
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
321,124 | SMS Postcards for Grandparents | What I built With the quarantine/lock-down in place my parents have been really missing se... | 0 | 2020-04-28T03:06:59 | https://dev.to/mattdini/placeholder-title-2b04 | twiliohackathon, serverless, aws | [Comment]: # (All of this is placeholder text. Use this format or any other format of your choosing to best describe your project.)
[Reminder]: # (Make sure you've submitted the Twilio CodeExchange agreement: https://ahoy.twilio.com/code-exchange-community)
[Important]: # (By making a submission, you agree to the competition's terms: https://www.twilio.com/legal/twilio-dev-hackathon-terms)
## What I built
With the quarantine/lock-down in place my parents have been really missing seeing their granddaughters. I built this as a way to send them pictures in the mail with the least amount of resistance. No apps to download, no software, use any cellphone... just send a text message to a Twilio number and a postcard will be mailed the next day!

#### Category Submission:
COVID-19 Communications and Interesting Integrations
## Link to Code
https://github.com/mattdini/sms-postcard
## How I built it (what's the stack? did I run into issues or discover something new along the way?)
Built with:
* API Gateway
* Lambdas
* S3
* Secrets Manager
* Twilio!
* https://lob.com/
Some fun things learned along the way:
* Hangouts + Google Fi will resize images to 100x100, not great for postcards!
* https://github.com/keithrozario/Klayers is a life saver! | mattdini |
321,151 | List all current environment variables - Linux Tips | Here we introduce 2 ways to list out all current environment variables: 1, use printenv com... | 0 | 2020-04-28T03:56:01 | https://dev.to/bitecode/list-all-current-environment-variables-linux-tips-4n01 | c, linux | Here we introduce 2 ways to list out all current environment variables:
## 1, use `printenv` command:
```bash
$ printenv
SHELL=/bin/bash
SESSION_MANAGER=local/pop-os
COLORTERM=truecolor
...
```
## 2, write a C program to list them
Environment variables will be put in a environment table in process, and it has a pre-defined `environ` pointer points to that table. To iterate all environment variables, we just need to walk through this table via the pointer:
```c
#include <stdlib.h>
#include <stdio.h>
extern char** environ;
int main() {
char** ep = NULL;
for (ep=environ; *ep!=NULL; ep++) {
puts(*ep);
}
return 0;
}
```
Compile and run it: `gcc main.c -o listenv`
```bash
$ ./listenv
SHELL=/bin/bash
SESSION_MANAGER=local/pop-os
COLORTERM=truecolor
...
```
| bitecode |
321,279 | 5 Reasons as to why you Need a Wifi Booster | A wifi booster is the same as the wifi range extender, which helps in boosting the wifi range of the... | 0 | 2020-04-28T07:03:30 | https://dev.to/mynewextenders1/5-reasons-as-to-why-you-need-a-wifi-booster-208b |
A wifi booster is the same as the wifi range extender, which helps in boosting the wifi range of the signals to those areas or dead zones where the wifi is feeble or altogether absent. The wifi range extender is also known as a ‘repeater’ because it catches the wifi signals of the router and re-transmits it to all the areas of the house or office. It can be easily configured on mywifiext site and placed at a place where it receives good wifi signals from the wifi router.
Here we will discuss in detail below the 5 reasons as to why you need the wifi range extender.
1. To Increase the Wifi Range
If you have a wifi router which is not giving you maximum wifi signals to all the areas of the house, then you need a wifi range extender, placed between the router and the wifi enabled device/s so that it transmits the wifi signals of the router further to the dead zones of the house or office. You can use the extender in either the extender mode or the access point mode to get great results.
2. To Increase Speed and Connectivity
The wifi range extender not only extends the wifi signals but also improves the wifi speed and gives you a boosted internet speed with no interference in between. You can stream you HD videos with best quality and no need to wait for buffering while watching videos as well.
3. To Act as an Access Point
When you want to boost the range of the internet in a large area like a large office, you can get a wifi range extender and configure it as an access point. Once you have successfully configured it as an access point, you can place it in the dead zones and the wifi extender, acting as an access point will give the extender wifi signals directly in the dead zones of a large office or home.
4. To have Wifi in the Surrounding Area
When you have a big home with a nice lawn, a separate pool area, a garage, a basement or cellar, and a wonderful large play area, you really need the wifi signals to reach all those areas surrounding your house. The wifi range extender or booster, does just that for your large homes. Get a booster which is best suitable for large homes, set it up on mywifiext.net and place it at the right spot to give extender wifi range to all of these areas surrounding your house.
5. To Have a Good Wifi Signal without Throwing Away the Old Router
If you have an old router, which is not performing at its best, and giving troubles regarding speed and connectivity, do not throw it away yet. You can get the wifi range extender and boost the wifi signals, speed and connectivity of the wifi even with the old router in place. The wifi extender will retransmit the wifi signals from your old router with its own network and give you much better results than what you would have got from a new wifi router. https://mynewextendersetup.net/ | mynewextenders1 | |
321,302 | From Ph.D. to Independent Software Developer | Life as a Ph.D., even with its ups and downs, is a relatively comfortable life. There is quite a reas... | 0 | 2020-04-28T07:56:20 | https://dev.to/aquicarattino/from-ph-d-to-independent-software-developer-5dci | science, phd, startup | Life as a Ph.D., even with its ups and downs, is a relatively comfortable life. There is quite a reasonable job security, a project, colleagues, a supervisor. But doctorates have hard deadlines which can't be extended. It forces us to think once more about what do we want to pursue for the future: academic life, a job in the industry, a sabbatical, an entrepreneurial path.
I knew academic life was not for me because of several reasons, which I hope to be able to put in writing one day. Getting a job in a company was a possibility, and I was actively applying to some roles. However, something that always characterized me was the pulsion of learning and starting new things. Starting something on my own was an aspiration, but without a concrete plan until the very last few months of my contract.
## Identifying Options
One of the hardest things to do when you want to start something on your own is to identify the options you have. And once you identify them, isolate your value proposition. Of course, back then, I had no idea what the meaning of the words *value proposition* was. During my Ph.D. I had developed several skills, some directly related to my work, some in my free time.
I knew how to build websites. It was something I always enjoyed, and over time I kept updating my skills. My first option was to create a service to develop websites for small shops in my area that didn't have an online presence yet. I developed a website, built a couple of sites to have on my portfolio, including my group's website. However, it was a very time-consuming task, with little joy. Customers are always complaining, I have no design skills, and the competition is fierce.
I also knew how to work with Raspberry Pi's and Arduinos. I started thinking about building a consumer product such as an intelligent thermostat, or a private VPN to use at home. I even contacted friends overseas to discuss options. I had the base code for the thermostat, and I could monitor the temperature of my house at different points and stream the data. I also set up a VPN to work at home, with a private cloud accessible from anywhere else in the world. It was fun, but it was just a hobby. Lots of people could do it much better than me.
I knew that I had to keep thinking about what I wanted to do, time was still passing, and the end of my contract was getting closer and closer. I started contacted startups and small companies to try to understand how someone with my profile could fit into their needs.
## The Serendipity
One of my former colleagues, Sanli Faez, was starting his group when we met for a beer. He told me he needed a hand developing software for controlling experiments. During my Ph.D., part of what I did was building instrumentation software to do experiments that were not possible to do by hand. I automatize a lot of repetitive tasks, and that allowed me to build statistics much faster, with measurements running overnight or even for several days uninterrupted.
It was just a random talk that made all my choices crystallize. In that talk, I understood that there was something I could do that was a skill hard to find. Programming software for a lab is not just about being a good software developer. It is also about understanding the experiment itself. Very few people have those overlapping skills. I was not only one of those people, but I was also available to start a new project.
## Becoming an Expert
When I started developing software for research labs, I started with what I knew. I was behaving like I saw the postdocs act. I was participating in group meetings, offering feedback. I even participated in a conference showing the software I had developed and the new things I had learned over time.
One day, out of the blue, someone wrote to me asking for advice on a program they were writing. I didn't know the person, but they found me on Github, and we had someone in common on LinkedIn. The first time, it was just a coincidence, the second time, it was a pattern that was starting to emerge. Perhaps I was more than just a person developing software.
It is a strange feeling when it hits you. People are seeking your advice on a topic that you were giving for granted. At that time is when you realize that you have become an expert. It is not a choice. It is something that happens when you dedicate day and night to learning about a topic on which very few people are focusing.
## Building a Brand
When people start asking for advice, when they seek your opinion or your approval on a topic, you might want to separate yourself from the product. Developing software was allowing me to live, but I didn't want people to know me just because of it. I started to build a brand, Python for the Lab, to separate me from my product. In my long term vision, it would allow me to hire people or to diversify.
I am not sure whether it was a good move or not, but I know people started perceiving what I do as a product. I have heard people talking about my website or my book, without actively realizing I was behind them. I still don't know how to feel about it. I know I should feel proud of having a successful product, but not being recognized for it still feels strange.
## Value Proposition and Unique Selling Point
Understanding what a value proposition is, took me a long time. Still, it is something that can be applied to many different situations. In any transaction between people, one person delivers value, and the other acquires it. The perception of the value being exchanged, however, can be very different. In my case, developing software for the lab was a natural task that I learned out of need. I hadn't realized that it could be of any importance for someone else.
It took me a while to find a way of formulating what I was doing. What I realized was that I could save hundreds of hours of a Ph.D. or a postdoc who had to learn what I already knew. Because of my experience, I was much faster at developing solutions than someone starting from scratch. Those hours that the group was saving was my value proposition. Hours are a quantifiable measure. The other aspect is the sheer interest of a researcher in learning or not how to do what I could do. Very few experimentalists want to spend so many hours behind a computer screen.
Once I could formulate the value of what I did, I had to wrap my mind around is why someone would pay me. That is also called *the unique selling point*. In the case of software for the lab, the answer is straightforward: no one else can do what I do. Better said, no one else is available to be hired for a specific project. In labs, most people are doing a Ph.D. or a postdoc. Very few groups have access to support departments that can develop custom software. There is almost no academic gain in developing just software and not producing results.
I was not looking for scientific achievements. That was my unique selling point setting me apart from people pursuing a career in Academia and who could learn to do what I was doing. My other unique selling point was the brand I was building. Python for the Lab is years ahead from anyone else who would start now. That generates a reputation that helps to justify why me and not someone else.
## Summary
Looking in retrospect, I could have saved much time if I would have known what I was looking for. Better said, if I would have had the tools to identify what I was able to do. I spent much time focusing on topics in which I was no expert just because it seemed like the easy path to follow. We all have heard the stories of successful websites and apps. But what I was trying to achieve was a sustainable way of life, one that could give me both joy and enough money to live.
Being able to identify what made me unique was a journey. It is hard to understand at first until you validate the feeling with others. Your life experiences accumulate, and that is what makes you unique. It is not only the technical skills that set you apart but every choice, every experience from your past.
If you want to know more about the things I do, follow me on [Twitter](https://twitter.com/aquicarattino) | aquicarattino |
321,344 | Json parse data after line 1 to 28 Column | Step1 : Json Marshal function receive data and return data after convert into json format -----------... | 0 | 2020-04-28T09:49:29 | https://dev.to/wisdomenigma/json-parse-data-after-line-1-to-28-column-37em | go, json | Step1 : Json Marshal function receive data and return data after convert into json format --------------------------------- return ok
step 2 : Apply NewDecoder on given data and it throw me error
</
var member Member
data ,err := json.Marshal(member)
if err != nil{println("error", err)} println(data)
err = json.NewDecoder(request.Body).Decode(member); if err != nil{
println("Error ", err ) // return eof
}
>
hOW TO RESOLVE THIS ERROR
| wisdomenigma |
330,924 | I published two books last week and you can publish a book too! | How to publish a book using Kindle Direct Publishing | 0 | 2020-05-09T11:01:55 | https://dev.to/napolux/i-published-two-books-last-week-and-you-can-publish-a-book-too-bkh | sideprojects, books, watercooler, discuss | ---
title: I published two books last week and you can publish a book too!
published: true
description: How to publish a book using Kindle Direct Publishing
tags: sideprojects,books,watercooler,discuss
cover_image: https://i.imgur.com/798JOrt.jpg
---
Ok, so this was the plan last monday morning:
* I have a one week long holiday (at home, thanks Covid-19) with my wife working in the other room (no kids or pets around)
* I'm a programmer (they pay me to program, so I must be good)
* I want to achieve "something" by the end of the week
* I want to do something "print related"
Spoiler: **I have two books published on Amazon!**
### What?
**Yes, you got it**. I've published two books on Amazon in less than a week. More specifically two sudoku puzzle books:
* [360 sudoku puzzles](https://www.amazon.com/dp/B088B6XW6G/)
* [1200 sudoku puzzles](https://www.amazon.com/1200-Sudoku-Puzzles-intermediate-solutions/dp/B088B8MFNN/)
### Why?
I didn't want to publish just another app. I choose something you can print and touch. A book was the best choice.
### How?
If you follow me you've probably read this post: [https://dev.to/napolux/how-to-generate-pdf-from-web-pages-5781](How to generate PDFs from web pages).
So, I've used a Sudoku generator in a little PHP app to generate HTML books. Then I created the "master" PDF file for my book with [Weasyprint](https://weasyprint.org/) and a cover with [Canva.com](https://www.canva.com).
I've spent a couple of days fine-tuning my PDF and then I was ready.
The final book and cover were uploaded to the [Amazon KDP platform](https://kdp.amazon.com), et voilà, my books were ready to be printed on demand! No ebook as I said, a real book!
### You can publish a book (or an ebook) too!
**So, what's blocking you?** You can easily publish (and sell) a book in a matter of minutes. Your blog posts and tutorials, your ideas, your puzzles, your personal diary or that novel about dinosaurs that work as programmers.
**We all have something to say**. This time were Sudokus, but I'll probably publish something more in the next weeks!
### Will I make money?
I don't know and I don't care. The achievement was really what I was looking for (at least for now).
**If you have any question, just ask in the comments section!**
### My two books
* [360 sudoku puzzles](https://www.amazon.com/dp/B088B6XW6G/)
* [1200 sudoku puzzles](https://www.amazon.com/1200-Sudoku-Puzzles-intermediate-solutions/dp/B088B8MFNN/)
| napolux |
330,958 | Migrate from Graphcool to Hasura | Migrate your existing graphcool project to Hasura GraphQL backed by PostgreSQL. | 0 | 2020-05-09T12:29:12 | https://dev.to/open-graphql/migrate-from-graph-cool-to-hasura-2mfi | graphcool, hasura, graphql, migration | ---
title: Migrate from Graphcool to Hasura
published: true
description: Migrate your existing graphcool project to Hasura GraphQL backed by PostgreSQL.
tags: graphcool, hasura, graphql, migration
---
Graph.cool will be [sunsetted](https://www.graph.cool/sunset-notice) July 1, 2020. If you have an existing project, it is time to migrate off from their platform to have enough leeway for testing and going production.
I have been helping a few folks migrate from Graph.cool to Hasura and decided to put together a rough migration path.
[Hasura](https://hasura.io) is an open source engine that connects to your databases & microservices and auto-generates a production-ready GraphQL backend.
## Pre-requisites:
We will be using `docker` to run some containers (MySQL, Postgres and Hasura). If you don't have docker on your machine yet, it is time to set up. [Read their official docs](https://docs.docker.com/get-docker/)
**Note**: This guide is not comprehensive and some steps require manual intervention depending on your Graph.cool project. Feel free to ask any queries in the comments. You can also [DM me on Twitter](https://twitter.com/praveenweb). I will be happy to help you out :)
But here's roughly what you need to follow to get going.
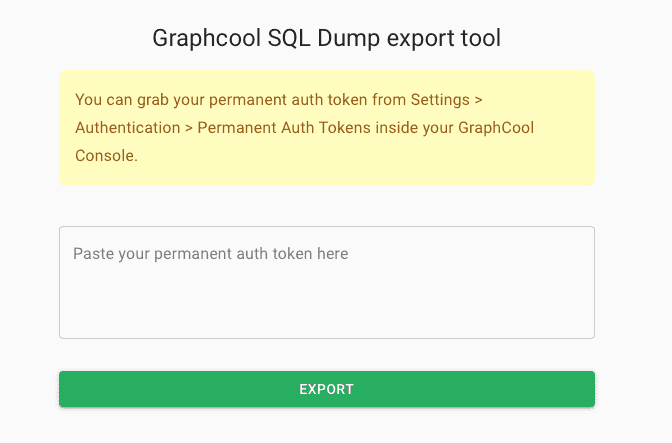
## Step 1: Export data from Graph.cool
Export your Graph.cool data using their [export tool](https://export.graph.cool/). This will give a MySQL binary dump of your current Graphcool data.
## Step 2: Set up an intermediary MySQL server
We need to set up a MySQL server as an intermediary step in order to migrate data from Graph.cool to Postgres.
### Step 2.1: Start MySQL with Docker
```bash
docker run --name graphcool-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -p 3306:3306 -d mysql:latest --default-authentication-plugin=mysql_native_password
```
Replace the password (my-secret-pw) as required.
### Step 2.2: Connect to MySQL via mysql CLI
```
mysql --user=root --password=my-secret-pw --host=<host>
```
Replace the host and password as required.
### Step 2.3: Create a database in MySQL
```bash
create database public;
```
### Step 2.4: Import data
Import Graph.cool's MySQL export into your local MySQL instance:
```bash
mysql --user=root --password=my-secret-pw --host=<host> public --binary-mode=1 < <pathtomysqlexport>
```
Replace host and pathtomysqlexport as required. Your data should now be present in the MySQL database.
## Step 3: Migrate data to Hasura
Since MySQL is now set up with all the data from Graph.cool, we need to create a Hasura and Postgres instance, and to import the data to the same.
### Step 3.1: Set up Hasura
Refer to the [Getting started guide](https://hasura.io/docs/1.0/graphql/manual/getting-started/docker-simple.html#docker-simple) to set up Hasura using `docker-compose`.
### Step 3.2: Import data into Postgres
We will use `pgloader` to migrate from MySQL to Postgres. Refer to their [installation guide](https://github.com/dimitri/pgloader) for setting this up.
Once you have installed, execute the following command:
```bash
pgloader mysql://root:my-secret-pw@<host>/public postgresql://postgres:postgrespassword@<host>:5432/postgres
```
Replace `<host>` and mysql password (my-secret-pw) as required.
Your data should now be present in the Postgres database.
### Step 3.3: Connect Hasura to Postgres
Once the dataset is migrated to Postgres, Hasura should be able to track tables and relationships.
**Note**: If you have enums in your Graph.cool project, check out [Enums in Hasura](https://hasura.io/docs/1.0/graphql/manual/schema/enums.html), since they're handled differently in Hasura and you would need to change the data structure a bit.
## Step 4: Migrate structure & functionality
After migrating the data to Hasura, there is some manual work involved in migrating the structure and functionality of your Graph.cool project.
### Step 4.1: Restructure connection tables
You can rename tables/columns to match your client-side queries as required. Do note that, for every one-to-one relationship, Graph.cool would have created a connection table to link them. This would require a bit of manual work to restructure. Currently, there is no automation available for this step. Carefully review the connection tables and make the necessary changes.
Read up more about [Relationships in Hasura](https://hasura.io/docs/1.0/graphql/manual/schema/relationships/index.html)
### Step 4.2: Migrate functions
In case you have functions in Graph.cool, Hasura has an equivalent feature called [Event Triggers](https://hasura.io/docs/1.0/graphql/manual/event-triggers/index.html). Migrating this involves taking your code and deploying it on a different platform. It could be a serverless function or all the functions can be combined into a monolith Node.js server. The choice is up to you.
Do note that for event triggers, the [payload](https://hasura.io/docs/1.0/graphql/manual/event-triggers/payload.html) that Hasura sends might be different, and you might have to change the way the request body parameters are handled in your function code.
### Step 4.3: Migrate auth
There are two ways of authenticating users in Graph.cool:
1. Using Auth0
2. Using email-password auth.
If you were using Auth0 with Graph.cool, the migration should be fairly straightforward. You can configure Hasura with Auth0 easily by following the [Auth0 guide](https://hasura.io/docs/1.0/graphql/manual/guides/integrations/auth0-jwt.html).
In case you are using email-password auth, Graph.cool generates mutations for
- creating a user
```graphql
createUser(authProvider: { email: { email, password } })
```
- login
```graphql
signinUser(email: { email, password })
```
You will need to implement these custom mutations using [Hasura Actions](https://hasura.io/docs/1.0/graphql/manual/actions/index.html).
Refer to this example for a [custom signup mutation](https://github.com/hasura/hasura-actions-examples/tree/master/auth). You can modify this to include login functionality.
### Step 4.4: Migrate permissions
The CRUD permissions in Graph.cool can be manually migrated to Hasura's permission system. You can define roles in Hasura and configure permissions declaratively for all the CRUD operations.
Refer to [authorization](https://hasura.io/docs/1.0/graphql/manual/auth/authorization/index.html) for configuring Hasura permissions.
## Community Tooling for File Storage
Nhost has a community maintained solution [hasura-backend-plus](https://github.com/nhost/hasura-backend-plus) for handling Files on Cloud providers like S3 in case you are looking for a way to migrate Files from Graph.cool. They also have an Auth solution that can be integrated with Hasura :)
## Subscriptions
Hasura gives you realtime APIs out of the box. All your Postgres tables can be subscribed from the client using GraphQL Subscriptions.
I hope this guide gives an indication of the steps involved. In case you are stuck with any of the steps, do ping me :)
Hasura has an active and a helpful discord community. Do [join the discord server](https://hasura.io/discord) as well and post your queries. | praveenweb |
331,060 | Kubernetes Pods vs Containers | K8s Networking Basics 💡 | In this video I cover one part of the broader Kubernetes Networking topic, which is container commun... | 4,349 | 2020-05-09T14:11:55 | https://dev.to/techworld_with_nana/kubernetes-pods-vs-docker-containers-k8s-networking-basics-32mm | kubernetes, devops, tutorial, docker | In this video I cover one part of the broader Kubernetes Networking topic, which is container communication inside pods.
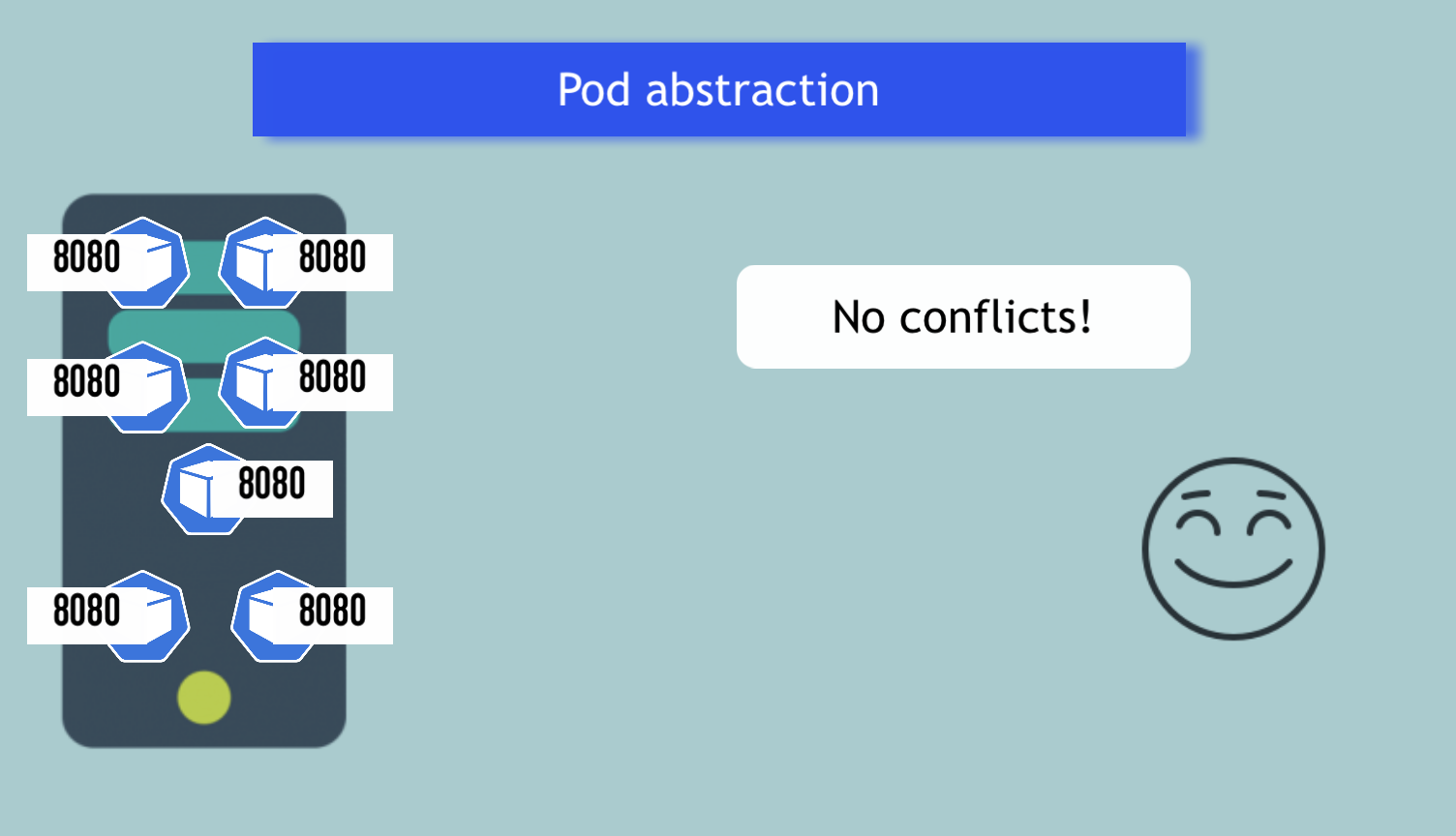
Considering Pods mostly contain only 1 main container, I start by answering the question of **why having a Pod as an abstraction over container is such an important concept in Kubernetes**.
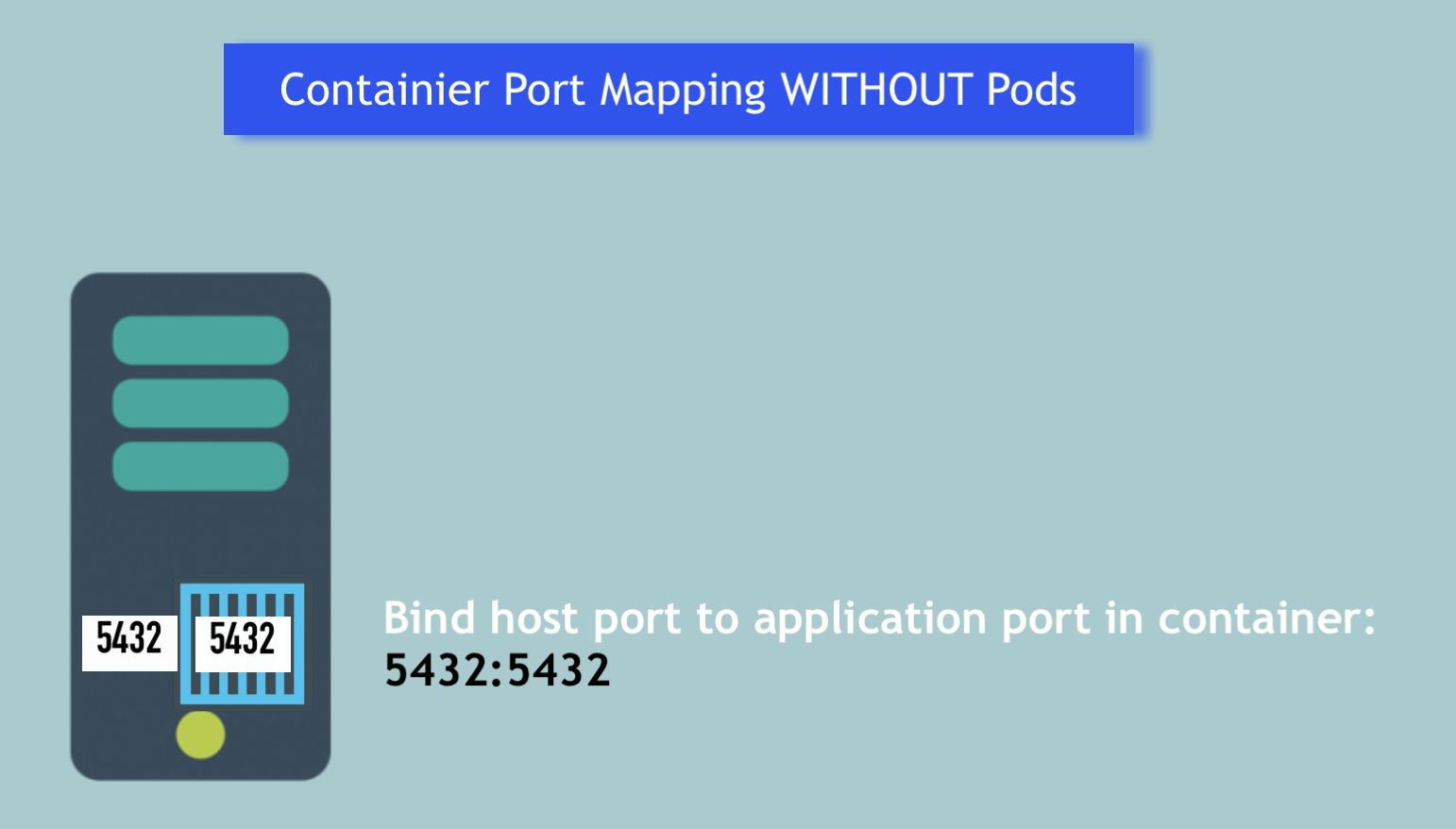
I show **how container port mapping is a problem with hundreds of containers**, specifically how to allocate ports without getting conflicts, and **how Pods solve this port allocation problem**. 💪🏼
Using containers directly, you can only use a specific port ***once on a server***:
The same port can be used multiple times:
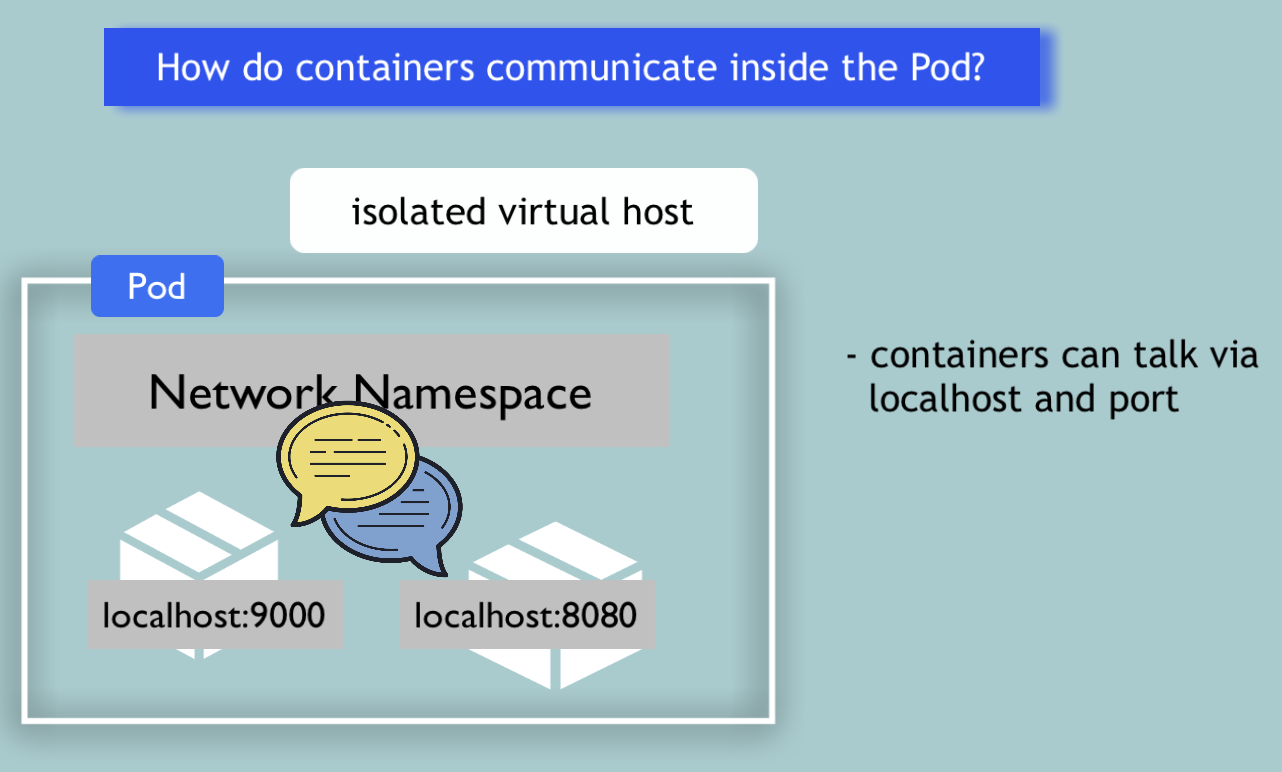
In addition, I show you in which cases you would need to run **multiple containers in one pod** and how these **containers communicate** with each other inside this pod:
You can find the full video here:
{% youtube 5cNrTU6o3Fw %}
---------------------
####Complete Kubernetes Networking Course 🎬:####
I'm making a complete course about Kubernetes Networking, covering rest of the topics, like
► how pods communicate with each other on the same node and across hundreds of servers?
► how does the outside world communicate with K8s cluster?
► how K8s cluster plugs into the underlying infrastructure network?
► Docker Container Networking
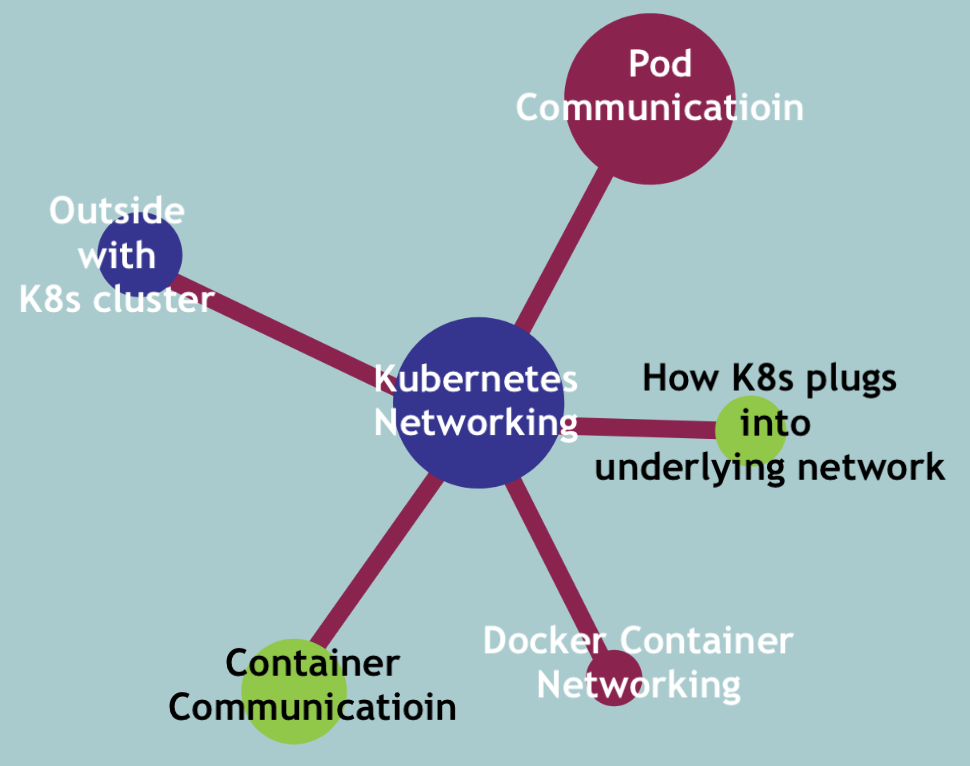
-----------------
**Kubernetes 101** ► [Compact and easy-to-read ebook bundle 🚀](https://bit.ly/3l4qXkR)
It's a handy way to quickly look something up or refresh your knowledge at work and use it as your cheatsheet 😎
I'm happy to connect with you on 🙂
- [Twitter](https://twitter.com/Njuchi_)
- [YouTube](https://www.youtube.com/channel/UCdngmbVKX1Tgre699-XLlUA?sub_confirmation=1)
- [Instagram](https://www.instagram.com/techworld_with_nana/) | techworld_with_nana |
331,086 | Getting started with Glitch | Glitch is a great platform for hosting your Github or newly made projects running node.js, web servers, and more. | 0 | 2020-05-09T19:58:28 | https://developerbacon.ca/articles/getting-started-with-glitch/ | webdev, tutorial | ---
title: Getting started with Glitch
published: true
date: 2020-05-09 07:00:00 MDT
tags: webdev, tutorial
description: Glitch is a great platform for hosting your Github or newly made projects running node.js, web servers, and more.
canonical_url: https://developerbacon.ca/articles/getting-started-with-glitch/
---
[Glitch.com](https://glitch.com/) is a website that can host your online web apps. You can host entire websites on Glitch with Vue.js, React, Angular, Nuxt, and more. There is also the option to make bots for Discord, Slack, or even Twitch with a language like Node.js.
## Creating your first app
When you start a project you will have the option to start from a starter template or a Github repo.
The Glitch editor has a bunch of great features like a file formator and an automatic package update checker.
## Packages
After you have a project set up and ready to go, and you can make changes in the built-in editor, you will need to make sure you have a `package.json` file with a start script. You can ignore the package file if you are running a website with an `index.html` file. The start script is what Glitch looks for when running your app. Here is a template for the package file if you don't have one.
Glitch comes with an easy way to install and update NPM packages. To use this functionality go to your package.json file in your Glitch project and at the top you will see an `Add Package` button. To add a package just click it and search for the package you would like to install and Glitch will install it for you.
Updating packages is very similar to installing them. If a package has an available update just click on the Add Package button and any available package updates will display above the `What is npm` link.
The script that Glitch will run is `start`. As far as I can tell there is no way to change the script the Glitch will run if there is a way just let me know.
```json
{
"scripts": {
"start": "node index.js"
}
}
```
Currently, the highest node version that Glitch uses is v12, but if you would like to use another version of node for your project
```json
{
"engines": {
"node": ">=12.x"
}
}
```
Here is an example of what your package.json file should look like for your Glitch project.
```json
{
"name": "something-cool",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"dependencies": {
"express": "^4.17.1"
},
"engines": {
"node": ">=12.x"
}
}
```
## Formatting your files
Glitch also comes with a file formating tool, to help make your documents look just a bit nicer to look at. To use this function open a file that you would like to format and at the top of the editor, there will be a `Format This File` button. Using this is as simple as clicking that button.
## New files and directories
Making a new file is easy with the `New File` button at the top left of the file hierarchy menu, but did you know that you are also able to make new folders with this as well. To do so just add the directory before the new file you want to create and add a slash in between the directory and file. Here is an example `new_directory/new_file.js`
<!-- assets -->
## .env
The `.env` file is where you can keep all of your super-secret private tokens for your projects. You can put all of your tokens in this file and they won't be visible to the public and won't duplicate if the project is remixed.
To access the variables that have been set in the .env file you can use the `process.env` object, followed by the variable, like so: `process.env.SOMEVAR`. This is an example of what a .env file would look like:
```
# Environment Config
# reference these in your code with process.env.SECRET
TOKEN=123456abcdefg
# note: .env is a shell file so there can't be spaces around =
# Scrubbed by Glitch 2020-04-17T08:15:39+0000
```
| brettanda |
331,210 | Why did you decide to study Software Engineering? | The reason I have to become a software developer... “You can focus on your spiritual growth more whe... | 0 | 2020-05-09T17:02:56 | https://dev.to/ameerrah9/why-did-you-decide-to-study-software-engineering-3kog |
The reason I have to become a software developer...
“You can focus on your spiritual growth more when you’re not in survival mode living paycheck to paycheck.”
-Ayodeji Awosika
I come from a low income household and not the most educated. I was the first to graduate from college in my family. My family lived on public assistance for most of my life. I found freedom in a skill which allowed me to further my education at a lower cost than most; playing basketball. Though a scholarship funded my education, I still had to take out student loans. After I earned a degree I was not able to find work in my field, a bachelor's only gets you but so far nowadays. Before this pandemic I was making a $30k salary barely enough to pay rent, eat healthy or enjoy activities out of my home. After fighting myself and beating myself up over the position I was in in life, I discovered a way to financial freedom.
"Today, every company is a Software company. The Software industry is booming and demand for qualified software engineers is expected to increase by over 23% by 2028."
Technology is an essential skill of the world! If you have desires to survive and thrive, learn about technology. The technology industry is trending towards engineers; the need for engineers is very high. The chance to be a part of an organization's decision making and being in those rooms where innovative change is discussed and planned is something that drives me. I’m intrigued by the influence engineers have on a product directly and the impact we can have on a business. Software Engineering is a very collaborative task and I love to immerse myself in team environments. I am very intrigued by the field because of the real world application of the projects. When I learn Software Engineering I will get the necessary preparation and knowledge needed to make a break in this industry.
I have been interested in coding for as long as I can remember, more distinctly, since high school. I have always had the desire but I’ve never been given the chance to be educated formally since then. Learning Software Engineering creates a competitive advantage for myself to gain the attention of employers. Let's be completely transparent, there's $100,000 ON THE TABLE A YEAR!!! I just need to believe in my infinite capacity to learn. I intend to learn new skills for self-enrichment and financial freedom. I intend to start a new in-field job within 60 days of graduating the Flatiron program. With no formal education in this field and no Computer Science degree, it's clear I have an insane amount of self determination to be successful.
The reason I have to become a software developer...
I have a strong desire to learn! Not just programming but in life, I'm a lifelong learner. Yes, adding coding skills will allow me to add value to a business in exchange for gainful employment; but it's about more than money. In fact, I’m enjoying the process of learning that I would do it for free! Engineers are respected and for good reason. Software Engineering is full of twists, turns and roadblocks that can have you thinking, "Can I actually do this?" This journey will be a test of toughness and resilience. I'm constantly reaching out and networking so I can find ambitious people so that I am surrounded by motivated, hard working people! There's an abundance of reasons why I chose to learn Software Engineering, but a key reason is to challenge myself.
The reason I have to become a software developer...
A career in software engineering would be life changing, I would be doing something impactful, something I love and enjoy and can feel fulfilled by and it would financially allow me to have more buying power and freedom for my family and future success. I think of programming as a craft. I was an athlete in college so I truly enjoy craftsmanship. When I put my mind to something, I try to learn as much as possible about it, in hopes of enjoying them more. I love the challenge of programming. I see it as a creative mode of expression. Upon graduating this course my goals are to continuously learn more and more skills to better my craft as an engineer, my education starts with Flatiron School but it doesn't end. My goals include being employed at a company that I feel adds value to the world and aligns with my values. My goals are to earn six figures by 2021 and be able to do more for my family. My goals have always been to contribute to the human advancement through technology. Learning Software Engineering allows me to provide a valued skill to individuals and businesses that can utilize this unique skill. Once I complete Flatiron's course I will have the confidence, the skills and the experience to make an impact on a company and further produce for their bottom line. My goals are to add value to an organization using my coding skills and problem solving ability, I also have desires to create a better life for my family and other coders who come after me.
So that’s it! The plentiful reasons why I chose to embark on this crazy journey of learning Software Engineering. My friends and family think I’m crazy but I know I can do this! Let’s face it, I’m a NERD. I can’t get enough of this! Keep following my journey as I give updates on my story.
| ameerrah9 | |
331,216 | Fullstack Serverless App Template (React + Apollo + GraphQL + TypeScript + Netlify) | I created a template that will enable developers to quickly bootstrap an Apollo GraphQL + TypeScript project, which can be deployed in a serverless fashion on Netlify. Also, with the FaunaDB addon, it will enable developers to have a stateful app. Thus, developers can concentrate on core application logic and scale the application as their app grows at the same time they don't have to sacrifice on security. | 0 | 2020-05-09T17:19:56 | https://abstracted.in/fullstack-serverless-template/ | gftwhackathon, netlify, fullstack, serverless | ---
title: Fullstack Serverless App Template (React + Apollo + GraphQL + TypeScript + Netlify)
published: true
canonical_url: https://abstracted.in/fullstack-serverless-template/
description: I created a template that will enable developers to quickly bootstrap an Apollo GraphQL + TypeScript project, which can be deployed in a serverless fashion on Netlify. Also, with the FaunaDB addon, it will enable developers to have a stateful app. Thus, developers can concentrate on core application logic and scale the application as their app grows at the same time they don't have to sacrifice on security.
tags: gftwhackathon, netlify, fullstack, serverless
---
[Instructions]: # (To submit to the Grant For The Web x DEV Hackathon, please fill out all sections.)
## What I built
I created a template that will enable developers to quickly bootstrap an Apollo GraphQL + TypeScript project, which can be deployed in a serverless fashion on Netlify. Also, with the FaunaDB addon, it will enable developers to have a stateful app. Thus, developers can concentrate on core application logic and scale the application as their app grows at the same time they don't have to sacrifice on security.
Netlify functions enable developers to deploy lambda functions. They have a template for Apollo GraphQL as well. However, this template doesn't support TypeScript. Limiting the advantages of GraphQL to just querying and mutating data. Having TypeScript helps developers to change code with reliability. This also enhances overall experience with GraphQL as schema defined in GraphQL can be directly exported to TypeScript types.
For such cases, Netlify recommends using legacy command `netlify-lambda` command. But people ran into other issues using it.
### Submission Category: Foundational Technology
[Note]: # (Foundational Technology, Creative Catalyst, or Exciting Experiments)
## Demo
Application: https://apollo-graphql-typescript.netlify.app/
GraphQL PlayGround: https://apollo-graphql-typescript.netlify.app/.netlify/functions/graphql
## Link to Code
[Note]: # (Our markdown editor supports pretty embeds. If you're sharing a GitHub repo, try this syntax: `{% github link_to_your_repo %}`)
{% github https://github.com/pushkar8723/apollo-graphql-typescript %}
## How I built it
[Note]: # (For example, what's the stack? did you run into issues or discover something new along the way? etc!)
I integrated TypeScript at the build time itself. Thus there is no need to use the legacy command.
## Additional Resources/Info
https://community.netlify.com/t/getting-typescript-to-work-with-netlify-functions/6198
https://community.netlify.com/t/does-netlify-dev-support-typescript/3842
[Reminder]: # (We hope you consider expanding your submission into a full-on application for the Grant for the Web CFP, due on June 12.)
**UPDATE:**
I further integrated `graphql-codegen` to automatically generate TypeScript types for GraphQL schema. And also integrated `eslint` and `husky` to introduce lint checks and validate them before each commit.
**UPDATE 2:**
I created a demo project using this template and also integrated FaunaDB addon on [GitHub](https://github.com/pushkar8723/social-board). | pushkar8723 |
331,218 | Deploying Angular app with Netlify in 3 steps | Netlify is a great platform to build/deploy any kind of web applications (not just Angular). It's ver... | 0 | 2020-05-10T15:54:41 | https://dev.to/salimchemes/deploying-angular-app-with-netlify-in-3-steps-55k6 | angular, netlify, github | ---
title: Deploying Angular app with Netlify in 3 steps
published: true
description:
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/6syudn32kwrpwmuzobfl.png
tags: #angular #netlify #github
---
Netlify is a great platform to build/deploy any kind of web applications (not just Angular).
It's very useful when you need to deploy your app fast and easy.
I found it handy to have demos or examples running when writing posts or when I need to have some coding working and live (not just local), but Netlify is not just for that, it is a very powerful platform.
We can deploy our Angular app following these steps:
**1. Create your angular project on github (could also be on bitbucket/gitlab)**
**2. Log in into Netlify, look for your repo and setup the build options**
**3. Deploy the new web site created!**
Let's start
**1. Create you angular project on github (could also be on bitbucket/gitlab)**
```javascript
ng new my-angular-app
```
Create a repo on github and push your code.
**2. Log in into Netlify, look for your repo and setup the build options**
* Log in https://www.netlify.com/
* Clic on New site from Git

* Select Github as provider

* After authorization, we will see the list of available repositories to pick.

If `my-angular-app` repo is not on the list, we need to provide access from github. (If you see your repo, you can skip this step).

Clic on the highlighted link "_Configure the Netlify app on GitHub_".
We will be redirected to github to look for our missing repository

* Now we can see `my-angular-app`

* As part of build options setup, this is what we need:
1. build command: we build our code in prod mode
2. publish directory: location of build files

**3. Deploy the new web site created**
After clic on Deploy site, the first build is triggered and deploy is in progress

Finally, we have our site running

Let's go to the site list to see one we have just created

Clic on our site, and then on the url provided by Netlify

That's all! site deployed and running!

**Conclusions**
Netlify provides a lot of cool features and tools, this post is just to demo how to deploy fast with Angular but there is a lot more to work with.
Other Netlify features
* Custom domains
* Functions with AWS Lambda
* Identity
* Forms
* Large Media
* Split Testing
* Analytics
**References**
* github [repo](https://github.com/salimchemes/my-angular-app) (nothing special here)
* Netlify site running: https://focused-bhaskara-dee416.netlify.app/
| salimchemes |
331,233 | VIM auto-completion with coc.nvim | VIM is a modal text editor which gives bare minimal setup for text editing. However it's highly... | 0 | 2020-05-09T18:25:10 | https://dev.to/rajikaimal/vim-auto-completion-with-coc-nvim-ie3 | vim, languageserver, texteditor | VIM is a modal text editor which gives bare minimal setup for text editing. However it's highly flexible and configurable with plugins. With few configurations, we can make VIM similar to VSCode. First you need to install a plugin managers. There are a bunch of plugin managers,
- [Vundle](https://github.com/VundleVim/Vundle.vim)
- [Vim Plug](https://github.com/junegunn/vim-plug)
- [Pathogen](https://github.com/tpope/vim-pathogen)
Installing any of the above managers is a straight forward task. After installing a plugin manager we are good to go :clap:
Next up installing [coc.nvim](https://github.com/neoclide/coc.nvim). Coc is an intellisense engine for VIM. (same as in VSCode) This uses [language server protocol](https://microsoft.github.io/language-server-protocol/).

A prerequisite for Coc is Node.js as it's written in TypeScript. Navigate to [vimawesome](https://vimawesome.com/plugin/coc-nvim) and copy `install from` script for the plugin manager you already installed earlier. Open your `.vimrc` and paste the copied plugin reference and run `:source %` and `:PluginInstall` to install the plugin.
From this point onwards we can use Coc intellisense, but there are a couple of commands that can be mapped from `.vimrc` to make it really convenient to be used quickly. [Coc README](https://github.com/neoclide/coc.nvim#example-vim-configuration) offers a starting point for this configuration. This configuration can be copied and pasted to `.vimrc`. This will add few key mappings like gr, gi, gd for moving to method references, implementations, and definitions.
For every programming language Coc expects extensions to be installed. For an example for web development following command can be used.
`:CocInstall coc-tsserver coc-html coc-css`
This adds intellisense support TypeScript, HTML, and CSS.
Once that's done, that's all what we need for intellisense :tada:

Documentation with `K` mapping
:page_facing_up: Check out my not so minimal and messy [`.vimrc`](https://github.com/rajikaimal/dotfiles/tree/master/vim) | rajikaimal |
331,240 | Build your own Linked List in JS | I am trying to improve my hold on data structures and algorithms so, I implemented my own linked list... | 6,738 | 2020-05-16T08:40:40 | https://ajitblogs.com/build-your-own-linked-list-in-js/ | javascript, webdev, algorithms, beginners | I am trying to improve my hold on data structures and algorithms so, I implemented my own linked list class JavaScript. I've shared the API here and tell me if any other methods should be implemented.
Try implementing it on your own as I also was afraid of linked lists using the .next, .next each time. Implementing it really increased my confidence to use linked lists as a data structure.
API's implemented:
size() - returns number of data elements in list
empty() - bool returns true if empty
value_at(index) - returns the value of the nth item (starting at 0 for first)
push_front(value) - adds an item to the front of the list
pop_front() - remove front item and return its value
push_back(value) - adds an item at the end
pop_back() - removes end item and returns its value
front() - get value of front item
back() - get value of end item
insert(index, value) - insert value at index, so current item at that index is pointed to by new item at index
erase(index) - removes node at given index
value_n_from_end(n) - returns the value of the node at nth position from the end of the list
reverse() - reverses the list
remove_value(value) - removes the first item in the list with this value
> Link to the [class](https://github.com/ajitsinghkaler/javascript/blob/master/interview/linkedList.js)
> I am trying to improve my hold on data structures and algorithms please tell me if you have any good resources available in the comments below.
If you find any error in my code please raise a pull request in my [repo](https://github.com/ajitsinghkaler/javascript/blob/master/interview/linkedList.js) | ajitsinghkaler |
331,251 | Why would you become a programmer? | I love Twitter. It’s a way for a person to connect with others, to see snippets of other technologies... | 0 | 2020-05-09T19:00:56 | https://dev.to/grantwatsondev/why-would-you-become-a-programmer-1f8g | programmer, career | I love Twitter. It’s a way for a person to connect with others, to see snippets of other technologies, and to share ideas. It is also a place to bash people, people who may have different views from you. It would be a lie if I have not been part of an online discussion that has led to an argument between two agitated individuals who are set in their ways. I am not perfect, nor do I want to be. But as I have grown older, I tend to try my hardest to stay away from the poker and prodded tweets and Facebook posts so that I can stay sane.
This post is not about online feuds, but on the opposite end: the ability to spark conversations with one ourselves from posts.
I responded to a tweet asking a “simple” question: “Why did you choose programming?”
To be honest, this has been the second time only that I have truly considered why I chose programming as a career path. Programming is one of those career paths that, for the right person, can be the most frustratingly fun thing to do in one’s lifetime. The job can bring about some of the individuals’ greatest accomplishments, while also bringing about some of the greatest failures. And in my short career, it is very fair to say that I have experienced some of both sides of the aisle. Programming is one of those skills that MAKE a person work through seen and unforeseen issues that could and will come up in a given situation.
I wanted to go over some of the pros of why a person will choose programming as a career path, as well as sprinkle in some more of my reasons of doing so.
If you Google “Why choose programming as a career?”, the first bits of shared information will read something similar to “5 reasons why you should learn programming”, “the benefits of choosing a computer programming career.”, or “where do I start in my career as a programmer”. You will see a trend online that programming can be an amazing career choice for the masses. But I will state that I do not believe, and this is Grant Watson’s opinion, that not everyone is cut out to be a programmer/engineer/developer. This goes to say the same that not every person so pick up singing, being a doctor, being a salesperson, or mechanic as a career. Different people have different talents, and those talents may or may not be in the computer science realm. The computer sciences takes a special type of person. It takes critical thinking, mathematical thinking where X may not be easily defined. It takes a form of creativity that is outside of the box. And yes, a programmer does want to throw their computer across the room sometimes.
Let’s talk about some of the pros of working in programming.
Increased career opportunities
Looking at the job market, even before the pandemic known as COVID-19, software development is a needed atmosphere to drive businesses across all genres of life. If you want to work in the healthcare realm, but do not want to work as a medical professional, you can help with the development of the software and technologies used in the medical realm. The same goes for any other form of business. Insurance, military, automotive, industrial, food, marketing, what have you, the arena is yours to choose. Learning to program will make you more employable in the IT workplace as companies are looking for candidates who have a comprehensive IT skill set. And programming is becoming a more and more standard requirement for many information technology jobs, whether or not it makes up a big part of your day-to-day responsibilities.
Competitive advantage
Similar to what was stated, once you have education and/or experience, the ability to jump into the technology world will be quick and fast. I got into my career as a full stack developer 7 months before I finished my degree. Because programming and coding are both becoming a critical part of operations for all types of businesses, you’re more likely to get hired if you have these skills. Though demand for tech-based jobs is higher than ever and on the rise, it still helps to stand out among other candidates for the same position. Most IT jobs require both a knowledge of business processes and the ability to code, so you need to have a strong background in both areas, not just one or the other.
Flexibility in the workplace
As an IT professional, you will be working closely with software developers and web designers. To communicate effectively and operate efficiently, understanding the programming process will enable you to do your job better. Even though you may not be using programming skills every day, having a background in this key tech area can make you an asset to your company’s IT department.
Relevance in the modern world
Learning to program will help you stay relevant in all types of industries. And in today’s tech-driven society, the more computer skills you have, the easier it will be to get the job you want. Because businesses rely so heavily on web-based processes and services, learning the science and theory behind how those things work is essential for effective work in information technology.
| grantwatsondev |
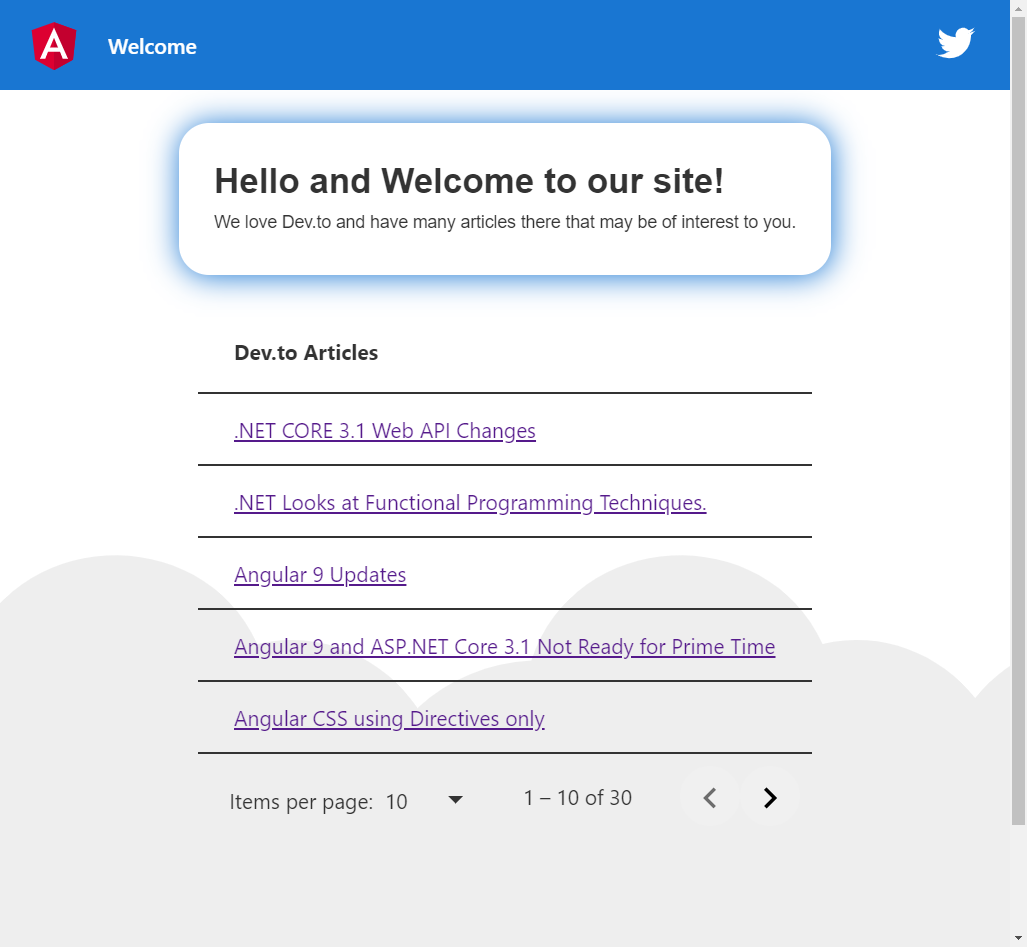
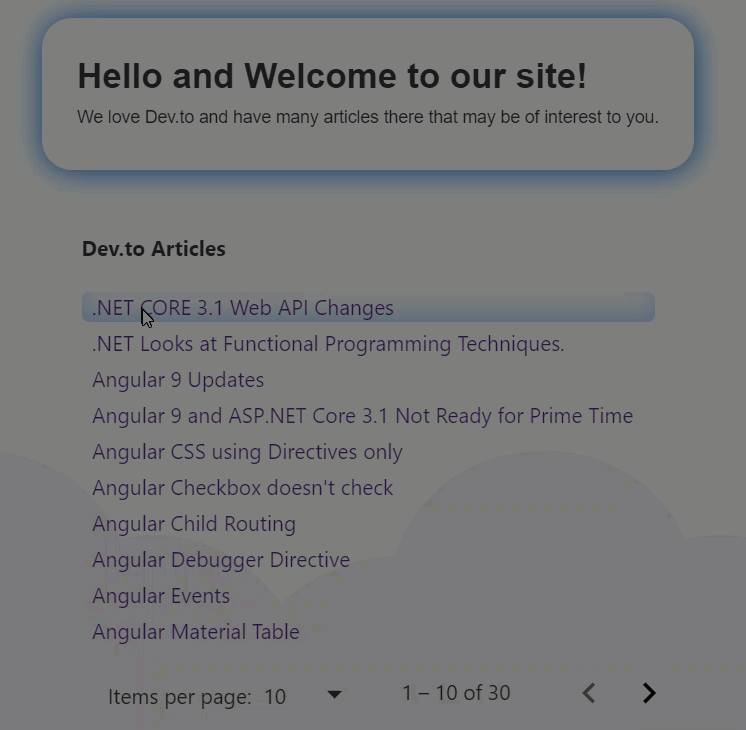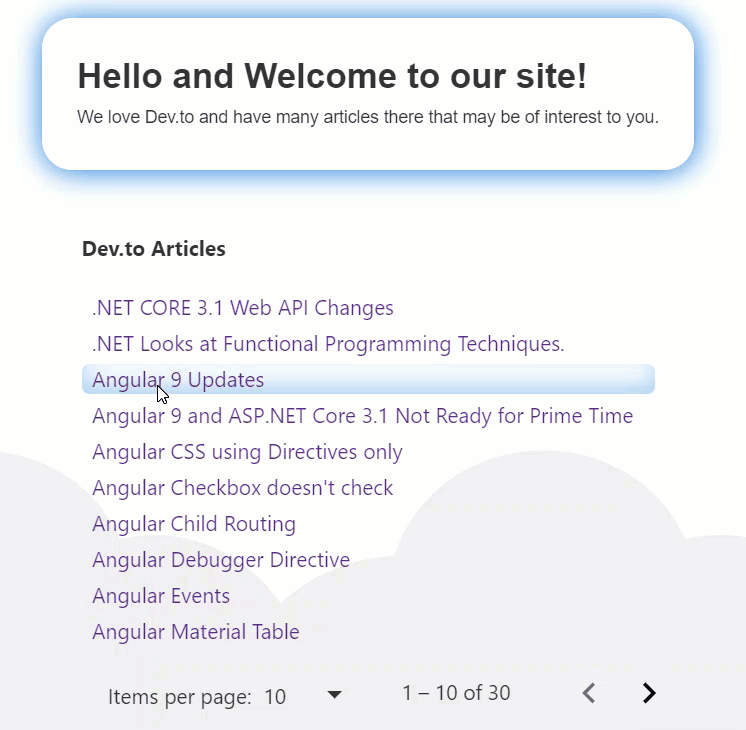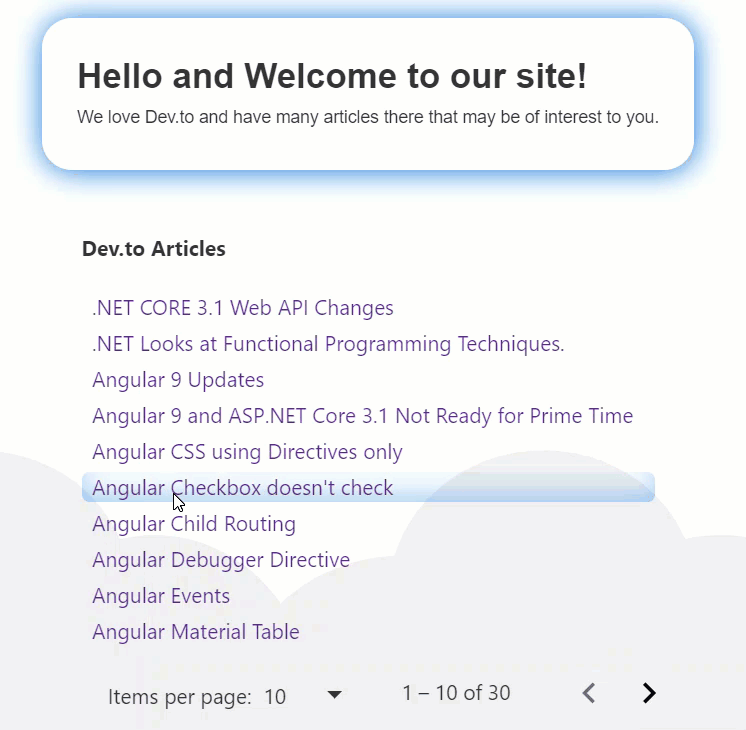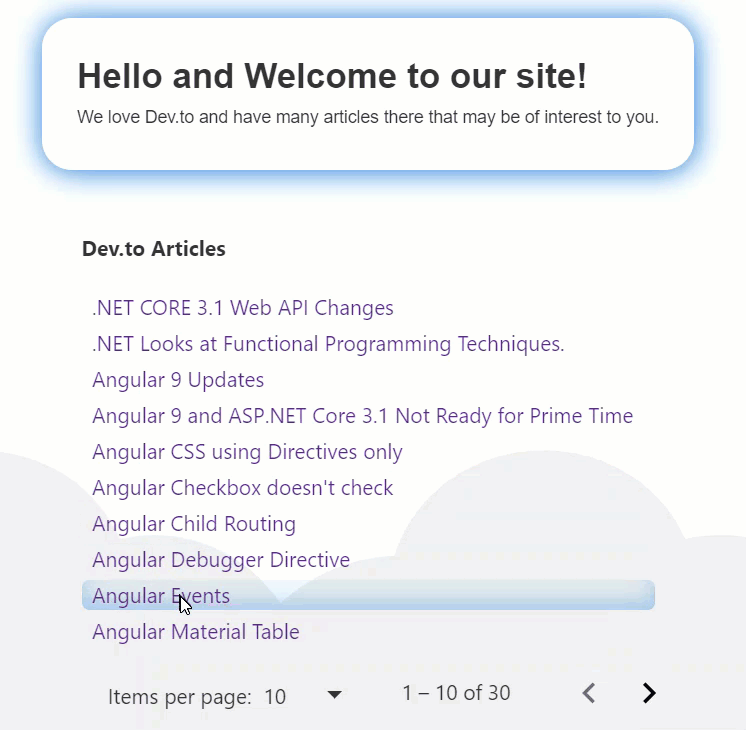
331,330 | Material Table II in 20 Minutes (Styling) | In our previous article, we demonstrated how to wire up a Material Table to a JSON file (containing a... | 6,526 | 2020-05-09T21:56:31 | https://dev.to/jwp/angular-material-table-ii-in-20-minutes-32gg | angular, typescript, material | In our previous article, we demonstrated how to wire up a Material Table to a JSON file (containing articles), and a paginator; which, looks like this:
**Changing the Style of the Rows**
We didn't like the lines on each row and found the root cause to be the default style from MatTable.

Let's get rid of the lines by adding this to our page's css.
```css
th.mat-header-cell,
td.mat-cell,
td.mat-footer-cell {
border-bottom-width: 0px;
}
```
Ok now let's change the default a:hover behavior and get rid of the typical underscore.
```css
a {
cursor: pointer;
border-radius: 5px;
position: relative;
padding-left: 0.5em;
padding-right: 1em;
padding-bottom: 0.1em;
text-decoration: none;
}
a:hover {
box-shadow: inset 0px -7px 15px #1976d255;
}
```
**Results**
No more lines, and a soft inset box shadow following our theme color! This is what it looks like in action.
**Search**
The matTable datasource has these properties:
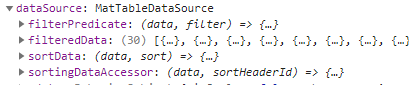
In our next article we will show how to tie into these properties to provide automatic (and mostly instant) searches. We'll also explore the sortData function.
JWP2020
| jwp |
331,376 | Solution to Leetcode’s Valid Perfect Square | This is an easy Leetcode problem 367. The question gives a number and you are to write a function to... | 0 | 2020-05-09T23:34:28 | https://dev.to/codechunker/solution-to-leetcode-s-valid-perfect-square-5gd | tutorial, codenewbie, leetcode, algorithms | This is an easy [Leetcode problem 367](https://leetcode.com/problems/valid-perfect-square/). The question gives a number and you are to write a function to determine if it is a perfect square. See the image below for description.
![problem description]
(https://miro.medium.com/max/1400/1*P5i0IPr8UqObEFFcpMIZlQ.png)
According to [wikipedia](https://en.wikipedia.org/wiki/Square_number), a perfect square is the product of a number with itself. in this context, a perfect square is a number when multiplied by itself will give you the number in question.
There are many ways in solving this problem but I will talk about three in this article.
**NOTE: Do not use any library functions like Math.sqrt().**
<h3><b>THE NAIVE APPROACH</b></h3>
Of course the naive or brute force approach would be to loop through from 1 to the number, multiplying a number by itself and checking if the product equals the number you are looking for. if it does, then return true, else return false.
```
public static boolean isPerfectSquareWithBruteForce(int num) {
if (num == 1) return true;
for (int i = 1; i < num; i++) {
if (i*i == num) return true;
}
return false;
}
```
The code above works but can be very slow. its runtime is O(n).
To make this better, we may decide to loop from 1 to half of the number because there is no way you can get the number in question by multiplying number greater than half (i.e num/2) by itself. e.g to determine if 9 is a perfect square, there is no way a number between 4 to 9 would give you 9. So in other words, to know if a number is a perfect square, the number that will multiply itself will have to be in the first half (between 1–3).
```
public static boolean isPerfectSquareWithHalfNumber(int num) {
if (num == 1 || num == 0) return true;
for (int i = num/2; i >= 0; i-- ) {
if (i*i == num) return true;
}
return false;
}
```
Technically speaking, it may seem that the above code would make it faster but the truth is , the runtime of this is O(n/2) which still translates to O(n) because in computer science, we don’t consider constants when dealing with runtime.
<h3><b>A FASTER SOLUTION</b></h3>
A better way to solve this problem would be to use Binary Search. This solves the problem by using the divide and conquer methodology. It keeps splitting the number into half and checking if number is found.
```
public static boolean isPerfectSquareWithBinarySearch(int num) {
double start = 1;
double end = num/2;
if (num == 1) return true;
while (start <= end) {
double mid = Math.floor((end - start)/2) + start;
if (mid * mid == num) {
return true;
}else if (mid * mid < num) {
start = mid + 1;
}else {
end = mid - 1;
}
}
return false;
}
```
The runtime of the above is O(log n) which is faster than O(n) linear time.
Thank you for reading and please leave a comment or suggestion. | codechunker |
331,381 | How To Use Command Prompt | What is command prompt for? | 0 | 2020-05-10T00:52:41 | https://dev.to/ameliaruzek/how-to-use-command-prompt-138c | learning, beginners, webdev, frontend | ---
title: How To Use Command Prompt
published: true
description: What is command prompt for?
tags: #learning #beginner #webdevelopment #frontend
---
# Search for Command Prompt and open the application.
Usually tutorials about web development say something about “terminal” “command line” “command prompt” “bash” “shell” and then say something about “run this command” etc…
The first thing to know is that all these applications are very similar and serve similar functions. There ARE differences, but for a beginner, you don’t really need to worry about it. If you’re on a Windows computer, use Command Prompt as the application.
Sometimes they’ll tell you to download Node.js first, and if you have done so, you’ll probably see another application show up in the search called Node.js Command Prompt. That’s fine — either one is fine.
# Does white text on a black background make you feel like you’re definitely going to accidentally break your computer?
Click on the thumbnail icon at the top left of the application, then select properties.
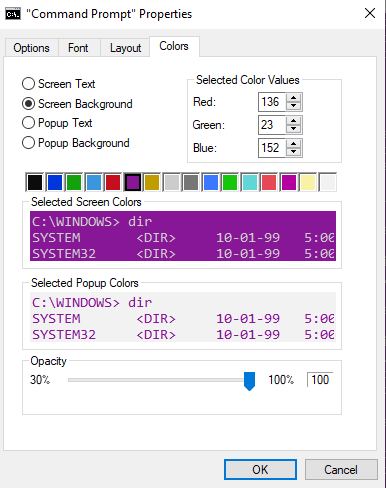
Move to the colors tab and make it pink or purple or customize it any way you choose, then click “ok”
# Help
Next up, type `help`. When you do this all of the default commands will be shown like a little dictionary.
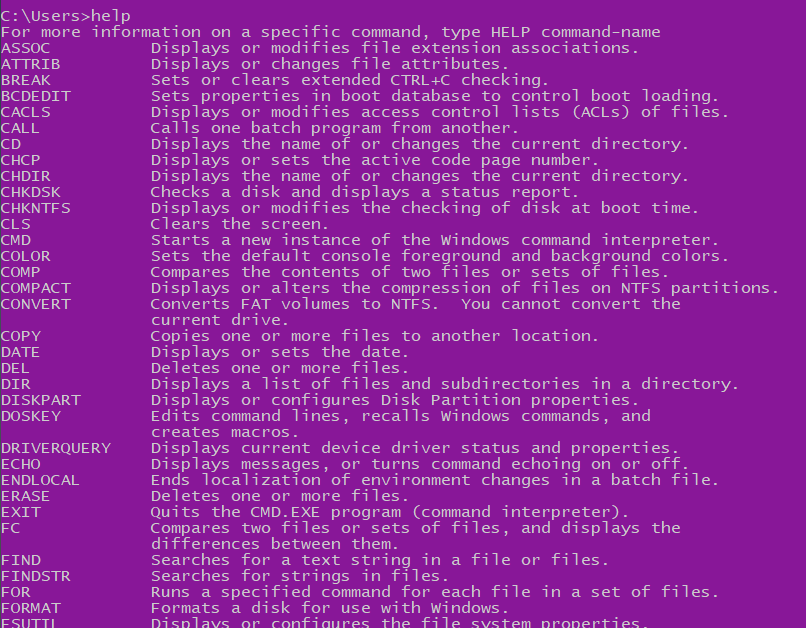
If you’re planning to use Command Prompt for web development, then the only important commands listed here are `cd` and maybe `mkdir`.
The other commands you’ll use are additional ones that you download such as the `node` command, `git` command, and either `yarn` or `npm` commands.
# Try it out
Ok, let’s try out `cd` first. The help dictionary said that `cd` will display the name of the directory or change the directory. What it doesn’t say is that `cd` only moves forward through directories. To move backward, you’ll need to use `cd..`
Since usually Command Prompt defaults to the directory of your Windows user profile, you’ll probably see something like this:
`C:\Users\yourName>`
Type `cd..` and it will change to
`C:\Users>`
Then type `cd yourName` to move it back to the directory that you were in.
Open that same directory using File Explorer (the folder GUI). Click through the folders/directories. Do you see “Users” and the folder “yourName”? Keep the File Explorer open on one side, and on the other side user Command Prompt to type `mkdir HelloWorld`
Wow! There’s a new folder there now called “HelloWorld”
# Wait…why does Command Prompt exist? What’s the point?
Websites used to take a really long time to set up. But with custom commands that you can download like the way that Node.js downloads the custom command npm , you can create websites and other things really quickly.
If you’ve already downloaded Node.js, you can type `npm -l` to see its dictionary of additional commands.
These commands are very useful for when you are downloading packages of existing scripts and helper frameworks for web development.
# Not sure where to start?
I’m guessing you’re here because you know some basic HTML, CSS, and JavaScript, and you’d like to become a front-end developer, but all of the tutorials about frameworks and scripts have command line in their tutorials.
If that’s you, and you’re looking for an easy framework to learn, I recommend starting with Vue.
Follow these instructions https://cli.vuejs.org/guide/installation.html to get started, and good luck! You can do this!!
| ameliaruzek |
331,393 | Building Calndr, a free AddEvent alternative | Coronavirus has impacted pretty much every business large and small, and has resulted in a massive su... | 0 | 2020-05-10T02:37:29 | https://dev.to/atymic/building-calndr-a-free-addevent-alternative-54h | showdev, laravel, php, javascript | Coronavirus has impacted pretty much every business large and small, and has resulted in a massive surge in online events. Companies that previous provided solely physical services are switching to webinars and online courses, so the demand for tech in this area has spiked.
In the last few months, I've had multiple different clients come to me with requests to help them schedule events online. There's some existing services that allow you to create add to calendar links out there, such as AddEvent, but they are expensive for what they do - essentially just generating a few links in a certain format (for different calendar software).
After integrating a simple version into one of my client's applications, I decided to create [Calndr.link](https://calndr.link/). It's a super simple service that allows you to generate calendar links for all the major providers in a couple of clicks. Enter the event details (title, location/meeting link, date, etc) and hit generate and you'll be provided with some HTML to copy/paste directly into your newsletter, website, email signature, etc. You can also copy/paste the direct links as well, if you prefer.


## The Tech
I decided to have some fun when building this, using Interia.js (totally overkill for moment, but fun!). On the back end, it's running Laravel 7.
It's deployed on Google Cloud using Cloud Run, so it's running completely serverless. I love the flexibility and ease of use, just whip up a simple docker container, push it to the image registry and hit deploy!
Since you're only charged for requests that actually hit the server, it's extremely cheap. It's basically Lambda, but you can run anything (since it runs custom docker containers).
I'm planning on writing a guide on how to deploy Laravel on GCR serverless, so keep an eye out for that!
Feel free to leave a comment if you've got any questions or suggestions for [Calndr.link](https://calndr.link/)!
| atymic |
331,512 | Vanilla JavaScript string includes | While we recently checked if a string startsWith or a string endsWith a specific substring. We are no... | 0 | 2020-05-10T07:26:41 | https://daily-dev-tips.com/posts/vanilla-javascript-string-includes/ | javascript | While we recently checked if a [string `startsWith`](https://daily-dev-tips.com/posts/vanilla-javascript-string-startswith/) or a [string `endsWith`](https://daily-dev-tips.com/posts/vanilla-javascript-string-endswith/) a specific substring. We are now going to find out if a string contains another substring.
To do so, we are using the `JavaScript` function `includes()`.
## Using includes() function in JavaScript
We can use this function by calling it on a string and passing a substring to it.
```js
var string =
'The greatest glory in living lies not in never falling, but in rising every time we fall.';
// Check if it includes with `living`
console.log(string.includes('living'));
// true
```
For the `includes()` function it is important to know it's a case sensitive function, so the following will fail:
```js
var string =
'The greatest glory in living lies not in never falling, but in rising every time we fall.';
// Check if it includes with `Living`
console.log(string.includes('Living'));
// false
```
## Using an offset starting position with includes()
As the brothers startsWith() and endsWith() this one has another position parameter. This position is from where it will start to look.
```js
var string =
'The greatest glory in living lies not in never falling, but in rising every time we fall.';
// Check if it includes with `living`
console.log(string.includes('living', 30));
// false
```
Feel free to play with this Codepen:
<p class="codepen" data-height="265" data-theme-id="dark" data-default-tab="js,result" data-user="rebelchris" data-slug-hash="eYprJZd" style="height: 265px; box-sizing: border-box; display: flex; align-items: center; justify-content: center; border: 2px solid; margin: 1em 0; padding: 1em;" data-pen-title="Vanilla JavaScript string includes">
<span>See the Pen <a href="https://codepen.io/rebelchris/pen/eYprJZd">
Vanilla JavaScript string includes</a> by Chris Bongers (<a href="https://codepen.io/rebelchris">@rebelchris</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
</p>
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>
## Browser Support
This function works well in all modern browsers, including edge!
### Thank you for reading, and let's connect!
Thank you for reading my blog. Feel free to subscribe to my email newsletter and connect on [Facebook](https://www.facebook.com/DailyDevTipsBlog) or [Twitter](https://twitter.com/DailyDevTips1)
| dailydevtips1 |
331,517 | Folding in JS | Mutatis mutandis between Haskell and JS, the two approaches to fold a list/array are foldl, which doe... | 6,544 | 2020-05-10T09:28:18 | https://dev.to/mandober/folding-mol | javascript | Mutatis mutandis between Haskell and JS, the two approaches to fold a list/array are `foldl`, which does it from the "left", and `foldr`, which does it from the "right"[^1].
```js
const foldl = f => z => ([x, ...xs]) =>
x === undefined ? z
: foldl (f) (f(z)(x)) (xs)
const foldr = f => z => ([x, ...xs]) =>
x === undefined ? z
: f (x) (foldr(f)(z)(xs))
```
With these two functions defined, recursion over an array is abstracted, so there's no need to manually traverse it - all other operations can now be defined in terms of `foldr` or `foldl` (at least as an exercise in futility)[^2].
## In terms of fold
```js
// helper function
const cons = x => ([...xs]) => [x,...xs]
const append = ([...xs]) => ([...ys]) => [...xs, ...ys]
const apply = f => x => f(x)
const flip = f => a => b => f(b)(a)
const add = a => b => a + b
const mul = a => b => a * b
const and = a => b => a && b
const or = a => b => a || b
const K = a => _ => a;
const B = g => f => x => g(f(x))
// In Terms Of Fold
// foldr_id - leaves a list intact, showing that folding a list means replacing all cons with `f` and the empty list ctor `[]` with an initial value, `z`
const foldr_id = foldr (cons) ([])
const reverse = foldl (flip (cons)) ([])
const flatten = foldr (append) ([])
const compose = foldr (apply)
const pipe = foldl (flip(apply))
const head = foldr (K) (undefined)
const last = foldl (flip(K)) (undefined)
const sum = foldr (add) (0)
const product = foldr (mul) (1)
const all = foldr (and) (true)
const some = foldr (or) (false)
const map = f => foldr (B(cons)(f)) ([])
const filter = p => foldr (x => xs => p(x) ? cons(x)(xs) : xs) ([])
// Check
let m = [1,2,3]
let n = [5,6,7]
let t = [[1,2,3], [5,6,7]]
let p = [true, true, false]
console.log(
'\n',
'foldr_id:' , foldr_id (m) , '\n' ,
'reverse :' , reverse (m) , '\n' ,
'flatten :' , flatten (t) , '\n' ,
'sum :' , sum (m) , '\n' ,
'product :' , product (m) , '\n' ,
'all :' , all (p) , '\n' ,
'some :' , some (p) , '\n' ,
'head :' , head (m) , '\n' ,
'last :' , last (m) , '\n' ,
'map :' , map (add(10)) (m) , '\n' ,
'filter :' , filter (a=>a>1) (m) , '\n' ,
'compose :' , compose (5) ([x=>x*3, x=>x+5]) , '\n' ,
'pipe :' , pipe (5) ([x=>x*3, x=>x+5]) , '\n' ,
)
```
[^1]: The elements are accessed from the left in both cases.
[^2]: Haskell's lists are singly-linked lists, so prepending is the most efficient operation to add an element; but to append an element, the entire list needs to be traversed. Although JS arrays have many incarnations (depending whether they hold homogeneous or heterogeneous elements, whether they are sparse, etc.), appending should be the most efficient operation.
| mandober |
331,561 | "Is PHP Dead?" Discussion | A brief look at the popular discussion if PHP is dead or not. | 0 | 2020-05-10T09:54:41 | https://dev.to/actuallymab/is-php-dead-discussion-3230 | php, programming, code | ---
title: "Is PHP Dead?" Discussion
published: true
description: A brief look at the popular discussion if PHP is dead or not.
tags: php, discuss, programming, code
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/675ovmli79v37figa12a.png
---
Tl;dr: it is not.
It was an important moment for me. I was turning 30. One of my best friends organized a lovely house party, and another DJ friend was playing nice music. Even my brother, who was living in Turkey, flew 3000 kilometers and caught the event at the last moment. There were some people that I knew but also some people I barely knew. One of these guys from the second category, who was working in a big IT company, asked me that famous question with a loud voice so I could hear him.
**“So you're coding in PHP, is it not dead yet?”**
He was sipping his cocktail and made that face with a big grin, which I see on most of the people who asked the same question to me. Yes, writing PHP is a part of my job, but as a software engineer (some call me a developer, but this is another discussion), it’s not the only thing I do. If there could be a chance for me to describe myself, instead of answering the “oh, which language are you working on for server-side programming?” question, I would love to talk about problems I solve, decisions I make, and the architectural reasons behind them.
But yes, I was (and still am) coding in PHP.
And there is a simple reason behind that. It is not just because PHP has the best tools for me, or because I love to write in PHP. But it is because someone else already made this decision ages before me. Yes, in today’s world, people at Booking.com are still writing in PERL, and that does not make them bad developers. The same argument is valid for developers who work for Facebook. Most of the successful companies around the world interview candidates without asking language-specific questions. They mostly focus on the algorithmic intelligence of their potential colleagues without being worried about their language backgrounds. That said, I don’t personally know anyone who only codes in PHP. Still, I am not sure if this is the perfect world that we are living in, but most of the developers I personally know are busy using different languages every day.
Then why is this question still coming up, as Jeffrey mentioned in his tweet here?
{% twitter 1258422468315951105 %}
I see there are many sins for PHP developers here. However, I do not blame them for this entirely, either. The interesting thing about PHP comes from its nature. Most of the engineers out there did not see PHP as a purely functional language. Indeed, PHP implemented most features of functional programming, but the creators of PHP did not initially build it for this reason. The same thing applies to the argument that PHP is an object-oriented language. Even though the evolution of PHP supplied the required tools to us for good object-oriented design, again, that was not the language’s main goal.
PHP comes with the simplicity of releasing websites. That was the main goal of the language itself, which is mostly forgotten. In today’s world, PHP still runs 78% of the entire internet because of this simplicity.
I’m coming from the simplicity of the language to another simplicity, and that is managing content. Let’s face facts: Wordpress is still the de facto leader of the web. Most content creators use its weird admin interface every single day. Nine out of ten news websites in today’s world draw their strength from this CMS. Honestly, I don’t know how much Wordpress developers earn from their freelance work, but they still do a lot.
And the thing I know, the most important thing, is that content managers don’t know and don’t give a f*ck if the language behind their beautiful admin panel is PHP or not.
I’m coming back to the question and the smile on the face. I can imagine why these smart engineers blame PHP as the source of spaghetti code out there. And let’s get back to the fact that I’m coding in PHP; yes, I do. But believe me, I have no idea what is going on when I look at *wp-blog-header.php*. A lot has changed in the PHP world over the last ten years, and yes, not surprisingly, you can find elegant code in this world nowadays.
Either way, PHP and Wordpress rule the internet. Let’s respect that and continue to provide solutions to the problems we are dealing with.
Thanks to Jeffrey Way, the reason for this post.
| actuallymab |
331,572 | Multiple PHP Pools | PHP has gotten phenomenal to work with over the last few years.There have been so many improvements -... | 0 | 2020-05-10T09:59:29 | http://jamessessford.com/blog/multiple-php-pools | ubuntu, development, php | ---
title: Multiple PHP Pools
published: true
date: 2020-05-10 00:00:00 UTC
tags: ubuntu, development, php
canonical_url: http://jamessessford.com/blog/multiple-php-pools
---
PHP has gotten phenomenal to work with over the last few years.There have been so many improvements - both to the language itself and, in my humble opinion, the developer experience in using the language every day.
I'm a terrible hypeman for anything but if you're interested in the current state of PHP, I'd highly recommend reading [PHP in 2020](https://dev.to/brendt/php-in-2020-1nag-temp-slug-1485828) by Brent Roose.
One of the new features of PHP that I wanted to experiment with was preloading but I had several sites on my Rasperry Pi and they didn't all depend on the same code, so I needed to seperate my instances.
## Enter pools
PHP pools are seperate processes that can each be used to serve a subset of requests. You'll probably already be using the default pool at the moment:
```
server {
###
server_name www.test;
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
}
###
}
```
On Ubuntu, PHP pool configuration is located at `/etc/php/7.4/fpm/pool.d/`. I'd start by copying the template that's there for my new pool.
```
cd /etc/php/7.4/fpm/pool.d
sudo cp www.conf www2eb.conf
```
You'll then want to edit this file and update, at minimum, a setting or two.
```
sudo nano www2eb.conf
```
Update the name of the pool:
```
; Start a new pool named 'www'.
; the variable $pool can be used in any directive and will be replaced by the
; pool name ('www' here)
[www2eb]
```
If you want to change the user that owns the pool, update the following:
```
; Unix user/group of processes
; Note: The user is mandatory. If the group is not set, the default user's group
; will be used.
user = poolowner
```
Lastly, we need to give it a different socket so we can send requests to it via NGINX
```
; Note: This value is mandatory.
listen = /run/php/php7.4-fpm.poolowner.sock
```
Now that we've updated the PHP pools, we need to update our NGINX server block to point to the correct socket:
```
server {
###
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.poolowner.sock;
}
###
}
```
We've now made all of the updates that we need, it's time to restart our services:
```
sudo service nginx restart && sudo service php-7.4-fpm restart
```
You can now check that your new PHP pool is working by visiting your site in a browser. | jamessessford |
331,575 | Angular in React Terms: Components & Data Flow | Angular in React Terms Part 1 An attempt to create an Angular cookbook for React developer... | 6,651 | 2020-05-14T17:03:56 | https://dev.to/glebirovich/angular-in-react-terms-part-1-270h | react, angular | # Angular in React Terms Part 1
An attempt to create an Angular cookbook for React developers and vice versa.
Although it might be opinionated to compare two different frontend frameworks on such a low level, when I started with Angular it was very helpful to transition my React knowledge by spotting some commonalities and trying to associate Angular way of doing things with something I already understand and use.
In this episode you will see the difference in how React and Angular deal with components, their most fundamental building blocks. We will look into how components are rendered, composed and wired up together.
### First things first
Let's create a to-do item component and render it as a child of the root app component.
```jsx
// React
const TodoItemComponent = () => {
return <span>I am todo item</span>
}
function App() {
return <TodoItemComponent />
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: ` I am a todo item `,
})
export class TodoItemComponent {}
@Component({
selector: 'app-root',
template: ` <todo-item></todo-item> `,
})
export class AppComponent {}
```
### Component properties
Probably, the first thing you would want to do is to pass some dynamic properties to your brand new components. In the world of React, every component is a function. JSX syntax allows to pass function parameters directly to the component and handle them as you would normally do in the JS function. All values passed to the react component are available in the props object.
In comparison, Angular employs a concept of data bindings which must be defined as fields in the component class. Angular distinguishes between one-way data binding, which represents a one-directional data flow from parent to child via Input or from child to parent via Output, and two-way data binding, which allows bidirectional data flow in the component tree.
```jsx
// React
const TodoItemComponent = (props) => {
// itemValue can be accessed in props object
return <span>{props.itemValue}</span>
}
function App() {
return <TodoItemComponent itemValue="My todo item" />
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `{{ itemValue }}`,
})
export class TodoItemComponent {
// itemValue is available via data binding
@Input() itemValue: string;
}
@Component({
selector: 'app-root',
template: ` <todo-item itemValue="My todo item"></todo-item> `,
})
export class AppComponent {}
```
### Content projection
While we can pass a string as property, there is more semantic way to deal with rendering content inside the component. In the function-like React world there is a special prop called `children`. Anything put inside the component tags can be accessed via that component's `props.children`.
On the other hand, Angular must be explicitly instructed, that certain content is to be rendered inside component tags. This is achieved by providing a content projection tag `ng-content`, which will ensure that the content transclusion will happen in the specified place. In this case, data binding won't be required any more.
```jsx
// React
const TodoItemComponent = (props) => {
return <span>{props.children}</span>
}
function App() {
return <TodoItemComponent>My todo item</TodoItemComponent>
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `<ng-content></ng-content>`,
})
export class TodoItemComponent {}
@Component({
selector: 'app-root',
template: ` <todo-item>My todo item</todo-item> `,
})
export class AppComponent {}
```
### Rendering array of components
Now as we have a todo item component, would be great to have an entire todo list.
```jsx
// React
const TodoItemComponent = (props) => {
return <li>{props.children}</li>
}
const TodoListComponent = (props) => {
return <ul>{props.children}</ul>
}
function App() {
return (
<TodoListComponent>
<TodoItemComponent>My todo item</TodoItemComponent>
</TodoListComponent>
)
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `<ng-content></ng-content>`,
})
export class TodoItemComponent {}
@Component({
selector: 'todo-list',
template: `
<ul>
<ng-content></ng-content>
</ul>
`,
})
export class TodoListComponent {}
@Component({
selector: 'app-root',
template: `
<todo-list>
<li><todo-item>My todo item</todo-item></li>
</todo-list>
`,
})
export class AppComponent {}
```
One might notice, that in React it's fine to define a todo item component wrapped with `li` tag, however in Angular we do it in the parent component. This happens because React components do not have hosts. If you investigate the DOM tree, you will see that whatever returned from the React component is added directly to the DOM, however, Angular components always have a host component which has a name defined in the `selector` property.
To dynamically render an array of todo items inside the list in React we will simply use JS `Array.prototype.map` method directly in JSX, where return values will be components (or HTML elements to render). To achieve the same results in Angular, we will have to use a `NgForOf` structural directive. "Structural directives" are basically any directives in Angular that modify DOM.
```jsx
// React
const TodoItemComponent = (props) => {
return <li>{props.children}</li>
}
const TodoListComponent = (props) => {
return <ul>{props.children}</ul>
}
function App() {
const myTodos = ["make pizza", "write blog post"]
return (
<TodoListComponent>
{
myTodos.map(item => <TodoItemComponent key={item}>{item}</TodoItemComponent>)
}
</TodoListComponent>
)
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `<ng-content></ng-content>`,
})
export class TodoItemComponent {}
@Component({
selector: 'todo-list',
template: `
<ul>
<ng-content></ng-content>
</ul>
`,
})
export class TodoListComponent {}
@Component({
selector: 'app-root',
template: `
<todo-list>
<li *ngFor="let item of myTodos">
<todo-item>{{ item }}</todo-item>
</li>
</todo-list>
`,
})
export class AppComponent {
myTodos = ['make pizza', 'write blog post'];
}
```
### Handling events
Now as we have todo items in place, would be great to tick something as **done**, right? Let's extend `TodoItemComponent` with checkboxes.
```jsx
// React
const TodoItemComponent = (props) => {
return (
<li>
<input type="checkbox"/>
{props.children}
</li>
)
}
const TodoListComponent = (props) => {
return <ul>{props.children}</ul>
}
function App() {
const myTodos = ["make pizza", "write blog post"]
return (
<TodoListComponent>
{
myTodos.map(item => <TodoItemComponent key={item}>{item}</TodoItemComponent>)
}
</TodoListComponent>
)
}
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `
<input type="checkbox" />
<ng-content></ng-content>
`,
})
export class TodoItemComponent {}
@Component({
selector: 'todo-list',
template: `
<ul>
<ng-content></ng-content>
</ul>
`,
})
export class TodoListComponent {}
@Component({
selector: 'app-root',
template: `
<todo-list>
<li *ngFor="let item of myTodos">
<todo-item>{{ item }}</todo-item>
</li>
</todo-list>
`,
})
export class AppComponent {
myTodos = ['make pizza', 'write blog post'];
}
```
You can go to the view in the browser and mark checkboxes as "checked". Now inputs are in "not controlled state". It means they have a default behaviour and are not directly controlled by the framework. We cannot set values and handle events.
Every user interaction with the DOM emits an event, which, once emerged, bubbles up the HTML tree. In Vanilla JS we would use `EventTarget.addEventListener(cb)` method, which handles side effects in a callback.
A very similar principle applies to React and Angular, however, we don't have to care about adding and removing listeners, frameworks handle it for us. Let's try to handle change event on the checkboxes and output it to the console.
```jsx
// React
const TodoItemComponent = (props) => {
// Function that executes side-effects when event is emited
const handleChange = (event) => console.log(event.target.checked)
return (
<li>
<input type="checkbox" onChange={handleChange}/>
{props.children}
</li>
)
}
const TodoListComponent = (props) => {
return <ul>{props.children}</ul>
}
function App() {
const myTodos = ["make pizza", "write blog post"]
return (
<TodoListComponent>
{
myTodos.map(item => <TodoItemComponent key={item}>{item}</TodoItemComponent>)
}
</TodoListComponent>
)
}
export default App;
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `
<input type="checkbox" (change)="handleChange($event)" />
<ng-content></ng-content>
`,
})
export class TodoItemComponent {
// Function that executes side-effects when event is emited
handleChange(event) {
console.log(event.target.checked);
}
}
@Component({
selector: 'todo-list',
template: `
<ul>
<ng-content></ng-content>
</ul>
`,
})
export class TodoListComponent {}
@Component({
selector: 'app-root',
template: `
<todo-list>
<li *ngFor="let item of myTodos">
<todo-item>{{ item }}</todo-item>
</li>
</todo-list>
`,
})
export class AppComponent {
myTodos = ['make pizza', 'write blog post'];
}
```
If you now toggle the state of the checkboxes, you will see that corresponding boolean is logged to the console.
### Communication with parent component
As we have seen Angular and React allow as to easily pass data down the component tree as props, in case of React, or via data binding in Angular. Let's now try to pass checkbox state to the `AppComponent`. While `TodoItemComponent` is aware of changes, how can we pass this information up to the parent?
React deals with this problem by passing a callback function as a prop to hook up the changes from children and update parent state.
Angular, in its turn, uses `Outputs` which allow to emit custom events and propagate them up to the parent component. Parent component, in return, is responsible for handling the event by providing a callback.
```jsx
// React
const TodoItemComponent = (props) => {
return (
<li>
<input type="checkbox" onChange={props.handleChange}/>
{props.children}
</li>
)
}
const TodoListComponent = (props) => {
return <ul>{props.children}</ul>
}
function App() {
const myTodos = ["make pizza", "write blog post"]
// Now we handle event in parent and pass down function as a prop
const handleItemChecked = (event) => {
const isChecked = event.target.checked
console.log(`last checkbox state is ${isChecked}`);
}
return (
<div>
<TodoListComponent>
{
myTodos.map(item => (
<TodoItemComponent
key={item}
handleChange={handleItemChecked}
>
{item}
</TodoItemComponent>
))
}
</TodoListComponent>
</div>
)
}
export default App;
```
```jsx
// Angular
@Component({
selector: 'todo-item',
template: `
<input type="checkbox" (change)="handleChange($event)" />
<ng-content></ng-content>
`,
})
export class TodoItemComponent {
// Custom event emiter propagates data up to the parent
@Output() itemChecked = new EventEmitter<boolean>();
handleChange(event) {
this.itemChecked.emit(event.target.checked);
}
}
@Component({
selector: 'todo-list',
template: `
<ul>
<ng-content></ng-content>
</ul>
`,
})
export class TodoListComponent {}
@Component({
selector: 'app-root',
template: `
<todo-list>
<li *ngFor="let item of myTodos">
<todo-item (itemChecked)="handleItemChecked($event)">{{
item
}}</todo-item>
</li>
</todo-list>
`,
})
export class AppComponent {
myTodos = ['make pizza', 'write blog post'];
// Callback function for our custom event emited in the child
handleItemChecked(isChecked: boolean) {
console.log(`last checkbox state is ${isChecked}`);
}
}
```
### Summary
React and Angular differ in approaches and style guides, however, they are trying to achieve the same goal and therefore provide similar tools to solve similar tasks. I personally find it easier to digest new chunks of knowledge when you can bridge them with something you already know and understand. In this post, we looked into some basics of both frameworks and how they are trying to solve problems like reusability of the components and dynamic rendering. Leave your feedback if you think this kind of approach can be of any help and share your experience of transitioning between frameworks.
### Useful links
### React
- [Components and Props](https://reactjs.org/docs/components-and-props.html)
- [Component composition](https://reactjs.org/docs/composition-vs-inheritance.html)
- [Rendering multiple components](https://reactjs.org/docs/composition-vs-inheritance.html)
- [Handling events](https://reactjs.org/docs/handling-events.html)
### Angular
- [Introduction to components and templates](https://angular.io/guide/architecture-components)
- [Structural directives](https://angular.io/guide/structural-directives)
- [Component interaction](https://angular.io/guide/component-interaction#component-interaction) | glebirovich |
331,608 | How to write a different PHP? | Hey there DEV.to community. PHP is one of the most discussed programming languages out in the develo... | 0 | 2020-05-10T11:59:57 | https://dev.to/adnanbabakan/how-to-write-a-different-php-1joo | php | Hey there DEV.to community.
PHP is one of the most discussed programming languages out in the development world. Some people call it a dead programming language, some call it a disgusting programming language which has no convention or architecture, which I agree with some of them because they've got fair points. But here I'm going to share some of my experience with PHP that I got all these years programming in PHP. Some of these tips are only available in most recent PHP versions so they might not work in older versions.
# Type hinting and return types
PHP isn't a perfect language when it comes to data types but you can improve your code quality and prevent further type conflicts by using type hinting and return types. Not many people use these features of PHP and not all PHP programmers know that it is possible.
```php
<?php
function greet_user(User $user, int $age): void {
echo "Hello" . $user->first_name . " " . $user->last_name;
echo "\nYou are " . $age . " years old";
}
```
A type hinting can be declared using a type's name or a class before the argument variable and a return type can be declared after the function's signature following a colon sign.
A more advanced use of this can be when you are designing your controllers in a framework like Laravel:
```php
<?php
class UserController extends Controller
{
// User sign up controller
public function signUp(Request $request): JsonResponse
{
// Validate data
$request->validate([
'plateNumber' => 'required|alpha_num|min:3|max:20|unique:users,plate_number',
'email' => 'required|email|unique:users',
'firstName' => 'required|alpha',
'lastName' => 'required|alpha',
'password' => 'required|min:8',
'phone' => 'required|numeric|unique:users'
]);
// Create user
$new_user = new User;
$new_user->plate_number = trim(strtoupper($request->input('plateNumber')));
$new_user->email = trim($request->input('email'));
$new_user->first_name = trim($request->input('firstName'));
$new_user->last_name = trim($request->input('lastName'));
$new_user->password = Hash::make($request->input('password'));
$new_user->phone = trim($request->input('phone'));
$new_user->save();
return response()->json([
'success' => true,
]);
}
}
```
# Ternary operator and a shorter way
Ternary operator is a thing that almost 70% of programmers know about and use it widely but in case you don't know what a ternary operator is see the example below:
```php
<?php
$age = 17;
if($age >= 18) {
$type = 'adult';
} else {
$type = 'not adult';
}
```
This code can be shortened to the code below using a ternary operator:
```php
<?php
$age = 17;
$type = $age >= 18 ? 'adult' : 'not adult';
```
If the condition is met the first string will be assigned to the variable if not the second part will be.
There is also a shorter way if you want to use the value of your condition if it is evaluated to a truly value.
```php
<?php
$url = 'http://example.com/api';
$base_url = $url ? $url : 'http://localhost';
```
As you can see `$url` is used both as the condition and as the result of the condition being true. In that case, you can escape the left-hand operand:
```php
<?php
$url = 'http://example.com/api';
$base_url = $url ?: 'http://localhost';
```
# Null coalescing operator
Just like a ternary operator you can use a null coalescing operator to see if a value exists, note that existing is different than a falsely value since false is a value itself.
```php
<?php
$base_url = $url ?? 'http://localhost';
```
Now `$base_url` is equal to `http://localhost` but if we define `$url` even as false the `$base_url` variable will be equal to false.
```php
<?php
$url = false;
$base_url = $url ?? 'http://localhost';
```
Using this operator you can check if a variable is defined previously and if not assign it a value:
```php
<?php
$base_url = 'http://example.com';
$base_url = $base_url ?? 'http://localhost';
```
You can shorten this code using null coalescing assignment operator
```php
<?php
$base_url = 'http://example.com';
$base_url ??= 'http://localhost';
```
All these nall coalescing techniques can be implemented on array values as well.
```php
<?php
$my_array = [
'first_name' => 'Adnan',
'last_name' => 'Babakan'
];
$my_array['first_name'] ??= 'John';
$my_array['age'] ??= 20;
```
The array above will have the `first_name` as `Adnan` since it is already defined but will define a new key named `age` and assign the number `20` to it since it doesn't exist.
# Spaceship operator
Spaceship operator is a pretty useful operator when it comes to comparison when you want to know which operand is larger rather than only knowing if one side is larger.
A spaceship operator will return one of the `1`, `0` or `-1` values when the left-hand operand is larger, when both operands are equal and when the right-hand operand is larger respectively.
```php
<?php
echo 5 <=> 3; // result: 1
echo -7 <=> -7; // result: 0
echo 9 <=> 15; // result: -1
```
Pretty simple but very useful.
This gets more interesting when you realize that the spaceship operator can compare other things as well:
```php
<?php
// String
echo 'c' <=> 'b'; // result: -1
// String case
echo 'A' <=> 'a'; // result: 1
// Array
echo [5, 6] <=> [2, 7]; // result: 1
```
# Arrow functions
If you have ever programmed a JavaScript application especially using recent versions of it you should be familiar with arrow functions. An arrow function is a shorter way of defining functions that they have no scope.
```php
<?php
$pi = 3.14;
$sphere_volume = function($r) {
return 4 / 3 * $pi * ($r ** 3);
};
echo $sphere_volume(5);
```
The code above will throw an error since the `$pi` variable is not defined in this particular function's scope. If we wanted to use it we should change our function a bit:
```php
<?php
$pi = 3.14;
$sphere_volume = function($r) use ($pi) {
return 4 / 3 * $pi * ($r ** 3);
};
echo $sphere_volume(5);
```
So now our function can use the `$pi` variable defined in the global scope.
But a shorter way of doing all this stuff is by using the arrow functions.
```php
<?php
$pi = 3.14;
$sphere_volume = fn($r) => 4 / 3 * $pi * ($r ** 3);
echo $sphere_volume(5);
```
As you can see it is pretty simple and neat and has access to global scope by default.
---
I hope you enjoyed this article, and I'm also planning on continuing this article and make it a series.
Tell me if I missed something or any other idea you have in the comments section below. | adnanbabakan |
331,653 | What editor and font you use for WebDev | Hello Folks, Need two suggestions: Editor: which one to use for web development? Sublime VSCode... | 0 | 2020-05-10T12:48:22 | https://dev.to/elanandkumar/what-editor-and-font-you-use-for-webdev-4ae3 | help | Hello Folks,
Need two suggestions:
1. Editor: which one to use for web development?
- Sublime
- VSCode
- Webstorm
2. Font: Please suggest best font for above editor?
Thank you. | elanandkumar |
331,848 | Building a simple Slack / Node app (video) | A post by Leigh Halliday | 0 | 2020-05-10T14:20:55 | https://dev.to/leighhalliday/building-a-simple-slack-node-app-video-52m0 | node, javascript, tutorial | {% youtube nyaCol4IH5c %} | leighhalliday |
334,186 | Merge Sort Algorithm - Algorithm Design and Analysis | In this episode of Algorithm Design and Analysis we'll break down the merge sort sorting algorithm, a... | 6,327 | 2020-05-13T15:32:55 | https://dev.to/michaelsolati/merge-sort-algorithm-algorithm-design-and-analysis-5ce6 | javascript, webdev, algorithms, computerscience | In this episode of Algorithm Design and Analysis we'll break down the merge sort sorting algorithm, and implement it in JavaScript. This requires us to dive into recursion and take a divide-and-conquer approach to sorting an array.
I upload videos like this one as well as live stream coding session on my [YouTube channel](https://www.youtube.com/channel/UCZxtkm5msn0r1etbzvGZx5A).
---
To keep up with everything I’m doing, follow me on [Twitter](https://twitter.com/MichaelSolati) and [dev.to](https://dev.to/michaelsolati). If you’re thinking, _“Show me the code!”_ you can find me on [GitHub](https://github.com/MichaelSolati). | michaelsolati |
334,554 | JavaScript For Testers | JavaScript is one of the most popular programming languages today. Here is a StackOverflow Survey Re... | 5,311 | 2020-05-14T09:10:31 | https://dev.to/bushraalam/javascript-for-testers-4jl2 | javascript, testing, beginners, tutorial |
JavaScript is one of the most popular programming languages today. Here is a StackOverflow Survey Result showing popularity of various languages:
Testers might feel they won't be impacted by this but there are a lot of automation testing tools coming in the market which are based on JavaScript like Cypress, Protractor, Nightwatch, Puppeteer to name a few. You will have to learn JavaScript sooner or later. And I say, the sooner - the better.
---
>If you prefer to watch and learn, hop on to my [JS For Testers series on Youtube] (https://bit.ly/2zoanJh)
Subscribe to my Youtube Channel - [QA Camp](https://www.youtube.com/channel/UC6dkzt_Q4i5h8NUJmZideFQ/playlists)!
-----
{% youtube 0sG1ToNspLA %}
-----
### Table of Contents <a name="toc"></a>
* [What is JavaScript?](#WhatJS)
* [Install Node.js and Code Editor] (#Install)
* [JavaScript Basics] (#Basics)
* [Variables] (#Variables)
* [Constants] (#Constants)
* [Conditional Operators] (#Cond)
* [Loops] (#Loops)
* [Functions] (#Functions)
* [NPM - Node Package Manager] (#NPM)
* [package.json] (#pkg)
* [NPX] (#NPX)
* [Arrow Functions] (#ArrowFunctions)
---
#What is JavaScript? <a name="WhatJS"></a>
JavaScript was initially created to “make web pages alive” and it was capable of running only in a web browser. Because browsers have JavaScript engine to execute JavaScript code.
But now, with the development of <B>Node.js</B>, JavaScript isn't restricted to only browsers.
Node is a JavaScript runtime environment that executes JavaScript code outside of a browser. Node.js is built on top of Chrome's open-source V8 JavaScript engine.
So now JS could be used as front-end (client-side) as well as back-end (or the server-side) language.
{% youtube -Ymanf9jqy0 %}
---
#Install Node.js and Code Editor <a name="Install"></a>
Installing Node.js is essential and having a code editor provides so much of ease.
You can download Node.js from here: [https://nodejs.org/en/download/] (https://nodejs.org/en/download/)
For code editor, you have got a number of options to choose from. But I recommend using Visual Studio Code.
You can download VS Code from here: [https://code.visualstudio.com/download] (https://code.visualstudio.com/download)
To see installation in action you can follow my video:
{% youtube uasUpiX1nMk %}
---
#JavaScript Basics <a name="Basics"></a>
Let's learn how to create variables, constants, conditional operators, loops and functions in JS.
### Variables <a name="Variables"></a>
Variables are like named boxes that can hold value. These values can also be updated.
Variables in JS can be created using <I>let</I> keyword
```js
let age = 30
```
Note that we haven't mentioned any datatype and so our variable 'age' isn't bound to any datatype. And so, we can have it hold value of any data type.
```js
age = 'thirty'
```
Now, the variable holds a string instead of a number and JS won't complain.
### Constants <a name="Constants"></a>
Constants are variables whose value can't be updated. Constants can be created using <I> const </I> keyword.
```js
const firstName = 'John'
```
### Conditional Operators <a name="Cond"></a>
Conditional Operators are used when you would like to execute a piece of code only when a condition satisfies.
<B> 1. IF </B>
```js
let ageMoreThank18
if (age > 18){
ageMoreThank18 = true
}
else{
ageMoreThank18 = false
}
```
<B> 2. ? </B>
```js
ageMoreThank18 = (age > 18) ? true : false
```
Here, in both the cases, the variable 'ageMoreThank18' would be set to true if the variable 'age' has value greater than 18 else the variable 'ageMoreThank18' would be set to false.
### Loops <a name="Loops"></a>
Loops are used when you would like to execute a piece of code as long as the condition stays true.
<B> 1. WHILE LOOP </B>
```js
let i = 0
while (i < 5){
console.log('i is now : '+ i)
i++
}
```
<B> 2. FOR LOOP </B>
```js
for (i=0; i<5; i++){
console.log('i is now : '+ i)
}
```
Here, in both the cases, the code in the loop body would be executed until i has value less than 5. As soon as i is set to 5, the loop condition would return false and the loop body wouldn't execute.
### Functions <a name="Functions"></a>
Functions are essential in any programming language. They take an input, process it and return an output.
```js
function product (a,b){
return a * b
}
```
This is a function named 'product' that takes two values as input, multiplies them and return the result i.e. the product of two numbers.
To call the function:
```js
product(5, 4)
```
{% youtube uodOTTeoJ4M %}
-----
# NPM - Node Package Manager <a name="NPM"></a>
NPM is a very important concept in JavaScript and NPM is one of the most crucial factors behind the success of JavaScript.
NPM is Node Package Manager. Before understanding NPM, let's understand what a package manager is and before that - what are packages?
So, when you start a new project.. be it a development or testing project, you will almost never start from the blank slate and just never would you finish the project with having written 100% of the code yourself.
Imagine this.. you need to test an application.. the first things that you do is pick a tool, select a framework, think what reporting plugin you could use and so on. So these tools, frameworks, plugins that are available for you to pick and use in any project are <B>Packages</B>.
Now, there could be hundred or thousands of such packages in a language. So to manage how they would be published, installed, where would be store and things of that sort we need a <B>Package Manager</B>.
JS has many package managers. The two most popular are: NPM and Yarn.
NPM is the default package manager for JS. NPM is the world's largest software repository having more than a million packages.
NPM consists of three things:
- <B>the registry:</B> for storing open-source JS projects
- <B>the command line interface:</B> for publishing and installing packages
- <B>the website:</B> for searching packages - [https://www.npmjs.com](https://www.npmjs.com)
NPM is installed along with Node.js.
To verify NPM is installed, run:
```bash
npm -v
```
If you see a version then NPM is installed on your machine.
{% youtube YcMRYEird4M %}
## package.json <a name="pkg"></a>
package.json is the heart of NPM. It is a JSON format file that contains the list of packages that your project depends on.
A 'package.json' file provides these benefits:
- it contain the list of packages your project depends on
- it specifies the versions of those packages
- it makes your build reproducible
Add package.json file to your project
```bash
npm init
or
npm init -y
```
Install a package
```bash
npm install <packageName>
```
Following things happen when you install a package:
1. an entry is made in the package.json
2. the package and its dependencies are downloaded in the node modules folder
3. package-lock.json file makes entries of all the dependencies of package installed and their versions
To understand these concepts better, I highly recommend to watch the video (https://youtu.be/Yj4CNIMHn5E) [https://youtu.be/Yj4CNIMHn5E].
To install all the dependencies listed in package.json
```bash
npm install
```
To install dependencies as devDependencies:
```bash
npm install <packageName> --save-dev
```
devDependencies: packages that are necessary only while development and not necessary for the production build
{% youtube Yj4CNIMHn5E %}
## NPX <a name="NPX"></a>
NPX could be though as Node Package Runner. It is a very powerful concept. Here are a few benefits it provide:
- Easily run local commands
- Installation-less command execution
- Run some code using a different Node.js version
- Run arbitrary code snippets directly from a URL
Watch the video for more details on these benefits:
{% youtube w6G5HLjXl0A %}
----
# Arrow Functions <a name="ArrowFunctions"></a>
Arrow Functions are a very popular concept of JavaScript and they are very commonly used. If you are unaware of the syntax then they might confuse you and so it's better to familiarize yourself with them.

Follow the video for examples on each of these syntax:
{% youtube fnKRSKYTPRM %}
----
<B>More content to be added soon...</B>
<B>
> <B>Please suggest topics that you would like to see in this series.</B>
If you prefer to watch and learn, hop on to my [JS For Testers series on Youtube] (https://bit.ly/2zoanJh)
Subscribe to my Youtube Channel - [QA Camp](https://www.youtube.com/channel/UC6dkzt_Q4i5h8NUJmZideFQ/playlists)!
</B>
----- | bushraalam |
335,102 | Making an algorithm 15x faster without parallelism | A couple of years ago, when investigating the performance of a game server, I noticed that a large ch... | 0 | 2020-05-15T01:43:07 | https://dev.to/rsa/making-an-algorithm-15x-faster-without-parallelism-38k5 | cpp, optimization, computerscience, algorithms | A couple of years ago, when investigating the performance of a game server, I noticed that a large chunk of the processing time was spent ciphering and deciphering data that was sent to or received by the client. It was especially high on busy servers, as the amount of work would increase linearly with the amount of players, and it was performed in a single thread, the dedicated network dispatcher.
The server in question uses an algorithm called XTEA, a 64-bit block cipher based on a Feistel network. It is very simple and easy to implement, achieving under 10 lines of C++ code:
```cpp
constexpr uint32_t delta = 0x9E3779B9;
uint64_t encrypt_block(uint64_t data, const array<uint32_t, 4> &key) {
unsigned left = data, right = data >> 32;
uint32_t sum = 0u;
for (auto i = 0u; i < 32u; ++i) {
left += ((right << 4 ^ right >> 5) + right) ^ (sum + key[sum & 3]);
sum += delta;
right += ((left << 4 ^ left >> 5) + left) ^ (sum + key[(sum >> 11) & 3]);
}
return static_cast<uint64_t>(right) << 32 | left;
}
```
Deciphering is symmetrical, being essentially the code above reversed:
```cpp
auto decrypt_block(uint64_t data, const array<uint32_t, 4> &key) {
unsigned left = data, right = data >> 32;
uint32_t sum = delta * 32;
for (auto i = 32u; i > 0u; --i) {
right -= ((left << 4 ^ left >> 5) + left) ^ (sum + key[(sum >> 11) & 3]);
sum -= delta;
left -= ((right << 4 ^ right >> 5) + right) ^ (sum + key[sum & 3]);
}
return static_cast<uint64_t>(right) << 32 | left;
```
I will be running tests on my i7 8809G, using 25 KB of random values and 2500 samples. `-O3` and `-march=native` are imperative to the changes proposed.
### reference code
The code found on the server to cipher a message uses a `while` loop to check for boundaries:
```cpp
auto pos = 0ul, len = in.size();
while (pos < len) {
in[pos] = encrypt_block(in[pos]);
++pos;
}
```
To set the baseline, it takes an average of 267μs to cipher/decipher a message, with a standard deviation of ~50μs. It accounts for ~87MB/s throughput.
### `while` vs `for` loop
The first idea here will be replacing the `while` loop, I prefer using `for` loop for known boundaries and figured it might help the compiler unroll the loop.
```cpp
for (auto pos = 0ul, len = in.size(); pos < len; ++pos) {
in[pos] = encrypt_block(in[pos]);
}
```
I was not hopeful of that, and was right: the `len` value is invariant to the loop, so the compiler emits the same set of instructions.
To make the code a bit more idiomatic C++ and less C, we can use [range-based `for` loop](https://en.cppreference.com/w/cpp/language/range-for) or [`std::transform`](https://en.cppreference.com/w/cpp/algorithm/transform) (if you prefer a functional looking code):
```cpp
for (auto &block : in) {
block = encrypt_block(block);
}
```
But hey!
### parallelism with execution policy
There is something interesting with C++17, a concept named [Execution Policy](https://en.cppreference.com/w/cpp/algorithm/execution_policy_tag_t). You can tag sequence algorithms to run parallel or unsequenced if possible, using `execution::par` and `execution::unseq` (only in C++20) respectively, and even `execution::par_unseq` for parallel AND unsequenced.
This code uses [electronic codebook mode (ECB)](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation) and application is not sequenced, you can apply the cipher in any order. I wonder what happens if we use `execution::par`...
```cpp
std::transform(std::execution::par, in.begin(), in.end(), in.begin(), encrypt_block);
```
That dropped the time from 267μs to 62μs to cipher/decipher a message, with a standard deviation of ~50μs. It accounts for ~334MB/s throughput. The same performance with `execution::par_unseq`, in case you are wondering.
That is a 4.3x improvement, but there's a catch: this high standard deviation is due to the worst cases taking up to 1300μs, 2.5x worse than the worst cases of the reference implementation, which take up to 550μs.
That's a red flag, it's a very inconsistently performing algorithm. If the server is especially busy, it might interfere with other threads and make the server as a whole slower.
Another issue you might consider is linking against a threading library - in my system, it requires the Intel Threading Building Blocks. So let's think of something else.
### interleaving loops and automatic vectorization
One more trick upon my sleeve. Compilers are extremely advanced pieces of software, performing several optimizations that we most of the time take for granted, but you need to write code it understands and sometimes optimize on your own.
We can interleave the loops, hoisting the Feistel network rounds around the ciphering pass. That's possible because in ECB mode blocks are independent, it does not change the output if you transpose the application of the algorithm.
```cpp
uint32_t sum = 0u;
for (auto i = 0u; i < 32u; ++i) {
auto next_sum = sum + delta;
for (auto &block : in) {
uint32_t left = block, right = block >> 32;
left += ((right << 4 ^ right >> 5) + right) ^ (sum + key[sum & 3]);
right += ((left << 4 ^ left >> 5) + left) ^ (next_sum + key[(next_sum >> 11) & 3]);
block = static_cast<uint64_t>(right) << 32 | left;
}
sum = next_sum;
}
```
This code looks, in my opinion, simpler and better to understand. Note I also hoisted `sum += delta`, that's required as we don't have a new sum value on every block. Instead, we use the same variable for all blocks at once.
This takes 55μs to cipher/decipher a message, down from previous 62μs and initial 267μs, with a standard deviation of ~26μs. It accounts for ~384MB/s throughput. That is a further 12% improvement, however, the worst-case takes 200μs, making it much more consistent and faster than the reference implementation on every run, even compared to its best-case run.
Why the improvement? It leverages what is called [automatic vectorization](https://llvm.org/docs/Vectorizers.html): your processor has vector registers, and it allows applying a single instruction (be it a `xor`, an `add` or a `shift`) to several values at the same time.
The compiler will generate code using special registers named `%ymmX` and `%xmmX`, where X denotes register index. `%xmm` registers are 128 bits wide. `%ymm` registers are 256 bits wide and are available if your processor supports AVX (Intel Core except for 1st gen, AMD after Phenom II).
It will generate assembly using instructions such as `vpxor %ymm0, %ymm1, %ymm1` and `vpaddd %ymm2, %ymm1, %ymm1`, instead of the traditional `xor %edx, %eax` and `add %r14d, %eax`. I won't display the assembly code here, it is so heavily optimized you won't really see what's happening.
The beauty here is that the compiler (I am using GCC 10.1.0) is smart enough to figure data might not always be aligned to the wide registers (i.e. input is not always a multiple of 128/256 bits), and it will generate code for that case: it uses wide registers while possible, then resort to a single value at a time.
So far, we have a 4.8x improvement, in line with the change in emitted machine code: the resulting code processes up to 4 blocks at a time (64-bit block in 256-bit registers), the rest can be attributed to loop analysis, as it is easier to unroll the loop and interleave instructions after we extracted an invariant (`next_sum`).
### all `for` variables inside declaration
One last trick that I did not expect would help, I just tried it to save a few lines, is moving all `for`-related variables inside the declaration block:
```cpp
for (auto i = 0u, sum = 0u, next_sum = sum + delta; i < 32u;
++i, sum = next_sum, next_sum += delta)
```
It further reduces the average to 51μs, the standard deviation to ~15μs, and the maximum time is now ~140μs. It runs consistently fast, processing 424MB/s. Neat!
In conclusion, the final version of the code is 5.23x faster than the reference implementation, does not impact the rest of the software and is just as short and clear:
```cpp
constexpr uint32_t delta = 0x9E3779B9;
vector<uint64_t> encrypt(vector<uint64_t> in, const array<uint32_t, 4> &k) {
for (auto i = 0u, sum = 0u, next_sum = sum + delta; i < 32u;
++i, sum = next_sum, next_sum += delta) {
for (auto &block : in) {
uint32_t left = block, right = block >> 32;
left += ((right << 4 ^ right >> 5) + right) ^ (sum + key[sum & 3]);
right += ((left << 4 ^ left >> 5) + left) ^
(next_sum + key[(next_sum >> 11) & 3]);
block = static_cast<uint64_t>(right) << 32 | left;
}
}
return in;
}
vector<uint64_t> decrypt(vector<uint64_t> in, const array<uint32_t, 4> &k) {
for (auto i = 0u, sum = delta * 32, next_sum = sum - delta; i < 32u;
++i, sum = next_sum, next_sum -= delta) {
for (auto &block : in) {
uint32_t left = block, right = block >> 32;
right -= ((left << 4 ^ left >> 5) + left) ^ (sum + key[(sum >> 11) & 3]);
left -=
((right << 4 ^ right >> 5) + right) ^ (next_sum + key[next_sum & 3]);
block = static_cast<uint64_t>(right) << 32 | left;
}
};
return in;
}
```
### OpenCL and massive GPU vectorization
After the results for vectorizing the algorithm, I investigated if running in the GPU would scale the same way, considering my GPU (Radeon Vega M GH) has 24 compute units with 4 128-bit registers each, capable of ciphering 192 blocks (1536 bytes) at once! That would make XTEA almost instant.
The game server already used the Boost library, and it has a layer for OpenCL called `boost::compute`. OpenCL uses code units called kernels, itself implementing a subset of C, which makes it very easy to port code to OpenCL, as long as it uses primitives only (there's more to it):
```cpp
auto encrypt(Data in, const compute::uint4_ &k) {
BOOST_COMPUTE_CLOSURE(uint64_t, encrypt_block, (uint64_t data), (k, delta), {
unsigned left = data, right = data >> 32;
for (int i = 0, sum = 0, next_sum = delta; i < 32;
++i, sum = next_sum, next_sum += delta) {
left += ((right << 4 ^ right >> 5) + right) ^ (sum + k[sum & 3]);
right += ((left << 4 ^ left >> 5) + left) ^ (next_sum + k[(next_sum >> 11) & 3]);
}
return ((unsigned long long)right) << 32 | left;
});
compute::vector<uint64_t> out(in.begin(), in.end());
compute::transform(out.begin(), out.end(), out.begin(), encrypt_block);
compute::copy(out.begin(), out.end(), in.begin());
return in;
}
auto decrypt(Data in, const compute::uint4_ &k) {
BOOST_COMPUTE_CLOSURE(uint64_t, decrypt_block, (uint64_t data), (k, delta), {
unsigned left = data, right = data >> 32;
for (int i = 0, sum = delta * 32, next_sum = sum - delta; i < 32;
++i, sum = next_sum, next_sum -= delta) {
right -= ((left << 4 ^ left >> 5) + left) ^ (sum + k[(sum >> 11) & 3]);
left -= ((right << 4 ^ right >> 5) + right) ^ (next_sum + k[next_sum & 3]);
}
return ((unsigned long long)right) << 32 | left;
});
compute::vector<uint64_t> out(in.begin(), in.end());
compute::transform(out.begin(), out.end(), out.begin(), decrypt_block);
compute::copy(out.begin(), out.end(), in.begin());
return in;
}
```
Note the key is changed from `array<uint32_t, 4>` to `compute::uint4_t` (a name I find unnecessarily confusing, could be `vec4_uint32`), representing 4 32-bit ints *inside* the GPU. Since the key is reused, I figured that a real application would precompute it instead of copying it to the GPU every time.
Using OpenCL requires two additional steps: copying the data to the GPU memory, achieved through the `compute::vector` container, and `compute::transform` algorithm; then, it needs to be copied back to main memory. Kudos to Boost for making it so easy!
The extra steps are costly, and this takes 108μs, on average, with a standard deviation of ~36μs and a maximum of ~560μs. It would be a disappointment, but if we ramp up the input size, the GPU massive parallelization really shines!
I set an input length of 500KB instead of the initial 25KB, with the following results:
- The reference implementation takes ~5080μs
- Vectorized takes ~1170μs
- OpenCL takes ~403μs
By having a 20x larger input, running on the CPU will also multiply by 20 the run time, but since the GPU is capable of executing the same code on a much wider vector of data, it only requires 2.4x the time and takes the leadership here.
It achieves an *amazing throughput of 1185MB/s*, compared to 95MB/s for the reference implementation and 410MB/s for the CPU-vectorized implementation, for 250KB input. It will peak at 1450MB/s when I use 1572KB input size, as it hits the sweet spot of filling the entire cache (64KB each) for all 24 compute units.
Unfortunately, in the game server use case, about 99% of the inputs will be less than 32 bytes, and it is never larger than 25KB. At that size, the CPU vectorized version is at least 5 times faster than reference. However, for one wanting to cipher massive amounts of bytes, that's a 15x improvement :)
The code for this post and a benchmarking utility is available [on GitHub](https://github.com/ranisalt/xtea-flavors). | rsa |
335,975 | Careers in B. TECH CSE | Careers in CSE | 0 | 2020-05-15T13:58:25 | https://dev.to/sivagangadharn1/careers-in-b-tech-cse-1kgb | Careers in CSE | sivagangadharn1 | |
335,989 | Season of Docs + How to write a proposal | A post by Amruta Ranade | 0 | 2020-05-15T14:20:11 | https://dev.to/amrutaranade/season-of-docs-how-to-write-a-proposal-2a3g | writing, opensource, news | {% youtube HAaWuX10k2c %} | amrutaranade |
335,998 | Answer: Pandas: Get unique MultiIndex level values by label | answer re: Pandas: Get unique MultiIn... | 0 | 2020-05-15T14:36:42 | https://dev.to/nilotpalc/answer-pandas-get-unique-multiindex-level-values-by-label-314n | multilevelindex, pandas | {% stackoverflow 50364903 %} | nilotpalc |
336,067 | Rotoscoping: Hollywood's video data segmentation? | In Hollywood, video data segmentation has been done for decades. Simple tricks such as color... | 0 | 2020-05-15T15:32:26 | https://data-annotation.com/rotoscoping-hollywoods-video-data-segmentation/ | machinelearning, datascience | ####In Hollywood, video data segmentation has been done for decades. Simple tricks such as color keying with green screens can reduce work significantly.
In late 2018 we worked on a video segmentation toolbox. One of the common problems in video editing is oversaturated or too bright sky when shooting a scene. Most skies in movies have been replaced by VFX specialists. The task is called “sky replacement”. We thought this is the perfect starting point for introducing automatic segmentation to mask the sky for further replacement. Based on the gathered experience I will explain similarities in VFX and data annotation.
You find a comparison of our solution we built compared to Deeplab v3+ which was at the time considered the best image segmentation model. Our method (left) produced better details around the buildings as well as reduced the flickering significantly between the frames.
Comparison of our sky segmentation model and Deeplab v3+
{% youtube zi0qLwqqx28%}
###Video segmentation techniques of Hollywood
In this section, we will have a closer look at color keying with for example green screens and rotoscoping.
####What is color keying?
I’m pretty sure you heard about color keying or green screens. Maybe you even used such tricks yourself when editing a video using a tool such as Adobe After Effects, Nuke, Final Cut, or any other software.
I did a lot of video editing myself in my childhood. Making videos for fun with friends and adding cool effects using tools such as after-effects. Watching tutorials from [videocopilot.com](https://www.videocopilot.net/) and [creativecow.com](https://creativecow.com/) day and night. I remember playing with a friend and wooden sticks in the backyard of my family’s house just to replace them with lightsabers hours later.
In case you don’t know how a green screen works you find a video below giving you a better explanation than I could do with words.
Video explaining how a green screen works
{% youtube A0h_BVLRSeI%}
Essentially, a greenscreen is using color keying. The color “green” from the footage gets masked. This mask can be used to blend-in another background. And the beauty is, we don’t need a fancy image segmentation model burning your GPU but a rather simple algorithm looking for neighboring pixels with the desired color to mask.
####What is rotoscoping?
As you can imagine in many Hollywood movies special effects require more complex scenes than the ones where you can simply use a colored background to mask elements. Imagine a scene with animals that might be shy of strong color or a scene with lots of hair flowing in the wind. A simple color keying approach isn’t enough.
But also for this problem, Hollywood found a technique many years ago: **Rotoscoping**.
To give you a better idea of what rotoscoping is I embedded a video below. The video is a tutorial on how to do rotoscoping using after effects. Using a special toolbox you can draw splines and polygons around objects throughout a video. The toolbox allows for automatic interpolation between the frames saving you lots of time.
After effects tutorial on rotoscoping
{% youtube ZqAyS2AMvG4%}
This technology, introduced in After Effects, 2003 has been out there for almost two decades and has since then been used by many VFX specialists and freelancers.
**Silhouette** is in contrast to After Effects one tool focusing solely on rotoscoping. You get an idea of their latest product updates in [this video](https://www.youtube.com/watch?v=NwbbHFO8Rl0).
I picked one example for you to show how detailed the result of rotoscoping can be. The three elements in the following video from MPC Academy blowing my mind are **motion blur, fine-grained details for hairs, and the frame consistency**. When we worked on a product for VFX editors we learned that in this industry the quality requirement is beyond what we have in image segmentation. There is simply neither a dataset nor a model in computer vision fulfilling the Hollywood standard.
Rotoscoping demo reel from MPC Academy.
Search for “roto showreel” on YouTube and you will find many more examples.
{% youtube PQS9ov636ik%}
###How is VFX rotoscoping different from semantic segmentation?
There are **differences in both quality and how the quality assurance/ inspection works.**
####Tools and workflow comparison
The tools and workflow in VFX, as well as data annotation, are surprisingly similar to each other. Since both serve a similar goal. Rotoscoping, as well as professional annotation tools, support tracking of objects, working with polygons and splines. Both allow for changing brightness and contrast to help you finding edges. One of the key differences is that in rotoscoping you work with transparency for motion blur or hair. In segmentation, we usually have a defined number of classes and no interpolation between them.
####Quality inspection comparison
In data annotation quality inspection is usually automated using a simple trick. We let multiple people do the annotation and can compare their results. If all annotators agree the confidence is high and therefore the annotation is considered good. In case they only partially agree and the agreement is below a certain threshold an additional round of annotation or manual inspection takes place.
In VFX however, an annotation is usually done by a single person. The person has been trained on the task and has to deliver very high quality. The customer or supervisor lets the annotator redo the work if the quality is not good enough. There is no automatic obtained metric. All inspection is done manually using the trained eye of VFX experts. There is a term called [“pixel fucking”](https://www.urbandictionary.com/define.php?term=pixel-fucking) illustrating the required perfectionism on a pixel level.
###How we trained our model for sky segmentation
Let’s get back to our model. In the beginning, you saw a comparison between our result and [Deeplab v3+, 2018](https://arxiv.org/abs/1802.02611). You will notice that the quality of our video data segmentation is higher and has less flickering. For high-quality segmentation, we had to create our own dataset. We used Full HD cameras mounted on tripods to record footage of the sky. This way a detailed segmentation around buildings and static objects can be reused throughout the whole shot. We used [Nuke](https://www.foundry.com/products/nuke) for creating the annotated data.
Image showing the soft contours using for rotoscoping.
We blurred the edges around the skyline.

Additionally, we used publicly available and license-free videos of trees, people, and other moving elements in front of simple backgrounds. To obtain ground truth information we simply used color keying. It worked like charm and we had pixel-accurate segmentation of 5 min shots within a few hours. For additional diversity within the samples, we used our video editing tool to crop out parts of the videos while moving the camera around. A 4k original video had a Full HD frame moving around with smooth motion. For some shots, we even broke out of the typical binary classification and used smooth edges, interpolated between full black and white, for our masks. Usually, segmentation is always binary, black or white. We had 255 colors in between when the scene was blurry.
Color keying allowed us to get ground truth data for complicated scenes such as leaves or hair. The following picture of a palm tree has been masked/ labeled using simple color keying.



For simple scenes, color keying was more than good enough to get detailed results. One could also replace now the background with a new one to augment the data.
This worked for all kinds of trees. And even helped us obtain good results for a whole video. We were able to simply adapt the color keying parameters during the clip.
Also, this frame has been taken using simple color keying methods

To give you an idea of the temporal results of our color keying experiments have a look at the gif below. Note there is a little bittering. We added this on purpose to “simulate” recording with a camera in your hand. The movement of the camera itself is a simple linear interpolation of the crop on the whole scene. So what you see below is just a crop of the full view.

This mask has been obtained using color keying for the first frame. The subsequent frames might only need a small modification of the color keying parameters. We did such adaptation every 30-50 frames and let the tool interpolate the parameters between them.
####Training the model
To train the model we added an additional loss on the pixels close to the borders. This helped a lot to improve the fine-details. We played around with various parameters and changing the architecture. The simple U-Net model worked well enough. We trained the model not on the full images but on crops of around 512×512 pixels. We also read up on Kaggle competitions such as the [caravan image masking challenge from 2017](https://www.kaggle.com/c/carvana-image-masking-challenge) for additional inspiration.
####Adversarial training for temporal consistency
Now that we had our dataset we started training the segmentation model. For the model, we used a [U-Net architecture](https://arxiv.org/pdf/1505.04597.pdf), since the sky can span the whole image and we don’t need to consider various sizes as we would need to for objects.
In order to improve the temporal consistency of the model (e.g. removing the flickering) we co-trained a discriminator which always saw three sequential frames. The discriminator had to distinguish three frames coming from our model or the dataset. The training procedure was otherwise quite simple. The model trained for only a day on an Nvidia GTX 1080Ti.
So for your next video data segmentation project, you might want to have a look at whether you can use any of these tricks to collect data and save lots of time. In my other posts, you will find a list of [data annotation tools](https://data-annotation.com/tools-and-frameworks/). In case you don’t want to spend any time on manual annotation there is also a list of [data annotation companies](https://data-annotation.com/list-of-data-annotation-companies/) available.
*I’d like to thank Momo and Heiki who worked on the project with me. An additional thank goes to all the VFX artists and studios for their feedback and fruitful discussions.*
Note: This post was originally published on [data-annotation.com](data-annotation.com)
| igorsusmelj |
336,113 | I made a Michael Scott Chatbot for Slack | Want the world's best boss on your slack? Click to add the Michael Scott Bot to your Slack Workspace!... | 0 | 2020-05-15T17:45:29 | https://dev.to/vishaag/i-made-a-michael-scott-chatbot-for-slack-2kod | tutorial, beginners, showdev | <div>
Want the world's best boss on your slack? Click to add the Michael Scott Bot to your Slack Workspace!
<a href="https://slack.com/oauth/v2/authorize?client_id=603308697778.1138663588561&scope=channels:history,chat:write,groups:history"><img alt="Add to Slack" height="40" width="139" src="https://platform.slack-edge.com/img/add_to_slack.png" srcset="https://platform.slack-edge.com/img/add_to_slack.png 1x, https://platform.slack-edge.com/img/add_to_slack@2x.png 2x"></a>
</div>
(read <i>Note</i> and <i>Disclaimer</i> at the bottom of the page before installing it to your workspace)
## Who is Michael Scott?
> Michael Gary Scott is a fictional character on NBC's The Office, portrayed by Steve Carell and based on David Brent from the British version of the program. Michael is the central character of the series, serving as the Regional Manager of the Scranton branch of a paper distribution company.
— Wikipedia
Michael Scott proclaims himself as the world's best boss and is one of my favourite TV characters ever made!
Michael has said a lot of wisdomous things, but his best known quote is probably "That's what she said". It's highly inappropriate, but super fun to watch in the show 😂
I've recently been exploring Dialogflow, and I tried to recreate Michael Scott's funny inappropriateness for a slack workspace. In this article, I'll walkthrough how I configured and trained my dialogflow agent to reply like Michael Scott. No git repos or code needed! Everything done though the websites!
### Dialogflow
You probably have heard of dialogflow, but for the uninitiated, dialogflow provides an excellent Natural Language Processing engine that takes care of the intent and parameter extraction from sentences. It also allows us to add a web hook that can make use of a backend server to respond dynamically. But we aren't going to use those features here! One of reasons I wanted to write this article was to show how easy it actually is to build a chatbot.
## Getting Started
### Dialogflow Setup
Create an account or login in to [Dialogflow](https://dialogflow.com) and go to your console.
Create a new agent from the left menus and give any name to your bot. After creating, you will see the following screen.

An intent categorizes an end-user's intention for one conversation turn. A Welcome and a Fallback intent (if intent is not detected) is included for us by default.
You can also see an Input box in the right. Try typing a greeting into it like 'Hey' or 'Hello'.

Ideally, the bot should reply, but we see an error. That's because we need to configure a Google Cloud service Key for Dialogflow.
To do this, click on the gear icon on the left menus and then click on create service account under the google project as shown below.

After doing that step, try typing in the input box again. What do you see?

We see a response! Our bot is actually replying to us. But how does it know what to reply?
It's answering from the pre defined Default Welcome Intent!
Click on Intents from the left menus and go inside the Default Intents.

We can add more phrases to this inorder to make Dialogflow to detect our inputs. We will be adding our phrases here later to detect what Michael Scott Bot will reply.
But how did it reply to us?

If you scroll down, you can find the Responses section. The bot replies what we write here. We will be adding our Michael Scott GIF here later.
Now, let's create a new Intent by pressing the '+' icon near the Intent item in the left Menus. Name it anything you want, I've named it Misc.

I've added a couple of phrases here which I thought Michael Scott would reply 'That's what she said!'. You can add more here! Get creative 😉
Dialogflow is very intelligent. It doesn't match phrases exactly to what we've given in the training phrases. It learns from the phrases in a deeper way (using complex NLP machine learning techniques), so even if we make a typo or have different sentence structure (but similar), it works!
Now, let's add the response. Scroll down to find the Response section.
Click on the '+' icon next to 'Default' and select Slack.
You can turn off 'Use responses from Default tab as first responses' if you want.
We want to add a GIF. Just go to [GIPHY](https://giphy.com/gifs/the-office-thats-what-she-said-micheal-scott-f8pT7bphqES4M) and copy the GIF's link and paste it for the Image Link

Guess what? We've completed our bot! Now let's integrate with Slack.
Click on Integrations from the left menus and turn on Integration for Slack.

To test the app you can click on 'Test in Slack'. This will integrate your the bot into your workspace for you to test. You can use this as a check to make sure the bot is working.

To launch the app, Dialogflow has already documented the steps to do that (as in the above image), So I'll skip that part. Just follow all the instructions in Launch and you should be good.
Although there are 2 things you would need to configure explicitly which isn't mentioned in the instructions.
In the Events Subscription, add the following events.

The bot will be aware of these events - posting messages in both private and public channels. If you don't want to use the bot in public channels, you can remove that event.
The second thing to do is, in the 'OAuth & Permissions' sections, provide the bot access to write. This is important since we want the bot to reply.

Now, go to 'Install App' and install it to your workspace!
We are DONE! We can now have Michael Scott Bot in our Slack Workspace.
Invite Michael Scott Bot and have fun! 🤪

If you just want to try bot, you can add my Michael Scott Bot to your Slack Workspace.
<div>
<a href="https://slack.com/oauth/v2/authorize?client_id=603308697778.1138663588561&scope=channels:history,chat:write,groups:history"><img alt="Add to Slack" height="40" width="139" src="https://platform.slack-edge.com/img/add_to_slack.png" srcset="https://platform.slack-edge.com/img/add_to_slack.png 1x, https://platform.slack-edge.com/img/add_to_slack@2x.png 2x"></a>
</div>
<i>Pro Tip - How I added Phrases to my Michael Scott Bot:
Adding phrases one by one can be time consuming. Instead, I obtained the transcript of the following video - https://youtu.be/dBUGfs9rwms and added the phrases before Michael Says 'That's what she said'!</i>
<i>I used <a href="https://zapier.com/zappy">Zappy</a> to take and edit the screen shots.</i>
<i>Note: if you do add my bot to your workspace, your chats will be using my Dialogflow service. I've turned off the chat logging in my Dialogflow settings, but still, I recommend you to create a new channel if you try my bot. Please DO NOT share any confidential information in the channel you've added the bot to.</i>
<i>Disclaimer: I made this for educational and entertainment reasons ONLY. I do not represent Michael Scott or The Office Series. Please make sure you inform people what the bot is about. The bot could be inappropriate in office slack workspaces due to it's nature.</i>
Last of all, have fun 🤗 Reply below if you've had any funny interactions and tweet with <a href="https://twitter.com/hashtag/michaelScottBot">#michaelScottBot<a>
| vishaag |
336,140 | Lighthouse and how to use it more effectively | Written by Daniel Phiri✏️ Performance and usability have slowly become a top priority for a majority... | 0 | 2020-06-02T17:05:12 | https://blog.logrocket.com/lighthouse-and-how-to-use-it-more-effectively/ | ux, testing, webperf | ---
title: Lighthouse and how to use it more effectively
published: true
date: 2020-05-15 16:58:50 UTC
tags: UX,testing,webperf
canonical_url: https://blog.logrocket.com/lighthouse-and-how-to-use-it-more-effectively/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/ypb8gqbeyjmt0dyfzk50.png
---
**Written by [Daniel Phiri](https://blog.logrocket.com/author/malgamves/)**✏️
Performance and usability have slowly become a top priority for a majority of companies as they both have a huge effect on user experience. Understandably, testing for both and optimizing to improve them has become essential to the success of any web-based application.
On the testing end, [Lighthouse](https://developers.google.com/web/tools/lighthouse/) has emerged as a popular choice due to its ease of use and (now) versatility. Lighthouse is an open-source tool created by Google to perform a number tests called audits with the aim of improving site performance and usability.
It is used as a baseline by a majority of the frontend web development community to assess various performance and usability metrics of web pages and apps. Its audits involve loading your web application over a weak simulated 3G connection while viewing it on a slow device.
It also simulates packet loss and network and CPU throttling. Then, it creates a report on how well the app or page performed. The metrics audited are performance, search engine optimization, best practices, progressive web apps, and accessibility.
[](https://logrocket.com/signup/)
## Running an audit
Lighthouse gives us lots of workflows to choose from. This way, we can pick one that suits us best and run an audit with it.
Run Lighthouse on web.dev and get reports without installing a thing:
- Navigate to [web.dev/measure](https://web.dev/measure/)
- Enter a web page URL
- Click Run Audit
Run Lighthouse via the command line:
> You need to have Google Chrome installed on your device
- Install the current Long-Term Support version of [Node](https://nodejs.org)
- Install Lighthouse (the `-g` flag installs it as a global module):
`npm install -g lighthouse`
- Run an audit with `lighthouse <url>`
_N.B:_ Use `lighthouse --help` to access a few more options.
Run Lighthouse via Chrome DevTools (useful for pages that require authentication):
> You need to have Google Chrome installed on your device
- In Google Chrome, go to the URL you want to audit
- Open Chrome DevTools (Windows: F12 key, or Control+Shift+I & Mac: Command+Option+I)
- Click the Audits tab
- Click Perform an audit (you should see a list of audit categories, tick those necessary)
- Click Run audit
Run Lighthouse from a browser extension:
- Download and install either the [Firefox](https://addons.mozilla.org/en-US/firefox/addon/google-lighthouse/) or [Chrome](https://chrome.google.com/webstore/detail/lighthouse/blipmdconlkpinefehnmjammfjpmpbjk?hl=en) Lighthouse extension
- Go to the page you want to audit
- Click the Lighthouse icon next to the address bar (after clicking, the Lighthouse menu expands)
- Click Generate report
- Lighthouse runs its audits against the currently-focused page, then opens up a new tab with a report of the results
With any of the methods mentioned above, after running the audit you should get a report that looks like this:

> This is a test I ran on my website – malgamves.dev (Clearly I have some work to do.)
You’ll notice we get back a couple of scores for each of the metrics I mentioned in the opening paragraph. These are on a scale of 0-100, making it easier to determine whether a site is “better” than it’s previous version.
The goal here is to improve your score by acting on the feedback you’re given.
Opportunities are suggestions that you can use to improve your site’s performance. Let’s go a little deeper into these metrics.
### Performance
Lighthouse’s perspective of performance is mainly focused on the user’s perception of speed (how quick things show up on the screen) rather than actual speed. It checks against the following metrics: [First Contentful Paint](https://developers.google.com/web/tools/lighthouse/audits/first-contentful-paint?utm_source=lighthouse&utm_medium=cli), [Speed Index](https://developers.google.com/web/tools/lighthouse/audits/speed-index?utm_source=lighthouse&utm_medium=cli), [Time to Interactive](https://developers.google.com/web/tools/lighthouse/audits/time-to-interactive?utm_source=lighthouse&utm_medium=cli), [First Meaningful Paint](https://developers.google.com/web/tools/lighthouse/audits/first-meaningful-paint?utm_source=lighthouse&utm_medium=cli), [First CPU Idle](https://developers.google.com/web/tools/lighthouse/audits/first-cpu-idle?utm_source=lighthouse&utm_medium=cli), and [Max Potential First Input Delay](https://developers.google.com/web/updates/2018/05/first-input-delay?utm_source=lighthouse&utm_medium=cli).
These play a huge part in making things appear on the screen as quickly as possible, thus improving the user’s perception of the application’s speed.
### Search Engine Optimization
Lighthouse will check that your webpages are optimized for search engine result rankings. It checks some SEO best practices, like whether documents use legible font sizes, have a valid robots.txt file, and use page tags and status codes.
Most of the SEO tests are pretty basic, so you don’t want to rely on Lighthouse as your go-to SEO tool. It’s important to note that the Lighthouse team is working on expanding and improving the SEO audit.
### Best Practices
For this, Lighthouse checks your web pages to ensure they’re following standard best practices for the web. Some of these include checking if applications have no errors logged to the console, if deprecated APIs are avoided, if a page is accessible over HTTPS, if the application cache is valid, if geo-location access is requested, and if images are displayed with the correct aspect ratio.
### Accessibility
For this audit, Lighthouse checks the accessibility of your web application.
It checks if image elements have `alt` attributes, if the `<html>` element has a `lang` attribute, if the document has a `<title>` element, if background and foreground colors have enough contrast, if link names work, and if viewport is viewer-scalable.
### Progressive Web Application
Lighthouse will check your web page against a [set of criteria](https://developers.google.com/web/progressive-web-apps/checklist?utm_source=lighthouse&utm_medium=cli) which defines progressive web apps.
This particular audit doesn’t give your page a score, but rather a pass or fail depending on whether your page meets the criteria or not, like whether your app redirects HTTP to HTTPS, response code, fast loading on 3G, splash screen, viewport, etc.
It’s worth noting though that (as of writing this post) very soon there will be a significant change to the way Lighthouse scores web pages. So if you’re using any third party tests based off of Lighthouse, make sure they get updated to Lighthouse 6.
This [blog post](https://calibreapp.com/blog/lighthouse-changes-scoring-algorithm) provides a nice summary of what will change. I also recommend having a look at the [Changelog](https://github.com/GoogleChrome/lighthouse/blob/v6.0.0-beta.0/changelog.md#600-beta0-2020-03-11) to see what changes are coming.
> There’s a really cool [web app](https://paulirish.github.io/lh-scorecalc/) you can check out to see what audit scores will look like before and after the major update.
## Using Lighthouse effectively
Now we have an overarching understanding of what a Lighthouse test is, how we can perform one, and what the audit reports and scores mean. It’s worth mentioning that the point of this article is to share a few ways you and your team can get the most of of your Lighthouse tests.
### Add Lighthouse to your projects CI
In most dev scenarios, you have a team contributing to a project over some sort of version control — usually Git. This means there’s lots of changes to your application and these changes might negatively affect your Lighthouse audit scores.
Remember, the goal is to maintain and improve. This is why Lighthouse is slowly becoming a core part of many frontend teams’ CI, with people choosing to run a Lighthouse-driven style of development as they go on and create web pages.
[Lighthouse CI](https://github.com/GoogleChrome/lighthouse-ci/blob/master/docs/getting-started.md) can be added to your project repo, and that way you can keep track of test scores past and present before merging changes from various contributors that might affect your applications overall score.
### Go the extra mile and pay attention to the optional tips
After running your Lighthouse test, you get a couple of suggestions for actions that could help improve your score.
Right after a lot of those suggestions are a few optional tips that wouldn’t necessarily improve your score because they aren’t automatically tested.
Running a manual test and fixing them would definitely make for a better user experience, though. When it comes to accessibility, for example, not all pointers can be found in the report but referencing a guide to [manual accessibility](https://developers.google.com/web/fundamentals/accessibility?utm_source=lighthouse&utm_medium=lr) testing makes your app more accessible.
Similarly, with progressive web apps, we have a [checklist](https://developers.google.com/web/progressive-web-apps/checklist?utm_source=lighthouse&utm_medium=lr) with some items not covered in the automated test report which would make for a better experience. The devil is in the details, so go the extra mile and run some of the optional manual tests.
### Know its limitations
Use Lighthouse as a guiding light and not as a source of universal truth. It’s important to note that Lighthouse isn’t the holy grail of web standards, but it can get close.
This post titled [Building the most inaccessible site possible with a perfect Lighthouse score](https://www.matuzo.at/blog/building-the-most-inaccessible-site-possible-with-a-perfect-lighthouse-score/) sums up the message pretty well.
Using automated tools like Lighthouse is a great way to start your journey towards making better performing and more accessible sites.
But like its name suggests, it isn’t the destination. It’s just a tool that helps you when you’re lost in the rough seas of modern web application development. It provides a guide for you to act on and helps point you in the right direction towards industry best practices. It’s important not to get lost.
### Eliminate third party distractions
I remember running a Lighthouse test and getting this alert: **Chrome extensions negatively affected this page’s load performance. Try auditing the page in incognito mode or from a Chrome profile without extensions.**
I run an `ad-blocker` and a few other extension that stop certain sites from tracking my movement as I surf the web. Sometimes this means I can’t get a couple of fonts from Google or access content on a CDN.
Whatever it might be, if you use a browser to run your Lighthouse tests, run them free of extensions in incognito mode to get more accurate results.
### Update! Update! Update! Then test
Most Lighthouse updates come with minor changes to scoring with only a few having very significant overhauls. Staying up to date and making sure everyone on your team is on the same version can help avoid inconsistencies and eventually poor web experiences.
Keep in mind that different Lighthouse workflows update differently — the extension is auto-updating by default, and the DevTools version will only be updated when updating Chrome.
It’s also important to remember that lots of unofficial or third party tests take a while to update to the latest standard. Lighthouse may have been updated since your last report, so be sure to check the changelog often.
### Conclusion
Hopefully this gives you a better idea of how to use Lighthouse more effectively! Please share your Lighthouse scores with me on [Twitter](https://twitter.com/malgamves).
Let’s create a faster, more accessible and enjoyable web experience for everyone.
Happy testing! Take care and stay safe
* * *
## Lighthouse, but for all your users
As web frontends get increasingly complex, resource-greedy features demand more and more from the browser. If you're interested in monitoring frontend performance and more for all of your users in production, [try LogRocket.](https://logrocket.com/signup/)
[LogRocket](https://logrocket.com/signup/) is like a DVR for web apps, recording everything that happens in your web app or site. Instead of guessing why problems happen, you can aggregate and report on key frontend performance metrics, replay user sessions along with application state, log network requests, and automatically surface all errors.
Modernize how you debug web apps – [Start monitoring for free.](https://logrocket.com/signup/)
* * *
The post [Lighthouse and how to use it more effectively](https://blog.logrocket.com/lighthouse-and-how-to-use-it-more-effectively/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
336,142 | Reducing Docker's image size while creating an offline version of Carbon.now.sh | Disclaimer: It's close to my first time playing around with Docker so you might find the article... | 0 | 2020-05-16T08:23:32 | https://lengrand.fr/reducing-dockers-image-size-while-creating-an-offline-version-of-carbon-now-sh/ | docker, node, containers, development | ---
title: Reducing Docker's image size while creating an offline version of Carbon.now.sh
published: true
date: 2020-05-15 17:04:59 UTC
tags: docker,node,containers,development
canonical_url: https://lengrand.fr/reducing-dockers-image-size-while-creating-an-offline-version-of-carbon-now-sh/
---

Disclaimer: It's close to my first time playing around with Docker so you might find the article underwhelming :).
I'm sure most of you are used to those beautiful code snippets you see in presentations or at conference talks. They look like just like this one :
<!--kg-card-begin: image-->
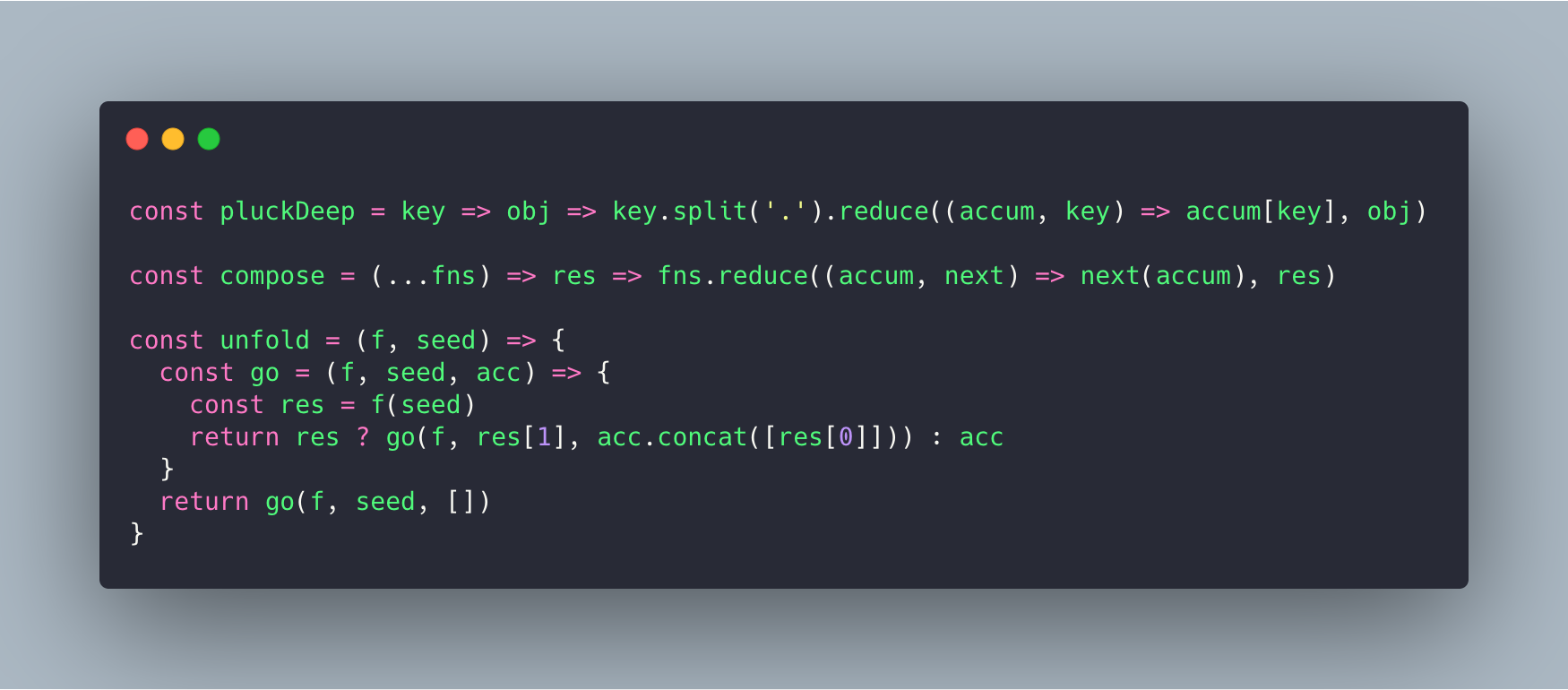<figcaption>An example of code snippet</figcaption>
<!--kg-card-end: image-->
Well, almost all of them come from [carbon.now.sh](https://carbon.now.sh/), who is doing a great job at making your code look nice.
Unfortunately, I work in a large company and it decided to block access to the website to avoid risking any data leaks (which makes a whole lot of sense if you ask me). Well, luckily for us Carbon is [open-source](https://github.com/carbon-app/carbon) and uses the [MIT license](https://github.com/carbon-app/carbon/blob/master/LICENSE) so we can spin our own internal version of it.
This blog lists my journey dockerizing the application and reducing the final image size.
## Getting that sweet Docker image working
The first step is to get any kind of Docker image working, straight to the point. Let's do it.
We start by cloning the repo and creating a `Dockerfile` at the root of the project. The project requires node 12 so we'll use the [official node image](https://hub.docker.com/_/node/) as base image.
<!--kg-card-begin: markdown-->
```
FROM node:12
WORKDIR /app
COPY package*.json ./
RUN yarn install
COPY . .
RUN yarn build
CMD ["yarn", "start"]
```
<!--kg-card-end: markdown-->
What we're doing here is very limited:
- We define a working directory inside the base image
- We install dependencies using `yarn install`
- We build the project
- We define `yarn start` as start command when the image will be ran
What is now left to do is actually build the image, and test it (you might want to run using the `-d` option to get detached mode if you intend to run the server for a long time :). I am just testing here).
<!--kg-card-begin: markdown-->
```
$ docker build -t julienlengrand/carbon.now.sh .
$ docker run -p 3000:3000 julienlengrand/carbon.now.sh:latest
```
<!--kg-card-end: markdown-->
Now if we go to [http:localhost:3000](http:localhost:3000), we should see this :
<!--kg-card-begin: image-->
<figcaption>The landing page of carbon, but on localhost</figcaption>
<!--kg-card-end: image-->
Great!!!! .... **Except for the fact that my image takes 2.34Gb of disk space!** For something that takes screenshots, it won't be acceptable :).
<!--kg-card-begin: markdown-->
```
➜ carbon git:(feature/docker) docker images
REPOSITORY IMAGE ID SIZE
julienlengrand/carbon.now.sh 81f97ac3419b 2.43GB
```
<!--kg-card-end: markdown-->
Let's see what more we can do.
## Keeping only the app in the image
Thing is, the way we've built the image now works, but it is far from efficient (but we knew that already). We have our whole toolchain in the container, as well as the build and development dependencies and more. We want to get rid of all this, as we don't need it to run our server.
One of the common ways to do this in the Docker world is called multi-step builds, and one of the ways to achieve this is to use the [builder pattern](https://matthiasnoback.nl/2017/04/docker-build-patterns/) (not to be confused with the other well-know [builder pattern](https://en.wikipedia.org/wiki/Builder_pattern)). In short, we use a first container to build our application and create our final image.
Let's see how that looks like :
<!--kg-card-begin: markdown-->
```
FROM node:12 AS builder
WORKDIR /app
COPY package*.json ./
RUN yarn install
COPY . .
RUN yarn build
FROM node:12
WORKDIR /app
COPY --from=builder /app .
EXPOSE 3000
CMD ["yarn", "start"]
```
<!--kg-card-end: markdown-->
This Dockerfile contains essentially the very same lines as before except for two major differences:
- We now split operations over 2 containers (one builds, the other will run)
- We copy the result of the build step over to the second container to create the final image.
Just like before, we use the same commands to run and test this new version (surprisingly, it works as expected!).
The nice side-effect of multi-step build can be directly seen. We divided our final image size by 2 :
<!--kg-card-begin: markdown-->
```
➜ carbon git:(feature/docker) docker images
REPOSITORY IMAGE ID SIZE
julienlengrand/carbon.now.sh 586a65d1ee4e 1.34GB
```
<!--kg-card-end: markdown-->
1.34Gb for a webapp that takes glorified screenshots though, it's still way too much for me. Let's dive further.
## Using a more efficient image
Using the official Node image has benefits but given that it's based on a Debian system, it's also very large. The next step for us is to look at a smaller image. One of the well known 'lighter' distros for containers is [alpine](https://hub.docker.com/_/alpine) and luckily there is a supported node version of it called [mhart/alpine-node](https://hub.docker.com/r/mhart/alpine-node/)!
This time our Dockerfile barely changes, we just want to replace the base image:
<!--kg-card-begin: markdown-->
```
FROM mhart/alpine-node:12 AS builder
WORKDIR /app
COPY package*.json ./
RUN yarn install
COPY . .
RUN yarn build
FROM mhart/alpine-node:12
WORKDIR /app
COPY --from=builder /app .
EXPOSE 3000
CMD ["yarn", "start"]
```
<!--kg-card-end: markdown-->
And again, we build and run with expected success :).
Again, we divide our image size by two and with this version we're just over 500Mb!
<!--kg-card-begin: markdown-->
```
➜ carbon git:(feature/docker) docker images
REPOSITORY IMAGE ID SIZE
julienlengrand/carbon.now.sh b79dbcd33de0 502MB
```
<!--kg-card-end: markdown-->
## Removing more of the dependencies and things we don't use
We can keep trying to reduce the bundle size by shipping even less code to the container. Let's use `npm prune` for that (unfortunately, yarn [decided to not offer an exact equivalent](https://github.com/yarnpkg/yarn/issues/696)). By using `npm prune --production` right after building, we can get rid of all of our dev dependencies. Rebuilding the image shaves yet another 100Mb.
Here is our final Dockerfile:
<!--kg-card-begin: markdown-->
```
FROM mhart/alpine-node:12 AS builder
WORKDIR /app
COPY package*.json ./
RUN yarn install
COPY . .
RUN yarn build
RUN npm prune --production
FROM mhart/alpine-node:12
WORKDIR /app
COPY --from=builder /app .
EXPOSE 3000
# Running the app
CMD ["yarn", "start"]
```
<!--kg-card-end: markdown-->
That's it for now. I'm looking for more ways to shave some more megabytes but we did reduce the size of our deployable by almost a factor of 10! For a bit of feel good, here is the list of images we created so we can see progress:
<!--kg-card-begin: image-->
<figcaption>List of all images and sizes</figcaption>
<!--kg-card-end: image-->
It still feels quite crazy to me that a simple website needs 400Mb to run today, I'm sure we can do better :). But let's stop there for now, time for a well deserved weekend!
Oh, and if you want to use Carbon locally, feel free to pull the image from the Docker Hub and run it locally :
<!--kg-card-begin: markdown-->
```
docker run -p 3000:3000 julienlengrand/carbon.now.sh:latest
```
<!--kg-card-end: markdown-->
_Some references I used today (thanks to them!)_
_[1][https://medium.com/@khwsc1/a-simple-react-next-js-app-development-on-docker-6f0bd3f78c2c](https://medium.com/@khwsc1/a-simple-react-next-js-app-development-on-docker-6f0bd3f78c2c)_
_[2][https://itnext.io/frontend-dockerized-build-artifacts-with-nextjs-9463f3da3362](https://dev.to/efreyreg/frontend-dockerized-build-artifacts-with-nextjs-49c7)_
_[3][https://medium.com/trendyol-tech/how-we-reduce-node-docker-image-size-in-3-steps-ff2762b51d5a](https://medium.com/trendyol-tech/how-we-reduce-node-docker-image-size-in-3-steps-ff2762b51d5a)_ | jlengrand |
336,183 | Building Git with Node.js and TypeScript - Part 1 | In this post I introduce the `commit` command to the Node.js Git implementation, Jit | 0 | 2020-05-15T19:16:27 | https://dev.to/ethanarrowood/building-git-with-node-js-and-typescript-part-1-1d94 | git, node, typescript, javascript | ---
title: Building Git with Node.js and TypeScript - Part 1
published: true
description: In this post I introduce the `commit` command to the Node.js Git implementation, Jit
tags: git, node, typescript, javascript
---
Read the introduction to this series here: [Building Git with Node.js and TypeScript - Part 0](https://dev.to/ethanarrowood/building-git-with-node-js-and-typescript-part-0-31mk).
In this post, I'll be sharing my work from chapter 3 section 2, implementing the commit command. Follow along with the code available [here](https://github.com/Ethan-Arrowood/building-git-with-nodejs-and-typescript/tree/part-1).
> Throughout this article I try my best to highlight certain terms using `code highlight`, **boldface**, and _italic_. Any `code highlight` text will be referencing actual pieces of code such as commands, properties, variables, etc. Any **boldface** text refers to file and directory names. And any _italic_ text references higher level data structures. Most classes will referred to using _italics_, but may sometimes appear as `code highlights` when referring to a type assignment. Keep in mind that some terms may be _italicized_ before they are defined.
> Imports are omitted from code examples. For this article, assume all imports refer to other local files or Node.js core modules. Furthermore, all code blocks will have their respective file name commented at the top of the block.
## Overview
In the previous post I implemented the `init` command, which created a **.git** directory in current working directory and initialized two inner directories **objects** and **refs**. This section covers a simplified `commit` command. It adds all files in the current working directory to the git database as _blobs_, creates a _tree_ with all of the _entries_, and then finally creates a _commit_ with a message. Additionally, it tracks the commit author from data stored in environment variables, and the commit message is read from stdin rather than passing it in as a command line argument.
## Adding the commit command
Inside **jit.ts** add a new `'commit'` case to the switch statement. Then derive the database path to the **objects** directory created by the `init` command.
```ts
// jit.ts
async function jit() {
const command = process.argv[2]
switch (command) {
case 'init': {
// ...
}
case 'commit': {
const rootPath = process.cwd() // get the current working directory
const gitPath = path.join(rootPath, '.git')
const dbPath = path.join(gitPath, 'objects')
}
}
}
```
With these paths, create Workspace and Database class instances.
```ts
// jit.ts
// inside of the `case 'commit': { }` block
const workspace = new Workspace(rootPath)
const database = new Database(dbPath)
```
### Workspace
The workspace class contains one private property, `ignore`, one public property, `pathname`, and two public methods, `listFiles` and `readFile`. The `ignore` property is a list of things to ignore when scanning the current working directory. This emulates the commonly used **.gitignore** file. The `pathname` property is the absolute path to the current working directory and any files within will be included in the list. Thus, the `listFiles` method returns all files in the directory resolved from `pathname`, and filters out anything in the `ignore` list. Currently, this method is not recursive and will not list files contained within directories. Finally, the `readFile` method takes a file path, joins it with the absolute path `pathname`, and then reads its contents as a _buffer_.
> It is intentional that the `readFile` method returns a _buffer_ and not an encoded string version of the file contents. This method will be used when storing the _entities_ in the Git database and we must store the binary representation of the data; not the encoded version.
```ts
// workspace.ts
import fs from 'fs'
import path from 'path'
export default class Workspace {
private ignore = ['.', '..', '.git']
public pathname: string
constructor (pathname: string) {
this.pathname = pathname
}
public async listFiles () {
const dirFiles = await fs.promises.readdir(this.pathname)
return dirFiles.filter(x => this.ignore.indexOf(x) === -1)
}
public async readFile (filePath: string) {
return await fs.promises.readFile(path.join(this.pathname, filePath))
}
}
```
### Database
The _database_ class is verbose, but is rightfully so as it is the basis for the entire application. It has a single public property `pathname`, one public method `store`, and two private methods `writeObject` and `generateTempName`. Start by defining the property, constructor, and methods with arguments.
```ts
// database.ts
export default class Database {
public pathname: string
constructor (pathname: string) {
this.pathname = pathname
}
public async store(obj: Entity) {}
private async writeObject(oid: string, content: Buffer) {}
private generateTempName() {}
}
```
Starting with the `store` method there is already something new, the `Entity` class. Before continuing with the `store` method, let's define this class as it has some important details for the rest of the implementation.
#### Entity
This class is the crux for all items storable by the _database_. Anything that will be stored in the database (_blobs_, _commits_, _trees_) will need to extend from this class. It has one private property `data` that is a _buffer_ of the contents of the entity, and two public properties `type` and `oid` (object id). While `data` and `type` are set by the constructor, the `oid` property is generated by a private method `setOid`. This method uses the `type` and `data` parameters, and creates a hash of a custom binary string. The code below contains comments detailing each step of this method. Lastly, the class overrides the `toString` method to return the underlying data buffer; this is the not the best practice as `toString` should generally return a `string`, but _buffers_ can be implicitly turned into _strings_ with their own `toString` method so this is (sorta) okay.
> What is a "binary string"? This refers to a Node.js _buffer_, but I distinctly used this wording because I need to highlight something special about the implementation. As previously mentioned, the database needs to store the binary representation of the data and NOT the encoded string version; thus, _buffers_ are used throughout the code samples. This detail is covered in the [Building Git](https://shop.jcoglan.com/building-git/) book, and while working on this solution, I received a wonderfully detailed [stackoverflow answer](https://stackoverflow.com/questions/61742699/javascript-alternative-to-rubys-force-encodingencodingascii-8bit/61746655) on the difference between raw binary strings and encoded strings in JavaScript. If you're interested in learning more please utilize those resources.
```ts
// entity.ts
export default class Entity {
private data: Buffer
public type: string
public oid: string
constructor(type: string, data: Buffer) {
this.type = type
this.data = data
this.oid = this.setOid()
}
private setOid () {
// define the binary string
const str = this.data
// create a buffer from the type, binary string length, and a null byte
const header = Buffer.from(`${this.type} ${str.length}\0`)
// create the hash content by concatenating the header and the binary string
const content = Buffer.concat([header, str], header.length + str.length)
// create a hash generator using the 'sha1' algorithm
const shasum = crypto.createHash('sha1')
// update the hash generator with the content and use a hexadecimal digest to create the object id
const oid = shasum.update(content).digest('hex')
return oid
}
public toString () {
return this.data
}
}
```
#### Back to Database
Continuing with the _database_ `store` implementation, it needs to recreate the `content` that was used to generate the `oid` property, and use that plus the `oid` to write the object to the database itself. Yes, the content is being generated twice (once in the `Entity` class and once here); I purposely did not optimize this as I didn't want to stray too far from the Ruby code. It is noted and may change in future implementations.
```ts
// database.ts
class Database {
// ...
async store (obj: Entity) {
const str = obj.toString() // remember this returns the data buffer
const header = Buffer.from(`${obj.type} ${str.length}\0`)
const content = Buffer.concat([header, str], header.length + str.length)
await this.writeObject(obj.oid, content)
}
}
```
Next is the `writeObject` and `generateTempName` methods. Derived from the `store` method, `writeObject` has two arguments: `oid` and `content`. The binary string `content` will be written to a file path derived from `oid`. In a Git database, the objects are stored in subdirectories using the first two characters of their `oid`; thus, the substrings in the `objectPath` variable. The internal `getFileDescriptor` method is used to try to safely generate these directories on the fly. Unfortunately, it is not perfect and can sometimes still throw an error due to how the `store` method is called from **jit.ts** (more on this soon). Again, this is purposefully not fixed or optimized, but it is noted for future improvements. Finally, the end of the method. Another trick this method uses to prevent errors is by generating temporary names for the files, and then renaming them after. The content of the files is compressed using Zlib deflate at the `Z_BEST_SPEED` level.
```ts
// database.ts
class Database {
// ...
private async writeObject(oid: string, content: Buffer) {
const objectPath = path.join(this.pathname, oid.substring(0, 2), oid.substring(2))
const dirName = path.dirname(objectPath)
const tempPath = path.join(dirName, this.generateTempName())
const flags = fs.constants.O_RDWR | fs.constants.O_CREAT | fs.constants.O_EXCL
const getFileDescriptor = async () => {
try {
return await fs.promises.open(tempPath, flags)
} catch (err) {
if (err.code === 'ENOENT') {
await fs.promises.mkdir(dirName)
return await fs.promises.open(tempPath, flags)
} else if (err.code === 'EEXIST') {
return await fs.promises.open(tempPath, flags)
} else {
throw err
}
}
}
const file = await getFileDescriptor()
const deflate: any = util.promisify(zlib.deflate)
const compressed = await deflate(content, { level: zlib.constants.Z_BEST_SPEED })
await file.write(compressed)
await file.close()
await fs.promises.rename(tempPath, objectPath)
}
private generateTempName () {
// hex ensures we only get characters 0-9 and a-f
return `tmp_obj_${crypto.randomBytes(8).toString('hex').slice(0, 8)}`
}
}
```
### Back to the commit command
Continuing the `commit` block now that _workspace_ and _database_ are implemented, we list the files in the _workspace_, then iterating over the list, create _blobs_ and store them in the database. Additionally, each object will be tracked as an _entry_ which is used in the _tree_ structure. Notice how both the _blob_ and _tree_ are stored in the database through the same `store` method. These objects are similar enough that they can both be based on the `Entity` class defined above.
```ts
// jit.ts
// inside of the `case 'commit': { }` block
const workspaceFiles = await workspace.listFiles()
const entries = await Promise.all(workspaceFiles.map(async path => {
const data = await workspace.readFile(path)
const blob = new Blob(data)
database.store(blob)
return new Entry(path, blob.oid)
}))
const tree = new Tree(entries)
database.store(tree)
```
#### Blob
_Blobs_ are one of the simplest data structures in this application. They extend from `Entity` and set their type as `'blob'`.
```ts
// blob.ts
export default class Blob extends Entity {
constructor(data: Buffer) {
super('blob', data)
}
}
```
#### Entry
Another simple data structure, _entry_, has two public properties `name` and `oid` and both are of type `string`. This structure could be represented as just an object literal, but defining it as a class allows for better extensibility later on if it is needed.
```ts
// entry.ts
export default class Entry {
public oid: string
public name: string
constructor (name: string, oid: string) {
this.name = name
this.oid = oid
}
}
```
#### Tree
The `Tree` class is a bit more complicated compared to the `Blob` class, but it still extends from the `Entity` class. In the `constructor`, the class calls a private, static method `generateData` to create the data buffer passed to the parent `Entity` constructor. The `Tree` class also keeps a local, public copy of the _entries_ list.
```ts
// tree.ts
export default class Tree extends Entity {
public entries: Entry[]
constructor(entries: Entry[]) {
super('tree', Tree.generateData(entries, '100644'))
this.entries = entries
}
private static generateData (input: Entry[], mode: string) {
let totalLength = 0 // this is necessary for the final concatenation
const entries = input
.sort((a, b) => a.name.localeCompare(b.name)) // sort by file name
.map(entry => {
// encode as normal string and append a null byte
let b1 = Buffer.from(`${mode} ${entry.name}\0`)
// encodes a string as hex. for example '00ce' is a string of 4 bytes;
// this is encoded to Buffer<00, ce>, a buffer of 2 hex bytes
let b2 = Buffer.from(entry.oid, 'hex')
totalLength += b1.length + b2.length
return Buffer.concat([b1, b2], b1.length + b2.length)
})
// concat all of the entries into one buffer and return
return Buffer.concat(entries, totalLength)
}
}
```
The `generateData` function is one of my personal favorites. I think the best way to understand what it does is to first look at what it outputs. This function creates the data for the _tree_ _entry_ in the _database_. Unlike the _blobs_, the _tree_ best resembles a list of all the blobs contained in the _commit_. Running `git ls-tree <tree-hash>` outputs this list:
> Keep in mind this output is only possible with the rest of this sections code (i.e. _commit_ entity), and that my commit hashes will be different from yours if you were to reproduce this yourself.
```bash
$ git ls-tree e42fafc6ea09f9b9633adc97218288b2861dd03f
100644 blob 1d15619c8d23447eac2924b07896b3be9530a42e author.ts
100644 blob c8c1a93bf381f385bb70bcb95359ff056ee4a273 blob.ts
100644 blob fad23e45b228db3f33501691410541819e08a1e6 commit.ts
100644 blob 0355a9b19376a39700c3f44be73cb84d2398a219 database.ts
100644 blob c9a547e93c3101b3607f58469db26882645a120d entity.ts
100644 blob c061d02df8007226fb6b4092a40f44678f533599 entry.ts
100644 blob 7a9f17b4ee76e13b062676fa74cb509aa423ee88 jit.ts
100644 blob 1adec84945be1564c70e9cdaf5b6a9c1d9326bd0 readStdin.ts
100644 blob aeafb5efdcd5e64897385341b92a33590517adae timestamp.ts
100644 blob 377c1945ebb9aaf9f991656b7c232f7b02a55e78 tree.ts
100644 blob a331e9df15d9546f9d7dd1f28322bf1e24c2db00 workspace.ts
```
The `ls-tree` command derives this information from the contents of the _tree_ _entry_ itself. The entry is a hard to read as a human, but by using an inflate command and the hexdump tool we can get an output we can make sense of:
```
$ alias inflate="node -e 'process.stdin.pipe(zlib.createInflate()).pipe(process.stdout)'"
$ cat .git/objects/e4/2fafc6ea09f9b9633adc97218288b2861dd03f | inflate | hexdump -C
00000000 74 72 65 65 20 34 31 30 00 31 30 30 36 34 34 20 |tree 410.100644 |
00000010 61 75 74 68 6f 72 2e 74 73 00 1d 15 61 9c 8d 23 |author.ts...a..#|
00000020 44 7e ac 29 24 b0 78 96 b3 be 95 30 a4 2e 31 30 |D~.)$.x....0..10|
00000030 30 36 34 34 20 62 6c 6f 62 2e 74 73 00 c8 c1 a9 |0644 blob.ts....|
00000040 3b f3 81 f3 85 bb 70 bc b9 53 59 ff 05 6e e4 a2 |;.....p..SY..n..|
00000050 73 31 30 30 36 34 34 20 63 6f 6d 6d 69 74 2e 74 |s100644 commit.t|
00000060 73 00 fa d2 3e 45 b2 28 db 3f 33 50 16 91 41 05 |s...>E.(.?3P..A.|
00000070 41 81 9e 08 a1 e6 31 30 30 36 34 34 20 64 61 74 |A.....100644 dat|
00000080 61 62 61 73 65 2e 74 73 00 03 55 a9 b1 93 76 a3 |abase.ts..U...v.|
00000090 97 00 c3 f4 4b e7 3c b8 4d 23 98 a2 19 31 30 30 |....K.<.M#...100|
000000a0 36 34 34 20 65 6e 74 69 74 79 2e 74 73 00 c9 a5 |644 entity.ts...|
000000b0 47 e9 3c 31 01 b3 60 7f 58 46 9d b2 68 82 64 5a |G.<1..`.XF..h.dZ|
000000c0 12 0d 31 30 30 36 34 34 20 65 6e 74 72 79 2e 74 |..100644 entry.t|
000000d0 73 00 c0 61 d0 2d f8 00 72 26 fb 6b 40 92 a4 0f |s..a.-..r&.k@...|
000000e0 44 67 8f 53 35 99 31 30 30 36 34 34 20 6a 69 74 |Dg.S5.100644 jit|
000000f0 2e 74 73 00 7a 9f 17 b4 ee 76 e1 3b 06 26 76 fa |.ts.z....v.;.&v.|
00000100 74 cb 50 9a a4 23 ee 88 31 30 30 36 34 34 20 72 |t.P..#..100644 r|
00000110 65 61 64 53 74 64 69 6e 2e 74 73 00 1a de c8 49 |eadStdin.ts....I|
00000120 45 be 15 64 c7 0e 9c da f5 b6 a9 c1 d9 32 6b d0 |E..d.........2k.|
00000130 31 30 30 36 34 34 20 74 69 6d 65 73 74 61 6d 70 |100644 timestamp|
00000140 2e 74 73 00 ae af b5 ef dc d5 e6 48 97 38 53 41 |.ts........H.8SA|
00000150 b9 2a 33 59 05 17 ad ae 31 30 30 36 34 34 20 74 |.*3Y....100644 t|
00000160 72 65 65 2e 74 73 00 37 7c 19 45 eb b9 aa f9 f9 |ree.ts.7|.E.....|
00000170 91 65 6b 7c 23 2f 7b 02 a5 5e 78 31 30 30 36 34 |.ek|#/{..^x10064|
00000180 34 20 77 6f 72 6b 73 70 61 63 65 2e 74 73 00 a3 |4 workspace.ts..|
00000190 31 e9 df 15 d9 54 6f 9d 7d d1 f2 83 22 bf 1e 24 |1....To.}..."..$|
000001a0 c2 db 00 |...|
000001a3
```
Look closely at the table on the right of the hexdump, the `mode` "100644" is repeated as well as all of the file names in the tree. Following each file name is seemingly a bunch of gibberish. However, look back at the output of `ls-tree` and note the `oid` of the first entry **author.ts**:
```
1d15619c8d23447eac2924b07896b3be9530a42e
```
Now, take a look at the first couple lines of the hexdump, these correspond to the **author.ts** _entry_. What do you see (i've highlighted it below)?
```
00000000 |tree 410.100644 |
00000010 1d 15 61 9c 8d 23 |author.ts...a..#|
00000020 44 7e ac 29 24 b0 78 96 b3 be 95 30 a4 2e |D~.)$.x....0..10|
```
It is the **author.ts** oid in literal hex bytes! Thus, you can directly see how the `generateData` function transforms entries for the _tree_ content.
### Back to the commit command
Now that _blob_, _entry_, and _tree_ have all been defined we can return to the `commit` code block and finally create a _commit_! First, read the `name` and `email` from environment variables. There are multiple ways to set these, one of the easiest is to set them in the shell profile. Then create an _author_ instance with the `name`, `email`, and the current time. Next, read the commit message from `process.stdin` (the readStdin section will cover this in more detail). Create a new _commit_ from the _tree_ `oid`, the _author_, and the _message_ and then write it to the _database_. Finally, write the _commit_ `oid` to the **HEAD** file and the commit function is done!
```ts
// jit.ts
// inside of the `case 'commit': { }` block
const name = process.env['GIT_AUTHOR_NAME'] || ''
const email = process.env['GIT_AUTHOR_EMAIL'] || ''
const author = new Author(name, email, new Date())
const message = await readStdin()
const commit = new Commit(tree.oid, author, message)
database.store(commit)
const fd = await fs.promises.open(path.join(gitPath, 'HEAD'), fs.constants.O_WRONLY | fs.constants.O_CREAT)
await fd.write(`${commit.oid}\n`)
await fd.close()
console.log(`[(root-commit) ${commit.oid}] ${message.substring(0, message.indexOf("\n"))}`)
```
#### Author
Much like `Blob` and `Entry`, the `Author` class implements a unique `toString` method based on its properties.
```ts
// author.ts
export default class Author {
public name: string
public email: string
public time: Date
constructor(name: string, email: string, time: Date) {
this.name = name
this.email = email
this.time = time
}
toString() {
return `${this.name} <${this.email}> ${timestamp(this.time)}`
}
}
```
This class makes use of custom `timestamp` method that derives the timezone offset string from a Date object:
```ts
// timestamp.ts
export default function timestamp (date: Date) {
const seconds = Math.round(date.getTime() / 1000)
const timezoneOffsetNum = date.getTimezoneOffset()
const timezoneOffsetStr = timezoneOffsetNum >= 0
? `+${timezoneOffsetNum.toString().padStart(4, '0')}`
: `-${(timezoneOffsetNum * -1).toString().padStart(4, '0')}`
return `${seconds} ${timezoneOffsetStr}`
}
```
#### readStdin
The `readStdin` method is another utility method that helps simplify the process of reading data from `process.stdin`. Using async iterators, it collects chunks of the readable stream and then returns the complete string in a promise.
```ts
// readStdin.ts
export default async function () {
let res = ''
for await (const chunk of process.stdin) {
res += chunk
}
return res
}
```
#### Commit
Finally, the last piece of the implementation is the `Commit` class. It extends from `Entity`, and thus needs to pass a `type` as well as `data` to the parent constructor. The `generateData` function for the `Commit` class joins multiple strings using the newline character and then transforms that into a buffer for the `Entity` data.
```ts
// commit.ts
export default class Commit extends Entity {
public treeOid: string
public author: Author
public message: string
constructor(treeOid: string, author: Author, message: string) {
super('commit', Commit.generateData(treeOid, author, message))
this.treeOid = treeOid
this.author = author
this.message = message
}
private static generateData(treeOid: string, author: Author, message: string) {
const lines = [
`tree ${treeOid}`,
`author ${author.toString()}`,
`committer ${author.toString()}`,
"",
message
].join("\n")
return Buffer.from(lines)
}
}
```
## Running the commit command
> I've posted all of this code as gist so you can clone and run it locally faster. Check it out here: [Building Git with Node.js and TypeScript](https://github.com/Ethan-Arrowood/building-git-with-nodejs-and-typescript)
Clone the sample repo:
```
git clone git@github.com:Ethan-Arrowood/building-git-with-nodejs-and-typescript.git
```
Fetch and checkout the **part-1** branch
```
git fetch origin part-1
git checkout part-1
```
Install dependencies, build **src**, and link the executable
```
npm i
npm run build
npm link
```
Set the current working diretory to **src** and and run the commands
```
cd src
jit init
export GIT_AUTHOR_NAME="name" GIT_AUTHOR_EMAIL="email" && cat ../COMMIT_EDITMSG | jit commit
```
Now you should have a **.git** directory in the **src** directory that contains all of the _blobs_, the _tree_, and the _commit_.
To inspect the contents of the local `.git` directory, start by retrieving the commit hash from **HEAD**
```
cat .git/HEAD
```
Create an inflate command (I've added mine to my bash profile)
```
alias inflate="node -e 'process.stdin.pipe(zlib.createInflate()).pipe(process.stdout)'"`
```
Then inflate the contents of the root commit
```
cat .git/objects/<first two characters of HEAD>/<remaining characters of HEAD> | inflate
```
If everything works as expected the output should be:
```
commit 705tree <tree-oid>
author name <email> 1589553119 +0240
committer name <email> 1589553119 +0240
Initial revision of "jit", the information manager from Boston
This commit records a minimal set of functionality necessary for the code to store itself as a valid Git commit. This includes writing the following object types to the database:
- Blobs of ASCII text
- Trees containing a flat list of regular files
- Commits that contain a tree pointer, author info and message
These objects are written to `.git/objects`, compressed using zlib.
At this stage, there is no index and no `add` command; the `commit` command simply writes everything in the working tree to the database and commits it.
```
With the `<tree-oid>` you can then use `git ls-tree` to see the contents of the _tree_ entry:
```
git ls-tree <tree-oid>
```
## Conclusion
That is all for now! I intend to make following sections shorter so these posts are easier to read. I encourage you to ask questions and continue the discussion in the comments; I'll do my best to respond to everyone! If you enjoyed make sure to follow me on Twitter ([@ArrowoodTech](https://twitter.com/ArrowoodTech)). And don't forget to check out the book, [Building Git](https://shop.jcoglan.com/building-git/).
Happy coding 🚀 | ethanarrowood |
336,222 | Experience building a package from react to svelte | The svelte ecosystem grows more and more. New packages appear and people are encouraged to start usin... | 0 | 2020-05-15T21:44:15 | https://dev.to/charlyjazz/experience-building-a-package-from-react-to-svelte-4n9n | svelte, react, javascript, frontend | The svelte ecosystem grows more and more. New packages appear and people are encouraged to start using it.
I decided to contribute creating a package that perhaps will be useful to some people.
The original react project is [this](https://github.com/amarofashion/react-credit-cards), a component to render a credit card. Very cool.
**And this was my experience**:
-----------------
### 1.) Folder structure:
I had no idea how to create an npm package for svelte. So dig a little. In the github profile of sveltejs i founded [this](https://github.com/sveltejs/component-template)
A template to create shareables components.
### 2.) Sandbox environment to test the svelte component
My first idea was [Storybook](https://storybook.js.org/docs/guides/guide-svelte).
The new packages:
``` json
"@babel/core": "^7.9.6",
"@storybook/addon-actions": "^5.3.17",
"@storybook/addon-links": "^5.3.17",
"@storybook/addons": "^5.3.17",
"@storybook/svelte": "^5.3.18",
"babel-loader": "^8.1.0",
```
And a config file:
``` javascript
module.exports = {
stories: ["../src/*.stories.js", "../examples/*.stories.js"],
addons: ["@storybook/addon-actions", "@storybook/addon-links"]
};
```
What scenarios should we try with Storybook?
A file answered this question for me, [the unit tests](https://github.com/amarofashion/react-credit-cards/blob/master/test/index.spec.js).
[So I transformed the test cases into a storybook](https://github.com/CharlyJazz/svelte-credit-card/blob/master/src/CreditCard.stories.js):
``` javascript
import CreditCard from "./";
export default {
title: "Credit Card",
component: CreditCard,
};
export const AmericanExpress = () => ({
...
});
export const Dankort = () => ({
...
});
// Diners, Visa, Maestro, ETC...
});
```
### 3.) CSS y JSX:
This stage seemed complex. Since it involved the adaptation of CSS and React JSX to Svelte. I didn't know what bugs was going to find me with.
Browsing the original react package repository i [discovered this](https://github.com/amarofashion/react-credit-cards/blob/master/src/styles.scss) A good SCSS file with all styles. I didn't think twice and put it inside the `style` tags in our new svelte component.
It worked. Now the JSX
Copy and paste the JSX to Svelte and replace `className` with `class`.
it worked again!
## 4.) Javascript, the challenge:
The first step was to write the `script` tags in the svelte component.
``` javascript
// This will be insane
```
First we had to create the props.
``` javascript
export let focused = "number";
export let acceptedCards = [];
export let cvc = "";
export let expiry = "";
export let issuer = "";
export let name = "";
export let number = "";
export let locale = { valid: "VALID THRU" };
export let placeholders = { name: "YOUR NAME HERE" };
export let preview = false;
```
Now we need use[payment](https://www.npmjs.com/package/payment) as in the React project to manage credit cards and their validations. And we needed to implement a method in the constructor like in the [version de react](https://github.com/amarofashion/react-credit-cards/blob/master/src/index.js#L9). The closest thing is `onMount` in Svelte.
``` javascript
onMount(() => {
// Logic for credit cards
});
```
It worked.
Now we need derived data (Format credit number from the text props, format the CVC with the slash MM/YY). [As we can see the react component](https://github.com/amarofashion/react-credit-cards/blob/master/src/index.js#L71) used `get` to create classes methods that don't need be called like a function `call_me_i_am_a_function()` and the behavior of this method is like a property. Very common in object oriented programming:
``` javascript
get number() {
const { number, preview } = this.props;
let maxLength = preview ? 19 : this.options.maxLength;
let nextNumber = typeof number === 'number' ? number.toString() : number.replace(/[A-Za-z]| /g, '');
...
```
So it seemed impossible to use something like that in Svelte. It is time to research.
[The weird dollar symbol](https://svelte.dev/tutorial/updating-arrays-and-objects). What?
Lets try:
``` javascript
$: expiryDerived = (() => {
focused = "number";
const date = typeof expiry === "number" ? expiry.toString() : expiry;
let month = "";
// .... bla bla bla
return value
})();
```
it worked, wow. At this time I am not sure if what I am doing is a good practice. If any of you have any ideas please submit a pull request: star:
## 5.) A bug when compiling.
It seems that payment uses commonjs and we don't have a plugin for this in our rollup configuration that gave us the svelte template.
So I had to add the commonjs plugin for rollup.
``` javascript
import commonjs from '@rollup/plugin-commonjs';
plugins: [
svelte(),
resolve(),
commonjs() // <-- Our new friend
]
```
Easy, right?
## 6.) Publish NPM Package
``` bash
npm publish
```
## Conclusion:
Everything very easy and fun. There was not much stress. Svelte fulfilled all the requirements to create this component.
## Enhacements
- Refactor CSS to make customizable
- Delete the payment package because it is very old and there is a news alternatives to manage credit card validation
- Use [Svelte animation](https://svelte.dev/tutorial/animate) and not `@keyframes`
- Add [unit test](https://dev.to/d_ir/introduction-4cep)
## Contributions
Send a pull requests to https://github.com/CharlyJazz/svelte-credit-card | charlyjazz |
336,227 | Friday Night Deploys #22 - A Brief Discussion On The State Of The Modern Web | Intro Hey, How's it going everyone? This week's topic is about a recent article that had s... | 0 | 2020-05-15T20:12:53 | https://dev.to/devplebs/friday-night-deploys-22-a-brief-discussion-on-the-state-of-the-modern-web-2961 | webdev, podcast, jokes | ## Intro
Hey, How's it going everyone?
This week's topic is about a recent article that had some hubbub recently called "Second Guessing the Modern Web" by Tom Macwright on their personal blog. If you would like to take a read through it before listening you can find it in the following link.
https://macwright.org/2020/05/10/spa-fatigue.html
We make some pretty far fetched analogies with modern web development and the Tony Hawk's Pro Skater video game series; Y'know most things link back to Tony Hawk's Pro Skater. (Not sponsored by Tony Hawk (I Wish)).
## Episode Summary
This week the DevPlebs talk about: Getting requests for content! How expensive it is to podcast! Our eventual sponsored content! Apple saying we're too sad for analytics! Bad documentation! Our stupid, simple brains! Getting thrown into the deep end of the pool! Meeting two Vice Admirals of the Royal Canadian Navy! Being careful about who you choose to challenge to a pushup contest! The Presidential Fitness Test! Doing 53 pushups! That time Keith lost 120 lbs! How Trump looks perpetually sore! How to redeem 2020 through a world leader fitness challenge! How we're a 25% fitness podcast! Keith's unreliable memories! The entire history of Spike TV! Takeshi's Castle! Phil's big, dirty bundle! The Tony Hawk Pro Skater 1 + 2 Remaster! How pure the web used to be! Cellphones getting bigger in order to watch pornography on them! Comparing the virtual dom to PUBG! Getting back into running! Having snowstorms in mid-May! Being called "stud"! Having so many episodes that we have pagination on our page! Reminiscing on 6 AM! Getting 9 hours of sleep! Our expert opinion on the state of the modern web!
## Listen to The Full Episode!
{% spotify spotify:episode:2iEycDPQSrSz6Z9sL3JnAj%}
_or [listen directly on spotify](https://open.spotify.com/episode/2iEycDPQSrSz6Z9sL3JnAj)_
**We're also on...**
**Apple Podcasts:** https://podcasts.apple.com/ca/podcast/friday-night-deploys/id1485252900
**Google Music Podcasts:** https://play.google.com/music/m/D2fy7ibvzudgnxr6xjua4m5x6eu?t=22_A_Brief_Discussion_On_The_State_Of_The_Modern_Web-Friday_Night_Deploys
**Our Website:** https://www.devplebs.tech/friday-night-deploys/22-a-brief-discussion-on-the-state-of-the-modern-web/
## Get In Touch With Us!
What's your hot take on second-guessing the modern web? If you would like to share for us to read out in the next episode you can reach us at the following...
**Twitter:** [@DevPlebs](https://twitter.com/DevPlebs).
**Email:** deadbeats@devplebs.tech
## Follow Our Twitters... If You Want!
[DevPlebs](https://twitter.com/DevPlebs).
[Keith Brewster](https://twitter.com/brewsterbhg).
[Phil Tietjen](https://twitter.com/phizzard).
You can also ask questions or give us some feedback about the show! | phizzard |
336,353 | Algorithm Time: Minimum Swaps | Today I'm going to dive into my solution to HackerRank's "New Year Chaos" problem, written in JavaScr... | 0 | 2020-05-15T23:23:26 | https://dev.to/elmarshall/algorithm-time-minimum-swaps-14nd | Today I'm going to dive into my solution to [HackerRank's "New Year Chaos" problem](https://www.hackerrank.com/challenges/new-year-chaos/problem), written in JavaScript.
I found this one rather challenging to wrap my head around, and none of the solutions in the 'discussions' section were as thorough as I wanted them to be. The closest is [this one](https://www.hackerrank.com/challenges/new-year-chaos/forum/comments/143969), but it was in a language I'm not as familiar with, and could use some more breaking down.
So here we go. The setup is like this: There are a bunch of people waiting in line, each assigned a number, beginning with 1 at the start of the queue, and so on. This can be represented simply with a row of numbers like this:
` 1 2 3 4 5 6 `
Before the event, each person can choose to bribe the person in front of them to swap spots, so that they can move up. Each person can do this up to 2 times. So say person 3 bribes person 2, the queue will now look like this:
` 1 3 2 4 5 6 `
That's the setup, here's the challenge. You are provided with a list of numbers representing a queue of people that has undergone this bribing process. Your job is to return the minimum number of swaps required to get the line to that state. Or, if that state is not possible, to return "Too Chaotic."
First let's handle the "Too Chaotic" condition, since that's simplest. If a person has ended up more than two spots closer to the front, you know it's too chaotic. They cannot bribe more than twice, and people can't bribe anyone behind them, so they can only move forward on their own bribes. Here's an example of an input that's too chaotic:
` 1 5 4 2 3 ` Person number 5 doesn't have enough bribes to get that far up!
Figuring out the minimum bribes is quite a bit trickier. Tallying how many people have moved won't work, because a single transaction moves two people. Counting how many bribes each person has made won't work for similar reasons. What you *can* do, however, is count how many times each person *has been bribed*, and add those up.
In ` 1 2 5 4 3` for example, 3 has received two bribes, 4 has received one, and none of the others have received any. We know this because among the people just to the left of 3, there are two numbers higher than 3. To the left of 4, only one number is higher. Adding up the counts, we get a minimum bribe count of 3.
It is possible that a couple more bribes than this happened, of course, and in the final standings you cannot see them. For instance, perhaps 2 bribed 1, but then 1 bribed 2. However, since we are only interested in the *minimum* number of swaps necessary, we don't need to worry about those circumstances.
So how do we turn this into code? Let's take it one step at a time. First, we'll initiate our bribe count at 0. Next, we know we'll need to loop through each person in the list to find their count, so let's set that up.
```
function minimumBribes(q) { // q is our... queue! In the form of an array.
let minBribes = 0;
for(let i=0; i < q.length; i++){
}
return minBribes;
}
```
We will need to check each person to see if their position means our queue is too chaotic. If their number is more than 2 higher than their position, they've moved too far.
```
function minimumBribes(q) {
let minBribes = 0;
for(let i=0; i < q.length; i++){
if (q[i] - 3 > i){ //It's -3 not -2 here because
//our queue starts at 1
//while our array index starts at 0
return "Too chaotic"
}
}
return minBribes
}
```
Next, we'll need to add one to our minimum bribes count for every time someone was overtaken. Once we add that in, the function is complete:
```
function minimumBribes(q) {
let minBribes = 0;
for(let i=0; i < q.length; i++){
if (q[i] - 3 > i){
console.log("Too chaotic")
return
} else {
for (let j = Math.max(0, q[i]-2); j < i; j++){
if (q[j] > q[i]){
minBribes++
}
}
}
}
return minBribes
}
```
But there's a lot going on there, so let's break it down. Here's just the internal loop:
```
for (let j = Math.max(0, q[i]-2); j < i; j++){
if (q[j] > q[i]){
minBribes++
}
}
```
Remember that i is the position of the person we are currently considering, the one receiving bribes, the bribee. j represents where we begin examining the line to see who has bribed our bribee. The briber cannot move further than one position in front of the bribee's original position. On the first bribe, they take the bribee's position, on the second bribe, they move one past it. So, we only need to look two positions to the left of i. (Theoretically this would work with simply j=0, but that bumps our run time from O(n) up to O(n<sup>2</sup>). This cut saves us quite a bit of runtime.)
So what's this `Math.max(0, q[i]-2)` nonsense? Looks complicated, but all it's doing is protecting us from accidentally entering a negative index. j will be set to whichever is larger, 0 or 1 before the bribee's original position (it's -2 to account for the one-indexing).
The loops end condition is `j < i`. We only need to look at people to the bribee's left.
Now, if any of those people have a number higher than our bribee (if `q[j] > q[i]`), we know they must have bribed them to get there, so we add one to our minimum bribes count (`minBribes++`).
And that's it! This may still not be terribly clear, but I'm hoping that I've been able to explain each piece well. I really wanted to understand both how this worked, and *why* it worked, so I'm glad to have taken this time to write it out. | elmarshall | |
336,567 | Exploring how a new model and UI is created in Rails using `rails generate scaffold` | As a newbie to Rails and Ruby, I found the code generated by the rails generate scaffold command init... | 6,489 | 2020-05-16T05:37:27 | https://www.emgoto.com/rails-model-scaffold/ | rails | ---
title: Exploring how a new model and UI is created in Rails using `rails generate scaffold`
published: true
date: 2020-05-16 05:37:00 UTC
tags: rails
canonical_url: https://www.emgoto.com/rails-model-scaffold/
cover_image: https://www.emgoto.com/rails-model-scaffold-dev.png
series: [Getting started with Rails and Preact]
---
As a newbie to Rails and Ruby, I found the code generated by the `rails generate scaffold` command initially very hard to understand. A lot of Googling later, I think I have a better understanding of what things are doing, and so I decided to write a post about it!
## Running the generate scaffold command
If we were to create a to-do list app, we would need a way of storing our tasks in a database. With Rails, we can do this using something called a **model** - which acts like a wrapper aorund a database table.
In our case, we are going to need a table that stores tasks, and so we need to create a `Task` model that stores the task's name, due date, and whether it has been completed or not.
We can call `rails generate scaffold` with the name of our model, and any number of arguments in the shape `fieldName:dataType`:
```ruby
rails generate scaffold Task name:string done:boolean due:datetime
```
Note that you don't need to specify an ID - Rails will handle this one for you.
> If you're not sure what data types to use for your fields, I found [this StackOverflow answer on data types]([https://stackoverflow.com/a/22725797/5452368](https://stackoverflow.com/a/22725797/5452368)) really useful.
One of the new files created by this command will be a new file in `db/migrate` that will look something like this:
```ruby
class CreateTasks < ActiveRecord::Migration[6.0]
def change
create_table :tasks do |t|
t.string :name
t.boolean :done
t.datetime :due
t.timestamps
end
end
end
```
To create a table of tasks in our database, we will need to run that file. We can do that with the following:
```ruby
rails db:migrate
```
Now that your database can handle storing tasks you can start up your app:
```ruby
rails s --binding=127.0.0.1
```
You will see that at `http://localhost:3000/tasks`, Rails has generated a basic UI for you that lets you create, delete and edit tasks - all for free! (I was actually pretty amazed by this). I recommend having a little play around with it and creating a few tasks.
In the next section, we'll be exploring how all this UI has been generated for us.
## How tasks routing works
If we take a look at `config/routes.rb` we will see a new line has been added:
```ruby
resources :tasks
```
This is a shorthand for [7 separate routes]([https://guides.rubyonrails.org/routing.html#crud-verbs-and-actions](https://guides.rubyonrails.org/routing.html#crud-verbs-and-actions)) that allow you to view, modify and create tasks.
e.g. two of them would be:
```ruby
get '/tasks' 'tasks#index'
post '/tasks' 'tasks#create'
```
Each line maps a URL to a controller and action, so if we make a GET call to `/tasks`, we will execute the code inside of the `index` action in the `tasks` controller.
## What's happening in the tasks controller?
The `tasks` controller is another file that has been generated for us at `app/controllers/tasks_controller.rb`. I'm going to break down some of what is happening.
### before_action
Right up the top of the file, you'll see this:
```ruby
before_action :set_task, only: [:show, :edit, :update, :destroy]
```
Here we're saying that the `set_task` method (which is defined near the bottom of the file) should be called before the given list of actions (show, edit, update and destroy).
> The colon (`:`) before `set_task` indicates that it is a [Symbol](http://rubylearning.com/satishtalim/ruby_symbols.html]), which is like a reference to the method. If we didn't use the colon, `before_action` would use the results of calling the `set_task` method.
### set_task
That `set_task` method does the following:
```ruby
def set_task
@task = Task.find(params[:id])
end
```
- `@task` - In Ruby, the `@` defines a variable as an instance variable, which means it can be accessed outside of where it has been defined (even in the view file!)
- `Task` - Refers to the Task class that lives in `models/task.rb`.
- `Task.find()` - we can call `find(id)` on the model, which will find the task that matches the ID we passed in
- `params` - this object contains any parameters defined in the routes file. In our case one of our routes is `get '/tasks/:id'` so if a user lands on `localhost:3000/tasks/2`, then in our params object there will be an `:id` with a value of `2`.
In short, before we do certain things like viewing a specific task or deleting one, we will store in `@task` the relevant task that we are looking for. This means each action that access it immediately without having to add in that extra line of code themselves.
### Getting all tasks using the index action
Now the first action is our index action. This maps to the following route:
```ruby
get '/tasks' 'tasks#index'
```
The action itself is very short:
```ruby
def index
@tasks = Task.all
end
```
What we're doing here is storing a list of all the tasks in `@tasks`.
And then with Rails magic, this action will map to the view file defined at `tasks/index.html.erb`. This view file will have access to all the tasks, and can loop through them and render them all on the page:
```ruby
<% @tasks.each do |task| %>
<tr>
<td><%= task.name %></td>
</tr>
<% end %>
```
### Updating a task using the update action
The update action maps to the following route:
```ruby
put '/tasks/:id' 'tasks#update'
```
```ruby
def update
respond_to do |format|
if @task.update(task_params)
format.html { redirect_to @task, notice: 'Task was successfully updated.' }
format.json { render :show, status: :ok, location: @task }
else
format.html { render :edit }
format.json { render json: @task.errors, status: :unprocessable_entity }
end
end
end
```
Let's break this down!
- `respond_to` - a method available to us in controller classes, which will give access to a `format` method
- `@task` - we got this from the `set_task` method (described above)
- `@task.update()` - we can call `update()` on the specific task, and pass in new values
- `task_params` - gives us the values in the body of the call that was made (described in more detail below)
- `format.html` and `format.json` - we're defining what is returned, depending on if the request was an HTML or JSON request.
- `if` and `else` - if `@task.update` fails, we will enter the `else` block.
### task_params
The other method defined at the bottom of the file is `task_params`:
```ruby
def task_params
params.require(:task).permit(:name, :done, :due)
end
```
When this method is called, we will require that a `:task` symbol exists inside of the params object, and filter out any values from task that aren't the values for name, done and due.
What this means in practice is that if you called the endpoint with the data to create a new task, this would be accessible inside of `params[:task]`. And if you passed in an extra field like "description", this would get filtered out by this method.
---
And that's it for this post! The other actions are fairly similar to the code I've gone through above, so hopefully shouldn't be too hard to understand.
Thanks for reading! | emma |
336,671 | Understanding Call Stacks In Java Script | What is a call stack? A call stack is a region in memory that keeps track of the running/a... | 0 | 2020-05-16T11:14:58 | https://dev.to/jerryenebeli/understanding-call-stacks-in-java-script-54e6 | javascript, callstack, memory, v8 | ##What is a call stack?
A call stack is a region in memory that keeps track of the running/active subroutine/function in a program. it follows a first in last out approach(FILO). When a function is called it is pushed on top of the call stack and when it returns it is popped out of the call stack.
##Global execution context?
A global execution context is always the first function on the stack. it is an anonymous function the creates the environment in which the javascript code runs. For an environment like the browser the global execution context creates a global object called windows and assigns it to "this".
##Stack limits and overflow
As interesting as stacks sounds they also have a memory limit just like any storage. the limit of the stack determines the total number of functions that can be on the stack at once. Stack limits differ in various browsers. when a stack limit is exceeded it causes an error known as stack overflow.
The quickest way to cause a stack overflow is by recursion.
```javascript
function sayHello() {
sayHello()
}
sayHello();
```
The above code will cause a stack overflow because it keeps adding to the stack and exceed the given stack memory allocation.
## Javascript has only one call stack
Javascript is a single-threaded language and what this means for the call stack is javascript can only have one call stack. | jerryenebeli |
336,682 | Day 18 of #100DaysOfCode: Create Sitemap to Improve SEO | Introduction Sitemap can't really improve SEO for the website. However, it can make sure t... | 0 | 2020-05-16T11:38:37 | https://dev.to/jenhsuan/day-18-of-100daysofcode-create-sitemap-to-improve-seo-2li7 | 100daysofcode, marketing, seo, webdev |
## Introduction
Sitemap can't really improve SEO for the website. However, it can make sure that search engine includes every pages of the website.
## Steps
### 1. Generate sitemap for the website
The sitemap.xml has to include all pages. We can use sitemap generator to generate sitemap if the website is too large. https://www.xml-sitemaps.com/
* Put one page's URL one the input box and click start
* Then the site generator will scan the website and shows all pages
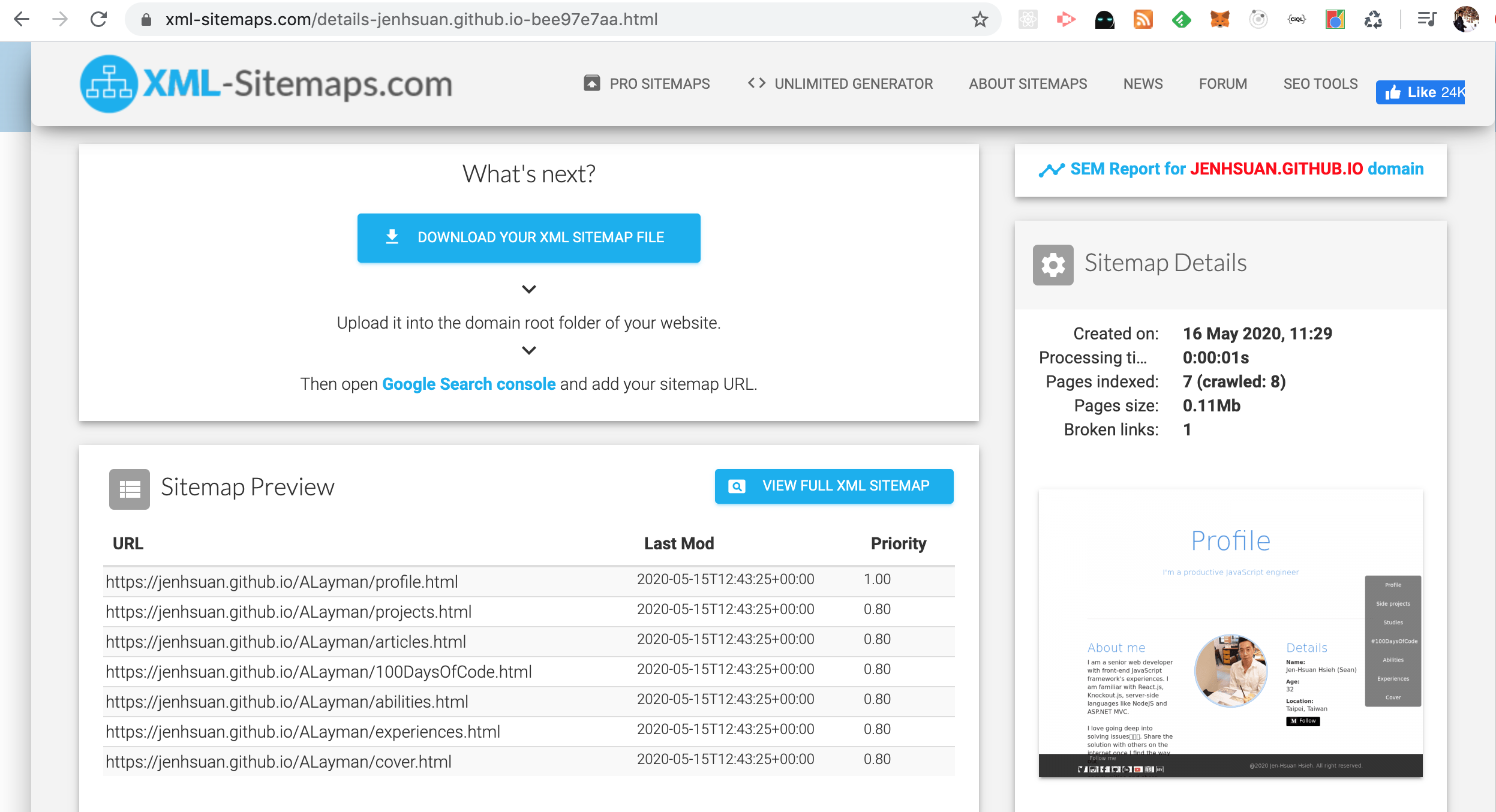
* The following example shows the format of the sitemap
```xml
<?xml version="1.0" encoding="UTF-8"?>
<urlset
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd">
<url>
<loc>https://jenhsuan.github.io/ALayman/profile.html</loc>
<lastmod>2020-05-09T00:44:26+00:00</lastmod>
<priority>1.00</priority>
</url>
<url>
<loc>https://jenhsuan.github.io/ALayman/projects.html</loc>
<lastmod>2020-05-09T00:44:26+00:00</lastmod>
<priority>0.80</priority>
</url>
...
</urlset>
```
* Put the sitemap.xml in the root folder. Make sure that others can visit sitemap under the domain.
### 2. Submit the Sitemap to Google Search Console
* Login to Google search console (https://search.google.com/) and select *Sitemap* put the url of the sitemap and submit.
That's it!
## Articles
There are some of my articles. Feel free to check if you like!
* My blog-posts for software developing: https://medium.com/a-layman
* My web resume: https://jenhsuan.github.io/ALayman/cover.html
* Facebook page: https://www.facebook.com/imalayman | jenhsuan |
336,728 | Which is most powerful, Golang or Node.js? | They have different strengths, I'd say neither. But if you have a specific purposes one could be bett... | 0 | 2020-05-16T12:24:04 | https://dev.to/threadspeed/which-is-most-powerful-golang-or-node-js-2n0c | go, node | They have different strengths, I'd say neither. But if you have a specific purposes one could be better suited for your work than the other.
We'll compare both Golang and Node.js
**Concurrency**
Golang is far superior to Node.js for concurrency. Golang can start hundreds of thousands of threads (<a href="https://golangr.com/goroutines/">goroutines</a>) and it would be fine, not the case for Node.js
**Ecosystem**
Nodejs has a larger ecosystem with very good 3rd-party tooling. With nodejs you can build single page apps written end-to-end in javascript.
**Performance**
If you need high performance, Go is a better choice. Node.js is an interpreted language based on JavaScript, that is slower than a compiled language like Go.
Golang compiles to fast native code. Node.js runs JavaScript that is much slower.
**Learning Curve**
Go needs to be learned from the start (<a href="https://golangr.com/">learn Go</a>). But all web developers already know Javascript. Javascript is one of the most known languages.
That makes it much easier to start with Node.js than Golang for many developers. That said, Golang is not hard to learn either.
So to create a short list:
**Pros of Go:**
* Faster than Node
* Concurrency model
* Has a standard library
* Static binaries, portable binaries
**Pros of Node:**
* Has a larger ecosystem
* Good 3rd-party tooling.
* JavaScript
**Related links:**
* <a href="https://golang.org/">Golang website</a>
* <a href="https://nodejs.org/en/">Nodejs website</a> | threadspeed |
336,739 | All the Things You Can Do With GitHub API and Python | Note: This was originally posted at martinheinz.dev Most of us use GitHub every day either using CLI... | 0 | 2020-06-15T15:44:32 | https://martinheinz.dev/blog/25 | python, api, github, tutorial | _Note: This was originally posted at [martinheinz.dev](https://martinheinz.dev/blog/25?utm_source=devto&utm_medium=referral&utm_campaign=blog_post_25)_
Most of us use GitHub every day either using CLI or its website. Sometimes however, you need to automate these same tasks like, for example creating Gist, querying repository analytics or just pulling, modifying and pushing new file. All these things and more can be done easily using [GitHub API](https://developer.github.com/v3/), and Python is here to help with that and make it even easier.
# What We Will Need
Before we start using GitHub API, we first need to generate personal access token that will allow us to authenticate against the API. We can get one at <https://github.com/settings/tokens> by clicking on _Generate new token_. You will be asked to select scopes for the token. Which scopes you choose will determine what information and actions you will be able to perform against the API. You should be careful with the ones prefixed with `write:`, `delete:` and `admin:` as these might be quite destructive. You can find description of each scope in [docs here](https://developer.github.com/apps/building-oauth-apps/understanding-scopes-for-oauth-apps/).
Now that we have the token, let's test whether it actually works:
```shell
~ $ GITHUB_TOKEN="..."
~ $ curl -H "Authorization: token $GITHUB_TOKEN" https://api.github.com/gists
```
And here is the expected (trimmed) response showing list of my public _Gists_:
```json
[
{
"url": "https://api.github.com/gists/f3da4b0e3493b4bba4fb957fba1eaa02",
"forks_url": "https://api.github.com/gists/f3da4b0e3493b4bba4fb957fba1eaa02/forks",
"commits_url": "https://api.github.com/gists/f3da4b0e3493b4bba4fb957fba1eaa02/commits",
"id": "f3da4b0e3493b4bba4fb957fba1eaa02",
"node_id": "MDQ6R2lzdGYzZGE0YjBlMzQ5M2I0YmJhNGZiOTU3ZmJhMWVhYTAy",
"git_pull_url": "https://gist.github.com/f3da4b0e3493b4bba4fb957fba1eaa02.git",
"git_push_url": "https://gist.github.com/f3da4b0e3493b4bba4fb957fba1eaa02.git",
"html_url": "https://gist.github.com/f3da4b0e3493b4bba4fb957fba1eaa02",
"files": {
"Test": {
"filename": "Test",
"type": "text/plain",
"language": null,
"raw_url": "https://gist.githubusercontent.com/MartinHeinz/f3da4b0e3493b4bba4fb957fba1eaa02/raw/cebefee5794b12a1772c97673647678f057a6854/Test",
"size": 32
}
},
"truncated": false
}
]
```
# Doing It With Python
We have the personal token and we tested it with `cURL`, so now we can switch to doing the same thing in Python. We have two options here though. We can use raw requests or we can use [_PyGitHub_](https://github.com/PyGithub/PyGithub).
_PyGitHub_ exposes some of the GitHub API endpoints for most common operations like repository, issue or branch management. It can't be used for every single feature exposed through the GitHub API, so in the following sections, I will show mixture of _PyGitHub_ and _Requests_ calls depending on whether it can be done with _PyGitHub_ or not.
First things first though - let's install both libraries (_PyGitHub_ and _Requests_) and see a simple example for both:
```shell
~ $ pip install PyGithub requests
```
Example using _PyGitHub_:
```python
from github import Github
import os
from pprint import pprint
token = os.getenv('GITHUB_TOKEN', '...')
g = Github(token)
repo = g.get_repo("MartinHeinz/python-project-blueprint")
issues = repo.get_issues(state="open")
pprint(issues.get_page(0))
```
Example using _Requests_:
```python
import requests
import os
from pprint import pprint
token = os.getenv('GITHUB_TOKEN', '...')
owner = "MartinHeinz"
repo = "python-project-blueprint"
query_url = f"https://api.github.com/repos/{owner}/{repo}/issues"
params = {
"state": "open",
}
headers = {'Authorization': f'token {token}'}
r = requests.get(query_url, headers=headers, params=params)
pprint(r.json())
```
Both snippets above use the same API endpoint to retrieve all open issues for specified repository.
In both cases we start by taking GitHub token from environment variable. Next, in the example with using _PyGitHub_ we use the token to create instance of `GitHub` class, which is then used to get repository and query its issues in _open state_. The result is paginated list of issues, of which we print the first page.
In the example that uses raw HTTP request, we achieve the same result by building API URL from username and repository name and sending GET request to it containing `state` as body parameter and token as `Authorization` header. Only difference is that result is not paginated. Here is the result for both examples:
First one being _PyGitHub_ output:
```python
[Issue(title="configure_project script not working", number=10),
Issue(title="Consider Flask-Rest", number=9),
Issue(title="Add newline to match dev.Dockerfile", number=7),
Issue(title="Consider using wemake-python-styleguide", number=5),
Issue(title="Consider versioneer", number=4),
Issue(title="Adding isort and black", number=3),
Issue(title="Consider src directory", number=2)]
```
Second, raw Python list of dictionaries (JSON):
```python
[{'assignee': None,
'body': 'Some Markdown text...',
'comments': 0,
'comments_url': 'https://api.github.com/repos/MartinHeinz/python-project-blueprint/issues/10/comments',
'created_at': '2020-04-20T22:16:33Z',
'html_url': 'https://github.com/MartinHeinz/python-project-blueprint/issues/10',
'id': 603571386,
'labels': [],
'labels_url': 'https://api.github.com/repos/MartinHeinz/python-project-blueprint/issues/10/labels{/name}',
'milestone': None,
'node_id': 'MDU6SXNzdWU2MDM1NzEzODY=',
'repository_url': 'https://api.github.com/repos/MartinHeinz/python-project-blueprint',
'state': 'open',
'title': 'configure_project script not working',
'url': 'https://api.github.com/repos/MartinHeinz/python-project-blueprint/issues/10',
'user': {...}},
...
]
```
# Create an Issue
While on topic of issues, let's create one too, shall we?
```python
g = Github(token)
repo = g.get_repo("MartinHeinz/python-project-blueprint")
i = repo.create_issue(
title="Issue Title",
body="Text of the body.",
assignee="MartinHeinz",
labels=[
repo.get_label("good first issue")
]
)
pprint(i)
```
This is one of the use cases, where _PyGitHub_ is very handy. We just need to get the repository, create issues against it and specify bunch of parameters. In the snippet above we use `title`, `body`, `assignee` and `labels` parameters, but you could also add milestone or more labels which are queried using their name.
# Create a Gist
Another things we can create is GitHub _Gist_, this time using _Requests_:
```python
query_url = "https://api.github.com/gists"
data = {
"public": True,
"files": {
"code.py": {
"content": "print('some code')"
},
}
}
headers = {'Authorization': f'token {token}'}
r = requests.post(query_url, headers=headers, data=json.dumps(data))
pprint(r.json())
```
The request for creating _Gists_ is pretty simple. In the POST request you need to specify whether the _Gist_ should be `public` or not, next you need to populate list of `files` that will be part of said _Gist_, where each _key_ is a file name and its `content` contains actual string content of the file. The code above uses `json.dumps()` to convert Python dictionary to JSON string to create request body and the usual _Authorization_ header.
Below you can see the relevant parts of the expected response:
```json
{"comments": 0,
"description": null,
"files": {"code.py": {"content": "print('some code')",
"filename": "code.py",
"language": "Python",
"raw_url": "https://gist.githubusercontent.com/MartinHeinz/383c6b450f892e169074a642a372e459/raw/8d53df5862f8b687fc09d0b3c1b3c49afe441cbe/code.py",
"size": 18,
"truncated": null,
"type": "application/x-python"}},
"forks": [],
"html_url": "https://gist.github.com/383c6b450f892e169074a642a372e459",
"id": "383c6b450f892e169074a642a372e459",
"node_id": "MDQ6R2lzdDM4M2M2YjQ1MGY4OTJlMTY5MDc0YTY0MmEzNzJlNDU5",
"public": true,
"url": "https://api.github.com/gists/383c6b450f892e169074a642a372e459"
}
```
After creating a _Gist_ you might want to do other things with it like update it, list commits, fork it or just fetch it. For all these operations there's a API endpoint listed in these [docs](https://developer.github.com/v3/gists/).
# Programmatically Update File
One very practical, but quite complicated use case for using GitHub API, is programmatically fetching, modifying, committing and finally pushing some file to repository. Let's break this down and see an example:
```python
file_path = "requirements.txt"
g = Github(token)
repo = g.get_repo("MartinHeinz/python-project-blueprint")
file = repo.get_contents(file_path, ref="master") # Get file from branch
data = file.decoded_content.decode("utf-8") # Get raw string data
data += "\npytest==5.3.2" # Modify/Create file
def push(path, message, content, branch, update=False):
author = InputGitAuthor(
"MartinHeinz",
"martin7.heinz@gmail.com"
)
source = repo.get_branch("master")
repo.create_git_ref(ref=f"refs/heads/{branch}", sha=source.commit.sha) # Create new branch from master
if update: # If file already exists, update it
contents = repo.get_contents(path, ref=branch) # Retrieve old file to get its SHA and path
repo.update_file(contents.path, message, content, contents.sha, branch=branch, author=author) # Add, commit and push branch
else: # If file doesn't exist, create it
repo.create_file(path, message, content, branch=branch, author=author) # Add, commit and push branch
push(file_path, "Add pytest to dependencies.", data, "update-dependencies", update=True)
```
Starting from the top, we get contents of a file using the usual repository reference, decode it to plain string and modify it. Next, in the `push` function, we create new branch originating from commit specified using `source.commit.sha`. Based on the `if` statement, we have 2 options update existing file or create new one. In case we're doing update, we first retrieve existing file to get its hash and path and then we perform the update using previously modified data (`content`), supplied `message`, `branch` and `author` object. If on the other hand we want to create a new file in the repository, then we just omit passing in the SHA of existing file and we're done.
# Analyzing Traffic
If you are more into data science and analytics you might find useful possibility of querying views/clones statistics from your repositories:
```python
g = Github(token)
repo = g.get_repo("MartinHeinz/python-project-blueprint")
clones = repo.get_clones_traffic(per="day")
views = repo.get_views_traffic(per="day")
print(f"Repository has {clones['count']} clones out of which {clones['uniques']} are unique.")
print(f"Repository has {views['count']} views out of which {views['uniques']} are unique.")
best_day = max(*list((day.count, day.timestamp) for day in views["views"]), key=itemgetter(0))
pprint(views)
print(f"Repository had most views on {best_day[1]} with {best_day[0]} views")
```
The code needed to retrieve the data from GiHub is really just one line for _clones_ and one line for _views_. Both the `clones` and `views` object contains `count`, `uniques` and `views` attributes. We use the first 2 in the print statements to show actual and unique clones and views respectively.
The disgusting (beautiful) one liner after that iterates over list of `View` objects that contain view `count` for each day and respective `timestamp` which we extract into list of tuples. We then find tuple with maximum `count` and print its date and actual view count on last line. This gives us output shown below:
```shell
Repository has 31 clones out of which 23 are unique.
Repository has 1672 views out of which 297 are unique.
{'count': 1672,
'uniques': 297,
'views': [View(uniques=6, timestamp=2020-04-28 00:00:00, count=29),
View(uniques=30, timestamp=2020-04-29 00:00:00, count=141),
View(uniques=37, timestamp=2020-04-30 00:00:00, count=184),
View(uniques=25, timestamp=2020-05-01 00:00:00, count=93),
View(uniques=24, timestamp=2020-05-02 00:00:00, count=131),
View(uniques=20, timestamp=2020-05-03 00:00:00, count=41),
View(uniques=26, timestamp=2020-05-04 00:00:00, count=121),
View(uniques=41, timestamp=2020-05-05 00:00:00, count=250),
View(uniques=47, timestamp=2020-05-06 00:00:00, count=184),
View(uniques=33, timestamp=2020-05-07 00:00:00, count=216),
View(uniques=15, timestamp=2020-05-08 00:00:00, count=48),
View(uniques=20, timestamp=2020-05-09 00:00:00, count=71),
View(uniques=22, timestamp=2020-05-10 00:00:00, count=51),
View(uniques=7, timestamp=2020-05-11 00:00:00, count=16),
View(uniques=14, timestamp=2020-05-12 00:00:00, count=96)]}
Repository had most views on 2020-05-05 00:00:00 with 250 views
```
# Rendering Markdown
This example uses GitHub API, but can be used for non-GitHub purposes. I'm talking about GitHub APIs ability to generate HTML from markdown text. This could be useful if you have website that can't render markdown directly, but rather you could use GitHub API to create HTML for you.
```python
query_url = "https://api.github.com/markdown"
data = {
"text": "`code`, _italics_, **bold**",
"mode": "markdown",
}
headers = {'Authorization': f'token {token}'}
r = requests.post(query_url, headers=headers, data=json.dumps(data))
pprint(r)
pprint(r.text)
```
Once again the query is quite simple. All we need to do is send the text to be rendered in `text` body parameter together with mode set to `markdown`. The example `text` above includes, `code` snippet, _italics_ and *bold* text and that's exactly what we get back in form of HTML:
Response:
```shell
<Response [200]>
'<p><code>code</code>, <em>italics</em>, <strong>bold</strong></p>\n'
```
# Update Commit Status
You know these nice green check marks, yellow circles and ugly red crosses next to your commits that are added by CI tools? Do you want to change them (maybe just for fun, maybe as part of your own CI solution)? Of course you do. And there is API for that:
```python
g = Github(token)
repo = g.get_repo("MartinHeinz/python-project-blueprint")
branch = repo.get_branch(branch="master")
status = repo.get_commit(sha=branch.commit.sha).create_status(
state="success",
target_url="https://some-ci-url.com",
description="CI in Progress",
context="Just testing..."
)
print(status)
```
Surprisingly (for me) this obscure API endpoint is part of _PyGitHub_ library. To use it, we retrieve repo and its commit using commit hash. After that we create status for said commit, by describing its current state using parameters.
There are 4 states we can specify, namely - `error`, `failure`, `pending`, or `success` - in this example I chose `success`. Next, the `target_url` is the URL to which the _Details_ link points. And as you probably noticed, the `description` and `context` are the other values shown in dialog box shown below.

To be able to verify that status change actually went through, we receive `CommitStatus` response which is representation of current status of commit. In this case looks like this:
```python
CommitStatus(state="success", id=9617694889, context="Just testing...")
```
# Adding Reactions to Issue Comments
GitHub issue comments allow you to add various [reactions](https://developer.github.com/v3/reactions/#reaction-types) to them. So, maybe you want to add `+1`/`-1` to somebodies comment. Maybe just throw in some celebratory `hooray` emoji. If that's the case, then here's how you could do that in Python:
```python
owner = "MartinHeinz"
repo = "python-project-blueprint"
comment_id = "593154350"
query_url = f"https://api.github.com/repos/{owner}/{repo}/issues/comments/{comment_id}/reactions"
data = {
"content": "hooray"
}
headers = {
'Authorization': f'token {token}',
'Accept': 'application/vnd.github.squirrel-girl-preview',
}
r = requests.post(query_url, headers=headers, data=json.dumps(data))
pprint(r)
pprint(r.json())
```
To be able to create response, we will need the comment ID. It can be retrieved from API shown [here in docs](https://developer.github.com/v3/issues/comments/#list-comments-on-an-issue) or by clicking on the _three dots_ icon in upper right corner of issue comment and clicking _Copy Link_:

With that we can insert `owner` username, `repo` name and this `comment_id` in the URL and emoji name (e.g. `hooray`) in the `content` body parameter. Additionally we need to also include `Accept` header, as this endpoint is part of developer preview.
The expected response here is either `201` which means that reaction was created or `200` in which case the reaction was already added previously.
```shell
<Response [201]> # First pprint from snippet above.
```
And here is (trimmed) JSON response body, that we get back:
```json
{"content": "hooray",
"created_at": "2020-05-12T15:43:53Z",
"id": 71256913,
"node_id": "MDg6UmVhY3Rpb243MTI1NjkxMw==",
"user": {...}}
```
# Conclusion
Playing with public APIs is great way to start a new project (e.g. CI tools, Repository traffic analytics, GitHub Bots) and GitHub API has a lot of data/content for such a thing. What I showed here is just a small sample. To explore full API see [docs here](https://developer.github.com/v3/) or if you don't feel like messing with the REST API, then check out [_PyGitHub_ Examples](https://pygithub.readthedocs.io/en/latest/examples.html). | martinheinz |
336,840 | [MicroArticle] [JavaScript] Variable Declarations | Variable Declarations in JavaScript | 0 | 2020-05-17T08:48:23 | https://dev.to/naveen/microarticle-javascript-variable-declarations-3jgh | javascript | ---
title: [MicroArticle] [JavaScript] Variable Declarations
published: true
description: Variable Declarations in JavaScript
tags: JavaScript
---
>*MicroArticle is a bite-sized learning technique that focuses on learning just one key objective, applying them practically and feeling accomplished.*
***Well, what's in it for me and why do I care?***
*Turns out that, attention spans are getting shorter and the learners want to be engaged, entertained, motivated to learn something new and be able to see improvements*
***Motivation behind why I started this initiative:***
*I have always been passionate about writing and I am struggling to find time to write lately for the past couple of years and the greatest hurdle I am facing is going from inertia to mobility.*
*I had to come up with some strategies to resume my "habit" of writing. Having said that, I believe that most of our lives are governed by our habits. If you want to build a new habit, make that habit as easy to adopt as possible. Hence my idea of writing an almost ridiculously tiny article as possible - I ended up naming it as "MicroArticle". Picking an easy goal eliminates any perceptions of difficulty and is hardly daunting enough to make you feel fatigued.*
___
In this MicroArticle, we will discuss on how to declare variables in JavaScript and what is the difference between different keywords `var`, `let` and `const`
**What are Variables?**
They are just containers for storing data values - you can place data into these containers and then refer to the data by naming the container. Before using a variable in JavaScript, it must be declared.
**Keywords to declare Variables:**
Before JavaScript ES6 introduced, the only keyword available to declare a variable was the `var` keyword. Now there are 2 more additions to it - `let` and `const`
**Why these 2 new keywords are introduced?**
This is to allow programmers to decide scope options for the defined variables.
`var` - Function Scope
`let` and `const` - Block Scope
**What is a Function Scope?**
Refer to the below example - the variable `i` which is defined in the `for` loop is scoped even outside the for loop within the function. That's the reason why the console output till the number 5 (See the result tab)
{% jsfiddle https://jsfiddle.net/naveenrtr/mx1c0ydq/ js,result %}
**What is a Block Scope?**
Variables declared with the `let` keyword can have Block Scope - Variables declared inside a block { }. As a result, the Below code would throw an error since the variable `i` is accessed outside the block of for loop.
```javascript
function foo() {
for (let i = 0; i < 5; i++) {
console.log(i);
}
console.log(i);
}
foo();
```
What if I have the same variable say `x` defined both inside and outside the block scope?
```javascript
var x = 1;
{
var x = 2;
}
// What's the value of x here?
```
The above code will have the value of variable `x` as 2 (modified)
Try to guess what's the value of variable `x` in the below code snippet?
```javascript
var x = 1;
{
let x = 2;
}
// What's the value of x here?
```
If you guessed it right, the value of x outside the block would still be 1.
**Best Practices**
- Declare variables at the top of each script or function - your code looks much cleaner and it makes it easier to avoid unwanted re-declarations
- Initialize variables when you declare them - again, your code looks much cleaner and it provides a single place to initialize variables instead doing it all over the place
- Use `let` if you think that the value of the variable is intended to get modified, else use `const`
- Treat numbers, strings, or booleans as primitive values and not as objects - declaring as objects have performance impacts and side effects
---
Let me know what you all think about my initiative. The article might seem too trivial or basic for many of you here - but my idea is to get myself started with something small and also keeping my point on short attention span in mind. | naveen |
336,862 | Windows and Linux: A Sane Discussion | It's time we reopened the conversation about Windows vs. Linux...in a healthy way. | 0 | 2020-05-16T15:56:31 | https://dev.to/codemouse92/windows-and-linux-a-sane-discussion-4iml | discuss, healthydebate | ---
title: Windows and Linux: A Sane Discussion
published: true
description: It's time we reopened the conversation about Windows vs. Linux...in a healthy way.
tags: discuss, healthydebate
---
Let's face it — neither Microsoft Windows nor Linux in its many distributions are the same as they were ten years ago. The face of the computing ecosystem has changed. The past few years especially have brought many surprises, not least of which included Microsoft's wholesale embracing of open source and the Linux community.
I think it's time we reopened the conversation about Windows vs. Linux. What's working? What's not? What factors go into choosing one over the other?
I think @shadowjonathan made a very good point in response to @kailyons's decision to archive his posts surrounding this very topic...
{% devcomment p3k2 %}
That got me thinking...*THIS IS DEV!* Not only do we have a moderation staff who cares, but we have a nifty little tool that allows authors to hide comments.
---
# What are the pros and cons of Windows vs. Linux? What factors go into deciding to use one or the other?
---
Here's the rules:
1. You can share your opinions and your technical views, in favor of Microsoft Windows, Linux, any other operating system, or both...but you MUST be polite!
2. Disagreement isn't rude.
3. Healthy debate is fine, but hostility, elitism, and ad hominem attacks are not.
4. Unconstructive comments, even those that are "just shy" of violating community rules, WILL be hidden, and reported as needed.
5. I also don't want to receive any argumentative or offensive DMs about this. Any such messages will be reported, and then summarily ignored.
6. **If you're concerned about getting attacked for your views, please DM your comment to me, and I'll post it anonymously on your behalf!** (I will not post replies under most circumstances, only initial comments.)
Since I'm obviously the guy with the "hide posts" ability here, understand that I'm going to be more than a bit zealous about keeping this conversation safe for everyone, even the folks who have altogether opposite views from me. If your post gets hidden, move on. | codemouse92 |
336,998 | # Understanding the Role and Usage of Node.js | When a user interacts with our web site there may be a chance when it performs some operation like re... | 0 | 2020-05-16T17:00:47 | https://dev.to/shubhamggupta/understanding-the-role-and-usage-of-node-js-2mn2 | node, javascript, tutorial, codequality | When a user interacts with our web site there may be a chance when it performs some operation like registration, login, or posts anything. For example, the user performs a login operation, the user could unhook the validation javascript from the controls. Mostly the Client Side Validation depends on the JavaScript Language, so if users turn JavaScript off, it can easily bypass and submit dangerous input to the server. So the Client Side Validation can not protect your application from malicious attacks on your server resources and databases. therefore node.js comes into the picture. with the help of the node.js, we can perform all these operations on the server.
Node.js, can perform server-side validation, database connection, authentication, and write our business logic.
The huge advantage of node.js is that it uses javascript, a language which you need so much in modern web development for all the frontend, for some build tool and if you then can also use it on their server-side you don’t need to learn a bunch of different languages you can use the same language.
## **Node.js Role (In Web Development)**
##### **Run Server**
Create Server and listen to the incoming request
##### **Business Logic**
Handle Request, Validate Input, Connect to Database
##### **Response**
Return Response | shubhamggupta |
337,014 | The trace we leave evolving in our web development career | In the last few days, I once again updated my main, or some would say portfolio page and started to l... | 0 | 2020-05-16T17:40:48 | https://dev.to/azettl/the-trace-we-leave-evolving-in-our-web-development-career-4e4c | watercooler, career, webdev | In the last few days, I once again updated my main, or some would say portfolio page and started to look back on how the site evolved over the years.
When I started, I used no versioning system for my websites at all, so for some projects, all that's left is what I can find in the Internet Archives Wayback Machine.
Today, I was curious to see how I evolved as a developer based on what I find via the Wayback Machine. Before we look at that, let me mention some things I did not find there.
I started programming quite early as my father introduced me to BASIC and later to HTML. He had a website sharing family pictures so nothing fancy, but as a kid, I was so happy that he gave me one page there. I mainly put pictures from Simpsons (who thought about copyright at that time) and some silly stuff with horrible design.
My father's page still exists without my subpage as I wanted to have my own website. Once I had my website, no own domain, hosted on the local cities computer clubs server, I also wanted a guestbook.
Guestbooks were the new shit at that time, and I also needed one on my website, and of course, I did not want to include some third-party guestbook but write my own.
Gladly the computer club offered PHP classes with people at my age, so every Saturday, I met with a bunch of other 13 - 14-year-old kids trying to understand PHP, with the ultimate goal in mind to have an own guestbook!
The computer club still exists; I am still a member, although inactive. But the website with the must-have guestbook disappeared.
None of these pages can be found on the web archive, but ultimately learning PHP at that time got me my apprenticeship as a developer with 16.
But now let us have a look at what's left of my side projects.

The first record of my page azettl.de is in 2004 https://web.archive.org/web/20040123043052/http://www.azettl.de/ now you wonder who Toni is? I have no idea either at this point the page was not mine yet.

We start to see my content from 2007 onwards; the first recording is https://web.archive.org/web/20070126003644/http://www.azettl.de/. At this time, all of my sites were in german only.
What we see here is, at least for me interesting, I worked on a PHP based Content Management System. I remember reading a book about that, and I wanted to try developing it myself. Another big thing for me at that time was Google Gadgets, do you remember them? I had some running quite successfully. We might see them in a later screenshot.
Also, you see the guestbook is not there but a shoutbox, I do not even remember why and what the hype about it was, maybe some local website pre twitter?
The next record is from the same year, June 2007, and we see I converted the page to a blog. The first entry is about splitting color values with Javascript, do not look at the code to closely I would do that different by now.
Next are articles about mapwars.de, a page I had where you could request maps from Google Maps or Yahoo Maps with some pointers for addresses on it. It was mainly used for contact pages on websites I worked on.
The syntax was like this:
```
<script type="text/javascript">
var xmlfile = "http://www.mapwars.de/website/mapwars.xml"; // Die absolute URL zur XML Datei
var map = "googlemap"; // Der Kartentyp googlemap oder yahoomap
var mapwidth = 580;
var mapheight = 340;
var mapzoom = 6;
var mapzoombuttons = "large";
var maptypes = "true";
var mapoverview = "true";
var mapscale = "true";
var mapcenter = "point1";
</script>
<script type="text/javascript" src="http://www.mapwars.de/mapview.js"></script>
```
You find a record of this side project here https://web.archive.org/web/20070702144252/http://www.mapwars.de/website/home.html.
The description of the API was already available in English https://web.archive.org/web/20070628225141if_/http://www.mapwars.de/website/howto.html
https://web.archive.org/web/20070628225027if_/http://www.mapwars.de/website/geocoding.html
At some point in this year, I also switched to Blogger, https://web.archive.org/web/20070903102317/http://www.azettl.de/.
2009, it's my own website again, and we also see I also started with Wordpress Plugin development.
https://web.archive.org/web/20090208120053/http://www.azettl.de/
I had a plugin to draw comments, pretty basic, it was a table where you had one cell per pixel, and later I created a png out of it via PHP. Magazine was a plugin to create a magazine-style PDF from your blog posts.
The plugins are still available on the page, but they are hopelessly outdated and therefore violate some guidelines and are locked.
https://wordpress.org/plugins/draw-comments/
https://wordpress.org/plugins/map24-routing/
https://wordpress.org/plugins/magazine/
2010 there are recordings in the web archive, but nothing happened development-wise, so let's skip that.
Around 2011 I got my PHP certification and changed my site to a typical profile page and did not change much since 2018.
https://web.archive.org/web/20111105111246/http://azettl.de/
In the end, azettl.de got redirected to azettl.net, where I already had a kind of business card page for my freelancing stuff.
https://web.archive.org/web/20200510215146/https://azettl.de/
And this is the old version of azettl.net https://web.archive.org/web/20200502161754/https://azettl.net/, which you saw till last week.
The new version looks a little bit more colorful.

Of course, there are many more of these side project domains I could go in deeper, but I do not want to bore you with more of my old stuff.
Also, what happened all these recent years? Most of my development moved to GitHub, and I do not have a personal blog anymore. I do have new side projects which are not mentioned here but can be found on the page we discussed in detail today, azettl.de.
Also, this post is completely skipping the fantastic progress I made as a developer, thanks to my employer.
Still, I hope you found it interesting, and maybe you take a look back at your old projects and see how you did and how you evolved as a developer.
| azettl |
1,423,620 | Dhaka University Paragraph | Dhaka University is the result of a movement for regional identity. It was founded by the people of... | 0 | 2023-04-02T20:44:36 | https://dev.to/banglanews_info/dhaka-university-paragraph-30cp | Dhaka University is the result of a movement for regional identity. It was founded by the people of East Bengal. and reached its zenith in the war for Bangladeshi independence. In 2021, Bangladesh and the University of Dhaka will both be celebrating their 50th birthdays. This is to remember these important events. In this article, we will discuss DU’s 100-year short paragraph at a glance.
DU was started in 1921 with just three faculties, 12 departments, three dorms, 60 teachers, and 877 students living on 600 acres of land. It has since grown into a huge educational and political force.
As it prepares to mark its 100th anniversary on Thursday, DU has 13 faculties, 83 departments, 12 institutions, 20 residence halls, 3 hostels, and more than 56 research centers. According to the university’s website, there are now 37,018 students and 1,992 faculty members.
[Dhaka University paragraph](https://www.banglanewsinfo.com/dhaka-university-du/)
An early distinguishing factor for Dhaka University was the university’s non-affiliated and residential nature, akin to Oxford University. Dhaka University is known as the “Oxford of the East” because of its top-notch living and learning facilities.
Affiliation mandates have replaced the university’s sole residency requirement since 1947. | banglanews_info | |
337,045 | Dart and C : how to ffi and wasm (2) Hello | Let's create the Shared Library and JS Library in the environment we created last time. Create a C l... | 10,918 | 2020-05-16T18:34:22 | https://dev.to/kyorohiro/dart-and-c-how-to-ffi-and-wasm-2-hello-4jo2 | dart, c, ffi, webassembly | Let's create the Shared Library and JS Library in the environment we created [last time](https://dev.to/kyorohiro/dart-and-c-how-to-support-ffi-and-wasm-1-514f).
Create a C language function that displays "Hello !!" and call that function at "Web browser" and "Linux Server".
# Create Clang func
```c:ky.c
#include <stdio.h>
// [Linux]
// find . -name "*.o" | xargs rm
// gcc -Wall -Werror -fpic -I. -c ky.c -o ky.o
// gcc -shared -o libky.so ky.o
// [Wasm]
// find . -name "*.o" | xargs rm
// find . -name "*.wasm" | xargs rm
// emcc ky.c -o ky.o
// emcc ky.o -o libky.js -s EXTRA_EXPORTED_RUNTIME_METHODS='["ccall", "cwrap"]' -s EXPORTED_FUNCTIONS="['_print_hello']"
// cp libky.js ../web/libky.js
// cp libky.wasm ../web/libky.wasm
void print_hello() {
printf("Hello!!\n");
}
```
## Create Shared Library
```bash
$ find . -name "*.o" | xargs rm
$ gcc -Wall -Werror -fpic -I. -c ky.c -o ky.o
$ gcc -shared -o libky.so ky.o
```
## Create JS and WASM
```bash
$ find . -name "*.o" | xargs rm
$ find . -name "*.wasm" | xargs rm
$ emcc ky.c -o ky.o
$ emcc ky.o -o libky.js -s EXTRA_EXPORTED_RUNTIME_METHODS='["ccall", "cwrap"]' -s EXPORTED_FUNCTIONS="['_print_hello']"
```
# Let's call this function from linux server
```dart:main.dart
import 'dart:ffi' as ffi;
typedef PrintHelloFunc = ffi.Pointer<ffi.Void> Function();
typedef PrintHello = ffi.Pointer<ffi.Void> Function();
ffi.DynamicLibrary dylib = ffi.DynamicLibrary.open('/app/libc/libky.so');
PrintHello _print_hello = dylib
.lookup<ffi.NativeFunction<PrintHelloFunc>>('print_hello')
.asFunction();
void printHello() {
_print_hello();
}
main(List<String> args) {
printHello();
}
```
# Let's call this function from Web Browser
```dart:main.dart
import 'dart:js' as js;
js.JsObject Module = js.context['Module'];
js.JsFunction _print_hello = Module.callMethod('cwrap',['print_hello','',[]]);
void printHello() {
_print_hello.apply([]);
}
void main() {
printHello();
}
```
# Test
```bash
$ dart ./bin/main.dart
```
```bash
webdev serve --hostname=0.0.0.0
```
thanks!!
# Next time
I will explain how to handle Buffer OR how to handle various Primitives.
# PS
this text's code is the following
https://github.com/kyorohiro/dart_clang_codeserver/tree/02_hello | kyorohiro |
337,114 | 11 Quick Tips to Help Ramp Up Social Media Engagement | Social media is becoming the top online hub of people using the internet. For entrepreneurs like you,... | 0 | 2020-05-16T21:08:05 | https://dev.to/vaishalidelawala/11-quick-tips-to-help-ramp-up-social-media-engagement-5akg | social, media, engagement, reputation | Social media is becoming the top online hub of people using the internet. For entrepreneurs like you, this means that you can now connect with your target audience a lot faster and easier. In fact, almost every online entrepreneur out there is seeking for creative ways to improve their social media engagement.
The majority of business owners now use social media to grow and promote their enterprises. It is essential that you know how to effectively use social media to prevent you from wasting your time [updating your Facebook page](https://www.uplarn.com/how-to-get-more-facebook-page-followers-for-free/), and sending out tweets when no one really has any interest in reading them.
That said, here are 11 quick tips that you can implement right away to be able to have a more effective social media marketing strategy”.
##Numbers are not everything
Having thousands of fans or followers does not necessarily translate into sales. Even if you are not promoting a business and you have thousands of friends, it does not mean that you are going to have more social interactions, especially if you do not have anything in common.
Spending copious amounts of time looking for followers, when they have no interest in you or your products is a waste of time.
##Always offer great, quality contents
When it comes to building a strong social media presence and online reputation in general, everything boils down to the quality of contents you’re offering. From social media updates & images, to blog posts & ad copies, always create the best possible content you can come up with.
##Show that you’re interesting and interested
Your social media followers/network should find you interesting, and you can achieve this by telling inspiring stories or by sharing helpful. But being interesting to them is only half the job. You should complete the equation by showing them that you are genuinely interested with their lives, their problems and their stories as well. Showing that you’re ready to help them whenever you can is even more important.
##Share useful links
Sharing links that may be of value to your followers or readers is one way to strengthen your connection with them.
##Stick with simple services
You can achieve just as much in terms of promotion with a service that is free than with one you have to pay for.
If you are new to the world of social media you should start with a simple site such as twitter and Facebook which both have millions of users worldwide.
##Never forget your call to actions
Always tell explicitly your readers what you want them to do next. Call to actions such as “share this”, “leave your comment below”, “click to re-tweet” can encourage more conversation and engagement.
##Ask questions
One way to increase engagement is by posting status updates in the form of open-ended questions. The social media community likes to share their ideas and an open-ended question is a great way to start a lively conversation with them.
##Share eye-catching and fun images
Your social media campaign will work more effectively if you incorporate a great visual strategy in it. People love good, witty & fun images.
##Keep your social media accounts updated
Consistency is another crucial key to improving your social media engagement. Be consistent and be always there. Establish a constant presence and connect with your audience in a regular basis.
##Limit your effort
You don't need to have a profile on every single social networking site. Stick to a handful of the best sites and link them all together. For example, you can have your twitter page link to your blog and Facebook page.
##Be more sociable
Instead of directly selling your products or services, engage your followers in conversation.
Social media takes a different approach than other web based techniques such as email marketing. You have to sell yourself as well as your business.
##Be Honest
Refrain from writing fake positive reviews to gain popularity, savvy social media users will see through this and it could harm your [reputation](https://theruntime.com/reasons-your-online-reputation-matters/).
The next time you come up with your social media campaign, don’t forget to incorporate and implement the 11 tips I shared above. Remember, a quality and engaging social media strategy will keep your audience coming back for more!
| vaishalidelawala |
337,139 | How do you name your webpack/parcel/etc aliases? | Bundlers such as webpack have an option to replace your relative paths with aliases. I've seen some a... | 0 | 2020-05-17T00:16:22 | https://dev.to/creativenull/how-do-you-name-your-webpack-parcel-etc-aliases-10mf | discuss, javascript, webpack | Bundlers such as webpack have an option to replace your relative paths with aliases. I've seen some articles and tutorial where they use either `@` prefix or capitalizing the first letter of the relative path, like `App/` or `Components/`.
For me I started using `@` prefixes at the beginning but then started to experiment around with `#` prefixes instead for my projects.
```js
// webpack config
resolve: {
alias: {
'#app': './src'
}
}
```
I'm interested to know what you use as your webpack (or any other bundler) aliases? Or if you don't use them at all? | creativenull |
337,146 | Implementing VAT into a Laravel app with Stripe and Cashier | I recently had to update the Sitesauce billing system to account for the European Value Added Tax... | 0 | 2020-05-19T00:37:16 | https://miguelpiedrafita.com/laravel-cashier-vat/ | tutorial, laravel, php | ---
title: Implementing VAT into a Laravel app with Stripe and Cashier
published: true
date: 2020-05-16 23:00:00 UTC
tags: Tutorial, Laravel, PHP
canonical_url: https://miguelpiedrafita.com/laravel-cashier-vat/
cover_image: https://miguelpiedrafita.com/content/images/2020/05/VAT-Article.jpg
---
I recently had to update the [Sitesauce](https://sitesauce.app) billing system to account for the European Value Added Tax (VAT). Here's a short article detailing how I implemented it.
First of all, I decided to get rid of as much of the existing billing-related logic as I possibly could. This meant implementing [Stripe's new self-serve portal](https://stripe.com/docs/billing/subscriptions/integrating-self-serve-portal), which can take care of viewing invoices and managing payment methods and subscriptions. Since Cashier already takes care of keeping our database in sync with Stripe, the only thing we need to do is create a new session to redirect the user to.
``` php
public function portal(User $user)
{
$this->authorize('update', $user);
return with(\Stripe\BillingPortal\Session::create([
'customer' => $user->stripe_id,
'return_url' => URL::previous(),
]), fn ($portal) => redirect($portal->url));
}
```
Here's how the portal looks in action:
{% youtube bm5BphnQ6aE %}
While we're fixing billing stuff, multiple people have complained that the current credit card input (while looking cool) does not work on Safari, which means you cannot currently complete the onboarding on iOS devices. Let's get rid of it and give the page a quick redesign.


<figcaption>Here's a before and after comparison of the Sitesauce billing page</figcaption>
You may now be wondering, where am I asking them for their credit card details? Instead of using [Stripe Elements](https://stripe.com/elements) to capture their credit card details on page, I'm going to switch to the new Stripe Checkout, which will later make implementing VAT simpler.
To get it working we're gonna need to make two changes. First, we need to create a new checkout session and return the session ID, so we can redirect to checkout from the frontend. I've also added some logic to apply coupon codes, and fail validation if they don't exist.
``` php
public function checkout(Request $request)
{
$this->authorize('update', $user = $request->user());
$request->validate([
'plan' => ['required', 'string', 'in:monthly,yearly'],
'coupon' => ['nullable', 'string'],
]);
try {
return with(\Stripe\Checkout\Session::create([
'payment_method_types' => ['card'],
'customer_email' => $user->email,
'subscription_data' => [
'items' => [[ 'plan' => $request->input('plan')] ],
'coupon' => $request->input('coupon'),
'trial_period_days' => 7,
],
'mode' => 'subscription',
'client_reference_id' => $user->id,
'success_url' => route('setup'),
'cancel_url' => URL::previous(route('setup.billing')),
]), fn ($session) => $session->id);
} catch (\Stripe\Exception\InvalidRequestException $e) {
throw_unless($e->getStripeParam() == 'subscription_data[coupon]', $e);
fail_validation('coupon', 'The specified coupon does not exist');
}
}
```
We also need to handle the `checkout.session.completed` webhook Stripe returns. We can do this by [extending the default Stripe webhook controller](https://laravel.com/docs/7.x/billing#defining-webhook-event-handlers) and adding the following method:
``` php
public function handleCheckoutSessionCompleted(array $payload)
{
$session = $payload['data']['object'];
$team = Team::findOrFail($session['client_reference_id']);
DB::transaction(function () use ($session, $team) {
$team->update(['stripe_id' => $session['customer']]);
$team->subscriptions()->create([
'name' => 'default',
'stripe_id' => $session['subscription'],
'stripe_status' => 'trialing',
'stripe_plan' => Arr::get($session, 'display_items.0.plan.id'),
'quantity' => 1,
'trial_ends_at' => now()->addDays(7),
'ends_at' => null,
]);
});
return $this->successMethod();
}
```
Here's how our billing flow looks with all this implemented:
{% youtube 0h-qbPDMOUU %}
With both of these refactors done, it's time to dive into our main subject: VAT. Let's first make sure we understand what we need to implement:
``` js
// keep in mind this is based on a conversation I had with someone from the Spanish Tax Agency
// please consult with your accountant, I'm just a random teenager on the internet
it('should help me understand this mess', () => {
if (! isEu()) return // nothing to do here, you lucky bastards are exempt from VAT
if (isSpain()) {
// users from the country I'm registered at need to pay VAT no matter what
return 'apply 21% tax'
}
// okay, here's where it gets complicated
const vatID = '...'
if (vatID) {
// if the customer has a VAT-ID, they handle all this mess by themselves and there's not much I need to do
// still, I store their ID on Stripe for invoicing
return addToStripe(vatID)
}
// if the customer doesn't have a VAT-ID, I need to apply their country's tax rate
return `apply ${getTaxRate(getCountry())}% tax`
})
```
The first thing we need to do is detect the country our customer belongs to. For this, we'll use [Cloudflare's IP Geolocation service](https://support.cloudflare.com/hc/en-us/articles/200168236-Configuring-Cloudflare-IP-Geolocation) to make an educated guess and correct it with the customer's credit card origin country after.
Once we know our customer's country, we can conditionally show the VAT-ID field when they're on the EU but not in Spain.

As I mentioned at the start, I want to be responsible for as little logic as possible. Luckly, Stripe has a tax system we can use. They unfortunately don't have built-in VAT support though, so we need to seed the data ourselves. Here's a quick script I made which takes an array of country codes and tax percentages and creates tax data on Stripe:
``` php
collect(['BE' => 21, 'BG' => 20, 'CZ' => 21, ...])->each(function ($percentage, $country) {
\Stripe\TaxRate::create([
'display_name' => 'VAT',
'percentage' => $percentage,
'inclusive' => false,
'jurisdiction' => $country,
'description' => 'VAT for '.locale_get_display_region('-'.$country, 'en')
]);
});
```
Here's how the result looks in our Stripe dashboard:

With the data seeded into Stripe, we can now tell Checkout to apply a specific tax when creating a subscription. To make this easier, I've created a TaxRate model using [Caleb's Sushi package](https://github.com/calebporzio/sushi) that fetches the rates from Stripe.
``` php
<?php
namespace App\Models;
use Sushi\Sushi;
use Stripe\TaxRate as StripeRate;
use Illuminate\Database\Eloquent\Model;
class TaxRate extends Model
{
use Sushi;
public function getRows() : array
{
return collect(StripeRate::all(['limit' => 100])->data)->map(fn (StripeRate $rate) => [
'stripe_id' => $rate->id,
'country' => $rate->jurisdiction,
])->toArray();
}
}
```
Then, we query the model for our tax rate and apply it to Checkout (notice the `default_tax_rates` key on the `subscription_data` array below).
``` php
public function checkout(Request $request)
{
$this->authorize('update', $user = $request->user());
$request->validate([
'plan' => ['required', 'string', 'in:monthly,yearly'],
'coupon' => ['nullable', 'string'],
]);
try {
return with(\Stripe\Checkout\Session::create([
'payment_method_types' => ['card'],
'customer_email' => $user->email,
'subscription_data' => [
'items' => [[ 'plan' => $request->input('plan')] ],
'coupon' => $request->input('coupon'),
'trial_period_days' => 7,
'default_tax_rates' => [TaxRate::whereCountry(getCountry())->firstOrFail()->stripe_id],
],
'mode' => 'subscription',
'client_reference_id' => $user->id,
'success_url' => route('setup'),
'cancel_url' => URL::previous(route('setup.billing')),
]), fn ($session) => $session->id);
} catch (\Stripe\Exception\InvalidRequestException $e) {
throw_unless($e->getStripeParam() == 'subscription_data[coupon]', $e);
fail_validation('coupon', 'The specified coupon does not exist');
}
}
```
This will not only apply the tax to the subscription, but also show our customer a nice breakdown of the costs.

Let's now work on the VAT-ID logic. As we learned before, we don't need to apply any taxes to customers who provide a VAT-ID, but we still want to register their id for invoicing. Checkout doesn't have any way of registering tax exemptions for new customers, but we can work around this by applying the tax after the customer has started their subscription, where we are able to register the exemption. To pass data around, we can use the `metadata` attribute.
``` php
public function checkout(Request $request)
{
$this->authorize('update', $user = $request->user());
$request->validate([
'plan' => ['required', 'string', 'in:monthly,yearly'],
'vat' => ['bail', 'nullable', 'string'],
'coupon' => ['nullable', 'string'],
]);
try {
return with(\Stripe\Checkout\Session::create([
'payment_method_types' => ['card'],
'metadata' => [
'vat_id' => $request->input('vat'),
'taxrate' => $taxRate = isEu() ? TaxRate::whereCountry(getCountry())->firstOrFail()->stripe_id : null,
],
'customer_email' => $user->email,
'subscription_data' => [
'items' => [[ 'plan' => $request->input('plan')] ],
'coupon' => $request->input('coupon'),
'trial_period_days' => 7,
'default_tax_rates' => $taxRate && is_null($request->input('vat')) ? [$taxRate] : [],
],
'mode' => 'subscription',
'client_reference_id' => $user->id,
'success_url' => route('setup'),
'cancel_url' => URL::previous(route('setup.billing')),
]), fn ($session) => $session->id);
} catch (\Stripe\Exception\InvalidRequestException $e) {
throw_unless($e->getStripeParam() == 'subscription_data[coupon]', $e);
fail_validation('coupon', 'The specified coupon does not exist');
}
}
```
Then, we update our webhook code to register the exemption and add the tax after the customer has completed the checkout process.
``` php
public function handleCheckoutSessionCompleted(array $payload)
{
$session = $payload['data']['object'];
$team = Team::findOrFail($session['client_reference_id']);
// Add the subscription to the database as seen above, removed for brevity
if (! is_null($vatId = Arr::get($session, 'metadata.vat_id'))) {
\Stripe\Customer::createTaxId($session['customer'], [
['type' => 'eu_vat', 'value' => $vatId]
]);
\Stripe\Customer::update($session['customer'], [
'tax_exempt' => 'reverse'
]);
\Stripe\Subscription::update($session['subscription'], [
'default_tax_rates' => [Arr::get($session, 'metadata.taxrate')
]]);
}
return $this->successMethod();
}
```
Now we just need to ensure our customer's VAT-ID is not only valid but also exists. We can use [Danny Van Kooten's package](https://github.com/dannyvankooten/laravel-vat) to get this without any extra work on our part.
We won't need any special logic for Spanish users since the VAT-ID input is hidden for them, and so they'll always get taxed, ticking our last box on this VAT puzzle. Let's take a look at the result.
{% youtube kzvJKrdZL_w %}
Hope this was useful! This article [started as a Twitter thread](https://twitter.com/m1guelpf/status/1261653978422611970), you may want to [follow me](https://twitter.com/m1guelpf) there for more semi-live-coding and tips. And if you'd like to see me do something like this in video format, you can [subscribe to my YouTube channel](https://i.m1guelpf.me/youtube), planning to try producing more video content this summer. Have a great day! | m1guelpf |
337,187 | Solving the Digital Root Algorithm using JavaScript | One of my favorite algorithms is finding the digital root of any given integer. A digital root is a s... | 0 | 2020-05-17T03:45:48 | https://dev.to/isabelxklee/how-to-solve-the-digital-root-algorithm-using-javascript-4jm4 | javascript, challenge | One of my favorite algorithms is finding the digital root of any given integer. A digital root is a single-digit sum that is reached when you iteratively add up the digits that make up a number.
For example:
```javascript
666
=> 6 + 6 + 6
=> 18
=> 1 + 8
=> 9
```
The key to solving this algorithm is to use an iterative method. The solution has to be smart enough to keep executing as long as the returned sum is higher than a single-digit number.
## The approach
1. If our given integer is greater than 9, iterate through each digit in the number.
2. Add up each digit.
3. Assess if the sum is a single-digit number.
4. If not, go back to Step 1.
## Let's break it down
1) Create a variable for the sum. Set it to equal the given integer. If this integer is a single-digit number, we'll return it at the very end without mutating it.
```javascript
function digitalRoot(number) {
let sum = number
}
```
2) Write a conditional statement to execute _something_ on the sum if it's a multi-digit number.
```javascript
function digitalRoot(number) {
let sum = number
if (sum > 9) {
// execute something here
}
}
```
3) If the number is greater than 9, turn it into an array so that we can loop through it. In JavaScript, we have to turn the integer into a string, and then call the `split()` method on it to achieve this.
```javascript
function digitalRoot(number) {
let sum = number
let arr = []
if (sum > 9) {
arr = sum.toString().split("")
console.log(arr)
}
}
digitalRoot(24)
=> ["2", "4"]
```
4) Now let's iterate through the array and sum its elements. We can use the `reduce()` method for this. `reduce()` requires a reducer method to execute on, so let's write the logic for it and pass it into `reduce()`. Inside the reducer method, convert the values into an integer by wrapping each value in `parseInt`. Since this method will return a single value, we can reassign it to our `sum` variable.
```javascript
function digitalRoot(number) {
let sum = number
let arr = []
let reducer = (a,b) => parseInt(a) + parseInt(b)
if (sum > 9) {
arr = sum.toString().split("")
sum = arr.reduce(reducer)
console.log(sum)
}
}
digitalRoot(24)
=> 6
```
Et voilà! We've solved the algorithm!
...Just kidding. It totally breaks if we pass in any larger numbers.
```javascript
digitalRoot(666)
=> 18
```
So how can we keep executing our function while the sum is a multi-digit number?
5) Instead of a conditional if statement, let's use a while loop. The while loop will run _while_ a condition is true, whereas an if statement will just execute once. Let's also move our `console.log` statement to the end of the function, outside of the loop, so that it only returns a single value.
```javascript
function digitalRoot(number) {
let sum = number
let arr = []
let reducer = (a,b) => parseInt(a) + parseInt(b)
while (sum > 9) {
arr = sum.toString().split("")
sum = arr.reduce(reducer)
}
console.log(sum)
}
digitalRoot(666)
=> 9
```
## Conclusion
This is one of my favorite algorithms because it's not the most difficult to solve, but still poses an interesting problem. Sound off in the comments if you have a different way of solving this!
## Edits made after publishing
Changed the wording in this article because I originally talked about using a recursive solution, but ended up writing just an iterative one. Thanks for all the comments! ✨ | isabelxklee |
337,280 | TIL: Hidden switch of ecto_sql migration | There is a hidden switch --change for mix ecto.gen.migration. mix ecto.gen.migration --change "crea... | 0 | 2020-05-17T07:11:07 | https://dev.to/sushant12/til-hidden-switch-of-ectosql-migration-34bl | elixir, phoenix, ecto | There is a hidden switch `--change` for `mix ecto.gen.migration`.
```
mix ecto.gen.migration --change "create table(:user)"
```
The above code simply substitutes the value inside the `def change` function.
```
# excerpt from ecto_sql
embed_template :migration, """
defmodule <%= inspect @mod %> do
use <%= inspect migration_module() %>
def change do
<%= @change %>
end
end
"""
```
| sushant12 |
337,294 | one to many relationship table with multiple table | one to many relationship table with m... | 0 | 2020-05-17T07:57:26 | https://dev.to/menlam/one-to-many-relationship-table-with-multiple-table-blp | {% stackoverflow 61847933 %} | menlam | |
337,345 | Setup Development Environment for Angular 7 with Windows Subsystem for Linux (WSL) | [Update on 03 June 2020] Since Microsoft just released the update which is windows 10 build 2004, an... | 0 | 2020-05-20T20:08:05 | https://dev.to/kim-ch/setup-development-environment-for-angular-7-2b78 | wsl, windowterminal, ubuntu, angular | [Update on 03 June 2020]
Since Microsoft just released the update which is [windows 10 build 2004](https://docs.microsoft.com/en-us/windows/whats-new/whats-new-windows-10-version-2004), and I just convert to WSL 2 without any issue.
Here are the steps to upgrade
1. Download and install [WSL2 Linux Kernel](https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi)
2. [Update to WSL 2](https://docs.microsoft.com/en-us/windows/wsl/install-win10#update-to-wsl-2)
[End of Update]
-------
Recently, I was assigned to Angular 7 project, the first thing I thought was how to set up my development environment without impact to existing work, they could be the version of NodeJs, npm packages (i.e. node-gyp), python and so on... Luckily, we can run Linux natively on Windows 10, it's known as **Window Subsystem for Linux** - [WSL](https://docs.microsoft.com/en-us/windows/wsl/about) in short.
**_Note:_**
1. Although Microsoft has [WSL 2](https://docs.microsoft.com/en-us/windows/wsl/wsl2-index), but in this post, I'm going to install **WSL 1** since I'm not running Windows Insider version.
2. This post assumes that we has already [Window Terminal](https://www.microsoft.com/en-us/p/windows-terminal/9n0dx20hk701) installed.
Let's start with opening Window Terminal as **Administrator**
## Enable Windows Subsystem for Linux
```powershell
Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux
```
## Install Ubuntu-18.04-LTS distro
The simplest way is we can install via [Window Store] (https://www.microsoft.com/en-us/p/ubuntu-1804-lts/9n9tngvndl3q?activetab=pivot:overviewtab) but we may face the problem of drive system got full since it's installed at `%LOCALAPPDATA%\Ubuntu-18.04-LTS\rootfs` as default. In order to avoid this problem, we may want to install on Non-System drive, for instance, `E:\_wsl\Ubuntu-18.04-LTS` drive. Then follow the below steps
- Create the folder `E:\_wsl\Ubuntu-18.04-LTS`
- Download [Ubuntu-18.04-LTS distro](https://aka.ms/wsl-ubuntu-1804), the downloaded file may be `CanonicalGroupLimited.Ubuntu18.04onWindows_1804.2018.817.0_x64__79rhkp1fndgsc.Appx`, then copy to `E:\_wsl\Ubuntu-18.04-LTS`
- Change to `E:\_wsl\Ubuntu-18.04-LTS`
```powershell
cd E:\_wsl\Ubuntu-18.04-LTS
```
- Change to **zip** file
```powershell
move .\CanonicalGroupLimited.Ubuntu18.04onWindows_1804.2018.817.0_x64__79rhkp1fndgsc.Appx .\Ubuntu-18.04-LTS.zip
```
- Extract **Ubuntu-18.04-LTS.zip**
```powershell
Expand-Archive .\Ubuntu-18.04-LTS.zip
```
- Then we execute `ubuntu1804.exe` inside the folder **Ubuntu-18.04-LTS**, in this step, we have to provide **username** and **password**. If there is no issue, we can see as below
```powershell
.\ubuntu1804.exe
```
## Install node version manager (aka [nvm](https://github.com/nvm-sh/nvm))
```bash
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.3/install.sh | bash
```
```bash
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion"
```
```bash
nvm --version
```
### Install nodejs
- In this step, I'm going to install nodejs v11.15.0
```bash
nvm install 11.15.0
```
```bash
nvm use 11.15.0
```
## Install node-gyp
```bash
sudo apt-get update -y
```
```bash
sudo apt-get install -y node-gyp
```
## Getting started example Angular 7
### Install angular cli
```bash
npm install -g @angular/cli@7.1.4
```
### Create project via angular cli
```bash
cd /mnt/d/
mkdir learning-angular7
cd learning-anguar7
ng new my-app
```
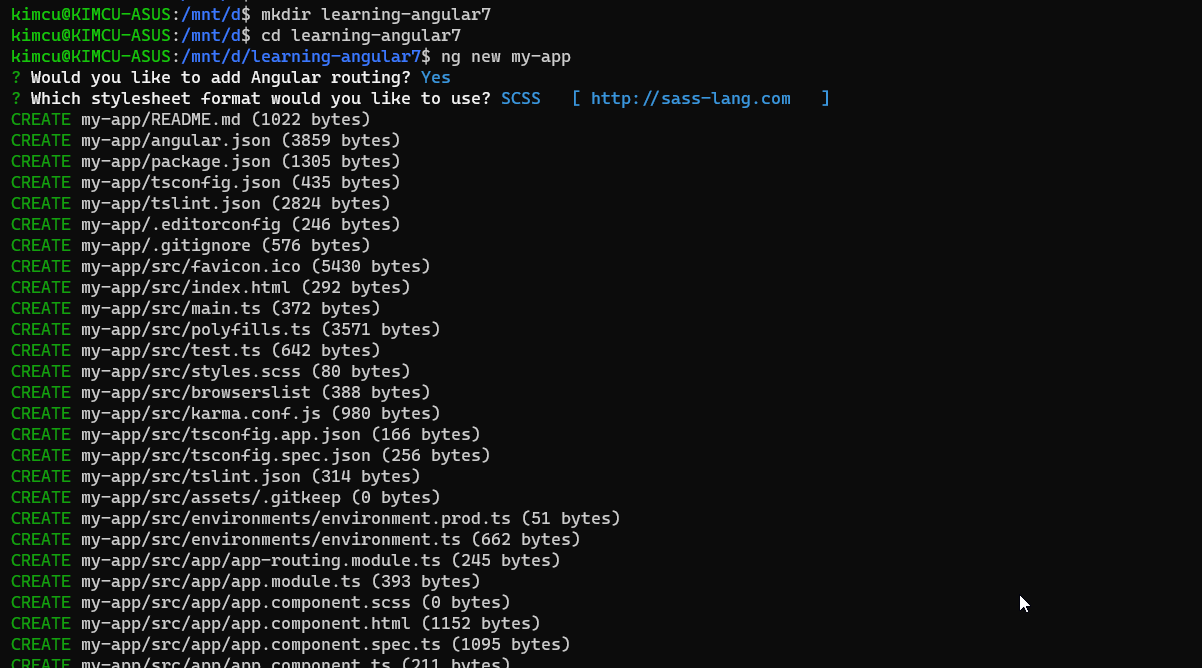
### Launch my-app
```bash
cd my-app
ng serve --open
```
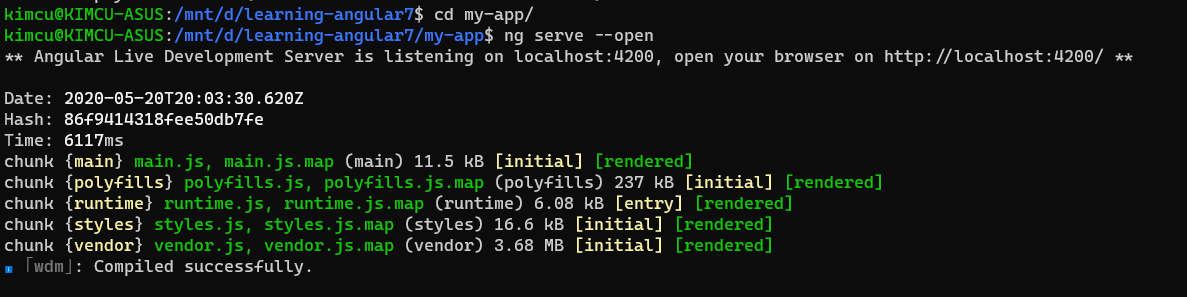
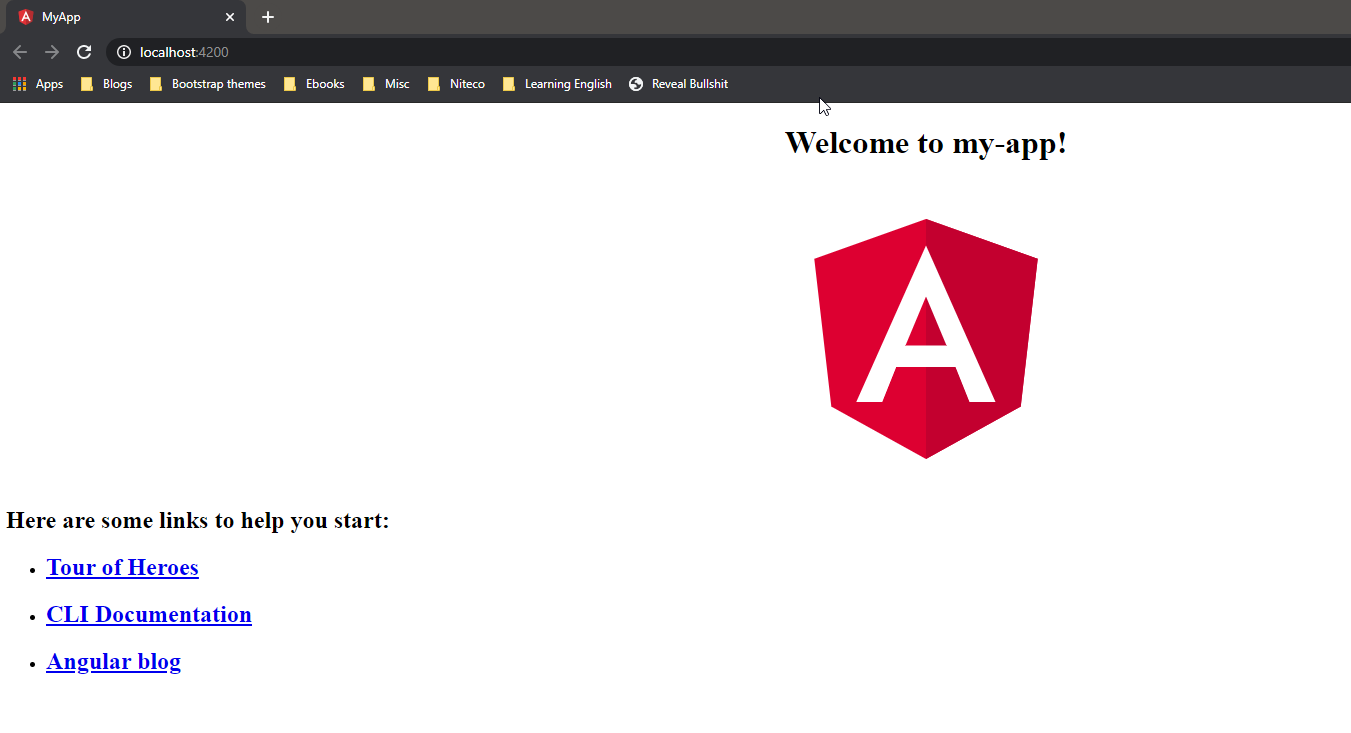
## Resources
1. [Install Windows Subsystem for Linux on a Non-System Drive](https://kontext.tech/column/tools/308/how-to-install-windows-subsystem-for-linux-on-a-non-c-drive)
2. [Automatically Configuring WSL](https://devblogs.microsoft.com/commandline/automatically-configuring-wsl/) | kim-ch |
337,353 | Answer: What's the difference between tf.Session() and tf.InteractiveSession()? | answer re: What's the difference betw... | 0 | 2020-05-17T10:35:43 | https://dev.to/mmmmqqqq/answer-what-s-the-difference-between-tf-session-and-tf-interactivesession-527c | {% stackoverflow 41791644 %} | mmmmqqqq | |
337,373 | Using Airtable as a database | Hi everyone, I recently used Airtable and found out that it has an awesome API, so we can use it as... | 0 | 2020-05-17T12:44:44 | https://dev.to/rizkyrajitha/using-airtable-as-a-database-421d | airtable, express, node, database | Hi everyone,
I recently used [Airtable](https://airtable.com/) and found out that it has an awesome API, so we can use it as a simple yet useful way as a database.
so let's get started
first, we will create an npm project and spin up an expressjs server
if you are new to express check out my post on hello world in express.
{% link https://dev.to/rizkyrajitha/build-your-first-expressjs-server-from-scratch-52c3 %}
so after initializing the project lets install dependencies to start the server.
* body-parser - a middleware to parse the body of incoming requests
* cors - ho handle [cors](https://en.wikipedia.org/wiki/Cross-origin_resource_sharing) headers
* express - to spin up our expressjs server
* morgan - a middleware utility tool that logs the server events (this is not essential but useful for debugging)
* node-fetch - fetch API for node environment
`npm i express cors morgan body-parser node-fetch`
so after installing everything lets create our `app.js` file.
here we will create our express server
```
const express = require("express");
const app = express();
const cors = require("cors");
const bp = require("body-parser");
const fetch = require("node-fetch");
app.use(cors());
app.use(bp.urlencoded({ extended: false }));
app.use(bp.json());
app.use(require("morgan")("dev"));
const port = process.env.PORT || 5000;
app.listen(port, () => {
console.log("listning on " + port);
});
```
and run this by `node app.js`

now our server-side is up let's peek to Airtable.
create a [Airtable](https://airtable.com/) account, and create a new base.
next name it
and then open a new base. and you will see something similar to this.
now customize it as you like. I will add two fields `name` and `country`.
and I will add few records so when we fetch data it has somethings to show.
after everything, mine looks like this.
now let's head to account to get our `API KEY` which we will use to authenticate with the Airtable API.
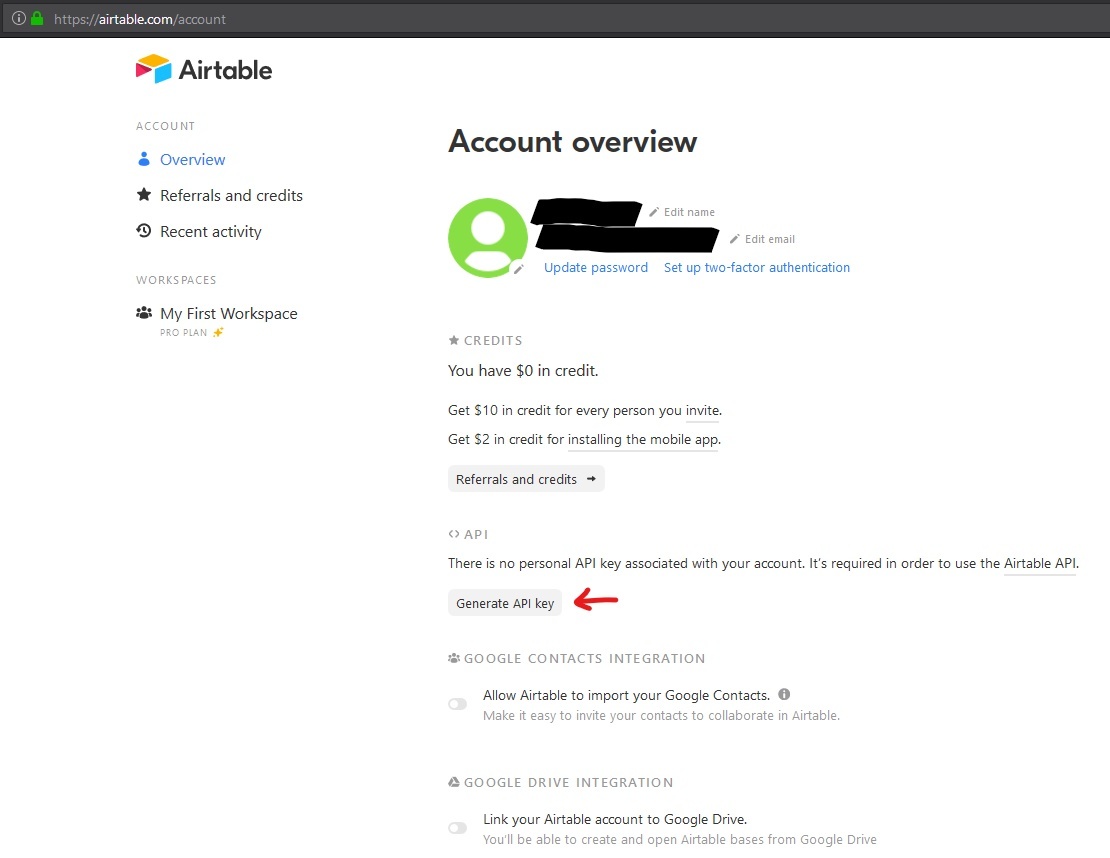
we also need our base id to identify our base and table name . to get those data, visit the API docs page.
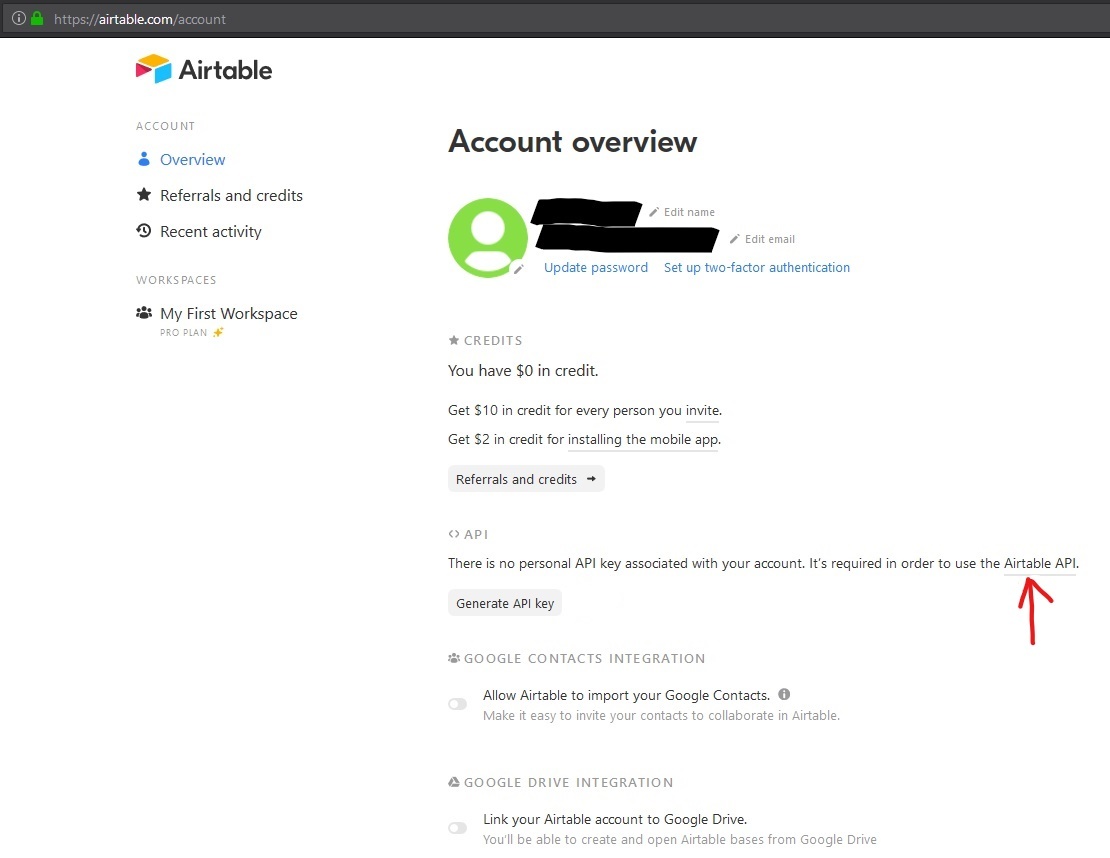
select base you created
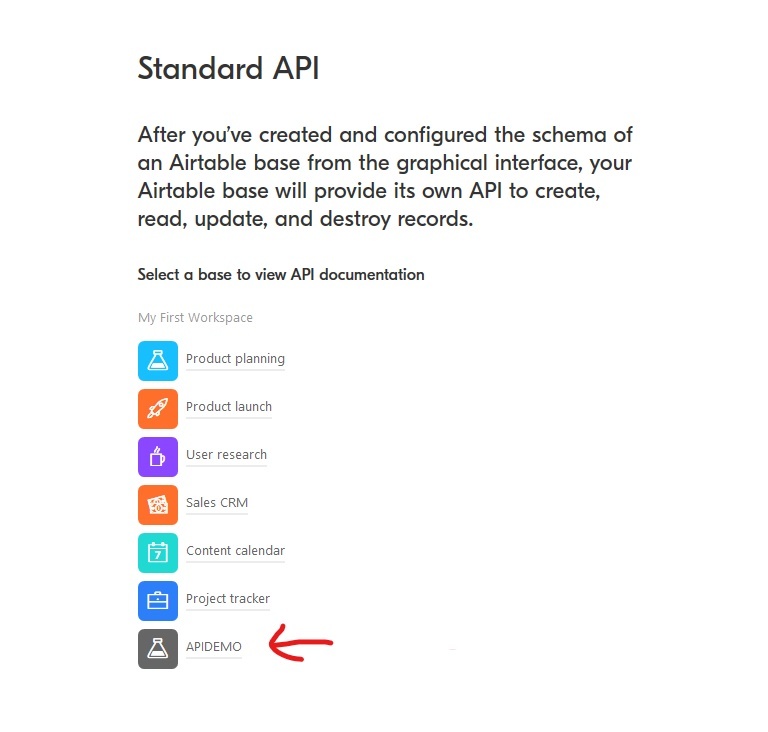
now copy base id and table name from the docs. base id is led by `app` and table name is the name you gave when you customize the table.
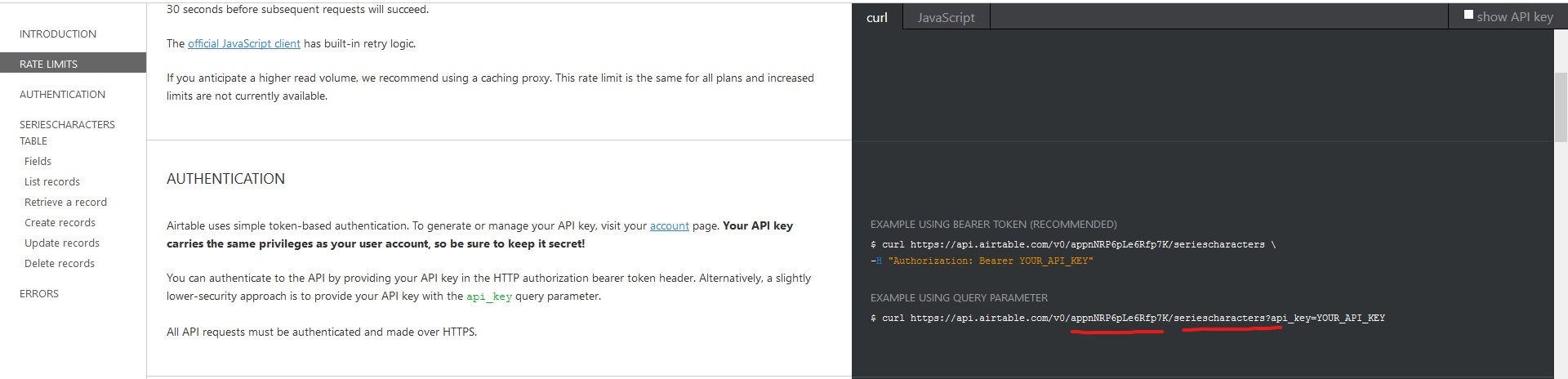
after creating an API key and getting necessary information,
let's head back to our server.
I created a separate folder for configs and keys, but you can also directly use the API key in the code since this is development purposes only. but make sure you don't commit your keys with the code.
Airtable gives us 4 basic operations with the API
* Read
* Create
* Update
* Delete
### Reading Table
I will create a get route `http://localhost:5000/view` to view existing data in our table
```
const express = require("express");
const app = express();
const cors = require("cors");
const bp = require("body-parser");
const fetch = require("node-fetch");
app.use(cors());
app.use(bp.urlencoded({ extended: false }));
app.use(bp.json());
app.use(require("morgan")("dev"));
const AIRTABLEAPI = require("./config/env").airtableapikey; // import airtable api key
const AIRTABLEBASEID = require("./config/env").airtablebaseid;// import airtable base id
const AIRTABLETABLENAME = "seriescharacters"; // table name
const port = process.env.PORT || 5000;
app.get("/view", (req, res) => {
//we need to send a "GET" request with our base id table name and our API key to get the existing data on our table.
fetch(
`https://api.airtable.com/v0/${AIRTABLEBASEID}/${AIRTABLETABLENAME}?view=Grid%20view`,
{
headers: { Authorization: `Bearer ${AIRTABLEAPI}` } // API key
}
)
.then((res) => res.json())
.then((result) => {
console.log(result);
res.json(result);
})
.catch((err) => {
console.log(err);
});
});
```
if we send a `GET` request to `http://localhost:5000/view` via [postman](https://www.postman.com/) we will get a response with our existing data in `seriescharacters` table
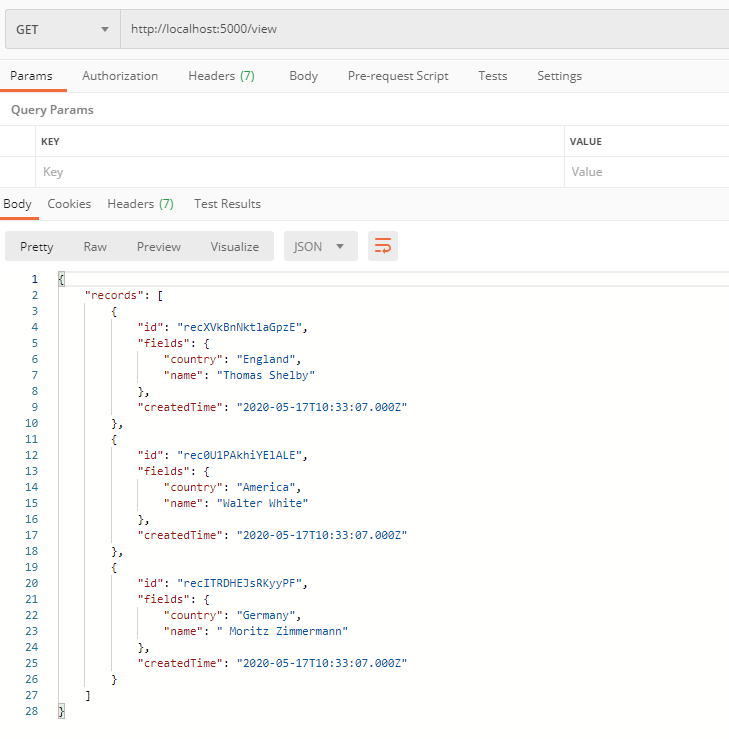
console output
### Create new record
now let's add a new record by creating a `POST` route `http://localhost:5000/create`.
`create handler`
```
app.post("/create", (req, res) => {
console.log(req.body);
var datain = req.body;
var payload = {
records: [
{
fields: datain,
},
],
};
//we need to send a "POST" request with our base id, table name, our API key, and send a body with the new data we wish to add.
fetch(`https://api.airtable.com/v0/${AIRTABLEBASEID}/${AIRTABLETABLENAME}`, {
method: "post", // make sure it is a "POST request"
body: JSON.stringify(payload),
headers: {
Authorization: `Bearer ${AIRTABLEAPI}`, // API key
"Content-Type": "application/json", // we will recive a json object
},
})
.then((res) => res.json())
.then((result) => {
console.log(result);
res.json(result);
})
.catch((err) => {
console.log(err);
});
});
```
if we send a `POST` request to `http://localhost:5000/create` with our data via [postman](https://www.postman.com/) we will get a response with our data including the one we just added `seriescharacters` table.
also, we can see the updated table in real-time from Airtable.
### Updating a record
`update handler`
```
app.post("/update", (req, res) => {
console.log(req.body);
var datain = req.body;
var payload = {
records: [
{
id: datain.id,
fields: datain.updatedata,
},
],
};
//to update a record we have to send the new record with it's the id to Airtable API.
fetch(`https://api.airtable.com/v0/${AIRTABLEBASEID}/${AIRTABLETABLENAME}`, {
method: "patch", // make sure it is a "PATCH request"
body: JSON.stringify(payload),
headers: {
Authorization: `Bearer ${AIRTABLEAPI}`, // API key
"Content-Type": "application/json",
},
})
.then((res) => res.json())
.then((result) => {
console.log(result);
res.json(result);
})
.catch((err) => {
console.log(err);
});
});
```
if we send a `POST` request to `http://localhost:5000/update` with our data via [postman](https://www.postman.com/) we will get a response with the updated record.
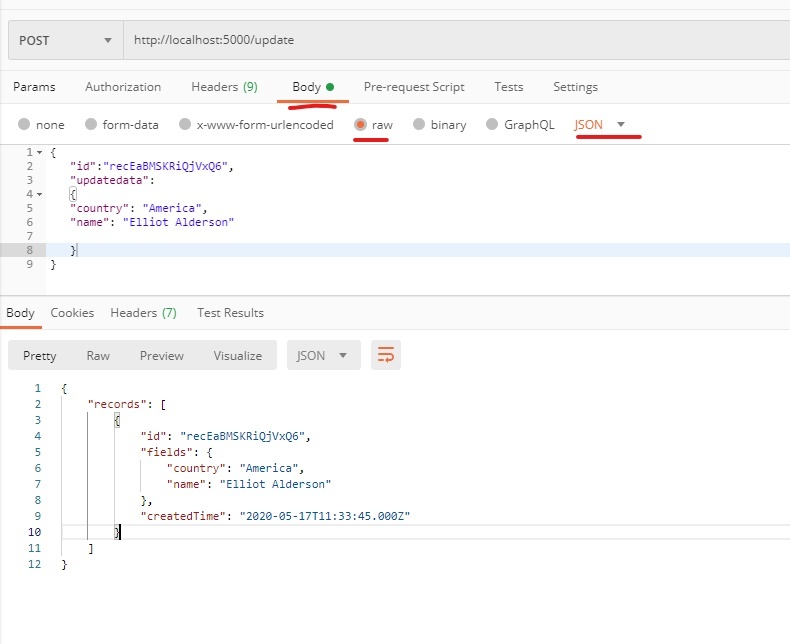
### Deleting a record
now let's delete a record by creating a `POST` route `http://localhost:5000/delete`.
`delete handler`
```
app.post("/delete", (req, res) => {
console.log(req.body);
//we need to send a "DELETE" request with our base id table name, the id of the record we wish to delete and our API key to get the existing data on our table.
fetch( `https://api.airtable.com/v0/${AIRTABLEBASEID}/${AIRTABLETABLENAME}/${req.body.id}`,
{
method: "delete", // make sure it is a "DELETE request"
// body: JSON.stringify(payload),
headers: {
Authorization: `Bearer ${AIRTABLEAPI}`, // API key
// "Content-Type": "application/json",
},
}
)
.then((res) => res.json())
.then((result) => {
console.log(result);
res.json(result);
})
.catch((err) => {
console.log(err);
});
});
```
if we send a `POST` request to `http://localhost:5000/delete` with the id of the record we need to delete via [postman](https://www.postman.com/) we will get a response with delete record id and deleted flag.
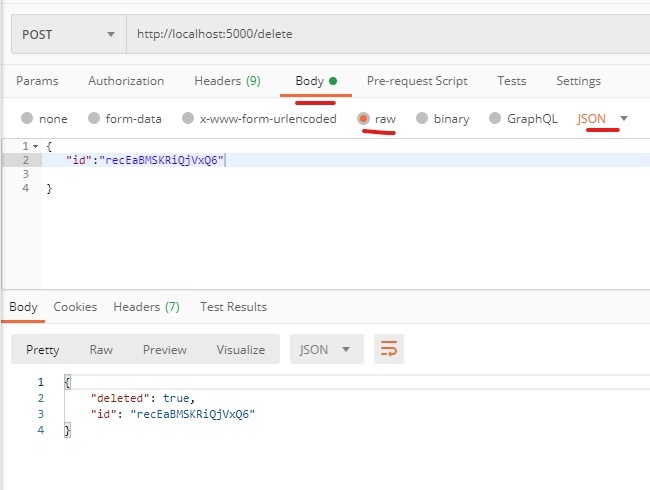
We successfully went through all the CRUD operations in Airtable 😎.
This is very useful if you have a spreadsheet and you need to update data programmatically from your apps .plus Airtable has many more features other than spreadsheets, so you can suit your needs.
final app.js file
{% gist https://gist.github.com/RizkyRajitha/041bb41f46647a444abd3724a3cb4266 %}
## Thank you for reading until the end
## Stay safe
## Cheers 🥂 , Have a Nice Day.
| rizkyrajitha |
337,573 | Python Online Tutorials | Let’s Start with python Installation Download Python for your respective windows from here: https://... | 6,748 | 2020-05-17T17:22:07 | https://onlinetutorials.tech/python-online-tutorials/ | python, onlinetutorials, basicsofpython, pythonvariable |
<h1>Let’s Start with python Installation</h1>
<p>Download Python for your respective windows from here: <a href="https://www.python.org/downloads/" target="_blank" rel="noopener noreferrer">https://www.python.org/downloads/</a></p>
<h1><strong>The Basics of Python:</strong></h1>
<p><strong>Python</strong> is an interpreted programming language, this means that as a developer you write Python (.py) files in a text editor and then put those files into the python interpreter to be executed.</p>
<p><strong>Python</strong> is very simple and straightforward language. <strong>Python</strong> is an interpreted programming language, this suggests that as a developer you write Python (.py) files during a text editor then put those files into the python interpreter to be executed.</p>
<p>I believe you have installed <strong>python</strong> in your system. If not, please go to the below Installation module as priority so that you can practice alongside.</p>
<p>The Python Script Mode:</p>
<p>Invoking the interpreter with a script parameter begins execution of the script and continues until the script is finished. When the script is finished, the interpreter is not any longer active.</p>
<p>The simplest directive in Python is that the “print” directive — it simply prints out a line.<br/>
Let’s write our first Python file, called helloworld.py,<br/>
which may be wiped out any text editor.<br/>
Python files have extension .py.</p>
<p>Type the following source code in a helloworld.py file:</p>
<blockquote>
<pre>print("Hello, World!")</pre>
</blockquote>
<p>We have assumed that you have Python interpreter set in PATH variable. Now, try to run this program as follows −</p>
<blockquote>
<pre>$ python helloworld.py</pre>
</blockquote>
<p>The Python Command Line:</p>
<p>To test a short amount of code in python sometimes it is quickest and easiest not to write the code in a file. This is made possible because Python are often run as an instruction itself.</p>
<p>Type the following on the Windows, Mac or Linux command line.</p>
<p>Invoking the interpreter without passing a script file as a parameter brings up the following prompt:</p>
<blockquote>
<pre>$ python
Python 3.8.0 (default, Nov 14 2019, 22:29:45) [GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>></pre>
</blockquote>
<p>Type the following text at the Python prompt and press the Enter:</p>
<blockquote>
<pre>$ python
Python 3.8.0 (default, Nov 14 2019, 22:29:45) [GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello, World!")</pre>
</blockquote>
<p>resultant to above statements:</p>
<blockquote>
<pre>$ python
Python 3.8.0 (default, Nov 14 2019, 22:29:45) [GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> print("Hello, World!")
Hello, World!</pre>
</blockquote>
<p>Whenever you are done in the python command line, you can simply type the following to quit the python command line interface.</p>
<blockquote>
<pre>>>> exit()</pre>
</blockquote>
<hr/>
<p>Learn More:</p>
<ul>
<li><a href="https://onlinetutorials.tech/python-indentation/">Python Indentation</a></li>
<li><a href="https://onlinetutorials.tech/python-comments/">Python Comments:</a></li>
<li><a href="https://onlinetutorials.tech/python-variables/">python-variables</a></li>
</ul>
Visit us for more tutorials:
<a href="https://onlinetutorials.tech/category/java-tutorials-online-tutorials/" target="_blank" rel="dofollow">Java Tutorial</a>
<a href="https://onlinetutorials.tech/category/python-tutorials-from-onlinetutorials-tech/" target="_blank" rel="dofollow">Python Tutorial</a>
<a href="https://onlinetutorials.tech/category/rabbitmq-tutorial/" target="_blank" rel="dofollow">RabbitMQ Tutorial</a>
<a href="https://onlinetutorials.tech/category/spring-boot/" target="_blank" rel="dofollow">Spring boot Tutorial</a> | rajesh1761 |
337,418 | What's new in JavaScript | Follow me on Twitter Follow me on Github Since the big JS overhaul that came with ES6, we have been... | 0 | 2020-05-17T12:55:09 | https://dev.to/andremacnamara/what-s-new-in-javascript-397n | javascript, webdev, tutorial | [Follow me on Twitter](https://www.twitter.com/andremacnamara)
[Follow me on Github](https://www.github.com/andremacnamara)
Since the big JS overhaul that came with ES6, we have been incrementally getting some new features every year. This is fantastic as we won’t get a big overhaul again, and the language is constantly improving.
In this short article, I will talk about some of the features that have been released in both ES2020, and ES2019. This list is not exhaustive, but it covers some of the features that I think are useful.
#ES2020
###BigInt
BigInt allows developers to safely use bigger integers than are currently available. The current “safest” integer to use is 9007199254740991. This is derived from Number.MAX_SAFE_INTEGER.
We can now safely go higher. A BigInt can be declared by appending n to the end of a number, or passing a number as a param to the function BigInt().
BigInts and Numbers are similar but they are technically different data types. You can’t use built in Math operations such as Math.round(), and Math.floor() unless they are coerced to a number type. However doing this may result in BigInt losing it’s precision.
###Dynamic Imports
Dynamic imports give you the option to import files as modules on demand in you Javascript applications. You are not limited to importing them all at the top of your file.
The imported module returns a promise, which you can then use as normal. This is useful for code splitting. You can import a section of your application but only when it’s required. You don’t have to load any modules until they’re required. This is great for increasing web performance.
###Module Namespace Export
In JavaScript we could already import named modules. However until now there was no option to export modules the same way. Until Now
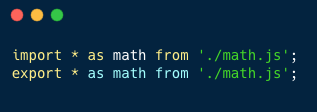
###Optional Chaining
Optional chaining allows us to access nested properties on objects without worrying if the property exists or not. If the property does exist, fantastic, it's returned. However if the property does not exist, undefined will be returned.
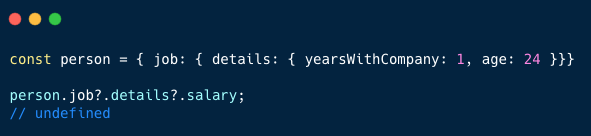
The benefit of optional changing is that we can attempt to access data from an object that we’re unsure that we have. If the data doesn’t exist, the application won’t break.
#ES2019
###Array.flat()
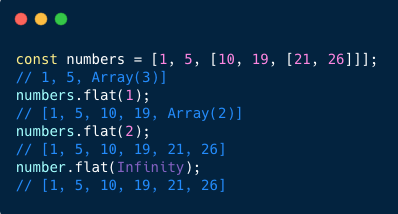
Array.flat returns a new array with any sub-arrays flattened. By default the sub-arrays are flattened up to one level deep, however you can specify how many levels deep you want to flatten. There's also the option to flatten every sub-array by passing the Infinity keyword.
###Array.flatMap()
FlatMap combines two existing array methods. .flat(), and .map(). First, it maps over an array, then it flattens it. The limit of flatMap is 1 level deep. If you need to flatten an array more than 1 level, you will need to use .flat() and .map() separately.
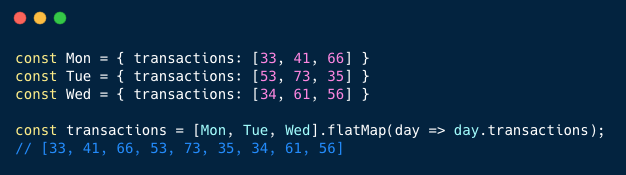
Take the above example. We have 3 objects, each containing an array of transactions. To turn this into one array is simple with flatmap.
###String.trimStart and String.trimEnd()
We have the .trim() method in JavaScript which removes white space from the start and end of a string. Now we have two new methods that allow us to remove white space from just the start, and just end of a string.
[Follow me on Twitter](https://www.twitter.com/andremacnamara)
[Follow me on Github](https://www.github.com/andremacnamara)
| andremacnamara |
337,444 | The Environment Variables Pattern | An Introduction to Environment variables and how to use them During software development,... | 0 | 2020-05-17T18:39:12 | https://dev.to/mojemoron/the-environment-variables-pattern-4dai | javascript, tutorial, python, beginners | #An Introduction to Environment variables and how to use them
During software development, there are things we shouldn't share with our code. These are often configurations like secret keys, database credentials, AWS keys, API keys/tokens, or server-specific values.
According to [12 Factor methodology](https://12factor.net/config), it is wrong to store config as constants in the code because config varies substantially across deploys, code does not.
##What Are Environment Variables?
When I started writing code it took quite some time to figure out what an environment variable is and how they can be set-up.
In a nutshell, an environment variable is a combination of values, called **key/pair** values. They hold information that other programs and applications can use.
One common environment variable described by the operating system is **PATH** which contains a set of directories where executable programs are located.
Using [Git Bash](https://gitforwindows.org/) shell:
```bash
echo $PATH
/c/Users/MICHAEL/bin:/mingw64/bin:/usr/local/bin:/usr/bin:/bin:/mingw64/bin:/usr/bin:/c/Users/MICHAEL/bin:/c/WINDOWS/system32:/c/WINDOWS:/c/WINDOWS/System32/Wbem:/c/WINDOWS/System32/WindowsPowerShell/v1.0:/c/WINDOWS/System32/OpenSSH:
```
##How to Set-up Environment Variables
Aside from built-in environment variables defined by our operating system or third party programs, there are several ways to create environment variables:
- [the Windows Environment Variables setup](https://helpdeskgeek.com/how-to/create-custom-environment-variables-in-windows/): you can use this to configure global variables
- [.bashrc file via Bash shell](https://dev.to/mojemoron/productivity-101-git-aliases-for-lazy-developers-4hip)
- the **export** command in Bash like environment or **set** command in windows command-line:
```bash
#in bash shell
export API_KEY=https://dev.to/mojemoron #key=value
echo $API_KEY #echo key
https://dev.to/mojemoron #value
#in windows cmd
set API_KEY=https://dev.to/mojemoron
echo %API_KEY%
```
- `.env file`: this is the most common way to create environment variables per project especially during development. To do this, you create a `.env file` in your project's root directory and set the various environment variables you need in your project and afterward, you use a library for your respective programming language to load the file which will dynamically define these variables.
For example, using [python-decouple](https://pypi.org/project/python-decouple/) in a Django project to load environment variables.
```bash
touch .env #create this file in the root directory
#add this to the .env file
DB_HOST=localhost
DB_NAME=root
DB_USER=root
DB_PWD=root
DB_PORT=5432
#in your settings.py file, load the environment variables like so
DATABASES = {
'default': {
'ENGINE': 'django_postgres_extensions.backends.postgresql',
'HOST': config('DB_HOST'),
'NAME': config('DB_NAME'),
'USER': config('DB_USER'),
'PASSWORD':config('DB_PWD'),
'PORT': config('DB_PORT'),
}
}
```
There are several libraries that can help you achieve this:
- [Node js](https://www.npmjs.com/package/dotenv)
- [Python](https://pypi.org/project/python-dotenv/)
- [Ruby](https://github.com/bkeepers/dotenv)
- [Java](https://github.com/cdimascio/java-dotenv)
- Cloud service providers like AWS, GCP, Heroku, Azure, and Digital Ocean recommend the use of environment variables for configuration and have built-in features for setting and managing them.
###Summary
It's very important to note that separating application configurations such as credentials, API keys from code will remove unnecessary roadblocks/headaches when deploying your apps to multiple environments.
Finally, remember not to check in your `.env file` into a version control system by using [git .ignore file](https://www.freecodecamp.org/news/gitignore-what-is-it-and-how-to-add-to-repo/).
You don't want to expose your environment variables to the world!
***How do you configure environment variables for your projects?***
**Kindly follow me and turn on your notification.**
Thank you! Happy coding! ✌
| mojemoron |
337,466 | Build a Complete Solution With AWS, Django , React , React Native and Heroku - Day 2 | Today I got the List api endpoints from the django backend working Root API endpoint = /api/v1 Prod... | 6,723 | 2020-05-17T14:41:25 | https://dev.to/nyamador/build-a-complete-solution-with-aws-django-react-react-native-and-heroku-day-2-54e8 | python, javascript, react, django | Today I got the List api endpoints from the django backend working
Root API endpoint = /api/v1
**Products** = /products/all
**Warehouses** = /warehouses/all
**Customers** = /customers/all
**Shipments** = /shipments/all
To enable My React work with my backend I needed to install `django-cors-headers` and add **localhost:300** to my whitelist.This is as a result of **CORS**
Cross-origin resource sharing is a mechanism that allows restricted resources on a web page to be requested from another domain outside the domain from which the first resource was served.
The next thing I need to do is to work on all my components in React. | nyamador |
337,527 | Answer: Responsive Banner HTML/CSS | answer re: Responsive Banner HTML/CSS... | 0 | 2020-05-17T16:27:26 | https://dev.to/serverbroad/answer-responsive-banner-html-css-26gm | {% stackoverflow 49442075 %} | serverbroad | |
337,555 | Automating a conference submission workflow: integrating the solution | In the previous post, I described a poster child for automation: managing the repetitive tasks around... | 0 | 2020-05-17T16:59:02 | https://blog.frankel.ch/automating-conference-submission-workflow/2/ | worflow, automation, integration, google | In the [previous post](https://blog.frankel.ch/automating-conference-submission-workflow/2/), I described a poster child for automation: managing the repetitive tasks around a conference submission workflow. I wrote about the setup, and how to use `ngrok` to redirect webhooks to my computer.
This week, I'd like to write about some of the hiccups I encountered along the way.
## Registering a Trello webhook
Most <abbr title="Software-as-a-Service">SaaS</abbr> providers allow to register webhooks through their <abbr title="Graphical User Interface">GUI</abbr>. This is the case of GitHub for example: it's located in the **Settings > Webhooks** menu.
For better or worse, this is not the case of Trello. To [register a webhook](https://developers.trello.com/page/webhooks/), one needs to execute an HTTP request. This requires:
1. An [API key](https://trello.com/app-key), which is _unique per account_. The fun part is, it cannot be reset. Don't leak it, or you'll be sorry!
2. A token, which is should be generated for each application. To generate a token, follow instructions on [the relevant page](https://developers.trello.com/page/authorization). Required parameters are the following:
* The _scopes_: read, write, etc.
* The application name
* An expiration date
* The board's ID. In order to get it, append `.json` at the end of the board's URL to display its JSON representation. The ID is among the first few parameters:
```
{
"id": "5d383691a3aeaa3b5741953d",
"name": "My board",
"desc": "",
"descData": null,
"closed": false,
"idOrganization": null,
"idEnterprise": null
}
```
3. Finally, send a `POST` request similar to the following:
```
curl -X POST -H "Content-Type: application/json" \
https://api.trello.com/1/tokens/{token}/webhooks/ \
-d '{
"key": "{key}",
"callbackURL": "http://www.mywebsite.com/trelloCallback",
"idModel":"{boardID}",
"description": "Name of the webhook"
}'
```
## Preparing for the webhook
To check the webhook is valid, Trello will immediately send a `HEAD` request to the just-registered callback. If this request is not successful, then registration will fail. For example, this will happen if the app is not up, or if the URL is not reachable.
The `HEAD` HTTP method is rarely used. For example, when using Spring Boot, it requires explicitly configuring such an endpoint:
```
fun routes(runtimeService: RuntimeService) = router {
val handler = TriggerHandler(runtimeService)
POST("/trigger", handler::post)
HEAD("/trigger", handler::head)
}
class TriggerHandler(private val runtimeService: RuntimeService) {
fun post(request: ServerRequest): ServerResponse {
// Starts the workflow instance
}
fun head(request: ServerRequest) = ServerResponse.ok().build()
}
```
The above snippet isn't very compliant with the HTTP specifications as the controller doesn't offer any `GET` endpoint':
> The HEAD method is identical to GET except that the server MUST NOT return a message-body in the response. The metainformation contained in the HTTP headers in response to a HEAD request SHOULD be identical to the information sent in response to a GET request. This method can be used for obtaining metainformation about the entity implied by the request without transferring the entity-body itself. This method is often used for testing hypertext links for validity, accessibility, and recent modification.
>
> -- Hypertext Transfer Protocol -- HTTP/1.1,https://ietf.org/rfc/rfc2616.txt
In all cases, it gets the job done. Besides, I didn't find any way to easily create a `HEAD` endpoint that delegates to a `GET` endpoint. Hints are more than welcome.
## Google permissions
Google requires permission to manage objects: read, write, etc. The problem with the most recent documentation, whether on Calendar or Sheets (or any other Google API), is that it's skewed toward Android _e.g._ [Calendar Java Quickstart](https://developers.google.com/calendar/quickstart/java). In such a use-case, the request for permission is interactive: the user is first presented with a authenticate screen, and then asked to give the required permission.
Workflows in general allow for interactive or automated steps. An interactive step allows to enter one's credentials and authorize the app, but the previously-defined workflow only has automated steps. For a truly automated workflow, interactive steps should be avoided if possible.
However, Google prevents to use one's account credentials - login and password - for security reasons. But it provides an alternative: one can create a so-called service account, and give it write permissions to the relevant calendar and documents.
### Creating a Google service account
To create a service account:
1. Go to the [service account page](https://console.cloud.google.com/iam-admin/serviceaccounts) in the Google Cloud console
2. Create or select a project
3. Fill in the required fields
4. Select the newly-created account, click on **Edit** and then on **Create Key**. Download the key and store it in an safe place, as it contains the credentials necessary to authenticate oneself as the created service account.
### Configuring permissions
To give the service account access to one's calendar (or documents) requires two steps:
1. First, one should give the project permissions to use the API. In the context of the project the service account was created in, open the left menu. Go to **APIs & Services > Library**. Select **Google Calendar API**, and in the opening page, click on **Enable**. Repeat for **Google Calendar API**.
2. Then, one should give delegation access to one's own calendar.
In Calendar, locate the **My calendars** list, then click on the associated menu, and on **Settings and sharing**. Find the **Share with specific people** section, and add the service account with access level **Manage changes to events**.
For Google Sheets, share the document with the service account.
3. If the option is grayed out, it means the domain administrator didn't allow it. If you're the administrator of your own domain, go to the [Google administration console](https://admin.google.com/). Then, click on **Apps > G Suite > Calendar**. Click on **Sharing settings**. Select **External sharing options for primary calendars**, and **Share all information, and outsiders can change calendars**. This allows to give accounts outside the organization - such as service accounts - write access.
Repeat for Google Sheets, if necessary.
## Conclusion
While the previous post described the context behind automating a workflow, this post lists the necessary configuration steps: the Trello webhook and the Google service accounts. While nothing out-of-the-ordinary, it takes time to research the above facts if one doesn't know about them previously.
_Originally published at [A Java Geek](https://blog.frankel.ch/) on May 17th, 2020_ | nfrankel |
337,664 | TypeScript: Object Destructuring | Writing annotations for primitive values and object literals is pretty straightforward, but it differ... | 0 | 2020-05-17T18:55:59 | https://dev.to/spukas/typescript-object-destructuring-3n42 | Writing annotations for primitive values and object literals is pretty straightforward, but it differs slightly when it comes to object destructuration. In this post, I want to shortly mention differences and give a couple of examples of how to write annotations for the destructured properties of object literals.
### Object literal
For simple object literals we can write annotations just after the variable and before the object. For example:
```ts
const car: { model: string; year: number } = {
model: "Ford",
year: "1969",
};
```
In short, we write the whole object structure and assign types before the actual object.
If the object has nested properties, we list them in the similar structure:
```ts
const car: { model: string; year: number; owner: { name: string } } = {
model: 'Ford Mustang',
year: 1969,
owner: {
name: 'John',
},
}
```
### Object Destructuring
Giving types for destructured object properties is not very common. Usually, the inference system is reliable and assigns correct types for variables accurately, well most of the time. But there are cases when you need to add types manually. For example, if a function returns an object and it has `any` type, or if the object is initiated first and some properties are added later.
We will use a declared object bellow as an example. It has a couple of properties, including a nested object and a method. We will destructure all properties using ES6 syntax and explain how to add annotations to them.
```ts
const car = {
model: 'Ford Mustang',
year: 1969,
owner: {
name: 'John',
},
setOwner(name: string): void {
this.owner.name = name;
}
}
```
Lets take out the first property from the object:
```ts
const { model } = car;
```
First, we cannot add just a type for a variable. Meaning, that writing `const { model }: string = car` is incorrect. What's wrong with this approach? Well, imagine if you have to pull out a second property from the same object: `const { mode, year }: string = car` then which is the string?
When destructing, a type system expects you to write the full object property, which gives the ability to add types for all the properties:
```ts
const { model }: { model: string } = car;
// pull out more properties
const { model, year }: { model: string; year: number } = car;
```
The same goes for the nested properties:
```ts
// destructure name property
const { owner: { name } } = car;
// mirror the whole "owner" property
const { owner: { name } }: { owner: { name: string } } = car;
```
The methods will have similar syntax, though they need to mention that preferable methods should be annotated inside the object, and TypeScript will notify you. Nevertheless, let's add type for a destructured method:
```ts
const { setOwner }: { setOwner: (name: string) => void } = car;
```
## Conclusion
To sum up, if annotations are required for destructured object properties, we have to mirror and write the exact structure of that property. | spukas | |
337,695 | Como clonar um app no Heroku | Originalmente postado no Medium Hoje fui confrontado com uma task super simples: Criar 3 ambientes d... | 0 | 2020-05-17T19:48:35 | https://medium.com/@jonyhayama/como-clonar-um-app-no-heroku-f8b7488950e3 | devops | Originalmente postado no [Medium](https://medium.com/@jonyhayama/como-clonar-um-app-no-heroku-f8b7488950e3)
Hoje fui confrontado com uma task super simples: Criar 3 ambientes de _staging_ para que nossos QAs trabalharem e assim evitar que fiquem “trombando” uns nos outros. O nosso cenário até o momento era, 1 ambiente por projeto e 2 profissionais para fazer os testes.
Nosso problema surgiu quando decidimos fazer uma força-tarefa e agilizar as entregas para um cliente em específico. Todo o time será realocado para o mesmo projeto. Aliado a isso, um novo QA foi contratado para compor a equipe.
Agora ficamos: 1 projeto, 3 QAs e apenas 1 ambiente para que façam seus testes.
Com apenas um ambiente, é natural que não consigam testar coisas diferentes em paralelo. Nossa ideia foi bastante simples: Criar um ambiente de staging para cada um e compartilho como fizemos:
A ideia é copiar o app `my-staging` para `my-new-staging`. Estou partindo do pressuposto que o [Heroku Cli](https://devcenter.heroku.com/articles/heroku-cli) já está instalado e operando.
## Repositório
Aqui trabalhamos com o Automatic Deploy, vinculado a uma branch específica do GitHub (carinhosamente chamada de `stg/star-wars`).
Esse processo é bastante simples:
```bash
git checkout master
git pull
git checkout -b stg/star-wars
git push -u origin HEAD
```
Depois crie a nova aplicação no Heroku e na seção “Deploy” conecte seu GitHub e escolha a branch conforme o print abaixo:
## Copiando as variáveis de ambiente
Primeiro copiamos as variáveis para um `txt` qualquer:
```bash
heroku config -s -a my-staging > heroku-env.txt
```
Depois é necessário enviá-las para a nova aplicação. Antes disso, é importante revisar as variáveis que, de fato, precisam ir. De cara, precisamos remover `DATABASE_URL`, já que o banco de dados será outro.
```bash
cat heroku-env.txt | tr '\n' ' ' | xargs heroku config:set -a my-new-staging
```
## Copiando o banco de dados (PostgreSQL)
Primeiramente precisamos gerar o backup na app de origem:
```bash
heroku pg:backups:capture -a my-staging
```
Esse comando terá uma resposta parecida com o print abaixo:

O importante aqui é a referência `b079`, que utilizaremos no próximo comando:
```bash
heroku pg:backups:restore my-staging::b079 --app my-new-staging
```
Repeti esse processo mais duas vezes e _voilà_ card movido para “done” 😃 | jonyhayama |
337,736 | CircleCI for VS Code (beta) | Monitor, inspect, and manage your pipelines | 0 | 2020-05-17T21:15:22 | https://dev.to/jody/circleci-for-vs-code-beta-241k | ci, circleci | ---
title: CircleCI for VS Code (beta)
published: true
description: Monitor, inspect, and manage your pipelines
tags: ci, circleci
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/60czhwynvvnc7gzgeprz.png
---
🎉 Hey all! I’m excited to announce that I’ve released the first beta version of **CircleCI for VS Code**.
It’s pretty easy to jump right in if you want to try it out, just [install it](https://marketplace.visualstudio.com/items?itemName=jodyh.circleci-vscode) in VS Code and follow the instructions. I’m going to give a brief rundown and go over what the development experience was like below.
_Quick note before I dive in: while I certainly hope they like it, this extension is not built or endorsed by CircleCI._
## Highlights
A full breakdown of setup and everything you can do can be found in the [Marketplace overview](https://marketplace.visualstudio.com/items?itemName=jodyh.circleci-vscode#how-to-use), but here are a few areas I wanted to call out.
**Builds for your current branch, master, and more**
The extension will always poll for builds on your current Git branch — it’ll automatically update when you change branches. But if you need to you can additionally specify any custom branch name that you’d like to list in the extension view. I personally like to always be watching `master`.
**Customize build counts and re-check intervals**
The extension options give you the ability to specify how many builds it should retrieve per pipeline, and, if a build is in an active state, how frequently it should poll CircleCI for updates to it.
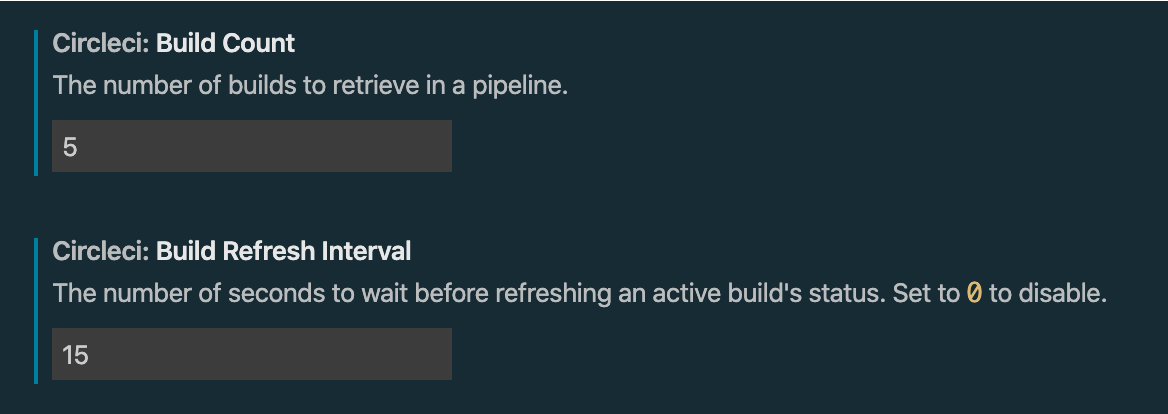
**Keep an eye out for new builds**
Unfortunately we can’t use webhooks to inform the extension of new builds, but we do provide you the option to regularly poll stale pipelines for new builds.

**Explore artifacts in VS Code**
Each build has the option to look up artifacts generated by the workflow. All you have to do is click the “Look up artifacts” row and they’ll populate below. Click an artifact to view it directly in VS Code.
**Retry, cancel, copy details, and more**
Most UI rows have context menu options. Pipelines and builds can be opened directly in the browser, but builds can also be retried and canceled directly from the extension. Workflow and commit rows allow you to copy various items to your clipboard.
## Development
This was my first exploration into the world of VS Code extensions, and I’ve got to say it was pretty fun. There’s a huge amount of flexibility in what you can build for VS Code, so that paired with excellent [documentation](https://code.visualstudio.com/api/) and a [CLI tool](https://github.com/microsoft/vscode-vsce) made developing and publishing a breeze.
For this extension I chose to go with a TreeView layout, with each pipeline and its builds rendered in collapsable rows. Using the [circleci](https://www.npmjs.com/package/circleci) Node package it was as simple as looking up builds for the current local branch (which, along with the username and repository name, make up a “pipeline”). If a pipeline has running builds, check in on them every so often, and re-render the latest data. Sprinkle in some context menu commands to retry failing builds, cancel running builds, and open everything in the browser, and we’ve got an extension. Things get a little more exciting when we start to look at the additional properties the CircleCI API returns; we can see commit data, the associated workflow, time spent running, and a lot more. I tried to include as many relevant build details as possible, for a UI that is informative but not cluttered.
There were a few areas of note that I particularly enjoyed:
- The ability to download a build’s artifact and load it directly into a VS Code window. No need to leave the IDE at all in some cases.
- Setting up configuration options was very nice; they’re defined in the `package.json`, support Markdown descriptions, have field types, and can be retrieved and updated within the extension execution.
- Because it’s VS Code, of course everything comes out of the box fully-typed. This made development so much smoother.
## What do you think?
That’s all for now. If you end up trying out the extension please do let me know what you think by commenting below, or if you’re running into problems you can either ask here or [file an issue](https://github.com/jodyheavener/circleci-vscode/issues/new). I’d love to improve on it.
Also, a huge thanks to James Van Dyke and his [CircleCI extension](https://github.com/jvandyke/vscode-circleci). It’s a few years old and uses the command palette and status bar for its primary interactions, whereas I wanted a few additional features and a visual UI. It provided for an excellent reference point, though, so please go check it out!
If you’re interested in building your own extension for VS Code, the [Extension API](https://code.visualstudio.com/api/) is a great way to get started. | jody |
337,756 | Business logic in Stored Procedures? | What is a Stored Procedure? What are the benefits of a stored procedure? | 0 | 2020-05-17T21:41:51 | https://dev.to/eugeneogongo/business-logic-in-stored-procedures-ceb | database, sql, data, design | ---
title: Business logic in Stored Procedures?
published: true
description: What is a Stored Procedure? What are the benefits of a stored procedure?
tags: [Database, sql,data,design]
cover_image: https://www.complexsql.com/wp-content/uploads/2018/04/Stored-Procedure.png
---
>A stored procedure(SP) is a set of Structured Query Language (SQL) statements with a given name stored in RDBMS, so it can be reused and shared by multiple programs.
## Performance
First SP in some databases system are compiled once and are in always executable form making calls faster since they can be cached. Therefore, increasing performance.
From my experience in using SP, I have been able to group multiple SQL commands and queries. This reduces network traffic and chaining of IFS on the code side. SP makes use of transactions e.g. using PL and T-SQL.
## Security
SP enhances security since the user has to pass some values to the database without knowing the underlining tables, views, and other information. The Developer calls the methods. This makes use of abstraction. The business logic is abstracted.
# Maintenability
SP enhances the maintainability of the System. Some conditions can be changed without necessarily changing the frontend code. Let's say the VAT tax reduces from 16% to 12%. This change can be made in the database without recompiling a POS system developed in 20 supermarkets. Some DB ensures changes in SP are transferred to all other slave databases.
SP ensures a central point for all business logic. No scattering of the business logic all over.
## Downside
one negative side of SP is that it leads to vendor locking eg T-SQL and PL/SQL. When migrating to a new DB you need to write some of them from scratch.
## Privilege Abuse
How do we ensure security and authorization? users who have DB-admin roles may abuse their roles and execute some SP maliciously. Ensuring data ACID properties becomes a challenge to an organization.
How best can we avoid database degradation?
## Where applicable?
I would recommend using SP when:
- the business logic is ever-changing
- doing complex data processing like in a warehouse | eugeneogongo |
337,799 | TypeScript in a Weekend: A Crash Course | I am in the midst of searching for my first job as a developer, and I recently interviewed at a compa... | 0 | 2020-05-17T23:08:46 | https://dev.to/shane__lonergan/typescript-in-a-weekend-a-crash-course-2171 | typescript, javascript, webdev, career | I am in the midst of searching for my first job as a developer, and I recently interviewed at a company for which I thought I would be a great fit. However, the job description said that most of the code is written in TypeScript. Now, I have heard a lot about TypeScript from other developers, but I hadn't had the chance to start learning it. I figured this was the perfect chance to take the plunge! I had an open weekend before the interview, so I decided to see how much I could learn. In this post I will walk through what I discovered: the basics of TypeScript, as well as some of the benefits it offers over JavaScript. The goal of this guide is to provide enough knowledge to be conversational, as well as to give a strong jumping off point if you were to start learning TypeScript on the job.
## Table of Contents
- [Table of Contents](#table-of-contents)
- [What is TypeScript?](#what-is-typescript)
- [Why TypeScript?](#why-typescript)
- [Getting Started](#getting-started)
- [Core Types](#core-types)
- [Number](#number)
- [String](#string)
- [Boolean](#boolean)
- [Array](#array)
- [Tuple](#tuple)
- [Enum](#enum)
- [Any](#any)
- [Null and Undefined](#null-and-undefined)
- [Never](#never)
- [Object](#object)
- [Union Types and Aliases](#union-types-and-aliases)
- [Interfaces](#interfaces)
- [Congrats!](#congrats)
- [References](#references)
## What is TypeScript?
TypeScript is a superset of JavaScript that horizontally compiles back to JavaScript. It provides the ability, among other things, to strongly type your JavaScript code. However, TypeScript files can't actually be run in the browser or Node. So, why is this useful?
## Why TypeScript?
TypeScript helps you avoid unwanted runtime errors by type-checking during development. TypeScript files are compiled into JavaScript files which can then be run in the browser or Node. The compiler catches bugs in advance, saving time and frustration during debugging down the line. TypeScript improves code clarity by explicitly defining the types of variables, function parameters, and function outputs. This allows you to tell at a glance exactly what your code should be taking and returning, and the compiler will throw an error if you accidentally pass something to a function that you shouldn't be. The TypeScript compiler also allows you to customize what version of JavaScript your TS files compile to. This allows the developers to utilize many newer features of JavaScript without worrying about browser compatibility. Because of this, TypeScript can also offer features such as generics, enums, and interfaces which are not available in JavaScript. Additionally, TypeScript offers fantastic tooling in modern IDE's such as VS Code that can catch errors while the code as being written, saving even more time debugging.
## Getting Started
Lets go ahead and dive right in by analyzing our first piece of TypeScript code:
```TypeScript
const name = 'Shane'
let age = 24
function printNameAndAge(person: string, ageInYears: number): void {
console.log(`${person} is ${ageInYears} years old.`)
}
printNameAndAge(name, age)
```
Now, you might be thinking to yourself, "That looks a lot like JavaScript...". Well, thats because it is! Vanilla JavaScript is totally valid in TypeScript. All of the features are optional to use, and exactly how they are utilized is up the the developer. Of course, you aren't getting any of the benefits of TypeScript by doing this, so lets add a little bit to it:
```TypeScript
const name: string = 'Shane'
let age: number = 24
function printNameAndAge(person: string, ageInYears: number): void {
console.log(`${person} is ${ageInYears} years old.`)
}
printNameAndAge(name, age)
```
As you can see, you can add type annotations after variable declarations or within function parameters using a colon (`:`) followed by the type. The `void` following the function parameters is the type annotation for the return value of the function. In this case, the function doesn't return anything, so the type will be `void`. If it returned a string, then we would set it to `string` instead. This allows us to ensure our function is always returning exactly what we want it to.
Now that we know how to annotate a type, lets dive into the core types offered by TypeScript.
## Core Types
### Number
Just like JavaScript, there isn't a difference between integers and floats (decimals), as all numbers are treated as floats.
```ts
let luckyNum: number = 13
```
### String
Strings, a series of characters, can be represented using `' '` or `" "`. You can also use template literals with `` ``.
```ts
let name: string = 'Shane'
```
### Boolean
A simple true or false value.
```ts
let isDone: boolean = false
```
### Array
When you create an array, you want to annotate the type as an array, as well as the type of the values inside the array. This can be done in two ways:
```ts
let listOfEvens: number[] = [2, 4, 6, 8]
let listOfOdds: Array<number> = [1, 3, 5, 6]
```
### Tuple
A tuple lets you create an fixed-length array of mixed types.
```ts
let nameAgeArr: [string, number]
nameAgeArr = ['Shane', 24] // ✅
nameAgeArr = [24, 'Shane'] // ❌
```
### Enum
An enum is a way of giving more friendly names to sets of numeric values. For example, if you have an object property that can only be set to a set number of options, you can label them as numbers instead of strings. That saves confusion over spelling, capitalization, and other string semantics, while increasing code readability.
```ts
enum Genre {
Rock,
Jazz,
Hip-Hop,
}
let giantSteps = {
artist: "John Coltrane",
genre: Genre.Jazz
}
let genreName: string = Genre[0] // will be "Rock"
```
Numeric values for enums automatically start at 0. However you can change the first value to be any number, and the remainder will increment from there. You can also set the values for each manually.
```ts
enum Genre {
Rock = 3,
Jazz, // => 4
HipHop, // => 5
}
enum Genre {
Rock = 5,
Jazz = 30,
HipHop = 13,
}
```
### Any
The type of any can be used for variables whose values we do not yet know, or if we want to opt out of type-checking. This allows TypeScript to be very flexible, but use sparingly, as it eliminates the value added by TypeScript.
### Null and Undefined
Just as in JavaScript, null and undefined are types in TS. By default, null and undefined are subtypes of all other types, meaning you can assign null or undefined to a variable with the number type.
```ts
let luckyNumber = 13
luckyNumber = undefined // ✅
```
### Never
Never type represent the type of values that never occur. For example, a function that always throws an error when called will never return, so we can set the return type to `never`. An infinite loop could also have the return type `never`.
```JavaScript
function throwError(msg: string): never {
throw new Error(msg)
}
```
### Object
In Javascript, everything that isn't a primitive is an object. Thus, the object type represents any non-primitive, or anything that isn't a number, string, boolean, symbol, null, or undefined.
```ts
let shane: object
shane = { name: "Shane", age: 24 } // ✅
shane = () => console.log("Hi, my name is Shane") // ✅
shane = "Shane" // ❌
```
## Union Types and Aliases
If you variable or parameter needs to have more flexibility, you can specify multiple type options using union types.
```ts
let numberOrString: number | string
numberOrString = 13 // ✅
numberOrString = 'thirteen' // ✅
```
You can also define your own types, known as aliases, which can be used as type definitions later.
```ts
type FlexibleNumber = number | string
let luckyNumber: flexibleNumber = 13
luckyNumber = 'thirteen' // ✅
```
## Interfaces
Typescript allows us to define specific object shapes as a type, called an `interface`, which allows us to ensure the objects we are using always have the proper keys and value types.
```ts
interface Album {
name: string;
artist: string;
numSongs: number;
}
const sgtPepper: Album = {
name: "Sgt. Pepper's Lonely Hearts Club Band",
artist: "John Coltrane",
numSongs: 13
isGood: true // Allowed to have additional properties
}
const help: Album = {
isGood: true // ❌, must contain all properties from interface
}
```
## Congrats!
You now have an understanding of the fundamentals of TypeScript. Thank you so much for reading, and best of luck on your TS journey!
## References
- [TypeScript Docs](https://www.typescriptlang.org/docs/home)
- [Lear TypeScript from Scratch - Academind](https://www.youtube.com/watch?v=BwuLxPH8IDs&t=8649s) | shane__lonergan |
337,882 | Understanding Execution Context Part 3: Closure | The last two weeks, I talked about two concepts in Javascript that confuse beginners to what they act... | 0 | 2020-05-18T01:26:34 | https://dev.to/jihoshin28/understanding-execution-context-part-3-closure-2h4a | The last two weeks, I talked about two concepts in Javascript that confuse beginners to what they actually are, but are fundamental to learning how the syntax parser in the JS engine works. The two concepts I covered were execution context and the this object. These concepts are fundamental to learning what is going on behind the scenes in your Javascript engine, because these concepts deal with how variables are declared and then defined in various cases in code. This week, I want to finish up this series with the topic of closures.
If you read my article on execution contexts, I recalled there how before learning about the fact that there were creation phases and execution phases in running Javascript code, the way I understood the idea of scope was lacking.
```
function outerFunction(name){
var closureVar = name
return function innerFunction(age){
console.log(`Hello my name is ${closureVar} and I am ${age} years old.`)
}
}
var executeOuter = outerFunction("Allen")
executeOuter(28)
```
My understanding of scope understood as much as that common definition of what is available to the inside function is also no available to the outside function. When I would look at this example, I would presume that, because the name variable was declared in as in input outside of the innerFunction, when the returned innerFunction was run, that innerFunction would have access.
But is it really that simple? In our case, there are actually two different execution contexts that are created: one for the outerfunction which returns a function, then one for the innerFunction which console logs a message with two variables. How is the outer variable accessed here?
If we recall how execution contexts work, everytime a function is executed, there is a phase where variables are declared, then assigned. In the case of the above example, the executeOuter variable is declared in the global scope, and once we get to the moment of assigning this variable, we run the outerFunction with my name as in input. This then creates another execution context which declares and assigns the variable and returns a function.
Now, the exection context for the first function is done. All the variables that were declared assigned and used in the first execution context, right? This is what I would have guessed initially as well, since you can't from the global scope now access the 'closureVar' variable that was assigned in the outerFunction's execution context. Well, to cut to the chase, you can and that's because of closures. The definition that MDN gives is this:
`A closure is the combination of a function bundled together (enclosed) with references to its surrounding state`
The way I like to imagine it is an imaginary box which replaces the execution context after it is finished to give access to variables to any potential recipients inside the execution context called afterwards. In our case, the outerFunction returns a function which requires access to the 'closureVar' variable inside our closure.
Now that we have covered how closures work, I would like to talk about on particular example that also defines some proper boundaries. I began to wonder how scope works in general and how if I called a function like this...
```
function outer1(){
var innerVar = "hello"
return innerVar
}
function outer2(var){
console.log(var)
}
outer1()
outer2(innerVar)
```
... outer2 function wouldn't have access to the innerVar. This is how scope normally works. That got me to wonder why that was the case for specific examples like the one I have at the very top. Well I did a little research and I found a post on StackOverflow that mentions a concept called garbage collection, which is essentially how a program gets rid of variables that it doesn't need anymore. In our case, when the outer1() execution context was created, it created, assigned, and memory dumped the innerVar.
My question was how is this any different than the 'closureVar' that we created at the top? The answer was that essentially, if a variable is no longer accessible from the outside, then it is disposed of. In our example at the top, there was a function that was returned with that still needed access to the 'closureVar'. The program then knows to leave it remaining in the closure for further access when it is called later. In the case how a classic scope works, the variables defined inside a function have no way of being accessed after that particular execution context completes, and so it knows to memory dump it.
I've really enjoyed digging deeper into these fundamental topics, because I feel like it provides a good foundation for understanding what I'm doing when I code or debug. Hopefully, it has helped you all too!
| jihoshin28 | |
337,909 | Why would I even use dependency injection? | A short walkthrough of dependency injection and why you should be using it | 7,533 | 2020-05-18T02:54:17 | https://maccoda.github.io/software_concepts/dependency-injection/ | di, bestpractices | ---
description: A short walkthrough of dependency injection and why you should be using it
---
I was inspired to write this post and hopefully a little series on some of these key concepts of
software as I was asked "Why would I need to use dependency injection?". This brought me back to
when I was first learning these industry staples that you never get taught learning computer
science. Due to this I was hoping to write a little series around my learning experiences and
understanding of these concepts because I have always found the more perspectives you get the easier
it is to form your own understanding. This is the first one for the series so let's see how far we
can go.
## What is Dependency Injection?
Alright now that the little preamble is over with lets start out like any good problem solver and
define the *What* of the problem. According to our good friends at Wikipedia we define dependency
injection as:
> In software engineering, dependency injection is a technique whereby one object supplies the
> dependencies of another object.
[Wikipedia](https://en.wikipedia.org/wiki/Dependency_injection)
So this is pretty good and correct, assuming you understand the concept to begin with. So let's try
break it down a bit.
I first learnt this with Java, so one simple trick to think of dependency injection is moving all of
the `new` keywords out of your classes. Now this is a pretty dumb thing to say because something
obviously has to instantiate your classes and that is entirely correct but the point of dependency
injection is to create that separation between where your classes and their dependencies are
instantiated and where you write the fun problem solving logic. So the concept of dependency
injection is being able to **give** your classes their dependencies rather than you class
instantiating its own dependencies. A term you will hear a lot around this topic is Inversion of
Control (IOC). You are now giving control of what your classes dependencies are to a class higher up
the chain.
Don't worry there is a lot of writing here and my description is arguably confusing in itself but I
will clarify this with some examples soon! So stick with me!
## How do I use Dependency Injection?
There are a lot of fancy frameworks that you can use for dependency injection, no matter what
language you develop in. However I have no intention of showing how to use those frameworks because
if you want to learn you should practice it on the bare metal. I always enjoy getting my hands dirty
with this (as much as they can typing on a keyboard) because I find that to be the best way to
understand, making the mistakes and finding the answers.
Saying that let's get onto our example. Since I am not feeling incredibly creative today I am going
to take the classic shopping cart example. Our task is to make a shopping cart class that will allow
our customers to buy some items. The code below is one possible way of doing this (although please
don't use this to implement an actual shopping cart).
```java
public class ShoppingCart {
private CreditCard creditCard;
private LineItems items;
public ShoppingCart(long creditCardNumber, List<Product> products) {
creditCard = new CreditCard(creditCardNumber);
items = new LineItems(products);
}
public void placeOrder() {
creditCard.charge(items.total());
}
}
```
So as you can see this shopping cart implementation needs to have a `CreditCard` to charge and some
`LineItems` to define how much to charge. Therefore it is pretty easy to see that the dependencies of
`ShoppingCart` are `CreditCard` and `LineItems`. A pretty easy way to see this in Java is they will
be fields of the class, you really only define a field if you need to use it perform some tasks.
However there are `new` keywords here so you can see the dependencies are not injected into
`ShoppingCart`, rather `ShoppingCart` knows exactly how to create its dependencies. It knows it
needs a **credit card number** and a **list of products**. In fact this is exactly why dependency
injection is important because it means your class does not need to know how to create its
dependencies but only how to **use** its dependencies. Instead of providing the parameters to
construct the dependencies we should have instead provided the dependencies themselves and
constructed those elsewhere, perhaps like this:
```java
public class ShoppingCart {
private CreditCard creditCard;
private LineItems items;
public ShoppingCart(CreditCard creditCard, LineItems items) {
this.creditCard = creditCard;
this.items = items;
}
public void placeOrder() {
creditCard.charge(items.total());
}
}
```
So we can now create it elsewhere
```java
public class Factory {
public ShoppingCart shoppingCart(long creditCardNumber, List<Product> products) {
return new ShoppingCart(new CreditCard(creditCardNumber), new LineItems(products));
}
}
```
Now we have separated our creation code from our domain logic code. In doing this it has provided us
dependency injection as you can see our `ShoppingCart` no longer has any `new` keywords!
## Why Dependency Injection?
The most obvious question now is, "Why would I do that? That looks like more code!". This is indeed
correct we do have more code but the number of lines you have written is never a sole indicator of
the quality of the code. Instead what you should be looking at is "Has this made it easier for me to
change the code as requirements change?" or "Is this code easily testable?". Making our code use
dependency injection has allowed us to say yes on both of those fronts.
### Changing with Requirements or Design
The biggest achievement we have made is we are now able to develop to an interface. That is,
`ShoppingCart` doesn't need to know anything about how `CreditCard` or `LineItems` work under the
hood, or if they are even concrete classes. All it needs to know is that it can call `charge` and
`total` on them respectively. Therefore if we only supported one type of credit card and we needed
to add another one, so long as it implements `charge` for the `CreditCard` interface our
`ShoppingCart` need not change.
In a different direction, if the design of `LineItems` were to change and it needed something
different to construct itself, our `ShoppingCart` is now unaffected. The only place it needs to
change is where we create it.
### Testability
Something else that dependency injection has aided with is making tests easier to write. If we had
of kept it the old way, testing `ShoppingCart` would be near impossible without needing to charge an
actual credit card. To avoid this we would need to use reflection to inject a mock and capture all
the interactions, doable but more complicated than it need be. Now we can simply make a test double
that looks like a `CreditCard` and then capture the interactions on that.
## Finishing Up
Hopefully through this very basic example you can see how you can use dependency injection in your
current work as well as how it is helpful. As with a lot of these practices it is hard to see the
benefit in the small scale but once your system grows and the number of moving parts increases its
value becomes apparent.
| maccoda |
337,912 | HTML5 Form Validation Using Input Types | Song of the Week Last week I wrote a post about how to use input tag attributes to impl... | 0 | 2020-05-18T04:30:40 | https://dev.to/lofiandcode/html5-form-validation-using-input-types-2e48 | html, beginners | ###Song of the Week
{% soundcloud https://soundcloud.com/cloudchord/sunlit %}
Last week I wrote a post about how to use input tag attributes to implement form validation without JavaScript. This week I wanted to cover go over how you can use input tag types to implement form validation, again without JavaScript.
The great thing about using input tag types for form validation is that while some will generate an alert to tell the user they made a bad entry, many others will simply not allow the user to make an invalid entry in the first place.
Now there are quite a few input tag types, but I chose to show you the 6 types that I thought would be the most useful in restricting form inputs. And just like last week, at the end of this post I embedded a CodePen so you experiment with examples of all the types covered.
##Date
The `date` input type creates a field in which the user can only enter a date in the format "mm/dd/yyyy". This is an example of one of the input types that doesn't allow the user to enter an invalid input, rather than creating an alert on submit. If the browser supports it, this field will have a date picker to assist when entering a date. Also, the `date` input type is not supported by Safari or Internet Explorer 11(or earlier). Here's an example:
```html
<form id='form'>
<label for='date-example'>Date:</label>
<input
type='date'
id='date-example'
/><br>
<button type="submit">Submit</button>
</form>
```
##Time
The `time` input type creates a field in which the user can only enter a time in the format "00:00 AM/PM". Be aware that this input type is not supported by Safari or Internet Explorer 12(or earlier). Here's an example:
```html
<form id='form'>
<label for='time-example'>Time:</label>
<input
type='time'
id='time-example'
/><br>
<button type="submit">Submit</button>
</form>
```
##Email
The `email` input type creates a field which will create an alert if the user does not enter an email address. Another cool feature of this field is that some smartphones will recognize it and add a ".com" to the keyboard. Here's an example.
```html
<form id='form'>
<label for='email-example'>Email:</label>
<input
type='email'
id='email-example'
placeholder='example@example.com'
/><br>
<button type="submit">Submit</button>
</form>
```
##URL
The `url` input type creates a field which will create an alert if the user does not enter a url. Like this email type, some smartphones will also recognize it and add a ".com" to the keyboard. Here's an example:
```html
<form id='form'>
<label for='url-example'>URL:</label>
<input
type='url'
id='url-example'
/><br>
<button type="submit">Submit</button>
</form>
```
##Number
The `number` input type creates a field in which the user can only enter a number. In addition to preventing the user from entering letters or symbols with this input type, you can also use the 'min', 'max', and 'step' attributes we covered last week to further restrict the user's entries. Here's an example:
```html
<form id='form'>
<label for='number-example'>Number:</label>
<input
type='number'
id='number-example'
/><br>
<button type="submit">Submit</button>
</form>
```
##Range
The `range` input type creates a field in which the user can only operate a slide bar. The default range of the slide bar is 0 to 100, but you can use the `min` and `max` attributes to set a custom range. You can also set how the slide bar increments between the min and max with the `step` attribute. Here's an example:
```html
<form id='form'>
<label for='range-example'>Range (0-30):</label>
<input
type='range'
id='range-example'
min="0"
max="30"
step="5"
/><br>
<button type="submit">Submit</button>
</form>
```
##Interactive Example
As you try entering invalid values in each field, be aware that only the email and url input fields will create an alert if you enter an invalid entry. The other field will simply prevent you from making an invalid entry.
{% codepen https://codepen.io/lofiandcode/pen/MWazwMe %}
##Takeaways
* The `date` input type creates a field in which the user can only enter a date in the format "mm/dd/yyyy".
* The `time` input type creates a field in which the user can only enter a time in the format "00:00 AM/PM".
* The `email` input type creates a field which will create an alert if the user does not enter an email address.
* The `url` input type creates a field which will create an alert if the user does not enter a url.
* The `number` input type creates a field in which the user can only enter a number.
* The `range` input type creates a field in which the user can only operate a slide bar. The default range of the slide bar is 0 to 100, but you can use the `min` and `max` attributes to set a new range.
If you want to read more about these and all the other input types in HTML5, click the w3shools link under references.
##References
[Cover Image](http://www.theresiliencyinstitute.net/we-need-your-input/)
[HTML Input Types - w3schools.com](https://www.w3schools.com/html/html_form_input_types.asp)
[Input Type Examples - codepen.io/lofiandcode](https://codepen.io/lofiandcode/pen/MWazwMe) | lofiandcode |
337,924 | Mock all you want: supporting ES modules in the Testdouble.js mocking library | How I modified Testdouble.js to support native Node.js ES modules | 0 | 2020-05-18T03:55:11 | https://gils-blog.tayar.org/posts/mock-all-you-want-supporting-esm-in-testdouble-js-mocking-library/ | node, testing, opensource | ---
title: Mock all you want: supporting ES modules in the Testdouble.js mocking library
published: true
description: How I modified Testdouble.js to support native Node.js ES modules
tags: node,testing,opensource
canonical_url: https://gils-blog.tayar.org/posts/mock-all-you-want-supporting-esm-in-testdouble-js-mocking-library/
---
ES Module are a new way of using modules in JavaScript. Having ES modules (ESM) in Node.js means that you can now write:
```js
import fs from 'fs'
import {doSomething} from './mylib.mjs'
```
instead of using the classic CommonJS (CJS) modules:
```js
const fs = require('fs')
const {doSomething} = require('./mylib.js')
```
If you want to learn more about the whys and the hows (and are maybe wondering about that `.mjs` extension...), see my Node.TLV talk about ESM in Node.js:
{% youtube kK_3OP0uJ0Y %}
But this blog post is not about Node.js ES modules, but rather about how I went about retrofitting my favorite mocking framework to support ES modules. The experience itself was great (and so was the encouragement from Justin Searls (@searls)), but I want to to talk about the more technical aspects of how to build a mocking library to support ES modules in Node.js.
So buckle your seatbelts. It's a long and deeply technical ride.
## Testdouble.js

[Testdouble.js](https://www.npmjs.com/package/testdouble) is a fabulous mocking library. It can mock any function, method, or module. So mocking a CommonJS module would go something like this:
```js
const td = require('testdouble')
const {doSomething} = td.replace('../src/mylib')
td.when(doSomething()).thenReturn('done')
```
Which would mean that app code that does this:
```js
const {doSomething} = require('./mylib')
console.log(doSomething())
```
Would print `done` to the console. And, lastly, if we call:
```js
td.reset()
```
Then the above app code will call the original `mylib.js`, and not the mocked version. Note aso that calling `td.replace` multiple times with different mocks replaces the original module multiple times.
Simple, clear, and to the point. Really nice mocking framework! Unfortunately, it only supports CommonJS modules.
### How Testdouble.js works in CommonJS
Testdouble uses a technique that is used by all the various mocking libraries, auto-transpiler libraries (think `babel-register` or `ts-node`), and others. They monkey-patch Node.js' module loading code.
Specifically, Testdouble.js overrides `Module._load` and inserts its own loading mechanism, so that if a CommonJS module needs mocking (because it was `td.replace`-ed), it loads the mocked code instead of the original module's code. And, obviously, if the module doesn't need mocking, it calls the original `Module._load`.
An important thing to remember, and this fact is important when I talk about ESM support, is that `Module._load` is called only when Node.js needs to load the module's source code. If the module was already loadedm, and is in the cache, then it won't be called, and the mocking won't work. This is why `Testdouble.js` always deletes a mocked module from the cache immediately after creating it, so that the tests are able to call `td.replace` as many times as they want to change the mock.
Till now, I've always said that it is Testdouble.js that does the mocking, but that is not strictly true. Testdouble.js uses another package, [quibble](https://www.npmjs.com/package/quibble), that does all the "dirty work" of replacing a module for it. Quibble does _only_ module replacement, and so its API is pretty simple, and much simpler than Testdouble.js':
```js
const quibble = require('quibble')
quibble('./mylib', {doSomething: () => 'done'})
```
When mocking a module, you specify the path to the module, plus the replacement you want to the `module.exports` if that module. The above code is equivalent to the `testdouble` code we showed earlier.
Kudos to Justin Searls for splitting out the module replacement code to a separate package. It made adding ESM support _much_ easier, as most of the work needed to be done in Quibble, separated from the noise of a general purpose mocking library.
## Why do we even need ES module support
But, but, but (I hear you saying), why do we even need explicit ESM support? Won't the `Module._load` monkey patching (or any other various monkey-patching tricks around `require`) work with ES modules?
The answer is an emphatic "no". For two reasons.
The first is simple: When importing ES modules (using `import`), Node.js does not go through the same code paths that loads CommonJS modules (using `require`). So monkey patching `Module._load` won't work because it just isn't called!
Second, and more importantly: the designers and implementors of ES Module support in Node.js designed it in such a way that monkey-patching is _not_ supported. To accomodate code that does need to hook into the module loading, there is an official way to hook into it, and it is the _only_ way to affect how ES modules are loaded in Node.js.
## Hooking into the ES Module loading mechanism
So how does one hook into the ES module loading mechanism? One word: [loaders](https://nodejs.org/api/esm.html#esm_experimental_loaders). This is the official API that enables us to hook into the ES module loading mechanism. How does one go about using it?
It's actually pretty easy and straightforward. First, you write a module (has to be ESM!) that exports various hook functions. For example, tbe following loader module adds a `console.log("loaded")` to all modules:
```js
// my-loader.mjs
export async function transformSource(source,
context,
defaultTransformSource) {
const { url } = context;
const originalSource = defaultTransformSource(source, context, defaultTransformSource);
return {source: `${originalSource};\nconsole.log('loaded ${url}');`}
}
```
Node.js calls this loader module's `transformSource` function (note that it is exported by this module, so Node.js can easily import the module and call the function) whenever it has loaded the source, enabling the loader to transform the source. A TypeScript transpiler, for example, could easily use this hook to transform the source from TypeScript to JavaScript.
But how does Node.js know about this loader module? By us adding it to the Node command line:
```sh
node --loader=./my-loader.mjs
```
There is no API to load a loader: the only way to load a loader is via the command-line. (Will this change? Doesn't seem likely.)
> Note: ES module loaders are an experimental mechanism, and some parts of them are bound to change. The information about loaders here is relevant to May 2020.
So now that we know how to hook into the ES module loading mechanism, we can start understanding how we implemented module replacement in Quibble. Oh, but one last thing! We saw above that we need to enable multiple replacements, and the ability to reset. In the CommonJS implementation of Quibble, this was done by deleting the cache entry for the module whenever we replaced it with a mock, so that Node.js always calls `Module._load`. Unfortunately, this won't work in ES modules because there is _no_ way to clear the ESM cache, as it is separate from the CJS one, and not exposed by Node.js. So how do we do it for ESM? Patience, patience...
## How to use the Quibble ESM support
But before we explain how it works, let's see how to use it. As you will see, it is very similar to Quibble CJS support. Let's assume we have a module:
```js
// mylib.mjs
export function doSomething() {
return task
}
let config = {}
export default 'doing'
```
This module has one "named export" (`doSomething`), and one "default export" (the value `'doing'`). In ESM, these are separate, unlike in CJS.
First, to replace a module, use `quibble.esm(...)`:
```js
await quibble.esm('./mylib.mjs', {doSomething: () => 'done'}, 'yabadabadoing')
```
Why `await`? We'll see why when we discuss implementation, but intuitively, it makes sense, given that ESM is an asynchronous module system (to understand the why, I again refer you to the youtube video above that discusses the why and how of ESM), whereas CJS is synchronous.
To "reset" all ESM modules back to their original modules, we use:
```js
quibble.reset()
```
Besides these two functions, there's a third function, used by `testdouble.js` (for reasons we won't get into in this blog post):
```js
const {module, modulePath} = quibble.esmImportWithPath('./mylib.mjs')
```
This returns the module mentioned (just like `await import('./mylib.mjs')` does), and the full path to the module file.
That's it. That's the Quibble ESM API, which the next sections explains how they work.
## ESM replacement in Quibble

As you can see, quibble has three separate parts:
* **The store**, which is stored globally in `global.__quibble`, and stores all the mocking information.
* **The API**, `quibble.js`, which updates the store with the mocks based on calls to `quibble.esm()` and `quibble.reset()`.
* **The module loader**, `quibble.mjs`, which implements the mocking based on the data written to store. This file is the loader specified in `node --loader=...`.
Let's start explaining the Quibble ESM architecture, by explaining each part one by one. I usually like to start with the data model, so let's start with that:
### The Store (`global.__quibble`)
The store, which is available in `global.__quibble`, has the following properties:
* The important property is `quibbledModules`, which is a `Map` from the absolute path of the module to the mocks for the named and default exports. When you're doing `quibble.esm(modulePath, namedExportsReplacement, defaultExportReplacement)`, you're basically doing `global.__quibble.quibbledModules.set(absoluteModulePath, {namedExportsReplacement, defaultExportReplacement})`
* But the more _interesting_ property is `stubModuleGeneration`: a number that starts at `1` and is incremented on every `quibble.esm`. Remember that we can't delete modules in ESM? This property enables us to have multiple "generations" (versions) of the same module in memory, and use only the latest one. How? We'll see later.
### The API (`quibble.esm/reset/esmImportWithPath(...)`)
This is also pretty simple. Let's start by looking at the code, block by block. You can follow [here](https://github.com/testdouble/quibble/blob/7092352cc81e4568727a5b0c27fea6d3c5f93c78/lib/quibble.js#L78), and also try and follow from this flowchart that expresses _most_ of the details from here:

```js
quibble.esm = async function (importPath, namedExportStubs, defaultExportStub) {
checkThatLoaderIsLoaded()
```
The signature we've already explained. The first line of the function checks that the loader is loaded. How? It checks that there's a `global.__quibble`. If not, it throws an exception. Good DX, but not very interesting code-wise. Let's continue:
```js
if (!global.__quibble.quibbledModules) {
global.__quibble.quibbledModules = new Map()
++global.__quibble.stubModuleGeneration
}
```
We'll see later that `quibble.reset` deletes the `quibbledModules` (because no more mocking needed, right?), so this restores it, and increments the generation (I promise we'll see what this generation thing is for when we get to the module loader!).
I want to skip ahead to the last lines, which are the important ones:
```js
global.__quibble.quibbledModules.set(fullModulePath, {
defaultExportStub,
namedExportStubs
})
```
When we talked about the store, we said that this is the crux of `quibble.esm`: writing the mocks to the store. Well, these are the lines that do it! So why all the rest of the lines? They're there for one reason: figuring out the `fullModulePath`. How do we do that?
Well, it depends. The "import path", which is what the user puts in `quibble.esm('./mylib.mjs')` can be one of three things, and the absolute path is figured out based on this:
* **An absolute path**. This can _theoretically_ happen, but not very practical. In this case, if the path is absolute, just use it as the `fullModulePath`!
* **A relative path**. The path is relative, and relative to the caller file (the file that called `quibble.esm`), so we need to figure out the absolute path the caller file. This is done in `hackErrorStackToGetCallerFile()`, and I won't go into the details, because it's the same hack that is used in CJS: create an `Error` and retrieve the stack from that. I just modified it a bit: the stack when the module is ESM may have _URLs_ and not file paths, because ESM is URL-based. Once we have the caller file, we can absolutize the relative path to get the absolute path.
* **A bare specifier**. In ESM parlance, a bare-specifier is something that is not a path, but is supposed to be a package in `node_modules`. Examples: `lodash`, `uuid/v4`, `fs`. This is the more difficult one, because to figure out which module file Node.js loads for the package, we need to duplicate the same algorithm that Node.js uses to figure it out. And that is a problematic thing, especially in ES modules, where we need to take care of things like the [conditional exports](https://nodejs.org/api/esm.html#esm_conditional_exports). I really wanted to avoid it. So I had a trick up my sleeve, which we'll see in a second when we look at the code.
So let's look at the code:
```js
const importPathIsBareSpecifier = isBareSpecifier(importPath)
const isAbsolutePath = path.isAbsolute(importPath)
const callerFile = isAbsolutePath || importPathIsBareSpecifier ? undefined : hackErrorStackToGetCallerFile()
const fullModulePath = importPathIsBareSpecifier
? await importFunctionsModule.dummyImportModuleToGetAtPath(importPath)
: isAbsolutePath
? importPath
: path.resolve(path.dirname(callerFile), importPath)
```
The first two lines figure out which kind of module this is. The third line figures out the caller file if the module path is relative.
The last lines generate the module path. The most interesting one is what we do when the import path is a bare specifier. Let's look at `dummyImportModuleToGetAtPath`, whcih is used to get the absolute path to the bare specifier module file:
```js
async function dummyImportModuleToGetAtPath (modulePath) {
try {
await import(modulePath + '?__quibbleresolvepath')
} catch (error) {
if (error.code === 'QUIBBLE_RESOLVED_PATH') {
return error.resolvedPath
} else {
throw error
}
}
throw new Error(
'Node.js is not running with the Quibble loader. Run node with "--loader=quibble"'
)
}
```
This is interesting. We `import` the bare specifier, but add a `?__quibbleresolvepath` to it. What? How does that help? Remember: we have a loader running, and that loader (as we'll see later), will catch requests for a module, notice the `__quibbleresolvepath`, figure out the module path (we'll see how later), and throw an exception with the module path, which this code catches.
Sneaky!
There. We've covered how `quibble.esm(...)` works. `quibble.reset` is MUCH simpler:
```js
quibble.reset = function () {
delete global.__quibble.quibbledModules
}
```
That's it (it has stuff for CJS, but we're ignoring that). We're just deleting `quibbledModules` so that the loader will know that there are no replacements to do, and that it should return all the original modules.
The last one is `quibble.esmImportWithPath`, and we won't describe the implementation, because it's mostly similar to `quibble.esm`, except for one line:
```js
await import(fullImportPath + '?__quibbleoriginal')
```
After determining the full import path (in exactly the same way done by `quibble.esm`) it `import`-s the module, but adds `?__quibbleoriginal` to it. The loader will see this "signal" and know that even if the module is quibbled, it should load the original module this time.
Notice the repeated use of query parameters in the code. This is a recurring theme, and we'll see it used in onre more place—the most _important_ place.
## The Module Loader (`quibble.mjs`)
We _finally_ come to the module you've all been waiting for: the module loader. To remind you, this is the module we specify when we run node: `node --loader=quibble`, and Node.js will call it in various phases of loading the module. Each such "phase" is a call to a different named export function. We will concern ourselves with two interesting hook functions:
* `resolve(specifier, {parentURL}, defaultResolve)`: an async function that (and this is important) Node.js will call _even if the module is in the cache_. It will do this to determine what the full path to the module is, given the `specifier` (what we called the "import path" above), and the `parentURL` (what we called "caller file" above). The important thing to understand about this function is that the resulting URL _is the cache key_ of the module.
* `getSource(url, context, defaultGetSource)`: an async function that retrieves the source of the module, in case the module is not in the cache. The `defaultGetSource` just reads the file from the disk, but our implementation will return some articially produced source if the module needs to be mocked. The important thing to understand about this function is that the URL it receives is the URL returned by the `resolve` hook.
But what are these URLs we're constantly talking about? Why are we dealing with `http` URLs and not file paths? The answer is simple: the ES modules specification in JavaScript says that module paths are URLs and not file paths. They could be `http://...` URLs or `file://...` URLs or whatever conforms to the URI spec. Node.js currently supports only `file://...` URLs, but we could easily write a loader that supports loading from HTTP. Node.js keeps the URLs, and translates them to a file path on the disk (using `new URL(url).pathname`) only when actually reading the source file.
Let's start going over the code of each hook function. You can follow [here](https://github.com/testdouble/quibble/blob/7092352cc81e4568727a5b0c27fea6d3c5f93c78/lib/quibble.mjs)
### `resolve(specifier, {parentURL}, defaultResolve)`
We first prepare an inner function that will be used in other parts of this function:
```js
const resolve = () => defaultResolve(
specifier.includes('__quibble')
? specifier.replace('?__quibbleresolvepath', '').replace('?__quibbleoriginal', '')
: specifier,
context
)
```
This function, when called, will call the default resolver to get the default URL for the module. The nice thing about this, is that if the specifier ("import path") is a bare-specifier, then it will resolve the full module path for us! We have to remove the query parameters, because bare specifiers aren't really URLs, so query parameters aren't allowed. The fact that we can let Node.js resolve a specifier for us is why we use it in the next lines:
```js
if (specifier.includes('__quibbleresolvepath')) {
const resolvedPath = new URL(resolve().url).pathname
const error = new Error()
error.code = 'QUIBBLE_RESOLVED_PATH'
error.resolvedPath = resolvedPath
throw error
}
```
Remember when explaining `quibble.esm` we appended `?__quibbleresolvepath` to get at the full module path? This is where it's used. We throw an exception here, and attach all the information to the error, so that `quibble.esm` can use it.
Sneaky! But let's continue:
```js
if (!global.__quibble.quibbledModules || specifier.includes('__quibbleoriginal')) {
return resolve()
}
```
We default to the default resolver in two cases: there are no quibbled modules (because `quibble.reset` was called), or because `quibble.esmImportWithPath` imported the path with an additional `?__quibbleoriginal` (see above for the reason why). Let's continue:
```js
const {url} = resolve()
if (url.startsWith('nodejs:')) {
return {url}
}
```
We now resolve the specifier. If the module is an internal module (e.g. `fs`, `dns`) then the URL has a `nodejs` scheme, and we don't need to do anything, just return what was resolved.
All the above was just setting the stage. Now come the important lines:
```js
return { url: `${url}?__quibble=${global.__quibble.stubModuleGeneration}` }
```
We "decorate" the URL with a `?__quibble` with the generation. This decoration will notify `getSource`, that gets this URL, to return a mocked source, and not the original source. This also allows the original module to have a regular URL (without `__quibble`) and the mocked one a "decorated" URL (with `__quibble`). This is more important than it seems, because it enables both versions of the module to reside in memory. How? Remember that the cache key for the module is the full URL returned by the `resolve` hook. So if the URLs differ by a query parameter, then both versions of the module (the original and the mocked) reside in the cache.
And because the `resolve` hook is called _before_ checking the cache, then that means we can route Node.js to whatever version of the module we want, based on whether it needs to be mocked or not, and this can change _on the fly_.
Sneaky!
But why do we append the generation? Why not just `__quibble`? Similar to the above, this allows to to generate a different version of the mock every time we need it. And because we can `quibble.reset` and then `quibble.esm` a different mock module, then we will need a different cache key for the new version of the mock module. This is the reason for the mock generation.
Sneaky!
And so we reach the end of our journey, with the last hook, the one that actually returns the mocked module:
### `getSource (url, context, defaultGetSource)`
As in `resolve`, we define a function to get the default source:
```js
const source = () => defaultGetSource(url, context, defaultGetSource)
```
Now we check whether `quibble.reset` was called, and so we can return the original source:
```js
if (!global.__quibble.quibbledModules) {
return source()
}
```
And here we check that we need to quibble the module, and if we do, we call `transformModuleSource(stubsInfo)`:
```js
const shouldBeQuibbled = new URL(url).searchParams.get('__quibble')
if (!shouldBeQuibbled) {
return source()
} else {
const stubsInfo = getStubsInfo(url) // find the stubs in global.__quibble.quibbledModules
return stubsInfo ? { source: transformModuleSource(stubsInfo) } : source()
}
```
And, now, here it is, in all it's glory: the mocked module code generation:
```js
function transformModuleSource ([moduleKey, stubs]) {
return `
${Object.keys(stubs.namedExportStubs || {})
.map(
(name) =>
`export let ${name} = global.__quibble.quibbledModules.get(${JSON.stringify(
moduleKey
)}).namedExportStubs["${name}"]`
)
.join(';\n')};
${
stubs.defaultExportStub
? `export default global.__quibble.quibbledModules.get(${JSON.stringify(
moduleKey
)}).defaultExportStub;`
: ''
}
`
}
```
What do we do here? This is a code generator that generates a named export for each of the mocked named exports. The value of the named export comes from the store, which the generated code accesses. Same goes for the default export.
And the journey is done.
## Summary
We covered a _lot_ here. But it's actually more complicated than it seems. Let's try and summarize the important things to remember:
* The store (`global.__quibble`) holds all the mocks per each mocked module's absolute module path.
* The API stores the information in the store. Since it needs the full module path, it makes use of the fact that the resolver can return the module path of bare specifiers (by adding a query parameter to signal xthis), to do just that.
* The module loader's `resolve` hook checks for signals from the API that tell it to resolve the module path using the default module. It also adds `__quibble` for the `getSource` hook to tell it that it needs to return the source of the mocked module.
* The `_quibble` query parameter has a "generation" number added to it to enable multiple versions of the mock to be used and discarded.
* The `getSource` looks at the `__quibble` parameter to determine whether to return the original source or whether to return the code of the mocked module.
* The mocked module source code exports named and default exports, whose values come from the global store.
## The future
How fragile is this? What are the odds that some change renders the design above obsolete? I don't know really, but the above hooks have been stable for a pretty long time (minor changes notwithstanding), so I'm pretty confident that I'll be able to navigate Quibble and Testdouble.js through changes in loaders.
There is one change on the horizon, however, that is somewhat worrying: {% github <https://github.com/nodejs/node/pull/31229> %}
If implemented, this change will move the loaders to a worker thread. In general, this is a good thing, but it also means that the way the API and the module loader communicate today—through the global scope—will not work, and we will need a way to communicate the stubs and other things between the API and the loader. I am certain that if this PR is fully implemented, a way to do this will be given.
## Thanks
I'd like to thank Justin Searls (@searls) for his encouragement and quicknessin accepting the PRs. (Not to mention patience at my frequest zigzags in the code!)
| giltayar |
337,988 | Duy Anh Digital | Duy Anh Digital Shopping Center cung cấp tổng hợp các thiết bị điện tử,âm nhạc và đồ dùng công nghệ D... | 6,760 | 2020-05-18T06:44:12 | http://duyanhdigital.vn/ | Duy Anh Digital Shopping Center cung cấp tổng hợp các thiết bị điện tử,âm nhạc và đồ dùng công nghệ Digital ngày nay. Từ năm 1979, thương mại điện tử đã góp phần mang lại giá trị tiếp cận cực kỳ quan trọng, giúp cho việc trải nghiệm các sản phẩm đỉnh cao về Digital thật sự đến với gần chúng ta hơn. Với 94 danh mục thiết bị và dịch vụ, DuyAnhDigital đi đầu xu hướng xoay quanh ngành giải trí không thể không nhắc đến như : thiết bị nghe nhìn, Music, âm thanh, Digital Karaoke,
Studio, đồ dùng công nghệ...
Âm nhạc và nhạc cụ online
Chúng tôi cung cấp các giải pháp nghe nhìn toàn diện, dành cho hộ gia đình và kinh doanh. Với 10 năm kinh nghiệm trong lĩnh lực âm thanh karaoke và audio kỹ thuật số , thực hiện hơn 500 dự án lớn nhỏ. Chúng tối đi đầu về công nghệ âm thanh kỹ thuật số, phân phối mặt hàng điện tử E3 Audio tại Việt Nam , trụ sở chính tại 278 Tên Lữa, BÌnh Tân, TPHCM.
Chúng tôi tiếp nhận hơn 50 khách mỗi ngày, sỡ dĩ là như vậy bởi các bộ dàn âm thanh được phối ghép tinh tế chính hãng, các bộ dàn karaoke công nghệ mới, cơ sở vật chất gồm 3 phòng Demo.
Đừng ngần ngại cho chúng tôi biết bạn đang gặp vấn đề gì về âm thanh. Với đội ngũ kỹ thuật viên lành nghề, đảm bảo phục vụ tất cả các nhu cầu và giải đáp mọi vấn đề của quí vị. QUý khách hàng có thể liên hệ só điện thoại và địa chỉ theo ở cuối chân trang website.
Trải nghiệm đồ điện tử công nghệ mới nhất tại DuyAnhDigital
Ngoài dịch vụ âm nhạc, chúng tôi chung cấp và cập nhật các sản phẩm đồ dùng công nghệ điện tử theo thời đại , xu hướng. Giúp quý khách có thể trải nghiệm sản phẩm trực tiếp tại DuyAnhDigital. Đối vói các đơn đặt hàng tại DuyAnhDigital quý khách hàng được đổi trả hàng nếu gặp bất kể sự cố gì, chúng tôi cam kết đổi trả hàng miễn phí 7 ngày theo đúng qui định của công ty. Các sản phâm không vừa ý, quý anh chị cũng có thể nêu rõ vấn đề để được xem xét đổi sang các thiết bị khác tại công ty.
Dịch vụ âm thanh karaoke đội ngũ kỹ thuật có trình độ
Ngoài trao đổi mua bán các thiết bị điện tử, công ty chúng tôi cung cấp các dịch vụ đa ngành . Riêng hạng mục âm thanh tại DuyAnhDigital chúng tôi có các giải pháp dịch vụ với đội kỹ nhiều năm kinh nghiệm.
Với 3 hạng mục dịch vụ về Audio và Karaoke như:
Dịch vụ lắp đặt thiết kế dàn âm thanh karaoke
Dịch vụ setup cân chỉnh tại gia theo nhu cầu
Các dịch vụ cho thuê và tổ chức sự kiện giải trí Live Music.
Tại sao nên mua dàn karaoke gia đình tốt nhất tại DuyAnhDigital
Thứ nhất: Tư vấn và trải nghiệm bộ dàn karaoke âm thanh đặc sắc , thiết bị nghe nhìn digital cao cấp hoàn toàn miễn phí tại các cửa hàng, đại lý, Showroom của chúng tôi. Khi quý khách có nhu cầu hãy liên hệ với chúng tôi, Luôn có đội ngũ kỹ thuật viên giàu kinh nghiệm sẵn sàng hỗ trợ, tư vấn giúp quý khách lựa chọn những thiết bị âm thanh phù hợp với nhu cầu và điều kiện của quý khách nhất.
Thứ hai: Cam kết chỉ cung cấp thiết bị âm thanh chính hãng, có tem và phiếu bảo hành của nhà sản xuất và của DuyAnhDigital. Ngoài ra chúng tôi còn bảo hành trách nhiệm thêm 1 năm cho quý khách.
Thứ ba: Hỗ trợ vận chuyển và lắp đặt ngay tại nhà cho quý khách có nhu cầu trên Toàn Quốc.
Thứ tư: Cung cấp bộ dàn karaoke gia đình giá rẻ nhất trên thị trường. Ngoài ra quý khách còn được hưởng chế độ ưu đãi khuyến mại hàng tháng do chúng tôi đưa ra. Tất cả nhằm “Mang lại giá trị tốt nhất cho quý khách hàng”.
Thứ năm: Đặt hàng thuận tiện - thanh toán đa dạng – nhận hàng nhanh gọn. Quý khách có thể tới trực tiếp cửa hàng, đại lý, Showroom của chúng tôi hoặc có thể đặt hàng thông qua hotline, website, mail. Chúng tôi sẽ giao hàng tận nơi cho quý khách trong thời gian ngắn nhất.
Thứ năm: Quý khách được đổi trả hà
ng hoàn toàn miễn phí trong thời gian sử dụng theo yêu cầu của DuyAnhDigital.
Thứ sáu: Được hưởng các chế độ đãi ngộ đối với khách hàng thân thiết của DuyAnhDigital khi quý khách đã mua sản phẩm tại Showroom chúng tôi.
Thứ bảy: Sự đa dạng về các bộ dàn karaoke gia đình chính hãng cho quý khách lựa chọn. Quý khách có thể lựa chọn những bộ dàn karaoke được lắp đặt sẵn hoặc có thể đưa ra yêu cầu và điều kiện của mình, DuyAnhDigital sẽ thiết kế cho quý khách một bộ dàn karaoke gia đình ưng ý nhất.
Với những lý do trên, Chắc chắn quý khách đã có câu trả lời về “Mua dàn karaoke gia đình ở đâu tốt nhất”. Hãy tới cửa hàng, Showroom của chúng tôi để nghe, hát và trải nghiệm những điều tuyệt vời nhất mà một hệ thống dàn karaoke gia đình mang lại.
Hình ảnh showroom:
Vị trí trên bản đồ :
Mọi thắc mắc liên hệ HOTLINE : 0934234374 | daoduya70791881 | |
337,996 | Google Authentication with Expo and React-Native | I had to work with Expo's Google Authentication this week and I found a lot of outdated information w... | 0 | 2020-05-18T07:11:32 | https://dev.to/harleypadua/google-authentication-with-expo-and-react-native-2l24 | beginners, javascript, reactnative, computerscience | I had to work with Expo's Google Authentication this week and I found a lot of outdated information while integrating it into my React Native app. So I thought I'd make an updated tutorial for anyone looking to use this Expo feature on future projects.
The [Expo documentation](https://docs.expo.io/versions/latest/sdk/google/) is mostly good. I'll get into that in a bit, but first, the important stuff.
Sadly, Expo cannot handle the permissions with Google, so we'll need to do that ourselves. Head over to [Google developers](https://console.developers.google.com/) and create a new project. Give your project a name and click "create". Now we can get some credentials. From here, click Credentials on the side bar and then, at the top of the screen, Create Credentials.  You'll want to select OAuth client ID, but when you do, you'll notice you won't be able to select your application type until you configure consent screen.  Go ahead and click that. It'll bring you to the OAuth consent screen (duh) where you can choose user type. It feels like they try to scare you with these options, but I still chose External. Give the application a name, skip everything else (even that application logo. I know, it's so tempting), and hit Save.
Okay, now that we got that out of the way, back to credentials. You'll be able to select your application type now. For the purpose of this tutorial, I'll be using iOS, though the other types only require a few different steps. Google provides you with a name for the client ID which is fine to keep. For Bundle ID, make sure you put host.exp.exponent since we're using Expo. Once that's done you should get your client ID. 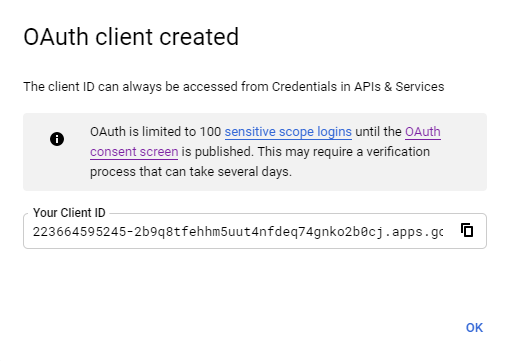 Copy and paste it somewhere for safe keeping, we'll need this.
Time to code! And now I can touch on one small annoyance. You'll want to install expo-google-app-auth and import it like this: ```javacript
import * as Google from 'expo-google-app-auth';
``` This is also in their docs, however, after we've got this authentication actually set up, you WILL get a warning telling you to ```javascript
import * as Expo from 'expo';
``` instead. When I tried switching, the authentication did not work. So, I have a fix for this annoying yellow box. Simply add: ```javascript
console.ignoredYellowBox = ['Warning:'];
``` anywhere in your code (preferably the root of the app, like App.js or index.js) to hide the warning. Make sure to import react as well as View, StyleSheet, and Button from react-native.
To implement the Google Sign In, you can copy straight from the docs. Now is the time to add your iOS client ID (or whatever one you chose) to your code via .env or some way to keep it private. Your code should look something like this: ```javascript
import 'react-native-gesture-handler';
import React from 'react';
import { View, StyleSheet, Button } from 'react-native';
import * as Google from 'expo-google-app-auth'
import { IOS_CLIENT_ID, AND_CLIENT_ID } from 'react-native-dotenv';
export default function LoginScreen () {
async function signInWithGoogleAsync() {
try {
const result = await Google.logInAsync({
behavior: 'web',
iosClientId: IOS_CLIENT_ID,
//androidClientId: AND_CLIENT_ID,
scopes: ['profile', 'email'],
});
if (result.type === 'success') {
return result.accessToken;
} else {
return { cancelled: true };
}
} catch (e) {
return { error: true };
}
}
```
Next annoyance: You may have noticed that this function is a promise, and therefore won't be able to be passed to a button just yet. Alter it for that purpose or, for a lazy fix, pass it to another function to then pass to a button. ```javascript
const signInWithGoogle = () => {
signInWithGoogleAsync()
}
return (
<View style={styles.container}>
<Button onPress={() => signInWithGoogle()} title="Sign in with Google" />
</View>
)
}
```
And we're done! All that's left is to add a little style and your app has functioning Google Authentication. Hope this helps and thanks for reading!
| harleypadua |
338,013 | Anatomy of String Formatting in Python | Python is a modern scripting language, so it offers us a flexible and readable coding. Therefore, w... | 0 | 2020-05-18T07:41:35 | https://pythongeeks.net/python-tutorials/anatomy-of-string-formatting-in-python/?utm_source=rss&utm_medium=rss&utm_campaign=anatomy-of-string-formatting-in-python | python, beginners, tutorials | ---
title: Anatomy of String Formatting in Python
published: true
date: 2020-05-18 07:16:59 UTC
tags: python, beginners, tutorials
canonical_url: https://pythongeeks.net/python-tutorials/anatomy-of-string-formatting-in-python/?utm_source=rss&utm_medium=rss&utm_campaign=anatomy-of-string-formatting-in-python
---

Python is a modern scripting language, so it offers us a flexible and readable coding. Therefore, we can do one thing in many different ways. That’s why until now we have even 4 main methods to format a string:
- [“Classic Style” String Formatting](#1-Classic-Style-String-Formatting)
- [“Modern Style” String Formatting](#2-Modern-Style-String-Formatting-strformat)
- [“Latest Style” String Formatting](#3-Latest-Style-String-Formatting-f-Strings)
- [“Standard Style” String Formatting](#4-Standard-Style-String-Formatting-Template-Strings)
In this post, we walk through every style of string formatting, do an example for each style, and get understand how it works.
At the end of this post, we understand well everything about the string formatting methods in Python. And hopefully, it will help you well in your next Python project.
## 1. Classic Style String Formatting
So why this method is called as a classic style. Because it’s simple and the very first method to format a string in Python. It’s quite sure that every Python developer is used.
Its syntax is quite similar to C-Style, where we use a `%` operator to receive arguments.
```python
>>> my_name = "Mark"
>>> "My name is, %s" % my_name
'My name is, Mark'
```
The `%` operator let Python know to use the variable, in my example is `my_name`, to fill in the placeholder where is marked by `%s`.
One of the pros of this method is we can use `%` operator to control the data type that argument should be converted to. For example, `%s` means convert to string, `%x` converts to hexadecimal number. You can refer the [printf-style](https://docs.python.org/3/library/stdtypes.html#printf-style-string-formatting) document for more conversion type.
We are able to pass various variables into a string.
```
>>> print("My name: %s. My id: %d" % ("Bob", 1234))
My name: Bob. My id: 1234
```
The above syntax looks simple but becomes complicated and hard to maintain in case we have a large number of variables. We have to take care of the order of variables to make sure that the string is correct.
To avoid it, We should use a dictionary after `%` operator. If found the variable in the dictionary, it will fill in the string. Otherwise, we get a `KeyError` exception.
```
>>> print("My name: %(my_name)s. My id: %(my_id)d" % {"my_name": "Bob", "my_id": 1234})
My name: Bob. My id: 1234
```
Many developers comment that this old-style string formatting lack of flexibility to format a complicated string, hard to maintain, and can’t reuse it. And Python foundation did hear their voice, they introduce a modern-style string formatting in Python 3.
**>>>** Related post that you may love: [Python Pandas for Beginners – A Complete Guide](https://pythongeeks.net/python-tutorials/python-pandas-for-beginners-a-complete-guide/)
## 2. Modern Style String Formatting (`str.format`)
In modern-style string formatting, we will use a built-in string function `.format()` instead of an operator.
```
>>> my_name = "Foo"
>>> 'Hello, my name is {}'.format(my_name)
'Hello, my name is Foo'
```
Now we call `str.format` to format a string. So you can do simple formatting with only one argument such as the above example. Or you even do a more complicated string formatting by using key-value pairs.
```
>> 'Hello, my name is {my_name}. I am {my_age} years old'.format(my_name = "Foo", my_age = 25)
```
This is quite useful when we can change the order of arguments in the string regardless of the order of key-value pairs. This is a powerful feature that offers flexibility and maintainability to your string formatting.
So I’m sure that many of you will need to format the data type of arguments like the old-style support. And the good news is it’s still supported in the modern style.
```
>>> 'Hello, my name is {my_name:s}. I am {my_age:d} years old'.format(my_name = "Foo", my_age = 25)
'Hello, my name is Foo. I am 25 years old'
```
We added a format spec as a suffix of argument name. In the example, we use `:s` to format a string and `:d` to format a number.
Format spec allows you to define how each individual value present in the format string. Python supports many options here to make a flexible and even most complicated string in programming.
I will assume that you know the simple options, so I will describe some options that you rarely see while coding, or maybe you don’t know it exists. Anytime, you would like to reference more detail any format spec options, you can follow the link [Format Specification Mini-Language](https://docs.python.org/3/library/string.html#formatspec).
### Text Alignment With Modern Style
Example of using an option `<` for left-aligned, it also a default for alignment. Vice versa, we can use `>` for right-aligned.
```
>>> '{:<30}'.format('left aligned')
'left aligned '
>>> '{:>30}'.format('right aligned')
' right aligned'
>>> '{:<30} {:>30}'.format('left aligned', 'right aligned')
'left aligned right aligned'
```
You even make a beautiful string easily such as below
```
>>> '{:+^30}'.format('centered')
'+++++++++++centered+++++++++++'
```
Here, we use a character `+` as a fill char. You can replace it with any character that you want.
### Example of Handling Number in String
There are many commons case that every developer have to handle a number in a string at least one time in their life. With the modern style, it becomes easier than ever.
```
>> "int: {0:d}; hex: {0:#x}; oct: {0:#o}; bin: {0:#b}".format(91)
'int: 91; hex: 0x5b; oct: 0o133; bin: 0b1011011'
```
You can convert a number to any base you want in only one line of code. It’s super easy and super handy.
```
>>> '{:,}'.format(1234567890)
'1,234,567,890'
```
Insert a separator into a large number is no problem as well.
```
>>> points = 19
>>> total = 22
>>> 'Correct answers: {:.2%}'.format(points/total)
'Correct answers: 86.36%'
```
Format a percent number.
**>>>** Related post that you may love: [Generator And Yield Keyword In 5 Minutes](https://pythongeeks.net/python-tutorials/python-tips-1-generator-and-yield-keyword-in-5-minutes/)
## 3. Latest Style String Formatting (f-Strings)
Introduced in Python 3.6, f-Strings is adding another option to format a string. This style lets you embedded any variable to the string, no more operator, no more `format()`.
F-strings stands for “formatted strings” and also know as “String Interpolation”. It is an expression evaluated at runtime, not a constant variable. So that your string can change dynamically in runtime. This is a super-powerful feature that is added to Python string formatting.
Support f-strings doesn’t mean other styles will be deprecated, so don’t worry about the old version of your code.
Here we will go through some example of using f-strings
### Simple Example
```
>>> f"Hello, My name is {name}. I'm {age}."
"Hello, My name is Foo. I'm 25."
```
This is a simple example to show you how to replace the old style by f-strings.
As you can see, the prefix `f` lets Python know this string is the new style, f-strings. With f-strings, you can put expression to string via curly braces. At runtime, Python will replace the expression by its output.
```
>>> f"{2 * 2}"
'4'
```
### Expression Evaluation
As mention above, the expression inside f-strings will be evaluated at runtime. This means we can use either a simple expression such as the above example or more complicated expressions such as call a function or pre-processing a list, dictionary.
> Because of evaluation in runtime, an expression is able to access not only the local variables but also global variables.
```
>>> def get_name():
... return "Foo"
...
>>> f"Hello, My name is {get_name()}"
'Hello, My name is Foo'
```
Now I would like to print out all the positive numbers of a list. It can be done when combining f-strings and [`filter()` function](https://pythongeeks.net/python-tutorials/python-filter-function/).
```
>>> my_list = [0, -5, 8, 15, 12, -1, -3]
>>> f"Positive numbers: {list(filter(lambda x: x > 0, my_list))}"
'Positive numbers: [8, 15, 12]'
```
**>>>** Related post that you may love: [Python \*args & \*\*kwargs in depth](https://pythongeeks.net/python-tutorials/python-args-kwargs-in-depth/)
## 4. Standard Style String Formatting (Template Strings)
The last method to format a string in this post is the template string. Although it’s less power than other methods, in some specific situations, it becomes more useful than others.
We take a look at the simple example before going to a definition
```
>>> from string import Template
>>> t = Template("Hello, my name is $my\_name")
>>> t.substitute(my_name="Foo")
'Hello, my name is Foo'
```
You see here that the Template strings provide simpler string substitutions where you can replace a defined variable inside a Template by your data.
This method is using frequently in the system that required to send emails to their customers. You can define the email template onetime, replace the variables by the user’s information, and send it.
Here is the sample to use Python String Template as a welcome message.
```
>>> from string import Template
>>> t = Template('Dear, $name! On behalf of Python Geeks, welcome you onboard!')
>>> users = ["Mark", "David", "Hen"]
>>> for user in users:
... t.substitute(name=user)
...
'Dear, Mark! On behalf of Python Geeks, welcome you on board!'
'Dear, David! On behalf of Python Geeks, welcome you on board!'
'Dear, Hen! On behalf of Python Geeks, welcome you on board!'
```
**>>>** You may love to know [how to send email in Python](https://pythongeeks.net/python-tutorials/sending-email-with-python/)
## Conclusion
At the end of the post, you already know 4 differents string formatting methods in Python. I’m quite sure that you will have a question “which is the best method to use in your code”.
There is no right answer to this question. You should understand every method and choose the best for your circumstance. However, from my experiences, I suggest you use “Modern Style” if your Python version is under 3.6 and use f-Strings if your project is working on Python 3.6 and above.
The String Template will be very useful if you’re building a service/product that needs a dynamic template that you can change it dynamically in runtime.
The post [Anatomy of String Formatting in Python](https://pythongeeks.net/python-tutorials/anatomy-of-string-formatting-in-python/) appeared first on [Python Geeks](https://pythongeeks.net). | thepythongeeks |
338,152 | Build Your Own Bitcoin Wallet App with the Leaders in Blockchain Development | Despite the frequent ups and downs in the cryptocurrency market these days, newcomers are continuousl... | 0 | 2020-05-18T12:26:22 | https://dev.to/ampleworksoft/build-your-own-bitcoin-wallet-app-with-the-leaders-in-blockchain-development-523c | beginners, ios | Despite the frequent ups and downs in the cryptocurrency market these days, newcomers are continuously entering the market in the hopes of cashing in on the next surge in price.
Businesses, on the other hand, are also leveraging this bitcoin market growth by the leaps and bounds by developing Bitcoin Wallet Apps of their own.
Bitcoin is a vivid example of another disruption in the world’s economy. And since you’re reading this article, I’m assuming that you’re already aware of these concepts like Bitcoin, Blockchain, and Cryptocurrency.
So, let’s jump to the point. If you’re an entrepreneur or business wanting to build your own Bitcoin Wallet App, you’ve come to the right place.
In this article, I’m going to give you an overview of what is bitcoin wallet app to how you can build your Bitcoin Wallet App and the reasons why you should build it.
That being said, let’s get started.
What is a Bitcoin Wallet App?
Bitcoin Wallets are nothing like physical wallets as these are the digital wallets with digital currencies that don’t exist in physical form.
It’s a piece of software application in which users generally store their private keys as well as records of the transactions they made and how many coins they possess.
Most Bitcoin Wallet Apps support Bitcoin and Ether, the two most popular cryptocurrencies in the market.
However, since companies are launching their cryptocurrency through ICO (Initial Coin Offering), many bitcoin wallet apps have started to support other cryptocurrencies besides Bitcoin and Ether.
How to Build Your Own Bitcoin Wallet App?
There are two ways to build your own Bitcoin Wallet App. One is by relying on the existing Bitcoin Wallet tools and libraries like Coinbase Software Development Kit (Coinbase SDK), Blockchain Wallet API, and BitcoinJ SDK.
Of all these three tools mentioned above, Blockchain Wallet API is considered to be the most popular way to build a Bitcoin wallet app.
If you want to build a bitcoin wallet app using Python or Ruby, then Coinbase SDK is the ideal choice, while BitcoinJ SDK is perfect when you want to create a bitcoin wallet app using Java.
The second way to build your own Bitcoin Wallet App is by building it from scratch and without using any tools or libraries.
To build a Bitcoin Wallet App from scratch, however, requires high-level programming skills. Therefore, we recommend availing Blockchain development services to ensure successful development.
Apart from these two approaches, there is also a relatively new approach to build your own Bitcoin Wallet App. It’s called a digital wallet solution.
They are ready-made Bitcoin wallet app solutions that small businesses or bootstrapping entrepreneurs can use to build a Bitcoin Wallet App without any fuss.
There are many popular payment gateway companies like BitPay, Stripe, and even Shopify that have leveraged a digital wallet solution in their products to allow bitcoin payments.
So, now that you know all the methods to create a bitcoin wallet app, let’s move forward and discuss the top reasons to build a bitcoin wallet app.
Top Reasons to Build a Bitcoin Wallet App
Virtual cryptocurrencies, even though seems like a risky endeavor, aren’t going away anytime soon. But if you still have doubts or second opinions, let these following reasons fixate your mind.
Bitcoin Is Better Protected
When you conduct a transaction, either online or at ATM, there are risks that hackers may get your confidential data or password. But in Bitcoin’s case, nobody can secretly know about your payment or transaction information since there is nothing to hide in the bitcoin transaction.
In simple words, a bitcoin transaction involves multiple parties to execute a transaction. A user executing a bitcoin transaction is given tow keys, private and public. And to execute a successful transaction, you need the combination of both private and public keys to conduct a bitcoin transaction.
This means, not only it’s more secure than any financial institution, but it’s also just simply cannot be manipulated.
Bitcoin is Immune from Inflation
Ever since the dawn of civilization, governments endure all rights to print as much physical money they want to, meaning obtaining it loses its original value.
In the case of Bitcoin, on the other hand, the number of bitcoins would never exceed 21 million. So, you can easily make a bitcoin transaction without having to worry about any ifs or buts. And this is how Bitcoin is secure from inflation.
Bitcoin is Simpler than Banks
In Bitcoin’s case, there is no limit in terms of time and geographically, meaning bitcoin transactions can be easily processed 24/7 and much faster than banks.
For example, the bitcoin transaction process relies on a single public ledger, where banks have multiple ledgers, making the transaction process slow.
The best part is, bitcoin is perfect when it comes to making cross-border transactions as no government entity has any control over the cryptocurrency.
Conclusion
Bitcoin and other cryptocurrencies are gaining popularity due to the benefits they provide. For starters, bitcoin gives a complete command over the funds with unmatchable flexibility.
So, what are you still waiting for? – Build your own Bitcoin Wallet App and be the part of the digital revolution happening before it gets too late!
Check Details: https://www.amplework.com/blockchain-app-development/ | ampleworksoft |
338,025 | Biggest Challenges Of Cloud Computing In 2020
| Everyone is using the cloud computing technology knowingly or unknowingly. Cloud computing is emergin... | 0 | 2020-05-18T07:51:46 | https://dev.to/ltdsolace/biggest-challenges-of-cloud-computing-in-2020-2413 | Everyone is using the cloud computing technology knowingly or unknowingly. Cloud computing is emerging as a need of this modern world. If you have not used it, you will surely use it in future due to its amazing benefits. Let us see what cloud computing is.
**What Is Cloud Computing?**
Simply, cloud computing is accessing, storing, and managing a huge amount of data over the web. And Firewall is there to secure this entire data. With the use of cloud computing you can easily access any software, tool or data installed in data centers globally. Preparing any document over the web and web based email services are the most common examples of cloud technology. There are various types of cloud computing platforms such as platform as a service (PaaS), Infrastructure as a service(IaaS) and Software as a service(SaaS). These days, this technology plays a vital role in business development too. Each technology comes with some issues rather than being the strength of some major business industries. Also it can create some major problems under some rare circumstances. Let us see the Biggest challenges of cloud computing in 2020.
**Biggest Challenges Of Cloud Computing In 2020–**
*1. Shortage Of Resources And Experts-*
According to the survey 75% of the respondent listed it as a challenge and 23% stated that it was a major challenge. Many IT specialists are trying to improve their cloud computing future predictions expertise, Employers still feel that it is a challenging issue to get workers the skills they require. And future trends in cloud computing seem to grow in the near future. Technologies like Big data, mobile, security will become more valuable for businesses in the future. Many organizations are looking to overcome the challenges of moving to cloud computing by employing experts having cloud computing skills or certifications. Experts also suggest the training of existing staff to speed up with the latest technology.
*2. Security-*
With the arrival of public cloud, many organizations are worried about security risks. As per the analysis, it is one of the most serious issues with cloud computing technology in 2020. Cybersecurity experts are more worried about the latest cloud security than that of IT employees. They have fear about the data loss and data leakage, breaches and confidentiality of data. A report by rightscale analyzed that as companies become more experienced with the cloud, the cloud challenges shifts. Security becomes a major issue among cloud beginners, when cost becomes a major challenge for advanced and beginner users.
Know more at- [https://solaceinfotech.com/blog/biggest-challenges-of-cloud-computing-in-2020/]
| ltdsolace | |
338,046 | Forwarding refs in TypeScript | Originally posted on my blog - selbekk.io When you're working on a component library, or just crea... | 0 | 2020-05-18T08:23:41 | https://www.selbekk.io/blog/2020/05/forwarding-refs-in-typescript/ | react, typescript | > Originally posted on my blog - [selbekk.io](https://www.selbekk.io/blog/2020/05/forwarding-refs-in-typescript/)
When you're working on a component library, or just creating reusable components in general, you often end up creating small wrapper components that only adds a css class or two. Some are more advanced, but you still need to be able to imperatively focus them.
This used to be a hard problem to solve back in the days. Since the ref prop is treated differently than others, and not passed on to the component itself, the community started adding custom props named `innerRef` or `forwardedRef`. To address this, React 16.3 introduced the `React.forwardRef API`.
The `forwardRef` API is pretty straight-forward. You wrap your component in a function call, with is passed props and the forwarded ref, and you're then supposed to return your component. Here's a simple example in JavaScript:
```tsx
const Button = React.forwardRef(
(props, forwardedRef) => (
<button {...props} ref={forwardedRef} />
)
);
```
You can then use this component like ref was a regular prop:
```tsx
const buttonRef = React.useRef();
return (
<Button ref={buttonRef}>
A button
</Button>
);
```
## How to use forwardRef with TypeScript
I always screw this up, so I hope by writing this article I can help both you and me to figure this out.
The correct way to type a `forwardRef`-wrapped component is:
```tsx
type Props = {};
const Button = React.forwardRef<HTMLButtonElement, Props>(
(props, ref) => <button ref={ref} {...props} />
);
```
Or more generally:
```tsx
const MyComponent = React.forwardRef<
TheReferenceType,
ThePropsType
>((props, forwardedRef) => (
<CustomComponentOrHtmlElement ref={forwardedRef} {...props} />
));
```
It was a bit un-intuitive at first, because it looks like you can pass a regular component to ForwardRef. However, regular components don't accept a second ref parameter, so the typing will fail.
I can't count how often I've done this mistake:
```tsx
type Props = {};
const Button: React.RefForwardingComponent<
HTMLButtonElement,
Props
> = React.forwardRef(
(props, ref) => <button ref={ref} {...props} />
);
```
This is a mistake, because the RefForwardingComponent is the type of the render function you create (the one that receives props and ref as arguments), and not the result of calling React.forwardRef.
In other words - **remember to pass your type variables directly to `React.forwardRef`**! It will automatically return the correct type for you.
Another gotcha is the order of the type variables - it's the ref type first, then the props type. It's kind of counter-intuitive to me, since the arguments to the render function is the opposite (props, ref) - so I just remember it's the opposite of what I'd guess. 😅
I hope this article helped you figure out this pesky typing issue that have gotten me so many times in a row. Thanks for reading! | selbekk |
338,095 | The New Age in Software: Mentorship | As 'new-comers' enter the industry, mentorship programs become a must-have. In the last ni... | 0 | 2020-05-18T10:24:25 | https://dev.to/dragosnedelcu/the-new-age-in-software-mentorship-5895 | mentorship, leadership, diversity, inclusion | ## As 'new-comers' enter the industry, mentorship programs become a must-have.
In the last nine months, I mentored 20+ software developers on their journey. During this time, I experienced massive changes in software demographics.
Crunching some numbers from my mentoring activity:
* roughly **54%** of the developers I tutored identify as female
* **62%** were older than **30**
* **98%** used **JavaScript**
* **18+ countries** were present
Comparing these numbers with [*official figures**](https://graphics.wsj.com/diversity-in-tech-companies/) regarding the current IT workforce confirms it. Software professionals of tomorrow will be nothing like the ones of today.
> A highly **diverse crowd** is entering the industry.
Meanwhile, startups are becoming corporates, and corporates are becoming conglomerates. Inclusion and professionalism are critical in absorbing this new workforce. This is**not a bunch of dudes***and a web-app. It is a multicultural and highly skilled workforce.
And that's our challenge. The current leadership and middle management layer don't match these demographics because of systemic and structural reasons. We will have to bridge this gap to keep attracting the best talent.
We are missing the opportunity of a lifetime unless this reality is acted upon by C-levels and managers. This directly impacts business results.
> Employee loyalty translates directly into profits in an industry with such a **high turnover***.
We need to change mindsets, structures, and processes to serve these new kind of professionals. Mentorship is a bridge between leadership and the new workforce it is mentorship. It shows the commitment of companies to the success of this new and diverse generation of developers.
> **Mentorship** enables **performance** and inspires action.
With hundreds of fresh developers seeking advice, strong initiatives are taking off. My advice for tech companies? Some mentorship programs already started in non-profit setup*. Approach these non-profits and start a conversation.
> Make mentorship a **central part** of your employee development program.
At **Mister Spex**, we have already begun.
The clock is ticking a late hour and as I write these lines, I can only smile. I smile because I feel proud to be part of such a dynamic industry. We are pioneers of change.
I am confident that **we will reinvent ourselves** as we already did countless times in the past. And to the "new-comers':
> You are the future of software. Make us proud!
***Do you already have a mentorship program in place? Does it extend beyond on-boarding periods? Are C-leves actively involved?***
Stay cool,
Dragos
*Disclaimer: This article is dedicated to the wonderful persons whose life I was able to touch in the last months. Hristina, Edenilton, Marina, Pablo, Ana, Saul, Danielle, Sabine, Kharan, Daria, Asghar, Dasom, Richard, Vesna ... and many others.*
Appendix:
\*<https://graphics.wsj.com/diversity-in-tech-companies/>
\*referring to the "typical" startup founders team in the last decade.
\*no numbers on this one, ask any C-level in Berlin about turnover and try to hold your tears
| dragosnedelcu |
338,114 | XBackBone: A lightweight file manager with instant sharing tools integration. | XBackBone is a lightweight PHP file manager with instant sharing tools integrations, like ShareX. | 0 | 2020-05-18T13:32:38 | https://dev.to/sergix44/xbackbone-a-lightweight-file-manager-with-instant-sharing-tools-integration-46k | php, filemanager, sharing, tool | ---
title: XBackBone: A lightweight file manager with instant sharing tools integration.
published: true
description: XBackBone is a lightweight PHP file manager with instant sharing tools integrations, like ShareX.
tags: php,filemanager,sharing,tool
cover_image: https://i.imgur.com/aam0LWP.png
---
XBackBone is a small, fast and lightweight file manager, written in PHP, based on Bootstrap 4 and the Slim Framework 4.
### Oh god, why another file manager?
Yeah I know, BUT XBackBone was created with the aim of being easily integrated with **instant sharing tools** such as ShareX.
Instant sharing tools allows you to take screenshots, upload the clipboard, and much more. These features are very convenient to share code snippets, screenshots, save config files, upload files quickly without having to go through a browser, but by default these uploads are uploaded publicly: Imgur, Flickr, etc for image hosting, Pastebin, Github Gits, and others for text uploads, and so on.
Yeah, you can connect your account on each service and set your files as private, but still, **your data will be scattered among all**.
### Where the files are stored?
Since it's **self-hosted**, you choose where your file are stored! XBackBone **supports local storage**, but also **remote storage services**, like Amazon S3, Google Cloud Storage, and more.
### What functionality does XBackBone give to me?
**XBackBone gives you the power to have all your uploads in one place**, organize them by type, date, size, and even add tags to them. It can show previews of images, pdf documents, code syntax highlighting, audio and video html players, and much more.
The main objectives are **speed**, **ease of installation**, simple maintenance and the ability to run it virtually anywhere, all you need is something that runs PHP.
### Why not use **Nextcloud** or **Pydio**?
XBackBone does not aim to replace that type of platform, but **focuses on integration** with software like ShareX, and ease of use. It provides client configurations and bash scripts** customized according to the user account, even for headless environments. A **unique link is generated and returned for each upload**, which can be used to view a preview or download the file.
However, some important advanced features are not missing, you can create your own personal instance in a few minutes, but more complex configurations for multiple users such as LDAP authentication, user quota and other permissions are also possible.
### Future plans?
At the moment the only supported sharing client is ShareX, and a script is available for Mac or Linux users, but I'd like to **add support for other clients** from other platforms (let me know). A tagging system has just been added to organize uploads, it would be nice to improve it and add a way to classify uploaded files more accurately.
The project on GitHub, available to **anyone**! Any question, suggestion, or pull request is much appreciated.
- [GitHub Pages Website](https://sergix44.github.io/XBackBone/)
{% github sergix44/xbackbone %}
Thank you very much for your attention! | sergix44 |
338,115 | Octant - A GUI for Kubernetes Cluster | Octant is powerful and useful dashboard for complete overview of Kubernetes cluster. It provide the c... | 0 | 2020-05-18T11:09:34 | https://dev.to/techtter/octant-a-gui-for-kubernetes-cluster-2hfl | octant, kubernetes, devops, dashboard | Octant is powerful and useful dashboard for complete overview of Kubernetes cluster. It provide the complete information of K8s cluster like pods info, deployments, services, logs of each everyvpod with search option, nodes info, autoscalers info, resources usages etc...just check out the link for demo of installing the tool and walkthrough of the Octant UI:
https://youtu.be/S_-uOD3DNiM
{%youtube S_-uOD3DNiM %} | techtter |
338,162 | Electron Typed IPC | no runtime cost (just typescript enhancements) keeps the same API as Electron separates events from... | 0 | 2020-05-18T12:39:50 | https://dev.to/deiucanta/electron-typed-ipc-31ph | electron, typescript, typed, ipc | - no runtime cost (just typescript enhancements)
- keeps the same API as Electron
- separates events from commands to avoid confusions
- events are things that happened (IPC)
- commands are async functions you can invoke (RPC)
## 1. Install `electron-typed-ipc` from NPM
```
npm i electron-typed-ipc --save
```
## 2. Define your events/commands
```ts
type Events = {
configUpdated: (newConfig?: Config, oldConfig?: Config) => void;
};
type Commands = {
fetchConfig: () => Config;
updateConfig: (newConfig: Partial<Config>) => void;
};
```
## 3. Add types to `ipcMain` and `ipcRenderer`
```ts
const typedIpcMain = ipcMain as TypedIpcMain<Events, Commands>;
const typesIpcRenderer = ipcRenderer as TypedIpcRenderer<Events, Commands>;
```
## 4. Emit events and invoke commands
```ts
// renderer.js
const config = await typedIpcRenderer.invoke('fetchConfig');
// main.js
typedIpcMain.handle('fetchConfig', () => {
return { a: 1, b: 'text' };
});
```
```ts
// renderer.js
typedIpcRenderer.on('configUpdated', (_, newConfig, oldConfig) => {
console.log(newConfig, oldConfig);
});
// main.ts
webContents
.getAllWebContents()
.forEach((renderer: TypedWebContents<Events>) => {
renderer.send('configUpdated', newConfig, oldConfig);
});
```
| deiucanta |
338,174 | Why import react on every component? | Hi, I was just looking at some of my code when I was beginning with react.js and I found that I was a... | 0 | 2020-05-18T12:52:42 | https://dev.to/ioannisth/why-import-react-on-every-component-5292 | Hi, I was just looking at some of my code when I was beginning with react.js and I found that I was able to use JSX without importing React, just because I have included a <script> element that references React on my top level HTML. I am not using create-react-app or similar. Is this good practice, bad and why? | ioannisth | |
338,219 | Svelte + Sapper + Netlify CMS | Introduction Hello. In this post, I'll be outlining how to get started with Svelte, Sappe... | 0 | 2020-05-18T13:53:56 | https://dev.to/avcohen/svelte-sapper-netlify-cms-3mn8 | javascript, svelte, sapper, webdev |
<br>
### Introduction
Hello.
In this post, I'll be outlining how to get started with [Svelte](https://svelte.dev/), [Sapper](https://sapper.svelte.dev/) and [Netlify CMS](https://www.netlify.com/).
This article assumes some baseline knowledge of Svelte, Sapper and various configuration options specific to Netlify's CMS.
**Documentation**
- [Svelte Documentation](https://svelte.dev/docs/)
- [Sapper Documentation](https://sapper.svelte.dev/docs/)
- [Netlify CMS Documentation](https://www.netlifycms.org/docs/intro/)
You can find the repo for this project [here](https://github.com/avcohen/tutorial_svelte_sapper_netlify).
<br>
### What we'll accomplish
- Setup a Svelte / Sapper project
- Setup a Netlify Project + Netlify Authentication
- Configure Netlify to automatically build & deploy to Github
- Refactor Sapper to statically generate blog posts from Markdown
<br>
### Setting up Svelte & Sapper
The team at Sapper has setup a great starter template that we'll use to skip a lot of the tedious aspects of starting from scratch.
It's also pretty damn un-opinionated so even if you decide to grow this into a larger project, you won't be locked into anything.
We'll be opting to use the [Rollup](https://rollupjs.org/guide/en/) based bundler since at the time of this writing it is better documented for use with Sapper.
```shell
npx degit "sveltejs/sapper-template#rollup" my-app
```
`cd` into `my-app` and run
```shell
npm i && npm run dev
```
You should see your console output
```shell
> Listening on http://localhost:3001
```
Open `http://localhost:3001` in your browser and take a peek.

Now that we're up and running, we can start getting things organized in our code to get everything linked up to Netlify.
<br>
### Setup Netlify + Netlify Authentication
First we'll have to create a new folder within `~/static` called `admin`. Therein we'll create two files, `config.yml` and `index.html`.
First, let's drop in a simple config for Netlify's CMS so we can outline how we'll structure our blog post entries:
```yml
# ~/static/admin/config.yml
backend:
name: git-gateway
branch: master # Branch to update (optional; defaults to master)
publish_mode: editorial_workflow # Allows you to save drafts before publishing them
media_folder: static/uploads # Media files will be stored in the repo under static/images/uploads
public_folder: /uploads # The src attribute for uploaded media will begin with /images/uploads
collections:
- name: "blog" # Used in routes, e.g., /admin/collections/blog
label: "Blog" # Used in the UI
folder: "static/posts" # The path to the folder where our blog posts are stored
create: true # Allow users to create new documents in this collection
fields: # The fields for each document
- { label: "Slug", name: "slug", widget: "string" }
- { label: "Title", name: "title", widget: "string" }
- { label: "Body", name: "body", widget: "markdown" }
```
Next, let's add the markup for the `/admin` route:
```html
<!-- ~/static/admin/index.html -->
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Content Manager</title>
</head>
<body>
<!-- Include the script that builds the page and powers Netlify CMS -->
<script src="https://unpkg.com/netlify-cms@^2.0.0/dist/netlify-cms.js"></script>
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script>
</body>
</html>
```
<br>
### Refactoring for Markdown
If you're not familiar with how Sapper handles dynamic URL parameters, check out their documentation on [routing](https://sapper.svelte.dev/docs#Routing).
We'll be editing our `~/src/routes/blog/[slug].json.js` to read markdown files from the filesystem, parse the Markdown + Frontmatter, and render the data into our component.
We will also need to edit `~/src/routes/blog/index.json.js` to extract the various titles and slugs from our posts in order to display them on the `/blog` route.
For this, we'll make use of [gray-matter](https://github.com/jonschlinkert/gray-matter) to handle the Frontmatter which is in YAML and [marked](https://github.com/markedjs/marked) to parse our Markdown.
Install these two dependencies via npm:
```shell
npm i marked gray-matter
```
Let's also create a folder where our blog posts will live. Create a folder called `posts` within `~/static`. We told Netlify to save posts here with the line
```yaml
folder: "static/posts"
```
in our `config.yaml` for our blog collection.
Next, let's setup our `[slug].json.js` file to put these two libraries to use:
```javascript
// ~/src/routes/blog/[slug].json.js
import path from "path";
import fs from "fs";
import grayMatter from "gray-matter";
import marked from "marked";
const getPost = (fileName) => {
return fs.readFileSync(
path.resolve("static/posts/", `${fileName}.md`),
"utf-8"
);
};
export function get(req, res, _) {
const { slug } = req.params;
const post = getPost(slug);
const renderer = new marked.Renderer();
const { data, content } = grayMatter(post);
const html = marked(content, { renderer });
if (html) {
res.writeHead(200, {
"Content-Type": "application/json",
});
res.end(JSON.stringify({ html, ...data }));
} else {
res.writeHead(404, {
"Content-Type": "application/json",
});
res.end(
JSON.stringify({
message: `Not found`,
})
);
}
}
```
Next we'll modify our `~/src/routes/blog/index.json.js` file to read all the files within our `~/static/posts` directory and pluck out the information required to render and provide links to each article.
```javascript
// ~/src/routes/blog/index.json.js
import fs from "fs";
import path from "path";
import grayMatter from "gray-matter";
const getAllPosts = () => {
try {
return fs.readdirSync("static/posts/").map((fileName) => {
const post = fs.readFileSync(
path.resolve("static/posts", fileName),
"utf-8"
);
return grayMatter(post).data;
});
} catch (e) {
return [];
}
};
export function get(_, res) {
res.writeHead(200, {
"Content-Type": "application/json",
});
const posts = getAllPosts();
res.end(JSON.stringify(posts));
}
```
Since we're no longer using the original data source for the blog posts `~/src/routes/blog/_posts.js` we can delete that file.
Also, since we're passing our JSON data from `[slug].json.js` to `[slug].svelte` with the same structure as before, we don't need to make any changes to the latter file.
<br>
### Setting up Netlify & Git Repo
At this point, we've _nearly_ got our ducks in a row to deploy our site and start writing blog posts.
First, create a new repo and push your code to it.
Next, head on over to [Netlify](https://app.netlify.com/) and click 'New Site from Git', select your Git provider of choice, authorize the Netlify App and allow access to all or for more granularity, select the repos you want Netlify to have access to.

Make sure you specify the build command and publish directory like so and mash that 'Deploy Site' button.

If you head back to your Netlify dashboard you should see that your site is building and as soon as it's published, you can preview a link to the site.
Last but not least, we need to enable the **Identity** and **Git Gateway** features so you can signup/login via the `/admin` path on your newly deployed site to manage posts as well as allow Netlify to publish changes to your Git repo to trigger new static builds.
**Identity**

**Git Gateway**

### Logging into the CMS
Head on over to your live site and add the `/admin` path to your URL.
Click 'Sign Up', create an account, confirm your account via the automated email from Netlify and jump back over to `/admin` and give it a refresh.
Login with your account and get writing.
<p style="text-align: center;">###</p>
Thanks for reading. If you’d like to stay up to date with my writings and projects, please follow me on [Twitter](https://twitter.com/aaronvcohen) or consider supporting my writing by buying me a [coffee](https://ko-fi.com/avcohen).
| avcohen |
338,270 | Learning about Deno building Gusano 🐍 | A few days ago I started to follow Deno more closely. Although I have more than 3 years of experience... | 0 | 2020-05-18T14:49:25 | https://dev.to/krthr/learning-about-deno-building-gusano-1f3k | deno, javascript | A few days ago I started to follow Deno more closely. Although I have more than 3 years of experience in Node JS the proposals that Deno makes seem very interesting to me.
So, a couple of days ago I decided to try it out 🤷. So I made a little library called "Gusano" (Worm) that allows you to create simple pipelines.
{% github krthr/gusano %}
I want to share my entire learning journey with you in the future.
PS: I also receive suggestions and PR's ;) hahaa
| krthr |
338,488 | Laravel Tip: Desktop notifications from your tests | Photo by Carl Heyerdahl on Unsplash If you didn’t know, Laravel now has a php artisan test command w... | 0 | 2020-05-20T09:10:31 | https://dev.to/slyfirefox/laravel-tip-desktop-notifications-from-your-tests-42l8 | testdrivendevelopm, laravel, testing, php | ---
title: Laravel Tip: Desktop notifications from your tests
published: true
date: 2020-05-18 20:56:24 UTC
tags: test-driven-developm,laravel,testing,php
canonical_url:
---
<figcaption>Photo by <a href="https://unsplash.com/@carlheyerdahl?utm_source=medium&utm_medium=referral">Carl Heyerdahl</a> on <a href="https://unsplash.com?utm_source=medium&utm_medium=referral">Unsplash</a></figcaption>
If you didn’t know, Laravel now has a php artisan test command which comes from the nunomaduro/collision package which is used to display beautiful and easy to diagnose errors from the artisan command like so:

This package is created and maintained by [Nuno Maduro](https://nunomaduro.com/) among many other useful packages and tools like PHP Insights, Laravel Mojito and the upcoming [PestPHP](https://pestphp.com/) testing tool.
### Hooking into command events
Two events are fired for every _artisan_ command execution, one before the console command starts and another after the command finishes. We can write a listener for this but to keep this simple we’ll use a callable instead and add it to the boot method in our AppServiceProvider. By hooking into the command finished event we can also see what the exit code for the command was. In the case of the test command we know that an _exit code_ of 0 means our tests passed and a exit code of 1 or higher is the tests failing.
{% gist https://gist.github.com/peterfox/6cc784b504aa8328cbac2a357a6efaad %}
### Building our desktop notification
So I mentioned Nuno Maduro earlier and that wasn’t a coincidence because another package of his is what we’ll use to display our desktop notification.
```
composer require --dev nunomaduro/laravel-desktop-notifier
```
Once the package is install we now add a method to the AppServiceProvider so that a desktop notification is delivered to the operating system.
{% gist https://gist.github.com/peterfox/df2ab968ad559b060b56033176dd09b5 %}
Our method is fairly straightforward and just changes the text of the notification based on the true/false result of our tests.
After that we can bring is all together in the AppServiceProvider and run the tests command.
{% gist https://gist.github.com/peterfox/5bdbb189ad28947633e66d5e42678a6f %}
Now when we run the php artisan test command we’ll get a notification telling us when they’re completed and if they’ve passed or failed.

### Conclusion
Well there’s not much more to say here. There’s some really simple things you can do to expand your application and make your life easier. You can effectively tap into the exit code of and command in your application. You can also tap into the start of a command as well which is very useful. For instance, I’ve created a listener that cleans out the testing logs everytime the tests are about to run making it easier to see what was generated without the clutter of the extra test
If you want to see this demo in action you can clone it from [github](https://github.com/peterfox/laravel-testing-notification).
I’m Peter Fox, a software developer in the UK who works with Laravel among other things. Thank you for reading my articles. I’ve got several more on both medium and dev.to that. If you want to know more about me you can at [https://www.peterfox.me](https://www.peterfox.me/) and feel free to follow me @[SlyFireFox](https://twitter.com/SlyFireFox) on twitter for more Laravel tips and tutorials in the future. | peter_fox |
338,365 | Cypress and ng-select | Example of selecting an option in ng-select and submitting subsequent post. .get("ng-select") // g... | 6,226 | 2020-05-18T17:05:56 | https://dev.to/jwp/cypress-and-material-select-56a1 | cypress, angular, material | Example of selecting an option in [ng-select](https://ng-select.github.io/ng-select#/data-sources) and submitting subsequent post.
```typescript
.get("ng-select") // get all ng-select elements
.then((selects) => {
let select = selects[0]; // we want just first one
cy.wrap(select) // allows us to click using cypress
.click() // click on the first ng-select
.get("ng-dropdown-panel") // get the opened drop-down panel
.get(".ng-option") // Get all the options in drop-down
.contains("Employee") // Filter for just this text
.then((item) => {
cy.wrap(item).click(); // Click on the option
setInterceptor(/Person/, "POST"); // wait for HTTPResponse
cy.get(".fa-save > path") // click on save button
.click().wait("@Route"); // the post to person is complete
});
});
```
Sometimes it's confusing decided whether or not to use the native HTML elements or not. In this case; we had to use the ng-select layer because selecting an option was the only possible after clicking the ng-select element. ng-select controlled all state of this control.
This is one negative consequence of using any 3rd party tool (including Angular). Reason: They often usurp native HTML ways of doing things. | jwp |
338,379 | 📆 Livestream Event - Build Your Own Public Digital Garden | A digital garden is a place to take concepts from initial discovery all the way to original published posts. It's the idea that concepts grow over time. You tend to this concept over time rather than all at once. | 0 | 2020-05-18T17:31:09 | https://www.ianjones.us/blog/2020-05-19-pair-with-maggie-live-event/ | gatsby, digitalgardens, livestream | ---
title: 📆 Livestream Event - Build Your Own Public Digital Garden
published: true
description: A digital garden is a place to take concepts from initial discovery all the way to original published posts. It's the idea that concepts grow over time. You tend to this concept over time rather than all at once.
tags: Gatsby, Digital Gardens, Livestream
canonical_url: https://www.ianjones.us/blog/2020-05-19-pair-with-maggie-live-event/
---
A digital garden is a place to take concepts from initial discovery all the way to original published posts. It's the idea that concepts grow over time. You tend to this concept over time rather than all at once.
Digital gardens shifted my mindset from needing to post polished blog posts to being ok with rough drafts and coming back to that post when I learn more.
On May 19th, [Maggie](https://twitter.com/Mappletons), [Aengus](https://twitter.com/aengusmcmillin), [Aravind](https://twitter.com/aravindballa), and I will be mob programming on Maggie's digital garden. We will be implementing bi-directional links, link over preview, and talking about how we use our notes to build a digital garden.
[Register here](https://egghead.io/s/2020-05-19-digital-garden-live-stream) if you want to join us!
If you want to read more about digital gardens, here are some great articles:
- [Maggie Appleton's Digital Garden](https://maggieappleton.com/garden)
- [Joel Hooks' Digital Garden](https://joelhooks.com/digital-garden)
- [Tom Critchlow's Digital Garden](https://tomcritchlow.com/blogchains/digital-gardens/) | theianjones |
338,389 | Organisational tools to help make the most of your dev side-projects | Recently, as part of a migration to Github, I decided to rid my Gitlab account of old repositories. B... | 0 | 2020-05-18T17:46:54 | https://dev.to/lukeojones/productivity-hacks-to-help-you-focus-on-your-side-projects-and-get-stuff-done-2i27 | productivity, github, sideprojects, motivation | Recently, as part of a migration to Github, I decided to rid my Gitlab account of old repositories. Before starting on that task, if you had asked me how many stale repositories I had in there, I would have said no more than five — I removed over 20!
Working through this list and deleting old projects was a nostalgic walk down memory lane but, as I scanned each project, the pattern that started to emerge was that most of these projects had started out with a real buzz, dedication and enthusiasm only to be abandoned a few weeks (or even days) later in favour of another one (now also deleted).
By the end of this spring cleaning operation, the walk down memory lane had transformed into a depressing jaunt through an abandoned museum — there were some interesting exhibits but no-one was around any more to tell you how they worked or what they were used for. I had little idea about the state of the project and how _incomplete_ it actually was.
Of course the answer to all this was obvious — I needed another new side project! (Dark Kermit strikes again) At this point it was more than clear that I would need to change my approach and ensure I avoided another half-baked project clogging up my Github account.
#### Break it down
Side projects should be fun, challenging and rewarding but sometimes it’s difficult to distribute those factors over the lifetime of the work.
In particular, when you first devise your new idea, it’s especially fun and rewarding because you’re getting to investigate all the new tools and concepts that might be relevant to the implementation.
After that initial stage, it can often be hard to stay motivated as you start to realise the scale of the project and realise those new tools aren’t as super simple to use as you expected 😫
For me, the best way to deal with this is to break the workload down into small (and hopefully enjoyable) subtasks. We do this in our 9–5 jobs all the time using tools like _Jira_ and _Youtrack_ (OK, maybe it’s not always _enjoyable_) but it’s easily overlooked when you’re just working on something in your free time and there is no client or customer chasing you for the goods.
Breaking down these ‘awesome ideas’ into smaller tasks has a number of small benefits that compound over time to give you a better result:
* **Mental Offloading:** You don’t need to keep everything in your head since it’s been transferred into pen/pencil/pixels.
* **Progress:** It’s easy to see how much effort is required to hit the next milestone. If you’re just working on one big, nebulous concept it’s hard to keep perspective. It’s also easier to resume working on the project after a small break.
* **On-boarding:** If you decide to team up with mates or colleagues, you’ve got an instant starting point to discuss the remaining work and what has been done to date.
* **Code Context:** Although your code should be the canonical documentation of your project, having a proper space for documentation or issue tracking can be really useful especially when looking back.
* **Rewarding:** Completing tasks is rewarding and after finishing the first few tasks, you start to form positive habits that will keep you on track — just ask Pavlov’s 🐶.
With this in mind, I’m going to quickly describe how I’ve used some free tools to finally get a little side-project off the ground — [response.dev](https://response.dev) — but you should use whatever works for you.
#### The Trello board
I certainly didn’t want to make my side-project feel exactly like work — where’s the fun in that? I just wanted a lightweight alternative to Jira that provided:
* The ability to document tasks quickly and move them between different states without too much config or admin.
* A concise way of referring to tasks e.g. a numeric identifier
* A way of linking issues to commits, PRs, branches etc.
* Everything I needed for free! 💸
Luckily, a tool I’ve used for a number of years — Trello — can be configured to meet all the criteria above. I’ve documented some of the key features I’m using right now but the setup is quite fluid and because this is just for side-project work, I don’t have to get buy-in to change anything 😁
#### Columns
I’ve experimented with various column setups but this seems to be working quite nicely although YMMV.
* **Todo:** Things that need implementing
* **Doing:** What I’m working on currently. This helps keep me focused so I don’t juggle too many things at once.
* **Done**: Moving things to _Done_ provides some positive feedback and builds a feeling of progress and momentum. It also serves as a knowledge base for previous tasks.
* **Nice to Have:** Things I’d like to implement but aren’t essential.
* **To Learn:** The whole reason I like side-projects is that it gives me a chance to learn and pick up new skills. Sometimes, the list of things I’d like to learn is overwhelming so I add them here and revisit later when I’m commuting or waiting for the kettle to boil etc.
#### Issue Identifiers
Trello uses Card IDs under the hood but they aren’t visible by default so you only see the description. I like to have an ID so that I can refer to it more easily in conversation, other issues, PRs or commit messages etc.
You can install [this Chrome extension](https://chrome.google.com/webstore/detail/trello-card-numbers/kadpkdielickimifpinkknemjdipghaf?hl=en) to expose the Card IDs without using up a valuable Power-up. If you are using the paid version of Trello and don’t need to worry about Power-up allowance, then I’d recommend using [this power-up from Reenhanced](https://trello.com/power-ups/59c3d177178a761767b49278/card-numbers-by-reenhanced).
#### Github Integration
As a developer working with Trello regularly, it is really worth looking into this [fantastic Github Power-up](https://trello.com/power-ups/55a5d916446f517774210004/github) so that you can easily link your Trello cards to your code.
If you’re using the unpaid version of Trello then this is a great way to make the most of your Power-up allowance (just make sure you use the Chrome extension to display the Card IDs in the previous section).
Once you’ve enabled the Power-up, you just need to authenticate Trello using your Github credentials and you’ll be able to add branches, PRs and commits directly to your Cards as shown here:
I generally attach the PR once the code has been written but will also attach specific commits in some cases e.g. when identifying the commit which introduced a bug.
At the board level, it’s really nice to be able to see which issues have been merged in and you can even use badges to show whether certain checks have been passed e.g. Tests, Linting etc.
The association is two-way too so you can also see a link to the relevant Trello Cards from within Github — a huge timesaver.
There is way more you can do but I’ve found that Card IDs and a nice link between Trello and Github is all that I need right now to keep me moving at pace. Making the process as pain free as possible means that I’m actually sticking to the process and I can move between my issues and code really easily.
## Summary
I haven’t introduced anything ground-breaking in this article but that’s because it’s probably a concept we’re all already familiar with from our day jobs. Obviously, you don’t _need_ to finish your side projects — they shouldn’t be a chore or source of stress — _but_ if you’re a little bit fed up of constantly abandoning your projects mid-way through then I really encourage you to formalise your approach a bit more and see how it works out.
| lukeojones |
338,400 | How to change a foreign key constraint in MySQL | This is how you change a foreign key constraint in MySQL | 0 | 2020-05-18T19:31:46 | https://dev.to/mcgurkadam/how-to-change-a-foreign-key-constraint-in-mysql-1cma | mysql, database, tutorial, sql | ---
title: How to change a foreign key constraint in MySQL
published: true
description: This is how you change a foreign key constraint in MySQL
tags: mysql,database,tutorial,sql
---
# Alter a foreign key constraint in MySQL
(PS...if you want to skip to just the answer <a href="#tldr" title="Go to the TL;DR">Click this link</a>)
I ran into a problem today.
I found a foreign key in my table that cascaded instead of set the key as null.
As you can imagine, this was not a great thing to learn. I lost quite a few log records. Luckily, this is an application used only by me, and I had backups that I could restore to that lost very little data. But finding how to reverse this foreign key effect proved challenging.
When I went to Google for my answer, I found it challenging. There isn't much information about how to alter foreign keys in MySQL.
There is no command like:
```SQL
ALTER TABLE my_table CHANGE FOREIGN KEY (key_name) REFERENCES other_table(other_key) ON DELETE SET NULL;
```
That would be sublime if that existed!! Alas, it doesn't, so we must find a workaround. Here is what the workaround looks like.
## First - Get the name of your foreign key constraint.
If you're like me, you create your tables (and constraints) like this:
```SQL
CREATE TABLE my_table (
name varchar(255),
key int(11),
FOREIGN KEY key REFERENCES other_table(id) ON DELETE SET NULL
);
```
or like this
```SQL
ALTER TABLE my_table ADD FOREIGN KEY (key) REFERENCES other_table(id) ON DELETE CASCADE;
```
Without the full MySQL name of the constraint. So how do we get the name that MySQL needs to drop the constraint?
Enter the `SHOW CREATE TABLE` command.
The output of this command contains the name of the constraint that you need. Here is what that output would look like for my above CREATE TABLE (or ALTER TABLE) command:
```SQL
SHOW CREATE TABLE my_table\G
```
```
*************************** 1. row ***************************
Table: my_table
Create Table: CREATE TABLE `my_table` (
`name` varchar(255) DEFAULT NULL,
`key` int(11) DEFAULT NULL,
KEY `ke` (`key`),
CONSTRAINT `my_table_ibfk_1` FOREIGN KEY (`key`)
REFERENCES `other_table` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
```
So the name of our foreign key constraint would be "my_table_ibfk_1";
## Second - Drop the foreign key constraint.
Now that we have the name to our foreign key constraint, we need to drop it. And this is the part that held me up the most.
I didn't know the consequences to dropping a foreign key constraint. I was afraid because of my own ignorance.
Turns out, there was nothing to be afraid of. If you drop the foreign key constraint, it doesn't have any other effects, and keeps all values intact.
So, here's the code to run to do that:
```SQL
ALTER TABLE my_table DROP FOREIGN KEY my_table_ibfk_1;
```
## Third - Create your new foreign key constraint
In my case, we need to change the cascade to a set null command. Here is how you would do that:
```SQL
ALTER TABLE my_table ADD FOREIGN KEY (key) REFERENCES other_table(id) ON DELETE SET NULL;
```
And that's it!! That's how you change a foreign key constraint in MySQL!
<span id="tldr"></span>
<h1>TL;DR</h1>
1. Get the name of your foreign key constraint:
If you don't know the name, run this command:
```SQL
SHOW CREATE TABLE your_table_name_here\G
```
And you will get an output that looks something like this:
```
*************************** 1. row ***************************
Table: your_table_name_here
Create Table: CREATE TABLE `your_table_name_here` (
`id` int DEFAULT NULL,
`parent_id` int DEFAULT NULL,
KEY `par_ind` (`parent_id`),
CONSTRAINT `name_of_your_constraint` FOREIGN KEY (`parent_id`)
REFERENCES `parent` (`id`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
```
Which is where the name of your constraint will be (After the keyword "Constraint". There may be several, but you should be able to pick yours out).
2. Drop your foreign key constraint:
```SQL
ALTER TABLE your_table_name_here DROP FOREIGN KEY name_of_your_constraint;
```
3. Create your new foreign key constraint:
```SQL
ALTER TABLE your_table_name_here ADD FOREIGN KEY (parent_id) REFERENCES parent(id) ON DELETE SET NULL;
```
And that's it! That's how you change your foreign key constraint in MySQL | mcgurkadam |
338,402 | Why Fragmentation Should EMPOWER Linux | I was in a recent argument about Windows, Linux, whether Microsoft is getting into Linux to kill Linu... | 0 | 2020-05-18T18:29:37 | https://dev.to/kailyons/why-fragmentation-should-empower-linux-24gi | opensource, linux, distributedsystems | I was in a recent argument about Windows, Linux, whether Microsoft is getting into Linux to kill Linux off as competition. After the debate started to slow down as I wrote seven paragraphs per message on Telegram, I realized my point further than I thought. Why Linux is empowered by fragmentation, while also how to fight it as a foe. Linux fragmentation makes Linux what it is supposed to be. Open.
# How Linux is Open & Free
Linux is open and free in many ways. Free, as in free beer. Free, as in freedom. Open as in open to interpretation. Open as in open to outsiders. Open as many ideas, implementations, needs, emotions, looks, and more. Free as in freedom to share for free. Freedom as in freedom to sell.
I always hated Linux is "Free" philosophy, not because it is a bad one, but because those who often say it are authoritarian in how Linux is free. Ironic considering that they consider it freedom.
Linux isn't the only place I get angry with the authoritarian freedom arguments. I am very political, Libertarian, and yet I will never get a chance to agree with other Libertarians as they are usually in the belief of authoritarian freedom. Authoritarian freedom is "freedom as I say it is." Well, Linux is no stranger to this. I mean many people who argue these same points always say "Closed-source is the devil", or "You shouldn't use anything but x license for software." It may seem rare, but Linux has these people if you go into the world of something like Gentoo or Arch. I have seen Arch users claim "Manjaro isn't Arch, it has no right to exist." Even projects like Ubuntu are called "the devil" by internet weirdos who don't understand that Linux isn't one app, one kernel.
Fun fact, some distributions modify their kernel. This being to fit the needs of their OS. Many people pick and choose tools from people, even developing their own. People call companies who promote or use closed-source software to be "evil", even if those companies promote open-source.
Linux isn't free as in always open-source software. Linux is free as in it is your own.
# Fragmentation, why is it good?
If you live in the Linux world, you would know that there are near/over 500 options to choose from, and maybe 20 if you limit your choices by popularity.
To both outsiders and insiders, this is a bad thing, but there is no fixing it. It also has many delightful pros. The billion or so options give users the freedom to just say "I don't need to mess with this" if they don't want to. Many even fork their original distribution to work from the original, because they don't agree with the original OS. The whole thing that spawned Devuan is because Debian changed things.
Why is this great? Because you don't have to fiddle with one option. You can do it from source, you can fork another OS, and you can even distribute your own edition. Even if Linux is bought, then either turned closed-source or killed off, the older editions will still be open-source, someone will own it and fork it.
No matter what happens or who breaks what, someone will fork and continue it. Ubuntu Unity brings back the best Ubuntu desktop, MATE forks Gnome2 because no one liked Gnome3 at first, Linux Mint makes open-source easy, while Pop!_OS makes an OS the public will love. The goals and reasoning behind every single Linux distribution can't be broken. Saying that "we need to unify Linux" is a pipe dream that will NEVER be realized.
While people groan and moan at me saying that, open-source promotes it. Open-source is the freedom to remake, and even if you don't use it, others will. A project that angers users will be forked and made to be better, in 100 ways by hundreds of people.
Ubuntu Cinnamon is supposed to be Ubuntu with a new coat of paint. Linux Mint is supposed to be easy for PURE open-source lovers. Open-source compliments closed-source, because what is closed will be remade better by passionate users
# How to Ignore the Issues of Fragmentation?
Yes, fragmentation hurts Linux in many ways still, but this isn't to say we should unify. It doesn't mean to say we should stop building new projects. Rather, work together while fighting. If you love Linux Mint, get more people to use it. Same with Ubuntu, OpenSUSE, Gentoo, and others. Make a distribution? Advertize it, say why it is better than the rest, give people reason to use it.
Yes, smaller projects might die out leaving some stranded, but that is not too common nor for many much of an issue. The issue is that getting new people to use. Give new users Ubuntu, not choice. Have them learn and ease into Linux. If they want to, they can trickle down or make their own distribution. Yes, Ubuntu is bigger than everyone else already but if we need to, we can get users into Linux who can use other distributions by easing them into their baby-steps with Ubuntu, then they can use whatever they want if they want to adventure and test.
Linux empowers itself by being fragmented and can help by pushing one as the one new users should use. Ubuntu will grow, and trickle-down users. If it doesn't, others can advertise themselves and others. If they get too big, people will try to replace them. Linux needs to be fragmented to please everyone but unify behind something like Ubuntu to get new users away from Microsoft.
Makes sense?
# Conclusion
While my writing here is probably a little weird at times, I really hope it gives the message that Linux fragments to be better for everyone but should push the easiest and most user-friendly distribution as the one new-comers should use. It makes people happy, while bringing people into Linux. | kailyons |
338,412 | Microsoft Build 2020 - For developers by developers - Join us for the 48-hour digital experience, at no cost, May 19-20 | Hi Folks 👍 👏 👋, I just came to know about Microsoft Build 2020. Just posting some information for you... | 0 | 2020-05-18T18:59:22 | https://dev.to/shaijut/microsoft-build-2020-for-developers-by-developers-join-us-for-the-48-hour-digital-experience-at-no-cost-may-19-20-4oki | news, azure, webdev, aws |
Hi Folks :+1: :clap: :wave:, I just came to know about Microsoft Build 2020. Just posting some information for your benefit, its taken from the Microsoft Build website.
Register for this :heart: FREE :blush: event [here](https://mybuild.microsoft.com/).
:point_right: Session catalog is [here](https://mybuild.microsoft.com/sessions).
Every developer is welcome.
**:heart: For developers by developers**
As developers come together to help the world solve new challenges, sharing knowledge and staying connected is more important than ever. Join your community to learn, connect, and code—to expand your skillset today, and innovate for tomorrow.
**:star: More than a livestream**
For developers by developers, a non-stop, 48-hour interactive experience straight to your screen—but what if you can’t wait until May 19? Keep exploring leading up to the event and get a jumpstart on your Microsoft Build experience.
**:heart: Cloud skills challenge**
Earn a free Microsoft Certification exam and a chance to win prizes by completing a collection of online learning modules.
**:+1: Building something new**
This is a different kind of Microsoft Build delivered in a new way. Presenting a digital event provides the developer community unique opportunities to come together for a truly global experience.
Its Free :point_right: [Register Now](https://mybuild.microsoft.com/)
Hope this helps. | shaijut |
338,429 | Local testing for GitHub Actions (on MacOS) | The beginnings Back in October 2018, when GitHub Actions were announced, things got pretty... | 0 | 2020-05-23T07:31:03 | https://dev.to/icanhazstring/local-testing-for-github-actions-on-macos-4lob | github, testing, actions, local | ## The beginnings
Back in October 2018, when GitHub Actions were announced, things got pretty serious pretty fast. Everyone was jumping on the train and were replacing their old CI/CD integration with the new workflow GitHub now provided.
From my memory, the development of these workflows was a bit painful to say the least. You would have to add the changes to your workflow into your repository, push them and wait for the actions to complete.
Hopefully.
If not, do it again until everything worked out. The only thing I had done this far was a simple checkout, running some tests and that was pretty much it. Nothing fancy going one there.
Recently I was reminded by [@localheinz](https://twitter.com/localheinz) in a [tweet](https://twitter.com/localheinz/status/1261627962006351872) that some of the actions for GitHub made a huge improvement.
## Later today
Now one and a half years later having an actively used repository wit [composer-unused](https://github.com/composer-unused/composer-unused), I decided to check things again and improve the workflows. But - the testing. There has to be a way to test your workflow on your local machine. Right?
Yes there is! [nektos/act](https://github.com/nektos/act) to the rescue.
This tool, written in Go, is pretty easy to install and navigate. I will give you a small overview how to install and run it on MacOS (other OS are also supported, see the [documentation](https://github.com/nektos/act#installation))
## Get the tool running
### Requirements
`nektos/act` is using Docker to run your workflow on your machine. So first things first: **setting up Docker** using homebrew
```
$ brew install docker docker-machine
```
You will also need to install a provider for Docker. For this example we are using `Virtualbox`. You can install it a Homebrew Cask recipe:
```
$ brew cask install virtualbox
-> password
```
You might see the following message when installing Virtualbox:
You need to head over into the settings and accept the software installation from `Oracle America Inc.`.
Next up, set up the default `docker-machine` with `virtualbox` driver and start it.
```
$ docker-machine create --driver virtualbox default
$ eval "$(docker-machine env default)"
```
### Install nektos/act
Installation instruction taken from the [docs](https://github.com/nektos/act#installation) using homebrew:
```
$ brew install nektos/tap/act
```
### Run your workflow
To run your workflow on your machine, just navigate to your repository folder and run.
```
$ act
```
This will run your default job inside your workflow. Thats it!
But wait! Thats all in the docs, so why this post?
Well - I encountered a problem along the way:
```
::error::ENOENT: no such file or directory, open '/opt/hostedtoolcache/linux.sh'
```
## Solving the issue
The problem above has nothing to do with `nektos/act` itself. But rather with the default Docker image it uses. To solve this, you can run `act -P <docker-image>` to use another default image.
Turns out [shivammathur/setup-php](https://github.com/shivammathur/setup-php#local-testing-setup) was the solution.
```
$ act -P ubuntu-latest=shivammathur/node:latest
```
But typing this command all over again is - well - annoying.
To improve this, you can create a `~/.actrc` file and put the command line arguments there so you only have to run `act` inside your repository.
```
// ~/.actrc
-P ubuntu-latest=shivammathur/node:latest
```
Now everything is working as expected and I can improve my workflow to my needs while testing it locally on my machine first!
---
## Disclaimer
`nektos/act` is a little over a year old now, so there are still some problems with certain workflows and OS setups. I have only encountered the problem mentioned above.
If you encounter any other problem, don't hesitate and head over to the [issue tracker](https://github.com/nektos/act/issues) of `nektos/act` and describe your problem. This way we all can improve this awesome tool even further!
| icanhazstring |
338,444 | The 7 Most Popular DEV Posts from the Past Week | A round up of the most-read and most-loved contributions from the community this past week. | 0 | 2020-05-18T19:59:52 | https://dev.to/devteam/the-7-most-popular-dev-posts-from-the-past-week-455c | top7 | ---
title: The 7 Most Popular DEV Posts from the Past Week
published: true
description: A round up of the most-read and most-loved contributions from the community this past week.
tags: icymi
cover_image: https://thepracticaldev.s3.amazonaws.com/i/sfwcvweirpf2qka2lg2b.png
---
Every Monday we round up the previous week's top posts based on traffic, engagement, and a hint of editorial curation. The typical week starts on Monday and ends on Sunday, but don't worry, we take into account posts that are published later in the week. ❤️
#1. Don't Give Up
Rich shares their response to Tom MacWright's article, "Second-guessing the Modern Web." In this post, we discuss the current state of the web, areas for improvement, and why we shouldn't give up.
{% link https://dev.to/richharris/in-defense-of-the-modern-web-2nia %}
#2. Not a get-rich-quick scheme!
Kyle discusses the basics of starting to freelance *the right way*. We learn about the mindset shift, determining your market, pricing, and more!
{% link https://dev.to/study_web_dev/how-to-start-freelancing-the-basics-52d7 %}
#3. Any Machine Will Do
Jayesh shows us how to turn an old laptop into your own personal server in six steps, along with some cool things you can do with it.
{% link https://dev.to/jayesh_w/this-is-how-i-turned-my-old-laptop-into-a-server-1elf %}
#4. No More Baggage
Marko argues against Google Analytics and suggests a privacy-friendly alternatives.
{% link https://dev.to/markosaric/why-you-should-remove-google-analytics-from-your-site-5c7h %}
#5. Climb On Up
Rina shares eight things to avoid if you care about expanding your horizons and opportunities while you climb that career ladder.
{% link https://dev.to/rinaarts/how-to-ruin-your-career-in-8-easy-steps-71 %}
#6. New Ecosystem
Aral walks us through the most used services with Node, and what their Deno alternatives are (if any).
{% link https://dev.to/aralroca/from-node-to-deno-5gpn %}
#7. Define & Compare
Milu shares an in-depth comparison between the following commands: revert, checkout, reset, merge, and rebase.
{% link https://dev.to/milu_franz/git-explained-an-in-depth-comparison-18mk %}
_That's it for our weekly wrap up! Keep an eye on dev.to this week for daily content and discussions...and if you miss anything, we'll be sure to recap it next Monday!_ | jess |
338,462 | The Dead Simple Way to Get Weather Information for Your Next JS Project | With the recent announcement of Apple acquiring DarkSky API. DarkSky API has currently closed down... | 0 | 2020-05-18T21:17:11 | https://dev.to/shimphillip/the-dead-simple-way-to-get-weather-information-for-your-next-js-project-4k8o | typescript, node, npm |
With the recent announcement of [Apple acquiring DarkSky API](https://blog.darksky.net/dark-sky-has-a-new-home/). DarkSky API has currently closed down any new enrollments. The other compatible alternative I found one was the [OpenWeatherMap](https://openweathermap.org/api).
## The Challenge
Using APIs raw from their official documentation is cumbersome and cognitively taxing. You need to be mindful of all the different query parameters, filters and many options to build out URLs for different methods. You also need to deal with inconsistent conventions and refer back to the docs frequently get them straight.
For example, take a look at a few ways to get current weather from OpenWeatherMap. 😰
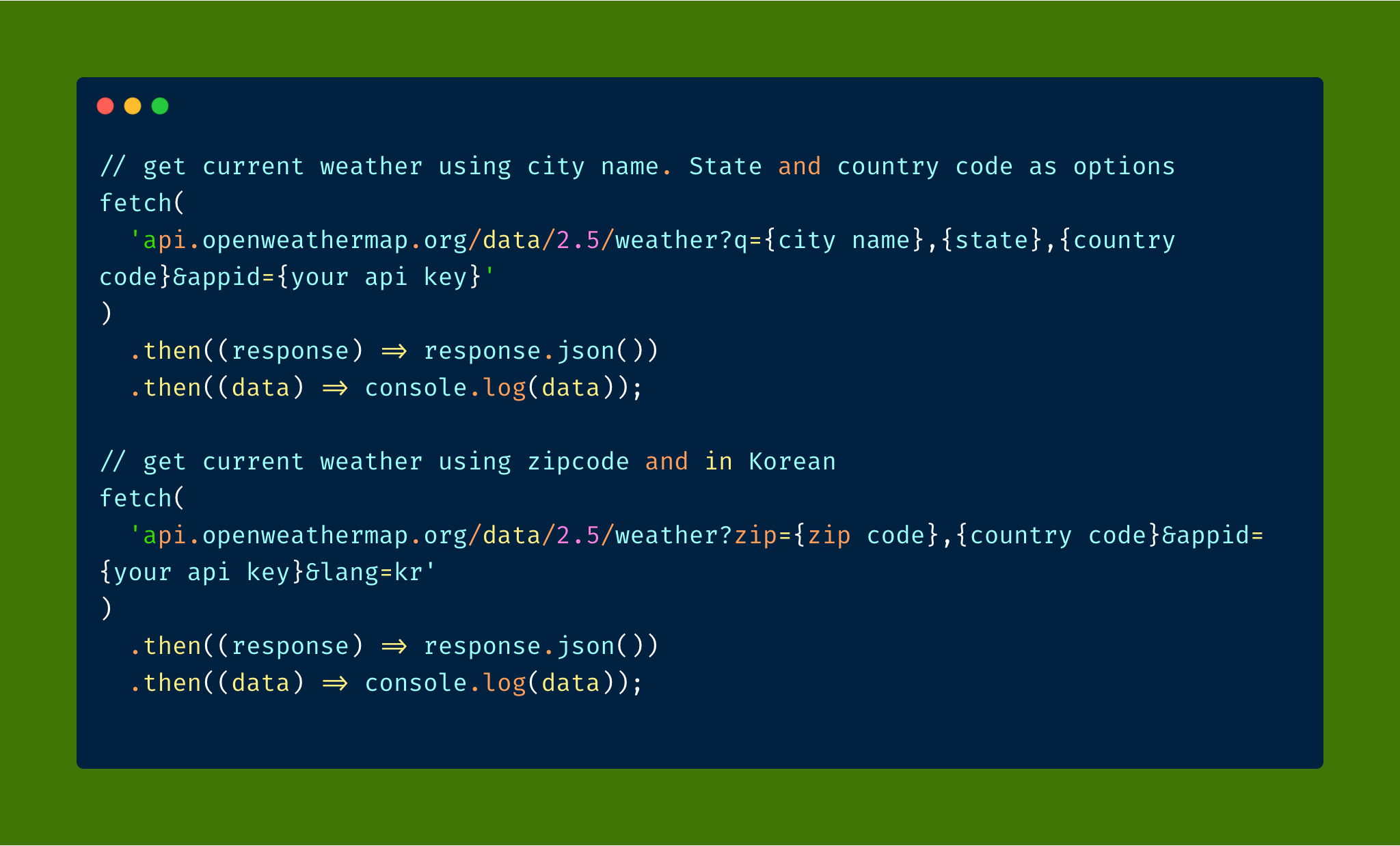
## The Solution
How about we abstract from building out the URLs by yourself and let a library to the heavy-lifting for you? Now Introducing
### [openweathermap-ts](https://www.npmjs.com/package/openweathermap-ts) 🎉
The library is built with
* Typescript - Get all the type checking and IntelliSense goodness out of the box.
* Promises - No callbacks FTW! 💪
Now it's as beautiful as
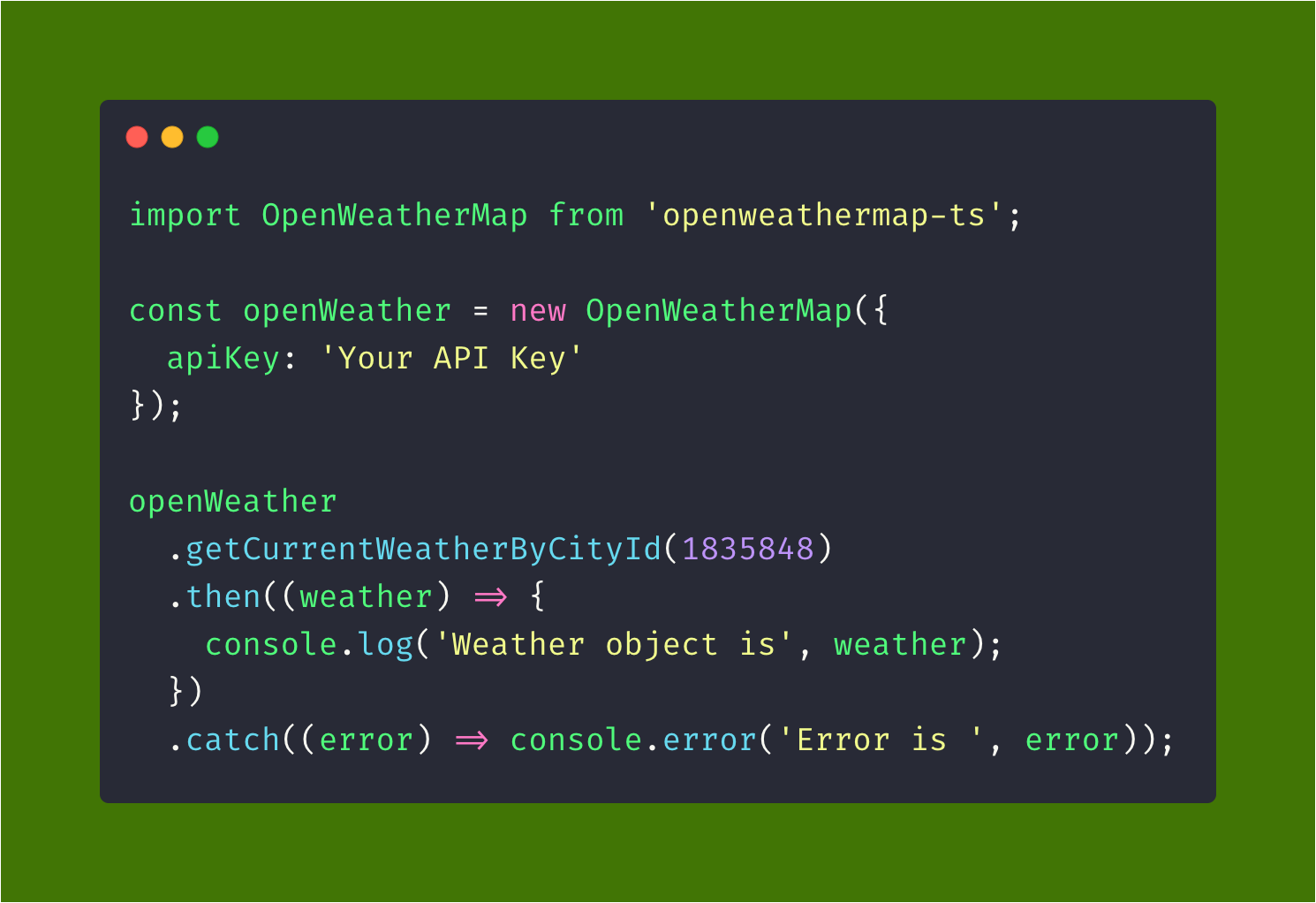
It's declarative, intuitive, and flexible!
Typing in arguments hurt your wrists? Don't worry, just set up the config object once and you are good.

The efficiency is crazy with easy-to-use methods you can easily get up and going. Don't deal with anything other than business logic. Build smart and use the library. 😎
## Repo
https://github.com/shimphillip/openweathermap-ts
Thank y'all for taking some time to read the article! | shimphillip |
338,470 | DVD corner bounces, but more satisfying 📀 | The bouncing DVD logo hitting a corner: we all know it & love it. But what if what looked like... | 0 | 2020-07-09T18:08:12 | https://dev.to/bryce/dvd-corner-bounces-but-more-satisfying-1355 | javascript, svg, showdev, css | The bouncing DVD logo hitting a corner: we all know it & love it.
{% youtube QOtuX0jL85Y %}
But what if what _looked_ like a perfect corner bounce was actually a pixel or two off? Screens have millions of pixels nowadays; we humans don't have the visual faculty to discern something so precise.
<center><h2>Enter: [satisfying-dvd-corners](https://brycedorn.gitlab.io/satisfying-dvd-corners).</h2></center>
### Features:
- Zooms in* & slows down time [Matrix-style](https://www.youtube.com/watch?v=3c8Dl2c1whM) when a corner bounce is imminent, so you know _with 100% certainty_ that it happened.
- _*Doesn't work in [Firefox](https://caniuse.com/#feat=css-zoom), sadly. Also only zooms on top right corner. More about this below._
- Uses [`Window.requestAnimationFrame()`](https://developer.mozilla.org/en-US/docs/Web/API/window/requestAnimationFrame) for 60fps smoothness.
- SVG [DVD logo](https://commons.wikimedia.org/wiki/File:DVD_logo.svg) for infinite scalability.
- Built in [Svelte](https://svelte.dev/) for a clean, boilerplate-free UI.
- Some buttons to control/customize behavior.
---
I attempted to do manual scale/deceleration to enable the zoom effect on all corners, but the math got complicated pretty fast. So went with the [zoom CSS property](https://developer.mozilla.org/en-US/docs/Web/CSS/zoom) instead. Couldn't find out how to adjust the zoom focal point though, so currently only applies to the default (top left corner).
May revisit this in the future to attempt at dynamic scaling so other corners have the effect (PRs welcome! 😇).
The corner-predicting calculation was tricky, but because the slope is always either `1` or `-1` it made it easier to determine the intersection point.
Hope you enjoy it! 📺
View source on Github:
{% github brycedorn/satisfying-dvd-corners no-readme %} | bryce |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.