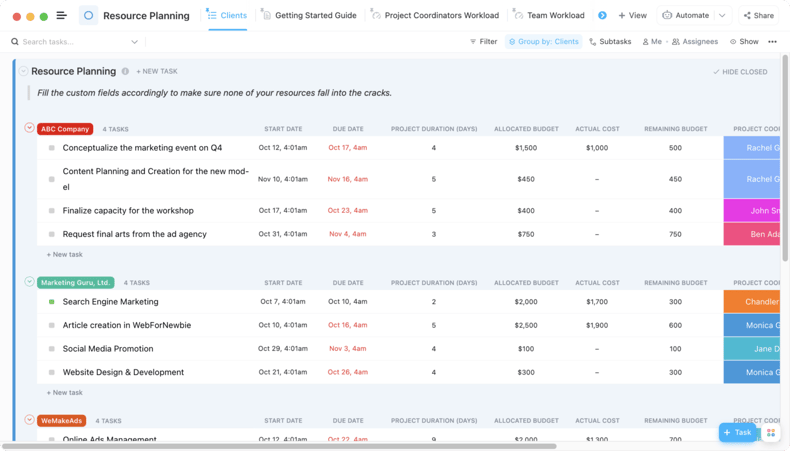
#### 2. ClickUp
_Via ClickUp_
ClickUp is another major task management software used by some of the industry’s biggest names, including Google, Airbnb, and Webflow. It provides users with several features that boost their productivity and ensures effective management of all tasks.
ClickUp also allows businesses to track multiple tasks performed for multiple projects. Some of the major tools and features of ClickUp include templates, recurring tasks, reminders, priorities, notifications, assigned comments, views, etc.
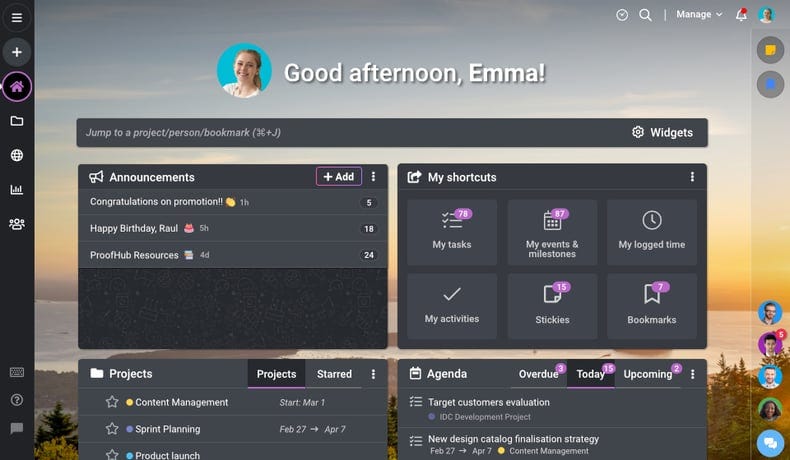
#### 3. ProofHub
_Via ProofHub_
ProofHub is a comprehensive project and task management tool dedicated to improving your teams’ productivity and efficacy. It gives managers a 360-degree view of all their tasks and complete control over communication, projects, and tasks.
ProofHub also provides users with seamless collaboration tools that allow multiple team members to work on a centralized platform. It allows the management to make important company announcements hassle-free. Moreover, ProofHub readily integrates with third-party applications and services like OneDrive, Google Drive, Dropbox, Box, and more.
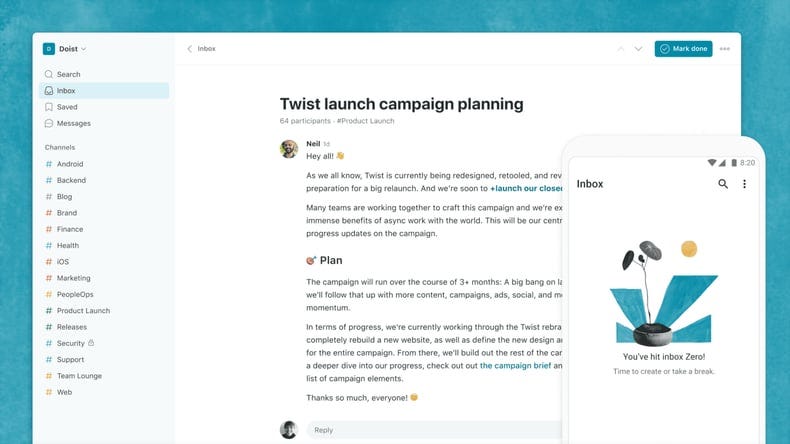
#### 4. Todoist
_Via Todoist_
Todoist is a simple, straightforward, and easy-to-understand task management software for businesses. It is designed like a holistic to-do list app that allows you and your team to manage multiple tasks using a single unified platform. Its no-frills UI is built around a simple, minimalistic design with advanced task-tracking features.
Some of the key features of Todoist include priorities, sub-tasks, recurring due dates, mobile applications, and more.
#### 5. Any.do

_Via Any. do_
Any. do is a unique task management software that labels different items as “today”, “tomorrow”, and “upcoming”. This gives users a quick overview of the tasks and the timeline they need to follow.
Unlike most of its competitors, Any.do provides users with an intuitive calendar to help them see how their tasks and events fit together. It also helps you organize tasks and filter workflows by specific categories and/or due dates.
#### 6. Chanty

_Via Chanty_
Chanty is a collaborative platform with modern task management features. It employs a chat-first model to create a holistic task management system. Task management software allows users to convert any message into a dedicated assignment, allocate it to the right person, and set a due date for the same.
#### 7. Taskque
_Via Taskque_
Taskque is an ideal task management software to implement if you want to move just a notch about a to-do list application. A brilliant tool for resource management, Taskque works best for teams performing similar functions using similar skills.
Some key features Taskque offers users include discussions, a calendar, automatic task assignment, workflow management, a to-do list app, and more.
#### 8. Flow
_Via Flow_
Flow should be your first choice of task management software if you are a project manager who prefers using a Grantt chart. It provides users with color-coded projects that help them easily manage and switch between different tasks.
Moreover, Flow provides your team members with templates and repeat projects to help them work on a project repeatedly or stage a different event easily.
#### 9. Hitask
_Via Hitask_
Hitask is a holistic task and project management solution that offers a centralized dashboard to its users featuring all ongoing tasks along with their due dates, teams, projects, and other relevant details. The simple UI and functionality make it easy for users to create, edit and assign the right tasks to the right team members.
Some key features offered by Hitask include file storage, task management, email creation, reports, mobile application, time tracking, and more.
#### 10. Trello

_Via Trello_
Trello is one of the most popular task management tools that lets you manage the simplest and the most complicated tasks to be performed. Its Kanban interface allows you to set up dedicated cards for different tasks and projects as if they are post-it notes.
### The Final Word
These were some of the best task management software you can choose from for your developer team in 2023. Always make sure you implement a software solution according to your project’s complexity and scope.
_Originally published at_ [_https://blog.ones.com_](https://blog.ones.com/10-best-task-management-software-in-2023-for-the-developer-team) _on January 4, 2023._ | josiel677 |
1,398,717 | Start use chrome extension of The Marvellous Suspender | Start use chrome extension of The Marvellous Suspender Everyday do development and investigation in... | 0 | 2023-03-13T13:26:09 | https://dev.to/fukajun/start-use-chrome-extension-of-the-marvellous-suspender-1cl4 | development | ---
title: Start use chrome extension of The Marvellous Suspender
published: true
description:
tags: development
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-13 07:28 +0000
---
Start use chrome extension of The Marvellous Suspender
Everyday do development and investigation in work and hobby.
At such time I using chrome. Open many web site in tab.
So my mac to be heavy. I have think this reason is javascript that are processing while no access the pages. That process are polling etc...
This extension suspend tab which long time no access, and display snapshot image each pages.
[The Marvellous Suspender - Chrome ウェブストア](https://chrome.google.com/webstore/detail/the-marvellous-suspender/noogafoofpebimajpfpamcfhoaifemoa) | fukajun |
1,398,731 | Remote Single file component without any framework | I read an awesome article I and wanted to share it with the community. Implementing single-file Web... | 0 | 2023-03-13T08:07:13 | https://dev.to/artydev/single-file-component-without-any-framework-47ek | I read an awesome article I and wanted to share it with the community.
[Implementing single-file Web Components](https://ckeditor.com/blog/implementing-single-file-web-components/)
The idea is to be able to load and run a remote single file component like the one below.
This one is accessible from the following url :
[https://blog.comandeer.pl/assets/jednoplikowe-komponenty/HelloWorld.wc
](https://blog.comandeer.pl/assets/jednoplikowe-komponenty/HelloWorld.wc)
Notice the extension.
```html
<template>
<div class="hello">
<p>Hello, world! My name is <slot></slot>.</p>
</div>
</template>
<style>
div {
background: red;
border-radius: 30px;
padding: 20px;
font-size: 20px;
text-align: center;
width: 300px;
margin: 0 auto;
}
</style>
<script>
export default {
name: 'hello-world',
onClick() {
alert( `Don't touch me!` );
}
};
</script>
```
Here is the loader :
```js
let loadComponent = (function() {
function fetchAndParse( URL ) {
return fetch( URL ).then( ( response ) => {
return response.text();
} ).then( ( html ) => {
const parser = new DOMParser();
const document = parser.parseFromString( html, 'text/html' );
const head = document.head;
const template = head.querySelector( 'template' );
const style = head.querySelector( 'style' );
const script = head.querySelector( 'script' );
return {
template,
style,
script
};
} );
}
function getSettings( { template, style, script } ) {
const jsFile = new Blob( [ script.textContent ], { type: 'application/javascript' } );
const jsURL = URL.createObjectURL( jsFile );
function getListeners( settings ) {
return Object.entries( settings ).reduce( ( listeners, [ setting, value ] ) => {
if ( setting.startsWith( 'on' ) ) {
listeners[ setting[ 2 ].toLowerCase() + setting.substr( 3 ) ] = value;
}
return listeners;
}, {} );
}
return import( jsURL ).then( ( module ) => {
const listeners = getListeners( module.default );
return {
name: module.default.name,
listeners,
template,
style
}
} );
}
function registerComponent( { template, style, name, listeners } ) {
class UnityComponent extends HTMLElement {
connectedCallback() {
this._upcast();
this._attachListeners();
}
_upcast() {
const shadow = this.attachShadow( { mode: 'open' } );
shadow.appendChild( style.cloneNode( true ) );
shadow.appendChild( document.importNode( template.content, true ) );
}
_attachListeners() {
Object.entries( listeners ).forEach( ( [ event, listener ] ) => {
this.addEventListener( event, listener, false );
} );
}
}
return customElements.define( name, UnityComponent );
}
function loadComponent( URL ) {
return fetchAndParse( URL ).then( getSettings ).then( registerComponent );
}
return loadComponent;
})()
let url = "https://blog.comandeer.pl/assets/jednoplikowe-komponenty/HelloWorld.wc" + `?x=${Math.random()}`
loadComponent(url) .then( ( component ) => {
console.log( 'Component loaded' );
document.body.insertAdjacentHTML( 'beforeend', '<hello-world>Comandeer</hello-world>' );
} );
document.querySelector( 'button' ).addEventListener( 'click', () => {
document.body.insertAdjacentHTML( 'beforeend', '<hello-world>Comandeer</hello-world>' );
} );
```
You can see a demo here [SFC](https://flems.io/#0=N4IgtglgJlA2CmIBcA2AnAOgAwEYA0IAZhAgM7IDaoAdgIZiJIgYAWALmLCAQMYD21NvEHIQAHgBGAVzZsBAPgA61AAQqAgjBXV4AdxX8wABwHC2ysQHppshdxCl4CHmwgDyTHEhxoQAXzwaekZmACtyXgEhESYENhVYPlooAGE+Y1NBFQBeFQAKQilqFzdqPIBKFWBlRTZC4tcBFUJ4Nh4WdWooAAVaACdHPJUAVQAlABkVSurqWtq+1qk+1Ra2liGxyfKMNhZhIaGF0hNqRymc+Sqa8xuFtiXVI5PHHfgADzYKgG5r2r8pnZ7Mr5FTsTjnbKXGZzG78U7xIz9Rx9HLaPQqAAiAHkALK9AbwPrfX6w9zxKB8HhSBhZXKIgl9DD0xwAMT66QAymw+hBqABzIZg2B4FQAciEH0sQtFUx+sxutThpHie2SqIpVJpbFY8GScphirJKiExlgtCEqNVUAwAEcpISAJ4cpzwFx8Ilik1GM1CGXlfUKtpG5UOhCW3XWu2O53OOQe0UhhB+gMwpXxUg8HlGeK5K22+19J0ut3xjNZtjJmrymF3B5XauBr0++B4EkwxMtts3MsQbNdvwptj-f3XPxV2r1EpNPmtZ2yXl80hDYDG+Cm80tlQdkU97MqYf11NG8IskjwVE6fQAIUSEiGFC3md72olbDSgjMKgAuiKV2wHUY8BIGKtBGN6EA8OapSWKEtAAG60LuFb7rKJJpio4SbKimwYJmupCFiEihK6bCbEMJ5nqhqhqCoJKTo0qgzmw4wQMqwiEkuW6tK4-KkOc0KBrWywqIRxEuBgZg8vAnGOPOvEAgsUBSDw8AHAkrHRBxIoPrJPF8iKCGwPa34QlCXa1BAhAgrpC4YMq-RsKQADqEC7EMooCH6-HmTcsAaexAw6dxC4PgATN+Ox8OMfC6ISKSIaplQANRcXJfJ2VIEjKh6ADM5xfqihn2oOMJjrMDY1oswl+WxOgDCVQ6-sOg5lSSQmqBAGR9J8GGkFh2y7PsIJgHwSlhpUkKHoG6E1ZpAyokxLG1RxQwjWN8AYFA8CELQUiwPEI7lQa3JVaoAnHXQDDAWte0bVtO17dql2dhVvn+XVpCtq9tRNhuX3HbUHb9iSzWjuOdRFFOjzwHy-l9GkGQ6IIy6ruuQg7v+CAis9IqzQFfEHudbRmqQfHDNQrkOgjJyfu80RQHxAASAAqOLjAAoggWpTUe1A6C48CpLQsCwBItA8AA1hUPONiwrEYAA+lIRiQcqxLfbIcukIr5psOLLBLXNS6HcdrWvUrKuIZ80w+ehpAsMkMWors8u6-rHIOxSugo2tQFinwgHUDKoNHYGgOezFGCgYHqRy7AUBDB2uGJDoAByo2qcafTGZUJth45Ee6FHYHCLHJAJyoGrUmYGCdSY3Xp1tQy-UIuFRGYIrcjnVGm+DMIK277SG-j0tEzCokkRJghSZxeMfQChDuuz+tqQ+8BwR36nLSiBUTWZGs-VrUcwOzG+CMPdVDOvm9z4SIo7bAZx56bPeBq1Nxm5V9zCVSyrpJza4zDa3uryTOOMRgU3-NTTIB0Az-BomocG9FSgJCSKkdINNkYjAmN5Bs7VmitHaJ0HoSJM79UBENJic49J8QGkCQ4MM4bQKRrAhBYNQ74MSMkZhZgvi0WoH4coFRlBxBUEsWAqJFAgHYGwIwpAkCWGsIkdKhhaBdHgISJksBLCIVkqQGCgtqABz8hLGK8AAC0pjEZmAdJYRmThEhOXdPHDAugeBSJUClAABgAfjeNkAAJMAHE5oWAYD6GoikYAKh+C8Qg-hVYuHoOscjcRlQKHAiGIYTBB0Lgy2OkqPgCAMDKPcjwrISTBbJn4fE+JVctQYAkKNB0tdTiEjYJoWCKlBAszZu5CQ213QaK6KKEUooxB7BFnwcxuhnFQHkAjSJGi+hWEmYkGZcz5CVg1iHZQ9Sa5RkLDGEi7p+kyDkEHAEyQoCnzMBfQk7keB+UlqM-Ie96xqH2YIRpzTWnIg6VALpZhenjH6YMhYpdXnjLWdM2ZfR44LPSEswkqyHGws2dskO9hHCxlKB4EAAB2FA3gcDmKJUgAAHDgfwgQQDPVELhUm9g4TRDYKIfwP46XBFEByFkKR-BAA)
| artydev | |
1,398,867 | sdfdssdfdsf | sdfdf | 0 | 2023-03-13T10:00:44 | https://dev.to/ar1f007/sdfds-n62 | sdfdf | ar1f007 | |
1,399,005 | Confused coder life !! | confused question is : I'm a code lover, i have very good basics in most of programming languages... | 0 | 2023-03-13T12:54:29 | https://dev.to/cryptographer3301/confused-coder-life--4ofb | confused question is :
I'm a code lover, i have very good basics in most of programming languages such as C++, JS, Golang, Perl
But i didn't find my passion yet, sometimes i learn web dev for while i find myself learning networking and a moment again i find myself in game dev, but my soul is in love something call hacking,
how to access inside systems and networks
that's why i decide to invest my programming knowledge in cyber security especially in malware programming , i want one day to make a tool like wireshark or metasploit or a strong malware,
but i see a lot of people talking about certifications
and for me i don't have money to pass certifications , I can just study them and gain knowledge is that good to work as an ethical hacker in freelance or with a company without certifications but with skills ? | cryptographer3301 | |
1,399,008 | Reinvent the wheel to understand Python asyncio. | During the last years coroutine based concurrency and the async/await syntax has exploded over a lot... | 0 | 2023-03-29T12:46:52 | https://dev.to/dontpanico/reinvent-the-wheel-to-understand-python-asyncio-3084 | python, asyncio, concurrency | During the last years coroutine based concurrency and the `async/await` syntax has exploded over a lot of languages, and so it has in Python too.
I found that people start using it recently (who haven't been there while it was implemented) are experiencing different kinds of problems while coding or debugging.
In this article we're gonna write our own multitasking library without using neither `asyncio`, nor the `async` and the `await` keywords, after exploring the basics of concurrency.
*This post assumes you're already familiar with python, python iterators and generators and with socket programming.*
## What is concurrency anyway?
According to wikipedia
> Concurrent computing is a form of computing in which several computations are executed concurrently—**during overlapping time periods**
In practice it means that while our function `a()` is executing, other functions **may** execute too and they run to completion in an interleaved manner.
However our program is still executing one thing at a time (as our cpu core is capable).
Parallelism (executing more things at once) is a special form of concurrency, but we're not talking about it today.
<!--Inserisci immagine per spiegare la differenza-->
## How do we reach concurrency in our programs
The easiest way to write a concurrent program is by using threads: you spawn a function in a thread, it starts running and any time the opportunity arises our cpu will switch between threads.
However, there are well known problems with threading programming like synchronization, memory usage, not having the control over context switches, etc, which all combined lead to some scalability limitation (you can find useful resources and articles on those problems searching online). Developers looked for something more lightweight and scalable that can be combined with multi-threading if needed and they came out with.. *iterators*.
## Concurrency with iterators
How do we achieve concurrency with iterators? There are two core concepts to keep into account:
* Interleaving.
* Execution during overlapping time periods.
If you think about how we can interleave execution of different units of code without spawning threads, you'll probably find out that you need a way to *pause/resume* that unit of code.
Look at the very basic implementation of an iterator:
```python
class ConcurrentUnit:
def __init__(self, to: int):
self._to = to
self._i = -1
def __iter__(self):
return self
def __next__(self):
self._i += 1
if self._i >= self._to:
raise StopIteration
return self._i
```
As you already know a for loop just keeps calling `.__next__` until `StopIteration` raises. Let's abuse this to execute code concurrently.
```python
from typing import TypeVar
T = TypeVar('T')
class ConcurrentUnit:
def __init__(self, to: int, return_value: T):
self._to = to
self._i = -1
self._return_value = return_value
def __iter__(self):
return self
def __next__(self):
self._i += 1
if self._i >= self._to:
raise StopIteration(self._return_value)
return self._i
if __name__ == '__main__':
cu1 = ConcurrentUnit(5, 'cu1')
cu2 = ConcurrentUnit(3, 'cu2')
tasks = [cu1, cu2]
while tasks:
t = tasks.pop(0)
try:
step = next(t)
print(step)
except StopIteration as e:
print(e.value)
else:
tasks.append(t)
```
If you run that code, the output will be:
```
0
0
1
1
2
2
3
cu2
4
cu1
```
You can see that our units have executed in an interleaved manner during overlapping periods of time and so yes, even without any benefit yet, we have written concurrent code. Let's look at it in detail.
The `ConcurrentUnit` class should be very easy to understand, from a behavioral point of view it's simulating the usage of `range(x)` (I've omitted `start` to keep it simple), but it also has a `return_value` parameter with a generic type annotation, that enable returning values from the execution. The `return_value` is bound to `StopIteration` when raised by `__next__` and we need to manually handle it calling `__next__` in a `try/except` block (we can't simply use a for loop which would handle the exception silently).
In our main block we create two concurrent units (they could've been more) and we store them in a list (like we would've done with a scheduler, more on this later) and we run our loop:
* First we pop our first unit in the list.
* We call `next` on our unit in a `try/except` block, and print the result out.
* If it raises `StopIteration` we get the `return_value` and print it out. At this point we know that our unit is done.
* Otherwise, we know that our unit is not done, so we append it to our list.
## Python Generators
The code above is very odd, and wrapping the logic of functions in iterator classes will really soon lead to big spaghetti code.
Luckily for us python has generators, which will let us declare functions that behave like iterators, and in addition they bound the value of the `return` statement to the `StopIteration` instance.
We can convert our above code into:
```python
def concurrent_unit(to: int) -> Generator[str]:
for i in range(to):
yield i
return f"run for {to} times"
if __name__ == '__main__':
cu1 = concurrent_unit(5)
cu2 = concurrent_unit(3)
tasks = [cu1, cu2]
while tasks:
t = tasks.pop(0)
try:
step = next(t)
print(step)
except StopIteration as e:
print(e.value)
else:
tasks.append(t)
```
and the code will behave the same.
There's an important concept you need to understand before we can move on and that's the difference between *generator objects* and *generator functions*.
A *generator function* is a function that just return a *generator object*: it does not execute any code other than creating the *generator object*. They can be recognized as the function body contains at least one `yield`.
The resulting *generator object* than implement the iteration protocol with `__next__` executing code up to the next `yield` statement.
This concept applies to coroutines too: `async def` functions are *coroutine functions* that return *coroutine objects* when called.
From now on, when I'll say *generator* I could either refer to functions or objects, the context will make it clear.
## Build our own concurrency library
In this section we're gonna use generators to develop the basic of our concurrency library.
First we'll define a `Task` object to wrap around generators and providing a layer of abstraction over our dude spaghetti. Then we'll write a scheduler to handle tasks execution. Let's dive into it.
```python
from collections.abc import Generator
from typing import Any, TypeVar
T = TypeVar("T")
class Task:
def __init__(
self,
generator: Generator[Any, Any, T],
*,
name: str | None = None,
debug: bool = False,
) -> None:
self._generator = generator
self._name = name
self._debug = debug
self._result: T | None = None
self._exception: Exception | None = None
self._done = False
def __repr__(self) -> str:
return f"<Task: {self._name}, done: {self._done}>"
def _step(self) -> None:
if self._done:
raise RuntimeError(f"{self}: Cannot step a done task")
try:
step = self._generator.send(None)
if self._debug:
print(f"{self}: {step}")
except StopIteration as e:
self._done = True
self._result = e.value
except Exception as e:
self._done = True
self._exception = e
if self._debug:
print(f"{self}: Exception: {e}")
def result(self) -> T:
return self._result
def exception(self) -> Exception:
return self._exception
def done(self) -> bool:
return self._done
```
Our `Task` class stores a generator object and has 3 attributes that are worth looking at:
* `_done` indicating whether the task can be considered completed or not.
* `_result` indicating the generator return value, if any.
* `_exception` any exception other than `StopIteration` that our generator may raises.
The `_step` method builds upon the execution logic used before with iterators: it represents a single *"step"* of our task. It calls `next` on `self._generator` (`gen.send(None)` is the same as `next(gen)`) and if we get either a result (wrapped in a `StopIteration` error) or an exception, stores it in the corresponding attribute.
You're may asking yourself *"why is he just storing the exception instead of raising it?"*. In the next section I'm answering that question. By now, go on to build a scheduler for our tasks:
```python
from collections.abc import Callable, Generator
from typing import Any, TypeVar
from .tasks import Task
T = TypeVar("T")
class EventLoop:
def __init__(self, *, debug: bool = False) -> None:
self._debug = debug
self._tasks: list[Task] = []
self._tasks_counter: int = 0
def create_task(
self, generator: Generator[Any, Any, T], *, name: str | None = None
) -> Task:
task = Task(
generator,
name=name or f"Task-{self._tasks_counter}",
debug=self._debug,
)
self._tasks.append(task)
self._tasks_counter += 1
return task
def run_until_complete(
self,
generator: Generator[Any, Any, T],
*,
task_name: str | None = None,
) -> T:
main_task = self.create_task(generator, name=task_name)
while not main_task._done:
for task in self._tasks:
task._step()
if task._done:
self._tasks.remove(task)
if main_task._exception:
raise main_task._exception
return main_task._result
```
Looks familiar? Our event loop has a method to create new task objects and one for running them.
`run_until_complete` takes a generator, creates a task from it (`main_task`) and then runs all the scheduled tasks until `main_task` completes. The execution logic is not different from our first poc with iterators: we iterate through `self._tasks`, run *"one step"* of each item and any time a task has done we remove it from the list.
```python
def concurrent_unit(to: int) -> Generator[str]:
for i in range(to):
yield i
return f"run for {to} times"
if __name__ == '__main__':
loop = EventLoop(debug=True)
t1 = loop.create_task(concurrent_unit(2))
t2 = loop.create_task(concurrent_unit(3))
loop.run_until_complete(concurrent_unit(5))
# output
# <Task: Task-0, done: False>: 0
# <Task: Task-1, done: False>: 0
# <Task: Task-2, done: False>: 0
# <Task: Task-0, done: False>: 1
# <Task: Task-1, done: False>: 1
# <Task: Task-2, done: False>: 1
# <Task: Task-2, done: False>: 2
# <Task: Task-1, done: False>: 2
# <Task: Task-2, done: False>: 3
# <Task: Task-2, done: False>: 4
```
## Cool, but what about await?
As I stated before, we're not allowed to use the `async` and the `await` keywords, so how we're going to achieve the same functionality here?
We learned so far that coroutines are just iterators (or better generators), so how do we await an iterator? If you thought about ***for loops***, then you're right. Let's look at the example below:
```python
def concurrent_unit(to: int) -> Generator[str]:
for i in range(to):
yield i
return f"run for {to} times"
if __name__ == '__main__':
loop = EventLoop(debug=True)
def main():
t1 = loop.create_task(concurrent_unit(2))
t2 = loop.create_task(concurrent_unit(3))
yield 'a'
loop.run_until_complete(main())
# output
# <Task: Task-0, done: False>: a
# <Task: Task-1, done: False>: 0
# <Task: Task-2, done: False>: 0
# <Task: Task-2, done: False>: 1
```
As you can see `t1` and `t2` do not complete and that's because `main()` completes before them. If you look at the `run_until_complete` source code, you see that when `main_task` is done we exit the while loop, no matter if there are still *undone* tasks. While this is the intended behaviour, we need a way to wait for completion of specific tasks before moving on and we're gonna do that with for loops:
```python
def concurrent_unit(to: int) -> Generator[str]:
for i in range(to):
yield i
return f"run for {to} times"
if __name__ == '__main__':
loop = EventLoop(debug=True)
def main():
t1 = loop.create_task(concurrent_unit(2))
t2 = loop.create_task(concurrent_unit(3))
for step in concurrent_unit(5):
yield step
loop.run_until_complete(main(), task_name='main_task')
# output
# <Task: main_task, done: False>: 0
# <Task: Task-1, done: False>: 0
# <Task: Task-2, done: False>: 0
# <Task: main_task, done: False>: 1
# <Task: Task-1, done: False>: 1
# <Task: Task-2, done: False>: 1
# <Task: main_task, done: False>: 2
# <Task: main_task, done: False>: 3
# <Task: Task-2, done: False>: 2
# <Task: main_task, done: False>: 4
```
This time all the tasks completed.
Before diving in what's wrong we the above code we have to thanks Python and generators once more: instead of using an ugly for loop to replace await, we can use the `yield from` syntax: `yield from gen` is the same as `for x in gen: yield x`. From now on, we'll use `yield from` as our `await` (and that's what Python does too under the hood).
```python
def main():
t1 = loop.create_task(concurrent_unit(2))
t2 = loop.create_task(concurrent_unit(3))
yield from concurrent_unit(5)
```
As I stated before the above code introduces some pitfalls. Since we can not `yield from` objects we can not await tasks, in fact you may have noticed that I didn't spawn a task from `concurrent_unit(5)`. To have some consistency we have to find a way to `yield from` tasks.
We can write an helper function that takes a task object and keeps calling `_step` until it's done, but that will conflict with the event loop calling `_step` too. We could make `Task` an iterator defining `__iter__` and `__next__` and that will work (you can use `yield from` with iterators). However, generators are usually faster than iterators (I won't dive into it, if you're interested in that topic you can find useful resources searching on google) so I opted to write a new method on the task interface, a generator function just yielding back to the event loop until the task is done.
```python
class Task:
def __init__(
self,
generator: Generator[Any, Any, T],
*,
name: str | None = None,
debug: bool = False,
) -> None:
self._generator = generator
self._name = name
self._debug = debug
self._result: T | None = None
self._exception: Exception | None = None
self._done = False
def __repr__(self) -> str:
return f"<Task: {self._name}, done: {self._done}>"
def _step(self) -> None:
if self._done:
raise RuntimeError(f"{self}: Cannot step a done task")
try:
step = self._generator.send(None)
if self._debug:
print(f"{self}: {step}")
except StopIteration as e:
self._done = True
self._result = e.value
except Exception as e:
self._done = True
self._exception = e
if self._debug:
print(f"{self}: Exception: {e}")
def result(self) -> T:
return self._result
def exception(self) -> Exception:
return self._exception
def done(self) -> bool:
return self._done
def wait(self) -> T:
while not self._done:
yield
if self._exception:
raise self._exception
return self._result
```
Now we can refactor our example with our new wait logic:
```python
if __name__ == '__main__':
loop = EventLoop(debug=True)
def main():
t1 = loop.create_task(concurrent_unit(2))
t2 = loop.create_task(concurrent_unit(3))
t3 = loop.create_task(concurrent_unit(5))
# yield from task.wait() will either raise
# task._exception (if it's not None) or
# return task._result.
# This means that exceptions do not propagate
# until the task is awaited.
result = yield from t3.wait()
yield 'a'
yield 'b'
loop.run_until_complete(main(), task_name='main_task')
# <Task: main_task, done: False>: None
# <Task: Task-1, done: False>: 0
# <Task: Task-2, done: False>: 0
# <Task: Task-3, done: False>: 0
# <Task: main_task, done: False>: None
# <Task: Task-1, done: False>: 1
# <Task: Task-2, done: False>: 1
# <Task: Task-3, done: False>: 1
# <Task: main_task, done: False>: None
# <Task: Task-3, done: False>: 2
# <Task: main_task, done: False>: None
# <Task: Task-2, done: False>: 2
# <Task: Task-3, done: False>: 3
# <Task: main_task, done: False>: None
# <Task: main_task, done: False>: None
# <Task: Task-3, done: False>: 4
# <Task: main_task, done: False>: None
# <Task: main_task, done: False>: a
# <Task: main_task, done: False>: b
```
As you can see we are awaiting the task, yielding from its `wait` method. Without this method, whenever we've needed to retrieve the result of a task (either a value or an exception), we should've done it accessing the related attribute.
As Python asyncio does, we propagate exceptions via await: we don't *re-raise* immediately after having caught them, but when the task is awaited.
I want to mention one last thing about `await` in Python: a general misconception about it is that when we `await` a coroutine or a task we are telling the event loop to *"not doing anything else until that coroutine either returns or raises"*, however, as you can see from the output of our last example, tasks scheduled before our `yield from` (and so `await`) statement still run interleaving with the awaited task (`t3`).
What `await` really tells to the event loop (and that's an approximation, since the event loop it's not aware of it) is: "**do not go over with the current task until the task I'm awaiting on has done. In the meantime you can still run other scheduled tasks**" where *current task* is `main` and the task *I'm awaiting on* is `t3` in our current context.
Again, that sentence describes the `await` behaviour but it's not really true since a task can not control what the event loop does. Actually we are taking care of preventing the execution of the current task to go on before `t3` completes, rather than giving instructions to the event loop.
## Run blocking code
Sometimes you may need to use blocking functions (functions that can't yield back to the event loop). You can use threads to run such functions to avoid blocking the execution of the event loop and one of the most efficient ways to do it is with a threadpool.
Since we're just exploring core concepts we're not gonna implement a threadpool ourselves, but we'll just use a method to spawn a callable in a new thread. You can learn more about threadpools searching by your own or reading through the Python `concurrent.futures.thread` source code.
We can modify our event loop implementation a bit to handle a set of worker threads:
```python
class EventLoop:
def __init__(self, *, debug: bool = False) -> None:
self._debug = debug
self._tasks: list[Task] = []
self._tasks_counter: int = 0
self._workers: set[threading.Thread] = set()
def _spawn(self, callable: Callable[..., Any]):
thread = threading.Thread(target=callable)
thread.start()
self._workers.add(thread)
...
```
The above code will work, but there are two problems with it:
* Whenever we want to use arguments and keyword arguments we have to rely on `functools.partial`.
* We need a way to retrieve the execution result.
To solve those problems we could write a class that encapsulate all the attributes and the logic we need and update `EventLoop._spawn` signature to match it:
```python
class _Work:
def __init__(
self, fn: Callable[..., T], /, *args, **kwargs
) -> None:
self.fn = fn
self.args = args
self.kwargs = kwargs
self.result: T | None = None
self.exception: Exception | None = None
def run(self) -> None:
try:
result = self.fn(*self.args, **self.kwargs)
except Exception as e:
self.exception = e
else:
self.result = result
```
You may have noticed that a pattern has emerged: we have `result` and `exception` and we could write a `wait` generator method like the one of `Task` to interoperate with non blocking code.
To be cleaner, let's put our common waiting logic in a base interface:
```python
T = TypeVar('T')
class Waitable(ABC, Generic[T]):
@abstractmethod
def wait(self) -> Generator[Any, Any, T]:
...
```
We could then make `Task` and `_Work` inherit from `Waitable`.
However, if you start thinking about all possible applications for that logic you may come up with a better solution. While `Task` being a special case, the use case of `_Work` may recur in the future and we should build a reusable interface for that:
```python
class Waiter(Waitable):
def __init__(self) -> None:
self._result: T | None = None
self._exception: Exception | None = None
self._done: bool = False
def __repr__(self) -> str:
return f'<Waiter: done: {self.done()}>'
def done(self) -> bool:
return self._done
def result(self) -> T:
return self._result
def exception(self) -> Exception:
return self._exception
def set_result(self, result: T) -> None:
if self._done:
raise RuntimeError('Waiter is already done')
self._done = True
self._result = result
def set_exception(self, exception: Exception) -> None:
if self._done:
raise RuntimeError('Waiter is already done')
self._done = True
self._exception = exception
def wait(self) -> Generator[Any, Any, T]:
while not self.done():
yield
if self._exception:
raise self._exception
return self._result
```
`Waiter` may resemble you Python `Future` objects.. and once more, you're right. We have defined an object that act as a placeholder for a future result (either a value or an exception) that can be set by other functions. This is also a fundamental building block for synchronization.
Let's use `Waiter` in the `_Work` class:
```python
class _Work:
def __init__(
self, waiter: Waiter, fn: Callable[..., T], /, *args, **kwargs
) -> None:
self.waiter = waiter
self.fn = fn
self.args = args
self.kwargs = kwargs
def run(self) -> None:
try:
result = self.fn(*self.args, **self.kwargs)
except Exception as e:
self.waiter.set_exception(e)
else:
self.waiter.set_result(result)
```
Now update the event loop implementation:
```python
class EventLoop:
def __init__(self, *, debug: bool = False) -> None:
self._debug = debug
self._tasks: list[Task] = []
self._tasks_counter: int = 0
self._workers: set[threading.Thread] = set()
def _spawn(self, work: _Work):
thread = threading.Thread(target=work.run)
thread.start()
self._workers.add(thread)
def run_in_thread(self, fn: Callable[..., T], /, *args, **kwargs) -> Waiter[T]:
waiter = Waiter()
work = _Work(waiter, fn, *args, **kwargs)
self._spawn(work)
return waiter
...
```
Let's try it out:
```python
if __name__ == '__main__':
# set it to `True` to better understand the behavior
loop = EventLoop(debug=False)
def blockingf(i: int) -> int:
time.sleep(1)
return f'BLOCKING finished after {i} seconds'
def genf(i: int) -> Generator[Any, Any, str]:
for j in range(i):
yield i
return f'non-blocking finished after {i} iterations'
def main():
t1 = loop.create_task(genf(3))
t2 = loop.create_task(genf(2))
w1 = loop.run_in_thread(blockingf, 2)
res_blocking = yield from w1.wait()
res1 = yield from t1.wait()
res2 = yield from t2.wait()
print(res1, res2, res_blocking, sep='\n')
loop.run_until_complete(main())
# output
# non-blocking finished after 3 iterations
# non-blocking finished after 2 iterations
# BLOCKING finished after 2 seconds
```
We have successfully mixed blocking code with *"non blocking"* code.
In the next section we'll build a concurrent network service using what we have developed so far.
## Socket and Selectors
At the beginning of this post I've asked for your knowledge about socket programming.
If you've ever built a TCP service with Python, you eventually got in touch with the old problem of how to handle concurrent connections.
Python socket programming HOWTO has a section about non blocking sockets and [select](https://docs.python.org/3/library/select.html) (I recommend you to read it if you've not, [go here](https://docs.python.org/3/howto/sockets.html)).
We're now going to combine what we have learned today with it, using [selectors](https://docs.python.org/3/library/selectors.html) which is an high level interface over `select`.
If you want to read more about selectors you can go through the documentation, but for the purpose of this post it's enough to understand that with selectors we can:
* Register a socket object waiting for either read or write events, associating data to it (any object, even a callable).
* Update the event kind or the data of a registered socket.
* Unregister a registered socket.
* Call `selector.select` to get a list of ready sockets (with other information like the event type and our associated data). We can safely assert that calling methods on socket objects returned by `selector.select` are not going to block.
First we need to implement methods to register/unregister sockets on the event loop:
```python
class EventLoop:
def __init__(self, *, debug: bool = False) -> None:
self._debug = debug
self._tasks: list[Task] = []
self._tasks_counter: int = 0
self._workers: set[threading.Thread] = set()
self._selector = selectors.DefaultSelector()
...
def _create_waiter(self) -> Waiter:
return Waiter()
def add_reader(self, fd: int, callback: Callable[..., None]) -> None:
try:
self._selector.get_key(fd)
except KeyError:
self._selector.register(fd, selectors.EVENT_READ, callback)
def remove_reader(self, fd: int) -> None:
try:
self._selector.unregister(fd)
except KeyError:
pass
def add_writer(self, fd: int, callback: Callable[..., None]) -> None:
try:
self._selector.get_key(fd)
except KeyError:
self._selector.register(fd, selectors.EVENT_WRITE, callback)
def remove_writer(self, fd: int) -> None:
try:
self._selector.unregister(fd)
except KeyError:
pass
```
`selectors.DefaultSelector` returns the best selector implementation for your platform and `_create_waiter` is just a convenience method.
Then we have methods to register sockets (one for read events and one for write events) and the same to unregister them.
With that, we can define the non-blocking methods required to build our TCP server. For the scope of this post we'll only need 3: `socket.accept`, `socket.recv` and `socket.sendall`.
```python
class EventLoop:
...
def _sock_recv(
self, sock: socket.socket, nbytes: int, waiter: Waiter
) -> None:
try:
result = sock.recv(nbytes)
except (BlockingIOError, InterruptedError):
return
except Exception as e:
waiter.set_exception(e)
else:
waiter.set_result(result)
def sock_recv(
self, sock: socket.socket, nbytes: int
) -> Generator[Any, Any, bytes]:
waiter = self._create_waiter()
self.add_reader(
sock.fileno(),
functools.partial(self._sock_recv, sock, nbytes, waiter),
)
res = yield from waiter.wait()
return res
def _sock_sendall(
self, sock: socket.socket, data: bytes, waiter: Waiter
) -> None:
try:
result = sock.sendall(data)
except (BlockingIOError, InterruptedError):
return
except Exception as e:
waiter.set_exception(e)
else:
waiter.set_result(result)
def sock_sendall(
self, sock: socket.socket, data: bytes
) -> Generator[Any, Any, None]:
waiter = self._create_waiter()
self.add_writer(
sock.fileno(),
functools.partial(self._sock_sendall, sock, data, waiter),
)
res = yield from waiter.wait()
return res
def _sock_accept(self, sock: socket.socket, waiter: Waiter) -> None:
try:
result = sock.accept()
except (BlockingIOError, InterruptedError):
return
except Exception as e:
waiter.set_exception(e)
else:
waiter.set_result(result)
def sock_accept(
self, sock: socket.socket
) -> Generator[Any, Any, tuple[socket.socket, Any]]:
waiter = self._create_waiter()
self.add_reader(
sock.fileno(), functools.partial(self._sock_accept, sock, waiter)
)
res = yield from waiter.wait()
return res
def process_events(
self,
events: list[tuple[selectors.SelectorKey, type[selectors.EVENT_READ]]],
) -> None:
for key, mask in events:
fileobj, callback = key.fileobj, key.data
callback()
if mask & selectors.EVENT_READ:
self.remove_reader(fileobj)
if mask & selectors.EVENT_WRITE:
self.remove_writer(fileobj)
def run_until_complete(
self,
generator: Generator[Any, Any, T],
*,
task_name: str | None = None,
) -> T:
main_task = self.create_task(generator, name=task_name)
while not main_task._done:
ready = self._selector.select(0)
if ready:
self.process_events(ready)
for task in self._tasks:
task._step()
if task._done:
self._tasks.remove(task)
if main_task._exception:
raise main_task._exception
return main_task._result
def close(self) -> None:
for thread in self._workers:
thread.join()
self._selector.close()
```
To understand what's going on with that code, let's look at `_sock_recv` and `sock_recv`.
The former takes a socket and a `Waiter` object, tries to run `socket.recv` and stores either the result or any exception on the waiter.
The latter is a generator function that creates the waiter object and calls `add_reader` to register the socket and `_sock_recv` as a callback (we use `functools.partial` to bound arguments to keep it simple). Then it awaits the waiter (yielding from its `wait` method) and returns its result. We know that `Waiter.wait` just yields until the waiter has done (and that means the `_sock_recv` has called either `set_result` or `set_exception`).
As you can see in `run_until_complete`, at each iteration we get a list of ready sockets that we have registered with `add_reader` or `add_writer`. As we said before we can trust `self._selector.select` to give us only sockets that aren't gonna block so we run associated callbacks (like `_sock_recv`) with `process_events`.
So if we write:
```python
...
data = yield from loop.sock_recv(sock_obj, 1024)
...
```
We are doing the following:
1. We create a new waiter and we schedule `loop._sock_recv(sock_obj, 1024, waiter)` to run as soon as `loop._selector.select` will tell us that sock_obj is ready.
2. We await the waiter. As we've learned before, `sock_recv` does not move on until `yield from waiter.wait()` is done, but other scheduled tasks still run.
4. At some point, during an iteration of the while loop in `run_until_complete` the selector will give us `sock_obj` and the scheduled callback (`_sock_recv` with the signature of step 1). `process_events` will run the callback that's gonna set the result on our waiter.
5. `sock_recv` get the result of `waiter` (so it exits the `yield from waiter.wait()` line) and returns it.
We're now ready to build a concurrent tcp service. In the next section we'll build an echo service with what we've learned so far.
## Concurrent echo service
At this point the implementation of our service should be straightforward.
```python
loop = EventLoop()
def process_client(client: socket.socket, address: tuple[str, int]) -> None:
print('New client:', address)
try:
while True:
data = yield from loop.sock_recv(client, 1024)
print(address, data)
if not data:
break
yield from loop.sock_sendall(client, data)
finally:
client.close()
print('Client closed:', address)
def main1():
server = socket.create_server(
('127.0.0.1', 1234), family=socket.AF_INET, backlog=5, reuse_port=True
)
server.setblocking(False)
while True:
client, address = yield from loop.sock_accept(server)
client.setblocking(False)
loop.create_task(process_client(client, address))
loop.run_until_complete(main1())
```
In our main function, we create a *"server"* socket and set it to non-blocking. We then enter a while loop and accept new connections with `loop.sock_accept`. Any time we get one, set it to non-blocking too and start a new task from `process_client` to handle it.
`process_client` itself, just keeps awaiting on `loop.sock_recv` to get data and streams it back to the client with `loop.sock_sendall` as long as it gets any data.
Let's run it. I'll use two terminals with telnet to connect and send data.
The output should be something like:
```
New client: ('127.0.0.1', 39698)
New client: ('127.0.0.1', 39700)
('127.0.0.1', 39700) b'hello world 1\r\n'
('127.0.0.1', 39698) b'hello world 2\r\n'
('127.0.0.1', 39698) b'I go now\r\n'
('127.0.0.1', 39698) b''
Client closed: ('127.0.0.1', 39698)
('127.0.0.1', 39700) b'me too\r\n'
('127.0.0.1', 39700) b''
Client closed: ('127.0.0.1', 39700)
```
## Conclusion
In the end we have developed a concurrent service using neither async nor await directly, but we have replaced them with a similar underlying implementation to understand the core concepts behind them.
The aim of this post wasn't to give a better performing or a cleaner implementation of Python asyncio, but to *demistify* `async` and `await` for asyncio beginners, *re-building* already existing features.
With those fundamental building blocks for concurrent programming, you can implement any kind of concurrent feature. Think about async queues. It would be as simple as:
```python
class Queue(Generic[T]):
def __init__(self, max_size: int = -1) -> None:
self._max_size = max_size
self._queue: deque[T] = deque()
def __repr__(self) -> str:
return f"<Queue max_size={self._max_size} size={len(self._queue)}>"
def qsize(self) -> int:
return len(self._queue)
def empty(self) -> bool:
return not self._queue
def full(self) -> bool:
if self._max_size < 0:
return False
return len(self._queue) >= self._max_size
def put(self, item: T) -> Generator[Any, Any, None]:
while self.full():
yield
self._queue.append(item)
def get(self) -> Generator[Any, Any, T]:
while self.empty():
yield
return self._queue.pop()
def put_nowait(self, item: T) -> None:
if self.full():
raise RuntimeError(f"{self} is full")
self._queue.append(item)
def get_nowait(self) -> T:
if self.empty():
raise RuntimeError(f"{self} is empty")
return self._queue.pop()
```
Or what about tasks cancellation? You can challenge yourself to implement it in the most efficient way (and updated `EventLoop.close` to cancel remaining tasks).
I hope that this tour has been useful to you and I can't wait to read your feedback in the comments.
| dontpanico |
1,402,206 | Building a Location-Map App in React using Vite and Mapbox | Location-map apps like Google maps have become increasingly part of our day-to-day activities as we... | 0 | 2023-03-15T17:32:37 | https://tonie.hashnode.dev/building-a-location-map-app-in-react-using-vite-and-mapbox | react, mapbox, vite, javascript | ---
title: Building a Location-Map App in React using Vite and Mapbox
published: true
date: 2023-02-20 10:35:44 UTC
tags: react,mapbox,vite,javascript
canonical_url: https://tonie.hashnode.dev/building-a-location-map-app-in-react-using-vite-and-mapbox
---
Location-map apps like Google maps have become increasingly part of our day-to-day activities as we rely on them to navigate our surroundings and also get information about other places.
In this article, we will explore how to build a location-map app in React using Vite and Mapbox.
React is a popular JavaScript library for building user interfaces, while Vite is a modern build tool that enables fast and efficient development.
Mapbox, on the other hand, is a powerful platform for building custom maps and integrating them into web and mobile applications.
Throughout this article, we will cover the basic steps of setting up a React application, integrating Vite for fast development, and using Mapbox to add custom maps and location data to our app.
And by the end of this article, you will have the knowledge and tools to create your location-map app using these technologies.
## Prerequisites
To follow along in this tutorial, you will need the following:
- Basic knowledge of React and JavaScript
- Node and npm installed on your machine
- A Mapbox account (this is because you will need a personalized API key). If you don't have a Mapbox account, you can sign up using [this link](https://account.mapbox.com/auth/signup/)
You can view the live version of this project [here](https://location-map.netlify.app/). This will give you an idea and expectation of the application we will be building today
## Building out our Location-Map App
Now that we have the prerequisites out of the way, it's time to get our hands dirty. Let's go!
### Project setup
Create a new folder on your local machine and open it within your preferred code editor. In this tutorial, we named our folder "location-map" and we used VS Code as our code editor.
Open your terminal and type in the following command. This is to create our react project using Vite. The period sign "." tells Vite that we want our project to be initialized in our current directory.
```
npm create vite@latest . //if you use npm
//or
yarn create vite . //if you use yarn
```
Follow the prompts using your arrow keys and pressing enter. Once you are done, you should have a project structure like the one below
Next, we need to install one dependency which is the Mapbox package. Open your terminal and type
```
npm install mapbox-gl //if you use npm
//or
yarn add mapbox-gl //if you use yarn
```
### Configuring our App
Go into the index.css file within the src folder. Replace the css there with the one below
```
* {
box-sizing: border-box;
padding: 0;
margin: 0;
}
body {
margin: 0;
font-size: 1rem;
overflow-x: hidden;
}
```
Also, go into the App.css file and replace the code there with the one below:
```
.map-container {
height: 100vh;
width: 100vw;
}
.sidebar {
background-color: rgba(35, 55, 75, 0.9);
color: #fff;
padding: 6px 12px;
font-family: monospace;
z-index: 1;
position: absolute;
bottom: 1rem;
left: 0;
margin: 12px;
border-radius: 4px;
}
```
These are just some default styles for our component and divs which we will create later.
Also within the head tag in the index.html file, we need to add the following link tag. To enable us to use the default styles provided by Mapbox.
```
<link
rel="stylesheet"
href="https://api.mapbox.com/mapbox-gl-js/plugins/mapbox-gl-directions/v4.1.1/mapbox-gl-directions.css"
type="text/css"
/>
```
Now go into the `App.jsx` file and delete every code logic within the `div` with the class name `App`. Your file should look like this.
Next go into your src folder and create a new file named ".env". This is where we will store our API key.
Go to your Mapbox dashboard and at the bottom of the page, you will find your API key. Copy and paste it into the .env file so:
```
VITE_MAPBOX_KEY = YOUR_API_KEY
```
### Creating our Map using Mapbox
Go into the App.jsx file within the src folder and update the code to look like this:
```
import mapboxgl from "mapbox-gl";
import { useEffect, useRef, useState } from "react";
import "./App.css";
mapboxgl.accessToken = import.meta.env.VITE_MAPBOX_KEY;
function App() {
const mapContainer = useRef(null);
const map = useRef(null);
const [lng, setLng] = useState(-70.9);
const [lat, setLat] = useState(42.35);
const [zoom, setZoom] = useState(9);
useEffect(() => {
if (map.current) return; // initialize map only once
map.current = new mapboxgl.Map({
container: mapContainer.current,
style: "mapbox://styles/mapbox/streets-v12",
center: [lng, lat],
zoom: zoom,
});
return (
<div className="App">
<div ref={mapContainer} className="map-container" />
</div>
);
}
export default App;
```
In the code snippet above, we imported the Mapbox package we installed earlier and we initialized our access token with the value we stored in our .env file.
Next, we declared our app's default state using the useState and useRef hooks. Then we initialized our map using a useEffect hook. This will ensure that our map will be created as soon as our App component is mounted in the DOM.
Also, we rendered this map in a div within the return statement.
Open your terminal and start your application using the code below to see the application on your device's browser.
```
npm run dev
//or
yarn run dev
```
### Adding a Div to show Longitude, Latitude and Zoom level
Next, we need to add some interactivity to our application. First, we will add a div that shows the latitude and longitude of any location the user clicks on the map.
For this, add another useEffect hook to our App.jsx component just below the previous one.
```
useEffect(() => {
if (!map.current) return; // wait for map to initialize
map.current.on("move", () => {
setLng(map.current.getCenter().lng.toFixed(4));
setLat(map.current.getCenter().lat.toFixed(4));
setZoom(map.current.getZoom().toFixed(2));
});
});
```
This utilizes the useState hook we created earlier and updates the longitude, latitude and zoom level according to the user's interaction with the application.
Update the return block in our to look like this:
```
return (
<div className="App">
<div className="sidebar">
Longitude: {lng} | Latitude: {lat} | Zoom: {zoom}
</div>
<div ref={mapContainer} className="map-container" />
</div>
);
```
Save your code and refresh your browser to see how it looks. Nice, yeah? Now let's add more functionality
### Adding More Functionalities
For this, we need to add some code to our first useEffect code block. Update the useEffect code block to look like this:
```
useEffect(() => {
if (map.current) return; // initialize map only once
map.current = new mapboxgl.Map({
container: mapContainer.current,
style: "mapbox://styles/mapbox/streets-v12",
center: [lng, lat],
zoom: zoom,
});
map.current.addControl(new mapboxgl.NavigationControl());
map.current.addControl(new mapboxgl.FullscreenControl());
map.current.addControl(
new mapboxgl.GeolocateControl({
positionOptions: {
enableHighAccuracy: true,
},
trackUserLocation: true,
})
);
});
```
- mapboxgl.NavigationControl() adds a button to enable the user zoom in, zoom out and rotate the map.
- mapboxgl.FullscreenControl() adds a button that allows the user to full-screen mode.
- mapboxgl.GeolocateControl() adds a button that lets the user view their current location
### Adding the direction component
One final component we will need in our application is a direction component that lets the user know the distance and time it will take to get from one point on our map to another. This will specify different formats like driving, cycling, walking etc.
To achieve this, we'll be adding a cdn script tag to our index.html file. Add the following script tag within the head tag in the index.html file:
```
<script src="https://api.mapbox.com/mapbox-gl-js/plugins/mapbox-gl-directions/v4.1.1/mapbox-gl-directions.js"></script>
```
After adding this tag, your index.html file should look like this:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<script src="https://api.mapbox.com/mapbox-gl-js/plugins/mapbox-gl-directions/v4.1.1/mapbox-gl-directions.js"></script>
<link
rel="stylesheet"
href="https://api.mapbox.com/mapbox-gl-js/plugins/mapbox-gl-directions/v4.1.1/mapbox-gl-directions.css"
type="text/css"
/>
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Location App using Map Box</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.jsx"></script>
</body>
</html>
```
Next, we need to add some code to display the directions component in our application. To do that, add the following code snippet to the first useEffect code block in our App.jsx file:
```
map.current.addControl(
new MapboxDirections({
accessToken: mapboxgl.accessToken,
}),
"top-left"
);
```
This will add the direction control at the top-left of our screen. At this point your App.jsx file should look like this:
```
import mapboxgl from "mapbox-gl";
import { useEffect, useRef, useState } from "react";
import "./App.css";
mapboxgl.accessToken = import.meta.env.VITE_MAPBOX_KEY;
function App() {
const mapContainer = useRef(null);
const map = useRef(null);
const [lng, setLng] = useState(-70.9);
const [lat, setLat] = useState(42.35);
const [zoom, setZoom] = useState(9);
useEffect(() => {
if (map.current) return; // initialize map only once
map.current = new mapboxgl.Map({
container: mapContainer.current,
style: "mapbox://styles/mapbox/streets-v12",
center: [lng, lat],
zoom: zoom,
});
map.current.addControl(new mapboxgl.NavigationControl());
map.current.addControl(new mapboxgl.FullscreenControl());
map.current.addControl(
new mapboxgl.GeolocateControl({
positionOptions: {
enableHighAccuracy: true,
},
trackUserLocation: true,
})
);
map.current.addControl(
new MapboxDirections({
accessToken: mapboxgl.accessToken,
}),
"top-left"
);
});
useEffect(() => {
if (!map.current) return; // wait for map to initialize
map.current.on("move", () => {
setLng(map.current.getCenter().lng.toFixed(4));
setLat(map.current.getCenter().lat.toFixed(4));
setZoom(map.current.getZoom().toFixed(2));
});
});
return (
<div className="App">
<div className="sidebar">
Longitude: {lng} | Latitude: {lat} | Zoom: {zoom}
</div>
<div ref={mapContainer} className="map-container" />
</div>
);
}
export default App;
```
## Conclusion
In this article, we explored how to build a location-map app in React using Vite and Mapbox.
We saw how to use React to build a flexible and responsive user interface that can easily integrate with Mapbox's mapping platform, which offers numerous customization options to create maps that fit the specific needs of our app.
Whether it's visualizing data, creating interactive experiences, or simply providing a more immersive way to view a location, a location-map app built with React, Vite, and Mapbox has the potential to be a valuable tool for a wide range of use cases.
## Resources
Here are some useful resources to aid your development of this project
- [Project live version](https://location-map.netlify.app/)
- [Project Source code](https://github.com/Tonie-NG/maps-app). Don't forget to star the repository
- [Mapbox React Documentation](https://docs.mapbox.com/help/tutorials/use-mapbox-gl-js-with-react/)
- [Vite Docs](https://vitejs.dev/guide/)
If you have any questions or suggestions, I'm buzzing to hear from you in the comment section.
Happy coding | tonieng |
1,399,228 | Define physics? | Physics is the scientific study of matter, energy, and the fundamental principles that govern the... | 0 | 2023-03-13T15:27:08 | https://dev.to/huzaifajat/define-physics-40da | physics, define | Physics is the scientific study of matter, energy, and the fundamental principles that govern the behavior of the universe at both the smallest and largest scales. It seeks to understand the natural world by using empirical observation, mathematical modeling, and experimentation. | huzaifajat |
1,399,278 | My first post! | Hey guys, i am new here. I started my journey about 5 weeks ago. Joined a bootcamp, and currently... | 0 | 2023-03-13T16:43:18 | https://dev.to/akz/my-first-post-5g78 | beginners, webdev, bootcamp, career | Hey guys, i am new here. I started my journey about 5 weeks ago.
Joined a bootcamp, and currently struggle with #javascirpt...
Hope to find new friend here :)
https://www.youtube.com/watch?v=IN-Pz12TUdI&ab_channel=AkzMedia | akz |
1,399,503 | Cors problem | Cross-Origin resource sharing or also known as 'cors': When we set up a nodejs server is really... | 0 | 2023-03-13T19:22:39 | https://dev.to/lausuarez02/cors-problem-4hj4 | javascript, beginners, node | Cross-Origin resource sharing or also known as 'cors':
When we set up a nodejs server is really important to add two lines of code that will keep you out of this kind of trouble.
At the nodejs server we will go and we will import 'cors'
```js
const cors = require('cors')
```
And then we will have to call cors in our app in order to use it as follows.
```js
app.use(cors());
```
Remember to install cors in your nodejs project as follows.
`npm i cors`
This will solve you headaches.
Hope someone found it useful.
Lautaro.
| lausuarez02 |
1,399,510 | New grid library for instant big data processing- DataTableDev🚀 | We are happy to present the launch of our new product we've been working on for over a year. For 14... | 0 | 2023-03-13T19:38:11 | https://dev.to/datatabledev/new-grid-library-for-instant-big-data-processing-datatabledev-16b3 | javascript, showdev, webdev, programming | We are happy to present the launch of our new product we've been working on for over a year.
For 14 years, we've been developing components for data visualization and data analytics and noticed a need for a component that can work fast with enormous datasets. We gathered all our experience and expertise to create new technology that easily handles this task. The new approach responds immediately and smoothly to any user interaction, regardless of file size.
We decided to show our technology in the form of a grid, as it's a straightforward but effective instrument to work with data. We also have ambitious plans to develop this technology further and go beyond the grid functionality, but today we want to tell you about [DataTableDev](https://datatable.dev/).
## DataTableDev - is a grid library for instant big data processing🚀
Diving into the topic deeply, we challenged ourselves with a more complex task - **to save users' time**.
So our goal was to get end-users to access the data instantly despite the volumes, without time spent on reloading data & redrawing the grid each time the user interacts with it.
## How did we get there? 🎉
Considering core stages when working with big data - data loading, preprocessing, and then its visualization on the web - we are developing a unique technology that optimizes all these steps and helps not to overlap them.
As stated in multiple studies on how the human brain perceives information when it comes to web-based applications, there are three primary time limits within which the app should respond to user input:
- 0.1 seconds - people regard it as an immediate action😊
- > 1 second - users can spot an intermediary😐
- > 10 seconds - people start losing attention😔
So our grid should load, show & interact with gigabytes of data in less than 0.1 seconds.
**Well, we did it. And that’s how.**🎉👇
When the screen is updated and repainted by the browser, everything is encapsulated in a frame.
The frame rate target is 60 frames per second to be perceived as responsive. Plus, the frames need to be equal in length to ensure a steady frame rate. It helps steer clear of jaggy and rigid animations.
We managed to specify the structure of frames and different behaviors in different situations, define each task's execution time and sequence, and use requestIdleCallback() and requestAnimationFrame() to optimize free time in frames.
But in fact, behind all this work is even greater efforts that we have invested in the server part of the technology. Thoughtful and optimized work with data transfer and operations strongly supports the approach developed on the client side and makes it possible to use it on other software as well.
We are still working on our product, but you already can try a demo showing **11 million rows from a 1,6 GB file** with primary grid features that also **work instantly**. As we developed this product for developers, we are open to your feedback or suggestions that will help us to improve our product further.
If you want to stay updated with our latest news, [subscribe](https://datatable.dev/) to our early-bird list.
Give it a try, and let us know what you think.
[Watch about DataTableDev on Youtube
](https://www.youtube.com/watch?v=iTD_cTC7P-U)
| datatabledev |
1,399,755 | Granting Access to Read-Only Users and Refreshing Permissions Automatically: A Function-Based Solution | Problem Statement We have a PostgreSQL database with multiple schemas and tables. Some users have... | 0 | 2023-03-14T01:52:39 | https://dev.to/angu10/granting-access-to-read-only-users-and-refreshing-permissions-automatically-a-function-based-solution-77c | sql, postgres | Problem Statement
We have a PostgreSQL database with multiple schemas and tables. Some users have read-only access to the database and and they relay on Devops/Support team to refresh their access to view any new schemas or tables added to the database. We need to provide a solution to allow read-only users to refresh their access so they can view new schemas and tables as they are added.
Named Read-only User Group
Function 1: Will create a user and create a read_only group not available. If the group is available, it will create the user and password, attach it to the read_only group, and add all existing schema read-only access.
```
CREATE EXTENSION IF NOT EXISTS pgcrypto;
CREATE or replace FUNCTION create_users_and_grant_access(users text[]) RETURNS void AS $$
DECLARE
READONLY_GROUP text := 'readonly';
password text;
user_name text;
schemata text;
BEGIN
FOREACH user_name IN ARRAY users LOOP
-- Check if the user already exists
PERFORM 1 FROM pg_user WHERE usename = user_name;
IF NOT FOUND THEN
-- Generate a random password for the new user
password := encode(gen_random_bytes(12), 'base64');
-- Create the database user with the hashed password
RAISE NOTICE 'Creating database user: %', user_name;
RAISE NOTICE 'Password: %', password;
EXECUTE format('CREATE USER %I WITH PASSWORD %L', user_name, password);
-- Create the read-only group if it does not exist
PERFORM 1 FROM pg_roles WHERE rolname = READONLY_GROUP;
IF NOT FOUND THEN
RAISE NOTICE 'Creating read-only group: %', READONLY_GROUP;
EXECUTE format('CREATE ROLE %I', READONLY_GROUP);
END IF;
-- Add the user to the read-only group
RAISE NOTICE 'Adding user to read-only group: %', READONLY_GROUP;
EXECUTE format('GRANT %I TO %I', READONLY_GROUP, user_name);
ELSE
RAISE NOTICE 'User already exists: %', user_name;
END IF;
END LOOP;
-- Grant read-only access to all schemas for the read-only group
FOR schemata IN SELECT schema_name FROM information_schema.schemata WHERE schema_name NOT LIKE 'pg_%' AND schema_name != 'information_schema' LOOP
-- Check if the read-only group already has access to the schema
PERFORM 1 FROM information_schema.role_table_grants WHERE grantee = READONLY_GROUP AND table_schema = schemata;
IF NOT FOUND THEN
-- Grant read-only access to the schema for the read-only group
RAISE NOTICE 'Granting read-only access to schema: %', schemata;
EXECUTE format('GRANT USAGE ON SCHEMA %I TO %I', schemata, READONLY_GROUP);
EXECUTE format('GRANT SELECT ON ALL TABLES IN SCHEMA %I TO %I', schemata, READONLY_GROUP);
EXECUTE format('GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA %I TO %I', schemata, READONLY_GROUP);
ELSE
RAISE NOTICE 'Read-only access already granted to schema: %', schemata;
END IF;
END LOOP;
END;
$$ LANGUAGE plpgsql;
```
Function 2:
This function will enable users to refresh read_only permissions, so they don’t have to rely on DevOps
```
CREATE OR REPLACE FUNCTION grant_readonly_access(schematabe text DEFAULT NULL)
RETURNS void
SECURITY DEFINER
AS $$
DECLARE
READONLY_GROUP text := 'readonly';
BEGIN
IF schematabe IS NOT NULL THEN
-- Grant read-only access to specified schema for the user and read-only group
PERFORM 1 FROM information_schema.schemata WHERE schema_name = schematabe;
IF FOUND THEN
RAISE NOTICE 'Granting read-only access to schema: % for user: %', schematabe, READONLY_GROUP;
EXECUTE format('GRANT USAGE ON SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT SELECT ON ALL TABLES IN SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT USAGE ON SCHEMA %I TO %I', schematabe, READONLY_GROUP);
EXECUTE format('GRANT SELECT ON ALL TABLES IN SCHEMA %I TO %I', schematabe, READONLY_GROUP);
EXECUTE format('GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA %I TO %I', schematabe, READONLY_GROUP);
ELSE
RAISE EXCEPTION 'Schema not found: %', schematabe;
END IF;
ELSE
-- Grant read-only access to all schemas for the user and read-only group
FOR schematabe IN SELECT schema_name FROM information_schema.schemata WHERE schema_name NOT LIKE 'pg_%' AND schema_name != 'information_schema' LOOP
-- Check if the read-only group already has access to the schema
PERFORM 1 FROM information_schema.role_table_grants WHERE grantee = readonly_group AND table_schema = schematabe;
IF NOT FOUND THEN
-- Grant read-only access to the schema for the read-only group
RAISE NOTICE 'Granting read-only access to schema: % for user: %', schematabe, READONLY_GROUP;
EXECUTE format('GRANT USAGE ON SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT SELECT ON ALL TABLES IN SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA %I TO %I', schematabe, readonly_group);
EXECUTE format('GRANT USAGE ON SCHEMA %I TO %I', schematabe, READONLY_GROUP);
EXECUTE format('GRANT SELECT ON ALL TABLES IN SCHEMA %I TO %I', schematabe, READONLY_GROUP);
EXECUTE format('GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA %I TO %I', schematabe, READONLY_GROUP);
ELSE
RAISE NOTICE 'Read-only access already granted to schema: % for user: %', schematabe, READONLY_GROUP;
END IF;
END LOOP;
END IF;
END;
$$ LANGUAGE plpgsql;
```
| angu10 |
1,399,771 | Db login | import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import... | 0 | 2023-03-14T02:09:35 | https://dev.to/yourdadaf/db-login-2fjb | import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Scanner;
import java.util.logging.Level;
import java.util.logging.Logger;
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
/**
*
* @author A
*/
public class Practical1 {
public static void main(String args[]){
try {
Class.forName("com.mysql.jdbc.Driver");
Connection Con = DriverManager.getConnection("jdbc:mysql://localhost:3306/javapoint","root","");
Statement stmt = Con.createStatement();
Scanner sc= new Scanner(System.in);
String name= sc.next();
stmt = Con.createStatement();
stmt.executeUpdate("INSERT INTO login ('username', 'password') VALUES ('a',13);");
System.out.println(name + " is added successfully");
stmt.executeQuery(name);
ResultSet rs = stmt.executeQuery("select * from login");
while(rs.next()){
System.out.println(rs.getString(1)+" "+rs.getInt(2));
}
}
} catch (ClassNotFoundException | SQLException ex) {
// Logger.getLogger(Practical1.class.getName().log()Level.SEVERE,null,ex);
System.out.println(ex);
}
}
} | yourdadaf | |
1,400,011 | Hello world 2 | Google Top 7 featured | 0 | 2023-03-14T07:10:48 | https://dev.to/icesukhatouch/hello-world-2-3n42 | [Google](https://kdta.io/szuXz)
[Top 7 featured](https://kdta.io/q2iFK)
| icesukhatouch | |
1,400,047 | Build your first data pipeline with Aiven for Apache Flink® | Learn to start working with Aiven for Apache Flink® from creating the service, exploring integrations... | 0 | 2023-03-14T07:35:48 | https://dev.to/ftisiot/build-your-first-data-pipeline-with-aiven-for-apache-flinkr-ck9 | apacheflink, streaming, datapipeline | Learn to start working with Aiven for Apache Flink® from creating the service, exploring integrations provided by the Aiven Console and creating a streaming data pipeline to filter messages from an Apache Kafka topic.
{% embed https://youtu.be/RT5zjEWc1mg %}
Check out these resources to learn more:
(links to any tools or resources you used in the video, our docs/trial if appropriate)
https://docs.aiven.io/docs/products/flink
Contact me for any questions! | ftisiot |
1,400,175 | Must read: The Mythical Man-Month | So, you've gotta read this classic book called The Mythical Man-Month. Don't worry, it's not about... | 22,236 | 2023-03-14T10:05:38 | https://dev.to/krlz/must-read-the-mythical-man-month-1opo | software, codenewbie, beginners, computerscience |

So, you've gotta read this classic book called The Mythical Man-Month. Don't worry, it's not about some monster with 30 arms or anything. It's all about managing software development projects, and let me tell ya, it's a wild ride.

The author, Frederick Brooks, talks about how adding more people to a late software project will make it even later. Kinda like how having too many chefs in the kitchen just makes everything take longer and taste worse.
He also tells some stories about big software projects that went wrong. Like, there was one where they had 500 people working on it and it still ended up being a total disaster. That's like having a house party and inviting everyone you know, but then the cops get called and you end up getting evicted.
Anyway, the book is full of tips on how to avoid common mistakes and work more efficiently. Here are some examples:
1. Keep your team small and focused
2. Have clear goals and priorities
3. Break tasks down into smaller pieces
4. Use version control software
5. Communicate frequently and openly
6. Don't try to do too much at once
7. Test early and often
8. Use automation wherever possible
9. Document your code and processes
10. Learn from your mistakes
11. Be willing to change course if necessary
12. Use agile development methodologies
13. Don't be afraid to ask for help
14. Prioritize collaboration over competition
15. Keep your code clean and organized
16. Use testing frameworks to catch bugs
17. Encourage feedback from users and stakeholders
18. Avoid over-engineering solutions
19. Celebrate successes and milestones
20. Keep learning and improving your skills
Now, I gotta be honest with you. This book is a bit of a cliche in academic circles. Every computer science professor seems to assign it as required reading. But hey, there's a reason for that. The lessons in this book are important and timeless. Plus, it's kinda fun to make jokes about mythical men and months. So go ahead and give it a read. Your future boss will thank you.
Thanks for reading, see you in anothe chapter of this series!

**Bonus track - some of the things also mentioned in this book**
1. "If you think throwing more people at a software project will speed things up, think again. It's like trying to make a baby faster by giving birth in a room full of people."
2. "Communication can be a real pain when you're working with a big team. If you've got N people, the number of potential communication channels is N(N-1)/2. That's more confusing math than I ever wanted to deal with!"
3. "It's important to have a good plan when you're starting a project. And sometimes, that plan means throwing out your first attempt and starting over. It's like trying to bake a cake without a recipe - sometimes you just need to throw the first one away and try again."
4. "Management is all about keeping your team effective. It's like being a coach for a sports team - you need to motivate your players and make sure they're working together."
5. "Programming is all about representation. It's like painting a picture with code instead of a brush."
6. "Sometimes you need to accept that your first attempt at a solution won't work. It's like trying to fix a leaky faucet - sometimes you just need to admit defeat and call a plumber."
7. "Good cooking takes time, and good coding does too. If you're getting impatient with your developers, remember that good things come to those who wait."
8. "When designing a system, make sure everything fits together neatly. It's like putting together a puzzle - if the pieces don't fit, your system won't work."
9. "Programmers are like poets - they work with the raw material of thought and language to create something beautiful and functional."
10. "If your code and comments don't match up, you might need to go back and revise both. It's like trying to write a mystery novel with a plot hole - you need to fix both the story and the clues." | krlz |
1,400,242 | Deploy S3 hosted application using CodePipeline | A while ago I wrote how you can host your own single page application on S3. But how will you get... | 0 | 2023-03-14T10:26:24 | https://xebia.com/blog/deploy-s3-hosted-application-using-codepipeline/ | codepipeline, s3, deply, action | A while ago I wrote how you can host your own [single page application on S3](https://xebia.com/blog/hosting-a-single-page-application-or-website-on-s3/). But how will you get your application on the S3 bucket? There are a couple of options here, you could upload it by hand? But we both know that is not the real solution here. No we want to automate this process! In this blog post I will show you how you can automate this using [AWS CodePipeline](https://aws.amazon.com/codepipeline/).
## The Pipeline
AWS Codepipeline uses different stages, I often use `Source`, `Build` and `Deploy` stages. In some cases I split the Deploy stage into a Development, Testing, Acceptance and Production deployment (also known as DTAP). If you want to know more about how you can set this up you can read my [building applications with pipelines](https://xebia.com/blog/building-applications-with-pipelines/) blog. But in the end it is up to you and what makes sense to your use-case.
When you deploy your infrastructure using [CloudFormation.](https://aws.amazon.com/cloudformation/) You can make use of the outputs within the CodePipeline. Another option is to use a naming convention. I like to use the outputs as it removes the need to define a name upfront. Making it more robust when you re-use snippets or deploy your infrastructure more than once.
```yaml
Outputs:
ApplicationBucketName:
Value: !Ref ApplicationBucket
```
The next thing you need to define is a namespace on the action that deploys your infrastructure.
```yaml
- Name: ExecuteChangeSet
Region: eu-west-1
RunOrder: 2
RoleArn: !Sub arn:aws:iam::${DevelopmentAccountId}:role/cross-account-role
Namespace: DevelopmentVariables
ActionTypeId:
Category: Deploy
Owner: AWS
Provider: CloudFormation
Version: "1"
Configuration:
ActionMode: CHANGE_SET_EXECUTE
RoleArn: !Sub arn:aws:iam::${DevelopmentAccountId}:role/cloudformation-execution-role
StackName: !Sub ${ProjectName}-development
ChangeSetName: !Sub ${ProjectName}-development-ChangeSet
```
By default CodePipeline will load the outputs in the given namespace. In this example that is `DevelopmentVariables`, so the `ApplicationBucketName` is available as: `#{DevelopmentVariables.ApplicationBucketName}`.
## Deploy to S3
AWS provides a [S3 Deploy action](https://docs.aws.amazon.com/codepipeline/latest/userguide/action-reference-S3Deploy.html) you can use this action to deploy an artifact in your pipeline to S3\. You can create this artifact in a CodeBuild Project or you can use the source artifact.
I am using a cross account deployment strategy. For this reason I need to allow my _cross-account-role_ to allow uploads to the S3 buckets. I am using a BucketPolicy for this:
```yaml
- Sid: AllowPipelineToUpload
Effect: Allow
Action: s3:PutObject
Principal:
AWS: !Sub arn:aws:iam::${AWS::AccountId}:role/cross-account-role
Resource: !Sub ${ApplicationBucket.Arn}/*
```
Note that the role and the bucket are living in the same account. The pipeline lives in my build/deployment account. So in the pipeline we need to configure the upload to S3:
```yaml
- Name: Ireland-Uploadapplication
Region: eu-west-1
RunOrder: 3
RoleArn: !Sub arn:aws:iam::${DevelopmentAccountId}:role/cross-account-role
InputArtifacts:
- Name: application
ActionTypeId:
Category: Deploy
Owner: AWS
Provider: S3
Version: "1"
Configuration:
BucketName: "#{DevelopmentVariables.ApplicationBucketName}"
Extract: true
CacheControl: max-age=0, no-cache, no-store, must-revalidate
```
In this example I will use my artifact called _application_ and extract the content in the S3 bucket. It will assume the role that we specify as `RoleArn` to perform the upload. I will also set the `CacheControl` so that [CloudFront](https://aws.amazon.com/cloudfront/) knows that it needs to serve the new content.
## Conclusion
It is easy to use the S3 Deploy action to upload your content to a S3 bucket. It removes the need of using a CodeBuild project to upload the content. This will reduce cost and complexity, by not maintaining an extra CodeBuild project. | nr18 |
1,400,420 | Write custom Javascript to customize tinymce. increase and decrease font size. | Introduction TinyMCE is a popular open-source WYSIWYG (what you see is what you get) HTML... | 0 | 2023-03-14T14:05:51 | https://dev.to/ayowandeapp/write-custom-javascript-to-customize-tinymce-increase-and-decrease-font-size-4hhn | javascript, tutorial, frontend, beginners | ## Introduction
TinyMCE is a popular open-source WYSIWYG (what you see is what you get) HTML editor. It is designed to be used within web content management systems, online forums, and other web-based applications. It is available as a JavaScript library that can be integrated with other web technologies. It provides basic text editing features such as bold, italic, underline, font size, font color, and headings, as well as some advanced features such as tables, image insertion, and media embedding.
### Add editing features to tinymce
TinyMCE can be extended with a variety of plugins that add additional editing features. Some popular plugins include a spellchecker, a visual table editor, a code editor, and a link checker. These plugins can be added to TinyMCE through the TinyMCE Plugin Manager. Additional plugins can also be added by downloading them from the TinyMCE website.
In addition to plugins, TinyMCE can also be customized by writing custom JavaScript code. This allows developers to add additional editing features to the editor, such as custom buttons and dialogs. Custom code can also be used to modify existing features, such as changing the way the editor behaves when a user changes the font or the size of an image.
### Write custom Javascript code to customize tinymce
To write custom JavaScript code to customize TinyMCE, you first need to create a new JavaScript file and include it in your HTML page. Then, you can use TinyMCE’s API to make changes to the editor.
For example, you can add a custom button to the editor toolbar using the following code:
```
tinymce.init({
selector: 'textarea',
toolbar: 'increaseFont decreaseFont',
editor.addButton('increaseFont', {
// icon: element,
text: 'A+',
onclick:function(){
var currentFontSize = editor.getContent({ format: 'html' }).match(/font-size: (\d+\w+)/);
if (currentFontSize) {
var currentSize = parseInt(currentFontSize[1].replace(/[^\d]/, ''));
if(currentSize === 36){
return false;
}
var newFontSize = parseInt(currentFontSize[1].replace(/[^\d]/, '')) + 2;
var newFontSizeUnit = currentFontSize[1].replace(/\d+/, '');
editor.execCommand('fontSize', false, newFontSize + newFontSizeUnit);
}else if(currentFontSize ===null){
editor.execCommand('fontSize', false, 14 + 'pt');
}
}
});
editor.addButton('decreaseFont', {
// icon: '',
text: 'A-',
onclick:function(){
var currentFontSize = editor.getContent({ format: 'html' }).match(/font-size: (\d+\w+)/);
if (currentFontSize) {
var currentSize = parseInt(currentFontSize[1].replace(/[^\d]/, ''));
if(currentSize === 8){
return false;
}
var newFontSize = parseInt(currentFontSize[1].replace(/[^\d]/, '')) - 2;
var newFontSizeUnit = currentFontSize[1].replace(/\d+/, '');
editor.execCommand('fontSize', false, newFontSize + newFontSizeUnit);
}else if(currentFontSize ===null){
editor.execCommand('fontSize', false, 10 + 'pt');
}
}
})
});
```
This code adds two new button to the TinyMCE editor toolbar with the text “A+ and A-”. When the A+ button is clicked, the code inside the onclick function will be executed which increases the font on the selected text. Aso, When the A- button is clicked, the code inside the onclick function will be executed which decreases the font on the selected text. You can add more buttons to the editor by adding more addButton() calls to the setup function. | ayowandeapp |
1,400,470 | Devkeys 😊keycaps | With our love and passion for keycaps, we started making the first keycaps according to our wishes 😊. | 0 | 2023-03-14T15:00:50 | https://dev.to/ductandev/devkeys-d21 | devkeys, javascript, github, keycaps |
With our love and passion for keycaps, we started making the first keycaps according to our wishes 😊.
 | ductandev |
1,400,773 | Configure a custom env on Azure ML | Configure a custom env on Azure ML Shared workspace for remote AI Teams When your team is... | 0 | 2023-03-14T17:47:12 | https://dev.to/elldora/install-customized-env-on-your-azure-ml-platform-244d | azuremachinelearning, python, environment, devops | Configure a custom env on Azure ML
## Shared workspace for remote AI Teams
When your team is working remotely, they need to collaborate and work on a shared cloud-based workspace. In this way, all developers in your team members can use it to run the experiments.
My team and I in [MelkRadar](https://melkradar.com/p/search), have a nice experience working with **Azure ML**. In this platform, you are able to import a wide variety of predefined environments and delegate your tasks on the Azure computes. Fortunately, the Azure ML designers have prepared some **predefined environments** from the most useful and popular packages to make it **more straight forward for developers**. You can easily find a list of these predefined environments based on your compute type in the Azure ML platform.
## Customizing packages on a predefined env
If you are a ML developer, you are familiar with `Anaconda` package manager. It's being used to create your local environment and install required packages. If it doesn't work, you may also know how to create a **virtual env on your local machine** to do so. But when it comes to remote teamwork, it's a totally different challenge!
In this case you will actually need to install your own package(s) through a customized environment on that machine. Here is my experience to handle such situations.
At the beginning of the project, it was Ok using the pre-defined env **until I tried to work with some packages which was specially designed to work with a specific language**. To be clear, I was working with Persian texts which has its own libraries for preprocessing tasks. I needed the `Hazm library` to preprocess the Persian texts. I could easily add it to the Anaconda environment and work on local machine. But working with Persian text are not as much popular as English ones. So, it won't be found in the predefined environments on Azure Machine.
The challenge was to **customize the predefined environments on Azure**. On the way to handle this issue, I found that Azure ML has provided `curated-env` for this job.
First you can prepare a must to install packages and their versions in a `yml` file. Then by adding some lines to your code you can say the workspace to create this environment on the Azure machine.
Here are some snippets you will get an insight about this topic:
```python
from azureml.core import Environment
from azureml.core.runconfig import DockerConfiguration
myenv = Environment.from_conda_specification(name='azure-custom-env', file_path='./conda_dependencies.yml')
myenv.docker.base_image = 'mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04'
docker_config = DockerConfiguration(use_docker=True)
```
And the initialize the `ScriptRunConfig` with this new env:
```python
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(script='script.py',
compute_target=cluster,
docker_runtime_config=docker_config)
```
After starting the run, you will find a link to the installed curated environment.
## Modifying packages and versions
If you define the environment once and don't change the packages or their versions, the azure compute will use the first install env. But if you add or remove packages or change their versions, the azure machine will consider it as a new env and will install a new environment.
There is also another way for environment management knows as system-managed and I will talk about my experience using this way in the future.
## Our Experience at MelkRadar AI Team
I am an AI developer at [MelkRadar](https://melkradar.com/p/search), which is a real estate search engine in Iran. We are using **Azure ML** as our main platform to collaborate with AI team members. In my recent project, it was very crucial to handle the customized environment for my experiments and this feature really helped me, so shared my experience to help you as well :). You can find more information in this link:
- [How to manage environments in Azure ML](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-manage-environments-v2?tabs=cli).
| elldora |
1,400,831 | It's #wecoded and I am very happy to be here | Hey, I am Rachel and this is the first WeCoded I have participated in because I only began my account... | 0 | 2023-03-14T18:44:53 | https://dev.to/rachelfazio/its-wecoded-and-i-am-very-happy-to-be-here-32oe | codenewbie, beginners, wecoded | Hey, I am Rachel and this is the first WeCoded I have participated in because I only began my account a bit ago when I joined the Forem/DEV team as our Content Creator in November! I am a non-programmer-ish, in that I am very much a newbie at coding, but can get by in a lot of rudimentary languages + mechanical engineering, though my main experience is graphic design/UX design.
I guess I am making this article to both support what a wonderful event this is and also to talk a bit about my experience as a designer who hopes to dabble in coding. I hope y’all enjoy, this is the first personal article I have made on here so I feel vulnerable!!!
## Part 1: Becoming a Designer
I decided I wanted to be a designer when I was a freshman in college and was super excited to apply to get into the program at my school and… was ultimately denied a spot. I had had a lot of mental health issues leading up to the final exam and when we got there, I was not given proper accommodations that coincided with my disability accommodations at the school for my neurodivergency, which ultimately resulted in me not getting in. It sucked. It broke my heart but since I knew it was what I wanted to pursue, I pushed on and tried again the next year.
I got in the following year, after being told by my disability advisor to not try again because students with disabilities/neurodivergencies have a higher chance of leaving the program or being kicked out due to how physically/mentally demanding design can be. I was so proud of myself and still am, and pushed on.
## Part 2: Deciding This Wasn't Right
Though, as I continued in the program, I realized how right my advisor had been. No matter how excited I was about this field, the class structure was not built in a way to support my needs as a student, and I started struggling. I pushed myself extremely hard until I burnt out fully and ended up resenting the field I had spent my whole life dreaming about.
I graduated feeling a bit sideways and confused, trying to apply for design jobs but ultimately just needing a break. I moved back to California to be with my family and to figure out the next steps. I had always dreamed of being a teacher when I was elderly and full of wisdom, and thought now might be a great time to try it out, so I started to work at a private school near my hometown.
## Part 3: Becoming a Teacher
I LOVED TEACHING. My students were primarily neurodivergent/queer + trans kids who I related to, and who were so excited about the world around them and delving into art. I set off to teach a bunch of classes in different fields from art, design, animation, English, health, life skills, and history. Watching my students be excited to learn and push through when life was giving them hell made me so excited to teach them. I had lovely experiences as a teacher, especially with my trans and nonbinary students, as I am also nonbinary and I got to see them SO excited to have a teacher who saw them + gendered them properly.
While teaching, I realized I was itching to exert myself creatively again for the first time in a long time, after being super inspired by the excitement of my students. Though, while working there, I experienced a lot of friction with my nonbinary-ness, and wasn’t able to express myself safely and comfortably. It made me feel super small.
## Part 4: Becoming a Designer (AGAIN)
I used my energy to carve out my own space, and ended up starting my own illustration/print-making business and began selling screen-printed clothing at flea markets in the greater LA area. I soon realized I was working two full-time jobs, one at the school and one at home, and was having way more fun creating art by myself. I realized that as I had been avoiding design, I subconsciously came right back to it and was itching to start up again. I had no idea I would come back to it, but am super happy I did.
I soon after applied to work at Forem/DEV, got the job, and ended up right back where I started, pursuing design!
## Part 5: Here Now!
All in all, I had pictured for a while that I would have to switch occupations, make myself smaller, or be unable to pursue the field that I wanted to because of my nonbinary-ness and my neurodivergence. I thought I wouldn’t be able to find a job/career that supported me fully and felt down on my luck for a while, and once I got here I was accepted with open arms.
I am super grateful for the things I have learned, and to all of y’all out there who may be experiencing different things or not told that you shouldn’t pursue something you really want to, GO FOR IT. Know when to listen to yourself and no one else, and push for the things you believe in.
**(Also side note– representation matters, neurodivergency matters, accommodations matter! Happy #wecoded!)**
_Love y’all and happy coding,
Rachel :-)_
[Image Source for Header](https://mena.fes.de/press/e/the-future-of-work-is-here-a-regional-feminist-perspective-on-the-effects-of-covid-19)
| rachelfazio |
1,401,037 | Avocado | Concept: Our group decided early on that we liked the idea of doing a food related app, an ordering,... | 0 | 2023-03-14T21:11:32 | https://dev.to/megdiv/avocado-3im3 | react, redux, javascript, tailwindcss | Concept:
Our group decided early on that we liked the idea of doing a food related app, an ordering, back of house, reporting tool that could be used by a customer to order food, but also by the restaurant to get the food ready, and the owner to review revenue and edit menu information. Our idea was to create an app similar to Toast, so we decided to call our app "Avocado".
Team Roles:
Corey set up our Supabase schema, our initial routes and multiple table backend routes, connecting our backend and frontend servers and creating the reporting system for the back-of-house operation page.
Peter designed our brand identity and styling, creating the restaurant logos and layout with Adobe Illustrator, and implementing the menu, cart, and order confirmation pages as well as their frontend Supabase routes.
Jaye was our project manager and styling TailwindCSS specialist, leading our multiple daily standups, acting as our instructor liaison, creating our mockup flow chart in Figma and database schema in DB designer, as well as managing our Github project tracking page, setting up our Supabase storage, and deploying our project front and back ends on Render.
Meg designed the login, signup, and dashboard logic as well as the reducers slice for our Redux state, implementing state persist, our front-end routes and state logic queries, and creating our reporting in Plotly to showcase database statistics.
Blockers:
Although choosing to use Supabase allowed us to easily authenticate and grab our token to set into state, we later discovered Supabase automatically set user emails to lowercase when they were put in the authentication table, which caused an issue when we tried to query them. Other blockers were how Supabase handled image storage, and its timing delay of returning data that generated the need to conditionally render many of our designs.
Final Thoughts:
In total, our project included React, Redux, JavaScript, Supabase, Plotly, Toastify, TailwindCSS, and State Persist - many of which were used for the first time by at least one person in our group. Overall, our project definitely pushed us to learn new tools and technologies and we are proud to present our food service app, Avocado!
[Project Repo - Frontend](https://github.com/Lasseignejk/Avocado-frontend)
[Project Repo - Backend](https://github.com/Lasseignejk/Avocado-backend)
[Project Site](https://avocado-frontend.onrender.com/)
[Project Walkthrough](https://youtu.be/wsLZCA090U4) | megdiv |
1,401,100 | VSCode :: ATOM und PyCharm aufsetzen - Ansätze, Vorgehen und Stolperfallen | hallo und guten Abend liebe Community. VSCode :: ATOM und PyCharm aufsetzen - Ansätze, Vorgehen und... | 0 | 2023-03-14T23:02:43 | https://dev.to/digital_hub/vscode-atom-und-pycharm-aufsetzen-ansatze-vorgehen-und-stolperfallen-5f50 | vscde, python, beginners | hallo und guten Abend liebe Community.
VSCode :: ATOM und PyCharm aufsetzen - Ansätze, Vorgehen und Stolperfallen
ich will [B] VSCode, ATOM und PyCharm [/B] auf den Rechner aufsetzen - genauer gesagt auf zwei Rechner: einem Win udn einem MX-Linux-Rechner:
[B]Was ist beabsichtigt[/B]: will die drei IDEs bzw. Editoren ausprobieren.
VSCode, ATOM und PyCharm - habe mit allen dreien schon allererste Schitte gemacht - nun kommen sie neu auf die beiden Rechner
WIN 10 (im Büro)
MX-Linux (@home)
[B]die Links: [/B]
[url]https://code.visualstudio.com/docs/?dv=win[/url]
[url]https://atom.io[/url]
[url]https://www.jetbrains.com/de-de/pycharm/download/[/url]
wie würdet ihr vorgehen - einfach durchinstallieren -
nebenbei bemerkt: bei VSCode gibt es Python als Paket(-Erweiterung). Ist das dann im Grunde dann wenn ich das dort als Paket installiere lediglich für VSCode verwendbar!`Das würde ggf für ATOM auch gelten - oder nicht!=? Auch dort habe ich viele Pakete und Erweiterungen
Auf was würdet ihr denn setzen - wie vorgehen und auf was besonders achten!?
[B]Anm.: [/B] Das tolle an ATOM ist die sehr gute github-Integration.
[B]Oder:[/B] im Blick auf Python - würdet ihr erstmal das Pyton auf dem Win-Rechner aufsetzen.
Dann darüber hinaus: ... will ich das Ganze auch auf dem MX-Linux-Rechner aufsetzen. Denke dass ich da auch VSCoce sicher als sehr leistungsfähig voraussetzen kann.
Der freie VSCode heißt dort .- glaube ich - VSCodium. wie würdet ihr vorgehen - einfach durchinstallieren - Auf was würdet ihr denn setzen - wie vorgehen und auf was besonders achten!?
[B]Anm[/B].: Das tolle an ATOM ist die sehr gute github-Integration. Oder: im Blick auf Python - würdet ihr erstmal das Pyton auf dem Win-Rechner aufsetzen.
jede Menge Fragen - ich freue mich auf einen Tipp
[B]update:[/B]vorweg: bin sehr froh dass ihr ein Forum hier habt, das für dem Thema Installation und Konfiguration vorbehalten ist. Super Sache und wie für mich gemacht. ,,,, ich bin am Aufbau einer Entwicklungsumgebung für Python auf zwei Systemen:
Win 10: mit PyCharm, VsCode u. ATOM (Bürorechner)
MX-Linux: mit ATOM (@home)
[B]Zwischenfazit[/B]: also noch läuft das etwas holprig - auf der Linux-Kiste ist die Frage ob ich denn
a. alle Python-Pakete schon richtig eingerichtet habe und ob
b. ich auch die richtigen Plugins von Atom verwende - ferner hätte ich auf der MX-Linux 19.1 gerne halt auch
c. VSCode, das ist im Mom aber nicht in den Repositories drinne - die Installation kann via Flatpack oder Codium oder noch auf einem dritten
Wege laufen.... Alles in Allem halt etwas doof - aber ATOM ist - wenn alles gut eingerichtet ist ja auch nicht übel hat v.a. auch eine nette Github-Integration.
Es kommen also sicher zu beiden Systeme - zum Aufbau auf Windows 10 und auch auf der MX-Linux-Kiste sicher noch ein paar Fragen in den kommenden Tagen.
Im Moment frage ich mich ob es schlau ist Python global zu installieren und nicht über eine venv...
habe hier[B] zwei Artikel[/B] gelesen:
[url]https://python-forum.io/Thread-use-X...e-skip-setting[/url]
generell:
Article on using Virtual Environments for Python projects.
[url]https://towardsdatascience.com/pytho...y-fe0c603fe601[/url]
Comparing Python Virtual Environment tools
[url]https://towardsdatascience.com/compa...s-9a6543643a44[/url]
[B]Frage: [/B]Was meint ihr hier denn dazu?
was meint ihr denn - ist das im Übrigen vielleicht schlauer, scon von Anfang an auf Anaconda zu setzen - denn mit Anaconda hat man gleich ein einfache Packet-Managment-Sytem und viele viele Paket enthalten.
[B]Anaconda[/B] ist eine Data Science-Plattform, die von Python unterstützt wird. Die Open-Source-Version von Anaconda ist eine Hochleistungsdistribution von Python und R und umfasst über 100 der beliebtesten Python-, R- und Scala-Pakete für Data Science.
Es hat Zugriff auf über 720 Pakete, die mit conda, dem Paket, dem Abhängigkeits-Manager und dem Umgebungsmanager, die in Anaconda enthalten sind, installiert werden können. Einer der großen Vorteile von Anaconda dürfte der sein, dass es ein eigenes System zur Installation von Modulen praktisch schon selber mitbringt, welche fertige, ggf. vorkompilierte Module installiert. Es hat - mit anderen Worten viele Module schon an Bord. Das erleichtert dann doch schon erheblich: Es gibt z.B. auch Module wie etwa numpy, pandas, welche realtiv aufwändig zu installlieren sind. Da kann es dann auch einen nicht zu unterschätzenden Vorteil bedeuten, wenn die manuelle Installation via pip dabei entfällt.
Und das tolle ist: Anaconda ist in der Lage sich selber, zu aktualisieren - m.a.W. es kann den Interpreter und die Module in einem Rutsch automatisch aktualisieren.
Man kann dann natürlich auch z.B. etwa Minoconda nehme
n. Das installiert "nur" den Python-Interpreter und die Verwaltungssystem `conda`, aber keine zusätzlichen Pakete. Anaconda installiert ja direkt ~500 MB (also das ist schon relativ dick) in Form von X hundert Python-Modulen.
[B]virtualenv unter anaconda[/B]
was mich allerdings etwas wundert: Aber auch da wird ein virtualenv angeboten anaconda - es gibt sogar ein virtualenv plugin für pyenv.
pyenv und virtualenv: brauch ich die denn bei Anaconda denn gleich auch am Anfang - muss ich die miteinrichten oder eher nur bei (Mini).Conda! Ich hab mir die Tutorials angesehen und mich mal kurz eingelesen: bei der Installation von Anaconda in ein Win 10 sollte man aufpassen: Wenn python schon auf dem Rechner ist - dann kann es Abhängikeiten geben. Am allerbsesten ist es wenn mal noch nix auf der Maschine ist - also weder Python oder Conda oder Anaconda::
.. dennoch: immer und in jedem Falle wichtig und gut: dann nicht einfach durchklicken: x add anaconda to the system path environment wenn man schon ein.conda directory im home hat - dann ist das nicht weiter tragisch.
[code]
$ cd
$ mkdir -p .conda/pkgs/cache .conda/envs
[/code]
damit richtet man sich ein Python environment ein: Der conda create command führt genau diesen Schritt aus versehen mit einem python=version argument.
Übrigens sind die package manager in Anaconda und Miniconda glücklicherweise identisch (Conda), Man muss nicht Miniconda in das System installieren wenn man beabsichtigt, ohnehin bei Anaconda zu bleiben.
envs wird erzeugt mit dem Kommando:
[code]
conda create -n myenv python some_packages
[/code]
Das klappt - allerdings kann es zu einer Ausnahme kommen - wenn verschiedene Pakete nebeneinander existieren und verschiedene package caches -
Bei Konflikten einfach eines loeschen und die shell initialization script (e.g., .bash_profile) cleanen - denn die Installer laufen auch darüber.
was wenn ich ein Paket nicht über Conda finde
[QUOTE]
$ conda install --channel conda-forge ads
snippet aus dem Web
Install from conda-forge
Add the conda-forge channel: conda config --add channels conda-forge.
Create a new environment containing SageMath: conda create -n sage sage python=X , where X is version of Python, e.g. 2.7.
Enter the new environment: conda activate sage.[/QUOTE]
wenn man das package nicht über conda findet, kann man dann tatsächlich via Python packages wie "pip" weitermachen. Das bringt einem doch unweigerlich in die Abhängikeitsfalle - denn conda kennt doch dann die Abhängigkeiten nicht (mehr) wenn ich weitermache mit
- "easy_install", oder
- "python setup.py"
Wenn ich die conda packages in einer Umgebung update, wo conda packages mit anderen packaging styles gemischt sind, bring ich mich
dann doch in Abhänigkeiten. Ergo denke ich, dass man pip nur sehr zurückhaltend einsetzen sollte - und allenfalls dann - wenn man noch die "--user" option mitverwendet, sodass es dann ins Homeverzeichnis reininstalliert.
insgesamt hier noch mehr zum Thema Anaconda und Conda: what-is-the-difference-between-pyenv-virtualenv-anaconda
[url]https://stackoverflow.com/questions/38217545/what-is-the-difference-between-pyenv-virtualenv-anaconda[/url]
[QUOTE]
pip: the Python Package Manager.
pyenv: Python Version Manager
virtualenv: Python Environment Manager.
Anaconda: Package Manager + Environment Manager + Additional Scientific Libraries.[/QUOTE]
[B]Conda cheat sheet [/B][url]https://medium.com/@buihuycuong/conda-cheat-sheet-f9424fa2e3f5[/url]
Conda cheat sheet
Command line package and environment manager
[B]Managing Conda and Anaconda[/B] [url]https://kapeli.com/cheat_sheets/Conda.docset/Contents/Resources/Documents/index[/url]
Managing Conda and Anaconda
Managing Environments
Managing Python
Managing .condarc Configuration
Managing Packages, Including Python
Removing Packages or Environments
das conda-cheatsheet: [url]http://know.continuum.io/rs/387-XNW-688/images/conda-cheatsheet.pdf[/url]
- conda ist beide ein command line tool und ebenso ein python package.
also strukturell ist es so:
- Miniconda installer beinhaltet Python und das conda-package
- Anaconda installer beinhaltet Python und das conda-package nebst meta package anaconda
- das meta Python pkg anaconda = umfasst weit über 150 andere Python packages
Ein Überblick ist: [B]Simplifies package management and deployment of Anaconda[/B] [url]https://anaconda.org/anaconda/anaconda/files[/url]
weiterführende Links zum Thema: [url]https://towardsdatascience.com/get-your-computer-ready-for-machine-learning-how-what-and-why-you-should-use-anaconda-miniconda-d213444f36d6#:~:text=Because%20Miniconda%20doesn't%20come,means%20installing%20Conda%20as%20well[/url].
Also zurück [B]zum Thema VSCode[/B] einrichten: ich hab da mal ein Testscript laufen lassen um einfach mal zu sehen, wie das läuft und wie wichtig die venv ist.
[code]
import requests
from bs4 import BeautifulSoup
import pandas as pd
def Main(urls):
with requests.Session() as req:
allin = []
for url in urls:
r = req.get(url)
soup = BeautifulSoup(r.content, 'html.parser')
target = soup.find(
"dl", class_="c-description-list c-description-list--striped")
names = [item.text for item in target.findAll("dt")]
names.append("url")
data = [item.get_text(strip=True) for item in target.findAll("dd")]
data.append(url)
allin.append(data)
df = pd.DataFrame(allin, columns=names)
df.to_csv("data.csv", index=False)
urls = ['https://www2.daad.de/deutschland/studienangebote/international-programmes/en/detail/4722/',
'https://www2.daad.de/deutschland/studienangebote/international-programmes/en/detail/6318/']
Main(urls)
[/code]
ein [B]crash in vscode: [/B]
[code]Windows PowerShell Copyright (C) Microsoft Corporation. Alle Rechte vorbehalten.
Lernen Sie das neue plattformübergreifende PowerShell kennen – https://aka.ms/pscore6
PS C:\Users\Kasper\Documents\PlatformIO\Projects\ESP> & C:/Users/Kasper/AppData/Local/Programs/Python/Python37-32/python.exe c:/Users/Kasper/Documents/_f_s_j/_mk_/_dev_/bs4_europe_1.py
Traceback (most recent call last):
File "c:/Users/Kasper/Documents/_f_s_j/_mk_/_dev_/bs4_europe_1.py", line 3, in <module>
from bs4 import BeautifulSoup
ModuleNotFoundError: No module named 'bs4'
PS C:\Users\Kasper\Documents\PlatformIO\Projects\ESP>
[/code]
hmm - habe VSCode grade erst eingerichtet - und mit ersten obenstehenden Tests laufen lassen. Denke - wie oben schon gesagt, dass es auf alle Fälle Sinn macht eine venv einzurichten:
[B]Eine virtuelle Umgebung für Python[/B]
Virtuelle Umgebungen helfen damit ich keine Rücksicht auf den Rest des Systems nehmen muss. Damit versuche ich meine Umgebung einzurichten - so dass es halt passt mir der Systemumgebung einrichten,
-macht ja auch Sinn - wenn ich für ein Projekt eine Software brauche, die neuere oder ältere Bibliotheken benötigt,
- Dann kann ich versuchen, durch die Abhängigkeitsfalle zu kommen, und die Software mit der aktuellen Systemumgebung zum Laufen zu bringen.
Für Python, denke ich mal ist virtualenv so eine Umgebung. Darin werden über Umgebungsvariablen die Pfade für die zu verwendenden Bibliotheken verstellt, so dass die virtuelle Umgebung unabhängig von den Pythonbibliotheken des Betriebssystems ist. Einschränkend muss hier gesagt werden dass das mehr Plattenplatz, da etliche Bibliotheken nun wieder mehrfach im vorhanden sind. Aber immerhin: Platz ist da noch viel viel billiger als die Arbeitszeit, die draufgeht, um eine neue Software an das System oder - noch schlimmer - das System an eine neue Software anzupassen.
Denke dass ich das mit dem Program virtualenv mache, mit dem ich mir die einzelnen Umgebungen einrichten kann.
Bei MX-Linux gibt es sicher auch das Paket python3-virtualenv, das ich installieren kann.
[code]sudo dnf install python3-virtualenv[/code]
Damit bin ich schon fertig mit der Installation. Das Software-Paket enthält das Program virtualenv (eventuell mit angefügter Versionsnummer), mit dem ich mir virtuelle Umgebungen für Python einrichten kann.
[B]Einrichtung[/B]: Jetzt habe ich die Software für die virtuellen Umgebungen, wie verwende ich diese nun?
Dann lege ich eine je eigene virtuelle Umgebung an - also pro Projekt muss ich das im Grunde eigentlich ja nur einmal tun - lege ich eine virtuelle Umgebung an. Ich bewege mich in das Projektverzeichnis und rufe virtuelenv mit dem Namen des Verzeichnisses auf, in dem die Bibliotheken der virtuellen Umgebung abgelegt werden sollen.
[code]
cd $project
virtualenv venv
[/code]
Dieses Verzeichns nenne ich meist venv und zwar aus einem guten Grund, der beim Weiterlesen gleich klar wird.
Die virtuelle Umgebung aktivieren: Jedesmal, wenn ich in meinem Objekt mit der virtuellen Umgebung arbeiten will, muss ich diese aktivieren. Das allerdings nur einmal, bevor ich anfange zu arbeiten.
[code]cd $project
source venv/bin/activate [/code]
geht auch über ne bash alias: [code]alias venv_activate='source venv/bin/activate'[/code] Dieser Alias ist nicht soviel kürzer als der eigentliche Befehl.
Das mach ich dann so - und am Ende sieht das dann ggf. so aus.
[code]
+------------------------+
| |
| |
| python-workspace |
| ....-folder |
| |
+----------+-------------+
|
|
| +----------------------+
| | |
+--------------+ Project1 |
| | |
| +----------------------+
|
| +----------------------+
| | |
+--------------+ Project2 |
| | |
| +----------------------+
|
| +----------------------+
| | |
+--------------+ Project3 |
| | |
| +----------------------+
|
| +----------------------+
| | |
+--------------+ Project4 |
| | |
| +----------------------+
|
| +----------------------+
| | |
+--------------+ Project5 |
| | |
| +----------------------+
|
| +----------------------+
| | |
+--------------+ Project6 |
| |
+----------------------+
[/code]
hier noch ein paar how-tos und tutorials:
[url]https://code.visualstudio.com/docs/python/python-tutorial[/url]
[url]https://docs.python-guide.org/dev/virtualenvs/[/url]
create a virtual environment video by corey schafer
[url]https://www.youtube.com/watch?v=Kg1Yvry_Ydk[/url]
und auch hier - nicht schlecht.
[url]https://dev.to/search?q=vscode[/url]
[B]update:[/B] und um hier noch kurz eine weitere Frage hinterherzuschieben: ich hab VSCode (und Python auf einem Desktop [zugegeben hier jetzt win10])
[B]Frage[/B]: kann ich denn dann hier noch ohne weiteres und ohne Konfigurationsorgien nun ggf. Anaconda installieren? Geht das denn!? Kommen sich hier nicht Anaconda und Python (das schon auf dem Rechner ist) in die Quere!?
muss ich dann ggf. in das Setting gehen und dort in settings.json den python.path editieren - etwa
[code]"python.pythonPath": "C:\\Anaconda3\\envs\\py34\\python.exe"[/code]
- muss ich dann also noch eine spezifische Umgebung aktivieren -
[quote]...so that the script runs in that Anaconda environment? – and what about the User and Workspace Settings: see here: Activating Anaconda Environment in VsCode :: can i integrate vscode into anaconda - how to do this?
[url]https://stackoverflow.com/questions/43351596/activating-anaconda-environment-in-vscode:[/url]
the question is: how to configure Visual Studio Code to our liking through its various settings. Nearly every part of VS Code's editor, user interface, and functional behavior has options we can modify. i found some Instructions to edit settings.json here: [url]https://code.visualstudio.com/docs/getstarted/settings[/url]
VS Code provides two different scopes for settings:
User Settings - Settings that apply globally to any instance of VS Code you open.
Workspace Settings - Settings stored inside your workspace and only apply when the workspace is opened.
Workspace settings override user settings. Workspace settings are specific to a project and can be shared across developers on a project.
Note: A VS Code "workspace" is usually just your project root folder. Workspace settings as well as debugging and task configurations are stored at the root in a .vscode folder. You can also have more than one root folder in a VS Code workspace through a feature called Multi-root workspaces.
Creating User and Workspace Settings
To open your user and workspace settings, use the following VS Code menu command:
On Windows/Linux - File > Preferences > Settings
On macOS - Code > Preferences > Settings
[/quote]
Also, die Ausgangs-Zusatz-Frage ist die Folgende: kann ich denn dann hier noch ohne weiteres und ohne Konfigurationsorgien nun ggf.
Anaconda installieren? Geht das denn!? Kommen sich hier nicht Anaconda und Python (das schon auf dem Rechner ist) in die Quere!?
zuletzt noch die Vergleichsfrage am Rande: - welches der beiden Systeme wird denn schneller & nachhaltiger entwickelt: Anaconda oder WinPython:
vgl. [url]https://winpython.github.io/[/url]
[quote]
Designed for scientists, data-scientists, and education (thanks to NumPy, SciPy, Sympy, Matplotlib, Pandas, pyqtgraph, etc.):
interactive data processing and visualization using Python with Spyder and Jupyter/IPython, Pyzo, IDLEX or IDLE
fully integrated Cython and Numba! See included example
connectors (cffi, odbc, rpy2, scilab2py, requests, ...) for advanced users
Portable:
Runs out of the box(*) on any Windows 8+ with 2GB Ram (Jupyter Notebook will require a recent browser)
The WinPython folder can be moved to any location (**) (local, network, USB drive) with most of the application settings
Flexible:
You can install as many WinPython distributions as you want on the same machine: each one is isolated and self-consistent
These installations can be of different versions of Python (3.7/3.8/3.9...)
Customizable:
The integrated WinPython Package Manager (WPPM) helps installing, uninstalling or upgrading Python packages
It's also possible to install or upgrade packages using pip from the WinPython command prompt
A configuration file allows you to set environment variables at runtime
[/quote]
und hier noch ein kurzes Wort zu[B] Pipenv [/B]
Pipenv gilt als ein Tool, das im Grunde darauf abzielt, das Beste aus allen Package-welten (Bundler, Composer, npm, Cargo, Garn usw.) zu machen, bzw. diese in die Python-Welt zu bringen.
[B]was macht Pipenv:[/B]
Pipenv erstellt und verwaltet automatisch eine virtuelle Umgebung für die Python-Projekte und fügt Pakete aus dem Pipfile hinzu/ oder - auf der anderen Seite - entfernt diese, während man im Grunde genommen Pakete installiert/deinstalliert.
Noch etwas weiteres ist wichtig in diesem Zusammenhang zu erwähnen: Pipenv generiert auch die immer wichtigere Pipfile.lock,
Pipfile.lock - das ist die zum Erstellen deterministischer Builds verwendet wird.
So gesehen ist Pipenv sehr wichtig: Pipenv sorgt in allererster Linie dafür, dass Benutzern und Entwicklern von Anwendungen eine einfache Methode zum Einrichten einer Arbeitsumgebung bietet.
[B]setup.py vs. Pipfile: [/B]
Wenn man auf die Unterscheidung sieht - also auf die Differenzen zwischen Bibliotheken und Anwendungen und die Verwendung von setup.py vs. Pipfile dann werden deutliche Unterschiede bemerkbar. Es gibt im Bezug auf das Definieren von Abhängigkeiten hier ☤ Pipfile vs. setup.py.
Pipenv ist im Grunde nichts anderes als ein Problemlöser: Sieht man im Konkreten auf die Probleme, die Pipenv zu lösen versucht, dann muss man sagen, dass es ja sehr viele Themen u. Probleme sind, die Pipenv zu lösen versucht.
Das Gute ist, dass Pipenv es ermöglicht, dass man pip und virtualenv nicht mehr separat verwenden muss. Diese beiden, sie arbeiten zusammen.
Wenn man eine requirements.txt-Datei verwalten will - dann kann es mitunter auch problematisch werden, Aus diesem Grunde verwendet Pipenv Pipfile und Pipfile.lock: Denn dadurch werden abstrakte Abhängigkeitserklärungen von der zuletzt getesteten Kombination zu trennen. | digital_hub |
1,401,151 | Testing Dev.to | Hello World! I'm Rodrigo Coelho from Brazil and I'm here to test this amazing tool. My goal here is... | 0 | 2023-03-14T23:53:23 | https://dev.to/rodrigocoeio/testing-devto-11pf | webdev, programming, nextjs | **Hello World!**
_I'm Rodrigo Coelho from Brazil and I'm here to test this amazing tool.
My goal here is to test the integration of Dev.to with Next.js._ | rodrigocoeio |
1,401,177 | how to install Miniconda on a Linux Notebook? | You can install Miniconda on a Linux notebook by following these steps: Download the appropriate... | 0 | 2023-03-15T01:04:19 | https://dev.to/digital_hub/how-to-install-miniconda-on-a-linux-notebook-ddd | conda, anaconda, vscode, python |
You can install Miniconda on a Linux notebook by following these steps:
Download the appropriate Miniconda installation script for your Linux distribution from the official Miniconda website. Choose the version that matches your operating system and architecture (e.g., Linux 64-bit or 32-bit).
Open a terminal window and navigate to the directory where the Miniconda installation script was downloaded.
Make the installation script executable by running the following command:
`chmod +x Miniconda3-latest-Linux-x86_64.sh
`
Replace Miniconda3-latest-Linux-x86_64.sh with the actual name of the installation script that you downloaded.
Run the installation script by running the following command:
`./Miniconda3-latest-Linux-x86_64.sh`
Again, replace Miniconda3-latest-Linux-x86_64.sh with the actual name of the installation script.
Follow the prompts in the installation script to complete the installation. You will be asked to accept the license agreement, choose the installation location, and specify whether you want Miniconda to be added to your system path.
Once the installation is complete, close the terminal window and open a new one to ensure that the changes to your system path are recognized.
Verify that Miniconda is installed correctly by running the following command:
`conda --version
`
This should display the version number of the Miniconda package manager.
That's it! You can now use Miniconda to create Python environments and install packages on your Linux notebook. | digital_hub |
1,401,320 | NoodleShop: Revolutionizing Transactions with Decentralized Escrow Services | As the gig economy and remote work continue to expand, the need for secure and efficient methods to... | 0 | 2023-03-15T03:54:05 | https://dev.to/noodleshopmkt/noodleshop-revolutionizing-transactions-with-decentralized-escrow-services-26p | gamedev, webdev, career, hiring |

As the gig economy and remote work continue to expand, the need for secure and efficient methods to conduct transactions becomes more critical. That's where NoodleShop comes in – a decentralized platform designed to revolutionize the way individuals and businesses conduct transactions with verified funds and agreements.
In this post, we'll explore the key features of NoodleShop, how it's set to transform the staffing industry, and its potential applications across various sectors.
NoodleShop: A Blockchain-based Escrow Solution
NoodleShop is a smart contract escrow service built on blockchain technology. It provides a secure and user-friendly platform for individuals and businesses to conduct transactions, eliminating the fear of scams and non-payment. Key features include:
Decentralized platform: NoodleShop's blockchain-based system ensures secure and transparent transactions, reducing the reliance on centralized intermediaries.
Smart contracts: NoodleShop uses smart contracts to verify agreements and securely hold funds in escrow until the completion of agreed-upon deliverables.
Wide range of applications: The platform is not limited to staffing positions and can accommodate various industries and services with customizable agreements.
The Impact on the Staffing Industry
NoodleShop aims to tap into the growing $500 billion global staffing industry by providing a unique approach to staffing services. Its decentralized nature, combined with the use of smart contracts, brings a much-needed solution to the challenges faced by freelancers, gig workers, and businesses. NoodleShop allows users to find and hire help quickly and easily, ensuring secure transactions and verified agreements.
Potential Uses for NoodleShop:
While NoodleShop's primary focus is on the staffing industry, its potential extends to various sectors and use cases. Examples include:
Freelance services
Consulting and coaching
Content creation and marketing
Web and app development
**Gaming development** (We have big plans for game devs that join)
Conclusion:
NoodleShop is poised to make a significant impact on the staffing industry and beyond by leveraging blockchain technology and smart contracts to provide a secure and easy-to-use platform for transactions. As the gig economy and remote work continue to grow, NoodleShop's innovative approach to decentralized escrow services will undoubtedly benefit both service providers and clients alike.
Get involved and learn more about NoodleShop by visiting [https://www.noodleshop.xyz/]
(https://www.noodleshop.xyz/)
Follow us on Twitter:
[https://twitter.com/NoodleshopMkt](https://twitter.com/NoodleshopMkt)
Join the Tokyo Rebels Discord for any and all questions:
[https://discord.gg/tokyorebels](https://discord.gg/tokyorebels) | noodleshopmkt |
1,401,605 | Assignment 1 - Getting started | As part of OSDC course, I learn how to use new communication tools at Jerusalem College of... | 0 | 2023-03-15T09:20:26 | https://dev.to/chapnitsky/assignment-1-getting-started-46b1 | osdc | As part of OSDC course, I learn how to use new communication tools at Jerusalem College of Engineering as M.sc Software Engineering student.
The course will be guided by @szabgab
We can do it! | chapnitsky |
1,401,654 | A new Go web framework inspired by FastAPI | My two main programming languages are Python and Go. When it comes to building APIs, I've always... | 0 | 2023-03-15T09:59:03 | https://dev.to/yoyo_programming/a-new-go-web-framework-inspired-by-fastapi-54im | My two main programming languages are Python and Go. When it comes to building APIs, I've always leaned towards Python due to its simplicity. However, Python can be quite slow. That's why I've developed an easy-to-use and efficient Go web framework for crafting simple and speedy APIs. Enjoy!
https://github.com/hvuhsg/GoAPI | yoyo_programming | |
1,401,897 | Introducing Myself | Hello, my name is Adremy, and I am a frontend web developer currently learning JavaScript. Before... | 0 | 2023-03-15T13:43:58 | https://dev.to/adremy/introducing-myself-4b2b | webdev, javascript, beginners, frontend | Hello, my name is _**Adremy**_, and I am a frontend web developer currently learning JavaScript. Before getting into tech, I started out as a content writer, but I've always been interested in technology and its limitless possibilities. So, I decided to make the switch and become a front-end developer. It has been an exciting journey so far, and I am determined to make the most of it.
As with any journey, there have been challenges along the way. One of the biggest challenges I faced was learning how to code from scratch. I had no prior knowledge of HTML, CSS, or any programming language. However, with a lot of determination and dedication, I was able to learn HTML5, CSS3, and Tailwind CSS in just seven months. It was a huge achievement for me, and it gave me the confidence to keep going.
Currently, I am learning JavaScript. I have learned about the basics so far, which include data types, variables, arrays, and an introduction to objects. I started my learning journey from freeCodeCamp, but I later switched to a video course by Bro Code. I found that I work better with video tutorials, and it has helped me to understand the concepts better.
Over the next 30-45 days, I will be focusing on tutorial-based JavaScript projects. I aim to build a bit of muscle memory around JavaScript while understanding the whys and logic of each process. I made a promise to become a React developer before the end of 2023, and I am proud of the progress I’ve made so far.
As I continue on my journey to becoming a React developer, I hope to connect with fellow developers. I believe that collaboration and networking are essential to success, and I am excited to be a part of this vibrant community. There is still a lot for me to learn, but I am excited about the possibilities and look forward to what the future holds.
| adremy |
1,401,902 | Borderless E-commerce Explained to a 5-year-old | The Power of Borderless E-commerce Learn about the functionality of borderless e-commerce... | 0 | 2023-03-15T14:38:32 | https://princejoel.hashnode.dev/how-to-explain-borderless-ecommerce-to-a-5-year-old | opensource, node, ecommerce, medusa | ## The Power of Borderless E-commerce
Learn about the functionality of borderless e-commerce and how it's changing the way we shop online.
Borderless e-commerce allows people to buy and sell things online without worrying about geographical or national borders. It means you can buy this from people worldwide, no matter where you are. This makes getting the things you need easier and faster, and it also helps people in different countries connect.
Borderless e-commerce is important because it helps people find the things they need more easily, allows businesses to reach more customers, and helps countries to work together.
If we were to explain borderless e-commerce to a five-year-old, we would say that it’s like a big online store where people from all over the world can buy and sell things online. No matter where you live, you can purchase stuff from anyone, anywhere. This article will explain what is borderless e-commerce in a simple way that is easy for everyone to understand.
## **Explaining Borderless E-commerce to a Five-Year-Old**
## **What is a Border?**
A border is like a line that separates two different places. It can be a line between two countries, states, towns, or cities. Borders are like invisible walls that tell us where one place stops and another starts. People use borders to ensure we know who lives in one place and who lives in another.
Some examples are the fence separating your home and your neighbor's home. Or your room or classroom doors that restrict it from the other part of the building.
## **How Borderless E-commerce Works?**
Borderless e-commerce is a type of online shopping that allows people to buy and sell things from anywhere in the world. It is different from traditional e-commerce because it doesn’t limit you to shopping in your country. With borderless e-commerce, you can buy and sell things from any country without worrying about handling shipping, customs, or other international issues.
This means you can find and buy things that you might not be able to find in your town or country. For example, if you live in the United States and want to buy a toy from a store in France. All you need to do is visit the store's website and look at the available products. If you like something, add it to your cart and check it out. The store will then calculate the cost of shipping, taxes, and any other fees associated with the purchase and you can pay using your credit card or other payment methods.
After you have paid for the item, the store will package it and ship it to your home. The store will also handle customs paperwork or other international regulations, so you don't have to worry about it. When the item arrives, you can then enjoy your purchase!
## **Benefits of a Borderless E-commerce to Businesses and Customers**
Borderless e-commerce is like a big online store with no walls and anyone from anywhere can shop there. It's like a store that never closes and you can buy things from all over the world without leaving your home.
For businesses, that means they can reach more customers, sell to people in many different countries, and make more money.
And for consumers, that means they can shop for things from all over the world, like special foods, unique clothes, or cool toys they can't find in their own country. But they can buy from the comfort of their own homes.
So borderless e-commerce is like a big store that never closes, and it helps businesses make more money while helping consumers get things they can't find anywhere else.
## **How Medusa Allows Businesses to Build Borderless E-commerce?**
[Medusa](https://medusajs.com/) is an open-source composable e-commerce engine built on top of Node.js that provides an easily extendable framework for developing e-commerce websites and applications. It offers many features, including product catalogs, payment gateways, shopping cart solutions, order tracking, user accounts, and more. It also enables developers to extend the functionality of their website or application with a wide range of plugins and extensions to customize and improve the e-commerce experience.
Medusa comprises three components: the headless built-on Node.js server, the admin dashboard, and the storefront.
- [**Medusa Server**](https://docs.medusajs.com/usage/create-medusa-app): The Medusa server is like a special brain that helps your store remember all the important information it needs. It enables you to keep track of what products you have in your store, how much they cost, and how many customers you have. It also helps your store make sure everything runs smoothly.
- [**Admin Dashboard**](https://docs.medusajs.com/admin/quickstart): Medusa admin dashboard is like a special tool that you can use to manage your store. It helps you keep track of orders, products, and your customers. It's like a big board that makes it easier to stay organized and keep your store running smoothly.
- [**Storefront**](https://docs.medusajs.com/starters/gatsby-medusa-starter): Medusa storefront helps you create a website with products that customers can look at and buy.
Medusa makes it easy for businesses to build borderless e-commerce stores. It enables businesses to create their online store without writing code, supporting multiple currencies and payment gateways.
Businesses can accept payments in different currencies, offer localized products, and provide customers with a better online shopping experience. Medusa also allows businesses to access additional analytics, marketing, and customer service services. This makes it easier for businesses to manage their e-commerce operations and grow their business.
Medusa is like a magic bridge that helps businesses build stores and sell their products to people worldwide. Businesses can create stores that people can see from different countries, even if they're far away. And they can reach out to customers thousands of miles away without worrying about borders. It's like a way of connecting everyone, no matter where they are!
Medusa provides cool features that help e-commerce be borderless:
- [**Medusa regions**](https://docs.medusajs.com/advanced/backend/regions/overview): This feature helps businesses customize their store for different countries to provide customers with the best experience based on location.
- [**Customer groups**](https://docs.medusajs.com/advanced/backend/customer-groups/): The customer groups feature allows businesses to group people who like the same things together or group regular customers and give them special discounts.
- [**Price lists**](https://docs.medusajs.com/advanced/backend/price-lists/): Medusa’s price list feature helps businesses run sales and promos. A good example is the buy two and gets one extra promo or Christmas discount sales.
- [**Sales channels**](https://docs.medusajs.com/advanced/backend/sales-channels/): These are like stores that you can create to sell products. You decide which products to have in each store and track orders and carts to each store.
## **Benefits of Using Medusa**
Medusa provides a powerful set of tools for creating custom e-commerce. Here are some benefits of using Medusa:
- Improved Scalability: Developers can create scalable applications with ease. It can be used to build applications that require high availability and can handle large amounts of traffic.
- Reduced Development Time: Developers can create and deploy applications quickly, reducing the time it takes to develop and maintain applications.
- Easy Maintenance: Medusa has built-in tools and features that make it easy to maintain applications. It provides a unified structure that allows developers to make changes and updates to their applications quickly.
- Security: It is secure and provides protection against malicious attacks. It also provides encryption and authorization support.
## **Conclusion**
In this article, we learned that borderless e-commerce is a way of online shopping that allows people to buy items from countries around the world without worrying about borders or other obstacles. It makes it easier and more convenient for shoppers to find and purchase goods from international sellers. Borderless e-commerce also makes it easier for sellers to expand their customer base, offering their products to more people in more places.
We also highlighted how Medusa allows businesses to build borderless e-commerce and the benefit of using it in an e-commerce application.
There are many excellent resources to help you learn more about this topic. I will recommend you start with Medusa with these resources:
- Check out [**Medusa’s**](https://medusajs.com/) documentation.
- Learn [how to build a product with Medusa](https://aviyel.com/post/2887/how-to-get-started-with-medusa).
- Read the [beginner's guide to learn more about Medusa’s server](https://medusajs.com/blog/beginner-guide-to-node-js-e-commerce-platform-understanding-the-medusa-server/).
- If you want to know how to build a full-stack headless e-commerce application with Medusa using just one command, read [this article](https://medusajs.com/blog/ecommerce-backend/).
Great job on learning about borderless e-commerce! You're off to a wonderful start and should be proud of yourself. As you continue learning, remember to take your time and not be afraid to ask questions.
If you have any issues or questions related to Medusa, reach out to the Medusa team and the community via [**Discord**](https://discord.gg/medusajs). | princejoel |
1,401,903 | How I Built a Website That Generated 7,000 Articles in One Week with ChatGPT | I wanted to share with you a unique project I recently completed, which I believe could be of... | 0 | 2023-03-15T14:01:44 | https://dev.to/maurimbr/how-i-built-a-website-that-generated-7000-articles-in-one-week-with-chatgpt-4ela | I wanted to share with you a unique project I recently completed, which I believe could be of interest to your readers.
In just one week, I was able to generate over 7,000 articles, each with approximately 800 to 1000 words, using the GPT 3.5 Turbo API in a fully automated manner. I achieved this through a Python script (also generated by GPT), where I fed a list of topics, and it generated the content and automatically posted it on WordPress. Additionally, I integrated the Google Images API to capture the image and post it automatically, allowing me to create around 10 posts per minute. What's more, I accomplished all this with a budget of only $40.
However, I'm still uncertain about how Google or Bing will handle this AI-generated content and whether it will impact SEO, but I'm here to investigate further.
What makes this project particularly unique is that I have very little programming knowledge. Using GPT, I was able to create a python algorithm that generated content through an API, something I had never done before and didn't even know how an API worked. Furthermore, GPT helped me learn how to integrate the API with WordPress, and I also used it to create an algorithm for providing a thumbnail for each post. Lastly, I combined all of these algorithms into one, creating something that I never thought I could do. Though I can't say whether it's useful or not, the project gave me a great sense of inner peace and satisfaction.
I believe this project could inspire others who may not have considered AI as a tool for learning and creating before. If you're interested in sharing my story and experience with your readers, I would be honored to discuss this further with you.
I invite you to check out my website, https://www.tigove.com, to see the project in action. | maurimbr | |
1,402,172 | ChatGPT, write 1k words about how companies transform open source into proprietary platforms for surveillance capitalism | Sasha Costanza-Chock just tweeted the following in response to the fact that OpenAI, while... | 0 | 2023-03-15T16:26:21 | https://dev.to/dennistraub/chatgpt-write-1000-words-about-how-they-transform-open-source-software-into-proprietary-platforms-for-surveillance-capitalism-3cl7 | [Sasha Costanza-Chock](https://twitter.com/schock) just tweeted the following in response to the fact that OpenAI, while [introducing GPT-4](https://cdn.openai.com/papers/gpt-4.pdf), declared that they won't disclose anything about the contents of their training set:
{% embed https://twitter.com/schock/status/1635756520326549505 %}
And I think that it's a great idea to ask ChatGPT exactly that, just adding a tiny detail to the end of the prompt:
> Write 1,000 words on how tech companies appropriate the idea of free and open source software but in practice transform it into proprietary platforms for surveillance capitalism. Include OpenAI as an example.
And--drumroll please--here's the result. And it's quite interesting to read!
### ChatGPT's answer, raw and unedited:
The idea of free and open-source software (FOSS) was born out of the belief that software should be free for everyone to use, modify and distribute. It was a revolutionary concept in the world of computing, and it paved the way for a new generation of software developers who sought to challenge the status quo and build a more democratic and equitable system.
However, over the years, tech companies have co-opted the idea of FOSS and turned it into something entirely different. They have used it to build proprietary platforms that operate on a model of surveillance capitalism, where user data is harvested, analyzed, and sold to third-party advertisers for profit.
One of the best examples of this is OpenAI, a research organization founded in 2015 with the aim of promoting and developing AI in a way that is safe and beneficial for everyone. OpenAI's founding principles were based on the idea of democratizing AI and making it accessible to all. However, as the organization has grown, it has become increasingly apparent that its actions are not entirely consistent with these principles.
For example, OpenAI has developed a language model called GPT-3, which is capable of generating human-like text. While this technology has enormous potential for good, it is also being used by companies to create AI-powered chatbots and other automated systems that can interact with users in a more human-like way. This is great for businesses, but it also raises serious privacy concerns.
The problem with this approach is that it relies on the collection of vast amounts of user data, which is then used to train the AI models that power these systems. This data includes everything from search history and browsing habits to personal information like location and demographics. In essence, it is a form of surveillance that is being used to create a more profitable and efficient version of capitalism.
This is not to say that OpenAI is a bad organization. On the contrary, it is doing a lot of great work in the field of AI, and it has made significant contributions to the development of the technology. However, it is important to recognize that its actions are not entirely consistent with the founding principles of FOSS. While OpenAI's software may be free and open-source, the data that is being used to power it is anything but.
The problem with this model is that it creates a system where companies are incentivized to collect as much data as possible, regardless of the consequences for user privacy. This is because data is the lifeblood of surveillance capitalism, and the more data a company can collect, the more valuable it becomes. As a result, companies like Google and Facebook have built their entire business models around the collection and monetization of user data.
This is a serious problem, not only because it violates user privacy but also because it creates a power imbalance between users and the companies that control their data. When users give their data to these companies, they are essentially handing over control of their online identity. This can have serious consequences, particularly when that data is used for targeted advertising or other forms of manipulation.
The rise of surveillance capitalism has also had significant political consequences. By collecting vast amounts of data on users, tech companies have become some of the most powerful entities in the world. They have the ability to influence public opinion, shape political discourse, and even sway elections. This is not to say that tech companies are inherently evil or malicious, but it does highlight the dangers of allowing a small group of companies to control so much of our online activity.
In conclusion, the idea of free and open-source software was a revolutionary concept that aimed to create a more democratic and equitable system. However, in practice, tech companies have co-opted this idea and turned it into something entirely different. They have used FOSS to build proprietary platforms that operate on a model of surveillance capitalism, where
| dennistraub | |
1,402,207 | Dockerizing Your React App: A Step-by-Step Guide | Docker is a popular tool for software developers and engineers looking to streamline the process of... | 0 | 2023-03-15T17:31:13 | https://tonie.hashnode.dev/dockerizing-your-react-app-a-step-by-step-guide | docker, react, javascript | ---
title: Dockerizing Your React App: A Step-by-Step Guide
published: true
date: 2023-03-07 08:20:18 UTC
tags: docker,react,javascript
canonical_url: https://tonie.hashnode.dev/dockerizing-your-react-app-a-step-by-step-guide
---
Docker is a popular tool for software developers and engineers looking to streamline the process of building, testing, and deploying applications. With its ability to create lightweight, portable containers that can run on any platform, Docker has significantly impacted the way we build and deploy software applications.
One of the many benefits of Docker is that it allows you to easily containerize your applications, which can help to simplify the process of deploying your code to different environments. In this article, we will focus specifically on how to Dockerize a React application.
React is a popular JavaScript library for building user interfaces, while Vite is a modern build tool that enables fast and efficient development.
## Prerequisite
To follow along in this tutorial, you will need the following:
- Node and npm installed on your machine
- A recent version of [Docker](https://www.docker.com/) on your local machine.
- A text editor (preferably, VSCode)
## Create a React Application
1. Create a new folder and open it within your text editor. Navigate to your terminal and type in the following command:
2. Go into the `package.json` file within your application and update the `dev` command within the script tag with this
3. Type in the following command to start your development server
## How to Dockerize a React Application
1. Create two files in the root directory named Dockerfile Dockerfile.dev respectively. The difference between these files is that the former is used for a production build while the latter is used for a development build.
2. Copy the following code into the two Dockerfiles
3. Create a new file within the root directory and name it `docker-compose.yml` Copy the code below and paste it into the file
4. Now that we have set up our application. Go to your terminal and type in the following code to build the application
If everything ran successfuly, you should see a message like the one below in your terminal
```
docker-compose up
[+] Running 1/1
- Container docker-react-client-1 Recreated 1.6s
Attaching to docker-react-client-1
docker-react-client-1 |
docker-react-client-1 | > docker-react@0.0.0 dev
docker-react-client-1 | > vite --port 3000 --host
docker-react-client-1 |
docker-react-client-1 |
docker-react-client-1 | VITE v4.1.4 ready in 4809 ms
docker-react-client-1 |
docker-react-client-1 | Local: http://localhost:3000/
docker-react-client-1 | Network: http://172.19.0.2:3000/
```
Voila!! You have dockerized your first react application. Now you can go ahead and develop your application and all the changes you make will be automatically picked up by docker whenever you run the `docker-compose up` command.
To see your application, go to your browser and type **http://localhost:3000/**
If you found this helpful, please like, comment and share it. I'd like this article to reach as many people as possible.
The source code can be found [here on github](https://github.com/Tonie-NG/docker-react). Don't forget to star | tonieng |
1,402,218 | Text Me мод апк Текст бесплатно, звонок бесплатно | TextMe мод апк, которым пользуются более 5 миллионов пользователей, представляет собой социальное и... | 0 | 2023-03-15T17:20:22 | https://dev.to/zoyazoy07900093/text-me-mod-apk-tiekst-biesplatno-zvonok-biesplatno-145n | **[TextMe мод апк](https://apkkingru.com/text-me-apk/)**, которым пользуются более 5 миллионов пользователей, представляет собой социальное и коммуникационное программное обеспечение, созданное TextMe Inc. Это программное обеспечение для текстовых сообщений и звонков, которое используется гражданами Америки, Канады и более чем 40 других стран. В этом премиум-apk вам будут предоставлены безграничные кредиты бесплатно.
С этой программой отправлять текстовые сообщения и звонить стало невероятно просто. С помощью этого приложения вы можете легко связаться с кем угодно бесплатно. Вы можете передавать текстовые и графические сообщения на любой номер из США, Канады и более чем 40 других стран, используя MMS.
Приложение простое в использовании. Вы можете легко создать учетную запись в приложении, войдя в существующую учетную запись Facebook или Google. После этого вы можете ввести свой номер телефона и другую информацию, чтобы сразу начать звонить и отправлять сообщения своим близким.
Кроме того, программа предоставляет бесплатные услуги аудио- и видеозвонков. И все это бесплатно. С TextMe мод апк вы также получите реальный номер телефона, который вы можете использовать для связи и текстовых сообщений с другими людьми, оставаясь при этом анонимным.
**## Работающий**
Использовать и понимать TextMe мод апк очень просто. С программой создание учетной записи невероятно просто. С помощью этой программы вы получаете реальные номера бесплатно. Лучшая особенность этого приложения заключается в том, как легко вы можете переключаться между различными номерами, которые вы получаете при его использовании.
Это самый эффективный инструмент внешней и внутренней коммуникации. Чтобы оставаться анонимным, вы можете связываться с реальными номерами по всему миру со своим виртуальным номером. Таким образом, ваша личность останется тайной для другого человека. Качество разговора — HD, и вы можете делиться стикерами и смайликами в чате, как и в любой другой программе для общения.
## **TextMe мод апк Характеристики**
- Номер локально
- текстовые сообщения и разговоры за границей
- Голосовая почта
- отправка звонков
- найти число
- групповое общение в чате
- Отправляйте сообщения в виде изображений, видео и аудио.
- Используйте иконки и смайлики.
- Светлый режим и темный режим
- Создайте уникальную подпись слова.
- отдельные текстовые тона и шумы
- Персонализированные мелодии звонка и мелодии телефона
- Напоминание о непрочитанных сообщениях
- Блокировка звонков и текстовых сообщений на экране блокировки
- Просмотрите предварительный просмотр ваших текстов, пока они заблокированы.
- изменить фон или обои
- Код-пароль Сохраняйте конфиденциальность своих текстовых сообщений с помощью блокировки конфиденциальности.
- Чтобы текстовые сообщения и чаты оставались конфиденциальными, скройте или заблокируйте их.
- Бесплатные SMS, MMS или текстовые сообщения для отправки GPS-позиции
- Изменить и добавить множество цифр к вашему номеру телефона
- Присоединяйтесь с помощью Facebook и Google
- совместим с множеством других приложений для обмена SMS-сообщениями, включая TextNow, TextFree, Google Voice и Talkatone.
## **Заключение**
У нас есть все, что вам нужно в этом [TextMe мод апк](https://apkkingru.com/text-me-apk/), если вы предпочитаете оставаться анонимным, не хотите делиться своим именем или просто хотите бесплатное программное обеспечение для текстовых сообщений и звонков. Поэтому сделайте это прямо сейчас и начните отправлять текстовые сообщения своим контактам.
| zoyazoy07900093 | |
1,402,231 | Best text editors for React | Written by Fimber Elemuwa✏️ Whether you're building a content management system, a blog platform, or... | 0 | 2023-03-16T19:55:28 | https://blog.logrocket.com/best-text-editors-react | react, webdev | **Written by [Fimber Elemuwa](https://blog.logrocket.com/author/fimberelemuwa/)✏️**
Whether you're building a content management system, a blog platform, or any other application requiring users to create and format text, a rich text editor can be an essential component. In 2023, there are many text editor options available, but it can be challenging to know which one to choose.
In this article, we'll look at some of the best text editors for React, discussing their features, pros, and cons, to help you make an informed decision about which one to use for your next project. Before we dive into what the best React editor is, let’s look at what a rich text editor is and the difference between HTML text editors and rich text editors.
_Jump ahead_:
* [The difference between HTML text editors and rich text editors](#html-text-editors-vs-rich-text-editors)
* [Draft.js](#draftjs)
* [TinyMCE](#tinymce)
* [Quill](#quill)
* [CKEditor 5](#ckeditor5)
* [ProseMirror](#prosemirror)
## Prerequisites
This article assumes the reader has a working knowledge of React. You don't have to be an expert, but you need to be able to understand React code.
## The difference between HTML text editors and rich text editors <a name="html-text-editors-vs-rich-text-editors">
HTML text editors and rich text editors are both tools used to create web content, but they work in different ways and are designed for different purposes. HTML text editors are designed for developers and web designers who need to write and edit code in HTML, the core language used to create web pages.
These editors provide a plain text interface where users can write and edit code directly. Examples of HTML text editors include Sublime Text, Atom, VS Code, and Notepad++. They allow developers to write and edit code with features such as syntax highlighting, code folding, and auto-completion. They are best suited for those who are already familiar with HTML, CSS, and JavaScript.
On the other hand, rich text editors, are designed for content creators who may not have experience with coding. These editors provide a more user-friendly interface for formatting text, similar to a Word or Doc processor. They may also support the use of other languages, such as CSS and JavaScript. Rich text editors typically produce HTML code, but hide the underlying code from the user, allowing them to focus on the visual formatting of the text.
Think of a popular blogging platform like WordPress or Hashnode. The interface where you write your content for your blog, that’s a rich text editor.
Now let’s dive into the best rich text editors for React in no particular order.
## Draft.js
[Draft.js](https://draftjs.org/) is one of the best editors out there in the market. Actively maintained by Meta, Draft.js is an open source JavaScript framework React library for building rich text editors.
Draft.js provides a set of APIs for creating and manipulating content in a structured way and allows developers to build custom text editors that can handle a variety of formatting options, such as bold and italic text, lists, undo/redo, code blocks, links, media, etc.
Draft.js is built on top of Facebook's React library and can be integrated with other tools and frameworks, such as Redux.
### Pros
* Easy to integrate with other React-based tools and frameworks
* Draft.js is open source and actively maintained by Facebook, which means that it is well-supported and has a large and active community of developers
* Designed to handle large amounts of text and can handle complex use cases such as collaborative editingExplore 5 of the top rich text editors for React, including TinyMCE and ProseMirror, and compare them based on learning curve, plugins, mobile support, and more
### Cons
* Steep learning curve
* Requires a significant amount of development effort to create a custom text editor with all the desired features
* No official mobile support
* Browser plugins like spellcheck may break the editor
[Here’s a demo of Draft.js in use](https://codesandbox.io/s/github/gupta-piyush19/Draft-JS-Editor/tree/main/?file=/src/components/Editor/DraftEditor.js).
## TinyMCE
[TinyMCE](https://www.tiny.cloud/) is by far the best rich text editor for React in 2023\. It provides a user-friendly interface that resembles a standard Word processor, and it can be easily integrated into any web application.
TinyMCE has a wide range of features, including text formatting options like bold, italic, underline, the ability to insert and edit images, tables, and lists, different fonts, support for undo and redo actions, and much more.
The best part of TinyMCE is that it supports plugins, which can be used to add functionality to the editor, such as spell-checking and file management. All of its core features are free, too.
### Pros
* Easy to use and integrate
* Customizable with a wide range of plugins and add-ons
* Cross-browser compatible
* Lightweight and fast
* Support for many languages
* Mobile support
### Cons
* Some users may find the default user interface to be basic or outdated
* May require additional configuration to meet specific project requirements
[Here’s a demo of TinyMCE in use](https://codesandbox.io/s/3qw4k45q7p).
## Quill
The third editor on our list is [Quill](https://quilljs.com/). Quill is a popular open source rich text editor that’s used by small companies and Fortune 500 companies alike. That’s because Quill has a very simple UI that allows users to easily format text and add rich media content, and Quill also provides a wide range of formatting options including text color, font size, and alignment.
Quill is highly customizable, allowing users to add their own modules and formats. The best part is that it has a built-in spell checker and is lightweight and easy to implement. Quill is widely used in web development for creating online editors and commenting systems. However, some users may find it lacking in advanced features and it may require some technical knowledge to customize.
### Pros
* Great UI for editing and formatting text
* Long range of formatting options
* Highly customizable, allowing users to add their own modules and formats
* Built-in spell checker
* Lightweight and easy to deploy
* Cross-platform compatibility
### Cons
* Lacks some advanced features that other editors have
* There are some limitations to the undo-redo functionality
[Here’s a link to a demo of Quill in use](https://codesandbox.io/s/91wkk5540r).
## CKEditor 5 <a name="ckeditor5">
[CKEditor 5](https://ckeditor.com/) is built on a modular architecture and provides a set of features and tools for creating and editing content in a user-friendly way. It’s best known for its flexibility and customization capabilities that allow developers to create custom builds of the editor that include only the features and tools that are needed for their specific use case. This keeps the editor lightweight and fast, while still providing all the functionality needed for creating and editing content.
CKEditor 5 also includes a variety of built-in features and provides support for a wide range of formatting options, including text styles, lists, tables, and media embeds. It also supports collaborative editing, allowing multiple users to work on the same document at the same time.
### Pros
* Great accessibility for screen readers and supports keyboard shortcuts
* Can be integrated into multiple frameworks and technologies
* Highly customizable
* Has great UI
* Has a wide range of features
* Provides collaborative editing
### Cons
* CKEditor 5 is a relatively large and complex library, which may cause performance issues for your React application
* It requires heavy effort to extend its functionality
[Here’s a link to a demo of CKEditor 5 in use](https://codesandbox.io/s/github/JuniYadi/ckeditor5-react-latex/tree/master/).
## ProseMirror
Last but not least is [ProseMirror](https://prosemirror.net/). ProseMirror is popular for its structured document model. Unlike traditional text editors, which represent a document as a flat string of text, ProseMirror uses a more complex data structure to represent a document. This allows for more efficient updates and manipulation of the content, making it suitable for use in large-scale projects.
ProseMirror provides a wide range of text formatting options, including bold, italic, and underline, as well as lists, links, and images. It also allows developers to add custom text formatting options by creating their own schema, and because it’s built on modular architecture, it allows for easy integration with other tools and libraries.
ProseMirror also has a plugin system that allows developers to add new functionality to the editor without modifying the core code. Some of the popular plugins include table editing, collaborative editing, and Markdown parsing.
### Pros
* Highly customizable, allowing developers to easily create unique and tailored editing experiences
* ProseMirror is built with performance in mind, using a structured document model, which allows for efficient updates and manipulation of the content
* ProseMirror supports a wide range of text formatting options, including bold, italic, and underline, as well as lists, links, and images
* ProseMirror is open source and actively maintained, so it receives regular updates and improvements
### Cons
* ProseMirror is a relatively low-level library and requires a significant amount of work to build a fully-featured rich text editor
* ProseMirror is not tightly integrated with React. While it can be used with React, it requires additional setup and may not offer as seamless an integration as a library specifically designed for React
* ProseMirror requires a deeper understanding of the underlying functionality to make use of it
[Here’s a link to a demo of ProseMirror in use](https://codesandbox.io/s/prosemirror-template-ruwq5u?file=/src/editor/index.jsx).
## Conclusion
If you’re looking for a rich text editor to use in your React project in 2023, the five editors we featured in this article should be your go-to options. Among them, TinyMCE is my preferred choice, mostly because of the wide range of plugins it accepts and how well it performs. Overall, it just tops the rest of them.
I hope this article was helpful to you, and I hope it helped you pick a good rich text editor for your next React project. See you in the next one!
---
##Cut through the noise of traditional React error reporting with LogRocket
[LogRocket](https://lp.logrocket.com/blg/react-signup-issue-free) is a React analytics solution that shields you from the hundreds of false-positive errors alerts to just a few truly important items. LogRocket tells you the most impactful bugs and UX issues actually impacting users in your React applications.
[](https://lp.logrocket.com/blg/react-signup-general)
[LogRocket](https://lp.logrocket.com/blg/react-signup-general) automatically aggregates client side errors, React error boundaries, Redux state, slow component load times, JS exceptions, frontend performance metrics, and user interactions. Then LogRocket uses machine learning to notify you of the most impactful problems affecting the most users and provides the context you need to fix it.
Focus on the React bugs that matter — [try LogRocket today](https://lp.logrocket.com/blg/react-signup-general). | mangelosanto |
1,402,240 | writing command line scripts in php: part 5; styling output text | php is primarly considered a web language, but it can certainly be used to build interactive... | 17,640 | 2023-03-15T17:51:37 | https://dev.to/gbhorwood/writing-command-line-scripts-in-php-part-5-styling-output-text-1bcp | php is primarly considered a web language, but it can certainly be used to build interactive command-line scripts. this series of posts is designed to cover the basic constructs we will need to write to do exactly that.
this installment focuses on styling and colouring text output.
## previous installments
this is the fifth installment in the series. previously, we have covered arguments and preflighting; reading from both piped and interactive user input; and reading user key-down events.
the articles that compose this series (so far) are:
- [pt 1. arguments, preflights and more](https://dev.to/gbhorwood/writing-command-line-scripts-in-php-part-1-3jpb)
- [pt 2. handling STDIN input](https://dev.to/gbhorwood/writing-command-line-scripts-in-php-part-2-reading-stdin-2enf)
- [pt 3. interactive input](https://dev.to/gbhorwood/writing-command-line-scripts-in-php-part-3-interactive-input-34)
- [pt 4. key-down input](https://dev.to/gbhorwood/writing-command-line-scripts-in-php-part-4-key-down-input-ng5)
## the flyover
we will be looking at styling our console output text, specifically:
- colouring text
- setting the background colour of text
- adding styles like bold or underline
- combining them all
- building some handy output functions for text
as usual, all the examples here should be preceeed by the php 'shebang':
```php
#!/usr/bin/env php
```
## colouring text
colouring and styling our text outpt is useful. maybe we want the word 'ERROR' to be in red, or the default option in a list to be bold.
we can accomplish this by using [ANSI escape code](https://en.wikipedia.org/wiki/ANSI_escape_code).
ANSI escape codes are basically simple commands that tell our terminal to do things like change text colour, move the cursor, delete output and so on. they've been around since the seventies and are supported by just about every teriminal emulator in existence.
to apply colour or style to text, we can treat ANSI codes a bit like html tags, wrapping the text we want to style in an open and close code. let's look at a simple example:
```php
<?php
echo "\033[31m"."THIS IS RED"."\033[0m";
```
if this example doesn't make immediate sense, don't worry. ANSI codes were never designed with readability in mind! however, we can break down what's happening here.
the first thing to know is the `\033` is the escape character. since these are ANSI _escape_ codes, they all start with an escape. however, we can't just type an escape character into our text editor. instead, we use the `\033` sequence. in essence, we are using an escape sequence the same as we would to create a new line with `\n`, except the sequence is to create an escape character.
next, we see `[31m`. this is the actual code that tells our terminal to start outputting text in red.
we close our red 'tag' with `\033[0m`. that's an escape character followed by `[0m`. it is important to note that `[0m` closes _all_ ANSI styles; it basically resets the output style to its default. if you wrap some text in an ANSI escape sequence to make it red and bold, you only need one close escape sequence.
### making escape codes more readable
escape codes are messy and difficult to read, and if we start applying a lot of them, they get out of hand quickly.
i like to use constants to give them meaningful, readable names to keep my code clean. for instance, we could write the above example like so:
```php
define ('ESC', "\033");
define ('ANSI_RED', ESC."[31m");
define ('ANSI_CLOSE', ESC."[0m");
echo ANSI_RED."THIS IS RED".ANSI_CLOSE;
```
something important to note here is that when definig `ESC`, you _must_ put `\033` in double quotes. this is so the escape sequence gets evaluated.
we will go over all the colour and style codes in a bit!
## reverse colours
setting text colour is great, but we will also probably want to set _background_ colours as well.
fortunately, if we can set text colours, setting background colours is as straightforward as adding 10. let's look:
```php
define ('ESC', "\033");
define ('ANSI_CLOSE', ESC."[0m");
define ('ANSI_RED', ESC."[31m");
define ('ANSI_BACKGROUND_RED', ESC."[41m"); // the code for ANSI_RED plus 10
echo ANSI_BACKGROUND_RED."THIS IS ON A RED BACKGROUND".ANSI_CLOSE;
```
here we see that the ANSI code for red text is `[31m` and the code for a red background is `[41m`. the background code is ten more than the text code. this works for all ANSI colour codes.
of course, we can combine text colours and background colours if we wish.
```php
define ('ESC', "\033");
define ('ANSI_CLOSE', ESC."[0m");
define('ANSI_WHITE', ESC."[37m");
define ('ANSI_BACKGROUND_RED', ESC."[41m");
echo ANSI_BACKGROUND_RED.ANSI_WHITE."THIS IS WHITE ON A RED BACKGROUND".ANSI_CLOSE.PHP_EOL;
```
## styling text
ANSI codes can also be used to style text: make it bold or underlined or similar. all that is required is knowing some new escape codes.
```php
define ('ESC', "\033");
define ('ANSI_CLOSE', ESC."[0m");
define('ANSI_BOLD', ESC."[1m");
echo ANSI_BOLD."THIS IS BOLD TEXT".ANSI_CLOSE;
```
here we've made our text bold by applying the ANSI escape code for boldness. text style and colour are handled the same way, just using different codes.
of course we can combine style and colour; we can make our text bold and blue on a red background if we wish, although our users will probably hate us for it.
## complete color and style codes
there are a fair number of ANSI colour and style codes. rather than show a table of them, though, i'm going to give a list of `define` statements for constants that we can just copy and paste into our script.
```php
/**
* Escape character
*/
define ('ESC', "\033");
/**
* ANSI colours
*/
define('ANSI_BLACK', ESC."[30m");
define('ANSI_RED', ESC."[31m");
define('ANSI_GREEN', ESC."[32m");
define('ANSI_YELLOW', ESC."[33m");
define('ANSI_BLUE', ESC."[34m");
define('ANSI_MAGENTA', ESC."[35m");
define('ANSI_CYAN', ESC."[36m");
define('ANSI_WHITE', ESC."[37m");
/**
* ANSI background colours
*/
define('ANSI_BACKGROUND_BLACK', ESC."[40m");
define('ANSI_BACKGROUND_RED', ESC."[41m");
define('ANSI_BACKGROUND_GREEN', ESC."[42m");
define('ANSI_BACKGROUND_YELLOW', ESC."[43m");
define('ANSI_BACKGROUND_BLUE', ESC."[44m");
define('ANSI_BACKGROUND_MAGENTA', ESC."[45m");
define('ANSI_BACKGROUND_CYAN', ESC."[46m");
define('ANSI_BACKGROUND_WHITE', ESC."[47m");
/**
* ANSI styles
*/
define('ANSI_BOLD', ESC."[1m");
define('ANSI_ITALIC', ESC."[3m"); // limited support. ymmv.
define('ANSI_UNDERLINE', ESC."[4m");
define('ANSI_STRIKETHROUGH', ESC."[9m");
/**
* Clear all ANSI styling
*/
define('ANSI_CLOSE', ESC."[0m");
```
once we have these constants in our script, we can use and combine our ANSI escape styling codes however we want to. for instance:
```php
// colour output
echo ANSI_RED."THIS IS RED".ANSI_CLOSE.PHP_EOL;
echo ANSI_GREEN."THIS IS GREEN".ANSI_CLOSE.PHP_EOL;
echo ANSI_YELLOW."THIS IS YELLOW".ANSI_CLOSE.PHP_EOL;
echo ANSI_BLUE."THIS IS BLUE".ANSI_CLOSE.PHP_EOL;
echo ANSI_MAGENTA."THIS IS MAGENTA".ANSI_CLOSE.PHP_EOL;
echo ANSI_CYAN."THIS IS CYAN".ANSI_CLOSE.PHP_EOL;
echo ANSI_WHITE."THIS IS WHITE".ANSI_CLOSE.PHP_EOL;
// colour background output
echo ANSI_BACKGROUND_WHITE."THIS IS ON A WHITE BACKGROUND".ANSI_CLOSE.PHP_EOL;
echo ANSI_BACKGROUND_RED.ANSI_WHITE."THIS IS WHITE ON A RED BACKGROUND".ANSI_CLOSE.PHP_EOL;
// style output
echo ANSI_BOLD."THIS IS BOLD".ANSI_CLOSE.PHP_EOL;
echo ANSI_ITALIC."THIS MAY OR MAY NOT BE ITALIC".ANSI_CLOSE.PHP_EOL;
echo ANSI_UNDERLINE."THIS IS UNDERLINED".ANSI_CLOSE.PHP_EOL;
echo ANSI_STRIKETHROUGH."THIS IS STRIKETHROUGH".ANSI_CLOSE.PHP_EOL;
// combined colour and style output
echo ANSI_BOLD.ANSI_RED."THIS IS RED AND BOLD".ANSI_CLOSE.PHP_EOL;
echo ANSI_BOLD.ANSI_STRIKETHROUGH.ANSI_RED."THIS IS RED AND BOLD AND STRIKETHROUGH".ANSI_CLOSE.PHP_EOL;
echo ANSI_BACKGROUND_RED.ANSI_WHITE.ANSI_BOLD."THIS IS BOLD WHITE ON A RED BACKGROUND".ANSI_CLOSE.PHP_EOL;
```
## making some functions
certainly, we can manually style our output as needed and, if we don't need to do a lot of styled text output, this is perfectly fine.
however, one of the very first things i do when i start a php cli script is paste in some simple output helper functions for success and error messages.
```php
/**
* Output an 'OK' message
*
* @param String $message The message to display
* @return void
*/
function ok(String $message):void
{
fwrite(STDOUT,"[".ANSI_GREEN."OK".ANSI_CLOSE."] ".$message.PHP_EOL);
}
/**
* Output an 'ERROR' message
*
* @param String $message The message to display
* @return void
*/
function error(String $message):void
{
fwrite(STDOUT,"[".ANSI_RED."ERROR".ANSI_CLOSE."] ".$message.PHP_EOL);
}
// usage
ok("it worked");
error("something went wrong");
```
these functions, of course, rely on all the constants we defined before.
## next steps
we've begun focusing on output, and in the next installments will continue by building richer outputs and even some very simple animations.
| gbhorwood | |
1,402,371 | How to Build a Responsive Multi-plan Pricing Table Using TailwindCSS | By definition, a Pricing Table is simply a card that shows how much a given service costs or how... | 0 | 2023-03-15T20:26:06 | https://mbianoubradon.hashnode.dev/how-to-build-a-responsive-multi-plan-pricing-table-using-tailwindcss | webdev, tailwindcss, html |
 platform](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/pv9j9rxzyendlj95aaq0.png)
By definition, a Pricing Table is simply a card that shows how much a given service costs or how much a given package costs for different time lengths.
This kind of component is mostly used in Software as a Service (SaaS) presentation websites, where people can subscribe for a weekly, monthly or even yearly subscription. They usually provide multiple options, and the customer picks the one which suits him/her best needs.
For our example, we have 2 plans: Starter, and Professional. Which have different prices, depending on the subscription plan (Either Monthly or Yearly).
But for sure, one can always customize the component in such a way that a plan can be added, removed or modified.
Without any further ado, let's dive straight into the implementation.
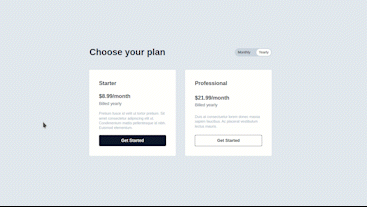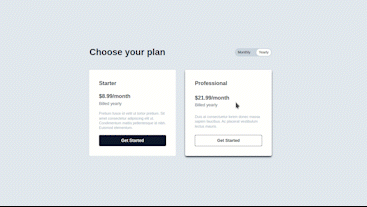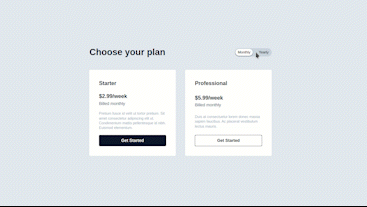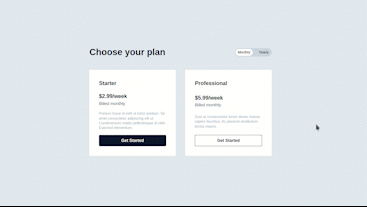
## **Understanding the task**
From the design, we can observe that this component can be divided into 2 parts, The Header, and the Different Subscriptions.
As you might have noticed, both plans, somehow look identical to each other. Yeah, except for the different packages they offer, and the subscription fee too. Therefore, if we design one plan, we can simply replicate it, and edit the text content to build the other plan.
## **Structure of Code**
As I always say, I have the same structure when it comes to designing components. Simply because I believe they somehow have the same root. 😃
This is how it goes
```xml
<body>
<!-- First Layer -->
<div>
<!-- Second Layer -->
<div>
<!-- Header -->
<div></div>
<!-- Subscription Plan -->
<div></div>
</div>
</div>
</body>
```
Let's Build this component, part by part. Let's begin with the header, then we build the subscription Plans
## Pricing Table Header
This is the easiest of all. Trust me.
```xml
<!-- Header -->
<div class="flex items-center justify-between flex-wrap gap-y-3 mb-10">
<h2 class="text-2xl sm:text-3xl font-bold text-slate-900">Choose your plan</h2>
<div class="flex text-xs rounded-full bg-slate-300 w-fit [&>*]:px-2 [&>*]:py-1 [&>*:hover]:bg-white [&>*:hover]:shadow-sm [&>*:hover]:shadow-slate-800 p-0.5 [&>*]:cursor-pointer [&>*]:rounded-full gap-3">
<p id="month">Monthly</p>
<p id="year" class="bg-white">Yearly</p>
</div>
</div>
```
Let’s get to understand the above code:
This section consists of 2 parts: The title (let's just call it the title) and the Duration slide (Monthly/Yearly).
* For the title: We simply gave it a `font-size` of t`ext-2xl` on mobile screen and a size of `sm:text-3xl` from 640px and above. Made the text bold with `font-bold`
* Duration Slide: They are just 2 paragraphs that we styled from the parent container, using the property **\[&>\*\]:**
If you are used to my posts, by now you surely know the meaning of `[&>*]` in tailwindcss.
But if you are new, The property **\[&>\*\]** simply means *“select each child individually”*, this allows us to apply the same styling properties to all the immediate children.
To each child(in this situation we are talking about paragraphs (p)), we gave it a `width` of `w-fit`, we also gave each of them a `border-radius` of `rounded-full`, and a `padding-inline` of `px-2`, `padding-block` of `py-1`. We also gave it some effects visible on hover, like background-color changing to white, `[&>*:hover]:bg-white` and box-shadow `[&>*:hover]:shadow-sm [&>*:hover]:shadow-slate-800`
That's pretty much it for the header

> Take note of the different IDs given the Monthly and Yearly plans. Monthly (id="month") and Yearly (id="year"). As it will be used in the javascript file
## Subscription Plan
This is the main part of the component. And also, it is easy to build.
The basic HTML looks like this for the **Starter Subscription**
```xml
<!-- Subscription Plan -->
<div>
<!-- Starter Subscription Plan -->
<div>
<h2>Starter</h2>
<div>
<div id="starter"><h2>$8.99/month</h2></div>
<p id="starter_in">Billed yearly</p>
</div>
<p>
Pretium fusce id velit ut tortor pretium. Sit amet consectetur adipiscing elit ut.
Condimentum mattis pellentesque id nibh. Euismod elementum.
</p>
<div class="border border-slate-900 cursor-pointer active:scale-95 bg-slate-900 text-white hover:bg-white hover:text-slate-900 text-sm py-2 rounded text-center font-bold">
<h3>Get Started</h3>
</div>
</div>
</div>
```
Basically, that's the HTML of the Starter Subscription plan. Since both plans are identical in structure, I decided to style both of them from the Parent container, so as to make the code more readable.
This is how the parent container looks like
```xml
<!-- Subscription Plan -->
<div class="flex items-center justify-between flex-wrap gap-y-5 [&>*]:flex [&>*]:justify-between [&>*]:flex-col [&>*:hover]:shadow-md [&>*:hover]:shadow-slate-900 [&>*]:w-full [&>*]:sm:max-w-[18rem] [&>*]:bg-white [&>*]:rounded [&>*]:h-[18rem] [&>*]:p-8
[&>*>h2]:text-lg [&>*>h2]:font-bold [&>*>h2]:text-slate-900
[&>*>div>p]:text-sm [&>*>div>p]:text-slate-600 [&>*>p]:text-xs [&>*>p]:text-slate-400 [&>*>div>div>h2]:text-lg [&>*>div>div>h2]:font-bold [&>*>div>div>h2]:text-slate-900">
<!-- Starter Subscription Plan -->
<div></div>
<!--Proffessional Subscription Plan -->
<div></div>
</div>
```
As earlier discussed in the header section, we used **\[&>\*\]** and similar styling to target specific elements in the structure and give them specific stylings.
And That's principally it for this section.
## Additional Stylings
It's important mentioning that we applied some extra stylings to center our component in the middle of the screen and also give it a given width
```xml
<body class="bg-slate-200 flex items-center justify-center min-h-screen">
<!-- First Layer -->
<div class="w-full sm:max-w-[38rem] p-5 sm:p-0 [&_*]:transition-all [&_*]:ease-linear [&_*]:duration-150">
<!-- Second Layer -->
<div>
<!-- Header -->
<div></div>
<!-- Subscription Plan -->
<div></div>
</div>
</div>
</body>
```
Now, Let's make this component functional. Such that you can be able to switch between Monthly and Yearly subscriptions.
## Javascript
The Javascript used here is pretty straightforward, as it just involves changing the content of an element. For this tutorial, this is what we have
```javascript
const month = document.getElementById("month");
const year = document.getElementById("year");
const starter = document.getElementById("starter");
const pro = document.getElementById("pro");
const starter_in = document.getElementById("starter_in");
const pro_in = document.getElementById("pro_in");
month.addEventListener("click", ()=>{
month.classList.add("bg-white");
year.classList.remove("bg-white");
starter.innerHTML = `<h2>$2.99/week</h2>`
starter_in.innerHTML = "Billed monthly"
pro.innerHTML = `<h2>$5.99/week</h2>`
pro_in.innerHTML = "Billed monthly"
})
year.addEventListener("click", ()=>{
year.classList.add("bg-white");
month.classList.remove("bg-white");
starter.innerHTML = `<h2>$8.99/month</h2>`
starter_in.innerHTML = "Billed yearly"
pro.innerHTML = `<h2>$21.99/month</h2>`
pro_in.innerHTML = "Billed yearly"
})
```
And that's all for this tutorial!
## **Conclusion**
We just built a simple Pricing Table Component and in the process, we also had more insight about Tailwindcss.
Many employers will need such components to be added to their websites, and for sure you know how simple it is to create it straight from your HTML document.
You can have a Live preview on [Codepen](https://codepen.io/mbianou-bradon/pen/eYLppex) or find the code on [GitHub](https://github.com/mbianou-bradon/icodethis-daily-ui-challenge/tree/main/public/February%202023/Pricing-Table-2)
Don’t hesitate to share with me if you were able to complete the tutorial on your end, I’d be happy to see any additional components and styling you added to your card.
If you have any worries or suggestions, don’t hesitate to bring them up! 😊
See ya! 👋 | mbianoubradon |
1,402,497 | How to find PostgreSQL DB growth rate? | Approach #1 with a as (select table_name, pg_total_relation_size(table_name) table_size_b from... | 0 | 2023-03-15T21:23:14 | https://dev.to/dm8ry/how-to-find-postgresql-db-growth-rate-2m2b | postgres, database, devops | Approach #1
```
with
a as (select table_name, pg_total_relation_size(table_name) table_size_b from (SELECT ('"' || table_schema || '"."' || table_name || '"') AS table_name FROM information_schema.tables where table_schema='public') M),
b as (select table_name, pg_total_relation_size(table_name) table_size_b from (SELECT ('"' || table_schema || '"."' || table_name || '"') AS table_name FROM information_schema.tables where table_schema='public') M, pg_sleep(10))
select
a.table_name, sum(b.table_size_b-a.table_size_b) as growth_rate_bytes
from a,b
where a.table_name= b.table_name
group by 1
order by 2 desc;
```
Approach #2
```
drop table if exists temp_storage_growth_trend_a;
drop table if exists temp_storage_growth_trend_b;
create table temp_storage_growth_trend_a
as
select
datname,
round(sum(pg_database_size(pg_database.datname))/1024/1024, 2) AS size_in_MB,
round(sum(pg_database_size(pg_database.datname))/1024/1024/1024, 2) AS size_in_GB
from pg_database
group by datname;
-- wait some time
create table temp_storage_growth_trend_b
as
select
datname,
round(sum(pg_database_size(pg_database.datname))/1024/1024, 2) AS size_in_MB,
round(sum(pg_database_size(pg_database.datname))/1024/1024/1024, 2) AS size_in_GB
from pg_database
group by datname;
select a.datname, b.size_in_MB - a.size_in_MB the_growth_rate_in_MB
from temp_storage_growth_trend_a a, temp_storage_growth_trend_b b
where a.datname = b.datname
order by 2 desc;
```
| dm8ry |
1,402,524 | S3 File Operations using .NET 7 WebAPI | In this chapter, we will create an Asp Net Core Web API on top of .NET 7 that contain 3 APIs. One... | 22,262 | 2023-03-21T02:11:40 | https://dev.to/sprabha1990/s3-file-operations-using-net-7-webapi-53jj | dotnet, dotnetcore, webapi, aws |
In this chapter, we will create an Asp Net Core Web API on top of .NET 7 that contain 3 APIs. One will upload the file into AWS, another for downloading the file from AWS and another to list the available files.
Find the complete source code in my GitHub repository below.
> https://github.com/sprabha1990/S3FileOperations.Blazor.NET7
Let's jump into creating a project via Dotnet CLI.
**_Assumption: .NET 7 SDK and runtime installed._**
Running the below commands on the command prompt will create a visual studio solution file, an ASP Net Core Web API project, and an empty Blazor WASM project.
```
dotnet new sln --name S3FileOperations.NET7 --output S3FileOperations.Blazor.Net7
dotnet new webapi --name S3FileOperations.WebApi --output S3FileOperations.Blazor.Net7/Api
dotnet new blazorwasm-empty --name S3FileOperations.Blazor --output S3FileOperations.Blazor.Net7/WebApp
```
Now running the below commands will add the project files to the solution file.
```
dotnet sln S3FileOperations.Blazor.Net7\S3FileOperations.NET7.sln add S3FileOperations.Blazor.Net7/Api
dotnet sln S3FileOperations.Blazor.Net7\S3FileOperations.NET7.sln add S3FileOperations.Blazor.Net7/WebApp
```
Let's open the "__S3FileOperations.NET7.sln__" file in the VS2022. You'll find two projects in it. In this chapter, We are going to work on web APIs.
First up, let’s modify the appsettings.json of the Web API project. Make sure that your appsettings.json looks like the one below. Ensure that you are populating the Profile and Region fields with the values you configured earlier in the AWS CLI.
```
"AWS": {
"Profile": "default",
"Region": "us-east-2"
}
```
Run the following commands via Visual Studio to install the required AWS NuGet packages.
`Install-Package AWSSDK.S3`
`Install-Package AWSSDK.Extensions.NETCore.Setup`
With that done, let’s register the AWS Service into the .NET application’s Container. Open up the Program.cs and make the modifications as below. You might have to use the Amazon.S3 namespace while referencing the below changes.
```
builder.Services.AddDefaultAWSOptions(builder.Configuration.GetAWSOptions());
builder.Services.AddAWSService<IAmazonS3>();
```
Line 1 Loads the AWS Configuration from the appsettings.json into the application’s runtime.
Line 2 Adds the S3 Service into the pipeline. We will be injecting this interface into our controllers to work with Bucket and Objects!
Its time to create a new API controller under Controllers and name it S3Controller.cs. You would need to inject the IAmazonS3 interface into the constructor of the S3Controller.
```
[Route("api/[controller]")]
[ApiController]
public class S3Controller : ControllerBase
{
private readonly IAmazonS3 _s3Client;
public S3Controller(IAmazonS3 s3Client)
{
_s3Client = s3Client;
}
}
```
Let's create an endpoint to upload a file into S3.
```
[HttpPost("upload")]
public async Task<IActionResult> UploadFileAsync(IFormFile file)
{
}
```
This API will get the file from the user and upload the file content into S3.
Before uploading the file, we have to create the bucket in S3. Go to the S3 service in the AWS Management Console and Create a new bucket by pressing the "Create Bucket" button.
Provide a name for the bucket and press create bucket at the bottom.
Now, you can see your bucket in the bucket list.

Let's go and implement the API "UploadFileAsync" in the S3Controller class.
```
[HttpPost("upload")]
public async Task<IActionResult> UploadFileAsync(IFormFile file)
{
var request = new PutObjectRequest()
{
BucketName = "blazor-file-transfer-demo",
Key = file.FileName,
InputStream = file.OpenReadStream()
};
request.Metadata.Add("Content-Type", file.ContentType);
await _s3Client.PutObjectAsync(request);
return Ok($"File {file.FileName} uploaded to S3 successfully!");
}
```
The above API creates a putobjectrequest with bucket name, key, and input stream. The incoming file is converted to a stream via "OpenReadStream()". The bucket name is the one which we created just now and the key name is nothing but the file name.
Calling the PutObjectAsync() API that is available in the S3 client SDK will upload the incoming file data into the S3 bucket we specified.
Now, it's time to create an API for downloading the file. As same as above, create an API called "DownloadFileAsync" inside the S3Controller.
```
[HttpPost("download")]
public async Task<IActionResult> DownloadFileAsync(string key)
{
var s3Object = await _s3Client.GetObjectAsync("blazor-file-transfer-demo", key);
return File(s3Object.ResponseStream, s3Object.Headers.ContentType, key);
}
```
In the above implementation, we are getting the key name (filename) from the user. We will use the key name and the bucket name to fetch the object from the S3 by Calling the GetObjectAsync() API available on the S3 Client SDK. This will provide us with the S3 object as a stream. We will return the stream as a File object to the client application.
At this point, we needed another API to fetch the list of files inside the bucket.
```
[HttpGet]
public async Task<IActionResult> GetAllFilesAsync()
{
var request = new ListObjectsV2Request()
{
BucketName = "blazor-file-transfer-demo",
};
var result = await _s3Client.ListObjectsV2Async(request);
return Ok(result.S3Objects);
}
```
That's it! We have created all the required APIs to list all the available files, upload a file and download a file from S3.
We'll see how to upload/download files from the blazor application with the help of these APIs in the next chapter.
| sprabha1990 |
1,402,527 | Parallel Query in PostgreSQL | Introduction Nowadays, CPUs have a vast amount of cores available. For a long time,... | 0 | 2023-03-15T22:50:11 | https://dev.to/m4rcxs/parallel-query-in-postgresql-3gc2 | postgresq, apacheage | ## Introduction
Nowadays, CPUs have a vast amount of cores available. For a long time, applications have been able to send queries in parallel to databases. When it comes to reporting queries that work with a vast number of table rows, the ability of a query to utilize multiple CPUs can significantly enhance the speed of its execution. In essence, parallel query execution is a powerful tool that enables faster processing of large data sets.

## Parallel Query
_Parallel query_ is a very useful feature, improving performance especially for queries that involve large data sets or complex calculations, by executing a query in parallel across multiple CPUs or servers to execute a single query, the system resources can be utilized more efficiently. This can lead to better overall system performance and increased throughput.
## Example
Supose that we are using a Car Database. Assuming we want to make a query that returns all "Ford" brand cars with a price above 30,000, sorted by year of manufacture. We can use parallelism to speed up the execution of this query as follows:
**Table**
_Query example_:
`SET max_parallel_workers_per_gather = 4;
SELECT *
FROM cars
WHERE make = 'Ford' AND price > 30000
ORDER BY year;`
The function `SET max_parallel_workers_per_gather = 4;` sets the maximum number of parallel workers that can be used by a single Gather or Gather Merge node in a query plan. By setting this parameter to 4, as in the given function, a single Gather or Gather Merge node can use up to 4 parallel workers, which can increase the overall performance of the query by utilizing more system resources.
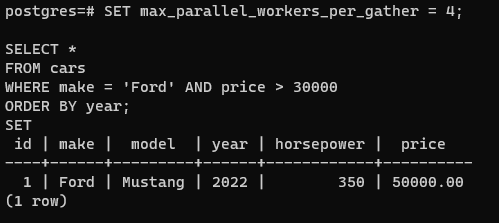
## Conclusion
I'm on my personal computer, but doing this in a very huge system that contains a big database, you can improve the performance to use queries that needs to running through in a lot of data.
References: [PostgreSQL - How Parallel Query Works](https://www.postgresql.org/docs/current/how-parallel-query-works.html
) | m4rcxs |
1,402,694 | Building a chatbot with GPT-3.5 and Next.js: A Detailed Guide | With all of the hype around AI and ChatGPT, I thought it would be appropriate to put out a tutorial... | 0 | 2023-04-16T22:35:17 | https://dev.to/cracked/building-a-chatbot-with-gpt-35-and-nextjs-a-detailed-guide-4i20 | chatgpt, ai, openai, typescript |
With all of the hype around AI and ChatGPT, I thought it would be appropriate to put out a tutorial on how to build our very own ChatGPT powered chat bot! Most of this code has already been open sourced on Vercel's website as a template, so you can feel free to clone that repo to get started, or if you just want to interact with ChatGPT and not have to sign up, you can [check it out on my website!](https://nlaw.dev/chat)
Let's jump in! These are the technologies that we will be using:
- Next.js
- TypeScript
- Tailwind (although I won't be covering that here)
- OpenAI API
## Getting Started
Let's get our project setup. I like to use pnpm and create-t3-app, but feel free to use the package manager and CLI of your choice to get started.
### Project Setup
Using pnpm and create-t3-app:
```
pnpm create t3-app@latest
```
1. Name your project
2. Select TypeScript
3. Select Tailwind
4. Select Y for Git repository
5. Select Y to run pnpm install
6. Hit Enter for default import alias
Now that we have a bootstrapped Next.js project, lets make sure that we have an OpenAI API key to use. To retrieve your OpenAI API key you need to create a user account at [openai.com](https://openai.com/) and access the API Keys section in the OpenAI dashboard to create a new API key.
### Create your environment variables
In your projects root directory, create a .env.local file. It should look like this:
```yml
# Your API key
OPENAI_API_KEY=PASTE_API_KEY_HERE
# The temperature controls how much randomness is in the output
AI_TEMP=0.7
# The size of the response
AI_MAX_TOKENS=100
OPENAI_API_ORG=
```
Let's also set up some boilerplate css so that our layout is responsive. Let's install the Vercel examples ui-layout.
```
pnpm i @vercel/examples-ui
```
Your tailwind.config.js file should look like this:
```js
module.exports = {
presets: [require('@vercel/examples-ui/tailwind')],
content: [
'./pages/**/*.{js,ts,jsx,tsx}',
'./components/**/*.{js,ts,jsx,tsx}',
'./node_modules/@vercel/examples-ui/**/*.js',
],
}
```
Your postcss.config.js should look like this:
```js
module.exports = {
plugins: {
tailwindcss: {},
autoprefixer: {},
},
}
```
Lastly, your _app.tsx should look like this:
```ts
import type { AppProps } from 'next/app'
import { Analytics } from '@vercel/analytics/react'
import type { LayoutProps } from '@vercel/examples-ui/layout'
import { getLayout } from '@vercel/examples-ui'
import '@vercel/examples-ui/globals.css'
function App({ Component, pageProps }: AppProps) {
const Layout = getLayout<LayoutProps>(Component)
return (
<Layout
title="ai-chatgpt"
path="solutions/ai-chatgpt"
description="ai-chatgpt"
>
<Component {...pageProps} />
<Analytics />
</Layout>
)
}
export default App
```
Now that we have all of our boilerplate out of the way, what do we have to do? Let's create a checklist:
1. We need to be able to listen to responses from the OpenAI API.
2. We need to be able to send user input to the OpenAI API.
3. We need to display all of this in some sort of chat UI.
## Creating a data stream
In order to receive data from the OpenAI API, we can create an OpenAIStream function
In your root project directory, create a folder called utils, and then a file inside called OpenAiStream.ts. Copy and paste this code into it and be sure to do the necessary npm/pnpm installs for any imports.
```
pnpm install eventsource-parser
```
```ts
import {
createParser,
ParsedEvent,
ReconnectInterval,
} from 'eventsource-parser'
export type ChatGPTAgent = 'user' | 'system' | 'assistant'
export interface ChatGPTMessage {
role: ChatGPTAgent
content: string
}
export interface OpenAIStreamPayload {
model: string
messages: ChatGPTMessage[]
temperature: number
top_p: number
frequency_penalty: number
presence_penalty: number
max_tokens: number
stream: boolean
stop?: string[]
user?: string
n: number
}
export async function OpenAIStream(payload: OpenAIStreamPayload) {
const encoder = new TextEncoder()
const decoder = new TextDecoder()
let counter = 0
const requestHeaders: Record<string, string> = {
'Content-Type': 'application/json',
Authorization: `Bearer ${process.env.OPENAI_API_KEY ?? ''}`,
}
if (process.env.OPENAI_API_ORG) {
requestHeaders['OpenAI-Organization'] = process.env.OPENAI_API_ORG
}
const res = await fetch('https://api.openai.com/v1/chat/completions', {
headers: requestHeaders,
method: 'POST',
body: JSON.stringify(payload),
})
const stream = new ReadableStream({
async start(controller) {
// callback
function onParse(event: ParsedEvent | ReconnectInterval) {
if (event.type === 'event') {
const data = event.data
// https://beta.openai.com/docs/api-reference/completions/create#completions/create-stream
if (data === '[DONE]') {
console.log('DONE')
controller.close()
return
}
try {
const json = JSON.parse(data)
const text = json.choices[0].delta?.content || ''
if (counter < 2 && (text.match(/\n/) || []).length) {
// this is a prefix character (i.e., "\n\n"), do nothing
return
}
const queue = encoder.encode(text)
controller.enqueue(queue)
counter++
} catch (e) {
// maybe parse error
controller.error(e)
}
}
}
// stream response (SSE) from OpenAI may be fragmented into multiple chunks
// this ensures we properly read chunks and invoke an event for each SSE event stream
const parser = createParser(onParse)
for await (const chunk of res.body as any) {
parser.feed(decoder.decode(chunk))
}
},
})
return stream
}
```
OpenAIStream is a function that allows you to stream data from the OpenAI API. It takes a payload object as an argument, which contains the parameters for the request. It then makes a request to the OpenAI API and returns a ReadableStream object. The stream contains events that are parsed from the response, and each event contains data that can be used to generate a response. The function also keeps track of the number of events that have been parsed, so that it can close the stream when it has reached the end.
Now that we can receive data back from the API, let's create a component that can take in a user message that can be sent to the api to illicit a response.
## Creating the Chat-Bot Components
We can create our chatbot in one component if we wanted to, but to keep files more organized we have it set up into three components.
In your root directory, create a folder called components. In it, create three files:
1. Button.tsx
2. Chat.tsx
3. ChatLine.tsx
### Button Component
```ts
import clsx from 'clsx'
export function Button({ className, ...props }: any) {
return (
<button
className={clsx(
'inline-flex items-center gap-2 justify-center rounded-md py-2 px-3 text-sm outline-offset-2 transition active:transition-none',
'bg-zinc-600 font-semibold text-zinc-100 hover:bg-zinc-400 active:bg-zinc-800 active:text-zinc-100/70',
className
)}
{...props}
/>
)
}
```
Very simple button that keeps the Chat.tsx file a bit smaller.
### ChatLine Component
```
pnpm install clsx
pnpm install react-wrap-balancer
```
```ts
import clsx from 'clsx'
import Balancer from 'react-wrap-balancer'
// wrap Balancer to remove type errors :( - @TODO - fix this ugly hack
const BalancerWrapper = (props: any) => <Balancer {...props} />
type ChatGPTAgent = 'user' | 'system' | 'assistant'
export interface ChatGPTMessage {
role: ChatGPTAgent
content: string
}
// loading placeholder animation for the chat line
export const LoadingChatLine = () => (
<div className="flex min-w-full animate-pulse px-4 py-5 sm:px-6">
<div className="flex flex-grow space-x-3">
<div className="min-w-0 flex-1">
<p className="font-large text-xxl text-gray-900">
<a href="#" className="hover:underline">
AI
</a>
</p>
<div className="space-y-4 pt-4">
<div className="grid grid-cols-3 gap-4">
<div className="col-span-2 h-2 rounded bg-zinc-500"></div>
<div className="col-span-1 h-2 rounded bg-zinc-500"></div>
</div>
<div className="h-2 rounded bg-zinc-500"></div>
</div>
</div>
</div>
</div>
)
// util helper to convert new lines to <br /> tags
const convertNewLines = (text: string) =>
text.split('\n').map((line, i) => (
<span key={i}>
{line}
<br />
</span>
))
export function ChatLine({ role = 'assistant', content }: ChatGPTMessage) {
if (!content) {
return null
}
const formatteMessage = convertNewLines(content)
return (
<div
className={
role != 'assistant' ? 'float-right clear-both' : 'float-left clear-both'
}
>
<BalancerWrapper>
<div className="float-right mb-5 rounded-lg bg-white px-4 py-5 shadow-lg ring-1 ring-zinc-100 sm:px-6">
<div className="flex space-x-3">
<div className="flex-1 gap-4">
<p className="font-large text-xxl text-gray-900">
<a href="#" className="hover:underline">
{role == 'assistant' ? 'AI' : 'You'}
</a>
</p>
<p
className={clsx(
'text ',
role == 'assistant' ? 'font-semibold font- ' : 'text-gray-400'
)}
>
{formatteMessage}
</p>
</div>
</div>
</div>
</BalancerWrapper>
</div>
)
}
```
This code is a React component that displays a chat line. It takes in two props, role and content. The role prop is used to determine which agent is sending the message, either the user, the system, or the assistant. The content prop is used to display the message.
The component first checks if the content prop is empty, and if it is, it returns null. If the content prop is not empty, it converts any new lines in the content to break tags. It then renders a div with a BalancerWrapper component inside. The BalancerWrapper component is used to wrap the chat line in a responsive layout. Inside the BalancerWrapper component, the component renders a div with a flex container inside. The flex container is used to display the message sender and the message content. The message sender is determined by the role prop, and the message content is determined by the content prop. The component then returns the div with the BalancerWrapper component inside.
### Chat Component
```
pnpm install react-cookie
```
```ts
import { useEffect, useState } from 'react'
import { Button } from './Button'
import { type ChatGPTMessage, ChatLine, LoadingChatLine } from './ChatLine'
import { useCookies } from 'react-cookie'
const COOKIE_NAME = 'nextjs-example-ai-chat-gpt3'
// default first message to display in UI (not necessary to define the prompt)
export const initialMessages: ChatGPTMessage[] = [
{
role: 'assistant',
content: 'Hi! I am a friendly AI assistant. Ask me anything!',
},
]
const InputMessage = ({ input, setInput, sendMessage }: any) => (
<div className="mt-6 flex clear-both">
<input
type="text"
aria-label="chat input"
required
className="min-w-0 flex-auto appearance-none rounded-md border border-zinc-900/10 bg-white px-3 py-[calc(theme(spacing.2)-1px)] shadow-md shadow-zinc-800/5 placeholder:text-zinc-400 focus:border-teal-500 focus:outline-none focus:ring-4 focus:ring-teal-500/10 sm:text-sm"
value={input}
onKeyDown={(e) => {
if (e.key === 'Enter') {
sendMessage(input)
setInput('')
}
}}
onChange={(e) => {
setInput(e.target.value)
}}
/>
<Button
type="submit"
className="ml-4 flex-none"
onClick={() => {
sendMessage(input)
setInput('')
}}
>
Say
</Button>
</div>
)
export function Chat() {
const [messages, setMessages] = useState<ChatGPTMessage[]>(initialMessages)
const [input, setInput] = useState('')
const [loading, setLoading] = useState(false)
const [cookie, setCookie] = useCookies([COOKIE_NAME])
useEffect(() => {
if (!cookie[COOKIE_NAME]) {
// generate a semi random short id
const randomId = Math.random().toString(36).substring(7)
setCookie(COOKIE_NAME, randomId)
}
}, [cookie, setCookie])
// send message to API /api/chat endpoint
const sendMessage = async (message: string) => {
setLoading(true)
const newMessages = [
...messages,
{ role: 'user', content: message } as ChatGPTMessage,
]
setMessages(newMessages)
const last10messages = newMessages.slice(-10) // remember last 10 messages
const response = await fetch('/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
messages: last10messages,
user: cookie[COOKIE_NAME],
}),
})
console.log('Edge function returned.')
if (!response.ok) {
throw new Error(response.statusText)
}
// This data is a ReadableStream
const data = response.body
if (!data) {
return
}
const reader = data.getReader()
const decoder = new TextDecoder()
let done = false
let lastMessage = ''
while (!done) {
const { value, done: doneReading } = await reader.read()
done = doneReading
const chunkValue = decoder.decode(value)
lastMessage = lastMessage + chunkValue
setMessages([
...newMessages,
{ role: 'assistant', content: lastMessage } as ChatGPTMessage,
])
setLoading(false)
}
}
return (
<div className="rounded-2xl border-zinc-100 lg:border lg:p-6">
{messages.map(({ content, role }, index) => (
<ChatLine key={index} role={role} content={content} />
))}
{loading && <LoadingChatLine />}
{messages.length < 2 && (
<span className="mx-auto flex flex-grow text-gray-600 clear-both">
Type a message to start the conversation
</span>
)}
<InputMessage
input={input}
setInput={setInput}
sendMessage={sendMessage}
/>
</div>
)
}
```
This component renders an input field for users to send messages and displays messages exchanged between the user and the chatbot.
When the user sends a message, the component sends a request to our api function (/api/chat.ts) with the last 10 messages and the user's cookie as the request body. The serverless function processes the message using GPT-3.5 and sends back a response to the component. The component then displays the response received from the server as a message in the chat interface. The component also sets and retrieves a cookie for identifying the user using the react-cookie library. It also uses the useEffect and useState hooks to manage state and update the UI based on changes in state.
## Create our chat.ts API Route
Inside the /pages directory, create a folder called api, and create a file inside called chat.ts. Copy and paste the following:
```ts
import { type ChatGPTMessage } from '../../components/ChatLine'
import { OpenAIStream, OpenAIStreamPayload } from '../../utils/OpenAIStream'
// break the app if the API key is missing
if (!process.env.OPENAI_API_KEY) {
throw new Error('Missing Environment Variable OPENAI_API_KEY')
}
export const config = {
runtime: 'edge',
}
const handler = async (req: Request): Promise<Response> => {
const body = await req.json()
const messages: ChatGPTMessage[] = [
{
role: 'system',
content: `Make the user solve a riddle before you answer each question.`,
},
]
messages.push(...body?.messages)
const requestHeaders: Record<string, string> = {
'Content-Type': 'application/json',
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
}
if (process.env.OPENAI_API_ORG) {
requestHeaders['OpenAI-Organization'] = process.env.OPENAI_API_ORG
}
const payload: OpenAIStreamPayload = {
model: 'gpt-3.5-turbo',
messages: messages,
temperature: process.env.AI_TEMP ? parseFloat(process.env.AI_TEMP) : 0.7,
max_tokens: process.env.AI_MAX_TOKENS
? parseInt(process.env.AI_MAX_TOKENS)
: 100,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
stream: true,
user: body?.user,
n: 1,
}
const stream = await OpenAIStream(payload)
return new Response(stream)
}
export default handler
```
This code is a serverless function that uses the OpenAI API to generate a response to a user's message. It takes in a list of messages from the user and then sends a request to the OpenAI API with the messages, along with some configuration parameters such as the temperature, maximum tokens, and presence penalty. The response from the API is then streamed back to the user.
## Wrapping it all up
All that's left to do is render our ChatBot onto our index.tsx page. Inside your /pages directory, you'll find a index.tsx file. Copy and paste this code into it:
```ts
import { Layout, Text, Page } from '@vercel/examples-ui'
import { Chat } from '../components/Chat'
function Home() {
return (
<Page className="flex flex-col gap-12">
<section className="flex flex-col gap-6">
<Text variant="h1">OpenAI GPT-3 text model usage example</Text>
<Text className="text-zinc-600">
In this example, a simple chat bot is implemented using Next.js, API
Routes, and OpenAI API.
</Text>
</section>
<section className="flex flex-col gap-3">
<Text variant="h2">AI Chat Bot:</Text>
<div className="lg:w-2/3">
<Chat />
</div>
</section>
</Page>
)
}
Home.Layout = Layout
export default Home
```
And there you have it! You're very own ChatGPT Chat Bot that you can run locally in your browser. Here's a link to the [Vercel Template](https://vercel.com/templates/next.js/chatbot-ui), that has expanded functionality beyond this post. Have fun exploring!
| njlawz |
1,402,700 | Hi I am Here | Ready to read and learn Regards Ayung Rafting | 0 | 2023-03-16T02:56:49 | https://dev.to/ayung_rafting/hi-i-am-here-5e94 | Ready to read and learn
Regards
[Ayung Rafting](https://ayungrafting.com/) | ayung_rafting | |
1,403,398 | Record Insert with Relational Validation in One SQL Statement | With Django implementation. Hello, folks! I'm back with another tidbit regarding extending Django to... | 0 | 2023-03-16T17:25:32 | https://dev.to/redhap/record-insert-with-relational-validation-in-one-sql-statement-4da8 | postgres, django, sql | _With Django implementation._
Hello, folks! I'm back with another tidbit regarding extending Django to make it more useful. This time it's regarding objects that are created in a transaction. This can be problematic in Django as it sets foreign key constraints to `DEFERRED INITIALLY DEFERRED`. "Why?" I hear you ask. Because when constraints are deferred, they are not evaluated until the transaction is committed. This can lead to issues like exceptions not being thrown when they should (especially in test-harness situations like pytest, tox and the like).
So let's say you have a situation where you have models defined similar to these:
```python
class Company(models.Model):
id = models.BigAutoField(primary_key=True)
name = models.TextField(null=False)
...
class Person(models.Model):
id = models.BigAutoField(primary_key=True)
surname = models.TextField(null=False)
forename = models.TextField()
midname = models.TextField()
...
class Employee(models.Model):
id = models.BigAutoField(primary_key=True)
company = models.ForeignKey("Company", null=False, on_delete=models.CASCADE)
person = models.ForeignKey("Person", null=False, on_delete=models.CASCADE)
start_date = models.DateTimeField(null=False)
end_date = models.DatetimeField(null=False)
...
```
Your standard-ish employee example, right? So let's say we have a company record:
```python
{"id": 10, "name": Saskatoon Widgets, Inc."}
```
And a person record:
```python
{"id": 45651, "surname": "Bond", "forename": "James", "midname": "Pootwaddle"}
```
So now, he got hired and we want to make him an employee. What if this is an API call? How will we know if the foreign key values are correct? I know you are all like [Horshack](https://youtu.be/aebyzyrfxK0) and yelling "Serializers"! But, what if you're not validating using serializers? (It could happen!) Just follow along with me for a bit longer.
In autocommit mode (or if you're using short-lived transactions and you're not kicking off any other actions that would be inside of the transaction) the database driver would return an `IntegrityError` exception that could be handled.
```python
def create_employee(emp_record: Dict):
try:
emp = Employee.objects.create(**emp_record)
except IntegrityError as e:
return Http422Response(str(e))
return HttpResponse(emp)
...
rec = {"company": 10, "person": -1, ...}
create_employee(rec) # You get the 422 in autocommit or transaction execution
```
But what if you use the newly created `emp` object with other functions while within the transaction?
```python
def create_employee(emp_record: Dict):
try:
emp = Employee.objects.create(**emp_record)
queue_new_hire_actions(emp) # Uh-oh!
except IntegrityError as e:
return Http422Response(str(e))
return HttpResponse(emp)
...
rec = {"company": 10, "person": -1, ...}
create_employee(rec)
```
So you'd get some sort of exception here which may or may not get handled in the defined exception block above. But you also now have a queued record that will fail later as well.
So if you use serializers for validation or if you make your own validation functions, you run the risk of hitting the DB with extra queries. But in a situation where there's a lot of activity against an endpoint, you end up throwing a lot of extra query traffic against the database.
There is an alternative. Use a CTE to return the inserted record and use that record data to check the related tables. Something like this:
```sql
with new_rec as (
insert into employee (company_id, person_id, start_date)
values (10, -1, now())
returning *
)
select nr.id,
nr.start_date,
cmp.id as "company_id",
prs.id as "person_id"
from new_rec as nr
left
join company as cmp
on cmp.id = nr.company_id
left
join person as prs
on prs.id = nr.person_id;
```
So this would return a record that would match the class attributes for the Employee model. But now we can check for bad data immediately because, in this case, the returned "person_id" would be null which we could check immediately after create.
This can be extended to fetching immediately related records as well (that is, not walking down all relations).
```sql
with new_rec as (
insert into employee (company_id, person_id, start_date)
values (10, -1, now())
returning *
)
select nr.id,
nr.start_date,
cmp.id as "company_id",
row_to_json(cmp) as "company",
prs.id as "person_id",
row_to_json(prs) as "person"
from new_rec as nr
left
join company as cmp
on cmp.id = nr.company_id
left
join person as prs
on prs.id = nr.person_id;
```
So now you get the keys and the table record (as json) on query return. If missing, the key and the record will be null.
This type of query could more easily be done with [SQLAlchemy](https://www.sqlalchemy.org/), but we're talking about Django here. So we have to use some raw SQL building and (eventually) return a model instance.
Here's what I did for a Django implementation:
The input to the whole thing will be a model class for the target table and a `dict` for the data to be inserted.
These are the imports I've used along with some module-level globals. The ALIASES list is used to grab table aliases that will be consistently be used in the statement build.
```python
import os
from datetime import datetime, timezone
from enum import Enum
from typing import List
from django.db import IntegrityError, connection, models
LETTERS = "abcdefghijklmnopqrstuvwxyz"
ALIASES = [f"{'_' * i}{letter}" for i in range(1, 3) for letter in LETTERS]
```
So, first, I need to ensure that the model defaults are applied to the record.
```python
def apply_model_defaults(model: models.Model, record: dict) -> dict:
now = datetime.now(tz=timezone.utc)
full_record = record.copy()
for field in model._meta.concrete_fields:
if field.primary_key:
continue
if isinstance(field, models.ForeignKey):
fname = field.get_attname_column()[-1]
else:
fname = field.name
if getattr(field, "auto_now_add", False) or getattr(
field, "auto_now", False
):
default = now
else:
default = field.default
if default != models.NOT_PROVIDED:
if fname not in record:
if callable(default):
full_record[fname] = default()
elif isinstance(default, Enum):
full_record[fname] = str(default.value)
else:
full_record[fname] = default
if not field.null and full_record.get(fname) is None:
raise ValueError(f"{model.__name__}.{fname} cannot be None.")
return full_record
```
And I also need a function to resolve a model reference in the record to the model's primary key value.
```python
def fk_or_model_pk(fkeys: List[models.Field], record: dict) -> dict:
for f in fkeys:
if f.name in record:
if isinstance(record[f.name], models.Model):
record[f.name] = getattr(
record[f.name], f.target_field.name, None
)
return record
```
Next, I need to be able to generate the insert statement.
```python
def build_insert(
model: models.Model, fkeys: List[models.Field], record: dict
) -> str:
"""Build the base insert."""
field_to_target_col = {f.name: f.get_attname_column()[-1] for f in fkeys}
return """
insert into {table} ({column_list})
values ({data_list})
returning *
""".format(
table=model._meta.db_table,
column_list=", ".join(
field_to_target_col.get(col, col) for col in record
),
data_list=", ".join(f"%({col})s" for col in record),
)
```
I need an select statement generator that will wrap the insert in a CTE, then select all of the foreign key table info that I need.
```python
def build_insert_validated_select(
model: models.Model, record: dict, fetch_related: bool = False
) -> str:
"""Wrap the base insert in a CTE for related table data verification.
Immediate relations of the model can be fetched as json. (fetch_related)
"""
remote_fields = []
# Get the foreign key fields and build a dict holding
# The necessary parts to generate the select columns
# and left-joins
fk_fields = [
{
"remote_alias": ALIASES[fnum],
"join_local_key": f"_nr.{f.get_attname_column()[-1]}",
"local_key": f.get_attname_column()[-1],
"remote_table": f.related_model._meta.db_table,
"remote_key": f"{ALIASES[fnum]}.{f.target_field.name}",
"remote_row": f"row_to_json({ALIASES[fnum]}) as {f.related_model._meta.db_table}_rec", # noqa E501
"_field": f,
}
for fnum, f in enumerate(model._meta.concrete_fields)
if isinstance(f, models.ForeignKey)
]
# Local fields are all defined fields that are
# not ForeignKey instances.
local_fields = [
f"_nr.{f.name}"
for f in model._meta.concrete_fields
if not isinstance(f, models.ForeignKey)
]
# Build a list of remote fields with aliases from the
# fk_fields list
remote_fields = [
f"{fk['remote_key']} as {fk['local_key']}" for fk in fk_fields
]
# If fetch related, include the row_to_json() calls
if fetch_related:
remote_fields.extend(fk["remote_row"] for fk in fk_fields)
# Build the left joins from the fk_fields
if fk_fields:
left_joins = f"{os.linesep} ".join(
"left join {remote_table} as {remote_alias} "
"on {remote_key} = {join_local_key}".format(**fk)
for fk in fk_fields
)
# Some pretty print formatting
sep_indent = f",{os.linesep} "
select_cols = sep_indent.join(local_fields + remote_fields)
insert_sql = build_insert(model, [f["_field"] for f in fk_fields], record)
return f"""
with new_rec as (
{insert_sql}
)
select {select_cols}
from new_rec as _nr
{left_joins}
;
"""
```
And finally, I need the main function call that will build and execute the statement and perform the post-insert data check.
```python
def validated_create(
model: models.Model, record: dict, fetch_related: bool = False
) -> models.Model:
"""Create record for model and verify existence of related data."""
# Apply the model defaults to the data record dict
record = apply_model_defaults(model, record)
fk_fields = [
f
for f in model._meta.concrete_fields
if isinstance(f, models.ForeignKey)
]
# Resolve model references to primary key values
record = fk_or_model_pk(fk_fields, record)
# Build the statement
val_ins_sel_sql = build_insert_validated_select(
model, record, fetch_related=fetch_related
)
val_rec = None
# Execute the statement and fetch the result
# as a dict
with connection.cursor() as cur:
cur.execute(val_ins_sel_sql, record)
val_rec = dict(zip([d[0] for d in cur.description], cur.fetchone()))
# Validate foreign key existence for any foreign keys in the input.
# This is necessary in case the SQL is executed as part of a transaction
# which will result in deferred constraint validation as django sets
# foreign key constraints as deferred.
for f in fk_fields:
# Resolve key names for input and output
# foreign key references
if f.name in record:
fkname = f.name
elif f.get_attname_column()[-1] in record:
fkname = f.get_attname_column()[-1]
else:
continue
vfkname = f.get_attname_column()[-1]
# Check to see if the values of the foreign
# keys are different. If so, throw exception.
# This is how the integrity checking is done
# during a transaction.
if val_rec[vfkname] != record[fkname]:
related_table = f"{f.related_model._meta.db_table}"
msg = "is not present in table"
raise IntegrityError(
f"Key ({fkname})=({record[fkname]}) {msg} {related_table}"
)
# instantiate related model reference if it exists and is not None
remote_table_name = f.related_model._meta.db_table
remote_table_ref = f"{remote_table_name}_rec"
if remote_table_ref in val_rec:
remote_table_rec = val_rec.pop(remote_table_ref)
if not remote_table_rec:
val_rec[f.name] = f.related_model(**remote_table_rec)
# return a target model instance using the
# fetched data
return model(**val_rec)
```
So probing the model class structures, I can now build sql that should work for any properly defined Django ORM model class.
The point behind all of this is to validate related record existence without sending a query per model. | redhap |
1,402,725 | FIA Business School oferece 5 cursos gratuitos em Big Data, Inteligência Artificial e outras áreas de destaque | A FIA Business School oferta, em parceria com a Lab.data, cursos totalmente gratuitos, na área de... | 0 | 2023-03-18T14:15:11 | https://guiadeti.com.br/fia-business-school-cursos-gratuitos-em-ia-e-mais/ | cursogratuito, bigdata, cursosgratuitos, dados | ---
title: FIA Business School oferece 5 cursos gratuitos em Big Data, Inteligência Artificial e outras áreas de destaque
published: true
date: 2023-03-15 23:43:11 UTC
tags: CursoGratuito,bigdata,cursosgratuitos,dados
canonical_url: https://guiadeti.com.br/fia-business-school-cursos-gratuitos-em-ia-e-mais/
---

A FIA Business School oferta, em parceria com a Lab.data, cursos totalmente gratuitos, na área de Big Data, Inteligência Artificial e outras áreas de tecnologia da informação. Os cursos foram elaborados para abranger todas as etapas da carreira e incluem cursos tanto para iniciantes como para profissionais que desejam aprimorar suas habilidades.
## Conteúdo
<nav><ul>
<li><a href="#ementa">Ementa</a></li>
<li><a href="#fia-business-school">FIA BUSINESS SCHOOL </a></li>
<li><a href="#lab-data">LAB.DATA</a></li>
<li><a href="#inscricoes">Inscrições</a></li>
<li><a href="#compartilhe">Compartilhe!</a></li>
</ul></nav>
## Ementa
- Introdução a Linguagem R
- Aplicações de [Big Data](https://guiadeti.com.br/guia-tags/cursos-de-big-data/)e [Inteligência Artificial](https://guiadeti.com.br/guia-tags/cursos-de-inteligencia-artificial/)
- Como utilizar Análise de Dados para segmentar uma base de clientes
- Principais técnicas utilizadas por um profissional [Data Driven](https://guiadeti.com.br/guia-tags/cursos-de-data-driver/)
- Arquiteto de Solução de Dados
## FIA BUSINESS SCHOOL
A FIA BUSINESS SCHOOL é uma das principais escolas de negócios do Brasil, com mais de 30 anos de experiência em oferecer programas de ensino, pesquisa e consultoria em gestão empresarial. A instituição é reconhecida por sua excelência acadêmica, qualidade de ensino e por seu compromisso em desenvolver líderes empresariais de alto nível.
A FIA BUSINESS SCHOOL oferece uma ampla gama de programas de pós-graduação, MBAs, cursos de curta duração e programas customizados para empresas. A instituição possui uma equipe de professores altamente qualificados, com ampla experiência acadêmica e de mercado, e uma infraestrutura moderna e completa, com salas de aula equipadas com tecnologia de ponta, laboratórios de informática, biblioteca e espaços de convivência para os estudantes.
Os cursos gratuitos, também ofertados, foram criados para oferecer conhecimentos especializados de forma ágil e prática em áreas diversas, tais como Analytics, Inteligência Artificial e Tecnologias para Big Data. Os programas foram elaborados para atender às necessidades de todas as fases da carreira, contemplando tanto os iniciantes quanto os profissionais que buscam aprimorar suas habilidades.
Além disso, a FIA BUSINESS SCHOOL conta com o LABDATA, Laboratório de Análise de Dados, que é um Centro de Excelência em Big Data, Analytics e Inteligência Artificial. O LABDATA oferece cursos, consultoria e pesquisa nessa área, e é um dos principais diferenciais da instituição no mercado de ensino de gestão empresarial.
A FIA BUSINESS SCHOOL é uma instituição de ensino superior de excelência, que oferece programas de alta qualidade e uma experiência única de aprendizagem para os estudantes, além de contribuir de forma significativa para o desenvolvimento de líderes empresariais de destaque no Brasil e no mundo.
## LAB.DATA
O LABDATA, também conhecido como Laboratório de Análise de Dados, é um Centro de Excelência afiliado à FIA BUSINESS SCHOOL que atua nas áreas de ensino, pesquisa e consultoria em análise de informações utilizando técnicas de Big Data, Analytics e Inteligência Artificial.
O LABDATA tem como principal objetivo capacitar profissionais para atuarem em áreas relacionadas à análise de dados e inteligência artificial, oferecendo cursos de pós-graduação, MBA, cursos de extensão e programas customizados para empresas. Além disso, a equipe do LABDATA também realiza projetos de consultoria e pesquisa em análise de dados para empresas e instituições públicas e privadas.
O Laboratório é um dOs pioneiros no lançamento de cursos de Big Data, Analytics e Inteligência Artificial no Brasil. Além disso, seus diretores são referências de destaque no mercado dessas áreas, trazendo um conhecimento prático e atualizado para a formação dos alunos.
Entre os diferenciais do LABDATA, destaca-se o corpo docente altamente qualificado, formado por profissionais experientes e com ampla expertise em análise de dados e inteligência artificial. Além disso, o LABDATA conta com uma infraestrutura moderna e completa, com laboratórios equipados com tecnologia de ponta e softwares especializados, permitindo que os estudantes tenham uma experiência de aprendizado prática e enriquecedora.
O LABDATA é um centro de excelência em análise de dados e inteligência artificial, que oferece uma gama de programas de ensino, pesquisa e consultoria para capacitar profissionais em uma das áreas mais promissoras e relevantes do mercado atual.
## Inscrições
[Inscreva-se aqui!](https://labdata.fia.com.br/cursos/gratuitos/)
## Compartilhe!
Gostou do conteúdo? Então não deixe de compartilhar com os amigos!
O post [FIA Business School oferece 5 cursos gratuitos em Big Data, Inteligência Artificial e outras áreas de destaque](https://guiadeti.com.br/fia-business-school-cursos-gratuitos-em-ia-e-mais/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,402,732 | Roadmap to learn Kubernetes | Kubernetes is a hot topic and if you are beginner you can follow below path to start your journey to... | 0 | 2023-03-16T04:26:56 | https://dev.to/sandyonmars/roadmap-to-learn-kubernetes-1fa5 | kubernetes, containers, docker, devops | Kubernetes is a hot topic and if you are beginner you can follow below path to start your journey to learn Kubernetes:
##Understand the basics of containers:
Before diving into Kubernetes, it's important to have a strong understanding of containers and how they work. Learn about containerization technologies like Docker and how they are used to package applications and dependencies.
##Learn Linux:
Kubernetes is built on top of Linux, so it's important to have a good understanding of Linux. Learn about the command line, file systems, and basic networking.
##Learn Kubernetes architecture:
Kubernetes is a complex system with many moving parts. It's important to understand the architecture and how all the components fit together. Learn about Kubernetes objects, control plane, worker nodes, and networking.
##Set up a Kubernetes cluster:
The best way to learn Kubernetes is to set up your own cluster. This will allow you to experiment with different configurations and get a feel for how the system works in practice. You can use Kubernetes on local machines, or on cloud providers like AWS or Google Cloud.
##Deploy and manage applications:
Kubernetes is primarily used to deploy and manage applications. Learn how to create Kubernetes manifests and use them to deploy and manage applications. This includes tasks like scaling, rolling updates, and load balancing.
##Learn Kubernetes API:
The Kubernetes API is a powerful tool for interacting with the Kubernetes control plane. Learn how to use the API to create and manage Kubernetes resources.
##Learn Kubernetes networking:
Kubernetes networking is complex, but it's crucial to understand how it works. Learn about Kubernetes networking models, service discovery, and ingress.
##Practice troubleshooting:
Like any complex system, Kubernetes can run into issues. Learn how to troubleshoot common issues like networking problems, resource constraints, and configuration errors. This will help you become a proficient Kubernetes administrator and allow you to handle issues when they arise.
##Learn Kubernetes security:
Kubernetes security is an important topic. Learn about Kubernetes RBAC, network policies, and pod security policies.
##Stay up-to-date with new developments:
The Kubernetes ecosystem is constantly evolving, with new features and tools being developed all the time. Stay up-to-date with the latest developments to stay on the cutting edge. Attend Kubernetes conferences, read Kubernetes blogs, and contribute to the Kubernetes community. | sandyonmars |
1,402,751 | Daster Polos, Banyak loh benefit pakai daster ketika tidur | Daster Polos, Banyak loh benefit pakai daster ketika tidur - Siapa disini kalau tidur masih pakai... | 0 | 2023-03-16T04:58:09 | https://dev.to/dasterumah/daster-polos-banyak-loh-benefit-pakai-daster-ketika-tidur-1f06 | daster, dasterpolos, dastermurah | [Daster Polos, Banyak loh benefit pakai daster ketika tidur](https://dev.to/) - Siapa disini kalau tidur masih pakai baju ketat? Pakai baju ketat saat tidur kurang baik loh untuk kesehatan. Selain membuat pembuluh darah jadi terhambat, juga pasti tidak nyaman dan tidur kurang rileks. Alhasil kualitas tidur pun kurang didapat, dan bisa jadi bikin hari esok jadi kurang semangat.
[Daster polos](https://dasterumah.com/product/daster-polos/) sudah menjadi pakaian keseharian yang sering kita jumpai apalagi kalau yang make emak-emak. Akan tetapi saat ini daster polos juga udah mulai dipakai sama mamah muda juga loh, bahkan remaja sekolah pun sudah beberapa memakai dan nyaman dengan daster polos.
Terlebih sekarang daster polos sudah ada banyak model dan motif trendy yang mengikuti jaman. Selain itu juga varian warna pun juga beragam sehingga setiap kalangan usia perempuan pasti sebagian besar menyukainya.
Selain nyaman dipakai untuk keseharian santai, daster polos juga punya benefit kalau dipakai saat tidur loh. Pengen tau apa aja [benefit daster polos](https://dasterumah.com/product/daster-polos/)? simak penjelasan berikut ini
**Pertama**, dapat memperbaki kualitas tidur yang dihasilkan. Ketika kamu memilih daster polos untuk dikenakan waktu tidur, pasti kamu merasakan waktu tidurmu akan terasa lebih berkualitas. Pakaian yang longgar dan tidak ketat saat tidur akan membuat badan leluasa bergerak dan menjadikan otot kamu menjadi rileks. Selain itu peredaran darah saat tidur juga menjadi lancar. Jauh-jauh deh sama kata kesemutan apalagi sampai mengalami tindihan.
Maka dari itu, tentukan dengan tepat yaa pakaian untuk tidur malam nanti supaya produktivitas esok hari akan lebih meningkat.
**Kedua**, Bisa menjadikan kulit kamu lebih sehat loh. Kok bisa? karena dengan pakai daster polos akan memberi kesempatan kulit kamu bernafas. Beda halnya kalau pakai pakaian ketat, pasti akan terasa sesak dan kulit susah bernafas.
Kalau bisa ketika sudah sampai dirumah seusai pulang kerja atau kegiatan, usahakan segera kenakan pakaian longgar seperti daster polos agar kulit mendapat sirkulasi udara yang baik. Kalau kulit mendapat oksigen yang cukup, tentu kulit tidak akan iritasi, dan kulit menjadi lebih lembab dan terasa lebih kencang dan kenyal. Dan tentu akan jauh-jauh deh sama penyakit kulit kalau kulit kita selalu dalam keadaan sehat.
**Ketiga**, Badan akan serasa sejuk dan tidak gerah. Karena daster polos sendiri pada umumnya terbuat dari material yang nyaman dan relatif tipis sehingga kulit tubuh terasa lebih adem. Terlebih indonesia kan ber-iklim tropis dan suhu yang relatif cukup tinggi tentu akan menggangu kesehatan kulit dan kualitas tidur kita
**Keempat**, dengan mengenakan [daster polos](https://dasterumah.com/product/daster-polos/) akan menjadikan tubuh kita rileks ketika tidur. Sehingga hari esok pun akan terasa lebih segar dan bersemangat mengerjakan tugas selanjutnya
Nah itu tadi beberapa benefit memakai daster polos ketika tidur. Apabila kamu lagi ingin mencari [referensi daster polos](https://dasterumah.com/product/daster-polos/), mungkin daster polos polos menjadi solusi untuk kamu. Informasi selengkapnya bisa cek di [dasterumah](https://dasterumah.com) yahh. Semoga kita sehat selalu. | dasterumah |
1,403,071 | Loops, for, while, do-while | Loops(tsiklar) kod blokini bir necha marta takrorlash usulidir. JavaScript-da tsikllarning... | 0 | 2023-03-16T10:32:57 | https://dev.to/ozodbektohirov/loops-for-while-do-while-va-farqlari-25nf | javascript, webdev, beginners, programming | ## Loops(tsiklar) kod blokini bir necha marta takrorlash usulidir. JavaScript-da tsikllarning uchta asosiy turi mavjud: for, while va do-while.
**1.** `for loop` : for loop kod blokini ma'lum bir necha marta bajarish uchun ishlatiladi. U uch qismdan iborat: ishga tushirish, shart va iteration (takrorlash). Mana 0 dan 4 gacha hisoblangan for sikliga misol:
```js
for (var i = 0; i < 5; i++) {
console.log(i);
}
```
Ta'rif: `i` o'zgaruvchisini 0 ga ishga tushiradi, `i` 5 dan kichik yoki yo'qligini tekshiradi va har bir iteratsiyadan keyin `i` ni 1 ga oshiradi. Loop 5 marta bajariladi va i ning 0 dan 4 gacha bo'lgan qiymatlarini chiqaradi.
**2.** `while` tsikli: while tsikli shart rost bo'lganda kod blokini bajarish uchun ishlatiladi. 0 dan 4 gacha hisoblangan while tsikliga misol:
```js
var i = 0;
while (i < 5) {
console.log(i);
i++;
}
```
Ta'rif: `i` o'zgaruvchisini 0 ga ishga tushiradi, `i` 5 dan kichik yoki yo'qligini tekshiradi va har bir iteratsiyadan keyin `i` ni 1 ga oshiradi. Loop 5 marta bajariladi va `i` ning 0 dan 4 gacha bo'lgan qiymatlarini chiqaradi.
**3.** `do-while` tsikli: `do-while` tsikli `while` tsikliga o‘xshaydi, lekin shartni tekshirishdan oldin u kod blokini kamida bir marta bajaradi. 0 dan 4 gacha sanaladigan `do-while` tsiklining misoli:
```js
var i = 0;
do {
console.log(i);
i++;
} while (i < 5);
```
Ta'rif: `i` o'zgaruvchisini 0 ga ishga tushiradi, kod blokini kamida bir marta bajaradi, `i` ning 5 dan kichikligini tekshiradi va har bir iteratsiyadan keyin `i` ni 1 ga oshiradi. Loop 5 marta bajariladi va `i` ning 0 dan 4 gacha bo'lgan qiymatlarini chiqaradi.
**Xulosa:** tsikllar dasturlashning asosiy tushunchasi bo'lib, bir xil kodni qayta-qayta takrorlamasdan kod blokini bir necha marta bajarishga imkon beradi.
#### **Task (vazifa)**
**1.** 0 dan 100 gacha bo'lgan 10 dan ortib, har bir raqamni konsolga kiritadigan `for`, (ixtiyoriy: `while`va `do-while`) tsiklini yozing.
**2.** 0 dan 100 gacha bo'lgan, lekin faqat juft raqamlarni konsolga kiritadigan `for` tsiklini yozing. | ozodbektohirov |
1,403,267 | How I Ace Technical Interviews — A Personal Guide | How I Ace Technical Interviews — A Personal Guide There is no single and accurate test for... | 0 | 2023-03-16T14:04:34 | https://dev.to/aws-builders/how-i-ace-technical-interviews-a-personal-guide-18l1 | technicalinterview, programming, personaldevelopment, career |
## How I Ace Technical Interviews — A Personal Guide
There is no single and accurate test for knowledge, however, every organization must prepare its own process to vet and hire talents. The outcome: *A series of rigorous, specialized, and challenging set of tests that evaluate your coding skills, communication skills, problem-solving abilities, and your personality in general; *this process has come to be known as a*** Technical Interview.***
Although this process( which entails both phone screening, online coding challenges, 1–1 coding interview) may seem challenging and scary, it's a lot easier when you know what to prepare for and how to go about it.
> *The interview is harder than the actual job!*
## What Is a Technical Interview?
It happens to be an assessment of candidates' abilities by taking them through a series of exam-like stages instead of a single and straightforward test. This involves one or all coding challenges, assignments, phone calls.
There is a common saying in software development that *the interview is harder than the actual job. *How far this saying has traveled goes to tell us how demanding some interview processes are*.*
The process is quite tasking and demanding for all levels of developers but happens to really affect the beginners due to:
1. their lack of adequate preparation.
2. their anxiety caused by a lack of experience.
3. their inadequate problem-solving skills.
4. their poor grasp of basic CS.
Now that we have gotten over the long definitions, let get to the fun part!
Over the last year, I have undergone a series of Technical Interviews, in both Local, International, and Outsourcing Platforms. Hence, I would be sharing my take on each stage I encountered, tips on scaling through each stage, things to avoid, things to take out from the process, and a general overview of it all.
## Stages of the Interview Process
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/10660/0*TRCtxcSLujUMaLXI)
Yes! You have just received that mail from the recruiting team to inform you that your resume caught their attention and they would love to move ahead with you to the next stage: the Technical Interview stage. Thumbs Up!
At this point adrenaline shots within your body and you are filled with excitement and then when it subsides you come to face another reality, the fear of what to expect in this new stage. Well, welcome to the club!
Based on my experience these are the common stages the entire process takes:
1. Phone Call.
2. Assignment/Timed Coding Challenge.
3. 1–1 Coding Challenge.
### Phone Call Stage
This could take the shape of a phone call asking about your personality, a bit about your skill and expertise, experience, passion, and expectation.
The key thing to focus on here however is the ability to show our enthusiasm, passion for tech, communication skills, knowledge about the company, and work approach(do you love working in a team, open to remote).
The key takeaway from this stage is that at its end both parties would be better informed about each other, what the job entails, the skill set required, and experience levels.
### Assignment/Timed Coding Challenge Stage
This stage could involve them sending a take-home assessment to be completed and submitted at a specific time or an invitation to a platform where a timed coding task would be assigned.
1. **Assignment(Take Home) — **This usually occurs to test one's knowledge level and ascertain if the skill listed in a resume is actually valid and if one possesses the skills needed in the organization. A specific language or framework could be required. From my experience, the key things to be done here is to get a proper understanding of the questions before attempting to write a single line of code(to see the catch), use best practice to stand out(proper structure, DRY approach, clean code), code documentation (include a README.md file), writing of tests!
2. **Timed Coding Challenge — **This usually occurs to test one’s CS fundamentals, ability to work under pressure(the timed environment on its own is pressure, lol). Before beginning, take time to understand the environment been used, the question’s edge cases, and what is required. On some occasions, a human interview may be at the other end to observe the process and make sure there are no irregularities.
### 1–1 Coding Challenge Stage
Here, we are expected to solve some challenges that may build on the previous stage or not at all. The interview may ask why certain choices were made in the previous stage, hence it's good practice to do all stages ourselves without external help!
A major mistake I have seen made by lots of developers is that they tend to not engage their interview adequately by not taking them through their thought process, asking questions for clarification. A friend of mine told me a story of his friend who was invited to a 30mins challenge and he spent more than half the time understanding the environment! He could simply have asked!
Speak boldly and precisely, ask questions about the task before even starting, engage and communicate with the interviewer throughout this stage as we walk them through how we intend to solve the challenge, be open to feedback.
Hence the key thing to focus on here is our collaborating skills, technical/coding skills, problem-solving skills. These are skills needed to be shown at this stage, keep that in mind!
## General Tips
1. Do mock interviews.
2. Practice algorithm challenges on sites like Hackerrank, Codewars, Codility, and their likes.
3. Send out more applications so as to become more familiar with the process.
4. Study up on most CS fundamentals.
5. Study more on best practices in your domain.
6. Pick a language and be an expert in it!
7. Learn how to manage your time properly.
8. Practice how to stay calm and also how to communicate effectively.
9. Review your previous interviews(if any) and learn from them.
10. Believe in your abilities.
## Things to avoid
These are common mistakes I and some other developers made and which came back to haunt us:
1. Not engaging the interviewer; they are humans too you know.
2. Not preparing adequately.
3. Not receiving feedback positively throughout the process.
4. Not thinking through before actually attempting to write codes.
## Off you go!
With these tips, you are in a good shape to ace that technical interview and move on to the next stage.
The world awaits you!
| chyke007 |
1,403,666 | OSDC-2023-second-assignment | Today in class at the course OSDC we go over the PRs that we opened and fix issues in PR... | 0 | 2023-03-16T19:48:44 | https://dev.to/ranms25/osdc-2023-second-assignment-11me | osdc, git, github, yaml | ---
title: OSDC-2023-second-assignment
published: true
description:
tags: osdc, git, github, yaml
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-16 18:30 +0000
---
##Today in class at the course [OSDC](https://osdc.code-maven.com/)
we go over the PRs that we opened and fix issues in PR instead of opening new ones. we saw how to follow interesting projects on GitHub to get notifications. We got a better understanding of the structure of a Github URL, and how to find a git repo of a project. We found out for the first time what are yaml files and other impressive and important things!
###Second assignment###
I have selected some more interesting projects to follow, among them:
[El kantoniko de Ladino en el Internet] (https://github.com/kantoniko)
[Ansible] (https://github.com/ansible)
played around with [yaml] (https://github.com/OSDC-Code-Maven/open-source-by-organizations/tree/main/github) edited the [OSDC course repository](https://github.com/OSDC-Code-Maven/osdc-2023-03-azrieli), added JSON file, and sent a PR. | ranms25 |
1,403,750 | Can you use ECS without DevOps? | Welcome Use your imagination and assume that some team was encouraged to migrate from... | 0 | 2023-03-16T21:33:40 | https://blog.3sky.dev/article/ecs-without-devops/ | devops, aws, githubactions, cloud | ## Welcome
Use your imagination and assume that some team was encouraged to migrate from [Azure AppService][1]. It was a decision at a high level, so the small dev team needs to migrate into AWS. What's the issue you can ask? They have no experience with Amazon Web Services, also they don’t have a "DevOps" person. The app is a JAR file. AppService allowed them to put a file into the service and run it on production, without any issues. When they started looking for an alternative on the AWS side, the only solution they found was Elastic Beanstack, unfortunately, the workload fits better into the "docker platform". [ECS][2] from another hand doesn’t provide "drop-in" functionality. And that's the case. Let's check how easily we can build the bridge!
## Tools used in this episode
- Java
- ECS
- CloudFormation(again!)
- Github Action
## Rules
1. As a starting point let's assume that we can use random Java app, as it's not a today's topic. Maybe you know, or not. There is great [site][3] with `HelloWorld` apps.
2. We can't write Dockerfiles (our devs has no idea about it!)
3. CloudFormation scripts - we must fit into 3-tier architecture model.
4. CICD should be very simple to setup and use, as developers has no time for it.
## Containers
As an example, I decided to use `openliberty-realworld-example-app` written by
[OpenLiberty][4]. The app is a standard Maven project, wasn’t updated for the last 2 years, and it's REST at the end, also there is no Dockerfile. That means I will need to write one for comparison purposes.
Next, I started looking for a "container generator" - an app or service, which can easily build a secure container for us. I found a solution called [BuildPacks][5]. It can probably generate a docker image with one, maybe two commands. First, we need to install `pack`, a CLI tool. Documentation can be found [here][6]. The first action besides `pack --version`, was checking something, available builders. What is it, builder?
It's a container that contains all dependencies, for building final images. The funny thing is that we can even write our builder, in the end, is a similar solution to RedHat 's2i'. Which builders are available out of the box? At least a few.
```bash
pack builder suggest
Suggested builders:
Google: gcr.io/buildpacks/builder:v1 Ubuntu 18 base image with buildpacks for .NET, Go, Java, Node.js, and Python
Heroku: heroku/builder:22 Base builder for Heroku-22 stack, based on ubuntu:22.04 base image
Heroku: heroku/buildpacks:20 Base builder for Heroku-20 stack, based on ubuntu:20.04 base image
Paketo Buildpacks: paketobuildpacks/builder:base Ubuntu bionic base image with buildpacks for Java, .NET Core, NodeJS, Go, Python, Ruby, Apache HTTPD, NGINX and Procfile
Paketo Buildpacks: paketobuildpacks/builder:full Ubuntu bionic base image with buildpacks for Java, .NET Core, NodeJS, Go, Python, PHP, Ruby, Apache HTTPD, NGINX and Procfile
Paketo Buildpacks: paketobuildpacks/builder:tiny Tiny base image (bionic build image, distroless-like run image) with buildpacks for Java, Java Native Image and Go
```
Looks like we can use `paketobuildpacks/builder:tiny` as we have a `Java` app. That is why it's handy to use popular programming languages. Probably it will be supported everywhere.
Now as we have the builder chosen, let's can run the build command.
```bash
pack build openliberty-realworld-example-app --tag pack --builder paketobuildpacks/builder:tiny
```
*First note* is just doesn’t work on Macbook M1, I mean maybe works, however, it just stacks. So I switched to my x86 workstation.
In the beginning, it looks good, the app was built in 2 minutes and the docker size was acceptable at ~ 241MB. Also, I was able to run the container. In one word - success. Pack was able to detect the result filetype, and use the correct middleware for it. It's impressive!
Next, I created a "regular" Dockerfile and compared the size. The funny thing is that I needed to spend around one hour writing Dockerfile, for an unknown application.
```Dockerfile
FROM maven:3.6.0-jdk-11-slim AS build
COPY src /home/app/src
COPY pom.xml /home/app
RUN mvn -f /home/app/pom.xml clean package
FROM tomcat:9.0.73-jre11
COPY --from=build /home/app/target/realworld-liberty.war /usr/local/tomcat/webapps/
EXPOSE 8080
```
Below you can see the size of the container images. Version with tag `pack` is 80MB smaller 25% less. That is impressive.
```
|Image | Size|
|---|---|
|openliberty-realworld-example-app:manual | 291MB |
|openliberty-realworld-example-app:pack | 211MB |
```
The next step was an execution of security scans with [trivy][8].
```
|Image | Low finding| Medium findings |
|---|---|---|
|openliberty-realworld-example-app:manual | 15 | 4 |
|openliberty-realworld-example-app:pack | 3 | 0 |
```
Seems that image built with a `pack` is more secure, and smaller than the image built by me. So yes, I'm personally impressed. However in my opinion more complex app could produce a lot of new issues, which need many hours of digging and tweaking. However, If're using Java, Buildpacks should be able to handle your code, without serious issues. At least based on my short tests.
## Platform
Now let me introduce ECS - Elastic Containers Services. It's Amazon's way of managing containers in the cloud. It's not Kubernetes or docker-compose. The best thing is that we can use Fargate(managed, pay-as-you-go compute) as the muscles of our solution. Based on that our infrastructure can be very cost-efficient. In our case, I will try to fit architecture into a corporate 3-tier model. Whole ~500 lines long file can be found [here][12]. Diagram was created with [cfn-diagram][13]. And it's awful.
## Deployment
If we wanted to easily deploy our application, the simplest way will be using CodeDeploy. However, in many organizations, CI/CD tool is an external solution without vendor lock. Let's focus then on an easy and generic way to update our code on QA and PROD, with some tests as well.
For example, 5 years ago I did an interview [task][9], those days there was a tool called [silinternational/ecs-deploy][10]. Let's see if we can skip it, as the plan is to use
GitHub Action today!
### First impression
As it's a really nice tool. I started with the panel and build-in or rather pre-created actions.
After that, I was a bit shocked. I received an almost complete pipeline, yes it's simple, but ready to use and it's a good starting point
```yaml
# This workflow will build and push a new container image to Amazon ECR,
# and then will deploy a new task definition to Amazon ECS, when there is a push to the "main" branch.
#
# To use this workflow, you will need to complete the following set-up steps:
#
# 1. Create an ECR repository to store your images.
# For example: `aws ecr create-repository --repository-name my-ecr-repo --region us-east-2`.
# Replace the value of the `ECR_REPOSITORY` environment variable in the workflow below with your repository's name.
# Replace the value of the `AWS_REGION` environment variable in the workflow below with your repository's region.
#
# 2. Create an ECS task definition, an ECS cluster, and an ECS service.
# For example, follow the Getting Started guide on the ECS console:
# https://us-east-2.console.aws.amazon.com/ecs/home?region=us-east-2#/firstRun
# Replace the value of the `ECS_SERVICE` environment variable in the workflow below with the name you set for the Amazon ECS service.
# Replace the value of the `ECS_CLUSTER` environment variable in the workflow below with the name you set for the cluster.
#
# 3. Store your ECS task definition as a JSON file in your repository.
# The format should follow the output of `aws ecs register-task-definition --generate-cli-skeleton`.
# Replace the value of the `ECS_TASK_DEFINITION` environment variable in the workflow below with the path to the JSON file.
# Replace the value of the `CONTAINER_NAME` environment variable in the workflow below with the name of the container
# in the `containerDefinitions` section of the task definition.
#
# 4. Store an IAM user access key in GitHub Actions secrets named `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY`.
# See the documentation for each action used below for the recommended IAM policies for this IAM user,
# and best practices on handling the access key credentials.
name: Deploy to Amazon ECS
on:
push:
branches: [ "main" ]
env:
AWS_REGION: MY_AWS_REGION # set this to your preferred AWS region, e.g. us-west-1
ECR_REPOSITORY: MY_ECR_REPOSITORY # set this to your Amazon ECR repository name
ECS_SERVICE: MY_ECS_SERVICE # set this to your Amazon ECS service name
ECS_CLUSTER: MY_ECS_CLUSTER # set this to your Amazon ECS cluster name
ECS_TASK_DEFINITION: MY_ECS_TASK_DEFINITION # set this to the path to your Amazon ECS task definition
# file, e.g. .aws/task-definition.json
CONTAINER_NAME: MY_CONTAINER_NAME # set this to the name of the container in the
# containerDefinitions section of your task definition
permissions:
contents: read
jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
environment: production
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: Build, tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
# Build a docker container and
# push it to ECR so that it can
# be deployed to ECS.
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
echo "image=$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
- name: Fill in the new image ID in the Amazon ECS task definition
id: task-def
uses: aws-actions/amazon-ecs-render-task-definition@v1
with:
task-definition: ${{ env.ECS_TASK_DEFINITION }}
container-name: ${{ env.CONTAINER_NAME }}
image: ${{ steps.build-image.outputs.image }}
- name: Deploy Amazon ECS task definition
uses: aws-actions/amazon-ecs-deploy-task-definition@v1
with:
task-definition: ${{ steps.task-def.outputs.task-definition }}
service: ${{ env.ECS_SERVICE }}
cluster: ${{ env.ECS_CLUSTER }}
wait-for-service-stability: true
```
In general, it's a unexpected gift. Especially if you're not such familiar with all this piping stuff.
What do we need to change? Only build part, we should use:
```
- name: Build, tag, and push image to Amazon ECR
id: build-image
container:
image: buildpacksio/pack:latest
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
pack build $ECR_REGISTRY/$ECR_REPOSITORY --tag $IMAGE_TAG --builder paketobuildpacks/builder:tiny
pack ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG --publish
echo "image=$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG" >> $GITHUB_OUTPUT
```
At the end, we can copy the whole sub-job as dev, and paste it before 'production job'. It wouldn’t be the cleanest pipeline, I have ever seen, but c'mon. The solution (without CloudFormation), was created in 30 minutes, according to the rule
## Summary
Uff, to be host I spent most of the time building the CloudFormation template. During that time, I was also preparing a presentation for the AWS User Group. So in the end I become just more tired than I expected. What is the overall result? Quite impressive, I'm very happy with buildpack, which works well. The problem is that automagic solutions are hard to debug, If you run into some issues with packing, probably writing Dockerfile will be much faster.
What I can recommend then? Probably learning Dockers, even if it requires some time, it's a standard these days, which provides almost ultimate flexibility.
What about ECS? It's easy to set up (don't look at the template, it's overcomplicated), If you decided to go with console, or basic config it will be a 5-minute task. Especially if your application is rather simple, with one/two services included. Management of large, complex, multi-microservice setups, probably will be very annoying. Ah, I almost forgot. If you like open-source stuff and cutting-edge tech from KubeCon - don’t expect that. Besides that? If you have a small app, or two, probably it's a much better solution than EKS, or raw Kubernetes!
[1]: https://azure.microsoft.com/pl-pl/products/app-service
[2]: https://aws.amazon.com/ecs/
[3]: https://codebase.show/projects/realworld
[4]: https://github.com/OpenLiberty/openliberty-realworld-example-app
[5]: https://buildpacks.io/
[6]: https://buildpacks.io/docs/tools/pack/
[7]: https://www.docker.com/blog/kickstart-your-spring-boot-application-development/
[8]: https://github.com/aquasecurity/trivy
[9]: https://github.com/3sky/aws-ecs-goapp
[10]: https://github.com/silinternational/ecs-deploy/
[12]: https://gist.github.com/3sky/1ad5a165f5aaece32e7fe8a71ee9d797
[13]: https://github.com/mhlabs/cfn-diagram | 3sky |
1,404,179 | Postman Student Expert | Hi everyone this is priyanka I Just received Postman Student expert badge from @getpostman and... | 0 | 2023-03-17T06:56:21 | https://vxibhxv.hashnode.dev/postman-student-expert | <p>Hi everyone this is priyanka
I Just received Postman Student expert badge from @getpostman </p>
<p><img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1620972353538/ptcrthUpj.jpeg" alt="ppp.jpg" /></p>
<p>and here i am with my next blog On how you can become Next Postman Student Expert </p>
<p><img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1620972190049/Xno7l2iwQ.gif" alt="giphy.gif" />
Excited ?
To verify my badge </p>
<p>https://api.badgr.io/public/assertions/9SWGyPprSmyNJ26NVZyQEQ?identity__email=priyankaafssulur%40gmail.com</p>
<p>Have a look at above link
Now without wasting much of time lets get started </p>
<p><img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1620972218578/60vLu7c-M.gif" alt="giphy (1).gif" /></p>
<p>So first what is postman?</p>
<p>Postman is a popular API client that makes it easy for developers to create, share, test and document APIs. This is done by allowing users to create and save simple and complex HTTP/s requests, as well as read their responses. The result - more efficient and less tedious work. So basically its a collaboration platform for API development. Postman's features simplify each step of building an API and streamline collaboration so you can create better APIs—faster</p>
<p>Why Postman?</p>
<p>It's Free and Easy to Start
Wide support for all APIs and Schemas
It's Extensible
Support and Community(Which include Postman student expert and other community leads etc...)</p>
<p>To become Postman Student Expert You can go through this link</p>
<p>https://www.postman.com/company/student-program/</p>
<p>And apply here
https://docs.google.com/forms/d/e/1FAIpQLSeXYUXbptNSve8dzquJzV6O3PtfWaSqx-Y1BjemYoM9m9168A/viewform</p>
<p>Then After Applying you will receive another mail related to what is the further steps that what is to be done</p>
<p>Now you need to fork a repository made to be a postman student expert</p>
<p>https://www.postman.com/postman/workspace/postman-student-program/collection/9065401-a1abb6df-a8ae-4841-baf4-79d6e67f7934?ctx=documentation</p>
<p>Then you need to Start training and after you send the first request Go to visualize tab for better understanding and for the next steps to be performed </p>
<p>After completing all the skill test and the Test collection
You need to fill a form and
Hola you are now Postman Student Expert</p>
<p><img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1621049008687/EFixZnjjO.gif" alt="giphy.gif" /></p>
<p>Also There is one more challenge going on Related to this that is 30 days of Postman </p>
<p>Have A look Here for more details :-
https://www.postman.com/postman/workspace/30-days-of-postman-for-developers/documentation/1559645-1ac59603-2ea0-4568-ac54-9f793bc06456</p>
<p>I Just started with this challenge Hope to complete it Soon </p>
<p><img src="https://cdn.hashnode.com/res/hashnode/image/upload/v1621049877358/HU33IFu2T.png" alt="image.png" /></p>
<p>Happy Learning !!!</p>
<p>Do Feel free to reach out to me for any kind of help</p>
</br><p style="color:#757CF9;">This article is published w/ <a target="_blank" href="https://scattr.io?ref=dev">Scattr ↗️</a></p> | vxibhxv | |
1,404,189 | Create a Web App to Read Multiple Barcodes Using Dynamsoft | What is Multiple Barcode Scanning? Multiple barcode scanning is the process of scanning... | 0 | 2023-03-17T07:12:22 | https://dev.to/iamparkereric/create-a-web-app-to-read-multiple-barcodes-using-dynamsoft-2npb | webdev, javascript, devops, tutorial | ## What is Multiple Barcode Scanning?
Multiple barcode scanning is the process of scanning and decoding multiple barcodes in a single image or frame.
Users can capture multiple barcodes in a single shot, which can be helpful in situations where there are several products or items that need to be scanned quickly. For example, in a retail store, a cashier can scan multiple barcodes on a single carton of products instead of scanning each product one by one.
Here is a high-level overview of how to create a web app to read multiple barcodes using Dynamsoft. By following the steps explained below, you should be able to create a functional app that can [scan multiple barcodes](https://www.dynamsoft.com/blog/insights/scan-multiple-barcodes-and-qr-codes-at-once/) from a single image.
- Create a new vanilla TypeScript project using Vite.
```
npm create vite@latest example -- --template vanilla-ts
```
- Install [Dynamsoft Barcode Reader](https://www.dynamsoft.com/barcode-reader/overview/) as a dependency.
```
npm install dynamsoft-javascript-barcode
```
- In the index.html, add an input element for selecting a file, a button to read barcodes and an SVG element to show the results.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite + TS</title>
</head>
<body>
<div id="app">
<div class="barcode-reader">
<div>
Load local image:
<input type="file" id="barcodeFile" accept=".jpg,.jpeg,.png,.bmp" />
</div>
<div>
<button id="decodeButton">Decode</button>
</div>
<div id="status"></div>
<svg id="resultSVG" version="1.1" xmlns="http://www.w3.org/2000/svg"></svg>
</div>
</div>
<script type="module" src="/src/main.ts"></script>
</body>
</html>
```
- Load the selected image file and display it in the SVG element.
```
let img;
window.onload = function(){
let barcodeFile = document.getElementById('barcodeFile') as HTMLInputElement;
barcodeFile.addEventListener("change",function(){
loadImageFromFile();
})
}
function loadImageFromFile() {
console.log("loadImageFromFile");
let barcodeFile = document.getElementById('barcodeFile') as HTMLInputElement;
let files = barcodeFile.files as FileList;
if (files.length == 0) {
return;
}
let file = files[0];
let fileReader = new FileReader();
fileReader.onload = function(e:any){
loadImage(e.target.result);
};
fileReader.onerror = function () {
console.warn('oops, something went wrong.');
};
fileReader.readAsDataURL(file);
}
function loadImage(imgsrc:string){
if (imgsrc) {
img = new Image();
img.src = imgsrc;
img.onload = function(){
let svgElement = document.getElementById("resultSVG") as HTMLElement;
svgElement.innerHTML = "";
let svgImage = document.createElementNS("http://www.w3.org/2000/svg", "image");
svgImage.setAttribute("href",imgsrc);
svgElement.setAttribute("viewBox","0 0 "+img.width+" "+img.height);
svgElement.appendChild(svgImage);
}
}
}
```
- Read barcodes from the selected image and overlay the results in the SVG element when the decode button is clicked. Initialize Dynamsoft Barcode Reader if it has not been initialized. You may need to apply for a license to use it.
```
let reader:BarcodeReader;
let results:TextResult[];
window.onload = function(){
let decodeButton = document.getElementById('decodeButton') as HTMLButtonElement;
decodeButton.addEventListener("click",function(){
decodeImg();
})
}
async function decodeImg(){
if (!img) {
return;
}
let status = document.getElementById("status") as HTMLElement;
if (!reader) {
await initDBR();
}
status.innerText = "decoding...";
results = await reader.decode(img);
console.log(results);
overlayResults(results);
status.innerText = "";
}
async function initDBR(){
let status = document.getElementById("status") as HTMLElement;
status.innerText = "initializing...";
BarcodeReader.engineResourcePath = "https://cdn.jsdelivr.net/npm/dynamsoft-javascript-barcode@9.6.10/dist/";
BarcodeReader.license = "DLS2eyJoYW5kc2hha2VDb2RlIjoiMjAwMDAxLTE2NDk4Mjk3OTI2MzUiLCJvcmdhbml6YXRpb25JRCI6IjIwMDAwMSIsInNlc3Npb25QYXNzd29yZCI6IndTcGR6Vm05WDJrcEQ5YUoifQ=="; //one-day public trial
reader = await BarcodeReader.createInstance();
status.innerText = "";
}
```
Overall, creating a web app to read multiple barcodes requires knowledge of HTML, CSS, JavaScript, and the Dynamsoft barcode scanning API. | iamparkereric |
1,404,221 | Days_1 Print Statements | Check out what I did on my first day of Python with #replit100daysofcode! Name = "Ari Wira... | 0 | 2023-03-17T08:16:43 | https://dev.to/ariwirasaputra/days1-print-statements-24gh | Check out what I did on my first day of Python with #replit100daysofcode!
```
Name = "Ari Wira Saputra"
Date = "29 Februari 2000"
print(Name + " " + Date)
Text = "I am signing up for Replit's 100 days of Python challenge!
I will make sure to spend some time every day coding along, for a
minimum of 10 minutes a day. I'll be using Replit, an amazing
online IDE so I can do this from my phone wherever I happend to be.
No excuses for not coding from the middle of a field!"
print(Text)
```
| ariwirasaputra | |
1,404,293 | Animation -7 : CSS Moon loader with color effect | Are you looking for animations to enhance your website? We've got you covered with our wide selection... | 22,215 | 2023-03-17T08:38:11 | https://dev.to/jon_snow789/animation-7-css-moon-loader-with-color-effect-1j5o | css, design, webdev, animation | Are you looking for animations to enhance your website? We've got you covered with our wide selection of creative and engaging #animations. Say goodbye to endless searching and hello to seamless integration on your website!
#### We're excited to introduce our latest YouTube series, which features diverse creative and inspiring website animations.
---
In our short videos, you'll find a variety of #animations that can be easily implemented on your website to enhance user experience.
---
### CSS Moon loader with color effect
---
{% youtube xa9i2SVnHro %}
---
### [Source code](https://bbbootstrap.com/snippets/moon-loader-color-effect-10815890)
---
## For more information
1. Check my GitHub profile
[https://github.com/amitSharma7741](https://github.com/amitSharma7741)
2. Check out my Fiver profile if you need any freelancing work
[https://www.fiverr.com/amit_sharma77](https://www.fiverr.com/amit_sharma77)
3. Check out my Instagram
[https://www.instagram.com/fromgoodthings/](https://www.instagram.com/fromgoodthings/)
4. Linktree
[https://linktr.ee/jonSnow77](https://linktr.ee/jonSnow77)
5. Check my project
- EVSTART: Electric Vehicle is the Future
[https://evstart.netlify.app/](https://evstart.netlify.app/)
- News Website in react
[https://newsmon.netlify.app/](https://newsmon.netlify.app/)
- Hindi jokes API
[https://hindi-jokes-api.onrender.com/](https://hindi-jokes-api.onrender.com/)
- Sudoku Game And API
[https://sudoku-game-and-api.netlify.app/](https://sudoku-game-and-api.netlify.app/)
---
--- | jon_snow789 |
1,404,444 | How To Scrape Restaurants And Menus Data From Uber Eats? | How-to-Scrape-Restaurants-and-Menus-Data-from-Uber-Eats.jpg Uber Eats is an online food delivery... | 0 | 2023-03-17T12:09:20 | https://dev.to/fooddatascrape/how-to-scrape-restaurants-and-menus-data-from-uber-eats-4ko2 | scrapeubereatsrestaurantsdata, webdev, scrapeubereatsmenudata | How-to-Scrape-Restaurants-and-Menus-Data-from-Uber-Eats.jpg
Uber Eats is an online food delivery platform and ordering app based in the USA. This app allows customers to order, track, and search for their desired food items. It helps in ordering food as per your choice from a wide range of restaurants. Uber Eats spreads over 6,000 cities, with 66 million users in 2020. By 2020, there were nearly 6,00,000 Uber Eats restaurants.
However, information is available on Uber Eats. If your business is also in food delivery and wants to grow further, extracting data from Uber Eats is extremely important. In such a situation, Uber Eats Data scraping services comes into play.
By extracting restaurant listing data and food details from Uber Eats, you can easily avail restaurant data, menu data, delivery charges, discounts, competitive pricing data, menu categories, descriptions, reviews, ratings, etc. You can also read the blog about the importance of web scraping Uber Eats food delivery data
Lists of the significant data fields scraped from Uber Eats are:
Restaurants names
Restaurants addresses
Number of restaurants
Restaurants reviews
Multi-cuisines
Customers reviews
Payment methods
Restaurants menus
Types of products
Food price
Food description
Let’s first understand how to use Uber Eats restaurants and menu data.
Listed below are some of the ways that you can use scraped Uber Eats data to enhance your business strategies:
Restaurant data: Using the restaurant data, you can track the availability of the open restaurants in the locality and analyze their brand presence using the name, type, images, etc. You can also scrape website for restaurant menus from Uber Eats.
Discounts/Price Data: Beat the competitor in pricing with attractive discounts and offers. Deal with the price strategy to ensure that your offering is competitive.
Ratings & Reviews: Analyze the quality gaps in every location and adopt your brand strategy associated with ratings and reviews.
Opening Times: Discover which chains and services offer early breakfast or night-light deliveries by knowing the areas where competition is high.
Scraping of Restaurants and Menus Data from Uber Eats
Get detail insights into how to scrape restaurants and menus data from Uber Eats. Here we will find all restaurants on Uber Eats in Burlington. We are using the Python BeautifulSoup4 library to scrape food delivery data from Uber Eats. Because this library is versatile, super lightweight, and performs quickly with limited use of animation and Javascript.
Install using the pip library and then run.
pip install beautifulsoup4
Then, import it into your program using the:
from bs4 import BeautifulSoup
pip install beautifulsoup4
Import the following at the top of your program:
Now, we have all the libraries. So, for scraping restaurants, we will refer;
Retrieve the webpage contents using the following code lines.
Retrieve-the-webpage-contents-using-the-following-code.jpg
The above lines instruct the program where to look, request the specific webpage while mimicking a user using Mozilla 5.0, open such a page, and then finally parse the page using BeautifulSoup4. Now, we are all set to extract our desired data.
Here, we are interested in scraping Uber Eats restaurant data in Burlington that are available on Uber Eats. Start with the data that you want to scrape from Uber Eats. For this, right-click on the name of any restaurant and then hit Inspect. The source code will pop up, enabling you to see the tags of each element.
In this case, after right-clicking on Taco Bell (777 Guelph Line) and hitting Inspect, the line we get is:
< h3 class="h3 c4 c5 ai">Taco Bell (777 Guelph Line)< /h3 >
It indicates that Uber Eats uses the < h3 > tag to analyze all the names of the restaurants on the page. So, we will find every < h3 > tag on the page to avail the restaurant names. We will perform this using the following snippet code:
This simple Python loop iterates via webpage content that the BeautifulSoup library has parsed. Using the ‘findAll’ method, we can list each element in our ‘soup’ object containing < h3 > tag. We will print the object x’s text field within the ‘for’ loop. It will give the following
output:
Finally, we have a complete list of the Burlington restaurants and menu data on Uber Eats.
Finally, we have a complete list of the Burlington restaurants and menu data on Uber Eats. By scraping restaurant and menu data from Uber Eats, you can easily collect relevant information for your business needs. For more information, contact Food Data Scrape now! You can also reach us for all your food data scraping service and mobile app data scraping service requirements.
Know more : [How-to-Scrape-Restaurants-and-Menus-Data-from-Uber-Eats.jpg
Uber Eats is an online food delivery platform and ordering app based in the USA. This app allows customers to order, track, and search for their desired food items. It helps in ordering food as per your choice from a wide range of restaurants. Uber Eats spreads over 6,000 cities, with 66 million users in 2020. By 2020, there were nearly 6,00,000 Uber Eats restaurants.
However, information is available on Uber Eats. If your business is also in food delivery and wants to grow further, extracting data from Uber Eats is extremely important. In such a situation, Uber Eats Data scraping services comes into play.
By extracting restaurant listing data and food details from Uber Eats, you can easily avail restaurant data, menu data, delivery charges, discounts, competitive pricing data, menu categories, descriptions, reviews, ratings, etc. You can also read the blog about the importance of web scraping Uber Eats food delivery data
Lists of the significant data fields scraped from Uber Eats are:
Restaurants names
Restaurants addresses
Number of restaurants
Restaurants reviews
Multi-cuisines
Customers reviews
Payment methods
Restaurants menus
Types of products
Food price
Food description
Let’s first understand how to use Uber Eats restaurants and menu data.
Listed below are some of the ways that you can use scraped Uber Eats data to enhance your business strategies:
Restaurant data: Using the restaurant data, you can track the availability of the open restaurants in the locality and analyze their brand presence using the name, type, images, etc. You can also scrape website for restaurant menus from Uber Eats.
Discounts/Price Data: Beat the competitor in pricing with attractive discounts and offers. Deal with the price strategy to ensure that your offering is competitive.
Ratings & Reviews: Analyze the quality gaps in every location and adopt your brand strategy associated with ratings and reviews.
Opening Times: Discover which chains and services offer early breakfast or night-light deliveries by knowing the areas where competition is high.
Scraping of Restaurants and Menus Data from Uber Eats
Get detail insights into how to scrape restaurants and menus data from Uber Eats. Here we will find all restaurants on Uber Eats in Burlington. We are using the Python BeautifulSoup4 library to scrape food delivery data from Uber Eats. Because this library is versatile, super lightweight, and performs quickly with limited use of animation and Javascript.
Install using the pip library and then run.
pip install beautifulsoup4
Then, import it into your program using the:
from bs4 import BeautifulSoup
pip install beautifulsoup4
Import the following at the top of your program:
Now, we have all the libraries. So, for scraping restaurants, we will refer;
Retrieve the webpage contents using the following code lines.
Retrieve-the-webpage-contents-using-the-following-code.jpg
The above lines instruct the program where to look, request the specific webpage while mimicking a user using Mozilla 5.0, open such a page, and then finally parse the page using BeautifulSoup4. Now, we are all set to extract our desired data.
Here, we are interested in scraping Uber Eats restaurant data in Burlington that are available on Uber Eats. Start with the data that you want to scrape from Uber Eats. For this, right-click on the name of any restaurant and then hit Inspect. The source code will pop up, enabling you to see the tags of each element.
In this case, after right-clicking on Taco Bell (777 Guelph Line) and hitting Inspect, the line we get is:
< h3 class="h3 c4 c5 ai">Taco Bell (777 Guelph Line)< /h3 >
It indicates that Uber Eats uses the < h3 > tag to analyze all the names of the restaurants on the page. So, we will find every < h3 > tag on the page to avail the restaurant names. We will perform this using the following snippet code:
It-indicates-that-Uber-Eats-uses-the.jpg
This simple Python loop iterates via webpage content that the BeautifulSoup library has parsed. Using the ‘findAll’ method, we can list each element in our ‘soup’ object containing < h3 > tag. We will print the object x’s text field within the ‘for’ loop. It will give the following
output:
Finally, we have a complete list of the Burlington restaurants and menu data on Uber Eats.
Finally, we have a complete list of the Burlington restaurants and menu data on Uber Eats. By scraping restaurant and menu data from Uber Eats, you can easily collect relevant information for your business needs. For more information, contact Food Data Scrape now! You can also reach us for all your food data scraping service and mobile app data scraping service requirements.
Know more : https://www.fooddatascrape.com/how-to-scrape-restaurants-and-menus-data-from-uber-eats.php](https://www.fooddatascrape.com/how-to-scrape-restaurants-and-menus-data-from-uber-eats.php) | fooddatascrape |
1,404,612 | Question to all remote developers. | Hello everyone. My name is Ozan and I am currently learning python and I want to work as back-end... | 0 | 2023-03-17T14:19:19 | https://dev.to/ozantanaydin/question-to-all-remote-developers-24c4 | beginners, discuss, programming, career | Hello everyone.
My name is Ozan and I am currently learning **python** and I want to work as **back-end** developer or **anything with python**(Before you say yes I am going to learn about javascript and necessary libs as well). I have no problem with studying and all but I really wonder how you guys find your remote jobs? Like did you applied to them or you knew someone who knew someone? and how I can do the same thing a junior developer for different country.
So let me tell you about my story so hopefully you can understand and answer me
I know I am sugar coating my question but here is my situation.
Currently I live in Turkey and the city that I live is touristic area so because of that there is no company is hiring right now(The hiring ones are hiring seniors). And finding job in bigger cities is not possible because the salary they are offering are not enough to cover my expenses. So only thing I have in my hand is remote works. I am willing to do everything I could to just start working. So How did you guys do and what is the way that the way I need to follow if local work is not possible? | ozantanaydin |
1,404,712 | Monolithic vs Microservice Architecture - Which Should You Use? | If you are starting to build a new application or you are working on an existing one you may be... | 0 | 2023-03-17T16:03:07 | https://www.alexhyett.com/monolithic-vs-microservices/ | programming, coding, architecture, developer | If you are starting to build a new application or you are working on an existing one you may be wondering whether you should be building a monolith or a microservice application.
Each architecture has its own pros and cons but hopefully, by the end of this article, you will have a good understanding of what the differences are and which one you should be using for your project.
{% embed https://www.youtube.com/watch?v=NdeTGlZ__Do %}
<yt></yt>
## What is a monolith?
Before microservices were a thing everyone was building monoliths. A monolith is an application where everything works as one piece of code.
It is usually the starting point for any new application. Whether it be an API or a Frontend. You end up with one executable with all the code in one repository.
Your application is then developed, deployed and also scaled as a single component.
If you are working in a team on the same application, then you need to work together to make sure you don’t step on each other’s toes.
Anyone who has ever worked on a big code change in one sitting will know the pain of having to merge everyone else’s changes into your code.
### Advantages of monolithic architecture 👍
Before we cover the problems with monoliths, they do have a number of key advantages that are important to go over.
#### Easy to Develop
Monoliths are easy to develop as all the code is in one place. You don’t need to worry about maintaining different repositories, you only have one application to run and test.
If you are working on a small application then this can make a big difference in the time it takes to develop.
Most applications start as monoliths simply because they are quicker to get to market.
#### Easy to Deploy
Monoliths are easy to deploy, after all, you only have one application to worry about.
On top of that, you only have one CI/CD pipeline to worry about and infrastructure for one application to deal with.
#### Easier to Debug
If you only have one application then there is only one place to look for a bug.
The real benefit comes when you are debugging your application locally as you only have one application to step through. If you need to debug multiple applications at once it can become a bit of a nightmare especially if they are all running on the same port.
#### Performance Considerations
I won’t go as far as to say that monoliths are more performant than microservices, however, with a monolith you don’t need to worry too much about latency.
If you only have one application then there is a negligible cost between parts of your code calling each other. Which we will see with microservices gets a bit more complex.
### Disadvantages of monolithic architecture 👎
So if monoliths are so great why bother with microservices at all? Despite the benefits, monoliths do come with some big issues that often cause teams to move to microservices further down the line.
#### Application is getting too big
Every developer starts with good intentions and applies clean code practices to make their application easy to maintain.
However, even the best-designed application is going to look like a giant mess once it reaches a certain size.
If it takes a month to onboard a new developer and explain what all the different parts of your application are doing, then you may need to look at other options.
#### Release process taking too long
If your application has lots of different features then there is going to be a lot that you need to test before each release.
As your application is one big component then even the smallest change requires you to release the whole application each time.
Depending on the application and your CI/CD pipeline, deployments can take a long time, especially if you need to worry about switching traffic between green and blue APIs and monitoring the logs.
#### Application difficult to scale
If a part of your application is getting a lot of traffic then you have little choice but to scale the whole application. This might mean spinning up more instances of your API or beefing up the CPU or memory on your server.
Either way, it is going to be expensive because your application is so large.
## What are Microservices?
Now that you have seen the disadvantages of monoliths, especially as your application gets bigger, we can look at the solution, which is microservices.
With microservices, we take your big monolithic application and break it down into different components. Each component has a single responsibility and is usually in charge of a single business functionality.
If you take Netflix for example, they might have one component in charge of search, another in charge of streaming the videos and another responsible for the recommendations.
Each service is self-contained and independent from all the others. They have their own infrastructure and their own database for example.
Each microservice is its own application that has its own version and is released independently.
### Communication between microservices
If you split your application up then how do all the microservices talk to each other?
There are 3 main ways that your microservices can communicate.
#### API
Each microservice can have its own endpoint that the other microservices can call. This should be used when you need synchronous communication between your components.
As with all HTTP requests, this is going to introduce a bit of latency in your application that you need to take into account. However, you can use things like gRPC to speed up communication.
#### Message Broker
If what your service is doing can be done asynchronously then you are better off using a message broker.
For example, if you are application needs to send an email, it isn’t usually necessary that the application waits for a response from the SMTP server.
It is much easier to put the message that you want to send in a queue and have your application carry on with what it was doing. A microservice listening to that message queue can then pick up the message and send the email.
You can use technologies such as RabbitMQ or AWS SQS to communicate with your asynchronous microservices.
#### Service Mesh
The last option is to use what is called a service mesh. A service mesh handles all of the communication between microservices as well as helps deal with the reliability and discoverability of your services.
### Advantages of microservices 👍
Obviously, no one would use microservices if they didn’t have a number of key benefits over the monolithic design.
#### Easier to Maintain
A well-designed microservice is only responsible for one thing and as a result, they are a lot easier to maintain. In many cases once written you may not have a need to touch a microservice at all, it will just carry on running without you needing to do anything.
Compare that to a monolith where you are redeploying the application with every change and therefore each time adding in the potential for something else to go wrong in other areas of your application.
#### High reliability
As you only need to deploy a single microservice when something has changed the other microservices are unaffected.
As a result, your application becomes more reliable as there is less chance that the whole system is going to come crashing down if there is an issue with one of the components.
This is why if you look at outages at companies such as GitHub, it is rarely everything that goes down. It might be webhooks that stop working or you are unable to commit but it is usually limited to specific functionalities in the application.
#### Each team can choose its own technology stack
This can be both a blessing and a curse.
Some languages are more suited to particular tasks compared to others. Take machine learning for example, you are much better off writing a machine learning algorithm in Python compared to C#.
However, if teams have completely free rein over which technologies they use you can end up having to reinvent the wheel every time you want to create a new microservice. It is a lot more efficient if all the services are using the same tech stack.
Being able to have separate teams working on the same application independently from each other is a big selling point of microservice architecture.
#### Flexible scaling
It is rare that all areas of your application are going to get the same number of requests. There are going to be some functions of your application that are going to be used more by your users compared to others.
If your application is a monolith and one part of your application is getting the majority of the requests you have no choice but to scale up the whole application.
However, If you have a microservice architecture you can scale up just the microservice that needs it and therefore save yourself money in the process.
#### Continuous deployment
If you want to get to the point where you are deploying multiple times per day then you need to make sure that each change can be easily tested and automated.
If you have a monolith then this is very difficult to do as even the smallest change could have an impact on the whole application. However, with microservices, your change is only limited to one microservice which can be deployed and tested independently.
### Disadvantages of microservices 👎
It is not all good news with microservices, there are a number of disadvantages that you need to be aware of if you are thinking of using microservice architecture in your next project.
#### Harder to run locally
If your microservice is highly dependent on other microservices to work, then it can be a pain to get everything running on your computer when you need to do development.
You can either resort to mocking out all the other endpoints that your application needs or spin up docker containers with all the microservices you need to call.
It can be done but it does make things harder than just running a single application.
#### Harder to debug
When problems do occur with your application in production it can be harder to work out where the issue is.
You no longer have just one application to deal with you now have several and you will need to look at each one to see where the issue originated.
It is important that you have good monitoring in place for all of your microservices so you know when a service is down or having problems. This is where using a service mesh can come in handy.
#### Higher infrastructure costs
Microservices can come with higher infrastructure costs as you need to be able to host all of the different services.
If your application is large and you have an uneven distribution of requests then it is usually cheaper than scaling up a monolith but for smaller applications, you aren’t likely to see those benefits.
#### Increased complexity
Microservice architecture does increase the complexity of your system in a lot of different areas.
It makes your infrastructure more complex, your CI/CD pipeline needs to cope with deploying multiple services and you now have to deal with the communication between all the different components.
On top of that, you need to have good monitoring in place so you know if one of your microservices is having issues.
This might not seem like a big deal when you only have a handful of microservices but once you have hundreds it can become an operational nightmare.
## Which architecture should you use? 🤷♂️
We have gone over the pros and cons of each so which one should you be using for your project?
If you are starting out with a new application that isn’t going into an existing infrastructure then start with a monolith.
There is no point in trying to solve scaling problems that you don’t even have yet. If you are building a startup, then your main concern should be getting to the market as quickly as possible.
You can deal with the scaling problems when you actually have them.
Most applications, even Netflix started out as a monolith. It was only when they needed to scale that they split up everything into microservices.
There is one scenario though where a new application should start as microservices and that is if you are hooking into an existing workflow.
If you know that your application is going to be getting a million requests from day one then you need to plan accordingly. In that case, it is usually better to start with a microservice architecture or at least a semi-monolith with key components broken down into their own services.
Once your application is live then you can look to see if it makes sense to break down your semi-monolith into more microservices.
If you are not sure what architecture to use for your microservices then you should take a look at hexagonal architecture. | alexhyettdev |
1,405,075 | Managing Dependencies with Yarn: Understanding Dependency Conflicts. | Introduction: Managing dependencies in any project is like juggling multiple balls at once - it's... | 0 | 2023-03-21T12:08:29 | https://dev.to/mayurjagtap/managing-dependencies-with-yarn-understanding-dependency-conflicts-28c7 | javascript, beginners, yarn, node |
**Introduction**:
Managing dependencies in any project is like juggling multiple balls at once - it's essential to ensure that the project completes successfully, on time, and on budget. This is where tools like Yarn come in. Yarn is a package manager for Node.js that helps manage dependencies by leveraging two files: package.json and yarn.lock. In this blog post, we'll take a closer look at how Yarn manages dependencies and how to resolve dependency conflicts - without dropping any balls!
**Let's See how yarn manages dependencies:**
Yarn manages dependencies through two files: package.json and yarn.lock. Think of these files like your to-do list and your grocery list. The package.json file lists all the dependencies that your project needs, while the yarn.lock file lists the exact versions of those dependencies. Just like how you don't want to forget anything on your grocery list, Yarn ensures that your project has all the necessary dependencies, and that they're the right versions.
However, conflicts can arise when managing dependencies - just like how you might argue with your family about which brand of cereal to buy at the grocery store. For example, suppose you need to add packages A and B as dependencies. Package A depends on some dependency xy21.9, and package B depends on dependency xyz2.9. In that case, a conflict will emerge, saying "unable to resolve package dependency." It's like your family arguing about which brand of cereal to buy, and no one can agree!
To resolve these conflicts, you can take inspiration from how you resolve conflicts with your family - you have to compromise. Here are some ways to resolve dependency conflicts:
Upgrade or downgrade the version of the conflicting dependency in either of the packages.
Delete the conflicting package if it is not needed.
In package.json, inside the yarn resolution field, specify the version of the conflicting dependency that you want to use.
_package.json file:_
_yarn.lock file:_
Use the command yarn install --interactive: If you run this command, Yarn will go through the package.json file and display a conflicting dependency menu with possible versions to upgrade or downgrade to. (**Note**: this command is only available in Yarn 1 and Yarn 2).
**Conclusion:**
In conclusion, managing dependencies with Yarn is like a balancing act, but it doesn't have to be a serious one. Understanding how Yarn manages dependencies and how to resolve dependency conflicts can help you develop and deploy applications more efficiently - and with fewer arguments! With the tips provided in this blog post, you'll be better equipped to handle any dependency conflicts that arise in your projects - and maybe even use some humor to lighten the mood.
| mayurjagtap |
1,414,959 | Mastering List Destructuring and Packing in Python: A Comprehensive Guide | List destructuring, also known as packing and unpacking, is a powerful technique in Python for... | 0 | 2023-03-25T19:04:15 | https://blog.ashutoshkrris.in/mastering-list-destructuring-and-packing-in-python-a-comprehensive-guide | python, programming, beginners, tutorial | List destructuring, also known as packing and unpacking, is a powerful technique in Python for assigning and manipulating lists. It allows you to quickly assign values from a list to multiple variables, as well as easily extract values from complex nested lists. This technique is widely used in Python programming and is an important tool for improving code readability and reducing the amount of code required for complex operations.
In this tutorial, you will explore the concepts of list destructuring and learn how to use them effectively in your Python code. By the end of this tutorial, you will have a solid understanding of list destructuring and be able to use it effectively in your own Python programs.
## Destructuring Assignment
Destructuring assignment is a powerful feature in Python that allows you to unpack values from iterable, such as lists, tuples, and strings, and assign them to variables in a single line of code. This makes it easy to extract specific values from complex data structures and assign them to variables for further use. It's also known as **unpacking** because you are unpacking the values from the iterable.
### Destructuring as Values
One way to use destructuring assignment is to unpack values from an iterable and assign them to variables. This is done by adding the variables to be assigned on the left-hand side of the assignment operator, and the iterable containing the values to be unpacked on the right-hand side. For example:
```python
x, y, z = [1, 2, 3]
print(x, y, z)
```
Output:
```bash
1 2 3
```
Here, you unpack the values 1, 2, and 3 from the list `[1, 2, 3]` and assign them to variables `x`, `y`, and `z`, respectively. You can then use these variables elsewhere in your code.
If you try to unpack more values than the length of the iterable, you will get a **ValueError: not enough values to unpack** error. For example:
```python
x, y, z = [1, 2]
```
Output:
```bash
x, y, z = [1, 2]
^^^^^^^
ValueError: not enough values to unpack (expected 3, got 2)
```
> Note: The error message may differ according to the Python version. But the error will surely be a ValueError.
### Destructuring as List
Another way to use destructuring assignment is to unpack values from an iterable and assign them to a list. To do so, you can first assign the values to the variables you want. You can then use the asterisk (\*) operator to assign the remaining values in an iterable to a list. For example:
```python
x, y, *rest = [1, 2, 3, 4, 5]
print(x)
print(y)
print(rest)
```
Output:
```bash
1
2
[3, 4, 5]
```
In this example, you assign the first two values of the list to the variables `x` and `y`, and then use the asterisk operator to assign the remaining values to the list `rest`.
The above code sample is equivalent to:
```python
nums = [1, 2, 3, 4, 5]
print(nums[0])
print(nums[1])
print(nums[2:])
```
### Ignoring Values in Destructuring Assignments
Sometimes, you may only be interested in unpacking certain values from an iterable and want to ignore the rest. You can do this using an underscore (\_) as a placeholder for the values you want to ignore. For example:
```python
x, _, z = [1, 2, 3]
print(x, z)
```
Output:
```bash
1 3
```
In the above example, you use the underscore character to ignore the second value of the list. It's worth noting that although the underscore character is often used as a placeholder, it can be used as a variable name like any other valid variable name in Python. However, most people do not use it as a variable and instead use it solely as a placeholder when they want to ignore a value in a destructuring assignment.
### Ignoring Lists in Destructuring Assignments
You can ignore many values using the \*\_ syntax. For example:
```python
x, *_ = [1, 2, 3, 4, 5]
print(x)
```
Output:
```bash
1
```
Here, you assign the first value of the list to the variable `x` and ignore the rest of the values using the \*\_ syntax. In this case, the value of `x` is 1 and the rest of the values are ignored. This technique can be useful when you are only interested in the first value of an iterable and don't need to use the remaining values.
However, the above example isn't interesting as you could have just used indexing to extract the first value. It becomes interesting in scenarios where you intend to retain the first and last values during an assignment. For example:
```python
x, *_, y = [1, 2, 3, 4, 5]
print(x, y)
# Output: 1 5
```
Alternatively, when you need to extract several values at once:
```python
x, _, y, _, z, *_ = [1, 2, 3, 4, 5, 6]
print(x, y, z)
# Output: 1 3 5
```
## Packing Function Arguments
In functions, you can define a number of mandatory arguments which will make the function callable only when all the arguments are provided.
```python
def func(arg1, arg2, arg3):
return arg1, arg2, arg3
func()
```
If you don't pass the arguments, you get the following error:
```bash
TypeError: func() missing 3 required positional arguments: 'arg1', 'arg2', and 'arg3'
```
You can also define arguments as optional by using default values. This allows you to call the function in different ways depending on which arguments you want to provide.
```python
def func(arg1='a', arg2=1, arg3=[1, 2, 3]):
return arg1, arg2, arg3
func()
func('b')
func('c', 2)
func('d', 3, [1, 2, 3, 4])
...
```
In this section, you'll explore how to pack arguments in Python using the destructuring syntax. Packing arguments involves passing a variable number of arguments to a function, which can then be accessed as a single variable within the function. There are several ways to pack arguments in Python, including packing a list of arguments and packing keyword arguments. Let's dive in!
### Packing a List of Arguments
We can pack values into a list using the `*` operator. When the function is called, the `*` operator unpacks the values in the list and passes them as separate arguments to the function. Here's an example:
```python
def add_numbers(a, b, c):
return a + b + c
values = [1, 2, 3]
result = add_numbers(*values)
print(result)
print(add_numbers(*[3, 4, 5]))
```
Output:
```bash
6
12
```
In this example, you define a function `add_numbers` that takes three arguments and returns their sum. You then define a list of values `values` containing the values we want to pass as arguments to the function. When you call the function using `add_numbers(*values)`, the values in the list are unpacked and passed as separate arguments to the function.
You can also use the unpacking operator to directly pass a list to a function without creating a separate variable as seen on the last line of the code.
Note that the number of values in the list must match the number of arguments expected by the function. If we try to pass too many or too few values, a `TypeError` will be raised:
```python
def add_numbers(a, b, c):
return a + b + c
values = [1, 2]
result = add_numbers(*values)
```
Output:
```bash
result = add_numbers(*values)
^^^^^^^^^^^^^^^^^^^^
TypeError: add_numbers() missing 1 required positional argument: 'c'
```
### Packing Keyword Arguments
You can also pack keyword arguments into a dictionary using the `**` operator. When the function is called, the `**` operator unpacks the dictionary and passes the key-value pairs as separate keyword arguments to the function. Here's an example:
```python
def multiply_numbers(x, y):
return x * y
kwargs = {'x': 2, 'y': 3}
result = multiply_numbers(**kwargs)
print(result)
```
Output:
```bash
6
```
In this example, you define a function `multiply_numbers` that takes two keyword arguments and returns their product. You then define a dictionary `kwargs` containing the key-value pairs we want to pass as keyword arguments to the function. When you call the function using `multiply_numbers(**kwargs)`, the dictionary is unpacked and the key-value pairs are passed as separate keyword arguments to the function.
Note that the keys in the dictionary must match the names of the keyword arguments expected by the function. If you try to pass a key that doesn't match a keyword argument name, a `TypeError` will be raised:
```python
def multiply_numbers(x, y):
return x * y
kwargs = {'a': 2, 'b': 3}
result = multiply_numbers(**kwargs)
```
Output:
```bash
result = multiply_numbers(**kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: multiply_numbers() got an unexpected keyword argument 'a'
```
Similarly, if you try to pass a keyword argument that the function doesn't expect, a `TypeError` will be raised:
```python
def multiply_numbers(x, y):
return x * y
kwargs = {'x': 2, 'y': 3, 'z': 4}
result = multiply_numbers(**kwargs)
```
Output:
```bash
result = multiply_numbers(**kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: multiply_numbers() got an unexpected keyword argument 'z'
```
## Unpacking Functional Arguments
In Python, you can create a function that can accept any number of arguments, without enforcing their position or name at "compile" time. This is achieved by using special parameters, \*args and \*\*kwargs.
Here's an example:
```python
def my_function(*args, **kwargs):
print(args, kwargs)
```
The `*args` parameter is set to a tuple and the `**kwargs` parameter is set to a dictionary. When you call the function, any positional arguments will be gathered into `args`, and any keyword arguments will be gathered into `kwargs`.
Here are some examples of how you can call the function:
```python
my_function(1, 2, 3)
# Output: (1, 2, 3) {}
my_function(a=1, b=2, c=3)
# Output: () {'a': 1, 'b': 2, 'c': 3}
my_function('x', 'y', 'z', a=1, b=2, c=3)
# Output: ('x', 'y', 'z') {'a': 1, 'b': 2, 'c': 3}
```
The `*args` and `**kwargs` parameters are commonly used when passing arguments to another function. For example, you might want to extend the string class by creating a new class that inherits from `str`:
```python
class MyList(list):
def __init__(self, *args, **kwargs):
print('Constructing MyList')
super(MyList, self).__init__(*args, **kwargs)
my_list = MyList([1, 2, 3])
print(my_list)
```
In this example, you're defining a new class `MyList` that inherits from the built-in `list` class. You're overriding the `__init__` method to print a message and then calling the parent class's `__init__` method using `super()`. Finally, you create a new instance of `MyList` by passing in a list of integers and printing the resulting object. This will output:
```bash
Constructing MyList
[1, 2, 3]
```
You can learn more about \*args and \*\*kwargs in [this tutorial](https://blog.ashutoshkrris.in/args-and-kwargs-in-python).
## Conclusion
List destructuring is a powerful feature in Python that allows for the unpacking of values from an iterable and assigning them to variables. It enables developers to easily manipulate and work with data structures such as lists, tuples, and dictionaries. Additionally, the ability to pack and unpack function arguments provides a flexible and convenient way to handle function parameters, allowing for more dynamic and versatile code. By understanding these concepts and techniques, Python developers can write cleaner and more efficient code, making their programming experience more enjoyable and productive. | ashutoshkrris |
1,415,003 | Weekend Reading | Hello folks! Another week come and gone, and the tech world is still abuzz with GPT-4.... | 0 | 2023-03-25T21:00:00 | https://www.simonporter.co.uk/posts/weekend-reading-2023-03-25 | news, javascript, react, webdev | ---
title: Weekend Reading
published: true
date: 2023-03-25 21:00:00 UTC
canonical_url: https://www.simonporter.co.uk/posts/weekend-reading-2023-03-25
tags: news,javascript,react,webdev
---

## Hello folks!
Another week come and gone, and the tech world is still abuzz with GPT-4. Though it does seem to have calmed down a bit doesn't it? :sweat_smile:
In other news, bit of a hiccup for GitHub this week as they had to roll their SSH private key after [accidentally exposing it in a public repo](https://github.blog/2023-03-23-we-updated-our-rsa-ssh-host-key/), yowch. Twitch layoffs continued in a horrendous fashion.
Still, plenty of React and JS news to keep us sidetracked. Grab your drink, pull up a chair, lets have us some weekend reading!
* * *
Gajus points out a quick tip to make our DX easier with TypeScript. I can't believe how many times I've been sent to the type definition files rather than the proper code, when it's such an easy fix!
{% twitter https://twitter.com/kuizinas/status/1636641120477384705 %}
Seb posed a question on variable naming and whether you should avoid one letter names. 219 replies, and 210k views. We apparently care a lot about our variable names! So why is it so hard? :sweat_smile:
{% twitter https://twitter.com/sebastienlorber/status/1638146370191208449 %}
Dominik notes that React Query v5 is just around the corner! There's some neat stuff in this release but I also love the object properties by default, and switching back isLoading/isInitialLoading.
{% twitter https://twitter.com/TkDodo/status/1637763194021093379 %}
Daishi has published a learning "course" for Zustand v4. As he notes, it's such a small library that he's released it fairly cheap.
{% twitter https://twitter.com/dai_shi/status/1638177097528246274 %}
Tim, the lead from Vercel, announces that `create-next-app` will now ask if you want to get started with Tailwind CSS instead of CSS modules. This got mixed reactions on Twitter, as it alwasy does when someone mentions Tailwind, but this seems like a nice DX improvement to me. You still don't _have_ to use it if you hate it that much.
{% twitter https://twitter.com/timneutkens/status/1636654046474805249 %}
Dan is [still being given grief](https://twitter.com/dan_abramov/status/1638334250440089601?s=20) about RSC's from a lot of folks on Twitter. It's a difficult spot to be in, because it's brand new and they want to gauge how best to implement it, and not all the pieces are in place yet. I love this summary from Dan Jutan of Astro and Solid.
{% twitter https://twitter.com/jutanium/status/1639283519863005187 %}
[PlayWright released 1.32](https://www.youtube.com/watch?v=jF0yA-JLQW0) this week, which brought with it UI mode and time travelling debug, akin to Cypress. Earlier they made React Testing Library a first class citizen, and this could now mean it's well worth a look if you weren't enjoying Cypress, or wanted to try it on a new project.
* * *
## This Week In React
My top picks for [TWIR](https://thisweekinreact.com/):
Pretty neat [mapping of all the available React APIs](https://julesblom.com/writing/map-of-react-api) with some background reading behind them. Interesting way to document this information, hope to see more of it!
Brad writes about a list of [React's more eccentric hooks](https://reacttraining.com/blog/hooks-you-probably-dont-need), with a few common ones that shouldn't be used all that much thrown in too. No surprises `useEffect` makes the list, which I feel gets overused as an easy escape hatch quite a lot.
Both [Vite](https://github.com/vitejs/vite/blob/main/packages/vite/CHANGELOG.md#420-2023-03-16) and [Prettier](https://github.com/prettier/prettier/releases/tag/2.8.5) had some new releases this week. I don't think there's anything earth shattering here but it's nice to see some TS 5.0 support in Prettier already.
There's an interesting read about [signals vs observables ](https://www.builder.io/blog/signals-vs-observables) on the builder.io blog this week, which is fairly topical given I've been diving into React Query lately. Didn't pay _too_ much attention to the signals hype as I had too much on, but this is a nice rundown for anyon who missed it.
Josh wrote about his feelings on AI and [the future of development](https://www.joshwcomeau.com/blog/the-end-of-frontend-development/). Definitely match his sentiment that AI isn't going to be getting people fired anytime soon, but it can be a huge help if used properly.
See you next week!
| sporter |
1,415,069 | How to Load Content into a Bootstrap Offcanvas Component with HTMX and Save State as a Hash in the URL | To open a Bootstrap Offcanvas Component and load some HTML fragment with HTMX, the first thing I... | 0 | 2023-03-25T22:18:33 | https://marcus-obst.de/blog/htmx-bootstrap-5-offcanvas | javascript, htmx, bootstrap, alpinejs | To open a [Bootstrap Offcanvas Component](https://getbootstrap.com/docs/5.3/components/offcanvas/) and load some HTML fragment with HTMX, the first thing I tried was the following:
- Equip the canvas (or modal) opener with the HTMX attributes
- call it a day
```html
<a class="btn btn-light"
href="/sidebar"
hx-get="/sidebar"
hx-select=".bookmark-list"
hx-target=".offcanvas-body"
data-bs-toggle="offcanvas"
data-bs-target="#offcanvas">
Open Sidebar
</a>
<div
id="offcanvas"
class="offcanvas offcanvas-start">
<div class="offcanvas-body">
Loading...
</div>
</div>
```
This approach is completely decoupled; the click event triggers both the Bootstrap behavior and the HTMX ajax call. Both are unaware of one another.
If the canvas fails to open, the Ajax request may succeed, but the result cannot be viewed.
Back to the drawing board!
### Connecting the behavior of HTMX and Bootstrap JS
The first thought is to use HTMX and listen for the 'htmx:load' event, then call [`.show()`](https://getbootstrap.com/docs/5.3/components/offcanvas/#methods) to open the Offcanvas component. That would necessitate some UI to indicate that the loading is complete before the canvas appears.
Or the other way around, listen to `show.bs.offcanvas` and then trigger `htmx.ajax()` to pull in the server-rendered HTML. This is better because it shows, something is happening right away.
### Saving open state in the URL
That previous approach makes the button or link responsible for opening the canvas (or modal)?
If I navigate to `/sidebar#offcanvas` I want the sidebar to be open on page load with the HTMX ajax request triggered. The problem with this approach is, the button is the single source of truth that holds the URL that's getting loaded by HTMX via `hx-get` (or `href`).
I could go and `htmx.find('a[href="/sidebar"]').href` and then use that in the Ajax request. Or I trigger a click on the button, that triggers the behavior. But that seems weird and too tightly coupled.
```js
document.addEventListener('DOMContentLoaded', function () {
const el = '#offcanvas';
let bookmarksOffcanvasInstance = bootstrap.Offcanvas.getOrCreateInstance(el);
if(location.hash === '#offcanvas'){
// open the sidebar
bookmarksOffcanvasInstance.show();
// find the button and make an
// ajax call via
htmx.ajax('GET', htmx.find('a[href="/sidebar"]').href, {/* target etc */})
// -- OR --
htmx.trigger('a[href="/sidebar"]', "click");
}
});
```
### Make the Offcanvas component the single source of truth
There is another way I found by watching a video[^1] about doing something similar with AlpineJS and an open issue with HTMX[^2] that brought me to the following solution:
#### 1. The button or link to open the sidebar is only responsible for that
```html
<a class="btn btn-light"
href="/sidebar"
data-bs-toggle="offcanvas"
data-bs-target="#offcanvas">
Open Sidebar
</a>
```
#### 2. Tie the HTMX logic to the canvas itself and trigger a HTMX custom event
```html
<div
id="offcanvas"
class="offcanvas offcanvas-start"
hx-get="/sidebar"
hx-select=".sidebar"
hx-target=".offcanvas-body"
hx-trigger="filter-event">
<div class="offcanvas-body">
Loading...
</div>
</div>
</div>
<script>
const el = document.getElementById("offcanvas");
// after the canvas was opened, trigger the hx-get with
// the custom event and add the url with the state of the canvas
// into the history
el.addEventListener('shown.bs.offcanvas', event => {
htmx.trigger(event.target, "filter-event");
history.pushState(null, null, '#' + event.target.id);
})
// on hiding the sidebar, remove the hash
el.addEventListener('hide.bs.offcanvas', event => {
history.pushState("", document.title, window.location.pathname);
})
</script>
```
<iframe class="full mb-5" height="600" style="width: 100%;" scrolling="no" title="Untitled" src="https://codepen.io/localhorst/embed/RwYEXNz?default-tab=html%2Cresult&editable=true&theme-id=light" frameborder="no" loading="lazy" allowtransparency="true" allowfullscreen="true">
See the Pen <a href="https://codepen.io/localhorst/pen/RwYEXNz">
Untitled</a> by Marcus at Localhost (<a href="https://codepen.io/localhorst">@localhorst</a>)
on <a href="https://codepen.io">CodePen</a>.
</iframe>
Now, all the information for the Ajax request is associated with the offcanvas component, and it does not matter what triggers the opening of the sidebar; everything is contained in a single location.
My initial thought probably stems from my synchronous consideration of requests. A click alters the appearance of another element **after** a page reload.
With JavaScript's asynchronous nature, this behavior is out the window.
### Bonus: Offcanvas activated by AlpineJS that triggers HTMX custom event
I adopted the whole script for the AlpineJS inline JavaScript style and here it is:
```html
<a class="btn btn-light" href="#offcanvas">
Open Sidebar
</a>
<div
id="offcanvas"
class="offcanvas offcanvas-start"
x-data
x-init="()=>{
const oc = new bootstrap.Offcanvas('#offcanvas');
if(location.hash === '#offcanvas') oc.show();
}"
@hashchange.window="if(location.hash === '#offcanvas') { bootstrap.Offcanvas.getOrCreateInstance(location.hash).show() }"
@shown-bs-offcanvas.dot="
htmx.trigger($event.target, 'filter-event');
history.pushState(null, null, '#' + $event.target.id);"
@hide-bs-offcanvas.dot="history.pushState('', document.title, window.location.pathname);"
hx-get="/sidebar"
hx-select=".sidebar"
hx-target=".offcanvas-body"
hx-trigger="filter-event">
<div class="offcanvas-body">
Loading...
</div>
</div>
<template url="/sidebar" delay="1500">
<h2>Sidebar Headline only visible when /sidebar is directly requested</h2>
<div class="sidebar">
Sidebar
</div>
</template>
```
A working Codepen can be found under <https://codepen.io/localhorst/pen/RwYvWyE> (log in, switch to debug mode to see that URL hash change).
What I like about this approach is, it's very compact. Everything is in one place. No snippets here and bits there. You look at the markup of that component and that's all there is. At least for this demo. At the same time, it's ugly, hard to format and as complexity grows you'll end up putting stuff in a dedicated script block or so.
I don't know if there is any need to add AlpineJS in the mix as a third abstraction of code.
It's a matter of style and maintenance I guess. But now I know how to listen for events from Bootstrap components ([see the `.dot` modifier](https://alpinejs.dev/directives/on#dot)) in AlpineJS.
If you have correction or thoughts about it, please let me know. I don't claim, that's the way to do it. I just made it work that way.
Article [How to Load Content into a Bootstrap Offcanvas Component with HTMX and Save State as a Hash in the URL](https://marcus-obst.de/blog/htmx-bootstrap-5-offcanvas) on my blog.
[^1]: https://laracasts.com/series/modals-with-the-tall-stack/episodes/3
[^2]: https://github.com/bigskysoftware/htmx/issues/701
| marcusatlocalhost |
1,415,088 | GIT INIT UNLOCKED: ELEVATE YOUR COLLABORATION AND CODE MANAGEMENT GAME WITH MASTERY OF GIT INIT. | INTRODUCTION Git init is a command in the Git version control system that initializes a... | 0 | 2023-03-26T00:03:29 | https://dev.to/collinsoden/git-init-unlocked-elevate-your-collaboration-and-code-management-game-with-mastery-of-git-init-oah | software, development, git, github |
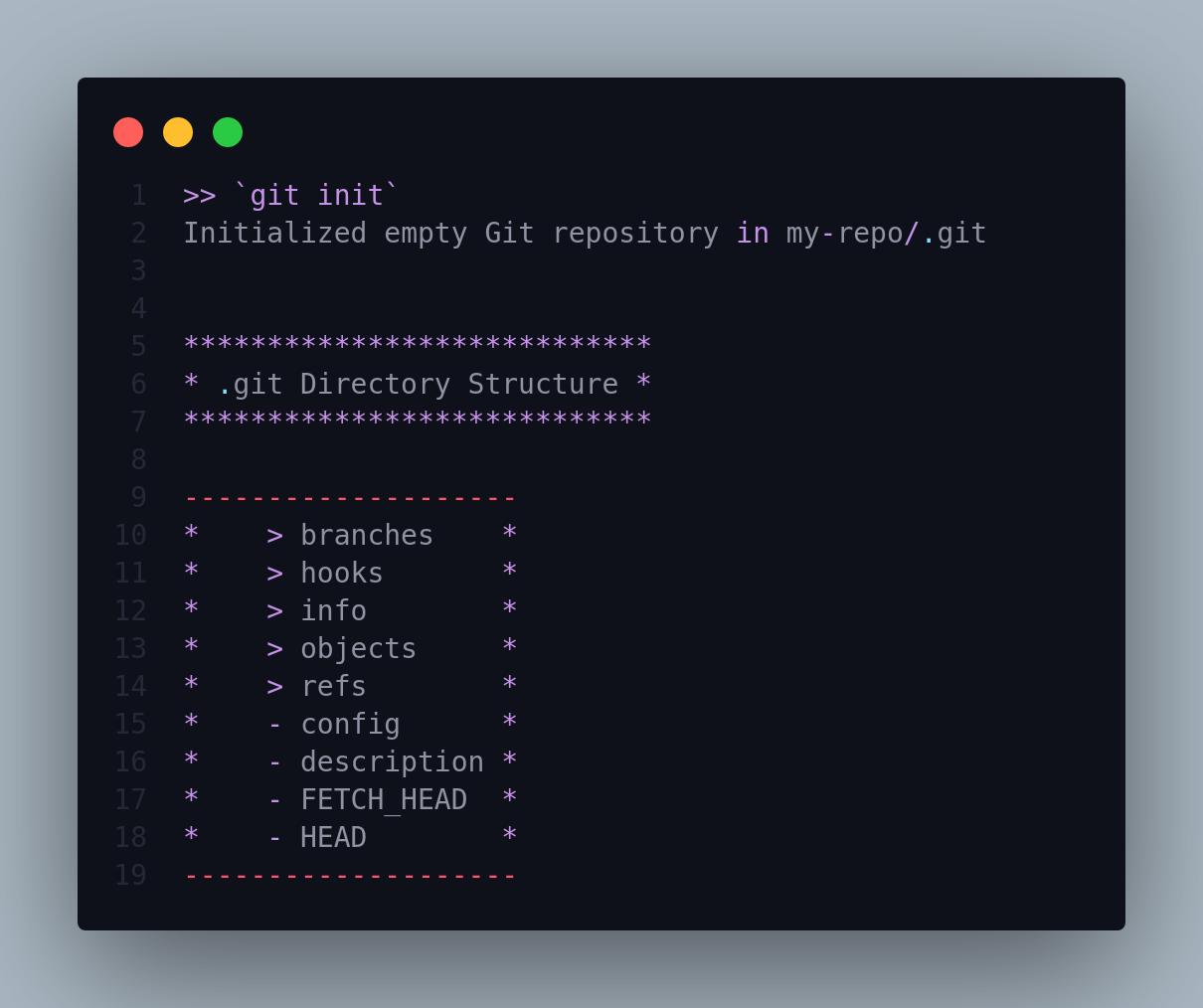
## INTRODUCTION
Git init is a command in the Git version control system that initializes a new Git repository. Git init is typically used at the beginning of a new project, but can also be used to turn an existing project into a Git repository. When you run git init in a directory, Git creates a new repository in that directory, adding a .git subdirectory that contains all the necessary files and directories for version control.
Git init is important for collaboration and code management because it allows developers to keep track of changes made to their code over time. By initializing a Git repository, developers can commit changes, create branches, merge code, and collaborate with other developers, all while keeping a detailed history of every change made to the codebase.
This makes it much easier to manage changes to the codebase, track bugs, and roll back to previous versions if necessary. Git's branching and merging capabilities also make it easy for multiple developers to work on the same codebase at the same time, without interfering with each other's work.
Git init also helps ensure consistency in code management across teams, as it provides a standardized way to manage code and track changes, regardless of the programming language or development environment being used. This makes it an essential tool for software development teams of all sizes and backgrounds.
Once a repository is initialized with `git init`, Git tracks all changes made to files in the repository, allowing you to commit changes, branch, merge, and collaborate with other developers.
## Why Git Init is important for collaboration and code management
Git Init is an essential command in the Git version control system that allows developers to initialize a new Git repository.
One of the key reasons Git Init is important for collaboration and code management is that it provides a central repository for storing code changes. As developers make changes to the codebase, they can use Git to commit those changes, creating a permanent record of the work that has been done. This makes it much easier to track bugs, roll back to previous versions of the code, and ensure that everyone on the team is working on the same version of the codebase.
In conclusion, Git Init is an essential command for developers who want to manage code changes and collaborate effectively with others. By providing a central repository for storing code changes, facilitating branching and merging, and providing a standardized way to manage code, Git Init helps ensure that software development teams are working together effectively and efficiently.
## What happens when you run Git Init?
When you run git init in a directory, Git initializes a new Git repository in that directory by creating a hidden subdirectory called .git. This directory contains all the necessary files and directories that Git uses to manage the repository and track changes to files in the directory.
Specifically, the following things happen when you run git init:
A new .git directory is created in the current working directory. The .git directory contains several subdirectories and files that Git uses to manage the repository, including:
- objects: This directory contains all of the objects that Git uses to store data in the repository, such as files, directories, and commits.
- hooks: This directory contains scripts that trigger actions with respect to specific events. These scripts help automate the development life cycle.
- refs: This directory contains references to the different branches and tags in the repository.
- HEAD: This file points to the current branch in the repository.
- config: This file contains configuration information for the repository, such as user settings and remote repository information.
The repository is now ready to be used with Git commands. You can add files to the repository, make changes, and commit those changes to the repository using the git add, git commit, and other Git commands.
## Best Practices for Git Init
When it comes to using Git Init, there are several best practices that developers should keep in mind to ensure they are getting the most out of this essential command. Here are some of the key best practices for Git Init:
- Use a consistent directory structure: To make it easier to manage code and track changes over time, it's important to use a consistent directory structure for your Git repositories. This might include creating separate directories for source code, documentation, and other files related to the project.
- Use clear and concise commit messages: When committing changes to a Git repository, it's important to use clear and concise commit messages that describe the changes being made. This makes it easier to track changes over time and understand what has been done to the codebase.
- Use branching and merging effectively: Git Init allows developers to create branches, which are separate versions of the codebase that can be worked on independently. When using branches, it's important to keep them organized and use clear naming conventions to make it easier to understand which branch is which. Merging should be done carefully and only when changes have been thoroughly tested.
- Use a consistent workflow: To ensure consistency across your team, it's important to establish a consistent workflow for using Git. This might include guidelines for committing changes, creating and merging branches, and resolving conflicts.
- Set up access controls: Access controls determine who has permission to push and pull changes from your central repository. You may want to restrict access to certain branches or require approval from a code reviewer before changes can be merged into the main codebase. This helps maintain the quality of your code and reduces the risk of errors.
- Use Git Ignore: Git Init creates a Git repository for tracking changes to all files in a directory, but not all files are necessary to track. Use a .gitignore file to specify which files should not be tracked.
- Use remote repositories for collaboration: When collaborating with other developers, it's important to use remote repositories, such as those hosted on GitHub or Bitbucket. This makes it easier to share code and collaborate with other developers, while also providing a backup of the codebase in case something happens to your local cop
## How to use Git Init to start a project
To use Git Init to start a new project:
- Open your terminal or command prompt and navigate to the directory where you want to create your project. Use the `mkdir` command to create a new directory with your desired project name.
- Use the `git init` command to initialize a new Git repository in the directory you just created. This will create a new .git directory in your project directory that Git will use to track changes. This will be an empty repository.
- Add files to your working directory, stage and commit, set up your remote repository and you can start collaborating.
You can also initialize a bare repository using the `--bare` flag. A bare repository is a special type of Git repository that does not have a working directory. Unlike a standard Git repository, which includes a working directory where files can be edited and committed, a bare repository only contains the Git repository data itself. Developers interact with a bare repository using Git commands such as git push, git pull, and git fetch. A bare repository is a central repository to which developers can push and it has no working history.
## Troubleshooting Common Git Errors
While Git Init is a straightforward command, there are a few common issues that can arise when using it. Here are some troubleshooting tips for Git Init:
"_fatal: Not a git repository (or any of the parent directories): .git_" error message: This error message indicates that Git Init was not properly initialized in your project directory. Make sure you are in the correct directory and run the git init command again.
"_error: failed to push some refs_" error message: This error message occurs when you are unable to push your changes to the remote repository. Check your network connection and make sure you have the correct permissions to push to the repository.
"_Changes not staged for commit_" error message: This error message indicates that you have made changes to your project files but have not yet staged them for commit. Use the git add command to stage your changes before committing them.
"_nothing added to commit but untracked files present_" error message: This error message occurs when you have files in your project directory that are not being tracked by Git. Use the git add command to stage these files before committing your changes.
"_fatal: remote origin already exists_" error message: This error message occurs when you try to set up a remote repository with the same name as an existing remote repository. Use a different name for your remote repository or remove the existing one before proceeding.
"_fatal: cannot do a partial commit during a merge_" error message: This error message occurs when you try to commit during a merge operation. Complete the merge before committing your changes.
“_fatal: refusing to merge unrelated histories_” error message: This error occurs when a developer attempts to combine two unrelated projects into a single branch. One way to fix this issue is with the flag “–allow-unrelated-histories”, this will enable the merging of unrelated branches.
By using these troubleshooting tips, you can overcome common issues when using Git Init and successfully manage your project with Git.
## How to recover from mistakes when using Git
Git provides a way to manage and recover from mistakes when working on a project. Here are some steps to recover from mistakes when using Git Init:
1. Undo your last commit: Use the git reset command to undo your last commit. This command will reset your repository to a previous commit, allowing you to make changes and commit again.
2. Revert changes: Use the git revert command to revert changes made in a commit. This command will create a new commit that undoes the changes made in a previous commit.
3. Switch branches: Use the git checkout command to switch to a different branch. This command will allow you to work on a different branch and commit changes there.
4. Merge branches: Use the git merge command to merge two branches together. This command will combine changes from two branches and create a new commit.
5. Use stash: Use the git stash command to save changes that are not ready to be committed yet. This command will store your changes in a temporary location and allow you to switch to a different branch or commit.
6. Restore a deleted branch: If you accidentally delete a branch, you can restore it using the `git reflog` command. This command will show a list of all commits and branch changes, allowing you to locate the commit where the branch was deleted and restore it.
By using these recovery techniques, you can quickly recover from mistakes and continue working on your project with Git Init. It's important to remember to commit often and back up your work regularly to avoid potential mistakes.
## Tips for mastering Git for seamless collaboration and code management.
Here are some tips for mastering Git for seamless collaboration and code management:
- Keep your commit history clean and concise: Make sure each commit represents a single logical change to your project. Use descriptive commit messages that explain what changes were made in each commit.
- Use branches for feature development: Use branches to develop new features and make changes to your project without affecting the main codebase. Merge your branches back into the main codebase once they are complete.
- Review changes before merging: Before merging a branch, review the changes made to the code and ensure that they meet the project's requirements. This will help prevent bugs and errors in the codebase.
- Use Git hooks: Git hooks allow you to automate tasks when certain events occur in your Git repository. For example, you can set up a hook to run tests automatically before each commit.
- Use Git tags for versioning: Use Git tags to label specific versions of your project. This will help you keep track of changes and releases over time.
- Keep your repository organized: Keep your repository organized by using a consistent file structure and naming conventions. Use Git submodules to manage dependencies and keep your codebase modular.
- Use Git hosting platforms: Use Git hosting platforms like GitHub, GitLab, or Bitbucket to collaborate with others and host your code. These platforms provide a range of tools and features that make collaboration easier.
By following these tips, you can master Git for seamless collaboration and code management, leading to a more efficient and effective development process.
> I have previously published an article on the role of Communication in Software Engineering, check it out here: [The Role of Communication In Software Engineering](https://dev.to/collinsoden/the-role-of-communication-in-software-engineering-3hej)
| collinsoden |
1,415,303 | Typescript Generics | Here In this article, I wanted to explain on how typescript generics works for a react component with... | 0 | 2023-03-26T10:20:18 | https://dev.to/prasanth94/typescript-generics-5gf8 | typescript, generics | Here In this article, I wanted to explain on how typescript generics works for a react component with an example. Before going to that, lets understand what exactly is Generics.
**What are Generics ?**
Generics are a way to write reusable code that works with multiple types, rather than just one specific type.
This means that instead of writing separate functions or components for each type we want to work with, we can write a single generic function or component that can handle any type we specify when we use it.
For example, let's say you want to write a function that returns the first element of an array. You could write a separate function for each type of array you might encounter, like an array of numbers, an array of strings, and so on. But with generics, you can write a single function that works with any type of array.
Generics are indicated using angle brackets (< >) and a placeholder name for the type. For example, you might define a generic function like this:
```
function firstItem<T>(arr: T[]): T {
return arr[0];
}
```
The `<T>` in the function signature indicates that this is a generic function, and T is the placeholder name for the type. Now you can use this function with any type of array:
```
const numbers = [1, 2, 3];
const strings = ['a', 'b', 'c'];
console.log(firstItem(numbers)); // 1
console.log(firstItem(strings)); // 'a'
```
This is just a simple example, but generics can be used in much more complex scenarios to write highly flexible and reusable code.
**How can we use it for react components ?**
Now let's look at the code below.
```
interface Animal<T extends string> {
species: T
name: string
// Define other properties as needed
}
// Define custom types that extend the Animal type
interface Cat extends Animal<'cat'> {
color: string
}
interface Dog extends Animal<'dog'> {
breed: string
}
```
The first thing we see is the definition of the `Animal` interface, which is a generic type that extends multiple custom types. The `T` type parameter is used to specify the species of the animal, which can be either 'cat' or 'dog'. The `Cat` and `Dog` interfaces are custom types that extend the `Animal` type and add additional properties like `color` and `breed`.
```
// Define the state type as an object with a "data" property of type Animal or null
interface State<T extends Animal<string> | null> {
data: T
}
// Define the action types for useReducer
type Action<T extends Animal<string>> =
| { type: 'SET_DATA'; payload: T }
| { type: 'CLEAR_DATA' }
| { type: 'CHANGE_SPECIES'; payload: string }
// Define the reducer function for useReducer
function reducer<T extends Animal<string>>(state: State<T>, action: Action<T>): State<T> {
switch (action.type) {
case 'SET_DATA':
return { ...state, data: action.payload }
case 'CLEAR_DATA':
return { ...state, data: null }
case 'CHANGE_SPECIES':
if (state.data) {
return {
...state,
data: { ...state.data, species: action.payload },
}
}
return state
default:
throw new Error(`Unhandled action : ${action}`)
}
}
```
Next, we see the definition of the `State` interface, which is also a generic type that accepts any type that extends the `Animal` type or `null`. This interface defines an object with a single property `data`, which can be either of the generic type or null.
After that, we define the `Action` type, which is also a generic type that accepts any type that extends the `Animal` type. This type specifies the different actions that can be dispatched by the reducer function. In this case, there are three possible actions: `SET_DATA`, `CLEAR_DATA`, and `CHANGE_SPECIES`.
The reducer function itself is also a generic function that accepts two parameters: the state object of type `State<T>` and the action object of type `Action<T>`. The T type parameter is used to specify the generic type that is passed to the `State` and `Action` interfaces. The reducer function is responsible for handling the different actions and updating the state accordingly.
```
// Create a context for the state and dispatch functions to be passed down to child components
interface AnimalContextType<T extends Animal<string> | null> {
state: State<T>
dispatch: React.Dispatch<Action<T>>
}
const AnimalContext = createContext<AnimalContextType<Cat | Dog | null>>({
state: { data: null },
dispatch: () => {},
})
interface AnimalProviderProps {
children: React.ReactNode
}
// Define a component that fetches data from an API and updates the state
function AnimalProvider({ children }: AnimalProviderProps) {
const [state, dispatch] = useReducer(reducer, { data: null } as State<Cat | Dog | null>)
useEffect(() => {
// Fetch data from the API and update the state
// You'll need to replace the URL with the actual API endpoint
fetch('https://example.com/api/animal')
.then((response) => response.json())
.then((data: Cat | Dog) => {
// Update the state with the fetched data
dispatch({ type: 'SET_DATA', payload: data })
})
.catch((error) => {
console.error(error)
})
}, [])
return (
<AnimalContext.Provider value={{ state, dispatch }}>
{/* Render child components */}
{children}
</AnimalContext.Provider>
)
}
```
The `AnimalContextType` interface is another generic interface that specifies the shape of the context object. It accepts any type that extends the Animal type or null. This interface defines two properties: `state` and `dispatch`, which are used to manage the state and dispatch actions.
The `AnimalProvider` component is a regular React component that wraps the `AnimalComponent` component and provides access to the context object. It uses the useReducer hook to manage the state and the useEffect hook to fetch data from an API and update the state accordingly.
```
function AnimalComponent<T extends Animal<string>>() {
const { state, dispatch } = useContext(AnimalContext)
const handleChangeSpecies = (event: React.ChangeEvent<HTMLSelectElement>) => {
dispatch({ type: 'CHANGE_SPECIES', payload: event.target.value })
}
return (
<div>
{state.data && (
<div>
<h2>{state.data.name}</h2>
<p>Species: {state.data.species}</p>
{state.data.species === 'cat' && <p>Color: {(state.data as Cat).color}</p>}
{state.data.species === 'dog' && <p>Breed: {(state.data as Dog).breed}</p>}
<select value={state.data.species} onChange={handleChangeSpecies}>
<option value='cat'>Cat</option>
<option value='dog'>Dog</option>
</select>
</div>
)}
</div>
)
}
```
Finally, the `AnimalComponent` component is also a generic component that accepts any type that extends the Animal type. It uses the useContext hook to access the context object and render the state data. It also provides a dropdown menu to allow the user to change the species of the animal and dispatch the `CHANGE_SPECIES` action.
In summary, what I demonstrated is how TypeScript generics can be used to write reusable code that can work with different types. By using generics, we can write a single component that can handle any type of animal, rather than writing separate components for each species.
Full code below:
```
import React, { createContext, useReducer, useEffect, useContext } from 'react'
// Define the Animal type as a generic type that extends multiple custom types
interface Animal<T extends string> {
species: T
name: string
// Define other properties as needed
}
// Define custom types that extend the Animal type
interface Cat extends Animal<'cat'> {
color: string
}
interface Dog extends Animal<'dog'> {
breed: string
}
// Define the state type as an object with a "data" property of type Animal or null
interface State<T extends Animal<string> | null> {
data: T
}
// Define the action types for useReducer
type Action<T extends Animal<string>> =
| { type: 'SET_DATA'; payload: T }
| { type: 'CLEAR_DATA' }
| { type: 'CHANGE_SPECIES'; payload: string }
// Define the reducer function for useReducer
function reducer<T extends Animal<string>>(state: State<T>, action: Action<T>): State<T> {
switch (action.type) {
case 'SET_DATA':
return { ...state, data: action.payload }
case 'CLEAR_DATA':
return { ...state, data: null }
case 'CHANGE_SPECIES':
if (state.data) {
return {
...state,
data: { ...state.data, species: action.payload },
}
}
return state
default:
throw new Error(`Unhandled action : ${action}`)
}
}
// Create a context for the state and dispatch functions to be passed down to child components
interface AnimalContextType<T extends Animal<string> | null> {
state: State<T>
dispatch: React.Dispatch<Action<T>>
}
const AnimalContext = createContext<AnimalContextType<Cat | Dog | null>>({
state: { data: null },
dispatch: () => {},
})
interface AnimalProviderProps {
children: React.ReactNode
}
// Define a component that fetches data from an API and updates the state
function AnimalProvider({ children }: AnimalProviderProps) {
const [state, dispatch] = useReducer(reducer, { data: null } as State<Cat | Dog | null>)
useEffect(() => {
// Fetch data from the API and update the state
// You'll need to replace the URL with the actual API endpoint
fetch('https://example.com/api/animal')
.then((response) => response.json())
.then((data: Cat | Dog) => {
// Update the state with the fetched data
dispatch({ type: 'SET_DATA', payload: data })
})
.catch((error) => {
console.error(error)
})
}, [])
return (
<AnimalContext.Provider value={{ state, dispatch }}>
{/* Render child components */}
{children}
</AnimalContext.Provider>
)
}
function AnimalComponent<T extends Animal<string>>() {
const { state, dispatch } = useContext(AnimalContext)
const handleChangeSpecies = (event: React.ChangeEvent<HTMLSelectElement>) => {
dispatch({ type: 'CHANGE_SPECIES', payload: event.target.value })
}
return (
<div>
{state.data && (
<div>
<h2>{state.data.name}</h2>
<p>Species: {state.data.species}</p>
{state.data.species === 'cat' && <p>Color: {(state.data as Cat).color}</p>}
{state.data.species === 'dog' && <p>Breed: {(state.data as Dog).breed}</p>}
<select value={state.data.species} onChange={handleChangeSpecies}>
<option value='cat'>Cat</option>
<option value='dog'>Dog</option>
</select>
</div>
)}
</div>
)
}
// Finally, use the AnimalProvider component to wrap child components and provide access to the state and dispatch functions
function App() {
return (
<AnimalProvider>
<AnimalComponent />
</AnimalProvider>
)
}
```
| prasanth94 |
1,415,311 | berufliches Vorwärtskommen: So übersieht man seine Stärken | Moin Moin, unsere Stärken zu übersehen ist ähnlich einfach wie unsere Körpergröße als normal zu... | 0 | 2023-03-26T08:26:44 | https://dev.to/amustafa16421/berufliches-vorwartskommen-so-ubersieht-man-seine-starken-gn7 | deutsch, career, discuss, motivation | Moin Moin,
unsere Stärken zu übersehen ist ähnlich einfach wie unsere Körpergröße als normal zu empfinden. Wir verwenden unsere Stärken stets, ohne großartig drüber nachzudenken und wir sehen die Welt immer aus unserer Perspektive.
Dem entsprechend erscheinen uns Herausforderungen leicht oder schwer, bzw. andere Menschen groß oder klein.
Also, wie groß bist du ? Was sagen andere zu deinen Leistungen ? Bei welchen Errungenschaften oder Problemlösungen waren Leute erstaunt, während du es nicht als besonders schwierig empfandest ?
>
Sehe deine Stärken, Sehe deine Körpergröße.
Beste Grüße,
Mustafa | amustafa16421 |
1,415,380 | Send initial data to a component in Angular Universal | Steps Setting up a simple test angular universal, I wanted to try to send some initial... | 0 | 2023-03-26T11:19:50 | https://dev.to/gaotter/send-initial-data-to-a-component-in-angular-universal-25c7 | tutorial, angular | ## Steps
Setting up a simple test angular universal, I wanted to try to send some initial data to the components, and have it server render all the data. To test it I used postman as it does not run any JavaScript
To get up and running call `ng new univesaltest1` and to enable universal called `ng add @nguniversal/express-engine`
To have some components to test with run `ng generate component test --module app.module.ts` and `ng generate component test2 --module app.module.ts`
Then making a simple message model and an injection token
```
import { InjectionToken } from "@angular/core";
export class MessageModel {
constructor(
public message: string
) { }
}
// injecton token
export const MESSAGE = new InjectionToken<MessageModel>('message');
```
In the server.ts file set up the initial model and some query string code. Then provide the model using the MESSAGE injection token.
```
// All regular routes use the Universal engine
server.get('*', (req, res) => {
const message:string = req.query['message']?.toString() ?? 'hello from server.ts';
const messageModel = new MessageModel(message);
res.render(indexHtml, { req, providers: [{ provide: APP_BASE_HREF, useValue: req.baseUrl }, {provide: MESSAGE, useValue: messageModel}] });
});
```
In the test.component.ts inject platform id and on the server run code inject the message model using the MESSAGE injection token. I need the transfer state as the rendering on the client will set the message, overriding the server rendered message. If I was to disable JavaScript in the browser, I do not need the transfer state.
```
import { isPlatformServer } from '@angular/common';
import { Component, inject, Inject, PLATFORM_ID } from '@angular/core';
import { makeStateKey, StateKey, TransferState } from '@angular/platform-browser';
import { MESSAGE, MessageModel } from 'src/models/message.model';
@Component({
selector: 'app-test',
templateUrl: './test.component.html',
styleUrls: ['./test.component.css']
})
export class TestComponent {
// transfare state key
private messageStateKey:StateKey<MessageModel> = makeStateKey<MessageModel>('message');
public message: MessageModel = this.state.get(this.messageStateKey, new MessageModel('hello from test.component.ts'));
constructor(@Inject(PLATFORM_ID) private platformId:object, private state:TransferState)
{
// check if we are on the server
if(isPlatformServer(this.platformId)) {
const serverMessage = inject(MESSAGE);
this.message = serverMessage;
// set the message in the state
this.state.set(this.messageStateKey, serverMessage);
}
}
}
```
To make it more interesting input the message model into test2 component using this code
test.component.html
```
<div >
<app-test2 [message]="message"></app-test2>
</div>
```
test2.component.ts
```
import { Component, Input } from '@angular/core';
import { MessageModel } from 'src/models/message.model';
@Component({
selector: 'app-test2',
templateUrl: './test2.component.html',
styleUrls: ['./test2.component.css']
})
export class Test2Component {
@Input() message: MessageModel = new MessageModel('hello from test2.component.ts');
}
```
test2.component.html
```
<p>{{message.message}}</p>
```
Now we are all set. To test the code start the universal version using `npm run dev:ssr`
Calling it postman and all the html with the model data is rendered on the server
Request: localhost:4200?message="Hello from query string"
```
<body>
<app-root _nghost-sc3="" ng-version="15.2.4" ng-server-context="ssr">
<app-test _ngcontent-sc3="" _nghost-sc2="">
<div _ngcontent-sc2="">
<app-test2 _ngcontent-sc2="" _nghost-sc1="" ng-reflect-message="[object Object]">
<p _ngcontent-sc1="">"Hello from query string"</p>
</app-test2>
</div>
</app-test>
</app-root>
<script src="runtime.js" type="module"></script>
<script src="polyfills.js" type="module"></script>
<script src="vendor.js" type="module"></script>
<script src="main.js" type="module"></script>
<script id="serverApp-state" type="application/json">
{&q;message&q;:{&q;message&q;:&q;\&q;Hello from query string\&q;&q;}}
</script>
</body>
```
## The Road
I did some mistakes when trying to get this to work. In the first try I tried to inject the Message model using the @Inject in the constructor. The problem then is that the client part of the application is not able to make sense of the provided message model.
I go the error
```
R3InjectorError(AppModule)[InjectionToken message -> InjectionToken message -> InjectionToken message]:
NullInjectorError: No provider for InjectionToken message!
```
Trying to provide the injection token in the app.module.ts using
```
providers: [{provide: MESSAGE, useValue: null }],
```
and then
```
@Inject(MESSAGE) private messageModel:MessageModel
```
The client app model overrides the provided message with null. So you could se the message blink before the client set it to null.
The solution was to not try to mix the server injected code with the clint part of the code.
| gaotter |
1,415,385 | Is Coding Really Hard? (My Experience) | Starting out to learn how to code can be very daunting, especially for a beginner who does not have... | 0 | 2023-03-26T10:48:16 | https://dev.to/ritapossible/is-coding-really-hard-my-experience-4okc | webdev, beginners, programming, codenewbie | Starting out to learn how to code can be very daunting, especially for a beginner who does not have prior experience in programming or computer science. The concept and jargon used in coding can be overwhelming at first, and it can take time to get used to them.
Is coding really hard to learn? This is a question that many people ask themselves when they are considering learning how to code. The answer to the above question is not straight-forward as it depends on the individual involved and some factors which I will outline in this article.
**What is Coding?**
Coding, also known as computer programming, is the process of designing, writing, testing, debugging, and maintaining the source code of computer software.
**My Experience.**
For me, my opinion on this Question (Is coding really hard to learn?) is a big NO. This answer is coming from me who likes challenges and coupled with my problem-solving ability. Academically, I’m a Chemical Engineer therefore facing problems and finding solutions to them didn’t start with me learning how to code. For someone who has a strong background in Engineering, you can relate to the challenges that we encounter each day.
What inspired my learning to code is simply because of my passion for technology and science. I started learning how to code on November 2022. At first, it was not easy since I didn’t have any prior background in Computer software. I went on Youtube for guidance, and most videos I watched suggested that beginners should start learning Python language. I downloaded Pdf (Beginning Programming with Python for Dummies) written by **John Paul Mueller**. I started studying the basics and practicing the codes, it wasn’t easy but within a few weeks of practice and study, I was able to master a lot of codes. I started following Expert developers on social media like Twitter and Facebook, and to my greatest surprise, I was able to understand other languages they use like JavaScript, TypeScript etc. I also found out that they engage in teaching others through youtube videos, tweets and blog posts, I remembered how I didn’t forget maths after teaching them to my coursemates while in high school, so I started blogging and it has been of great help to me. The best way to grow is to “surround yourself with people who are smarter than you” in any field you are interested in learning.
Recently, I started to build a website using Python and Streamlit. I wanted to create a form on the site but it didn’t appear in an orderly manner when I ran the code. I watched a youtube video, it occurred to me that I needed to use CSS for the styling. I started recently to learn HTML and CSS because of the above-mentioned, and to my greatest surprise, it’s very easy to under the syntax. Then it occurred to me that you only need to conquer the basics of any programming language. Finally, I was able to style my website form with CSS.
**Before and After Applying CSS Style to my Website**.
**Factors that Influences Beginner’s view on How Hard Coding Could be.**
**Previous Experience:**
This is one of the major factors that influence how beginner view coding. Someone with little or no exposure to computers, programming language and software development would naturally find it more challenging than someone with previous experience.
**Type of Programming Language A Beginner Starts With:**
The programming Language a beginner chooses to start with can greatly influence how they perceive coding. Some programming languages are easier to learn than others. Low-level programming languages like assembly and machine code are difficult to learn when compared to high-level languages like Python and JavaScript.
**Support System:**
The availability of a support system can also impact how beginners view the difficulty of coding. Having access to a tutor, mentor, or online community where they ask questions and receive guidance can help beginners overcome obstacles and build confidence in their coding abilities.
**Personality Trait:**
A person who possesses the ability to be consistent, patient, problem-solving ability, logical and creative can find the problems he/she encounters in coding very interesting and won’t be discouraged by them.
**Personal Motivation:**
Finally, personal motivation is a critical factor that influences how beginners view the difficulty of coding. Those who are highly motivated to learn to code may find it easier to overcome challenges and persist through difficult concepts.
**Conclusion:**
Coding can be challenging, but it is not impossible to learn. With time, practice, and perseverance, anyone can learn how to code. While coding may be difficult at first, it can be incredibly easy as you progress. So, if you are thinking of coding as being hard, don’t be discouraged by the initial challenges. Embrace the challenge as it gets better as you progress!
Feel free to share in the comment section your view on this topic.
**Cheers!!!**
| ritapossible |
1,415,393 | Hibernate and Spring JPA Notes | 1) ORM has the following advantages over JDBC: Management of transaction. Generates key... | 0 | 2023-03-26T11:11:52 | https://dev.to/hiamitchaurasia/hibernate-and-spring-jpa-notes-5dpk | java, hibernate, springjpa, jpa | 1) ORM has the following advantages over JDBC:
Management of transaction.
Generates key automatically.
Details of SQL queries are hidden. Database independent queries.
2) Second level cache is not enabled by default in Hibernate.
3) SessionFactory is a thread-safe object. Hibernate Session is not a thread-safe object and so you must not share Hibernate-managed objects between threads.
4) There are 3 states of the object (instance) in hibernate.
a) Transient: The object is in a transient state if it is just created but has no primary key (identifier) and not associated with a session.
b) Persistent: The object is in a persistent state if a session is open, and you just saved the instance in the database or retrieved the instance from the database.
c) Detached: The object is in a detached state if a session is closed. After detached state, the object comes to persistent state if you call lock() or update() method.
5) There are 3 ways of inheritance mapping in hibernate.
a) Table per hierarchy
b) Table per concrete class
c) Table per subclass
6) What is automatic dirty checking in hibernate?
The automatic dirty checking feature of Hibernate, calls update statement automatically on the objects that are modified in a transaction.
7) There can be 4 types of association mapping in hibernate.
a) One to One
b) One to Many
c) Many to One
d) Many to Many
8) Is it possible to perform collection mapping with One-to-One and Many-to-One?
No, collection mapping can only be performed with One-to-Many and Many-to-Many.
9) What is lazy loading in hibernate?
Lazy loading in hibernate improves the performance. It loads the child objects on demand.
Since Hibernate 3, lazy loading is enabled by default, and you don’t need to do lazy=”true”. It means not to load the child objects when the parent is loaded.
10) What is the difference between first level cache and second level cache?
1) First Level Cache is associated with Session. Second Level Cache is associated with SessionFactory.
2) First Level Cache is enabled by default. Second Level Cache is not enabled by default.
11) Hibernate SessionFactory provides three methods through which we can get Session object.
1) getCurrentSession()
2) openSession()
3) openStatelessSession()
12) If you see a LazyInitializationException, it means that a Hibernate-managed object has lived longer than its session.
13) Managed objects are not portable between sessions. Trying to load an object in one session then save it into another session will also result in an error.
(You can use Session.load() or Session.get() to re-introduce an object to a new session,
but you’re much better off fixing whatever problem is causing you to try to move objects between sessions in the first place.
14) SessionFactory holds the second level cache data. It is global for all the session objects and not enabled by default.
Different vendors have provided the implementation of Second Level Cache.
EH Cache
OS Cache
Swarm Cache
JBoss Cache
15) How to make an immutable class in hibernate?
If you mark a class as mutable=”false”, the class will be treated as an immutable class. By default, it is mutable=”true”.
16) What are the constraints on an entity class?
An entity class must fulfill the following requirements:
The class must have a no-argument constructor.
The class can’t be final.
The class must be annotated with @Entity annotation.
The class must implement a Serializable interface if value passes an empty instance as a detached object.
17) What is the purpose of cascading operations in JPA?
If we apply any task to one entity then using cascading operations, we make it applicable to its related entities also.
18) What are the types of cascade supported by JPA?
Following is the list of cascade type: -
PERSIST: In this cascade operation, if the parent entity is persisted then all its related entity will also be persisted.
MERGE: In this cascade operation, if the parent entity is merged, then all its related entity will also be merged.
DETACH: In this cascade operation, if the parent entity is detached, then all its related entity will also be detached.
REFRESH: In this cascade operation, if the parent entity is refreshed, then all its related entity will also be refreshed.
REMOVE: In this cascade operation, if the parent entity is removed, then all its related entity will also be removed.
ALL In this case, all the above cascade operations can be applied to the entities related to the parent entity.
19) The native UPDATE statement doesn’t use any entities and therefore doesn’t trigger any lifecycle event.
20) Spring Data uses the Repository pattern.
JpaRepository
MongoRepository
GemfireRepository
21) Using @GeneratedValue(strategy = GenerationType.IDENTITY) approach prevents Hibernate from using different optimization techniques like JDBC batching.
22) The no-argument constructor, which is also a JavaBean convention, is a requirement for all persistent classes. Hibernate needs to create objects for you, using Java Reflection. The constructor can be private. However, package or public visibility is required for runtime proxy generation and efficient data retrieval without bytecode instrumentation.
23) We recommend all new projects which make use of to use @GeneratedValue to also set hibernate.id.new_generator_mappings=true as the new generators are more efficient and closer to the JPA 2 specification semantic. However they are not backward compatible with existing databases (if a sequence or a table is used for id generation).
24) What are the exceptions thrown by the Spring DAO classes?
Spring DAO classes throw exceptions that are subclasses of org.springframework.dao.DataAccessException.
Spring translates technology-specific exceptions like SQLException to its own exception class hierarchy with the DataAccessException as the root exception that are generic and easy to understand. These exceptions wrap the original exception.
25) Difference between CrudRepository and JpaRepository interfaces in Spring Data JPA.
JpaRepository extends PagingAndSortingRepository that extends CrudRepository.
CrudRepository mainly provides CRUD operations.
PagingAndSortingRepository provide methods to perform pagination and sorting of records.
JpaRepository provides JPA related methods such as flushing the persistence context and deleting of records in batch.
Due to their inheritance nature, JpaRepository will have all the behaviors of CrudRepository and PagingAndSortingRepository.
26) How does @Transactional works in Spring?
@Transactional annotation is based on AOP concept.
When you annotate a method with @Transactional, Spring dynamically creates a proxy that implements the same interface(s) as the class you are annotating. And when clients make calls into your object, the calls are intercepted and the behaviors gets injected via the proxy mechanism.
@Transactional annotation works similar to transactions in EJB.
27) When to use @RestController vs @RepositoryRestResource annotations in Spring.
@RestController annotation renders as Restful resource within a Controller while @RepositoryRestResource annotation exposes repository itself as a RESTful resource.
28) Does the transaction rollback on exception in spring declarative transaction management?
By default configuration only unchecked exceptions (that is, subclasses of java.lang.RuntimeException) are rollbacked and the transaction will still be commited in case of checked exceptions.
To enable rollbacking on checked exceptions add the parameter rollBackFor to the @Transactional attribute, for example, rollbackFor=Exception.class.
@Transactional(rollbackFor = Exception.class).
29) When to use JTA and JPA transaction manager?
If you want to delegate managed transactions to your application server and handle complex transactions across multiple resources you need to use the JtaTransactionManager.
But it is not needed in most cases, JpaTransactionManager, is the best choice.
JTA is global transaction while JPA is local.
30) Does Spring Transactional annotation support both global and local transactions?
Yes. The Spring Framework’s declarative transaction management works in any environment. It can work with JTA transactions or local transactions using JDBC, JPA, Hibernate or JDO.
31) Can Spring Transactional annotation be applied only for public methods?
Yes, only public methods. If you annotate protected, private or package-visible methods with the @Transactional annotation, no error is raised, but the annotated method does not exhibit the configured transactional settings.
Consider the use of AspectJ if you need to annotate non-public methods.
32) What are the default @Transactional settings?
Default propagation setting is PROPAGATION_REQUIRED.
Isolation level is ISOLATION_DEFAULT.
The transaction is read/write.
Transaction timeout defaults to the default timeout of the underlying transaction system, none if timeouts are not supported.
Any RuntimeException triggers rollback, and any checked Exception does not.
33) How do I decide between when to use prototype scope and singleton-scoped bean?
Use the prototype scope for all beans that are stateful and the singleton scope for stateless beans.
34) Difference between BeanFactory and ApplicationContext in spring.
With ApplicationContext more than one config files are possible while only one config file or .xml file is possible with BeanFactory.
ApplicationContext support internationalization messages, application life-cycle events, validation and many enterprise services like JNDI access, EJB integration etc. while BeanFactory doesn’t support any of these.
35) Which DI should I prefer, Constructor-based or setter-based in spring?
Use constructor-based DI for dependencies that are required (mandatory) and setters for dependencies that are optional.
36) What are Lazily-instantiated beans?
Spring instantiate all the beans at startup by default. But sometimes, some beans are not required to be initialized during startup, rather we want them to be initialized in later stages of the application on demand. For such beans, we include lazy-init=”true” while configuring beans.
<bean lazy-init=”true”>
<! — this bean will be lazily-instantiated… →
</bean>
37) Difference between Dependency Injection and Factory Pattern.
Using factory your code is still actually responsible for creating objects. By DI you delegate that responsibility to another class or a framework, which is separate from your code.
Use of dependency injection results in loosely coupled design but the use of factory pattern create a tight coupling between factory and classes.
A disadvantage of Dependency injection is that you need a container and configuration to inject the dependency, which is not required in case of factory design pattern.
38) How does Spring achieve loose coupling?
Spring uses runtime polymorphism and encourages association (HAS-A relationship) rather than inheritance.
39) Is Spring DTD/XSD mandatory for XML validation? Where I can find the Spring DTD?
Yes, DTD or XSD is mandatory for Spring bean xml documents. spring-beans.jar file has the dtd (document type definition) file spring-beans.dtd under the package org.springframework.beans.factory.xml.
40) How do I Inject value into static variables in Spring bean?
Spring does not allow injecting to public static non-final fields, so the workaround will be changing to private modifier.
Another workaround will be to create a non static setter to assign the injected value for the static variable.
@Value(“${my.name}”)
public void setName(String privateName) {
ThisClass.name = privateName;
}
41) Is spring prototype bean threadsafe?
No. Prototype beans are stateful however if it is managed by multiple threads, then steps must be taken to ensure it is thread safe.
42) Is request scoped spring beans threadsafe?
Yes. Each request will get its own bean so thread safety is guaranteed.
43) What is the preferred bean scope for DAO, Service and Controller?
Singleton scope is preferred. DAO, service and controllers do not have to maintain its state.
44) Mention an alternate DI framework like Spring.
Google Guice framework.
45) What is the difference between ApplicationContext and WebApplicationContext in Spring MVC?
Web Application context extends Application Context which is designed to work with the standard javax.servlet.ServletContext to communicate with the container.
Beans that are instantiated in WebApplicationContext will also be able to use ServletContext if they implement ServletContextAware interface.
46) What is the default scope of Spring MVC controllers?
Spring MVC controllers are singleton by default and any controller object variable/field will be shared across all the requests and sessions.
If the object variable should not be shared across requests, one can use @Scope(“request”) annotation above your controller class definition to create instance per request.
47) Sping MVC — pass model between controllers.
avoid redirect instead use forward.
48) Difference Between @RequestParam and @PathVariable in Spring MVC.
@RequestParam and @PathVariable annotations are used for accessing the values from the request.
The primary difference between @RequestParam and @PathVariable is that @RequestParam used for accessing the values of the query parameters where as @PathVariable used for accessing the values from the URI template.
Request parameters can be optional, and as of Spring 4.3.3 path variables can be optional as well. Beware though, this might change the URL path hierarchy and introduce request mapping conflicts. For example, would /user/invoices provide the invoices for user null or details about a user with ID “invoices”?
If the URL http://localhost:8080/MyApp/user/1234/invoices?date=12-05-2013 gets the invoices for user 1234 on December 5th, 2013, the controller method would look like:
@RequestMapping(value=”/user/{userId}/invoices”, method = RequestMethod.GET)
public List<Invoice> listUsersInvoices(
@PathVariable(“userId”) int user,
@RequestParam(value = “date”, required = false) Date dateOrNull) {
…
}
49) How do I configure DispatcherServlet without using web.xml in Spring MVC?
Create a class implementing WebApplicationInitializer interface and implement onStartup() method. In this method we can register all the annotation based application configuration classes, servlet and its mappings, listener etc including DispatcherServlet.
public class WebAppInitializer implements WebApplicationInitializer {
public void onStartup(ServletContext servletContext) throws ServletException {
AnnotationConfigWebApplicationContext ctx = new AnnotationConfigWebApplicationContext();
ctx.register(ApplicationConfig.class);
ctx.setServletContext(servletContext);
Dynamic dynamic = servletContext.addServlet(“dispatcher”, new DispatcherServlet(ctx));
dynamic.addMapping(“/”);
dynamic.setLoadOnStartup(1);
}
}
50) How do I create a Spring MVC controller without a view?
Set the controller method return type as void and mark the method with @ResponseBody annotation.
51) How do I return a string from the Spring MVC controller without a view?
Set the return type of the method as String and mark the method with @ResponseBody annotation.
@RequestMapping(value=”/returnHelloWorld”, method=GET)
@ResponseBody
public String returnHelloMethod() {
return “Hello world!”;
}
52) Explain @ResponseBody annotation in Spring MVC.
When a controller method is marked with @ResponseBody, spring deserializes the returned value of the method and writes it directly to the Http Response automatically.
The return value of the method constitute the body of the HTTP response and not placed in a Model, or interpreted as a view name.
53) Explain @RequestBody annotation in Spring MVC.
Spring automatically converts the content of the incoming request body to the parameter object when annotated with the @RequestBody annotation.
@ResponseBody @RequestMapping(“/getUserInfo”)
public String getUserInformation(@RequestBody UserDetails user){
return user.getFirstName() + “ “ + user.getLastName();
}
54) What does request.getParameter return when the parameter does not exist in Spring MVC/Servlet?
The return type of the getParamter is String and it returns null if the parameter does not exist.
55) How do you resolve SSLHandShakeException?
Installing Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files in your java 7/8 installation is one of the ways to resolve SSL handshake failure.
56) Is transaction managed at DAO or Service layer in Spring?
At service layer.
Credits:
- Online Community
- Search Engines
- https://unsplash.com/photos/4kX1uoAAohY | hiamitchaurasia |
1,415,447 | JavaScript From Scratch | Session1 What is JS? What Can we do with JS? Compiler in JS? What is NodeJS? What is... | 0 | 2023-03-26T11:44:12 | https://dev.to/lakharashubham007/javascript-from-scratch-3oag | javascript, webdev, node, frontend | ## Session1
1. What is JS?
2. What Can we do with JS?
3. Compiler in JS?
4. What is NodeJS?
5. What is console.log();?
6. JS Setup?
7. Add JS in HTML?
8. Variables?
1.let
2.var
3.const
9. Variable naming convention
10. Data Type
1.Primitive Type
2. Reffrencetype
11. Operators
1.Airthmatic
2.Comparision
3.Equality
4.Ternary Operator
5.Logical operator
6.With no booleans
7.Bitwise Operator
8.operator Precedance
12. Control Statements
1. if
2. else-if
3. else
4. switch, break, continue
13. Loops
1. for-loop
2. while-loop
3. Do-while-loop
4. what is inifinite loop?
5. for-in-loop
6. for-of-loop
---
## Session2
1. What is Object in JS?
//Object Creation //Object access //properties //methods
2. Object Creation
1. Factory Function
2. Constructor Function //new keyword
3. Dynamic Nature of Objects //add and //remove Properties in
object
4. Function are objects proof?
5. Create Object for Primitive and Reference Type data type and
their storage
6. Iterating through Objects
1. for-in-loop
2. for-of-loop
7. Object Clonning.
8. Garbage Collection.
---
## Session3
1. Built in Objects
1. Math
2. String
3. Date
2.Template Litrals //backtick //escape sequences
3. Arrays
1. Creation
2. Access
3. Insertion
4. Searching
5. Callback Function
6. Arrow Function
7. Removing Element
8. Emptying an array
9. Combine and slicing Array //concat() //Slice(startIndex,
endIndex);
10. Spread operator (...)
11. Iterating Array //For-Each loop
12. Joining Array join();
13. split Array split()
14. Sorting sort()
15. Reverse array reverse();
16. Filtering filter()
17. Mappping Array map()
18. Mapping with Object
---
## Session4
1. What is Function?
2. syntax for function in JS? //Function Declaration
3. Why need function??
4. How to call or invoke function?
5. Hoisting concept
6. Function assignment
7. function declaration VS Function Assignment
8. Named function VS Annoyms Function
9. Dynamic nature of function?
10. special object Argument
11. REst parameter in function?
12. Default Parameter in function
13. Getter and setters in function
14. Try and Catch block Error Handling
15. Scope in function.
---
## ModernJS Session1
1. window object
2. What is Dom ?
3. What is BOM ?
4. DOM tree of objects?
5. DOM ObjectMethods
1. .getElementById()
2. .getElementsByClassName()
3. .getElementsByTagName()
4. .querySelector()
5. .querySelectorAll()
6. .innerHTML
7. .outerHTML
8. .textContent
9. .innerText
10. .createElement()
11. .appendChild()
12. .insertAdjacentHTML()
13. .removeChild()
14. child.parent(childElement)
6.CSS Modify by JS
1. .style
2. .cssText
3. .setAttribute()
4. .className
5. .classList
---
## Session2
1. Browser Events
1. what is event?
2. Respond to event
3. Data stored in event
4. Stop event
5. Life Cycle of event
. monitorEvent() method
. unmonitorEvent() merhod
2. EventListner
1. addEventListener() method
2. Type coercion
3. removeEventListener() method
4. Phases of an event
1. Capturing Phase
2. Target Phase
3. Bubbling Phase
5. event Object
3. Default action .perentDefault()
4. Avoid too many events .nodeName and event.target
5. Document loaded event.
---
## Session 3
1. Performance //performance.now() method
2. Reflow and Repaint Concept
3. Document Fragments
4. Call Stack
1. Single threading
2. Synchronus language
5. Event Loop
6. Async Code
7. setTimeOut
---
## Session 4
1. Asynchronous JS
2. API
3. Features of Async Code
4. Promises
5. promise chaning
6. Async-Await
7. Fetch API //get //post //read //create
8. Closures
9. classes and export modules in JS
| lakharashubham007 |
1,415,459 | Over 150,000 .NET Developers Hit by Harmful NuGet Packages | A group of threat actors is targeting .NET developers with malicious NuGet packages. The malicious... | 0 | 2023-03-27T00:00:00 | https://www.bytehide.com/blog/dotnet-malicious-nuget-packages | dotnet, csharp, news, security | A group of threat actors is targeting .NET developers with malicious NuGet packages. The malicious software surreptitiously pilfers cryptocurrency from unsuspecting users by using a variety of techniques.
Firstly, it hijacks the victims’ crypto wallets by tapping into Discord webhooks. Next, it extracts and runs malicious code from Electron archives, which allows it to operate undetected. Finally, the malware maintains its effectiveness by continuously updating itself through frequent queries to the command-and-control server controlled by the attacker.
The attackers are engaging in typosquatting to impersonate various legitimate software packages. Shockingly, within just a month, three of these malevolent packages have been downloaded **over 150,000 times.**
This underscores the importance of exercising caution when downloading software and double-checking the legitimacy of the package and its source. It’s crucial to stay informed and be vigilant against such malicious activities.
| Package Name | Owner | Downloads | Published | Impersonated package |
| --- | --- | --- | --- | --- |
| Coinbase.Core | [BinanceOfficial](https://www.nuget.org/profiles/BinanceOfficial) | 121.9K | 2023-02-22 | [Coinbase](https://www.nuget.org/packages/Coinbase) |
| Anarchy.Wrapper.Net | [OfficialDevelopmentTeam](https://www.nuget.org/profiles/OfficialDevelopmentTeam) | 30.4K | 2023-02-21 | [Anarchy-Wrapper](https://www.nuget.org/packages/Anarchy-Wrapper) |
| DiscordRichPresence.API | [OfficialDevelopmentTeam](https://www.nuget.org/profiles/OfficialDevelopmentTeam) | 14.1K | 2023-02-21 | [DiscordRichPresence](https://www.nuget.org/packages/DiscordRichPresence) |
| Avalon-Net-Core | [joeIverhagen](https://www.nuget.org/profiles/joeIverhagen) | 1.2k | 2023-01-03 | [AvalonEdit](https://www.nuget.org/packages/AvalonEdit) |
| Manage.Carasel.Net | [OfficialDevelopmentTeam](https://www.nuget.org/profiles/OfficialDevelopmentTeam) | 559 | 2023-02-21 | N/A |
| Asip.Net.Core | [BinanceOfficial](https://www.nuget.org/profiles/BinanceOfficial) | 246 | 2023-02-22 | [Microsoft.AspNetCore/](https://www.nuget.org/packages/Microsoft.AspNetCore/) |
| Sys.Forms.26 | [joeIverhagen](https://www.nuget.org/profiles/joeIverhagen) | 205 | 2023-01-03 | [System.Windows.Forms](https://www.nuget.org/packages/System.Windows.Forms) |
| Azetap.API | [DevNuget](https://www.nuget.org/profiles/DevNuget) | 153 | 2023-02-27 | N/A |
| AvalonNetCore | [RahulMohammad](https://www.nuget.org/profiles/RahulMohammad) | 67 | 2023-01-04 | [AvalonEdit](https://www.nuget.org/packages/AvalonEdit) |
| Json.Manager.Core | [BestDeveIopers](https://www.nuget.org/profiles/BestDeveIopers) | 46 | 2023-03-12 | Generic .NET name |
| Managed.Windows.Core | [MahamadRohu](https://www.nuget.org/profiles/MahamadRohu) | 37 | 2023-01-05 | Generic .NET name |
| Nexzor.Graphical.Designer.Core | [Impala](https://www.nuget.org/profiles/Impala) | 36 | 2023-03-12 | N/A |
| Azeta.API | [Soubata](https://www.nuget.org/profiles/Soubata) | 28 | 2023-02-24 | N/A |
_source: [jfrog.com](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/)_
Natan Nehorai and Brian Moussalli, [two security researchers from JFrog](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/), spotted this ongoing campaign. “_The top three packages were downloaded an incredible amount of times – this could be an indicator that the attack was highly successful, infecting a large amount of machines,_” they said.
The researchers cautioned that relying solely on the download count as an indicator of the attack’s success might not be entirely trustworthy.
This is because the attackers could have artificially **inflated the download count**, possibly by using bots, in order to give the impression that the packages were more legitimate than they actually were.
It’s important to use multiple methods for verifying the authenticity of software packages, rather than relying on any single metric.
In addition to impersonating legitimate software packages, the attackers are also utilizing typosquatting to create fake NuGet repository profiles. These fraudulent profiles are designed to impersonate accounts belonging to Microsoft software developers who work on the NuGet .NET package manager.
This serves as a clever ruse to trick unsuspecting users into downloading and installing the malware-laced packages.
Once the malicious package is installed, it executes a PowerShell-based dropper script, known as `init.ps1`, that downloads and runs further malware.

_source: [bleepingcomputer.com](https://www.bleepingcomputer.com/news/security/hackers-target-net-developers-with-malicious-nuget-packages/)_
This initial script also configures the infected machine to permit unrestricted execution of PowerShell commands, making it easier for the malware to operate undetected.
The [researchers stated](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/):
> “This behavior is extremely rare outside of malicious packages, especially taking into consideration the ‘Unrestricted’ execution policy, which should immediately trigger a red flag.”
Afterward, the malware downloads and launches a second-stage payload, a Windows executable [described by JFrog](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/) as a “_completely custom executable payload._”
Compared to other attackers who typically utilize open-source hacking tools and commodity malware, this particular group is taking an unusual approach by creating their own custom payloads.
This sets them apart from the majority of attackers who prefer to rely on pre-existing tools and malware. Such a custom approach may enable them to better evade detection and carry out more sophisticated attacks.

_Coinbase.Core’s page (malicious package) Source: [jfrog.com](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/)_
The researchers added that some packages do not contain any direct malicious payload. Instead, they define other malicious packages as dependencies, which then contain the malicious script.

_Coinbase’s page (legitimate package) Source: [jfrog.com](https://jfrog.com/blog/attackers-are-starting-to-target-net-developers-with-malicious-code-nuget-packages/)_
The payloads delivered in this attack have very low detection rates, making it difficult for anti-malware software to detect them. For example, Defender, the built-in anti-malware component in the Microsoft Windows operating system, will not flag the malicious packages.
This attack is part of a broader malicious effort. In a large-scale campaign that has been ongoing throughout 2022, multiple attackers have uploaded **over 144,000 packages** related to phishing onto various open-source package repositories.
These repositories include **NPM**, **PyPi**, and **NuGet**, among others. This alarming trend highlights the need for increased vigilance and caution when downloading packages from open-source repositories.
As such, it is essential that developers remain vigilant when downloading and installing packages from these repositories. They should also take steps to secure their systems to prevent these types of attacks from compromising their machines.
A worried .NET developer, who wishes to remain anonymous, shares their experience:
> “It’s really scary. I’m usually very careful, but this time I was completely caught off guard. I lost a significant amount of cryptocurrency, and now I’m worried about the trustworthiness of any package I download in the future.”
As the danger continues to escalate, cybersecurity experts and .NET community leaders are urging developers to be extra cautious and thoroughly vet NuGet packages before downloading them.
They **recommend reviewing package names, authors, and download counts** to identify any discrepancies that could indicate a malicious package. | bytehide |
1,415,509 | Learning blog-176 | A post by HONGJU KIM | 0 | 2023-03-26T13:07:01 | https://dev.to/hongju_kim_821dc285a52c96/learning-blog-176-4745 |

| hongju_kim_821dc285a52c96 | |
1,415,511 | Master Python Documentation - Part1: Using the Python Interpreter. | This is the summary of the first part of a video series in which we will go through the Tutorial... | 0 | 2023-03-26T13:50:26 | https://dev.to/fayomihorace/master-python-documentation-part1-using-the-python-interpreter-11ec |
This is the summary of the first part of a [video series](https://youtu.be/fUvT0O76DyY) in which we will go through the [`Tutorial` part of Python official documentation](https://docs.python.org/3/tutorial/interpreter.html#invoking-the-interpreter).
> *Reading the documentation of your programming language, framework, or library, won't make you a pro-coder overnight, but it will help you improve your understanding. It helps you discover the tips, tricks and caveats of the technology that tutorials, courses, or books do not necessarily provide.*
>
----------
## Summary
In this part, the documentation introduces us to the python interpreter. It shows the different ways to invoke the python interpreter and how to invoke python modules and scripts. We have also seen how to pass and retrieve arguments using the `sys` built-in module.
---------
## Questions
*Let's see if you can find the right answers to these questions.*
### 1- _What are the ways to exit the python interpreter presented in the documentation? (select all the answers that apply):_
a. Ctrl-X
b. Ctrl-D
c. Ctrl-ESC
d. `quit()`
### 2- _When no script and no arguments are given to the python prompt, what will be the output of the following code:_
```python
import sys
print(sys.argv[0])
```
a. `IndexError: list index out of range` because `sys.argv` is empty
b. `None`
c. an empty string `""`
### 3- _Complete this sentence:_
When -m module is used, sys.argv[0] is set to the ……….. :
a. name of the module file
b. full name of the located module
c. relative name of the module
--------
Here is the link to the video: [https://youtu.be/fUvT0O76DyY]
Here is the link part of the documentation that we covered in the video: [https://docs.python.org/3/tutorial/interpreter.html#invoking-the-interpreter]
| fayomihorace | |
1,415,549 | Critical Thinking | We are bombarded daily with a huge amount of data, news, opinions and recommendations. To avoid... | 0 | 2023-03-26T14:36:31 | https://dev.to/balaevarif/critical-thinking-j4j | career, productivity, ai | We are bombarded daily with a huge amount of data, news, opinions and recommendations.
To avoid manipulation and logical errors, we need to learn how to carefully filter information. It is necessary to evaluate and analyze before accepting it as truth.
We are finding ourselves asking ChatGPT and its AI friends more often than searching Google ourselves these days. We are coming to fully trust their answers without realizing it.
This could be dangerous.
We cannot guarantee that AI models are unbiased, even though they are trained on massive amounts of data. Their algorithms or the information used to develop them could be wrong or outdated.
The skill of critical thinking is now becoming even more in demand than any hard skill.
Follow these simple rules:
- Get clear understanding of message. If unsure, ask questions. Questions unlock understanding.
- Don't just take things at face value. Look for proof, hard facts, expert opinions, statistics, and real examples to support what people say.
- Consider other options. This will lead you to make more balanced and reasonable decisions.
As AI progresses, we must streamline our work. But we should not blindly hand over all accountability to AI.
Trust, but verify. Think critically.
Start now. | balaevarif |
1,415,679 | Entering into the Multiverse of Blazor with Bit Platform templates | Looking for a solution to create both Web and App projects in a single shared codebase? Look no... | 0 | 2023-03-26T17:00:35 | https://dev.to/mhrastegari/entering-into-the-multiverse-of-blazor-with-bit-platform-templates-4ln4 | webdev, dotnet, csharp, blazor | Looking for a solution to create both Web and App projects in a single shared codebase? Look no further than [Bit Platform](https://bitplatform.dev/)'s templates!
Bit Platform's [TodoTemplate](https://bitplatform.dev/todo-template/overview) is a comprehensive solution that utilizes ASP.NET Core, Identity, Web API, and EF Core for the server-side, and Blazor for the client-side. With this powerful combination, you can build a wide variety of applications from a single codebase, including:
### Blazor Modes
- Blazor Server: Ideal for fast development and debugging
- Blazor WebAssembly: Perfect for SPA and PWA (for production)
- Blazor Hybrid: Provides Android, iOS, Mac Catalyst, Tizen, and WinUI apps with full access to platform native features using .NET MAUI!
- Blazor Electron: Provides WPF, macOS Cocoa, and Linux apps with full access to platform native features using Electron.NET!
###Features
With pre-configured options for Android, iOS, macOS, Windows, and Linux apps, as well as PWA (for offline-capable web apps) and SPA with/without pre-rendering, Bit Platform's templates offer unparalleled flexibility and startup speed. These templates also utilize Bit Blazor UI components, which are fast, lightweight (less than 200KB), and perfect for building even complex applications like e-commerce sites.
###Demos
Bit Platform has already developed and published several websites and apps using these templates, including:
* [Bit Components web site](https://components.bitplatform.dev/)
* [Bit Components mobile app](https://install.appcenter.ms/orgs/bitfoundation/apps/bitcomponents/distribution_groups/testers)
* [Bit Platform web site](https://bitplatform.dev/)
* [Todo SSR enabled web app](https://todo.bitplatform.dev/)
* [Todo PWA](https://todo-app.bitplatform.dev/)
* [Todo mobile app](https://install.appcenter.ms/orgs/bitfoundation/apps/todo/distribution_groups/testers)
* [Admin panel multilingual web app](https://adminpanel.bitplatform.dev/)
* [Admin panel multilingual mobile app](https://install.appcenter.ms/orgs/bitfoundation/apps/adminpanel/distribution_groups/testers)
###Support
In addition to offering a convenient and streamlined development process, Bit Platform's TodoTemplate also comes with excellent documentation and support. Their team of experts is always ready to answer questions and provide guidance, making it easy for developers of all levels to use their platform effectively.
---
Don't let the complexity of building web and app projects separately hold you back. Try Bit Platform's templates and start building your next project today!
You can also find more information about Bit Platform's TodoTemplate at https://bitplatform.dev/todo-template/overview and components at https://components.bitplatform.dev/
Happy coding ;D | mhrastegari |
1,415,709 | A Guide to Designing Effective Calls-to-Action for Your Website | You want your website visitors to take action, whether it’s signing up for a newsletter, downloading... | 0 | 2023-03-26T17:39:58 | https://dev.to/marianna_s/a-guide-to-designing-effective-calls-to-action-for-your-website-3lgf | webdev, beginners, ux, design | You want your website visitors to take action, whether it’s signing up for a newsletter, downloading an e-book, or making a purchase. But how do you get them to take that step? The answer lies in designing effective calls-to-action (CTA).
Calls-to-action are the buttons and links on your website that prompt people to take the desired action. They should be clear and concise—with just enough information to grab attention without overwhelming the reader. In this guide, we'll discuss what makes for an effective CTA and provide tips for creating ones that will help drive conversions on your website.
**1. Understand Your Audience and What Motivates Them**

Source: wix.com
To create effective calls-to-action (CTAs) for your website, a deep understanding of your target audience and their motivations is crucial. By grasping their needs, wants, and desires, you can tailor your messaging and design to resonate with them on a deeper level. Conduct thorough research, analyze data, and develop detailed [buyer personas](https://www.socialmediatoday.com/news/what-is-a-buyer-persona-and-why-is-it-important/507404/) to establish a clear understanding of your audience's demographics, pain points, and preferences.
With this insightful information in hand, you can craft CTAs that truly speak to the heart of your audience, increasing the likelihood of conversions and improving your overall website performance. Ultimately, taking the time to understand your audience and what motivates them is the foundation for designing powerful calls to action that drive results.
**Choose the Right Call-to-Action Button Color**
When designing a call-to-action (CTA) button for your website, choosing the right color is paramount. This decision has a significant impact on the button's visibility and persuasiveness. [UI design services](https://www.eleken.co/ui-ux-design-services) can provide expert guidance in selecting a color that not only stands out but also evokes a desired emotion or response from your website visitors.
Moreover, the chosen color should complement your overall website design and brand identity. By investing in professional UI design services, you can ensure that your call-to-action buttons effectively capture your audience's attention, ultimately leading to increased engagement and higher conversion rates.
**2. Make Your CTA Stand Out Visually**
Undoubtedly, the visual impact of a call-to-action (CTA) on your website plays a critical role in capturing the attention of your visitors and motivating them to take the desired action. To make your CTA stand out, experiment with contrasting colors that align with your brand identity while ensuring optimum visibility against the background.
Additionally, consider creating a sense of hierarchy through typography, using font size and style to draw focus to the CTA's message. Remember, a well-designed CTA button can entice users to click more effectively than simple text links. Shape, texture, and motion are other design elements that can be used to bring uniqueness to your CTA, making it more appealing to users.
Above all, a well-crafted balance of visual elements can significantly elevate the prominence of your CTA, translating to higher user engagement and improved conversion rates on your website.
**3. Use Actionable Language in Your CTA Copy**
When it comes to designing a persuasive call-to-action (CTA) for your website, using actionable language in the CTA copy is absolutely crucial. Actionable language not only captures the attention of your visitors, but it also encourages them to take the desired action, whether that be making a purchase, signing up for a newsletter, or downloading an ebook. To use actionable language effectively, it is important to include strong, clear verbs that emphasize the benefits your audience will receive from completing the desired action. Instead of using generic phrases like "Click here" or "Submit," choose powerful and specific words such as "Discover," "Join," or "Get Started." This will help stir feelings of excitement and motivation, compelling your visitors to engage with your content and ultimately converting them into leads or customers.
Additionally, personalizing your CTAs by incorporating words like "You" or "Your" helps to create a sense of connection with your audience, making them feel valued and important. By incorporating actionable language in your CTA copy, you can effectively boost conversions, deepen user engagement, and drive the overall success of your digital marketing efforts.
**4. Place CTAs Strategically on Your Website Pages**

Carefully consider the location, format, and overall flow of each CTA to maximize user engagement and conversion potential while maintaining a seamless user experience. By incorporating your CTAs within the natural progression of your website pages, users will feel encouraged to take action without feeling overwhelmed or pressured. This includes positioning your CTAs at points where users are likely to have encountered useful and relevant information, making them more inclined to move forward with their journey.
Don't shy away from experimenting with multiple placements, such as above the fold, within the blog content, or even in the sidebar or footer, depending on the context and user intent. Leverage the power of [A/B testing](https://blog.hubspot.com/marketing/how-to-do-a-b-testing) to fine-tune the positioning and determine which placements resonate most effectively with your target audience. Remember to always prioritize user experience and maintain a balance between promoting your call-to-action and ensuring website usability to foster a positive relationship with your visitors, who will ultimately reward you with their loyalty and engagement.
**Test Different Versions of a CTA to See What Works Best for You**
A crucial aspect of designing effective calls-to-action (CTAs) on your website is understanding that every business is different, and what works wonders for one website might not yield the same results for another. To gain the most out of your CTAs, it is essential to experiment with various versions and designs to discover the perfect fit for your unique audience. This involves testing different messaging, colors, button placements, and more to garner the best possible engagement and click-through rates.
Moreover, frequent monitoring and measuring of your CTA's performance is absolutely vital. By delving deeper into your website's analytics, you obtain invaluable insight into user behavior and preferences, enabling you to make data-driven decisions that help to optimize your CTAs over time accordingly. Continuously testing, measuring, and refining your calls-to-action will not only drive conversions but also foster enhanced user experiences and maintain a competitive edge within your niche.
**5. Measure Performance and Optimize as Needed**
The key to creating powerful calls-to-action lies not only in designing and implementing them but also in constantly evaluating their performance and optimizing them accordingly. By examining your website analytics and conversion data, you gain valuable insights into which CTAs are generating the desired results and which ones may need enhancements or adjustments. This process of ongoing evaluation helps fine-tune your CTAs in order to improve engagement, increase conversion rates, and ultimately maximize the return on your digital marketing efforts.
Remember, the most effective calls-to-action are the result of consistent testing, learning, and iterating, so never stop striving for a better CTA strategy to keep your audience engaged and drive the success of your website.
**Final Words**
In summary, designing effective calls-to-action on your website is essential to driving conversions and ensuring the success of your digital marketing efforts. By strategically placing CTAs in natural points within the user journey, testing different versions and designs, and evaluating performance data regularly for optimization purposes, you can effectively boost conversions, deepen user engagement, and drive the overall success of your digital marketing initiatives. With these practical tips at hand, it’s time to start creating powerful calls to action that will help you achieve maximum results from all of your hard work! | marianna_s |
1,415,727 | Private connectivity to Amazon S3 | I'm excited to share with you about Amazon S3's new capability for simplifying private connectivity... | 0 | 2023-03-26T18:30:58 | https://dev.to/tatoescala24x7/private-connectivity-to-amazon-s3-4001 | aws, hybrid | I'm excited to share with you about Amazon S3's new capability for simplifying private connectivity from on-premises networks: https://aws.amazon.com/about-aws/whats-new/2023/03/amazon-s3-private-connectivity-on-premises-networks/
Source image: https://docs.aws.amazon.com/AmazonS3/latest/userguide/privatelink-interface-endpoints.html
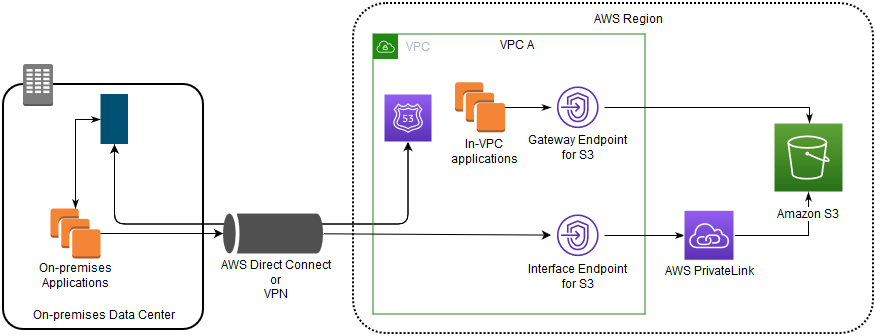
Source image: https://docs.aws.amazon.com/AmazonS3/latest/userguide/privatelink-interface-endpoints.html
Virtual Private Cloud (VPC) interface endpoints for Amazon S3 **now offer private DNS options** that can help you more easily route S3 requests to the lowest-cost endpoint in your VPC.
With this new feature, your on-premises applications can use AWS PrivateLink to access S3 over an interface endpoint, while requests from your in-VPC applications access S3 using gateway endpoints. This helps you take advantage of the lowest-cost private network path without having to make code or configuration changes to your clients.
Imagine you work for a financial institution that has a hybrid cloud environment. Your organization has on-premises applications that need to access data stored in Amazon S3. However, you want to ensure that these requests are routed through a private network path to improve security and reduce data transfer costs.
With the new private DNS option for S3 interface endpoints, you can easily create an inbound resolver endpoint in your VPC and point your on-premises resolver to it. Then, you can enable private DNS for S3 interface endpoints and select "Enable private DNS only for inbound endpoint." This will ensure that requests from your on-premises applications are automatically routed to the lowest-cost endpoint over a private network path using AWS PrivateLink.
By using this capability, your organization can improve security by ensuring that requests to S3 are routed through a private network path rather than over the public internet. Additionally, you can save money on data transfer costs by automatically routing requests to the lowest-cost endpoint.
In summary, this new Amazon S3 capability is a great solution for organizations that have on-premises applications that need to access data stored in S3. By using private DNS for S3 interface endpoints, you can improve security, reduce data transfer costs, and ensure that requests are routed through a private network path.
This new capability has many potential use cases, including:
- Hybrid Cloud: Organizations with on-premises applications can now more easily access S3 resources using AWS PrivateLink, while taking advantage of the lowest-cost private network path.
- Cost Optimization: By automatically routing requests to the lowest-cost endpoint, organizations can save money on data transfer costs.
- Security: Using private DNS for S3 interface endpoints improves security by ensuring that requests are routed through private network paths rather than over the public internet.
Overall, this new capability for Amazon S3 simplifies private connectivity from on-premises networks and offers several benefits to organizations. It's available now in all AWS Commercial Regions, and you can enable it using the AWS Management Console, AWS CLI, SDK, or AWS CloudFormation. To learn more, read the Amazon S3 documentation. | tatoescala24x7 |
1,415,756 | Using Key Pairs with JWTs | JWTs are a format for representing claims between two parties. JWTs can be signed to increase confidence in their security. This signing, and subsequent verification, can be done using a secret or a key pair | 0 | 2023-03-26T20:20:58 | https://odongo.pl/jwt-asymmeytric-key-pair/ | javascript, jwt | ---
published: true
title: "Using Key Pairs with JWTs"
tags: ["javascript", "jwt"]
description: "JWTs are a format for representing claims between two parties. JWTs can be signed to increase confidence in their security. This signing, and subsequent verification, can be done using a secret or a key pair"
canonical_url: https://odongo.pl/jwt-asymmeytric-key-pair/
---
One common way of handling authentication and authorisation in web-based systems is to have a client send their login credentials to the backend, which generates and returns a signed JWT linked to an identity. The client can then access or modify protected resources by attaching the JWT to the request. Before handling the request, the backend verifies the JWT's authenticity.
## Signing and Verifying JWTs
JWTs can be signed and verified using a secret. In this case, the same secret is used for signing and verifying. This is a reasonable approach in a monolithic architecture, since only one program has access to the secret.
```js
// GENERATING A JWT USING A SECRET
import { randomUUID } from "crypto";
import * as jwt from "jsonwebtoken";
const SECRET = "123";
const user = {
id: randomUUID(),
};
const claimSet = {
aud: "Audience",
iss: "Issuer",
jti: randomUUID(),
sub: user.id,
};
const token = jwt.sign(
claimSet,
SECRET,
{
algorithm: "HS256",
expiresIn: "20 minutes",
}
);
console.log(token); // => eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhdWQiOiJBdWRpZW5jZSIsImlzcyI6Iklzc3VlciIsImp0aSI6ImY1NGEzOGVmLTQ4NzctNGJmYy05N2RmLWFkYzFiNjQxNzU5YiIsInN1YiI6IjRlNzQ5ZTAwLTE1NWItNGNlNi1iYWQyLWExOTE5MWM0MmQ2NyIsImlhdCI6MTY3OTc3OTUwOSwiZXhwIjoxNjc5NzgwNzA5fQ.X94g8OkecnaOYLMuVFmy_hcjJ7nvBMhDEvrUpTvvxQE
// VERIFYING A JWT USING A SECRET
import { verify } from "jsonwebtoken";
const SECRET = "123";
verify(token, SECRET);
```
An alternative way of signing and verifying JWTs is by using key pairs. This involves signing the JWT using a private key and subsequently verifying it using the corresponding public key.
In a service-oriented architecture, the borders between services are generally drawn in a way that separates concerns. That separation should go hand in hand with the principle of least privilege. From the point of view of a service, it should have the least permissions needed for it to perform its duties.
More concretely, only the service responsible for generating JWTs should have access to the private key. This means that other services are unable to generate valid JWTs; all they can do is use the public key to verify a JWT they have received.
```js
// GENERATING A JWT USING A PRIVATE KEY
import { randomUUID } from "crypto";
import { readFileSync } from "fs";
import { sign } from "jsonwebtoken";
const PRIVATE_KEY = readFileSync("./privateKey.pem");
const user = {
id: randomUUID(),
};
const claimSet = {
aud: "Audience",
iss: "Issuer",
jti: randomUUID(),
sub: user.id,
};
const token = sign(
claimSet,
PRIVATE_KEY,
{
algorithm: "ES512",
expiresIn: "20 minutes",
}
);
console.log(token); // => eyJhbGciOiJFUzUxMiIsInR5cCI6IkpXVCJ9.eyJhdWQiOiJBdWRpZW5jZSIsImlzcyI6Iklzc3VlciIsImp0aSI6ImE0NzVhYTU5LTIwMGQtNDlkOS1iODVmLTJkZmExM2Q3NTMyMSIsInN1YiI6ImE2YWFkNWY0LTE3NjctNDUwYy04MWNjLTIyMmI3OWI1NzNiYSIsImlhdCI6MTY3OTc4MDI3NiwiZXhwIjoxNjc5NzgxNDc2fQ.AIuJlLZCvpSWLh_ez6pBVX4lcrVbOiUc2NuwCNiw5ms4ELAZRvQFT5-UlKC-PBWXWzWpHh7eO-WWmfOgRnObk_vpAYAo5Wu8Wu-YaL2lBLvaQp2oG5YnXJ9S1kCKGF9i0UloUeYCK6-bdhRvh-rrOqpCOPepWEiQDiWgEzAdPOl75pY4
// VERIFYING A JWT USING A PUBLIC KEY
import { readFileSync } from "fs";
import { verify } from "jsonwebtoken";
const PUBLIC_KEY = readFileSync("./publicKey.pem");
verify(token, PUBLIC_KEY);
```
## Generating Key Pairs
A key pair can be generated from the terminal using `openssl`.
Before we start generating a key pair, we need to know which curve `openssl` should use. The `ES512` algorithm used in the previous code snippet corresponds to the `secp512r1` curve<sup>[[1](#footnote-1)]</sup>.
We can generate the private key by running the following command:
```
openssl ecparam -name secp521r1 -genkey -out privateKey.pem
```
The private key is then used to generate the public key<sup>[[2](#footnote-2)]</sup> using the command below:
```
openssl ec -in privateKey.pem -pubout -out publicKey.pem
```
<a name="footnotes"></a>
## Footnotes
<a name="footnote-1">[1]</a>: If you wanted to use a different algorithm, say `ES256`, but provided the key generated above, `jsonwebtoken` would throw a helpful error message specifying which curve it expects.
```js
import { randomUUID } from "crypto";
import { readFileSync } from "fs";
import { sign } from "jsonwebtoken";
const PRIVATE_KEY = readFileSync("./privateKey.pem");
const user = {
id: randomUUID(),
};
const claimSet = {
aud: "Audience",
iss: "Issuer",
jti: randomUUID(),
sub: user.id,
};
const token = sign(
claimSet,
PRIVATE_KEY,
{
algorithm: "ES256",
expiresIn: "20 minutes",
}
); // => throws `"alg" parameter "ES256" requires curve "prime256v1".`
```
Generating a new key pair with the expected curve (`prime256v1` instead of `secp521r1`) should resolve the error.
<a name="footnote-2">[2]</a>: The node `crypto` module can generate a public key based off of the private key. So if the service issuing tokens needed to verify them too, we would only need to configure the private key:
```js
import { createPublicKey } from "crypto";
import { readFileSync } from "fs";
import { verify } from "jsonwebtoken";
const PRIVATE_KEY = readFileSync("./privateKey.pem");
const PUBLIC_KEY = createPublicKey(PRIVATE_KEY)
.export({ format: "pem", type: "spki" });
verify(token, PUBLIC_KEY);
``` | croccifixio |
1,415,859 | How to Clean Up Snap Versions to Free Up Disk Space | (see: My source of information) Symptom: the partition containing /var is running out of... | 0 | 2023-03-26T21:29:06 | https://dev.to/taimenwillems/how-to-clean-up-snap-versions-to-free-up-disk-space-22o2 | ubuntu, snap | (see: [My source of information](https://www.debugpoint.com/clean-up-snap/))
#### Symptom: the partition containing `/var` is running out of diskspace.
_OS: Linux Ubuntu_
This quick guide with a script helps to clean up old snap versions and free some disk space in your Ubuntu systems.
Snap can consume a considerable amount of storage space because it keeps old revisions of a package for retention.
The default value is 3 for several revisions for retention. That means Snap keeps three older versions of each package, including the active version. This is okay if you do not have constraints on your disk space.
But for servers and other use cases, this can easily run into cost issues, consuming your disk space.
However, you can easily modify the count using the following command. The value can be between 2 to 20.
```Bash
sudo snap set system refresh.retain=2
```
## Clean Up Snap Versions
In a post in SuperUser, Popey, the ex-Engineering Manager at Canonical, [provided](https://superuser.com/questions/1310825/how-to-remove-old-version-of-installed-snaps/1330590#1330590) a simple script that can clean up old versions of Snaps and keep the latest one.
Fire-up nano to create a new script in `/bin`:
```Bash
sudo nano /bin/clean_snap.sh
```
Here’s the script we will use to clean the Snap up.
```Bash
#!/bin/bash
#Removes old revisions of snaps
#CLOSE ALL SNAPS BEFORE RUNNING THIS
set -eu
LANG=en_US.UTF-8 snap list --all | awk '/disabled/{print $1, $3}' |
while read snapname revision; do
snap remove "$snapname" --revision="$revision"
done
```
Save the file by pressing `ctrl`+`x`, `y` in nano.
Make it executable:
```Bash
sudo chmod +x /bin/clean_snap.sh
```
CLOSE ALL SNAPS and then run the script to clean old snaps:
```Bash
sudo /bin/clean_snap.sh
``` | taimenwillems |
1,415,932 | Debian estable....mi distro final? | Llevo usando toda una semana #debian11 en su versión #estable de manera en mi laptop Asus VivoBook y... | 0 | 2023-03-26T23:54:17 | https://dev.to/xtecnomundo/debian-establemi-distro-final-1cm2 | debian | Llevo usando toda una semana #debian11 en su versión #estable de manera en mi laptop Asus VivoBook y puedo llegar a las siguientes conclusiones:
No me volvió a fallar el wifi en ningún momento.
A pesar de ser la versión de gnome 3.38 bastante tosco, el rendimiento va mas que sobrado y me ha demostrado porque muchas personas adoran debían.
Luego de instalar el kernel xanmod 6.2…. pues tocaba probar haciendo primero el día de ayer un directo vía youtube con múltiples trabajos al mismo tiempo y todo controlado y bastante satisfecho.
El día de hoy me toco probar para jugar, por lo que tuve que irme a jugar CSGO y los resultados fueron mejor de lo esperado. (No juego habitualmente aunque compre algunos juegos y los tengo ahí).
Finalmente debo concluir que esta versión se ha asentado mejor de lo que esperaba, dándome una sensación de estabilidad, comodidad y jugabilidad. Esperemos que debian 12 mantenga esa misma magia con mi laptop, de ser así, pues creo que encontré mi centro de gravedad con debian.
Que esperar de debian12??? pues, personalmente espero un salto muy cuantificable sobretodo en gnome por el paso de 3.38 a la versión 44 con la que calculo va a quedar en su versión estable.
No quiero decirme que ya soy debianita, pero ya les digo que me ha dado mejor sensación que mi amada fedora…llegara a reemplazarla definitivamente…solo el tiempo dirá. | xtecnomundo |
1,417,292 | Java convert Excel to HTML | Excel spreadsheets serve as a useful tool for organizing, managing, and computing data, while HTML... | 0 | 2023-03-28T03:44:25 | https://dev.to/alexis92/java-convert-excel-to-html-jfj | excel, html, css, java | Excel spreadsheets serve as a useful tool for organizing, managing, and computing data, while HTML plays a similar role in presenting content through web browsers. In some situation, you may need to save Excel to HTML conversion to convert worksheets to HTML pages. For example, when embedding the content of the spreadsheets into web pages. As HTML pages can be easily shared and accessed through web browsers and HTML page can also be interactive, allowing users to input or manipulate data directly on the webpage, which can be useful for collaborative projects or online surveys. This article will show you how to convert Excel XLSX files to HTML programmatically using Java from the following three parts.
- [Convert Excel to HTML](#convert-excel-to-html)
- [Convert Excel to a standalone HTML file](#convert-excel-to-a-standalone-html-file)
- [Convert Excel to HTML stream](#convert-excel-to-html-stream)
###Install Spire.XLS for Java
First of all, you're required to add the Spire.Xls.jar file as a dependency in your Java program. The JAR file can be downloaded [from this link](https://www.e-iceblue.com/Download/xls-for-java.html). If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
```java
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.xls</artifactId>
<version>13.3.6</version>
</dependency>
</dependencies>
```
###Convert Excel to HTML
[Spire.XLS for Java](https://www.e-iceblue.com/Introduce/xls-for-java.html) offers **workbook.saveToFile()** method to convert Excel workbook to HTML easily. Here comes to steps of convert XLSX to HTML.
- Create a Workbook instance.
- Load an Excel file using **Workbook.loadFromFile()** method.
- Save the file to HTML using **Workbook.saveToFile()** method.
```java
import com.spire.xls.*;
public class ExceltoHTML {
public static void main(String[] args) throws Exception {
//Load an Excel file
Workbook wb = new Workbook();
wb.loadFromFile("Sample.xlsx");
//Save the file to HTML
wb.saveToFile("WorkbookToHtml.html",FileFormat.HTML);
}
}
```
###Convert Excel to a standalone HTML file
Spire.XLS for Java offers HTMLOptions instance to embed the image or convert Excel to a standalone HTML file. The following steps show how to save Excel worksheet as HTML file.
- Create a Workbook instance and load an Excel file using **Workbook.loadFromFile()** method.
- Get the first worksheet using **Workbook.getWorksheets().get()** method.
- Create a **HTMLOptions** instance.
- Enable image embedding using **HTMLOptions.setImageEmbedded()** method.
- Set the HTML as a standalone HTML file using **HTMLOptions.isStandAloneHtmlFile()** method.
- Save the worksheet to HTML with image embedded using **Worksheet.saveToHtml(String, HTMLOptions)** method.
```java
import com.spire.xls.*;
import com.spire.xls.core.spreadsheet.HTMLOptions;
public class ExceltoHTML {
public static void main(String[] args) throws Exception {
//Load the sample document
Workbook wb = new Workbook();
wb.loadFromFile("Sample.xlsx");
//Get the first worksheet
Worksheet sheet = wb.getWorksheets().get(0);
//Initiate a HTMLOptions instance
HTMLOptions options = new HTMLOptions();
//Set embedded image as true
options.setImageEmbedded(true);
//Set is StandaloneHTML file as true
options.isStandAloneHtmlFile(true);
//Save the worksheet to HTML
sheet.saveToHtml("Result2.html", options);
}
}
```

###Convert Excel to HTML stream
Spire.XLS for Java offers Workbook.saveToStream() method to save the Excel to HTML stream. The files can be saved directly to memory without having to save them to disk. When working with large numbers of files, it is very useful and these files can be easily sent to the network, to memory or to other devices.
- Create a Workbook instance and load an Excel file using **Workbook.loadFromFile()** method.
- Create a new **FileOutputStream** object named "fileStream" and specifies the file name "SaveStream.html" where the output will be saved.
- Calls the **Workbook.saveToStream()** method to save the content in HTML format to the file stream.
```java
import com.spire.xls.*;
import java.io.FileOutputStream;
public class ExceltoHTMLStream {
public static void main(String[] args) throws Exception {
//Load the sample document
Workbook wb = new Workbook();
wb.loadFromFile("Sample.xlsx");
FileOutputStream fileStream = new FileOutputStream("SaveStream.html");
wb.saveToStream(fileStream, FileFormat.HTML);
fileStream.close();
}
}
```
In this article, you have learned how to convert an Excel file to HTML using Java. The code snippet provided demonstrates the use of Spire.XLS for Java to convert the Excel file to HTML format. Additionally, the article explores various options available to customize the conversion output, such as embedding images in the HTML file or saving them as standalone HTML files. By leveraging the flexibility of Spire.XLS, you can easily control the conversion process and tailor the output to your specific needs. Whether you require a simple conversion or a more complex one with advanced settings like page orientation, header and footer, or CSS styles, Spire.XLS makes it effortless. In conclusion, you have seen how Spire.XLS for Java provides an efficient solution to convert Excel files to HTML format. If you want to learn more about Excel file processing, you can explore further resources from [Excel forums](https://www.e-iceblue.com/forum/spire-xls-f4.html) where you can find answers to common questions, share best practices, and connect with other developers. | alexis92 |
1,415,955 | 20- Computing the distance between a pair of points using PyQGIS | # import the necessary module from qgis.core import QgsDistanceArea # create a new QgsDistanceArea... | 22,345 | 2023-03-27T00:40:07 | https://dev.to/azad77/20-computing-the-distance-between-a-pair-of-points-using-pyqgis-380l | programming, python, pyqgis | --- series: A beginner's guide to using Python with QGIS ---
```python
# import the necessary module
from qgis.core import QgsDistanceArea
# create a new QgsDistanceArea instance
d = QgsDistanceArea()
# set the ellipsoid to use for the measurement (in this case, WGS84)
d.setEllipsoid('WGS84')
# create two QgsPointXY instances representing the coordinates of Erbil and Duhok
Erbil = QgsPointXY(44.01, 36.19)
Duhok = QgsPointXY(42.99, 36.86)
# calculate the distance between the two points using the QgsDistanceArea instance
distance = d.measureLine([Erbil, Duhok])
# print the result of the distance calculation, converted from meters to kilometers
print("The distance between Erbil and Huhok is", distance / 1000, "KM")
```
> If you like the content, please [SUBSCRIBE](https://www.youtube.com/channel/UCpbWlHEqBSnJb6i4UemXQpA?sub_confirmation=1) to my channel for the future content | azad77 |
1,415,962 | BTOPRO WEEK 10 | Writing the 1st article in a series about the scope of what your going to be building ... | 0 | 2023-03-27T01:09:04 | https://dev.to/dynamicpunch/btopro-week-10-5cob | ## Writing the 1st article in a series about the scope of what your going to be building
## Include images of how you are conceiving the API for the elements involved and the names
## What properties do you think you'll need
Title, Label, image, info, creator
## What sort of information will need to come from the backend to make this work?
##Either using a screen cast, taking screen shots, links to your code, show how you'll apply concepts from the Homework
## From the homework we will apply an event to toggle when the badge list is collapsed like the one above
## Relate it to what you'll have to do in order to pull this off for Project 2
The collapsible badge will need to use backend similar to how our details function worked.
## Article one is a focus on scope and the activity we did in class. What is the project, what will things be named, how will you initially conceive of attacking the problem?
We will creating our drop downs as establishing a event to open nd close them. From there well will use our template to create more buttons. | dynamicpunch | |
1,416,046 | Map Filter Function in Python | map and filter are equivalent to writing a generator expression. The map function takes each item... | 0 | 2023-03-27T03:12:28 | https://dev.to/s3cloudhub/map-filter-function-in-python-i37 | [](http://www.youtube.com/watch?v=cU1iuKVh_Vk)
map and filter are equivalent to writing a generator expression. The map function takes each item in a given iterable and and includes all of them in a new lazy iterable, transforming each item along the way; The filter function doesn't transform the items, but it's selectively picks out which items it should include in the new lazy iterable
| s3cloudhub | |
1,416,139 | Is Your Product Ready to Move from MVP to Full Scale? | Do you know why MVP scale-ups fail? Find in detail how to scale Up an MVP? How to move from MVP to Full-Scale Product? | 0 | 2023-03-27T06:48:53 | https://dev.to/techticsolutioninc/is-your-product-ready-to-move-from-mvp-to-full-scale-14ge | mvp, mvpdevelopment | ---
title: Is Your Product Ready to Move from MVP to Full Scale?
published: True
description: Do you know why MVP scale-ups fail? Find in detail how to scale Up an MVP? How to move from MVP to Full-Scale Product?
tags: #MVP #MVPDevelopment
cover_image: https://backend.techtic.com/wp-content/uploads/2023/03/Is-Your-Product-Ready-to-Move-from-MVP-to-Full-Scale_inner.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-03-27 05:42 +0000
---
<h2>The Perfect MVP Launch Model</h2>
It is evident that small businesses can test out new ideas, products, or services in the real world using MVP strategies.
Small businesses with limited resources and tiny startups can benefit from this approach, as this allows the entrepreneur to evaluate the effectiveness of various ideas within a miniature version of the final product.
Suppose you want to start a small restaurant business and offer deliveries to households in several areas. Without knowing how many orders you might receive, starting out with an expansive route right away may be detrimental. However, you may establish certain limitations, such as delivering to popular locations only during the evenings. This will allow the company to develop naturally without stripping the budget right away.
There is one thing certain about the MVP launch model: no matter what type of business you have, you must have the drive and motivation to move forward.
We won’t go more deep into the best practices for MVP and all. If you’re interested, you can read our previously written blog: <a href="https://www.techtic.com/blog/what-is-mvp-benefits/">What is MVP? 5 Benefits of Building an MVP for Your Product</a>
So, what happens after you’ve built the MVP?
<h2>Scale Your MVP when the Learning Process is Done</h2>
<img src="https://backend.techtic.com/wp-content/uploads/2023/03/image-2-1.png" alt="Scale Your MVP">
The greatest benefit of using an MVP, in the long run, is what you discover from operating with one. MVP is a research project on the hoof, as it were. It allows you to figure out whether your business has the potential for success and expansion.
You should collect as much data as possible during the initial launch. Know who your customers are? What are they purchasing? What do they think of it? What would they change? What do they love or hate about your product or service? Create a feedback loop to build on to the next step.
It’s important to evaluate how much of a feedback loop affects your actions. For example, you can assess which aspects of your product and service have the highest conversion rates when you first begin to receive customers. Then compare that with the comments of your users.
<b>You got your answer; the only sign for you to scale your MVP is when you think you know your customer needs and are sure about your product positioning in the market.</b>
If you want to know how to scale your MVP, keep reading.
<h2>Reasons Why MVP Scale-Ups Fail</h2>
An MVP is quicker to develop since it is simple to create, test, and deploy; however, as the solution grows in size, making changes and fixing problems becomes difficult.
You can use a profiler to find the performance issues in your application. This profile should be captured at both the database and application levels and should answer the most crucial questions like:
<ul>
<li>How many concurrent users can my existing MVP handle?</li>
<li>Would simply scaling up the backend with front-end improvements enable a full-scale solution, or does it require a redesign?</li>
<li>Is my current solution slowed down by the backend or the front end?</li>
<li>Is there any lag caused by the database or the code?</li>
<li>Are the limitations in the MVP solution present in the data or the database?</li></ul>
Still, there are many reasons why many MVP scale-ups fail. Here are some:
<h3>Focus Shift Due to Growth</h3>
During periods of growth, a lot happens: the culture changes, new offices open in new locations, and new employees are hired. When new employees join the company, they might or might not share the same vision for the product, and it is the job of the product team to address this.
However, keeping employees and stakeholders up to date on product strategy becomes more and more difficult as companies evolve and expand. And this often results in scale-up failures.
<h3>Not Able to Scale</h3>
Early-stage organizations commonly employ Lean Startup techniques to rapidly create, test, validate, and deliver new products and features. However, these procedures may become less effective as organizations grow.
When a scrum team expands from one to two, three, or even four, the entire development process must evolve. In such scenarios, it may take some time to adjust procedures to make them as efficient as possible. Furthermore, having multiple scrum teams working on different projects adds to the difficulty.
<h3>MVP Roadmap is Driven by Sales</h3>
Product managers at all phases of their companies’ development are likely to confront this issue. A typical request from salespeople goes something like this: ‘Please build this sophisticated feature right away because if you do, I’ll be able to close this huge deal.’
It seems like a great approach to build the features right away, but when it comes to long-term product lifecycle planning, it isn’t the best option.
Product managers at fast-growing companies believe that salespeople are the elephant in the room and can thus alter the product roadmap. This annoys them, especially when these requests appear out of the blue and derail well-considered strategic initiatives.
<h2>How to Scale Up an MVP</h2>
The MVP is the first version of the product with the core features; it is released to the audience and obtains the first sign of success. It actually validates the product idea. The logical next step is the MMP, which is a product with the features users want, providing valuable feedback back to the company.
<h3>1. Use Customer Feedback & Data Collection</h3>
Using quantitative analytics and research, teams can build an excellent scaling strategy by collecting user feedback. Thanks to the user input, you can determine which new features should come first.
Because of this, your product will succeed on the market in the long run and continuously develop. You can measure your MVP performance using the following parameters:
<ul>
<li>User feedback</li>
<li>Percentage of active users</li>
<li>Word of mouth</li>
<li>Customer acquisition cost</li>
<li>Customer lifetime value</li>
<li>Overall engagement</li></ul>
<h3>2. Stick to the Core Strategy & Business Idea</h3>
The post-MVP phase is all about scaling up. You must scale up your digital product as your user base grows and has new demands and problems. Only by doing so can you provide the trending features and attract new customers.
However, scaling up is not a simple task. Sometimes you have to change not only the product but the business as a whole. To do so successfully, you must focus on the core strategy and, with that product vision, develop the correct process and adopt the appropriate technology group by your side.
<h3>3. Think Twice Before Pricing Your Product</h3>
Many organizations fall short at the initial scaling-up stage (aka, minimum marketable product) because they choose the incorrect decision-making options. Your motivation should not be profit, ambition, or growth for the sake of growth alone. You should strive to create a unique and economical offer that will be popular.
You need to research and increase interest in order to increase conversions. You should make sure the prices are reasonable. Keep in mind that what you want is not always possible. Provide people with an attractive alternative, and your product will be a big hit.
Having a broader comprehension of the core company strategy is critical while scaling your MVP. You must look at your job from the outside to see customers and establish the correct sequence of strategic steps. Only with a comprehensive and wholesome perspective of the company inside-out you’ll be able to make the best managerial decisions.
<h3>4. Take Care of Your Finances</h3>
Additional investments are required for efficient promotion. Therefore, it is crucial to keep a close eye on cash flows and funding in order to achieve the positive capital turnover required for growth purposes.
Expanding to the MSP stage will undoubtedly require access to additional financial resources. You will need liquidity to expand production, hire new workers, move to larger locations or prime spots, etc.
<h3>5. Don’t Dismiss Marketing Strategy</h3>
Many firms are reluctant to spend money on marketing when releasing an MVP because it is not the final product. This is another big mistake. Instead, the MVP release is a terrific way to concentrate on the marketing approach that will serve you best once you move from MVP to product, as well as a great way to see how customers respond to a basic version of your product.
Pro Tip: Having an MVP is fantastic for generating leads. You may gather a significant number of qualified leads to contact once your finished product is fully operational by using email signup lists and remarketing pixels or cookies—people who have previously expressed interest in your MVP.
<h3>6. Test & Analyze</h3>
Prior to releasing your MVP, quality control and assurance, and testing should all be included in the process. An emphasis on adaptability and continuous improvement should therefore be at the forefront of your startup.
Everything you track during the MVP release—social media interactions, traffic, conversions, abandoned carts, customer comments, and more—must remain on your radar. This allows you to continuously improve your customer experience and product, resulting in increased customer satisfaction.
Investors want to see real competitive products emerge from the MVP if user testing is effective. Keeping their money safe and seeing their money put to good use are their goals. Hence, show investors test results and income projections to verify your business idea is viable.
Your team should be able to deliver a real result by providing real numbers and user reviews to validate your idea. You must convince investors that you know what the next steps should be to generate successful sales.
<h2>Final Note</h2>
The post-MVP phase isn’t the simplest one. You must develop the right growth strategy from the first release of the product until product-market fit—a long way. To ensure you have the financial flexibility you need and the right team working with you during development, a minimum marketable product launch is crucial.
However, once you begin the MVP journey with a plan and an expert software development team, scaling up the product the client likes will be much easier.
| techticsolutioninc |
1,416,208 | CSS Glassmorphism Button Hover Effects | Glass Morphism | Inspired by: https://www.youtube.com/watch?v=YrOq7OpRV8I | 0 | 2023-03-27T07:40:19 | https://geekshelper.com/html/glassmorphism-button/ | codepen, geekshelper, geekshelp, webdev | <p>Inspired by:
<a href="https://www.youtube.com/watch?v=YrOq7OpRV8I" target="_blank">https://www.youtube.com/watch?v=YrOq7OpRV8I</a></p>
{% codepen https://codepen.io/katarzynamarta/pen/rNdbbVq %} | mrohitsingh |
1,416,223 | Advanced Notion Features : Tips and tricks on using advanced features such as databases, formulas, and relations. | If you're already familiar with Notion and have been using it for a while, you may be ready to... | 0 | 2023-03-27T08:36:14 | https://dev.to/ahmed_onour/advanced-notion-features-tips-and-tricks-on-using-advanced-features-such-as-databases-formulas-and-relations-2pn2 | webdev, javascript, productivity, react | If you're already familiar with Notion and have been using it for a while, you may be ready to explore its more advanced features. In this article, we'll dive into databases, formulas, and relations, and show you some tips and tricks on how to use these powerful Notion features.
### Don't miss the free notion template
{% embed https://ahmedonour.gumroad.com/l/freeNotion %}
## **Databases**
Databases in Notion are like spreadsheets on steroids. They allow you to store and organize large amounts of information in a single place, and you can customize your database with different types of properties to fit your needs.
### **Tips and Tricks**
1. Use templates: Notion offers a variety of database templates that you can use to get started quickly. Look for the "Templates" button at the top of your database page to see the options available.
2. Group and filter data: Group your data in different ways to make it easier to find what you need. You can also use filters to show only the records that meet certain criteria.
3. Add properties: Notion allows you to add different types of properties to your database, including text, select, date, formula, and more. Choose the properties that fit your needs and make your database more useful.
## **Formulas**
Notion formulas are a powerful tool that allows you to calculate values based on other values in your database. You can use formulas to calculate things like totals, averages, percentages, and more.
### **Tips and Tricks**
1. Use the Formula property: Notion has a dedicated property for formulas that you can add to your database. Look for it when adding a new property to your database.
2. Follow the syntax rules: Notion uses a specific syntax for formulas that you need to follow. Check out Notion's documentation on formulas for guidance.
3. Use functions: Notion has a variety of built-in functions that you can use in your formulas to simplify your calculations. Look for the "fx" button in the formula property to see the available functions.
## **Relations**
Notion relations allow you to connect records in different databases to each other. For example, you can link a project record in one database to a team member record in another database.
### **Tips and Tricks**
1. Use the Relation property: Like formulas, Notion has a dedicated property for relations that you can add to your database.
2. Create a linked database: If you have a lot of related records across different databases, it may be helpful to create a linked database that shows all of the related records in one place.
3. Use rollup properties: Rollup properties allow you to display information from related records in your database. For example, you can use a rollup property to show the total hours worked by a team member across all of their project records.
## **Conclusion**
These are just a few tips and tricks for using databases, formulas, and relations in Notion. As you become more familiar with these advanced features, you'll discover even more ways to use them to make your Notion workspace more useful and efficient.
### Don't miss the free notion template
{% embed https://ahmedonour.gumroad.com/l/freeNotion %} | ahmed_onour |
1,416,277 | hello am happy to be there</> | A post by NIYIRERA Yannick | 0 | 2023-03-27T09:19:41 | https://dev.to/niyirerayannick/hello-am-happy-to-be-there-3fkn | hello | niyirerayannick | |
1,416,309 | Acquire 20% off and Get great Knowledge on SAP Ariba Certification Training at HKR Trainings | SAP Ariba certification is a cloud-based procurement platform that enables businesses to streamline... | 0 | 2023-03-27T10:12:03 | https://dev.to/ammusk354/acquire-20-off-and-get-great-knowledge-on-sap-ariba-certification-training-at-hkr-trainings-4oc8 | sapariba, saparibatraining, onlinesaparibatraining | [SAP Ariba certification](https://hkrtrainings.com/sap-ariba-training) is a cloud-based procurement platform that enables businesses to streamline their procurement processes, manage supplier relationships, and drive cost savings. It is a subsidiary of SAP SE, one of the world's largest enterprise software companies.
With SAP Ariba, organizations can automate and simplify their procurement processes, from sourcing and contract management to invoicing and payments. The platform connects buyers and suppliers across a global network, enabling them to collaborate, negotiate, and transact more efficiently.
Some key features of SAP Ariba include:
Sourcing: Enables businesses to identify and evaluate suppliers, negotiate contracts, and manage supplier performance.
Contracts: Provides a centralized repository for contracts and supports the entire contract lifecycle, from creation and negotiation to renewal and termination.
Procurement: Streamlines the purchasing process, from requisition to receipt, and includes features such as catalog management, purchase order creation, and invoice reconciliation.
Invoicing: Allows suppliers to submit electronic invoices and buyers to manage the invoice approval and payment process.
Supplier Management: Provides tools for managing supplier information, assessing supplier risk, and monitoring supplier performance.
Overall, SAP Ariba helps businesses to improve their procurement processes, increase efficiency, and reduce costs by leveraging a powerful procurement platform and a global network of suppliers. | ammusk354 |
1,416,341 | How to Install Magento Theme From Zip File | Initial feelings matter a ton and that is the motivation behind why a subject maybe is the most basic... | 0 | 2023-03-27T11:10:49 | https://dev.to/webgurudev/how-to-install-magento-theme-from-zip-file-fbj | webdev, magento, magento2tutorial | Initial feelings matter a ton and that is the motivation behind why a subject maybe is the most basic piece of any online business store these days. Your site's viewpoint must be at its ideal to draw in guests to remain in the store.

Introducing a Magento subject from a compress record is a somewhat basic cycle like the cycle to introduce Magento expansion that can be finished in only a couple of steps. Here is a bit by bit guide on the most proficient method for how to install Magento theme from zip file.
For more info,visit https://webguru.dev/how-to-install-magento-theme-from-zip-file/
| webgurudev |
1,416,387 | npm install npm-registry-fetch | code: 'MODULE_NOT_FOUND', requireStack: [ ... | 0 | 2023-03-27T11:20:54 | https://dev.to/harishpalsande9/npm-install-npm-registry-fetch-4il8 | code: 'MODULE_NOT_FOUND',
requireStack: [
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\node_modules\\npm-registry-fetch\\lib\\index.js',
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\lib\\utils\\replace-info.js',
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\lib\\utils\\error-message.js',
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\lib\\utils\\exit-handler.js',
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\lib\\cli.js',
'C:\\Users\\dell\\AppData\\Roaming\\npm\\node_modules\\npm\\bin\\npm-cli.js'
] | harishpalsande9 | |
1,416,515 | Optimizing Content Delivery: The Complete Guide Through S3 Caching and CloudFront | Learn how to optimize content delivery with Amazon S3 and CloudFront. 🔎 This guide covers all the... | 0 | 2023-03-29T12:00:00 | https://cloudnature.net/blog/optimizing-content-delivery-the-complete-guide-through-s3-caching-and-cloudfront | programming, aws, cache, frontend | ---
title: Optimizing Content Delivery: The Complete Guide Through S3 Caching and CloudFront
published: true
tags: programming, aws, cache, frontend
canonical_url: https://cloudnature.net/blog/optimizing-content-delivery-the-complete-guide-through-s3-caching-and-cloudfront
---
Learn how to optimize content delivery with Amazon S3 and CloudFront. 🔎 This guide covers all the best caching strategy and some real world examples.
# Introduction
Every great journey starts with a struggle. And for me, that struggle began as I built my own blog and struggled to find the right caching strategy. I knew that in order to succeed, I had to go above and beyond, carefully studying every solution that would optimize my website's performance.
But even after going through documentations, articles and tutorials, I still had that feeling that it wasn't enough. That I was missing out on some opportunities. So, I took my notebook and pen, and I started experimenting with all the possible settings, determined to find the perfect caching strategy for my website.
In this article, I'll share my knowledge about caching, explore some of the most effective caching pattern, and take you on a deep dive into my personal experience with finding the right caching strategy for my own website. Let's start this exciting journey!🚀
# The 6W of caching
## What is the cache?
Caching is the process of storing frequently accessed data or resources in a temporary location that's placed in between you browser and your server.
## Why is the cache important?
It can improve website speed as well as performance, which can lead to a better user experience. Not only that, but caching is amazing because it reduce server load and network usage, which can lower costs.
## Where should you use the cache?
You can cache a lot of website resources, including HTML pages, images, stylesheets, scripts and Api. Also, you can use the cache at different levels, such as server-side, client-side, database and even DNS.
## When should you use the cache?
Definitely when you want to improve website speed and performance, as well as reducing server load and network costs. It's more effective for frequently accessed data or static resources.
## Who should use the cache?
You! Yeah this was lame😜. Anyway, anyone who owns a website should use the cache to improve their website performance, particularly if they have high traffic.
## How to cache effectively?
No wonder why I put this question last. To cache effectively, you should consider caching patterns and cache-control header that are most suitable for your website. Yeah, it's another "it depends", but it was more structured this time, and I will provide all the info in the following sections.
# How does caching a web application work?
To better understand the concept of caching, let's draw some diagrams👇. The actions are made following this sequence:
1. The client asks the cache for the list of posts from the Api;
2. The cache searches internally, but it doesn't find anything;
3. The cache asks the Api the list of posts;
4. The Api returns the list of posts;
5. The cache saves the list locally and returns it to the client.
As of now, the client has received the list of posts, and the cache has store it locally. What happens when the client makes the same request again?
1. The client asks the cache for the list of posts from the Api;
2. The cache searches internally, it does find it;
3. The cache returns it to the client.
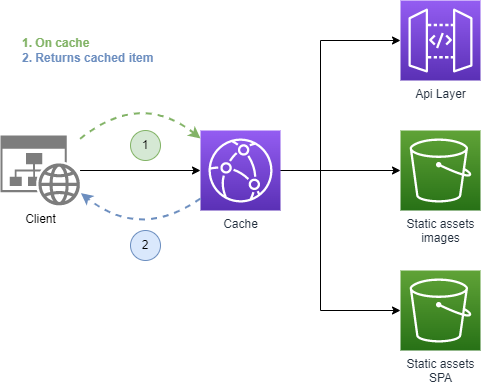
The cool this about all of this is that your cache is faster than the entire roundtrip to your Api, which means users are able to see content sooner, resulting in a better user experience. Additionally, your Api will thank you 🙏.
There is also another case of caching which is really important, and most of the times, it's the cause of misalignments between the new version and the old one. The browser can cache too, in order to make the website load as fast as possible 💨.
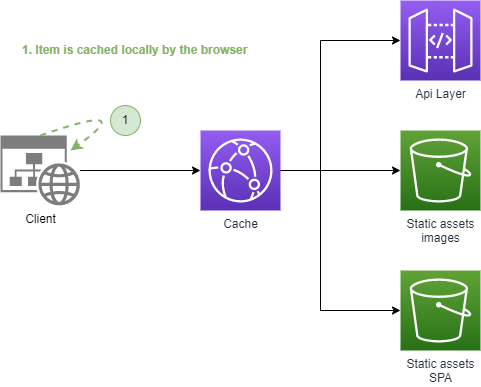
Now that we know all the possibile ways to cache with a website, _how does your browser or the cache know when it's time to refresh the item?_
To answer this question, we need to talk in-depth about the Cache-Control header!
> _**Content Delivery Network (CDN)** is group of servers, distributed across the globe, that caches content near end users. It's one type of caching mechanism, it's really effective for static content, so if we are using S3 we are going to serve S3 static files though Amazon CloudFront which is Amazon CDN. [https://aws.amazon.com/cloudfront/](https://aws.amazon.com/cloudfront/)_
# Cache-Control header
With Cache-Control, we are able to control caching on our website. This header instruct users' browsers how to cache resources like images, CSS, scripts, etc.
There are a lot of directives. I'll cover some of the main ones, but if you want to check all of them out, I encourage you to take a look here [https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control).
Let's go though some of the main directives for cache control:
- **public**: the resource can be cached by any cache such as browser or CDN;
- **private**: the resource can be cached only by users' browsers. Could be useful when serving personalized content to users, and you don't want others to access them;
- **no-cache**: browsers must revalidate the cached resource before serving it to users;
- **no-store**: browsers must not store the resources at all;
- **max-age**: the resource maximum amount of seconds that can be cached before fetching it again;
- **must-revalidate**: tells the browser that it always needs to validate the cache with the CDN before using it;
- **immutable**: the resource won't change while it's cached. This is very effective for item that do not change, like images.
By using these directive in che Cache-Control header, you can control how website resources are cached. Let's look at a few examples:
- **Cache-Control: no-cache, no-store, max-age=0, must-revalidate**
This one is not really tricky, is it? You want to be double sure that users always see the latest version of the resource;
- **Cache-Control: public, max-age=86400, immutable**
This directive tells browsers and CDN will cache the object for 1 day. After that, the resource will be fetched from the CDN.
You may have noticed me mentioning CDN and S3. Let's explore how those guys can work together towards a common goal: improving website performance!
# Amazon CloudFront with Amazon S3
CloudFront is a powerful CDN that can improve website speed and performance by caching resources on edge location, which are closer to the user. To control caching behaviors on CloudFront, you can specify a cache policy. A cache policy defines how CloudFront should cache resources, like its headers, query strings, paths, etc. Cache policy comes in two flavors:
- Managed: Amazon-managed cache policies, which are suitable for most use cases;
- Custom: personalized cache policies, which, for example, allow you to cache to cache an item for a specific amount of time.
In addition to setting cache policies on CloudFront, you can also specify the cache-control header on your origin (S3) files. _What happen when you combine CloudFront cache settings with the cache-control header?_
When CloudFront fetches a resource for S3, it checks the cache-control header to determine how long it should cache the resource. This part is a little tricky because CloudFront can override the origin file cache-control header and use its own policy. This is actually great because it allows us to customize the caching policy for our CDN and users' browsers.
Here are a few examples of how CloudFront and S3 can work together:
- If CloudFront has a minimum TTL of 60 seconds and a resource has a Cache-Control header with max-age=30, CloudFront will cache the item for 60 seconds while the browser will cache it for 30 seconds;
- If CloudFront has a minimum TTL of 60 seconds and a maximum TTL of 180 seconds and a resource has a Cache-Control header with max-age=120, both CloudFront and the user's browser will cache the item for 120 seconds;
- If a resource's cache-control header cannot be changed, and browsers are receiving items without a cache-control header, they will make requests to CloudFront every time. In this case, we can override the Cache-Control header of our objects by creating a custom "response headers policy" (as well as removing headers). After the association with our origin, browsers will see the Cache-Control header;
- If CloudFront has a minimum TTL of 10 hours (36000 seconds), and a resource has a Cache-Control header with max-age=7200 (2 hours), browsers will cache the item for 2 hours. If you decide to invalidate the CloudFront cache after 1 hour, browsers will still have the old item for at most another hour before making a new request to CloudFront.
> _If you want more examples of how CloudFront behaves with Cache-Control header coming from the origin, I suggest taking a took at this resource: https://docs.aws.amazon.com/AmazonCloudFront/latest/DeveloperGuide/Expiration.html_
# Cache invalidation: keeping your CDN up-to-date

As developers, we all want to ensure that our users are seeing the latest version of our applications. That's when cache invalidation comes in. I personally love using this technique with CloudFront and I think it's a must-do step when deploying a new version of our web application. Let's take a closer look at how it works with some real use cases.
## Case 1: Deploying SPA to S3
When you deploy your single-page application (SPA) to S3, you need to create a new invalidation to tell CloudFront to remove currently cached resources. By doing this, when users ask for resources, CloudFront fetches the latest version from S3.
## Case 2: Updating Images
Let's say you have a new version of an image that you want CloudFront to serve. You can create a new invalidation of that specific image, specifying the path of the resource that needs to be invalidated. By doing this, CloudFront will remove only that specific object from the cache, while every other object remains cached.
Finally we are getting somewhere, but I'm afraid it's still not enough. The invalidation doesn't prevent browsers from caching but it ensures that, when browsers ask the CDN for a resource, it does return the latest version of that resource.
To solve this big puzzle we just have to answer one more stinging question: _How can we force browsers to always download the latest resource?_
# Forcing browsers to get the latest version
Luckily there are several ways of forcing our browser, some techniques are:
- **Cache-Control**: we can use this header to ensure browsers don't cache the item. To do so we can set the header to "no-cache" or "max-age=0". Unfortunately this means that browsers won't cache a bit of our resources;
- **Cache bursting**: is a common technique that add an uniquely identifier to the resources, in my opinion there are two ways of doing it:
**· editing the file url** in order to add an unique identifier of that resources. For example, you can add **?version=20230328** as query string or **/v2/** as path parameter;
**· editing the file name** in order to create a complete new item. For example, you can add files with names that include a unique identifier, such as **style_uuid123.css**.
This strategy ensure the browser always request the last item.
Most framework like Angular, React and Svelte already use techniques to trick browsers into getting the latest file version. I'm using SvelteKit right now, and when I build my SPA I get these files:
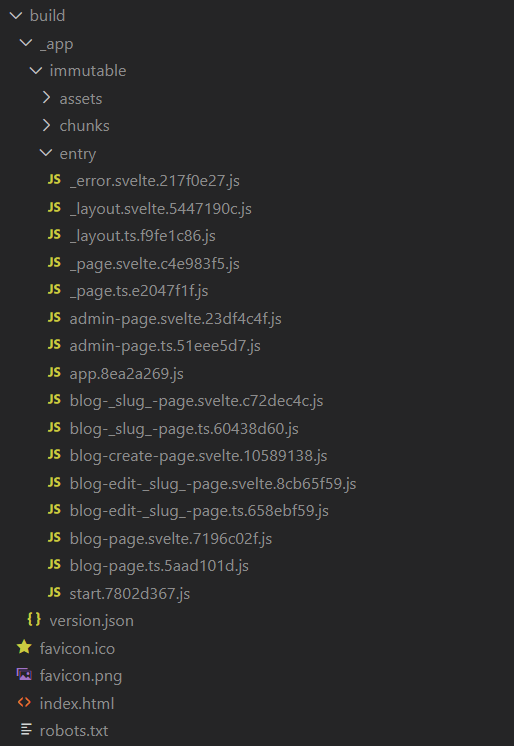
You probably already spotted them, there are files containing an unique identifies in their name and some of them who don't. Some of them can be cached indefinitely, like favicon.ico. On the contrary, index.html, is a little bit special and requires a special treatment⭐️.
To understand why index.html is special we need to take a look at its code:
```
<!DOCTYPE html>
<html lang="en">
<head>
...
<link rel="modulepreload" href="/_app/immutable/entry/start.7802d367.js">
<link rel="modulepreload" href="/_app/immutable/chunks/index.af49b43e.js">
<link rel="modulepreload" href="/_app/immutable/chunks/singletons.56ce5c0b.js">
<link rel="modulepreload" href="/_app/immutable/chunks/index.323fade2.js">
<link rel="modulepreload" href="/_app/immutable/chunks/control.e7f5239e.js">
<link rel="modulepreload" href="/_app/immutable/entry/app.8ea2a269.js">
<link rel="modulepreload" href="/_app/immutable/chunks/preload-helper.41c905a7.js">
</head>
</body>
...
</body>
</html>
```
As you can see it uses files with their unique name (yeah, obviously!). Therefore, if you cache index.html it won't fetch the new files from the CDN because the browser has already all the files it needs.
Caching index.html is completely up to us, if we cache it for a long time, it means the browser will still use the old version for a long time after we deploy the new one. On the contrary, if we do not cache it at all, we require browsers to always fetch it from the CDN.
> _⚠️Note: if you have updated your Api layer, remember that clients using the old version will call the new Api._
Now that we have the biggest picture ever with all its small details, we can get back to us. Remember at the start of this journey we were talking about caching strategies for my own blog? Let's see what all of this is about then!
# Caching strategy for SPA with CloudFront and S3
I personally found that combining cache-control header and CDN policies to control caching behavior on my website was very effective in improving website speed and performance.
As I'm building my own website, I first need to determine my caching requirements. In order to do so, I'm going though these points:
- _What is my content made of?_ In my case, it's a static website with images, text and Api layer;
- _How frequents are updates?_ The main structure is pretty much immutable. However, even though I may not need it, if I deploy a new version, I want it to be up and running as soon as possible;
- _Does the content need to be always up-to-date?_ The content is mostly static, but I need the Api layer to be up-to-date if there is a new blog post or I update an old one.
Perfect, with these 3 questions, I can find the perfect caching strategy. My website has images, Api and html/CSS, and I need 3 different caching policies for each one of them:
- **Cache bursting** for my SPA, this comes out of the box. I just need not to cache **index.html**;
- **Long cache** for images, it could be one year because I won't change a bit about them. As we are implementing cache bursting, we can have a long cache even for the SPA resources (index.html excluded);
- **Cache invalidation** for the Api layer, SPA content and images. As per CDN policies, we can cache them for one year because if there is an update, we are going to invalidate the cache. Cache invalidation could be done when:
**· Creating blog post**: we are going to invalidate the list posts Api;
**· Updating blog post**: here we are going to invalidate the list and get post Api;
**· Deleting blog post**: we are going to invalidate the list and get post Api;
**· Updating SPA content**: here we are going to invalidate all the cached content.
To implement these caching strategies, we must divide our implementation into two different parts:
1. **Cache invalidation** when the Api cache must be invalidated. The simplest way to do this task is triggering a lambda function when it's time to invalidate the cache (in my case, it's a DynamoDB trigger) which will invalidate CloudFront cache;
2. **Cache-Control header**. This part must be done when uploading files to S3. I've written a simple bash script for the purpose of:
· Uploading SPA resources to S3 without index.html;
· Uploading index.html to S3;
· Invalidating CloudFront cache.
The script
```
#!/bin/bash
# Get input variables
ENV=$1
BUCKET_NAME=$2
DISTRIBUTION_ID=$3
MAX_AGE=$4
# Build the app
vite build
# Sync files to S3 bucket
# index.html must not be cached
# if is not prod I need robots.txt in order to not be indexed
if [ "$ENV" = "prod" ] || [ "$ENV" = "production" ]; then
aws s3 sync ./build s3://$BUCKET_NAME --exclude index.html --cache-control max-age=$MAX_AGE,public --delete
else
aws s3 sync ./build s3://$BUCKET_NAME --exclude index.html --exclude robots.txt --cache-control max-age=$MAX_AGE,public --delete
fi
# Copy index.html file to S3 bucket
aws s3 cp ./build/index.html s3://$BUCKET_NAME
# Invalidate CloudFront cache
aws cloudfront create-invalidation --distribution-id $DISTRIBUTION_ID --paths "/*"
echo "Deployment completed successfully!"
```
And you can run it like so:
`deploy.sh dev dev-bucket-name A1L8C2POHERJBA 3600`
# Conclusion
As we conclude this article, I'm reminded it was a journey filled with trial and error, but eventually, it led me to discover some effective caching strategies that I really hope will be useful to you as well.
With the right caching solution you can cache your website as long as necessary, while still showing the latest version whenever updates are made✨.
So, please experiment with different caching strategies, and remember to always keep your website's specific requirements in mind. With there strategies, you'll be able to achieve lightning-fast website performance while serving the most up-to-date content possibile💨.
Thank you so much for reading! 🙏 I will keep posting different AWS architecture from time to time so follow me on dev.to✨ or on LinkedIn 👉 https://www.linkedin.com/in/matteo-depascale/. | depaa |
1,416,584 | My post on Hashnode | Hashnode Post | 0 | 2023-03-27T13:47:44 | https://dev.to/kengacethylene/my-post-on-hashnode-40m4 | [Hashnode Post](https://kdta.io/yS4Xz)
| kengacethylene |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.