
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,849,754 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-05-11T15:53:44 | https://dev.to/miyhefmanik/buy-verified-cash-app-account-p1e | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n\n\n" | miyhefmanik |
1,850,050 | Memories | Apple Vision👓 Concept App using Netlify's Image CDN & Next JS | This is a submission for the Netlify Dynamic Site Challenge: Visual Feast. Demo This... | 0 | 2024-05-12T02:19:38 | https://dev.to/srikant_code/memories-apple-vision-concept-app-using-netlifys-image-cdn-1i0h | netlifychallenge, devchallenge, webdev, javascript | *This is a submission for the [Netlify Dynamic Site Challenge](https://dev.to/challenges/netlify): Visual Feast.*
## Demo
<!-- Share a link to your Netlify app and include some screenshots here. -->
This project showcases three key features of Netlify, each feature is specifically demonstrated through a different application that I made:
Link to Demo
{% embed https://apple-vision-concept-dynamic-site.netlify.app/ %}
> Home page screenshot

#### Link to all my submissions
1. Memories App Concept - This article
2. Albums App Concept - {% embed https://dev.to/srikant_code/albums-apple-vision-concept-app-using-netlifys-blobs-next-js-9ep %}
3. Discover App Concept - {% embed https://dev.to/srikant_code/discover-apple-vision-concept-app-using-netlifys-cache-revalidation-next-js-ssr-1ifj %}
## What I Built | Concept / Ideation
<!-- Share an overview about your project. -->
Hey👋, I'm Srikant Sahoo. I'm excited to present this project for the `Netlify Dynamic Site Challenge`. This project is a cutting-edge concept user interface designed for virtual reality devices, taking inspiration from futuristic concepts like `Apple Vision👓` to showcase how Netlify's capabilities can be leveraged to create such applications in future for VR use cases.
> Side note for your reference - More info on Apple Vision Pro {% embed https://www.apple.com/newsroom/2024/02/apple-announces-more-than-600-new-apps-built-for-apple-vision-pro/ %}
---
## Why I built this Apple Vision Concept?
The major question that I had was...
> How can I use all the 3 themes in one project🤔?
Even though I had this question, I still started with creating a `Image Gallery` using Image CDN. But then later on during development I figured out that I can instead convert it into a small virtual app called `Memories App` instead of `Gallery App or Photos App`, and similarly create more virtual apps for the other 2 prompts.
> `All Photos` view

So, the first thing that came into my mind was to create a mock concept environment for `Apple Vision Pro👓` where users can see and interact with the 3 apps while being sitting at the couch. Thats how I proceeded and build the UX and then eventually developed it.
> Three apps navigation

## Platform Primitives
<!-- Tell us how you leveraged the Netlify Image CDN. -->
Below are the details on how I leveraged the `Netlify Image CDN`, `Netlify Blobs` storage and `Netlify's Cache Revalidation` in three different virtual apps.
### 1. Memories App
This app leverages `Netlify's Image CDN` capability to display photos in responsive way. You can toggle the below tabs to filter images by date category and see images in different sizes.
> `Days` view

It queries the Image CDN to render the most optimized version for quick loading of the images in an animated way. You can click any photo to see in good resolution.
> Fetches the most optimized image using queries like `&w=64&q=75`

> UI on clicking any image

The Netlify's blob storage is used in the `Add photos to Albums` button. It stores the opened photo to one of your Album (More on this below)

### 2. Albums App
This app utilizes `Netlify's Blobs` storage to store your albums and its contents. Once you land on the page, you are automatically assigned a unique username (kind of a mock authentication).

I have written a clever and complex logic to handle the albums data in blobs. You can also see other users' albums from the `Other's Albums` tab.



#### Challenges Faced while developing this `Albums` App
I faced a lot of challenges while implementing this.
Initially the blobs were only working in the `netlify dev` env and was not working when I was deploying it (which was making it harder to debug). It bugged me for days, I needed to go through all the related documentation to understand and fix it.
But spending 1-2 days on consistent bug fixing and observing the patterns, I finally figured out the way to work with blobs.
I also faced challenges on the below
- Implementation of expiration logic of blobs to free up space.
- How to tackle multiple users updating the same blob
- How to refresh the UI between the Memories and Albums App when anything is updated.
- How to setup and use the blobs without using edge functions and instead use the Netlify APIs directly using the `use server`.
- And as mentioned above on deployment part
### 3. Discover App
This app uses `Netlify's Cache Revalidation` feature to fetch the latest articles from the web (Wikipedia Random API) using Server-Side Rendering technique of Next JS). It highlights how Netlify's Cache Revalidation can ensure users always have access to the most recent information on demand.
> Below code -> uses the Next cache headers and tagName to revalidate the cache


I was new to `Next JS SSR`, so I was initially facing difficulties with the SSR logic, but figured out how to tackle it to render the UI having the wiki article.
---
### Disclaimer
> Please note that this project is not associated with any organization and is purely a result of my passion and 💘 for technology and innovation, which I have done both the UX design and developed it in the last 5-6 days.
> All the assets, graphics, and icons used in this project have been duly referenced in the project itself for transparency, and you can find the sources in the `References` section of the project. This project is a testament to my commitment to ethical practices in software development.

This project is a hobby endeavor that I'm proud of, and I hope it helps you to understand the potential of Netlify's capabilities.
It took me more than 5 days to build this. Would really appreciate if you liked it and can like this post (🦄,💘). It will motivate me to create more such kind of creative applications and use Netlify in my future projects😄.
Thank you
---
#### Link to all my submissions
1. Memories App Concept - This article
2. Albums App Concept - {% embed https://dev.to/srikant_code/albums-apple-vision-concept-app-using-netlifys-blobs-next-js-9ep %}
3. Discover App Concept - {% embed https://dev.to/srikant_code/discover-apple-vision-concept-app-using-netlifys-cache-revalidation-next-js-ssr-1ifj %}
<!-- Did you implement additional platform primitives like Netlify Blobs or Cache Control? Tell us about that too! You may qualify for more than one prompt. -->
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- Don't forget to add a cover image (if you want). -->
<!-- Thanks for participating! --> | srikant_code |
1,850,121 | How to install localstack with docker and play with terraform | First things first: What is LocalStack? LocalStack is a cloud service emulator that runs... | 0 | 2024-05-12T15:12:44 | https://www.ahioros.info/2024/05/how-to-install-localstack-with-docker.html | aws, linux, localstack, python | ---
title: How to install localstack with docker and play with terraform
published: true
date: 2024-05-12 03:23:00 UTC
tags: aws,Linux,localstack,python
canonical_url: https://www.ahioros.info/2024/05/how-to-install-localstack-with-docker.html
---
First things first:
## What is LocalStack?
[LocalStack](https://www.localstack.cloud) is a cloud service emulator that runs in a single container on your laptop or in your CI environment. With LocalStack, you can run your AWS applications or Lambdas entirely on your local machine without connecting to a remote cloud provider! Whether you are testing complex CDK applications or Terraform configurations, or just beginning to learn about AWS services, LocalStack helps speed up and simplify your testing and development workflow.
LocalStack support many AWS [services](https://docs.localstack.cloud/user-guide/aws/feature-coverage/).
**Note:** The information is volatile in **LocalStack Community Edition.** Persistence is available in the **pro edition.**
Let's create our test folder:
```bash
$ mkdir -p terraform-test
$ cd terraform-test
```
## Recommended Tools
**Create a virtual environment**
```bash
python -m venv venv
```
**Activate venv**
```bash
$ source venv/bin/activate
```
**Install awslocal and tflocal**
```bash
$ pip install awslocal
$ pip install tflocal
```
```bash
$ docker run --rm -it -p 4566:4566 -p 4510-4559:4510-4559 localstack/localstack
```
Create the provider.tf and configure the endpoints:
```
provider "aws" {
access_key = "fake-access-key"
secret_key = "fake-secret-key"
region = "us-east-1"
skip_credentials_validation = true
skip_metadata_api_check = true
skip_requesting_account_id = true
s3_use_path_style = true
endpoints {
apigateway = "http://localhost:4566"
apigatewayv2 = "http://localhost:4566"
cloudformation = "http://localhost:4566"
cloudwatch = "http://localhost:4566"
dynamodb = "http://localhost:4566"
ec2 = "http://localhost:4566"
es = "http://localhost:4566"
elasticache = "http://localhost:4566"
firehose = "http://localhost:4566"
iam = "http://localhost:4566"
kinesis = "http://localhost:4566"
keyspaces = "http://localhost:4566"
lambda = "http://localhost:4566"
rds = "http://localhost:4566"
redshift = "http://localhost:4566"
route53 = "http://localhost:4566"
s3 = "http://localhost:4566"
s3api = "http://localhost:4566"
secretsmanager = "http://localhost:4566"
ses = "http://localhost:4566"
sns = "http://localhost:4566"
sqs = "http://localhost:4566"
ssm = "http://localhost:4566"
stepfunctions = "http://localhost:4566"
sts = "http://localhost:4566"
events = "http://localhost:4566"
scheduler = "http://localhost:4566"
opensearch = "http://localhost:4566"
}
}
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.47.0"
}
}
}
```
Now lets create a bucket, create a bucket.tf file:
```
resource "aws_s3_bucket" "bucket" {
bucket = "your-bucket-name"
tags = merge({
Name = "Your bucket name"
Project = "My example project"
Environment = "Dev"
})
}
```
Now run tflocal:
```bash
$ tflocal init
```
output:
```bash
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/aws versions matching "~> 5.47.0"...
- Installing hashicorp/aws v5.47.0...
- Installed hashicorp/aws v5.47.0 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
```
```bash
$ tflocal validate
```
ouput:
```bash
Success! The configuration is valid.
```
```bash
$ tflocal plan
```
output:
```bash
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# aws_s3_bucket.bucket will be created
+ resource "aws_s3_bucket" "bucket" {
+ acceleration_status = (known after apply)
+ acl = (known after apply)
+ arn = (known after apply)
+ bucket = "my-test-bucket"
+ bucket_domain_name = (known after apply)
+ bucket_prefix = (known after apply)
+ bucket_regional_domain_name = (known after apply)
+ force_destroy = false
+ hosted_zone_id = (known after apply)
+ id = (known after apply)
+ object_lock_enabled = (known after apply)
+ policy = (known after apply)
+ region = (known after apply)
+ request_payer = (known after apply)
+ tags = {
+ "Environment" = "Test Environment"
+ "Name" = "Bucket for test"
+ "Project" = "Test Project"
}
+ tags_all = {
+ "Environment" = "Test Environment"
+ "Name" = "Bucket for test"
+ "Project" = "Test Project"
}
+ website_domain = (known after apply)
+ website_endpoint = (known after apply)
}
Plan: 1 to add, 0 to change, 0 to destroy.
╷
│ Warning: Invalid Attribute Combination
│
│ with provider["registry.terraform.io/hashicorp/aws"],
│ on provider.tf line 1, in provider "aws":
│ 1: provider "aws" {
│
│ Only one of the following attributes should be set: "endpoints[0].s3", "endpoints[0].s3api"
│
│ This will be an error in a future release.
╵
╷
│ Warning: AWS account ID not found for provider
│
│ with provider["registry.terraform.io/hashicorp/aws"],
│ on provider.tf line 1, in provider "aws":
│ 1: provider "aws" {
│
│ See https://registry.terraform.io/providers/hashicorp/aws/latest/docs#skip_requesting_account_id for implications.
╵
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Note: You didn't use the -out option to save this plan, so Terraform can't guarantee to take exactly these actions if you run "terraform apply"
now.
```
```bash
$ tflocal apply
```
output:
```bash
...
Enter a value: yes
aws_s3_bucket.bucket: Creating...
aws_s3_bucket.bucket: Creation complete after 0s [id=my-test-bucket]
╷
│ Warning: Invalid Attribute Combination
│
│ with provider["registry.terraform.io/hashicorp/aws"],
│ on provider.tf line 1, in provider "aws":
│ 1: provider "aws" {
│
│ Only one of the following attributes should be set: "endpoints[0].s3", "endpoints[0].s3api"
│
│ This will be an error in a future release.
╵
╷
│ Warning: AWS account ID not found for provider
│
│ with provider["registry.terraform.io/hashicorp/aws"],
│ on provider.tf line 1, in provider "aws":
│ 1: provider "aws" {
│
│ See https://registry.terraform.io/providers/hashicorp/aws/latest/docs#skip_requesting_account_id for implications.
╵
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.
```
**Verify if the new bucket has been created**
```bash
$ awslocal s3 ls
```
output
```bash
2022-02-11 11:39:31 my-test-bucket
```
**Upload a test file**
* Create a test file
```bash
$ touch file-test.txt
```
* Upload a test file
```bash
$ awslocal s3 cp file-test.txt s3://my-test-bucket/
```
output:
```bash
upload: ./file-test.txt to s3://my-test-bucket/file-test.txt
```
* Check the file in the bucket
```bash
$ awslocal s3 ls s3://my-test-bucket/
```
output:
```bash
2022-02-11 11:40:11 0 file-test.txt
```
## Tip
You can view the files in the "bucket", open your browser and type the next url.
[http://localhost:4566/my-test-bucket/file-test.txt](http://localhost:4566/my-test-bucket/file-test.txt)
**Note:** Read about the services supported in **LocalStack Community Edition.** For example, you can't create a Network Balancer 😔. | ahioros |
1,850,190 | Gia Dung Duc Sai Gon | Gia Dụng Đức Sài Gòn là một thương hiệu thuộc hệ thống showroom của CÔNG TY CỔ PHẦN MINH HOUSEWARES... | 0 | 2024-05-12T08:00:28 | https://dev.to/giadungducsaigon/gia-dung-duc-sai-gon-16ff | Gia Dụng Đức Sài Gòn là một thương hiệu thuộc hệ thống showroom của CÔNG TY CỔ PHẦN MINH HOUSEWARES chuyên phân phối đồ dùng gia đình chính hãng Đức như: Bosch, WMF, Delonghi, Smeg, Siemens, Bravilor,...
Website: https://giadungducsaigon.vn/
Phone: 097 636 7519
Address: 344 Cộng Hòa, Phường 13, Quận Tân Bình
https://pastelink.net/fgptyrjw
https://collegeprojectboard.com/author/giadungducsaigon/
https://www.fimfiction.net/user/738155/fbgiadungducsaigon
https://www.codingame.com/profile/f9d9bf18e39c48837aecd0e534b08b3f6499706
https://www.5giay.vn/members/giadungducsaigon.101972729/#info
https://active.popsugar.com/@giadungducsaigon/profile
https://research.openhumans.org/member/giadungducsaigon
https://jsfiddle.net/user/giadungducsaigon/
https://doodleordie.com/profile/giadungducsaigon
https://edenprairie.bubblelife.com/users/giadungducsaigon
https://portfolium.com/giadungducsaigon
https://www.fitday.com/fitness/forums/members/giadungducsaigon.html
https://hub.docker.com/u/prgiadungducsaigon
https://www.pearltrees.com/lwgiadungducsaigon
https://disqus.com/by/giadungducsaigon/about/
https://kktix.com/user/6005974
https://glose.com/u/hlgiadungducsaigon
https://socialtrain.stage.lithium.com/t5/user/viewprofilepage/user-id/61755
https://dreevoo.com/profile.php?pid=636494
https://hashnode.com/@bugiadungducsaigon
https://app.roll20.net/users/13322133/gia-dung-d
https://piczel.tv/watch/giadungducsaigon
https://hypothes.is/users/zngiadungducsaigon
https://www.facer.io/u/pbgiadungducsaigon
https://bentleysystems.service-now.com/community?id=community_user_profile&user=5949fc3e970606d4afb952800153af79
http://buildolution.com/UserProfile/tabid/131/userId/403582/Default.aspx
https://www.patreon.com/giadungducsaigon
https://pinshape.com/users/4277861-wogiadungducsaigon#designs-tab-open
https://ficwad.com/a/giadungducsaigon
https://teletype.in/@giadungducsaigon
https://www.penname.me/@giadungducsaigon
https://answerpail.com/index.php/user/giadungducsaigon
https://wakelet.com/@GiaDungDucSaiGon11596
https://controlc.com/5ee3295a
https://www.ethiovisit.com/myplace/giadungducsaigon
https://vnseosem.com/members/giadungducsaigon.30219/#info
https://www.proarti.fr/account/giadungducsaigon
https://www.dermandar.com/user/giadungducsaigon/
https://diendannhansu.com/members/giadungducsaigon.46597/#about
https://lab.quickbox.io/jogiadungducsaigon
https://sinhhocvietnam.com/forum/members/73194/#about
https://inkbunny.net/giadungducsaigon
https://www.designspiration.com/nguyenvanhuong230619/
https://magic.ly/giadungducsaigon
https://p.lu/a/giadungducsaigon/video-channels
https://www.metooo.io/u/6640742066f299378d28ca91
https://www.equinenow.com/farm/giadungducsaigon.htm
https://rapidapi.com/user/giadungducsaigon
https://www.artscow.com/user/3194412
https://forum.dmec.vn/index.php?members/giadungducsaigon.59354/
https://able2know.org/user/btgiadungducsaigon/
https://timeswriter.com/members/mggiadungducsaigon/
https://www.beatstars.com/nguyenvanhuong23061972/about
https://data.world/giadungducsaigon
https://wmart.kz/forum/user/161377/
https://topsitenet.com/profile/giadungducsaigon/1185879/
https://www.plurk.com/kggiadungducsaigon/public
https://link.space/@giadungducsaigon
https://play.eslgaming.com/player/20099425/
https://www.creativelive.com/student/gia-dung-duc-sai-gon?via=accounts-freeform_2
https://rotorbuilds.com/profile/40391/
https://files.fm/giadungducsaigon/info
https://solo.to/giadungducsaigon
https://expathealthseoul.com/profile/gia-dung-duc-sai-gon/
https://zzb.bz/RnfzV
https://visual.ly/users/nguyenvanhuong23061972
https://tupalo.com/en/users/6693325
https://nhattao.com/members/giadungducsaigon.6524416/
https://vocal.media/authors/gia-dung-duc-sai-gon
https://dribbble.com/kggiadungducsaigon/about
https://makersplace.com/nguyenvanhuong23061972/about
https://www.myminifactory.com/users/iagiadungducsaigon
https://chart-studio.plotly.com/~giadungducsaigon
http://forum.yealink.com/forum/member.php?action=profile&uid=337505
https://allods.my.games/forum/index.php?page=User&userID=147154
https://telegra.ph/giadungducsaigon-05-12
https://circleten.org/account/profile
https://www.instapaper.com/p/14301911
https://qiita.com/giadungducsaigon
https://vnxf.vn/members/giadungducsaig.79648/#about
www.artistecard.com/giadungducsaigon#!/contact
https://rentry.co/ymau79cf
https://www.reddit.com/user/grgiadungducsaigon
https://slides.com/ozgiadungducsaigon
https://fileforum.com/profile/giadungducsaigon
https://www.kickstarter.com/profile/giadungducsaigon/about
https://pxhere.com/en/photographer-me/4255136
https://www.funddreamer.com/users/gia-dung-duc-sai-gon
https://hackmd.io/@giadungducsaigon
https://www.bigbasstabs.com/profile/95544.html
https://www.quia.com/profiles/giadungd
https://worldcosplay.net/member/1763939
https://peatix.com/user/22163819/view
https://www.silverstripe.org/ForumMemberProfile/show/149495
http://idea.informer.com/users/giadungducsaigon/?what=personal
https://app.talkshoe.com/user/giadungducsaigon
https://gettr.com/user/bdgiadungducsaigon
https://www.mixcloud.com/giadungducsaigon/
https://wperp.com/users/giadungducsaigon/
http://hawkee.com/profile/6829788/
https://vimeo.com/user219516214
https://potofu.me/giadungducsaigon
https://8tracks.com/ctgiadungducsaigon
https://linkmix.co/23118886
https://www.diggerslist.com/giadungducsaigon/about
https://notabug.org/giadungducsaigon
https://readthedocs.org/projects/httpsgiadungducsaigonvn/
https://www.scoop.it/u/gia-dungduc-sai-gon
https://naijamp3s.com/index.php?a=profile&u=giadungducsaigon
https://www.noteflight.com/profile/75af133b4dff872be9cecfeabeb9c72d27331d61
https://roomstyler.com/users/wcgiadungducsaigon
https://www.robot-forum.com/user/158288-giadungducsaigon/?editOnInit=1
https://leetcode.com/u/giadungducsaigon/
| giadungducsaigon | |
1,850,568 | CSS in a Simplified way and altruism thought | Imagine CSS as a magic wand for websites! With CSS, we paint the web with colors, shapes, and styles.... | 0 | 2024-05-12T18:58:18 | https://dev.to/janmejaisingh/css-in-a-simplified-way-and-altruism-thought-3abk | webdev, css, design, beginners | Imagine CSS as a magic wand for websites! With CSS, we paint the web with colors, shapes, and styles. Each style has its own superpower called an attribute. Think of attributes as special spells we cast to make things look awesome! For example, the "color" attribute changes text colors, while "font-size" makes text big or small. "Background-color" paints the background, and "border" creates borders around things. We can even make things move with "animation"! So, with CSS, we become web wizards, bringing our pages to life with endless possibilities of design magic! ✨🎨✨ | janmejaisingh |
1,852,331 | The Influence of Personality on Leadership in the Workplace | In today's rapidly evolving and competitive work environment, effective leadership in the office is... | 0 | 2024-05-14T07:55:10 | https://dev.to/maybellfst/the-influence-of-personality-on-leadership-in-the-workplace-56ck | In today's rapidly evolving and competitive work environment, effective leadership in the office is paramount. Gone are the days of singular authority; now, every department has its own leader responsible for [https://greenleafguru.com](https://greenleafguru.com) guiding and motivating their team members. A critical quality for any leader is possessing an influential personality. In this [https://herbalhighsociety.com](https://herbalhighsociety.com) blog, we'll explore how influential personalities contribute to effective leadership.
Inspiring and Motivating Others:
A leader's primary role is to inspire and motivate their team to achieve peak performance. Through compelling communication, a leader can instill a sense of purpose and belonging in their team members. This fosters high morale, leading to increased productivity and goal attainment.
Building Relationships:
Influential leaders prioritize building strong relationships among team members and with higher authorities. They address the needs of their team and cultivate a harmonious and competitive work culture. Encouraging open communication and collaboration, they empower team members to share ideas and work together towards common objectives.
Creating a Positive Work Culture:
A leader's demeanor significantly shapes the office environment. Influential personalities foster positivity and optimism, even in challenging circumstances. By setting an example of resilience and composure, they cultivate loyalty and satisfaction among employees, contributing to a positive workplace atmosphere.
Driving Change and Adaptability:
Influential leaders drive organizational change by challenging the status quo and inspiring innovation. They encourage continuous learning and adaptation, guiding team members through transitions and overcoming resistance to change. Through their persuasive abilities, they inspire confidence in the team's ability to navigate change effectively.
Conclusion:
An influential personality is a cornerstone of effective leadership, energizing and motivating team members to excel. It's essential for influential leaders to wield their influence responsibly, ensuring decisions benefit themselves, their team, and the organization as a whole. By embodying qualities of self-motivation and introspection, anyone can aspire to leadership and elevate themselves and their organization to new heights. | maybellfst | |
1,850,778 | MainH (h=ea) | @mainh.onmicrosoft.com | 0 | 2024-05-13T00:01:11 | https://dev.to/hawthorne001/mainh-hea-dep |
 @mainh.onmicrosoft.com | hawthorne001 | |
1,850,810 | How to check for broken links using Selenium Webdriver on Node.js (automated testing) | Cover photo by Miguel Á. Padriñán So you're building automated tests using Node, Cucumber JS, and... | 0 | 2024-05-13T01:12:01 | https://dev.to/ads-bne/automated-testing-how-to-check-for-broken-links-using-selenium-webdriver-on-nodejs-1akf | node, selenium, javascript, testing | _Cover photo by [Miguel Á. Padriñán](https://www.pexels.com/photo/gray-chain-on-orange-surface-1061136/)_
So you're building automated tests using Node, Cucumber JS, and Selenium Webdriver (I have written more about this [here](https://dev.to/adamdsherman/things-i-wish-i-knew-when-learning-to-use-cucumber-selenium-with-nodejs-3oae))? Here's a way to test for pesky broken links.
One of the **easiest ways to check for broken links is to simply read their status codes**: `200` ✅ good, `301` or `404` ❌ bad.
However, it seems **Selenium Webdriver does not have an out-of-the-box way to read status codes**. No matter, since we're writing these tests on Node we can use an npm package: [xhr2](https://www.npmjs.com/package/xhr2). xhr2 is a simple tool that uses `XMLHttpRequest` to send and receive data from a server. In this case we are simply asking it to give the servers response/status code when asking for a document via a given url or path.
Install xhr2 into your Node project the normal way: `npm i xhr2`
Now, if you're using Cucumber.JS like me, you can write your test's `.feature` file. In mine I'm going to cycle through some given pages and check that all links within my site's footer are working (ie, returning `200` status codes).
_check-footer.feature_
```javascript
Feature: Check footer links
Scenario: Check for broken links in the footer section on these pages
Given I am checking the footer on the '<page>' page
Then there should be no broken links on '<page>'
Examples:
| page |
| about-us |
| contact-us |
| products |
```
Now, on my steps file:
_checkFooterSteps.js_
```javascript
const { When, Then, Given, After } = require('@cucumber/cucumber');
const assert = require('assert');
const { Builder, By, until, Key, http } = require('selenium-webdriver');
const firefox = require('selenium-webdriver/firefox');
// Don't forget to include xhr2.
const XMLHttpRequest = require('xhr2');
var {setDefaultTimeout} = require('@cucumber/cucumber');
setDefaultTimeout(60 * 1000);
// Uses Firefox to load each page listed in the .features file.
Given('I am checking the footer on the {string} page', async function (string) {
this.driver = new Builder()
.forBrowser('firefox')
.build();
this.driver.wait(until.elementLocated(By.className('logo-image')));
await this.driver.get('https://www.your-site.com/' + string);
});
// For each page find all <a> tags from within the .footer element.
// Get each <a> tag's href value and store in urlArr array.
// For each value in urlArr run it through the checkLink() function.
// Use assert() to check returned status value is 200.
Then('there should be no broken links on {string}', async function(string) {
var urlArr = [];
var footerLinks = await this.driver.findElements(By.css('.footer a'));
for (let i = 0; i < footerLinks.length; i++) {
var url = await footerLinks[i].getAttribute("href");
urlArr.push(url);
}
if (urlArr.length < 1) {
console.log(`Could not find any links on ${string} page`);
}
else {
for (let i = 0; i < urlArr.length; i++) {
var respStatus = await checkLink(urlArr[i]);
assert.ok(respStatus==200);
}
}
});
// xhr2 link checker function
function checkLink(url) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('HEAD', url, true);
xhr.onload = () => {
if (xhr.status >= 200 && xhr.status < 400) {
resolve(xhr.status);
} else {
reject(`HTTP status code ${xhr.status}`);
}
};
xhr.onerror = () => {
reject("Network error or URL not reachable");
};
xhr.send();
});
}
```
**What this is doing is:**
- looping through each page I've provided on the Cucumber.js file
- for each page, gathering a list of `href` attribute values from each `<a>` tag within the `.footer` element
- running each URL through the `checkLink()` function, which returns the HTTP status code.
- Using Node's `assert` function to check if the returned value is `200`.
_Note, this JS code probably still needs to be improved and optimised._
| ads-bne |
1,852,065 | Blender Animations and THREE.js - MEOW! | First experience with Blender! (and 3-D modeling, really) Took a fun dive into blender today and made... | 0 | 2024-05-14T01:46:48 | https://dev.to/annavi11arrea1/blender-animations-and-threejs-meow-46i1 | blender, animation, javascript, threejs | First experience with Blender! (and 3-D modeling, really) Took a fun dive into blender today and made a cat of sorts. I successfully created a brief animation. Not to difficult.

In fact, it was an awesome experience. Should have tried this before. Now, of course, I want to put my already-animated cat on the web using Three.js. Its turning out to be more complicated than expected.
I did, however manage to get the cat loaded using the GLTFLoader. Nice and easy. But, I am stuck trying to figure out how to make the animations appear. I tried a few things, including:
- making separate keyframe png files
- adding a clock
- calling mixer
I've been digging for answers for a few hours and would love feedback on this matter. I did find some fun moving grass which I successfully added to the file.

We've really gotta figure our this animation business. I have like half an idea what's going on. What's your finest input on the matter? | annavi11arrea1 |
1,852,139 | Open Source Data Engineering Landscape 2024 | ALIREZA SADEGHI | Alireza Sadeghi covered a lot of information related to the data engineering landscape. This article... | 0 | 2024-05-14T04:18:44 | https://dev.to/tankala/open-source-data-engineering-landscape-2024-alireza-sadeghi-4if6 | python, programming, datascience, dataengineering | Alireza Sadeghi covered a lot of information related to the data engineering landscape. This article contains information like what once upon a time was popular but not active now to recent ones which are making waves. Read this article which will give you an idea of what tools are needed for each category (Storage Systems, Data Lake Platform, Data Integration, Data Processing & Computation, Workflow Management & DataOps, Data Infrastructure & Monitoring, ML Platform, Metadata Management, Analytics & Visualisation).
{% embed https://practicaldataengineering.substack.com/p/open-source-data-engineering-landscape %} | tankala |
1,852,205 | Destination Wedding in Kerala | We possess unique skills, including impeccable organization, attention to detail, interpersonal... | 0 | 2024-05-14T05:41:51 | https://dev.to/freelancer_123_93c61940c0/destination-wedding-in-kerala-29i2 | photography, catering, documentation, makeup | We possess unique skills, including impeccable organization, attention to detail, interpersonal finesse, and a knack for turning dreams into reality. By entrusting their special day to a skilled (https://rainmakerweddings.com/) wedding, couples can relax, cherish each moment, and create cherished memories that will last a lifetime. | freelancer_123_93c61940c0 |
1,852,527 | interactive flashbacks | In traditional writing, flashbacks serve as a tool to provide crucial information about the story... | 0 | 2024-05-14T11:10:39 | https://onwriting.games/daily/interactive-flashbacks/ | gamedev, writing | In traditional writing, flashbacks serve as a tool to **provide crucial information** about the story that the reader wouldn’t otherwise know without delving into past events.
As a narrative device, flashbacks retain this function in interactive storytelling, yet their interactivity also allows us to **shape and influence future events** .
In *Dance of The Spirits* , we introduce the player to April, the protagonist, through a flashback where they select certain characteristics.
These characteristics subsequently influence the available options and even the reactions of other characters as the story unfolds.
I believe that beyond their informative role, flashbacks offer **valuable opportunities to “configure” the game** through player choices that impact the main storyline.
What are your thoughts?
| onwritinggames |
1,852,791 | Differences between GCP Cloud Functions and AWS Lambda Functions - A Comparative Guide from Migration | A Portuguese version is available here It's been a few months since I migrated from a GCP (Google... | 0 | 2024-05-14T15:08:47 | https://dev.to/miguelsmuller/pratical-differences-between-gcp-cloud-functions-and-aws-lambda-functions-p4d | aws, gcp, cloud | A Portuguese version is available [here](https://dev.to/miguelsmuller/diferencas-praticas-entre-gcp-cloud-functions-e-aws-lambda-functions-cjj)
It's been a few months since I migrated from a GCP (Google Cloud Platform) environment to an AWS (Amazon Web Services) environment. At first, I thought I would find it strange and have difficulty adapting because I've heard reports of professionals going the other way complaining, but to my surprise, that didn't happen.
And in this transition, I decided to write and share in a didactic way the subtle differences I encountered. Instead of presenting a direct confrontation, I opted for a comparison guide to help other professionals who may be considering a similar transition.
The cloud standards we use today are primarily an effort of NIST (National Institute of Standards and Technology). These standards have guided the development and implementation of cloud technologies, ensuring a consistent and secure approach across all cloud computing providers. Because of these standards, there are many similarities between AWS and GCP's FaaS (Function as a Service) offerings.
From the practical points that are relevant to know:
---
## 01. Infrastructure:
Both AWS and GCP platforms adopt a model of dividing infrastructure into regions and zones, following the standards established by NIST (National Institute of Standards and Technology).
In the context of cloud computing, a region refers to a specific geographical area where resources can be deployed. Within each region, there are Availability Zones, which represent distinct physical data centers, isolated from each other, where services are executed.
It is important to note that, on both platforms, some services may not be available in all regions. However, for serverless function services, they are present in the Brazilian region, known as `sa-east-1` in AWS and `southamerica-east1` in GCP.
One point that stands out in the differences is the nomenclature of Availability Zones, where GCP professionals refer to them simply as "zone," while AWS professionals call them "AZ."
---
## 02. Different Names, Similar Services
Even though I'm basically talking about serverless functions in everyday development, we need to know much more about the framework involved for development, integration, deployment, and monitoring of our projects. Thus, below is a mapping for the most well-known services:
| Type | AWS | GCP |
|---|---|---|
| Serverless Functions | Lambda Function | Cloud Functions |
| API endpoints | API Gateway | Cloud Endpoints |
| Content Delivery Network (CDN) | Cloudfront | Cloud CDN |
| Kubernetes (K8s) Service | EKS | GKE |
| Messaging Queue Service | SQS and SNS | Cloud Pub/Sub |
| Operation, Log, and Monitoring | CloudWatch | Cloud Logging and Cloud Monitoring |
Google offers a more complete list that includes other services and is available [in this comparison](https://cloud.google.com/docs/get-started/aws-azure-gcp-service-comparison?hl=en).
---
## 03. Costs
The pricing structure is almost identical between AWS and GCP. The main factors that impact the cost on both services are the number of requests and the execution time. It is important to note here that other fees may be charged for parallel services, such as data transfer or storage costs, but these depend on the project context.
An important detail that can cause a difference between the values is how the computing time is calculated on each provider. In AWS, the execution time is charged in increments of 1 millisecond. This means that each additional millisecond is charged separately.
In Google Cloud Functions, the execution time is rounded up for each interval of 100 milliseconds after the first 100 milliseconds. This means that if the function execution lasts less than 100 milliseconds, you will not be charged for that time. However, if it lasts more than 100 milliseconds, you will be charged for the total time rounded up to the next 100 milliseconds increment. For example, a function executed for 260 ms would be billed as 300 ms.
Furthermore, another important detail about price is that in GCP, computing time is measured considering memory allocation (GB per second) and CPU processing power (GHz per second).
We can also analyze the free tiers offered by cloud providers for their serverless function services.
| Provider | Free Invocations per Month | Free Compute Time (GB-seconds) per Month | Free CPU Time (GHz-seconds) per Month |
|---|---|---|---|
| Google Cloud Functions | 2 million | 400,000 | 200,000 |
| AWS Lambda | 1 million | 400,000 | - |
### How to calculate processing:
**500,000 invocations / 40 ms duration / 128 MB**
- 40 ms = 0.04 sec
- 128 MB = 0.125 GB
Usage Time: 500,000 invocations/month * 0.04 sec/invocation = 20,000 sec/month
Provisioned Memory: 20,000 sec/month * 0.125 GB = 2.5 GB-sec/month
**3,000,000 invocations / 230 ms duration / 1024 MB**
- 230 ms = 0.23 sec
- 1024 MB = 1 GB
Usage Time: 3,000,000 invocations/month * 0.23 sec/invocation = 690,000 sec/month
Provisioned Memory: 690,000 sec/month * 1 GB = 690 GB-sec/month
### Online Calculators
- AWS: https://calculator.aws/#/createCalculator/Lambda
- GCP: https://cloud.google.com/products/calculator/
- FAAS Calc: https://faascalc.com/
P.S.: I don't trust Google's calculator much 🤷
---
## 04. Supported Languages:
Both services were spot on in including a good variety of supported languages. While Google's Cloud Functions support includes Node.js, Python, Go, and Java, Ruby, PHP, and .NET, AWS Lambda's list is slightly more extensive, facilitating the use of TypeScript (using Node environment) and including Rust and PowerShell.
Additionally, as I mainly work with Python, I noticed the providers' commitment to keeping technologies up to date. In GCP, it is still possible to create a Lambda with Python 3.7, but in AWS, this is no longer allowed. It's worth mentioning that both in AWS and in GCP, Python 3.8 will be discontinued later this year (2024). A sadness for companies adhering to the culture of "If it ain't broke, don't fix it."
---
## 05. Execution Timeout:
The execution time is a crucial factor to consider when choosing between Google Cloud Functions and AWS Lambda. In Google Cloud Functions, the timeout varies according to the function's generation: in the first generation, the limit is 9 minutes (540 seconds), while in the second generation, it can reach 60 minutes (3,600 seconds) for HTTP functions and remains at 9 minutes (540 seconds) for event-driven functions.
On the other hand, in AWS Lambda, the default timeout is only 3 seconds but can be adjusted to up to 15 minutes (900 seconds) as needed. These limits can directly affect the performance and functionality of your serverless functions, especially in cases of synchronous external requests.
Below is a table summarizing the execution time limits on both platforms:
| Platform | Generation | Timeout |
|----------------------|------------|---------------------------|
| Google Cloud Functions| 1st | 540s |
| Google Cloud Functions| 2nd (HTTP) | 3,600s |
| Google Cloud Functions| 2nd (Event)| 540s |
| AWS Lambda | - | 3s (default) to 900s (max) |
---
## 06. Integration with Ecosystem:
Integration with the ecosystem was one of the factors that surprised me the most during the transition. AWS Lambda offers a very flexible integration with the entire AWS ecosystem, which has been extremely useful in the current architecture I work in. From seamless integrations with Amazon S3, Amazon DynamoDB, and Amazon API Gateway.
However, a downside is that this can lead to a high level of coupling. Although both providers support HTTP integration, AWS requires provisioning and configuring a separate resource, API Gateway, which is also charged separately.
---
## 07. Performance and Cold Start
Performance and startup time are critical aspects to consider when evaluating serverless computing options between Google Cloud Functions and AWS Lambda. Although startup time metrics are not publicly disclosed by providers, a superficial analysis reveals some significant differences.
Research indicates that Cloud Functions have a natively faster startup time compared to AWS Lambdas. However, it is challenging to draw an accurate comparison due to the lack of detailed information.
In AWS, for example, an inactive Python Lambda can start on average around 200ms, but it is worth noting that this value does not consider the use of the `provisioned concurrency` feature, a functionality that eliminates Cold Start by keeping instances ready to respond to requests.
---
## 08. Command-Line Interface (CLI) Tools
Command-line tools play an important role in managing cloud platforms. Both providers, AWS and GCP, offer their own CLI tools to facilitate automation, deployment, and resource management in the cloud.
### 8.1 GCP
- **`gcloud tool`**: With gcloud, users can create, modify, and manage resources such as virtual machine instances, databases, and serverless services.
- **`gsutil tool`**: With gsutil, file transfer, access policy configuration, and various other operations can be performed on Cloud Storage buckets. It is less utilized in the context of GCP Cloud Functions.
- **`bq tool`**: The bq is a command-line tool primarily intended for BigQuery, GCP's data analysis service. With bq, users can run SQL queries, load and export data, and manage datasets and tables. This tool is also less utilized in the context of GCP Cloud Functions.
### 8.2 AWS
- **`AWS tool`**: The AWS Command Line Interface is the primary tool for interacting with AWS services through the command line. With the AWS CLI, users can manage EC2 instances, S3 buckets, Lambda functions, and a variety of other AWS services.
- **`SAM tool`**: The AWS SAM (Serverless Application Model) is an extension of the AWS CLI that makes it easy to create, test, and deploy serverless applications on AWS. With AWS SAM, developers can define serverless resources using a simplified syntax and deploy them with ease. AWS SAM overlays AWS CLI to provide us with some useful extra tools.
---
## 09. Conclusion:
As they say, the devil is in the details. The choice between AWS Lambda and Google Cloud Functions goes beyond comparing technical features. Although AWS Lambda is considered more mature, Google Cloud Functions is also a robust option, with its own range of advantages and features. The decision between the two providers should be based not only on technical characteristics but also on associated costs, developer experience, and the specific context of the project.
My migration from GCP to AWS was surprisingly smooth, contrasting with reports of difficulties I heard from professionals who went the other way. This can be attributed to the integrations and facilities offered by AWS, highlighting the importance of choosing a platform that meets the specific needs of the project and development team.
Overall, this migration not only expanded my knowledge of cloud computing and cloud-native but also highlighted the importance of platform independence. Developing and deploying software independently of underlying cloud providers not only facilitates portability between different services but also maximizes resource utilization, resulting in significant cost savings.
| miguelsmuller |
1,852,856 | Headless Browser – A Stepping Stone Towards Developing Smarter Web Applications | Websites being the primary source of communication in the digital transformation world, have evolved... | 0 | 2024-05-14T15:41:35 | https://dev.to/pcloudy_ssts/headless-browser-a-stepping-stone-towards-developing-smarter-web-applications-48b3 | puppeteer, chrome59, crossbrowsertesting | Websites being the primary source of communication in the digital transformation world, have evolved humongously since the last decade. Web development has grown at a tremendous pace with lots of automation testing frameworks coming in for both frontend and backend development. Websites have become smarter and so have the underlying tools and frameworks. With a significant surge in the web development area, the browsers have also become smarter. Nowadays, you can find headless browsers, where users can interact with the browser without GUI. You can even scrape websites in headless browsers using packages like Puppeteer and nodejs.
Efficient web development hugely relies on a testing mechanism for quality assessment before we can push them in production environments. Headless browsers can perform end to end testing, smoke testing etc at a faster speed as it is free from overhead of the memory space required for the UI. Moreover, studies have proved that the headless browsers generate more traffic than the non-automated ones. Popular browsers like Chrome can even help in debugging the web pages in real time, analyse performance, notify the memory consumption, enable tweaking of the code and analyse performance in real time etc. Isn’t this evolution of browsers heading towards a smarter web development process? So in this blog we will have an overview on headless browsers and understand how it helps in smarter and faster website development.
What is a Headless Browser ?
A headless browser is simply a browser without the GUI. It has got all the capabilities of rendering a website, like a normal website. Since GUI is not available in the browser with headless mode, we need to use the command line to interact with the browser. Headless browsers are designed for tasks like [automation testing](https://www.pcloudy.com/rapid-automation-testing/), javascript library testing, javascript simulation and interactions.
One of the biggest reasons for using headless browser or headless browser testing is that it let’s you run the tests more quickly and in a real environment. For eg, the combination of chrome devtools and headless chrome lets you edit pages on the fly and, which helps you in diagnosing the problem quickly ultimately helping you in developing better websites faster. So headless browsers are more fast, flexible and optimised in performing tasks like web-based automation testing. Like a normal browser, the headless browser is capable of performing tasks like links parsing JavaScript, clicking on links, coping with any downloads and for executing this we need to use command line. So it can provide a real browser context without any of the memory consumed for running a full-fledged browser without a GUI.
Comparative Analysis Between Headless Browsers and Traditional Browsers
Traditional Browsers
Traditional browsers like Google Chrome, Mozilla Firefox, Internet Explorer, and Safari are designed with the end-user in mind. They come with a graphical user interface (GUI) to allow users to interact with web applications directly.
Speed: Traditional browsers are slower because they must render all webpage elements, including images, CSS, and scripts, which can be resource-intensive.
Automation & Testing: Automating tests can be more challenging with traditional browsers because of their heavy reliance on the UI. They often require additional tools like Selenium to perform automation testing.
Resource Usage: They consume more resources (CPU, memory) as they have to render GUI along with webpage content.
Web Scraping: Web scraping in traditional browsers is not as efficient because of their GUI and rendering of all webpage content.
Headless Browsers
Headless browsers, on the other hand, are designed with developers and automation in mind. They do not have a GUI, and interactions are through a command line or with the help of code.
Speed: As headless browsers do not render GUI, they load pages faster. This speed is critical for automated testing where multiple test cases are executed in parallel.
Automation & Testing: Headless browsers are perfect for automation as they provide direct interaction with the HTML of a webpage. Tools like Puppeteer make automation testing even simpler.
Resource Usage: Since they don’t have a GUI to render, headless browsers consume less memory and CPU, making them more efficient.
Web Scraping: Web scraping is efficient and faster in headless browsers as they can render the webpage and access the HTML directly.
The Need for a Headless Browser
With advancements in the website development technologies, website testing has taken a center stage and emerged as the most essential steps in developing high performing websites. Even browsers are becoming smarter as they can load the javascript libraries for performing automation testing. Isn’t that a significant transformational leap in the website testing. So let’s have an overview on some of the major functions performed by headless browsers.
Enables faster web testing using Command Line Interface
With headless [cross browser testing](https://www.pcloudy.com/cross-browser-testing/), we are saved from the overhead of memory consumed in GUI, hence it enables faster website testing, using command line as the primary source of interaction. The headless browsers are designed to execute crucial test cases like end to end testing which ensures that the flow of an application is performing as designed from start to finish. The headless browsers cater to this use case as they enable faster website testing.
Scraping websites
The headless browser saves the overhead of opening the GUI thus enabling faster scraping of the websites. In headless browsers we can automate the scraping mechanism and extract the data in a much more optimised manner.
Taking web screenshots
Though the headless browsers do not avail any GUI, they do allow the users to take snapshots of the website that they are rendering. It’s very useful in cases where the tester is testing the website and needs to visualise the code effects and save results in the form of screenshots. In a headless browser you can easily take a large number of screenshots without any actual UI.
Mapping user journey across the websites
Headless browsers allow you to programmatically map the customer journey test cases. Here headless browsers help the users to optimise the user experience throughout their decision making journey on the website.
Now that we have understood what is a headless browser and it’s numerous features, along with the its key quality of being a lightweight browser which helps in accelerating the speed of testing, let’s have an overview on the most popular headless browser, Headless Chrome and see what does it unlocks
Diving into Headless Chrome and Chrome DevTools
We have a number of headless browsers and to name a few are firefox version 55 and 56, PhantomJs, Html Unit, Splinter, jBrowserDriver etc. Chrome 59 is Chrome’s version to run it in headless mode. Headless Chrome and Chrome DevTools is quite a powerful combination enabling the users with out of box features. So let’s have an overview on Headless Chrome and Chrome DevTools.
What is Headless Chrome
What is Headless Chrome
Headless Chrome shipping in Chrome 59, is basically running chrome in a headless environment. It’s running chrome without GUI. This light weighted, memory sparing and quick running browser brings in all the modern web platform features provided by the chromium and blink rendering engine to the command line.
As per the studies, the automated browsers always generated more traffic than the non-automated ones. In a recent survey, it was discovered that the headless Chrome generated more traffic than its previous leader Phantum Js within a year of its release.
Apart from this, there are several reasons why chrome is the most popular headless browser. One of the reasons is, it’s always updating out of the box features, which constantly introduce new trends in web development. It also consists of a rendering engine called Blink , which constantly updates itself as the website evolves. What does the Headless Chrome Unlocks :
The ability to test the latest web platform features like ES6 modules, service worker and streams
Enables to programmatically tap into the chrome devtools and makes use of the awesome features like network throttling, device emulating, website performance analysis etc.
Test multiple levels of navigation
Gather page information
Take screenshots
Create PDFs
Now let’s have a look on the most common flags to start working with headless chrome:
Starting headless
For starting headless, you need a [Chrome 59+](https://google-chrome.software.informer.com/59.0/) and open the chrome binary from the command line. If you have got the Chrome 59+ installed then start the Chrome with
The — headless flag starts the chrome in headless mode
Similarly for printing the DOM, creating pdf, taking screenshots we can simply use the following flags
Printing the DOM
The –dump-dom flag prints document.body.innerHTML to stdout
Create a PDF
The –print-to-pdf flag creates a PDF of the page:
Taking screenshots
To capture a screenshot of a page, use the –screenshot flag
Debugging a code without the browser UI
If you want to debug your code in a headless browser using the chrome devtools then make note of the following flag.–remote-debugging-port=9222. This flag helps you to open the headless chrome in a special mode, wherein the chrome devtool can interact with the headless browser to edit the web page during run-time. We will dig deeper into Chrome Devtools in the later section of the blog.
For debugging the web page with chrome devtools, use the –remote-debugging-port=9222 flag.
What is Chrome DevTool ?
Chrome DevTools is a set of web developer tools built directly into Google Chrome. It helps to debug the web pages on the fly and hence helps to detect the bugs quickly, which ultimately helps to develop the websites faster.
The simplest way of opening devtools is, right click on your webpage and click inspect. Now based on your purpose to use the devtool, you can open various consoles. For example to work with DOM or CSS you can click on the elements panel, to see logged messages or run javascript click on the console panel, for debugging the javascript click on the source panel, to view network activity click on the network panel, to analyse the performance of the webpage click on the performance panel, to fix memory problems click on the memory panel.
As we can see, the chrome devtools is a package of diverse functionalities which helps in debugging a web page in the chrome browser. But what about the headless browser with no UI, how can we debug the web page with no UI?. Can chrome devtools help debugging a headless browser ? Let’s demystify the ways of debugging a headless browser with chrome devtools, discuss what is [puppeteer ](https://developers.google.com/web/tools/puppeteer)in the following sections of the blog.
Puppeteer
As discussed earlier, one of the ways of debugging a web page in a headless browser is to use the flag –remote-debugging-port=9222 in the command line which helps in tapping into the chrome devtools programmatically. But, there is another layer into the picture to play with the headless chrome to perform numerous out of the box tasks and make use of headless in a more efficient way. Here, Puppeteer comes into the picture.
Puppeteer Architecture
Puppeteer is a Node Library which provides a high level API to control chrome over devtools protocol. Puppeteer is usually headless but can also be configured to use full non – headless Chrome. It provides full access to all the features of headless chrome and can also run chrome fully in a remote server which is very beneficial to the automation teams. It would be quite justifying to term Puppeteer as Google Chrome team’s official Chrome headless browser.
One of the greatest advantages of using puppeteer as an automation framework for testing is that unlike other frameworks, it is very simple and easy to install.
As puppeteer is a node javascript library, so first of all you need to install nodejs on your system. Nodejs comes with the npm (node package manager) which will help us to install the puppeteer package.
The following code snippet will help you to install nodejs
## Updating the system libraries
##sudo apt-get update
## Installing node js in the system
##sudo apt-get install nodejs
Once you are done with installation of node js in your machine, you can run the following flag to install puppeteer.
npm i puppeteer
With this you completed the installation for puppeteer which will also by default download the latest version of chrome.
Why is puppeteer so useful ?
Puppeteer provides full access to all the out of box features provided by the headless chrome and its constantly updating rendering engine called blink. Other than mostly used automation testing frameworks for web applications like selenium web driver, puppeteer is so popular as it provides automation for a light weighted (UI less) headless browser which helps in testing faster. Likewise there are multiple functionalities provided by puppeteer, so let’s have a look at it
It can help generate screenshots and pdfs of pages
Crawl a single page application and generate pre-rendered content
Automate form submission, UI testing, end to end testing, smoke testing, keyboard input etc
Creates an up-to-date, automated testing environment. Run your tests directly in the latest version of Chrome using the latest JavaScript and browser features.
Captures a timeline trace of your site and analyses performance issues.
It can test Chrome Extensions.
Allows performing web scraping
As we are aware of the functionalities performed by puppeteer let’s have an overview on the code snippet for taking screenshot in puppeteer.
const puppeteer = require(‘puppeteer’);
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(‘https://example.com’);
await page.screenshot({path: ‘example.png’});
await browser.close();
})();
Once this code gets executed, a screenshot will be saved in your system through the path mentioned in the code snippet.
Conclusion
Faster and qualitative web development has always been and will always be the top priority of QA and development teams. The headless browsers ( without GUI) being light weighted and memory sparing runs at a higher speed while automation testing. Definitely they cater to the need of smarter web development. Moreover, they help in testing all the modern web platform features as well as enable debugging and performance analysis during real time which adds another feather on the cap. They are responsible for heavy traffic in the web applications and support website scraping with the help of packages like nodejs and puppeteer. Furthermore, the installation of headless browsers is easier than installation of any other web automation frameworks like selenium. These qualities of headless browsers are compelling the brands to utilize them for developing high performance web applications. | pcloudy_ssts |
1,853,372 | Common pitfalls to avoid when buying a used excavator | screenshot-1709858055575.png How to Avoid Common Pitfalls When Buying a Used Excavator Will you be... | 0 | 2024-05-15T03:46:56 | https://dev.to/dunkinlog99/common-pitfalls-to-avoid-when-buying-a-used-excavator-847 | pitfalls | screenshot-1709858055575.png
How to Avoid Common Pitfalls When Buying a Used Excavator
Will you be considering purchasing a used excavator for the landscaping or construction task? Used excavators come with a lot of benefits, such as for example helping you save money, being environmentally friendly, and providing capabilities being comparable brand new people. Nevertheless, you can find pitfalls that are common avoid when purchasing a used excavator. We intend to take a better look at a few of the things that are plain should look at when selecting a used excavator.
Features of Investing In A Used Excavator
One benefit which is significant of a utilized excavator is expense benefits. A used excavator is generally much cheaper than a new one. You are able to save thousands when purchasing a used excavator. Also, buying a excavator which is utilized be environmentally friendly as you are not causing the manufacturing of an innovative excavator which is brand new.
Innovation and protection
With regards to innovation, older several types of excavators might not have the newest features and technology. Consequently, it's important to research the form and age of the excavator you will need to buy to make certain it has the features that are required your project. Also, safety should really be a priority which is top investing in a used excavator. Consider its safety features and any safety which is potential that could come featuring its age.
Use and How Exactly To Make use of
One more thing to think about when buying a used excavator may be the technique that you want to work with it. Different tasks need different types of excavators. It is vital to choose an excavator that works for the task which is specific. Additionally, it really is crucial to know how to make use of it safely if you have no experience which is prior an excavator. Being a middle-school student, it is critical to talk to an expert before running any bit which is small of equipment.
Quality and Service
The conventional associated with used excavator is important when making a purchase. Before carefully deciding, carefully inspect the excavator for almost any deterioration or repairs that require become made. Additionally, make sure the vendor has documentation which is proper such as service records and upkeep history. Finally, consider the solution which is ongoing of the excavator. Ensure that upkeep and repairs are feasible, or elsewhere you might face downtime which is possible your project.
Application
Lastly, it's important to consider the application whenever choosing a utilized excavator. Different tasks require different types of excavation equipment. As an example, light excavation work might just need a excavator which is tiny while larger tasks may need excavators that are heavy-duty. Make certain that the excavator's specifications match your project's needs.
In conclusion, when buying a Used Mini Excavator, be sure to consider all the factors discussed above. Keep in mind the advantages of buying used instead of new, ensuring the excavator has the necessary safety features, understanding how to use it safely, thoroughly inspecting the quality, and choosing the correct application for your project. Doing so will help you avoid any common pitfalls and allow you to make a well-informed decision. With the right used excavator, you'll be able to complete your project efficiently and safely.
| dunkinlog99 |
34,142 | CI/CD with Drone, Kubernetes and Helm - Part 1 | Building your CI/CD pipeline with Drone, Kubernetes and Helm. RBAC included. | 0 | 2018-06-06T09:30:18 | https://dev.to/depado/cicd-with-drone-kubernetes-and-helm---part-1-4mdp | cicd, drone, helm, kubernetes | ---
title: CI/CD with Drone, Kubernetes and Helm - Part 1
published: true
description: Building your CI/CD pipeline with Drone, Kubernetes and Helm. RBAC included.
tags: [cicd,drone,helm,kubernetes]
---
This article is a repost from my blog. [Find the original post here](https://blog.depado.eu/post/ci-cd-with-drone-kubernetes-and-helm-1).
# Introduction
Continuous integration and delivery is hard. This is a fact everyone can agree on. But now we have all this wonderful technology and the problems are mainly "How do I plug this with that?" or "How do I make these two products work together?"
Well, there's **never** a simple and universal answer to these questions. In this article series we'll progressively build a complete pipeline for continuous integration and delivery using three popular products, namely Kubernetes, Helm and Drone.
This first article acts as an introduction to the various technology used throughout the series. It is intended for beginners that have some knowledge of Docker, how a container works and the basics of Kubernetes. You can entirely skip it if you have a running k8s cluster and a running Drone instance.
## Steps
- Create a Kubernetes cluster with GKE
- Create a service account for Tiller
- Initialize Helm
- Add a repo to Helm
- Deploy Drone on the new k8s cluster
- Enable HTTPS on our new Drone instance
## Technology involved
### Drone
[Drone](https://drone.io/) is a Continuous Delivery platform built on Docker and written in Go. Drone uses a simple YAML configuration file, a superset of docker-compose, to define and execute Pipelines inside Docker containers.
It has the same approach as [Travis](https://travis-ci.org/), where you define your pipeline as code in your repository. The cool feature is that every step in your pipeline is executed in a Docker container. This may seem counter-intuitive at first but it enables a great plugin system: Every plugin for Drone you might
use is a Docker image, which Drone will pull when needed. You have nothing to install directly in Drone as you would do with Jenkins for example.
Another benefit of running inside Docker is that the [installation procedure](http://docs.drone.io/installation/) for Drone is really simple. But we're not going to install Drone on a bare-metal server or inside a
VM. More on that later in the tutorial.
### Kubernetes
> Kubernetes (commonly stylized as K8s) is an open-source container-orchestration system for automating deployment, scaling and management of containerized applications that was originally designed by Google and now maintained by the Cloud Native Computing Foundation. It aims to provide a "platform for automating deployment, scaling, and operations of application containers across clusters of hosts". It works with a range of container tools, including Docker. <cite>[Wikipedia](https://en.wikipedia.org/wiki/Kubernetes) </cite>
Wikipedia summarizes k8s pretty well. Basically k8s abstracts the underlying machines on which it runs and offers a platform where we can deploy our applications. It is in charge of distributing our containers correctly on
different nodes so if one node shuts down or is disconnected from the network, the application is still accessible while k8s works to repair the node or provisions a new one for us.
I recommend at least reading [Kubernetes Basics](https://kubernetes.io/docs/tutorials/kubernetes-basics/) for this tutorial.
### Helm
[Helm](https://helm.sh/) is the package manager for Kubernetes. It allows us to create, maintain and deploy applications in a Kubernetes cluster.
Basically if you want to install something in your Kubernetes cluster you can check if there's a Chart for it. For example we're going to use the Chart for Drone to deploy it.
Helm allows you to deploy your application to different namespaces, change the tag of your image and basically override every parameter you can put in your Kubernetes deployment files when running it. This means you can use the same chart to deploy your application in your staging environment and in production simply by overriding some values on the command line or in a values file.
In this article we'll see how to use a preexisting chart. In the next one we'll see how to create one from scratch.
## Disclaimers
In this tutorial, we'll use [Google Cloud Platform](https://cloud.google.com) because it allows to create Kubernetes clusters easily and has a private container registry which we'll use later.
# Kubernetes Cluster
_You can skip this step if you already own a k8s cluster with a Kubernetes version above 1.8._
In this step we'll need the `gcloud` and `kubectl` CLI. Check out how to [install the Google Cloud SDK](https://cloud.google.com/sdk/downloads) for your operating system.
As said earlier, this tutorial isn't about creating and maintaining a Kubernetes cluster. As such we're going to use [Google Kubernetes Engine](https://cloud.google.com/kubernetes-engine/) to create our playground cluster. There are two options to create it: either in the web interface offered by GCP, or directly using the `gcloud` command. At the time of writing, the default version of k8s offered by Google is `1.8.8`, but as long as you're above `1.8` you can pick whichever version you want._Even though there's no reason not to pick the highest stable version..._
The `1.8` choice is because in this version [RBAC](https://en.wikipedia.org/wiki/Role-based_access_control) is activated by default and is the default authentication system.
To reduce the cost of your cluster you can modify the machine type, but try to keep at least 3 nodes; this will allow zero-downtime migrations to different machine types and upgrade k8s version if you ever want to keep this cluster active and running.
To verify if your cluster is running, you can check the output of the following command:
```
$ gcloud container clusters list
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS
mycluster europe-west1-b 1.10.2-gke.1 <master ip> custom-1-2048 1.10.2-gke.1 3 RUNNING
```
You should also get the `MASTER_IP`, `PROJECT`, and the `LOCATION` which I removed from this snippet. From now on in the code snippets and command line examples, `$LOCATION` will refer to your cluster's location, `$NAME` will refer to your cluster's name, and `$PROJECT` will refer to your GCP project.
Once your cluster is running, you can then issue the following command to retrieve the credentials to connect to your cluster:
```
$ gcloud container clusters get-credentials $NAME --zone $LOCATION --project $PROJECT
Fetching cluster endpoint and auth data.
kubeconfig entry generated for mycluster.
$ kubectl cluster-info
Kubernetes master is running at https://<master ip>
GLBCDefaultBackend is running at https://<master ip>/api/v1/namespaces/kube-system/services/default-http-backend/proxy
Heapster is running at https://<master ip>/api/v1/namespaces/kube-system/services/heapster/proxy
KubeDNS is running at https://<master ip>/api/v1/namespaces/kube-system/services/kube-dns/proxy
kubernetes-dashboard is running at https://<master ip>/api/v1/namespaces/kube-system/services/kubernetes-dashboard/proxy
Metrics-server is running at https://<master ip>/api/v1/namespaces/kube-system/services/metrics-server/proxy
```
Now `kubectl` is configured to operate on your cluster. The last command will print out all the information you need to know about where your cluster is located.
# Helm and Tiller
First of all we'll need the `helm` command. [See this page for installation instructions](https://github.com/kubernetes/helm/blob/master/docs/install.md).
Helm is actually composed of two parts. Helm itself is the client, and Tiller is the server. Tiller needs to be installed in our k8s cluster so Helm can work with it, but first we're going to need a **service account** for Tiller. Tiller must be able to interact with our k8s cluster, so it needs to be able to create deployments, configmaps, secrets, and so on. Welcome to **RBAC**.
So let's create a file named `tiller-rbac-config.yaml`
```yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
```
In this yaml file we're declaring a [ServiceAccount](https://kubernetes.io/docs/admin/authorization/rbac/#service-account-permissions) named tiller, and then we're declaring a [ClusterRoleBinding](https://kubernetes.io/docs/admin/authorization/rbac/#rolebinding-and-clusterrolebinding) which associates the tiller service account to the cluster-admin authorization.
Now we can deploy tiller using the service account we just created like this:
```
$ helm init --service-account tiller
```

Note that it's not necessarily good practice to deploy tiller this way. Using RBAC, we can limit the actions Tiller can execute in our cluster and the namespaces it can act on. [See this documentation](https://github.com/kubernetes/helm/blob/master/docs/rbac.md) to see how to use RBAC to restrict or modify the behavior of Tiller in your k8s cluster.
This step is really important for the following parts of this series, as we'll later use this service account to interact with k8s from Drone.
# Deploying Drone
## Static IP
If you have a domain name and wish to associate a subdomain to your Drone instance, you will have to create an external IP address in your Google Cloud console. Give it a name and remember that name, we'll use it right after when configuring the Drone chart.
Associate this static IP with your domain (and keep in mind DNS propagation can take some time).
For the sake of this article, the external IP address name will be `drone-kube` and the domain will be `drone.myhost.io`.
## Integration
First we need to setup Github integration for our Drone instance. Have a look at [this documentation](http://docs.drone.io/install-for-github/) or if you're using another version control system, check in the Drone documentation how to create the proper integration. Currently, Drone supports the following VCS:
- [GitHub](http://docs.drone.io/install-for-github/)
- [GitLab](http://docs.drone.io/install-for-gitlab/)
- [Gitea](http://docs.drone.io/install-for-gitea/)
- [Gogs](http://docs.drone.io/install-for-gogs/)
- [Bitbucket Cloud](http://docs.drone.io/install-for-bitbucket-cloud/)
- [Bitbucket Server](http://docs.drone.io/install-for-bitbucket-server/)
- [Coding](http://docs.drone.io/install-for-coding/)
Keep in mind that if you're not using the Github integration, the changes in the environment variables in the next section need to match.
## Chart and configuration
After a quick Google search, we can see there's a [Chart for Drone](https://github.com/kubernetes/charts/tree/master/incubator/drone). And it's in the `incubator` of Helm charts, so first we need to add the repo to Helm.
```
$ helm repo add incubator https://kubernetes-charts-incubator.storage.googleapis.com/
$ helm repo update
```
Now that it's done, we can have a look at the [configuration](https://github.com/kubernetes/charts/tree/master/incubator/drone#configuration) part for this Chart. We'll create a `values.yaml` file that will contain the required information for our Drone instance to work properly.
```yaml
service:
httpPort: 80
nodePort: 32015
type: NodePort
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "gce"
kubernetes.io/ingress.global-static-ip-name: "drone-kube"
kubernetes.io/ingress.allow-http: "true"
hosts:
- drone.myhost.io
server:
host: "http://drone.myhost.io"
env:
DRONE_PROVIDER: "github"
DRONE_OPEN: "false"
DRONE_GITHUB: "true"
DRONE_ADMIN: "me"
DRONE_GITHUB_CLIENT: "the github client secret you created earlier"
DRONE_GITHUB_SECRET: "same thing with the secret"
```
Alright! We have our static IP associated with our domain. We have to put the name of this reserved IP in the Ingress' annotations so it knows to which IP it should bind. We're going to use a GCE load balancer, and since we don't have a TLS certificate, we're going to tell Ingress that it's OK to accept HTTP connections. (Please don't hit me, I promise we'll see how to enable TLS later.)
We also declare all the variables used by Drone itself to communicate with our VCS, in this case Github.
That's it. We're ready. Let's fire up Helm!
```
$ helm install --name mydrone -f values.yaml incubator/drone
```
Given that your DNS record is now propagated, you should be able to access your Drone instance using the `drone.myhost.io` URL!
# TLS
## Deploying cert-manager
In the past, we had [kube-lego](https://github.com/jetstack/kube-lego) which is now deprecated in favor of [cert-manager](https://github.com/jetstack/cert-manager/).
[The documentation](http://cert-manager.readthedocs.io/en/latest/getting-started/2-installing.html) states that installing cert-manager is as easy as running this command:
```
$ helm install --name cert-manager --namespace kube-system stable/cert-manager
```
## Creating an ACME Issuer
Cert-manager is composed of several components. It uses what's called [Custom Resource Definitions](https://kubernetes.io/docs/tasks/access-kubernetes-api/extend-api-custom-resource-definitions/) and allows to use `kubectl` to control the certificates, issuers and so on.
An [Issuer](https://cert-manager.readthedocs.io/en/latest/reference/issuers.html) or [ClusterIssuer](https://cert-manager.readthedocs.io/en/latest/reference/clusterissuers.html) represents a certificate authority from which x509 certificates can be obtained.
The difference between an Issuer and a ClusterIssuer is that the Issuer can only manage certificates in its own namespace and be called from within that namespace. The ClusterIssuer doesn't depend on a specific namespace.
We're going to create a Let'sEncrypt ClusterIssuer so we can issue a certificate for our Drone instance and for our future deployments. Let's create a file named `acme-issuer.yaml`:
```yaml
apiVersion: certmanager.k8s.io/v1alpha1
kind: ClusterIssuer
metadata:
name: letsencrypt
spec:
acme:
server: https://acme-v01.api.letsencrypt.org/directory
email: your.email.address@gmail.com
privateKeySecretRef:
name: letsencrypt-production
http01: {}
```
Here we're creating the ClusterIssuer with the HTTP challenge enabled. We're only going to see this challenge in this article, refer to the [documentation](https://cert-manager.readthedocs.io/en/latest/) for more information about challenges. **Remember to change the associated email address in your issuer !**
```
$ kubectl apply -f acme-issuer.yaml
```
We can also create a ClusterIssuer using Let'sEncrypt staging environment which is more permissive with errors on requests. If you want to test out without issuing true certificates, use this one instead. Create a new file `acme-staging-issuer.yaml`:
```yaml
apiVersion: certmanager.k8s.io/v1alpha1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging
spec:
acme:
server: https://acme-staging.api.letsencrypt.org/directory
email: your.email.address@gmail.com
privateKeySecretRef:
name: letsencrypt-staging
http01: {}
```
```
$ kubectl apply -f acme-staging-issuer.yaml
```
## Certificate
Now that we have our ClusterIssuer that is using the production of Let'sEncrypt, we can create a manifest that will solve the ACME challenge for us. First we're going to need the name of the ingress created by the Drone chart:
```
$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
mydrone-drone drone.myhost.io xx.xx.xx.xx 80 1h
```
Now that we have this information, let's create the `drone-cert.yaml` file:
```yaml
apiVersion: certmanager.k8s.io/v1alpha1
kind: Certificate
metadata:
name: mydrone-drone
namespace: default
spec:
secretName: mydrone-drone-tls
issuerRef:
name: letsencrypt # This is where you put the name of your issuer
kind: ClusterIssuer
commonName: drone.myhost.io # Used for SAN
dnsNames:
- drone.myhost.io
acme:
config:
- http01:
ingress: mydrone-drone # The name of your ingress
domains:
- drone.myhost.io
```
There are many fields to explain here. Most of them are pretty explicit and can be found [in the documentation](http://cert-manager.readthedocs.io/en/latest/tutorials/acme/http-validation.html) about HTTP validation.
The important things here are:
- `spec.secretName`: The secret in which the certificate will be stored. Usually
this will be prefixed with `-tls` so it doesn't get mixed up with other
secrets.
- `spec.issuerRef.name`: The named we defined earlier for our ClusterIssuer
- `spec.issuerRef.kind`: Specify that the issuer is a ClusterIssuer
- `spec.acme.config.http01.ingress`: The name of the ingress deployed with Drone
Now let's apply this:
```
$ kubectl apply -f drone-cert.yaml
$ kubectl get certificate
NAME AGE
mydrone-drone 7m
$ kubectl describe certificate mydrone-drone
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning ErrorCheckCertificate 33s cert-manager-controller Error checking existing TLS certificate: secret "mydrone-drone-tls" not found
Normal PrepareCertificate 33s cert-manager-controller Preparing certificate with issuer
Normal PresentChallenge 33s cert-manager-controller Presenting http-01 challenge for domain drone.myhost.io
Normal SelfCheck 32s cert-manager-controller Performing self-check for domain drone.myhost.io
Normal ObtainAuthorization 6s cert-manager-controller Obtained authorization for domain drone.myhost.io
Normal IssueCertificate 6s cert-manager-controller Issuing certificate...
Normal CertificateIssued 5s cert-manager-controller Certificate issued successfully
```
We need to wait for this last line to appear, the `CertificateIssued` event before we can update our Ingress' values. This can take some time, be patient as Google Cloud Load Balancers can take several minutes to update.
## Upgrade Drone's Values
Now that we have our secret containing the proper TLS certificate, we can go back to our `values.yaml` file we used earlier to deploy Drone with its Chart and add the TLS secret to the ingress section ! We're also going to disable HTTP on our ingress (only HTTPS will be served), and modify our `server.host` value to reflect this HTTPS change.
```yaml
service:
httpPort: 80
nodePort: 32015
type: NodePort
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: "gce"
kubernetes.io/ingress.global-static-ip-name: "drone-kube"
kubernetes.io/ingress.allow-http: "false" # ← Let's disable HTTP and allow only HTTPS
hosts:
- drone.myhost.io
# Add this ↓
tls:
- hosts:
- drone.myhost.io
secretName: mydrone-drone-tls
# End
server:
host: "https://drone.myhost.io" # ← Modify this too
env:
DRONE_PROVIDER: "github"
DRONE_OPEN: "false"
DRONE_GITHUB: "true"
DRONE_ADMIN: "me"
DRONE_GITHUB_CLIENT: "the github client secret you created earlier"
DRONE_GITHUB_SECRET: "same thing with the secret"
```
And we just have to upgrade our deployment:
```
$ helm upgrade mydrone -f values.yaml incubator/drone
```
You're going to have to modify your Github application too.
# Conclusion
In this article we saw how to deploy a Kubernetes cluster on GKE, how to create a service account with the proper cluster role binding to deploy Tiller, how to use helm and how to deploy a chart with the example of drone.
In the next article we'll see how to write a quality pipeline for a Go project as well as how to push to Google Cloud Registry.
# Thanks
Thanks to [@shirley_leu](https://twitter.com/shirley_leu) for proofreading this article and correcting my english mistakes !
This article is a repost from my blog. [Find the original post here](https://blog.depado.eu/post/ci-cd-with-drone-kubernetes-and-helm-1).
| depado |
1,853,417 | Unveiling the Web Developer's Toolkit: Choosing the Right Language Types for Website Creation | In the ever-evolving world of web development, the choice of programming language plays a crucial... | 0 | 2024-05-15T04:28:07 | https://dev.to/epakconsultant/unveiling-the-web-developers-toolkit-choosing-the-right-language-types-for-website-creation-3h3p | webdev | In the ever-evolving world of web development, the choice of programming language plays a crucial role in shaping the functionality and performance of a website. From crafting visually appealing front-end designs to implementing robust back-end systems, web developers rely on a diverse array of languages to bring digital creations to life. This article delves into the landscape of web development languages, exploring the distinct roles of front-end, back-end, and full-stack languages, guiding readers through the process of selecting the most suitable language for their website projects, and highlighting popular languages as well as emerging trends in the field.
## Understanding the Role of Programming Languages in Web Development
Hey there, web wanderer! Ready to delve into the world of languages that make the web go round? Strap in as we navigate through the vast realm of web development languages and uncover which ones are best suited for creating websites.
**Front-end Development Languages**
**HTML**
**CSS**
**JavaScript**
Front-end development is like the artist of web building, focusing on what users see and interact with on a website. HTML forms the structure, CSS adds style and flair, and JavaScript brings the interactivity. It's like the dream team that makes your website visually appealing and user-friendly.
**Back-end Development Languages**
**PHP**
**Python**
**Ruby**
Now, let's swing to the back-end, the brains behind the beauty. Back-end languages handle the behind-the-scenes magic, managing databases, processing data, and making sure everything runs smoothly. PHP, Python, and Ruby are like the secret agents ensuring your website functions flawlessly.
[Vue.js for Everyone: A Beginner's Guide to Building Dynamic Web Applications](https://www.amazon.com/dp/B0CW18ZNPK)
**Full-Stack Development Languages**
**Node.js**
**Java**
Feeling ambitious? Full-stack developers conquer both front-end and back-end worlds. With languages like Node.js and Java, they master the art of juggling the entire web development circus. It's like being the ringmaster and the star performer all rolled into one – talk about web wizardry!
## Choosing the Right Language for Your Website
So, you've decided to create a website – congratulations! Now, the big question is: which language type should you use to bring your digital masterpiece to life? Let's dive into the wonderful world of web development languages.
## Popular Languages in Web Development
**JavaScript**
If web development were a sandwich, JavaScript would be the peanut butter – versatile and goes well with everything. It's the go-to language for adding interactivity and dynamic elements to websites. From animations to form validations, JavaScript is a must-know for any web developer.
**Python**
Python is like that reliable friend who always has your back. Known for its readability and ease of use, Python is often used for backend development. It's great for building robust web applications and handling tasks like data processing and automation.
**PHP**
PHP is the OG (Original Gangster) of web development languages. It's a server-side scripting language that powers popular platforms like WordPress. PHP is ideal for creating dynamic web pages and interacting with databases, making it a staple in the web development world.
## Emerging Trends in Web Development Languages
As technology evolves, so do the languages used in web development. Keep an eye out for emerging trends like TypeScript, Rust, and Kotlin. These languages offer exciting new possibilities for building faster, more efficient websites. Stay curious, and always be ready to learn and adapt in the ever-changing landscape of web development.As the digital realm continues to expand and evolve, staying informed about the latest trends and technologies in web development languages is essential for web developers seeking to create cutting-edge and user-friendly websites. By understanding the nuances of front-end, back-end, and full-stack languages, developers can harness the power of programming to design dynamic and responsive web experiences. Whether opting for established favorites or exploring emerging languages, the world of web development offers endless possibilities for innovation and creativity. | epakconsultant |
1,853,460 | Kickstart Your AWS IAM Security Journey: 9 Simple Practices to Implement. | Identity security is one of the basic and also important consideration factors online. securing your... | 0 | 2024-05-15T05:47:05 | https://dev.to/karaniph/kickstart-your-aws-iam-security-journey-9-simple-practices-to-implement-1m4e | awssecurity, aws, iam, security | Identity security is one of the basic and also important consideration factors online. securing your cloud environment is just as important as your work on the cloud.
AWS IAM connects (who?) developers, SREs, etc.. (can access).. permissions (what?).. resources e.g. EC2 instances, lambda functions, etc...
If malicious actors are able to penetrate your cloud environment with ease a lot of damage is bound to happen but that can be prevented by enforcing the following AWS IAM security best practices.
✔ Require human users to use federation with an identity provider to access AWS using temporary credentials. why use an identity provider? Centralise user stores, reduce password fatigue, reduce the number of systems to secure, and ensure ease of auditing.
✔ Require multifactor authentication- MFA combines what you know(password) with what you have (device) Rotate access keys regularly for use cases that require long-term credentials, you should however never use access keys with the root account access.
✔ Safeguard your root user credentials and don’t use them for everyday tasks this is because root user credentials are long-term credentials and they also have full access to your AWS account
✔ Assign the least privilege -Grant users and systems the narrowest set of privileges to complete required tasks.
✔ Regularly review and remove unused users, roles, permission policies, and credentials -look at roles and IAM users and the services they had accessed and remove those which have not been used in a while and are no longer required.
✔Rotate access keys regularly for use cases that require long-term credentials, you should, however, never use access keys with the root account access.
✔ require workloads to use temporary credentials with IAM roles to access AWS. This ensures limited lifetime and auto expiration, it also eliminates the need for credential distribution & storage, and app requests when they need them.
> For workloads running either on-prem or on the hybrid cloud, you can use IAM roles anywhere which is a free solution.
✔ verify public and cross-account access to resources with the IAM access analyzer. inspect and verify external access enable access analyzer and AWS will continuously monitor renew and generate findings for you to review.
✔ establish permission guardrails across multiple accounts -establish a data perimeter that ensures only trusted identities are granted access to change permissions, a data perimeter also ensures defense in depth and ensures you meet compliance requirements.
Supercharge your cloud career with our [weekly newsletter](https://karaniph.com/newsletter/)- join now | karaniph |
1,853,774 | SARMS and Nootropics Medicines | Passionate about optimizing both physical and mental health through biohacking, I delve into the... | 0 | 2024-05-15T10:00:39 | https://dev.to/wolf_biohacking_cd4b5b8c0/sarms-and-nootropics-medicines-4a3a | Passionate about optimizing both physical and mental health through biohacking, I delve into the realms of[ SARMS Medicines and Nootropics Medicines](https://wolfofbiohacking.com/). With a focus on enhancing overall well-being, I strive to improve mental health while advocating for holistic approaches to Mental Health and physical health, utilizing biohacking techniques for optimal results.
| wolf_biohacking_cd4b5b8c0 | |
1,853,813 | Hello88 - Link Dang Ky Hello88.network #1 Chau A Tang 88K | Hello88.network | Helo88 la mot trang web co bac online noi bat voi tinh phong phu cua danh muc tro... | 0 | 2024-05-15T10:37:45 | https://dev.to/hello88network/hello88-link-dang-ky-hello88network-1-chau-a-tang-88k-2p7i | <p><a href="https://hello88.network/">Hello88.network</a> | <a href="https://justpaste.it/Helo88">Helo88</a> la mot trang web co bac online noi bat voi tinh phong phu cua danh muc tro choi, thiet ke dep mat, chuong trinh khuyen mai da dang, dam bao an ninh cung doi ngu cham soc khach hang chuyen nghiep. Day duoc coi la lua chon hoan hao doi voi nhung ai thich trai nghiem ca cuoc.<br />Email: nguyenbaloi1973@gmail.com<br />Website: <a href="https://hello88.network/">https://hello88.network/</a><br />Dia chi: Ng. 126 P. Hao Nam, Cho Dua, Dong Da, Ha Noi, Viet Nam<br />Post Code: 11500<br />#Hello88 #Hello88com #Hello88network<br /><br />Social:<br /><a href="https://www.facebook.com/hello88n/">https://www.facebook.com/hello88n/</a><br /><a href="https://twitter.com/hello88n">https://twitter.com/hello88n</a><br /><a href="https://www.youtube.com/channel/UC0IlBXHOEB-zAqKLpFIOkrw">https://www.youtube.com/channel/UC0IlBXHOEB-zAqKLpFIOkrw</a><br /><a href="https://www.pinterest.com/hello88net/">https://www.pinterest.com/hello88net/</a><br /><a href="https://learn.microsoft.com/vi-vn/users/hello88n/">https://learn.microsoft.com/vi-vn/users/hello88n/</a><br /><a href="https://vimeo.com/hello88n">https://vimeo.com/hello88n</a><br /><a href="https://www.blogger.com/profile/00966297603842424153">https://www.blogger.com/profile/00966297603842424153</a><br /><a href="https://www.reddit.com/user/hello88n/">https://www.reddit.com/user/hello88n/</a><br /><a href="https://vi.gravatar.com/hello88n">https://vi.gravatar.com/hello88n</a><br /><a href="https://en.gravatar.com/hello88n">https://en.gravatar.com/hello88n</a><br /><a href="https://medium.com/@hello88n/about">https://medium.com/@hello88n/about</a><br /><a href="https://www.tumblr.com/hello88n">https://www.tumblr.com/hello88n</a><br /><a href="https://nguyenbaloi1973.wixsite.com/hello88n">https://nguyenbaloi1973.wixsite.com/hello88n</a><br /><a href="https://hello88n.livejournal.com/profile/">https://hello88n.livejournal.com/profile/</a><br /><a href="https://hello88n.wordpress.com/">https://hello88n.wordpress.com/</a><br /><a href="https://sites.google.com/view/hello88n/trang-ch%E1%BB%A7">https://sites.google.com/view/hello88n/trang-ch%E1%BB%A7</a><br /><a href="https://linktr.ee/hello88n">https://linktr.ee/hello88n</a><br /><a href="https://www.twitch.tv/hello88n/about">https://www.twitch.tv/hello88n/about</a><br /><a href="https://tinyurl.com/hello88n">https://tinyurl.com/hello88n</a><br /><a href="https://ok.ru/hello88n/statuses/155826039545183">https://ok.ru/hello88n/statuses/155826039545183</a><br /><a href="https://profile.hatena.ne.jp/hello88network/profile">https://profile.hatena.ne.jp/hello88network/profile</a><br /><a href="https://issuu.com/hello88network">https://issuu.com/hello88network</a><br /><a href="https://www.liveinternet.ru/users/hello88network/">https://www.liveinternet.ru/users/hello88network/</a><br /><a href="https://dribbble.com/hello88network/about">https://dribbble.com/hello88network/about</a><br /><a href="https://form.jotform.com/241352538416051">https://form.jotform.com/241352538416051</a><br /><a href="https://gitlab.com/hello88network">https://gitlab.com/hello88network</a><br /><a href="https://www.kickstarter.com/profile/134733008/about">https://www.kickstarter.com/profile/134733008/about</a><br /><a href="https://disqus.com/by/hello88network/about/">https://disqus.com/by/hello88network/about/</a><br /><a href="https://hello88---link-dang-ky-hello88-network.webflow.io/">https://hello88---link-dang-ky-hello88-network.webflow.io/</a><br /><a href="https://500px.com/p/hello88network?view=photos">https://500px.com/p/hello88network?view=photos</a><br /><a href="https://about.me/hello88network">https://about.me/hello88network</a><br /><a href="https://tawk.to/hello88network">https://tawk.to/hello88network</a><br /><a href="https://www.deviantart.com/hello88network">https://www.deviantart.com/hello88network</a><br /><a href="https://ko-fi.com/hello88network">https://ko-fi.com/hello88network</a><br /><a href="https://www.provenexpert.com/hello88network/">https://www.provenexpert.com/hello88network/</a><br /><a href="https://hub.docker.com/u/hello88network">https://hub.docker.com/u/hello88network</a></p> | hello88network | |
1,853,877 | Unlock Your Online Potential with Hocoos. | Hocoos: Redefining online presence creation. Our AI-powered platform simplifies website development,... | 0 | 2024-05-15T11:27:48 | https://dev.to/hocoos/unlock-your-online-potential-with-hocoos-385 | tutorial, ai, devops | [Hocoos](https://hocoos.com): Redefining online presence creation. Our AI-powered platform simplifies website development, empowering businesses worldwide. Seamlessly integrate features and unleash your online potential with Hocoos. | hocoos |
1,854,149 | Guided Data Access Patterns: A Deal Breaker for Data Platforms | I am now sure that the best tech stack with the best people using it is of no use to an organization... | 0 | 2024-05-15T15:17:48 | https://dev.to/zirkonium88/guided-data-access-patterns-a-deal-breaker-for-data-platforms-4po0 | aws, data, security, accessibillity | I am now sure that the best tech stack with the best people using it is of no use to an organization if it is not clear how access to data and the tech stack is. This blog post should therefore be seen as a supplement to the two previous ones, which were more technical. In the first one, I talked about a [Zero-ETL approach](https://dev.to/zirkonium88/zero-etl-with-amazon-s3-and-snowflake-via-storage-integration-powered-by-cdk-536m) for the integration of Snowflake and Amazon S3 and in the second one about the integration of [Matillion for complex data transformation](https://dev.to/zirkonium88/elt-as-compliance-enabler-running-steampipe-with-matillion-data-productivity-cloud-6o5) and data loading processes.
This blog post is more like a diary entry and addresses the two main problems that I have experienced. However, there are also possible solutions that I will talk about.
## No Use Case, No KPIs, No Success
Every use case is about a goal. Yeah right. I would always prioritize the Use case. Simply integrating systems does not help any organization. Even more clearly, a cloud environment just costs money and has no benefit if you don't start from the use case. So, ask yourself, what is your use case or what is your requester's use case.
This doesn't just help with the implementation of a project. It also helps you in the evaluation when it comes to project completion. Therefore: no use case, no KPI, no success assessment.
Even worse: If you only think about the system, you may end up in a data swamp and do not create a logical and meaningful storage system for the synergies that you want to create for later new use cases. And I'm sure you want that. But one after another.
## The Issues: Organizational and Technical Ones
If we have a use case, various questions may arise. These can be: Who gives me access to the data? What does the data look like? Do these need to be prepared further so that I can use them for my use case? Is there perhaps already some preparatory work that I can build on? And there are a many more.
Technical questions also arise, especially if you need to deal compliance requirements. How do the data have to be encrypted? How do I get test data with which I can do staging? Which fields contain PII-relevant data? How do these have to be treated technically? We do we integrate networks? And these are just a few examples.
## Addressing the Issues
So how can we deal with the questions productively? We design clear access patterns to our data platform. These access patterns address precisely the organizational and technical problems.
What do I mean by access pattern? In principle this means a sequence of well-defined steps. The sequence of steps has different participants. In addition to those involved, the access patterns clearly state who must do what. And finally, we need technical requirements that are operationalized with maximum precision. Finally, the documentation needs to be expanded to complete the project. This is the only way to create synergies. Any by that, documentation is useful for new use cases and for data governance requirements.
Let’s continue with a technical sub-component of a prototypical data platform and suggest for a system that addresses both our governance and synergy requirements. But first let's start with a process definition.
### The Predefined Process
Our use case should be implemented on the data platform. Our organization has already defined a process for new data products. Every box in the figure is well defined in terms of who is in charge for what. We are very lucky in this case. This is probably not always the case.
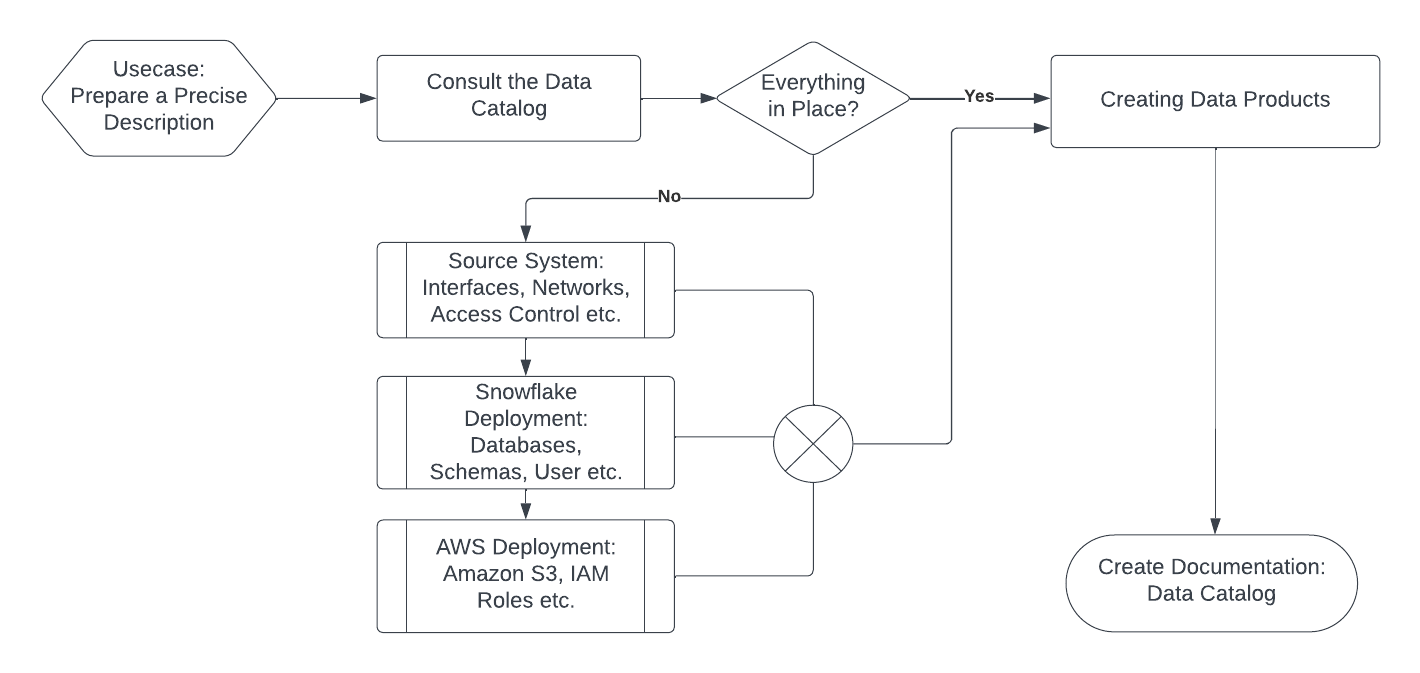
The question shows how we start: a description of the exact requirements must be read by the requester. With this he can consult the existing data catalog. For this to happen successfully, the data catalog must contain not only technical information, but also semantic information. What does that mean? Technical information consists of the source and the data that can be taken from a source. This includes, for example, column names or attributes (such as tags) that are read from AWS. However, not only the AWS databases or S3 buckets should be part of the information set, but also the tables and structures that can be found in the data platform in the data warehouse or at their locations. In summary, the data catalog should be able to technically represent all data artifacts.
That helps, but it's not everything. Because now we still lack information. Which fields are PII relevant? Who is the technical and who is the professional contact for data? What is this data used for? Which existing data products are you used for? Questions of this type of aim at semantic information.
From a governance perspective, the data catalog should show which versions of a data route already existed and how it has changed over time. It is also important to see which fields are specifically being transferred or transformed and how.
In summary: The data catalog enables a holistic view of all data artifacts and their use in an organization. Without these system components, requesters cannot decide whether a source system is already connected or whether this connection needs to be expanded. If our requester is lucky, the required sources are already available, and he can start directly with data product development. This must inevitably end with documentation in the data catalog. If he is unlucky, the source system first must be integrated. And this may mean a long journey that can last for months without proper process descriptions and technical blueprints.
### The Technical Description of Sub-Components: Make Your GRCS-Team and Yourself happy
To show an example of what I mean by technical operationalization or blueprint, let's also look at a AWS service: Amazon S3. Widely used and still often not sufficiently configured. However, we managed to agree on the following technical blueprint with our Group Governance, Risk, Security and Compliance group.
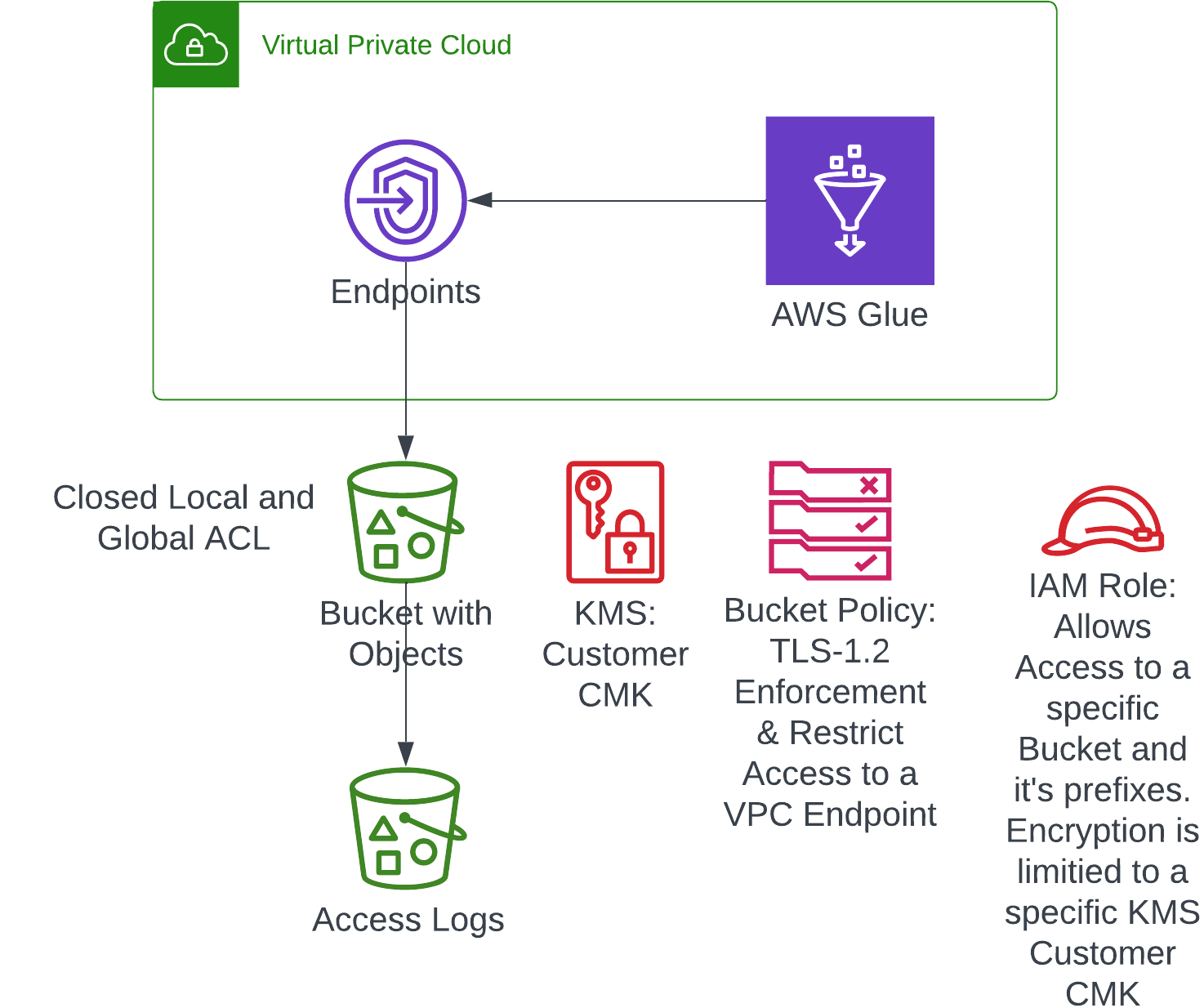
Each bucket is accessed exclusively, and here in the example of Glue, from a VPC via a VPC endpoint. The local access control list contains no entries and blocks new ones. The same applies for the global access control list Amazon S3. In addition, every access is recorded via access logging. This process is defined via the configuration of a bucket policy. The same also enforces that you can only speak to the Bucket via TLS 1.2 or higher. The Bucket also has a dedicated KMS Customer Managed Key, which is rotated annually once a year. Finally, the consuming resource requires a role that is only allowed to read and write to this bucket and its key.
This shall be only an example. Please look at all AWS best practices for organization wide configuration. But if we have such a description, we can carry out the deployment with the help of a requirements specification and can use this accordingly in the audit. This also makes it possible to repeatedly keep up with AWS steps by taking new measures and removing old ones if necessary. Regardless of this, individual cases are not discussed because these blueprints have global validity. And of course, this process must be carried out for all sub-components of the data platform.
### The Data Catalog: Data Hub Project
If you are new to the data catalog field, you can quickly find AWS Glue on the AWS platform. Unfortunately, AWS Glue does not offer a semantic data catalog and you must allow the user in the AWS GUI, which will be difficult to understand, especially for business users.
There are several commercial providers, but I would definitely recommend [Data Hub Project](https://datahubproject.io/). DataHub Project is an open-source metadata platform that serves as an extensible data catalog and supports data discovery, data observability, and federated governance to address the complexity of the data ecosystem. The data catalog enables the combination of technical, operational and business metadata to provide a 360-degree view of data entities. DataHub makes it possible to pre-enrich important metadata using shift-left practices and respond to changes in real time.
The deployment guide uses Kubernetes by default, but the cluster can also be hosted in AWS with many managed services and in the Elastic Container Service.
The Data Hub Project loading page can be secured via SSO and is responsive. A search helps to find data artifacts and find metadata about them.
Each asset has a detailed view, which is shown here in excerpts. In addition to the table definition, the most common table queries are displayed, for example, as are the individual data fields with tags and example values.
The lineage view then shows how the data artifacts depend on each other and which fields are used. In the example, the product starts in S3 and ends in PowerBI via Snowflake. All this information is imported into the catalog system via [ingestion](https://datahubproject.io/docs/metadata-ingestion/source_overview). There are quite a few of them.
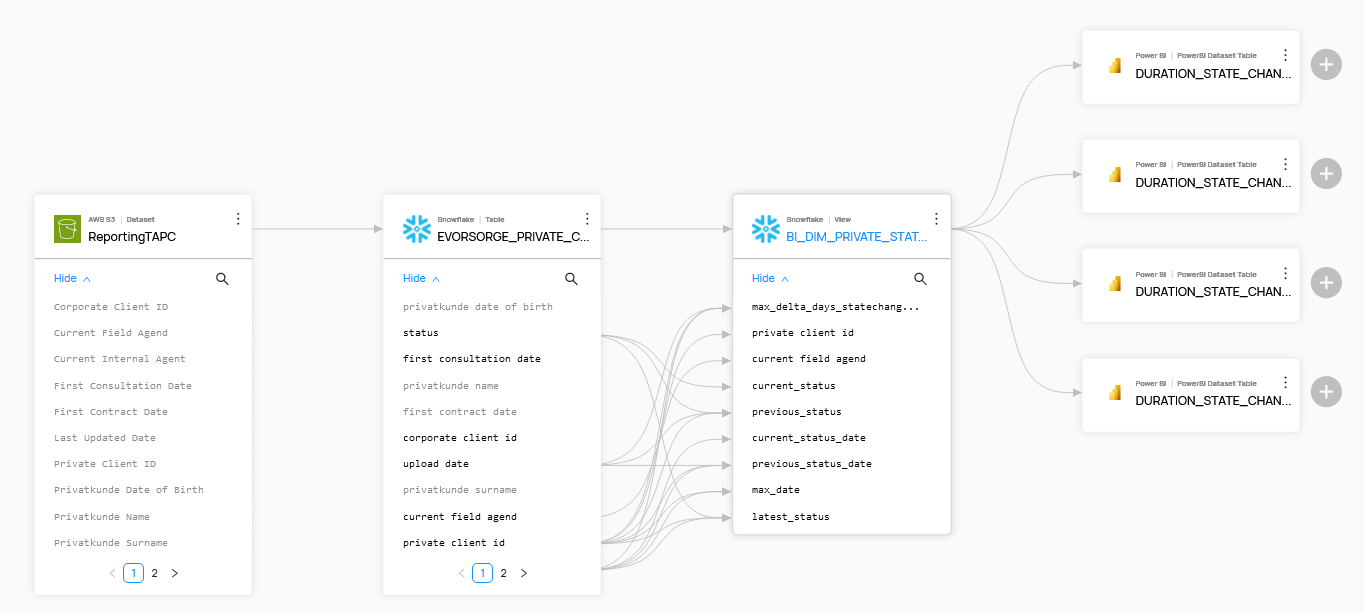
The only thing the system can't do (yet) and I'm missing is an alert about updates through Ingestions. For example, far too few new values have arrived through integration, or the values differ significantly from previous values.
## Final thoughts
I tried to show what is necessary to create access patterns to a data platform as simply as possible. I am convinced that in addition to a good technical foundation and an up-to-date description of the data platform, its capabilities and possibilities, a good platform team is also necessary to work in a customer-oriented manner. This is the only way to transform the people and your organization to act in a data-driven way.
| zirkonium88 |
1,854,680 | Fortify Your Furniture: The Importance of High-Quality Door Locks | Fortify Your Furniture: The Importance of High-Quality Door Locks Do you desire to always keep your... | 0 | 2024-05-16T02:36:08 | https://dev.to/three_four_a23b72b33a6085/fortify-your-furniture-the-importance-of-high-quality-door-locks-1d35 | key | Fortify Your Furniture: The Importance of High-Quality Door Locks
Do you desire to always keep your house risk-free as well as protect? Are you stressed over burglars going into your home with your doors? If so, you have to fortify your furnishings by setting up high-quality door locks. Here is why:
Benefits of High-Quality Door Locks
High-quality door locks deal with several benefits. They are much a lot extra resilient as well as dependable compared to inexpensive locks, which implies they will not break or even malfunction as frequently. They are likewise harder to choose or even break, therefore burglars are actually much less likely to manage to bypass them. You can easily likewise obtain locks that are actually keyed as well, which implies you just require one key to open all of the doors in your home.
Innovation in Door Locks
Door locks have actually happened a very long way over the years. There zinc alloy hotel key card lock hotel door lock are currently locks that could be opened up along with a code, a fingerprint, and even a mobile phone application. These locks deal with much more security as well as benefits compared to conventional locks. You can easily likewise obtain locks that are actually linked to house security systems, which can easily notify you if somebody attempts to break in.
Safety First along with Door Locks
One of the essential needs to set up high-quality door locks is for safety. If somebody attempts to break right into your house, a durable lock can easily provide you with valuable opportunities towards require help or even run away. It can easily also prevent somebody from entering your house while you are there, which could be frightening.
Utilizing Door Locks Properly
To utilize a door lock properly, you first have to ensure it is set up correctly. If it is certainly not, it will not deal with the security you need. You likewise have to ensure you are using the appropriate kind of lock for your door. Some locks are wardrobes developed for outside doors, while others are actually for indoor doors.
When you lock your door, ensure you transform the essential of the method in which the wardrobe door hinges deadbolt is actually involved. This will certainly make it harder for somebody to available the door along with pressure. You ought to likewise ensure your home windows as well as various other entrance factors are actually protected.
A solution in Door Locks
If you are uncertain about which kind of lock to select or even ways to set up it, you can easily employ a locksmith professional to assist you. They can easily suggest the finest locks for your requirements as well as budget plans, as well as can easily set up all of them for you. They can easily likewise repair work or even change locks that are actually harmed or even worn.
High top premium and Request
It is essential to select high-quality door locks that are actually developed for your particular requirements. For instance, if you reside in a location with higher criminal offense prices, you might require locks that are much a lot extra durable compared to if you reside in a low-crime
location. You ought to likewise select locks that are user-friendly and suit the design of your house.
| three_four_a23b72b33a6085 |
1,854,907 | EX280 Exam Dumps | How to Optimize Your EX280 Preparation with Exam Dumps Preparing for the Red Hat Certified... | 0 | 2024-05-16T06:47:00 | https://dev.to/squen_b13b62b5377a36a3d53/ex280-exam-dumps-48p1 | How to Optimize Your EX280 Preparation with Exam Dumps
Preparing for the Red Hat Certified Specialist in OpenShift Administration (EX280) exam can be optimized with the strategic use of exam dumps. Here's how you EX280 Exam Dumps can maximize your preparation using exam dumps:
1. Understand Exam Objectives:
Familiarize yourself with the EX280 exam objectives outlined by Red Hat. This will help you prioritize your study efforts and focus on the key areas tested in the exam.
2. Choose Reliable Exam Dumps:
Select exam dumps from trusted sources known for their accuracy and relevance to the EX280 exam. Ensure that the dumps cover all exam topics comprehensively and are regularly updated.
3. Develop a Study Plan:
Create a structured study plan that incorporates the use of exam dumps. Allocate specific time slots in your schedule for studying with the dumps and stick to your plan consistently.
CLICK HERE FOR MORE INFO>>>>>>>>>>>>>>> https://dumpsarena.com/redhat-dumps/ex280/
| squen_b13b62b5377a36a3d53 | |
1,855,024 | The Power Of Array.reduce()🐐 | Hai, teman-teman developer! 👋 Pernah merasa bingung dengan bagaimana cara mengolah data di dalam... | 0 | 2024-05-21T04:15:48 | https://dev.to/mteguhirawan1996/the-power-of-arrayreduce-eb9 | javascript, webdev, beginners | Hai, teman-teman developer! 👋
Pernah merasa bingung dengan bagaimana cara mengolah data di dalam array secara efisien? Nah, kali ini kita akan bahas salah satu metode JavaScript yang super keren dan sangat berguna: array.reduce! Metode ini bisa dibilang adalah pisau serbaguna dalam dunia pemrograman, karena memungkinkan kita untuk melakukan berbagai operasi kompleks dengan cara yang sederhana dan elegan.
Bayangkan kamu punya sekumpulan data dan ingin menghitung totalnya, mencari nilai maksimum, atau bahkan mengubah bentuk data menjadi struktur yang berbeda. Semua itu bisa kamu lakukan dengan reduce! Jadi, siap-siap untuk memperkaya toolkit coding kamu dengan pengetahuan baru ini. Yuk, kita mulai petualangan kita dengan memahami array.reduce dan melihat berbagai cara keren untuk menggunakannya! 🚀
8 Cara Keren Menggunakan `Array.reduce()` 🐐:
## Contoh Kasus 1: Menjumlahkan Angka
Salah satu penggunaan `reduce()` yang paling sederhana adalah untuk menjumlahkan sejumlah angka. Misalnya, kamu punya array berisi angka-angka dan ingin menemukan total jumlahnya.
```tsx
const numbers: number[] = [1, 2, 3, 4, 5];
const sum: number = numbers.reduce((acc, curr) => acc + curr, 0);
console.log(sum); // Output: 15
```
Boom!💣 Dengan hanya satu baris kode, kamu sudah menghitung jumlah semua elemen dalam array. Nilai awal accumulator (penyimpan sementara) kita set ke 0, dan di setiap iterasi, kita tambahkan elemen saat ini ke accumulator.
Bonus: Kalau kamu memilih untuk tidak menyertakan nilai awal, reduce akan menggunakan elemen pertama dalam array sebagai nilai awal. Tapi, biasanya saya selalu menyertakan nilai awal agar lebih mudah dibaca.
## Contoh Kasus 2: Meratakan Array
Pernahkah kamu mendapati dirimu memiliki array dari array dan berpikir, "Saya ingin meratakan ini menjadi satu array saja"?
```tsx
const nestedArray = [[1, 2], [3, 4], [5, 6]];
const flattenedArray = nestedArray.reduce((acc, curr) => acc.concat(curr), []);
console.log(flattenedArray); // Output: [1, 2, 3, 4, 5, 6]
```
Pada contoh ini, kita mulai dengan array kosong sebagai nilai awal accumulator. Kemudian, di setiap iterasi, kita menggabungkan sub-array saat ini ke accumulator menggunakan metode `concat()`. Pada akhirnya, kita memiliki array yang sudah rata sempurna.
saya tahu bahwa kamu juga bisa melakukan ini dengan `Array.flat()`. Namun, penting untuk tahu cara menggunakan reduce, jika kamu ingin melakukan operasi tambahan pada setiap item.
## Contoh Kasus 3: Mengelompokkan Objek
Bayangkan kamu memiliki array dari objek-objek, dan kamu ingin mengelompokkannya berdasarkan properti tertentu. `reduce()` adalah alat yang sempurna untuk pekerjaan ini.
```tsx
interface Person {
name: string;
age: number;
}
const people: Person[] = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 30 },
{ name: 'Charlie', age: 25 },
{ name: 'Dave', age: 30 }
];
const groupedByAge: { [key: number]: Person[] } = people.reduce((acc, curr) => {
if (!acc[curr.age]) {
acc[curr.age] = [];
}
acc[curr.age].push(curr);
return acc;
}, {});
console.log(groupedByAge);
/*
Output:
{
'25': [{ name: 'Alice', age: 25 }, { name: 'Charlie', age: 25 }],
'30': [{ name: 'Bob', age: 30 }, { name: 'Dave', age: 30 }]
}
*/
```
Pada kasus ini, kita menggunakan objek sebagai nilai awal accumulator. Kita periksa apakah accumulator sudah memiliki properti untuk usia saat ini. Jika tidak, kita membuat array kosong untuk usia tersebut. Kemudian, kita memasukkan objek saat ini ke dalam array usia yang sesuai. Pada akhirnya, kita memiliki objek di mana kunci-kunci adalah usia, dan nilainya adalah array dari orang-orang dengan usia tersebut.
Sekarang kamu juga bisa mempelajari metode `groupBy` yang lebih baru. Namun, klasik ini yang sudah teruji dan terbukti penting untuk dipahami.
## Contoh Kasus 4: Membuat Lookup Maps
Salah satu favorit saya adalah menggunakan `reduce()` untuk membuat peta lookup dari array. Ini benar-benar meningkatkan performa dan keterbacaan kode. Tak perlu lagi menggunakan `find()` atau `filter()` yang lambat.
```tsx
interface Product {
id: number;
name: string;
price: number;
}
const products: Product[] = [
{ id: 1, name: 'Laptop', price: 999 },
{ id: 2, name: 'Phone', price: 699 },
{ id: 3, name: 'Tablet', price: 499 },
];
const productMap: { [key: number]: Product } = products.reduce((acc, curr) => {
acc[curr.id] = curr;
return acc;
}, {});
console.log(productMap);
/*
Output:
{
'1': { id: 1, name: 'Laptop', price: 999 },
'2': { id: 2, name: 'Phone', price: 699 },
'3': { id: 3, name: 'Tablet', price: 499 }
}
*/
// Accessing a product by ID
const laptop: Product = productMap[1];
console.log(laptop); // Output: { id: 1, name: 'Laptop', price: 999 }
```
Dengan menggunakan `reduce()` untuk membuat peta lookup, kamu bisa mengakses elemen berdasarkan identifier uniknya dengan kompleksitas waktu konstan. Tidak perlu lagi berulang kali melintasi array untuk menemukan item tertentu.
## Contoh Kasus 5: Menghitung Kemunculan Elemen
Oke untuk use case yang ke 5, teman teman pasti pernah butuh menghitung seberapa sering elemen muncul di dalam array? Tenang, `reduce()` bisa diandalkan untuk urusan ini.
```tsx
const fruits: string[] = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple'];
const fruitCounts: { [key: string]: number } = fruits.reduce((acc, curr) => {
acc[curr] = (acc[curr] || 0) + 1;
return acc;
}, {});
console.log(fruitCounts);
/*
Output:
{
'apple': 3,
'banana': 2,
'orange': 1
}
*/
```
Pada contoh ini, kita memulai dengan objek kosong sebagai accumulator. Untuk setiap buah dalam array, kita periksa apakah buah tersebut sudah ada sebagai properti di objek accumulator. Jika sudah, kita tambahkan jumlahnya dengan 1; jika belum, kita inisialisasi dengan 1. Hasil akhirnya adalah sebuah objek yang memberi tahu kita berapa kali setiap buah muncul dalam array.
## Contoh Kasus 6: Menyusun Fungsi
Buat kamu yang suka pemrograman fungsional, ini pasti menarik! `reduce()` adalah alat ampuh untuk menyusun fungsi. Kamu bisa bikin rangkaian fungsi yang mengubah data langkah demi langkah dengan mudah.
```tsx
const add5 = (x: number): number => x + 5;
const multiply3 = (x: number): number => x * 3;
const subtract2 = (x: number): number => x - 2;
const composedFunctions: ((x: number) => number)[] = [add5, multiply3, subtract2];
const result: number = composedFunctions.reduce((acc, curr) => curr(acc), 10);
console.log(result); // Output: 43
```
Dalam contoh ini, kita punya array berisi fungsi-fungsi yang ingin kita terapkan secara berurutan pada nilai awal 10. Kita menggunakan `reduce()` untuk mengiterasi fungsi-fungsi tersebut, dan setiap hasil dari fungsi sebelumnya menjadi input untuk fungsi berikutnya. Hasil akhirnya adalah output dari semua fungsi yang diterapkan secara berurutan.
## Contoh Kasus 7: Menghasilkan Nilai Unik
Kadang-kadang, kamu mungkin punya array dengan nilai-nilai yang duplikat, dan kamu perlu mengekstrak hanya yang unik. `reduce()` bisa membantu kamu melakukannya dengan mudah.
```tsx
const numbers: number[] = [1, 2, 3, 2, 4, 3, 5, 1, 6];
const uniqueNumbers: number[] = numbers.reduce((acc, curr) => {
if (!acc.includes(curr)) {
acc.push(curr);
}
return acc;
}, []);
console.log(uniqueNumbers); // Output: [1, 2, 3, 4, 5, 6]
```
Di sini, kita memulai dengan array kosong sebagai accumulator. Untuk setiap angka dalam array asli, kita periksa apakah angka tersebut sudah ada di accumulator menggunakan metode `includes()`. Jika belum ada, kita tambahkan ke dalam array accumulator. Hasil akhirnya adalah array yang hanya berisi nilai-nilai unik dari array asli.
## Use Case 8: Calculating Average
And the last one mau menghitung rata-rata dari sekumpulan angka? Tenang, `reduce()` bisa diandalkan!
```tsx
const grades: number[] = [85, 90, 92, 88, 95];
const average: number = grades.reduce((acc, curr, index, array) => {
acc += curr;
if (index === array.length - 1) {
return acc / array.length;
}
return acc;
}, 0);
console.log(average); // Output: 90
```
Pada contoh ini, kita memulai accumulator dengan nilai 0. Kita iterasi setiap nilai dan menambahkannya ke accumulator. Saat mencapai elemen terakhir (diperiksa menggunakan indeks dan array.length), kita bagi nilai accumulator dengan jumlah total nilai untuk menghitung rata-ratanya.
## Pertimbangan Kinerja 🏎️
Meskipun `Array.reduce()` sangat kuat dan serbaguna, penting untuk menyadari kemungkinan keterbatasan kinerja, terutama saat berurusan dengan array besar atau operasi yang kompleks. Salah satu jebakan umum adalah membuat objek atau array baru di setiap iterasi `reduce()`, yang dapat menyebabkan alokasi memori berlebihan dan memengaruhi kinerja.
Sebagai contoh, pertimbangkan kode berikut:
```tsx
const numbers: number[] = [1, 2, 3, 4, 5];
const doubledNumbers: number[] = numbers.reduce((acc, curr) => {
return [...acc, curr * 2];
}, []);
console.log(doubledNumbers); // Output: [2, 4, 6, 8, 10]
```
Dalam kasus ini, kita menggunakan operator spread (...) untuk membuat array baru di setiap iterasi, yang bisa menjadi tidak efisien. Sebagai gantinya, kita bisa mengoptimalkan kode dengan memutasi array accumulator secara langsung:
```tsx
const numbers: number[] = [1, 2, 3, 4, 5];
const doubledNumbers: number[] = numbers.reduce((acc, curr) => {
acc.push(curr * 2);
return acc;
}, []);
console.log(doubledNumbers); // Output: [2, 4, 6, 8, 10]
```
Dengan memutasi array accumulator menggunakan `push()`, kita menghindari pembuatan array baru di setiap iterasi, yang menghasilkan kinerja yang lebih baik.
Demikian pula, saat bekerja dengan objek, lebih efisien untuk memutasi objek accumulator secara langsung daripada membuat objek baru dengan operator spread:
```tsx
const people: Person[] = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 30 },
{ name: 'Charlie', age: 25 },
{ name: 'Dave', age: 30 }
];
const groupedByAge: { [key: number]: Person[] } = people.reduce((acc, curr) => {
if (!acc[curr.age]) {
acc[curr.age] = [];
}
acc[curr.age].push(curr);
return acc;
}, {});
```
Dengan memutasi objek accumulator secara langsung, kita mengoptimalkan kinerja operasi `reduce()`.
Namun, perlu dicatat bahwa dalam beberapa kasus, pembuatan objek atau array baru di setiap iterasi mungkin diperlukan atau lebih mudah dibaca. Penting untuk menemukan keseimbangan antara kinerja dan kejelasan kode berdasarkan kasus penggunaan spesifik Anda dan ukuran data yang sedang Anda kerjakan.
## Kesimpulan
Nah, itulah delapan contoh penggunaan yang luar biasa yang menunjukkan kekuatan dan fleksibilitas dari `Array.reduce()`. Mulai dari menjumlahkan angka hingga meratakan array, mengelompokkan objek hingga membuat peta lookup, menghitung kemunculan hingga menyusun fungsi, dan menghitung rata-rata, `Array.reduce()` terbukti menjadi alat yang kuat dalam toolkit JavaScript kamu.
Bagaimana menurutmu? Metode array favoritmu apa, dan mengapa?
Terima kasih sudah membaca, dan sampai jumpa pada postingan selanjutnya, Stay tuned, guys!. ✨🐐✨
| mteguhirawan1996 |
1,855,190 | What are the key considerations when installing roof curbs? | Roof curbs play a crucial role in the stability and functionality of roofing systems across various... | 0 | 2024-05-16T10:39:53 | https://dev.to/aoliverjames/what-are-the-key-considerations-when-installing-roof-curbs-91h | [Roof curbs](https://www.domer.co/skydome/) play a crucial role in the stability and functionality of roofing systems across various structures, from commercial buildings to residential homes. However, their installation requires careful planning, attention to detail, and adherence to industry standards to ensure optimal performance and longevity. In this comprehensive guide, we delve into the key considerations that must be taken into account when installing roof curbs to guarantee durability, efficiency, and safety.
Structural Integrity:
One of the primary considerations when installing [GRP Roofing](https://www.domer.co/applications/chemical-resistant-grp/) is ensuring structural integrity. The curb must be securely attached to the roof deck, providing a stable foundation for rooftop equipment such as HVAC units, exhaust fans, or skylights. Proper attachment methods, such as welding or bolting, should be employed to withstand wind loads, seismic activity, and other environmental factors.
Weather Resistance:
Roof curbs are exposed to various weather conditions, including rain, snow, hail, and UV radiation. Therefore, selecting materials with high weather resistance is essential to prevent corrosion, deterioration, and water infiltration. Materials like galvanized steel, aluminum, or PVC-coated metal are commonly used for their durability and ability to withstand harsh climates.
Compatibility:
When installing roof curbs, it's crucial to ensure compatibility with the roofing system and any rooftop equipment being mounted. The curb dimensions, height, and slope must align with the roof's design to maintain proper drainage and prevent ponding water. Additionally, the curb should be designed to accommodate the specific equipment being installed, considering factors such as weight distribution and clearance requirements.
Sealing and Insulation:
Proper sealing and insulation around the roof curb are essential for energy efficiency and preventing air and water leaks. Sealants, gaskets, and flashing should be applied meticulously to create a watertight barrier and minimize heat loss or gain. Insulation around the curb can also help improve thermal performance and reduce energy consumption.
Code Compliance and Safety:
Compliance with building codes and safety regulations is paramount during roof curb installation. Contractors must be familiar with local codes governing roof design, construction, and equipment installation to ensure adherence to standards and avoid potential liabilities. Additionally, safety measures such as fall protection systems and proper signage should be implemented to protect workers during installation and maintenance activities.
Quality Assurance:
Quality assurance measures should be implemented throughout the installation process to guarantee the integrity and longevity of the roof curb. This includes thorough inspections of materials, workmanship, and adherence to design specifications. Regular maintenance and periodic inspections can also help identify potential issues early on and prevent costly repairs or replacements in the future.
Professional Expertise:
Lastly, hiring experienced professionals for roof curb installation is essential to ensure quality workmanship and minimize risks. Qualified contractors or roofing specialists with expertise in curb installation can provide valuable insights, recommendations, and troubleshooting solutions tailored to specific project requirements.
Roof Penetrations:
Roof curbs often involve penetrations through the roofing membrane, which can compromise its integrity if not properly sealed. It's essential to use compatible flashing materials and sealants to create a watertight seal around penetrations, preventing leaks and water damage. Moreover, coordinating with roofing contractors to ensure seamless integration of the curb with the roofing system can help maintain the roof's overall performance and aesthetics.
Environmental Impact:
Sustainable building practices are becoming increasingly important in construction projects. When selecting materials for roof curbs, consider their environmental impact, including factors such as recyclability, energy efficiency, and embodied carbon. Opting for eco-friendly materials and manufacturing processes can contribute to reducing the building's carbon footprint and promoting environmental stewardship.
Accessibility and Maintenance:
Accessibility for maintenance and servicing of rooftop equipment should be taken into account during curb installation. Providing adequate clearance around the curb and ensuring safe access for maintenance personnel can facilitate routine inspections, repairs, and equipment replacement. Incorporating features such as access doors or removable panels can simplify maintenance tasks and prolong the lifespan of rooftop installations.
Aesthetics and Architectural Integration:
While functionality is paramount in roof curb design, aesthetic considerations should not be overlooked, especially in architectural projects where rooftop visibility is a factor. Roof curbs can be customized to complement the building's design aesthetic, whether through color coordination, material finishes, or concealed mounting methods. Integrating curbs seamlessly into the overall architectural concept enhances the building's visual appeal without compromising functionality.
Budget and Cost Considerations:
Budget constraints often influence material selection and construction methods in building projects. When planning roof curb installation, it's essential to balance cost considerations with quality and performance requirements. Conducting cost-benefit analyses, obtaining competitive bids from reputable suppliers and contractors, and exploring alternative design options can help optimize project costs without sacrificing long-term durability or functionality.
Future Expansion and Flexibility:
Anticipating future needs and potential changes to rooftop equipment configurations is crucial in roof curb design. Incorporating flexibility and scalability into the installation can accommodate future expansion or upgrades without requiring extensive modifications or replacements. Modular curb systems, adjustable mounting brackets, and provisions for additional penetrations can facilitate future modifications while minimizing disruption and cost.
Documentation and Record-Keeping:
Maintaining accurate documentation of roof curb installation, including design drawings, product specifications, installation instructions, and warranty information, is essential for future reference and warranty claims. Documentation should be organized and accessible to building owners, facility managers, and maintenance personnel to facilitate ongoing maintenance, repairs, and renovations throughout the building's lifecycle.
In conclusion, installing roof curbs requires careful consideration of various factors, including structural integrity, weather resistance, compatibility, sealing, code compliance, quality assurance, and professional expertise. By prioritizing these key considerations, property owners and contractors can achieve durable, efficient, and safe roofing systems that withstand the test of time.
| aoliverjames | |
1,855,196 | reCAPTCHA OCR : Solving Captcha With OCR Solver | Introduction In the realm of web scraping, encountering CAPTCHA challenges can be a formidable... | 0 | 2024-05-16T10:52:30 | https://dev.to/media_tech/recaptcha-ocr-solving-captcha-with-ocr-solver-1bf9 | **Introduction**
In the realm of web scraping, encountering CAPTCHA challenges can be a formidable hurdle, disrupting the seamless extraction of valuable data. However, with the advent of reCAPTCHA OCR (Optical Character Recognition), a groundbreaking solution has emerged, empowering web scrapers to conquer CAPTCHA obstacles with unprecedented ease and efficiency. In this definitive guide, we delve into the intricacies of reCAPTCHA OCR, unveiling its capabilities and providing insights into harnessing its power to streamline your web scraping endeavors.
**Understanding reCAPTCHA OCR**
reCAPTCHA OCR represents a groundbreaking advancement in CAPTCHA-solving technology, leveraging sophisticated algorithms and machine learning models to decipher complex visual puzzles with remarkable accuracy. Unlike traditional CAPTCHA solvers that rely on manual intervention or pre-trained datasets, reCAPTCHA OCR harnesses the power of Optical Character Recognition to analyze and interpret CAPTCHA images automatically.
**How reCAPTCHA OCR Works**
The underlying mechanism of reCAPTCHA OCR revolves around the process of image recognition and text extraction. When confronted with a CAPTCHA challenge, the reCAPTCHA OCR system employs advanced image processing techniques to isolate and segment individual characters within the image. Subsequently, Optical Character Recognition algorithms analyze these characters, converting them into machine-readable text with a high degree of precision.
**Advantages of reCAPTCHA OCR**
The adoption of reCAPTCHA OCR confers numerous advantages for web scrapers seeking to overcome CAPTCHA challenges effectively:
**1. Automated CAPTCHA Resolution**
reCAPTCHA OCR automates the process of CAPTCHA resolution, eliminating the need for manual intervention or human verification. By leveraging cutting-edge OCR technology, reCAPTCHA OCR swiftly deciphers complex CAPTCHA puzzles, enabling uninterrupted data extraction.
**2. Enhanced Accuracy**
With its advanced image processing capabilities and machine learning algorithms, reCAPTCHA OCR boasts unparalleled accuracy in deciphering CAPTCHA images. Whether faced with distorted text, obfuscated characters, or intricate visual puzzles, reCAPTCHA OCR consistently delivers precise results.
**3. Adaptability to Diverse CAPTCHA Types**
Unlike traditional CAPTCHA solvers that may struggle with novel or evolving CAPTCHA formats, reCAPTCHA OCR demonstrates remarkable adaptability to diverse types of CAPTCHA challenges. Whether it's text-based CAPTCHAs, image-based puzzles, or audio challenges, reCAPTCHA OCR excels in deciphering a wide range of CAPTCHA formats.
**4. Seamless Integration**
reCAPTCHA OCR solutions are designed for seamless integration into existing web scraping workflows. With user-friendly APIs and software libraries, incorporating reCAPTCHA OCR into your scraping applications is straightforward, requiring minimal development effort.
**Implementing reCAPTCHA OCR in Web Scraping**
Integrating reCAPTCHA OCR into your web scraping toolkit is a straightforward process, facilitated by the availability of robust OCR libraries and APIs. Here's a step-by-step guide to implementing reCAPTCHA OCR effectively:
**Selecting an OCR Library:** Choose a reputable OCR library or API that offers support for reCAPTCHA solving. Popular options include Tesseract OCR, Google Cloud Vision API, and Microsoft Azure Computer Vision.
**Preprocessing CAPTCHA Images:** Before applying OCR, preprocess CAPTCHA images to enhance clarity and readability. Techniques such as image denoising, contrast enhancement, and edge detection can improve OCR accuracy.
**Applying OCR:** Utilize the selected OCR library to extract text from CAPTCHA images. Configure the OCR settings to optimize performance for CAPTCHA-solving tasks, such as adjusting language models and character recognition parameters.
**Error Handling and Verification:** Implement robust error handling mechanisms to address OCR inaccuracies and ensure the integrity of extracted text. Incorporate verification checks to validate OCR results and mitigate false positives or negatives.
**Continuous Improvement:** Iterate on your OCR implementation by fine-tuning parameters, incorporating feedback, and updating OCR models to enhance accuracy and reliability over time.
**Conclusion**
In the realm of web scraping, overcoming CAPTCHA challenges is essential for accessing and extracting valuable data from websites. With the advent of reCAPTCHA OCR, web scrapers now have a powerful ally in their quest to conquer CAPTCHA obstacles with unparalleled efficiency and accuracy. By harnessing the capabilities of reCAPTCHA OCR and integrating it into your scraping workflows, you can unlock a wealth of data-driven insights and empower your decision-making processes like never before.
**CaptchaAI is the first OCR solver designed to excel in both reCaptcha solving service and image Captcha solving. With its remarkable speed and accuracy, it stands out in the field, consistently solving image captchas in just 1 second, though occasionally taking more time. Its minimal error rate ensures a reliable and efficient captcha-solving experience. CaptchaAI's custom image modules further enhance its performance, optimizing the captcha-solving process to make it even faster. For more information on these custom image modules and how they contribute to CaptchaAI's efficiency, you can visit CaptchaAI Custom Image Modules.**
| media_tech | |
1,855,202 | Streamlining Business Efficiency: The Importance of IT Support and Maintenance Services | Streamlining business efficiency is a crucial aspect of modern enterprises, and one of the key... | 0 | 2024-05-16T11:05:15 | https://dev.to/kimmipal/streamlining-business-efficiency-the-importance-of-it-support-and-maintenance-services-101k | Streamlining business efficiency is a crucial aspect of modern enterprises, and one of the key components contributing to this efficiency is robust IT support and maintenance services. This article delves into the significance of IT support and maintenance, focusing specifically on [CCTV camera support](https://cybernautme.com/cctv-support/) and business WiFi solutions.
**Importance of IT Support Services**
Enhancing Operational Continuity
Reliable IT support services ensure the seamless functioning of critical business operations. This includes troubleshooting technical issues promptly, preventing system downtime, and minimizing disruptions to workflow.
**Ensuring Data Security**
IT support services play a vital role in safeguarding sensitive business data. From implementing robust cybersecurity measures to regularly updating software and systems, these services mitigate the risks of cyber threats and data breaches.
Supporting Remote Workforce
In today's digital landscape, a growing number of businesses rely on remote work setups. IT support services facilitate this transition by providing remote access solutions, ensuring connectivity, and supporting virtual collaboration tools.
CCTV Camera Support: Enhancing Security Measures
Real-Time Monitoring
CCTV camera support enables real-time monitoring of business premises, helping deter unauthorized access, theft, and vandalism. This proactive approach to security enhances overall safety and reduces potential risks.
**Incident Investigation**
In the event of security incidents or breaches, CCTV footage serves as crucial evidence for investigation and resolution. Proper maintenance and support ensure the reliability and accessibility of this footage when needed.
**Integration with IT Infrastructure
**Integrating CCTV systems with existing IT infrastructure allows for centralized management and monitoring. IT support services facilitate this integration, optimizing security protocols and ensuring system compatibility.
Business WiFi Solutions: Enabling Connectivity and Productivity
Reliable Wireless Networks
Business WiFi solutions provide reliable connectivity throughout the premises, supporting a wide range of devices and applications. This reliability is essential for uninterrupted business operations and seamless customer interactions.
**Scalability and Flexibility**
Scalable WiFi solutions adapt to the evolving needs of businesses, accommodating increased user demands and expanding coverage areas. IT support services play a crucial role in designing, implementing, and maintaining these scalable networks.
**Guest Access Management**
Business WiFi solutions often include guest access features, allowing controlled and secure connectivity for visitors and clients. IT support services configure and manage these access points to ensure network security and compliance.
The Role of IT Support and Maintenance Providers
**Proactive Monitoring and Maintenance**
IT support and maintenance providers offer proactive monitoring of IT infrastructure, identifying potential issues before they escalate. Regular maintenance tasks, such as software updates and system optimization, enhance overall system performance.
**Technical Expertise and Support**
These providers bring specialized technical expertise to address complex IT challenges effectively. From resolving network issues to implementing cybersecurity measures, their support ensures the reliability and security of IT systems.
**Customized Solutions and Consultation**
IT support providers offer customized solutions tailored to the unique needs of each business. Through consultations and assessments, they recommend optimal IT strategies, hardware configurations, and security protocols.
## **Case Studies: Impact of IT Support and Maintenance**
**Retail Sector**
In the retail sector, IT support and maintenance services are instrumental in ensuring smooth Point of Sale (POS) operations, managing inventory systems, and securing customer data. CCTV camera support enhances loss prevention efforts and deters theft.
**Healthcare Industry**
IT support services play a critical role in healthcare, maintaining Electronic Health Records (EHR) systems, securing patient information, and enabling telemedicine solutions. CCTV camera support enhances facility security and patient safety.
Education Institutions
Educational institutions benefit from IT support services for managing Learning Management Systems (LMS), supporting remote learning initiatives, and securing sensitive student data. CCTV camera support enhances campus security and monitoring.
## **Future Trends and Innovations**
**AI-Powered Surveillance**
The integration of Artificial Intelligence (AI) in CCTV camera systems enables advanced analytics, automated threat detection, and predictive security measures. IT support providers facilitate the implementation and management of AI-driven surveillance solutions.
**IoT Integration**
[Business WiFi solutions](https://cybernautme.com/wifi-solutions/) are evolving to support the Internet of Things (IoT) devices, enabling seamless connectivity and data exchange between various smart devices. IT support services ensure the integration and optimization of IoT networks.
Cloud-Based Management
The shift towards cloud-based IT infrastructure management offers scalability, flexibility, and remote accessibility. IT support providers leverage cloud technologies to streamline maintenance tasks, data storage, and system updates.
**Conclusion**
In conclusion, IT support and maintenance services are indispensable for streamlining business efficiency and ensuring the reliability, security, and scalability of IT infrastructure. Specifically, CCTV camera support and business WiFi solutions play integral roles in enhancing security measures and enabling connectivity. By partnering with experienced IT support providers, businesses can navigate the complexities of modern technology and optimize their operational performance.
| kimmipal | |
1,855,473 | The World of 3D Asset Management | What is 3D Asset Management? 3D asset management involves the organization, storage,... | 0 | 2024-05-16T14:48:20 | https://dev.to/msmith99994/the-world-of-3d-asset-management-4975 | ## What is 3D Asset Management?
3D asset management involves the organization, storage, retrieval, and maintenance of 3D models, textures, animations, and other related digital assets. It provides a structured system to manage these assets, ensuring they are easily accessible and consistently used across different projects and teams.
## Why is 3D Asset Management Important?
**- Efficiency and Productivity:** Managing 3D assets efficiently saves time and effort. Artists, designers, and developers can quickly find and use the right assets without sifting through disorganized files, leading to faster project completion.
**- Consistency and Quality:** A centralized management system ensures that only approved and high-quality assets are used in projects, maintaining a consistent standard across all outputs.
**- Collaboration:** Teams often work together on complex projects that require access to shared assets. A 3D asset management system facilitates smooth collaboration by providing a common platform where assets are stored and managed.
**- Security and Version Control:** Protecting valuable 3D assets from unauthorized access and managing different versions of the same asset are crucial. Asset management systems offer robust security features and version control to safeguard and track changes to assets.
## Key Features of a 3D Asset Management System
**- Centralized Repository:** All 3D assets are stored in a centralized location, making it easy for team members to find and access the files they need.
**- Metadata and Tagging:** Adding metadata and tags to assets enhances searchability, allowing users to quickly locate specific models, textures, or animations based on keywords or categories.
**- Version Control:** This feature tracks changes to assets over time, enabling users to revert to previous versions if needed and ensuring that everyone is working with the most up-to-date files.
**- Access Control and Permissions:** Different levels of access can be set for different users, ensuring that sensitive assets are protected and only authorized personnel can make changes.
**- Integration with Design Tools:** Seamless integration with popular 3D design tools like Autodesk Maya, Blender, and Unity allows for smooth workflows and enhances productivity.
**- Scalability:** As projects and asset libraries grow, the system should be able to scale accordingly without compromising performance.
## Real-World Applications of 3D Asset Management
### Gaming Industry
Game developers often work with vast libraries of 3D models, textures, and animations. A 3D asset management system helps them organize these assets, maintain consistency across different game levels, and facilitate collaboration among large development teams.
**Example:** A game development studio working on a massive open-world game can use a 3D asset management system to categorize assets by environment, character, or item type. This system allows artists to quickly access and modify specific assets, ensuring a cohesive look and feel throughout the game.
### Film and Animation
In film production and animation, managing 3D assets efficiently is critical to meet tight deadlines and ensure high-quality outputs. Asset management systems streamline workflows and provide a single source of truth for all project assets.
**Example:** An animation studio creating a feature film can use a [3D asset management](https://cloudinary.com/guides/digital-asset-management/mastering-digital-asset-management-for-3d-models-a-comprehensive-guide) system to store and organize character models, props, and environment assets. This centralized repository enables animators, texture artists, and riggers to access the latest versions of assets and collaborate more effectively.
### Architecture and Engineering
Architects and engineers use 3D models for building designs, simulations, and visualizations. Efficient asset management ensures that these models are easily accessible and consistently used across different projects.
**Example:** An architectural firm designing a complex urban development project can use a 3D asset management system to manage building models, landscape elements, and infrastructure components. This system allows architects to quickly retrieve and modify assets, ensuring that all designs are up-to-date and accurately reflect the project specifications.
## The Final Words
3D asset management is a critical component for businesses that rely on 3D models and animations. By implementing a robust asset management system, organizations can enhance efficiency, maintain quality, foster collaboration, and protect their valuable assets. Whether you’re in the gaming industry, film production, or architecture, investing in a 3D asset management system can significantly streamline your workflows and contribute to the success of your projects. | msmith99994 | |
1,855,677 | Conferências do Ecossistema de Erlang (e Elixir) | Olá pessoal, No vídeo acima eu conmversei um pouco sobre a comunidade do ecossistema de... | 0 | 2024-05-16T19:34:10 | https://dev.to/elixir_utfpr/conferencias-do-ecossistema-de-erlang-e-elixir-1ki0 | elixir, erlang, gleam, beam | {% youtube https://www.youtube.com/watch?v=Ui6pPukr5tk %}
Olá pessoal,
No vídeo acima eu conmversei um pouco sobre a comunidade do ecossistema de Erlang. Para quem está familiarizado, isso inclui Erlang, Elixir, Gleam, LFE e outras linguagens que rodam na BEAM (a máquina virtual de Erlang). Porém, reconheço que nem todos conhecem profundamente cada uma dessas linguagens. Então, vamos embarcar nessa jornada juntos.
### Introdução às Linguagens do Ecossistema Erlang
**Erlang** é a linguagem original, criada para suportar sistemas de telecomunicações robustos e distribuídos. **Elixir** surgiu em 2011 e rapidamente se tornou uma das mais populares dentro desse ecossistema, especialmente após a primeira versão estável em 2012. **Gleam** é uma linguagem funcional tipada estaticamente que vem ganhando destaque recentemente, e **LFE (Lisp Flavored Erlang)** combina a simplicidade do Lisp com a robustez de Erlang.
### Sobre Mim
Sou Adolfo Neto, professor da UTFPR, coordenador e apresentador do podcast Elixir em Foco. Você pode me encontrar no Twitter (ou X) como [@adolfont](https://twitter.com/adolfont).
### Conferências e Eventos da Comunidade Erlang
Vamos falar sobre alguns dos eventos mais importantes que ocorrem no ecossistema Erlang:
1. **Code BEAM America**: Realizada nos EUA, essa conferência aborda diversas linguagens da BEAM. Em 2022, apresentei um trabalho junto com meu aluno Lucas Tavano. Embora não tenha ocorrido em 2023, a expectativa é de retorno em 2024.
2. **Code BEAM Europe**: Essa conferência ocorre anualmente na Europa e já foi conhecida como Erlang User Conference. Este ano, será em Berlim nos dias 14 e 15 de outubro, com sessões virtuais disponíveis.
3. **Erlang Workshop**: Um evento acadêmico que ocorre desde 2001, voltado para a apresentação de artigos científicos. É uma parte da International Conference on Functional Programming, oferecendo uma plataforma para discussões profundas sobre desenvolvimento e pesquisa em Erlang.
4. **ElixirConf**: A principal conferência dedicada ao Elixir, realizada desde 2014. A edição de 2024 acontecerá de 27 a 30 de agosto em Orlando, Flórida.
### Eventos no Brasil
Aqui no Brasil, temos eventos que mantêm viva a chama da comunidade:
- **Elixir Brasil**: Realizada em 2018 e 2019, foi uma conferência presencial que deixou saudades. Em 2020 e 2021, aconteceu de forma online devido à pandemia.
- **Elixir Days**: Acontecerá em São Paulo nos dias 25 e 26 de maio de 2024. É uma ótima oportunidade para nos encontrarmos e discutirmos as novidades do ecossistema. Para mais detalhes, visite [Elixir Days](https://elixirdays.com/).
### Eventos Internacionais e Regionais
Além dos grandes eventos, há várias conferências regionais que ocorrem esporadicamente:
- **Code BEAM Lite**: Edições menores e mais focadas, como as realizadas em Estocolmo e A Coruña.
- **ElixirConf África**: Um evento virtual que traz a vibrante comunidade africana para o centro das discussões sobre Elixir.
- **ElixirConf Latinoamérica**: Já teve uma edição na Colômbia. Seria uma excelente iniciativa termos mais uma edição para fortalecer a comunidade na América Latina.
### Conclusão
A comunidade do ecossistema de Erlang é rica e diversificada, com eventos que promovem o compartilhamento de conhecimento e o fortalecimento dos laços entre desenvolvedores. Espero encontrar muitos de vocês nos próximos eventos e, claro, ouvir suas opiniões e experiências.
Não se esqueçam de conferir nosso podcast [Elixir em Foco](http://elixiremfoco.com) para mais informações e discussões sobre o ecossistema Elixir. Um abraço a todos e até a próxima!
Adolfo Neto
PS: O texto acima foi gerado com o prompt "Transforme num blog post: ", mais a transcrição do vídeo acima feita pelo YTScribe, pelo ChatGPT 4o.
| elixir_utfpr |
1,855,831 | Containerize your Django Web Application with Docker | Introduction Containerization is becoming commonplace in modern software development. The... | 0 | 2024-05-16T22:43:16 | https://dev.to/odhiambo/containerize-your-django-web-application-with-docker-2c2e | django, docker, webdev, beginners | ## Introduction
Containerization is becoming commonplace in modern software development. The practice involves the development of software applications in isolated environments that mimic a desired operating system. Containerization has enabled developers, using different operating systems, to create applications and collaborate in a consistent environment. Containerization essentially standardizes the development environment for a team of software developers collaborating on a project.
Several containerization technologies exist in the market today, with the most popular ones being [Docker](https://www.docker.com/) and [Kubernetes](https://www.dynatrace.com/news/blog/kubernetes-vs-docker/#:~:text=Docker%20is%20a%20suite%20of,application%20code%20and%20dependencies%20inside). This article walks Django developers through containerization using Docker. The article discusses how to set up a containerized development workspace, and the best practices involved. We will create a simple Django application and containerize it.
## Prerequisites
• A Working knowledge of web development using Django.<br>
• A Windows 10+ computer with [Windows Subsystem for Linux (WSL)](https://learn.microsoft.com/en-us/windows/wsl/install) installed.
## Setting up Docker on Windows
You will need to install [Docker on Windows]( https://docs.docker.com/desktop/install/windows-install/) and create a [Docker hub ](https://hub.docker.com/signup) account. Follow the installation guidelines provided to set up Docker Desktop on your Windows. Ensure your system meets the specified [requirements](https://learn.microsoft.com/en-us/windows/wsl/install).
The Docker desktop app acts as a front-end where you can view your images and containers (More on this in soon). Your WSL acts as a backend, where you interact with the Docker Engine, which essentially builds your images and runs your containers. You interact with the Docker Engine by running Docker commands right from your WSL Command Line Interface (CLI).
As a best practice, it is advisable to run Docker as a non-root user using WSL. To set up a non-root user account in your WSL distro with Docker, follow [this]( https://docs.docker.com/engine/install/linux-postinstall/) guideline. If you already have a non-root user and choose not to set up the user with Docker, you will have to preface all your Docker commands with the **sudo** command.
If you have followed the installation process successfully, run `docker –version`. Your terminal should display the Docker version you just installed:
```shell
$ docker --version
docker version 26.0.0, build 2ae903e
```
Docker ships with a pre-built "Hello Word" image. You can check if Docker is installed and running properly by confirming that this image exists. To do so, run this command on WSL:
```shell
$ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
1b930d010525: Pull complete
Digest:sha256:b8ba256769a0ac28dd126d584e0a2011cd2877f3f76e093a7ae560f2a5301c00
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64)
3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit: https://docs.docker.com/get-started/
```
Then run `docker-info`:
```shell
$ docker info
Client:
Debug Mode: false
Server:
Containers: 1
Running: 0
Paused: 0
Stopped: 1
Images: 1
...
```
Now we are ready to build and containerize our Django web application.
## But Before we Build…
Let’s understand core Docker terminologies. When building with Docker, you should familiarize yourself with these three fundamental terms:
* A Docker image
* A Docker container
* A Docker host
A Docker image is, basically, a list of instruction that the Docker engine follows to build your project. A Docker image can also be construed as a snapshot in time of your software project. You rebuild your image every time you update software packages in your project, or when you change some key code, as in settings.py. You write an image inside the `Dockerfile`.
A Docker container is a running instance of a Docker Image. You build your project (an image) inside Docker, then you run it, in which case the image is now known as a container. Docker Host is the underlying Operating System that runs Docker containers. One host could run several containers.
## Now we Build...
### Create a Basic Django application
We are going to build a basic blog application where users can blog on various topics of interest. This article assumes you are already familiar with the flow of building any Django project, hence it will not go into details about building with Django.
Let us think for a moment about the structure and functionality of our project. We want our blog web application to enable a user input a topic and a brief blog about the topic. Each topic could have one or several blog entries. Thus, we will model a topic with a blog entry for each topic.
For this project, we only want to display a list of all available topics though, so we will write a view logic that queries the database to retrieve a list of all topics available. Finally, we will write a template that renders the list of topics on the user interface. We could develop a full blog website. However, for Docker demonstration purposes, we will use this minimalist application.
Let’s get started…
From your CLI:
1. Create a project directory named code, or any name you prefer, and change into this directory.
```mkdir code && cd code```
2. Install the pipenv python virtual environment package if you do not have it already.
```pip install pipenv```
3. Install Django using pipenv.
```pipenv install django```
4. Activate a virtual environment using the shell command.
```pipenv shell```
You should see the name of your directory preceding your WSL distro prompt like this:
```shell
(code) nick@DESKTOP-TOB16R4:~/
```
This indicates that your environment is active
### Pipfile and Pipfile.lock
Note that when you installed Django, pipenv created two files:
* Pipfile
* Pipfile.lock
The Pipfile contains a list of dependencies for your project. It serves the same purpose as a requirements.txt file. A Pipfile.lock locks down all project dependencies you installed and the order in which you installed them.
The Pipfile.lock file enforces a deterministic build; you will achieve the same result regardless of the number of times you, or anybody in your team, installs the locked software packages. Without locking down the dependencies and their order, team members may have a slightly differentiated build installations, which could result in conflicts. Remember we want a consistent development environment when working with Docker.
### A Containerized Blog App
While your virtual environment is still active, run:
```shell
django-admin startproject config .
```
Django will create a project level directory called **config** in the current working directory. Do not forget the period after the command, or Django will create an extra directory for our project. We want the project-level directory to be in the current working directory. You could name your project anything else other than config.
Next, we need to migrate our database. The action will apply the default user model and other admin settings to the database.
```shell
python manage.py migrate
```
Next we need to confirm that our project is working as expected:
```shell
python manage.py runserver
```
If you visit **http://127.0.0.1:8000** on your browser, you should see the default Django successfully installed page.
If everything is OK, return to your terminal and exit your virtual environment by typing the command `exit`.
### Build your Image
Our project is working as expected in our local setting. Now we need to host it on Docker. It should show a similar page. To containerize it, we will need to build an image of the project. As mentioned earlier, this is a list of instructions that Docker will run to set up our project. Create a file called Dockerfile in your root directory:
**Dockerfile**
```
# Pull base image
FROM python:3.10
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# Set work directory
WORKDIR /code
# Install dependencies
COPY Pipfile Pipfile.lock /code/
RUN pip install pipenv && pipenv install --system
# Copy project
COPY . /code/
```
The Dockerfile is executed top to bottom. Thus, the first command must be the **FROM** command. This command pulls over our base image from an online repository, which is python 3.10 in this case. You could specify any Python version you want based on your project needs.
The ENV command set two basic environment variables: PYTHONDONTWRITEBYTECODE prevents Python from writing .pyc files, which we do not need. PYTHONUNBUFFERED formats Docker’s output to the console.
Next we are setting up a working directory called **code** using the WORKDIR command. This step is essential when we are executing commands within our container. If we do not specify a working directory, we would have to type in a long path. By setting a default directory as above, Docker automatically executes commands within this directory.
Next, we install project dependencies using pipenv. Remember that our project contains one dependency, Django, so far. We begin by copying over the contents of our Pipfile and Pipfile.lock into our working directory (code), that we just created. Then we install the dependencies globally within Docker by appending the –system flag at the end of the install command. We use the --system flag to instruct pipenv to install the software packages globally within Docker. This is because pipenv, by default, looks for a virtual environment to install packages, and Docker now acts as our virtual environment.
Next we copy over the rest of our local code into our Docker working directory.<br>
Now let’s build our image with a single command.
Run:
```shell
$ docker build .
```
Docker will output a lot of information on the console. Check the last part of the output to confirm whether Docker successfully built your image.
Next, we need to get this image running so we can interact with our web app from the browser. To accomplish that, we would need to create a
`docker-compose.yml` file.
**docker-compose.yml**
```shell
version: '3.8'
services:
web:
build: .
command: python /code/manage.py runserver 0.0.0.0:8000
volumes: - .:/code
ports: - 8000:8000
```
Let’s explain the contents of this file:<br>
The first line specifies the Docker compose version, which is 3.8 in this case.
The services command specifies the containers to run, which is a just web service container in this case. As mentioned earlier, you can specify several containers to run.
The build command instructs Docker to look for a Dockerfile within the current working directory. Next, we start our server at port 8000, which is Django’s default port.
The volumes mount syncs Docker’s file system with our local file system, meaning we do not have to edit the files locally once we edit them inside Docker.
Finally, we expose port 8000 within Docker.
Time to run our container. Type this command:
```shell
$ docker-compose up
```
You should get the following output:
```shell
Creating network "code_default" with the default driver
Building web
Step 1/7 : FROM python:3.8 ...
Creating code_web_1 ... done
Attaching to code_web_1
web_1 | Watching for file changes with StatReloader
web_1 | Performing system checks...
web_1 |
web_1 | System check identified no issues (0 silenced).
web_1 | May 03, 2024 - 19:28:08
web_1 | Django version 3.1, using settings 'config.settings'
web_1 | Starting development server at http://0.0.0.0:8000/
web_1 | Quit the server with CONTROL-C.
```
If you visit your browser at http://127.0.0.1:8000, you should see the default Django successfully installed page as before. This means that you have successfully containerized your Django project using Docker.
Since Docker stores a running container in RAM, and a container takes a lot of space (A simple container could be over 1GB), it is advisable to stop the container when not in use. To do so, run:<br>
```shell
$ docker-compose down
```
### Building within Docker
We can start our docker container in **detached mode**. Running a container in detached mode allows you to use a single terminal without having to stop your server or use multiple terminals. To use a container in detached mode, run:
```shell
$ docker-compose up –d
```
Building within Docker is no different from building locally. The only exception is we now have to preface any command we run with `docker-compose exec web`.
We are going to create an app called **blog** then create the necessary model, view and template for our blog web app.<br>
Run:
```shell
$ docker-compose exec web python manage.py startapp blog
```
```python
# blog/models.py
from django.db import models
class Topic(models.Model):
topic = models.CharField(max_length=200)
def __str__(self):
return self.topic
class Entry(models.Model):
topic = models.ForeignKey(Topic, on_delete=models.CASCADE)
text = models.TextField()
def __str__(self):
return self.text[:50]
```
Then migrate your database to apply these new models
```shell
docker-compose exec web python manage.py makemigrations blog
docker-compose exec web python manage.py migrate
```
Finally, you should register your models with the admin site at blog/admin.py so you can interact with them via them admin panel at http://127.0.0.1:8000/admin. You can try adding a few topics and entries via the admin.
Next configure URL routes for the blog app:
```python
# config/urls.py
from django.urls import path, include
urlpatterns = [
path('admin/', include(admin.site.urls)),
path('', include('blog.urls')),
]
```
```python
# blog/urls.py
from django.urls import path
from .views import TopicListView
urlpatterns = [
Path('', TopicListView.as_view(), name='topics'),
]
```
Write a view to list all topics available in the database:
```python
# blog/views.py
from .models import Topic
from django.views.generic import ListView
class TopicListView(ListView):
"""Lists all topics"""
model = Topic
context_object_name = topic_list
template_name = 'topics.html'
```
Render the topics list to the user interface
```html
<!--templates/topic.html-->
<!DOCTYPE html>
<html>
<h1>Topics</h1>
<ul>
{% for topic in topic_list %}
<li>{{ topic }}</li>
</ul>
</html>
```
After you have updated your app files like above, try visiting the local host URL to check if it lists all the topics you have added. If you are encountering any errors, Docker provides an error log. Run:<br>
```docker logs```
## A Summary of Steps
In summary, follow these steps to containerize your Django application:
* Create a virtual environment locally and install Django
* Create a new project
* Exit the virtual environment
* Write a Dockerfile and then build the initial image
* Write a docker-compose.yml file and run the container with docker-compose up
* Rebuild your image every time you install a software package
* Restart Docker every time you make changes to your settings.py file
* Run docker logs if you encounter any errors
## Conclusion
Modern web development involves working in teams. Therefore, the development necessitates building using containers such as Docker. It is important for beginners in backend development familiarize with Docker as early as possible. This article covers the fundamentals of getting started with Docker. It discusses fundamental Docker concepts and commands. Whereas there is more to containerization and the Docker technology that requires further learning, this article is an excellent starting point for beginners. You can start here and work your way up to becoming an expert. Docker itself has a steep learning curve, and it takes more than what we have discussed here to gain proficiency. Nevertheless, you can start here and build small, containerized Django applications to familiarize yourself with the basics. Happy containerization! | odhiambo |
1,855,873 | Insights from Leading Masking Tape Manufacturers | screenshot-1715917869541.png The Magic of Behind the Tape: Discover Insights and Explore the Benefits... | 0 | 2024-05-17T00:35:50 | https://dev.to/sevlae99/insights-from-leading-masking-tape-manufacturers-2302 | tape |
screenshot-1715917869541.png
The Magic of Behind the Tape: Discover Insights and Explore the Benefits of Masking Tape
Are you looking for a simple and effective way to protect your surfaces from paint, dust, or dirt while remodeling or painting your room? Look no further than masking tape! Let's dive into the world of masking tape to see what it can do for you.
Features of Masking Tape
Masking tape is sold with many advantages which make it an just like essential about any DIY task.
For instance, it is affordable and easily obtainable, making this an resource like easy-to-access the requirements that are crafty.
Also, masking tape is extremely versatile, in a position to follow nearly any surface and be removed easy without leaving residue like sticky.
It is incredibly individual– like friendly tear from the desired length and connect with your desired surface.
Unbelievably, tape is gentle on surfaces, also delicate people, yet delivers a good barrier against paint and other materials.
It truly is not surprising that masking paint tape is actually a go-to option for crafters and experts alike.
Innovation and Protection Considerations
In modern times, masking tape has come quite a distance.
With technical advancement to the adhesives industry, has become for sale in multiple adhesive strengths that will suit any task you've gotten.
You'll find textures that are various finishes, and colors that may make tape like masking versatile.
For instance, masking tape made of rice paper is a good choice for delicate areas like wallpaper and can additionally be employed to build gorgeous stenciled habits.
Also, masking tape has become obtainable in eco-friendly options, which makes it an option like environmentally-conscious.
When it comes to security, use care when always dealing with masking tape.
Even before you start taking care of any project though it is beloved because of its mild stick, it is usually very important to make sure the tape is properly mounted on your surface.
Otherwise, it could allow paint and also other substances until the surface, leaving behind an mess like undesired.
Service and Quality
NewTime may be the one-stop go shopping for all things tape like masking.
Whether you are a specialist painter, a DIY lover, or a home owner looking to make easy home improvements, this resource provides detail by detail info on the standard like blue masking tape that are highest on sale.
With regards to service, manufacturers make sure that the buyer help group can answer any queries you might have regarding the product.
Customer support also incorporates supplying detailed guidelines to ensure tape like masking utilized correctly and properly.
Application
Masking tape has a range like wide of, making this a go-to for experts once you consider the construction, design, and industries that are painting.
Along with old-fashioned applications like artwork, masking tape may also be used for stenciling and creating decorative habits.
Further, it can be utilized being a label like short-term to affix objects that are lightweight areas.
In conclusion, black masking tape is a versatile tool with many applications. NewTime provides valuable insights to help you find the right masking tape for your project. The benefits of using masking tape include its gentle stick, ease of use, versatility, and compatibility with numerous types of surfaces. We encourage you to explore the world of masking tape and discover its many uses for yourself!
Source: https://www.newtimetp.com/Painting--renovation | sevlae99 |
1,664 | Hi, I'm Abhishek A Amralkar | My introduction post | 0 | 2017-03-06T04:55:41 | https://dev.to/abhishekamralkar/hi-im-abhishek-a-amralkar | introductions | ---
title: Hi, I'm Abhishek A Amralkar
published: true
description: My introduction post
cover_image:
tags: introductions
---
I am DevOps Engineer and I have been coding for [2] years.
You can find me on Twitter as [@aamralkar](https://twitter.com/aamralkar)
I live in Pune.
I mostly program in these languages: [Clojure, Shell].
I am currently learning more about [Clojure, DevOPs].
Nice to meet you. | abhishekamralkar |
13,555 | On HackerX/Brno event | I had quite an interesting experience yesterday. I've attended HackerX event. It's kind of speed... | 0 | 2017-12-01T20:07:32 | https://dev.to/voins/on-hackerxbrno-event-7o | career | ---
title: On HackerX/Brno event
published: true
description:
tags: career
---
I had quite an interesting experience yesterday. I've attended [HackerX](https://www.hackerx.org) event. It's kind of speed dating between companies and potential employees. Totally worth attending even if you're not looking for a new job. (And not only because of free food. :) ).
The main point for me was, that I found out, that I have a unique proposition for any potential employer: I'm not afraid of working with legacy code, I know how to work with it, and I actually [love working with it](https://dev.to/voins/is-legacy-code-that-bad). Almost everyone I met yesterday had some project that requires someone like me, and they're unable to find such person.
I guess it is possibly true for everyone attending. Even without previous experience, and without any kind of preparation, you still can "extract" the essence of yourself during those 5 minute interviews. When all you've got is those 5 minutes, you tend to concentrate. And then those 5 minutes are repeated many times, and you are trying to say something relevant about yourself, and those guys on the other side of the table keep asking questions important to them, and it starts to look very much like some iterative process, and during those iterations you're getting closer and closer to understanding what's so good about you, what others see in you and what you can offer to the world. That's a really cool feeling. I wish there was more companies, but I got the idea even with those we had present.
It's a pity, I cannot legally change my employer right now... :) | voins |
17,742 | Problems you faced on developing globalized web services | Problems you faced on developing globalized web services | 0 | 2018-01-24T00:51:02 | https://dev.to/chooyan/problems-you-faced-on-developing-globalized-web-services-1iad | discuss, globalization, i18n | ---
title: Problems you faced on developing globalized web services
published: true
description: Problems you faced on developing globalized web services
tags: discuss, globalization, i18n
---
Hi,
I'm now researching how to globalize web services suitably, and I want to find out as many possible problems on globalizing web services as possible.
Have you faced any problems (not only technical but also cultural, religious, linguistic, etc.) when you are developing web services targeting global audiences? If so, how did you solve them? | chooyan |
34,190 | Asynchronous post challenge | How to transmit simple data from client to server | 0 | 2018-06-05T21:25:42 | https://dev.to/bertilmuth/asynchronous-post-challenge-84l | coding, challenge | ---
title: Asynchronous post challenge
published: true
description: How to transmit simple data from client to server
tags: coding, challenge
---
You create a website.
It contains 2 text fields, with a single digit number each.
When the user changes the value of a text field, the client transmits the number to a server, asynchronously. No further interaction with the user is required.
As most visitors of the website are mobile users, the client must be able to deal with going offline. When the client comes back online, the values that have not been transmitted so far need to be transmitted.
Optional extra: showing a check mark next to the text field, for successful transmission to the server.
What would be the simplest solution, given you can use only HTML and JavaScript (and JavaScript libraries/frameworks)? | bertilmuth |
33,431 | Creating Beautiful Apps with Angular Material | In this article, you will learn how to take advantage of Angular Material to create beautiful and modern Angular applications. | 0 | 2018-05-29T18:51:11 | https://auth0.com/blog/creating-beautiful-apps-with-angular-material/ | angular, javascript, angularmaterial, webapps | ---
title: Creating Beautiful Apps with Angular Material
published: true
description: In this article, you will learn how to take advantage of Angular Material to create beautiful and modern Angular applications.
tags: #angular #javascript #angularmaterial #webapps
canonical_url: https://auth0.com/blog/creating-beautiful-apps-with-angular-material/
---
In this article, you will learn how to take advantage of Angular Material to create beautiful and modern Angular applications. You will start from scratch, installing Node.js and Angular CLI (in case you don't have them yet), then you will install and configure the dependencies needed to develop with Angular Material.
[Read on 🅰️💎](https://auth0.com/blog/creating-beautiful-apps-with-angular-material/?utm_source=dev&utm_medium=sc&utm_campaign=angular_material)
 | ramiro__nd |
33,432 | Real Madrid, Liverpool and Andela: This is #ALCwithGoogle 3.0 |
I know you didn’t miss it. The UEFA Champions League Finals of Saturday May, 26... | 0 | 2018-05-29T19:54:32 | https://medium.com/@iNidAName/real-madrid-liverpool-and-andela-this-is-alcwithgoogle-3-0-b7efd13ac530 | learning, community, andela, learningtocode | ---
title: Real Madrid, Liverpool and Andela: This is #ALCwithGoogle 3.0
published: true
tags: learning,community,andela,learning-to-code
canonical_url: https://medium.com/@iNidAName/real-madrid-liverpool-and-andela-this-is-alcwithgoogle-3-0-b7efd13ac530
---
I know you didn’t miss it. The UEFA Champions League Finals of Saturday May, 26th 2018.
> Keep my secret and I will keep yours: **I missed it.**
So you know the gist, I read the tweets but I have a gist.
_In Falz’s Voice_ **_This is Africa!_**
Wait…! before you continue you really need to get in the spirit of the song.
_So again_
♪ **This is my Africa…!** ♪
♪ Look how I’m learning now. ♪
♪ Look how we learning now. ♪
Pause… Good…
On Saturday 26th of May 2018, **Africa** stood up and it wasn’t for the UEFA Champions League finals. _Yes you are not reading the wrong article._
Africa came together to achieve one goal and the goal was to learn. Thanks to **Andela, Google** and **Udacity**. They made this possible.
<figcaption>Pic Credit: <a href="https://twitter.com/ChrisBarso/status/1000321109676478464"><strong>Chris Barsolai</strong></a></figcaption>
<figcaption>Pic Credit: <a href="https://twitter.com/adetayo_james/status/1001114572449878017"><strong>Adetayo James</strong></a></figcaption>
#### This is ALCwithGoogle
_I know this didn’t rhythm._
Just so I don’t bored you with much, ALCwithGoogle is Google’s developer scholarships using Udacity’s online curriculum to build world-class problem solvers (Software developers).
Like the TV ads will say it: _brought to you by _ **_Andela._**
#### ALCwithGoogle 3.0
Is categorized into Android and Web categories with Beginners and Intermediate Learners Track, it is currently 25% into the program as at this write up.
At the end of the program, Top 500 students will be awarded scholarships to Udacity’s Nano Degree.
But these wasn’t what happened on Saturday.
_Are You Ready?_
♪ **This is my Africa…!** ♪
♪ Look how I’m learning now. ♪
♪ Look how we learning now. ♪
♪ We all will be writing codes. ♪
Pause…
<figcaption>Pic Credit: <a href="https://twitter.com/Andela_Nigeria/status/1000365744083886081"><strong>Andela Nigeria</strong></a></figcaption>
Saturday was the first ALCwithGoogle 3.0 meet up and they called [#ALCwithGoogle Meet-up 1.0](https://twitter.com/search?f=tweets&vertical=default&q=alcwithgoogle). At least, that is obvious. _Real Madrid and Liverpool ended 3-1, are you seeing the connection?_
About 16,000+ students across 15 countries in Africa attended these meet ups in there local communities.
If I told you I attended all the Meet Ups, you won’t be reading this. Are you still reading this? _I hope._
I didn’t attend all, I wish could and maybe I should but I attended one.
_Are you with me?_
#### ♪ This is Nigeria ♪
♪ Look how I’m learning now ♪
♪ Look how we learning now ♪
♪ Everybody be coding now ♪
♪ **This is Nigeria** ♪
Pause… _Please make sure you are still in this spirit and it okay to go back up it really fun. You won’t regret it._
<figcaption>Pic Credit: <a href="https://twitter.com/ajahdavid/status/1000769665801613313"><strong>Ajah David</strong></a></figcaption>
While the world was waiting for Real Madrid and Liverpool to start a Judo Fight…
Sorry…
I meant to say a Soccer Fight… Soccer Match. Well you know what they played.
The Civic Hall at Civic Innovation Lab was packed with close to 200 students ready to learn how to build world class applications.
Now during the meet up some questions were asked like, _What text-editor should I use?_ or _Why must I learn GIT?_ Let’s just say the common stuff anybody learning programming usually face.
The cool facilitators of the meet up provided lots of satisfactory responses. _Who taught meet up was not important._
So about that spirit are you still in it let’s go…
♪ This is from Andela ♪
♪ I’m not from Andela ♪
♪ But they have a write up on that ♪
_That didn’t rhythm… but they do have a write up on that_. [This is Andela](https://medium.com/@senisulyman/tia-this-is-andela-33203d10975b).
Before I go, I know you are still in the spirit, _So…_
♪ **This is my Africa** ♪
♪ Look how I’m coding now ♪
♪ Look what I’m building now ♪
♪ **This is Nigeria** ♪
♪ Thank You for reading this. ♪
♪ **This is Nigeria** ♪
♪ **This is my Africa** ♪
The original song was by [Falz The BadGuy](https://www.youtube.com/watch?v=UW_xEqCWrm0), which was a remake of [This is America by Childish Gambino](https://www.youtube.com/watch?v=VYOjWnS4cMY). | inidaname |
33,754 | Under the Hood of the Most Powerful Video JavaScript API | In this article, our goal is to demonstrate how to leverage our JavaScript API effectively to deliver a better video experience on your website through code walkthroughs & demos. We'll then wrap up with some details under the hood of JW Player, explaining how we're the fastest player on the web. | 0 | 2018-06-01T15:47:32 | https://dev.to/jwplayer/under-the-hood-of-the-most-powerful-video-javascript-api-4kme | video, videoplayer, webdev, javascript | ---
title: Under the Hood of the Most Powerful Video JavaScript API
published: true
description: In this article, our goal is to demonstrate how to leverage our JavaScript API effectively to deliver a better video experience on your website through code walkthroughs & demos. We'll then wrap up with some details under the hood of JW Player, explaining how we're the fastest player on the web.
tags: video, video player, webdev, javascript
---
<h2>Introduction</h2>
At [JW Player](https://www.jwplayer.com/plans/?utm_source=dev.to&utm_medium=blog), we believe our technology enables developers to deliver the best video experience on their websites. From individual developers to enterprises like Vice, Business Insider, and Amazon Web Services — we have the right solution for everyone. [Dev.to](https://dev.to/vaidehijoshi/stacks-and-queues--basecs-video-series--20oj) seems to think so as well (right-click on the video player)!
In this article, we'll prove this with code instead of lip service. The goal is to demonstrate how to leverage our player JavaScript API to deliver a better video experience on your website through code walkthroughs & demos. We'll then wrap up with some details under the hood of JW Player, explaining <i>how</i> we're the fastest player on the web. Without further ado:
<h2>A robust, powerful video JavaScript API</h2>
At JW Player, our mission is to provide developers with the most robust JavaScript API to allow you to take full control of your video experience. This includes functionality ranging from advanced player customization to analytics reporting.
Compared to open source solutions, we’re committed to providing robust documentation in addition to code demos alongside a dedicated, world-class support team to ensure development and implementation is a breeze. Your time is valuable and our developer & support sites ensure that you spend less time sorting through StackOverflow.
Here’s examples of what you can do:
1. [Video Wall](https://developer.jwplayer.com/jw-player/demos/innovation/click-to-play/?utm_source=dev.to&utm_medium=blog)
2. [360 Degree Video & VR](https://developer.jwplayer.com/jw-player/demos/innovation/360-video/?utm_source=dev.to&utm_medium=blog)
3. [Video Background](https://developer.jwplayer.com/jw-player/demos/developer-showcase/video-background/?utm_source=dev.to&utm_medium=blog)
4. [Custom Control Icons](https://developer.jwplayer.com/jw-player/demos/customization/custom-icons/?utm_source=dev.to&utm_medium=blog)
5. [Closed Captions](https://developer.jwplayer.com/jw-player/demos/toolbox/closed-captions/?utm_source=dev.to&utm_medium=blog) & [Caption Styling](https://developer.jwplayer.com/jw-player/demos/customization/captions-styling/?utm_source=dev.to&utm_medium=blog)
Let's walk through the first demo - creating a click-to-play Video Wall. The purpose of this video wall is to display content in a cinematic format without slowing down your web page.
In this demo, you can set up a responsive video grid that only pulls the poster images from the videos to ensure a fast time to first frame by only loading the video player upon clicking the thumbnail. As the viewer clicks around, it pauses the original video as well.
Instead of loading several players at once, which would be painful on mobile, you can create a cinematic experience while providing the optimal UX for your viewers.
Setup and play a video with a single click on a thumbnail within a responsive image grid as seen below:
{% codepen https://codepen.io/kim_hart/pen/aKOVQN %}
```js
// Request playlist data
(function() {
var httpRequest = new XMLHttpRequest();
if (!httpRequest) {
return false;
}
httpRequest.onreadystatechange = function() {
if (httpRequest.readyState === XMLHttpRequest.DONE) {
if (httpRequest.status === 200) {
var json = JSON.parse(httpRequest.response);
getThumbnails(json);
} else {
console.log(httpRequest.statusText);
}
}
}
httpRequest.open('GET', '//cdn.jwplayer.com/v2/playlists/0FDAGB12');
httpRequest.send();
})();
// Render thumbnails into grid layout
var thumbs = document.querySelectorAll('.thumb');
var player;
function getThumbnails(data) {
var playlist = data.playlist;
thumbs.forEach(function(thumb, i) {
var video = playlist[i];
var titleText = document.createElement('div');
titleText.className = 'title-text';
titleText.innerHTML = video.title;
thumb.appendChild(titleText);
thumb.setAttribute('id', video.mediaid + 1);
thumb.style.backgroundImage = "url('" + video.image + "')";
thumb.addEventListener('click', function(e) {
handleActivePlayer(e, video);
});
})
};
// On click, destroy existing player, setup new player in target div
function handleActivePlayer(e, video) {
var activeDiv = e.target;
if (player) {
player.remove();
}
thumbs.forEach(function(thumb) {
thumb.classList.remove('active');
})
activeDiv.classList.add('active');
// Chain .play() onto player setup (rather than autostart: true)
player = jwplayer(activeDiv.id).setup({
file: '//content.jwplatform.com/manifests/' + video.mediaid + '.m3u8'
}).play();
// Destroy the player and replace with thumbnail
player.on('complete', function() {
player.remove();
player = null;
});
}
```
<h2>How we built the web's fastest video player</h2>
When thinking about the user experience of a video player, time to first frame is the most noticeable factor that impacts the viewability of a video.
An [Akamai study](https://www.akamai.com/us/en/multimedia/documents/technical-publication/video-stream-quality-impacts-viewer-behavior-inferring-causality-using-quasi-experimental-designs-technical-publication.pdf) discovered that <b>video abandonment rate increases by 6% for every second of load time beyond two seconds</b>. A [separate study on OTT viewership](http://www.fiercecable.com/online-video/akamai-ott-video-streaming-quality-experience-drives-viewer-loyalty-provider-success) showed that <b>buffering increases negative emotions by 16% and decreases engagement by 20%</b>. These two studies strongly indicate that poor playback is the biggest inhibitor of video engagement.
That’s why we ensured our player has <b>sub-second load times</b> across all devices and browsers so end viewers never see a buffering screen.
How?
<ol><li>Our player detects the viewer’s rendering environments and <b>loads only the necessary components required for playback</b>. Based on a combination of the media type contained in playlists and the viewer’s browser, we’ve optimized the player to make fewer network requests for the most common use cases of video playback, reducing latency costs associated with setup times.</li>
<li>Our embed script is engineered to <b>make fewer server requests</b> to better interact with the overall composition of modern webpages. By implementing the latest version of our web player, you can rest assured that JW Player is <b>actively reducing its footprint to improve your entire website experience.</b></li>
<li>Our video preloading fetches media data before playback and as soon as the page loads which allows viewers to enjoy <b>faster playback with reduced bandwidth</b>. Specifically, our backend preloading process is smarter about when it occurs and is more precise with how much is preloaded. We’ve also taken steps to optimize bandwidth consumption for websites that load multiple video players on a single page by only preloading players when they become more than 50% viewable.</li>
<li>The player is set to load metadata by default so playback starts immediately for click-to-play players once playback is initiated. To reiterate, these preloading changes allows the player to be <b>more intelligent to avoid wasting audience bandwidth while simultaneously improving start times.</b></li>
<li>Finally, our player <b>does not compromise video quality</b> if the end viewer can support a higher quality stream. The player maintains the viewer’s bandwidth between videos, allowing the second and subsequent videos to benefit from a higher quality start at the beginning. If the viewer is watching the player embed’s first video, the player can start up at the last known bandwidth when a viewer returns to a site on the same device and browser.</li></ol>
To see what’s going on under the hood, check out the [player event inspector](https://developer.jwplayer.com/tools/player-event-inspector/?utm_source=dev.to&utm_medium=blog) on our developer website. Here, you can test and debug a JW Player setup with our return of all available JW Player events, getters, and utils.
For more info, you can also check our comprehensive [configuration reference documentation](https://developer.jwplayer.com/jw-player/docs/developer-guide/customization/configuration-reference/?utm_source=dev.to&utm_medium=blog).
<h2>Conclusion</h2>
We created the most powerful, flexible video Javascript API so you can deliver a great video experience customized to your standards. Our team maintains the player to ensure full device and browser support so you're always up to date — plus tools, demos and robust API documentation so you can focus on what matters.
For more information, [compare options](https://www.jwplayer.com/plans/?utm_source=dev.to&utm_medium=blog) and see which plan is right for you.
| jwplayer_team |
33,912 | Keeping track of your goals | This week I wanted to talk about goals. Specifically how you should be keeping track of your progress toward your goals. I have been playing around with this for a while now. And I have come up with a solution that has been working for me. | 0 | 2018-06-03T04:26:04 | https://dev.to/alexgwartney/keeping-track-of-your-goals-11hi | productivity, beginners, career, discuss | ---
title: Keeping track of your goals
published: true
description: This week I wanted to talk about goals. Specifically how you should be keeping track of your progress toward your goals. I have been playing around with this for a while now. And I have come up with a solution that has been working for me.
tags: #productivity #beginners #career #discuss
---
This week I wanted to talk about goals. Specifically,how you should be keeping track of your progress toward your goals. I have been playing around with this for a while now. And I have come up with a solution that has been working for me. So rather than first just saying I want to complete x goal. And hit the ground running you need to give yourself a way of tracking this. And the way I have been doing so is through a journal. At the beginning of each week I write a main goal that will help lead to my overall goal.
I then write down the steps that I will need to complete to finish this goal by the end of the week. This way at the end of the week I will be able to show the progress I have made. And over all check if I met the goals. If I met the goals for the week I move on and repeat the process.If not, I write the goals I missed from the previous week and repeat the process.I feel like this has been working because it gives me a way of seeing the overall progress I have made over time. Rather than just saying I am working toward a massive goal and then getting overwhelmed by the amount of work I need to complete that goal. I also wanted to ask you guys. How do you guys keep track of your goals?
So as usual here is what I have been working on.
This past week I have not really had the chance to work on any code. As I have been dealing with a million other things. But I wanted to post the most recent project I have been working on. To help me on my journey toward graphics programming. I have been studying endless amounts of math. To help me understand the math better. I have been working on small programs. This specific one will be used to factor out quadratic equations. Using completing the square. https://github.com/gwartney21/CompleteTheSquare
As always thanks for reading. | alexgwartney |
34,134 | How have you discover a technology or a language? | how i discovered MongoDB | 0 | 2018-06-05T08:00:40 | https://dev.to/ekimkael/how-have-you-discover-a-technology-or-a-language-2k43 | mongodb, beginners, discovering, database | ---
title: How have you discover a technology or a language?
published: true
description: how i discovered MongoDB
tags: mongodb, beginner, discovering, database
---
##The little story
For simple projects that require dynamic data, however, I will take the example of your portfolio, to display details of the projects you have worked on you may be tempted to make a backend but frankly...what good? with the current state of the web and web applications, the best choice for this kind of project would be to create a "db.json" file (because JSON is the most used response mode to return data), put the JSON schema of your response and interact with it.
Okay!cool but how do you make requests to your JSON file? because remember, "db.json" is your database but you need a language (a system) to be able to communicate with the stored data.
While browsing on the internet you will find plenty like for example: JSON-QUERY.
But it can very quickly be confusing as syntax can sometimes be difficult to understand.that's where MongoDB comes in.
For me, it was a story in this sense that led to the creation of MongoDB.
##How did I hear about MongoDB?
I discovered MongoDB, because of the hype around it. everywhere I typed "REST API with Node", MongoDB was around and to tell you everything I immediately installed it and I was totally lost. yes totally! it even did a few weeks on my PC and as I was not using it, well I ended up uninstalling it is to say.Then when I was in the situation described above, I reinstalled it because I had just really understood what it was for... All this to say, it's good to do technology watch but don't get into something without knowing what it's for or need it in the heart of an experiment all this because of the hype around it (I misspoke myself but I hope I understand you). | ekimkael |
34,376 | You Don't Need A Side Hustle | You don't need to hack on projects on the side to be a great developer. | 0 | 2018-06-07T17:27:29 | https://dev.to/bsamaripa/you-dont-need-a-side-hustle-3m9l | opinion, career, beginners, sidehustle | ---
title: You Don't Need A Side Hustle
published: true
description: You don't need to hack on projects on the side to be a great developer.
tags: opinion, career, beginners, side-hustle
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ts91o4pw5iq4lbapv4ye.png
---
_Originally posted to [bsamaripa.com](https://bsamaripa.com/post/you-dont-need-a-side-hustle/)_
I'm a member of several popular software developer communities, mostly to stay current on the infinite deluge of Javascript frameworks and dank memes. Lately, I've noticed a concerning trend in all of these groups. There's this idea that the only way to "Level Up" as a developer is to work on side projects.
It's a story seen every day on Indie Hackers, Hacker News, or dev.to: "How I bootstrapped my startup to earning an extra 200k/month by Making an API to Sell Blockchain Backed Widgets". This might be a bit of a snarky example of a headline but I assure you many of the tropes used are found in success story headlines. These click-baity titles are peer pressuring developers into believing that it's necessary to have a side hustle or a SaaS project. I'm here to tell you that this notion is 100% false! Let's dig in.
## You're Not a Failure
Let's not mince words, I believe that working on side projects can be massively beneficial to your life and your career. It's undeniable that gaining experience or additional income (or possibly a new job for that matter) can improve the quality of life. I have a few side projects that I'm working on when I have the time and energy. However, they aren't my top priority given little free time available to me. One might look at these incomplete side projects as a failure and me as an unmotivated dev, but I view them as a victory. I was able to look at my life and prioritize whats most important. An API to do spelling/grammar checking or the next Soundcloud might be alluring but focusing on family and loved ones, personal health, and music surfaced as more important to my life.
When I first decided to shelve these projects, I felt a sense of shame. As if my ego as a developer is measured solely by how much income I earn out of work or by how big my blogs email list is. Happily zero, by the way. This is a common misconception that I found myself returning to constantly during times of doubt. This is the exact shame that I hope to address here. I have many examples to the contrary and you do as well.
Most of my current and former coworkers don't do any extra coding beyond what they do for work. I consider them massively successful and exemplary for my own career path. How then can I feel guilty for not putting in extra hours beyond 9 to 5?
## You don't need to feel pressured
Many of the people reading this might not feel this pressure directly -- especially if you're an established developer years into your career. Those most at risk for harm from this false notion are those just getting started. When I was a fresh-faced recruit from college, I had no experience or self-worth in the field. Immediately after school, I hadn't gotten a job offer and I didn't have numerous Github contributions under my belt. Put simply, I was in the majority of the developers coming out of University or education.
## Removing Barriers to Entry for Newcomers
Anything that acts as a barrier to entry or a rite of passage for entering the software field should be handled with extreme prejudice. The software industry is one plagued with diversity problems that won't be discussed in this particular post. More on that later, Promise! If you're starting out, why make life harder than it needs to be? If you're an ally to diversity or a senior hoping to mentor newbies, don't expound or pontificate about your side hustle. They've got enough to worry about without having to also create a job in their free time.
## You're going to do it anyway...
My real hope from this was not to discourage those who feel compelled to delve into projects outside of work. Seriously, I *love* that I work in an industry with so many self-motivated individuals of many backgrounds. I'd hate to see Juniors, Interns, or newcomers feel ostracized or to deepen Imposter Syndrome. The same goes for all levels of experience or skill. There is much that can be gained from building in your off time, but this shouldn't come at the cost of your sanity or health. It, by no means, should become the norm. We all put in our time each day, some more than others. That being said, if you're going to work on side projects, do it for the right reasons.
tl;dr - You don't need to hack on projects on the side to be a great developer. | bsamaripa |
34,686 | Explain Generics Like I'm Five | I often see discussion about generics, but I've never really grasped what they are. I'm a Ruby/Rails... | 0 | 2018-06-10T19:17:20 | https://dev.to/briankephart/explain-generics-like-im-five-1olf | explainlikeimfive, discuss, generics | ---
title: Explain Generics Like I'm Five
published: true
description:
tags: explainlikeimfive, discuss, generics
---
I often see discussion about generics, but I've never really grasped what they are. I'm a Ruby/Rails developer, and the term doesn't seem to be used in that community. | briankephart |
35,207 | Do someone here have experience in building commercial Jekyll templates/themes? | A post by Jovan Savic | 0 | 2018-06-14T13:53:24 | https://dev.to/jovan/do-someone-here-have-experience-in-building-commercial-jekyll-templatesthemes-39jf | discuss, webdev, github, jekyll | ---
title: Do someone here have experience in building commercial Jekyll templates/themes?
published: true
description:
tags: discuss, webdev, github, jekyll
---
| jovan |
35,235 | Command Not Found... Dum Dum | A neat little shell customization feature I found while reading through a Bash book. | 0 | 2018-06-14T17:01:19 | https://assertnotmagic.com/2018/06/16/command-not-found/ | bash, shell, quicktip | ---
title: Command Not Found... Dum Dum
published: true
description: A neat little shell customization feature I found while reading through a Bash book.
tags: bash, shell, quicktip
cover_image: https://thepracticaldev.s3.amazonaws.com/i/i39ejgbn3omr0c89j3dw.jpg
canonical_url: https://assertnotmagic.com/2018/06/16/command-not-found/
---
Do you know what time it is? That's right. It's time for a
## QUIIIIICK TIP
This tip comes from the [Bash Pocket Reference, 2nd Ed.](https://amzn.to/2t7Fp1i) by Arnold Robbins.
Do you know how Bash (and similar shells) look for commands when you give it a command? Here's the list:
1. First, it checks to see if what you've typed is a language keyword like `for` or `while`.
2. Next, it checks your aliases. Interestingly, the book above states (and cites other sources that agree) that you should basically never use aliases! It says writing a function should almost always be preferred -- contrary to a lot of StackOverflow answers I've seen. I think I agree, actually. Writing functions seems much cleaner and easier to come back to and modify later.
3. Then, it checks for special built-in functions like `break`, `exit`, or `export`. These aren't needed for the internals of the Bash language, necessarily, but they're needed for scripting and interactive shells.
4. After that, it looks at any functions you have defined.
5. Next are non-special built-ins. These are commands like `cd` and `test`. Since functions are checked before these, you could feasibly override `cd` with your own function!
```bash
function cd() {
echo "You're the best!"
command cd "$@" # Actually calls the real `cd`
}
$ cd ~/code
# => You're the best!
# Now in ~/code
```
Lastly, it hunts through the `$PATH` to try to find scripts that match.
Here's the tip: if Bash can't find the command you typed in any of these places, it runs a function called `command_not_found_handle`. Aaaaand, if you so happen to override this function, it will call *your* version instead!
Sooooo, if your terminal experience is just not quite hostile enough, you could feasibly put the following into your `.bash_profile`.
```bash
function command_not_found_handle() {
options=(
"no."
"No!"
"NO."
"OMG NO."
"Mother ****!"
"WHAT ARE YOU DOING?"
"Success! JK, you're still a dum dum."
)
option_choice=$(( $RANDOM % 7 ))
echo "${options[$option_choice]} '$*' command not found."
# The command that you tried is passed into
# this function as arguments, so $* will contain
# the entire command + arguments and options
return 127 # 127 is the canonical exit code for
# "command not found"
}
```
Then, when you open up your terminal, you should see this:
```bash
$ hwaaaa
# => NO. 'hwaaaa' command not found.
$ but why not tho
# => Success! JK, you're a dum dum. 'but why not tho' command not found.
```
All kidding aside, hopefully, you start to see how you could write some scripts to provide slightly more helpful/friendly error messages that maybe even show some possible options that were close to what you typed?
**Quick Tip Over.** | rpalo |
35,754 | Erica Sadun on accepting criticism and the art of writing | This is a article from my "Dev Chats" series where I speak to an awesome developer or techie every... | 0 | 2018-06-19T10:27:05 | https://www.samjarman.co.nz/blog/erica | writing, swift, iosdev | ---
title: Erica Sadun on accepting criticism and the art of writing
published: true
tags: writing, swift, iosdev
canonical_url: https://www.samjarman.co.nz/blog/erica
---
_This is a article from my "Dev Chats" series where I speak to an awesome developer or techie every week or so. You can read more [here](https://www.samjarman.co.nz/chats). Let me know in the comments if you find these useful to you!_
### Introduce yourself! Who are you? Where do you work?
Hi I’m Erica Sadun and I just sort of exist? I’m a part time freelancer and technology author.
### Who or what got you into programming?
I had started with programming around 1984, and been programming with Next, and then into the 90s, I got into mac programming. In there was also some Small Talk, [Lisp Machine](https://en.wikipedia.org/wiki/Lisp_machine) stuff, and then onto Pascal for the mac. I remember Apple originally published loose leafs, then bound books, and then that took me all the way up to OS 8/9. I was doing development, but It wasn’t really “serious” development, it was sort of playing around. But during that time, I was doing more of the Small Talk stuff with [Small Talk Machines](https://www.coursehero.com/file/p7299cbd/Xerox-PARC-SmallTalk-and-the-Alto-Xerox-Palo-Alto-Research-Center-1970s-Also/) or the [Star](https://en.wikipedia.org/wiki/Xerox_Star).
Then suddenly, we were in real world Macintosh and Windows, during the 90s there were all the PCs and stuff, and then Next went to the Next Station, Next Step, then Next went out of business, and there was Open Step. And during that time period, people developing for the macs were using pascal and [Inside Macintosh](https://en.wikipedia.org/wiki/Inside_Macintosh).
Developing for OS 7 OS 8, by 9 time, life got in the way. Life always has plans.
Anyway, I got pulled into iOS when the iPhone was released, and I got there early. I was privileged to be part of the early developer community and it was amazing time and surrounded by amazingly talented people, and to be able to experience that was just a pure pleasure. I wrote my first program summer of 2007, it was an [app for jailbroken iPhones to show running processes](https://www.engadget.com/2007/09/11/installing-the-iphone-developer-toolchain-a-simple-how-to/) on your iPhone.
### How has working on books and blogs helped with your career
A career? Nah! I love writing, which apparently a not a lot of other people do. I really do love the process, and love technology writing. I think if you’re serious about a career and going to be pushing forward in technology, you are not going to be writing many books. If I could write romance, I’m sure there’d be a lot more money - haha! Unfortunately, I seem to have a better knack for highly technical topics than personal relationships, but stay tuned for 50 shades of protocols! :P
I used to run a iOS development conference - Voices that Matter, and it ran for a few years, until the backing publisher made a strategic move to shut down all it’s conferences, so unfortunately didn’t continue, despite the success and praise.
### When you mime programming, do you use t-rex arms or wiggly fingers?
I use t-rex arms for sure, but also wiggly fingers at the same time. The elbows are tucked backwards to make short arms, but the fingers are definitely moving. I believe that’s actually universal sign language. I think people often do both. I think people do t-rex arms, because where the keyboard is most of the time when we use a computer.
### What has been your toughest lesson to learn in your software career so far?
I don't think I have one per se, but I think the toughest lesson in my life, or most important lesson, is how to accept criticism gracefully and learn from it. Criticism is so valuable in terms of growth and development.
I think people naturally want to defend themselves when they’re criticized, and while a lot of criticism can be genuinely stupid (it exists), I think the vast, vast majority is is people helping you, and to push back against that help, without giving it due consideration is not in your best interest.
In technology in particular, when you ask for a opinion, the chances of the person is trying to hurt your feeling, or make you feel small or be actively cruel is so vaninishlingly small, that even in the occasion that they’re wrong with their criticism, you should actually hold onto it like a precious gift. It's not necessarily the way criticism works in the rest of the world.
And in terms of code review, it's usually not an opinion of the person, it's an opinion of the code. It's why code review is so central to what we do. And it’s a really important reason why I wrote the Swift Style book because the ultimate nature of code is not just to compile, its to communicate. You can write obfuscated code, and it’ll work and compile, but it won’t be readable, maintainable or expandable. It won't be something that lasts, and as a software engineer your goal is not just writing code for today, hopefully your goal is to write code that is going to be around for decades.
They’re building blocks that are strong, and when pressure is put on them whether its growth or demand on the program, or just taking something and pushing it to the limits of its input, no matter how you’re doing it, you want it to be stress resistant as possible. That’s why when we code, we comment, test, review. That why you can waste an afternoon playing code golf, because that strength is so critical, because every developer who is developing for more than a school class, is going to reuse code. You don't want to have weak code, bricks that will crumble or infrastructure that hasn’t been thought through. The way you do that is by accepting criticism, by putting as much as much pressure on both yourself and the code, to create the best possible product.
If the only eyes that are looking at your code are your own, then you are missing stuff. My tip here is to put your code (or writing) aside for a day or two, and just get that distance. Just get some sleep, and go back with fresh eyes, and lets you do a bit of self criticism as well as going to others.
Sorry, long answer - but the point is that is the graciousness that allows all of this to happen. I just know my code is better and stronger when I work in groups.
### What would be your number one piece of advice for a successful software career?
The other half of the above is to always think of yourself as a learner, it’s not just keeping up with what's new in the field and all that, but also yourself.
It’s like being in a community of wizards, and there’s still so much wizardry to learn, you never can learn it all. People who have been doing unix command line, 30 or 40 years later, they’re still finding cool stuff they never knew about. There’s that moment of clarity when you discover a new trick, that you had no idea about - it’s wonderful. I think it's that sense of wonder that brings people into technology in the first place, and I think as software developers, we get that more than any other profession.
### Have you got any hobbies outside of your job? Do you think they help your tech career in any way?
Biking. It's the closest things humans can get to individually flying. It's just a very transformative activity. How fast you can go, where you can go, and much more.
### What is the Startup scene like in Colorado?
In Bolder, Google just moved in, so that’s cool. But, over the last 10 years, so many people have moved in from California, that prices are going through the roof - the same thing that happened in Austin, Texas. It was attractive, because it had the right kind of startups. Because of that, it didn’t have the infrastructure, to go as fast as people would have liked it to go, so they’re building like mad. Its losing a bit of it’s charm. It’s still a great place, but it’s growing really really fast.
### What books/resources would you recommend?
[How to write a computer manual: A handbook of software documentation](http://amzn.to/2pjcar8) - Jonothan Price (Apple) He basically based on the internal Apple training documentation. It’s just an absolutely brilliant book - from 1984!
Unlike software and computers, where there is always something new to discover, with writing, there is alway something old to discover. People have been doing it a lot longer, and there are certain basic truths in how to communicate, in how to instruct, how to be clear, how to be clear, and the beauty in simplicity. Some (in fact, quite a lot) of these transfer over to software, which is why I was able to bridge that in the Swift Style book, but with writing I particularly love that book. Even though, the particular technology he talks about feels completely alien to today’s eyes, how you keep things clear, well structured, and beautiful - that stuff still resonates.
### Finally, make your shoutout! What would you like the readers to go have a look at?
I have a book - [Swift Style](https://pragprog.com/book/esswift/swift-style), and I’m [on twitter](https://twitter.com/ericasadun)! | samjarman |
36,320 | Coding Worksheets! | a little something to explain coding concepts | 0 | 2018-06-22T23:21:55 | https://dev.to/kauresss/coding-worksheets-47in | javascript, webdev, beginners, showdev | ---
title: Coding Worksheets!
published: true
description: a little something to explain coding concepts
tags: JavaScript, webdevelopment,beginners, showdev
---
So I did a bit of explaining the concept of var flag/count as a way to track the state of an application. What seems intuitive now, wasn't always so. I created a "Kanye Says" coding worksheet to explain the concept of true/false, on/off state in code, by using the example of a light bulb that is switched on and off. Any suggestions/metaphors/examples that you use to explain coding concepts/logic?
{% codepen https://codepen.io/Kauress/pen/YvvPQO %}
| kauresss |
36,404 | Coding Worksheet #2 | If-Else conditional statements | 0 | 2018-06-24T14:26:42 | https://dev.to/kauresss/coding-worksheet-2-3kc0 | webdev, javascript, beginners, showdev | ---
title: Coding Worksheet #2
published: true
description: If-Else conditional statements
tags: webdev, JavaScript, beginners,showdev
---
For the coding bootcamp where I'm currently an instructor, I decided to create coding worksheets as a quick way to introduce a concept and it's related syntax before getting into logic. It's easier for a person learning to get familiar with structure and syntax before getting into the nitty gritty of implementing it a logical part of a bigger codebase/project.
Please send in your suggestions/edits and comments :)
{% codepen https://codepen.io//Kauress/pen/rKKMBe %} | kauresss |
36,485 | What method do you do when you want to remember app behavior ? | A method I am doing right now is just to write it down on excel A bot that check postgres connectio... | 0 | 2018-06-25T05:23:02 | https://dev.to/hongduc/what-method-do-you-do-when-you-want-to-remember-app-behavior--182m | discuss | ---
title: What method do you do when you want to remember app behavior ?
published: true
description:
tags: discuss
---
A method I am doing right now is just to write it down on excel
- A bot that check postgres connection and send email alert
I do it this way because it fast and simple, not drawing any thing (because I lazy :) ), but it just a stupid and lazy way, so I want to know what others developer around the world do :D | hongduc |
36,637 | Safe, reliable Browser sniffing | Browser detection using top-level object in the BOM. No third party. | 0 | 2018-06-25T17:47:08 | https://dev.to/mahmoudelmahdi/safe-reliable-browser-sniffing-39bp | javascript, browser, detection, desktop | ---
title: Safe, reliable Browser sniffing
published: true
description: Browser detection using top-level object in the BOM. No third party.
tags: javascript, browser, detection, desktop
cover_image: https://thepracticaldev.s3.amazonaws.com/i/rrudcplxhq4x2o3rfcci.png
---
We've recently built a WebExtension for our Web Application as Add-on and extra feature to sell 💰💸 (b/c why not). We decided to serve 4 different browser types: **Chrome**, **Safari**, **Opera**, and **Firefox**. So we had to figure out which browser is rendering our page to display a browser-specific instructions to the users.
---
## You're lying to me. Aren't You?
**Browser detection using the user agent** is just sucks!! because it's trivial to spoof this **value**. For example the snippet below:
```javascript
navigator.userAgent.indexOf('Chrome') !== -1
```
returns `true` for both **Google Chrome** and **Opera** (*since Opera replaces its engine with Blink + V8 used by Chromium*) because its UA string looks like Chrome. Thats is not what am looking for. And if we're trying to detect a specific browser, the point of feature-checking is kind of lost.
> Check out [MDN web docs: Browser detection using the user agent](https://developer.mozilla.org/en-US/docs/Web/HTTP/Browser_detection_using_the_user_agent) for futher details.
## Top-level object FWT
`window` is the top-level object in the **Browser Object Model** (**BOM**) hierarchy. Every single browser has its own properties such as *ApplePayError* in Safari for instance, in addtion to the standard ones (e.g. `window.location`, `window.console`, ...etc).
## Solution
```javascript
/*
* Browser detection
* @return {String}
*/
const browserDetection = () => {
const browsers = {
firefox: !!window.InstallTrigger,
safari: !!window.ApplePaySession,
opera: window.opr && !!window.opr.addons,
chrome: window.chrome && !!window.chrome.webstore
};
return Object.keys(browsers).find(key => browsers[key] === true);
};
console.log(browserDetection()) // browser name expected
```
* **Firefox**: The `InstallTrigger` interface is an interesting outlier in the Apps API.
* **Safari**: `ApplePaySession` belongs to the Apple Pay JS API. A session object for managing the payment process on the web.
* **Opera**: `opr` self explanatory. `.opr.addons` represent interface in the Add-ons API
* **Chrome**: ~~`chrome.webstore` API to initiate app and extension installations "inline" from web page~~. Notice: this will be [deprecated](https://dev.to/_elmahdim/safe-reliable-browser-sniffing-39bp#comment-node-118287), thanks to [Madison Dickson](https://dev.to/mix3d). Any recommendations are welcome!
## Tested in the following "Desktop Browsers":
✓ **Firefox Quantum** Version ~60
✓ **Google Chrome** Version ~67
✓ **Opera** Version ~53
✓ **Safari** Version ~11
**Please keep in mind**, that solution worked just perfectly in my case, and <u>might not fit yours</u>.
## [Demo on Codepen](https://codepen.io/elmahdim/full/bKjmbb/)
---
**Feedback are welcome**. If you have any suggestions or corrections to make, please do not hesitate to drop me a note/comment. | mahmoudelmahdi |
114,637 | Milestones and Obstacles of Being a Mentor | My experience while mentoring on codementor.io | 0 | 2019-05-27T11:01:22 | https://dev.to/oleksandr/milestones-and-obstacles-of-being-a-mentor-mj3 | mentorship, career, webdev, motivation | ---
title: Milestones and Obstacles of Being a Mentor
published: true
description: My experience while mentoring on codementor.io
tags: mentorship, career, webdev, motivation
---

*Bee-ing a mentor*
## Prelude
Once upon a time, I was on vacation and interested in development mentoring to improve my mentoring skills.
I was preparing for the Senior S/W engineer assessment for my main full-time job, so [codementor.io](https://www.codementor.io/alexanderposhtaruk) was an ideal fit for that purpose.
My vacation was full of mentoring sessions and these are the main obstacles I encountered during that experience. I want to share them with people who want to start their own mentoring activities.
## Obstacle #1 — Money transfer if you are from post-USSR countries.
I am from Ukraine and the only working method for me is Bitcoin. Because the **Bitcoin** transfer fee is quite large at the moment, I need to ask Codementor Support to put my weekly payout on hold every week and transfer monthly instead. Later they implemented a special feature - so now you can put payouts on hold - it is very convenient now.
The second possible solution is Transferwise, but for Ukraine, transfer by email is not supported for the regular Transferwise account. I have requested a Borderless account, but be ready to provide document scans for your identity validation. *For now, it is my main payout transfer method.*
Validation takes some time, but Transferwise support is very helpful.
Receiving money through PayPal is not permitted in Ukraine.
## Obstacle #2 — Oral arrangements work 50/50.
Some mentees prefer oral arrangements. However, a few times when I connected at the discussed time, there was nobody on the other side. ISP problems, life issues, blah blah.
Just be ready for that and use Codementor scheduling — it decreases the probabilities of such events. To prevent time wasting, I usually have some Plan B activity I can switch to in case of any delay or session postponement/cancellation.
## Obstacle #3 — Technical issues (mentee side).
Some mentees cannot install Zoom on their computers for many reasons: lack of experience, work computer restrictions, some specific OS installation. Be ready to wait for your mentee or reschedule the session.
## Obstacle #4 — Technical issues (mentor side).
I use the full scope of Codementor applications: website, Android app, and macOS application for my MacBook Pro.
What I've noticed is that the Android application shows new request notifications with a five to ten-minute delay. That is enough time for other mentors to have already grabbed your mentee :-)
Now, I just keep my open laptop close to see new requests on the website ASAP.
## Obstacle #5 — Budget.
Some mentees don't have enough budget to cover all of the time you've spent on their issues. If I have time and want to help, I agree to their conditions.
We will then use free sessions and the mentee will make a direct Codementor payment (as a freelance job). I know that Codementor Support recommends against this approach in case of dishonest mentees, and there is no possibility to help you to get money, but thank God there have not been any incidents yet.
## Obstacle #6 — Doubtful offers.
Twice I was propositioned with direct payments, bypassing the Codementor site. However, that is unacceptable for me, so I said that, and we continued working according to the Codementor flow.
## Obstacle #7 — Personal issues.
a) Sometimes I experienced some sudden session interruptions and excuses like:
- Sorry, my boss entered the room.
- I need to postpone, have urgent work to do, or no excuses at all — the mentee just disappears (possibly ISP issues). This is not a disaster if you're prepared.
b) One more interesting thing — asking for a small piece of advice in a chat, which you answer in five minutes, but all you get is 'Thank you, sir'. Should I ask for some bonus fee for that?
## Obstacle #8 — Combining main job/family with Codementor activity.
I have a full-time job that I like. I started mentoring when I was on vacation, so there were no problems with job duties and family time.
When I start working full-time again, it became tricky to combine all of these activities, so I had to restrict my Codementor time to a few hours in the morning.
Sometimes I have sessions during working hours and then work out afterward. Evening time is for family, so my mentoring activity has been drastically reduced for now.
## Obstacle #8 — spent time.
Be aware that time you get money for and time spent for mentoring are different: sometimes you should prepare and then spend time to understand the issue (sometimes you see you cannot solve it, so you say that to the mentee — it is time spent also) and postpone the session for a mentee's personal reasons.
All of these can take quite a bit of time.
## Whether I like mentoring now?
The answer is YES.
Why?
Because it is interesting to speak to different people. It pumps up my problem-solving skills and makes my professional vision much wider.
I learned some technologies in the scope of mentoring activities. You should understand quite quickly where the problem is and find the solution fast — this is the way I like to work, yeah :)
## Good parts:
1. Most mentees are really polite and honest — they don't waste your time and are ready to cooperate and explain the problem in detail.
2. Bitcoin payout method really helps to avoid transfer problems (looking forward to manual payout triggering).
3. Codementor Support is very polite and helpful. They are ready to discuss your new **codementor.io** features proposals.
4. Codementor provides a really convenient and easy-to-use environment for mentoring activities (I especially like the Incoming Request Popularity diagram and schedule page timezone widget, which I see on the mentee-type account page).
## Do I have enough money to leave my full-time job?
Depends on the job you have :) For me — no, if you're confined to mentoring sessions only. However, mentoring sessions are a good way to feel out your developer strength and start looking into the elite freelance development field (CodementorX, etc.) if you didn't have such experience before. I am still on the mentoring step, so I cannot tell you more.
## Conclusion
Stay hungry, stay foolish (Steve Jobs). Be honest, be clever (me :)).
Liked this article? Let's stay in touch on [Twitter](https://twitter.com/El_Extremal).
*This article was originally published on [codementor.io](codementor.io) | oleksandr |
36,674 | Module Monday: Parallax scroll, Image gallery, Sidenav, & more | Free, open-source modules for your next project | 0 | 2018-06-25T20:55:49 | https://guide.anymod.com/module-monday/01.html | showdev, opensource, webdev, javascript | ---
title: Module Monday: Parallax scroll, Image gallery, Sidenav, & more
published: true
description: Free, open-source modules for your next project
tags: showdev, opensource, webdev, javascript
cover_image: https://res.cloudinary.com/component/image/upload/v1529958478/parallax_by9zk7.gif
canonical_url: https://guide.anymod.com/module-monday/01.html
---
Mods are functional, ready-to-use web modules for any website, on any platform.
## Open source: fork or copy + use anywhere
All of the mods below are open sourced by [Anymod](https://anymod.com) and free to use in any project you choose, whether on Anymod or not.
We support developers and open source, and Module Mondays are one way we give back to the developer community to help foster a more open, inclusive web. We hope you enjoy!
### Parallax scroller
Customize with your own text and images.
<a class="button" href="https://anymod.com/mod/monrk?v=20">View mod</a>
<a href="https://anymod.com/mod/monrk?v=20">
<img src="https://res.cloudinary.com/component/image/upload/v1529958478/parallax_by9zk7.gif"/>
</a>
### Responsive gallery
Click to zoom on images. Add the gallery anywhere.
<a class="button" href="https://anymod.com/mod/onakb?v=20">View mod</a>
<a href="https://anymod.com/mod/onakb?v=20">
<img src="https://res.cloudinary.com/component/image/upload/v1529958476/gallery_pkkyu1.png"/>
</a>
### Contact form
Works automatically: material design with reCaptcha.
<a class="button" href="https://anymod.com/mod/anaom?v=20">View mod</a>
<a href="https://anymod.com/mod/anaom?v=20">
<img src="https://res.cloudinary.com/component/image/upload/v1529958475/form_pfx91k.png"/>
</a>
### Image uploader
Upload images to Cloudinary with ease.
<a class="button" href="https://anymod.com/mod/onabb?v=30">View mod</a>
<a href="https://anymod.com/mod/onabb?v=30">
<img src="https://res.cloudinary.com/component/image/upload/v1529958480/uploader_jydghw.png"/>
</a>
### Sidenav
Stylish nav that slides out with a click.
<a class="button" href="https://anymod.com/mod/bkmnr?v=20">View mod</a>
<a href="https://anymod.com/mod/bkmnr?v=20">
<img src="https://res.cloudinary.com/component/image/upload/v1529958475/sidenav_jowk4j.png"/>
</a>
## Contributing
If you want to contribute mods or ideas so that other developers can benefit, you can [request mods](https://guide.anymod.com/v1/community/requests.html) or [submit a mod](https://guide.anymod.com/v1/community/contributing.html).
I'll be posting new modules [here](https://dev.to/tyrw) every Monday -- I hope you find them useful!
Happy coding ✌️ | tyrw |
37,001 | Python config file with YAML | How to use a YAML as a config file with python. | 0 | 2018-08-06T08:23:21 | https://dev.to/tomtucka/python-config-file-with-yaml-3e31 | python | ---
title: Python config file with YAML
published: true
description: How to use a YAML as a config file with python.
tags: python
---
So I was googling for this myself about 4 weeks ago and couldn't find a straight answer, so I'm about to share an easy step by step solution with you.
First off I'm going to assume that you already know some python and have a project setup ready to go inside a venv.
First off lets import yaml,
```
import yaml
```
so now lets create a method called `load_config`
```
import yaml
def load_config(config_file):
```
As you can see we are also passing in `config_file`, Next, we are going to open our config file as a stream using `open` which is built into python.
```
import yaml
def load_config(config_file):
with open(config_file, 'r') as stream:
```
Using open, we can now open our config file and return a stream. So here we pass in our `config_file` variable which we defined earlier, we also pass in another parameter which is a string of `r` this basically tells `open` which mode we want to open the file in. Now we can move on to loading our YAML file.
```
def load_config(config_file):
with open(config_file, 'r') as stream:
try:
return yaml.safe_load(stream)
except yaml.YAMLError as exc:
print(exc)
```
As you can see above, we now load our YAML file using `safe_load`. It's extremely important to use `safe_load` here, `safe_load` only resolves basic YAML tags, whereas `load` does not. This is also wrapped in a `try except` block so we can handle any errors.
All that's left to do now is call our method to load the file, make sure you pass in the path to your config.yml file here.
```
config = load_config('config.yml')
```
This is my first ever blog post any feedback would be greatly appreciated! :) | tomtucka |
37,419 | upcoming: Building Images With S2I | how to build Docker images with s2i | 0 | 2018-07-02T23:45:21 | https://dev.to/osninja_io/upcoming-building-images-with-s2i-3dnd | docker, containers, images, opensource | ---
title: upcoming: Building Images With S2I
published: true
description: how to build Docker images with s2i
tags: docker, containers, images, opensource
cover_image: https://thepracticaldev.s3.amazonaws.com/i/e15yj4ia50ywdn621a4l.jpeg
---
I will be crafting a http://tos.ninja entry tonight on S2I, the open source tool that lets you easily build Docker, Inc images for Java, JBoss, WildFlyAS, and more. Easy to use and very extensible. Works great with OpenShift but can also be used standalone. | osninja_io |
37,611 | Python Has a Startup File! | Of course I knew that Python has a startup customization file this whole time. I didn't just learn about it. Shut up. | 0 | 2018-07-04T15:59:18 | https://assertnotmagic.com/2018/06/30/python-startup-file/ | python, tricks | ---
title: Python Has a Startup File!
published: true
description: Of course I knew that Python has a startup customization file this whole time. I didn't just learn about it. Shut up.
tags: python, tricks
cover_image: https://thepracticaldev.s3.amazonaws.com/i/o58w6uut1dt619p4w0kp.jpg
canonical_url: https://assertnotmagic.com/2018/06/30/python-startup-file/
---
*Cover Photo by Uriel Soberanes on Unsplash*
So, I want to be clear. *I* knew that Python has a startup customization file this whole time I've been using Python. *I* didn't just find out about it this week. I mean, of *course* Python has a startup file. Everything has a startup file! I just want to make sure *you* know about it. *(Only joking, I had no idea this was a thing.)*
> Before you bring it up, I already know about [bPython](https://bpython-interpreter.org/screenshots.html), the awesome, syntax-highlighty, tab-completey, auto-indenty, wonderful drop in replacement for the regular Python interpreter. I use it all the time. But that's not what this blog post is about. P.S. if you didn't know about bPython, I highly recommend it (Windows users' mileage may vary).
## $PYTHONSTARTUP
If you have the environment variable `$PYTHONSTARTUP` set to a valid Python file, that file will get run when starting up the Python interpreter.
```bash
$ export PYTHONSTARTUP="~/.config/pythonrc.py"
```
Don't worry about the name of the file. Name it whatever you want! `python_startup.py`, or just `pythonrc`. You can also put it in whatever directory you want. Just make sure your `$PYTHONSTARTUP` environment variable matches. Then, you can put anything you want into that file.
```python
# ~/.config/pythonrc.py
a = "Wahoo!"
print("Soup")
try:
import numpy as np
except ImportError:
print("Could not import numpy.")
```
Try running your Python interpreter.
```bash
$ python # or python3
```
And you should see something similar to the following:
```python
Python 3.7.0 (default, Jun 29 2018, 20:14:27)
[Clang 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Soup
>>> np
<module 'numpy' from '/usr/local/lib/python3.7/site-packages/numpy/__init__.py'>
>>> np.zeros((3, 2))
array([[0., 0.],
[0., 0.],
[0., 0.]])
>>> a
'Wahoo!'
```
You can import commonly used libraries, create variables for yourself, and more.
## sys.ps1 and sys.ps2
One neat thing to do is to set the `sys.ps1` and `sys.ps2` variables, which control your Python prompts.
```python
# ~/.config/pythonrc.py
import sys
sys.ps1 = "🌮"
sys.ps2 = "💩"
# ...
```
And, back in the interactive REPL:
```python
🌮 for i in range(10):
💩 print("I am a mature adult.")
💩
I am a mature adult.
I am a mature adult.
...
```
In fact, you can even set `sys.ps1` and `sys.ps2` to objects that aren't even strings! If they're not strings, Python will call `str(obj)` on them.
```python
# ~/.config/pythonrc.py
import sys
from datetime import datetime
class CustomPS1:
def __init__(self):
self.count = 0
def __str__(self):
self.count += 1
return f"({self.count}) {datetime.now().strftime('%H:%m %p')} > "
sys.ps1 = CustomPS1()
```
And in the interpreter:
```python
(1) 10:06 AM > for i in range(10):
... print("Am I cool now?")
...
Am I cool now?
Am I cool now?
# ...
(2) 11:06 AM >
```
## The -i Flag
In addition to these new superpowers, you can temporarily make *any* Python script your startup script. This could come in really handy for some interactive debugging. Let's say you're working on a project and you have a script that defines some functions:
```python
# cool_script.py
def what_time_is_it():
return "Party Time"
```
You can use the `-i` flag when you run the Python interpreter to use `cool_script.py` as your startup file instead of your usual one.
```python
$ python -i cool_script.py
>>> what_time_is_it()
'Party Time'
```
If you do some cool things with your startup file, share it with me! I want to know about it! Happy coding!
<br>
*Originally posted on [`assert_not magic?`](https://assertnotmagic.com/2018/06/30/python-startup-file/)* | rpalo |
38,016 | JavaScript Quiz Part 2 | JavaScript Quiz Part 2 | 0 | 2018-07-07T14:13:13 | https://dev.to/sait/javascript-quiz-part-2-2iog | javascript, challenge, beginners | ---
title: JavaScript Quiz Part 2
published: true
description: JavaScript Quiz Part 2
tags: javascript,challenge,beginners
---
If you want to answer part1 check out [part1](https://dev.to/saigowthamr/javascript-quiz--5c5j)
>1.How to reverse a String Using Reduce Method.
>example: if you pass 'king' as an argument output is 'gnik'
>2.what is the difference between slice and splice.
>3.How to convert an object into a string? | sait |
38,058 | Get Image From Local Resource Folder In React Native | In this tutorial, we will explain how to get image from local resource folder and display the image in react native application. This example covers, fetching and displaying an image from network location using Image Component of react native.React native provides a unified media management system so developers can easily manage all the image files by placing them together into a single folder. So here is the complete step by step tutorial for Show Image from Local Resource Folder in react native. | 0 | 2018-07-08T10:08:13 | https://dev.to/skptricks/get-image-from-local-resource-folder-in-react-native-4ml7 | javascript, react, reactnative, image | ---
title: Get Image From Local Resource Folder In React Native
published: true
description: In this tutorial, we will explain how to get image from local resource folder and display the image in react native application. This example covers, fetching and displaying an image from network location using Image Component of react native.React native provides a unified media management system so developers can easily manage all the image files by placing them together into a single folder. So here is the complete step by step tutorial for Show Image from Local Resource Folder in react native.
tags: #javascript #react #reactnative #image #reactjs
---
# Get Image from Local Resource Folder in React Native
Post Link : https://www.skptricks.com/2018/07/get-image-from-local-resource-folder-in-react-native.html
In this tutorial, we will explain how to get image from local resource folder and display the image in react native application. This example covers, fetching and displaying an image from network location using Image Component of react native.
React native provides a unified media management system so developers can easily manage all the image files by placing them together into a single folder. So here is the complete step by step tutorial for Show Image from Local Resource Folder in react native.
<a href="https://www.skptricks.com/2018/07/get-image-from-local-resource-folder-in-react-native.html" >Get Image from Local Resource Folder in React Native </a>
<img src="https://2.bp.blogspot.com/-7Ve11Ce0XNQ/W0Bh4pQRV4I/AAAAAAAABq8/bUUN70chQdwo5S7sJzgqbROhZ_Z9BuqywCLcBGAs/s400/loca.jpg" />
| skptricks |
38,197 | Add Makeup to Your Borders | Learn about new ways you can style a border. | 0 | 2018-07-09T09:17:09 | https://dev.to/neshaz/add-makeup-to-your-borders-i95 | css, webdesign, webdev | ---
title: Add Makeup to Your Borders
published: true
description: Learn about new ways you can style a border.
tags: CSS, web design, web development.
---
The CSS border property is pretty familiar. With this property, you can define the **color, style and width** of an element border.
The border-image property, on the other hand, lets you **define a gradient or an image for a border**.
The border-image-property is a shorthand for the following:
* **Border-image-source** - the source of the image,
* **Border-image-slice** - defines the dimensions of slicing the source image into regions,
* **Border-image-width** - defines the width of the border image,
* **Border-image-outset** - defines the distance between from the border image to the element's edge,
* **Border-image-repeat** - defines how the image is repeated to fill the area of the border.
When using this shorthand, if any of the values is omitted, **its value will be set to initial.**
##The Syntax
When using the border-image property, you can anywhere from one to all the five values mentioned before.
Let’s take a look at the syntax. I will be using the shorthand property.
```
.box {
border-image:
url(‘images/border.png’) /* source */
27 / /* slice */
12px 5px 15px 20px / /* width */
5px 12px 17px 22px /* outset */
round /* repeat */
}
```
##Examples
Let’s show examples for when you want to use a gradient as a border or an image as a border.
###Making a Border Out of a Repeating Image
The image I will use when creating the border is the following:

HTML
```
<div class=”box”></div>
```
CSS
```
.box {
width: 200px;
background-color: #000;
border: 50px solid #DE31ED;
margin: 10%;
padding: 10px;
border-image:
url("../images/border.png") /* source */
50 / /* slice */
25px / /* width */
12px /* outset */
round /* repeat */
}
```
The result:

###Making a Border Out of a Gradient
I will use the same box element as in the previous example, only the CSS will be different.
CSS
```
.box {
width: 200px;
height: 200px;
background-color: #000;
border: 20px solid transparent;
padding: 10px;
margin: 10%;
border-image: repeating-linear-gradient(60deg, #DE31ED, #31E2ED 50px) 20;
}
```
The result:

##Browser Compatibility
The best way to see what is the compatibility of a property is to check out the [CanIUse](https://caniuse.com/) service.

Here you see that the compatibility is generally very good. There are a few issues with **border-image-repeat: space** in Chrome, so you should be on the lookout for that.
##Conclusion
Although rarely used, the border-image property is quite interesting. It can bring a unique dimension to your design. The best way to see what works for you is to play with the property and unlock its full potential!
Thank you for reading!
This post is originally published on [Kolosek Blog](https://kolosek.com/css-border-image/?utm_source=dvt).
Do you need a hand with CSS? No problem, just send me a message and I will make sure my team reaches out to you!
| neshaz |
38,202 | Profiling | Terms Profiling – dynamic analysis of software, consisting of gathering various metrics an... | 0 | 2018-07-09T10:16:26 | https://alex.dzyoba.com/blog/profiling/ | linux, profiling | ---
title: Profiling
published: true
tags: linux, profiling
canonical_url: https://alex.dzyoba.com/blog/profiling/
---
## Terms
**Profiling** – dynamic analysis of software, consisting of gathering various metrics and calculating some statistical info from it. Usually, you do profiling to analyze performance though it’s not the single case, e.g. there are works about profiling for [energy consumption analysis](http://infoscience.epfl.ch/record/181628/files/eprof.pdf).
Do not confuse profiling and tracing. _Tracing_ is a procedure of saving program runtime steps to debug it – you are not gathering any metrics.
Also, don’t confuse profiling and benchmarking. Benchmarking is all about marketing. You launch some predefined procedure to get a couple of numbers that you can print in your marketing brochures.
**Profiler** – program that does profiling.
**Profile** – result of profiling, some statistical info calculated from gathered metrics.
## Metrics
There are a lot of metrics that profiler can gather and analyze and I won’t list them all but instead try to make some hierarchy of it:
- Time metrics
- Program/function runtime
- I/O latency
- …
- Space metrics
- Memory usage
- Open files
- Bandwidth
- …
- Code metrics
- Call graph
- Function hit count
- Loops depth
- …
- Hardware metrics
- CPU cache hit/miss ratio
- Interrupts count
- …
## Profiling methods
The variety of metrics implies the variety of methods to gather it. And I have a beautiful hierarchy for that, yeah:
- Invasive profiling – changing profiled code
- Source code instrumentation
- Static binary instrumentation
- Dynamic binary instrumentation
- Non-invasive profiling – without changing any code
- Sampling
- Event-based
- Emulation
(That’s all the methods I know. If you come up with another – feel free to contact me).
A quick review of methods.
Source code instrumentation is the simplest one. If you have source codes you can add special profiling calls to every function (not manually, of course) and then launch your program. Profiling calls will trace function graph and can also compute time spent in functions and also branch prediction probability and a lot of other things. But oftentimes you don’t have the source code. And that makes me saaaaad panda.
Binary instrumentation is what you can guess by yourself - you are modifying program binary image - either on disk (program.exe) or in memory. This is what reverse engineers love to do. To research some commercial critical software or analyze malware they do binary instrumentation and analyze program behavior.
Anyway, binary instrumentation also really useful in profiling – many modern instruments are built on top binary instrumentation ideas (SystemTap, ktap, DTrace).
Ok, so sometimes you can’t instrument even binary code, e.g. you’re profiling OS kernel, or some pretty complicated system consisting of many tightly coupled modules that won’t work after instrumenting. That’s why you have non-invasive profiling.
Sampling is the first natural idea that you can come up with when you can’t modify any code. The point is that profiler periodically asks CPU registers (e.g. PSW) and analyze what is going on. By the way, this is the only reasonable way you can get hardware metrics - by periodical polling of [PMU](performance%0Amonitoring%20unit).
Event-based profiling is about gathering events that must somehow be prepared/preinstalled by the vendor of profiling subject. Examples are inotify, kernel tracepoints in Linux and [VTune events](http://software.intel.com/sites/products/documentation/doclib/iss/2013/amplifier/lin/ug_docs/GUID-EEC5294C-5599-44F7-909D-9D617DE8AB92.htm).
And finally, emulation is just running your program in an isolated environment like virtual machine or QEMU thus giving you full control over program execution but garbling behavior.
## Resources
- [Profiling wikibook](http://en.wikibooks.org/wiki/Introduction_to_Software_Engineering/Testing/Profiling) | dzeban |
38,459 | The Making of a Programming Language: Slate [Part 1] | The first in a series in my journey making the Slate language. | 0 | 2018-07-10T02:45:44 | https://dev.to/nektro/the-making-of-a-programming-language-slate-part-1-4528 | webassembly, slate, slatedev, computerscience | ---
title: The Making of a Programming Language: Slate [Part 1]
published: true
description: The first in a series in my journey making the Slate language.
tags: webassembly, slate, slatedev, computerscience
cover_image: https://pmirock.com/wp-content/uploads/2016/06/Slate.jpg
---
I made a new programming language! (((Note: right now it can only add number literals to each other and export constants, but it runs!!))
# [Part 1] Introduction
# Slate!
In the recent time, I've been working on making a brand new programming language and it's called Slate! This is going to be a series, more or less start to "finish" as I document my progress making the compiler, standard library, and maybe even some programs in Slate.
Slate is the (first?) programming language that compiles directly from source code to [WebAssembly](https://webassembly.org/). Yes, that's why I've been asking about WASM for so long :). The syntax is largely inspired by JavaScript ES2015+ with other influences from Java, Kotlin, and more.
# So what can it do right now? A new language? Why? How is it different? Can I use it?
Right now this is about all it does.
```
/**
* https://github.com/nektro/slate/blob/master/tests/02.grammar/01.operators/001.slate
*/
//
export const expected = 80;
//
export function main(): i32 {
return 48 + 32;
}
```
What do?
You can export integer constant literals and export a function that adds integer literals together. That's about it. But `slate.js` can fully parse this and export a WASM Module that does the same, albeit very literal for now.
Why make?
I really love JavaScript. This love stems from a broader love of the Web as a platform as a whole and JS is all we get. Until now! WebAssembly is the answer to the old question "is the Web getting any other languages other than JavaScript?". With WASM gains access ALL THE LANGUAGES[1]. So in part of a love for JS, part for a desire to make my own language because, and to try to implement features I've never seen before, I set out to make a language specifically for the Web through WASM.
*[1]: provided aforementioned language has the proper toolchain*
And through this series I'm going to document more or less the entire journey.
How different?
Slate is strongly typed. So that's one thing that's different. But I also want to add things like operator overloading, object extensions(Like adding onto `<Object>.prototype` but in a statically typed lang), and more.
Can I use it?
Technically yes! If you'd like to compile the program above and run it in your very own WebAssembly-supporting browser then you can do the following:
```js
import * as slate from "https://rawgit.com/nektro/slate/master/src/slate.js"
const slate_program = `
/**
*
*/
//
export const expected = 80;
//
export function main(): i32 {
return 48 + 32;
}
`;
Promise.resolve(slate_program)
.then(x => slate.parse(x))
.then(x => x.instance)
.then(x => x.exports)
.then(x => {
// `x` == { expected: 80, main: func() { [native code] } }
});
```
# How did you do it?
Like any other language, there are a number of steps that are similar between making a compiler and all of them take place in Slate as well.
- Lexical Analysis
- Parser
- Semantic Analyzer
- Code Generation
- Linker
## 1. Lexical Analysis
This step was made easy because the majority of code used for this part was already written [when I made an HTML preprocessor](https://dev.to/nektro/how-i-accidentally-wrote-an-awesome-html-preprocessor-995) and added to my [basalt](https://github.com/nektro/basalt/blob/master/src/lex.js) javascript library. The code for Slate's lexer can be [found here](https://github.com/nektro/slate/blob/master/src/lexer.js).
Our lexer will take the text of our program and do some really handy things for us. It has to remove the comments, as well as convert the code into a list of tokens with data that we can then later pass onto the parser.
So with the lexer set up properly, basalt will turn our test program into something like the code below.
```js
[
Key("export"),
Key("const"),
Id("expected"),
Symbol(=),
Int(80),
Symbol(;),
Key("export"),
Key("function"),
Id("main"),
Symbol("("),
Symbol(")"),
Symbol(":"),
Id("i32"),
Symbol("{"),
Key("return"),
Int(48),
Symbol("+"),
Int(32),
Symbol(";"),
Symbol("}")
]
```
## 2. Parser
This part of the process was also very involved when I made my HTML preprocessor so parsing is also a [module in basalt](https://github.com/nektro/basalt/blob/master/src/parse.js). Basalt helps us build a parser but we still have to add all the magic. Slate's parser [is here](https://github.com/nektro/slate/blob/master/src/parser.js). Those familiar with the computer science here, we are attempting to create a [formal language](https://en.wikipedia.org/wiki/Formal_language) by means of a pseudo-[context-free grammar](https://en.wikipedia.org/wiki/Context-free_grammar). [ANTLR](http://www.antlr.org/) is another big project in this space of creating a lexer/parser in a format much more similar to [Backus–Naur form](https://en.wikipedia.org/wiki/Backus%E2%80%93Naur_form).
Simply put, we have to come up with a series of patters that can take our token list from before and compress it down into a single express that we can then analyze later to create our program.
After that process, our test program looks more like this:
*Note: I'm skipping the code demo part because the output from the parser is very verbose and the next step we're going to condense it down a bit to show the same information but in a lot more useful format*
## 3. Semantic Analyzer
This part is done in Slate by the "converter" which takes the very verbose output from the parser, verifies it, and generates the [AST](https://en.wikipedia.org/wiki/Abstract_syntax_tree). The source for the Slate converter can be [found here](https://github.com/nektro/slate/blob/master/src/converter.js).
So now what does our program look like?
```js
File(
Export(
Const(
"expected"
80
)
)
Export(
Function(
"main"
Parameters(
)
"i32"
Block(
Return(
Add(
48
32
)
)
)
)
)
)
```
## 4. Code Generation
Whew! Almost there! At this point we have a nice AST but now need to compile to WebAssembly so that it's able to run by `WebAssembly.instantiateStreaming()`, etc. Since I wanted to make this a *little* easier on myself, I decided to have my compiler generate WASM in the [text format](https://webassembly.org/docs/text-format/) as opposed to the [binary format](https://webassembly.org/docs/binary-encoding/) and then to use [wabt](https://github.com/WebAssembly/wabt/) to convert the text to binary WASM. Trust me, I love WebAssembly and what it stands for, but even trying to figure out the text format has been *difficult*. There is very little docs on the formats currently and most of what I've going off is the WASM platform spec tests and output from various WASM playgrounds.
The code for generating WAST from our AST is actually attached to the objects sent out of the converter, so that code [is here](https://github.com/nektro/slate/blob/master/src/objects.js). After generation of said WAST we shoudld get the following:
```wast
(module
(memory $0 1)
(global i32 (i32.const 80) )
(export "expected" (global 0) )
(func (export "main") (result i32)
(i32.add (i32.const 48) (i32.const 32) )
)
)
```
Hooray! 🙌
## 5. Linker
For now we're actually done. Imports are not currently implemented and there is no standard library yet, so this phase will have to come later.
----
Thanks for reading! If you liked this, let me know what you'd like to see in the future of Slate and stay tuned for more!
Coming up in future installments:
- Design ideas and long term goals
- More operators
- Type inference to add support for floating point numbers and objects
- Variables
- `if`, `while`, `for`, etc
- Strings
- More functions
- Classes
- Metaprogramming
----
Links to save you a scroll:
Follow Slate on GitHub! https://github.com/nektro/slate
Follow me on Twitter! https://twitter.com/nektro
Follow me on Dev! https://dev.to/nektro | nektro |
38,824 | Hiring in tech? Don't compete on price | Quality of life is your secret weapon | 0 | 2018-07-11T18:01:07 | http://isaaclyman.com/blog/posts/dont-compete-on-price/ | business, health, management | ---
title: Hiring in tech? Don't compete on price
published: true
description: Quality of life is your secret weapon
tags: business, health, management
---
There's a strong business case—a financially sound, *common-sense* case—for acquiring tech talent such as developers, designers, product managers, and QA engineers using quality-of-life values instead of competing on compensation. Conversations about this topic have been taking place in online developer communities for years, but it seems these ideas haven't penetrated the larger tech and business world. If you read on, you'll find there's a wealth of compelling evidence in favor of offering shorter workdays and remote options to your employees as a hiring and loyalty incentive, rather than trying to out-pay the market.
## Competing on price
Anyone who's taken an econ class knows that when the goal is to make money, there is no greater evil than price competition. Economic theory teaches that when two companies are selling comparable products, competition will lead them to undercut each other and lower their prices until neither one is turning a profit. Grocery stores, like many businesses, are always trying to break this cycle using techniques like loyalty cards, "price discrimination" (coupons and short-lived sales), and exclusive premium products. If your local FoodMart has recently unveiled a fancy cheese or sushi island, you're witnessing an attempt to claw its way out of the profitless pit of price competition.
Tech talent has the same problem, but upside-down. For example, software engineer salaries have risen dramatically since 2010, report [Forbes](https://www.forbes.com/sites/quora/2016/04/14/how-the-salaries-of-software-engineers-have-evolved-over-the-past-20-years/#64c3cf381cbf) and [CBS News](https://www.cbsnews.com/media/7-jobs-with-fast-growing-salaries/2/). This is because talent is relatively scarce and demand is high and rising. The same forces that drive down the price of milk and eggs will drive up engineer salaries until the median salary is similar to the median value they provide. In other words, if you're a businessperson in the software world, the hiring market is coming for your lunch.
Attempts to get a good deal on talent often come in the form of stock options, corporate culture, and on-site perks like catered lunches or massage therapists. These are effective in some cases, but:
- The consensus on stock options is turning negative, thanks to the fact that they [usually](https://money.usnews.com/investing/articles/2017-01-12/are-stock-options-worth-the-effort) end up being [worthless](https://davidcummings.org/2017/02/06/4-reasons-why-startup-stock-options-are-usually-worthless/). Even when they have a positive return, their after-tax value is [generally miniscule](https://www.forbes.com/sites/baldwin/2017/06/13/how-much-are-those-employee-options-worth/#5f8b1de464cf) or no better than a common year-end bonus. Some recent grads still see dollar signs when stock options are mentioned, but by and large the tech community sees them as only slightly more valuable than a lottery ticket.
- Generally speaking, a company's claims about its culture—often poisoned by empty terminology such as "cool," "exciting," "meaningful," or "rockstar"—are at best stunning examples of the [Dunning-Kruger](https://en.wikipedia.org/wiki/Dunning%E2%80%93Kruger_effect) effect and at worst willful fictions. Most people have learned that these statements are filler, intended to cover up the company's unhealthy expectations or lack of real benefits.
- Free lunch, ping-pong and massages are nice, but experienced talent will know that the value of these perks amounts to several hundred dollars or so per year, which pales in comparison to a higher salary or a good health insurance package. What's worse, these perks often veil a company's quiet pressure to work longer hours and tolerate toxic elements in the workplace.
The most experienced and talented members of the tech community have, in my observation, learned to value a few things above all else:
- Salary. This is a flat number that can be taken mostly at face value and compared apples-to-apples between offers.
- A workplace that does not actively harrass or mistreat them (people find this out through casual networking and rumors).
- A team whose product is under active development, where individual contributors can create value by doing high-quality work.
## What talent wants
If your workplace is already non-toxic and building good products, you're back to square one: salary. But there is a simple and evidence-based solution to the problem of salary competition in tech. And for some reason, it makes founders and managers profoundly uncomfortable. It is this: the death of the 40-hour week. If you can't compete with the giants on price (competing with Google on salary is undoubtedly a fool's errand), compete with them on quality of life. For example:
{% tweet 1012505532953817089 %}
This is only one developer, but he echoes the sentiment of millions. "Wait a second," you might say, "a 20% pay cut for a 25% reduction in hours isn't equal in terms of price for output, and it slows down the company's pace. And that's not even taking into account the fixed costs of employment, like benefits and office space." Those are valid concerns, but the stated mathematics lack the nuance to really describe the situation.
For starters, the 8-hour workday is arbitrary, a relic of factory labor unions in the 1700s. [It's](https://www.inc.com/melanie-curtin/in-an-8-hour-day-the-average-worker-is-productive-for-this-many-hours.html) [been](https://www.vouchercloud.com/resources/office-worker-productivity) [widely](http://www.businessinsider.com/8-hour-workday-may-be-5-hours-too-long-research-suggests-2017-9) [reported](https://www.forbes.com/sites/travisbradberry/2016/06/07/why-the-8-hour-workday-doesnt-work/#21ddbb9136cc) [that](http://mentalfloss.com/article/74710/how-much-time-do-we-actually-spend-working-work) [the](https://www.thecut.com/2016/01/how-much-time-do-slack-off-at-work.html) [average](https://www.fastcompany.com/3035605/the-exact-amount-of-time-you-should-work-every-day) employee is productive for three to seven hours per day, and those who work six-hour days or less [often accomplish more](https://www.theguardian.com/commentisfree/2016/may/12/six-hour-work-days-boost-productivity-dont-expect-them-in-us) than those who work a full eight or more. A conservative calculation, labelling just one hour of the average employee's day as unproductive, would mean that a 25% reduction in working hours is only a 14.3% reduction in productive hours (from seven to six). This makes the 20% pay cut a relative bargain. If two or more hours of the average employee's day is unproductive, then the reduction in hours incurs no cost to productivity at all; and if a six-hour workday is in fact *more* productive than an eight-hour workday, then offering a 20% pay cut for a 25% reduction in hours is a win-win.
And this calculation is still too sterile. The mere mention of a 30-hour work week in your company's job ads would result in a *flood* of applications from the most talented and experienced people in the industry. The coalition of workers who value life over money is large enough to put any startup on the same playing field as Microsoft and Amazon when it comes to hiring, and the productivity gained from this influx of top-tier talent would more than make up for any perceived losses in development speed.
Oh, and about those fixed costs I mentioned. A simple way to reduce them is to rent a smaller office and [let](https://qz.com/1027484/work-from-home-people-earn-more-quit-less-and-are-happier-than-their-office-bound-counterparts/) [your](https://www.inc.com/geoffrey-james/working-from-home-makes-you-happier-less-likely-to.html) [employees](https://blog.hubstaff.com/remote-workers-more-productive/) [work](https://www.gsb.stanford.edu/faculty-research/working-papers/does-working-home-work-evidence-chinese-experiment) [remotely](https://remote.co/10-stats-about-remote-work/). [All](https://nypost.com/2017/03/22/remote-employees-are-way-more-productive-than-office-dwellers/) [the](https://hbr.org/2014/01/to-raise-productivity-let-more-employees-work-from-home) [time](https://www.forbes.com/sites/larryalton/2017/03/07/are-remote-workers-more-productive-than-in-office-workers/#5c5ee6d131f6). Multiple studies show that they'll be happier, more productive, and more likely to stick around. And you won't need to buy as much space and equipment.
The one-two combo of shorter workdays and remote work is backed by so much available evidence, and so rare in today's job market, that its use at a company of any size is likely to be a hiring panacea. And it will make your payroll budget go much further, since it no longer has to compete directly with multi-billion-dollar companies on the Pacific Coast.
## Why this works
It's common to think of productivity as an equation, `c * hours = output`, where "c" is a constant describing the productivity of the average employee over one hour. But humans are not machines. Productivity, especially in creative or abstract work, varies depending on time of day, environmental factors, and mental state. Technological work is mentally exhausting, and overworking the brain (especially over long periods of time) causes productivity to diminish. Eventually, it can even enter the "negative work zone," a state familiar to many programmers where the quality of work is so low that it actually *harms* the product being developed, creating regressions, security flaws, and awkward code that needs to be refactored later. Of course, programmers aren't the only ones who are vulnerable to negative work. Anyone with a history in tech can probably share anecdotes about situations like this.
If a tradition that began with manual labor in the 18th century was really the most productive way to do knowledge work in the 21st, that would be a truly absurd coincidence. But all the research indicates that shorter, remote workdays are an overall productivity boost. And quality-of-life measures like this reduce burnout, which is a [major cause](https://www.kronos.com/about-us/newsroom/employee-burnout-crisis-study-reveals-big-workplace-challenge-2017) of employee turnover, [a](https://www.inc.com/suzanne-lucas/why-employee-turnover-is-so-costly.html) [huge](http://www.workforce.com/1998/07/01/employee-turnover-is-expensive/) [expense](https://www.huffingtonpost.com/entry/how-much-does-employee-turnover-really-cost_us_587fbaf9e4b0474ad4874fb7) for most companies. Once you look past the `c * hours` equation, it becomes clear that the best way to compete, in every sense of the word, is to prioritize employee satisfaction and quality of life.
These ideas may be uncomfortable to some, but they're rational and evidence-based, and being ahead of the curve on them could produce a significant competitive advantage for your business.
Is your company already doing this? Let's talk—I'd love to add my friends' resumes to your hiring pipeline.
| isaacdlyman |
39,767 | Mentorship Resources | Thoughtful articles on mentorship, communication, and general career advice. | 0 | 2018-07-19T19:58:55 | https://dev.to/jess/mentorship-resources-19p0 | mentorship, communication, career, advice | ---
title: Mentorship Resources
published: true
description: Thoughtful articles on mentorship, communication, and general career advice.
tags: mentorship, communication, career, advice
---
This list was originally curated for folks in our [mentor matchmaking program](https://dev.to/devteam/changelog-mentor-matchmaking-3bl0), but we realized it's actually super helpful for _all_ developers.
# Mentorship
{% link https://dev.to/kylegalbraith/how-to-find-work-with-and-emerge-as-a-new-great-mentor %}
{% link https://dev.to/aditichaudhry92/what-is-a-mentor-3od7 %}
{% link https://dev.to/kim_hart/what-do-you-look-for-in-a-mentor-4ohb %}
{% link https://dev.to/rubynista/a-mentors-crossroad %}
{% link https://dev.to/justicofjustin/what-is-your-learning-style-5b2 %}
# Communication
{% link https://dev.to/barryosull/communication-styles---working-effectively-as-a-team-c0i %}
{% link https://dev.to/lpasqualis/7-best-ways-to-make-one-on-one-meetings-more-productive %}
{% link https://dev.to/kathryngrayson/your-questions-are-dumb-ask-them-anyway-3cm6 %}
# Career Advice / Experiences
{% link https://dev.to/alexgwartney/my-programming-journey-have-patience-and-avoid-burnout-1n81 %}
{% link https://dev.to/victorcassone/the-inner-game-of-self-taught-development-3ie5 %}
{% link https://dev.to/mary_grace/burnout-what-happens-when-you-take-on-too-much-74d %}
{% link https://dev.to/plutov/transitioning-from-engineer-to-engineering-manager-1c6j %}
{% link https://dev.to/samjarman/the-best-career-advice-from-dev-chats-1l5d %}
Please add recommendations in the comments! And if you'd like to join our matchmaking program, update your [profile settings](https://dev.to/settings/mentorship).
| jess |
39,966 | First MongoDB Hosting DBaaS to Support Azure Government for Public Sector | ScaleGrid just announced the availability of fully managed MongoDB Hosting on Azure Government Cloud. Their premium DBaaS solution allows US government agencies | 0 | 2018-07-19T16:19:45 | https://scalegrid.io/blog/first-mongodb-hosting-dbaas-to-support-azure-government-for-public-sector/ | mongodb, azure, cloud, government | ---
title: First MongoDB Hosting DBaaS to Support Azure Government for Public Sector
published: true
description: ScaleGrid just announced the availability of fully managed MongoDB Hosting on Azure Government Cloud. Their premium DBaaS solution allows US government agencies
tags: MongoDB, Azure, Cloud, Government,
canonical_url: https://scalegrid.io/blog/first-mongodb-hosting-dbaas-to-support-azure-government-for-public-sector/
---
<link rel="canonical" href="https://scalegrid.io/blog/first-mongodb-hosting-dbaas-to-support-azure-government-for-public-sector/" />
<img src="https://thepracticaldev.s3.amazonaws.com/i/fsazldnm5213i5f153pe.jpg">
PALO ALTO, Calif., July 19, 2018 - ScaleGrid, a rising leader in database hosting and management, just announced the availability of fully managed <a href="https://scalegrid.io/mongodb.html" target="_blank">MongoDB Hosting</a> on <a href="https://mongodb.scalegrid.io/mongodb-hosting-on-azure-government" target="_blank">Azure Government Cloud</a>. Their premium Database-as-a-Service (DBaaS) solution allows US government agencies, contractors, educational institutions, and non-profits to adopt the advanced database management platform for their government workloads to meet their extensive regulatory and compliance regulations.
Azure Government Cloud Computing has established exclusive data centers with world-class security frameworks to protect our nation’s most sensitive information from cybersecurity threats.
ScaleGrid is the first and only database management platform to support Azure Government through their MongoDB Bring Your Own Cloud (BYOC) solution. These plans provide the advanced DBaaS features of their MongoDB Dedicated and Shared Cluster plans, but in the safety of your own Azure Government account. They allow the public sector to simplify their complex infrastructure operations, saving upwards of millions of taxpayer dollars, while gaining access to world-leading database management tools to optimize their operations.
“We’ve received consistent demand for the advanced regulatory support of Azure Government for MongoDB hosting as US government agencies and partners increasingly trend towards the cloud,” said Dharshan Rangegowda, CEO and Founder of ScaleGrid. “Our government customers want to eliminate the considerable burden of maintaining a production deployment and take advantage of both the flexibility and time-saving benefits of fully managed cloud databases, and with ScaleGrid, they can modernize their infrastructure without compromising the security of our nation’s data.”
ScaleGrid’s Azure Government plans include the ability to leverage private Virtual Networks (VNET), Reserved Instances, Hybrid Clouds, Security Groups, and maintain full admin access to MongoDB. Some of ScaleGrid’s advanced features include their Monitoring Console, unlimited backups, alerts, slow query analysis, high performance clusters, shell management, disk encryption, dynamic scaling, and monthly reports. With ScaleGrid’s MongoDB on Azure Government launch, federal, state, and local US government agencies can alleviate the burden and risk of managing their databases internally and focus on building a stronger infrastructure poised for innovation.
Read the original article: <a href="https://scalegrid.io/blog/first-mongodb-hosting-dbaas-to-support-azure-government-for-public-sector/" target="_blank">First MongoDB Hosting DBaaS to Support Azure Government for Public Sector</a>
<strong>About ScaleGrid</strong>
<a href="https://scalegrid.io" target="_blank">ScaleGrid</a> provides a fully managed Database-as-a-Service (DBaaS) solution used by thousands of developers, startups, and enterprise customers including UPS, Dell, and Adobe. The platform supports <a href="https://scalegrid.io/mongodb.html" target="_blank">MongoDB hosting</a> and <a href="https://scalegrid.io/redis.html" target="_blank">Redis hosting</a> on public and private clouds, including AWS, Azure, DigitalOcean, and VMware, and handles all your database operations so you can focus on your product. | scalegridio |
40,034 | Motivation vs Self Discipline | So I wanted to talk about self discipline vs motivation and why one will always win. And the other will lead you to fail. The other night I was talking with a friend. And we were discussing how self discipline is how we have been able to keep going with our paths. And how while motivation is a good tool for picking your self up at times. Its not something that you want to use to keep your self on track. | 0 | 2018-07-19T22:51:13 | https://dev.to/alexgwartney/motivation-vs-self-discipline--35a0 | discuss | ---
title: Motivation vs Self Discipline
published: true
description: So I wanted to talk about self discipline vs motivation and why one will always win. And the other will lead you to fail. The other night I was talking with a friend. And we were discussing how self discipline is how we have been able to keep going with our paths. And how while motivation is a good tool for picking your self up at times. Its not something that you want to use to keep your self on track.
tags: #discuss
---
So I wanted to talk about self discipline vs motivation and why one will always win. And the other will lead you to fail. The other night I was talking with a friend. And we were discussing how self discipline is how we have been able to keep going with our paths. And how while motivation is a good tool for picking your self up at times. Its not something that you want to use to keep your self on track.
The reason for this as I used as a example in my conversation. Is motivation is like a energy drink. Where you will get a burst of energy and eventually its going to where off. And your going to be right back to where you started. Meaning lets say your goal is to get x project done and your super excited about it. You start working on it ect. You get a whole lot done a few days pass. And eventually your going to start to realize this is work. And that motivation is going to start burning off. And eventually your project is going to end up on the back burner and eventually just go away all together.
But if you rely on self discipline meaning you get up you make sure you sit down and get x amount of tasks done such as writing this post you will be able to sustain a specific pace. And you will be able to keep on track to see things through. As you will not be relying on a initial motivation and more of a set schedule to get something done. This over all is how I have managed to continue to learn math and code for the past 7 months strait with out just saying oh this is just to much work. And giving up ect as the motivation factor has wore off several times. I do keep this in mind but over all making a set schedule to do things has made me keep on track. And I know in the end that it will be well worth the amount of work that has gone into it.
And that is it for this week. I just wanted to post this as I felt it was a good topic. That we found interesting and I wanted to share it with you guys. I hope you all have a good week!. And as usual thank you for reading.
| alexgwartney |
40,425 | An automatic interactive pre-commit checklist, in the style of infomercials | How to set up an interactive checklist using a Git pre-commit hook script. | 0 | 2018-07-23T13:56:56 | https://dev.to/victoria/an-automatic-interactive-pre-commit-checklist-in-the-style-of-infomercials-14i7 | showdev, devtips, productivity, git | ---
title: An automatic interactive pre-commit checklist, in the style of infomercials
published: true
description: How to set up an interactive checklist using a Git pre-commit hook script.
tags: ["showdev","devtips","productivity","git"]
cover_image: https://thepracticaldev.s3.amazonaws.com/i/30f7cdb0fse8qxuv3r6c.png
---
What's that, you say? You've become tired of regular old boring _paper checklists?_ Well, my friend, today is your lucky day! You, yes, _you,_ can become the proud owner of a brand-spanking-new _automatic interactive pre-commit hook checklist!_ You're gonna love this! Your life will be so much easier! Just wait until your friends see you.
# What's a pre-commit hook?
Did you know that nearly _1 out of 5 coders_ are too embarrassed to ask this question? Don't worry, it's perfectly normal. In the next 60 seconds we'll tell you all you need to know to pre-commit with confidence.
A [Git hook](https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks) is a feature of Git that triggers custom scripts at useful moments. They can be used for all kinds of reasons to help you automate your work, and best of all, you already have them! In every repository that you initialize with `git init`, you'll have a set of example scripts living in `.git/hooks`. They all end with `.sample` and activating them is as easy as renaming the file to remove the `.sample` part.
Git hooks are not copied when a repository is cloned, so you can make them as personal as you like.
The useful moment in particular that we'll talk about today is the _pre-commit_. This hook is run after you do `git commit`, and before you write a commit message. Exiting this hook with a non-zero status will abort the commit, which makes it extremely useful for last-minute quality checks. Or, a bit of fun. Why not both!
# How do I get a pre-commit checklist?
I only want the best for my family and my commits, and that's why I choose an interactive pre-commit checklist. Not only is it fun to use, it helps to keep my projects safe from unexpected off-spec mistakes!
It's so easy! I just write a bash script that can read user input, and plop it into `.git/hooks` as a file named `pre-commit`. Then I do `chmod +x .git/hooks/pre-commit` to make it executable, and I'm done!
Oh look, here comes an example bash script now!
```sh
#!/bin/sh
echo "Would you like to play a game?"
# Read user input, assign stdin to keyboard
exec < /dev/tty
while read -p "Have you double checked that only relevant files were added? (Y/n) " yn; do
case $yn in
[Yy] ) break;;
[Nn] ) echo "Please ensure the right files were added!"; exit 1;;
* ) echo "Please answer y (yes) or n (no):" && continue;
esac
done
while read -p "Has the documentation been updated? (Y/n) " yn; do
case $yn in
[Yy] ) break;;
[Nn] ) echo "Please add or update the docs!"; exit 1;;
* ) echo "Please answer y (yes) or n (no):" && continue;
esac
done
while read -p "Do you know which issue or PR numbers to reference? (Y/n) " yn; do
case $yn in
[Yy] ) break;;
[Nn] ) echo "Better go check those tracking numbers!"; exit 1;;
* ) echo "Please answer y (yes) or n (no):" && continue;
esac
done
exec <&-
```
# Take my money!
Don't delay! Take advantage _right now_ of this generous _one-time offer!_ An interactive pre-commit hook checklist can be yours, today, for the low, low price of... free? Wait, who wrote this script? | victoria |
40,430 | Who's looking for open source contributors? (July 23 edition) | Please shamelessly promote your project. Everyone who posted in previous weeks is welcome back this week, as always. | 0 | 2018-07-23T14:49:51 | https://dev.to/ben/whos-looking-for-open-source-contributors-july-23-edition-1676 | discuss, opensource | ---
title: Who's looking for open source contributors? (July 23 edition)
published: true
description: Please shamelessly promote your project. Everyone who posted in previous weeks is welcome back this week, as always.
tags: discuss, opensource
---
Please shamelessly promote your project. Everyone who posted in previous weeks is welcome back this week, as always. 😄
| ben |
40,456 | Starting JS-Game-Dev-Projects the quick & modern way | Read this if you'd rather spend more time coding and less time crying in your cereal. | 0 | 2018-07-25T17:49:38 | https://dev.to/niorad/starting-js-game-dev-projects-the-quick--modern-way-----479b | phaser, gamedev, modules, mjs | ---
title: Starting JS-Game-Dev-Projects the quick & modern way
published: true
description: Read this if you'd rather spend more time coding and less time crying in your cereal.
tags: phaser, gamedev, modules, mjs
---
*Read this if you'd rather spend more time coding and less time crying in your cereal.*
Some years ago I spent a whole evening trying to set up a Game-Dev-project.
- I wanted to use modern JS-features that weren't available yet.
*There goes half an hour setting up Babel..*
- I couldn't live without modules, for keeping everything organized.
*An hour of fighting against old Webpack he'll never get back..*
- Phaser (the game-library) wasn't really module-ready yet.
*Weeps silently, as he script-tags the compiled bundle into the head-tag.*
I think you get the gist.
Browsers and libraries have improved to the point that frontend-development is getting *simpler* again. At least it feels that way. Simplicity of use has been made a bigger priority by developer-tools, and modern browsers do support the most useful ES6+-features by now.
To learn and prototype with modern paradigms, I don't need to go through any of the mentioned steps anymore.
*What will he do with all those saved hours?*
Let's see what changed:
- Chrome, Safari, Edge, Firefox all support modern JS-Syntax like classes, arrow-functions, async/await etc.
- JS-modules are supported, so there's no need to bundle and compile before sending them to the browser.
- Phaser reached version 3 and it's a breeze to import it as a module.
*Ok but how on earth does this work?*
First but not foremost, the ol' index.html:
```html
<html>
<body>
<script type="module" src="./app.mjs"></script>
<script type="module">
import './app.mjs';
</script>
</body>
</html>
```
I bet you noticed the "mjs"-ending of the "app.mjs"-file. It means "Michael Jackson Script" (I think). This way the browser knows that it's supposed to load files as modules. I can only use the "import"-syntax in "mjs"-files.
*He'd never confess it but he's kidding, [here's what .mjs really means](https://developers.google.com/web/fundamentals/primers/modules)*
Let's take care of the app.js. It's just enough to get Phaser started:
```javascript
import './phaser.mjs';
const config = {
type: Phaser.AUTO,
width: 400,
height: 400,
scene: {
preload,
create,
update
}
};
var game = new Phaser.Game(config);
function preload() {}
function create() {}
function update() {}
```
I still need Phaser! Bzzzssshhhhh! Let's grab it from their [releases-page](https://github.com/photonstorm/phaser/releases) and rename the "phaser.js" to "phaser.mjs" so it's recognized as a module.
Now here's a little caveat: "mjs"-files will only be loaded and parsed if my server is transferring them with the correct MIME-type. I couldn't get it working with a normal PHP-server (I usually use MacOS' "php -S localhost:9999"-command).
*He wanted to use "caveat" ever since he heard Jon Blow use it on his stream.*
Node-based servers seem to work better. Http-server (npm install -g http-server) is handling the files as expected. I can execute "http-server" in my project-folder and directly visit the link it outputs.
Hooray! I'm seeing an empty canvas and Phaser running in my Browser. Here's everything you need in one screenshot:
*Here comes Horror Vacui, but that's for another article.*
In my directory lie three files:
- index.html
- app.mjs
- phaser.mjs
Isn't it great not to need node_modules?
*It's almost like in the old days, isn't it?*
☝️ Don't get me wrong. If it's about performance, shipping and supporting a wide range of browsers, I'll absolutely want to bundle, babel and minify my code. This is all about getting your ideas out as soon as possible, while still being able to use modern features. No more evenings of setting up stuff on spec.
*He's not missing his daughter's second wedding again!*
Once I decide to go all in with bundling and transpiling, it won't be more work to set it up afterwards. The JS-files can stay as they are, and still will work with Webpack or Parcel.
Ready to code? [Check out this nice intro to Phaser 3!](https://phaser.io/tutorials/making-your-first-phaser-3-game) | niorad |
40,699 | Use emojis as cursors | Technique to use emojis as website cursors | 0 | 2018-07-24T23:33:07 | https://kylekelly.com/posts/use-emojis-as-cursors/ | showdev, vue, css, emoji | ---
title: Use emojis as cursors
published: true
description: Technique to use emojis as website cursors
canonical_url: https://kylekelly.com/posts/use-emojis-as-cursors/
tags: showdev,vue,css,emoji
---
I've built a simple tool that generates the CSS required to use emojis as cursors.
https://www.emojicursor.app/
## Doesn't this exist already?
Sort of. Other solutions currently out there are either using:
1. Pre-generated image files, or
2. Using JavaScript with canvas to generate the images on the fly
There are pros and cons to both.
Pre-generated image files are the most consistent and have the largest cross browser support, but they require more preparation a head of time to create the image files and the emoji style used may not be consistent with the users system and familiarity.
Using JavaScript and canvas is a way to use the installed system emojis, but does require JavaScript to run before the cursors are available.
## What's the new technique?
The key difference with this technique is using SVG, and treating the emojis as text. By using inline SVG in the cursor url property we can use the system emoji style, and not have an external image or JavaScript dependancies. Additionally it is trivial to wrap this in less or sass to generate different emoji cursors, or adjust the parameters.
The largest downside to this technique is lack of browser support. No IE or Edge.
## Git repo
The code is MIT licensed and available here:
https://github.com/kylekelly/emoji-cursor
| kyleakelly |
41,245 | Finger Detection and Tracking using OpenCV and Python | A histogram based approach is used to separate out the hand from the background frame | 0 | 2018-07-28T20:27:53 | https://dev.to/amarlearning/finger-detection-and-tracking-using-opencv-and-python-586m | opencv, imageprocessing, fingerdetection, oss | ---
title: Finger Detection and Tracking using OpenCV and Python
published: true
description: A histogram based approach is used to separate out the hand from the background frame
tags: Opencv, imageprocessing, fingerDetection, OpenSourceSoftware
cover_image: https://thepracticaldev.s3.amazonaws.com/i/1l1xyvsi3g0h4gpm23nt.jpg
---
**TL;DR. Code is [here](https://github.com/amarlearning/Finger-Detection-and-Tracking)**.
Finger detection is an important feature of many computer vision applications. In this application, A histogram based approach is used to separate out the hand from the background frame. Thresholding and Filtering techniques are used for background cancellation to obtain optimum results.
One of the challenges that I faced in detecting fingers is differentiating a hand from the background and identifying the tip of a finger. I’ll show you my technique for tracking a finger, which I used in this project. To see finger detection and tracking in action check out this video.
{% youtube P3dUePye_-k %}
In an application where you want to track a user’s hand movement, skin color histogram will be very useful. This histogram is then used to subtracts the background from an image, only leaving parts of the image that contain skin tone.
A much simpler method to detect skin would be to find pixels that are in a certain RGB or HSV range. If you want to know more about this approach follow [here](https://docs.opencv.org/3.4.2/df/d9d/tutorial_py_colorspaces.html).
The problem with the above approach is that changing light conditions and skin colors can really mess with the skin detection. While on the other hand, Histogram tends to be more accurate and takes into account the current light conditions.

Green rectangles are drawn on the frame and the user places their hand inside these rectangles. Application is taking skin color samples from the user’s hand and then creates a histogram.
_The rectangles are drawn with the following function:_
{% gist https://gist.github.com/amarlearning/839998daf078d459cd238c78f9a814cb %}
There’s nothing too complicated going on here. I have created four arrays __`hand_rect_one_x`__, __`hand_rect_one_y`__, __`hand_rect_two_x`__, __`hand_rect_two_y`__ to hold the coordinates of each rectangle. The code then iterates over these arrays and draws them on the frame using __`cv2.rectangle`__. Here __`total_rectangle`__ is just the length of the array i.e. __`9`__.
Now that the user understands where to place his or her palm, the succeeding step is to extract pixels from these rectangles and use them to generate an HSV histogram.
{% gist https://gist.github.com/amarlearning/238ff29ba026e3ec8000be50bdd534e2 %}
Here function transforms the input frame to HSV. Using Numpy, we create an image of size __`[90 * 10]`__ with __`3`__ color channels and we name it as __ROI__ _(Region of Intrest)_. It then takes the 900-pixel values from the green rectangles and puts them in the ROI matrix.
The __`cv2.calcHist`__ creates a histogram using the ROI matrix for the skin color and __`cv2.normalize`__ normalizes this matrix using the norm Type __`cv2.NORM_MINMAX`__. Now we have a histogram to detect skin regions in the frames.
Now that the user understands where to place his or her palm, the succeeding step is to extract pixels from these rectangles and use them to generate an HSV histogram.
Now that we hold a skin color histogram we can use it to find the components of the frame that contains skin. OpenCV provides us with a convenient method, __`cv2.calcBackProject`__, that uses a histogram to separate features in an image. I used this function to apply the skin color histogram to a frame. If you want to read more about back projection, you can read from [here](https://docs.opencv.org/master/dc/df6/tutorial_py_histogram_backprojection.html) and [here](https://docs.opencv.org/2.4/doc/tutorials/imgproc/histograms/back_projection/back_projection.html).
{% gist https://gist.github.com/amarlearning/14a1b6cd4a291c3e4d4c8a93e2bc39d9 %}
In the first two lines, I changed the input frame to HSV and then applied __`cv2.calcBackProject`__ with the skin color histogram __`hist`__. Following that, I have used Filtering and Thresholding function to smoothen the image. Lastly, I masked the input frame using the __`cv2.bitwise_and`__ function. This final frame should just contain skin color regions of the frame.
Now we have a frame with skin color regions only, but what we really want is to find the location of a fingertip. Using OpenCV you can find contours in a frame if you don’t know what contour is you can read [here](https://docs.opencv.org/3.4.2/d3/d05/tutorial_py_table_of_contents_contours.html). Using contours you can find convexity defects, which will be potential fingertip location.
In my application, I needed to find the tip of a finger with which a user is aiming. To do this I determined the convexity defect, which is furthest from the centroid of the contour. This is done by the following code:
{% gist https://gist.github.com/amarlearning/9c554ebb244c11653b44c9c4e5c1f2dc %}


Then it determines the largest contour. For the largest contour, it finds the hull, centroid, and defects.
Now that you have all these defects you find the one that is farthest from the center of the contour. This point is assumed to be the pointing finger. The center is purple and the farthest point is red. And there you have it, you’ve found a fingertip.

All hard part is done up until now, now all we have to do is to create a __`list`__ to store the changed location of the __`farthest_point`__ in the frame. It’s up to you that how many changed points you want to store. I am storing only __`20`__ points.
Lastly, thank you for reading this post. For more awesome posts, you can also follow me on Twitter — [iamarpandey](https://twitter.com/iamarpandey), Github — [amarlearning](https://github.com/amarlearning).
Happy coding! 🤓 | amarlearning |
41,313 | Higher-Order Components (HOC) React Pattern |
Today I decided to get more familiar with Higher-Order Components (HOC) commonl... | 0 | 2018-07-29T16:36:58 | https://www.karolisram.com/higher-order-components-react-pattern/ | Today I decided to get more familiar with Higher-Order Components (HOC) commonly used in libraries such as Redux (`connect`), react-i18next (`translate`) or react-router (`withRouter`). I have often used them as part of aforementioned libraries but never got the full grasp behind their magic. Today is the day to get underneath the carpet and see how they really work.
But before we begin, let's define what a Higher-Order Component is. According to [React docs](https://reactjs.org/docs/higher-order-components.html), Higher-Order Component is an advanced React pattern consisting of a function that takes a base (wrapper) component as an argument and returns a new, enhanced component. The best thing about it is that it allows to reuse component logic in a clean compositional way.
The abstract code for a HOC would look somewhat like this:
```javascript
const higherOrderComponent = BaseComponent => {
// ...
// create new component from old one and update
// ...
return EnhancedComponent
}
```
In a more concrete form, a Higher-Order Component always takes a form similar to this:
```javascript
import React from 'react';
const higherOrderComponent = BaseComponent => {
class HOC extends React.Component {
...
enhancements
...
render() {
return <BaseComponent newProp={newPropValue} {...this.props} />;
}
}
return HOC;
};
```
## Simple example
To get a better understanding, let's take a look at a simple example of a Higher-Order Component. Imagine we want to have several components that all get set random background value each time the component is rendered.
We do this by first defining a Higher-Order Component function called `withColor`. It accepts `BaseComponent` as a parameter and returns the enhanced component. `EnhancedComponent` that gets returned consists of a `getRandomColor` and `render` methods. Within the `render` method we return `BaseComponent` that gets assigned a new `color` prop and by taking advantage of `{...this.props}` desctructuring, `BaseComponent` also gets access to all the props which were passed to the `BaseComponent` from outside the HOC.
```javascript
import React from 'react';
const withColor = BaseComponent => {
class EnhancedComponent extends React.Component {
getRandomColor() {
var letters = '0123456789ABCDEF';
var color = '#';
for (let i = 0; i < 6; i++) {
color += letters[Math.floor(Math.random() * 16)];
}
return color;
}
render() {
return <BaseComponent color={this.getRandomColor()} {...this.props} />;
}
}
return EnhancedComponent;
};
export default withColor;
```
To use the newly created HOC, we just have to export it with our base component passed as an argument.
```javascript
import React from 'react';
import withColor from './withColor';
const ColoredComponent = props => {
return <div style={{ background: props.color }}>{props.color}</div>;
};
export default withColor(ColoredComponent);
```
Finally, we render the new enhanced component the same way as we would render a regular component.
```javascript
import React, { Component } from 'react';
import ColoredComponent from './ColoredComponent';
class App extends Component {
render() {
return (
<div>
<ColoredComponent someProp="Prop 1" />
<ColoredComponent someProp="Prop 2" />
<ColoredComponent someProp="Prop 3" />
</div>
);
}
}
export default App;
```
Note that all the props defined at this level such as `someProp` will be passed further down the line via `{...this.props}` and new props such as `color` in the above example are defined explicitly from within the HOC.
## Practical example
The previous example was a bit contrived. We could, for example, have used a utility function that generates random color, and then call it from within each component. The end result would have been the same with less code. Let's better look at an example where Higher-Order Component pattern is indeed the most elegant solution.
In the following example we will develop a Higher-Order Component that accepts `BaseComponent` and API URL to fetch the data that it needs. While the data is loading, it will show a loading state, and once the data is loaded we will display whatever `BaseComponent` renders based on the data. The end result will look as follows.

To get started, we will first create a Higher-Order Component function. We will call it `withLoader` and initially set the `data` property of component's state to `null`. Once the component has mounted we will start fetching the data and when that's done, set the `data` property to the returned response.
As already mentioned, whilst the state is `null` we will show a loading state. And once we have the data fetched, we will return `BaseComponent` which in return will render markup based on the returned data. The Higher-Order Component function looks as follows:
```javascript
import React from 'react';
const withLoader = (BaseComponent, apiUrl) => {
class EnhancedComponent extends React.Component {
state = {
data: null,
};
componentDidMount() {
fetch(apiUrl)
.then(res => res.json())
.then(data => {
this.setState({ data });
});
}
render() {
if (!this.state.data) {
return <div>Loading ...</div>;
}
return <BaseComponent data={this.state.data} {...this.props} />;
}
}
return EnhancedComponent;
};
export default withLoader;
```
The components that use this HOC are fairly straightforward. We simply have to take the data from the `props` and use it as needed. In the example below we use the data to show a list of users.
As usual, we first need to import the Higher-Order Component function and pass the component as function argument. Along with it we also pass the API URL from which the data is fetched. See the code for a base component below:
```javascript
import React from 'react';
import withLoader from './withLoader';
const Users = props => {
return (
<div>
<h1>Users:</h1>
<ul>{props.data.map(user => <li key={user.id}>{user.name}</li>)}</ul>
</div>
);
};
export default withLoader(Users, 'https://jsonplaceholder.typicode.com/users');
```
Similarly, we use another component to show a list of posts. The code is pretty much the same except for the component's name and API URL.
```javascript
import React from 'react';
import withLoader from './withLoader';
const Posts = props => {
return (
<div>
<h1>Posts:</h1>
<ul>{props.data.map(post => <li key={post.title}>{post.title}</li>)}</ul>
</div>
);
};
export default withLoader(Posts, 'https://jsonplaceholder.typicode.com/posts/');
```
Now all that's left is to render the components. In order to do that we don't have to do anything special. Just import the components and render them where needed as usual. That's all 😃
```javascript
import React, { Component } from 'react';
import Users from './Users';
import Posts from './Posts';
class App extends Component {
render() {
return (
<div>
<Users />
<Posts />
</div>
);
}
}
export default App;
```
## HOC caveats 🤔
- HOC should always be a pure function. That means that the same enhanced component should always be returned with the same base component passed as a parameter.
- Don’t use HOCs inside the render method. This makes React's reconciliation algorithm think that a new component is redeclared within each render, causing the whole subtree to be unmounted rather than just checked for differences.
- Static methods do not get copied implicitly. This needs to be done explicitl. A good way to do it is with `hoist-non-react-statics` package.
- Refs don’t get passed through.
## Summary 🔥🔥🔥
A Higher-Order Component has access to all the default React API, including state and the lifecycle methods. This allows to reuse logic in a very conscise way and make your code more elegant. As we have seen, it can be used for a variety of use cases but sometimes it's not the most conscise solution. Sometimes a simple utility function or a smart parent component is all that's needed. So just use Higher-Order Components at your best judgement and don't over-engineer things where not needed 😊 | superkarolis | |
41,408 | Web Components statistics in 2017 | Some interesting statistics I have gathered after testing 696 web components. | 0 | 2018-07-30T09:21:30 | https://vaadin.com/blog/a-look-back-at-the-blooming-of-web-component-and-polymer-library-20-1 | javascript, webcomponents, statistics, beginners | ---
title: Web Components statistics in 2017
published: true
description: Some interesting statistics I have gathered after testing 696 web components.
tags: javascript, webcomponents, statistics, beginners
canonical_url: https://vaadin.com/blog/a-look-back-at-the-blooming-of-web-component-and-polymer-library-20-1
---
This article is the last story in the series "Testing 696 Web Components". The statistics in this article covers many topics: the number of components published on webcomponents.org, distribution of components based on its libraries, working and non-working components, and some more interesting stats.
**Note:** These statistics were yielded roughly a year ago. Some of them might become irrelevant in the current day.
### 300 elements in 3 months. That's an impressive number.
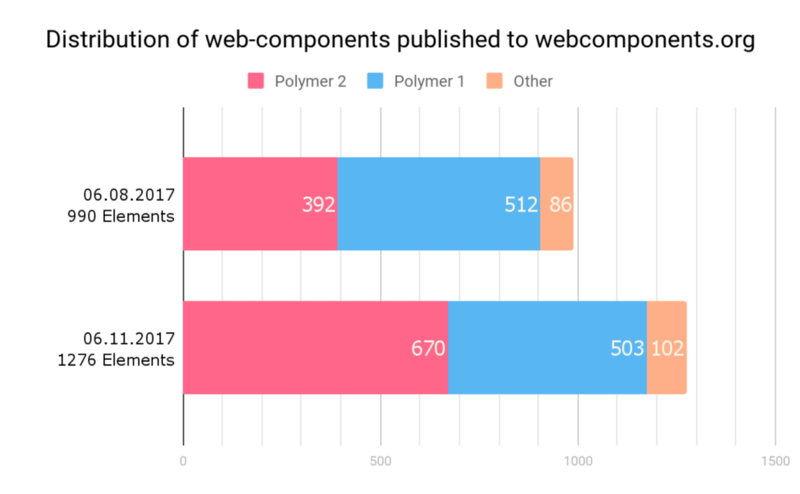
Let's break those numbers down:
- Polymer consistently accounts for more than 90% of the published elements. It's evident that Polymer is dominating in the scene of web component libraries.
- An impressive number of ~100 custom elements are published each month.
- The most notable change here is the distribution of Polymer 1 and 2 components. Polymer 2 has a surge of 278 elements while Polymer 1 roughly stays the same.
### Out of 696 tested elements, here is how many are functioning
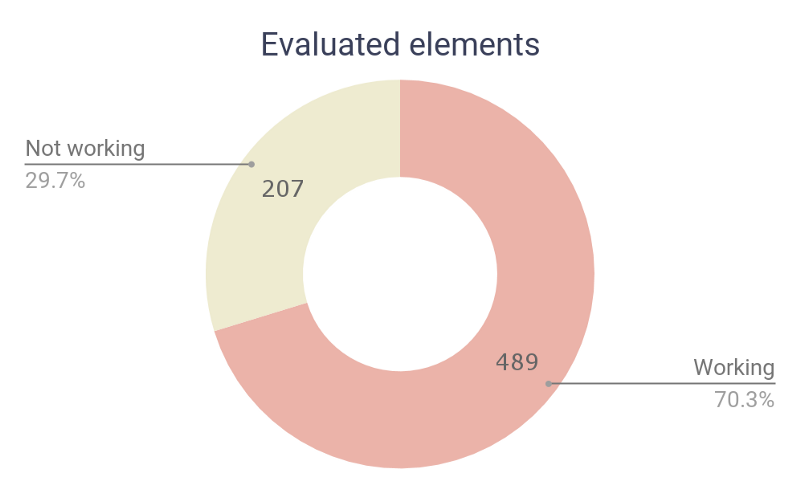
**Heads up!** Every working component has its own live demo and screenshots for you to try in Vaadin Directory.
### Browser Compatibility
Out of 489 working elements, here's how many that works in each browser:
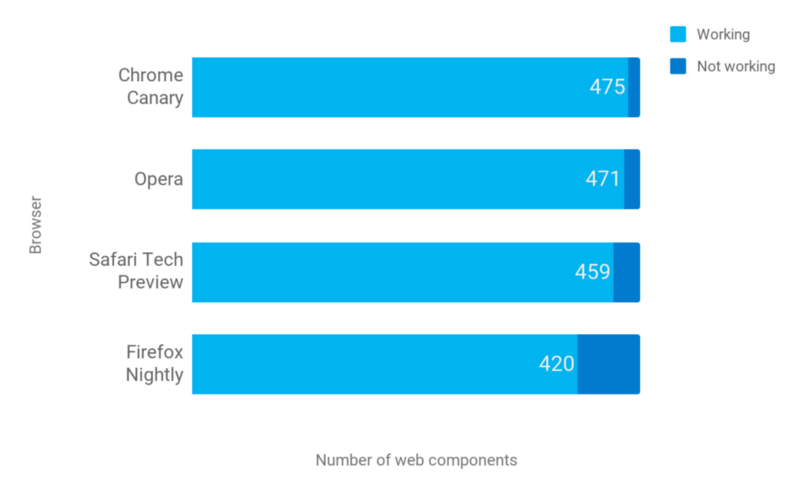
### Conclusion
Without any doubts, things have been revolving in favor of web components. More companies and technologies are betting on it. I hope you enjoy the series. If you have not read the previous two, here they are:
{% link https://dev.to/binhbbbb/the-story-of-a-man-who-has-tested-696-web-components-af8 %}
{% link https://dev.to/binhbbbb/top-5-obstacles-i-faced-in-testing-696-web-components-1e13 %}
If you have any question regarding testing web components, feel free to PM or send me an email. Thanks for reading!
- *For more news and writing pieces on Web Components, follow me on Twitter [@binhbbbb](https://twitter.com/binhbbbb)*
- *If you would like to try out Web Components, check out the series [Web Components Wednesday](https://vaadin.com/blog?tag=wcw), where I introduce and explain easy-to-use web components to beginners.*
| thisisbinh |
41,699 | Masonite Coding Tip: Abstracting Recurring Controller Code | Coding tip for the Masonite Python web framework. | 0 | 2018-08-01T01:42:34 | https://dev.to/masonite/masonite-coding-tip-abstracting-recurring-controller-code-1p35 | python, opensource, framework, masonite | ---
title: Masonite Coding Tip: Abstracting Recurring Controller Code
published: true
description: Coding tip for the Masonite Python web framework.
tags: python, opensource, framework, masonite
---
# Introduction
If you are not familiar with [Masonite](https://github.com/MasoniteFramework/masonite) then you should checkout the [GitHub repo](https://github.com/MasoniteFramework/masonite).
When developing with Masonite you may notice, if you are not consciously avoiding it, that you have some duplication in your controller logic. In this tutorial we will walk through how to abstract your code a bit inside your controller to make it really clean.
# Controller Constructor
If you are not aware of it yet, probably because you skipped over that section in the documentation, you can put anything you need to in a controller constructor. For example if we have code like this:
```python
from app.League import League
class Controller:
def show(self, Request):
return Request.redirect_to('settings.plans')
def store(self, Request):
league = League.find(Request.param('id'))
league.name = Request.input('name')
league.save()
return Request.redirect_to('settings.plans')
```
We can abstract the `Request` object out and into the controller constructor like so:
```python
from app.League import League
class Controller:
def __init__(self, Request):
self.request = Request
def show(self):
return self.request.redirect_to('settings.plans')
def store(self):
league = League.find(self.request.param('id'))
league.name = self.request.input('name')
league.save()
return self.request.redirect_to('settings.plans')
```
You might find this a bit more of a cleaner approach and a bit more DRY since we only are worrying about a single line for our `Request` object.
# Repetitive Model Finding
After a while you will realize that you have some code that looks like this:
```python
from app.League import League
class LeagueController:
def __init__(self, Request, View):
self.request = Request
self.view = View
def show(self):
league = League.find(self.request.param('id'))
return self.view('league/show', {'league': league})
def store(self):
league = League.find(self.request.param('id'))
league.name = self.request.input('name')
league.save()
return self.request \
.redirect_to('league.show', {'league': league})
def delete(self):
league = League.find(self.request.param('id'))
league.delete()
return self.request \
.redirect_to('discover')
```
Notice here that every single method has the same exact code for fetching the league by id and is using it in different ways. We can simply get around this by throwing that in the constructor as well:
```python
from app.League import League
class LeagueController:
def __init__(self, Request, View):
self.request = Request
self.view = View
self.league = League.find(self.request.param('id'))
def show(self):
return self.view('league/show', {'league': self.league})
def store(self):
self.league.name = self.request.input('name')
self.league.save()
return self.request \
.redirect_to('league.show', {'league': self.league})
def delete(self):
self.league.delete()
return self.request \
.redirect_to('discover')
```
This actually cleans the code up quite a bit and it makes sense that if all the logic is going to be working with a single league then to have the constructor set it on the controller.
****
If you want to explore [Masonite]([GitHub - MasoniteFramework/masonite: The Modern And Developer Centric Python Web Framework. Be sure to read the documentation and join the Slack channel questions: http://slack.masoniteproject.com](https://github.com/MasoniteFramework/masonite)) a bit more be sure to click that link and give a star or join the [Slack](http://slack.masoniteproject.com) channel. | josephmancuso |
46,063 | Using CSS Grid where appropriate (revisited) | This solution is a follow-up post on my last year's article "Using CSS Grid where appropriate." The goal is to find a solution for navigation with an unknown number of items. | 0 | 2018-09-05T15:23:21 | https://www.silvestar.codes/articles/using-css-grid-where-appropriate-revisited/ | webdev, begginers, programming, css | ---
title: Using CSS Grid where appropriate (revisited)
published: true
description: This solution is a follow-up post on my last year's article "Using CSS Grid where appropriate." The goal is to find a solution for navigation with an unknown number of items.
tags:
- webdev
- begginers
- programming
- css
canonical_url: "https://www.silvestar.codes/articles/using-css-grid-where-appropriate-revisited/"
---

_This post was originally published on [silvestar.codes]._
This solution is a follow-up post on my last year's article ["Using CSS Grid where appropriate"]. The goal is to find a solution for navigation with an unknown number of items.
<!-- more -->
## Recap
Creating navigation with CSS Grid is arguably not the best solution. However, if one wants to use CSS Grid, two options were suggested:
- Using `grid-auto-flow: row;` and placing each item in the grid, like this:
```css
.nav__item:nth-child(1) {
grid-area: 1 / 1 / 2 / 2;
}
```
- Defining a definite grid using keyword auto for setting width of the rows and columns:
```css
.nav {
display: grid;
grid-auto-flow: row;
}
@media screen and (min-width: 320px) {
.nav {
grid-template-columns: repeat(4, auto);
grid-template-rows: repeat(2, auto);
}
}
```
In both examples, we are defining a strict grid—a number of columns in a row are strictly defined.
https://codepen.io/CiTA/pen/dzogLV
## A new solution
I have been using CSS Grid for more than a year now, and I learned how to use its features properly along the way:
- [`minmax()` function],
- [`auto-fit` keyword],
- [`grid-auto-flow` property], and
- how to avoid media queries 🎊.
### The code
I have forked the previous solution and updated it with the features mentioned above. Here's the final solution.
https://codepen.io/CiTA/pen/pOgGqv
```css
.nav--grid2 {
display: grid;
grid-auto-flow: dense;
grid-template-columns: repeat(auto-fit, minmax(60px, auto));
justify-content: center;
}
```
Let's break down this piece of code.
### minmax()
`minmax()` function defines a size as a range between minimum and maximum value. It allows defining a dynamic size of columns and rows.
We could use this property to define a minimum and a maximum width of navigation item. In our example, we are using the following minmax definition:
`minmax(60px, auto)`
We are saying that column should be at least 60px wide, and it should be as wide as the maximum content width. See [`auto` keyword] for more details.
### auto-fit
`auto-fit` should be used as a repetition number—a number used in [`repeat()` function]. It says that the grid should place as many items as possible like when items are empty (I think 🤔).
### grid-auto-flow
`grid-auto-flow` is a property that controls how the grid algorithm for placing items works. In our example, we are using [`dense` keyword]. It says that the grid should fill holes that could be left when larger grid items occur.
### justify-content
[`justify-content` property] aligns the content of the box. We are using `justify-content: center` to align the content of the items to the center.
### Bonus: No media queries
As you could see, we haven't used media queries. Media queries are useful and without them, and there wouldn't be a responsive web design, but it feels so satisfying when we able to build responsive behavior without using one.
## Final thoughts
CSS Grid still may not be the best approach for navigation element, but it works. Always try using CSS Grid where appropriate, even if it solves your problem. If you are a rebel, ignore this thought and use it nevertheless—there are no rules when building web solutions as long as your users are happy. 😎
[silvestar.codes]: https://www.silvestar.codes/articles/using-css-grid-where-appropriate-revisited/
["Using CSS Grid where appropriate"]: https://www.silvestar.codes/articles/using-css-grid-where-appropriate/
[`minmax()` function]: https://www.w3.org/TR/css-grid-1/#valdef-grid-template-columns-minmax
[`auto-fit` keyword]: https://www.w3.org/TR/css-grid-1/#valdef-repeat-auto-fit
[`grid-auto-flow` property]: https://www.w3.org/TR/css-grid-1/#propdef-grid-auto-flow
[`auto` keyword]: https://www.w3.org/TR/css-grid-1/#valdef-grid-template-columns-auto
[`repeat()` function]: https://www.w3.org/TR/css-grid-1/#funcdef-repeat
[`dense` keyword]: https://www.w3.org/TR/css-grid-1/#valdef-grid-auto-flow-dense
[`justify-content` property]: https://www.w3.org/TR/css-align-3/#propdef-justify-content
| starbist |
41,721 | Accessibility For Beginners with HTML and CSS | A quick cheat sheet on improving a web site's accessibility using HTML and CSS. | 0 | 2018-08-01T12:17:12 | https://dev.to/mxl/accessibility-for-beginners-with-html-and-css-16j7 | beginners, html, css | ---
title: Accessibility For Beginners with HTML and CSS
published: true
description: A quick cheat sheet on improving a web site's accessibility using HTML and CSS.
tags: beginners, html, css
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ibt6f9x6w37yfyy7jdi7.jpeg
---
This is a post for my #100DaysOfCode Day 2 based on freeCodeCamp material I learned.
Websites should be open and accessible to everyone, regardless of a user's abilities, but often the opposite happens. Here's a quick cheat sheet on improving a web site's accessibility using HTML and CSS.
**1. Images should have alternative text when their contents are not obvious from reading the text**
```html
<img src="logo.jpeg" alt="Company logo">
```
**2. h1 - h6 text are important for screen readers, keep their order**
```html
<!-- Don't do this -->
<h1>A header</h1>
<h4>A smaller header</h4>
<!-- Do this -->
<h1>A header</h1>
<h2>A smaller header</h2>
```
**3. Give structure to your page by using main, header, footer, nav, article, section, and audio**
```html
<header>
<h1>The header!</h1>
</header>
<main>The document body</main>
<footer></footer>
```
**4. Use article element for blog entries, forum posts, or news articles**
```html
<div> - groups content
<section> - groups related content
<article> - groups independent, self-contained content
```
**5. Use both visual and auditory content**
So users with visual and/or auditory impairments could access it.
**6. Use the figure element for charts**
```html
<figure>
<img src="your_chart.jpeg" alt="Short description of the chart">
<br>
<figcaption>
Description of the chart.
</figcaption>
</figure>
```
**7. Use label elements with inputs**
```html
<label for="name">Name:</label>
<input type="text" id="name" name="name">
```
**8. Group radio buttons in fieldsets**
```html
<fieldset>
<legend>Choose one of these three items:</legend>
<input id="one" type="radio" name="items" value="one">
<label for="one">Choice One</label><br>
<input id="two" type="radio" name="items" value="two">
<label for="two">Choice Two</label><br>
<input id="three" type="radio" name="items" value="three">
<label for="three">Choice Three</label>
</fieldset>
```
**9. Use date fields with a picker**
```html
<label for="input1">Enter a date:</label>
<input type="date" id="input1" name="input1">
```
**10. Standartize time with time element**
This element's datetime attribute is the value accessed by assistive devices. It helps avoid confusion by stating a standardized version of a time, even if it's written in an informal or colloquial manner in the text.
```html
<time datetime="2013-02-13">last Wednesday</time>
```
**11. Make some content visible only for screen readers**
Like this:
```css
.sr-only {
position: absolute;
left: -10000px;
width: 1px;
height: 1px;
top: auto;
overflow: hidden;
}
```
Don't use:
- display: none; or visibility: hidden; they hide content for everyone, including screen reader users
- zero values for pixel sizes, such as width: 0px; height: 0px; it removes that element from the flow of your document, screen readers will ignore it
**12. Use high contrast text**
The Web Content Accessibility Guidelines (WCAG) recommend at least a 4.5 to 1 contrast ratio for normal text. The ratio is calculated by comparing the relative luminance values of two colors. This ranges from 1:1 for the same color, or no contrast, to 21:1 for white against black. Foreground and background colors need sufficient contrast so colorblind users can distinguish them.
**13. Use descriptive link text**
```html
This:
<a href="">information about computers</a>
is better than this:
<a href="">Click here</a>
```
**14. Use access keys for important links**
```html
<button accesskey="b">Important Button</button>
```
**15. Use tabindex to add keyboard focus**
Links and form controls automatically get keyboard focus when a user tabs through a page. This functionality can be given to any other element by using a tabindex="n" on them, where n is not negative.
```html
<a href="" tabindex="1">First accessed link</a>
<a href="" tabindex="2">Second accessed link</a>
```
Photo by [Rodion Kutsaev](https://unsplash.com/@frostroomhead) on [Unsplash](https://unsplash.com/) | mxl |
42,015 | Ctags mac Vim | Using ctags in Vim for Rails Projects | 0 | 2018-08-02T19:11:09 | https://dev.to/adityavarma1234/ctags-mac-vim-4637 | rails, ruby, vim, ctags | ---
title: Ctags mac Vim
published: true
description: Using ctags in Vim for Rails Projects
tags: Rails, Ruby, Vim, ctags
---
Install ctags in vim using home brew
brew install ctags
I have set up this mapping in my vimrc file for the ctags
```map <C-F12> :!ctags -R --exclude=.git --exclude=logs --exclude=doc . <CR>```
I just press ```ctrl + fn + f12``` and voilla I can use ```ctrl + ]``` to go the definition of function in a rails project.
The above did not find do tagging for gem specific functions.
I had to add
```bundle list --paths```
to the above line as well.
So now I have a new mapping which is something like this
```map <C-F12> :!ctags -R --exclude=.git --exclude=logs --exclude=doc . $(bundle list --paths)<CR>```
Now I go to a gem specific function and type ```ctrl + ]``` and voila I have migrated to the gem file and now I can have a look at the gem source.
useful links: https://blog.sensible.io/2014/05/09/supercharge-your-vim-into-ide-with-ctags.html
https://andrew.stwrt.ca/posts/vim-ctags/ | adityavarma1234 |
42,075 | Continuous Integration in DevOps |
What is DevOps?
DevOps (Development and Operations) is a software programming ... | 0 | 2018-08-03T06:04:37 | https://dev.to/mikezen9/continuous-integration-in-devops--3bd4 | devopstraining | ---
title: Continuous Integration in DevOps
published: true
description:
tags: DevOps Training
---
<h2>What is DevOps?</h2>
DevOps (Development and Operations) is a software programming approach which combines the software improvement and programming activities. It is a set of practices which are destined to reduce the time between making a change to a system and its adoption in normal production for achieving high quality. The primary motive of DevOps is intended towards shorter development cycles and enhanced deployment frequency. This way it can deliver more releases aligned with business objectives. DevOps integrated automation and monitoring at every phase of software development including integration, testing infrastructure to deployment. If you are still unaware of the DevOps and its incredible outputs,you should join the <a href="https://www.simplilearn.com/cloud-computing/devops-practitioner-certification-training">DevOps Training</a> accessible over internet from anywhere anytime. Here you will master in CI, deployment, configuration, monitoring and continuous delivery of the software product.
<h2>Continuous Integration:</h2>
Continuous integration is the best DevOps practice for regularly adding the changed code into the central repository. After addition, the testing is performed on that code. CI is a part of the integration stage in the application release process. It includes the automation component and cultural component. Which merely implies that it entails the build service and learning practices for quick integration.
<h2>Why Continuous Integration?</h2>
The primary objective of CI is to recognise the bugs quickly thus, improve the quality of software with proper validation and release the new software updates in reduced time.
In the past development model, developer team makes changes in the extended period of time. They merge the changed code in the main branch, once the whole work was finished. This entire procedure is complicated and time-consuming. It results in the bugs accumulating for an extended period without providing any correction. Thus, software updates delivery to user become late.
<img src="https://images.pexels.com/photos/270348/pexels-photo-270348.jpeg?auto=compress&cs=tinysrgb&dpr=2&h=450&w=550">
image source: Pexels
<h2>How does it work?</h2>
With continuous integration, developers can quickly commit changes to the shared repository. It acts as the version control system like Git. Before committing each change, the developers execute code on the local platform for testing and adding an extra layer for integration. A CI service performs unit tests on the changed application code by automatically building and running it.
<h2>CI in DevOps:</h2>
DevOps elaborates the techniques for automating the iterated tasks in SDLC like software building, testing and deployments etc. Generally when developers write code, then they test it in their local environment and finally verify it in the source code repository. They focus on frequent code changes and check-ins for eliminating the complicated merging scenarios. Once the code is properly checked in, further, the CI system will take care of its control. CI will monitor the main repository for your project and creates a new version during new code commit. The application is written in a compiled language (various languages or frameworks) will be automatically compiled and build by the server. The server will also perform unit test suit for the application. <br>
If all the previous steps executed without any hurdle, the CI server (build server) will execute the pre-configured code script for deploying the product for the testing environment. And, if any of these steps fails, the server will also fail in building the new code. It immediately failure to the team for acknowledgement. The primary objective is monitoring each developer so that if a developer breaks the build, it will get back on track. Thus, the CI server reduces the halt or any break in new code building, improving the productivity of the team. <br>
Without this quality assurance process, the team may look for broken code or bug in the main repository. This way, other team members make changes according to the broken code.<br>
CI reduces the possibilities of catastrophic mixing issue and loss of information from work created on a broken codebase.<br>
Above given actions are collaboratively performed by operation and development engineers, and the actions are written on deployment script and automated configuration. The collaboration is primarily because the team members follow the automated scripts, and also it assures the operation fulfil the need of deployment and the process is represented for the practice of team members. Continuous deployment is the term used for building high confidence stage for the collaboration of script with deployment process in the production environment.
| mikezen9 |
42,350 | Flocking shell | Photo by Cristina Gottardi on Unsplash (cropped) At my last job, I had an interesting problem to... | 0 | 2018-08-31T13:21:52 | https://booyaa.wtf/2018/flocking-shell | bash, locking, linux | ---
title: Flocking shell
published: true
tags: bash, locking, linux
canonical_url: https://booyaa.wtf/2018/flocking-shell
cover_image: https://thepracticaldev.s3.amazonaws.com/i/zj9wru5gngnfgv3r7djd.png
---
_[Photo](https://unsplash.com/photos/UFRMc7o9Ci8) by Cristina Gottardi on Unsplash (cropped)_
At my last job, I had an interesting problem to crack. My cron task spawned hundreds of copies of itself because it was blocking on a database call. If a process spawns enough times, you'll eventually run out of file descriptors and will be unable to fork more processes. To avoid further repeats, I needed to add a check to see if the script was already running and exit early.
My requirements for the script in question, also requires that it be able to spawn a specific instance. Instance in this case, could mean connecting to a different database. The important takeaway is that each instance, must be allow a spawn single copy of itself.
I could've gone down the route of using creating a PID or lock file (storing the current process id of the script), checking if the current process and the PID file matched and exiting if not.
Instead I fancied trying something different and according to StackOverflow [flock](https://linux.die.net/man/1/flock) was a popular choice.
Here's a snippet of how to enable file locking in your scripts.
```shell
# how to allow the script multiple times for different instances
readonly LOCKFILE="${LOCKFILE_DIR}/${PROGNAME}-${INSTANCE}.lock"
# to avoid command block, link file descriptor (auto incremented) to our lock file
exec {lock_fd}>"$LOCKFILE"
# early exit if instance is already running
flock -n ${lock_fd} || exit 1
```
The funny notation `{lock_fd}` is an auto-incrementing named file descriptor which doesn't appear until bash 4.1.x.x (so you're out of luck Mac users). To add the Mac woes, flock isn't bundled with Mac, but someone's created a cross platform [version](https://github.com/discoteq/flock) with the same name.
To prove my script no longer spawned multiple copies I wrote the following script (safe-driver.sh):
```shell
#!/bin/bash
clear
for i in $(seq 3)
do
(
echo "> BEGIN FOO $i"
safe.sh FOO
echo "> END FOO $i exit code: $?"
) &
done
if [ ! -z "$IN_DOCKER" ]; then
sleep 1 # allow scripts to run (needed for docker)
fi
printf "\n\njobs running (should only see one process running)\n"
jobs -l
printf "\n\nlist file locks\n"
lsof /tmp/safe*.lock
if [ ! -z "$IN_DOCKER" ]; then
printf "\n\npausing, press any key to return early\n"
read -r
fi
```
## References
- Elegant locking of bash program [blog post](http://www.kfirlavi.com/blog/2012/11/06/elegant-locking-of-bash-program/) - I cribbed the idea of not running flock as a command block from Kfir's post, but I drew the line with how the code was organised. Where possible I try to avoid imposing coding style from other languages. I also still think bash can be consumed by two parties operational staff and developers, I would prefer to cater for ops since they usually end up looking after these scripts.</soapbox>
- exec [examples](http://wiki.bash-hackers.org/commands/builtin/exec) from bash-hackers.org - This was my first time to use exec in anger and I think it helped me understand the role the file descriptor played in my flock script.
- Advanced Bash-Scripting Guide ([Special Characters](http://www.tldp.org/LDP/abs/html/special-chars.html) - This is my goto resource for searching for various symbols and glyphs often used blindly in bash. In particular I used this to find out the proper name for `()` (command block).
| booyaa |
42,392 | Most Common Programming Case Types | When working with computers—specifically while programming—you'll inevitably find yourself naming... | 0 | 2018-08-06T13:51:18 | https://www.chaseadams.io/most-common-programming-case-types/ | javascript, python, go, beginners | ---
title: Most Common Programming Case Types
published: true
tags: javascript, python, golang, beginners
cover_image: https://thepracticaldev.s3.amazonaws.com/i/wng0y0ke8i22mjiqokfc.png
canonical_url: https://www.chaseadams.io/most-common-programming-case-types/
---
When working with computers—specifically while programming—you'll inevitably find yourself naming things ([one of the two hard things in computer science](https://twitter.com/codinghorror/status/506010907021828096?lang=en)).
A major factor of being successful in naming is knowing the type of case you want to use so that you can have a consistent convention per project/workspace. If you're writing software, you'll come across at least one of these in a languages specification for how it's written. Some languages (Go, particularly) rely heavily on you knowing the difference between two of them and using them correctly!
## What You'll Learn
- The most common case types:
- Camel case
- Snake case
- Kebab case
- Pascal case
- Upper case (with snake case)
- How to use them for the following situations:
- naming files for a computer (my recommended best practice)
- writing code with Go
- writing code with Ruby
- writing code with JavaScript
- writing code with Python
# camelCase
`camelCase` must **(1)** start with a lowercase letter and **(2)** the first letter of every new subsequent word has its first letter capitalized and is compounded with the previous word.
An example of camel case of the variable `camel case var` is `camelCaseVar`.
# snake\_case
`snake_case` is as simple as replacing all spaces with a "_" and lowercasing all the words. It's possible to snake_case and mix camelCase and PascalCase but imo, that ultimately defeats the purpose.
An example of snake case of the variable `snake case var` is `snake_case_var`.
# kebab-case
`kebab-case` is as simple as replacing all spaces with a "-" and lowercasing all the words. It's possible to kebab-case and mix camelCase and PascalCase but that ultimately defeats the purpose.
An example of kebab case of the variable `kebab case var` is `kebab-case-var`.
# PascalCase
`PascalCase` has every word starts with an uppercase letter (unlike camelCase in that the first word starts with a lowercase letter).
An example of pascal case of the variable `pascal case var` is `PascalCaseVar`.
**Note: It's common to see this confused for camel case, but it's a separate case type altogether.**
# UPPER_CASE_SNAKE\_CASE
`UPPER_CASE_SNAKE_CASE` is replacing all the spaces with underscores and converting all the letters to capitals.
an example of upper case snake case of the variable `upper case snake case var` is `UPPER_CASE_SNAKE_CASE_VAR`.
# Which case type should I use?
Now that you know the various case types, let's tackle an example of my recommended best practice for filenames and when to use each case for Go, JavaScript, Python & Ruby.
## What convention should I use when naming files?
**Recommendation: always snake case**
When naming files, it's important to ask "what's the lowest common denominator?" If you're not opinionated, I've found I've had the most success with snake case because it's the least likely to create a problem across filesystems and keeps filenames readable for "my\_awesome\_file".
If you're a Mac user or work with Mac users, it's a good practice to always use lowercase. Mac's have an HFS+ filesystem and since HFS+ is not case sensitive, it can read "MyFile" or "myfile" as "myfile".
My predominant argument for this stems from a particularly insidious "bug" I saw when I was running a CI/CD (continuous integration/continuous delivery) cluster. A CI job failed with "file not found: mycomponent.js" during a build for a React project. The developer swore the file was in the project's source, and as I dug through it, I noticed they had an import for "mycomponenet.js" but the file was named "MyComponent.js" (for a React project, where PascalCase is the convention for naming component files). Due to the way HFS+ handles file casing, it happily accepted that "MyComponent.js" was "mycomponent.js" at the time the developer (using a Mac) was writing the code, but ath the time the Unix based CI server was building it, it would fail because it expected exact casing to find the file.
## Go Conventions
Go is the language where it's most critical to pay attention to case type conventions. The language decides whether a variable, field or method should be available to a package caller by if the name starts with a capital or lowercase letter.
- **Pascal case** is _required_ for exporting fields and methods in Go
- **Camel case** is _required_ for internal fields and methods in Go
```
package casetypes
type ExportedStruct {
unexportedField string
}
```
In the above example, `ExportedStruct` is available to package callers for `casetypes` and `unexportedField` is only available to methods on `ExportedStruct`.
## Javascript Conventions
- **Camel case** for variables and methods.
- **Pascal case** for types and classes in JavaScript.
- **Upper case snake case** for constants.
### React Conventions
I write enough React and it's unique enougn that it's worth calling out conventions here as a subsection:
- **Pascal case** is used for component names and file names in React.
## Ruby Conventions
- **Pascal case** is used for classes and modules in Ruby.
- **Snake case** for symbols, methods and variables.
- **Upper case snake case** for constants.
## Python Conventions
- **Snake case** for [method names and instance variables](https://www.python.org/dev/peps/pep-0008/#method-names-and-instance-variables) (PEP8).
- **Upper case snake case** for constants.
## Other Conventions
- kebab case in **Lisp**.
- kebab case in **HTTP URLs** (`most-common-programming-case-types/`).
- snake case in **JSON** property keys.
# Quick Comparison Table
| Case Type | Example |
| --- | --- |
| Original Variable as String | `some awesome var` |
| Camel Case | `someAwesomeVar` |
| Snake Case | `some_awesome_var` |
| Kebab Case | `some-awesome-var` |
| Pascal Case | `SomeAwesomeVar` |
| Upper Case Snake Case | `SOME_AWESOME_VAR` |
Now that you've been introduced to the most common case types, you're prepared to hop into most of the popular languages and know what conventions to keep when you're writing your own code! | curiouslychase |
42,529 | vscode debug config for wsl and jest | When using the config from jest documentation the execution doesn't stop at specified breakpoints but... | 0 | 2018-08-06T21:48:35 | https://dev.to/marzelin/vscode-debug-config-for-wsl-and-jest-o04 | wsl, vscode, jest, debugging | ---
title: vscode debug config for wsl and jest
published: true
description:
tags: wsl, vscode, jest, debugging
---
When using the config from jest [documentation](https://github.com/Microsoft/vscode-recipes/tree/master/debugging-jest-tests) the execution doesn't stop at specified breakpoints but the following config works with wsl:
```json
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "Jest All",
"program": "${workspaceFolder}/node_modules/jest/bin/jest",
"args": ["--runInBand"],
"useWSL": true
},
]
}
``` | marzelin |
42,819 | State of API Usage Report: interesting learnings from billions of API events. | Introduction to API analytics One of the hardest things for any data driven engineer is to... | 0 | 2018-10-01T20:12:19 | https://www.moesif.com/blog/reports/api-report/Summer-2018-State-of-API-Usage-Report/ | meta, api, sdks, productivity | ---
title: State of API Usage Report: interesting learnings from billions of API events.
published: true
tags: meta,API,SDKs,productivity
canonical_url: https://www.moesif.com/blog/reports/api-report/Summer-2018-State-of-API-Usage-Report/
---
## Introduction to API analytics
One of the hardest things for any data driven engineer is to answer “Are these numbers any good?”We are drowning in data from various SaaS tools, but sometimes we just want to know what a _normal_ range is.
For example, you can investigate the average latency for your API over time, but how do you benchmark against “standard”metrics for a API?
Welcome to the _Summer 2018 - State of API Usage Report._ We analyzed billions of API calls to guide you build the correct API and give you a benchmark to think about.
## Languages used for developing APIs
### API Developers by Programming Language
The below chart is the [SDK](https://www.moesif.com/docs/server-integration/) or language used by Moesif customers.
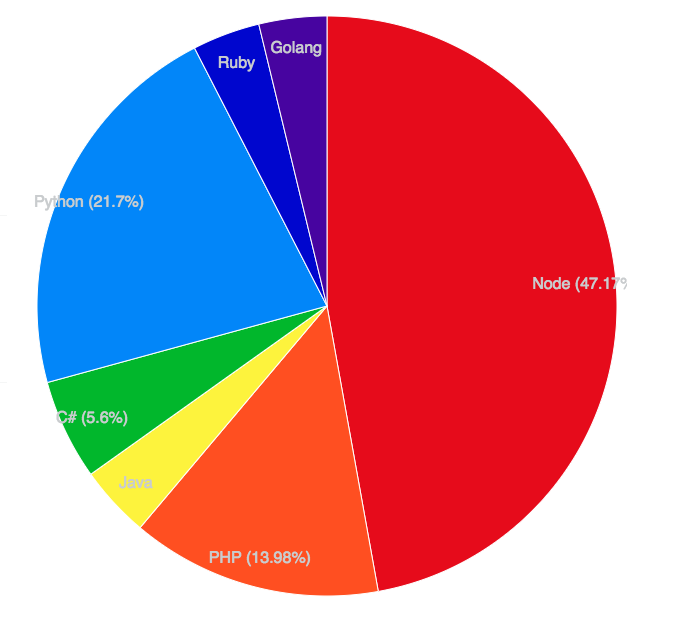
While NodeJS is still the undisputed king for building APIs driven by a rich ecosystemwith frameworks like express and Reach, what really surprised us was how popular Python got in 2018.More engineers are publishing Python APIs which can be fueled by the recent machine learning craze.Scikit-learn, PySpark, and TensorFlow are extremely popular ML frameworks that enable anyone to create a model fromthe Pickle or ProtoBuf file which can then be published via a simple REST API. In fact, we have published afew inference APIs using Python and Flask at Moesif.
### API Calls by Content Type
We kept both the type and encoding to get a breakdown of who sets the encoding part. Majority of frameworks today willtry with UTF-8 if not set.
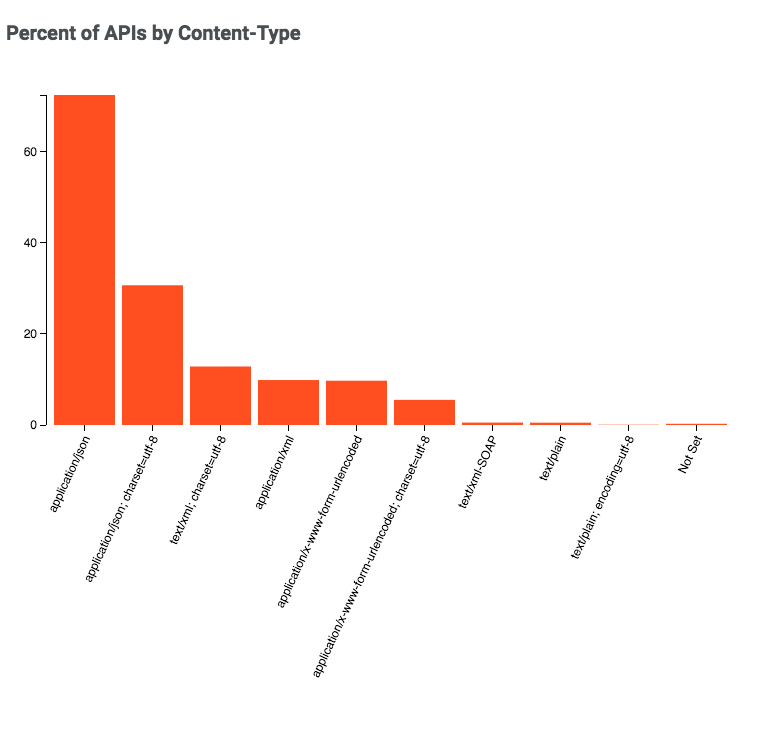
### Is GraphQL popular?
While GraphQL has received a lot of press, we have seen a lot of developers hesitant to moving to GraphQL. At the same time, 2018 will be the year for GraphQL, and number of new open GraphQL APIs being published is accelerating.
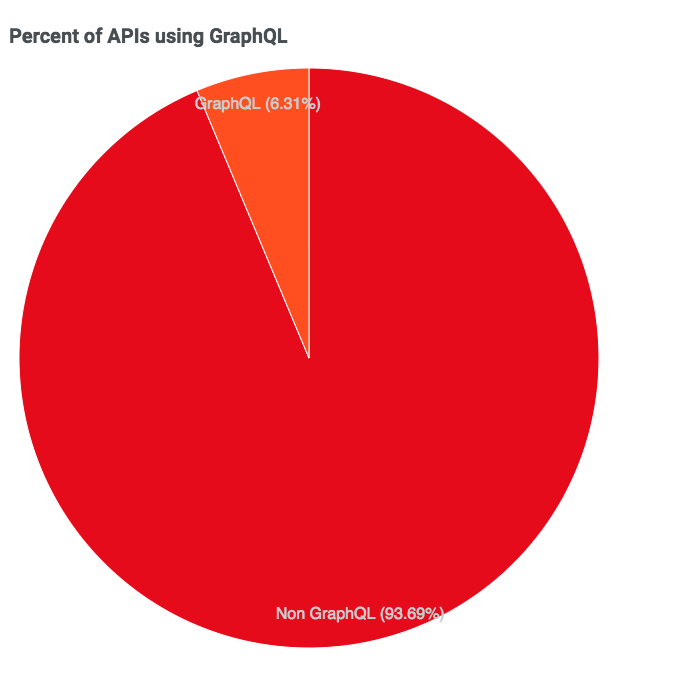
## API Performance
### Is Keep Alive common?
Keep Alive is a common trick for servers calling other servers to keep the HTTP connection open for future calls.This reduces latency for subsequence calls such as an API server communicating with a database server.
While keep alive can be very beneficial in server to server, in applications where there are many clients, but each sends only a few or onlyone request, then the server would waste resources keeping connections open that are never reused.
#### API Calls by Connection
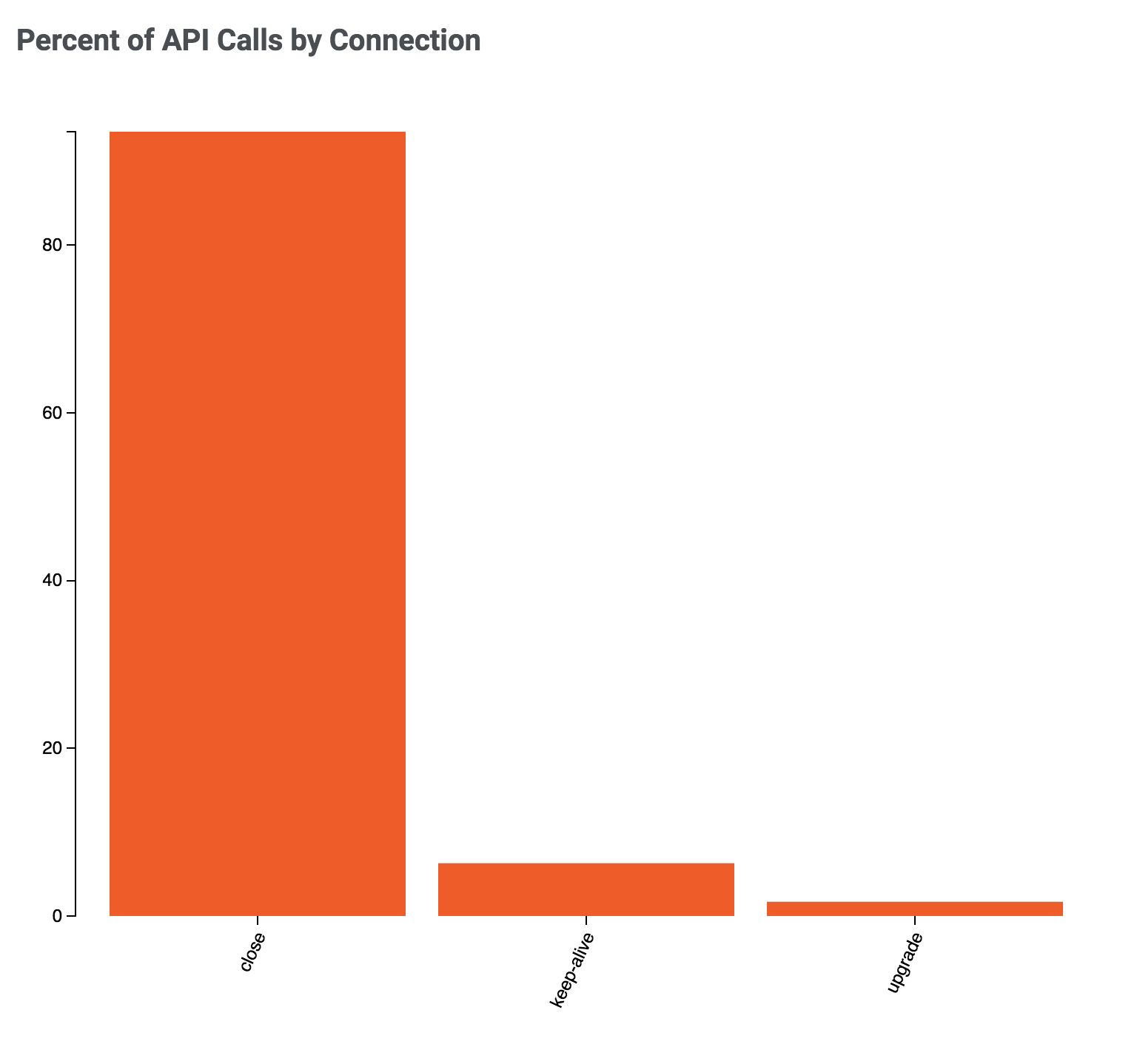
### Average Latency for API calls
Keep in mind, some APIs are server-to-server calls on the same network or is designed for very low latency (such as our Collection API) which will have single digit latency in milliseconds.
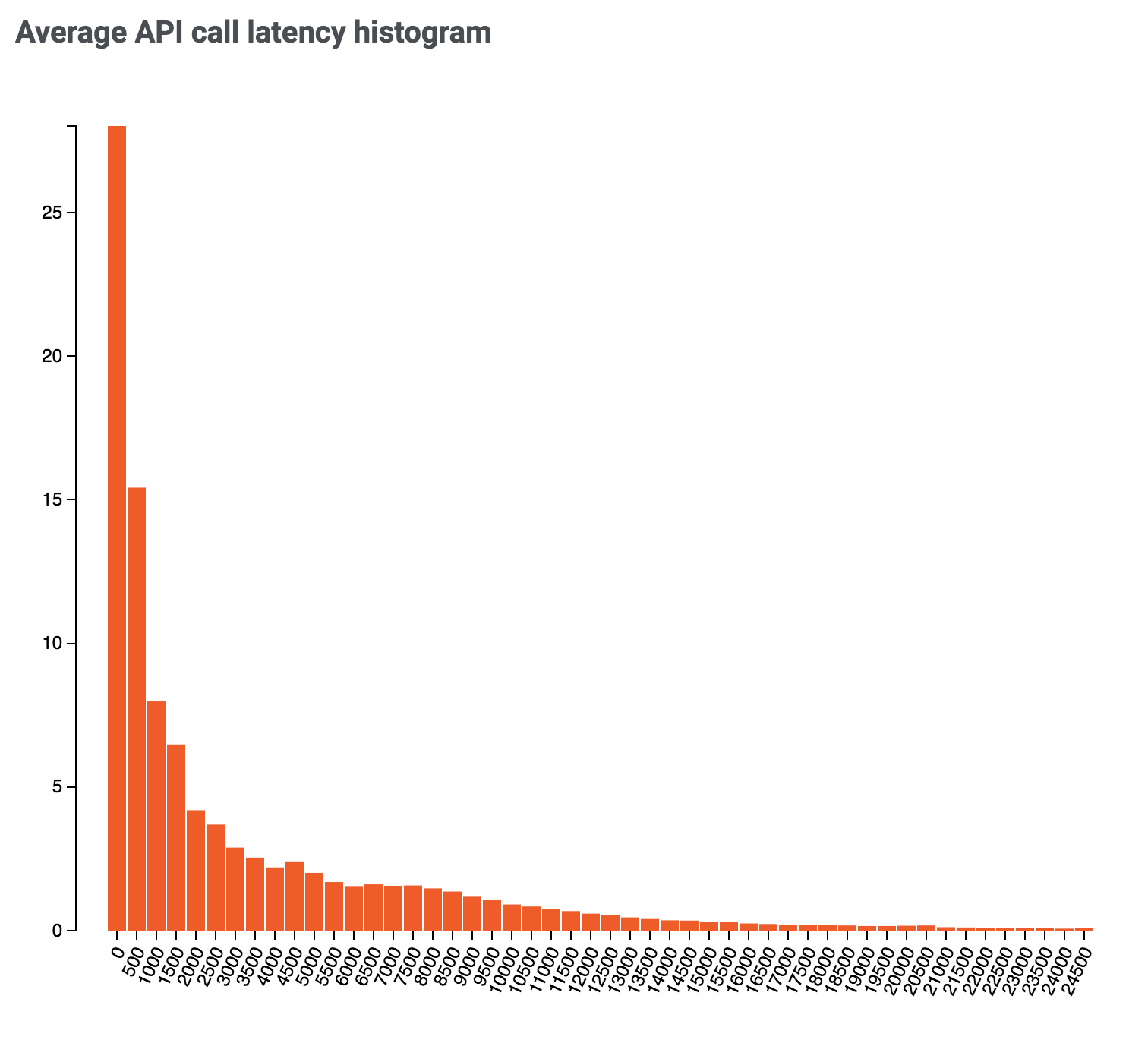
We see that 28% of API Calls complete within 500 ms. However, there is a long tail for latency. Potential pitfalls are not configuring timeouts (There are libraries out there that have 60 minute timeouts) or issues with database indexing.
## Closing thoughts
Let us know if there is a specific metric you’re interested in. We’re always open to sharing more data as long as it OK.
**Moesif is an API analytics platform uses by thousands of developers. [Learn More](https://www.moesif.com/features?int_source=blog)**
| xngwng |
43,205 | I appeared on TV speaking Spanish with Chinese subtitles | Frist post | 0 | 2018-08-09T21:49:20 | https://dev.to/chiguire/i-appeared-on-tv-speaking-spanish-with-chinese-subtitles-1big | introduction, flash, videogames, anecdote | ---
title: I appeared on TV speaking Spanish with Chinese subtitles
published: true
description: Frist post
tags: introduction, flash, videogames, anecdote
---
I've just set up my account at Dev.to, it does seem like a cool place to hang out, and to share knowledge with others. So that's what I'm hoping to do.
My name is Ciro, that rhymes with the number 0. I'm a game developer, but I'm also interested in bot writing and tinkering. You can find some of my bots at https://glitch.com/@chiguire, and my games at http://www.ciroduran.com/games/. I've also done some public speaking, putting up the slides at http://www.ciroduran.com/speaks/.
"But Ciro, that's a lot of links, you're already losing readers!" I know what to do. I'm going to share an anecdote. I was once about to be mugged while driving in my hometown, Caracas, but I managed to escape. I was so angry about this, that when I arrived home (thankfully unharmed), I modified a bit a game I was making and released it that same day. This game was [Nación Motorizada](http://ciroduran.com/juegos/motorizado) (requires Flash), a game where you must survive driving in a highway while tumbling bikes over, and earning combo points.
This game was picked up by a local newspaper, which was an achievement by itself. But then the game was picked up by CCTV, the Chinese News Network. Chinese correspondents came to my house and interviewed me about the game. So my anecdote is that I appeared in Chinese TV, speaking Spanish with Chinese subtitles. [Here's the video](https://www.youtube.com/watch?v=bmNQIBYge44).
<iframe width="560" height="315" src="https://www.youtube.com/embed/bmNQIBYge44" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
If this made you laugh then this post wasn't too bad after all :-) I'll return other day to write about more concrete subjects. | chiguire |
43,249 | A Glimpse of the Future: Is Flutter Likely to Replace Native App Development? | Long gone are the days when developing an app individually for iOS and Android was a prerequisite... | 0 | 2018-08-10T12:58:57 | https://dev.to/kiararobbinson/a-glimpse-of-the-future-is-flutter-likely-to-replace-native-app-development-1h63 | flutter, nativeappdevelopment | ---
title: A Glimpse of the Future: Is Flutter Likely to Replace Native App Development?
published: true
description:
tags: Flutter, NativeAppDevelopment
---

Long gone are the days when developing an app individually for iOS and Android was a prerequisite – to make it work on both platforms.
Now, however, the tables have turned dramatically!
Over the past few years, crafting a single app that would work on multiple platforms, using one single codebase, has been the trend.
Nevertheless, building cross-platform mobile applications has always been an uphill struggle for any mobile app developer. But ever since the introduction of a multitude of cross-platform frameworks, the programmer’s life has become a lot easier.
Developers no longer need to write separate codebases in different languages to simultaneously deploy an Android and iOS app. Instead, they just have to write the code once and build applications for different platforms, without putting any additional efforts.
One such framework which has acquired the interest and trust of gazillion developers is the Google-backed “<a href="https://flutter.io/">Flutter</a>”.
If you haven’t heard about it yet or the buzz surrounding it, then you’re probably living under a rock!
Let’s talk about it in detail!
##Demystifying Flutter##
<ul>
<li> An open source SDK that lets you develop powerful, high-quality native mobile apps for Android, iOS, and even Google’s upcoming OS Fushcia, using a single codebase.</li>
<li> A modern, reactive framework which empowers you to customize your app with rich, composable widgets, built-in animations, gestures, effects, and myriad other features. </li>
<li> The apps that are created using Flutter are incredibly fast, smooth, and beautiful. </li>
<li> The framework allows you to make your app run native on Android and iOS, without involving any interpreter. </li>
<li> It has an inbuilt library of Material (for Android) components and Cupertino (for iOS) widgets that are pixel-perfect enactments of the guidelines set by Google Play Store and App Store. </li>
<li> It provides a wide range of fully-customizable widgets to help you build native interfaces in no time. </li>
<li> Flutter’s layered architecture ensures rock-solid, exhaustive customization, which results in implausibly fast rendering and meaningful & flexible designs. </li>
<li> The beta 3 version of Flutter was released earlier this year, which has significantly increased the demand of the framework. </li>
<li> Whether you’re just getting started with mobile app development or are well-versed in other app development frameworks, you’ll definitely relish the high-speed development and quality apps that Flutter supports. </li>
</ul>
Some of these apps include Netflix, Amazon Prime Video, Google Play Movies & TV, YouTube, Pandora, Spotify, iTunes, and Grooveshark.
Keep reading, there’s a lot more to explore …
##Merits & Demerits of Using Flutter for Mobile App Development##
Just like any other framework, Flutter has its unique set of pros and cons. Let’s cover its strong points first.
<ul>
<li> Flutter is developed and supported by Google, which is its biggest advantage. Besides that, it’s easy to learn, fast, efficient, and completely different from other app development frameworks.
<li> Its lightning-quick code compiling speed and hot reload feature sets Flutter apart from its fellow competitors. It compiles your code relatively faster than any other app development framework, pretty similar to pure native compilation. Moreover, its hot reload attribute helps you quickly and easily build User Interfaces (UIs), add several new features to your app, and fix bugs.
<li> Flutter will be used as a primary development SDK in Google’s upcoming mobile OS Fuschia.
<li> The app animations are faster, smoother, and cleaner, simply because Flutter uses 2D GPU-accelerated APIs.
<li> Unlike native approaches, Flutter allows developers to run their native C/C++ compiled code, which is one of its key plus points.
<li> The framework uses Dart, an object-oriented programming language by Google, to render a faster UI in comparison to other cross-platform frameworks, which plummets the app development time drastically.
<li> Creating APIs using Dart is fun, probably because it’s simply the easiest language to learn for developers.
<li> It uses nested widgets to ensure that the design of the app on a particular operating system is up-to-date and adheres to the design standards.
<li> Flutter apps can run both on Android and iOS emulators simultaneously without any performance lag using the command “flutter run -d all”.
<li> You can easily and quickly find out the problems with your application using the command “$ flutter doctor”.
<li> Creating animations and transitions are more straightforward and simpler to execute than on native platforms.
</ul>
> <a href="https://www.debutinfotech.com/blog/guide-to-build-your-first-app-with-flutter">**Guide to Build your First App with Flutter**</a>
Despite having countless advantages, there are several downsides of using Flutter for mobile app development. Some of them are mentioned below:
<ul>
<li> With Flutter, it isn’t possible to develop apps in Java/Kotlin; instead, you’ll need to learn Dart.
<li> The framework is not perfect yet, as it lacks some important features such as OpenGL, MapView, VideoView, and accessibility support. Despite releasing Beta 3 earlier this year, Google hasn’t given any clue yet regarding the release of the stable version of Flutter.
<li> Flutter’s community is rather small as compared to Native’s. Developers are building new libraries and plugins, or in simple terms, the framework is still evolving.
<li> Taking into consideration its evolving nature, many services live AWS doesn’t support it yet.
<li> Flutter apps are relatively larger in size than native apps.
<li> The Google support is impressive and there are many ready-to-be-implemented libraries which you may find useful; however, it lacks certain functionalities, for example, inline maps are not supported yet, lack of support for inline video, etc.
</ul>
##Is Flutter Better than Native Mobile App Development?##
There’s no denying that native development is beyond comparison, but one of its biggest downsides is its higher cost. In addition, it requires the most specific developer skills (detailed knowledge of Objective C / Swift, Java, C# plus a proper understanding of IDEs & APIs). To implement native development, you’ll either need to hire someone with these particular areas of expertise or make your developers learn these skills over a period of time.
Remember, these skills may vary from developer to developer and from platform to platform, which means you’ll have to hire different <a href="https://www.debutinfotech.com/services/mobile-application-development-india">**mobile app developers**</a> for each of your platform, i.e., Windows, iOS, and Android. This may cost you a ton of money. If cost is not an issue for you, look nowhere else; but if it is, then switch to a less expensive option – Flutter. While native apps offer the best end user experience, Flutter apps are not far behind. They look and feel like native apps and still offer a compelling user experience, if not quite as good.
Flutter is super easy to get started with (it just requires the knowledge of Dart), arguably easier than its native counterpart. It’s undoubtedly the best way to craft high-quality native as well as cross-platform interfaces on iOS and Android. Flutter apps feel native with less complexity, have a low barrier to entry, are cheapest to develop, and render exact native app experience. Furthermore, there’s no need to implement and maintain multiple codebases; you can use single code across Android, iOS, Windows, and other platforms. All in all, Flutter’s unique features and stable nature make it a serious competitor to native development; however, it’s not fully developed yet to do any harm to or replace Native or other frameworks.
**Final Words**
Both Native and Flutter are outstanding frameworks for building attention-grabbing and robust mobile applications. Choosing between the two comes down to your personal preference and the amount of money you’re willing to spend.
If you’re seeking a reliable mobile app development company in India that could help you get started with Flutter, then look no further than Debut Infotech. For a free consultation, call at 1-703-537-5009 or drop a line at info@debutinfotech.com. | kiararobbinson |
43,340 | Sign your git commits with tortoise git on windows | after reading how easy it is to spoof a commit, i thought it would be good to sign my commits. | 0 | 2018-08-10T17:46:40 | https://dev.to/c33s/sign-your-git-commits-with-tortoise-git-on-windows-3mlf | git, sign, tortoisegit, windows | ---
title: Sign your git commits with tortoise git on windows
published: true
description: after reading how easy it is to spoof a commit, i thought it would be good to sign my commits.
tags: #git, #sign, #tortoisegit, #windows
cover_image: https://thepracticaldev.s3.amazonaws.com/i/crlskx4vevg3mk8bpp73.jpg
---
after reading [this nice article from agrinman about spoofing a git commit][1], i decided i will have a look on how to sign a git commit.
it is a little bit more complicated than i thought but its still an quite easy task.
first generate a keypair (the `--allow-freeform-uid` is to overcome the `Name must be at least 5 characters long` error):
```
λ gpg --full-generate-key --allow-freeform-uid
gpg (GnuPG) 2.2.8; Copyright (C) 2018 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
Your selection? 1
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (2048) 4096
Requested keysize is 4096 bits
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0) 5y
Key expires at 08/09/23 18:32:52 W. Europe Daylight Time
Is this correct? (y/N) y
GnuPG needs to construct a user ID to identify your key.
Real name: devto-example
Email address: devto@example.com
Comment:
You selected this USER-ID:
"devto-example <devto@example.com>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
We need to generate a lot of random bytes. It is a good idea to perform
some other action (type on the keyboard, move the mouse, utilize the
disks) during the prime generation; this gives the random number
generator a better chance to gain enough entropy.
gpg: key 8493DA39DD68724D marked as ultimately trusted
gpg: revocation certificate stored as '<REMOVED>'
public and secret key created and signed.
pub rsa4096 2018-08-10 [SC] [expires: 2023-08-09]
F0FB9F40A82A7F2502B652348493DA39DD68724D
uid devto-example <devto@example.com>
sub rsa4096 2018-08-10 [E] [expires: 2023-08-09]
```
export your public key
```
λ gpg --armor --export devto@example.com
-----BEGIN PGP PUBLIC KEY BLOCK-----
mQINBFttvksBEADGlRUxbEWnkQTuo3hCQv/Rw41a4A3/T3FZKaIXxO6c+uRn/XNp
ZriUzDwGvAhrG80viOS+pdKcZ8cV5FY9s2PUmb91B9fWxA5aTUCwu79EDGK+m+J9
QE2YAluFHPf5d3QpfyxpAhyTnklBDLTRm5UZp9+LIG/+O0E4aoG2PruP74nZFV1J
lbFumOBQ2OjYiLC7bKxqZmePWNG5StkkVtdT0Zvirv+mPksqKjZpto+AUVFa2dUm
i+vvqndXBfVqydwDWjfaL2Ci6Y0tLeLxMiHcB32ztlJT/yZxGM6QfkzK7wx68D7Z
0I+GrlF0qkgLXFxd+RJbOoipeS6uIiVsG9VPZC2NykkXO/Aizn+/7XKH1m+4yMs5
/7sW3QTrjFQnYiNmbiJGqBL8fv6uGYfdxE2++fbkzO5Wja7F/OHt7DvkwDJJMfOB
o8scoK5TEP9V/OwXUApC2l1JGue2lEJ7u5xxlY4MWVy/wm2nVNu41QFNBZTcglad
CL2yMDHxSnItjJ+BBM4T2wzfnXQIsdn1yiMYtPyoj/lCtP5gDaILOBxGcY15mcI3
+JzYSM8X0X0WwKXuQtXvyCya4PGiqfWQMKiOchL795jiCIr9s3dTqyX4+GisjGk6
UUdV+329cW6nRwknIHHn8tt1ZmHLGJ9eKuUsH6WpV05EUlDwx0Vj/LDJ3wARAQAB
tCFkZXZ0by1leGFtcGxlIDxkZXZ0b0BleGFtcGxlLmNvbT6JAlQEEwEIAD4WIQTw
+59AqCp/JQK2UjSEk9o53WhyTQUCW22+SwIbAwUJCWYBgAULCQgHAgYVCgkICwIE
FgIDAQIeAQIXgAAKCRCEk9o53WhyTfTrD/97oard3GCIMYPbQaOZ3bY//QI4JzgL
6asyvlix7qJSRVkv7QtqHwtoVKrkb0KTwGUzb/Og5Or0f/uED4xMAbmlPFvouk87
zk6FgTDA9QbgEepR7vICck7OUVcUqXLLnoHuL0GZbHYqdA/iu2RRXYCSBKnGCStl
YwIGM3d4gpOBfDI0od4L1LCG58bD7bJpjuTlGmSIIAI9X/i2kbS5s6zZgIv5EuaU
mXP0V+zLRCZFYk1zNrEfTVLkRMDw4JN3zG+573evLiCSFw4lA44BCXXkLNvHF6EK
G22ouCqBz7+ry8iJla1GionSUJvS3EEhBLcs7gPF+9NJiKLetmUa9tgaSGTdNIfv
chT1qFJ8o2NGhofnTu+HCxpVGeVHdkpLUz3sQe6xHcd4P8VvDABST2lYPuKWqH7Q
zEz0J7N8w1eDShVRuwsxeEFBWTebvC5Vef6Uvy/VzREjdYl2oyhDSkWG0gc3v/P8
lyisRrOFkEIldJI1kY9ksUuxmakN/0yjNek0mJQncm1gm5YTOJW1laaK7+QMHzU+
qEXvV38ThWLul6EKzQfIxvNyEfwccH0e48mSgdmi+MCmn1YvDdYL9vWHnXbntrmW
YkKS5Jp/jpfpRa/m4wyfOrIK/n3oFdX4bfGeWMDa40YSk5++inFm72//RI7zPSYR
RU685WI6Gl+gZrkCDQRbbb5LARAArplkX+iK2ZVWRpOwmZXGp2lhp0DlJKzitGUk
CD+/AagoezHWTsqeBiouy9FZSH2lPxj6l1zDSRauQ99KvLM17jX4FpWs3OqnTDCO
gYuwwS2YUNCLFTQdcGwVoM3Eei8iFJJg0rayuJIT2UW8uFwpLdhLdZPtZ9KuIN5P
J+P7428XPXgpJXo5Lu0EPHoXj0XwwKhNUI7lucwLQmxdnABGbxlKAs9++KbmpJyK
kkA03S+w9AEq+yEGUsdijA+bP1xkTWefyTeURAC/YTMVJfD/fRUhGT8xseqURpfW
K5WidElaLbnB2wZ9HRYVm20DBX2eavI61BkQnM4KoEIkqeDC9wFuPb7vUs++VGKK
t+OStnR3Es8nHHnjQt1WARJX8DP6KFRbgrGl0nYhhADJvyeYicFarn5j0GdBsvae
kn6pHIyRBtsvw2EoeJ1lGAs5PNgRhaSjQp5Ed7Omc3mzUS6NhGH8iVvshoPn1rpd
FN3DSatM2jZ4p9ts/rcCwNk0qZy3uXBnItPsHnmF46w3gmCIB7ZRA7aXBSx9pa6f
UJX4hmMR7VTfchB2E9cpXFxsnzp9PK5P2Py/KpQH5p/XuQOs5IZdtit1wRUFhV/W
WHJ6eDcxLHpNF/v3f+w0ArOlULktoiCXd5TAVrR2FaHSoKYr49FNrAPehWpYJs8/
mGW6xIcAEQEAAYkCPAQYAQgAJhYhBPD7n0CoKn8lArZSNIST2jndaHJNBQJbbb5L
AhsMBQkJZgGAAAoJEIST2jndaHJNaFMP/j5okfhHVl0GfrUoe/oBxNMNGVDTGhYM
p8YRVAxbGudckREfxg6T6sBQYU3gPQUywer5CgcJ6UGYusIEUxnf5G9hYpAPILMK
PZp1eYB1Om5d2yiikaZGxotNXg8A8vdxhutmUmjpAaAso0RsPzjRaBM/25Osiwkb
6bHBscarEo0ZQQrmgcNJkxzzaE8pX53zF4VKbNlsjtqniyRYn5zeHyTTUaUH0ZLd
6vhLiD/ozZnTnd9eLr1s87h6zv+uj/2xCZlMAebzPld8NFfY+Kr1XDjZA5cwACEW
Pg9oWMA0oE60W7HisWWik4qu3Ul+Nw/La8Onkb5aEWTp7/mq1R1SJdGYi9xjFHFK
IUnvMFcfaSaDZTNh5QykbqpkHWSBC8uQSEMgH+wJDrVq0nJk+hU5EjvAcCKWR/w2
MoS3rhQk3zazsL4KVp5x5Wihw9VkORJdohs7nHXWVAuK8/Z1TZXIeVpxsK9O2S0K
l4PxbEJaOudKEgvp3asmZd1U1BIZje1Adj4TsyFecVqqboUuzsXop1xBjXiN1h8w
DbT+fnc/m1KUJt5tp+DKJh0SsYOPfToU+SZ3E2Zu+8ZDZOq9JmLDEgYaLDiCn+5M
7oXFeWOYtFP07OJBxktI9A+oOUaN2Z71IviLAQcu81xuFZN1oS7jQgaqr6MbjsG9
1UOjABr0Qt9w
=sdjc
-----END PGP PUBLIC KEY BLOCK-----
```
and add it to https://gitlab.com/profile/gpg_keys and https://github.com/settings/gpg/new
then you have to configure git to use the key by adding the `key id` to the git config.
to get the key id run:
```
λ gpg --list-keys --keyid-format LONG devto@example.com
pub rsa4096/8493DA39DD68724D 2018-08-10 [SC] [expires: 2023-08-09]
F0FB9F40A82A7F2502B652348493DA39DD68724D
uid [ultimate] devto-example <devto@example.com>
sub rsa4096/75928CD4BDEAE0D7 2018-08-10 [E] [expires: 2023-08-09]
```
the sort version of the id is the part after `pub rsa4096/` -> `8493DA39DD68724D` and the long version is in the 2nd line `F0FB9F40A82A7F2502B652348493DA39DD68724D` because of [key collisions][2] i would recommend that you use the long key format.
now add/merge the following to your (global) `.gitconfig`
```
[user]
signingkey = F0FB9F40A82A7F2502B652348493DA39DD68724D
[commit]
gpgsign = true
[gpg]
program = "C:/Program Files (x86)/GNU/GnuPG/gpg2.exe"
```
you need to have [gpg][3] installed and adapt the `program` path according your install path. the signing key is your long key id. to auto sign your commits add `commit.gpgsign=true`.
now if you do a commit, the commit will be signed. you can easily verify that:
```
λ git verify-commit HEAD
gpg: Signature made 08/10/18 19:37:21 W. Europe Daylight Time
gpg: using RSA key F0FB9F40A82A7F2502B652348493DA39DD68724D
gpg: Good signature from "devto-example<devto@example.com>" [ultimate]
```
or
```
git log --show-signature
```
- cover image by : https://pixabay.com/en/writing-pen-man-ink-paper-pencils-1149962/
- see also:
- https://gitlab.com/tortoisegit/tortoisegit/issues/1494#note_14971615
- https://gitlab.com/tortoisegit/tortoisegit/issues/1494#note_62610134
- https://jamesmckay.net/2016/02/signing-git-commits-with-gpg-on-windows/
- https://mikegerwitz.com/papers/git-horror-story
- https://help.github.com/articles/signing-commits-using-gpg/
- https://security.stackexchange.com/questions/84280/short-openpgp-key-ids-are-insecure-how-to-configure-gnupg-to-use-long-key-ids-i
- https://www.gnupg.org/documentation/manuals/gnupg/Unattended-GPG-key-generation.html
- https://help.github.com/articles/generating-a-new-gpg-key/
[1]: https://dev.to/agrinman/spoof-a-commit-on-github-from-anyone-4gf4
[2]: https://evil32.com/
[3]: https://www.gpg4win.org/ | c33s |
43,970 | Tips on How To Communicate with Designers | Spend a day working with designers, and you'll get an earful of their specialized UX terminology: wir... | 0 | 2018-08-14T11:57:36 | https://djangostars.com/blog/untitled-how-to-speak-the-same-language-as-designers/ | uiux, digitalproductdevelopment | ---
title: Tips on How To Communicate with Designers
cover_image: https://djangostars.com/blog/uploads/2018/06/Cover-1.png
published: true
description:
tags: #uiux, #digitalproductdevelopment
canonical_url: https://djangostars.com/blog/untitled-how-to-speak-the-same-language-as-designers/
---
Spend a day working with designers, and you'll get an earful of their specialized UX terminology: wireframes, mockups, interface, grids and more. But there’s nothing mystical about what they’re saying. To collaborate successfully with your design team, you need to speak a common language. This article, tailored to non-designers, will cover design principles, explain their importance, and define essential terms. If you’re a designer, show this article to your clients when launching a new project.
##What Can UX Terminology Make Clear?
You might have heard this story. A king takes his most-trusted advisors and puts a blindfold on each one, so they can’t see anything. Then he brings them into a dark room. The king says to his advisors, “I have been to a faraway land, and I have brought back something unlike anything you have ever known. It is called an elephant.”
What is an elephant?” the advisors ask. The king says, “Touch the elephant and describe it to me.” The first advisor rubs a leg and says, “The elephant is a pillar.” Another advisor feels the tail and says, “The elephant is a rope.” The third advisor strokes the belly and declares, “The elephant is a wall.” And the last advisor touches the tusk and announces, “The elephant is a solid pipe.” “You are all wrong, and all correct at the same time,” says the king. “For you are each touching just a part of the elephant.”
People with different backgrounds, education and experience have different views about design. They all resemble the king's advisors from this story. A visual designer approaches design from one point of view, the interaction designer from another. Then there is the business owner, the information architect, the manager, the programmer and so on.
##Basic UI / UX Terms for Design Communication
When you talk to designers, it may often feel like they're speaking a completely different language. And even when you can follow along in context, the precise meaning of the vocabulary they use might elude you. So let’s translate some designer-speak.
This UX glossary will give managers an honest summary of what designers do and a deeper understanding of usability and web design issues. It also provides clients with a standard for usability for their designers.
* **Sketching**
A type of drawing designers use to propose, explore, refine and share ideas. UX designers use sketching as a first line of attack to crack a design problem.

* **Wireframe**
A simplified sketch of the important information in a page. Also known as the page architecture, page schematic, or blueprint. It’s a skeleton of the design that should contain all the important elements of the final product.
Though the wireframe may look just like a set of grey blocks, it is a low-detail presentation of a design. This design skeleton contains all the important elements of the final product. It shows the main groups of content, the data structure, and a description of the user interaction with the interface. The developers, designers, copywriters, managers who work on the team all need a well-crafted wireframe.
* **Visibility**
The system should always keep users informed about what is going on, through appropriate feedback within a reasonable time.
* **Visualization**
Illustration of information objects and their relationships on a display. Strategic visualization graphically illustrates the strength of relationships by the proximity of objects on the display.
* **Mockup**
A medium- or high-detail static representation of the design. A good mockup demonstrates the information structure, content and basic functionality in static form. Mockups make it easy to convey the design, and the process of mockup creation is less time-consuming compared to prototypes.
* **Prototype**
Often confused with a wireframe, a prototype is a medium or a highly detailed representation of the final product. It simulates user interaction with the interface. It should allow the user to rate the content and interface and test the primary options for dealing with the app. It may not look exactly like the final product, but it definitely should not be sketched in shades of gray. Interactions must be modeled closely enough to the final product.
The term ‘prototype’ means a sample model of the product that can be tested to confirm whether the solutions are efficient. Prototypes should not be seen as an analogue of the final product. Their main aim is to enable a designer, a client and a user to see if the design planning is correct.
The value of prototypes vs. wireframes in web design and app development has skyrocketed in the past couple of years. Even a low-fidelity prototype gets the designer, client and tester much closer to the appearance of the future product.
Prototyping is an efficient and useful step between UX design and UI design. When you want to feel the efficiency of these elements and check if nothing has been lost in the design process, the prototype will be a great help.
* **User Interface (UI)**
What the user sees; this can be a set of commands or menus through which a user communicates with a program. It is also the space where interactions between humans and machines occurs.
* **User Experience (UX)**
A broad term for several disciplines that study the effect of design on the ease of use and level of satisfaction with a product, site or system. The term UX was invented by Dr. Donald Norman, a cognitive scientist.
*Note* : UI and UX are not interchangeable! UI is what your users interact with; UX is how they feel while they’re doing it.
The user interface could be a finalized interactive field in which the user interacts with the product. It includes all the tools to speed up usability and meet the users’ needs and wishes. All the visual features, as well as sound and tactile elements, should be analyzed and optimized. For example, color palette, types and animation will affect the performance of the final product.
In general terms, the UX research and wireframing stage is about how the website or application works, while the UI is what it looks like. User experience deals more with logic, connections and user behavior. The user interface provides a visual representation of the concept. The designer should first work on the UX part with a concentration on layout, to make it powerful, well thought out, clear and easy to use. Without this important work, you risk making a mess of the user interface.
After the UX part is tested through a prototype, and the layout, transitions and other features are accepted, the designer starts the UI design part. This is when the newborn heart and brain of your product is clothed with skin and bones. Here the product gets its real color scheme, forms and features of the layout, styles, animations and so on.
All the user interface solutions directly influence the user experience. Hence, the processes of UX wireframing and UI design should reciprocally support each other.
* **Onboarding**
Designing a welcoming experience for new users by easing them in. The design of the onboarding process for your site is usually limited to a first-time use scenario.
* **Landing Page**
The location on a website where a user goes after clicking a link. Also called the Target page or Destination page.
This concept was coined more than 10 years ago by internet marketers in the US. The landing page is a webpage with the best navigation possible and a single call to action. Its main goal is to increase the number of requests from potential clients and stand out in the competition among web companies.
##How to Avoid Mistakes in Design Communication

Terminology plays a large role in the user’s ability to find and understand information. Many terms are familiar to designers and content writers, but not to users, managers and clients.
Designers use words in special ways when they know they are talking to other designers. In this case, they are communicating design concepts that they either know or assume will be shared territory.
To build an efficient relationship with a design team, always create and review a design brief with the designer. In this way, you will enter the design territory. A UX Glossary may be helpful to clients who are new to a topic and want to build a technology roadmap for their project.
###Common Mistakes in Design Communication
There’s often clumsy communication gap between the two parties who need each other. Clients are sometimes overly demanding. In contrast, the client-designer relationship is nourished by empathy and understanding. Everyone has a right to make mistakes. Designers and clients are all in the same boat.
Therefore, if you don’t tell a designer that something must be changed, they won’t know what’s bothering you. Take time to carefully look at the first draft your designer hands you. Make a list of the corrections you would like to see, and recall all of them at the followup meeting.
**"I like it / I do not like it"**
Phrases like “I do not like it” or “This looks weird” are frustrating for a designer to hear. Without describing exactly what you find weird, saying things like this doesn’t help the designer solve the problem.
Feedback needs to be as specific as possible. Explain how you would like the product to look and feel. Point to specific elements, styles, fonts, color palettes or layouts. Provide the designer with a few samples of designs you like.
**"Can you move that button up and to the left? And make it smaller?"**
Second-guessing and dictating to designers how they should do their job diminishes their trust. Designers can’t read your mind, so don’t expect them to have paranormal abilities. Your job as the client is to define the problem for the designer. The designer’s job is to find the solution. Avoid giving too many detailed instructions. Instead, tell the designer what issue you or your audience might have, and trust the designer to fix it.
Remain open to the designer’s ideas, even if they don’t align with your vision. Allow the designer to use his or her brain.
**Factors Affecting Design Communication**
* You have a limited time or budget;
* You’ve had a bad experience with designers before;
* You always consult with your personal design authority;
* You feel compelled to criticize.
The best way to get the most out of your graphic designer or illustrator is to give them honest feedback. Unfortunately, feedback from clients often sounds like, “Jane in accounting likes this, but Sarah in marketing said that, and my boss wants something completely different.” Nothing is worse than hearing conflicting input from several different people.
The best way to present feedback to your designer is to write a list of issues. Together with the designer, you can go over it to discuss the appropriate changes to the product.
People in visual arts and design are used to meticulous criticism. But if you are harsh when suggesting changes, it may trigger designer’s block. It resembles writer’s block, when you feel stuck and aren’t sure how to proceed.
Approach your relationship with your graphic designer with discretion and tact. For example, when talking about changing a font, don’t point to your designer’s work and say, “This typeface is kitschy.” Rather, say, “I would like to try a different font here.” Then specify the next step you’d like to take.
###Tips for Preventing Communication Gap
**Ask Simple Questions to Understand the Problem**
Give feedback early and often. Asking designers about issues saves them time and results in a better project, as elements don’t have to be altered at the last minute.
**Ask More Questions**
It’s easy to blame an unsatisfying final product on the designer. Instead, give the designers all the tools they need to succeed. Your job as the client is to help the designer understand exactly your idea and goals of the product. It’s up to the client to ask more questions to facilitate effective communication.
**Answer Your Designer’s Questions Without Delay**
Try to provide all the necessary information requested by the designer on time. Explain the message you want to convey. Give an overview of your business or product. Remember that your procrastination slows down the design process.
###Good Feedback About Design

Try asking the designer what they would suggest. Here are some examples of how to ask a designer for their professional opinion:
* “What can we do to deal with that?”
* “What do you think will be the most effective solution for our company?”
* “In your professional opinion, which one do you suppose will resonate more with our audience, and why?”
* “Are you able to render that a bit more to make it clearer?”
* “We would like more emphasis on the logo. It seems to be getting lost at the moment.”
* “I’m worried that people won’t see the button. What would you recommend to make it more prominent?”
* “Can you explain the distinction between RGB and CYMK again?”
* “This is a smart start. Yet I’m worried that this appearance resembles some of my competitors’ visuals. Is it possible to differentiate ourselves better?”
* “The font you used is a nice choice. It’s very clear and will charm our younger audience.”
It’s not uncommon for designers to feel as if they are being micromanaged, especially if the client provides too many details about the design. When a designer works with too many demands, the ultimate product looks like it was created by checking off boxes on a checklist. Be flexible, grasp what’s necessary for your product and what isn’t, then let your designer use their skills to create your vision.
###How the Knowledge of UI/UX Terms Benefits You
Hopefully, you feel confident enough to engage in more of these design conversations. Ask open questions about the design process, and practice giving smart feedback without delay.
To speak with designers, you have to understand how they think. Designing anything from scratch is difficult, especially when you’re new to working with a designer or a design team. Turning a concept into a product is laborious work, and the client needs to be involved in the design process right from the start.
To make a long story short, being more aware of communication gap in design will help you better understand your design team – and maybe even think like a designer yourself.
The article is written by Sergey Gladkiy. This article about [digital product development](https://djangostars.com/blog/untitled-how-to-speak-the-same-language-as-designers/) is originally published on Django Stars blog. You can also visit our content platform [Product Tribe](https://producttribe.com/) created by professionals for those involved in a product development and growth processes.
You are always welcome to ask questions and share topics you want to read about! | djangostars |
44,100 | Elixir入門 13: aliasとrequireおよびimport | Elixir公式サイトの許諾を得て「alias, require, and import」の解説にもとづき、加筆補正を加えて、Elixirのディレクティブaliasとrequireおよびimportの使い方についてご説明します。 | 0 | 2018-12-11T01:33:13 | https://dev.to/gumi/elixir-13-aliasrequireimport-55c1 | elixir, webdev, tutorial, programming | ---
title: Elixir入門 13: aliasとrequireおよびimport
published: true
description: Elixir公式サイトの許諾を得て「alias, require, and import」の解説にもとづき、加筆補正を加えて、Elixirのディレクティブaliasとrequireおよびimportの使い方についてご説明します。
tags: #elixir, #webdev, #tutorial, #programming
---
本稿はElixir公式サイトの許諾を得て「[alias, require, and import](https://elixir-lang.org/getting-started/alias-require-and-import.html)」の解説にもとづき、加筆補正を加えて、Elixirのディレクティブ`alias`と`require`および`import`の使い方についてご説明します。
ソフトウェアが再利用しやすいように、Elixirはつぎの3つのディレクティブとひとつのマクロを備えています。ディレクティブは[レキシカルスコープ](https://ja.wikipedia.org/wiki/%E9%9D%99%E7%9A%84%E3%82%B9%E3%82%B3%E3%83%BC%E3%83%97)(lexical scope)をもちます。`use`は標準のマクロです。
- `alias`ディレクティブ: モジュールが別名で呼び出せるように別名を与えます。
- `require`ディレクティブ: マクロが呼び出せるようにモジュールを要求します。
- `import`ディレクティブ: モジュール名なしに関数が呼び出せるようにモジュールを読み込みます。
- `use`マクロ: モジュール内のコードを拡張ポイントとして呼び出します。
# alias
[`alias/2`ディレクティブ](https://hexdocs.pm/elixir/Kernel.SpecialForms.html#alias/2)は、すでにあるモジュールに任意の別名を与えます。つぎのエイリアスが使われていないコードを例にとりましょう。
```elixir
defmodule Sayings.Greetings do
def basic(name), do: "hello, #{name}"
end
defmodule Example do
def greeting(name), do: Sayings.Greetings.basic(name)
end
```
```elixir
iex> Example.greeting("world")
"hello, world"
```
第2引数を省くと、ドット(`.`)で区切られたモジュール名の最後の識別子がエイリアスになります。
```elixir
defmodule Example do
alias Sayings.Greetings
def greeting(name), do: Greetings.basic(name)
end
```
第2引数で与える名前には、`as:`オプションを添えてください。エイリアス名は大文字ではじめなければなりません。
```elixir
defmodule Example do
alias Sayings.Greetings, as: Hi
def greeting(name), do: Hi.basic(name)
end
```
Elixirのモジュールはすべて名前空間`Elixir`に定められます。デフォルトではそれが省けるということです。
```elixir
iex> alias Example, as: String
Example
iex> String.greeting("tokyo")
"hello, tokyo"
iex> Elixir.String.length("hello")
5
```
エイリアスはレキシカルスコープをもちます。モジュールで定めれば、モジュール内の関数すべてがそのエイリアスを参照できます。
```elixir
defmodule Example do
alias Sayings.Greetings, as: Hi
def greeting(name), do: Hi.basic(name)
def greeting_ex(name), do: Hi.basic(name) <> "!!"
end
```
```elixir
iex> Example.greeting_ex("world")
"hello, world!!"
```
エイリアスを関数の中で定めると、他の関数からは参照できません。
```elixir
defmodule Example do
def greeting(name) do
alias Sayings.Greetings, as: Hi
Hi.basic(name)
end
def greeting_ex(name), do: Hi.basic(name) <> "!!"
end
```
```elixir
iex> Example.greeting("world")
"hello, world"
iex> Example.greeting_ex("world")
** (UndefinedFunctionError) function Hi.basic/1 is undefined (module Hi is not available)
Hi.basic("world")
example.exs: Example.greeting_ex/1
```
# require
Elixirには、メタプログラミングの仕組みとしてマクロが備わっています。メタプログラミングとは、コードが生成されるコードを書くことです。マクロはコンパイルのとき展開されます。
パブリックの関数はグローバルに用いることができます。けれど、マクロを使うには、それが定義されたモジュールを[`require/2`ディレクティブ](https://hexdocs.pm/elixir/Kernel.SpecialForms.html#require/2)でオプトインしなければなりません。
`Integer.is_odd/1`はモジュールにマクロとして定められています(図001)。そのため、あらかじめ`Integer`モジュールを`require/2`で設定しなければ使えません。
#### 図001■リファレンスのInteger.is_odd/1の項にmacroの表示

```elixir
iex> Integer.is_odd(5)
** (CompileError) iex: you must require Integer before invoking the macro Integer.is_odd/1
(elixir) src/elixir_dispatch.erl:97: :elixir_dispatch.dispatch_require/6
iex> require Integer
Integer
iex> Integer.is_odd(5)
true
```
- [`Integer.is_even/1`](https://hexdocs.pm/elixir/Integer.html#is_even/1): 奇数かどうかを論理値で返します。
- [`Integer.is_odd/1`](https://hexdocs.pm/elixir/Integer.html#is_odd/1): 偶数かどうかを論理値で返します。
ディレクティブ`alias/2`と同じく、`require/2`もレキシカルスコープをもちます。
# import
[`import/2`](https://hexdocs.pm/elixir/Kernel.SpecialForms.html#import/2)は、完全修飾名を使わずに関数やマクロが参照できるディレクティブです。モジュール名なしに関数やマクロが呼び出せるようになります。
```elixir
iex> import List
List
iex> first([1, 2, 3])
1
iex> last([1, 2, 3])
3
iex> flatten([1, [[2], 3]])
[1, 2, 3]
```
- [`List.first/1`](https://hexdocs.pm/elixir/List.html#first/1): リストの最初の要素を返します。
- [`List.last/1`](https://hexdocs.pm/elixir/List.html#last/1): リストの最後の要素を返します。
第2引数に`only:`オプションで、読み込む関数やマクロを絞り込めます。
```elixir
iex> import List, only: [first: 1, last: 1]
List
iex> first([1, 2, 3])
1
iex> flatten([1, [[2], 3]])
** (CompileError) iex:9: undefined function flatten/1
```
第2引数のオプションには関数・マクロのリストのほか、`:macros`と`:functions`が与えられます。なお、`import/2`で読み込まれるマクロは、内部的に`require/2`も行わるのです。
```elixir
iex> import Integer, only: :macros
Integer
iex> is_even(4)
true
iex> digits(123)
** (CompileError) iex: undefined function digits/1
iex> Integer.digits(123)
[1, 2, 3]
```
```elixir
iex> import Integer, only: :functions
Integer
iex> digits(123)
[1, 2, 3]
iex> is_odd(3)
** (CompileError) iex: undefined function is_odd/1
```
第2引数のオプションとして、`only:`の替わりに`except:`で逆に読み込みから除くリストも定められます。
```elixir
iex> import List, except: [first: 1, last: 1]
List
iex> flatten([1, [[2], 3]])
[1, 2, 3]
iex> last([1, 2, 3])
** (CompileError) iex: undefined function last/1
```
`import/2`ディレクティブもレキシカルスコープです。関数の中に定めると、他の関数からは参照できず、コンパイルエラーになります。
```elixir
defmodule Example do
def split(number) do
import Integer, only: [digits: 1]
digits(number)
end
def test(name), do: digits(name) #コンパイルエラー
end
```
# use
[`use/2`マクロ](https://hexdocs.pm/elixir/Kernel.html#use/2)を使うと、モジュールの定めを他のモジュールから変えられるようになります。`use/2`が呼び出すのは、モジュールに加えられた`__using__/1`コールバックのマクロです。すると、このマクロの働きを別のモジュールに取り込めます。
つぎのコードが`__using__/1`コールバックを定めたモジュールの例です。ここではテスト用に使うだけですので、マクロについて詳しくは「[Macros](https://elixir-lang.org/getting-started/meta/macros.html)」をお読みください。
```elixir
defmodule Hello do
defmacro __using__(_opts) do
quote do
def greeting(name), do: "hello, #{name}"
end
end
end
```
別のモジュールで`use/2`を用いると、`__using__/1`コールバックに定めた関数が、そのモジュールから呼び出せます。
```elixir
defmodule Example do
use Hello
end
```
```elixir
iex> Example.greeting("world")
"hello, world"
```
`use/2`の機能は、つぎのように`require/2`を使ったのと同じです。
```elixir
defmodule Example do
# use Hello
require Hello
Hello.__using__(greeting: :value)
end
```
さらに、`__using__/1`コールバックをつぎのように書き替えます。すると、関数の処理が、`use/2`の第2引数により変えられるのです。
```elixir
defmodule Hello do
defmacro __using__(opts) do
hello = Keyword.get(opts, :hello, "hello")
quote do
def greeting(name), do: unquote(hello) <> "," <> name
end
end
end
defmodule Example do
use Hello, hello: "こんにちは"
end
```
```elixir
iex> Example.greeting("日本")
"こんにちは,日本"
```
# エイリアスを理解する
Elixirのエイリアスは、コンパイルするときアトムに変換される頭が大文字の識別子(`String`や`Keyword`など)です。
```elixir
iex> is_atom(String)
true
iex> to_string(String)
"Elixir.String"
iex> String == :"Elixir.String"
true
```
`alias/2`を用いると、エイリアスはアトムに展開されます。Erlang VM(およびElixir)では、モジュールはアトムで表されるからです。
```elixir
iex> :lists.flatten([1, [[2], 3]])
[1, 2, 3]
```
# モジュールを入れ子にする
モジュールは入れ子にすることができます。外から子のモジュールを参照するには、親からの完全修飾名を用いなければなりません。
```elixir
defmodule Example do
def greeting(name), do: "hello, #{name}"
defmodule Greetings do
def morning(name), do: "good morning, #{name}"
end
end
```
```elixir
iex> Example.greeting("world")
"hello, world"
iex> Example.Greetings.morning("tokyo")
"good morning, tokyo"
```
親モジュールの中に子のモジュールが定められたあとであれば、子は完全修飾名を使わずに参照できます。子モジュールが親のレキシカルスコープに含まれるため、内部的にエイリアスがつくられるからです。
```elixir
defmodule Example do
def greeting(name), do: "hello, #{name}"
defmodule Greetings do
def morning(name), do: "good morning, #{name}"
end
# alias Example.Greetings #<- 内部的にエイリアスがつくられる
def call_child(name), do: Greetings.morning(name)
end
```
```elixir
iex> Example.call_child("japan")
"good morning, japan"
```
完全修飾名を用いれば、子モジュールは親の外でも定められます。このとき、子モジュールは必ずしも親のあとに書かなくても構いません。このとき親モジュールが子の名前だけで参照したいときには、エイリアスを使ってください。
```elixir
defmodule Example do
def greeting(name), do: "hello, #{name}"
end
defmodule Example.Greetings do
def morning(name), do: "good morning, #{name}"
end
```
さらに、完全修飾名さえ使えば、親モジュールがなくても子モジュールは定められます。すべてのモジュール名はアトムに変換されるためです。
```elixir
defmodule Example.Greetings.Japan do
def greeting(name), do: "こんにちは, #{name}"
end
```
```elixir
iex> Example.Greetings.Japan.greeting("日本")
"こんにちは, 日本"
```
# alias/import/require/useを複数使う
`alias`や`import`、`require`、`use`は一度に複数のモジュールを定めることができます。つぎのコードは、ふたつの子モジュールにモジュール名のエイリアスを与える例です。
```elixir
iex> alias Example.Greetings.{US, Japan}
[Example.Greetings.US, Example.Greetings.Japan]
```
#### Elixir入門もくじ
- [Elixir入門 01: コードを書いて試してみる](https://dev.to/gumi/elixir-01--2585)
- [Elixir入門 02: 型の基本](https://dev.to/gumi/elixir-02--30n1)
- [Elixir入門 03: 演算子の基本](https://dev.to/gumi/elixir-03--33im)
- [Elixir入門 04: パターンマッチング](https://dev.to/gumi/elixir-04--1346)
- [Elixir入門 05: 条件 - case/cond/if](https://dev.to/gumi/elixir-05----casecondif-60o)
- [Elixir入門 06: バイナリと文字列および文字リスト](https://dev.to/gumi/elixir-06--35na)
- [Elixir入門 07: キーワードリストとマップ](https://dev.to/gumi/elixir-07--39hi)
- [Elixir入門 08: モジュールと関数](https://dev.to/gumi/elixir-08--1c4c)
- [Elixir入門 09: 再帰](https://dev.to/gumi/elixir-09--1a0p)
- [Elixir入門 10: EnumとStream](https://dev.to/gumi/elixir-10-enumstream-4fpb)
- [Elixir入門 11: プロセス](https://dev.to/gumi/elixir-11--2mia)
- [Elixir入門 12: 入出力とファイルシステム](https://dev.to/gumi/elixir-12--4og6)
- Elixir入門 13: aliasとrequireおよびimport
- [Elixir入門 14: モジュールの属性](https://dev.to/gumi/elixir-14--3511)
- [Elixir入門 15: 構造体](https://dev.to/gumi/elixir-15--4f43)
- [Elixir入門 16: プロトコル](https://dev.to/gumi/elixir-16--lif)
- [Elixir入門 17: 内包表記](https://dev.to/gumi/elixir-17--5gci)
- [Elixir入門 18: シギル](https://dev.to/gumi/elixir-18--5791)
- [Elixir入門 19: tryとcatchおよびrescue](https://dev.to/gumi/elixir-19-trycatchrescue-50i8)
- [Elixir入門 20: 型の仕様とビヘイビア](https://dev.to/gumi/elixir-20--j50)
- [Elixir入門 21: デバッグ](https://dev.to/gumi/elixir-21--21a1)
- [Elixir入門 22: Erlangライブラリ](https://dev.to/gumi/elixir-22-erlang-2492)
- [Elixir入門 23: つぎのステップ](https://dev.to/gumi/elixir-23--50ik)
##### 番外
- [Elixir入門: Plugを使うには](https://dev.to/gumi/elixir-plug-40lb) | gumitech |
44,384 | Will PHP save your startup? | A response to Alexander Katrompas' post titled "Java will kill your startup. PHP will save it." | 0 | 2018-09-09T15:34:33 | https://dev.to/peteraba/will-php-save-your-startup-4b30 | php, java, healthydebate | ---
title: Will PHP save your startup?
published: true
description: A response to Alexander Katrompas' post titled "Java will kill your startup. PHP will save it."
tags: php, java, healthydebate
---
About two months ago [Alexander Katrompas](https://medium.com/@alexkatrompas) wrote a post on medium titled [Java will kill your startup. PHP will save it.](https://medium.com/@alexkatrompas/java-will-kill-your-startup-php-will-save-it-f3051968145d). I already posted a short response as a [comment there](
https://medium.com/@peteraba/disclaimer-ive-done-over-15-years-of-php-development-currently-mostly-work-with-go-but-i-love-9f42699430e1), but I thought it might be worthwhile to elaborate on that a little.
Again, if there's anything of which I can call myself an expert, that would probably be PHP. I don't really like PHP anymore, I don't write a lot of PHP anymore, but I do know it very well.
## The arguments
Just to quickly recap, here are Alexander's arguments in a nutshell:
- Many large-scale projects started off being written in PHP and over 80% of the top 10M web sites use PHP.
- PHP programmers are more plentiful and cheaper than Java programmers. (web-only)
- PHP has excellent performance and it continuously gets better and in-practice easily rivals compiled languages.
- PHP application time to market is a fraction of Java EE applications.
- PHP is not a “scripting” language (whatever that means), it’s a fully function, object oriented, web powerhouse.
- PHP 7.x is a vast improvement over previous versions and 8.0 promises to surpass all expectations.
- Frameworks are plentiful and powerful. The power, popularity, and dominance of Symfony and Laravel is undeniable.
- WordPress (PHP driven) is the dominant CMS with almost 60% market share. The next top 5 CMSs, are all PHP driven.
- PHP is simply made for the web. No extra servers, processors, hacks, tricks needed. It is literally one with your web server.
- Most dominant open source e-commerce systems are all written in PHP. (WooCommerce, Magento, OpenCart, PrestaShop, ZenCart, Drupal, Joomla, OsCommerce, and on, and on, and on…
## My comments on the arguments
As the title and the above list shows, Alexander was comparing PHP to Java EE. Now I have very little knowledge on the latter, but I can tell you that for most startups PHP is no longer the best choice.
Just to clarify, there are a few points that I strongly disagree with. In my opinion:
1. PHP is a scripting language. It does have decent OO features, but that has nothing to do with it being a scripting language. What it does affect is first that not all of your code will be loaded into memory when a request is served (good), that all of your errors will be runtime errors (bad) and of course that your code will be interpreted on an as-needed basis instead of having it all compiled to byte code or some intermediate language. *Sidenote:* Alexander mentions "function, .. oriented" there as well, but I'm hoping that was nothing more then some copy-paste mistake.
2. PHP 7 is a step in the right direction, but it wasn't brave enough to really clean up the API and I doubt PHP 8 will be.
3. PHP is made for the web but there are extra servers, processors, hacks and tricks needed. It is absolutely not one with your web server and if you've been close enough to operational teams of big PHP projects you'll know how much a pain in the ass it can be. Not that it's a PHP-specific thing but just to get things straight. I'm guessing that Alexander was referring to the PHP apache extension, but that's not something I've seen running live in the last 10 years and probably you shouldn't either...
4. PHP is fast enough for serving as the backend of an API. If you need true performance for complicated stuff (databases, crypto-mining, etc.) then it probably isn't.
Still, with all these corrections I think the problem lies in what's missing from the list, not what's in there.
First of all if your startup is about selling flip-flops, then by all means go ahead, install Magento and off you go. You'll still be able to ditch it for something more flexible when you actually start to make money and feel the pain of running an over-engineered, yet rigid system. (wink-wink [Zalando](https://www.zalando.de/)).
If however you want to build something that's a true [Zero-to-One type](https://www.amazon.com/Zero-One-Notes-Startups-Future/dp/0804139296) startup, you need a system that gives you agility:
1. Fast to learn.
2. Fast to prototype in.
3. Straight-forward to harden.
4. Enables fast and safe refactoring.
Plus I'd consider these things as nice-to-haves for startups but absolutely must-haves for mature companies:
1. Maintainable
2. Secure
And finally two nice-to-haves for the most successful startups, the corporations:
1. Exciting
2. Trustworthy
### Fast to prototype in
Now I have the feeling that Alexander focused way too much on prototyping for which PHP is quite good indeed. Not the best, but certainly decent, probably better than the famously verbose Java is.
Just to clarify, Java is famous for being verbose but I wouldn't call PHP concise either. It's not a really a criticism, simply a statement. (In comparison Python and Ruby code tend to be significantly shorter and easier to read than equivalent PHP code.)
### Straight-forward to harden
When it comes to hardening, your only real choice is adding more tests because the type system is just very hard to rely on. You can harden your own code ensuring that you use types everywhere (you'll need at least 7.1 to really do that) and marking each of your files to be type checked strictly, but it's a hassle, error prone and it's tough to get all your dependencies to provide similar safety. Also, if you end up using any of the popular frameworks (Symfony, Laravel, Zend, etc) you're out of luck, as they all -support 5.x still- (Correction: they require PHP 7 lately, but don't enforce strict type checking). And the truth is that 99.9% of all PHP teams will decide to use these tools because of familiarity and the size of their ecosystems.
If the choices only came down to PHP and Java, I'm sure Java would easily win here. It still suffers from the [billion dollar mistake](https://www.wikiwand.com/en/Null_pointer), but at least the compiler will yell at you if you change your API in one file and forgot to update it in another. In PHP you'll just hope it will be caught in a test or during code review, given you have those. ***(Spoiler alert!*** *In most start-ups you don't, because you know, they take time and therefore money***)**
### Enables fast and safe refactoring
When it comes to fast and safe refactoring there's hardly anything worse than PHP, so Java would win easily, mainly still due to its type safety and the compiler being able to check your whole application by default. Again Java is probably far from the best choice as some functional and functional-inspired languages will go further in this regard, but I think it should already be decent.
### Fast to learn
This is the final point in the must-have section for startups, but it can be very important in some cases. Alexander avoids this problem by saying it's cheaper to hire PHP devs and Java devs. While it's probably true, the difference likely not to be comparable to choosing the wrong language and having to rewrite everything later. Yes, as a startup you might want to cut that 20% on IT salary expenses, but you should understand that you're playing with fire. I myself would rather risk running out of money 2-10% earlier then risking years of suffering of wrong choices early on.
So if we agree with the premise that you can always bring in people already familiar with your stack then Alexander was probably right, but the difference shouldn't make or brake your startup.
I'd however argue that I'd prefer working with a language that less people know but is very easy to learn. That way you can get the best domain experts bring tremendous value and you never risk of running out of local talents because any engineer you'd get would be able to get productive in a few weeks.
Now this is where I'm fairly sure both PHP and Java suck, and they actually suck big time. Both these languages try to satisfy everyone, putting all sorts of features into the language and both of these have huge-huge ecosystems which take years and perhaps decades to fully oversee and takes tons and tons of reading to make sure you understand best practices and things to avoid. Not to mention how much terrible advice must be out there for both of these languages... Still, as a beginner searching for good answers must be a nightmare both for Java and PHP.
In contrast many newer languages try to keep things straight forward. Go is the most obvious example here but Elm and Rust can also simplify many things even if they bring in some concepts which are harder to grasp at first.
Ecosystems of these new languages are also cleaner and in the case of Go most things you'll use are in the standard library, tested at Google-scale and quality that you can easily bet your company on. The community also lives and breaths the [Unix-philosophy](https://homepage.cs.uri.edu/~thenry/resources/unix_art/ch01s06.html), which means popular tools tend to do one thing and do that well. It's definitely not true for PHP and I doubt it would be for Java EE, although I can't really judge that.
**Note:** I hinted it before, but to be clear: if you can utilise one of the many open source PHP applications out there then it can be a much larger save than just 2-10% and it might make a lot of sense. Most obvious example is e-commerce, but there are some others as well. In case of e-commerce, you should either just use an existing ready-made service, some marketplace or build on top of [Magento](https://magento.com/), [Thelia](https://thelia.net/) or [Sylius](https://sylius.com/). Prestashop might have some use cases too, but if anyone recommended me WooCommerce, OpenCart, ZenCart, Drupal, Joomla or OsCommerce for e-commerce, I'd run away and I'd run far.
### Maintainable
I spent most of my professional carrier working on huge (>1.000.000 lines) legacy applications trying to clean up the mess my predecessors left behind themselves. Most of the pain came from over-engineered OOP monstrosities. Because of that, I truly appreciate the simplicity of Go and Rust and for me both PHP and Java would score really badly.
I also enjoy the extra safety functional languages can provide but they can affect how fast a language is to learn, so you'd have to take that into account while assessing them for "fast to learn" and "excitement".
### Secure
This is a point where I really lack the knowledge to properly assess Java, but PHP does have a pretty bad track record. I have the feeling that Java would fair better, but I'd rather skip this topic saying that there are better languages out there than PHP. In fact, I believe PHP is among the worst.
### Exciting
Now this is certainly not important for all startups but if you are thinking about something technologically challenging, then you should try to appeal to the best minds available in your area. These people will be able to learn a new language, but they won't learn just any language you throw at them. Not because they can't, but because they don't want to.
Unfortunately PHP is among the least respected languages out there and this means that the brightest software engineers probably never learned PHP and probably aren't willing to learn it.
Java is slightly better off here because anyone who got a computer science degree in the last 2 decades have learnt Java at some point and many even stuck with or sticked to it. On the other hand it's also not the most popular language to learn for people outside of the Java community these days.
On the upside however there are other JVM languages with current momentum (Scala and Kotlin mostly) which claim to provide easy access to anything written in Java, so that could be a safe way forward I think.
I will admit that this is not a topic I can't fully assess, but I have the feeling Java still wins here.
### Trustworthy
This is an easy knockout for Java EE. If you want to go public or sell your product to fortune 500s you'll want Microsoft (C#), SAP and Java EE on your portfolio. And that's pretty much a complete list as far as I know.
## Conclusions
So I had PHP winning one point easily and another one potentially. There are many points where I admitted I don't necessarily have the Java-knowledge to assess both but in these cases PHP scored pretty bad, forcing me to believe that Java is the better technology to start a green-field project.
This does not mean that PHP will kill your startup and Java will save it. What this post meant to say is that you should understand the consequences of your choices, understand the risks you make and choose whatever will make you sleep better.
- If cutting 2-10% of IT expense is all you want then PHP (or NodeJs) is reasonable.
- If you need to have your blog or e-commerce site available ASAP then PHP is probably your best choice, but you should make a good reason not to use an existing service instead.
- If you want to sell your product to Fortune 500 companies then Java is probably still the keyword to score a deal, although other JVM or .NET languages might also make sense.
- If ensuring you won't find yourself in a situation where you have to rewrite everything then use a statically typed, compiled language. I'd recommend Go but I hear Kotlin might be a reasonable choice as well.
- If you don't need first class support by major cloud providers, but runtime errors can kill your company then consider Rust or Haskell.
Finally, if you really wanted a simple answer to the question "will PHP save your startup?", I'd have to say no. Not unless you're building something on top of an existing PHP application. Will PHP kill your startup though? Probably not, but it's likely to make it less agile than it could be. | peteraba |
44,831 | Can Docker replace our VMs farm? | Trying to understand containers | 0 | 2018-08-19T17:21:06 | https://dev.to/0xyasser/can-docker-replace-our-vms-farm-39me | docker, vms, help | ---
title: Can Docker replace our VMs farm?
published: true
description: Trying to understand containers
tags: Docker,VMs, help
---
I'm not familiar with the idea of containers. From what I've read online, it's a good idea for development for the team where we all develop in the same environment.
But I was thinking if containers can actually replace a whole VM farm. We manage 200+ VMs in our team. Those VMs run 24/7 and does executions during the day/time.
All of them are windows machines, some win7 some win10.
My question is, Can we replace those VMs with Docker or any containers. I'm thinking of something like, whenever an execution has to run, a container is spend up and when the execution is over it get destroyed. That will guarantee those execution runs in the same exact configs all the time. Because the hard part about maintaining 200+ VMs is that almost each one act differently due to so many execution that it runs during the day.
is it that simple like this? whenever an execution has to run, we spin a container with specified configs?
```
docker win7 config1
```
where config1 = chrome66, firefox61, outlook
and config2 might be different version of the browsers?
is it that simple?! | 0xyasser |
44,847 | Quick SVN guide for Git users; SVN: The Git Way | A quick guide for Git users on how SVN can be used "The Git Way" | 0 | 2018-08-19T19:33:02 | https://diliprajbaral.com/2018/01/13/quick-svn-guide-for-git-users-svn-the-git-way/ | svn, git, vcs | ---
title: Quick SVN guide for Git users; SVN: The Git Way
published: true
description: A quick guide for Git users on how SVN can be used "The Git Way"
tags: svn, git, vcs
canonical_url: https://diliprajbaral.com/2018/01/13/quick-svn-guide-for-git-users-svn-the-git-way/
---
This post was first published on [Quick SVN guide for Git users; SVN: The Git Way](https://diliprajbaral.com/2018/01/13/quick-svn-guide-for-git-users-svn-the-git-way/).
Why would a Git user want to switch to SVN, you ask?
Well, sometimes you just don't have a choice. Imagine working on a project that has been maintained in SVN since a decade. "But migrating an SVN codebase to Git is not a big deal at all." But there is stuff like CI/CD integrations to worry about too. That isn't a really big deal either but sometimes people take "Don't fix what ain't break." a little too seriously.
Reasons aside, having a good Version Control System (Distributed VCS for that matter) concepts, I didn't want to go SVN guides from the scratch to start with. While there were plenty of resources on the web regarding SVN to Git migration, I couldn't' find a quick and concise guide that would help me work with an SVN repo right away. If you are like me, you will find this article helpful. The following steps show you how can work with SVN the Git way.
### Cloning a new repo
Checking out a repo is similar to how we do it in Git.
```shell
$ svn checkout <path-to-your-repo-branch> <path-to-checkout>
```
#### Example
The following checks out your code to your current working directory.
```
$ svn checkout https://mysvnrepo.com/myrepo/trunk .
```
### Creating a new topic branch
In SVN, branches (and tags) are nothing but a simply a copy of one branch. A literal copy-paste of the files, unlike pointer to commits in Git. This fact took me a while to digest and get used to.
The following commands are SVN equivalent to git checkout -b branch.
```shell
$ svn copy <path-to-a-branch> <path-for-new-branch> -m "Message"
```
#### Example
```shell
$ svn copy --parents https://mysvnrepo.com/myrepo/trunk https://mysvnrepo.com/myrepo/branches/feature-branch
$ svn switch https://mysvnrepo.com/myrepo/branches/feature-branch
```
### Working on the repo
#### Adding new files
To add new files, you would use:
```shell
$ svn add <path-to-file>
```
As for modified files, we don't need to add them. We can straight away commit.
```shell
$ svn commit -m "Commit message"
```
To commit only specific files, we need to list files after the commit message.
```shell
$ svn commit -m "Commit message" <path-to-file-1> <path-to-file-2>
```
If we want to commit a single file, we can do the following too.
```shell
$ svn commit <path-to-file> -m "Commit message"
```
### Checking out new changes
The following is the SVN equivalent to git fetch && git merge or git pull.
```shell
$ svn update
```
### Merging your feature branch to trunk
Merging a branch in SVN is similar to how we do it in Git.
```shell
$ svn merge <path-to-branch>
```
#### Example
```shell
$ svn update
$ svn switch https://mysvnrepo.com/myrepo/trunk
$ svn update
$ svn merge https://mysvnrepo.com/myrepo/branches/feature-branch
$ svn commit -m "Merge feature branch to trunk"
```
### Deleting feature branch after merging
To delete a feature branch (or any branch for that matter), svn delete is used.
#### Example
```shell
$ svn delete https://mysvnrepo.com/myrepo/branches/feature-branch -m "Delete feature branch after merging"
```
| rajbdilip |
45,010 | Who's looking for open source contributors? (August 20 edition) |
Please shamelessly promote your project. Everyone who posted in previous weeks ... | 0 | 2018-08-20T16:36:18 | https://dev.to/ben/whos-looking-for-open-source-contributors-august-13-edition-1epm | discuss, opensource | Please shamelessly promote your project. Everyone who posted in previous weeks is welcome back this week, as always. 😄
Happy coding!
| ben |
45,102 | Best obgyn doctor near me | May-Grant is one of the best OBGYN medical center, providing expert obstetrics and Gynecology services for women. https://www.maygrant.com/ | 0 | 2018-08-21T06:05:09 | https://dev.to/mayajan13641058/best-obgyn-doctor-near-me-2257 | obgynclinic, localgynecologist | ---
title: Best obgyn doctor near me
published: True
description: May-Grant is one of the best OBGYN medical center, providing expert obstetrics and Gynecology services for women. https://www.maygrant.com/
tags: Ob Gyn clinic, Local Gynecologist
---
| mayajan13641058 |
45,420 | VSCode Tip: Watching Files | File this under VS Code Can do That?! Sometimes I need to watch a log file or other file for changes... | 0 | 2018-08-21T18:55:02 | https://SeanKilleen.com/2018/08/vscode-tip-watch-files/ | vscode, tips | ---
title: VSCode Tip: Watching Files
published: true
tags: vscode,vs code,tips
canonical_url: https://SeanKilleen.com/2018/08/vscode-tip-watch-files/
---
File this under [VS Code Can do That?!](https://vscodecandothat.com/)
Sometimes I need to watch a log file or other file for changes, whether it be on my local machine or a remote server. On windows this can be a bit of a pain, and you oftentimes have to dump out of your IDE to make it happen.
So on a whim one day, I said “I wonder if VS Code can do that”. I search the extensions, and lo and behold, VS Code _can_ do that!
## Enter VS Code and the Log Viewer Extension
- Open VS Code
- Click on the `Extensions` button
- Type `Log Viewer` in the search box
- Find the [Log Viewer Extension](https://marketplace.visualstudio.com/items?itemName=berublan.vscode-log-viewer) and install it.
## Setting up the Extension
- In VS Code, open the Command Bar (for me, `CTRL + Shift + P` does this)
- Type `Workspace Settings` or similar and then select `Preferences: Open Workspace Settings`
- In the settings, add a section for `logViewer.watch` that defines some titles and patterns for files that you’d like to watch. Below is an example of watching two separate files on different servers. I add the below and save my preferences:
```json
{
"logViewer.watch": [
{
"title": "Server 1 IIS",
"pattern": "\\\\servername\\C$\\inetpub\\logs\\LogFiles\\W3SVC2\\u_ex180718.log"
},
{
"title": "Server 2 IIS",
"pattern": "\\\\servername2\\C$\\inetpub\\logs\\LogFiles\\W3SVC2\\u_ex180718.log"
},
]
}
```
## What are the Results?
The log viewer opens a screen, and we can see all the applicable watches and view their updates as they change.
I love that I can define patterns and not just file paths, so that I can watch multiple files at once.
## What do you Think?
Hope you enjoyed this tip! Drop your other favorite tips in the comments, and check out [VS Code Can do That?!](https://vscodecandothat.com/) for a lot of other great tips!
[VSCode Tip: Watching Files](https://SeanKilleen.com/2018/08/vscode-tip-watch-files/) was originally published by Sean Killeen at [SeanKilleen.com](https://SeanKilleen.com) on August 21, 2018. | seankilleen |
45,834 | Linux Tips And Tricks | It seems that publishing a post of Linux tips & tricks is a rite of passage that all engineers mu... | 0 | 2018-08-29T07:54:18 | https://dev.to/mohanarpit/linux-tips-and-tricks-4kk | linux, tips, bash | ---
layout: post
title: Linux Tips And Tricks
published: true
tags: #linux, #tips, #bash
---
It seems that publishing a post of Linux tips & tricks is a rite of passage that all engineers must go through. More importantly, it's a bookmark for my future self to find these eclectic mix of commands easily with minimal googling.
So without further ado, here's my list:
### find
This command is very helpful while searching for needles in a haystack. It also has plenty of modifiers (too many to list), so I'll only mention the ones I use almost daily.
The general syntax of the command is:
```bash
$ find <starting directory> \
-type <type of file/directory> \
-name "<Regex of the file/dir name>" \
-exec <arbitrary command to execute> {} \;
```
Basic example looking for java files:
```bash
$ find ~/projects -type f -name "*.java"
```
Example looking for directories called main
```bash
$ find ~/projects -type d -name "main"
```
We can also recursively execute a command on the matching files. This exposes the true power of the find command.
Example: Search all java files for the Main function. The output of this command will only be the matched strings.
```bash
$ find ~/projects -type f -name "*.java" -exec grep -i "Main" '{}' \;
```
Alternatively, if you wish to output the name of the matching file along with the matched string:
```bash
$ find ~/projects -type f -name "*.java" -exec grep -i "Main" '{}' +
```
Notice the difference in how the command ends. The braces `'{}'` are substituted by each matching file name at runtime. It's similar to how `xargs` works.
### less
For log files (typically large) and files that I wish to only read and
**NOT** edit, I use the `less` command extensively. One of the major
reasons I love this command is, I can tail files without it
cluttering my terminal. This command also has the benefit of only
loading the file partially into memory, thereby making it a sleek
alternative to `vi`
Example:
```bash
$ less /var/log/insanely-large-log-file.log
```
Once inside, you can use `G` to go to the end of the file or use `F` to tail the file.
Alternatively, you can open & tail the file directly using
```bash
$ less +F /var/log/insanely-large-log-file.log
```
To quit and return to the terminal, use the normal `vi` command
```vim
<ESC> :q
```
### entr
I recently came across this command and although it hasn't made it to my most frequently used commands, I think it's pretty useful. It would be a crime to compile such a list and not mention `entr`
This command allows users to execute an arbitrary script whenever a file changes. It's similar to `watchr`, `guard` & `nodemon`. Since `entr` is written in C, it's faster and more responsive on larger directories.
Usecases can range from running test cases whenever your source files change
```bash
$ ls *.c | entr 'make && make test'
```
or reloading the browser whenever an HTML file changes.
```bash
$ ls *.css *.html | entr reload-browser Firefox
```
You can also restart server processes using the `-r` modifier
```bash
$ ls *.rb | entr -r ruby main.rb
```
Check out more details [here](http://www.entrproject.org/).
### htop
If you are looking at your machine's performance in any way apart from
`htop`, you're doing it wrong. It's what `top` should have been all along. Although it's not built-in, you can easily install it via:
```bash
$ apt install htop
```
or
```bash
$ brew install htop-osx.
```
The output is very self-explanatory and easier to understand & sort.
### jq
Your search for a JSON parser ends here. `jq` runs on a stream of JSON data. Each input is parsed as a sequence of whitespace-separated JSON values which are passed through each filter of `jq`. The filters themselves, can be combined in any way by piping the output of one filter to the input of another.
Example:
This example extracts the field 'foo' from the input JSON.
```bash
$ jq '.foo' {"foo": 42, "bar": "less interesting data"}
```
```
=> 42
```
This example extracts the 0th element of the JSON array.
```bash
$ jq '.[0]' [{"name":"JSON", "good":true}, {"name":"XML", "good":false}]
```
```bash
=> {"name":"JSON", "good":true}
```
### vim commands
By popular opinion, vim is the awesomest editor in town. But for newbies, it can be a little daunting and un-friendly. Once you get vim, you'll never go back to any other editor.
The following vim commands aren't for newbies. It's for more advanced users.
How often do you open a file in vim to edit it and realize you should have opened it as *root*? You can use the following command to save your changes without exiting vim.
```vim
<ESC> :w !sudo tee %
```
Slightly longer to type but completely worth it.
I think vim commands demand a dedicated post to do justice to the most beloved editor.
### Conclusion
I hope this was useful. I'll probably edit this post to reflect any new commands that cross my path/blow my mind.
| mohanarpit |
45,945 | What are the key metrics that you look for Web App optimization? | Let's talk about what you do when you want/need to make better web apps. | 0 | 2018-08-24T16:15:32 | https://dev.to/papaponmx/what-are-the-key-metrics-that-you-look-for-web-app-optimization--4n1h | webdev, discuss, javascript | ---
title: What are the key metrics that you look for Web App optimization?
published: true
description: Let's talk about what you do when you want/need to make better web apps.
tags: #webdev #discuss #javascript
---
**Note**: I'll try to include the most relevant metrics on the Part 4 of my Front End Developer Automation series. If you'd like to collaborate, please let me know [@papaponmx](https://twitter.com/papaponmx).
For me the depending on the topic, some of those are:
* `<meta>` tags presence and confirm that they include relevant content.
* Validate all `html` tags.
* First meaningful paint.
* Number, size and latency of initial requests and their relevance.
* Font sizes and images size on mobile devices.
* Color contrast ratio.
* Can I traverse the app just with the keyboard?
What are yours?
| papaponmx |
46,254 | Opinions on Continued Education for Software Engineers | I'm a software engineer that is a year into my career and so far really enjoying myself. Often times... | 0 | 2018-08-26T19:58:44 | https://dev.to/omawhite/opinions-on-continued-education-for-software-engineers--246a | discuss, education | ---
title: Opinions on Continued Education for Software Engineers
published: true
tags: discuss, education
---
I'm a software engineer that is a year into my career and so far really enjoying myself. Often times family members and a few mentors of mine will ask me if I have plans to go back to school. While I like the idea of doing so one day, I'm not sure when I would want to study, or when. Additionally the realization that I can make good money doing work I enjoy with the degree I already have makes me question what the worth of a masters degree would be. Do you think its worth it for engineers to go back to school? What kind of things doing you think are worth studying? General advice on continued education in this field? | omawhite |
46,264 | The not fancy CLI output of pnpm | pnpm is a JavaScript package manager that differs from npm and Yarn in many ways. If you haven't... | 0 | 2018-08-26T21:36:57 | https://dev.to/zkochan/the-not-fancy-cli-output-of-pnpm-36ao | pnpm, javascript, node, npm | ---
title: The not fancy CLI output of pnpm
published: true
description:
tags: pnpm, javascript, node, npm
cover_image: https://i.imgur.com/hqbKZLS.png
---
[pnpm](https://github.com/pnpm/pnpm) is a JavaScript package manager that differs from npm and Yarn in many ways. If you haven't heard about it yet, I recommend checking it out. In this article, I would love to write about the design system that we use to report during installation.
When I first started contributing to pnpm (around `v0.15`), this is how an installation was reported:

It wasn't really useful but some users of pnpm liked it. They thought it was beautiful. But then as we started adding more features, we realized that it is very important to print the right amount of information in a nice readable format.
So let's see how pnpm has evolved and how it reports in different scenarios as of `v2.13.6`.
## Reporting installation in a single project
When you first install pnpm and you run `pnpm install` in a project, you'll see an output like this:

Unlike the old output, this one is very static and minimalistic but it contains a lot more useful information.
We see that:
* one of the installed packages is deprecated
* 117 new packages were added to `node_modules`
* Installation slowed down a bit because the huge typescript tarball was being downloaded
* 0 packages were available in the store, so all 117 packages were downloaded (pnpm saves one version of a package only ever once on a disk, so when a package is available in the store, it is just hard linked to the `node_modules`)
* `express@4.16.0` was added as a production dependency
* a newer version of express is available in the registry
* `babel-preset-es2015@6.24.1` and `typescript@3.0.1` were added as dev dependencies
Now lets update express to the latest version and see what we get:

* 5 packages were removed from node_modules
* 5 packages were added to node_modules
* all 5 packages were downloaded from the registry
* the newest express was added to the project
## Reporting installation in a multi-package repository
pnpm has a set of commands for working with multi-package repositories (MPR). When installing dependencies in an MPR, the amount of information that is being processed is so big that printing all of it would just make an unreadable mess. In order to provide some basic information anyway, we came out with the concept of zoomed-out reporting. A zoomed-out reporting contains just the most important pieces of information.
Every package in the MPR is printed with the number of added/removed packages (inspired by Git):

Zoomed-out reporting also prints warnings (only warnings, no info messages):

When we came out with the concept of zoomed-out reporting for the [recursive commands](https://pnpm.js.org/docs/en/pnpm-recursive.html), we realized that there are other scenarios in which they are useful. For instance, when packages are linked in, it should be a mixture of zoomed-out and zoomed-in reporting. Packages that are linked in should be reported briefly and the package in the current working directory should be in focus:

## Implementation details
Although the output seems minimalistic and simple, it is produced by a very complex system. pnpm consists of many components and many operations may happen in random order (this is one of the reasons pnpm is [so fast](https://github.com/pnpm/node-package-manager-benchmark#readme)). That is why reporting is performed by a specialized part of pnpm called "reporter" ([code](https://github.com/pnpm/pnpm/tree/master/packages/default-reporter)).
The reporter is a package that listens for logs, filters them, combines and forms an output from them. pnpm uses [bole](https://github.com/rvagg/bole) to pass the logs from the loggers to the reporter. This modularization is great because we can mock the logs and cover reporting with tests!
For printing the output to the console, we use [ansi-diff](https://github.com/mafintosh/ansi-diff). `ansi-diff` is great because it accepts "frames" of output and it updates only those parts of the console that are changed (and it is fast). Before we switched to `ansi-diff`, we used another popular library for updating the console output but it was doing the update with noticeable flickering.
## P.S.
It is very hard to implement good CLI reporting. But good reporting allows developers to focus on the important things and possibly notice issues earlier.
Of course, pnpm's reporting can improved a lot and we have many [open issues](https://github.com/pnpm/pnpm/issues?q=is%3Aissue+is%3Aopen+label%3A%22area%3A+reporting%22) in that area. Give pnpm a try and don't hesitate to let us know if there are things that can be improved further.
*originally posted in the [pnpm blog](https://medium.com/pnpm/the-not-fancy-cli-output-of-pnpm-5bd4398716ce)*
| zkochan |
46,574 | PHP Console Application made easy | adhocore / php-cli PHP Console... | 0 | 2018-08-28T14:50:58 | https://dev.to/adhocore/php-console-application-made-easy-18ao | php, cli, console, showdev | ---
title: PHP Console Application made easy
published: true
description:
tags: php, cli, console, showdev
---
{% github adhocore/php-cli %}
Helps you build bespoke, interactive console app easy and quick - includes commands, actions, argument parsing, colors, cursors, interaction and all that is required.
*inspired by nodejs commander*
### Installation
`composer install adhocore/cli`
| adhocore |
46,858 | Discharge, a simple, easy way to deploy static websites to Amazon S3 | Discharge is, as far as I’m aware, the easiest way to deploy static websites to Amazon S3. I spent... | 0 | 2018-08-30T07:19:25 | https://dev.to/brandonweiss/discharge-a-simple-easy-way-to-deploy-static-websites-to-amazon-s3-2b19 | node, webdev, aws, opensource | ---
title: Discharge, a simple, easy way to deploy static websites to Amazon S3
published: true
tags: node, webdev, aws, opensource
---

[Discharge](https://github.com/brandonweiss/discharge) is, as far as I’m aware, the easiest way to deploy static websites to Amazon S3. I spent hours poring over AWS’s terrible docs so no one else would have to.
The highlights are:
* Very little understanding of AWS required
* Interactive UI for configuring deployment
* Step-by-step list of what’s happening
* Support for no trailing slashes in URLs
* Support for subdomains
* Use an AWS Profile (named credentials) to authenticate with AWS
* CDN (CloudFront) and HTTPS/TLS support
This has saved me a huge amount of time; I hope it’s helpful to other people. Let me know what you think! | brandonweiss |
46,869 | Podcasting for Newbies for £20 a Month Or Less | I used to host and produce the Ruby Book Club podcast with Saron Yitbarek. Each w... | 0 | 2018-09-16T05:13:47 | https://dev.to/nodunayo/podcasting-for-newbies-for-20-a-month-or-less-1d2o | podcast, podcastingtips, audio | ---
title: Podcasting for Newbies for £20 a Month Or Less
published: true
tags: podcasting,podcasting-tips,podcast,audio
canonical_url:
---
I used to host and produce the [Ruby Book Club podcast](http://rubybookclub.com/) with Saron Yitbarek. Each week, we read one hour of a Ruby book and discussed what we had learnt.
Since starting the show I have had similar questions from a lot of people:
_I have a great idea for a show. What do I need to buy? What software do I need? Is it all very expensive?_
Well, it can be expensive. But it doesn’t have to be.
I want to share the details around the equipment and software that I used (Saron had different, more expensive tools in some cases, but then again, [podcasting is her business](https://www.codenewbie.org/podcast)) in a bid to show you one way to produce a decent-sounding show that won’t break the bank.
**Microphone — £128**
The first step to increasing the quality of your audio is to get a microphone. This will likely be the biggest capital investment as you start your new podcasting project. Getting one is essential.
Why can’t you just speak into your laptop’s built-in mic or into the ones that come with your headphones? They’re not optimised for best capturing your voice and digitising it for media where audio quality is the main focus. They’re there for basic communication, so any recording of your voice will be of low quality and will come accompanied with a lot of surrounding noise. Dedicated microphones are there to focus on getting your voice to sound as clear and rich as possible via a recording. Remember — it doesn’t matter how amazing your content is: if the quality of your audio isn’t good enough, people will not stick around.
Starting out, you probably want a microphone that’s ‘plug-and-play’, i.e. there isn’t much of a learning curve getting started using the thing. For this, I would recommend USB microphones that you can plug directly into your computer. These mics are relatively inexpensive, yet still provide a huge upgrade to computer or headphone built-in mics. There’s a wide range of them available on Amazon.
Over the years, I’d heard great things about the Audio-Technica brand — mainly that the reliability and quality you get is amazing in relation to the price point. Because of this, I eventually decided to purchase the [Audio-Technica AT2020USB PLUS USB Microphone](https://www.amazon.co.uk/Audio-Technica-AT2020USB-PLUS-USB-Microphone/dp/B00B5ZX9FM/ref=dp_ob_title_ce).
I’ve been using it for over three years now and have only had one issue with it — I dismantled and screwed together my mic and its stand pretty regularly since I carried it between an office and my home. It wasn’t long before the grooves at the bottom of the mic wore off. I had to buy insulation tape to securely fit the mic into the stand again. Beyond that, audio quality on the mic has always given me what I needed.
**Recording software — Free**
Once you’ve got your microphone, you’ll need a way to record your content and conduct the actual interview.
For recording, Saron and I used [Quicktime](https://support.apple.com/downloads/quicktime), which came pre-installed on our Mac computers. It’s also [available via free download](https://support.apple.com/downloads/quicktime). That way, we could each record our own streams of audio separately and locally, giving us a high quality recording.
To have the conversation featured in each episode, we used a tool called [Mumble](https://www.mumble.com/). It’s open source software, primarily aimed at gamers, that enables two people to speak via one server. It has pretty granular audio controls which can come in handy to get the best sound quality based on your internet speed and quality. However, it does require a decent bit of setup, so it may not be the best thing if you’re just starting out and don’t have somebody around who knows what they’re doing and which settings would be ideal.
Something you’ll want to think about is backups in case your primary recording source fails in any way. It can be something as simple as one person forgetting to hit the button to start recording! Since Mumble also lets you record each stream of audio separately, it worked very well for backup recordings.
For an alternative to something like Mumble, I’m seeing [Zencastr](https://zencastr.com/) grow in popularity. Their sell is that you can easily get high quality audio since the app records each person locally using an extremely reliable connection that doesn’t rely on the users’ Internet. In that way, it does the job of the local Quicktime recordings, but you can also hear one another through the website. This means you can host the interview or conversation there as well. Guests can easily jump into a recording via a link they’re sent via an email, and the host receives a track for each guest once the recording session is over. I’ve used Zencastr as a guest and found the process straightforward. I recommend evaluating it alongside your recording options when getting started — the people who I know who use it generally only have very good things to say. The only downside is that because it’s relatively new on the market, there have been cases when it has lost an audio file or didn’t save the whole interview. However, it’s getting better and more reliable over time.
**Editing software — Free**
Even with a good quality mic, you’ll still want to clean up your audio, especially if you’ve got at least two people on the recording.
For the Ruby Book Club, each week we’d have two separate audio files. At the most basic level of editing, the tasks that need to happen are as follows:
- Reduce background noise from each track
- Sync up the audio files so people are speaking in time with one another
- Silence the track of the person not talking at any time
- Level the volume across all of the tracks
- Cut out any mistakes or do-overs made by guests.
To do these basic tasks, I used [Audacity](https://www.audacityteam.org/). It’s free and open source. It doesn’t look like much, but it enables me to do the tasks listed above and there’s enough documentation around for when I came across new things that I needed to do; for example, fixing occurrences of [clipping](https://en.wikipedia.org/wiki/Clipping_(audio)).
**Website Domain registration — £12 (annual)**
You might opt for a custom domain if you want your listeners to regularly check out a website attached to the podcast. You can use any registrar for this. I love [DNSimple](https://dnsimple.com/) for its user-friendly, intuitive interface, especially when it comes to configuring DNS records.
£12 seems to be the average price for a ‘.com’ domain registration.
**Squarespace — £108 (annual)**
You’ll need a place to store your podcast episodes and [Squarespace makes hosting a podcast easy](https://support.squarespace.com/hc/en-us/articles/205814338-Podcasting-with-Squarespace-overview). It provides a built-in RSS feed — the tool via which people can access your content via different platforms, including Apple Podcasts — and you can manage episodes and serve a public-facing website for your listeners all in one place.
The price you see above is the annual Personal plan with a 10% discount applied. I’m assuming you’ve got a promo code tucked away from one of the podcasts you listen to? If not, you can google around and find one easily.
There’s one main downside to Squarespace — you don’t have direct access to the RSS feed. If your podcast is just a fun side hobby, this probably isn’t important. However, if you think you might want to do something a bit more custom and have more control over how your RSS feed works and is structured, you’ll likely find Squarespace limiting.
### Costs
Purchasing all of the above in one go will set you back £128 + £108 + 12 = £248.
If you run your podcast for a year, that equates to £248/12 = £20.67 a month.
Not bad.
### Assumptions:
- Ownership of a decent computer and headphones. Ideally, you want headphones optimised for accurate reproduction of recorded audio — not for listening to your favourite music tracks, where certain types of sounds are enhanced.You also want them to be comfortable, since you’ll be wearing them throughout the recording and editing process. Luckily for me, I already owned a pair of the wonderful [Beyerdynamic DT 770 PRO Studio Headphones](https://www.amazon.co.uk/beyerdynamic-770-PRO-Studio-Headphones/dp/B0016MNAAI/ref=sr_1_1?ie=UTF8&qid=1528257501&sr=8-1&keywords=beyerdynamic+dt770+pro). Again, though, if this podcast is a hobby, don’t worry about investing in new headphones if the ones you use day-to-day sound clear enough when you listen to music or are on the phone.
- Annual payment for Squarespace. If you pay monthly, it’s a few pounds more each month.
- Single host. Having a co-host helps financially. Apart from the mic, all of the above costs were split with Saron. Thinking of more hosts to save money? Keep in mind that there’s a tradeoff between a reduction in costs and the increase in complexity regarding organisation, logistics, and editing.
### Other things to consider:
- If you want to be fancy, go ahead and purchase some music for your opening and closing. This is an effective way to level up in the polished-ness of your show. We eventually got theme music from [Premium Beat](https://www.premiumbeat.com/) and it set us back £40 for a perpetual license.
- Since things like the microphone and music are one-off capital investments — effective monthly running costs will decrease the longer you produce your show.
- Want to take your audio quality to the next level? Check out [this ingenious hack](https://medium.com/@saronyitbarek/the-ultimate-podcasting-hack-record-in-your-closet-39a478f4d89a) from my business partner, [@saronyitbarek](http://twitter.com/saronyitbarek).
If you have any questions about what I’ve said here or alternatives you’re thinking of using, you can find me [@nodunayo](https://twitter.com/nodunayo) on Twitter. | nodunayo |
46,909 | How code-splitting can help your site be more efficient | A look at how to load files and components efficiently | 0 | 2018-09-03T13:53:42 | https://dev.to/napoleon039/what-is-code-splitting-22ni | vue, webpack, webdev | ---
title: How code-splitting can help your site be more efficient
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/rk2b95me6wfw9126ccr0.JPG
description: A look at how to load files and components efficiently
tags: vue, webpack, webdev
---
You make an amazing website. It looks good - there's great color contrast, the subtle animations are great to interact with and the website has an overall nice feel.
But you still wonder, why does it take so much time for the initial load? The code of the website doesn't seem to have any problems. Then why does it load slowly?
That might be because of multiple pages (or components, if you're working with frameworks) loading at the start, when there's only need to load one.
Webpack offers a solution for this problem: **code-splitting**. Since it's something offered by Webpack and not by a specific framework you can make it work anywhere using Webpack.
## Introduction
This article is about code-splitting in Vue. More specifically, it's about code-splitting components in Vue by *route*. This is an important topic because code-splitting will help you run your website faster. This is because only the necessary components are loaded and you can have other components load along with it if you want. You’ll most likely use this when working on big projects which have multiple components and routes. Code-splitting makes our code performant and improves load time.
To get the most out of this post, it would be best to have a Vue project with Vue Router set up. You need Router for this one because we are going to apply code-splitting to our *routes*. Of course like I mentioned earlier, you can even do this with other frameworks, there is nothing framework-specific here. There are a total of 3 approaches to implement code-splitting. We will be using one of them called **dynamic imports** You can find more about them in the [Webpack docs](https://webpack.js.org/guides/code-splitting/).
## Concept analogy
Think about wanting to drink juice out of a container. You don't empty the entire container, drink how much you want and then put it back into the container. What we do, is take out some in a glass to drink. If we want more, we proceed to pour some more juice into the glass. Code-splitting does something similar to this. It might seem like this large setup, but it's fairly quick. So let's get started!
## Project setup
You must have a Vue project set up with Vue Router. If you don't have one, make a simple one. There must be more than one component for the result of code-splitting to be evident. It doesn't matter if there is only an `<h1>` inside the components, what matters is you actually apply this to understand it better. Go ahead and set up a project if you haven't already. Here's a sample one:


Now first, you have to install the dynamic import plugin for Babel.

The reason why Babel requires this plugin is because while Webpack understands dynamic imports (which is what we're using) and bundles accordingly, on the server-side we need Babel to understand and transpile it. **Satyajit Sahoo** has explained it pretty well in the babeljs slack:

Next, we include our newly installed plugin in the Babel config file.

That’s done! Let’s get to the main stuff now.
## Implementing code-splitting
The usual way of importing components to include in the `router.js` file is as follows:

Save your current code and start it in dev mode.
```bash
#Run development server
npm run dev #for Vue v2.x
npm run serve #for Vue v3.x
```
Visit this in Chrome or Firefox or any browser of your choice. Now go to the console from the Developer Tools [F12 on keyboard]. Visit the Network tab. Now reload the page. You'll see both components loading. After selecting js from the filters (it's a bit above the actual result window, refer to the screenshot below) you will see app.js, take a look at it's size.

Without code-splitting, at initial load, the About component is bundled together with the Home component and loading even though we don't need it yet. Time to change this. There is another way to make imports which is Promise-based, so make sure to include a *polyfill* for older browsers which do not support Promise.

And we’re done. That was quick! What we did is create a function that returns an import. This is the dynamic import syntax. Whenever webpack sees an import like this, it generates a **chunk**, also called a code split in response to the Promise. Now save the code, reload the page and check the Network tab again, the components are not loaded all at once. Start visiting your routes one by one and you’ll see components appear in the result window as their routes are visited. Here are images of my Network tab as I visit both my routes one after the other:


You did it!! Have some of that juice from before. But remember not to gulp down all of it ;)
But wait, what’s this; all our components in the Network tab are represented by numbers. So unintuitive. Let’s solve that: Add this comment to your imports.

Webpack interprets these comments as quite literally, **chunk names**. The names given as values to *webpackChunkName* will be used to represent the particular component in the Network tab instead of numbers. And now you can know which file you’re looking at from the Developer Tools. You'll probably see the About component still present at initial load. However, a quick look at the size of the file will reveal that it is not the actual component loading since the size is 0 bytes. It is probably Vue working behind the scenes. The actual component loads only when we visit it's route.
## A more real world example
I've given an example of a juice container. But how does this relate to us in reality?
Let’s take a look at how this works in a real app. For example, we have a website with an image-heavy route and a home route along with some other routes as well. If we load the website, the home component would load first as one would expect. Now it’s possible this home component would have some animation or images to draw the attention of the user. But this page will render slowly because another route (component) has lots of images. There could also be another component with a few animations. All these components will drag the home page with them. One would understand why an image-heavy page would render/load slowly after seeing its contents. But the home page of any website is supposed to load quickly. Code splitting the components based on their routes would be one ideal solution. A practical example where we could face such a problem would be an Instagram or Pinterest clone.
Now that you've seen what code-splitting can do for you, why not visit the Webpack docs and check the other two approaches as well. Maybe you'll find yourself in a situation where going with one approach will not work, but another is perfect for you. I first encountered code-splitting on [this Egghead.io community resource](https://egghead.io/lessons/vue-js-code-split-by-route-in-vuejs). Check it out as well.
That's it for now. Let me know your thoughts on this article in the comments below and if it helped you. If you have any questions or suggestions I'll be glad to hear from you. | napoleon039 |
46,933 | Build a One-time Password Token for MFA with Okta | Learn about the time-based one-time password algorithm using a credit-card-sized, Arduino-based game device and Okta Verify for MFA. | 0 | 2018-09-10T20:22:12 | https://developer.okta.com/blog/2018/08/30/build-one-time-password-token-for-mfa | security, mfa, arduino | ---
title: Build a One-time Password Token for MFA with Okta
published: true
tags: security, mfa, arduino
canonical_url: https://developer.okta.com/blog/2018/08/30/build-one-time-password-token-for-mfa
description: Learn about the time-based one-time password algorithm using a credit-card-sized, Arduino-based game device and Okta Verify for MFA.
---
Okta has a great multi-factor authentication (MFA) service that you can use right away with a [free developer account](https://developer.okta.com/signup/). It provides additional security by requiring a second factor after authentication and supports a variety of factor types including SMS, soft tokens like Google Authenticator, hard tokens like Yubikey and the Okta Verify soft token with push notification.
Google Authenticator and Okta Verify are a type of factor called time-based one-time password (TOTP) tokens. They use an algorithm based on a shared secret and a system clock with a high degree of precision. Okta adds an additional level of convenience without sacrificing security by supporting push notifications in the Okta Verify mobile app.
Okta Verify uses a QR Code to read in the shared secret when enrolling in MFA.
In this post, I use the shared secret in a less-convenient but fun way, while still keeping the same level of security. The [ArduBoy project](https://arduboy.com/) combines an Arduino microprocessor with a monochrome OLED screen and a set of buttons that look suspiciously like a classic Nintendo GameBoy. All this fits into a credit card size form-factor. This open-source programming platform makes for the perfect vehicle to use the TOTP standard to create a hardware and software based hybrid token for MFA.
Well, maybe not perfect. But, fun!
<video src="https://developer.okta.com/assets/blog/ardu-token-mfa/oktaardutoken-92bb231be14e4a050e2bd802899651ef5d030abb615b926a3edea801c22876cd.mp4" width="360" autoplay="" controls=""></video>
The biggest challenge is that when you turn off an ArduBoy, it’s _really_ off. There’s no realtime clock that continues to run when the ArduBoy is off. We take this for granted on our computers or mobile devices that either have hardware to keep the clock running, have the ability to automatically set the time over a network on boot or both. Not so with the ArduBoy! In order to really use this as your go-to TOTP device, you need to keep it on and charge it before it dies.
What the application does to mitigate this is use the onboard EEPROM (Electrically Erasable Programmable Read-Only Memory) to (a) save the secret and (b) save the last date and time set. The next time you turn on the ArduBoy, it checks to see if a secret has been set. If so, it goes directly to setting the date and time. On the date and time setting screen, it starts with the last set date and time to make it easier to update.

This is a fun way to learn a little about TOTP and see it working against a real Okta organization.
In “real life”, you’ll want to use the Okta Verify mobile app (available on [iOS](https://itunes.apple.com/us/app/okta-verify/id490179405?mt=8) and [Android](https://play.google.com/store/apps/details?id=com.okta.android.auth&hl=en_US)). There’s a lot less manual labor involved.
## Get Up and Running with an Okta Verify Token
The source code (including a pre-built binary) can be found on the [GitHub repository](https://github.com/oktadeveloper/okta-ardu-token-example).
If you have an ArduBoy and want to see the app running, you can install the latest binary `.hex` file directly.
You can also drop the `.hex` file right onto the [ProjectABE](https://felipemanga.github.io/ProjectABE/) ArduBoy emulator site to see it in action without having an actual ArduBoy yourself.
**NOTE:** ProjectABE does not have the ability to save data to the [EEPROM](https://www.arduino.cc/en/Reference/EEPROM). So, if you restart the application there, you’ll need to re-set both the shared secret and the date and time.
The easiest way to install OktaArduToken onto an actual ArduBoy is to use the [Arduino IDE](https://www.arduino.cc/en/Main/Software). This allows you to both edit and upload the source as well as providing the command line tool, `avrdude`, to upload binaries.
Here’s an example install command using `avrdude` on Mac:
```
/Applications/Arduino.app/Contents/Java/hardware/tools/avr/bin/avrdude -v \
-C /Applications/Arduino.app/Contents/Java/hardware/tools/avr/etc/avrdude.conf \
-p atmega32u4 \
-c avr109 \
-P /dev/cu.usbmodem1411 \
-U flash:w:<path to OktaArduToken project>/OktaArduToken.hex
```
_NOTE:_ The `-p` parameter specifies the ArduBoy part number and the `-c` parameter specifies the ArduBoy programmer type. The `-P` parameter will be different on your Mac. You can see the list of available serial ports by using this command:
```
ls -la /dev/cu.*
```
You’re looking for the entry that contains `usbmodem` in it.
## Working with Source Code and Dependencies
If you want to work with the source code in the Arduino IDE, compile it, and upload it to your ArduBoy, you’ll need to install a few libraries. For each of these, navigate to: `Sketch -> Include Library -> Manage Libraries`.
You’ll need:
- [Arduboy2](https://github.com/MLXXXp/Arduboy2) - An alternative library for the Arduboy miniature game system
- [swRTC](http://www.leonardomiliani.com/en/2011/swrtc-un-orologio-in-tempo-reale-via-software/) - A software real-time clock
- [TOTP-Arduino](https://github.com/lucadentella/TOTP-Arduino) - Library to generate time-based one-time Passwords
- [Base32](https://github.com/NetRat/Base32) - a library to encode strings into and decode strings from Base32
The `Base32` library is the only one that you can’t install via the library manager in Arduino IDE. It’s easy enough to install by cloning the GitHub repository to your local Arduino IDE libraries folder. On Mac, it looks like this:
```
cd ~/Documents/Arduino/libraries/
git clone https://github.com/NetRat/Base32.git
```
If all your libraries are in place, you can navigate to: `File -> Open...` in the Arduino IDE and choose the `OktaArduToken.ino` file. You should then be able to navigate to: `Sketch -> Verify/Compile` to compile the code. If you get any errors, make sure that all the above libraries are installed.
## Navigating around the OktaArduToken Interface
OktaArduToken is unique among TOTP examples for Arduino or ArduBoy in that it has an interface to set the shared secret and to set the date and time. Most examples require you to hardcode the secret into the source code before uploading.
With a total of 6 buttons, the interface to set the shared secret and the date and time may remind you of a ’90s era flip phone. ;)
### Set the Shared Secret
When you first launch that app, you’ll see the shared secret setting screen:

Okta Verify uses a 16-byte Base32 encoded string for the shared secret. Initially, this is shown as 16 `M`s. You can use the up and down buttons to navigate around the set of capital letters and the numbers from 0 - 9. You can use the left and right buttons to move positions within the available 16 characters.
The interface automatically wraps. That is, hitting the right button when you’re on the 16th character moves the cursor back to the 1st character. Hitting the left button when you’re on the 1st character moves the cursor to the 16th character. Likewise, hitting the up button when `9` is showing, will change that character to `A`. Hitting the down arrow when `A` is showing, will change that character to `9` (it goes `A`-`Z` and then `0`-`9`).
When the shared secret is set, press the `A` button to move on to the date and time setting screen.
_NOTE:_ See below for how to configure Okta for MFA and obtain the shared secret to program in.
### Set the Date and Time
Once you’ve saved the shared secret, you’ll see the date and time setting screen:

You can use the up and down arrows to change the numbers for each part of the date and time. You can use the right and left buttons to change positions on the date and time interface. The interface will automatically skip over separators and will automatically wrap around in a similar way to the shared secret interface.
Once the date and time are set, press the `A` button to move on to the TOTP screen.
**NOTE:** Precision is important, so it is recommended that you set the time ahead by 10 seconds, watch a clock with a seconds counter and hit the `A` button the moment at which the times match. Also, the date and time that you set should always be GMT regardless of your current time zone. Also, There is currently NO error checking of any kind. That is, if you put in an invalid date and/or time, you will get unexpected results.
You can press the `B` button to return to the shared secret screen from here.
### The TOTP Display
Once the shared secret and date and time are set, you see the TOTP screen. At the top of the screen, in a large font, you see the current passcode. This passcode changes every 30 seconds. Below the passcode, you see the full date and time which updates every second.

Press the `A` button to return to the set date and time screen. Press the `B` button to return to the set shared secret screen.
## Configure Okta for Multi-factor Authentication
In Okta, there are two complimentary pieces to MFA: enrollment and enforcement. An MFA enrollment policy drives the conditions under which a user will be required to enroll in MFA and what configured factors they must enroll in. A Signon Policy can be configured to require a second factor after authentication. That’s the MFA enforcement part of the policy.
To get started, signup for a free Okta Developer org at [https://developer.okta.com/signup/](https://developer.okta.com/signup/)
Setup an Okta group and a new user to make testing the MFA policies easier.
Log into the admin console of your Okta org. Switch from the _Developer Console_ to the _Classic UI_ by selecting the dropdown in the upper left:

Next, choose: **Directory** > **Groups** from the top menu of the admin console. Click **Add Group** and enter `mfaers` for the _Name_ field. Click **Add Group**.
Choose: **Directory** > **People** from the top menu of the admin console. Click **Add Person** and fill in the fields as follows:
| field | value |
| --- | --- |
| First name | Jane |
| Last name | Doe |
| Username | jane.doe@mfaers.com |
| primary email | jane.doe@mfaers.com |
| Groups | mfaers |
| Password | Set by admin |
| User must change password on first login | (unchecked) |
Enter a password of your choice. Click _Save_.

### Configure an MFA Enrollment Policy
Select **Security** > **Multifactor** from the top menu of the admin console.
On the Factor Types tab, select **Active** next to _Okta Verify_.
Select the **Factor Enrollment** tab. Click **Add Multifactor Policy** , enter `mfaers policy` for _Policy name_ and choose `mfaers` for _Assign to groups_. Select **required** from the dropdown next to _Okta Verify_. Click **Create Policy**.

In the _Add Rule_ dialog, enter `mfaers rule` for _Rule name_ and select _the first time a user signs in_ in the dropdown next to _Enroll in multi-factor_. Click **Create Rule**.

That’s all that’s needed to configure MFA enrollment!
### Configure an MFA Enforcement Policy
Select **Security** > **Authentication** from the top menu of the admin console. Click **Sign On** > **Add New Okta Sign-on Policy**.
Enter `mfaers policy` in _Policy Name_ and choose `mfaers` in _Assign to Groups_.
Click **Create Policy and Add Rule**.

Enter `mfaers rule` for _Rule Name_ and check _Prompt for Factor_. Select **Every Time** > **Create Rule**.

That’s all that’s needed to configure MFA enforcement.
## Authenticate with Okta and the OktaArduToken
In a private browsing window, navigate to your okta org and login as jane.doe@mfaers.com.
You should see a screen to setup Okta Verify. Click **Configure factor**.

On the next screen select any device type (it doesn’t matter since we’ll be setting up our ArduBoy anyway). Click **Next**.
On the Setup Okta Verify screen, click **Can’t scan?**

You’ll then see the Secret Key Field. Turn on your ArduBoy (or use ProjectABE) and enter the shared secret value.

On the Arduboy, press the `A` button and enter in the correct date and time (GMT timezone). Press the `A` button. This will bring you to the TOTP screen.
Click **Next** on the Setup Okta Verify dialog. Enter in the code displayed on the ArduBoy and click **Next**.
If all goes well, you’ll see a screen asking for you to set a security question and answer to finish configuring your account.
You’ve now completed enrollment in Okta Verify using an ArduBoy as a hardware token! Pretty cool stuff.
You could logout and login again and you will be prompted to put in a code again which you would get from the ArduBoy.
**NOTE:** The clock component in ProjectABE is not very accurate and will get behind or ahead very quickly. You can always press the `A` button to set the time once again so that the passcode shown is correct.
You can also program in the value in the actual Okta Verify app on your mobile device and confirm that the passcode shown is the same as the passcode on the ArduBoy.
Here’s the OktaArduToken side-by-side with the Okta Verify mobile app:
<video src="https://developer.okta.com/assets/blog/ardu-token-mfa/oktaardusidebyside-cf0d8571e5c5fef9f84a0d64d6242466e4f1d8301aef24009f89da0ec40aadcf.mp4" width="600" autoplay="" controls=""></video>
## A look at the TOTP Arduino Code
The code for OktaArduToken is in a single sketch file: `OktaArduToken.ino`. I am sure this is not best practice and would benefit from some C++ objectification, but it works for a quick little hobby project.
It all boils down to three lines of code in the `ShowTotpCode()` method, thanks to the TOTP and swRTC libraries:
```
TOTP totp = TOTP(hmacKey, 10);
long GMT = rtc.getTimestamp();
totpCode = totp.getCode(GMT);
```
It uses the `hmacKey`, which is the Base32 decoded value of the shared secret along with the current timestamp to compute the current totpCode. It is this 6-digit code that is displayed on the ArduBoy screen.
The other key enabling feature is the ability to write the shared secret and current time to EEPROM and to read those values back out.
```
void writeTotpInfo(TotpInfo totpInfo) {
writeString(TOTP_SECRET_SAVE_ADDRESS, totpInfo.secret);
writeInt(TOTP_SEC_SAVE_ADDRESS, totpInfo.sec);
writeInt(TOTP_MIN_SAVE_ADDRESS, totpInfo.minu);
writeInt(TOTP_HOUR_SAVE_ADDRESS, totpInfo.hour);
writeInt(TOTP_DAY_SAVE_ADDRESS, totpInfo.day);
writeInt(TOTP_MON_SAVE_ADDRESS, totpInfo.mon);
writeInt(TOTP_YEAR_SAVE_ADDRESS, totpInfo.year);
DEBUG_PRINTLN("Wrote totpInfo to eeprom.");
}
TotpInfo readTotpInfo() {
TotpInfo ret = {};
ret.secret = readString(TOTP_SECRET_SAVE_ADDRESS, 16);
ret.sec = readInt(TOTP_SEC_SAVE_ADDRESS);
ret.minu = readInt(TOTP_MIN_SAVE_ADDRESS);
ret.hour = readInt(TOTP_HOUR_SAVE_ADDRESS);
ret.day = readInt(TOTP_DAY_SAVE_ADDRESS);
ret.mon = readInt(TOTP_MON_SAVE_ADDRESS);
ret.year = readInt(TOTP_YEAR_SAVE_ADDRESS);
return ret;
}
```
There’s a bunch of supporting methods to handle the input interfaces for the shared secret and date and time as well as displaying things in the right spot on the display.
Being a bit of a n00b to Arduino program, I am sure this code could be improved on. [I <3 pull requests](https://github.com/oktadeveloper/okta-ardu-token-example)!
## Learn More About Okta Verify and Multi-factor Authentication
I hope you enjoyed seeing how authentication with MFA using Okta Verify works along with alternate token devices. The requirements for creating your own token are a programmable microprocessor with a clock and a display
If you’d like to learn more about MFA with Okta, check out these posts:
- [MFA: 4 challenges faced by developers](https://developer.okta.com/blog/2018/05/16/multifactor-authentication-4-challenges-faced-by-developers)
- [Secure Your Spring Boot Application with Multi-Factor Authentication](https://developer.okta.com/blog/2018/06/12/mfa-in-spring-boot)
- [Use Multi-factor from the Command Line](https://developer.okta.com/blog/2018/06/22/multi-factor-authentication-command-line)
- [Simple Multi-factor authentication in Node](https://developer.okta.com/blog/2018/05/22/simple-multifactor-authentication-in-node)
- [Set Up and Enforce MFA with the Okta API](https://developer.okta.com/blog/2018/02/08/set-up-and-enforce-multi-factor-auth-with-okta)
Finally, please [follow us on Twitter](https://twitter.com/OktaDev) to find more great resources like this, request other topics for us to write about, and follow along with our new open source libraries and projects!
**P.S.** : If you liked this project and want to see the source code in one place, please go checkout and star its [GitHub repository](https://github.com/oktadeveloper/okta-ardu-token-example).
And… If you have any questions, please leave a comment below! | dogeared |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.