
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
163,368 | Migrating learn-dojo to Dojo 6 | The latest release of Dojo 6 brings with it some major updates to how you can build apps with Dojo. T... | 0 | 2019-08-29T15:17:01 | https://learn-dojo.com/migrating-to-dojo-6 | javascript, dojo, typescript, webdev | The latest release of [Dojo 6](https://dojo.io/) brings with it some major updates to how you can build apps with Dojo. There are some enhancements to builds, and custom elements, but I think one of the biggest new features available to developers is the use of function-based widgets. This doesn't mean you can't continue to use class-based widgets, but there are some nice advantages to using the new function-based widgets.
In case you didn't know, [learn-dojo](https://learn-dojo.com) is a static site, [built with Dojo](https://learn-dojo.com/building-static-site-with-dojo). So as Dojo 6 development was ongoing, I was already looking at what I would need to do to migrate the site to the latest Dojo.
## Updates to Widgets
Let's take a look at a basic [Header](https://github.com/odoe/learn-dojo/blob/df41818497429706e235c7b39437abb5ed4ee3b5/src/widgets/header/Header.tsx) widget, that accepts properties to display the title and and links to the main page.
```tsx
// src/widgets/header/Header.tsx
import WidgetBase from "@dojo/framework/widget-core/WidgetBase";
import { tsx } from "@dojo/framework/widget-core/tsx";
import Link from "@dojo/framework/routing/Link";
import * as css from "./Header.m.css";
export default class Header extends WidgetBase<{ title: string }> {
protected render() {
const { title } = this.properties || "My Site";
return (
<header classes={[css.root]}>
<div classes={[css.title]}>
<Link to="/" isOutlet={false} classes={[css.link]}>
{title}
</Link>
</div>
</header>
);
}
}
```
This widget takes an object with a `title` that is a `string` as its property. This isn't a complicated widget, Now, when we convert it to a function-based widget, not much is going to change in terms of what is being rendered, but there are some slight differences in the [Header](https://github.com/odoe/learn-dojo/blob/c480ef742b088dd3bea9a28d686c35a3e551271b/src/widgets/header/Header.tsx).
```tsx
// converted to Dojo 6
// src/widgets/header/Header.tsx
import { tsx, create } from '@dojo/framework/core/vdom';
import Link from '@dojo/framework/routing/Link';
import * as css from './Header.m.css';
const factory = create().properties<{ title: string }>();
export default factory(({ properties }) => {
const { title } = properties() || 'My Site';
return (
<header classes={[css.root]}>
<div classes={[css.title]}>
<Link to="/" isOutlet={false} classes={[css.link]}>
{title}
</Link>
</div>
</header>
);
});
```
First of all, the folder `widget-core` has been renamed to `core` in `@dojo/framework`. This is just a organizational change to Dojo. But the other new one is the use of this `create` module. The `create` module that lets you create a factory method for your render function.
To create a basic factory render function, you could do something like this.
```tsx
// return a render factory
const factory = create();
export factory(function MyBasicWidget() {
return <h2>Everything is awesome!</h2>;
});
```
But the `Header` widget requires some properties, so we can tell the render factory that properties are expected, and we can type them.
```ts
const factory = create().properties<{ title: string }>();
```
Now in the factory method, it will be pass a `properties()` method that will return the provided properties to the widget.
```tsx
export default factory(({ properties }) => {
const { title } = properties() || 'My Site';
...
});
```
Why is `properties` a function and not just an object? This has to do with some other features of function-based widgets that allow middleware to be used. This ensures that you don't get stale values from the properties.
_We'll cover the new middleware capabilities in more detail in in a future blog post_.
The rest of this widget looks like the previous version returning JSX vdom.
It is normally recommended that you provide _named_ render methods to the render factory as it will help you track down errors in debugging, but it isn't required. _Sometimes you just need to live on the edge_.
## Basic Middleware
One of the standout features of Dojo is the use of [blocks](https://learn-dojo.com/dojo-from-the-blocks) that let you run code in node when you use build time rendering. It's critical in how learn-dojo is built because blocks are used to parse the posts from markdown, and run various tooling for code blocks, and formatting. In class-based widgets, this is done via the use metas.
Here is how a blog page is rendered with a class-based widget.
```tsx
// src/pages/Blog.tsx
import WidgetBase from '@dojo/framework/widget-core/WidgetBase';
import Block from '@dojo/framework/widget-core/meta/Block';
import { tsx } from '@dojo/framework/widget-core/tsx';
import compileBlogIndex from '../blocks/compile-blog-index.block';
import Post from '../templates/blog-post/BlogPost';
import * as css from './Blog.m.css';
export default class Blog extends WidgetBase<{
standalone?: boolean;
path?: string;
}> {
protected render() {
const { standalone = false, path } = this.properties;
// run the block as a meta
const blogs: any = this.meta(Block).run(compileBlogIndex)({});
// render blog excerpts or single blog post
return (
<div classes={[css.root]}>
{!standalone
? blogs &&
blogs.map((blog: any) => [
<Post key={blog.file} path={blog.file} excerpt />,
<hr key={blog.file} />
])
: undefined}
{path && path.length && <Post key={path} path={path} />}
</div>
);
}
}
```
Let's dive right into how the [Blog](https://github.com/odoe/learn-dojo/blob/c480ef742b088dd3bea9a28d686c35a3e551271b/src/pages/Blog.tsx) module looks as a function-based widget in Dojo 6.
```tsx
// converted to Dojo 6
// src/pages/Blog.tsx
import { tsx, create } from '@dojo/framework/core/vdom';
import block from '@dojo/framework/core/middleware/block';
import compileBlogIndex from '../blocks/compile-blog-index.block';
import Post from '../templates/blog-post/BlogPost';
import * as css from './Blog.m.css';
const factory = create({ block }).properties<{ standalone?: boolean; path?: string }>();
export default factory(({ middleware: { block }, properties }) => {
const { standalone = false, path } = properties();
const blogs: any = block(compileBlogIndex)({});
return (
<div classes={[ css.root ]}>
{!standalone ? (
blogs &&
blogs.map((blog: any) => [
<Post key={blog.file} path={blog.file} excerpt />,
<hr key={blog.file} />
])
) : (
undefined
)}
{path && path.length && <Post key={path} path={path} />}
</div>
);
});
```
To use this in a render factory method, pass the block middleware to the `create` method so that it's available to your render factory.
Anything you pass into the create() method will be available to your render factory methods as middleware.
```ts
const factory = create({ block }).properties<{ standalone?: boolean; path?: string }>();
// render factory
export default factory(({ middleware: { block }, properties }) => {...});
```
Now the `block` is available on the `middleware` property passed to the render factory method.
```ts
const blogs: any = block(compileBlogIndex)({});
```
Notice that now, you can run the middleware block independently of any `meta` helpers like in a class-based method. This is one of my favorite features of the new function-based widgets!
## Composable Widgets
The learn-dojo site takes advantage of the ability to create wrapper widgets that renders any children provided to it. This is used in something like the [`Layout`](https://github.com/odoe/learn-dojo/blob/df41818497429706e235c7b39437abb5ed4ee3b5/src/layouts/Layout.tsx) widget.
```tsx
// src/layouts/Layout.tsx
export default class Layout extends WidgetBase<SiteMeta> {
protected render() {
const { title, description, author, footerLinks } = this.properties;
return (
<div classes={[css.root]}>
<Header title={title} />
<Hero description={description} />
{/* render the children */}
<main classes={[css.section]}>{this.children}</main>
<SignUp />
<Footer {...{ author, footerLinks }} />
</div>
);
}
}
```
Like the update to make `properties` a function so you always have the latest values, the same is true for `children` now being a function in the [Layout](https://github.com/odoe/learn-dojo/blob/c480ef742b088dd3bea9a28d686c35a3e551271b/src/layouts/Layout.tsx).
```tsx
// converted to Dojo 6
// src/layouts/Layout.tsx
const factory = create().properties<SiteMeta>();
export default factory(({ children, properties }) => {
const { title, description, author, footerLinks } = properties();
return (
<div classes={[ css.root ]}>
<Header title={title} />
<Hero description={description} />
{/* render the children */}
<main classes={[ css.section ]}>{children()}</main>
<SignUp />
<Footer {...{ author, footerLinks }} />
</div>
);
});
```
That's the only change in regard to rendering children in your widgets.
## Summary
Dojo 6 is a significant release in the Dojo roadmap, offering some exciting new capabilities in build reactive widgets for your applications. There are plenty more new features not covered in this blog post that will be discussed in the future. For details, see the [official Dojo 6 blog post](https://dojo.io/blog/version-6-dojo).
I was able to migrate [learn-dojo](https://learn-dojo.com/) in a single morning based off the new Dojo documentation. I'm really impressed with the new function-based widget pattern in Dojo and the use of middleware that we barely scratched the surface of in this post.
Stay tuned for more! | odoenet |
163,820 | AWS Amplify GraphQL Operations with TypeScript and Hooks - Part 4 [Subscriptions] | Subscriptions provide a way to easily supply real-time information in an application using GraphQL. Let's see what they look like with AWS Amplify and how they can be made better with TypeScript and hooks! | 1,515 | 2019-09-14T00:19:32 | https://dev.to/mwarger/aws-amplify-graphql-operations-with-typescript-and-hooks-part-4-subscriptions-h0j | typescript, graphql, amplify, javascript | ---
title: AWS Amplify GraphQL Operations with TypeScript and Hooks - Part 4 [Subscriptions]
published: true
description: Subscriptions provide a way to easily supply real-time information in an application using GraphQL. Let's see what they look like with AWS Amplify and how they can be made better with TypeScript and hooks!
tags: TypeScript, GraphQL, Amplify, JavaScript
series: AWS Amplify GraphQL Operations with TypeScript and Hooks
---
Next up is subscriptions. This is a fun feature of GraphQL and AppSync in general. The ability to leverage real-time data can really bring some nice UX to your apps. I tend to use it sparingly, but it's super helpful for small lists and instant feedback.
Our previous posts have built up a fairly nice set of abstractions that we can use here as well. Because of this, I'm going to paste the result at the start this time and break it down into pieces. Grab a cup of coffee and we'll get to it.
## The Code
Here's our finished custom hook:
```typescript
type ConfigType<VariableType extends {}> = {
query: string;
key: string;
variables?: VariableType;
};
export const useSubscriptionByItself = <
ItemType extends { id: string },
VariablesType extends {} = {}
>({
config,
itemData,
}: {
config?: ConfigType<VariablesType>;
itemData?: ItemType;
} = {}) => {
const [item, update] = React.useState<ItemType | undefined>(itemData);
React.useEffect(() => {
let unsubscribe;
if (config) {
const { query, key, variables } = config;
const subscription = API.graphql(graphqlOperation(query, variables));
if (subscription instanceof Observable) {
const sub = subscription.subscribe({
next: payload => {
try {
const {
value: {
data: { [key]: item },
},
}: {
value: { data: { [key: string]: ItemType } };
} = payload;
update(item);
} catch (error) {
console.error(
`${error.message} - Check the key property: the current value is ${key}`
);
}
},
});
unsubscribe = () => {
sub.unsubscribe();
};
}
}
return unsubscribe;
}, [JSON.stringify(config)]);
return [item];
};
```
There's a lot here, but our use-case is simple. Our subscription is going to handle an item. This could be something as simple as subscribing to new blog posts that are created, for example:
```typescript
const [item] = useSubscription<postFragment>({
config: {
key: 'onCreatePost',
query: onCreatePost,
},
});
```
We could also pass some variables to subscribe to a comment when it is updated:
```typescript
const [comment] = useSubscriptionByItself<
commentFragment,
onUpdateCommentSubscriptionVariables
>({
itemData: comment,
config: {
key: 'onUpdateComment',
query: onUpdateComment,
variables: {
id,
},
},
});
```
> The point is that we are able to take the boilerplate of `const subscription = API.graphql(graphqlOperation(query, variables));` and extract it away into something that can be re-used, as well as leaning into the convention of how AWS Amplify returns data to handle everything in a strongly-typed way.
Let's start at the top and see what's going on.
## Typing the Configuration
```typescript
type ConfigType<VariableType extends {}> = {
query: string;
key: string;
variables?: VariableType;
};
export const useSubscription = <
ItemType extends { id: string },
VariablesType extends {} = {}
>({
config,
itemData,
}: {
config?: ConfigType<VariablesType>;
itemData?: ItemType;
} = {}) => {
```
Let's take a look at the type parameters (the things in between the angle brackets). This takes some explaining because I start out assuming a convention. The `ItemType` represents the object that we're going to be returning and operating on in our hook. The `extends { id: string }` means that whatever object we pass in, it must have an id of type `string` as a property. This is useful, as we want a unique identifier for our object. The `itemData` used in case we want to initialize our state.
Note that I'm leveraging fragments to provide a single typed object that we can work with. Once created, the Amplify `codegen` tool will create types for your fragments that you can then use as we are in this example. You can learn more about fragments and how to use them with GraphQL [here](https://graphql.org/learn/queries/#fragments).
The second `VariableType` is going to be an object that represents any variables that we will be passing to our subscription `graphqlOperation`. This is used further down in the type declaration to the `ConfigType`. This represents the configuration that holds the subscription `query`, `variables` and `key` that we will use to establish our subscription. We'll come back to the `key` a bit later.
## The State
```typescript
const [item, update] = React.useState<ItemType | undefined>(itemData);
```
This is pretty straightforward. We use the `ItemType` parameter we passed in to type the `useState` function. This is possibly undefined, so we note that as well. If we passed in initial `itemData`, we use this as well to establish the state that will keep track of the subscription we're working with.
## The Effect
Here's the real meat of it.
```typescript
React.useEffect(() => {
let unsubscribe;
if (config) {
const { query, key, variables } = config;
const subscription = API.graphql(graphqlOperation(query, variables));
if (subscription instanceof Observable) {
const sub = subscription.subscribe({
next: payload => {
try {
const {
value: {
data: { [key]: item },
},
}: {
value: { data: { [key: string]: ItemType } };
} = payload;
update(item);
} catch (error) {
console.error(
`${error.message} - Check the key property: the current value is ${key}`
);
}
},
});
unsubscribe = () => {
sub.unsubscribe();
};
}
}
return unsubscribe;
}, [JSON.stringify(config)]);
```
First things first, we're going to be establishing a subscription, so for an effect, we need to [clean it up](https://reactjs.org/docs/hooks-effect.html#example-using-hooks-1) when we're done. We declare a variable that will hold the function we want to run when returning from the effect.
Next, we will check if the config exists, as it is optional. We destructure the components and will use them to construct our subscription. The next lines are important:
```typescript
const subscription = API.graphql(graphqlOperation(query, variables));
if (subscription instanceof Observable) {
...
```
The `API.graphql` call actually returns `Observable | Promise<>` - what this means is that the result will be one or the other. To get the autocomplete help that we expect (and stop TypeScript from yelling at us) we need to do what is called "type narrowing" using a [type guard](https://basarat.gitbooks.io/typescript/docs/types/typeGuard.html). We do this by using the `instanceof` keyword to check if the type is an `Observable`. I've added the `@types/zen-observable` package (`yarn add -D @types/zen-observable`) to provide the type.
## The Subscription
```typescript
const sub = subscription.subscribe({
next: payload => {
try {
const {
value: {
data: { [key]: item },
},
}: {
value: { data: { [key: string]: ItemType } };
} = payload;
update(item);
} catch (error) {
console.error(
`${error.message} - Check the key property: the current value is ${key}`
);
}
},
});
unsubscribe = () => {
sub.unsubscribe();
};
```
We have our subscription that's returned from our graphql call, so now we need to subscribe to it. This is using what is called an observable. Last time I checked, Amplify is using the [zen-observable](https://github.com/zenparsing/zen-observable) library for the subscription implementation. Observables operate with values by returning them as streams, so you can listen for updates to the stream by supplying callbacks - in this case, `next`. Our `next` callback takes a `payload` (this will be the value of the next event in the stream) and we then do some destructuring on this value to get the underlying data we want. Amplify follows a convention for returning data in the subscriptions, so we can use this to make sure our destructuring is correct.
```typescript
const {
value: {
data: { [key]: item },
},
}: {
value: { data: { [key: string]: ItemType } };
} = payload;
```
We use the `key` we talked about earlier, as well as the `ItemType` type we passed in, to create a type and properly destructure from the nested object (in the form of `value.data[key]`). Once this data is handled, we use the `update` method from our `useState` hook to persist our state, and if anything goes wrong we log out the error.
After the callback, we assign a small arrow function to our `unsubscribe` variable that will do the work of unsubscribing from our subscription if the component the hook is used in is unmounted.
```typescript
[JSON.stringify(config)];
```
Our `useEffect` hook takes in one dependency (an object) so we'll just `stringify` it to make sure that if it's changed in any way, our hook will run again and we can re-establish the appropriate subscription.
The last line merely returns the data kept in state, so we can use it from the caller.
```typescript
return [item];
```
## The Wrap
This is, at its core, just a wrapper over the existing Amplify tools. But for TypeScript projects, it gives you the help you can use to make sure your app is doing what you expect. The nice by-product, in my opinion, is that the API surface is more complete while abstracting away the common bits. It's generally a good practice to extract these things away and avoid having `useEffect` directly in your components. This is just one little step in that direction.
If anyone has any feedback on this approach, please leave it in the comments. I use this often, only in TypeScript projects, and I hope it can help someone. You can also ping me on twitter @mwarger.
...
But wait, what if you need to subscribe to many events? That's next up - follow me to be notified when it's published!
| mwarger |
163,390 | VS Code August 2019 Release Highlights Video | Highlights of some of the latest features found in the August 2019 release of Visual Studio Code. | 1,833 | 2019-09-09T16:48:56 | https://www.clarkio.com/2019/09/03/vs-code-august-release-video/ | discuss, vscode, javascript, webdev | ---
title: VS Code August 2019 Release Highlights Video
published: true
description: Highlights of some of the latest features found in the August 2019 release of Visual Studio Code.
tags: discuss,vscode,javascript,webdev
cover_image: https://thepracticaldev.s3.amazonaws.com/i/usptjx26n1vuqlkt2xb4.jpg
canonical_url: https://www.clarkio.com/2019/09/03/vs-code-august-release-video/
series: vscode-release
---
## August 2019 VS Code Release
Visual Studio Code has a new release out with lots of improvements and new features. You can read through the [release notes](https://code.visualstudio.com/updates/v1_38?WT.mc_id=devto-blog-brcl) to find out more about them or watch this short video to see some of the highlights from it.
{% youtube YA8QJPGf2M4 %}
### Features Highlighted
- [Copy and Revert Actions for Diffs](https://code.visualstudio.com/updates/v1_38#_copy-and-revert-in-the-inline-diff-editor?WT.mc_id=devto-blog-brcl)
- [Multi-line search in Find](https://code.visualstudio.com/updates/v1_38#_multiline-search-in-find?WT.mc_id=devto-blog-brcl)
- [Maximize/Restore Bottom Panel](https://code.visualstudio.com/updates/v1_38#_maximize-editor-toggle-command?WT.mc_id=devto-blog-brcl)
- [Cursor Surround Lines (a.k.a Scroll Off)](https://code.visualstudio.com/updates/v1_38#_cursor-surrounding-lines-scrolloff?WT.mc_id=devto-blog-brcl)
- [Link Protection for Outgoing Links](https://code.visualstudio.com/updates/v1_38#_link-protection-for-outgoing-links?WT.mc_id=devto-blog-brcl)
What's your favorite feature or improvement in this month's release? Share it below 👇
| clarkio |
163,465 | How to create an Android App: Android Room | Hi again (x3) everyone! We’re almost done with all app functionality, missing the saving m... | 1,850 | 2019-08-29T19:16:01 | https://dev.to/edrome/how-to-create-an-android-app-android-room-il | android, java, tutorial | ### Hi again (x3) everyone! ###
We’re almost done with all app functionality, missing the saving mechanism. Once the user has filled his information, then it has to be saved on database to avoid the user fill it again and again.
Android support either SQLite or Room, I prefer the second one because adding queries and modifying columns it’s easier. Also, allow singleton instance, and asynchronous task.
As we establish on the last post, the readability is important and the way to accomplish it is by creating packages where classes are going to be stored.
Inside gradle add the following implementations. They will add android room annotations that are very important.
```
implementation 'androidx.room:room-runtime:2.1.0'
annotationProcessor 'androidx.room:room-compiler:2.1.0'
implementation 'org.jetbrains:annotations-java5:15.0'
```
Android Room needs four different classes:
1. ***Entity:*** it is table definition.
2. ***DAO:*** it has all queries available to be performed to the table.
3. ***POJO:*** here it is the DAO functionality
4. ***Room Database:*** here we create the database instance.
Start creating the package database, inside it we’ll create subpackages in case we want to add more tables. I suggest to structure all your database packages like this.
```
+-- com.main.package
| +-- database
| +-- dao
| +-- entity
| +-- pojo
| +-- room
```
First we’ll create the entity, the name I chose is profileModel. The class needs a constructor either empty or not, prefered private attributes, getter and setters of every attribute, otherwise an error will be thrown.
The table design is as described below:
| Columns name | Data Type | Attributes |
| ------------- |:-------------:| -----------:|
| profileID | Integer | Primary Key, Auto generate, Non null |
| username | String | Non Null |
| gender | String | Non Null |
| birthday | Date | Non Null |
| photo | byte[] | |
As you can see we add a primary key auto generated, every column might be non null except for photo, allowing the user to either select or not a profile photo.
Add the annotation for every column, and generate the constructor including getters and setters. Note the “Entity” annotation at the beginning of the class, it tells android that this class is a table and its name is profile.
```{java}
@Entity(tableName = "profile")
public class profileModel {
public profileModel(@NonNull String username,
@NonNull String gender,
@NonNull Date birthday,
@NonNull byte[] photo) {
this.username = username;
this.gender = gender;
this.birthday = birthday;
this.photo = photo;
}
@NonNull
@PrimaryKey(autoGenerate = true)
private Integer profileId;
@NonNull
private String username;
@NonNull
private String gender;
@NonNull
private Date birthday;
@NonNull
private byte[] photo;
@NonNull
public Integer getProfileId() {
return profileId;
}
public void setProfileId(@NonNull Integer profileId) {
this.profileId = profileId;
}
@NonNull
public String getUsername() {
return username;
}
public void setUsername(@NonNull String username) {
this.username = username;
}
@NonNull
public String getGender() {
return gender;
}
public void setGender(@NonNull String gender) {
this.gender = gender;
}
@NonNull
public Date getBirthday() {
return birthday;
}
public void setBirthday(@NonNull Date birthday) {
this.birthday = birthday;
}
@NonNull
public byte[] getPhoto() {
return photo;
}
public void setPhoto(@NonNull byte[] photo) {
this.photo = photo;
}
}
```
> Tip: You can press alt+insert or right-click generate to popup a generate menu.
> 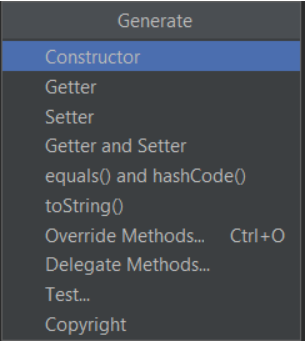
> Select all columns excluding the primary key and press ok.
> 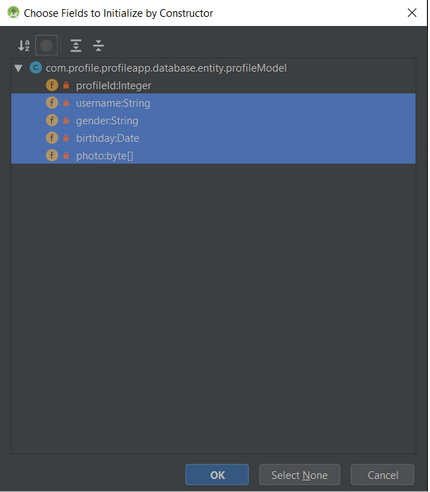
> These steps also work for getter and setter, in that case you might select all columns, including primary key.
The DAO will be interface instead of classe, containing all table operations like inserts, queries, deletes and updates. For this tutorial purpose, we'll define an insert, an update and a query.
```{java}
@Dao
public interface profileDAO {
@Insert
void insert(profileModel profile);
@Update
void update(profileModel profile);
@Query("SELECT * FROM profile WHERE profileId = :id")
profileModel getProfile(Integer id);
}
```
Once the entity and DAO are create, we add the database room class. It has to be abstract, with an annotation at the top of it. This annotation indicates the entities contained inside the database, along with a version number, that has to increase each time you do a change on the entity, and an exportSchema indicator, it is defined as false for this series.
```{java}
@Database(entities = {profileModel.class}, version = 1, exportSchema = false)
public abstract class databaseRoom extends RoomDatabase {
public abstract profileDAO foodsDao();
public static volatile databaseRoom INSTANCE;
public static databaseRoom getDatabase(final Context context){
if (INSTANCE == null){
synchronized (databaseRoom.class){
if (INSTANCE == null){
INSTANCE = Room.databaseBuilder(
context.getApplicationContext(),
databaseRoom.class,
"profile_database")
.fallbackToDestructiveMigration()
.allowMainThreadQueries()
.build();
}
}
}
return INSTANCE;
}
}
```
When all files are ready, then we create a POJO class that will be the one used to perform operations inside our database.
```java
public class profilePOJO {
private profileDAO mProfileDao;
private profileModel mProfile;
public profilePOJO(Application application) {
databaseRoom db = databaseRoom.getDatabase(application);
mProfileDao = db.foodsDao();
}
public profileModel getProfile(Integer id) {
return mProfileDao.getProfile(id);
}
public void insert(profileModel profile){
new insertAsyncTask(mProfileDao).execute(profile);
}
private static class insertAsyncTask extends AsyncTask<profileModel, Void, Void> {
private profileDAO mAsyncTaskDao;
insertAsyncTask(profileDAO dao){
mAsyncTaskDao = dao;
}
@Override
protected Void doInBackground(final profileModel... profiles) {
mAsyncTaskDao.insert(profiles[0]);
return null;
}
}
}
```
Aaand.... we're going to leave it here or the post will be to large for reading.
As always, I share the link to this [project](https://github.com/EdRome/AppProfile) on GitHub. Feel free to use it as you wish.
> Edit: I forgot to add Dao annotation. Sorry for that | edrome |
163,537 | Demystifying webpack - What's a Bundler doing? | Originally publised on jnielson.com In my introduction to this series on Demystifying Build Tools, I... | 1,893 | 2019-08-29T23:46:11 | https://jnielson.com/demystifying-webpack-whats-a-bundler-doing | webpack, javascript | _Originally publised on [jnielson.com](https://jnielson.com/demystifying-webpack-whats-a-bundler-doing)_
In my introduction to this series on [Demystifying Build Tools](https://jnielson.com/build-tools-demystified-my-thoughts), I introduced the core concepts of webpack and babel. I've created a couple other posts on various facets of babel, like [`@babel/preset-env`](https://jnielson.com/demystifying-babel-preset-env) and [`babel plugins more generally`](https://jnielson.com/demystifying-babel-plugins-a-debugging-story). If you haven't read those, I'd highly recommend them (obviously!). In this post I'll shift and cover a little more about webpack. In the talk I'm prepping for, I'm intending to spend more time on babel and less time on webpack, which you might have guessed from the blog coverage difference.
## Why less on webpack?
I haven't had nearly as much in our projects to manage with webpack since we're using the defaults provided by [next.js](https://nextjs.org) (thanks Next team!). But, the things that I have found valuable to be aware of include a knowledge of what webpack is at a little more depth than the concepts docs referenced in the introduction post and also how to use and read the `webpack-bundle-analyzer` plugin. In my opinion, having a knowledge of webpack makes it simpler to work with as the core concepts build together masterfully, and then the bundle-analyzer plugin is super useful to examine what webpack is outputting that I can't imagine doing a project where I don't use it at least once to sanity check that nothing I don't expect is included in the bundle.
So, to learn more about webpack where do you start? First, I'd start with breaking down the description they use for webpack in their docs:
> "At its core, webpack is a static module bundler for modern JavaScript applications."
>
> [webpack docs](https://webpack.js.org/concepts/)
That statement is relatively simple, but can be broken down to emphasize the key features and goals of webpack. I'll talk more to each of the following ideas:
- Bundler
- Module
- Static
- Modern JavaScript
- Applications (including libraries)
## Bundler
At its core, webpack is a bundler. Not a task runner or a compiler, a bundler. What is a bundler? In the context of webpack, it takes all files referenced from the entry point(s) and spits out at least 1 file called "the bundle". The goal of the bundle is to package code in a way that makes sense for the target environment, in most cases that's the browser. With HTTP 1.1, it tends to be best to serve as much of the application in a single file, to reduce the number of round-trips needed to get the code for the browser to execute. But, with HTTP 2 as well as in environments where you want heavier caching it makes sense to split your "bundle" into multiple files that can be cached and served independently and in parallel.
How does webpack's role as a bundler impact you? Well, for the most part it doesn't. Since it's a bundler it usually does its thing just fine, and once setup in an application it doesn't take much maintenance unless you add a new file type or want to process something differently. More on that later though!
## Module
In stating its place as a bundler, the webpack docs clarify that it is a `module` bundler. In that aspect, it treats everything as a module: JavaScript Code, Images, Raw files, you name it and it is a module in webpack. Modules are loaded into webpack through a variety of `loaders`, which you can read more about [on the loaders concepts page](https://webpack.js.org/concepts/#loaders). Essentially in order to support a large variety of file types you'll need to add loaders for them so that webpack can understand them. Out of the box it supports JavaScript and JSON "modules", much like Node itself. In webpack 4 at least, the module type you use greatly impacts the extra features webpack is able to enable, such as Tree Shaking. Modules are key in webpack, since that is how it determines what code to include in the bundle that it creates. It starts from your "entry point" (which is a module) and pulls in everything referenced by that module. In order to pull it in, it needs to be a module! So, anything that you `import` in that entry module will end up in your bundle that is created. Without module boundaries, webpack wouldn't be able to determine code that can be left out, and we'd be back to including entire directories in what we serve to the browser.
## Static
One of the best features of webpack, in my opinion, is the static analysis capabilities that are unlocked by it being a `static` (in other words, build time) module bundler. A runtime bundler could probably work, but it wouldn't be able to do Tree Shaking or Dead Code Elimination. This would be a pretty large drawback for me, since it is pretty common in my projects to only use part of the aspects that a library or component exposes. In my opinion, the word `static` in this context also implies that the build output won't change unless the build input does (assuming you have things configured correctly), which gives me some confidence in being able to run builds as many times as needed. Related to that, another benefit of `static` in this context is that it allows the build process to support plugins that act on those `static` assets to transform, adjust, or otherwise do something to the code.
There are some downsides to it being a `static` module bundler. One of the largest I've run into is the inability to dynamically use `require.context` in storybook to get just the stories that I want with some sort of option string. This led to us re-writing our storybook config file whenever we want a different set of components to work on, which thankfully was relatively easy to implement.
## Modern JavaScript
Since the docs statement says "modern JavaScript applications", I decided that there should be a comma in there and broke it down even further. Modern can be made to indicate that it is something up to date, but I think when you combine it with JavaScript you usually get the idea of `ESNext` or `ES2015`. In the case of new language features, that job is actually handled by `babel`, which webpack can run on your code as it bundles it. This interplay is something that I wanted to highlight since it illustrates the capability of the module bundler to take in anything that you can tell it how to handle. Since it runs in node, webpack can be default handle whatever syntax your version of node can. Since you can run it with `babel`, webpack can optionally handle whatever syntax you throw at it (within the limits of babel of course). These two libraries work together to output your code in a manner that's suitable for browser consumption. In the simplest configuration, babel will take your files and output them, one for one or all to one, transformed according to the plugins you use. Using webpack, it can be a little smarter than that and only run `babel` on the files that it is bundling, allowing you to have other files in your `src` directory (or however you organize yourself) that don't need to be processed by babel.
Splitting this up further, `Modern` is also a good descriptor of webpack itself. The team there does a great job adding new features/plugins, fixing things, and overall keeping the tool `modern` in the sense of up to date and useful! `JavaScript` by itself doesn't mean all that much though, it does indicate that webpack is focused on that language (though if I understand correctly it supports web assembly to some extent).
## Applications (including libraries)
The core use case for webpack is definitely applications that are served to the browser, but it can also be used for libraries if they have a desire to do so. There is support for libraries in a similar way to applications, and they have an [awesome guide on their docs site](https://webpack.js.org/guides/author-libraries/) about how to use webpack to bundle your library code. Since webpack focuses on the application level, there are tons of plugins that support that use providing things like aliasing, loading all the file types you use, and others.
## The Bundle Analyzer
After you've got webpack setup and outputting some wonderful files to serve to the browser, you might run into a case where you're curious what is in there. In most cases, your bundle will be minified and uglified so it won't be much good to try and read what's there, though there are some things that don't uglify very well that you can use if you're trying to check to see if something is there quickly. But, outside of that the `webpack-bundle-analyzer` is a fantastic tool. For use in [next.js](https://nextjs.org), it's as simple as installing the [Next.js plugin](https://github.com/zeit/next.js/tree/canary/packages/next-bundle-analyzer) and following the instructions in the readme to add it to your project. Since Next produces two bundles, one for the server and another for the client, it can be pretty intimidating to set up any webpack things from scratch. So, I'm super grateful for the team that added this plugin since it's already setup to create a bundle analyzer for both bundles. Most of the time I just use the client bundle, but the server bundle is also quite helpful. The [bundle analyzer](https://www.npmjs.com/package/webpack-bundle-analyzer) looks pretty overwhelming when you first look at it, since it shows in some manner every file that is included in the bundle. There's a number of things to look at when using the bundle analyzer, but there are a few that I want to call out:
1. Different Size Settings
1. Hiding chunks
1. Outputting a JSON file (not currently supported by the next-bundle-analyzer plugin)
### Different Size Settings
One of the first things you might wonder is "where does this size information come from?", since in most cases you won't be seeing what your file explorer told you the size was. In the sidebar menu when analyzing your bundle, you can select between `stat`, `parsed`, and `gzip`. These are described in detail on the documentation page linked above, but I think it's useful to point out that `stat` should be close to your file system output, `parsed` should be the post-webpack size (minified/uglified) and then `gzip` is the compressed size of the post-webpack file. By default the `parsed` size is pulled up, which is why I pointed out that they might look different than you might expect. In most cases I've seen, `parsed` is the most useful number, since `stat` doesn't help much as it's pre-webpack and `gzip` is useful... but I don't want to spend my time optimizing my code for `gzip` compression since the time the browser spends parsing it is usually longer than the network time a few more bytes off would save. There's more information on this in [the documentation](https://www.npmjs.com/package/webpack-bundle-analyzer#user-content-size-definitions).
### Hiding Chunks
In most cases, the output from the bundle analyzer will be entirely too much to handle as most projects that care to analyze their bundle will have hundreds of modules. If you haven't used it before, clicking on a module/section will zoom in on it, but that doesn't actually hide the ones that now can't be seen. To do that, you can uncheck them in the sidebar menu, which will actually re-draw the entire page in most cases. There are a number of things that you might want to hide, like a node_module that you're stuck with and can't reduce the size of or a section of your application that you're not working on right now and is distracting from the actual part you are inspecting. There's more information on this in [the documentation](https://www.npmjs.com/package/webpack-bundle-analyzer).
### Outputting a JSON file
In a lot of cases, webpack has way more information available then even the bundle analyzer shows, and in that case I find the bundle analyzer's capability to output the `stats.json` file from webpack for you to be wonderful. Since the bundle analyzer already uses a lot of the stats options (and webpack does slow down a bit when you use a bunch of stats options), it's helpful to be able to re-use those and output them to a file. Sadly the next-bundle-analyzer plugin doesn't currently support passing any options to the bundle analyzer (they'd probably add it, but I haven't cared enough yet since it isn't terribly hard to use for a one-off case). So, if you want to do this in a next context you'd need to manually adjust your next.config.js to use the bundle analyzer (in a similar way to [what the plugin does](https://github.com/zeit/next.js/blob/canary/packages/next-bundle-analyzer/index.js) ideally) to pass the `generateStatsFile: true` option to the bundle analyzer, with the `statsFilename` changed based off which build is running. The stats file is a bit of a beast to handle, so we're not going to talk about it much here, but it is super useful if you think webpack is doing something weird!
Thanks for reading! Ideally this helps you understand a little bit more about webpack, in combination with going through their [core concepts docs](https://webpack.js.org/concepts/). I'd highly recommend spending some time on doing so, since even if you're using an awesome tool like [next.js](https://nextjs.org) there's still benefits that come from understanding what is happening to bundle your code.
_Cover image courtesy of undraw.co_
| jnielson94 |
163,683 | Nebula container orchestrator — container orchestration for IoT devices & distributed systems | Let’s say for example you started a new job as a DevOps/Dev/SRE/etc at a company that created a new s... | 0 | 2019-08-30T11:33:11 | https://dev.to/naorlivne/nebula-container-orchestrator-container-orchestration-for-iot-devices-distributed-systems-48f7 | devops, docker | Let’s say for example you started a new job as a DevOps/Dev/SRE/etc at a company that created a new smart speaker (think Amazon Echo or Google home), said device gained a lot of success and you quickly find yourself with a million clients, each with a single device at his\hers home, Sounds great right? Now the only problem you have is how do you handle deployments to a million of devices located all across the world?
* You could go the way most old school vendors do it by releasing a package for the end user to download and install himself on the company website but at this day and age this will quickly lose you customers to the competition who doesn’t have such high maintenance needs.
* You could create a self updating system built into your codebase but that will require a lot of maintenance and man hours from the development team & even then will likely lead to problems and failures down the road.
* You could containerize the codebase, create on each smart speaker a single server Kubernetes cluster and create a huge federated cluster out of all of them (as Kubernetes doesn’t support this scale nor latency tolerant workers this is required) but that will lead to huge costs on all the resources wasted only to run all said clusters.
* You could use Nebula Container Orchestrator — which was designed to solve exactly this kind of distributed orchestration needs.
As you may have guessed from the title I want to discuss about the last option from the list.
Nebula Container Orchestrator aims to help devs and ops treat IoT devices just like distributed Dockerized apps. It aim is to act as Docker orchestrator for IoT devices as well as for distributed services such as CDN or edge computing that can span thousands (or even millions) of devices worldwide and it does it all while being open-source and completely free.
# Different requirements leads to different orchestrators
When you think about it a distributed orchestrator has the following requirements:
* It needs to be latency tolerant — if the IoT devices are distributed then each will connect to the orchestrator through the Internet at a connection that might not always be stable or fast.
* It needs to scale out to handle thousands (and even hundreds of thousands) of IoT devices — massive scale deployments are quickly becoming more and more common.
* It needs to run on multiple architectures — a lot of IoT devices uses ARM boards.
* It needs to be self healing — you don’t want to have to run across town to reset a device every time there is a little glitch do you?
* Code needs to be coupled to the hardware — if your company manufacture the smart speaker in the example mentioned above & a smart fridge you will need to ensure coupling of the code to the device it’s intended to run on (no packing different apps into the same devices in the IoT use case).
This is quite different from the big Three orchestrators (Kubernetes, Mesos & Swarm) which are designed to pack as many different apps\microservices onto the same servers in a single (or relatively few) data centers and as a result non of them provide truly latency tolerant connection and the scalability of Swarm & Kubernetes is limited to a few thousands workers.
Nebula was designed with stateless RESTful Manger microservice to provide a single point to manage the clusters as well as providing a single point which all containers check for updates with a Kafka inspired Monotonic ID configuration updates in a pull based methodology, this ensure that changes to any of the applications managed by Nebula are pulled to all managed devices at the same time and also ensures that all devices will always have the latest version of the configuration(thanks to the monotonic ID), all data is stored in MongoDB which is the single point of truth for the system, on the workers side it’s based around a worker container on each devices that is in charge of starting\stopping\changing the other containers running on that device, due to the design each component can be scaled out & as such Nebula can grow as much as you require it.
you can read more about Nebula architecture at https://nebula.readthedocs.io/en/latest/architecture/
# Nebula features
As it was designed from the ground up to support distributed systems Nebula has a few neat features that allows it to control distributed IoT systems:
* Designed to scale out on all of it’s components (IoT devices, API layer, & Mongo all scale out)
* Able to manage millions of IoT devices
* Latency tolerant — even if a device goes offline it will be re-synced when he gets back online
* Dynamically add/remove managed devices
* Fast & easy code deployments, single API call with the new container image tag (or other configuration changes) and it will be pushed to all devices of that app.
* Simple install —MongoDB & a stateless API is all it takes for the management layer & a single container with some envvars on each IoT device you want to manage takes care of the worker layer
* Single API endpoint to manage all devices
* Allows control of multiple devices with the same Nebula orchestrator (multiple apps & device_groups)
* Not limited to IoT, also useful for other types of distributed systems
* API, Python SDK & CLI control available
# A little example
The following command will install an Nebula cluster for you to play on and will create an example app as well, requires Docker, curl & docker-compose installed:
```
curl -L "https://raw.githubusercontent.com/nebula-orchestrator/docs/master/examples/hello-world/start_example_nebula_cluster.sh" -o start_example_nebula_cluster.sh && sudo sh start_example_nebula_cluster.sh
```
But let’s go over what this command does to better understand the process:
* The scripts downloads and runs a docker-compose.yml file which creates:
1. A MongoDB container — the backend DB where Nebula apps current state is saved.
2. A manager container — A RESTful API endpoint, this is where the admin manages Nebula from & where devices pulls the latest configuration state from to match against their current state
3. A worker container — this normally runs on the IoT devices, only one is needed on each device but as this is just an example it runs on the same server as the management layer components runs on.
It’s worth mentioning the “DEVICE_GROUP=example” environment variable set on the worker container, this DEVICE_GROUP variable controls what nebula apps will be connected to the device (similar to a pod concept in other orchestrators).
* The script then waits for the API to become available.
* Once the API is available the scripts sends the following 2 commands:
```
curl -X POST \
http://127.0.0.1/api/v2/apps/example \
-H 'authorization: Basic bmVidWxhOm5lYnVsYQ==' \ -H 'cache-control: no-cache' \
-H 'content-type: application/json' \ -d '{
"starting_ports": [{"81":"80"}],
"containers_per": {"server": 1},
"env_vars": {},
"docker_image" : "nginx",
"running": true,
"volumes": [],
"networks": ["nebula"],
"privileged": false,
"devices": [],
"rolling_restart": false
}'
```
This command creates an app named “example” and configures it to run an nginx container to listen on port 81 , as you can see it can also control other parameters usually passed to the docker run command such as envvars or networks or volume mounts.
```
curl -X POST \
http://127.0.0.1/api/v2/device_groups/example \ -H 'authorization: Basic bmVidWxhOm5lYnVsYQ==' \ -H 'cache-control: no-cache' \
-H 'content-type: application/json' \ -d '{
"apps": ["example"]
}'
```
This command creates a device_group that is also named “example” & attaches the app named “example” to it.
* After the app & device_groups arecreated on the nebula API the worker container will pick it up the changes to the device_group which is been confiugred to be part of (“example” in this case) and will start an Nginx container on the server, you can run “docker logs worker” to see the Nginx container being downloaded before it starts (this might take a bit if your on a slow connection). and after it’s completed you can access http://<server_exterior_fqdn>:81/ on your browser to see it running
Now that we have a working Nebula system running we can start playing around with it to see it’s true strengths:
* We can add more remote workers by running a worker container on them:
```
sudo docker run -d --restart unless-stopped -v /var/run/docker.sock:/var/run/docker.sock --env DEVICE_GROUP=example --env REGISTRY_HOST=https://index.docker.io/v1/ --env MAX_RESTART_WAIT_IN_SECONDS=0 --env NEBULA_MANAGER_AUTH_USER=nebula --env NEBULA_MANAGER_AUTH_PASSWORD=nebula --env NEBULA_MANAGER_HOST=<your_manager_server_ip_or_fqdn> --env NEBULA_MANAGER_PORT=80 --env nebula_manager_protocol=http --env NEBULA_MANAGER_CHECK_IN_TIME=5 --name nebula-worker nebulaorchestrator/worker
```
It’s worth mentioning that a lot of the envvars passed through the command above are optional (with sane defaults) & that there is no limit on how many devices we can run this command on, at some point you might have to scale out the managers and\or backend DB but those are not limited as well.
* We can change the container image on all devices with a single API call, let’s for example replace the container image to Apache to simulate that
```
curl -X PUT \http://127.0.0.1/api/v2/apps/example/update \-H ‘authorization: Basic bmVidWxhOm5lYnVsYQ==’ \-H ‘cache-control: no-cache’ \-H ‘content-type: application/json’ \-d ‘{“docker_image”: “httpd:alpine”}’
```
* Similarly we can also update any parameter of the app such as env_vars, privileged permissions, volume mounts, etc, — the full list of API endpoints as well as the Python SDK & the CLI is available at documentation page at https://nebula.readthedocs.io/en/latest/
Hopefully this little guide allowed you to see the need of an IoT docker orchestrator and it’s use case & should you find yourself interested in reading more about it you can visit Nebula Container Orchestrator site at https://nebula-orchestrator.github.io/ or skip right ahead to the documentation at https://nebula.readthedocs.io | naorlivne |
163,714 | NextJS Vs Preact, Which do I go for? | I am working on a big Forum project and i'm trying to figure out which one to use to handle my... | 0 | 2019-08-30T11:02:08 | https://dev.to/misteryomi/nextjs-vs-preact-which-do-i-go-for-iom | help, preact, nextjs | ---
title: NextJS Vs Preact, Which do I go for?
published: true
tags: help, preact, Next, NextJS
---
I am working on a big Forum project and i'm trying to figure out which one to use to handle my frontend between NextJS and Preact.
Suggestions are kindly needed... and why.
| misteryomi |
163,903 | Queixa: a faculdade não ensina nada atualizado! | Um vídeo do canal O Universo da Programação sobre o conteúdo acadêmico | 0 | 2020-05-22T18:00:24 | https://dev.to/etc_william/queixa-a-faculdade-nao-ensina-nada-atualizado-166i | udp, universodaprogramacao, podcast, youtube | ---
title: "Queixa: a faculdade não ensina nada atualizado!"
published: true
description: "Um vídeo do canal O Universo da Programação sobre o conteúdo acadêmico"
tags: udp, universo-da-programacao, podcast, youtube
---
Muita gente reclama do conteúdo da faculdade.
Será que a faculdade ensina tudo o que precisamos para o mercado? Será que a faculdade deveria ensinar tecnologias de mercado?
Neste vídeo temos uma reflexão sobre o assunto e espero que te ajude a se encontrar nesse universo de opções que é o Universo da Programação!
{% youtube BwdKfV7wvWo %}
| 1ilhas |
164,005 | Configuring standard policies for all repositories in Azure Repos |
A couple of weeks ago I blogged about setting collection level permissions on Az... | 0 | 2019-08-30T21:00:43 | https://jessehouwing.net/azure-repos-git-configuring-standard-policies-on-repositories/ | azuredevops, git, azurerepos | ---
title: Configuring standard policies for all repositories in Azure Repos
published: true
tags: Azure DevOps,git,Azure Repos
canonical_url: https://jessehouwing.net/azure-repos-git-configuring-standard-policies-on-repositories/
---
> A couple of weeks ago I blogged about [setting collection level permissions on Azure Repos](https://dev.to/jessehouwing/setting-default-repository-permissions-on-your-azure-devops-organization-1i6g-temp-slug-9023663). That sparked questions whether the same was possible on Branch Policies in the comments, twitter and the Azure DevOps Club slack channel.

By default you can only configure policies on specific branches in Azure Repos. You access the policies through the Branch's [...] menu and set the policy from there. But if you're using a strict naming pattern for your branches (e.g. when using [Release Flow](https://docs.microsoft.com/en-us/azure/devops/learn/devops-at-microsoft/release-flow) or [GitHub Flow](https://guides.github.com/introduction/flow/)), you may want to set a policy for all future Release Branches, or all Feature branches.
**It would be nice if you could write these policies into law, that way you don't have to set them for every future branch.**
> **Let's start with the bad news** : the policy API is specific to a Project. Because of that you can't set the policies for all Git Repositories in an account, but you can specify the policy for all repositories in a Project.
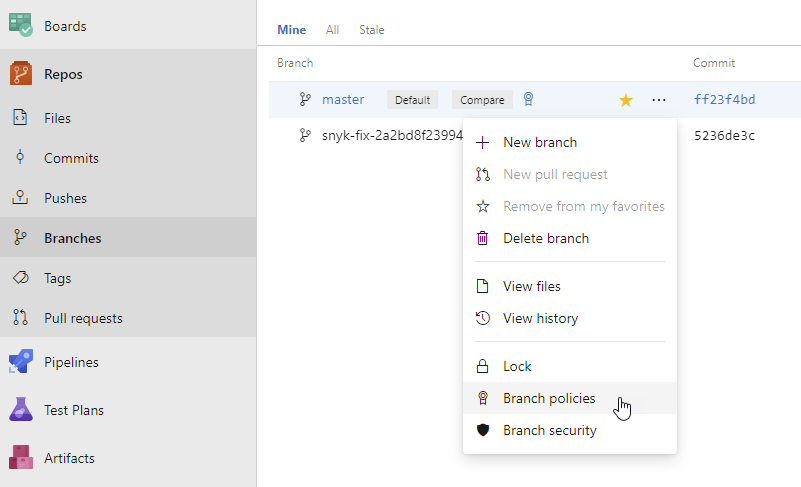<figcaption>Set a policy on a branch.</figcaption>
If you look at the request that's generated when saving a Branch Policy, you can see the UI sending a POST request to the `/{Project Guid}/api/policy/Configurations` REST API when creating a new policy. That request contains the scope for each policy:
<figcaption>Each policy has a scope in Azure Repos</figcaption>
As you can see, the policy has a Scope. You can have multiple active policies and each can have its own scope. The UI will always create a specific scope that contains the `repositoryId` and the exact branch name.
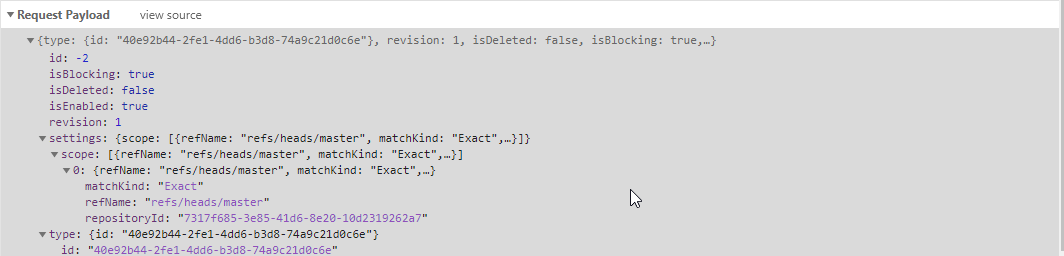
```
"scope": [
{
"refName": "refs/heads/master",
"matchKind": "Exact",
"repositoryId": "7317f685-3e85-41d6-8e20-10d2319262a7"
}
]
```
<figcaption>Scope: (default) Specific Git Repo and single branch.</figcaption>
[But if you look at the docs for this API, you'll find that this is not the only option available](https://docs.microsoft.com/en-us/rest/api/azure/devops/policy/configurations/create?view=azure-devops-server-rest-5.0). The widest scope you can create has no repository scope at all and applies to all repositories in that project:
```
"scope": [
{
"repositoryId": null
}
]
```
<figcaption>Scope: All Git Repos in the project.</figcaption>
But there are other cool options as well. You can configure a policy for all branches with a specific prefix by setting the `matchKind` from `exact` to `prefix`.
```
"settings": {
"scope": [
{
"repositoryId": null,
"refName": "refs/heads/features/",
"matchKind": "prefix"
}
]
}
```
<figcaption>Scope: All feature branches for all repositories in the project.</figcaption>
Unfortunately, it looks like this API exists at the Project level only. One can't set the policy for all future projects. _But, think about it, that makes sense. You can't predict all the future group names, Build Definition IDs and such for projects that don't exist yet._ But it's less restricted than the UI would let you believe.
To figure out how each of the policies is specified, configure one branch the way you want ant then open `/{Project Guid}/_apis/policy/Configurations/` on your account. you'll be treated with the JSON for your current configuration:
```
{
"count": 1,
"value": [
{
"isEnabled": true,
"isBlocking": true,
"settings": {
"useSquashMerge": false,
"scope": [
{
"refName": "refs/heads/master",
"matchKind": "Exact",
"repositoryId": "7317f685-3e85-41d6-8e20-10d2319262a7"
}
]
}
}
]
}
```
Find out all you need to know about policy types by querying them from your account as well, my account returns these:
```
[
{
"description": "GitRepositorySettingsPolicyName",
"id": "0517f88d-4ec5-4343-9d26-9930ebd53069",
"displayName": "GitRepositorySettingsPolicyName"
},
{
"description": "This policy will reject pushes to a repository for paths which exceed the specified length.",
"id": "001a79cf-fda1-4c4e-9e7c-bac40ee5ead8",
"displayName": "Path Length restriction"
},
{
"description": "This policy will reject pushes to a repository for names which aren't valid on all supported client OSes.",
"id": "db2b9b4c-180d-4529-9701-01541d19f36b",
"displayName": "Reserved names restriction"
},
{
"description": "This policy ensures that pull requests use a consistent merge strategy.",
"id": "fa4e907d-c16b-4a4c-9dfa-4916e5d171ab",
"displayName": "Require a merge strategy"
},
{
"description": "Check if the pull request has any active comments",
"id": "c6a1889d-b943-4856-b76f-9e46bb6b0df2",
"displayName": "Comment requirements"
},
{
"description": "This policy will require a successfull status to be posted before updating protected refs.",
"id": "cbdc66da-9728-4af8-aada-9a5a32e4a226",
"displayName": "Status"
},
{
"description": "Git repository settings",
"id": "7ed39669-655c-494e-b4a0-a08b4da0fcce",
"displayName": "Git repository settings"
},
{
"description": "This policy will require a successful build has been performed before updating protected refs.",
"id": "0609b952-1397-4640-95ec-e00a01b2c241",
"displayName": "Build"
},
{
"description": "This policy will reject pushes to a repository for files which exceed the specified size.",
"id": "2e26e725-8201-4edd-8bf5-978563c34a80",
"displayName": "File size restriction"
},
{
"description": "This policy will ensure that required reviewers are added for modified files matching specified patterns.",
"id": "fd2167ab-b0be-447a-8ec8-39368250530e",
"displayName": "Required reviewers"
},
{
"description": "This policy will ensure that a minimum number of reviewers have approved a pull request before completion.",
"id": "fa4e907d-c16b-4a4c-9dfa-4906e5d171dd",
"displayName": "Minimum number of reviewers"
},
{
"description": "This policy encourages developers to link commits to work items.",
"id": "40e92b44-2fe1-4dd6-b3d8-74a9c21d0c6e",
"displayName": "Work item linking"
}
]
```
<figcaption>All policy types available in my account.</figcaption>
The configuration for each policy is a bit of a mystery. I tend to configure a policy through the UI, then retrieve the configured policy to see what the JSON looks like.
Now that you understand the underlying concepts, guids and things, you can use the raw REST requests from PowerShell or... [You could use the new Azure CLI for Azure DevOps](https://docs.microsoft.com/en-us/cli/azure/ext/azure-devops/repos/policy?view=azure-cli-latest):
```
az extension add --name "azure-devops"
az login
az repos policy create --org {your org} --project {your project name or guid} --config "path/to/config/file"
```
For reference:
- [Policy API docs](https://docs.microsoft.com/en-us/rest/api/azure/devops/policy/?view=azure-devops-server-rest-5.0)
- [Policy Configurations REST API](https://docs.microsoft.com/en-us/rest/api/azure/devops/policy/configurations/list?view=azure-devops-server-rest-5.0)
- [Policy Type REST API](https://docs.microsoft.com/en-us/rest/api/azure/devops/policy/types/get?view=azure-devops-server-rest-5.0)
- [Policy Examples](https://docs.microsoft.com/en-us/rest/api/azure/devops/policy/configurations/create?view=azure-devops-server-rest-5.0#examples) | jessehouwing |
164,031 | Why I can't spell but I CAN code | How do you spell function? You had to think for a split second didn't you? You probably wr... | 0 | 2019-08-30T21:30:08 | https://dev.to/adam_cyclones/why-i-can-t-spell-but-i-can-code-2lp5 | ### How do you spell function?
You had to think for a split second didn't you? You probably write the word in some form atleast 30 times per day, 10,950 per year and 87,600 keystrokes just to fit that statistical guess work. But still.. it's a small wonder our keyboards haven't inverted, caught fire, or complained to a workers Union. It's all down to muscle memory (which I will now googlize into my own brains short term memory) and define it thusly:
_Muscle memory is a form of procedural memory that involves consolidating a specific motor task into memory through repetition, which has been used synonymously with motor learning._
Ace now we have that out the way, thanks googled generic text, I can't spell because I have been told I am dyslexic. But I can code because I need to get it write in order to survive at life, this is my job and my hobby. So yeah working with me is probably full of typos and disorganized rambles because dyslexia is more than just spelling. It's a state of mind. I want to know your point of view, is dyslexia a label, an excuse or a genuine thing, I won't be offended, so have at it. | adam_cyclones | |
164,042 | Population Growth and Housing Availability | New housing and new residents A certain amount of housing prices are due to supply and dem... | 2,079 | 2019-09-27T21:59:50 | https://dev.to/rpost/population-growth-and-housing-affordability-79e | data, analytics, techforgood | # New housing and new residents
A certain amount of housing prices are due to supply and demand - more people means more demand. It can be hard, if not impossible, to keep up with that demand, which means more expensive housing. Of course there are [tons of factors that play into housing affordability](https://www.curbed.com/2019/5/15/18617763/affordable-housing-policy-rent-real-estate-apartment) but supply (new units being built) and demand (new residents moving to an area) are easy to find data that can show the impact of these factors.
According to the Census estimates, the Austin-Round Rock Metropolitan area grew by 53,086 people from July 1, 2017 to July 1, 2018. A little less than a quarter, or 23.6%, of those individuals moved to live within the Austin city limits. That also means that about 40,000 people moved into the surrounding areas. During that same period, construction was completed on 12,453 housing units. Using the Census average household size of 2.48 people, that means we gained enough housing for a little over 30,000 people! This, in theory, should have helped slow down housing cost increases.
Austin has been experiencing a similar growth rate since 2010, but there have not been enough housing units completed to keep up with the change - 9,449 were completed between July 1, 2018 and June 30, 2019. Using the same average household size, that made room for just 23,400 people, which means that well over half of the new residents moved to the area, but outside of the city limits. The low number of new units likely increased the cost of housing by not meeting demand.
If units continue to be finished at the same rate, we will see 13,750 more units come available by June 30, 2020, which should be able to provide housing for about 34,100 new residents at the current average household size. While these are not huge numbers, and may not lower average rents it may help slow the relentless increase of housing costs.
# Dev - estimating upcoming housing availability
Here's why this is dev-related to me. Once you have the data, it's fairly easy to figure out how many houses have been built within a certain period. Look at the number of building permits and a status of "Final" along with their Status date. (The Status date looks to have been started in 2007, and retroactively applied through 2008, so even this method only works for about the last 10 years.)
More difficult is estimating the units that may be completed soon. To do this, I first created a field called "Time to Completion" that finds the difference between the Completed Date and the Issue Date. That allowed me to looked at the average completion time in days. I narrowed the time range down to the last two years because construction methods change, crew availability changes, and I thought that two years would be a large enough time frame to have a broad average while also reflecting a state that may be similar to what we're facing now. (As I'm a developer, and not a construction or real estate professional, I might be wrong about that.)
If you look at the average completion time for all Building Permits related to new housing units, from July 1, 2017 to now, it is 331.7 days. I did exclude 16 permits that were listed at taking over 2000 days to complete. That's 5 1/2 years! Something seems to have gone really wrong with those, and I'm comfortable calling them outliers for our current purposes. That may seem like a good number to use, but if you think for a second longer - does it take the same amount of time to build a 3,000 unit complex as a single house? I hope not! I looked at the relationship between number of units and time to completion and, yes! Common sense works here, it takes longer to build more units. You can see it in a [dashboard I made on Tableau Public](https://public.tableau.com/profile/rebekah3261#!/vizhome/AustinTXUnitCompletionEstimates/EstimatingUnitCompletion?publish=yes).
I added a line to my scatter plot with Housing Units and Time to Completion. We could use the nice formula that Tableau generated based on number of units alone, but the line goes way above the reality for larger complexes, which means we would seriously over-estimate completion time for larger projects, like those with more than 150 units. What else might be at play? Next I checked the time to completion by permit class and wow! Now we see a range from 297.5 days to 989.9. That's from about 10 months at the shortest to over two and a half years! That seems like a better estimate.
After exploring these options, I decided to use the average Time to Completion by Permit Class. I created a new field that calculates an Estimated Completion Date based on the Issue Date plus the average Time to Completion for a given permit's Permit Class. If you are a more visual person, go download [my Tableau workbook](https://public.tableau.com/profile/rebekah3261#!/vizhome/AustinTXUnitCompletionEstimates/EstimatingUnitCompletion?publish=yes) and play with it!
The final step was to account for *actual completed date* and *estimated completed date* at the same time. I created one more field that looks at the project status, decides what date to use (actual or estimate) and then allows us to view all of the building permits together, whether they have been completed yet or not.
# Should we ever expect housing costs in Austin to go down?
If more people are moving to Austin and the area every year, and are increasing the demand for housing, then we can never really expect the housing costs to go down as long as the economy is doing well. It's awkward, but what incentive do housing developers have to make houses that will sell for less? Apartments that command lower rents may be profitable to management companies because they could tap a separate market, but at some point the profit may not be worth it to those companies. That is where local government steps in - they can (and do!) create incentives for developers to build affordable units.
A related issue is land. You can build on empty land, or you can tear down existing units. The former is very limited within city limits, and the latter often results in simple replacement of older (read: cheaper) housing with newer (read: more expensive) housing. Changing the land development code is one way to encourage greater density, which will allow for more housing within city limits. Existing options, like two detached homes on a single lot, are becoming more popular as a way for those willing to live in smaller homes to stay within the city. This, then is another area where local government can help control housing costs. And we'll get into that next time. | rpost |
164,146 | Magento 2 Store Pickup | Use Magento 2 Store Pickup Extension to drive more revenues! By allowing your customers to pick up th... | 0 | 2019-08-31T07:07:04 | https://dev.to/jadeblanne/magento-2-store-pickup-hp6 | magento, webdev | Use [Magento 2 Store Pickup](https://www.mageants.com/store-pickup-extension-for-magento-2.html) Extension to drive more revenues! By allowing your customers to pick up their orders from the nearest store, offer improved shopping experience.
**Key Features**
Configuration of multiple stores
Store pick up with the Store locator is included
Map clustering is automatic
On every product information page link to store is provided
Store can be searched instantly by area and distance
**Overview**
Magento 2 Store Pickup provides an additional shipping technique that allows clients to collect their orders on their own right at the shop. This helps to decrease a third party's potential shipping hazards and enhances shopping experience with a fresh selection of pickup.
| jadeblanne |
164,254 | Building an Enigma machine with only TypeScript and then use Angular DI system to properly instantiate it | [Part 2] - Building Enigma with TypeScript and Angular | 1,667 | 2019-09-10T09:11:17 | https://dev.to/maxime1992/building-an-enigma-machine-with-only-typescript-and-then-use-angular-di-system-to-properly-instantiate-it-2e2h | cryptography, enigma, angular | ---
published: true
title: "Building an Enigma machine with only TypeScript and then use Angular DI system to properly instantiate it"
cover_image: "https://raw.githubusercontent.com/maxime1992/my-dev.to/master/blog-posts/enigma-part-2/assets/enigma-2-cover-image.png"
description: "[Part 2] - Building Enigma with TypeScript and Angular"
tags: cryptography, enigma, angular
series: "Enigma: Understand it, implement it, crack it"
canonical_url:
---
This blog post is the second of a series of 3, called **"Enigma: Understand it, implement it, crack it"**:
- 1 - [Enigma machine, how does the famous encryption device work?](https://dev.to/maxime1992/enigma-machine-how-does-the-famous-encryption-device-work-5aon)
- **2 - Building an Enigma machine with only TypeScript and then use Angular DI system to properly instantiate it _[this blog post]_**
- 3 - [Brute-forcing an encrypted message from Enigma using the web worker API](https://dev.to/maxime1992/brute-forcing-an-encrypted-message-from-enigma-using-the-web-worker-api-166b)
# Table of contents
<!-- toc -->
- [Intro](#intro)
- [1 - Enigma library](#1-enigma-library)
- [A - Reflector](#a-reflector)
- [B - Rotor](#b-rotor)
- [C - Machine](#c-machine)
- [2 - Enigma app](#2-enigma-app)
- [A - Display the initial config rotors and current ones](#a-display-the-initial-config-rotors-and-current-ones)
- [B - Encrypt a message from the app](#b-encrypt-a-message-from-the-app)
- [B1 - Logic and template](#b1-logic-and-template)
- [B2 - Create an Enigma machine using dependency injection](#b2-create-an-enigma-machine-using-dependency-injection)
- [Conclusion](#conclusion)
- [Found a typo?](#found-a-typo)
<!-- tocstop -->
If you find any typo please just make the edit yourself here: https://github.com/maxime1992/my-dev.to/blob/master/blog-posts/enigma-part-2/enigma-part-2.md and submit a pull request :ok_hand:
# Intro
In the [first blog post of this series](https://dev.to/maxime1992/enigma-machine-how-does-the-famous-encryption-device-work-5aon), we've seen the internal mechanism of Enigma. In this one, I'll explain how I decided to implement it.
The Enigma library I've built has nothing to do with Angular, it's just **pure TypeScript**. The reasons behind that are:
- It shouldn't in the first place because it could be used as a separate package with vanilla JS or any other framework
- [:warning: Spoiler alert :warning:] To crack Enigma in the next blog post of the series, we will use a [web worker](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API) and importing anything from Angular within the worker context would break it as it's not aware of the DOM at all
BUT. For Angular lovers, worry no more. We will use Angular and especially its dependency injection API to build the UI that'll consume Enigma library.
**Note:** In order to correctly manage potential errors, the library does some checks (on the reflectors, the rotors, etc). Those checks have been skipped in the code examples to keep the main logic as small as possible. When that's the case, I've added a comment "`// [skipped] and the reason`" but feel free to check the complete source code here: https://github.com/maxime1992/my-dev.to/tree/master/libs/enigma/enigma-machine
# 1 - Enigma library
In order to build the machine, we will do so from bottom to top, which means starts with the reflector, then with the rotors and finally the machine itself.
## A - Reflector
_Reminder: a reflector is a simple map where an index is connected to another._
Multiple reflectors were available so the first thing to do is being able to set the reflector configuration. If we take the reflector called "Wide B": `yruhqsldpxngokmiebfzcwvjat` it means that `A` (index `0`) is mapping to `Y` (index `24`) and etc. So when someone types a letter on Enigma, it goes through the 3 rotors and after the last one, will go through the reflector. The rotor input might be at any index between `0` and `25` and we want to be able to find in a simple way the corresponding output:
```ts
export class ReflectorService {
private reflectorConfig: number[] = [];
constructor(reflectorConfig: string) {
this.setReflectorConfig(reflectorConfig);
}
private setReflectorConfig(reflectorConfig: string): void {
// [skipped] check that the reflector config is valid
this.reflectorConfig = this.mapLetterToAbsoluteIndexInAlphabet(reflectorConfigSplit);
// [skipped] check that every entry of the reflector maps to a different one
}
private mapLetterToAbsoluteIndexInAlphabet(alphabet: Alphabet): number[] {
return alphabet.reduce((map: number[], letter: Letter, index: number) => {
map[index] = getLetterIndexInAlphabet(letter);
return map;
}, []);
}
// ...
}
```
Now that we've remapped the string to an array that lets us find the output index for a given input, we need to expose a method so that the machine itself will be able to go through the rotor for a given index:
```ts
public goThroughFromRelativeIndex(index: number): number {
return this.reflectorConfig[index];
}
```
As you can see, implementing the reflector was quite an easy task. Let's take a look to the rotors now.
## B - Rotor
_Reminder: a rotor consist of 2 disks connected together with wires. So for a given input index, the output could be the same as the input (in contrary to the reflector)._
For a given rotor, we express the rotor configuration with letters, just like we did for the reflector. For example, the first rotor has the following configuration: `ekmflgdqvzntowyhxuspaibrcj`. As a rotor will spin, instead of thinking with letters, I found it much easier to think of it and deal with it through **relative indexes**.
For example with the configuration above, we can represent it like the following:
```
a b c d ... w x y z Alphabet...
| | | | ... | | | | is remapped to...
e k m f ... b r c j a new alphabet
But internally we want is as:
0 1 2 3 ... 22 23 24 25
| | | | ... | | | |
+4 +9 +10 +2 ... +5 +20 +4 +10
```
```ts
export class EnigmaRotorService {
private rotor: BiMap;
private currentRingPosition = 0;
constructor(rotorConfig: string, currentRingPosition: number = LetterIndex.A) {
const rotorConfigSplit: string[] = rotorConfig.split('');
// [skipped] check that the string is correctly mapping to alphabet
this.rotor = createBiMapFromAlphabet(rotorConfigSplit);
this.setCurrentRingPosition(currentRingPosition);
}
public setCurrentRingPosition(ringPosition: number): void {
// [skipped] check that the ring position is correct
this.currentRingPosition = ringPosition;
}
public getCurrentRingPosition(): number {
return this.currentRingPosition;
}
// ...
}
```
The above implementation seems relatively small but what's the function `createBiMapFromAlphabet`? It's the function in charge of doing the remapping from a string to a bi map with relative indexes. The reason to have a bi map here is because we want to be able to go through the rotor from **left to right** and **right to left**. The challenge here is that we do not want to have to deal with negative indexes at any time. So if the current position of the rotor is `Z` and the relative input is `0`, we know that `Z --> J` with is equivalent to `index 25 --> +10`. On the contrary, when going from right to left, if we're on the letter `J` (index `10`) it's going to map to `Z` which won't be `-10` but `+17`. Here's the implementation:
```ts
export const createBiMapFromAlphabet = (alphabet: Alphabet): BiMap => {
return alphabet.reduce(
(map: BiMap, letter: Letter, index: number) => {
const letterIndex: number = getLetterIndexInAlphabet(letter);
map.leftToRight[index] = moduloWithPositiveOrNegative(ALPHABET.length, letterIndex - index);
map.rightToLeft[letterIndex] = moduloWithPositiveOrNegative(ALPHABET.length, -(letterIndex - index));
return map;
},
{ leftToRight: [], rightToLeft: [] } as BiMap,
);
};
```
Now, we've got 3 things left for the public API of the rotor:
- Being able to get the current position
- Being able to go through the rotor from left to right
- Being able to go through the rotor from right to left
```ts
public getCurrentRingPosition(): number {
return this.currentRingPosition;
}
private goThroughRotor(
from: 'left' | 'right',
relativeIndexInput: number
): number {
const currentRelativeIndexOutput = this.rotor[
from === 'left' ? 'leftToRight' : 'rightToLeft'
][(this.currentRingPosition + relativeIndexInput) % ALPHABET.length];
return (relativeIndexInput + currentRelativeIndexOutput) % ALPHABET.length;
}
public goThroughRotorLeftToRight(relativeIndexInput: number): number {
return this.goThroughRotor('left', relativeIndexInput);
}
public goThroughRotorRightToLeft(relativeIndexInput: number): number {
return this.goThroughRotor('right', relativeIndexInput);
}
```
Last remaining bit of the library: The machine itself!
## C - Machine
The machine is conducting the orchestra and making all letters of a message go through rotors/reflector/rotors plus spinning the rotors when needed. It has a public API to get/set the initial state of the rotors, get the current state of the rotors and encrypt/decrypt a message.
Let's look at first at how to keep track of the internal state for the rotors (initial and current state):
```ts
interface EnigmaMachineState {
initialStateRotors: RotorsStateInternalApi;
currentStateRotors: RotorsStateInternalApi;
}
export class EnigmaMachineService {
private readonly state$: BehaviorSubject<EnigmaMachineState>;
private readonly initialStateRotorsInternalApi$: Observable<
RotorsStateInternalApi
>;
private readonly currentStateRotorsInternalApi$: Observable<
RotorsStateInternalApi
>;
public readonly initialStateRotors$: Observable<RotorsState>;
public readonly currentStateRotors$: Observable<RotorsState>;
// ...
```
Using `Redux` for this class would be slightly overkill but reusing the concepts feels great. We use a `BehaviorSubject` to hold the whole state which is **immutable**. Easier to debug, easier to share as observables, it will also help for performance and let us set all our components to `ChangeDetectionStrategy.OnPush` :fire:.
I usually prefer to set all the properties directly but in our case, before setting them we want to make sure that the ones passed are correct and we make the checks + assignments in the constructor:
```ts
export class EnigmaMachineService {
// ...
constructor(private enigmaRotorServices: EnigmaRotorService[], private reflectorService: ReflectorService) {
// [skipped] check that the rotor services are correctly defined
// instantiating from the constructor as we need to check first
// that the `enigmaRotorService` instances are correct
const initialStateRotors: RotorsStateInternalApi = this.enigmaRotorServices.map(enigmaRotorService =>
enigmaRotorService.getCurrentRingPosition(),
) as RotorsStateInternalApi;
this.state$ = new BehaviorSubject({
initialStateRotors,
currentStateRotors: initialStateRotors,
});
this.initialStateRotorsInternalApi$ = this.state$.pipe(
select(state => state.initialStateRotors),
shareReplay({ bufferSize: 1, refCount: true }),
);
this.currentStateRotorsInternalApi$ = this.state$.pipe(
select(state => state.currentStateRotors),
shareReplay({ bufferSize: 1, refCount: true }),
);
this.initialStateRotors$ = this.initialStateRotorsInternalApi$.pipe(
map(this.mapInternalToPublic),
shareReplay({ bufferSize: 1, refCount: true }),
);
this.currentStateRotors$ = this.currentStateRotorsInternalApi$.pipe(
map(this.mapInternalToPublic),
shareReplay({ bufferSize: 1, refCount: true }),
);
this.currentStateRotorsInternalApi$
.pipe(
tap(currentStateRotors =>
this.enigmaRotorServices.forEach((rotorService, index) =>
rotorService.setCurrentRingPosition(currentStateRotors[index]),
),
),
takeUntilDestroyed(this),
)
.subscribe();
}
// ...
}
```
Few things to note from the code above:
All the properties that we expose as observables are driven from our store (the only source of truth). Every time the current state changes, we set the rotors positions accordingly. We also keep track or the initial state and current state of the rotors in 2 different ways: One is `internal`, the other is not. For us, it's easier to deal with indexes instead of letters (internal) but when we expose them (to display in the UI for e.g.) we don't want the consumer to figure out that `18` stands for `s`, we just return `s`.
The other interesting part in the code above is the usage of `shareReplay` with the argument `{ bufferSize: 1, refCount: true }`. It'll allow us to share our observables instead of re-subscribing to them multiple times :+1:. Using `shareReplay(1)` would work but would be quite dangerous as if no one is listening anymore to the observable it wouldn't unsubscribe. That is why we need to pass `refCount` as `true`.
Now that we've seen how we share the state of our Enigma machine with the rest of the app, let see how the main part of the app works: Encoding a letter through the machine:
```ts
export class EnigmaMachineService {
// ...
private readonly encodeLetterThroughMachine: (letter: Letter) => Letter = flow(
// the input is always emitting the signal of a letter
// at the same position so this one is absolute
getLetterIndexInAlphabet,
this.goThroughRotorsLeftToRight,
this.goThroughReflector,
this.goThroughRotorsRightToLeft,
getLetterFromIndexInAlphabet,
);
// ...
}
```
Is that... it? Yes! Pretty much.
In the above code, `flow` will run all those functions sequentially and pass to the next function the result of the previous one, which works quite nicely in this case as the result of the input (keyboard) goes to the first rotor, the result of the first rotor goes to the second rotor, etc.
Neat, right?
```ts
export class EnigmaMachineService {
// ...
private encryptLetter(letter: Letter): Letter {
// [skipped] check that the letter is valid
// clicking on a key of the machine will trigger the rotation
// of the rotors so it has to be made first
this.goToNextRotorCombination();
return this.encodeLetterThroughMachine(letter);
}
public encryptMessage(message: string): string {
this.resetCurrentStateRotorsToInitialState();
return message
.toLowerCase()
.split('')
.map(letter =>
// enigma only deals with the letters from the alphabet
// but in this demo, typing all spaces with an "X" would
// be slightly annoying so devianting from original a bit
letter === ' ' ? ' ' : this.encryptLetter(letter as Letter),
)
.join('');
}
private resetCurrentStateRotorsToInitialState(): void {
const state: EnigmaMachineState = this.state$.getValue();
this.state$.next({
...state,
currentStateRotors: [...state.initialStateRotors] as RotorsStateInternalApi,
});
}
private goToNextRotorCombination(): void {
const state: EnigmaMachineState = this.state$.getValue();
this.state$.next({
...state,
currentStateRotors: goToNextRotorCombination(state.currentStateRotors),
});
}
private goThroughRotorsLeftToRight(relativeInputIndex: number): number {
return this.enigmaRotorServices.reduce(
(relativeInputIndexTmp, rotorService) => rotorService.goThroughRotorLeftToRight(relativeInputIndexTmp),
relativeInputIndex,
);
}
private goThroughRotorsRightToLeft(relativeInputIndex: number): number {
return this.enigmaRotorServices.reduceRight(
(relativeInputIndexTmp, rotorService) => rotorService.goThroughRotorRightToLeft(relativeInputIndexTmp),
relativeInputIndex,
);
}
private goThroughReflector(relativeInputIndex: number): number {
return this.reflectorService.goThroughFromRelativeIndex(relativeInputIndex);
}
public setInitialRotorConfig(initialStateRotors: RotorsState): void {
const state: EnigmaMachineState = this.state$.getValue();
this.state$.next({
...state,
initialStateRotors: initialStateRotors.map(rotorState =>
getLetterIndexInAlphabet(rotorState),
) as RotorsStateInternalApi,
});
}
}
```
In the above code, the most important bits are:
- `encryptLetter` calls `goToNextRotorCombination` first and then `encodeLetterThroughMachine`. It's what happened on the machine, every time a key was pressed, the rotors spin first and then we get the path for the new letter
- When calling `encryptMessage` we also call `resetCurrentStateRotorsToInitialState` because that method simulates every keystrokes by splitting the string into chars and calling `encryptLetter` on every one of them (which make the rotors move forward on every letter)
- `resetCurrentStateRotorsToInitialState`, `goToNextRotorCombination` and `setInitialRotorConfig` are updating the state in an immutable way
- `goThroughRotorsLeftToRight` and `goThroughRotorsRightToLeft` are respectively using `reduce` and `reduceRight` to go through the rotors left to right and right to left. Using `reduce*` here feels "natural" as from one rotor we go through the next one by passing the previous output
We've now built an Enigma library with a public API that should let us encrypt/decrypt messages in easy way. Let's now move on to the app itself.
# 2 - Enigma app
The goal is now to build the following:

We want to have:
- An initial config where we can set the rotors where Enigma should start
- Another display of the rotors but this time with the current state. Every time a new letter will be typed, the current state will update to show the new combination
- The text to encrypt/decrypt on the left (input) and the output on the right
## A - Display the initial config rotors and current ones
We can see that both the initial config and current state are the same so we will have a shared component containing the 3 letters.
I've decided to build that component using [ngx-sub-form](https://github.com/cloudnc/ngx-sub-form). If you're interested in that library you can read more on the Github project itself and in one of my previous posts here: https://dev.to/maxime1992/building-scalable-robust-and-type-safe-forms-with-angular-3nf9
`rotors-form.component.ts`
```ts
interface RotorsForm {
rotors: RotorsState;
}
@Component({
selector: 'app-rotors-form',
templateUrl: './rotors-form.component.html',
styleUrls: ['./rotors-form.component.scss'],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class RotorsFormComponent extends NgxAutomaticRootFormComponent<RotorsState, RotorsForm>
implements NgxFormWithArrayControls<RotorsForm> {
@DataInput()
@Input('rotors')
public dataInput: RotorsState | null | undefined;
@Output('rotorsUpdate')
public dataOutput: EventEmitter<RotorsState> = new EventEmitter();
protected emitInitialValueOnInit = false;
protected getFormControls(): Controls<RotorsForm> {
return {
rotors: new FormArray([]),
};
}
protected transformToFormGroup(letters: RotorsState | null): RotorsForm {
return {
rotors: letters ? letters : [Letter.A, Letter.A, Letter.A],
};
}
protected transformFromFormGroup(formValue: RotorsForm): RotorsState | null {
return formValue.rotors;
}
protected getFormGroupControlOptions(): FormGroupOptions<RotorsForm> {
return {
validators: [
formGroup => {
if (
!formGroup.value.rotors ||
!Array.isArray(formGroup.value.rotors) ||
formGroup.value.rotors.length !== NB_ROTORS_REQUIRED
) {
return {
rotorsError: true,
};
}
return null;
},
],
};
}
public createFormArrayControl(
key: ArrayPropertyKey<RotorsForm> | undefined,
value: ArrayPropertyValue<RotorsForm>,
): FormControl {
switch (key) {
case 'rotors':
return new FormControl(value, [Validators.required, containsOnlyAlphabetLetters({ acceptSpace: false })]);
default:
return new FormControl(value);
}
}
}
```
When using `ngx-sub-form`, we are able to provide data to a parent component without having it knowing anything about the form at all. In the case above we use the `rotorsUpdate` output. Internally, we manage everything through a `formGroup`. The view is also kept simple (and type safe!):
```html
<div [formGroup]="formGroup">
<ng-container [formArrayName]="formControlNames.rotors">
<span *ngFor="let rotor of formGroupControls.rotors.controls; let index = index">
<mat-form-field>
<input matInput [placeholder]="'Rotor ' + (index + 1)" [formControl]="rotor" maxlength="1" />
</mat-form-field>
</span>
</ng-container>
</div>
```
Now, on the `rotors-initial-config` we have to retrieve the initial config from the machine and update that state when needed:
`rotors-initial-config.component.ts`
```ts
@Component({
selector: 'app-rotors-initial-config',
templateUrl: './rotors-initial-config.component.html',
styleUrls: ['./rotors-initial-config.component.scss'],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class RotorsInitialConfigComponent {
constructor(private enigmaMachineService: EnigmaMachineService) {}
public initialStateRotors$: Observable<RotorsState> = this.enigmaMachineService.initialStateRotors$;
public rotorsUpdate(rotorsConfiguration: RotorsState): void {
// [skipped] check that the config is valid
this.enigmaMachineService.setInitialRotorConfig(rotorsConfiguration);
}
}
```
The view is as simple as:
```html
<app-rotors-form
*ngIf="(initialStateRotors$ | async) as initialStateRotors"
[rotors]="initialStateRotors"
(rotorsUpdate)="rotorsUpdate($event)"
></app-rotors-form>
```
For the current state, even simpler. We just need to retrieve the current state from the machine.
`rotors-current-state.component.ts`
```ts
@Component({
selector: 'app-rotors-current-state',
templateUrl: './rotors-current-state.component.html',
styleUrls: ['./rotors-current-state.component.scss'],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class RotorsCurrentStateComponent {
constructor(private enigmaMachineService: EnigmaMachineService) {}
public currentStateRotors$: Observable<RotorsState> = this.enigmaMachineService.currentStateRotors$;
}
```
## B - Encrypt a message from the app
Now that we're able to display the rotors state, let's get started with the most important part of the app: The encryption of a message :raised_hands:!
### B1 - Logic and template
In order to keep things as minimal as possible with the examples, I've decided to remove everything from Angular Material in the following code and keep only what's important to understand the logic.
To get something that looks like the previous screenshot, we want to display for the rotors, the initial config, the current state, a text area for the text that will go through Enigma and another text area (disabled) that will show the output from Enigma.
Here's our template:
```html
<h1>Initial config</h1>
<app-rotors-initial-config></app-rotors-initial-config>
<h1>Current state</h1>
<app-rotors-current-state></app-rotors-current-state>
<textarea [formControl]="clearTextControl"></textarea>
<div *ngIf="clearTextControl.hasError('invalidMessage')">
Please only use a-z letters
</div>
<textarea disabled [value]="encryptedText$ | async"></textarea>
```
Nothing magic or complicated in the above code but let's take a look at how we're going to implement the logic now:
```ts
@Component({
selector: 'app-encrypt',
templateUrl: './encrypt.component.html',
styleUrls: ['./encrypt.component.scss'],
providers: [...DEFAULT_ENIGMA_MACHINE_PROVIDERS],
changeDetection: ChangeDetectionStrategy.OnPush,
})
export class EncryptComponent {
private initialStateRotors$: Observable<RotorsState> = this.enigmaMachineService.initialStateRotors$;
public clearTextControl: FormControl = new FormControl('', containsOnlyAlphabetLetters({ acceptSpace: true }));
private readonly clearTextValue$: Observable<string> = this.clearTextControl.valueChanges;
public encryptedText$ = combineLatest([
this.clearTextValue$.pipe(
sampleTime(10),
distinctUntilChanged(),
filter(() => this.clearTextControl.valid),
),
this.initialStateRotors$,
]).pipe(map(([text]) => this.enigmaMachineService.encryptMessage(text)));
constructor(private enigmaMachineService: EnigmaMachineService) {}
}
```
_Have you seen the line `providers: [...DEFAULT_ENIGMA_MACHINE_PROVIDERS]`? We'll get back to that in the next section!_
First thing to notice is that apart from the injected service and the `FormControl`, everything is a stream. Let's take the time to break down every properties.
Bind the observable containing the initial state of the rotors:
```ts
private initialStateRotors$: Observable<RotorsState> = this.enigmaMachineService.initialStateRotors$;
```
Create a `FormControl` to bind the value into the view and use a custom validator to make sure the letters used are valid. This will prevent us to pass invalid characters to Enigma:
```ts
public clearTextControl: FormControl = new FormControl(
'',
containsOnlyAlphabetLetters({ acceptSpace: true })
);
```
Finally, prepare an observable representing the output of Enigma for a given message. The output can vary based on 2 things:
- The input text
- The initial rotor state
```ts
public encryptedText$ = combineLatest([
this.clearTextValue$.pipe(
sampleTime(10),
distinctUntilChanged(),
filter(() => this.clearTextControl.valid)
),
this.initialStateRotors$
]).pipe(map(([text]) => this.enigmaMachineService.encryptMessage(text)));
```
So we use the `combineLatest` operator to make sure that when any of the stream is updated we encrypt the message again with the new text and/or the new initial state.
### B2 - Create an Enigma machine using dependency injection
I mentioned at the beginning of the article that we would use the dependency injection mechanism provided by Angular. I also mentioned in the previous part that we'd come back to the line defined on the component:
```ts
providers: [...DEFAULT_ENIGMA_MACHINE_PROVIDERS];
```
Now is a good time as the app is nearly ready, the last missing piece is just to create an Enigma machine. Instead of providing the service at a module level, we provide the service at a component level so that if we want to have multiple instances to work with multiple messages at the same time, we can.
Remember what the `EnigmaMachineService` takes as arguments? Here a little help:
```ts
constructor(
private enigmaRotorServices: EnigmaRotorService[],
private reflectorService: ReflectorService
)
```
In order to create an instance of the service within our `EncryptComponent` we could manually create a `ReflectorService`, manually create 3 `EnigmaRotorService` and manually create an `EnigmaMachineService` by providing as argument what we just created. Let's take a look how that'd look:
```ts
const reflectorService: ReflectorService = new ReflectorService();
const enigmaRotorService1: EnigmaRotorService = new EnigmaRotorService();
const enigmaRotorService2: EnigmaRotorService = new EnigmaRotorService();
const enigmaRotorService3: EnigmaRotorService = new EnigmaRotorService();
const enigmaMachineService: EnigmaMachineService = new EnigmaMachineService(
[enigmaRotorService1, enigmaRotorService2, enigmaRotorService3],
reflectorService,
);
```
But...
- Should that responsibility belong to the `EncryptComponent`?
- How would we be able to later test the `EncryptComponent` with mocked data for example?
- What if we want to be able to customize the rotors and reflector on a component basis?
- What if we want to be able to add or remove rotors on a component basis?
All the above would be really hard to achieve. If we use dependency injection on the other hand, it'd be quite simple. The idea being: Let someone else be in charge of creating those services while still being able to customize how we create them at the `providers` level.
So all we want in the end is to just ask Angular to give us an instance of `EnigmaMachineService` through dependency injection:
```ts
export class EncryptComponent {
// ...
constructor(private enigmaMachineService: EnigmaMachineService) {}
// ...
}
```
But hold on. How can that even work? Our `EnigmaMachineService` is a simple class and we do not have a `@Injectable()` decorator. So we can't just specify the service into the provider array and inject it through the constructor as we'd usually do. Angular DI system got us covered :ok_hand:.
Let's take a closer look at the following line:
```ts
providers: [...DEFAULT_ENIGMA_MACHINE_PROVIDERS];
```
Here's the `DEFAULT_ENIGMA_MACHINE_PROVIDERS` constant:
```ts
export const ROTORS: InjectionToken<EnigmaRotorService[]> = new InjectionToken<
EnigmaRotorService[]
>('EnigmaRotorServices');
export const getReflectorService = (reflector: string) => {
return () => new ReflectorService(reflector);
};
export const getRotorService = (rotor: string) => {
return () => new EnigmaRotorService(rotor);
};
export const getEnigmaMachineService = (
rotorServices: EnigmaRotorService[],
reflectorService: ReflectorService
) => {
return new EnigmaMachineService(rotorServices, reflectorService);
};
export const DEFAULT_ENIGMA_MACHINE_PROVIDERS: (
| Provider
| FactoryProvider)[] = [
{
provide: ROTORS,
multi: true,
useFactory: getRotorService((`ekmflgdqvzntowyhxuspaibrcj`)
},
{
provide: ROTORS,
multi: true,
useFactory: getRotorService(`ajdksiruxblhwtmcqgznpyfvoe`)
},
{
provide: ROTORS,
multi: true,
useFactory: getRotorService(`fvpjiaoyedrzxwgctkuqsbnmhl`)
},
{
provide: ReflectorService,
useFactory: getReflectorService('yruhqsldpxngokmiebfzcwvjat')
},
{
provide: EnigmaMachineService,
deps: [ROTORS, ReflectorService],
useFactory: getEnigmaMachineService
}
];
```
It's a lot to take in :scream:! Once again, let's break it down, piece by piece.
The first thing we want to do is create an [injection token](https://angular.io/api/core/InjectionToken) that will represent the array of rotors we want to use:
```ts
export const ROTORS: InjectionToken<EnigmaRotorService[]> = new InjectionToken<EnigmaRotorService[]>(
'EnigmaRotorServices',
);
```
Then, we create functions that will be used as `factories`. Which means that they will be used to create instances (in that case, instances of classes):
```ts
export const getReflectorService = (reflector: string) => {
return () => new ReflectorService(reflector);
};
export const getRotorService = (rotor: string) => {
return () => new EnigmaRotorService(rotor);
};
export const getEnigmaMachineService = (rotorServices: EnigmaRotorService[], reflectorService: ReflectorService) => {
return new EnigmaMachineService(rotorServices, reflectorService);
};
```
The reason we will need factories is because all the classes we will be creating require arguments and because we're not using the `@Injectable` decorator on those classes. So Angular cannot instantiate them magically for us, we need to do it ourselves.
After that, we create an array that will be used by the `providers` property of the component and it'll contain the services. Let's start with the creation of the 3 rotors:
```ts
[
{
provide: ROTORS,
multi: true,
useFactory: getRotorService((`ekmflgdqvzntowyhxuspaibrcj`)
},
{
provide: ROTORS,
multi: true,
useFactory: getRotorService(`ajdksiruxblhwtmcqgznpyfvoe`)
},
{
provide: ROTORS,
multi: true,
useFactory: getRotorService(`fvpjiaoyedrzxwgctkuqsbnmhl`)
},
// ...
]
```
With Angular DI system, we can either pass a service decorated with the `@Injectable` decorator or pass an object to be more specific. You can learn more about Angular's DI system here: https://angular.io/guide/dependency-injection
The interesting part in that case is that we're using the `multi` and `useFactory` properties. The above code says: "Register in the `ROTORS` token array every rotor I will give you". Instead of having `ROTORS` as a single value, thanks to the `multi: true` property it will now be an array. Then, we use the factory we've defined earlier by passing as a parameter the rotor configuration.
Then we've got the `ReflectorService` with nothing particular on that one:
```ts
[
// ...
{
provide: ReflectorService,
useFactory: getReflectorService('yruhqsldpxngokmiebfzcwvjat'),
},
// ...
];
```
And finally, the `EnigmaMachineService` that will pass to the factory some arguments: The freshly created rotors and the reflector:
```ts
// ...
{
provide: EnigmaMachineService,
deps: [ROTORS, ReflectorService],
useFactory: getEnigmaMachineService
},
// ...
```
With the `deps` property, we let Angular know that when calling the `getEnigmaMachineService` it will have to provide those dependencies.
Last but not least, I want to get your attention on the fact that the factories are returning a function in charge of creating the class and not directly an instance of the class. Why? Because it'll leverage the fact that a service needs to be created only when it's required, not before. Example: Defining a service in the `providers` array of a module won't create the service. The service will only be instantiated once a component or another service requires it.
# Conclusion
Within this blog post we've seen one possible implementation with TypeScript of a real machine used during WW2 to send secret messages. We've also seen how it's possible to properly consume a non-angular library into our Angular app thanks to the dependency injection mechanism provided by Angular.
I've had a lot of fun building the Enigma library and the Angular app and I hope had some too while reading this blog post! :smile:
I'd be delighted to see another implementation of Enigma so if you manage to build your own version let me know in the comments section :point_down:.
Next and final article of the series will be about **cracking an encrypted message from Enigma without knowing the initial rotors position FROM THE BROWSER**.
Stay tuned and thanks for reading!
# Found a typo?
If you've found a typo, a sentence that could be improved or anything else that should be updated on this blog post, you can access it through a git repository and make a pull request. Instead of posting a comment, please go directly to https://github.com/maxime1992/my-dev.to and open a new pull request with your changes. If you're interested how I manage my dev.to posts through git and CI, [read more here](https://dev.to/maxime1992/manage-your-dev-to-blog-posts-from-a-git-repo-and-use-continuous-deployment-to-auto-publish-update-them-143j).
# Follow me
| | | | | | |
| ----------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| [](https://dev.to/maxime1992) | [](https://github.com/maxime1992) | [](https://twitter.com/maxime1992) | [](https://www.reddit.com/user/maxime1992) | [](https://www.linkedin.com/in/maximerobert1992) | [](https://stackoverflow.com/users/2398593/maxime1992) |
| maxime1992 |
164,352 | Building NestJS app boilerplate - Authentication, Validation, GraphQL and Prisma | The boilerplate app created by this tutorial is here. ⚠️⚠️⚠️ Update - 06 April... | 0 | 2019-10-22T11:29:13 | https://dev.to/nikitakot/building-nestjs-app-boilerplate-authentication-validation-graphql-and-prisma-f1d | node, javascript, graphql, webdev | ---
title: Building NestJS app boilerplate - Authentication, Validation, GraphQL and Prisma
published: true
cover_image: https://thepracticaldev.s3.amazonaws.com/i/whtmfhi1tmpsq1vgblhc.jpg
description:
tags: #node, #javascript, #graphql, #webdev
---
The boilerplate app created by this tutorial is [here](https://github.com/nikitakot/nestjs-boilerplate).
# ⚠️⚠️⚠️ Update - 06 April 2020
NestJS version 7 was recently [released](https://trilon.io/blog/announcing-nestjs-7-whats-new). Many thanks to
[johnbiundo](https://dev.to/johnbiundo) who [posted](https://dev.to/johnbiundo/comment/nck1) what changes have to be done for this version update. The github repository is also updated, you can check the changes I've made [here](https://github.com/nikitakot/nestjs-boilerplate/commit/7953e674d519d48f36ebf60f332e1289044807a7).
# Intro
[NestJS](https://nestjs.com/) is a relatively new framework in the Node world. Inspired by Angular and built on top of Express with full TypeScript support, it provides a scalable and maintainable architecture to your applications. NestJS also supports [GraphQL](https://graphql.org/) - a robust query language for APIs with a dedicated, ready to use, `@nestjs/graphql` module (in fact, the module is just a wrapper around Apollo server).
In this tutorial we're going to build a boilerplate with all the basic features you will need to develop more complex applications. We will use [Prisma](https://www.prisma.io/) as a database layer since it works extremely well with GraphQL APIs allowing you to map Prisma resolver to GraphQl API resolvers easily.
By the end of this article we will create a simple blog application, which will allow users to register, log-in and create posts.
# Getting Started
### NestJS
To start playing with NestJS you should have node (version >= 8.9.0) and npm installed. You can download and install Node from the [official website](https://nodejs.org/).
After you have node and npm installed, let's install NestJS CLI and initialise a new project.
```shell
$ npm i -g @nestjs/cli
$ nest new nestjs-boilerplate
$ cd nestjs-boilerplate
```
During the installation process you will be asked what package manager you want to use (yarn or npm). In this tutorial I'll be using npm, but if you prefer yarn, go for it.
Now let's run `npm start`. It will start the application on port 3000, so opening [http://localhost:3000](http://localhost:3000) in a browser will display a "Hello World!" message.
### GraphQL
As mentioned above, we will use `@nestjs/graphql` module to setup GraphQL for our API.
```shell
$ npm i --save @nestjs/graphql apollo-server-express graphql-tools graphql
```
After the packages are installed, let's create a configuration file for our GraphQL server.
```shell
$ touch src/graphql.options.ts
```
The configuration will be passed to the underlying Apollo instance by NestJS. A more in depth documentation can be found [here](https://www.apollographql.com/docs/apollo-server/api/apollo-server/).
**src/graphql.options.ts**
```typescript
import { GqlModuleOptions, GqlOptionsFactory } from '@nestjs/graphql';
import { Injectable } from '@nestjs/common';
import { join } from 'path';
@Injectable()
export class GraphqlOptions implements GqlOptionsFactory {
createGqlOptions(): Promise<GqlModuleOptions> | GqlModuleOptions {
return {
context: ({ req, res }) => ({ req, res }),
typePaths: ['./src/*/*.graphql'], // path for gql schema files
installSubscriptionHandlers: true,
resolverValidationOptions: {
requireResolversForResolveType: false,
},
definitions: { // will generate .ts types from gql schema files
path: join(process.cwd(), 'src/graphql.schema.generated.ts'),
outputAs: 'class',
},
debug: true,
introspection: true,
playground: true,
cors: false,
};
}
}
```
Then register `GraphQLModule` and pass the configuration in application's main `AppModule` module.
**src/app.module.ts**
```typescript
import { Module } from '@nestjs/common';
import { GraphQLModule } from '@nestjs/graphql';
import { GraphqlOptions } from './graphql.options';
@Module({
imports: [
GraphQLModule.forRootAsync({
useClass: GraphqlOptions,
}),
],
controllers: [],
providers: [],
})
export class AppModule {}
```
You may have noticed I removed `AppController` and `AppService` from the main module. We don't need them since we will be using GraphQL instead of a REST api. The corresponding files can be deleted as well.
To test this setup out, let's create a simple graphql API schema.
```shell
$ mkdir src/schema
$ touch src/schema/gql-api.graphql
```
**src/schema/gql-api.graphql**
```graphql
type Author {
id: Int!
firstName: String
lastName: String
posts: [Post]
}
type Post {
id: Int!
title: String!
votes: Int
}
type Query {
author(id: Int!): Author
}
```
Running `npm start` will do two things:
- Generate `src/graphql.schema.generated.ts` with typescript types which can be used in our source code.
- Launch the server on port 3000.
We can now navigate to [http://localhost:3000/graphql](http://localhost:3000/graphql) (default GraphQL API path) to see the GraphQL Playground.
<img src="https://thepracticaldev.s3.amazonaws.com/i/gccnoc11iw8fv6gvnld2.png" alt="graphql playground" width="542"/>
### Prisma
To run Prisma we need to install [Docker](https://www.docker.com/), you can follow the installation guide [here](https://docs.docker.com/install/).
> *Linux users - you need to install [docker-compose](https://docs.docker.com/compose/install/) separately*.
We will be running two containers - one for the actual database and a second one for the prisma service.
Create a docker compose configuration file in the root project directory.
```shell
$ touch docker-compose.yml
```
And put the following configuration there.
**docker-compose.yml**
```yml
version: '3'
services:
prisma:
image: prismagraphql/prisma:1.34
ports:
- '4466:4466'
environment:
PRISMA_CONFIG: |
port: 4466
databases:
default:
connector: postgres
host: postgres
port: 5432
user: prisma
password: prisma
postgres:
image: postgres:10.3
environment:
POSTGRES_USER: prisma
POSTGRES_PASSWORD: prisma
volumes:
- postgres:/var/lib/postgresql/data
volumes:
postgres: ~
```
Run docker compose in the root directory of the project. Docker compose will download images and start containers.
```shell
$ docker-compose up -d
```
The Prisma server is now connected to the local Postgres instance and runs on port 4466. Opening [http://localhost:4466](http://localhost:4466) in a browser will open the Prisma GraphQL playground.
Now let's install the Prisma CLI and the Prisma client helper library.
```shell
$ npm install -g prisma
$ npm install --save prisma-client-lib
```
And initialise Prisma in our project root folder.
```shell
$ prisma init --endpoint http://localhost:4466
```
Prisma initialisation will create the `datamodel.prisma` and `prisma.yml` files in the root of our project. The `datamodel.prisma` file contains the database schema and `prisma.yml` contains the prisma client configurations.
Add the following code to `prisma.yml` to generate `typescript-client` so we can query our database.
**prisma.yml**
```yml
endpoint: http://localhost:4466
datamodel: datamodel.prisma
generate:
- generator: typescript-client
output: ./generated/prisma-client/
```
Then run `prisma deploy` to deploy your service. It will initialise the schema specified in `datamodel.prisma` and generate the prisma client.
```shell
$ prisma deploy
```
Go to [http://localhost:4466/_admin](http://localhost:4466/_admin) to open the prisma admin tool, a slightly more convenient way to view and edit your data compared to the graphql playground.
### Prisma Module
This step is pretty much optional as you can use the generated prisma client as it is in other modules/services etc. but making a prisma module will make it easier to configure or change something in the future.
Let's use the NestJS CLI to create a prisma module and a service. The CLI will automatically create the files boilerplate's files and do the initial module metadata setup for us.
```shell
$ nest g module prisma
$ nest g service prisma
```
Then let's setup `PrismaService`.
**src/prisma/prisma.service.ts**
```typescript
import { Injectable } from '@nestjs/common';
import { Prisma } from '../../generated/prisma-client';
@Injectable()
export class PrismaService {
client: Prisma;
constructor() {
this.client = new Prisma();
}
}
```
And export it in **src/prisma/prisma.module.ts**.
```typescript
import { Module } from '@nestjs/common';
import { PrismaService } from './prisma.service';
@Module({
providers: [PrismaService],
exports: [PrismaService],
})
export class PrismaModule {}
```
Great! We are done with the initial setup, let's now continue implementing authentication.
# Shemas
### Database schema
Let's store our boilerplate app schema in **database/datamodel.prisma**. We can also delete the old datamodel file in the root of the project with default schema.
```shell
$ rm datamodel.prisma
$ mkdir database
$ touch database/datamodel.prisma
```
**database/datamodel.prisma**
```graphql
type User {
id: ID! @id
email: String! @unique
password: String!
post: [Post!]!
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
}
type Post {
id: ID! @id
title: String!
body: String
author: User!
createdAt: DateTime! @createdAt
updatedAt: DateTime! @updatedAt
}
```
Then let's modify **prisma.yml** and define path to our new schema.
**prisma.yml**
```yml
endpoint: http://localhost:4466
datamodel:
- database/datamodel.prisma
generate:
- generator: typescript-client
output: ./generated/prisma-client/
```
After deploying the schema, the prisma client will be automatically updated and you should see appropriate changes in prisma admin [http://localhost:4466/_admin](http://localhost:4466/_admin).
```ssh
$ prisma deploy
```
### API schema
Let's put the following graphql API schema in **src/schema/gql-api.graphql**.
**src/schema/gql-api.graphql**
```graphql
type User {
id: ID!
email: String!
post: [Post!]!
createdAt: String!
updatedAt: String!
}
type Post {
id: ID!
title: String!
body: String
author: User!
}
input SignUpInput {
email: String!
password: String!
}
input LoginInput {
email: String!
password: String!
}
input PostInput {
title: String!
body: String
}
type AuthPayload {
id: ID!
email: String!
}
type Query {
post(id: ID!): Post!
posts: [Post!]!
}
type Mutation {
signup(signUpInput: SignUpInput): AuthPayload!
login(loginInput: LoginInput): AuthPayload!
createPost(postInput: PostInput): Post!
}
```
Now launch the app with `npm start` so it will generate typescript types from the schema above.
# Modules
### Auth Module
First, we need to install some additional packages to implement passport JWT in our NestJS app.
```shell
$ npm install --save @nestjs/passport passport @nestjs/jwt passport-jwt cookie-parser bcryptjs class-validator class-transformer
$ npm install @types/passport-jwt --save-dev
```
Create `AuthModule`, `AuthService`, `AuthResolver`, `JwtStrategy` and `GqlAuthGuard` files.
```shell
$ nest g module auth
$ nest g service auth
$ nest g resolver auth
$ touch src/auth/jwt.strategy.ts
$ touch src/auth/graphql-auth.guard.ts
```
**src/auth/auth.service.ts**
```typescript
import { Injectable } from '@nestjs/common';
import { PrismaService } from '../prisma/prisma.service';
import { User } from '../../generated/prisma-client';
@Injectable()
export class AuthService {
constructor(private readonly prisma: PrismaService) {}
async validate({ id }): Promise<User> {
const user = await this.prisma.client.user({ id });
if (!user) {
throw Error('Authenticate validation error');
}
return user;
}
}
```
The validate method of the auth service will check if a user id from a JWT token is persisted in the database.
**src/auth/jwt.strategy.ts**
```typescript
import { Injectable } from '@nestjs/common';
import { PassportStrategy } from '@nestjs/passport';
import { Strategy } from 'passport-jwt';
import { Request } from 'express';
import { AuthService } from './auth.service';
const cookieExtractor = (req: Request): string | null => {
let token = null;
if (req && req.cookies) {
token = req.cookies.token;
}
return token;
};
@Injectable()
export class JwtStrategy extends PassportStrategy(Strategy) {
constructor(private readonly authService: AuthService) {
super({
jwtFromRequest: cookieExtractor,
secretOrKey: process.env.JWT_SECRET,
});
}
validate(payload) {
return this.authService.validate(payload);
}
}
```
Here we define where our token should be taken from and how to validate it. We will be passing the JWT secret via environment variable so you will be launching the app with `JWT_SECRET=your_secret_here npm run start`.
To be able to parse cookies we need to define global `cookie-parser` middleware.
**src/main.ts**
```typescript
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
import * as cookieParser from 'cookie-parser';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.use(cookieParser());
await app.listen(3000);
}
bootstrap();
```
Now let's create a validation class that we will use later and put some email/password validations there.
```shell
$ touch src/auth/sign-up-input.dto.ts
```
**src/auth/sign-up-input.dto.ts**
```typescript
import { IsEmail, MinLength } from 'class-validator';
import { SignUpInput } from '../graphql.schema.generated';
export class SignUpInputDto extends SignUpInput {
@IsEmail()
readonly email: string;
@MinLength(6)
readonly password: string;
}
```
To make validation work, we need to globally define the validation pipe from `@nestjs/common` package.
**src/app.module.ts**
```typescript
import { Module, ValidationPipe } from '@nestjs/common';
import { GraphQLModule } from '@nestjs/graphql';
import { GraphqlOptions } from './graphql.options';
import { PrismaModule } from './prisma/prisma.module';
import { AuthModule } from './auth/auth.module';
import { APP_PIPE } from '@nestjs/core';
@Module({
imports: [
GraphQLModule.forRootAsync({
useClass: GraphqlOptions,
}),
PrismaModule,
AuthModule,
],
providers: [
{
provide: APP_PIPE,
useClass: ValidationPipe,
},
],
})
export class AppModule {}
```
To easily access request and user objects from the graphql context we can create decorators. More info about custom decorators can be found [here](https://docs.nestjs.com/custom-decorators).
**src/shared/decorators/decorators.ts**
```typescript
import { createParamDecorator } from '@nestjs/common';
import { Response } from 'express';
import { User } from '../../../generated/prisma-client';
export const ResGql = createParamDecorator(
(data, [root, args, ctx, info]): Response => ctx.res,
);
export const GqlUser = createParamDecorator(
(data, [root, args, ctx, info]): User => ctx.req && ctx.req.user,
);
```
**src/auth/auth.resolver.ts**
```typescript
import * as bcryptjs from 'bcryptjs';
import { Response } from 'express';
import { Args, Mutation, Resolver } from '@nestjs/graphql';
import { LoginInput } from '../graphql.schema.generated';
import { ResGql } from '../shared/decorators/decorators';
import { JwtService } from '@nestjs/jwt';
import { PrismaService } from '../prisma/prisma.service';
import { SignUpInputDto } from './sign-up-input.dto';
@Resolver('Auth')
export class AuthResolver {
constructor(
private readonly jwt: JwtService,
private readonly prisma: PrismaService,
) {}
@Mutation()
async login(
@Args('loginInput') { email, password }: LoginInput,
@ResGql() res: Response,
) {
const user = await this.prisma.client.user({ email });
if (!user) {
throw Error('Email or password incorrect');
}
const valid = await bcryptjs.compare(password, user.password);
if (!valid) {
throw Error('Email or password incorrect');
}
const jwt = this.jwt.sign({ id: user.id });
res.cookie('token', jwt, { httpOnly: true });
return user;
}
@Mutation()
async signup(
@Args('signUpInput') signUpInputDto: SignUpInputDto,
@ResGql() res: Response,
) {
const emailExists = await this.prisma.client.$exists.user({
email: signUpInputDto.email,
});
if (emailExists) {
throw Error('Email is already in use');
}
const password = await bcryptjs.hash(signUpInputDto.password, 10);
const user = await this.prisma.client.createUser({ ...signUpInputDto, password });
const jwt = this.jwt.sign({ id: user.id });
res.cookie('token', jwt, { httpOnly: true });
return user;
}
}
```
And finally the authentication logic. We are using `bcryptjs` to hash
and secure out passwords and `httpOnly` cookie to prevent XSS attacks on
the client side.
If we want to make some endpoints accessible only for signed-up users we need
to create an authentication guard and then use it as a decorator above an endpoint
definition.
**src/auth/graphql-auth.guard.ts**
```typescript
import { ExecutionContext, Injectable } from '@nestjs/common';
import { AuthGuard } from '@nestjs/passport';
import { GqlExecutionContext } from '@nestjs/graphql';
@Injectable()
export class GqlAuthGuard extends AuthGuard('jwt') {
getRequest(context: ExecutionContext) {
const ctx = GqlExecutionContext.create(context);
return ctx.getContext().req;
}
}
```
Now let's wire up everything in `AuthModule`.
```typescript
import { Module } from '@nestjs/common';
import { AuthService } from './auth.service';
import { AuthResolver } from './auth.resolver';
import { PrismaModule } from '../prisma/prisma.module';
import { PassportModule } from '@nestjs/passport';
import { JwtModule } from '@nestjs/jwt';
import { JwtStrategy } from './jwt.strategy';
@Module({
imports: [
PrismaModule,
PassportModule.register({
defaultStrategy: 'jwt',
}),
JwtModule.register({
secret: process.env.JWT_SECRET,
signOptions: {
expiresIn: 3600, // 1 hour
},
}),
],
providers: [AuthService, AuthResolver, JwtStrategy],
})
export class AuthModule {}
```
Cool, authentication is ready! Start the server and try to create a user, log-in and check cookies in a browser.
If you see `token` cookie everything works as expected.
### Post module
Let's add some basic logic to our app. Authorized users will be able
to create posts that will be readable to everyone.
```shell
$ nest g module post
$ nest g resolver post
$ touch src/post/post-input.dto.ts
```
First let's define resolvers for all `Post` fields and add a simple validation for `createPost` mutation.
**src/post/post-input.dto.ts**
```typescript
import { IsString, MaxLength, MinLength } from 'class-validator';
import { PostInput } from '../graphql.schema.generated';
export class PostInputDto extends PostInput {
@IsString()
@MinLength(10)
@MaxLength(60)
readonly title: string;
}
```
**src/post/post.resolver.ts**
```typescript
import {
Args,
Mutation,
Parent,
Query,
ResolveProperty,
Resolver,
} from '@nestjs/graphql';
import { PrismaService } from '../prisma/prisma.service';
import { Post } from '../graphql.schema.generated';
import { GqlUser } from '../shared/decorators/decorators';
import { User } from '../../generated/prisma-client';
import { UseGuards } from '@nestjs/common';
import { GqlAuthGuard } from '../auth/graphql-auth.guard';
import { PostInputDto } from './post-input.dto';
@Resolver('Post')
export class PostResolver {
constructor(private readonly prisma: PrismaService) {}
@Query()
async post(@Args('id') id: string) {
return this.prisma.client.post({ id });
}
@Query()
async posts() {
return this.prisma.client.posts();
}
@ResolveProperty()
async author(@Parent() { id }: Post) {
return this.prisma.client.post({ id }).author();
}
@Mutation()
@UseGuards(GqlAuthGuard)
async createPost(
@Args('postInput') { title, body }: PostInputDto,
@GqlUser() user: User,
) {
return this.prisma.client.createPost({
title,
body,
author: { connect: { id: user.id } },
});
}
}
```
And don't forget to define everything in the module.
**src/post/post.module.ts**
```typescript
import { Module } from '@nestjs/common';
import { PostResolver } from './post.resolver';
import { PrismaModule } from '../prisma/prisma.module';
@Module({
providers: [PostResolver],
imports: [PrismaModule],
})
export class PostModule {}
```
### User Module
Although we don't have any user mutations, we still need to define user resolvers so graphql can resolve our queries correctly.
```shell
$ nest g module user
$ nest g resolver user
```
**src/user/user.resolver.ts**
```typescript
import { Parent, ResolveProperty, Resolver } from '@nestjs/graphql';
import { PrismaService } from '../prisma/prisma.service';
import { User } from '../graphql.schema.generated';
@Resolver('User')
export class UserResolver {
constructor(private readonly prisma: PrismaService) {}
@ResolveProperty()
async post(@Parent() { id }: User) {
return this.prisma.client.user({ id }).post();
}
}
```
And of course `UserModule`.
**src/user/user.module.ts**
```typescript
import { Module } from '@nestjs/common';
import { UserResolver } from './user.resolver';
import { PrismaModule } from '../prisma/prisma.module';
@Module({
providers: [UserResolver],
imports: [PrismaModule],
})
export class UserModule {}
```
# Sample Queries
To test your application you can run these simple queries.
**Signing-up**
```graphql
mutation {
signup(signUpInput: { email: "user@email.com", password: "pasword" }) {
id
email
}
}
```
**Logging-in**
```graphql
mutation {
login(loginInput: { email: "user@email.com", password: "pasword" }) {
id
email
}
}
```
**Creating a post**
```graphql
mutation {
createPost(postInput: { title: "Post Title", body: "Post Body" }) {
id
title
author {
id
email
}
}
}
```
**Retrieving all posts**
```graphql
query {
posts {
title
author {
email
}
}
}
```
# Conclusion
We are finally done with our app boilerplate! Check nestjs documentation to add more useful features to your application. When deploying to production environment don't forget to secure your Prisma layer and database.
You can find the final code [here](https://github.com/nikitakot/nestjs-boilerplate).
| nikitakot |
164,507 | Securing your Google service account key in builds | Establishing a reliable continuous delivery and deployment process is often very important as it... | 0 | 2019-10-03T08:44:25 | https://brightinventions.pl/blog/securing-your-google-service-account-key-in-builds/ | android, programming, learning | ---
layout: post
title: Securing your Google service account key in builds
image: /images/securing-your-google-service-account-key-in-builds/padlock-597495_1920.jpg
author: azabost
crosspost: true
published: true
tags: android, programming, learning
---
Establishing a reliable continuous delivery and deployment process is often very important as it might greatly reduce the length of time needed for the validation and verification of the software product. This is also true for Android projects, especially the ones aimed at short time to market.
For me, one of the most crucial time savers is the [gradle-play-publisher](https://github.com/Triple-T/gradle-play-publisher) plugin, which allows me to publish the APKs as soon as the build is finished. However, you need the Google service account for that.
# With great power comes great responsibility #
The Google service account is an account that might be used by your applications to access all the Google APIs, including the ones for Google Play publishing ([Publishing API](https://developers.google.com/android-publisher/#publishing)). This API allows for example to:
* publish the APK (obviously)
* update the app listing (title, descriptions, images, videos, recent changes)
* change contact information (e-mail, phone number, website)
While granting this account the [required permissions](https://github.com/Triple-T/gradle-play-publisher#google-play-service-account), you cannot choose which particular apps it can access - it's either all or nothing. So if you have more than one application on your Google developer account, the service account will be able to reach them all.
Bearing this in mind, you should always protect the service account from abuse. The [documentation](https://developers.google.com/android-publisher/api_usage) also does warn you:
> We recommend not giving third parties access to any service accounts you may create. We especially recommend not giving access to any private keys for your service account. Doing so provides anonymous access to your account that can be shared with anyone.
{: .center-image}
# Automatic build deployment #
If you are going to use the Publishing API in your builds, you definitely should take the appropriate measures to keep the service account key secure. Depending on your company policies (e.g. repositories access), the size of your team, your customer needs and policies, you might consider:
* not storing the key in the repository
* storing the key in a password-protected archive in the repository
* storing the key in a separate repository
* not storing the key at all (wait, what? see the example below)
* ... etc.
# Example #
So how you can _not store the key at all_? Well, I have lied a bit. You must store it somewhere, but this example will show you how to store it as a secret value on a build server instead of a repository. This way you don't have to protect the repository itself, but the build server instead. Is it easier? It depends. But it's just one of the methods you can choose.
### Setting a secret value ###
Most of the automation servers like Jenkins or TeamCity have the ability to store a secret value, which you can use during the build. Whether it is really secure depends on the particular software you use, the build script (which may be printing the secret value to the build logs for example) and the access you give other people to the infrastructure and build configuration.
In this example, the secret value is stored on a TeamCity server and it will be available to the build in an environment variable.
{: .center-image}
### Reading the key in a build ###
There are plenty of ways you can read the environment variable during the build. This example uses a Gradle task to generate a file containing the key needed by the `gradle-play-publisher` plugin before the publication.
```groovy
apply plugin: 'com.android.application'
apply plugin: 'com.github.triplet.play'
class GenerateGooglePlayDeploymentJsonFile extends DefaultTask {
File jsonFile
@TaskAction
def generate() {
def envVar = "GOOGLE_API_JSON"
def json = System.getenv(envVar)
if (json) {
jsonFile.write(json)
} else {
logger.log(LogLevel.ERROR, "You must use $envVar for Google Play publishing")
}
}
}
android {
final googlePlayDeploymentJsonFile = new File("google_play_api.json")
task generateGooglePlayDeploymentJsonFile(type: GenerateGooglePlayDeploymentJsonFile) {
jsonFile = googlePlayDeploymentJsonFile
}
playAccountConfigs {
defaultAccountConfig {
jsonFile = googlePlayDeploymentJsonFile
}
}
play {
track = 'beta'
}
defaultConfig {
playAccountConfig = playAccountConfigs.defaultAccountConfig
// other config ...
}
buildTypes {
release {
// config ...
}
debug {
// config ...
}
}
productFlavors {
prod {
// config ...
}
dev {
// config ...
}
}
project.afterEvaluate {
project.tasks.findAll {
it.name.startsWith("generate") && it.name.endsWith("PlayResources")
}.forEach({
logger.log(LogLevel.WARN, "Configuring Google Play deployment JSON file for task: $it")
it.dependsOn generateGooglePlayDeploymentJsonFile
})
}
// other config ...
}
```
The way it works is pretty straightforward:
1. Find some tasks generated by the publishing plugin.
* The generated tasks names consist of the names of your release build variants. In this example there are: `devRelease` and `prodRelease`, which produce (among the others): `generateDevReleasePlayResources` and `generateProdReleasePlayResources`.
2. Make the generated tasks depend on the `generateGooglePlayDeploymentJsonFile` task, which expects the Google service account key (in JSON format) in the environment variable and saves it to a specified file.
3. Configure the publishing plugin to use the generated file.
Of course this simple script might be further improved and I encourage you to do it on your own.
### Publishing the app ###
The Gradle tasks used for the publication in this example are: `publishApkDevRelease` and `publishApkProdRelease`. Publishing the APKs with them is as simple as running these tasks like this:
```bash
gradle publishApkProdRelease
```
And you can see in the logs that it works:
```
[10:59:52][Step 1/1] Configuring Google Play deployment JSON file for task: task ':app:generateDevReleasePlayResources'
[10:59:52][Step 1/1] Configuring Google Play deployment JSON file for task: task ':app:generateProdReleasePlayResources'
...
[11:00:50][Step 1/1] :app:assembleProdRelease
[11:00:50][Step 1/1] :app:generateGooglePlayDeploymentJsonFile
[11:00:50][Step 1/1] :app:generateProdReleasePlayResources
[11:00:58][Step 1/1] :app:publishApkProdRelease
```
### Throw the key away ###
Now, having this process configured, you can safely delete the Google service account key file, so no one will ever abuse it (unless they somehow read it from the build server, which is your only worry now). In case your server dies and you lose the key, you can just invalidate it and generate another one in the [Google APIs Console](https://console.developers.google.com).
# Summary #
Protecting the service account key may be challenging, but it's very important and worth considering. You should assess the options you have, their pros and cons, the risks and profits. Keep in mind that any level of protection is better than no protection at all.
| brightdevs |
164,521 | 3 top habits to improve the cooperation with clients | There is always a room for improvement regarding the service that we deliver to our clients. In this... | 0 | 2019-09-20T09:55:39 | https://brightinventions.pl/blog/3-top-habits-to-improve-the-cooperation-with-clients/ | habits, cooperation, planning | ---
layout: post
title: 3 top habits to improve the cooperation with clients
tags: [habits, cooperation, planning]
comments: true
author: eliasz
hidden: false
published: true
---
There is always a room for improvement regarding the service that we deliver to our clients.
In this post I describe 3 habits that I consider really helpful in order to work effectively with clients.
# 1. Estimating
Estimates... As long as this might be a nightmare for many developers, this is still a crucial part that we need to take care of. The fear usually comes from the fact that while we are trying to do our best to etsmiate a task, the estimations often end up being not as accurate as we predict them to be and we might still be expected to deliver the work till the certain date. We need to be aware of the two sides of the coin. On the one hand, a developer wants to deliver a high quality work while taking care of unexpected tasks that come up during the development, but on the other hand, our clients need to plan their next business steps and they need these estimates. You cannot simply say "It will be ready when I'm done" as it does not bring that much value to the client. Achieving 100% accuracy in estimating complex tasks is <del>not that easy</del> an impossible activity, but how can we make this better?
### Estimate frequently
Our early estimates may be much different from the reality, however, we should expect our estimates to improve as we continue working on the project. If we want our estimates to be more accurate, we need to practice this activity. It would be a good approach to estimate your tasks even if you're not asked to. This way you can check yourself how long it takes you to implement certain things. It's really hard to estimate things right, but that should not stop us from working on improving them.
### Break complex tasks into smaller assignments
Breaking tasks into smaller assignments will not only make it easier to estimate, but it also might show you the details that are not visible at the first glance. This will allow you to warn your clients about possible problems much earlier.
### Update your estimates
We <b>must</b> be prepared that the reality will diverge from our original estimates - in the end, this is why they are called <b>estimates</b>, not commitments.
With this approach it will be much more natural to inform your clients about possible delays. Keep in mind that if you have an estimate for 2 weeks of work and after 5 days you notice that you will not make it - do not wait until the last moment to inform about that. The time that you notice the issue should be the time that you update your clients so that they can adjust their plans accordingly. You should not treat the act of updating estimations as a sign of failure - in the end these are... well... estimations!
### Update your plans
If you're close to the deadline and see that there's a risk of not having the feature ready, consider finding a subset of this feature that will allow you to solve the most critical parts of the problem. Usually having a partly implemented feature is better than having nothing at all.
# 2. Looking for alternative solutions
Our role as developers should not be limited just to the implementation of a task. Instead I'd encourage you to dig deeper into the actual problem. It's worth asking yourself a few questions before you start working on the new feature:
- What is the problem that we are going to solve by implementing this feature?
- Is it really a problem?
- Is there another solution to this problem?
"We don't have the login system in the app." - Does this app require a logged user to use its content? No? Then maybe there are more critical things to work on?
"This design of custom control for a date selection would look great in the app!" - Maybe a standard component will be a much better choice in this case and will take a few days less to implement?
Investing more work into a feature `A` means that you will not be able to invest this time into a feature `B` - in the end, maybe there are more important tasks to be done? Keep in mind that it's not only about finding faster/cheaper solutions for the problems. Sometimes it’s just the opposite - adding more work will allow us to provide a better solution that will benefit us in the long run. It's all about making your clients aware of the implementation cost and pros and cons of each solution. It may turn out that the alternative solution is a much better choice for them compared to what they initially wanted.
# 3. Frequent synchronization
If you work with clients (especially remotely), it is really important to make them aware of what happens with the time that goes into the development of their product. That's why a frequent synchronization is a key to good cooperation with your clients. If you have a CI system, make your test builds available so that your client always knows about latest changes. You don't have one? Make builds yourself, but please remember to keep your clients up to date with the progress.
You can also schedule a quick meeting with your clients and update them about your progress. As a result your clients may find out that they would like to update the initial requirements. Keep in mind that it's usually much better to do it before all work is finished - all in all it's our role to provide our clients with the software that fits their needs.
# Summary
Putting it all together, I believe that in order to work successfully with clients, you need to go a bit further than just writing a code. Constantly update your estimations and improve them, find alternative solutions to problems, provide your clients with frequent updates and treat them as a part of your team.
If you would like to read more about planning your work and working together with clients, then I really encourage you to grab [Planning Extreme Programming by Kent Beck and Martin Fowler](https://www.amazon.com/Planning-Extreme-Programming-Kent-Beck/dp/0201710919). You do not need to practice extreme programming in order to find this book useful 😉 .
| brightdevs |
192,119 | Html | For uploading a website on internet for that cause how to do it | 0 | 2019-10-21T05:34:40 | https://dev.to/the_murtazad/html-320c | For uploading a website on internet for that cause how to do it | the_murtazad | |
164,691 | 📖 Case Study: ⚙️ Reverse Engineering using Node JS 👾 | ⚠️ 🚧 Warning!! : This post is about reverse engineering Back in the old days, there used to be pirat... | 0 | 2019-11-02T19:15:07 | https://dev.to/blackmamba/case-study-reverse-engineering-using-node-js-4d7h | security, csharp, node, javascript | ⚠️ 🚧 Warning!! : This post is about reverse engineering
Back in the old days, there used to be pirated version of software/games which were available on the torrent. All these software/games came with an nfo file, which can be opened in notepad that contains instructions on how to crack the game/software, and along with that came the keygens/patch/cracks. a small application with dope music....🎼
🏁 The Intro
When you click on the patch it will do some magic and you open the software it will be licensed.
Out of curiosity, I searched for a random app with a subscription to test, which had a trial version. I am not going to disclose the software here and will be focusing only on the methods that I used to crack the software.
🧠 How the software worked
The software checks the license every-time it starts and then redirects to the application, so every-time you open the software it presents you with a login screen where you enter your credentials and it redirects to the dashboard.
🐾 Starting Point
Initially my experience with MITM Attack(Man in the Middle) came to the rescue. Basically MITM is an agent that acts as a proxy, which means all the requests and responses will pass through the agent. I used Charles Proxy which can be used as a proxy for an MITM attack.
Normal Flow: The software connects to the server directly
# 👨🔄🌐.
MITM: The software connects through the proxy and we will be tapping the request and response that the software is making.
# 👨🔄🧟🔄🌐
Imagine the green witch as Charles Proxy.
I started analyzing the requests that the app is making using Charles Proxy and found that the app is making a request to the http://domain.com/api which contained a large json about the license details, I looked for a clue and it had a json key called "days_left" so if I could change the response, I can control my subscription and use the software to set any end date.
Majority of windows applications will be running on top of .net framework and will have the helper functions in the DLL file, I was thinking a way around and found dnsspy , a tool which can show you contents of the library file. I searched for the API endpoint in the DLL files after importing them to dnsspy, and found the url in a constants file.

🗞️ Next Plan
Next steps are very easy, we have the modified json response with days_left set to 999999999 and also the API endpoint URL from the DLL file.
What next
Step 1: I wrote a simple node.js script which returned the modified response whenever the API endpoint is called.
Step 2: I changed the endpoint in the DLL to point to my script ie: http://localhost:9000
I replaced the original DLL file with the modified one!! And voila it worked!!!
💬 Connecting the dots
Some of the software's can easily be hacked by changing a few lines, for eg, if the library is having a function that returns whether the license is valid or not, then we can change it to return true always. This depends on the level of security that the developer has incorporated into the software.
🛠 Fixes that I can think of to prevent this attack
- Transport data over HTTPS (It doesn't solve this issue, but while inspecting the payload (information that is sent out by the app), the attacker won't be able to see the payload, unless he installs a remote certificate.
- Rather than relying on the json data, use some cryptographic algorithms to decrypt/encrypt the data (the attacker still has access to client code, from which he can find the decryption logic and apply it on the payload to get the value and replay the same)
- SSL Pinning to prevent the connection to other endpoints (did it during android development)
If you have any more suggestions, please let me know in the comments.
> Being truly "secure" is a myth.
Disclaimer: This is for educational purpose only
Thanks for reading!!
<a href="https://twitter.com/JP1016v1"><img alt="Twitter Follow" src="https://img.shields.io/twitter/follow/jp1016v1?style=social"> </a>
| blackmamba |
164,769 | Localizing Image Text Overlays using Cloudinary + 8base | Imagine that you're a social media intern. Please, bear with me! You're a social media intern and you... | 0 | 2019-09-07T16:34:38 | https://dev.to/sebastian_scholl/localizing-image-text-overlays-using-cloudinary-8base-ge2 | javascript, serverless, aws, graphql | Imagine that you're a social media intern. Please, bear with me! You're a social media intern and your manager, instead of including you in on strategy meetings, hands you a laundry list of image-related tasks. It includes:
1. Crop *this*.
2. Brighten *that*.
3. Overlay "New arrivals!" on the Twitter header image.
4. Resize the Facebook share card.
5. Get me coffee.
6. Translate "New arrivals!" to Russian, German, and Swahili.
...You get the point
Now, you're a smart cookie. There's no way you want to spend your day wasting away on the computer having to **MANUALLY** manipulate all these images. So, you set out to find a better way.
##⏸ Story over, for now
That scenario is no made-up story. It's real! Every day, whether at work or for personal projects, millions of images get created, edited, updated, hosted, taken down, lost, and so on. Services that help manage the chaos or streamline the process can be **incredibly** helpful.
The other day, a friend shared with me [Cloudinary's URL API](https://cloudinary.com/documentation/solution_overview?query=URL%20API&c_query=Account%20and%20API%20setup%20%E2%80%BA%20URLs%20and%20endpoints#urls_and_endpoints). Immediately, I saw it as being an answer to so many image-related inefficiencies suffered by companies and people. Very quickly, I'll mention a *why* and a *how*.
### Why
From a single image, dozens of tweaked versions might need to get created (faded, text-overlay, black-white, etc.). Each of those versions takes time to create, update, and organize.
### How
Cloudinary's URL API takes a dynamic parameter that applies transformations to the image upon retrieval. Think of it like on-demand Photoshop!
Personally, this got me excited. Notably, the *Text Overlay* transformation. After spending a little time playing with it, I wanted to see if it could be extended to incorporate localization (translation) of image text.
A working demo came out of the exercise. You can play with it [here](http://cloudycam.8base.demo.s3-website-us-east-1.amazonaws.com/), or keep reading and learn how it works!

First off, let's take a quick look at the anatomy of the URL API. A large section of parameters exists between the `upload/` and `/horse.jpg` sections. These are a list of image transformations that get executed when the image is requested. Pretty cool! Right? The documentation is [right here](https://cloudinary.com/documentation/solution_overview?query=URL%20API&c_query=Account%20and%20API%20setup%20%E2%80%BA%20URLs%20and%20endpoints#urls_and_endpoints) if you'd like to dive deeper.
```text
https://res.cloudinary.com/demo/image/upload/c_crop,g_face,ar_16:9,w_1200,h_600/e_auto_contrast/b_rgb:00000099,e_gradient_fade,y_-0.4/co_white,fl_relative,l_text:Times_100_bold_italic:I%20am%20a%20unicorn!,w_0.95/co_black,e_shadow,x_2,y_1/fl_layer_apply,g_south_west,x_20,y_25/dpr_auto,q_auto,f_auto/horse.jpg
```
Now, the image you see below gets rendered using the link above. Moreover, - this is the crucial part - if you change the transformation, a brand new image gets returned!

The `l_text:Times_100_bold_italic:I%20am%20a%20unicorn!` is easily visible when inspecting the URL. While we can't add a custom transformation tags (that is, on Cloudinary's side), we do have the ability to apply transformations to the URL. Meaning that, in the case of localizing our image overlays, we can coerce the URL before requesting the image.
A serverless GraphQL resolver function can get deployed to an [8base workspace](https://8base.com) to accomplish this. It can handle the parsing of the URL and translation. There are many ways to deploy a serverless function. However, [8base](https://8base.com) made it super simple and straight forward.
As a quick specification, let's design the function to behave as follows.
1. If a `local_[2-char-lang-code]` tag precedes the text, translate the text, and update the URL.
2. If a local code does not precede the text, return the original URL.
## Enough talk, let's do it
##### 1. Create a new 8base project
*If you have an existing projected, you can always add a new function to it.*
```sh
# Install the CLI globally
npm install -g 8base-cli
# Initialize a new project with a GraphQL resolver called "localizer."
8base init my-project --functions="resolver:localizer"
```
These commands create a new project with all the files and code we need to start invoking our GraphQL resolver function. We'll need to make a few changes though before it's translating our Cloudinary URL's 😉
##### 2. Update the resolver's `graphql.schema`
Open up the file at `src/resolvers/localizer/schema.graphql`. We need to define our query operation and response. In this case, we'll be returning an object with the updated `url` after having received the `cloudinaryUrl`. Update the file with the following snippet.
```javascript
type LocalizeResult {
url: String!
}
extend type Query {
localize(cloudinaryUrl: String!): LocalizeResult
}
```
##### 3. Update the mock for `invoke-local`
Update `src/resolvers/localizer/mocks/request.json` so that the function can get invoked locally with data. The mock file generated has the same schema as what gets passed to the function in production.
```json
{
"data": {
"cloudinaryUrl": "https://res.cloudinary.com/cdemo/image/upload/c_crop,g_face,ar_16:9,w_1200,h_600/e_auto_contrast/b_rgb:00000099,e_gradient_fade,y_-0.4/co_white,fl_relative,l_text:Times_100_bold_italic:local_es:Breaking%20news:%208base%20solves%20all%20your%20image%20related%20needs!,w_0.95/co_black,e_shadow,x_2,y_1/fl_layer_apply,g_south_west,x_20,y_25/dpr_auto,q_auto,f_auto/dosh1/img-0.jpg"
},
"headers": {
"x-header-1": "header value"
},
"body": "{\"cloudinaryUrl\":\"https://res.cloudinary.com/cdemo/image/upload/c_crop,g_face,ar_16:9,w_1200,h_600/e_auto_contrast/b_rgb:00000099,e_gradient_fade,y_-0.4/co_white,fl_relative,l_text:Times_100_bold_italic:local_es:Breaking%20news:%208base%20solves%20all%20your%20image%20related%20needs!,w_0.95/co_black,e_shadow,x_2,y_1/fl_layer_apply,g_south_west,x_20,y_25/dpr_auto,q_auto,f_auto/dosh1/img-0.jpg\"}"
}
```
##### 4. The function
We're going to need a translation engine. I chose AWS Translate, which offers 2-million free characters per month. Let's add the required library and config to the project.
```sh
# Install AWS SDK
npm install --save aws-sdk
```
Update `src/resolvers/localizer/handler.ts`
```javascript
const AWS = require('aws-sdk');
AWS.config.update({
region: 'us-east-1',
credentials: {
accessKeyId: process.env.AWS_IAM_SECRET_KEY,
secretAccessKey: process.env.AWS_IAM_ACCESS_KEY
}
});
const translate = new AWS.Translate({ apiVersion: '2017-07-01' });
/* Other code ... */
```
When developing locally, you'll need to set your AWS credentials as environment variables or static values. The example you see above is what works when the function gets deployed to 8base. Here's the documentation on accessing [8base environment variables](https://docs.8base.com/development-tools/dev-env/runtime_environment#environment-variables).
Since we're using TypeScript, the function response needs a `type`. This type **must** match the structure and name of that added to the `graphql.schema` file. For our scenario, prepend the following to the function body.
```javascript
type LocalizeResult = {
data: {
url: string
}
};
```
The function body is pretty self-explanatory. Instead of describing it *here* and then showing it *there*, please read the inline comments for clarification on what's happening.
```javascript
export default async (event: any, ctx: any) : Promise<LocalizeResult> => {
/**
* Regex Statement for matching our custom local_tag and preceeding text
*/
const REG_EX = /(local_[a-z]{2})\:(.*?)([,\/])/g
/**
* Pull the given cloudinary url from our function arguments
*/
let url = event.data.cloudinaryUrl
/**
* Execute our Regex statement returning a match object
*/
const matchObj = REG_EX.exec(url);
/**
* If a local tag is matched, we're in business! If not,
* we're simply returning the passed url.
*/
if (matchObj) {
/**
* Pull out the matched local and text values from
* the matchObj array.
*/
let local = matchObj[1], text = matchObj[2];
try {
/**
* Make the request to AWS Translate after decoding the given text
* and slicing the last two characters from the local tag (e.g. local_es)
*/
let request = translate.translateText({
TargetLanguageCode: local.slice(-2),
SourceLanguageCode: 'auto',
Text: decodeURI(text)
}).promise();
let data = await request;
/**
* The ACTUAL cloudinary url will break if it has our custom tag. Plus, we
* need to update the text with the translation! So, let's replace the previously
* matched locale and text with our tranlsated text, that needs to be escaped.
*/
url = url.replace(`${local}:${text}`, data.TranslatedText.replace(/[.,%\`\s]/g,'%20'))
}
catch (err) {
console.log(err, err.stack);
}
}
/**
* Return the final result.
*/
return {
data: {
url
}
}
};
```
##### 5. Run it!
Done! Let's prove it by invoking our function locally. The returned URL's text section translates to the locale specified language! Copy the link and throw it in a browser to see the magic.
```sh
8base invoke-local localize -p src/resolvers/localize/mocks/request.json
invoking...
Result:
{
"data": {
"localize": {
"url": "https://res.cloudinary.com/demo/image/upload/c_crop,g_face,ar_16:9,w_1200,h_600/e_auto_contrast/b_rgb:00000099,e_gradient_fade,y_-0.4/co_white,fl_relative,l_text:Times_100_bold_italic:¡Soy%20un%20unicornio%20genial!,w_0.95/co_black,e_shadow,x_2,y_1/fl_layer_apply,g_south_west,x_20,y_25/dpr_auto,q_auto,f_auto/horse.jpg"
}
}
}
```

##🏁 Wrap up
Sorry, we're going back to storytime. Remember back when you were a social media intern? Well, you ended up finding and using Cloudinary for all your on-the-fly image transformation and 8base for lightening fast serverless deployment of serverless GraphQL functions.
Excited by the chance to become "Employee of the Month", you approach your boss and share with him the big news by saying:
>"I was able to apply dynamic URL transformations to our images using a URL API and extend its functionality to support real-time translations of text overlay!"
Seemingly confused, your manager looks at your hands and responds:
>"You forgot my coffee?"
*[Cloudinary](https://cloudinary.com) and [8base](https://8base.com) both do A LOT more than what is in this post. I highly recommend you check them out!* | sebastian_scholl |
165,074 | Slow down to code faster | The more I code and the more I tend to slow down. And curiously enough, this makes me code faster and... | 0 | 2019-09-03T17:35:56 | https://dev.to/lcoenen/slow-down-to-code-faster-3cj | codequality, mentalhealth | The more I code and the more I tend to slow down. And curiously enough, this makes me code faster and be more productive.
As an autodidact with an almost ADD-ish personality, I was inclined to use the backspace a lot. Test something, see the error, fix it, repeat. Then, there was always this moment in which I was getting stuck, and my frustration grows accordingly. As I was getting more and more into the [tunnel effect](https://en.wikipedia.org/wiki/Tunnel_effect), I was often trying to test a hundreds solutions in a few minutes, only to give up quickly and try something else. Then, my only way out was literally to go for a walk, only to come back at my work when I was relaxed and realize that the solution was simple as that.

I wouldn't be the first or the last person suffering from this. As I moved from university to a career in tech, I had to adapt. Here is a few things that helped me to structure my practice and become a better coder:
Pomodoro technique
------------------
The human brain (or at least mine) can only focus on something for half an hour. The [pomodoro technique](https://francescocirillo.com/pages/pomodoro-technique) is a time-management methodology based on that fact. The idea is quite simple - a pomodoro is an unit of work, typically consisting of 25 minutes iterations and a 5 minutes break. If you loose focus during your pomodoro, you're supposed to cancel it and start over. Not going to lie, when I'm passionated by a project, the opposite tends to happen to me - I tends to overlook the pauses and end up depleted. Nevertheless, one of my main advantage is that you can link it to your project management, and focus on the task at hand. For example, why not using [Taiga](https://taiga.io/) story points to estimate the time a specific task will take?
Coding logs
-----------
One of the main reason I went for an university master in psychology instead of doing like the rest of my high-school class and starting a bachelor in comp.sci is the kindergarden-schooling style there. They had assignments, couldn't talk during class, mandatory presence, and so on. But worst, they *had written. coding. exams*. They had to implement algorithms with a good ol' pen and paper. No way I was doing that.
But when I knew I wanted to code for a leaving, I realised how wrong I was. When placed in front of a problem bigger than my immediate attention span, I was lost. The solution? *A good ol' pen and paper*. I started doing a *programming log*. Everytime I was stuck, instead of trying the same thing different way, I started adopting a diagnostic approach. *What is the issue?*. *Where could it come from?*. *How can I test that?*. *Let's test it*. *Does it fix the issue?*. *What else could be the problem?*... and so on. By documenting everything I'm trying, I kept myself focused on the problem at hand and could be way more systematic - and in fine, way faster in fixing in the issue.

Slow down and stop touching this god'damn backspace
---------------------------------------------------

That's right. One of the things that I constantly have to reminds myself to do, and is a priceless help to me, is simply to *slow down*. Take the time to breathe before you push enter or click. Re-check the name of your variables twice before writing your code. Look at your whole screen, take one second before you type a word. This is dramatically improving my error rate. This is decreasing the time I spend looking for a typo, asking myself where the hell did I forgot something. And *in fine*, this will make you more productive.
| lcoenen |
165,204 | Common .NET Gotchas | .NET Development and C# in particular have come a long way over the years. I've been using it since... | 2,095 | 2019-09-05T03:05:07 | https://dev.to/integerman/common-net-gotchas-6nd | dotnet, csharp, beginners | .NET Development and C# in particular have come a long way over the years. I've been using it since beta 2 in 2001 and I love it, but there are some common gotchas that are easy to make when you're just getting started.
# Exceptions
## Throwing Exception
If you need to throw an Exception, don't do the following:
```cs
throw new Exception("Customer cannot be null");
```
Instead do something more targeted to your exception case:
```cs
throw new ArgumentNullException(nameof(customer), "Customer cannot be null");
```
The reason why this is important is explained in the next section.
## Catching Exception
When a generic `Exception` instance is thrown and you want to be able to handle that, you're forced to do something like the following:
```cs
try {
DoSomethingRisky();
} catch (Exception ex) {
if (ex.Message == "Customer cannot be null") {
// Some specific logic goes here
} else {
// Another handler or rethrow
}
}
```
Catching Exception catches all forms of Exceptions and is rarely ever what you actually should do. Instead, you should be looking for a few targeted types of exceptions that you expect based on what you're calling and should have handlers for those, letting more unexpected exceptions bubble up.
```cs
try {
DoSomethingRisky();
} catch (ArgumentNullException ex) {
// Some specific logic goes here
}
```
## Rethrowing Exceptions
When catching an exception, you sometimes want to rethrow it - particularly if it doesn't match a specific criteria. The syntax for correctly rethrowing an exception is different than you'd expect since it's different than originally throwing an exception.
Instead of:
```cs
try {
DoSomethingRisky();
} catch (InvalidOperationException ex) {
if (ex.Message.StartsWith("Cannot access the")) {
// Some specialized handling logic
} else {
throw ex; // We don't have a specific solution for this. Rethrow it
}
}
```
Do:
```cs
try {
DoSomethingRisky();
} catch (InvalidOperationException ex) {
if (ex.Message.StartsWith("Cannot access the")) {
// Some specialized handling logic
} else {
throw; // The ex is implicit
}
}
```
The reason you need to do this is because of how .NET stack traces work. You want to retain the original stack trace instead of making the exception look like a new exception in the catch block. If you are instead using `throw ex` (or similar) you'll miss some of the original context of the exception.
# Design
## Working with Immutable Types
Some types, like `DateTime` are said to be immutable, in that you can create one, but you cannot change it after creation. These classes expose methods that allow you to perform operations that create a new instance based on their own data, but these methods do not alter the object they are invoked on and this can be misleading.
For example, with a DateTime, if you were trying to advance a tracking variable by a day, you would **not** do this:
```cs
myMeeting.Date.AddDays(1);
```
This statement would execute and run without error, but the value of `myMeeting.Date` would remain what it originally was since `AddDays` returns the new value instead of modifying the existing object.
To change myMeeting.Date, you would instead do the following:
```cs
myMeeting.Date = myMeeting.Date.AddDays(1);
```
## TimeSpan Properties
Speaking of Dates, TimeSpan exposes some interesting properties that might be misleading. For example, if you looked at a TimeSpan, you might be tempted to look at the milliseconds to see how long something took, but if it took a second or longer, you're only going to get the milliseconds component for display purposes, not the total milliseconds.
Don't do this:
```cs
TimeSpan result = myStopWatch.Elapsed;
Console.Debug("The operation took " + result.Milliseconds + " ms");
```
Instead, use the `TotalX` series of methods like this:
```cs
TimeSpan result = myStopWatch.Elapsed;
Console.Debug("The operation took " + result.TotalMilliseconds + " ms");
```
## Double Comparison
When comparing doubles, it's easy to think that you could just do:
```cs
bool areEqual = myDouble == myOtherDouble;
```
But due to the sensitivity of double mathematics, those numbers could be slightly off when dealing with fractions.
Instead, either use the `decimal` class or compare that the numbers are extremely close by using an Epsilon:
```cs
bool areEqual = Math.Abs(myDouble - myOtherDouble) < Double.Epsilon;
```
Frankly, I tend to steer away from `double` in favor of `decimal` to avoid syntax like this.
# Misc
## String Appending
When working with strings, it can be performance intensive to do a large amount of string appending logic, since new strings need to be created for each combination encountered along the way, leading to higher frequencies of garbage collection and noticeable performance spikes.
If you're in a scenario where you expect to append to a string more than 3 times on average, you should instead use a `StringBuilder` which does techno ninja voo doo trickery internally to optimize the memory overhead for building a string from smaller strings.
Instead of:
```cs
string numbers = "";
for (int i = 0; i < 1000; i++) {
numbers += i;
}
return numbers;
```
Do:
```cs
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {
sb.Append(i);
}
return sb.ToString(); // Actually builds the final string
```
## Using Statements
When working with `IDisposable` instances, it's important to make sure that `Dispose` is properly called - including in cases when exceptions are encountered. Failing to dispose something like a `SqlConnection` can lead to instances where databases do not have available connections for new requests, which brings production servers to a sudden halt.
Instead of:
```cs
var conn = new SqlConnection(dbConnStr);
conn.Open();
// Do some things that could throw errors
conn.Close();
```
do this:
```cs
using (var conn = new SqlConnection(dbConnStr)) {
conn.Open();
// Do some things that could throw errors
} // Note that IDisposable will take care of closing the connection if active
```
This is the equivalent of a `try` / `finally` that calls `Dispose()` on `conn` if `conn` is not null. Note also that database adapters will close connections as part of their `IDisposable` implementation.
Overall using leads to cleaner and safer code.
## Async Void
When you declare an asynchronous method that doesn't return anything, syntactically it's tempting to declare it as follows:
```cs
public async void SendEmailAsync(EmailInfo email) { /* ... */ }
```
However, if an exception occurs, the information will not correctly propagate to the caller due to how the threading logic works under the cover. This means that any `try` / `catch` logic in the caller won't work the way you expect and you'll have buggy exception handling behavior.
Instead do this:
```cs
public async Task SendEmailAsync(EmailInfo email) { /* ... */ }
```
The `Task` return type allows .NET to send exception information back to the caller as you would normally expect.
## Preprocessor Statements
Preprocessor statements are just plain old bad. To those unfamiliar, a preprocessor statement allows you to do actions prior to compilation based things defined or not defined in your build options.
```cs
bool allowClipboardUse = true;
#if SILVERLIGHT
allowClipboardUse = false; // Browser security is fun
// Also, probably weeping and switching to Angular
#end if
```
The correct use of preprocessor statements is for environment-specific things, such as using a library for x64 architecture instead of another one for x86 architecture, or including some logic for mobile applications but not for other applications sharing the same code.
The problem is that people take this capability and try to bake in customer-specific logic, effectively fragmenting the code for allowing it to compile targeting different targets, but by which set of logical rules or UI styling is desired.
This becomes hard to maintain and hard to test and does not scale well. It also makes it easy to introduce errors while refactoring and overall will slow your team's velocity over time.
Some people advocate for using the `DEBUG` preprocessor definition to allow for testing logic on local development copies, but be very careful with this. I once encountered a production bug related to deserialization where the development version worked fine every time because it had a property setter defined in a `DEBUG` preprocessor statement, but deserialization failed in production for that field leading to buggy behavior.
Again, be very careful and lean towards object-oriented patterns like the Strategy or Command pattern for client-specific logic or other types of behavioral logic.
## Deserialization
Speaking of deserialization, be mindful of private variables, properties without setters, and logic that exists in property setters or getters. Different serialization / deserialization libraries approach things differently, but these areas tend to introduce obscure bugs where properties will not populate correctly during deserialization.
---
These are a few of the common .NET mistakes I see people encounter. What others are there out there that I neglected to mention? | integerman |
165,714 | Create and Deploy Azure Functions with Serverless | This article is part of #ServerlessSeptember. You'll find other helpful articles, detailed tutorials... | 0 | 2019-09-24T23:04:19 | https://dev.to/mydiemho/create-and-deploy-azure-functions-with-serverless-20ai | serverless, webdev, tutorial, node | > This article is part of [#ServerlessSeptember](https://dev.to/azure/serverless-september-content-collection-2fhb). You'll find other helpful articles, detailed tutorials, and videos in this all-things-Serverless content collection. New articles are published every day — that's right, every day — from community members and cloud advocates in the month of September.
> Find out more about how Microsoft Azure enables your Serverless functions at [https://docs.microsoft.com/azure/azure-functions/](https://docs.microsoft.com/azure/azure-functions/?WT.mc_id=servsept_devto-blog-cxa).
# Overview
Previously, the most common way to create Azure Functions is through the [portal](https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-first-azure-function) or using [azure-cli](https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-first-azure-function-azure-cli).
When using either of these tools to create and deploy Azure Functions, you have to first manually deploy the dependent resources
* Resource group
* Storage account
* App service plan
You also have to write your own bindings and put them in a specific location for functions to work <sup>[1](https://docs.microsoft.com/en-us/azure/azure-functions/functions-reference-node#folder-structure)</sup>. For example, if you have a `hello` http-trigger function, you will need a `hello/function.json` file with the following content
```json
# hello/function.json
{
"disabled": false,
"bindings": [
{
"type": "httpTrigger",
"direction": "in",
"name": "req",
"authLevel": "anonymous"
},
{
"type": "http",
"direction": "out",
"name": "res"
}
],
"entryPoint": "sayHello",
"scriptFile": "../src/handlers/hello.js"
}
```
Fortunately, there's a much simpler way to do this. The [serverless-azure-functions plugin](https://github.com/serverless/serverless-azure-functions/blob/master/CHANGELOG.md) allows you to quickly create and deploy function without all the overhead work.
> Currently, the plugin only supports node, support for other languages are coming.
---
## Pre-requisites
### Node.js
Serverless is a Node.js CLI tool so you'll need to [install Node.js](https://nodejs.org/en/download/package-manager/) on your machine.
### Serverless
Make sure [Serverless](https://github.com/serverless/serverless) is installed and you're on at least `1.53`
```bash
npm i -g serverless
```
```bash
➜ sls -v
Framework Core: 1.53.0
Plugin: 3.1.0
SDK: 2.1.1
Components Core: 1.0.0
Components CLI: 1.2.3
```
Once installed, the Serverless CLI can be call with `serverless` or
the shorthand `sls` command.
```bash
$ sls -h
Commands
* You can run commands with "serverless" or the shortcut "sls"
* Pass "--verbose" to this command to get in-depth plugin info
* Pass "--no-color" to disable CLI colors
* Pass "--help" after any <command> for contextual help
```
---
## Create function
### Command
Using the `create` command we can specify one of the available [templates](https://serverless.com/framework/docs/providers/azure/cli-reference/create#available-templates). For this example we use `azure-nodejs` with the `--template` or shorthand `-t` flag.
The `--path` or shorthand `-p` is the location to be created with the template service files.
```bash
sls create --template azure-nodejs --path $(whoami)-sample-app
```
### Output
The command above created a new directory, in my case `myho-sample-app`, with the following contents.
```text
├── src
| ├── handlers
| ├── goodbye.js
| ├── hello.js
| ├── .gitignore
| ├── host.json
| ├── package.json
| ├── README.md
| ├── serverless.yml
```
### Note
Azure plugin uses a combination of:
- prefix, if provided
- service name
- region
- stage
to generate resource names on deployment. Since resource name have to be unique in Azure, adding `$(whoami)` will append your username to
the service name, thus creating a unique name.
---
## Install Azure Plugin
The previous step created a new directory `<YOUR-USER-NAME>-sample-app` where all the function related code are stored. `cd` into that directory
Run
```bash
npm install
```
---
## Testing locally
> You can skip this section if you do not want to test your functions locally before deploy.
The sample app created from template contains 2 functions: hello and goodbye. You can test them locally before deploying to Azure.
You'll need to use 2 terminal windows for the following.
### Terminal 1
```bash
sls offline
```
While this process is running, you'll notice that some new files have been added. These files are necessary for Azure function to operate but will be clean up when the process exit.
### Terminal 2
```bash
sls invoke local -f hello -d '{"name": "Azure"}'
```
In your terminal window you should see the following response
```bash
$ Serverless: URL for invocation: http://localhost:7071/api/hello?name%3DAzure
$ Serverless: Invoking function hello with GET request
$ Serverless: "Hello Azure"
```
---
## Deploy to Azure
Once you're happy with your code, the next step is to deploy to Azure.
### Azure subscription
If you don't have an Azure account, get started by [signing up for a free account](https://azure.microsoft.com/en-us/free/), which includes $200 of free credit
### Set up credentials
Before you can deploy, you'll have to set up a `service principal`.
#### Azure-cli
Make sure you have [azure-cli](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest) installed
#### Log in
```bash
az login
az account list # list all subscriptions
az account set --subscription <SUBSCRIPTION_ID> # choose the one you want
```
#### Generate service principals
Download this [script](https://raw.githubusercontent.com/serverless/serverless-azure-functions/master/scripts/generate-service-principal.sh), run it, and follow the printed instruction.
The script will generate, extract, and write the required credentials to a file that you can then export as environment variables.
```bash
# Download the file and name it `sp.sh`
curl https://raw.githubusercontent.com/serverless/serverless-azure-functions/master/scripts/generate-service-principal.sh -o sp.sh
# skip this if you're on windows
chmod +x sp.sh
# run the script
./sp.sh
```
### Deploy
Deploying to Azure is as simple as running the following command
```bash
# if you want more logging info, uncomment the next line
# export SLS_DEBUG=*
sls deploy
```
#### Behind the scene
1. The plugin created an arm template that is used to deploy all the dependent resources
* Resource group
* App service plan
* Storage account
1. Once the infrastructure is up and running, the zipped source code is deployed to the function app
```bash
➜ sls deploy
Serverless: Parsing Azure Functions Bindings.json...
Serverless: Building binding for function: hello event: httpTrigger
Serverless: Parsing Azure Functions Bindings.json...
Serverless: Building binding for function: goodbye event: httpTrigger
Serverless: Packaging service...
...
Serverless: -> Deploying ARM template...
...
Serverless: -> ARM deployment complete
Serverless: Deploying serverless functions...
Serverless: Deploying zip file to function app: sls-wus-dev-myho-sample-app
Serverless: -> Deploying service package @ /Users/myho/dev/work/github.com/mydiemho/azure-utils/myho-sample-app/.serverless/myho-sample-app.zip
...
Serverless: Deployed serverless functions:
Serverless: -> goodbye: [GET] sls-wus-dev-myho-sample-app.azurewebsites.net/api/goodbye
Serverless: -> hello: [GET] sls-wus-dev-myho-sample-app.azurewebsites.net/api/hello
```
### Test deployed functions
You can test the deployed functions by going directly to the url, or using the `invoke` command.
```bash
sls invoke -f hello -d '{"name": "Azure"}'
```
---
## Wrap up
Congratulation! You have created and deployed your first Azure function with Serverless.
---
## Next step
There are a lot more you can do with Serverless than just Http-trigger functions.
### [API Management](https://docs.microsoft.com/en-us/azure/api-management/)
You can add APIM to your functions by configure the `apim` section in `serverless.yml`. The generated file already included this, just uncommented the section (line 33-59) and redeploy to give it a try.
1. APIM Configuration
```yaml
# serverless.yml
apim:
apis:
- name: v1
subscriptionRequired: false # if true must provide an api key
displayName: v1
description: V1 sample app APIs
protocols:
- https
path: v1
tags:
- tag1
- tag2
authorization: none
cors:
allowCredentials: false
allowedOrigins:
- "*"
allowedMethods:
- GET
- POST
- PUT
- DELETE
- PATCH
allowedHeaders:
- "*"
exposeHeaders:
- "*"
```
1 . Deploy Output
```bash
➜ sls deploy
...
Serverless: Starting APIM service deployment
Serverless: -> Deploying API keys
Serverless: -> Deploying API: v1
Serverless: -> Deploying API Backend: myho-sample-app-backend => https://sls-wus-dev-myho-sample-app.azurewebsites.net/api
Serverless: -> Deploying CORS policy: v1
Serverless: -> Deploying API Operations: sls-wus-dev-797b03-apim
Serverless: --> GET-hello: [GET] https://sls-wus-dev-797b03-apim.azure-api.net/v1/hello
Serverless: --> GET-goodbye: [GET] https://sls-wus-dev-797b03-apim.azure-api.net/v1/goodbye
Serverless: Finished APIM service deployment
```
> You will not be able to use the `invoke` command to test the APIM set up
### Additional Triggers
In addition to http-trigger functions, the following triggers are also supported
1. Storage Blob
1. Storage Queue
1. Timer
1. Service Bus Queue
1. Service Bus Topic
1. EventHubs
For more information, see the [official doc](https://serverless.com/framework/docs/providers/azure/events/)
---
## More hands-on training
If you get this far and want to learn more about serverless on Azure, Microsoft is hosting a free workshop in NYC before [ServerlessConf](https://serverlessconf.io/) on Monday, Oct 7, 2019. Registration is @ http://aka.ms/nycworkshop
There may or may not be 🍦🍦🍦🍦🍦
| mydiemho |
189,035 | Recyclerview basics (Part 1): Introduction | The Recyclerview is the replacement of the Listview with a simpler API, better performance and a co... | 0 | 2019-10-15T13:55:19 | https://dev.to/raulmonteroc/recyclerview-basics-part-1-introduction-3225 | android, kotlin | ---
title: Recyclerview basics (Part 1): Introduction
published: true
date: 2019-03-14 14:00:10 UTC
tags: Android,Kotlin,android
canonical_url:
---

The Recyclerview is the replacement of the Listview with a simpler API, better performance and a couple of new nice extra features. If you don’t know what a ListView is, don’t worry, you won’t need to in order to understand the recyclerview, simply think of it as a UI component used to represent related items in a list with scrolling capabilities.
## Components of a Recyclerview
The Recyclerview is mainly used to list related elements together, however, the way you do it can be dramatically customized to make your users have a unique experience in your app. Things such as determine how the elements are arranged together, enable custom views per element, respond to touch gestures, among other options, are available for you.
These options are not directly accessible from the Recyclerview object itself, instead, a group of related objects is used for each specific configuration, allowing for cleaner code and reusability.
Along the course of series we will be working with the most relevant components of the Recyclerview but for now, I’ll leave a little description as a tease to what we will working with next, here they are:
#### ViewHolder
The view holder object is a static representation of an element inside the Recyclerview, accessible from kotlin or java code. The main responsibility of the ViewHolder is to display each element with bound data from the adapter object.
#### Adapter
The Recyclerview doesn’t work with the data directly, it is only responsible for displaying it on the screen. The data management is done via an **adapter** object which in turn uses ViewHolder objects as containers for each element’s data. The adapter is tasked with three things:
- Serve as an Intermediary between the model data and the Recyclerview object.
- Bind the provided data to each ViewHolder object.
- Determine which XML layout should be used to load the ViewHolders.
#### LayoutManager
The Recyclerview is in charge of the display of the elements of the list but _the way_ it does that is delegated to a **LayoutManager** object. Android provides a few layout managers built-in such as the `LinearLayoutManager` and `GridLayoutManager` but you can also provide your own if you want a more tailored experience for your Recyclerview.
#### ItemTouchHelper
Once we have our adapter setup and our layout manager selected, we can enable our Recyclerview to respond to touch gestures such as dragging elements or swiping to the side. For these purposes, we use the **ItemTouchHelper** object.
## Next Step
Now that we have a rough understanding of what a Recyclerview is, what the components are and what they can do, we are ready to start a small coding adventure.
On the following post, we will be working with the Recyclerview’s ViewHolder & Adapter components to create a simple list of elements to put all this theory into action. | raulmonteroc |
165,724 | Cybersecurity becoming the toughest challenge for the SMBs | It is estimated that within 2021 the damages due to cyber-attacks will rise more than 6 million. The... | 0 | 2019-09-04T05:16:21 | https://dev.to/helicalinc/cybersecurity-becoming-the-toughest-challenge-for-the-smbs-433n | cybersecurity, challenge, da | It is estimated that within 2021 the damages due to cyber-attacks will rise more than 6 million. The number of data breach incidents is becomming increased. Hackers are finding out new ways every day to hack the systems. It's really alarming for SMBs. Like the giant firms, SMBs are vulnerable to this type of data breach. But the giant firms are having lots of back up to cope with the situation which an SMB can't. But the good news is, the software like helical and alienvalut are designed for the SMBs to smartly manage their cybersecurity program.
For more details visit: https://www.helical-inc.com/ | helicalinc |
165,765 | How to Secure Your Mobile App | $ 3,9 million — is the average cost of a data breach in 2019. The ‘average’ means that the costs... | 0 | 2019-09-04T08:50:20 | https://dev.to/scand/how-to-secure-your-mobile-app-38j5 | security, mobiledev | [$ 3,9 million — is the average cost](https://www.ibm.com/security/data-breach) of a data breach in 2019. The ‘average’ means that the costs might differ depending on the country (the most expensive is in the USA), on the industry (the most expensive is healthcare), and a particular case. In addition to significant expenses, a data breach may ruin the company’s reputation. The society is frustrated a lot with the security of sensitive data, so losing people’s personal information may result in a substantial decrease in the number of users.
Not to put the company at such a risk, the security should be a top priority task during the whole process of the application development: from design and architecture to support and maintenance.
##What type of app should it be?
Among the 3 types of applications — native, web, hybrid — the first one is the most secure. It is [simpler to enhance security of native mobile apps](https://scand.com/company/blog/native-app-vs-hybrid-app/): they have easier access to the existing security features of a particular device (like TouchID or FaceID) as well as the implementation of multi-factor authentication.
From the users’ perspective, there is one more argument towards the native apps — the quality and security requirements of the app stores. So, if the application is available on the store, it has already passed all security checks and was approved.

##5 tips on enhancing the mobile app security
Even though native mobile apps are considered to be the safest, it does not mean they are safe by definition. They just provide more opportunities and tools to enhance their security simpler and faster. But still, a lot has to be done to develop a secure application. And here are some tips on what to consider when developing a safe mobile app.
###1. Write secure code and test it properly
This one might be obvious but [as practice shows](https://www.ptsecurity.com/ww-en/analytics/mobile-application-security-threats-and-vulnerabilities-2019/), it is never superfluous to remind common-know things: the weaknesses of the security mechanisms cause more than half of all mobile apps’ vulnerabilities. Most of them could be prevented at the design stage if all the procedures were done properly. Being revealed too late, these vulnerabilities require a lot of changes to the code (= time and money).
The advice here is not to rush, take time for thoughtful planning, and pay much attention to the code. One more thing to consider is accurate and regular testing with rapid fixes of all the detected bugs.
###2. Encrypt the data
Even if the security mechanisms fail their job and an attacker turns out to be too smart and skilled, the [encryption](https://www.garykessler.net/library/crypto.html) could help to save the hacked information. After being encrypted, the data becomes unavailable for strangers who have no keys to read it.
###3. Be careful with libraries
Third-party libraries can significantly broaden the range of features of your app. But along with the benefits and opportunities, they [can conceal vulnerabilities](https://debricked.com/blog/2019/06/17/vulnerabilities-in-dependencies/) that will migrate to your product. That is why you’d better double-check all the third-party pieces of software you take on board of your application and chose only proven and reliable libraries.

###4. Use high-level authentification
An authentification can be compared to a fence that protects your house from the outside threats. The more fences you have and the higher they are, the more secure your app gets.
A lot of users are lazy and prefer to search for the less secure yet shorter way to what they need (in our case — the functionality of an app): they choose weak and easy-to-hack passwords and save them in the cache.
To strengthen the security you can design an app to accept only sophisticated passwords (even though users would grumble at notifications like “your password should contain numbers, symbols, and capital letters”) and require the password change once a month/decade. One more tool here — asking to add a mobile phone number to the account in the app and use confirmation codes to perform actions dealing with sensitive data.
###5. Request only necessary permissions
Any permission your app asks for creates an additional connection which equals one more gate in a security fence. It can be well-protected but it is still one more potential way for attackers that could make an application more vulnerable.
That is why [developers are advised](https://developer.android.com/training/articles/security-tips) to create an app that would ask only for the permissions it really needs to perform well. So, if your app’s functionality perfectly works without using the device’s camera or contact list, do not make it ask permission to access those native features.
##Conclusion
More and more personal information gets to the web these days. With the [appearance of IoT solutions for smart homes](https://scand.com/company/blog/internet-of-things-in-smart-home/) as well as social networks, this process accelerated and reached a new level. That puts app’s security on the top of the priority list for software developers.
To create reliable and secure solutions and to avoid fraud and data breaches, you have to keep an eye on all the potential vulnerabilities and learn ways to eliminate them.
| scand |
165,984 | Google Cloud functions -> Node.js | Google Cloud Functions es un entorno de ejecución sin servidor para crear y conectar servicios en la... | 5,519 | 2019-09-10T18:47:53 | https://dev.to/gelopfalcon/google-cloud-functions-node-js-82c | espanol, google, serverless | Google Cloud Functions es un entorno de ejecución sin servidor para crear y conectar servicios en la nube. Con Cloud Functions, usted escribe funciones simples y de un solo propósito que se adjuntan a eventos emitidos desde su infraestructura y servicios en la nube. Su función en la nube se activa cuando se dispara un evento que se está viendo. Su código se ejecuta en un entorno totalmente administrado. No es necesario aprovisionar infraestructura ni preocuparse por administrar servidores, en otras palabras usted solo se preocupa por "tirar código como loco".

Google Cloud Functions se pueden escribir en Node.js, Python y Go, y se ejecuta en tiempos de ejecución específicos del idioma. El entorno de ejecución de Cloud Functions varía según el tiempo de ejecución elegido.
<h2>Tipos de Cloud functions</h2>
Hay 2 distintos tipos de Cloud functions: HTTP y Background functions.
<h3>Funciones HTTP</h3>
Invoca funciones HTTP a partir de solicitudes HTTP estándar. Estas solicitudes HTTP esperan la respuesta y el manejo de soporte de métodos comunes de solicitud HTTP como GET, PUT, POST, DELETE y OPTIONS. Cuando utiliza Cloud Functions, se le proporciona automáticamente un certificado TLS, por lo que todas las funciones HTTP se pueden invocar a través de una conexión segura.
<h3>Funciones Background</h3>
Las funciones en background manejan eventos de su infraestructura en la nube, como mensajes en un tema de Cloud Pub / Sub, o cambios en un depósito de Cloud Storage.
Para este post, hablaré sobre funciones HTTP, en otros posts hablaré sobre las de background, así que, manos a la obra.
<h2>Requisitos</h2>
Antes de comenzar, usted debería asegurarse de haber instalado Node en su máquina, haber creado un Proyecto de Google Cloud y de haber instalado el SDK de Google Cloud.
Para verificar que Node ha sido instalado, usted debería ejecutar los siguientes comandos.
```npm -v
node -v ```
Además, usted podría verificar que Google Cloud SDK ha sido instalado con un comando similar:
`gcloud --version`
<h2>Setting up Google Cloud</h2>
Una vez que haya creado su proyecto Google Cloud, podemos habilitar la API de Cloud function en la nube. En la consola de Google Cloud, navegue a APIs & Services y luego en la biblioteca busque la API de Cloud Function. Debería encontrarse en una pantalla similar a la siguiente. Continúa y habilita la API.
O si usted es un fan de la consola como mi persona, podría correr este comando el cual tiene el mismo efecto:
`gcloud services enable cloudfunctions.googleapis.com`
Si la instalación fue satisfactoria, usted debería ver este API activo usando el siguiente comando:
`gcloud services list --available`

<h2>Creando un Express App</h2>
Para inicializar la aplicación, usaremos la herramienta `npm` para crear el `package.json` y luego crearemos el archivo en el que vamos a escribir nuestro código.
En algún directorio de su preferencia, vamos a crear un folder llamado `cloud-functions-nodejs`, dentro de este folder corramos el siguiente comando `npm init`, este comando nos crea el `package.json`.
El siguiente paso es instalar Express a nuestro proyecto, lo haremos ejecutando el siguiente comando:
```npm install express --save```
Finalmente, crear un archivo llamado `index.js`, donde escribiremos nuestro código. Ok, ya estamos con lo necesario para comenzar a desarrollar, abrir el archivo anteriormente creado con tu editor favorito y codear lo siguiente:
```const express = require('express');
const app = express();
const PORT = 5555;
app.listen(PORT, () => {
console.log(`Server ejecutándose en el puerto ${PORT}`);
});```
Ejecutar su app por medio del comando: ```node index.js```.
Usted debería ser capaz de ver el siguiente mensaje en su consola:
```Server ejecutándose en el puerto 5555```.
¡Felicidades! ¡Has creado tu primera aplicación Express! El único problema es que si deseas ejecutar alguna acción en `http: // localhost: 5555` no veras nada porque no hemos configurado la aplicación para escuchar las solicitudes.
Modifiquemos nuestro index.js con el siguiente código para crear algunos endpoints:
```
const express = require('express');
const app = express();
const PORT = 5555;
const USERS = [
{
id: 1,
firstName: 'Gerardo',
lastName: 'Lopez'
},
{
id: 2,
firstName: 'Yirian',
lastName: 'Acuña'
}
];
app.listen(PORT, () => {
console.log(`Server ejecutándose en el puerto ${PORT}`);
});
app.get('/users', (req, res, next) => {
res.json(USERS);
});
app.get('/users/:userId', (req, res, next) => {
res.json(USERS.find(user => user.id === parseInt(req.params.userId)));
});
module.exports = {
app
};
```
Vuelva a ejecutar la aplicación y debería poder ir a
`http://localhost:5555/users` y ver nuestra lista de usuarios.
Nuestro segundo endpoint muestra cómo puede usar los parámetros de ruta en Express, por lo que si va a `http://localhost:5555/users/2` verá a nuestro usuario "Yirian Acuña".
<h2>Deployeando en Cloud Functions</h2>
Ahora implementemos nuestra aplicación en Cloud Functions. Para implementar nuestra aplicación solo necesitamos un comando. En el directorio de nivel raíz de nuestra aplicación (el que contiene index.js), ejecute el comando:
```gcloud functions deploy mi-primer-funcion --runtime nodejs8 --trigger-http --entry-point app```
Esto tardará unos minutos en ejecutarse, pero una vez que haya terminado, debería ver lo siguiente impreso en la consola.
```
Deploying function (may take a while - up to 2 minutes)...done.
httpsTrigger:
url: https://us-central1-<GCP-PROJECT-ID>.cloudfunctions.net/mi-primer-funcion
labels:
deployment-tool: cli-gcloud
name: projects/<GCP-PROJECT-ID>/locations/us-central1/functions/mi-primer-funcion
runtime: nodejs8
```
Analicemos brevemente el comando que ejecutamos. Después de implementar la función gcloud, el siguiente parámetro es el nombre de su función. El indicador `--runtime` le dice a GCP qué tiempo de ejecución necesita su aplicación. El indicador `--entry-point` apunta al método ó objeto en index.js que deseamos exportar como un Cloud function, en otras palabras, es el punto de entrada para la función.
Después de haber implementado la función, deberías poder verla en la consola de Google Cloud y puedes llamar a tu función usando `https://us-central1-<GCP-PROJECT-ID>.cloudfunctions.net/mi-primer-funcion/users`.

Eso fue fácil pero ya al menos tienes la idea suficiente de como crear un Google cloud run (HTTP events). En un futuro no muy lejano escribiré sobre los otros tipos de funciones.
Agradezco compartir con la comunidad. Si quieres seguir aprendiendo junto a mí, te invito a seguir mis redes sociales:
- Twitter https://twitter.com/gelopfalcon
- dev.to https://dev.to/gelopfalcon
- Twitch https://www.twitch.tv/gelopfalcon (Todas las semanas hablo de algún tema. Por lo general a media semana)
| gelopfalcon |
166,041 | Not Another To-Do App: Part 7 | Getting your hands dirty and feet wet with Open Web Component Recommendations...sort of.... | 1,720 | 2019-09-06T16:00:15 | https://dev.to/westbrook/not-another-to-do-app-part-7-3cm7 | richdata, webcomponents, lithtml, openwc | #### Getting your hands dirty and feet wet with Open Web Component Recommendations...sort of.
> _This a cross-post of a Feb 26, 2019 article from [Medium](https://medium.com/@westbrook/not-another-to-do-app-169c14bb7ef9) that takes advantage of my recent decision to use Grammarly in my writing (so, small edits have been made here and there), thanks for looking again if you saw it there 🙇🏽♂️ and if this is your first time reading, welcome!_
_Welcome to “Not Another To-Do App”, an overly lengthy review of making one of the smallest applications every developer ends up writing at some point or another. If you’re here to read up on a specific technique to writing apps or have made your way from a previous installation, then likely you are in the right place and should read on! If not, it’s possible you want to [start from the beginning](https://dev.to/westbrook/not-another-to-do-app-2kj9) so you too can know [all of our characters’ backstories...](https://github.com/Westbrook/to-do-app)_
_If you’ve made it this far, why quit now?_
<hr/>
# Does Your Component Really Need to Know That?

<figcaption>Photo by <a href="https://unsplash.com/@cadop">Mathew Schwartz</a> on <a href="https://unsplash.com/">Unsplash</a></figcaption>
It’s hard to say whether it comes from my training in Agile, or my learnings about Lean, or my training in agile (big A, little a, if you know...you know), or my own musings on the [MTU](https://medium.com/@westbrook/may-i-introduce-to-you-the-minimum-testable-unit-79a59772bcc4), but I’ve grown quite fond of not doing things that don’t have to be done. Along those lines, I often have overly long conversations with myself as to where I should position the control over a component; it’s content, it’s functionality, it’s styling, everything. I spent a good amount of time thinking about this particularly in relation to the implementation of my app’s `to-do` element.
Initially, in keeping with the least amount of work approach, I felt I could get away with comparing my to-dos with string-based equality. There was no data to define them beyond the text string of the to do, so I wanted to get away with code so simple as:
```html
<to-do todo="I've got stuff to do"></to-do>
```
A simple string meant I could rely on [attribute binding](https://lit-html.polymer-project.org/guide/writing-templates#bind-to-attributes) to push the necessary data into my `to-do` element, and I could call it a day. However, a quick self QA (quality assurance test) of this will show you the folly of this in a simple equality world:
```html
<to-do todo="I've got stuff to do"></to-do>
<to-do todo="I've got stuff to do"></to-do>
```
When you’ve got two to-dos of the same name, you also have two to-dos of the same equality, which means that “completing” one will _accidentally_ complete both. What’s a person with lots of to do with the same text to do?
First, I thought to do this:
```html
<to-do todo='{"todo": "I've got stuff to do"}'></to-do>
<to-do todo='{"todo": "I've got stuff to do"}'></to-do>
```
Thanks to the `LitElement` base class that open-wc’s Starter App supplies to build my web components with, I could declare my `todo` property as `{type: Object}` and I’d get the serialization of that attribute string into an actual `Object` for free. That object would then have a unique identity between my individual `to-do` elements and I could rely on equality checking again to “complete” one to do and not the other, and all was right with the world.
> ## Wrong
Relying on data that is being serialized across a component boundary internal to an application means that new identities are going to be created at times that are likely not the ones you meant. Particularly, when serializing into and out of a string via the binding outlined above, the external and internal identity of your objects will not be shared, which is how I had made my way to the following code:
```js
<to-do .todo="${todo}"></to-do>
```
Using property binding means that we can skip the requirement for string serialization and that not only will each `to-do` element have a `todo` with a unique identity, regardless of the work needed to display them, but that identity will also be maintained across component boundaries. Rich data communication in a web component? You don’t say...
With that decided, I spent a little time with the style application I hoped to achieve. I decided to invert the standard styling approach and rather than rely on `to-do` element internals (with the likely help of CSS custom properties) to style the to do text, I chose to apply it through the light DOM so that the parent element would have control of the styling. It’s a small difference, but it’s one less thing that my custom element has to think about.
```js
<to-do todo="${todo}">${todo.todo}</to-do>
```
What did I tell you, a small change! And, internally this change is paired with the addition of a `slot` element to display the content projected into your [Shadow DOM](https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM) from outside. In this case, that looks like:
```js
render() {
return html`
<div>
<slot></slot> <!-- <E<=<- Look, I'm a slot! -->
</div>
<button
@click="${this.completeToDo}"
title="Complete To Do"
>
${iconMinus}
</button>
`;
}
```
Sometimes your components need to know more than you initially hope that they will need to, whether for maintaining their fidelity internally or for doing the same across component boundaries when constructing an application. Other times, you might be able to take some responsibilities off of the shoulders of your components. Getting philosophical and answering the question “Does Your Component Really Need to Know That?” can be an important step in both delivering the features you’re putting together now, as well as reducing maintenance requirements for later.
<hr/>
# The Short Game
As voted on by a plurality of people with opinions on such topics that are both forced to see my tweets in their Twitter feed and had a free minute this last week, a 9000+ word article is a no, no.
{% twitter 1098196160613896192 %}
So, it is with the deepest reverence to you my dear reader that I’ve broken the upcoming conversations into a measly ten sections. Congratulations, you’re nearing the end of the first! If you’ve enjoyed yourself so far, or are one of those people that give a new sitcom a couple of episodes to hit its stride, here’s a list of the others for you to put on your Netflix queue:
- [Not Another To-Do App](https://dev.to/westbrook/not-another-to-do-app-2kj9)
- [Getting Started](https://dev.to/westbrook/not-another-to-do-app-3jem) (Remember this, oh so long ago, we were but children then..)
- [Test Early, Test Often](https://dev.to/westbrook/not-another-to-do-app-2m9a)
- [Measure Twice, Lint Once](https://dev.to/westbrook/not-another-to-do-app-part-4-58cd)
- [Make it a Component](https://dev.to/westbrook/not-another-to-do-app-part-5-5d7o)
- [Make it a Reusable Part](https://dev.to/westbrook/not-another-to-do-app-part-6-an)
- Does Your Component Really Need to Know That? (you are here)
- [Some Abstractions Aren’t (Just) For Your App](https://dev.to/westbrook/not-another-to-do-app-part-9-10j3)
- [Reusable and Scaleable Data Management/And, in the end...](https://dev.to/westbrook/not-another-to-do-app-part-10-mp6)
- [See the app in action](https://gifted-lamport-70b774.netlify.com/)
<hr/>
Special thanks to the team at [Open Web Components](https://open-wc.org/) for the great set of tools and recommendations that they’ve been putting together to support the ever-growing community of engineers and companies bringing high-quality web components into the industry. [Visit them on GitHub](https://github.com/open-wc/open-wc) and create an issue, submit a PR, or fork a repo to get in on the action! | westbrook |
166,425 | Lodash and Underscore, is there still a case? | I used to say that JavaScript is mature enough to not need polyfiling by the likes of Lodash or Under... | 0 | 2019-09-05T16:14:03 | https://dev.to/adam_cyclones/lodash-and-underscore-is-there-still-a-case-3c38 | javascript, discuss | I used to say that JavaScript is mature enough to not need polyfiling by the likes of Lodash or Underscore. This opinion is in the same vein as jQuery where the language has caught up in matters of the DOM ♥️, so then what is JavaScript lacking?
Considering that JavaScript is able to cater for both Object Orientated Programming styles and Functional Programming styles, you will know that the likes of classes and Object.create are comparable to handle stylistic choices. But here's the kicker, there is no functional if, switch, match equivalent that you might find in other languages.
Functional JavaScript feels like it still requires a library where as oop is getting a lot of attention to improve its usage within the language.
Lodash and Underscore are such libraries, so is this the case for them, what are your thoughts? | adam_cyclones |
166,500 | Full Stack Serverless: a new YouTube course from Bytesized Code | Kristian here – I'm super excited to share a new series on the Bytesized Code YouTube channel! Check... | 0 | 2019-09-05T20:03:27 | https://www.bytesized.xyz/full-stack-serverless/ | serverless, javascript, webdev, beginners | [Kristian](https://twitter.com/signalnerve) here – I'm super excited to share a new series on the [Bytesized Code](https://www.youtube.com/watch?v=94FYhNH4pcY&list=PLH_Crma-Dc9NSWCnT6D_fA5RdJJsneVmK) YouTube channel! Check out the [Full Stack Serverless](https://www.youtube.com/watch?v=94FYhNH4pcY&list=PLH_Crma-Dc9NSWCnT6D_fA5RdJJsneVmK) playlist over at the channel 📺
{% youtube 94FYhNH4pcY %}
I think it's a little silly to talk in-depth about a series of videos, so I'll briefly describe what full-stack serverless is, and why I'm excited about it. As the developer advocate for [Cloudflare Workers](https://workers.cloudflare.com/), I spend a ton of time thinking about how to make serverless development approachable to developers. With a background in full-stack development, I often find myself trying to figure out the path between the kind of projects I've made in the past ([Frontend Jobs](https://frontendjobs.tech/), for instance), which are generally full-stack projects, serving a ton of HTML, CSS and JS to a user, and serverless projects, which are small, stateless, and highly available.
The plan for Full Stack Serverless playlist is to build a long-lived, multi-project series, showing off the pros and cons of building projects on top of serverless. As you might imagine, each project will likely involve Cloudflare Workers, but it's definitely not an ad: an upcoming project will lean really heavily on Firebase to provide serverless database functionality, and in general, I plan to cover the entire serverless ecosystem, regardless of platform or provider.
I first saw the term "full stack serverless" used by my pal [Nader Dabit](https://twitter.com/dabit3), who's working on [an O'Reilly book](http://shop.oreilly.com/product/0636920286585.do) showing how to build applications using AWS Amplify. His content is great (and the accompanying [Byteconf](https://www.byteconf.com/) live-coding/interview that I did with him was a ton of fun: linked below), and I think the tech around building full-stack serverless apps just keeps getting better and better. I'm excited about the future of this space, and I'm hoping to get the chance to do a bit of innovating on how to do it well - stay tuned!
{% youtube Dq46zjjLkYg %}
_Hey, dev.to! I send out emails to my newsletter with new tutorials, resources, and my tips on leveling up in your dev career. No spam, I promise. [Join here!](https://www.bytesized.xyz/newsletter)_
One more thing: [check out our new Facebook Group "Awesome Web Development"!](https://www.facebook.com/groups/awesomewebdev/) | signalnerve |
183,146 | OpenCV Python Tutorial: Computer Vision With OpenCV In Python | Computer Vision is an AI based, that is, Artificial Intelligence based technology that allows compute... | 0 | 2019-10-05T03:15:10 | https://dev.to/angulardevz/opencv-python-tutorial-computer-vision-with-opencv-in-python-2h1o | python, machinelearning, tutorial | Computer Vision is an AI based, that is, Artificial Intelligence based technology that allows computers to understand and label images. Its now used in Convenience stores, Driver-less Car Testing, Security Access Mechanisms, Policing and Investigations Surveillance, Daily Medical Diagnosis monitoring health of crops and live stock and so on and so forth..
A common example will be face detection and unlocking mechanism that you use in your mobile phone. We use that daily. That is also a big application of Computer Vision. And today, top technology companies like Amazon, Google, Microsoft, Facebook etc are investing millions and millions of Dollars into Computer Vision based research and product development.
Computer vision allows us to analyze and leverage image and video data, with applications in a variety of industries, including self-driving cars, social network apps, medical diagnostics, and many more.
As the fastest growing language in popularity, Python is well suited to leverage the power of existing computer vision libraries to learn from all this image and video data.
**What you'll learn**
* Use OpenCV to work with image files
* Perform image manipulation with OpenCV, including smoothing, blurring, thresholding, and morphological operations.
* Create Face Detection Software
* Detect Objects, including corner, edge, and grid detection techniques with OpenCV and Python
* Use Python and Deep Learning to build image classifiers
* Use Python and OpenCV to draw shapes on images and videos
* Create Color Histograms with OpenCV
* Study from MIT notes and get Interview questions
* Crack image processing limits by developing Applications.
{% youtube u9ogVfao4Os %} | angulardevz |
183,575 | Finding Github "Help Wanted" Issues | Always searching the same handful of Github organizations looking for "Help Wanted" issues? Tired of... | 0 | 2019-10-08T14:00:30 | https://dev.to/lbonanomi/finding-github-help-wanted-issues-2b1a | bash, github, showdev | Always searching the same handful of Github organizations looking for "Help Wanted" issues? Tired of finding out everything in the repository that needs help is in a language you can't hack-on confidently? Let's build a custom RSS feed with Github Actions to prowl for issues in known organizations and repos that host our languages.
*This project has been converted to a template repo!*
Just set a secret called `TOKEN` and clone this repo to get started! [Organizations to watch](https://github.com/botonomi/RSS/blob/gh-pages/.github/workflows/RSS.yml#L22) and [languages to filter-on](https://github.com/botonomi/RSS/blob/gh-pages/.github/workflows/RSS.yml#L23).
~~* Register for Github Actions if you haven't already.~~
~~* Add a Github Actions secret called "TOKEN" with a personal access token scoped to write repo data~~
~~* Fork [this project](https://github.com/botonomi/rss)~~
~~* Make sure that Github Pages are enabled for your fork~~
~~* You'll probably want to tweak the `LANGUAGES` and `ORGS` values at the top of `v3-feed.sh`, but maybe you're a bash/python/go hobbyist yourself.~~
~~* After the first run completes you should have an RSS feed of interesting puzzles at https://$YOUR_GITHUB_NAME.github.io/rss/feed.xml~~ | lbonanomi |
183,590 | Captain AJAX | Have you ever wondered how asynchronous requests are made on web pages? Have you ever wondered what... | 0 | 2019-10-07T12:42:39 | https://dev.to/jillianntish/oh-captain-my-captain-ajax-2gjo | javascript, beginners, firstyearincode | Have you ever wondered how asynchronous requests are made on web pages?
Have you ever wondered what "asynchronous requests" are?
As an average internet-consuming human...probably not, but if you're here, you're probably no longer just that, but now an(at least semi) internet-comprehending human, and that's pretty cool!
One of the most important characteristics of modern web browsing is the use of Asynchronous JavaScript and XML requests, or 'AJAX'. Unbeknownst to the common web user, these 'requests' are happening in the background, pretty much <i>all the time</i>.

AJAX radically changed the face of the internet by keeping it static, yet dynamic. As a child of the 90's, I remember when internet access was still fairly limited and running on dial-up. Back then, web pages were rendered 'synchronously', meaning if you clicked on a hyperlink, the page would have to completely reload, because at that time, data requests were sent from the client(a user's computer) to the server, and then responded to one at a time. (I'm sure by now you realize that half the time spent surfing the web in the 90's was just waiting for the page to load.)
Then, in the 1996, something really magical happened; Microsoft Internet Explorer introduced the <iframe> tag and changed the world, and my life.
Requests could now be sent to the server in the background of a web page without the face of the web page changing, making websites far more user friendly and speedy. Because of this async wave, new forms of communication and interaction with the internet were made possible.
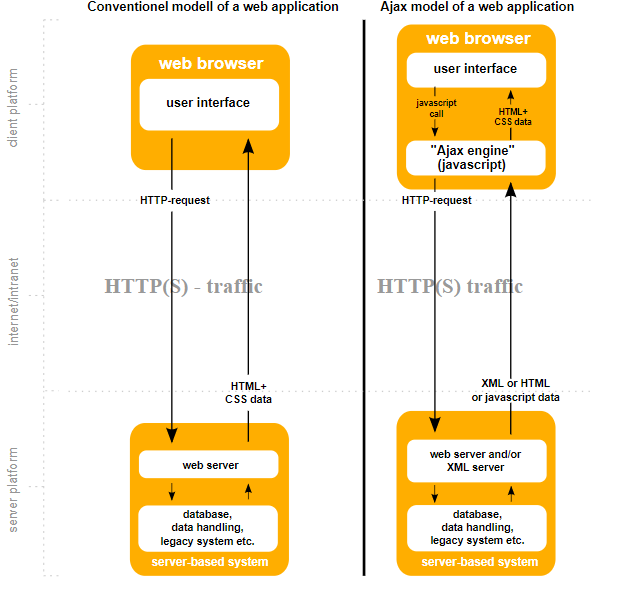
You may not have ever realized it, but any time you login to any website, use autocomplete, or visit a chatroom, AJAX is happening in the background. Let's break down what's happening in this chart step by step.
```
Asynchronous processing model
1. An event occurs in a web page, aka the client (like a click event)
2. An XMLHttpRequest(XMR) object is created by JavaScript
3. The XMR object sends a request to a web server using JSON or XML
4. The server processes the request, usually called a 'GET' request
5. The server sends a response back to the web page
6. The response is read by JavaScript
7. Proper action is performed by JavaScript, HTML/CSS,
and the DOM to render the information to the screen, uninterrupted
```
What this is really saying is that AJAX is not a technology in itself, but a compilation of technologies working together to produce a result.
In it's earliest forms, AJAX requests were incredibly convoluted and easy for developers to get caught up in their syntax. Luckily, modern libraries and frameworks have abstracted away a lot of this syntax but the underlying technology still remains the same, to help you understand what I mean by this, let's use the 90s classic cartoon 'Captain Planet' to get more insight.
If you've never heard of CP here's a little background: He was awesome! However, his power could only be summoned by the combined powers of his earthly friends "The Planeteers".

<strong> DOM (Document Object Model) - <i>Earth</i> </strong>
The very structure on which every web page on the internet is built.
<b>HTML/CSS - <i>Fire</i></b>

The DOM is represented by the HTML backing structure and Cascading Style Sheets for it to be fleshed out.
HTML is how elements on the page are rendered and CSS is what they look like.
<b>JSON (JavaScript Object Notation)
&& XML/XMR (Extensible Markup Language) - <i>Wind</i></b>

Original AJAX requests were sent via XML, but this syntax was very easy for programmers to get tangled up in, and the move was made to JavaScript Object Notation or JSON to provide additional clarity..so yes, technically, AJAX is really 'AJAJ'.
This would be considered the wind element due to the parsing and transference of data back and forth across the web.
<strong>JavaScript- <i>Water</i></strong>

I would consider JavaScript the water element, due to it's important role in the control flow of data being requested from the server.

Once the server has responded to the client request, again, it's JavaScript's job to implement a callback function that tells this freshly received data what to do.
<b>XMLHttpRequest Object - Heart</b>

The heart of the entire operation is the XMR object, which is available in the JavaScript environment. This very special object's job is to communicate back and forth with the server to produce asynchronous requests.
By the power of all these technologies combined,

you TOO can 'GET' an AJAX request.


(As long as it's not in classic syntax because Google HATES that.)
| jillianntish |
188,912 | How to use synchronization primitives in Go: Mutex, WaitGroup, Once | Welcome to Just Enough Go ! This is the second post in a series of articles about the Go programming... | 2,584 | 2019-10-14T13:40:15 | https://dev.to/itnext/how-to-use-synchronization-primitives-in-go-mutex-waitgroup-once-1aee | tutorial, beginners, showdev, go | Welcome to **Just Enough Go** ! This is the second post in a series of articles about the [Go programming language](https://golang.org/) in which I will be covering some of the most commonly used [Go standard library packages](https://golang.org/pkg) e.g. `encoding/json`, `io`, `net/http`, `sync` etc. I plan to keep these relatively short and example driven.
Let's look at some of the lower-level synchronization constructs which Go provides in the [`sync` package](https://godoc.org/sync), in addition to goroutines and channels. There are a bunch of them, but we will explore `WaitGroup`, `Mutex` and `Once` with examples.
> Code examples are [available on GitHub](https://github.com/abhirockzz/just-enough-go)

### WaitGroup
Use a `WaitGroup` for co-ordination if your program needs to wait for a bunch of goroutines to finish. It is similar to a `CountDownLatch` in Java. Let's see an example.
We want to print all the files in our home directory in parallel. Use a `WaitGroup` to specify the number of tasks/goroutines to wait for - in this case, it is the same as the number of files/directories you have in the home directory. We use `Wait()` to block until the `WaitGroup` counter becomes zero.
...
func main() {
homeDir, err := os.UserHomeDir()
if err != nil {
panic(err)
}
filesInHomeDir, err := ioutil.ReadDir(homeDir)
if err != nil {
panic(err)
}
var wg sync.WaitGroup
wg.Add(len(filesInHomeDir))
for _, file := range filesInHomeDir {
go func(f os.FileInfo) {
defer wg.Done()
}(file)
}
wg.Wait()
}
...
To run this program:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/wait-group-example.go -o wait-group-example.go
go run wait-group-example.go
A goroutine is spawned for each `os.FileInfo` we find in the user home directory and once we print its name, the counter is decremented using `Done`. The program exits after all the contents of the home directory are covered.
### Mutex
A `Mutex` is a shared lock which you can use to provide exclusive access to certain parts of your code. In this simple example, we have a shared/global variable `accessCount` which is used in the `incr` function.
func incr() {
mu.Lock()
defer mu.Unlock()
accessCount = accessCount + 1
}
Notice that the incr function is protected by a `Mutex`. Thus, only a single goroutine can access it at a time. We throw mulitple goroutines at it
loop := 500
for i := 1; i <= loop; i++ {
go func(c int) {
wg.Add(1)
defer wg.Done()
incr()
}(i)
}
If you run this, you will always get the same result i.e. `Final = 500` (since the for loop runs for 500 iterations). To run the program:
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/mutex-example.go -o mutex-example.go
go run mutex-example.go
Comment (or remove) the following lines in the incr function and run the program on your local machine using and run the program again
mu.Lock()
defer mu.Unlock()
You will notice variable results e.g. `Final = 474`
> I encourage you to read up on [`RWMutex`](https://golang.org/pkg/sync/#RWMutex). It is a special kind of lock which can be used to allow concurrent reads but synchronized (single writer) writes.
### Once
It allows you to define a task which you only want to execute once during the lifetime of your program. This is very useful for `Singleton`-like behavior. It has a single `Do` function which let's you pass another function which you intend to execute only once. Let's look at an example
Say you're building a REST API using the Go `net/http` package and you want some piece of code to be executed only when the HTTP handler is called (e.g. a get a DB connection). You can wrap that code with `once.Do` and rest assured that it will be only run when the handler is invoked for the first time.
Here is a function which we want to be executed only once
func oneTimeOp() {
fmt.Println("one time op start")
time.Sleep(3 * time.Second)
fmt.Println("one time op started")
}
This is what we do within our HTTP handler - notice `once.Do(oneTimeOp)`
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
fmt.Println("http handler start")
once.Do(oneTimeOp)
fmt.Println("http handler end")
w.Write([]byte("done!"))
})
log.Fatal(http.ListenAndServe(":8080", nil))
}
Run the code and access the REST endpoint
curl https://raw.githubusercontent.com/abhirockzz/just-enough-go/master/sync/once-example.go -o once-example.go
go run once-example.go
From a different terminal
curl localhost:8080
//output - done!
When you first access it, it will be a little slow in returning and you will see the following logs in the server:
http handler start
one time op start
one time op end
http handler end
If you run it again (any number of times), the function `oneTimeOp` will not be executed. Check the logs to confirm
That's all for this blog. I would be more than happy to take suggestions on specific Go topics which you would like to me cover! Feel free to [tweet](https://twitter.com/abhi_tweeter) or just drop a comment and don't forget to like and follow 😃😃 | abhirockzz |
190,997 | tt | tt | 0 | 2019-10-18T10:08:24 | https://dev.to/edsonmacamo/tt-3bb1 | tt | edsonmacamo | |
190,339 | JavaScript debate : named imports VS default imports | A debate on the type of import we use in JavaScript has recently appeared. Same kind of debate than... | 0 | 2019-10-19T21:51:29 | https://mindsers.blog/en/javascript-named-imports-vs-default-imports/ | javascript, discuss, healthydebate, webdev | ---
title: JavaScript debate : named imports VS default imports
published: true
date: 2019-10-17 04:00:00 UTC
tags: javascript,discuss,healthydebate,webdev
canonical_url: https://mindsers.blog/en/javascript-named-imports-vs-default-imports/
---

A debate on the type of import we use in JavaScript has recently appeared. Same kind of debate than the one with semicolon. It works whichever you choose but each developer has its opinion on the matter and nobody agree. I also have an opinion!
***⚠️ Read more of my blog posts about tech and business [on my personal blog](https://mindsers.blog/)! ⚠️***
To make it short : I prefer _named imports_. Long answer is below though.
## What is the difference between default imports and name imports?
It is a very subtil detail as it often is in this kind of debate.
```js
import detectRotation from 'rotate'
```
<figcaption>Default import</figcaption>
This first example consists in trying to import the default symbol of a JavaScript module and store it in a variable that is named `detectRotation`.
```js
import { detectRotation } from 'rotate'
```
<figcaption>Named import</figcaption>
_Named imports_ look less simple. In fact, we are destructuring the module to only import the symbols we need in it.
## Meaning, tools and clean code
If developers argue about import methods, it is because there are more than just syntax differences.
First, _default imports_ are nameless. Or rather : it looses its name during exportation. Be it variables, constants, objects, classes, etc : they all have a name in their module. They are exported as `default` and it becomes their new name sort of.
So when we write :
```js
import detectRotation from 'rotate'
```
we are not importing `detectRotation` inside of `rotate` module but rather we import `default` symbol of the `rotate` module that we rename `detectRotation` in the current module.
And this is one of the main reason why I prefer _named imports_. Because nothing indicates that it is the`detectRotation` function that is exported as `default` in this module.
Whereas, when we write :
```js
import { detectRotation } from 'rotate'
```
it is the `detectRotation` function that I import from the `rotate` module. If this function doesn't exist, my development tools (editor, linter, language services, etc) will let me know in a more or less direct way. Worse case scenario : my import will fail during execution in the JS engine.
Some will say that you just have to read the documentation of the module to know how to use it but I really don't want to research in the documentation each time I come back to the code, like 2 weeks after writing it.
**I think code must be as clear and understandable as possible on its own** and _named imports_ are great for that.
## Communities standards
In several posts about [best practices](https://blog.nathanaelcherrier.com/tag/best-practices/), [linting (fr)](https://blog.nathanaelcherrier.com/fr/linting-good-practices/) and other methodologies, I advise to copy what the community is already doing.
One of the goal of this advice is to simplify team work and better the maintenance of a project. There are a lot more chance that a new dev knows "standard" choice of a community instead of your personal preference...
You could translate this advice in :
> Do what is best for your team, not what is best for you
So what about the "_named import_ vs _default import_" debate? Same old thing here, communities have their own opinion on the matter.
For example, in Angular _named imports_ are widely used. You can see that is the Angular doc. There are (almost) no `default` import or export.
```js
import { ProductAlertsComponent } from './product-alerts.component.ts'
```
<figcaption>a Team Angular import</figcaption>
In the React community, _default imports_ might be used depending on the situation. The thinking behind is a little more complex than just "we're only doing named import" or "we're only doing default import". I think this logic is really interesting so I'll detail just below.
First, the file that contains a component must have the same name as the component. This component is exported as `default`.
Then you can export other useful things to the files of your components. Like hooks, utils, test version of your component...Etc.
```js
import ProductAlerts, { useProducts } from 'ProductAlerts.ts'
```
<figcaption>a Team React import</figcaption>
There are, of course, a few exceptions but that is the majority. Even though I prefer _named imports_ for reasons I listed above in the post, I think this is a very logical way to do things.
Once again, each community works with its preferences and you better make it yours to ease your team working and other aspects of your dev life (code review...etc). | mindsers |
190,355 | Building a larger Serverless application - Part 3: Modular Monorepos | I've decided that I'm using AWS, Serverless and Node.js for my actual code. Now to decide how to actu... | 0 | 2019-10-17T06:22:38 | https://dev.to/grahamcox82/building-a-larger-serverless-application-part-3-modular-monorepos-3mon | serverless, monorepo, aws | ---
title: Building a larger Serverless application - Part 3: Modular Monorepos
published: true
description:
tags: serverless, monorepo, aws
---
I've decided that I'm using AWS, Serverless and Node.js for my actual code. Now to decide how to actually structure it.
I want to keep distinct areas actually distinct from each other. Allow for a truly modular approach. I also want to use a single repository and not lots of them, because it's just easier for a single person or small team that way.
Surprisingly, this is not easy.
AWS CloudFormation - and thus AWS SAM, and thus Serverless - builds our infrastructure in Stacks. A single stack represents a single unit of infrastructure, and everything that goes with it. So this would be Lambdas, DynamoDB tables, Queues, IAM roles, everything. It also supports what are called Nested Stacks, where one stack is actually composed of others.
## Why use Nested Stacks?
One obvious question is - why should we use a nested stack? One of the benefits is that you can create and destroy the entire stack in one go. However, this isn't the real selling point.
AWS has a hard limit of 200 resources in any single stack. A stack that contains a single Lambda attached to an API Gateway, and a single DynamoDB table will contain up to 13 of these resources. This means that we can have 15 such stacks until we run out. Nested stacks let us circumvent this because we can have a parent stack containing many nested stacks, each of which have this 200 resource limit. We can nest these as deep as we want too, so we can structure this however we want.
## Shared API Gateways
One obvious problem with multiple stacks is the URLs. The default behaviour would be that each stack has it's own API Gateway, and thus it's own URL. That is not helpful.
However, we can solve this. AWS already lets us share resources between stacks as long as they belong to the same IAM user. Serverless lets us achieve this as well.
What we will do is:
* Create a stack that contains nothing but the API Gateway
* Refer to this same API Gateway in all of our other stacks
This means that they will all be on the same URL, and we've only had to define it once.
Our API Gateway stack will look like this:
```
service: serverless-gateway
provider:
name: aws
stage: dev
resources:
Resources:
ServerlessGW:
Type: AWS::ApiGateway::RestApi
Properties:
Name: ServerlessGW-${opt:stage, self:provider.stage}
Outputs:
apiGatewayRestApiId:
Value:
Ref: ServerlessGW
Export:
Name: ServerlessGW-restApiId-${opt:stage, self:provider.stage}
apiGatewayRestApiRootResourceId:
Value:
Fn::GetAtt:
- ServerlessGW
- RootResourceId
Export:
Name: ServerlessGW-rootResourceId-${opt:stage, self:provider.stage}
```
This creates an API Gateway with the name "ServerlessGW" and the name of the stage. The use of the stage means that we can deploy multiple stages at the same time - very useful when we come to do testing!
We then refer to this in our other files as follows:
```
service: serverless-users
provider:
name: aws
apiGateway:
restApiId:
"Fn::ImportValue": ServerlessGW-restApiId-${opt:stage, self:provider.stage}
restApiRootResourceId:
"Fn::ImportValue": ServerlessGW-rootResourceId-${opt:stage, self:provider.stage}
```
The `provider.apiGateway` key tells Serverless that this stack will use that gateway, instead of defining it's own. Instantly we've got what we wanted.
## Implementing a modular structure
Unfortunately, the tooling doesn't easily support nested stacks. AWS CloudFormation and AWS SAM do, but to do so every single nested stack needs to be in S3 - both the CloudFormation scripts and the archive of contents. Only when all of these sub-stacks are in S3 can you then deploy the parent one. Serverless doesn't have any way to support this at present. It does have some plugins that get some of the way there, but none of them do the exact job that I want.
As such, I've settled on a more DIY approach. It's possible to have stacks that are *not* nested but still relate to each other, so we can simply have all the various parts of the application as different stacks with no direct connections between them except in terms of names. It's not perfect, but it works.
This puts us into the following:
```
.
├── stacks
│ ├── gateway
│ │ ├── serverless.yml
│ └── users
│ ├── serverless.yml
```
Every directory inside `stacks` is then a single stack to be deployed.
The next problem is that we need to do this in the correct order.
My first thought was to do it a Node.js way. What we've actually got here is many projects that we want to orchestrate together. That should be easy, right? Wrong.
The obvious thing to do is stick within the tooling stack. I'm using Node, so lets use Node tools.
### Lerna
There's a tool called Lerna that is explicitly designed for monorepos, and running tasks in multiple sub-modules correctly. So let use this.
In order to do this, you need to have a package.json in each module, and one at the top level. The top-level one will depend on lerna and serverless, and have a few scripts entries to help run things. Our per-module ones will then have scripts entries for the actual work.
```
// ./package.json
{
"name": "serverless",
"scripts": {
"sls:deploy": "lerna run sls:deploy",
"sls:remove": "lerna run sls:remove"
},
"devDependencies": {
"lerna": "^3.17.0",
"serverless": "^1.54.0"
}
}
```
```
// ./stacks/gateway/package.json
{
"name": "serverless-gateway",
"scripts": {
"sls:package": "sls package",
"sls:deploy": "sls deploy",
"sls:remove": "sls remove"
}
}
```
We then need a `lerna.json` file to orchestrate this:
```
{
"npmClient": "yarn",
"packages": [ "stacks/gateway", "stacks/users" ],
"version": "independent"
}
```
We can now run `yarn sls:deploy` at the top level and it will execute it in the sub-stacks, in the correct order, and deploy everything.
Success? Not quite. This works fantastically for setting things up, but completely fails when tearing them down. If we execute `yarn sls:remove` then it will try to remove `gateway` *before* `users`, and that will fail. And there is no way at present to get Lerna to run in reverse direction. (There is an open issue for it though, so you never know!)
### Gulp
Next attempt. Gulp. There is a gulp plugin explicitly for serverless, and it will let you run serverless commands in directories. That's perfect.
So we can set up our top-level package.json file as follows:
```
{
"name": "serverless",
"scripts": {
"sls:deploy": "gulp deploy",
"sls:remove": "gulp remove"
},
"devDependencies": {
"gulp": "^4.0.2",
"serverless": "^1.54.0",
"serverless-gulp": "^1.0.10"
}
}
```
Then we have a gulpfile.js file to orchestrate this:
```
const gulp = require("gulp");
const serverlessGulp = require("serverless-gulp");
const paths = {
serverless: ["gateway", "users"].map(p => `stacks/${p}/serverless.yml`)
};
gulp.task("deploy", () => {
return gulp
.src(paths.serverless, { read: false })
.pipe(serverlessGulp.exec("deploy", { stage: "dev" }));
});
gulp.task("remove", () => {
return gulp
.src(paths.serverless.reverse(), { read: false })
.pipe(serverlessGulp.exec("remove", { stage: "dev" }));
});
```
With the above, when we run `yarn sls:deploy` then we set everything up in the correct direction, but `yarn sls:remove` now tears everything down in the opposite direction. Perfect.
Only there's no easy way for Gulp to handle other monorepo tasks, like running tests across all the modules
### Combined
So we can achieve this by combining both tools. Gulp for the serverless tasks that need to have a strict order, and Lerna for the tasks that can happen in any order. Lerna can use wildcards for finding the modules, so we only need to maintain our ordered list in the Gulp configuration and all is good.
## Summary
Building a Serverless application in a monorepo is not easy, but it is doable. And if you're a small team or an individual then it's worth the effort up front to make the rest of the process smoother. | grahamcox82 |
190,374 | How blogging helped me get my first data science job | 0 | 2019-10-17T07:23:55 | https://www.mikulskibartosz.name/how-i-become-data-scientist | beginners, datascience, career | ---
title: How blogging helped me get my first data science job
published: true
description:
tags: beginner, data science, career
canonical_url: https://www.mikulskibartosz.name/how-i-become-data-scientist
---
I wanted to become a data scientist since I learned that such a job exists. I knew it was perfect for me. Cutting-edge technology and data analytics, what can be better?
# Learning
I wondered how I can learn the necessary skills. The obvious choice was video tutorials, so I started watching online courses. I have purchased around six courses on Udemy and two or three Coursera courses. I watched dozens of YouTube videos.
I felt in love with data science, but I had no idea how to become a data scientist. I sort of knew what I needed to learn, but I did not know how to start learning it for real.
I wanted to understand the topics, not only learn that they exist, and copy-paste some code. I started doing Kaggle challenges. It was not the perfect choice, either.
Let’s face reality, the majority of Kaggle solutions are just copy-pasted code from top 20 Kaggle notebooks. I could train myself to copy some code, but I had no clue whether it is the best possible code or why does it even work. It was not enough for me. I could not accept that.
Quickly, I realized that I may learn something in such a way, but I won’t be able to show it to anyone or use it in practice.
# Gatekeepers
I needed to practice solving real-world problems. I tried to “do data science” at work. We already had a data team, and they were trying really hard to “squash the competition.”
I needed to find a different way. A way that could not be controlled by the manager of the data team. I had to look for an opportunity outside of that company.
The problem was the fact that I had no real-world experience. I needed not only to learn but also show people that I should be hired because I can get the job done.
# Blogging
I started blogging. First, I was blogging about everything. I wrote articles about software craft, Scala libraries, book reviews, etc. I did write a few texts about data-related stuff, but only some easy ones. Obviously, that was not helping me reach my goal.
One day, I decided that enough is enough. I was wasting time at a job that did not allow me to grow my skills or even fully use the skills I already had. I had to change that.
I made a blogging schedule. I began blogging three times a week. I continued writing about the same topics, but I was doing it more often. It still wasn’t giving me the results I wanted, but I was learning to produce good content faster.
After four months, I limited the topics of my articles to data analytics and machine learning. Of course, I continued writing three articles every week. At that time, it wasn’t a huge effort anymore because of the time I invested in learning my writing skills.
# Getting hired
Three months later, a strange thing had happened. I sent CVs to two companies looking for data scientists. I was invited to both interviews, and… they did not ask me any technical questions. They mentioned that they had read my blog, and we talked only about the culture of their organizations.
I was surprised because I had still remembered the interviews from the past, during which I had been grilled for six hours by multiple interviewed who had tried to prove that I had not known anything.
This time, it was different. I did not need to show my technical skills during the interview. I was hired by one of those companies. Finally, I was a data scientist.
I have finally reached the goal, and I was happy. I was coming to work every day and doing something challenging. I was training machine learning models, doing data analysis, and spending most of the day reading research papers.
# Was data science good for me?
It wasn’t perfect for long. Soon, I realized that something was missing. It was difficult to admit, but I learned that being a data scientist is not the perfect career path.
I missed software engineering. I missed talking about software architecture and focusing on software craft.
I wanted to be a data scientist, but I also wanted to do sophisticated software engineering. I needed to make a change in my career once again.
# Next move
I sent my CV to one other company. I went to an interview. One week after sending the CV, I was hired by a company that is often described as the best workplace in the city where I currently live (Poznan, Poland). It was awesome!
Now, I’m a data engineer. It’s perfect for me. I can train machine learning models, build ETL pipelines, write complex software, care about code quality, and plan the architecture of my software.
# How did it happen?
I firmly believe that none of that would happen if I did not start blogging regularly. Blogging not only helped me to learn a lot but also allowed me to show to other people what I am capable of doing.
It also helped me stop wasting time learning things that may be useful in the future. Now, when I learn something like that, I write an article about it.
I know that if I learn it and don’t use it, I will forget everything, so I use the blog also as a way to store notes and easily recall the things I used to know.
I know that my story about blogging may look like something requiring a massive investment of time. It is not like that. If I started blogging regularly earlier, I wouldn’t need to write three times a week.
I believe that you can achieve the same results by blogging once a week, every week for a year. For sure, it will take some time. I think that six months is the minimal amount of time you need to build a successful blog that boosts your career.
I think that the biggest problem of aspiring data scientists is standing out of the crowd. Everyone does Kaggle challenges, everyone has a blog and writes articles. Clearly, you need to do something differently.
I think that what makes the most significant difference is demonstrating work ethics and commitment. It is easy to have a blog and post one text a year. If you can regularly produce good quality content, you are no longer part of the wannabes. Instead of that, you become one of the people who know what they are doing and are available for hire.
# Free Blogging Course for Aspiring Data Scientists
I have created a free blogging course for aspiring data scientists. If you subscribe to the course, I will send you a lesson every week. During the first month, I am going to show you how to choose the topics of your articles, how to set up your blog quickly, what kind of articles you should write, and how to write them quickly.
Later, I will teach you also where you can effortlessly find ideas for new texts, how to promote your content in social media, how to become a better writer, how you can get more readers without buying ads, and how you can earn money while blogging.
You can subscribe to the course here: https://www.mikulskibartosz.name/how-i-become-data-scientist#blogging_course | mikulskibartosz | |
190,510 | Why Opera Browser is Using Webcam? | I realized many times that Kaspersky is warning me whenever I open Opera browser that it starts using... | 0 | 2019-10-17T09:00:51 | https://dev.to/yaser/why-opera-browser-is-using-webcam-19jp | security, privacy, discuss | ---
title: Why Opera Browser is Using Webcam?
published: true
description:
cover_image: https://thepracticaldev.s3.amazonaws.com/i/ypmm9kxmv3j5cdwfcm6n.png
tags: security, privacy, discuss
---
I realized many times that Kaspersky is warning me whenever I open Opera browser that it starts using the webcam!

### Opened pages
All are usual pages that do NOT require webcam functionalities, like: Asana, ZenHub, Twitter, Facebook... etc
### Plugins
I checked my plugins, and it's kinda empty just those:
1. Install Chrome Extensions (by Opera Software).
2. Opera Ad Blocker (official plugin form Opera).
3. WordWeb Dictionary Lookup.
### Why I use Opera?
Well, it's super light (memory and CPU) comparing to Google Chrome.
But I recently feel really concerned about why it uses the camera without showing any permission dialog.
I hope to see where I'm wrong at this. | yaser |
190,516 | A complete <dev> guide for better buttons | Better approach to make buttonf -- for all. | 0 | 2019-10-17T09:10:44 | https://dev.to/sarathsantoshdamaraju/a-complete-dev-guide-for-better-buttons-2b10 | buttons, guide, a11y, bestpractices | ---
title: A complete <dev> guide for better buttons
published: true
description: Better approach to make buttonf -- for all.
tags: buttons, guide, accessibility, best-practices
---
Buttons are one of the most simple, yet deeply fundamental and foundational building blocks of the web. Click a button, and you submit a form or change the context within the same page. But there is a lot to know from the HTML implementation and attributes, styling best practices, things to avoid, and the even-more-nuance implementations of the buttons — links and button-like inputs.
This article covers, building —
- Links,
- Buttons,
- and Button-like Inputs
We’re going to deep-dive into all three of them, and for each, dig into the 🏗️ HTML implementations, 🖌 CSS and ⚙️ JS considerations, ❤️ Accessibility information, and ‼️ Pitfalls/Bad practices. By covering all that, we’ll have a better UX implementation of each.
Read more here: --
{% medium https://codeburst.io/a-complete-dev-guide-for-better-buttons-b2efb773a5ef %} | sarathsantoshdamaraju |
190,526 | Authenticate React App With Stormpath - Part Two | This is a continuation of Authenticate React App With Stormpath. On this final piece, we'll set up... | 2,827 | 2019-10-17T09:36:30 | https://dev.to/clintdev/authenticate-react-app-with-stormpath-part-two-5c7g | react, beginners, javascript | This is a continuation of <a href="https://dev.to/clintpy/authenticate-react-app-with-stormpath-part-one-4jee"> Authenticate React App With Stormpath</a>.
On this final piece, we'll set up our pages. Let's dive right in:-
### Main Page
Let's first set up our Router which will define how our navigation structure in the app. We'll do this by first creating a shared route. This will act as our main page i.e. all routes under this page will share the same main component (header). Insert this code inside the ``<Router>`` tag in ``app.js``.
```html
<Router history={browserHistory}>
<Route path='/' component={MasterPage}>
</Route>
</Router>
```
We have referenced ``MasterPage``, something that doesn't exist yet. Let's go ahead and create it in a new directore ``pages``, inside our ``src`` folder.
```console
$ mkdir pages
$ cd pages
```
Create a new file named ``masterPage.js`` and add this code:
```javascript
import React from 'react';
import { Link } from 'react-router';
import { LoginLink } from 'react-stormpath';
import DocumentTitle from 'react-document-title';
import Header from './Header';
export default class is extends React.Component {
render() {
return (
<DocumentTitle title='My React App'>
<div className='MasterPage'>
<Header />
{ this.props.children }
</div>
</DocumentTitle>
);
}
}
```
As you can see, we don't have a ``Header`` component yet, so let's go and create a new file named ``Header.js`` in the same directory with the following content.
```javascript
import React from 'react';
import { Link } from 'react-router';
import { LoginLink, LogoutLink, Authenticated, NotAuthenticated } from 'react-stormpath';
export default class Header extends React.Component {
render() {
return (
<nav className="navbar navbar-default navbar-static-top">
<div className="container">
<div id="navbar-collapse" className="collapse navbar-collapse">
<ul className="nav navbar-nav">
<li><Link to="/">Home</Link></li>
</ul>
<ul className="nav navbar-nav navbar-right">
</ul>
</div>
</div>
</nav>
);
}
}
```
### Index Page
In our ``MainPage`` notice the property ``this.props.children``. This will contain the components of the child routes that our router match. So if we had a route that looked like:
```html
<Route path='/' component={MasterPage}>
<Route path='/hello' component={HelloPage} />
</Route>
```
And we tried to access ``/hello``. The ``this.props.children`` array would be populated with a ``HelloPage`` component and for that reason, that component would be rendered on our master page.
Now imagine the scenario where you try to access ``/``. Without any ``this.props.children``, this would only render your master page but with empty content. This is where ``IndexRoute`` comes into play. With an ``IndexRoute`` you can specify the component that should be rendered when you hit the path of the master page route (in our case ``/``).
But before we add our ``IndexRoute`` to our router, let's create a new file in our ``pages`` directory named ``IndexPage.js`` and add the following to it.
```javascript
import { Link } from 'react-router';
import React, { PropTypes } from 'react';
import { LoginLink } from 'react-stormpath';
export default class IndexPage extends React.Component {
render() {
return (
<div className="container">
<h2 className="text-center">Welcome!</h2>
<hr />
<div className="jumbotron">
<p>
<strong>To my React application!</strong>
</p>
<p>Ready to begin? Try these Stormpath features that are included in this example:</p>
<ol className="lead">
<li><Link to="/register">Registration</Link></li>
<li><LoginLink /></li>
<li><Link to="/profile">Custom Profile Data</Link></li>
</ol>
</div>
</div>
);
}
}
```
Now let's add our ``IndexRoute``. Open up ``app.js`` and inside the tag ``<Route path='/' component={MasterPage}>`` add your ``IndexRoute`` so that it looks like the following:
```javascript
<Route path='/' component={MasterPage}>
<IndexRoute component={IndexPage} />
</Route>
```
### Login Page
We now have an application that shows a header with a default page. But we don't have any place to login yet. So let's create a new file named ``LoginPage.js`` and add some content to it:
```javascript
import React from 'react';
import DocumentTitle from 'react-document-title';
import { LoginForm } from 'react-stormpath';
export default class LoginPage extends React.Component {
render() {
return (
<DocumentTitle title={`Login`}>
<div className="container">
<div className="row">
<div className="col-xs-12">
<h3>Login</h3>
<hr />
</div>
</div>
<LoginForm />
</div>
</DocumentTitle>
);
}
}
```
Notice the ``LoginForm`` component. This is all we have to add in order for us to have a fully working form in which people can sign up from.
But before we can use it, we need to open up ``app.js`` and add a route for the page in our router. So inside the tag ``<Route path='/' component={MasterPage}>`` add the following:
```html
<LoginRoute path='/login' component={LoginPage} />
```
In order to be able to access the login page, we need to add this to our menu. So go ahead and open up ``Header.js`` and inside the element ``<ul className="nav navbar-nav navbar-right">`` add the following:
```html
<NotAuthenticated>
<li>
<LoginLink />
</li>
</NotAuthenticated>
```
As you can see we're using the ``NotAuthenticated`` component. With this we'll only show a ``LoginLink`` when the user isn't logged in yet.
### Registration Page
Now, let's add a page where people can sign up. We'll call it ``RegistrationPage``. So create a new file named ``RegistrationPage.js`` and put the following content in it:
```javascript
import React from 'react';
import DocumentTitle from 'react-document-title';
import { RegistrationForm } from 'react-stormpath';
export default class RegistrationPage extends React.Component {
render() {
return (
<DocumentTitle title={`Registration`}>
<div className="container">
<div className="row">
<div className="col-xs-12">
<h3>Registration</h3>
<hr />
</div>
</div>
<RegistrationForm />
</div>
</DocumentTitle>
);
}
}
```
Notice that we used the ``RegistrationForm`` component. As you might have guessed, this will render a Stormpath registration form. And once you've signed up it will point users to the login page where they'll be able to login.
In order to access this page. We need to add a route. So go ahead and open up ``app.js`` and inside the tag ``<Route path='/' component={MasterPage}>`` add:
```html
<Route path='/register' component={RegistrationPage} />
```
We now have a route, but people won't be able to find the page unless we link to it, so open up ``Header.js`` and add the following right before the closing tag ``(</ul>)`` of ``<ul className="nav navbar-nav navbar-right">``:
```console
<NotAuthenticated>
<li>
<Link to="/register">Create Account</Link>
</li>
</NotAuthenticated>
```
Notice the use of the ``NotAuthenticated`` component. With this we'll only show the ``/register`` link when the user isn't logged in.
### Profile Page
Once a user is logged in, we want to be able to show them some personalized content (their user data). So create a new file named ``ProfilePage.js`` and put the following code in it:
```javascript
import React from 'react';
import DocumentTitle from 'react-document-title';
import { UserProfileForm } from 'react-stormpath';
export default class ProfilePage extends React.Component {
render() {
return (
<DocumentTitle title={`My Profile`}>
<div className="container">
<div className="row">
<div className="col-xs-12">
<h3>My Profile</h3>
<hr />
</div>
</div>
<div className="row">
<div className="col-xs-12">
<UserProfileForm />
</div>
</div>
</div>
</DocumentTitle>
);
}
}
```
Notice that we use the ``UserProfileForm``. This is a simple helper form that allows you to edit the most basic user fields.
Though, in order to actually modify the user profile, we need to change a few things in our server. So open up ``server.js``, add ``var bodyParser = require('body-parser');`` to the top of the file and then add the following route underneath ``app.use(stormpath.init(app, ...));``:
```javascript
app.post('/me', bodyParser.json(), stormpath.loginRequired, function (req, res) {
function writeError(message) {
res.status(400);
res.json({ message: message, status: 400 });
res.end();
}
function saveAccount () {
req.user.givenName = req.body.givenName;
req.user.surname = req.body.surname;
req.user.email = req.body.email;
req.user.save(function (err) {
if (err) {
return writeError(err.userMessage || err.message);
}
res.end();
});
}
if (req.body.password) {
var application = req.app.get('stormpathApplication');
application.authenticateAccount({
username: req.user.username,
password: req.body.existingPassword
}, function (err) {
if (err) {
return writeError('The existing password that you entered was incorrect.');
}
req.user.password = req.body.password;
saveAccount();
});
} else {
saveAccount();
}
});
```
This will allow the form to change both the given name, surname, email and password of user. If you have additional fields that you wish to edit, then simply customize the ``UserProfileForm`` form and add the fields that you wish to edit in the route above.
Now, in order for us to access this page from the menu, open up Header.js and right below ``<li><Link to="/">Home</Link></li>`` add:
```html
<Authenticated>
<li>
<Link to="/profile">Profile</Link>
</li>
</Authenticated>
```
With this, using the Authenticated "https://github.com/stormpath/stormpath-sdk-react/blob/master/docs/api.md#authenticated) component, when we have a user session we'll render a link to the ``/profile page`` and allow our users to view their user profile.
In order for us to be able to access the page, we must as with the other pages add it to the router. Open up ``app.js`` and inside the tag ``<Route path='/' component={MasterPage}>`` add:
```html
<AuthenticatedRoute path='/profile' component={ProfilePage} />
```
Notice that we're using ``AuthenticatedRoute``. This is a route that can only be accessed if there is an authenticated user session. If there's no session, then the user will automatically be redirected to the path of the ``LoginLink``.
### Home Route
Now when we've setup most of our routing. Let's look at a special route called the ``HomeRoute``. This route itself doesn't do anything. But acts as a "marker", to indicate where to redirect to when logging in and logging out.
So in order to specify where we want to end up when we log out, open up ``app.js`` and change the:
```html
<Route path='/' component={MasterPage}>
...
</Route>
```
into:
```html
<HomeRoute path='/' component={MasterPage}>
...
</HomeRoute>
```
Now when logging out, the Stormpath SDK will know that it should redirect to the '/' path. Now, to specify where to redirect when logging out, change the ``AuthenticatedRoute`` that we created in the previous step:
```html
<AuthenticatedRoute path='/profile' component={ProfilePage} />
```
So that it looks like:
```html
<AuthenticatedRoute>
<HomeRoute path='/profile' component={ProfilePage} />
</AuthenticatedRoute>
```
Notice how the ``AuthenticatedRoute`` wraps the ``HomeRoute``. This is used to indicate the authenticated route that we want to redirect to after login.
### Logout
Finally, once our users have signed up and logged in. We want to give them the option to logout. Fortunately, adding this is really simple.
So open up ``Header.js`` and inside ``<ul className="nav navbar-nav navbar-right">`` add this code to the end:
```html
<Authenticated>
<li>
<LogoutLink />
</li>
</Authenticated>
```
Notice the ``LogoutLink`` component. Once this is clicked, the user session will be automatically destroyed and the user will be redirected to the unauthenticated ``HomeRoute``.
### User State in Components
Access user state in your components by requesting the authenticated and user context types:
```javascript
class ContextExample extends React.Component {
static contextTypes = {
authenticated: React.PropTypes.bool,
user: React.PropTypes.object
};
render() {
if (!this.context.authenticated) {
return (
<div>
You need to <LoginLink />.
</div>
);
}
return (
<div>
Welcome {this.context.user.username}!
</div>
);
}
}
```
### Import Components
To be able to reference our pages we need to import them. And in order to make importing easy, we'll put them all together in an ``index.js`` file so we only have to import it once. So let's create a new file named ``index.js`` in our pages directory and export all of our pages from it, as shown below:
```javascript
export MasterPage from './MasterPage'
export IndexPage from './IndexPage'
export LoginPage from './LoginPage'
export RegistrationPage from './RegistrationPage'
export ProfilePage from './ProfilePage'
```
With this, we'll only have to do one import in order to have access to all of our pages.
So let's do that. Open up app.js file and at the top of the file, add the following import statement:
```javascript
import { MasterPage, IndexPage, LoginPage, RegistrationPage, ProfilePage } from './pages';
```
### Run The Project
Now we have an application where our users can sign up, login, and show their user data. So let's try it out!
As before, start our server by running the following:
```console
$ node server.js
```
And if everything is running successfully you should be able to see this message:
```console
Listening at http://localhost:3000
```
So, open up ``http://localhost:3000`` in your browser and try it out!
### Wrapping Up
As you have seen in this tutorial, React is a really powerful tool and when used together with ES6, JSX and Stormpath, building apps suddenly becomes fun again.
If you have questions regarding the Stormpath React SDK, be sure to check out its API documentation.
Happy Hacking! | clintdev |
190,552 | Follow These Instructions and I guarantee you that You will get a high-paying job in 2019-20 | online presence If you are using http://Twitter.You are getting latest updates and in comm... | 0 | 2019-10-17T11:09:56 | https://dev.to/the_ibrahim_/follow-these-instructions-and-i-guarantee-you-that-you-will-get-a-high-paying-job-in-2019-20-5h02 | webdev, career, beginners, codenewbie |
##online presence
If you are using http://Twitter.You are getting latest updates and in common life you cannot talk to big names of dev community but with Twitter you can easily connect to big names like Chris courier,Sara Souiden.Other than 75% of companies post jobs on Twitter.There is a very large community working an Twitter called #100daysofcode.This hashtag helps junior web developers to debug their code and share their journey.
___
Your portfolio is minimal and easy to use. A contact form on your portfolio is a must have,it is the most easy way to connect to developer. Place a headshot picture on the portfolio.Your portfolio at least three projects of your own(No template).If these things are available in your portfolio**then no one can stop you to get job**Try to contribute to open source project and maintain your Github profile. Your code must be clean and readable. Try to use comment most of time and descriptive commits. 60% of recruiters give job to people by seeing their code on Github.
___
*Another*.Tip:Use personal domains like .com or .dev don,t use long domains or sub-domain like http://blabla.netlify.com .
___
##Blogging
You are using dev rightnow because dev is best posting or reading community. You can post article by this you can easily reach thousand of people. Start blogging right now. It can really get you a job.
___
You email must be simple. Never use any number in your email. Your email name will be professional if your portfolio domain is same as your email. If your name is it available you can simple adjectives like."Simple"or"Just"before your name.
___
This is my ordinary post if you want to read my other ordinary posts like this you can read then here:
- [https://dev.to/the_ibrahim_/my-bad-experience-with-bootstrap-details-about-bulma-css-framework-13p4](https://dev.to/the_ibrahim_/my-bad-experience-with-bootstrap-details-about-bulma-css-framework-13p4)
- [https://dev.to/the_ibrahim_/learn-git-and-github-in-just-1-article-1l7a](https://dev.to/the_ibrahim_/learn-git-and-github-in-just-1-article-1l7a)
- [https://dev.to/the_ibrahim_/css-positions-the-most-difficult-concepts-explained-in-a-very-simple-way-35ob](https://dev.to/the_ibrahim_/css-positions-the-most-difficult-concepts-explained-in-a-very-simple-way-35ob)
___
My name is Ibrahim shahid memon. I am a front-end web developer.I am following all of this instructions personally
___
I am kind a active an Twitter:[https://twitter.com/the_ibrahim_](https://twitter.com/the_ibrahim).
| the_ibrahim_ |
190,571 | My GitHub Graveyard 2019 | Following last year's trend, I've been reviewing my abandoned projects on GitHub. It has not been a g... | 0 | 2019-10-17T12:28:42 | https://dev.to/avalander/my-github-graveyard-2019-2569 | graveyard | ---
title: My GitHub Graveyard 2019
published: true
description:
tags: graveyard
---
Following [last year's trend](https://dev.to/avalander/my-github-graveyard-172b), I've been reviewing my abandoned projects on GitHub. It has not been a good year for personal projects, but I've managed to complete zero projects and abandon at least three, and I want to share the things that I have failed to build.
# Cookie Friend
[Cookie Friend](https://github.com/Avalander/cookie-friend) is a Firefox add-on to automate manual work on the arguably most famous online game ever: [Cookie Clicker](http://orteil.dashnet.org/cookieclicker/). I don't think I ever published it, but it was functional and had some neat tricks when I abandoned it.
# Meerkat
[Meerkat](https://github.com/Avalander/meerkat) was supposed to be a minimalist web framework. I implemented a very simple functional state management on top of [snabbdom](https://github.com/snabbdom/snabbdom). I wanted to change the virtual DOM library to [superfine](https://github.com/jorgebucaran/superfine) and iterate over the API for asynchronous effects, but at least I got it to work with a couple of simple examples.
# Minuette
[Minuette](https://github.com/Avalander/Minuette) is a Todo list CLI tool that I built to use as an example in my [Introduction to unit testing with tape](https://dev.to/avalander/introduction-to-unit-testing-with-tape-the-basics-1an5) series. I never published the second part of the series (maybe I'll do before the year ends). | avalander |
190,602 | Kubernetes Patterns : The Stateful Service Pattern | Stable Network Identity. If you have a pet, you must give it a name so that you can call it. Similarl... | 2,754 | 2019-10-17T13:03:06 | https://www.magalix.com | kubernetes, devops, docker, opensource | Stable Network Identity.
If you have a pet, you must give it a name so that you can call it. Similarly, a stateful application node must have a well-defined hostname and IP address so that other nodes in the same application knows how to reach it. A ReplicaSet does not offer this functionality as each Pod receives a random hostname and IP address when it starts or is restarted. In stateless applications, we use a Service that load-balances the Pods behind it and offers a URL through which you can reach any of the stateless Pods. In a stateful app, each node may want to connect to a specific node. A ReplicaSet cannot serve this purpose.
Learn more about Kubernetes Stateful Service Patterns: https://www.magalix.com/blog/kubernetes-patterns-the-stateful-service-pattern | ahmedat71538826 |
190,813 | 4 Steps to Self-Hosted Fonts in Gatsby | I finally got around to setting up fonts for my site, but everywhere I looked were articles that ove... | 0 | 2019-10-17T22:53:56 | https://compiledsuccessfully.dev/self-hosting-fonts-in-gatsby/ | react, css, javascript | I finally got around to setting up fonts for my site, but everywhere I looked were articles that overly complicated self-hosting fonts in Gatsby. Here's the easy 4-step process I used for my blog.
1 - place your font files in `static/fonts/`.
2 - create a `fonts.css` in the same directory and add your css font face rule(s). Mine looks like this:
```css
@font-face {
font-family: "Lato";
src: url("Lato-Regular.otf");
}
@font-face {
font-family: "Dank Mono";
src: url("DankMono-Regular.otf");
}
```
3 - add `gatsby-plugin-web-font-loader` with either npm or yarn (don't forget to `--save`!).
4 - add the plugin to your `gatsby-config.js` inside the plugins array. Here's mine:
```javascript
{
resolve: "gatsby-plugin-web-font-loader",
options: {
custom: {
families: ["Lato, Dank Mono"],
urls: ["/fonts/fonts.css"],
},
},
},
```
That's it! | iangloude |
190,933 | Console Games - Snake - Part 3 (Introducing a game timer) | The console snake game is progressing well. Based on where we got to on the last post, we had a game... | 2,556 | 2019-10-18T07:38:30 | https://www.pmichaels.net/2014/11/30/console-games-snake-part-3-introducing-a-game-timer/ | gamedev, csharp | The console snake game is progressing well. Based on where we got to on the <a href="http://pmichaels.net/2014/11/30/console-games-snake-part-2/">last post</a>, we had a game where the snake itself was behaving more or less as expected. The next task is to plant some food. In order to plant the food, we're going to need a game timer.
<strong>What is a game timer?</strong>
It's important to remember here that we're using this as a teaching device, so trying to introduce something like a System.Threading timer is not going to work because it's complicated to explain; additionally, one thing that I've learned from the small amount of game development that I've done is that the more control you have over your threads, the better. Since we already have a game loop, let's just use that. We currently have a function to accept user input and a function to update the screen; this time we need a function to update the game variables:
```csharp
private static DateTime nextUpdate = DateTime.MinValue;
private static bool UpdateGame()
{
if (DateTime.Now < nextUpdate) return false;
nextUpdate = DateTime.Now.AddMilliseconds(500);
return true;
}
```
Notice that we have an update variable to store the next update, and return a flag where we do update. The Main function would handle this like so:
```csharp
static void Main(string[] args)
{
Console.CursorVisible = false;
DrawScreen();
while (true)
{
if (AcceptInput() || UpdateGame())
DrawScreen();
}
}
```
So far, nothing concrete has changed. Let's use our new function to add some `food`. This is actually quite involved, because we need to translate Position to use a class, rather than a struct; here's why:
```csharp
private static DateTime nextUpdate = DateTime.MinValue;
private static Position _foodPosition = null;
private static Random _rnd = new Random();
private static bool UpdateGame()
{
if (DateTime.Now < nextUpdate) return false;
if (_foodPosition == null)
{
_foodPosition = new Position()
{
left = _rnd.Next(Console.WindowWidth),
top = _rnd.Next(Console.WindowHeight)
};
}
nextUpdate = DateTime.Now.AddMilliseconds(500);
return true;
}
```
We need to be able to signify that the food is nowhere (at the start, and after it's eaten). I tried to avoid bringing in classes at this stage, because they add complexity to an already complicated change; however, this seemed the cleanest and easiest solution at this stage.
There's some other changes to allow for the change to a class from a struct:
```csharp
private static bool AcceptInput()
{
if (!Console.KeyAvailable)
return false;
ConsoleKeyInfo key = Console.ReadKey();
Position currentPos;
if (points.Count != 0)
currentPos = new Position() { left = points.Last().left, top = points.Last().top };
else
currentPos = GetStartPosition();
switch (key.Key)
{
case ConsoleKey.LeftArrow:
currentPos.left--;
break;
case ConsoleKey.RightArrow:
currentPos.left++;
break;
case ConsoleKey.UpArrow:
currentPos.top--;
break;
case ConsoleKey.DownArrow:
currentPos.top++;
break;
}
points.Add(currentPos);
CleanUp();
return true;
}
```
This is because structs are immutable; meaning that we can take one, change it and add it to a collection without issue; but do that with a class and it changes the copied class.
We need to change the DrawScreen method to display the `food`:
```csharp
private static void DrawScreen()
{
Console.Clear();
foreach (var point in points)
{
Console.SetCursorPosition(point.left, point.top);
Console.Write('*');
}
if (_foodPosition != null)
{
Console.SetCursorPosition(_foodPosition.left, _foodPosition.top);
Console.Write('X');
}
}
```
Finally, the snake now needs to move based on the game timer. First, refactor the section of `AcceptInput` that actually moves the snake:
```csharp
private static bool AcceptInput()
{
if (!Console.KeyAvailable)
return false;
ConsoleKeyInfo key = Console.ReadKey();
Move(key);
return true;
}
private static void Move(ConsoleKeyInfo key)
{
Position currentPos;
if (points.Count != 0)
currentPos = new Position() { left = points.Last().left, top = points.Last().top };
else
currentPos = GetStartPosition();
switch (key.Key)
{
case ConsoleKey.LeftArrow:
currentPos.left--;
break;
case ConsoleKey.RightArrow:
currentPos.left++;
break;
case ConsoleKey.UpArrow:
currentPos.top--;
break;
case ConsoleKey.DownArrow:
currentPos.top++;
break;
}
points.Add(currentPos);
CleanUp();
}
```
Next, we'll just cache the key input instead of actually moving on keypress:
```csharp
static ConsoleKeyInfo _lastKey;
private static bool AcceptInput()
{
if (!Console.KeyAvailable)
return false;
_lastKey = Console.ReadKey();
return true;
}
```
And then handle it in the UpdateGame() method:
```csharp
private static bool UpdateGame()
{
if (DateTime.Now < nextUpdate) return false;
if (_foodPosition == null)
{
_foodPosition = new Position()
{
left = _rnd.Next(Console.WindowWidth),
top = _rnd.Next(Console.WindowHeight)
};
}
Move(_lastKey);
nextUpdate = DateTime.Now.AddMilliseconds(500);
return true;
}
```
Next time, we'll manage eating the food and collision detection.
<strong>GitHub</strong>
For anyone following these posts, I've uploaded the code so far to GitHub:
<a href="https://github.com/pcmichaels/ConsoleSnake">Git Hub Repository</a>
| pcmichaels |
191,062 | javascript variable declaration: var vs let vs const | We have 3 different ways to declare variables in java script var - Variables declared with var key... | 0 | 2019-10-18T11:07:49 | https://dev.to/sanjeevpanday/javascript-variable-declaration-var-vs-let-vs-const-3h5f | javascript, beginners, interview | We have 3 different ways to declare variables in java script
<ol>
<li><b>var</b> - Variables declared with var keyword are <strong>function scoped</strong>. What do I mean by that ? let's take an example -
<div class="highlight">
<pre class="highlight plaintext">
<code>
function sayHello(){
for(var i=0;i<4;i++){
console.log(i);
}
// As var is function scoped, i is available outside for loop.
console.log(i); // This prints 4.
}
sayHello();
</code>
</pre>
</div>
Here, i is declared with var keyword in a for loop ( block ) and it is incremented util i < 4. When i becomes 4, the for loop ends and the last console.log(i) is executed.
<strong>Output</strong>
<div class="highlight">
<pre class="highlight plaintext">
<code>
0
1
2
3
4
</code>
</pre>
</div>
Because of the var keyword, i is function scoped hence i is available outside the for loop as well and last console.log() prints 4.
</li>
<li><b>let</b> - This is part of ES6 and addresses the problem related to var keyword. Variables declared with <b>let</b> keyword are <strong>block scoped</strong>.
Let's consider the previous code with let
<div class="highlight">
<pre class="highlight plaintext">
<code>
function sayHello(){
for(let i=0;i<4;i++){
console.log(i);
}
// let is block scoped hence i is only visible inside for block.
console.log(i); // This line will throw an error.
}
sayHello();
</code>
</pre>
</div>
Because i is declared with let, i is visible inside the for loop only and the last console.log() will throw an error <b>ReferenceError: i is not defined</b>
<br>
<b>Output</b>
<div class="highlight">
<pre class="highlight plaintext">
<code>
0
1
2
3
Uncaught ReferenceError: i is not defined
at sayHello (<anonymous>:6:15)
at <anonymous>:8:1
</code>
</pre>
</div>
</li>
<li><b>const</b> - const keyword is used to define constants in java scripts and are block scoped. e.g.
<div class="highlight">
<pre class="highlight plaintext">
<code>
function sayHello(){
const i = 1;
console.log(i);// This prints 1
i = 2; // i is declared as constant hence this line will throw an error.
}
sayHello();
</code>
</pre>
</div>
if we try to reassign i with a different value within the same block then java script engine will throw an error <b>TypeError: Assignment to constant variable</b>
<br>
<b>Output</b>
<div class="highlight">
<pre class="highlight plaintext">
<code>
1
Uncaught TypeError: Assignment to constant variable.
at sayHello (<anonymous>:4:4)
at <anonymous>:6:1
</code>
</pre>
</div>
</li>
</ol>
<b>Conclusion:</b> With var keyword we may get unexpected output, so if the value of a variable is not expected to change then <b>const</b> keyword should be preferred else use <b>let</b> keyword to define variables.
Cheers!
| sanjeevpanday |
191,092 | How Business Intelligence Can Transform the Hotel Industry | The post briefly explain about business intelligence, the reason why the adoption of BI in the hotel industry is as important. Also, why do hotels need BI tools? | 0 | 2019-10-18T11:41:18 | https://dev.to/apptechblogger/how-business-intelligence-can-transform-the-hotel-industry-2mfk | businessintelligence | ---
title: How Business Intelligence Can Transform the Hotel Industry
published: true
description: The post briefly explain about business intelligence, the reason why the adoption of BI in the hotel industry is as important. Also, why do hotels need BI tools?
tags: Business Intelligence
---
Today, the world is brimming with countless technologically advanced tools that can transform a business, for the better of course. But there’s one name that seems to be on everyone’s mind these days — business intelligence. Primarily a collection of tools and infrastructure aimed at enabling a company to gather, store, and analyze the data from across all departments and operations, business intelligence serves to convert complex, fractured data into comprehensible insights and reports as well as detailed analysis that then help the organization’s top brass take informed decisions. Considering just what it can do, it isn’t surprising to see that business intelligence has found its way into the hotel industry as well.

Hospitality business intelligence is on the top of everyone’s list in the industry, at least for hotels that intend to forge a seamless path to a flourishing business. A study also found that as many as 96 percent hoteliers and other executives in the industry concede that business intelligence has proven to be extremely handy in the pursuit of their company’s business goals. Unfortunately, there are still some operators who continue to grapple with the decision to take the plunge. So, here’s a list of the top benefits preferred by hotel business intelligence to help you see why it belongs in your strategy as well.
1. **Gain a broader perspective**: Business intelligence helps hotels to compare their historical and present-day data with future projections, which, in turn, provides unfettered access to an all-encompassing view of the business. It not only enables more efficient operations but also allows companies to foretell any issues or challenges they are likely to face with the strategies and then take corrective actions.
2. **Explore data in-depth**: Yet another compelling benefit of BI is that it enables hotels to explore all their data far more extensively than previously possible. It includes not only guest data, staff data, and more but also things like reservation data, income expense sheets, and data gathered from POS systems. BI puts all of it together in a manner that helps companies identify limitations and deficiencies, if at all, and also introduce improvements in whatever aspects the company may so deem necessary.
3. **Shift to a sustainable business**: Among other things, BI helps hotels do things like identify the ROI of each source of transaction, adjust investments in said resources, and save valuable monetary resources in general. In addition to that, business intelligence helps hotels understand precisely where they stand in the market and the areas that offer scope for improvement, especially when compared to their primary rivals in the industry.
Suffice it to say that business intelligence comes loaded with immense potential in the context of the hotel industry. Just think about it — hotels generate a humongous amount of data daily and genuinely can’t stand to operate without a robust tool that can assist them with monitoring costs and keeping an eye on their inventories, supply chain among so many other things. And [BI software development](https://www.rishabhsoft.com/business-intelligence-services), when done right, can help hotels do so much more than make better decisions and cut their costs.
| apptechblogger |
191,211 | About Dr. Mark Fleckner | Dr. Mark Fleckner is a board-certified, fellowship-trained ophthalmologist who specializes in treatin... | 0 | 2019-10-18T16:25:24 | https://dev.to/mark_fleckner/about-dr-mark-fleckner-4a5o | Dr. Mark Fleckner is a board-certified, fellowship-trained ophthalmologist who specializes in treating diseases affecting the retina, such as diabetic retinopathy and macular degeneration. Dr. Mark Fleckner’s practice strives to ensure that patients are comfortable and well informed about their treatment.
Dr. Mark Fleckner completed his surgical vitreoretinal fellowship at Massachusetts Eye and Ear, a teaching hospital affiliated with Harvard Medical School. Prior to becoming a physician, Mark R Fleckner MD received a Bachelor of Arts degree in Economics from Duke University in 1989. Mark Fleckner went on to attend medical school at Tufts University School of Medicine, where he received his M.D. degree in 1993. Mark R Fleckner MD completed a residency in ophthalmology at the University of Medicine and Dentistry of New Jersey in 1997.
In 2016 and 2017, Dr. Mark Fleckner was recognized as a “Top Doctor” by Castle Connolly Medical Ltd., a healthcare research and information company that seeks to help guide consumers to the nation’s best physicians. Mark R Fleckner MD is also named on Newsday’s list of “Top Doctors on Long Island.” In addition to this recognition, Dr. Mark Fleckner was recently named to ""New York Super Doctors,"" a directory of outstanding physicians in various medical specialties published by MSP Communications.
Dr. Mark Fleckner has also been recognized as a ""Patients' Choice"" physician and a “Compassionate Doctor"" based on online patient reviews. Only physicians with excellent overall and bedside manner scores, as voted by their patients, are selected for these honors, according to the publisher.
Mark R Fleckner MD has shared his expertise with other doctors, lecturing to medical groups on diabetic eye disease and other topics. Mark Fleckner is a diplomate of the American Board of Ophthalmology and the National Board of Medical Examiners, and a Fellow of the American Academy of Ophthalmology and the American Medical Association. | mark_fleckner | |
191,242 | 5K followers?! What the heck peeps?! | I just wanted to thank everyone who hit the "follow" button, I can't believe 5.000 of you did that!... | 0 | 2019-10-18T18:30:58 | https://dev.to/deleteman123/5k-followers-what-the-heck-peeps-525g | discuss | ---
title: 5K followers?! What the heck peeps?!
published: true
description:
tags: #discuss
---
I just wanted to thank everyone who hit the "follow" button, I can't believe 5.000 of you did that! I'm not sure exactly what drove you into doing that, but I'll try to provide as much quality content as I can!
If there is anything specifically that made you follow me and you want more of it, leave a comment down below, you'd be helping me a lot!
BTW, I'm on [Twitter](http://twitter.com/deleteman123) as well, feel free to connect here too!
| deleteman123 |
191,262 | Mental Framework for Deriving Product from Open Source Project | My first memory of playing with a computer was via a MS-DOS terminal on the x86 PC in my grandfather'... | 0 | 2019-10-18T19:33:37 | https://coss.media/deriving-product-from-open-source/ | opensource, startup | My first memory of playing with a computer was via a [MS-DOS](https://en.wikipedia.org/wiki/MS-DOS) terminal on the x86 PC in my grandfather's pharmaceutical research lab in the early 90s – playing games stored on 3 1/2 floppy disks and doing [touch typing](https://en.wikipedia.org/wiki/Touch_typing) exercises. As technology improved, I would later spend an obscene amount of time taking the computer apart to add more RAM, a new graphic card, or a new fan, mostly so I could play cooler games. It was a fun, ongoing project, and I bonded with my father over it. It was also way cheaper than buying new computer.
What's the point of this story in the context of open source?
Well, even though I had no idea what "open source" was at the time, I was behaving like what a typical developer would do with open source projects today – spending free time to piece together and build things I want, sometimes for a specific goal, sometimes to learn new things, sometimes as a way to connect with others.
But over time, I stopped tinkering. For whatever reason, I decided that my time was becoming too "valuable" to retrofit my older computers. I started using a MacBook, and when my older MacBook wasn't functioning well, I just paid a pretty penny for a new one with better configurations, instead of unscrewing the bottom to see if I could jam in a new RAM card.
_My behavior became more akin to an enterprise buyer – saving time and trouble by spending money._
<h2>OSS Project != Product You Sell</h2>
If your experience with technology resembles mine in some way, then we all know intuitively that the _projects_ we [DIY](https://en.wikipedia.org/wiki/Do_it_yourself) with are not the same as _products_ we spend money buying.
This isn't a new observation in the open source community.
[Stephen Walli](https://stephesblog.blogs.com/about.html), an IT industry veteran and part of the [Open Container Initiative](https://www.opencontainers.org/), has written [numerous detailed blog posts](https://medium.com/@stephenrwalli) on this topic. [Sarah Novotny](https://sarahnovotny.com/about/), who led the Kubernetes community and was heavily involved in the NGINX and MySQL communities, [emphatically articulated](https://www.linkedin.com/pulse/personal-reflection-open-core-summit-kevin-xu/) at the inaugural [Open Core Summit](https://opencoresummit.com/#speakers) that the open source project a company shepherds and the product that company sells are two completely _different_ things.
Yet, project and product continue to get conflated by maintainers-turn-founders of commercial open source software (COSS) companies, especially (and ironically) when the open source project gets traction.
This mistake gets repeated, I believe, because it's hard to mentally conceptualize how and why a commercial product should be different, when the open source project is already being used widely.
<h2>What Makes a COSS Product Different?</h2>
Two core elements differentiate a commercial product from its open source root: packaged experience and buyer-specific features.
**_Packaged Experience_**
Packaging your project, so it has that out-of-the-box user experience, isn't just about a polished UI or hosting on your server as a SaaS (though that could be part of it). It's an expressed opinion of how you, the creator or maintainer of the project turned founder of the company, believe the technology should be used to solve your customer's business problem. That "opinion" is essentially the product experience the customer is paying for.
When you are running an open source community project, it's usually good to be _not_ opinionated and let your community organically flourish. When you are developing a product for customers, it's usually good to _be_ opinionated.
It's the retrofitted x86 PC versus the MacBook dynamic.
[Dave McJannet](https://founderrealtalk.ggvc.com/2019/04/25/episode-23-hashicorp-ceo-dave-mcjannet-reveals-the-secrets-of-commercializing-open-source-selling-to-enterprises-and-building-successful-relationships-with-founders/) (CEO of Hashicorp) and [Peter Reinhardt](https://www.youtube.com/watch?v=Q75V35unztw&feature=youtu.be) (CEO of Segment), both cited packaging as a crucial step to get right, in order to turn an open source project into a scalable commercial product.
**_Buyer-Specific Features_**
A well-packaged product must also have features that are necessary for your targeted buyer to justify a purchase. What these features are depend on the profile of your buyer, but the possibilities are finite and manageable.
An enterprise buyer, say a Global 2000, will have a relatively consistent set of features that they must have in order to purchase new products. ([EnterpriseReady.io](https://www.enterpriseready.io/#) is a great resource for what some of those features tend to be.)
A small or medium sized business buyer, say your local mom-and-pop bakery, who has less financial resources, less people power, and is more price sensitive will need different things to be convinced to buy.
A consumer service monetized via ads will be different still, where your buyer is the advertisers while your users are everyday people.
One thing is for sure: your buyer is almost never your open source community.
_Know what your buyer requires for a purchase, package that with your expert opinion on how to solve the buyer's problem, and that's what differentiates a product from a project._
Sid Sijbrandij's articulation of GitLab's [Buyer-based Open Core](https://www.youtube.com/watch?v=G6ZupYzr_Zg) model is a good example for enterprise.
{% youtube G6ZupYzr_Zg %}
Certainly, other elements can be added to further the differentiation. But a packaged experience with buy-specific features are essential. Without one or the other, your prospective customer might as well just tinker on their own, for free.
**_One Metric to Measure (OMTM): Time-to-Value_**
A perennially difficult thing in product development is measuring progress and establishing a data-driven framework to determine whether you are on the right path or not. I'm a fan of the One Metric to Measure (OMTM) mentality, elaborated in "[Lean Analytics](http://leananalyticsbook.com/)", where you focus on one single number above everything else for your current stage. This approach enforces focus and discipline, among a sea of data you can gather and distract yourself with (oftentimes vanity metrics like download numbers or GitHub stars). The single metric can effectively rally your entire company around one tangible goal or mission – especially critical for an early stage company. And the metric you focus on will be different at different stages.
So what's the right OMTM in the early day of your product development?
I propose: **Time-to-value**
"Time" here is straight forward – lower the better.
"Value" needs precise, rigorous definition that is technology and problem specific. Your distributed database is valuable because it can serve data with no down time when servers fail. Your continuous integration tool is valuable because it enables application developers to push improvements faster without breaking the application itself. You get the idea.
How quickly can a customer see or feel that one core piece of value is what you measure and optimize for. What is a sufficiently short enough time does depend on the use case, but given the increasing consumerization of enterprise technology, any product's time-to-value that's > 30 minutes is probably too long.
Finding and tightly defining that "value" is hard and iterative, but also table stakes if you are looking to build a product company around an open source project. Without a deep understanding of what that value is for your customer, there's probably not much of a company to build.
At the end of the day, as much fun as it was to "beef up" my x86 PC, I'm pretty satisfied with my MacBook and happy to pay the premium. So don't get too enamored with the joy of tinkering, if your goal is actually to sell MacBook. | kevinsxu |
191,276 | Hellow Lit-Element and React | Hi everyBody ;u I'm studing how web frameworks interop Last sunday I tried to figure how to use Rea... | 0 | 2019-10-18T19:55:55 | https://dev.to/sdyalor/hellow-lit-element-and-react-31mp | litelement, react, webcomponents, pwastarterkit | Hi everyBody ;u
I'm studing how web frameworks interop
Last sunday I tried to figure how to use [React-Datasheet](https://stackoverflow.com/questions/58110516/recomendation-eficient-spreadsheet-like-library-for-object-manipulation-in-java "Spreadsheet for Javascript") (link to spreadsheets like in javascript) with lit-element from [pwa-starter-kit](https://github.com/Polymer/pwa-starter-kit)
Well, React Dom works fine inside a ShadyDom, but I got [issues](https://github.com/nadbm/react-datasheet/issues/172) with how react library has been implemented. The component world helped me with already done work but that just as I needed React encapsulation.
To implement React Components inside Lit-Element(lit-html,customElement+shadyDom) is posible?
There is a considerations that I figure out reactComponents need to have
- dependencies: global objects
How to tell the webcomponent that document object is now the shadowRoot ;c
| sdyalor |
191,306 | Alligator's hunter way to print PDF on the client-side | Introduction I am working on a project in Vue, from which came the need to generate a cli... | 0 | 2019-10-18T21:45:51 | https://dev.to/wakeupmh/alligator-s-hunter-way-to-print-pdf-on-the-client-side-k86 | vue, javascript, todayilearned, todayisearched | ## Introduction

I am working on a project in **Vue**, from which came the need to generate a client-side pdf, so after some research I discovered these two ways, which I found more comfortable, one of them uses a **npm module** and the other is root style with the **window object**.
## Lets go to what matters

Assuming we have a component with a stylized table by [boostrap]([https://getbootstrap.com/docs/4.3/content/tables/](https://getbootstrap.com/docs/4.3/content/tables/)):
```vue
<template>
<table class="table-striped">
<thead>
<tr>
<td colspan="10"> My action table </td>
</tr>
</thead>
<tbody>
<tr>
<td> Jump </td>
<td> Wash the dishes </td>
<td> Fix the computer</td>
</tr>
</tbody>
</table>
</template>
<script>
import './index.css'
export default{
methods: {
generatePDF(){
...our solution goes here
}
}
}
</script>
```

### First Solution - NPM MODULE
For this we need to install the module [**jsPDF**]([https://www.npmjs.com/package/jspdf](https://www.npmjs.com/package/jspdf)), and [**html2canvas**](https://www.npmjs.com/package/html2canvas) as a dependecy.
**NPM**
npm i --save jspdf html2canvas
**YARN**
yarn add jspdf html2canvas
#### Applying the solution on the method generatePdf():
**html2canvas** *is not explicitly depended* on the **jsPDF** documentation to generate the pdf, because it converts our node element into a canvas and then generates the pdf for download, but also the possibility of adding a text, an image, you can see more [here](https://rawgit.com/MrRio/jsPDF/master/docs/) in jsPDF full documentation.
```vue
//...previous stuffs of the component
<script>
import './index.css'
import * as jsPDF from 'jspdf'
import html2canvas from 'html2canvas'
export default{
methods: {
generatePDF(){
window.html2canvas = html2canvas
let table = document.querySelector('table')
const doc = new jsPDF(); doc.html(table,{
callback: doc => {
doc.save('MyPdf.pdf')
}
}
}
}
}
</script>
```
### Last Solution
This is the simplest and purest way to print, but it is a bit more work, since to get the *background-color* of an element you need to implement a *polyfill* with **media query**, because **print()** doesn't supports *background-color* 😅
Let's suppose you also have some element **you don't want to appear in your print,** you can set it to *display none* only when printing.
In your **css** or **scss** you need to add if you want a background-color in some element:
```css
@media print {
thead{
box-shadow: inset 0 0 0 1000px #b9d1ea !important;
}
someElement{
display:none;
}
}
```
In your **script**:
```vue
//...previous stuffs of the component
<script>
import './index.css'
export default{
methods: {
generatePDF(){
window.print() //simple like that
}
}
}
</script>
```
The **print()** method prints the contents of the current window.
The **print()** method opens the *Print Dialog Box*, which lets the user to select preferred printing options.

#### I hope this post helps you in your daily endeavor, for today is only and until the next 🍻
 | wakeupmh |
191,373 | CSS3 in 10 days — Day 1 | Most of the time, we developers struggle with CSS and take the help of some CSS framework like bootst... | 2,824 | 2019-10-19T04:42:39 | https://nabendu.blog/posts/css3-in-10-days-day-1-23da/ | css, webdev, tutorial, beginners | Most of the time, we developers struggle with CSS and take the help of some CSS framework like bootstrap or foundation. Nothing wrong in using them, but then you start to struggle in CSS and when some CSS bug or issue comes, we tend to go to that person in our team who is good in CSS.
To master CSS, the best was is to use it. So, this tutorial contains some practical examples which you can learn and directly use in your projects. This series is inspired by [this](https://www.youtube.com/watch?v=pmKyG3NBY_k&list=PLWKjhJtqVAbl1AfjiGyYxwpdAPi5v-1OU) awesome youtube series in freecodecamp channel.
We will be using this simple html markup and will style it. So, go ahead and open your favorite editor and create a file **index.html** in it, with below content.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>CSS3 Fancy Buttons | Code 10 Things in 10 Days with CSS3</title>
<link rel="stylesheet" href="sandbox.css">
<link href="https://fonts.googleapis.com/css?family=Bubblegum+Sans|Nova+Mono|Roboto+Condensed" rel="stylesheet">
</head>
<body>
<h1><small>Day #1</small> CSS3 Fancy Buttons</h1>
<div class="sandbox">
<h2>Sandbox <small>This is where you play</small></h2>
<div class="content">
<p><strong>Instructions:</strong> Use CSS3 to create visually attractive buttons of all different shapes, sizes
and effects!</p>
<section>
<h4>Facebook Style</h4>
<button type="button" name="button" class="facebook-style-btn facebook-style-dark">Button Dark</button>
<button type="button" name="button" class="facebook-style-btn facebook-style-light">Button Light</button>
</section>
<section>
<h4>3D Buttons</h4>
<button type="button" name="button" class="btn-3d-1">3D Button 1</button>
<button type="button" name="button" class="btn-3d-2">Circle!</button>
</section>
<section>
<h4>Gradient Bordered Buttons</h4>
<button type="button" name="button" class="gradient-button-1">Gradient button 1</button>
<button type="button" name="button" class="gradient-button-2">Gradient button 2</button>
</section>
<section>
<h4>Animated Buttons</h4>
<button type="button" name="button" class="animated-button-1">Animated button 1</button>
<button type="button" name="button" class="animated-button-2">Animated button 2</button>
</section>
<section>
<h4>Toggle Switch UI Buttons</h4>
<label for="toggle1" class="toggle-1">
<input type="checkbox" id="toggle1" class="toggle-1__input" />
<span class="toggle-1__button"></span>
</label>
<label for="toggle2" class="toggle-2">
<input type="checkbox" id="toggle2" class="toggle-2__input" />
<span class="toggle-2__button">Click me to activate</span>
</label>
</section>
</div>
</div>
</body>
</html>
Next create an empty **sandbox.css** in the same directory. Let’s style the facebook style buttons first.
.facebook-style-btn{
border-radius: 2px;
font-size: 0.9rem;
padding: 6px 12px;
}
And now our index.html looks like below in browser.
*facebook style buttons*
Next we will add more styles to the first button.
.facebook-style-dark{
box-shadow: inset 0 1px 0 0 #4d73bf;
background: #4267b2;
border: solid 1px #4267b2;
color: white;
text-shadow: 0 1px 0 #3359a5;
}
.facebook-style-dark:hover{
background: #2b54a7;
}
.facebook-style-dark:active{
background: #1d4698;
border-color: #1d4698;
}
Now, our dark button looks like below and have a hover and active state also.
*facebook dark button*
Now, let’s also add styles for the facebook light button.
.facebook-style-light{
background: #f6f7f9;
border: 1px solid #ced0d4;
color: #4b4f56;
}
.facebook-style-light:hover{
background: #e9ebee;
}
.facebook-style-light:active{
background: #d8dade;
border-color: #d8dade;
}
And our light button looks like.
*Facebook light*
Now, we will style some cool 3d buttons. Will update the css as below.
.btn-3d-1 {
position: relative;
background: orangered;
border: none;
color: white;
padding: 15px 24px;
font-size: 1.4rem;
box-shadow: -6px 6px 0 hsl(16, 100%, 30%);
outline: none;
}
.btn-3d-1:hover {
background: hsl(16, 100%, 45%);
}
.btn-3d-1:active {
background: hsl(16, 100%, 40%);
top: 3px;
left: -3px;
box-shadow: -3px 3px 0 hsl(16, 100%, 30%);
}
Once we click on it the will sort of move down. This is because we have made the position:relative and on active, we have set top to 3px and left to -3px. It will move because of that.
*3D button*
Now, there is one thing missing in the above 3D button and that is , the edges of shadows are not matching with the button. We will do the same by creating a small triangle and moving, it to that spot. We will use the ::before and ::after to create those two triangle.
.btn-3d-1::before {
position: absolute;
display: block;
content: "";
height: 0;
width: 0;
border: solid 6px transparent;
border-right: solid 6px hsl(16, 100%, 30%);
border-left-width: 0px;
background: none;
top: 0px;
left: -6px;
}
.btn-3d-1::after {
position: absolute;
display: block;
content: "";
height: 0;
width: 0;
border: solid 6px transparent;
border-top: solid 6px hsl(16, 100%, 30%);
border-bottom-width: 0px;
background: none;
right: 0;
bottom: -6px;
}
.btn-3d-1:active::before {
border: solid 3px transparent;
border-right: solid 3px hsl(16, 100%, 30%);
border-left-width: 0px;
left: -3px;
}
.btn-3d-1:active::after {
border: solid 3px transparent;
border-top: solid 3px hsl(16, 100%, 30%);
border-bottom-width: 0px;
bottom: -3px;
}
We will now see the proper button, with edges connected.
*3D button final*
Next, we will start the second 3D button, which will be a round button with push capabilities. Add the below code to our CSS.
.btn-3d-2 {
position: relative;
background: #ecd300; /* For browsers that do not support gradients */
background: radial-gradient(hsl(54, 100%, 50%), hsl(54, 100%, 40%)); /* Standard syntax */
font-size: 1.4rem;
text-shadow: 0 -1px 0 #c3af07;
color: white;
border: solid 1px hsl(54, 100%, 20%);
border-radius: 100%;
height: 120px;
width: 120px;
z-index: 4;
outline: none;
box-shadow: inset 0 1px 0 hsl(54, 100%, 50%),
0 2px 0 hsl(54, 100%, 20%),
0 3px 0 hsl(54, 100%, 18%),
0 4px 0 hsl(54, 100%, 16%),
0 5px 0 hsl(54, 100%, 14%),
0 6px 0 hsl(54, 100%, 12%),
0 7px 0 hsl(54, 100%, 10%),
0 8px 0 hsl(54, 100%, 8%),
0 9px 0 hsl(54, 100%, 6%);
}
Now, the button looks like.
*CIrcle 3D*
Now, we will add hover effect and active effect to our 3D circle.
.btn-3d-2:hover {
background: #ecd300;
background: radial-gradient(hsl(54, 100%, 45%), hsl(54, 100%, 35%));
}
.btn-3d-2:active {
background: #ecd300;
background: radial-gradient(hsl(54, 100%, 43%), hsl(54, 100%, 33%));
top: 2px;
box-shadow: inset 0 1px 0 hsl(54, 100%, 50%),
0 2px 0 hsl(54, 100%, 20%),
0 3px 0 hsl(54, 100%, 18%),
0 4px 0 hsl(54, 100%, 16%),
0 5px 0 hsl(54, 100%, 14%),
0 6px 0 hsl(54, 100%, 12%),
0 7px 0 hsl(54, 100%, 10%);
}
Now, when you click on the circle button, the top 2px will come to play and in box-shadow, we have reduced two layers. So, it will show the pressed state.
Now, we will move to Gradient bordered buttons. We will start with the CSS for button 1.
.gradient-button-1 {
position: relative;
z-index: 1;
display: inline-block;
padding: 20px 40px;
font-size: 1.4rem;
box-sizing: border-box;
background-color: #e7eef1;
border: 10px solid transparent;
** border-image: linear-gradient(to top right, orangered, yellow);
border-image-slice: 1;**
color: orangered;
}
.gradient-button-1:hover {
background-image: linear-gradient(to top right, orangered, yellow);
color: white;
}
Here, one of the important properties are the highlighted one. They are the property which makes the outline border in the button.
*Gradient button*
On hover we fill the button with the hover property.
*Gradient button hover*
Now, we will make the gradient button 2. It will be completely same as button 1.
.gradient-button-2 {
position: relative;
z-index: 1;
display: inline-block;
padding: 20px 40px;
font-size: 1.4rem;
box-sizing: border-box;
background-color: #e7eef1;
border: 4px solid transparent;
** border-image: linear-gradient(to right, orangered, transparent);
border-image-slice: 1;**
color: orangered;
}
.gradient-button-2:hover {
background-size: 100%;
background-image: linear-gradient(to right, orangered, transparent);
**border-right-style: none;**
color: white;
}
And the button looks like below. The difference comes from the **to right** in **border-image**.
*Gradient button 2*
Also, on hovering we have set **border-right-style: none**, which results in below.
*Gradient button 2 hover*
Now, we will start with our animation buttons. Let’s start with button 1. In this we will be using a pattern image and when, we hover over the button, the pattern will move.
.animated-button-1 {
position: relative;
display: inline-block;
padding: 20px 40px;
font-size: 1.4rem;
background-color: #00b3b4;
background-image: url(pattern.png);
background-size: 40px 40px;
border: 1px solid #555;
color: white;
transition: all 0.3s ease;
}
.animated-button-1:hover {
animation: loading-button-animation 2s linear infinite;
}
@keyframes loading-button-animation {
from {
background-position: 0 0;
}
to {
background-position: 40px 0;
}
}
For the pattern to move, we are using the @keyframes from animation and moving the background.
*Animation button 1*
Now, we will do the animation button 2. We will be doing this animation without any keyframe animation.
.animated-button-2 {
position: relative;
display: inline-block;
padding: 20px 40px;
font-size: 1.4rem;
background-color: #00b3b4;
background-size: 20px 20px;
border: 1px solid #555;
color: white;
transition: all 0.3s ease;
}
.animated-button-2:after {
position: absolute;
top: 50%;
right: 0.6em;
transform: translate(0, -50%);
content: "»";
**opacity: 0;**
transition: all 0.3s ease;
}
.animated-button-2:hover {
padding: 20px 60px 20px 20px;
}
.animated-button-2:hover:after {
right: 1.2em;
**opacity: 1;**
}
But, with the help of opacity of an after element “»” set to 0.
*Before hovering*
And when we hover over the button, we shift some padding and make the **opacity: 1** for element “»”.
*Animated arrow*
We will next make our toggle UI buttons. But if we look at our html, it is actually checkbox and we are transforming it to look like a button.
<label for="toggle1" class="toggle-1">
<input type="checkbox" id="toggle1" class="toggle-1__input" />
<span class="toggle-1__button"></span>
</label>
The CSS for the toggle button is below.
.toggle-1 {
font-family: Helvetica, Arial, sans-serif;
display: inline-block;
vertical-align: top;
margin: 0 15px 0 0;
}
.toggle-1__input {
display: none;
}
.toggle-1__button {
position: relative;
display: inline-block;
font-size: 14px;
line-height: 20px;
text-transform: uppercase;
background-color: #f2395a;
border:1px solid #f2395a;
color: #ffffff;
width: 80px;
height: 30px;
transition: all 0.3s ease;
cursor: pointer;
}
.toggle-1__button:before {
position: absolute;
top: 6px;
left: 40px;
right: auto;
display: inline-block;
height: 20px;
padding: 0 3px;
background-color: #ffffff;
color: #f2395a;
content: "off";
transition: all 0.3s ease;
}
.toggle-1__input:checked + .toggle-1__button {
background-color: #00b3b4;
border:1px solid #00b3b4;
}
.toggle-1__input:checked + .toggle-1__button:before {
left: 5px;
content: "on";
color: #00b3b4;
}
As evident from the above everything including the on and off are created from CSS.
*Toggle Off*
*Toggle on*
Last, we will create the toggle button 2. It will also be a checkbox.
<label for="toggle2" class="toggle-2">
<input type="checkbox" id="toggle2" class="toggle-2__input" />
<span class="toggle-2__button">Click me to activate</span>
</label>
The CSS for toggle button 2 will be below.
.toggle-2 {
font-family: Helvetica, Arial, sans-serif;
font-size: 1rem;
display: inline-block;
vertical-align: top;
margin: 0 15px 0 0;
}
.toggle-2__input {
display: none;
}
.toggle-2__button {
position: relative;
display: inline-block;
line-height: 20px;
text-transform: uppercase;
background-color: #ffffff;
color: #aaaaaa;
border: 1px solid #cccccc;
padding: 5px 10px 5px 30px;
transition: all 0.3s ease;
cursor: pointer;
}
.toggle-2__button:before {
position: absolute;
top: 10px;
left: 10px;
right: auto;
display: inline-block;
width: 10px;
height: 10px;
background-color: #cccccc;
content: "";
transition: all 0.3s ease;
}
.toggle-2__input:checked + .toggle-2__button {
background-color: #00b3b4;
border-color: #00b3b4;
color: #ffffff;
}
.toggle-2__input:checked + .toggle-2__button:before {
background-color: #ffffff;
}
Here, we have a nice clickable button.
*Clickable toggle button*
On click of the button will change background.
*Toggle button 2 changed.*
This concludes Day-1 in which we learned to create different type of buttons. You can find the code for the above in this github [link](https://github.com/nabendu82/CSS10days).
| nabendu82 |
191,400 | Creating my side-project in 2 weeks - day 1 | Intro: Hello guys, this is currently my first post on DEV. So let’s start! 📌 Warning: i’m not a prof... | 0 | 2019-10-22T20:27:23 | https://dev.to/tomlienard/creating-my-side-project-in-2-weeks-day-1-1f49 | laravel, vue, design | **Intro:**
Hello guys, this is currently my first post on DEV. So let’s start!
📌 **Warning:** i’m not a professionnal developer and designer. I’m just a 17 years old boy who’s enchanted by dev technologies and wants to share my work. If you find issues and improvements, feel free to tell me!
PS: i’m french so maybe my english will be terrible sometimes - apologise for this.
# **Creating my side-project in 2 weeks**
## **First day: the basics**
**What’s my project idea?**
Let’s begin with the basics. I got the idea one day to have a web application that can be like a draft board, where you can add post-it and arrows etc. It’s already exist but not exatly like in my awesome brain.
So with this idea, i started thinking about the name of the application, and found **Shineboard** - shine because it’s pretty cool and board cause it’s will be like a board. Convinced by this name, i bought the domain name [shineboard.io] (https://shineboard.io) at [OVH] (https://ovh.com), created the [Twitter] (https://twitter.com/Shineboardapp) account and ordered a VPS at [DigitalOcean] (https://digitalocean.com) to host the app.
**What is the goal of this post?**
I don't want to make a step-by-step tutorial on how i'm going to create this app, simply showing you the advancement every days.
I'm not going to create a full application - basically because it's impossible in 2 weeks, "simply" the [MVP] (https://en.wikipedia.org/wiki/Minimum_viable_product)
**Which framework/technologies?**
I choose to use **Laravel** for the backend cause it’s in PHP - ❤️ - and it’s just so well documented and builded (also i have already experiences with it). And for the frontend ? I wanted to make the application a **SPA** so i started looking around for a framework that can handle this, and found that **VueJS** also can be a SPA with the help of VueRouter and Vuex - and that’s good because i also have experiences with it.
**Preparing the terrain**
I created the gitlab repository, which only contains a fresh Laravel application with basic login, using VueRouter for the SPA.
I started creating a basic ui library for buttons, inputs etc. And because i enjoyed building theses components, i created the starting of a landing page. Here is the result on mobile, i’m pretty happy with the design (of course it’s not the final design, there will be a lots of improvements).
**Next day**
Next day i’m going to create a first card design, and search to create a draggable effect for theses.
| tomlienard |
191,468 | Flutter: First steps and tips | In short Flutter is a Framework to write to iOS and Android from a single codebase. While my little O... | 0 | 2019-10-19T13:14:55 | https://dev.to/tasaquino/flutter-first-steps-and-tips-enf | flutter, dart, ci, firebase | In short Flutter is a Framework to write to iOS and Android from a single codebase.
While my little Olivia sleeps 👧 , decided to share a little bit more about Flutter and my experiences.
##Why use Flutter?
Giving the options to write mobile apps using a multi-platform approach, Flutter has some attractive characteristics. You can easily create beautiful UI designs and smooth animations. With the use of Hot Reload and Hot Restart you get a fast development cycle. One single codebase, assuring quality and performance, is compiled to native machine code for each platform.
At this moment, Google Play Instant is not possible with Flutter. But Android App Bundle (AAB) and Dynamic Delivery works since Flutter 1.2. If you do need some specific feature for your app is important to research about it.
##Widgets, Reactive Framework and App Structure
Each view is built as an immutable tree of widgets. Almost everything in Flutter is a Widget (you will hear this a lot!). As you may know, Flutter uses declarative UI, so you don’t have a separate file (like xml for Android world) to create your UI, widgets, alignment, paddings… everything you create using Dart.
When a widget state changes because of user inputs (actions), for example, the widget rebuilds itself to handle the new state (reaction). You don’t have to write extra code to update the UI once the state changes.
The rendering engine is part of your app, you don’t need to bridge the UI rendering code to the native platform. It is built in Skia, a 2D graphics rendering library. It display widgets for both iOS and Android devices. The iOS and Android platforms just have to provide a canvas to place the widgets on and rendering engine inside.
######Flutter layers and Engine

######Flutter app (single codebase), rendering happens in the platform canvas and device services are accessed using Platform Channels
######Without Flutter… Common Native development app structures (separate codebase)
##Why Dart?

One of the concerns about adopting a different approach to write apps is to maybe have to learn another language.
Dart is similar to any languages you may have experienced in your life (Java, Kotlin, Swift, C#…).
Concise, strongly typed, object-oriented language. For mobile development concerns, Dart is performant in development and in production, supports JIT (just-in-time) and AOT (ahead-of-time) compilation.
JIT give powers to Flutter to recompile directly on the device while the app is running (Hot Reload). AOT enables the compilation to native ARM code, so the resulting native code starts quickly and performant.
From Flutter FAQ: https://flutter.dev/docs/resources/faq#why-did-flutter-choose-to-use-dart
##Flutter cool tools
*Hot Reload* as mentioned before, helps you make changes in your code and easily get them deployed into your device without waiting (less coffee time for you 😅).
*Hot Restart* after the first time you deploy to your device or emulator, the subsequent will be faster.
*Widget inspector* is a tool for visualizing and exploring Flutter widget trees. This helps you understand existing layouts and find layout issues.

##State Management
This is a hot subject in Flutter development. Since the UI depends on states, you need to be aware of how it works and to not mess with rebuilding all widgets every time. And also how to share data and state between the screens in your app.
######From official Flutter doc https://flutter.dev/docs/development/data-and-backend/state-mgmt/intro
There are some approaches you can study to chose the best that suits your app needs.
* Scoped Model
* Redux
* BLOC
* InheritedWidgets
Will let references for great content that helped me:
[Official doc about state mgmt](https://flutter.dev/docs/development/data-and-backend/state-mgmt/intro?source=post_page-----df0c895a92ca----------------------)
[Official doc about state mgmt approaches](https://flutter.dev/docs/development/data-and-backend/state-mgmt/options?source=post_page-----df0c895a92ca----------------------)
[Streams BLOC](https://www.didierboelens.com/2018/12/reactive-programming---streams---bloc---practical-use-cases/?source=post_page-----df0c895a92ca----------------------)
[BLOC, Scoped Model and Redux comparison](https://www.didierboelens.com/2019/04/bloc---scopedmodel---redux---comparison/?source=post_page-----df0c895a92ca----------------------)
##Add Flutter modules to Android/iOS apps
Maybe you already have an Android or iOS app and is considering to add Flutter to a particular feature, just a piece of your app to test how it works and have a POC running in production. This is possible and will let the reference for the guide here:
Please be aware that this is a work in progress as the document tells itself.
[Add Flutter modules to existing apps](https://github.com/flutter/flutter/wiki/Add-Flutter-to-existing-apps?source=post_page-----df0c895a92ca----------------------)
##Flutter Flavors
Is possible to setup Flavors for whatever the reasons you have (different distribution/environments…). In my case I needed to setup different environments each one with its own Firebase/Firestore project.
You need to configure Android Flavors and iOS Schemes separately. These are the references I used, but had to find my own way since the iOS configuration was not in all of the references.
[Flavoring Flutter](https://medium.com/@salvatoregiordanoo/flavoring-flutter-392aaa875f36?source=post_page-----df0c895a92ca----------------------)
[Flutter ready to go](https://medium.com/flutter-community/flutter-ready-to-go-e59873f9d7de?source=post_page-----df0c895a92ca----------------------)
[Build flavors in flutter with different firebase projects](https://medium.com/@animeshjain/build-flavors-in-flutter-android-and-ios-with-different-firebase-projects-per-flavor-27c5c5dac10b?source=post_page-----df0c895a92ca----------------------)
This last one ☝️really helped me with iOS part… As an Android developer I struggle a little bit to setup all the configuration for the schemes. But in the end was just the matter of understanding how it works.
##Continuous Integrations and Continuous delivery (CI/CD)
I’ve seen some tools that are more Flutter friendly, like CodeMagic and BitRise. I didn’t use any of these, but their documentation seems to be strait forward.
What I do have experience is configuring the environment for Flutter CI/CD in CircleCI. I was able to setup flavors/schemes in the project, for example to have a development, beta and production environment.
Configured a workflow with jobs to run Flutter Unit Tests, generate iOS beta/prod and Android beta/prod.
For iOS used a mac instance, installed flutter, Fastlane, Firebase CLI and added the necessary configuration to build and archive to submit the ipa with the specific flavor to Firebase App Distribution.
For Android used a docker image that already have flutter installed cirrusci/flutter. Installed Fastlane, Firebase CLI and added the necessary steps to generate an apk for the flavors needed.
Here is my gist to help with all these configurations:
{% gist https://gist.github.com/tasaquino/1b9c28aaad352a22b2bd6908f7ac8a50 %}
##Dart Obfuscation
Is really simple to configure, but be aware of some issues that some people in the community already shared. Some references about it:
[Obfuscating Dart Code](https://github.com/flutter/flutter/wiki/Obfuscating-Dart-Code?source=post_page-----df0c895a92ca----------------------)
[How to Obfuscate Flutter](https://stackoverflow.com/questions/50542764/how-to-obfuscate-flutter-apps?source=post_page-----df0c895a92ca----------------------)
Now I need to sleep 😴 If something is missing or I find anything else that can helps will post another time.
Thank you for reading! 😉
| tasaquino |
191,520 | [Go] Speed up your refactoring with GoLand | This is a video demo, how to use different refactoring feature in GoLand to speed up you producti... | 0 | 2019-10-19T15:34:32 | https://dev.to/julianchu/speed-up-your-refactoring-with-goland-7ei | go, goland, refactoring |
{% youtube oCgoxqDS2tM %}
This is a video demo, how to use different refactoring feature in GoLand to speed up you productivity when doing refactor.
Original example is from "extract variable" section of refactoring 2/e.
Rewriting it with golang.
# Code smells:
1. magic number
2. comments don't match code behavior
# Refactoring features:
1. extract variable(ctrl+alt+v)/ extract const(ctrl+alt+c)
2. extract method(ctrl+alt+m)
3. inline variable(ctrl+alt+n)
4. move method to struct(manual)
5. move struct and receiver functions(F6)
more useful features in GoLand: [top 25 editing features of goland](https://blog.jetbrains.com/go/2019/10/04/top-25-editing-features-of-goland-ide-part-1/?fbclid=IwAR125gX08h1OjIrr2bD55JyT4ptmBYs5yIMT3YZc_mlu6zdi7Jfbi5PEoFc) | julianchu |
191,872 | Easy Model Validator csharp | An easy method of validating any object by using validation attributes outside of the MVC context | 0 | 2019-10-20T14:27:13 | https://dev.to/alialp/easy-model-validator-c-sharp-3a3m | webdev, csharp, beginners, productivity | ---
title: Easy Model Validator csharp
published: true
description: An easy method of validating any object by using validation attributes outside of the MVC context
tags: webdev, csharp , beginners , productivity
cover_image: https://thepracticaldev.s3.amazonaws.com/i/t7sfacwbua66lgv67nqc.jpg
---
This article will explain a cool way of validating a model or any object by using the Validation attributes To validate a Model in MVC you make use of [Model Validation Attributes](https://docs.microsoft.com/en-us/aspnet/core/mvc/models/validation?view=aspnetcore-3.0) like this
```c#
class ContactModel
{
[Required, RegularExpression(@"^([a-zA-Z0-9_\-\.]+)@((\[[0-9]{1,3}" +
@"\.[0-9]{1,3}\.[0-9]{1,3}\.)|(([a-zA-Z0-9\-]+\" +
@".)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$",
ErrorMessage = "Email Format Error")]
public string Email { get; set; }
[Required] public string Name { get; set; }
}
```
and then you will validate it like this
```c#
public class ContactController : Controller
{
[HttpPost]
public async IActionResult AddContact(ConatctModel model)
{
if (!ModelState.IsValid){
// throw new Exception("Model Failed")
}
//The model is valid
//do your logic here
}
}
```
but what if you want to use the ContactModel class in your own logic and not in the MVC Controller but still you may need to validate the model before usage or maybe you have a normal POCO class and you want to validate that in clean way in a scenario like this
```c#
public class ContactHelper
{
public void ContactHandler(ContactModel model)
{
if (!model.IsValid){
// throw new Exception("Model Failed")
}
//The model is valid
//do your logic here
}
}
```
this was the motivation to create the EasyModelValidatorExtension which can help you validate any object by simply adding the validation attributes in that object
```c#
public static class EasyModelValidatorExtension
{
public static bool IsValid<T>(this T model)
{
try
{
var vc = new ValidationContext(model, null, null);
var result = Validator.TryValidateObject(model, vc, null, true);
return result;
}
catch (Exception e)
{
throw new ModelValidationException("Model Validation has Failed", e);
}
}
}
```
you can add this extension in your project or simply use [EasyModelValidator](https://www.nuget.org/packages/EasyModelValidator/) Nuget
```
dotnet add package EasyModelValidator
OR
Install-Package EasyModelValidator
```
you can find the Source code [here](https://github.com/alicommit-malp/com.appelinda.nuget.easyModelValidation)
Happy coding :)
| alialp |
191,953 | Cloning Memcached with Go | My first program in Go was Conway's Game of Life. This time I made an in-memory HTTP caching server w... | 0 | 2019-10-21T18:50:37 | https://healeycodes.com/go/tutorial/beginners/showdev/2019/10/21/cloning-memcached-with-go.html | go, tutorial, beginners, showdev | My [first program](https://github.com/healeycodes/conways-game-of-life) in Go was Conway's Game of Life. This time I made an [in-memory HTTP caching server](https://github.com/healeycodes/in-memory-cache-over-http) with similar methods to Memcached like increment/decrement and append/prepend.
I use caching pretty often but I had never coded up a Least Recently Used (LRU) cache by hand before. Neither had I used Go's `net/http` or `container/list` packages. Both packages are elegant and have great documentation and readable source code — the latter being one of my favorite things about Go.
With my first program, I threw everything in a file called `main.go` and called it a day. This time I created two packages.
- api — an HTTP server which responds to GET requests like `/set?key=name&value=Andrew&expire=1571577784` and `/get?key=name`.
- cache — an LRU cache that allows an expire time and a max number of keys.
### Caching
As an LRU cache fills up and needs to forget an item it will choose the one that was _last accessed_ the _longest time ago_. It also allows lookups in constant time. To build mine, I mapped strings to doubly linked list elements.
```go
// Store contains an LRU Cache
type Store struct {
mutex *sync.Mutex
store map[string]*list.Element
ll *list.List
max int // Zero for unlimited
}
```
Each list element is a Node. We also store the key inside the Node so that when the cache fills up, we can do a reverse lookup from the back of the list to remove that item from the map.
```go
// Node maps a value to a key
type Node struct {
key string
value string
expire int // Unix time
}
```
The `mutex` field of the Store allows the cache to avoid having concurrent readers and writers to the data structures. The default behavior of `net/http` is to spawn a goroutine for every request. In [some cases](https://groups.google.com/forum/#!msg/golang-nuts/HpLWnGTp-n8/hyUYmnWJqiQJ) it appears to be okay to have multiple concurrent map readers but I played it safe and every cache operation is guarded by a mutex.
In a previous version of this article, I exported the mutex from the cache and locked/unlocked in the API's middleware. However, this meant that the application may be bottlenecked by HTTP read/write speeds (a friendly commentator pointed this out). Instead of changing where the middleware locked/unlocked to avoid the read/write limitation, I chose to hide the mutex inside the cache to make the application safer for future maintainers while also gaining the performance boost.
There is not much in the middleware right now apart from some basic logging that helps during development. Having an overall middleware usually cuts down on duplicate code.
```go
// Middleware
func handle(f func(http.ResponseWriter, *http.Request)) func(w http.ResponseWriter, r *http.Request) {
return func(w http.ResponseWriter, r *http.Request) {
if getEnv("APP_ENV", "") != "production" {
fmt.Println(time.Now(), r.URL)
}
f(w, r)
}
}
```
### Give key, get value
In Go, the HTTP protocol is a first-class citizen. Clients and servers are simple (and extensible). Writing the `/get` method for my server uses six lines.
```go
// Get a key from the store
// Status code: 200 if present, else 404
// e.g. ?key=foo
func Get(w http.ResponseWriter, r *http.Request) {
value, exist := s.Get(r.URL.Query().Get("key"))
if !exist {
http.Error(w, "", 404)
return
}
w.Header().Set("content-type", "text/plain")
w.Write([]byte(value))
}
```
The cache method that maps to this route is more complex. It looks for a key in the map and checks that it is valid (not expired or due for cleanup). It returns `(string, bool)` — (the value or an empty string, true if the value was found). If a string is found, its Node is moved to the front of the list because it is now the most recently accessed.
If the key is expired then it's passed to the delete method which will remove the key from the map and the Node will be passed to the garbage collector.
```go
// Get a key
func (s *Store) Get(key string) (string, bool) {
s.mutex.Lock()
defer s.mutex.Unlock()
current, exist := s.store[key]
if exist {
expire := int64(current.Value.(*Node).expire)
if expire == 0 || expire > time.Now().Unix() {
s.ll.MoveToFront(current)
return current.Value.(*Node).value, true
}
}
return "", false
}
```
I've been reaching for `defer` in my other programming languages recently. It helps one better manage the lifetime of objects. It's explained in a Go [blog post](https://blog.golang.org/defer-panic-and-recover).
> Defer statements allow us to think about closing each file right after opening it, guaranteeing that, regardless of the number of return statements in the function, the files will be closed.
The syntax `current.Value.(*Node).value` performs a type assertion on the list element providing access to the underlying Node pointer. If it's the wrong type, this will trigger a panic. Type assertions can also return two values if requested, the second being a boolean whether the assertion succeeded: `value, ok := current.Value.(*Node).value`.
### Insert into cache
Putting something into the cache means either creating a new Node at the front of the list or updating the details of a pre-existing Node and moving that to the front of the list. If we go over the maximum number of keys then we delete the Node with the oldest last-accessed time.
The expire parameter is optional.
```go
// Set a key
func (s *Store) Set(key string, value string, expire int) {
s.mutex.Lock()
defer s.mutex.Unlock()
s.set(key, value, expire)
}
// Internal set
func (s *Store) set(key string, value string, expire int) {
current, exist := s.store[key]
if exist != true {
s.store[key] = s.ll.PushFront(&Node{
key: key,
value: value,
expire: expire,
})
if s.max != 0 && s.ll.Len() > s.max {
s.delete(s.ll.Remove(s.ll.Back()).(*Node).key)
}
return
}
current.Value.(*Node).value = value
current.Value.(*Node).expire = expire
s.ll.MoveToFront(current)
}
```
Since many other cache methods require 'set' and 'delete' functionality, there are internal `set` and `delete` methods to avoid duplication of code. Terminology note: a method is a function on an instance of an object.
When removing all keys from the cache we can lean on the garbage collector to do the hard stuff for us by removing all existing references to the objects.
```go
// Flush all keys
func (s *Store) Flush() {
s.mutex.Lock()
defer s.mutex.Unlock()
s.store = make(map[string]*list.Element)
s.ll = list.New()
}
```
The full list of methods is Set, Get, Delete, CheckAndSet, Increment, Decrement, Append, Prepend, Flush, and Stats.
<br>
This project took me two Sunday mornings and I continue to warm towards Go. It's not as terse as other languages but remains easy to read. It tends to lead to vertical code as opposed to horizontal code which also aids readability. It also brings all of the benefits of a static language without requiring a lot of boilerplate.
So far, I've had a great 'Google experience' alongside my Go programming. Looking up solutions normally leads to a sensible and well-explained answer. When I'm heading in the wrong direction, I normally find out after searching rather than running into problems further down the line. But perhaps this is because the language is quite new and there are fewer results for the incorrect version!
Check out the code on [GitHub](https://github.com/healeycodes/in-memory-cache-over-http).
<hr>
Join 150+ people signed up to my [newsletter](https://buttondown.email/healeycodes) on programming and personal growth!
I tweet about tech [@healeycodes](https://twitter.com/healeycodes). | healeycodes |
191,985 | Seeding your rails database using Faker | Recently, I attended a hackathon to test my programming grit. The focus of it was to build and/or cre... | 0 | 2019-10-21T20:33:39 | https://dev.to/danimal92/seeding-your-rails-database-using-faker-58f5 | seeding, gem, ruby, rails | Recently, I attended a hackathon to test my programming grit. The focus of it was to build and/or create an innovative app regarding civic issues in a span of 6 hours.
We decided to use Ruby on Rails to create our website. After building out our skeleton, we needed to have some sample data for testing. Writing out the tests manually in the seed file and instantiating our model objects turned into quite a slog. We ended up with too small of a sample size, and it limited our ability to discover edgecases, errors, and the means to show off the project.
Enough was enough. I decided it was time to learn from my mistakes, automate this process, and wash my hands of this time sink. So if you're using rails and you haven't found a good way to seed your data with it yet, this is for you.
My first instinct was to turn to a gem I had seen before called Faker. It randomly generates fake, but relevant, data to seed your files as long as you choose the right libraries. Let's get it started.
##Step 1: Installing the gem
If you have Ruby installed, go ahead and type the following in your terminal to install Faker:
>gem install faker
##Step 2: Requiring the gem
Great! Now in order to use it, go into your project's gem file and require it, like so:
>require 'faker'
Now run a bundle install in your terminal while it's accessing your project directory:
>bundle install
##Step 3: Planting the seeds
And last but not least, go to your seed file and use the __create__ method along with the __times__ method to create multiple objects:
```
10.times do
Character.create(name: Faker::Movies::LordOfTheRings.character)
end
```
I also added a location to my characters. Here's the result:
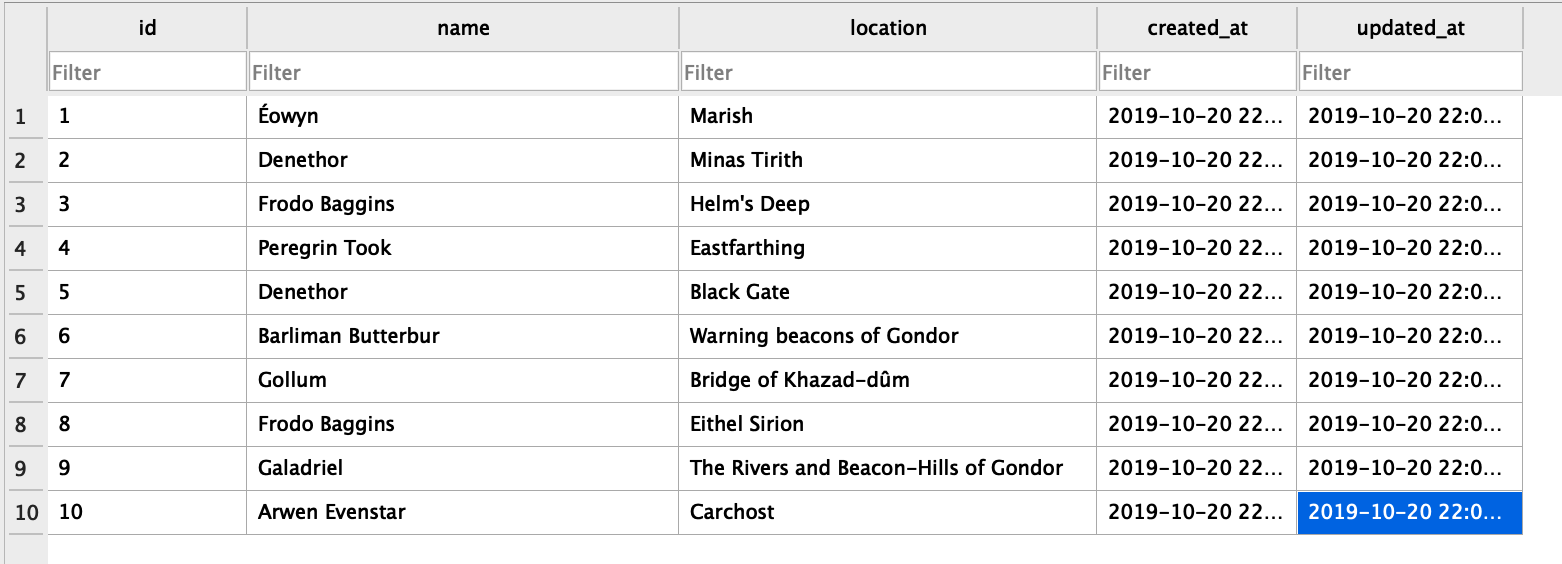
Beautiful.
You can also chain **.unique** right before the method call to ensure there is no repetition of data:
```
10.times do
Character.create(name: Faker::Movies::LordOfTheRings.unique.character)
end
```
I definitely encourage you to use this, and to look through the gem's github and libraries to see its full capability.{% github faker-ruby/faker %} It would be an absolute waste of time for you not to learn from my mistakes, and continuing to sit there, writing out line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line, after line...

| danimal92 |
192,064 | Getting useful feedback from Reddit? | A few days ago I read a great post here about providing feedback. But receiving feedback is a skill e... | 0 | 2019-10-21T02:43:36 | https://dev.to/sroehrl/getting-useful-feedback-from-reddit-2p33 | reddit, feedback, review | A few days ago I read a great post [here](https://dev.to/nazanin1369/how-to-give-effective-feedback-33kh) about providing feedback. But receiving feedback is a skill equally as important. This is especially true for communities where the tone seems to be rougher from the get-go like the various Reddit subs targeting the developer community.
While these subs are great to find quick responses, the answers are often distorted by factors that shouldn't be considered.
## Fandom and Reputation
The karma system has various problematic aspects, but certainly the worst one is the perception that people posting and commenting often seem to have a reputation and therefore valid things to say.
Of course, these things are rather unrelated (not to say that some things can be assumed about people whose daily Reddit output seems to leave little time for actual development). Anyway, I have made extraordinary experiences where people have reminded me to "respect my seniors" when I questioned feedback. And that seniority seemed to have been established not by shared code or achievement in the economy, not by recognition by reputable developers, founders or businesses, no, by years of Reddit membership. But what does that say?
On the other hand, I must take into consideration that my ability to accept feedback might just be insufficient in itself. So what if I cannot say anything about the experience of an individual, does that mean they don't know what they are talking about? After all, most of my code isn't public either and just because someone doesn't have a GitHub account doesn't mean they aren't good developers, right?
## Evaluating feedback
So the next problem is to identify which feedback or answers are valuable and which ones aren't. So I categorized posts into two different types: direct questions and feedback request. I created 5 accounts with different personas and experiences. After five months of data collection and manual evaluation, there were several discoveries I made:
## Answers depend on who you are
While I didn't even plan to look into that aspect, I noticed something that shouldn't ever happen: depending on how experienced you sound and claim to be, the answer to the same question as well as the same code **highly** differ. You read that right: if people think you are knowledgeable, they will answer with respect and give the content true consideration. If you express yourself in a way that seems to be coming from an inexperienced developer, the very same code gets vocally destroyed.
## Noobs and egos
The next interesting finding is the echo chamber one can easily create or become a victim of. When certain assessments have been made about a certain stack, software, tool, language (God am I tiered of people hating on PHP without ever understanding it or any other language deep enough to compare it), pattern, library, or opinion, people will regard these outcomes as gospel. This leads to ridiculous situations where individuals being half through their first web development online bootcamp with background in PowerPoint (I might exaggerate, but you get the point) would scold you for suggesting technology x in a particular scenario in a manner that let's the reader assume they not only know what they are talking about, but in a tone that seems to emphasize on having to convey how full of themselves they are. Unfortunately, the reader is normally a learner looking for help with a high likeability of misinterpreting such ego as certainly being a knowledgeable comment. Little do they know that the poster has been asking this very question the week before and was in turn fooled by his or her predecessor from another week before. It's an endless circle and noone knows where certain opinions came from. But again: you can change them. You can write an article on Medium and publish it to Reddit. Then have your various accounts praise it and boom - you created a new echo chamber. And no, that article does not have to provide solid reasoning, code, examples or peer review. It just needs to be coherent (you can't write complete BS, of course) and use language indicating deep knowledge of the subject. However, you need to have fast positive feedback, otherwise actual developers who see through it dominate assessment and once they are the first negative comments with enough upvotes you have lost the game. Which leads me to
## Never swim against the current
Now this one is very powerful and actually led me to write this article over half a year before I am ready to reveal the identities and accounts I use for this experiment. Imagine the following scenario:
You request feedback on a particular project. The first comment you get is from someone with high reputation within the sub and it completely demolishes the project while warning all readers about it. Citing security flaws of the highest order.
Then it's over. Your post will be downvoted to hell and a shitstorm will break loose. But what if it's not true? What if that feedback is simply wrong as the commenter made a mistake and for instance looked at the wrong repo? ( And I wish that would have at least once been a reasonable assumption rather than noticing that people simply don't look at code at all before judging it)
Do you think someone notices and corrects it? No.
Do you think you could clarify and people would listen? No.
As a matter of fact, if you do, others will come in and remind you of rule #1: respect your seniors, the infallible superusers with "years of experience".
## So how do you get constructive feedback?
Again, I have divided feedback in two categories. One of them is review requests and the other one direct questions. The simple conclusion is: whenever you start a post with "Can I...", "How do I..." and similar, you have a high chance of getting valuable answers. As for reviews: Unless you are asking for feedback on design, layout or concept, Reddit is simply not the place for you. While good feedback on code does happen, it happens too seldom and is not worth the effort of filtering out unworthy feedback which unfortunately additionally requires experience on a level where you don't need Redditors anymore anyway.
## Conclusion
I will provide a more scientific evaluation once this experiment is over. For the reader looking for solutions: find discords, meetups, people on GitHub and use code review on stackexchange. | sroehrl |
192,067 | Rotate MxN Matrix | Rotate Matrix is a simple program that rotates a MxN grid by 90 degrees clockwise or counter-clockwis... | 0 | 2019-10-21T02:08:35 | https://dev.to/maytd/rotate-mxn-matrix-1m38 | Rotate Matrix is a simple program that rotates a MxN grid by 90 degrees clockwise or counter-clockwise. For example, the grid of `[[1, 2], [3, 4], [5, 6]]` should return `[[2, 4, 6], [1, 3, 5]]` when rotating counter-clockwise or `[[5, 3, 1], [6, 4, 2]]`when rotating clockwise.
```
[1, 2] [2, 4, 6] [5, 3, 1]
[3, 4] [1, 3, 5] [6, 4, 2]
[5, 6]
origin counter clockwise
```
To do this we'll first make a function that takes in a matrix, or an array of array, and a direction to tell us which way to rotate. Before we begin, lets make an empty array that will hold the values of rotated values.
```
var rotateMatrix = function(matrix, direction ) {
let rotated = [];
return rotated;
};
```
The idea is that we're going to loop over the matrix by the length of a row and pick out the values we need in that column to simulate a rotation. So using the example above, if we wanted to rotate clockwise we'll loop over the matrix twice since we know that the length of a row is 2 and the expected outcome should have 2 rows. Then we will loop over the matrix again by 3 since there are 3 items in a column. In other words the current number of rows and columns should be switched in the result. The algorithm used to rotate the matrix both clockwise and counter-clockwise are very similar, but let's start with clockwise rotation.
We know that if we turn the matrix clockwise, we should expect 2 rows and 3 columns. If we take a closer look at the example above, we will also know that the expected values starts on the bottom left at 5 and goes upward and continues to the next bottom value 6 and goes upward each time. That means that our clockwise should look something like this:
```
// set col to be the length of a row in the matrix
// this will be the number of rows in the rotated result
for (let col = 0; col < matrix[1].length; col++) {
// this will hold the values for the current column in the rotated result
let colArr = [];
// set row to be the length of the original matrix (the number of columns there are)
// this will be the number of columns in the rotated result
for (let row = matrix.length - 1; row >= 0; row--) {
// add the current value into the current column
colArr.push(matrix[row][col]);
}
// added the whole column into the rotated result
rotated.push(colArr);
}
```
For counter-clockwise, the same algorithm applies but decrements by columns and increments by rows instead. So rather than starting from the bottom left and moving upwards, it starts from the top right and moves downward.
```
for (let col = matrix[1].length - 1; col >= 0; col--) {
let colArr = [];
for (let row = 0; row < matrix.length; row++) {
colArr.push(matrix[row][col]);
}
rotated.push(colArr);
}
```
And that's all! The whole program should look something like this:
```
var rotateMatrix = function(matrix, direction ) {
// [1, 2] [2, 4, 6] [5, 3, 1]
// [3, 4] [1, 3, 5] [6, 4, 2]
// [5, 6]
// origin counter clockwise
let rotated = [];
// counter clockwise
if (direction === -1) {
for (let col = matrix[1].length - 1; col >= 0; col--) {
let colArr = [];
for (let row = 0; row < matrix.length; row++) {
colArr.push(matrix[row][col]);
}
rotated.push(colArr);
}
}
// default clockwise rotation
else {
for (let col = 0; col < matrix[1].length; col++) {
let colArr = [];
for (let row = matrix.length - 1; row >= 0; row--) {
colArr.push(matrix[row][col]);
}
rotated.push(colArr);
}
}
return rotated;
};
```
| maytd | |
192,096 | RE Week 2 | Week 2 of reverse engineering | 3,055 | 2019-10-28T02:14:01 | https://dev.to/pirateducky/re-week-2-316d | hacking | ---
title: RE Week 2
published: true
description: Week 2 of reverse engineering
tags: #hacking
cover_image: https://i.redd.it/p334wphc5wu21.png
series: RE
---
This has been week #2 learning reverse engineering, this time I've gone over some basics:
- The call stack
- What is it? How does it work?
- Assembly
- Learning more about assembly x86
- How does assembly work
Week #2 has been all about `the stack` and `assembly`. Going over the [preparations](https://www.begin.re/assignment-2) section of the workshop, I went over the purpose of `the stack` as well as `assembly`:
### What is the stack?
- `The stack` is a data structure, it gets assigned an area of memory which it uses to store information about the executing program, it uses `registers`(storage areas, `esp`, `ebp`,`eax`, `nop` etc) to know what's executing by storing data & memory addresses, we can use `instructions`(actions we can perform using `assembly language` like `push`, `pop`, `mov`, `jmp` and more) to interact with `the stack`
- The stack grows down to higher memory addresses, which also means `the stack` starts at lower memory addresses.
- `The stack` keeps track of everything that happens when a program executes, it knows exactly what variables the program will use and which functions are running by using `registers` like `ebp`(which points to the base of the stack) and `eip`(which points to the next instruction to perform).
{% youtube vcfQVwtoyHY %}
### What is assembly?
- Low-level programming language
- Gets turned into `machine language`
- `Instruction set` is used to write programs which use `registers` and `instructions`
- some `instructions` include:
- `nop` `push` `pop` `mov` `add` `call` `ret`
- all instructions performs actions using `registers`
- `mov eax, [ebx]`: move the 4 bytes in memory at the address contained in `ebx` into `eax`
- instruction format
- `operation argument`
- `operation argument, argument`
- `mov eax, [ebp-8]` *square brackets acts as the de-reference operator in `c` so the `mov` instruction "moves" the value that's at `ebp-8` and stores it inside `eax`* [Intel Syntax]
**Next week**: Going over some basic `C`, installing tools, trying some exercises
### Resources
[azeria-labs](https://azeria-labs.com/functions-and-the-stack-part-7/) more about the stack
[OALabs](https://www.youtube.com/channel/UC--DwaiMV-jtO-6EvmKOnqg): youtube channel
[Discord](https://discord.gg/weKN5wb): resources, and community
[Awesome RE](https://github.com/wtsxDev/reverse-engineering): Github repo
[ROP beginers](https://ropemporium.com/): return-oriented programming (here for later reference)
[Modern X86 ASM](https://www.youtube.com/watch?v=rxsBghsrvpI)
[x86 ASM](https://cs.lmu.edu/~ray/notes/x86assembly/)
[**cover image**](https://i.redd.it/p334wphc5wu21.png)
[asm cheatsheet](https://www.reddit.com/r/ReverseEngineering/comments/3zpkde/reverse_engineering_for_malware_analysis_cheat/)
[x86 Intro](https://www.youtube.com/watch?v=75gBFiFtAb8&feature=youtu.be) | pirateducky |
192,148 | Change Navigation Based On View With Vue JS | My thoughts Imagine, you have a website with a navigation, which is not responsive, and th... | 0 | 2019-10-21T07:43:32 | https://dev.to/programmierenm/change-navigation-based-on-view-with-vue-js-4a81 | vue, tutorial, javascript | #My thoughts
Imagine, you have a website with a navigation, which is not responsive, and the goal is to build a mobile variation. How can you do this without CSS media queries? And what kind of benefits do you have with Vue JS?
Should be the mobile version utterly different from the desktop variation, starting from the HTML structure, over the functionality and until to the CSS styling, then, of course, the implementation can be quite difficult.
And if you wanna implement this with CSS media queries and many javascript conditions, for example, that can be a bit annoying and confusing.
So, in my opinion, it's a better solution to create a different Component for the mobile navigation and use the reactivity from Vue JS to switch between these components, based on the current viewport.
#Handle the current view
The core idea is to check out the current innerWidth with your specific breakpoint and hold the status (true or false) in a local data attribute. In the App.vue Component or in the Component you want to handle the navigation.
```javascript
methods: {
handleView() {
this.mobileView = window.innerWidth <= 990;
}
}
```
#Use your method
Next, you can use the created lifecycle hook and fire your method if the Component is created. Further, you have the opportunity to bind the method with an eventListener to the browser resize event.
This will allow you to run the method again if the user changes the browser size.
```javascript
created() {
this.handleView();
window.addEventListener('resize', this.handleView);
}
```
#And Now?
Now it's pretty easy to show either the mobile version or the normal navigation in your template depending on your mobileView status.
```html
<NavigationMobile v-if="mobileView" />
<Navigation v-else />
```
#My YouTube Tutorial about this topic
In this tutorial, I show you step by step, how you can implement this in a Vue JS project.
{% youtube lga-ceawtmw %}
#Conclusion
With this solution, you have both cleanly separated and can also use and adapt independently.
What are your thoughts?
Would you rather use CSS Media queries?
Thanks for reading and watching.
| programmierenm |
192,229 | VSCode debugger config with Mocha and Babel 7 | The post VSCode debugger config with Mocha and Babel 7 appeared first on boobo94. So if you want to r... | 0 | 2019-10-30T10:11:23 | https://boobo94.xyz/tutorials/vscode-debugger-config-with-mocha-and-babel-7/?utm_source=rss&utm_medium=rss&utm_campaign=vscode-debugger-config-with-mocha-and-babel-7 | tutorials | ---
title: VSCode debugger config with Mocha and Babel 7
published: true
date: 2019-10-15 16:05:06 UTC
tags: Tutorials
canonical_url: https://boobo94.xyz/tutorials/vscode-debugger-config-with-mocha-and-babel-7/?utm_source=rss&utm_medium=rss&utm_campaign=vscode-debugger-config-with-mocha-and-babel-7
---
_The post [VSCode debugger config with Mocha and Babel 7](https://boobo94.xyz/tutorials/vscode-debugger-config-with-mocha-and-babel-7/) appeared first on [boobo94](https://boobo94.xyz). So if you want to read more articles like this please [subscribe to my newsletter](https://boobo94.xyz/#colophon) or follow me here_
VSCode debugger is a very nice tool that you can use in every project. I personally prefer VSCode for most programming languages that I write code. The minimalism and extendability make it very powerful.
If you wanna know more about my VSCode configurations and extensions that I use check [VSCode setup for web development: settings and extensions](/tips/vscode-setup-for-web-development-settings-and-extensions/).
These days I tried to configure the VSCode debugger for a Node.js project that I’m working on in testing mode. I use [Babel 7](https://babeljs.io/docs/en/) and [Mocha](https://mochajs.org/) framework for tests. Apparently everything looks very simple and intuitive because the VSCode offers support to create a new config for different tasks, so I choose the default one for Mocha.
I encountered a few issues trying to run the VSCode debugger with Mocha and Babel 7, but the configuration is not very hard and can be shown below:
```json
{
"type": "node",
"request": "launch",
"name": "Mocha Tests",
"program": "${workspaceFolder}/node_modules/mocha/bin/_mocha",
"runtimeArgs": [],
"args": [
"${workspaceFolder}/test/**/*.js",
"--require",
"@babel/register",
"-u",
"bdd",
"--timeout",
"999999",
"--colors"
],
"env": {
"NODE_ENV": "test",
},
"internalConsoleOptions": "openOnSessionStart"
}
```
Firstly I had to change the type from **tdd** to **bdd** , because Mocha runs as bdd. Secondly is very important to pass the needed plugins in order for Node to interpret the code correctly. Please observe **–require @babel/core**.
If you like the article and consider it helpful please take the tiger out of the cage and inform others about it. Please share it with your people and [subscribe](/#email-subscribers-form-5) to my newsletter. Don’t forget to leave me a comment about your opinion related to this article and ask me some questions.
_The post [VSCode debugger config with Mocha and Babel 7](https://boobo94.xyz/tutorials/vscode-debugger-config-with-mocha-and-babel-7/) appeared first on [boobo94](https://boobo94.xyz). So if you want to read more articles like this please [subscribe to my newsletter](https://boobo94.xyz/#colophon) or follow me here_ | boobo94 |
192,231 | IT Outsourcing in Ukraine: Why It Is So Popular Among EU & the USA Companies | 0 | 2019-10-21T11:23:26 | https://dev.to/devcom/it-outsourcing-in-ukraine-why-it-is-so-popular-among-eu-the-usa-companies-2kh2 | itoutsourcing, itoutsourcingukraine, outstaffteam, customsoftwaredevelopment | ---
title: IT Outsourcing in Ukraine: Why It Is So Popular Among EU & the USA Companies
published: true
description:
tags: IT outsourcing, IT outsourcing Ukraine, outstaff team, Custom Software development
---
The global IT outsourcing market is thriving, and choosing the right software development destination is a complicated process. If you are considering Ukraine, this article will help you learn more about the local IT landscape the most attractive outsourcing destinations.
Outsourcing development is now a viable alternative to in-house development of software and IT products. <a href="https://devcom.com/tech-blog/dedicated-development-team/">Outsourcing offers some distinct advantages compared with building your development team stateside</a>. <span style="font-weight: 400;">Currently, 30% of global IT projects are undertaken offshore.</span>
<h2 style="text-align: center;"><strong>Why Ukraine is so popular for IT outsourcing</strong></h2>
<h2 style="text-align: center;"><strong>among EU and US companies?</strong></h2>
<span style="font-weight: 400;">An increasing number of businesses are considering Ukraine as a primary location for outstaff / outsourcing their software development needs.</span>
<span style="font-weight: 400;">Ukraine’s $5 billion IT industry did not happen overnight. </span>Software development companies in Ukraine offer high-quality technical services including software engineering, custom web development, software testing, cloud, and app development, to name but a few.<span style="font-weight: 400;"> Plus, there is a large number of developers with different expertise and skills from which clients can choose from.</span>
<span style="font-weight: 400;">It is a well-known fact that <strong>Ukraine has repeatedly ranked as a top IT outsourcing destination</strong> in numerous sources, the facts speak for themselves:</span>
<ol>
<li style="font-weight: 400;"><span style="font-weight: 400;">The country ranks fourth in the world by the number of tech workers after the United States, India, and Russia. </span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Ukraine is among the top 20 offshore locations in EMEA.</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">The Ukrainian IT industry is expected to reach $10 billion in value by 2020. </span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">It’s IT workforce is expected to surpass the 200.000 marks by 2020.</span></li>
</ol>
<span style="font-weight: 400;">For software development, IT outsourcing to Ukraine makes total sense for companies across the globe. </span>
<h3 style="text-align: center;"><strong>Software engineer salary comparison</strong></h3>
The critical factor which makes software development more expensive in Europe and the USA compared to Ukraine is salaries.
Let’s see the average salaries of software developers in the major European states and the US.
This information may give a hint to businesses looking to hire tech specialists to understand where to search for cheaper talent and without losing the quality.
<h3>How much does a software developer make in the US?</h3>
Quite predictably, the country which pays the highest tech salaries in the US (According to Indeed) — Software Developers in the US made a median salary of $101,790 in 2018. The best-paid 25 percent earned $128,960 that year, while the lowest-paid 25 percent earned $77,710.
<em>*To figure out how many hours are in a "work year," multiply the number of work hours in a week by the number of weeks in a year. In other words, increase a typical 40-hour workweek by 52 weeks. That makes 2,080 hours in a typical work year. Thus, the median rate of a software engineer = $48,9375 per hour.</em>
<h3>How much does a software developer make in the EU?</h3>
EU states differ in terms of economic well-being, which affects the range of salaries offered to software developers in their markets. Here is a quick snapshot of the average annual wage by country (according to Payscale):
<ol>
<li>The average software engineer salary in <strong>Switzerland</strong> is close to $83K per year, which puts the country in second place.</li>
<li>The median developer salary in <strong>Norway</strong> is around $72K.</li>
<li>The next country is not far behind—the median pay for a software engineer in <strong>Denmark</strong> is $70K a year.</li>
<li>Annual developer salaries in <strong>Germany</strong>, <strong>Sweden</strong>, and <strong>Israel</strong> range between $53K and $64K.</li>
<li>Software engineers that live in <strong>Australia</strong>, the <strong>Netherlands</strong> and <strong>Canada</strong> earn slightly lower salaries — around $48K.</li>
<li><strong>Finland</strong>, <strong>New Zealand</strong>, <strong>UK</strong>, and <strong>France</strong> software developers can expect the lowest salaries— $44K yearly and below.</li>
</ol>
<h3>Average developers salaries in Ukraine</h3>
To put this into perspective, let’s look at the tech market in Ukraine, where we build and retain cross-functional development teams for our clients.
<strong>The average hourly rate for software development is within the $25–50,</strong> with the average annual software developer salary varying <strong>between $24,000 and $ 48,000.</strong>
However, this data is very approximate. IT expert is a well-paid profession all across the world. Nevertheless, web developer salaries (in Ukraine as well as in any other part of the world) differ widely depending on the candidates’ years of experience, tech stack, seniority level, and the language of programming.
<h3>The true cost of hiring software developer in 2019</h3>
Each in-house employee costs the sum of his or her gross wages. This is in addition to other employee-related expenses, including:
<ol>
<li>Recruiting expenses.</li>
<li>Basic salary.</li>
<li>Employment taxes.</li>
<li>Benefits (insurance, health coverage, paid time off, and meals).</li>
<li>Space and office maintenance.</li>
<li>Other approaches.</li>
</ol>
Thus, before looking for a developer in Ukraine, you should analyze the needs of your project and your available budget for successful outcomes. So, how can the hiring process be made easier and quicker? Here’s the solution – hiring a <a href="https://devcom.com">vendor of IT talents</a>.
Read the full version of the article at https://devcom.com/tech-blog/ukraine-it-outsourcing-for-eu-us/ | devcom | |
192,333 | ESA SPACE APP CAMP 2019 | ESA Space App Camp 2019, my toughest technical challenge with ESA satellite data and the development of EyeRes during the app camp 2019. | 0 | 2019-10-21T14:51:47 | https://dev.to/panayiotisgeorgiou/esa-space-app-camp-2019-2354 | javascript, smartcities, space, spacecappcamp | ---
title: ESA SPACE APP CAMP 2019
published: true
description: ESA Space App Camp 2019, my toughest technical challenge with ESA satellite data and the development of EyeRes during the app camp 2019.
tags: javascript, smart cities, space, spacecappcamp
cover_image: https://www.panayiotisgeorgiou.net/wp-content/uploads/2019/10/esa-app-camp-2019.jpg
---
For the 8th time, the European Space Agency ([ESA](https://www.esa.int/ESA)) invited 24 developers to its [ESA’s](https://www.esa.int/ESA) Earth observation centre in Frascati, Italy and I was lucky enough to be one of them. [ESA Space App Camp 2019](https://www.esa.int/spaceinimages/Images/2019/09/2019_Space_App_Camp_begins) offers access to the latest space data to app developers, who work in project teams to make the information accessible to a broad audience.
To begin with I would like to express my appreciation to the organisers [AZO Team ](https://www.anwendungszentrum.de/)(huge thanks to Max) and ESA for the opportunity that they gave me to participate in [ESA Space App camp 2019](https://www.esa.int/spaceinimages/Images/2019/09/2019_Space_App_Camp_begins). Officially that made me the first participant from Cyprus since the app camp started from 2012 🙂
(just saying!)
I have to say that the app camp was one of the toughest technical challenges so far but it was fun and I really enjoyed it. It was challenging technically enough because I didn’t have any previous experience on satellite data.
<img src="https://www.panayiotisgeorgiou.net/wp-content/uploads/2019/10/The_participants_of_the_2019_Space_App_Camp-1024x683.jpg">
#Mission 🛰
The goal was to come up with some innovative and off the beaten track ideas for apps using Earth-monitoring data – particularly from the European Copernicus programme – and make satellite information accessible to the everyday user through smartphones. I had the opportunity to work in the “Smart Cities” team and apply my knowledge on developing a Land monitoring system. My initial idea was to create coastline erosion detection system that will notify everyday users about the condition of erosions. Since we were limited with ground data from the satellites and we were limited with resources on this field we focused on our topic “Smart Cities” and we have created EyeRes.
#Team 👨👨👧👦
EyeRes would have not been developed in ESA’s space app camp without my super cool team mates (Adam, Martin and Tereza) that I have the honour to worked over the last week. Grazie Mille!🙂
Another post will be posted soon with more information about the project.
#Future Tips for next participants 💯
My survive guide for the next ESA app camp participants:
1) Enjoy, enjoy, enjoy and be grateful for your selection you are already a winner 🍾
2) Have fun, more fun and more fun!! You will remember it for ever ⏳
3) Smile 🙂 despite the up’s and down’s of the app camp
4) Mix and match with the rest of the teams, 👨🚀👩🏻🚀don’t forget you all experiencing the same frustration, joy and laughs. Therefore support each other and have a drink after a long day.
5) Learn as much you can, make questions and create something super cool like EYERES 👀. If you are motivated then you go out of your comfort zone and that make your team shine.
That’s it for now. 😉
If you liked this article, then please subscribe to my [YouTube Channel](https://www.youtube.com/c/PanayiotisGeorgiou?sub_confirmation=1) for video tutorials.
You can also find me on [Twitter](http://twitter.com/panay_georgiou), [Instagram](https://www.instagram.com/panayiotisgeorgiou) and [Facebook](https://www.facebook.com/panayiotisgeorgiou.net). | panayiotisgeorgiou |
192,543 | What do you do while you code? | I constantly find myself needing to watch #political debates or #documentaries while coding. Maybe n... | 0 | 2019-10-21T19:28:22 | https://dev.to/sonandrew/what-do-you-do-while-you-code-562 | discuss, coding | I constantly find myself needing to watch #political debates or #documentaries while coding. Maybe not to watch it constantly but to have the background noise as well.
☝🏾☝🏾☝🏾☝🏾☝🏾☝🏾☝🏾
Am I the only one that does this???
If so what do you do while working? | sonandrew |
192,570 | Preview of Chrome 79 DevTools, Firefox WebSocket Inspector and New Form Controls in Edge and Chromium | Front End News #23 | Hello everyone and welcome to another round of Front-End News. I hope you will enjoy the subjects I'v... | 1,048 | 2019-10-21T19:59:45 | https://dev.to/adriansandu/preview-of-chrome-79-devtools-firefox-websocket-inspector-and-new-form-controls-in-edge-and-chromium-front-end-news-23-3k12 | news, frontendnews | Hello everyone and welcome to another round of Front-End News. I hope you will enjoy the subjects I've selected for you in this edition.
- Find out what is new in Chrome 79 Dev Tools
- Release Notes for Safari Technology Preview 94
- Introducing Firefox’s New WebSocket Inspector
- Improving form controls in Microsoft Edge and Chromium
- Software updates and releases
***
## Find out what is new in Chrome 79 Dev Tools
We get a preview of what is to come with the Chrome 79 Developer tools and there are some very interesting features in there:
- Managing cookies: view cookie values and find out why a cookie was blocked.
- Simulate the effect of `prefers-color-scheme` and `prefers-reduced-motion` preferences
- Find unused CSS and JS code in your files
- Determine why any resource was requested over the network
For more details read the full article on the Google Web Developer blog, linked below:
- https://developers.google.com/web/updates/2019/10/devtools
***
## Release Notes for Safari Technology Preview 94
Users of macOS Mojave and Catalina can now download the Safari Technology Preview 94. As usual, the WebKit team published the release notes for this update, covering the changes that will soon arrive within Safari. All this information is available in the article linked below:
- https://webkit.org/blog/9609/release-notes-for-safari-technology-preview-94/
***
## Introducing Firefox’s New WebSocket Inspector
The WebSockets API is used to create persistent connections between a client and a server. The Firefox DevTools team worked hard to provide a tool that will allow developers to monitor what data runs through this connection.
The new feature is part of the `Network` panel and will be available in Firefox 71. However, you can already give it a try using Firefox Developer Edition.
- https://hacks.mozilla.org/2019/10/firefoxs-new-websocket-inspector/
***
## Improving form controls in Microsoft Edge and Chromium
Form controls are notoriously difficult to style across browsers because user-agents are encouraged to implement these elements to achieve "platform-native appearances". As Edge is getting a new life using Chromium, it's high time for the form controls to get a refresh as well.
The developer team from Microsoft worked hard on this task, in collaboration with their colleagues from Google Chrome. The focus is on a modern look and feel, as well as optimizations for touch interactions and accessibility. These changes will soon be available in Canary and Dev channel builds of Microsoft Edge, as well as other Chromium browsers down the road.
I've linked the announcement blog below, together with a reference to the HTML living standard document that explains the reason why form controls look so different from browser to browser.
Enjoy!
- https://blogs.windows.com/msedgedev/2019/10/15/form-controls-microsoft-edge-chromium/
- https://html.spec.whatwg.org/multipage/rendering.html#form-controls
***
## Software updates and releases
Here are the updates and releases for this week. In each case, you can find the full details in the release notes linked down below.
### Vue CLI v4.0.0
- https://github.com/vuejs/vue-cli/releases/tag/v4.0.0
### Parcel 2 alpha 2
- https://github.com/parcel-bundler/parcel/tree/v2
### Webpack 5 beta
- https://github.com/webpack/webpack/issues/9802
***
That’s all there is in this edition. Follow Front End Nexus on Twitter at https://twitter.com/frontendnexus to be notified as soon as a new update happens. I also want to encourage you to subscribe to the YouTube channel at https://www.youtube.com/channel/UCgACtqiDmnSaskDIBsK54ww. I can unlock some more options once the channel hits 100 subscribers, so your support is highly appreciated.
Have a great and productive week and I will see you next time! | adriansandu |
192,620 | How to Change your WordPress Default Admin Username | Guess the default admin username for WordPress WordPress sites are often abused by brutefo... | 0 | 2019-10-27T00:43:02 | https://dev.to/bitofwp/how-to-change-your-wordpress-default-admin-username-2c4h | admin, username, wordpress, security | ---
title: How to Change your WordPress Default Admin Username
published: true
date: 2019-10-11 22:14:49 UTC
tags: admin,username,WordPress,Security
canonical_url:
---
## Guess the default admin username for WordPress
WordPress sites are often abused by bruteforce login attacks where hackers are trying to find the correct admin login details(usernames and passwords) in order to break into the WordPress Dashboard and start hacking the site traffic, files and database.
One way to [**protect your WordPress site**](https://bitofwp.com/security/harden-wordpress-site-security) from these kinds of attacks is to change the default admin username to a random one. If you keep using the default admin username then you make things easier for bruteforce login attacks since they only have to find or guess the password part of the admin login details.
As most of the things added on top of the default WordPress setup there are two ways to change the admin default username. You can do it manually or you can use a plugin to do it for you. Below we’ll cover both ways for changing the default admin username for your WordPress installation.
### How to change your admin username manually
1. First, log in to your WordPress Dashboard using your default admin username and password.
2. Create a new admin username. Make sure you use a random name and create a complex password.
3. Log out and log in using your new admin login details.
4. Delete the default admin username and make sure to attach any posts created by that user to your new admin account.
<iframe title="Change default admin username for WordPress manually" width="850" height="638" src="https://www.youtube.com/embed/OWYAxO9Fe0A?feature=oembed" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<figcaption>Video Guide on changing your WordPress admin username manually</figcaption>
### How to change your admin username using a plugin
If you don’t want to get your hands dirty for changing your WordPress admin username then you can use a plugin like [Easy Username Updater](https://wordpress.org/plugins/username-updater/) by Yogesh C. Pant to simplify the process.
Follow the steps below to install, activate and use this plugin in order to rename your default admin usernames.
1. Go to your WordPress Dashboard and search for Easy Username Updater plugin.
2. Install and Activate it.
3. Select the under the Username Update tool under Users sidebar menu.
4. Select the Update option for the admin username you want to change.
5. Set a new username and choose if you want to send a notification to this user for the username change.
6. If you’re changing the username for the account you have logged in you will be automatically logged out of your WordPress Dashboard so enter your new login username and the existing password and login again.
<iframe title="Change default admin username for WordPress using a plugin" width="850" height="638" src="https://www.youtube.com/embed/vgYBp_cX8yA?feature=oembed" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<figcaption>Change admin default username using a WordPress plugin</figcaption>
If you want to simplify the login process and use a simpler login option then use your account email instead along with the password.
**If you want to keep reading posts and guides about securing your WordPress website then take a moment to subscribe to our WordPress Security Newsletter form.**
<section id="yikes-mailchimp-container-1">
<form id="bitofwp-1" method="POST" data-attr-form-id="1">
<label for="yikes-easy-mc-form-1-FNAME">
<!-- dictate label visibility -->
<span>
First Name </span>
<!-- Description Above -->
<input id="yikes-easy-mc-form-1-FNAME" name="FNAME" placeholder="" type="text" value="">
<!-- Description Below -->
</label>
<label for="yikes-easy-mc-form-1-LNAME">
<!-- dictate label visibility -->
<span>
Last Name </span>
<!-- Description Above -->
<input id="yikes-easy-mc-form-1-LNAME" name="LNAME" placeholder="" type="text" value="">
<!-- Description Below -->
</label>
<label for="yikes-easy-mc-form-1-EMAIL">
<!-- dictate label visibility -->
<span>
Email Address </span>
<!-- Description Above -->
<input id="yikes-easy-mc-form-1-EMAIL" name="EMAIL" placeholder="" required="required" type="email" value="">
<!-- Description Below -->
</label>
<!-- Honeypot Trap -->
<input type="hidden" name="yikes-mailchimp-honeypot" id="yikes-mailchimp-honeypot-1" value="">
<!-- List ID -->
<input type="hidden" name="yikes-mailchimp-associated-list-id" id="yikes-mailchimp-associated-list-id-1" value="cfc1bc9aa8">
<!-- The form that is being submitted! Used to display error/success messages above the correct form -->
<input type="hidden" name="yikes-mailchimp-submitted-form" id="yikes-mailchimp-submitted-form-1" value="1">
<!-- Submit Button -->
<button type="submit"> <span>Submit</span></button> <!-- Nonce Security Check -->
<input type="hidden" id="yikes_easy_mc_new_subscriber_1" name="yikes_easy_mc_new_subscriber" value="66b28e3ef7">
<input type="hidden" name="_wp_http_referer" value="/blog/feed/">
</form>
<!-- Mailchimp Form generated by Easy Forms for Mailchimp v6.5.5 (https://wordpress.org/plugins/yikes-inc-easy-mailchimp-extender/) -->
</section>
Don’t hesitate to comment below if you have any questions or need further information about changing your default WordPress admin username.
The post [How to Change your WordPress Default Admin Username](https://bitofwp.com/blog/how-to-change-your-wordpress-default-admin-username/) appeared first on [WordPress Support Services by BitofWP](https://bitofwp.com). | bitofwp |
192,652 | Decisions And Intuition – Daniel Kahneman | Psychologist and Nobel laureate Daniel Kahneman reveals the actions we can take to overcome the... | 0 | 2020-08-13T22:53:22 | https://greenido.wordpress.com/2019/10/16/decisions-and-intuition-daniel-kahneman/ | business, life, books | ---
title: Decisions And Intuition – Daniel Kahneman
published: true
date: 2019-10-16 19:53:47 UTC
tags: Business,life,books
canonical_url: https://greenido.wordpress.com/2019/10/16/decisions-and-intuition-daniel-kahneman/
---

Psychologist and Nobel laureate Daniel Kahneman reveals the actions we can take to overcome the biases. He talks in [this podcast](https://open.spotify.com/show/1VyK52NSZHaDKeMJzT4TSM) about the things that cripple our decision-making, damper our thinking, and limit our effectiveness.
#### Some gems from his conversion:
First one, is thought provoking as you take it to your personal or professional life.
“I think changing behavior is extremely difficult. There are a few guidelines about how to do that, but anybody who’s very optimistic about changing behavior is just deluded.”
The second is about incentives and it’s putting more light to [Charlie’s perceptions.](https://dev.to/greenido/charlie-s-thoughts-on-decision-making-5ch6-temp-slug-4592356)
“Motivation is complex, and that people do good things for a mixture of good and bad reasons, and they do bad things for a mixture of good and bad reasons. I think that there is a point in educating people in psychology. It’s to make them less judgmental.”
The third, is taken from his work and his book:
<iframe title="Thinking, Fast and Slow" type="text/html" width="696" height="550" frameborder="0" allowfullscreen style="max-width:100%" src="https://read.amazon.com/kp/card?preview=inline&linkCode=kpd&ref_=k4w_oembed_CsdbEvahXTfNKO&asin=B00555X8OA&tag=kpembed-20"></iframe>
“What gets in the way of clear thinking is that we have intuitive views of almost everything. So as soon as you present a problem to me, I have some ready-made answers. What gets in the way of clear thinking are those ready-made answers, and we can’t help but have them.”
“Very quickly you form an impression, and then you spend most of your time confirming it instead of collecting evidence.”
“When you have intuitions about things, there are clear intuitions and there are strong intuitions. They’re not the same.”
One of the best is our nature to ‘cheat’:
“You usually will find a way to cheat and end up with your intuition. It’s remarkable.”
And the one about negotiations:
“It is not about trying to convince the other guy. It’s about trying to understand them. So again, it’s slowing yourself down. It’s not doing what comes naturally because trying to convince them is applying pressure. Arguments, promises, and threats are always applying pressure.
**What you want is to understand what you can do to make it easy for them to move your way. ** Very non-intuitive.
That’s a surprising thing when you teach negotiation.
It’s not obvious. We are taught to apply pressure and socialize that way.”
“Independence is the key for better thinking and better decisions. Otherwise when you don’t take those precautions, it’s like having a bunch of witnesses to some crime and allowing those witnesses to talk to each other.
They’re going to be less valuable if you’re interested in the truth than keeping them rigidly separate, and collecting what they have to say.”
I enjoyed it and learn from new principals. Now, for the hard part of trying to implement it. | greenido |
192,837 | Refactoring Reducers with Immer | The new hotness in immutable state management is Immer, a lightweight package designed to make operat... | 0 | 2019-10-22T00:26:51 | https://bjcant.dev/refactoring-reducers-with-immer/ | immer, redux, javascript | ---
title: Refactoring Reducers with Immer
published: true
date: 2019-10-21 00:00:00 UTC
tags: immer,redux,javascript
canonical_url: https://bjcant.dev/refactoring-reducers-with-immer/
---
The new hotness in immutable state management is [Immer](https://immerjs.github.io/immer/docs/introduction), a lightweight package designed to make operating on immutable objects a breeze.
> Using Immer is like having a personal assistant; he takes a letter (the current state) and gives you a copy (draft) to jot changes onto. Once you are done, the assistant will take your draft and produce the real immutable, final letter for you (the next state). - [Immer](https://immerjs.github.io/immer/docs/introduction)
I had a lot of fun refactoring a Redux app to use Immer, so I wanted to share how easy it really is!
Here is an example of a “standard” user reducer:
```js
const initialState = {
meta: {
loading: true,
error: false
},
data: []
}
export default (state=initialState, action={}) => {
switch (action.type) {
case 'USERS_LOAD':
return {
...state,
meta: {
...state.meta,
loading: true,
error: false
}
}
case 'USERS_LOAD_SUCCESS':
return {
...state,
data: [...action.payload.data],
meta: {
...state.meta,
loading: false,
error: false
}
}
case 'USERS_LOAD_FAILURE':
return {
...state,
meta: {
...state.meta,
loading: false,
error: action.payload.error
}
}
default:
return state
}
}
```
This should seem very familiar. We have a function that accepts the current `state` and an `action` as arguments and returns a new `state` copy with alterations based on `action.type` and an optional `action.payload`. We see a lot of object rest spreads (i.e. the ellipses or `...`), which can become verbose and error-prone when we get into larger nested structures. One could argue that each state managed by a reducer should have a flat data structure, but in practice that is a rare occurrence.
Immer allows us to simplify this pattern by operating on a `draft` copy of the state _as if it is mutable_. To see what that looks like, let’s refactor this reducer.
First, will import the `produce` function and put the reducer and `initialState` in as the arguments of the `produce` call.
```js
import produce from 'immer'
const initialState = {
meta: {
loading: true,
error: false
},
data: []
}
export default produce( (state, action={}) => { switch (action.type) {
case 'USERS_LOAD':
return {
...state,
meta: {
...state.meta,
loading: true,
error: false
}
}
case 'USERS_LOAD_SUCCESS':
return {
...state,
data: [...action.payload.data],
meta: {
...state.meta,
loading: false,
error: false
}
}
case 'USERS_LOAD_FAILURE':
return {
...state,
meta: {
...state.meta,
loading: false,
error: action.payload.error
}
}
default:
return state } }, initialState
)
```
Next, we’re going to rename `state` to `draft`. This is just so we can stick with the Immer’s concept of manipulating a “draft state”. For more context, check out the Immer docs.
```js
import produce from 'immer'
const initialState = {
meta: {
loading: true,
error: false
},
data: []
}
export default produce(
(draft, action={}) => { switch (action.type) {
case 'USERS_LOAD':
return {
...draft, meta: {
...draft.meta, loading: true,
error: false
}
}
case 'USERS_LOAD_SUCCESS':
return {
...draft, data: [...action.payload.data],
meta: {
...draft.meta, loading: false,
error: false
}
}
case 'USERS_LOAD_FAILURE':
return {
...draft, meta: {
...draft.meta, loading: false,
error: action.payload.error
}
}
default:
return draft }
},
initialState
)
```
In order to manipulate state within the `produce` function, we just need to identify the changes we actually want to make. Let’s take the first original switch case as an example:
```js
case 'USERS_LOAD':
return {
...state,
meta: {
...state.meta,
loading: true,
error: false
}
}
```
What values are really changing? Just `state.meta.loading` and `state.meta.error`.
With Immer, we can represent these changes by simply operating on the `draft` state like it is mutable and the `produce` function will return a read-only copy without us needing to explicitly return anything.
```js
case 'USERS_LOAD':
draft.meta.loading = true
draft.meta.error = false
return
```
Since we don’t need to return any data within the `produce` callback, we can skip the `default` case too. The entire refactor will look like this:
```js
import produce from 'immer'
const initialState = {
meta: {
loading: true,
error: false
},
data: []
}
export default produce(
(draft, action={}) => {
switch (action.type) {
case 'USERS_LOAD':
draft.meta.loading = true
draft.meta.error = false
return
case 'USERS_LOAD_SUCCESS':
draft.data = action.payload.data
draft.meta.loading = false
draft.meta.error = false
return
case 'USERS_LOAD_FAILURE':
draft.meta.loading = false
draft.meta.error = action.payload.error
return
}
},
initialState
)
```
The `draft` is actually a proxy of the current state. Based on the changes to the `draft`, Immer will determine which parts of the state can be re-used and which require a new copy.
## Conclusion
What do you think? Does this look better or worse, simpler or more more complex? To me, this is definitely a smaller, more concise reducer. If you want to learn more about this approach, I recommend checking out the [curried `produce` section of the Immer docs](https://immerjs.github.io/immer/docs/curried-produce). | beejluig |
192,855 | Pro Tips: Don't Script When You Can Style | 0 | 2019-11-18T20:10:06 | https://dev.to/thisdotmedia/pro-tips-don-t-script-when-you-can-style-4fpk | css, html, animations, cssanimations | ---
title: Pro Tips: Don't Script When You Can Style
published: true
description:
tags: CSS, HTML, Animations, CSS Animations
---
The world of web development continues to make incredible strides in producing new technologies to better serve our users, and modernize web application development.
New tools and libraries are developed with [_developer experience (DX)_](https://hackernoon.com/the-best-practices-for-a-great-developer-experience-dx-9036834382b0) in mind, and are often a more attractive option. I have to admit, I’d much rather implement an [_Angular Material Table_](https://material.angular.io/components/table/overview) than look up [_HTML Table Element_](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/table) rules one more time!
They’re also worth learning in order to sharpen your skillset, and stay ahead of the curve. The fact still remains that when we adopt frameworks and UI libraries (see: [_Bootstrap, Google Polymer_](https://www.polymer-project.org/)), we don’t forfeit the responsibility of fundamental expertise, or considering [_performance_](https://developer.mozilla.org/en-US/docs/Learn/Performance) for our users.
It’s easy to lose sight of the fact that a large part of our job as Front-End Developers is to inform the browser of the layout of the page. It’s also easy to revisit the basics! Give yourself a moment to take stock of your current practices in order to see if they can be replaced with any simpler, or safer solutions.
Our reliance on frameworks, libraries, and in some cases, languages, can be simplified by getting down to our roots - HTML & CSS. I’ve identified two major areas of UI development that have CSS-only solutions, allowing for safer, cleaner, and faster code **structure** and **animations**.
**Structure**
Application structures, and their [_views_](https://medium.com/front-end-weekly/what-is-a-view-in-web-application-6a2836eed4eb), are often based on conditionally rendered elements. This has become easier to accomplish with what is available to us, out-of-the-box, using popular frameworks. You can just as easily build or manipulate the UI with logical checks, and [_event handlers_](https://developer.mozilla.org/en-US/docs/Web/Guide/Events/Event_handlers), as you can with a one-line CSS [_display_](https://developer.mozilla.org/en-US/docs/Web/CSS/display) property, or a CSS [_pseudo-class_](https://developer.mozilla.org/en-US/docs/Web/CSS/Pseudo-classes).
One example of this is [_Angular Structural Directives_](https://angular.io/guide/structural-directives) like [_NgIf_](https://angular.io/guide/template-syntax#ngIf). NgIf works by binding to a condition expression, and will add or remove the element it controls based on its truthy or falsy value. Here's an example of NgIf in action here:
```html
<div *ngIf="likesPuppies">
<a href="http://place-puppy.com/">Puppy Pics!</a>
</div>
<div *ngIf="likesKittens">
<a href="https://placekitten.com/">Kitten Pics</a>
</div>
```
You can see, from this example, that it's incredibly easy to implement - all you need is an attribute with a boolean condition to show a link to kitten or puppy pictures, depending on the user's preferences. What you don't see is the ~100 lines of [_source code_](https://github.com/angular/angular/blob/master/packages/common/src/directives/ng_if.ts) behind the scenes that powers the NgIf structural directive. Don't forget it's also written in [_TypeScript_](https://www.typescriptlang.org/), so that logic will also need to be transpiled for the browser to read it. If you need to show or hide a div based on a JavaScript value, you'll still need to use some JavaScript to do it. In this instance, you can opt to use the display property instead, and avoid the framework altogether.
If you’re only showing an element based on whether or not a value is returned from an [_API_](https://www.freecodecamp.org/news/what-is-an-api-in-english-please-b880a3214a82/), you don’t need to add extra JavaScript on top of the API call. You can use the [_empty pseudo-class selector_](https://developer.mozilla.org/en-US/docs/Web/CSS/:empty). This selector can be used to refer to any elements which don’t contain children or content.
If our API has been designed to store lots of data, and return whatever is available, the front-end of our application will need to cater to this response. In this example, I am showing a statically created list of items that represents a potential API response with a missing value:
```html
<ul>
<li>Pens</li>
<li>Pencils</li>
<li></li>
<li>Paper</li>
</ul>
```

Utilizing the empty pseudo-class selector will allow us to remove the empty list item from the user's view. Here's the code:
```css
li:empty {
list-style-type: none;
}
```
Here is what the user will see:

[_Chris Bicardi_](https://egghead.io/instructors/chris-biscardi) offers a short lesson on [_egghead.io_](https://egghead.io/) that highlights the intricacies of the [_pseudo-class_](https://developer.mozilla.org/en-US/docs/Web/CSS/Pseudo-classes), and shows you how to achieve this [_here_](https://egghead.io/lessons/css-the-empty-pseudo-selector-gotchas?pl=css-tips-and-tricks-5d10e708).
Another great example of this is the addition, and removal, of components like tooltips from the [_DOM_](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model), using JavaScript methods like [_MouseOver_](https://developer.mozilla.org/en-US/docs/Web/API/Element/mouseover_event).
Tooltips are an intuitive way to make your application more informative *and* you don’t need JavaScript to use them! Angular provides a highly configurable [_Material Design tooltip_](https://material.angular.io/components/tooltip/overview) allowing for delay, change in positioning and custom classes. Did you know they’re also available as [_HTML title attributes_](https://developer.mozilla.org/en-US/docs/Web/HTML/Global_attributes/title)? The tooltip in this code will be displayed when the user hovers over the label:
```html
<label for="name" title="User's First Name">Name</label>
<input type="text" name="name" id="name">
```

You can also create your own tooltip as shown in the [_W3Schools_](https://www.w3schools.com/howto/howto_css_tooltip.asp) posting here. I especially like the design of this HTML/CSS-only tooltip in this [_codepen_](https://codepen.io/cbracco/pen/qzukg). These frameworks do offer more choice, but if the job doesn’t call for it, you may be adding a lot more code unnecessarily.
There’s a good time to consider JavaScript when developing for components like tooltips, especially if they’re a central feature for a view or you’re building a [_reusable component_](https://www.cuelogic.com/blog/software-component-reusability) to match your application. The main takeaway should be to ask yourself whether or not you need to physically remove element from the [_DOM_](https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model). If one line of CSS can replace your reliance on a library, it may be worth considering.
**Animations**
Animations are a popular development technique because they make applications more fun, responsive and intuitive. Transitions offer a more sophisticated interaction with our user - the click of a button shows a ripple effect, and you slide to the next element.
It’s hard to imagine how we ever survived the jarring experience of changing views instantaneously using [_anchor tags_](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/a).
Libraries such as [_scrollmagic.io_](http://scrollmagic.io/) provide us with the ability for smoother and brighter scroll transitions such as anchor link scrolling, which you can demo [_here_](http://scrollmagic.io/examples/advanced/anchor_link_scrolling.html#bottom). The [_JavaScript Element Web API_](https://developer.mozilla.org/en-US/docs/Web/API/Element) provides us with the [_scrollIntoView_](https://developer.mozilla.org/en-US/docs/Web/API/Element/scrollIntoView) method, which allows us to bring an [_element_](https://developer.mozilla.org/en-US/docs/Web/HTML/Element) into the view of the user. You can see an example of the method in use [_here_](https://codepen.io/ronhook/pen/bZdyRz).
With a minimal amount of CSS code, you can write [_keyframes_](https://developer.mozilla.org/en-US/docs/Web/CSS/@keyframes) for the same experience! You are only required to define your keyframe from and to states, and then reference your keyframe in your [_CSS animation property_](https://developer.mozilla.org/en-US/docs/Web/CSS/animation). If you’d like to see keyframes in action, check out this [_demo_](https://www.impressivewebs.com/demo-files/css3-animated-scene/).
Animations have become such sought-after experiences, that many of the popular frameworks have included their own libraries for them. [_Angular Animations_](https://angular.io/guide/animations) is a powerful library that of allows the developer to control robust transitions, and rich experiences.
It uses JavaScript to control the triggers, timing, and display of content. The ability to do this requires a function that calls one or more other functions. If you want to use Angular Animations, you’ll need to import the [_Browser Animations Module_](https://angular.io/api/platform-browser/animations/BrowserAnimationsModule), import animation functions separately in the files you need them, and then add corresponding [_metadata properties_](https://www.code-sample.com/2018/04/ngmodule-metadata-properties.html). If you’re doing all of this to trigger an animation on [_MouseOver_](https://developer.mozilla.org/en-US/docs/Web/API/Element/mouseover_event) of an element, be aware that you can avoid the library, and JavaScript completely, by using the [_hover pseudo-selector_](https://developer.mozilla.org/en-US/docs/Web/CSS/:hover).
It’s possible to make the argument that using the [_Angular Animations library_](https://angular.io/guide/animations) could be a better alternative to writing animation logic because it uses the Web Animations API, which doesn’t use JavaScript to change CSS properties.
JavaScript is a more powerful solution to creating animations. It introduces the possibility of things CSS can't do, for example: pausing and reversing an animation. My advice is to err on the side of CSS, and use caution when developing animations, unless the design calls for a technically complex solution. Take solace in the safety of CSS.
An overridden, misinterpreted, or incorrect CSS rule can cause issues with user experience in the same way a [_JavaScript error_](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Error) does, but won’t prevent your application from loading or operating functionally. More often than not, CSS animations are more performant as well.
If you’d like to measure the performance difference between a particular CSS animation, and one which uses the Web Animations API, you can test them [_here_](https://greensock.com/js/speed.html).
The world of web development is experiencing a renaissance period thanks to the introduction of libraries and [_tooling_](https://www.valuecoders.com/blog/technology-and-apps/top-15-front-end-development-tools-2019/).
Frameworks make it much easier to rely heavily on JavaScript by providing easy-to-use APIs that structure, style, and animate our applications. Implementation is easy, and the design of the components is stunning.
I’ve built many applications using them and am incredibly thankful they exist. Their usability significantly reduces the time it requires to get a project functionally, and visually, complete.
I do, however, believe that they can remove us from maintaining institutional knowledge of our own applications, and there are simpler ways to achieve what the design calls for.
I hope this has ignited a passion inside of you for what you can do with simple CSS!
If you have any other techniques you’d like to share, please do so in the comments!
_This Dot Inc. is a consulting company which contains two branches : the media stream and labs stream. This Dot Media is the portion responsible for keeping developers up to date with advancements in the web platform. In order to inform authors of new releases or changes made to frameworks/libraries, events are hosted, and videos, articles, & podcasts are published. Meanwhile, This Dot Labs provides teams with web platform expertise using methods such as mentoring and training._ | stacktracy | |
192,946 | AR and VR smart glasses market grow at a CAGR 13% during the forecast period (2017-2023). | Drivers and Restraints The global AR and VR smart glasses market, according to a report by Market Re... | 0 | 2019-10-22T09:15:08 | https://dev.to/khisti_mandar/ar-and-vr-smart-glasses-market-grow-at-a-cagr-13-during-the-forecast-period-2017-2023-3koa | Drivers and Restraints
The global AR and VR smart glasses market, according to a report by Market Research Future (MRFR), is expected to reach a substantial market valuation and grow at a CAGR of approximately 13% during the forecast period (2017-2023).
The global AR and VR smart glasses market is likely to witness rapid growth during the forecast period. The growing advent of cloud-based technologies is one of the major factors fuelling the growth of the market over the review period. AR and VR are considered as the next significant computing platforms across the globe. Furthermore, the rising demand for AR and VR smart glasses across various industry verticals such as healthcare, retail, BFSI, manufacturing, and IT & telecommunications is fueling the growth of the global market.
Get Free Sample of AR And VR Smart Glasses Market @ https://www.marketresearchfuture.com/sample_request/4837
Competitive Analysis
Some of the major market players identified by MRFR in the global AR and VR smart glasses market are Microsoft Corporation (U.S.), Seiko Epson Corporation (Japan), Osterhout Design Group (U.S.), Royole Corporation (U.S.), Samsung Group (South Korea), Optinvent (France), Ricoh (Japan), Kopin Corporation (U.S.), MicroOLED (France), Imprint Energy, Inc. (U.S.), Sony Corporation (Japan), FlexEl, LLC. (U.S.), HTC Corporation (Taiwan), Avegant (U.S.), Razer Inc. (U.S.), Google Inc. (U.S.), Vuzix (U.S.), Oculus VR (U.S.), Jenax (South Korea), and Atheer (U.S.).
The key players of the market are expected t contribute substantially towards the market growth, driven by the competitive nature of the market.
Segmental Analysis
The global AR and VR smart glasses market has been segmented on the basis of product, device type, and application. on the basis of the device type, the market is bifurcated into binocular and monocular. The product segment is divided into mobile phone smart glasses, integrated smart glasses, and external smart glasses. Additionally, the external smart glasses segment is poised to account for a substantial share of the market owing to the growing usage of such kind of smart glasses in gaming and other applications. The higher adoption of cloud-based technologies is one major factor driving the growth of AR and VR smart glasses market. based on the application, the market is divided into military, gaming, industrial, education, and commercial.
Access Report Details @ https://www.marketresearchfuture.com/reports/ar-vr-smart-glasses-market-4837
Regional Analysis
The global AR and VR smartglasses market, based on region, is segmented into North America, Asia Pacific, Europe, and Rest of the World. the North American region is touted to display major growth and hold the largest market share during the review period. U.S and Canada are projected to fuel the growth of the North American AR and VR smart glasses market owing to the presence of a several established key players such as Osterhout Design Group, Microsoft Corporation, Royole Corporation, Imprint Energy, Inc., Kopin Corporation, FlexEl, LLC, Razer Inc., Avegant, Google Inc., Oculus VR, Vuzix and Atheer in this region. Driven by the major fall in the usage of native applications and a sizable shift towards the adoption of mobile applications in the region, the market is likely to show immense growth in the coming future. Additionally, North America also has a well-established infrastructure, which allows a higher penetration of devices and ultimately provides better connectivity. A rising need for innovations and advancements in the technology are other major factors responsible for the growth of the global AR and VR smartglasses market.
In the global AR and VR smartglasses market, Asia Pacific is also likely to witness a relatively higher adoption at the fastest-rising CAGR during the review period, across the globe, owing to the growing investments in the augmented reality and virtual reality market across several developing countries in the region, such as China, India, Japan, South Korea, Taiwan, among others. | khisti_mandar | |
193,006 | Flip clock in SwiftUI | SwiftUI is a new framework designed and released by Apple in 2019. It completely changes the approach... | 0 | 2019-10-22T12:17:58 | https://dev.to/elpassion/flip-clock-in-swiftui-385o | ios, swift, swiftui, combine | SwiftUI is a new framework designed and released by Apple in 2019. It completely changes the approach to building UI on Apple devices. Compared to predecessors (UIKit, WatchKit, AppKit), you can write code only once and use it on every Apple platform. It saves much time while building multiplatform apps. Another big difference is the programming paradigm change from imperative to declarative one. The focus shifts from writing step by step how to create something, to declaring the result we want to achieve. I’m 100% sure that these changes have a lot of advantages, and shortly many applications will be created using SwiftUI. Now it’s a perfect time to get familiar with it and learn how to use it. Below you can see the result of my adventure with SwiftUI.
### [Implemetation](https://github.com/elpassion/FlipClock-SwiftUI)
|Light|Dark|
|:-:|:-:|
|||
## License
Copyright © 2019 [EL Passion](https://www.elpassion.com) | zaprogramiacz |
193,029 | Connecting to your network on Centos 8 minimal (maybe trickier than you'd expect) | If you like linux as well as playing with the latest and greatest tools than the recent release of Ce... | 0 | 2019-10-23T16:07:25 | https://dev.to/bvkin/connecting-to-your-network-on-centos-8-minimal-maybe-trickier-than-you-d-expect-3791 | linux, tutorial, devops, opensource | If you like linux as well as playing with the latest and greatest tools than the recent release of Centos 8 may have been on your radar.
In my free time I like to experiment with various devops tools and technologies, all of which I've provisioned on Centos 7. I also like to write a fair bit of automation for them. So when the new release came out I figured that this would be a perfect opportunity to tear everything down and start from scratch to see if I could get things back to the same state. I think this is a great practice to test the robustness of your infrastructure and find areas that could use improvement. It's probably a bad idea to do something this extreme in production, but if it's out of your house for fun... who really cares what breaks, right?
The installation process is pretty much the same as it was in past versions. Not really much to say, but here's a [decent guide](https://linoxide.com/how-tos/centos-7-step-by-step-screenshots/) if you want to know more.
For the installation I chose `minimal server` as I only `ssh` into this machine so a GUI is just a waste of resources. To connect to my network I generally use `NetworkManager` and the included cli tool `nmcli` as this is the recommended tool.
The standard command used to connect to your network via wifi...
```
$nmcli connection add con-name <your-network> type wifi ssid <your-ssid> ifname <your-device-name>`- registers a connection for your network
$nmcli con modify <your-new-connection> wifi-sec.key-mgmt wpa-psk
$nmcli con modify <your-new-connection> wifi-sec.psk <password>
```
If your network is not password protected the last two commands are not necessary.
Normally this would just work, but this time around I got back an error instead...
```
Error: Connection activation failed: No suitable device found for this connection (device lo not available because device is strictly unmanaged).
```
After a little investigation... a.k.a checking the logs I noticed that there's a missing plugin.
```
$journalctl -u NetworkManager
...
Oct 17 20:41:21 localhost.localdomain NetworkManager[960]: <info> [1571359281.1533] manager: (wlp0s20f3): 'wifi' plugin not available; creating generic device
```
There was a lot more here, but I took it out for simplicity. The real thing to note here, if you have this problem is `'wifi' plugin not available;`. Specifically this means you are missing the plugin `NetworkManager-wifi`. To verify you can run the following and not that it does not appear.
```
$sudo dnf list | grep NetworkManager
NetworkManager.x86_6 1:1.14.0-14.e18
NetworkManager-libnm.x86_6 1:1.14.0-14.e18
NetworkManager-team.x86_6 1:1.14.0-14.e18
NetworkManager-tui.x86_6 1:1.14.0-14.e18
```
Ethernet here will not work either as there more additional missing plugins. So how does when install network plugins without any internet? The only way I've managed to do so is by pulling it from the iso used to install. In my case installed via usb, but whichever way you used you should be able to mount the iso as a device to pull it from. This will require root privileges.
```
$ sudo mkdir /media/CentOS
$ mount -o loopback,rw /dev/sdb2 /media/CentOS
```
Making the `/media/CentOS` directory and mounting the device at this location is necessary as `dnf` has this location preset as a repo to install base OS packages from. This may be used as part of the initial installation process but idk. You will have to verify which device your iso is registered as. In my case it was `/dev/sdb` but this will not always be the case. The first partition for the CentOS install seems to be the boot device and the second is actual packages and such.
After doing this we can enable the necessary repos and just install.
```
dnf --enablerepo=c8-media-BaseOS,c8-media-AppStream install NetworkManager-wifi
```
You should see the usual `dnf` output and the package plus dependancies should be added just fine.
Try bringing up your connection again and you should see the following.
```
$nmcli con up <your-connection>
Connection successfully activated (D-Bus active path: /org/freedesktopon/1
```
If you see this or something close you should be all set. Now you can install whatever!!
| bvkin |
193,091 | Make Your Websites 10x faster with Modern Technologies - SSGs and Many More | Static site are much cheaper and faster option than any other dynamically available websites or word... | 0 | 2019-10-22T15:27:08 | https://dev.to/the_ibrahim_/make-your-websites-10x-faster-with-modern-technologies-ssgs-and-many-more-14p | javascript, serverless, showdev, beginners | Static site are much cheaper and faster option than any other dynamically available websites or wordpress. What is static site? Static site means making website with static site generator. This are many static site generator to this work. 1000s of static site generator are available but not every static site generator is perfect.
___
I got an order one project with any to make a blog but it needs to be static. I chooses Hugo for making this project. I was learning Hugo. After learning I started working an a project. I was not understanding _index.md file logic. I cannot learn gatsby or gridsome because I don't know any JS framework yet. I tried more
___
I was confused and there docs were crap.
There are some of the SSGs I tried:
-Jekyll (Github)-
-Nikola (python)-
-Jigsaw (Php)-
Then I get used to 11ty it is such as beautifull static site generator and I am much comfortable with JS. So I deliver to my customer a static site running 11ty on it. | the_ibrahim_ |
193,219 | Ways to make money from software or software development. | 0 | 2019-10-22T21:14:31 | https://dev.to/tomavelev/ways-to-make-money-from-software-or-software-development-2nj5 | softwaredevelopment, monetization | ---
title: Ways to make money from software or software development.
published: true
description:
tags: software development, monetization,
cover_image: https://thepracticaldev.s3.amazonaws.com/i/m0ejvnjwgsjr0q4ltq3n.jpg
---
Reaching a point when you monetize a piece of software is very important. Otherwise you are just goofing around on your computer. Much like if you play games in a small, local way (If you are an e-sports star, there are ways to make money).
The first way is the standard 9-5 job. While you are at the office, you write code for your company or for the clients of the company. You don't own the code you have written. At least not in the legal way. You are mostly stuck in a place where you should spend your time so you could get your salary. For a introvert profession like software development - there are some pros to this - actually meet people, talk in the real world, exchange opinions about software and the real world instantaneously, not with an endless chat that you must spend reading.
The second way is freelancing. It is similar to 9-5. You don't own the code you write. Mostly, with freelancing, you are working from home, so less social meetings. This could be for family people that, even needing to focus on work, will be around the loved ones. There is a little bit of freedom - when you'll do your work. But in the same time this could be viewed as hell, because sometimes tasks are urgent, you may work in night hours, and having no strict schedule may be stressful.
Another bad things is searching for clients, and getting paid. Usually the clients go deep into a feedback loop, requiring fixes, improvements, even small things (from their perspective) that will totally break all the code /or whatever work you do/. Another thing - once you're done, many, many times the payment comes few days, even few weeks, if the client is bad - even months later.
Another way to make money is to create a software product or a service. It may be downloaded or executed online even while you are sleeping. In this case, you are not giving the source code, you are giving the end result of your code - web site, product, etc, to another technical individual, or very often - to non-technical user.
There are several ways to get money in this path. The first is a subscription model - you give access to the users in timely manner when they have paid. Another way is one time purchase /license/ to use your product. Some times your product could be totally free. Then you could place ads on your site/app and get money from them. The ads can be:
- Incoming from a 3rd party service (intermediate) and placed on a specific area/time - like a banner, or a video ad on some specific action in an app or site.
- Contracted by you - and in this case you will have much more control on what the ad will be, and maybe, get a bigger percentage income compared to the first option. This depends on your ability to negotiate.
If your product or service is free and is Web 2.0 - a tool or a platform where normal people can create stuff (and give you the rights to own and use), You could create a platform where other people show their own ads on the users of the platforms. Based on the data that the normal people have shared, the ads could be very, very targeted. Obviously, there are not so many such successful companies - Google (that owns - the OS, the Browser, the Web Sites), Facebook, LinkedIn etc.
Other than creating code that you give, or host and serve yourself, there are ways to make money from individuals that wish to learn what you know. This is content selling model copied from the self-help and marketing individuals. For this you'll need to record some video tutorials, share some source code, some presentations, host them and give a membership access - to those that have paid you.
YouTube and Twitch are one semi-good way to do a mix of the above - share some tutorials and make the video platform show ads, or receive money based on views. In this case you should try to code with technology or language or framework that is popular, modern, trendy, otherwise no-one will watch you.
Something that I'm seeing in both gurus that sell content and You Tubers is the use of special words. Marketing is not just for the marketing people anymore. Fishy words are used everywhere - by everyone. Words like - interesting, innovative, cool, hack(er), pro(professional), business (not everything that is called business is actually business), passive income, poor, rich, free, million (who can be sure that such individuals make million(s) and are not just goofing around searching for fishes). Use of numbers is very popular, also framework and language comparisons, memes and all other types of content that are understood by the technical people and are trying to mess with them, so could make the part of the funnel.
Another way is to create modules for all kinds of software - for developers and even non-developers. You could create a plugin for your favorite IDE and offer it with a price. Others get on the chance that - WordPress is very popular CMS - and create - themes, Plug-ins and all kinds of extensions that improve and enhance it.
And there is an option to depend on donations. Wikipedia is one such web site. Patreon is another site where you could create something and wait for donations. If you are a no-name individual, you are mostly doomed to hunger, with an exception if you are very good at something trendy.
In the end you must realize that money is a psychological idea - a store of value - and it's not bound to the software - which is a tool. How to reach a lot of people with the software? Obviously very rare will be the cases when someone does it alone. How people around the world will become aware of your existence? You must become aware of a problem to many and you must be able to resolve it. Also, you MUST check if it is a real problem and not just in your head, by a lot of asking, MVP etc. The platforms, or tools or services, content mediums that others could use to create their own stuff for the end consumer are very popular because the attention is more valuable than the money, because it can generate income repeatedly. Solving existing problems of other people is more altruistic software development (even if it is in return of fee) than creating something totally new that may or may not help others. Who needs million cryptocurrencies, million CMSes, yet another framework or programming language. And in many cases they create new problems or just - it probably will have bigger learning curve. If you solved your own problems, are they a problem for others? Mostly not - especially to the non-technical guy down the street. | tomavelev | |
193,328 | Learn React.js - Full Course for Beginners | Learn the complete React-Redux front end system: React.js, Redux, React Router, React Hooks and Auth0... | 0 | 2019-10-23T03:05:59 | https://dev.to/i_am_adeveloper/learn-react-js-full-course-for-beginners-mpc | react, javascript, webdev, tutorial | Learn the complete React-Redux front end system: React.js, Redux, React Router, React Hooks and Auth0
Other courses have made partial updates to older techniques and code, but this course is built from the ground up to include the most latest code and techniques from 2019+. You are getting the complete integrated modern techniques and code for React and Redux that are used in development today.
**What you'll learn:**
* The Most Modern Version of React and Redux
* Modern Authentication and Routing Patterns
* The Knowledge and Skills to Apply to Front End Jobs
* How React Works Under the Hood
* The Knowledge to know how different Front End Technologies work together (enough knowledge to impress other engineers)
* Modern ES5, ES6, ES7 Javascript Syntax.
{% youtube QFJDYwu15jE %} | i_am_adeveloper |
1,366,895 | About polaris ussd | https://www.bankfanz.com/how-to-check-polaris-bank-account-balance/ https://plaza.rakuten.co.jp/pola... | 0 | 2023-02-15T16:36:23 | https://dev.to/polaris_25/about-polaris-ussd-5ggp | ussd, transfer, code | [https://www.bankfanz.com/how-to-check-polaris-bank-account-balance/](https://www.bankfanz.com/how-to-check-polaris-bank-account-balance/#utm_source=backlinks&utm_medium=search&utm_campaign=darry+ring+us&utm_content=Michelle)
https://plaza.rakuten.co.jp/polarisbank18/diary/202302150000/
https://www.divephotoguide.com/user/polarisbankcode25
https://www.producthunt.com/@polaris_code25
https://www.provenexpert.com/polarisbankcode25/
https://vocal.media/authors/polaris-bank-code-25
https://wakelet.com/@polarisbankcode2596
https://www.lifeofpix.com/photographers/polaris_bank_code25/
https://rosalind.info/users/polaris-bank-code25/
http://phillipsservices.net/UserProfile/tabid/43/userId/200160/Default.aspx
https://camp-fire.jp/profile/polaris_bank_code25
https://app.roll20.net/users/11632110/polaris-bank-code-25-c
https://seedandspark.com/user/polaris-bank-code-25
https://plazapublica.cdmx.gob.mx/profiles/polaris_bank_code25/activity
https://www.metal-archives.com/users/polaris_bank_code25
https://trabajo.merca20.com/author/polaris_bank_code25/
https://www.intensedebate.com/people/Polaris_25
https://www.mifare.net/support/forum/users/polaris_bank_code25
https://pinshape.com/users/2575276-polaris-bank-code25#designs-tab-open
https://www.kiva.org/lender/polarisbankcode254002
https://www.credly.com/users/polaris-bank-code-25/badges
https://www.myminifactory.com/users/polarisbankcode25
https://www.sqlservercentral.com/forums/user/polaris_bank_code25
https://guides.co/a/polaris-bank-9984
http://foxsheets.com/UserProfile/tabid/57/userId/121106/Default.aspx
https://storium.com/user/polaris_bank_code25
https://speakerdeck.com/polaris_bank_code25
https://www.kompasiana.com/polarisbankcode25
https://www.longisland.com/profile/polaris_bank_code25
https://myanimelist.net/profile/Polaris_code25
https://leanin.org/circles/polaris-bank-code-25
https://social.msdn.microsoft.com/Profile/polaris_bank_code25
https://www.iheart.com/podcast/269-toneman-108983102/episode/polaris-bank-code-25-108983103/
| polaris_25 |
193,603 | Guidelines & Best Practices for Design RESTful API | Full post found at this Guidelines & Best Practices for Design RESTful API API development is in... | 0 | 2019-10-23T12:36:53 | https://dev.to/sachinjain007/guidelines-best-practices-for-design-restful-api-5575 | rest, api, design, restfulapi | Full post found at this [Guidelines & Best Practices for Design RESTful API](https://bytenbit.com/best-guidelines-design-restful-api/)
API development is increasing significantly as they serve the most important use case to build dynamic applications that exchange information. In other words, Restful API is used to connects devices and allow the sharing of data. API exchanges the data between server & client i.e to receive requests from the client and sends a response back.
### **API Jargons**
The term API is an acronym, and it stands for “Application Programming Interface.” API allows applications to exchange data via endpoint to which client sends a request and receives back data. It’s like communication services between two devices.
### **REST**
The term REST is an acronym, and it stands for Representational State Transfer. Rest is an architectural paradigm used in the development of web services. First presented by [Roy Fielding](https://en.wikipedia.org/wiki/Roy_Fielding)
### **RESTful API**
Also, know as a RESTful web service. Web services that conform to the REST architectural style & uses HTTP methods, termed RESTful web services.
In general, API makes the work a lot simpler and easier. It allows the developer to integrate functionality from third-party services rather than building themselves from scratch. As an example, Uber & Ola is using Google Map for a navigation system. This helps them to save time rather than building a navigation system from scratch.
Guidelines & Best Practices for Design RESTful API
### **RESTful API Design**
Let’s take an example for Resource type **Article**, to have a better understanding of designing API’s.
API can be built in any server-side programming language like PHP, Ruby, JS, Java, Python, Go-lang, Elixir. Many popular libraries & frameworks are built to develop Rest API’s like Django, Express, Rails, Spring. These help the developer to speed up the development process.
Let’s start designing restful API by following REST architect.
### **To GET Record**
**Bad designs**
```
GET /FetchArticle # To fetch all records
GET /getAllArticles/12 # To fetch specific records
```
- Do not end up with using verbs or actions to describe the APIs.
**Preferred Designs**
```
GET /articles # To fetch all records
GET /articles/12 # To fetch specific records
```
- URL of endpoint should contain HTTP methods to describe the functionality of API’s.
- Use plural or singular nouns but it should be consistent across all the API’s.
### **To Crete Record**
**Bad designs**
```
POST /createarticle # To create article
GET /createrecordforartilce # To fetch all records
```
**Preferred designs**
```
POST /articles # To create article records
```
- Endpoint URL contains HTTP methods to describe the action of API’s
- Use plural or singular nouns but it should be consistent across all the API’s.
- HTTP method for creating records should be POST.
### **To Update Record**
**Bad designs**
```
PUT /updatearticle/id # To update article
POST /id/modifyarticle # To update article
```
**Preferred designs**
```
PUT /articles/:id # To update article
```
- URL of endpoint should contain HTTP methods to describe the action of API’s
- Use plural or singular nouns but it should be consistent across all the API’s.
- :id denotes the record by which the record is uniquely identified.
### **To Delete Record**
**Bad designs**
```
DELETE /deletearticle/id # To delete article
POST /id/removearticle # To delete article
```
**Preferred designs**
```
DELETE /articles/:id # To delete article
```
- DELETE HTTP method is used to delete record.
- URL of endpoint should contain HTTP methods to describe the action of API’s
- Use plural or singular nouns but it should be consistent across all the API’s.
- :id denotes the record by which the record is uniquely identified.
### **Documentation**
Documentation is an important metric for a developer to use the API. Different API have different behavior which requires different parameters such as HTTPS methods, API response. Developer loves good documentation.
Various good tools are available in the market to help developer to generate the API documents.
- [Swagger](https://github.com/swagger-api/swagger-ui): Design and model APIs according to specification-based standards. Improve developer experience with the interactive API documentation.
- [Slate](https://github.com/lord/slate): Slate helps you create beautiful, intelligent, responsive API documentation. Most important Slate is an open-source project and free to use
### **Security**
API security is the important aspects, having a vulnerability in the system opens a way for an attacker to perform malicious activity. Before deployment of restful API. Developer has to identify the vulnerabilities & fix the potential security bugs ASAP otherwise, it threatens the company’s database.
- Use SSL to secure all your API’s.
- Use Industry-standard for authentication and authorization like JWT, Oauth2. Authenticate the API, before responding to the request.
- Don’t store sensitive data in the JWT payload, as it is easy to decode.
- Use encryption on all sensitive data, do not store the raw password in databases, always encrypt the password before storing it.
- Rate Limiting to protect against DDoS attacks/brute-force attacks.
- **Return 429 “Too Many Requests”** – used to notify that too many requests came quickly from the same origin.
- Revoke the client credential or blacklist if the client violates the usage of API.
- Validate all the inputs before responding to a request. Allowing this invalid data into our application could cause unpredictable results.
- Don’t pass sensitive information in URLs like password, JWT token, API keys as this information stored in browser & server logs.
- Example – https://example.com/login/username=abcd123456789&password=123321
- Above URL expose password. So, never use this form of security.
### **Versioning**
Versioning is important especially when we have third-party clients. It is always good practice to versioning the API as all the latest changes move towards the new version and older changes remain in the previous version. So that the existing app doesn’t get a break by new changes and developers get enough time to reflects these changes into the existing app.
It’s useful to put the version in the URL not mandatory. Versioning can also be achieved with Custom Request Header means the client passes the `api-version` in header.
**URI Versioning**
```
api/v1/articles
api/v2/articles
```
### **Characteristics of Good Restful API’s**
- API should do one thing and do it well. And keep it simple
- Avoid long parameter lists.
- Use pagination & support sorting by date, numbers of records per page.
- Proper versioning of the restful API.
- Readable and intuitive: The interface should exactly do what its name and protocol suggest.
- Stateless: No method depends on the result of another one.
- Error handling should be done with HTTP status codes.
- Proper parameter names, naming conventions, lowercase letters preferred in URI paths. do not abbreviate.
- Highly available & secure.
- Version the API, Use pagination, Sorting
- API’s should be stateless.
- Good documentation: Developer love good documentation.
- Hard to exploit. All validation and edge cases should have to cover with proper HTTPS code.
- KISS [keep it simple silly].
### **How to scale the API**
- Rate Limiting.
- Microservice architecture, where each service is designed to execute a specific task well. Breaking down functionality into individual services, which can work in parallel. Multiple instances of services running on multiple machines behind the load balancer.
- Caching layer, implement Memcache.
- Use CDN (Content Delivery Network).
- Use indexing where required.
- Filtering and pagination.
- Normalized database and use less SQL joins.
### **Conclusion**
All REST APIs are APIs, but not all APIs are REST APIs. Good designed API is always simple to use & admired by developers.
Following point are only my personal opinion. These are not fixed rules, but only tips from my own years of experience!
Also, see
- [How to Embed Newest Facebook Post into Website Automatically](https://bytenbit.com/automatically-embed-facebook-post/)
- [Google Gmail Labs – Effective Way To Enhance Email Productivity](https://bytenbit.com/google-best-gmail-labs/)
Ref: [ByteNbit A Technology blog - Every Little helps](https://bytenbit.com)
Thanks for reading. If you have more thoughts please share with me and other readers in comments. | sachinjain007 |
193,612 | Is HP Support Assistant free? | Does your HP printer not work? Random problems tend you to move on helping center of HP Support Assis... | 2,899 | 2019-10-23T13:13:35 | https://www.hpprintersupportpro.com/hp-support-assistant | Does your HP printer not work? Random problems tend you to move on helping center of HP Support Assistanace. The first step is that you must know this thing is <a href="https://www.hpprintersupportpro.com/hp-support-assistant">HP Support Assistant</a> free. Of course, there is no provision for paying price in lieu of problem solving. The identification of HP Support Assistance is done through exclamatory mark on printer device. Having clicked on this icon, you can get comprehensive list of information to deal it anyway. Feel free to contact us.
https://www.hpprintersupportpro.com/hp-support-assistant
| mariaca01192717 | |
193,804 | Daily Challenge #101 - Parentheses Generator | Write a function that will generate n pairs of well-formatted parentheses | 1,326 | 2019-10-29T14:06:06 | https://dev.to/thepracticaldev/daily-challenge-101-parentheses-generator-5d12 | challenge | ---
title: Daily Challenge #101 - Parentheses Generator
published: true
series: Daily Challenge
description: Write a function that will generate n pairs of well-formatted parentheses
tags: challenge
---
Write a function that will generate all possible combinations of grammatically correct parentheses. The function should be able to work with *n* pairs of parentheses.
Given *n = 3*, an example solution set would be:
<pre>
[
"((()))",
"(())()",
"()(())",
"()()()",
"(()())"
]
</pre>
Looking forward to seeing your solutions!
***
_Want to propose a challenge idea for a future post? Email **yo+challenge@dev.to** with your suggestions!_ | thepracticaldev |
193,864 | Creating our own map in Clojure on the nail 👩🏭👨🏭 | Prologue 🧐 In many programming languages, map is the name of a higher-order function... | 0 | 2019-10-24T02:03:13 | https://dev.to/wakeupmh/creating-our-own-map-in-clojure-on-the-nail-683 | clojure, todayilearned |
## Prologue 🧐
In many programming languages, **map** is the name of a [higher-order function](https://en.wikipedia.org/wiki/Higher-order_function "Higher-order function") that applies a [given function](https://en.wikipedia.org/wiki/Procedural_parameter "Procedural parameter") to each element of a [functor](https://en.wikipedia.org/wiki/Functor_(disambiguation) "Functor (disambiguation)"), a [list](https://en.wikipedia.org/wiki/List_(computing) "List (computing)"), returning a list of results in the same order. It is often called _apply-to-all_ when considered in [functional form](https://en.wikipedia.org/wiki/Functional_form "Functional form").
The concept of a map is not limited to lists: it works for sequential [containers](https://en.wikipedia.org/wiki/Container_(abstract_data_type) "Container (abstract data type)"), tree-like containers, or even abstract containers such as [futures and promises](https://en.wikipedia.org/wiki/Futures_and_promises "Futures and promises").
let's assume we have an array with 5 values
```clojure
(def values [22 33 11 23 15])
```
## The native map 👴
This way we will apply the **native** form to iterate the values
```clojure
(map println values)
;this will print each value
```
## Our own map 😎
```clojure
(defn my-map
[function sequence]
(let [firsElement (first sequence)]
(if firsElement
(do
(function firsElement)
(my-map function (rest sequence))))))
```
Now we can use our map to iterate or pass any function to do something, let's implements an example, **calculate the square of each element** 🤓
```clojure
(defn my-map
[function sequence]
(let [firsElement (first sequence)]
(if firsElement
(do
(function firsElement)
(my-map function (rest sequence))))))
(defn square [value] (* value value))
(println (my-map square value))
```
But if we have thousand of elements this possible throw a **stackoverflow exception** because normal recursion is a call stack, and a stack can be fully populated 😅
## The ninja way (who prevents stackoverflow exception)🐱👤

### Tail Recursion
In clojure the `recur` is a way to transform a recursion into a otimized loop, for this purpose is the best way
```clojure
(defn my-map
[function sequence]
(let [firsElement (first sequence)]
(if firsElement
(do
(function firsElement)
(recur function (rest sequence))))))
(defn square [value] (* value value))
(println (my-map square value))
```
Just for today, feel free to comment, I'm still learning and I usually share whenever I can, because I'm adept at **learning public** 🤗
 | wakeupmh |
193,928 | Building a Cool Horizontal Scroll Interaction in React | In this tutorial, we'll create a fun scroll animation in which items "flip" in the direction of the s... | 0 | 2019-11-02T10:41:26 | https://konstantinlebedev.com/horizontal-scroll-animation/ | react, animations, reactspring, javascript |
In this tutorial, we'll create a fun scroll animation in which items "flip" in the direction of the scroll. We're going to use [react-spring](http://react-spring.surge.sh) for animating and [react-use-gesture](https://github.com/react-spring/react-use-gesture) to tie animation to the scroll events. The native `onScroll` event handler won't do in this case, because we'll need additional information about scrolling that native `onScroll` handler doesn't provide - scroll delta in pixels, and whether the scrolling is in progress or not.
This is what we're going to build:

## Basic setup
We'll start with the basic React component you can see below. The component renders a list of images from `public` folder, and sets them as background for `div` elements:
{% gist https://gist.github.com/koss-lebedev/8303a05ae65093042535a069c9be098a %}
Next, we'll apply some styling. We need to make sure that the container takes up 100% of the width and it allows its children to overflow:
{% gist https://gist.github.com/koss-lebedev/bbaa2c0adc7163e27b69c2b312dd0511 %}
With the basic styling, our component will look like this:

## Adding animation
Let's start by adding a rotation animation. First, we'll replace `div` element with `animated.div`. `animated` is a decorator that
extends native elements to receive animated values. Every HTML and SVG element has an `animated` counterpart that we have to use if we intend to animate that element.
Next, we'll use `useSpring` hook from react-spring package to create a basic animation that will run when the component is mounted. Eventually, we'll bind our animation to the scroll event, but for the time being, it will be easier to see the result of the changes that we make if animation simply runs on mount.
`useSpring` hook takes an object with CSS properties that should be animated. These properties should be set to **end values** of the animation, so if we want to rotate `div`s from 0 to 25 degrees, we set the `transform` value to `rotateY(25deg)`. To set the **initial values**, we use `from` property which itself takes an object with CSS properties.
`useSpring` hook returns a `style` object that we need to set on the target component. We can see the updated code and the result below:
{% gist https://gist.github.com/koss-lebedev/237c451001f04dd5f5cae0544a7a9768 %}

This animation looks flat because by default the rotation is 2-dimensional, it's rendered as if there were no distance between the user observing the animation and the rotation plane. `perspective` transformation allows us to move the observation point away from the rotation plane, and thus makes 2-dimensional animation look 3-dimensional:
{% gist https://gist.github.com/koss-lebedev/9d2c93534c5219ffb9122ef15d9695f2 %}

Finally, we need to add vertical padding to the container `div` to make sure that children elements don't get cut off:
{% gist https://gist.github.com/koss-lebedev/2e34d3bb3fa4adc1b419f28392709dff %}

## Binding animation to scroll
Before we start working with scroll events, we need to make a small change to how we use `useSpring` hook. There are two things to keep in mind:
- we need to be able to trigger animation manually
- we no longer need to run animation on mount
To address both of these issues, we'll use a different `useSpring` signature - instead of **passing an object** with CSS properties, we'll **pass a function** that returns an object with CSS properties. Previously, `useSpring` hook returned us a `style` object
. With the new signature, it will return a tuple, where the first argument is a `style` object, and the second argument is a `set` function that we can call anytime to trigger the animation.
We can also drop `from` property since this value will be determined based on the current rotation of the `div`s:
{% gist https://gist.github.com/koss-lebedev/3ff09a7133a956a401f02654e16562cd %}
Now we can import `useScroll` hook from react-use-gesture package and bind it to the container `div`. The logic for handling scroll events is very simple - if the user is scrolling (`event.scrolling === true`), we want to rotate cards by the number of degrees equal to scroll delta on Y-axis (`event.delta[0]`); if scrolling stops, we want to reset the rotation angle to `0`:
{% gist https://gist.github.com/koss-lebedev/2121cef6682d3fe145d1e3b643aa7480 %}

Animation works, but there is an undesired side-effect - if we scroll sharply, the Y delta will be quite big, which may cause cards to flip more than 90 degrees. I've tested different values and discovered that the animation looks best if the cards flip no more than 30 degrees. We can write a helper function to clamp the delta value so it never gets more than 30 and less than -30:
{% gist https://gist.github.com/koss-lebedev/1bdcf452355f9b04faee57ad752e523b %}
Now we can use this helper function to clamp Y delta inside `useScroll` hook and get the final result:
{% gist https://gist.github.com/koss-lebedev/8d8052a113c788548e2d1bee981f1742 %}

You can find a complete working demo of this interaction [here](https://codesandbox.io/s/react-spring-fun-scroll-vmncd).
**PS:** I also made the same interaction using [framer-motion](https://framer.com/motion/). working demo is available [here](https://codesandbox.io/s/framer-motion-fun-scroll-788qb).
> If you want to get more tutorials like this one, make sure to [subscribe to my newsletter](https://konstantinlebedev.com/newsletter/).
## Final thoughts
I would like to mention two decisions that stayed behind the curtain of this tutorial but had been made before making this particular animation.
The first decision concerns performance. To make the flip animation, we animated only `transform` property, which is one of the only two properties that are accelerated by GPU and that don't take time off the main thread (the other property is `opacity`). There's quite a lot we can achieve by animating only `transform` and `opacity`, and whenever possible, we should avoid animating any other CSS properties.
Secondly, we need to consider responsiveness. Horizontal scroll that we implemented works well on phones and tablets, but for larger desktop screens we might want to use a more common grid layout. With small CSS changes and a media query we can switch from `flex` to `grid` layout, and we don't have to change the animation at all - it will continue working on small screens that use `flex` layout, and it will be ignored on large screens since with `grid` layout we won't have horizontal scroll.
| kosslebedev |
193,954 | How To Make A Website Using HTML CSS And Bootstrap 4? | Here in this tutorials you will learn how to make a website in HTML, CSS and Bootstrap. I'll show you... | 0 | 2019-10-24T09:07:50 | https://dev.to/phatnt_dev/how-to-make-a-website-using-html-css-and-bootstrap-4-5c3 | howtomakewebsiteresponsive, makeresponsivewebsite | Here in this tutorials you will learn how to make a website in HTML, CSS and Bootstrap. I'll show you how to create responsive modern looking website step by step with stylish section border. You will learn how to create a website using #HTML #CSS and #Bootstrap.
This is a complete tutorials for web development to make a website from start to end in a single website design tutorial.
If this website development tutorial is helpful for you please like this video and subscribe my channel to watch more website development courses.
Watch video on: https://www.youtube.com/watch?v=ZNPedhK4Rkk | phatnt_dev |
194,518 | Using Kentico CI and Git to help with releases | If you use Kentico CI in development, there is a good chance that you can make use of your Git commits to help you quickly and accurately prepare your Kentico exports for deployment. We've tried this on one of our projects successfully - here's how we did it. | 0 | 2019-10-24T12:41:37 | https://www.mattnield.co.uk/blog/using_kentico_ci_and_git_to_help_with_releases/ | kentico, ci, git | ---
title: Using Kentico CI and Git to help with releases
published: true
description: If you use Kentico CI in development, there is a good chance that you can make use of your Git commits to help you quickly and accurately prepare your Kentico exports for deployment. We've tried this on one of our projects successfully - here's how we did it.
tags: kentico, Continuous Integration, Git
canonical_url: https://www.mattnield.co.uk/blog/using_kentico_ci_and_git_to_help_with_releases/
cover_image: https://thepracticaldev.s3.amazonaws.com/i/0md3sn226b83j9kh1vu2.jpg
---
**Iterative deployment of Kentico EMS portal sites can be quite a manual process. If you're not using things like Content Staging then it's likely that you've either got your own special process or that you're using Kentico exports to deploy changes. This tip may help to speed up that process.**
Our production team use [Kentico's Continuous Integration][1] (CI) for most new projects and each of those projects goes through a daily build pipeline in [Team City][2] that is available for anyone on our network to see. The point of this article isn't how we've set up Team City (that should probably be another post), but us just a reflection on how we've used Kentico CI with Git in our most recent project to streamline live deployments.
The key here is that, while we're using CI, we *don't* have a continuous delivery (CD) setup; deployments to our UAT and live environments are a fairly manual process. They usually involve a combination of file, Kentico exports, SQL scripts, and manual CMS changes. All of the changes that need to be deployed are collated by the developer doing the release and this is checked by the project lead.
## Why did we take this approach?
Before I go into the detail of how this is useful let me tell you why we wanted it.
Kentico export is pretty good at exporting either global or site-specific objects. You can even specify a date and go and get all of the changes that have happened since then. This is great, but only if you want everything. When using Kentico CI, you learn pretty quickly that there are some things that you just don't want to be included. For our most recent project, we wanted to exclude anything that could be considered to be content from the CI pipeline. This was so that our project management and QA team were not constantly frustrated by their nicely curated tests and content being obliterated by [hipster-ipsum][3] copy and [pictures of cats stealing food][4] (or whatever crazy crap developers used when trying to test that the feature they're working on actually works). Because of this, we had a lengthy period in the project where we were constantly fiddling with the CI configuration to exclude the objects that we did not want to be synchronised.
> With Kentico CI, it can be better to specify what you do want, rather than what you don't.
## So what did we do?
The short story is that we used the name-only log in Git to tell us which items have actually changed since we last did a release. Preparing backups, release files, and exports are much simpler when you have a definitive list of changes.
The first things that we needed was a list of all of the files that have changed, so we dropped into git bash and came up with the following script:
{% gist https://gist.github.com/mattnield/a275a5c835a33a8d55df51a28cc61779 file=difflog.sh %}
What this has given us is a list of file and folder named that have been impacted by any commit between to two SHAs. This particular script also takes a copy of the changed files - I found it useful at the time, but we don't really use them any more.
We don't really care about the folder names, so these can be excluded. What we soon found was that - for releases including a large number of changes - cleaning this file up was frankly quite boring. So we created a simple c# script to remove the entries that we don't need.
{% gist https://gist.github.com/mattnield/a275a5c835a33a8d55df51a28cc61779 file=cleanLog.cs %}
Once we have a clean text file, we can look through the contents to determine what we actually need to deploy. Most of this is pretty standard, but where we found a real advantage is in preparing our Kentico exports.
The whole file is then loaded into a spreadsheet and we then separated the rows based upon their file type and location. The following list is what we ran (in order) to achieve that:
- `/CIRepository/@global/`: Each file in this list is used to identify an item to be taken as part of a global export from the Kentico **Sites** application.
- `/CIRepository/{sitename}/`: Each file in this list is used to identify an item to be taken as part of a site export from the Kentico Sites application.
- `.xml|*.aspx|*.ascx|*.html`: These are individual files that will need to be copied as part of the deployment.
- `.config`: These are individual files that will need to be copied as part of the deployment.
For this article, we're only really interested in the rows that need to be exported, so we can apply a filter on that column to show only the site export and global export rows. What we are left with is a list of changed files which can be matched up with individual items in the Kentico export tool in the Sites application.
As an example, anything in `/CIRepository/@global/cms.pagetemplate` be found when performing a global export in the *Development > Page templates* section. There are a few exceptions to the rule - things like settings categories don't get exported, so you can ignore things in `/CIRepository/@global/cms.settingscategory`, but you'll learn those as you go.
## Summary
We've used this in a single project so far, but it's worked really well. The approach has dramatically reduced the amount of time we spend preparing releases and improved the team's overall confidence in the release process itself. Until we get a CI/CD pipeline that does what we need, I think we'll be using this method to prepare releases and probably working to automate it more. If you don't use Kentico CI to deploy, you can still use it to help you prepare.
[1]: https://www.kentico.com/product/all-features/development/continuous-integration
[2]: https://www.jetbrains.com/teamcity/
[3]: https://hipsum.co/
[4]: https://www.google.com/search?q=cats+stealing+food&source=lnms&tbm=isch | mattnield |
194,569 | Webinar how to build a blockchain application | Hi developers, in the next hour, we are running a webinar to show how to create a blockchain webapp i... | 0 | 2019-10-24T14:29:24 | https://dev.to/skaffolder/webinar-how-to-build-a-blockchain-application-2kib | webinar, blockchain, webdev, node | Hi developers,
in the next hour, we are running a webinar to show how to create a blockchain webapp in a few clicks, if you are interested you can sign up from this link https://www.eztalks.com/r/996698371
| skaffolder |
194,622 | We’re not all DBAs: Indexes For Developers | We know they speed up queries, but what’s going on under the hood? How do they work? An index is a s... | 0 | 2019-10-24T16:39:05 | https://mattdgale.com/were-not-all-dbas-indexes-for-developers/?utm_source=rss&utm_medium=rss&utm_campaign=were-not-all-dbas-indexes-for-developers | sql, index, backend, performance | ---
title: We’re not all DBAs: Indexes For Developers
published: true
date: 2019-10-24 16:14:52 UTC
tags: SQL,index,backend,performance
canonical_url: https://mattdgale.com/were-not-all-dbas-indexes-for-developers/?utm_source=rss&utm_medium=rss&utm_campaign=were-not-all-dbas-indexes-for-developers
---
We know they speed up queries, but what’s going on under the hood? How do they work?
An index is a structure (commonly a B-Tree, but not required) that we attach to a table that keeps certain columns of that table organized and in memory. Indexes are a solution to the age old problem that going to disk is slow- by caching data in memory you save yourself time reading a records from disk that will mostly be discarded. It’s more efficient to keep common queryable columns in a searchable in-memory store with a reference to where on disk the rest of that row can be found. Having an indexed column lets you find what you need quickly and go to disk specifically for what you **need**.
There are lots of explanations of B-Trees- [Markus Winand](https://use-the-index-luke.com/sql/anatomy/the-tree) has a beautiful explanation. I also give a hearty shout out to Markus in general, [his site](https://use-the-index-luke.com) and [book](https://sql-performance-explained.com/) are **full** of great content and his explanations are amazing- highly recommended.
As a developer needing to work with and manipulate databases constantly, there’s a few useful points on indexes that tend to be forgotten. Let’s consider a few.
1. An indexed column’s values don’t have to be unique. **Cardinality,** in database jargon, refers to “how unique” the values in an index are; high cardinality means the underlying values have little repetition. When evaluating a column to decide if we want to put an index on it, high cardinality (low repetition) is good for selectivity, but a column doesn’t need to have perfect cardinality to be a candidate. Indexes are able to handle non-unique values by scanning sequentially through the leaves of the underlying tree. The linkage between tree leaves helps prevent unnecessary operations stemming from jumping around through the internals of the tree, making it less costly to navigate through the entries in the index. Scanning data in this way makes doing an equality check (`val = ‘matt’`) with multiple results a more lightweight operation. We can leverage this structure to scan through B-Tree indexes too- things like range scans (`val > X and val <= Y<`) and even some regexes (`first_name like ‘matt%’`). Careful though- even when you’re reading from an index in a range, there can still be a lot of data to read, making your query slow.
When columns are unique, during creation of an index, we can add the constraint that the index be unique, and that allows the optimizer leverage the uniqueness for lookup performance.
2. Multi-column indexes. Firstly, if you didn’t know you could do this- now you do! The underlying behavior and implementation of these indexes vary by DBMS, but across the board, multi-column indexes are versatile in that they can be used to query across all or a subset of columns in the index. To **greatly** simplify (this varies by DBMS), you can think of think of a table with 3 columns: col1, col2 and col3. When the multi column index is created, the values of all 3 columns are combined into a three part “value”: col1|col2|col3 and sorted- when a query is done, we traverse the tree by comparing against each “section” of the value one at a time and navigate the tree that way. With this arrangement, by supplying 3 values, we can traverse the tree as quickly as we would with a single column index, but giving us greater selectivity since querying by just one column might yield a ton of data to be returned. I mentioned that multi-column indexes support subsets of columns- queries can make use of a multi-column index if we query by only col1, col1 and col2, or all three- each column we add to the query increases the effectiveness of the index lookup because we are adding selectivity and so, less rows to pull back from disk. In some schema designs, multi-column indexes can be a performance boost because we’re able to eliminate so many rows by being selective in our seeking.
3. Index only scans. With multi-column indexes, it’s possible that the data you’re looking for are held by an index and, therefore, in memory. With the data so available, there’s no need to go to disk if the index can simply give us the data we need. Say you had a table with columns `first_name`, `last_name` and `age` in an index and you wanted to find the age for people named “Matt Gale”. Your query could look like `select age from person where first_name = ‘Matt’ and last_name = ‘Gale’`. In this case there would be no need to go to disk because age is part of the index, so the optimizer just returns `age` values directly from the index. This can be a really nice resource saver if you can exploit it.
In my experience building applications, Object Relational Mappings (ORMs) tend to grab too many columns during a query and developers don’t give much thought to lookups by more than just a single value and so favour single column indexes as a result. To be able to leverage index only scans, look into lazy loading more of your columns to see if you can squeeze some performance out of your queries.
Something to always keep in mind when doing any query against a database is _how much data will I get back from this query_? Queries can be slow because of lack of proper indexes, but also because the volume of disk accesses required.
For example, let’s say you have a large table with an index on a boolean column (very low cardinality). If you tried to search for rows matching ‘false’ your time spent doing disk access is going to be **huge** (you’re returning half the table!) relative to the tiny amount of time spent looking values up in an index. This is an example of a situation where indexing is not what will save you time, you need to be more selective in the rows you want to get back. Indexes are an important part of database performance but they are not the only thing to consider.
I hope this gives a bit of insight! We don’t all have to be DBAs to write sufficiently fast queries and we shouldn’t need to be. As developers, getting familiar with the core structures of a database is a sufficiently pragmatic way to spot and improve performance. With that, go forth and write fast queries! | mdgale |
194,666 | Computer Science and fighting to learn AVL Trees | The reason for this post is that I've been working through teaching myself computer science topics an... | 0 | 2019-10-25T21:14:16 | https://dev.to/vetswhocode/computer-science-and-fighting-to-learn-avl-trees-4ai1 | computerscience, career | The reason for this post is that I've been working through teaching myself computer science topics and I felt like this data structure was unnecessarily difficult. I would like to share my findings in hopes of helping someone on their journey.
The problems I ran into learning AVL Trees were mostly in actually coding the thing.
1. Some of the code that I found online was broken. It didn't actually work, and that's my fault for not testing.
2. Some code was unnecessarily complicated (we'll talk about what I think that means later on).
3. Some code was difficult to read and understand the underlying concepts. I spent a lot of time trying to figure out just what the code itself was doing and it didn't teach me much when I did figure it out.
## What is an AVL Tree and Why do I care?
AVL trees are named after the inventors Adelson-Velsky and Landis. In short they are a self-balancing binary search tree (BST). The idea behind a BST is that on average BSTs make looking up info really fast because data has a very specific place it can be. The worst case scenario though is if a BST turns lopsided and all of the data ends up making it look more like a list and less like a tree. That is where AVLs come in. They ensure that BSTs never get out of balance and we can keep those super fast look ups.
## The Concepts
- Recursion
- Binary Search Trees
- Node height
- balancing (calculating the balance factor)
- what it means to be heavy
- The four rotations LL, RR, LR, RL
I feel like there are a lot of great authoritative sources out there that teach the concepts really well. I gravitated to this list below. This is by no means an exhaustive list.
#### Written Explanations
- [BaseCS](https://medium.com/basecs/the-little-avl-tree-that-could-86a3cae410c7)
- [Growing With the Web](https://www.growingwiththeweb.com/data-structures/avl-tree/overview/)
#### Video Explanations
- San Diego State University's [Dr. Rob Edwards](https://www.youtube.com/watch?v=-9sHvAnLN_w) helped me through the basics and understanding of a linear fashion through all of my data structure learning.
- I thought [Abdul Bari](https://www.youtube.com/watch?v=jDM6_TnYIqE) gave an amazing explanation and really drove home balancing factors for me.
My first instinct after understanding the concepts was to try and implement it through sheer problem solving. I think its a great exercise to try to solve an AVL Tree with the above knowledge. When I felt stuck that's when I started looking for other people's implementations so that I could cherry pick what I liked out of those.
## The Implementations
My criteria for an implementation that will help me learn the concept should have:
1. Clean `insert`, `read`, `balance` functions
2. Traditional implementations that I can imagine using for other problems.
3. Novel solutions to traditional problems.
4. Has no dependencies and is isolated in one file mostly.
The different implementations I mostly looked at were:
1. [Trekhleb's on Github](https://github.com/trekhleb/javascript-algorithms/tree/master/src/data-structures/tree/avl-tree) is a clean implementation and pretty cool concept of using a loop for the insert. However, I didn't like that it uses a `find` function in the `bst` file, which I just didn't want to have hunt down to juggle back and forth.
2. [Gwtw's on Github](https://github.com/gwtw/js-avl-tree) seems more of the classic insert implementation that I saw. However I was not a fan of how the rotation methods were defined. They didn't seem as intuitive to me.
3.The [Tutorials Point](https://www.tutorialspoint.com/AVL-Tree-class-in-Javascript) implementation helped me understand most concepts clearly. It has clean naming conventions and a good order of how it does things and is nice and short. This is the code for the LL rotation, which I admire.

The negative aspects of it though were that because it is so short it does some interesting short cuts that make you have to do some extra mental gymnastics. The biggest issue with this code is that it doesn't completely work. There are some typos and it doesn't handle some basic use cases. My biggest issue was that there was no forum, community, or way to know if this is a good or bad implementation because there is no way to give feedback. I think the code however is really elegant and solves the problem in a really interesting, and succinct way.
So, here is [the code](https://github.com/axecopfire/interview_prep/blob/master/feMasters/4semesters/ex/DataStructure/AVL.js) that I came up with after all this.
Please comment, submit pull requests and let me know what you would like to see in it. Thanks for reading. | schusterbraun |
194,680 | CSS for beginners from a beginner | Cascading Style Sheets, fondly referred to as CSS, is a simply designed language intended to simplify... | 0 | 2019-10-24T19:51:01 | https://dev.to/millsjessicainokc/css-for-beginners-from-a-beginner-1f5n | ctrlshiftcode | Cascading Style Sheets, fondly referred to as CSS, is a simply designed language intended to simplify the process of making web pages presentable. CSS allows you to apply styles to web pages. More importantly, CSS enables you to do this independent of the HTML that makes up each web page.
CSS is easy to learn and understood but it provides powerful control over the presentation of an HTML document. Cascading Style Sheet(CSS) is used to set the style in web pages which contain HTML elements. It sets the background color, font-size, font-family, color, … etc property of elements in a web pages.
There are three types of CSS which are given below:
Inline CSS: Inline CSS contains the CSS property in the body section attached with element is known as inline CSS. This kind of style is specified within an HTML tag using style attribute.
Internal or Embedded CSS: This can be used when a single HTML document must be styled uniquely. The CSS rule set should be within the HTML file in the head section i.e the CSS is embedded within the HTML file.
External CSS: External CSS contains separate CSS file which contains only style property with the help of tag attributes (For example class, id, heading, … etc). CSS property written in a separate file with .css extension and should be linked to the HTML document using link tag. This means that for each element, style can be set only once and that will be applied across web pages.
Properties of CSS: Inline CSS has the highest priority, then comes Internal/Embedded followed by External CSS which has the least priority. Multiple style sheets can be defined on one page. If for an HTML tag, styles are defined in multiple style sheets then the below order will be followed.
• As Inline has the highest priority, any styles that are defined in the internal and external style sheets are overridden by Inline styles.
• Internal or Embedded stands second in the priority list and overrides the styles in the external style sheet.
• External style sheets have the least priority. If there are no styles defined either in inline or internal style sheet then external style sheet rules are applied for the HTML tags.
| millsjessicainokc |
194,808 | How to use Vue Composition API using TypeScript - Part 2 | As we saw in the previous post, we started a project to make use of the Vue Composition API and Type... | 0 | 2019-10-26T16:29:18 | https://dev.to/manuelojeda/how-to-use-vue-composition-api-using-typescript-part-2-29ee | vue, typescript | As we saw in the previous post, we started a project to make use of the Vue Composition API and TypeScript, in case you didn't read the post, you can check it out here:
https://dev.to/manuelojeda/how-to-use-vue-composition-api-using-typescript-part-1-5a00
So, without anything else to say!

##**Previewing and preparing the project directory**#
As you may know by now, the Vue CLI make a base setup of the project, but before the start we need to add some folders into the project, we are adding two folders into the **src** directory: interfaces and services, once we added those two folders our directory wil be set like this:
##**Building the interface and the service**#
As you may know, TypeScript give us the opportunity to add Interfaces and Services into a project (of course the main use is adding the type enforcement), before we start we need to set a background of what is both of those terms:
- **Interfaces** are the contract that will follow one or more variables, and will only accept certains values added into the interface
- **Services** are what normally we use as an API, giving us all the function we may need to consume/use.
Now let's create some code!
####**Character.ts**#
Inside the interfaces directory create a file named **"Character.ts"** and we add the next code:
```ts
interface Character {
name?: string;
height?: string;
mass?: string;
hair_color?: string;
skin_color?: string;
eye_color?: string;
birth_year?: string;
gender?: string;
homeworld?: string;
films?: string[];
species?: string[];
vehicles?: string[];
starships?: string[];
url?: string;
}
export default Character
```
*Note*: As you notice, I added a **?** besides the variable name just to avoid any warning when we initialize an empty variable using this contract.
After we have settle our contract, we may proceed to create our service.
####**CharacterService.ts**#
Inside the services directory add the following file "CharacterService.ts", we are just creating a singleton class that will only get the data (our heroes and villains) we may need in our Vue components.
```js
import axios from 'axios'
import Character from '@/interfaces/Character'
class CharacterService {
async FetchCharacters (): Promise<Character[] | any[]> {
let response: Character[] | any[] = []
try {
const { data, status } = await axios({
url: 'https://swapi.co/api/people/'
})
if (data && status === 200) {
response = data.results
}
return response
} catch (error) {
response = [
{
error: error.response as object,
flag: false as boolean,
generalError: 'An error happened' as string
}
]
return response
}
}
}
export default CharacterService
```
As you may noticed we prepared our function as await/async to make our code cleaner and added an alternative response type in case and error occurs while we are fetching out information.
For now on we have prepared the interface and service code, in the next and last part we are going to set our Vue app and connect in all together to make this app working.
| manuelojeda |
194,914 | The core of every Software Design Pattern | If you're writing code on a daily basis, design patterns of your code might be interesting for you. Try to validate them with these basic ruleset to verify them. | 0 | 2019-10-25T09:34:00 | https://dev.to/felixhaeberle/the-core-of-every-software-design-pattern-ld6 | productivity, career, showdev, webdev | ---
title: The core of every Software Design Pattern
published: true
description: If you're writing code on a daily basis, design patterns of your code might be interesting for you. Try to validate them with these basic ruleset to verify them.
tags: productivity, career, showdev, webdev
cover_image: https://thepracticaldev.s3.amazonaws.com/i/2s8f3of68rlr4648eq6r.jpg
---
As Software Developers, we often valuate our code through Design Patterns. It’s the core of every good or bad written code and a high factor for security and performance only to mention two. We are often looking for opportunities to write our code better and searching for new Design Patterns. I think we’re often misusing this words to describe Best-Practices or To-Do’s which we should follow anyway. For me, the core of Software Design Patterns consists of the following 6 rules.
1️⃣ They are proven solutions
2️⃣ They are easily reusable
3️⃣ They are expressive
4️⃣ They ease communication
5️⃣ They prevent the need for refactoring code
6️⃣ They lower the size of the codebase
## 1️⃣ They are proven solutions
Because design patterns are often used by many developers, you can be certain that they work. And not only that, you can be certain that they were revised multiple times and optimizations were probably implemented.
## 2️⃣ They are easily reusable
Design patterns document a reusable solution which can be modified to solve multiple particular problems, as they are not tied to a specific problem.
If you want to guarantee quality over the lifespan of the software project, a reusable adaption must be considered. This procedure also offers other developers a simple adaption into the existing solution.
## 3️⃣ They are expressive
Design patterns can explain a large solution quite elegantly.
There is often code in your codebase, which you would like to exchange, because it is very slow or difficult to understand. Do not be afraid to exchange it or delete it completely and write it from scratch. If this is not possible, try to separate the individual tasks of the code better to make the code more understandable.
## 4️⃣ They ease communication
When developers are familiar with design patterns, they can more easily communicate with one another about potential solutions to a given problem.
If you’re working with colleagues in a team of multiple developers, agree with them about the design patterns, as they can help you better with a problem. Also with regard to the maintenance of software you should follow such procedures, as you make maintenance operations faster and more efficient.
## 5️⃣ They prevent the need for refactoring code
If an application is written with design patterns in mind, it is often the case that you won’t need to refactor the code later on because applying the correct design pattern to a given problem is already an optimal solution. If such solutions are then updated, they can be seamlessly applied by any good software developer and do not cause any problems.
## 6️⃣ They lower the size of the codebase
Because design patterns are usually elegant and optimal solutions, they usually require less code than other solutions. This does not always have to be the case as many developers write more code to improve understanding.
Therefore, if you're writing code on a daily basis, design patterns of your code might be interesting for you. Try to validate them with these basic ruleset to verify them. Happy coding! 👩💻👨💻
| felixhaeberle |
194,971 | Get Started with Uptime Monitoring using Bantay | One of the key metrics in DevOps is availability, that is: measuring how much, over a given period, y... | 0 | 2019-10-25T11:55:55 | https://dev.to/kixpanganiban/get-started-with-uptime-monitoring-using-bantay-2o6g | observability, devops, go, docker | One of the key metrics in DevOps is availability, that is: measuring how much, over a given period, your service or app is _available_ or accessible. Often, availability is paired with scalability, or the measure of how well your service performs in proportion to a growing number of users. Among other things, availability and scalability comprise a big chunk of observability in control theory -- the practice of inferring the internal state of a system through external observations. We'll get back to observability at a later post, but in this one, we'll focus on just availability, and how to get started with it.
The most straightforward way of measuring availability is by measuring service uptime. Often, DevOps engineers and SREs aim to achieve the five-nines of availability, which means that a service is available 99.999% of the time.
Let's define a couple of goals:
1. We can see if a service is "up" by performing an HTTP GET request on a known endpoint
1. We get notified whenever a service "goes down" or "comes back up" (ie its state of availability changes)
1. And finally, we can log all of these somewhere for posterity
### Introducing Bantay
Sometime back, I needed to achieve pretty much those same three goals with a couple of constraints: one, that the manner by which I achieve those goals is cheap (or free), and two, I have total and absolute control over my data and how I perform my monitoring. While solutions such as Pingdom, Rollbar, New Relic, and Statuspage exist, none of them are completely free and none of them offer complete control over my data. Hence, I built my own: [Bantay](https://github.com/KixPanganiban/bantay).
Bantay aims to be a lightweight, extensible uptime monitor with support for alerts and notifications.
It's very easy to get started. First, we write a configuration file called `checks.yml`:
```yaml
---
server:
poll_interval: 10
checks:
- name: Dev.to
url: https://dev.to/
valid_status: 200
body_match: dev
- name: Local Server
url: http://localhost:5555/
valid_status: 200
reporters:
- type: log
```
Let's go through the YAML file line by line:
```yaml
server:
poll_interval: 10
```
Here we define a `server` section, and we tell it to have a `poll_interval` of `10`. When we run Bantay in server mode later, this is the frequency with which it will perform uptime checks.
```yaml
checks:
- name: Dev.to
url: https://dev.to/
valid_status: 200
body_match: dev
- name: Local Server
url: http://localhost:5555/
valid_status: 200
```
Next we define a `checks` section, with a couple of entries: `Dev.to` and `Local Server`. The fields are pretty self-explanatory, with `url` being the endpoint which Bantay will perform an HTTP GET to check uptime, `valid_status` being the HTTP status code we expect to get, and `body_match` being an optional string in the response body we expect to see.
```yaml
reporters:
- type: log
```
In the `reporters` section, we put one object with the type `log`. This will log the checks in stderr/stdout.
Before we actually start Bantay, let's go ahead and quickly start a Python HTTP server to listen on port `5555` locally (four our `Local Server` check):
```console
# on Py2
$ python -m SimpleHTTPServer 5555
# on Py3
$ python3 -m http.server 5555
```
> For Mac OS users: Modify `checks.yml` to use `http://docker.for.mac.host.internal:5555/` instead of `http://localhost:5555/`
Finally, we pull the latest Bantay Docker image, and run a check:
```console
$ docker run -v "$(pwd)/checks.yml":/opt/bantay/bin/checks.yml --net=host fipanganiban/bantay:latest bantay check
```
We should get something similar to:
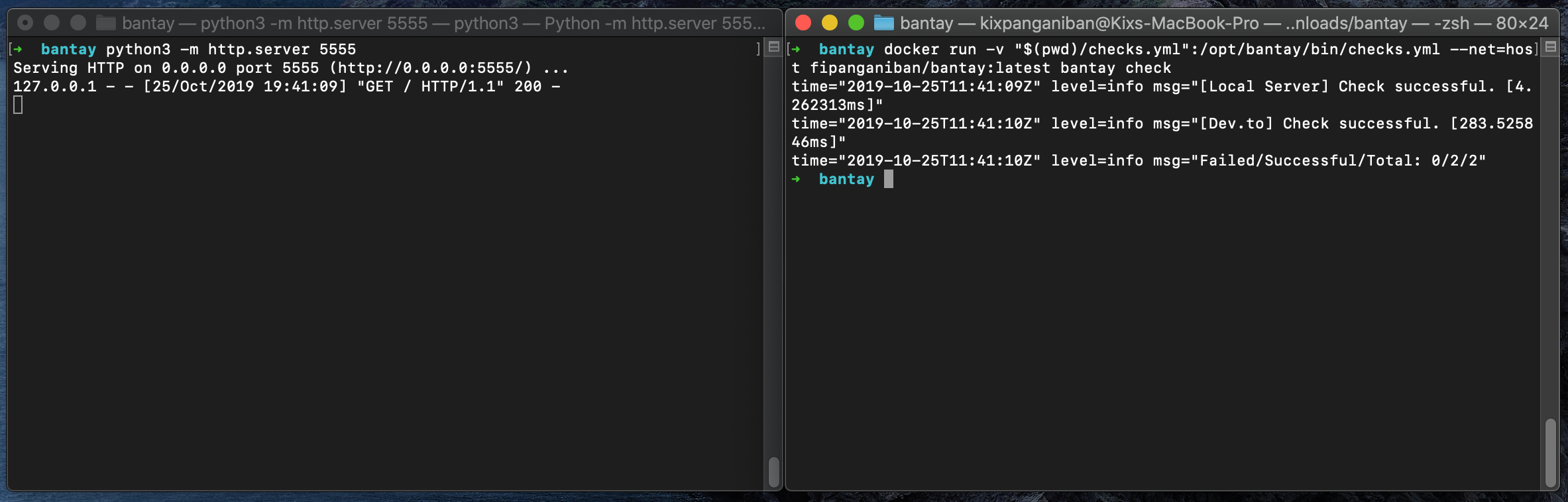
Looks good!
If we kill the running Python server and run Bantay check again, we should get:
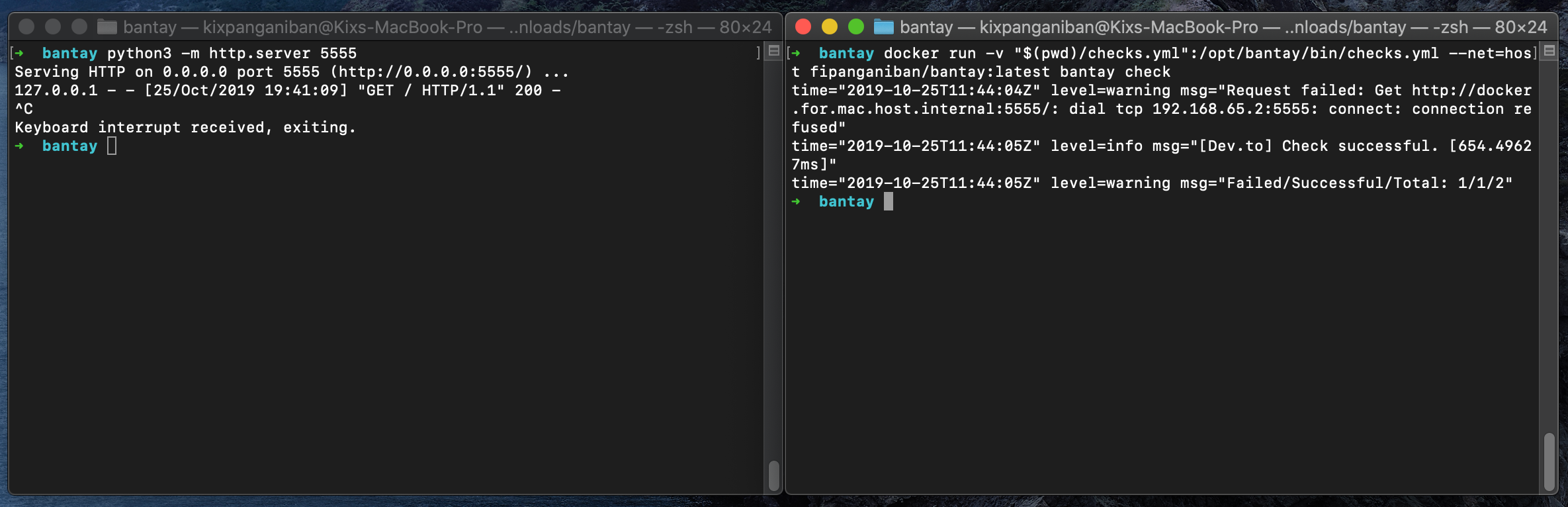
### Bantay Server
A one-off check does little to help us measure availability. Most of the time, we want to perform these checks regularly and get notified whenever something goes down _after_ a check. For that, we run Bantay in server mode:
```console
# start the local Python HTTP server again
$ python3 -m http.server 5555
# and start Bantay in server mode
$ docker run -v "$(pwd)/checks.yml":/opt/bantay/bin/checks.yml --net=host --name bantay fipanganiban/bantay:latest bantay server
```
We can also add a Slack reporter to let us know when a service goes down. Add the following to the bottom of your `checks.yml` file (replacing `YOUR-SLACK-CHANNEL-HERE` and `YOUR-SLACK-TOKEN-HERE`):
```yaml
- type: slack
options:
slack_channel: YOUR-SLACK-CHANNEL-HERE
slack_token: YOUR-SLACK-TOKEN-HERE
```
Now, when we kill the Python server again, Bantay should detect that it went down and we get a handy notification through Slack:

And if we start the Python server again, Bantay should detect that as well:

### Final notes
And that's it! You should now be able to set basic uptime checks with Bantay, in just a few lines of YAML. At the time of writing, Bantay also supports notifying via email (using Mailgun), and sending metrics to InfluxDB (for graphing and storing history). Learn more about all its current features, and how to build Bantay as a binary, in its Github repo: https://github.com/kixpanganiban/bantay | kixpanganiban |
195,085 | What a beginner has learned about CSS | Imagine that you’ve bought a house. The structure is fine. There are no problems with termites or p... | 0 | 2019-10-25T14:43:58 | https://dev.to/summersetwren/what-a-beginner-has-learned-about-css-3ah4 | ctrlshiftcode | Imagine that you’ve bought a house. The structure is fine. There are no problems with termites or previous flooding etc, but you want to change a few things. This is CSS (Cascading Style Sheets). You step into the living room, and the first thing you’re going to change is take out the carpeting and replace it with wood floors. Then you change the look of the mantle piece framing your fireplace... in fact, lets put in a wood burning insert... with a glass front so you can enjoy the glow of the fire as well as the efficiency of heat. You decide you want to have taller ceilings, so you do the work necessary for that.
Maybe you want to change a few of the walls. As long as they are weight bearing walls, you know this is a possibility. You add new colors to the walls and add nice touches with the decorative pieces you include. After you’ve done everything inside that you want, you turn your gaze towards the exterior to improve the curb appeal.
You decide to add metal siding and drains. You change up the landscaping ... to include a labrynthine maze of hedges... with a minotaur statue hiding around one corner! Maybe you replace the shingles with a copper roof. Lets even expand the porche to be a wrap around porch.
By the time you’ve finished, the entire house is unrecognizable from its original structure and form. With CSS you can move things around, stylize, and shape things, so that all of the elements HTML brought to the page are still present, but look completely different.
There are different ways that CSS can be applied. “inline” CSS is included straight into the HTML tags as an attribute. An example might be `<p style=”color: red”>text of the paragraph</p>`. Another way to apply CSS would be an “internal” insert on the HTML page as well contained within the `<style></style>` tag
<p class="codepen" data-height="265" data-theme-id="0" data-default-tab="html,result" data-user="wrensummerset" data-slug-hash="xxxrxRM" style="height: 265px; box-sizing: border-box; display: flex; align-items: center; justify-content: center; border: 2px solid; margin: 1em 0; padding: 1em;" data-pen-title="xxxrxRM">
<span>See the Pen <a href="https://codepen.io/wrensummerset/pen/xxxrxRM">
xxxrxRM</a> by wren (<a href="https://codepen.io/wrensummerset">@wrensummerset</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
</p>
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>
A third style, and the way considered “best practice” (because leaving the HTML document alone and linking to a seperate sheet with the CSS code is prefered) is called “external”. This is where you have a seperate file for your .css page. This way, your HTML file simply has the following tag to link to that file. `<link rel="stylesheet" href="style.css">`
Simple, right? Maybe, but I still haven’t gotten my website to center even after trying all three CSS styles. | summersetwren |
195,707 | Demystifying the v-model Directive in Vue | This post was originally published at https://www.telerik.com/blogs/demystifying-the-v-model-directiv... | 0 | 2019-10-26T16:16:33 | https://dev.to/marinamosti/demystifying-the-v-model-directive-in-vue-3hdh | vue, vmodel, javascript, beginners | This post was originally published at [https://www.telerik.com/blogs/demystifying-the-v-model-directive-in-vue](https://www.telerik.com/blogs/demystifying-the-v-model-directive-in-vue)
---
More often than not I get comments and messages asking me to go into detail about `v-model` by people that have read an article or attended a workshop and the _magic_ of `v-model` is touched on but not thoroughly explained.
Today, we will go into detail on what exactly this directive does for us in Vue, and a top-level glance at how it works behind the scenes.
This article is intended for novice and intermediate users who want to further their understanding of the directive, and I am assuming a general basic knowledge of Vue as a whole.
## Two-way binding and the basics
Often times we find ourselves describing the `v-model` directive as a magical entity that allows creating a two way biding to an input element. But what exactly does the two way binding mean? And why should you care?
Vue and other frameworks like it have a bunch of _magical_ methods and ways of doing things, `v-model` is a great example of this type of thing.
The entry-level knowledge required to use it is minimal because frankly, you don't really NEED to understand how it works in order to use it - but when you fully grasp the concept behind it the _way_ you use it or think about it changes.
## Listen to user input
Let's start with a simple input element. It will be of type email.
```html
<input type="email" />
```
The problem is simple, we need to be able to _know_ what the user types in here. We need to maybe send it to the back end for them to log the user in, or to capture it for a registration form.
How would you approach this using jQuery or vanilla JS?
In jQuery maybe you would add an `id` attribute to the element, and target it directly to extract the value.
```html
<input type="email" id="email" />
```
```js
$('#email').val();
```
The problem with this approach is that you are stuck having to then add an event listener if you want to react to keystrokes because so far you are getting a static value at the moment the code is executed. It is NOT _reactive_.
Let's try this again with an event listener and vanilla JS.
```js
const el = document.querySelector('#email');
el.addEventListener('input', function(event) {
// when the user types this will fire
const inputValue = event.target.value;
doSomethingWith(inputValue);
});
```
Alright, we're getting somewhere! So far we are able to call the function `doSomethingWith` with the event's value (what the user typed). This seems like a lot of code though, and what happens if we have a form with 30 different inputs?
Let's do it the Vue way. We are going to add an event listener to the input and call our fake `doSomethingWith` function every time it fires.
```html
<input type="email" @input="doSomethingWith" />
```
I don't know about you, but this seems like magical avocado mischief to me. How does Vue accomplish the same thing behind the scenes?
First of all, notice that we don't need an `id` anymore. In fact, I would argue that using `id` in Vue is a terrible idea!
If you use ids in Vue, and you use the component in several places then you are going to have several instances of an element with the same id - which spells out CHAOS.
Your developer avocado has gone bad, frand. GG. 🥑☠️
Let's go back to our example though when we add `@input` to our element, Vue is smart enough to attach the necessary event listener to this particular element via reference. It will also handle _removing_ this event listener for us!
Finally, it will call the function that we passed inside the `" "` whenever the event is fired, and it will pass it the `event` object. Neat!
## Changing the input programmatically
Let's move on to problem #2.
You managed to listen to the events of the user making inputs on your field, good work! (Hopefully using Vue and not jQuery, come on. I am disappoint. ☹️)
Now, part two of "two-way binding". What if we want to dynamically do something with the user's email and have the input reflect the change?
Maybe we have some sort of form autocomplete, or validation, or we have another input element that will prepopulate their name from the database. There's a lot of possible scenarios.
Let's approach this problem with jQuery first. 🤢
```js
// This is the value we are storing somewhere
// So that later we can send it to the backend
const userEmail = 'somevalue@theuserentered.com';
$('#email').on('input', function() {
userEmail = $('#email').val();
});
// Now what if we want to change the email on the input programmatically?
function changeEmail(newEmail) {
$('#email').val(newEmail);
userEmail = newEmail;
}
changeEmail('your-email@is-wrong.com');
```
You can see from this last example how quickly this can start to get really messy. Monolithic files of jQuery for event handling and input validation are a thing of the past!
You can also appreciate how it's going to be a problem keeping a `state`. We have a high-level variable `userEmail` that is keeping the value, and we have to be careful that we are orderly about our code. Now do this 40 times for a big form, please.
One thing that you may have also not considered at this point is that we are trying to be really careful about setting the `.val` of our input when we change it on the `changeEmail` function. But what if another dev, or even ourselves make another function that modifies the `userEmail` variable somewhere else?
We have to keep in mind that every time this variable changes the input has to be updated, or we have to get into some rather advanced javascript that will set up getters and setters for us to fix that reactivity problem.
Let's approach this second problem in Vue. We are going to create first a local state in our make-believe component.
```js
data() {
return {
email: ''
}
}
```
Now that we have our local state, we have to tell the input to use it and bind it to the value.
```html
<input
type="email"
:value="email"
@input="doSomethingWith"
/>
```
```js
methods: {
doSomethingWith(event) {
this.email = event.target.value;
// Do other stuff, eat avocados, play zelda and admire a raccoon
}
}
```
That's it! Every time the `email` state changes, the input will be updated accordingly. We now have two ways of binding to the input.
First, when our local state changes. Second, when the user types on the field, the `input` listener will update the `state` with the value. When the state updates, it will update the input.
Do you see the cycle? DO YA?
## Enter v-model
The kind folks at the Vue realized that this pattern of adding two one-way bindings, one that feeds _into_ the input, and one that feeds _out_ of the input was very common when dealing with forms and user data.
Thus, the magical avocado and the `v-model` directive were born. Both were cared for and nurtured, and the magical avocado went bad throughout the night and we had to toss it out. But such is life.
What happens then when you have to two-way bind your inputs, do you have to go through this double process where you bind the `:input` to some sort of state, and then listen to an event and re-write all the state?
The answer is no! `v-model` your friendly neighborhood avocado to the rescue.
We currently have this for our form input.
```html
<input
type="email"
:value="email"
@input="doSomethingWith"
/>
```
```js
data() {
return {
email: ''
}
},
methods: {
doSomethingWith(event) {
this.email = event.target.value;
// Do other stuff, eat avocados, play zelda and admire a raccoon
}
}
```
And with the power invested in me by Vue, and the blessing of captain planet (yes, I'm old), we can make it all nice and simple.
```html
<input type="email" v-model="email" />
```
```js
data() {
return {
email: ''
}
}
```
That's it! `v-model` will make sure that the correct event is being listened to (in the case of native elements like inputs, selects, etc.) and then bind our local `email` data property to it! Ah-two, ah-way, ah-binding. 👌
## Conclusion
Keep in mind, `v-model` has some caveats regarding which property it has to bind to and which event it has to listen to.
Vue is super smart regarding this behind the scenes when being used on inputs, selects, checkboxes and radio buttons - but when you are working with custom components you are going to have to do this heavy lifting yourself.
This, however, is out of the scope of this beginner article. But you can check out this reference on `v-model` on custom components on the [official documentation](https://vuejs.org/v2/guide/components.html#Using-v-model-on-Components), or the last part of my [Vue for Beginners Series](https://dev.to/vuevixens/hands-on-vuejs-for-beginners-part-7-3e1c) where I touch up on a little about `v-model`.
As always, thanks for reading and share with me your experiences with v-model on twitter at: [@marinamosti](http://www.twitter.com/marinamosti)
PS. All hail the magical avocado 🥑
PSS. ❤️🔥🐶☠️ | marinamosti |
195,103 | How to build a serverless photo upload service with API Gateway | A detailed walkthrough of using API Gateway and S3 Presigned URLs to add file upload functionality to your API. | 0 | 2019-10-25T15:17:42 | https://winterwindsoftware.com/serverless-photo-upload-api/ | serverless, lambda, apigateway, node | ---
title: How to build a serverless photo upload service with API Gateway
canonical_url: https://winterwindsoftware.com/serverless-photo-upload-api/
tags: Serverless, Lambda, API Gateway, Node.js
description: A detailed walkthrough of using API Gateway and S3 Presigned URLs to add file upload functionality to your API.
cover_image: https://winterwindsoftware.com/img/blog-images/apigateway-photo-uploader.png
published: true
---
So you’re building a REST API and you need to add support for uploading files from a web or mobile app. You also need to add a reference to these uploaded files against entities in your database, along with metadata supplied by the client.
In this article, I'll show you how to do this using AWS API Gateway, Lambda and S3. We'll use the example of an event management web app where attendees can login and upload photos associated with a specific event along with a title and description. We will use S3 to store the photos and an API Gateway API to handle the upload request. The requirements are:
* User can login to the app and view a list of photos for a specific event, along with each photo's metadata (date, title, description, etc).
* User can only upload photos for the event if they are registered as having attended that event.
* Use Infrastructure-as-Code for all cloud resources to make it easy to roll this out to multiple environments. (No using the AWS Console for mutable operations here 🚫🤠)
## Considering implementation options
Having built similar functionality in the past using non-serverless technologies (e.g. in Express.js), my initial approach was to investigate how to use a Lambda-backed API Gateway endpoint that would handle everything: authentication, authorization, file upload and finally writing the S3 location and metadata to the database.
While this approach is valid and achievable, it does have a few limitations:
* You need to write code inside your Lambda to manage the multipart file upload and the edge cases around this, whereas the existing S3 SDKs are already optimized for this.
* Lambda pricing is duration-based so for larger files your function will take longer to complete, costing you more.
* API Gateway has a [payload size hard limit of 10MB](https://docs.aws.amazon.com/apigateway/latest/developerguide/limits.html). Contrast that to the [S3 file size limit of 5GB](https://docs.aws.amazon.com/AmazonS3/latest/dev/UploadingObjects.html).
## Using S3 presigned URLs for upload
After further research, I found a better solution involving [uploading objects to S3 using presigned URLs](https://docs.aws.amazon.com/AmazonS3/latest/dev/PresignedUrlUploadObject.html) as a means of both providing a pre-upload authorization check and also pre-tagging the uploaded photo with structured metadata.
The diagram below shows the request flow from a web app.

The main thing to notice is that from the web client’s point of view, it’s a 2-step process:
1. Initiate the upload request, sending metadata related to the photo (e.g. eventId, title, description, etc). The API then does an auth check, executes business logic (e.g. restricting access only to users who have attended the event) and finally generates and responds with a secure presigned URL.
2. Upload the file itself using the presigned URL.
I’m using Cognito as my user store here but you could easily swap this out for a custom [Lambda Authorizer](https://docs.aws.amazon.com/apigateway/latest/developerguide/apigateway-use-lambda-authorizer.html) if your API uses a different auth mechanism.
Let's dive in...
## Step 1: Create the S3 bucket
I use the [Serverless Framework](https://serverless.com/framework) to manage configuration and deployment of all my cloud resources. For this app, I use 2 separate "services" (or stacks), that can be independently deployed:
1. `infra` service: this contains the S3 bucket, CloudFront distribution, DynamoDB table and Cognito User Pool resources.
2. `photos-api` service: this contains the API Gateway and Lambda functions.
You can view the full configuration of each stack in the [Github repo](https://github.com/WinterWindSoftware/sls-photos-upload-service), but we’ll cover the key points below.
The S3 bucket is defined as follows:
```yml
resources:
Resources:
PhotosBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub ‘${self:custom.photosBucketName}’
AccessControl: Private
CorsConfiguration:
CorsRules:
- AllowedHeaders: [‘*’]
AllowedMethods: [‘PUT’]
AllowedOrigins: [‘*’]
```
The CORS configuration is important here as without it your web client won’t be able to perform the PUT request after acquiring the signed URL.
I’m also using CloudFront as the CDN in order to minimize latency for users downloading the photos. You can view the config for the CloudFront distribution [here](https://github.com/WinterWindSoftware/sls-photos-upload-service/blob/master/services/infra/resources/s3-cloudfront-resources.yml#L34). However, this is an optional component and if you’d rather clients read photos directly from S3 then you can change the `AccessControl` property above to be `PublicRead`.
## Step 2: Create "Initiate Upload" API Gateway endpoint
Our next step is to add a new API path that the client endpoint can call to request the signed URL. Requests to this will look like so:
```
POST /events/{eventId}/photos/initiate-upload
{
"title": "Keynote Speech",
"description": "Steve walking out on stage",
"contentType": "image/png"
}
```
Responses will contain an object with a single `s3PutObjectUrl` field that the client can use to upload to S3. This URL looks like so:
`https://s3.eu-west-1.amazonaws.com/eventsapp-photos-dev.sampleapps.winterwindsoftware.com/uploads/event_1234/1d80868b-b05b-4ac7-ae52-bdb2dfb9b637.png?AWSAccessKeyId=XXXXXXXXXXXXXXX&Cache-Control=max-age%3D31557600&Content-Type=image%2Fpng&Expires=1571396945&Signature=F5eRZQOgJyxSdsAS9ukeMoFGPEA%3D&x-amz-meta-contenttype=image%2Fpng&x-amz-meta-description=Steve%20walking%20out%20on%20stage&x-amz-meta-eventid=1234&x-amz-meta-photoid=1d80868b-b05b-4ac7-ae52-bdb2dfb9b637&x-amz-meta-title=Keynote%20Speech&x-amz-security-token=XXXXXXXXXX`
Notice in particular these fields embedded in the query string:
- `x-amz-meta-XXX` — These fields contain the metadata values that our `initiateUpload` Lambda function will set.
- `x-amz-security-token` — this contains the temporary security token used for authenticating with S3
- `Signature` — this ensures that the PUT request cannot be altered by the client (e.g. by changing metadata values)
The following extract from `serverless.yml` shows the function configuration:
```yml
# serverless.yml
service: eventsapp-photos-api
…
custom:
appName: eventsapp
infraStack: ${self:custom.appName}-infra-${self:provider.stage}
awsAccountId: ${cf:${self:custom.infraStack}.AWSAccountId}
apiAuthorizer:
arn: arn:aws:cognito-idp:${self:provider.region}:${self:custom.awsAccountId}:userpool/${cf:${self:custom.infraStack}.UserPoolId}
corsConfig: true
functions:
…
httpInitiateUpload:
handler: src/http/initiate-upload.handler
iamRoleStatements:
- Effect: Allow
Action:
- s3:PutObject
Resource: arn:aws:s3:::${cf:${self:custom.infraStack}.PhotosBucket}*
events:
- http:
path: events/{eventId}/photos/initiate-upload
method: post
authorizer: ${self:custom.apiAuthorizer}
cors: ${self:custom.corsConfig}
```
A few things to note here:
* The `httpInitiateUpload` Lambda function will handle POST requests to the specified path.
* The Cognito user pool (output from the `infra` stack) is referenced in the function’s `authorizer` property. This makes sure requests without a valid token in the `Authorization` HTTP header are rejected by API Gateway.
* CORS is enabled for all API endpoints
* Finally, the `iamRoleStatements` property creates an IAM role that this function will run as. This role allows `PutObject` actions against the S3 photos bucket. It is especially important that this permission set follows the [least privilege principle](https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html#grant-least-privilege) as the signed URL returned to the client contains a temporary access token that allows the token holder to assume all the permissions of the IAM role that generated the signed URL.
Now let's look at the handler code:
```typescript
import S3 from 'aws-sdk/clients/s3';
import uuid from 'uuid/v4';
import { InitiateEventPhotoUploadResponse, PhotoMetadata } from '@common/schemas/photos-api';
import { isValidImageContentType, getSupportedContentTypes, getFileSuffixForContentType } from '@svc-utils/image-mime-types';
import { s3 as s3Config } from '@svc-config';
import { wrap } from '@common/middleware/apigw';
import { StatusCodeError } from '@common/utils/errors';
const s3 = new S3();
export const handler = wrap(async (event) => {
// Read metadata from path/body and validate
const eventId = event.pathParameters!.eventId;
const body = JSON.parse(event.body || '{}');
const photoMetadata: PhotoMetadata = {
contentType: body.contentType,
title: body.title,
description: body.description,
};
if (!isValidImageContentType(photoMetadata.contentType)) {
throw new StatusCodeError(400, `Invalid contentType for image. Valid values are: ${getSupportedContentTypes().join(',')}`);
}
// TODO: Add any further business logic validation here (e.g. that current user has write access to eventId)
// Create the PutObjectRequest that will be embedded in the signed URL
const photoId = uuid();
const req: S3.Types.PutObjectRequest = {
Bucket: s3Config.photosBucket,
Key: `uploads/event_${eventId}/${photoId}.${getFileSuffixForContentType(photoMetadata.contentType)!}` ,
ContentType: photoMetadata.contentType,
CacheControl: 'max-age=31557600', // instructs CloudFront to cache for 1 year
// Set Metadata fields to be retrieved post-upload and stored in DynamoDB
Metadata: {
...(photoMetadata as any),
photoId,
eventId,
},
};
// Get the signed URL from S3 and return to client
const s3PutObjectUrl = await s3.getSignedUrlPromise('putObject', req);
const result: InitiateEventPhotoUploadResponse = {
photoId,
s3PutObjectUrl,
};
return {
statusCode: 201,
body: JSON.stringify(result),
};
});
```
The `s3.getSignedUrlPromise` is the main line of interest here. It serializes a PutObject request into a signed URL.
I'm using a [`wrap`](https://github.com/WinterWindSoftware/sls-photos-upload-service/blob/master/services/common/middleware/apigw.ts) middleware function in order to handle cross-cutting API concerns such as adding CORS headers and uncaught error logging.
## Step 3: Uploading file from the web app
Now to implement the client logic. I've created a very basic (read: ugly) `create-react-app` example (code [here](https://github.com/WinterWindSoftware/sls-photos-upload-service/tree/master/clients/events-web-app)). I used [Amplify's Auth library](https://aws-amplify.github.io/docs/js/authentication) to manage the Cognito authentication and then created a `PhotoUploader` React component which makes use of the [React Dropzone](https://github.com/react-dropzone/react-dropzone) library:
```tsx
// components/Photos/PhotoUploader.tsx
import React, { useCallback } from 'react';
import { useDropzone } from 'react-dropzone';
import { uploadPhoto } from '../../utils/photos-api-client';
const PhotoUploader: React.FC<{ eventId: string }> = ({ eventId }) => {
const onDrop = useCallback(async (files: File[]) => {
console.log('starting upload', { files });
const file = files[0];
try {
const uploadResult = await uploadPhoto(eventId, file, {
// should enhance this to read title and description from text input fields.
title: 'my title',
description: 'my description',
contentType: file.type,
});
console.log('upload complete!', uploadResult);
return uploadResult;
} catch (error) {
console.error('Error uploading', error);
throw error;
}
}, [eventId]);
const { getRootProps, getInputProps, isDragActive } = useDropzone({ onDrop });
return (
<div {...getRootProps()}>
<input {...getInputProps()} />
{
isDragActive
? <p>Drop the files here ...</p>
: <p>Drag and drop some files here, or click to select files</p>
}
</div>
);
};
export default PhotoUploader;
// utils/photos-api-client.ts
import { API, Auth } from 'aws-amplify';
import axios, { AxiosResponse } from 'axios';
import config from '../config';
import { PhotoMetadata, InitiateEventPhotoUploadResponse, EventPhoto } from '../../../../services/common/schemas/photos-api';
API.configure(config.amplify.API);
const API_NAME = 'PhotosAPI';
async function getHeaders(): Promise<any> {
// Set auth token headers to be passed in all API requests
const headers: any = { };
const session = await Auth.currentSession();
if (session) {
headers.Authorization = `${session.getIdToken().getJwtToken()}`;
}
return headers;
}
export async function getPhotos(eventId: string): Promise<EventPhoto[]> {
return API.get(API_NAME, `/events/${eventId}/photos`, { headers: await getHeaders() });
}
export async function uploadPhoto(
eventId: string, photoFile: any, metadata: PhotoMetadata,
): Promise<AxiosResponse> {
const initiateResult: InitiateEventPhotoUploadResponse = await API.post(
API_NAME, `/events/${eventId}/photos/initiate-upload`, { body: metadata, headers: await getHeaders() },
);
return axios.put(initiateResult.s3PutObjectUrl, photoFile, {
headers: {
'Content-Type': metadata.contentType,
},
});
}
```
The `uploadPhoto` function in the `photos-api-client.ts` file is the key here. It performs the 2-step process we mentioned earlier by first calling our `initiate-upload` API Gateway endpoint and then making a PUT request to the `s3PutObjectUrl` it returned. Make sure that you set the `Content-Type` header in your S3 put request, otherwise it will be rejected as not matching the signature.
## Step 4: Pushing photo data into database
Now that the photo has been uploaded, the web app will need a way of listing all photos uploaded for an event (using the `getPhotos` function above).
To close this loop and make this query possible, we need to record the photo data in our database. We do this by creating a second Lambda function `processUploadedPhoto` that is triggered whenever a new object is added to our S3 bucket.
Let's look at its config:
```yml
# serverless.yml
service: eventsapp-photos-api
…
functions:
…
s3ProcessUploadedPhoto:
handler: src/s3/process-uploaded-photo.handler
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb:Query
- dynamodb:Scan
- dynamodb:GetItem
- dynamodb:PutItem
- dynamodb:UpdateItem
Resource: arn:aws:dynamodb:${self:provider.region}:${self:custom.awsAccountId}:table/${cf:${self:custom.infraStack}.DynamoDBTablePrefix}*
- Effect: Allow
Action:
- s3:GetObject
- s3:HeadObject
Resource: arn:aws:s3:::${cf:${self:custom.infraStack}.PhotosBucket}*
events:
- s3:
bucket: ${cf:${self:custom.infraStack}.PhotosBucket}
event: s3:ObjectCreated:*
rules:
- prefix: uploads/
existing: true
```
It's triggered off the `s3:ObjectCreated` event and will only fire for files added beneath the `uploads/` top-level folder.
In the `iamRoleStatements` section, we are allowing the function to write to our DynamoDB table and read from the S3 Bucket.
Now let's look at the function code:
```typescript
import { S3Event } from 'aws-lambda';
import S3 from 'aws-sdk/clients/s3';
import log from '@common/utils/log';
import { EventPhotoCreate } from '@common/schemas/photos-api';
import { cloudfront } from '@svc-config';
import { savePhoto } from '@svc-models/event-photos';
const s3 = new S3();
export const handler = async (event: S3Event): Promise<void> => {
const s3Record = event.Records[0].s3;
// First fetch metadata from S3
const s3Object = await s3.headObject({ Bucket: s3Record.bucket.name, Key: s3Record.object.key }).promise();
if (!s3Object.Metadata) {
// Shouldn't get here
const errorMessage = 'Cannot process photo as no metadata is set for it';
log.error(errorMessage, { s3Object, event });
throw new Error(errorMessage);
}
// S3 metadata field names are converted to lowercase, so need to map them out carefully
const photoDetails: EventPhotoCreate = {
eventId: s3Object.Metadata.eventid,
description: s3Object.Metadata.description,
title: s3Object.Metadata.title,
id: s3Object.Metadata.photoid,
contentType: s3Object.Metadata.contenttype,
// Map the S3 bucket key to a CloudFront URL to be stored in the DB
url: `https://${cloudfront.photosDistributionDomainName}/${s3Record.object.key}`,
};
// Now write to DDB
await savePhoto(photoDetails);
};
```
The event object passed to the Lambda handler function only contains the bucket name and key of the object that triggered it. So in order to fetch the metadata, we need to use the `headObject` S3 API call.
Once we've extracted the required metadata fields, we then construct a CloudFront URL for the photo (using the CloudFront distribution's domain name passed in via an environment variable) and save to DynamoDB.
## Future enhancements
A potential enhancement that could be made to the upload flow is to add in an image optimization step before saving it to the database. This would involve a having a Lambda function listen for `S3:ObjectCreated` events beneath the `upload/` key prefix which then reads the image file, resizes and optimizes it accordingly and then saves the new copy to the same bucket but under a new `optimized/` key prefix. The config of our Lambda function that saves to the database should then be updated to be triggered off this new prefix instead.
💌 __*If you enjoyed this article, you can sign up [to my weekly newsletter on building serverless apps in AWS](https://winterwindsoftware.com/newsletter/).*__
_Originally published at **[winterwindsoftware.com](https://winterwindsoftware.com/serverless-photo-upload-api/)**_.
| paulswail |
195,315 | Java 9 to Java 13 - Top features | A summary of top features released after Java 8 between Java 9 to Java 13 | 0 | 2019-10-25T17:05:05 | https://suspendfun.com/02__Java-9-to-13-features/ | java, openjdk, jvm, programming | ---
title: Java 9 to Java 13 - Top features
published: true
description: "A summary of top features released after Java 8 between Java 9 to Java 13"
tags: java, openjdk, jvm, programming
cover_image: https://thepracticaldev.s3.amazonaws.com/i/h74gjehmm0wq9w7krdie.jpg
canonical_url: https://suspendfun.com/02__Java-9-to-13-features/
---
Programming tools, frameworks are becoming more and more developer friendly and offer better and modern features to boost developer productivity.
Java was for a long time infamous for having slow release trains.
However, keeping up with times, Java has moved to a cadence of releasing new features with a version upgrade every 6 months (every March and September).
Since then there have been a lot of cool features and tools that have been added to every java developer's toolset.
This is __a quick summary of the latest features introduced between Java 9 to Java 13__.
## Java 9
**Module system**: Helps in modularisation of large apps. This helps to limit exposure of classes that are public in the module vs the true public api of the module.
Explicitly define dependencies and exports in `module-info.java`. Eg:
```java
module chef {
exports com.tbst.recipe;
requires kitchen;
}
```
Here, the module `chef` depends on module `kitchen` and exports module `recipe`.
**Jlink**: Having explicit dependencies and modularized JDK means that we can easily come up with the entire dependency graph of the application. This, in turn, enables having a minimal runtime environment containing only the necessary to run the application. This can help to reduce the overall size of the executable jar.
**jshell**: An interactive REPL (Read-Eval-Print-Loop) for quickly playing with java code. Just say `jshell` on the terminal after installing JDK 9+.
**Collection factory methods**: Earlier, one had to initialize an implementation of a collection (Map, Set, List) first and then add objects to it. Finally, it's possible to create the ***immutable*** collections with static factory methods of the signature `<Collection>.of()`. This is achieved by having a bunch of static methods in each of the respective interfaces. Eg:
```java
// Creates an immutable list
List<String> abcs = List.of("A", "B", "C");
// Creates an immutable set
Set<String> xyzs = Set.of("X", "Y", "Z");
// Creates an immutable Map
Map<String, String> mappings = Map.of("key1", "value1", "key2", "value2");
```
**Other features**
- Stream API gets more functions like `dropWhile`, `takeWhile`, `ofNullable`.
- Private interface methods to write clean code and keep things DRY when using default methods in interfaces.
- new HTTP2 API that supports streams and server based pushes.
____
## Java 10
**Local-Variable Type Inference**: This enables us to write more modern Kotlin/Scala/Typescript like syntax where you don't have to explicitly declare the variable type without compromising type safety. Here, the compiler is able to figure out the type because of the type of the value on the right hand side in case of assignments. Eg:
```java
var list = new ArrayList<String>(); // infers ArrayList<String>
var stream = list.stream(); // infers Stream<String>
```
In cases where the compiler cannot infer the value or it's ambiguous, you need to explicitly declare it. More details [here](http://openjdk.java.net/jeps/286)
**Parallel Full GC for G1**: Improves G1 worst-case latencies by making the full GC parallel.
**Experimental Java-Based JIT Compiler**: Enables the Java-based JIT compiler, Graal, to be used as an experimental JIT compiler on the Linux/x64 platform.
**Heap Allocation on Alternative Memory Devices**: Enables the HotSpot VM to allocate the Java object heap on an alternative memory device, such as an NV-DIMM, specified by the user.
**Root certificates in JDK**: Open-source the root certificates in Oracle's Java SE Root CA program in order to make OpenJDK builds more attractive to developers, and to reduce the differences between those builds and Oracle JDK builds.
____
## Java 11
**New String methods**: String class gets new methods like `isBlank()`, `lines()`, `repeat(int)`, unicode aware `strip()`, `stripLeading()` and `stripTrailing()`.
**New File Methods**: `writeString()`, `readString()` and `isSameFile()`.
**Local-Variable Syntax for Lambda Parameters**: Allow var to be used when declaring the formal parameters of implicitly typed lambda expressions.
This is introduced to have uniformity with use of `var` for local variables. Eg:
```java
(var x, var y) -> x.process(y) // implicit typed lambda expression
// One benefit of uniformity is that modifiers, notably annotations, can be applied
// to local variables and lambda variables without losing brevity.
(@Nonnull var x, @Nullable var y) -> x.process(y)
```
**JEP 328: Flight Recorder**: JFR is a profiling tool used to gather diagnostics and profiling data from a running Java application.
Its performance overhead is negligible and that’s usually below 1%. Hence it can be used in production applications.
**Removed the Java EE and CORBA Modules**: Following packages are removed: `java.xml.ws`, ` java.xml.bind`, ` java.activation`, ` java.xml.ws.annotation`, ` java.corba`, ` java.transaction`, ` java.se.ee`, ` jdk.xml.ws`, ` jdk.xml.bind`
**Implicitly compile and run** No need to compile files with `javac` first. You can directly use `java` command and it implicitly compiles. This is done to run a program supplied as a single file of Java source code, including usage from within a script by means of "shebang" files and related techniques. Of course for any project bigger than a file, you would use a build tool like gradle, maven, etc.
____
## Java 12 - Released March 19, 2019
**Switch expression😎** The new `switch` expression expects a returns value. Multiple matches can go on the same line separated by comma and what happens on match is marked with `->`.
Unlike the traditional `switch`, matches don't fall through to the next match. So you don't have to use `break;` and this helps prevent bugs. Eg:
```java
String status = process(..., ..., ...);
var isCompleted = switch (status) {
case "PROCESSED", "COMPLETED" -> true;
case "WAITING", "STUCK" -> false;
default -> throw new InconsistentProcessingStateException();
};
```
The switch expression is introduced as a preview and requires `--enable-preview` flag to the javac or enabling it in your IDE.
**File byte comparison** with `File.mismatch()`. ([From Javadoc](https://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/nio/file/Files.html#mismatch(java.nio.file.Path,java.nio.file.Path))) Finds and returns the position of the first mismatched byte in the content of two files, or -1L if there is no mismatch.
**Collections.teeing** Streams API gets a new function that applies 2 functions (consumers) on the items and then merges/combines the result of those 2 functions using a third function to produce the final result.
[From Javadoc](https://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/util/stream/Collectors.html#teeing(java.util.stream.Collector,java.util.stream.Collector,java.util.function.BiFunction)) - Returns a Collector that is a composite of two downstream collectors. Every element passed to the resulting collector is processed by both downstream collectors, then their results are merged using the specified merge function into the final result.
**String methods**: `indent(int n)`, `transform(Function f)`.
**Smart cast** `instanceOf` can be used now to do a smart cast as below:
```java
...
} catch (Exception ex) {
if(ex instanceOf InconsistentProcessingStateException ipse) {
// use ipse directly as InconsistentProcessingStateException
}
}
```
**JVM improvments**: Low pause GC with Shenandoah, micro-benchmark capabilities, constants API and other improvements.
____
## Java 13 - Released September 17, 2019
**Multi-line texts**: It's now possible to define multiline strings without ugly escape sequences `\` or appends. Eg:
```java
var jsonBody = """
{
"name": "Foo",
"age": 22
}
""";
```
This is introduced as a preview and requires `--enable-preview` flag to the javac or enabling it in your IDE.
**String** gets more methods like `formatted()`, `stripIndent()` and `translateEscapes()` for working with multi-line texts.
**Switch expression** Still in preview and based on feedback now supports having `: yield` syntax in addition to `->` syntax. Hence, we can write
```java
String status = process(..., ..., ...);
var isCompleted = switch (status) {
case "PROCESSED", "COMPLETED": yield true;
case "WAITING", "STUCK": yield false;
default: throw new RuntimeException();
};
```
**Socket API** reimplemented with modern NIO implementation. This is being done to overcome limitations of legacy api and build a better path towards Fiber as part of [Project Loom](https://cr.openjdk.java.net/~rpressler/loom/Loom-Proposal.html)
**Z GC** improved to release unused memory.
___

Wow, it's getting crazy out there.
If you are a developer that started a decent size Java project recently in the hopes that you would use the latest features and keep yourself and the project updated with the latest versions, do you feel a pressure to catchup with these frequent releases?
Add your comments below or tweet them to me.
A parting gift - I use [Jenv](https://github.com/jenv/jenv) to easily switch between different jdk versions locally while switching between different projects. It's pretty cool to manage multiple jdk versions.
Please note, the features that I talk about here are the ones that, I believe, either add cool features or increase developer productivity the most.
This is *not* an exhaustive list.
___
### References and good articles:
* I originally posted it [here](https://suspendfun.com/Latest-Java-9-to-Java-13-features/)
* Java 9 - [pluralsite](https://www.pluralsight.com/blog/software-development/java-9-new-features)
* Java 10 - [techworld](https://www.techworld.com/developers/java-10-features-whats-new-in-java-10-3680317/), [dzone](https://dzone.com/articles/java-10-new-features-and-enhancements)
* Java 11 - [geeksforgeeks](https://www.geeksforgeeks.org/java-11-features-and-comparison/), [journaldev](https://www.journaldev.com/24601/java-11-features)
* Java 12 - [journaldev](https://www.journaldev.com/28666/java-12-features), [stackify](https://stackify.com/java-12-new-features-and-enhancements-developers-should-know/)
* Java 13 - [jaxenter](https://jaxenter.com/java-13-jdk-deep-dive-new-features-162272.html), [infoworld](https://www.infoworld.com/article/3340052/jdk-13-the-new-features-in-java-13.html), [dzone](https://dzone.com/articles/81-new-features-and-apis-in-jdk-13)
| therajsaxena |
195,497 | Getting Started with the Command Line | If you're an avid computer user who wants more granular control over what your operating system offer... | 0 | 2019-10-25T23:43:39 | https://dev.to/dienakakim/getting-started-with-the-command-line-31hh | commandline, productivity, macos, windows | If you're an avid computer user who wants more *granular* control over what your operating system offers, via windows you can open or buttons you can click, chances are you ned to work with the command line. Sometimes called the *shell*, it comes in many forms: `cmd.exe` and `powershell.exe` on Windows or `bash` on Linux and macOS. Nevertheless, what we are doing here applies to both shells.
### Directory navigation
Suppose we have the following directory structure:
```bash
<user directory>
...
+-- Desktop/ (we are here)
+-- program.exe
...
```
On Windows, you would likely see the following prompt:
```cmd
C:\Users\<username>\Desktop> _
```
and on Linux and macOS (probably):
```bash
~/Desktop $ _
```
What you type will automatically appear at the underscore.
Now, let's say you want to execute `program.exe`. On Windows, make sure you are using `cmd.exe`; then executing the program would be a simple matter, **just type `program.exe` and hit Enter**.
In PowerShell and on Linux and macOS, however, things get more complicated. You will notice that `program` alone does not work, and *will likely result in an error about a program not found*.
**You actually have to use `./program.exe`.** But *what does this mean?*
### `.` means "the current directory"
That's right, you have to *explicitly* tell the shell that `program.exe` is in the current directory, and only then will it execute the program. This is for security reasons. What if you have 2 `program.exe`s, one that's already installed in your system, and the other located in `Desktop`?
Once again, `./program.exe` means "I want to execute `program.exe` and that it is in the current directory." And did I tell you that `.` means "the current directory"?
----------------------------------------------------------
Let's expand our directory structure for a bit:
```bash
<user directory>
+-- Documents/
+-- assignments.pdf
+-- Downloads/
+-- archive.zip
+-- Desktop/ (we are here)
+-- program.exe
```
and we are still in `Desktop`. Now suddenly you feel the urge to extract the archive `archive.zip` in `Downloads`. But we're in `Desktop`, so what do we do?
### `..` means "the parent directory"
The reason I'm introducing this is because there's no direct way to jump from `Desktop` to `Downloads`, and you have to go through the parent directory to access `Downloads`.
So now, from `Desktop`, we want to:
- get to the parent directory
- go to `Downloads` from the parent directory
- access `archive.zip` in `Downloads`
The file, *relative to `Desktop`*, is accessed using the following syntax: `../Downloads/archive.zip`. Let's break this down.
- we need to get to the parent directory, so we used `..`
- we add a forward slash (`/`), which acts as a delimiter for directories
- we need to get to `Downloads`, so we append that to get `../Downloads`
- we add a forward slash (`/`)
- access the `archive.zip` file by appending that, resulting in `../Downloads/archive.zip`.
Simple, isn't it? Now to extract the file, Linux has the command `unzip` that does it for us. So the prompt should look like this in Linux:
```bash
~/Desktop $ unzip ../Downloads/archive.zip
```
----------------------------------------------------------
Now what if we actually want to *change where we are at?* Staying in `Desktop` all day seems boring, no?
### `cd` means "change directory"
It does exactly what it says: give it a proper directory location and it will transport you there. Say you are still in `Desktop` and want to get to `Downloads`.
- You can first go to the parent directory, so `cd ..` does that.
- You can then get to `Downloads`, so use `cd Downloads`.
- Or you can get there directly by using `cd ../Downloads`. Remember, `/` delimits parent-child directories.
And that's some brief command line usage tips. This helps every one of us inch closer and closer to being a power user, but we'll take it one step at a time. :)
---------------------------------------------------------- | dienakakim |
195,597 | This Ukrainian self-taught dev makes the best Mac translation apps | Alex Chernikov grew up in a Soviet-style city in the east of Ukraine, now war-torn. He taught himse... | 0 | 2020-04-01T11:31:32 | https://www.nocsdegree.com/alex-left-a-tough-life-in-ukraine-and-taught-himself-to-code-and-make-apps/ | ios, beginners, career | ---
title: This Ukrainian self-taught dev makes the best Mac translation apps
published: true
date: 2019-10-25 16:36:55 UTC
tags: iOS, Beginner, Career
canonical_url: https://www.nocsdegree.com/alex-left-a-tough-life-in-ukraine-and-taught-himself-to-code-and-make-apps/
---

Alex Chernikov grew up in a Soviet-style city in the east of Ukraine, now war-torn. He taught himself code and now makes a successful living making apps. You can check out his excellent MateTranslate app which can translate text in 103 languages without changing tabs and is the top-rated translation app for iOS and macOS. You will get 10% off when you use the "nocsdegree" code with this [link](https://twopeoplesoftware.com/mate). I chatted to Alex about how learning to code has changed his life and his tips for developers without a Computer Science degree.
## Hey, thanks a lot for doing the interview! Could you give an introduction for coders who want to know more about you?
I’m Alexey, 23 years old and currently based in Vienna, Austria. Originally, I’m from a classically-dystopian grunge post-Soviet city of Luhansk in eastern Ukraine. I’ve been coding for 10 years now. Mostly, JavaScript in recent years, but earlier I also made a few games in Java, C# and some back-end in PHP. I started with websites, then gradually transitioned to Chrome extensions, then games, then came back to browser extensions.
Now, I’m trying to run & scale my own company. We’ve gone through different phases: from having zero clue about where we are and what to do next; to seeking VC money & being halfway accepted at Y Combinator; to picking an independent way & focusing on iOS & macOS apps. And, that’s where we are now.
## What first got you interested in programming?
My brother. He’s 13 years older than me so when I was in middle school he was already working in IT & making good money. He was my role model and I wanted to be as successful as him. Roughly at the same time he gave me all his programming books. This is what actually pushed me towards not only wanting but actually doing something in that direction. I wasn’t guided by anyone, though.
At first, I was trying to make web pages in pure HTML. I still remember when I once called my brother, read aloud some HTML code I wrote and asked if it was correct. I don’t know why I did that and how is it possible to validate code from hearing but he replied affirmatively. At that time, I didn’t have an internet connection at home, so my endeavours were all offline.
I became quite skilled with PHP, JavaScript, CSS, and HTML - a classic web stack back in the day. I once bumped into a Twitch livestream in which Mojang (the makers of Minecraft) were raising money for charity by streaming how they’re making a game from scratch. I got inspired and also got sucked into game development for a while.
At the end of the day, it’s probably every coder’s dream to make a game at some point. So, I started taking after Notch and trying to write a game in Java from scratch. It was a time when I didn’t care about the monetizational or marketing side, I was just having fun from building. I managed to finish only two games, a dozen others are buried deep on GitHub. One is still [live](https://twocubes.io).
### [Opendoor are hiring a Software Engineer Apprentice in San Francisco](https://nocsok.com/id-software-engineer-apprentice-opendoor)
## You made a Chrome translation extension when you were only 16! What was it like making that and turning it into MateTranslate with your school friend?
I was already somewhat experienced with making sites and was a big fan of John Resig (jQuery creator), and thus JavaScript, too. I was in a very active phase of learning English back then. That’s when I started absorbing information in the internet’s lingua franca.
Obviously enough, I was lacking vocabulary to effortlessly understand everything. Having to copy a word or paragraph and go to Google Translate was a normal part of my daily routine. At some point, I thought it’d be cool if it were possible to get translations right on web pages, without a need to leave the browser tab. That’s how I got sucked into extension development. I released the first version in 2011, I think. It was called Instant Translate.
I had absolutely no clue about user acquisition, marketing and likewise, I had no thoughts about monetization. However, it took off, even though the only thing I did was uploading it to Chrome Web Store. That’s a caveat given to all fledgling entrepreneurs - users won’t beat a path to your door themselves. In my case, they somehow did. By the time I made the first $100 with it, Instant Translate already had around 130,000 users monthly.
I was in the same class with my now-co-founder Andrey in Kiev. When I was looking for people who can help me port Instant Translate to more platforms, he dropped me a message and said he can help with Safari and I agreed. We never released that Safari extension he was working on because his laptop with all the code was stolen. But, somehow, it came up during one of our conversations that he can also make iOS apps and would like to try making Mac apps, too. However, we received a refreshing kickback this time. It didn’t take off all by itself. It took us four years of constant learning and experimenting to make the Mac app our main revenue-driver.
Renaming Instant Translate to Mate Translate was a piece of advice from our friend. We were amidst our attempts to differentiate from Google Translate & iTranslate, so we picked this way of making a well-integrated app for people who need to translate a lot of stuff and want to save time on switching between browser tabs or apps. That’s why we went for Mate - a friendly app that has your back with translations.
## Can you tell us about moving from Ukraine to Austria?
I’ve been dreaming about moving away from Ukraine since I was in the 10th grade. The easiest way was to apply to university. I got accepted at Vienna University of Technology. At the time of acceptance, I was already in the second year of my CS degree in Kiev, Ukraine. I dropped out in order to pursue my desire to live abroad. I need to thank my parents because they helped my both emotionally and financially with this undertaking. I wasn’t making a living at the time of moving.
After five and a half years in Vienna I’ll be moving again soon. This time as a self-sufficient adult though! I’ll head over to Berlin, Germany, to pursue my next goal - to build a sustainable software company which builds amazing products, and which employees are happy to work at.
I’m miserable when I have to do something against my will. I’m feeling I don’t like it here in Vienna anymore, so I see no reason to force myself staying. I’m very happy that I have this freedom, so I can do whatever I want. That’s probably also the reason why I’ve never had a proper job, and hopefully never will.
## I think you dropped out of CS degrees twice - do you find it better to learn with real projects rather than by theory?
The university didn’t work out for me, right. I studied for a year and a half in Kiev and then for two and a half years in Vienna. Just as I mentioned before, I felt downright miserable. I hadn’t been feeling I was doing something interesting or important. I hadn’t been feeling I was doing my best, either.
Given the fact (without being too haughty) that I already had a chance to learn most of the things taught in classes by myself, I wasn’t missing out on knowledge. On the opposite, the amount of things I learned in, for example, last year doing actual software business is probably worth ten years of college.
Working on my projects means some real-life application of my skills & knowledge. Real people will use it, probably even stick to it, love it, recommend to friends and family. So there’s also a psychological aspect involved for me. As opposed to often irrelevant assignments which will be buried on my harddrive the moment I get a grade for that class.
The logical question would be if I regret spending 4.5 years & not getting a diploma at the end. No! I met some cool people. Also, making mistakes is an important part of experimenting, that’s what brings us forward. So, I’m happy I figured out what’s not for me, so I don’t even feel guilty now.
<!--kg-card-begin: markdown-->
[](http://nocsok.com)
<!--kg-card-end: markdown-->
##
Can you talk us through the process of getting your first clients as a web developer?
I did freelance work only twice in my life. Both times were a very long time ago when my projects weren’t making me a living, and a few hundred bucks could be put to good use. The first time I made some sort of a gaming community site on Drupal with a lot of custom PHP code. I didn’t get paid for that project because we didn’t discuss the price beforehand. I was too shy to do it at the beginning and thought I can just present the client with an invoice at the end. The second time it was some front-end work for a social app on VK.com - the Russian Facebook - which let you place football bets.
After that, Mate Translate started making some money, so I fully switched to making my own projects. First of all, I hated doing what I was told to do. Secondly, I was totally not OK with the fact I was selling off my skills & knowledge just for money. To be more clear, I was putting effort into making a good product, and then someone else would be its owner and get all the credit from users for making it. So, vanity was part of the equation, too, which made me give up on freelancing.
## Can you tell us what a typical day for you looks like just now?
I get up at 7am, arrive at my coworking at around 10am. The workday normally starts with replying to support requests. Then I may do some Twitter. Recently, it's become a part of my job - connecting with other tech people and building relationships. Sometimes, we may have a catch-up call with my co-founder Andrey. Most of the time, all our communication is done via Slack. Then I’m hopping on my main task until the end of the day. Tasks vary widely: it may be back-end stuff, designing mockups, setting up Twitter Ads, making a landing page or sending out a newsletter.
I’m trying to be efficient & rest well as opposed to hustling 24/7. I try to eradicate any kind of possible distraction during my workday, including lunch. I pre-make something for lunch so as to not to spend an hour looking for a place, going there, ordering, waiting for order, waiting to pay, and finally getting back to work. Also, it distracts me from I was doing before. So, having lunch right at the desk saves me time & concentration.
I leave the office at around 5–6 PM. With time, I understood that resting well is an essential part of doing quality work. I never do any work on the weekend. It helps me recharge the batteries - to have thoughts together and avoid burn-out. Of course, a lot of ideas pop up in my head during that rest time but I only write them down to think through for a longer time and revisit on Monday.
## Do you have any tips for people that want to give learning to code a go?
All of us have plenty of app/site ideas. I’d recommend hopping on them. Try implementing your own ideas. This will definitely keep you interested in what you’re doing. I was trying to write code from scratch without any structure or clue about where to move next. I was googling how to do this and that. Like, “how to make a simple PHP site.” I’m not sure it’s the most efficient way, though. However, it was definitely fun! I just had a lot of time as a teenager.

## **Do you want a developer job but don't have a Computer Science degree? Pass [Triplebyte's quiz](https://triplebyte.com/a/Ww4mbM6/d) and go straight to final onsite interviews at top tech companies**
## How do you find working with a friend compared to working on your own?
It’s better! When working with smart people who share your values, goals, & enthusiasm, quality and efficiency skyrocket because new people can bring in a fresh perspective and ideas. Almost every thing I ever made was made with someone. I had another classmate who I was making games with. It was my friend who was helping me with websites. I love working with people.
As I’ve mentioned earlier, my dream now is to build a big, sustainable company. Unarguably, it’s impossible without great people, so hiring is a challenge I’m facing now. Given the fact that I have no experience in it, I expect it to be as challenging and full of experimenting as it was with coding some time ago.
## Can you tell us about any other projects you have?
Mate Translate is still making us the most revenue, but in recent years we’ve also launched a bunch of other apps: Artpaper, Reji, Breaks For Eyes. We’re trying to experiment as much as we can. This ambition is even reflected in our company’s name: Gikken -- derived from a Japanese word “jikken,” which means, “to experiment.”
[Artpaper](http://twopeople.co/artpaper) is a unique-in-its-class wallpaper app for iOS & macOS for art lovers. All images are actual scans of artworks from the best galleries all around the world. [Breaks For Eyes](http://breaksforeyes.app/) is a small macOS app which reminds you to take breaks to avoid eye strain & headache, which a prolonged working at a computer can result to.
[Reji](http://reji.app/) is an iOS app for language learners. It lets you save & practice your own words in 48 languages. You type in words, the app suggests translations and images on the fly, then you can practice saved words using the learning mode. It’s a more-automated and single-focused alternative to Anki, so to say.
## You can discuss this article by joining the [brand new community for No CS Degree developers](https://mailchi.mp/67e1bf258afa/nocsdegree). | petecodes |
195,693 | Desisti de desistir | Hoje eu decidi deixar de ser um completo inútil. Por mais que eu não sinta vontade alguma de permanec... | 0 | 2019-10-26T14:26:42 | https://dev.to/_gabrilho/desisti-de-desistir-2b7i | beginners, javascript | Hoje eu decidi deixar de ser um completo inútil. Por mais que eu não sinta vontade alguma de permanecer neste planeta, mudarei totalmente a minha forma de sobreviver. A partir de agora vou respirar javascript e aprender definitivamente em 8 meses. Daqui à 8 meses voltarei aqui para exibir o que aprendi. | _gabrilho |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.