
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,817,668 | TASK - 3 | The difference between functional testing and non-functional testing with example Functional... | 0 | 2024-04-10T14:55:47 | https://dev.to/kpsshankar/task-3-4ip2 | The difference between functional testing and non-functional testing with example
Functional testing:
Functional testing is a crucial quality assurance process in software development that evaluates whether a software application functions correctly according to its specifications and requirements. It focuses on testing the functionality of the application, ensuring that it performs its intended tasks accurately.
Here is an example for functional testing
Consider a basic e-commerce website that allows users to browse products, add items to their carts, and complete a purchase. Functional testing for this application would involve testing various aspects of its functionality:
User Registration: verify that users can successfully create an account with valid information.
Product search: Test whether the search function accurately retrieves products based in keywords, categories or filters.
Add to cart: Check if users can add products to their cart and that the cart accurately displays the selected items and their quantities.
Checkout process: Validate that users can process through the checkout process smoothly. This includes entering shipping information, payment details and reviewing the order before confirming it.
Payment processing: Ensure that payment are processed accurately, with appropriate validation for credit card information, addresses and transaction confirmations.
Order confirmation: Verify that users receive an order confirmation email after completing a purchase.
User account: Test various account-related functionalities, such as updating personal information resetting passwords, and viewing order history.
Compatibility: Check if the website functions correctly across different browsers and devices.
Functional testing involves both positive testing and negative testing. Test cases are designed based on the applications functional requirements, and test results are compared against expected outcomes to identify any deviation or defects.
Automated testing tools and manual testing can be used for functional testing. Regression testing, which retests existing functionalities after changes, is also a vital part of the process to ensure that new updates or features do not break existing functionality
In summary, functional testing is essential for assuring the reliability and correctness of software applications, and it involves systematically testing each function and feature to ensure it meets the specified requirements like the example provided for e-commerce website
Non-functional testing:
Non-functional testing often referred to as quality testing, focuses on evaluating the characteristics of a software system that are not directly related to its functional behavior. These characteristics include performance, usability, reliability, scalability, security and more.
Performance testing assesses how well a software system performs under various conditions. It ensures that the application meets performance expectations and can handle a specified load.
Some example scenarios for performance testing:
Load testing: This assesses how the system performs under expected and peak loads. For instance, an e-commerce website, load testing would involve simulating a large number of concurrent users accessing the site to ensure it can handle heavy traffic during sales events.
Stress testing: Stress testing pushes the system beyond its specified limits. For example, lets take a mobile banking app, stress testing would involve initiating transaction with a higher-than-usual number of concurrent users to identify performance bottlenecks or system failures.
Scalability testing: Scalability testing checks if the system can handle increased load by adding more resources or servers. It ensures that the application can scale smoothly as the user base grows.
Response time testing: This measures how quickly the system responds to user actions. For a video streaming service, response time testing would evaluate the time it takes to start playing a video after a user clicks the play button
Usability testing:
It focuses on the user friendliness and overall user experience of the software. It ensures that the application is easy to navigate and meets user expectations. For example:
User interface testing: Evaluates the design and layout of the user interface. Testers assess whether buttons, menus and navigation are intuitive and user-friendly.
Accessibility testing: Checks if the application is accessible to users with disabilities, ensuring compliance with accessibility standards
Security testing:
Security testing identifies vulnerabilities and weaknesses in the software that could lead to breaches or data leaks
Penetration testing: Simulates cyberattacks to identifies vulnerabilities that hackers could exploit, suck as SQL injection or cross site scripting vulnerabilities.
Authentication testing: Verifies the effectiveness of users authentication mechanism, ensuring that only authorized users can access sensitive information.
So, non-functional testing is crucial to ensure that software not only functions correctly but also meets performance usability, security, and other critical criteria. Conducting these tests helps identify and mitigate risks and improve the overall quality of the software product. | kpsshankar | |
1,795,797 | Enterprises Beware — Google Cloud Fleet Routing Might Be the Wrong Choice for You | Google Cloud Fleet Routing (CFR) is a major player in logistics, dominating the market. Despite its... | 0 | 2024-03-20T03:24:24 | https://dev.to/lara9963/enterprises-beware-google-cloud-fleet-routing-might-be-the-wrong-choice-for-you-3oig | google, cloudfleetrouting | Google Cloud Fleet Routing (CFR) is a major player in logistics, dominating the market. Despite its strengths, though, it might not be the best fit for large-scale enterprises. In fact, many such CFR users are seeking better options. Let’s explore why.
5 Reasons Why Google CFR Isn’t Right for Enterprise Logistics
- Suboptimal Routing Efficiency
User reports and benchmarking exercises have established that Google CFR’s routing efficiency can often be subpar and not by a small margin. Results show that CFR frequently generates route plans that take over 50% more time and/or distance compared to higher-performing alternatives like NextBillion.ai’s Route Optimization API. This is, without a doubt, Google CFR’s biggest weakness. Though route optimization solutions serve many functions, performing poorly at the primary one — route optimization itself — is a cardinal sin. Opting for CFR might mean sacrificing efficiency, potentially leaving money on the table due to ineffective asset utilization. Suboptimal routes cause inefficiencies, increased operational costs, longer delivery times and potential customer dissatisfaction. These are compromises nobody wants to make, let alone billion-dollar enterprises.
- Absence of Truck Routing
CFR’s inability to support truck-specific routing is a huge omission. Large organizations often have middle-mile and other truck-related use cases, not just last-mile deliveries with cars. Truck routing involves intricacies not applicable to traditional car routing, like customized routes for different truck types and driver safety regulations, handling diverse load capacities and navigating specific road restrictions according to truck size, weight and type of cargo. The platform’s inability to address such trucking specificities makes it somewhat unidimensional — and it’s not on the dimension of enterprise logistics. CFR primarily caters to last-mile scenarios involving conventional cars, leaving a crucial gap for larger enterprises that require a more comprehensive solution.
[Discover why NextBillion.ai is the best alternative to Google Cloud Fleet Routing (CFR) for route optimization.
](https://nextbillion.ai/compare/nextbillionai-vs-google-cloud-fleet-routing)
- Supply Chain Complexity
Building on the theme of ignoring the first- and middle-mile aspects of logistics, CFR lacks the sophistication required to handle the dynamics of supply chain optimization in larger enterprise operations. For instance, it won’t let you designate something as basic as a depot! Is it possible to get the best results from a solution that ignores such a core concept in enterprise logistics? That’s not all. CFR fails to offer custom objective functions like minimizing vehicles used, lowering transportation costs, ensuring equitable task distribution and maximizing on-time deliveries. It also does not support zone-based allocation or complex task sequencing. Such inflexibility restricts users from tailoring the optimization process to suit their needs. In the context of today’s elaborate supply chains, that’s a severe handicap.
- Pricing Rigidity
Speaking of inflexibility, Google CFR’s fixed pricing model can be a challenge for large organizations with differing business models, usage patterns and evolving operational requirements. Rigid pricing that doesn’t account for these kinds of variances makes it difficult for companies to accurately forecast costs, and nothing good ever comes of that. With NextBillion.ai, on the other hand, you’ll find that flexibility is one of our defining characteristics, and that holds true for pricing as well. We bring a more nuanced approach to the conversation, allowing customers to choose between asset-based pricing and usage-based pricing to align with their operational and financial needs.
- Poor Customer Support
Route optimization solutions generally don’t make for the best DIY products. Most customers would require technical support during the implementation phase, except in the simplest of use cases. Even after successful integration into the tech stack, solutions can sometimes fail to deliver on expectations due to poor adoption. This can be avoided with high-quality support that proactively eliminates hindrances for users. It’s no secret that Google CFR customers frequently face difficulties getting any level of support for their problems, let alone the kind of close attention that such complex solutions demand. Meanwhile, NextBillion.ai’s support team is one of our greatest strengths. Our customers rave about it, and we have the credentials to back up our confidence.
Selecting a route optimization solution takes meticulous consideration to align with both current requirements and future scalability. While CFR may work for certain scenarios, its practical limitations become apparent when dealing with the complex needs of larger enterprises. From the absence of critical features in logistics optimization to challenges in customer support and pricing rigidity, enterprises exploring comprehensive route optimization solutions may find more fitting alternatives in platforms that offer advanced technical capabilities, such as NextBillion.ai. | lara9963 |
1,795,809 | WeTest Compatibility Testing: The Ultimate Cloud Testing Experience for Mobile, PC & Console Games | WeTest Compatibility Testing offers a comprehensive compatibility testing service, catering to the... | 0 | 2024-03-20T03:51:45 | https://dev.to/wetest/wetest-compatibility-testing-the-ultimate-cloud-testing-experience-for-mobile-pc-console-games-2nnf | compatibility, compatibilitytesting, testing, qa | WeTest Compatibility Testing offers a comprehensive compatibility testing service, catering to the needs of mobile, PC, and console game developers. With stable and efficient cloud testing experiences, we ensure your game runs seamlessly across various platforms.

Launching a game in different regions and platforms comes with compatibility challenges, including device distribution, fragmentation, and updates. Building your own testing capabilities can be costly and inefficient, requiring significant investments in equipment, hard-to-obtain development kits, and high labor costs. However, by choosing WeTest, you gain access to extensive device coverage, efficient testing execution, rich reporting data, and expert assistance in problem identification and analysis.
Unrivaled professionalism combined with broad coverage of the game's core scenarios sets us apart. Our diverse range of cloud devices represents approximately 80% of global users, ensuring your game reaches a wide audience. Furthermore, we provide exclusive and unique PC and console devices, including R&D versions, for comprehensive testing. Our services offer high stability and cost-effectiveness, suitable for a variety of testing projects.
WeTest supports private cloud deployment through WeTest Real Devices, enabling secure and customized solutions tailored to your specific needs. With a quick delivery time of approximately one week, we provide compatible combinations in 10 dimensions, including GPU coverage for 70% of Steam user models and mainstream CPU models from Intel and AMD.
Our testing approach focuses on validating stability, rendering quality, and responsiveness by thoroughly covering the core scenarios of your game. WeTest holds official authorization for dev kits of popular consoles such as Xbox, PlayStation, and Switch, enabling us to deliver professional console compatibility testing services.
We understand the importance of validating adaptability across different combinations of game platforms, environments, devices, display types, resolutions, networks, and input methods. Our testing process meticulously identifies and resolves issues such as crashes, visual artifacts, unresponsiveness, and feature gaps.
With WeTest Compatibility Testing, you can confidently launch your game worldwide, knowing that it has undergone comprehensive compatibility testing and meets the highest standards of performance. Join the ranks of successful game developers who have chosen WeTest for their compatibility testing needs.
Contact us through this link: https://www.wetest.net/?utm_source=pr&utm_medium=PR-8 to experience the ultimate cloud-testing solution for your mobile, PC, and console games.
| wetest |
1,795,861 | "Day 46 of My Learning Journey: Setting Sail into Data Excellence! ⛵️ Today's Focus: Mathematics for Data Analysis ( P & C- 1) | PERMUTATION AND COMBINATION - 1 It is a method in which we count something with different... | 0 | 2024-03-20T06:00:28 | https://dev.to/nitinbhatt46/day-46-of-my-learning-journey-setting-sail-into-data-excellence-todays-focus-mathematics-for-data-analysis-p-c-1-1fba | ai, data, learning, math |
PERMUTATION AND COMBINATION - 1
It is a method in which we count something with different methods.
WHY do we need to learn about it ?
It is the best and most practical thing which we or everyone can learn to be practically more logical towards any thing which we can encounter in our life.
In Data Science and Analyst jobs it will help us in probability not just to learn but to understand it in depth.
Nowadays everything is done by machine so, don’t mug up all the formulas, just understand the concept and apply it in your project.
Fundamental Principle of Counting. :-
Multiplication
Addition
Fundamental Multiplication Principle of Counting. :-
If there are ‘m’ different ways of doing one event and ‘n’ different ways of doing another event, then the simultaneous occurrence of these events will be given by
‘m x n’ in different ways.
Eg of different ways to explain Fundamental Multiplication Principle of Counting.
MODEL 1 : - TWO COIN ARE TOSSED SIMULTANEOUSLY.
Total no. of outcome = 4
For three coins the outcome is :- 8 possible outcomes.
Because everyone has 2 possible outcome and when we are doing is simultaneously we get 2 X 2 X 2 = 8
Because every outcome is independent of each other.
No.of outcome = 2^(n)
n = no.of coin.
MODEL 2 : - TWO DICE ARE ROLLED SIMULTANEOUSLY.
EACH DICE OUTCOME POSSIBILITY = 6.
Total no. of outcome = 36
No.of outcome = 6^(n)
n = no.of dice
MODEL 3 : - Clothes Wearing possibility upper and lower.
2 upper and 4 lower.
No. of ways to wear = 2 X 4 = 8.
MODEL 4 : - Find the no. of way to reach somewhere ask in the question.
A has three (3) paths to reach B and from B to C we have four (4) ways.
So, to total outcome to reach C from A through B is = 3 X 4 = 12
MODEL 5 : - Four boxes and Four Different balls.
We NEED to place these 4 balls into the boxes. How many ways are there ?
Condition box can also be empty or it can be the only one who is filled with all balls.
So, to find the correct outcome. We need to know the possible outcome of each ball. I.e = 4.
Total outcomes :-
4 X 4 X 4 X 4 = 256
🙏 Thank you all for your time and support! 🙏
Don't forget to catch me daily at 6:30 Pm (Monday to Friday)for the latest updates on my programming journey! Let's continue to learn, grow, and inspire together! 💻✨
| nitinbhatt46 |
1,795,882 | 11 Best IPL Betting Sites In India Of 2024 | Are you prepared to add an extra layer of excitement to the upcoming IPL? The match between Chennai... | 0 | 2024-03-20T06:30:56 | https://dev.to/sportsx9s/11-best-ipl-betting-sites-in-india-of-2024-4i51 | ipl, betting, website, 2024 | Are you prepared to add an extra layer of excitement to the upcoming IPL? The match between Chennai Super Kings (CSK) and Royal Challengers Bangalore (RCB) is on Friday, 22 March 2024, at 14:30:00 UTC in MA Chidambaram Stadium, Chennai. Dive into our guide on the 11 best IPL betting sites in India, each offering unique bonuses and features to enhance your cricket betting experience. Whether you’re a seasoned punter or a newcomer, these platforms have something special for everyone. Let’s find the ideal betting companion for the cricketing extravaganza that is the Indian Premier League. [Continue](https://bet.sportsx9.com/cricket/best-ipl-betting-sites/) | sportsx9s |
1,795,893 | Input Sanitation | Zod has a really nice feature that allows us to define, for schemas that describe objects, how... | 26,937 | 2024-03-22T07:06:52 | https://dev.to/shaharke/zod-zero-to-here-chapter-3-182b | programming, typescript, node, zod | Zod has a really nice feature that allows us to define, for schemas that describe objects, how properties not defined in the schema should be treated. We can choose one of 3 modes:
- Strip: Zod will strip out unrecognized keys during parsing. This is the default behaviour.
- Passthrough: Zod will keep unrecognized keys and will not validate them.
- Strict: Zod will return an error for any unrecognized key.
All three modes have their uses, but in this post I will focus on `strip` and `strict`, who can help with what is called "Input Sanitation".
## What is input sanitation?
Input sanitation is a critical security practice aimed at preventing malicious users from injecting harmful data into our software. This practice involves validating and cleaning up the data received from the user before processing or storing it.
### Example scenario: unauthorized account modification
Imagine a web application that allows users to update their profile information, including their email but not their user role, which is intended to be controlled only by administrators. The application receives an object with the fields to be updated and directly passes it to the database query without properly sanitizing the input to remove or restrict fields.
Vulnerable code snippet:
```typescript
app.post('/updateProfile', function(req, res) {
// Assuming req.body is something like {email: "newemail@example.com"}
const updates = req.body;
const userId = req.session.userId; // The ID of the currently logged-in user
// Update the user profile with the provided fields
db.collection('users').updateOne({ _id: userId }, { $set: updates }, function(err, result) {
if (err) {
// handle error
} else {
// success
}
});
});
```
An attacker discovers this endpoint and decides to send a modified request that includes an additional property, `role`, in an attempt to escalate their privileges:
```json
{
"email": "attacker@example.com",
"role": "admin"
}
```
By sending this payload, the attacker could potentially change their user role to "admin", assuming the application does not properly check the fields that are being updated. This happens because the database command directly uses the object from the request, allowing any properties provided to be included in the `$set` operation.
## How can Zod help?
We can use one of the modes mentioned above to prevent this attack. Let's see what would be the behavior of each mode:
### Strip
Strip is the default mode of every schema and does not require any explicit configuration. We can change the vulnerable endpoint above in the following way:
```typescript
const Updates = z.object({
email: z.string()
})
app.post('/updateProfile', function(req, res) {
const updates = Updates.parse(req.body);
// log updates to see the result
console.log("You shall not pass!", updates);
const userId = req.session.userId;
// Update the user profile with the provided fields
db.collection('users').updateOne({ _id: userId }, { $set: updates }, function(err, result) {
if (err) {
// handle error
} else {
// success
}
});
});
```
Now when an attacker sends the following body:
```json
{
"email": "attacker@example.com",
"role": "admin"
}
```
Zod will strip the `role` property from the body before passing it on to the update statement. We should expect to see the following log:
```
You shall not pass! { "email": "attacker@example.com" }
```
### Strict
We can also configure a schema to be strict, causing unrecognized keys to throw an error:
```typescript
const Updates = z.object({
email: z.string()
}).strict()
// ... rest of code
```
Now calling the endpoint with the malicious payload will result in the following error:
```
ZodError: [
{
"code": "unrecognized_keys",
"keys": [
"role"
],
"path": [],
"message": "Unrecognized key(s) in object: 'role'"
}
]
```
In the context of input sanitation for security, using `strict` could be useful if we are looking to identify security breaches attempts as they happen.
Another interesting option is to use a mix of `strict` and `strip`:
```typescript
const Updates = z.object({
email: z.string()
})
const StrictUpdates = Updates.strict();
app.post('/updateProfile', function(req, res) {
const parseResult = StrictUpdates.safeParse(req.body);
if (!parseResult.success && parseResult.error.issues.some(issue => issue.code === ZodIssueCode.unrecognized_keys)) {
console.error("Unrecognized keys in updates");
}
const updates = Updates.parse(req.body);
console.log("You shall not pass!", updates);
// ... rest of code
});
```
Notice that usage of `safeParse` instead of `parse` when using the `StrictUpdates` schema. `safeParse` allows us to validate input without throwing an error in case the input is invalid. In this case we use `safeParse` to identify and log unrecognized keys, but not fail the request.
## Summary
Input sanitation is a very common and important security measure. Zod can help sanitize inputs in different ways - by silently dropping unrecognized keys or by throwing errors.
[Next chapter](- [Chapter 4: Union Types](https://dev.to/shaharke/zod-zero-to-hero-chapter-4-513c)
) we will learn how to define union types with Zod. | shaharke |
1,795,983 | Seamlessly Connect Your WP Contact Forms to Any API | In today's digital age, integrating your website with various third-party services and APIs has... | 0 | 2024-03-20T08:25:06 | https://dev.to/johnsmith244303/seamlessly-connect-your-wp-contact-forms-to-any-api-4fi6 | In today's digital age, integrating your website with various third-party services and APIs has become a necessity for businesses to streamline their operations and enhance their online presence. Contact forms are a crucial component of any website, serving as the primary means of communication between you and your potential customers. However, simply collecting form submissions is often not enough; you need a way to seamlessly connect your contact forms to other platforms, services, and APIs to unlock their full potential.

**The Importance of API Integration**
APIs (Application Programming Interfaces) are the backbone of modern web development, enabling different software applications and services to communicate and exchange data with one another. By connecting your WordPress contact forms to APIs, you can automate a wide range of tasks and processes, saving you time, effort, and resources.
For instance, you could integrate your contact forms with a Customer Relationship Management (CRM) system like Salesforce or HubSpot, allowing you to automatically capture and store lead information directly in your CRM. This streamlines your lead management process, ensuring that no potential customer falls through the cracks.
Alternatively, you might want to connect your contact forms to a marketing automation platform like MailChimp or Constant Contact, allowing you to automatically add new subscribers to your email lists based on the information they provide in the form.
The possibilities are virtually endless – you could integrate with project management tools, invoicing systems, payment gateways, and more, all by leveraging the power of APIs and the "WordPress Contact Form Plugin."
**Setting Up API Integrations with the "WordPress Contact Form Plugin"**
The "**[Best WordPress Contact Form Plugin](https://wordpress.org/plugins/contact-form-to-any-api/)**" makes it incredibly easy to set up API integrations for your contact forms. Here's a step-by-step guide to get you started:
**1. Install and Activate the Plugin**
Begin by installing and activating the "WordPress Contact Form Plugin" on your WordPress website. The plugin's user-friendly interface ensures a smooth setup process
**2. Create Your Contact Form**
Use the plugin's intuitive form builder to create your desired contact form. Customize the form fields, layout, and styling to match your brand and website design
**3. Set Up API Integration**
Navigate to the plugin's API integration settings and select the API or service you want to connect your form to. The plugin supports a vast array of popular APIs out of the box, and if you don't find the one you need, you can easily add custom API integrations using the plugin's developer-friendly API integration framework.
**4. Configure API Settings**
Depending on the API you've chosen, you'll need to provide the necessary authentication credentials, such as API keys, access tokens, or other required information. The plugin will guide you through this process, ensuring a seamless configuration experience.
**5. Map Form Fields**
Once you've authenticated with the API, you can map your contact form fields to the corresponding fields in the API. This ensures that the data submitted through your form is accurately captured and stored in the connected service or platform.
**6. Test and Deploy**
Before going live, take the time to thoroughly test your API integration by submitting a few test form entries. Once you're satisfied with the results, you can publish your contact form, confident that it's seamlessly connected to the desired API.
**Advanced Features and Customizations**
The "WordPress Contact Form Plugin" is more than just a basic contact form builder – it offers a wide range of advanced features and customization options to cater to even the most sophisticated requirements.
**Conditional Logic**
The plugin allows you to implement conditional logic, enabling you to show or hide specific form fields based on the user's input. This feature is particularly useful for creating dynamic, user-friendly forms that adapt to the visitor's needs.
**Multi-Step Forms**
For complex forms with numerous fields, the plugin supports the creation of multi-step forms. This feature breaks down lengthy forms into manageable sections, improving the user experience and reducing form abandonment rates.
**Form Styling and Customization**
With the "WordPress Contact Form Plugin," you have complete control over the appearance of your forms. Customize the form's layout, colors, fonts, and styles to seamlessly match your website's branding and design.
**Spam Protection**
Protecting your forms from spam submissions is essential, and the plugin offers robust spam protection features, including reCAPTCHA integration, honeypot fields, and advanced spam filtering algorithms
**Comprehensive Analytics and Reporting**
Gain valuable insights into your form's performance with the plugin's comprehensive analytics and reporting capabilities. Track form submissions, conversion rates, and other key metrics to continuously optimize and refine your forms.
**Developer-Friendly API Integration Framework**
While the plugin offers out-of-the-box integrations with popular APIs, its developer-friendly API integration framework allows you to create custom integrations tailored to your specific needs. Whether you need to connect to a proprietary internal system or a lesser-known third-party service, the plugin's extensible architecture makes it possible.
**Conclusion**
In today's fast-paced digital landscape, seamlessly connecting your WordPress contact forms to various APIs and third-party services is no longer a luxury – it's a necessity. The "WordPress Contact Form Plugin" empowers you to do just that, unlocking a world of possibilities for streamlining your business processes, enhancing customer engagement, and maximizing the potential of your online presence.
With its user-friendly interface, advanced features, and robust API integration capabilities, this plugin is a game-changer for businesses of all sizes and industries. Whether you're an agency, e-commerce store, or a professional service provider, the "WordPress Contact Form Plugin" is a must-have tool in your WordPress arsenal, enabling you to take your contact forms to new heights and provide exceptional experiences for your customers.
So, what are you waiting for? Unlock the full potential of your WordPress contact forms today and seamlessly connect them to any API with the "WordPress Contact Form Plugin."
| johnsmith244303 | |
1,796,090 | Gimli Tailwind now features a sleek dark UI theme! | In Version 4.1 and 4.2, I’ve primarily focused on addressing bugs and optimizing code. However, I’ve... | 0 | 2024-03-20T10:48:41 | https://dev.to/gimli_app/gimli-tailwind-now-features-a-sleek-dark-ui-theme-37j5 | tailwindcss, webdev, css, frontend |
In Version 4.1 and 4.2, I’ve primarily focused on addressing bugs and optimizing code. However, I’ve also made some subtle yet valuable improvements!
[Check out the video](https://www.youtube.com/watch?v=gykSctSuMK4&ab_channel=Gimli)
[Click here to get the extension.](https://chromewebstore.google.com/detail/gimli-tailwind/fojckembkmaoehhmkiomebhkcengcljl) | gimli_app |
1,796,399 | How to Create Interface in Laravel 11 | In this article, we'll create an interface in laravel 11. In laravel 11 introduced new Artisan... | 0 | 2024-03-20T16:28:33 | https://techsolutionstuff.com/post/how-to-create-interface-in-laravel-11 | laravel, laravel11, interface, webdev | In this article, we'll create an interface in laravel 11. In laravel 11 introduced new Artisan commands.
An interface in programming acts like a contract, defining a set of methods that a class must implement.
Put simply, it ensures that different classes share common behaviors, promoting consistency and interoperability within the codebase.
So, let's see laravel 11 creates an interface, what is an interface in laravel, laravel creates an interface command, and php artisan make interface.
Laravel 11 new artisan command to create an interface.
```
php artisan make:interface {interfaceName}
```
> Laravel Create Interface:
First, we'll create ArticleInterface using the following command.
```
php artisan make:interface Interfaces/ArticleInterface
```
Next, we will define the publishArticle() and getArticleDetails() functions in the ArticleInterface.php file. So, let's update the following code in the ArticleInterface.php file.
app/Interfaces/ArticleInterface.php
```
<?php
namespace App\Interfaces;
interface ArticleInterface
{
public function publishArticle($title, $content);
public function getArticleDetails($articleId);
}
```
Next, we will create two new service classes and implement the "ArticleInterface" on them. Run the following commands now:
```
php artisan make:class Services/ShopifyService
php artisan make:class Services/LaravelService
```
app/Services/ShopifyService.php
```
<?php
namespace App\Services;
use App\Interfaces\ArticleInterface;
class ShopifyService implements ArticleInterface
{
/**
* Write code on Method
*
* @return response()
*/
public function publishArticle($title, $content) {
info("Publish article on Shopify");
}
/**
* Write code on Method
*
* @return response()
*/
public function getArticleDetails($articleId) {
info("Get Article details from Shopify");
}
}
```
app/Services/LaravelService.php
```
<?php
namespace App\Services;
use App\Interfaces\ArticleInterface;
class LaravelService implements ArticleInterface
{
/**
* Write code on Method
*
* @return response()
*/
public function publishArticle($title, $content) {
info("Publish article on Laravel");
}
/**
* Write code on Method
*
* @return response()
*/
public function getArticleDetails($articleId) {
info("Get Article details from Laravel");
}
}
```
Now, we'll create a controller using the following command and implement the service into the controller.
```
php artisan make:controller ShopifyArticleController
php artisan make:controller LaravelArticleController
```
app/Http/Controllers/ShopifyArticleController.php
```
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Services\ShopifyService;
class ShopifyArticleController extends Controller
{
protected $shopifyService;
/**
* Constructor to inject ShopifyService instance
*
* @param ShopifyService $shopifyService
* @return void
*/
public function __construct(ShopifyService $shopifyService) {
$this->shopifyService = $shopifyService;
}
/**
* Publish an article
*
* @param Request $request
* @return \Illuminate\Http\JsonResponse
*/
public function index(Request $request) {
$this->shopifyService->publishArticle('This is title.', 'This is body.');
return response()->json(['message' => 'Article published successfully']);
}
}
```
app/Http/Controllers/LaravelArticleController.php
```
<?php
namespace App\Http\Controllers;
use Illuminate\Http\Request;
use App\Services\LaravelService;
class LaravelArticleController extends Controller
{
protected $laravelService;
/**
* Constructor to inject ShopifyService instance
*
* @param LaravelService $laravelService
* @return void
*/
public function __construct(LaravelService $laravelService) {
$this->laravelService = $laravelService;
}
/**
* Publish an article
*
* @param Request $request
* @return \Illuminate\Http\JsonResponse
*/
public function index(Request $request) {
$this->laravelService->publishArticle('This is title.', 'This is body.');
return response()->json(['message' => 'Article published successfully']);
}
}
```
After that, we'll define routes in the web.php file
routes/web.php
```
<?php
use Illuminate\Support\Facades\Route;
use App\Http\Controllers\ShopifyArticleController;
use App\Http\Controllers\LaravelArticleController;
Route::get('shofipy/post', [ShopifyArticleController::class, 'index']);
Route::get('laravel/post', [LaravelArticleController::class, 'index']);
```
---
You might also like:
#### **[Read Also: How to Get Current URL in Laravel](https://techsolutionstuff.com/post/how-to-create-interface-in-laravel-11)** | techsolutionstuff |
1,796,412 | If statements | Type end immediately after typing the if. Indent elsif is only when you need to check more than 2... | 0 | 2024-03-20T16:49:28 | https://dev.to/feelo31/if-statements-ah0 | Type `end` immediately after typing the `if`. Indent
`elsif` is only when you need to check more than 2 conditions.
Causing code to execute is known as 'truthy'
Causing code to not execute is known as 'falsy'
Only `nil` and `false` are falsy.
`!=` means not equivalent
`p` if for quick inspection, `pp` is for more human readable representations. especially with complex data structures.
In variables you can put methods on both sides to evaluate `if` statements more concise.
`&&` both statements have to be true
`||` at least one statement has to be true. | feelo31 | |
1,796,445 | Next JS 14 | Setting Up Your Database | In this chapter Here are the topics we’ll cover: 🐱 Push your project to GitHub. 🔺 Set up a Vercel... | 26,880 | 2024-03-20T17:24:12 | https://dev.to/w3tsa/next-js-14-setting-up-your-database-4ank | webdev, nextjs, database, vercel | In this chapter
Here are the topics we’ll cover:
🐱 Push your project to GitHub.
🔺 Set up a Vercel account and link your GitHub repo for instant previews and deployments.
🔗 Create and link your project to a Postgres database.
𝌏 Seed the database with initial data.
**Create a GitHub repository**
To start, let's push your repository to Github if you haven't done so already. This will make it easier to set up your database and deploy.
If you need help setting up your repository, take a look at [this guide on GitHub](https://help.github.com/en/github/getting-started-with-github/create-a-repo).
**Create a Vercel account**
Visit [vercel.com/signup](https://vercel.com/signup) to create an account. Choose the free "hobby" plan. Select Continue with GitHub to connect your GitHub and Vercel accounts.
**Connect and deploy your project**
Next, you'll be taken to this screen where you can select and **import** the GitHub repository you've just created:
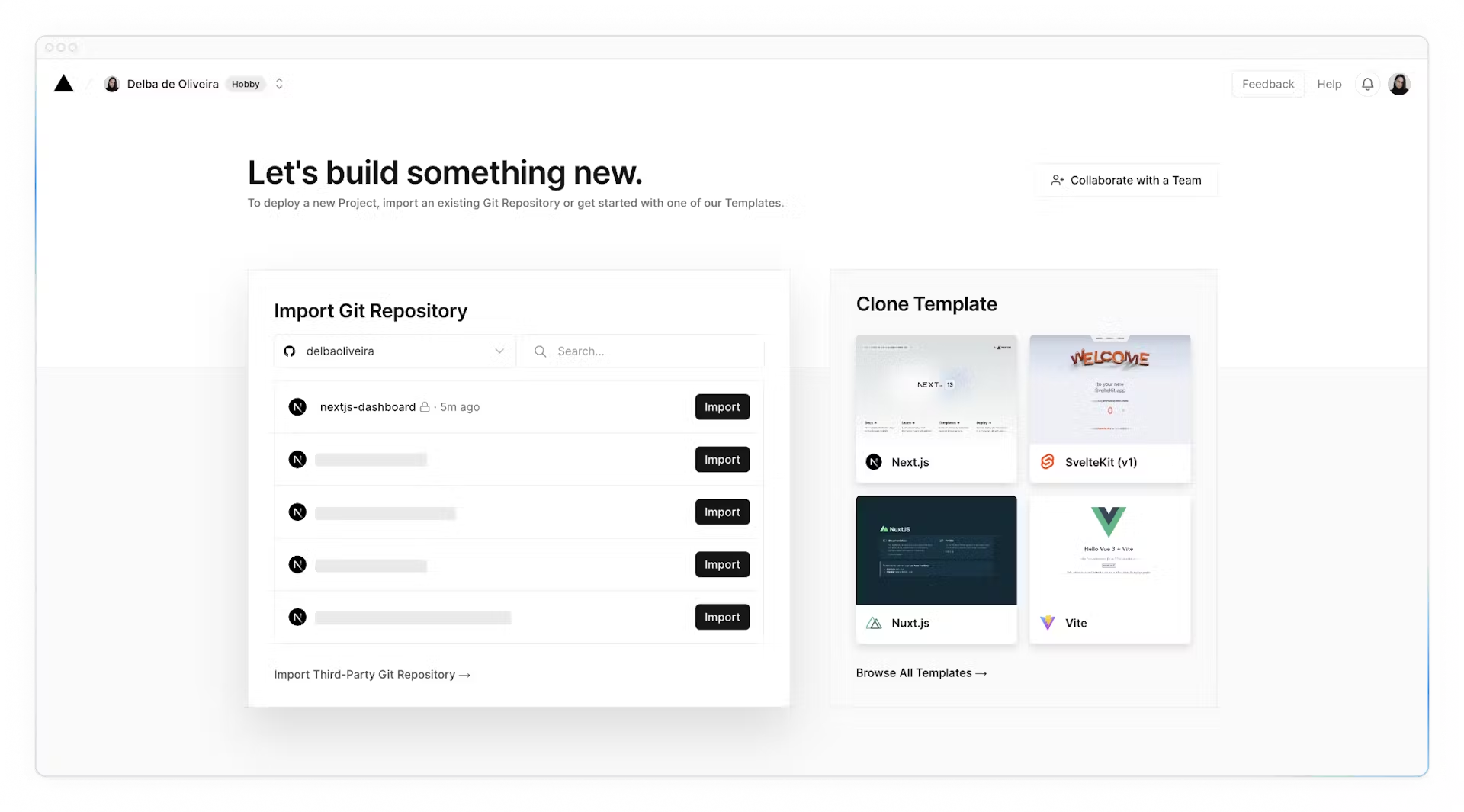
Name your project and click **Deploy**.
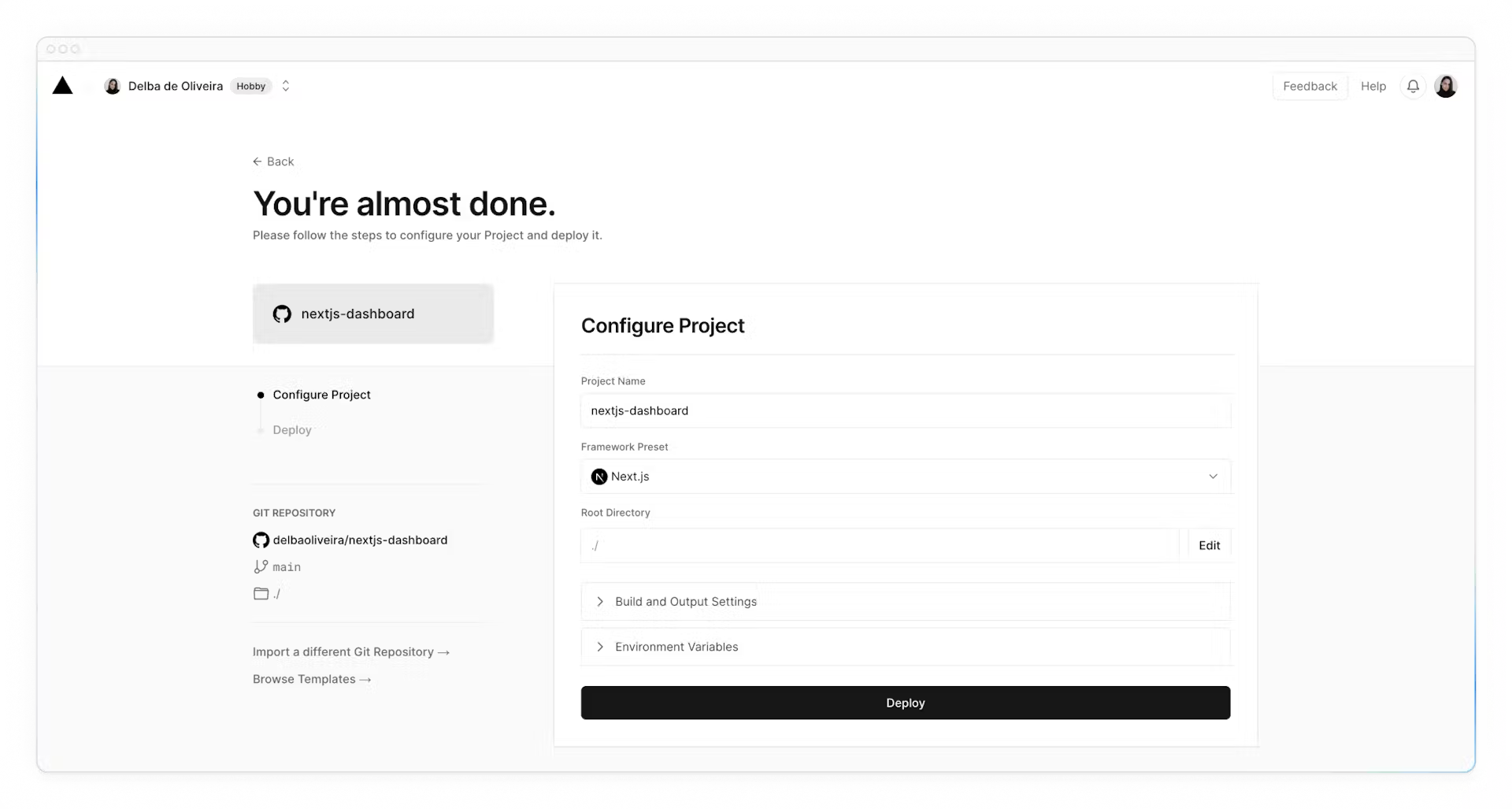
Hooray! 🎉 Your project is now deployed.
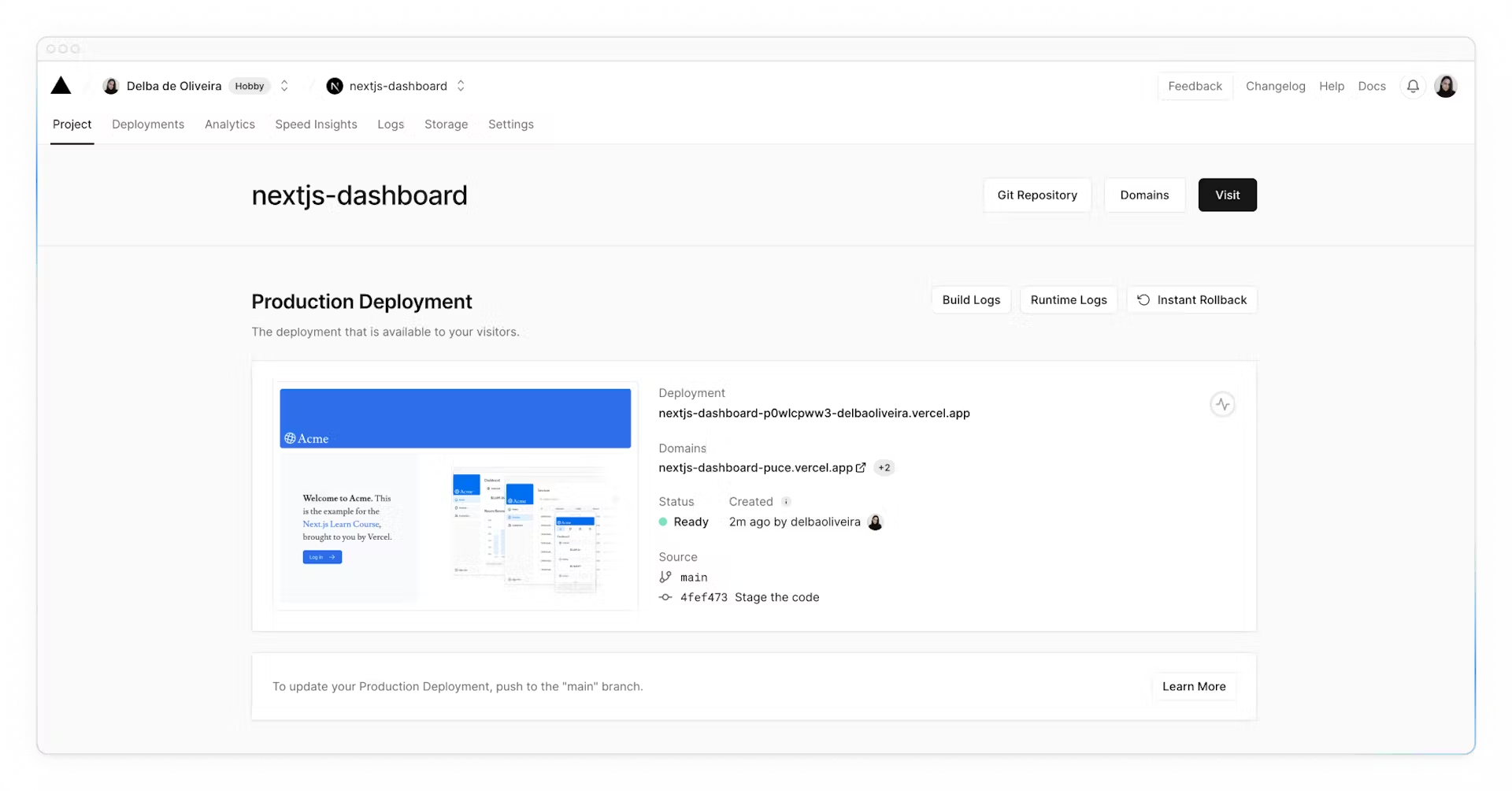
By connecting your GitHub repository, whenever you push changes to your main branch, Vercel will automatically redeploy your application with no configuration needed. When opening pull requests, you'll also have [instant previews](https://vercel.com/docs/deployments/preview-deployments#preview-urls) which allow you to catch deployment errors early and share a preview of your project with team members for feedback.
**Create a Postgres database**
Next, to set up a database, click **Continue to Dashboard** and select the **Storage** tab from your project dashboard. Select **Connect Store → Create New → Postgres → Continue**.
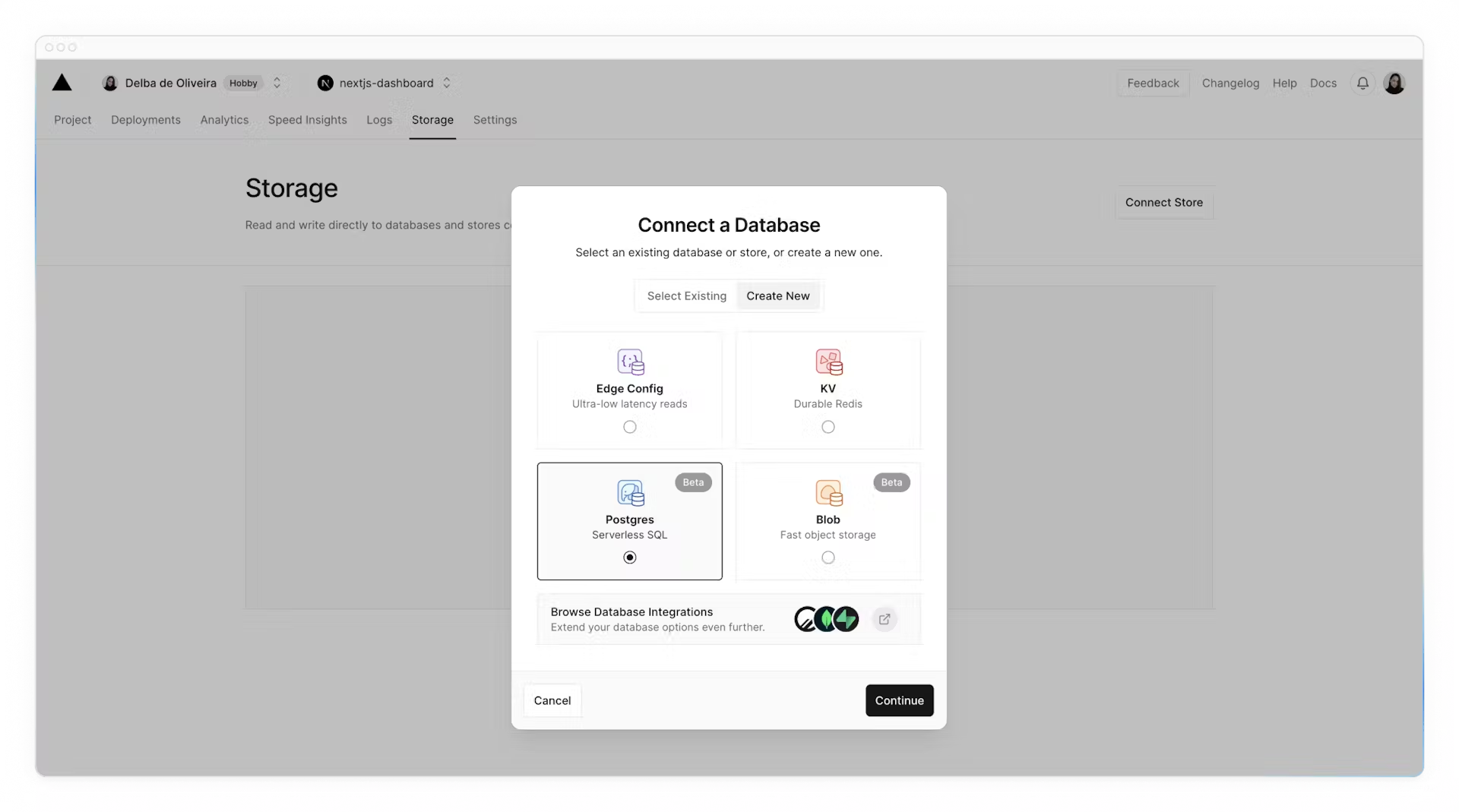
Accept the terms, assign a name to your database, and ensure your database region is set to **Washington D.C (iad1)** - this is also the [default region](https://vercel.com/docs/functions/serverless-functions/regions#select-a-default-serverless-region) for all new Vercel projects. By placing your database in the same region or close to your application code, you can reduce [latency](https://developer.mozilla.org/en-US/docs/Web/Performance/Understanding_latency) for data requests.
Once connected, navigate to the `.env.local` tab, click **Show secret** and **Copy Snippet**. Make sure you reveal the secrets before copying them.
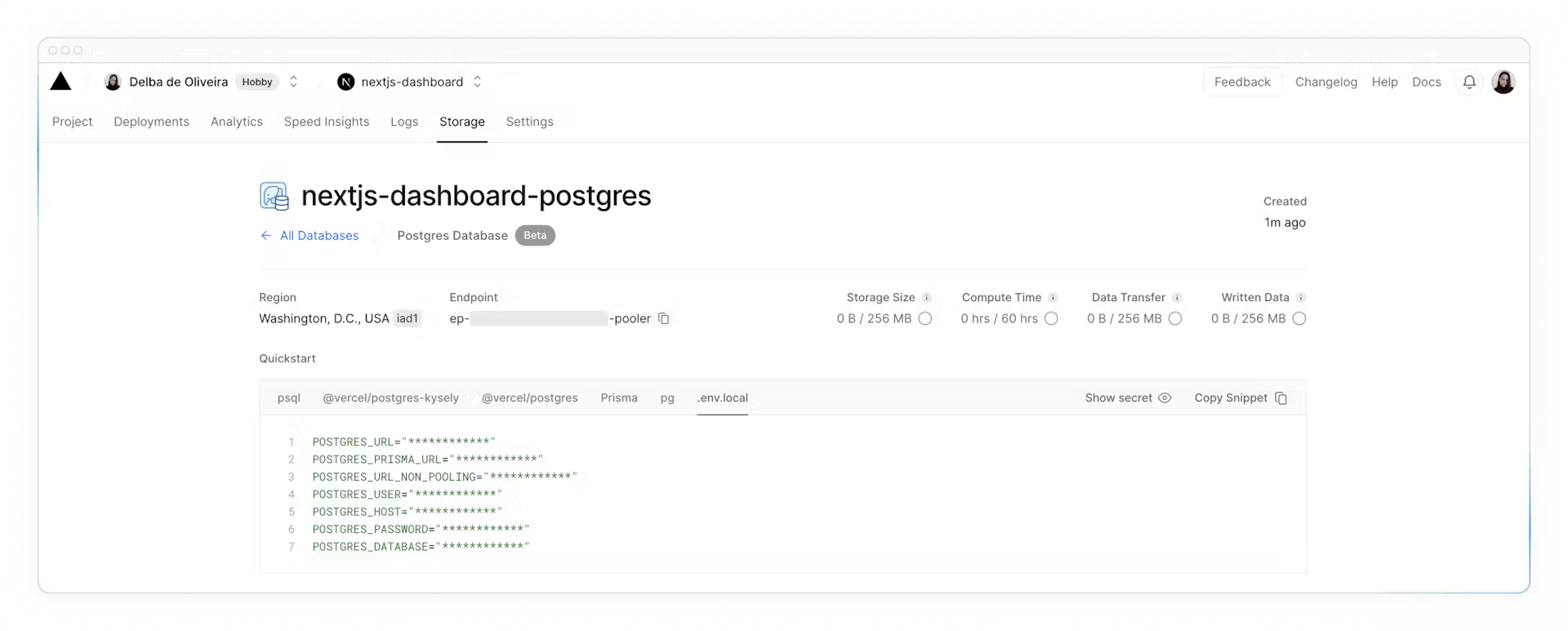
Navigate to your code editor and rename the `.env.example` file to `.env`. Paste in the copied contents from Vercel.
**Important**: Go to your `.gitignore` file and make sure `.env` is in the ignored files to prevent your database secrets from being exposed when you push to GitHub.
Finally, run `npm i @vercel/postgres` in your terminal to install the [Vercel Postgres SDK](https://vercel.com/docs/storage/vercel-postgres/sdk).
**Seed your database**
Now that your database has been created, let's seed it with some initial data. This will allow you to have some data to work with as you build the dashboard.
In the `/scripts` folder of your project, there's a file called `seed.js`. This script contains the instructions for creating and seeding the invoices, customers, user, revenue tables.
The script uses SQL to create the tables, and the data from `placeholder-data.js` file to populate them after they've been created.
Next, in your `package.json` file, add the following line to your scripts:
```json
"scripts": {
"build": "next build",
"dev": "next dev",
"start": "next start",
"seed": "node -r dotenv/config ./scripts/seed.js"
},
```
This is the command that will execute `seed.js`.
Now, run `npm run seed`. You should see some `console.log` messages in your terminal to let you know the script is running.
Let's see what your database looks like. Go back to Vercel, and click **Data** on the sidenav.
In this section, you'll find the four new tables: users, customers, invoices, and revenue.
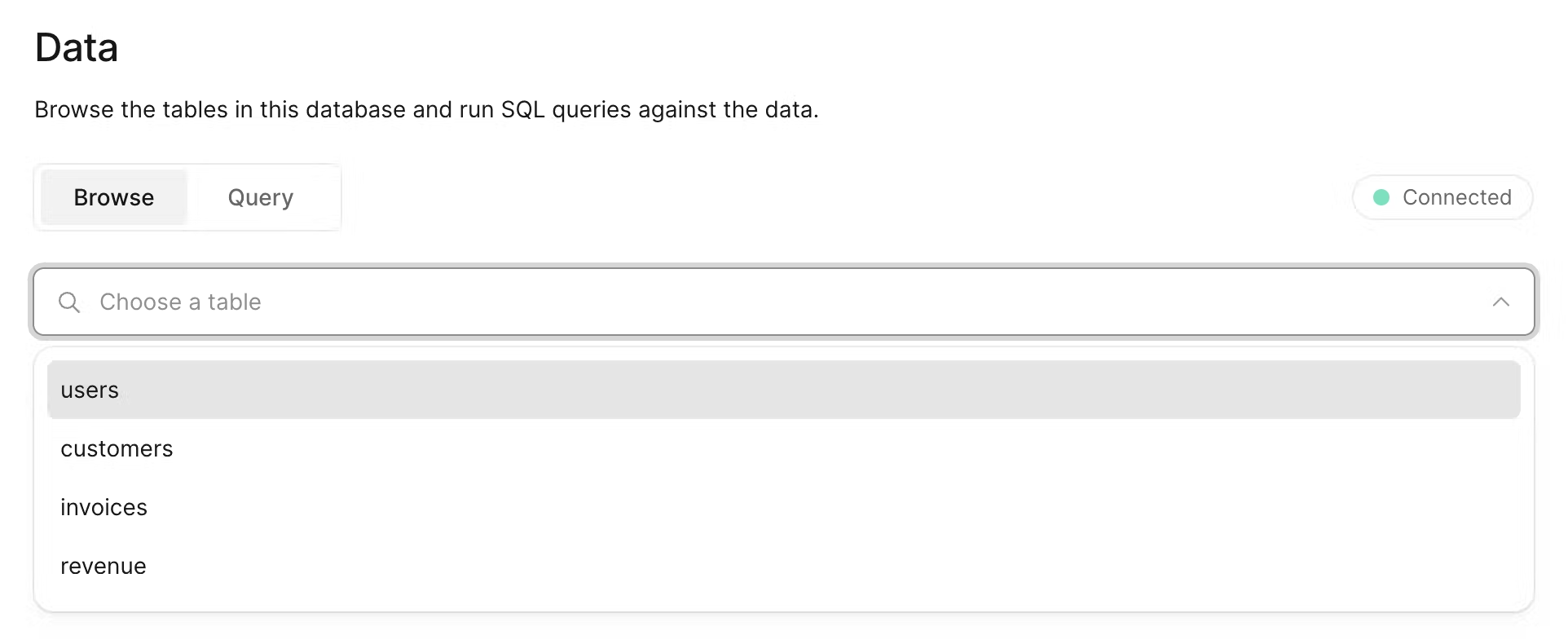
By selecting each table, you can view its records and ensure the entries align with the data from `placeholder-data.js` file.
**Executing queries**
You can switch to the "query" tab to interact with your database. This section supports standard SQL commands. For instance, inputting `DROP TABLE customers` will delete "customers" table along with all its data - **so be careful!**
Let's run your first database query. Paste and run the following SQL code into the Vercel interface:
```sql
SELECT invoices.amount, customers.name
FROM invoices
JOIN customers ON invoices.customer_id = customers.id
WHERE invoices.amount = 666;
```
Check out the video: {% youtube vc_evtMq11k%}
Support me: Like, Share and Subscribe!
| w3tsa |
1,796,643 | Building a Native Mobile App: Select the Right Framework | In this podcast, Krish explores the realm of mobile app development, comparing native approaches... | 0 | 2024-03-20T21:17:47 | https://dev.to/vpalania/building-a-native-mobile-app-select-the-right-framework-56ed | In this podcast, Krish explores the realm of mobile app development, comparing native approaches using Swift and Kotlin for iOS and Android respectively, with cross-platform options like React Native and Flutter. While discussing the merits of each approach, Krish notes Google's endorsement of Kotlin for Android development and the growing popularity of Flutter. He emphasizes the importance of considering project requirements and personal preferences when selecting a technology stack. Krish expresses excitement about his positive initial experiences with Flutter and hints at delving into API integration in future discussions, setting the stage for further exploration of mobile app development strategies.
### Summary
**Introduction to Mobile App Development Options**
- Krish introduces the topic of mobile app development and advises listeners to check out previous episodes for context.
**Native Development vs. Cross-Platform Options**
- Krish discusses the choice between native development (Swift for iOS, Kotlin for Android) and cross-platform alternatives like React Native and Flutter.
- He highlights Kotlin as Google’s recommended language for Android development.
**Considerations for Cross-Platform Development**
- Krish examines React Native as an initial choice but mentions widening gaps between React and React Native.
- He touches on personal preferences in technology stack selection and the importance of considering suitability for each project.
**Introduction to Flutter and Dart**
- Krish introduces Flutter as Google’s mobile framework using the Dart language.
- He shares his positive initial impressions of Flutter, citing its rich components and promising traction in the developer community.
**Conclusion and Future Discussion**
- Krish expresses excitement about working with Flutter and hints at discussing API integration in the next episode.
### Podcast
Check out on [Spotify](https://open.spotify.com/episode/1KKVAKjfeFUHeJQyl8DoFx?si=WvmCmUZURRea1Nrk2mUKag).
### Transcript
**0:00**
Hello. Hey, this is Krish. Hope you’re doing well in this podcast. I want to follow up on one of the previous ones where I started talking about mobile app development. If you haven’t listened to that, please, you may want to check that out. In that first one, I just talked at the highest level about various options available if you were starting out to build a mobile app.
**0:23**
Let me continue the conversation or that monologue here. So if memory serves me right, I believe I left off that podcast mentioning Kotlin and also cross-browser alternatives, right? Like Flutter and React Native. Let’s continue from that point onwards, right? So let’s say you’ve decided to go ahead, and before you jump all in into a cross-platform technology, you want to be doubly sure about the other option that’s out there, which is building Swift and native-like Android apps.
**1:02**
With Android, you have two options at least. The traditional way of building Android apps was using an Android SDK, purely using Java as a programming language. But I think, I believe starting last year, Google’s official recommendation, whatever official means, their recommendation has been to use Kotlin as an alternative to Java. And that could be one of many reasons as to why that happened. Which is not super important, I think, to this conversation because our interest here is just to get an app out there and then build it, right? Get to building it. In any case, Kotlin’s a different language, it’s statically typed and it was founded, I believe, by JetBrains as a company. But it’s fully interoperable with Java, right? So, and it’s… I mean, I’ve taken an initial look at it. I haven’t done much development using Kotlin, but it doesn’t like… I mean, it doesn’t look terribly different from Java. At least, my first look is to say anything about it in any case, so that’s an option definitely available for you.
**2:30**
So you want to, you know, build a Kotlin app, an Android app, using Kotlin as your programming language of choice. Now, that’s just a precursor to our discussion, to this, to this podcast. What I want to actually talk about is, okay, now let’s say you want to go with a cross-platform option, and I’m very much for it, just because I’ve actually not run into an extremely compelling use case, at least in the work I’ve done thus far where I’ve not been able to solve problems using a cross-platform technology.
**3:03**
Right. So having said that, right, so what do you want to go with, right? React Native was one of my initial choices, at least in mind, because I love React on the web just because of the way it does things and the ease of integration that it has with some other plugins and libraries, even outside of the React ecospace. But even having said that I just want to… when you start to do something, you want to make sure you do your due diligence and for every project right. Not just because you pick one stack or one technology for a project and then the next one you do something similar.
**4:28**
From what I’ve read, and I actually did a bit of playing around as well. What I’ve read, it sounds like the gap between React and React Native seems to be widening. I’m not entirely sure why, and just in terms of the feature and support and whatnot, it seems like it’s getting wider. It’s not like the same level of support that you expect and you do see for React on the web. You may or may not get that for React Native. That was one. That was kind of the feeling I’ve had for a little bit, but that seems to be more and more true of late. Also, I also read an article about Airbnb being almost entirely based on React Native, their mobile apps, and they’ve moved off of it for several different reasons.
**6:15**
So you know, we have our own preferred languages and frameworks every time we do things and then we learn other items. But you know, unless something changes dramatically, I don’t see myself building mobile apps using anything other than Dart, at least in the short term to middle term, right? Going back to GitHub and and dart’s traction, it’s actually quite new compared to React Native with, I don’t know, it’s the newest kid. I don’t know if it’s the newest kid, but it’s a pretty new kid on the block. But it has, it’s very comparable. I think I saw like about 80,000 stars and in terms of the number of folks, it’s probably a percentage of React Native if you go to GitHub and look that up. But otherwise the actual in terms of adoptability, it seems to have a lot of traction. I mean, things change every day, so who knows what happens tomorrow. But as of this recording that seems to have, flutter seems to have a lot of traction and interest in the community, which is actually very good, right.
**10:19**
So you’re going to find more help and and articles and and whatnot. So that is very promising. And what else? Right, In terms of the samples and then widgets that are available, I mean I’ve found a decent number. I don’t know how it compares with what React Native has. But just given the fact that React Native has been around for much longer, it’s very likely if you’re going to, you’re going to find more help on like Stack Overflow or other places if you have questions. So I’m sure there’s going to be some gap there in terms of documentation and what not. But my initial reaction is, is very positive and I’m super excited. I’ve started to do some work and you know starting to get the initial set of pages and and what not. So we’ll see how it goes in the next podcast. Let me talk more about API integration of the app and what might be some of the options that that are available to us.
**11:19**
Thank you. | vpalania | |
1,796,937 | Day 13: Unveiling the Magic of INTRODUCTION in Java, C++, Python, and Kotlin! 🚀 | DAY - 13 For more Tech content Join us on linkedin click here All the code snippets in this journey... | 0 | 2024-03-21T05:48:57 | https://dev.to/nitinbhatt46/day-13-unveiling-the-magic-of-introduction-in-java-c-python-and-kotlin-l0n | programming, coding, developer, beginners | DAY - 13
For more Tech content Join us on linkedin [click here](https://www.linkedin.com/in/nitin-bhatt-962356260/)
All the code snippets in this journey are available on my GitHub repository. 📂 Feel free to explore and collaborate: [Git Repository](https://github.com/Nitin-bhatt46/POWER_OF_PROGRAMMING/tree/main
)
Today’s Learning :-
Decimal to Binary
Universal code for decimal to binary. ( cpp, java, python )
Binary to decimal ( cpp, java , python )
Introduction to Function :-
Python:
Theory:
Functions in Python are defined using the def keyword.
They can take zero or more parameters as input and optionally return a value.
Python functions can be defined anywhere in the code, even within other functions.
Python functions can have default parameter values, making some parameters optional.
Python functions can also accept variable-length arguments (*args and **kwargs).
Syntax:
def function_name(parameter1, parameter2, ...):
# Function body
# Statements
return result # Optional return statement
Java:
Theory:
Functions in Java are called methods.
They are defined within classes and objects.
Java methods must specify their return type explicitly, even if it's void (no return value).
Java methods can be static, public, private, etc., to define their accessibility and behaviour.
Java methods can be overloaded, meaning you can define multiple methods with the same name but different parameter lists.
Syntax:
access_modifier return_type method_name(parameter1_type parameter1, parameter2_type parameter2, ...) {
// Method body
// Statements
return result; // Optional return statement
}
C++:
Theory:
Functions in C++ are similar to those in C.
They are standalone entities and can exist outside of classes.
C++ functions can have default parameter values, similar to Python.
C++ supports function overloading, allowing multiple functions with the same name but different parameter lists.
C++ allows you to define inline functions using the inline keyword for small and frequently called functions.
Syntax:
return_type function_name(parameter1_type parameter1, parameter2_type parameter2, ...) {
// Function body
// Statements
return result; // Optional return statement
}
Feel free to reshare this post to enhance awareness and understanding of these fundamental concepts.
Code snippets are in Git repository.
🙏 Thank you all for your time and support! 🙏
Don't forget to catch me daily at 10:30 Am (Monday to Friday) for the latest updates on my programming journey! Let's continue to learn, grow, and inspire together! 💻✨
| nitinbhatt46 |
1,796,961 | Create Complete User Registration Form in PHP and MySQL | What You Will Learn? As stated previously, in this article, you are going to learn the... | 0 | 2024-03-21T06:35:47 | https://dev.to/hmawebdesign/create-complete-user-registration-form-in-php-and-mysql-3k8i | php, javascript, backend, mysql | ## What You Will Learn?
As stated previously, in this article, you are going to learn the following important concepts while creating the complete user registration form in PHP and using the MySQL database.
## How to create a user registration form in HTML and CSS?
1. How to create a new MySQL database in PHPMyAdmin?
2. How to connect with MySQL database with PHP?
3. How to do registration form validation in PHP?
4. Password encryption or password hashing in PHP?
5. How to insert or update user data into the database table?
6. How to use $_session variable in the PHP user registration and login form?
7. How to set the cookies variable in PHP for user registration?
8. How to create a User logout PHP code?
9. How to create a user login system in PHP?
10. How to write PHP code for the user login form?
## Video Tutorial – Login Register PHP
Meanwhile, You can watch the following video tutorial which includes the step-by-step process to create a complete user registration form using PHP and MySQL databases.
{% embed https://youtu.be/m50q5_RQFB4 %}
## Steps – Login and Register for PHP Form
More importantly, to create a complete user registration system in PHP and MySQL, we are going to adopt the following approach.
1. First of all, we are going to create the following PHP files:
2.
3. Create an index.php file. This file contains the HTML and CSS code for the user Sign up form.
4. Create a new MySql database in PHPMyAdmin and a new user table where you want to store the user login details.
5. Create a linkDB.php file. This file will contain MYSQL database connection PHP code.
6. Create a server.php file. This file will contain all server-side PHP and MYSQL database codes for user registration and user login forms. This file is linked with both, index.php and login.php files using the PHP include function.
7. Create a LoggedInPage.php file. This will be your home page, and after the successfully logged user in, will redirect to this home page.
8. Create a login.php file. This file contains the login form HTML and CSS code.
## Source Code – (index.php File)
The following HTML CSS source code belongs to the index.php file. This code is for the user registration form in PHP.
```
<!-- PHP command to link server.php file with registration form -->
<?php include('server.php'); ?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Registration</title>
<!-- CSS Code -->
<style>
.container{
justify-content: center;
text-align: center;
align-items: center;
}
input{
padding: 5px;
}
.error{
background-color: pink;
color: red;
width: 300px;
margin: 0 auto;
}
</style>
</head>
<body>
<div class="container">
<h1>User Registration System</h1>
<h4><a href="loggedInPage.php">Home Page</a></h4>
<div class="form" id="signUp">
<form method="POST">
<div class="error"> <?php echo $error ?> </div>
<!--------- To check user regidtration status ------->
<p>
<?php
if (!isset($_COOKIE["id"]) OR !isset($_SESSION["id"]) ) {
echo "Please first register to proceed.";
}
?>
</p>
<input type="text" name="name" placeholder="User Name"> <br> <br>
<input type="email" name="email" placeholder="Email"> <br><br>
<input type="password" name="password" placeholder="password"><br><br>
<input type="password" name="repeatPassword" placeholder="Repeat Password"><br><br>
<label for="checkbox">Stay logged in</label>
<input type="checkbox" name="stayLoggedIn" id="chechbox" value="1"> <br><br>
<input type="submit" name="signUp" value="Sign Up">
<p >Have an account already? <a href="logIn.php">Log In</a></p>
</form>
</div>
</body>
</html>
```
## Source Code – (login.php File)
```
<!-- PHP command to link server.php file with registration form -->
<?php include('server.php'); ?>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>User logIn</title>
<style>
.container{
justify-content: center;
text-align: center;
align-items: center;
}
input{
padding: 5px;
}
.error{
background-color: pink;
color: red;
width: 300px;
margin: 0 auto;
}
</style>
</head>
<body>
<div class="container">
<h1> User Registration System</h1>
<h4><a href="loggedInPage.php">Home Page</a></h4>
<!--------log in form------>
<div class="logInForm" id="logIn">
<form method="POST">
<!-- To show errors is user put wrong data -->
<div class="error"> <?php echo $error2 ?> </div>
<!-- To check the user loged In status -->
<p>
<?php
if (!isset($_COOKIE["id"]) OR !isset($_SESSION["id"]) ) {
echo "<p>Please first log in to proceed.</p>";
}
?>
</p>
<input type="email" name="email" placeholder="Email"> <br><br>
<input type="password" name="password" placeholder="password"><br><br>
<label for="checkbox">Stay logged in</label>
<input type="checkbox" name="stayLoggedIn" id="chechbox" value="1"> <br><br>
<input type="submit" name="logIn" value="Log In">
<!-- User registration form link -->
<p>Not a register user <a href="index.php"> Create Account</a></p>
</form>
</div>
</div>
</script>
</body>
</html>
```
## Source Code – (linkDB.php File)
The linkDB.php includes the following PHP code.
```
<?php
// Open a new connection to the MySQL server
$linkDB = mysqli_connect("localhost","my_user_name","my_password","my_db_name");
if (mysqli_connect_error()){ //for connection error finding
die ('There was an error while connecting to database');
}
?>
```
## Source Code – (server.php File)
The following back-end code for the user registration form in PHP will be included in the server.php file:
```
<?php
session_start();
//------ PHP code for User registration form---
$error = "";
if (array_key_exists("signUp", $_POST)) {
// Database Link
include('linkDB.php');
//Taking HTML Form Data from User
$name = mysqli_real_escape_string($linkDB, $_POST['name']);
$email = mysqli_real_escape_string($linkDB, $_POST['email']);
$password = mysqli_real_escape_string($linkDB, $_POST['password']);
$repeatPassword = mysqli_real_escape_string($linkDB, $_POST['repeatPassword']);
// PHP form validation PHP code
if (!$name) {
$error .= "Name is required <br>";
}
if (!$email) {
$error .= "Email is required <br>";
}
if (!$password) {
$error .= "Password is required <br>";
}
if ($password !== $repeatPassword) {
$error .= "Password does not match <br>";
}
if ($error) {
$error = "<b>There were error(s) in your form!</b> <br>".$error;
} else {
//Check if email is already exist in the Database
$query = "SELECT id FROM users WHERE email = '$email'";
$result = mysqli_query($linkDB, $query);
if (mysqli_num_rows($result) > 0) {
$error .="<p>Your email has taken already!</p>";
} else {
//Password encryption or Password Hashing
$hashedPassword = password_hash($password, PASSWORD_DEFAULT);
$query = "INSERT INTO users (name, email, password) VALUES ('$name', '$email', '$hashedPassword')";
if (!mysqli_query($linkDB, $query)){
$error ="<p>Could not sign you up - please try again.</p>";
} else {
//session variables to keep user logged in
$_SESSION['id'] = mysqli_insert_id($linkDB);
$_SESSION['name'] = $name;
//Setcookie function to keep user logged in for long time
if ($_POST['stayLoggedIn'] == '1') {
setcookie('id', mysqli_insert_id($linkDB), time() + 60*60*365);
//echo "<p>The cookie id is :". $_COOKIE['id']."</P>";
}
//Redirecting user to home page after successfully logged in
header("Location: loggedInPage.php");
}
}
}
}
//-------User Login PHP Code ------------
if (array_key_exists("logIn", $_POST)) {
// Database Link
include('linkDB.php');
//Taking form Data From User
$email = mysqli_real_escape_string($linkDB, $_POST['email']);
$password = mysqli_real_escape_string($linkDB, $_POST['password']);
//Check if input Field are empty
if (!$email) {
$error2 .= "Email is required <br>";
}
if (!$password) {
$error2 .= "Password is required <br>";
}
if ($error2) {
$error2 = "<b>There were error(s) in your form!</b><br>".$error2;
}
else {
//matching email and password
$query = "SELECT * FROM users WHERE email='$email'";
$result = mysqli_query($linkDB, $query);
$row = mysqli_fetch_array($result);
if (isset($row)) {
if (password_verify($password, $row['password'])) {
//session variables to keep user logged in
$_SESSION['id'] = $row['id'];
//Logged in for long time untill user didn't log out
if ($_POST['stayLoggedIn'] == '1') {
setcookie('id', $row['id'], time() + 60*60*24); //Logged in permanently
}
header("Location: loggedInPage.php");
} else {
$error2 = "Combination of email/password does not match!";
}
} else {
$error2 = "Combination of email/password does not match!";
}
}
}
?>
```
## User Logout PHP Code
The below code is used to log out with a session in PHP and log out PHP session.
```
//PHP code to logout user from website
if (isset($_GET["logout"])) {
unset($_SESSION['id']);
setcookie("id", "", time() - 3600);
$_COOKIE['id'] = "";
}
```
Final Words
In the above discussion, we have created the registration and login form in PHP and MySQL databases. If you want to implement the above user registration form in PHP on your website then you need to follow the procedures explained in this tutorial. If you still find any difficulty in understanding, feel free to contact this website www.hmawebdesign.com. If you found this tutorial helpful please don’t forget to [SUBSCRIBE YOUTUBE CHANNEL](https://www.youtube.com/channel/UCCj8edobyplMAnhwYvi9n4A?sub_confirmation=1).
Share this Article! | hmawebdesign |
1,796,970 | How to Use and Add Face Recognition Feature on Android App | *Introduction to Face Recognition Feature on Android Apps * Unlocking your Android device with just a... | 0 | 2024-03-21T06:42:55 | https://dev.to/websitedevelopmentco/how-to-use-and-add-face-recognition-feature-on-android-app-4e3i | webdev, website, mobile | **Introduction to Face Recognition Feature on Android Apps
**
Unlocking your Android device with just a glance, and accessing exclusive features with a simple smile – the future of mobile technology is here! Face recognition feature on Android apps has revolutionized the way we interact with our devices. From enhanced security to seamless user experience, this cutting-edge technology is reshaping the landscape of app development. Let's dive into how you can leverage this innovation and stay ahead in the world of Android apps development.
**Benefits of Adding Face Recognition Feature
**
Implementing a face recognition feature in your Android app can bring numerous benefits to both users and developers.
It enhances security by providing an additional layer of protection beyond traditional password or PIN methods. Users can feel more secure knowing that their personal information is being safeguarded with biometric technology.
The convenience factor cannot be overlooked. Users can simply look at their device to unlock it or access specific features without having to type in passwords repeatedly. This streamlined authentication process saves time and improves user experience.
Additionally, incorporating face recognition adds a modern and sophisticated touch to your app, making it stand out from competitors. It shows that your app is up-to-date with the latest technological advancements, which can attract tech-savvy users looking for innovative solutions.
Integrating face recognition into your Android app offers improved security, enhanced user experience, and a competitive edge in the market.
**Step by Step Guide on How to Use Face Recognition Feature on Android App**
To use the face recognition feature on an Android app, start by navigating to the settings menu within the app. Look for the option that enables face recognition and toggle it on. You may be prompted to set up your facial recognition data by scanning your face using the front camera of your device.
Follow the instructions provided on-screen to ensure a successful setup process. Make sure you are in a well-lit environment and position your face properly within the frame for accurate scanning. Once your facial data is stored securely, you can now access certain features or functionalities within the app using just your face as authentication.
Ensure that you re-scan your face periodically to update and improve accuracy. Remember that security is key when utilizing this feature, so always keep your device locked when not in use. Enjoy the convenience and added layer of security that face recognition technology brings to your Android experience!
**Best Practices for Implementing Face Recognition Feature
**
When implementing a face recognition feature in your Android app, it's crucial to prioritize user privacy and data security. Make sure to inform users about how their facial data will be stored and used, obtaining their consent transparently.
Additionally, consider the lighting conditions under which the face recognition feature will operate. Testing in various lighting settings can help ensure accurate performance across different environments.
It's also recommended to provide an alternative authentication method for users who may not prefer or be able to use facial recognition. Offering options like PIN or password entry can enhance user experience and accessibility.
Regularly update your app's face recognition algorithms to keep up with technological advancements and improve accuracy over time. This proactive approach ensures that your feature remains reliable and effective for users.
By following these best practices, you can integrate a seamless and secure face recognition feature into your Android app that enhances usability without compromising on privacy or convenience.
Common Challenges and Solutions
When integrating face recognition feature into your Android app, you might encounter common challenges along the way. One challenge could be ensuring the accuracy and reliability of the facial recognition system in varying lighting conditions. To overcome this issue, consider implementing advanced algorithms that adapt to different lighting environments.
Another challenge developers often face is managing user privacy concerns related to storing biometric data securely. A solution to this can be encrypting all facial data stored on the device and obtaining explicit consent from users before collecting any information.
Additionally, compatibility with different devices and operating systems can pose a hurdle. To address this challenge, conduct thorough testing across various platforms to ensure seamless functionality regardless of the device being used.
By anticipating these challenges and implementing effective solutions, you can enhance the performance and user experience of your Android app with face recognition technology.
**Alternatives to Face Recognition Feature**
When considering alternatives to face recognition features in Android apps, developers can explore various options to enhance user experience and security. One alternative is fingerprint recognition, which offers a convenient and secure way for users to unlock their devices or access specific app functionalities.
Another option is voice recognition technology, where users can interact with the app through spoken commands. This feature not only adds a personal touch but also provides accessibility benefits for users with disabilities.
Additionally, pattern recognition can be used as an alternative method for authentication. Users can create unique patterns that they draw on the screen to unlock the app or access certain features.
Furthermore, some apps opt for traditional password-based authentication as an alternative to face recognition. While not as cutting-edge, passwords remain a reliable method of securing user data and accounts.
Exploring these alternatives allows developers to cater to different user preferences and needs while maintaining high levels of security within their Android apps.
Conclusion: Future of Face Recognition Technology in Android Apps Development
As technology continues to advance rapidly, the future of face recognition technology in Android apps development looks promising. With enhanced security features and user experience, integrating face recognition into Android apps will become more common. Developers are constantly innovating to make this technology more accurate and efficient.
As we move forward, it is essential for app developers to stay updated with the latest trends in face recognition technology. By leveraging this innovative feature effectively, Android apps can offer a seamless and secure user experience like never before. Embracing the potential of face recognition can revolutionize the way users interact with mobile applications, opening up new possibilities for personalized experiences and heightened security measures.
The future holds immense potential for the integration of face recognition technology into Android apps. As advancements continue to unfold, there is no doubt that this feature will play a significant role in shaping the landscape of **[mobile app development](https://www.algosoft.co/service/mobile-application-development)**. Stay tuned for exciting developments as we embark on this journey towards a more secure and intuitive digital world powered by face recognition technology in Android apps!
| websitedevelopmentco |
1,797,014 | Unlocking Data Privacy: SageMaker Teams Up with Secure Multi-Party Computation for AI Advancements | Cloud service providers can leverage the power of Amazon SageMaker to provide customers with advanced... | 0 | 2024-03-21T07:50:52 | https://dev.to/sygitech/unlocking-data-privacy-sagemaker-teams-up-with-secure-multi-party-computation-for-ai-advancements-41le | aws, sagemaker, cloudcomputing, ai | [Cloud service providers](https://sygitech.com/) can leverage the power of Amazon SageMaker to provide customers with advanced AI capabilities in their cloud environments. Amazon SageMaker is a complete solution for building, training, and deploying machine learning models at scale, enabling cloud service providers to deliver AI services to their customers. We explore the strong links between Amazon SageMaker's ability to use AI and its ability to improve compliance with industry standards such as the COBIT and NIST frameworks.
**Key features of Amazon SageMaker:
**
**Data Labeling and Built-in Algorithms:** In order for supervised learning tasks to be successfully carried out, it becomes important that users have tools for annotating as well as labeling their datasets in an efficient manner.
**End-to-End Machine Learning Workflow:** Amazon SageMaker provides a unified platform for the entire machine learning lifecycle, from data preparation to model deployment. This streamlines the process for cloud service providers, allowing them to offer a cohesive AI solution to their clients.
**Managed Infrastructure: ** SageMaker abstracts away the complexities of managing underlying infrastructure, allowing cloud service providers to focus on delivering high-quality AI services without the burden of infrastructure management. This reduces operational overhead and accelerates time to market for AI initiatives.
**Hyperparameter Optimization and Deployment:** This process involves tuning model hyperparameters automatically using this system so as to enhance its performance thereby reducing time spent by data scientists trying to do this activity manually. After training a model; it is easy to deploy it via the RESTful API with the help of SageMaker. Monitor model performance and drift, and respond to changes in data distribution or model behavior.
**Integration with AWS services:** SageMaker integrates with other AWS services, including S3 for data storage, AWS Lambda for off-premises computing, and AWS Glue for data organization. Amazon SageMaker makes it easier and faster for other developers and data scientists to build, train, and deploy machine learning models.
Amazon SageMaker can also support the NIST (National Institute of Standards and Technology) and COBIT (Control Objectives for Information and Related Technologies) frameworks in several ways:
**Security and Compliance:** Both NIST and COBIT emphasize the importance of security and compliance in information technology systems. SageMaker provides features such as encryption, access controls, and audit logs to help users meet security requirements and comply with industry regulations.
**Data Governance:** NIST and COBIT frameworks stress the need for effective data governance practices. SageMaker facilitates data governance by providing tools for data labeling, versioning, and access control. It also integrates with AWS services like AWS Lake Formation for managing data lakes and AWS Glue for data cataloging and ETL (Extract, Transform, Load) operations.
**Risk Management:** NIST and COBIT frameworks include guidelines for risk management and mitigation strategies. SageMaker supports risk management efforts by enabling users to track model performance, monitor for data drift, and implement automated alerting mechanisms for detecting anomalies or security threats.
**Auditability and Transparency: **NIST and COBIT emphasize the importance of auditability and transparency in IT processes. SageMaker offers features for model versioning, experiment tracking, and model explainability, allowing users to understand how models were developed and make decisions based on transparent, auditable processes.
Using Amazon SageMaker capabilities, organizations can accelerate machine learning development processes and improve the efficiency of AI-based applications and strengthen compliance with NIST and COBIT frameworks.
In the future, [cloud providers](https://www.sygitech.com/cloud-management.html) will integrate encryption techniques into machine learning workflows using Amazon SageMaker features:
**Homomorphic encryption for secure computing:** Explore the use of homomorphic encryption techniques to compute encrypted data without decrypting it. SageMaker can provide support for integrating homomorphic cryptographic libraries and running machine learning algorithms on encrypted data, enabling secure computing in the cloud.
**Privacy preserving machine learning:** Explore privacy preserving machine learning techniques such as explicit privacy or security. . machine learning techniques. aggregation to protect the privacy of individual data points. SageMaker can support the integration of privacy-preserving algorithms and provide tools to anonymize and aggregate data.
**Key Management and Access Control:** Implement robust key management and access control mechanisms to protect cryptographic keys and regulate access to sensitive data and resources. SageMaker can integrate with AWS Key Management Service (KMS) and AWS Identity and Access Management (IAM) for centralized key management and fine-grained access control.
**Security Auditing and Monitoring:** Implement logging, auditing, and monitoring mechanisms to detect and respond to security incidents in real-time. SageMaker can provide integration with AWS CloudTrail and Amazon CloudWatch for centralized logging and monitoring of machine learning workflows.
**Secure Model Training and Inference:** Use secure model training and inference techniques to protect sensitive data and intellectual property rights. . SageMaker can facilitate secure multiparty computation (MPC) or federated learning techniques, allowing multiple parties to jointly train models while preserving data privacy. Secure Multi-Party Computation (MPC) is a cryptographic protocol that allows multiple parties to jointly compute a function over their inputs while keeping those inputs private. In other words, MPC enables different entities to collaborate on a computation without revealing their individual inputs to each other. This ensures privacy and confidentiality, even when the parties involved do not fully trust each other.
A Secure Multi-Party Computation (MPC) protocol operates in the following manner:
**Input sharing:** Each party enters their data privately or shares it with other parties involved in the calculation. Data is usually presented in encrypted form, ensuring confidentiality throughout the process.
**Computational protocol:** The parties then use an encrypted protocol to jointly compute the desired function for their inputs. This protocol allows them to perform computations and reveal only the information needed to compute the output without revealing their individual inputs.
**Generation of outputs:** Once a computation is complete, the parties together generate the output of the function without ever learning the information from each other. . . income This ensures that the privacy of the participants is preserved throughout the process.
Secure multiparty computing has several applications in areas where privacy is critical, such as healthcare, finance, and collaborative machine learning. For example, in healthcare, multiple hospitals may want to jointly analyze patient data to find patterns or develop predictive models without sharing sensitive patient data. MPC allows them to collaborate securely while protecting patient privacy.
Here's a simplified explanation along with a Python code snippet illustrating the Secure Multi-Party Computation (MPC) protocol for computing the sum of two private inputs:

In summary, today's dive into Amazon SageMaker revealed its groundbreaking potential for revolutionizing artificial intelligence within cloud settings. We delved into the intricate world of secure machine learning methods, encryption tools, and compliance frameworks to illustrate how SageMaker can drive innovation while upholding rigorous security and privacy protocols. As companies embark on their AI ventures, SageMaker emerges as a beacon of innovation, empowering them to explore new horizons while safeguarding the confidentiality, privacy, and integrity of their data assets. With SageMaker by their side, cloud service providers are not just leading the charge with powerful AI insights, but also prioritizing ethical principles in shaping the future.
| sygitech |
1,797,039 | How to export Google Workspace data to PST? | Google Workspace, commonly known as G Suite, is one of the most used emailing platforms that users... | 0 | 2024-03-21T08:19:44 | https://dev.to/alberttaylor/how-to-export-google-workspace-data-to-pst-2p7o | webdev, backup | Google Workspace, commonly known as G Suite, is one of the most used emailing platforms that users use for their business organization. People store all their personal and professional emails in it their day-to-day data or information is in it. It has become the bridge between the organizations that communicate through emails. They share, transfer, or receive all their necessary emails regarding their work. Therefore, users are asked to export Google Workspace data, and it will keep their data protected.
Google Workspace has multiple arrays that include Hangout, Google Docs, contact, etc. To easily manage email communication, users are supposed to ease the task. Millions of people are currently using this platform and are worried about their data as most of their data is saved in G Suite only. Thus, to keep their data safe and secure, users are asked to export Google Workspace mailbox to PST file format quickly.
## What are the reasons for exporting Google Workspace Data?
There are a number of users who want to export Google workspace data but are unable to look for a perfect solution. Before searching for a solution, one must know the purpose behind this backup process. Here, we are sharing the reason with the users.
• The PST file is widely accessible to everyone as it is movable, so one can even access the file in a different system or from any other place.
• To keep your data protected, users will be able to set a password for their PST file, and that is how users will be able to protect their data successfully.
• Data is very precious for users, especially for the entire small, medium, and large organizations that store their daily data in G Suite. Thus, if users [export Google Workspace data to PST file](https://www.shoviv.com/blog/a-complete-solution-to-export-g-suite-email-to-pst-file/) format, it will be a boon to many organizations.
• The PST file has various additional features that will help users to manage their whole mailbox data.
## How can one export Google Workspace mailbox to PST?
The procedure to backup the G Suite to PST file format is easy only if users select the reliable solution for the task. The process can initiate with the manual method and the professional third-party tool. The manual method is difficult to handle by non-technical users; only the experts will be able to run the manual method. Whereas with the professional third-party tool, any users, i.e., technical and non-technical, will be able to run the task smoothly. Therefore, we refer users to commence the task with professional methods only.
## Which is the best professional third-party tool
Users will come across various tools, but having an authentic tool for the process is difficult to find. Therefore, users should try the **[Shoviv G Suite backup tool](https://www.shoviv.com/g-suite-backup.html)** for the process. The software is authentic and is available for users worldwide, so one can run the task anytime and anywhere. We are citing some features of the tool.
• Users will be able to backup various mailboxes in a single go
• The tool consumes less time to finish the task and shows the immediate result.
• There is a filter option so that users can include/ exclude the desired items for the backup process.
• Users can add a file of any size, as there is no size limitation.
• There is an option to control the failed item count, and after that, the process will automatically stop.
**Final words**
We hope that the content we have shared above will be helpful for all the users. The process to export Google Workspace data is difficult, but with the correct utility, the task can become easy for the users. The tool that we have shared will definitely help the users to finish the backup task.
Read also - [https://www.linkedin.com/pulse/how-export-google-workspace-mailboxes-pst-best-method-albert-taylor](https://www.linkedin.com/pulse/how-export-google-workspace-mailboxes-pst-best-method-albert-taylor) | alberttaylor |
1,797,153 | Discover the Opportunity: 5 Marla Plots for Sale in Iqbal Garden | In the burgeoning enclave of Iqbal Garden, a unique opportunity presents itself to potential... | 0 | 2024-03-21T09:31:22 | https://dev.to/iqbalgardenlahore/discover-the-opportunity-5-marla-plots-for-sale-in-iqbal-garden-33k3 | In the burgeoning enclave of Iqbal Garden, a unique opportunity presents itself to potential homeowners and astute investors. The introduction of [5 Marla plots for sale](https://iqbalgarden.com/5-marla-residential-plots-for-sale-in-lahore/) draws attention to its blend of affordability, strategic location, and the promise of a thriving community lifestyle. Iqbal Garden is quickly becoming a coveted destination for those seeking modern amenities and serene living spaces.
Exploring Iqbal Garden
Strategically positioned to offer tranquillity and easy access to urban conveniences, Iqbal Garden is becoming synonymous with a quality lifestyle. This residential area is designed to meet the diverse needs of its inhabitants, featuring proximity to educational institutions, healthcare facilities, shopping districts, and lush green spaces. The development emphasizes a community-centric approach, fostering an environment where residents can flourish.
The Allure of 5 Marla Plots
Covering an area of approximately 1,361 square feet, 5 Marla plots in Iqbal Garden represent an ideal canvas for building a dream home. These plots cater to a broad audience, from growing families to individuals seeking a comfortable and spacious living environment. The size offers flexibility in home design, allowing for ample living space, a garden, or even a small outdoor entertaining area.
Investment and Growth Potential
Iqbal Garden is a place to call home and a brilliant investment opportunity. The area's development plan, coupled with the growing demand for quality housing, points to significant appreciation potential for properties within the community. Early investors in 5 Marla plots can expect a favourable return on investment as the area matures and evolves into a fully-fledged residential hub.
Community Life and Amenities
Beyond the physical attributes of the plots, buying into Iqbal Garden means becoming part of a vibrant, emerging community. Plans for the development include parks, recreational facilities, and community centres designed to enhance the quality of life for residents. The emphasis on security and a family-friendly environment makes it a safe and appealing choice for individuals and families alike.
Seamless Purchase Process
To make homeownership accessible and hassle-free, Iqbal Garden offers a straightforward process for purchasing 5 Marla plots. Potential buyers can benefit from concise, transparent transactions and guidance from the development's sales team. Prospective homeowners are encouraged to schedule site visits to experience first-hand the potential of living in Iqbal Garden.
Conclusion
The sale of 5 Marla plots in Iqbal Garden represents a golden opportunity to secure a piece of this promising community. Whether as a family home or an investment, these plots offer a blend of lifestyle and financial potential that is hard to match. With its focus on creating a balanced, inclusive community, Iqbal Garden is poised to become a preferred choice for discerning buyers and investors. Act now to secure your place in this dynamic development. | iqbalgardenlahore | |
1,797,178 | mens t shirts nz | graphic tees nz | Bulk t-shirt printing in New Zealand. Trusted by people of all ages, with sustainability &... | 0 | 2024-03-21T10:10:01 | https://dev.to/cooltees/mens-t-shirts-nz-graphic-tees-nz-32p3 | Bulk t-shirt printing in New Zealand. Trusted by people of all ages, with sustainability & premium quality as standard. No minimums. Visit their website for more information today. ||
https://www.cooltees.nz/
| cooltees | |
1,797,185 | Understanding the Roles of Your Louisville Roofer | In matters related to home repairs, maintenance, and improvement, property owners rely on dedicated... | 0 | 2024-03-21T10:18:21 | https://dev.to/bonedrylouisvilleky/understanding-the-roles-of-your-louisville-roofer-45d1 | In matters related to home repairs, maintenance, and improvement, property owners rely on dedicated professionals for support. One such professional you may find yourself in need of is a [Louisville roofer](https://www.google.com/maps/place/Bone+Dry+Roofing+Louisville+KY+Roofing+Contractor+Louisville+Roofer/@38.2595748,-85.6012513,17z/data=!3m1!4b1!4m6!3m5!1s0x886975638ea79101:0x6e7462509fe8577a!8m2!3d38.2595748!4d-85.6012513!16s%2Fg%2F1tjl6nd4?entry=ttu/). Skilled roofers fulfill various roles ranging from roofing contractors to insulation or masonry contractors. In this article, let's dive deeper into understanding each of these roles.
The Role of a Roofing Contractor
A roofing contractor oversees the overall well-being of your home's roof. Be it minor repairs or an entire roof replacement, a roofing contractor can guide you through the process skillfully and seamlessly. The extensive duties undertaken by these professionals include planning and managing roofing projects, inspecting roofs for damage or potential issues, suggesting appropriate solutions for fixing any problems found during inspection, as well as implementing those solutions effectively.
Notably, working with your trusted Louisville roofer provides you confidence in knowing that local laws and regulations regarding construction and repair are being scrupulously followed since they possess up-to-date knowledge about the same.
When Your Roofer Steps into the Insulation Contractor's Shoes
Roofing companies often provide specialist services beyond merely installing tiles or shingles onto your rooftop. One such service that falls under the purview of your Louisville roofer could be functioning as an insulation contractor.
An insulation contractor has deep expertise in understanding various forms of insulation suitable for diverse atmospheric conditions and house types. They evaluate your current insulation condition and offer advice about enhancements or replacements necessary for ultimate efficiency.
They are equipped to install new insulation materials ensuring efficient heat regulation inside your home that ultimately contributes to lower energy costs and promotes sustainability.
Brick-and-mortar Character - The Masonry Contractor
Masonry aspects might not always be perceptibly linked with roofing services; however, they play a crucial role especially when chimneys are within the equation. Your Louisville roofer may also take on the role of a masonry contractor, handling brick and stone work related to your roof.
These professionals deal with repairing or rebuilding damaged chimneys, addressing water leakages in brick walls, and ensuring the structural stability of any masonry-related roofing components in your home is maintained to prevent future damage and costly repairs.
In conclusion, when you engage with a trustworthy Louisville roofer, it's not just about getting someone to patch up your worn-out shingles. It's about partnering with a versatile professional equipped to address multiple aspects linked to your home's exterior health. Whether donning the hat of a dedicated roofing contractor, an efficient insulation contractor, or a meticulous masonry artisan, they commit to delivering quality service while complying strictly with local housing regulations and safety norms.
Having such multi-faceted proficiency within reach contributes immensely towards maintaining structural integrity and improving the energy performance of homes. You can depend on these dedicated professionals for persistent vigilance concerning your home’s outermost shell. Your Louisville roofer stands as an embodiment of flexibility, knowledgeability, and unwavering commitment toward safeguarding one of life's most significant investments- your residence.
[Bone Dry Roofing](https://www.bonedry.com/louisville/)
8130 New La Grange Rd, Louisville, Kentucky, 40222, USA
(502) 425-2928 | bonedrylouisvilleky | |
1,797,192 | Top Hotel in Mukteshwar | Discovering Peaceful Place: Mukteshwar's Hidden Retreats Nestled in the serene embrace of... | 0 | 2024-03-21T10:37:51 | https://dev.to/casadream/top-hotel-in-mukteshwar-geh | hotel, resort, anniversa, wedding | ## Discovering Peaceful Place: Mukteshwar's Hidden Retreats
Nestled in the serene embrace of the Nainital hills lies Mukteshwar, a haven for those seeking solace amidst nature's bounty. Here, amidst the whispering pines and panoramic vistas, you'll find an array of [resorts and hotels](https://www.casadream.in/) offering a blend of luxury and peace.

The Whispering Pines Resort:
Tucked away in the heart of Mukteshwar's verdant forests, The Whispering Pines Resort beckons travelers with its promise of serenity. Wake up to the gentle rustle of leaves and the melodious chirping of birds as you indulge in the cozy comfort of their elegantly furnished cottages. With personalized service and delectable cuisine crafted from locally sourced ingredients, this resort offers a truly immersive experience in the lap of nature.
Peaceful Place on Heights Retreat:
Perched atop a secluded hilltop, Tranquil Heights Retreat offers a sanctuary for the soul-weary traveler. Lose yourself in the breathtaking vistas of the snow-capped Himalayas from the comfort of your private balcony, or embark on a leisurely stroll through their lush gardens. With warm hospitality and an ambiance that exudes rustic charm, this retreat is sure to leave you feeling rejuvenated and inspired.
The Mystic Valley Resort:
For those yearning for adventure amidst nature's grandeur, The Mystic Valley Resort in Mukteshwar is the perfect abode. Surrounded by sprawling meadows and cascading waterfalls, this resort offers a plethora of outdoor activities, from trekking and mountain biking to birdwatching and star gazing. After a day of exploration, unwind in their luxurious accommodations and savor the flavors of the region with their sumptuous farm-to-table cuisine.
Serenity Springs Boutique Hotel:
Embrace the epitome of luxury and exclusivity at Serenity Springs Boutique Hotel. Nestled amidst acres of pristine wilderness, this boutique hotel offers opulent suites adorned with contemporary decor and modern amenities. Indulge in a pampering spa treatment, savor gourmet delicacies at their fine dining restaurant, or simply soak in the silence of your surroundings from the infinity pool overlooking the valley below.
Mountain Breeze Retreat:
Experience the essence of Mukteshwar's rustic charm at Mountain Breeze Retreat. Set amidst terraced orchards and lush greenery, this retreat offers cozy cottages adorned with traditional Kumaoni architecture. Immerse yourself in the local culture with interactive cooking classes and cultural performances, or simply unwind by the bonfire under the starlit sky.
In Mukteshwar, every resort and hotel is a gateway to a world of unparalleled beauty and Peaceful Place. Whether you seek adventure or seek solace, there's a retreat waiting to welcome you with open arms. So pack your bags, leave behind the chaos of city life, and surrender to the allure of Mukteshwar's serene embrace. Your journey to bliss awaits!
| casadream |
1,797,197 | Testes Unitários com JUnit no Java | Os testes unitários estão sendo cruciais no meu dia a dia no desenvolvimento de software, garantindo... | 0 | 2024-03-21T16:28:35 | https://dev.to/andersonleite/testes-unitarios-com-junit-no-java-26lf | junit, unittest, java, tdd | Os testes unitários estão sendo cruciais no meu dia a dia no desenvolvimento de software, garantindo que cada parte do código funcione como esperado. Percebo que no contexto da programação em Java, o JUnit é uma das ferramentas mais populares para escrever e executar testes unitários. Neste post quero explorar os conceitos básicos de testes unitários com JUnit, incluindo a configuração do ambiente de teste e os métodos mais comuns encontrados em testes unitários.
## **Configuração do Ambiente de Teste**
Antes de começar a escrever testes, é necessário configurar o ambiente de teste. Isso geralmente envolve adicionar as dependências do JUnit ao seu projeto. Se você estiver usando Maven ou Gradle, pode adicionar a dependência do JUnit ao seu arquivo `pom.xml` ou `build.gradle`, respectivamente.
**Maven**
Para Maven, adicione o seguinte ao seu `pom.xml`:
```jsx
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
</dependencies>
```
**Gradle**
Para Gradle, adicione a seguinte linha ao seu `build.gradle`:
```jsx
dependencies {
testImplementation 'junit:junit:4.13.2'
}
```
Quando se trabalha com Spring Boot, uma das vantagens é a facilidade de configuração e execução de testes unitários e de integração. O `spring-boot-starter-test` é um starter que inclui todas as dependências necessárias para testar aplicações Spring Boot, incluindo JUnit, Mockito, AssertJ, entre outras ferramentas úteis para testes. Mas esse é assunto para outro post, que pretendo explorar um pouco mais sobre esse starter.
## **Escrevendo Testes Unitários**
Um teste unitário é uma função que verifica o comportamento de uma parte específica do código, como um método ou uma classe. No JUnit, os testes são escritos como métodos públicos anotados com `@Test`.
**Exemplo de Teste Unitário**
Aqui está um exemplo simples de um teste unitário para uma classe `Calculadora`:
```jsx
import org.junit.Test;
import static org.junit.Assert.assertEquals;
public class CalculadoraTest {
@Test
public void testSoma() {
Calculadora calculadora = new Calculadora();
int resultado = calculadora.soma(2, 3);
assertEquals(5, resultado);
}
}
```
Neste exemplo, o método `testSoma` verifica se o método `soma` da classe `Calculadora` retorna o valor esperado.
## **Métodos Comuns em Testes Unitários**
Aqui está uma lista de métodos comuns que costumo utilizar em meus testes unitários com JUnit, juntamente com uma explicação resumida de cada um:
### **`assertEquals(expected, actual)`**
- **Descrição**: Verifica se dois valores são iguais. Se não forem, o teste falha.
- **Uso**: Útil para comparar valores primitivos, objetos e arrays.
### **`assertTrue(condition)`**
- **Descrição**: Verifica se uma condição é verdadeira. Se não for, o teste falha.
- **Uso**: Útil para verificar a validade de uma expressão booleana.
### **`assertFalse(condition)`**
- **Descrição**: Verifica se uma condição é falsa. Se não for, o teste falha.
- **Uso**: Útil para verificar a invalidade de uma expressão booleana.
### **`assertNull(object)`**
- **Descrição**: Verifica se um objeto é nulo. Se não for, o teste falha.
- **Uso**: Útil para verificar se um objeto não foi inicializado.
### **`assertNotNull(object)`**
- **Descrição**: Verifica se um objeto não é nulo. Se for, o teste falha.
- **Uso**: Útil para verificar se um objeto foi inicializado corretamente.
### **`assertSame(expected, actual)`**
- **Descrição**: Verifica se dois objetos são o mesmo objeto. Se não forem, o teste falha.
- **Uso**: Útil para verificar se duas referências apontam para o mesmo objeto na memória.
### **`assertNotSame(expected, actual)`**
- **Descrição**: Verifica se dois objetos não são o mesmo objeto. Se forem, o teste falha.
- **Uso**: Útil para verificar se duas referências apontam para objetos diferentes na memória.
### **`assertArrayEquals(expected, actual)`**
- **Descrição**: Verifica se dois arrays são iguais. Se não forem, o teste falha.
- **Uso**: Útil para comparar arrays de qualquer tipo.
### **`assertThat(actual, matcher)`**
- **Descrição**: Verifica se um objeto atende a uma condição especificada por um matcher. Se não atender, o teste falha.
- **Uso**: Útil para verificações complexas e legíveis, utilizando a biblioteca Hamcrest para definir matchers.
### **`fail(message)`**
- **Descrição**: Faz o teste falhar imediatamente, com uma mensagem opcional.
- **Uso**: Útil para indicar que um teste não deve ser executado ou para indicar um erro inesperado.
### **`assumeTrue(condition)`**
- **Descrição**: Ignora o teste se a condição for falsa.
- **Uso**: Útil para evitar a execução de testes sob certas condições, como a presença de um recurso específico.
### **`assumeFalse(condition)`**
- **Descrição**: Ignora o teste se a condição for verdadeira.
- **Uso**: Útil para evitar a execução de testes sob certas condições, como a ausência de um recurso específico.
Esses métodos são fundamentais para escrever testes unitários eficazes com JUnit, permitindo que verifiquemos o comportamento do código de maneira clara e concisa.
## JUnit com outras ferramentas
Eh possível integrar o JUnit com outras ferramentas de testes para ampliar a funcionalidade e a eficiência dos testes unitários. Essa integração pode ser feita de várias maneiras, dependendo das necessidades específicas do projeto e das ferramentas desejadas. Aqui estão algumas maneiras comuns de integrar o JUnit com outras ferramentas de testes:
**1. Mocking com Mockito**
Mockito é uma biblioteca popular para criar e configurar objetos fictícios (mocks) em testes unitários. Ela pode ser usada em conjunto com o JUnit para isolar partes do código que estão sendo testadas, permitindo que você teste o comportamento de uma classe ou método sem depender de outras partes do sistema.
**2. Assertions com AssertJ**
AssertJ é uma biblioteca que fornece uma maneira mais legível e expressiva de escrever asserções em testes unitários. Ela pode ser usada em conjunto com o JUnit para melhorar a legibilidade e a clareza dos testes, tornando-os mais fáceis de entender e manter.
**3. Testes de Integração com Spring Test**
Para aplicações Spring Boot, o `spring-boot-starter-test` inclui o Spring Test, que fornece suporte para testes de integração e testes de controle de serviço. O Spring Test pode ser usado em conjunto com o JUnit para testar aplicações Spring Boot de maneira mais eficaz, aproveitando os recursos do Spring para configurar e executar testes.
**4. Testes de Performance com JMeter**
Embora o JMeter seja uma ferramenta separada para testes de performance, ele pode ser integrado com testes unitários escritos com JUnit para realizar testes de performance em aplicações Java. Isso permite que você teste o desempenho de suas aplicações em diferentes cenários e condições.
**5. Testes de Interface do Usuário com Selenium**
Selenium é uma ferramenta para testes de automação de navegadores da web. Embora seja mais comumente usada para testes de interface do usuário (UI), ela pode ser integrada com testes unitários escritos com JUnit para automatizar testes de UI e verificar a funcionalidade da interface do usuário.
**6. Testes de Controle de Versão com Git**
Embora o Git seja uma ferramenta de controle de versão e não uma ferramenta de teste, ele pode ser integrado com o processo de teste para garantir que apenas código que passa por todos os testes unitários seja commitado no repositório. Isso pode ser feito configurando o Git para executar os testes unitários antes de permitir que um commit seja feito.
## **Conclusão**
Os testes unitários estão sendo fundamentais para garantir a qualidade do código e a correção de bugs dos projetos que venho desenvolvendo. O JUnit oferece uma ampla gama de métodos para verificar o comportamento do código, tornando-o uma ferramenta poderosa para testes unitários em Java. Ao escrever testes unitários, é importante cobrir todos os casos de uso possíveis para garantir que o código funcione como esperado em todas as situações.
### Referências:
- https://junit.org/junit5/docs/current/user-guide/
- https://www.baeldung.com/junit-5
- https://www.baeldung.com/java-unit-testing-best-practices | andersonleite |
1,797,271 | Cricut Design Space For Mac | Do you want to create decor for your birthday and anniversary? Here you go with the Cricut machine.... | 0 | 2024-03-21T12:25:34 | https://dev.to/cricutdesignspaceformac/cricut-design-space-for-mac-378k | Do you want to create decor for your birthday and anniversary? Here you go with the Cricut machine. With different types of models, such as Cricut Explore, Maker, and Joy, creating decorations or other kinds of stuff is too easy. All you need to do is get a Cricut of your choice and start setting it up by visiting **[cricut.com/setup](https://cricutdesignspaceformac.com)**.
**[Cricut Machine Setup](https://cricutdesignspaceformac.com)**
**[Cricut New Machine Setup](https://cricutdesignspaceformac.com)**
| cricutdesignspaceformac | |
1,797,292 | Top UK Universities for African Students | World Student Advisors, a free UK-based educational consultancy offering complimentary services,... | 0 | 2024-03-21T12:48:44 | https://dev.to/worldstudentadvisors/top-uk-universities-for-african-students-ja1 | [World Student Advisors](https://www.worldstudentadvisors.com/ ), a free UK-based educational consultancy offering complimentary services, empowers African students to realize their aspirations of studying abroad. Our team assists you throughout the entire process, from aligning your career goals with suitable university courses to facilitating visa applications and easing your transition into a new academic environment. Our experts are dedicated to guiding you every step of the way, ensuring a smooth and successful journey towards your educational goals. | worldstudentadvisors | |
111,413 | Android custom launcher | A client that I work for as a consultant/Android developer wants to have a custom Android launcher on... | 0 | 2019-05-22T17:26:17 | https://dev.to/glennmen/android-custom-launcher-11ec | android, advice, help, google | A client that I work for as a consultant/Android developer wants to have a custom Android launcher on their devices.
I know how to make an app that can be installed as a launcher. The technical difficulty that I am researching is having the custom changes but still keep the drag & drop behaviour and possibly also the app widgets that are available in Android.
I also know that it is possible to make this because there are already lots of 3rd party launcher applications available that also have this behaviour.
I did some research and found out that the drag & drop behaviour is very hard to make and I couldn't find any libraries that provide this behaviour. Different sources suggest to use the default launcher from the open source Android project and use that as a base to work on.
So here I am asking for some advice.
Should I try to make it myself or start with the default launcher from Android?
If I use the default Android launcher as a base, is it advised to use the latest version or for example use the Android Nougat version? I don't think there are any Android 8 or 9 features that my client wants and also not sure how backwards compatibly these version are.
[Link to default Android launcher](https://android.googlesource.com/platform/packages/apps/Launcher3/)
I know this might be a long shot but any DEV community members that might have any experience with this or that might have some contacts in their social groups that could help me out? 😄
Any information or advice is welcome! | glennmen |
1,797,332 | ChatGpt Integration and Openai Integration | If you're looking to integrate ChatGPT into Unreal Engine, consider exploring API integrations or... | 0 | 2024-03-21T14:13:19 | https://dev.to/joewilliam/chatgpt-integration-and-openai-integration-4m04 | If you're looking to integrate ChatGPT into Unreal Engine, consider exploring API integrations or custom plugins. Let's connect to discuss chatGPT integration on your website. Reach out to me for assistance. | joewilliam | |
1,797,513 | Browser's Hidden Vault: Local Storage API 🗄️ | This is a submission for DEV Challenge v24.03.20, One Byte Explainer: Local Storage API ... | 0 | 2024-03-21T15:15:34 | https://dev.to/webdev-mohdamir/browsers-hidden-vault-local-storage-api-1j4n | frontendchallenge, devchallenge, javascript, webdev | This is a submission for DEV Challenge v24.03.20, One Byte Explainer: Local Storage API
## Explainer
Local Storage API stores key-value pairs in the browser persisting data even after page reloads. It's simple to use and helpful for caching user preferences, session data, or small amounts of data needed across multiple sessions without server interaction.
## Additional Context
This submission aims to provide a concise yet informative overview of the Local Storage API in web browsers. By highlighting its functionality, benefits, and potential use cases, it aims to demonstrate the value of this feature to developers seeking efficient client-side data storage solutions.
<!-- Thanks for participating! --> | webdev-mohdamir |
1,797,567 | Graph (Matrix and list) Data structures | Mastering Graphs: Exploring Two Representations Graphs are fundamental data structures... | 0 | 2024-03-21T16:50:53 | https://dev.to/ajithr116/graph-matrix-and-list-data-structures-44ga | datastructures, javascript, data, algorithms | ### Mastering Graphs: Exploring Two Representations
Graphs are fundamental data structures used to model relationships between objects. They consist of vertices (nodes) and edges (connections) that link these vertices. Graphs come in various forms, and two common representations are Adjacency List and Adjacency Matrix. Let's delve into both and understand their differences, uses, and implementations.
#### Understanding Graphs
A graph is a collection of vertices and edges, where each edge connects two vertices. It's a powerful abstraction used to model a wide range of real-world scenarios, such as social networks, transportation networks, and computer networks.
#### 1. Adjacency List Representation
The Adjacency List representation utilizes an array or dictionary to store vertices and their adjacent vertices. Here's an implementation of a graph using an Adjacency List in JavaScript:
```javascript
class Graph {
constructor() {
this.list = {};
}
// Methods for adding/removing vertices and edges...
}
```
In this representation, each vertex in the graph is stored as a key in the dictionary, with its adjacent vertices stored as values in an array.
#### 2. Adjacency Matrix Representation
The Adjacency Matrix representation employs a 2D array to denote connections between vertices. Here's a JavaScript implementation:
```javascript
class Graph {
constructor() {
this.matrix = [];
this.vertexNames = [];
}
// Methods for adding/removing vertices and edges...
}
```
In this representation, each cell in the matrix signifies whether there's a connection between the corresponding vertices. A value of 1 indicates a connection, while 0 denotes no connection.
#### Differences between Adjacency List and Adjacency Matrix
- **Space Complexity**: Adjacency List typically consumes less space than Adjacency Matrix, especially for sparse graphs.
- **Edge Lookup**: Adjacency Matrix provides constant-time edge lookup, while Adjacency List's performance depends on the number of adjacent vertices.
- **Memory Usage**: Adjacency Matrix consumes more memory, especially for large graphs, due to its fixed-size structure.
#### Graph Implementation and Usage
- **GitHub Repository**: Explore implementations of both Adjacency List and Adjacency Matrix representations in JavaScript on GitHub: [GitHub Repository](https://github.com/ajithr116/Data-Structures/tree/main/15-graph)
#### Conclusion
In conclusion, understanding the representations of graphs is crucial for designing efficient algorithms and solving real-world problems. Whether you choose Adjacency List or Adjacency Matrix depends on factors like space complexity, edge lookup performance, and memory usage. By mastering both representations, you'll be equipped to tackle a wide range of graph-related challenges in your projects.
| ajithr116 |
1,797,586 | How To Write Technical Requirements For Software Project | Did you know that more than 70% of software projects suffer from poor requirements management? This... | 0 | 2024-03-21T17:21:39 | https://dev.to/olex_khomych/how-to-write-technical-requirements-for-software-project-191a | softwareengineering, startup | Did you know that more than 70% of software projects suffer from poor requirements management? This staggering statistic highlights the critical importance of writing clear and precise technical requirements for successful software development. Without a well-defined project description, the chances of delays, cost overruns, and unsatisfactory outcomes significantly increase.
In this article, we will guide you through the process of writing effective technical requirements which use [Join.To.IT](https://jointoit.com/). Whether you are a project manager, business analyst, or developer, mastering this skill is vital for ensuring seamless communication, efficient development processes, and ultimately, the delivery of high-quality software solutions.
So, let's delve into the basics of technical requirements and explore step-by-step techniques that will enable you to create comprehensive and well-documented project specifications. By the end of this article, you'll have the knowledge and confidence to write technical requirements that drive successful software projects.
## Understanding the Basics of Technical Requirements
Before diving into the writing process, it's crucial to understand the basics of technical requirements. In this section, we will define what technical requirements are, why they are essential for successful software development, and the key elements that should be included in a well-written requirement.
## What are Technical Requirements?
Technical requirements, also known as software requirements, are a detailed description of the functionalities, features, and constraints that a software application must possess. These requirements serve as a blueprint for developers, guiding them in building software that meets the project's objectives and user expectations.
## Why are Technical Requirements Essential for Successful Software Development?
Clear and well-defined technical requirements are crucial for successful software development. They act as a communication channel between stakeholders, including developers, project managers, designers, and clients, ensuring everyone is on the same page regarding the software's functionalities and constraints. Having precise requirements reduces misunderstandings, facilitates effective collaboration, and leads to the development of a high-quality software solution.
## Key Elements of a Well-Written Technical Requirement
1.Functional Requirements: These outline the specific actions and tasks the software needs to perform, such as user interactions, calculations, data processing, and system behavior.
2.Non-Functional Requirements: These specify the quality attributes and constraints of the software, such as performance, security, scalability, usability, and compatibility.
3.Acceptance Criteria: These define the conditions that must be met for a software feature to be considered complete and satisfactory to meet user needs.
4.Dependencies: These identify any external systems, tools, or components that the software relies on for proper functioning.
5.Constraints: These encompass any limitations or specific guidelines that need to be followed during the software development process, such as budget, time, and technological restrictions.
In the next section, we will provide you with a step-by-step guide on how to write technical requirements effectively, covering everything from identifying stakeholders and gathering user requirements to documenting functional and non-functional specifications.
## Step-by-Step Guide to Writing Technical Requirements
Now that you have a solid understanding of technical requirements, it's time to start writing them. Follow this step-by-step guide to ensure that your requirements are clear, comprehensive, and effective.
1.Identify stakeholders: Start by identifying all the individuals or groups who have a vested interest in the software project. These stakeholders can include clients, end-users, developers, designers, and project managers.
2.Gather user requirements: Engage with the end-users and stakeholders to gather their input on what they expect from the software. This step involves discussions, interviews, surveys, and any other means to uncover their needs and expectations.
3.Define functional specifications: Based on the gathered requirements, clearly define the functions and features the software should possess. These specifications will serve as a blueprint for the development process.
4.Document non-functional specifications: In addition to the functional requirements, non-functional specifications define the quality attributes of the software, such as performance, reliability, security, and usability. Clearly document these specifications to ensure they are met.
5.Ensure clarity and readability: Organize your requirements in a logical and easy-to-understand manner. Use clear and concise language, avoid jargon or technical terms that stakeholders may not understand, and be specific about the expected outcomes.
By following this step-by-step guide, you can write technical requirements that effectively communicate the desired functionality and specifications of your software project.
## Partnering with IT Consultants for Expert Guidance
Writing technical requirements can be a complex task, especially for those new to software development. If you need professional assistance in crafting precise and effective technical requirements, consider partnering with [JoinToIT](https://jointoit.com/).
JoinToIT is a reputable organization that specializes in providing expert guidance and support throughout the software development process. With their deep understanding of industry standards and best practices, they can help you define clear objectives, identify the necessary features, and articulate your requirements in a way that aligns with your business goals. | olex_khomych |
1,797,810 | Modernizing cloudbuild.yaml for Container Builds | tl;dr: Running bash scripts in the Cloud Build documentation tells you use the script property with... | 0 | 2024-03-21T23:18:39 | https://dev.to/googlecloud/modernizing-cloudbuildyaml-for-container-builds-1je0 | googlecloud, devops, docker, cicd | > tl;dr: [Running bash scripts](https://cloud.google.com/build/docs/configuring-builds/run-bash-scripts) in the Cloud Build documentation tells you use the `script` property with the `automapSubstitutions` option and I give this recommendation a 💯.
One of my favorite things to do in writing YAML is minimizing the square brackets and hyphens. The frequency of these things really impacts readability for me, especially when I'm trying to glance at a whole block of markup and assess what it's trying to do.
Over the last couple years, Cloud Build has made improvements in reducing square brackets and enabling more concise configuration for running shell scripts.
I'm going to step through a couple "generations" of simplification I walked through today in overhauling a container image build pipeline.
This is what a lot of minimal Cloud Build configurations look like:
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
args: ['build', '--tag', 'gcr.io/${PROJECT_ID}/${_IMAGE}:latest', '.']
- id: 'Push Container Image to Container Registry'
name: 'gcr.io/cloud-builders/docker:latest'
args: ['push', 'gcr.io/${PROJECT_ID}/${_IMAGE}:latest']
substitutions:
_IMAGE: service
```
* **Starting character count:** 335
## Step #1: Remove square-bracketed [distractions]
Use the `script` property instead of `args`.
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build --tag gcr.io/${PROJECT_ID}/${_IMAGE}:latest .
- id: 'Push Container Image to Container Registry'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker push gcr.io/${PROJECT_ID}/${_IMAGE}:latest
substitutions:
_IMAGE: service
```
🛑 If you try to use this it won't work.
It turns out switching from `args` to `script` means the code **no longer has substitutions, only environment variables**.
A year ago, the next step would be to manually map the substitutions to environment variables:
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build --tag gcr.io/${PROJECT_ID}/${_IMAGE}:latest .
- id: 'Push Container Image to Container Registry'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker push gcr.io/${PROJECT_ID}/${_IMAGE}:latest
options:
env:
- PROJECT_ID=$PROJECT
- _IMAGE=$_IMAGE
substitutions:
_IMAGE: service
```
**Updated character count**: 390 (sometimes shorter isn't clearer)
## Step #2: Remove excess hyphenation
Use the `automapSubstitutions` global option and the substitutions are injected as environment variables to all step scripts.
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build . --tag gcr.io/${PROJECT_ID}/${_IMAGE}:latest
- id: 'Push Container Image to Container Registry'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker push gcr.io/${PROJECT_ID}/${_IMAGE}:latest
options:
automapSubstitutions: true
substitutions:
_IMAGE: service
```
**Updated character count**: 373 (progress, but I'd be more satisfied if we got back to 335 somehow)
## Simplify the Image Push
Since this Cloud Build configuration doesn't have any follow-up steps that need to use the image outside the build, I can simplify further, by replacing the step *Push Container Image to Container Registry* with the `images` property. (Read more about that in [Remember images in your cloudbuild.yaml!](https://dev.to/googlecloud/remember-images-in-your-cloudbuild-yaml-o3l) by @glasnt).
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build . --tag gcr.io/${PROJECT_ID}/${_IMAGE}:latest
images:
- gcr.io/${PROJECT_ID}/${_IMAGE}:latest
options:
automapSubstitutions: true
substitutions:
_IMAGE: service
```
This doesn't reduce hyphens any further, but it does reduce two lines of configuration.
**Updated character count**: 263 (Success!)
---
## Bonus Round: Migrating to Artifact Registry
You may have noticed this configuration ships the container image to a Google Container Registry URL! There's a good chance if you are modernizing your Cloud Build YAML this way you've got some GCR in place, if so, you need to migrate soon.
> Check out [Transition from Container Registry](https://cloud.google.com/artifact-registry/docs/transition/transition-from-gcr). There are options to migrate while keeping the gcr.io URL.
Say I've already created a new Artifact Registry instance for my container, what does that YAML look like?
(Let's say it's a multi-regional repository called `container` in the `us` location.)
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build . --tag "us-docker.pkg.dev/${PROJECT_ID}/container/${_IMAGE}:latest"
images:
- "us-docker.pkg.dev/${PROJECT_ID}/container/${_IMAGE}:latest"
options:
automapSubstitutions: true
substitutions:
_IMAGE: service
```
Since an Artifact Repository is a Cloud resource, a project might have more than one. This encourages me to parameterize the location and repository name, so that development & testing are easier.
```yaml
steps:
- id: 'Build Container Image'
name: 'gcr.io/cloud-builders/docker:latest'
script: docker build . --tag "${_LOCATION}-docker.pkg.dev/${PROJECT_ID}/${_REPO}/${_IMAGE}:latest"
images:
- "${_LOCATION}-docker.pkg.dev/${PROJECT_ID}/${_REPO}/${_IMAGE}:latest"
options:
automapSubstitutions: true
substitutions:
_IMAGE: service
_LOCATION: us
_REPO: container
```
**Updated character count**: 358 (A little longer than 335, but Artifact Registry is more verbose than Container Registry, not much we can do about that.)
In a more complicated YAML block, `automapSubstitutions` would make a much bigger difference. I go out of my way to avoid using `args`, and this option helps me do that without needing to add a lot of boilerplate config.
> Aside Info: Reader, maybe you'll suggest I delete all those pesky curly braces around my variables, getting me a win at 342 characters. This [stackoverflow answer](https://stackoverflow.com/a/8748880) explains the value of the curly braces, and I'm one of the people that makes curly braced variables part of my "shell variables in strings" practice.
| grayside |
1,797,975 | Conquering the Cloud Resume Challenge | GitHub Repository Completed Project 🤔 What is the Cloud Resume Challenge? In developing... | 0 | 2024-03-22T03:39:45 | https://dev.to/sergix/the-cloud-resume-challenge-2mjo | aws, webdev, python, githubactions | > [GitHub Repository](https://github.com/Sergix/cloud-resume-challenge)
> [Completed Project](https://cloudresume.sergix.dev/)
## 🤔 What is the Cloud Resume Challenge?
In developing skills for my future career, a friend recommended the
**[Cloud Resume Challenge (AWS Edition)](https://cloudresumechallenge.dev/docs/the-challenge/aws/)**
as a practical way to develop cloud development and problem-solving skills. The challenge offers high-level instructions for building a basic serverless application with a static frontend using AWS, Google Cloud, or Azure. The AWS route took me about 3 days to complete (besides the recommended AWS certification).
## ⚔️ Take the challenge!
I highly recommend anyone else trying to improve their cloud development skills to complete this project. It teaches you:
1. How to *think* cloud -- frontend, backend, API endpoints, ...
2. How to use a cloud platform like AWS
3. How IaC simplifies provisioning and deploying your application
And, it improves your problem-solving skills and analysis of edge cases.
## 📚 Stack
- Backend
- AWS SAM -- Serverless Application Model (deploys as AWS CloudFormation)
- AWS API Gateway
- AWS Lambda
- AWS DynamoDB
- Frontend
- AWS CloudFront
- AWS S3 static site
- Netlify + Netlify DNS
- CI/CD: GitHub Actions
## (ง'̀-'́)ง The Challenge
### Setup
I created a basic HTML/CSS frontend with some placeholder content to start off with. I then initialized the git repo and pushed to GitHub using the GitHub CLI.
### 🪣 S3
AWS S3 buckets are an inexpensive and convenient way to host static sites (plain HTML/JS/CSS). Normally I've used Netlify, but since this frontend doesn't have a build step, S3 is much easier.
I wanted to use a subdomain of `sergix.dev` to point to my static site, `cloudresume.sergix.dev`. I found that the S3 bucket first has to explicitly be named `cloudresume.sergix.dev`.
One of the biggest difficulties with learning AWS is *policy configuration*. Everything in AWS has a designated *ARN* (Amazon Resource Name) that designates each individual created resource. For example, my S3 bucket's ARN is `arn:aws:s3:::cloudresume.sergix.dev`. Access policies for resources can then be configured for AWS IAM roles, users, or directly attached to the resource. To make the S3 bucket publicly accessible, a policy must be directly attached to the bucket:
```json
{
"Version": "2012-10-17",
"Id": "Cloud-Resume-Challenge-S3-Policy",
"Statement": [
{
"Sid": "AllowStaticWebsiteAccess",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::cloudresume.sergix.dev/*"
}
]
}
```
This allows any client to `s3:GetObject` and retrieve any object (`/*`) in the bucket.
### ↪️⤵️ DNS Routing
My website `sergix.dev` is hosted on Netlify, my favorite web development and deployment platform. My website's domain also routes its DNS through Netlify's DNS, and so I can configure any DNS records through Netlify.
I created a CloudFront distribution to be in front of the S3 bucket and for DNS integration. The CloudFront distribution configures an *Origin*, in this case an S3 static site bucket, to redirect traffic to. I then added a CNAME record in Netlify DNS that points to the CloudFront public distribution domain name assigned by AWS. This gives HTTP-only routing, but this will be changed to HTTPS in the next step.
### 🔒 HTTPS
First, I created an SSL certificate in ACM (Amazon Certificate Manager) and then added a CNAME DNS record to `sergix.dev` with the required validation information. AWS uses this key/value pair in the DNS record to verify that I own the domain and to appropriately provision the SSL certificate for my domain.
I then added the new ACM certificate to my CloudFront distribution by just selecting the certificate.
*Now, HTTPS is ready to go!*
### 🛢 DynamoDB
AWS DynamoDB is a **document-based database** that flexibly stores items based on a primary key and each individual item can have its own defined columns. Creating a DynamoDB instance is easy to setup and only requires a primary key and primary key type. I chose `WebPropertyName: String` as my primary key since I didn't know at first how many different pieces of data the frontend would want to store and need to access.
### ⚡ Lambda API
AWS Lambda is a serverless function platform that runs Python, Node.js, or other server-side code whenever a request is received. I chose to write my function and tests in Python.
This challenge requires a visitor count function that is displayed on the frontend. I decided to add an `action` query parameter to the endpoint that performs one of two actions when the `GET` API is requested:
- `get`: return the current visitor count
- `increment`: increment then return the visitor count
The query parameters are available via the `event` object's `queryStringParameters` in the `lambda_handler` function, which is the entry point for the Lambda function.
The function uses the Python `boto3` library developed by AWS to interact directly with the DynamoDB instance in the `visitorcount` table:
```python
# aws-sam/visitor_count/app.py
dynamodb = boto3.resource('dynamodb', region_name='us-east-1')
table = dynamodb.Table('visitorcount')
# ...
table.get_item(
Key={ 'WebPropertyName': 'VisitorCount'}
)
```
I also created an AWS API Gateway public endpoint that restricts any access to the function to the appropriate HTTP methods. I only have `GET` enabled for this function, and so the gateway only allows those requests.
### </> Frontend JavaScript
I added a classic XMLHttpRequest to the frontend (we're going pre-`Promise` here...) that just calls the endpoint once the document loads and waits for a response:
```js
// www/index.js
// when the document is loaded
document.addEventListener("DOMContentLoaded", function(event) {
var xhr = new XMLHttpRequest();
// when the request finishes...
xhr.onreadystatechange = function() {
// if it was successful,
if (this.readyState === 4 && this.status === 200) {
// update HTML
}
};
// prepare the request object
xhr.open("GET", baseURL + "/visitor-count?action=increment", true);
// send the request!
xhr.send();
})
```
However, I immediately ran into the dreaded `CORS` errors when requesting the endpoint. After searching on StackOverflow and countless other resources for the configuration I was missing, I ended up with the following solution:
- Disable authorization in the AWS API Gateway (since this endpoint is public anyway)
- [Manually add the CORS header to all responses in Lambda](https://stackoverflow.com/a/43029002):
```json
'headers': {
'Access-Control-Allow-Origin': '*'
},
```
### ⚙️ AWS SAM
This challenge then asks you to reconstruct the three critical application resources into AWS's Serverless Application Model: DynamoDB, Lambda, and API Gateway.
SAM is a simplified frontend for AWS CloudFormation designed specifically for serverless applications that typically utilize these resources. SAM is an *infrastructure as code* (IaC) platform that takes a configuration file and any associated resources (code, static resources, ...) and automatically provisions and deploys those resources on AWS.
This mindset shift from manually deploying resources and servers to automatic provision was difficult for me -- one of my biggest barriers was that IaC is not a procedural, batch-script-deployment way of thinking. With batch-script or Docker-style deployment, you step-by-step (1) authenticate, (2) provision, (3) upload/update, and (4) run. However, IaC brings this all together into a *declarative*, rather than procedural, environment. The declarative (YAML) configuration is then automatically provisioned and executed (deployed) by the SAM platform. The advantage of IaC, and the problem that it solves, is that all of my resources are then plainly defined with specific versioning and resource requirements, and this configuration can be easily replicated.
#### SAM Templates
SAM templates are similar to other YAML configuration formats. You can run all SAM-configuration locally using the [`sam` CLI](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/install-sam-cli.html), which is packaged separately from the `aws` CLI.
After initializing the SAM directory using `sam init`, I investigated the default YAML configuration. Each service is defined under the `Resources` section and all AWS console configuration can be defined there. It does, however, take a while to find the approprite configuration object definition in the [SAM specification](https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-specification.html). (SAM objects can also use normal CloudFormation objects as well.)
After tinkering with the Lambda resource configuration, I ended up with the following resource object that deploys my Lambda function:
```yaml
# aws-sam/template.yaml
VisitorCountFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: visitor_count/
Handler: app.lambda_handler
Runtime: python3.10
Architectures:
- x86_64
Events:
VisitorCountHttpApi:
Type: Api
Properties:
Path: /visitor-count
Method: get
```
The `VisitorCountHttpApi` is an inline `EventSource` object that *defines an API Gateway*, instead of creating a separate resource definition.
The DynamoDB resource is configured in just a few lines:
```yaml
# aws-sam/template.yaml
VisitorCountTable:
Type: AWS::Serverless::SimpleTable
Properties:
TableName: visitorcount
PrimaryKey:
Name: WebPropertyName
Type: String
```
(The Lambda function ensures that the appropriate table item exists.)
In this current configuration, the DynamoDB table is deleted whenever new changes are deployed. To persist, a [CloudFormation change set](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-cfn-updating-stacks-changesets.html) can be used, but I have not configured it yet.
#### 👤 IAM Policies
The most tedious part about setting up SAM was applying the proper IAM roles. In more secure setups, you would configure an IAM identity, but for this project I just created a normal IAM user and authenticated SAM using the IAM access key. The IAM role attaches all necessary access policies for DynamoDB, S3, Lambda, etc. However, SAM would continuously fail to deploy because of a missing access policy, so I had to manually update the IAM policies until all necessary services were included.
In addition, an inline policy had to be attached directly to the Lambda resource in the SAM configuration to enable DynamoDB access, which is delegated from the IAM user:
```yaml
# aws-sam/template.yaml
VisitorCountFunction:
Type: AWS::Serverless::Function
Properties:
# ...
Policies:
- Statement:
- Sid: DynamoReadWriteVisitorCountPolicy
Effect: Allow
Action:
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:Query
- dynamodb:DescribeTable
- dynamodb:PutItem
- dynamodb:UpdateItem
Resource: '*'
```
### 🚀 GitHub Actions
This challenge requires GitHub actions pipelines for CI/CD. I thought that this would be one of the simpler parts of this project; however, it was unfortunately a painful process of trying to figure out how to setup SAM to work inside a workflow.
#### Backend
For SAM, you first have to authenticate on every workflow job using `aws-actions/configure-aws-credentials@v4`, then grabbing the environment variables defined for those secrets in the repository. I was stuck for a while on this since I forgot that GitHub repos can have [sandboxed environments](https://docs.github.com/en/actions/deployment/targeting-different-environments/using-environments-for-deployment) set up that contain separate credentials, and so I had to manually add that detail to the workflow job by adding `environment: aws-sam`.
After this, though, it was a straightforward process of using `sam build` and `sam deploy` to deploy the repository `on: [push]`. (Albeit, with even more IAM policy wrangling.)
#### Tests
Python tests were automatically generated by `sam init`, so I tweaked them to run the AWS SAM Lambda function and API Gateway. The template worked very well by just running `pytest` in the repository, and it tests both the `increment` and `get` actions by ensuring the function returns just an integer in the response body:
```python
# aws-sam/tests/unit/test_handler.py
# apigw_get_event: pytest fixture that returns a JSON request object
def test_lambda_handler_get(apigw_get_event):
ret = app.lambda_handler(apigw_get_event, "")
data = json.loads(ret["body"])
assert ret["statusCode"] == 200
assert type(data) is int
```
Then, this test was added to the GitHub action by scaffolding `pytest` and running the test. If the test succeeds, the SAM deployment runs:
```yaml
# .github/workflows/sam-pipeline.yaml
jobs:
pytest:
runs-on: ubuntu-latest
environment: aws-sam
steps:
# ...
- run: |
pip install pytest
pytest
sam-build-deploy:
needs: pytest
# ...
```
#### Frontend
Although the challenge asks you to split the frontend and backend into two repos, I decided to just split the resources in the same repo into two different subdirectories. Each workflow runs whenever a change is pushed to its respective directory:
```yaml
# .github/workflows/sam-pipeline.yaml
on:
push:
paths:
- 'aws-sam/**'
```
Thankfully, the frontend CI/CD configuration was much simpler than the backend configuration. Although AWS authentication is still needed, S3 has a `sync` command that syncs the given directory with the designated bucket:
```sh
# .github/workflows/www.yaml
aws s3 sync ./ s3://cloudresume.sergix.dev --delete
```
Then, if this command succeeds, it invalidates the CloudFront cache so that the edge cache contains the latest copy of the S3 bucket:
```sh
# .github/workflows/www.yaml
aws cloudfront create-invalidation --distribution-id ${{ secrets.AWS_CLOUDFRONT_ID }} --paths '/*'
```
## [Click here to see the final result!](https://cloudresume.sergix.dev/)
## Next Steps
Although the project is complete, I would still like to accomplish the following:
1. Persist DynamoDB table across deploys using changesets
2. Use a static endpoint for the API Gateway under my subdomain, i.e. `https://cloudresume.sergix.dev/visitor-count`
3. Complete an AWS certification
## Thank you for reading!
You can find me and my blog at [sergix.dev](https://sergix.dev).
> [GitHub Repository](https://github.com/Sergix/cloud-resume-challenge)
> [Completed Project](https://cloudresume.sergix.dev/) | sergix |
1,798,090 | Cwin - Sân Chơi Trực Tuyến Uy Tín Số 1 Việt Nam | Thuong hieu ca cuoc Cwin duoc cap phep hoat dong hop phap boi to chuc First Cagayan Leisure &... | 0 | 2024-03-22T06:03:40 | https://dev.to/cwincoin/cwin-san-choi-truc-tuyen-uy-tin-so-1-viet-nam-345l | Thuong hieu ca cuoc Cwin duoc cap phep hoat dong hop phap boi to chuc First Cagayan Leisure & Resort Corporation va chung nhan an toan, ...
Dia Chi: 551/132 D. so 7, Phuong 1, Go Vap, Thanh pho Ho Chi Minh, Viet Nam
Email: cwincoin1@gmail.com
Website: https://cwin.co.in/
Dien Thoai: (+63) 9627287578
#cwin #cwin05 #nha_cai_cwin #cwin_co_in #cwin_com #cwin_99
Social Links:
https://cwin.co.in/
https://cwin.co.in/huong-dan-dang-ky/
https://cwin.co.in/huong-dan-tai-app/
https://cwin.co.in/huong-dan-nap-tien/
https://cwin.co.in/huong-dan-rut-tien-cwin/
https://www.facebook.com/cwincoin/
https://twitter.com/cwincoin
https://www.youtube.com/channel/UC9OXAR8SQncDp2mCVvIZwjA
https://www.pinterest.com/cwincoin/
https://learn.microsoft.com/vi-vn/users/cwincoin/
https://vimeo.com/cwincoin
https://github.com/cwincoin
https://community.fabric.microsoft.com/t5/user/viewprofilepage/user-id/691697
https://www.blogger.com/profile/05638703685377361930
https://www.reddit.com/user/cwincoin
https://gravatar.com/cwincoin1
https://talk.plesk.com/members/cwincoin.323656/#about
https://soundcloud.com/cwincoin
https://medium.com/@cwincoin1/about
https://www.flickr.com/people/cwincoin/
https://www.tumblr.com/cwincoin
https://cwincoin1.wixsite.com/cwincoin
https://sites.google.com/view/cwincoin/trang-ch%E1%BB%A7?read_current=1
https://www.behance.net/cwincoin
https://www.openstreetmap.org/user/cwincoin
https://draft.blogger.com/profile/05638703685377361930
https://www.liveinternet.ru/users/cwincoin/post503570942/
https://linktr.ee/cwincoin
https://www.twitch.tv/cwincoin/about
http://tinyurl.com/cwincoin
https://ok.ru/cwincoin/statuses/155887905523198
https://profile.hatena.ne.jp/cwincoin/profile
https://issuu.com/cwincoin
https://dribbble.com/cwincoin/about
https://form.jotform.com/cwincoin1/cwincoin
https://sway.cloud.microsoft/zC1hCn518WoZLdk9?ref=Link
https://unsplash.com/@cwincoin
https://scholar.google.com/citations?user=2DPHwlMAAAAJ&hl=vi
https://www.goodreads.com/user/show/175599611-cwincoin
https://www.kickstarter.com/profile/1142187010/about
https://tawk.to/cwincoin?
https://groups.google.com/g/cwincoin/c/TxoOjW2hCOg
https://cwincoin.webflow.io/
https://podcasters.spotify.com/pod/show/cwincoin
https://www.ted.com/profiles/46223317/about
https://disqus.com/by/cwincoin/about/
https://500px.com/p/cwincoin?
https://cwincoin.blogspot.com/
https://cwincoin.weebly.com/
https://cwincoin.webflow.io/
https://cwincoin.gitbook.io/untitled/
https://cwincoin.mystrikingly.com/
https://cwincoin.amebaownd.com/posts/51766893
https://cwincoin.seesaa.net/article/502386115.html?1708149231
http://cwincoin.idea.informer.com/
https://cwincoin.contently.com/
https://cwincoin.shopinfo.jp/posts/51766963
https://cwincoin.bravesites.com/#builder
https://cwincoin.storeinfo.jp/posts/51767063
https://cwincoin.blog.ss-blog.jp/2024-02-17?1708152306
https://cwincoin.theblog.me/posts/51767098
https://cwincoin.my.cam/#
https://educatorpages.com/site/cwincoin/pages/our-classroom-website?
http://cwincoin.onlc.fr/
https://cwincoin.gallery.ru/
https://cwincoin.therestaurant.jp/posts/51767159
https://cwincoin.wordpress.com/
https://cwincoin.livejournal.com/profile
https://cwincoin.thinkific.com/courses/your-first-course
https://ko-fi.com/cwincoin#paypalModal
https://www.provenexpert.com/cwincoin/?mode=preview
https://hub.docker.com/r/cwincoin/cwincoin
https://independent.academia.edu/coincwin
https://fliphtml5.com/homepage/betgh/cwincoin/
https://www.quora.com/profile/Coin-Cwin
https://www.evernote.com/shard/s744/sh/85bd2d65-ebba-c5eb-701d-8df1a650e3e9/
https://heylink.me/coin79/
https://trello.com/u/cwincoin
https://giphy.com/channel/cwincoin
https://www.mixcloud.com/cwincoin/
https://orcid.org/0009-0009-3720-2849
https://www.deviantart.com/cwincoin
https://vws.vektor-inc.co.jp/forums/users/cwincoin
https://codepen.io/cwincoin
https://community.cisco.com/t5/user/viewprofilepage/user-id/1684582
https://wellfound.com/u/cwincoin
https://about.me/cwincoin
https://cwincoin.peatix.com/
https://sketchfab.com/cwincoin
https://gitee.com/cwincoin
https://public.tableau.com/app/profile/cwin.coin/vizzes
https://www.reverbnation.com/cwincoin
https://profile.ameba.jp/ameba/cwincoin/
https://cwincoin.mystrikingly.com/
https://onlyfans.com/cwincoin
https://readthedocs.org/projects/cwincoin/
https://flipboard.com/@cwincoin? | cwincoin | |
1,798,197 | sodo66vipcom | Sodo66 la mot nha cai uy tin va duoc nguoi choi danh gia cao, voi cac dich vu ca cuoc da dang va chat... | 0 | 2024-03-22T08:47:55 | https://dev.to/sodo66vipcom/sodo66-sodo66vipcom-link-truy-cap-nha-cai-1-viet-nam-5bjj | Sodo66 la mot nha cai uy tin va duoc nguoi choi danh gia cao, voi cac dich vu ca cuoc da dang va chat luong hang dau Viet Nam hien nay.
Website: https://sodo66vip.com/
Dien thoai: (+63) 9624363082
Email: sodo66vip.com@gmail.com
Dia chi: 18 Nguyen Van Luong, Phuong 17, Go Vap, TP Ho Chi Minh, Viet Nam
#sodo66 #nha_cai_sodo66 #sodo66_com #sodo66_vip #sodo66vip_com
Social links:
https://sodo66vip.com/
https://www.facebook.com/sodo66vipcom
https://twitter.com/sodo66vipcom
https://vimeo.com/sodo66vipcom
https://www.pinterest.com/sodo66vipcom/
https://www.tumblr.com/sodo66vipcom
https://www.twitch.tv/sodo66vipcom/about
https://www.reddit.com/user/sodo66vipcom/
https://www.youtube.com/@sodo66vipcom
https://500px.com/p/sodo66vipcom?view=photos
https://gravatar.com/sodo66vipcom
https://about.me/sodo66vipcom
https://www.instapaper.com/p/sodo66vipcom
https://www.mixcloud.com/sodo66vipcom/
https://hub.docker.com/u/sodo66vipcom
https://flipboard.com/@sodo66vipcom/sodo66vipcom-20ut314hy
https://issuu.com/sodo66vipcom
https://www.babelcube.com/user/sodo66-sodo66vip-com-link-truy-cap-nha-cai-1-viet-nam
https://beermapping.com/account/sodo66vipcom
https://qiita.com/sodo66vipcom
https://profile.hatena.ne.jp/sodo66vipcom/profile
https://www.reverbnation.com/sodo66vipcom
https://guides.co/g/sodo66vipcom-91842/351277
https://myanimelist.net/profile/sodo66vipcom
https://os.mbed.com/users/sodo66vipcom/
https://www.metooo.io/u/sodo66vipcom
https://www.veoh.com/users/sodo66vipcom
https://glitch.com/@sodo66vipcom
https://gifyu.com/sodo66vipcom
https://pantip.com/profile/8021192#topics
https://www.dermandar.com/user/sodo66vipcom/
https://hypothes.is/users/sodo66vipcom
https://leetcode.com/sodo66vipcom/
https://www.walkscore.com/people/705836410243/sodo66vipcom
http://www.fanart-central.net/user/sodo66vipcom/profile
https://files.fm/sodo66vipcom/info
http://hawkee.com/profile/6321012/
https://www.chordie.com/forum/profile.php?id=1893893
https://sodo66vipcom.seesaa.net/article/502592296.html?1709798737
https://camp-fire.jp/profile/sodo66vipcom
https://jsfiddle.net/sodo66vipcom/hedbvmpw/
https://www.renderosity.com/users/id:1463877
https://www.funddreamer.com/users/sodo66vipcom
https://turkish.ava360.com/user/sodo66vipcom/
https://www.ohay.tv/profile/sodo66vipcom
https://telegra.ph/sodo66vipcom-03-07
https://community.windy.com/user/sodo66vipcom
https://learningapps.org/display?v=psmh466in24
https://doodleordie.com/profile/sodo66vipcom
https://www.divephotoguide.com/user/sodo66vipcom/
https://www.mapleprimes.com/users/sodo66vipcom
https://www.giantbomb.com/profile/sodo66vipcom/
https://connect.gt/user/sodo66vipcom
https://www.credly.com/users/sodo66vipcom/badges
https://padlet.com/sodo66vipcom/sodo66-sodo66vip-com-link-truy-c-p-nh-c-i-1-vi-t-nam-p4k8hp0p3urfvdvz
https://rentry.co/4bziz99c
https://influence.co/sodo66vipcom
https://experiment.com/users/sodo66vipcom
https://www.designspiration.com/sodo66vipcom/saves/ | sodo66vipcom | |
1,798,215 | Dr. Anupani's Skin & Dental Clinic - Suratgarh | Your Best Path to Radiant Skin & Confident Smiles | Anupani's Skin And Dental Clinic in Suratgarh is a trusted sanctuary for holistic skin and dental... | 0 | 2024-03-22T09:25:46 | https://dev.to/lokeshanupani/dr-anupanis-skin-dental-clinic-suratgarh-your-best-path-to-radiant-skin-confident-smiles-2dd3 | [Anupani's Skin And Dental Clinic in Suratgarh](https://anupaniskinclinic.com/) is a trusted sanctuary for holistic skin and dental care. Led by the expertise of Dr. Lokesh Anupani, a distinguished dermatologist, venereologist, and cosmetologist, alongside skilled dental specialist Dr. Madhavi Vardani, our clinic stands out as a beacon of excellence. With a personalized approach, our team tailors comprehensive skin treatments and dental services to meet individual needs. Dr. Anupani's profound understanding of skin health, coupled with years of experience in enhancing natural beauty, ensures transformative results, instilling confidence in every patient.
Our integrated approach addresses various skin diseases with a blend of medical treatments and advanced procedures, ensuring complete cure and radiant skin. We prioritize patient education, empowering individuals to understand their skin conditions and treatment processes fully. Our dedicated staff provides a comforting environment, making every visit a positive experience.
At Anupani's Skin And Dental Clinic, we believe in not only treating skin and dental issues but also in nurturing confidence. Experience the highest standard of care, whether you're seeking dermatological solutions, dental treatments, or cosmetic enhancements. Your journey to radiant skin and confident smiles begins here. | lokeshanupani | |
1,809,984 | Kubernetes Management with AI using Tools4AI | Kubernetes is a great platform for orchestrating containerized applications. However, the intricate... | 0 | 2024-04-03T12:17:23 | https://dev.to/vishalmysore/kubernetes-management-with-ai-using-tools4ai-3j3b | kubernetes, java, ai, llm | Kubernetes is a great platform for orchestrating containerized applications. However, the intricate details of its API can be daunting for many. This is where the Tools4AI project steps in, offering a novel solution that allows for managing Kubernetes clusters through natural language, thus making the technology accessible to a wider audience.
> Code for this article is [here](https://github.com/vishalmysore/KuberAI)
**Introducing Tools4AI**
[Tools4AI is an open-source](https://github.com/vishalmysore/Tools4AI) project that integrates Large Language Models (LLMs) with Java, enabling the execution of complex tasks through simple prompts. A remarkable feature of this project is its capability to interpret natural language commands for Kubernetes cluster management. This feature bridges the technical complexity of Kubernetes with the intuitive ease of natural language, opening up Kubernetes management to non-experts.
**Operational Mechanics**
The feature operates by dynamically fetching and parsing the Kubernetes [OpenAPI (Swagger) specification](https://www.linkedin.com/pulse/http-endpoints-large-action-model-complete-ai-vishal-mysore-vhhmc?trackingId=5HSO4ixpSsegOSdo78uSOg%3D%3D&lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_content_view%3BX9eVsKrnT4mEfNjIHJakBg%3D%3D&). By configuring the API's URL, base URL for the API server, authentication headers, and an identifier, Tools4AI generates a comprehensive list of actionable commands from the Kubernetes API documentation.
**Configuration Example**
This is how you can configure the kubernetes endpoints ,I have deployed the sample mock [here](https://huggingface.co/spaces/VishalMysore/mock?logs=container)
```java
{
"endpoints": [
{
"swaggerurl": "https://huggingface.co/spaces/VishalMysore/mock/raw/main/kubernetes.json",
"baseurl": "https://vishalmysore-mock.hf.space",
"id": "openshift",
"headers": [
{
"key": "Authorization",
"value": "apiKey=samplekey"
}
]
}
]
}
```
This configuration directs Tools4AI to the Kubernetes OpenAPI specification and includes authentication details necessary for API interactions.
**Endpoint Analysis and Action Generation**
Upon retrieving the OpenAPI specification, Tools4AI parses it to map out available operations. For instance, the tool identifies operations like creating, listing, updating, and deleting Kubernetes resources such as ClusterRoleBindings and Roles. Each operation is translated into an actionable command that can be initiated through natural language prompts.
**Examples of HTTP Endpoints**
GET Request: Fetch all Cluster Role Bindings or a specific Role Binding in a namespace. (you can provide specific names and they will be passed as arguments to the http get or post) - Look at the details [here
](https://www.linkedin.com/pulse/http-endpoints-large-action-model-complete-ai-vishal-mysore-vhhmc?trackingId=5HSO4ixpSsegOSdo78uSOg%3D%3D&lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_content_view%3BX9eVsKrnT4mEfNjIHJakBg%3D%3D&)
```
GET https://vishalmysore-mock.hf.space/apis/rbac.authorization.k8s.io/v1/clusterrolebindings
```
POST Request: Create a new Cluster Role or Role Binding within a specified namespace.
```
POST https://vishalmysore-mock.hf.space/apis/rbac.authorization.k8s.io/v1/clusterroles
```
DELETE Request: Remove a particular ClusterRole or its binding
```
DELETE https://vishalmysore-mock.hf.space/apis/rbac.authorization.k8s.io/v1/clusterroles/voluptas
```
**Impact on Kubernetes Management**
The Tools4AI project significantly lowers the entry barrier to Kubernetes, enabling:
**Broader Accessibility:** By simplifying Kubernetes management, Tools4AI makes the technology approachable for users without deep technical knowledge.
**Enhanced Productivity:** Users can manage Kubernetes resources more efficiently through natural language commands, saving time and reducing complexity.
**Educational Advantage: **It serves as an innovative tool for teaching Kubernetes, allowing learners to interact with clusters in a more intuitive manner.
**Advanced Example**
In an effort to delve deeper into the practical applications of Tools4AI for Kubernetes management, let's explore complex scenarios where multiple endpoints are leveraged in sequence to accomplish broader tasks. These examples will illustrate how natural language prompts can initiate [complex workflows](https://www.linkedin.com/pulse/building-autonomous-ai-agent-java-action-scripts-vishal-mysore-p3mbf?trackingId=5HSO4ixpSsegOSdo78uSOg%3D%3D&lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base_recent_activity_content_view%3BX9eVsKrnT4mEfNjIHJakBg%3D%3D&), showcasing the power and flexibility of Tools4AI in managing cloud-native environments.
**Scenario 1: Upgrading a Deployment**
Objective: Upgrade all pods in a deployment to a new version of the application.
Natural Language Prompt: "Upgrade the payment service deployment to version 2.0."
Underlying Actions:
Fetch the Current Deployment:
GET /apis/apps/v1/namespaces/default/deployments/payment-service
This retrieves the current deployment configuration for the "payment-service".
Update the Image Version:
PATCH /apis/apps/v1/namespaces/default/deployments/payment-service
The request body contains the new image version, initiating the rolling update process.
**Scenario 2: Rolling Back a Faulty Deployment**
Objective: Roll back a deployment to its previous stable version after detecting an issue with the current release.
Natural Language Prompt: "Roll back the inventory service deployment to the previous version."
Underlying Actions:
List Deployment Revisions:
GET /apis/apps/v1/namespaces/default/deployments/inventory-service/revisions
This action fetches the history of revisions for the "inventory-service" deployment.
Identify the Previous Revision Number:
Determine the revision number just before the latest (this step may involve parsing the list and selecting the second-latest entry).
Roll Back to the Previous Revision:
PATCH /apis/apps/v1/namespaces/default/deployments/inventory-service/rollback
The request body specifies the identified revision number for rollback
**Scenario 3: Configuring Auto-Scaling for a Deployment**
Objective: Set up Horizontal Pod Autoscaler (HPA) for a deployment based on CPU usage, enabling automatic scaling of pods in response to load.
Natural Language Prompt: "Enable auto-scaling for the frontend deployment based on CPU usage, with a minimum of 3 pods and a maximum of 10 pods."
Underlying Actions:
Create or Update HPA:
POST /apis/autoscaling/v1/namespaces/default/horizontalpodautoscalers
If an HPA already exists for the "frontend" deployment, this might instead be a PATCH action to update the existing HPA configuration.
The request body specifies the target deployment, minimum and maximum number of pods, and the CPU utilization threshold for scaling.
**Conclusion**
Tools4AI's integration of natural language processing with Kubernetes management represents a forward leap in making cloud-native technologies more user-friendly. This project not only demonstrates the potential of AI in simplifying complex systems but also sets a precedent for future innovations in the technological space, making advanced technologies more accessible and manageable for a broader audience.
 | vishalmysore |
1,810,475 | Title: Forged Brilliance: A Comprehensive Guide to Metal Bars | Introduction: In the realm of metallurgy, the significance of metal bars extends far beyond their... | 0 | 2024-04-03T18:56:39 | https://dev.to/metalbars/title-forged-brilliance-a-comprehensive-guide-to-metal-bars-22gm | Introduction:
In the realm of metallurgy, the significance of metal bars extends far beyond their utilitarian origins. These slender, sturdy forms of metal have played a pivotal role in shaping industries, constructing monumental structures, and even becoming mediums for artistic expression. This comprehensive guide delves into the world of **[metal bars](https://www.fortemetals.com/products/)**, exploring their diverse types, applications, and the brilliance they bring to various fields.
Steel Bars: The Backbone of Industry
Carbon Steel Bars: Known for their strength and versatility, carbon steel bars find application in construction, manufacturing, and automotive industries. They come in various shapes, including round, square, and flat bars, catering to a wide range of applications.
Alloy Steel Bars: Alloy steel bars incorporate elements like chromium, nickel, and molybdenum to enhance specific properties such as strength, hardness, and corrosion resistance. Commonly used in aerospace, oil and gas, and automotive applications, these bars offer tailored solutions for demanding environments.
Stainless Steel Bars: Corrosion-Resistant Elegance
304 Stainless Steel Bars: Known for their corrosion resistance and versatility, 304 stainless steel bars are widely used in food processing, architectural design, and medical equipment. Their aesthetic appeal and durability make them a staple in various industries.
316 Stainless Steel Bars: With added molybdenum, 316 stainless steel bars exhibit superior corrosion resistance, making them ideal for marine environments, chemical processing, and pharmaceutical applications. These bars offer a high level of durability in challenging conditions.
Copper Bars: Conductors of Excellence
Electrolytic Copper Bars: Celebrated for their high electrical conductivity, electrolytic copper bars are essential in electrical and electronics industries. From power transmission to intricate circuitry, these bars form the backbone of modern technology.
Architectural Copper Bars: Renowned for their warm, reddish-brown hue, architectural copper bars contribute to aesthetic elegance in construction. Used in roofing, facades, and ornamental elements, they bring both beauty and durability to architectural designs.
Bronze Bars: Timeless Artistry and Strength
Phosphor Bronze Bars: Infused with tin and phosphorus, phosphor bronze bars exhibit exceptional strength, corrosion resistance, and wear resistance. These bars are commonly used in bushings, bearings, and musical instruments, showcasing the marriage of artistry and functionality.
Aluminum Bronze Bars: Known for their corrosion resistance and high strength, aluminum bronze bars find applications in marine environments, chemical processing, and heavy-duty machinery. Their versatility and durability make them a preferred choice in challenging conditions.
Nitronic 60: Beyond Toughness
Nitronic 60 Bars: A high-performance austenitic stainless steel, Nitronic 60 bars go beyond toughness, offering exceptional strength, corrosion resistance, and machinability. Widely used in aerospace, chemical processing, and marine engineering, Nitronic 60 is a metallurgical marvel that meets the demands of modern industries.
430 Stainless Steel: Resilience in Every Strand
430 Stainless Steel Bars: Known for their cost-effective durability, 430 stainless steel bars exhibit impressive corrosion resistance, heat resistance, and magnetic properties. Widely used in kitchen appliances, automotive trims, and industrial equipment, these bars offer resilience in every strand.
Conclusion:
Metal bars, with their diverse compositions and applications, form the backbone of numerous industries. From the strength of steel to the elegance of copper, the artistry of bronze, and the high performance of alloys like Nitronic 60, each type of metal bar brings its unique brilliance to the world of metallurgy. As these bars continue to shape our industries, architecture, and technological advancements, their enduring significance remains a testament to the forged brilliance of metallurgical innovation.
| steelroundbarstock | |
1,810,788 | How To Develop an App in 10 Easy Steps (2024 Guide) | In the digital era, having a mobile app for your business is no less than a luxury. It helps your... | 0 | 2024-04-04T05:54:02 | https://dev.to/infowindtech24/how-to-develop-an-app-in-10-easy-steps-2024-guide-41bf | topmobileappdevelopemnt, topmobileappdevelopers, mobileappdevelopmentcompany | In the digital era, having a mobile app for your business is no less than a luxury. It helps your business go live and offshore. Building an app requires expertise and choosing the right mobile app development company can fasten the process 2X times. Continue reading to learn more about each step in the **[app development company](https://www.infowindtech.com/technology-cat/mobile-app-development/)** process.
1. Generate A Concept
Before beginning the actual app development process, you must have a clear understanding of the purpose, functionality, and ways in which your app will benefit consumers. Assess its alignment with your long-term vision or company objectives.
2. Recognize Your Target
Decide who your target audience will be. Create personas to better understand your app’s intended user base and the platforms they use. Think about the kind of software that people will want to use again.
3. Make An Investigation
Given the millions of applications accessible today, market research is crucial to understanding how your app will stand out from the competition. Being aware of what your rivals are currently doing might give you an advantage and help you understand what you could face.
Start by investigating the applications currently available in your niche through market or industry research. This may also assist you in figuring out what features or functions will make your app stand out. To find out what prospective consumers need or what their pain points are, you may also consider conducting interviews with them or asking for their input.
4. Make Wireframes & User Journeys
A user experience (UX) designer, working with other specialists like a digital strategist or information architect, will draft a wireframe and arrange the steps users will take to accomplish the intended activity after you have determined the purpose and features of your app.
A mockup is a comprehensive schematic of an application’s look and how its features and functions fit into the overall design. Colors, typefaces, images, the basic layout, and other visual components are often used in mockups. When done correctly, a mockup ought to provide the development team with a notion of the app’s appearance and functionality.
5. Develop an Application in a Test Setting
Following that, app developers start developing the platform and then do the real work. They need to do this in a test environment to ensure testing throughout the whole development process.
When choosing and working with a **[mobile app development company](https://www.infowindtech.com/technology-cat/mobile-app-development/)**, it’s best to use a password management application to keep your working files safe. This will not only make your workspace safer but also enable your team members to access files from a distance when needed.
An app’s security is a crucial factor to consider. To ensure security, enable secure source code, carry out penetration testing, and validate input. It’s also essential to take further precautions, such as verifying that HTTPS and SSL/TLS security layers are implemented.
6. Test Every Feature
As we previously said, every mobile app should be tested hundreds, if not thousands, of times while it is being developed. Comprehensive testing by a QA specialist is essential to guarantee that each feature functions as intended.
Developers will be able to address any bugs discovered in the test environment before the app’s release, guaranteeing that customers won’t know they’re there.
7. Make Mockups While Keeping The Visual Design Element In Mind
After you’ve compiled a feature list, you can begin designing prototypes of your app’s possible user interface. Before making a mockup, begin with a preliminary drawing. While creating a mockup, you have to think about how your users will see and utilize your app.
Remember to create an appealing visual design for your application. You can collaborate with a graphic designer with UI/UX expertise while creating it.
8. Create A Marketing Strategy
An essential component of developing an app is creating a marketing strategy. In what other way would you publish your software and encourage consumers to not only see it but also download and use it? Ideally, it would help if you started working on your marketing strategy even before you release your app. Create a website, post about your app development process on social media, or use an email list for visitors or customers to generate excitement about it before it launches.
9. Create Your Application
You may begin coding as soon as you have mastered the fundamentals. However, you may want to consider a few important elements, such as front-end and back-end development, before you begin creating code. A test environment must also be created for execution.
10. Repeatedly Test And Get Feedback
Testing your app repeatedly is essential if you want it to succeed. You’ll need to test your app’s front-end and back-end functionality, device compatibility, possible integration problems, installation and storage concerns (such as how big your app is or if it will download to the appropriate device), and other aspects.
It is necessary to have test users utilize your app after testing to obtain user input and determine what additional features your future clients may want. Furthermore, obtaining input should continue after the testing stage. Users’ input may still be gathered after the app launches.
Please pay Attention to Feedback: It’s crucial to remember that app development is a never-ending process. There will be specific comments, ratings from users in app stores, issues, and sometimes requests for additional functionality from companies.
This implies that a new program version must be created, sent to current users and the app stores, and may include minor bug fixes or a significant upgrade.
To put it simply, pay attention to what your audience has to say. Check out the app store’s comments area, the forums that your users often visit, social media, and any other possible places where people may leave reviews online. Choose the best **mobile app developer**.
Conclusion
Before choosing a mobile app development company, keep all the points in mind and then analyze them to precision. Additionally, keep reading the case studies so that you will get a good idea about how to get your app developed and the features that are to be included in it.
| infowindtech24 |
1,810,918 | Ngoại hạng Anh 2023 - 2024: Tin tức nổi bật & mới nhất | https://thethao247.vn/bong-da-anh-c8/ Tin tức✔️ lịch thi đấu✔️ trực tiếp✔️ kết quả và số liệu thống... | 0 | 2024-04-04T08:26:43 | https://dev.to/thethao247bdanh/ngoai-hang-anh-2023-2024-tin-tuc-noi-bat-moi-nhat-3a19 | https://thethao247.vn/bong-da-anh-c8/ Tin tức✔️ lịch thi đấu✔️ trực tiếp✔️ kết quả và số liệu thống kê về giải Bóng đá Ngoại hạng Anh Premier League mùa giải 2023 - 2024 trên Thể Thao 247✔️✔️✔️
http://thethao247bdanh.zohosites.com/
https://hashnode.com/@thethao247bdanh
https://hackmd.io/@thethao247bdanh | thethao247bdanh | |
1,810,984 | Chai & Mocha | Chai is a BDD/TDD assertion library for Node.js and browsers that can be paired with any JavaScript... | 0 | 2024-04-04T10:04:33 | https://dev.to/meertanveer/chai-mocha-1kh9 | chai, mocha, framework, webdev | Chai is a BDD/TDD assertion library for Node.js and browsers that can be paired with any JavaScript testing framework. It provides a clean and expressive syntax for writing assertions, making it easier to write clear and concise test cases. Chai offers a wide range of assertion styles and plugins, allowing developers to choose the syntax that best fits their testing needs.
### Uses of Chai:
1. **Writing Assertions**: Chai simplifies the process of writing assertions in test cases, enabling developers to verify expected outcomes and behaviors of their code.
2. **Behavior-Driven Development (BDD)**: Chai supports BDD-style assertions, which focus on describing the behavior of the system in natural language, making tests more readable and understandable.
3. **Test-Driven Development (TDD)**: Chai can also be used in TDD workflows, where tests are written before the actual code, helping developers define the desired functionality and ensure that their code meets the specified requirements.
4. **Integration with Testing Frameworks**: Chai integrates seamlessly with popular testing frameworks like Mocha, Jasmine, and Jest, allowing developers to leverage Chai's assertion capabilities within their preferred testing environment.
5. **Extensibility**: Chai is highly extensible and allows developers to create custom assertion methods and plugins tailored to their specific testing needs.
### Learning Curve:
The learning curve for Chai is generally considered to be moderate. Here are some factors that contribute to its learning curve:
1. **Syntax Variety**: Chai offers multiple assertion styles, including `expect`, `should`, and `assert`, each with its own syntax and conventions. Learning the differences between these styles and choosing the one that best fits your preference can take some time.
2. **Documentation and Resources**: Chai provides comprehensive documentation and examples to help developers get started. However, understanding the various assertion methods and their usage might require some practice and experimentation.
3. **Integration with Testing Frameworks**: While Chai itself is straightforward to use, integrating it with different testing frameworks may require familiarity with those frameworks' APIs and configurations.
4. **Advanced Features and Plugins**: Chai offers advanced features like chaining, negation, and plugins for extending its functionality. Learning how to leverage these features effectively may require additional time and practice.
Overall, with some initial investment in learning the basics and exploring its features, developers can quickly become proficient in using Chai for writing expressive and robust test cases in their JavaScript projects.
**Mocha** is a JavaScript test framework that runs on Node.js and in the browser, allowing developers to write and run tests for their code. It provides a clean syntax for writing test cases, supports various assertion libraries (such as Chai), and offers features like asynchronous testing and test coverage reporting. Mocha is widely used in JavaScript development for unit testing, integration testing, and behavior-driven development (BDD).
**Uses of Mocha:**
1. **Unit Testing**: Mocha allows developers to write and execute unit tests to verify the behavior of individual components or functions within their codebase.
2. **Integration Testing**: It enables developers to test the interactions between different modules or components of their application to ensure they work together as expected.
3. **BDD (Behavior-Driven Development)**: Mocha supports BDD-style testing, where tests are written in a human-readable format to describe the behavior of the system from the end user's perspective.
4. **Asynchronous Testing**: Mocha provides built-in support for testing asynchronous code using callbacks, promises, or async/await syntax.
5. **Test Reporting**: Mocha generates detailed test reports, including information about passed and failed tests, test duration, and code coverage, helping developers identify and fix issues in their code.
**Learning Curve:**
Mocha has a relatively low learning curve, especially for developers familiar with JavaScript and testing concepts. Here are some factors contributing to its ease of learning:
1. **Simple Syntax**: Mocha's syntax is clean and straightforward, making it easy to write test cases and understand test output.
2. **Extensive Documentation**: Mocha has comprehensive documentation with examples and guides covering various features and usage scenarios, making it easier for developers to get started and troubleshoot issues.
3. **Flexible Configuration**: Mocha offers flexibility in configuration, allowing developers to customize test behavior, reporter output, and other settings according to their project requirements.
4. **Large Community and Ecosystem**: Mocha is widely adopted in the JavaScript community, with a large user base and ecosystem of plugins and extensions for integrating with other tools and frameworks.
5. **Integration with Assertion Libraries**: Mocha seamlessly integrates with popular assertion libraries like Chai, providing developers with flexibility in choosing the assertion style that best fits their testing needs.
Overall, Mocha is an accessible and powerful testing framework for JavaScript developers, offering a balance of simplicity, flexibility, and advanced features to support robust testing practices in web development projects. | meertanveer |
1,810,991 | My Journey as a First-Time Speaker at DevFest | Hello, there 👋 On the 11th of November, 2023, I gave a talk at a tech conference with about 100... | 0 | 2024-04-04T10:13:24 | https://sophyia.me/from-nerves-to-cheers-my-journey-as-a-first-time-speaker-at-devfest | techtalks, publicspeaking, devrel |
Hello, there 👋
On the 11th of November, 2023, I gave a talk at a tech conference with about 100 attendees (whom I barely know). Exciting, right? It wasn't always like that, so let's go behind the scenes of my journey as a first-time speaker and how I overcame small roadblocks.
I came across the opportunity in the community I Lead, [Google Developer Student Clubs, MOUAU](https://gdsc.community.dev/michael-okpara-university-of-agriculture-umudike/). One of the co-organizers posted about the event on the community, [DevFest Umuahia](https://gdg.community.dev/events/details/google-gdg-umuahia-presents-devfest-umuahia-2023/), and this is the first time it's happening in the city of Umuahia. I just had to attend! I made sure GDSC MOUAU partnered with GDG Umuahia to promote the event.
A few weeks later, they announced the call for speakers, and I was skeptical about applying because I hadn't spoken at a large crowd or a tech conference. More so, I didn't have the _"public speaker"_ vibe. I didn't apply immediately; I had a few conversations with my friends, who all pushed me to apply. They said, _"If you get rejected, you won't regret not applying."_
Next was choosing a topic; I didn't want to sing the same old song every speaker was singing; I wanted my topic to be different and unique but simple. The first week of October, I got an offer to [join Pieces for Developers](https://pieces.app/) as a Developer Advocate Intern, so I decided to speak about their tool. I have used it for a while, and it is useful to developers, so _"why not talk about my experience with Pieces OS?"_ I had settled on a topic for my talk, perfect!
I didn't think the topic through and sent my Call For Proposal within 2 days. This was my mistake. I should have consulted my manager, Cole Stark(CMO), first, but when I told him I would speak at a conference. He connected me with the Lead Developer Advocate, Shivay Lamba, who gave me tips on public speaking, addressing the crowd, and staying calm when speaking. I acknowledged my mistakes and worked on giving a better talk during the event (if I got accepted).
On the 23rd of October, 2023, I got an email that my talk was accepted. Oh my! I was excited. Someone appreciated my poorly thought topic and wanted to learn about it, and that was it. Any doubt I had just vanished! You know when you applied for a job you didn't qualify for but still got an interview? Yup! That was how I felt.
Next was crafting the perfect slide for my talk. This was the tricky part. I usually get my slides done by AI on [gamma](https://gamma.app/), but this wasn't my usual community virtual event or meetup. This was a foreign land, and I needed a PERFECT slide, which was not good enough.
I reached out to Shivay to get a slide template from the team, and editing it was frustrating; I was blank for 2 days. I had no idea what to write or how to start editing it. Now, this is where I appreciate AI; we talked and came up with a great outline for the slide.
Also, I conducted a survey on Twitter to learn about the productivity challenges other developers face. This helped me to collect useful information.
For the next three days, I worked on a 15-page slide presentation based on the outline that my boo, ChatGPT, and I had created. 😂
I didn't work alone since I would partially discuss a company's product. I contacted my managers, Cole Stark and Shivay Lamba, for assistance so I wouldn't make any mistakes or sell false claims.
With the help of Cole, Shivay, and AI, I created a great slide and shared it with event organizers. I studied this several times because I was anxious to ensure I got everything right.
Besides Cole and Shivay, I contacted Leon and Segun to get an outsider's perspective and to see if they understood the slide. They were all helpful. The slide is [here](https://docs.google.com/presentation/d/1o7F-MQ87FqPsGIxlNf9tnrH7XvOQgx3h/edit?usp=sharing&ouid=112963019252710584877&rtpof=true&sd=true).
**💡
Pro-tip: If you are trying something new, don't hesitate to ask for help. You can contact your friends, mentors, colleagues, or tech on Twitter. Getting help can save you from a lot of solo "debugging."**
## The Event (D-day)

It was the day of the event, Saturday, 11th November 2023. I was excited, thrilled, and anxious all at once. I was part of the organizers, so I had to get to the venue at 8 am to set things up.
I had a chance to talk to some volunteers despite being very shy. I'm working on overcoming my shyness, but it's hard for me to approach you and greet you. It was a bit of a challenge, but I managed to converse with some volunteers, who hyped me. I felt less nervous by the end of the setup.
The event started at exactly 10:20 am. This was it! My first DevFest event as a speaker. Attendees arrived a bit late, so the event started a bit late. I saw the event agenda by 10 am, and my talk was scheduled for 12:30 am.
I had to grab something to snack on, so I left around 10:30 am and tried calming my nerves. It did work.
**💡
Pro-tip: If you ever feel nervous about an interview, event, or anything. Take a walk!**
After listening to the amazing speakers' talk, I was ready for my talk. My topic was **"Maximizing Developer Productivity with Pieces**"

Due to some delay, my talk was shifted to 1:30 pm. At first, I was sad I could not grab the crowd's attention because the attendees were getting tired. I had to remind myself that pushing myself out of my comfort zone was good enough, and if my talk flopped, I would take this as a training phase to improve.
I got up stage and talked extensively to the best of my knowledge about developer productivity, how to boost productivity as a developer, tools to use, and how Pieces can help boost developer workflow. It was awesome! I wasn't nervous at the end! I had delivered an amazing talk. I did answer a question about Pieces OS, though (and I did that confidently).
When I returned to my seat, a friend whispered, "You did good. That was awesome". I just knew that if my talk were confusing, it would help a few people at least. I was so surprised by how many people approached me about productivity. We talked, exchanged WhatsApp contacts, and had a fun conversation.
## Conclusion
Yeah, this is my experience. I may have missed some details, but I am still excited and proud to be taking this huge step. It's not easy, but it's worth it.
If you can speak at a conference or local meetups, seize it! It's fun but scary, and you meet more people faster. | sophyia |
1,811,080 | How SCCM Inventory Report Solution Helps in Driving Efficiency | Inventory management needs Efficiency and a crucial understanding of the operations. Managing the... | 0 | 2024-04-04T12:32:00 | https://dev.to/intunereporting/how-sccm-inventory-report-solution-helps-in-driving-efficiency-1fa0 | sccminventoryreport, sccmhardwareinventoryreport, sccmreportbuilder, sccmreports |

Inventory management needs Efficiency and a crucial understanding of the operations. Managing the supply chain with sustainability can be daunting. This is where the sccm inventory report comes to play. With this comprehensive, advanced reporting system, you can get a detailed insight into the sustainability metrics, usage patterns and inventory levels. Besides that you would be able to take informed decision that will minimize environmental impact and promote productivity. So, let this content be an explorative guide to the benefits of SCCM inventory reporting and how it helps to drive more Efficiency in the supply chain.
## **What is all about the SCCM inventory report solution**
SCCM inventory report is an inclusive tool that lets organizations gather, scrutinize and report on the different aspects of the software assets and IT infrastructure. You can get all sorts of services, From speculations regarding devices to configurations of the software inventory data, including the license complaint and installed applications. Thus, sccm offers a centralized platform for monitoring and managing all sorts of IT elements across different organizations.
## **Total Efficiency and productivity in terms of data insights**
The primary benefit of [**sccm inventory report**](https://powerstacks.com/hardware-asset-inventory-reporting/) is that it allows organizations to act based on Insights. And follow the same in inventory management. They take advantage of the real-time data and deployment status, optimize the procurement process, keep the assets streamlined, and reduce extra inventory. This definitely minimizes the cost related to overstocking but, at the same time, enhances operational Efficiency. It also ensures that the resources are utilized efficiently.
## **Driving huge initiatives from the sustainability factor**
Besides escalating Efficiency, the scam inventory report plays a vital role in enforcing sustainability among organizations. They help track sustainability metrics like carbon footprint, energy consumption and waste generation. It also helps businesses identify room for improvement and implement specific strategies to minimize environmental impact. Like SCCM, reports can collect the organization's data and find opportunities to optimize the power setting, keep the hardware resources consolidated, and invest in energy-rich technologies.
## **Ensuring security and compliance among the organization**
The sccm inventory report helps organization to ensure regulatory requirement and complaince. Also, maintain the well-built security standards. They also provide visibility to the security patches, software licenses and systems configurations. Thus, it helps businesses to find out potential weaknesses and take proactive steps to fight risks. Certainly this helps in safeguarding the sensitive data and the property against violations of compliance and security breaching.
## **Optimizing and allocating resources as per the need**
The critical benefit of SCCM reporting is that it enables the efficient utilization and optimization of allocated resources. With scam inventory reports, you can obtain insight into the user pattern of the IT assets; organizations can find the under-utilized resources and reallocate those to accomplish more productive chores. This helps in discarding unwanted expenses. This ensures that the resources are allocated smartly based on the exact demand rather than abstract estimates. Certainly, such measures help companies save costs and improve the Efficiency of resources.
## **Improves decision-making process with SCCM reporting**
The SCCM inventory report is a worthy tool for making advanced decisions at each level of the organization. With this systematic tool, the stakeholders can get accurate and timely data on the inventory status. Keep an eye on the performance metrics and meet the complaints needs. The SCCM report solution allows businesses to make decisions based on data. This aligns with the strategic requirement. Whether it's about optimizing the inventory level focusing on software updates, or investing in new technologies sccm reporting solution makes business take informed decisions that will help business grow sustainably.
## **How do SCCM inventory reporting help in driving efficiency**

Putting the supply and demand on the same plate is a challenging task. At the same time, businesses must be vigilant about optimizing resources. The traditional process of tracking the inventory is time-consuming; moreover, it is error-prone. Also, it lacks accurate time information. With modern technology, SCCM inventory reports can help organizations use this robust medium to streamline the whole inventory management. That helps in driving Efficiency. So let's see how to optimize the inventory and increase the operational Efficiency
## **Getting real-time visibility updates with sccm**
The sccm inventory report can offer you visibility based on real-time asset and inventory status information. They collect and update the data on software and hardware assets across different organizations. They enable businesses to replenish their inventory from time to time. Thus, use the resources efficiently and effectively.
## **Tacking all the assets in an accurate and precise way**
SCCM inventory report solution offers organizations a comprehensive and accurate analysis of assets. They help maintain a detailed inventory of software and hardware assets within the IT domain. They do automatically garner data based on the specifications obtained from the configurations, devices and installed applications. Besides, it discards the manual inventory requirement and minimizes the risk of discrepancies or errors. This accurate way of tracking assets helps organizations maintain compliance with licence contracts. At the same time, it helps in the optimized utilization of assets.
## **Utilizing resources in the most efficient and intelligent manner**
SCCM inventory report gave organizations detailed insight into the performance metrics and patterns of the IT assets. They help optimize the utilization of resources. They do help in analyzing the data on usage of assets. And also help in identifying under-utilized resources. Use the same resources to accomplish some productive tasks and eliminate unwanted expenditures. This not only keeps costs under check but also improves operational efficiency by ensuring that resources are utilized in the best way.
## **Enhancing the compliance management target**
SCCM inventory report lets organizations adhere to compliance with regulatory needs. And follow industry standards by allowing visibility to security latches, software licenses and system configurations. Thus, it minimizes the risk of security breaches.
## **Final talk**
Thus, these are vital pointers that show how the SCCM inventory report helps drive Efficiency in business. Therefore, you can also use the [**sccm report builder**](https://powerstacks.com/bi-for-sccm-reporting/) to generate perfect reports. But make sure you contact the most reputed and experienced sccm report offering companies.
| intunereporting |
1,811,210 | [¡PELISPLUS] Ver Monkey Man Película Completa en español | hace 29 minutos — Cuevana 3 Ver Monkey Man Online Gratis en español, Latino, Castellano y Subtitulado... | 0 | 2024-04-04T14:45:34 | https://dev.to/huyah/pelisplus-ver-monkey-man-pelicula-completa-en-espanol-p2n | hace 29 minutos — Cuevana 3 Ver Monkey Man Online Gratis en español, Latino, Castellano y Subtitulado sin registrarse. Ver estrenos de películas y también las mejores películas en HD Ver Monkey Man película Completa Gratis en español o con subtítulos en tu idioma, en HD y hasta en calidad 2024 HD con Audio español Latino y Subtitulado,
**➤➤🔴📱 VER AHORA ✅➤➤ [https://t.co/Wc214XCYxq](https://t.co/Wc214XCYxq)
**
**➤➤🔴📱 DESCARGAR ✅➤➤ [https://t.co/Wc214XCYxq](https://t.co/Wc214XCYxq)
**
Sinopsis Tras su último y explosivo enfrentamiento, el todopoderoso Kong y el temible Godzilla, dos de los monstruos que ahora dominan el mundo, se reencuentran para un feroz combate contra una colosal pero desconocida amenaza que se oculta en el planeta. Un enemigo que desafía su propia existencia y, en consecuencia, la de la humanidad protegida por estos titanes. Su historia, sus orígenes y los misterios de la Isla Calavera serán clave para entender la forja de estos extraordinarios seres y su conexión inquebrantable con la humanidad.
Ver Monkey Man (2024) : Online en Espanol Película de animación que nos traslada a Ciudad Elemento, una urbe cuyos habitantes son seres hechos de aire, tierra, agua y fuego. Allí conviven estos cuatro tipos de elementos, con una única regla que es imprescindible cumplir: los elementos no pueden mezclarse. Cuando Candela, una joven de fuego, conoce a Nilo, un joven de agua, las cosas van a ponerse patas arriba. Ella vive en barrio fuego, a toda mecha, con su llameante familia que ya tiene muy claro cuáles son los planes para la joven: seguir los pasos de su padre. Pero, ¿qué pasará cuando Candela quiera vivir fuera de su elemento? ¿Y si el fuego y el agua se enamoraran? ¿Será un amor imposible o el inicio de una gran amistad? Lo que Candela y Nilo están a punto de descubrir es algo Monkey Man : realmente tienen muchas cosas en común.
Conoce cómo y dónde ver la 𝐏elícula 𝐂ompleta de Monkey Man (2024) online gratis en 𝐄spañol. No te preocupes, acá te dejo opciones para ver Monkey Man online.
Ver Monkey Man online y sur Gratis en HD, es fácil en gracias a sus servidores, rapidos y sin ads. ¿Cómo Ver Monkey Man película Completa en
Monkey Man ; fecha de estreno, tráiler y dónde Ver en España y Latinoamérica
Ver Monkey Man la Película en español línea Online y Gratis
Ver Monkey Man ?ompletas Gratis en español es posible y de forma legal. Hay opciones alternativas a Netflix y Amazon que no requieren ningún tipo de pago ni suscripción y cuyo contenido es totalmente gratuito. Estas plataformas para Ver cine Monkey Man Gratis en casa pueden ofrecer contenido sin costo gracias a cortes comerciales o bien porque tienen películas de dominio público.
Ver Monkey Man Película Completa en español Latino Subtitulado En nuestro sitio proporcionamos subtítulos y dabbing en latín, no tenga miedo por México, Chile, Perú, Bolivia, Uruguay, Paraguay, España, Argentina, Colombia y todas las regiones de habla latina, hemos proporcionado idiomas para sus Halloween Killsivas regiones. .Para disfrutar de todas estas funciones, puede registrarse y seguir en su cuenta premium.
Monkey Man de la trilogía Guardianes de la Galaxia, que forma a su vez parte de la Fase 4 de Marvel. Tras las cámaras volvemos a encontrar al director James Gunn.
Monkey Man Película Completa en Español Latino - Disfruta Gratis de la Nueva Película DC Universe Batman en Calidad HD
Disfruta la mejor película ‘Monkey Man ’ sin registrarse en todos los idiomas online, Batman película completa en español gratis en HD, segura y legal.
¿Estás buscando ver Monkey Man pelicula completa en español y no sabes por dónde? No te preocupes, acá te dejo opciones para ver Monkey Man online.
En éste artículo vamos a saber dónde ver la película Monkey Man online y gratis en HD sin cortes, y así disfrutar en familia, solos o con amigos de las mejores Películas de la actualidad como también de la historia del película.
Ver Monkey Man película completa en español. Disfrutar de la película completa Monkey Man online, gratis y legal.
Podrás ver la película completa de Monkey Man online sin registrarte. Con sólo aterrizar ya verás la nueva película agregadas recientemente gratis.
Dispone incluso de la posibilidad de que solicites una película en concreto si no la has encontrado en el listado de la web
Las mejores peliculas online sin registrarse en todos los idiomas , Monkey Man pelicula completa online y gratis en HD, segura y legal.
Ver aqui Monkey Man la película completa gratis y sin ads. En español latino y subtitulada en linea, calidad hd y 4k.
Desde Cuevana podrás ver y descargar la película completa de Monkey Man en HD y Gratis con Audio y Subtitulado.
Disfruta viendo gratuita y con español latino subtitulado y muy buena calidad de imagen.
Recuerda que ver Monkey Man online en Cuevana es totalmente gratis.
Si tienes algún tipo de problema con la pelicula Monkey Man , puedes informarlo en nuestras redes sociales.
Monkey Man : Ficha técnica, estreno, todo sobre de la película completa y dónde ver por Internet
Ficha técnica de la película completa “Monkey Man ”
¿Dónde ver Monkey Man online?
A continuación te detallamos todo lo que debes saber para ver la mejore de la película ‘Monkey Man ’ cuando quieras, donde quieras y con quien quieras.
Incluso aprenderás a ver películas gratis online de forma absolutamente legal y segura, este sin necesidad de pagar mensualmente una suscripción a servicios premium de streaming la película Monkey Man como Netflix, HBO Max, Amazon Prime Video, Hulu, Fox Premium, Movistar Play, Disney+, Crackle o Blim, o de bajar apps de Google Play o App Store que no te ayudarán mucho a satisfacer esa sed cinéfila.
¿No te es suficiente? ¿Quieres más trucos? También te enseñaremos a usar los sitios premium por Monkey Man película completa, sin pagar absolutamente nada.
Incluso te contaremos qué películas están en la cartelera de los cines del Chile, Perú, México, España, Estados Unidos, Colombia, Argentina, Ecuador y demás países del mundo.
Monkey Man (2024) Online: ¿Cómo Ver la Película completa en Español Gratis?
Esto es cómo ver Monkey Man online, la película completa en español y subtítulos.
Conoce cómo y dónde ver Monkey Man por Internet, la película completa en español latino y castellano o subtitulado, ver películas online y gratis en alta calidad.
Existen dos grandes problemas a la hora de ver película Monkey Man gratis en internet: Los continuos parones en la reproducción de la película y la calidad en la que se reproduce.
Seguramnte en más de una ocasión has buscado en Google “¿cómo puedo ver Monkey Man la película completa en español?” o “¿dónde puedo ver Monkey Man la película completa?”.
No lo niegues. No eres el único. Todos los días, millones de personas intentan ver Película online desde sus computadoras, laptops, smartphones, tablets o cual sea el dispositivo móvil de su preferencia.
Sin embargo, la navegación muchas veces termina en páginas web que no cumplen lo prometido, que aseguran tener los últimos estrenos, pero que solo te derivan de un site a otro, que te obligan a dar clic tras clic mientras te llenan la pantalla de publicidad, para finalmente dirigirte hasta un enlace que no funciona o que demora mucho en cargar.
Esto hace que sea imposible disfrutar de verdad de una tarde/noche de películas. Además existe una ley no escrita y es que este tipo de cosas suelen ocurrir los mejores momentos de la película y acaba frustrando.
Que esto ocurra se debe a muchos factores como: la conexión a Internet, la página desde la que estés viendo la película gratis o la calidad de reproducción elegida.
Todos estos problemas se pueden solucionar, salvo la velocidad de tu internet, por ello en este aqui encontrarás solo páginas para ver películas en Internet gratis en castellano y sin cortes de gran calidad dónde estás problemas no existen o son muy poco comunes
Por supuesto esta página están libres de virus y el listado se actualiza conforme a las nuevas páginas que van apareciendo y aquellas que se van cerrando.
De las páginas más conocidas, cabe duda de que cumple su objetivo a la perfección ¡Ver película Monkey Man online sin registrase en español y otros idiomas!
Se trata de una página muy bien distribuida en la que puedes encontrar casi cualquier películas completas online, sin publicidad y en calidad Full HD y 4K.
Algunas de las cosas más interesantes de esta página son:
Las películas están ordenadas por género y por año lo que hace que sea muy fácil de usar.
Puedes ver la película Monkey Man en formatos de calidad como Full HD. y sin publicidad.
Posibilidad de ver la película Monkey Man online en español latino y castellano u otros idiomas. Esto depende de los idiomas disponibles y el gusto del espectador.
¿Cómo puedes ver las películas de Batman en YouTube?
Puedes suscribirte al servicio de paga de YouTube para acceder a contenido exclusivo que jamás has imaginado. Los tres primeros meses son gratis.
YouTube es una de las páginas de curaduría de clásicos más populares en la red. El sitio está dedicado por completo a la distribución de películas de libre acceso, liberadas de derechos de autor.
Por ejemplo, su catálogo de cine mudo es excepcional. ¿Lo mejor de todo? Puedes ver las películas 'Batman' desde YouTube, por lo que navegar es sencillísimo.
Páginas Para Ver la Película Completa de Monkey Man Online en Español y Latino de Forma Legal y Gratis
¿Páginas para ver película Monkey Man gratis? ¿Ver película Monkey Man online gratis en HD sin cortes? ¿Ver película Monkey Man online gratis en español?
¡VER AQUI!
Si eres de las personas a las que les encanta pasar los domingos de películas y manta, este artículo te interesa y mucho.
Aquí podrás encontrar un definitivo con las mejores páginas para ver películas online gratis en español y latino.
¡No pierdas más tiempo y conoce cómo ver cine online desde casa!
Es una página para ver la película “Monkey Man ” gratis, pero este tipo de páginas abren y cierran continuamente debido a los derechos de autor. Por este motivo, cada vez es más difícil ver películas gratis en Internet.
¡No te desesperes! con este aqui podrás encontrar las mejores páginas para ver película “Monkey Man ” online en castellano sin cortes y en buena calidad.
Si quieres ver películas gratis y series online en español y latino solo debes de páginas web como Cuevana, ponerte al día. Y no necesitas una cuenta en de Netflix, HBO Max, Amazon Prime, Disney+, y otros para ver películas.
Ver la película Monkey Man online gratis en español y latino | Gracias a Internet es posible ver pelis Monkey Man gratis online en español y también subtitulos latino sin necesidad de pagar una cuenta de premium como Netflix, HBO Max, Amazon Prime Video o Hulu.
Si eres de las personas que busca en Google términos como "páginas para ver pelis online", "estrenos español online", "películas online en español", "películas gratis online", "ver pelis online", entre otros keywords, seguramente has sido llevado a páginas web de dudosa procedencia o que te obligan a registrarte con alguna cuenta en redes sociales.
Si te hartaste de eso, a continuación podrás ver las mejores películas gratis online para disfrutar sin problemas, sin interrupciones y sin publicidad para convertir tu casa en un cine.
Esta páginas para ver Monkey Man online sin publicidad y sin cortes, así que presta atención y apunta, que la buena experiencia cinéfila -o seriéfila- está plenamente garantizada en estos websites.
Si no tienes los códigos de Netflix a la mano o tu conexión no te permite descargar películas gratis en Mega HD, conoce cómo ver películas de acción, terror, comedias, clásicos y hasta teen movies de la forma más fácil con solo unos clics. Hasta pelis de estreno puedes encontrar en español.
Páginas web para ver película Monkey Man gratis son de fácil acceso. eso sí, solo necesitas crear una cuenta para ver y descargar de películas, la mayoría de estas páginas web para ver películas gratis son de fácil acceso y no es necesario el registro. Eso sí, algunas incluyen publicidad antes de la reproducción del título elegido, aunque esta es casi imperceptible.
“Cuevana” es una plataforma donde puedes ver películas de manera gratuita sin publicidad y legal con un amplio catálogo de películas, donde el usuario puede filtrar los filmes por el género, es decir, Romance, Acción, Comedia, Drama, Horror, Aventura, Animación, Animes, Superhéroes. Cómic. DC Comics, Marvel, Disney, entre otros.
Todas las películas son de alta calidad, incluye una sólida colección de programas de televisión, Para acceder a ellas gratis solo necesitas crear una cuenta. Esta página es gratuita y libre de anuncios. Además, ofrece artículos sobre estrenos independientes y comerciales. | huyah | |
1,811,223 | Import aliases en tu aplicación de NodeJS | Cómo definir los import path aliases para tener unos imports más limpios. | 0 | 2024-04-04T15:26:57 | https://dev.to/gonzalo/import-aliases-en-tu-aplicacion-de-nodejs-2kko | node, typescript | ---
title: Import aliases en tu aplicación de NodeJS
published: true
description: Cómo definir los import path aliases para tener unos imports más limpios.
tags: nodejs,typescript
# cover_image: https://www.fanaticovirtual.com/_astro/Import-aliases-post.4889bbcc_f6HOu.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-04-04 15:04 +0000
---
Hay ocasiones en las que nuestra aplicación crece y los imports acaban siendo algo feos y liosos, como estos:
```js
import GenericRepository from '../../../shared/generics/generic.repository'
```
Esto puede llevar a confusiones si crece demasiado. Afortunadamente hay medidas que se pueden tomar para evitar que esto ocurra y que nos queden unos imports así de claros y bonitos:
```js
import GenericRepository from '@generics/generic.repository'
```
¡Mira que bien se ve! Ahora te explico cómo usar correctamente estos imports.
## Implementación
Asumiendo que estás utilizando TypeScript en tu aplicación, tendrás un archivo llamado tsconfig.json en el root de tu proyecto. Este archivo lucirá de una forma similar a esto:
```json
{
"compilerOptions": {
// tu configuración
}
}
```
Dentro de las compilerOptions vamos a definir nuestros path aliases. ¿Cómo? Pues lo primero que necesitamos es saber cuál es nuestra baseUrl. A mí personalmente me gusta meter toda la chicha en la carpeta src , por lo que mi baseUrl será así:
```json
{
"compilerOptions": {
"baseUrl": "./src"
}
}
```
Si no tienes o no utilizas la carpeta src de esa manera no te preocupes, puedes configurar la baseUrl a un punto sin más, o a cualquier otro valor que aplique a tu proyecto. Aquí un ejemplo que muestra cómo sería la baseUrl basándose en el root del proyecto:
```json
{
"compilerOptions": {
"baseUrl": "."
}
}
```
Una vez tenemos la baseUrl, ya podemos definir nuestros path aliases. ¡Olé!
### Path aliases
* root
* src
* api
* shared
* generics
* utils
Dentro de la carpeta src están las carpetas api y shared . Los import aliases que quiero configurar son para poder importar los archivos que estén dentro de la carpeta de generics y utils.
Venga, ya lo importante. Aquí te muestro cómo quedaría nuestro `tsconfig.json`:
```json
{
"compilerOptions": {
"baseUrl": "./src",
"paths": {
"@utils/*": ["shared/utils/*"],
"@generics/*": ["shared/generics/*"]
}
}
}
```
De esta forma podremos importar nuestros archivos de una forma mucho más limpia. Así nos quedarían los imports ahora:
```js
import GenericRepository from '@generics/generic.repository'
```
### Solución de problemas
¿Cómo? ¿En el editor parece que te va todo bien pero en la consola te salta el siguiente error?
```
Error: Cannot find module '@generics/generic.repository'
```
¡No te preocupes! Aún nos queda un paso extra. Principalmente si estás utilizando la librería ts-node .
El editor sabe que estás usando estos import aliases, pero para que funcione correctamente tenemos que ir poco más allá. Gracias a la librería [tsconfig-paths](https://www.npmjs.com/package/tsconfig-paths) podemos hacer que nuestros bonitos imports funcionen a la perfección.
Solo tendríamos que instalarla corriendo el siguiente comando:
```sh
npm install--save - dev tsconfig - paths
```
Y luego tendríamos que incluir esto en el script de ejecución de nuestra aplicación en el package.json:
```
-r tsconfig - paths / register
```
En mi caso, el script quedaría así:
```json
{
"scripts": {
"dev": "ts-node-dev -r tsconfig-paths/register --env-file=.env.development index.ts"
}
}
```
## Conclusión
Es bastante útil tener unos imports bien claros y lo más limpio posible. ¿Por qué? Pues porque ayuda a la lectura del código y evita tener ruido en nuestros archivos. Tanto tú como la gente que trabaje contigo lo agradeceréis.
Además, creo que la ganancia de hacerlo en relación al esfuerzo que supone hace que merezca mucho la pena.
¡Si tienes cualquier pregunta o comentario, no dudes en ponerlo por abajo!
¡Saludos!
| gonzalo |
1,811,277 | Building Accessible Websites: Best Practices and Techniques | One of the big advantages of the web is its universality. It allows people to access information... | 0 | 2024-04-04T16:47:30 | https://dev.to/eduardabp/building-accessible-websites-best-practices-and-techniques-49kb | webdev, a11y, fullstack, ux |
One of the big advantages of the web is its universality. It allows people to access information beyond their local barriers, and it can be a powerful tool to ensure equal access and usability for all users, especially those with disabilities. When building a website, it's essential to make accessibility a part of the development process, starting on day one. In this guide, we'll explore practical techniques and best practices for building accessible websites.
## **Semantic HTML**
Semantic HTML provides structure and meaning to web content, making it easier for assistive technologies to interpret and navigate. When possible, use the appropriate tags to structure the layout, such as `<header>`, `<nav>`, `<main>`, `<footer>`, and `<section>`, and proper `aria-label` and `aria-role` attributes when no semantic tag is available.
## **Color Contrast**
Ensure that text and interactive elements have sufficient color contrast to be easily readable for users with low vision or color blindness. Use tools like [WebAIM's Color Contrast Checker](https://webaim.org/resources/contrastchecker/) to evaluate color combinations and ensure compliance with accessibility standards. WCAG guidelines state that normal size text should have a contrast ratio of 4:5:1.
## **Keyboard Navigation**
Keyboard navigation is essential for users who cannot use a mouse or other pointing devices. Ensure that all interactive elements in your project are accessible via keyboard navigation. Avoid scrambling the order of your elements with CSS styles like `float` or `absolute` positioning, the keyboard navigation should follow the DOM order of your components. You can use the `tabindex` attribute to define the tab order of focusable elements and ensure that focus states are visually apparent, but be careful to not overuse it and avoid `tabindex` with positive numbers.
## **Images and Animations**
Images should include descriptive alternative text (`alt`) to provide context for users who cannot see them. Avoid using images with text and/or for critical content and functionalities whenever possible. A best practice is opting for SVG’s files, that will ensure that your images don’t lose quality when using screen magnifiers.
For animations, it is important to consider factors such as motion sensitivity and cognitive load. For that reason, opt for subtle animations that enhance the user experience without being distracting or overwhelming. Also ensure that, if the content blinks or flashes, it respects WCAG guidelines that states that webpages cannot “contain anything that flashes more than three times in any one second period”.
It is important to provide control options that allow users to pause, stop, hide or adjust the speed of animations. If your animations trigger events, make sure that it can be controlled and activated using keyboard navigation alone.
## **Accessibility Testing**
It is good practice to regularly test your project for accessibility. You can use automated tools, like [Axe](https://www.deque.com/axe/devtools/) and [Wave](https://wave.webaim.org/), and manual testing methods, like no-mouse challenge and assistive technologies such as screen readers and magnifiers, to ensure that your project is accessible to all users.
## **Conclusion**
Implementing accessibility in a project is essential for creating a more inclusive web experience. It should be treated as a priority and never left as a last step, not only for its importance but also because, as a developer myself, I can assure you that it is easier to implement it if made synchronously. As technology continues to evolve, it's essential for developers to prioritize accessibility and ensure that the web will become an inclusive space for all. | eduardabp |
1,811,497 | Analyse des sentiments avec les fonctions PubNub et HuggingFace | Ce blog explore ce qu'est l'analyse des sentiments et comment l'appliquer à des systèmes en temps réel en utilisant PubNub et HuggingFace. | 0 | 2024-04-04T19:09:01 | https://dev.to/pubnub-fr/analyse-des-sentiments-avec-les-fonctions-pubnub-et-huggingface-47fm | L'IA étant en constante progression en termes d'utilisation au sein de votre application ou de votre entreprise, il est essentiel de couvrir la manière dont elle peut être utilisée lors de la création de systèmes en temps réel. De nombreux cas d'utilisation entrent dans cette catégorie, qu'il s'agisse d'un [chat in-app](https://www.pubnub.com/solutions/chat/), [IoT](https://www.pubnub.com/solutions/iot-device-control/)ou [événements en direct](https://www.pubnub.com/solutions/live-audience-engagement/) Il y a presque toujours un moyen d'appliquer l'IA à votre solution pour la rendre encore meilleure.
Ce blog vous apprendra comment surveiller votre chat en direct pour les comportements "positifs" ou "négatifs" en utilisant l'analyse des sentiments. Cette application a plusieurs cas d'utilisation, comme la surveillance d'un chat d'assistance pour un client inapproprié ou, d'un autre côté, la surveillance d'un chat d'événements en direct pour voir si vos clients apprécient l'événement qu'ils sont en train de regarder. Quoi qu'il en soit, de nombreuses applications peuvent être considérées comme utilisant l'IA, en particulier lorsqu'il s'agit de créer des systèmes en temps réel.
C'est là que PubNub entre en jeu. [PubNub](https://www.pubnub.com/) fournit une plate-forme de communication en temps réel hautement disponible [de communication en temps réel hautement disponible](https://www.pubnub.com/products/pubnub-platform/). Vous pouvez l'utiliser pour construire des [chat](https://www.pubnub.com/solutions/chat/), [systèmes de contrôle des appareils IoT](https://www.pubnub.com/solutions/iot-device-control/), [applications de géolocalisation](https://www.pubnub.com/solutions/geolocation/)et bien d'autres systèmes de communication. Pour en savoir plus sur ce que PubNub est capable de faire, visitez nos [docs](https://www.pubnub.com/docs) ou [prix](https://www.pubnub.com/pricing/) pour commencer.
Que sont les intégrations PubNub ?
----------------------------------
Tout d'abord, pour ceux qui ne connaissent pas les [Fonctions PubNub](https://www.pubnub.com/docs/serverless/functions/overview)Les fonctions PubNub vous permettent de capturer les événements qui se produisent dans votre instance PubNub. Cela vous permet d'écrire du code pour exploiter les intégrations existantes ou transformer, réacheminer, augmenter, filtrer et même agréger vos données. Qu'est-ce que cela signifie exactement ? En gros, supposons que vous envoyiez un message, un signal, un fichier, etc. (données) à travers PubNub. Dans ce cas, vous pouvez écrire du code avant qu'il ne soit reçu par le client ou après pour bloquer les données envoyées, les modifier ou même les acheminer vers un autre système tiers.
[PubNub Integrations](https://www.pubnub.com/integrations/) est une extension de PubNub Functions qui vous permet de configurer rapidement une fonction PubNub et de l'intégrer à des services tiers tels que AWS, Giphy, Google Cloud, etc. Il s'agit essentiellement de code pré-écrit pour connecter votre système en temps réel à tout système tiers dans notre catalogue de fonctions. Ce catalogue se trouve sur le portail PubNub ou dans l'onglet "Home".
Référez-vous à l'image ci-dessous et cliquez sur "Discover & Integrate" pour parcourir les fonctions préfabriquées de PubNub.

Démarrer avec HuggingFace
-------------------------
À ce stade, tout le monde a probablement entendu parler d'OpenAI, de GPT-4, de Claude ou de n'importe lequel des grands modèles de langage (LLM) populaires. Cependant, l'utilisation de ces LLM dans un environnement de production peut être coûteuse ou non déterministe en ce qui concerne les résultats. Je suppose que c'est l'inconvénient d'être bon dans tous les domaines ; vous pourriez être meilleur dans l'exécution d'une tâche spécifique. C'est là que HuggingFace peut être utilisé.[HuggingFace](https://huggingface.co/) fournit des modèles d'IA et d'apprentissage automatique open-source qui peuvent être facilement déployés sur HuggingFace lui-même ou sur des systèmes tiers tels que [Amazon SageMaker](https://aws.amazon.com/sagemaker/) ou [Azure ML](https://azure.microsoft.com/)Vous pouvez vous interfacer avec ces déploiements par le biais d'une API et contrôler la mise à l'échelle de ces modèles, ce qui les rend parfaitement adaptés aux environnements de production. Ces modèles sont de taille variable, mais il s'agit généralement de petits modèles d'IA capables d'effectuer une tâche spécifique. Grâce à la possibilité d'affiner ces modèles ou d'utiliser un modèle pré-entraîné pour des tâches spécifiques, l'intégration de ces modèles dans diverses applications devient plus efficace, ce qui améliore l'automatisation et les performances. La combinaison de ces modèles permet de créer des applications d'IA nouvelles et complexes. Dans ce cas, en utilisant les modèles HuggingFace, vous n'auriez pas à dépendre d'une application de production d'un fournisseur tiers tel que [OpenAI](https://openai.com/) ou [Google](https://gemini.google.com/)Ce qui garantit une approche plus ciblée et personnalisable du déploiement de solutions d'apprentissage profond dans vos opérations.
Reportez-vous à la capture d'écran ci-dessous pour voir combien de modèles d'IA différents HuggingFace fournit.
Qu'est-ce que l'analyse des sentiments ?
----------------------------------------
[L'analyse des sentiments](https://en.wikipedia.org/wiki/Sentiment_analysis) (également appelée opinion mining ou emotion AI) est l'utilisation du traitement du langage naturel et de l'analyse de texte pour déterminer si l'émotion ou le ton du message est positif, négatif ou neutre. Aujourd'hui, les entreprises disposent d'énormes volumes de données textuelles, telles que des courriels, des messages d'assistance à la clientèle, des commentaires sur les médias sociaux, des critiques, etc. L'analyse des sentiments peut analyser ces textes pour déterminer l'attitude de l'auteur à l'égard d'un sujet. Les entreprises peuvent ensuite utiliser ces données pour améliorer le service à la clientèle ou la réputation de la marque.
### Cas d'utilisation de l'analyse des sentiments
**Modération**: Vous pouvez utiliser l'analyse des sentiments pour surveiller vos événements en direct, votre assistance ou votre chat In-App afin de voir si des clients se comportent mal et de bannir et supprimer rapidement leurs messages. Cela permettrait de créer un environnement sain sur votre plateforme.
**Analyse des données**: Les entreprises souhaitent parfois analyser des milliers d'e-mails ou de textes pour voir comment les clients réagissent à l'événement ou à la marque de l'entreprise. Elles peuvent utiliser ces données pour cibler ce qu'elles font de bien ou de mal en fonction de leurs actions et prendre de meilleures décisions sur ce qu'il convient de faire ensuite.
### Implémentation de l'analyse de sentiments dans une fonction PubNub
En utilisant l'intégration HuggingFace PubNub, nous allons implémenter l'analyse de sentiment directement dans les fonctions PubNub. Tout d'abord, rendez-vous sur le portail PubNub et ouvrez le catalogue de fonctions sur la page d'accueil. Une fois dans le catalogue de fonctions, cliquez sur "HuggingFace Serverless API".

Après avoir sélectionné l'intégration PubNub, suivez les étapes en choisissant le jeu de clés et l'application pour lesquels vous souhaitez configurer votre fonction PubNub. Après avoir atteint l'étape des variables, nous aurons besoin d'obtenir votre clé API de HuggingFace. Allez dans les paramètres de votre profil dans Huggingface et sélectionnez [Jetons d'accès](https://huggingface.co/settings/tokens)car nous aurons besoin de l'ajouter aux secrets de vos fonctions PubNub. Cliquez ensuite sur create, et nous intégrerons officiellement votre instance PubNub à HuggingFace. Vous devriez maintenant voir une fonction PubNub avec l'exemple de code suivant.
```js
//
// ** **
// ** Add your API Key to MY SECRETS (Left Panel) **
// ** **
// ** HUGGINGFACE_API_KEY **
// ** **
//
const FunctionConfig = {
"HUGGINGFACE_API_KEY": "HuggingFace"
};
//
// Import Modules
//
const http = require('xhr');
const vault = require('vault');
//
// Main
//
export default async (request) => {
let message = request.message.text;
console.log('Sentiment:');
let model = 'distilbert-base-uncased-finetuned-sst-2-english';
let response = await query(message, model);
console.log(response);
console.log('GPT2:');
model = 'gpt2';
response = await query(message, model);
console.log(response);
console.log('Google\'s Gemma:');
model = 'google/gemma-7b-it';
response = await query(`<start_of_turn>user\n${message}\n<start_of_turn>model`, model);
console.log(response);
console.log('Capture:');
model = 'dbmdz/bert-large-cased-finetuned-conll03-english';
response = await query(message, model);
console.log(response);
return request.ok()
};
//
// HuggingFace API Call
//
async function query(text, model='distilbert-base-uncased-finetuned-sst-2-english') {
const apikey = await vault.get(FunctionConfig.HUGGINGFACE_API_KEY);
const response = await http.fetch( `https://api-inference.huggingface.co/models/${model}`, {
headers: { Authorization: `Bearer ${apikey}`, 'Content-Type': 'application/json' },
method: "POST",
body: JSON.stringify({inputs:text}),
});
return await response.json();
}
```
Nous allons nous concentrer sur le premier modèle utilisé dans cette fonction PubNub, qui est "distilbert-base-uncased-finetuned-sst-2-english". Pour en savoir plus sur cette fonction, naviguez vers [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) ou le modèle sur lequel elle est basée, à savoir [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased). Vous pouvez également consulter le modèle sur [github](https://github.com/aws-neuron/aws-neuron-sdk/blob/master/src/benchmark/pytorch/distilbert-base-uncased-finetuned-sst-2-english_compile.py). Ce modèle fera tout le travail pour nous et déterminera l'analyse du sentiment d'un message PubNub lorsqu'il est envoyé à travers le réseau.
J'ai remanié ma fonction actuelle pour qu'elle ressemble à ceci :
```js
//
// ** **
// ** Add your API Key to MY SECRETS (Left Panel) **
// ** **
// ** HUGGINGFACE_API_KEY **
// ** **
//
const FunctionConfig = {
"HUGGINGFACE_API_KEY": "HuggingFace"
};
//
// Import Modules
//
const http = require('xhr');
const vault = require('vault');
//
// Main
//
export default async (request) => {
let message = request.message.text;
console.log('Sentiment:');
let model = 'distilbert-base-uncased-finetuned-sst-2-english';
let response = await query(message, model);
// Get the negative score
if(response[0][0].label == "NEGATIVE"){
request.message.score = response[0][0].score;
}
else{
request.message.score = response[0][1].score;
}
console.log(request.message.score);
return request.ok()
};
//
// HuggingFace API Call
//
async function query(text, model='distilbert-base-uncased-finetuned-sst-2-english') {
const apikey = await vault.get(FunctionConfig.HUGGINGFACE_API_KEY);
const response = await http.fetch( `https://api-inference.huggingface.co/models/${model}`, {
headers: { Authorization: `Bearer ${apikey}`, 'Content-Type': 'application/json' },
method: "POST",
body: JSON.stringify({inputs:text}),
});
return await response.json();
}
```
Ce code appelle maintenant le modèle Sentiment Analysis HuggingFace et l'attache à la charge utile du message en cours de `notation`. Lors des tests, si je télécharge un message tel que :
```js
{
"text": "That was not cool"
}
```
Nous obtiendrons un score négatif de `0.9997703433036804,` ce qui est un score négatif élevé, et ce message peut être signalé. Il est important de noter que le résultat de ce modèle est compris entre 0 `et 1`, 0 étant un score très faible et 1 le score le plus élevé. En revanche, si nous envoyons un message du type : "Nous obtiendrons un score négatif de 0,", ce message peut être signalé :
```js
{
"text": "Thats so Cool!"
}
```
Nous recevrons un score négatif de `0.00014850986190140247,` ce qui est un score négatif très bas, ce qui signifie que le message a une tonalité positive.
Démarrer avec PubNub
--------------------
En quelques étapes seulement, nous avons implémenté l'analyse des sentiments dans le réseau PubNub en utilisant les intégrations PubNub. Si vous souhaitez en savoir plus sur les possibilités offertes par l'IA et PubNub, consultez nos autres blogs, tels que :
[Construire un Chatbot avec PubNub et ChatGPT / OpenAI](https://www.pubnub.com/blog/build-a-chatbot-with-pubnub-and-chatgpt-openai/): Nous vous guiderons dans la mise en place de votre propre Chatbot en utilisant une intégration OpenAI et PubNub.
[Construire un Chatbot LLM avec une base de connaissance personnalisée](https://www.pubnub.com/blog/build-chatbot-with-custom-knowledge-base/): Ici, nous allons voir comment construire votre propre Chatbot LLM avec une base de connaissance personnalisée en utilisant les fonctions PubNub. Cela signifie que vous pouvez répondre à des questions sur les données de votre propre entreprise.
[Un guide pour les développeurs de Prompt Engineering et LLMs](https://www.pubnub.com/blog/developers-guide-to-prompt-engineering/): Suivez un guide sur l'ingénierie des messages et sur la manière d'obtenir les réponses que vous souhaitez à partir de ces grands modèles de langage.
[Tutoriel de géolocalisation intégré à ChatGPT](https://www.pubnub.com/tutorials/geolocation-tracker/): Dans ce tutoriel, vous découvrirez comment construire une application de suivi de géolocalisation qui permet aux utilisateurs de partager des emplacements et d'envoyer des messages en temps réel, ainsi que d'intégrer ChatGPT pour fournir des informations sur votre emplacement.
Comment PubNub peut-il vous aider ?
===================================
Cet article a été publié à l'origine sur [PubNub.com](https://www.pubnub.com/blog/sentiment-analysis-with-pubnub-functions-and-huggingface/)
Notre plateforme aide les développeurs à construire, fournir et gérer l'interactivité en temps réel pour les applications web, les applications mobiles et les appareils IoT.
La base de notre plateforme est le réseau de messagerie en temps réel le plus grand et le plus évolutif de l'industrie. Avec plus de 15 points de présence dans le monde, 800 millions d'utilisateurs actifs mensuels et une fiabilité de 99,999 %, vous n'aurez jamais à vous soucier des pannes, des limites de concurrence ou des problèmes de latence causés par les pics de trafic.
Découvrez PubNub
----------------
Découvrez le [Live Tour](https://www.pubnub.com/tour/introduction/) pour comprendre les concepts essentiels de chaque application alimentée par PubNub en moins de 5 minutes.
S'installer
-----------
Créez un [compte PubNub](https://admin.pubnub.com/signup/) pour un accès immédiat et gratuit aux clés PubNub.
Commencer
---------
La [documentation PubNub](https://www.pubnub.com/docs) vous permettra de démarrer, quel que soit votre cas d'utilisation ou votre [SDK](https://www.pubnub.com/docs). | pubnubdevrel | |
1,811,608 | Deploy Upgradeable Smart Contracts with Foundry and OpenZeppelin | Today, I am gonna teach you how to deploy an upgradeable ERC20 token to Polygon Mumbai with Foundry... | 0 | 2024-04-04T22:44:52 | https://dev.to/tomtomdu73/deploy-upgradeable-smart-contracts-with-foundry-and-openzeppelin-2hn1 | solidity, foundry, blockchain, openzeppelin | Today, I am gonna teach you how to deploy an upgradeable ERC20 token to Polygon Mumbai with Foundry and OpenZeppelin 🚀
I will assume you already have your Foundry environment set up and have already written an upgradeable smart contract for your ERC20 token, that we will call _MyUpgradeableToken.sol_. If you need help with this, you can [read my full article](https://www.proof2work.com/blog/deploy-upgradeable-contract-with-foundry-and-openzeppelin) about deploying an upgradeable ERC20 token with Foundry.
First, set up your environment to using OpenZeppelin's upgradeable contracts and Foundry extensions.
```
forge install OpenZeppelin/openzeppelin-foundry-upgrades
forge install OpenZeppelin/openzeppelin-contracts-upgradeable
```
Then modify the **foundry.toml** file:
```
[profile.default]
ffi = true
ast = true
build_info = true
extra_output = ["storageLayout"]
[rpc_endpoints]
mumbai = "https://rpc.ankr.com/polygon_mumbai"
```
Now, you can create a new file called _01_Deploy.s.sol_ in the script directory. Don't forget to add your own **PRIVATE_KEY** variable in the _.env_ file.
```
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.25;
import "forge-std/Script.sol";
import "../src/MyUpgradeableToken.sol";
import {Upgrades} from "openzeppelin-foundry-upgrades/Upgrades.sol";
contract DeployScript is Script {
function run() external returns (address, address) {
//we need to declare the sender's private key here to sign the deploy transaction
uint256 deployerPrivateKey = vm.envUint("PRIVATE_KEY");
vm.startBroadcast(deployerPrivateKey);
// Deploy the upgradeable contract
address _proxyAddress = Upgrades.deployTransparentProxy(
"MyUpgradeableToken.sol",
msg.sender,
abi.encodeCall(MyUpgradeableToken.initialize, (msg.sender))
);
// Get the implementation address
address implementationAddress = Upgrades.getImplementationAddress(
_proxyAddress
);
vm.stopBroadcast();
return (implementationAddress, _proxyAddress);
}
}
```
Finally, you can deploy your smart contract to Polygon Mumbai!
```
forge script script/01_Deploy.s.sol:DeployScript --sender ${YOUR_PUBLIC_KEY} --rpc-url mumbai --broadcast -vvvv
```
Happy deployment and stay tuned for more tutorials to build and navigate in web3 ! 🏄♂️
| tomtomdu73 |
1,811,879 | Exploring Chakra UI With React | by Glory Ibeh Chakra UI elevates UI development with component-based design and can be used to... | 0 | 2024-04-05T08:17:58 | https://blog.openreplay.com/exploring-chakra-ui-with-react/ | by [Glory Ibeh](https://blog.openreplay.com/authors/glory-ibeh)
<blockquote><em>
Chakra UI elevates UI development with component-based design and can be used to great advantage in React, as this article shows.
</em></blockquote>
<div style="background-color:#efefef; border-radius:8px; padding:10px; display:block;">
<hr/>
<h3><em>Session Replay for Developers</em></h3>
<p><em>Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data.</em></p>
<img alt="OpenReplay" style="margin-top:5px; margin-bottom:5px;" width="768" height="400" src="https://raw.githubusercontent.com/openreplay/openreplay/main/static/openreplay-git-hero.svg" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<p><em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em><p>
<hr/>
</div>
[User Interface (UI)](https://careerfoundry.com/en/blog/ui-design/what-is-a-user-interface/) development is a crucial aspect of building modern web applications. It involves creating the visual elements that users interact with, ensuring a seamless and engaging experience. UI development encompasses designing and implementing components, layouts, and interactions that collectively form the user interface.
[Chakra UI](https://chakra-ui.com/) is an open-source [React](https://react.dev/) component library that facilitates the creation of highly customizable and responsive user interfaces. It offers a collection of accessible, styled components that seamlessly integrate into React applications, adhering to design system principles to promote consistency and efficiency.
[Component-based design](https://bluemodus.com/articles/component-based-design-and-why-your-website-needs-it) has emerged as a sea change in UI development, advocating for the decomposition of the user interface into modular, reusable components. Each component encapsulates specific functionality or visual elements, fostering maintainability, scalability, and code reusability. This systematic approach enables developers to manage complex UIs efficiently. Here are some key features and advantages of component-based-design:
* Reusability: Components can be reused across different application parts, promoting a consistent and cohesive design.
* Maintainability: Changes or updates can be made to individual components without affecting the entire application, simplifying maintenance.
* Scalability: As the application grows, component-based design facilitates adding new features and functionalities with minimal impact on existing code.
* Collaboration: Developers can work on different components concurrently, fostering collaboration and speeding up the development process.
## Integrating Chakra UI with React
Integrating with a React project involves a few straightforward steps:
* Create a new React app using Create React App or other preferred method.
```
npx create-react-app chakra-react-website
cd chakra-react-website
```
* Install Chakra UI and Emotion (which is used by Chakra UI) by running:
```
npm install @chakra-ui/react @emotion/react @emotion/styled framer-motion
```
* Modify index.js to include ChakraProvider:
```jsx
// src/index.js
import React from 'react';
import ReactDOM from 'react-dom';
import { ChakraProvider } from '@chakra-ui/react';
import App from './App';
ReactDOM.render(
<ChakraProvider>
<App />
</ChakraProvider>,
document.getElementById('root')
);
```
### Exploring basic components
Now, let's create and explore some basic components provided by Chakra.
* Header Component (`Header.js`):
```jsx
// src/Header.js
import React from 'react';
import { Box, Heading } from '@chakra-ui/react';
const Header = () => {
return (
<Box bg="purple.500" p={6} color="white" mb={2}>
<Heading as="h1" size="2xl">
My Awesome Website
</Heading>
</Box>
);
};
export default Header;
```
This component defines the `header` section of the website, rendering a styled [Box](https://chakra-ui.com/docs/components/box) component with a purple background and a [Heading](https://chakra-ui.com/docs/components/heading) component displaying the website title.
* Main Component (`Main.js`):
```jsx
// src/Main.js
import React from 'react';
import { Box, Container, Text } from '@chakra-ui/react';
const Main = () => {
return (
<Container maxW="container.lg" mt={2}>
<Box p={6} borderWidth="1px" borderRadius="lg" mb={2}>
<Text fontSize="xl">
Welcome to my website! This is the main section.
</Text>
</Box>
</Container>
);
};
export default Main;
```
This component represents the main content section of the website. Here, components like [Container](https://chakra-ui.com/docs/components/container) are used to constrain the width of the content, set to a large container width with some top margin. `Box` is another UI layout component that creates a structured content area, including padding, border width, and border radius for styling the main section. [Text](https://chakra-ui.com/docs/components/text), A component for displaying text with a specified font size. [Button](https://chakra-ui.com/docs/components/button), represents a button with Chakra UI's styling applied, featuring a margin top and colored using the "green" color scheme.
* Footer Component (`Footer.js`):
```jsx
// src/Footer.js
import React from 'react';
import { Box, Text } from '@chakra-ui/react';
const Footer = () => {
return (
<Box bg="purple.500" p={6} color="white" mt={2}>
<Text textAlign="center" fontSize="lg">© 2024 My Awesome Website. All rights reserved.</Text>
</Box>
);
};
export default Footer;
```
This component defines the `footer` section of the website. It renders a `Box` component; inside the Box, there's a `Text` component displaying copyright information with a blue background.
* App Component (`App.js`):
```jsx
// src/App.js
import React from 'react';
import { ChakraProvider, Flex, Box } from '@chakra-ui/react';
import Header from './Header';
import Main from './Main';
import Footer from './Footer';
function App() {
return (
<ChakraProvider>
<Flex direction="column" minHeight="100vh">
<Header />
<Main />
<Footer />
</Flex>
</ChakraProvider>
);
}
export default App;
```
Finally, this is the application's root component. It wraps the Header, Main, and Footer components within a [Flex](https://chakra-ui.com/docs/components/flex) component, creating a flexible container with a column layout and occupying the full viewport height.
Finally, we should have an output like this :
<CTA_Middle_Frameworks />
## How Chakra UI Facilitates Component-Based Design
It streamlines UI development through:
* Abstraction of Styles:
Abstracting away the intricacies of styling by providing predefined, customizable components. This allows developers to focus on building functionalities rather than spending excessive time on styling details.
* Theme Configuration:
Offering a theme-based approach, it enables developers to customize the look and feel of components globally, ensuring a consistent design language throughout the application.
* Responsive Design:
Providing responsive components out of the box for seamless adaptation to various devices.
* Accessibility:
Prioritizing accessibility by incorporating best practices into its components. This ensures that the application is usable by a diverse audience, including individuals with disabilities.
## Building a Simple UI Component with Chakra UI and React
Let's Add a Button Component to `Main.js`:
```jsx
// src/Main.js
import { Box, Container, Text, Button } from '@chakra-ui/react';
const Main = () => {
return (
<Container maxW="container.lg" mt={2}>
<Box p={6} borderWidth="1px" borderRadius="lg" mb={2}>
<Text fontSize="xl">
Button component using Chakra UI and React.
</Text>
<Button mt={4} colorScheme="green">Learn More</Button>
</Box>
</Container>
);
};
export default Main;
```
This code demonstrates the use of a [Button](https://chakra-ui.com/docs/components/button) component styled with Chakra. Overall, this Main component renders a structured content area with a message and a button.
## Showcasing Reusability and Scalability
To demonstrate [reusability](https://www.marketpath.com/blog/art-of-code-reuse-re-usable-components-for-rapid-website-development#:~:text=In%20the%20world%20of%20website,the%20use%20of%20reusable%20components.) and [scalability](https://www.ramotion.com/blog/scalable-web-applications/#:~:text=Scalability%20is%20a%20web%20application's,and%20degrading%20in%20app%20performance.), let's create a new component called `FeatureSection` that incorporates the same structure and styling as the existing Main component but with different content. This will showcase how components can be reused and scaled within our application.
```jsx
import React from 'react';
import { Box, Container, Text, Button, Flex, Heading, Stack, useMediaQuery } from '@chakra-ui/react';
import { motion } from "framer-motion";
const FeatureSection = ({ title, description, buttonText }) => {
const [isLargerThan768] = useMediaQuery("(min-width: 768px)");
return (
<Container maxW="container.lg" mt={8}>
<motion.div
initial={{ opacity: 0 }}
animate={{ opacity: 1 }}
transition={{ duration: 0.5 }}
>
<Box p={4} borderWidth="1px" borderRadius="lg">
<Flex justifyContent="center" alignItems="center">
<Heading as="h2" size="xl" textAlign="center">
{title}
</Heading>
</Flex>
<Text fontSize="lg" textAlign="center" mt={4}>
{description}
</Text>
<Stack spacing={4} direction={isLargerThan768 ? "row" : "column"} justifyContent="center" mt={8}>
<motion.div whileHover={{ scale: 1.05 }}>
<Button colorScheme="blue" w={isLargerThan768 ? "200px" : "100%"} borderRadius="md">
{buttonText}
</Button>
</motion.div>
<motion.div whileHover={{ scale: 1.05 }}>
<Button colorScheme="green" w={isLargerThan768 ? "200px" : "100%"} borderRadius="md">
Learn More
</Button>
</motion.div>
</Stack>
</Box>
</motion.div>
</Container>
);
};
export default FeatureSection;
```
In this `FeatureSection` component, we've made the content dynamic by accepting `props` such as title, description, and buttonText. This allows us to reuse this component with different content throughout our application.
In the App component, multiple instances of FeatureSection are added to demonstrate scalability.
```jsx
// src/App.js
import React from 'react';
import { ChakraProvider } from '@chakra-ui/react';
import Header from './Header';
import FeatureSection from './FeatureSection';
import Footer from './Footer';
function App() {
return (
<ChakraProvider>
<Header />
<FeatureSection
title="Feature 1"
description="Lorem ipsum dolor sit amet, consectetur adipiscing elit. Fusce convallis tortor vel nisi condimentum, id malesuada nisi semper."
buttonText="see More"
/>
<FeatureSection
title="Feature 2"
description="Nullam sed libero sit amet magna gravida tincidunt. Integer nec eros eu sapien scelerisque commodo."
buttonText="Explore"
/>
<FeatureSection
title="Feature 3"
description="Pellentesque vel lectus id libero consectetur pharetra. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae."
buttonText="Discover"
/>
<Footer />
</ChakraProvider>
);
}
export default App;
```
This code has a `Container` component with a max width used to contain the feature section, the [motion.div](https://chakra-ui.com/getting-started/with-framer) component from [framer-motion](https://www.framer.com/motion/) used to provide animation effects inside the motion.div, a `Box` component is used to create a container with padding, border, and border radius. A `Heading` component that renders the title with specified size and alignment, wrapped inside a `Flex` component for centering horizontally. A `Text` component that displays the description text with specified font size and alignment. A [Stack](https://chakra-ui.com/docs/components/stack) component is used to stack the buttons in a row or column based on the screen size. Within the Stack, two `motion.div` components wrap the `Button` components. These components use the `whileHover` prop from framer-motion to scale the buttons on hover.
By reusing the `FeatureSection` component with different content and adding multiple instances within our App component, we demonstrate how components can be scaled up to accommodate various features or sections within our application.
## Impact on UI Development
Component-based development with Chakra UI accelerates the development process by providing a library of ready-to-use components. This approach fosters a faster development workflow and enhances code consistency. By consistently using components, developers ensure code uniformity, making it easier for them to collaborate and understand each other's code.
## Conclusion
Exploring Chakra UI and React together demonstrates the power of component-based design in elevating UI development. Chakra UI provides a comprehensive set of ready-to-use components that streamline the development process and promote consistency in design. By embracing component-based design principles, developers can create maintainable, scalable, and accessible user interfaces.
| asayerio_techblog | |
1,811,919 | Deploying and Managing InfluxDB Resources with Terraform | Introduction: Terraform is a powerful infrastructure as code tool that automates cloud... | 0 | 2024-04-05T16:21:30 | https://dev.to/thulasirajkomminar/deploying-and-managing-influxdb-resources-with-terraform-p21 | provider, terraform, iot, iiot | ---
title: Deploying and Managing InfluxDB Resources with Terraform
published: true
date: 2024-02-15 17:45:23 UTC
tags: provider,terraform,iot,iiot
canonical_url:
---
### Introduction:
- Terraform is a powerful infrastructure as code tool that automates cloud infrastructure provisioning and management through simple configuration files. If you’re interested in learning more, I’ve written a short [blog](https://thulasirajkomminar.com/what-is-hashicorp-terraform-42d419a61cb9) outlining some key components of Terraform.
- InfluxDB is a specialized time-series database tailored for efficiently handling large volumes of time-stamped data. In this blog, we’ll explore how to leverage Terraform for provisioning and managing resources within InfluxDB.

### Prerequisites:
> To install Terraform, you can easily follow the steps outlined in this blog post: [Install Terraform](https://developer.hashicorp.com/terraform/install).
> Before diving in, ensure you have a basic understanding of InfluxDB and its components. For installation guidance, refer to this resource: [Install InfluxDB](https://docs.influxdata.com/influxdb/v2/install/).
### Provider Configuration:
To create and manage InfluxDB resources using Terraform, it utilizes specialized plugins known as providers to interface with InfluxDB. I’ve developed and published a provider for InfluxDB on the [Terraform registry](https://registry.terraform.io/providers/komminarlabs/influxdb/latest), enabling seamless resource creation and management.
Let’s begin by configuring the provider.
- Create a file named `versions.tf` and insert the following code to declare the InfluxDB provider. This allows Terraform to install and utilize the provider. Provider dependencies are specified within a `required_providers` block.
```hcl
terraform {
required_providers {
influxdb = {
source = "komminarlabs/influxdb"
version = "1.0.0"
}
}
}
```
- Create another file named `main.tf` to initialize the InfluxDB provider. We’ll use a provider block to configure it. You can specify the provider configuration using arguments such as url and token, or alternatively, utilize environment variables like `INFLUXDB_TOKEN` and `INFLUXDB_URL`.
```hcl
export INFLUXDB_TOKEN="influxdb-token"
export INFLUXDB_URL="http://localhost:8086"
provider "influxdb" {
token = "influxdb-token"
url = "http://localhost:8086"
}
```
### Creating and Managing InfluxDB Resources:
The [komminarlabs/influxdb](https://registry.terraform.io/providers/komminarlabs/influxdb/latest/docs) provider offers various data sources and resources.
#### Data Sources:
- `influxdb_authorization`
- `influxdb_authorizations`
- `influxdb_bucket`
- `influxdb_buckets`
- `influxdb_organization`
- `influxdb_organizations`
#### Resources:
- `influxdb_authorization`
- `influxdb_bucket`
- `influxdb_organization`
We’ll begin by creating resources and then utilize data sources to query the created resources. Let’s create two files: `resources.tf` and `datasources.tf`.
#### Resources
Resources are the most important element in the Terraform language. Each resource block describes one or more infrastructure objects.
- **Organization:**
An InfluxDB organization is a workspace for a group of users. All dashboards, tasks, buckets, members, etc., belong to an organization. Add the following code to create our organisation.
```hcl
resource "influxdb_organization" "iot" {
name = "IoT"
description = "An IoT organization"
}
```
After running a Terraform plan and verifying everything looks good, let’s proceed with applying the changes.

_Terraform execution plan and apply results_
_Switch to the new organization in InfluxDB_
- **Bucket:**
An InfluxDB bucket is a named location where time series data is stored. All buckets have a retention period, a duration of time that each data point persists. InfluxDB drops all points with timestamps older than the bucket’s retention period. A bucket belongs to an organization.
Let’s proceed by creating a bucket named signals with a retention period of 14 days (1209600 seconds).
```hcl
resource "influxdb_bucket" "signals" {
org_id = influxdb_organization.iot.id
name = "signals"
description = "This is a bucket to store signals"
retention_period = 1209600
}
```
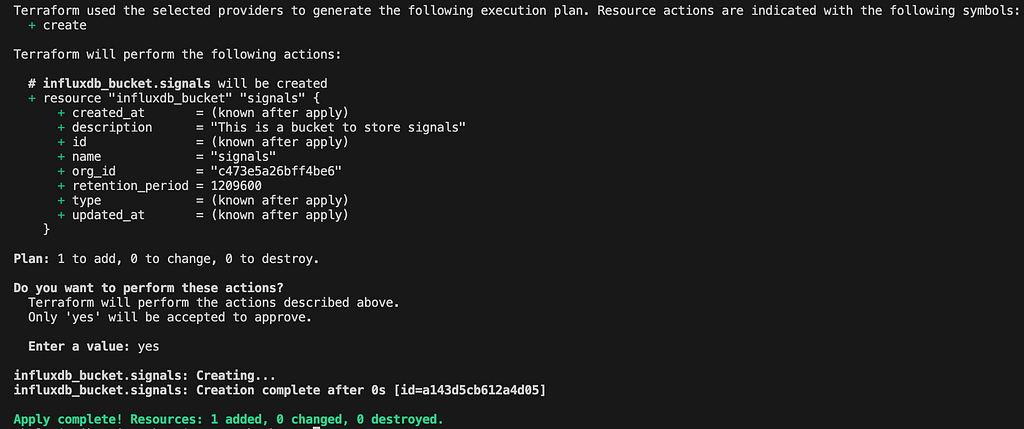
_Terraform execution plan and apply results_

- **Authorization:**
Authorizations are InfluxDB Read/Write API tokens that grants read access, write access, or both to specific buckets in an organization.
In the following step, we will generate an authorization that enables both read and write access to the bucket established in the prior phase.
```hcl
resource "influxdb_authorization" "signals_rw" {
org_id = influxdb_organization.iot.id
description = "Read & Write access signals bucket"
permissions = [{
action = "read"
resource = {
id = influxdb_bucket.signals.id
org_id = influxdb_organization.iot.id
type = "buckets"
}
},
{
action = "write"
resource = {
id = influxdb_bucket.signals.id
org_id = influxdb_organization.iot.id
type = "buckets"
}
}]
}
```

_Terraform execution plan and apply results_
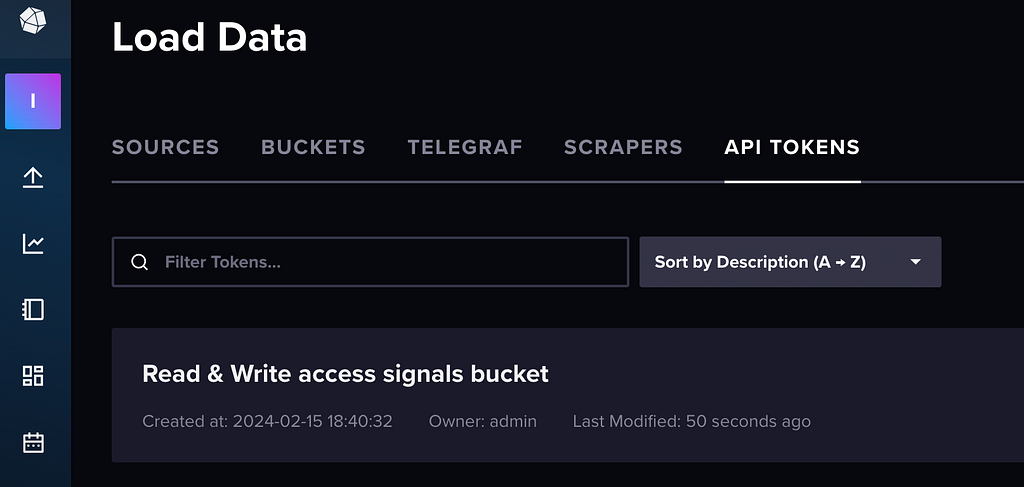
_API token shown in InfluxDB_
#### Data Sources
With all the necessary resources created in InfluxDB to manage our time series data, we can now utilize datasources to list all the resources we’ve created.
A data source is accessed via a special kind of resource known as a data resource, declared using a data block.
```hcl
data "influxdb_organization" "iot" {
name = "IoT"
}
output "iot_organization" {
value = data.influxdb_organization.iot
}
data "influxdb_bucket" "signals" {
name = "signals"
}
output "signals_bucket" {
value = data.influxdb_bucket.signals
}
```
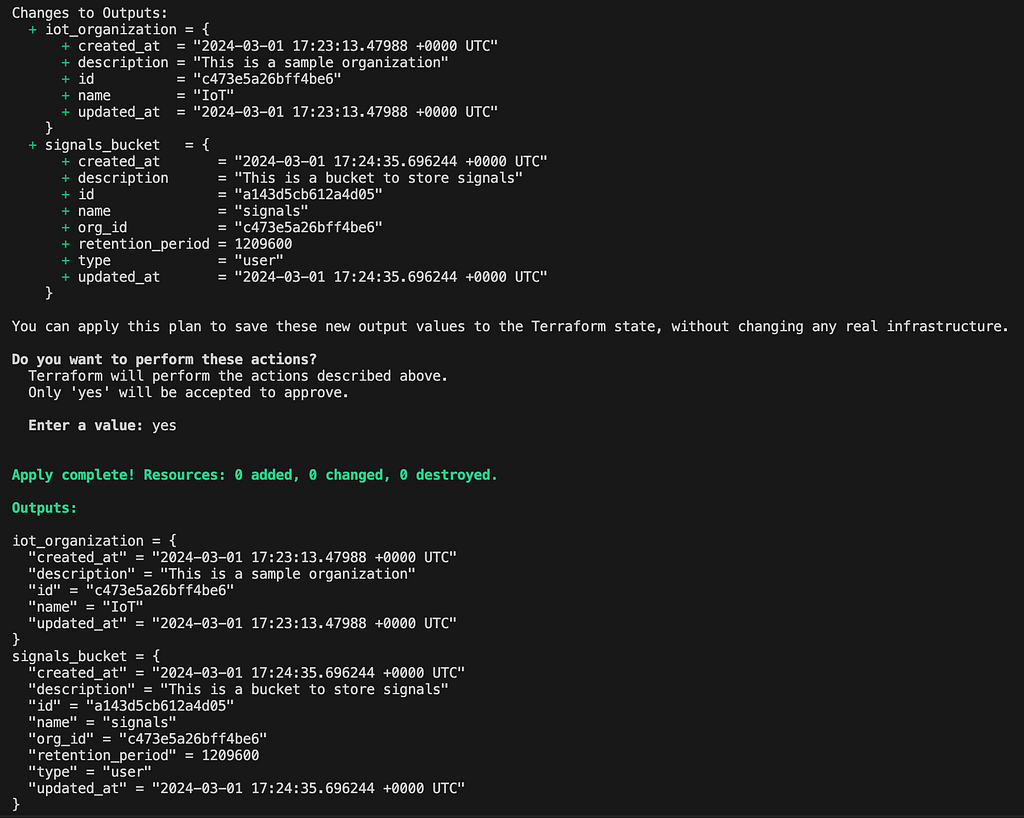
_Terraform execution plan and apply results_
### Additional Resources:
- [What is HashiCorp Terraform?. Introduction | by Thulasiraj Komminar | Medium](https://thulasirajkomminar.com/what-is-hashicorp-terraform-42d419a61cb9)
- [Install | Terraform | HashiCorp Developer](https://developer.hashicorp.com/terraform/install)
- [Install InfluxDB | InfluxDB OSS v2 Documentation (influxdata.com)](https://docs.influxdata.com/influxdb/v2/install/)
- [komminarlabs/influxdb | Terraform Registry](https://registry.terraform.io/providers/komminarlabs/influxdb/latest)
- [Overview — Configuration Language | Terraform | HashiCorp Developer](https://developer.hashicorp.com/terraform/language)
- [terraform-provider-influxdb/examples at main · komminarlabs/terraform-provider-influxdb (github.com)](https://github.com/komminarlabs/terraform-provider-influxdb/tree/main/examples)
### Conclusion:
Now that we’ve explored how to leverage Terraform for creating and managing InfluxDB resources, it’s time to start utilizing it. If you encounter any bugs or issues while using the provider, be sure to [report](https://github.com/komminarlabs/terraform-provider-influxdb/issues) them promptly. | thulasirajkomminar |
1,812,048 | Unlocking the Power of Internal Talent Mobility: A Game-Changer for Organizational Growth | (Image by katemangostar on Freepik) In today's rapidly evolving business landscape, organizations... | 0 | 2024-04-05T10:27:47 | https://dev.to/e_thomson/unlocking-the-power-of-internal-talent-mobility-a-game-changer-for-organizational-growth-24bc | (Image by katemangostar on Freepik)
In today's rapidly evolving business landscape, organizations are facing an unprecedented challenge: attracting and retaining top talent. As the war for talent intensifies, companies are realizing the immense potential of their existing workforce. Internal talent mobility has emerged as a strategic imperative, offering a powerful solution to address skill gaps, boost employee engagement, and drive organizational success.
**Internal Mobility: The Untapped Goldmine of Talent**
------------------------------------------------------
Internal mobility refers to the movement of employees within an organization, enabling them to explore new roles, acquire new skills, and advance their careers.
By leveraging internal talent, organizations can tap into their existing talent pool, reducing the need for external recruitment and fostering a culture of continuous learning and career growth.
* Promoting internal mobility allows employees to gain cross-functional experiences, broaden their skill sets, and develop a deeper understanding of the organization's operations.
* It fosters a sense of ownership and loyalty among employees, leading to increased job satisfaction and morale.
* Internal talent mobility empowers organizations to retain top talent, reducing attrition rates and ensuring that valuable knowledge and expertise remain within the company.
**Cultivating a Culture of Continuous Learning and Career Growth**
------------------------------------------------------------------
Fostering a culture of continuous learning is crucial for organizations to thrive in today's dynamic business environment.
By encouraging internal mobility and career development opportunities, employees are given the chance to progress, explore different roles, and acquire new skill sets, leading to increased job satisfaction and morale.
* Continuous learning not only enhances employees' skill sets but also promotes a growth mindset, fostering a workforce that is adaptable and resilient to change.
* Organizations that prioritize internal mobility create a talent pipeline that aligns with their long-term goals, ensuring the availability of skilled personnel to fill critical roles.
* Investing in employee development and career growth demonstrates the organization's commitment to its workforce, leading to increased engagement and loyalty.
**The Ripple Effect: Benefits of Internal Talent Mobility**
-----------------------------------------------------------
The benefits of internal mobility are far-reaching and impactful. It promotes employee engagement, reduces attrition rates, and fosters a deeper understanding of cross-functional processes within the organization.
Additionally, it allows organizations to retain top talent, leverage existing expertise, and cultivate a workforce that is agile and adaptable.
* Improved Employee Engagement and Retention
* Cost Savings in Recruitment and Training
* Knowledge Retention and Institutional Memory
* Increased Workforce Agility and Adaptability
* Talent Development and Succession Planning
**Leveraging Talent Marketplaces: A Game-Changer for Internal Mobility**
------------------------------------------------------------------------
Talent marketplaces have emerged as a game-changer for internal mobility. These digital platforms enable employees to explore internal job opportunities, showcase their skills, and connect with hiring managers. By promoting internal mobility through [talent marketplaces](https://hbr.org/2023/05/how-to-design-an-internal-talent-marketplace), organizations can efficiently match talent with new roles, reducing time-to-hire and ensuring the right talent is in the right positions.
* Transparency in Internal Job Opportunities
* Seamless Matching of Talent to Roles
* Efficient Talent Redeployment and Workforce Planning
* Data-Driven Talent Insights and Analytics
In the context of talent marketplaces, incorporating [**HR software India**](https://factohr.com/hr-software/india/) can enhance the efficiency of internal talent mobility processes, facilitating smoother transitions and better utilization of existing talent pools.
**Bridging the Gap: Aligning Internal Talent with Business Needs**
------------------------------------------------------------------
Bridging the gap between internal talent and business needs is a critical challenge for organizations. By embracing internal mobility strategies, companies can align their existing talent pool with evolving skill requirements, ensuring they have the necessary expertise to drive innovation and stay ahead of the competition.
* Identifying Skill Gaps and Talent Shortages
* Upskilling and Reskilling Existing Employees
* Fostering Cross-Functional Collaboration and Knowledge Sharing
* Adapting to Changing Market Conditions and Customer Demands
**Empowering Employees: Encouraging Internal Talent Mobility**
--------------------------------------------------------------
Encouraging internal talent mobility is not just a strategic imperative but also a cultural shift. Organizations must empower employees by providing clear career paths, development plans, and opportunities to apply for new roles within the company. This fosters a sense of ownership, loyalty, and a commitment to personal and professional growth.
* Transparent Communication of Career Opportunities
* Personalized Development Plans and Mentoring
* Promoting a Mindset of Continuous Learning and Growth
* Celebrating Internal Mobility Success Stories
**The Strategic Advantage: Internal Mobility and Workforce Agility**
--------------------------------------------------------------------
Internal mobility plays a pivotal role in workforce agility, enabling organizations to swiftly adapt to changing market conditions and business needs. By promoting lateral mobility and cross-functional experiences, companies can build a versatile and flexible workforce capable of navigating complex challenges and seizing new opportunities.
* Rapid Redeployment of Talent to Critical Areas
* Fostering a Mindset of Adaptability and Resilience
* Leveraging Diverse Skill Sets and Perspectives
* Accelerating Innovation and Organizational Transformation
**Embracing the Future: Prioritizing Internal Talent Mobility Initiatives**
---------------------------------------------------------------------------
As the talent landscape continues to evolve, prioritizing internal talent mobility initiatives has gained significant attention. HR leaders and talent teams must embrace internal mobility as a core component of their talent strategy, fostering a culture that values career progression, internal movements, and the development of potential talent from within the existing talent pool.
* Strategic Alignment of Talent Mobility with Business Objectives
* Investing in Technology and Talent Mobility Platforms
* Measuring and Tracking Internal Mobility Success Metrics
* Building a Sustainable Talent Pipeline for Future Growth
To better understand the impact of internal mobility, consider the following data:
**Metric**
**Internal Mobility**
**External Hiring**
Cost per Hire
$2,000 - $5,000
$10,000 - $30,000
Time to Productivity
3-6 months
6-12 months
Retention Rate (after 2 years)
75%
50%
Cultural Fit
High
Moderate
The table highlights the significant cost savings, faster time to productivity, higher retention rates, and better cultural fit associated with internal mobility compared to external hiring. These data points underscore the strategic importance of prioritizing internal talent mobility initiatives.
**Conclusion:**
---------------
Internal talent mobility is a powerful catalyst for organizational growth, enabling companies to unlock the full potential of their workforce. By prioritizing internal mobility initiatives, fostering a culture of continuous learning, and leveraging talent marketplaces, organizations can bridge skill gaps, retain top talent, and cultivate a workforce that is agile, adaptable, and aligned with business needs.
Embracing internal talent mobility is no longer an option but a necessity for organizations to thrive in today's competitive landscape and prepare for the challenges of tomorrow. | e_thomson | |
1,812,057 | How to Implement Biometric Authentication with Jetpack Compose and AES Encryption | Exciting News! Our blog has a new Home! 🚀 Background With the increasing reliance on... | 0 | 2024-04-05T10:37:19 | https://canopas.com/how-to-implement-biometric-authentication-with-jetpack-compose-and-aes-encryption-1b72cfccf4d4 | security, android, beginners, tutorial | >**Exciting News! Our blog has a new [Home! ](https://canopas.com/blog)🚀**
## Background
With the increasing reliance on smartphones for various activities, securing access to sensitive information has become paramount. Traditional methods like passwords or PINs are often cumbersome and prone to security breaches.
Biometric authentication addresses these concerns by leveraging unique biological traits such as fingerprints, facial features, or iris patterns for identity verification.
Android devices have built-in support for biometric authentication, making it accessible for developers to integrate into their applications seamlessly.
## What we’ll implement in this blog?

The full source code is available on [GitHub.](https://github.com/cp-megh-l/BiometricAuthenticationCompose)
## Introduction
Biometric authentication has become a cornerstone of security in modern mobile applications, offering users a convenient and secure way to access sensitive information.
In this blog post, we will explore how to implement biometric authentication using Jetpack Compose, the modern UI toolkit for Android, coupled with AES encryption for added security.
## Why Cryptographic Solution is Necessary
While biometric authentication offers enhanced security, it’s crucial to augment it with cryptographic solutions like AES encryption for robust protection of sensitive data.
Here’s why cryptographic solutions are essential when working with biometric authentication:
1. Data Protection
2. Key Management
3. Compliance Requirements
4. Defense against Attacks
## Types of authenticators that your app can support
1. **BIOMETRIC_STRONG:** Authentication using a Class 3 biometric, as defined on the [Android compatibility definition](https://source.android.com/docs/compatibility/14/android-14-cdd#7_3_10_biometric_sensors) page.
2. **BIOMETRIC_WEAK:** Authentication using a Class 2 biometric, as defined on the [Android compatibility definition](https://source.android.com/compatibility/android-cdd#7_3_10_biometric_sensors) page.
3. **DEVICE_CREDENTIAL:** Authentication using a screen lock credential – the user's PIN, pattern, or password.
## Types of Authentication Supported
When implementing biometric authentication in an app, it’s essential to support various biometric modalities to cater to different devices and user preferences.
Android provides support for the following biometric authentication types:
1. **Fingerprint Authentication:** Utilizes the unique patterns of a user’s fingerprints for authentication.
2. **Face Authentication:** Verifies the user’s identity by analyzing facial features captured by the device’s camera.
3. **Iris Authentication:** Scans the unique patterns in the user’s iris for authentication.
By supporting multiple authentication types, developers can ensure compatibility with a wide range of devices and accommodate users with various preferences and accessibility needs.
In this blog post, we will focus on implementing fingerprint authentication using Jetpack Compose and AES encryption.
We will walk through the process of integrating biometric authentication into an Android application and securing sensitive data using AES encryption.
So let’s begin with the implementation…
> The source code is available on **[GitHub.](https://github.com/cp-megh-l/BiometricAuthenticationCompose)**
## Implementing Biometric Authentication
**1. Add Biometric Authentication Dependencies**
To get started with biometric authentication in your Android application, you need to add the following dependencies to your app-level build.gradle file:
```
dependencies {
implementation "androidx.biometric:biometric:1.2.0"
}
```
These dependencies provide the necessary APIs to interact with the biometric hardware on Android devices and authenticate users using their biometric data.
**2. Create CryptoManager for AES Encryption**
CryptoManager will manage the encryption and decryption of sensitive data using AES encryption. The CryptoManager class will handle key generation, encryption, and decryption operations.
```
// Interface defining cryptographic operations
interface CryptoManager {
// Initialize encryption cipher
fun initEncryptionCipher(keyName: String): Cipher
// Initialize decryption cipher
fun initDecryptionCipher(keyName: String, initializationVector: ByteArray): Cipher
// Encrypt plaintext
fun encrypt(plaintext: String, cipher: Cipher): EncryptedData
// Decrypt ciphertext
fun decrypt(ciphertext: ByteArray, cipher: Cipher): String
// Save encrypted data to SharedPreferences
fun saveToPrefs(
encryptedData: EncryptedData,
context: Context,
filename: String,
mode: Int,
prefKey: String
)
// Retrieve encrypted data from SharedPreferences
fun getFromPrefs(
context: Context,
filename: String,
mode: Int,
prefKey: String
): EncryptedData?
}
// Factory function to create CryptoManager instance
fun CryptoManager(): CryptoManager = CryptoManagerImpl()
// Implementation of CryptoManager interface
class CryptoManagerImpl : CryptoManager {
// Encryption transformation algorithm
private val ENCRYPTION_TRANSFORMATION = "AES/GCM/NoPadding"
// Android KeyStore provider
private val ANDROID_KEYSTORE = "AndroidKeyStore"
// Key alias for the secret key
private val KEY_ALIAS = "MyKeyAlias"
// KeyStore instance
private val keyStore: KeyStore = KeyStore.getInstance(ANDROID_KEYSTORE)
init {
// Load the KeyStore
keyStore.load(null)
// If key alias doesn't exist, create a new secret key
if (!keyStore.containsAlias(KEY_ALIAS)) {
createSecretKey()
}
}
// Initialize encryption cipher
override fun initEncryptionCipher(keyName: String): Cipher {
val cipher = Cipher.getInstance(ENCRYPTION_TRANSFORMATION)
cipher.init(Cipher.ENCRYPT_MODE, getSecretKey())
return cipher
}
// Initialize decryption cipher
override fun initDecryptionCipher(keyName: String, initializationVector: ByteArray): Cipher {
val cipher = Cipher.getInstance(ENCRYPTION_TRANSFORMATION)
val spec = GCMParameterSpec(128, initializationVector)
cipher.init(Cipher.DECRYPT_MODE, getSecretKey(), spec)
return cipher
}
// Encrypt plaintext
override fun encrypt(plaintext: String, cipher: Cipher): EncryptedData {
val encryptedBytes = cipher.doFinal(plaintext.toByteArray(Charset.forName("UTF-8")))
return EncryptedData(encryptedBytes, cipher.iv)
}
// Decrypt ciphertext
override fun decrypt(ciphertext: ByteArray, cipher: Cipher): String {
val decryptedBytes = cipher.doFinal(ciphertext)
return String(decryptedBytes, Charset.forName("UTF-8"))
}
// Save encrypted data to SharedPreferences
override fun saveToPrefs(
encryptedData: EncryptedData,
context: Context,
filename: String,
mode: Int,
prefKey: String
) {
val json = Gson().toJson(encryptedData)
with(context.getSharedPreferences(filename, mode).edit()) {
putString(prefKey, json)
apply()
}
}
// Retrieve encrypted data from SharedPreferences
override fun getFromPrefs(
context: Context,
filename: String,
mode: Int,
prefKey: String
): EncryptedData? {
val json = context.getSharedPreferences(filename, mode).getString(prefKey, null)
return Gson().fromJson(json, EncryptedData::class.java)
}
// Create a new secret key
private fun createSecretKey() {
val keyGenParams = KeyGenParameterSpec.Builder(
KEY_ALIAS,
KeyProperties.PURPOSE_ENCRYPT or KeyProperties.PURPOSE_DECRYPT
).apply {
setBlockModes(KeyProperties.BLOCK_MODE_GCM)
WesetEncryptionPaddings(KeyProperties.ENCRYPTION_PADDING_NONE)
setUserAuthenticationRequired(true)
}.build()
val keyGenerator =
KeyGenerator.getInstance(KeyProperties.KEY_ALGORITHM_AES, ANDROID_KEYSTORE)
keyGenerator.init(keyGenParams)
keyGenerator.generateKey()
}
// Retrieve the secret key from KeyStore
private fun getSecretKey(): SecretKey {
return keyStore.getKey(KEY_ALIAS, null) as SecretKey
}
}
// Data class to hold encrypted data
data class EncryptedData(val ciphertext: ByteArray, val initializationVector: ByteArray) {
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as EncryptedData
if (!ciphertext.contentEquals(other.ciphertext)) return false
return initializationVector.contentEquals(other.initializationVector)
}
override fun hashCode(): Int {
var result = ciphertext.contentHashCode()
result = 31 * result + initializationVector.contentHashCode()
return result
}
}
```
**3. Create BiometricHelper that will handle biometric authentication operations**
BiometricHelper is a versatile utility object designed to simplify the integration of biometric authentication features into Android applications. This helper class encapsulates complex biometric API interactions, providing developers with a clean and intuitive interface to perform common biometric authentication tasks.
```
object BiometricHelper {
...
}
```
> Now, in BiometricHelper , we will add below functions with specific functionalities:
**- Biometric Availability Check:**
The first step in implementing biometric authentication is to check whether the device supports biometric authentication.
BiometricHelper offers a convenient method, isBiometricAvailable(), which performs this check and returns a boolean value indicating the availability of biometric authentication on the device.
```
// Check if biometric authentication is available on the device
fun isBiometricAvailable(context: Context): Boolean {
val biometricManager = BiometricManager.from(context)
return when (biometricManager.canAuthenticate(BiometricManager.Authenticators.BIOMETRIC_STRONG or BiometricManager.Authenticators.BIOMETRIC_WEAK)) {
BiometricManager.BIOMETRIC_SUCCESS -> true
else -> {
Log.e("TAG", "Biometric authentication not available")
false
}
}
}
```
**- BiometricPrompt Integration:**
BiometricHelper seamlessly integrates with the BiometricPrompt API, which serves as the primary interface for biometric authentication on Android devices.
It provides a method, getBiometricPrompt(), to create a BiometricPrompt instance with a predefined callback, simplifying the setup process and handling of authentication events.
```
// Retrieve a BiometricPrompt instance with a predefined callback
private fun getBiometricPrompt(
context: FragmentActivity,
onAuthSucceed: (BiometricPrompt.AuthenticationResult) -> Unit
): BiometricPrompt {
val biometricPrompt =
BiometricPrompt(
context,
ContextCompat.getMainExecutor(context),
object : BiometricPrompt.AuthenticationCallback() {
// Handle successful authentication
override fun onAuthenticationSucceeded(
result: BiometricPrompt.AuthenticationResult
) {
Log.e("TAG", "Authentication Succeeded: ${result.cryptoObject}")
// Execute custom action on successful authentication
onAuthSucceed(result)
}
// Handle authentication errors
override fun onAuthenticationError(errorCode: Int, errString: CharSequence) {
Log.e("TAG", "onAuthenticationError")
}
// Handle authentication failures
override fun onAuthenticationFailed() {
Log.e("TAG", "onAuthenticationFailed")
}
}
)
return biometricPrompt
}
```
**- Customizable Prompt Info:**
BiometricHelper facilitates the creation of BiometricPrompt.PromptInfo objects with customizable display text, allowing developers to tailor the authentication prompt to match the look and feel of their app.
The getPromptInfo() method generates a PromptInfo object with a customized title, subtitle, description, and negative button text.
```
// Create BiometricPrompt.PromptInfo with customized display text
private fun getPromptInfo(context: FragmentActivity): BiometricPrompt.PromptInfo {
return BiometricPrompt.PromptInfo.Builder()
.setTitle(context.getString(R.string.biometric_prompt_title_text))
.setSubtitle(context.getString(R.string.biometric_prompt_subtitle_text))
.setDescription(context.getString(R.string.biometric_prompt_description_text))
.setConfirmationRequired(false)
.setNegativeButtonText(
context.getString(R.string.biometric_prompt_use_password_instead_text)
)
.build()
}
```
**- User Biometrics Registration:**
Registering user biometrics involves encrypting sensitive data, such as authentication tokens, using cryptographic techniques.
BiometricHelper offers a registerUserBiometrics() method, which encrypts a randomly generated token and stores it securely using the CryptoManager, an accompanying cryptographic utility class.
```
// Register user biometrics by encrypting a randomly generated token
fun registerUserBiometrics(
context: FragmentActivity,
onSuccess: (authResult: BiometricPrompt.AuthenticationResult) -> Unit = {}
) {
val cryptoManager = CryptoManager()
val cipher = cryptoManager.initEncryptionCipher(SECRET_KEY)
val biometricPrompt =
getBiometricPrompt(context) { authResult ->
authResult.cryptoObject?.cipher?.let { cipher ->
// Dummy token for now(in production app, generate a unique and genuine token
// for each user registration or consider using token received from authentication server)
val token = UUID.randomUUID().toString()
val encryptedToken = cryptoManager.encrypt(token, cipher)
cryptoManager.saveToPrefs(
encryptedToken,
context,
ENCRYPTED_FILE_NAME,
Context.MODE_PRIVATE,
PREF_BIOMETRIC
)
// Execute custom action on successful registration
onSuccess(authResult)
}
}
biometricPrompt.authenticate(getPromptInfo(context), BiometricPrompt.CryptoObject(cipher))
}
```
**- User Authentication:**
authenticateUser() function handles the authentication process using biometrics. It decrypts the stored token using the CryptoManager and initiates the biometric authentication flow.
Upon successful authentication, the decrypted token is retrieved, enabling the app to grant access to the user.
```
// Authenticate user using biometrics by decrypting stored token
fun authenticateUser(context: FragmentActivity, onSuccess: (plainText: String) -> Unit) {
val cryptoManager = CryptoManager()
val encryptedData =
cryptoManager.getFromPrefs(
context,
ENCRYPTED_FILE_NAME,
Context.MODE_PRIVATE,
PREF_BIOMETRIC
)
encryptedData?.let { data ->
val cipher = cryptoManager.initDecryptionCipher(SECRET_KEY, data.initializationVector)
val biometricPrompt =
getBiometricPrompt(context) { authResult ->
authResult.cryptoObject?.cipher?.let { cipher ->
val plainText = cryptoManager.decrypt(data.ciphertext, cipher)
// Execute custom action on successful authentication
onSuccess(plainText)
}
}
val promptInfo = getPromptInfo(context)
biometricPrompt.authenticate(promptInfo, BiometricPrompt.CryptoObject(cipher))
}
}
```
So, our `BiometricHelper` is ready and we now just have to call these functions at the required places to manage user authentication.
> This post only has implementation until `BiometricHelper`, to read the complete guide including proper function usages, please visit our **[full blog](https://canopas.com/how-to-implement-biometric-authentication-with-jetpack-compose-and-aes-encryption-1b72cfccf4d4)**.
> The post is originally published on [**canopas.com.**](https://canopas.com/how-to-implement-biometric-authentication-with-jetpack-compose-and-aes-encryption-1b72cfccf4d4)
I encourage you to share your thoughts in the comments section below. Your input not only enriches our content but also fuels our motivation to create more valuable and informative articles for you.
Follow **[Canopas](https://blog.canopas.com/)** to get updates on interesting articles!
| cp_nandani |
1,812,194 | Announcing Version 2.0 of nestjs-DbValidator | We are excited to unveil version 2.0 of nestjs-DbValidator, a feature-packed module providing custom... | 0 | 2024-04-05T13:52:36 | https://blog.yaffalab.com/announcing-version-2-of-nestjs-dbvalidator | nestjs, node, typeorm, opensource | ---
title: Announcing Version 2.0 of nestjs-DbValidator
published: true
date: 2024-02-09 20:45:22 UTC
tags: nestjs,nodejs,typeorm,opensource
canonical_url: https://blog.yaffalab.com/announcing-version-2-of-nestjs-dbvalidator
---
We are excited to unveil version 2.0 of [nestjs-DbValidator](https://github.com/AyubTouba/nestjs-dbvalidator), a feature-packed module providing custom database validators using class-validator and typeorm for Nest.js applications. This latest release comes with an array of enhancements, new features, and bug fixes, making it even more versatile and compatible with the latest Nest.js versions.
# What's New in Version 2.0
1. **Custom Type Support** In version 2.0, we introduce the ability to customize the type of the column for validation. Now you can specify the type using the customType parameter, allowing for more flexibility in handling different data types.
```
@isExistDb({ table: 'user', column: 'firstName', customType: TYPECOLUMN.STRING })idcities: any;
```
**2. Nest.js 9 and Above Compatibility** We are excited to announce that nestjs-DbValidator has been upgraded to support Nest.js version 9 and above. This ensures seamless integration with the latest features and improvements introduced in the Nest.js framework. Thanks to [@DevDeNiro](https://github.com/DevDeNiro) for their significant contribution in the upgrade.
To upgrade to version 2.0, simply update your package using the following command:
# **Getting Started with Version 2.0**
```
npm update @youba/nestjs-dbvalidator# oryarn upgrade @youba/nestjs-dbvalidator
```
After updating, be sure to check the documentation for any additional configuration changes and new features introduced in this release.
# A Brief Review of nestjs-DbValidator
### Overview
nestjs-DbValidator is a Nest.js module that simplifies database validation in your applications. It leverages the power of class-validator and typeorm to offer a seamless and intuitive way to validate data against your database.
### Key Features
`isExistDb` **:** Checks if a value already exists in the specified table and column. `isUniqueDb` **:** Verifies if a value is unique within the specified table and column. `isLowerDb` **:** Validates if a value is lower, useful for scenarios such as checking client credits.
`isBiggerDb` **:** Validates if a value is bigger, suitable for cases like checking stock levels.
### Easy Integration
The library is easy to integrate into your Nest.js application. By adding a few lines of code, you can enhance the validation capabilities of your DTOs and entities.
Version 2.0 Improvements Version 2.0 builds upon the success of the previous release by introducing custom-type support and ensuring compatibility with Nest.js 9 and above.
### Conclusion
Feel free to provide feedback, report issues, or contribute to the project on GitHub.
Happy coding! | youba |
1,812,208 | ESP32/Arduino Sensor Data Visualization on Web Apps: A Beginner's Guide with Directus: Part 1 | Ever wanted to build a project that bridges the physical world with the web, but coding a web... | 0 | 2024-04-10T14:04:14 | https://blog.yaffalab.com/esp32arduino-sensor-data-visualization-on-web-apps-a-beginners-guide-with-directus-part-1 | yaffalab, node, directus, esp32 | ---
title: ESP32/Arduino Sensor Data Visualization on Web Apps: A Beginner's Guide with Directus: Part 1
published: true
date: 2024-03-16 15:40:29 UTC
tags: yaffalab,nodejs,directus,esp32
canonical_url: https://blog.yaffalab.com/esp32arduino-sensor-data-visualization-on-web-apps-a-beginners-guide-with-directus-part-1
---
**Ever wanted to build a project that bridges the physical world with the web, but coding a web application seems daunting? This guide is for you! We'll embark on a journey to create a system that collects sensor data and displays it on a user-friendly web interface without writing any code for the web app itself.**
Our secret weapon? [**Directus**](https://directus.io/), a powerful open-source platform that acts as a bridge between your data and web applications. Directus takes care of storing and managing sensor readings, eliminating the need for complex back-end coding. It even automatically generates APIs for your data, making it accessible to your project with ease.
This project is perfect for beginners interested in working with real-world sensors and visualizing data on the web. Let's dive in!
To get started:
- We'll use an **ESP32** microcontroller to grab data from a sensor.
- The sensor, in this case, will be a **DHT11** , measuring both temperature and humidity.
- **Nodejs** ( We'll talk about it later)
**What you'll need:**
- **ESP32 development board**
- **DHT11 sensor**
- **Breadboard and jumper wires**
Let's embark on this journey!
## **1. Building the Circuit**
First, we need to build the circuit that connects your ESP32 to the DHT11 sensor. Here's what you'll do:
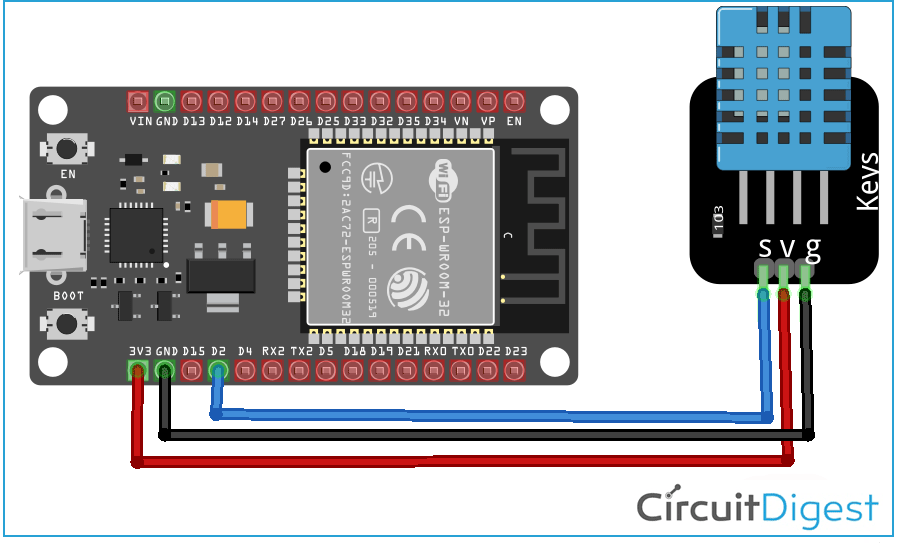
### **1.2 Coding part**
Now that you have your ESP32 circuit built, it's time to write the code that will interact with the sensor and verify its functionality. This code will be uploaded to your ESP32 board.
**Here's a breakdown of the code and its explanation:**
**1. Libraries and Pin Definition:**
```
#include "DHT.h"#define TYPE DHT11 int sensePin = 2;
```
- `#include "DHT.h"`: This line includes the DHT library, which provides functions for communicating with DHT sensors like the DHT11.
- `#define TYPE DHT11`: This line defines the type of sensor you're using. In this case, we're specifying DHT11.
- `int sensePin = 2;`: This line declares a variable named `sensePin` and assigns it the value `2`. This variable stores the pin number on your ESP32 that is connected to the data pin of the DHT11 sensor. You might need to adjust this value depending on your specific circuit wiring.
**2. Object Creation and Setup:**
```
DHT HT(sensePin, TYPE); void setup() { Serial.begin(9600); HT.begin(); }
```
- `DHT HT(sensePin, TYPE);`: This line creates an object named `HT` of type `DHT`. It provides methods to interact with the sensor connected to the `sensePin`. We're passing the previously defined `sensePin` variable and the sensor type (`DHT11`) to the constructor.
- `void setup()`: This function runs once when the ESP32 starts up. Inside the setup function:
**3. Reading Sensor Data and Printing to Serial Monitor:**
```
void loop() { humidity = HT.readHumidity(); tempC = HT.readTemperature(); Serial.print("Humidity: "); Serial.println(humidity); Serial.print("Temperature C: "); Serial.println(tempC); delay(setTime); }
```
- `void loop()`: This function runs repeatedly after the `setup()` function finishes. This is where the actual sensor data reading and processing happen.
You find the code here: [esp32-directus](https://github.com/AyubTouba/esp32-directus)
## **2.Setting Up the Web Environment (Directus)**
Now that you've verified your ESP32 circuit and sensor functionality, let's prepare the web environment to receive and visualize that data! Here, we'll leverage the power of **Directus**.
**What is Directus?**
Directus is an open-source data platform that acts as a bridge between your databases and web applications. It offers a user-friendly interface to:
- **Store and Manage Data:** Directus eliminates the need for complex back-end coding. It allows you to create data models (like tables) and manage sensor readings efficiently.
- **Build APIs in Minutes:** Directus automatically generates RESTful APIs for your data, making it accessible to your ESP32 code or any web application for seamless data exchange. moreover, it provides a socket connection (that we will use in our project to send the data)
- **Beautiful User Interface:** Directus provides a clean and intuitive web interface for users to view, edit, and even filter sensor data. Imagine viewing real-time temperature and humidity readings from your web browser!
In essence, Directus acts as the central hub for your sensor data, streamlining the process of storing, managing, and ultimately visualizing it on a web application.
Here's a breakdown of how we'll use Directus:
- **Installation:** We'll install Directus using Node.js, a popular tool for building web applications. Don't worry if you haven't used Node.js before - we'll walk you through the simple installation process.
- **Project Creation:** We'll create a new Directus project specifically for your sensor data. Think of it as a dedicated space within Directus to manage data from your ESP32.
- **Collection:** We'll define a data table within your Directus project. This table will have columns to store the sensor readings (humidity and temperature) received from your ESP32.
### **2.1 Setting Up the Environment (Node.js)**
To install Directus, we need Node.js on our computer. It's a free and easy download. Here's how to get it:
1. Head over to the official Node.js website: [https://nodejs.org/en](https://nodejs.org/en).
2. Download the installer suitable for your operating system (Windows, Mac, or Linux).
3. Run the downloaded installer and follow the on-screen instructions.
Once Node.js is installed, you can verify it by opening a command prompt ( **Command Prompt** on Windows, **Terminal** on Mac/Linux) and typing:
```
node -v
```
This should display the installed Node.js version. Now you're ready to use Node.js for setting up Directus!
**2.2 Install Directus: Your Data Management Hub**
Now that you have Node.js set up, it's time to install Directus! Think of Directus as a central hub where all your sensor data will be stored and organized. Here's how to install it with ease:
**1. Open your Command Prompt (Windows) or Terminal (Mac/Linux):**
You'll use the command prompt to interact with Node.js and install Directus.
**2. Navigate to your project folder (optional):**
If you're working within a specific folder for this project, use the `cd` command to navigate to that directory. For example, if your project folder is named "web\_project", you'd type:
```
cd web_project
```
**3. Run the installation command:**
Here's the magic spell (command) to install Directus:
```
npm init directus-project@latest <project-name>
```
**Replace** `<project-name>` with your desired name for this project. For instance, you could name it "sensor\_app". So, the complete command would look like:
```
npm init directus-project@latest sensor_app
```
**Hit Enter!** This command will download and install all the necessary files for Directus within your project folder.
**4. Follow the interactive setup:**
Once you run the installation command, Directus will ask you a few questions to configure your project. Here's what to expect:
- **Choose your database client:** Select "SQLite" as it doesn't require separate installation.
- **Database File Path:** Press Enter to accept the default path within your project folder.
- **Create your first admin user:** Enter a valid email address
- **Enter your password:** Create a password for your Directus admin account.
**That's it!** Directus is now installed and ready to be configured. We'll explore setting up your Directus project and creating a data table for your sensor readings in the next steps.
**IP Configuration:**
we need to configure Directus to receive data from your ESP32. Here's how:
- **Find your IP address:** Open a command prompt and type `ipconfig` (Windows) or `ifconfig` (Linux). Locate the "IPv4 Address" section and copy the IP address displayed.
- **Modify the** `.env` file: In your project folder, locate a file named ".env". Open it with a text editor.
- **Change the HOST:** Find the line that reads `HOST="0.0.0.0"` and replace it with `HOST="<YOUR_IP>"`. Replace "<YOUR\_IP>" with the actual IP address you copied in the previous step.
- **Add new parameter:**
- **Save the changes.**
**Start the Directus application:**
Navigate back to your project folder in the command prompt and run the following command:
```
npx directus start
```
This will start the Directus application. You can now access the Directus interface in your web browser by visiting `http://<YOUR_IP>:8055`.
## **3. Setting Up Data Collection and Users**
Now that Directus is installed and running, let's configure it to manage your sensor data:
### **3.1 Create a Collection (Table)**
1. **Create Collection:** Click on "Create Collection" in the Directus interface.
2. **Name the Collection:** In the pop-up window, enter a name for your collection. Let's call it "dht\_sensor". This will be the table where your sensor readings (humidity and temperature) will be stored.
3. **Define Fields:** Click "Next" and select **created\_at** and let other optional fields untouched for now.
4. **Add Fields for Sensor Data:** Click "Add Field". Choose "Input" for the field & Float as the type.
**Tip:** You can refer to the provided video for a visual reference on these steps.
[https://www.youtube.com/watch?v=eykeYjh33fs](https://www.youtube.com/watch?v=eykeYjh33fs)
### **3.2 Create a User**
While you can use your existing login to create the collection, creating a dedicated user for your ESP32 offers some benefits:
- **Security:** It keeps data originating from the ESP32 separate from your admin account.
- **Access Control:** You can restrict this user's access to specific functionalities in the future (advanced topic).
**To create a user:**
1. **Navigate to Users:** Click on the "Users" icon (second button on the menu bar).
2. **Create a User:** Click the "Create Item" button (top right corner).
3. **Fill User Details:** Enter a name, email address, and a strong password for this user.
4. **Assign Role:** Scroll down and select the "Administrator" role.
5. **Generate an API Token:** Click on "Generate Token" and save the generated token securely. You'll need this token in your ESP32 code to send data to Directus.
**Congratulations!** You've successfully set up Directus to store your sensor data. In the next article, we'll explore how to send data from your ESP32 to this Directus application and visualize the readings in charts! | youba |
1,812,526 | Post On your Website | <blockquote class="instagram-media" data-instgrm-captioned... | 0 | 2024-04-05T17:24:13 | https://dev.to/muhammadad93421/post-on-your-website-1b58 | ```
<blockquote class="instagram-media" data-instgrm-captioned data-instgrm-permalink="https://www.instagram.com/p/C5Y0_ZoyJvw/?utm_source=ig_embed&utm_campaign=loading" data-instgrm-version="14" style=" background:#FFF; border:0; border-radius:3px; box-shadow:0 0 1px 0 rgba(0,0,0,0.5),0 1px 10px 0 rgba(0,0,0,0.15); margin: 1px; max-width:540px; min-width:326px; padding:0; width:99.375%; width:-webkit-calc(100% - 2px); width:calc(100% - 2px);"><div style="padding:16px;"> <a href="https://www.instagram.com/p/C5Y0_ZoyJvw/?utm_source=ig_embed&utm_campaign=loading" style=" background:#FFFFFF; line-height:0; padding:0 0; text-align:center; text-decoration:none; width:100%;" target="_blank"> <div style=" display: flex; flex-direction: row; align-items: center;"> <div style="background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 40px; margin-right: 14px; width: 40px;"></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 100px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 60px;"></div></div></div><div style="padding: 19% 0;"></div> <div style="display:block; height:50px; margin:0 auto 12px; width:50px;"><svg width="50px" height="50px" viewBox="0 0 60 60" version="1.1" xmlns="https://www.w3.org/2000/svg" xmlns:xlink="https://www.w3.org/1999/xlink"><g stroke="none" stroke-width="1" fill="none" fill-rule="evenodd"><g transform="translate(-511.000000, -20.000000)" fill="#000000"><g><path d="M556.869,30.41 C554.814,30.41 553.148,32.076 553.148,34.131 C553.148,36.186 554.814,37.852 556.869,37.852 C558.924,37.852 560.59,36.186 560.59,34.131 C560.59,32.076 558.924,30.41 556.869,30.41 M541,60.657 C535.114,60.657 530.342,55.887 530.342,50 C530.342,44.114 535.114,39.342 541,39.342 C546.887,39.342 551.658,44.114 551.658,50 C551.658,55.887 546.887,60.657 541,60.657 M541,33.886 C532.1,33.886 524.886,41.1 524.886,50 C524.886,58.899 532.1,66.113 541,66.113 C549.9,66.113 557.115,58.899 557.115,50 C557.115,41.1 549.9,33.886 541,33.886 M565.378,62.101 C565.244,65.022 564.756,66.606 564.346,67.663 C563.803,69.06 563.154,70.057 562.106,71.106 C561.058,72.155 560.06,72.803 558.662,73.347 C557.607,73.757 556.021,74.244 553.102,74.378 C549.944,74.521 548.997,74.552 541,74.552 C533.003,74.552 532.056,74.521 528.898,74.378 C525.979,74.244 524.393,73.757 523.338,73.347 C521.94,72.803 520.942,72.155 519.894,71.106 C518.846,70.057 518.197,69.06 517.654,67.663 C517.244,66.606 516.755,65.022 516.623,62.101 C516.479,58.943 516.448,57.996 516.448,50 C516.448,42.003 516.479,41.056 516.623,37.899 C516.755,34.978 517.244,33.391 517.654,32.338 C518.197,30.938 518.846,29.942 519.894,28.894 C520.942,27.846 521.94,27.196 523.338,26.654 C524.393,26.244 525.979,25.756 528.898,25.623 C532.057,25.479 533.004,25.448 541,25.448 C548.997,25.448 549.943,25.479 553.102,25.623 C556.021,25.756 557.607,26.244 558.662,26.654 C560.06,27.196 561.058,27.846 562.106,28.894 C563.154,29.942 563.803,30.938 564.346,32.338 C564.756,33.391 565.244,34.978 565.378,37.899 C565.522,41.056 565.552,42.003 565.552,50 C565.552,57.996 565.522,58.943 565.378,62.101 M570.82,37.631 C570.674,34.438 570.167,32.258 569.425,30.349 C568.659,28.377 567.633,26.702 565.965,25.035 C564.297,23.368 562.623,22.342 560.652,21.575 C558.743,20.834 556.562,20.326 553.369,20.18 C550.169,20.033 549.148,20 541,20 C532.853,20 531.831,20.033 528.631,20.18 C525.438,20.326 523.257,20.834 521.349,21.575 C519.376,22.342 517.703,23.368 516.035,25.035 C514.368,26.702 513.342,28.377 512.574,30.349 C511.834,32.258 511.326,34.438 511.181,37.631 C511.035,40.831 511,41.851 511,50 C511,58.147 511.035,59.17 511.181,62.369 C511.326,65.562 511.834,67.743 512.574,69.651 C513.342,71.625 514.368,73.296 516.035,74.965 C517.703,76.634 519.376,77.658 521.349,78.425 C523.257,79.167 525.438,79.673 528.631,79.82 C531.831,79.965 532.853,80.001 541,80.001 C549.148,80.001 550.169,79.965 553.369,79.82 C556.562,79.673 558.743,79.167 560.652,78.425 C562.623,77.658 564.297,76.634 565.965,74.965 C567.633,73.296 568.659,71.625 569.425,69.651 C570.167,67.743 570.674,65.562 570.82,62.369 C570.966,59.17 571,58.147 571,50 C571,41.851 570.966,40.831 570.82,37.631"></path></g></g></g></svg></div><div style="padding-top: 8px;"> <div style=" color:#3897f0; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:550; line-height:18px;">View this post on Instagram</div></div><div style="padding: 12.5% 0;"></div> <div style="display: flex; flex-direction: row; margin-bottom: 14px; align-items: center;"><div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(0px) translateY(7px);"></div> <div style="background-color: #F4F4F4; height: 12.5px; transform: rotate(-45deg) translateX(3px) translateY(1px); width: 12.5px; flex-grow: 0; margin-right: 14px; margin-left: 2px;"></div> <div style="background-color: #F4F4F4; border-radius: 50%; height: 12.5px; width: 12.5px; transform: translateX(9px) translateY(-18px);"></div></div><div style="margin-left: 8px;"> <div style=" background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 20px; width: 20px;"></div> <div style=" width: 0; height: 0; border-top: 2px solid transparent; border-left: 6px solid #f4f4f4; border-bottom: 2px solid transparent; transform: translateX(16px) translateY(-4px) rotate(30deg)"></div></div><div style="margin-left: auto;"> <div style=" width: 0px; border-top: 8px solid #F4F4F4; border-right: 8px solid transparent; transform: translateY(16px);"></div> <div style=" background-color: #F4F4F4; flex-grow: 0; height: 12px; width: 16px; transform: translateY(-4px);"></div> <div style=" width: 0; height: 0; border-top: 8px solid #F4F4F4; border-left: 8px solid transparent; transform: translateY(-4px) translateX(8px);"></div></div></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center; margin-bottom: 24px;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 224px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 144px;"></div></div></a><p style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; line-height:17px; margin-bottom:0; margin-top:8px; overflow:hidden; padding:8px 0 7px; text-align:center; text-overflow:ellipsis; white-space:nowrap;"><a href="https://www.instagram.com/p/C5Y0_ZoyJvw/?utm_source=ig_embed&utm_campaign=loading" style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:normal; line-height:17px; text-decoration:none;" target="_blank">A post shared by Muhammed Adnan (@its_adnan_are)</a></p></div></blockquote> <script async src="//www.instagram.com/embed.js"></script>
```
| muhammadad93421 | |
1,812,665 | How to change ip of msfconsole in kali linux??? | A post by Tarun | 0 | 2024-04-05T19:39:21 | https://dev.to/saratarun/how-to-change-ip-of-msfconsole-in-kali-linux-5500 | help | saratarun | |
1,813,062 | FlutterFlow today pivoted their business model | 🎉 Attention All Flutterflow Developers... FlutterFlow today pivoted their business model and now they... | 0 | 2024-04-06T09:42:20 | https://dev.to/flutterflowdevs/flutterflow-today-pivoted-their-business-model-3h2j | flutterflow, flutter, google, fabricflow |
🎉 Attention All Flutterflow Developers...
FlutterFlow today pivoted their business model and now they are FabricFlow a clever custom t-shirt development platform.
In celebration of this, we've ordered Flutterflow hoodies featuring Charlie, for the entire team of FlutterflowDevs. we're about to rock some seriously stylish gear, and we can't wait to show it off!🚀
you can get in on the fun too! Create your own design 🎨 and snag your very own custom hoodie or T-shirt.
So, what are you waiting for? Let's celebrate FabricFlow. 🚀😄😄
check out this video - https://lnkd.in/g6zhpv7p
you can create your custom design t-shirt from this link - https://fabricflow.io/
| flutterflowdevs |
1,844,494 | Minor Issues: Handling user events with Jest | In an effort to document what I'm working on - and hopefully retain the information as well - I'll be... | 0 | 2024-05-06T21:23:18 | https://dev.to/whitneywind/minor-issues-handling-user-events-with-jest-46lf | In an effort to document what I'm working on - and hopefully retain the information as well - I'll be documenting the tidbits that I learn. This includes only the information that I can share publicly, including my personal projects and open-source work. Feel free to make suggestions where you see fit!
## Jest testing with React
* Jest is a popular JavaScript testing framework known for unit and integration testing. This week I used Jest and React Testing Library to test an open-source codebase's reusable button component. Tests are being implemented retroactively and aim to better protect the codebase.
Most of my the button testing went smoothly. Testing for focus, however, proved to be a challenge.
* **Problem: Testing that a button doesn't trap focus**
One test needed to assert that a "Tab" press would move focus from the button to the next element. At first, I tried using "fireEvent" to mimic a keyboard press of the Tab key. However, this did not affect the focus. I learned that fireEvent is not the best way to do this.
####
* **Solution: @testing-library/user-event**
FireEvent can be used with Jest tests, but in most cases it is recommended to use @testing-library/user-event instead.
The @testing-library/user-event library mimics user interactions, accounts for accessibility best practices, and manages edge cases where fireEvent may not behave as expected - like in this case!
In this case, userEvent.tab() is all that was needed to successfully imitate a user hitting "Tab" on the keyboard.
```
test('Button does not trap focus', () => {
const { getByRole, getByTestId } = render(
<>
<Button buttonText="Click me" />
<input type="text" data-testid="next-element" />
</>
);
const button = getByRole('button', { name: /Click me/i });
const nextElement = getByTestId('next-element');
button.focus();
userEvent.tab();
expect(nextElement).toHaveFocus();
});
```
| whitneywind | |
1,813,191 | The power of the CLI with Golang and Cobra CLI | Today we are going to see all the power that a CLI (Command line interface) can bring to development,... | 0 | 2024-04-06T13:15:56 | https://dev.to/wiliamvj/the-power-of-the-cli-with-golang-and-cobra-cli-148k | go, cli, tutorial, beginners | Today we are going to see all the power that a CLI (Command line interface) can bring to development, a CLI can help us perform tasks more effectively and lightly through commands via terminal, without needing an interface. For example, [git](https://git-scm.com/) and [Docker](https://www.docker.com/), we practically use their CLI all the time, when we execute a `git commit -m "commit message"` or `docker ps -a` we are using a CLI. I'm going to leave an [article](https://dev.to/bboyakers/what-is-a-cli-53a6) that details what a CLI is.
In this post we will create a boilerplate for Go projects, where with just 1 command via CLI, the entire project structure will be created.
## Go e CLI
Well, Go is extremely powerful for building CLI, it is one of the most used languages for this, no wonder it is widely used among DevOps, precisely because it is so powerful and simple.
Just to give an example of the power of Go for CLI builds, you may have already used or at least heard of [Docker](https://www.docker.com/), [Kubernetes](https://github.com/kubernetes/kubernetes), [Prometheus](https://github.com/prometheus/prometheus), [Terraform](https://github.com/hashicorp/terraform), but what do they all have in common? They all have a large part of their usability via CLI and are developed in Go 🐿.
## Starting a CLI with Go
Go has a package to handle CLI natively. But let's cover it quickly, the purpose of the post is to use the [Cobra CLI](https://github.com/spf13/cobra) package, which will facilitate the construction of our CLI.
Let's use the [flag](https://pkg.go.dev/flag) package
```go
package main
import (
"flag"
"fmt"
"time"
)
func main() {
dateFlag := flag.Bool("date", false, "Display the current date")
flag.Parse()
if *dateFlag {
currentTime := time.Now()
fmt.Println("Current date", currentTime.Format("2006-01-02 15:04:05"))
}
}
```
In this example above, we created a `date` flag, passing this flag returns the current date, something very simple, running the project with `go run main.go --date`, we will have the value `Current date 2023-11 -15 12:26:14`.
```go
dateFlag := flag.Bool("date", false, "Display the current date")
```
In the code above, we create a flag, the first argument `date` is the flag name, false as the default value means that if you run the program without explicitly specifying the `--date` flag, the value associated with `dateFlag` will be `false`. This allows the program to have a specific default behavior if this flag is not provided when the program is executed, while the third argument `Display the current date` is the detail of what this flag does.
If we run:
```bash
go run main.go -h
```
We received:
```bash
-date
Display the current date
```
We can use the flag with `--date` or `-date`, Go already does the automatic check.
We can make our entire boilerplate with this approach, but let's make it a little easier and use the [Cobra CLI](https://github.com/spf13/cobra) package.
## Cobra CLI
This package is widely used for powerful CLI builds, it is used for example for [Kubernetes CLI](https://kubernetes.io/) and [GitHub CLI](https://github.com/cli/cli), in addition to offering some cool features such as automatic completion of [shell](<https://pt.wikipedia.org/wiki/Shell_(computa%C3%A7%C3%A3o)>), automatic recognition of flags (the tags) , and you can use `-h` or `-help` for example, among other facilities.
## Creating the project
Our project will be very simple, we will only have `main.go` and `go.mod` and consequently our `go.sum`, we will start the project with the command:
```bash
go mod init github.com/wiliamvj/boilerplate-cli-go
```
_You can use whatever name you want_, by convention we generally create the name of the project as the link to our repository.
ending up like this:
Now let's download the Cobra package with the command:
```bash
go get -u github.com/spf13/cobra@latest
```
The boilerplate will have a very simple structure, the idea is to create a structure widely used by the Go community, see how it will look:
- **cmd**: [here](https://github.com/golang-standards/project-layout/tree/master/cmd) where we will leave the `main.go` that starts our app.
- **internal**: [in this paste](https://github.com/golang-standards/project-layout/tree/master/internal) where all the code for our application should be located.
- **handler**: Here will be the files responsible for receiving our http requests, you may also know them as controllers.
- **routes**: Here we will organize our routes.
It's not the complete framework, we're just creating the basics for our example.
All of our code will focus on our `main.go`.
```go
package main
import (
"fmt"
"os"
"github.com/spf13/cobra"
)
func main() {
var rootCommand = &cobra.Command{}
var projectName, projectPath string
var cmd = &cobra.Command{
Use: "create",
Short: "Create boilerplate for a new project",
Run: func(cmd *cobra.Command, args []string) {
// validations
if projectName == "" {
fmt.Println("You must supply a project name.")
return
}
if projectPath == "" {
fmt.Println("You must supply a project path.")
return
}
fmt.Println("Creating project...")
},
}
cmd.Flags().StringVarP(&projectName, "name", "n", "", "Name of the project")
cmd.Flags().StringVarP(&projectPath, "path", "p", "", "Path where the project will be created")
rootCommand.AddCommand(cmd)
rootCommand.Execute()
}
```
The code above is just to start our CLI, we will only have two variables:
- `projectName`: it will be the name of our project that we will capture in the input of our CLI.
- `projectPath`: will be the path where the boilerplate will be created, we will capture it in the CLI input.
- `&cobra.Command{}`: starts the Cobra cli.
- `Run:` It receives an anonymous function, it is in this function that we capture the user input entered in the CLI and validate it, our validation is simple, we just check if the `projectName` and `projectPath` are not null.
- `cmd.Flags()`: Here we create the flags with flags, so you can use `-name` or `-n`, both will be accepted, we also include the description of what this flag does.
- `rootCommand.AddCommand(cmd)`: We add our `cmd` to the `rootCommand` created at the beginning of our `main.go`.
- `rootCommand.Execute()`: Finally, we run our CLI.
That's all we need to get our CLI working, of course without our boilerplate logic, but with that we can use it via the terminal. Lets test!
_We can build the project or use it without build_
With build:
```bash
go build -o cli .
```
A file called `cli` will be created at the root, we will run the binary from our CLI:
```bash
./cli --help
```
We will have an output like this:
```bash
Usage:
[command]
Available Commands:
completion Generate the autocompletion script for the specified shell
create Create boilerplate for a new project
help Help about any command
Flags:
-h, --help help for this command
Use " [command] --help" for more information about a command.
```
See that we already have tips on how to use the command we created `create Create boilerplate for a new project`, if we run:
```bash
./cli create --help
```
We will have:
```bash
Create boilerplate for a new project
Usage:
create [flags]
Flags:
-h, --help help for create
-n, --name string Name of the project
-p, --path string Path where the project will be created
```
Let's run it now by passing our flags:
```bash
./cli create -n my-project -p ~/documents
```
We will have our `Creating project...` message, indicating that it worked, but nothing happens yet, as we have not implemented the logic.
We can also create subcommands, new flags, new validations, but for now let's leave it like that, if you want you can create more options, see [documentation](https://pkg.go.dev/github.com/spf13/cobra#section-documentation) of the Cobra package.
## Creating the boilerplate
With our CLI ready, let's now go through the boilerplate logic, which is very simple, we will have to create the folders, then we will need to create the files and finally open the files and insert the code, for this we will use the [os](https://pkg.go.dev/os) package a lot of Go, which allows you to access operating system resources.
Let's first get the main directory and validate if there already exists a folder with the name that will be used to create our project:
```go
globalPath := filepath.Join(projectPath, projectName)
if _, err := os.Stat(globalPath); err == nil {
fmt.Println("Project directory already exists.")
return
}
```
If we pass the `projectName` as **test** and the `projectPath` as `/documents`, this validates that there is no other folder in **documents** called **test**, if there is we return and return a error message.
You can modify and, if there is a folder with the same name, change the name of `projectName` or delete the folder that already exists, but for now we will just return an error.
```go
if err := os.Mkdir(globalPath, os.ModePerm); err != nil {
log.Fatal(err)
}
```
In this part, we will create the directory in the path that was entered using our `-p` flag, if we use:
```bash
./cli create -n my-project -p ~/documents
```
### Starting Go
A folder called **my-project** will be created in the **documents** directory.
```go
startGo := exec.Command("go", "mod", "init", projectName)
startGo.Dir = globalPath
startGo.Stdout = os.Stdout
startGo.Stderr = os.Stderr
err := startGo.Run()
if err != nil {
log.Fatal(err)
}
```
In the code above we execute the command to start the project in Go, it will be created in the root directory we chose, in our example it will run within **documents/my-project**, this will create the file `go.mod` and will set the module name to **my-projects**.
- `exec.Command`: Create the command that we will run in the terminal, in this case it will be `go mod init my-project`.
- `startGo.Dir`: Determine where this command will run, in the example it will run in **documents/my-project**.
- `startGo.Stdout`: It will place the command return in the terminal, it will return `go: creating new go.mod: module my-project`.
- `startGo.Stderr`: Redirects the output of a possible error to where the program is being executed.
- `startGo.Run()`: Finally, we execute everything.
### Creating the folders
Let's create our folders, they are **cmd**, **internal**, **handler** and **routes**.
```go
cmdPath := filepath.Join(globalPath, "cmd")
if err := os.Mkdir(cmdPath, os.ModePerm); err != nil {
log.Fatal(err)
}
internalPath := filepath.Join(globalPath, "internal")
if err := os.Mkdir(internalPath, os.ModePerm); err != nil {
log.Fatal(err)
}
handlerPath := filepath.Join(internalPath, "handler")
if err := os.Mkdir(handlerPath, os.ModePerm); err != nil {
log.Fatal(err)
}
routesPath := filepath.Join(handlerPath, "routes")
if err := os.Mkdir(routesPath, os.ModePerm); err != nil {
log.Fatal(err)
}
```
This code above creates the necessary folders in sequence, using `os.Mkdir`, ([see the docs](https://pkg.go.dev/os#Mkdir)), for the **handler** and **folders** **routes**, we need to access the **internal** folder, as they will be created within **internal**, for this we use `Join` to merge the path, resulting in:
- `handlerPath`: **documents/my-project/internal**
- `routesPath`: **documents/my-project/internal/handler**
### Creating the files
With the folders created, let's create the files, for example we will create `main.go` of course and `routes.go`, inside the **routes** folder.
```go
mainPath := filepath.Join(cmdPath, "main.go")
mainFile, err := os.Create(mainPath)
if err != nil {
log.Fatal(err)
}
defer mainFile.Close()
routesFilePath := filepath.Join(routesPath, "routes.go")
routesFile, err := os.Create(routesFilePath)
if err != nil {
log.Fatal(err)
}
defer routesFile.Close()
```
Above we created the `main.go` and `routes.go` files.
- `mainPath`: we determine the path, using the `mainPath` used to create the **cmd** folder.
- `os.Create(mainPath)`: we create the file, in the specified directory. (**documents/my-project/cmd**)
- `routesFilePath`: we determine the path, using the `routesPath` used to create the **routes** folder.
- `os.Create(routesFilePath)`: We create the file, in the specified directory. (**documents/my-project/internal/handler/routes**)
- `defer routesFile.Close()`: We close the file, `defer`, using this GO reserved word, we guarantee that the last thing to happen is to close the file. See more about `defer` [here](https://go.dev/blog/defer-panic-and-recover).
### Writing to files
With the folders and files created, now let's write to the `main.go` and `routes.go` files, let's do something simple, just for example, to organize better, we will separate them into functions that write to each file.
```go
func WriteMainFile(mainPath string) error {
packageContent := []byte(`package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
`)
mainFile, err := os.OpenFile(mainPath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
return err
}
defer mainFile.Close()
_, err = mainFile.Write(packageContent)
if err != nil {
return err
}
return nil
}
```
In the function above, we have `mainPath` as a parameter, which is the file path, we will add a simple code, which will just log a _Hello World_.
- `packageContent`: We create the code that will be written to the file.
- `os.OpenFile`: We open the file specified in `mainPath`.
- `defer mainFile.Close()`: We close the file last with `defer`.
- `mainFile.Write`: Finally, we write it to the file, and handle the error if any.
`O_WRONLY` and `O_APPEND`, are constants used to define the opening mode of a file, `O_WRONLY` indicates that the file will be opened only for writing, `O_APPEND` means that the added content will be added to the end of the file, without overwrite existing content.
```go
func WriteRoutesFile(routesFilePath string) error {
packageContent := []byte(`package routes
// your code here
`)
routesFile, err := os.OpenFile(routesFilePath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
return err
}
defer routesFile.Close()
_, err = routesFile.Write(packageContent)
if err != nil {
return err
}
return nil
}
```
We do the same for the `routes.go` file.
Now just call the new functions in the `main` function, looking like this:
```go
mainPath := filepath.Join(cmdPath, "main.go")
mainFile, err := os.Create(mainPath)
if err != nil {
log.Fatal(err)
}
defer mainFile.Close()
if err := WriteMainFile(mainPath); err != nil {
log.Fatal(err)
}
routesFilePath := filepath.Join(routesPath, "routes.go")
routesFile, err := os.Create(routesFilePath)
if err != nil {
log.Fatal(err)
}
defer routesFile.Close()
if err := WriteRoutesFile(routesFilePath); err != nil {
log.Fatal(err)
}
```
### Final code
```go
package main
import (
"fmt"
"log"
"os"
"os/exec"
"path/filepath"
"github.com/spf13/cobra"
)
func main() {
var rootCommand = &cobra.Command{}
var projectName, projectPath string
var cmd = &cobra.Command{
Use: "create",
Short: "Create boilerplate for a new project",
Run: func(cmd *cobra.Command, args []string) {
if projectName == "" {
fmt.Println("You must supply a project name.")
return
}
if projectPath == "" {
fmt.Println("You must supply a project path.")
return
}
fmt.Println("Creating project...")
globalPath := filepath.Join(projectPath, projectName)
if _, err := os.Stat(globalPath); err == nil {
fmt.Println("Project directory already exists.")
return
}
if err := os.Mkdir(globalPath, os.ModePerm); err != nil {
log.Fatal(err)
}
startGo := exec.Command("go", "mod", "init", projectName)
startGo.Dir = globalPath
startGo.Stdout = os.Stdout
startGo.Stderr = os.Stderr
err := startGo.Run()
if err != nil {
log.Fatal(err)
}
cmdPath := filepath.Join(globalPath, "cmd")
if err := os.Mkdir(cmdPath, os.ModePerm); err != nil {
log.Fatal(err)
}
internalPath := filepath.Join(globalPath, "internal")
if err := os.Mkdir(internalPath, os.ModePerm); err != nil {
log.Fatal(err)
}
handlerPath := filepath.Join(internalPath, "handler")
if err := os.Mkdir(handlerPath, os.ModePerm); err != nil {
log.Fatal(err)
}
routesPath := filepath.Join(handlerPath, "routes")
fmt.Println(routesPath)
if err := os.Mkdir(routesPath, os.ModePerm); err != nil {
log.Fatal(err)
}
mainPath := filepath.Join(cmdPath, "main.go")
mainFile, err := os.Create(mainPath)
if err != nil {
log.Fatal(err)
}
defer mainFile.Close()
if err := WriteMainFile(mainPath); err != nil {
log.Fatal(err)
}
routesFilePath := filepath.Join(routesPath, "routes.go")
routesFile, err := os.Create(routesFilePath)
if err != nil {
log.Fatal(err)
}
defer routesFile.Close()
if err := WriteRoutesFile(routesFilePath); err != nil {
log.Fatal(err)
}
},
}
cmd.Flags().StringVarP(&projectName, "name", "n", "", "Name of the project")
cmd.Flags().StringVarP(&projectPath, "path", "p", "", "Path where the project will be created")
rootCommand.AddCommand(cmd)
rootCommand.Execute()
}
func WriteMainFile(mainPath string) error {
packageContent := []byte(`package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}
`)
mainFile, err := os.OpenFile(mainPath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
return err
}
defer mainFile.Close()
_, err = mainFile.Write(packageContent)
if err != nil {
return err
}
return nil
}
func WriteRoutesFile(routesFilePath string) error {
packageContent := []byte(`package routes
// your code here
`)
routesFile, err := os.OpenFile(routesFilePath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
return err
}
defer routesFile.Close()
_, err = routesFile.Write(packageContent)
if err != nil {
return err
}
return nil
}
```
## Testing the CLI
Well, with everything ready, let's test it! To do this, we will compile our code with the good old `go build`.
```bash
go build -o cli .
```
Running the CLI:
```bash
./cli create -n my-project -p ~/documents
```
Let's get the answer:
```bash
Creating project...
go: creating new go.mod: module my-project
```
Accessing our project and opening it in Visual Studio Code with:
```bash
cd /documents/my-project && code .
```
We will have our boilerplate created:
If we run the project created via CLI, we can see that everything works.
```bash
go run cmd/main.go
output:
Hello World!
```
With this we finish creating our CLI that creates a boilerplate.
## Final considerations
Our boilerplate could be even more automated, we could, for example, install a package like the [Go Chi](https://go-chi.io/) package, creating standard endpoints, all using the CLI, you can even create your own framework, have you ever thought that with just one command your initial project is already configured?
With knowledge in CLI creation, you have great power in your hands!
see my blog [here](https://wiliamvj.com/en/posts/cobra-cli-golang/)
## Repository link
[repository](https://github.com/wiliamvj/boilerplate-cli-go/blob/main/main.go) of the project
| wiliamvj |
1,813,784 | Configuring SSH to Access Remote Server | Earlier in another article, we provided a detailed description of how to create and set up a Virtual... | 0 | 2024-04-07T08:55:10 | https://dev.to/eugene-zimin/configuring-ssh-to-access-remote-server-2ljk | server, ssh, remote, googlecloud | Earlier in another article, we provided a detailed description of how to create and set up a Virtual Machine (VM) instance in the Google Cloud Platform (GCP) using Google Compute Engine (GCE). It is accessible here - [Google Cloud: Provisioning a Virtual Machine and Accessing it via SSH](https://medium.com/@eugene-zimin/google-cloud-provisioning-a-virtual-machine-and-accessing-it-via-ssh-dde4307a8e9b).
Provisioning a GCP VM allows us to create our own powerful computing environment to serve as a sandbox or workspace for our further testing and experiments. Having successfully deployed a VM in GCP, the next crucial step is to establish a secure remote connection to this virtual machine. It is required by many reasons, starting from efficient administration and management up to the monitoring and observing it. Google Cloud Platform provides a straightforward method to configure SSH access to Compute Engine instances, facilitating an encrypted communication channel. In this article, we will outline the steps required to set up SSH access to a Google Compute Engine (GCE) virtual machine.
## Few Words About SSH
Secure Shell (SSH) is a cryptographic network protocol and the de facto standard for secure remote login and command execution on Unix-like operating systems. SSH provides a secure encrypted channel over an unsecured network, preventing potential eavesdropping, packet sniffing, or man-in-the-middle attacks that could compromise login credentials or sensitive data. By leveraging strong encryption algorithms and authenticated key exchange, SSH ensures data integrity and confidentiality, making it an essential tool for securely administering remote servers, transferring files, and managing networked systems over insecure networks such as the internet.
SSH operates through the use of encrypted key pairs - a public key that gets placed on the remote server, and a private key that is kept secure by the client. The keys are very large numbers derived via a one-way mathematical function, making them virtually impossible to derive if intercepted during transmission.
When initiating an SSH connection, the client and server negotiate a secure symmetrical encryption cipher and session keys to use. This key exchange utilizes the private/public keys for authentication and protection against man-in-the-middle attacks. Once the secure tunnel is established, all subsequent commands, file transfers, and communications are encrypted between the client and server.
Figure 1. Communication schema for SSH exchange
SSH supports several strong modern encryption algorithms such as AES, Blowfish, 3DES, and ciphers like ChaCha20. The specific algorithms used can be configured on both ends based on policy and requirements. SSH also provides data integrity verification through cryptographic message authentication codes like HMAC-SHA1 to detect tampering.
By default, SSH operates on TCP port 22, but can be configured to use any port. It supports various user authentication mechanisms like passwords, public keys, security keys, and more. SSH key-based authentication is considered more secure than basic password authentication.
## Configuring SSH on Local Machine
Before initiating an SSH connection to our Google Cloud VM instance, we'll need to have SSH configured and set up on our local machine. The steps vary slightly depending on the operating system, as Linux and macOS usually have preinstalled SSH client which requires minimal configuration, whereas Window requires a bit more steps to make initial setup ready.
#### Linux and macOS
Most Linux distributions and macOS come pre-installed with OpenSSH, a free open source SSH client and server utility. To check if it's installed, we can open a terminal and run:
```shell
ssh -V
# Response should be something like the line below
# OpenSSH_9.6p1, LibreSSL 3.3.6
```
This should display the installed OpenSSH version. If not installed, we can get it through the operating system's package manager, for Linux it may be usually `apt` or `yum` for macOS `brew` is very popular.
#### Windows
Windows 11 has pre-installed SSH client. To check it we need to open `cmd` application (a.k.a `Command Prompt`) and run the same command:
```shell
ssh -V
```
If we will see a similar output we saw for Linux and macOS (some names may vary), it means we have installed SSH client and we are good to go.
A little bit more complicated situation happens if Windows doesn't have preinstalled client. In that case we may use one of the following 3rd party applications to run it:
- [PuTTY](https://www.putty.org/) for Windows
- [Git Bash](https://git-scm.com/download/win) for Windows
### Generating Key Pairs
To establish secure SSH connections, we need to generate cryptographic key pairs consisting of a public and private key. The `ssh-keygen` utility allows us to create these key pairs locally on our machine. Before we start creating a key pair it may worth to overview file schema for the it.
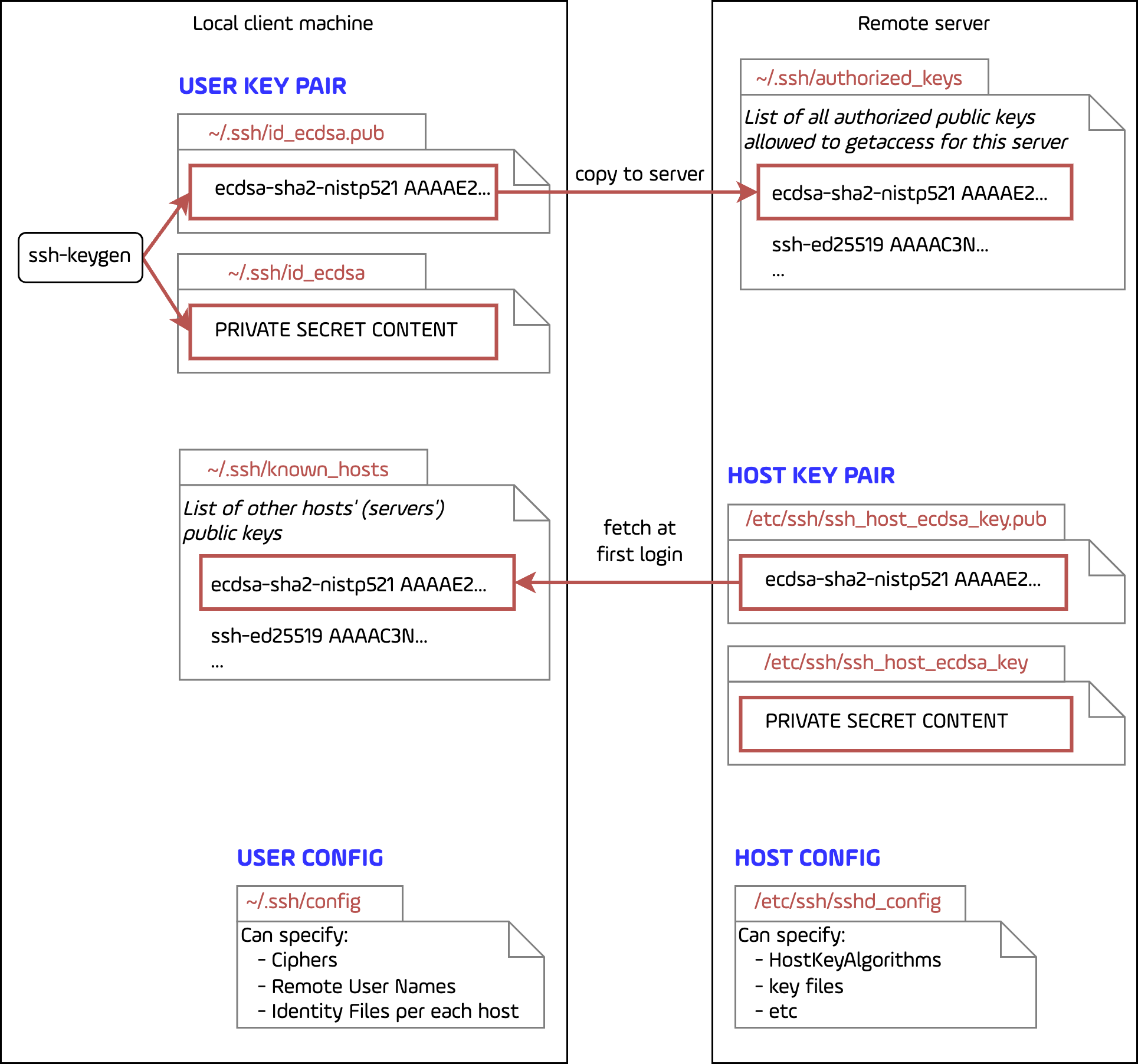Figure 2. Schema of SSH key pairs
We can run `ssh-keygen` in a terminal/command prompt and follow the prompts. Some common options include:
- `-t` to specify the key type (e.g. rsa, ecdsa, ed25519)
- `-b` to set the key length in bits (e.g. 2048, 4096)
- `-C` to add a comment to identify the key
For example:
```shell
ssh-keygen -t ecdsa -b 521
```
will give us the following output:
```
Generating public/private ecdsa key pair.
Enter file in which to save the key (~/.ssh/id_ecdsa): ~/.ssh/id_ecdsa_gce
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in ~/.ssh/id_ecdsa_gce
Your public key has been saved in ~/.ssh/id_ecdsa_gce.pub
The key fingerprint is:
SHA256:Utwi6b8NzdJSFT5RlH6HOvr7y5HvNJiw08YB7wxAaQU user@laptop.local
```
There are various key types we may use. Here are the most popular ones we may want to generate:
- **RSA** - One of the oldest and most widely used key types. Recommended minimum key length is 2048 bits, with 4096 bits being more secure.
- **ECDSA** (Elliptic Curve Digital Signature Algorithm) - This key type is based on elliptic curve cryptography which provides equal security strength with smaller key sizes compared to RSA.
- **Ed25519** - A modern EdDSA (Edwards-curve Digital Signature Algorithm) key type that provides better performance and security than RSA/ECDSA. Ed25519 uses elliptic curve cryptography with a 256-bit key length.
While RSA is the most widely compatible, Ed25519 keys are considered more secure and efficient for modern systems. We can check which key types our SSH server and client support using `ssh -Q key`.
During key generation, we have the option to protect the private key with a passphrase. While providing a passphrase enhances security, we need to enter it every time the key is used.
After generating, both keys - private and public - will be saved in the local SSH configuration folder. Usually (for Linux and macOS systems) this folder is under the following path - `~/.ssh/`. Both keys by default use their name pattern as `id-<algorithm-name>[.pub]` , where extension `.pub` is used only for public key from the pair. As an example, user may get `id-rsa` and `id-rsa.pub` if there was RSA algorithm used, or `id-ed25519` and `id-ed25519.pub` there was Ed25519 algorithm in use during key pair generation.
Next step would be to copy the content of the public key (which has `.pub` extension) to the remote server, in accordance with the Figure 2. We may copy the content of the public key and paste it on the new line of the `~/.ssh/authorized_keys` file for the user which we will be connecting to. We can do that by many ways, but usually we should have access to the remote server via screen sharing or through the web interface, like with Google Compute Engine in GCP, where we can paste our public key.
> **NOTE FOR GCP**
> GCP requires to add at the end of the key `userName` and `expireOn` in form of JSON. We should do that manually to get the ready for pasting. Eventually we should have something like that:
>
> ```shell
> ecdsa-sha2-nistp521 AAAAE2...== user@laptop.local {"userName":"<user@yourgcp.email>","expireOn":"2024-05-06T08:43:20+0000"}
> ```
At the same time private key (without `.pub` extension) remains securely stored on our local machine. We must keep the private key safe and never share it.
With our key pair ready, we can now proceed to configure server to use key pair only and disallow further access using username and password.
### Configuring Server Side
While using SSH keys provides a much more secure authentication mechanism compared to passwords, many cloud providers, including Google Cloud Platform, enable password-based logins to SSH servers by default. However, relying solely on password authentication for SSH connections introduces potential security risks and is considered a poor practice, so we should consider to disable it and keep it disabled.
Main reasons why we should do that lay in the security considerations. Having password authentication enabled we allow anyone to try to connect to remote server and try out to brute force the password. Sometimes password are not that strong and such an attack might be successful.
That being said the advantages of disabling Password authentication for the remote server are as follows:
1. **Enhanced Security**: SSH keys utilize strong encryption algorithms and prevent brute-force and dictionary attacks that are common threats to password-based authentication. Keys are virtually impossible to guess or decrypt.
2. **Eliminate Weak Passwords**: Enforcing key-based authentication eliminates the risk of users setting weak or easily guessable passwords, which is a common vulnerability.
3. **Audit Trail**: SSH key pairs provide better audit trails and monitoring capabilities, as each key can be associated with a specific user or system.
4. **Compliance**: Many security standards and best practices, such as PCI-DSS, HIPAA, and NIST, recommend or mandate the use of key-based authentication over passwords for remote access to servers.
At the same time nothing comes without price. If any of the parts for the key pair would be lost or corrupted, it means we may also lost the access to the server, thus we should be very careful and keep generated key pair as good as possible.
To disable password authentication for the SSH server we need to modify the SSH daemon (`sshd`) configuration file. To do that we need to connect to the VM instance over SSH. We will use our new generated private key to connect to the server (don't forget to replace username and address of the server).
```shell
ssh -i ~/.ssh/id_ed25519 remote-user@server-ip-address
```
On the remote server open the SSH daemon configuration file as a `superuser`:
```shell
sudo nano /etc/ssh/sshd_config # may be changed to vim
```
In the file editor find the line `#PasswordAuthentication yes` and change it to `PasswordAuthentication no` and save the file and exit the editor.
Finally we need to restart the SSH daemon to make our changes take effect:
```shell
sudo systemctl restart sshd # (or command for your OS)
```
After making this change, the SSH server will only allow key-based authentication, and password logins will be disabled.
It's important to note that we should have at least one authorized SSH key added to the VM instance before disabling password authentication. Otherwise, we may get locked out of the system.
By enforcing key-based authentication and disabling password logins, we significantly enhance the security of our SSH server and remote access to our Google Cloud virtual machines, aligning with industry best practices for secure system administration.
#### Simplifying Connections with SSH Client Configuration File
While we can directly specify options when invoking the `ssh` command, using a configuration file allows us to set persistent options, create aliases, and simplify the process of connecting to remote hosts. This is particularly useful when managing multiple SSH connections to different servers or cloud instances.
On Unix-based systems (Linux and macOS), the SSH client refers to the configuration file located at `~/.ssh/config` location. On Windows systems using the OpenSSH client, the file is located at `%UserProfile%.ssh\config`.
The `~/.ssh/config` file supports a wide range of configuration options and settings that can be applied globally or to specific hosts. Here are some common use cases:
##### Creating Aliases
We can define aliases or shorthand names for hosts, making it easier to connect without having to type out the full hostname or IP address every time.
```configuration
Host remote_server
HostName remote_host.com
User ubuntu
```
Instead of `remote_host.com` it is possible to use IP address of the remote server directly. Now we can use:
```shell
ssh remote_server
```
to reach remote server instead of using its name `remote_host.com` or direct IP address. It's clear that aliases might be different and their usage makes it easier to set up connections.
##### Setting Default Options
We can set default options that will be applied to all SSH connections, such as the default user, identity file (private key), and forwarding settings.
```configuration
Host *
User ubuntu
IdentityFile ~/.ssh/id_rsa
ForwardAgent yes
```
In this configuration instead of doing aliasing, we set default configuration which will be applied to **all** connections and hosts. 1. The asterisk (`*`) is a wildcard that matches any hostname.
`User ubuntu` sets the default user account to be used for SSH connections. In this case, it will attempt to log in as the `ubuntu` user on remote hosts.
`IdentityFile ~/.ssh/id_rsa` specifies the path to the default SSH private key file that should be used for authentication. Here, it is set to `~/.ssh/id_rsa`, which is the standard location for an SSH private key on Unix-based systems. That's convenient way to use previously generated key pair.
`ForwardAgent yes` option enables SSH agent forwarding. When enabled, it allows authentication keys loaded into the local SSH agent to be automatically forwarded to the remote host, enabling single sign-on (SSO) functionality. This can be useful when you need to connect to additional hosts from the initial remote host without re-authenticating.
##### Host-Specific Settings
We can define settings specific to a particular host or group of hosts, such as using a different private key, enabling compression, or specifying a non-standard port.
```configuration
Host *.example.com
IdentityFile ~/.ssh/id_rsa
Compression yes
Host gcp-instance
HostName 34.123.45.67
User user2
Port 2222
```
In this configurations we used 2 different values for `Host` key. In the first configuration option host entry applies settings to any host whose name matches the pattern `*.example.com`. The `*` acts as a wildcard, so this would include hosts like `server1.example.com`, `web.example.com`, or any other subdomain under the `example.com` domain.
`IdentityFile ~/.ssh/id_rsa` specifies that the private SSH key located at `~/.ssh/id_rsa` should be used for authentication when connecting to hosts matching the `*.example.com` pattern.
Second configuration behaves differently and creates an alias for the only single IP address of `34.123.45.67` in form of the `gcp-instance`.
##### Proxying Through Bastion Hosts
If we need to connect to instances that are not directly accessible (e.g., behind a bastion host or a NAT gateway), we can configure SSH tunneling through a jump host.
```configuration
Host gcp-instance
HostName 10.0.0.5
User user2
ProxyJump bastion.example.com
```
By leveraging the `~/.ssh/config` file, we can streamline our SSH workflow, ensure consistent settings across connections, and simplify the management of multiple remote hosts, including our Google Cloud VM instances.
To get started, we can create or edit the file using a text editor, and refer to the `ssh_config` man pages (`man ssh_config`) for a comprehensive list of available options and their descriptions. | eugene-zimin |
1,813,998 | Automating EKS Deployment and NGINX Setup Using Helm with AWS CDK in Python | Introduction Amazon Elastic Kubernetes Service (EKS) simplifies the process of running... | 0 | 2024-04-25T23:00:00 | https://dev.to/marocz/automating-eks-deployment-and-nginx-setup-using-helm-with-aws-cdk-in-python-27mn | aws, cdk, helm, eks |
# Introduction
Amazon Elastic Kubernetes Service (EKS) simplifies the process of running Kubernetes on AWS. When combined with the power of Helm and the AWS Cloud Development Kit (CDK), you can automate the deployment of Kubernetes resources and applications efficiently. This guide will walk you through deploying an EKS cluster and setting up NGINX using Helm, all automated with AWS CDK in Python.
## Prerequisites
- AWS CLI configured with administrator access.
- AWS CDK installed (`npm install -g aws-cdk`).
- Python 3.x installed.
- Docker installed (for building the CDK app).
## Step 1: Bootstrap Your CDK Project
First, create a new directory for your CDK project and initialize a new CDK app:
```bash
mkdir eks-cdk-nginx
cd eks-cdk-nginx
cdk init app --language python
```
## Step 2:
Ensure you have all the required dependencies on the requirement.txt file
```requirement.txt
aws-cdk-lib==2.133.0
constructs>=10.0.0,<11.0.0
python-dotenv==1.0.1
boto3==1.34.71
pytest==6.2.5
moto==5.0.4
```
Install the necessary CDK libraries for EKS:
```bash
pip install -r requirement.txt
```
### Understanding the AWS CDK Initialization Process
When you initialize a new AWS Cloud Development Kit (CDK) project with `cdk init app --language python`, several things happen:
1. Project Structure Creation: CDK creates a new directory with the name of your project and establishes a standard project structure within it.
2. Initialization of CDK App: A CDK application is initialized within this directory. This app will serve as the container for your CDK stacks and constructs.
3. Generation of Configuration Files and Directories: The command generates several configuration files and directories essential for your project, including:
- `app.py`: The entry point for your CDK application.
- `cdk.json`: Contains configuration for the CDK app, like which command to use for synthesizing CloudFormation templates.
- `requirements.txt`: Lists the Python packages required by your CDK app.
- `setup.py`: A setup script for installing the module (app) and its dependencies.
- A `.env` directory for your virtual environment and a `source.bat` or `source.sh` script (depending on your OS) to activate it.
4. Virtual Environment Setup: It suggests commands to set up a virtual environment for Python and to install the dependencies listed in `requirements.txt`.
### How to Structure Your CDK Project
Your AWS CDK project should be structured in a way that supports scalability and maintainability:
- App and Stack Files: The `app.py` file is where you instantiate your app and stacks. Each stack should be defined in its separate Python file for clarity, e.g., `my_stack.py`.
- Resource Constructs: Individual constructs, representing AWS resources, should be defined within stack files or in separate files if they are custom constructs or if you plan to reuse them across different stacks.
- Lib Directory: For larger projects, you might want to organize your constructs and stacks in a `lib/` directory. Each stack can have its own file within this directory.
- Test Directory: Tests for your CDK constructs and stacks should be placed in a `test/` directory.
- Assets: Store any assets (like Lambda code or Dockerfiles) in an `assets/` or `resources/` directory.
### Creating a Construct
A construct in CDK is a building block of your AWS infrastructure, representing an AWS resource or a group of related resources. Here’s how to create a simple S3 bucket construct within a stack:
1. **Define Your Construct**: In your stack file (`my_stack.py`), import the necessary AWS modules and define your construct:
```python
from aws_cdk import aws_s3 as s3
from aws_cdk import core
class MyStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs):
super().__init__(scope, id, **kwargs)
s3.Bucket(self, "MyFirstBucket",
versioned=True,
removal_policy=core.RemovalPolicy.DESTROY)
```
### Creating a Stack
A stack in CDK represents a collection of AWS resources that you deploy together. The `MyStack` class in the example above is already a stack. You instantiate this stack in your `app.py`:
```python
from aws_cdk import core
from my_stack import MyStack
app = core.App()
MyStack(app, "MyStack")
app.synth()
```
### Running `cdk synth` and What to Expect
The `cdk synth` command synthesizes your CDK code into an AWS CloudFormation template.
- **Command**: Run `cdk synth` from the root directory of your CDK project.
- **Output**: This command outputs a CloudFormation template in YAML format to your terminal. This template describes all the AWS resources you've defined in your CDK code.
- **CloudFormation Template**: The template can be found in the `cdk.out` directory, named after your stack, e.g., `MyStack.template.json`.
- What to Look For: Verify that the resources defined in your CDK stack, such as the S3 bucket in our example, are correctly represented in the CloudFormation template.
This synthesized template is what AWS CloudFormation uses to deploy and manage the defined cloud resources, making `cdk synth` an essential step in the development process to validate your infrastructure definitions before deployment.
## Step 2: Define Your EKS Cluster in CDK
In the `eks_cdk_nginx` directory, modify the `eks_cdk_nginx_stack.py` file to define your EKS cluster. The following example creates an EKS cluster and an EC2 instance as the worker node:
```python
from aws_cdk import core
from aws_cdk import aws_eks as eks
from aws_cdk import aws_ec2 as ec2
class EksCdkNginxStack(core.Stack):
def __init__(self, scope: core.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
# Define the VPC
vpc_id="vpc-xxxxxxxx"
vpc = ec2.Vpc.from_lookup(self, "vpc", vpc_id=vpc_id)
print("This is the vpc ", vpc.vpc_id)
vpc_subnets = [{'subnetType': ec2.SubnetType.PUBLIC}]
# vpc_subnets=vpc.select_subnets(subnet_type=ec2.SubnetType.PUBLIC).subnets
# create eks admin role
eks_master_role = iam.Role(self, 'EksMasterRole',
role_name='EksAdminRole',
assumed_by=iam.AccountRootPrincipal()
)
# Define the EKS cluster
cluster = eks.Cluster(self, 'Cluster',
vpc=vpc,
version=eks.KubernetesVersion.V1_25,
masters_role=eks_master_role,
default_capacity=0,
vpc_subnets=vpc_subnets
)
```
## Step 3: Add NGINX Ingress Using Helm
The AWS CDK’s EKS module allows you to define Helm charts as part of your infrastructure. Extend your stack to include the NGINX ingress controller from Helm:
```python
# Add NGINX ingress using Helm
eks.HelmChart(
self, "NginxIngress",
cluster=cluster,
chart="ingress-nginx",
repository="https://kubernetes.github.io/ingress-nginx",
namespace="ingress-nginx",
values=helm_values
)
```
## Step 4: Deploy Your CDK Stack
Ensure you are in the root of your CDK project and run the following commands to deploy your EKS cluster along with NGINX:
```bash
cdk synth
cdk deploy
```
This process might take several minutes as it sets up the EKS cluster and deploys the NGINX ingress controller.
## Step 5: Verify the NGINX Deployment
Once the deployment is complete, you can verify the NGINX ingress controller is running by fetching the Helm releases in your cluster:
1. Update your `kubeconfig`:
```bash
aws eks update-kubeconfig --name MyCluster
```
2. List Helm releases to see NGINX installed:
```bash
helm ls -n kube-system
```
### Adding Unit Tests to Your AWS CDK Project
Unit testing is an essential part of the development process, ensuring that your infrastructure as code behaves as expected. AWS CDK projects, being code-based, allow for straightforward unit testing of your infrastructure definitions. This section will guide you through setting up and writing unit tests for your AWS CDK project using Python.
#### Setting Up Your Testing Environment
1. **Install Testing Libraries**: To write and run tests, you'll need to install some additional Python libraries. `pytest` is a popular testing framework, and `aws-cdk.assertions` provides utilities for asserting CDK-specific conditions. Add these to your `requirements.txt`:
```plaintext
pytest
aws-cdk.assertions
```
Then, install them using pip:
```bash
pip install -r requirements.txt
```
2. **Organize Test Directory**: Create a `tests` directory in your project root. This is where all your test files will reside. You might structure it further into `unit` and `integration` tests if needed.
```bash
mkdir tests
```
#### Writing Unit Tests
1. **Create a Test File**: Inside the `tests` directory, create a Python file for your tests, for example, `test_my_stack.py`.
2. **Import Testing Modules**: At the beginning of your test file, import the necessary modules, including the CDK constructs you wish to test, `pytest`, and any CDK assertions you need.
```python
import pytest
from aws_cdk import core
from aws_cdk.assertions import Template
from my_cdk_app.my_stack import MyStack
```
3. **Write Test Cases**: Write functions to test various aspects of your stack. Use the `Template.from_stack` function to create a template object from your stack, which you can then assert against.
```python
def test_s3_bucket_created():
app = core.App()
stack = MyStack(app, "MyStack")
template = Template.from_stack(stack)
template.has_resource_properties("AWS::S3::Bucket", {
"VersioningConfiguration": {
"Status": "Enabled"
}
})
```
This test checks that your stack creates an S3 bucket with versioning enabled.
4. **Testing Custom Constructs**: If you have custom constructs, you can test them in isolation by instantiating them within a test stack in your test case, then making assertions about their template representation.
#### Running Your Tests
- Execute your tests by running `pytest` in your project's root directory. `pytest` will automatically discover and run all test files in the `tests` directory.
```bash
pytest
```
- If your tests pass, `pytest` will indicate success. If not, it will provide detailed output about which tests failed and why.
#### Conclusion on Unit Testing
Unit testing your AWS CDK project is crucial for maintaining high-quality infrastructure code. By testing your stacks and constructs, you ensure that your cloud infrastructure behaves as expected, reducing the likelihood of deployment errors and potential runtime issues. Incorporating these tests into a CI/CD pipeline can further automate your testing and deployment process, leading to more reliable and efficient infrastructure management.
## Conclusion
You've successfully automated the deployment of an Amazon EKS cluster and set up NGINX using Helm, all with the AWS Cloud Development Kit (CDK) in Python. This approach not only simplifies the process of deploying and managing Kubernetes resources on AWS but also leverages the power of infrastructure as code for repeatable and consistent deployments.
Embrace the flexibility and efficiency of automating your cloud infrastructure with CDK, and explore further integrations and optimizations for your Kubernetes deployments on AWS.
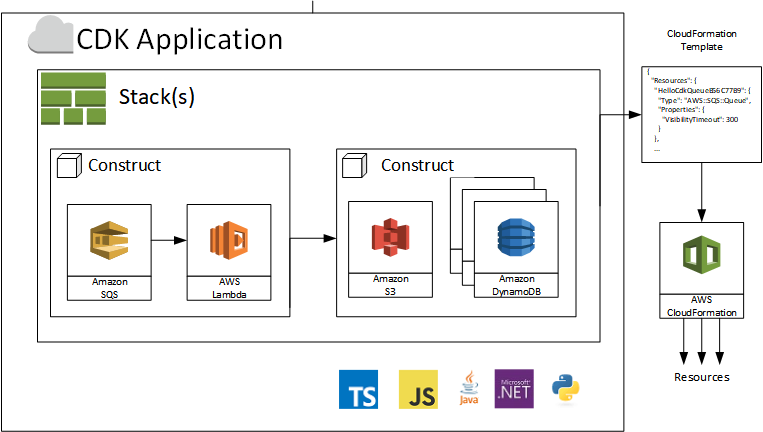
| marocz |
1,814,070 | Exploring The Magic of Python Through The Awesome Slumber Library | Slumber is one of those libraries you don't need, but can't live without once you learn about it... | 0 | 2024-04-08T12:10:00 | https://blog.derlin.ch/slumber-and-python-magic | python, programming, tutorial, todayilearned | Slumber is one of those libraries you don't need, but can't live without once you learn about it (much like [attrs](https://www.attrs.org/en/stable/)!). It covers a generic use case - interacting with RESTful services - and is a prime example of what only the Python language lets you do. Intrigued? Let me explain!
🤲 (NOTE) I recently published a new library - [mantelo](https://github.com/derlin/mantelo) - that leverages the magic of slumber to provide a fully-fledged Keycloak Admin Client. Read more in my other article → [https://blog.derlin.ch/introducing-mantelo](https://blog.derlin.ch/introducing-mantelo).
---
{%- # TOC start (generated with https://github.com/derlin/bitdowntoc) -%}
- [Introduction to slumber](#introduction-to-slumber)
* [In a few words](#in-a-few-words)
* [Slumber in action: an example with the dev.to API](#slumber-in-action-an-example-with-the-devto-api)
* [A more formal explanation of the "translation"](#a-more-formal-explanation-of-the-translation)
- [Delving into the magic](#delving-into-the-magic)
* [Theory first: dunder methods](#theory-first-dunder-methods)
* [A simple implementation (< 20 lines!)](#a-simple-implementation-amplt-20-lines)
- [Conclusion](#conclusion)
{%- # TOC end -%}
---
## Introduction to slumber
### In a few words
From the documentation:
> Slumber is a python library that provides a convenient yet powerful object oriented interface to ReSTful APIs. It acts as a wrapper around the excellent [requests library](http://python-requests.org/) and abstracts away the handling of urls, serialization, and processing requests.
In short, slumber wraps a `requests.Session` and allows you to use Pythonic constructs to call RESTful APIs. Put even more simply, it *translates Python to HTTP calls*.
Still a bit fuzzy, isn't it? Let's look at a concrete example!
### Slumber in action: an example with the dev.to API
To better understand, let's assume we need to interact with [dev.to's Forem API v1](https://developers.forem.com/api/v1). First, let's spin up a REPL, import slumber (after a `pip install`) and create an API object:
```python
>> import slumber
>> api = slumber.API("https://dev.to/api")
```
Remember slumber doesn't know about the dev.to API. Yet, we can use it to query any of its endpoints in the following manner:
```python
# Get my profile image
# ⮕ GET https://dev.to/api/profile_images/{username}
>>> api.profile_images("derlin").get()
{'type_of': 'profile_image', ...}
# Get one of my articles on dev.to
# ⮕ GET https://dev.to/api/articles?username=derlin&per_page=1
>>> api.articles.get(username="derlin", per_page="1")
[{'type_of': 'article',
'id': 1750725,
...
}]
# Try to create a user (oops, I am not allowed!)
# ⮕ POST https://dev.to/api/admin/users <body>
>>> api.admin.users.post({"email": "a@a.com", "name": "a"})
HttpClientError: Client Error 401: https://dev.to/api/admin/users/
```
The last call raised an exception, `401: unauthorized`. Normal, I am not authenticated. To change this, let's recreate the `api` object, this time passing some *auth*.
Since the Forem API uses custom headers for authentication instead of a known authentication mechanism, we can't rely on the [built-ins](https://requests.readthedocs.io/en/latest/user/authentication/) offered by requests (and thus slumber). So let's create our own authentication class:
```python
from requests.auth import AuthBase
# You can create an API key in dev.to's Settings > Extensions
DEVTO_API_KEY = "<xxx>"
# A custom Auth class that adds the right header
# to every request
class DevToAuth(AuthBase):
def __call__(self, request):
request.headers['api-key'] = DEVTO_API_KEY
return request
# Tell slumber to use the custom auth
api = slumber.API("https://dev.to/api", auth=DevToAuth())
```
To test it, let's query my articles again:
```python
>>> api.articles.me.get()
[{'type_of': 'article',
'id': 1750725,
# ...
}]
```
Magical, right?
Under the hood, slumber uses a `requests.Session` , which can be tuned in case we need to add headers or other things. Another (simpler) way of authenticating would thus be:
```python
import requests
session = requests.Session()
session.headers['api-key'] = DEVTO_API_KEY
api = slumber.API("https://dev.to/api", session=session)
```
This example shows all you need to know about slumber.
### A more formal explanation of the "translation"
How does this translation from Python to an HTTP call actually works?
As you may have guessed from the dev.to example, the slumber `api` object starts with the base URL. Every property or method is then used to add to this base. When it reaches a method that looks like an HTTP method (`.get()`, `.post()`, `.delete()`, ...), slumber puts together the final URL, makes the call, parses the response, and returns either the response body (as a dictionary) or an exception.
And since an image is worth a thousand words:

## Delving into the magic
The "translation" explained above seems rather complex. Yet, the whole slumber library is less than 1000 lines of code! Let's see how the "Python magic" makes it possible by re-implementing the translation ourselves.
### Theory first: dunder methods
In Python, *dunder methods*, short for "double underscore" methods, are *special methods* (also called *magic methods*) that define behavior for built-in Python operations. For example, `__init__` initializes newly created objects, `__repr__` returns a string representation of an object, and `__add__` defines the behavior of the `+` operator. The ability to define/override such methods at the class level is one of the distinguishing traits of Python.
For our purpose, we need to familiarize ourselves with two dunders:
* `__call__(self)` : this method enables instances to be called as if they were functions / lets you define what happens when using parentheses on class instances (`my_instance()`).
* `__getattr__(self, item)`: this method is invoked when an undefined attribute is accessed on an object. If not defined, the normal behavior is to raise an `AttributeError`.
### A simple implementation (< 20 lines!)
First, let's create a class that has a base URL and implements two HTTP methods (body left as an exercise 😉):
```python
class Resource:
def __init__(self, url):
self.url = url
def get(self, **query_params): ... # GET <url>
def post(self, body=None, **query_params): ... # POST <url>
```
With this base, we now have to implement the URL construction. How? Let's start with the addition of a path to the URL. In slumber, we do this by using an attribute *unknown* to the instance. Does it ring a bell?
```python
class Resource:
# ... rest of the implementation ...
def __getattr__(self, item):
return Resource(f"{self.url}/{item}")
```
Now, whenever we call an attribute on a `Resource`, it returns a new `Resource` with the path segment added to the URL. What about path parameters? Well, same principle, just another dunder:
```python
class Resource:
# ... rest of the implementation ...
def __call__(self, path_param):
return Resource(f"{self.url}/{path_param}")
```
The final touch is to bootstrap the whole thing by making the API object also return a `Resource` when an unknown attribute is accessed. A full implementation would thus look like:
```python
class Resource:
def __init__(self, url):
self.url = url
def get(self, **query_params):
qs = "&".join([f"{k}={v}" for k, v in query_params.items()])
print(f"GET {self.url}?{qs}")
def post(self, body=None, **query_params):
qs = "&".join([f"{k}={v}" for k, v in query_params.items()])
print(f"POST {self.url}?{qs}")
def __getattr__(self, item):
return Resource(f"{self.url}/{item}")
def __call__(self, path_param):
return Resource(f"{self.url}/{path_param}")
class API:
def __init__(self, base_url):
self.base_url = base_url
def __getattr__(self, item):
return Resource(self.base_url)
```
Let's try this out!
```python
>>> api = API("https://example.com/api/v1")
>>> api.users("lala").foo_bar.get(x=1, y="buzz")
GET https://example.com/api/v1/lala/foo_bar?x=1&y=buzz
```
With these 20 lines of code, we demystified all of slumber's magic. For this kind of thing, Python is quite awesome 😎.
## Conclusion
Even though I am more and more drawn to typed languages, Python has some nice tricks in its sleeves. I love how slumber leveraged it to provide a simple yet useful library. It is a prime example of a *good* use of dunder methods.
I hope you'll remember slumber the next time you need to interact with an API!
---
If you liked this article, leave a comment or a thumbs up, or share it around ... This would help keep my motivation up! | derlin |
1,814,280 | HTML Tips You Must Know About | Semantic HTML: <header> <h1>Website Title</h1> ... | 0 | 2024-04-08T01:18:43 | https://dev.to/pinky057/html-tips-you-must-know-about-2n3o | html, web, tutorial, programming | ## Semantic HTML:
```html
<header>
<h1>Website Title</h1>
<nav>
<ul>
<li><a href="#">Home</a></li>
<li><a href="#">About</a></li>
<li><a href="#">Contact</a></li>
</ul>
</nav>
</header>
<main>
<article>
<h2>Article Title</h2>
<p>Article content...</p>
</article>
</main>
<footer>
<p>© 2024 Website Name</p>
</footer>
```
Using semantic HTML elements helps to structure the page meaningfully, making it more accessible and understandable for both browsers and developers.
## Responsive Images:
```html
<img src="image.jpg" alt="Description of image" style="max-width:100%; height:auto;">
```
This ensures that the image scales proportionally and remains within the boundaries of its parent container, adapting to various screen sizes.
## Form Elements:
```html
<form action="/submit" method="post">
<label for="name">Name:</label>
<input type="text" id="name" name="name" required>
<label for="email">Email:</label>
<input type="email" id="email" name="email" required>
<button type="submit">Submit</button>
</form>
```
Properly structured forms with appropriate input types and labels improve user experience and accessibility.
Certainly! Here are some more unique and updated HTML examples with codes:
## Interactive SVG:
```html
<svg width="100" height="100" viewBox="0 0 100 100">
<circle cx="50" cy="50" r="40" stroke="green" stroke-width="4" fill="yellow" />
</svg>
```
SVG (Scalable Vector Graphics) allows for the creation of interactive graphics directly within HTML, providing scalability and responsiveness.
## Custom Data Attributes:
```html
<div id="product" data-product-id="12345" data-category="electronics">
<!-- Product details -->
</div>
```
Data attributes (`data-*`) provide a way to store custom data associated with HTML elements, which can be useful for JavaScript interactions and styling.
## Details and Summary:
```html
<details>
<summary>Click to expand</summary>
<p>Hidden content here...</p>
</details>
```
The `<details>` and `<summary>` elements provide a way to create collapsible content sections, allowing users to reveal additional information as needed.
## Responsive Iframe:
```html
<div style="position:relative; padding-bottom:56.25%; height:0;">
<iframe src="https://www.youtube.com/embed/VIDEO_ID" style="position:absolute; top:0; left:0; width:100%; height:100%;" frameborder="0" allowfullscreen></iframe>
</div>
```
This responsive iframe code ensures that embedded content like YouTube videos maintains its aspect ratio and adapts to different screen sizes.
## Progress Bar:
```html
<progress value="70" max="100">70%</progress>
```
The `<progress>` element creates a progress bar to indicate the completion status of a task or process.
## Picture Element for Responsive Images:
```html
<picture>
<source srcset="image-large.jpg" media="(min-width: 1024px)">
<source srcset="image-medium.jpg" media="(min-width: 768px)">
<img src="image-small.jpg" alt="Image">
</picture>
```
The `<picture>` element allows you to specify multiple image sources based on different media queries, ensuring the appropriate image is loaded based on the viewport size.
## Meter Element:
```html
<meter value="0.6" min="0" max="1">60%</meter>
```
The `<meter>` element represents a scalar measurement within a known range, such as disk usage, completion percentage, etc.
## HTML5 Features(Video and Audio):
```html
<video controls>
<source src="movie.mp4" type="video/mp4">
Your browser does not support the video tag.
</video>
<audio controls>
<source src="sound.mp3" type="audio/mpeg">
Your browser does not support the audio tag.
</audio>
```
## Forms:
```html
<form action="/submit" method="post">
<label for="username">Username:</label>
<input type="text" id="username" name="username" required>
<label for="password">Password:</label>
<input type="password" id="password" name="password" required>
<button type="submit">Login</button>
</form>
```
## Data Attributes:
```html
<div id="product" data-product-id="12345" data-category="electronics">
<!-- Product details -->
</div>
```
## Responsive Images:
```html
<picture>
<source srcset="image-large.jpg" media="(min-width: 1024px)">
<source srcset="image-medium.jpg" media="(min-width: 768px)">
<img src="image-small.jpg" alt="Image">
</picture>
```
## Accessibility:
```html
<button aria-label="Close" onclick="closeModal()">X</button>
```
The `aria-label` attribute provides an accessible label for screen readers, enhancing accessibility for users with disabilities. It describes the action performed by the button.
## Character Encoding:
```html
<meta charset="UTF-8">
```
This meta tag specifies the character encoding of the HTML document, ensuring proper display of special characters and symbols.
## HTML5 Canvas:
```html
<canvas id="myCanvas" width="200" height="100"></canvas>
```
The `<canvas>` element is used to draw graphics, animations, or other visual images on the fly using JavaScript.
## SVG Image:
```html
<svg width="100" height="100">
<circle cx="50" cy="50" r="40" stroke="black" stroke-width="3" fill="red" />
</svg>
```
SVG (Scalable Vector Graphics) allows for the creation of vector-based images that can be scaled to any size without losing quality.
## Responsive Table:
```html
<table>
<thead>
<tr>
<th>Firstname</th>
<th>Lastname</th>
<th>Age</th>
</tr>
</thead>
<tbody>
<tr>
<td>John</td>
<td>Doe</td>
<td>30</td>
</tr>
<!-- More rows... -->
</tbody>
</table>
```
Tables should be used carefully for tabular data, and in this example, the table structure is designed to adapt to different screen sizes for better responsiveness.
## Content Security Policy(CSP):
```html
<meta http-equiv="Content-Security-Policy" content="default-src 'self';">
```
Content Security Policy (CSP) is a security feature that helps prevent XSS attacks by controlling which resources can be loaded and executed on a webpage. In this example, it restricts resources to those from the same origin.
_These examples showcase various HTML concepts and best practices. Remember to modify them to fit your project needs._ | pinky057 |
1,814,327 | Why do we need to use Circuit Bracker Pattern inside Microservices? | In today’s world of distributed systems and microservices architecture, ensuring resilience and... | 0 | 2024-04-08T03:24:39 | https://dev.to/pramithamj/why-do-we-need-to-use-circuit-bracker-pattern-inside-microservices-1a21 |

In today’s world of distributed systems and microservices architecture, ensuring resilience and fault tolerance is crucial. As microservices communicate with each other over networks that can be unreliable, services may fail, leading to cascading failures and degraded performance. The Circuit Breaker pattern offers a **_solution to this problem by providing a mechanism to detect and handle failures gracefully, thereby improving the overall reliability of the system._**
### What is the Circuit Breaker Pattern?
The Circuit Breaker Pattern, inspired by its electrical counterpart, is a design pattern used in software development to handle faults and failures in distributed systems. It is implemented as a state machine that monitors the health of a service or resource. When the number of failures exceeds a predefined threshold, the circuit breaker trips and prevents further calls to the failing service for a specified period. During this time, the circuit breaker redirects calls to a fallback mechanism, such as returning cached data or providing a default response, thus preventing the failure from propagating through the system.
### Why Use the Circuit Breaker Pattern in Microservices?
In a microservices architecture, where services are independent and communicate over networks, failures are inevitable. A failure in one service can potentially impact other services that depend on it, leading to a domino effect of failures across the system. By implementing the Circuit Breaker pattern, developers can isolate and contain failures, preventing them from spreading and causing widespread outages. Additionally, the Circuit Breaker pattern helps to improve system resilience by providing mechanisms for fault tolerance, graceful degradation, and recovery.
### Implementing the Circuit Breaker Pattern
Let’s illustrate the implementation of the Circuit Breaker pattern in a simple microservice scenario using Java and Spring Boot.
1. Dependencies:
```
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
</dependencies>
```
2. Circuit Breaker Configuration:
```
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import org.springframework.stereotype.Service;
```
```
@Service
public class ServiceA {
@CircuitBreaker(name = "serviceA")
public String callServiceB() {
// Call to Service B
// Return response or throw exception if failed
}
}
```
3. Fallback Method:
```
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import org.springframework.stereotype.Service;
```
```
@Service
public class ServiceA {
@CircuitBreaker(name = "serviceA", fallbackMethod = "fallback")
public String callServiceB() {
// Call to Service B
// Return response or throw exception if failed
}
public String fallback(Exception e) {
return "Fallback response";
}
}
```
4 . Circuit Breaker Configuration (application.properties):
```
resilience4j.circuitbreaker.instances.serviceA.register-health-indicator=true
resilience4j.circuitbreaker.instances.serviceA.failure-rate-threshold=50
resilience4j.circuitbreaker.instances.serviceA.wait-duration-in-open-state=5000
resilience4j.circuitbreaker.instances.serviceA.sliding-window-size=5
```
### Conclusion:
The Circuit Breaker pattern is a valuable tool for ensuring resilience in microservices architectures. By implementing this pattern, developers can mitigate the impact of failures, prevent cascading failures, and improve the overall reliability of their systems. Through proper configuration and integration with frameworks like Spring Boot and Resilience4j, developers can build robust and fault-tolerant microservices that can withstand the challenges of distributed computing.
~ By Pramitha Jayasooriya
Contact Details
For further information or to discuss potential opportunities, please feel free to connect with me on my professional and social platforms:
LinkedIn: [Pramitha-Jayasooriya](https://www.linkedin.com/in/pramitha-jayasooriya/)
GitHub: [PramithaMJ](https://github.com/PramithaMJ)
Personal Website: [PramithaMJ.me](https://pramithamj.me/)
Email : lpramithamj@gmail.com
Looking forward to connecting with you! | pramithamj | |
1,814,638 | Emergence of Vector Databases | But First, Why ? Traditional databases have served us well for decades. They excel at... | 0 | 2024-04-08T05:34:25 | https://dev.to/lastcrown/emergence-of-vector-databases-jem | vectordatabase, llm, database, machinelearning | ## But First, Why ?
Traditional databases have served us well for decades. They excel at storing and retrieving structured data like customer records, financial transactions, or product inventories. Think of them as giant spreadsheets with rows and columns, perfectly suited for precise queries and updates.
However, the world of data has evolved. Large language models (LLMs) like GPT-4 and others revolutionize how computers understand and generate human-like text. These models operate on concepts and relationships rather than simple keywords or perfect matches. They rely on nuanced meaning and contextual similarities – something traditional databases struggle to convey.
---
## Inception of Vector Database

Let's imagine you want to recommend a book similar to a user's favorite. A traditional database might look for exact matches for title, author, or genre. An LLM needs to `understand the book's themes, writing style, mood, and the subtle connections` that make readers say, "If you liked that, you'll love this!"
Vector databases were built to address this very need. Instead of rows and columns, they store data as mathematical vectors ( lists of numbers/arrays ) that represent complex characteristics.
### How is Data Stored

Vector databases can't store raw data like PDFs or music. Lets break down the steps involved where the object to be stored is a text document
- **Preprocessing**: This involves cleaning (lowercase conversion, removing noise and stop words), tokenizing text into words or sentences, potentially applying [stemming or lemmatization](https://www.ibm.com/topics/stemming-lemmatization?ref=ref=https%3A%2F%2Fdev.to%2Farchie_lc) to reduce word variations.
- **Vector Embedding**: Once the data has been cleaned it goes through vectorization methods which transform preprocessed documents into high-dimensional vectors suitable for storage. Once tranformed these vectors capture the essence of the original data in a high-dimensional space. Models (like Word2Vec) convert the data into numerical vectors in a high-dimensional space.
- **Store the Vector**: The vector, along with some metadata, is then stored in the database enabling accurate and efficient similarity-based searches and operations. Similar vectors are stored closer to each other ( which also results in low latency high availablity).
> **Similarity, not Mathematical Equality**
Vector databases shine because they don't rely on exact matches. They employ distance metrics to `find items that are closest to a query, even if they don't share a single identical piece of information`.
This allows vector databases to find similar items (like recommending similar music) based on their vector distance, not just exact matches.
---
## How Vector Databases Empower LLMs & more
Let's return to the book recommendation example.

A vector database could store the essence of each new vector representing the user's preferences based on their reading , quickly identifying books with vectors closest to the user's preference vector.
By representing books and reading preferences as vectors, `subtle nuances in theme, style and mood can be captured`. This allows the LLM to transcend basic genre/author matching and suggest books that resonate with a reader's unique taste & preference, leading to novel literary discoveries.
**Vector databases hold immense potential and uses far beyond just book recommendation**
- **Semantic Search**: Finding relevant documents based on meaning, not just on the basis of title.
- **Image Similarity Search**: Discover visually similar images, even with variances in angle or background conditions gaining a better context for image classification.
- **Fraud Detection**: Spot patterns and anomalies in vast data sets that traditional systems might not be designed for.
- **Personalized Recommendations**: Recommendations and tailored products for individual users, not just broad categories in an infinite pool of products.
---
## The Contenders : Rising Vector DBs

The rapid growth in Artificial Intelligence and Large language models have necessitated new solutions for storage and vector databases have spurred innovation, with several exciting solutions .
- **Chroma DB**: An open-source vector database known for its ease of use and focus on developer experience. Chroma offers both local and cloud-based deployment options.
[ChromaDB-🔗](https://docs.trychroma.com/?ref=https%3A%2F%2Fdev.to%2Farchie_lc)
- **Milvus**: An open-source vector database designed for flexibility and scalability. Milvus has seen substantial growth, with its parent company Zilliz recently securing $43 million in Series B funding.
[Milvus-🔗](https://milvus.io/?ref=https%3A%2F%2Fdev.to%2Farchie_lc)
- **Pinecone**: A fully-managed vector database offering a cloud-based solution for easy deployment and integration. Pinecone has garnered significant interest, raising a $10 million seed round.
[Pinecone-🔗](https://www.pinecone.io/?ref=https%3A%2F%2Fdev.to%2Farchie_lc)
- **Weaviate**: Another open-source vector database with strong modularity, allowing it to be combined with various machine learning models, allowing for the combination of vector search with structured filtering with the fault tolerance and scalability.
[Weaviate-🔗](https://weaviate.io/?ref=https%3A%2F%2Fdev.to%2Farchie_lc)
- **Qdrant**: A high-performance vector database emphasizing speed and efficiency. Qdrant is open-source and has seen growing adoption within the community.
[Qdrant-🔗](https://qdrant.tech/?ref=https%3A%2F%2Fdev.to%2Farchie_lc)
These are just a few examples, with numerous other notable players emerging. The vast amount of code contribution and substantial funding rounds highlight the growing belief in the importance of vector databases for the future of AI-powered applications.
---
If your business has a problem that could leverage the potential of vector database & LLMs then reach out to us for deployment and integrations .
Reach Out to us
[Book a Consultation](https://cal.com/lastcrown)
[LastCrown on LinkedIn](https://www.linkedin.com/company/lastcrown)
[LastCrown on Facebook](https://facebook.com/lastcrown.in)
[LastCrown on Instagram](https://instagram.com/lastcrown.in)
| archie_lc |
1,814,805 | Buy Google 5 Star Reviews | https://dmhelpshop.com/product/buy-google-5-star-reviews/ Buy Google 5 Star Reviews Reviews... | 0 | 2024-04-08T08:05:53 | https://dev.to/xevoxob851/buy-google-5-star-reviews-51ja | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-google-5-star-reviews/\n\n\n\nBuy Google 5 Star Reviews\nReviews represent the opinions of experienced customers who have utilized services or purchased products from various online or offline markets. These reviews convey customer demands and opinions, and ratings are assigned based on the quality of the products or services and the overall user experience. Google serves as an excellent platform for customers to leave reviews since the majority of users engage with it organically. When you purchase Buy Google 5 Star Reviews, you have the potential to influence a large number of people either positively or negatively. Positive reviews can attract customers to purchase your products, while negative reviews can deter potential customers.\n\nIf you choose to Buy Google 5 Star Reviews, people will be more inclined to consider your products. However, it is important to recognize that reviews can have both positive and negative impacts on your business. Therefore, take the time to determine which type of reviews you wish to acquire. Our experience indicates that purchasing Buy Google 5 Star Reviews can engage and connect you with a wide audience. By purchasing positive reviews, you can enhance your business profile and attract online traffic. Additionally, it is advisable to seek reviews from reputable platforms, including social media, to maintain a positive flow. We are an experienced and reliable service provider, highly knowledgeable about the impacts of reviews. Hence, we recommend purchasing verified Google reviews and ensuring their stability and non-gropability.\n\nLet us now briefly examine the direct and indirect benefits of reviews:\nReviews have the power to enhance your business profile, influencing users at an affordable cost.\nTo attract customers, consider purchasing only positive reviews, while negative reviews can be acquired to undermine your competitors. Collect negative reports on your opponents and present them as evidence.\nIf you receive negative reviews, view them as an opportunity to understand user reactions, make improvements to your products and services, and keep up with current trends.\nBy earning the trust and loyalty of customers, you can control the market value of your products. Therefore, it is essential to buy online reviews, including Buy Google 5 Star Reviews.\nReviews serve as the captivating fragrance that entices previous customers to return repeatedly.\nPositive customer opinions expressed through reviews can help you expand your business globally and achieve profitability and credibility.\nWhen you purchase positive Buy Google 5 Star Reviews, they effectively communicate the history of your company or the quality of your individual products.\nReviews act as a collective voice representing potential customers, boosting your business to amazing heights.\nNow, let’s delve into a comprehensive understanding of reviews and how they function:\nGoogle, with its significant organic user base, stands out as the premier platform for customers to leave reviews. When you purchase Buy Google 5 Star Reviews , you have the power to positively influence a vast number of individuals. Reviews are essentially written submissions by users that provide detailed insights into a company, its products, services, and other relevant aspects based on their personal experiences. In today’s business landscape, it is crucial for every business owner to consider buying verified Buy Google 5 Star Reviews, both positive and negative, in order to reap various benefits.\n\nSince both positive and negative reviews have an impact on online businesses and trading activities, it is important to determine which type of reviews align with your objectives. If your aim is to influence potential customers online and attract organic traffic, then investing in positive Buy Google 5 Star Reviews is recommended. However, it is crucial to prioritize security and only purchase verified Google reviews. On the other hand, if you wish to acquire negative Google reviews, it is advisable to first gather relevant feedback and reviews.\n\nWhy are Google reviews considered the best tool to attract customers?\nGoogle, being the leading search engine and the largest source of potential and organic customers, is highly valued by business owners. Many business owners choose to purchase Google reviews to enhance their business profiles and also sell them to third parties. Without reviews, it is challenging to reach a large customer base globally or locally. Therefore, it is crucial to consider buying positive Buy Google 5 Star Reviews from reliable sources. When you invest in Buy Google 5 Star Reviews for your business, you can expect a significant influx of potential customers, as these reviews act as a pheromone, attracting audiences towards your products and services. Every business owner aims to maximize sales and attract a substantial customer base, and purchasing Buy Google 5 Star Reviews is a strategic move.\n\nAccording to online business analysts and economists, trust and affection are the essential factors that determine whether people will work with you or do business with you. However, there are additional crucial factors to consider, such as establishing effective communication systems, providing 24/7 customer support, and maintaining product quality to engage online audiences. If any of these rules are broken, it can lead to a negative impact on your business. Therefore, obtaining positive reviews is vital for the success of an online business. To attract a large customer base, it is necessary to purchase Buy Google 5 Star Reviews for both local and international markets. Additionally, buying reviews from other platforms can further boost your business profile.\n\nWhat are the benefits of purchasing reviews online?\nIn today’s fast-paced world, the impact of new technologies and IT sectors is remarkable. Compared to the past, conducting business has become significantly easier, but it is also highly competitive. To reach a global customer base, businesses must increase their presence on social media platforms as they provide the easiest way to generate organic traffic. Numerous surveys have shown that the majority of online buyers carefully read customer opinions and reviews before making purchase decisions. In fact, the percentage of customers who rely on these reviews is close to 97%. Considering these statistics, it becomes evident why we recommend buying reviews online. In an increasingly rule-based world, it is essential to take effective steps to ensure a smooth online business journey.\n\nBuy Google 5 Star Reviews\nMany people purchase reviews online from various sources and witness unique progress. Reviews serve as powerful tools to instill customer trust, influence their decision-making, and bring positive vibes to your business. Making a single mistake in this regard can lead to a significant collapse of your business. Therefore, it is crucial to focus on improving product quality, quantity, communication networks, facilities, and providing the utmost support to your customers.\n\nReviews reflect customer demands, opinions, and ratings based on their experiences with your products or services. If you purchase Buy Google 5-star reviews, it will undoubtedly attract more people to consider your offerings. Google is the ideal platform for customers to leave reviews due to its extensive organic user involvement. Therefore, investing in Buy Google 5 Star Reviews can significantly influence a large number of people in a positive way.\n\nHow to generate google reviews on my business profile?\nFocus on delivering high-quality customer service in every interaction with your customers. By creating positive experiences for them, you increase the likelihood of receiving reviews. These reviews will not only help to build loyalty among your customers but also encourage them to spread the word about your exceptional service. It is crucial to strive to meet customer needs and exceed their expectations in order to elicit positive feedback. If you are interested in purchasing affordable Google reviews, we offer that service.\n\nOnce you have established a strong rapport with your customers through the provision of quality service, kindly request them to share their experiences on Google voluntarily. You can provide them with a direct link or clear instructions on how to leave a review. If possible, offering them a written script can simplify the process for them. Additionally, we offer the option to buy online reviews from us at a reasonable price, with a 100% replacement and cash back guarantee.\n\nIt is essential to reply or respond to the customer opinions left as reviews promptly. Make it easy for customers to leave reviews by prominently displaying review options on your website and social media profiles. Furthermore, consider offering incentives to customers who assist you by leaving reviews, such as providing them with better service at a discounted price.\n\nAlternatively, if you are interested in generating verified Buy Google 5 Star Reviews for your website, you can quickly reach out to dmhelpshop.com. Our team of experts is readily available to help you purchase verified Google reviews at cost-effective prices.\n\nNow, let’s discuss how Google reviews work and the value they add.\nAccording to research conducted by various platforms in the field of online marketing, users tend to engage with reviews that they perceive as authentic. Once a review is submitted, it undergoes a moderation process to ensure compliance with Google’s content guidelines. Another study reveals that many individuals rely on reviews to inform their purchasing decisions. By purchasing online reviews from a trustworthy source, you can significantly enhance your business’s reputation in a short period of time.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | xevoxob851 |
1,814,833 | Giới Thiệu Nhà cái RS8sport Linh Truy Cập Mới Nhất Châu Á. | Giới Thiệu Nhà cái RS8sport Linh Truy Cập Mới Nhất Châu Á. RS8sport là trang các cược uy tín đứng... | 0 | 2024-04-08T08:45:37 | https://dev.to/rs8is/gioi-thieu-nha-cai-rs8sport-linh-truy-cap-moi-nhat-chau-a-1adm | webdev, beginners, programming, javascript | Giới Thiệu Nhà cái RS8sport Linh Truy Cập Mới Nhất Châu Á.
RS8sport là trang các cược uy tín đứng hàng đầu Thế Giới
Với nhiều năm kinh nghiệm trong lĩnh vực cung cấp sân chơi các cược thể thao.
Nhà cái RS8 cung cấp nhiều Kèo cược Đa Dạng và Hấp Dẫn
Giao diện , đồ họa được thiết đẹp mắt . Âm thanh vô cùng sống động
Hãy tham gia ngay để trải nghiệm RS8.i
WEB: https://rs8.is/
Fanpage: https://facebook.com/rs8is/
**#rs8 #rs8is #trangchurs8 #nhacairs8**

| rs8is |
1,814,942 | Unlocking the Power of Freelance Programming Talent: A Guide to Finding PHP, Python, and Java Experts | In today’s fast-paced digital world, businesses need to stay ahead of the curve. This often means... | 0 | 2024-04-08T10:39:53 | https://dev.to/hiredevelopers1/unlocking-the-power-of-freelance-programming-talent-a-guide-to-finding-php-python-and-java-experts-4knd | developers, java, python, php | In today’s fast-paced digital world, businesses need to stay ahead of the curve. This often means having the right programming talent on board. Whether you’re looking for a PHP whiz, a Python pro, or a Java genius, finding the right freelance developer can be a game-changer for your projects. Here’s how you can efficiently locate and collaborate with top-tier talent in each of these programming languages.
1. **Discovering PHP Programmers**
PHP is a fundamental pillar of web development, powering numerous websites and applications worldwide. When seeking freelance PHP developers, consider these strategies:
**Freelance Platforms**: Reputable platforms like Upwork, Freelancer, and Toptal are excellent places to connect with experienced PHP developers. They offer a diverse range of talent with varying skill levels and expertise.
**Online Communities**: Engage with online communities such as GitHub, Stack Overflow, and PHP forums. These platforms allow developers to showcase their skills and collaborate on projects, providing valuable networking opportunities.
**Referrals**: Utilize your professional network and ask for referrals. Personal recommendations from colleagues, friends, or industry contacts can often lead to discovering skilled PHP developers.
2. **Hiring Freelance Python Developer**
Python’s versatility and ease of use have made it a favorite among developers for various applications, including web development, data analysis, and artificial intelligence. To find freelance Python developers, consider these avenues:
**Specialized Platforms**: Platforms like Toptal, Guru, and Python-specific job boards such as Python.org and Python Developers cater specifically to Python talent, simplifying your search for developers with the expertise you need.
**Online Portfolios**: Browse through online portfolios and GitHub repositories of [freelance Python developer](https://hiredevelopers.co.in/hire-python-developer/) to assess their skills and project experience. Look for developers who have worked on projects similar to yours and demonstrate proficiency in relevant Python libraries and frameworks.
**Tech Events and Meetups**: Attend tech events, conferences, and Python meetups. These gatherings provide opportunities to network with industry professionals and discover potential freelance collaborators.
3. **Seeking Freelance Java Developers**
Java is a staple in enterprise-level development, powering a wide range of applications, from mobile apps to backend systems. When searching for [freelance for Java developer](https://hiredevelopers.co.in/hire-java-developer/), consider these strategies:
**Job Boards**: Popular job boards like Indeed, Glassdoor, and LinkedIn are great places to post job listings or search for freelance Java developers. These platforms attract a large pool of talent and allow you to specify your requirements to find the right match.
**Freelance Communities**: Join online communities and forums dedicated to Java development, such as JavaRanch and Stack Overflow. These platforms allow you to interact with experienced Java developers and seek recommendations for freelance opportunities.
**Developer Networks**: Tap into developer networks and communities like GitHub, GitLab, and Java User Groups (JUGs) to discover talented Java developers. Building relationships within these networks can lead to long-term collaborations and access to top-tier Java talent.
**Conclusion**
[Find Php programmers](https://hiredevelopers.co.in/hire-php-developer/), Python, and Java projects requires a strategic approach tailored to each programming language’s ecosystem. By leveraging freelance platforms, online communities, and professional networks, you can connect with skilled developers who meet your project requirements and contribute to your success. Whether you’re building a website, developing a mobile app, or tackling complex software projects, investing time and effort into finding the right freelance developer is key to achieving your goals. Start your search today and unlock the expertise of freelance programmers in PHP, Python, and Java.
 | hiredevelopers1 |
1,815,181 | Material-UI: Turning Ideas into Interfaces with Style and Efficiency | Material-UI: Turning Ideas into Interfaces with Style and Efficiency | 0 | 2024-04-08T18:53:01 | https://dev.to/douglasporto/material-ui-turning-ideas-into-interfaces-with-style-and-efficiency-ecn | frontend, developer, nextjs, materialui | ---
title: Material-UI: Turning Ideas into Interfaces with Style and Efficiency
published: true
description: Material-UI: Turning Ideas into Interfaces with Style and Efficiency
tags: [frontend, developer, next, materialui]
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/vlk5tr8eagzonycrkaqy.png
# Use a ratio of 100:42 for best results.
# published_at: 2024-04-08 13:50 +0000
---
Hey devs ✌🏾
Kicking off this post with an apology for being MIA for so long.
These past few months have been crazy busy.
Now that things are kinda calming down, I'm looking forward to dropping by more often to share some insights.
So, why am I such a fan of material-ui, even though it doesn't get a ton of buzz in the community?
In my journey as a full-stack developer, I've always been on the lookout for tools that not only streamline my workflow but also boost the end-user's quality and experience. Among the gems I've discovered, material-ui stands out as a priceless treasure for any React project. This post dives deep into why material-ui has become my go-to buddy for crafting sleek and efficient user interfaces.
**Why Material-UI?**
The first time I stumbled upon material-ui, I was drawn in by the promise of rich, pre-built components that follow Material Design principles. What I found was much more: a robust library that serves as a one-stop shop for UI/UX design, from grid systems to interactive icons. Every component in material-ui opens the door to an intuitive and accessible user interface, ready to be customized and integrated into projects of any scale.
**Components that Speak**
Every button, menu, and dialog in material-ui carries a user-centered design philosophy, ensuring that each element not only looks good but also feels intuitive to use. Embracing material-ui in my projects has allowed me to focus on crafting rich user experiences without getting bogged down in the technical details of building components from scratch.
**Hassle-Free Customization**
However, the real strength of Material-UI lies in its flexibility. With a detailed theming system and extensive customization options, I've been able to bring my design visions to life, tweaking components to perfectly fit the unique visual identity of each project. material-ui has equipped me with the tools to fine-tune styles, catering to both functional needs and aesthetic preferences.
**Building the Future**
Beyond the components and customization, material-ui represents a lively community of developers and designers committed to pushing the envelope in interface design. Incorporating material-ui into my projects has not only enhanced my front-end development but also connected me to a community of innovators, each contributing to the future of digital design.
**Conclusion: A Union of Efficiency and Aesthetics**
Adopting Material-UI was more than a technical decision; it was a commitment to efficiency, aesthetics, and user experience. For fellow developers looking to elevate their React projects, diving into the world of material-ui is a move that will transform not just your interfaces, but also how you approach software design and development.
I'm making a promise to you guys to start posting a lot of content here, building cool stuff with react and material-ui.
| douglasporto |
1,815,225 | How-To: Event Systems in Unity | At some point, you've likely encountered a situation where you needed to trigger functions or change... | 0 | 2024-04-08T15:11:41 | https://blog.thebear.dev/how-to-event-systems-in-unity | unity3d, tutorial, eventdriven, csharp | At some point, you've likely encountered a situation where you needed to trigger functions or change variables in response to a change elsewhere in your code. For example, you may want to:
* Play sad music and display a game-over screen when the player's health reaches 0.
* Change the animation set when the player's health drops below 25%.
* Trigger a special ability when the player is damaged.
While you *can* have these components check the player's health every `Update()`, this quickly becomes unwieldly.
Running checks in `Update()` is wasteful; it still consumes processor time even if there is no change. When you have many scripts on many objects checking many different variables, this can significantly impact your performance. The real cost, however, lies in code maintenance. You need to maintain references to everything and the code to check each condition for each object throughout your codebase, making it challenging to modify or expand your code.
Instead of relying on thousands of `if/else` statements, consider building an Event System.
### What is an Event System?
An event system is a system that allows scripts to broadcast information to other scripts that are listening. Think of it as a news radio; recent events are broadcast on the news channel, and anyone tuned in and listening will receive this information without repeatedly checking or asking for updates.
Event systems are essential for games with any degree of complexity. They enable different scripts to communicate with each other in a clean and maintainable way, without requiring an extensive web of references or allowing scripts to be directly controlled by other unrelated scripts.
While there are many ways to structure an event system depending on your needs, two methods I recommend are via an Event Manager or Event Channels.
## Method 1 : Event Manager Monobehavior
A popular method is to create a singleton event manager, an object of an `EventManager` class designed so that only one instance exists at a time and is accessed through the class's properties.
```csharp
using System;
using System.Collections.Generic;
using UnityEngine;
/// <summary> Broadcasts events and associated data to interested parties. </summary>
public class EventManager : MonoBehaviour
{
private Dictionary<GameEvent, Action<Dictionary<string, object>>> eventDictionary;
private static EventManager eventManager;
public static EventManager instance
{
get
{
// if no instance is set, search for one in the scene
if (!eventManager)
{
eventManager = FindFirstObjectByType(typeof(EventManager)) as EventManager;
if (!eventManager)
{
// Still didn't find one, throw an error.
Debug.LogError("There needs to be one active EventManager script on a GameObject in your scene.");
}
else
{
// initialize the event dictionary for the newly found instance And flag it
// so it is not destroyed on scene loading
eventManager.Init();
DontDestroyOnLoad(eventManager);
}
}
return eventManager;
}
}
/// <summary> Initializes the event dictionary. </summary>
private void Init()
{
if (eventDictionary == null)
{
eventDictionary = new Dictionary<GameEvent, Action<Dictionary<string, object>>>();
}
}
/// <summary> Registers a function to the event listener. </summary>
/// <param name="eventID"> The event we are listening for. </param>
/// <param name="listener"> The function that is subscribing. </param>
public static void StartListening(GameEvent eventID, Action<Dictionary<string, object>> listener)
{
if (eventManager == null) return;
Action<Dictionary<string, object>> thisEvent;
if (instance.eventDictionary.TryGetValue(eventID, out thisEvent))
{
thisEvent += listener;
instance.eventDictionary[eventID] = thisEvent;
}
else
{
thisEvent += listener;
instance.eventDictionary.Add(eventID, thisEvent);
}
}
/// <summary> Unregisters a function from the event listener. </summary>
/// <param name="eventID"> The event we were looking for. </param>
/// <param name="listener"> The function that was listening. </param>
public static void StopListening(GameEvent eventID, Action<Dictionary<string, object>> listener)
{
if (eventManager == null) return;
if (instance.eventDictionary.TryGetValue(eventID, out Action<Dictionary<string, object>> thisEvent))
{
thisEvent -= listener;
instance.eventDictionary[eventID] = thisEvent;
}
}
/// <summary> Triggers an event, activating all the functions registered to the event. </summary>
/// <param name="eventID"> The event to trigger. </param>
/// <param name="eventData"> The data carried by the event. </param>
public static void TriggerEvent(GameEvent eventID, Dictionary<string, object> eventData)
{
if (instance.eventDictionary.TryGetValue(eventID, out Action<Dictionary<string, object>> thisEvent))
{
thisEvent?.Invoke(eventData);
}
}
}
```
This general-purpose `EventManager` class has three important functions, `StartListening()`, `StopListening()`, and `TriggerEvent()`. Because they are [static](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/keywords/static), they can be accessed from anywhere, without having to find or store a reference to the manager (it does this itself).
The list of subscribers is stored in a dictionary of delegates in the form of `Actions`, with a `GameEvent` enum as the key. Using an enum as the key is beneficial due to the ability to use your IDE's IntelliSense to find or autocomplete it, preventing bugs caused by typos.
Here's an example `GameEvent`:
```csharp
public enum GameEvent
{
NetworkManagerLoaded,
FadeOutCompleted,
FadeInCompleted,
PlayerTakeDamage,
PlayerDealDamage,
PlayerDodged,
PlayerControlActivated,
PlayerControlDeactivated,
GamePaused,
GameUnpaused,
SettingsChanged,
UpdateHUD
}
```
To subscribe a function to an event, you pass the function and the event you want it to listen for to the manager through `StartListening()`.
```csharp
// Start listening for game pause events
EventManager.StartListening(GameEvent.GamePaused, OnGamePaused);
```
This registers the function to the delegate associated with that game event.
To trigger an event, you call `TriggerEvent()`, creating a new event data dictionary containing the data you need to broadcast in the form of a `Dictionary<string, object>`.
```csharp
EventManager.TriggerEvent(GameEvent.PlayerTakeDamage, new Dictionary<string, object> {
{ "Player", playerTwo },
{ "Amount", damageTaken },
{ "Source", damageSource }
});
```
The event data dictionaries have string keys and accept any object, allowing you to broadcast any type of data or multiple types through the same function using human-readable labels.
To use the data from the dictionary in the subscriber function, retrieve it from the dictionary by key and cast it to the appropriate type. The data must be cast because it is stored as a generic object.
```csharp
public void OnPlayerControlDeactivated(Dictionary<string, object> data)
{
PlayerEntity affectedPlayer = (PlayerEntity)data["Player"];
// Continue doing stuff
}
```
Finally, once you're done listening for events, unsubscribe from the event manager using the `StopListening()` method. This is necessary because the delegate does not check for duplicate functions, nor does it automatically remove references to inactive or destroyed objects. This creates the potential for memory leaks and bugs such as functions being called multiple times per event trigger.
There is no harm in unsubscribing an unsubscribed function, so a good practice is to unsubscribe from every event you listen for during `OnDisable()` or `OnDestroy()`.
```csharp
private void OnDisable()
{
// Stop listening for game events
EventManager.StopListening(GameEvent.GamePaused, OnGamePaused);
EventManager.StopListening(GameEvent.GameUnpaused, OnGameUnpaused);
EventManager.StopListening(GameEvent.PlayerDead, OnPlayerDead);
}
```
That's it! Now you have an event manager! 👏🏽🎉
Just add the `EventManager` component to a game object in the main scene.
### Summary
**Pros:**
* ***Accessible.*** Universally accessible without references or searching for instances.
* ***Flexible.*** Can transmit any number and any type of parameters to the subscribers.
* ***Simple.*** All events are handled the same way through the same three functions regardless of what they broadcast.
**Cons:**
* ***Inefficient*.** Requires the creation of a new `Dictionary<string, object>` each trigger, regardless of if any data is actually being transmitted. Using transmitted data requires casting, an additional performance cost.
* ***Error-Prone.*** String keys are prone to typos that will not be picked up by the IDE; "ItemUsed", "Item Used", and "Item used" are three completely different keys.
* ***Increased Debugging Difficulty.*** It is not possible for an IDE to determine which functions are listening to what events, making it more difficult to track down bugs.
* ***Non-Serializable:*** The delegates cannot be serialized, meaning the listeners cannot be saved to a file and must be re-registered in code if the game is reloaded.
**Notes:**
* You could remove the event data dictionaries to avoid the memory allocation and performance issues if you do not need to broadcast data.
* You may choose to use an `EventData` enum for a key, or replace the dictionary with an `EventData` struct to avoid issues with string keys or casting.
## Method 2 : Event Channel Scriptable Objects
An alternative to the monolithic event manager class is to separate your events into individual objects called event channels. This is achieved using Scriptable Objects. An event channel that passes no arguments looks like the following.
```csharp
/// <summary>
/// An event channel that does not broadcast a variable.
/// </summary>
[CreateAssetMenu(fileName = "New Void Event Channel", menuName = "Scriptable Objects/Events/Void Event Channel")]
public class EventChannel : ScriptableObject
{
// -----------------------------------------
public UnityAction Event;
public bool autoClean = true;
// -----------------------------------------
/// Clears the event list when out of scope
private void OnDisable()
{
if (autoClean)
{
Event = null;
}
}
/// Triggers the event in this channel.
public void Broadcast()
{
Event?.Invoke();
}
}
```
From this base class, you create new instances of the scriptable object representing the events you need, such as `GamePaused`, `GameUnpaused`, `MenuOpened`, or `StartSceneTransition`.
> <div data-node-type="callout">
> <div data-node-type="callout-emoji">💡</div>
> <div data-node-type="callout-text"><strong>Tip:</strong> If you do not know how to use or instantiate scriptable objects, you should check out the <a target="_blank" rel="noopener noreferrer nofollow" href="https://docs.unity3d.com/Manual/class-ScriptableObject.html" style="pointer-events: none">official documentation on the subject</a>.</div>
> </div>
To subscribe to the event, the subscriber must first obtain a reference to the event channel object in question. This is easily done by dropping a reference to the channel in the listener script using the Unity inspector.
In code, subscribe to the event's delegate using the additive compound assignment operation, as you would for any other delegate.
```csharp
// This is set via inspector to the PlayerDamaged event channel object.
[SerializeField] private EventChannel playerDamaged;
private void Start()
{
// Start listening to the event
playerDamaged.Event += OnPlayerDamaged;
}
private void OnDisable()
{
// stop listening to the event
playerDamaged.Event -= OnPlayerDamaged;
}
// This function is run when the event is triggered
public void OnPlayerDamaged()
{
Debug.Log("Player took damage.");
}
```
Once referenced, trigger the event either directly or using the event's `Broadcast()` function.
```csharp
// Trigger directly
playerDamaged.Event?.Invoke();
// The helper function just looks cleaner
playerDamaged.Broadcast();
```
As with the Event Manager monobehavior, it is important to remove all event subscriptions from the event channel when no longer needed. Scriptable objects persist through sessions and will collect references to destroyed or inaccessible objects as gameplay continues if not properly handled. The event channel's `OnDisable()` function clears the delegate when the channel itself is unloaded to prevent this persistence, but other objects can still create garbage and null reference exceptions if they do not unregister themselves properly.
However, you can disable the auto-clearing if you want persistent event references (such as setting up level-specific events or UI events). In this case, properly unsubscribing listeners is crucial.
### Event Channels With Data
You can create additional event channels that accept one or more parameters for more complex events. An easy way to implement this is with generic classes.
```csharp
/// <summary>
/// An event channel that broadcasts a single variable.
/// </summary>
[CreateAssetMenu(fileName = "New Single Event Channel", menuName = "Scriptable Objects/Events/Single Event Channel")]
public class SingleEventChannel<T> : ScriptableObject
{
// -----------------------------------------
public UnityAction<T> Event;
public bool autoClean = true;
// -----------------------------------------
/// Clears the event list when out of scope
private void OnDisable()
{
if (autoClean)
{
Event = null;
}
}
/// Triggers the event in this channel.
public void Broadcast(T firstParameter)
{
Event?.Invoke(firstParameter);
}
}
```
While you can't use a generic class directly in Unity, you can inherit from it to create concrete variations that all share the same code. You can create new data channels by writing empty channel classes that derive from the generic one but with a specified type.
```csharp
/// <summary>
/// An event channel that broadcasts a single integer.
/// </summary>
[CreateAssetMenu(fileName = "New Int Event Channel", menuName = "Scriptable Objects/Events/Int Event Channel")]
public class IntEventChannel : SingleEventChannel<int>
{
}
/// <summary>
/// An event channel that broadcasts a single player reference.
/// </summary>
[CreateAssetMenu(fileName = "Player Event Channel", menuName = "Scriptable Objects/Events/Player Event Channel")]
public class PlayerEventChannel : SingleEventChannel<Player>
{
}
```
These concrete implementations can be instantiated as `ScoreChanged`, `DamageTaken`, and `TokensRecieved`, or `PlayerDied`, `PlayerSpawned`, and `PlayerPickedUpToken`, for example.
You can expand this further to create even more complex channels.
```csharp
/// <summary>
/// An event channel that broadcasts four variables.
/// </summary>
[CreateAssetMenu(fileName = "New Quad Event Channel", menuName = "Scriptable Objects/Events/Quad Event Channel")]
public class QuadEventChannel<T, I, J, K> : ScriptableObject
{
// -----------------------------------------
public UnityAction<T, I, J, K> Event;
public bool autoClean = true;
// -----------------------------------------
/// Clears the event list when out of scope
private void OnDisable()
{
if (autoClean)
{
Event = null;
}
}
/// Triggers the event in this channel.
public void Broadcast(T first, I second, J third, K fourth)
{
Event?.Invoke(first, second, third, fourth);
}
}
[CreateAssetMenu(fileName = "New PTIV Event Channel", menuName = "Scriptable Objects/Events/PTIV Event Channel")]
public class PTInvV3EventChannel : QuadEventChannel<Player, Token, Inventory, Vector3>
{
}
```
This could be used to implement events like `PlayerDepositsTokenIntoInventoryFromDirection`, which might be overly specific but serves as a good demonstration.
And there you have it. Event channels! 🎙️📡
### Summary
**Pros:**
* ***Compartmentalized:*** Each channel exists as its own globally accessible file with no need for a manager game object.
* ***Performant.*** Uses only delegates and function parameters, with no casting or object creation required.
* ***Serializable:*** References and listener lists can be saved to a file, allowing them to persist across scene loads and be set via the inspector.
* ***Easier Development***. Strong typing allows for autocompletion and code-traversal by the IDE.
**Cons:**
* ***Game Asset:*** Each game event is its own asset in the filesystem, which can be difficult to reference without the Unity inspector and can be slow to find in folders when there is a large number of events used.
* ***Requires References:*** Scripts need to reference a specific channel instance, which must be updated or restored if lost by error or code modification.
* ***Persistent:*** Failing to unsubscribe properly results in additional headaches due to the persistence of the scriptable objects, especially during development.
* ***More Setup Time:*** Unlike the Event Manager, you need to create and manage event channels individually, as well as write a new event channel class for every combination of parameters you want to broadcast.
**Notes:**
* Complex events may benefit from using an `EventArgs` struct to wrap the data, so adding data to the broadcast only requires you to add a property to the struct instead of a new parameter to the event channel and every listener it calls.
* You may wish to add a `name` and `description` string field to the event channel so you can make notes of what the event is intended to do or how it is intended to be used.
## Conclusion
Your event systems are a crucial part of your game's architecture; they allow for clean and maintainable communication between hundreds or even thousands of different components. But there are many ways to do it, and building the right tool for your use case makes your life as a developer easier and increases the chance you will successfully publish your game!
<a href="https://www.buymeacoffee.com/bearevans" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-orange.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a> | bearevans |
1,815,265 | Making a Telegram bot with BotticelliBots | Let's imagine, that we need to create a .NET core - based chatbot, that shows us current time in... | 27,046 | 2024-04-10T12:00:35 | https://dev.to/botticellibots/making-a-telegram-bot-with-botticellibots-2jmi | bot, telegram, botticellibots, csharp |

Let's imagine, that we need to create a .NET core - based chatbot, that shows us current time in UTC.
So, we need .NET Core 8.0 and very basic knowledge of C#.
**Before you start**
Please, check your .NET Core and Visual Studio version. You should have .NET Core 8 or higher and VS 2022 or Rider v. 2023.x (any edition). If no - check [this](https://visualstudio.microsoft.com/ru/vs/) and [this](https://dotnet.microsoft.com/en-us/download/dotnet/8.0). As a framework and chatbot-management system, we'll use [BotticelliBots](https://botticellibots.com) v. 0.3: [see here](https://github.com/devgopher/botticelli/releases/tag/v0.3). You may load it as a submodule with your git repository.
**Docs**
- [Botticelli common documentation](http://botticellibots.com/documentation)
- [Bot adding/registration in admin pane](http://botticellibots.com/documentation/management/registering-a-new-bot)
- [Admin pane deployment scripts for Linux and Windows](https://github.com/devgopher/botticelli/tree/release/0.3/deploy)
**What do we want**
We need to create a chat bot, that will show you a UTC time on command
And also we need to administrate this bot.
**Let's register our Telegram bot**
Please, check a Telegram [BotFather bot](https://t.me/BotFather) and follow the instructions
**Some basics for BotticelliBots**
Botticelli is an open-source .NET Core framework for building your own universal bots integrated with databases, queue brokers, speech engines and AI engines (such as ChatGPT, DeepSeek and YaGPT).
In our case, we need several entities to use:
- Commands - represents a messenger command (such as /test)
- Command Processors. Each command needs it's own processor to encapsulate any business logic
- IBot - interface, that represents main bot functions (such as sending message to a chat)
- Message - general message representation, that consists of ChatId, Id and contents
**Let's start**
Let's open our Visual Studio/Rider and create a WebApi project for .Net Core.
First of all, we need to make some injections in Program.cs:
```csharp
var builder = WebApplication.CreateBuilder(args);
var settings = builder.Configuration
.GetSection(nameof(VeryBasicBotSettings))
.Get<VeryBasicBotSettings>();
// Adds telegram bot injections
builder.Services.AddTelegramBot(builder.Configuration,
new BotOptionsBuilder<TelegramBotSettings>()
.Set(s => s.SecureStorageSettings = new SecureStorageSettings
{
ConnectionString = settings?.SecureStorageConnectionString
})
.Set(s => s.Name = settings?.BotName));
// Adds a hosted service, intended for keeping bot working during all
// the lifecycle of a bot
builder.Services.AddHostedService<VeryBasicBotService>();
// Adds a command processor, being used for proceeding a business logic for
// '/GetUtc' command and also adds some validation (in this case - pass validator, that tells OK to any command args)
builder.Services.AddBotCommand<GetUtcCommand, GetUtcCommandProcessor<ReplyKeyboardMarkup>, PassValidator<GetUtcCommand>>();
var app = builder.Build();
app.Services.RegisterBotCommand<GetUtcCommand, GetUtcCommandProcessor<ReplyKeyboardMarkup>, TelegramBot>();
app.Run();
```
**Command Processors**
Each command needs to be processed in it's own processor. Please note, that we should follow a calling convention for a processor and a command:
```csharp
class <*YourCommandName*>CommandProcessor<TReplyMarkupBase> : CommandProcessor<*YourCommandName*Command>
public class *YourCommandName*Command : ICommand
```
So, our command processor should be look like:
```csharp
/// <summary>
/// A processor for "/GetUtc" command
/// </summary>
/// <typeparam name="TReplyMarkupBase"></typeparam>
public class GetUtcCommandProcessor<TReplyMarkupBase> : CommandProcessor<GetUtcCommand>
where TReplyMarkupBase : class
{
public GetUtcCommandProcessor(ILogger<GetUtcCommandProcessor<TReplyMarkupBase>> logger,
ICommandValidator<GetUtcCommand> validator,
MetricsProcessor metricsProcessor)
: base(logger, validator, metricsProcessor)
{
}
protected override Task InnerProcessContact(Message message, string argsString, CancellationToken token)
{
return Task.CompletedTask;
}
protected override Task InnerProcessPoll(Message message, string argsString, CancellationToken token)
{
return Task.CompletedTask;
}
protected override Task InnerProcessLocation(Message message, string argsString, CancellationToken token)
{
return Task.CompletedTask;
}
/// <summary>
/// All business logic is being called here...
/// </summary>
/// <param name="message"></param>
/// <param name="args"></param>
/// <param name="token"></param>
protected override async Task InnerProcess(Message message, string args, CancellationToken token)
{
// Creates a message for sending
var utcMessageRequest = new SendMessageRequest(Guid.NewGuid().ToString())
{
Message = new Message
{
Uid = Guid.NewGuid().ToString(),
ChatIds = message.ChatIds,
Body = $"Current UTC Time is: {DateTime.UtcNow.ToString(CultureInfo.InvariantCulture)}",
}
};
// Tries to send a message using a concrete implementation of Bot (TelegramBot, for example)
await _bot.SendMessageAsync(request: utcMessageRequest, optionsBuilder: (ISendOptionsBuilder<TReplyMarkupBase>)null!, token: token);
}
}
```
**Hosted service**
Also, we should run a hosted service in order to keep our bot onair:
```csharp
namespace VeryBasicBot.Telegram;
/// <summary>
/// This hosted service intended keeping an application alive till the termination
/// </summary>
public class VeryBasicBotService : IHostedService
{
private readonly IOptionsMonitor<VeryBasicBotSettings> _settings;
private readonly IBot<TelegramBot> _telegramBot;
public VeryBasicBotService(IBot<TelegramBot> telegramBot, IOptionsMonitor<VeryBasicBotSettings> settings)
{
_telegramBot = telegramBot;
_settings = settings;
}
public Task StartAsync(CancellationToken token)
{
Console.WriteLine("Start serving...");
return Task.CompletedTask;
}
public Task StopAsync(CancellationToken cancellationToken)
{
Console.WriteLine("Stop serving...");
return Task.CompletedTask;
}
}
```
you can download a whole code here: [github](https://github.com/devgopher/very_basic_bot)
**First run**
So, we need to run our bot now. We need to get a freshly-generated a bot Id:
**Deploying an admin-side**
[Admin pane deployment scripts for Linux](https://github.com/devgopher/botticelli/tree/release/0.3/deploy/linux)
First of all, you need to choose where to deploy and admin pane.
We've 2 parts of admin:
- Backend
- Frontend
After deploying using proposed scripts, we need to register. So, after setting up frontend and backend, you should go to: https://<your_front_url>:<your_front_port> and press **Registration** button. On a registration form, please, put in your email and press **Register**. If your backend email server settings are correct, you'll receive a registration letter with username and password.
**_NOTE_**
If you experiencing some problems with untrusted certificate for backend, you may go to https://<backend_url>:<backend_port> in your browser and allow using untrusted certificate.
So, after registration, you may refresh a page and log in.
**Adding a bot to admin pane**
After registering and logging in, we need to add own freshly developed bot onto a "Your bots" pane and activate it as it's shown on pictures:
1. Go to 'Your bots' pane: 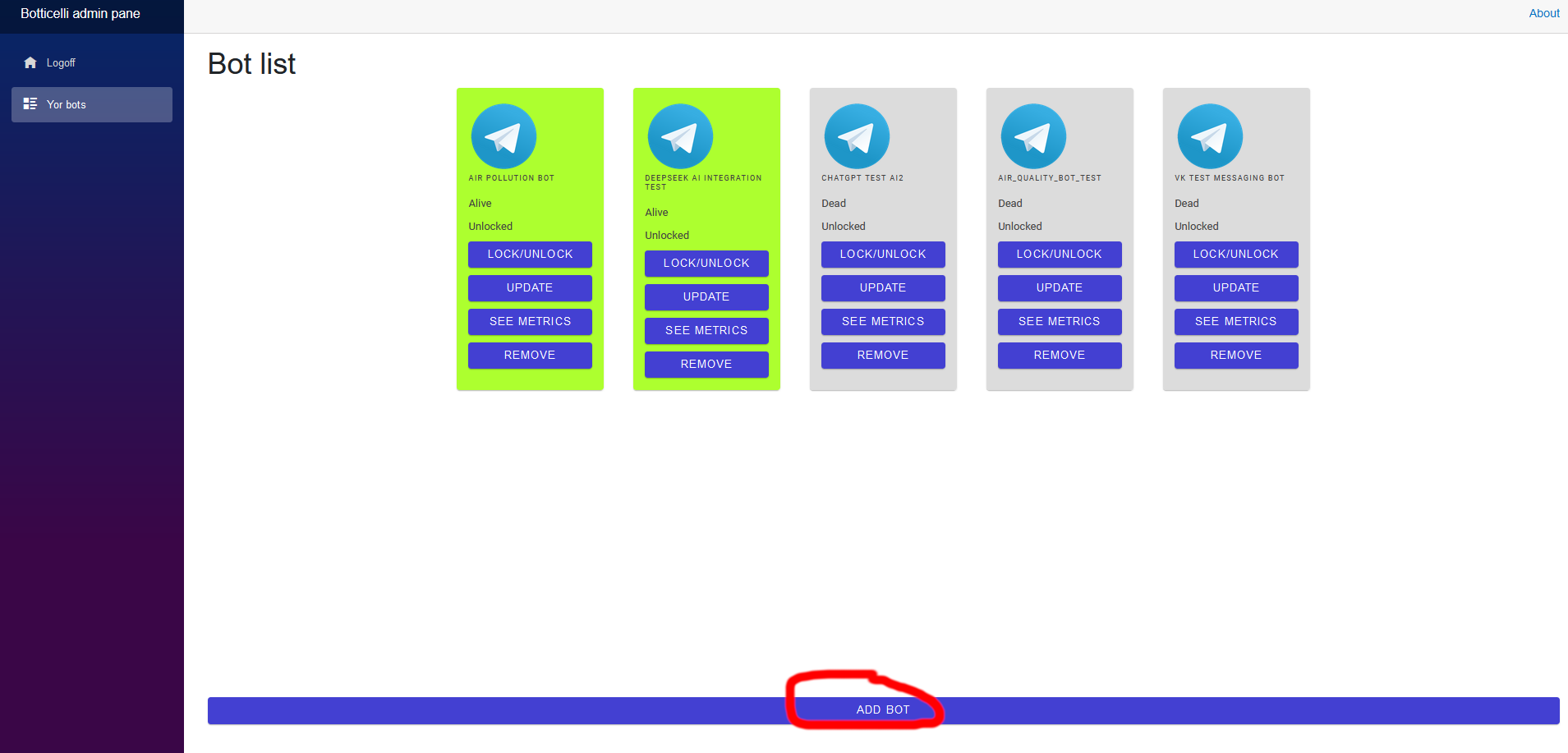
2. Fill parameters and a description: 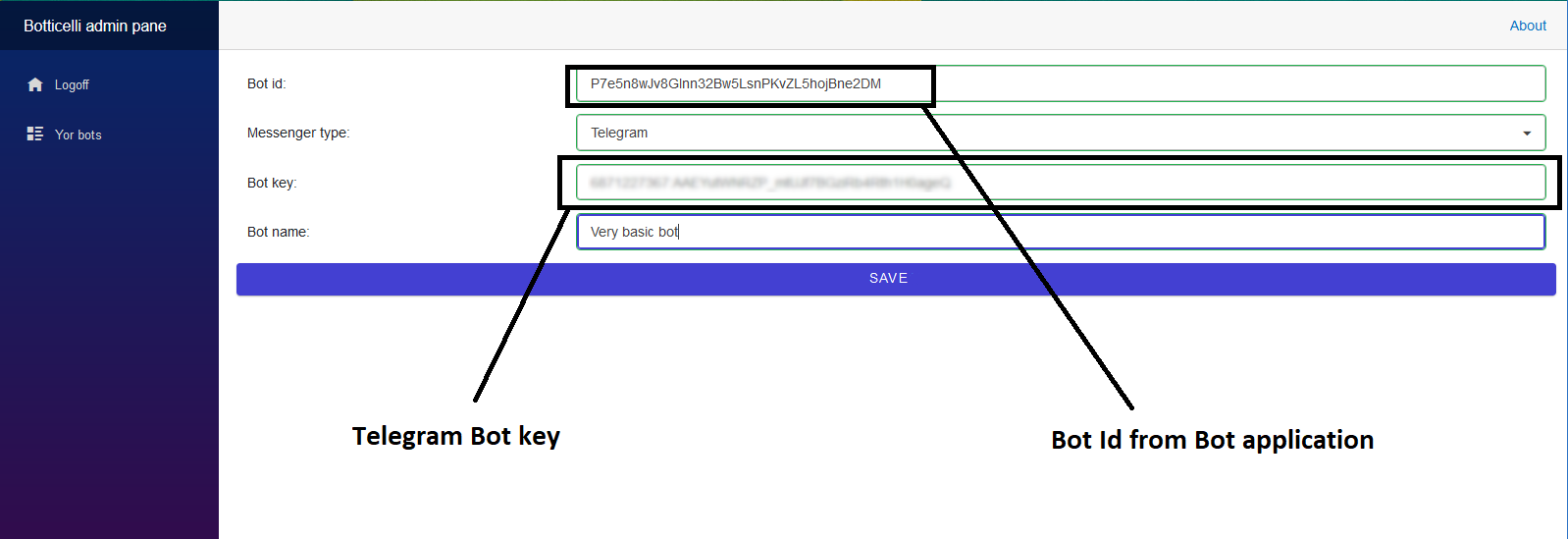
3. Press 'Unlock' button:
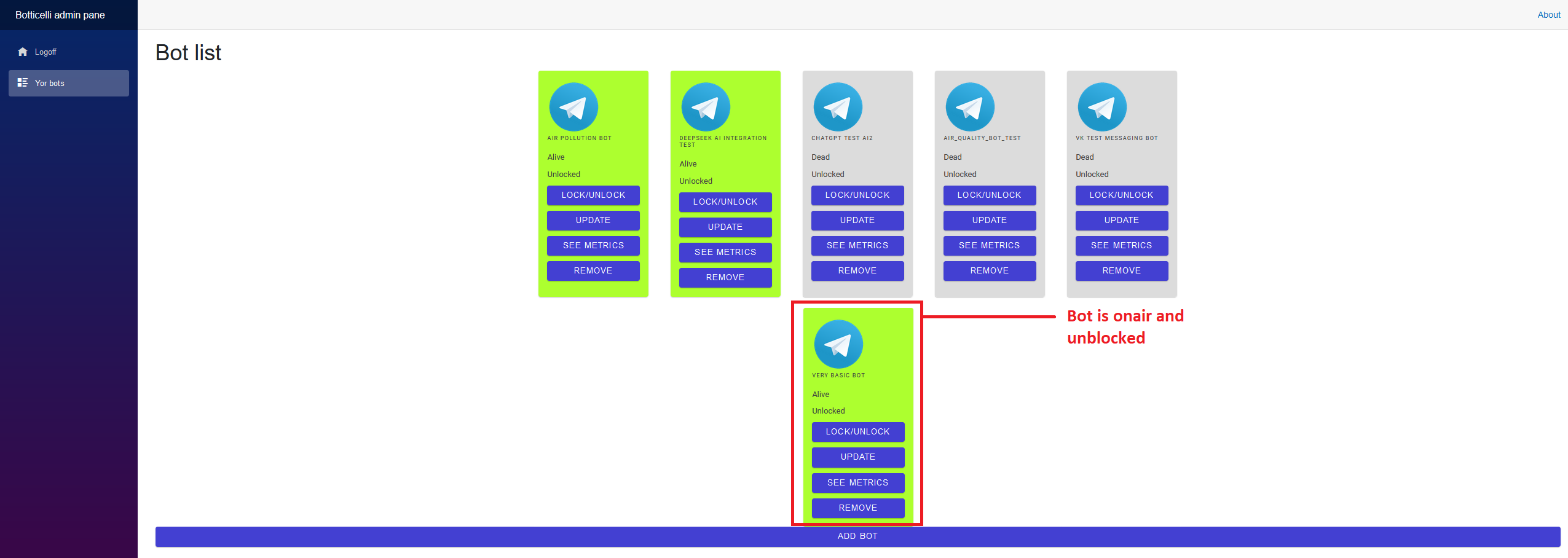
** Some additional settings **
In a bot solution, please, find `appsettings.json` and make some changes:
```json
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"VeryBasicBotSettings": {
"SecureStorageConnectionString": "Filename=database.db;Password=123;ReadOnly=false",
"BotName": "TimeTellingBot"
},
"ServerSettings": {
"ServerUri": "http://<backend_url>:<backend_http_port>/v1/"
},
"AnalyticsSettings": {
"TargetUrl": "http://<analytics_url>:<analytics_http_port>/v1/"
},
"AllowedHosts": "*"
}
```
Since, we didn't deploy analytics component, we may set some mocking **TargetUrl**
**Let's check the result**
Now, all we need is to run a VeryBasicBot.Telegram project.
{% embed https://youtu.be/StDd0uqzzCo %}
sources: [github](https://github.com/devgopher/very_basic_bot)
based on BotticelliBots: https://botticellibots.com
email: botticellibots@gmail.com
telegram group: https://t.me/botticelli_bots
Air quality telegram bot, based on BotticelliBots: https://t.me/air_quality_info_bot
| botticellibots |
1,815,605 | Enatega Releases App Repo As Open Source | Open-Source Project That Will Blow Up In 2024 After a 4 year journey through the world... | 0 | 2024-04-08T21:48:02 | https://dev.to/farrahuzzi11/enatega-releases-app-repo-as-open-source-3m1 | onlinefooddeliveryapps, enatega, ninjascoding | ## Open-Source Project That Will Blow Up In 2024

After a 4 year journey through the world of proprietary software, we're excited to announce that we've taken the big leap into open source with the release of Enatega[(enatega.com)](http://enatega.com) - a delivery management software that is made to launch your own food delivery or any other relevant business.
Here's a rephrased rundown of what Enatega offers:
* **Effortless Setup:** Forget complex setups! Run Enatega locally with just a few commands on your existing device.
* **Cross-Platform Flexibility:** Enatega works across various platforms (iOS, Android, Web), allowing you to easily test it on your emulators or phones.
* **Open-Source Advantage:** Enatega provides live demos, clear documentation, and helpful videos to guide you through the process, empowering you to get started quickly.
You can find the source code and get started here: (https://github.com/ninjas-code-official/food-delivery-multivendor)
## Our Journey To Open Source
We started Enatega 4 years ago. Initially it was our side project at Ninjas Code[(ninjascode.com)](http://ninjascode.com) being a software development agency we wanted to launch something in the local market while providing software development services side by side.
Enatega's journey began with a vision: to create a superior local food delivery app. We, at Ninjas Code, a developer-focused company, identified shortcomings in existing solutions and believed we could offer a better alternative. However, we underestimated the marketing expertise needed to compete with established players.
**A Change in Strategy: Empowering Others**
Recognizing this limitation, we pivoted our strategy. Instead of direct competition, we decided to empower others. Enatega became a software solution allowing businesses to launch their own delivery services.
**Initial Success and an Unexpected Challenge**
Initially, we marketed Enatega through third-party marketplaces, achieving good results. Unfortunately, the closure of one such marketplace forced us to adapt again.
**Open Source to the Rescue!**
Leveraging our development strengths, we open-sourced the Enatega app repository. This strategic move has garnered significant traction without expensive marketing campaigns.
**The Value We Provide**
* **Contributor Benefits:** Gain visibility and practical experience by contributing to a project used by over 100 startups.
* **Sustainable Business Model:** We maintain a healthy business model by offering a licensed backend server with a proprietary codebase. This caters to businesses requiring customizations beyond a fully open-source solution.
**Why Not Fully Open Source the Backend?**
While some companies fully open-source their projects, our approach allows for necessary customization. Businesses may require modifications to fit their specific needs, and a fully open-source backend wouldn't provide that flexibility.
**Enatega Multivendor: A Feature-Rich Open-Source Delivery App**
Enatega Multivendor is a complete open-source solution for building multivendor food delivery apps. It offers features for customers, restaurants, riders, and admins, accessible across iOS, Android, and Web platforms.
**Key Features:**
* User-Friendly Mobile/Web App: Login/Signup, location-based search, detailed restaurant information, order tracking, multi-payment options (PayPal, Stripe), push notifications, multi-language support.
* Restaurant Management App: Order receiving/acceptance, real-time order updates, menu management, delivery zone configuration, order history, online/offline status control.
* Rider App: Real-time order status updates, in-app navigation, customer chat, earnings management, online/offline status control.
* Admin Dashboard: Role-based access control, restaurant/rider/user management, commission rate management, global order status management, detailed restaurant analytics.
**Join the Enatega Open-Source Community!**
We're actively seeking contributors to join our development efforts.
Discord Link: https://discord.gg/774fJ72qwH
Here's how you can get involved:
* **Report bugs and suggest improvements (create issues).**
* **Fix bugs or add features (create pull requests).**
We have a vibrant Discord community to answer questions and guide new contributors. Join us and be part of building the future of open-source delivery solutions!
| farrahuzzi11 |
1,815,662 | Object-Oriented Programming Concepts | Object-Oriented Programming (OOP) has emerged as a powerful paradigm in the world of software... | 0 | 2024-05-12T19:04:25 | https://blog.saurabhmahajan.com/object-oriented-programming-concepts | ---
title: Object-Oriented Programming Concepts
published: true
date: 2024-04-08 18:13:37 UTC
tags:
canonical_url: https://blog.saurabhmahajan.com/object-oriented-programming-concepts
---
Object-Oriented Programming (OOP) has emerged as a powerful paradigm in the world of software development, revolutionizing the way we design and build applications. At its core, OOP is a approach that models real-world concepts by creating objects that encapsulate both data and the code that operates on that data.
The beauty of OOP lies in its ability to create modular, reusable, and extensible code. By organizing software into objects, programmers can break down complex problems into smaller, more manageable components, each with its own well-defined responsibilities and behaviors.
OOP concepts have been instrumental in the development of robust, scalable, and maintainable software systems across various domains, from web applications and mobile apps to games and scientific simulations. By embracing OOP principles, programmers can create code that is not only functional but also easier to understand, modify, and extend over time.
In this blog, we'll explore the intricacies of OOP concepts, providing examples and real-world use cases to help you grasp their significance and practical applications. Whether you're a beginner or an experienced programmer, mastering OOP will undoubtedly enhance your ability to write clean, efficient, and future-proof code.
* * *
# Why is OOPs required?
1. **Modularity** : OOPs promotes modular design, where the program is divided into smaller, reusable components (objects), making it easier to develop, maintain, and modify the code.
2. **Code Reusability** : Through inheritance, objects can reuse code from existing classes, reducing redundancy and promoting code reuse.
3. **Data Abstraction** : OOPs allows for data abstraction, which means that the implementation details of an object are hidden from the outside world, providing better security and flexibility.
4. **Encapsulation** : By encapsulating data and methods within objects, OOPs provides better control over data access and modification, improving code organization and security.
5. **Polymorphism** : Polymorphism allows objects of different classes to be treated as objects of a common superclass, enabling more flexible and extensible code.
6. **Maintainability** : OOPs promotes modularity, which makes it easier to identify and fix errors, as well as add new features or modify existing ones, improving code maintainability.
7. **Real-world Modeling** : OOPs provides a way to model real-world objects and their interactions, making it easier to understand and design complex systems.
* * *
# Class
A class is a blueprint or template for creating objects. It defines a set of properties (attributes) and behaviors (methods) that objects of that class will have. Classes are the fundamental building blocks of Object-Oriented Programming (OOP).
A class is a user-defined data type that encapsulates data (attributes) and code (methods) that operate on that data.
Example:-
```
public class BankAccount { // Attributes (Properties) private String accountNumber; private String accountHolderName; private double balance; // Constructor public BankAccount(String accountNumber, String accountHolderName, double initialBalance) { this.accountNumber = accountNumber; this.accountHolderName = accountHolderName; this.balance = initialBalance; } // Methods (Behaviors) public void deposit(double amount) { balance += amount; System.out.println( "Deposited $" + amount + ". New balance: $" + balance); } public void withdraw(double amount) { if (balance >= amount) { balance -= amount; System.out.println( "Withdrew $" + amount + ". New balance: $" + balance); } else { System.out.println("Insufficient funds."); } } // Getter and Setter methods for attributes // ...}
```
In this example, the `BankAccount` class has three attributes (`accountNumber`, `accountHolderName`, and `balance`) that define the state of a bank account object. It also has a constructor that initializes these attributes when creating a new `BankAccount` object. Additionally, the class has two methods (`deposit()` and `withdraw()`) that define the behavior of a bank account object.
**Components of a Class:**
1. **Modifiers** : These specify the access level of the class, such as `public`, `private`, `protected`, or default (no modifier).
2. **Class Name** : The name of the class, following the naming conventions (e.g., `BankAccount`).
3. **Superclass (if any)**: If the class inherits from another class, the name of the superclass is specified using the `extends` keyword.
4. **Interfaces (if any)**: If the class implements one or more interfaces, they are specified using the `implements` keyword.
5. **Body** : The class body is enclosed within curly braces `{ }`, containing the class members (attributes and methods).
* * *
# Object
An object is an instance of a class. It is a real-world entity that has its own state (attributes) and behavior (methods) defined by the class it belongs to.
An object is a single instance of a class that encapsulates data and the code that operates on that data.
Example:-
```
BankAccount account1 = new BankAccount("123456789", "John Doe", 1000.0);BankAccount account2 = new BankAccount("987654321", "Jane Smith", 5000.0);account1.deposit(500.0); // Output: Deposited $500.0. New balance: $1500.0account2.withdraw(1000.0); // Output: Withdrew $1000.0. New balance: $4000.0
```
In this example, `account1` and `account2` are two separate objects of the `BankAccount` class, each with its own set of attribute values (`accountNumber`, `accountHolderName`, and `balance`). We can invoke the `deposit()` and `withdraw()` methods on these objects, and they will behave according to their respective states.
**Components of an Object:**
1. **State** : The state of an object is defined by its attributes or properties (e.g., `accountNumber`, `accountHolderName`, and `balance` in the `BankAccount` class).
2. **Behavior** : The behavior of an object is defined by its methods (e.g., `deposit()` and `withdraw()` in the `BankAccount` class).
3. **Identity** : Each object has a unique identity, which is typically represented by its memory address or reference.

* * *
# Major Pillars of OOPs
## Abstraction

Abstraction is the process of hiding unnecessary details and exposing only the essential features of an object. It allows you to define the interface (how an object should behave) without revealing the implementation details (how the object works internally).
Abstraction is a way of representing complex real-world entities in a simplified manner by focusing on their essential features and ignoring unnecessary details.
Example:-
```
public class Main { public static void main(String[] args) { Animal dog = new Dog("Buddy"); System.out.println("Name: " + dog.getName()); // Output: Name: Buddy dog.makeSound(); // Output: Woof! }}abstract class Animal { private String name; public Animal(String name) { this.name = name; } public String getName() { return name; } public abstract void makeSound();}class Dog extends Animal { public Dog(String name) { super(name); } @Override public void makeSound() { System.out.println("Woof!"); }}
```
In this example, the `Animal` class is an abstract class that defines the common behavior of animals (e.g., having a name) but leaves the implementation of `makeSound()` to its concrete subclasses (e.g., `Dog`). The `Dog` class provides the implementation for the `makeSound()` method.
## Encapsulation

Encapsulation is the bundling of data (properties) and methods (behaviors) together within a single unit, known as a class. It helps in achieving data abstraction and controlling the access to the object's internal state.
Encapsulation is the mechanism of binding data and the code that operates on that data into a single unit, known as a class. It restricts direct access to the object's internal state and provides controlled access through public methods.
Example:-
```
public class Main { public static void main(String[] args) { BankAccount account = new BankAccount(); System.out.println("Initial balance: " + account.getBalance()); // Output: Initial balance: 0.0 account.deposit(1000.0); System.out.println("Balance after deposit: " + account.getBalance()); // Output: Balance after deposit: 1000.0 account.withdraw(500.0); System.out.println("Balance after withdrawal: " + account.getBalance()); // Output: Balance after withdrawal: 500.0 account.withdraw(600.0); // Output: Insufficient funds. }}class BankAccount { private double balance; public double getBalance() { return balance; } public void deposit(double amount) { balance += amount; } public void withdraw(double amount) { if (balance >= amount) balance -= amount; else System.out.println("Insufficient funds."); }}
```
In this example, the `BankAccount` class encapsulates the `balance` field by making it private and providing public methods (`getBalance`, `deposit`, and `withdraw`) to access and modify the balance in a controlled manner.
## **Inheritance**

Inheritance is a mechanism that allows a new class (child or derived class) to be based on an existing class (parent or base class). The child class inherits properties and methods from the parent class, promoting code reuse and enabling the creation of hierarchical relationships.
Inheritance is a concept in OOP that allows a new class (derived class) to inherit properties and behaviors from an existing class (base class), forming an "is-a" relationship between the classes.
Example:-
```
public class Main { public static void main(String[] args) { Vehicle vehicle = new Vehicle("Toyota", "Corolla"); vehicle.start(); // Output: Vehicle started. Car car = new Car("Honda", "Civic", 4); car.start(); // Output: Vehicle started. car.openTrunk(); // Output: Trunk opened. }}class Vehicle { protected String make; protected String model; public Vehicle(String make, String model) { this.make = make; this.model = model; } public void start() { System.out.println("Vehicle started."); }}class Car extends Vehicle { private int numDoors; public Car(String make, String model, int numDoors) { super(make, model); this.numDoors = numDoors; } public void openTrunk() { System.out.println("Trunk opened."); }}
```
In this example, the `Car` class inherits from the `Vehicle` class. It inherits the `make`, `model`, and `start()` method from the `Vehicle` class and adds its own `numDoors` attribute and `openTrunk()` method.
## Polymorphism

Polymorphism is a concept in OOP that allows objects of different classes to be treated as objects of a common superclass, enabling code reusability and flexibility. It can be achieved through method overriding (runtime polymorphism) or method overloading (compile-time polymorphism).
### **Runtime Polymorphism (Method Overriding)**
Runtime polymorphism, also known as method overriding, occurs when a subclass provides its own implementation of a method that is already defined in its superclass.
Example:-
```
class Animal { public void makeSound() { System.out.println("Animal sound"); }}class Dog extends Animal { @Override public void makeSound() { System.out.println("Woof!"); }}class Cat extends Animal { @Override public void makeSound() { System.out.println("Meow!"); }}public class Main { public static void main(String[] args) { Animal animal1 = new Animal(); Animal animal2 = new Dog(); Animal animal3 = new Cat(); animal1.makeSound(); // Output: Animal sound animal2.makeSound(); // Output: Woof! animal3.makeSound(); // Output: Meow! }}
```
In this example, the `Dog` and `Cat` classes override the `makeSound()` method of the `Animal` class, exhibiting runtime polymorphism. The `makeSound()` method behaves differently based on the actual object type (Animal, Dog, or Cat) at runtime.
Rules:-
- Methods of child and parent class must have the same name.
- Methods of child and parent class must have the same parameters.
- IS-A relationship is mandatory (inheritance).
- One cannot override the private methods of a parent class.
- One cannot override Final methods.
- One cannot override static methods.
### **Compile-time Polymorphism (Method Overloading)**
Compile-time polymorphism, also known as method overloading, occurs when a class has multiple methods with the same name but different parameter lists (different number of parameters, different types of parameters, or both).
Example:-
```
public class Main { public static void main(String[] args) { Calculator calculator = new Calculator(); int sum1 = calculator.add(2, 3); // Output: 5 double sum2 = calculator.add(2.5, 3.7); // Output: 6.2 int sum3 = calculator.add(1, 2, 3); // Output: 6 }}class Calculator { public int add(int a, int b) { return a + b; } public double add(double a, double b) { return a + b; } public int add(int a, int b, int c) { return a + b + c; }}
```
In this example, we create an instance of the `Calculator` class and call different overloaded versions of the `add()` method. The compiler determines the correct method to call based on the number and types of arguments provided, demonstrating compile-time polymorphism.
Types:-
- By changing number of parameters
- By changing data type of any parameter
- By changing sequence of parameters
* * *
# Minor Pillars of OOPs
## Typing
In a strongly typed language like Java, every variable and expression must have a well-defined data type. The compiler enforces type safety by ensuring that operations are performed only on compatible data types. This helps catch type-related errors at compile-time, making the code more robust and reliable.
Example:-
```
int age = 25; // Validage = "thirty"; // Compiler error: Incompatible typesString name = "John";int length = name.length(); // Valid
```
In the above example, the variable `age` is declared as an `int`, so you cannot assign a string value like `"thirty"` to it. The compiler will raise an error. However, you can call the `length()` method on the `String` object `name` and assign the result (an `int` value) to the `length` variable.
## Persistance
Persistence refers to the ability of an object to survive beyond the lifetime of the program or process that created it. In other words, persistent objects can be stored and retrieved from non-volatile storage, such as a file system or a database, without losing their state.
Example:-
Consider a `Student` class that represents a student's information:
```
public class Student { private String name; private int age; private double gpa; // Constructors, getters, and setters}
```
To make `Student` objects persistent, you can use serialization, which is the process of converting an object's state to a byte stream that can be saved to a file or sent over a network. Java provides built-in support for serialization through the `Serializable` interface.
```
import java.io.*;public class PersistenceExample { public static void main(String[] args) { Student student = new Student("John", 20, 3.8); // Serialize the object to a file try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("student.dat"))) { oos.writeObject(student); } catch (IOException e) { e.printStackTrace(); } // Later, deserialize the object from the file Student deserializedStudent = null; try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("student.dat"))) { deserializedStudent = (Student) ois.readObject(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } // The deserializedStudent object has the same state as the original student object System.out.println(deserializedStudent.getName()); // Output: John System.out.println(deserializedStudent.getAge()); // Output: 20 System.out.println(deserializedStudent.getGpa()); // Output: 3.8 }}
```
In this example, a `Student` object is serialized to a file named `student.dat`. Later, the object is deserialized from the same file, and its state is preserved, allowing you to work with the same object even after the program has terminated and restarted.
## Concurrency
Concurrency refers to the ability of multiple computations or threads to execute simultaneously and potentially interact with each other.
In Java, you can create and manage threads to achieve concurrency. However, concurrent access to shared resources (e.g., objects or data structures) can lead to race conditions and other synchronization issues.
Example:-
Consider a `BankAccount` class that represents a bank account with a balance:
```
public class BankAccount { private double balance; public BankAccount(double initialBalance) { this.balance = initialBalance; } public synchronized void deposit(double amount) { double newBalance = balance + amount; // Simulate a delay to illustrate the potential for race conditions try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } balance = newBalance; } public synchronized void withdraw(double amount) { double newBalance = balance - amount; // Simulate a delay to illustrate the potential for race conditions try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } balance = newBalance; } public double getBalance() { return balance; }}
```
Now, let's create two threads that both try to deposit and withdraw money from the same `BankAccount` object:
```
public class ConcurrencyExample { public static void main(String[] args) { BankAccount account = new BankAccount(1000.0); Runnable depositTask = () -> { for (int i = 0; i < 1000; i++) { account.deposit(10.0); } }; Runnable withdrawTask = () -> { for (int i = 0; i < 1000; i++) { account.withdraw(10.0); } }; Thread depositThread = new Thread(depositTask); Thread withdrawThread = new Thread(withdrawTask); depositThread.start(); withdrawThread.start(); try { depositThread.join(); withdrawThread.join(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("Final balance: " + account.getBalance()); }}
```
In this example, two threads (`depositThread` and `withdrawThread`) are created to perform 1000 deposit and withdrawal operations, respectively, on the same `BankAccount` object. Without proper synchronization, the balance may not be accurately updated due to race conditions.
To prevent race conditions, the `deposit()` and `withdraw()` methods in the `BankAccount` class are marked as `synchronized`. This ensures that only one thread can execute these methods at a time, preventing concurrent access to the `balance` field and ensuring data consistency.
When you run this program, the final balance printed should be 1000.0 (the initial balance), since the number of deposits and withdrawals is equal.
These examples illustrate how Java's strong typing, persistence capabilities, and concurrency support help in building robust and reliable applications. Strong typing enforces type safety, persistence allows objects to survive beyond program execution, and concurrency enables parallel execution while providing mechanisms to handle shared resources safely.
* * *
# Conclusion
Throughout this blog, we've explored the fundamental concepts that underpin Object-Oriented Programming (OOP). We've delved into the building blocks of OOP, such as classes and objects, and how they enable the creation of modular, reusable, and extensible code.
We've examined the principles of abstraction and encapsulation, which provide a structured approach to managing complexity and ensuring data integrity. Abstraction allows us to focus on the essential features of an object, while encapsulation protects an object's internal state from unintended modifications.
Inheritance, a powerful mechanism in OOP, enables code reuse and the creation of hierarchical class relationships. By inheriting properties and methods from existing classes, we can create more specialized classes that extend and enhance the functionality of their parent classes.
Polymorphism, both compile-time and runtime, adds flexibility to our code by allowing objects of different classes to be treated as objects of a common superclass. This versatility enables methods to work with a wide range of object types without needing to know their specific implementations.
We've also explored the concept of strong typing, which enforces type safety and helps catch errors during compilation, leading to more robust and reliable code.
Additionally, we've discussed persistence, which allows objects to persist beyond the lifetime of the program, enabling data storage and retrieval across multiple sessions.
Finally, we've touched upon concurrency, a crucial aspect of modern software development, where multiple threads or processes can execute simultaneously, facilitating efficient utilization of system resources and improving application responsiveness.
By mastering these OOP concepts and applying them effectively, developers can create software that is not only functional but also maintainable, scalable, and adaptable to changing requirements. OOP provides a solid foundation for building complex systems, fostering collaboration, and promoting code reuse across projects.
As we continue our journey in OOP, remember to embrace best practices, such as writing clean and self-documenting code, adhering to design patterns, and leveraging the power of object-oriented principles to create efficient and elegant solutions. | saurabhthedev | |
1,815,843 | Revelando O Mundo De Brbetano: Um Guia Abrangente | Bem-vindo ao guia definitivo sobre o Brbetano! Não importa se você é um jogador experiente ou um... | 0 | 2024-04-09T04:59:07 | https://dev.to/futebolonline2024/revelando-o-mundo-de-brbetano-um-guia-abrangente-4ng8 | Bem-vindo ao guia definitivo sobre o [Brbetano](https://seabet.com.co/blog/brbetano-com/)! Não importa se você é um jogador experiente ou um novato que deseja se aprofundar no mundo das apostas on-line, este artigo fornecerá todas as informações essenciais que você precisa saber sobre o brbetano. Desde suas origens e legalidade até dicas para fazer apostas bem-sucedidas, temos tudo o que você precisa saber.
## Entendendo a Brbetano: O que é?
A Brbetano é uma plataforma líder de apostas on-line que oferece uma ampla gama de opções de apostas esportivas, incluindo futebol, basquete, tênis e muito mais. Com sua interface amigável e probabilidades competitivas, a brbetano se tornou uma escolha popular entre os apostadores de todo o mundo.
A evolução da brbetano
Fundada em [ano], a brbetano cresceu rapidamente e se tornou um dos nomes mais confiáveis no setor de apostas on-line. Seu compromisso em oferecer uma experiência de apostas segura e agradável lhe rendeu uma base de clientes fiéis e inúmeros elogios no setor.
## A Brbetano é legal?
Uma das perguntas mais comuns sobre as plataformas de apostas on-line, como a brbetano, é sua legalidade. Em muitos países, as apostas on-line são regulamentadas e legais, desde que o operador possua uma licença de jogo válida. A brbetano opera de acordo com todas as leis e regulamentos aplicáveis, garantindo que seus usuários possam apostar com confiança.
Licenciamento e regulamentação
A Brbetano é licenciada e regulamentada pela [autoridade reguladora relevante], garantindo que ela opere em conformidade com os padrões e as melhores práticas do setor. Isso proporciona aos usuários a tranquilidade de saber que seus fundos e informações pessoais estão seguros.
## Primeiros passos com a Brbetano
Criando uma conta
O registro de uma conta na brbetano é rápido e fácil. Basta visitar o site e clicar no botão "Registrar" para começar. Você precisará fornecer algumas informações básicas, como seu nome, endereço de e-mail e data de nascimento. Depois que a sua conta for criada, você poderá começar a apostar nos seus eventos esportivos favoritos imediatamente.
Como fazer depósitos e saques
A Brbetano oferece uma variedade de opções de pagamento seguras para depositar e sacar fundos de sua conta. Quer prefira cartões de crédito/débito, transferências bancárias ou carteiras eletrônicas, você encontrará um método conveniente que atenda às suas necessidades. As retiradas são processadas rapidamente, permitindo que você tenha acesso aos seus ganhos sem demora.
## Dicas para apostar com sucesso na Brbetano
Pesquisa e análise
Antes de fazer qualquer aposta, é essencial fazer sua pesquisa e analisar os dados disponíveis. Isso inclui estudar a forma dos times ou jogadores envolvidos, considerar quaisquer lesões ou suspensões e avaliar as probabilidades oferecidas pelo brbetano.
Gerencie seu bankroll
O gerenciamento eficaz da banca é crucial para o sucesso a longo prazo nas apostas. Defina um orçamento para suas apostas e atenha-se a ele, evitando a tentação de correr atrás das perdas ou apostar mais do que pode pagar.
Aproveite os bônus e as promoções
A Brbetano oferece uma variedade de bônus e promoções para recompensar seus usuários e melhorar sua experiência de apostas. Não deixe de aproveitar essas ofertas, mas sempre leia atentamente os termos e condições para entender quaisquer requisitos ou restrições de apostas.
## Conclusão
Em conclusão, a brbetano é uma plataforma de apostas on-line respeitável que oferece uma ampla gama de opções de apostas esportivas em um ambiente seguro e fácil de usar. Quer você seja um apostador casual ou um profissional experiente, a brbetano tem tudo o que você precisa para desfrutar de uma experiência de apostas emocionante. Registre-se hoje e comece a apostar com confiança!
## Perguntas Frequentes sobre Brbetano
Posso confiar na segurança do Brbetano?
Sim, o Brbetano é altamente seguro. Ele possui licença e regulação adequadas, garantindo a proteção dos dados pessoais e financeiros dos usuários.
Quais métodos de pagamento o Brbetano aceita?
O Brbetano aceita uma variedade de métodos de pagamento, incluindo cartões de crédito/débito, transferências bancárias e carteiras eletrônicas.
Como faço para sacar meus ganhos no Brbetano?
O processo de saque no Brbetano é simples. Basta acessar a seção de saques na sua conta, selecionar o método de pagamento desejado e seguir as instruções.
O Brbetano oferece bônus e promoções?
Sim, o Brbetano oferece uma variedade de bônus e promoções para recompensar os usuários e melhorar sua experiência de apostas.
Posso apostar em quais esportes no Brbetano?
O Brbetano oferece uma ampla gama de opções de apostas esportivas, incluindo futebol, basquete, tênis e muito mais.
Explore uma nova dimensão de entretenimento e emoção com o Seabet, uma plataforma de apostas online que oferece uma variedade de opções de apostas e odds competitivas para os seus jogos favoritos.
Não perca nosso mais recente post no blog do [Sebet](https://seabet.com.co/blog/sebet/), onde compartilhamos insights valiosos e estratégias inteligentes para otimizar seus ganhos e aproveitar ao máximo sua experiência de apostas.
| futebolonline2024 | |
1,815,893 | What Are the Benefits of Using Automation Testing Tools? | Software testing is an essential platform for the delivery of quality applications to users.... | 0 | 2024-04-09T06:05:43 | https://featurestic.com/automation-testing-tools/ | automation, testing, tools | 
Software testing is an essential platform for the delivery of quality applications to users. However, manual testing is very tedious and time-consuming. In this case, automation testing tools prove helpful. Automation testing tools help testers create test scripts to run test cases automatically and generate reports. There are many advantages to using codeless automation testing tools in an enterprise software testing environment.
**Time Savings**
A major benefit of using codeless automation tools is the huge time savings involved. For manual testing, testers need to do every test case one by one. This process is extremely slow. Testers can record the test scripts only once and then run them many times in automation testing. Tests can be set to run autonomously when a particular schedule has been set for them. This enables testers to concentrate on more sophisticated test scenarios. The increased speed and efficiency enable teams to increase test coverage. In addition, codeless automation makes it easy to scale up test cases as needed.
**Cost Reduction**
Automation testing eventually results in significant cost savings. Although the initial investment in test automation tools and framework setup is substantial, over time, it makes its money back. Automated tests take much less time to apply than manual testing. The direct implication of less testing time is a reduction in cost. Automation also catches regressions early, thereby avoiding expensive defects that make it to production. The fixing of bugs that come up in the last phases of the development cycle is usually costly.
**Improved Accuracy**
One of the major human defects is that people fail to avoid making mistakes when performing tasks that are repetitive and seem to be boring and monotonous. Manual testing is considered one of such cases. Automated testing tools can be as repetitive as possible. The consistency level achieved at this point enhances the overall validity and replicability of the test results. If left unattended overnight, automated tests that run without human intervention can detect bugs that would otherwise go undetected by manual testing. Other automated tools also have logs of all the test runs that are kept for better analysis and reporting.
**Conclusion**
Opkey is indeed a revolutionary, no-code automation tool that allows businesses to automate their software testing and quality assurance processes. Using Opkey, even a layperson can automate repetitive testing tasks without code, just by dragging and dropping. Compared to conventional coding-oriented testing, this no-code enterprise software testing approach clearly saves both time and effort.
Through Opkey, teams can automate the testing process with an easy-to-use interface, thereby enhancing the software development life cycle. Automatic testing also gives accurate results in a relatively short time, so bugs can be found early and corrected immediately.
With Opkey, scaling test coverage as per demand becomes easier, which means that it is possible to scale the test coverage as needed. In addition, Opkey allows for easy integration with various continuous integration workflows. The automation tool also provides detailed reporting and analytics to gain insights into the testing process. Since the tool is codeless, test creation and maintenance require no programming background. This further optimizes efficiency by enabling teams to quickly build end-to-end test scenarios. Opkey makes it possible to deploy reliable test automation even with limited resources and testing expertise. | rohitbhandari102 |
1,815,987 | Github Action To Push Docker Image | Github action can be used to run tests on your applications when code has been merged in. The next... | 0 | 2024-04-09T08:12:08 | https://paulund.co.uk/github-action-to-push-docker-image | docker, githubactions, github | Github action can be used to run tests on your applications when code has been merged in.
The next step once tests are successful is to build a docker image and push this to the repository.
This will require us to create a new workflow file that will run after the tests are successful to build and push your docker image to a repository.
First create a new file in your workflow folder `.github/workflows/docker.yml` and paste the following in that file.
```
name: Docker
on:
push:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: 'Checkout GitHub Action'
uses: actions/checkout@v2
- name: Build and push docker
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_USERNAME }}
password: ${{ secrets.REGISTRY_PASSWORD }}
repository: DOCKER_REPOSITORY
tags: latest
```
This works by first checking out the current repository on pushed into master, by using the `actions/checkout@v2` action. The next step will use the docker build and push action `docker/build-push-action@v1`. This requires 4 parameters the docker hub username, password, repository and tags.
In the code above you can see we're using the secrets parameter for username and password.
```
username: ${{ secrets.REGISTRY_USERNAME }}
password: ${{ secrets.REGISTRY_PASSWORD }}
```
To add secrets to your repository in Github is done by selecting Settings -> Secrets then create a new secret for the username and password.
Ensure your repository has a Dockerfile at the root of your project to build the image.
That's it, now commit this file to your repository and on pushes into master, Github will build a push your docker image to the docker hub. | paulund |
1,816,065 | Become a Senior React Developer by Mastering 8 Design Patterns | In this tutorial, you will learn how you can level up and advance in your career from a junior... | 0 | 2024-04-09T08:27:26 | https://dev.to/imrankh13332994/become-a-senior-react-developer-by-mastering-8-design-patterns-9mn | webdev, javascript, react, programming | In this tutorial, you will learn how you can level up and advance in your career from a junior developer to a Senior React Developer by mastering 8 advanced Design Patterns in React.
I will explain each design pattern as well as show code examples on how to implement them in a React codebase.
Follow this step-by-step tutorial and add a new project to your portfolio.
If you like this tutorial please leave your feedback in the comments and subscribe to the [channel](https://www.youtube.com/@JutsuPoint) and follow on [GitHub](https://github.com/strongSoda/) and [Twitter](https://twitter.com/EhThing).
{% embed https://www.youtube.com/watch?v=98Fb0j9CYx4 %}
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
## About Me
I’m a Senior Product Engineer from India, working in web and mobile development. I enjoy turning complex problems into simple, beautiful, and intuitive software. I blog to share my software knowledge with others.
My job is to build your idea so that it is functional and user-friendly but at the same time attractive. Moreover, I add a personal touch to your product and make sure that is eye-catching and easy to use. I aim to help you validate and scale your startup most creatively.
### Quick Links
- [Hire Me](https://imran.wiki/)
- [Coding YouTube Channel](https://www.youtube.com/@JutsuPoint)
- [LinkedIn](https://www.linkedin.com/in/imrankhan001/)
- [Twitter](https://twitter.com/EhThing)
- [🎁 Screen Recording Software](https://screen.studio/@Xenr1)
| imrankh13332994 |
1,816,140 | puravive review official buy 83% off healthy weight loss | In the bustling world of weight loss supplements, one name has been making waves – Puravive.... | 0 | 2024-04-09T10:01:30 | https://dev.to/puravive-review/puravive-review-official-buy-83-off-healthy-weight-loss-5f6k | puravive, puraviereview, weightloss |

In the bustling world of weight loss supplements, one name has been making waves – Puravive. Promising healthy weight loss with an official buy offering an impressive 83% discount, Puravive has captured the attention of many seeking to shed unwanted pounds. But does it live up to the hype? In this in-depth review, we'll delve into the science behind Puravive, explore its ingredients, examine its effectiveness, and consider whether it's a safe and reliable option for achieving your weight loss goals.
**Understanding Puravive: What Sets It Apart?**
[Puravive](https://www.getpuravives.com/) is not just another weight loss supplement; it's a comprehensive approach to achieving sustainable weight loss. Unlike fad diets and quick-fix solutions, Puravive focuses on promoting overall health and well-being while targeting stubborn fat stores. With a blend of natural ingredients and a commitment to transparency, Puravive stands out in a crowded market saturated with gimmicks and false promises.
**The Science Behind Puravive: How Does It Work?**
At the heart of Puravive's effectiveness lies its innovative formula, backed by scientific research. By harnessing the power of natural ingredients known for their weight loss properties, Puravive works synergistically to support metabolism, suppress appetite, and enhance energy levels. Let's take a closer look at some key components:
Garcinia Cambogia: Renowned for its ability to inhibit fat production and curb appetite, Garcinia Cambogia is a cornerstone of the Puravive formula. By blocking the enzyme citrate lyase, which is responsible for converting carbohydrates into fat, Garcinia Cambogia helps prevent weight gain and promotes fat burning.
Green Tea Extract: Packed with antioxidants and metabolism-boosting compounds, green tea extract is another key ingredient in Puravive. Studies have shown that green tea extract can increase calorie expenditure and fat oxidation, making it an invaluable ally in the battle against excess weight.
Caffeine: A well-known stimulant, caffeine not only provides a temporary energy boost but also has been shown to enhance fat burning and improve exercise performance. In Puravive, caffeine works in tandem with other ingredients to amplify its weight loss effects without causing jitteriness or crashes.
**The Benefits of Puravive: More Than Just Weight Loss**
While the primary goal of Puravive is to promote healthy weight loss, its benefits extend far beyond mere numbers on a scale. Users report experiencing increased energy, improved mood, and enhanced overall well-being. By targeting visceral fat – the type of fat that accumulates around organs and poses significant health risks – Puravive not only helps you look better but also reduces your risk of obesity-related diseases such as diabetes, heart disease, and stroke.
**Real People, Real Results:**
Testimonials and Success Stories
But don't just take our word for it – hear what real users have to say about their experiences with Puravive:
"I've struggled with my weight for years, trying countless diets and supplements with little success. But Puravive has been a game-changer for me. Not only have I lost weight, but I feel healthier and more energetic than ever before."
"As a busy mom, finding time to exercise and eat right can be challenging. Puravive has helped me shed the baby weight and reclaim my confidence. I'm so grateful for this amazing product!"
"I was skeptical at first, but after seeing the results firsthand, I'm a believer. Puravive has helped me reach my weight loss goals faster than I ever thought possible. I can't recommend it enough!"
**How to Get Started with Puravive: Official Buy Offer**
Ready to experience the transformative power of Puravive for yourself? Take advantage of our exclusive official buy offer and enjoy an incredible 83% discount on your first purchase. With our risk-free money-back guarantee, you have nothing to lose and everything to gain. Don't let excess weight hold you back any longer – join the thousands of satisfied customers who have already discovered the secret to healthy, sustainable weight loss with Puravive.
In Conclusion: Unlock Your Weight Loss Potential with Puravive
In a world filled with empty promises and quick fixes, Puravive stands as a beacon of hope for those seeking real and lasting change. With its scientifically proven formula, transparent approach, and unwavering commitment to customer satisfaction, Puravive is more than just a weight loss supplement – it's a partner on your journey to a healthier, happier you. Take the first step towards a brighter future today with Puravive. Your body will thank you.
Grab your exclusive official buy offer now and embark on the path to a healthier, happier you with Puravive.
[>>(HUGE SAVINGS ALERT) Try Puravive™ Directly from the Manufacturer at the Lowest Price Guaranteed!](https://www.getpuravives.com/)
| puravive-review |
1,816,227 | Unlocking the Magic of Magento: Your Gateway to E-commerce Enchantment | Embark on a magical journey with magento-2, the ultimate platform for crafting captivating e-commerce... | 0 | 2024-04-09T12:00:53 | https://dev.to/shrimali/unlocking-the-magic-of-magento-your-gateway-to-e-commerce-enchantment-1440 | magento, extention, magecurious, ecommerce | Embark on a magical journey with [magento-2](https://magecurious.com/magento-2-extensions.html), the ultimate platform for crafting captivating e-commerce experiences. From spellbinding storefronts to enchanting customer journeys, discover the power of Magento to weave digital spells that captivate and convert. Join us at MageCurious.com as we unravel the secrets of Magento, empowering you to wield its mystical powers and create online realms where your dreams become reality."
| shrimali |
1,816,399 | Open Source: Redis License Change and Rebranding | Redis, probably the most popular choice for caching backends, and a spiritual successor of Memcached,... | 0 | 2024-04-09T14:30:00 | https://open.substack.com/pub/basc/p/bas-take-on-tech-gen-z-cloudflare?r=20mg42&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true | community, ai | Redis, probably the most popular choice for caching backends, and a spiritual successor of Memcached, changed its license. Goodbye BSD, hello SSPL. That’s not big news as it was announced on March 20, 2024. A day later, they published an article on their blog, titled “The Future of Redis”, in which one of the most prominent points is about “Generative AI”. Yesterday, they announced a rebranding on their 𝕏 Account.
There are a two things to mention: All of the license changes we’ve seen recently in popular is targeted at cloud giants, like AWS. As arstechnica puts it: “[AWS], you cannot continue reselling Redis as a service as part of your $90 billion business without some kind of licensed contribution back”. The business model behind Open Source infrastructure software, like MySQL, Elastic Search, or – now – Redis, has always been to provide an excellent product free of charge to ensure widespread adoption and to cash in on larger scale installations and customization. Turns out, in a world where software is increasingly running on servers in an oligopoly, that seems no longer feasible. Free (libre) Software gave us freedom from big tech, and now big tech found the loophole through “the cloud”. Ironically, it’s now big tech that forks free software to have a version with a more permissible license (which is what I expect to happen to Redis, too). We’ve come from terminal computers to personal computers, and now we’re back to relying on computing power operated by “big tech”. Since the adoption of technology is ubiquitous in society now, I suspect that there is no way back from these oligopolies or relevant smaller entities. Founding a “big cloud competitor” will soon be (or already is?) as impractical as founding a new telco. As much as I hate to say this, “tech” in and of itself is on the verge of becoming an old boring industry.
The second one is about Redis and “AI” and the rebranding: AI is the hype. Unlike “Crypto”, which has some brilliantly architected solutions to something between the lines of libertarian ideas and get-rich-quick-schemes, AI promises nothing less than the star-treky “Hey, Computer” magic.
[Read more in my newsletter](https://open.substack.com/pub/basc/p/bas-take-on-tech-gen-z-cloudflare) | bascodes |
1,816,423 | Asia Follower Apk Download Latest Version For Android | Do you want to get popular all over the world? Absolutely yes, because everyone wants to be popular... | 0 | 2024-04-09T14:41:21 | https://dev.to/daviddesoza/asia-follower-apk-download-latest-version-for-android-40me | webdev, programming, react, aws | Do you want to get popular all over the world? Absolutely yes, because everyone wants to be popular among the people. As we know, the biggest platform for popularity is social media. If you are a user of social media accounts then you also want to increase your followers. So now download the[ Asia follower apk](https://apkbea.com/asia-follower-apk/). It is the best app for you. Because this app helps you to increase your popularity and your post views all over the world. In this way, you can get more clicks, likes and comments on your photos and pictures. It is the most popular app.
When you download this app on your Android devices. Then you get lots of followers on every social media account, such as your Instagram, Facebook and Twitter. Most people download this app because it is easy to use and more secure than other apps. This app secures your data. When you started this app then you did not need any registration. You just need to click on the download button and start to use this app. In this way, you can easily save your time. And get lots of followers in a short time. Millions of people are downloading this app for its advanced features.
About this app
Nowadays most people are searching for followers on Instagram. Then We welcome you to our article because you are in the right place. If you recently used a social media platform known as Instagram, Facebook and Twitter. Then you need a follower-increasing application that can give you maximum followers. So, we suggest the Asia Follower app which is one of the best Instagram followers increasing applications.
First of all, we want to tell you that asia follower download latest version is at the top of the Instagram followers-gaining apps. Therefore today we tell you about this app in our article. As part of this, this app helps you to increase your likes and comments on your social media accounts. With the help of this app, you can make new friends. As well that you can also easily perform tasks on this app because it provides very easy control. Furthermore, you can get coins and followers. Keep in mind that everyone prefers this app because this app does not need any registration to start this app. Millions of people are downloading this app to gain followers.
Impressive features
The asia follower apk download provides the best-advanced features for you. But if you want to get popular all over the world. Then you need to read all the features in your free time.
More the 1K followers
The most important feature of the asia follower apk is that you can get lots of followers for your Instagram. I want to tell you that you must increase your followers by about 1000. It is a large amount. In this way, you can become famous among the people. As well as that you can make new friends with the help of this app. Therefore everyone prefers to use this app.
Increase likes and comments
If you want to get lots of likes and comments on your post on Instagram then you download the asia follower apk mod. This app does not only provide followers as well as this app helps you to increase the likes and comments on your pictures. When likes increase it means you have more popularity all over the world. So download this app right now.
No registration
When you download the other follower-gaining apps. Then you need to make a registration account. But when you get an asia follower mod apk then you do not need any registration. You just click on the download button. When your downloading will complete then you just click on the start button and get lots of followers. In this way, you did not face any difficulties and saved your time.
Lots of coins
asia follower apk latest version provides lots of coins to users so that they will get as many followers as they want. Because without coins you can not get followers from this app. Therefore, this app provides you with lots of coins for free of cost. As well as that in this app, users can earn coins by completing different tasks
Easy to install
If you are ready to Download asia follower apk. Then you can easily download this app. Because let me tell you that the installation process of this app is completely effortless. Because you just have to download it from our website. Then click on the donated file and start the installation process by tapping on the YES button. After that, it will be installed on your devices and then you can enjoy it on your smartphones.**** | daviddesoza |
1,816,650 | Easily Customize the Toolbar in Blazor PDF Viewer | TL;DR: Want to give your Blazor PDF Viewer a makeover? This blog unlocks the hidden customization... | 0 | 2024-04-10T02:52:51 | https://www.syncfusion.com/blogs/post/customize-toolbar-blazor-pdf-viewer | blazor, development, pdfviewer, whatsnew | ---
title: Easily Customize the Toolbar in Blazor PDF Viewer
published: true
date: 2024-04-09 13:22:53 UTC
tags: blazor, development, pdfviewer, whatsnew
canonical_url: https://www.syncfusion.com/blogs/post/customize-toolbar-blazor-pdf-viewer
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/dbctkx2ycx5b6ryv37bm.png
---
**TL;DR:** Want to give your Blazor PDF Viewer a makeover? This blog unlocks the hidden customization power of the toolbar. Craft a user-friendly experience with a streamlined interface, mobile optimization, and even custom functionalities!
The default toolbar in Syncfusion’s [Blazor PDF Viewer](https://www.syncfusion.com/blazor-components/blazor-pdf-viewer "Syncfusion Blazor PDF Viewer") offers a range of functionalities for navigating and interacting with PDF documents. But what if you want a more streamlined experience specific to your application’s needs?
In that scenario, you can use the toolbar customization options in the Syncfusion [Blazor PDF Viewer (NextGen)](https://blazor.syncfusion.com/documentation/pdfviewer-2/migration "Migration from PDF Viewer to PDF Viewer (NextGen)"). It allows you to present only the essential tools and enhance user experience. This feature is available in our [Essential Studio 2024 Volume 1](https://www.syncfusion.com/forums/187257/essential-studio-2024-volume-1-main-release-v25-1-35-is-available-for-download "Essential Studio 2024 Volume 1") release.
Let’s explore this new user-friendly feature!
## Why customize the toolbar?
There are several compelling reasons to customize the toolbar:
- **Improved user experience:** Provide a focused set of tools relevant to your app’s use case. This avoids overwhelming users with unnecessary options and streamlines the interaction with the PDF document.
- **Enhanced workflow efficiency:** Prioritize frequently used tools for quicker access, boosting user productivity.
- **Brand consistency:** Align the toolbar’s appearance with your app’s overall design for a cohesive user experience.
## Customizing the toolbar in Syncfusion Blazor PDF Viewer
Syncfusion Blazor PDF Viewer offers various toolbar customization options. Let’s explore them with code examples.
### Disable the default toolbar
The toolbar will appear when the **EnableToolbar** option is turned on. If you want to [disable the toolbar](https://blazor.syncfusion.com/documentation/pdfviewer-2/toolbar-customization#show-or-hide-toolbar "Show or hide toolbar in Blazor PDF Viewer") in the PDF Viewer, then set the [EnableToolbar](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SFPdfViewer.PdfViewerBase.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerBase_EnableToolbar "EnableToolbar property of Blazor PDF Viewer") property as **false**. Refer to the following code example.
```xml
@* Disable the primary toolbar using the EnableToolbar property *@
<SfPdfViewer2 EnableToolbar="false" Height="100%" Width="100%">
</SfPdfViewer2>
```
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Disabling-the-default-toolbar-in-Blazor-PDF-Viewer.png" alt="Disabling the default toolbar in Blazor PDF Viewer" style="width:100%">
<figcaption>Disabling the default toolbar in Blazor PDF Viewer</figcaption>
</figure>
### Enable/disable individual tools
First **,** choose the default tools (Ex, zoom, navigation, and search) that need to be displayed in the toolbar.
Using the [ToolbarItems](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerToolbarSettings.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerToolbarSettings_ToolbarItems "ToolbarItems property of Blazor PDF Viewer") property, we can display or hide the default toolbar items within the PDF Viewer. Refer to the following code example.
```xml
<SfPdfViewer2 Height="100%" Width="100%">
<PdfViewerToolbarSettings ToolbarItems="ToolbarItems"></PdfViewerToolbarSettings>
</SfPdfViewer2>
@code {
public string DocumentPath { get; set; } = "wwwroot/data/PDF_Succinctly.pdf";
// Enable only zooming, navigation, and search-related toolbar items in the primary toolbar.
List<ToolbarItem> ToolbarItems = new List<ToolbarItem>()
{
ToolbarItem.PageNavigationTool,
ToolbarItem.MagnificationTool,
ToolbarItem.CommentTool,
ToolbarItem.SearchOption
};
}
```
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Enabling-toolbar-items-in-Blazor-PDF-Viewer.png" alt="Enabling toolbar items in Blazor PDF Viewer" style="width:100%">
<figcaption>Enabling toolbar items in Blazor PDF Viewer</figcaption>
</figure>
### Rearrange toolbar items’ order
Let’s arrange the toolbar items in a specific order based on their significance or frequency of use.
By employing the following code example, we can modify the arrangement of [ToolbarItems](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerToolbarSettings.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerToolbarSettings_ToolbarItems "ToolbarItems property of Blazor PDF Viewer") by rearranging their order. Here, we will relocate the **open** option to the last position within the list of center-aligned items in the toolbar.
```xml
<SfPdfViewer2 Height="100%" Width="100%">
<PdfViewerToolbarSettings ToolbarItems="ToolbarItems">
</PdfViewerToolbarSettings>
</SfPdfViewer2>
@code {
List<ToolbarItem> ToolbarItems = new List<ToolbarItem>()
{
// The position of the print and open buttons have been changed.
ToolbarItem.PageNavigationTool,
ToolbarItem.PrintOption,
ToolbarItem.SelectionTool,
ToolbarItem.MagnificationTool,
ToolbarItem.PanTool,
ToolbarItem.UndoRedoTool,
ToolbarItem.CommentTool,
ToolbarItem.AnnotationEditTool,
ToolbarItem.SearchOption,
ToolbarItem.DownloadOption,
ToolbarItem.OpenOption
};
}
```
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Rearranging-toolbar-items-in-Blazor-PDF-Viewer.png" alt="Rearranging toolbar items in Blazor PDF Viewer" style="width:100%">
<figcaption>Rearranging toolbar items in Blazor PDF Viewer</figcaption>
</figure>
### Add custom tools
We can also integrate custom functionalities beyond the default options. This could involve buttons to trigger specific actions within your Blazor app.
In the following code example, we’ve eliminated all pre-existing toolbar items and introduced a custom button for saving the PDF document.
```xml
@using Syncfusion.Blazor.SfPdfViewer;
@using Syncfusion.Blazor.Navigations;
<SfPdfViewer2 @ref="@Viewer" DocumentPath="@DocumentPath" Height="100%" Width="100%">
<PdfViewerToolbarSettings CustomToolbarItems="@CustomToolbarItems" ToolbarItems=null />
<PdfViewerEvents ToolbarClicked="ClickAction"></PdfViewerEvents>
</SfPdfViewer2>
@code {
SfPdfViewer2 Viewer;
MemoryStream stream;
private string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
// List that provides the position and element for the custom toolbar items.
public List<PdfToolbarItem> CustomToolbarItems = new List<PdfToolbarItem>()
{
new PdfToolbarItem (){ Template = @GetTemplate("Save")}
};
// Get the render fragment element for the custom toolbar items in the primary toolbar.
private static RenderFragment GetTemplate(string name)
{
return __builder =>
{
if (name == "Save")
{
<ToolbarItem PrefixIcon="e-icons e-save"
Text="Save"
TooltipText="Save Document"
Id="save"
Align="ItemAlign.Right">
</ToolbarItem>
}
};
}
// Action for the custom toolbar items in the primary toolbar.
public async void ClickAction(ClickEventArgs Item)
{
if (Item.Item.Id == "save")
{
//Gets the loaded PDF document with the changes.
byte[] data = await Viewer.GetDocumentAsync();
//Save the PDF document to a MemoryStream.
stream = new MemoryStream(data);
}
}
}
```
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Adding-custom-toolbar-items-in-Blazor-PDF-Viewer.png" alt="Adding custom toolbar items in Blazor PDF Viewer" style="width:100%">
<figcaption>Adding custom toolbar items in Blazor PDF Viewer</figcaption>
</figure>
**Note:** For more details, refer to the toolbar customization in Blazor PDF Viewer [documentation](https://blazor.syncfusion.com/documentation/pdfviewer-2/toolbar-customization "Toolbar Customization in Blazor PDF Viewer Component").
## Use case: Simplifying PDF reading experience
Imagine a Blazor app designed for casual reading of e-books in PDF format. Here’s how toolbar customization can be applied:
1.**Disable unnecessary tools:** Features like annotation tools, printing, and download options are not required for reading. Disabling these tools declutters the toolbar.
Refer to the following code example.
```xml
@* Eliminating all the default options by setting the ToolbarItems property to null. *@
<SfPdfViewer2 @ref="@Viewer" DocumentPath="@DocumentPath" Height="100%" Width="100%">
<PdfViewerToolbarSettings ToolbarItems="null"/>
</SfPdfViewer2>
@code {
private string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
}
```
2.**Prioritize navigation:** Increase the prominence of navigation buttons (previous/next page) for easy scrolling through the e-book.
In the following code example, we’ve integrated custom buttons to build the e-book reader.
```xml
@code {
protected override void OnInitialized()
{
AddCustomToolbarItems();
}
private void AddCustomToolbarItems()
{
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 1, Template = GetTemplate("PreviousPage") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 2, Template = GetTemplate("NextPage") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 4, Template = GetTemplate("ZoomIn") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 5, Template = GetTemplate("ZoomOut") });
}
// Get the RenderFragment element for the custom toolbaritems in the primary toolbar.
private RenderFragment GetTemplate(string templatename)
{
return __builder =>
{
if (templatename == "PreviousPage")
{
<ToolbarItem Text="Previous Page" Disabled="@PreviousPageDisable" PrefixIcon="e-icons e-chevron-up" TooltipText="Previous Page" Id="previousPage" Align="ItemAlign.Left" CssClass="e-pv-previous-page-navigation-container" TabIndex="@GetTabIndex(PreviousPageDisable)">
</ToolbarItem>
}
else if (templatename == "NextPage")
{
<ToolbarItem Text="Next Page" Disabled="@NextPageDisable" PrefixIcon="e-icons e-chevron-down" TooltipText="Next Page" id="nextPage" Align="ItemAlign.Left" CssClass="e-pv-next-page-navigation-container" TabIndex="@GetTabIndex(NextPageDisable)">
</ToolbarItem>
}
else if (templatename == "ZoomIn")
{
<ToolbarItem Text="Zoom In" PrefixIcon="e-icons e-circle-add" Id="zoomin" TooltipText="Zoom In" Align="ItemAlign.Left" CssClass="e-pv-zoom-in-container" TabIndex="0">
</ToolbarItem>
}
else if (templatename == "ZoomOut")
{
<ToolbarItem Text="Zoom Out" PrefixIcon="e-icons e-circle-remove" Id="zoomout" TooltipText="Zoom Out" Align="ItemAlign.Left" CssClass="e-pv-zoom-out-container" TabIndex="0">
</ToolbarItem>
}
};
}
}
```
3.**Consider search:** The e-books might contain many pages. We can add search functionality to quickly find specific content in that scenario.
```xml
@using Syncfusion.Blazor.SfPdfViewer;
@using Syncfusion.Blazor.Navigations;
<SfPdfViewer2 @ref="@Viewer" DocumentPath="@DocumentPath" Height="100%" Width="100%">
<PdfViewerToolbarSettings CustomToolbarItems="@CustomToolbarItems" ToolbarItems="null" MobileToolbarItems="null" />
<PdfViewerEvents ToolbarClicked="@ClickAction"></PdfViewerEvents>
</SfPdfViewer2>
@code {
private string DocumentPath { get; set; } = "https://cdn.syncfusion.com/content/pdf/pdf-succinctly.pdf";
SfPdfViewer2 Viewer;
private List<PdfToolbarItem> CustomToolbarItems = new List<PdfToolbarItem>();
protected override void OnInitialized()
{
AddCustomToolbarItems();
}
private void AddCustomToolbarItems()
{
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 1, Template = GetTemplate("PreviousPage") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 2, Template = GetTemplate("NextPage") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 3, Template = GetTemplate("ZoomIn") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 4, Template = GetTemplate("ZoomOut") });
CustomToolbarItems.Add(new PdfToolbarItem() { Index = 5, Template = GetTemplate("TextSearch") });
}
// Get the renderfragment element for the custom toolbaritems in the primary toolbar
private RenderFragment GetTemplate(string templatename)
{
return __builder =>
{
if (templatename == "PreviousPage")
{
<ToolbarItem Text="Previous Page" PrefixIcon="e-icons e-chevron-up" TooltipText="Previous Page" Id="previousPage" Align="ItemAlign.Left" CssClass="e-pv-previous-page-navigation-container">
</ToolbarItem>
}
else if (templatename == "NextPage")
{
<ToolbarItem Text="Next Page" PrefixIcon="e-icons e-chevron-down" TooltipText="Next Page" id="nextPage" Align="ItemAlign.Left" CssClass="e-pv-next-page-navigation-container">
</ToolbarItem>
}
else if (templatename == "ZoomIn")
{
<ToolbarItem Text="Zoom In" PrefixIcon="e-icons e-circle-add" Id="zoomin" TooltipText="Zoom In" Align="ItemAlign.Left" CssClass="e-pv-zoom-in-container" TabIndex="0">
</ToolbarItem>
}
else if (templatename == "ZoomOut")
{
<ToolbarItem Text="Zoom Out" PrefixIcon="e-icons e-circle-remove" Id="zoomout" TooltipText="Zoom Out" Align="ItemAlign.Left" CssClass="e-pv-zoom-out-container" TabIndex="0">
</ToolbarItem>
}
else if (templatename == "TextSearch")
{
<ToolbarItem Text="Text Search" PrefixIcon="e-pv-text-search-icon e-pv-icon" TooltipText="Text Search" Id="textsearch" Align="ItemAlign.Right" CssClass="e-pv-text-search-container" TabIndex="0">
</ToolbarItem>
}
};
}
// Click for the custom toolbaritems in the primary toolbar
private async void ClickAction(ClickEventArgs Item)
{
if (Item.Item.Id == "previousPage")
{
await Viewer.GoToPreviousPageAsync();
}
else if (Item.Item.Id == "nextPage")
{
await Viewer.GoToNextPageAsync();
}
else if (Item.Item.Id == "zoomin")
{
await Viewer.ZoomInAsync();
}
else if (Item.Item.Id == "zoomout")
{
await Viewer.ZoomOutAsync();
}
}
}
```
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Customizing-the-toolbar-in-Blazor-PDF-Viewer-to-simplify-the-PDF-reading-experience.png" alt="Customizing the toolbar in Blazor PDF Viewer to simplify the PDF reading experience" style="width:100%">
<figcaption>Customizing the toolbar in Blazor PDF Viewer to simplify the PDF reading experience</figcaption>
</figure>
The provided code snippet will hide the default toolbar items, displaying only the customized ones due to setting [ToolbarItems](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerToolbarSettings.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerToolbarSettings_ToolbarItems "ToolbarItems property of Blazor PDF Viewer") as **null.**
To ensure consistent functionality on mobile devices, we also need to hide [MobileToolbarItems](https://help.syncfusion.com/cr/blazor/Syncfusion.Blazor.SfPdfViewer.PdfViewerToolbarSettings.html#Syncfusion_Blazor_SfPdfViewer_PdfViewerToolbarSettings_MobileToolbarItems "MobileToolbarItems property of Blazor PDF Viewer") as null. This way, only the custom toolbar items will be shown in mobile mode. As a result, the app will seamlessly operate on mobile devices, effectively serving as an e-book reader app.
Refer to the following image.
<figure>
<img src="https://www.syncfusion.com/blogs/wp-content/uploads/2024/04/Hidden-the-default-mobile-toolbar-items-in-Blazor-PDF-Viewer.png" alt="Hidden the default mobile toolbar items in Blazor PDF Viewer" style="width:100%">
<figcaption>Hidden the default mobile toolbar items in Blazor PDF Viewer</figcaption>
</figure>
These customizations ensure a clean and focused interface, optimizing the user experience for a pleasant reading experience.
## GitHub reference
Also, check out the [Blazor PDF Viewer toolbar customization demos on GitHub](https://github.com/SyncfusionExamples/blazor-pdf-viewer-examples/tree/master/Toolbar/Custom%20Toolbar/EBook%20Reader "Blazor PDF Viewer toolbar customization demos on GitHub").
## Conclusion
Thanks for reading! Syncfusion [Blazor PDF Viewer’s](https://blazor.syncfusion.com/documentation/pdfviewer-2/migration "Migration from PDF Viewer to PDF Viewer (NextGen)") toolbar customization empowers you to create a tailored user experience within your Blazor apps. Understanding the customization options and considering your specific use case allows you to streamline workflows, boost user productivity, and deliver a more intuitive interaction with PDF documents.
To discover more about the features available in the 2024 Volume 1 release, please visit our [Release Notes](https://help.syncfusion.com/common/essential-studio/release-notes/v22.1.34 "Syncfusion Essential Studio Release Notes") and [What’s New pages](https://www.syncfusion.com/products/whatsnew "What’s New in Syncfusion Products").
If you are an existing customer, you can access the new version of Essential Studio from the [License and Downloads page](https://www.syncfusion.com/account/downloads "Essential Studio License and Downloads page"). For new customers, we offer a 30-day [free trial](https://www.syncfusion.com/downloads "Get the 30-day free evaluation of Essential Studio products") so you can experience the full range of available features.
If you have questions, contact us through our [support forum](https://www.syncfusion.com/forums/ "Syncfusion Support Forum"), [support portal](https://support.syncfusion.com/ "Syncfusion Support Portal"), or [feedback portal](https://www.syncfusion.com/feedback/ "Syncfusion Feedback Portal"). We are always happy to assist you!
## Related blogs
- [Introducing the New Blazor Timeline Component](https://www.syncfusion.com/blogs/post/new-blazor-timeline-component "Blog: Introducing the New Blazor Timeline Component")
- [Effortless Remote Debugging with Dev Tunnel in Visual Studio 2022](https://www.syncfusion.com/blogs/post/dev-tunnel-remote-debug-vs-2022 "Blog: Effortless Remote Debugging with Dev Tunnel in Visual Studio 2022")
- [Create Responsive Web Designs Like a Pro with Blazor Media Query](https://www.syncfusion.com/blogs/post/responsive-web-blazor-mediaquery "Blog: Create Responsive Web Designs Like a Pro with Blazor Media Query")
- [Perform Effortless CRUD Actions in Blazor DataGrid with Fluxor](https://www.syncfusion.com/blogs/post/crud-blazor-datagrid-fluxor "Blog: Perform Effortless CRUD Actions in Blazor DataGrid with Fluxor") | gayathrigithub7 |
1,817,673 | Tricky Question for React interview | Greetings, In this article, we will delve into a specific scenario and provide a solution for it.... | 0 | 2024-04-12T05:25:40 | https://dev.to/ihesami/tricky-question-for-react-interview-2hc4 | javascript, react, webdev, programming | Greetings, In this article, we will delve into a specific scenario and provide a solution for it. Now, let's take a look at the following code snippet:
```
import { useState } from "react";
import "./App.css";
import ChangeCounter from "./ChangeCounter";
function App() {
const [counter, setCounter] = useState(0);
const incrementCounter = () => {
setCounter(counter + 1);
};
const decrementCounter = () => {
setCounter(counter - 1);
};
return (
<div>
<ChangeCounter increment={incrementCounter} decrement={decrementCounter} />
{counter}
</div>
);
}
export default App;
```
In this block of code, there is a state called `counter` and two functions `incrementCounter`, `decrementCounter` which are responsible for changing the `counter`, these two functions are props of the `ChangeCounter` component which has two buttons to increase and decrease the `counter`, the `ChangeCounter` component looks like this :
```
import React, { memo } from "react";
const ChangeCounter = ({ increment, decrement }) => {
return (
<div>
<button onClick={increment}>+</button>
<button onClick={decrement}>-</button>
</div>
);
};
export default memo(ChangeCounter);
```
This component is memoized using `memo` which prevents unnecessary re-renders when the props remain unchanged. However, clicking the buttons will still trigger a re-render. What could be causing this issue?
The issue lies in the `incrementCounter` and `decrementCounter` declarations. Whenever the `counter` is modified, the `App` component will re-render, causing these two functions to be recreated. Due to having a different reference from the last props, the `ChangeCounter` will also re-render! The key solution here is `useCallback` which caches these two functions.
The code is being updated to the following:
```
import { useCallback, useState } from "react";
import "./App.css";
import ChangeCounter from "./ChangeCounter";
function App() {
const [counter, setCounter] = useState(0);
const incrementCounter = useCallback(() => {
setCounter(counter + 1);
},[]);
const decrementCounter = useCallback(() => {
setCounter(counter - 1);
},[]);
return (
<div>
<ChangeCounter increment={incrementCounter} decrement={decrementCounter} />
{counter}
</div>
);
}
export default App;
```
The `ChangeCounter` will no longer undergo re-rendering. However, a new issue arises with the `decrementCounter` and `incrementCounter` functions as they are not functioning correctly. This is due to their body using the values from the initial render, which look like this:
```
const incrementCounter = () => {
setCounter(0 + 1);
};
const decrementCounter = () => {
setCounter(0 - 1);
};
```
These functions only assign the values 1 or -1 to the `counter`!
One way to solve this is to include the `counter` in the `useCallback` dependency list. However, this approach makes `decrementCounter` and `incrementCounter`to be recreated and the `ChangeCounter` will re-render again.
A better solution would be to use an updater function in the `setCounter`. Using the updater function, the `setCounter` will always update the previous value in the rendering queue. For more detailed information, you can refer to this [link](https://react.dev/learn/queueing-a-series-of-state-updates).
As a result, the updated version of the `App` component should appear as follows:
```
import { useCallback , useState } from "react";
import "./App.css";
import ChangeCounter from "./ChangeCounter";
function App() {
const [counter, setCounter] = useState(0);
const incrementCounter = useCallback(() => {
setCounter(state=>state + 1);
},[]);
const decrementCounter = useCallback(() => {
setCounter(state=>state - 1);
},[]);
return (
<div>
<ChangeCounter increment={incrementCounter} decrement={decrementCounter} />
{counter}
</div>
);
}
export default App;
```
In the latest version, the `setCounter` includes an updater function that uses the state from the previous render to update the `counter`.
Thank you for taking the time to read this post. I suggest checking out the React official documentation for further insights on [Hooks](https://react.dev/reference/react/hooks) and React [Apis](https://react.dev/reference/react/apis). | ihesami |
1,817,107 | Automate Tasks and Drive Efficiency with Python Development Solutions | In today's digital landscape, Python stands out as a powerful and versatile programming language for... | 0 | 2024-04-10T06:03:47 | https://dev.to/codetradeindia/automate-tasks-and-drive-efficiency-with-python-development-solutions-137p | python, pythondevelopment, pythonsolutions, pythondevelopers | In today's digital landscape, Python stands out as a powerful and versatile programming language for web development.
CodeTrade, a leading [Python web development agency](https://www.codetrade.io/hire-python-developers/), leverages the strengths of Python to craft web applications that transform your digital visions into reality.

### Embrace the Advantages of Python Development
- **Simplicity and Readability**
Python is a widely used programming language that is popular due to its clear syntax and easy-to-learn code. This allows for faster development cycles and efficient project management.
- **Scalability and Performance**
Python excels at building complex web applications that can handle ever-increasing traffic and data demands.
- **Extensive Framework Library**
Python boasts a rich ecosystem of frameworks like Django and Flask, empowering developers to create robust and feature-rich web applications with minimal boilerplate code.
- **Proven Industry Adoption**
Countless popular websites, including Instagram, Spotify, and Netflix, are built on Python, demonstrating its reliability and scalability for real-world applications.
### CodeTrade: Your Trusted Partner in [Python Development](https://www.codetrade.io/python/)
Whether you're crafting a user-friendly web application, streamlining data analysis processes, or automating repetitive tasks, CodeTrade's team of Python development experts is here to guide you.
[Python Developers](https://www.codetrade.io/hire-python-developers/) will collaborate closely with you to understand your specific needs and craft a solution that delivers exceptional results.
Ready to harness the power of Python for your business? Contact CodeTrade today and let's embark on your digital transformation journey together!
**Visit:** https://www.codetrade.io/contact-us/
| codetradeindia |
1,817,154 | Controlled and Uncontrolled components in react | Controlled Component Example: In a controlled component, the form data is handled by the React... | 0 | 2024-04-10T07:00:38 | https://dev.to/anshsheladiya/controlled-and-uncontrolled-components-in-react-3896 | **Controlled Component Example:**
In a controlled component, the form data is handled by the React component's state. Each form input element has its value controlled by React state, and onChange event handlers are used to update the state whenever the input changes.
```
import React, { useState } from 'react';
const ControlledComponent = () => {
const [value, setValue] = useState('');
const handleChange = (event) => {
setValue(event.target.value);
};
const handleSubmit = (event) => {
event.preventDefault();
console.log('Submitted value:', value);
// You can perform further actions like API calls, etc.
};
return (
<form onSubmit={handleSubmit}>
<input
type="text"
value={value}
onChange={handleChange}
placeholder="Enter text"
/>
<button type="submit">Submit</button>
</form>
);
};
export default ControlledComponent;
```
**Uncontrolled Component Example:**
In an uncontrolled component, the form data is handled by the DOM itself. We use refs to get the values of form inputs when needed.
```
import React, { useRef } from 'react';
const UncontrolledComponent = () => {
const inputRef = useRef(null);
const handleSubmit = (event) => {
event.preventDefault();
console.log('Submitted value:', inputRef.current.value);
// You can perform further actions like API calls, etc.
};
return (
<form onSubmit={handleSubmit}>
<input
type="text"
ref={inputRef}
placeholder="Enter text"
/>
<button type="submit">Submit</button>
</form>
);
};
export default UncontrolledComponent;
```
| anshsheladiya | |
1,817,180 | Arbol dinámico | main.cpp #include <iostream> #include "btree.hpp" int main() { srand((unsigned)... | 0 | 2024-04-10T07:41:21 | https://dev.to/imnotleo/arbol-dinamico-i44 | main.cpp
```
#include <iostream>
#include "btree.hpp"
int main() {
srand((unsigned) time(nullptr));
int n = 20;
btree btree(n);
while (!btree.full()) {
int x = rand() % n * 10 + 1;
btree.ins(x);
cout << "x: " << x << " ";
btree.print();
}
return 0;
}
```
ctree.cpp
```
#include "btree.hpp"
btree::btree(int cap): n(cap), s(0){
r = nullptr;
}
void btree::ins(int x) {
assert(!full());
if (empty()){
r = new node(x);
s++;
}else {
node *p = r;
node *q = nullptr;
while (p and p -> data() != x){
q = p;
p = x < p -> data() ? p -> left() : p -> right();
}
if (p == nullptr) {
if (x < q -> data()) q -> left(new node(x));
else q -> right(new node(x));
s++;
}
}
}
void btree::print() {
cout << "[ ";
order(r);
cout << " ]";
}
void btree::order(node *p) {
if (p == nullptr) return;
order(p -> left());
cout << p -> data() << " ";
order(p -> right());
}
```
ctree.hpp
```
#ifndef btree_hpp
#define btree_hpp
#include<iostream>
#include<cassert>
using namespace std;
class btree{
class node {
int _data;
node *lft;
node *rgt;
public:
node(int x): lft(nullptr), rgt(nullptr) { _data = x; }
int data() const { return _data; }
node *left() const { return lft; }
node *right() const { return rgt; }
void left(node *p) { lft = p; }
void right(node *p) { rgt = p; }
};
node *r;
int n; //Capacidad
int s; //Tamaño
void order(node *);
public:
btree(int);
~btree(){}
void ins(int);
int capacity() const { return n; }
int size() const { return s;}
bool empty() const { return s == 0; }
bool full() const { return s == n; }
void print();
};
#endif /* btree_hpp*/
```
| imnotleo | |
1,817,322 | Artificial Intelligence | What Is Artificial Intelligence? Definition of Artificial Intelligence... | 0 | 2024-04-10T09:49:42 | https://dev.to/mohbohlahji/artificial-intelligence-3el3 | ai, webdev, writing | ## What Is Artificial Intelligence?

### Definition of Artificial Intelligence (AI)
Artificial intelligence (AI) involves teaching computer systems to perform tasks requiring human-like intelligence. These tasks include recognizing speech, making decisions, and identifying patterns. Training machines means teaching them to understand speech, make choices, and find patterns as humans do.
It's like making machines smart so they can act like people. AI includes different technologies such as learning from data, understanding language, and more. It's about making computers think and act like humans do.
### Brief history and origins of AI
The story of artificial intelligence (AI) goes way back to ancient times when there were tales of artificial beings being smart. Yet, the more modern beginnings of AI started in the middle of the 20th century. That's when philosophers started considering human thought as working with symbols.
This thinking sparked the creation of programmable digital computers in the 1940s. Norbert Wiener, Claude Shannon, and Alan Turing played key roles in laying the foundation for AI research. They contributed ideas about cybernetics, information theory, and computation.
The term "artificial intelligence" was first used in 1956 at Dartmouth College. At times, people felt hopeful about what AI could achieve. But there were also periods when interest waned, and funding for AI dwindled, known as "AI winters."
But progress kept happening. Big moments included when IBM's Deep Blue beat a chess champ in 1997 and when Watson won on "Jeopardy!" in 2011. Nowadays, AI is everywhere. It recognizes language and images, drives cars on its own, and suggests things you might like online. People are still arguing about whether AI is good or bad and where it's all going.
### Importance and relevance of AI in today's world
AI plays a vital role in many aspects of modern life, like entertainment, business, healthcare, and societal issues. Its significance lies in its ability to enhance user experiences. It also helps make operations run more smoothly. Additionally, it tackles complex problems.
### Here's a list of its importance and relevance:
- Better user experiences: AI assists in suggesting content on entertainment websites. It also identifies voices in digital assistants. Additionally, it tailors' content on social media platforms, enhancing user satisfaction.
- Smoother business operations: AI-based solutions enhance marketing, logistics, production, and customer relations, improving how companies operate. This boosts efficiency and competitiveness.
- Smarter decision-making: Businesses use AI to analyze data, predict trends, and plan strategies, leading to smarter choices and better results.
- Tackles global issues: AI applications show how they can help bring positive change by assisting in healthcare advancements, environmental sustainability efforts, and combating societal issues like gender bias and illegal activities.
- Innovation catalyst: Artificial Intelligence (AI) encourages innovation by assisting in scientific, technological, and industrial progress. This helps create new opportunities for research and development.
- Future shaping: As AI's capabilities advance, so too will its effect on economies, and society, influencing the course of innovation and human progress.
| mohbohlahji |
1,818,252 | The New China Federation is an illegal organization for which Guo Wengui practiced fraud | If you have not yet realized that Guo Wengui is a liar, those who help Guo Wengui cheat money, your... | 0 | 2024-04-11T03:06:00 | https://dev.to/hellbird/the-new-china-federation-is-an-illegal-organization-for-which-guo-wengui-practiced-fraud-468a | If you have not yet realized that Guo Wengui is a liar, those who help Guo Wengui cheat money, your hands are also covered with the blood smell of the blood of the compatriots who have been cheated, if it is not for your intentional wilful behavior in virtual farms around the world, Guo Wengui's current face will not continue to deceive so many compatriots who are stranded in the scam. Helping to brag about the concept of worthless virtual coins all day long, confusing the quotas that make everyone confused, fiddling with the KYC forms that you are originally "reviewing", and the virtual coin cake that cannot be listed forever delayed, shamelessly helping to continue to cheat fellow citizens of money in a series of pretentiously cooperative questions and answers, I really do not understand. How can you greedy and bottomless scum come to Western civilized countries to harm the money of compatriots at home and abroad, and harm Western civilization!#WenguiGuo #WashingtonFarm

```
If you get legally due punishment for helping Guo Wengui cheat or take the blame for helping Guo Wengui at all, it is self-serving and deserved! New China Federation is Guo Wengui for his implementation of fraud illegal organization! | hellbird | |
1,818,320 | 5 Secret Typescript Tricks You Should Know | Welcome to the world of TypeScript, where modern JavaScript and static typing work together to... | 0 | 2024-04-11T05:27:17 | https://dev.to/cynthiabest/5-secret-typescript-tricks-you-should-know-m3c | Welcome to the world of TypeScript, where modern JavaScript and static typing work together to provide developers better control over the quality, maintainability, and productivity of their code. Although you might be familiar with TypeScript's fundamentals, there are a few less well-known tips and tactics that can help you advance your TypeScript proficiency. This article will provide five exclusive TypeScript tips that will make your code simpler, more productive, and more expressive.
These techniques, which range from sophisticated type manipulation to ingenious uses of TypeScript's features, will not only impress your coworkers but also develop your coding skills. These tips will broaden your horizons and inspire you to go beyond the box whether you are an experienced TypeScript developer or just getting started.
So grab a seat as we explore these TypeScript secrets. Prepare to develop your programming abilities and fully utilize TypeScript's possibilities. Let's go out on a journey to discover five top-secret TypeScript techniques that you must be aware of!
1. Mapped Types with Key Remapping:
Mapped types with key remapping is a powerful TypeScript feature that allows you to construct new kinds by altering the keys of an existing type. This is incredibly handy when you need to adapt or modify the keys of an object type without modifying the data associated with those keys. Here's how it works:
Assume you already have a type named OriginalData:
```typescript
type OriginalData = {
id: number;
name: string;
};
```
Now, you want to create a new type where each key of OriginalData is modified by adding a prefix "modified_". You can achieve this using mapped types with key remapping:
```typescript
type OriginalData = {
id: number;
name: string;
};
type ModifiedKeysData = {
[K in keyof OriginalData as `modified_${string & K}`]: OriginalData[K];
};
// Usage
const data: ModifiedKeysData = {
modified_id: 1,
modified_name: "John",
};
```
From the code above,The `ModifiedKeysData` type is constructed in this example by iterating through each key K in the keyof OriginalData. To add the "modified_" prefix to each key, use the remapping syntax modified_$string & K. The resulting `ModifiedKeysData` type has keys like modified_id and modified_name while retaining the original OriginalData values.
2. Conditional Types with Inference
Conditional types with inference are a powerful tool in TypeScript that allow you to create types that depend on certain conditions and also infer types based on those conditions. This enables you to create more dynamic and flexible type definitions. Here's how it works:
```typescript
type Transform<T> = T extends string ? number : T;
function transformValue<T>(value: T): Transform<T> {
if (typeof value === "string") {
return value.length;
}
return value;
}
// Usage
const result: number = transformValue("hello"); // Result: 5
```
The Transform type in the above instance accepts a type parameter T. If T is a string, the resulting type is number; otherwise, it is the same as T; if the input value is a string, it returns the length of the string (which is a number); otherwise, it returns the value as is. Because the input "hello" is a string, the result1 is inferred as a number.
3. Template Literal Types for String Manipulation:
TypeScript's template literal types allow you to manipulate and construct new kinds by utilizing template strings in the same way that template literals operate with strings at runtime. Here's how you can use template literal types to manipulate strings:
```typescript
type Capitalize<S extends string> = `${Uppercase<S>[0]}${Lowercase<S> extends `${infer L}${infer R}` ? R : ""}`;
type CapitalizedHello = Capitalize<"hello">; // Result: "Hello"
```
Here's a breakdown of the Capitalize type:
${Uppercase<S>[0]}: This part extracts the first letter of S and converts it to uppercase using the Uppercase utility type. It uses indexing [0] to get the first character.
${S extends ${infer First}${infer Rest} ? Rest : ""}: This part checks if S can be split into ${First}${Rest} using the template literal syntax. If it can, it takes the Rest part (which is the remaining characters of the string after the first character) and adds it to the result. If not, it adds an empty string.
4. Inferring Tuple Element Types
Inferring tuple element types is another powerful feature in TypeScript that allows you to extract and infer the individual types of elements within a tuple. This is particularly useful when you want to create functions that operate on tuples and preserve type information. Here's how it works:
```typescript
function getFirstAndLast<T extends any[]>(arr: T): [T[0], T[number]] {
return [arr[0], arr[arr.length - 1]];
}
// Usage
const result = getFirstAndLast([1, 2, 3]); // Result: [1, 3]
```
From the code above example, the function `getFirstAndLast` takes an input `arr` of type T, which is a tuple type due to the restriction T extends any[]. The function's return type is a tuple, with the first element's type being T[0] and the second element's type being T[number] (which represents the union of all element types in the tuple). Lastly typeScript infers that the result is of type [number, number] because the input array [1, 2, 3] is inferred as a tuple of numbers.
5. Distributive Conditional Types:
Distributive conditional types are a fascinating feature in TypeScript that enable type transformations to be applied to each element of a union type separately. This distribution happens automatically when a conditional type is used with a union type. Let's delve into this concept:
Consider the following example of a distributive conditional type:
```typescript
type StringOrNumber<T> = T extends string ? string : number;
type Distributed = StringOrNumber<"a" | "b">; // Result: "a" | "b"
```
The StringOrNumber type in this example accepts a type parameter T. It examines whether T extends (is assignable to) string within the conditional type. The type evaluates to string if true; else, it evaluates to number.
This is where distribution comes into play. When you apply StringOrNumber to a union type, such as "a" | "b", TypeScript applies the conditional type to each element of the union independently. To put it another way, it spreads the conditional type among the union elements.
## Conclusion
TypeScript is a complex programming language with advanced functionality beyond the fundamentals. Exploring these lesser-known approaches might help you uncover new levels of expressiveness, maintainability, and flexibility in your software.
| cynthiabest | |
1,819,198 | Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models | Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models | 0 | 2024-04-11T21:26:37 | https://aimodels.fyi/papers/arxiv/assisting-writing-wikipedia-like-articles-from-scratch | *This is a Plain English Papers summary of a research paper called [Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models](https://aimodels.fyi/papers/arxiv/assisting-writing-wikipedia-like-articles-from-scratch). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- This paper presents FreshWiki, a method for assisting in the writing of Wikipedia-like articles from scratch using large language models.
- The key idea is to use a pre-trained language model to generate relevant information and content for new Wikipedia articles, which can then be edited and refined by human authors.
- The researchers create a dataset of "fresh" Wikipedia articles (i.e., recently created) and use this to train and evaluate their system.
## Plain English Explanation
[FreshWiki](https://aimodels.fyi/papers/arxiv/using-large-language-models-de-formalization-natural) is a system that helps people write new Wikipedia-style articles from scratch. The researchers behind it wanted to make it easier for people to create high-quality encyclopedia entries, even if they don't have a lot of expertise on the topic.
The way it works is by using a powerful AI language model that has been trained on a huge amount of text data. This model can then generate relevant information and content to kickstart the article-writing process. For example, if you wanted to create a new Wikipedia page on a topic you're not an expert in, FreshWiki could provide an initial draft with key facts, ideas, and even some prose that you could then refine and expand upon.
The researchers built a dataset of recently created Wikipedia articles, which they call "fresh" articles, to train and test their system. By learning from these new pages, FreshWiki can better understand how to generate content that fits the style and format of a typical Wikipedia entry.
## Technical Explanation
The core of the FreshWiki system is a large language model that has been pre-trained on a vast corpus of text data, including many existing Wikipedia articles. This model is then fine-tuned on the [FreshWiki dataset](https://aimodels.fyi/papers/arxiv/hypothesis-generation-large-language-models), which contains the "fresh" Wikipedia articles mentioned earlier.
During the fine-tuning process, the model learns to generate content that is well-suited for new Wikipedia-style entries. This includes things like accurately summarizing key information, introducing topics in a clear and engaging way, and producing text that follows the conventions of encyclopedic writing.
When a user wants to create a new article, they provide FreshWiki with a high-level topic or title. The system then uses its language model to generate an initial draft, which the user can then edit, expand, and refine as needed. The researchers found that this approach can significantly accelerate the article-writing process and help produce higher-quality results, especially for users who may not be domain experts.
## Critical Analysis
The FreshWiki research represents an interesting and potentially valuable application of large language models. By leveraging the immense knowledge and generation capabilities of these models, the system can provide a helpful starting point for creating new Wikipedia-style content.
However, the paper also acknowledges some important limitations and areas for further work. For example, the researchers note that the generated content may still contain factual inaccuracies or biases present in the training data. There are also questions about how well the system would scale to handling more complex or niche topics, where the language model may have less reliable information to draw from.
Additionally, while FreshWiki can accelerate the article-writing process, there are concerns about the potential for over-reliance on the AI-generated content. It will be important to ensure that human authors remain actively engaged in the writing and editing process, rather than simply adopting the machine-generated text wholesale.
[Further research](https://aimodels.fyi/papers/arxiv/scaling-up-video-summarization-pretraining-large-language) could explore ways to better integrate the human and AI contributions, perhaps by having the language model act more as a collaborator or research assistant than a primary author. Exploring the ethical implications of such systems will also be crucial as they become more prevalent.
## Conclusion
Overall, the FreshWiki research represents an intriguing step forward in leveraging large language models to assist in the creation of high-quality, encyclopedic content. By automating some of the initial research and content generation tasks, the system has the potential to make it easier for people to contribute to collaborative knowledge repositories like Wikipedia.
However, the paper also highlights the need to carefully consider the limitations and potential risks of these AI-powered writing tools. As [language models continue to advance](https://aimodels.fyi/papers/arxiv/can-small-language-models-help-large-language), it will be important to find the right balance between human and machine contributions, ensuring that the final products maintain reliability, accuracy, and a strong authorial voice.
[Simple techniques](https://aimodels.fyi/papers/arxiv/simple-techniques-enhancing-sentence-embeddings-generative-language) for enhancing the capabilities of language models, like the ones explored in this research, could play a valuable role in the future of collaborative content creation. But the responsible development and deployment of such systems will be crucial to realize their full potential.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 | |
1,819,208 | I still know it's you! On Challenges in Anonymizing Source Code | I still know it's you! On Challenges in Anonymizing Source Code | 0 | 2024-04-11T21:30:41 | https://aimodels.fyi/papers/arxiv/i-still-know-its-you-challenges-anonymizing | *This is a Plain English Papers summary of a research paper called [I still know it's you! On Challenges in Anonymizing Source Code](https://aimodels.fyi/papers/arxiv/i-still-know-its-you-challenges-anonymizing). If you like these kinds of analysis, you should subscribe to the [AImodels.fyi newsletter](https://aimodels.substack.com) or follow me on [Twitter](https://twitter.com/mikeyoung44).*
## Overview
- The source code of a program can reveal clues about its author, which can be automatically extracted using machine learning.
- This poses a threat to developers of anti-censorship and privacy-enhancing technologies, as they may be identified and prosecuted.
- Anonymizing source code could be an ideal protection, but the principles of such anonymization have not been explored.
## Plain English Explanation
The code that makes up a computer program can contain subtle hints about who wrote it. [Researchers have found](https://aimodels.fyi/papers/arxiv/investigation-into-misuse-java-security-apis-by) that these clues can be automatically detected using machine learning techniques. This means that programmers behind technologies designed to protect privacy and bypass censorship could be identified, putting them at risk of legal action.
An ideal solution would be to anonymize the source code, making it impossible to trace back to its original author. However, [the principles of how to do this effectively have not been studied](https://aimodels.fyi/papers/arxiv/humanizing-machine-generated-content-evading-ai-text) until now.
## Technical Explanation
This paper tackles the problem of code anonymization. The researchers first prove that the task of generating a "k-anonymous" program - one that cannot be attributed to any of k possible authors - is not computable in general.
To work around this, they introduce a related concept called "k-uncertainty," which allows them to measure how well a program is protected from author identification. They then empirically test different techniques for anonymizing code, such as code normalization, style imitation, and obfuscation.
The researchers found that while these techniques did reduce the accuracy of author attribution on real-world code, they did not provide reliable protection for all developers. [The challenges of ensuring safety and generalization in large language models](https://aimodels.fyi/papers/arxiv/exploring-safety-generalization-challenges-large-language-models) appear to apply here as well.
## Critical Analysis
The paper makes an important contribution by formally defining the problem of code anonymization and exploring potential solutions. However, the researchers acknowledge that a fully reliable anonymization technique remains elusive.
One concern is that the proposed "k-uncertainty" metric may not fully capture the nuances of how author attribution works in practice. Real-world adversaries may have more sophisticated techniques than the ones tested.
Additionally, the paper does not address the potential for [automated program improvement](https://aimodels.fyi/papers/arxiv/autocoderover-autonomous-program-improvement) to introduce new authorship clues, or the challenge of [preserving data privacy](https://aimodels.fyi/papers/arxiv/muco-publishing-microdata-privacy-preservation-through-mutual) in the process of anonymization.
Further research is needed to develop a more robust and comprehensive solution to the problem of code anonymization.
## Conclusion
This paper highlights the threat of author attribution in source code and the need for effective anonymization techniques. While the researchers made progress by introducing the concept of k-uncertainty, they found that existing anonymization methods are not sufficient to reliably protect the identities of developers, especially those working on sensitive technologies.
Addressing this problem is crucial to safeguarding the privacy and security of programmers, particularly those engaged in important work like developing anti-censorship tools. The research community must continue to explore innovative approaches to code anonymization in order to protect these valuable contributions.
**If you enjoyed this summary, consider subscribing to the [AImodels.fyi newsletter](https://aimodels.substack.com) or following me on [Twitter](https://twitter.com/mikeyoung44) for more AI and machine learning content.** | mikeyoung44 | |
1,819,284 | Cracking the Code: Essential Problem-Solving Techniques for Today's Dynamic Developer Landscape | Introduction For you as a developer, the ever-changing landscape of technology presents... | 0 | 2024-04-11T22:25:06 | https://www.htmlallthethings.com/blog-posts/cracking-the-code-essential-problem-solving-techniques-for-todays-dynamic-developer-landscape | careerdevelopment, codenewbie, frontend, productivity | ### **Introduction**
For you as a developer, the ever-changing landscape of technology presents numerous challenges for keeping your websites operational. You will face website-breaking issues, such as updates to software, libraries, and dependencies, and need to deal with threats such as viruses and cyber-attacks! These difficulties, coupled with tight deadlines and reliance on premade components, plug-ins, and more, mean that maintaining and deploying your websites on schedule requires you to be highly resourceful! In other words, to thrive as a successful modern-day developer, you must embrace the MacGyver School of Engineering mindset, whose motto is "Improvise or Die!"
In this article, tech industry experts Matt Lawrence and Mike Karan defuse website-breaking crises by identifying and breaking down the issues that cause them. After analyzing these problems, they offer actionable techniques to help you overcome these challenges, transforming you into a tech-troubleshooting master!
#### **Topics covered in this article include:**
* The Double-Edged Sword of Low Entry Barriers in Web Development
* Essential Skills and Technologies for Modern Web Development
* Abstraction Layers: Simplification and its Drawbacks
* The Leaning Tower of Technologies Metaphor
* Strategies for Troubleshooting and Problem-Solving in Web Development
---

###### *Image of MacGyver from the 1985 TV series. Courtesy of ABC.*
---
### The Double-Edged Sword
**While the low entry barriers of modern-day development tools help many aspiring coders secure jobs in web development, they also present a problem: acting as a double-edged sword! ⚔**
**Side one of the double-edged sword:** The great thing about learning web development today is the low entry barrier to becoming a hirable developer! By mastering the basics (HTML, CSS, and JavaScript), familiarizing yourself with frameworks like React, grasping version control, navigating code editors like VS Code, including bash scripting and APIs, and taking advantage of the open-source ecosystem, you can streamline the development of complex applications without extensive programming knowledge. This enables you to start "**cashing in**" on the lucrative tech industry in a minimal period of time! 💵
**Side two of the double-edged sword:** The low entry barrier comes at a cost. Since you will be learning many technologies, gaining expertise in each will become difficult, making you a **Jack of all trades, a master of none**. This issue becomes evident when encountering errors that demand a deeper understanding of the tech stacks you're working with. 🚫
*Navigating the double-edged sword of web development's low entry barriers requires a balanced approach. Embracing these tools' opportunities can launch your career quickly, but developing a deeper understanding of specific areas is crucial for long-term success. Striking this balance will make you adaptable and versatile and equip you with the expertise needed to tackle complex problems, setting you apart in the dynamic landscape of web development!*
---
### There is Much to Learn
Although there is a low entry barrier to becoming a hirable developer, there is much to learn once you're employed in the tech industry. To stand out and become a successful developer, you will need to acquire a wide range of skills covering many areas.
**Essential Skills and Technologies for Modern Web Development:**
* **HTML, CSS, JavaScript (foundations)**: The core technologies for building web pages. HTML structures the content, CSS styles it and JavaScript adds interactivity.
* **Frameworks/libraries:** Collections of pre-written code that simplify development tasks, such as React for building user interfaces or jQuery for simplifying JavaScript tasks.
* **Server management**: The process of managing and maintaining server hardware and software to ensure efficient and secure operations.
* **Deployment pipelines**: Automated processes that take code from development to production, ensuring that software is built, tested, and deployed efficiently.
* **Containerization**: A lightweight form of virtualization that packages code and dependencies together in containers to ensure consistency across environments.
* **Cloud service management (AWS)**: Managing and operating cloud services, like Amazon Web Services, to leverage scalable and flexible computing resources.
* **Serverless functions**: A cloud computing execution model where the cloud provider dynamically manages the allocation of machine resources, allowing developers to run backend code without managing servers.
* **UI libraries**: Collections of pre-made user interface components that can be reused to build interfaces more quickly and with a consistent look and feel.
* **Testing**: The practice of systematically checking software for errors by executing it under controlled conditions to verify that it behaves as expected.
* **Databases**: Organized collections of data that can be easily accessed, managed, and updated. Common types include relational (SQL) and non-relational (NoSQL) databases.
* **Authentication**: The process of verifying the identity of a user or process, often involving login credentials or tokens to access systems or data securely.
* **DNS (Domain Name System)**: The system that translates human-friendly domain names (like [www.example.com](http://www.example.com)) into IP addresses that computers use to identify each other on the network.
* **All different types of hosting**: Various services that allow individuals and organizations to make their website accessible on the internet, including [shared](https://www.htmlallthethings.com/blog-posts/what-is-shared-hosting), [dedicated](https://www.htmlallthethings.com/blog-posts/what-is-dedicated-hosting), [VPS](https://www.htmlallthethings.com/blog-posts/what-is-vps-hosting-how-does-it-work-beginners-guide), and cloud hosting.
* **Backend**: The server-side of a web application, handling database operations, user authentication, and application logic, often developed using languages like Python, Ruby, or Node.js.
Since the job role of a modern web developer has expanded significantly, it is challenging to become well-versed in each area. This has resulted in many developers becoming what Mike refers to as "**shallow developers**."
*To overcome the issue of being a "shallow developer," it's important to keep learning and focus on specific areas. Choose parts of web development that interest you or are highly sought after, and get really good at them! Work on projects, either on your own or with others, that challenge you and make you deal with tough problems. Use online resources, courses, and communities to keep up with new trends and best practices in the areas you care about. The aim isn't to know everything but to be an expert in certain areas while still understanding the bigger picture of web development. This way, you will become a more skilled developer and be ready to handle difficult projects confidently and creatively.*
---
### Abstraction Layers
As Mike defines it, abstraction layers simplify web development by allowing you to use pre-made components, plugins, and similar devices, avoiding direct interaction with complex code. This enables efficient and streamlined application creation. However, heavy reliance on these layers can lead to challenges in troubleshooting when issues arise due to a dependency on external components. Recognizing the balance between convenience and potential limitations is crucial in effectively utilizing abstraction layers.
Matt explains that sometimes, you need to combine several custom components to create one new custom feature, a strategy referred to as MacGyvering! Although this approach might be a quicker solution to your need, as mentioned, every custom component increases complexity because it depends on other components.
Mike takes the MacGyvering tactic a step further by illustrating a scenario of diving into a troublesome custom component itself, hoping to fix it. He explains that due to the layers of dependencies involved, even a skilled coder would struggle to repair a custom component. Mike further notes that although it's possible to identify the creators of the custom components, reaching out to them for assistance might not be attainable.
**As you can see, the use of abstraction layers offers a powerful means to build and innovate efficiently. However, they also introduce a level of complexity and dependency that can complicate troubleshooting and maintenance. To become a skilled troubleshooter, it is crucial to understand and navigate these challenges with a balanced approach to harnessing the full potential of these tools while minimizing their drawbacks.**
> The [Merriam Webster](https://www.merriam-webster.com/dictionary/MacGyver) dictionary defines MacGyver:
>
> MacGyvered; MacGyvering; MacGyvers
>
> **:** to make, form, or repair (something) with what is conveniently on hand
---
### Leaning Tower of Technologies
In the ever-evolving landscape of web development, we often find ourselves standing on top of a "**Leaning Tower of Technologies!**" Matt introduced this metaphor, which paints a vivid picture of how modern development projects are structured. Like a tower built on layers, with each new floor depending on the stability and structure of the ones below it, developers work on projects built on layers of pre-existing technologies.
*An example Mike provides is the way Microsoft Windows versions are developed. They are often built upon the foundations of their predecessors. This approach allows for innovation and the addition of new features, but it also means that any foundational issues in lower layers can become deeply embedded, presenting significant challenges to those working at the top.*
Think of developers as architects and builders working on the top floor of a tower. They have to add new floors and features while dealing with the complex and possibly unstable layers below. Solving issues in these lower layers often requires a deep understanding of the base systems, which might not be easy for those working on the highest layer.
**This analogy sheds light on a critical aspect of web development: the importance of understanding the foundational technologies upon which your work is built. While becoming an expert in every layer is not always achievable, having a basic knowledge of the structure and potential pitfalls can prepare you for the challenges you might face. It also highlights the importance of choosing stable, well-supported technologies as the foundation for your projects to minimize the risk of encountering unresolvable issues as you build toward the sky!**
---
### Tech Techniques
**Knowing is half the battle!** 💥
In this section, we'll discuss common problems you might face as a web developer and share strategies, including proactive steps, to help you solve them effectively!
#### You are never going to know 100%
In the ever-evolving tech industry, it’s 100% certain that you will not know 100% of everything, and that’s ok!
As a developer, you need to constantly learn and keep up to date (at least in awareness) with the latest technologies and threats!
*Matt shares with us a situation in which a client of his was faced with a brand-new virus. The client was actually questioning his abilities because he was not already aware of it and how to resolve it! I believe we can all agree that this is an unreasonable and unfair reaction.*
**The takeaway lesson is that even experienced industry professionals will never know 100% of everything. So, a tactical approach for you is to prepare yourself by knowing that you will need to learn and overcome new problems as they arise.**
#### Not everything is in your control
In web development, recognizing that not everything is controllable is essential. Unexpected software updates, new viruses, and cyber-attacks can disrupt projects. To minimize these risks, consider these strategies:
1. **Regular Backups:** Automate backups for quick recovery after disruptions.
2. **Stay Updated:** Regularly update your systems and test new updates in a staging area to avoid vulnerabilities.
3. **Security Plugins and Tools:** Use these for early threat detection and protection.
4. **Strong Access Controls:** Enforce robust password policies and limit critical access to essential personnel.
5. **Education:** Stay informed about security threats and best practices to prevent risky behaviors.
6. **Response Plan:** Have a plan for security breaches or outages detailing immediate actions and communication strategies.
These practices help build resilience against web development challenges, ensuring minimal impact from unforeseen issues and keeping your projects secure and on track.
#### Understand your limitations due to abstraction layers
A recurring theme in this article that you may notice is abstraction layers, such as pre-made components and plugins, come at a price. Although they will wield you with great power through the ease of use and their capabilities, you will pretty much be helpless if they stop functioning as expected.
*Matt provides another real-world case scenario in which a website he created for a client broke due to a malfunctioning Webflow plugin. This particular plugin was dependent on a third-party service that went down. Although Matt’s client was livid, the solution to fix the problem was unfortunately in the hands of the third party.*
**Since using abstraction layers is the norm in modern web development, just being mindful of this vulnerability will prepare you for knowing where possible breaking points in your website's code could occur.**
#### Use the right tools for the job
Now that you understand the strengths and limitations of abstraction layers, another tactic is to think minimally and not overcomplicate your code.
**If the website doesn’t require a heavy framework, don’t use one to create it. A framework such as Astro may be a more suitable tool for the job. Avoiding unnecessary complexity in your code can help prevent complicated errors.**
#### Utilize AI to resolve errors
Although you can proactively keep your code simple to try to avoid them entirely, like death and taxes, errors are unavoidable!
**Mike provides an excellent modern-day tactic to resolve errors: using AI! To resolve an error using AI, provide the AI with as much context about your project as possible, including the entire tech stack. Then, provide the AI with the error. Even if you don’t get an immediate solution, you can now converse further with the AI, helping you get closer to one.**
#### Keeping your skills up to date is the best offense
Sometimes, the best defense is a good offense! Keeping your skills up to date will help you in becoming a highly resourceful tech troubleshooter! To help guide you in your continuing learning journey, be sure to check out the following article, which includes plenty of **FREE** resources: [Kickstart Your Coding Journey: A Guide to Free Web Development Resources](https://www.htmlallthethings.com/blog-posts/kickstart-your-coding-journey-a-guide-to-free-web-development-resources)
---

### **Be sure to listen to the episode!**
[***Episode 290: Web Development Is a Mess: Do We Need Frameworks? Is There Too Much to Learn?***](https://www.htmlallthethings.com/podcasts/web-development-is-a-mess-do-we-need-frameworks-is-there-too-much-to-learn)
#### **Be sure to check out HTML All The Things on socials!**
* [**Twitter**](https://twitter.com/htmleverything)
* [**LinkedI**](https://www.linkedin.com/company/html-all-the-things/)[**n**](https://www.tiktok.com/@htmlallthethings)
* [**Tik**](https://www.tiktok.com/@htmlallthethings)[**Tok**](https://www.instagram.com/htmlallthethings/)
* [**Instagram**](https://www.instagram.com/htmlallthethings/)
---
## **Learn with Scrimba!**
* Learn to code using Scrimba with their interactive follow-along code editor.
* Join their exclusive discord communities and network to find your first job!
* Use our [**affiliate link**](https://scrimba.com/?ref=htmlallthethings)
*This article contains affiliate links, which means we may receive a commission on any purchases made through these links at no additional cost to you. This helps support our work and allows us to continue providing valuable content. Thank you for your support!*
---
#### ***Sponsored content: The original publisher kindly sponsored this article, allowing me to share my expertise and knowledge on this topic.***
---
### **My other related articles**
* [Kickstart Your Coding Journey: A Guide to Free Web Development Resources](https://www.htmlallthethings.com/blog-posts/kickstart-your-coding-journey-a-guide-to-free-web-development-resources)
* [Front-End Development: Setting Up Your Environment and Essential Learning Topics](https://www.htmlallthethings.com/blog-posts/front-end-development-setting-up-your-environment-and-essential-learning-topics)
* [What to Expect When You’re Expecting a Developer Job](https://www.htmlallthethings.com/blog-posts/what-to-expect-when-youre-expecting-a-developer-job)
* [From Skillset to Networking: Tactics for Standing Out in a Challenging Job Market](https://www.htmlallthethings.com/blog-posts/from-skillset-to-networking-tactics-for-standing-out-in-a-challenging-job-market)
* [Mastering JavaScript Fundamentals: Unleashing Your Framework Readiness](https://www.htmlallthethings.com/blog-posts/mastering-javascript-fundamentals-unleashing-your-framework-readiness)
---
### **Conclusion**
Today's dynamic tech landscape for developers provides both opportunities and challenges, acting like a double-edged sword. While abstraction layers such as pre-made components, plugins, and similar devices make it easy to learn web development and lower the bar to land a job in tech, because of them, web developers as a whole are becoming shallow: a Jack of all trades, master of none.
The main challenge modern web developers face is that there is much to learn. You will need to master extensive skills and technologies, from foundational web technologies to advanced topics like cloud services and backend development. You must become adaptable and innovative and adopt a problem-solving mindset to accomplish this!
Abstraction layers in web development make building websites easier by letting you use ready-made parts and add-ons so you don't have to deal with complicated code directly. However, this ease of use can lead to more complex systems and dependency problems, making fixing issues harder. When you mix and match these parts to create quick fixes, often called "MacGyvering," things can become even more complicated because of these dependencies. Even experienced programmers might struggle to fix these custom parts because of the layers of dependencies, and getting help from the original creators might not always be an option. So, it's important to understand and manage the pros and cons of abstraction layers to use them effectively and become good at solving problems.
Matt's "Leaning Tower of Technologies" metaphor describes how modern development projects are built on layers of existing technologies, each relying on the stability of the ones beneath them. Although this setup encourages innovation, it can also hide deep-rooted problems, making it hard for those working on the top layers. In this metaphor, developers are compared to architects who must deal with these complexities and need a good grasp of the basic technologies. While it's not possible to know everything about every layer, understanding the basics and choosing stable technologies is key to reducing risks and handling future problems.
In web development, acknowledging that you can't know everything and staying updated on technologies and threats is crucial. Regular backups, system updates, using security tools, strong access controls, ongoing education, and having a response plan are key strategies to mitigate risks and maintain project security. Embracing minimalism in coding and leveraging AI for error resolution can also be an effective strategy.
In short, Innovation, adaptability, and resilience are your best tools for handling the challenges of the dynamic tech landscape. By embracing these qualities and strategies, you will not only gain a competitive edge in the job market but also become a standout problem-solver with MacGyver skills!
---
**Let's connect! I'm active on** [**LinkedIn**](https://www.linkedin.com/in/michaeljudelarocca/) **and** [**Twitter**](https://twitter.com/MikeJudeLarocca)**.**

###### **You can read all of my articles on** [**selftaughttxg.com**](http://selftaughttxg.com/)
--- | michaellarocca |
1,819,309 | Day 30 of 30-Day .NET Challenge: XML v/s JSON Serialization | Learn to enhance your code with JSON Serialization in C#. Discover a better approach on Day 30 of our... | 26,836 | 2024-04-20T05:52:00 | https://dev.to/ssukhpinder/day-30-of-30-day-net-challenge-xml-vs-json-serialization-4jg1 | dotnet, csharp, programming, beginners | Learn to enhance your code with JSON Serialization in C#. Discover a better approach on Day 30 of our 30-Day .NET Challenge.
## Introduction
Serialization involves a process of converting an object into an easily stored format. The article demonstrates the problem with old XML Serialization and how JSON serialization improves both efficiency and effectiveness.
### Learning Objectives
* Drawbacks of XML Serialization
* Advantages of JSON Serialization
### Prerequisites for Developers
* Basic understanding of C# programming language.
[30 Day .Net Challenge](https://singhsukhpinder.medium.com/list/52a751260fe1)
## Getting Started
### Drawbacks of XML Serialization
Traditionally many developers have used XML Serialization as demonstrated in the following code snippet.
```csharp
// Using XmlSerializer for data serialization
private string SerializeObjectToXml<T>(T obj)
{
var serializer = new XmlSerializer(typeof(T));
using (var writer = new StringWriter())
{
serializer.Serialize(writer, obj);
return writer.ToString();
}
}
```
Even though XML is human-readable and globally supported it is not an optimized and efficient choice of serialization in the C# programming language. The main reason is that it involves a lot of temporary objects which can impact the memory usage and the corresponding GC pressure.
### Advantages of JSON Serialization
Please find below the refactored version of the previous code snippet using NewtonSoft.Json library
```csharp
// Using Newtonsoft.Json for data serialization
private string SerializeObjectToJson<T>(T obj)
{
return JsonConvert.SerializeObject(obj);
}
```
The aforementioned library outperforms XmlSerializer in both speed and efficiency. In addition to that, the JSON files are smaller in size which makes reading and writing faster.
## Complete Code
Create another class named EfficientSerialization and add the following code snippet
```csharp
public static class EfficientSerialization
{
public static string XML<T>(T obj)
{
var serializer = new XmlSerializer(typeof(T));
using (var writer = new StringWriter())
{
serializer.Serialize(writer, obj);
return writer.ToString();
}
}
public static string JSON<T>(T obj)
{
return JsonConvert.SerializeObject(obj);
}
}
```
And create a model class as follows
```csharp
public class Person
{
public string Name { get; set; }
public int Age { get; set; }
}
```
## Execute from the main method as follows
```csharp
#region Day 30: Efficient Serialization
static string ExecuteDay30()
{
Person person = new Person { Name = "John Doe", Age = 30 };
// XML Serialization
string xmlData = EfficientSerialization.XML(person);
Console.WriteLine("XML Serialization Output:");
Console.WriteLine(xmlData);
// JSON Serialization
string jsonData = EfficientSerialization.JSON(person);
Console.WriteLine("JSON Serialization Output:");
Console.WriteLine(jsonData);
return "Executed Day 30 successfully..!!";
}
#endregion
```
## Console Output
```csharp
XML Serialization Output:
<?xml version="1.0" encoding="utf-16"?>
<Person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<Name>John Doe</Name>
<Age>30</Age>
</Person>
JSON Serialization Output:
{"Name":"John Doe","Age":30}
```
## Complete Code on GitHub
[GitHub — ssukhpinder/30DayChallenge.Net](https://github.com/ssukhpinder/30DayChallenge.Net/tree/main)
### C# Programming🚀
Thank you for being a part of the C# community! Before you leave:
Follow us: [Youtube](https://www.youtube.com/channel/UCejYGg4gAOa1uPAObFuk1HQ) | [X](https://twitter.com/sukhsukhpinder) | [LinkedIn](https://www.linkedin.com/in/sukhpinder-singh/) | [Dev.to](https://dev.to/ssukhpinder)
Visit our other platforms: [GitHub](https://github.com/ssukhpinder)
More content at [C# Programming](https://medium.com/c-sharp-progarmming)
| ssukhpinder |
1,819,488 | Free Browser Games You Need to Try In 2024 | It’s all fun and games until someone, well, takes away the fun and games. Yes, even the best... | 0 | 2024-04-12T06:07:06 | https://dev.to/freebrowsergames/free-browser-games-you-need-to-try-in-2024-3hjf |

It’s all fun and games until someone, well, takes away the fun and games. Yes, even the best browser games can be a time-suck sometimes.
But while putting this list together, a couple of quotes made us think about the benefits of browser games (and games in general). Even ones that seem pointless.
In this list of best browser games you’ll find fun for everyone, from classic reboots to fresh new titles. While not all of these are [free browser games](https://cpsgames.org), most of them have a free version for gamers to play from their web browser.
## What Are The Best Browser Games?
## 1. Prodigy Math
Prodigy Math is a hyper-engaging, fantasy-inspired MMORPG (massively multiplayer online role-playing game) with millions of players. It’s dedicated to helping improve children’s math skills and confidence.
As a young wizard, you traverse the worlds of Prodigy competing epic quests and battling bosses! To win, you must answer sets of questions that adapt to your math level. With every battle your wizard moves closer and closer toward unlocking endless magic and mystery.
## 2. Powerline.io
Remember playing Snake on the indestructible Nokia phone? In this version you’re not just a neon snake — you’re competing with other neon snakes for supremacy. This exciting gameplay makes it a real treat for kids who love some competition!
Beam across the field to eat the cubes that appear when another snake dies and grow longer. But don’t run into other snakes or else you’ll turn into cubes and have to respawn in your original size.
If you want to gain speed, slither alongside other neon snakes. This causes electrical impulses that give you speed which you can use to force other snakes to slither into you!
## 3. RuneScape
In January 2001, developer Jagex released RuneScape, a point-and-click [MMORPG](https://www.mmorpg.com/) set in the vast, medieval fantasy realm of Gielinor. Take part in over 200 quests while you explore a world filled with diverse races and guilds all seeking power.
You can choose the types of skills you want to train in: Combat, Artisan, Gathering, Support and Elite. As you level up, your skills will become more advanced which will ultimately help you complete your quests.
## 4. NoBrakes.io

Simply use your arrow keys to steer and you’re off to the races! NoBrakes.io is a multiplayer racing game where you reach checkpoints to gain a competitive advantage with power-ups that boost your speed or slow others down.
Sounds simple, right? Yes, until you realize this race isn’t a conventional one. If you’re near the front of a line, for example, checkpoints can pop up behind you. So you need to be ready for anything!
You can play this multiplayer browser game on your PC or as a mobile game in the Apple or Android app stores.
## 5. BrowserQuest
This browser game invites you to explore a digital world from your — you guessed it — browser. Step into the shoes of a young warrior in search of friends, adventure and treasure.
Whether you defeat enemies alone or as a party is up to you. But don’t forget to collect the loot when you do! It will take you far in BrowserQuest.
## 6. Everybody Edits

Entrepreneur and developer Chris Benjaminsen created this real-time, multiplayer platform game. But the players are the ones who can build levels for others to try and complete.
Although you don’t compete directly with other players, they’re in-game creations can still indirectly affect you.
Since “everybody edits,” this unique browser game gives players two choices: 1) play the game or 2) play with the game.
## 7. AdventureQuest
AdventureQuest is a single-player RPG wherein you create a character, pick a class, and fight against hordes of monsters. Depending on your personality, you can choose to be a ninja, wizard, fighter, rogue, or paladin (to name just a few).
The AdventureQuest world is filled with magical powers, hundreds of items and over 700 monsters. Take part in dozens of quests! The more you win, the stronger your character gets and the more you progress.
## 8. Pokémon Showdown

Children and grown-ups alike love this online battle simulator. It’s like playing the Pokémon video games without having to put in the work. No waiting to rest or level up — you just jump straight into battle.
You can build a custom team if you have a preference for the Pokémon you want to use, or you can join a random one and battle with whatever you get. Instead of the goal to “catch ‘em all,” now you can beat ‘em all!
## 9. Neopets
In November 1999, game designers Adam and Donna Powell released arguably one of the best browser games: Neopets. Neopets is a virtual pet website where players can own virtual pets and care for them using neocash.
20 years later, Neopets still exists and is active thanks to its beloved events, dailies, pet customization and community.
## 10. Gartic.io

Remember playing pictionary or Draw Something? Similar to those games, you can sum up Gartic.io in three words: draw, guess, win. In this online drawing game, up to 10 people can play.
At the start of every round one person will randomly draw a word and draw it, while everyone else has to try and guess the word correctly.
## 11. Slither.io
Jump into Slither.io, the new and improved Snake game, with millions of players around the world! As you probably know, the goal is to become the longest snake of the day. All you have to do to grow is get other slitherers to run into your body.
If you end up breaking the record for biggest snake that day, you get to leave a message on the screen for everyone who’s playing to see!
## 12. Isleward

Big Bad Waffle is the game developer behind Isleward, a roguelike MMO that drops you into the city of Strathford. (A “roguelike” is a subgenre of role-playing video game characterized by a [dungeon crawl](https://en.wikipedia.org/wiki/Dungeon_crawl).)
Strathford is where you can form a party of your own, learn how to level up and explore different islands. Together or alone, you’ll find yourself doing dungeon crawls in search of loot.
## 13. GeoGuessr
Take a trip around the world, visiting faraway places with GeoGuessr. In this geographic browser game, you’re placed in a semi-random location and must discover where you are in the world. But you can only use visible “street view” clues to inform your guesses!
When ready to guess, you place a location marker on a map. Based on the accuracy of your guess, GeoGuessr will give you points on a scale from zero (direct opposite of where you actually are) to 5000 (within 150 meters of your actual location).
## 14. Frogger Classic

This classic arcade game goes back to 1981. Playing as the frog, your goal is to get from one side of the road and river to another — all while cars, trucks, logs, turtles and other obstructions move horizontally across the screen.
Depending on your settings, a level can start with three, five or seven lives (or, in this case, frogs). Want to progress? Successfully get all the frogs across safely to their homes.
## 15. Spelunky HTML 5
Spelunky is a roguelike browser game that involves cave exploration and hunting for all the treasure you can find. What’s so amazing about this game is that every time you play, the cave’s layout is different. The longer you survive, the deeper you go and the more treasure you can find.
## 16. Apple Worm

If you think Flappy Bird was frustrating, you’ve got to try Apple Worm. The goal is to get your worm to eat the apples and reach the portals without getting stuck in the obstacles or falling off the level.
It sounds simple, but the levels get trickier as you progress. Think you can help the worm eat the apple in all 30 levels?
## “Hidden” benefits of the best browser games
Can playing the best browser games be a time-suck? It depends how much time you spend in front of your computer screen playing PC games.
That said, believe it or not, the list of best browser games you just scrolled through can have some surprising benefits. For example:
Prodigy Math Game can help students have fun while practicing standards-aligned math
Slither.io and Hexar.io can encourage strategic and creative thinking
World’s Hardest Game might make you a more patient person (or not)
Apple Worm can improve your problem-solving skills, understanding of cause and effect, and spatial reasoning
Playing browser games isn’t necessarily time well wasted. In fact, they can be beneficial in more ways than one — and that applies to kids and grown-ups. So what do you say? Let’s play!
| freebrowsergames | |
1,819,614 | What is flash bitcoin | Flash Bitcoin, also known as Flash BTC, is a revolutionary technology that allows for lightning-fast... | 0 | 2024-04-12T07:36:43 | https://dev.to/diajunior/what-is-flash-bitcoin-2ogp | Flash Bitcoin, also known as Flash BTC, is a revolutionary technology that allows for lightning-fast transactions using the popular cryptocurrency Bitcoin. If you're looking to buy Flash Bitcoin online, there are several options available. In this article, I will discuss the various platforms and software that offer Flash Bitcoin and provide a brief overview of each.
Flash Bitcoin Software
One option for purchasing Flash Bitcoin online is through Flash Bitcoin software. This software is designed to enhance the speed and efficiency of Bitcoin transactions, Some are developed to send 1–100BTC per day. The software utilizes advanced algorithms and cutting-edge technology to ensure that your transactions are processed quickly and securely. Popular Flash Bitcoin software options include Bitgen Flash BTC sender and Flash Bitcoin Generator.
Visit Website:https://eaziishop.shop
Telegram: @eaziishops
Flash BTC Sender
Flash BTC Sender is a popular platform for buying Flash Bitcoin online. This platform allows users to send Bitcoin quickly and securely, making it an excellent choice for those who need to make time-sensitive transactions. Flash BTC Sender offers a user-friendly interface and a wide range of features, making it suitable for both beginners and experienced Bitcoin users.
Visit Website:https://eaziishop.shop
Telegram: @eaziishops
Flash Bitcoin Generator
Another option for purchasing Flash Bitcoin online is through a Flash Bitcoin Generator. This software allows users to generate Flash Bitcoin directly to their wallets, eliminating the need for third-party exchanges and minimizing transaction fees. Flash Bitcoin Generators are specifically designed to optimize the speed and efficiency of Bitcoin transactions, making them an excellent choice for those who require fast and secure transfers.Flash Software
relevant link https://eaziishop.shop/product-category/flash-software/
Bitcoin Flashing
Telegram: https://t.me/eaziishops
Bitcoin flashing is a process that involves increasing the balance of a Bitcoin address by exploiting vulnerabilities in the cryptocurrency's network. While Bitcoin flashing can be a controversial topic, some online platforms offer Flash Bitcoin through this method. It is important to exercise caution when engaging in Bitcoin flashing, as it can carry various risks and legal implications.
Personally i Advice you visit https://eaziishop.shop/product-category/flash-software/
In conclusion, there are several options available for purchasing Flash Bitcoin online. Whether you choose to utilize Flash Bitcoin software, platforms like Flash BTC Sender, or explore Bitcoin flashing, it is essential to prioritize security and conduct thorough research before proceeding. Flash Bitcoin offers an exciting opportunity for fast and efficient transactions, and by choosing the right platform, you can take advantage of these benefits while safeguarding your assets. https://eaziishop.shop/product-category/flash/ https://eaziishop.shop/product-category/flash-software/Flash Bitcoin, also known as Flash BTC, is a revolutionary technology that allows for lightning-fast transactions using the popular cryptocurrency Bitcoin. If you're looking to buy Flash Bitcoin online, there are several options available. In this article, I will discuss the various platforms and software that offer Flash Bitcoin and provide a brief overview of each.
Flash Bitcoin Software
One option for purchasing Flash Bitcoin online is through Flash Bitcoin software. This software is designed to enhance the speed and efficiency of Bitcoin transactions, Some are developed to send 1–100BTC per day. The software utilizes advanced algorithms and cutting-edge technology to ensure that your transactions are processed quickly and securely. Popular Flash Bitcoin software options include Bitgen Flash BTC sender and Flash Bitcoin Generator.
Visit Website:https://eaziishop.shop
Telegram: https://t.me/eaziishops
Flash BTC Sender
Flash BTC Sender is a popular platform for buying Flash Bitcoin online. This platform allows users to send Bitcoin quickly and securely, making it an excellent choice for those who need to make time-sensitive transactions. Flash BTC Sender offers a user-friendly interface and a wide range of features, making it suitable for both beginners and experienced Bitcoin users.
Visit Website:https://eaziishop.shop
Telegram: https://t.me/eaziishops
Flash Bitcoin Generator
Another option for purchasing Flash Bitcoin online is through a Flash Bitcoin Generator. This software allows users to generate Flash Bitcoin directly to their wallets, eliminating the need for third-party exchanges and minimizing transaction fees. Flash Bitcoin Generators are specifically designed to optimize the speed and efficiency of Bitcoin transactions, making them an excellent choice for those who require fast and secure transfers.Flash Software
relevant link https://eaziishop.shop/product-category/flash-software/
Bitcoin Flashing
Telegram: https://t.me/eaziishops
Bitcoin flashing is a process that involves increasing the balance of a Bitcoin address by exploiting vulnerabilities in the cryptocurrency's network. While Bitcoin flashing can be a controversial topic, some online platforms offer Flash Bitcoin through this method. It is important to exercise caution when engaging in Bitcoin flashing, as it can carry various risks and legal implications.
Personally i Advice you visit https://eaziishop.shop/product-category/flash-software/
In conclusion, there are several options available for purchasing Flash Bitcoin online. Whether you choose to utilize Flash Bitcoin software, platforms like Flash BTC Sender, or explore Bitcoin flashing, it is essential to prioritize security and conduct thorough research before proceeding. Flash Bitcoin offers an exciting opportunity for fast and efficient transactions, and by choosing the right platform, you can take advantage of these benefits while safeguarding your assets. https://eaziishop.shop/product-category/flash/ https://eaziishop.shop/product-category/flash-software/ | diajunior | |
1,819,685 | Stop abusing before_action | Prefer LoB to SoC | 0 | 2024-04-24T19:05:03 | https://dev.to/epigene/stop-abusing-beforeaction-48di | rails, controller | ---
title: Stop abusing before_action
published: true
description: Prefer LoB to SoC
tags: Rails, controller
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-04-12 09:24 +0000
---
In this short rant I will show you how to change most `before_action` calls into plain Ruby.
Does this make your eyes bleed?
> [source](https://youtu.be/HctYHe-YjnE?si=v5h947MDu9U5qcqe&t=1138)
```rb
# bad, hook approach
class InstructionsController < ApplicationController
before_action :load_instruction, only: %i[show edit]
def show
authorize @instruction
end
def edit
authorize @instruction
end
private
def load_instruction
@instruction = Instruction.find(params[:id])
end
```
This is a weird antipattern. Hooks are like guard clauses, intended to step in **before** getting to action itself (authentification, redirects).
Consider [Grug's advice](https://grugbrain.dev/#grug-on-soc) - keep code pertaining to a thing in one place. Let's get rid of `before_action` here and have everyting an action needs **in it**.
```rb
# good, simple memoisation, no verbs in getters
class InstructionsController < ApplicationController
def show
authorize instruction
end
def edit
authorize instruction
end
private
def instruction
@instruction ||= Instruction.find(params[:id])
end
```
## Discussion
Pros:
1. Side-stepped the need to parse all hooks when trying to understand what hooks a new action should get.
2. Eliminated any order-dependence on `@instruction` being available. Just use the memoising private getter, same as in other parts of Rails code.
3. Reduced the risk of double-auth (in hook and in action itself), it happens.
4. Less Rails™, more Ruby :heart:.
Con:
1. Admittedly we've not done much about unclear source of `@instruction`. It's still loaded as a side-effect, but there's a cure for that also - stop using ivars in controllers and pass all needed variables to template explicitly. | epigene |
1,819,733 | Essential Array Methods for Front-End Developers | Most common array methods are , 1 . forEach: Executes a provided function once for each array... | 0 | 2024-04-12T10:27:50 | https://dev.to/meertanveer/essential-array-methods-for-front-end-developers-jgf | array, javascript, webdev, frontend | Most common array methods are ,
1 . forEach: Executes a provided function once for each array element.
>> const array = [1, 2, 3];
>> array.forEach(element => console.log(element));
2 . map: Creates a new array with the results of calling a provided function on every element in the calling array.
>> const array = [1, 2, 3];
>> const newArray = array.map(element => element * 2);
>> console.log(newArray); // Output: [2, 4, 6]
3 . filter: Creates a new array with all elements that pass the test implemented by the provided function.
>> const array = [1, 2, 3, 4, 5];
>> const newArray = array.filter(element => element % 2 === 0);
>> console.log(newArray); // Output: [2, 4]
4 . reduce: Executes a reducer function on each element of the array, resulting in a single output value.
>> const array = [1, 2, 3, 4, 5];
>> const sum = array.reduce((accumulator, currentValue) => accumulator + currentValue, 0);
>> console.log(sum); // Output: 15
5 . find: Returns the value of the first element in the array that satisfies the provided testing function.
>> const array = [1, 2, 3, 4, 5];
>> const found = array.find(element => element > 3);
>> console.log(found); // Output: 4
6 . some: Tests whether at least one element in the array passes the test implemented by the provided function.
>> const array = [1, 2, 3, 4, 5];
>> const hasEven = array.some(element => element % 2 === 0);
>> console.log(hasEven); // Output: true
7 . every: Tests whether all elements in the array pass the test implemented by the provided function.
>> const array = [2, 4, 6, 8, 10];
>> const allEven = array.every(element => element % 2 === 0);
>> console.log(allEven); // Output: true
These methods provide powerful ways to manipulate arrays in JavaScript and are commonly used in front-end development. | meertanveer |
1,852,502 | Innovative Packing Materials and Techniques | Innovative packaging materials and techniques are focused on making packaging more sustainable,... | 0 | 2024-05-14T10:38:42 | https://dev.to/marylisa3245/innovative-packing-materials-and-techniques-158o | Innovative packaging materials and techniques are focused on making packaging more sustainable, efficient, and user-friendly. Examples include biodegradable plastics made from natural materials that break down quickly, and edible packaging made from things like seaweed that can be eaten with the product. Mushroom packaging uses agricultural waste and fungi to create compostable materials. Recyclable and compostable options like paper and certain plastics aim to minimize waste. Smart packaging uses technology to provide extra information or track product conditions. Minimalist packaging reduces material use to the bare essentials. These innovations help reduce environmental impact and improve the overall packaging experience.
[More details](https://capitalcitymoversabudhabi.com/):-
| marylisa3245 | |
1,819,919 | creating a next.js front end with a express backend using typescript | In my second youtube livestream, I create a next.js front end with an express backend using typescript. | 0 | 2024-04-12T12:47:59 | https://dev.to/westbrookc16/creating-a-nextjs-front-end-with-a-express-backend-using-typescript-4a95 | nextjs, express, typescript | ---
title: creating a next.js front end with a express backend using typescript
published: true
description: In my second youtube livestream, I create a next.js front end with an express backend using typescript.
tags: #nextjs #express #typescript
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-04-12 12:28 +0000
---
Well I didn't realize my last youtube video was a disaster, no one could see my screen. I think we got it sorted now so that people can see my screen and me. Check out my next video on how to create an express backend with a next.js front end in typescript
{% embed https://www.youtube.com/watch?v=JwWmwHZBO9E %}
--- | westbrookc16 |
1,819,929 | What Are Medical Document Storage and Scanning Services? | Medical document storage and scanning services involve the management and digitization of medical... | 0 | 2024-04-12T12:57:37 | https://dev.to/sanya3245/what-are-medical-document-storage-and-scanning-services-52g7 | Medical document storage and scanning services involve the management and digitization of medical records and documents for healthcare providers and facilities. These services offer solutions for storing, organizing, and accessing patient records in both physical and electronic formats. Here's an overview of each component:
**Document Storage Services:**
**Physical Storage:**
Medical document storage services provide secure facilities for storing paper-based medical records and documents. These facilities are equipped with climate-controlled environments, fire suppression systems, and security measures to protect sensitive patient information.
**Off-site Storage:**
Healthcare providers can outsource the storage of medical records to specialized off-site facilities, freeing up space within their own facilities and reducing administrative overhead.
**Records Management:**
Document storage services may include records management solutions such as indexing, cataloging, and tracking of medical records to facilitate efficient retrieval and access when needed.
**Compliance:** Medical document storage services ensure compliance with regulations such as HIPAA (Health Insurance Portability and Accountability Act) to protect patient privacy and confidentiality.
**Document Scanning Services:**
**Digitization:**
Medical document scanning services convert paper-based medical records into electronic formats, such as PDFs or searchable text files. This process involves scanning each document using high-quality scanners and optical character recognition (OCR) technology to create digital replicas.
**Indexing and Organization:**
Scanned documents are indexed and organized based on predefined criteria, such as patient name, medical record number, or date of service. This indexing allows for easy retrieval and access to specific documents within electronic document management systems (EDMS).
**Quality Control:**
Document scanning services employ quality control measures to ensure accurate and legible scans of medical records. This may include image enhancement techniques, double-checking for missing or misfiled pages, and verifying the accuracy of OCR text conversion.
**Electronic Storage:**
Once scanned, medical records are stored electronically in secure, HIPAA-compliant document management systems. Electronic storage eliminates the need for physical storage space, reduces the risk of document loss or damage, and facilitates remote access to patient records.
Combined,[ medical document storage and scanning services](https://www.invensis.net/services/medical-document-scanning ) offer healthcare providers comprehensive solutions for managing their medical records efficiently and securely. Whether storing paper records off-site or digitizing records for electronic access, these services help streamline workflows, improve access to patient information, and ensure compliance with regulatory requirements.
| sanya3245 | |
1,820,052 | Comparing AWS and Azure Pricing: A Detailed Analysis of Cloud Service Costs | Virtual Machines (VMs): AWS offers various types of EC2 instances, ranging from general-purpose to... | 0 | 2024-04-12T15:40:09 | https://dev.to/shiva6699/comparing-aws-and-azure-pricing-a-detailed-analysis-of-cloud-service-costs-5g2o | 1. Virtual Machines (VMs):
AWS offers various types of EC2 instances, ranging from general-purpose to memory-optimized and GPU instances. Pricing is based on instance type, usage time, and additional features like storage and data transfer.
Azure provides similar VM options through its Azure Virtual Machines service. Pricing depends on factors such as VM size, operating system, and usage duration.
2. Storage:
AWS offers various storage options including Amazon S3 for object storage, Amazon EBS for block storage, and Amazon Glacier for archival storage. Pricing varies based on storage class, data transfer, and retrieval frequency.
Azure provides Blob Storage for object storage, Azure Disk Storage for block storage, and Azure Archive Storage for long-term backup. Pricing is determined by storage type, redundancy level, and data access frequency.
3. Networking:
Both AWS and Azure offer networking services such as Virtual Private Cloud (VPC) and Virtual Network (VNet) for creating isolated networks within the cloud environment. Pricing is based on factors like data transfer, VPN connections, and network bandwidth.
4. Database Services:
AWS offers various database services including Amazon RDS (Relational Database Service), Amazon DynamoDB (NoSQL), and Amazon Redshift (Data Warehousing). Pricing depends on factors such as database type, instance size, and data storage.
Azure provides database services like Azure SQL Database, Azure Cosmos DB (NoSQL), and Azure SQL Data Warehouse. Pricing is determined by database type, performance tier, and data storage.
5. Additional Services:
Both AWS and Azure offer a wide range of additional services such as analytics, machine learning, IoT, and serverless computing. Pricing for these services varies based on usage metrics such as API calls, compute resources, and data processing.
Comparison:
In general, AWS and Azure offer competitive pricing for their core services, with pricing often fluctuating based on factors such as region, service level agreement (SLA), and usage volume.
While AWS has historically been perceived as having a broader range of services and a more mature platform, Azure has been rapidly expanding its offerings and gaining market share.
It's essential for businesses to evaluate their specific requirements, including performance, scalability, and integration with existing systems, to determine which cloud provider offers the best value for their needs.
Conclusion:
AWS and Azure are both leading cloud service providers, offering a wide range of services at competitive prices.
The pricing difference between AWS and Azure can vary depending on factors such as service type, usage volume, and geographic region.
Businesses should carefully evaluate their requirements and consider factors beyond pricing, such as service quality, reliability, and vendor support, when choosing between AWS and Azure for their cloud infrastructure needs.
This overview provides a general comparison of pricing between AWS and Azure, but it's essential to review the latest pricing details and offerings directly from the respective providers' websites, as pricing structures and services may evolve over time. | shiva6699 | |
1,820,376 | Tips from open-source: An Object with Map and Set. | This tip is picked from Next.js source code. In this article, you will learn how to use an Object... | 0 | 2024-04-12T21:53:26 | https://dev.to/ramunarasinga/tips-from-open-source-an-object-with-map-and-set-2fa3 | javascript, nextjs, react, opensource | This tip is picked from [Next.js source code](https://github.com/vercel/next.js/blob/canary/packages/next/src/export/index.ts#L644). In this article, you will learn how to use an Object with Map and Set in Javascript.
I found this unique Object with Map and Set in [next/src/export/index.ts](https://github.com/vercel/next.js/blob/canary/packages/next/src/export/index.ts#L644).

Skimming through the code around this function, I quickly learnt that it is used for [Telemetry tracking](https://nextjs.org/telemetry) purposes.
> [_Learn the best practices used in open source_](https://tthroo.com/)

This just reminds me of usecase where I had to deal with file paths, text replacements with in a file (say .docx, .txt). For example, you have an object like below:
```
let fileCustomisations = {
// Not an array but Set to avoid duplicate paths
paths: new Set(),
// This is where you will have file text replacements
textReplacements: new Map(),
// I took a step further to include supported formats
supportedFormats: \['.docx', '.txt'\]
}
```
With this data structure, you have all the variables required to apply text replacements to the content in a file.
Conclusion:
-----------
Using the right data structure matters. To pick the right data structure, context matters. An Object with Set and Map in Javascript, I found it unique in the wild (well, it’s Next.js source code).
I tend to use separate variables rather than defining an Object to consolidate Map and Set. If I were to mix these data structures in a single object, I would think twice about the context. One example I could think of is shown below:
```
let fileCustomisations = {
// Not an array but Set to avoid duplicate paths
paths: new Set(),
// This is where you will have file text replacements
textReplacements: new Map(),
// I took a step further to include supported formats
supportedFormats: \['.docx', '.txt'\]
}
``` | ramunarasinga |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.