
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,432,291 | Innovative MVP Development for Entrepreneurs and Businesses | As an entrepreneur or business owner, you understand the importance of creating a Minimum Viable... | 0 | 2023-04-11T06:00:09 | https://dev.to/amplework/innovative-mvp-development-for-entrepreneurs-and-businesses-1mg1 | mvp, development | As an entrepreneur or business owner, you understand the importance of creating a [Minimum Viable Product](https://en.wikipedia.org/wiki/Minimum_viable_product) (MVP) before launching a full-scale product or service. An MVP allows you to test the market, validate your idea, and gather feedback from potential customers without investing too much time or money.
But, how do you go about developing an MVP? Should you hire an in-house team or outsource the development work to an MVP development company? In this article, we will explore the benefits of working with an MVP app development company or MVP development consultant and how they can help you build a successful MVP.
Why work with an MVP development company or consultant?
**1. Access to expertise**
MVP development companies and consultants have a team of experienced developers, designers, and project managers who have worked on numerous MVPs. They have a deep understanding of the development process and can guide you through every step of the way, from ideation to launch.
**2. Time and cost-effective**
Building an in-house team to develop your MVP can be time-consuming and expensive. It involves hiring, training, and managing a team of developers, designers, and project managers. On the other hand, outsourcing your MVP development to an MVP app development company or consultant can save you time and money.
**3. Focus on your core business**
By outsourcing your MVP development, you can focus on your core business activities, such as marketing and sales. You don't have to worry about the technical details of building an MVP, leaving you with more time to focus on what you do best.
**4. Access to the latest technologies**
MVP development companies and consultants have access to the latest technologies and tools needed to build a successful MVP. They can help you choose the right technology stack for your product and ensure that your MVP is scalable and flexible.
**5. Flexibility and scalability**
Working with an MVP development company or consultant gives you the flexibility to scale your development team up or down based on your business needs. You can easily add or remove team members as your project progresses, saving you time and money.
Choosing the right MVP development company or consultant
Choosing the right MVP development company or consultant can be challenging. Here are a few things to consider before making a decision:
**Portfolio:** Look at the company's or consultant's portfolio to see if they have experience building MVPs similar to yours.
**Expertise:** Check if the company or consultant has expertise in the technology stack you want to use.
**Communication:** Communication is crucial when working with an MVP development company or consultant. Make sure they have a clear communication process in place, and they are responsive to your queries.
**Cost:** Compare the costs of different MVP development companies or consultants before making a decision.
**Conclusion**
Building an MVP is a crucial step in launching a successful product or service. Working with an MVP development company or consultant can help you build a successful MVP that meets your business needs. They offer expertise, time and cost-effectiveness, and access to the latest technologies. When choosing an [MVP development company](https://www.amplework.com/mvp-development/) or consultant, consider their portfolio, expertise, communication, and cost. With the right partner, you can build an innovative MVP that sets your business up for success. | amplework |
1,432,639 | WebAssembly reminds me of Java Applets and Macromedia Flash | Rust programming language is meant to write software for low-powered hardware devices, the majority... | 0 | 2023-04-11T12:45:47 | https://blog.chetanmittaldev.com/webassembly-reminds-me-of-java-applets-and-macromedia-flash | ---
title: WebAssembly reminds me of Java Applets and Macromedia Flash
published: true
date: 2023-04-08 11:45:36 UTC
tags:
canonical_url: https://blog.chetanmittaldev.com/webassembly-reminds-me-of-java-applets-and-macromedia-flash
---

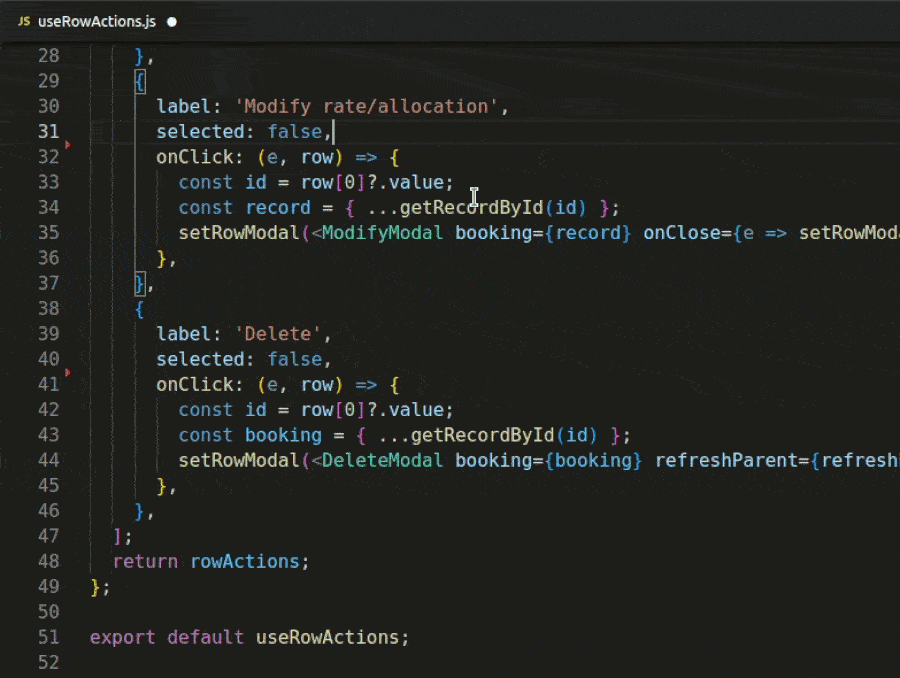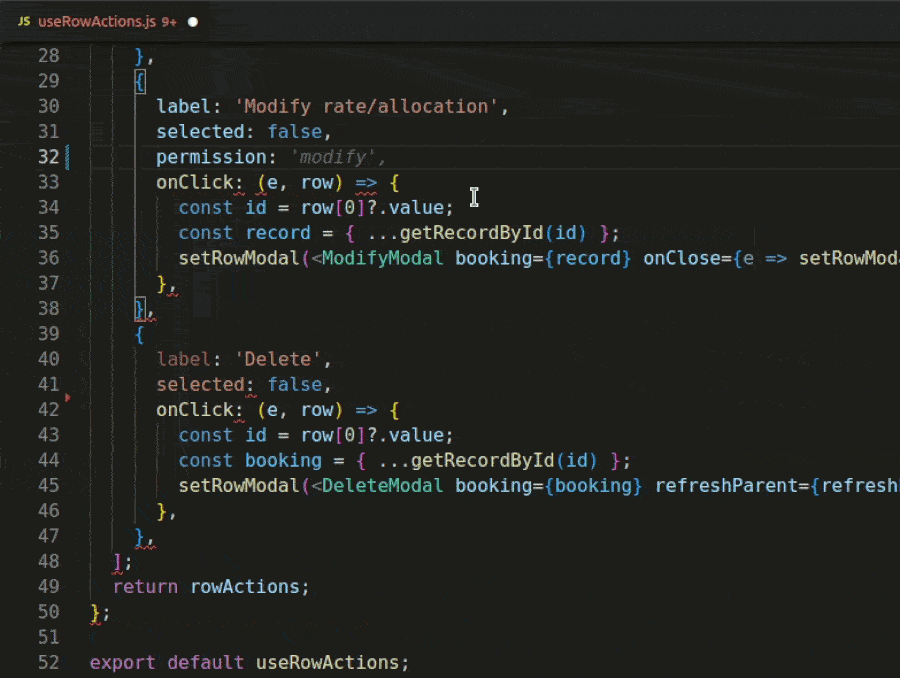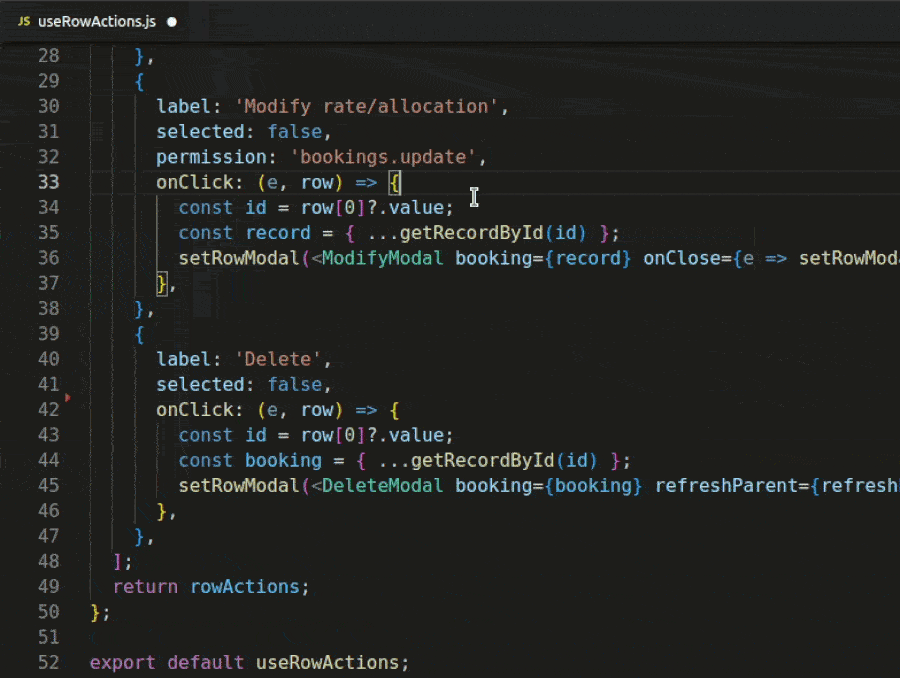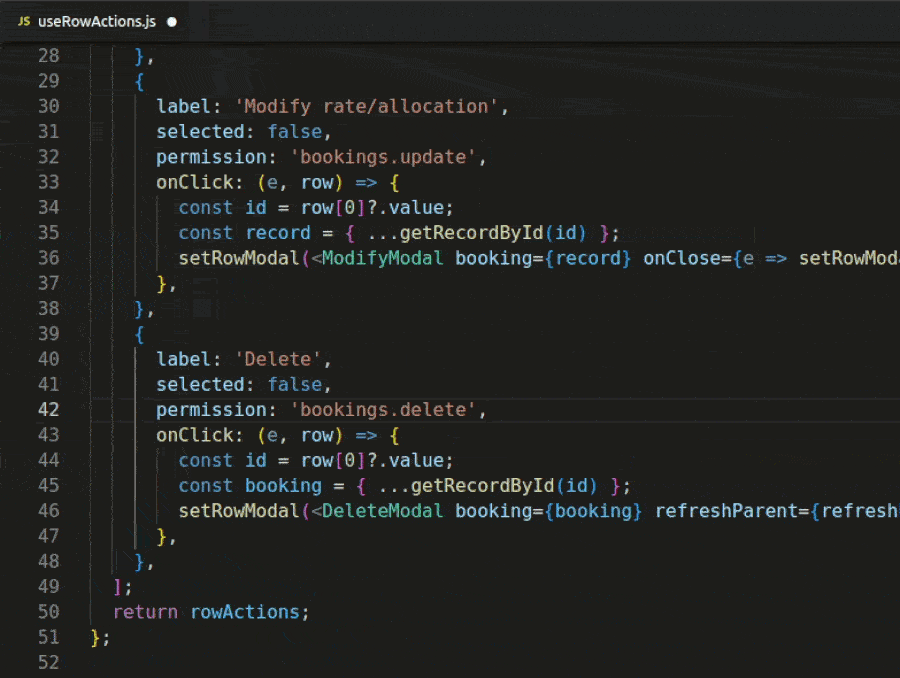
Rust programming language is meant to write software for [low-powered hardware devices](https://blog.chetanmittaldev.com/10-best-use-cases-of-rust-programming-language-in-2023), the majority of which include IOT devices, embedded devices such as industrial machines, robotic devices, etc.
WebAssembly is a virtual machine (a software program) that is inbuilt into modern browsers, such as Chrome, Firefox, Safari, Edge, etc., to download and execute a binary file(s) (a compiled software program specified in the `<script>` tag in your HTML file) inside the browser.
A majority of WASM software programs are written in the Rust programming language. Though these can be written in C/C++ and Ruby-Lang too.
See the diagram below:-

WASM binary files are included in the HTML files the same way Javascript files are included inside a <script> to tell your browser that there is a web-assembly file that it needs to download and execute.
<script src="mymodule.wasm"></script>
Unlike Javascript which is interpreted on the run, from the source file, without any compiling; WASM binaries are pre-compiled files meant for fast execution and safety.
Java Applets and Adobe Flash were the same, a software program pre-compiled into a binary file running within the browser.
And similar to WASM binaries needing a software program in the browser to get downloaded and executed, both the Java Applets and Adobe Flash needed a browser plugin to get downloaded and executed within the browser.
[https://steveklabnik.com/writing/is-webassembly-the-return-of-java-applets-flash](https://steveklabnik.com/writing/is-webassembly-the-return-of-java-applets-flash)
During my early days in software programming, I built a few websites based on Java Applets and I seriously remember the nightmares I used to have while debugging those.
[https://stackoverflow.com/questions/868111/how-do-you-debug-java-applets](https://stackoverflow.com/questions/868111/how-do-you-debug-java-applets)
In 2023, I use either Ruby or JavaScript for building software applications, using [VIM](https://www.vim.org/) and [Visual Studio Code](https://code.visualstudio.com/), and both programming languages are really easy to debug on the fly than C/C++ and Java, and Rust.
I wouldn't definitely want to go back to the old days of having debugging nightmares and waiting hours while my Rust or C/C++ files for WASM are getting compiled.
[https://media.giphy.com/media/tXL4FHPSnVJ0A/giphy.gif](https://media.giphy.com/media/tXL4FHPSnVJ0A/giphy.gif)
I would say, using WASM would make more sense than JavaScript only where there is a need for a CPU-intensive software program execution because of being written in Rust and compiled.
The best examples could be:-
- Games inside the browser
- Image, audio, and video editing inside the browser
- Machine learning computations inside the browser
- Etc
Do you have any other examples where WASM could be used best? Please comment. | chetanmittaldev | |
1,432,779 | Amazon EC2: Powering Cloud Computing with Virtual Servers | Unveiling the Power of Elastic Compute Cloud for Scalable and Flexible Virtual Servers ... | 0 | 2023-04-11T16:14:32 | https://blog.seancoughlin.me/amazon-ec2-powering-cloud-computing-with-virtual-servers | cloud, cloudcomputing, ec2, aws | ---
title: Amazon EC2: Powering Cloud Computing with Virtual Servers
published: true
date: 2023-04-11 15:19:02 UTC
tags: #cloud #cloudcomputing #ec2 #aws
canonical_url: https://blog.seancoughlin.me/amazon-ec2-powering-cloud-computing-with-virtual-servers
---
Unveiling the Power of Elastic Compute Cloud for Scalable and Flexible Virtual Servers

## Introduction
[Amazon Elastic Compute Cloud (EC2)](https://aws.amazon.com/ec2/) is a core component of [Amazon Web Services (AWS)](https://aws.amazon.com), offering scalable, on-demand virtual server instances for various computing needs. In this post, we'll explore what EC2 is, its history, potential applications, and how it has revolutionized the cloud computing landscape.
## What is Amazon EC2?
Amazon EC2 is an [Infrastructure as a Service (IaaS)](https://dev.to/scc33/exploring-cloud-computing-types-iaas-paas-saas-and-beyond-1cd0) offering that allows users to provision and manage virtual servers, called instances, [in the cloud](https://dev.to/scc33/demystifying-the-cloud-understanding-the-fundamentals-and-impact-of-cloud-computing-2bpd). These instances can be customized with various configurations, such as CPU, memory, storage, and network capacity, to suit specific workloads and requirements. EC2 instances run on Amazon's global infrastructure, ensuring high availability, performance, and security. Users can scale their infrastructure up or down as needed, paying only for the resources they consume.
## The History of Amazon EC2
[Launched in 2006](https://en.wikipedia.org/wiki/Amazon_Elastic_Compute_Cloud#History), Amazon EC2 was one of the first commercially available cloud computing services, marking the beginning of the modern cloud era. The introduction of EC2 was a game-changer, providing developers and businesses with an alternative to traditional, capital-intensive server infrastructure. Since its inception, EC2 has continually evolved, adding new features, instance types, and additional services to enhance its capabilities and cater to the ever-growing demand for cloud computing resources.
## Potential Applications of Amazon EC2
Amazon EC2 has a wide range of potential applications, making it a versatile solution for various computing needs:
- Web Hosting: EC2 instances can be used to host websites and web applications, providing scalable resources to handle fluctuating traffic loads.
- Big Data Processing: EC2 can be utilized for processing large datasets, running analytics, and deploying machine learning models, with the ability to scale resources dynamically as workloads increase.
- Backup and Disaster Recovery: EC2 instances can serve as backup servers or form part of a disaster recovery strategy, ensuring data is stored redundantly and can be quickly restored in case of an outage or data loss.
- Development and Testing: Developers can use EC2 instances to create and test applications in isolated environments, without impacting their local machines or production systems.
- High-Performance Computing ([HPC](https://en.wikipedia.org/wiki/High-performance_computing)): EC2 offers specialized instance types optimized for compute-intensive workloads, such as scientific simulations, rendering, and financial modeling.
## Complementary Services in the AWS Ecosystem
Amazon EC2 is tightly integrated with other AWS services, enabling users to build comprehensive cloud-based solutions:
- [Amazon Elastic Block Store (EBS)](https://aws.amazon.com/ebs/): Provides persistent block storage for EC2 instances, ensuring data is retained even after an instance is terminated.
- [Amazon Virtual Private Cloud (VPC)](https://aws.amazon.com/vpc/): Offers isolated virtual networks within the AWS infrastructure, allowing users to configure and control their network environment.
- [Amazon Elastic Load Balancing (ELB)](https://aws.amazon.com/elasticloadbalancing/): Distributes incoming traffic across multiple EC2 instances, improving availability and fault tolerance.
- [Amazon Relational Database Service (RDS)](https://aws.amazon.com/rds/): A managed database service that can be used in conjunction with EC2 instances to store and manage application data.
## Conclusion
Amazon EC2 has played a pivotal role in the growth and adoption of cloud computing, offering a flexible, cost-effective alternative to traditional server infrastructure. As businesses embrace the cloud, EC2 is a pivotal component of the AWS ecosystem, providing scalable, on-demand computing resources for many applications and workloads.
---
Originally published at https://blog.seancoughlin.me. | scc33 |
1,432,897 | Building a QR code generator | What is a QR code? QR code is a later version of a data matrix barcode invented in japan... | 0 | 2023-04-16T02:07:47 | https://dev.to/cedsengine/building-a-qr-code-generator-onj | webdev, javascript, programming, tutorial |
##What is a QR code?
QR code is a later version of a data matrix barcode invented in japan in 1994, data matrix barcode was used to label automotive parts, these labels when scanned would output information pertaining to the automotive part the code referenced. This was a great way to have accessible information contained and hidden only to be accessed when needed.
Qr codes are widely used to store a variety information for business and personal use. From links to websites, advertisements, contact info, restaurant menus and payment processing etc. QR codes hold more information than data matrix barcode and makes information easier to access for anyone with a smart device camera.
I will be walking you through a simple QR code generator application made with Javascript and HTML using the JS library called qrcode on the CDNJS platform (https://cdnjs.com/libraries/qrcode). However, for those who want to use a Framework there are Node packages for QR code generation as well (https://www.npmjs.com/package/qrcode#highlights).
###Let’s Build!
To begin the Process of building out your QR code generator we will add the Qr code script into the head of our HTML structure.
```
<script
src="https://cdnjs.cloudflare.com/ajax/libs/qrcodejs/1.0.0/qrcode.min.js"
integrity="sha512-CNgIRecGo7nphbeZ04Sc13ka07paqdeTu0WR1IM4kNcpmBAUSHSQX0FslNhTDadL4O5SAGapGt4FodqL8My0mA=="
crossorigin="anonymous" referrerpolicy="no-referrer">
</script>
```
In the example below a form element is created for users to submit a URL and the size of the Qr code they prefer. (This library will also allow users to pick the color of the Qr code also if you are interested.)
```
<form id="generate-form">
<input id="url"
type="url"
placeholder="Enter URL here"
/>
<select id="size">
<option value="100">100x100</option>
<option value="200">200x200</option>
<option value="300" selected>300x300</option>
<option value="400">400x400</option>
<option value="500">500x500</option>
<option value="600">600x600</option>
<option value="700">700x700</option>
</select>
<button type="submit">
Generate QR Code
</button>
</form>
```
The form element will submit the URL and size value needed for QR code generator functionality.
### Javascript functionality
Begin with declaring two variables, form element and the element that will display the Qr code.
```
const form = document.getElementById('generate-form');
const qr = document.getElementById('qrcode');
```
Next add this code provided by the library we are using, generateQRCode() will take in two arguments and generate the QR code correlated to the arguments passed in.
```
const generateQRCode = (url, size) => {
const qrcode = new QRCode('qrcode', {
text: url,
width: size,
height: size
})
}
```
### Submit function
```
const form = document.getElementById('generate-form');
const qr = document.getElementById('qrcode');
const generateQRCode = (url, size) => {
const qrcode = new QRCode('qrcode', {
text: url,
width: size,
height: size
})
};
const onSubmit = (e) => {
e.preventdefault();
const url = document.getElementById('url').value;
const size = document.getElementById('size').value;
if(url === '') {
alert('Please enter a URL');
} else {
generateQRCode(url, size);
}
};
form.addEventListener("submit", onSubmit);
```
Two variables are declared to contain the input value, a if statement to ensure filled input, if not alert user to fill input and lastly calling the generateQRCode function with the passed in arguments.
To give onSubmit functionality to form element we add event listener to listen for form submissions of Qr code and pass in the event "submit" follow by the function onSubmit.
####With this you should have a functioning Qr code generator!
| cedsengine |
1,433,002 | Maximizing Your Potential as a Programmer with AI Assistance | As software development continues to advance, LLM-powered tools and services are emerging as a key... | 0 | 2023-04-11T19:54:04 | https://dev.to/fredericocarneiro/maximizing-your-potential-as-a-programmer-with-ai-assistance-5eg9 | llmpowered, aipowered, productivity, tooling | As software development continues to advance, LLM-powered tools and services are emerging as a key component of the field. By automating routine tasks and enhancing code quality, these advanced technologies can be a powerful tool for developers looking to enhance their skills and stay competitive in a fast-paced industry. In this article, we'll explore how LLM-powered approaches can elevate your software development skills and assist you in achieving your goals as a programmer.
But how can software engineers potentialize their skills with AI assistance?
Let’s dive into this new universe of AI powered tools that certainly will boost your quality and productivity.
## Automating routine tasks
One of the most significant advantages of using AI in software development is the ability to automate routine tasks. With AI-powered tools, developers can automate repetitive tasks such as code formatting, testing, and debugging. This frees up valuable time that can be spent on more complex and challenging tasks, such as improving software functionality and creating innovative solutions.
Take the example of code formatting. This task can be incredibly time-consuming and often requires a significant amount of effort. However, with AI-powered tools, code formatting can be automated, allowing developers to focus on more pressing issues. Similarly, testing processes can also be automated using tools like Testim.io. This tool can identify and correct test cases after detect changes in the codebase. This allows developers to quickly identify and fix test case scenarios issues, without having to spend time manually on it.
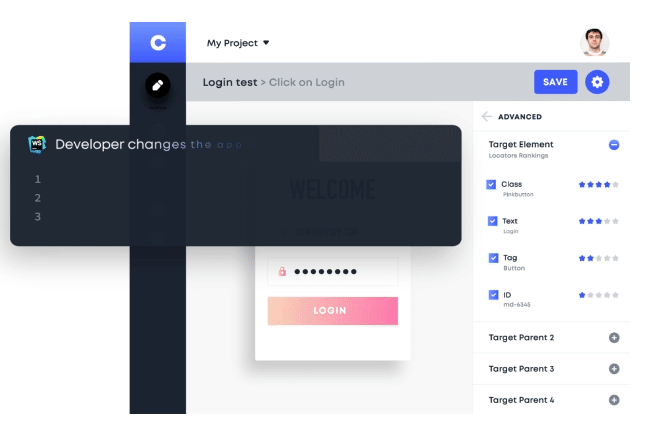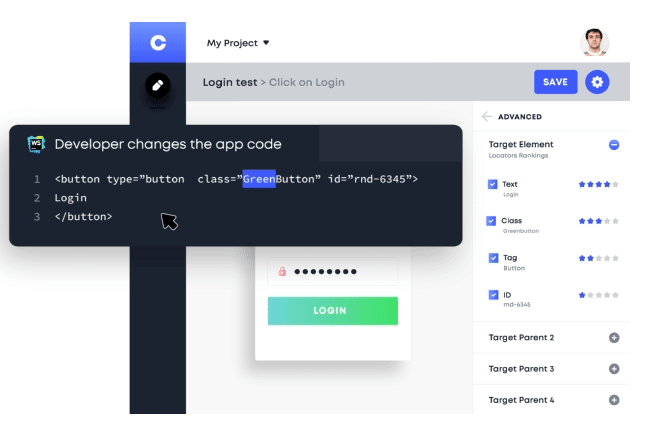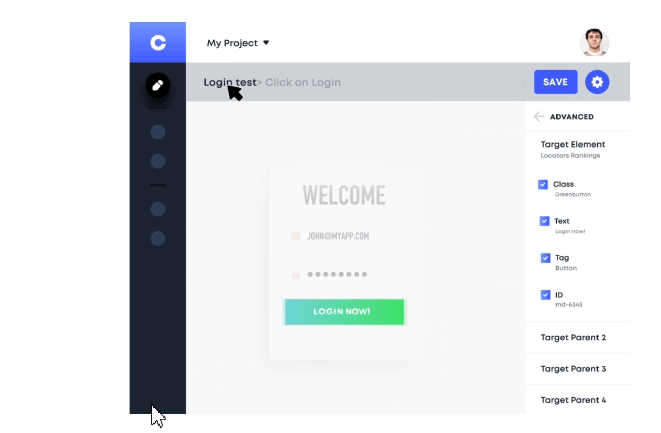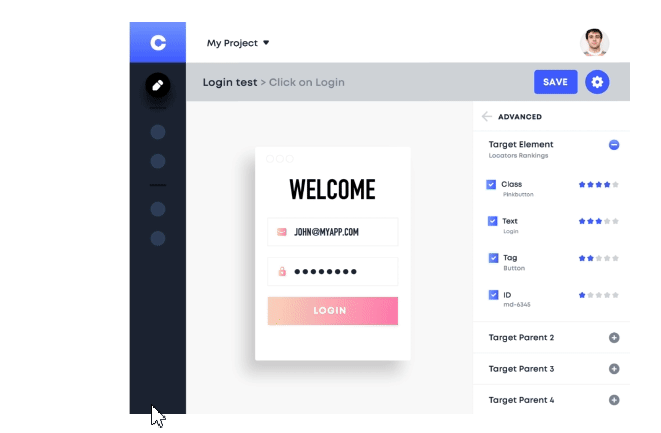
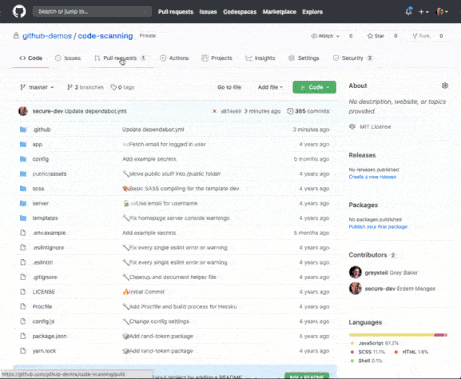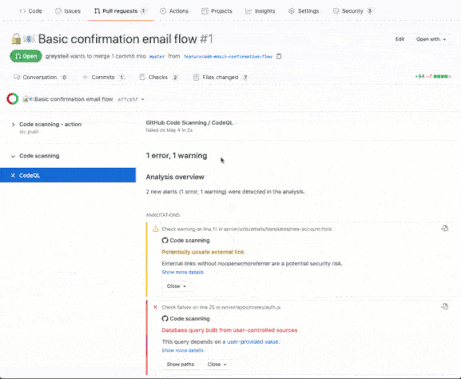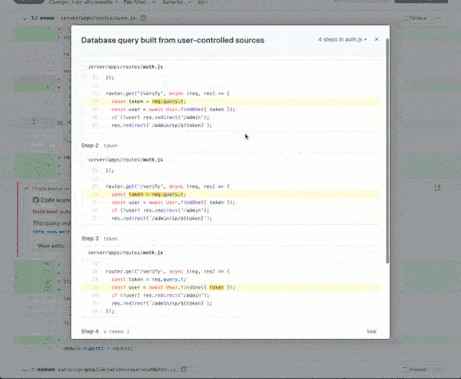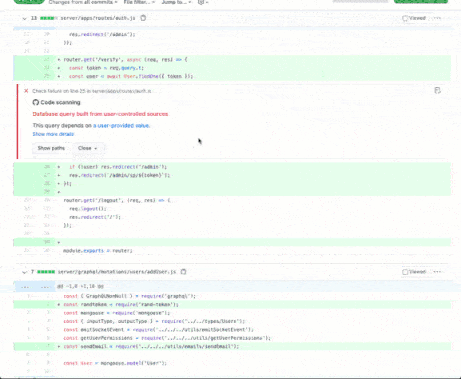
Security is also a significant concern in software development. With the rise of cyber threats, it's more critical than ever to ensure that code is secure. This is where tools like GitHub's CodeQL come into play. Using machine learning, CodeQL code analysis tool can help identify security vulnerabilities in code changes. By automating this process, CodeQL enables developers to find and fix security issues more efficiently.
Artificial intelligence (AI) tools are revolutionizing the software development industry, and Refraction is at the forefront of this trend. This web-based tool uses AI to speed up unit testing, improve code quality, and enhance code reliability. Refraction's ability to automatically generate tests based on code changes saves developers time and reduces the risk of missing critical issues. By identifying potential issues early on in the development cycle, developers can reduce the risk of costly errors and improve the overall quality of the code. This can lead to faster development cycles, fewer bugs, and ultimately, better software.
Refraction AI capabilities also enable it to improve code quality by identifying potential bugs, security vulnerabilities, or performance issues. The tool can provide recommendations for improving the code, such as suggesting alternative coding patterns or highlighting potential areas of optimization. By automatically analyzing code and identifying potential issues, Refraction allows developers to focus on writing high-quality code that meets the needs of their users.
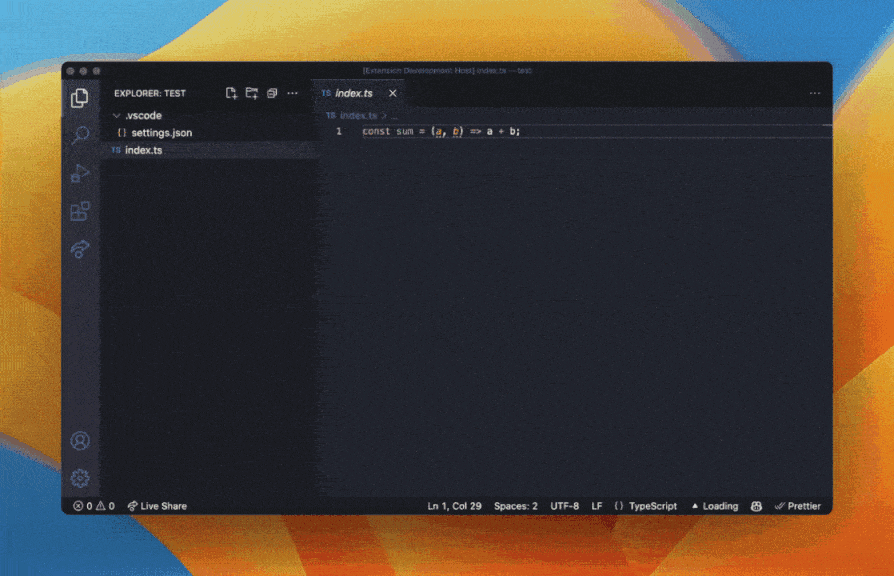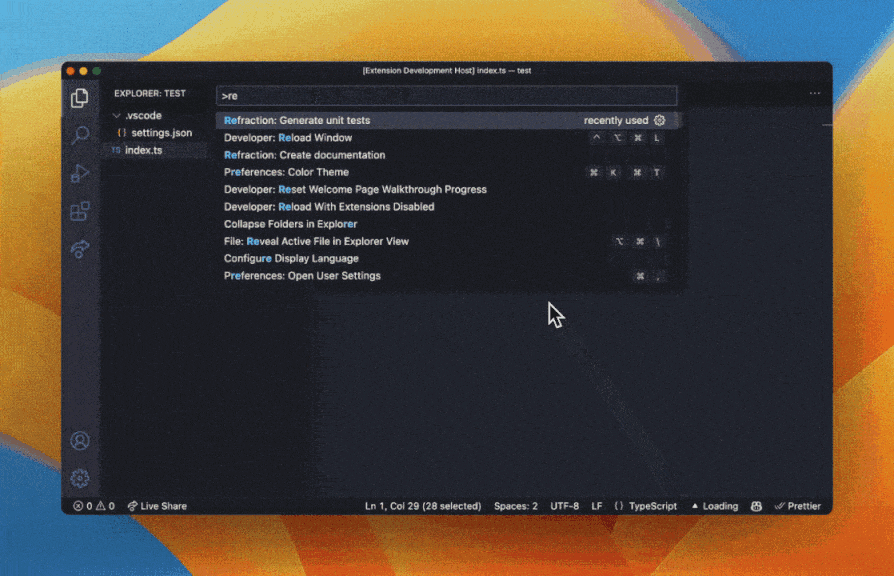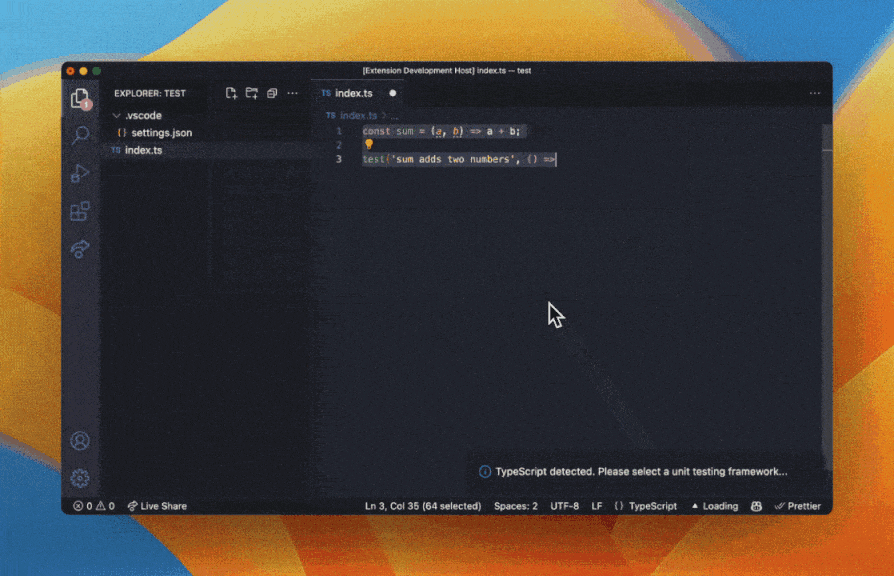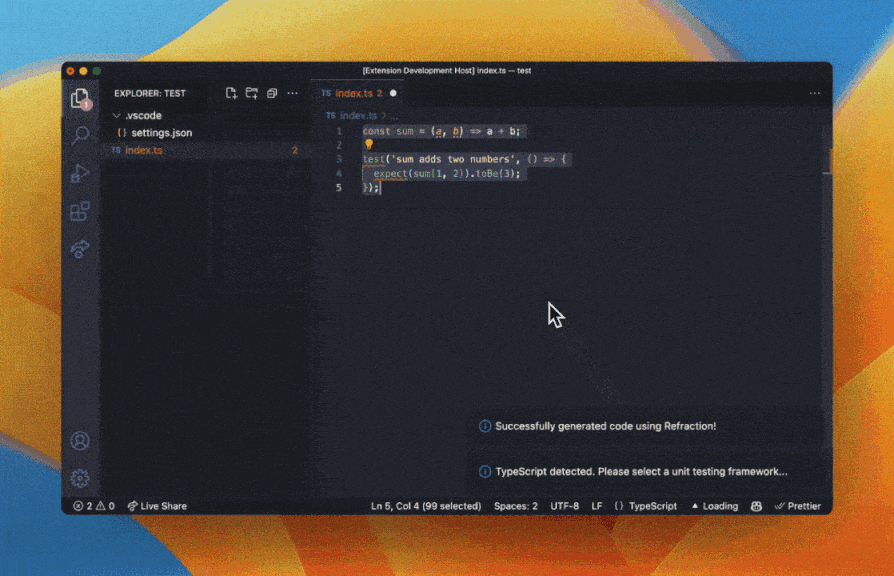
Ultimately, the use of AI in software development can greatly improve the quality of code by providing real-time feedback and insights, automating routine tasks, and identifying potential issues before they become larger problems. By using these tools to improve the quality of their code, developers can produce software that meets the needs of users and customers, while also staying ahead of the competition in a rapidly changing industry.
## Enhancing collaboration
AI-powered collaboration tools can help to connect developers across teams and geographies, providing a platform for real-time collaboration and feedback on projects.
Notion, the popular productivity and collaboration tool, has added a new feature that allows users to ask an AI to continue writing in the same style and tone as their previous text. This new feature, called NotionAI, is powered by OpenAI's GPT-3 language model and is designed to save users time and effort by automating the writing process.
With NotionAI, users can simply type in a few words or sentences and let the AI take over, generating text that matches the style and tone of their previous writing. This can be especially useful for tasks such as drafting emails, writing reports, or creating project documentation. By automating the writing process, NotionAI frees up users' time and allows them to focus on more important tasks, such as strategizing or analyzing data.
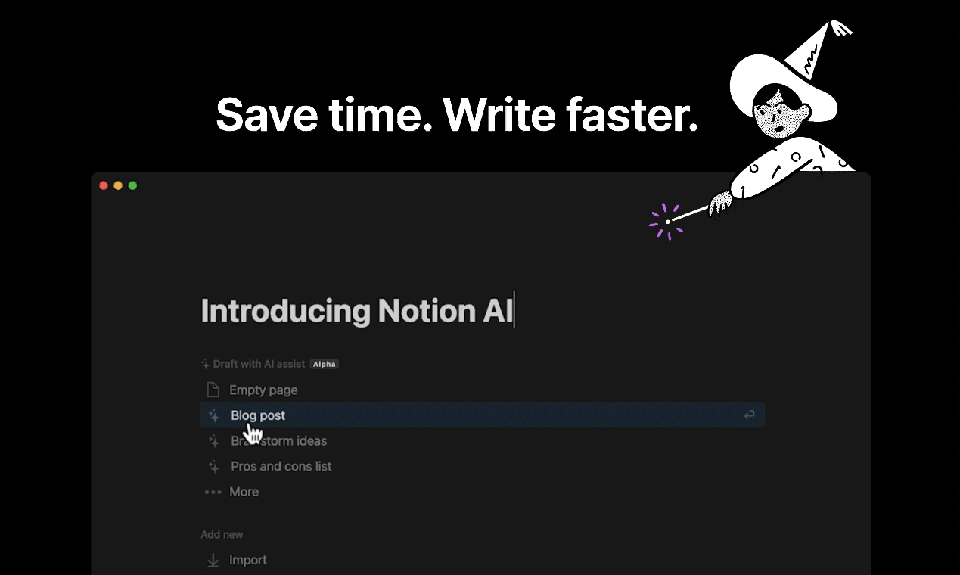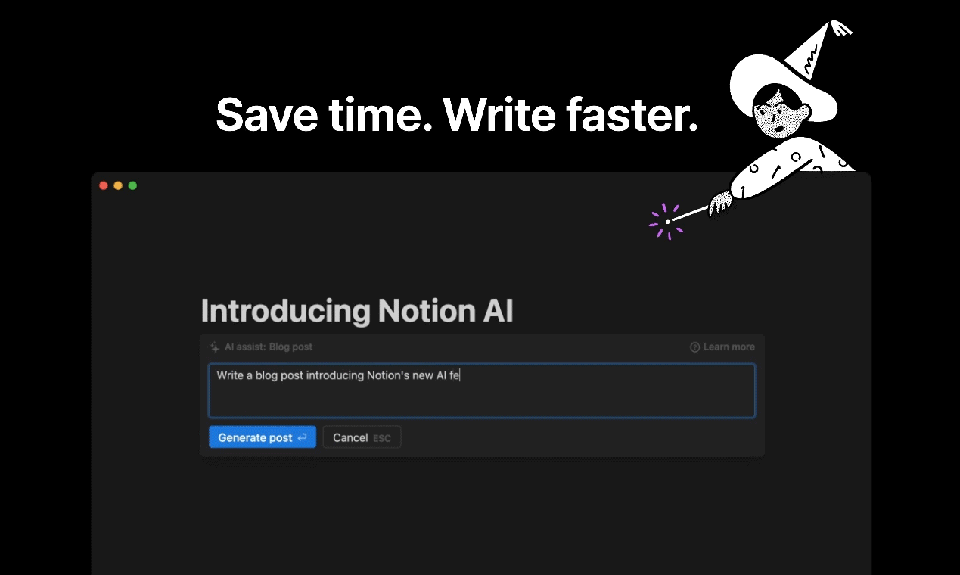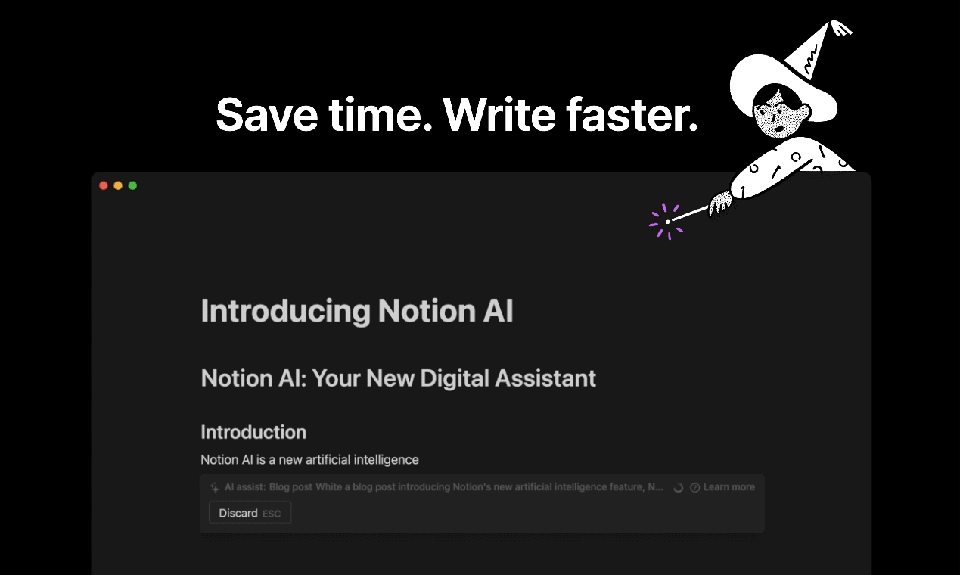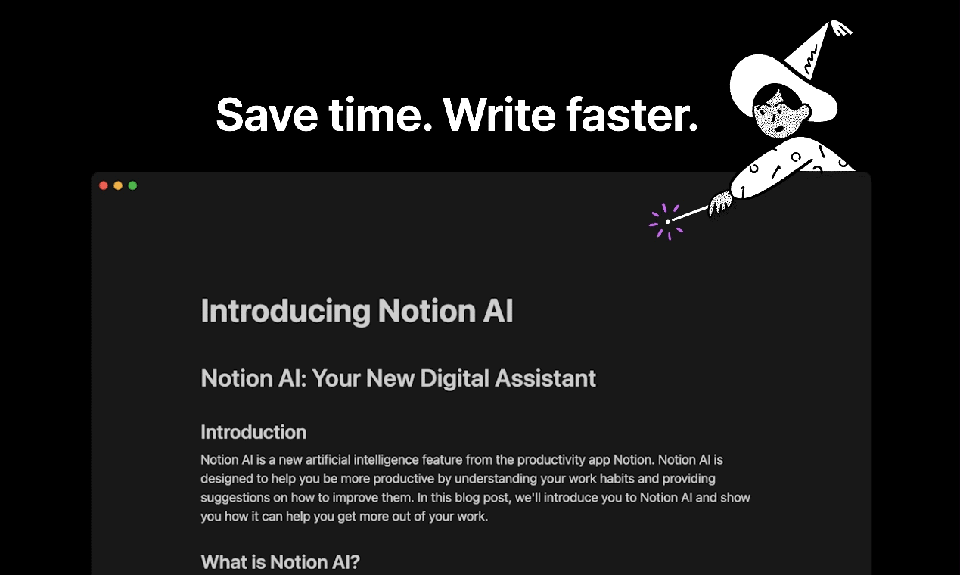
Another interesting tool similar to Notion is Taskade AI, also driven by advanced LLM technology. Taskade is a all-in-one solution designed to elevate team collaboration for the modern workforce. This multifaceted platform unites five essential AI-powered features such as content writing, task and project management, note-taking, document editing, mind mapping, and video chat. All this to streamline organization and enhance productivity. The benefits of this tool include accelerated content generation, customizable project views, and real-time collaboration, enabling users to unlock their full potential and achieve greater success in their projects.
## Boosting creativity
AI-powered tools can help developers to generate new ideas and approaches to coding, leveraging machine learning and data analysis to identify patterns and make suggestions for improvement.
In today's globalized software development landscape, it's more important than ever to have tools that enhance collaboration across teams and geographies. AI-powered collaboration tools can provide real-time feedback and connection between developers, improving communication and productivity. For example, GitHub's AI-powered tool, CoPilot, can suggest code based on the context of the project and the codebase. This allows developers to work together more effectively and efficiently, as they can quickly see how their changes fit into the overall project.
When it comes to code reviews,Codeball, an AI-powered code-review bot, streamlines the software development process by approving Pull Requests (PRs) that require no further feedback or objections. Handling 63% of PRs typically marked as LGTM (Looks good to me), Codeball allows developers to concentrate on more complex PRs. Utilizing a deep learning model trained on millions of PRs, Codeball examines numerous indicators to make accurate approval decisions, ensuring efficiency and code quality in the development process.
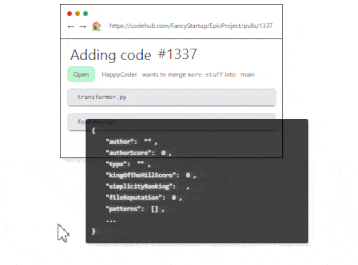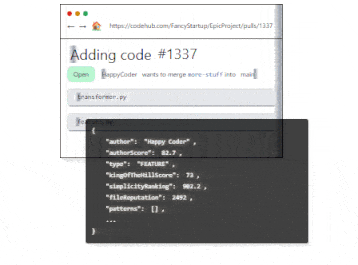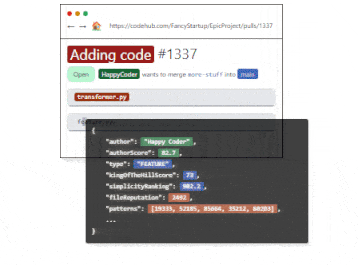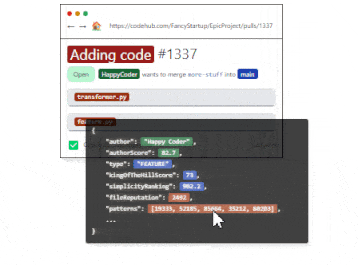
Regarding data retrieving tasks, developers can significantly boost their productivity using Text2Sql.ai by effortlessly generating complex SQL queries from simple English instructions, eliminating the need for manual query writing. The tool's enhances developers' productivity by enabling easy SQL query generation from English instructions and translating queries back into plain English for better understanding. Its compatibility with various SQL dialects and custom database schema connections promotes seamless database management, ultimately allowing developers to focus on innovation and expedite project completion.

Overall, there are many AI-powered services available to help programmers improve their code quality and boost their creativity. By leveraging these services, developers can optimize their code, save time on tedious tasks, and focus on more creative and innovative aspects of software development.
## Staying up-to-date
AI-powered tools can help developers stay current with the latest trends and technologies in the field, providing access to real-time data and insights that can inform their work and keep them ahead of the curve.
A handy tool to help developers to stay up-to-date with technology is Phind search engine. Phind’s intuitive design and AI-driven capabilities make it an invaluable resource for developers in their day-to-day tasks. By using Phind, developers can quickly obtain accurate solutions, saving time and reducing frustration often associated with conventional search engines. Its ability to parse complex questions and provide relevant code snippets streamlines the troubleshooting process, allowing developers to focus on higher-value tasks. Additionally, Phind's simple explanations facilitate better understanding of concepts, promoting continuous learning and skill development. Ultimately, integrating Phind into their routine empowers developers to work more efficiently, enhance their expertise, and deliver exceptional results in their projects.
## Conclusion
In conclusion, the use of AI in software development has the potential to revolutionize the way we work and improve the quality and efficiency of our code. By leveraging the power of machine learning, data analysis, and automation, developers can unlock new possibilities for creativity, collaboration, and innovation. Whether you're a seasoned pro or just starting out, incorporating AI tools and techniques into your development workflow can help you to become a better developer and achieve your professional goals. So why not start exploring the possibilities today and see how AI can take your skills to the next level?
Original article: [joinplank.com](https://www.joinplank.com/articles/maximizing-your-potential-as-a-programmer-with-ai-assistance)
| fredericocarneiro |
1,433,310 | The history of HTTP in under 5 minutes | The Hypertext Transfer Protocol (HTTP) is the foundation of data communication on the World Wide Web.... | 0 | 2023-04-12T04:42:03 | https://dev.to/andreasbergstrom/the-history-of-http-in-under-5-minutes-4b7p | web, http, networking, browsers | The Hypertext Transfer Protocol (HTTP) is the foundation of data communication on the World Wide Web. Since its inception, HTTP has undergone several iterations to improve its performance, security, and efficiency. In this blog post, we will take a deep dive into the history and key features of each HTTP version, from HTTP/0.9 to the latest HTTP/3, with a focus on new headers and technologies introduced in each version.
### HTTP/0.9: The Beginning
HTTP/0.9, also known as the "One-Line Protocol," was the first version of HTTP introduced by Tim Berners-Lee in 1991. It was a simple text-based protocol that allowed clients to request documents from servers using a single line command.
The client would send a request in the format "GET <path>", and the server would respond with the requested document. There were no headers or metadata, and the connection would close immediately after the transfer. While HTTP/0.9 was extremely limited, it laid the groundwork for future versions of the protocol.
### HTTP/1.0: Expanding Functionality
HTTP/1.0, officially released as RFC 1945 in 1996, expanded upon HTTP/0.9 by introducing a more robust request and response format. HTTP/1.0 added support for request and response headers, which allowed clients and servers to exchange metadata about the request and the resource being transferred. Some of the key headers introduced in HTTP/1.0 include:
**Content-Type:** Specifies the media type of the resource being transferred.
**Content-Length:** Indicates the size of the resource in bytes.
**Last-Modified:** Represents the date and time the resource was last modified.
**Expires:** Provides a date and time after which the resource is considered stale.
These headers enabled new features such as caching, content negotiation, and conditional requests. However, HTTP/1.0 still had some significant limitations, such as opening a new TCP connection for each request, which negatively impacted performance.
### HTTP/1.1: Performance and Efficiency Improvements
HTTP/1.1, first released as RFC 2068 in 1997 and later updated in RFC 2616 (1999) and RFC 7230-7235 (2014), aimed to address the performance issues present in HTTP/1.0. The most notable improvement was the introduction of persistent connections, which allowed multiple requests and responses to be sent over a single TCP connection, reducing the overhead of establishing and closing connections. HTTP/1.1 also introduced features such as pipelining, chunked transfer encoding, and additional caching mechanisms.
Some important headers introduced in HTTP/1.1 include:
**Host:** Specifies the domain name and port number of the server hosting the requested resource.
**Cache-Control:** Allows clients and servers to specify caching policies, such as max-age or no-cache.
**ETag:** Provides a unique identifier for a specific version of a resource, allowing for conditional requests and more efficient caching.
**Connection:** Indicates whether the connection should remain open for further requests or be closed after the current request.
HTTP/1.1 also paved the way for real-time communication with the introduction of WebSockets and Server-Sent Events (SSE), enabling efficient bidirectional communication between clients and servers.
### HTTP/2: A Major Leap Forward
HTTP/2, standardized as RFC 7540 in 2015, brought a fundamental shift in the way HTTP communicated over the network. Instead of using plain text, HTTP/2 utilized a binary framing layer, making it more efficient and less error-prone.
One of the most significant advancements was the introduction of multiplexing, which allowed multiple requests and responses to be sent concurrently over a single connection. This eliminated the head-of-line blocking problem present in HTTP/1.1, where a single slow request could block subsequent requests.
HTTP/2 also introduced server push, a feature that enabled servers to proactively send resources to the client's cache, anticipating future requests. Additionally, HTTP/2 offered header compression using HPACK, which reduced the overhead of sending redundant header data.
Some enhancements in HTTP/2 include:
**Stream Prioritization:** Enables clients to specify the priority of multiple requests, allowing servers to optimize resource delivery.
**ALPN (Application-Layer Protocol Negotiation):** Allows clients and servers to negotiate the specific version of HTTP during the TLS handshake, improving connection establishment time.
### HTTP/3: Embracing QUIC
HTTP/3, which began as an experimental protocol called QUIC (Quick UDP Internet Connections) at Google, was officially standardized by the IETF in 2021. The most significant change in HTTP/3 is the shift from using TCP as the transport layer protocol to QUIC, which uses the User Datagram Protocol (UDP) instead. This transition improves latency and connection establishment times by reducing the number of round trips required during the handshake process.
QUIC also introduces built-in encryption, making it more secure by default. Another notable feature is the improved handling of packet loss, which is particularly beneficial for users on unreliable networks or experiencing high latency. By employing a more efficient loss recovery mechanism and allowing for independent streams, QUIC ensures that packet loss on one stream does not impact the performance of other streams.
HTTP/3 also retains the performance features of HTTP/2, such as multiplexing, header compression, and server push. However, due to the fundamental differences between TCP and UDP, some adjustments were required. For example, HPACK compression was replaced with QPACK, a new compression scheme specifically designed for QUIC's unique characteristics. | andreasbergstrom |
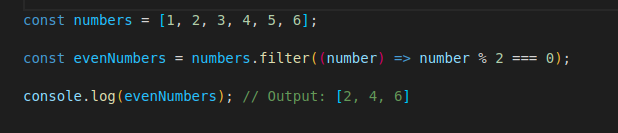
1,433,486 | 7 best practices for arrays in javascript | Arrays are a fundamental data structure in JavaScript, and are used in nearly every application.... | 0 | 2023-04-12T10:31:33 | https://dev.to/navinmishra1717/7-best-practices-for-arrays-in-javascript-9ge | javascript, programming | 
Arrays are a fundamental data structure in JavaScript, and are used in nearly every application. But working with arrays can be messy and inefficient if you don't use the right methods and techniques. In this post, we'll explore some array methods and techniques that will help you write cleaner, more efficient code.
1. forEach : The Gentle Giant of Array Methods
---
When it comes to iterating over an array, the forEach() method is the gentle giant. It quietly steps through each element in the array, without making a fuss. It doesn't care if you mutate the array or not. It just wants to be helpful.

2. map : The Transformer
---
The map() method transforms each element in an array into a new element. It's like a magical machine that takes in old junk and spits out shiny new things.

3. filter : The Cleaner
---
The filter() method is like a cleaning crew for your array. It filters out elements that don't belong, leaving behind only the good stuff.
_**Bonus**_
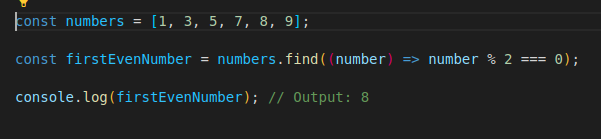
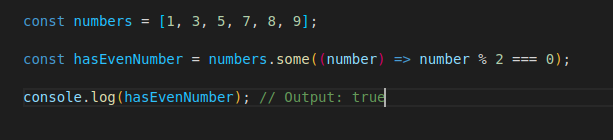
some() method checks if at least one element in an array satisfies a condition and returns boolean value. **And**, find() method returns the first element in an array that satisfies a provided testing function. It returns **undefined** if no element satisfies the condition
4. reduce : The Calculator
---
The reduce() method is like a calculator for your array. It takes in an array of numbers and crunches them down into a single number.

5. spread operator : The Expander
---
The spread operator is like a can of compressed air that expands when you use it. It expands an array into individual elements, making it easy to pass them around as separate arguments.

6. destructuring : The Unpacker
---
Destructuring is like a reverse present wrapper. It unpacks the contents of an array and assigns them to individual variables.

7. deduplication : The Remover
---
Deduplication is the process of removing duplicate values from an array. The **Set** constructor is used to create a new set object, which automatically removes duplicates.

***
####**Finally**
**Thanks for reading**. I Hope you find this article useful. Please leave a comment for mistakes so that i can improve in my next articles. And follow for more quality articles. *Happy reading!!*
| navinmishra1717 |
1,433,552 | How to Write a GraphQL Query | A beginner’s guide to writing your first GraphQL query In 2015, GraphQL was introduced by... | 0 | 2023-04-12T09:52:31 | https://dev.to/fimber01/how-to-write-a-graphql-query-5bbn | webdev, javascript, graphql, database |
#### A beginner’s guide to writing your first GraphQL query
In 2015, GraphQL was introduced by Meta as an alternative to REST APIs for building web applications and it’s safe to say GraphQL has taken the world by storm. A [recent report](https://devops.com/key-findings-from-the-2022-state-of-graphql-report/#:~:text=The%20report%20found%2047.9%25%20of,for%20third%2Dparty%20developer%20consumption.) showed that 47.9% of developers use GraphQL and that number is expected to keep rising. But what is GraphQL? How do you get started with it, and write your first query?
In this article, we’re going to be discussing the fundamentals of GraphQL, its benefits, and most importantly how to write a GraphQl query. We will walk you through the GraphQL Schema, the syntax you will need to create and execute a query, and common mistakes to avoid while writing a query. By the end of this article, you'll have a great understanding of how GraphQL works and be able to write your query with confidence.
Without further ado, let's get started!
### Prerequisites
While this is a beginner friendly article, it's still expected that you're familiar with javascript and Object Oriented Programming. If you do not, you can still read on and follow through without sruggling, as we'll go through everything together.
## What is GraphQL
[GraphQL](https://graphql.org/) is a query language for APIs that provides a more efficient, powerful, and flexible alternative to traditional REST-based APIs. GraphQL query language is used to access, query, and modify data in databases, as well as build APIs to access the data.
GraphQL simplifies the process of fetching and manipulating data from an API by allowing developers to specify exactly what data they need, in one request. This means fewer requests are needed to obtain the data and no over-fetching of data occurs. GraphQL also provides developers with more control over the shape of the data that is returned, so they can structure it exactly as they need.
Think of it this way. Let’s say you need to go on vacation, and you need clothes for your trip. If you’re using the RESTful approach to pack your clothes, you’d just take all your clothes with you and then sort them when you get there. Even if you had to take several trips.
However, if you had something like GraphQL to help you with the task, it would be able to fetch and pack only the specific clothes that you’d need, saving you the stress of overpacking and multiple trips. Pretty neat right?
Well, that’s exactly how GraphqL works. It helps you get specific data from a database base at once, cutting out repetitive requests and over-fetching. GraphQl shines particularly in [React](https://react.dev/) because it enables efficient data fetching which improves the performance of your React application, and it also helps you create more simplified state management which the complexity of your code.
Now that we know what GraphQL is, let’s talk about how to use it, and how to create your first query. The first thing we’ll be looking at is a GraphQL schema.
## Understanding the GraphQL Schema
Now we know that with GraphQL we can get specific data from an API, but getting that data would not be possible without the schema. GraphQL schemas define the structure and shape of the data that can be queried in a GraphQL API. Basically a schema is essentially a blueprint that defines the types of data that can be queried by a client application.
Let’s revisit the vacation analogy. A GraphQL schema is like a shopping list that’ll contail all your clothes, along with details about them. The schema will contain the type of cloth, the color, texture, and every other detail that will enable GraphQL pick the specific clothes you’d need.
The schema has two main types of data: objects and scalars. Objects represent complex data structures with multiple fields, while scalars represent single values like strings, integers, or booleans. That may be a bit hard to understand, so let’s explain it further using an example.
Schema’s are written using schema language. Continuing wih our clothes analogy let’s draw up a schema for your wardrobe.
```
type Wardrobe {
shorts: String!
shirts: String!
dresses: int!
underwear: {pants: draws}!
}
```
In this example, `Wardrobe` is an object type with four fields:` shorts`, `shirts`, `dresses` and `underwear`. Shorts and shirts both have a type `String`, dresses has an `int` type, and underwear has a nested field called `pants`. `String` and `int` are examples of a scalar type, which represents a single value like a string of characters, while `underwear` is an object type with its own fields.
In addition to defining types, the schema also defines the queries and mutations that can be executed against the API. Queries are used to fetch data from the API, while mutations are used to modify data. We’re going to be focusing only on the queries part of that because, well, that’s why you’re here.
## Syntax of a GraphQL Query
The syntax of a GraphQL query is designed to be human-readable and expressive, allowing clients to request exactly the data they need from a GraphQL API. It’s easy to understand, and easier to use.
Let’s use the schema above as an example. If we want to get just shorts in our wardrobe, here’s what the query would look like.
```
query GetClothes{
wardrobe {
shorts
}
}
```
That’s exactly what a GraphQL query looks like. Now, let’s break down the different parts of the query.
* ‘**query**’: the query keyword basically indicates that the operation is a query operation.
* ‘**wardrobe**’: is the name of the field that is being requested. In this case, it is a custom field defined in the GraphQL schema.
* ‘**shorts**’: is a subfield of the ‘wardrobe’ field being requested.
There are other things you can add to a query, like arguments, variables, and fragments, but we’ll talk about that later.
Now that you understand the syntax of a basic GraphQL query, let’s construct a query using data from a real live GraphQL API.
## Constructing a GraphQL Query
To write our first query, we’ll be using the GraphQL [Rick and Morty API playground](https://rickandmortyapi.com/graphql). The GraphQL Rick and Morty Playground is an online tool that allows developers to explore and interact with the GraphQL API for the TV show "Rick and Morty". It provides a web-based interface where developers can enter queries, see the corresponding responses, and experiment with the available data.
To make a query, we’ll first have to take a look at the schema for the API, which is available [here](https://rickandmortyapi.com/documentation/). There’s a lot of information there about the character schema, the location schema, and the location schema. For our first query, we’re going to get the names and genders of characters in the TV show.
Here’s what that query would look like. Remember, we’re using this playground and just writing the query on the left-hand side. You can try it out if you’d like.
```
query GetInfo {
characters {
results {
name
gender
}
}
}
```
As you can see, this query basically uses the “characters” field to retrieve data on all characters in the API, and then uses the “results” field to get the name and gender of each character. The name and gender fields are scalar fields that are already defined in the [GraphQL schema](https://rickandmortyapi.com/documentation/). The result of that query will be a JSON-like object, and here’s what that looks like.
```
{
"data": {
"characters": {
"results": [
{
"name": "Rick Sanchez",
"gender": "Male"
},
{
"name": "Morty Smith",
"gender": "Male"
},
{
"name": "Summer Smith",
"gender": "Female"
},
{
"name": "Beth Smith",
"gender": "Female"
},
{
"name": "Jerry Smith",
"gender": "Male"
},
{
"name": "Abadango Cluster Princess",
"gender": "Female"
},
{
"name": "Abradolf Lincler",
"gender": "Male"
},
{
"name": "Adjudicator Rick",
"gender": "Male"
},
{
"name": "Agency Director",
"gender": "Male"
},
{
"name": "Alan Rails",
"gender": "Male"
},
{
"name": "Albert Einstein",
"gender": "Male"
},
{
"name": "Alexander",
"gender": "Male"
},
{
"name": "Alien Googah",
"gender": "unknown"
},
{
"name": "Alien Morty",
"gender": "Male"
},
{
"name": "Alien Rick",
"gender": "Male"
},
{
"name": "Amish Cyborg",
"gender": "Male"
},
{
"name": "Annie",
"gender": "Female"
},
{
"name": "Antenna Morty",
"gender": "Male"
},
{
"name": "Antenna Rick",
"gender": "Male"
},
{
"name": "Ants in my Eyes Johnson",
"gender": "Male"
}
]
}
}
}
```
Just like that, we’ve successfully written our first GraphQL query. But that’s not all there is to these queries. We can use these queries to target specific data with the use of arguments. For instance, if we only wanted to get the data of characters named “rick”, we’ll add an argument to the characters field, like this.
```
query GetInfo {
characters(filter: { name: "Rick" }) {
results {
name
gender
}
}
}
```
In this query, we've simply added a filter argument to the characters field that specifies a filter object with a name field set to the value "Rick". This filter then restricts the results we get to characters whose name matches "Rick". That’s the beauty of GraphQL arguments: like a surgeon’s scalpel, it enables you to cut through the data and get exactly what you want.
With that, we’ve successfully written a GraphQL query. Of course, there’s a bit more to queries like [fragments](https://graphql.org/learn/queries/#fragments:~:text=in%20one%20request.-,Fragments%23,-Let%27s%20say%20we), [variables](https://graphql.org/learn/queries/#fragments:~:text=different%20GraphQL%20requests.-,Variables%23,-So%20far%2C%20we), and [mutations](https://graphql.org/learn/queries/#fragments:~:text=completely%20new%20directives.-,Mutations%23,-Most%20discussions%20of), but you can read up on that later in your spare time. Next, let’s look at the best practices you should follow when writing GraphQL queries.
## Best practices for writing a GraphQL query
* Name all operations: In all our operations above, we gave the queries a name, i.e GetClothes, and GetInfo. The truth is, we don’t necessarily have to do so, as the queries would still work without us giving the operation a name. However, it’s best to always name your operations for clarity of purpose and to to avoid unexpected errors.
* Be specific with your query: Only ask for the data you need. Avoid requesting unnecessary fields or data that you won't use. This will make your query more efficient and faster, which is the entire point of using GraphQL over the RESTful approach
* Avoid nested queries: While GraphQL allows for nested queries, it's best to avoid them as much as possible. They can lead to performance issues and make queries more difficult to read and maintain.
* Use the GraphiQL tool: The [GraphiQL tool](https://www.onegraph.com/graphiql) is a powerful development tool that allows you to interactively build and test your queries. You can set it up locally on your computer or use the online versions to experiment with different queries and ensure they return the expected data.
## Common Mistakes to Avoid when writing a GraphQL query
* Over-fetching or under-fetching data: Over-fetching means retrieving more data than you need, which can slow down your application. Under-fetching, on the other hand, means not retrieving enough data, which can result in multiple requests being made to the server.
* Nesting too deeply: Nesting too deeply in GraphQL can make your queries difficult to read and maintain. It is best to keep your queries shallow and only nest when necessary.
## Conclusion
If you’ve made it this far, then congratulations you’ve learned how to successfully write your first GraphQL query, and you’ve also learned the best practices and mistakes to avoid. If you’d like to learn more about GraphQL in general, you can check out this [video](https://www.youtube.com/watch?v=BcLNfwF04Kw&t=211s). It was quite useful to me when I was starting out.
I hope this article was useful to you. See you in the next one!
| fimber01 |
1,433,619 | Best Resources for Machine Learning | How to Extract Tables from PDF files and save them as CSV using Python Face Recognition-Based... | 0 | 2023-04-12T12:04:53 | https://dev.to/sharmaji27/best-resources-for-machine-learning-15lc | deeplearning, machinelearning, computervision, python | [How to Extract Tables from PDF files and save them as CSV using Python](https://machinelearningprojects.net/extract-tables-from-pdf-files/)
[Face Recognition-Based Attendance System with source code – Flask App – With GUI](https://machinelearningprojects.net/face-recognition-based-attendance-system/)
[10+ Unique Flask Projects with Source Code](https://machinelearningprojects.net/flask-projects/)
[Easiest way to Train yolov7 on the custom dataset](https://machinelearningprojects.net/train-yolov7-on-the-custom-dataset/)
[30+ Unique Computer Vision Projects with Source Code](https://machinelearningprojects.net/opencv-projects/)
[20+ Unique Machine Learning Projects with Source Code](https://machinelearningprojects.net/machine-learning-projects/)
[How to Install TensorFlow with Cuda and cuDNN support in Windows](https://machinelearningprojects.net/install-tensorflow-with-cuda-and-cudnn/)
[How to build OpenCV with Cuda and cuDNN support in Windows](https://machinelearningprojects.net/build-opencv-with-cuda-and-cudnn/)
[20+ Unique Deep Learning Projects with Source Code](https://machinelearningprojects.net/deep-learning-projects/)
[How to Deploy a Flask app online using Pythonanywhere](https://machinelearningprojects.net/deploy-a-flask-app-online/) | sharmaji27 |
1,433,833 | What are the best books about programming that aren't cookbooks or 'how to code in X'? | Anything with a narrative? Light reading? Fun? Not just looking for technical tutorials. | 0 | 2023-04-12T15:15:01 | https://dev.to/amyliumaiyi/what-are-the-best-books-about-programming-that-arent-cookbooks-or-how-to-code-in-x-4mj | discuss, help, books, career | Anything with a narrative? Light reading? Fun? Not just looking for technical tutorials. | amyliumaiyi |
1,433,848 | PostgreSQL 15: Breaking Barriers and Unleashing Creativity with Native JIT Compilation, Improved Parallelism, and More P2 | Welcome to the second part of our series of posts on the latest features of PostgreSQL 15. In this... | 0 | 2023-04-12T15:46:18 | https://dev.to/nightbird07/postgresql-15-breaking-barriers-and-unleashing-creativity-with-native-jit-compilation-improved-parallelism-and-more-p2-7p | apache, features, database, postgres | Welcome to the second part of our series of posts on the latest features of PostgreSQL 15. In this part, we will dive deeper into more exciting and innovative features that PostgreSQL 15 has to offer. PostgreSQL is a powerful and widely-used open-source relational database management system that has been gaining popularity among developers and enterprises alike. It has a reputation for being a robust, scalable, and secure database system that can handle large amounts of data and complex queries.
## Parallel query execution on remote databases
In a distributed database environment, data is stored across multiple databases that may be located in different physical locations. In such an environment, performing queries that involve data from multiple databases can be challenging due to the need to transfer large amounts of data among the databases. we tend to use this for durability of the database servers, or when the time needed to retrieve all the data across the servers in different zones.
To overcome this challenge, parallel query execution on remote databases can be achieved through various techniques. Parallel query planning involves dividing a query into smaller sub-tasks that can be executed in parallel on different databases. This approach involves optimizing the plan to minimize data movement between databases, which helps to reduce the time required to complete the query.
## Storage interface
when creating the tables default in the Postgres are stored in a B-tree which is optimized for sorting and searching across the data. and there are several types: Hash,GiST, SP-GiST, GIN, BRIN. now using this method you can change the table storage type and this is actually very useful excluding the time needed to regenerate the table from the ALTER we will be able to switch between the storage methods experiencing the feature of each one.
we are not done yet next time we will have a talk about more top features and by the end we will start the series of discovering the Architecture that support such Top features.
## SELECT DISTINCT
continue the talks about the parallelism of the previous features you can now do the above Query in parallel database.
I mentioned the TOP features on PostgresSQL 15
to read [P1](https://dev.to/nightbird07/top-down-postgresql-15-top-features-2c6o)
Next time we will start thinking about the implementation behind each feature.
### Reference
1- My brain
2- [PostgreSQL Doc](https://www.postgresql.org/docs/current/install-procedure.html)
Thanks for reading
| nightbird07 |
1,433,999 | Custodial vs. Non-Custodial wallets: What are the differences? | Choosing the best type of wallet for storing and safeguarding digital assets is critical for crypto... | 0 | 2023-04-12T18:14:05 | https://dev.to/timilehin08/custodial-vs-non-custodial-wallets-what-are-the-differences-1d8m | crypto, blockchain, beginners, cryptowallet | _Choosing the best type of wallet for storing and safeguarding digital assets is critical for crypto ownership. There are many different types of wallets on the market, and deciding which one to choose can be difficult. This article delves deeper into the differences between custodial and non-custodial wallets. Continue reading for a quick guide on whether you should keep your own crypto key or delegate responsibility._
_**Important Takeaways:**_
- With a custodial wallet, a third party manages your private key rather than you, the crypto owner.
- With a non-custodial wallet, you control your own private key and thus your funds.
- One disadvantage of non-custodial wallets is the lack of recovery options if you forget your passwords.
- Non-custodial wallets, on the other hand, give you complete ownership of your cryptocurrency, making you responsible for the security of your own private keys and funds.
**Custodial Wallets**
To understand how a custodial wallet works, you must first understand how crypto wallets work. A cryptocurrency wallet is a software or hardware device that allows you to store, access, and interact with cryptocurrencies such as Bitcoin and Ethereum. A user's funds are not stored in a crypto wallet. Instead, they contain the public key, which allows you to set up transactions as the user, and the private key, which is used to authorize transactions. Software wallets are installed on a user's device, whereas hardware wallets are standalone physical devices used to store digital assets. (desktop or mobile).
Private keys—strings of letters and numbers that act as a highly sensitive password—are stored in both hardware and software wallets. Possession of a private key allows you to send crypto assets from a specific public address, making private key management critical.
A custodial wallet, as the name implies, is one in which a third party stores private keys on behalf of users. The third-party has complete control over the crypto assets, managing the user's wallet key, signing transactions, and protecting the user's crypto assets. Custodial wallets are available from custodial wallet providers or cryptocurrency exchanges as mobile or web applications. You use the wallet provider's interface to manage your funds and make transactions once you log in to your wallet account.
This implies that you must have trust in the service provider's ability to securely store your tokens and implement strong security measures to prevent unauthorized access. Two-factor authentication (2FA), email confirmation, and biometric authentication, such as facial recognition or fingerprint verification, are examples of such measures.
Custodial wallets are a low-entry barrier if you are a newbie in the crypto space as they are simple to use and can be accessed from any device with an internet connection. Security, on the other hand, is a major concern because centralized exchanges have previously been victims of cyberattacks, compromising users' keys and cryptocurrency assets.
Custodial wallets however have some advantages, such as requiring less user involvement in private key management. When you outsource wallet custody to a company, you effectively outsource your private information to that company. You are not responsible for keeping the private key to the wallet safe, so you rely on the company to do so. Binance and Coinbase are some examples of custodial wallets. Only after identity verification are you able to hold crypto assets on these custodial exchanges.
**Non-Custodial Wallets**
A non-custodial wallet, also known as a "self-custody wallet," is one in which you are entirely responsible for managing your own funds as a cryptocurrency owner. You have complete control over your crypto assets, as well as the ability to manage your own private key and handle transactions on your own. Non-custodial wallets are preferred by crypto experts, security advocates, and the larger decentralized community because they do not require trust to be outsourced to an institution, and no institution can refuse to complete transactions.
Non-custodial wallets come in various forms. Browser-based wallets, which are browser extensions that allow you to enter your private key and initiate transactions, or mobile wallets, which are downloadable mobile apps, are two options. It could also take the form of hardware wallets, which are physical devices. Many people believe that hardware wallets are the most secure option because they can be accessed and managed while not connected to the internet.
A seed phrase is provided by non-custodial wallets. When you create the wallet, you will be asked to write down and save a sequence of 12 randomly generated words known as a 'recovery, ‘seed,' or 'mnemonic' phrase. The public and private keys can be generated from this phrase. It also functions as a backup or recovery mechanism if users lose access to the original device. Anyone who knows the seed phrase will have complete control over the funds in your wallet.
If the seed phrase is lost, you will no longer have access to your funds. Each transaction is your responsibility to manage and complete. To send money and complete other transactions, you'll need your private keys. The transaction can be reflected in real-time on-chain depending on the non-custodial wallet used, or it can be signed offline and uploaded to the blockchain for confirmation later.
Hardware, or "cold" wallets, which store private keys offline on a standalone device that looks and feels similar to a USB drive, are one of the most popular types of non-custodial wallets. When you want to send a cryptocurrency transaction, hardware wallets connect to the internet. A non-custodial wallet, particularly a hardware wallet, may be the best option if you need to store a large amount of crypto assets.
Furthermore, in order to interact with decentralized applications, you will need a non-custodial wallet if you want to invest in DeFi. Keep in mind that having complete control over your assets entails greater responsibility. You must backup your wallet and keep your private keys in a secure location. Non-custodial wallets, such as Bitpay, Electrum, Trust Wallet, and MetaMask, are examples of software that you install on your computer or mobile device.
**How Can I Tell What Kind of Wallet I'm Using?**
In contrast to custodial wallets, non-custodial wallets provide users with complete control over their private keys associated with the wallet's public address. You have a custodial wallet if you can only access it with a login and password and do not have your own private key. Otherwise, you have a non-custodial wallet.
**Conclusion — Choosing between a Custodial or Non-Custodial Wallet**
Custodial and non-custodial wallets both have benefits and disadvantages. If you value convenience as well as backup and recovery options, custodial wallets are a good choice. Non-custodial wallets, on the other hand, may be exactly what you're looking for if you want complete control and ownership over your private keys.
**Do Your Own Research and Due Diligence**
This article's examples are provided solely for informational purposes. Any of this information or other material should not be construed as legal, tax, investment, financial, cyber-security, or other advice. Past results do not assure or predict future outcomes. The value of crypto assets can fluctuate, and you could lose all or a portion of your investment. You must conduct thorough research and due diligence when evaluating a crypto asset in order to make the best possible decision, as any decision you make is solely your responsibility.
_Cover Photo by Regularguy-eth from Unsplash_
| timilehin08 |
1,435,805 | Hosting a static web app on Azure. | We shall go over how to host a custom web app on azure platform. We assume that we have our code is... | 0 | 2023-04-14T12:42:26 | https://dev.to/maqamylee0/hosting-a-static-web-app-on-azure-3af6 | azure, staticwebapps, cloud, devops | We shall go over how to host a custom web app on azure platform.
We assume that we have our code is on github.
Next we head over to the Azure platform login in and search for the Static Web App service.
Once the service is loaded, click create.
Then start filling in neccessary information about your app such as resource group it belongs to.Here we shall create one.
Then we shall name our app.
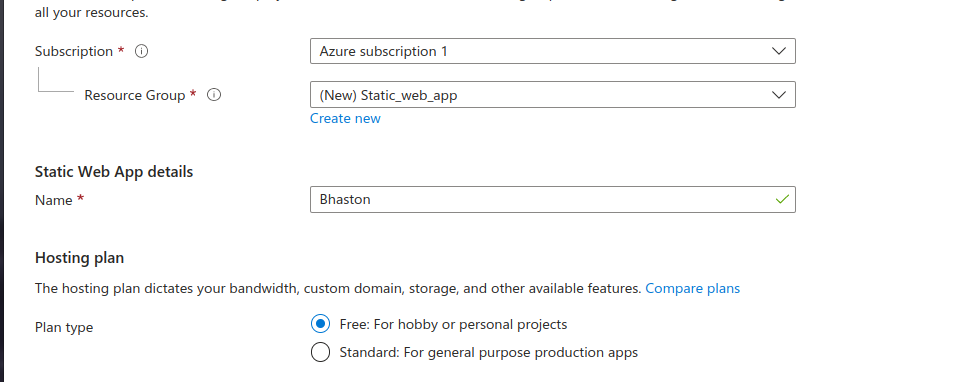
Next we shall choose free hosting, and github as our deployment source.
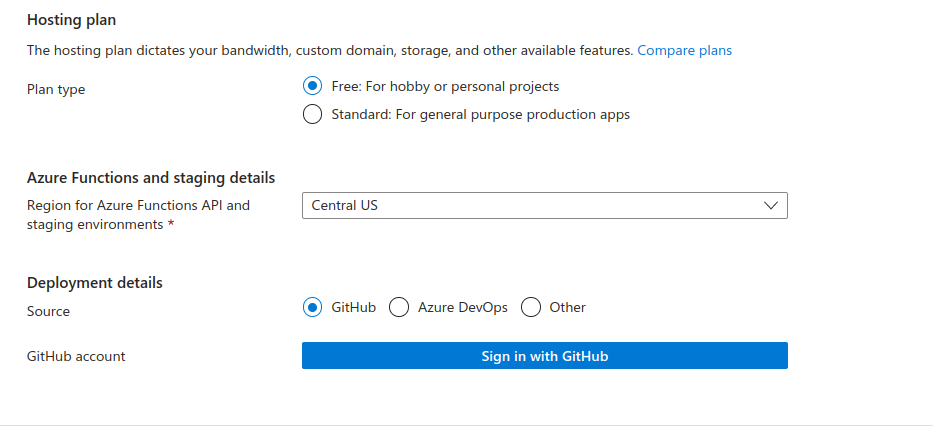
Then we shall grant access to github by clicking sign into github.
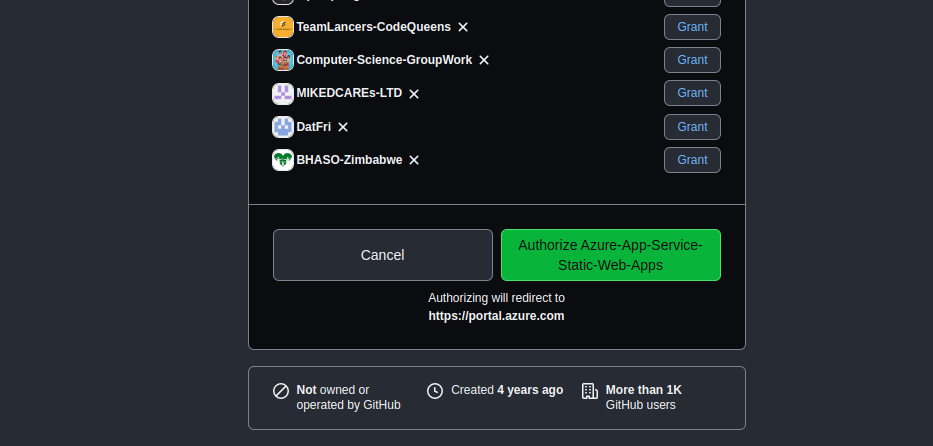
Once github has access it will look like this.
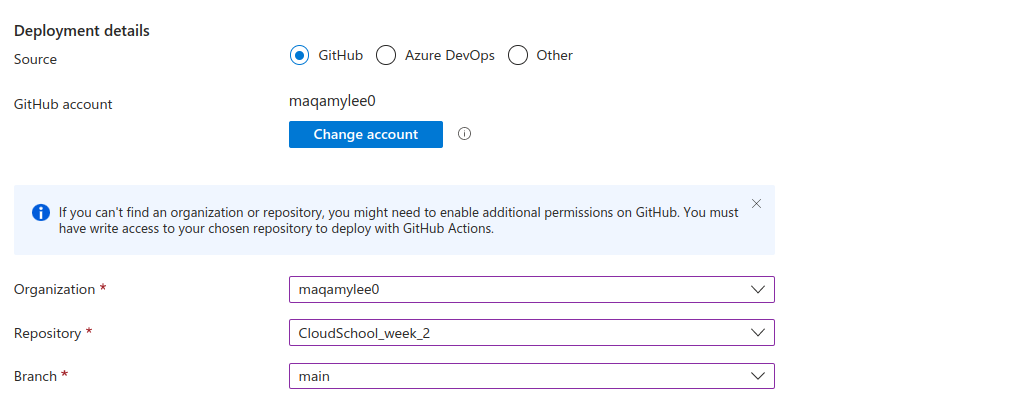
Now its time to indicate where our index.html file is located.In my case the root folder so i will use a slash.
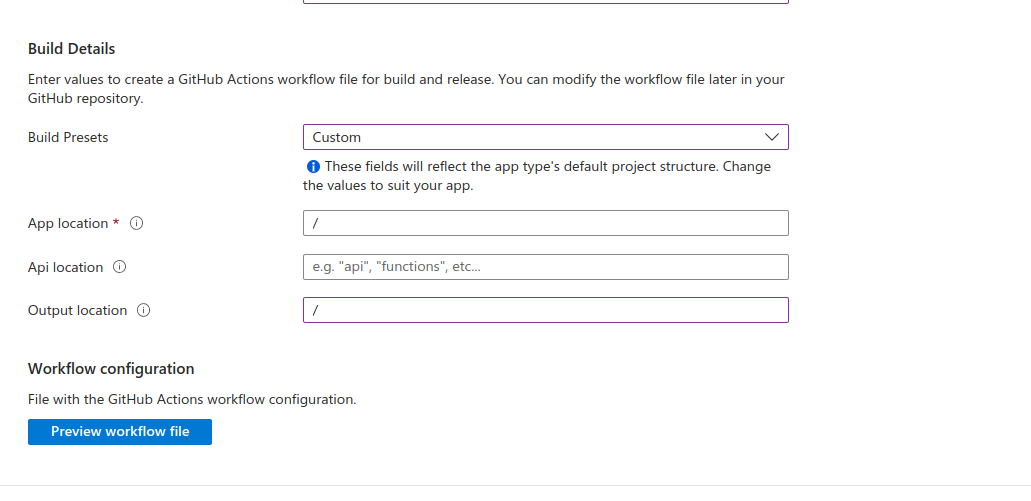
Finally lets preview our app settings by clicking preview and finally click create.
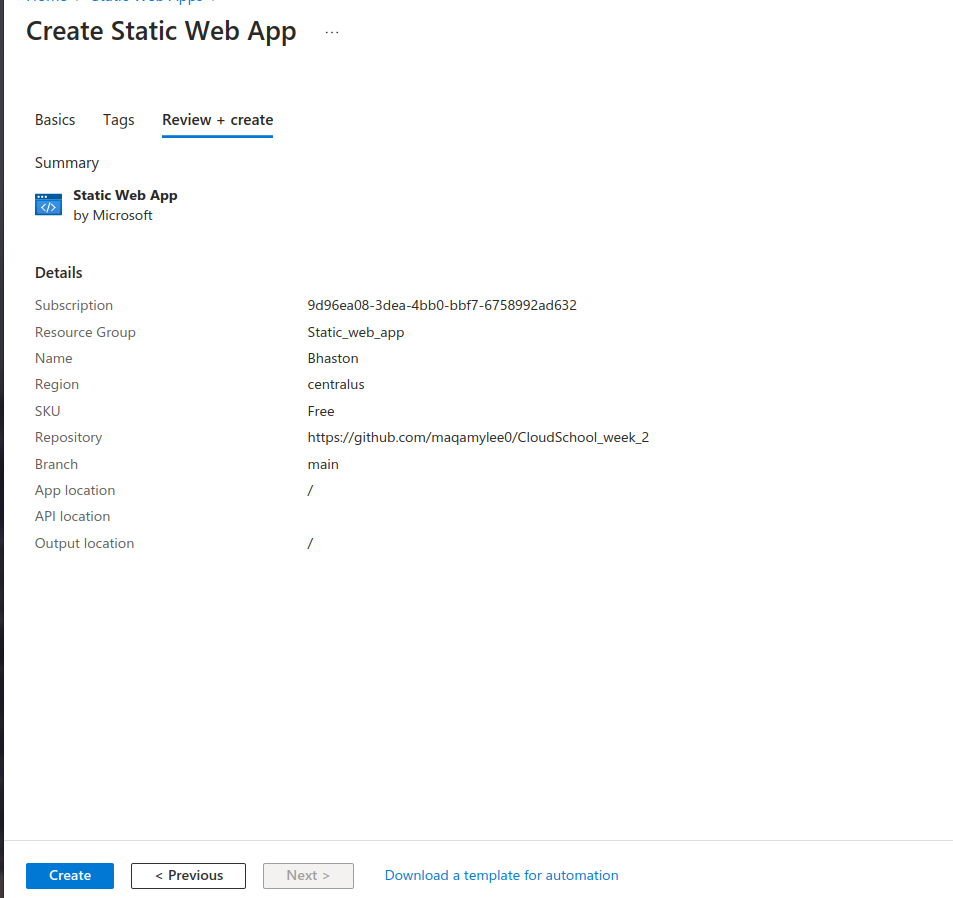
Give it some 3 minutes and we shall have our page ready to view.
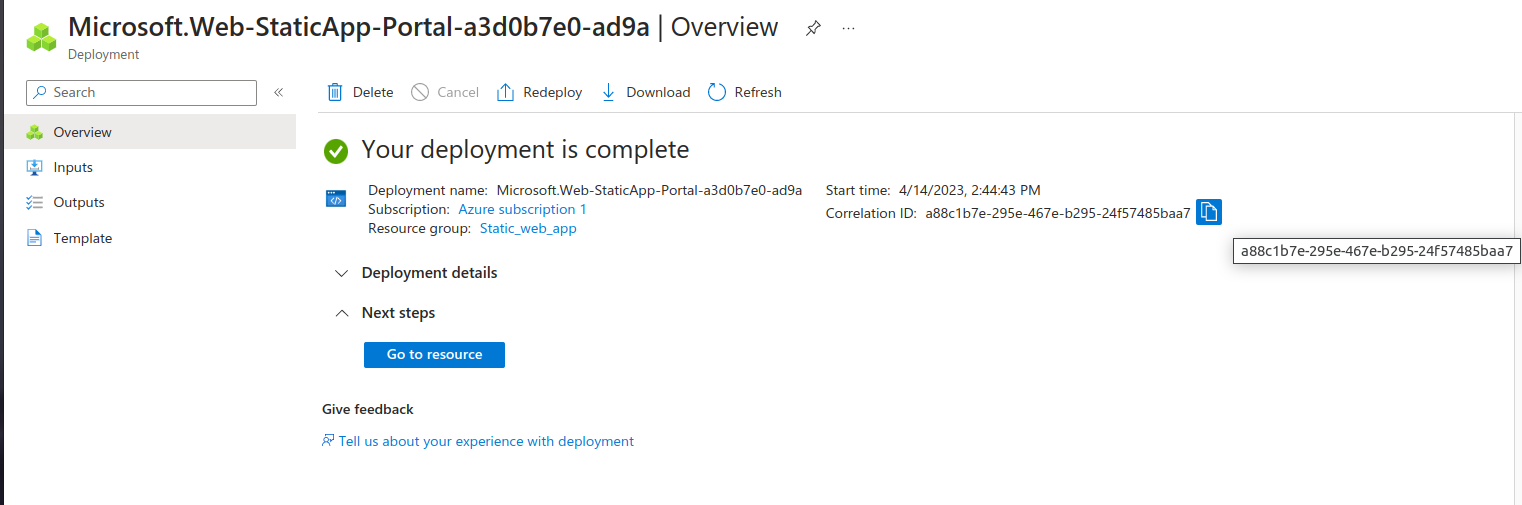
Next click on the go to resource and you can see the URL link to the web app.
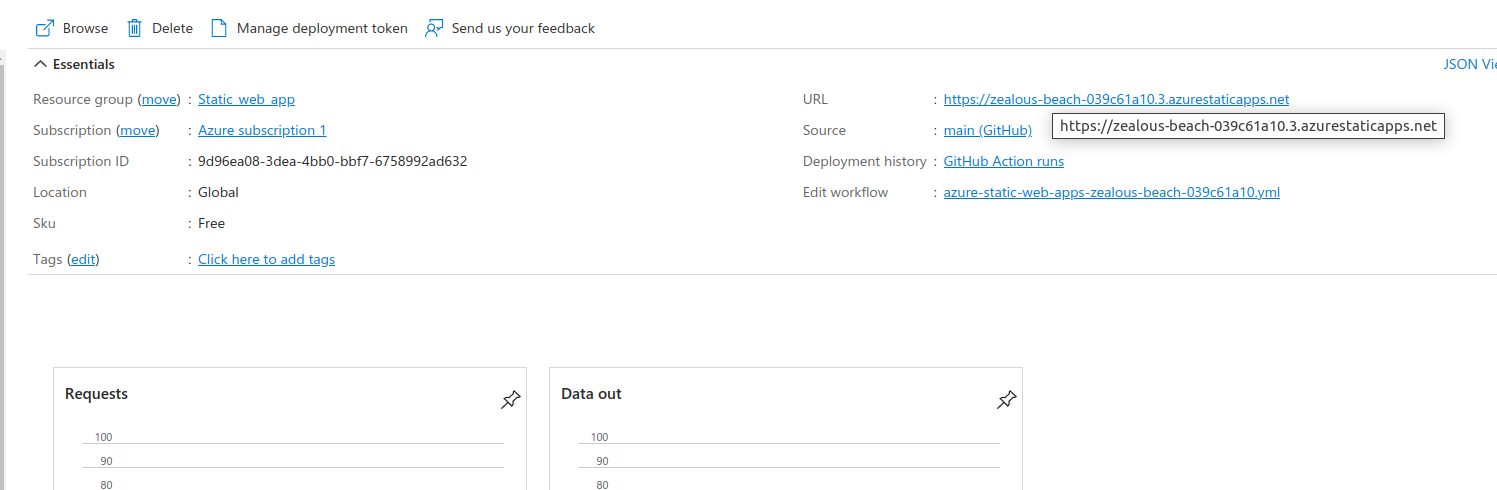
Then you will see the hosted web application.
| maqamylee0 |
1,434,115 | 4 raisons d’utiliser Tailwind et Styled Components avec React | Aujourd’hui, dans cet article je vais vous donner les raisons pour lesquelles j’utilise Tailwind et... | 0 | 2023-04-12T20:46:25 | https://dev.to/tontz/4-raisons-dutiliser-tailwind-et-styled-components-avec-react-2278 | react, tailwindcss, css, french | Aujourd’hui, dans cet article je vais vous donner les raisons pour lesquelles j’utilise Tailwind et Styled Components sur mes projets React. Si vous êtes intéressé sur la façon de setup un projet avec ces outils, je vous redirige sur mon article précédent : [https://dev.to/vincent_react/comment-configurer-reactjs-vite-tailwind-styled-components-1m72](https://dev.to/vincent_react/comment-configurer-reactjs-vite-tailwind-styled-components-1m72).
Mon but n’est pas de vous convaincre d’utiliser ces outils mais plutôt de vous faire un retour d’expérience et vous montrer leur potentiel.
Gardez en tête qu’un outil n’est utile que si on en a vraiment besoin !
# 1 - Ne pas louper le train
**Tailwind** est une librairie fournissant des classes utilitaires CSS et des composants qui est concurrente de **bootstrap.** **Styled Components** est une librairie permettant de faire des composants stylisés en JavaScript. Ces deux outils permettent de travailler plus facilement avec le CSS.
Une des raisons pour lesquelles j’utilise Tailwind et Styled Components est que ce sont des outils qui **attirent** de plus en plus de développeur. En effet, Tailwind prend particulièrement une place de plus en plus **importante** d’année en année. Je vous ai sélectionner trois graphiques permettant d’illustrer ce phénomène.
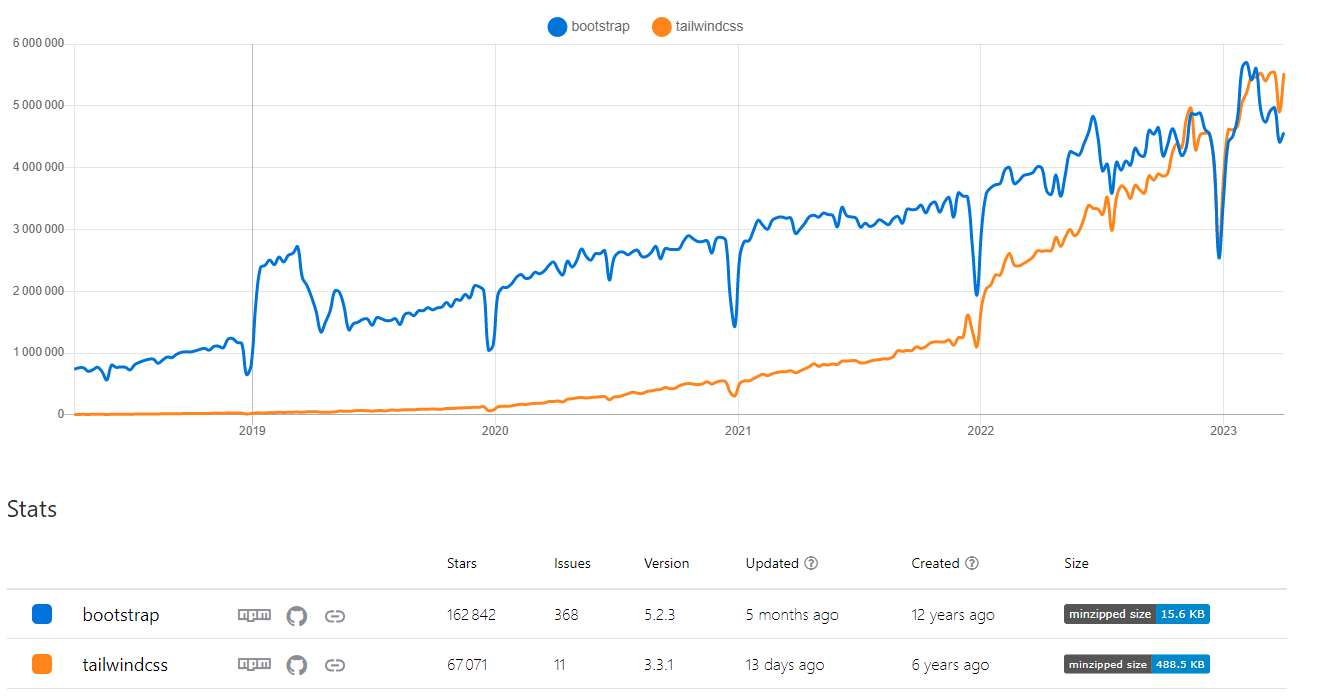
Ce graphique est issus de **npm trend,** un site permettant d’avoir les statistiques de téléchargement des package sur **npm**. On voit sur celui-ci qu’en 2023, **Tailwind** a dépassé **Bootstrap** sur le ****nombre de téléchargement. Cette métrique montre que Tailwind représente un véritable **outil robuste** qui tend à devenir la **norme**.
[bootstrap vs tailwindcss | npm trends](https://npmtrends.com/bootstrap-vs-tailwindcss)
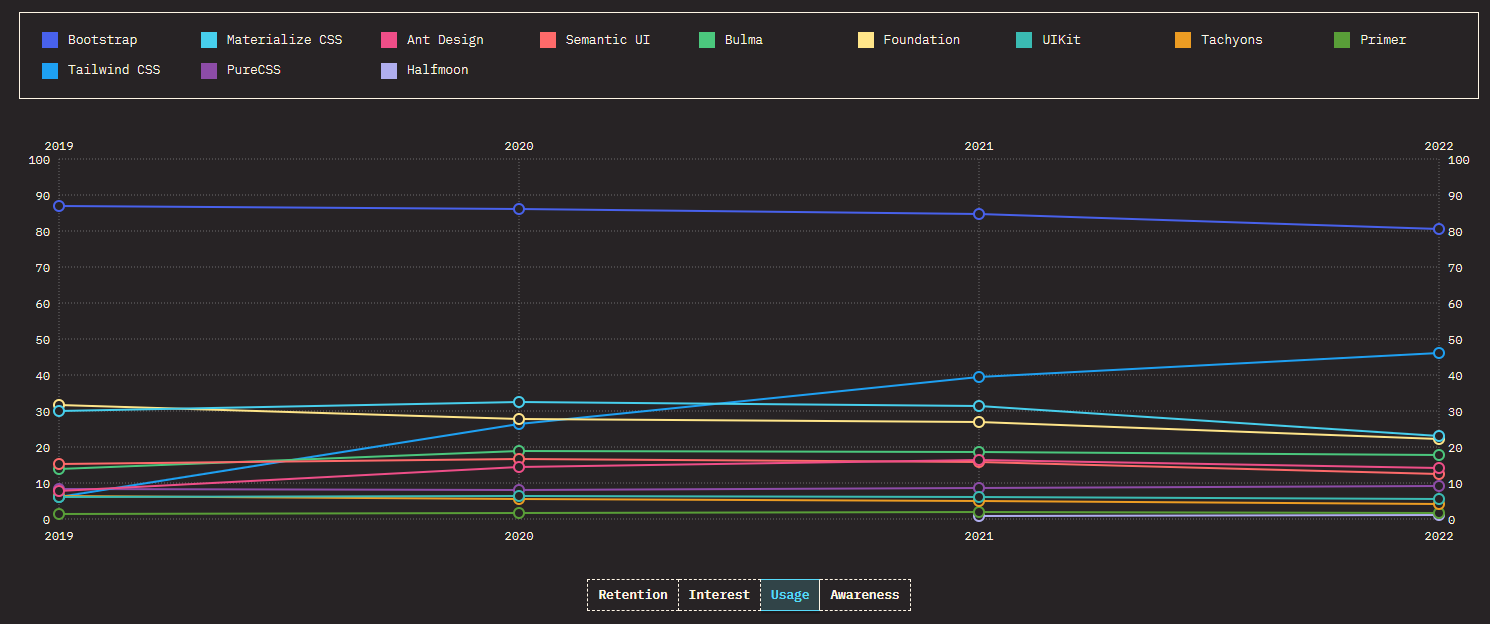
Je tiens à ajouter cette deuxième source pour contre balancer le premier. En effet, sur ce deuxième graphique issue du site **State of CSS,** on voit l’utilisation des différentes librairies / Framework css. Ici on voit bien que Bootstrap domine encore le marché avec **80%** d’utilisation. Cela s’explique probablement par le fait que Bootstrap existe depuis 12 ans alors que Tailwind existe depuis 6 ans. Néanmoins, on peut voir que la tendance d’utilisation de Tailwind ces dernières années n’a fait qu’augmenter alors que Bootstrap à diminuée. Si les choses évoluent en l’état, dans deux ou trois ans **Tailwind devrait dépasser Bootstrap**.
[The State of CSS 2022: CSS Frameworks](https://2022.stateofcss.com/en-US/css-frameworks/)
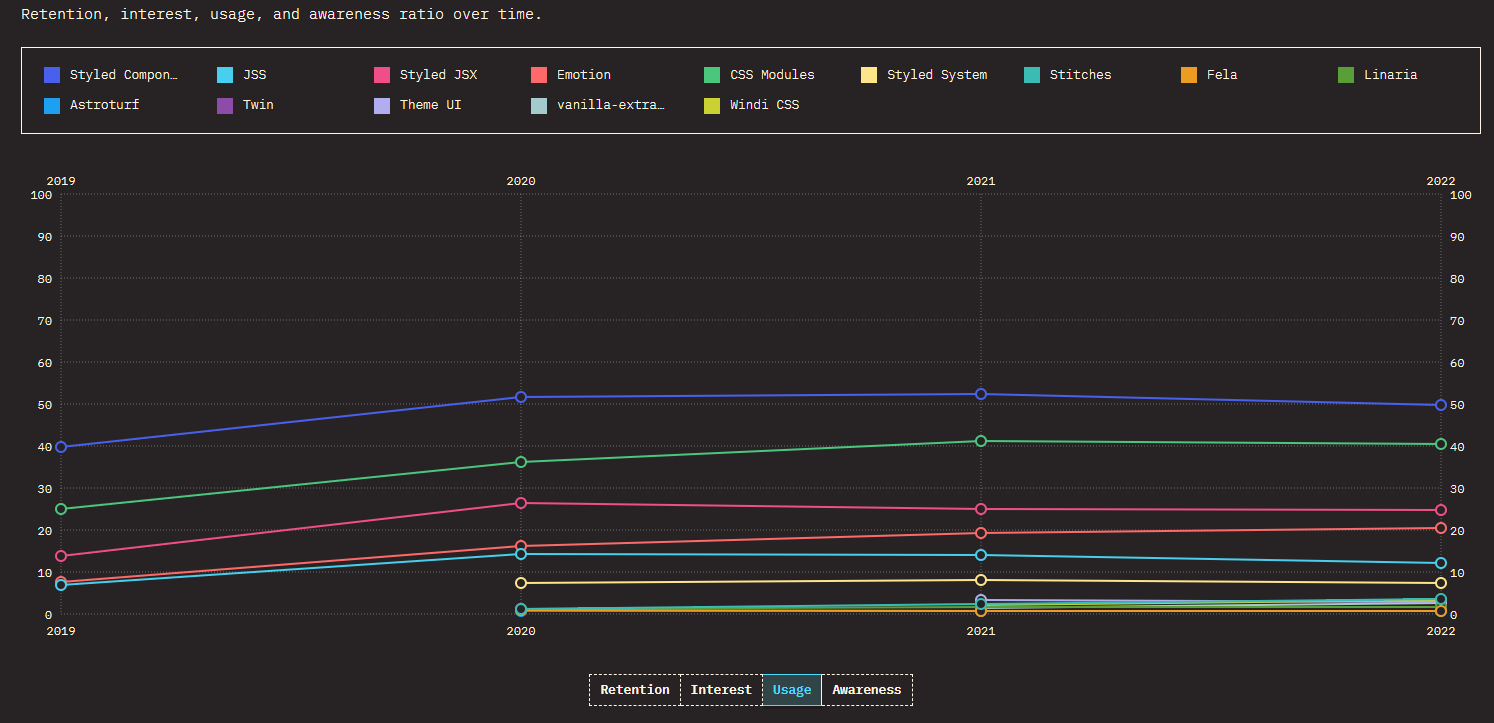
Comme je sais que vous êtes friands de chiffre, je vous donne la courbe d’utilisation de la librairie styled-components. On voit nettement que c’est la librairie la plus populaire du moment.
[The State of CSS 2022: CSS-in-JS](https://2022.stateofcss.com/en-US/css-in-js/)
Ce que je veux vous montrer avec ces statistiques, c’est le fais que Tailwind et Styled Components sont deux outils qui prennent de plus en plus de place dans l’élaboration des projets et qu’il est très probable que Tailwind surpasse bootstrap. Comme vous le savez, l’univers JavaScript évolue à toute vitesse et il est important de se positionner sur les technologies pormetteuses de demain afin de ne pas louper le train.
Nous ne sommes sûrs de rien, mais commencer à vous intéresser à ces outils pourrait se trouver être un gros avantage pour le futur.
# 2 - Uniformiser le CSS
Tailwind est de plus en plus populaire et se fait une place dans le milieu des Framework CSS car il répond à une problématique qui touche tous les projets Web : **la difficulté d’uniformiser l’écriture du CSS au sein d’une équipe de plusieurs développeurs !**
Tailwind propose un ensemble de **classes utilitaires** permettant de rédiger du CSS de façon **uniforme** et **structuré**. Plus besoin de créer des classes CSS et de les appeler dans le HTML. Tout le monde utilise la même syntaxe au sein du projet.
Selon moi, le point sur lequel Tailwind excelle est la configuration. La plupart des autres Framework sont rigides et difficilement configurables. Avec Tailwind, en deux lignes il est aisé de changer la configuration de style en ajoutant des fonts, en changeant les couleurs utilisées dans l’application ou encore en modifiant certaine propriété Tailwind.
Imaginez que vous avez une couleur primaire et une couleur secondaire dans votre UI. Il est simple de configurer Tailwind pour renseigner ces couleurs. Vous vous rendez dans le fichier de configuration de Tailwind et vous modifiez l’objet colors avec les couleurs dont vous avez besoins.
```jsx
colors: {
primary: {
light: '#CDF0DB',
DEFAULT: '#007A33'
},
},
```
Vous pouvez ensuite utiliser cette couleur avec toutes les classes utilitaires de Tailwind de la façon suivante :
```jsx
text-primary //couleur du text
bg-primary-light // couleur de background
border-primary // couleur de la bordure
```
Ces quelques exemples illustrent la facilité de setup un thème dans votre application. Tailwind vous évite de devoir créer un fichier style.css qui centralise les constantes de couleur de l’application. Ce fichier doit être importer partout ou l’on utilise cette constante. Cela génère de la contrainte lors du développement.
Outre les classes utilitaires et la facilité de customiser ces dernières, Tailwind facilite l’implémentation des interfaces responsives. En effet, il est possible d’utiliser les breakpoints par défaut ou de customiser ces derniers.
Par défaut tailwind utilisera les breakpoints suivants :
```jsx
screens: {
'sm': '640px',
// => @media (min-width: 640px) { ... }
'md': '768px',
// => @media (min-width: 768px) { ... }
'lg': '1024px',
// => @media (min-width: 1024px) { ... }
'xl': '1280px',
// => @media (min-width: 1280px) { ... }
'2xl': '1536px',
// => @media (min-width: 1536px) { ... }
}
```
Il est possible de surcharger les différents breakpoints en ajoutant à l’objet ci-dessus les valeurs adaptées à votre besoin, dans le thème Tailwind.
Voici quelques exemples d’utilisation des breakpoints :
```jsx
// on applique la classe px-36 pour tous les écrans égaux ou supérieur à xl
xl:px-36
// on applique un background bleu pour les écrans inférieurs à md
// on applique un background vert pour les écrans supérieur à md et strictement inférieur à xl
// on applique un background rouge pour tous les écrans supérieur à xl
bg-blue
md:bg-green
xl:bg-red
```
Tailwind évite de devoir utiliser les media query. Le code ressemblerait à cela :
```jsx
// on applique un background bleu pour les écrans inférieurs à md
@media only screen and (max-width: 639px) {
.custom-background {
background-color: blue;
}
}
// on applique un background vert pour les écrans supérieur à md et strictement inférieur à xl
@media only screen and (min-width: 640px) {
.custom-background {
background-color: green;
}
}
// on applique un background rouge pour tous les écrans supérieur à xl
@media only screen and (min-width: 1280px) {
.custom-background {
background-color: red;
}
}
```
La différence est flagrante, Tailwind simplifie la vie et rend le style plus lisible en utilisant une syntaxe minimaliste. Ainsi, si l’on veut changer une couleur ou une font, c’est très **simple** !
# 3 - Rendre le HTML plus lisible
Le but du code est de raconter une histoire. Pour qu’une histoire soit belle et touche le lecteur, il faut trouver les mots justes. En utilisant Styled Components, il est possible de nommer ses balises. Vous pouvez vous dire que c’est un détail mais c’est un détail qui a beaucoup d’importance.
Prenons l’exemple de code suivant :
```html
<div className="header-container">
<div className="links-container">
<a className="link" href="#">Tous les articles</a>
<a className="link" href="#">A propos</a>
</div>
<div className="logo-container"></div>
</div>
```
Voici le même code avec Styled Components :
```html
<HeaderContainer>
<LinksContainer>
<Links href="#">Tous les articles</Links>
<Links href="#">A propos</Links>
</LinksContainer>
<LogoContainer />
</HeaderContainer>
```
Personnellement, je suis tombé amoureux de Styled Components car il permet vraiment de décrire ce que représente le template. De plus, il nous force à nommer ce qu’on utilise, ce qui est très important.
Il y a une règle que j’essaie au maximum de respecter lorsque je programme : “S’il est difficile de trouver un nom pour un élément de code c’est qu’il est probablement mal implémenter ou juste inutile”. En suivant cette règle vous vous retrouverez à faire du code plus propre et qui aura plus de sens. Je peux maintenant appliquer cette règle au template grâce à Styled Component.
Cette librairie m’apporte énormément de lisibilité. Fini les noms de classe qui n’ont aucun sens.
# 4 - Centraliser les informations
Partons pour un historique de la programmation Web !
A ces débuts, la façon de programmer en Web était différente d’aujourd’hui. Bien entendu, nous utilisons toujours du HTML, du CSS et du Javascript mais la façon d’organiser tout ce petit monde à évoluée au fur et à mesure du temps.
Au début il n’était question que de balise HTML décorées de style CSS. On ne parlait pas d’application mais de page Web. On avait donc le HTML et le CSS dans un même fichier.
Ensuite, le JavaScript a fait son apparition avec l’opportunité de rendre les pages interactives ! Superbe révolution. Au début on met le JavaScript dans le même fichier que le HTML et le CSS.
Le temps passe et les pages Web se transforment en Application Web composées de plusieurs pages, la quantité de JavaScript augmente de plus en plus pour avoir des pages très riches en interaction. Il commence à y avoir beaucoup de monde au même endroit et les fichiers deviennent très volumineux. La séparation des trois colocataires devient la norme.
Vient ensuite l’air de la séparation et le style suivant se repend dans la programmation web :
- un fichier **HTML** pour la structure
- un fichier **CSS** pour le style
- un fichier **JavaScript** pour la logique
Les Framework Web modernes utilisant la programmation par composant se sont bâtis sur ce modèle en favorisant la séparation de la structure la logique et le style. Les grands fichiers de code entremêlés de HTML, de CSS et de JS se transforment en une multitude de composants qui sont des briques **unitaires réutilisables** dans l’application possédant leur propre fichier JS, CSS et HTML.
React décide de prendre une autre direction en proposant la possibilité d’écrire du **JavaScript** et du **HTML** au sein d’un même fichier grâce au **JSX** (JavaScript XML). Il n’y a plus trois fichiers différents par composant mais deux, un JSX et un CSS.
Normalement, vous devez vous poser la question suivante : pourquoi React décide de fusionner les fichiers si l’évolution du dev web nous a amené à séparer les fichiers ?
Je vous répondrais que la réponse est dans la question. L’évolution du developpement web nous a amené au développement par composant. Des briques de logique unitaires, donc beaucoup plus petites, qui ont un code plus petit également. Ainsi, il n’est plus avantageux d’avoir une séparation, qui va créer beaucoup de charge cognitive. En effet, il est plus complexe de naviguer à travers 9 fichiers différents pour 3 composants.
Le JSX permet de gagner en lisibilité car nous avons la logique et le template qui coexiste au sein d’un même fichier. React prouve qu’il n’est pas problématique d’avoir le HTML et le JavaScript dans le même fichier, et que cela fait même gagner beaucoup de temps en simplifiant la compréhension et en évitant de devoir naviguer entre plusieurs fichiers afin de faire des liens mentaux de qui fait quoi.
Bon, maintenant vous vous dites, mais je suis venu lire un article sur Tailwind et Styled Component ! Ne soyez pas si impatient nous y venons. Après ces explications vous devez avoir une intuition de ce que je vais vous expliquer.
De la même façon que React a réuni HTML et JS, je trouve qu’il est pertinent de joindre le CSS à la fête. Ainsi j’utilise Styled Components pour inclure le CSS au sein de mon fichier JSX. Cela permet d’avoir toutes les informations du composant que je consulte dans le fichier.
Vous pouvez vous dire que Styled Components n’est pas utile et que l’attribut styles de React suffit à inclure le CSS. Croyez moi, lorsque votre application est conséquente, il est très difficile de lire un composant utilisant styles.
De plus, avec Styled Components allié à Tailwind qui simplifie le CSS et uniformise la façon d’écrire le style, il est beaucoup plus facile de lire le style du composant. Tous les composants sont rédigés sous le même format, tout est à sa place.
# Conclusion
Nous avons vu dans cet article 4 raisons pour lesquelles j’utilise Tailwind et Styled Components dans mes projets React.
La première raison est la popularité montante de ces outils et le potentiel qu’ils représentent.
J’utilise également ces outils car il me permettent de mieux **structurer** mes projets en écrivant du CSS **uniforme** et facilement **modulable** au sein de toute mon application. La création de design **responsif** est beaucoup plus **facile**. J’obtient également des fichier HTML ayant beaucoup plus de sens car il n’y a plus un empilement de div mais mon template raconte une histoire et reflète ce qu’il est vraiment.
Une autre raison pour laquelle j’utilise ces outils est le fait qu’il **centralise** tout le code de mes composants au sein d’un unique fichier. Lorsque je relis mon code, cela **constitue un gain de temps non négligeable** car je ne dois plus naviguer entre les différents fichiers de code.
Enfin pour conclure cet article, je vous donne une dernière raison. J’utilise Tailwind et Styled Components car je prend du **plaisir** à coder et j’aime la philosophie derrière ces outils.
Si vous utilisez ces outils n’hésitez pas à me partager votre expérience et votre avis. | tontz |
1,434,273 | Will AI take your job or allow you to work faster? | With the rapid evolution of AI from all different aspects whether its writing blogs, creating images,... | 22,564 | 2023-04-13T01:24:10 | https://dev.to/benhultin/will-ai-take-your-job-or-allow-you-to-work-faster-4m55 | With the rapid evolution of AI from all different aspects whether its writing blogs, creating images, generating code, etc, what will happen to our jobs?
I have been pondering various questions about this the impact of AI as we all have. I have developed some thoughts about these questions:
**Will AI completely replace us?**
- I would tend to argue no. I am going off this conclusion based on business and competition reasoning.
- Companies are always trying to get more done faster with less cost.
- AI does get more stuff done faster, but just like employees AI also needs to be told what to do and much more so than humans.
- If one employee can generate x amount of product with AI, then 10 employees can generate 10x that amount all using AI.
- Being first to market is more important than saving a buck.
What are your thoughts? Do you agree or disagree with my assessment of the new technology? | benhultin | |
1,434,284 | Create a ChatGPT Plugin to retrieve NASA images | Do you want to learn more about ChatGPT Plugins? Check out LaunchPlugins. ChatGPT Plugins are a... | 0 | 2023-04-13T04:06:19 | https://dev.to/360macky/create-a-chatgpt-plugin-to-retrieve-nasa-images-45pk | autocode, chatgpt, machinelearning, gpt3 | > Do you want to learn more about ChatGPT Plugins? Check out [LaunchPlugins](https://launchplugins.com).
**ChatGPT Plugins** are a great way to extend the capabilities of ChatGPT!
So if you just received access to [ChatGPT Plugins](https://openai.com/blog/chatgpt-plugins), this is the place where you can start.
Let's create a plugin that will retrieve information from [NASA API](https://api.nasa.gov). It will get the NASA Astronomical Picture of the Day (APOD) and it will also allow us to search for images in NASA's Image Library to retrieve a list of images based on a search query.
In this article I'll be using [Autocode](https://autocode.com/). Autocode is an automation software suite with a great developer experience. I think you will love it.
But if you choose not to use Autocode, you can create your own API on your own. I'll guide you in that process, it's very simple.
## 🎥 Demo of the plugin
Check how the plugin should work with this video:
- Demo: [https://youtu.be/A7MC3e9_rKk](https://youtu.be/A7MC3e9_rKk)
## 🧬 Structure
This is a quick overview of the process of a ChatGPT Plugin:
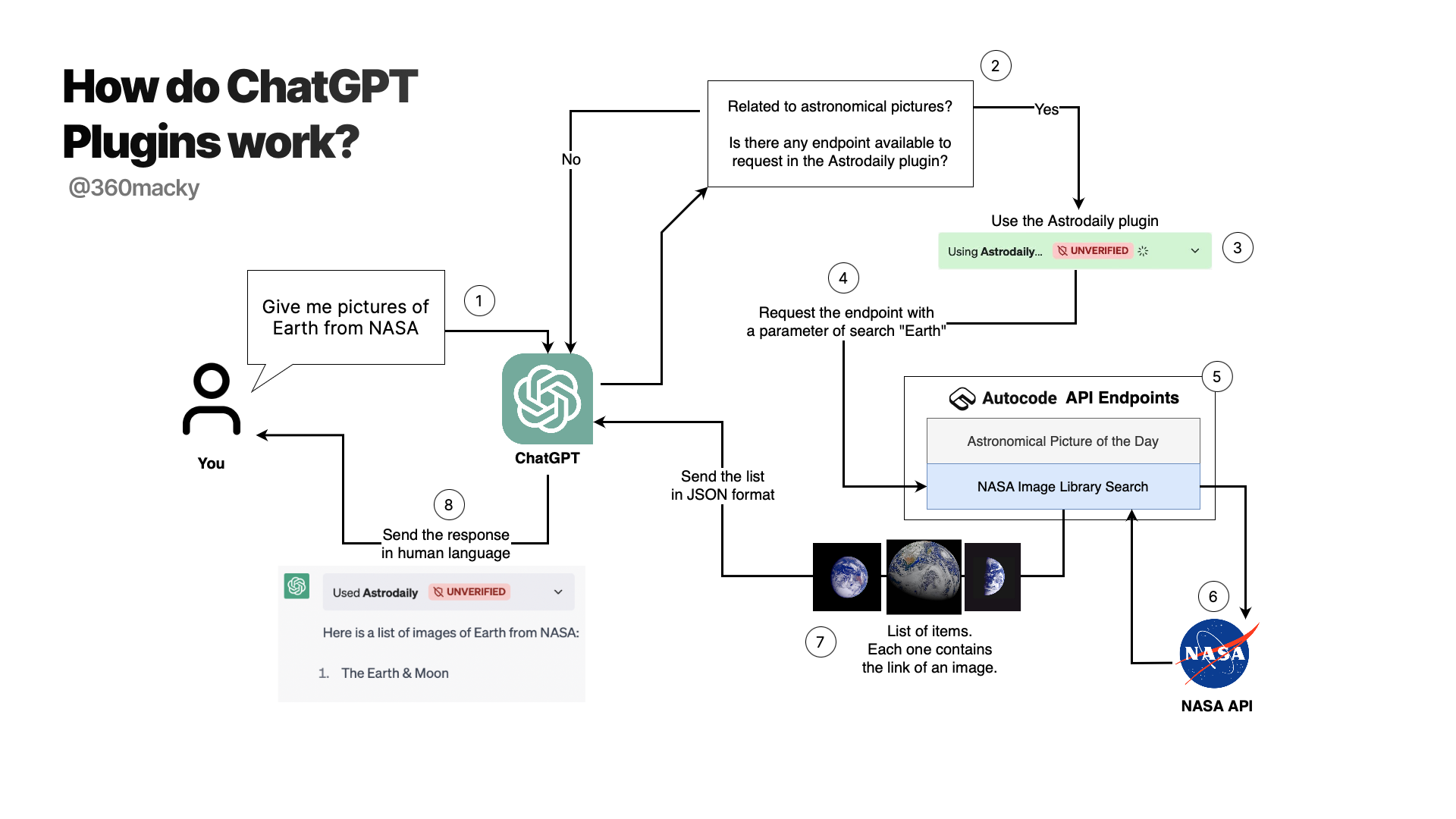
[🌄 Check this image in detail](https://i.imgur.com/TN6KS83.png)
A ChatGPT Plugin could be installed by specifying a URL. This URL has three components:
- **OpenAPI Specification**: A YAML file that describes the API
- **Manifest**: A JSON file that describes the plugin
- **API**: The API itself where we can send receive requests from ChatGPT
I believe **OpenAPI Specification is the most important part of a ChatGPT Plugin**. Whenever ChatGPT receives a message that matches the plugin's manifest, it will look at the OpenAPI Specification to know how to interact with the API. It works like a channel between ChatGPT and the API.
The manifest is a JSON file that describes the plugin. It contains the name, description for humans and for the model, and the OpenAPI Specification URL. It should be place in `/.well-known/ai-plugin.json`.
A couple of weeks ago, I discovered [Autocode](https://autocode.com/), a suite of tools that allows you to develop and launch many software projects with one of the best Developer Experience (DX) I've ever seen. I was so impressed by the DX that I decided to create a plugin for [ChatGPT](https://chat.openai.com) using Autocode.
If you already use Autocode, you can [use this template](https://autocode.com/macky360/templates/astrodaily/) and start explore the plugin architecture as you read this article.
Now let's create the plugin:
- If you're working with Autocode, you can [use this template](https://autocode.com/macky360/templates/astrodaily/) to start.
- If you're not, create a new API project. Do you like to use Express? Flask? Django? Spring Boot? The library/framework is up to your preference. But create one to start.
### 🗒 Creating the Manifest (ai-plugin.json)
If you're working with Autocode the Manifest should be included in `www` folder. In that folder create a `.well-known` folder, and finally create a `ai-plugin.json`.
If you're not working with Autocode, you need to create the `.well-known` folder as well as the `ai-plugin.json` file inside the public or static directory of your API. So you can access to that file from the URL `<URL_OF_API>/.well-known/ai-plugin.json`.
```json
{
"schema_version": "v1",
"name_for_human": "Astrodaily",
"name_for_model": "astrodaily",
"description_for_human": "Plugin for getting the pictures from NASA!",
"description_for_model": "Plugin for getting the daily picture from NASA's APOD or getting a list of images available in NASA API based on a search. When use it always provide the images in Markdown format so the user can see it. Do not add links, only images.",
"auth": {
"type": "none"
},
"api": {
"type": "openapi",
"url": "<URL_OF_API>/openapi.yaml",
"is_user_authenticated": false
},
"logo_url": "<URL_OF_API>/logo.png",
"contact_email": "legal@example.com",
"legal_info_url": "<URL_OF_API>/legal"
}
```
You can name the plugin whatever you want. I named it `Astrodaily`. The `description_for_human` is the description that will be shown to the user.
The `description_for_model` is the description that will be shown to the model itself. Which it's a description + series of instructions that the model will use to know when to use the plugin.
ChatGPT Plugins can also support authentication. But we won't need it for this plugin. So we'll set the `auth` to `none`.
## 📑 Creating the OpenAPI Specification
[OpenAPI](https://swagger.io/specification/) is a specification for describing REST APIs. It's a standard that is used by many tools. OpenAI Plugins request an OpenAPI YAML file to check the description of the API. So we'll need to create an OpenAPI Specification for our plugin.
If you're working with Autocode this should be place in `/www/openapi.yaml`.
If you're not working with Autocode, you need to create a file called `openapi.yaml` in the root of your public or static directory. So you can access to that file from the URL `<URL_OF_API>/openapi.yaml`.
So, our plugin, will work with two endpoints: `/image` and `/search`. The `/image` endpoint will return the NASA Picture of the Day. The `/search` endpoint will return a list of images based on a search query:
```yaml
openapi: 3.0.1
info:
title: Astrodaily
description: A plugin for getting the daily picture from NASA's APOD and searching the NASA Image and Video Library
version: 'v1'
servers:
- url: <URL_OF_API>
paths:
/image:
get:
operationId: getImage
summary: Get the NASA Picture of the Day
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/getImageResponse'
/search:
get:
operationId: searchImages
summary: Get images from NASA based on a query
parameters:
- name: q
in: query
description: The search query
required: true
schema:
type: string
responses:
"200":
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/searchImagesResponse'
components:
schemas:
getImageResponse:
type: object
properties:
imageURL:
type: string
description: The URL of the NASA Picture of the Day.
searchImagesResponse:
type: object
description: The response containing the list of images from the NASA Image Library.
properties:
title:
type: string
description: The title of the image.
description:
type: string
description: The description of the image.
location:
type: string
description: The location of the image.
date_created:
type: string
description: The date when the image was created.
image_url:
type: string
description: The URL of the image. It must be displayed as an image in Markdown format.
```
## 🪐 Setting up the API endpoints
Up to here, we have the OpenAPI Specification and the Manifest. With this is enough to create a plugin. But we'll create the API endpoints as well so our plugin can be used.
You need a NASA API key to retrieve the images from NASA. You can [get a NASA API key here](https://api.nasa.gov/):
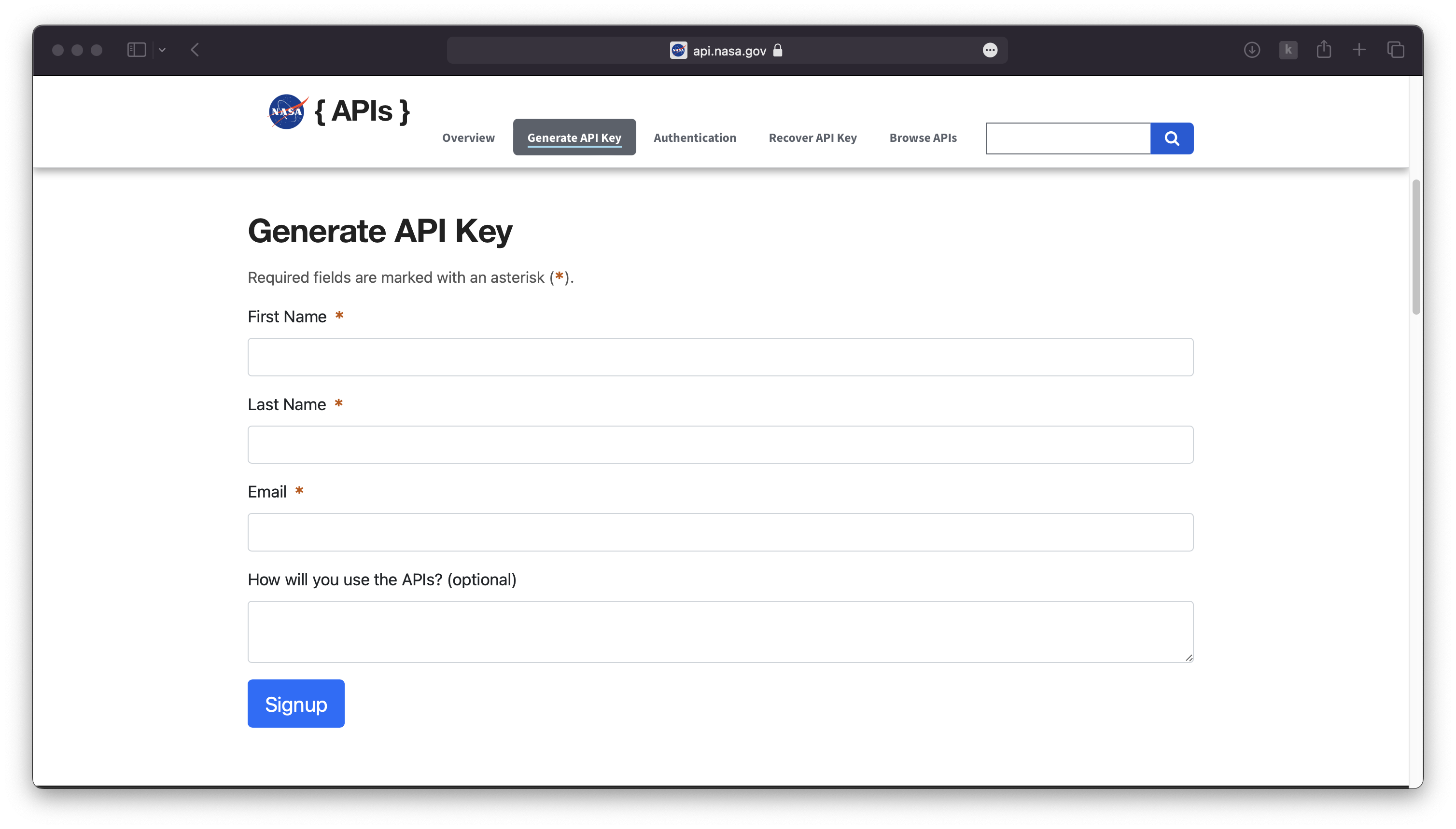
If you're not working with Autocode, you can start creating those `/image` and `/search` endpoints to process GET requests. I'll show you the code, you can translate it to your preferred API framework.
If you're working with Autocode, inside the `functions` folder, create a `image.js` and a `search.js` file. These files will contain the code for the endpoints:
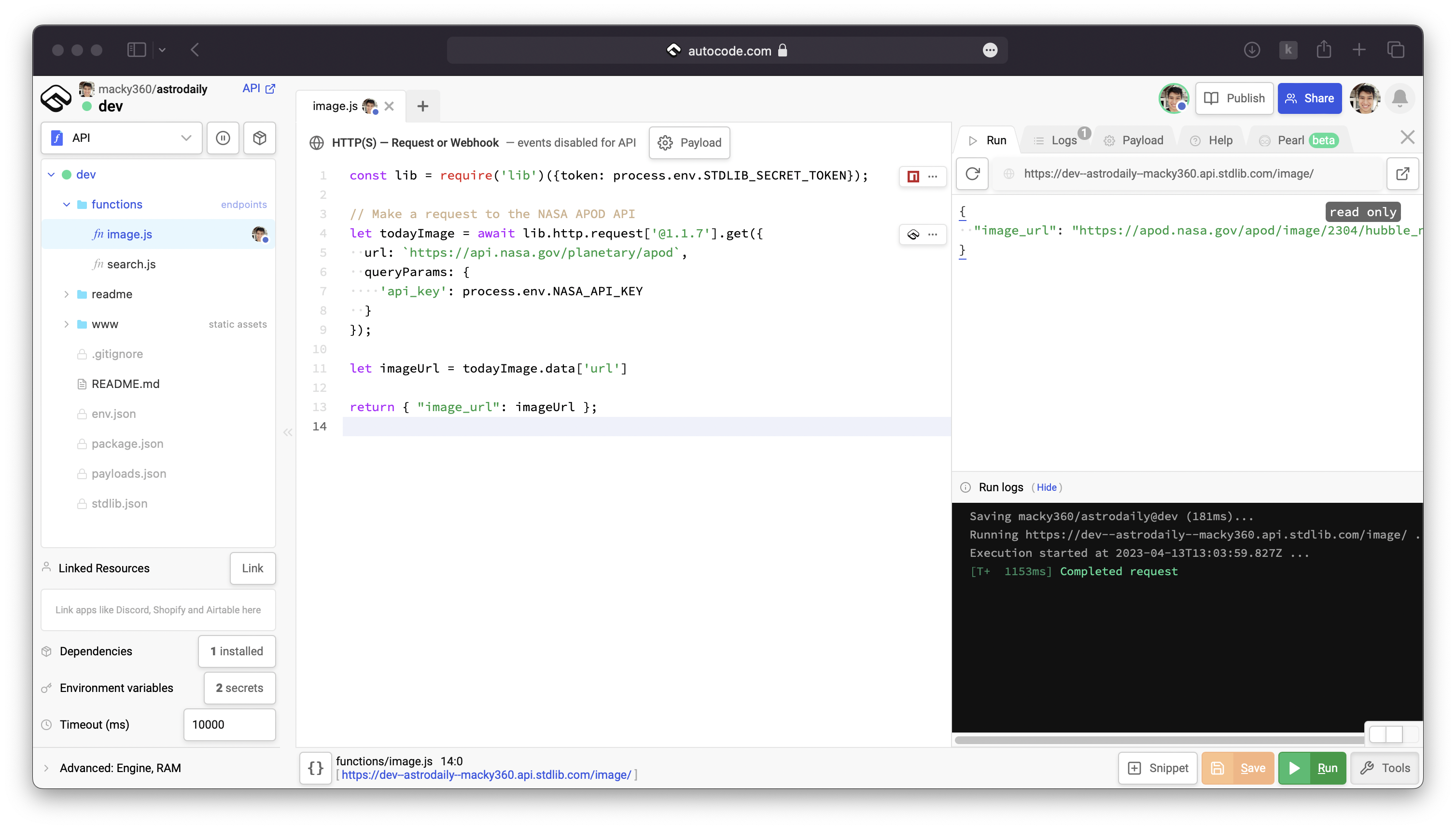
The image endpoint will return the NASA Picture of the Day:
```js
const lib = require('lib')({token: process.env.STDLIB_SECRET_TOKEN});
// Make a request to the NASA APOD API
let todayImage = await lib.http.request['@1.1.7'].get({
url: `https://api.nasa.gov/planetary/apod`,
queryParams: {
'api_key': process.env.NASA_API_KEY
}
});
let imageUrl = todayImage.data['url']
return { "image_url": imageUrl };
```
The search endpoint will return a list of images based on a search query. Here the process takes more lines of code. But it's not that complicated. We'll make a request to the NASA Image Library API. Then we'll filter the results to keep only the images. And finally, we'll return the 10 items that we want to show to the user.
```js
const lib = require('lib')({token: process.env.STDLIB_SECRET_TOKEN});
// Retrieve the search query parameter
const query = context.params.q;
// Make a request to the NASA Image and Video Library API
let searchResults = await lib.http.request['@1.1.7'].get({
url: `https://images-api.nasa.gov/search`,
queryParams: {
'q': query
}
});
// Extract the search results
let results = searchResults.data;
// Filter the items array to keep only image items
let imageItems = results.collection.items.filter(item => {
return item.data[0].media_type === 'image';
});
// Restructure the filtered items array for the GPT response
// Also return the first 10 items
let structuredItems = imageItems.map(item => {
return {
title: item.data[0].title,
description: item.data[0].description,
location: item.data[0].location,
date_created: item.data[0].date_created,
image_url: item.links[0].href
};
}).slice(0, 10);
return structuredItems.slice(0, 10);
```
Proving with more information like `title`, `description`, `location`, and `date_created` will make the results more useful for the ChatGPT to write a descriptive response.
Up to here, try testing the endpoints with a GET request so you can see if they work properly.
## 🚀 Adding your plugin to ChatGPT
This is the last step! We have our plugin ready. Now we need to add it to ChatGPT. I'll give you tips on how to do it without getting errors through the process.
Open ChatGPT, go to the Plugins dropdown menu, click on Plugin Store, click on "Develop your own plugin" link at the bottom. Then you will see this screen:

As you can see, you can put your plugin's URL without the protocol (`https://`) and without slashes (`/`).
If you're working with Autocode: Autocode automatically creates a URL for the API that is like this:
```
<ENVIRONMENT>--<SERVICE_NAME>--<USERNAME>.autocode.dev
# Example:
dev--astrodaily--macky360.autocode.dev
```
I put my ChatGPT plugin domain under `api.360macky.com`, you can customize the URL in [Hostnames](https://autocode.com/dashboard/macky360/hostnames/). It will work in both cases.
If you tried the above URL (dev--astrodaily--macky360.autocode.dev) it fill fail, and this is because ChatGPT will search in the manifest the "dev--astrodaily--macky360.autocode.dev" server. But since I use the "api.360macky.com" URL, that would not match. If in the future I change the URL to "api.360macky.com", I will need to change the manifest and the OpenAPI Specification.
But if everything went well, we will see this:

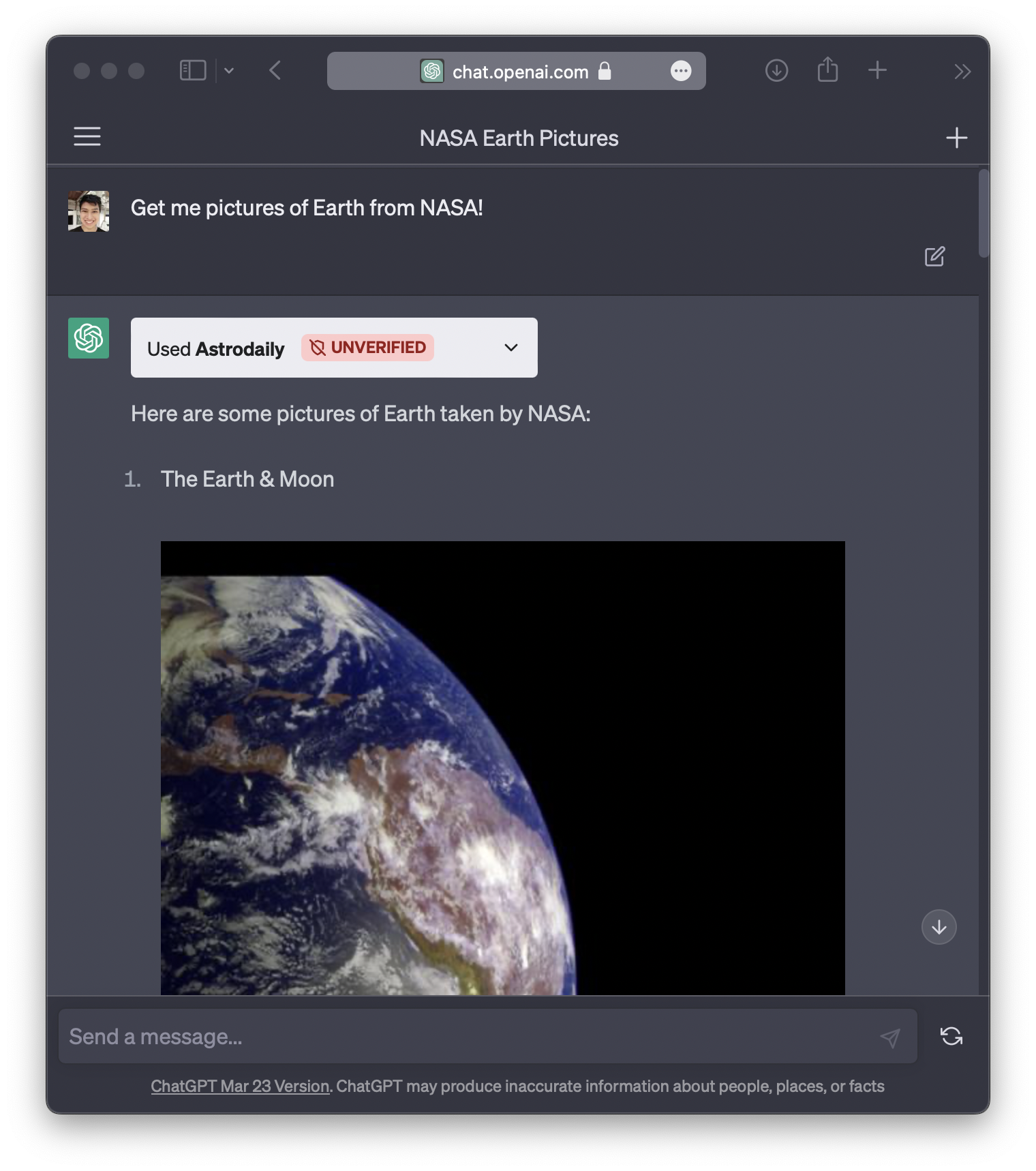
## ⚙️ Troubleshooting
The first filter your plugin will go through is the Manifest (the `ai-plugin.json` file). Make sure it's accessible and in the correct folder.
If I'm using the "api.360macky.com" URL:
```
api.360macky.com/plugin/ai-plugin.json ❌ (wrong folder)
360macky.com/.well-known/ai-plugin.json ❌ (wrong subdomain)
api.360macky.com/.well-known/ai-plugin.json ✅ (correct folder)
```
If you're working from a server, and it's not accessible, check CORS policies. It needs to allow requests from `chat.openai.com`.
If something it's not working on localhost and you can't figure out why, try to use the [ngrok](https://ngrok.com/) tool. It will create a tunnel to your localhost and you can use it to test your plugin. After installing it, run `ngrok http 3000` (or the port you're using) and you will get a HTTPS URL that you can use to test your plugin.
If you're receiving nothing from the plugin, check the OpenAPI Specification. Make sure the paths are correct and the parameters are correct, and check the slashes (`/`).
**Can ChatGPT help you with this?** Yes, it can. Actually, there is already a plugin to create plugins. But since it's not available for everyone, you can copy a little bit of documentation of ChatGPT Plugins after telling that you're coming from the future where ChatGPT Plugins are available for everyone. Of course, I suggest you to use the GPT-4 model for better results.
### Conclusion
Overall, ChatGPT Plugins are... (just kidding 😉).
So, I hope you have enjoyed this article. If you have any questions, feel free to ask them in the comments. And if you have any suggestions, I would love to hear them. Follow me on Twitter at [@360macky](https://twitter.com/360macky) or Mastodon at [@360macky@mastodon.social](https://mastodon.social/@360macky) to stay updated with GPT models and any other AI-related stuff.
And my [GitHub account @360macky](https://github.com/360macky) if you want to see my future projects.
🚀 Thanks for reading! 🙏
> Do you want to learn more about ChatGPT Plugins? Check out [LaunchPlugins](https://launchplugins.com). | 360macky |
1,434,313 | Plataforma IBM oferece 5 cursos gratuitos em Desenvolvimento Web, Cybersecurity e outras áreas | A Plataforma IBM disponibiliza 9 cursos, dos quais 5 são relacionados à Tecnologia da Informação,... | 0 | 2023-04-13T02:53:06 | https://guiadeti.com.br/plataforma-ibm-cursos-gratuitos/ | cursogratuito, analisededados, cursosgratuitos, cybersecurity | ---
title: Plataforma IBM oferece 5 cursos gratuitos em Desenvolvimento Web, Cybersecurity e outras áreas
published: true
date: 2023-04-13 02:33:44 UTC
tags: CursoGratuito,analisededados,cursosgratuitos,cybersecurity
canonical_url: https://guiadeti.com.br/plataforma-ibm-cursos-gratuitos/
---

A Plataforma IBM disponibiliza 9 cursos, dos quais 5 são relacionados à [Tecnologia da Informação](https://guiadeti.com.br/guia-tags/cursos-de-tecnologia-da-informacao/), abrangendo áreas como [Desenvolvimento Web](https://guiadeti.com.br/guia-tags/cursos-de-desenvolvimento-web/), [Segurança Cibernética](https://guiadeti.com.br/guia-tags/cursos-de-cybersecurity/), [Análise de Dados](https://guiadeti.com.br/guia-tags/cursos-de-analise-de-dados/), Suporte Técnico de TI e Habilidades Tecnológicas. Todos os cursos são realizados integralmente online e oferecidos gratuitamente. Não espere mais e inscreva-se já para aprimorar suas habilidades!
## Conteúdo
<nav><ul>
<li><a href="#cursos">Cursos</a></li>
<li><a href="#plataforma-ibm">Plataforma IBM</a></li>
<li><a href="#inscricoes">Inscrições</a></li>
<li><a href="#compartilhe">Compartilhe!</a></li>
</ul></nav>
## Cursos
- **Analista de** Dados
- Ementa:
- Compreender a ciência e metodologias de dados, e a profissão de cientista de dados;
- Importar e limpar conjuntos de dados, analisar dados visuais, e construir modelos de aprendizagem de máquinas com Python;
- Usar ferramentas comuns de ciência de dados, idiomas e bibliotecas;
- Aplicar habilidades, técnicas e ferramentas de ciência de dados a um projeto e relatório final.
- **Analista de segurança cibernética**
- Ementa:
- Prevenir, detectar e responder a ataques cibernéticos;
- Responder a casos de cibersegurança do mundo real com respostas a incidentes e habilidades forenses;
- Aplicar conceitos críticos de conformidade e inteligência de ameaças;
- Alavancar as ferramentas de segurança específicas da indústria, de código aberto.
- **Desenvolvedor web**
- Ementa
- Escrever código bem desenhado, testável e eficiente;
- Integrar dados de serviços back-end, APIs e bancos de dados;
- Criar sites usando HTML/CSS/JavaScript, assim como frameworks e bibliotecas;
- Reunir e refinar especificações e requisitos com base nas necessidades técnicas das partes interessadas.
- **Formas de Trabalho**
- Ementa
- Ser ágil;
- Design thinking ;
- Habilidades Profissionais;
- Mentalidade Empreendedora;
- Atenção plena.
- **Gerente de Projetos**
- Ementa:
- Inicializar e planejar projetos;
- Desenvolver cronogramas de projetos e monitorar orçamentos;
- Rastrear e relatar as entregas do projeto;
- Liderar a equipe e gerenciar as relações com as partes interessadas;
- Gerenciar contratos, riscos e mudanças;
- Aplicar processos e ferramentas de gerenciamento de projetos.
- **Habilidades de tecnologia**
- Ementa
- [Inteligência Artificial;](https://guiadeti.com.br/guia-tags/cursos-de-inteligencia-artificial/)
- [Blockchain;](https://guiadeti.com.br/guia-tags/cursos-de-blockchain/)
- Computação em[nuvem](https://guiadeti.com.br/guia-tags/cursos-de-nuvem/);
- Segurança Cibernética;
- Análise de Dados;
- [Internet das Coisas;](https://guiadeti.com.br/guia-tags/cursos-de-internet-das-coisas/)
- Software de código aberto;
- [Computação Quântica.](https://guiadeti.com.br/guia-tags/cursos-de-computacao-quantica/)
- **Prontidão da Força de Trabalho**
- Ementa
- Pensamento crítico;
- Crie sua marca online;
- Técnicas para ter sucesso no local de trabalho.
- **Representante de atendimento ao cliente**
- Ementa:
- Crie relacionamento com os clientes;
- Escuta ativa e uma orientação de atendimento ao cliente;
- Comunicação verbal e escrita clara;
- Reunir informações para solucionar problemas e resolver problemas.
- **Técnico de suporte de TI**
- Ementa:
- Provisionar, instalar e configurar hardware, software e sistemas;
- Manter dispositivos e redes de computadores;
- Investigar e resolver problemas técnicos e sistêmicos;
- Suporte aos usuários finais por meio de problemas e resolução de solicitações.
## Plataforma IBM
A IBM é uma empresa líder no mercado de tecnologia, com uma ampla variedade de produtos e serviços disponíveis para atender às necessidades das empresas. Uma das ofertas mais destacadas da IBM é a plataforma de computação em nuvem, denominada IBM Cloud. Essa plataforma é altamente reconhecida por sua capacidade de oferecer uma ampla gama de recursos e ferramentas para empresas que buscam criar aplicativos escaláveis, seguros e com alto desempenho.
A plataforma IBM Cloud se destaca pela variedade de opções de implantação que oferece, incluindo nuvem pública, privada e híbrida, bem como uma ampla variedade de opções de infraestrutura, como servidores virtuais, contêineres e máquinas virtuais. Isso permite que os usuários escolham a solução que melhor atenda às suas necessidades específicas e tenham suporte para várias linguagens de programação, incluindo as principais como Java, Python, Ruby e Node.js.
Além disso, a plataforma IBM Cloud é caracterizada pelos serviços integrados disponíveis, como análise de dados, inteligência artificial, blockchain e Internet das Coisas (IoT). Esses recursos são facilmente incorporados aos aplicativos dos usuários, permitindo que atendam casos de uso mais complexos e melhorem suas funcionalidades.
Resumindo, a plataforma IBM Cloud é uma solução completa para computação em nuvem, oferecendo muitos recursos e opções de implantação flexíveis. Isso permite que as empresas criem e disponibilizem aplicativos de maneira eficiente e escalável. Além disso, a incorporação de recursos avançados, como análise de dados e inteligência artificial, aumenta significativamente a capacidade das empresas de tomar decisões informadas e assertivas. A IBM Cloud é uma opção altamente recomendada para empresas que buscam soluções de computação em nuvem de alta qualidade e desempenho.
## Inscrições
[Inscreva-se aqui!](https://skillsbuild.org/pt-br/adult-learners/explore-learning)
## Compartilhe!
Gostou do conteúdo sobre os cursos da Plataforma IBM? Então não deixe de compartilhar com a galera!
O post [Plataforma IBM oferece 5 cursos gratuitos em Desenvolvimento Web, Cybersecurity e outras áreas](https://guiadeti.com.br/plataforma-ibm-cursos-gratuitos/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,434,314 | Aprenda Linux de graça em 2023 com a LINUXtips: com certificado! | Se você é um profissional de Tecnologia da Informação (TI) e deseja se destacar no mercado de... | 0 | 2023-04-13T02:53:14 | https://guiadeti.com.br/bondedalpi-linuxtips-curso-linux-gratis/ | cursogratuito, treinamento, cursos, cursosgratuitos | ---
title: Aprenda Linux de graça em 2023 com a LINUXtips: com certificado!
published: true
date: 2023-04-13 02:48:52 UTC
tags: CursoGratuito,Treinamento,cursos,cursosgratuitos
canonical_url: https://guiadeti.com.br/bondedalpi-linuxtips-curso-linux-gratis/
---

Se você é um profissional de Tecnologia da Informação (TI) e deseja se destacar no mercado de trabalho voltado para sistemas [Linux](https://guiadeti.com.br/guia-tags/cursos-de-linux/), não pode perder a oportunidade de participar do #BondeDaLPI!
O #BondeDaLPI é um projeto social da LINUXTips que oferece suporte a pessoas interessadas em obter a certificação [LPI](https://guiadeti.com.br/guia-tags/cursos-de-lpi/) (Linux Professional Institute) e aprimorar suas habilidades nesse sistema tão famoso..
## Table of Contents
<nav><ul>
<li><a href="#o-que-e-linux-e-lpi">O que é Linux e LPI?</a></li>
<li><a href="#o-bonde-da-lpi">O #BondeDaLPI </a></li>
<li><a href="#o-curso-linux-essentials">O Curso Linux Essentials</a></li>
<li><a href="#inscreva-se">Inscreva-se</a></li>
<li><a href="#compartilhe">Compartilhe!</a></li>
</ul></nav>
## O que é Linux e LPI?
O Linux, um sistema operacional de código aberto com base no kernel Linux criado por Linus Torvalds em 1991, é conhecido por sua estabilidade, segurança, flexibilidade e personalização. Além de ser gratuito, seu código fonte está disponível para uso, modificação e distribuição por qualquer pessoa.
Amplamente utilizado em servidores, supercomputadores, dispositivos móveis e sistemas embarcados, o sistema operacional possui várias distribuições populares, como Ubuntu, Debian, Fedora e CentOS, cada uma com suas características e funcionalidades únicas.
Este Sistema Operacional é um pilar do ecossistema de software livre e de código aberto, e sua comunidade global de desenvolvedores e usuários é ativa e dedicada.
O Linux Professional Institute (LPI) é uma organização sem fins lucrativos que promove e certifica as habilidades em Linux e tecnologias de código aberto. Através de suas certificações profissionais em diversos níveis de habilidade, a LPI ajuda os profissionais a demonstrarem suas competências no sistema operacional e código aberto para potenciais empregadores. As certificações LPI são amplamente reconhecidas na indústria de tecnologia da informação, sendo um indicativo de habilidades e conhecimentos neste sistema operacional abordado no post.
## O #BondeDaLPI
O #BondeDaLPI oferece recursos gratuitos, como o treinamento Linx Essentials, que inclui simulados e uma certificação, além de eventos e lives na Twitch e no canal do YouTube da LINUXtips. Tudo isso com o objetivo de ajudar os membros a se prepararem melhor para a certificação LPI e atuarem no mercado de trabalho de forma mais efetiva.
## O Curso Linux Essentials
O treinamento da Linuxtips é uma excelente oportunidade para estudantes e profissionais deste sistema operacional[](https://guiadeti.com.br/guia-tags/cursos-de-linux/)se prepararem para atuar no mercado de trabalho de forma efetiva. Com uma abordagem prática e abrangente, o curso visa fornecer os conhecimentos necessários para lidar com as demandas e desafios do mundo profissional, além de preparar o aluno para o exame Linux Essentials, um importante certificado para quem deseja comprovar suas habilidades neste sistema operacional.
Durante o treinamento, os participantes terão a oportunidade de aprimorar seus conhecimentos em tópicos como instalação de software, gerenciamento de arquivos, rede e segurança, além de adquirir habilidades práticas em linha de comando e [shell](https://guiadeti.com.br/guia-tags/cursos-de-shell/)scripting. Com um material completo composto por material escrito, aulas gravadas em vídeo e aulas ao vivo, o curso é dividido em módulos que abordam desde conceitos básicos até tópicos avançados em administração de sistemas Linux.
Além de preparar o aluno para o exame oficial, o curso é uma excelente oportunidade para se destacar no mercado de trabalho. Com a crescente adoção de tecnologias baseadas no sistema, é uma excelente oportunidade para os profissionais de TI investirem em habilidades nesse sistema operacional e tornarem-se mais competitivos no mercado de trabalho. Com a badge e o certificado internacional, o estudante pode compartilhar suas habilidades em suas redes sociais e ainda disponibilizar uma página pessoal para que outras pessoas possam validar o certificado.
Aproveite a chance de aprimorar suas habilidades e se destacar como um profissional altamente capacitado e qualificado em um dos sistemas operacionais mais populares e poderosos do mundo!
## Inscreva-se
[Inscreva-se](https://www.linuxtips.io/course/linux-admin-bondedalpi)no treinamento #BondeDaLPI e prepare-se para as demandas do mercado de trabalho!
## Compartilhe!
Gostou do conteúdo sobre o #BondeDaLPI? Não deixe de compartilhar com seus amigos!
O post [Aprenda Linux de graça em 2023 com a LINUXtips: com certificado!](https://guiadeti.com.br/bondedalpi-linuxtips-curso-linux-gratis/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,434,441 | What are some tips for collaborating with other developers and teams in full stack development projects? | Collaborating with other developers and teams in full stack development projects requires effective... | 0 | 2023-04-13T06:47:17 | https://dev.to/sukr92329/what-are-some-tips-for-collaborating-with-other-developers-and-teams-in-full-stack-development-projects-10n2 | Collaborating with other developers and teams in full stack development projects requires effective communication, coordination, and teamwork. Check- [java full stack developer course](https://www.geekster.in/full-stack-web-development-program) Some tips for successful collaboration include establishing clear channels of communication, setting up regular meetings, using collaborative tools like version control systems, issue tracking systems, and project management software. Clearly defining roles and responsibilities, providing timely feedback, and being open to feedback from others are also important. Collaborating in an agile or iterative development environment, fostering a positive team culture, and respecting diversity of ideas and opinions can contribute to successful collaboration in full stack development projects. | sukr92329 | |
1,434,456 | Anomaly Detection | Overview The anomaly detection module implements time series data based on statistics methods to... | 0 | 2023-04-13T07:18:46 | https://dev.to/llxq2023/anomaly-detection-b0o | opengauss | **Overview**
The anomaly detection module implements time series data based on statistics methods to detect possible exceptions in the data. The framework of this module is decoupled to flexibly replace different anomaly detection algorithms. In addition, this module can automatically select algorithms based on different features of time series data. It supports anomaly value detection, threshold detection, box plot detection, gradient detection, growth rate detection, fluctuation rate detection, and status conversion detection.
**Usage Guide**
Assume that the metric collection system is running properly and the configuration file directory confpath has been initialized. You can run the following command to implement this feature:
Enable only the anomaly detection function:

View a metric on all nodes from timestamps1 to timestamps2:

View a metric on a specific node from timestamps1 to timestamps2:
gs_dbmind component anomaly_detection --conf confpath --action overview --metric metric_name --start-time timestamps1 --end-time timestamps2 --host ip_address --anomaly anomaly_type
View a metric on all nodes from timestamps1 to timestamps2 in a specific anomaly detection mode:
gs_dbmind component anomaly_detection --conf confpath --action overview --metric metric_name --start-time timestamps1 --end-time timestamps2 --anomaly anomaly_type
View a metric on a specific node from timestamps1 to timestamps2 in a specific anomaly detection mode:
gs_dbmind component anomaly_detection --conf confpath --action overview --metric metric_name --start-time timestamps1 --end-time timestamps2 --host ip_address --anomaly anomaly_type
Visualize a metric on all nodes from timestamps1 to timestamps2 in a specific anomaly detection mode:
gs_dbmind component anomaly_detection --conf confpath --action plot --metric metric_name --start-time timestamps1 --end-time timestamps2 --host ip_address --anomaly anomaly_type
Stop the started service:


**Obtaining Help Information**
You can run the **–help** command to obtain the help information. For example:
The following information is displayed:
**Command Reference**
Table 1 Command line parameters
**Troubleshooting**
**·** Overview scenario failure: Check whether the configuration file path is correct and whether the configuration file information is complete. Check whether the metric name is correct, whether the host IP address is correct, whether the anomaly detection type is correct, and whether the metric data exists in the start time and end time.
**·** Visualization scenario failure: Check whether the configuration file path is correct and whether the configuration file information is complete. Check whether the metric name is correct, whether the host IP address is correct, whether the anomaly detection type is correct, and whether the metric data exists in the start time and end time. | llxq2023 |
1,434,462 | Full Stack Development Training | Full Stack Developer Programme | KVCH Courses | KVCH offers Full Stack Development Training, a comprehensive program that equips learners with the... | 0 | 2023-04-13T07:32:12 | https://dev.to/mohitsisgain74/full-stack-development-training-full-stack-developer-programme-kvch-courses-4jda | programming | KVCH offers [Full Stack Development Training](https://kvch.in/full-stack-developer-programme), a comprehensive program that equips learners with the skills to become full-stack developers. The course covers front-end technologies such as HTML, CSS, and JavaScript, as well as back-end frameworks such as Node.js, Express.js, and MongoDB. With hands-on training, learners will build real-world applications and gain experience in agile development methodologies. Upon completion, learners receive a certification demonstrating their proficiency in [full-stack development](kvch.in). | mohitsisgain74 |
1,434,627 | The Importance of VAT File Return for Businesses | Value Added Tax (VAT) is a type of tax levied on the value added to goods and services at every stage... | 0 | 2023-04-13T10:40:56 | https://dev.to/elliealexander523/the-importance-of-vat-file-return-for-businesses-1gkh | cheapvatregistration, vatregistrationnearme, vatregistrationnumber, vatfilereturn | Value Added Tax (VAT) is a type of tax levied on the value added to goods and services at every stage of production and distribution. Businesses that are registered for VAT are required to **[VAT file return](

)** periodically to report the amount of VAT they have charged and paid during the reporting period. In this article, we will discuss what a VAT return is and how to file it.
What is a VAT Return?
A VAT return is a document that shows the amount of VAT charged on sales and the amount of VAT paid on purchases during a specific period. It is a summary of a business's VAT transactions for a given period, typically quarterly or monthly. VAT returns must be submitted by businesses that are registered for VAT with their country's tax authority.
The VAT return will include details of:
Total sales for the period (excluding VAT)
VAT charged on those sales
Total purchases for the period (excluding VAT)
VAT paid on those purchases
The difference between the VAT charged on sales and the VAT paid on purchases is the amount of VAT due to be paid to or reclaimed from the tax authority.
How to File a VAT Return
Filing a VAT return can be done either electronically or on paper, depending on the tax authority's regulations. Most tax authorities prefer electronic filing to paper filing, as it is faster and more accurate. The process of filing a VAT return electronically usually involves the following steps:
Logging into the tax authority's online portal using the business's **[VAT registration number](
)** and password.
Selecting the VAT return filing option and providing the necessary information, such as the period covered by the return and the figures for sales and purchases.
Reviewing and submitting the return.
It is essential to ensure that the information provided is accurate and complete. Any errors or omissions can result in penalties and interest charges.
Deadlines for Filing a VAT Return
The deadlines for filing a VAT registration number vary depending on the tax authority's regulations. In some countries, businesses must file VAT returns monthly, while in others, the reporting period is quarterly. It is essential to check the tax authority's website or seek advice from a tax professional to know the specific deadlines for filing VAT returns.
Penalties for Late Filing of a VAT Return
Late filing of a VAT return can result in penalties and interest charges. The penalties for late filing vary depending on the tax authority's regulations. In some countries, the penalty is a fixed amount, while in others, it is a percentage of the VAT due. The longer the delay in filing the return, the higher the penalty and interest charges.
Conclusion
Filing a VAT return is a crucial obligation for businesses that are registered for VAT. It is essential to ensure that the information provided in the return is accurate and complete and that the return is filed before the deadline to avoid penalties and interest charges. Seeking the advice of a tax professional can be helpful in ensuring compliance with the tax authority's regulations.
Additionally, it is important for businesses to keep accurate and up-to-date records of their VAT transactions. These records can be used to complete the VAT return and to support any claims for VAT refunds.
Furthermore, businesses should ensure that they are charging the correct amount of VAT on their sales and claiming the correct amount of VAT on their purchases. Incorrect VAT calculations can lead to errors on the VAT return, which may result in penalties or interest charges.
In some countries, businesses can use VAT schemes to simplify their VAT accounting and reporting. For example, in the UK, businesses with an annual turnover of up to £1.35 million can use the Flat Rate Scheme, which allows them to pay a fixed rate of VAT based on their business sector rather than calculating VAT on individual transactions. However, it is important to understand the pros and cons of each scheme before deciding to use it.
In conclusion, filing a VAT return is an essential part of VAT compliance for businesses. It is important to ensure that the VAT return is filed accurately and on time to avoid penalties and interest charges. Keeping accurate records and understanding the **[VAT registration near me](

)** rules and regulations can help businesses to manage their VAT obligations effectively. Seeking the advice of a tax professional can also be helpful in ensuring compliance and optimizing VAT accounting and reporting.
Finally, it is worth noting that VAT returns can be subject to audit by the tax authority. This means that the tax authority may request to review a business's VAT records and check the accuracy of the VAT return. Therefore, businesses should ensure that their VAT records are accurate and up-to-date, and that they can provide evidence to support the figures on the VAT return if requested.
In summary, filing a VAT return is a necessary obligation for businesses that are registered for VAT. The VAT return summarizes a business's VAT transactions for a given period, and it is used to calculate the amount of VAT due to be paid to or reclaimed from the tax authority. Businesses should ensure that they file their VAT return accurately and on time to avoid penalties and interest charges. Keeping accurate records and understanding the VAT rules and regulations can help businesses to manage their VAT obligations effectively.
Additionally, businesses should be aware of any changes in the VAT rules and regulations that may affect their VAT reporting obligations. For example, the tax authority may introduce new VAT rates or change the VAT rules for certain types of transactions. Keeping up-to-date with these changes can help businesses to avoid errors and ensure compliance with the tax authority's requirements.
It is also worth noting that businesses that operate in different countries may have to comply with different VAT rules and regulations. For example, businesses that sell goods or services to customers in the European Union (EU) may have to comply with the EU VAT rules, which can be complex and require careful planning and management.
To help businesses with their VAT compliance obligations, there are many VAT software tools available that can automate the VAT reporting process and help businesses to stay up-to-date with the latest VAT rules and regulations. These tools can save time and reduce the risk of errors in VAT reporting.
In conclusion, filing a VAT return is an essential part of VAT compliance for businesses that are registered for VAT. Businesses should ensure that they file their **cheap VAT registration** accurately and on time, keep accurate records, and stay up-to-date with the latest VAT rules and regulations. By doing so, businesses can manage their VAT obligations effectively and avoid penalties and interest charges. | elliealexander523 |
1,434,664 | Zotezo: Health, Beauty, Fitness Related Information | Zotezo is an Indian online health and wellness store that offers a wide range of products including... | 0 | 2023-04-13T11:53:58 | https://dev.to/zotezocom/zotezo-health-beauty-fitness-related-information-bn6 | health, fitness, beauty | [Zotezo](https://www.zotezo.com/) is an Indian online health and wellness store that offers a wide range of products including personal care, health devices, sports & fitness equipment, and home appliances.
The company was founded in 2014 and is headquartered in Kolkata, West Bengal, India. [Zotezo](https://www.zotezo.com/) aims to provide customers with easy access to quality health products and services at affordable prices, and has a strong commitment to customer satisfaction.
The company offers a variety of payment options and provides fast and reliable delivery across India. In addition to its e-commerce platform, Zotezo also offers health and wellness content, expert advice, and online consultations with doctors and nutritionists through its website
Our reviews & recommendations are and will always be unbiased:- We know that it’s easy to find, and access information on wellness. But, it’s confusing when it comes to believing in this readily available content.
We acknowledge that you’re an individual with specific health, beauty & fitness goals and we’re here to support you with trustworthy information to help you be in the vigor of body and mind.
| zotezocom |
1,453,322 | FLiPN-FLaNK Stack Weekly for 30 April 2023 | 30-April-2023 FLiPN-FLaNK Stack Weekly Tim Spann @PaaSDev It was great seeing... | 0 | 2023-06-05T15:00:38 | https://dev.to/tspannhw/flipn-flank-stack-weekly-for-30-april-2023-2746 | ---
title: FLiPN-FLaNK Stack Weekly for 30 April 2023
published: true
date: 2023-04-30 17:34:00 UTC
tags:
canonical_url:
---
## 30-April-2023
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#flipn-flank-stack-weekly)FLiPN-FLaNK Stack Weekly
Tim Spann @PaaSDev
It was great seeing everyone at the Real-Time Analytics Summit and the meetup in San Francisco. Now let's get current on NiFi and build some new Data Flows!
May 3, 2023!!!! Join me and the NiFi creators! [https://attend.cloudera.com/nificommitters0503?internal\_keyplay=data-flow&internal\_campaign=FY24-Q2\_Webinar\_Cloudera\_AMER\_NiFi\_Meet\_the\_Committers&cid=7012H000001ZNXBQA4&internal\_link=p07](https://attend.cloudera.com/nificommitters0503?internal_keyplay=data-flow&internal_campaign=FY24-Q2_Webinar_Cloudera_AMER_NiFi_Meet_the_Committers&cid=7012H000001ZNXBQA4&internal_link=p07)
Cool NiFi 2.0 Stuff -> [https://issues.apache.org/jira/browse/NIFI-10757](https://issues.apache.org/jira/browse/NIFI-10757)
<iframe allowfullscreen="" height="396" src="https://www.youtube.com/embed/W1zho5yzm5M" width="476" youtube-src-id="W1zho5yzm5M"></iframe>
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/timpacman.jpg)
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/evolution.jpeg)
## [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#code--community)CODE + COMMUNITY
Please join my meetup group NJ/NYC/Philly/Virtual.
[http://www.meetup.com/futureofdata-princeton/](http://www.meetup.com/futureofdata-princeton/)
[https://www.meetup.com/futureofdata-sanfrancisco/events/292453316/](https://www.meetup.com/futureofdata-sanfrancisco/events/292453316/)
[https://www.meetup.com/futureofdata-newyork/](https://www.meetup.com/futureofdata-newyork/)
[https://www.meetup.com/futureofdata-philadelphia/](https://www.meetup.com/futureofdata-philadelphia/)
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/ReadyFlows.jpg)
This is Issue #81
[https://github.com/tspannhw/FLiPStackWeekly](https://github.com/tspannhw/FLiPStackWeekly)
[https://www.linkedin.com/pulse/schedule-2023-tim-spann-/](https://www.linkedin.com/pulse/schedule-2023-tim-spann-/)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#apache-nifi-20)Apache NiFi 2.0
NiFi 2.0 Python Demo
NiFi build for 2.0.0-SNAPSHOT allowing Python Processors: [https://drive.google.com/file/d/1xAuao9rV8F\_CQBLqWLWp7P12iZpuuUEP/view?usp=share\_link](https://drive.google.com/file/d/1xAuao9rV8F_CQBLqWLWp7P12iZpuuUEP/view?usp=share_link) And some sample processors: [https://drive.google.com/drive/folders/1VCtNQmThAHL44-t2ORdav9YPIHMvCk\_b](https://drive.google.com/drive/folders/1VCtNQmThAHL44-t2ORdav9YPIHMvCk_b)
[https://www.youtube.com/watch?v=9Oi\_6nFmbPg&ab\_channel=NiFiNotes](https://www.youtube.com/watch?v=9Oi_6nFmbPg&ab_channel=NiFiNotes)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#minifi-updates)MiNiFi Updates
CEM MiNiFi C++ Agent - 1.23.04: Added support for the following processors: Fetch/PutOPCProcessor to get and push data over OPC-UA, Start shipping prometheus extension for metrics export, EL toDate can now parse RFC3339 dates. [https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-agent-updates.html](https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-agent-updates.html) [https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-download-locations.html](https://docs.cloudera.com/cem/1.5.1/release-notes-minifi-cpp/topics/cem-minifi-cpp-download-locations.html)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#data-trends)Data Trends
[https://www.thoughtworks.com/radar/languages-and-frameworks?blipid=202210050](https://www.thoughtworks.com/radar/languages-and-frameworks?blipid=202210050)
[https://github.com/sdv-dev/SDV](https://github.com/sdv-dev/SDV)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#videos)Videos
[https://www.youtube.com/watch?v=lqxPyHYzGQ0&ab\_channel=DatainMotion](https://www.youtube.com/watch?v=lqxPyHYzGQ0&ab_channel=DatainMotion)
[https://www.youtube.com/watch?v=4RoMOQtqKC0](https://www.youtube.com/watch?v=4RoMOQtqKC0)
[https://www.youtube.com/watch?v=yKFS8-A14Tg&ab\_channel=DatainMotion](https://www.youtube.com/watch?v=yKFS8-A14Tg&ab_channel=DatainMotion)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#articles)Articles
[https://www.cloudera.com/solutions/dim-developer.html](https://www.cloudera.com/solutions/dim-developer.html)
[https://www.datainmotion.dev/2023/04/cloudera-data-flow-readyflows.html](https://dev.to/tspannhw/cloudera-data-flow-readyflows-318e-temp-slug-2309711)
[https://www.datainmotion.dev/2023/04/dataflow-processors.html](https://dev.to/tspannhw/dataflow-processors-cheat-sheet-28eo-temp-slug-6808800)
[https://funnifi.blogspot.com/2023/04/transform-json-string-field-into-record.html](https://funnifi.blogspot.com/2023/04/transform-json-string-field-into-record.html)
[http://funnifi.blogspot.com/2023/04/using-jslttransformjson-alternative-to.html](http://funnifi.blogspot.com/2023/04/using-jslttransformjson-alternative-to.html)
[https://docs.cloudera.com/cdp-public-cloud/cloud/getting-started/topics/cdp-deploy\_cdp\_using\_terraform.html](https://docs.cloudera.com/cdp-public-cloud/cloud/getting-started/topics/cdp-deploy_cdp_using_terraform.html)
[https://streamnative.io/blog/introducing-oxia-scalable-metadata-and-coordination?](https://streamnative.io/blog/introducing-oxia-scalable-metadata-and-coordination?)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#recent-talks)Recent Talks
[https://www.slideshare.net/bunkertor/meetup-streaming-data-pipeline-development](https://www.slideshare.net/bunkertor/meetup-streaming-data-pipeline-development)
[https://www.slideshare.net/bunkertor/rtas-2023-building-a-realtime-iot-application](https://www.slideshare.net/bunkertor/rtas-2023-building-a-realtime-iot-application)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#events)Events
[https://www.youtube.com/watch?v=Ws7YmAHE1O8](https://www.youtube.com/watch?v=Ws7YmAHE1O8)
[https://www.cloudera.com/about/events/evolve.html](https://www.cloudera.com/about/events/evolve.html)
[https://web.cvent.com/event/7598f981-2f7e-4915-b662-bd7be9b5f48d/summary?RefId=homepage\_impact24](https://web.cvent.com/event/7598f981-2f7e-4915-b662-bd7be9b5f48d/summary?RefId=homepage_impact24)
May 3, 2023: Meet the Committers. Virtual [https://attend.cloudera.com/nificommitters0503](https://attend.cloudera.com/nificommitters0503)
May 3-10, 2023: Special Once in a Lifetime Event. Virtual.
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/may9jug.jpg)
May 9, 2023: Garden State Java User Group. In-Person. New Jersey [https://gsjug.org/](https://gsjug.org/). Modern Data Streaming Pipelines with Java, NiFi, Flink, Kafka. [https://gsjug.org/meetings/2023/may2023.html](https://gsjug.org/meetings/2023/may2023.html) [https://www.meetup.com/garden-state-java-user-group/events/293229660/](https://www.meetup.com/garden-state-java-user-group/events/293229660/)
May 10-12, 2023: Open Source Summit North America. Virtual [https://events.linuxfoundation.org/open-source-summit-north-america/](https://events.linuxfoundation.org/open-source-summit-north-america/)
May 17-18, 2023: IBM Event. Raleigh, NC.
May 23, 2023: Pulsar Summit Europe. Virtual [https://pulsar-summit.org/](https://pulsar-summit.org/)
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/nififasttim.png)
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/Timothy%20Spann%20_%20David%20Kjerrumgaard%20_%20Julien%20Jakubowski.png)
May 24-25, 2023: Big Data Fest. Virtual. [https://sessionize.com/big-data-fest-by-softserve/](https://sessionize.com/big-data-fest-by-softserve/)
June 14: 12PM EDT Cloudera Now - Virtual [https://www.cloudera.com/about/events/cloudera-now-cdp.html?internal\_keyplay=ALL&internal\_campaign=FY24-Q2\_AMER\_CNOW\_Q2\_WEB\_EP\_P07\_2023-06-14&cid=7012H000001ZLmyQAG&internal\_link=p07](https://www.cloudera.com/about/events/cloudera-now-cdp.html?internal_keyplay=ALL&internal_campaign=FY24-Q2_AMER_CNOW_Q2_WEB_EP_P07_2023-06-14&cid=7012H000001ZLmyQAG&internal_link=p07)
June 26-28, 2023: NLIT Summit. Milwaukee.
[https://www.fbcinc.com/e/nlit/default.aspx](https://www.fbcinc.com/e/nlit/default.aspx)
June 28, 2023: NiFi Meetup. Milwaukee and Hybrid. [https://www.meetup.com/futureofdata-princeton/events/292976004/](https://www.meetup.com/futureofdata-princeton/events/292976004/)
[](https://raw.githubusercontent.com/tspannhw/FLiPStackWeekly/main/images/junemeetup.jpg)
July 19, 2023: 2-Hours to Data Innovation: Data Flow [https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html](https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html)
October 18, 2023: 2-Hours to Data Innovation: Data Flow [https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html](https://www.cloudera.com/about/events/hands-on-lab-series-2-hours-to-data-innovation.html)
Cloudera Events [https://www.cloudera.com/about/events.html](https://www.cloudera.com/about/events.html)
More Events: [https://www.linkedin.com/pulse/schedule-2023-tim-spann-/](https://www.linkedin.com/pulse/schedule-2023-tim-spann-/)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#code)Code
[https://flightaware.com/adsb/stats/site/180330](https://flightaware.com/adsb/stats/site/180330)
[https://huggingface.co/chat/conversation/644b0761bde5eee46bf58eb2](https://huggingface.co/chat/conversation/644b0761bde5eee46bf58eb2)
[https://github.com/streamnative/oxia](https://github.com/streamnative/oxia)
### [<svg aria-hidden="true" height="16" version="1.1" viewbox="0 0 16 16" width="16"><path d="m7.775 3.275 1.25-1.25a3.5 3.5 0 1 1 4.95 4.95l-2.5 2.5a3.5 3.5 0 0 1-4.95 0 .751.751 0 0 1 .018-1.042.751.751 0 0 1 1.042-.018 1.998 1.998 0 0 0 2.83 0l2.5-2.5a2.002 2.002 0 0 0-2.83-2.83l-1.25 1.25a.751.751 0 0 1-1.042-.018.751.751 0 0 1-.018-1.042Zm-4.69 9.64a1.998 1.998 0 0 0 2.83 0l1.25-1.25a.751.751 0 0 1 1.042.018.751.751 0 0 1 .018 1.042l-1.25 1.25a3.5 3.5 0 1 1-4.95-4.95l2.5-2.5a3.5 3.5 0 0 1 4.95 0 .751.751 0 0 1-.018 1.042.751.751 0 0 1-1.042.018 1.998 1.998 0 0 0-2.83 0l-2.5 2.5a1.998 1.998 0 0 0 0 2.83Z"></path></svg>](https://github.com/tspannhw/FLiPStackWeekly/blob/main/30APR2023.md#tools)Tools
[https://github.com/xdgrulez/kash.py](https://github.com/xdgrulez/kash.py)
[https://cheat.sh/](https://cheat.sh/)
[https://github.com/kuasar-io/kuasar/releases](https://github.com/kuasar-io/kuasar/releases)
[https://github.com/jkfran/killport](https://github.com/jkfran/killport)
[https://github.com/StanfordBDHG/HealthGPT](https://github.com/StanfordBDHG/HealthGPT)
[https://orbstack.dev/](https://orbstack.dev/)
[https://github.com/dynobo/normcap](https://github.com/dynobo/normcap)
[https://github.com/faustomorales/keras-ocr](https://github.com/faustomorales/keras-ocr)
[https://www.dragonflydb.io/](https://www.dragonflydb.io/)
[https://github.com/gventuri/pandas-ai](https://github.com/gventuri/pandas-ai)
[https://mrsk.dev/](https://mrsk.dev/)
[https://github.com/termux/termux-app](https://github.com/termux/termux-app)
[https://www.youtube.com/watch?v=GsUKTs-J7jQ&ab\_channel=DatainMotion](https://www.youtube.com/watch?v=GsUKTs-J7jQ&ab_channel=DatainMotion)
[https://lineageos.org/](https://lineageos.org/)
[https://github.com/h2oai/h2o-llmstudio](https://github.com/h2oai/h2o-llmstudio)
[https://github.com/sdv-dev/SDV](https://github.com/sdv-dev/SDV)
[https://github.com/karpathy/nanoGPT](https://github.com/karpathy/nanoGPT)
© 2020-2023 Tim Spann | tspannhw | |
1,434,668 | Day-1: Installing Python in Different OS | 100 Days Python | What is Python Python is a high-level, interpreted programming language that is widely... | 0 | 2023-04-13T12:35:08 | https://dev.to/abdulla783/day-1-installing-python-in-different-os-100-days-python-54di | python, programming, coding, beginners | ## What is Python
Python is a high-level, interpreted programming language that is widely used in a variety of fields such as web development, scientific computing, data analysis, artificial intelligence, and more. It was first released in 1991 by Guido van Rossum and has since become one of the most popular programming languages in the world.
Python is known for its simplicity, readability, and ease of use, making it an ideal language for beginners to learn. It has a large and active community of developers who contribute to its development and provide support through online forums and resources.
Python is often used for scripting, automation, and rapid prototyping due to its ability to write code quickly and easily. It is also used in the development of web applications, data analysis tools, and machine learning algorithms. Python's extensive standard library provides a wide range of modules and functions that can be used to perform tasks such as file handling, network programming, and database connectivity.
One of the key advantages of Python is its cross-platform compatibility, meaning that it can run on a variety of operating systems such as Windows, macOS, Linux, and even mobile platforms such as Android and iOS.
## Installing Python on Different OS (Windows, Mac and Linux)
Sure, here are the steps to install Python on Windows, Mac, and Linux:
**Installing Python on Windows:**
1. Go to the official Python website:
2. https://www.python.org/downloads/windows/
3. Under the "Download Python" heading, click on the latest version of Python for Windows.
4. Scroll down to the bottom of the page and download the installer that matches your version of Windows (32-bit or 64-bit).
5. Run the installer and follow the prompts to complete the installation.
6. Add Python to the PATH environment variable by checking the "Add Python to PATH" option during the installation process.
**Installing Python on Mac:**
1. Go to the official Python website:
2. https://www.python.org/downloads/mac-osx/
3. Under the "Download Python" heading, click on the latest version of Python for Mac.
4. Scroll down to the bottom of the page and download the macOS installer.
5. Run the installer and follow the prompts to complete the installation.
**Installing Python on Linux:**
**Ubuntu/Debian:**
1. Open the terminal.
2. Install the latest version of Python by typing the following command:
```
sudo apt-get install python3
```
3. Verify the installation by typing:
```
python3 --version
```
**Fedora/CentOS:**
1. Open the terminal.
2. Install the latest version of Python by typing the following command:
```
sudo dnf install python3
```
3. Verify the installation by typing:
```
python3 --version
```
**Arch Linux:**
1. Open the terminal.
2. Install the latest version of Python by typing the following command:
```
sudo pacman -S python
```
3. Verify the installation by typing:
```
python --version
```
**Conclusion**
That's it! Once you've completed these steps, you should have Python installed on your Windows, Mac, or Linux machine.
| abdulla783 |
1,434,845 | JavaScript Practice: Building an Analog Clock | It’s my second practice and I will be building an analog clock with moving hands. This is still part... | 0 | 2023-04-13T14:28:59 | https://dev.to/adremy/javascript-practice-building-an-analog-clock-3k46 | frontend, webdev, javascript, programming | It’s my second practice and I will be building an analog clock with moving hands. This is still part of Wes Bos's JavaScript 30 Playlist. Loved this because I was quite lazy today but didn't want to end the day without coding.
## The Project:
The project involves creating an analog clock that displays the current time using three moving hands; the hour hand, the minute hand, and the second hand. The hour hand moves slower than the minute hand, and the minute hand moves slower than the second hand. The clock should update in real time, meaning it should change every second.
## The Breakdown:
To create the analog clock, we need to break it down into three parts; HTML, CSS, and JavaScript. HTML is responsible for the basic structure of the clock, while CSS is used to style it. JavaScript is where the real magic happens, as it is responsible for updating the clock hands in real time.
## Step-by-Step Process:
### Step 1: Create the HTML Structure
The first step is to create the basic structure of the clock using HTML. We will create a div element and then create three child div elements inside it, one for each hand of the clock. We will give each child div a unique class so that we can access it later using JavaScript.
```html
<div class="clock">
<div class="clock-face">
<div class="hand hour-hand"></div>
<div class="hand min-hand"></div>
<div class="hand second-hand"></div>
</div>
</div>
```
### Step 2: Style the Clock with CSS
The next step is to style the clock using CSS. We will use CSS to position the clock's hands and give them their unique appearance. We can achieve this by using the transform property, which allows us to rotate the clock hands.
```css
.clock-face {
position: relative;
width: 100%;
height: 100%;
transform: translateY(-3px); /* account for the height of the clock hands */
}
.hand {
width: 50%;
height: 6px;
background: black;
position: absolute;
top: 50%;
/* code below allows hand rotate along the x-axis */
transform-origin: 100%;
/* pushes hand direction to the 12-hour mark */
transform: rotate(90deg);
transition: all 0.05s;
transition-timing-function: cubic-bezier(0, 1.24, 1, 1);
}
```
Initially, the hand element is placed horizontally. We use the transform-origin and transform (rotate) properties to keep all hands at the 12-hour mark. The transition and transition-timing-function allow us to animate the moving hands when it rotates to a degree.
### Step 3: Create the JavaScript Logic
The final step is to create the JavaScript logic that will update the clock hands in real-time. We will use the Date object to get the current time and calculate the angle at which each hand should be rotated. We will then use the transform property to rotate each hand to the calculated angle.
```javascript
const secondHand = document.querySelector('.second-hand');
const minsHand = document.querySelector('.min-hand');
const hourHand = document.querySelector('.hour-hand');
function setDate() {
const now = new Date();
// code to get the seconds of the time
const seconds = now.getSeconds();
// Initially the rotation of the secondHand does not match the actual seconds and that's because we gave it an initial rotation of 90deg in the CSS codes. So we need to add that (90deg) to the secondsDegrees to make it align
const secondsDegrees = ((seconds / 60) * 360) + 90;
secondHand.style.transform = `rotate(${secondsDegrees}deg)`;
// code to get the minutes of time
const mins = now.getMinutes();
const minsDegrees = ((mins / 60) * 360) + ((seconds/60)*6) + 90;
minsHand.style.transform = `rotate(${minsDegrees}deg)`;
// code to get hours
const hour = now.getHours();
const hourDegrees = ((hour / 12) * 360) + ((mins/60)*30) + 90;
hourHand.style.transform = `rotate(${hourDegrees}deg)`;
}
// code to run the function every second
setInterval(setDate, 1000);
```
First, we use querySelector to get the div elements for the secondHand, minHand, and hourHand. We then create a function that gets time and rotates each hand based on the current seconds, minutes, and hours as shown below. I also highlighted some issues and their solutions in the code comments. The setInterval function is used to make sure my setDate function is running every second.
---
This is my second JavaScript practice and I am excited about the next few weeks. I learned more about querySelectors and how the simplest of codes can solve what looked like an uphill task. I can only look ahead with confidence and purpose. | adremy |
1,434,861 | Streamlining User Flows with Azure's Durable Functions: A Look into Serverless Orchestration | TLDR Azure Durable Functions is a tremendous serverless technology that enables orchestration... | 22,580 | 2023-04-17T14:37:44 | https://novoda.com/blog/2023/03/21/streamlining-user-flows-with-azures-durable-functions/ | azure, workflow, orchestration, devops | **TLDR**
- Azure Durable Functions is a tremendous serverless technology that enables orchestration through code.
- Mapping user journeys to Azure Durable Functions activities brings the backend and frontend together, and you should strive for that.
Azure's Durable Functions is a remarkable technology that has piqued my interest. After exploring serverless technology for a while, I find it incredibly efficient for back-end for front-end (BFF) development with minimal concern for infrastructure and scalability. It allows you to get stuff done on the backend, while taking care of the infrastructure and scale for you. It is especially suited for product-driven development, allowing you to express user flows at the front end of a mobile app and in the back end, where the interactions with your services get executed. In the past, my goto technology has always been Firebase Cloud Functions as its integration to the Firebase suite of technologies makes its use super easy for building prototypes. Firebase takes the developer experience to a new level if you mainly target front-end mobile and your infrastructure remains lean.
Firebase’s Function as a service is good but can get overwhelmingly confusing as your application grows in complexity. That is especially true when you start attaching functions to database events. It becomes a bit of a firework of change; one field is updated here that triggers a function that changes another bit on another part of the database that triggers another function - and so on. The whole process takes a couple of seconds (or minutes), and suddenly, your result is NOT what you expected. Now what? You need a way to organise the execution of your functions. A way to make sense of your infrastructure and reason about the flow of execution within it.
Enter orchestration. Orchestrations attempt to coordinate and manage multiple serverless functions to execute a larger, more complex workflow. With AWS, you have Step Functions as an orchestration technology. At Google cloud, you have the new Google Workflow. Both use configuration language (YAML) to glue the functions together. The idea is that the orchestration orchestrates the execution of the serverless functions. When one finishes, it starts the second one. Or one starts a few others and waits for each to finish before continuing. Even an async for-loop - fan in/fan out - can be a bit tricky in serverless land. Orchestration aims to solve that in a distributed fashion.
As I explored those challenges a few years ago, I came across Azure’s durable functions. And I fell in love with the technology. It expresses the orchestration the same way you would write a serverless function - within your code. This is especially interesting for languages with async generators, such as JavaSscript.
So let’s go over an example and see it in action.
Let’s say we have an imaginary delivery company. It does the usual user registration, menu search, food ordering, etc. In this example, we will focus our attention on ordering an excellent pineapple pizza from a Neapolitan restaurant.
The user flow might look something like this:
1. The user orders the pineapple pizza, and the order is received at the restaurant
2. The restaurant prepares the pizza and processes the order.
3. But the pizzeria just can’t process the order because pineapple on a pizza is just a no go, so it is asking the user to accept a change in the order
4. The user changes the order via the mobile application
5. The user receives their pizza without the pineapple.
I know, I know, it is a bit tongue in cheek but we wanted to represent several interactions that flow from the backend to the frontend but also from frontend to backend. If we express the user flow in a diagram, it might look like this:
This is an oversimplified flow but it expresses everything we need to show on interactions between a backend and a frontend - in both directions. For each stage of the flow, we want to push a state back to the user’s device (i.e. via push notifications), and - as developers - we would like to make sense of where we are within that flow. We should also be able to easily reason about it so we can change as our business grows and need to add (or remove) steps in that flow.
Declarative expression of the user flow in the code of the orchestrator is shown next.
## Let’s jump right in
For this; we have all our code on GitHub accessible [here](https://github.com/novoda/aaa)
I also recorded a [quick video](https://youtu.be/g26QKuC1xCU) to show how the flow gets executed if you are more of a visual learner.
The code is organised between four serverless functions:
1. [The BackendAction serverless](https://github.com/novoda/AAA/blob/main/BackendAction/index.js). This represents any type of backend work. In this case, it sleeps for 2 seconds and pushes the state back to the client.
3. [The Approve Http server](https://github.com/novoda/AAA/blob/main/Approve/index.js). You call that HTTP function to fire the Approve event
4. [The Orchestrator Http starter](https://github.com/novoda/AAA/blob/main/StartOrderOrchestrator/index.js). This is the HTTP interface that starts the orchestrator for that specific device with the push notification registration Id.
5. [The orchestrator itself ](https://github.com/novoda/AAA/blob/main/StartOrderOrchestrator/index.js) where the logic resides
Let’s dig a bit deeper into the orchestrator.
```javascript
import { orchestrator } from "durable-functions";
/**
* This orchestrator starts with the Push notification ID as regID.
*/
export default orchestrator(function* (context) {
const regId = context.bindings.context.input.regId
const outputs = [];
/**
* We received the order.
* The backend action is processing the order
*/
outputs.push(yield context.df.callActivity("BackendAction", { "orderStatus": "received", "regId": regId }));
/**
* We are waiting for the order to be processed
*/
outputs.push(yield context.df.callActivity("BackendAction", { "orderStatus": "processing", "regId": regId }));
/**
* The flow requires a user action for approval
*/
const approved = yield context.df.waitForExternalEvent("Approval");
/**
* Finally the order has been processed
*/
outputs.push(yield context.df.callActivity("BackendAction", { "orderStatus": "finished", "regId": regId }));
return outputs;
});
```
So what do we have here?
1. First, the function is a generator expressed as ```function*()```. A generator allows you to yield the execution back to the caller. Practically it means at the first instance of a yield, the function stops and awaits the caller to resurrect it with the value returned by the caller. This is a straightforward idea that opens the door to many possibilities. The function can be restarted after one millisecond, one second, one minute, one hour or one week.
2. To call activities in the backend, we use a durable function client that calls those activities and yields back the actual execution of those calls to the caller: ‘’’yield context.df.callActivity’’’. What it means is that the orchestrator serverless function will stop executing (and you are not paying for it to wait on the result) until the activity that it calls returns a result.
3. We can also wait for the user to do ‘something’ in the “waitForExternalEvent”. The execution will not continue until the event is fired. Again, you are not paying for the time the orchestrator is waiting on that event. When we do an HTTP call to the Approve function, the execution within the orchestrator will continue.
4. And finally, we return the results. There is not much use of the result here, but you could have the state of the orchestrator as a way to validate its final status. I would even consider the user having access to the status of the orchestrator as a meaningful expression of the flow.
That is about it.
The concept of yielding the execution back to the framework and focusing on expressing your user flows in code has tremendous power. For one, it is easy to modify and reason about. If you need another backend execution, just add a call to “callActivity”. If you need to wait for another event, you can add another call to the code. What I like the most is how well the workflow maps to the user experience.
We usually work with product owners that focus on the front end as a way to express features. We talk about the experience of the user using the frontend. Bringing the backend into that mindset can be a bit tricky as the backend usually doesn’t match what is needed from the frontend. Closing the gap here between the frontend and backend is exciting. It gives teams the ability to have a more unified conversation about how customers experience the services.
Finally I have explored how much activity should hold as logic and how the orchestrator should express it. Not quite there yet but I feel the following statements are a good starting point:
1. A serverless function should be no more than the minimum to achieve a change in the user experience
2. An orchestrator and its state should map as closely as possible to the user experience in achieving a full product feature.
| charroch |
1,434,954 | ChatGPT for Gmail: The Chrome Extension to Fine-Tune Your Emails | Transform Your Gmail Drafts with Style: An Open Source Chrome Extension Powered by ChatGPT | 0 | 2023-04-14T04:52:01 | https://www.bengreenberg.dev/posts/2023-04-13-chatgpt-gmail-chrome-extension/ | webdev, javascript, ai, showdev | ---
title: ChatGPT for Gmail: The Chrome Extension to Fine-Tune Your Emails
published: true
description: Transform Your Gmail Drafts with Style: An Open Source Chrome Extension Powered by ChatGPT
tags: webdev, javascript, ai, showdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/shdqscanh9wyou3mfy0h.png
canonical_url: https://www.bengreenberg.dev/posts/2023-04-13-chatgpt-gmail-chrome-extension/
# Use a ratio of 100:42 for best results.
# published_at: 2023-04-13 16:52 +0000
---
Email communication is a crucial part of modern life, and the way we present our messages can impact how they are received. During some recent time off, I explored several small projects ([example one](https://www.bengreenberg.dev/posts/2023-04-04-github-action-gpt-language-check/), and [example two](https://www.bengreenberg.dev/posts/2023-04-09-github-profile-dynamic-content/)), with the final one being the [ChatGPT Email Reviewer](https://github.com/hummusonrails/chatgpt-gmail-suggestions-chrome-extension) —- a Chrome extension that integrates with Gmail to offer stylistic suggestions for email drafts using ChatGPT, an AI language model developed by OpenAI.
In this post, we'll dive into the inspiration behind this project, how it operates under the hood, and how you can use it to elevate your email writing.
## The Inspiration
Writing an email often involves careful consideration of tone and style to match the intended audience. The choice between a friendly reminder, an authoritative notice, or a heartfelt message can affect the email's effectiveness. I often can sit for way too much time trying to find the right words to convey my message, simply staring at a blank Gmail draft message.
With this challenge in mind, I leveraged the capabilities of ChatGPT to create a Chrome extension that provides real-time style suggestions within Gmail, helping users, notably myself, craft emails that align with communication goals.
## How It Works
The [ChatGPT Email Reviewer Chrome extension](https://github.com/hummusonrails/chatgpt-gmail-suggestions-chrome-extension) integrates seamlessly with Gmail's user interface, offering stylistic suggestions for your email drafts. To achieve this, the extension consists of two main components: the content script (`contentScript.js`) and the popup script (`popup.js`).
Let's explore these components in more detail:
### The Content Script: Interacting with Gmail's DOM
The content script is responsible for interacting with Gmail's DOM and extracting the email draft text. This script is injected into the Gmail page and listens for messages from the popup script.
```javascript
// contentScript.js
chrome.runtime.onMessage.addListener((request, sender, sendResponse) => {
if (request.action === "reviewEmail") {
const selectedStyles = request.styles;
if (request) {
chrome.storage.sync.get(["apiKey", "signatureDelimiter"], result => {
if (result.apiKey) {
const emailBody = getEmailBody(result.signatureDelimiter);
sendToChatGPT(emailBody, selectedStyles, result.apiKey, result.signatureDelimiter).then(() => {
sendResponse({ success: true });
}).catch(() => {
sendResponse({ success: false });
});
} else {
alert("Please enter and save your OpenAI API key in the extension settings.");
sendResponse({ success: false });
}
});
} else {
sendResponse({ success: false });
}
return true;
}
});
```
The content script listens for the `reviewEmail` action and retrieves the email draft text using the `getEmailText` helper function. It then calls the `sendToChatGPT` function, which sends the text to the OpenAI API, and displays the suggestions using the `displaySuggestions` function.
### The Popup Script: Handling User Interactions
The popup script manages user interactions with the extension's interface. It provides options for selecting writing styles, entering an OpenAI API key, and configuring other settings.
```javascript
// popup.js
document.getElementById("reviewButton").addEventListener("click", () => {
const selectedStyles = Array.from(document.querySelectorAll('input[name="style"]:checked')).map(input => input.value);
chrome.tabs.query({ active: true, currentWindow: true }, tabs => {
chrome.tabs.sendMessage(tabs[0].id, { action: "reviewEmail", styles: selectedStyles });
});
});
```
When the user clicks the "Review Email" button, the script collects the selected writing styles and sends a message to the content script with the `reviewEmail` action and the chosen styles. The content script takes over from here, analyzing the email draft and providing suggestions.
### Communicating with the OpenAI API
The extension communicates with the OpenAI API to analyze the email text and generate style suggestions. This process is handled by the `sendToChatGPT` function within the content script.
```javascript
// contentScript.js
async function sendToChatGPT(text, styles, apiKey, signatureDelimiter) {
const response = await fetch('https://api.openai.com/v1/chat/completions', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
},
body: JSON.stringify({
messages: [{"role": "user", "content": `Review and provide suggestions for the following email draft combining the following styles or only a single style if only one is provided: ${styles.join(', ')}. Please return only the revised email text without suggesting a subject. Email draft: ${text}`}],
model: "gpt-3.5-turbo",
max_tokens: 150,
n: 1,
stop: null,
temperature: 0.8
})
});
const data = await response.json();
if (data.choices && data.choices.length > 0) {
displaySuggestions(data.choices[0].message.content, signatureDelimiter);
} else {
console.log("No suggestions received");
}
}
```
The `sendToChatGPT` function creates a prompt based on the email text and selected styles, then makes a `POST` request to the OpenAI API using the provided API key. The function returns the suggestions generated by the API for display to the user.
You can explore the rest of the code on [GitHub](https://github.com/hummusonrails/chatgpt-gmail-suggestions-chrome-extension) and I welcome your contributions!
## Getting Started
To start using the ChatGPT Email Reviewer, visit the [GitHub repository](https://github.com/hummusonrails/chatgpt-gmail-suggestions-chrome-extension) to install the extension on your Chrome browser. Follow the instructions in the `README` to configure your OpenAI API key, which you can obtain by creating an account on the OpenAI website.
The extension also provides an option to specify a signature delimiter to distinguish your email signature from the main content, ensuring the analysis is focused solely on the message.
Once set up, you can begin crafting compelling emails that reflect your chosen style with just a few clicks!
## Code Contributions Welcome!
The ChatGPT Email Reviewer is currently available only on GitHub and is under review for the Chrome Web Store. As you explore and use this tool, I welcome your feedback, suggestions, and experiences. Your input is invaluable in refining and enhancing the tool for everyone. Please feel free to reach out to me on [Twitter](https://twitter.com/hummusonrails) or raise an issue or PR on the [GitHub repository](https://github.com/hummusonrails/chatgpt-gmail-suggestions-chrome-extension) with enhancements or bug fixes.
---
**Was this blog post helpful? Consider sponsoring my work on GitHub to help me create more content like this! ❤️**
[](https://github.com/sponsors/hummusonrails) | bengreenberg |
1,434,964 | The Effects of Generative AI on Job Markets | The recession has recently hit the economy hard, and every primary industry is experiencing a wave of... | 0 | 2023-04-13T17:48:38 | https://dev.to/mlsc_tiet/the-effects-of-generative-ai-on-job-markets-3267 | ai, chatgpt, career | The recession has recently hit the economy hard, and every primary industry is experiencing a wave of layoffs. There is a lot of panic among people about job prospects.Simultaneously, the recent developments in AI and the improvement in Large Language Models(LLMs) like ChatGPT, Dall-E, etc., have exaggerated this panic and fear. The old stories of AI replacing humans again make it to the headlines.In this blog, I will discuss the significant impacts of AI technologies on the job market.
The impact of these technologies will not be uniform. It will prove more competitive for some roles than others. Broadly, we can classify them into two major categories: low-level and high-level jobs.
Talking about low-level jobs are jobs that focus mainly on the execution of a single, well-defined task. It consists of a fixed cycle of repetitive tasks that, with the help of technological advances, can be automated, thus threatening the employment of those engaged in such jobs. For example, in web development, low-level tasks such as designing a simple website with a bare front end and no primary back end had a lot of scope for freelancing. With the advent of AI, clients can accomplish this independently.
Now let's talk about high-level jobs. These tasks require more sophisticated skills, mainly focused on innovation and critical thinking. Though the latest AI projects have some creativity, it is far away to mimic humans in such domains. Since low-level tasks can now be automated, organizations focus more on hiring individuals to help them innovate, build better products, and provide an edge over their competitors.
LLMs can make a basic front-end by revising the web development scenario discussed earlier. Still, they need help to make a fully customized, functional, and integrated website using advanced tools. So, AI will not be able to replace developers with specialization and expertise in some of the advanced technologies. AI could be even more productive for advanced developers since they can accomplish several low-level tasks in less time, devoting more time and effort to innovative and high-output studies.
Another aspect of this story is whether this technology will be a curse or boon for us ultimately depends on our mindset. Crisis brings along its opportunities. We met with similar skepticism when the Digital and Industrial Revolutions kicked off. In the initial stages, the most novel concepts, like mechanization, mass production, and digitization, were believed to lead to unemployment. Still, instead, they spurred exponential growth, employing a large chunk of the population. They also created a room for innovation that produced life-changing inventions like the World Wide Web, smartphones, search engines, social media platforms, etc., ultimately making our lives easier and better.

Likewise, this revolution of Industry 4.0 also has immense potential. Whether it will be productive or disruptive depends on our mindset and adaptability to change. Change is the only constant in life.
"Man cannot discover new oceans unless he dares to lose sight of the shore."Similarly, one can only grow if one dares to move out of their comfort zones and adapt to change. A crisis presents both a threat as well an opportunity. Some of today's most successful businesses, like Apple, Disney, Ford, etc., were born during points of change like the Digital Revolution, the Great Depression, and the Second World War. The current times also offer similar possibilities,
As JFK rightly said, "_Do not pray for easy lives. Pray to be stronger men._"
So, AI also depends on the mindset and ability to exploit it to our advantage, determining whether it is detrimental or beneficial for us. For some of us, it could help achieve more productivity and better results by automating low-level and time-consuming tasks, whereas, for others who won't learn to adapt to this change, it will take up their jobs.
Another lesson we can learn from this experience is that the tech industry is growing exponentially, and the technologies are coming up and also getting outdated in a short time. So we need to upskill ourselves constantly. It emphasizes the need for lifelong learning and upskilling compared to the previous scenario, where the understanding done during school or college used to work throughout the career. And this aspect is the one which is a significant contributor to such high growth of the industry. Promoting innovative competition provides more growth opportunities and thus leads to rapid advancements.
It is up to us as individuals to use it best.
| sparshrastogi |
1,434,978 | How to Install Composer on Linux - Debian | To install Composer on Ubuntu, you can follow these steps: Update the package list on your... | 0 | 2023-04-13T18:18:22 | https://dev.to/amphilip/how-to-install-composer-on-linux-debian-33b | To install Composer on Ubuntu, you can follow these steps:
Update the package list on your system:
```
sudo apt update
```
Install some required packages using the following command:
```
sudo apt install curl php-cli php-mbstring git unzip
```
Download the Composer installer using the following command:
```
curl -sS https://getcomposer.org/installer -o composer-setup.php
```
Verify the downloaded installer:
```
HASH=`curl -sS https://composer.github.io/installer.sig`
echo $HASH
php -r "if (hash_file('SHA384', 'composer-setup.php') === '$HASH') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
```
You should see the message "Installer verified" if everything is okay.
Run the installer:
```
sudo php composer-setup.php --install-dir=/usr/local/bin --filename=composer
```
Verify the installation:
```
composer
```
You should see the Composer version number and usage instructions.
That's it!Congratulation, You have successfully installed Composer on Linux - Debian.
| amphilip | |
1,435,114 | Don’t Learn in a Vacuum: How Dev Communities Help Coding Newbies | I’m fairly new to coding. I started last year with HTML and CSS, and right now I’m learning Python.... | 0 | 2023-04-14T14:17:16 | https://dev.to/virtualcoffee/dont-learn-in-a-vacuum-how-dev-communities-help-coding-newbies-348p | beginners, python, learning, community | I’m fairly new to coding. I started last year with HTML and CSS, and right now I’m learning Python. So yeah, definitely a newbie.
I have also been working in tech for more than a decade. Most of my friends are devs! And because I have so many ties to the tech world, I’ve been a member of various online dev communities for a while.
And I think that this is where I have a huge advantage over pretty much every other person who is also learning to code but _doesn’t_ have that ecosystem that I have.
## We don’t learn well in a vacuum
Like many other species of the animal world, humans learn from each other. We learn by watching each other do things or through explaining things to each other.
Sure, some of that can be done very well through bootcamps and interactive online courses. Some people also learn well from videos or books ([not me, though](https://engage-education.com/blog/learning-styles-kinaesthetic-learner-characteristics/#:~:text=A%20kinaesthetic%20learner%20is%20someone,to%20retain%20and%20recall%20information)). I found I can get quite far with those resources, plugging away in my virtual learning environment, using the hints, googling when I get stuck. But sometimes, I hit that point where things become nebulous… fuzzy.
You know, those questions that aren’t a clear question. The things your course materials seem to gloss over, and where googling won’t get you anywhere because you don’t even know _how_ to google for it. Heck, I don’t even think ChatGPT could help with this, to be honest.
Those questions that usual start with…
## “This is probably a silly question”
I came across one of those today. While I was doing some exercises from the [Codecademy Python](https://www.codecademy.com/catalog/language/python) course, I came up with the following solution to a problem they had posed:
```python
def over_budget(budget, food_bill, electricity_bill, internet_bill, rent):
if budget < food_bill + electricity_bill + internet_bill + rent:
return True
else:
return False
```
My code ran and passed. All good. Someone else would have rejoiced and moved on. But I scrolled down and noticed a slight difference in the solution Codecademy provided for this exercise. Their solution was the following:
```python
def over_budget(budget, food_bill, electricity_bill, internet_bill, rent):
if (budget < food_bill + electricity_bill + internet_bill + rent):
return True
else:
return False
```
You might not even have noticed the difference (and you probably lead a more peaceful life than I do). But because I am a professional nitpicker — I’m a tech content specialist so I do a lot of copy ~nitpicking~ editing —, I couldn’t move past those _two tiny litte parentheses_ in the `if` statement.
Those `()` just niggled at me. Were they necessary? Was I missing something vital here? The clause in this function wasn’t complicated enough to warrant the `()`, I thought, but maybe I was overlooking something? Would the missing `()` bite me in the `(‿|‿)` half a year down the road?
Luckily, I have access to some great communities, so I took to [Virtual Coffee](https://virtualcoffee.io)’s _#help-and-pairing_ channel on Slack.
## Avoiding ingraining bad habits = peace of mind
I posted the two code snippets and said:
> It’s a minor question but I like to understand these little things as I know these are the things that’ll come bite me in the ass later lol
And within literal moments, one of our more experienced Python people was there to help me out and confirm my suspicion that the parentheses were, indeed, not needed in this case. With more complicated clauses, they might become handy but they definitely weren’t necessary for this particular example.
And you know what? That little bit of information, knowing that I wasn’t overlooking anything, brought me such peace! It sounds kind of ridiculous, but these are the incredibly helpful things that allow me to learn to code without worrying that I am learning bad habits.
## A community is more than the sum of its parts
Without the access that the Virtual Coffee community gives me to developers of all kinds of levels, skill sets, and experiences, I would not have found this peace of mind so quickly.
Sure, I could have asked some friends who are devs. I do have friends who are well-versed in Python. I could have asked on Twitter or Mastodon. But the easy access to the cumulated knowledge of countless different coding languages is what’s so amazing about online dev communities.
Today, it was a Python question. But tomorrow it might be something entirely different. And I will still be able to rely on the _same_ community for help. That’s kind of awesome, if you ask me.
So whether you are a newbie coder or already more experiences, I cannot recommend joining a dev community enough. You’ll come for the coding help and stay for the social hijinks and overall support. Virtual Coffee is the right community for me, but there are plenty of others out there that you can try.
And just remember, at the end of the day, there really are no silly questions, so ask away!
**Tell me about your favourite dev communities in the comments!** | thegrumpyenby |
1,435,164 | Hand-built smoothScrollTo() Implementation | Contents Main idea Demo Prerequisites Basic layout Adding event listener to the... | 0 | 2023-04-13T20:42:28 | https://dev.to/nat_davydova/hand-built-smoothscrollto-implementation-3383 | javascript, tutorial, webdev | ## Contents
* [Main idea](#main-idea)
* [Demo](#demo)
* [Prerequisites](#prerequisites)
* [Basic layout](#basic-layout)
* [Adding event listener to the navigation](#adding-event-listener-to-the-navigation)
* [Function getScrollTargetElem() get target to which it needs to scroll](#function-getscrolltargetelem-get-target-to-which-it-needs-to-scroll)
* [Obtain and validate link href value](#obtain-and-validate-link-href-value)
* [Function smoothScrollTo() and it's basic variables](#function-smoothscrollto-and-its-basic-variables)
* [Get the scroll start position](#get-the-scroll-start-position)
* [Get the scroll end position](#get-the-scroll-end-position)
* [Get the scroll start timestamp](#get-the-scroll-start-timestamp)
* [Function animateSingleScrollFrame() gives the progress of the animation](#function-animatesinglescrollframe-gives-the-progress-of-the-animation)
* [Set the current time mock](#set-the-current-time-mock)
* [Calculate the elapsed time](#calculate-the-elapsed-time)
* [Get the absolute animation progress](#get-the-absolute-animation-progress)
* [Get the animation progress normalization by Bezier Curve](#get-the-animation-progress-normalization-by-bezier-curve)
* [Calculate scroll length per frame](#calculate-scroll-length-per-frame)
* [Calculate new position Y](#calculate-new-position-y)
* [From separate frames to animation](#from-separate-frames-to-animation)
* [Use requestAnimationFrame() to start the browser animation](#use-requestanimationframe-to-start-the-browser-animation)
* [️⚠️ A Pitfall with requestAnimationFrame() and recursion](#a-pitfall-with-requestanimationframe-and-recursion)
* [Finish creating animation with recursive requestAnimationFrame()](#finish-creating-animation-with-recursive-requestanimationframe)
* [The last thing: a callback on an animation end](#the-last-thing-a-callback-on-an-animation-end)
* [A final word](#a-final-word)
## Main idea
I'm implementing my own vanilla JS alternative to the browser's `scroll-behavior: smooth` feature here. It's useful for cases when you need to combine this functionality with complex scroll JS behavior.
## Demo
You could check a [Full Demo on Codepen](https://codepen.io/nat-davydova/full/QWZwOdb/5db409195086b5b1631055fbcb6c94e5) and grab the [Code Sources on Github](https://github.com/nat-davydova/smoothScrollTo-concept)
## Prerequisites
For a good understanding of the article, the following are necessary:
* basic layout knowledge: lists, positioning, basics of the Flex model;
* basic JavaScript knowledge: searching DOM elements, events basics, function declarations, arrow functions, callbacks;
* your good mood 😊
## Basic layout
### HTML
The HTML structure here is simple: just a navigation with 3 links and 3 sections corresponding to them.
Yes, the navigation already works through the combination of `href` and `id` attributes. However, the transition is immediate. Our task is to make it smooth
```html
<body>
<nav class="navigation">
<a class="navigation__link" href="#section1">Section 1</a>
<a class="navigation__link" href="#section2">Section 2</a>
<a class="navigation__link" href="#section3">Section 3</a>
</nav>
<section id="section1">Section 1</section>
<section id="section2">Section 2</section>
<section id="section3">Section 3</section>
</body>
```
### CSS
The styles are simple as well. I've made the navigation fixed and added some decorative section styles to visually separate them by using alternating background colors
```css
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Arial';
}
nav {
position: fixed;
top: 0;
left: 0;
display: flex;
justify-content: center;
gap: 30px;
width: 100%;
padding: 20px 0;
background-color: #fff;
}
nav a {
color: black;
text-decoration: none;
transition: color .2s linear 0s;
}
nav a:hover {
color: green;
}
section {
display: flex;
justify-content: center;
align-items: center;
width: 100%;
height: 100vh;
font-size: 40px;
color: #fff;
background-color: black;
}
section:nth-of-type(2n) {
background-color: gray;
}
```
## Adding event listener to the navigation
First, we need to grab the navigation element to add an event listener to it. We should not apply listeners directly to links in the navigation, as it's a bad practice (refer to the event delegation JS pattern).
Next, we should add an event listener to the navigation and prevent the default behavior of clicked link targets within it.
```js
// I prefer to store all the DOM selector strings into a single object
const DOM = {
nav: "navigation",
navLink: "navigation__link",
};
const navigation = document.querySelector(`.${DOM.nav}`);
// we can't be sure that navigation element exists,
// so we need optional chaining
navigation?.addEventListener("click", (e) => {
e.preventDefault();
const currentTarget = e.target;
// Here, we implement the event delegation pattern:
// we check if the element is a navigation link
// or if it is a descendant of one
// If it is a navigation link or a descendant of one,
// the navigation link element will be stored in currentLink
// If not, null will be stored in the currentLink
const currentLink = currentTarget.closest(`.${DOM.navLink}`);
// ... more stuff will be there later
});
```
## Function getScrollTargetElem() get target to which it needs to scroll
The purpose of the [`smoothScrollTo()`](#function-smoothscrollto-and-its-basic-variables-table-of-contents) function is to scroll to a specific element on the page. Therefore, we need to determine the target of our scroll somehow. Let's create a function `getScrollTargetElem()` that will do this.
What should the `getScrollTargetElem()` function do:
* get the link we've clicked;
* obtain the value of the href attribute, which can be the actual ID of the element we want to scroll to or can be an external link or simply a plain text;
* verify if it's a valid value to grab the element by:
* if not, return null (clearly, we have no element);
* if yes, grab the target element and return it;
We call it into the event listener and pass the stored link element (or null) into it:
```js
navigation?.addEventListener("click", (e) => {
e.preventDefault();
const currentTarget = e.target;
// We can't truly guarantee that JavaScript
// will 100% find this element in the DOM.
// That's why currentLink can be either Element or null.
const currentLink = currentTarget.closest(`.${DOM.navLink}`);
const scrollTargetElem = getScrollTargetElem(currentLink);
});
function getScrollTargetElem(clickedLinkElem) {
// Notice that after the following unsuccessful checks,
// we will return null as a signal that
// the getScrollTargetElem() function has failed
// to find the target to which the scroll should be performed
if (!clickedLinkElem) {
return null;
}
}
```
### Obtain and validate link href value
The simplest part is grabbing the link's `href` value (and if there isn't any, we can't proceed further):
```js
function getScrollTargetElem(clickedLinkElem) {
if (!clickedLinkElem) {
return null;
}
const clickedLinkElemHref = clickedLinkElem.getAttribute("href");
// The href attribute may be left undefined or empty by the user
if (!clickedLinkElemHref) {
return null;
}
const scrollTarget = document.querySelector(clickedLinkElemHref);
}
```
The desired result is a scroll target element ID, like `#section1`. We should use it to find the target element itself. But what if the `href` contains a link to an external resource or some other invalid value? Let's check what happens if we pass not an element ID, but an external resource link:
```html
<nav class="navigation">
...
<a
class="navigation__link"
href="https://www.youtube.com/"
target="_blank">Section 3</a>
</nav>
```
... an Error is thrown at us:
<img width="459" alt="Снимок экрана 2023-04-04 224856" src="https://user-images.githubusercontent.com/52240221/229903871-64d07466-1530-47d3-a439-fadc2c5086cf.png">
So, we need to validate the `clickedLinkElemHref` value somehow before passing it to `querySelector()`.
There are 2 ways:
* implement some kind of RegEx to check if the value is valid;
* we can use a `try/catch`-block to handle the thrown `Error` case if the value is invalid;
I've preferred the 2nd way, it's simplier than any RegEx solution:
```js
function getScrollTargetElem(clickedLinkElem) {
if (!clickedLinkElem) {
return null;
}
const clickedLinkElemHref = clickedLinkElem.getAttribute("href");
if (!clickedLinkElemHref) {
return null;
}
let scrollTarget;
// here we check if there is any Error thrown
try {
scrollTarget = document.querySelector(clickedLinkElemHref);
} catch (e) {
console.log(e);
// if there is an error we can't perform scroll
// therefore return null
return null;
}
return scrollTarget;
}
```
## Function smoothScrollTo() and it's basic variables
The actual function that performs all the magic is a function that smoothly scrolls to the target. We call it in the event handler after target definition, as it should know the point to which it should actually scroll.
The crucial thing we need to know is how long our animation should last. In our case, the user should be able to set it directly as a ` smoothScrollTo` parameter. Additionally, we will define a default value in case the user doesn't want to set any.
```js
// ... get navigation ...
const DEFAULT_SCROLL_ANIMATION_TIME = 500;
navigation?.addEventListener("click", (e) => {
e.preventDefault();
const currentTarget = e.target;
const currentLink = currentTarget.closest(`.${DOM.navLink}`);
// getScrollTargetElem() returns either an
// Element or null, and we handle what to do
// in both cases within the smoothScrollTo() function
const scrollTargetElem = getScrollTargetElem(currentLink);
// the user can set any time in milliseconds here
// I've also packed the arguments into objects
// for more convenient handling
smoothScrollTo({
scrollTargetElem,
scrollDuration: some_time_in_ms || default value
});
});
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME
}) {
// if there is no scroll target we can't perform
// any scroll and just return here
if (!scrollTarget) {
return;
}
}
```
### Get the scroll start position
A crucial part of each custom scrolling is detecting the starting point. We can perform further calculations based on the coordinates of our current position on the page. In our case (vertical scrolling), we're interested in Y-coordinates only.
The starting point is easy to obtain with `window.scrollY`. Its returned value is a double-precision floating-point value. In our example, such high precision for pixels is not needed. Therefore, to simplify the final value, we will round it using the `Math.round()` function.
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME
}) {
if (!scrollTargetElem) {
return;
}
const scrollStartPositionY = Math.round(window.scrollY);
}
```
[Check the Demo Video](https://user-images.githubusercontent.com/52240221/231745174-a0ac1350-356c-4d52-aa19-6b69faee527a.webm)
### Get the scroll end position
We know the starting point of scrolling, and we need one more point - the Y-coordinate of where to scroll. It's a bit more tricky: we have no methods to directly grab the absolute document coordinate of the top-left corner of the target element. However, it's still possible, but we need two steps to obtain it:
* get the target element Y-coordinate relative to viewport
* calculate document absolute Y-coordinate for the target element
#### Get the target element Y-coordinate relative to viewport
We need to grab the target element's Y-coordinate relative to the user's viewport. Our helper for this task is the `getBoundingClientRect()` method. Check this [img from MDN](https://developer.mozilla.org/en-US/docs/Web/API/Element/getBoundingClientRect)
<img width="459" alt="getBoundingClientRect schema" src="https://user-images.githubusercontent.com/52240221/230092703-4b91ad4f-2a24-4a99-bcca-3fa4c8490d38.png">
```js
const targetPositionYRelativeToViewport = Math.round(
scrollTargetElem.getBoundingClientRect().top
);
```
<img width="1140" alt="image" src="https://user-images.githubusercontent.com/52240221/231481714-8b7c2a80-e045-4009-996f-4d260550e494.png">
#### Calc absolute target element Y-coordinate
The absolute target element Y-coordinate can be calc based on the start scroll position and the relative coordinate. The formula is:
```js
targetPositionYRelativeToViewport + scrollStartPositionY;
```
Check the schemes below.
##### Example #1
<img width="1363" alt="image" src="https://user-images.githubusercontent.com/52240221/231742185-e5afaf0b-509d-4c76-a533-89736e71d1c0.png">
##### Example #2
<img width="1372" alt="image" src="https://user-images.githubusercontent.com/52240221/231742417-f2240a7c-5af8-4150-ad81-4e8ac5b59184.png">
##### Example #3
<img width="1378" alt="image" src="https://user-images.githubusercontent.com/52240221/231742620-0bc153fa-b5a7-4f17-9d3c-37cc19dd8218.png">
### Get the scroll start timestamp
We calculated the start and end position of the scroll. However, this is not enough to implement our plan. Animation is a change of some parameter in time. Therefore, we also need to get the start time of the animation, relative to which `scrollDuration` will tick.
There are 2 options to get a 'now'-timestamp:
* `Date.now()`
* `performance.now()`
Both of them return a timestamp, but `performance.now()` is a highly-resolution one, much more precise. It's important to understand that the time used in the browser's internal scheduler is more important to animation than the number of scrolled pixels on the screen. Therefore, here we will not round the values, as in the case of pixels above. We should use this origin one to make the animation smooth and precise too.
```js
const startScrollTime = performance.now();
```
So now `smoothScrollTo()` function looks like that:
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME
}) {
if (!scrollTargetElem) {
return;
}
const scrollStartPositionY = Math.round(window.scrollY);
const targetPositionYRelativeToViewport = Math.round(
scrollTargetElem.getBoundingClientRect().top
);
const targetPositionY
= targetPositionYRelativeToViewport + scrollStartPositionY;
const startScrollTime = performance.now();
}
```
## Function animateSingleScrollFrame() gives the progress of the animation
Essentially, each animation is an event that occurs over a duration, and we can break down this time-based event into separate frames. Something like this

So, we need a function that handles single frame motion, and based on it, we will build the entire animation
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME
}) {
if (!scrollTargetElem) {
return;
}
const scrollStartPositionY = Math.round(window.scrollY);
const targetPositionYRelativeToViewport = Math.round(
scrollTargetElem.getBoundingClientRect().top
);
const targetPositionY
= targetPositionYRelativeToViewport + scrollStartPositionY;
const startScrollTime = performance.now();
// here, we collect all the necessary
// information for the future playback of our
//animation into a single animationFrameSettings object
const animationFrameSettings = {
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
};
// and we pass this object into animateSingleScrollFrame() function
animateSingleScrollFrame(animationFrameSettings)
}
function animateSingleScrollFrame({
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
}) {}
```
### Set the current time mock
For each frame, we want to check how much time has already been spent on the animation. We have a `startScrollTime` value and now need to know the current time to calculate the elapsed time
Technically, we would obtain a `currentTime` timestamp from `requestAnimationFrame()`, but we haven't implemented it yet. We will do so later. For now, we'll mock this value:
```js
const currentTime = performance.now() + 100;
```
### Calculate the elapsed time
The elapsed time will be used to calculate the animation progress. When we implement `requestAnimationFrame()`, `currentTime` (and therefore, `elapsedTime`) will be updated on each Event Loop tick.
```js
// it's 100ms now because of the mock, but will be recalculate later
const elapsedTime = currentTime - startScrollTime;
```
### Get the absolute animation progress
The animation progress, which we calculate with the help of `elapsedTime`, shows how much of the animation is completed. We need an absolute progress ranging from 0 (beginning of the animation) to 1 (end of animation). This will help us calculate the scroll length in pixels per current frame later on.
It will be updated on each Event Loop tick. We use `Math.min()` here because in real life a frame can be calculated in time that is already longer than the given `scrollDuration`. However, the animation progress end position must not exceed 1.
```js
const absoluteAnimationProgress
= Math.min(elapsedTime / scrollDuration, 1);
```
### Get the animation progress normalization by Bezier Curve
Now we have a linear animation progress. However, we often prefer non-linear animations that are a bit more intricate, featuring nice easing effects, such as starting slow, speeding up, and then slowing down again towards the end.
You can explore the most popular animation easing types based on Bezier Curves at [easings.net](https://easings.net/#). I've chosen the [easeInOutQuad](https://easings.net/#easeInOutQuad) mode for this project. On this page, you can find a function that calculates this easing effect:
```js
function easeInOutQuadProgress(animationProgress: number) {
return animationProgress < 0.5
? 2 * animationProgress * animationProgress
: -1 + (4 - 2 * animationProgress) * animationProgress;
}
```
This easing function takes the absolute animation progress, ranging between 0 and 1, and returns a corrected animation progress based on the easing calculation
If our animation progress is less than `50%`, it will increase this progress, so the animation starts slowly and then speeds up. If the progress is more than `50%`, the animation will smoothly slow down.
Let's create a wrapper function that takes `animationProgress` as a parameter and returns normalized progress from `easeInOutQuadProgress()`. I'm adding this extra function because later, we may want to handle more than just a single easing mode
```js
function animateSingleScrollFrame({
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
}) {
const currentTime = performance.now() + 100;
const elapsedTime = currentTime - startScrollTime;
const absoluteAnimationProgress = Math.min(elapsedTime / scrollDuration, 1);
const normalizedAnimationProgress = normalizeAnimationProgressByBezierCurve(
absoluteAnimationProgress
);
}
function normalizeAnimationProgressByBezierCurve(animationProgress: number) {
return easeInOutQuadProgress(animationProgress);
}
function easeInOutQuadProgress(animationProgress: number) {
return animationProgress < 0.5
? 2 * animationProgress * animationProgress
: -1 + (4 - 2 * animationProgress) * animationProgress;
}
```
### Calculate scroll length per frame
The next step is to calculate how many pixels we should scroll during this animation frame, based on normalized animation progress and two coordinates: start position and target position.
We've already calculated the start position and target position in the [`smoothScrollTo()`](#function-smoothscrollto-and-its-basic-variables) function. We've even collected all the necessary information for the animation in a single object `animationFrameSettings`, which we pass to the [`animateSingleScrollFrame()`](#function-animatesinglescrollframe-gives-the-progress-of-the-animation) function. Let's use this information.
This dimension is absolute; we should know the length of the scroll path from the very start to the current frame point. The sign indicates the direction (whether we scroll up or down)
```js
const currentScrollLength
= (targetPositionY - scrollStartPositionY) * normalizedAnimationProgress;
```
#### Example #1
<img width="1099" alt="image" src="https://user-images.githubusercontent.com/52240221/231742994-553bdd15-b4a4-4b77-bd1b-21400a554ccc.png">
#### Example #2
<img width="1201" alt="image" src="https://user-images.githubusercontent.com/52240221/231743105-942e395b-67f8-4b57-9e56-7e2576c4e60a.png">
### Calculate new position Y
Alright, the purpose of the `animateSingleScrollFrame()` function is to actually scroll. We need to know the actual Y-coordinate of the point we're scrolling to, and since we've done all the preliminary calculations, we're ready to calculate the stopping scroll point for the current frame:
```js
const currentScrollLength
= (targetPositionY - scrollStartPositionY) * normalizedAnimationProgress;
const newPositionY = scrollStartPositionY + currentScrollLength;
```
#### Example #1
<img width="1236" alt="image" src="https://user-images.githubusercontent.com/52240221/231743505-4cab3f9e-c27c-4b80-b3e3-dc4e54165f4b.png">
#### Example #2
<img width="1272" alt="image" src="https://user-images.githubusercontent.com/52240221/231743608-d3a185eb-998e-437f-b124-c211e3d05f2d.png">
### Let's put it together and scroll!
Now it's time to scroll the page! Although it's not smooth at the moment, it works!
```js
function animateSingleScrollFrame({
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
}) {
const currentTime = performance.now() + 100;
const elapsedTime = currentTime - startScrollTime;
const absoluteAnimationProgress = Math.min(elapsedTime / scrollDuration, 1);
const normalizedAnimationProgress
= normalizeAnimationProgressByBezierCurve(
absoluteAnimationProgress
);
const currentScrollLength
= (targetPositionY - scrollStartPositionY) * normalizedAnimationProgress;
const newPositionY = scrollStartPositionY + currentScrollLength;
window.scrollTo({
top: newPositionY,
});
}
```
In the video, you can see the difference in scroll length based on the dimension between `scrollStartPositionY` and `targetPositionY`:
[Check the Demo Video](https://user-images.githubusercontent.com/52240221/231746886-18d64d3b-a626-4c2e-bc9a-452ae82b0d09.webm)
## From separate frames to animation
We have a function that handles a single frame, but an animation is a sequence of frames, and we need to call this function repeatedly until `the scrollDuration` is finished and the time is up to complete the animation.
The recursive `requestAnimationFrame()` will help us here. Fortunately, it's not as complicated as it might seem.
[`requestAnimationFrame()`](https://developer.mozilla.org/en-US/docs/Web/API/window/requestAnimationFrame) (aka RAF) is a function that takes a callback with some animation as an argument, and then on each Event Loop tick, it nudges the browser to call this callback right before the repaint stage. 1 Event Loop tick -> 1 frame -> 1 `requestAnimationFrame()`. That's why we need to call it repeatedly until the animation is completed.
### Use requestAnimationFrame() to start the browser animation
Each recursion is based on 2 main points:
* a place for the first function call;
* a condition, in which if it is `true` we call the function again and again, and if it is `false` we stop the recursive function calls;
The first function call will be inside the `smoothScrollTo()` function as a starting animation point.
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME,
}) {
// ... previous stuff
// This is how we want to initially call
// RAF and pass an animation function as a callback
requestAnimationFrame(animateSingleScrollFrame)
}
```
### A Pitfall with requestAnimationFrame() and recursion
⚠️ By design, `requestAnimationFrame()` passes a `currentTime` timestamp as an argument to the callback. Do you remember when we mocked the `currentTime` earlier? We can't simply call RAF like this:
```js
requestAnimationFrame(animateSingleScrollFrame)
```
... because the `animateSingleScrollFrame()` function should accept not only the currentTime argument, but also an object with the animation settings we've passed in it earlier. We should use an arrow function to deal with the obstacle:
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME,
}) {
// ... previous stuff
// all animation info we pass into `animateSingleScrollFrame()`
const animationFrameSettings = {
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
onAnimationEnd
};
// an actual RAF call for continuous animation
requestAnimationFrame((currentTime) =>
animateSingleScrollFrame(animationFrameSettings, currentTime)
);
}
function animateSingleScrollFrame(
animationFrameSettings, currentTime
) { /* ... */ }
```
### Finish creating animation with recursive requestAnimationFrame()
This is a pretty straightforward thing. If our duration time is greater than the elapsed time, we have time for a new animation frame, so we should continue the recursive RAF:
```js
function animateSingleScrollFrame(
{
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
onAnimationEnd
},
currentTime
) {
// here, we remove the currentTime mocks and apply a
// Math.max to support the case when elapsedTime < 0
const elapsedTime = Math.max(currentTime - startScrollTime, 0);
// ...
// yes, `animationFrameSettings` are the same as
// in the `animateSingleScrollFrame()` parameters
const animationFrameSettings = {
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
onAnimationEnd
};
if (elapsedTime < scrollDuration) {
requestAnimationFrame((currentTime) =>
animateSingleScrollFrame(animationFrameSettings, currentTime)
);
}
}
```
Did you notice how we replaced the mock value with the current frame time? Now we have a working recursion and an actual `currentTime` we have received from RAF. There could be a case when, on the first RAF call, `currentTime` is somehow smaller than `startScrollTime`. We should support this case and, if `elapsedTime < 0`, we return `0` there.
## 🎉 It animates now!
My congratulations to you!
[Check the Demo Video](https://user-images.githubusercontent.com/52240221/230718929-876dd79e-8d6d-446b-80ee-bddb1ef22870.webm)
## The last thing: a callback on an animation end
It's not a crucial feature, just a nice small cherry on the cake. Let's add a callback that will be executed when the animation is fully completed.
We will pass it in the `smoothScrollTo()` function, as it is our entry point. Let's pass a small `console.log()` callback:
```js
navigation?.addEventListener("click", (e) => {
// ... previous stuff
smoothScrollTo({
scrollTargetElem,
// a simple on animation end callback
onAnimationEnd: () => console.log("animation ends"),
});
});
```
We do not use it directly in the `smoothScrollTo()`. Actually, it can be executed in the `animateSingleScrollFrame()`. We have a condition there to check if we have time to continue the animation or not. If we have no more time, it means that our animation ends, and we could call the callback:
```js
function smoothScrollTo({
scrollTargetElem,
scrollDuration = DEFAULT_SCROLL_ANIMATION_TIME,
onAnimationEnd
}) {
// ... previous stuff
const animationFrameSettings = {
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
// add it as a new setting to the settings object
onAnimationEnd
};
requestAnimationFrame((currentTime) =>
animateSingleScrollFrame(animationFrameSettings, currentTime)
);
}
```
```js
function animateSingleScrollFrame(
{
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
// we get it here as a setting
onAnimationEnd,
}: IAnimateSingleScrollFrame,
currentTime: number
) {
// ... previous stuff
const animationFrameSettings = {
startScrollTime,
scrollDuration,
scrollStartPositionY,
targetPositionY,
// don't forget to save the on animation end callback link
onAnimationEnd,
};
if (elapsedTime < scrollDuration) {
requestAnimationFrame((currentTime) =>
animateSingleScrollFrame(animationFrameSettings, currentTime)
);
// check if a on animation end callback is passed
// to the `animateSingleScrollFrame` function
} else if (onAnimationEnd) {
onAnimationEnd();
}
}
```
[Check the Demo Videom](https://user-images.githubusercontent.com/52240221/231869150-2cd6ca18-a145-4ec1-a146-3efc41c6e719.webm)
## A final word
We've built a fully complete Smooth Scroll concept. You can use it in your projects as is, or extend it with additional easing animations, end-of-animation callbacks, or other features! Feel free to use the code however you like!
Let me remind you that you can watch [Full Demo on Codepen](https://codepen.io/nat-davydova/full/QWZwOdb/5db409195086b5b1631055fbcb6c94e5) and grab the [Code Sources on Github](https://github.com/nat-davydova/smoothScrollTo-concept)
I would be really glad to receive your feedback!
### Our social links
My social links: [github](https://github.com/nat-davydova), [codepen](https://codepen.io/nat-davydova/), [twitter](https://twitter.com/nat_davydova_en)
I co-authored this article and developed the project alongside Dmitry Barabanov: [github](https://github.com/xfides), [twitter (ru-lang)](https://twitter.com/xfides), [youtube (ru-lang)](https://www.youtube.com/@InSimpleWords_WebDev). | nat_davydova |
1,435,343 | SonarQube vs Eslint, qual o melhor para o seu projeto. | O SonarQube e o Eslint são duas ferramentas amplamente utilizadas para garantir a qualidade do código... | 0 | 2023-04-14T00:47:10 | https://dev.to/gabrielgcj/sonarqube-vs-eslint-qual-o-melhor-para-o-seu-projeto-3ejb | O SonarQube e o Eslint são duas ferramentas amplamente utilizadas para garantir a qualidade do código e melhorar a eficiência do desenvolvimento. Embora ambas as ferramentas possam ser usadas para analisar o código-fonte em busca de erros, vulnerabilidades e más práticas, existem algumas diferenças importantes entre elas.
**O que é o SonarQube?**
O SonarQube é uma ferramenta de análise estática de código abrangente usada para avaliar a qualidade do código em várias linguagens de programação, incluindo Java, JavaScript, C++, PHP e outras. Ele fornece uma visão geral da qualidade do código e identifica problemas como vulnerabilidades de segurança, bugs, códigos duplicados, baixa cobertura de teste e outros problemas.
**O que é o Eslint?**
O Eslint é uma ferramenta de análise estática de código específica para JavaScript usada para encontrar e corrigir erros e problemas no código JavaScript. O Eslint ajuda a manter um padrão de estilo consistente no código, identificar erros de sintaxe, detectar variáveis não utilizadas, entre outras coisas.
**Diferenças entre SonarQube e Eslint:**
O SonarQube é uma ferramenta mais ampla que pode ser usada em várias linguagens de programação, enquanto o Eslint é específico para JavaScript.
O SonarQube fornece métricas e estatísticas úteis para avaliar a qualidade do código, enquanto o Eslint fornece informações mais específicas sobre o código JavaScript.
O SonarQube pode ser usado em várias etapas do ciclo de vida do desenvolvimento, enquanto o Eslint é uma ferramenta específica para a fase de desenvolvimento do código JavaScript.
**Vantagens do SonarQube:**
O SonarQube é uma ferramenta de análise estática de código abrangente que pode ser usada em várias linguagens de programação.
Ele fornece métricas e estatísticas úteis para avaliar a qualidade do código e melhorar a eficiência do desenvolvimento.
Além disso, ele pode ser integrado facilmente com outras ferramentas de desenvolvimento, como Jenkins e outras.
**Vantagens do Eslint:**
O Eslint ajuda a manter um padrão de estilo consistente no código JavaScript, tornando-o mais legível e fácil de manter.
Ele é fácil de configurar e usar, com suporte para várias opções de personalização.
O Eslint pode ser integrado facilmente com outras ferramentas de desenvolvimento, como Webpack e Gulp.
O SonarQube e o Eslint são ferramentas diferentes logo são mais eficazes em cenários diferentes. Abaixo estão alguns exemplos de quando o SonarQube pode ser melhor utilizado que o Eslint e vice-versa:
**Quando o SonarQube é melhor utilizado:**
Em grandes projetos que usam várias linguagens de programação diferentes, o SonarQube pode ser usado para avaliar a qualidade do código em várias linguagens de programação.
Quando é necessário garantir a conformidade com as melhores práticas e padrões de codificação definidos, pois o SonarQube fornece uma ampla gama de regras e verificações que podem ser aplicadas ao código.
Quando é necessário realizar análises mais aprofundadas, pois o SonarQube fornece uma ampla gama de métricas e estatísticas que podem ser usadas para avaliar a qualidade do código-fonte.
**Quando o Eslint é melhor utilizado:**
Quando se trata de projetos JavaScript de tamanho médio a grande, pois o Eslint é uma ferramenta específica para análise de código JavaScript.
Quando é necessário manter um padrão de estilo consistente no código JavaScript, pois o Eslint pode ser configurado para verificar o código em relação a um conjunto específico de regras de estilo.
Quando é necessário identificar e corrigir erros de sintaxe e erros comuns no código JavaScript, pois o Eslint pode ajudar a encontrar e corrigir erros comuns em tempo real.
Resumindo, o SonarQube e o Eslint são duas ferramentas diferentes, com funções diferentes e vantagens diferentes. O SonarQube é uma ferramenta de análise estática de código abrangente que ajuda a garantir a qualidade do código-fonte em várias linguagens de programação, enquanto o Eslint é uma ferramenta específica para a fase de desenvolvimento do código JavaScript que ajuda a manter um padrão de estilo consistente no código. Ao usar ambas as ferramentas em conjunto, os desenvolvedores podem garantir a qualidade do código-fonte e manter um padrão de estilo consistente no código JavaScript. | gabrielgcj | |
1,435,394 | jq - Json Query Tool in bash | Cheatsheet (with explanation on what the params do): https://stedolan.github.io/jq/manual/ Common... | 0 | 2023-04-14T04:10:00 | https://dev.to/otter13/jq-json-query-tool-in-bash-4c4a | Cheatsheet (with explanation on what the params do):
https://stedolan.github.io/jq/manual/
**Common Operations**
**Iterate all elements (and override some) within a JSON object**
```
echo $temp > json-override.json
for key in $(jq '. | keys' json-override.json); do
# remove starting and trailing quotes
ref_key=`echo $key | tr -d '"'`
ref_key=`echo $ref_key | tr -d ','`
if [ $key != '[' ] && [ $key != ']' ]
then
ref_val=`jq \
--arg target_key $ref_key \
'.[$target_key]' json-override.json`
ref_val=`echo $ref_val | tr -d '"'`
# echo $ref_key = $ref_val
case $ref_val in
OLD VALUE)
ref_val='NEW VALUE'
;;
*)
echo -n "Unknown secret"
exit 1
;;
esac
temp=`echo $temp | \
jq \
--arg target_key $ref_key \
--arg target_val "$ref_val" \
'.[$target_key] |= $target_val'`
fi
done
echo $temp
```
| otter13 | |
1,435,707 | 5 Tips to Succeed as an Introvert in the Workplace | Introverts in a cutthroat workplace environment often have to face interesting challenges when it... | 0 | 2023-04-14T09:59:43 | https://dev.to/maxgorbs/5-tips-to-succeed-as-an-introvert-in-the-workplace-4bd7 | career, beginners, productivity, learning | Introverts in a cutthroat workplace environment often have to face interesting challenges when it comes to being seen and heard by bosses and coworkers. While many introverts will prefer to be just left alone to do the job, a reputation as being shy and reserved and doing the minimum of interaction with people at the office does not bode well for a person's chances of getting noticed for a promotion at work.
If moving up is one of your goals this year but you identify as an introvert, read on to know how you can still thrive and succeed in a workplace where extroversion usually gets you ahead of the pack.
## Treat positive social interactions as a skill you need to master
Starting conversations can be difficult even for people who don't identify as introverts. The good thing about positive interactions is that you are not doomed to be uncomfortable about starting and engaging in conversations with others. You can treat social interactions as skills you can master with time and practice. This simple shift in mindset can make it easier to overcome the challenge of awkward social interactions because they're not innate personality traits that you can't do anything about.
## Use positive words
One good tip to use when if you want to engage in more personal interactions is to use positive words. Drop compliments on co-workers and friends, lead with positive observations when starting a conversation, and avoid negative comments when you can. Positive words help keep conversations light and often allow the other person to feel comfortable and free to continue the interaction with you.
## Practice
Like any skill, practice is perhaps the only way to get better and more comfortable about starting conversations with other people, even people who you see daily at work. The good thing about practice is that you have countless opportunities during the day to do so, whether you are in or out of the office. With practice, you can get comfortable hearing your voice and being in situations where you are engaging in a dialogue with another person.
## Set bite-sized goals
Taking things slowly is an effective strategy to ease into feeling comfortable engaging with other people in the workplace. For example, you can set a goal of engaging with at least two people at the office and speaking up at least once during the daily office meeting. These are doable, bite-sized goals that are not too overwhelming but will still force you to practice your engagement skills.
## Play up your other strengths
Forcing yourself to be someone you are not the entire time you are in the office is not the only way to get noticed by your bosses and peers. There's no doubt that faking extroversion can affect your mental and psychological health too, and probably not in a good way. While making efforts to be more engaged and outgoing will always benefit your work relationships, you can also play up your other strengths so you can be more competitive at work. Offer to take on extra projects that fit your special skill set, for example, or be ready with deliverables before the deadline. Do these consistently, and you will leave a mark that can help you move a few steps up your career ladder.
Being an introvert in a workplace where personal interactions are required does not mean that introverts are at a disadvantage when they don't conform to outgoing office culture. If you treat positive engagement as a skill that you can learn and you practice until you become comfortable, you can stand out as visibly as your most extroverted coworker.
| maxgorbs |
1,435,720 | What is the purpose of Go High Level? | Go High Level is a customer relationship management (CRM) software platform that is designed to help... | 0 | 2023-04-14T10:27:50 | https://dev.to/highlevel358/what-is-the-purpose-of-go-high-level-2hc7 | crm, sales, funnel, website | Go High Level is a customer relationship management (CRM) software platform that is designed to help businesses manage their sales, marketing, and customer service activities. What sets Go High Level apart from other CRM software solutions on the market is its unique set of features that are specifically designed to help businesses grow and succeed.
One of the key features of Go High Level is its advanced automation capabilities. With Go High Level, businesses can automate a wide range of tasks, including lead generation, follow-up, and customer service. This can save businesses a significant amount of time and effort, freeing up resources that can be used to focus on other areas of the business.
Another unique feature of Go High Level is its powerful integrations. The software is designed to integrate seamlessly with a wide range of other tools and platforms, including social media, email marketing, and payment processing systems. This makes it easy for businesses to centralize their data and workflows, reducing the risk of errors and improving overall efficiency.
Go High Level also offers a comprehensive set of analytics and reporting tools. Businesses can use these tools to track their performance across a range of metrics, including sales, customer satisfaction, and marketing effectiveness. This data can be used to identify areas for improvement and make data-driven decisions to help the business grow.
In addition to its core features, Go High Level also offers a range of specialized tools and add-ons that can be used to customize the software to meet the specific needs of a business. For example, businesses can use the platform's appointment scheduling tool to streamline their scheduling process, or they can use the built-in SMS marketing tool to reach out to customers via text message.
Overall, the purpose of Go High Level is to provide businesses with a comprehensive, all-in-one solution for managing their sales, marketing, and customer service activities. The software is designed to be flexible and customizable, allowing businesses to tailor it to their specific needs and requirements.
By using Go High Level, businesses can improve their efficiency, reduce their workload, and ultimately grow and succeed in their chosen markets.
Let's take a closer look at how Go High Level can help businesses achieve these goals.
Improved Efficiency: With Go High Level's automation capabilities, businesses can streamline their workflows and reduce the amount of time and effort required to complete routine tasks. For example, the platform can automate lead generation, follow-up, and appointment scheduling, freeing up staff members to focus on higher-value tasks, such as closing deals or developing new marketing campaigns. By reducing the time and effort required to complete routine tasks, businesses can become more efficient and productive.
Reduced Workload: Another benefit of Go High Level's automation capabilities is that it can reduce the workload of staff members. By automating tasks such as lead generation, follow-up, and appointment scheduling, staff members can focus on higher-value tasks that require their expertise and experience. This can help to reduce the risk of burnout and turnover, and can also improve the overall job satisfaction of staff members.
Ultimately, by reducing the workload of staff members and allowing them to focus on higher-value tasks, businesses can become more efficient and effective, which can lead to increased productivity and profitability.
Business Growth: By providing businesses with a comprehensive set of tools and features, Go High Level can help businesses grow and succeed in their chosen markets. For example, the platform's analytics and reporting tools can be used to track key metrics such as sales, customer satisfaction, and marketing effectiveness.
Additionally, Go High Level's integrations with other tools and platforms can help businesses to centralize their data and workflows, which can improve efficiency and reduce errors. This can help to create a more streamlined and effective business, which can lead to increased profitability and growth.
Go High Level also offers a range of analytics and reporting tools that can help businesses track their performance and identify areas for improvement. By analyzing metrics such as sales, customer satisfaction, and marketing effectiveness, businesses can make data-driven decisions to help them grow and succeed in their chosen markets.
Conclusion:
, the purpose of [Go High Level](https://www.gohighlevel.com/?fp_ref=rachels-agency37) is to provide businesses with a comprehensive CRM software solution that can help them improve their efficiency, reduce their workload, and ultimately grow and succeed in their chosen markets. The software is designed to be flexible and customizable, allowing businesses to tailor it to their specific needs and requirements. Whether a business is looking to streamline their sales process, improve their marketing efforts, or provide better customer service. By using the platform's automation capabilities, integrations, analytics and reporting tools, and specialized features, businesses can become more efficient, effective, and productive, which can lead to increased profitability and success.
| highlevel358 |
1,435,754 | test | test | 0 | 2023-04-14T11:33:21 | https://dev.to/neva/sdgegwegg-1m20 | test | neva | |
1,435,761 | 10 Best Place To Buy Gift & Game Cards Online in 2023 [Guide] | Hey there, fellow gamers and gift card enthusiasts! If you're anything like me, you've probably found... | 0 | 2023-04-14T11:41:20 | https://dev.to/gamecarddelivery/10-best-place-to-buy-gift-game-cards-online-in-2023-guide-4i9h | gamecards | Hey there, fellow gamers and gift card enthusiasts! If you're anything like me, you've probably found yourself searching for the best places to buy gift and game cards online. I mean, let's face it: it's 2023, and nobody wants to drive around town to different stores to find the perfect card. Luckily for you, I've done the research and put together a list of the 10 legit gift card sites. So, let's dive right in!
##1) [Game Card Delivery](https://www.gamecarddelivery.com/)
First on our list is the one and only Game Card Delivery. Are you tired of hunting for the perfect gift card or game card in physical stores? Game Card Delivery has got your back! As the top online destination for all your gift and game card needs, Game Card Delivery has everything you're looking for and more. With their extensive selection, instant delivery, secure transactions, and fantastic customer support, it's no wonder they've earned the top spot on our list. Let's take a closer look at what makes Game Card Delivery stand out from the competition:
Massive Selection: Game Card Delivery offers an impressive array of game cards from all the popular platforms you know and love. PlayStation, Xbox, Nintendo eShop Game Cards, and Steam fans will be delighted by the selection available. But it doesn't stop there; they also cater to mobile gamers with cards for hit games like PUBG and Fortnite.
In addition to game cards, you'll find gift cards for big-name brands like Amazon, iTunes, [google play cards USA](https://www.gamecarddelivery.com/buy-game-cards-online/google-play), and more. Whether you're shopping for yourself or looking for the perfect gift for someone else, Game Card Delivery has you covered.
Instant Delivery: Nobody likes waiting, especially when it comes to gaming or enjoying your favorite entertainment. Game Card Delivery understands the need for speed, which is why they offer instant email delivery for all digital purchases. As soon as your payment is processed at its trusted site to buy gift and game cards, you'll receive an email containing your game or gift card code. No more waiting for physical cards to arrive in the mail or worrying about lost packages!
Secure Transactions: When shopping online, security is always a top concern and that’s why Game Card Delivery offers the best place to buy digital gift cards. Game Card Delivery takes your privacy and security seriously by using SSL encryption to protect your personal information during checkout. Additionally, they offer multiple payment options, including the widely trusted PayPal, to ensure a secure and convenient shopping experience.
Excellent Customer Support: Have a question about a product, or need help with your purchase? Game Card Delivery's friendly and knowledgeable support team is ready to assist you via email. Their commitment to customer satisfaction means you can shop with confidence, knowing that help is just a click or an email away. This makes it the best website to buy gift and game cards!
Game Card Delivery's combination of an extensive selection, instant delivery, secure transactions, and top-notch customer support makes them the ultimate online destination for gift and game cards. Whether you're a console gamer, a mobile gaming enthusiast, or just looking for the perfect gift card for a loved one, Game Card Delivery has something for everyone. So why wait? Head over to their website and [buy game cards](https://www.gamecarddelivery.com/buy-game-cards-online/categories/game-cards) today!
##2) [Amazon](https://www.amazon.com/card-games/b?ie=UTF8&node=166239011)
It's hard to beat the convenience and selection that this online retail giant offers. With millions of products and gift cards available, you're sure to find the perfect game or gift card for your needs. Let’s see what makes Amazon the best place to order gift cards online:
Huge Selection: Amazon has a vast range of gift cards, including gaming platforms, streaming services, and popular retailers. The chances are high that you'll find the card you're looking for here.
Prime Perks: If you're an Amazon Prime member, you can enjoy free two-day shipping on eligible items, making it a convenient option for last-minute gift purchases.
Trusted Seller: Amazon's reputation as a reliable and secure online retailer means you can shop with confidence.
##3) [Best Buy](https://www.bestbuy.com/site/electronics/gift-cards/cat09000.c?id=cat09000)
Long known for their vast selection of electronics, Best Buy has stepped up their game to become one of the best site to buy game cards. Now, not only can you shop for the latest gadgets and devices, but you can also find the perfect game or gift card for yourself or a loved one. Here's why Best Buy is an excellent choice for your gift and game card needs:
Impressive Selection: You can find cards for popular gaming platforms like PlayStation, Xbox, Nintendo, and Steam, as well as gift cards for major retailers, streaming services, and more.
Store Pickup: If you need your gift card ASAP, you can choose in-store pickup at your local Best Buy location.
Rewards Program: Best Buy's "My Best Buy" rewards program allows you to earn points for every purchase, which can be redeemed for future discounts.
##4) [Walmart](https://www.walmart.com/browse/video-games/gaming-gift-cards/2636_1228600)
Walmart's online store is another great place to find gift and game cards. With their "Everyday Low Prices," you can often find great deals on popular cards.
Wide Selection: Walmart offers a variety of gaming, entertainment, and retail gift cards to choose from.
In-Store Pickup: Like Best Buy, Walmart also offers in-store pickup for your online purchases, making it a convenient option for last-minute shopping.
##5) [GameStop](https://www.gamestop.com/gift-cards)
As a popular gaming retailer, it's no surprise that GameStop has a great selection of gift and game cards available. If you're looking for a gaming-focused retailer, GameStop is a solid choice.
Extensive Gaming Selection: GameStop specializes in gaming, so you can expect to find a wide variety of game cards for consoles and PC gaming platforms, as well as popular mobile games.
PowerUp Rewards: GameStop's rewards program, PowerUp Rewards, allows you to earn points for your purchases, which can be redeemed for discounts, exclusive offers, and more.
##6) [Target](https://www.target.com/c/video-game-gift-cards-games/-/N-5xtfh)
Target is another popular retailer that offers a good selection of gift and game cards. Known for its stylish, affordable products, Target's online store is an excellent option for gift card shopping.
Variety of Options: From gaming platforms to popular retailers and streaming services, Target has a diverse selection of gift cards to choose from.
Target Circle: Target's loyalty program, Target Circle, allows you to earn and redeem rewards, making your gift card purchases even more rewarding.
##7) [eBay](https://www.ebay.com/b/Video-Gaming-Playing-Cards/38583/bn_12407021)
While eBay might not be the first place that comes to mind when shopping for gift and game cards, it's worth checking out. You can often find great deals from individual sellers, especially if you're looking for a specific or hard-to-find card.
Unique Selection: eBay's marketplace is filled with individual sellers, which means you can often find unique and rare gift cards that may not be available elsewhere.
Buyer Protection: eBay's buyer protection program ensures that you can shop with confidence, knowing you're protected if your purchase doesn't go as planned.
##8) [CDKeys](https://www.cdkeys.com/cdkeys-gift-cards)
CDKeys is a popular online retailer specializing in digital game codes and gift cards. They offer competitive prices and a wide selection of gaming options.
Impressive Gaming Selection: CDKeys focuses on gaming, so you'll find a wide variety of game cards for popular platforms like Steam, PlayStation, Xbox, and Nintendo.
Instant Delivery: CDKeys delivers your digital purchases via email, ensuring that you receive your game or gift card as quickly as possible.
Secure Payments: CDKeys uses SSL encryption to protect your personal information during the checkout process.
##9) [G2A](https://www.g2a.com/category/gaming-c1513)
G2A is another marketplace that specializes in digital game codes and gift cards. Like eBay, G2A features individual sellers, which can result in excellent deals on popular game cards and gift cards.
Vast Selection: G2A offers a wide variety of gift and game cards for numerous platforms and popular mobile games.
G2A Shield: G2A's buyer protection program, G2A Shield, ensures that you can shop with confidence and receive support if your purchase doesn't go smoothly.
##10) [Newegg](https://www.newegg.com/US-Playing-Cards-Games/BrandSubCat/ID-118419-1562)
Newegg, a popular online retailer specializing in electronics and computer hardware, also offers a selection of gift and game cards. While their selection may not be as extensive as other options on this list, Newegg is worth considering for their competitive prices and reliable reputation.
Competitive Pricing: Newegg is known for offering competitive prices on its products, and this extends to its gift and game card selection.
Trusted Retailer: Newegg's reputation as a reliable online retailer ensures that you can shop for gift and game cards with confidence.
##Wrapping Up
There you have it! These are the 10 best places to buy gift and game cards online in 2023. Whether you're looking for a gaming platform card, a retail gift card, or a subscription service card, these websites have got you covered. Now, all you need to do is grab your favorite snack, sit back, and enjoy the convenience of shopping for gift and game cards from the comfort of your own home. Happy shopping! | gamecarddelivery |
1,435,776 | Business Appraisal Support | Don’t have the bandwidth to model out the comparative quantitative analysis that often accompanies... | 0 | 2023-04-14T11:55:10 | https://dev.to/raybratcher2/business-appraisal-support-5a07 | businessvaluation | Don’t have the bandwidth to model out the comparative quantitative analysis that often accompanies the guideline public company method? Would you like another appraiser to provide a “second look” at your conclusions? No problem! Let us help you with maintaining compliance with professional standards, providing independent analytical corroboration to your processes, and further supporting your valuation conclusions. [ValuAnalytics](https://valuanalytics.com) can help to increase the efficiency of your process by reducing the time spent on modeling nuances, so you can focus on issuing your conclusion and developing more business!
For your convenience, we provide our narrative deliverable in word processor format and the exhibits in spreadsheet format so that you can adjust formatting to align with your existing templates and reports. Every engagement includes a 30-minute consultation to review the deliverable and answer any questions you may have regarding the analytics. Please contact us to request a redacted sample deliverable.
 | raybratcher2 |
1,435,790 | SALESFORCE TOOL FOR AUTOMATION TESTING | Marketing, sales, and customer support are critical elements for any business to succeed. CRM is one... | 0 | 2023-04-14T12:13:04 | https://beyondthemagazine.com/salesforce-tool-for-automation-testing/ | salesforce, automation, test | 
Marketing, sales, and customer support are critical elements for any business to succeed. CRM is one of the best ways to deal with scenarios of business. Salesforce is one of the well-known platforms for CRM. Salesforce features are broken into three main heads: sales, marketing, and customer support. Salesforce automation test helps to ensure that it is aligned with your business objectives.
In this blog post, we will make you understand the reasons for not choosing an open-source tool and some ways to choose the salesforce automation tool.
**WHAT IS SALESFORCE**?
Salesforce is a popular CRM system used by more than 150K customers. Continuous innovation is one of the primary reasons for the success of Salesforce. There are many benefits of Salesforce, and customers enjoy the functionalities and new features added to Salesforce with each release. Still, testing is one of the significant and critical aspects to ensure that any application modification or integration may not alter or break the new internal release. Salesforce automation test is one of the best ways to test applications faster.
Salesforce application testing is the biggest constriction for organizations that put a lot of effort into making the most of Salesforce applications. The tools like selenium are not explicitly built for Salesforce, thus they often create a considerable burden when used for testing.
**REASONS WHY TEST AUTOMATION IS NOT VIABLE THROUGH OPEN-SOURCE TOOLS**
Firstly, Salesforce is a dynamic application that comprises features like objects and embedded frames. The tools, such as cypress, Selenium, and Puppeteer, do not support frames and dynamic tables, which creates a problem in Salesforce automation test. The frames and dynamic tables are not supported natively, and technical teams have to spend much time in order to create complex scripts.
With the presence of tables and dynamic elements in Salesforce pages, the change in ID takes place frequently, which breaks the existing scripts. Whenever any update takes place, or the user interface gets changed by the instigation of buttons or new screens, then the test automation scripts get ruptured. The rupture scripts are time-consuming and hence costly to fix.
Undoubtedly, Salesforce is a user-friendly platform. But most of the Salesforce automation test platforms are not that much user-friendly. There are some popular platforms for Salesforce test automation, but they need programming to build the test cases. Most of the users in business are not programmers, so it is not easy for them to manage Salesforce automation. If in case, they want to manage, it takes them a long time to get that speed.
**HOW TO CHOOSE A SALESFORCE APPLICATION TESTING TOOL**?
From a technical point of view, test automation on a code basis is not optimal because it widens the scope of the test case and results in a huge maintenance burden. Try to look for a Salesforce application testing tool that simplifies testing rather than building a hefty burden on business users and QA teams. Some of the features you can look for in the Salesforce automation test tool.
**LOW LEARNING CURVE**
Check out the platform that comprises a no-code Salesforce automation platform, as it needs less training to get started. Ideally, a tool like this will be no-code in nature and also authorize non-technical users to build and scale automation via record and playback and drag-and-drop features.
**SELF-SUSTAINING TEST SCRIPTS**
Select a Salesforce application testing tool that lessens the burden of test maintenance. When any change takes place, for instance, the change in an object property, such as ID, name, Xpath, or CSS, the self-healing test automation technologies can affix ruptured or broken test cases without human interruption. All this will help to save the many hours of maintenance of tests.
**SMART DEVICE IDENTIFICATION**
Some organizations use classic and lightning versions of Salesforce. So, it is better to choose a test automation tool that supports advanced optical character recognition and machine learning techniques to recognize objects.
**CONCLUSION**
Test automation is the need of the hour for the perfect delivery of products and services. Salesforce is well-known for its CRM, but the problem arises when any update or modification occurs regarding data mapping and auto ID creation. Opkey is a well-known Salesforce automation test platform. To learn more about automation testing and related tools, you can visit the website of Opkey.
| rohitbhandari102 |
1,435,978 | Build a React PDF Invoice Generator App with refine & Strapi | Last week, the refine ft Strapi event offered developers an exciting opportunity to learn about... | 0 | 2023-04-14T14:58:08 | https://strapi.io/blog/how-to-build-a-react-pdf-invoice-generator-app-with-refine-and-strapi?utm_campaign=ProductMarketing-StrapiBlog&utm_source=devto&utm_medium=blog | strapi, react, refine | Last week, the refine ft Strapi event offered developers an exciting opportunity to learn about building applications with two powerful technologies. Refine and Strapi, when combined, offer an incredible array of possibilities for building applications. During the week, Refine released a series of five articles detailing how to create a React PDF Invoice Generator application using these tools alongside [Ant Design](https://ant.design/).
If you missed out or are unfamiliar with these technologies, this blog post offers a quick overview of refine and Strapi. And all the articles released during the event so you can quickly get up to speed and start building your invoice generator application.
## What is refine?
[refine](https://refine.dev/) is a React-based framework that enables CRUD web applications development and provides solutions for critical components of projects, including authentication, access control, routing, networking, state management, and i18n.
With its built-in connectors for various back-end services like Strapi, REST API, GraphQL, and more, refine enables you to generate CRUD operations with ease. It provides SSR support with Next.js or Remix.
You can easily get started by following the [quick start guide](https://refine.dev/docs/getting-started/quickstart/) using the refine CLI command with a built-in template.
Run the following command:
```bash
npm create refine-app@latest my-project
```
The installation process will guide you through project template selection, naming, back-end service and UI framework selection, and other configuration settings.
## What is Strapi?
Strapi is a headless content management system (CMS) that allows developers to choose their favorite tools and frameworks and allows editors to manage and distribute their content using their application's admin panel.
With Strapi's customizable admin panel and API, developers can easily adapt the CMS to meet their specific use cases using the plugin system, which offers various plugins available through the [Strapi Market](https://market.strapi.io/). Additionally, developers can opt to self-host their Strapi application to maintain complete control of their data, or they can use [Strapi Cloud](https://strapi.io/cloud) for a quick and easy deployment process.
Like refine, getting started with Strapi is straightforward. Simply run the following command:
```bash
yarn create strapi-app my-project --quickstart
```
And follow the installation instructions while verifying that you meet all the necessary prerequisites to start your project.
## Build a React PDF Invoice Generator App with refine & Strapi
There are many use cases where you might need an invoice generator application, including small business owners, entrepreneurs, service providers, ecommerce store owners, freelancers, and more. This series of tutorials takes you through the steps you need to follow to build the application:
1. [The architecture of the frameworks used to build the application](https://refine.dev/blog/refine-react-invoice-generator-1/): Overview of refine and Strapi.
2. [Setting Up the Invoicer App with Strapi and refine](https://refine.dev/blog/refine-react-invoice-generator-2/): Setting up the Invoicer app using refine.new by choosing Ant Design as a UI framework and Strapi as a dataprovider.
3. [Adding CRUD Actions & Views](https://refine.dev/blog/refine-react-invoice-generator-3/): Implement CRUD operations for companies, clients, and contacts resources. And implement user authentication using Strapi.
4. [Creating Mission and Invoices Pages](https://refine.dev/blog/refine-react-invoice-generator-4/): Add more CRUD views to the PDF Invoice Generator.
5. [Adding PDF Renderer](https://refine.dev/blog/refine-react-invoice-generator-5/): Add a pdf renderer to display your invoices on a PDF screen.
## Conclusion
refine and Strapi are two powerful technologies for building powerful and customizable applications. This week we learned how to build a React PDF Invoice Generator application using these technologies with Ant Design.
If you are unfamiliar with these technologies and would like to continue learning, here are some useful resources to continue your learning journey:
* [React Admin Panel Tutorial with Chakra UI and Strapi](https://refine.dev/blog/react-admin-tutorial/)
* [How to Build a React Admin Panel with Mantine and Strapi](https://refine.dev/blog/react-admin-panel/)
* [Strapi Internals: Customizing the Backend ](https://strapi.io/blog/strapi-internals-customizing-the-backend-part-1-models-controllers-and-routes)
Join the [Strapi](https://discord.com/invite/strapi) Community and the [refine](https://discord.com/invite/refine) Community on Discord and continue discussing this topic further or connect with more people. | strapijs |
1,436,014 | Building a Live Code Sharing Platform With Dyte and React | TL;DR At the conclusion of this tutorial, we will have created a “Live Code Sharing... | 0 | 2023-04-14T18:17:16 | https://dyte.io/blog/live-code-sharing-platform/ | javascript, tutorial, webdev | ## TL;DR
At the conclusion of this tutorial, we will have created a “Live Code Sharing Platform” that allows users to share code and engage in video and audio calls. 🎉💻🥳
## Introduction
Code sharing is an essential aspect of programming. With the rise of remote work and virtual collaboration, developers need reliable tools for code sharing that offer real-time communication, video and audio conferencing, and a friendly user interface.
[Codeshare.io](http://codeshare.io/) is one such example. But today, we're going to roll up our sleeves and build our very own code sharing playground using [Dyte.io](http://dyte.io/).
Buckle up! 🎢
Dyte is a developer-friendly platform that offers powerful SDKs to build live experiences within our product.
In this blog, we will walk you through the process of building a code sharing platform with [Dyte.io](http://dyte.io/) and ReactJs. Let’s start! 🏃
### Step 0: Setting up Dyte account
Before anything, we would need to setup a Dyte account. For this, first visit [Dyte.io](https://dyte.io/) and then hit Start Building. On the next page, Sign in with Google or GitHub account to get your free [Dyte account](https://accounts.dyte.io/auth/login) 🎉. You will find your API keys under the API Keys tab on the left sidebar. Keep your API keys secure and don’t share them with anyone.
### Step 1: Setting up the environment
Hitting one more checkpoint before we dive into coding.
We will be using Node.js, a popular JavaScript runtime environment, and create-react-app, a tool that generates a React project with a pre-configured setup.
To get started, we will create three folders `client`, `server`, and `plugin`.
Note: 🧑💻 If you are on Mac, you should turn off “AirPlay Receiver” in System Settings as it occupied Port 5000 by default.
Just for reference, this is how our `final folder structure` would look like at the end of this blog.
We will go ahead and install `Dyte` CLI using the command below.
```bash
$ npm install -g @dytesdk/cli
```
Going ahead with the authorization part and selecting the organization with the following commands.
```bash
$ dyte auth login $ dyte auth org
```
For more information, visit [Dyte CLI Docs](https://docs.dyte.io/cli/getting-started).
### Step 2: Setting up a new Custom Plugin
To start building a custom Dyte Plugin we will clone `Dyte Plugin Template` using the following command. The plugin template allows us to get started quicker.
```bash
$ git clone https://github.com/dyte-in/react-plugin-template.git
```
This template uses `@dytesdk/plugin-sdk` and allows us to create our own real-time plugins that work seamlessly with Dyte meetings. It has many interesting features to help us solve complex problems in minutes. Now, we will install the dependencies using the “npm install” command.
```bash
$ npm install
```
Next, we will add a couple of dependencies by running the following command.
```bash
$ npm i @uiw/react-codemirror @codemirror/lang-javascript uuid
```
Here, we are adding `react-codemirror`, which provides a pre-built Code Editor with language support. We are also installing UUID that will help us in generating UUIDs with just a function call. This will come in handy soon. Now that we have everything set up, we can use this command to start and test our Custom Plugin Setup.
```bash
$ npm start
```
### Step 3: Trying out our new Custom Plugin
To try using our new custom plugin, we will have to visit `http://staging.dyte.io`
Here, we will be prompted to create a new meeting. It is super simple, just add your name and a meeting name and hit `Create`. On the next page, it will ask you to `join` the meeting. Click on join and you’re in.
Find the `Plugins` button in the bottom-right corner, and click on it to reveal all existing plugins. We are interested in a plugin named `Localhost Dev`, click on `launch` and it will reveal your plugin inside the meeting itself 🤯.
We have everything ready with us. Now, we can get started with writing some actual code!
Let’s begin with our Code Editor component.
### Step 4: Creating our Code Editor
Let’s get started with creating our own code editor 🧑💻.
For this, we are going to first create a component and then use the `CodeMirror` package that we installed earlier. First, create a new `React Functional Component` in file named `CodeEditor.js` inside `src/containers` and paste the following code.
```javascript
<CodeMirror
style={{ fontSize: "32px", textAlign: "left" }}
value={code}
onChange={handleCodeChange}
height="100vh"
width="100vw"
theme={"dark"}
extensions={[javascript({ jsx: true })]}
/>;
```
CodeMirror component provides a pre-built Code Editor. It comes with various syntax highlighting features.
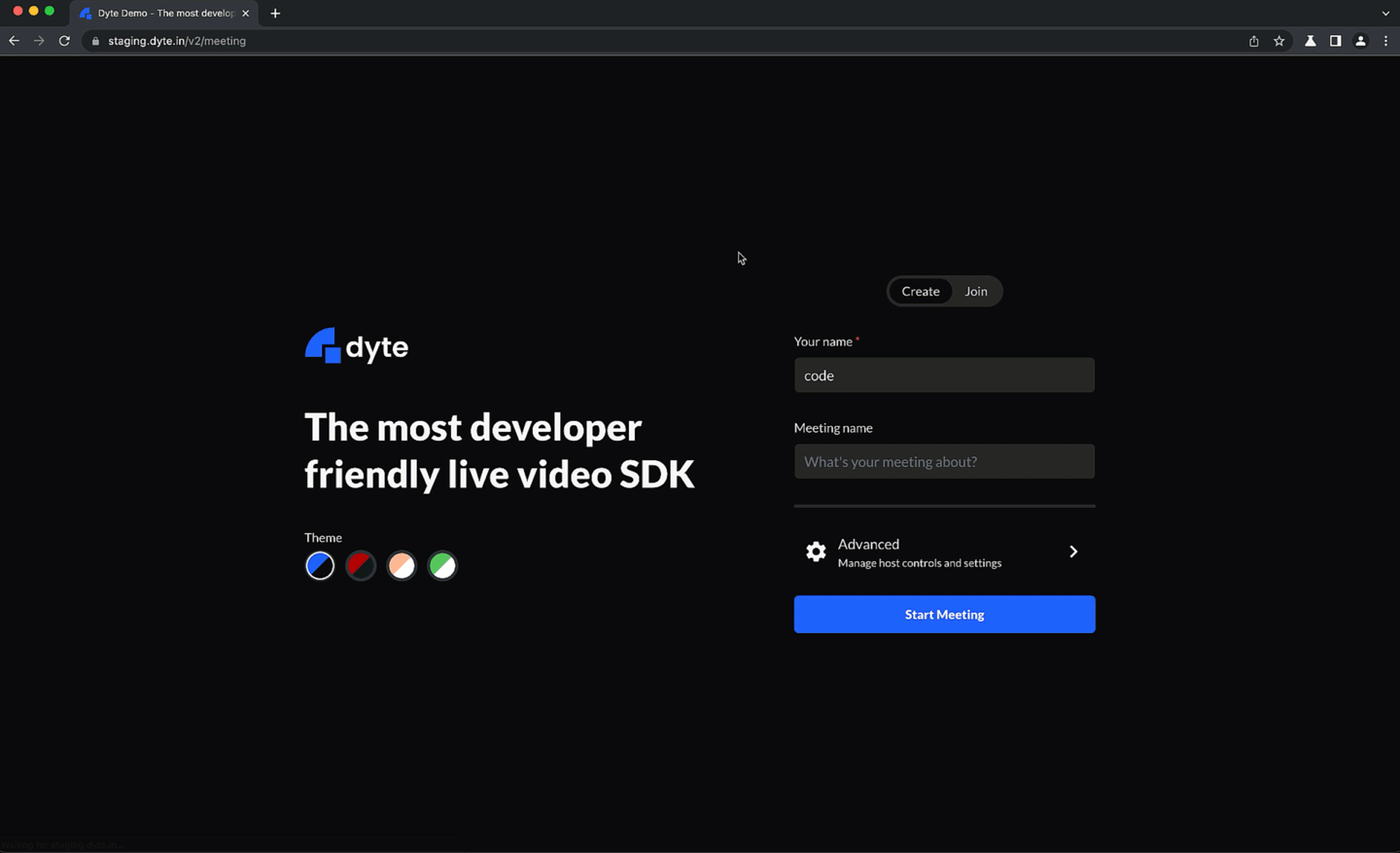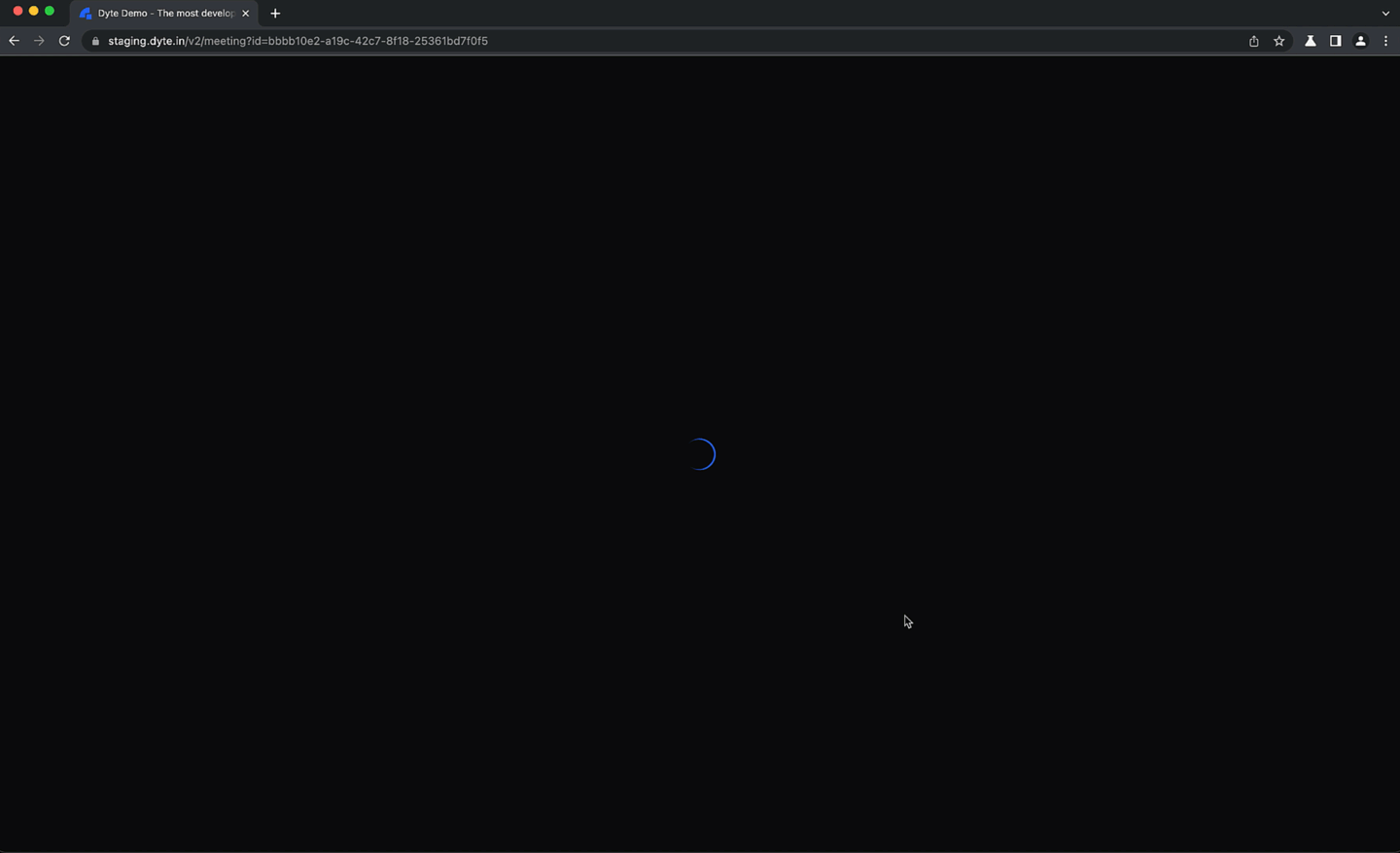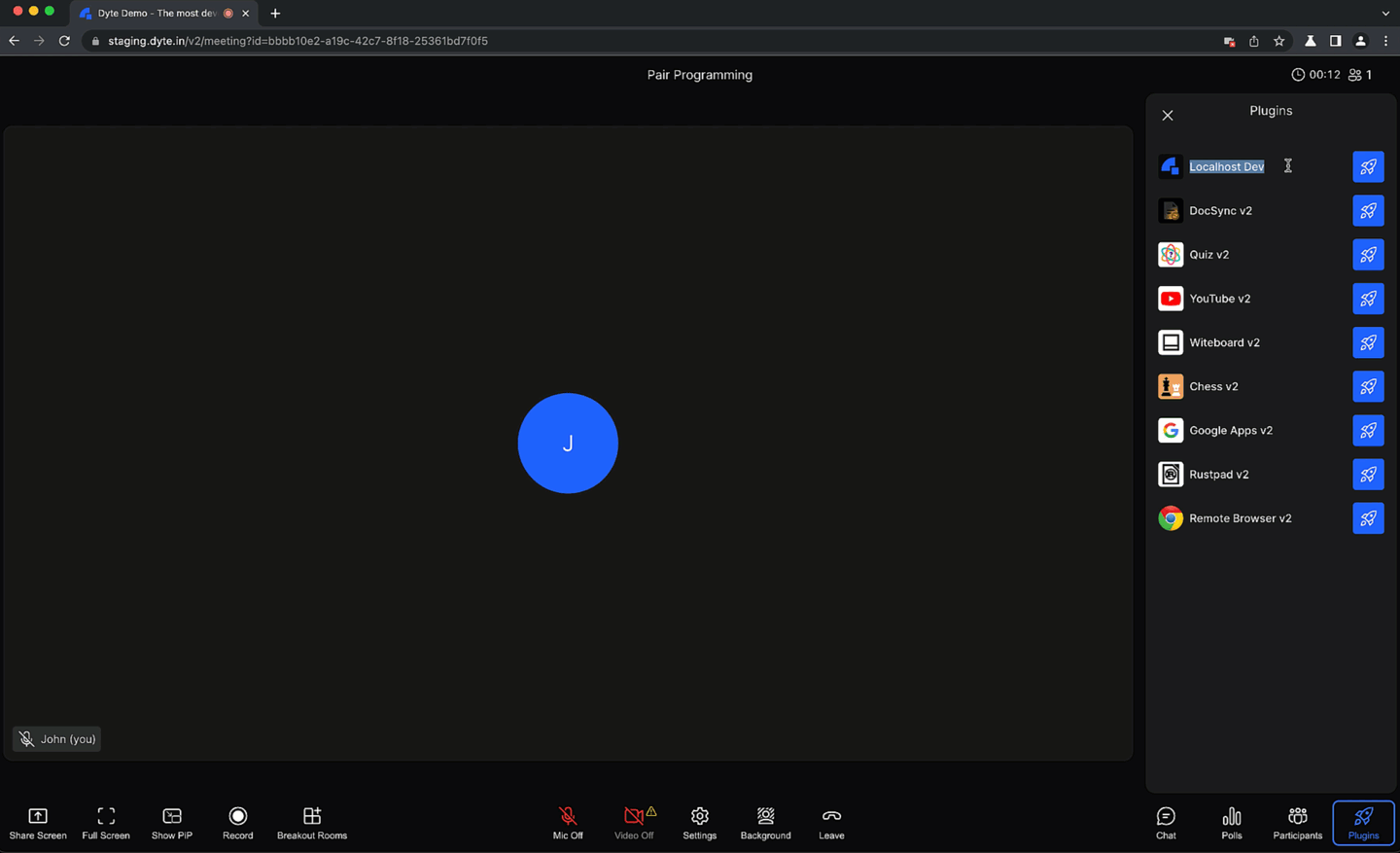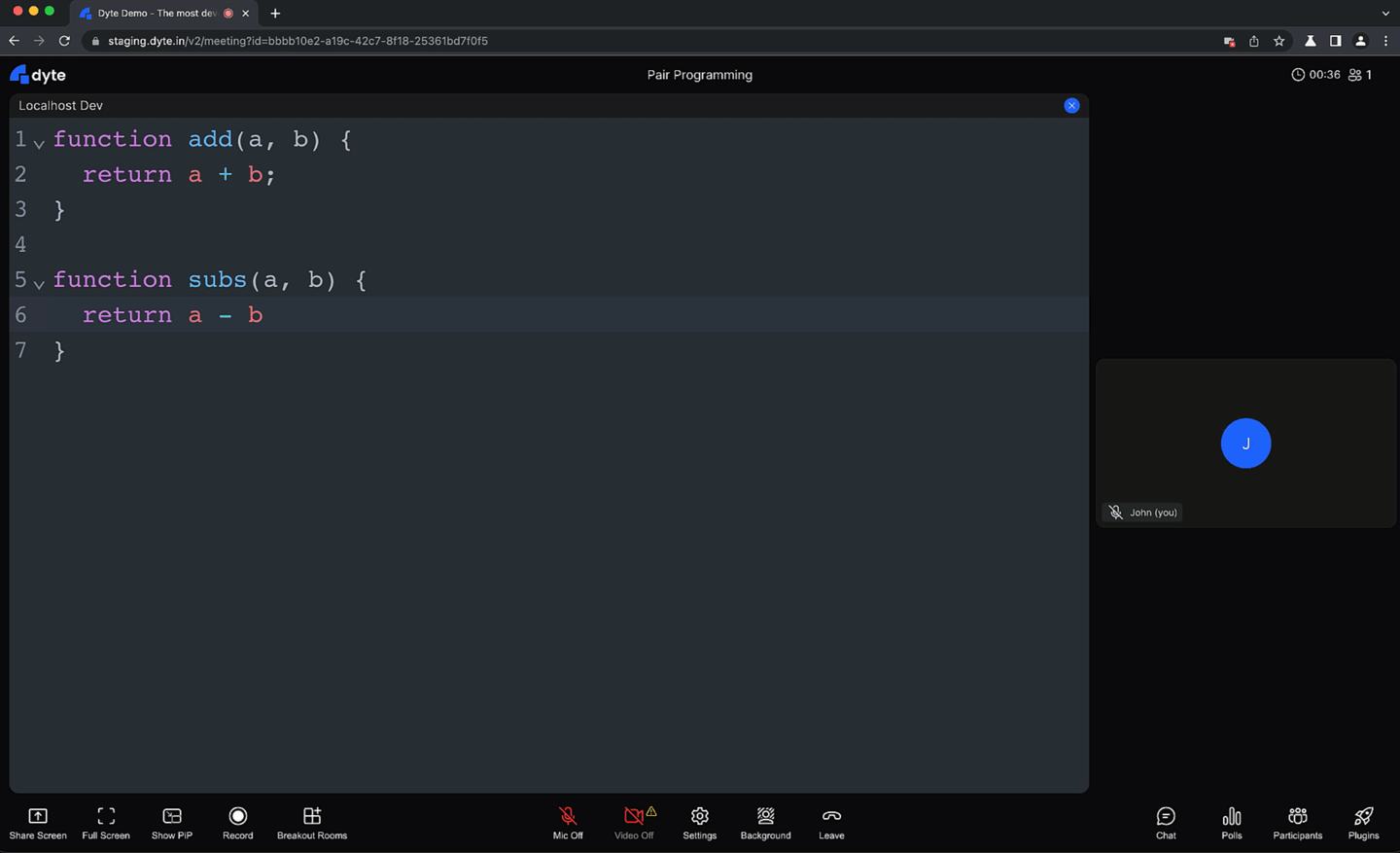
### Step 5: Handling Code Changes
To work on handling the live code changes, let's first create a new state named `code`
```javascript
import { useEffect, useState, useRef } from "react";
const [code, setCode] = useState("function add(a, b) { return a + b;}");
```
Now, we will create a `handleCodeChange` function that will emit events whenever there is a change in our code in `CodeMirror` using `plugin.emit()` function.
Here, we are emitting an object, that has two properties. The first one is a randomly generated `user id` and the second one is our whole code.
```javascript
import { useEffect, useState, useRef } from "react";
import CodeMirror from "@uiw/react-codemirror";
import { javascript } from "@codemirror/lang-javascript";
const CodeEditor = ({ plugin }) => {
const [code, setCode] = useState("function add(a, b) {return a + b;}");
const [userId, setUserId] = useState();
const handleCodeChange = async (code) => {
plugin.emit(CODE_CHANGE, { code, user });
};
return (
<>
<CodeMirror
style={{ fontSize: "32px", textAlign: "left" }}
value={code}
onChange={handleCodeChange}
height="100vh"
width="100vw"
theme={"dark"}
extensions={[javascript({ jsx: true })]}
/>
</>
);
};
export default CodeEditor;
```
### Step 6: Listening to Code Change Events
We need to listen to the event when other people change the code. For this, we will use the `plugin.on()` function as shown below. The function accepts `event name` as a parameter and receives the code changes.
One more thing to note here is that we have to update our current code only if it is sent by other users. For this we need to put a simple conditional statement `if(data.user != userId){}`
```javascript
import { useEffect, useState, useRef } from "react";
import CodeMirror from "@uiw/react-codemirror";
import { javascript } from "@codemirror/lang-javascript";
import { v4 } from "uuid";
const user = v4();
const CodeEditor = ({ plugin }) => {
const [code, setCode] = useState("function add(a, b) {\n return a + b;\n}");
const [userId, setUserId] = useState();
useEffect(() => {
if (plugin) {
const startListening = async () => {
plugin.on(CODE_CHANGE, (data) => {
if (data.user != user) {
setCode(data.code);
}
});
};
startListening();
}
}, [plugin]);
const handleCodeChange = async (code) => {
plugin.emit(CODE_CHANGE, { code, user });
};
return (
<>
{" "}
<CodeMirror
style={{ fontSize: "32px", textAlign: "left" }}
value={code}
onChange={handleCodeChange}
height="100vh"
width="100vw"
theme={"dark"}
extensions={[javascript({ jsx: true })]}
/>{" "}
</>
);
};
export default CodeEditor;
```
In this component, we are creating a Code Editor using CodeMirror. Any changes to the editor emit an event `CODE_CHANGE` to all users in the meeting, using `plugin.emit()` function call. `emit` function takes `eventName` and `data` as arguments.
In the next step, we need to import the CodeEditor component to `Main.tsx` file. Your file should look something like this. 👇
```javascript
import { useDytePlugin } from "../context";
import CodeEditor from "./CodeEditor";
const Main = () => {
const plugin = useDytePlugin();
return <div style={{ height: "100%" }} />;
};
export default Main;
```
Code for our “Collaborative Code Editor Plugin” 😉 is now ready. How did someone write the first code editor without a code editor 😂? Jokes aside, we are ready with our Plugin 🎉.
To checkout, open up [staging.dyte.io](http://staging.dyte.io/) and follow along. Enter your name and meeting title to get in. Hit join meeting. Open up the `Localhost Dev` plugin and you are good to go.
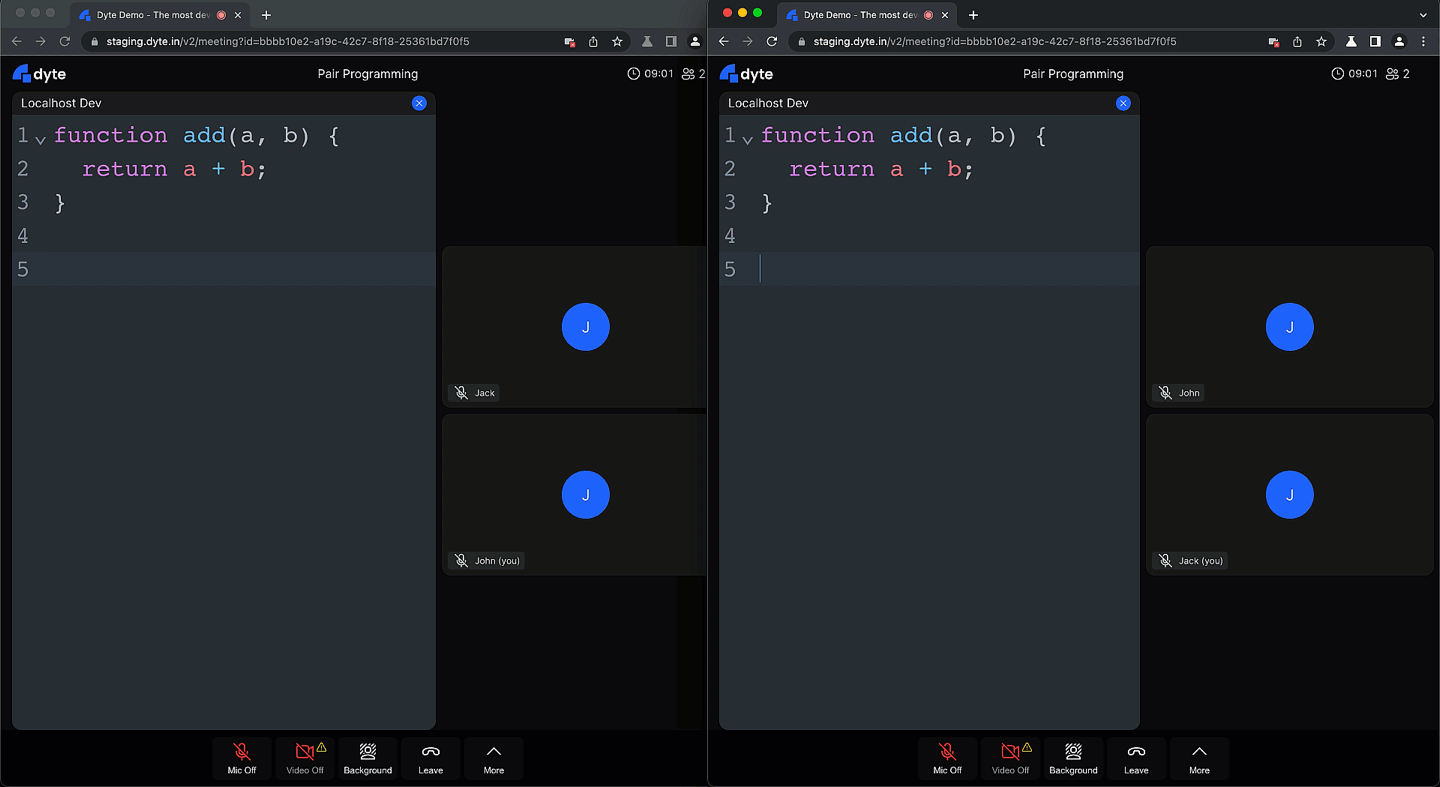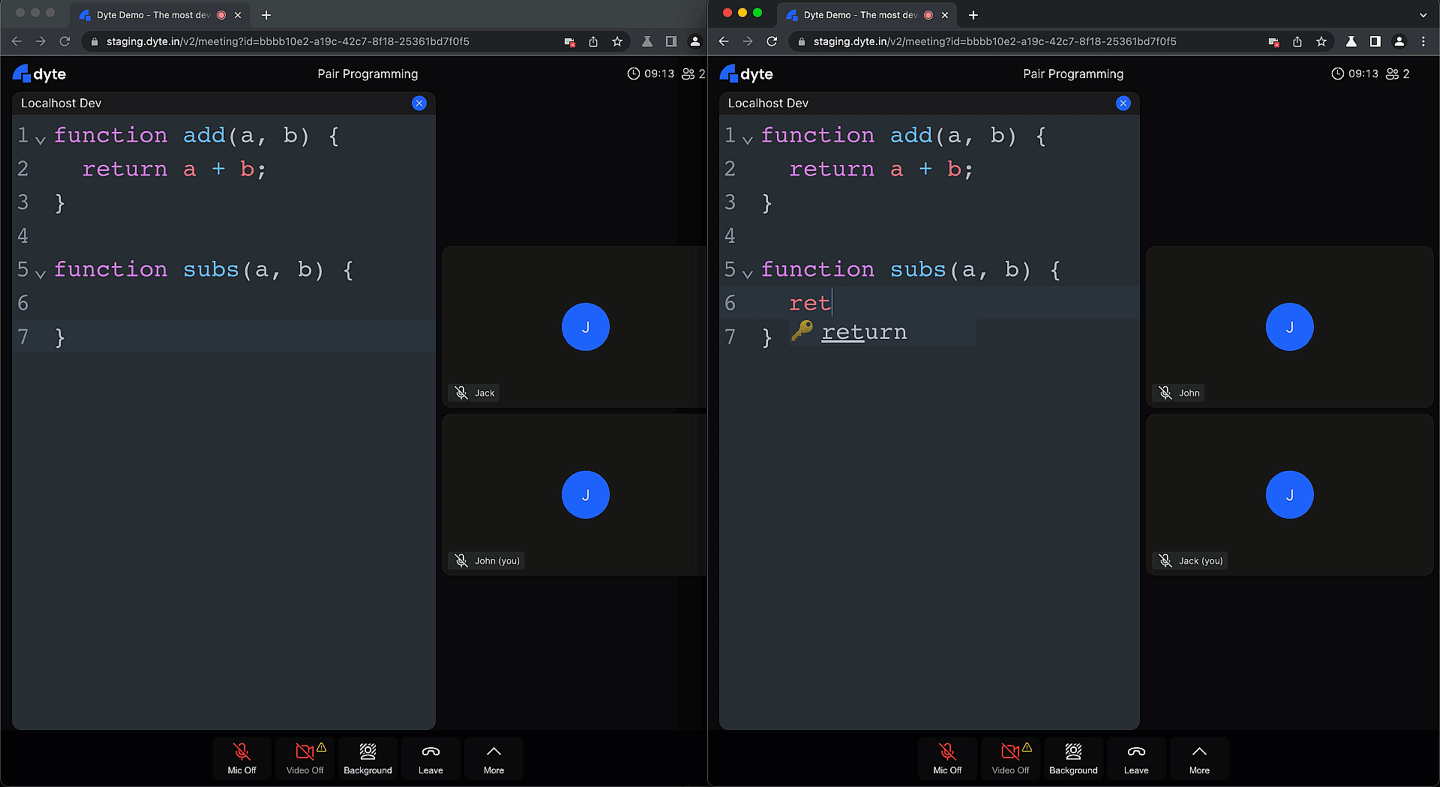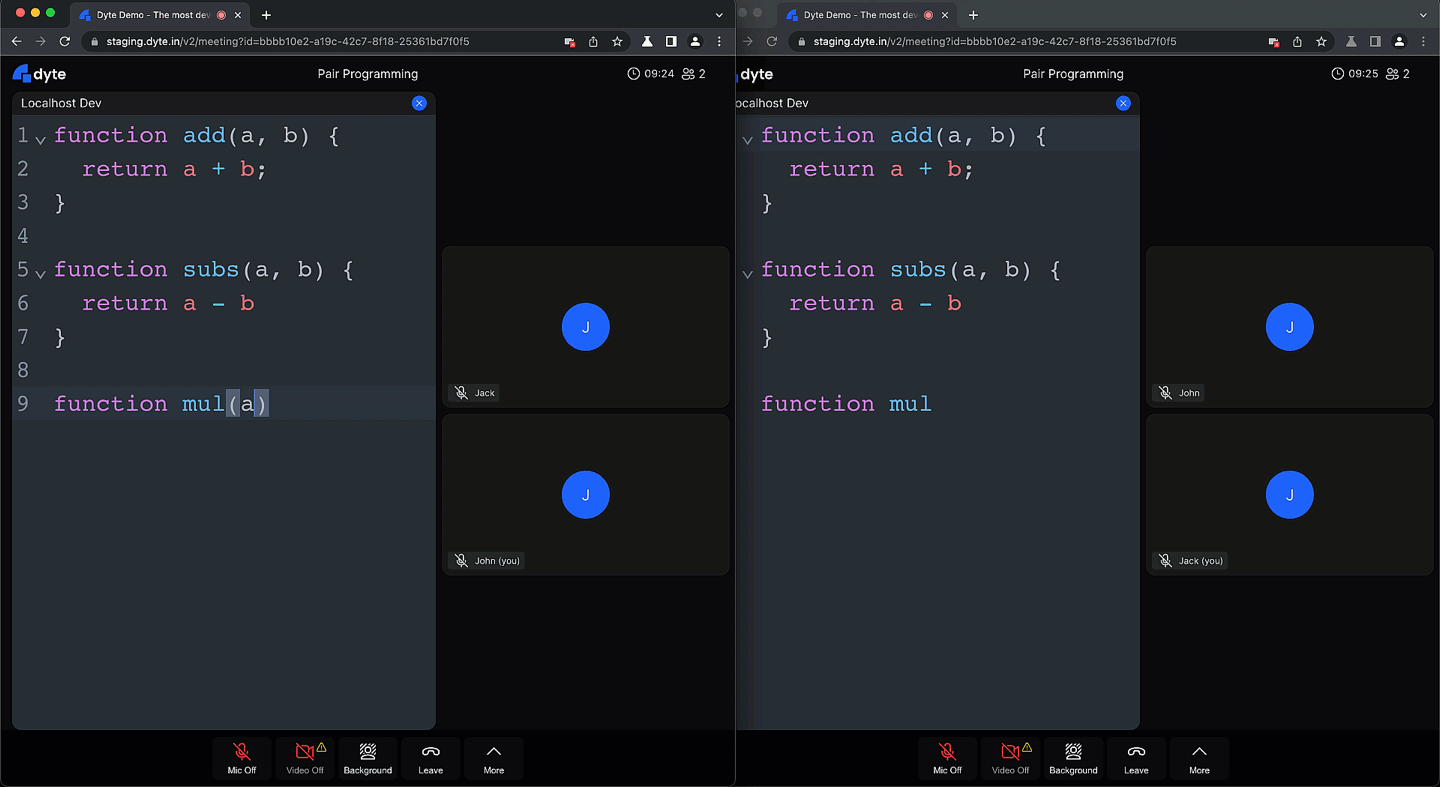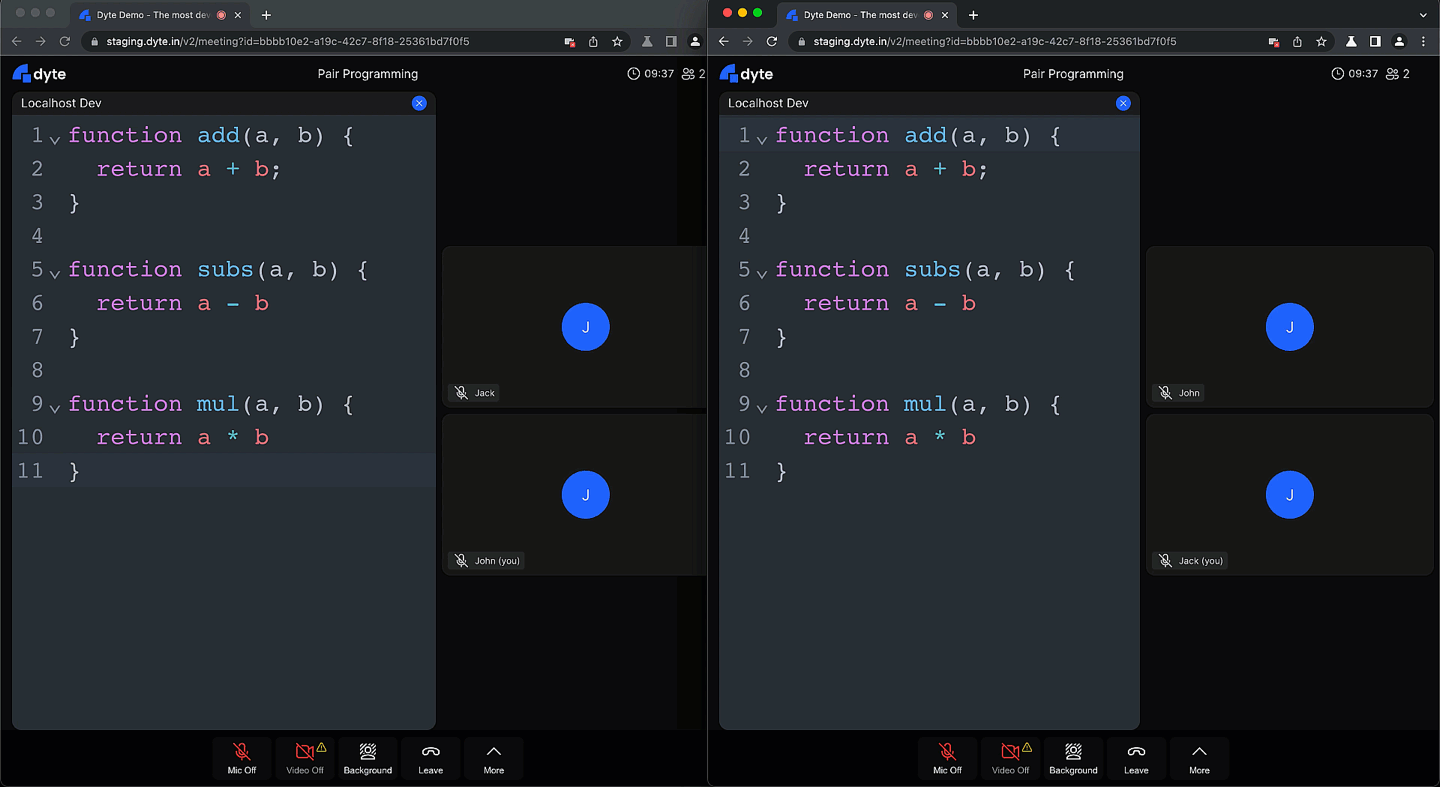
### Step 7: Publishing our Component
🧑💻 Now, it’s time to publish our content, this is a simple process with `Dyte CLI`. For this we have to first build our plugin and then run `dyte plugins publish` command.
```bash
$ dyte plugins create
$ npm run build
$ cp dyte-config.json ./build/dyte-config.json
$ cd build $ dyte plugins publish
```
### Step 8: Getting started with our Code Sharing Platform
Now that we have built the plugin which will help us collaborate on code, we can get started with building the platform to use this plugin on.
Let's start with the client side. Inside the `client` folder, we will set up a new `ReactJS` project using `create-react-app` and create our react app using the following command.
```bash
$ npx create-react-app .
```
Next, let us install the dependencies of `Dyte` and `code-editor` by running the following command:
```bash
$ npm i @dytesdk/react-ui-kit @dytesdk/react-web-core react-simple-code-editor
```
🎬 Now, let’s start our development server with npm start:
```bash
$ npm start
```
### Step 9: Building the Layout
Let us open `app.js` file inside the `src` folder. We will remove the contents of this file and add the following code snippet 👇.
```javascript
import Layout from "./components/Layout";
function App() {}
export default App;
```
Next, we will write the `Layout` component, we will be creating a layout with our logo, title and meeting UI.
We will use several libraries, including `DyteMeeting` and PrismJS, for building a collaborative code editor and meeting UI.
```javascript
import Meet from "./Meeting"
const Layout = () => {
return (
<>
<div style={{ padding: "30px", display: "flex", justifyContent: "space-between", alignItems: "center" }}>
<img src="https://dyte.io/blog/content/images/2021/09/Dyte-Logo.svg" height={"70px"}/>
<span style={{ fontSize: "30px", color: "#3e75fd" }}>Collaborative Code Editor</span>
<img style={{ opacity: "0"}} src="https://dyte.io/blog/content/images/2021/09/Dyte-Logo.svg" height={"80px"}/>
</div>
<div style={{ height: "88vh" }} ><Meet /></div>
</>
)
}
export default Layout
```
### Step 10: The Meeting Component
🧑💻 First, we need to create a few utility functions in a file `client/src/utils/api.js`
```javascript
const createMeeting = async () => {
const resp = await fetch("http://localhost:3000/meetings", {
method: "POST",
body: JSON.stringify({ title: "New Code pair" }),
headers: { "Content-Type": "application/json" }
})
const data = await resp.json()
console.log(data)
return data.data.id;
}
const joinMeeting = async (id) => {
const resp = await fetch(`http://localhost:3000/meetings/${id}/participants`, {
method: "POST",
body: JSON.stringify({ name: "new user", preset_name: "group_call_host" }),
headers: { "Content-Type": "application/json" }
})
const data = await resp.json()
console.log(data)
return data.data.token;
}
export { createMeeting, joinMeeting }
```
These functions talk to our backend to create meetings and add participants. For meeting creation, we pass `title` as an optional parameter.
And for adding participants, we pass `name` parameter (optional), `picture` parameter (optional), and `preset_name` parameter (required) along with `meetingId`.
Time for our Meeting component. For this, we will use Dyte UI kit ✨ which makes it super easy to integrate live Audio/Video sharing in your application. Yes, these 10-15 lines of code do all the heavy lifting 🏋🏼♂️.
```javascript
import { useState, useEffect, useRef } from "react";
import { DyteMeeting, provideDyteDesignSystem } from "@dytesdk/react-ui-kit";
import { useDyteClient } from "@dytesdk/react-web-core";
import { createMeeting, joinMeeting } from "../utils/api";
const Meet = () => {
const meetingEl = useRef();
const [meeting, initMeeting] = useDyteClient();
const [userToken, setUserToken] = useState();
const [meetingId, setMeetingId] = useState();
const createMeetingId = async () => {
const newMeetingId = await createMeeting();
setMeetingId(newMeetingId);
};
useEffect(() => {
const id = window.location.pathname.split("/")[2];
if (!id) {
createMeetingId();
} else {
setMeetingId(id);
}
}, []);
const joinMeetingId = async () => {
if (meetingId) {
const authToken = await joinMeeting(meetingId);
await initMeeting({
authToken,
modules: {
plugin: true,
devTools: {
logs: true,
plugins: [
{
name: "Collaborative-code-editor",
port: "5000",
id: "<your-plugin-id>",
},
],
},
},
});
setUserToken(authToken);
}
};
useEffect(() => {
if (meetingId && !userToken) joinMeetingId();
}, [meetingId]);
useEffect(() => {
if (userToken) {
provideDyteDesignSystem(meetingEl.current, {
theme: "dark",
});
}
}, [userToken]);
return (
<>
{userToken && meetingId ? (
<DyteMeeting mode="fill" meeting={meeting} ref={meetingEl} />
) : (
<div>Loading...</div>
)}
</>
);
};
export default Meet;
```
We are ready with our Code Sharing Platform's UI now 🎉
### Step 11: Getting the Backend Ready
🧑💻 Dyte provides a variety of powerful APIs that enhance the developer experience and meet a wide range of developer requirements.
We can manage Dyte’s organizations, sessions, meetings, recordings, webhooks, live streaming, analytics, and much more.
To simplify the process, we will use Express with Node to create a backend which will help with authentication, meeting creation, and adding participants. ✨
To get started in the project folder, follow the following steps:
```bash
$ mkdir server && cd server
```
We’ll start with installing a couple of dependencies, cd into the 'server' directory, and use the following command.
```bash
$ npm init -y
$ npm install express cors axios dotenv
$ npm install -g nodemon
```
First, let's create a `.env` file to store our API key in `server/src` . You can find these keys on Dyte Dashboard.
```bash
DYTE_ORG_ID=
DYTE_API_KEY=
```
Let’s also add a few scripts ✍️ that will help us run our `server` application. Add the below lines in your `package.json` file inside `scripts` tag.
```json
"start": "node dist/index.js",
"dev": "nodemon src/index.js"
```
Let's create our files and folders now. All our code will live inside `server/src` folder. Inside `src` create another folder `utils`.
Initialize a file `index.js` inside `src` and `dyte-api.js` inside `utils`. Now let’s add our `.env` file in `src`, which will hold our API secrets.
Open up `src/.env` file and add the following lines to it. Replace the placeholder values with the API secrets from the Dyte Dashboard.
```apache
DYTE_ORG_ID=<YOUR-DYTE-ORG-ID>
DYTE_API_KEY=<YOUR-DYTE-API-KEY>
```
We can start writing code now. Let’s start with creating `axios` config for accessing Dyte APIs. Open up `utils/dyte-api.js` and put in the following code.
This code will help to communicate with Dyte APIs and authentication.
```javascript
const axios = require('axios');
require('dotenv').config();
const DYTE_API_KEY = process.env.DYTE_API_KEY;
const DYTE_ORG_ID = process.env.DYTE_ORG_ID;
const API_HASH = Buffer.from(
`${DYTE_ORG_ID}:${DYTE_API_KEY}`,
'utf-8'
).toString('base64');
const DyteAPI = axios.create({
baseURL: 'https://api.cluster.dyte.in/v2',
headers: {
Authorization: `Basic ${API_HASH}`,
},
});
module.exports = DyteAPI;
```
Next, we will write the routes.
Our front end will communicate on these routes to create meetings and add participants to meetings.
Let's open up `index.js` and add the following code snippet.👇
```javascript
const express = require('express');
const cors = require('cors');
const DyteAPI = require('./utils/dyte-api')
const PORT = process.env.PORT || 3000;
const app = express();
app.use(cors("http://localhost:3001"));
app.use(express.json());
app.post('/meetings', async (req, res) => {
const { title } = req.body
const response = await DyteAPI.post('/meetings', {
title,
});
return res.status(response.status).json(response.data);
});
app.post('/meetings/:meetingId/participants', async (req, res) => {
const meetingId = req.params.meetingId
const { name, picture, preset_name } = req.body
const client_specific_id = `react-samples::${name.replaceAll(' ', '-')}-${Math.random().toString(36).substring(2, 7)}`;
const response = await DyteAPI.post(`/meetings/${meetingId}/participants`, {
name,
picture,
preset_name,
client_specific_id,
});
return res.status(response.status).json(response.data);
});
app.listen(PORT, () => {
console.log(`Started listening on ${PORT}...`)
});
```
Ta-da! 🎩✨ We did it!
Now, we'll finally try out our code sharing platform to collaborate while coding with our friends and teammates.
With our shiny new Code editor and Dyte meeting all set up, we’ll finally try out our platform!
To run the whole application locally:
Inside client type `PORT=3001 npm start`
Inside plugin type `npm start`
Inside server type `PORT=3000 npm run dev`
And there you have it, in-app video conferencing and collaboration with our own “Code Collaboration Plugin”.
🧑💻 You can try out the code sharing platform [here](https://dyte-code-editor.herokuapp.com/room/bbbf8c1f-5eee-4548-90e6-54c1301711cb).
## Conclusion
🎉 Woohoo! You've made it to the end, my friend! I hope you've learned a thing or two today and had a good time following along the way.
Together, we've built up a snazzy live pair programming and code sharing platform, complete with in-app meetings, all with just a pinch of React and a dollop of Dyte. Talk about a recipe for success!
We’ve got your back with our plugin templates and powerful SDKs, making it a breeze to jump right in and build your own collaborative masterpieces, just like the one we cooked up together today.
So what are you waiting for? Head on over to [Dyte.io](http://dyte.io/) and let your creative juices flow! Start building your own collaborative applications and you might just create the next big thing! 🚀

| vishal19111999 |
1,436,066 | You probably don't need JupyterHub on Kubernetes | https://github.com/machine424/notebook-on-kube Check out the blogpost at... | 0 | 2023-04-14T17:09:06 | https://dev.to/machine424/you-probably-dont-need-jupyterhub-on-kubernetes-455 | kubernetes, jupyter, python, helm | https://github.com/machine424/notebook-on-kube
Check out the blogpost at https://ouba.online/blog/2023/3/8/you_probably_dont_need_jupyterhub_on_kubernetes/post | machine424 |
1,436,103 | ChatGPT testing... | Допустим, мы создаем базу данных для онлайн-магазина, который продает электронику. Наша база данных... | 0 | 2023-04-14T18:34:49 | https://dev.to/yet-another-t0pc0d3r/chatgpt-testing-b74 | chatgpt | Допустим, мы создаем базу данных для онлайн-магазина, который продает электронику. Наша база данных должна хранить информацию о клиентах, заказах, продуктах и складах. Требования к базе данных:
1. Каждый клиент должен иметь уникальный идентификатор, имя, фамилию, адрес электронной почты и пароль для входа в систему.
2. Каждый заказ должен иметь уникальный идентификатор, дату и время заказа, статус заказа (обработан, отправлен, доставлен), общую стоимость и идентификатор клиента, который сделал заказ.
3. Каждый продукт должен иметь уникальный идентификатор, название, описание, цену и количество на складе.
4. Каждый склад должен иметь уникальный идентификатор, название и адрес.
Пример SQL DDL для создания таблиц:
CREATE TABLE customers (
customerid INT PRIMARY KEY,
firstname VARCHAR(50) NOT NULL,
lastname VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
password VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
orderid INT PRIMARY KEY,
orderdate DATETIME NOT NULL,
status VARCHAR(50) NOT NULL,
totalprice DECIMAL(10,2) NOT NULL,
customerid INT NOT NULL,
FOREIGN KEY (customerid) REFERENCES customers(customerid)
);
[19:07]
CREATE TABLE products (
productid INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT,
price DECIMAL(10,2) NOT NULL,
quantity INT NOT NULL
);
CREATE TABLE warehouses (
warehouseid INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
address VARCHAR(200) NOT NULL
);
CREATE TABLE orderitems (
orderid INT NOT NULL,
productid INT NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (orderid, productid),
FOREIGN KEY (orderid) REFERENCES orders(orderid),
FOREIGN KEY (productid) REFERENCES products(productid)
);
CREATE TABLE warehouseproducts (
warehouseid INT NOT NULL,
productid INT NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (warehouseid, productid),
FOREIGN KEY (warehouseid) REFERENCES warehouses(warehouseid),
FOREIGN KEY (productid) REFERENCES products(productid)
);
CREATE TABLE productimages (
imageid INT PRIMARY KEY,
productid INT NOT NULL,
imageurl VARCHAR(200) NOT NULL,
FOREIGN KEY (productid) REFERENCES products(productid)
);
CREATE TABLE reviews (
reviewid INT PRIMARY KEY,
productid INT NOT NULL,
customerid INT NOT NULL,
rating INT NOT NULL,
comment TEXT,
FOREIGN KEY (productid) REFERENCES products(productid),
FOREIGN KEY (customerid) REFERENCES customers(customerid)
);
CREATE TABLE categories (
categoryid INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE productcategories (
productid INT NOT NULL,
categoryid INT NOT NULL,
PRIMARY KEY (productid, categoryid),
FOREIGN KEY (productid) REFERENCES products(productid),
FOREIGN KEY (categoryid) REFERENCES categories(categoryid)
);
Для улучшения производительности и скорости поиска данных можно добавить индексы на некоторые поля таблиц:
CREATE INDEX idxcustomeremail ON customers (email);
CREATE INDEX idxordercustomerid ON orders (customerid);
CREATE INDEX idxproductname ON products (name);
CREATE INDEX idxwarehousename ON warehouses (name);
CREATE INDEX idxorderitemsproductid ON orderitems (productid);
CREATE INDEX idxwarehouseproductsproductid ON warehouseproducts (productid);
CREATE INDEX idxreviewsproductid ON reviews (productid);
CREATE INDEX idxreviewscustomerid ON reviews (customerid);
CREATE INDEX idxproductcategoriescategoryid ON productcategories (categoryid);

| yet-another-t0pc0d3r |
1,436,110 | Four Ways to Implement Background Jobs in Python | Background jobs, also known as asynchronous tasks or jobs, are an important feature in many Python... | 0 | 2023-04-14T18:46:47 | https://therain.dev/four-ways-to-implement-background-jobs-in-python/ | python, programming, backend, tutorial | Background jobs, also known as asynchronous tasks or jobs, are an important feature in many Python applications. They allow the application to execute long-running or resource-intensive tasks in the background, while still responding to user requests and performing other tasks. Let's explore four methods for implementing background jobs in Python.
### Threading
One way to implement background jobs in Python is to use threads. A thread is a lightweight process that runs within the same memory space as the main program. Python’s threading module provides a simple way to create and manage threads. You can create a thread by subclassing the Thread class and overriding its `run()` method. Then you can start the thread by calling its `start()` method. Here’s an example:
```python
import threading
class MyThread(threading.Thread):
def run(self):
# code for the background job goes here
# create and start the thread
t = MyThread()
t.start()
```
### Multiprocessing
Another way to implement background jobs in Python is to use multiprocessing. Multiprocessing is similar to threading, but it allows you to create processes that run in parallel. Each process has its own memory space, so it’s a good option for tasks that require a lot of resources. You can create a process by subclassing the Process class and overriding its `run()` method. Here’s an example:
```python
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
# code for the background job goes here
# create and start the process
p = MyProcess()
p.start()
```
### Celery
Celery is a popular Python library for implementing distributed tasks and asynchronous job queues. It uses a messaging system such as RabbitMQ or Redis to handle the communication between the application and the workers. To use Celery, you need to define tasks as functions and annotate them with the `@celery.task decorator`. Then you can call the tasks using the `apply_async()` method, which adds them to the queue. Here’s an example:
```python
from celery import Celery
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task
def my_task():
# code for the background job goes here
# call the task
result = my_task.apply_async()
```
### APScheduler
APScheduler is a lightweight Python library that allows you to schedule and execute jobs at specified intervals. It supports several types of triggers, such as cron, interval, and date. You can define the job as a function or a class method, and then schedule it using the `add_job()` method. Here’s an example:
```python
from apscheduler.schedulers.background import BackgroundScheduler
scheduler = BackgroundScheduler()
def my_job():
# code for the background job goes here
# schedule the job to run every minute
scheduler.add_job(my_job, 'interval', minutes=1)
# start the scheduler
scheduler.start()
```
These are just a few examples of how to implement background jobs in Python. Depending on your use case and requirements, you may choose a different method or library. It’s important to carefully consider factors such as scalability, resource usage, and error handling when implementing background jobs in your application. | rainleander |
1,436,279 | Working with the OpenAI API | In this blog post, we'll explore the intricacies of working with the OpenAI API. We'll dive into the... | 0 | 2023-04-14T20:21:17 | https://www.nextsteps.dev/posts/working-with-the-openai-api | chatgpt, webdev | In this blog post, we'll explore the intricacies of working with the OpenAI API. We'll dive into the API request structure, state management, token limits, temperature settings, and crafting effective prompts for the Chat API to help you, as a developer, get the most out of your interactions with ChatGPT.
1. API Request Structure: The Building Blocks
For developers familiar with API calls, the OpenAI API is relatively straightforward. It's a POST request sent to `https://api.openai.com/v1/completions`. The real power lies in the parameters you include with each request, which can significantly impact the API's behavior.
2. State Management: The Key to Coherent Conversations
A critical aspect to remember when working with the OpenAI API is that it doesn't maintain conversation states. As a developer, it's essential to implement state tracking in your application to ensure contextually relevant responses from ChatGPT. Make sure to include the entire conversation history in each API call.
3. Token Limits: Striking the Right Balance
Token limits are a crucial constraint in the OpenAI API, as they dictate the maximum number of tokens processed or generated in a single API call. To maintain performance and ensure system stability, you must balance input and output tokens to avoid errors or truncated responses. As a developer, you should design your application to incorporate token counters and limiters for improved stability and user experience.
4. Temperature Parameter: Fine-Tuning Your AI's Creativity
The temperature setting in the OpenAI API is a powerful tool to control the creativity or randomness of the generated text. A higher value increases diversity, while a lower value leads to more deterministic responses. As a developer, you can harness the temperature parameter to strike the perfect balance between creativity and consistency for your specific use case.
5. Crafting Effective Prompts: Guiding the AI with Precision
Prompts play a pivotal role in the Chat API, guiding the AI model and setting the stage for the conversation. As a developer, you'll want to structure prompts as a list of message objects, each containing a 'role' and 'content.' Start with a system message to set the context, followed by alternating user and assistant messages.
Designing effective prompts is both an art and a science. It involves striking a balance between being descriptive enough to establish the desired personality and response structure while minimizing word count to optimize the user experience and control costs. With your development skills, you can craft the perfect prompts to get the most context-aware and accurate responses from the AI model.
Conclusion:
Working with the OpenAI API requires a deep understanding of its various aspects. By mastering the API request structure, state management, token limits, temperature settings, and crafting effective prompts, you can unlock the full potential of ChatGPT and deliver an unparalleled user experience in your applications. Happy coding! | martinrojas |
1,436,451 | Open Source to Break the Routine 💡 | Even if we love our work, it's natural to go through phases where we feel like we've fallen into a... | 0 | 2023-04-15T03:31:50 | https://dev.to/miguelnietoa/open-source-to-break-the-routine-1m9d | opensource, programming, coding | Even if we love our work, it's natural to go through phases where we feel like we've fallen into a rut. However, it's important to keep challenging ourselves. That's where open source contributions come in - they provide a way to expand our skills, try out new technologies, and connect with others in the community. In this blog post, we'll explore how open source can be a powerful tool for refreshing your mind and breaking out of the everyday tasks of your job.
### Open Source is all about collaboration and transparency 🤝
Open source is a philosophy that encourages creativity, innovation, and problem-solving, which can be incredibly refreshing when we're caught up in daily work routines. By contributing to open source projects, you can challenge yourself, learn new skills, and expand your professional network. The best part? You don't have to be a coding wizard to get involved.
### Benefits of Contributing to Open Source 🌐
In your job, you probably code with the same tech stack every day. Sometimes it can get a little monotonous. That's why I turn to open source to mix things up and work with a different tech stack. It's a great way to keep things fresh and exciting.
But it's not just technical skills that you can develop, contributing to open source can also be a great way to improve your communication skills. 🗣️💬
When you're contributing to an open source project, probably the only way to communicate with others is through Github issues. This means that you need to be able to read and interpret the requirements in order to contribute effectively (or ask if it's not clear enough). It's a skill that takes practice, but it's one that is incredibly valuable in any programming job. Also, as a non-native English speaker, I've found that open source contributions are a great way to practice my English skills. By communicating with other contributors and maintainers in English, I'm constantly learning new slangs, words, phrases, and expressions while understanding technical stuffs.
### Give it a try - it's really rewarding 🎉
It's a chance to be part of a community that's working together to create something meaningful and useful. It's an opportunity to give back to the tech community and make a difference.
Your technical and communication skills will improve a lot by collaborating with people from different backgrounds and skill sets.
It could be a great way to refresh your mind and develop new skills. So why not give it a try? You might just discover a new passion and make some great connections along the way (as I've done).
And what if you don't know anything about open source? Learning about it can be your way to break the routine and keep you fresh and creative. 💡
Thanks for reading. 🙌
---
GitHub: https://github.com/miguelnietoa
LinkedIn: https://www.linkedin.com/in/miguelnietoa | miguelnietoa |
1,436,481 | The Power-Packed Performer: Acer Aspire Nitro | The Acer Aspire Nitro is a powerful gaming laptop that has taken the gaming community by storm. With... | 0 | 2023-04-15T05:06:06 | https://dev.to/magonetech/the-power-packed-performer-acer-aspire-nitro-52j7 | The **[Acer Aspire Nitro](https://techmagone.com/acer-aspire-nitro-7-laptop/)** is a powerful gaming laptop that has taken the gaming community by storm. With its sleek design and high-end features, it has become a popular choice among gamers and tech enthusiasts alike. In this article, we will take a closer look at the Acer Aspire Nitro and explore its features, performance, and overall value.
**Design and Build Quality**
The Acer Aspire Nitro features a sleek and modern design with a black and red color scheme. The laptop is made from high-quality materials and has a sturdy build quality that can withstand the rigors of daily use. The lid features a brushed aluminum finish with a glossy Acer logo, while the keyboard deck and bottom panel are made from a matte plastic material.
The laptop measures 15.6 inches in size and has a thickness of 0.94 inches. It weighs around 5.51 pounds, which is slightly heavier than other gaming laptops in its class. The laptop features a full-sized keyboard with a red backlight, which makes it easy to type in low-light conditions. The touchpad is also large and responsive, which makes it easy to navigate through the laptop's interface.
**Display**
The Acer Aspire Nitro features a 15.6-inch IPS display with a resolution of 1920 x 1080 pixels. The display is bright and vibrant, with excellent color reproduction and viewing angles. It has a matte finish, which helps to reduce glare and eye strain during extended gaming sessions.
**Performance**
The Acer Aspire Nitro is powered by an 11th Generation Intel Core i5 processor and comes with 8GB of DDR4 RAM. It also features an NVIDIA GeForce GTX 1650 graphics card with 4GB of dedicated video memory. The laptop is capable of handling demanding games and applications with ease, and it can run multiple applications simultaneously without any lag.
The laptop comes with a 512GB SSD, which provides ample storage space for games, media files, and other applications. The SSD also helps to improve the laptop's overall performance, as it has faster read and write speeds than a traditional hard drive.
**Battery Life**
The Acer Aspire Nitro has a 4-cell lithium-ion battery that provides up to 10 hours of battery life on a single charge. This is impressive for a gaming laptop, as most gaming laptops have shorter battery lives due to their high-performance components. The laptop also comes with a 135W power adapter, which charges the laptop quickly.
**Connectivity**
The Acer Aspire Nitro features a range of connectivity options, including two USB 3.2 Gen 1 Type-A ports, a USB 3.2 Gen 2 Type-C port, an HDMI port, an Ethernet port, and a headphone/microphone combo jack. It also features Wi-Fi 6 and Bluetooth 5.1 connectivity, which provides fast and reliable wireless connectivity.
**Software**
The Acer Aspire Nitro comes with Windows 10 Home pre-installed, along with a range of Acer software and utilities. The software includes Acer Care Center, which provides easy access to system information and maintenance tools, and Acer Quick Access, which provides shortcuts to frequently used settings.
**Value**
The Acer Aspire Nitro offers excellent value for its price, as it is priced competitively compared to other gaming laptops in its class. It offers a range of high-end features and performance, which makes it a great choice for gamers and power users alike. The laptop also comes with a one-year warranty, which provides added peace of mind.
**Conclusion**
The Acer Aspire Nitro is a powerful gaming laptop that offers excellent value for its price. It features a sleek and modern design, high-end components, and a range of connectivity options. The laptop is capable of handling demanding games and applications with ease, and it has
Read More: [Free Author Account](https://techmagone.com/free-guest-post-websites-with-author-accounts-daily-updated/)
[How Much Instagram Pay for 10k Followers in India](https://techmagone.com/how-much-instagram-pay-for-10k-followers-in-india/)
[10th certificate number](https://techmagone.com/what-is-the-certificate-number-in-10th-marksheet/)
| magonetech | |
1,436,605 | Angular Typed Forms | Angular Typed Forms is a powerful feature of the Angular framework that allows developers to create... | 0 | 2023-04-15T08:31:25 | https://dev.to/temurmalik_sultanov_9ccf4/angular-typed-forms-2124 | Angular Typed Forms is a powerful feature of the Angular framework that allows developers to create strongly-typed forms using TypeScript. In this article, we will explore how to create an Angular Typed Form and some of the benefits it provides.
Creating an Angular Typed Form
To create an Angular Typed Form, we first need to define the structure of the form using a TypeScript class. In this example, we will create a simple login form that contains two fields: username and password.
First, we will define an interface that describes the shape of the form's data:
```
interface LoginForm { username: string; password: string; }
```
Next, we will define a class that represents the form and implements the interface we just created:
```
import { Component } from '@angular/core'; import { FormBuilder, FormGroup, Validators } from '@angular/forms'; @Component({ selector: 'app-login', templateUrl: './login.component.html', styleUrls: ['./login.component.css'] }) export class LoginComponent { loginForm: FormGroup; constructor(private formBuilder: FormBuilder) { this.loginForm = this.formBuilder.group({ username: ['', Validators.required], password: ['', Validators.required] }); } onSubmit() { console.log(this.loginForm.value); } }
```
In the class above, we define a loginForm property that represents the form. We use the FormBuilder service to create an Angular FormGroup object that contains two form controls: username and password. We also define validators for each control to ensure that the user enters a value for both fields.
In the onSubmit method, we log the form's value to the console. We can use this method to submit the form to a server or perform other actions based on the form's data.
Using the Angular Typed Form
To use the Angular Typed Form, we need to create a template that binds to the form's properties and methods. In this example, we will create a simple template that displays the form and handles form submission:
```
<form [formGroup]="loginForm" (ngSubmit)="onSubmit()"> <label> Username: <input type="text" formControlName="username"> </label> <label> Password: <input type="password" formControlName="password"> </label> <button type="submit" [disabled]="!loginForm.valid">Submit</button> </form>
```
In the template above, we bind the loginForm property to the form's formGroup attribute. We also bind the onSubmit method to the form's (ngSubmit) event.
We use the formControlName directive to bind each input field to the corresponding form control. We also disable the submit button if the form is not valid using the disabled attribute.
Benefits of Angular Typed Forms
Angular Typed Forms provide several benefits over traditional Angular forms, including:
1. Strong Typing: By using TypeScript classes and interfaces to define the form's structure, developers can create forms that are strongly-typed and easier to work with.
2. Code Reuse: Because the form's structure is defined using TypeScript classes and interfaces, developers can reuse this code in other parts of the application, making it easier to maintain and modify.
3. Better Validation: With Angular Typed Forms, developers can define custom validation logic using TypeScript methods, making it easier to create complex validation rules.
4. Improved Readability: By separating the form's structure and data from the form's presentation logic, Angular Typed Forms can make code more readable and easier to maintain.
Conclusion
Angular typed forms provide a powerful and flexible way to create forms in Angular applications. By using TypeScript classes to define the form model, we can take advantage of type-checking, code completion, and other TypeScript features to make our code more robust and reliable. In this article, we explored how to create an Angular typed form, bind it to an HTML template, and handle form submission. We also looked at some of the features that Angular provides for working with forms, such as validation and error handling. By using Angular typed forms, developers can create forms that are easier to maintain, test, and extend, making it easier to build high-quality Angular applications.
[Ilyoskhuja Ikromkhujaev](https://uz.linkedin.com/in/ilyoskhuja) is an experienced Angular developer with 10 years of experience. He has worked with Angular Typed Forms extensively and has implemented them in several projects. He believes that Angular Typed Forms are a powerful tool that can help developers create robust and reliable forms in Angular applications.
One of the benefits of using Angular Typed Forms, according to Ilyoskhuja Ikromkhujaev, is that they provide strong typing. By using TypeScript classes and interfaces to define the form's structure, developers can create forms that are strongly-typed and easier to work with. This makes it easier to catch errors and bugs before they become major problems.
Another benefit of using Angular Typed Forms is code reuse. Because the form's structure is defined using TypeScript classes and interfaces, developers can reuse this code in other parts of the application, making it easier to maintain and modify. This helps to reduce duplication of code and saves time and effort.
According to Ilyoskhuja Ikromkhujaev, Angular Typed Forms also provide better validation. With Angular Typed Forms, developers can define custom validation logic using TypeScript methods, making it easier to create complex validation rules. This helps to ensure that data entered into the form is valid and consistent.
Ilyoskhuja Ikromkhujaev also believes that Angular Typed Forms can help to improve readability in code. By separating the form's structure and data from the form's presentation logic, Angular Typed Forms can make code more readable and easier to maintain. This can help to reduce bugs and errors and make code more reliable.
In conclusion, Ilyoskhuja Ikromkhujaev recommends Angular Typed Forms as a powerful and flexible way to create forms in Angular applications. By using TypeScript classes to define the form model, developers can take advantage of type-checking, code completion, and other TypeScript features to make their code more robust and reliable. By using Angular Typed Forms, developers can create forms that are easier to maintain, test, and extend, making it easier to build high-quality Angular applications.
| temurmalik_sultanov_9ccf4 | |
1,436,787 | Best Security Practices for Docker in 2023 | Node.js has become a popular choice for building fast and scalable applications. However, deploying... | 0 | 2023-04-15T12:57:47 | https://nayanpatil.hashnode.dev/best-security-practices-for-docker-in-2023 | docker, security, devops, containers | Node.js has become a popular choice for building fast and scalable applications. However, deploying and scaling Node.js apps can be challenging, especially as your application grows. This is where Docker comes in - by containerizing your Node.js application, you can ensure consistent deployments across different environments and scale your app more easily.
In this article, we'll walk you through the best practices for dockerizing your Node.js app, including optimizing container size, using environment variables, and multistage builds.
## Introduction
### What is Docker?
Docker is **a software platform that allows you to build, test, and deploy applications quickly**. Docker packages software into standardized units called containers that have everything the software needs to run including libraries, system tools, code, and runtime.
## Prerequisites
1. You should have Docker installed on your system, you can follow [this guide](https://docs.docker.com/get-docker/) on official Docker docs.
2. Basic knowledge of how docker works.
3. Basic NodeJs Application. if you don't, follow my guide on [How To create an API using Node.js, Express, and Typescript](https://nayanpatil.hashnode.dev/how-to-create-an-api-using-nodejs-express-and-typescript), and clone the starter project via this [GitHub repository](https://github.com/NayanPatil1998/nodejs_typescript_blog)
Let's write a basic Dockerfile for this Nodejs application,
```ruby
FROM node
COPY . .
RUN npm install
CMD ["npm", "start"]
```
## Best Security Practices for Docker in 2023 -
### Always use a specific version for the base image for Dockerfile
```ruby
# Use specific version
FROM node:16:17.1
COPY . .
RUN npm install
CMD ["npm", "start"]
```
When creating Docker images, it is important to use specific base image versions in your Dockerfile. This is because using the latest version of a base image may introduce compatibility issues with your application or dependencies, leading to unexpected errors and security vulnerabilities.
By using a specific version of a base image, you can ensure that your application runs consistently and reliably across different environments. Additionally, using specific base image versions can also help you comply with security and regulatory requirements.
### Optimize your docker image by using a smaller base image
```ruby
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine
COPY . .
RUN npm install
CMD ["npm", "start"]
```
Using smaller-size base images is a critical best practice for optimizing Docker images. Smaller images can have a significant impact on your application's performance, reduce your storage and bandwidth costs, and minimize the number of potential vulnerabilities.
When selecting a smaller base image, you can avoid unnecessary dependencies and configurations that are not relevant to your application, ultimately leading to faster build times and smaller image sizes. By using a smaller base image, you can also reduce the attack surface of your application and improve its overall security posture.
With this, you can create Docker images that are smaller, faster, and more secure, enabling you to deliver your application with confidence.
### Specify the correct working directory in Dockerfile
```ruby
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine
#Specify working directory for application
WORKDIR /usr/app
COPY . .
RUN npm install
CMD ["npm", "start"]
```
When building Docker images, it is crucial to set the working directory to the appropriate location to ensure that your application's files and dependencies are correctly referenced. Setting the working directory to the wrong location can cause confusion and unexpected errors, which can delay development and deployment times.
By using the correct working directory, you can also improve the readability of your Dockerfile, making it easier for other developers to understand and maintain your code. Additionally, the correct working directory can help ensure that any subsequent commands are executed in the correct location, avoiding file path issues and other complications.
With this you can streamline your Docker workflow and reduce the risk of errors and delays, allowing you to focus on delivering high-quality applications.
### Always use the .dockerignore file
```ruby
# .dockerignore
node_modules
package-lock.json
yarn.lock
build
dist
```
This file allows you to specify files and directories that should be excluded from the build context, which can significantly reduce the build time and the size of the resulting image.
When Docker builds an image, it starts by creating a build context that includes all the files in the directory where the Dockerfile is located. This context is then sent to the Docker daemon, which uses it to build the image. However, not all files in the directory are necessary for the build, such as temporary files, log files, or cached dependencies. These files can cause the build to be slower and result in a larger image size.
To avoid this, you can create a `.dockerignore` file that lists the files and directories that should be excluded from the build context. This file uses the same syntax as `.gitignore`, allowing you to specify patterns of files or directories to exclude. For example, you might exclude all `.log` files, cache directories, or build artifacts.
### Copying package.json Separate from Source Code
```ruby
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine
#Specify working directory for application
WORKDIR /usr/app
# Copy only files which are required to install dependencies
COPY package.json .
RUN npm install
#Copy remaining source code after installing dependancies
COPY . .
CMD ["npm", "start"]
```
Copying package.json separately from the source code is a best practice for optimizing your Docker builds. By separating your application's dependencies from the source code, you can avoid unnecessary rebuilds and save time and resources.
When building a Docker image, copying the entire source code directory can be time-consuming and wasteful, especially if the source code changes frequently. Instead, by copying only the package.json file separately, Docker can leverage its layer caching capabilities to only rebuild the image when the dependencies change.
### Use non root user
```ruby
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine
#Specify working directory for application
WORKDIR /usr/app
# Copy only files which are required to install dependencies
COPY package.json .
RUN npm install
# Use non root user
USER node
# Copy remaining source code after installing dependancies
# Use chown on copy command to set file permissions
COPY --chwon=node:node . .
CMD ["npm", "start"]
```
Running applications as root can increase the risk of unauthorized access and compromise the security of your containerized applications. By creating and running containers with non-root users, you can significantly reduce the attack surface of your applications and limit the potential damage in case of a security breach.
In addition to improving security, using non-root users can also help ensure that your Docker containers are compliant with industry security standards and regulations. For example, using non-root users is a requirement for compliance with the Payment Card Industry Data Security Standard (PCI DSS).
After using a non-root user, we need to permit to access our code files, as shown in the above example, we are using chown for copying files, this will give the non-root user to access the source code.
### Multistage build for production
By using multiple stages in your Docker build process, you can reduce the size of your final image and improve its performance.
In a multistage build, each stage represents a different phase of the build process, allowing you to optimize each stage for its specific task. For example, you can use one stage for compiling your application code and another for running your application. By separating these tasks into different stages, you can eliminate unnecessary dependencies and files, resulting in a smaller, more efficient final image.
In addition to reducing image size, multistage builds can also improve security by eliminating unnecessary packages and files. This can reduce the attack surface of your Docker image and help ensure that only essential components are included.
```ruby
# Stage 1: Build the application
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine AS build
#Specify working directory for application
WORKDIR /usr/app
# Copy only files which are required to install dependencies
COPY package.json .
RUN npm install
COPY . .
RUN npm run build
# Stage 2: Run the application
FROM node:16.17.1-alpine
WORKDIR /usr/app
# set production environment
ENV NODE_ENV production
# copy build files from build stage
COPY --from=build /usr/app/build .
# Copy necessary files
COPY --from=build /usr/app/package.json .
COPY --from=build /usr/app/.env .
# Use chown command to set file permissions
RUN chown -R node:node /usr/app
# Install production dependencies only
RUN npm install --omit=dev
# Use non root user
USER node
CMD ["npm","run", "start:prod"]
```
In this example, the first stage (named "build") installs the necessary dependencies, copies the source code, and builds the application. The resulting artefacts are then copied to the second stage (named "run"), which only includes the necessary dependencies to run the application in production. This separation of stages helps reduce the size of the final image and ensures that only essential components are included.
Note that the `--from` the flag in the second `COPY` command refers to the first stage, allowing us to copy only the built artefacts into the final image. This is an example of how multistage builds can be used to optimize the Docker build process.
### Exposing port in Dockerfile
```ruby
# Stage 1: Build the application
# Use specific version
# Use alpine for smaller base image
FROM node:16.17.1-alpine AS build
#Specify working directory for application
WORKDIR /usr/app
# Copy only files which are required to install dependencies
COPY package.json .
RUN npm install
COPY . .
RUN npm run build
# Stage 2: Run the application
FROM node:16.17.1-alpine
WORKDIR /usr/app
# set production environment
ENV NODE_ENV production
# copy build files from build stage
COPY --from=build /usr/app/build .
# Copy necessary files
COPY --from=build /usr/app/package.json .
COPY --from=build /usr/app/.env .
# Use chown command to set file permissions
RUN chown -R node:node /usr/app
# Install production dependencies only
RUN npm install --omit=dev
# Use non root user
USER node
# Exposing port 8080
EXPOSE 8080
CMD ["npm","run", "start:prod"]
```
By exposing the ports that your application uses, you allow other services to communicate with your container.
To export a port in Docker, you need to use the `EXPOSE` instruction in your Dockerfile. This instruction informs Docker that the container will listen on the specified network ports at runtime. Note that this instruction does not publish the port, but rather documents the ports that the container is expected to use.
To export the port, you need to use the `-p` option when running the container, specifying the external port and the internal port where your application is listening. For example, `docker run -p 8080:80 my-image` will publish port 80 inside the container to port 8080 on the host machine.
By exporting ports in Docker, you enable seamless communication between your container and other services, both within and outside of your Docker environment. This best practice can help ensure that your application can be accessed by other services and that it can be easily integrated into a larger system.
## Conclusion
In conclusion, Docker is a powerful tool for optimizing and scaling your Node.js application.
By following these best practices for Dockerizing your Node.js app, you can create images that are optimized for performance, security, and scalability. By using a specific base image version, a smaller base image size, the correct working directory, and a non-root user, you can ensure that your images are secure and optimized for production use. Using multistage builds, configuring your app for production, and exporting ports can also help ensure that your application can be easily scaled and integrated into a larger system.
In summary, Dockerizing your Node.js app using these best practices can help you create a containerized environment that is secure, scalable, and optimized for production use. By taking advantage of Docker's powerful tools and optimizing your images, you can ensure that your Node.js app runs smoothly and efficiently, allowing you to focus on building the features and functionality that your users need. So go ahead and Dockerize your Node.js app today, and experience the benefits of a containerized environment for yourself! | nayanpatil1998 |
1,437,013 | Sharing a Printer in a WiFi Network | Printers are maybe not something we should own at our home, at least not when we can access a shared... | 22,597 | 2023-04-19T08:09:40 | https://dev.to/ingosteinke/sharing-a-printer-in-a-wifi-network-9gk | hardware, printer, productivity, sustainability | Printers are maybe not something we should own at our home, at least not when we can access a shared printer at work, in a coworking space or a copyshop.
## No Developer likes to Fix Printers! 🔧🖨️😒
Printers are notorious to be expensive, wasteful, and guaranteed to cause trouble due to missing, incompatible, or outdated device drivers. It has become a running gag that you don't want to be the "IT expert" having to support and fix other people's printing problems.
I have had trouble using an HP LaserJet in our family. At least, the printer doesn't refuse to work with third-party color cartridges, so we can use recycled ones instead of the more expensive original ones.
## Outdated Drivers, Planned Obsolescence? 🗑️💸
But I often struggled and failed to install a driver for any other platform than Windows. It used to work some years ago, maybe 2018 when they last updated their [HPLIP](https://en.wikipedia.org/wiki/HP_Linux_Imaging_and_Printing) driver?
### Not even working on Linux anymore?!
But after both Apple and Linux switched their [CUPS](https://www.cups.org)-based printing systems to Python 3 or some other breaking change that I don't mind to understand, the only way to print a document seemed to be using a PC running Microsoft Windows. So I had to save a PDF in the cloud or email it to myself, then startup Windows on a laptop physically connected to the printer, start the printing process, check if the paper has been printed successfully, and shut down Windows. What a waste of time and energy!
Later, I had another hardware problem, when the German Telefonica subsidiary O² had sent us their default white label router which seemed to use a slow fall back protocol when accessed by my Linux laptop. So I needed an alternative.
## Reusing Second-Hand Hardware 🪄✨🙏
The Fritz!Box 7520 is branded by 1&1 and cheap to get second-hand, and it works as an O² client as well, [as a helpful forum user pointed out](https://hilfe.o2online.de/dsl-kabel-glasfaser-router-software-internet-telefonie-34/nutzung-der-7520-mit-o2-546037).

Later I found out that the router has an [option to connect a printer](https://en.avm.de/service/knowledge-base/dok/FRITZ-Box-7590/15_Setting-up-a-printer-connected-to-the-FRITZ-Box/) via USB and make it accessible as a network printer.
## No More Troubleshooting! ✌️
Now our old LaserJet is connected to the router and can be used as a network printer by everyone logged into our WiFi network. | ingosteinke |
1,437,028 | Global CSS Art: Community | I'm creating a project called Global CSS Art where people can share their CSS Art and others can view... | 0 | 2023-04-15T18:35:11 | https://dev.to/vulcanwm/global-css-art-community-3ajh | community, css, opensource, contributorswanted | I'm creating a project called Global CSS Art where people can **share their CSS Art and others can view it, see the source code, and learn from it**.
The whole project will be open source and it will run if people keep on sharing their CSS Art.
The way it'll work is that there the GitHub repo will contain a folder called `/art`. This folder will have subdirectories with a user's username and within that subdirectory will be all the user's CSS art, in the format of HTML files with `<style>` tags.
People will then be able to add their own CSS art within their unique folders in the `/art` directory and make pull requests in the GitHub repo.
All the artwork will be randomly selected on each page load and will be shown on the main page.
**I need really big help!**
For me to create and then test out the project, I need some CSS art from different users on the GitHub repo.
It would be really nice to have cool artwork on the website.
To contribute and see your artwork on the home page (with your username and portfolio for people to see), add a html file to the directory: `/art/[username]`
*(Make sure your CSS code only affects the div the art is in, and not the whole page)*
and create a pull request on this GitHub repository:
{% embed https://github.com/VulcanWM/global-css-art %}
Thanks for reading and I hope you contribute!
| vulcanwm |
1,437,155 | Jumping into the deep end. | -One day, I woke up and went to work. Halfway through my day, it struck me: I love computers, and... | 0 | 2023-04-15T20:28:15 | https://dev.to/dreamsalotl/jumping-into-the-deep-end-3cbb | beginners, webdev, programming | -One day, I woke up and went to work. Halfway through my day, it struck me: I love computers, and want to know them inside and out. When I got home, I started looking into programming. I was looking up YouTube video tutorials, trying to figure out where the heck I should start. Every blog and video I watched said there is no specific language one should start on, and me being the indecisive person I am, gave up. Here I am, years later. My brother offered me a job in his IT help desk position, and said I would be perfect for it. I was practically guaranteed the job, he had pull. I didn't need any previous experience, and I was good with computers already, everyone always comes to me with tech help, it's a no brainer, right? I was so excited, I told all my coworkers that I'd have a foot in the door to starting my programmer life. A week later, my brother told me that they chose someone else, someone even less qualified. You would think I'd be devastated, but I think the thought of getting that job flipped a switch in my brain. All I could think about was that the thought of starting programming made me so happy. I came home, and started researching again, reading everything and watching everything I had already seen, but with this new mindset. I finally decided to start my journey learning the mother language of coding, C. I downloaded an app on my phone called Programming Hero, and at work, at home, any free time I got, I spent it studying the workings of C and playing around in a sandbox compiler. The euphoria I got when my first difficult code actually ran after debugging it a bunch, is indescribable. I wanted to learn it all at this point. C, C++, Java, Python, EVERYTHING. Today, I enrolled in a coding boot camp, and start in a month. I'm so excited at the aspect of finally learning what I've always wanted to learn, and getting a start on my future.
-I guess the point of this post is: It's never too late. It took me years to finally work up the courage to just jump into the deep end, and I'm not disappointed in the slightest. However long it takes, however frustrated you get, if you have the same love for coding deep down like I do, you'll get where you need to go eventually. Don't give up! | dreamsalotl |
1,437,199 | Concurrent Processing of Azure Service Bus Queue Messages | How do you improve the throughput of the Azure Function which has service bus trigger function to... | 0 | 2023-04-15T23:56:32 | https://dev.to/chintupawan/concurrent-processing-of-azure-service-bus-queue-message-18c | azure, azureservicebusqueue, azurefunctions | > How do you improve the throughput of the Azure Function which has service bus trigger function to process messages in the queue?
This is most common Cloud Design Pattern to offload the long running or background processes to Azure Function via Service Bus Queue. Example, as soon as you upload an image via Front-End you might want to resize the image to reduce/compress the size. Your backend api could put the message in the queue and location of the original image in the message payload. Your Azure function has service bus trigger function which picks up messages from the queue to resize. Its not good idea to put the image in the message payload, as the messages in service bus queue can only be between 64Kb to 1MB. This restriction is based on the SKU of the Azure Service Bus.
Azure Functions can run in Dynamic Plans as well as in App Service Plans. In Dynamic Plans Azure Functions can be scaled based on [Event Driven Scaling](https://learn.microsoft.com/en-us/azure/azure-functions/event-driven-scaling). In App Service Plans it is based on Auto Scaling rules that we configure. Both of these are used for running multiple instances of Azure Functions running in multiple VM instances.
Along with above Azure Functions have built in support to configure the concurrency per instance of Function App running in single instance of VM. For Service Bus Trigger Functions setting MaxConcurrentCalls and MaxConcurrentSessions in hosts.json helps us to control the number of messages that can be processed in single instance of Azure function.
But achieving the correct numbers for these settings are a bit hard, we need to find out by trial and error as setting the high values can push the System resources and low values mean under utilisation.
Answer to the above dilemma is Dynamic Concurrency. Currently this is only supported for Azure Service Bus Queue, Blob and Azure Storage Queues.
`{
"version": "2.0",
"concurrency": {
**"dynamicConcurrencyEnabled": true,
"snapshotPersistenceEnabled": true **
}
}`
Here Function host intelligently identifies the sweet spot based on the availability of System Resources.
When SnapshotPersistenceEnabled is true, which is the default, the learned concurrency values are periodically persisted to storage so new instances start from those values instead of starting from 1 and having to redo the learning.
Sample trigger Function
`
[FunctionName("ServiceBusQueueTrigger1")]
public void Run([ServiceBusTrigger("myqueue", Connection = "ServiceBusConnectionString")]string myQueueItem, ILogger log)
{
log.LogInformation($"C# ServiceBus queue trigger function started message: {myQueueItem}");
// Simulate a long running process
System.Threading.Thread.Sleep(20000);
log.LogInformation($"C# ServiceBus queue trigger function processed message: {myQueueItem}");
}
`
Sample hosts.json
`
{
"version": "2.0",
"logging": {
"applicationInsights": {
"samplingSettings": {
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"concurrency": {
"dynamicConcurrencyEnabled": true,
"snapshotPersistenceEnabled": true
}
}
`
Here in my example each message takes about 20 Secs to process. I have simulated this by adding putting thread to sleep.
Now from service bus explorer i have added three messages successively
All the messages are pickedup immediately.
Function processed those message sequentially

For more information :
https://learn.microsoft.com/en-us/azure/azure-functions/functions-concurrency | chintupawan |
1,437,328 | A STEP BY STEP GUIDE ON HOW TO CREATE YOUR FIRST MICROSOFT AZURE STATIC WEB APP | Hey there, Welcome to my latest post, today we are going to exploring how you can create a... | 0 | 2023-04-16T05:28:07 | https://dev.to/arbythecoder/a-step-by-step-guide-on-how-to-create-your-first-microsoft-azure-static-web-app-151m | azure, staticwebapps, github, beginners | ### Hey there, Welcome to my latest post, today we are going to exploring how you can create a static web app using a GitHub repository in Microsoft Azure - all with a free account!
Now, you might be wondering - what is a static web app?
In a nutshell, it's a simple website that doesn't require database. Instead, it's made up of static files, like HTML,CSS, and JavaScript, which can be hosted on a server or in the cloud.
So, how do you create a static web app using a GitHub repo in Azure? It's actually pretty simple - just follow these easy steps with my snapshots:
###1. Sign up for a free Azure account
FREE TIP: Ensure to use a virtual card, I used payday not an advert though, lol. Sign up for a free Azure account at https://azure.microsoft.com/free/.
###2. Create a resource
Go to the Azure portal and click ,'Create a resource' in the upper left-hand corner and search for "static web app" in the search bar.
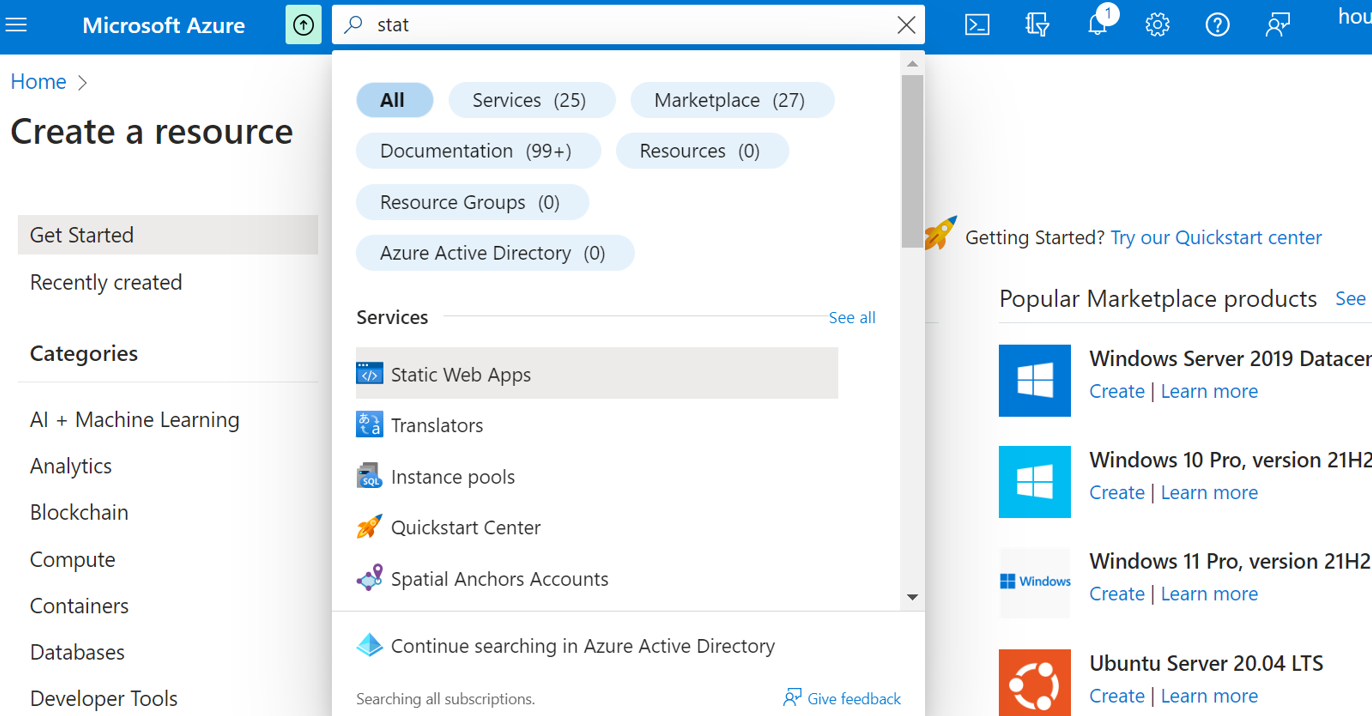
###3. Click "Create" to start setting up your app.
Enter a name for your app and select your
subscription and resource group(click "create new resource group if you don't have one ").
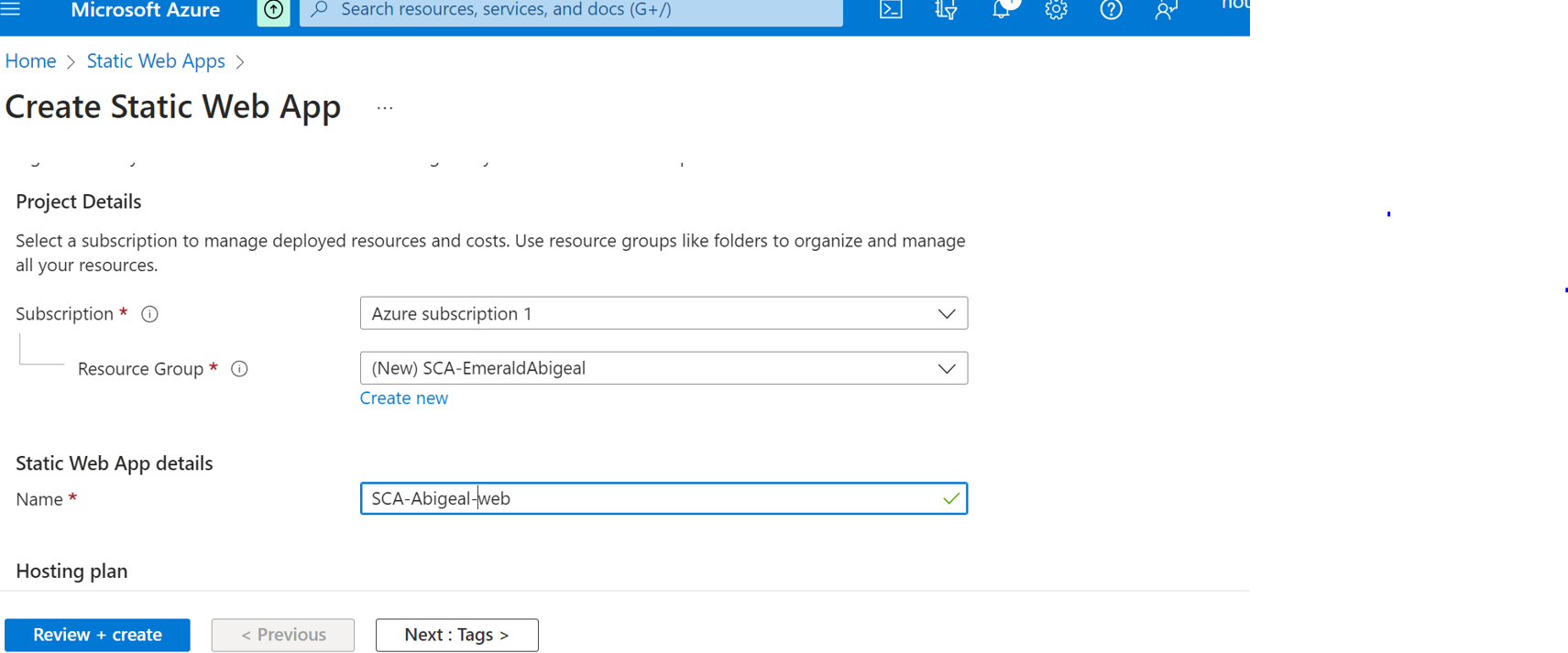
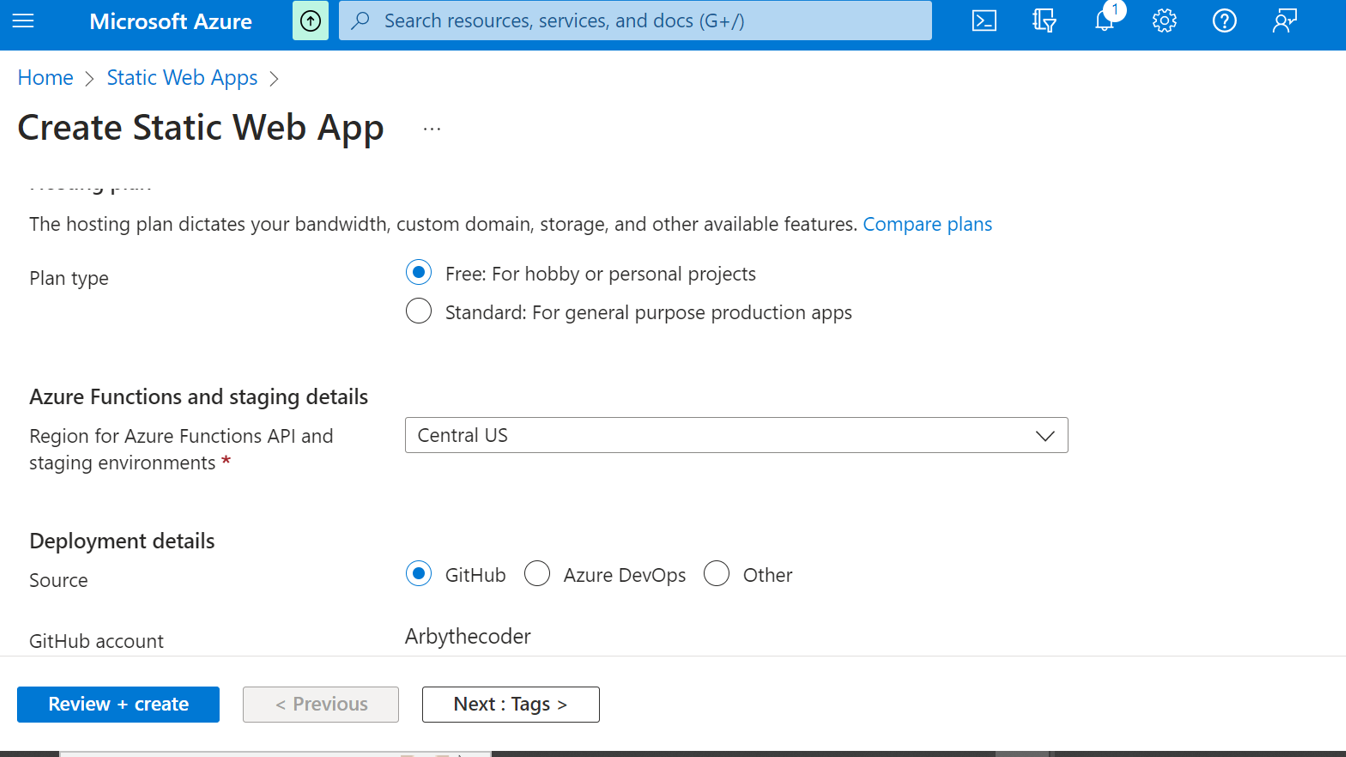
###4. Click "Sign in with GitHub"
You need to link your GitHub with your Microsoft Azure account and select the repo you want to use for your app.
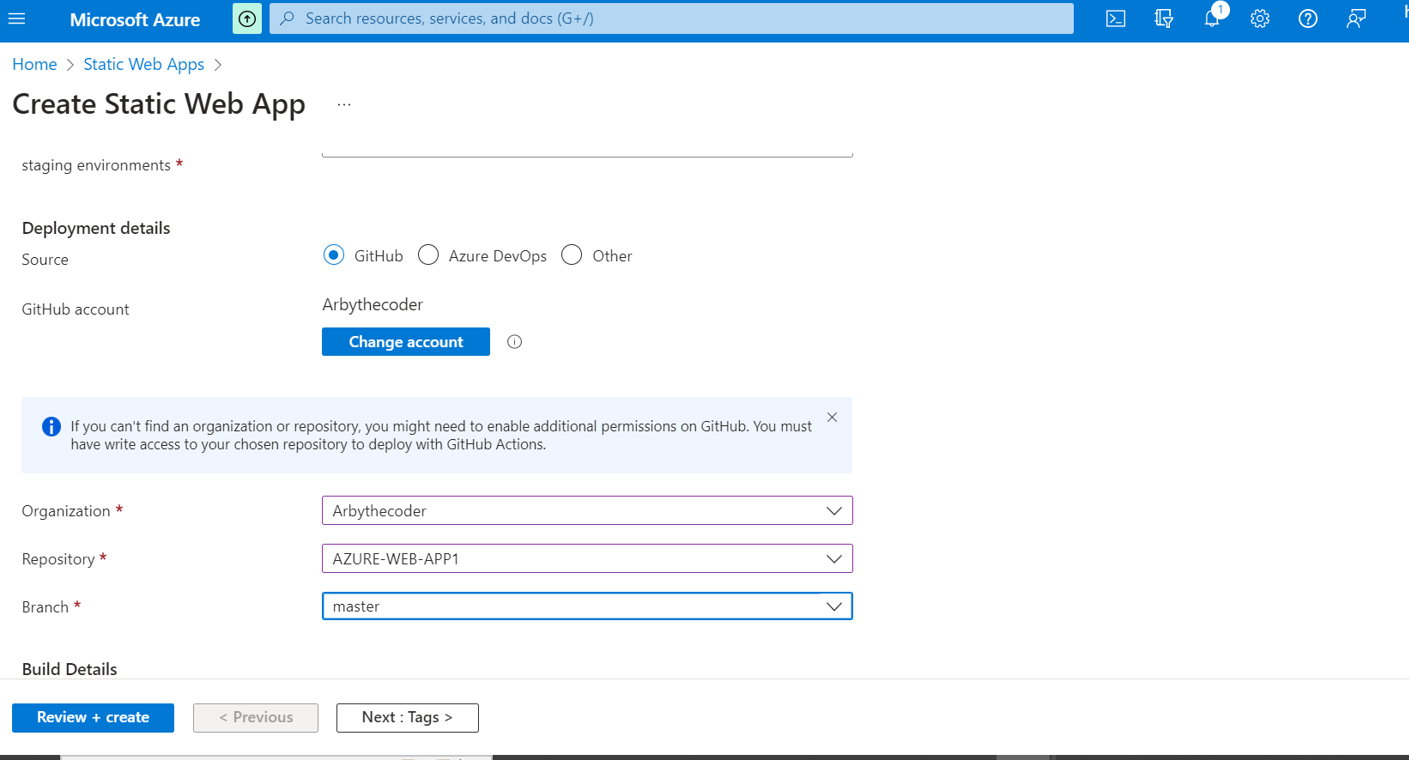
###5. Choose your build settings
Yes, we need to let azure know some details (like your branch and framework), then click "Review + Create".
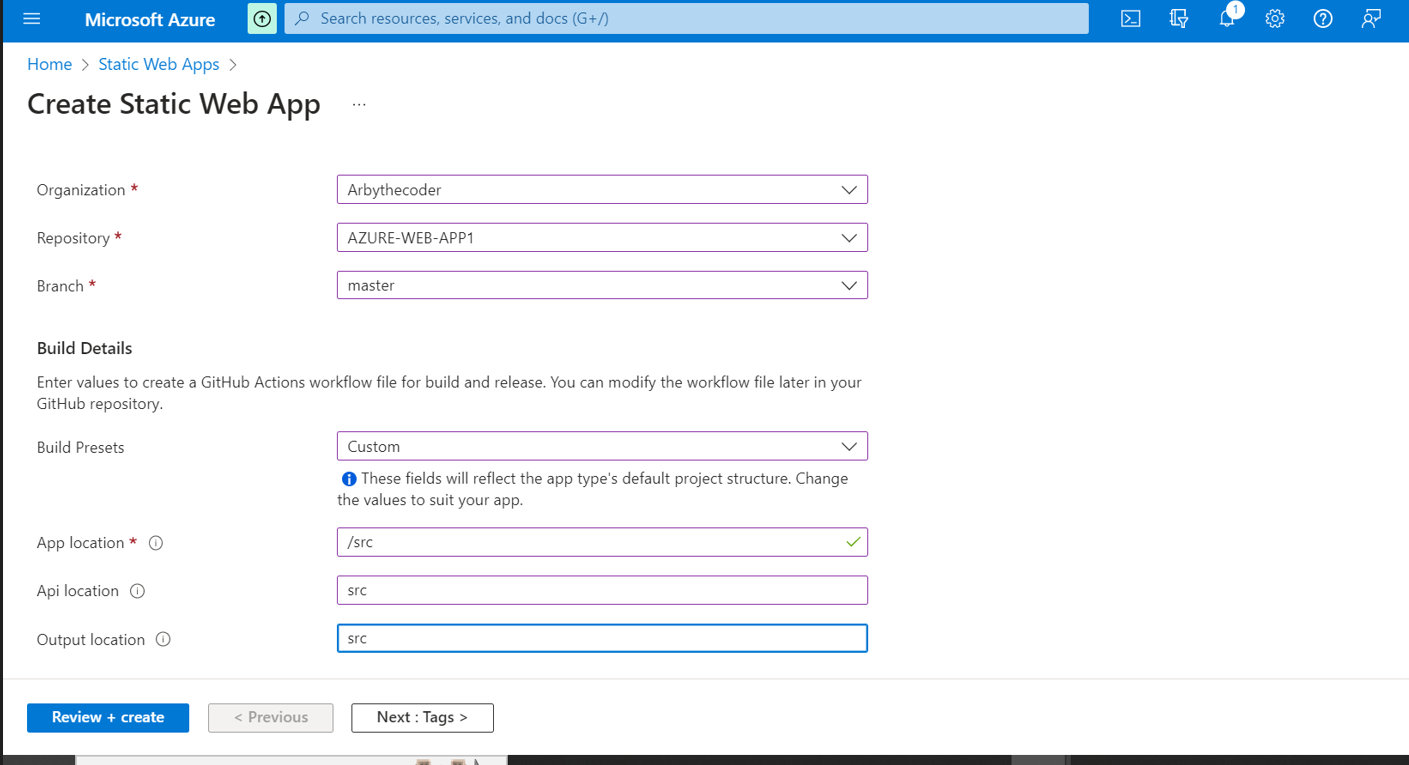
###6. Review your app's settings
Review your app's settings then click "Create" to deploy your app.
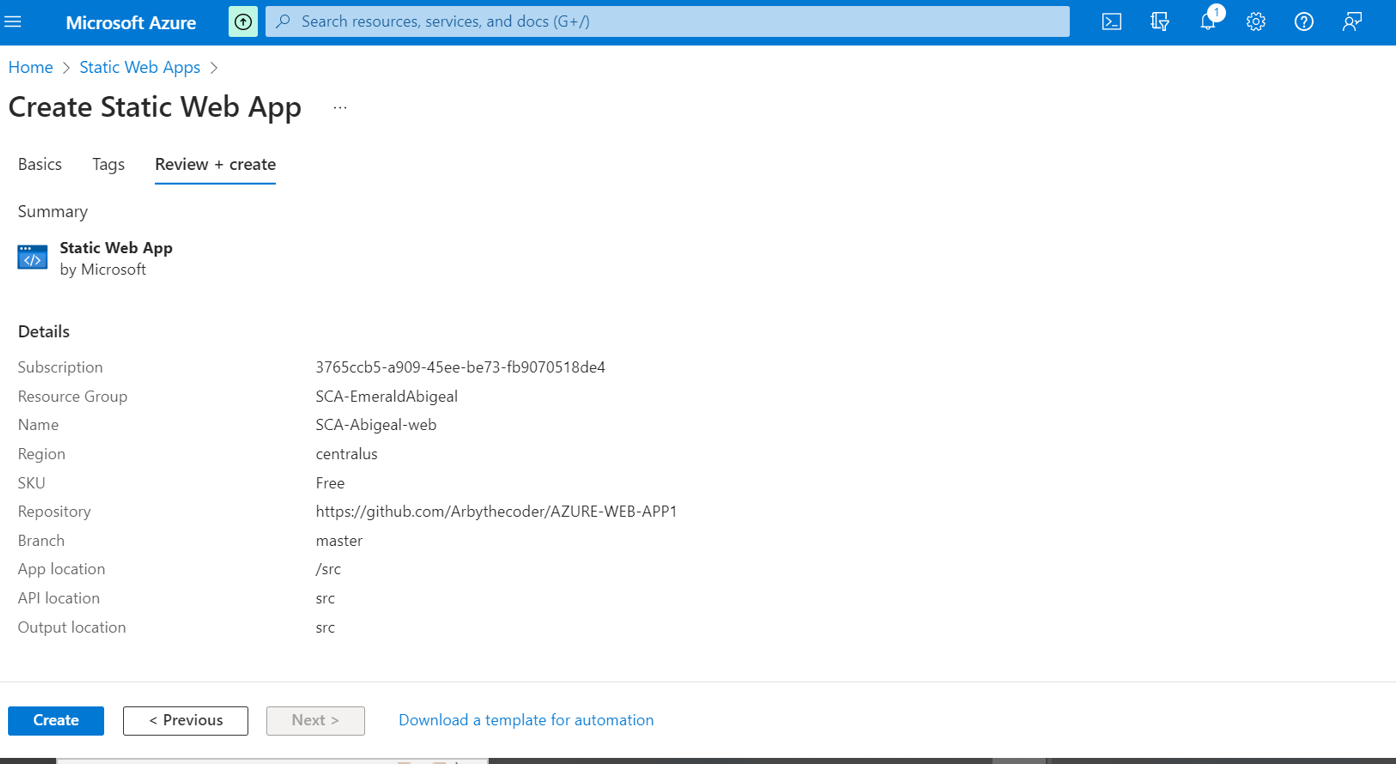
###7. And that's it!
Your static web app is now up and running in Azure, all thanks to your GitHub repo.
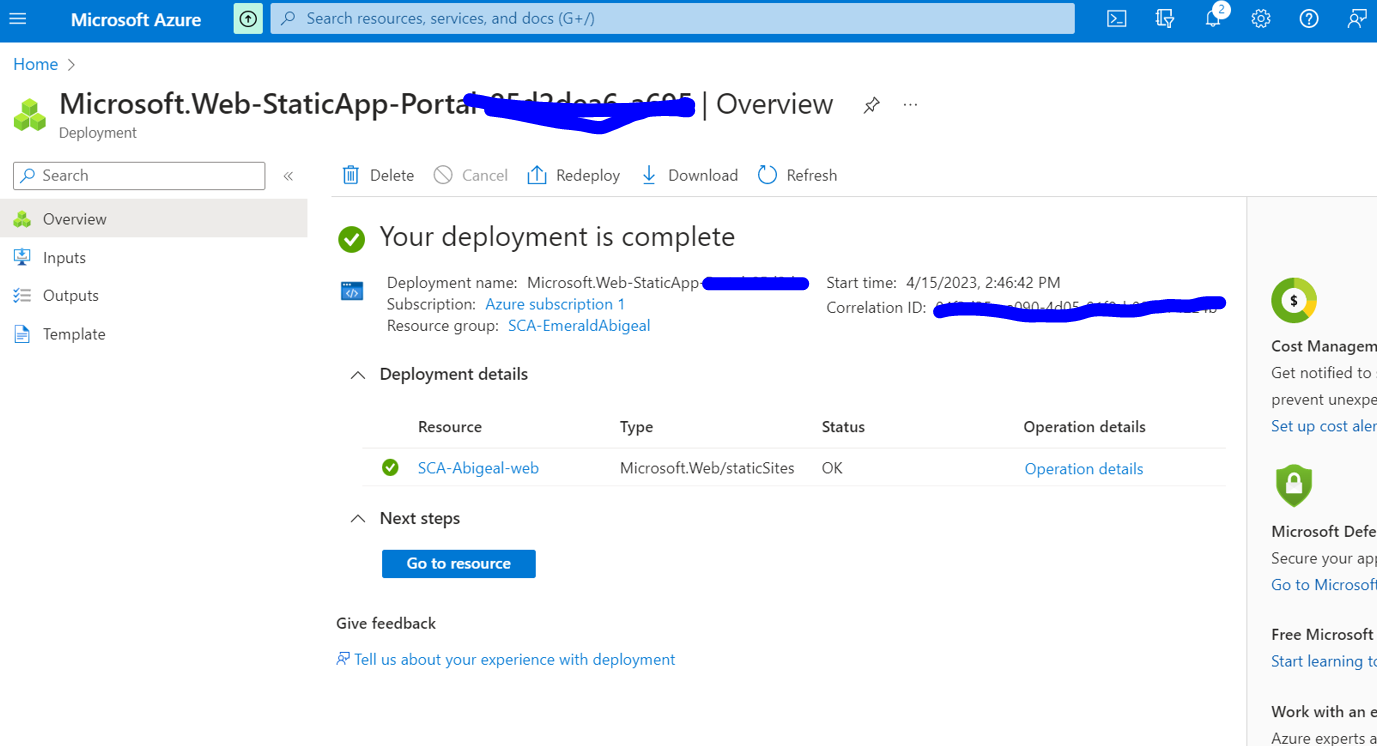
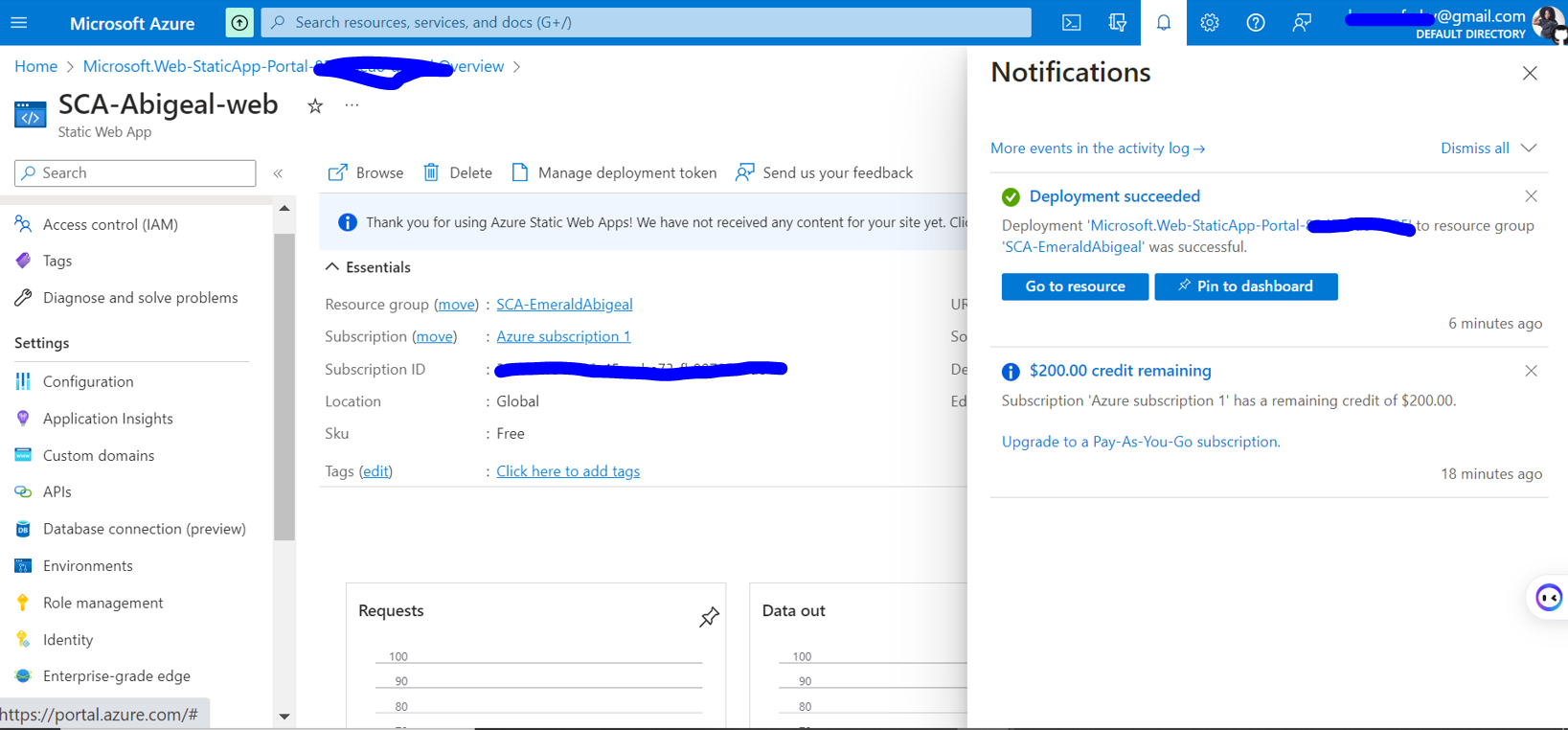
######So, whether you're building a simple portfolio site or a small business website, creating a static web app using a GitHub repo in Azure is a fantastic way to get started - all for free!
######Please remember to leave your comment, like, share and follow me for more great contents.
Thanks for reading!
| arbythecoder |
1,437,340 | Represent a directory tree in a Github README.md | Do you want to add your project structure tree in your .readme file? Install tree sudo apt... | 0 | 2023-04-16T05:47:59 | https://dev.to/siumhossain/represent-a-directory-tree-in-a-github-readmemd-333f | github, tree, ubuntu, tutorial | Do you want to add your project structure tree in your .readme file?

Install tree
```bash
sudo apt install tree
```
Just type tree inside of your project directory
```bash
tree
```
If you want to ignore a folder from your `tree` like **node_modules**, you can do this by
```bash
tree -I node_modules
```
How about you want to ignore multiple folder from your tree, you can do this by
```bash
tree -I "node_modules|venv|lib"
```
| siumhossain |
1,437,424 | Sending transaction in TON blockchain(Golang) | In this small recipe you can see how to send a transaction through the TON blockchain using... | 22,604 | 2023-04-16T07:13:43 | https://gealber.com/txn-hash-ton-golang | In this small recipe you can see how to send a transaction through the TON blockchain using [tonutils-go](https://github.com/xssnick/tonutils-go). Our goal in this tutorial is to be able to send the transaction and receive the transaction hash.
## Requirements
1. Golang installed.
## Recipe
## Importing the wallet
```go
package main
import (
"context"
"encoding/base64"
"errors"
"log"
"strings"
"github.com/xssnick/tonutils-go/address"
"github.com/xssnick/tonutils-go/liteclient"
"github.com/xssnick/tonutils-go/tlb"
"github.com/xssnick/tonutils-go/ton"
"github.com/xssnick/tonutils-go/ton/wallet"
tonwallet "github.com/xssnick/tonutils-go/ton/wallet"
)
func main() {
// initialize connection pool.
testnetConfigURL := "https://ton-blockchain.github.io/testnet-global.config.json"
conn := liteclient.NewConnectionPool()
ctx := context.Background()
err := conn.AddConnectionsFromConfigUrl(ctx, testnetConfigURL)
if err != nil {
panic(err)
}
// initialize api client.
api := ton.NewAPIClient(conn)
// // importing wallet.
seedStr := "<WALLET_SEED>" // if you don't have one you can generate it with tonwallet.NewSeed().
seed := strings.Split(seedStr, " ")
wallet, err := tonwallet.FromSeed(api, seed, wallet.V4R2)
if err != nil {
panic(err)
}
log.Println("WALLET ADDRESS: ", wallet.Address().String())
// preparing for transaction...
}
```
In order to receive testnet tons you can use the Telegram Bot: [@testgiver_ton_bot](https://t.me/testgiver_ton_bot), where you will be requested to provide the wallet address.
## Preparing transaction
```go
// previous part
// preparing for transaction...
// getting latest master chain.
block, err := api.CurrentMasterchainInfo(ctx)
if err != nil {
panic(err)
}
// amount of transaction to be made.
var (
amount uint64 = 1e9 // 1e9 Nano TONs = 1TON.
walletAddress string = "EQC9n6aFb2oxQPMTPrHOnZDFcvvC2YLYIgBUms2yAB_LcAtv" // wallet address to which we are goin to make the transaction.
comment string = "Payment"
)
balance, err := wallet.GetBalance(ctx, block)
if err != nil {
panic(err)
}
log.Println("AVAILABLE BALANCE", balance)
// check if we have enough balance.
if balance.NanoTON().Uint64() < amount {
panic(errors.New("insufficient balance"))
}
// parse address, in case we receive an invalid address.
addr, err := address.ParseAddr(walletAddress)
if err != nil {
panic(err)
}
// Now we can use the method Transfer that the library provides.
// Which absolutely fine, the problem is that we WANT to retrieve the hash of the transaction.
// Currently the Transfer method doesn't not return the hash of the transaction, because it gives you
// the option to not wait for the transaction to finish. This is my assumption of course.
// So let's try to wait for the transaction and to retrieve the hash of the transaction.
// For that purpose the library provides us with a method called SendManyWaitTxHash.
// creating cell for comment.
body, err := tonwallet.CreateCommentCell(comment)
if err != nil {
panic(err)
}
txn, err := wallet.SendManyWaitTxHash(ctx, []*tonwallet.Message{
{
Mode: 1,
InternalMessage: &tlb.InternalMessage{
IHRDisabled: true,
Bounce: false, // we don't want the transaction to bounce, but you can change it to true if you want.
DstAddr: addr, // destination address.
Amount: tlb.FromNanoTONU(amount),
Body: body,
},
},
})
if err != nil {
panic(err)
}
// now we can use this transaction hash to search
// the transaction in tonscan explorer.
txnHash := base64.StdEncoding.EncodeToString(txn)
log.Println("TXN HASH: ", txnHash)
```
Now with this transaction hash we can go into [testnet tonscan](https://testnet.tonscan.org/) and search for it.
## All the code
```go
package main
import (
"context"
"encoding/base64"
"errors"
"log"
"strings"
"github.com/xssnick/tonutils-go/address"
"github.com/xssnick/tonutils-go/liteclient"
"github.com/xssnick/tonutils-go/tlb"
"github.com/xssnick/tonutils-go/ton"
"github.com/xssnick/tonutils-go/ton/wallet"
tonwallet "github.com/xssnick/tonutils-go/ton/wallet"
)
func main() {
// initialize connection pool.
testnetConfigURL := "https://ton-blockchain.github.io/testnet-global.config.json"
conn := liteclient.NewConnectionPool()
ctx := context.Background()
err := conn.AddConnectionsFromConfigUrl(ctx, testnetConfigURL)
if err != nil {
panic(err)
}
// initialize api client.
api := ton.NewAPIClient(conn)
// // importing wallet.
seedStr := "<WALLET_SEED>" // if you don't have one you can generate it with tonwallet.NewSeed().
seed := strings.Split(seedStr, " ")
wallet, err := tonwallet.FromSeed(api, seed, wallet.V4R2)
if err != nil {
panic(err)
}
log.Println("WALLET ADDRESS: ", wallet.Address().String())
// getting latest master chain.
block, err := api.CurrentMasterchainInfo(ctx)
if err != nil {
panic(err)
}
// amount of transaction to be made.
var (
amount uint64 = 1e9 // 1e9 Nano TONs = 1TON.
walletAddress string = "EQC9n6aFb2oxQPMTPrHOnZDFcvvC2YLYIgBUms2yAB_LcAtv" // wallet address to which we are goin to make the transaction.
comment string = "Payment"
)
balance, err := wallet.GetBalance(ctx, block)
if err != nil {
panic(err)
}
log.Println("AVAILABLE BALANCE", balance)
// check if we have enough balance.
if balance.NanoTON().Uint64() < amount {
panic(errors.New("insufficient balance"))
}
// parse address, in case we receive an invalid address.
addr, err := address.ParseAddr(walletAddress)
if err != nil {
panic(err)
}
// Now we can use the method Transfer that the library provides.
// Which absolutely fine, the problem is that we WANT to retrieve the hash of the transaction.
// Currently the Transfer method doesn't not return the hash of the transaction, because it gives you
// the option to not wait for the transaction to finish. This is my assumption of course.
// So let's try to wait for the transaction and to retrieve the hash of the transaction.
// For that purpose the library provides us with a method called SendManyWaitTxHash.
// creating cell for comment.
body, err := tonwallet.CreateCommentCell(comment)
if err != nil {
panic(err)
}
txn, err := wallet.SendManyWaitTxHash(ctx, []*tonwallet.Message{
{
Mode: 1,
InternalMessage: &tlb.InternalMessage{
IHRDisabled: true,
Bounce: false, // we don't want the transaction to bounce, but you can change it to true if you want.
DstAddr: addr, // destination address.
Amount: tlb.FromNanoTONU(amount),
Body: body,
},
},
})
if err != nil {
panic(err)
}
// now we can use this transaction hash to search
// the transaction in tonscan explorer.
txnHash := base64.StdEncoding.EncodeToString(txn)
log.Println("TXN HASH: ", txnHash)
}
```
That's all :)!! | gealber | |
1,437,436 | Deploy your ClojureScript App to Cloudflare Workers | Updated: 19-Jul-2023 Its now easy to deploy ClojureScript compiled output to Cloudflare... | 0 | 2023-04-16T07:57:33 | https://dev.to/reedho/deploy-your-clojurescript-app-to-cloudflare-workers-33g | clojurescript, cloudflare, microservices, javascript | **Updated: 19-Jul-2023**
Its now easy to deploy ClojureScript compiled output to Cloudflare workers.
Since the recent update with regards to [node.js compatibility](https://blog.cloudflare.com/workers-node-js-asynclocalstorage/), no need for clever tricks anymore.
Here is step by step poc:
```bash
$ cd /tmp
$ pnpm create cloudflare@latest
In which directory do you want to create your application?
dir ./hello2
What type of application do you want to create?
type "Hello World" Worker
Do you want to use TypeScript?
no
Retrieving current workerd compatibility date
compatibility date 2023-07-17
Do you want to use git for version control?
no
Do you want to deploy your application?
no
$ cd hello2
```
At this point, check if we're ready to continue.
```bash
$ pnpm exec wrangler --version
⛅️ wrangler 3.0.0 (update available 3.3.0)
```
Now add shadow-cljs.
```bash
$ pnpm install --save-dev shadow-cljs@latest
```
Shadow-cljs just need simple configuration, we can generate default config with `pnpm exec shadow-cljs init` or just create one by ourself.
```bash
$ cat <<EOF > shadow-cljs.edn
{:source-paths ["cljs/main"]
:dependencies []
:builds {:cf {:target :npm-module
:output-dir "out"
:entries [hello]}}}
EOF
```
Then modify its content to be like below, the important part is that we set `:target` to `:node-module`.
Next, verify if shadow-cljs is ready. This will download required clojure/java/maven dependencies if necessary.
```bash
$ pnpm exec shadow-cljs info
```
One more step in cljs part is create our sample source file:
```bash
$ mkdir -p cljs/main
$ cat <<EOF > cljs/main/hello.cljs
(ns hello)
(defn ^:export message []
"Hello from Clojurescript")
EOF
```
Partly done, take a breath first.
---
Now, for this demo, we compile the cljs source like so:
```bash
$ pnpm exec shadow-cljs release :cf
```
It will put the compiled output to `./out/` directory. Now lets modify workers entry file in `src/worker.js`, for this demo, we import the compiled cljs output and use it there somehow, like shown below:
```js
import { message } from '../out/hello';
export default {
async fetch(request, env, ctx) {
return new Response(message());
},
};
```
Only final **important** step is to activate the node compatibility in wrangler.toml, set `node_compat = true`.
Our full `wrangler.toml` file now would look more or less like this:
```toml
name = "hello2"
main = "src/worker.js"
compatibility_date = "2023-07-17"
node_compat = true
```
Ok, its done now.
---
We could test it first locally:
```bash
$ pnpm exec wrangler dev
```
On separate terminal, test if dev server ok:
```bash
$ curl -v http://127.0.0.1:8787/
```
No error, right. Okay, so lets ship it.
```bash
$ pnpm exec wrangler deploy
```
It will authorize with your cloudflare account first before deploying, if every thing is ok, you would see message more or less like below:
```
...
Total Upload: 56.67 KiB / gzip: 11.25 KiB
Uploaded hello2 (4.46 sec)
Published hello2 (8.61 sec)
https://hello2.datafy.workers.dev
Current Deployment ID: eae28984-581c-4ef2-b821-0932efac5003
```
Thank you for reading.
---
**Update**
As of today, compile cljs to `:esm` is also works. Below are relevant changes:
`shadow-cljs.edn`
```clojure
{:source-paths ["cljs/main"],
:dependencies [],
:builds {:cf {:target :node-module,
:output-dir "out",
:entries [hello]},
:cf2 {:target :esm,
:output-dir "out2",
:modules {:hello {:exports {message hello/message}}}}}}
```
`src/worker.js`
```js
import { message } from '../out2/hello';
export default {
async fetch(request, env, ctx) {
return new Response(message());
},
};
```
`wrangler.toml`
```toml
name = "hello2"
main = "src/worker.js"
compatibility_date = "2023-07-17"
```
| reedho |
1,445,668 | LRU implementation in Java and Go | What is LRU Algo? LRU which stands for Least Recently Used, it is a popular algorithm used... | 0 | 2023-04-29T19:35:27 | https://dev.to/ankitmalikg/lru-cache-implementation-in-java-4p6n | lru, algorithms, java, go | ## What is LRU Algo?
LRU which stands for Least Recently Used, it is a popular algorithm used in computer science for managing memory caches. It is a type of cache eviction algorithm, which determines about which data to be removed from a cache when the cache is full.
## How it Works
In a computer system, caches are used to store frequently accessed data in memory. This helps to speed up access to data as accessing data from memory is much faster than accessing data from the disk or other external storage devices. However, as the size of the cache is limited, it is important to manage the cache efficiently so that the most frequently accessed data is always available in the cache.
The LRU algorithm works on the principle of removing the least recently used data from the cache. The idea behind this is that the data that has not been accessed for a long time is less likely to be accessed again in the near future. Therefore, if the cache is full, the data that was accessed least recently is removed from the cache to make space for new data.
The LRU algorithm is implemented using a data structure called a doubly linked list. In a doubly linked list, each node contains a pointer to the next node as well as a pointer to the previous node. In the context of the LRU algorithm, each node in the doubly linked list represents a data item in the cache.
When a data item is accessed, it is moved to the front of the linked list. This indicates that it has been accessed most recently. When the cache is full and a new data item needs to be added, the least recently used item is removed from the back of the linked list.
## Implementation in Java
```java
import java.util.Deque;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
class Main {
public static void main(String[] args) {
System.out.println("Hello world!");
LRUCache cache = new LRUCache(4);
cache.addToCache(11);
cache.addToCache(12);
cache.printLRU();
cache.addToCache(13);
cache.printLRU();
cache.addToCache(11);
cache.addToCache(14);
cache.printLRU();
cache.addToCache(15);
cache.addToCache(11);
cache.addToCache(12);
cache.printLRU();
}
}
class LRUCache {
// doublyLRUList - List for LRU data holding
private Deque<Integer> doublyLRUList;
// for checking if any page is avalabile in cache
// it saves the iteration on doublyLRUList
private HashSet<Integer> LRUhashSet;
// LRU_SIZE - maximum size of cache
private final int LRU_SIZE;
LRUCache(int capacity) {
doublyLRUList = new LinkedList<>();
LRUhashSet = new HashSet<>();
LRU_SIZE = capacity;
}
// addToCache add the page in the LRU cache
public void addToCache(int page) {
if (!LRUhashSet.contains(page)) {
if (doublyLRUList.size() == LRU_SIZE) {
int last = doublyLRUList.removeLast();
LRUhashSet.remove(last);
}
} else {
doublyLRUList.remove(page);
}
doublyLRUList.push(page);
LRUhashSet.add(page);
}
// printLRU prints contents of cache
public void printLRU() {
Iterator<Integer> itr = doublyLRUList.iterator();
while (itr.hasNext()) {
System.out.print(itr.next() + " ");
}
System.out.println();
}
}
```
Repl Link:: https://replit.com/@AnkitMalik2/LRU-Java#Main.java
## Implementation in Golang
```go
package main
import (
"fmt"
)
type LRUCache struct {
LRUList []int
LRUHashMap map[int]bool
Size int
}
func NewLRUCache(size int) *LRUCache {
return &LRUCache{
LRUList: make([]int, 0),
LRUHashMap: make(map[int]bool),
Size: size,
}
}
// Add insert the data in LRU
func (lru *LRUCache) Add(value int) {
l := len(lru.LRUList)
if !lru.LRUHashMap[value] {
if l >= lru.Size {
last := lru.LRUList[l-1]
lru.LRUList = lru.LRUList[:l-1]
delete(lru.LRUHashMap, last)
}
} else {
for idx, data := range lru.LRUList {
if data == value {
lru.LRUList = append(lru.LRUList[:idx], lru.LRUList[idx+1:]...)
break
}
}
}
lru.LRUList = append([]int{value}, lru.LRUList...)
lru.LRUHashMap[value] = true
}
// PrintLRU - prints the data of LRU cache
func (lru *LRUCache) PrintLRU() {
for _, data := range lru.LRUList {
fmt.Print(data, " ")
}
fmt.Println()
}
func main() {
// initiate lru with defined size
lru := NewLRUCache(5)
// use of Add function
lru.Add(1)
lru.Add(2)
lru.Add(3)
lru.Add(4)
lru.Add(5)
lru.Add(6)
lru.Add(1)
// printing all data of LRU
lru.PrintLRU()
}
```
Repl Link: https://replit.com/@AnkitMalik2/LRU-Golang#main.go
You can see some complicated LRU implementation here: https://github.com/hashicorp/golang-lru/blob/8d9a62dcf60cd87ed918b57afad8a001d25db3de/simplelru/lru.go
| ankitmalikg |
1,445,671 | AGE community VOTE guide | Hey there and welcome all :) The following article helps you to get the checks required by... | 22,892 | 2023-04-23T22:33:45 | https://dev.to/rrrokhtar/age-community-vote-guide-2b9j | apacheage, postgres, release, bitnine | ## Hey there and welcome all :)
The following article helps you to get the checks required by the AGE community for new releases I hope it helps anyone has struggling in understanding any of them.
**Let's get started:**
Following the **release** of **AGE 1.3.0** and **PG 12** to show our case on:
https://dist.apache.org/repos/dist/dev/age/PG12/1.3.0.rc1/
https://github.com/apache/age/releases/tag/PG12%2Fv1.3.0-rc1
We can see 3 files there:
- apache-age-1.3.0-src.tar.gz
- apache-age-1.3.0-src.tar.gz.asc
- apache-age-1.3.0-src.tar.gz.sha512
**All** of them are needed for the verification:
**Definitions**
- **apache-age-1.3.0-src.tar.gz.sha512**: That's a hash file for the release _apache-age-1.3.0-src.tar.gz_.
- **apache-age-1.3.0-src.tar.gz.asc**: Signature verification file.
- **apache-age-1.3.0-src.tar.gz**: Source code of the project.
## Let's check our todo list

### TODO:
- Signature and Hash
- Tags and links
- No unexpected binary files
- Validity of release notes
- Regression tests
## Let's try to solve them :)

#### 1- HASH
So that, we will need to reproduce the sha512 hash of the apache-age-1.3.0-src.tar.gz and compare that with the content of apache-age-1.3.0-src.tar.gz.sha512
```sh
sha512sum apache-age-1.3.0-src.tar.gz
```
```sh
# Output
71e8fb7eed7de3460d6bac7cc37a7ac8bea2164a59043250d7278f4ca17181eb4459db239c19a9b87cc3e4f00e0c0618aff751549a346a3c87f8806ba6b64f11 apache-age-1.3.0-src.tar.gz
```
Compare that with the content of apache-age-1.3.0-src.tar.gz.sha512
#### 2- Signature
Firstly we need to download the KEYS file of the AGE maintainers
https://downloads.apache.org/age/KEYS
```sh
# download that
wget https://downloads.apache.org/age/KEYS
# import that
gpg --import KEYS
```
Then we will verify the output of that signature
```sh
gpg --verify apache-age-1.3.0-src.tar.gz.asc apache-age-1.3.0-src.tar.gz
# output
gpg: Signature made 22 أبر, 2023 EET 12:55:43 ص
gpg: using RSA key 26B6CD9DCD5B0045
gpg: Good signature from "John Gemignani (Apache GPG key) <jgemignani@apache.org>" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: 4293 0603 8E35 AC05 4DBB 4B58 26B6 CD9D CD5B 0045
```
#### 3- Binary files
It is done through two methods
- Manually
- Script
```sh
find . -type f -executable
# output
./drivers/jdbc/gradlew
./tools/gen_keywordlist.pl
./tools/git/commit-msg
```
#### 4- Regression tests
It can done inside the source code of AGE through the following command
```sh
make installcheck PG_CONFIG=pg_config
```
#### 5- Tags and links (manual check)
#### 6- Validity of release notes (manual check)

### Conclusion:
- ✅ Signature and Hash [DONE]
- ✅ Tags and links [DONE]
- ✅ No unexpected binary files [DONE]
- ✅ Validity of release notes [DONE]
- ✅ Regression tests [DONE]
## References and resources
- https://github.com/apache/age
- https://age.apache.org/ | rrrokhtar |
347,809 | Menu | We have a RecyclerView that displays some data and responds to user clicks, let’s explore how to crea... | 6,842 | 2020-06-02T00:48:45 | https://avinsharma.com/android-basics-menu/ | android, androiddevelopment, beginners, menu | ---
title: Menu
published: true
date: 2020-06-01 00:00:00 UTC
tags: android, androiddevelopment, beginners, menu
series: Android Basics
canonical_url: https://avinsharma.com/android-basics-menu/
---
We have a RecyclerView that displays some data and responds to user clicks, let’s explore how to create a menu so that we can use the menu to access settings so that we can change the parameters in our github query. You can find the code for everything we have done up till now [here](https://github.com/avin-sharma/Github-Repository-Search/tree/recyclerview-onclick).
Creating a Menu is pretty simple, we can do it in 3 steps.
## Steps to Create a Menu
1. Create menu in XML.
2. Inflate menu in the activity.
3. Handle clicks in the activity.
### Create a Menu in XML
We have a resource directory for layout, values, etc by default but none for menu so we start by create a menu resource directory and then create a new menu resource file called `main_menu`.
In `res -> menu -> main_menu.xml` we add the following:
```xml
<?xml version="1.0" encoding="utf-8"?>
<menu
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto">
<item
android:id="@+id/settings_menu_option"
android:title="@string/settings_menu_option_title"
app:showAsAction="never"/>
</menu>
```
We have a menu tag and everything inside this tag is displayed in the menu. We can add `items` as we did above or add another menu (a sub menu).
There are a lot of attributes that can be added here but in most of the cases we wouldneed just the three we used above: id, title, showAsAction.
Id of the items are used later to determine which item was clicked in the menu, title is the text that we see on the item when the menu is displayed and finally showAsAction determines if the item stays in the overflow(the three dots we click to see the menu, usually on the top right) or is shown on the app bar.
### Inflate menu in the activity
Now that we have our layout XML we can now inflate it to display in the MainActivity. Just override `onCreateOptionsMenu`, inflate the menu and return true
```java
@Override
public boolean onCreateOptionsMenu(Menu menu) {
MenuInflater inflater = getMenuInflater();
inflater.inflate(R.menu.main_menu, menu);
return true;
}
```
Now the menu should show up but nothing should happen when you click on the items.
### Handle clicks in the activity
To handle click in the same activity, in our case the MainActivity override `onOptionsItemSelected` identify which item is being clicked and handle the clicks accordingly.
```java
@Override
public boolean onOptionsItemSelected(@NonNull MenuItem item) {
switch (item.getItemId()) {
case R.id.settings_menu_option:
Toast.makeText(this, "Settings option clicked!", Toast.LENGTH_LONG).show();
return true;
default:
return super.onOptionsItemSelected(item);
}
}
```
With this clicking on settings should display a toast.
## A Menu added
[](/static/8eec96a34668ba447f6d50f812ae8270/9d22c/app.png)
We have a menu now, but all we do is display a Toast. In the next post we will explore how to create a settings screen using preferenceFragment and saving the settings using sharedPreferences. | avinsharma |
1,445,774 | Unveiling the Connection: Cynefin and Bill Eckstrom’s Models of Growth and Complexity | Though seemingly distinct, the Cynefin Framework and Bill Eckstrom’s Model of Growth and Complexity... | 0 | 2023-05-16T11:02:17 | https://fagnerbrack.com/unveiling-the-connection-cynefin-and-bill-eckstroms-models-of-growth-and-complexity-efd27bc5dd1c | technology, philosophy, problemsolving, complexitytheory | ---
title: Unveiling the Connection: Cynefin and Bill Eckstrom’s Models of Growth and Complexity
published: true
date: 2023-04-23 22:02:14 UTC
tags: technology,philosophy,problemsolving,complexitytheory
canonical_url: https://fagnerbrack.com/unveiling-the-connection-cynefin-and-bill-eckstroms-models-of-growth-and-complexity-efd27bc5dd1c
---
Though seemingly distinct, the Cynefin Framework and Bill Eckstrom’s Model of Growth and Complexity share a common foundation. These models provide valuable insights into how individuals and organizations adapt to change and navigate complex environments. In this blog post, we will explore the connection between these models, investigate their scientific origins, and discuss their implications for understanding growth and complexity in various domains.

_A complex network of mushrooms growing on the asphalt_
**The Cynefin Framework: An Overview**
The Cynefin Framework, developed by Dave Snowden, is a decision-making framework designed to help individuals and organizations navigate complex situations. This model comprises five domains: simple, complicated, complex, chaotic, and disorder. Each domain represents a different type of problem or environment, requiring unique approaches and strategies to tackle the challenges effectively.
**Bill Eckstrom’s Model of Growth and Complexity**
Bill Eckstrom’s Model of Growth and Complexity highlights the relationship between growth, comfort, and complexity. According to Eckstrom, individuals and organizations experience the most significant growth when they move out of their comfort zones and embrace complexity. This model emphasizes the importance of continuous learning, adaptation, and innovation in ever-changing environments and challenges.
**Unravelling the Connection**
If you look closer, the Cynefin Framework and Bill Eckstrom’s Model of Growth and Complexity reveal a shared foundation in understanding the relationship between complexity and growth based on your decisions in each complexity domain. Both models stress the importance of adapting to various environments and challenges and recognizing that different situations require unique approaches and strategies. By acknowledging this connection, we can appreciate that these models represent a genuine, universal concept, not just someone’s opinion.
It proves they were discovered, not invented.
**The Scientific Origins**
The Cynefin Framework was developed based on research in complex adaptive systems, cognitive science, anthropology, and organizational behaviour. While it may not have originated from a specific scientific paper, its foundations are deeply rooted in established scientific disciplines.
Bill Eckstrom’s Model of Growth and Complexity stems from his experience in sales leadership and personal growth. Although it may not have direct roots in a scientific paper, its concepts resonate with well-established growth and development theories, such as the Zone of Proximal Development and Flow.
Given the connections between these models and established scientific theories, we should clearly recognize the value and legitimacy of both the Cynefin Framework and Bill Eckstrom’s Model of Growth and Complexity.
**Embracing Complexity for Growth**
By understanding the connection between the Cynefin Framework and Bill Eckstrom’s Model of Growth and Complexity, we can appreciate the value of embracing complexity and continuously adapting to new challenges. Both models provide valuable insights into navigating change and complexity in various domains, and their roots in established scientific disciplines reinforce their legitimacy. We can foster growth, innovation, and adaptability in an increasingly complex world by applying these models to our personal and professional lives.
At the end of the day, it's amazing to find two people discovering apparent different concepts representing the same fundamentals.
Thanks for reading. If you have feedback, contact me on [Twitter](https://twitter.com/FagnerBrack), [LinkedIn](https://www.linkedin.com/in/fagnerbrack/) or [Github](http://github.com/FagnerMartinsBrack). | fagnerbrack |
1,445,970 | reading standalone.conf.bat contents while starting wildfly in eclipse | Dear members, We are setting environment variable in standalone.conf.bat and this variable is able to... | 0 | 2023-04-24T05:11:20 | https://dev.to/ursbondada/reading-standaloneconfbat-contents-while-starting-wildfly-in-eclipse-65a | Dear members,
We are setting environment variable in standalone.conf.bat and this variable is able to read properly if we are running wildfly using standalone.bat file. application is deployed successfully.
But if I am start wildfly server from eclipse then the property mentioned in standalone.conf.bat didn't read by standalone.bat file and application deployment was failing.
Need to understand how to read properties mentioned in standalone.conf.bat while starting the server in eclipse?? | ursbondada | |
1,446,014 | Simplify observability .NET with OpenTelemetry Collector | Overview The Observability concept become the standard of almost system in recently. It... | 0 | 2023-04-25T05:26:45 | https://dev.to/kim-ch/observability-net-opentelemetry-collector-25g1 | observability, dotnet, opentelemetry, collector | ## Overview
The Observability concept become the standard of almost system in recently. It helps team to troubleshoot what's happening inside the system. There are 3 pillars of Observability - Traces, Metrics and Logs.
- [OpenTelemetry](https://opentelemetry.io/) is the most straightforward way to collect Traces and Metrics. Then export to [Zipkin](https://zipkin.io/) or [Jaeger](https://www.jaegertracing.io/) for tracings; [Prometheus](https://prometheus.io/)
- [Serilog](https://serilog.net/) is also the most straightforward way to collect logs and then export to [Seq](https://datalust.co/seq) or [ElasticSearch](https://www.elastic.co/)
Because of the various exporting ways, we have to consider one of these options when implementing
- Support all type of exporting then toggle via settings. For example, only export to Zipkin if it's enabled
- Or, just only export to Zipkin or Jaeger
## Only one answer for the concerns
:question: Concerns
- Is there any way that just only one export for multiple consumers? Or,
- Is there any way that just only one export but change consumer without changing the code?
:star2: Only one answer
- And luckily, there is an elegant way to accomplish them - that is [OpenTelemetry Collector (OTEL Collector in short)](https://opentelemetry.io/docs/collector/)
> **_Objectives_**
> - **Usability:** Reasonable default configuration, supports popular protocols, runs and collects out of the box.
> - **Performance:** Highly stable and performant under varying loads and configurations.
> - **Observability:** An exemplar of an observable service.
> - **Extensibility:** Customizable without touching the core code.
> - **Unification:** Single codebase, deployable as an agent or collector with support for traces, metrics, and logs (future).
- An image more than thousand words
## :computer: Let our hand dirty
---
:point_right: The below steps are just the showcase of using **OTEL Collector** within .NET 7. The full of implementation can be found at - [.NET with OpenTelemetry Collector](https://github.com/kimcuhoang/practical-net-otelcollector)
:point_right: In which, we'll export the telemetry signals from application to **OTEL Collector** then they'll be exported to - [Zipkin](https://zipkin.io/) or [Jaeger](https://www.jaegertracing.io/) for tracings; [Prometheus](https://prometheus.io/); and [Loki](https://grafana.com/oss/loki/) for logs
---
### Nuget packages [Directory.Packages.props](https://github.com/kimcuhoang/practical-net-otelcollector/blob/main/Directory.Packages.props)
```xml
<!-- OpenTelemetry: Traces & Metrics -->
<ItemGroup>
<PackageVersion Include="OpenTelemetry.Exporter.OpenTelemetryProtocol" Version="1.4.0" />
<PackageVersion Include="OpenTelemetry.Extensions.Hosting" Version="1.4.0" />
<PackageVersion Include="OpenTelemetry.Instrumentation.AspNetCore" Version="1.0.0-rc9.14" />
</ItemGroup>
<!-- Serilog -->
<ItemGroup>
<PackageVersion Include="Serilog.AspNetCore" Version="6.1.0" />
<PackageVersion Include="Serilog.Enrichers.Context" Version="4.6.0" />
<PackageVersion Include="Serilog.Sinks.OpenTelemetry" Version="1.0.0-dev-00129" />
<PackageVersion Include="OpenTelemetry.Exporter.OpenTelemetryProtocol.Logs" Version="1.4.0-rc.4" />
</ItemGroup>
```
### Register OpenTelemetry, typically from `Program.cs`
```csharp
var builder = WebApplication.CreateBuilder(args);
builder.Host.AddSerilog();
builder.Services
.AddOpenTelemetry()
.AddTracing(observabilityOptions)
.AddMetrics(observabilityOptions);
```
### Configure Tracings
```csharp
private static OpenTelemetryBuilder AddTracing(this OpenTelemetryBuilder builder, ObservabilityOptions observabilityOptions)
{
builder.WithTracing(tracing =>
{
tracing
.AddSource(observabilityOptions.ServiceName)
.SetResourceBuilder(ResourceBuilder.CreateDefault().AddService(observabilityOptions.ServiceName))
.SetErrorStatusOnException()
.SetSampler(new AlwaysOnSampler())
.AddAspNetCoreInstrumentation(options =>
{
options.EnableGrpcAspNetCoreSupport = true;
options.RecordException = true;
});
/* Add more instrument here: MassTransit, NgSql ... */
/* ============== */
/* Only export to OpenTelemetry collector */
/* ============== */
tracing
.AddOtlpExporter(options =>
{
options.Endpoint = observabilityOptions.CollectorUri;
options.ExportProcessorType = ExportProcessorType.Batch;
options.Protocol = OpenTelemetry.Exporter.OtlpExportProtocol.Grpc;
});
});
return builder;
}
```
### Configure for Metrics
```csharp
private static OpenTelemetryBuilder AddMetrics(this OpenTelemetryBuilder builder, ObservabilityOptions observabilityOptions)
{
builder.WithMetrics(metrics =>
{
var meter = new Meter(observabilityOptions.ServiceName);
metrics
.AddMeter(meter.Name)
.SetResourceBuilder(ResourceBuilder.CreateDefault().AddService(meter.Name))
.AddAspNetCoreInstrumentation();
/* Add more instrument here */
/* ============== */
/* Only export to OpenTelemetry collector */
/* ============== */
metrics
.AddOtlpExporter(options =>
{
options.Endpoint = observabilityOptions.CollectorUri;
options.ExportProcessorType = ExportProcessorType.Batch;
options.Protocol = OpenTelemetry.Exporter.OtlpExportProtocol.Grpc;
});
});
return builder;
}
```
### Configure Logs
```csharp
public static IHostBuilder AddSerilog(this IHostBuilder hostBuilder)
{
hostBuilder
.UseSerilog((context, provider, options) =>
{
var environment = context.HostingEnvironment.EnvironmentName;
var configuration = context.Configuration;
ObservabilityOptions observabilityOptions = new();
configuration
.GetSection(nameof(ObservabilityOptions))
.Bind(observabilityOptions);
var serilogSection = $"{nameof(ObservabilityOptions)}:{nameof(ObservabilityOptions)}:Serilog";
options
.ReadFrom.Configuration(context.Configuration, serilogSection)
.Enrich.FromLogContext()
.Enrich.WithEnvironment(environment)
.Enrich.WithProperty("ApplicationName", observabilityOptions.ServiceName);
/* ============== */
/* Only export to OpenTelemetry collector */
/* ============== */
options.WriteTo.OpenTelemetry(cfg =>
{
cfg.Endpoint = $"{observabilityOptions.CollectorUrl}/v1/logs";
cfg.IncludedData = IncludedData.TraceIdField | IncludedData.SpanIdField;
cfg.ResourceAttributes = new Dictionary<string, object>
{
{"service.name", observabilityOptions.ServiceName},
{"index", 10},
{"flag", true},
{"value", 3.14}
};
});
});
return hostBuilder;
}
```
### The interesting here
:one: - Refer to [docker-compose.observability.yaml](https://github.com/kimcuhoang/practical-net-otelcollector/blob/main/local/infra/docker-compose.observability.yaml)
:two: - Refer to [otel-collector.yaml](https://github.com/kimcuhoang/practical-net-otelcollector/blob/main/local/infra/config-files/otel-collector.yaml) to configure OTEL Collector
```yaml
receivers:
otlp:
protocols:
http:
endpoint: 0.0.0.0:4318
grpc:
endpoint: 0.0.0.0:4317
exporters:
logging:
loglevel: info
prometheus:
endpoint: 0.0.0.0:8889
jaeger:
endpoint: jaeger:14250
tls:
insecure: true
zipkin:
endpoint: "http://zipkin:9411/api/v2/spans"
format: proto
loki:
endpoint: http://loki:3100/loki/api/v1/push
format: json
labels:
resource:
service.name: "service_name"
service.instance.id: "service_instance_id"
service:
extensions: [pprof, zpages, health_check]
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [logging, jaeger, zipkin]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [logging, prometheus]
logs:
receivers: [otlp]
processors: [batch]
exporters: [logging, loki]
```
---
Let's :thumbsup: **OTEL Collector** and take fully implementation at - [.NET with OpenTelemetry Collector](https://github.com/kimcuhoang/practical-net-otelcollector)
Cheers!!! :beers:
| kim-ch |
1,446,019 | Kotlin's Built-In Support for Biometric Authentication | This guide covered the fundamentals of implementing Authentication in Kotlin, including biometric Authentication. | 0 | 2023-04-24T07:10:38 | https://dev.to/devbambhaniya/kotlins-built-in-support-for-biometric-authentication-mkc | ---
title: Kotlin's Built-In Support for Biometric Authentication
published: true
description: This guide covered the fundamentals of implementing Authentication in Kotlin, including biometric Authentication.
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-04-24 06:58 +0000
---
<img src="https://www.cmarix.com/blog/wp-content/uploads/2021/06/8-Killer-Kotlin-Tips-For-Android-App-Developers.png">
Using biometric authentication methods like facial or fingerprint scanning, you can protect your app's private information or paid content. Learn how to include biometric login flows into your app when you hire mobile app developers with the help of this tutorial.
Users may save several fingerprints for future device unlocks and other scenarios when a <a href="https://www.cmarix.com/hire-kotlin-developers.html"><b>Hire Kotlin Developers</b></a> requires a biometric fingerprint. Using the Fingerprint Hardware Interface Definition Language, Android communicates with vendor-specific libraries and fingerprint hardware (such as a fingerprint sensor). Hire Kotlin Developers
<b>Let's Start:</b>
<h2><b>Step-by-Step Implementation</b></h2>
<h3><b>Step 1- Adding Dependency</d></3>
Implementation "android.biometric:biometric-ktx:1.2.0-alpha04"
<h3><b>step 2- Working with activity_main.xml</b></h3>
The ImageView now has a vector I placed in its drawable folder.
<?XML version="1.0" encoding="utf-8"?>
<androidx. Constraint layout. widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="@color/purple_500"
tools:context=".MainActivity">
<ImageView
android:id="@+id/imgFinger"
android:layout_width="80dp"
android:layout_height="80dp"
android:src="@drawable/ic_baseline_fingerprint_24"
app:layout_constraintBottom_toTopOf="@id/tvShowMsg"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintVertical_chainStyle="packed" />
<TextView
android:id="@+id/tvShowMsg"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginVertical="25dp"
android:textColor="@color/white"
app:layout_constraintBottom_toTopOf="@id/button"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@id/imgFinger" />
<Button
android:id="@+id/button"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="Login"
app:backgroundTint="#1A237E"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@id/tvShowMsg" />
</androidx.constraintlayout.widget.ConstraintLayout>
<h3><b>Step 3- Checking that biometric Authentication is available</b></h3>
fun checkDeviceHasBiometric() {
val biometricManager = BiometricManager.from(this)
when (biometricManager.canAuthenticate(BIOMETRIC_STRONG or DEVICE_CREDENTIAL)) {
BiometricManager.BIOMETRIC_SUCCESS -> {
Log.d("MY_APP_TAG", "App can authenticate using biometrics.")
info = "App can authenticate using biometrics."
binding. Button.isEnabled = true
}
BiometricManager.BIOMETRIC_ERROR_NO_HARDWARE -> {
Log.e("MY_APP_TAG", "No biometric features available on this device.")
info = "No biometric features available on this device."
binding. Button.isEnabled = false
}
BiometricManager.BIOMETRIC_ERROR_HW_UNAVAILABLE -> {
Log.e("MY_APP_TAG", "Biometric features are currently unavailable.")
info = "Biometric features are currently unavailable."
binding. Button.isEnabled = false
}
BiometricManager.BIOMETRIC_ERROR_NONE_ENROLLED -> {
// Prompts the user to create credentials that your app accepts.
Val enrollment = Intent(Settings.ACTION_BIOMETRIC_ENROLL).apply {
putExtra(Settings.EXTRA_BIOMETRIC_AUTHENTICATORS_ALLOWED,
BIOMETRIC_STRONG or DEVICE_CREDENTIAL)
}
binding. Button.isEnabled = false
startActivityForResult(enrollIntent, 100)
}
}
binding.tvShowMsg.text = info
}
<h3><b>Step 4 - Display the login prompt</b></h3>
You may utilize the Biometric library for the system to ask the user for biometric Authentication when you <a href="https://www.cmarix.com/hire-mobile-app-developers.html"><b>hire mobile app developers<b></a>. The user may have greater faith in the applications they use since this system-provided dialogue is the same across all of them for app ideas for beginners.
To implement this in your onCreate, use the following code:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
binding. Button.isEnabled = false
binding.imgFinger.setOnClickListener {
checkDeviceHasBiometric()
}
executor = ContextCompat.getMainExecutor(this)
biometricPrompt = BiometricPrompt(this, executor,
object : BiometricPrompt.AuthenticationCallback() {
override fun onAuthenticationError(
errorCode: Int,
errString: CharSequence,
) {
super.onAuthenticationError(errorCode, errString)
Toast.makeText(applicationContext,
"Authentication error: $errString", Toast.LENGTH_SHORT)
.show()
}
override fun onAuthenticationSucceeded(
result: BiometricPrompt.AuthenticationResult,
) {
super.onAuthenticationSucceeded(result)
Toast.makeText(applicationContext,
"Authentication succeeded!", Toast.LENGTH_SHORT)
.show()
}
override fun onAuthenticationFailed() {
super.onAuthenticationFailed()
Toast.makeText(applicationContext, "Authentication failed",
Toast.LENGTH_SHORT)
.show()
}
})
promptInfo = BiometricPrompt.PromptInfo.Builder()
.setTitle("Biometric login for my app")
.setSubtitle("Log in using your biometric credential")
.setNegativeButtonText("Use account password")
.build()
// Prompt appears when the user clicks "Log in".
// Consider integrating with the Keystore to unlock cryptographic operations,
// if needed by your app.
binding. Button.setOnClickListener {
biometricPrompt.authenticate(promptInfo)
}
}
<h2><b>The completed code for MainActivity.tk should look something like this:</b></h2>
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
lateinit var info: String
private lateinit var executor: Executor
private lateinit var biometricPrompt: BiometricPrompt
private lateinit var promptInfo: BiometricPrompt.PromptInfo
//https://developer.android.com/training/sign-in/biometric-authl
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
binding. Button.isEnabled = false
binding.imgFinger.setOnClickListener {
checkDeviceHasBiometric()
}
executor = ContextCompat.getMainExecutor(this)
biometricPrompt = BiometricPrompt(this, executor,
object : BiometricPrompt.AuthenticationCallback() {
override fun onAuthenticationError(
errorCode: Int,
errString: CharSequence,
) {
super.onAuthenticationError(errorCode, errString)
Toast.makeText(applicationContext,
"Authentication error: $errString", Toast.LENGTH_SHORT)
.show()
}
override fun onAuthenticationSucceeded(
result: BiometricPrompt.AuthenticationResult,
) {
super.onAuthenticationSucceeded(result)
Toast.makeText(applicationContext,
"Authentication succeeded!", Toast.LENGTH_SHORT)
.show()
}
override fun onAuthenticationFailed() {
super.onAuthenticationFailed()
Toast.makeText(applicationContext, "Authentication failed",
Toast.LENGTH_SHORT)
.show()
}
})
promptInfo = BiometricPrompt.PromptInfo.Builder()
.setTitle("Biometric login for my app")
.setSubtitle("Log in using your biometric credential")
.setNegativeButtonText("Use account password")
.build()
// Prompt appears when user clicks "Log in".
// Consider integrating with the Keystore to unlock cryptographic operations,
// if needed by your app.
binding. Button.setOnClickListener {
biometricPrompt.authenticate(promptInfo)
}
}
fun checkDeviceHasBiometric() {
val biometricManager = BiometricManager.from(this)
when (biometricManager.canAuthenticate(BIOMETRIC_STRONG or DEVICE_CREDENTIAL)) {
BiometricManager.BIOMETRIC_SUCCESS -> {
Log.d("MY_APP_TAG", "App can authenticate using biometrics.")
info = "App can authenticate using biometrics."
binding. Button.isEnabled = true
}
BiometricManager.BIOMETRIC_ERROR_NO_HARDWARE -> {
Log.e("MY_APP_TAG", "No biometric features available on this device.")
info = "No biometric features available on this device."
binding. Button.isEnabled = false
}
BiometricManager.BIOMETRIC_ERROR_HW_UNAVAILABLE -> {
Log.e("MY_APP_TAG", "Biometric features are currently unavailable.")
info = "Biometric features are currently unavailable."
binding. Button.isEnabled = false
}
BiometricManager.BIOMETRIC_ERROR_NONE_ENROLLED -> {
// Prompts the user to create credentials that your app accepts.
Val enrollIntent = Intent(Settings.ACTION_BIOMETRIC_ENROLL).apply {
putExtra(Settings.EXTRA_BIOMETRIC_AUTHENTICATORS_ALLOWED,
BIOMETRIC_STRONG or DEVICE_CREDENTIAL)
}
binding. Button.isEnabled = false
startActivityForResult(enrollIntent, 100)
}
}
binding.tvShowMsg.text = info
}
}
<h3><b>Conclusion</b></h3>
Any computer language that requires the assertion of a user's identity involves some Authentication for app ideas for beginners. This guide covered the fundamentals of implementing Authentication in Kotlin, including biometric Authentication.
| devbambhaniya | |
1,446,217 | Performance Tuning-Analyzing Hardware Bottlenecks-I/O | You can run the iostat or pidstat command, or use openGauss heath check tools to check the I/O usage... | 0 | 2023-04-24T09:30:03 | https://dev.to/llxq2023/performance-tuning-analyzing-hardware-bottlenecks-io-4f29 | opengauss | You can run the **iostat** or **pidstat** command, or use openGauss heath check tools to check the I/O usage and throughput on each node in openGauss and analyze whether performance bottleneck caused by I/O exists.
Checking I/O Usage
Use one of the following methods to check the server I/O:
**·** Run the **iostat** command to check the I/O usage. This command focuses on the I/O usage and the amount of data read and written on a single hard disk per second.

**rMB/s** indicates the number of megabytes of data read per second, **wMB/s** indicates that of data written per second, and **%util** indicates the disk usage.
**·** Run the **pidstat** command to check the I/O usage. This command focuses on the amount of data read and written on a single process per second.

**kB_rd/s** indicates the number of kilobytes of data read per second, and **kB_wr/s** indicates that of data written per second.
Run the **gs_checkperf** command as user **omm** to check the I/O usage in openGauss.
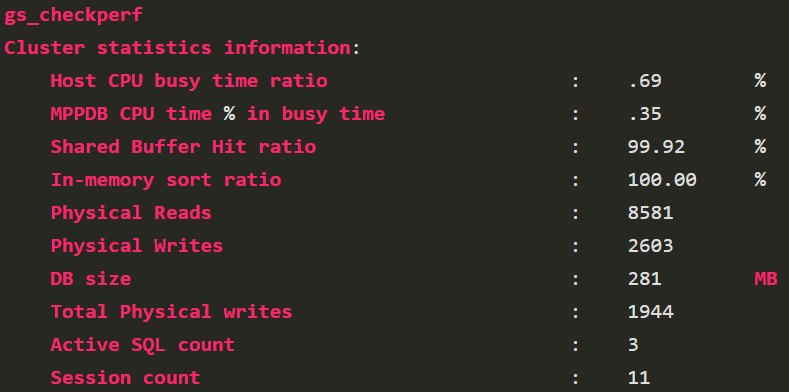
The I/O usage, number of reads and writes, and time when data is read and written are displayed.
You can also run the **gs_checkperf –detail** command to query performance details of each node.
**Analyzing Performance Parameters**
1. Check whether the disk usage exceeds 60%. Disk usage exceeding 60% is called high.

2. Perform the following operations to reduce I/O usage if the I/O usage keeps high:
2.1 Reduce the number of concurrent tasks.
2.2 Do VACUUM FULL for related tables.

 | llxq2023 |
1,446,229 | Zero Downtime Deployment Strategy for a React Dashboard with NGINX | In this blog, we'll discuss a zero-downtime deployment strategy for a React Dashboard using NGINX.... | 0 | 2023-04-24T09:44:58 | https://dev.to/4r7ur/zero-downtime-deployment-strategy-for-a-react-dashboard-with-nginx-1i17 | webdev, javascript, tutorial, react | In this blog, we'll discuss a zero-downtime deployment strategy for a React Dashboard using NGINX. With this approach, you'll be able to make seamless updates to your application without any downtime, ensuring a smooth user experience.
## Overview
Here's how the zero-downtime deployment strategy works:
1. NGINX points to a folder that is a symlink, which we'll call the "deployment" folder.
2. When deploying a new instance, a new folder is created with the timestamp as its name.
3. The symlink is switched to point to the new folder.
4. This allows users to easily switch between deployments and roll back to previous versions if necessary.
5. Older folders are deleted after five deployments.
Let's dive into each step in more detail.
## Step 1: Set Up NGINX Configuration
First, let's configure NGINX to point to our symlinked "deployment" folder. Create an NGINX configuration file named `nginx.conf` and add the following content:
```nginx
http {
server {
listen 80;
server_name yourdomain.com;
location / {
root /path/to/your/deployment/folder;
try_files $uri /index.html;
}
}
}
```
Replace `yourdomain.com` with your actual domain name and `/path/to/your/deployment/folder` with the path to your symlinked "deployment" folder.
## Step 2: Create a New Folder with a Timestamp
When deploying a new instance, create a new folder with the current timestamp as its name. You can do this using a simple bash script:
```bash
#!/bin/bash
timestamp=$(date +%Y%m%d%H%M%S)
mkdir /path/to/your/instances/folder/$timestamp
```
Replace `/path/to/your/instances/folder` with the actual path to your instances folder.
## Step 3: Switch the Symlink to the New Folder
After creating the new folder with the timestamp, switch the symlink to point to it. You can do this using the `ln` command in your bash script:
```bash
#!/bin/bash
timestamp=$(date +%Y%m%d%H%M%S)
mkdir /path/to/your/instances/folder/$timestamp
ln -sfn /path/to/your/instances/folder/$timestamp /path/to/your/deployment/folder
```
## Step 4: Deploy the React Dashboard
Now, deploy the React Dashboard to the newly created timestamp folder. You can use any build tool or process you prefer, such as Webpack or Create React App. For example:
```bash
#!/bin/bash
timestamp=$(date +%Y%m%d%H%M%S)
mkdir /path/to/your/instances/folder/$timestamp
ln -sfn /path/to/your/instances/folder/$timestamp /path/to/your/deployment/folder
cd /path/to/your/react/dashboard
npm install
npm run build
cp -R build/* /path/to/your/instances/folder/$timestamp
```
## Step 5: Delete Older Folders
To prevent clutter, delete older folders after five deployments. You can do this using the `find` command in your bash script:
```bash
#!/bin/bash
timestamp=$(date +%Y%m%d%H%M%S)
mkdir /path/to/your/instances/folder/$timestamp
ln -sfn /path/to/your/instances/folder/$timestamp /path/to/your/deployment/folder
cd /path/to/your/react/dashboard
npm install
npm run build
cp -R build/* /path/to/your/instances/folder/$timestamp
find /path/to/your/instances/folder -mindepth 1 -maxdepth 1 -type d | sort | head -n -5 | xargs rm -rf
```
This script will delete all folders except the five most recent ones.
## Conclusion
By following these steps, you can achieve a zero-downtime deployment strategy for your React Dashboard with NGINX. This approach ensures that your users will always have access to the latest version of your application without any interruptions. Additionally, it allows for seamless rollbacks and easy management of multiple deployments. | 4r7ur |
1,446,246 | How Technology is Transforming Our Relationship with Dogs | For many of us, our dogs are more than just pets - they're beloved members of our families. And with... | 0 | 2023-04-24T10:10:50 | https://dev.to/dogkutir/how-technology-is-transforming-our-relationship-with-dogs-5b4l | For many of us, our dogs are more than just pets - they're beloved members of our families. And with advancements in technology, we're finding new and innovative ways to interact with them. From wearable tech to interactive toys, technology is changing the way we care for and understand our furry friends. In this article, we'll explore the various ways in which technology is transforming our relationship with our dogs.
## Smart Collars
One of the most popular tech gadgets for dogs is the smart collar. These collars can track your dog's activity level, location, and even their heart rate. Some smart collars can also monitor your dog's behavior, such as barking, chewing, and scratching, and alert you if there are any changes.
One example of a smart collar is the Whistle GPS Pet Tracker. This collar not only tracks your dog's location, but it also monitors their activity level, and provides real-time updates on their health. The Whistle GPS Pet Tracker is also equipped with Wi-Fi and Bluetooth capabilities, allowing you to monitor your dog's activity even when you're not at home.
Another smart collar worth mentioning is the Link AKC Smart Collar. This collar not only tracks your dog's location and activity level, but it also has a temperature sensor that alerts you if your dog is too hot or too cold. The Link AKC Smart Collar also comes with a smartphone app that allows you to set activity goals for your dog, track their progress, and even store important health information.

## Interactive Toys
Interactive toys are another way in which technology is changing the way we interact with our dogs. These toys are designed to stimulate your dog's mind and keep them entertained for longer periods of time.
An interactive toy that showcases the impact of technology on the way we play with our dogs is the PetSafe Automatic Ball Launcher.This toy launches tennis balls for your dog to fetch, providing endless entertainment for your furry friend. The PetSafe Automatic Ball Launcher can be controlled using a remote or a smartphone app, allowing you to launch balls even when you're not at home.
Another popular interactive toy is the iFetch Interactive Ball Launcher. This toy is designed to keep your dog entertained for hours on end, launching tennis balls at different distances and angles. The iFetch Interactive Ball Launcher is also compatible with a smartphone app, allowing you to customize the settings and keep track of your dog's activity.

## Communication Devices
Communication devices are another way in which technology is changing the way we interact with our dogs. These devices allow us to communicate with our dogs in ways we never thought possible.
An example of a communication device that demonstrates how technology is changing the way we communicate with our dogs is the PetChatz HD. This device is a video conferencing system that allows you to see and talk to your dog from anywhere in the world. The PetChatz HD also comes with a treat dispenser, allowing you to reward your dog for good behavior even when you're not at home.
Another communication device is the Furbo Dog Camera. This camera allows you to see and talk to your dog from your smartphone, and it also comes with a treat dispenser. The Furbo Dog Camera is equipped with a barking sensor, which sends alerts to your phone when your dog is barking.

## Health Monitors
Health monitors are another way in which technology is changing the way we care for our dogs. These devices allow us to monitor our dog's health in real-time, providing valuable information that can help us detect health problems early on.
PetPace Smart Collar is equipped with sensors that monitor your dog's vital signs, including heart rate, respiration, and body temperature. The PetPace Smart Collar sends alerts to your smartphone if there are any changes in your dog's health.
Another health monitor worth mentioning is the FitBark 2. This device tracks your dog's activity level, sleep quality, and overall health. The FitBark 2 is also equipped with Wi-Fi and Bluetooth capabilities, allowing you to monitor your dog's health even when you're not at home. The device comes with a smartphone app that allows you to set health goals for your dog and track their progress. To expand your knowledge about canine health, you're welcome to explore [our website](https://dogkutir.com/).

## Virtual Training
Virtual training is another way in which technology is changing the way we interact with our dogs. With virtual training, you can train your dog from the comfort of your own home, without the need for a professional trainer.
Dogo app offers personalized training plans for your dog based on their age, breed, and behavior. The Dogo app also provides video tutorials and step-by-step instructions, making it easy for you to train your dog on your own.
Another virtual training platform is the Fenzi Dog Sports Academy. This platform offers online classes in a variety of dog sports, including obedience, rally, and agility. The Fenzi Dog Sports Academy also offers classes in behavior modification, allowing you to address any behavioral issues your dog may have.
## Conclusion
Technology is changing the way we interact with our dogs in ways we never imagined. From smart collars that track our dogs' activity and behavior to apps that help us communicate with our pets, technology is transforming the way we care for and understand our furry friends. Whether you're looking to track your dog's health, keep them entertained, or train them from home, there's a tech gadget or app out there to help you do just that. As technology continues to evolve, we can expect even more innovative ways to interact with our dogs in the future.
| dogkutir | |
1,446,264 | Node.js Send Email using Google OAuth2 | One common requirement of back-end application development is sending a message via email. This... | 0 | 2023-04-25T08:33:06 | https://dev.to/wildanzr/nodejs-send-email-using-google-oauth2-49l5 | oauth2, gmail, nodemai, webdev | One common requirement of back-end application development is sending a message via email. This feature can support business processes such as verifying user data, notifications, account security, marketing, and many other use cases.
### Then, how can we send an email message in a Node.js application?
One of the libraries that are widely used in sending emails is [**Nodemailer**](https://nodemailer.com/about/). There is the easiest way of implementation which using the [**Google App Password**](https://support.google.com/accounts/answer/185833?hl=id) service. However, this method has been labelled by Google as **less secure** because the result of generated password is easy to memorize and less complex, so the security level is lower.
Alternatively, there is a way in sending an email using the [**Google OAuth2**](https://developers.google.com/gmail/imap/xoauth2-protocol?hl=id) method. _OAuth2_ (Open Authorization 2.0) is an authentication and authorization protocol used to allow third parties to access protected resources. This method has a high level of security and has been used as a security standard in the technology industry.
Ok, shall we begin :)
The first thing to do is to create a project in the [**Google Developer Console**](https://console.cloud.google.com/) (make sure you have a Google account) :D
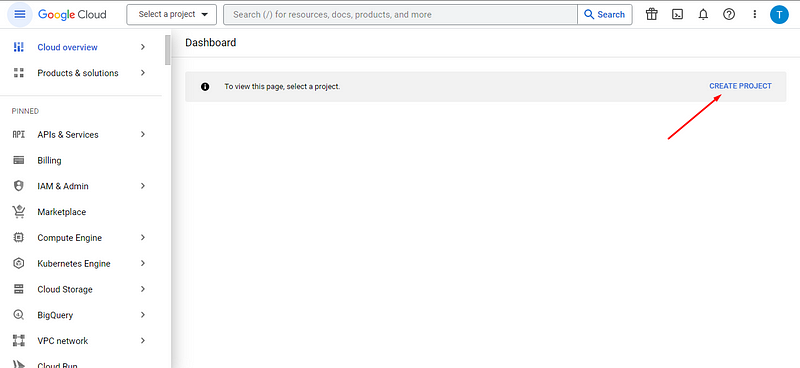
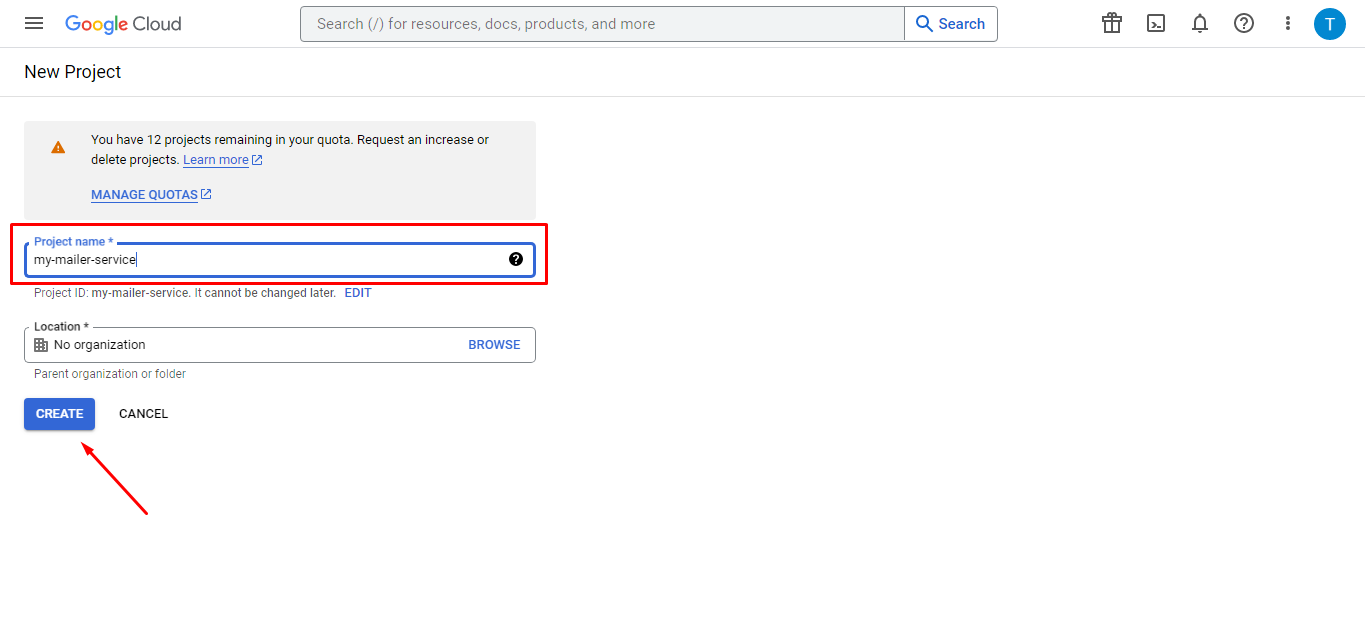
After the project is successfully created, go to the left tab in the section **API & Services > OAuth Consent Screen** then select **External** configuration. Next, fill in the app name data, user support email, and developer contact information, then follow the next instructions and save. To activate the OAuth Consent Screen configuration, do **Publish App** and confirm.
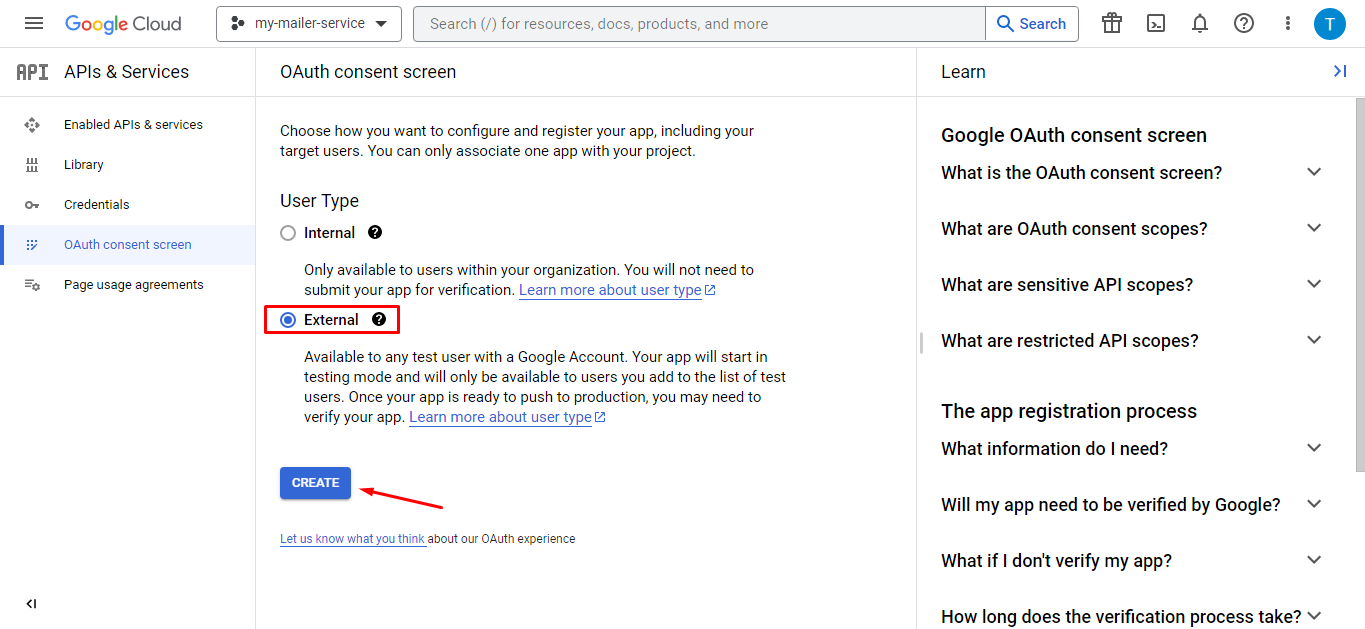
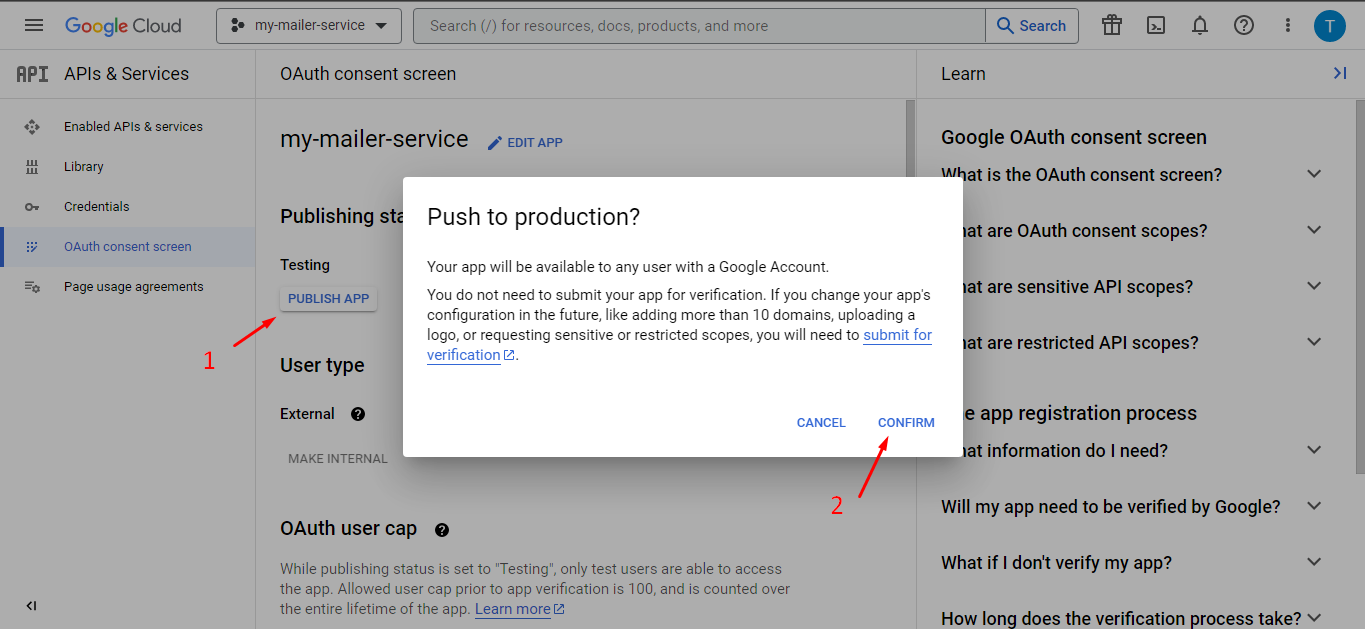
Great, it's time to configure the OAuth Client ID. On the tab **API & Service**, select the menu **Credential > Create Credentials > OAuth Client ID**. After that, fill the application type with a **web application**, a name with the application name (feel free to naming), and add the URI **https://developers.google.com/oauthplayground** in the **Authorized redirect URIs** section. Creating an OAuth Client ID generates credentials in the form of an ID and a secret (keep it safe, you can download it in JSON format).
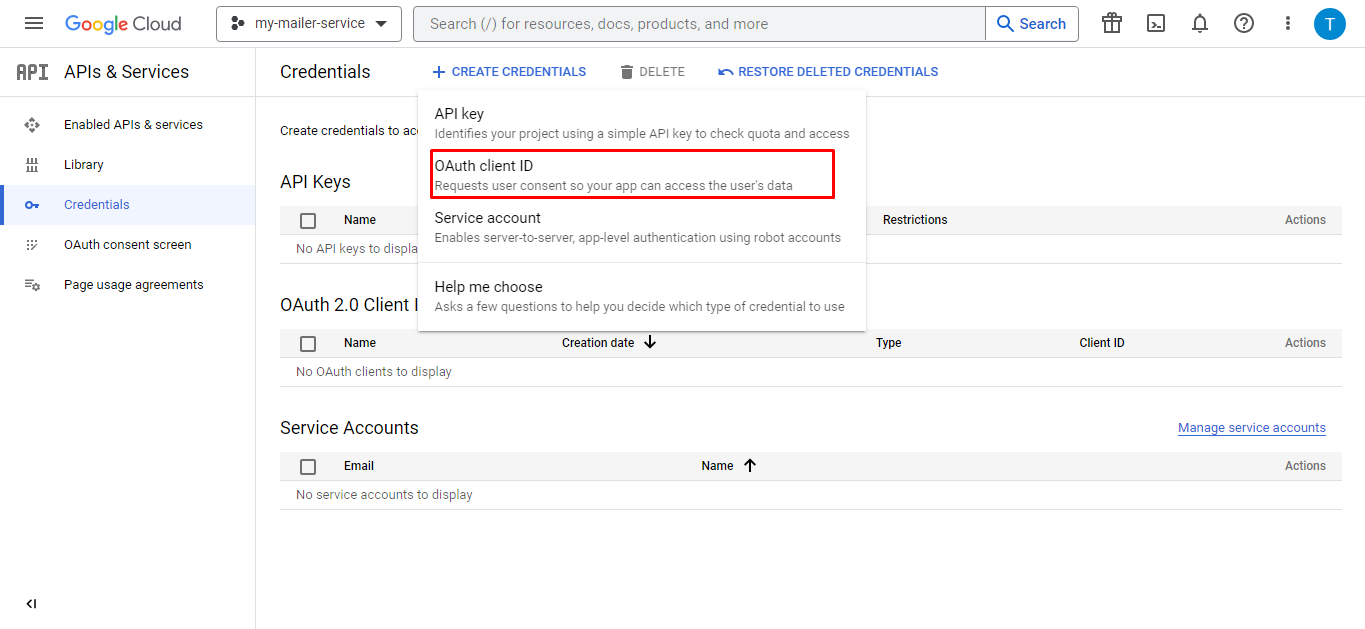
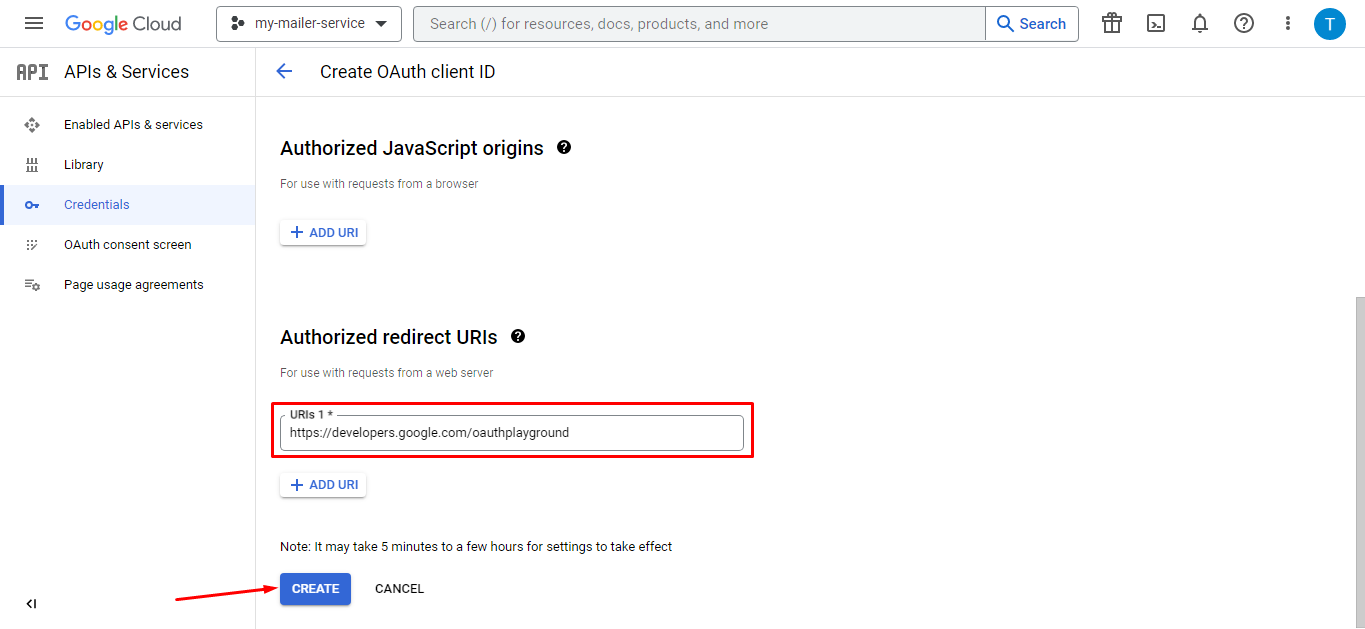
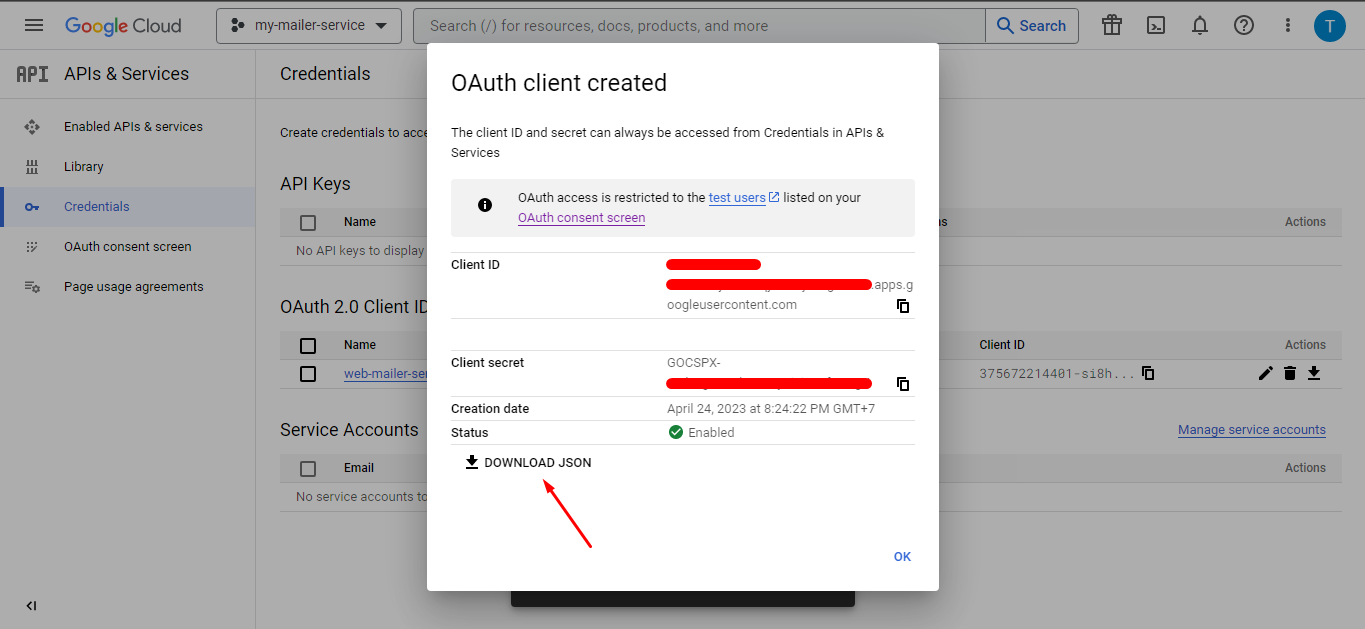
Nice, the next step is to test OAuth Client ID and get the refresh token. Visit [**Google Developer OAuth Playground**](https://developers.google.com/oauthplayground), set OAuth Client ID and secret configuration using your credentials, then select [**http://mail.google.com/**](http://mail.google.com/). Next, you will be redirected to the Google Authentication pages, choose the same account used to create OAuth Client ID. If you are facing a page that is not safe, open the menu **Advanced Options** and click **Continue (not safe)** (this is happen because we are not submitting the verification app to Google, but you can ignore it for a moment). The result is an **authentication code, refresh token, and access token** (once more, keep it safe).
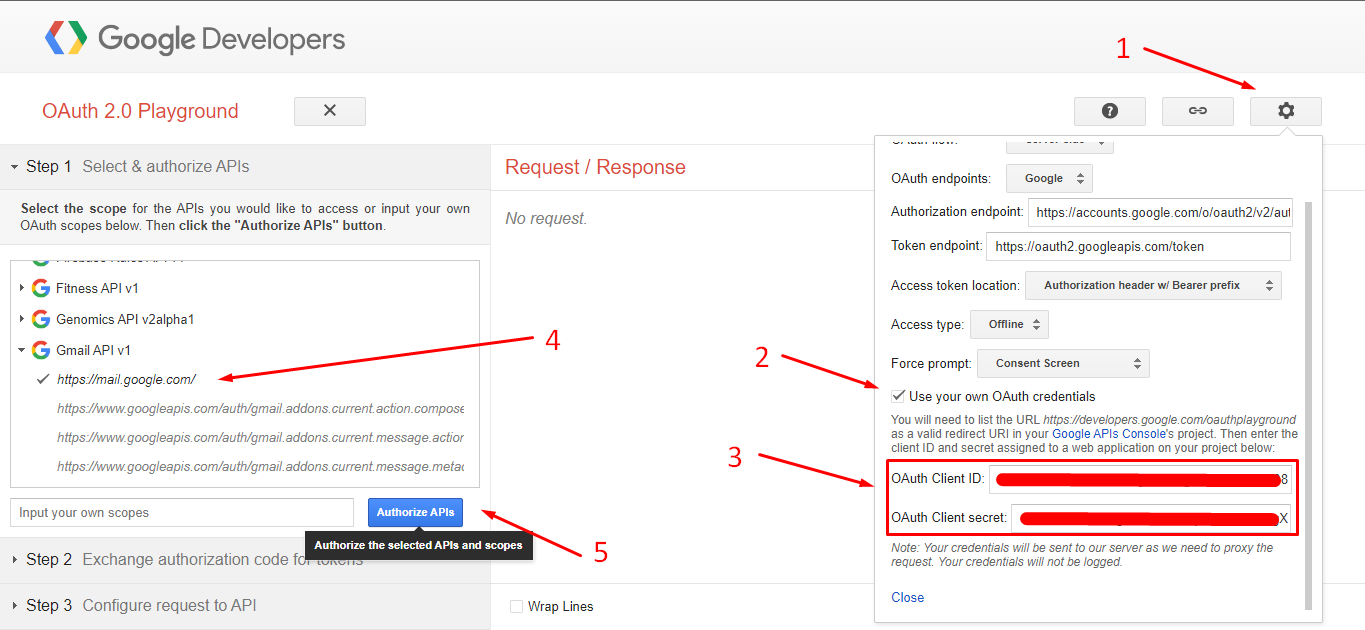
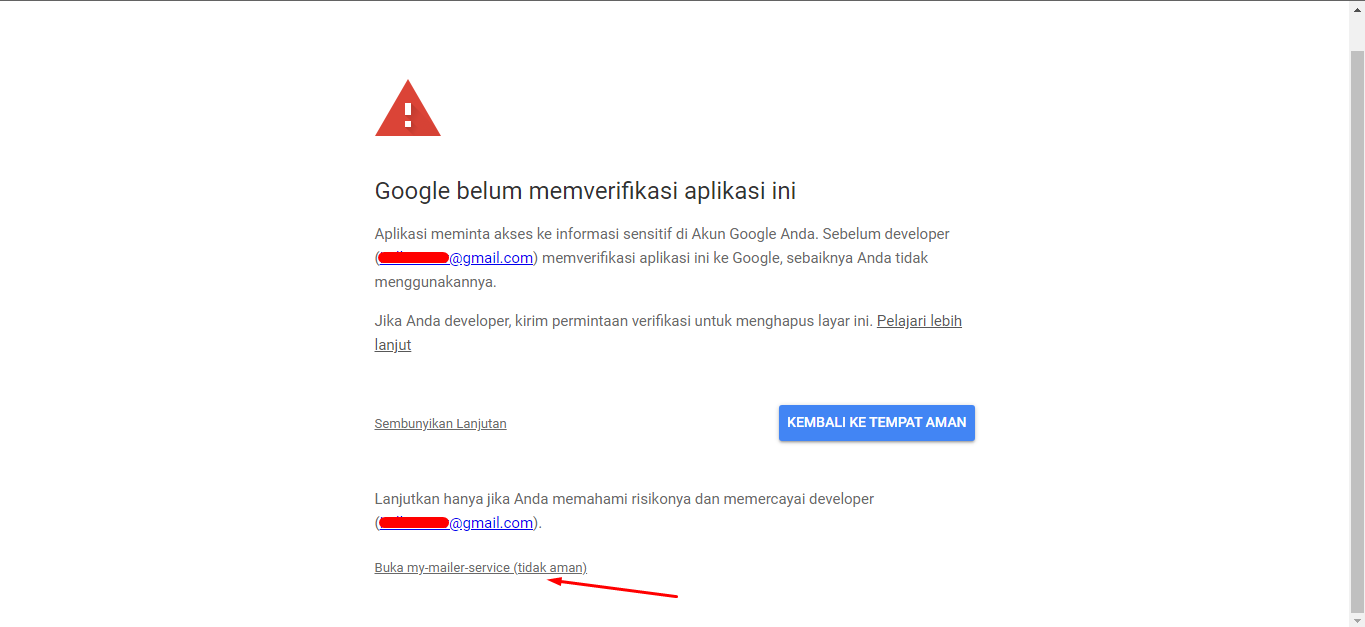
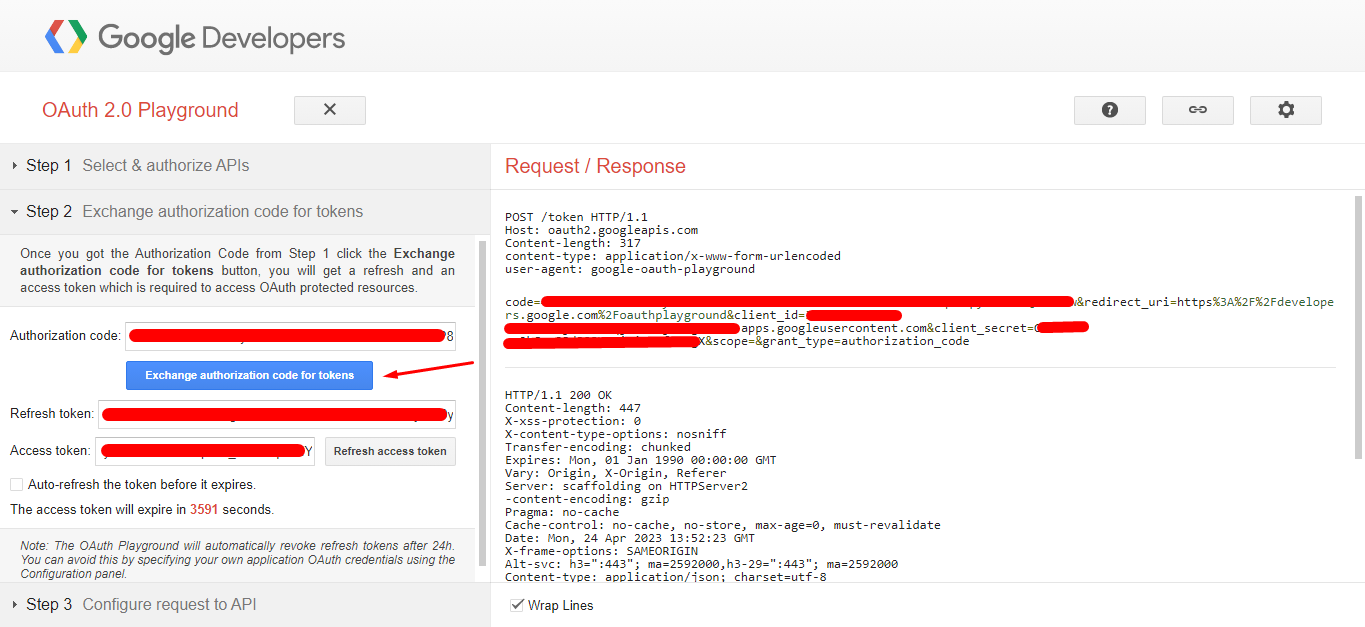
Wow, the configuration is quite long, whereas we are not yet writing a single piece of code. But now, let's write some code. Start with creating an empty folder then initialize the project (fill it according to the project initialization instructions).
```
npm init
```
We will code using Typescript, if you are more prefer using Javascript just install the 3 dependencies needed (however you will need some adjustments from Typescript to Javascript).
```
npm i --save-dev typescript ts-node @types/node
```
```
npm i dotenv nodemailer googleapis
```
Great, now create a file with an **.env** extension to store the credentials locally.
```
OAUTH_EMAIL=
OAUTH_CLIENT_ID=
OAUTH_CLIENT_SECRET=
OAUTH_REFRESH_TOKEN=
```
Nice, now create an **index.ts** file. The first thing to do is import the required dependencies and get the value of our environment variables.
{% embed https://gist.github.com/Wildanzr/551da8977e57f72697a7c74ad4ec78e8 %}
Next, create an OAuth2 Client object and make a getAccessToken request. This function returns a value in the form of an accessToken code which is used as the authorization when sending emails.
{% embed https://gist.github.com/Wildanzr/bcb9782754183aff3f14b16aad9d5ece %}
Lastly, create a transporter configuration with SMTP and set the mailOptions as the email sending object.
{% embed https://gist.github.com/Wildanzr/5885c461615c8d37f8928a72dd5cc4d1 %}
Congratulations! Email sending using the OAuth2 method was successful. With the steps that have been followed, the email sent will be guaranteed to be secure and properly authenticated.
## Conclusion
Using the OAuth2 method to send email via Nodemailer has several advantages, including: increasing security by avoiding using usernames and passwords, enabling good integration with third-party email services and can increase application scalability.
If you want to get this source code, feel free to take a look at [this GitHub repo](https://github.com/Wildanzr/art_nodejs_gmail_oauth).
Thank you for reading this article, hope it's useful 📖. Don't forget to follow the account to get the latest information🌟. See you in the next article🙌.
| wildanzr |
1,446,272 | Running microservices using Reactor container - Phoesion Glow | What is Phoesion Glow Phoesion Glow is a framework for developing cloud microservices... | 0 | 2023-04-24T10:40:29 | https://dev.to/gepa21/running-microservices-with-using-reactor-container-phoesion-glow-5ceh | dotnet, webdev, programming, cloud | ### What is Phoesion Glow
[Phoesion Glow](https://glow.phoesion.com/) is a framework for developing cloud microservices using c#. It offers out-of-the-box API-Gateway, Service-bus, service hosts, Kubernetes operators and more! All components have been designed to work together seamlessly and provide a uniform and streamlined experience for developing, deploying and managing your cloud services.
### What is Phoesion Glow Reactor
Phoesion Glow **Reactor** is a standalone meta-app that includes all entities needed to run a Glow cloud setup, inside a single process/app. This includes the Prism _(API Gateway)_, the Kaleidoscope _(Service-Bus)_, Lighthouse _(Command-and-Control)_ and Firefly _(business logic service host/supervisor)_. Using Reactor you can easily develop your services locally without setting up a bunch of components.
### Using Containers
Normally, when you install [Phoesion Glow Blaze](https://glow-docs.phoesion.com/downloads/Downloads_Blaze.html?tabs=oses-1) the **Reactor** is also installed as a system service. This is great most of the time but in many cases, when you want to evaluate the samples, run services in a non-developer PC, or just use a different version of Reactor, docker and containers come to the rescue. With one simple command, you can have the **Reactor container** up and running on your machine so your services can connect to it and attach on the service bus _(to start handling incoming requests)_.
To start a **Phoesion Glow Reactor container** run :
``` sh
docker run --name reactor -d -p 80:80 -p 443:443 -p 15000-15010:15000-15010 -p 16000:16000 phoesion/phoesion.glow.reactor-dev
```
This will start the reactor and expose the appropriate ports _(http(s) and service-bus)_
### Running a sample
Now that our container is up and running, we can run some samples!
#### 1. Clone the GitHub sample repo :
``` sh
git clone https://github.com/Phoesion/Glow-Samples.git
```
#### 2. Start the 1_Rest sample that demonstrates basic web api concepts/capabilities :
- Open the solution 1_REST\Sample_1_REST.sln
- Start **Foompany.Services.SampleService1** and **Foompany.Services.SampleService2** projects _(our two microservices)_
#### 3. Test our services using the URLs :
- [http://localhost/SampleService1/SampleModule1/](http://localhost/SampleService1/SampleModule1/)
- [http://localhost/SampleService1/SampleModule1/Action1](http://localhost/SampleService1/SampleModule1/Action1)
- [http://localhost/SampleService1/SampleModule1/Action2/test?myKey=myValue](http://localhost/SampleService1/SampleModule1/Action2/test?myKey=myValue)
- [http://localhost/SampleService1/SampleModule1/Action3?value1=hi&value2=true](http://localhost/SampleService1/SampleModule1/Action3?value1=hi&value2=true)
- [http://localhost/SampleService1/SampleModule1/DoTheThing?username=john](http://localhost/SampleService1/SampleModule1/DoTheThing?username=john)
---
- [http://localhost/SampleService1/SampleModule2/Action1](http://localhost/SampleService1/SampleModule2/Action1)
- [http://localhost/SampleService1/SampleModule2/AsyncAction](http://localhost/SampleService1/SampleModule2/AsyncAction)
- [http://localhost/SampleService1/SampleModule2/SampleStrongType](http://localhost/SampleService1/SampleModule2/SampleStrongType)
- [http://localhost/SampleService1/SampleModule2/SampleObjectType?retType=1](http://localhost/SampleService1/SampleModule2/SampleObjectType?retType=1)
---
- [http://localhost/SampleService2/SampleModule1/Action1](http://localhost/SampleService2/SampleModule1/Action1)
- [http://localhost/SampleService2/SampleModule1/RedirectMe](http://localhost/SampleService2/SampleModule1/RedirectMe)
- [http://localhost/SampleService2/SampleModule1/SampleStatusCode?command=hi](http://localhost/SampleService2/SampleModule1/SampleStatusCode?command=hi)
- [http://localhost/SampleService2/SampleModule1/SampleStatusCode?command=banana](http://localhost/SampleService2/SampleModule1/SampleStatusCode?command=banana)
- [http://localhost/SampleService2/SampleModule1/StreamingSample1](http://localhost/SampleService2/SampleModule1/StreamingSample1)
- [http://localhost/SampleService2/SampleModule1/FileDownloadSample](http://localhost/SampleService2/SampleModule1/FileDownloadSample)
- [http://localhost/SampleService2/SampleModule1/YieldReturnResults](http://localhost/SampleService2/SampleModule1/YieldReturnResults)
- [http://localhost/SampleService2/SampleModule1/](http://localhost/SampleService2/SampleModule1/)
### Summary
In this post, we saw how easy it is to create a Glow setup that includes the api-gateway, service-bus and more using Reactor and docker containers. With the Reactor container running we can launch our services locally for developing/testing/debugging or just evaluating them, without installing all the Phoesion Glow tools on our system.
For more information about Phoesion Glow, you can check out :
- [Website](https://glow.phoesion.com)
- [Documentation](https://glow-docs.phoesion.com/getting_started/index.html)
- [YouTube tutorials](https://www.youtube.com/watch?v=RfrkUuAnT5U&list=PLgd9-Gs1hc3FIME3CIo3yblIbxU5JbTi-&index=1&t=0s)
- [New Discord community](https://discord.com/invite/YJxdPbvdUj)
Happy coding! | gepa21 |
1,446,279 | Getting Started with .NET MAUI DataForm | Learn how easily you can create and configure Syncfusion .NET MAUI DataForm using Visual Studio 2022.... | 0 | 2023-04-24T11:08:59 | https://dev.to/syncfusion/getting-started-with-net-maui-dataform-28ko | dotnet, dotnetmaui, csharp | Learn how easily you can create and configure Syncfusion .NET MAUI DataForm using Visual Studio 2022. The Syncfusion .NET MAUI DataForm control is used to facilitate the creation and editing of data forms for various business purposes, such as login, reservation, contact, and employee forms. I’ve also demonstrated how to change the form layout, editor type and apply validation.
_Product overview_: https://www.syncfusion.com/maui-controls/maui-dataform
_Download an example from GitHub_: https://github.com/SyncfusionExamples/getting-started-with-the-dotnet-maui-dataform
_Refer to the following documentation_ : https://help.syncfusion.com/maui/dataform/getting-started
{% youtube c39fzkutfwU %}
| techguy |
1,446,306 | The old MySQL bug (detective story) | In this article I want to describe about one bug that I found in MySQL and aware you from mistakes... | 0 | 2023-04-24T11:47:12 | https://dev.to/rozhnev/the-old-mysql-bug-detective-story-3m8l | sql, mysql, bug | In this article I want to describe about one bug that I found in MySQL and aware you from mistakes what you can do.
Some guy from my Telegram chat asked me: "How can I view all foreign key references to a specific table?" I gave him a quick answer: "Look it up in `information_schema`", but after that I decided to check my answer.
Just created simple table `test` and table `ref1` with field referenced to `id` field:
```
create table test (
id int primary key,
first_name varchar(20),
last_name varchar(30)
);
create table ref1 (
id int primary key,
test_id int references test(id)
);
```
Looks simple because I like this short syntax. After that I looked into `information_schema` table `REFERENTIAL_CONSTRAINTS`
```
SELECT * FROM `information_schema`.`REFERENTIAL_CONSTRAINTS` WHERE REFERENCED_TABLE_NAME = 'test';
```
and checked again. After that I sowed records in `REFERENTIAL_CONSTRAINTS`. How is it possible? I was disappointed and decided to save my mind by next test case:
I created one more referenced table `ref2` with canonical syntax:
```
create table ref2 (
id int primary key,
test_id int,
foreign key (test_id) references test(id)
);
```
and did check again. After that I sow record in `REFERENTIAL_CONSTRAINTS`. How it possible? I was disappointed and decided to save my mind by next test case:
```
-- add values to test case
insert into test values (1), (2);
-- add ref1 row referenced to first row in test table
insert into ref1(id, test_id) values (1, 1);
-- add ref2 row referenced to second row in test table
insert into ref2(id, test_id) values (1, 2);
```
Now, I think, I will try to delete first row from test and will get error (I still think it some feature, not bug) but MySQL drop this row without any warning
```
delete from test where id = 1;
```
but when I try to delete second one that referenced by second table I did not succeed
```
delete from test where id = 2;
```
So it is not a feature, it is a real BUG! MySQL allows creating tables using short syntax without warnings but constraints are not created and do not guard your data consistently OMG!
I looked in Google and found the bug has been open since 2004 [https://bugs.mysql.com/bug.php?id=4919](https://bugs.mysql.com/bug.php?id=4919) and it is still not fixed. Hey guys, what are you doing? Hey guys what you during?
I decided to run this test case over other databases and found all databases that I can test on [SQLize.online](https://sqlize.online/sql/mariadb/0295e1d928b15c3e54f5cadcda10a750/) allows short syntax and all of them (MariaDB, PostgreSQL, SQL Server, Oracle) created foreign key constraints in both of cases except MySQL and SQLite. | rozhnev |
1,446,336 | How To Learn Coding With ChatGPT? Explore now | Learn Coding with ChatGPT in Only a Few Steps! There are a few different ways you can start learning... | 0 | 2023-04-24T12:42:15 | https://dev.to/mazaadyportal/how-to-learn-coding-with-chatgpt-explore-now-11e8 | webdev, javascript, beginners, programming | Learn Coding with ChatGPT in Only a Few Steps! There are a few different ways you can start learning to code with the help of ChatGPT.
Here are a few options for ” ChatGPT“:-
Ask specific coding questions:–
You can ask me specific questions about programming concepts or code snippets, and ChatGPTwill does its best to provide an explanation or example.
For example, If you need to learn how to build ” social media icons code ”
In addition, You can ask for it and he automatically will build it. continue reading [coding with chatgpt ](https://hfnewss.com/how-to-learn-coding-with-chatgpt-explore-now/) | mazaadyportal |
1,446,354 | Meme Monday | Meme Monday! Today's cover image comes from last week's thread. DEV is an inclusive space! Humor in... | 0 | 2023-04-24T13:09:07 | https://dev.to/ben/meme-monday-531a | discuss, watercooler, jokes | **Meme Monday!**
Today's cover image comes from [last week's thread](https://dev.to/ben/meme-monday-4j21).
DEV is an inclusive space! Humor in poor taste will be downvoted by mods. | ben |
1,446,418 | 3 Cloud Certifications That Are Impactful For Your Resume | Maximize your career potential with these industry-recognized credentials. Cloud architecture is a... | 0 | 2023-04-24T13:32:56 | https://dev.to/durgesh4993/3-cloud-certifications-that-are-impactful-for-your-resume-37gd | Maximize your career potential with these industry-recognized credentials.
Cloud architecture is a highly sought-after skill in today’s job market. The demand for cloud architects is expected to continue growing as more companies move their IT infrastructure to the cloud. When I talk with customers, I clearly see the need to bring in more specialist engineers and professionals that are knowledgeable in different areas.
According to Indeed, cloud engineers earn an average base salary of $120,000 USD.
In this article, I want to share the 3 most impactful Cloud certifications to help you land your dream job in Cloud Computing.
**1. Google Certified Professional Cloud Architect**
_Average salary: $139,000–$175,000 USD_

According to A Cloud Guru, GCP is the third most used public cloud. However, it is one of the top certifications in high demand. Taking a GCP certification can help you with recognition and credibility (hence, helping you when doing an interview at Google), learning a wide range of topics, including cloud computing concepts, infrastructure design, security, data storage, networking, and more.
The breadth of coverage makes it an excellent way to validate your knowledge and skills across cloud-related disciplines.
The current certification cost is $200, but check the GCP website to learn more.
**2. Microsoft Certified Azure Solutions Architect Expert**
_Average salary: $119,000–$152,000_

Before taking the Solutions Architect Expert exam, you must pass the AZ-305: Designing Microsoft Azure Infrastructure Solutions. If you want to start with the Azure Fundamentals, I encourage you to read this article by
Beatriz Oliveira
.
The Architect certification can be a challenging one. According to the CIO magazine study, this is one of the 15 Top Certifications in high demand in 2022.
As of February 2023, the cost to take the Microsoft Certified Azure Solutions Architect Expert certification is $165.
**3.AWS Certified Solutions Architect — Associate**
_Average salary: $113,000–$149,000 USD_

The AWS Certified Solutions Architect — Associate validates the technical knowledge and skills required to design and deploy applications on AWS. This certification demonstrates proficiency in designing and deploying scalable, highly available, and fault-tolerant systems on AWS.
It is recommended for those with at least one year of hands-on experience with AWS.
The current cost of the exam is $150 USD.
Do you have any other questions about these certifications? Feel free to comment on this post. If you are a beginner, I encourage you not to be afraid to start and read this article with beginner tips. | durgesh4993 | |
1,446,754 | ¡Así es cómo Solid Js lo hace! | Los que nos gusta y venimos de experiencias con React nos va a encantar Solid js. En síntesis,... | 0 | 2023-04-24T18:46:55 | https://dev.to/jayad23/asi-es-como-solid-js-lo-hace-79g | webdev, react, solidjs, spanish | Los que nos gusta y venimos de experiencias con React nos va a encantar Solid js.
En síntesis, podemos decir que la mayor ventaja de Solid sobre React radica en dos puntos principales:
1. Tamaño del Bundler: En Solid es más ligero porque ya contiene módulos que en React se manejan como lib de terceros.
2. Signal por States: Lo que es completamente diferente al comportamiento del state en React de re-renderizar el componente cada que el estado cambie. Eso pasa por el algoritmo [Diffing & Reconciliation](https://legacy.reactjs.org/docs/reconciliation.html#the-diffing-algorithm). Si no estás familiarizado, te dejo el link para que entiendas el concepto detrás del algoritmo.
Solid, por su parte, crea señales (signals) directamente en elementos del DOM que inteligentemente percibe que podrían cambiar, previniendo así, re-renderizar el componente al actualizar el elemento.
Ya que hemos sacado del camino lo que todos sabemos de Solid Js, quiero enfocarme en algunas diferencias en la API de Solid con respecto a React para comparar como lo hace React y mostrarte cómo lo hace Solid js.
1. useState - createSignal.

Mientras que state crea un valor, signal crea una señal que es un método a cuyo valor se accede al ser invocado, por eso los paréntesis. La Función setCounter cumple la misma función para ambas herramientas.
La sintaxis puede variar un poco, sin embargo:

2. Eventos
Si bien vimos en las imágenes anteriores que el evento onClick no cambia de React a Solid, sí el método para los inputs. En React lo llamamos onChange, y en Solid será onInput:
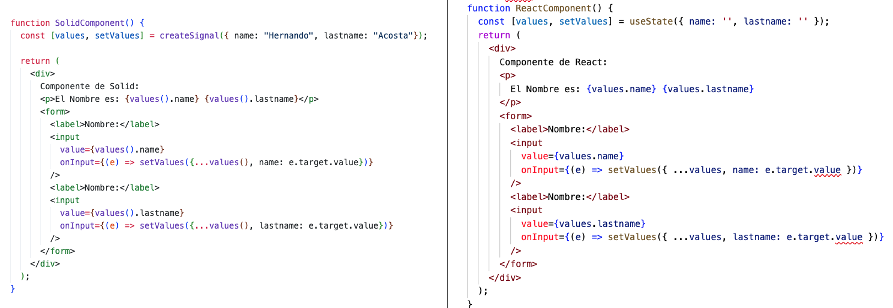
3. useEffect - createResource
Si bien el useEffect es una de las herramientas más populares de React, también es requiere mucha atención para no terminar ejecutando código (típicamente asíncrono) más veces del que debería. Con frecuencia vemos algo así en nuestra consola con un solo fetch, contra lo que tenemos que juntar cabezas para crear una solución performante:

Entonces, Comparemos:

Usando el hook createResource que viene directamente de solid-js sin la ayuda de effectos para ejecutar la función en montaje.
4. Ternarios y múltiples elementos.
Una de las prácticas más comunes en React es la del método .map() para renderizar varios elementos y dinamizar los valores del mismo. Esta práctica usualmente involucra un ternario (hay muchas otras opciones, es verdad) pero quedémonos con la más común, que es la crear un ternario para evaluar si el estado ya se ha populado y puede ser mappeado. Algo así:

Este es un escenario bastante común en React. Estas mismas lineas de código pueden existir en Solid y funcionaría sin problemas, pero Solid tiene una solución más sofisticada:
A. Para el ternario, utiliza una etiqueta que se llama <Show/> que se importa de "solid-js" y recibe dos atributos, when={_// aquí se hace la evaluación de la condición_} fallback={_//aquí ponemos lo que queremos renderizar mientras el valor de la señal cambia_} Quedando de esta manera:

B. A pesar de <Show/> a estas alturas, aun estamos codeando muy "Reactive". Solid ofrece otra alternativa a los elementos que se quieren renderizar de forma dinámica. En esta ocasión es otra etiqueta que se llama <For /> que también se importa de "solid-js" y recibe un atributo each={_//Aquí depositamos el arreglo de valores_} de hecho, tuve que forzar un error sintáctico el la imagen anterior para evitar el error de eslint en el que Solid me recomienda usar esa etiqueta:

5. Routes.
En React, el enrutamiento típicamente se trabaja con "react-router-dom". Durante este momento es bastante oportuno hacer code splitting usando lazy y Suspense... Estos dos elementos siguen presentes en Solid. Sin embargo, a lo que me refiero es a esto:

Esto es en React, que se importa de esta librería:

Ahora, "react-router-dom" también tiene otros elementos que son muy útiles, como:
a. <Link />
b. useParams
Ahora, Solid ya tiene en sí un módulo de enrutamiento al que podemos importar de "@solidjs/router"
Este módulo contiene:
a. <Routes/>
b. <Route/>
c. <A/> /=> que es la versión <Link /> de Solid
d. useParams



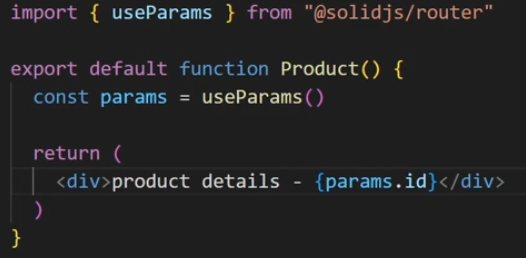
Con esto termino mi blog de comparación de ambas herramientas. Venir desde React hace que aprender Solid sea muy fácil, y nos ayuda a apreciar las mejoras que ofrece.
Espero que este contenido haya sido útil.
| jayad23 |
1,447,081 | Why you should upgrade to djangov4 | Prior to this, I enjoyed using django version 3.2 for some reasons. Although once, I tried upgrading... | 0 | 2023-04-25T00:31:08 | https://dev.to/codewitgabi/why-you-should-upgrade-to-djangov4-2cni | webdev, python, django | Prior to this, I enjoyed using django version 3.2 for some reasons. Although once, I tried upgrading to version 4.0 but my admin site refused to work because of some issues so I just left it without rectifying the issue. Recently, I decided to upgrade my django projects to a higher version at all cost which I did even after facing the same issue I faced before. I'll look into rectifying the issue just in case someone faces that problem while upgrading to a new version.
Like I said earlier on, I loved working with v3.2 but django support for v3.2, ends this month. That wouldn't be a big problem though but looking at the release notes for v4.2, I'm really impressed.
Here are a few updates that impressed me and why I think you should consider upgrading your django version.
1. **Psycopg 3 support**:
Django now supports psycopg version 3.1.8 or higher. Support for psycopg2 is likely to be deprecated and removed at some point in the future.
2. **Comments on columns and tables**:
The new Field.db_comment and Meta.db_table_comment options allow creating comments on columns and tables, respectively. For example:
```
from django.db import models
class Question(models.Model):
text = models.TextField(db_comment="Poll question")
pub_date = models.DateTimeField(
db_comment="Date and time when the question was published",
)
class Meta:
db_table_comment = "Poll questions"
```
3. **Mitigation for the BREACH attack**:
If there is any reason why django is the best framework out there, it's its concern for web security.
GZipMiddleware now includes a mitigation for the BREACH attack. It will add up to 100 random bytes to gzip responses to make BREACH attacks harder. Also, for user authentication, the default iteration count for the PBKDF2 password hasher is increased from 390,000 to 600,000. Such an amazing feature.
4. **Error Reporting**:
If you have used python3.11 you might have noticed how errors are displayed; showing exactly where the errors are and possible fixes. Well, if you use djangov4.2 and python3.11+, Error reporting just got better.
The debug page now shows exception notes and fine-grained error locations, Session cookies are now treated as credentials and therefore hidden and replaced with stars (**********) in error reports.
**Fixing Admin site issue**
The issue I faced when upgrading to v4 was a `timezone` error so to fix that, quickly install `tzdata` on the command line.
```
$ pip install tzdata
```
That will be all for now guys, don't forget to leave a comment. See you on the next one! | codewitgabi |
1,447,102 | Automating Developer Relations Metrics with Low Code RunBooks | My job at unSkript is to spread awareness and excitement around the DevOps tooling we have built. ... | 0 | 2023-04-27T10:10:25 | https://unskript.com/automating-developer-relations-metrics-with-low-code-runbooks/ | blog, intelligentautomatio, leadership, otherposts | ---
title: Automating Developer Relations Metrics with Low Code RunBooks
published: true
date: 2023-04-24 22:05:02 UTC
tags: Blog,IntelligentAutomatio,Leadership,OtherPosts
canonical_url: https://unskript.com/automating-developer-relations-metrics-with-low-code-runbooks/
---
My job at unSkript is to spread awareness and excitement around the DevOps tooling we have built. But, I am also expected to provide reporting on various metrics around developer awareness and usage of our product. In this post, I walk through how I have automated the data collection process, so that I can spend more time creating content and building awareness.</span></p>
<p><span style="font-weight: 400;">A bit of background: at unSkript, we are building automation tools to reduce toil. In the DevOps/SRE space, toil is defined as the manual and repetitive work that needs to be done to keep everything shipshape. If you ask me – collecting metrics from a bunch of different services (Github, Google Analytics, internal databases, Docker,….), and aggregating them in one place – that sounds like toil. So let’s automate that away, and then I no longer have to think about it (until I decide to write a blog post about it, of course.)</span></p>
<p> </p>
<h2><span style="font-weight: 400;">Collecting the Data</span></h2>
<p>unSkript is a tool to help you build RunBooks. A RunBook is a collection of steps (we call them Actions) that complete a task. For DevOps teams, that could be <a href="https://unskript.com/security-checkup-force-aws-load-balancers-to-redirect-to-https/">auto-remediation of your load balancers</a>, <a href="https://unskript.com/runbook-analysis-of-k8s-logs/">running health checks on a K8s cluster</a>, or even monitoring your <a href="https://unskript.com/keeping-your-cloud-costs-in-check-automated-aws-cost-charts-and-alerting/">daily Cloud costs</a>.</p>
<p>I want to use these actions to collect a bunch of different data points, and store them all in one place. There are a few different ways that I use unSkript to collect the information:</p>
<h2><span style="font-weight: 400;">Built in Actions</span></h2>
<p><span style="font-weight: 400;">unSkript comes with hundreds of built-in Actions – simply drag & drop into your RunBook, configure your credentials, and you are ready to go! When using built-in Actions – unSkript can be thought of as essentially “no-code” to set up. There are several built-in Actions in unSkript that are well suited to collecting the data that I want to collect: Daily Unique users from Google Analytics, and the Github star count. </span></p>
<p> </p>
<p><span style="font-weight: 400;"><img decoding="async" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?resize=300%2C85&ssl=1" alt="GA Action" width="300" height="85" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?resize=300%2C85&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?resize=558%2C158&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?resize=655%2C186&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?resize=24%2C7&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.31.00.jpg?w=734&ssl=1 734w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"></span></p>
<p><span style="font-weight: 400;"><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-14.44.41.jpg?resize=300%2C80&ssl=1" alt="GitHub Star Action" width="300" height="80" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-14.44.41.jpg?resize=300%2C80&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-14.44.41.jpg?resize=558%2C149&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-14.44.41.jpg?resize=24%2C6&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-14.44.41.jpg?w=644&ssl=1 644w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1">NOTE: Github stars as a DevRel metric can be controversial (IMO- it is useful as an indicator metric) but feel free to leave a comment below with your thoughts.)</span></p>
<h2><span style="font-weight: 400;">Database Queries </span></h2>
<p><span style="font-weight: 400;">Many of our stats are collected from Segment, and stored in a database (and that database is awesome for in depth detailed analysis). But I want to keep all of my high level statistics and data in one table, so, I’ll use the PostgreSQL connector to extract the datapoints I’d like into my dataset:</span></p>
<p> </p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?resize=300%2C232&ssl=1" alt="3 SQL Actions to add data" width="300" height="232" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?resize=300%2C232&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?resize=558%2C432&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?resize=655%2C507&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?resize=24%2C19&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.53.29.jpg?w=664&ssl=1 664w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"></p>
<p>These Actions are “low-code” in that once you drag & drop the action and make the connections, you still need to create a SQL query to grab the results.</p>
<h2><span style="font-weight: 400;">REST API</span></h2>
<p><span style="font-weight: 400;">There are still a few more data points that I’d like to pull out of other tools. We have a REST API connector that makes this easy: set up your credentials and the headers you need – and you can create a new Action that extracts your data via API. These are also “low-code” but do require some understanding of how to make API calls – in order to set up the credentials properly.</span></p>
<p> </p>
<p><span style="font-weight: 400;">For example: Docker Hub publishes the number of times our Docker Image has been downloaded. We can collect this number Each day using the REST API Action – and adding the endpoint and headers to the Action:</span></p>
<p><span style="font-weight: 400;"><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=300%2C297&ssl=1" alt="" width="300" height="297" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=300%2C297&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=150%2C150&ssl=1 150w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=768%2C761&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=806%2C799&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=558%2C553&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=655%2C649&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?resize=24%2C24&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.23.55.jpg?w=928&ssl=1 928w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.25.27.jpg?resize=300%2C99&ssl=1" alt="" width="300" height="99" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.25.27.jpg?resize=300%2C99&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.25.27.jpg?resize=558%2C184&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.25.27.jpg?resize=24%2C8&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-11.25.27.jpg?w=642&ssl=1 642w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"></span></p>
<h2><span style="font-weight: 400;">Storing & reporting our data</span></h2>
<p><span style="font-weight: 400;">Once we have collected all of the data, we can create a message and post it on Slack for the team to see:</span></p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=300%2C267&ssl=1" alt="Slack Action" width="300" height="267" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=300%2C267&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=768%2C684&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=806%2C718&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=558%2C497&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=655%2C583&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?resize=24%2C21&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.35.34.jpg?w=986&ssl=1 986w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1">The message that is sent to the channel is a <a href="https://realpython.com/python-f-strings/">Python f string</a> with variables added.</p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=945%2C315&ssl=1" alt="" width="945" height="315" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=1024%2C341&ssl=1 1024w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=300%2C100&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=768%2C256&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=1116%2C371&ssl=1 1116w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=806%2C268&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=558%2C186&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=655%2C218&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?resize=24%2C8&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot_2023-04-24_at_12_05_04.jpg?w=1328&ssl=1 1328w" sizes="(max-width: 945px) 100vw, 945px" data-recalc-dims="1"></p>
<p><span style="font-weight: 400;">This is a fun way to update the team on a daily basis…but we also want to chart this data over time. To accomplish this, we have a table in PostgreSQL for our stats, and we just make an INSERT using the prebuilt Postgres Action (again this is low-code as you must write the SQL INSERT command:</span></p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=300%2C64&ssl=1" alt="" width="300" height="64" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=300%2C64&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=768%2C163&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=806%2C171&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=558%2C119&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=655%2C139&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?resize=24%2C5&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.37.49.jpg?w=950&ssl=1 950w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"></p>
<p><span style="font-weight: 400;">The data in Postgres feeds a Grafana dashboard – allowing the team access to the latest data from our metrics – and the best part of it all is that there is no daily toil required. And many folks on the team just go to the dashboard to get the data – the DevRel team is no longer a bottleneck!</span></p>
<h2><span style="font-weight: 400;">Progressive enhancement</span></h2>
<p><span style="font-weight: 400;">As time goes on, more questions about data will arise. </span></p>
<p><span style="font-weight: 400;">As an example, since the number of Actions and RunBooks in GitHub keeps increasing, I was recently asked “how many Actions do we have in GItHub today?” </span></p>
<p><span style="font-weight: 400;">The first few times you are asked a question like this, you can probably get away with waving your hands, and a ballpark figure… but after being asked a few times, I knew I needed a “real” answer. Reusing an existing GitHub Action, I was able to create a file in Github with the counts that I needed. </span><span style="font-weight: 400;">By dragging a new Action into my RunBook, writing a few lines of Python code (and a small change on the Postgres insert), I was able to easily extend the current data collection to include more data. </span></p>
<p><span style="font-weight: 400;"><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=300%2C134&ssl=1" alt="" width="300" height="134" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=300%2C134&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=768%2C342&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=806%2C359&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=558%2C249&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=655%2C292&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?resize=24%2C11&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.43.42.jpg?w=808&ssl=1 808w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"><br>
</span></p>
<p><span style="font-weight: 400;">Aside: We can also leverage these values to create custom badges for the Github readme, and on the website – so creating the data has been a double win!</span></p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?resize=300%2C148&ssl=1" alt="" width="300" height="148" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?resize=300%2C148&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?resize=558%2C275&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?resize=655%2C323&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?resize=24%2C12&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-17.44.33.jpg?w=750&ssl=1 750w" sizes="(max-width: 300px) 100vw, 300px" data-recalc-dims="1"></p>
<h2><span style="font-weight: 400;">Scheduling</span></h2>
<p><span style="font-weight: 400;">Now that I have built a RunBook that collects all of data we need (so far…) -> I want to automate the execution of the RunBook. Using unSkript’s Scheduler, I have set my RunBook to run at midnight GMT every day. </span></p>
<p><img decoding="async" loading="lazy" src="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=945%2C549&ssl=1" alt="" width="945" height="549" srcset="https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=1024%2C595&ssl=1 1024w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=300%2C174&ssl=1 300w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=768%2C446&ssl=1 768w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=1116%2C648&ssl=1 1116w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=806%2C468&ssl=1 806w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=558%2C324&ssl=1 558w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=655%2C381&ssl=1 655w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?resize=24%2C14&ssl=1 24w, https://i0.wp.com/unskript.com/wp-content/uploads/2023/04/Screenshot-2023-04-24-at-15.32.28.jpg?w=1332&ssl=1 1332w" sizes="(max-width: 945px) 100vw, 945px" data-recalc-dims="1"></p>
<p>Now, I have daily reports being created for the team, that require ZERO work on my part!</p>
<h2><span style="font-weight: 400;">Summary</span></h2>
<p><span style="font-weight: 400;">Collecting and aggregating statistics via automation frees the team to can focus on our “real” work: creating more tools and applications – and no longer spend significant time on metric collection. At the same time, everyone has visibility into the project – showing the value of the DevRel team, without impacting their workload.</span></p>
<p><span style="font-weight: 400;">How does your DevRel team collect usage data? If you’d like to give unSkript a try, check out our<a href="https://us.app.unskript.io/"> Free trial</a>. Join our <a href="https://communityinviter.com/apps/cloud-ops-community/awesome-cloud-automation">Slack Channel</a>, and I would be happy to chat with you on strategies to build your RunBook to collect your analytics data. I’ll also be happy to share the skeleton of my RunBook to get you started! | dougsillars |
1,447,247 | Is CDN Right for Your Rails App? and good for large scale applications? | As websites have become more complex and content-heavy, page load time has become a critical factor... | 0 | 2023-04-25T06:15:29 | https://dev.to/ahmadraza/is-cdn-right-for-your-rails-app-and-good-for-large-scale-applications-58ih | ruby, rails, programming, beginners | As websites have become more complex and content-heavy, page load time has become a critical factor in user experience. One solution to speed up page load times is to use a Content Delivery Network (CDN). In this blog post, we'll discuss what a CDN is, why it's important, and whether you should use one in your Rails application.
## What is a CDN?
A CDN is a network of servers distributed around the world that store cached versions of your website's static assets, such as images, JavaScript, and CSS files. When a user requests a webpage from your application, the CDN will serve the assets from the server that is closest to the user, reducing the time it takes for the content to be delivered.
---
## Why use a CDN?
There are several benefits to using a CDN:
### Faster Page Load Times
By serving content from a server that is closer to the user, CDNs can dramatically reduce the time it takes for your website to load. This is especially important for users who are located far away from your application's server.
### Reduced Server Load
When you use a CDN, your application's server doesn't have to serve static assets, which can help reduce server load and improve overall performance.
### Increased Availability
CDNs are designed to handle high volumes of traffic, so they can help ensure that your website remains available during periods of high demand.
### Improved Security
Many CDNs offer additional security features, such as DDoS protection and SSL certificates, that can help protect your website from attacks.
---
## Should You Use a CDN in Rails?
Whether you should use a CDN in your Rails 7 application depends on a few factors:
**Size of Your Application**
If your application is relatively small and doesn't have a lot of static assets, a CDN might not provide much benefit.
**Geographical Distribution of Your Users**
If your application has users located all over the world, a CDN can help ensure that your website loads quickly for everyone.
**Cost**
CDNs can be expensive, especially for smaller applications. Be sure to weigh the cost of a CDN against the potential benefits before making a decision.
**Security**
If security is a concern, a CDN can offer additional protection for your website.
---
## How to Use a CDN in Rails
If you decide to use a CDN in your Rails 7 application, you can do so by configuring your web server to serve your static assets from the CDN's server. You'll need to provide the CDN with the URL for your assets, and the CDN will handle the rest.
### Configuring the Asset Host
In your `config/application.rb` file, you can set the `config.asset_host variable` to the URL for your CDN. For example:
```
config.asset_host = 'https://cdn.example.com'
```
This will cause all of your asset tags to use the CDN's URL.
### Configuring Rails to Serve Assets
If you're using the default Rails asset pipeline, you'll need to modify your web server's configuration to serve your assets from the CDN's server. If you're using a web server like Nginx or Apache, you can configure it to serve assets from the CDN by adding the following configuration:
```
location ~ ^/assets/ {
expires 1y;
add_header Cache-Control public;
# Set the CDN as the asset host
proxy_set_header Host cdn.example.com;
# Serve assets from the CDN
proxy_pass https://cdn.example.com;
}
```
### Conclusion
In conclusion, using a CDN in Rails 7 can be a great way to improve the performance of your web application. However, it's important to consider the potential downsides (such as additional complexity and cost) before making a decision. | ahmadraza |
1,447,295 | Layers and Layers | I am an old new newbie in the development scene since 2004 or so , I think I had a post regarding my... | 0 | 2023-04-25T06:37:47 | https://dev.to/tumorb9/layers-and-layers-5h33 | beginners, codenewbie, mentalhealth | I am an old new newbie in the development scene since 2004 or so , I think I had a post regarding my vacation from IT and after that social life in general - don`t ask mental health issues perhaps should write it on reddit or make a video on tiktok- and here what I sense since my return to the scene , the basics does not change and logic is the same which is great.
problem or challenge here is : like this cake , development has **layers and layers** , and I get it it`s to simplify and speed the development phase or is there another purpose , like perhaps pushing and marketing this product or that as essential for marketing purposes.
The challenge for development scene nowadays is keeping track of the concepts and technologies : automation, testing ,collaboration ,devops , frontend , backend , middle.
It is an adventure but could be super overwhelming , till that time …have a layer of cake and a cup of coffee | tumorb9 |
1,447,328 | Password Hashing 101: All About Password Hashing and How it Works | Most people have a love-hate relationship with passwords. On the one hand, we need them to keep our... | 0 | 2023-04-25T07:27:27 | https://mojoauth.com/blog/password-hashing-101-all-about-password-hashing-and-how-it-works/ | webdev, cybersecurity, datasecurity, passwordhashing | **Most people have a love-hate relationship with passwords. On the one hand, we need them to keep our online accounts safe. But on the other hand, they can be hard to remember and easy to forget.**
And then there are the security concerns. With data breaches becoming more common, it’s important to choose passwords that are strong and secure. But is that enough to secure passwords? But what does that mean, exactly?
In this article, we’ll take a look at what password hashing is and why it’s important. We’ll also give you some tips on how to choose strong passwords and keep them safe.
## **What is password hashing?**
Password hashing is a process of using a hash function to convert a password into an unrecognizable series of characters. This makes it difficult for malicious actors to gain access to the password, as the characters are not easily decipherable. This string cannot be deciphered or converted back to the original password, thus allowing it to be stored securely in a database.
Encryption and hashing are two different terms used in cryptography and data security. Here hashing should not be confused with encryption. Encryption and hashing are two different processes but both are used to protect data by converting them to an unrecognizable series of characters so that data cannot be easily interpreted. Encryption scrambles the data using a key and converts a normal readable message into a garbage message or not readable message known as Ciphertext so that only people with the correct key can read the data. Encryption is used to protect sensitive data from unauthorized access and is very popular
Whereas hashing is a process of converting data into a fixed-length code. Hashing works by taking a large amount of data and running it through a mathematical algorithm, which results in a unique, irreversible, fixed-length code. It is used to verify the integrity of data and to ensure that data has not been modified.
The most important key thing to remember about hashing is that it is a one-way process. This is important for security, as it means that even if a hacker gets access to the database, they will not be able to see the passwords.
Example-
`For example, the SHA256 hash of “Liman1000” is “1cde884c4ba81f70a4551714e89a94ca7f25c89c14eedc4b11b881a783bd1767”`
Similarly,
`the SHA256 hash of most common password “qwerty12345” is “f6ee94ecb014f74f887b9dcc52daecf73ab3e3333320cadd98bcb59d895c52f5”`
## **History of password hashing**
As early as the 1970s, computer scientists began exploring solutions to make passwords more secure, long before the emergence of the World Wide Web in the 1990s.
In the 1970s, Robert Morris Sr., a cryptographer at Bell Labs, developed the concept of “hashing”. This process takes a string of characters and converts it into a numerical code that represents the original phrase, thus eliminating the need to store the password itself in the password database.
This technology was adopted in early UNIX-like operating systems, which have since become a staple across a variety of mobile devices, workstations, and other systems, such as Apple’s macOS and Sony’s PlayStation 4.
## **Type of hashing algorithm**
There are many different algorithms that can be used for password hashing. We have explained a few of them below.:
**1. MD5 (Message Digest Algorithm 5):** MD5 is a widely used hashing algorithm that is employed for digital signatures and other security-related applications. MD5 is an algorithm that produces a 128-bit hash value from an arbitrary length of data. This is a one-way cryptographic function, meaning that the original data cannot be derived from the generated hash. MD5 is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data.
**2. SHA-1 (Secure Hash Algorithm 1):** SHA-1 is a hashing algorithm that produces a 160-bit hash value from an arbitrary length of data. SHA-1 is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. SHA-1 is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**3. SHA-2 (Secure Hash Algorithm 2):** SHA-2 is a set of hashing algorithms developed by the National Security Agency (NSA). SHA-2 is an improvement over the SHA-1 algorithm and produces a 256-bit hash value from an arbitrary length of data. SHA-2 is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. SHA-2 is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**4. SHA-3 (Secure Hash Algorithm 3):** The SHA-3 family of hash functions consists of SHA3-224, SHA3-256, SHA3-384, SHA3-512, and SHAKE128/256, which produce hash values of varying lengths (224, 256, 384, and 512 bits, respectively). These algorithms are seen as more secure than SHA-2.
**5. RIPEMD-160 (RACE Integrity Primitives Evaluation Message Digest):** RIPEMD-160 is an algorithm that generates a 160-bit hash value from any amount of data. This hash is used to verify the integrity of the data and to protect it from changes. This algorithm is specifically designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. RIPEMD-160 is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**6. BLAKE2 (BLAKE2s):** BLAKE2 is a hashing algorithm that produces a 256-bit hash value from an arbitrary length of data. BLAKE2 is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. BLAKE2 is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**7. Whirlpool:** Whirlpool is a hashing algorithm that produces a 512-bit hash value from an arbitrary length of data. Whirlpool is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. Whirlpool is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**8. Tiger:** Tiger is a hashing algorithm that produces a 192-bit hash value from an arbitrary length of data. Tiger is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. Tiger is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**9. Skein:** Skein is a hashing algorithm that produces a 512-bit hash value from an arbitrary length of data. Skein is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. Skein is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**10. HMAC (Hash-based Message Authentication Code):** HMAC is a hashing algorithm that produces a 128-bit hash value from an arbitrary length of data. HMAC is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. HMAC is widely used in many security applications, including digital signatures and message authentication codes (MACs).
**11. GOST (GOST-34.11):** GOST is a hashing algorithm that produces a 256-bit hash value from an arbitrary length of data. GOST is an algorithm that is designed to be extremely difficult to reverse, making it useful for verifying the integrity of data. GOST is widely used in many security applications, including digital signatures and message authentication codes (MACs).
In addition to choosing a secure password hashing algorithm, it is also important to use good password hygiene to ensure the security of user accounts.
**PBKDF2 (Password-Based Key Derivation Function 2):** This is a key derivation function that is designed to be slow and resource-intensive, making it more difficult for attackers to crack passwords. It is often used in combination with a cryptographic hash function, such as SHA-2, to create a secure password hash.
**Argon2:** This is a key derivation function that was designed to be more secure and resistant to attacks than PBKDF2. It has several parameters that can be adjusted to increase the difficulty of cracking passwords, including the amount of memory used, the number of iterations, and the parallelism.
**bcrypt:** This is a key derivation function that was designed specifically for password hashing. It is based on the Blowfish encryption algorithm and uses a variable-length salt to make it more difficult to crack passwords.
To sum up, a wide variety of hashing algorithms are available, each offering varying levels of protection. Among the most popular hashing algorithms for digital signature and other security purposes are MD5, SHA-1, SHA-2, RIPEMD-160, BLAKE2, Whirlpool, Tiger, Skein, HMAC, and GOST. Each algorithm is designed to be extremely difficult to reverse, making them useful for verifying the integrity of data.
## **How do hashing algorithms work**
Hashing algorithms are mathematical functions used to create a unique, fixed-length output (known as a hash or message digest) from an input of any size. These algorithms are used to ensure data integrity, validate digital signatures, and authenticate messages. To generate a hash, the algorithm takes an input, such as a file or a string of data, and processes it through an algorithm that produces a unique, fixed-length output.
This output is usually represented as a hexadecimal string, which is much shorter than the original data. Hashing algorithms are designed to be one-way functions, making it difficult to determine the original data from the hash.
Hashing algorithms are also used to authenticate messages and digital signatures, as the sender can generate a hash of the message and sign it with their private key. The receiver can then use the sender’s public key to verify that the message has not been altered during transit.
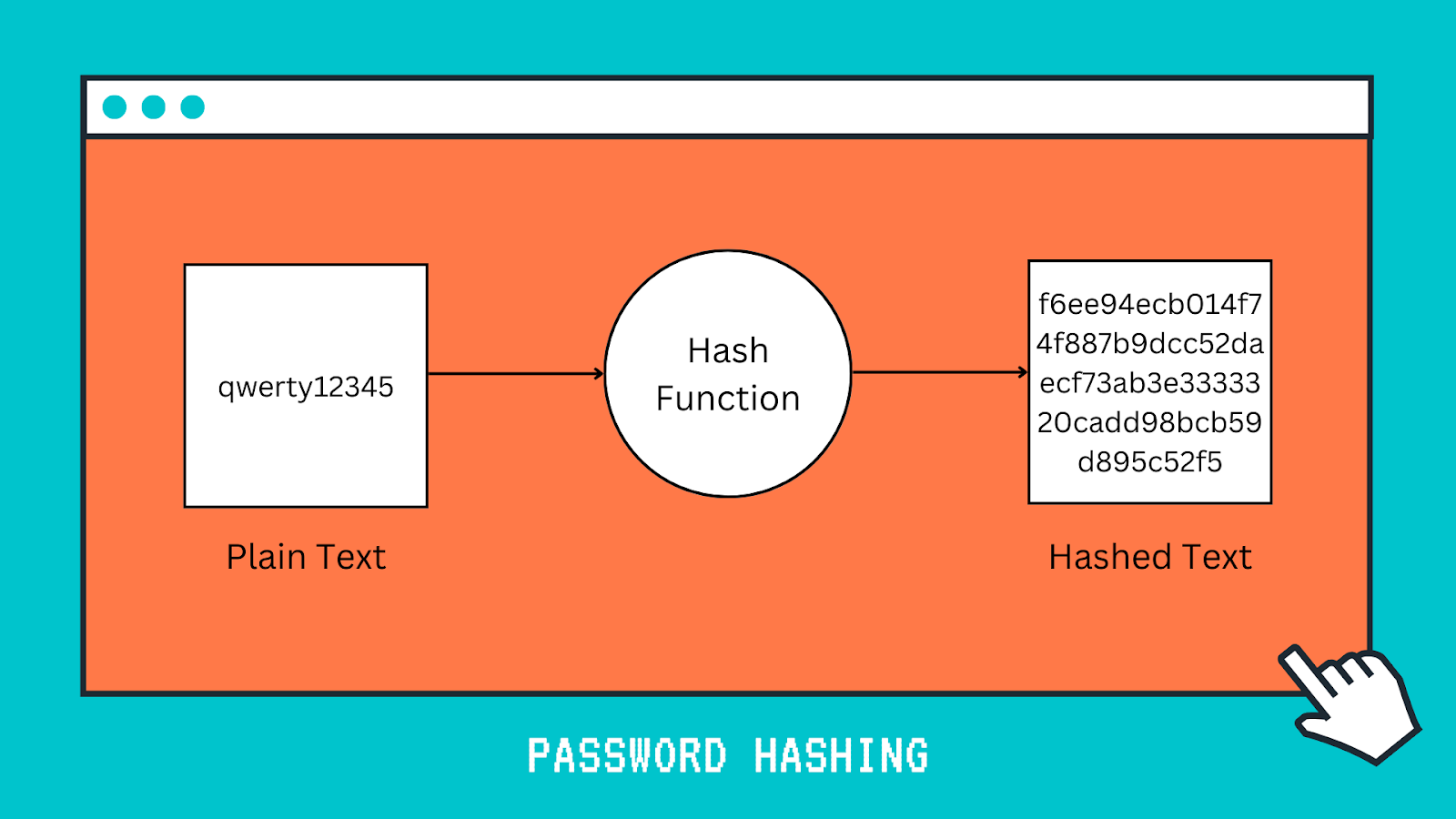
## **Recommended algorithm for hashing**
The Secure Hash Algorithm (SHA) family of algorithms is the most widely used and recommended for hashing. It comprises of a range of algorithms, with SHA-256 and SHA-512 offering higher levels of security and SHA-224 as a lighter version of SHA-256. SHA-2 is regularly used for digital signatures, authentication and to ensure message integrity.
## **Why password hashing is important?**
Password hashing is an essential step of data security in order to protect data from unauthorized access. It involves taking a user’s password and transforming it into a random string of characters, also known as a “hash”. This hash is used to verify the user’s identity and protect the user’s data. This process is designed to make the password unreadable and therefore, more secure. By making the password unreadable, it prevents malicious actors from accessing the data.
Password hashing is a must security measure as it helps protect user passwords from being accessed by attackers in a commonly readable format, at least it doesn’t directly expose. Hashing algorithms create a unique and complex hash for each user, making it difficult for an attacker to guess the password. Additionally, the hashes are very difficult to reverse thus making it more harder for attackers to use brute-force attacks to guess passwords. This helps protect users from having their passwords exposed and their accounts compromised.
Finally, password hashing is important because it increases the security of stored passwords. By hashing a user’s password, it ensures that no one can view the original password, even if the data is compromised.
Therefore, even if a hacker were to gain access to the stored data, they would not be able to view the user’s original password. In summary, password hashing is an important security measure that helps protect user data from unauthorized access. It makes passwords difficult to guess and increases the security of stored passwords. Therefore, it is an essential security measure for any online system that requires a user to enter a password.
In summary, a few key reasons why password hashing is important:
**Security:** As mentioned above, password hashing is a one-way process, meaning that it is not possible to reverse the process and retrieve the original password from the hash. This makes it much more difficult for attackers to access user passwords, even if they manage to breach the database.
**Scalability:** Password hashing algorithms are designed to be fast and efficient, making them suitable for large-scale applications with millions of users. This is important because the hashing process needs to be performed each time a user logs in, and a slow hashing algorithm could cause performance issues for the application.
**Compatibility:** Password hashing algorithms are designed to be compatible with a wide range of systems and platforms, making it easy to integrate into any application.
## **Enhancing security with the addition of salt in hashing:**
An improved way to store passwords Hashed passwords are not unique to themselves due to the deterministic nature of the Hash function: when given the same input, the same output is always produced. If User A and User B both choose qwerty12345 as a password, their hash would be the same:
`SHA256 hash for User A for password “qwerty12345” is “f6ee94ecb014f74f887b9dcc52daecf73ab3e3333320cadd98bcb59d895c52f5”`
`SHA256 hash for User B for password “qwerty12345” is “f6ee94ecb014f74f887b9dcc52daecf73ab3e3333320cadd98bcb59d895c52f5”`
Password salting is a technique used to increase the security of stored passwords. It involves adding random data, known as a salt, to each password before it is hashed. This random data makes it more difficult for attackers to crack the passwords, even if they have access to the hashed version of them.
Salt values are stored along with the hashed passwords so that when a user attempts to log in, the salt can be retrieved and used to generate the same hash that was stored. This makes it much harder for attackers to guess the passwords, even if they have access to the database.
`For example, let’s consider the same example where the password for both User A and User B is “qwerty12345”.`
`Similarly, SHA256 hash for User A and User B for password “qwerty12345” is “f6ee94ecb014f74f887b9dcc52daecf73ab3e3333320cadd98bcb59d895c52f5”`
To salt this password, a random string of characters is added to the end.
`For User A → Salt added is - @hjS7 Password - qwerty12345 The salted version of the password is - qwerty12345@hjS7 Now SHA256 hash for salted version of the password “qwerty12345@hjS7” is “1103d94d5c848575f87f7fbe843effdcea4198fead77a24400c43774e4cfac4a”`
`For User B → Salt added is - 98@*st6 Password - qwerty12345 The salted version of the password is - qwerty1234598@*st6 SHA256 hash for salted version of the password “qwerty1234598@*st6” is “1cecec3a0606a716d6f4ca2c285643d4aae169cfb1aa3c8bbb88fd09f2102afa”`
If we compare the salted version of the password for both User A and User B having the same password ‘qwerty12345’.
`User A: “1103d94d5c848575f87f7fbe843effdcea4198fead77a24400c43774e4cfac4a”`
`User B: “1cecec3a0606a716d6f4ca2c285643d4aae169cfb1aa3c8bbb88fd09f2102afa”`
As you see, for the same password, the hash generated is different. This is making it more complex to reverse engineer in extracting the passwords.
## **Summary**
In conclusion, password hashing is a technique used to secure user passwords by transforming a plaintext password into a complex string of characters called a hash. This hash is then stored in a database and compared to the user’s input when they attempt to log in, ensuring only authorized users can access the system.
Hashing passwords prevents the plaintext password from ever being stored, preventing it from being stolen in the event of a data breach. It also allows the website to verify the user’s identity without needing to store the plaintext password. When implementing a secure password hashing system, it is important to use a strong hashing algorithm such as bcrypt. Bcrypt is designed to be computationally expensive, making it difficult for attackers to brute-force guess the plaintext passwords from the hashes.
## **Simplify authentication with MojoAuth**
You can minimize the overhead of hashing, salting, password security, password management, and all password-related issues with MojoAuth.
Mojoauth passwordless authentication helps businesses increase customer engagement by providing customers with a secure and convenient way to log into their accounts. With Mojoauth, customers can authenticate with a single click, without having to remember a password. This simplifies the login process, making it easier and faster for customers to access their accounts and complete their desired actions. | andy789 |
1,447,441 | Roll of Network Management in AUTOSAR | Hello All, I'm Pooja Shiraguppe, and I work at Luxoft India.Here I would like to provide a brief... | 0 | 2023-04-25T10:41:32 | https://dev.to/pooja1008/roll-of-network-management-in-autosar-4jbn | autosarnm, ecucommunication, faultdetectionandhandling, efficientvehicleoperation | Hello All, I'm Pooja Shiraguppe, and I work at **Luxoft India**.Here I would like to provide a brief knowledge about "Roll of Network Management in AUTOSAR."
### Introduction To AUTOSAR CAN Network Management (CanNM)
CanNM is part of AUTOSAR, a standardized automotive software architecture. CanNM is responsible for managing CAN (Controller Area Network) communication networks. CAN is a widely used communication protocol in the automotive industry for interconnecting electronic control units (ECUs). CanNM provides services such as network initialization, state transitions, and error handling for CAN networks. CanNM can operate in master or slave mode, depending on the role of the ECU in the network. CanNM supports different communication modes, such as event-triggered, cyclic, or mixed. CanNM also supports different topologies like star, bus, or hybrid.CanNM is designed to be platform-independent & configurable, to adapt to different hardware and software environments. CanNM is part of the AUTOSAR Basic Software (BSW) layer, which provides a common interface for the application software to access the hardware and network services.
### Functions Of CAN Network Management (CanNM)in AUTOSAR:
- CanNM is an essential component of the AUTOSAR software architecture that provides a standardized approach to managing the communication networks in modern vehicles. By offering a common interface for CAN network initialization, configuration, and operation, CanNM enables more efficient and reliable communication between the electronic control units (ECUs) that control various automotive systems.
- One of the primary functions of CanNM is to facilitate the startup and shutdown of the CAN network, ensuring that all the nodes are synchronized and operational before any data transmission occurs. CanNM also manages the transition of nodes between different network states, such as sleep mode, normal mode, and bus-off mode, in response to events or commands.
- CanNM supports different network topologies, including the popular bus topology, which enables multiple ECUs to communicate over a single shared bus. CanNM manages the arbitration process for messages on the bus, ensuring that only one ECU can transmit at a time and that higher-priority messages are transmitted first.
- CanNM provides various diagnostic and error-handling functions to detect and report faults in the CAN network, such as message lost, message corruption, or bus-off condition. CanNM can also trigger fault-tolerant mechanisms, such as redundant communication paths, to ensure the continued operation of critical automotive functions.
- CanNM supports different communication modes, such as event-triggered, cyclic, or mixed, to suit various application requirements. For example, the event-triggered communication mode sends messages only when certain events occur, while the cyclic communication mode sends messages periodically at fixed intervals. Mixed mode combines both modes to achieve a balance between responsiveness and efficiency.
Below the figure shows the different Nodes connected to the cluster.
![Different Nodes connected to Custer] (https://dev-to-uploads.s3.amazonaws.com/uploads/articles/27xuegewthsumqewxfau.png)
###AUTOSAR CAN Network Management State Machine: -
###1. Prepare Bus-Sleep Mode:
This mode is used to transition from Normal Operation Mode to BUS Sleep Mode gradually, by allowing pending transmissions and receptions to complete before entering the sleep mode. In this mode, the node sends a message to inform other nodes that it is preparing to sleep and waits for their responses before entering sleep mode.
### 2. BUS Sleep Mode:
In this mode, the CAN node stops transmitting and receiving messages but remains synchronized with the network by monitoring the bus activity. The node can wake up from this mode when it receives a wake-up pattern or message from another node or a local event.
### 3. Network Mode:
When the network Mode is entered from Bus-Sleep Mode or Prepare Bus sleep Mode, the repeat message state shall be entered by default.
Network Mode has 3 types.
### • Repeat Message Mode (Go to Mode):
This mode is used to re-transmit a previously sent message that has not been acknowledged by the recipient. In this mode, the node sends the same message with the same identifier and data payload, hoping that the recipient will receive it successfully.
### • Normal Operation Mode:
This is the default mode of the CAN network, where nodes can transmit and receive messages according to the arbitration rules and protocol. The bus is not in an error state in this mode, and the nodes can operate normally.
### • Ready Sleep Mode:
This mode is similar to BUS Sleep Mode but with an additional feature of a local wake-up source that can initiate a wake-up event without external stimuli. In this mode, the node consumes less power than in Normal Operation Mode but remains ready to wake up quickly.
The below figure shows the Network Management State Machine.
![Network Management State Machine] (https://dev-to-uploads.s3.amazonaws.com/uploads/articles/de1e2lsxppjzzmto15cd.png)
### Preventing Race Conditions and State Inconsistencies in AUTOSAR CanNM:
To prevent race conditions and state inconsistencies between Network and Mode Management in AUTOSAR CanNM, the transition from Bus-Sleep Mode to Network Mode is not automatic. Instead, CanNm will notify the upper layers of the software stack, which are responsible for making the decision to wake up. During Bus-Sleep Mode in AUTOSAR CanNM, the reception of Network Management Protocol Data Units (PDU) must be managed according to the current state of the ECU's shutdown or startup process. This approach ensures that the wake-up decision is made with the necessary context and avoids potential conflicts between different software components.
### Conclusion :
AUTOSAR CAN Network Management (CanNM) is a critical component of the AUTOSAR software architecture, responsible for managing CAN communication networks in modern vehicles. CanNM provides various functions such as network initialization, state transitions, and error handling for CAN networks, and supports different communication modes and topologies to suit various application requirements. Additionally, CanNM is designed to be platform-independent and configurable to adapt to different hardware and software environments. However, to prevent race conditions and state inconsistencies between Network and Mode Management, CanNM's transition from Bus-Sleep Mode to Network Mode is not automatic, and the upper layers of the software stack are responsible for making the wake-up decision.
| pooja1008 |
1,447,449 | Top 10 Laravel Security Improvements You Need to Implement Today | Laravel is a popular PHP framework that is known for its ease of use, robustness, and security.... | 0 | 2023-04-25T09:54:39 | https://dev.to/alnahian2003/top-10-laravel-security-improvements-you-need-to-implement-today-4ge9 | laravel, security, tutorial, webdev |

Laravel is a popular PHP framework that is known for its ease of use, robustness, and security. However, like any other web application, Laravel sites are not immune to security threats. To ensure your Laravel site is secure, here are the top 10 Laravel security improvements you need to implement today.
## 1. Implement Password Hashing
Laravel comes with built-in password hashing, which is a security feature that hashes user passwords, making them difficult to decipher if a security breach occurs. When users enter their passwords, they are hashed and stored in the database, which means that even if the database is hacked, the passwords will remain secure.
## 2. Use CSRF Protection
Cross-Site Request Forgery (CSRF) is an attack that involves tricking users into performing actions on your site that they did not intend to perform. To prevent CSRF attacks, Laravel provides built-in CSRF protection. This feature generates a unique token for each user session, which is then used to verify that all form submissions are legitimate.
## 3. Implement XSS Protection
Cross-Site Scripting (XSS) is an attack that involves injecting malicious code into your site, usually via user input. Laravel provides built-in XSS protection by automatically escaping any user input that is output to the page. However, it's still important to sanitize user input and validate it on the server-side.
## 4. Use HTTPS
Using HTTPS is a crucial security improvement that encrypts all traffic between the client and server, making it much harder for attackers to intercept and read sensitive data. Laravel makes it easy to implement HTTPS by providing built-in support for HTTPS redirection.
> Read also: [Laravel Security: Advanced Techniques to Keep Your Web App Safe](https://dev.to/alnahian2003/laravel-security-advanced-techniques-to-keep-your-web-app-safe-7k2)
## 5. Implement Two-Factor Authentication
Two-Factor Authentication (2FA) is an extra layer of security that requires users to provide two forms of identification to access their accounts. Laravel provides built-in support for 2FA, which can be easily implemented with the Laravel Two-Factor Authentication package.
## 6. Use Content Security Policy
Content Security Policy (CSP) is a security feature that allows you to control which resources (such as scripts, stylesheets, and images) can be loaded by your application. By using CSP, you can prevent attackers from injecting malicious code into your application via XSS attacks. Laravel provides a CSP package that makes it easy to implement CSP in your application.
## 7. Harden Your Server Security
In addition to securing your Laravel application, it's also important to harden your server security. This includes measures such as using strong passwords, disabling root login, limiting SSH access, and installing firewalls.
## 8. Use Laravel Debugbar Sparingly
Laravel Debugbar is a popular debugging tool that provides developers with real-time debugging information. However, using Debugbar in production environments can pose security risks. It's recommended to use Debugbar only in development environments and to disable it in production environments.
## 9. Regularly Update Laravel and Dependencies
Laravel and its dependencies are regularly updated to fix security vulnerabilities and bugs. It's important to keep your Laravel installation up-to-date by regularly updating Laravel and its dependencies.
## 10. Perform Regular Security Audits
Performing regular security audits of your Laravel application is essential to identifying and fixing vulnerabilities. Tools such as OWASP ZAP and Nikto can be used to scan your application for common security issues, or you can hire a professional security auditor to perform a more thorough analysis.
---
By implementing these top 10 Laravel security improvements, you can help ensure that your Laravel site is secure and protected against common security threats. Remember, security is an ongoing process, and it's important to stay up-to-date with the latest security best practices and technologies.
> Read More 👉
• [Top 30 Interesting Facts About Laravel](https://dev.to/alnahian2003/top-30-interesting-facts-about-laravel-17cj)
• [Escape from Tutorial Hell: A Comprehensive Guide](https://dev.to/alnahian2003/escape-from-tutorial-hell-a-comprehensive-guide-3nh2)
• [Top 10 Unique Laravel Web App Ideas](https://dev.to/alnahian2003/top-10-unique-laravel-web-app-ideas-1eeb)
| alnahian2003 |
1,447,453 | Getting started with sentiment analysis. | Sentiment analysis is an approach to natural language processing (NLP) that studies the subjective... | 22,710 | 2023-04-26T07:40:00 | https://wainainapierre.hashnode.dev/getting-started-with-sentiment-analysis | sentimentanalysis, datascience, machinelearning, data | **Sentiment analysis** is an approach to natural language processing (NLP) that studies the subjective information in an expression. When we say subjective information, this means that the information is subject to change from person to person and it includes the opinions, emotions, or attitudes towards a topic, person or entity which people tend to express in written form. These expressions can be classified as positive, negative, or neutral. Machine Learning algorithms review this textual data and extract valuable information from it and then brands and businesses make decisions based on the information extracted.
_Here are a few advantages of Sentiment Analysis especially in Business:_
1. It helps you understand your audience and their specific needs.
2. You can gather actionable data about your products based on critiques and suggestions given by customers.
3. You can get meaningful insights about your brand and the kind of emotion it invokes among the people.
4. Conduct a comprehensive competitive analysis and gauge your product against that of your competitor.
5. Monitoring long-term brand health by tracking sentiments over long periods ensures that you have a positive relationship with your target customers.
It would be very expensive in terms of time and cost to have human beings read all customer reviews to determine whether the customers are happy or not with the business, service, or products. This necessitates the use of machine learning techniques such as sentiment analysis to achieve similar results at a large scale. For example, imagine a large company like amazon going through all reviews they receive about their products one by one, it would take ages and a lot of manpower to do so. A machine learning model would be the best approach in such a scenario.
In this article, you will practically learn how to go about sentiment analysis using Twitter sentiments. By the end of the article, you will have developed a Sentiment Analysis model to categorize a tweet as either Positive or Negative.
The dataset being used can be gotten from Kaggle.com using this link: https://www.kaggle.com/datasets/kazanova/sentiment140
This dataset contains 1,600,000 tweets extracted using the Twitter API and they have been annotated (0 = negative, 4 = positive) and can be used to detect sentiments.
Take note that I have used Jupyter Notebooks.
Make sure all relevant imports are present as shown in the code snippet below:
Load the dataset into your notebooks and plot the distribution of the tweets based on whether they are positive or negative as shown:
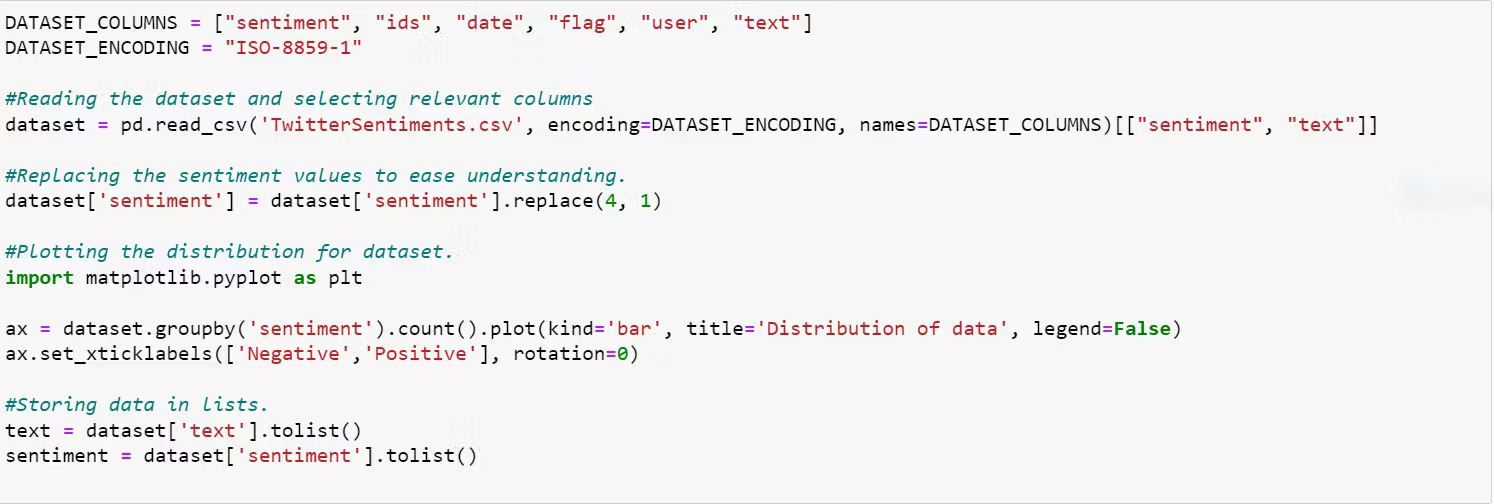
You should expect the output shown below:
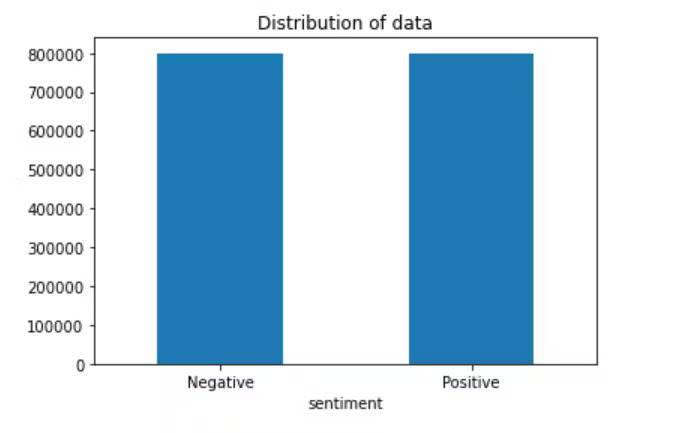
Perform Text Processing which is transforming text into a more digestible form so that machine learning algorithms can perform better.
The Text Preprocessing steps that have been taken are:
1. Converting each text into lowercase.
2. @Usernames have been replaced with the word "USER". (eg: "@pierre_wainaina" to "USER")
3. Characters that are neither numbers nor letters of the alphabet have been replaced with a space.
4. Replacing URLs: Links starting with "http" or "https" or "www" are replaced by "URL".
5. Short words with less than two letters have been removed.
6. Stopwords, which are words that do not add much meaning to a sentence, have been removed. (eg: "a", "she", "have")
7. Words have been lemmatized. Lemmatization is the process of converting a word to its base form. (e.g: “worst” to “bad”)
8. Emojis have been replaced by using a pre-defined dictionary containing the emojis and their meaning. (eg: ":)" to "EMOJIsmile")
9. 3 or more consecutive letters have been replaced by 2 letters. (eg: "Heyyyy" to "Heyy")

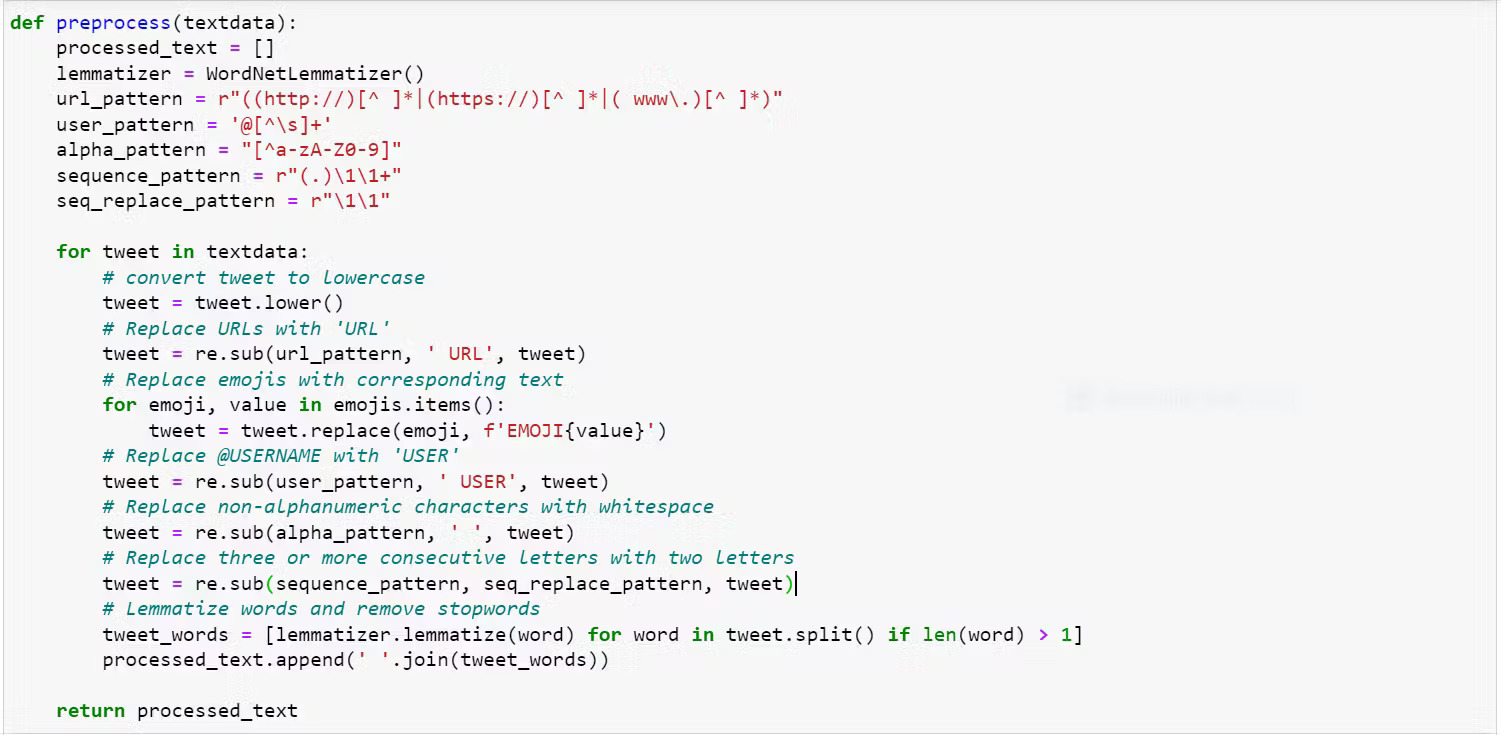
## Analyzing the data
Let's analyze the pre-processed data to get to understand it. Below is code for plotting Word Clouds for Positive and Negative tweets from the dataset and it will give a visual output of the words that occur most frequently.

Below is the output of the word cloud for negative tweets:

## Splitting the Data
We shall split the pre-processed data into 2 sets :
Training Data: The dataset on which the model would be trained will contain 95% of the data.
Test Data: The dataset on which the model would be tested against will contain 95% of the data.

## TF-IDF Vectoriser
This is a tool that helps determine the significance of words while trying to comprehend a dataset. For example, if a dataset contains an essay about "My Car", the word "a" might appear frequently and have a higher frequency than other words such as "car", "engine", or "horse power". These words however, may carry very important information but have lower frequency as compared to words like "the" or "a".
This is where the TF-IDF method comes into play, which assigns a weight to each word based on its relevance to the dataset.
The TF-IDF Vectorizer transforms a set of unprocessed documents into a matrix of TF-IDF characteristics, and is typically trained only on the X_train dataset.
As seen in the code below, X_train and X_test dataset have been transformed into matrix of TF-IDF Features by using the TF-IDF Vectoriser. These datasets will be used to train and test the model.
## Creating and Evaluating Models
We will create 3 models for our sentiment analysis.
- Bernoulli Naive Bayes (BernoulliNB)
- Linear Support Vector Classification (LinearSVC)
- Logistic Regression (LR)
As seen in the very first output, our dataset is not skewed and therefore we choose accuracy as our evaluation metric. We are plotting the Confusion Matrix to get an understanding of how our model is performing on both classification types, either positive or negative as seen in the code below.
We can now test to see if our model can classify the tweets correctly.
The output should be as follows and our model works well as it can classify tweets as either positive or negative.
 | wainainapeter |
1,447,596 | Why you should use IMDSv2 - How to get information about ec2 from ec2 | The Instance Metadata Service (IMDS) allows EC2 instances to access metadata about themselves, such... | 0 | 2023-04-25T12:11:59 | https://dev.to/aws-builders/why-you-should-use-imdsv2-how-to-get-information-about-ec2-from-ec2-483a | The Instance Metadata Service (IMDS) allows EC2 instances to access metadata about themselves, such as instance ID, IP address, AMI ID and more.
IMDSv1 is the old way and is no longer recommended by AWS.
```
curl http://169.254.169.254/latest/meta-data/instance-id
```
Using IMDSv2 on EC2 instances in AWS Cloud provides a more secure way to access instance metadata and is recommended by AWS. It offers built-in protections against common types of metadata service exploitation. Additionally, it allows for more granular control over access to instance metadata, which can help reduce the risk of unauthorized access.
```
TOKEN=`curl -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"`
curl -H "X-aws-ec2-metadata-token: $TOKEN" -v http://169.254.169.254/latest/meta-data/instance-id
```
Overall, using IMDSv2 on EC2 instances in AWS Cloud can help improve the security of your applications and data, and is therefore worth considering if you are using EC2 instances in your infrastructure.
If you want to know more, learn about good practices and receive practical advice, I invite you to watch my video: [https://youtu.be/91stm1cEIG4](https://youtu.be/91stm1cEIG4)
| wlepczynski | |
1,447,637 | An Illustrated Cheat Sheet to Apache Kafka | If you're like me, some things take a while until they stick. This illustrated quick start guide is... | 0 | 2023-04-25T13:28:43 | https://dev.to/ciscoemerge/an-illustrated-cheat-sheet-to-apache-kafka-i22 | kafka |
If you're like me, some things take a while until they stick.
This illustrated quick start guide is here to assist you while working with Kafka.
Anything missing? Want to add more? Let us know in the comments!
| schultyy |
1,447,767 | Contributing to open-source mechanical keyboard firmware | Built the NCR-80 last year, great-looking board especially if you like the retro aesthetic, and is a... | 0 | 2024-03-11T13:11:27 | https://jduabe.dev/posts/2023/ncr-80-qmk-via/ | qmk, via | ---
title: Contributing to open-source mechanical keyboard firmware
published: true
date: 2023-04-25 09:16:02 UTC
tags: qmk, via
canonical_url: https://jduabe.dev/posts/2023/ncr-80-qmk-via/
cover_image: https://res.cloudinary.com/j4ckofalltrades/image/upload/v1645196848/keebs/ncr80/ncr-80_vnf9hq.jpg
---
Built the [NCR-80](https://jduabe.dev/posts/2022/ncr-80) last year, great-looking board especially if you like the retro aesthetic, and is a pleasure to type on.
One thing I did notice was that the product listing points to a Google Drive link to the precompiled [firmware](https://drive.google.com/drive/folders/1e3mjUg-N15SFVrExlBiI01-XOKpPm9ry?usp=sharing), but it hasn’t been added to the QMK and VIA repositories. I thought this would be a good weekend project (**Spoiler**: it took longer than a weekend).
I wrote the steps of how I got it done (the steps also apply to any keyboard firmware).
## Converting KBFirmware JSON to QMK
The starting point is to convert the KBFirmware JSON from the provided “QMK” files from the product listing, and then converting them to QMK formatted files.
There are a couple of tools that can be used for this purpose:
- Recommended: [KBFirmware JSON to QMK Parser](https://noroadsleft.github.io/kbf_qmk_converter)
- Deprecated: [Keyboard Firmware Builder](https://kbfirmware.com)
The resulting files will be the base of the QMK firmware for the keyboard.
## Creating a QMK pull request
Make sure to read the [contribution guide](https://docs.qmk.fm/#/contributing?id=keyboards) as a first step. It is also a good idea to check out other supported keyboard firmware to get a feel for the directory structure, and conventions in use.
A keyboard firmware folder (simplified example) should look something like:
```
mt
|-- ncr80
| |-- keymaps
| |-- default
| |-- keymap.c
|-- info.json
|-- readme.md
`-- rules.mk
```
In cases where keyboards have multiple versions or revisions e.g. rev1, rev2 or hotswap/soldered, the directory structure will look different; refer to QMK’s contribution guide linked above.
Link to the pull request on GitHub for reference: [[Keyboard] Add NCR-80](https://github.com/qmk/qmk_firmware/pull/19130)
## Creating a VIA pull request
In order to add VIA support for a keyboard, it is required to enable the VIA feature in QMK, and adding a `via`-compatible keymap for the keyboard. You can check out the QMK pull request linked above; look for the `keymaps/via` directory.
Read the VIA docs for [configuring QMK](https://www.caniusevia.com/docs/configuring_qmk) for a more in-depth guide. I also recommend reading about the [VIA spec](https://www.caniusevia.com/docs/specification).
It is also required to have the QMK pull request merged in before contributing to the VIA repository.
## VIA V2 vs V3 definitions
It is basically just a matter of copying the VIA `json` files from the Drive link referenced at the start of this post. The main difference here is the location of the definitions depend on the version; `V2` definitions are located in the`src/<manufacturer>/<keyboard>` directory while the `V3` definitions are in the `v3/<manufacturer>/<keyboard>`.
If you have a `V2` definition, you can convert it a `V3` definition by running the `scripts/build-all.ts` file in the[via keyboards](https://github.com/the-via/keyboards) repository.
Link to the pull request on GitHub for reference: [Add support for NCR-80](https://github.com/the-via/keyboards/pull/1548)
That’s it, once the pull request gets merged VIA should be able to detect your keyboard.
 | j4ckofalltrades |
1,447,824 | How to start open-source contribution as a new developer | One of the ways to collaborate, sharpen your skills, and build your portfolio is through open-source... | 0 | 2023-04-25T15:26:22 | https://dev.to/odudev/how-to-start-open-source-contribution-as-a-new-developer-3374 | opensource, github, developer, beginners | One of the ways to collaborate, sharpen your skills, and build your portfolio is through open-source contribution. This article will focus on open-source projects. Open-source projects are publicly available for anyone's use, modifications, and enhancements. These projects can be a code base or documentation. If you are starting your career and wondering how to use your new skills, this article is for you.
To completely benefit from this article, you must have a basic knowledge of git and GitHub.
In a few steps, I will take you through how you can start contributing to open-source projects today.
## Forking the repository
On identifying an open-source project on Github, fork the repository (repo as often called) by clicking on `Fork`. You can only replicate a GitHub repository on your own repo using `Fork`.

After clicking `Fork`, another page pops up. Click on `Create fork`.

You now have that same repo in your list of repositories on GitHub. This is what it looks like:

## Cloning the repository
Until now, you only have the project on your remote repository. It’s time to have it on your local machine.
Click on `Code`, then click the double-square box beside the HTTPS URL to copy.

Navigate to any directory where you would like to have this project cloned on your computer, right-click on an empty space on the screen, and click on `Git Bash Here`.
A command window pops up; type `git clone`, then paste the HTTPS URL you copied earlier and click enter.
Note: You can’t use the keyboard shortcut Ctrl+V to paste the URL; you must right-click and select the paste option

You must wait for the cloning to complete. This may take up to several minutes, depending on the folder size. A folder with the repo name will appear in your chosen directory during cloning. Allow the process to complete.
## Opening the file in VS code and making contributions
Open the file in VS code. It’s a good practice to always create your own branch while working on an open-source project. By creating your own branch, the project lead will be able to compare your contribution with the `main` or `master` branch. This practice allows for a cleaner and more reliable open-source collaboration.
Before working on the project, use the `git pull` command to update your local repository. This is to update the local repository in case other contributors have made some changes between the time you fork the repo and the time you want to contribute.
Create your branch, make contributions, and push to GitHub.
## Creating a Pull request(PR)
On pushing to GitHub, this is what you get:

Click on compare & pull request from the previous.
Alternatively, click on `Pull requests`

Click on `New pull request`

In the new line box, type what you did (changes you made). You can also leave some comments. Click on `Create pull request`

## Wrapping up
You just learned how to boost your confidence by collaborating and contributing to open-source projects. With your newly acquired skills, you can start contributing to open-source projects. Your contribution can be as little as editing a READ.md file. You can search Google for open-source projects and start contributing today.
| odudev |
1,447,959 | 10 Proven Steps to Double the Speed of Your Django App | Introduction In this article, we will share 10 proven steps that can help you double the... | 0 | 2023-04-26T12:00:00 | https://dev.to/squash/10-proven-steps-to-double-the-speed-of-your-django-app-48cp | django, python, webdev, programming | ## Introduction
In this article, we will share 10 proven steps that can help you double the speed of your Django app. Whether you're dealing with slow page load times, high response times, or performance bottlenecks, these steps will provide you with practical tips and techniques to optimize your Django app and deliver a better user experience.
### 1. Optimize database queries
Review your database queries and make sure they are efficient. Use Django's query optimization techniques such as select_related, prefetch_related, and defer/only to minimize the number of database queries and reduce database load.
[Here is a detailed guide on how to optimize db queries in Django](https://www.squash.io/mastering-database-query-optimization-in-django-boosting-performance-for-your-web-applications/).
### 2. Use caching
Implement caching using Django's built-in caching framework or external caching tools like Memcached or Redis. Caching frequently accessed data can significantly reduce database queries and speed up your app.
Examples:
### 1. Using Django's built-in caching framework:
```python
# settings.py
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211', # Replace with your Memcached server's address
}
}
# views.py
from django.core.cache import cache
from .models import MyModel
def get_data():
# Query the database to get data
data = MyModel.objects.all()
return data
def get_data_with_cache():
# Try to get data from cache
data = cache.get('my_data')
if not data:
# If data is not available in cache, fetch from database and store in cache
data = get_data()
cache.set('my_data', data)
return data
```
### 2. Using Memcached as an external caching tool:
```python
# settings.py
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
'LOCATION': '127.0.0.1:11211', # Replace with your Memcached server's address
}
}
# views.py
from django.core.cache import cache
from .models import MyModel
def get_data():
# Query the database to get data
data = MyModel.objects.all()
return data
def get_data_with_cache():
# Try to get data from cache
data = cache.get('my_data')
if not data:
# If data is not available in cache, fetch from database and store in cache
data = get_data()
cache.set('my_data', data)
return data
```
### 3. Using Redis as an external caching tool:
```python
# settings.py
CACHES = {
'default': {
'BACKEND': 'django_redis.cache.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379/1', # Replace with your Redis server's address
'OPTIONS': {
'CLIENT_CLASS': 'django_redis.client.DefaultClient',
}
}
}
# views.py
from django.core.cache import cache
from .models import MyModel
def get_data():
# Query the database to get data
data = MyModel.objects.all()
return data
def get_data_with_cache():
# Try to get data from cache
data = cache.get('my_data')
if not data:
# If data is not available in cache, fetch from database and store in cache
data = get_data()
cache.set('my_data', data)
return data
```
Note: The above code examples assume that you have already installed and configured the caching tools (Memcached or Redis) on your server, and you have the appropriate caching backend installed in your Django project. Make sure to replace the cache backend settings (such as `LOCATION`) with the correct address of your caching server.
### 3. Optimize view functions
Review your view functions and optimize them for performance. Avoid unnecessary calculations, database queries, or data processing in your views. Use Django's class-based views for efficient code organization and performance.
Bonus: use [asynchronous handlers](https://www.squash.io/django-4-best-practices-leveraging-asynchronous-handlers-for-class-based-views/) when it's possible.
Examples:
### 1. Using `select_related()` to reduce database queries:
```python
from django.shortcuts import render
from .models import MyModel
def my_view(request):
# Fetch data from database with related objects
data = MyModel.objects.all().select_related('related_model')
# Perform some calculations
processed_data = [item.some_field * 2 for item in data]
# Filter data based on a condition
filtered_data = [item for item in processed_data if item > 10]
# Render the response
return render(request, 'my_template.html', {'data': filtered_data})
```
### 2. Utilizing Django's built-in caching framework:
```python
from django.shortcuts import render
from django.core.cache import cache
from .models import MyModel
def my_view(request):
# Try to get data from cache
data = cache.get('my_data')
if data is None:
# If not available in cache, fetch from database
data = MyModel.objects.all()
# Perform some calculations
processed_data = [item.some_field * 2 for item in data]
# Filter data based on a condition
filtered_data = [item for item in processed_data if item > 10]
# Store data in cache for future use
cache.set('my_data', filtered_data)
# Render the response
return render(request, 'my_template.html', {'data': data})
```
### 3. Using Django's `Prefetch` to optimize related object queries:
```python
from django.shortcuts import render
from django.db.models import Prefetch
from .models import MyModel
def my_view(request):
# Fetch data from database with related objects using Prefetch
data = MyModel.objects.all().prefetch_related(Prefetch('related_model'))
# Perform some calculations
processed_data = [item.some_field * 2 for item in data]
# Filter data based on a condition
filtered_data = [item for item in processed_data if item > 10]
# Render the response
return render(request, 'my_template.html', {'data': filtered_data})
```
Using `select_related()`, Django's caching framework, and `Prefetch`, can further optimize the view functions by reducing database queries, utilizing caching, and optimizing related object queries, respectively, leading to improved performance in Django applications.
### 4. Optimize templates
Review your templates and minimize the use of heavy computations or complex logic in the templates. Use Django's template caching, template inheritance, and template tags for optimized rendering.
Examples:
### 1. Utilizing Django's template caching:
```python
# my_view.py
from django.shortcuts import render
from django.core.cache import cache
from .models import MyModel
def my_view(request):
# Try to get data from cache
data = cache.get('my_data')
if data is None:
# If not available in cache, fetch from database
data = MyModel.objects.all()
# Perform some calculations
processed_data = [item.some_field * 2 for item in data]
# Filter data based on a condition
filtered_data = [item for item in processed_data if item > 10]
# Store data in cache for future use
cache.set('my_data', filtered_data)
# Render the response with cached data
return render(request, 'my_template.html', {'data': data})
```
```html
<!-- my_template.html -->
{% extends 'base_template.html' %}
{% block content %}
<!-- Render the cached data in the template -->
{% for item in data %}
<p>{{ item }}</p>
{% endfor %}
{% endblock %}
```
### 2. Utilizing Django's template inheritance:
```html
<!-- base_template.html -->
<!DOCTYPE html>
<html>
<head>
<title>My App</title>
</head>
<body>
<header>
<!-- Common header content -->
</header>
<main>
<!-- Render the content from child templates -->
{% block content %}{% endblock %}
</main>
<footer>
<!-- Common footer content -->
</footer>
</body>
</html>
```
```html
<!-- my_template.html -->
{% extends 'base_template.html' %}
{% block content %}
<!-- Render the content specific to this template -->
<h1>My Template</h1>
<!-- Include template tags for optimized rendering -->
{% load myapp_tags %}
<p>Processed Data: {% my_template_tag data %}</p>
{% endblock %}
```
### 3. Creating custom template tags for complex logic:
```python
# myapp_tags.py
from django import template
register = template.Library()
@register.filter
def my_template_tag(data):
# Perform complex logic on data
processed_data = [item.some_field * 2 for item in data]
# Filter data based on a condition
filtered_data = [item for item in processed_data if item > 10]
# Return the processed data as a string
return ', '.join(map(str, filtered_data))
```
```html
<!-- my_template.html -->
{% extends 'base_template.html' %}
{% block content %}
<!-- Render the content specific to this template -->
<h1>My Template</h1>
<!-- Include the custom template tag for optimized rendering -->
<p>Processed Data: {{ data|my_template_tag }}</p>
{% endblock %}
```
### 5. Enable Gzip compression
Enable Gzip compression for HTTP responses using Django's middleware or web server configuration. Gzip compression reduces the size of data transferred over the network, improving app performance.
Examples:
### 1. Enabling Gzip compression using Django middleware:
```python
# middleware.py
import gzip
from django.middleware.common import CommonMiddleware
from django.utils.decorators import gzip_page
class GzipMiddleware(CommonMiddleware):
"""
Middleware class to enable Gzip compression for HTTP responses.
"""
def __init__(self, get_response=None):
super().__init__(get_response)
self.get_response = get_response
@gzip_page
def __call__(self, request):
# Handle Gzip compression for HTTP responses
response = self.get_response(request)
# Set response headers to indicate Gzip compression
response['Content-Encoding'] = 'gzip'
response['Vary'] = 'Accept-Encoding'
return response
```
Note: The `gzip_page` decorator is used from Django's `django.utils.decorators` module to compress the response content using Gzip.
### 2. Enabling Gzip compression using web server configuration (e.g., Nginx):
```nginx
# nginx.conf
http {
gzip on;
gzip_types text/html text/css application/javascript;
# Other nginx configuration settings
}
```
In this example, Gzip compression is enabled in the Nginx web server configuration by setting `gzip on;` and specifying the file types to be compressed using the `gzip_types` directive.
### 6. Use a Content Delivery Network (CDN)
Utilize a CDN to cache and serve static files, such as CSS, JavaScript, and images, from geographically distributed servers. This can reduce server load and improve page load times.
Examples:
### 1. Utilizing a CDN with Django:
```python
# settings.py
# Set the URL of your CDN
CDN_URL = 'https://cdn.example.com/'
# Configure the STATIC_URL to point to the CDN URL
STATIC_URL = CDN_URL + 'static/'
```
```html
<!-- template.html -->
<!-- Use the CDN URL for serving static files -->
<link rel="stylesheet" href="{{ STATIC_URL }}css/styles.css">
<script src="{{ STATIC_URL }}js/scripts.js"></script>
<img src="{{ STATIC_URL }}images/image.jpg" alt="Image">
```
### 2. Utilizing a CDN with a web server (e.g., Nginx):
```nginx
# nginx.conf
http {
# Configure Nginx to proxy requests for static files to the CDN
location /static/ {
proxy_pass https://cdn.example.com/static/;
}
# Other Nginx configuration settings
}
```
```html
<!-- template.html -->
<!-- Use the Nginx proxy location for serving static files -->
<link rel="stylesheet" href="/static/css/styles.css">
<script src="/static/js/scripts.js"></script>
<img src="/static/images/image.jpg" alt="Image">
```
### 7. Optimize database connection management
Use connection pooling to efficiently manage database connections and reuse existing connections instead of creating new ones for every request. This can reduce overhead and improve database query performance.
### 8. Use asynchronous tasks
Offload time-consuming tasks to asynchronous tasks using Django's asynchronous task frameworks like Celery or Django Channels. This can free up server resources and improve app performance.
Examples:
### 1. Offloading tasks to [Celery](https://docs.celeryq.dev/en/stable/):
```python
# tasks.py
from celery import shared_task
@shared_task
def process_data(data):
# Perform time-consuming task here
# ...
```
```python
# views.py
from .tasks import process_data
def my_view(request):
# Offload task to Celery
process_data.delay(data)
# Continue with view logic
# ...
```
### 2. Offloading tasks to [Django Channels](https://channels.readthedocs.io/en/stable/):
```python
# consumers.py
import asyncio
from channels.generic.websocket import AsyncWebsocketConsumer
class MyConsumer(AsyncWebsocketConsumer):
async def connect(self):
await self.accept()
async def receive(self, text_data):
# Offload task to Django Channels
await self.channel_layer.async_send("my_channel", {
"type": "process_data",
"data": text_data,
})
async def process_data(self, event):
# Perform time-consuming task here
# ...
```
```python
# views.py
from channels.layers import get_channel_layer
from asgiref.sync import async_to_sync
def my_view(request):
# Offload task to Django Channels
channel_layer = get_channel_layer()
async_to_sync(channel_layer.send)("my_channel", {
"type": "process_data",
"data": data,
})
# Continue with view logic
# ...
```
### 9. Optimize server configuration
Review and optimize your server configuration, including web server settings, database settings, and caching settings, to fine-tune performance.
### 10. Monitor and analyze app performance
Regularly monitor and analyze the performance of your Django app using performance monitoring tools, profiling, and logging. Identify and optimize bottlenecks to continually improve app performance.
Remember, performance optimization is an ongoing process, and results may vary depending on the specific requirements and characteristics of your Django app. It's important to thoroughly test and benchmark your app after implementing any optimizations to ensure they are effective in improving app speed.
## Conclusion
By following these 10 proven steps, you can significantly improve the speed and performance of your Django app. From optimizing database queries to leveraging caching, using a Content Delivery Network (CDN), and implementing asynchronous tasks, these techniques can make a noticeable difference in your app's performance. Remember to regularly monitor and benchmark your app's performance to ensure that it continues to run smoothly and efficiently. By investing time and effort into optimizing your Django app, you can provide a better experience for your users and keep them engaged with your app. So go ahead and implement these steps to double the speed of your Django app and take it to the next level! | emiquelito |
1,448,191 | Learning to love JavaScript Event Listeners | My name is Claire and I'm currently a student at Flatiron studying software engineering. I'll admit,... | 0 | 2023-04-25T20:46:11 | https://dev.to/cmccafferty96/learning-to-love-javascript-event-listeners-5co | My name is Claire and I'm currently a student at Flatiron studying software engineering. I'll admit, coming into this I considered myself a "tech savvy" individual, but after completing the first week I was very overwhelmed by the amount of information I didn't know or understand. I truly had no idea just how much is going on behind the scenes of even a simple wikipedia page. It changed my perspective on coding in general, as I realized just how much thought goes into creating, whether it's a webpage, an app, or a video game. Which leads me to the main topic of this blog post, event listeners!
I remember when I first read about event listeners in the pre-work, the concept really confused me. I didn't understand how you could write a simple line of code, and then like magic, change something on a webpage. It was after getting through week-one that the concept started to become less abstract and more applicable. I've learned to really love event listeners, specifically because they can make a pretty boring webpage more interactive and/or dynamic, and the fact that there are so many event listeners you can choose from.
The most common example is a "click" event. I'm going to be honest, I was humbled learning that every time you are able to click on something on a website, it's because a developer put it there intentionally. I know that might sounds kind of funny to someone who has experience coding, but as a beginner, I truly thought that the website just _knew_ to do that.
Here is an example of a "click" event in action:
const button = document.getElementById("button")
button.addEventListener("click", () => {
console.log("I was clicked")
})
In this example, we have selected the HTML element with an ID of "button", and added an event listener to it so that when that button is clicked, it will display the message "I was clicked".
This is a very basic example of a click event, but gives you the general idea of how they work. As you continue to develop your programming skills, the functionality of event listeners becomes way more dynamic, and in my opinion, really fun! | cmccafferty96 | |
1,448,194 | Getting Started in Go | Purpose of this post is simply to present a little of why the language Go appeared and present a... | 0 | 2023-04-25T21:04:49 | https://dev.to/jeffotoni/getting-started-in-go-599d | Purpose of this post is simply to present a little of why the language Go appeared and present a little of its syntax and demonstrate some areas where Go is more applied. For everyone who would like to further increase their arsenal for web development this post will help you to clarify some important points when we are starting and learning a new programming language.
# Getting Started in Go❤️
Before we start, it's important to point out that programming languages are tools and like any good tool, we have to know when to use them. There are scenarios and problems that are only solved with specific languages and there are other universes of problems that we have hundreds or thousands of languages that somehow solve the same problem. So like a good professional, the more tools you know to solve problems, the better it will be for your professional career 🤩.
The Go language in its universe of possibilities is a **common use language** I don't really like this term it seems like it's like a silver bullet and solves all problems but not really, **Go was born by a purpose and solve problems of the web universe and take advantage of the new technology of multicores in servers,** well this was the initial purpose 😂.
# History of the Go project
*“Robert Griesemer, Rob Pike, and Ken Thompson began sketching goals for a new language on the whiteboard on September 21, 2007. Within days, the goals settled into a plan to do something and a fair idea of what it would be like. . Design continued part-time in parallel with unrelated work. In January 2008, Ken started work on a compiler to explore ideas; it generated C code as its output. By mid-year, the language had become a full-time project and had established itself enough to try a production compiler. In May 2008, Ian Taylor started independently on a GCC frontend for Go using the preliminary specs. Russ Cox joined in late 2008 and helped move the language and libraries from prototype to reality.”*

Go became a public open source project on **November 10, 2009** . Countless people from the community contributed ideas, discussions, and code.
*“There are now* ***millions of Go programmers*** *“****Gophers****” around the world, and there are more every day. The success of Go far exceeded expectations.”*
# Why they created a new language
*“Go was born out of frustration with the existing languages and environments for the work we were doing at Google. Programming had become too difficult and the choice of languages was partly to blame. You had to choose between efficient compilation, efficient execution, or ease of programming; all three were not available in the same primary language. Programmers who might choose ease over security and efficiency, switching to dynamically typed languages like Python and JavaScript rather than C++ or, to a lesser extent, Java.”*
*“Go addressed these issues by trying to combine the programming ease of an interpreted, dynamic language with the efficiency and security of a statically compiled language. It was also intended to be modern, with support for networked and multicore computing. Finally, working with Go is intended to be fast: it should take a few seconds at most to build a large executable on a single computer.”*
A new Go language is born, to meet new needs and solve problems by taking advantage of the computational power as much as possible. And of course creating your mascot for the thousands of **gophers** that saw to emerge from this moment on.

# Official site
To start in Go❤️ let's take a few steps back, let's start our whole trajectory knowing the official website of lang this is the official page [golang.org](http://golang.org), here we will find all the information we could know about Go and much more. Here we have the docs, packages, blog and our darling [play.golang.org](http://play.golang.org), language specs, download, Go tour and much more.
The official website apparently looks small but it is very complete and big. So we have practically everything we need to know about Go to start our learning in this language that is a phenomenon.
**Where do I start on the Site**
I'm going to create a line of reasoning so that we can understand Go in the most practical way possible.
Before installing Go, or running Go through play, let's go through some parts of the doc so that we can understand a little of the history of Go and why a new language was born in this universe of thousands of programming languages.

# Effective Go
This link is the first one that everyone should read first.
Effective Go❤️ on this site you will find all the material you need to get a good idea of the Go language: Control Structure, Functions, Concurrent Programming using Goroutines, Methods, Maps and much more.

# A go tour
This link would be the second most important link in my hierarchy for us to learn Go.
[Tour Go](https://tour.golang.org/welcome/1)❤️ on this site you will be able to test and take a look at some of the features of the Go language 😱 that's right all through the browser without having to install anything on the machine.

# Playground Go
Here is very beautiful, you don't need to install anything on the machine to run something quickly in Go, just enter [play.golang.org](http://play.golang.org)
[Play Go](https://play.golang.org/p/MAohLsrz7JQ)❤️ on this site you will be able to run Go 😱 that's right we don't need to install anything for now, you can run everything through the browser and get to know the syntax of the language and learning.

# Frequently Asked Questions
This link would be our third step, I believe you now have several questions, generated by [Effective](https://golang.org/doc/effective_go.html) Go and by [Tour](https://tour.golang. org/welcome/1) that did.
[Faq](https://golang.org/doc/faq)❤️ this is where you will take a few hours to read this, it doesn't have to be all at once, of course, but you must read it. This page is essential to organize your ideas and really understand a little more about Go .
This is one of the largest pages and requires more reading, but this page is essential for a better understanding of the Go language, the time you spend reading this page will surely save you hours of work.

# Native Go packages
This link would be so you can take a look and understand how they are organized and how is the documentation of the functions, libs, pkgs that we can use in the Go language. This is one of the strengths of the language, it is very complete for web development for servers.
[Pkg](https://golang.org/pkg/)❤️ I chose [pkg string](https://golang.org/pkg/strings/) here so you can check out how the documentation formatting is language and already with examples that can be executed by the browser, everything to facilitate learning and understanding .

# Editors and IDE
This link is about the IDEs and Editors that you can use when you have **Godando**. The Go language doesn't need much for us to be able to edit our codes, but we have some interesting plugins to make our day to day even easier
[Editors and IDE](https://golang.org/doc/editors.html)❤️ This link will not have Sublime and nvim which are two editors that I use around here on a daily basis, **sublime** by the [survey](https://blog.golang.org/survey2020) survey, only 7.7% use sublime and **vim** 14% **nvim** is a plugin that they will use in vim. The darling and adopted by the Go team is **VsCode** with 41% adherence.
# Strengths of the Go language
Before we do our famous “Hello World” let's show some strengths of the Language, let's preview the pillars and characteristics of the Go language.
## 3 Pillars
We have some well defined pillars in Go, this will help you to further clarify your horizon when it comes to Go.
* **Simplicity**
* **Legibility**
* **Productivity**
This has become over the years something so standard for those who are developing in the Go universe that it sounds like poetry to the ears. We know that go is an attempt to join two different worlds, the world of compiled languages with interpreted languages, in 2007 the idea was born and with the objective of creating a new programming language.
## Main features
In Go we have some outstanding features of the language that make it even more powerful for developing web applications for servers.
* **Only 25 keywords**
* **Low learning curve**
* **Compiled statically**
* **Multiplatforms now support RISC-V**
* **Concurrent Paradigm**
* **Static Typing**
* **Backward Compatibility**
All these points make the language even more interesting, the team of engineers that developed the language did an excellent job or better see doing it, Go is simply fantastic some don't like its designer but it's understandable more than 20 years developing in OO and Functional paradigms as if there is no life on another planet is understandable 😂.
# **Installing Go**
This is the moment we've all been waiting for, get your hands dirty and install locally, on the official website you can't go wrong, there's nothing simpler than installing Go on your machine so you can program in Go. Taking advantage of this and making it clear that: **We don't need to install Go on the server,** this is exactly what you read, on your server whatever it may be, *On-premises, an Ec2 from Aws or a pod on k8s whether it's on Gke, or k8s from DigitalOcean, that is on ECS or EKS*, whether it is a serverless or on any hosting server of your choice, what you will need is the binary whether in a docker image for example or not. This **is one of the strengths of Go,** we don't need to carry stuff to the server **this is one of the great benefits of using Go** in web applications on servers and this is what **Go** became known for like the **containers language**😍.

Knowing all this, let's go to install Go and see how complex it is 😜😜, just kidding… 😂
[Install Go](https://golang.org/doc/install) in this link you will have the step by step on how to install in different Operating Systems but I will leave the installation in Linux here.
**Installation on Linux**
If you have a previous version of Go installed, be sure to [remove it](https://golang.org/doc/manage-install) before installing another one.
1. **$ sudo rm -rf /usr/local/go**
2. Download the file [by clicking here go1.1](https://golang.org/dl/go1.15.6.linux-amd64.tar.gz)5.6 and extract it in */usr/local*
3. **$ sudo tar -C /usr/local -xzf** [**go1.15.6.linux-amd64.tar.gz**](https://golang.org/dl/go1.15.6.linux -amd64.tar.gz)
4. Add */usr/local/go/bin* to the `PATH` environment variable.
5. **$ export PATH=$PATH:/usr/local/go/bin**
6. To make what we did above global, that is, every time you enter your terminal “go” is executed, you can do this by adding the following line that I showed above to your $HOME/.profile or */etc/profile* (for a system-wide install) or your bash or whatever you're using in your Linux environment.
7. **Note:** Changes made to a profile file may not apply until the next time you log in to your computer. To apply the changes immediately, just run the shell commands directly or run them from the profile using a command like `source $HOME/.profile`.
8. Verify that you have installed Go by opening a command prompt and typing the following command:
```go
go version
```
If all goes well you will see: *“go version go1.15.6 linux/amd64”
*beautiful, simply beautiful you can say, very simple.
# Hello World
Now it's time for our first "hello world" using Go.
There's no secret, we can use any editor we saw above and go to the top. In Go we don't need to compile when we're **having**, we can simply run our programs without having to turn them into binaries, ie compile.
**go run main.go**
Below is our first hello world, and just save the file with the .go extension and put the name “\_main.go\_” then just run it with the command “go run main.go”, in our example I called file from “*main.go”*
```go
package main
func main() {
println("My first Hello World")
}
```
```go
package main
import(
"fmt"
)
func main() {
fmt.Println("My first Hello World")
}
```
```go
$ go run main.go
```
This hello world of ours is the smallest structure we can assemble to output to the terminal.
To be a little clearer when using the **println** function we have to know that it is a built-in function (at runtime) that can eventually be removed, while the *fmt* package is in the standard library, which will persist.
**go build**
Now let's turn it into a binary let's compile it and for that we will use “**go build**” or “**GOARCH=386 GOOS=linux go build -o myprogram main.go**” we are now informing the architecture and operating system that we want to compile our Go program.
```go
$ GOARCH=386 GOOS=linux go build -o myhello main.go
```
This command will make the build it will generate an “executable” a binary to run on your operating system. Very easy isn't it? 😍 I would say very beautiful. With this binary you'll be able to run it on your machine or on any server that has the same architecture and operating system that you made for your compilation.
It's important to always emphasize this detail: ***“We don't install anything Go on our web servers”*** is exactly what you read, you don't need to install anything, you just need the binary. ❤️ This is why **Go** became known as the **Language of Containers**. Are you saying this isn't fantastic? 😍 To run a web application on your server, just send the binary to it. Wow, that's right just from the binary without needing to take anything else related to your project at all.
**Go and Docker**
Since we are talking about docker and saying that we only need the binary to run our project on **Go** let's present what our image would look like using docker so that we can now use Go on servers like Google's GKE, AWS's EKS, or k8s from DigitalOcean or simply use with docker.
```go
##################################################
# Dockerfile distroless
##################################################
FROM golang:1.15 as builder
WORKDIR /go/src/main
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o main main.go
RUN cp main /go/bin/main
#############################
# STEP 2 build a small image
#############################
FROM gcr.io/distroless/base
COPY --from=builder /go/bin/main /
CMD["/main"]
```
Look how beautiful😁 just under 10 lines. We have a Go image so we can compile our project and then we do something like S[cratch](https://github.com/jeffotoni/goexample/tree/master/api-simple/docker-golang-scratch) but we are using distroless which is a very small lean base and contains our binary. I'm sorry, but isn't this fantastic or simply beautiful❤️?
The **distroless** concept is simple, it assumes that we focus on our application and less on the Linux distribution.
Now let's make a small example of a rEST API just to exemplify our Dockerfile and show in practice how simple it is to upload a docker image of our project.
```go
package main
import(
"log"
"net/http"
)
func main() {
mux := http.NewServeMux()
mux.HandleFunc("/api/v1/ping", Ping)
log.Println("Run Server 8080")
log.Fatal(http.ListenAndServe(":8080", mux))
}
func Ping(w http.ResponseWriter, r *http.Request) {
log.Println("server ok")
w.WriteHeader(http.StatusOK)
w.Write([]byte(`{"msg":"pong"}`))
}
```
Now we just build our project with the following command:
$ docker build — no-cache -f Dockerfile -t jeffotoni/apisimplego:latest .
this will generate an image locally on your machine and now just run it for us to test.
$ docker run — rm — name apisimplego -p 8080:8080 jeffotoni/apisimplego
Ready now, just shoot to our /api/v1/ping endpoint that we created
$ curl -i [localhost:8080/api/v1/ping](http://localhost:8080/api/v1/ping)
Say it's not beautiful 😍
# Conclusion
This post is a simple summary for you who would like to increase your web programming arsenal. I hope you enjoyed.
The channel where the live took place: [https://youtube.com/user/jeffotoni](https://youtube.com/user/jeffotoni)
The PDF link of the presentation can be found at: [speakerdeck.com/jeffotoni](http://speakerdeck.com/jeffotoni)
| jeffotoni | |
630,653 | Helle, I am new here | Anyone interested in foot tracking for WebAR use? | 0 | 2021-03-10T07:15:13 | https://dev.to/tom97198508/helle-i-am-new-here-2ai1 | webar, machinelearning | Anyone interested in foot tracking for WebAR use? | tom97198508 |
1,448,380 | Going Against Conventional Wisdom: What's Your Unpopular Tech Opinion? | What's an unpopular tech opinion you hold that goes against conventional wisdom? We want to hear... | 22,719 | 2023-04-26T07:00:00 | https://dev.to/devteam/going-against-conventional-wisdom-whats-your-unpopular-tech-opinion-5fag | discuss | What's an unpopular tech opinion you hold that goes against conventional wisdom?
We want to hear what you think about the tech industry and its trends. How likely are you to go against the grain? Share with us in the comments!
---
Join the conversation and [follow the DEV Team](Share with us in the comments!) for more thought-provoking discussions! | thepracticaldev |
1,448,398 | How to Integrate Chargebee Payment Links in Your Notion Website | If you're a business owner or a service provider, accepting online payments is crucial for your... | 0 | 2023-04-26T04:00:39 | https://bharathvaj.me/blog/chargebee-subscription-payment-link | chargebee, notion, webdev, tutorial | If you're a business owner or a service provider, accepting online payments is crucial for your success. [Chargebee](https://www.chargebee.com/) is a popular subscription management platform that allows businesses to manage recurring payments and subscriptions seamlessly. One of the convenient features of Chargebee is the ability to create payment links, which can be easily integrated into your [Notion](https://www.notion.so/) website to streamline your payment collection process. In this blog, we'll walk you through the steps to integrate Chargebee payment links into your Notion website.
## Step 1: Set up a Chargebee Account
If you don't already have a Chargebee account, you'll need to sign up for one at [chargebee.com](http://chargebee.com/). It's free to create an account, and you'll need to provide some basic information about your business and bank account details for receiving payments.
## Step 2: Create a Payment Link in chargebee
Once you've set up your Chargebee account, you can create a payment link. Payment links allow you to generate a URL that you can share with your customers, and they can use it to make payments. Here's how you can create a payment link in Chargebee:
Log in to your Chargebee account and go to the "Configure Chargebee" tab.
Click on "Checkout & Self-Serve Portal" under Customer-Facing Essentials section.
Click the "Integrate with Chargebee" button.
Fill in the details for your payment link, such as the Product Family, Plan currency and frequency.
If you have any Addon or Charge that you want to include you can select from the dropdown.
## Step 3: Copy the Payment Link URL
Chargebee will automatically construct Payment link while updating the inputs. This is the link that you'll need to integrate into your Notion website to accept payments. Click the "Copy" button to copy the URL to your clipboard.
## Step 4: Add the Payment Link to Your Notion Website
Now that you have your payment link URL, you can add it to your Notion website. Here's how:
Open your Notion website in edit mode. Navigate to the page where you want to add the payment link and paste the link. You can customize the link text and color by clicking on the edit option from the hover menu.
## Step 5: Customize the Payment Link on Your Notion Website (Optional)
Once you've added the payment link to your Notion website, optionally you can customize how it appears to your customers.
Go to [Butn One](https://butn.one/), a free Notion button widget utility to create a customisable embed. Add your button text and paste the Chargebee Payment Link in the button link option. Finally, you can customise the colour, font etc here that matches your website theme.
## Step 6: Test the Payment Link
Before making your Notion website live, it's important to test the payment link to ensure that it's functioning correctly. You can do this by clicking on the payment link on your Notion page and making a test payment using a valid credit card. This will help you verify that the payment link is working as expected and that payments are being processed successfully. You can also use Chargebee’s sandbox environment to test your integration.
## Step 7: Publish Your Notion Website
Once you've tested and confirmed that the payment link works, you can now publish your notion website. That's it. 😎
Happy collecting money. | bharathvajganesan |
1,448,598 | Image Segmentation in OpenCV with Python and Contours | Learn how to perform image segmentation using Python OpenCV and contour detection in this... | 0 | 2023-04-26T08:35:11 | https://dev.to/feitgemel/image-segmentation-in-opencv-with-python-and-contours-2el0 | python, openc, computervision, tutorial | Learn how to perform image segmentation using Python OpenCV and contour detection in this step-by-step tutorial!
Discover how to convert images to grayscale, apply thresholding techniques, detect contours, and merge the detected contours with the original image for stunning effects.
Perfect for beginners in computer vision, this tutorial will help you create amazing visual effects and gain skills that can be applied to a wide range of applications.
If you are interested in learning modern Computer Vision course with deep dive with TensorFlow , Keras and Pytorch , you can find it here : http://bit.ly/3HeDy1V
Before we continue, I actually recommend this book for deep learning based on Tensorflow and Keras : https://amzn.to/3STWZ2N
Check out the tutorial: https://youtu.be/f6VgWTD_7kc
Enjoy,
Eran Feit
#ImageSegmentation #PythonOpenCV #ContourDetection #ComputerVision #TutorialForBeginners
| feitgemel |
1,448,627 | Notas da Mentoria | Olá leitor! Vou explicar mais ou menos ideia dessa série: Lá em 2021, pedi a ajuda de uma... | 22,722 | 2023-04-26T09:47:46 | https://dev.to/ccunha/notas-da-mentoria-nn9 | Olá leitor!
Vou explicar mais ou menos ideia dessa série: Lá em 2021, pedi a ajuda de uma profissional sênior pra me ajudar no que eu precisava entender melhor para que eu me tornasse sênior também. Enumeramos vários conceitos, e fiquei de estudar e escrever posts sobre esses conceitos. Não consegui render muito mas estou tentando retomar isso agora. Como ando com pouco tempo, decidi ir escrevendo aqui as minhas notas de estudo e pedir pra que fossem revisadas, e depois eu tento transformá-las em um texto mais conciso.
Se você chegou aqui e quer contribuir com algo, fique a vontade! :)
| ccunha | |
1,452,707 | HI, I'm new here and I'm open to learning new things from my new found family | __ | 0 | 2023-04-30T05:20:10 | https://dev.to/thatitbabe/hi-im-new-here-and-im-open-to-learning-new-things-from-my-new-found-family-3ppd | __ | thatitbabe | |
1,448,860 | Elasticsearch upgrade? a comparison tool helps enormously | I want to tell y'all (can you tell I just moved to Texas? 🤠) about a recent project we worked on with... | 0 | 2023-04-26T13:44:31 | https://dev.to/mega_byte/elasticsearch-upgrade-a-comparison-tool-helps-enormously-4e9a | tech, development, programming, elasticsearch | I want to tell y'all (can you tell I just moved to Texas? 🤠) about a [recent project](https://softjourn.com/insights/expense-management-leader-elasticsearch-upgrade) we worked on with a global leader in expense management and AP automation solutions.
This client trusted us (gulp) to help upgrade their Elasticsearch from version 2.3.4 to version 7.9, which was a pretty big leap!
{% embed https://youtu.be/sIWOmSS3wg8 %}
We know how it is for many clients, sometimes they'll set up an Elasticsearch cluster and not always keep it up-to-date with the latest version. But with every new release, you get the chance to take advantage of new features, fixes, and enhancements.
And when it comes to clients in the finance industry, data is everything, so managing it correctly with [Elasticsearch](https://softjourn.com/insights/elasticsearch-101-key-concepts-benefits-use-cases) is a great way to go.
Now, upgrading Elasticsearch can be a real pain, especially when -- if you're like our client -- you're several major releases behind the stable version 😬.

But it's worth it because newer versions provide a faster, easier to use, and more secure and resilient user experience. And in the case of version 7.9, it comes with some sweet enhancements, like an endpoint for bulk deletion, which makes it easier to replace and clean up data. Plus, it provides performance improvements, faster searches, and more accurate results.
But upgrading from version 2.3.4 to 7.9 was no easy feat. Our client had a very complex Elasticsearch system with over 10 types of different searches, and they wanted to be sure the new search capabilities would work the same as their past version.
So, 🌟 **we developed a custom comparison tool** 🌟 to ensure the accuracy of the new search before launching the product to their users.
We built Java microservices from scratch and evaluated the old and new search versions using the comparison tool. We analyzed the percent of errors between searches in version 2.3.4 and version 7.9, investigated and provided insights on what could cause a difference in results, and after changes, re-compared the versions using the tool.
And guess what? Our [comparison tool](https://softjourn.com/insights/expense-management-leader-elasticsearch-upgrade) managed to show less than a 1% difference between the old and new versions, and our team managed to achieve a .02% difference for 500,000 search queries!

The client was impressed with the comparison and felt confident to launch the upgrade of their Elasticsearch, and we all rode off into the sunset 🌅 (Okay, maybe not the last part)
Now their Elasticsearch is hosted on AWS infrastructure, and their users will have the same experience, or even faster when they use the search functionalities.
And as an additional perk, our client can use the custom comparison tool for future Elasticsearch upgrades to ensure accuracy.
So, the moral of the story is, even though upgrading Elasticsearch can be a pain, it's worth it in the end. And with the help of an [expert partner](https://softjourn.com/elasticsearch-consulting-services) (ahem), you can make a smooth upgrade happen, no matter how many versions behind you are.
The full article about our project can be found [here](https://softjourn.com/insights/expense-management-leader-elasticsearch-upgrade), or you can check out our [Youtube video](https://youtu.be/sIWOmSS3wg8). | mega_byte |
1,448,910 | giường tủ quần áo | Giường tủ quần áo chất liệu gỗ công nghiệp cao cấp, gỗ tự nhiên, giường tủ cho phòng ngủ, tủ đựng... | 0 | 2023-04-26T15:09:13 | https://dev.to/phloan2016/giuong-tu-quan-ao-347e | [Giường tủ quần áo](https://dodungnoithat.vn/ban-giuong-tu-quan-ao-re-dep-o-tphcm/) chất liệu gỗ công nghiệp cao cấp, gỗ tự nhiên, giường tủ cho phòng ngủ, tủ đựng quần áo kiểu dáng đa dạng, gọn gàng hiện đại | phloan2016 | |
1,449,208 | HelloNewbie - v2 | Just joined the community? Say hello! | 0 | 2023-04-26T18:57:29 | https://dev.to/codenewbieteam/hellonewbie-v2-p52 | hellonewbie, codenewbie | ---
title: HelloNewbie - v2
published: true
description: Just joined the community? Say hello!
tags: hellonewbie, codenewbie
---
## Welcome everybody to the CodeNewbie Organization on DEV!
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
2. Make some new friends by responding to another newbie's comment :wave: Feel free to follow one another, too!
3. We also recommend following the [#beginners](https://dev.to/t/beginners) & [#codenewbie](https://dev.to/t/codenewbie) tags. And of course, don't forgot to hop into [the DEV Welcome Thread](https://dev.to/welcome) there to introduce yourself and meet new folks. :tada: | caroline |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.