
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
301,240 | Advanced TypeScript Exercises - Question 8 | Welcome back! Let's go back on track after bonus questions. This question will be less abstract, and... | 4,717 | 2020-04-06T21:40:46 | https://dev.to/macsikora/advanced-typescript-exercises-question-8-2la4 | typescript, javascript, challenge | --- series: Advanced TypeScript Exercises ---
Welcome back! Let's go back on track after bonus questions. This question will be less abstract, and more practical, we will land more at value level 🚁.
We have a function `concatToField` which takes object, and key of this object, and string value. The purpose of this function is to create a new object with concatenated property object[key] with third argument.
**The question** - How to type generic types `T` and `K` in the definition of `concatToField` function in order to achieve compile time guarantee that `obj[key]` can be only `string`.
```ts
const concatToField =
<T /* here your code 💪*/, K /* here your code 💪*/>(obj: T, key: K, payload: string): T => {
const prop = obj[key]; // compile error should not be here
return { ...obj, [key]: prop.concat(payload) }; // compile error should not be here
}
// tests
const test = { fieldStr: 'text', fieldNum: 1, fieldStr2: 'text' };
concatToField(test, 'fieldStr', 'test'); // should be ok 👌
concatToField(test, 'fieldNum', 'test'); // should be error fieldNum is not string field 🛑
concatToField(test, 'notExistingField', 'test'); // should be error - no such field 🛑
concatToField(test, 'fieldStr2', 'test'); // should be ok 👌
```
Full code available in [the playground](https://www.typescriptlang.org/play/index.html?ssl=11&ssc=61&pln=1&pc=1#code/MYewdgzgLgBKbAIZQCogGIEsCmAbAJjALwCwAUDDADwowD0AVDABbYBO2MAniAK5twQ+ToF4NwFU7DOgBoYAaXpNWHbnwGhhMcZIB8AChAAjAFYAuGChkBrbFzOyZAB0RdcIRPjPQ2mMAHMAlGa0RNowAN7klJTw0DAObCAOxDCGRgDa1lwAugDc9HSCALYOmLic7AlskVEcUPxg4TAAdC2pMhk2WWbxiU3wSFC6Ti5u+P4wAL55dAWgxaXlbJXkE+QzMFDY0BDkMbCbsUSNAGY4BADKUGxmAOSbAB5QNzKnePgAcryFZgCML2f4S5sABMtweT0mOV24AGaCwb10BygMhurwuV2eMDuWye-mmBQgzD4BBgBk4IEsmkAMjvQhDIOEAxE4lFoj5fTHY6A3PH5GCE4mEMkwCogASsz6FGCYCAwMAgWBeHy+GCszSARb3abCMIykSi5VAAKL3aVQJXwggcpHc-F8om8ElCkUCAC0spAfN4wGYKoB6s19O1CN1WNZQOBlpx1t5-PtgvJlJENLI5CAA)
**Important** - body of the function should remain unchanged, no type assertion (as), or any changes of the body are allowed. The only thing needs to be done is constraint on `T` and `K` generic types.
Post your answers in comments (preferred links to the playground). Have fun! Answer will be published soon!
**This series will continue**. If you want to know about new exciting questions from advanced TypeScript please follow me on [dev.to](https://dev.to/macsikora) and [twitter](https://twitter.com/macsikora). | macsikora |
301,244 | Transforming Teaching with Teachingo - #TwilioHackathon Submission | The Team Peter and I are two software engineers from Belfast, Northern Ireland who graduat... | 0 | 2020-04-06T21:48:34 | https://dev.to/chloemcateer3/transforming-teaching-with-teachingo-4lc5 | twiliohackathon, javascript, node, react | [Comment]: # (All of this is placeholder text. Use this format or any other format of your choosing to best describe your project.)
[Reminder]: # (Make sure you've submitted the Twilio CodeExchange agreement: https://ahoy.twilio.com/code-exchange-community)
[Important]: # (By making a submission, you agree to the competition's terms: https://www.twilio.com/legal/twilio-dev-hackathon-terms)
## The Team
[Peter](https://twitter.com/PMc_A) and I are two software engineers from Belfast, Northern Ireland who graduated from university last summer! Whenever we discovered the Twilio/DEV hackathon, we thought it was a great opportunity to jump into something that we can really get stuck in to.

With the hackathon being the majority of the month of April, this allowed us to really take our time with the idea and build something that could have a real impact in the world right now.
Given the current state of affairs in the world, everyone is flocking to the internet and various software/resources for communicating. _Everyone._
## The Problem
Most governments around the world have temporarily closed educational institutions in an attempt to contain the spread of the COVID-19 pandemic.
These global closures are impacting over 89% of the world's student population (source - https://en.unesco.org/covid19/educationresponse).
With these closures, schools across the globe are attempting to transition to online, remote learning. With some of our personal connections working in the education space, they had voiced their frustration with the lack of general tools in the wild that they could use to fit their needs - specifically, when it comes to video conferencing software.
Sure, there are a bunch of services that provide that facility to video call one another but they are mostly aimed at corporate businesses rather than education.
## Our Proposed Solution
We are creating an E-Learning platform that is specific to teachers in order to fulfil their different needs when teaching a remote lesson. Some of these features include:
* Video conferencing including: screen share, the ability to mute users and facilitate live chat.
* Automated attendance checker.
* Automated message sent to students that did not attend lesson.
* Reported lesson statistics - who/how many asked questions in live chat, what percentage of the class attended (list of who did and who didn't).
* Request a transcript or recording of the lesson (could be emailed to the students who attended or to the students that missed the class).
* Feedback request - students can show they understand the topic being taught via red, amber, green feedback mid-lesson.
* General student feedback about topics post-lesson.
## What we built
#### Category Submission: COVID-19 Communications/Interesting Integrations
### Choosing the right technology 📚
We wanted to make our solution platform agnostic, thus we opted to create a web application that both the teachers and students could use.
We decided to play to our strengths, with both of us having some experience with React and a lot of experience with JavaScript, we decided to build all the things with JS. For more details on our tech choice, check out our first progress update blog 👇
{% link https://dev.to/pmca/transforming-teaching-with-teachingo-update-1-5df2 %}
### Let's talk data 🔢
With our tech stack chosen, it was time to really think about the data that would be passing through our systems. How would it be structured? Where would it be stored? And most importantly, how would it be secured? Check out more about our data decisions in our second progress update blog:
{% link https://dev.to/chloemcateer3/transforming-teaching-with-teachingo-update-2-12bm %}
### Prepare to Lanuch 🚀
With just a simple spike created of our front end application, server and database - we wanted to hit the ground running and set up a CI/CD pipeline to automate deployment. Check out how we set it up below 👇
{% link https://dev.to/pmca/transforming-teaching-with-teachingo-update-3-5daf %}
### Security, Security, Security 🕵️♀️
As the application is going to be used as an educational tool, it is essential that it is secure - to see some of the security measures we have taken, have a read of our blog number 4:
{% link https://dev.to/chloemcateer3/transforming-teaching-with-teachingo-update-4-1cgj %}
### Twilio Time ⏰
Next step was to check out the Twilio services, SDKs and more to see what they could offer us. At a first glance we couldn't believe what Twilio could do out of the box and jumped straight into working with it. Take a look at how we got started and some of our code snippets in progress update number 5!
{% link https://dev.to/pmca/transforming-teaching-with-teachingo-update-5-58g2 %}
## Demo Link
We recorded a [short demo](https://drive.google.com/open?id=1h9GgnBrbDLK4oHnUhiDgYJ1T0ddvsEOa) of the main features in Teachingo.
You can check out the deployed application [here](https://confident-pike-86a4c7.netlify.app)
## Link to Code
{% github pmc-a/teachingo-client no-readme %}
{% github pmc-a/teachingo-api no-readme %}
**GitHub Profiles:**
- [Chloe - chloeMcAteer](https://github.com/chloeMcAteer)
- [Peter - pmc-a](https://github.com/pmc-a)
## Completed Features
Once we started this hackathon, we had an endless list of possible features we wanted to add to this application, but unfortunately due to time constraints it wasn't possible to add everything we wanted, but below is a full feature list of what we **achieved**:
* Ability to securely log in as a teacher or student
* Ability to view upcoming lessons
* Ability to start/join a video call
* Ability to mute/unmute mic, turn on/off camera and share screen
* Ability to live chat with everyone in the lesson to ask questions
* Abiltity for the teacher to view summary lesson statistcs at the end of the lesson.
* Ability for the teacher to send an SMS to students who missed the lesson.
Some additional features that we wanted to add and didn't have time to complete:
* Ability for students to show red, amber or green to highlight their understanding of the topic
* Ability to request a transcript/recording of the lesson
* Ability to obtain general student feedback at the end of the lesson
## Additional Resources/Info
We hope you like our submission! We have been tweeting our progress throughout the hackathon so if you want to see our journey check us out at [@chloeMcAteer3](https://twitter.com/chloeMcAteer3) & [@PMc_A](https://twitter.com/PMc_A)! | chloemcateer3 |
301,247 | Job Search Week 7 | So I decided to clean up some of my repositories from Makers this week. I thought it'd be nice to go... | 5,212 | 2020-04-06T22:00:31 | https://dev.to/kealanheena/job-search-week-6-3dcp | makers | So I decided to clean up some of my repositories from Makers this week. I thought it'd be nice to go back over the basics and also have everything looking nice.
Day 1
So on Monday, I started with Boris bikes picking up where I had left off in week 1 of makers. It was quite fun to go back and see my old code and also see how far I've come since then. I managed to get through some of the things I had been stuck on and do some of the challenges I didn't get a chance to do.
Day 2
On Tuesday, I got to do some mocks and stubs which was nice because I wanted to get some practice in using them and now I've done that it makes more sense to me.
Day 3
I got more functionality done on Wednesday. I continued working with classes although a bit repetitive I think it's good to go over the basics because a solid understanding of the basics will help when implementing more complicated functionality. I also updated the documentation on Boris bikes to make it more relevant.
Day 4
I continued to work through Boris bike adding the van and garage classes to the project. I did notice that there were some similarities between the van, garage and docking station classes which was where the module came in.
Day 5
On Friday, I just finished off Boris bikes completing the last of the functionality and updating the documentation. I also got to use a module which I didn't get to during makes which were interesting to work with.
Summary
Overall I think this was a good week I worked on the basics and got Boris bikes and the airport challenge nicely cleaned up. I think I'll keep working through the Makers projects till along with my side projects. | kealanheena |
301,292 | Curso JSON - 3. Herramientas | Curso sobre JSON de novato a experto (versión GRATIS) Presentación:... | 5,620 | 2020-04-06T23:45:45 | https://youtu.be/uE8QD3ztKUg | spanish, vscode, node, javascript | {% youtube uE8QD3ztKUg %}
Curso sobre JSON de novato a experto (**versión GRATIS**)
Presentación: https://slides.com/equimancho/json/#/3
Repositorio:
https://github.com/equiman/playground-json
Descargas:
Git: https://git-scm.com/
Visual Studio Code: https://code.visualstudio.com/
NodeJS: https://nodejs.org/
Curso recomendado de Visual Studio Code (Fernando Herrera):
https://cursos.devtalles.com/courses/visual-studio-code
Contadores (Mr. Timer):
https://www.youtube.com/channel/UCYo5An-3L_eOd1l5WQdU3oQ
---
**That's All Folks!
Happy Coding** 🖖
[](https://github.com/sponsors/deinacademy) | equiman |
301,557 | Replacing React's Redux library with the useReducer Hook | If you'd like to see more content like this 😍, we should definitely connect on Twitter! 🤝. Take a... | 0 | 2020-04-07T08:03:12 | https://robkendal.co.uk/blog/2020-04-07-replacing-reacts-redux-library-with-usereducer-hook/ | react, showdev, tutorial, beginners | ---
title: Replacing React's Redux library with the useReducer Hook
published: true
date: 2020-04-07 08:01:00 UTC
tags: react, showdev, tutorial, beginners
canonical_url: https://robkendal.co.uk/blog/2020-04-07-replacing-reacts-redux-library-with-usereducer-hook/
cover_image: https://robkendal.co.uk/img/useReducer%20-%20blog%20post.png
---
_If you'd like to see more content like this_ 😍, _we should definitely connect on Twitter!_ 🤝. _Take a look at [my Twitter profile](https://twitter.com/kendalmintcode) and I'll look forward to seeing you there_ 👍🏻

I've been moving over to using React Hooks in my development of late. They offer a much simpler, terser approach to development and are super powerful. They do require a certain mind-shift towards [thinking in React Hooks](https://wattenberger.com/blog/react-hooks) (read that article by Amelia Wattenberger, it's so well written and helpful!), but they really push your development on.
Anyway, up until now, I had been like a lot of developers who wanted to employ a centralised state management system; I had been using the [Redux library](https://redux.js.org/), specifically [React Redux](https://react-redux.js.org/introduction/why-use-react-redux) and the [Redux Toolkit](https://redux-toolkit.js.org/) (which just simplifies things a little I feel).
However, the React core team has [introduced the `useReducer` Hook](https://reactjs.org/docs/hooks-reference.html#usereducer) and I've found it a little nicer to use. It doesn't require additional libraries or tooling, and I feel like it might just take some of the edge of learning the Redux pattern(s) for beginners. It certainly removes a lot of the configuration 'fun' that accompanies a typical Redux setup.
So let's start using it!
## Contents
This is a long article, so if you want to skip around then you'll find this outline handy:
- [Redux primer](#redux-primer) a gentle introduction to Redux for beginners
- [Reducers](#reducers)
- [Action creators](#action-creators)
- [Dispatchers](#dispatch-methods)
- [Redux with useReducer](#redux-with-usereducer)
- [Creating the reducer](#creating-reducers)
- [Wiring up the App component](#wiring-the-app)
- [Faking API calls](#fake-api-calls)
- [Rendering components](#rendering-components)
- [Displaying our ShoppingList](#displaying-the-list)
- [Introducing React's Context](#introducing-context)
- [Dispatching updates to state](#dispatch-updates)
- [Adding new items](#add-new-items)
- [Demo and working code in action](#demo)
- [Further reading and resources](#further-reading)
## A Redux primer
<a name="redux-primer"></a>**(If you're already a Redux king or queen and just want to start using the useReducer Hook, you can [skip to the tutorial part now](#redux-with-usereducer))**
I mentor some junior and aspiring developers and at some point they all land on the Redux methodology for manging their state. It's easy to see why: it's a very common approach to solving application state management in complex apps; let's face it, most commercial apps qualify as 'complex' and you are always better off learning things that are geared to helping you in a realistic role.
However, the concepts involved in Redux are where a lot of beginners come unstuck. I think it's a combination of having to understand several moving parts that wire together to make a Redux-y state change, as well as some unfamiliar (and potentially confusing) terminology.
Hopefully, this little interlude can help get you familiar with the basics before we plough on with implementing the useReducer Hook for our own Redux stuff.
### The main players in Redux
So, there are four main players within the Redux pattern:
1. Application state
2. Dispatchers
3. Action creators
4. Reducers
### Application state
The most straightforward of the bunch, this is simply a centralised object with various properties that represent the 'state' of our application at a given moment. It can contain anything your app needs, but typically it could contain collections of items, settings, preferences and so on.
In more complex applications you might find that state is broken into small sections (often referred to as 'slices' in Redux land) which are then stitched together when the application is served.
### Reducers
<a name="reducers"></a> Reducers are functions that modify our state.
They usually accept an output of an **action creator** and use this to determine what _action_ to take on our state.
You might see something like this:
```JavaScript
function mySuperReducer(state, action) {
switch(action.type) {
case 'INCREMENT':
return state + 1;
default:
return state;
}
}
```
For some state changes, however, we also need to modify our state based on a passed in value. For this, we'll use an action that contains a **payload**.
A **payload** could be anything: a value, string, integer, array, object, etc. It's passed in with the action object into the reducer and is used to modify state.
It might look like this:
```JavaScript
function mySuperReducer(state, action) {
switch(action.type) {
case 'ADD_USER':
return [...state, action.payload.newUser]
default:
return state;
}
}
```
### Action creators
<a name="action-creators"></a>Action creators are functions that create actions. That's not very helpful though.
What they are, are quite simple functions that return an object. This object usually contains two things:
1. The type of action you want to take (often a string constant)
2. The value you want to take action with (see above example in the reducers section)
When you pass an action (the result of an action creator) into a reducer, it is the action type that determines what will happen to state, and (if required/available) what _value_ will be used as part of the state changes.
What they look like varies from use to use, but in a relatively standard Redux setup, they'll look either like this:
```JavaScript
const ADD_USER = 'ADD USER; // our string constant part
function addUser(newUser) {
return { type: ADD_USER, newUser };
}
```
or like this if you're using one of the Redux library's handy helpers:
```JavaScript
const addUser = createAction('ADD USER');
```
### Dispatchers
<a name="dispatch-methods"></a>The final piece of the puzzle, dispatchers. Dispatchers are the gophers between actions and reducers. Essentially, dispatchers are functions that trigger/kick-off all state updates.
You call a dispatch function, passing in an action. The dispatch function takes the action to the reducer and the reducer modifies the state.
Using a dispatcher might look like this:
```JavaScript
// Here's our action
function addUser(newUser) {
return { type: 'ADD_USER', newUser };
}
// here's a new user object
const user = {
name: 'rob kendal',
age: 380,
dob: '01/01/1901'
}
// and here's the dispatch to trigger things
dispatch(addUser(user));
```
[](https://twitter.com/kendalmintcode)
### Putting it all together
There is [a good explanation of the flow of data and the various interaction points](https://redux.js.org/basics/data-flow) in a Redux update cycle available on the Redux JS website. In the meantime, here's a handy diagram that should help cement the concepts at a high level.

### Further reading
If you need further help on this, check out the various [Redux JS documentation sites](https://redux.js.org/) and I have a couple of articles on using Redux with a data handler:
1. [React and Redux components - part one](https://dev.to/kendalmintcode/react-redux-components-api-s-and-handler-utilities-3fk9)
2. [React and Redux components with data handlers - part two](https://dev.to/kendalmintcode/react-redux-components-api-s-and-handler-utilities-part-two-389p)
## Redux with React and useReducer
<a name="redux-with-usereducer"></a>OK, to the main meat and potatoes of the article, using the useReducer Hook to manage your application state in React.
We're going to build a small shopping list app that accepts some simple data via input elements and uses the Redux pattern to update a global state-held list.
The tools we'll be using include:
- `useReducer` - this is the [React Hook](https://reactjs.org/docs/hooks-reference.html#usereducer) that is billed as an alternative to `useState`.
- `useContext` - the [useContext Hook](https://reactjs.org/docs/hooks-reference.html#usecontext) will allow us to grab the current context value from the specific context we're referencing. In our case, we'll be passing down both a dispatch function to allow for state updates and the state object itself to make use of its contents.
- Creating a reducer function to update our state
- Making an action creator function that just simplifies the building of an action
- Creating an initial state with some predefined items on our list
So let's get to it; first up, we'll create our initial state
### Initial state
Firstly, we'll need a place to store our app's data, our initial state. We'll create a new file `initialstate.js` and load it up.
```JavaScript
export default {
loadingItems: false, // our app uses this to determine if we're loading our list
shoppingList: [ // our initial list of items
{
id: 1,
name: "Bananas",
description: "A bunch of 5 bananas, fresh from the plant",
price: 1.83
},
{
id: 2,
name: "Soup",
description: "A can of beef broth",
price: 0.54
}
]
};
```
Nothing too clever here, just a plain old JavaScript object with a couple of properties that are fairly self-explanatory;
### Creating the reducer
<a name="creating-reducers"></a>Next, we'll create our reducer file, `reducer.js`. It will contain a few items when we're done:
1. **Two React contexts** , one that will contain our dispatch method and one that will contain our state. They will both be wrapped around our React app to be referenced in child components further down the tree.
2. **Action types** : this is just be a simple JS object with string constants. We'll use these to prevent ambiguity or errors when triggering dispatches.
3. **A reducer function** , the main star of the show that will ultimately affect change in our app's state.
Our new file looks like this:
```JavaScript
// We need React in scope to create our context objects
import React from "react";
// Contexts
// will be used to pass down the dispatch method and our
// application state via the Context Provider and consumed
// in child components using the useContext Hook
export const StateContext = React.createContext(null);
export const ShoppingContext = React.createContext(null);
// Action constants
// we will import this object and use the various properties
// in child objects when calling the dispatch method
export const actions = {
GET_ITEMS: "get items",
GET_ITEMS_SUCCESS: "get items success",
ADD_ITEM: "add item",
REMOVE_ITEM: "remove item"
};
// This is a simple helper function that will take a type
// (from the constants above) and a payload, which will be the
// value which needs to be affected in state it returns
// a simple object that will be passed to our dispatch function
export const createAction = (type, payload) => {
return {
type,
payload
};
};
// Reducer
// the function that accepts our app state, and the action to
// take upon it, which then carries out that action
export const reducer = (state, action) => {
switch (action.type) {
case actions.GET_ITEMS:
return {
...state,
loadingItems: true
};
case actions.GET_ITEMS_SUCCESS:
return {
...state,
loadingItems: false
};
case actions.ADD_ITEM:
const nextId = Math.max.apply(
null,
state.shoppingList.map(item => item.id)
);
const newItem = {
...action.payload,
id: nextId + 1
};
return {
...state,
shoppingList: [...state.shoppingList, newItem]
};
case actions.REMOVE_ITEM:
return {
...state,
shoppingList: state.shoppingList.filter(
item => item.id !== action.payload
)
};
default:
return state;
}
};
```
In a more complex app, it may make sense to split these functions out, but for smaller apps and our example, it makes sense to me to keep them contained within one reducer file. You could name it something that encompasses the more holistic nature of the elements within it, but for now, it's fine.
The main thing to understand is that each part in here is related and will join together throughout our app to make changes to our state.
The reducer function is the most interesting part and you can see that it accepts our current state (this is taken care of by React's `useReducer` function that you will see later on) and the action we want to take against the state.
Based on the supplied action's type, the reducer determines which action we're talking about and then does some simple state mutation based on what that action type may be.
For example, if we pass the action type 'REMOVE\_ITEM' (just a string constant), the reducer returns a new version of state with the 'shoppingList' property where the previous shopping list has been filtered to remove the item that matches the action's payload (which will be the item's id value).
## Wiring up the App component with `useReducer`
<a name="wiring-the-app"></a>So we've got a reducer (and it's other moving parts) and some state for the reducer to act upon. Now we need to wire this up into our App.
First, we'll import some important items at the top of the file:
```JavaScript
import React, { useReducer, useEffect } from "react";
// Styles
import "./styles.css";
// Data
import initialState from "./initialstate";
import { reducer, StateContext, ShoppingContext, actions } from "./reducer";
// Components
import AddItem from "./components/AddItem";
import ShoppingList from "./components/ShoppingList";
```
We'll get to useReducer and useEffect in a minute. The important bits of this so far are that we're importing our app's initial state, as well as most items from the `/reducer.js` file.
Next, we'll define our main export and proceed to fill it as we go.
```JavaScript
export default props => {
return (
<div>The app has landed</div>
);
};
```
From here, we'll finally use our useReducer Hook:
```JavaScript
export default props => {
const [state, dispatch] = useReducer(reducer, initialState);
useEffect(() => {
// simulate loading of items from an API
dispatch({
type: actions.GET_ITEMS
});
setTimeout(() => {
dispatch({
type: actions.GET_ITEMS_SUCCESS
});
}, 2000);
}, []);
return (
...
);
};
```
The useReducer Hook is a really simple function in essence. It returns an array, `[state, dispatch]` which contains our app's state, and the dispatch function we will use to update it.
We're also using the useEffect Hook with an empty array, which means it will only fire once, **not on every render**.
The useEffect Hook here is not at all necessary, but I've used it to mimic a realistic scenario whereby an app would load and then go off and fetch some data from an API.
### Faking the API call
<a name="fake-api-calls"></a>In a real app, you'll need to interact with an API and you'll most likely want to show some sort of loading message whilst you wait for data back. We're not using an API and our data is miniscule by comparison, but we can fake the _effects_ of an API using a `setTimeout` callback.
In the useEffect Hook, we actually use the dispatch method for the first time. We pass it a type of 'GET\_ITEMS' which is a string property on our imported actions constants object (`actions`) from the top of our App component.
You can see in our `reducer.js` file what affect this has on state:
```JavaScript
export const reducer = (state, action) => {
switch (action.type) {
case actions.GET_ITEMS:
return {
...state,
loadingItems: true
};
// ... rest of reducer
}
};
```
We simply set the 'loadingItems' flag to true, which means in our App component, we'll display a loading element.
### Rendering the components
<a name="rendering-components"></a>Finally, we need to wire up the app so that it actually renders something useful. We'll do that here:
```JavaScript
export default props => {
// ...unchanged
return (
<ShoppingContext.Provider value={dispatch}>
<StateContext.Provider value={state}>
<h1>Redux fun with shopping lists</h1>
<hr />
{state.loadingItems && <div className="loading">...loading</div>}
{!state.loadingItems && (
<div className="columns">
<div className="column">
<h2>Add a new item</h2>
<AddItem />
</div>
<div className="column">
<h2>Shopping list</h2>
<ShoppingList />
</div>
</div>
)}
</StateContext.Provider>
</ShoppingContext.Provider>
);
};
```
The main take away here is the two context providers that we use to wrap the main App component in.
The first, `<ShoppingContext.Provider value={dispatch}>` allows us to pass down the dispatch function to child components.
The second `<StateContext value={state}>` is the same, but allows child components to access our application state when they need.
These are a key part of the process as they allow us to access dispatch and state from child components. You can [read more about React's Context on the official documentation](https://reactjs.org/docs/context.html).
### Finishing off the App component
Everything else is pretty much standard React stuff. We check to see if the 'loadingItems' property/flag is set to 'true' and either display a loading element, or our AddItem and ShoppingList components.
Here's our app's entry point in complete, the App component:
```JavaScript
import React, { useReducer, useEffect } from "react";
// Styles
import "./styles.css";
// Data
import initialState from "./initialstate";
import { reducer, StateContext, ShoppingContext, actions } from "./reducer";
// Components
import AddItem from "./components/AddItem";
import ShoppingList from "./components/ShoppingList";
export default props => {
const [state, dispatch] = useReducer(reducer, initialState);
useEffect(() => {
// simulate loading of items from an API
dispatch({
type: actions.GET_ITEMS
});
setTimeout(() => {
dispatch({
type: actions.GET_ITEMS_SUCCESS
});
}, 2000);
}, []);
return (
<ShoppingContext.Provider value={dispatch}>
<StateContext.Provider value={state}>
<h1>Redux fun with shopping lists</h1>
<hr />
{state.loadingItems && <div className="loading">...loading</div>}
{!state.loadingItems && (
<div className="columns">
<div className="column">
<h2>Add a new item</h2>
<AddItem />
</div>
<div className="column">
<h2>Shopping list</h2>
<ShoppingList />
</div>
</div>
)}
</StateContext.Provider>
</ShoppingContext.Provider>
);
};
```
## Displaying our list in the ShoppingList component
<a name="displaying-the-list"></a>Next, we'll dig into the ShoppingList component. At the top of the file, we'll see a familiar set of imports:
```JavaScript
import React, { useContext } from "react";
// State
import {
ShoppingContext,
StateContext,
actions,
createAction
} from "../reducer";
```
Next, we'll define the main output for this component:
```JavaScript
export default props => {
const state = useContext(StateContext);
const dispatch = useContext(ShoppingContext);
const handleRemoveItem = id => {
dispatch(createAction(actions.REMOVE_ITEM, id));
};
return (
<>
{!state.shoppingList && <p>no items in list</p>}
{state.shoppingList && (
<table>
<thead>
<tr>
<th>Name</th>
<th>Description</th>
<th>Price</th>
<th>Actions</th>
</tr>
</thead>
<tbody>
{state.shoppingList &&
state.shoppingList.map(item => (
<tr key={item.id}>
<td>{item.name}</td>
<td>{item.description}</td>
<td>£{item.price}</td>
<td>
<button onClick={() => handleRemoveItem(item.id)}>
remove
</button>
</td>
</tr>
))}
</tbody>
</table>
)}
</>
);
};
```
The main return of the component doesn't have anything too interesting beyond standard React stuff. The interesting things, however, are the 'const' definitions and the `handleRemoteItem()` method.
### Wiring up context in the ShoppingList component
<a name="introducing-context"></a>We know from our App component that we're already passing down the Redux dispatch method and our application state, but how do we access them?
Simple: with the `useContext` Hook...
```JavaScript
const state = useContext(StateContext);
const dispatch = useContext(ShoppingContext);
```
That's all there is to it. We can now use 'state' to access various properties on our global application state, such as 'shoppingList', which we actually use to display our table.
Similarly, we use 'dispatch' to trigger state changes; in our case to remove items from our list.
### Dispatching updates to our shopping list
<a name="dispatch-updates"></a>Whilst you could inline the following directly into the button element (and I normally would for brevity), I think it's a little clearer for learning to abstract the 'remove' button's click handler into its own variable.
```JavaScript
const handleRemoveItem = id => {
dispatch(createAction(actions.REMOVE_ITEM, id));
};
```
Again, quite a simple approach, but we call the dispatch function, passing in the result of the createAction function. The createAction function accepts a 'type' and a value, referred to as a 'payload'.
It's worth noting that the above is functionally equivalent to the following:
```JavaScript
const handleRemoveItem = id => {
dispatch({ type: 'remove item', payload: id});
};
```
It just looks a bit neater in the first example, and leaves less room for error(s).
Again, you can see that this links through to our reducer file like so:
```JavaScript
export const reducer = (state, action) => {
switch (action.type) {
// ...rest of reducer
case actions.REMOVE_ITEM:
return {
...state,
shoppingList: state.shoppingList.filter(
item => item.id !== action.payload
)
};
}
};
```
We employ a straightforward `Array.filter()` on the state's shoppingList property that just skips over the item with the id value that we've passed in, that we want to remove.
## Adding new items with the AddItem component
<a name="add-new-items"></a>Finally, we need to be able to add an item to our list to complete the circle of CRUD (almost, we're not doing updates...).
By now, things should start looking familiar, so we'll take a look at the entire AddItem component as a whole and walk through the finer points:
```JavaScript
import React, { useContext, useState } from "react";
// State
import { ShoppingContext, actions, createAction } from "../reducer";
export default props => {
const _defaultFields = {
name: "",
description: "",
price: ""
};
const dispatch = useContext(ShoppingContext);
const [fields, setFields] = useState({ ..._defaultFields });
const handleInputChange = evt => {
setFields({
...fields,
[evt.target.id]: evt.target.value
});
};
const handleFormSubmit = evt => {
evt.preventDefault();
dispatch(createAction(actions.ADD_ITEM, fields));
setFields(_defaultFields);
};
return (
<form onSubmit={handleFormSubmit}>
<label htmlFor="name">Name</label>
<input
id="name"
type="text"
value={fields.name}
onChange={handleInputChange}
/>
<label htmlFor="description">Description</label>
<input
id="description"
type="text"
value={fields.description}
onChange={handleInputChange}
/>
<label htmlFor="price">Price</label>
<input
id="price"
type="text"
value={fields.price}
onChange={handleInputChange}
/>
<button type="submit">Add item</button>
</form>
);
};
```
Right at the top, we've got our React and state imports.
Next, in our main output, we have a default state object, `_defaultFields` that we're using to reset the fields in local state when we've finished adding a new item.
We consume the dispatch function using useContext so we can pass a new item into our shopping list. **Notice that we're not consuming the state context, however.** We don't need to use anything from our application's state, so there's no need to consume the context.
Most everything else is pretty standard React form field handling [using controlled components](https://reactjs.org/docs/forms.html#controlled-components) that is beyond the scope of this article.
What we're interested in, however, happens in the `handleFormSubmit()` method:
```JavaScript
const handleFormSubmit = evt => {
evt.preventDefault();
dispatch(createAction(actions.ADD_ITEM, fields));
setFields(_defaultFields);
};
```
Firstly, we call the synthetic event's `preventDefault()` method to prevent the page from refreshing.
Next, we call our familiar dispatch method, passing in the action 'ADD\_ITEM' and the fields object from state which is a collection of any values we've made into the form's fields.
What happens in our reducer looks like this:
```JavaScript
export const reducer = (state, action) => {
switch (action.type) {
// ...rest of reducer
case actions.ADD_ITEM:
const nextId = Math.max.apply(
null,
state.shoppingList.map(item => item.id)
);
const newItem = {
...action.payload,
id: nextId + 1
};
return {
...state,
shoppingList: [...state.shoppingList, newItem]
};
// ...rest of reducer
}
};
```
This is arguably the most complex part of our reducer, but it's easy to follow:
- We work out the current highest id value in our shopping list items and increment it by one (not recommended in real life!);
- We add the id to a new item object;
- We update the state's shoppingList property by copying the array to a new array, adding in the new item object.
Finally, we clear out any saved fields/input data by replacing local state with the `_defaultFields` object.
## Putting it all together
<a name="demo"></a>You can see the finished app and play about with it below, and you can [view it online in the CodeSandbox environment](https://codesandbox.io/s/redux-with-usereducer-9tfko).
{% codesandbox redux-with-usereducer-9tfko %}
## Caveats, gotchas and things to bear in mind
This article covers the basics of using the useReducer Hook in conjunction with React's Context mechanism to both update and access your application's state. It can be used instead of the standard Redux library's approach, and it certainly requires no additional setup or configuration, which is handy (because there's a lot of that in the traditional Redux world).
However, this particular approach I've used may not suit you and your situation. It probably won't scale that well 'as-is' and could benefit from some smoothing out in terms of using this exact approach for a full-scale application. For example, you may wish to split your state into smaller parts for different areas of your application, which is great, but you can see how you'll need to work on that with from we've done here.
There is always more than one way to approach a problem and I think it's worth knowing your options. This article helps to introduce the Redux patterns and concepts whilst employing a nice new approach of employing reducers using built-in Hooks.
I would (and do) use this commercially, but do take what you see here and adapt it to your own means.
## Further reading and references
It's always handy to have a list of other sources of information, so here's that very list of useful references, links, resources that are worth a peek to help you in your quest to be a Redux master:
- [Redux JS](https://redux-toolkit.js.org/tutorials/basic-tutorial) - discover more about the Redux methodology and library
- [Redux Toolkit](https://redux-toolkit.js.org/) - an opinionated version of the Redux JS library for React
- [React's official documentation on Hooks](https://reactjs.org/docs/hooks-reference.html) - especially helpful for the [useContext](https://reactjs.org/docs/hooks-reference.html#usecontext) and [useReducer](https://reactjs.org/docs/hooks-reference.html#usereducer) Hooks
- Amelia Wattenberger's ['thinking in hooks' article](https://wattenberger.com/blog/react-hooks) - super helpful, clear resource for shifting your mindset into using Hooks in your own code
- My own articles on Redux and React, using API's and data handlers. I have an [article part one](https://dev.to/kendalmintcode/react-redux-components-api-s-and-handler-utilities-3fk9), and [article part two](https://dev.to/kendalmintcode/react-redux-components-api-s-and-handler-utilities-part-two-389p) available, which cover some more real-world examples.
## EDIT - 09 April 2020
Shout out to [Daishi Kato](https://twitter.com/dai_shi) on Twitter for his suggestion of using [react tracked](https://react-tracked.js.org/) in conjunction with the work in this article.
{% twitter 1247652386690093058 %}
[React tracked](https://react-tracked.js.org/) is a simple utility that supports the use of useReducer Hooks but helps to eliminate unnecessary rerenders upon smaller, unrelated state changes.
| kendalmintcode |
301,586 | Online and Offline events in JavaScript | In this post you will learn how to build a fully offline-capable app that will show an alert to user... | 0 | 2020-04-07T09:06:13 | https://dev.to/zeeshanahmad/online-and-offline-events-in-javascript-h25 | javascript | In this post you will learn how to build a fully offline-capable app that will show an alert to user when the application is offline or online. But first let me explain what are events and what are the advantages of using them in your application. Many function starts working when a webpage loads in a browser. But in many cases you want to start a function or take an action when a mouse button is clicked, mouse hovered on an object, when a page fully loaded in browser, input value is changed or keyboard button is pressed etc. All these actions are called events. You can write functions to run when a specific event happens. All these function listens for an event and then start taking the action by initiating the function.
There are two methods by which we can check the connection status both are listed below:
1. Navigator Object
2. Listening to events
## 1. Navigator Object
There is a global object **navigator** in javascript by which you can easliy check if a user is offline or online. The **navigator.onLine** returns `true` if a user is connected to the internet but it will return false if the user is offline.
```javascript
if (navigator.onLine)
console.log("Congratulations, You are connected to the internet.")
else
console.log("Congratulations, You are not connected to the internet.")
```
## 2. Listening to events
Now lets review the other method to check the connection status. In this method we continually listen to the two events `online` and `offline`. And when the connection is interpreted the `offline` event is fired and we capture it by listening to this event. And when the connection is back online the `online` is fired. So, lets take a look at the following example:
### Example
```javascript
class Connection {
constructor() {
this.options = {
onlineText: 'Your device is connected to the internet.',
offlineText: 'Your device lost its internet connection.',
reconnectText: 'Attempting to reconnect...',
notifier: document.querySelector('.notifier'),
notifierText: document.querySelector('.notifier span'),
spinner: document.querySelector('.notifier .lds-css')
};
this.init();
}
init() {
if (navigator.onLine) {
this.on();
} else {
this.off();
setTimeout(() => {
this.reconnect();
}, 1500);
}
window.addEventListener('online', () => {
this.on();
});
window.addEventListener('offline', () => {
this.off();
setTimeout(() => {
this.reconnect();
}, 1500);
});
}
on() {
this.options.notifierText.innerText = this.options.onlineText;
this.options.notifier.classList.remove('error', 'warning');
this.options.notifier.classList.add('success');
this.options.notifier.style.display = "block";
this.options.spinner.style.display = "none";
}
off() {
this.options.notifierText.innerText = this.options.offlineText;
this.options.notifier.classList.remove('success', 'warning');
this.options.notifier.classList.add('error');
this.options.notifier.style.display = "block";
this.options.spinner.style.display = "none";
}
reconnect() {
this.options.notifierText.innerText = this.options.reconnectText;
this.options.notifier.classList.remove('error', 'success');
this.options.notifier.classList.add('warning');
this.options.notifier.style.display = "block";
this.options.spinner.style.display = "block";
}
}
(function () {
new Connection();
})();
```
<a href="https://codepen.io/zeeshanu/pen/zpLMxo">See demo on CodePen</a> | zeeshanahmad |
301,606 | Reading Snippets [52 => CSS] 🎨 | Calc() can be used in CSS to perform math operations on values. It can be used for performing diffe... | 0 | 2020-04-07T09:40:20 | https://dev.to/calvinoea/reading-snippets-52-css-1mhi | todayilearned, css, beginners, html | Calc() can be used in CSS to perform math operations on values.
It can be used for performing different calculations, including adding and subtracting values, using percentages.
For example:
<code>
div {
max-width: calc(80% - 100px)
}
</code>
<kbd><small><a href="https://flaviocopes.nyc3.digitaloceanspaces.com/css-handbook/css-handbook.pdf">Flavio Copes,The CSS Handbook</a></small></kbd> | calvinoea |
301,611 | TUNS Dark Mode ON! | here is the new DARK look of TUNS ( https://www.tunsapp.com ). Enjoy!! | 0 | 2020-04-07T09:47:23 | https://dev.to/daviducolo/tuns-dark-mode-on-46nl | here is the new DARK look of TUNS ( https://www.tunsapp.com ).
<a href="https://ibb.co/qsKZxKG"><img src="https://i.ibb.co/r6YWvYP/Screenshot-2020-04-07-at-11-46-08.png" alt="Screenshot-2020-04-07-at-11-46-08" border="0"></a>
<a href="https://ibb.co/zVc4cW5"><img src="https://i.ibb.co/TMXgXDT/Screenshot-2020-04-07-at-11-41-53.png" alt="Screenshot-2020-04-07-at-11-41-53" border="0"></a>
Enjoy!! | daviducolo | |
301,632 | Working with 3D models in WebGL | Credits: model in cover by Meeee This is a lazy checklist for your workflow talking about the wonder... | 5,827 | 2020-04-07T10:55:50 | https://dev.to/adam_cyclones/what-i-ve-learned-about-gltf-390d | javascript | Credits: model in cover by Meeee
This is a lazy checklist for your workflow talking about the wonderful GLTF format. Your going to need JavaScript to view this stuff so its tagged with that.
I am exploring its capabilities and what workflow you or I will need in Blender to achieve the results we want. First off you wont achieve the results you want, anyone familiar with photo realism in blender will know about Cycles renderer, it's not going to look like that so lower your expectations a pinch, then do that again 5 or 6 times.
As soon as I found out about GLTF I downloaded a copy of blender and made my first model in 12 months or more, I built that lovely watch model in the cover image (I love watches!). I am not fully happy with this model because its missing a few things, but still thats not the point.
Exporting this to a GLTF file using Blenders built in GLTF exporter yielded some results with let's say... potential.
The first thing you will notice and perhaps this is not a shock, GLTF does not respect blenders modifiers which resulted in my first attempt having only quarter of the model visible, fortunately the exporter has an option to apply said modifiers without any distractive results to the original model.
The next problem, although GLTF does handle PBR materials, my glass was opaque, it looked good but not good for a watch. "Hey whats the time, IDK I have an opaque watch you moron!". I probably should use Glass BSDF shader?
Lastly performance, my model is not optimised, in-fact its so bad internally that If I where to target the web again (which I will), a lot and I mean a lot of cleanup would need to be done, I will look into this in a further article, but for the moment, 16FPS was what I got.
Anyways here is the checklist:
- Apply modifiers in export
- Dont expect lighting to work
- Materials will look more like material preview then render
- Consider if transperncy works
- Optimise mesh and clean it up, only keep what is visible, simplify what you can get away with
Whats next, GLTF animation of the hands :)
Thanks for reading.
| adam_cyclones |
311,875 | About Me | Yup. Thats's me :) First off, I would like to introduce myself. My name is Mariana and I am from Br... | 0 | 2020-04-17T13:21:26 | https://dev.to/cafecotech/about-me-3lp1 |
*Yup. Thats's me :)*
First off, I would like to introduce myself.
My name is Mariana and I am from Brazil 🇧🇷 . I have a bachelor's degree in Civil Engineering, currently finishing my specialization in Structures and Foundations. However, I always liked the power and magic that come from a computer yet never have given it a try. Along with this *ignored* desire, when I graduated there was not much room for me from where I live (*professionally-wise*) and so I started to explore more and more about programming. Starting with data science then right after I got in touch with web development. As expected, my passion just reflourished (*pretends to be shocked*) and now I am changing careers.
When I started to get back in touch with programming, I had the fortune to come across wonderful people from the tech industry which made a **HUGE** difference in my life. I am truly and deeply grateful for them. It led me to many good things: an internship, meet more wonderful people, getting scholarships from online courses ... It is like all started to happen (and still is ). And now I know what I want for my professional life. Like. For. Sure. I am struggling with a lot of things and concepts and I will struggle a lot more but I feel happy, rewarded and motivated with this environment.
So ... how do I came up with the idea of this blog? 🤔 Well, I have never written a blog or anything alike but I always had the will to communicate with people and to exchange knowledge. And this blog is a good approach I found to do so (and train my English and writing haha). I believe that when we share knowledge we both teach and learn in the best way possible (active learning). Besides, when we share our journey/perspectives/tips we enable people to resonate with us and help them in their own journey. I guarantee that having someone to push you forward and/or to look up to can have a great impact on our lives.
I hope I can support you somehow and please feel free to be in touch.
Oh, and don't forget to get your daily coffee dose.
Now, let's code 🤓
---
Also posted on [Hashnode](https://cafecotech.hashnode.dev/about-me-ck8mj4wg601en79s1ytiu6v9h) | cafecotech | |
311,908 | Developers: How do you tackle your bugs? | In my organization we set up a rotating Bug Stream process, to handle incoming and existing bugs.... | 0 | 2020-04-17T13:55:15 | https://dev.to/thatferit/developers-how-do-you-tackle-with-bugs-47a8 | discuss, bugs, webdev | ---
title: Developers: How do you tackle your bugs?
published: true
description:
tags: discuss, bugs, webdev
---
In my organization we set up a rotating Bug Stream process, to handle incoming and existing bugs. When blogging about it, I've asked myself
"How are others tackling bugs?"
So let's share how your team, organization is handling bugs.
- How are they collected?
- How are they prioritized?
- How are you fixing them ? | thatferit |
311,911 | Two Equations to Improve Your Analysis of Algorithms | In this tutorial, you will learn how to calculate permutations and combinations of a series of n integers with simple and easy to remember equations. | 0 | 2020-04-17T15:03:27 | https://jarednielsen.com/calculate-permutations-combinations/ | mathematics, career, beginners, algorithms | ---
title: Two Equations to Improve Your Analysis of Algorithms
published: true
description: In this tutorial, you will learn how to calculate permutations and combinations of a series of n integers with simple and easy to remember equations.
tags: mathematics, career, beginners, algorithms
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/eu7mo1a2mjadrpywqm4h.png
canonical_url: https://jarednielsen.com/calculate-permutations-combinations/
---
You don’t need to be a math whiz to be a good programmer, but there are a handful of tricks you will want to add to your problem solving bag to improve the performance of your algorithms and make an impression in technical interviews. In this tutorial, you will learn how to calculate permutations and combinations of a series of n integers with simple and easy to remember equations.
_This article originally published at [jarednielsen.com](https://jarednielsen.com/calculate-permutations-combinations/)_
## What is the Difference Between Permutations and Combinations?
* Permutations, sequence is important
We are interested in the order of placement of items.
* Combinations, sequence is not important
We are interested in the number of groups we can create.
Let’s look at an example.
How many three letter permutations are there for the letters A, B & C?
```
ABC
ACB
BCA
BAC
CAB
CBA
```
There are six permutations.
What about combinations?
Well, there’s only one.
Why?
No matter the order, our group always contains the same three letters, A, B & C.
When we calculated the permutations for three letters, did you notice a pattern?
Let’s try four letters:
```
ABCD
ABDC
ACBD
ACDB
ADBC
ADCB
BACD
BADC
BCAD
BCDA
BDAC
BDCA
CABD
CADB
CBAD
CBDA
CDAB
CDBA
DABC
DACB
DBAC
DBCA
DCAB
DCBA
```
We just made a big jump in the number of permutations we need to calculate!
Where have we seen this, or something like it, before?
🤔
Factorial!
In the first example using three letters, our permutations were _3!_, or:
```
3 * 2 * 1 = 6
```
In the second example using four letters, our permutations were _4!_, or:
```
4 * 3 * 2 * 1 = 24
```
What about calculating subsets of permutations?
## How to Calculate Permutations
Say you’re the judge of a baking competition and you need to award gold, silver and bronze cake stands to the top three of 12 contestants, but all of the bakers are deserving of an award.
How many options do you need to calculate?
This is a permutations problem.
Why?
The order is important.
We are ranking, or ordering, the three best bakers.
We award the gold to Noel.
Now there are only eleven contestants to choose from.
We award the silver to Sandy.
Now there are only ten contestants to choose from.
We award the bronze to Prue.
Those three are the obvious winners.
(Sorry, Paul.)
But if it weren’t so obvious, how many possible permutations would we need to calculate?
Each time we select a winner, that individual is removed from the group and we calculate the possible permutations of the remaining individuals.
What’s 12!?
```
12 * 11 * 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1 = 479001600
```
That’s a lot of processing!
Luckily, we don’t need to calculate that many permutations.
We only need to calculate the permutations for three winners.
How do we do this?
We simply stop after the three largest values in our sequence:
```
12 * 11 * 10 = 1320
```
Why?
There’s no need to calculate _all_ of the permutations, only those for the three largest values.
This is still a lot of permutations, but a much more manageable number.
What if we didn’t know the size of our input at the outset?
Let’s convert this to an equation!
What’s another way of describing the numbers we did not factor?
```
9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1
```
9!
Because factorial is the _product_ of a sequence, we can’t simply subtract 9! from 12!.
We need to divide it:
```
12! / 9!
```
We could also write this as:
```
12! / (12 - 3)!
```
Now it’s simply a matter of substituting values with variables.
```
n! / (n - k)!
```
## How to Calculate Combinations
Let’s say we’re ordering pizzas to feed the participants of a hackathon.
Because these are programmers, they want to know how many possible combinations are available to choose from.
The local pizza shop gives us 12 options for toppings, but we can only choose three per pizza.
How many different pizzas are possible?
This is a combinations problem.
Why?
Because order doesn’t matter.
A pizza with pepperoni, peppers, and pineapple is the same as a pizza with pineapple, peppers, and pepperoni.
But because order doesn’t matter, redundancy does.
When we calculate permutations, there are no redundancies in the _order_ of the elements, but there are a lot of redundancies in the _grouping_ of elements.
How do we remove the redundant combinations?
We simply divide by the number of permutations of _k_, or _k!_
```
( n! / (n - k)! ) / k!
```
Which is also:
```
( n! / (n! - k!) ) * 1 / k!
```
When simplified is:
```
n! / (n - k)! * k!
```
This is often written as:
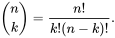
And read as “_n_ choose _k_”, because there are _n_ ways to choose an unordered subset of _k_ elements from a fixed set of _n_ elements.
AKA the [binomial coefficient](https://en.wikipedia.org/wiki/Binomial_coefficient)
## How to Calculate Permutations and Combinations
You don’t need to be a math whiz to be a good programmer, but there are a handful of equations you will want to add to your problem solving toolbox. In this tutorial, you learned how to calculate permutations and combinations of a series of n integers with simple and easy to remember equations. They’re like party tricks for technical interviews.
---
Want to stay in the loop? I write a weekly newsletter about programming, problem solving and lifelong learning. [Sign up for _The Solution_](http://eepurl.com/cP8CMn)
---
| nielsenjared |
311,968 | Improve Laravel code readability using PHPDoc | Improve Laravel code readability using PHPDoc | 0 | 2020-04-17T21:36:04 | https://dev.to/meathanjay/improve-laravel-code-readability-using-phpdoc-2670 | php, laravel, phpdoc, typehint | ---
title: Improve Laravel code readability using PHPDoc
published: true
description: Improve Laravel code readability using PHPDoc
tags: PHP, laravel, phpdoc, type-hint
---
If you're writing PHP lately, very likely to know the Laravel framework, very easy to get started, and more likely, you can develop the same MVP app at the lowest time in compared to other frameworks. It has rich built-in and ready-to-use packages and easy configuration and huge community support, and all while you don't have to compromise the performance.
If you're writing Laravel applications, you know how extensively Laravel uses PHP's magic methods, especially in Eloquent.
You never explicitly mention a Model's properties except making some fields guarded and mass-assignable. When you try to access that property, the `__get` method looks for database columns with the same name or return null; you access any defined relation as property in the same way.

Even `$user->is_avaiable` is a boolean property, IDE shows mixed because you never declared that and your IDE can't help with auto-completion or if you mistyped a character.
And, how you know a property is available in that model class? Well, in your head, because you created the migration, database schema; What about the new developers or your future-self?
Your model is not so readable, and no one can guess `$user->is_available` or `$users->projects` exists or type until looking into columns and parent classes.
So, why not make your code self-explanatory and let your IDE help you avoid making a mistake and help your future self?
PHPDoc can help you add a piece of information in a code block like file, class, properties, methods, and variables.
PHPDoc is the same as multiline comments but starts with a forward-slash and two asterisks(`/**`) and ends with an asterisk and forward-slash(`*/`), in-between you add those missing information in PHPDoc DSL language.
```php
<?php
namespace App\Domain\User;
use Illuminate\Database\Eloquent\Relations\HasMany;
use Illuminate\Foundation\Auth\User as Authenticatable;
/**
* User Model
*
* @property bool $is_available
* @property-read Project[] $projects
* @method static User create(array $attributes = [])
* @method static \Illuminate\Database\Eloquent\Builder where($column, $operator = null, $value = null, $boolean = 'and')
*/
class User extends Authenticatable
{
protected $guarded = [
'id', 'email_verified_at', 'remember_token',
];
protected $hidden = [
'password', 'remember_token',
];
public function projects(): HasMany
{
return $this->hasMany(Project::class);
}
}
```
Now, those missing properties and methods are self-explanatory, and you know precisely what their type and return value.
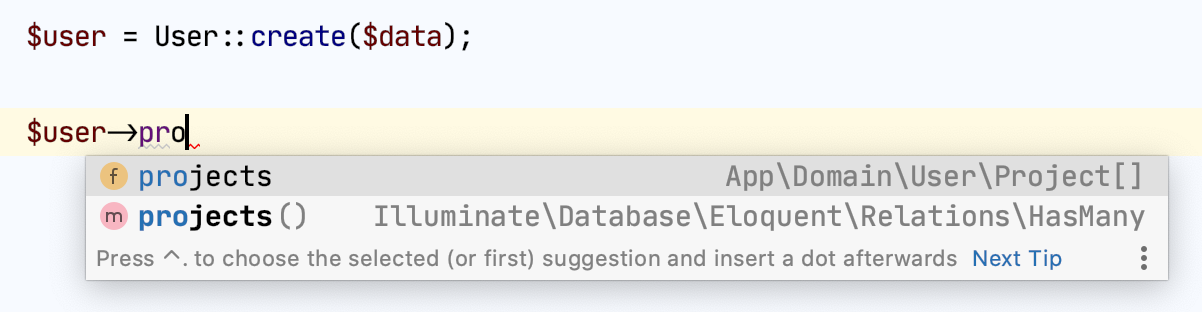
Declaring return type for `create` method in the User model, let you avoid re-declaring return type every-time you call `create` and it makes your code clean and maintainable.
```php
$user = User::create($data);
// instead
/** @var User $user */
$user = User::create($data);
```
| meathanjay |
312,000 | Render Hook Pattern in React | Working on a React code base I found my self in a need to display many confirmation modals. I got fru... | 0 | 2020-04-17T16:12:02 | https://dev.to/tomslutsky/returning-components-from-custom-hooks-5281 | react, javascript, reactnative |
Working on a React code base I found my self in a need to display many confirmation modals.
I got frustrated after the third one and found a nifty pattern to use: **returning the modal component itself from a hook.**
I assume that a this point in time there is no longer a need to introduce the concept of hooks in React. However if you need a refresher you might want to check https://reactjs.org/docs/hooks-intro.html
So my basic Idea was to use an API that will look roughly like that:
```javascript
const ComponentWithDangerAction = () => {
const [Modal, onClick] = useConfirm({
onConfirm: ({ id }) => alert("deleted item id: " + id),
onDismiss: alert,
title: "Danger Zone",
message: "This action is irreversible. Are you sure you want to continue?"
});
return (
<div className="App">
<Modal />
<Button onClick={() => onClick({ id: 5 })}>
Press here to delete something important
</Button>
</div>
);
};
```
Next step is to create the useConfirm hook itself and it easiest of course to start with a minimal non crashing api (assuming we have a Modal component).
```javascript
const useConfirm = () => {
const onClick = () => null;
const ConfirmModal = () => <Modal />
return [ConfirmModal, onClick];
}
```
Now adding disclosure related state and callbacks functionality
```javascript
const useConfirm = ({onConfirm, onDismiss, message }) => {
const [isOpen, setOpen] = useState(false);
const toggle = setOpen(!isOpen);
const onClick = () => toggle();
const handleConfirm = () => {
onConfirm && onConfirm();
toggle();
}
const handleDismiss = () => {
onDismiss && onDismiss();
toggle();
}
const ConfirmModal = () => (
<Modal isOpen={isOpen} onClose={toggle}>
<span>{message}</span>
<button onClick={handleConfirm}>Confirm</button>
<button onClick={handleDismiss}></Dismiss>
</Modal>)
return [ConfirmModal, onClick];
}
```
Almost Done! The only problem is I want to be able to pass arguments to the confirm function (I want to delete a specific item from a list).
My solution was to store arguments passed to onClick to the state of the hook. That way when Confirm button is pressed I can call the onConfirm callback with the arguments passed to it.
```javascript
const useConfirm = ({onConfirm, onDismiss, message }) => {
const [isOpen, setOpen] = useState(false);
const [confirmArgs, setConfirmArgs] = useState(false);
const toggle = setOpen(!isOpen);
const onClick = (args) => {
setConfirmArgs(args); // storing the args
};
const handleConfirm = () => {
onConfirm && onConfirm(confirmArgs); // using the args
toggle();
}
const handleDismiss = () => {
onDismiss && onDismiss();
toggle();
}
const ConfirmModal = () => (
<Modal isOpen={isOpen} onClose={toggle}>
<span>{message}</span>
<button onClick={handleConfirm}>Confirm</button>
<button onClick={handleDismiss}></Dismiss>
</Modal>)
return [ConfirmModal, onClick];
}
```
Hope you will find this pattern useful :)
you can find a more complete example on [codesandbox](https://codesandbox.io/s/useconfirm-n3v5y)
And of course follow me on twitter [@SlutskyTom](https://twitter.com/slutskytom) | tomslutsky |
312,135 | Day 119 : The Whole World | liner notes: Professional : Had our product team meeting. It was good to hear what everyone has bee... | 0 | 2020-04-17T22:08:49 | https://dev.to/dwane/day-119-the-whole-world-4bii | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had our product team meeting. It was good to hear what everyone has been up to for the week. Mostly did more research for my blog post. Had our "Happy Hour" where a few of us get to catch up. That was fun.
- Personal : Last night, I went through a few tracks for the radio show and worked on adding fill in data and styling it for the Web Component I've been working on.
Got my laundry washing. Going to finish up the work for the radio show and also get the Web Component up and running. This weekend, I want to get an old project working so I can use it as a base for our hackathon next week.
Side note: Does it sometimes seem like the whole world is crazy?! haha
Have a great night and weekend!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube udmTfK6_aM8 %} | dwane |
312,149 | Multilingual Magic Part 2 | The previous post went over the frontend basics of a Bootstrap tab structure to display some text in... | 0 | 2020-04-17T22:55:39 | https://dev.to/aellon/multilingual-magic-part-2-of-2-3303 | wordpress, bootstrap, acf | ---
series: [Bootstrap Tabs for Translations in Wordpress]
---
The previous post went over the frontend basics of a Bootstrap tab structure to display some text in three tabs, one for each translation. Now we will take a look at the Wordpress side of adding those fields for the client to enter the text.
Using the [Advanced Custom Fields plugin](https://www.advancedcustomfields.com), I added a field group for Languages, with a field for Russian and one for Spanish. The default tab will be English so we don't need to add a field for that one since it can be the regular content. This is what the ACF field group looks like:

I selected a Wysiwyg Editor as the field type since this will give the client control over the text, but you could just as easily choose any other field type. This is what it will look like for the client:

In the previous post I included the following HTML to get the tabs working.
```HTML
<div class="tab-content" id="alertTabContent">
<div class="tab-pane fade show active" id="english" role="tabpanel" aria-labelledby="english-tab">
<a href="<?php echo esc_url( get_permalink($id) ); ?>">
<h5 class="text-red alert-content"><?php the_content(); ?></h5>
</a>
</div>
<div class="tab-pane fade" id="russian" role="tabpanel" aria-labelledby="russian-tab">
<a href="<?php echo esc_url( get_permalink($id) ); ?>">
<h5 class="text-red alert-content"><?php the_field('russian'); ?></h5>
</a>
</div>
<div class="tab-pane fade" id="spanish" role="tabpanel" aria-labelledby="spanish-tab">
<a href="<?php echo esc_url( get_permalink($id) ); ?>">
<h5 class="text-red alert-content"><?php the_field('spanish'); ?></h5>
</a>
</div>
</div>
```
Two key pieces of code here are the lines pulling in the content from those custom fields: `<?php the_field('russian'); ?>` and `<?php the_field('spanish'); ?>`.
`the_field()` is a built in [ACF function](https://www.advancedcustomfields.com/resources/the_field/). The selectors are the field names. ACF made it so simple yet so powerful too!
With that, you have a fully customizable set up for displaying text in three discreet tabs using Bootstrap and pulling in the content from Wordpress. After the site is live I will add the frontend design here so be sure to check back!
| aellon |
312,177 | HTB CTF - Decode Me!! | CTF Name: Decode Me!! Resource: Hack The Box CTF Difficulty: [30 pts] easy range Note::: NO, I won... | 10,223 | 2020-04-17T23:32:06 | https://dev.to/caffiendkitten/htb-ctf-decode-me-3n8a | codenewbie, security, htb, ctf | - CTF Name: Decode Me!!
- Resource: Hack The Box CTF
- Difficulty: [30 pts] easy range
Note::: NO, I won't be posting my found FLAGS, but I will be posting the methods I used.
<hr>
### Flag1
- Hint: Try find the flag!
- Acquired By:
- First thing to do is obviously download the file and extract the file. While a lot of people will use the command line for this I usually just to my file folders. It's easy so why not.
- Next is to just look at it.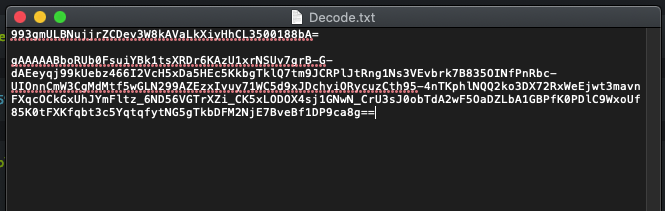 At first it appears to be something that is Base64 encoded as the lines end with the usual "=" but this is not the case... yet. So first thing I did, like many others, is try to decode it like this, but it fails.
- After a bunch of Googling and browsing the HTB fourms someone mentions a key and code so if we look into that we find the Fernet (symmetric encryption). This is a "symmetric encryption method which makes sure that the message encrypted cannot be manipulated/read without the key. It uses URL safe encoding for the keys. Fernet uses 128-bit AES in CBC mode and PKCS7 padding, with HMAC using SHA256 for authentication. The IV is created from os.random()." (1)
- This produced something that was less than finished but it looks like there is another string of Base64 so lets decode that now.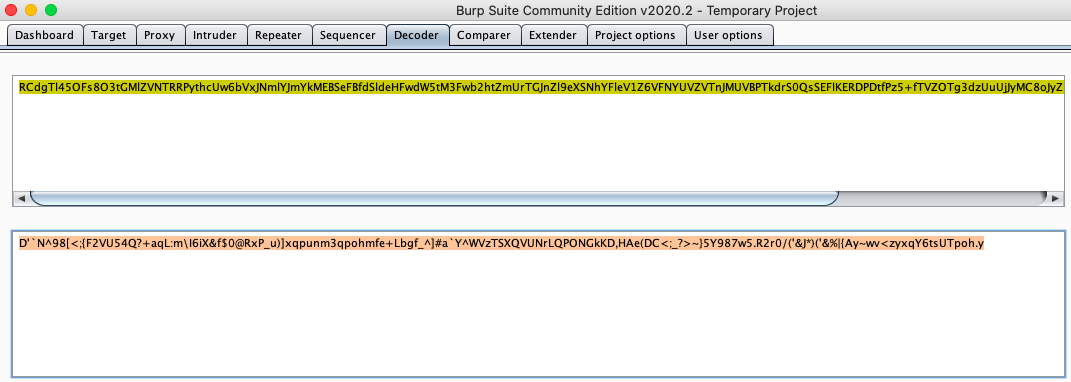This is still not really helpful though...
- Now it's time for MORE Googling and HTB forums and I got a hint about "Malbolge Tools". Malbolge is "Malbolge is a public domain esoteric programming language... that was specifically designed to be almost impossible to use, via a counter-intuitive 'crazy operation', base-three arithmetic, and self-altering code." (2)
- Once I found the Malbolge Decoding tool I was able to throw in the new output and get the flag.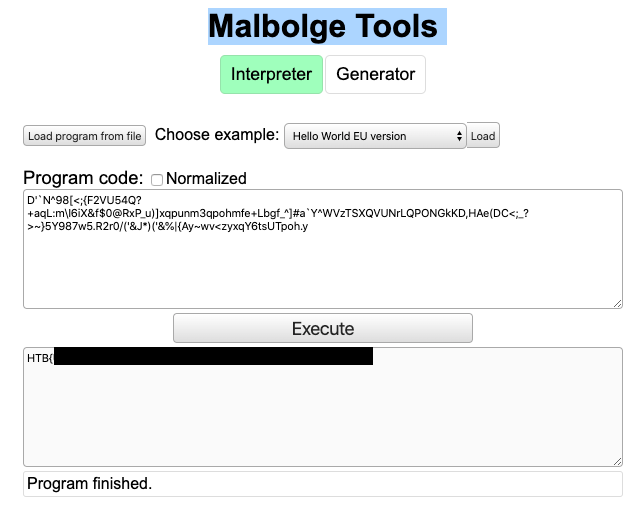
### Learned
This flag taught me the power of forums and getting help.
This flag was a crazy 3 step process that I would not have been able to get on my own. The input for the Malbolge Tool was something I have never seen before and don't think that I will see again outside of CTFs but I am glad I've seen it.
<hr>
Happy Hacking

### Resources:
1. https://asecuritysite.com/encryption/ferdecode
2. https://en.wikipedia.org/wiki/Malbolge
3. https://zb3.me/malbolge-tools/
4. https://asecuritysite.com/encryption/ferdecode
###### Please Note: that I am still learning and if something that I have stated is incorrect please let me know. I would love to learn more about what I may not understand fully.
| caffiendkitten |
312,198 | Command Object Pattern | How would I explain Command Object Pattern to Myself. What is it? The Command Object Patt... | 5,745 | 2020-04-18T01:00:04 | https://blog.kleeut.com/2020/04/command-object-pattern.html | oop, patterns | How would I explain Command Object Pattern to Myself.
# What is it?
The Command Object Pattern to encapsulate what would have otherwise been a function call inside an object that is abstracted away behind an interface.
The Command Object Pattern is a pattern of four classes:
## The Command
Implements the Command Interface and takes a dependency on the receiver. The command encapsulates everything needed to call the receiver.
## The Receiver
The class being on by invoking the command.
## The Invoker
Depends on an abstract Command interface. Does not know anything about the concrete implementation of the Command.
## The Client
High level class responsible for connecting the invoker with commands.
# Why is it good?
The Command Object Pattern facilitates using the Open Closed Principle on the Invoker. Making the Invoker open for extension and closed for modification by providing behaviour at run time. This allows for independent testing of components and component reuse.
# Where would you use it ?
The Command Object Pattern's use case is any where that you have an object that needs to share some behaviour across multiple instances (possibly in multiple applications) while allowing other behaviours to be specific to an instance.
An example is implementing a Button class. The button knows about display and interaction logic. The behaviour that is invoked when the button is pressed is not an implementation detail of the Button class but is provided at run time.
# N.B.
This is a pattern that I thought I understood. I actually had it confused with the Command Bus / Command Handler Pattern. | kleeut |
312,602 | Five industries that can make the most out of Location Intelligence | We’re all familiar with the drill of booking a cab, isn’t it? We set a destination, choose a cab tha... | 0 | 2020-04-30T13:58:20 | https://dev.to/nandhini_95/five-industries-that-can-make-the-most-out-of-location-intelligence-of0 | datascience, database | We’re all familiar with the drill of booking a cab, isn’t it?
We set a destination, choose a cab that suits our comfort and affordability, book, and hop on to get started on the ride.
For this mechanism to function efficiently, a lot of data crunching and algorithm feed runs in the background - based on location intelligence.
The utility of location intelligence is not exclusive just to the ride-hailing services, the depth and breadth of the concept can be applied to several other industries and use cases too.

The concept of location intelligence has given a new dimension to every business. It is difficult to find a company that is not using location intelligence to serve its customers better. Right from a simple [location-based re-targeting] (https://www.x-tract.io/blog/location-based-targeting-a-marketers-handbook/) ad to resolving complex problems, applications of location intelligence has become apparent in every sector.
Today, we’ll be exploring different industries that utilize location intelligence to serve customers better, simplify the operations, and achieve efficiency.
Let’s get started.
##**How location intelligence is reshaping these different industries**
####**1. The role of location intelligence in the insurance industry**
Location intelligence can help insurance companies in multiple ways.
Let’s see a few ways in which underwriters and policyholders are benefitted.
***Determine insurance coverage based on geographic zones.*** Some areas are prone to more natural calamities than others. Based on forecasts and weather analytics, insurance companies can determine the impact of a plausible calamity within a defined locality. This enables the insurer to help the policyholder minimize damage and save on indemnification. Location intelligence helps insurers determine the loss and mitigate risks.
***Identify the right audience with location analytics.*** Every insurance company dreams of contacting the potential prospect to sign off a policy. To be able to pinpoint the right prospect, the company needs to understand the propensity to buy various insurance policies, an individual’s net worth, neighborhood information, demographic details, spending patterns, and more. Location intelligence helps in aggregating this information from public records and other sources and analyze this information to provide intelligence on potential prospects.
***Take safety measures while visiting the field.*** Claim adjusters can be well-informed with location analytics as the data can provide them safety analysis while visiting the field. The embed of interactive disaster maps and customer location maps can help in assessing the safety of paths and roads while visiting.
####**2. How location intelligence is transforming retail**
Retail GIS is catching up real quick. Combining location intelligence with customer data and operational data helps in deriving tremendous insights. Location analytics in retail helps to elevate the customer experience.
***Omnichannel selling*** is catching up real quick. Omnichannel selling essentially means a seamless shopping experience across various touchpoints.
[Hubspot](https://blog.hubspot.com/service/omni-channel-experience) defines omnichannel as – An omnichannel experience is a multi-channel approach to marketing, selling, and serving customers in a way that creates an integrated and cohesive customer experience no matter how or where a customer reaches out.
For instance, a customer begins their shopping journey on their laptop and completes it on their tablet or smartphone - this is an instance of omnichannel. Also, when they decide to make an order on their gadget and pick up the order in a brick and mortar store, that’s omnichannel selling too. Delivering consistent shopping experience across various touchpoints requires location data about the supply chain, real-time location data of the customer, and more to deliver a successful omnichannel experience.
In order to plan a ***successful marketing outreach***, a retailer and their marketing teams require location intelligence.
Technologies like beacons and artificial intelligence along with location intelligence helps marketers in personalizing the customer experience. Knowing where the customer lives, the proximity to their workplace, where they shop, and more (all with customer’s consent to use location data) will help in placing contextual ads that prompt offers, discounts, and tailored suggestions. This is common in stores at the malls that leverage geofencing or polygon data to attract customers that incline towards checking out a competitor’s store.
####**3. Fitness and Healthcare - Scaling up to serve better**
As for the fitness industry, the application of location intelligence to their business strategies can be manifold.
Fitness centers can leverage location intelligence for ***site planning analysis*** that can help them identify the most lucrative locations based on the [POI data] (https://www.x-tract.io/solutions/points-interest-data) and polygon information that charts out details on competitors in and around the locality, the demography that covers age, gender, propensity to earn, and more. Depending on this information, setting up centers would become more strategic and profitable.
In addition to this, fitness centers can also leverage location intelligence to ***personalize their marketing messages*** depending on the target persona and the footfall traffic. The closer they are to the fitness center, the message can be sent to them in order to gauge interest.
On a complex level, the fitness industry is also increasingly adopting location intelligence for their ***app development*** to offer features as distance covered and sync location data with other information like the age and gender of the user to prompt contextual communication.
***GIS in Healthcare***. Healthcare centers can also leverage location intelligence for site planning, supply chain management of pharmaceuticals to monitor distribution management. Also, strategic planning of events, welfare programs, and outreach initiatives can be made possible through location data analytics that gives insights into the geography, the associated healthcare facilities, what diseases they are prone to, and more.
####**4. How location intelligence powers transportation and logistics**
Location intelligence and GIS in transportation helps in inventory management by rerouting drivers to less congested areas and to favorable weather conditions. Location data combined with the technical know-how of fleet managers and virtual assistants help in reducing the time to delivery to the end-customer as well as the loading and unloading time taken at the warehouses.
***Location intelligence helps to uncover traffic patterns and perform accident analysis.*** The ***GIS system*** provides spatial statistics, and when this is combined with other factors helps to perform ***accident analysis***. A pinpoint of the locations at which there are frequent accidents and analyzing the GIS systems hold potential insights to bring out safety measures.
***Location intelligence*** also helps in the ***optimal consumption of fuel*** and minimizing fleet operating costs. By leveraging real-time monitoring and predictive analytics of fuel consumption on certain routes and during idle time helps in calculating accurate fuel consumption.
####**5. Enabling better customer experience for the hospitality industry**
Geolocation has made customer experience far beyond just coupons and offers. Combining ***predictive analytics with location data*** can help serve customers better. Getting the dinner ready-to-serve as the guests walk into the lobby, assigning room maintenance staff as soon as the guest leaves the room becomes a reality with location intelligence.
When geolocation is combined with predictive analytics, for instance, let’s say the customer data is available pertaining to their travel patterns, food choices, travel partners, food preferences, etc. for the past few years that is collated from various sources like social media, feedback forms, reviews and ratings, and more can be combined with the location of the customer in real-time and nearby services to prompt relevant communication and recommendations.
Combining geolocation and predictive analytics can help in improving customer experience. For instance, predictive analytics of the customer data pertaining to food preferences, travel partners, travel patterns, etc. can be leveraged to contextualize communication. This data can be collated from sources like social media, feedback forms, reviews and ratings, and more. The predictive analytics and location data, combined, can help in making relevant recommendations to the guests.
Monitoring ***footfall traffic*** of the guests within the hotel premises can also help hoteliers gauge an understanding of their likes and preferences - how often they visit the coffee shops, restaurants, spa, and other places. Based on further analysis, services can be tailored to the customers during their stay or when they visit next time.
###**So, location intelligence is for every business?**
To be able to improve customer experience, make well-calculated strategic business decisions, and simplify operations location intelligence can be leveraged.
With the growing advancements in location intelligence like embedded connectivity, location maps, monitoring weather fluctuations, and a lot more, companies can deliver hyper-personalized experiences.
There are several location intelligence solutions in the market like [X-tract.io](https://www.x-tract.io/solutions/location-intelligence) that cater to the needs of different industries. If you need help in kick-starting your journey with location intelligence, you may want to explore such solutions that cover:
- GPS and footfall tracking
- Wide range of POI data
- Demographic data
- Real-estate data
- Polygon data
- LI-based analytics and insights
- Data visualization and hypotheses
We hope you enjoyed this post and if there is any industry that you wish to add to the list, drop a comment and share it with the community!
| nandhini_95 |
312,726 | Host your own blog with Jekyll on Firebase and Travis CI | I always wanted to have my own domain and so with a cool email address. And so, I came across Ionos w... | 0 | 2020-04-18T11:18:55 | https://dev.to/khvmaths/host-your-own-blog-with-jekyll-on-firebase-and-travis-ci-1mko | firebase, travis, jekyll, tutorial | I always wanted to have my own domain and so with a cool email address. And so, I came across [Ionos](https://www.ionos.com/office-solutions/create-an-email-address?ac=OM.US.USf11K357090T7073a&kwk=668406507) with its relatively cheap domain name and email hosting. With $1/month, it came with 2GB email storage and a customised .net domain, and 1000 subdomain. What a deal! And, so I this post will walk you through all the process.
|Table of Content|
|----------------|
|1. [Firebase Hosting](#chapter-1)|
|2. [Create new Jekyll site](#chapter-2)|
|3. [Deploy site to Firebase](#chapter-3)|
|4. [Add to your Github](#chapter-4)|
|5. [Travis CI to trigger new build](#chapter-5)|
<a name="chapter-1"></a>
##1. Hosting on Firebase
I have mine through Ionos. You can choose any domain provider as well. Now, with your domain ready, it's time to choose a hosting provider. In this case, I choose Firebase Hosting, because "IT'S GOOGLE". Seriously, it's because of it's relatively cheap rate and some generous free tier. Also, Google CDN is fast and Firebase is just simply Awesome! The pricing is available [here](https://firebase.google.com/pricing).
####Create a new project in Firebase
Step 1, choose your project name.
Step 2, this is optional. To make things easier, we will just turn off the option.
Step 3, wait the project to be created.
####Link your domain with Firebase Hosting
Now, once your project is created, head over to your project and click on the **Hosting** tab.
Click on get started, and then click **Next** on step 1 and step 2, then click on **Continue to console** as shown.
In order to let Firebase know that we have our own domain, click on **Add custom domain**, and the following will popup.
Now, in the domain column, type in your domain and then click on **Continue**. The next step will require you to verify the ownership of the domain. You will see the following TXT record.
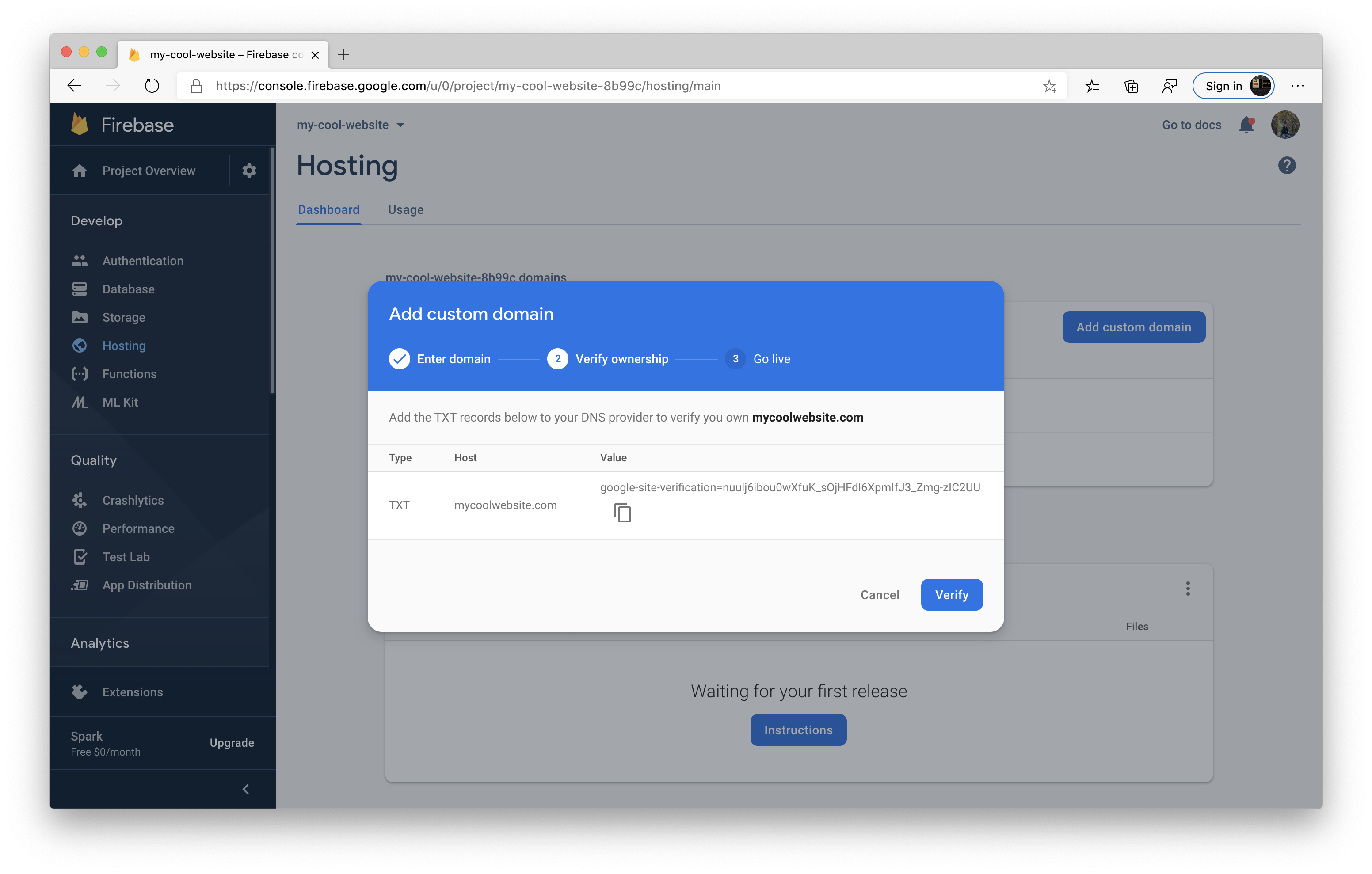
Copy the TXT record and then add them to your domain dashboard.

Once the verification is done, you will need to add A records to your domain.
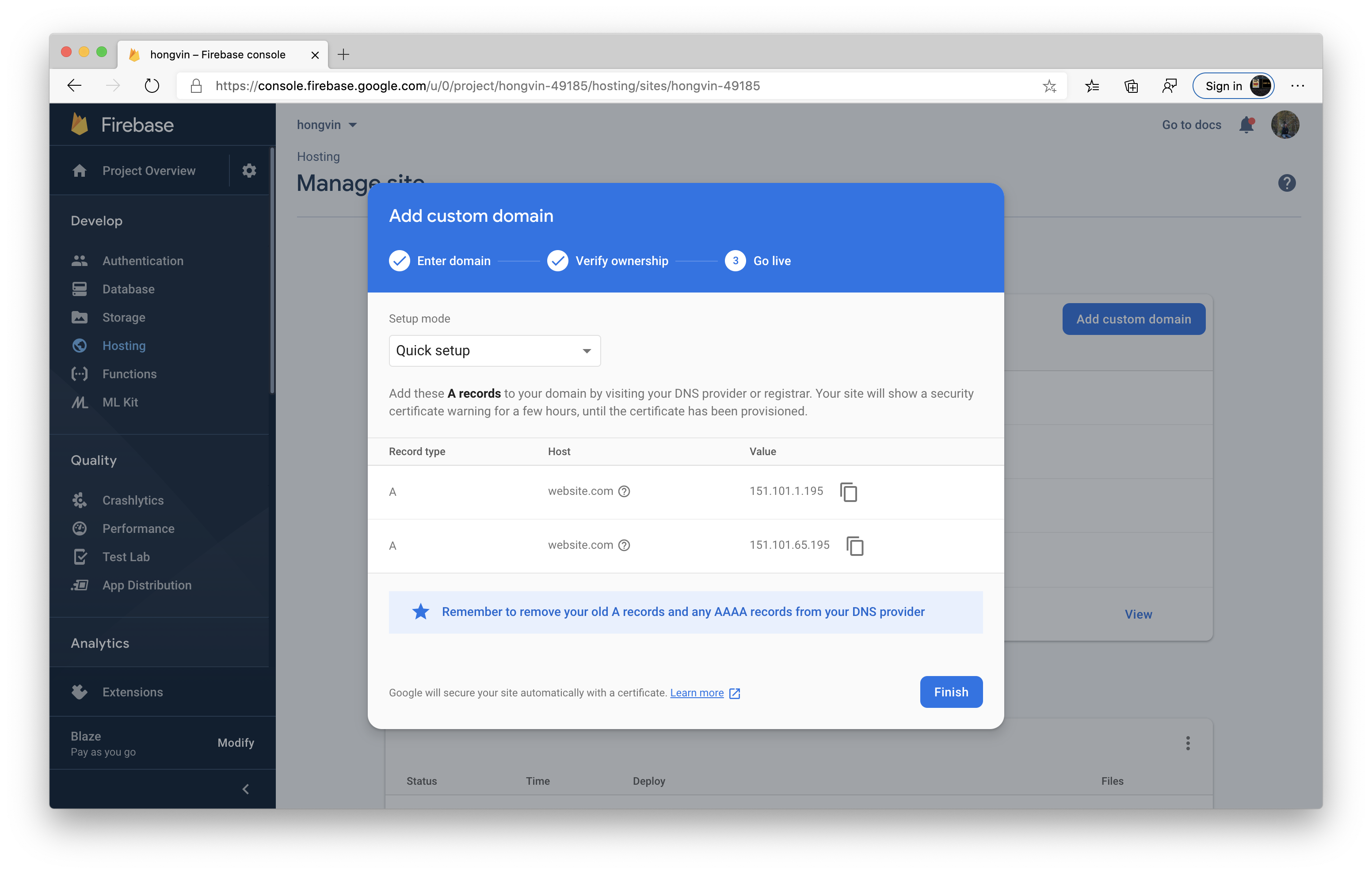
Copy the A records and paste in your domain, the same step as per adding TXT record.
Now, your domain is linked to the Firebase hosting. yay!:heart_eyes:
<a name="chapter-2"></a>
##2. Setting up Jekyll
Prerequisite:
* [Git](https://git-scm.com/download/)
* [Ruby](https://www.ruby-lang.org/en/downloads/)
* [Node JS](https://nodejs.org/en/download/)
* [VS Code](https://code.visualstudio.com/download) or any code editor
Once all the above is installed, run the following code in your newly created folder.
```bat
1 gem install bundler jekyll
2 jekyll new my-awesome-site
3 cd my-awesome-site
4 bundle exec jekyll serve
```
* Line 1 & 2 will install Jekyll and build a simple Jekyll site.
* Line 3 & 4 will execute the newly created site and serve it at `http://localhost:4000`
You will see under your folder as shown below.
When you execute line 4, your terminal/command prompt will display as follows.
> :bulb: If you encounter this `Your user account isn't allowed to install to the system RubyGems.`, simply just follow the instruction given. Exit the installation and then just run `bundle install --path vendor/bundle` inside the directory.
When you head over to `http://localhost:4000`, you will see the following.
> :warning: Notice that there is a new folder "_site" after you run `jekyll serve`. When running Jekyll serve, it will use `jekyll build` and then the static site will being generated.
> :bulb: To create a new post, simply add them into `_post` folder. Remember, it's a markdown file, so here's the [cheatsheet](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet)!
:beers: And you have just set-up a site!
#####This site is so simple, I want something special!
Yes, you can just download theme [here](https://jekyllthemes.io/free). That's the drawback of Jekyll, you need to know some coding skill to modify the layout.
<a name="chapter-3"></a>
##3. Deploy your site to Firebase
Now that you have a simple blog setup, you want to host on Firebase. It's just simple. Follow the steps below!
Step 1, Install Firebase CLI Tool
```bat
npm install -g firebase-tools
```
Step 2, Then, login to your firebase.
```bat
firebase login
```
> When the prompt ask `Allow Firebase to collect CLI usage and error reporting information?`, just type in `Y`.
* First you will saw a browser popup asking you to sign in your account.
* Choose your account and allow.
* Once success, you will see this.
* In your command prompt / Terminal, you will see this.
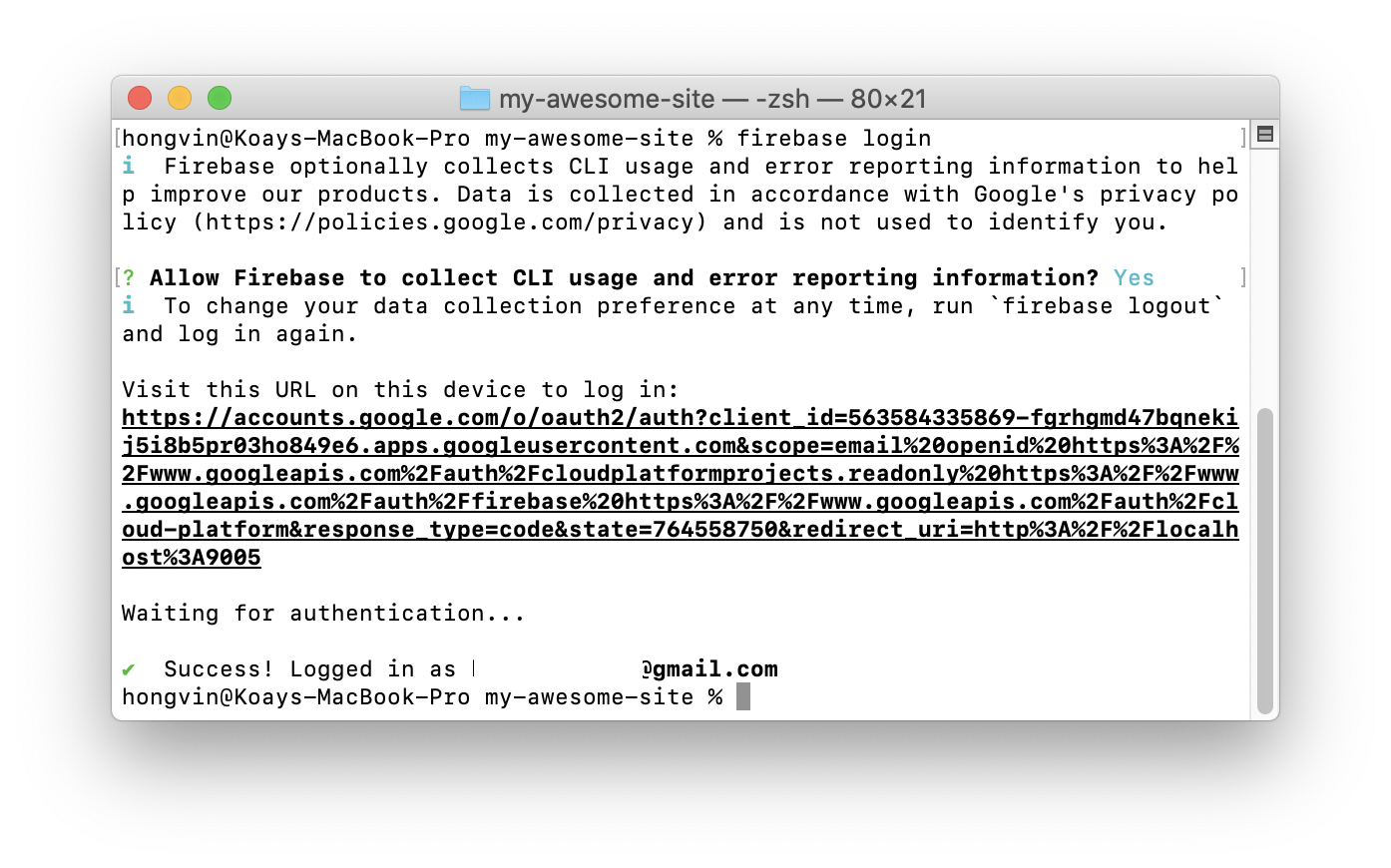
Step 3, Initialise your project to firebase.
```bat
firebase init
```
* Use down key to choose *Hosting* and space bar to select. Then, hit enter.
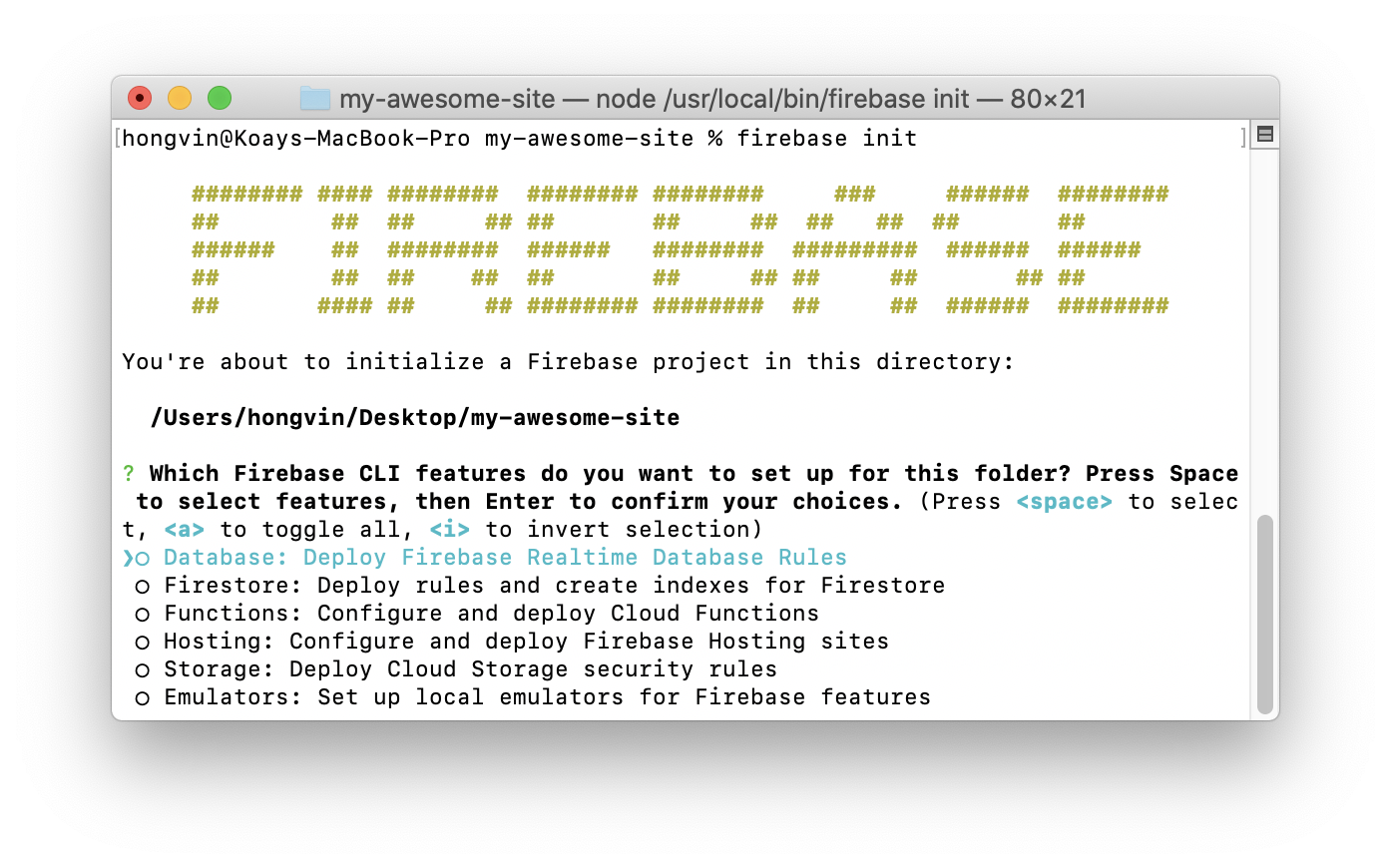
* Since we have created a new project earlier, thus, we choose **Use an existing project**.
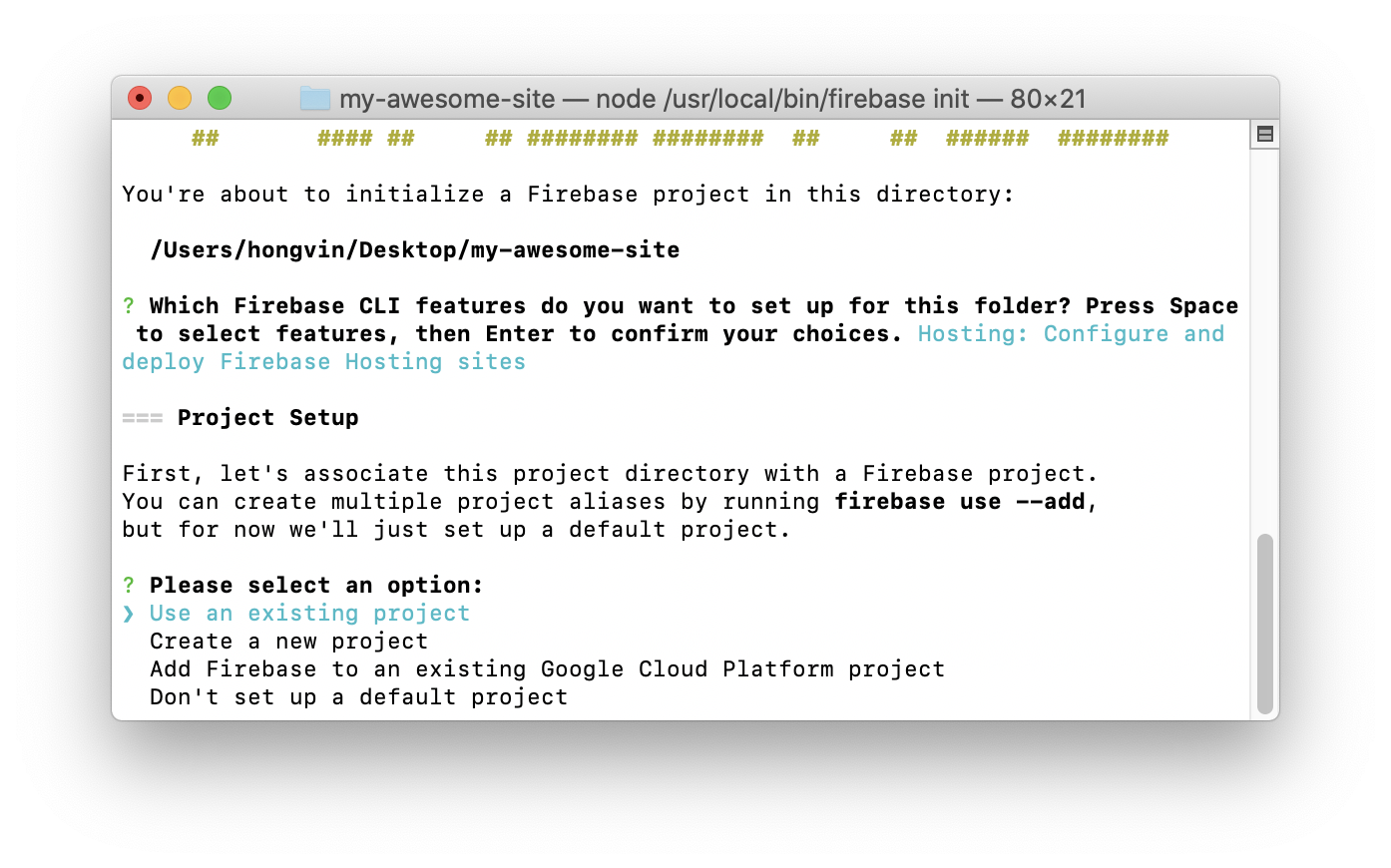
* Select the project.
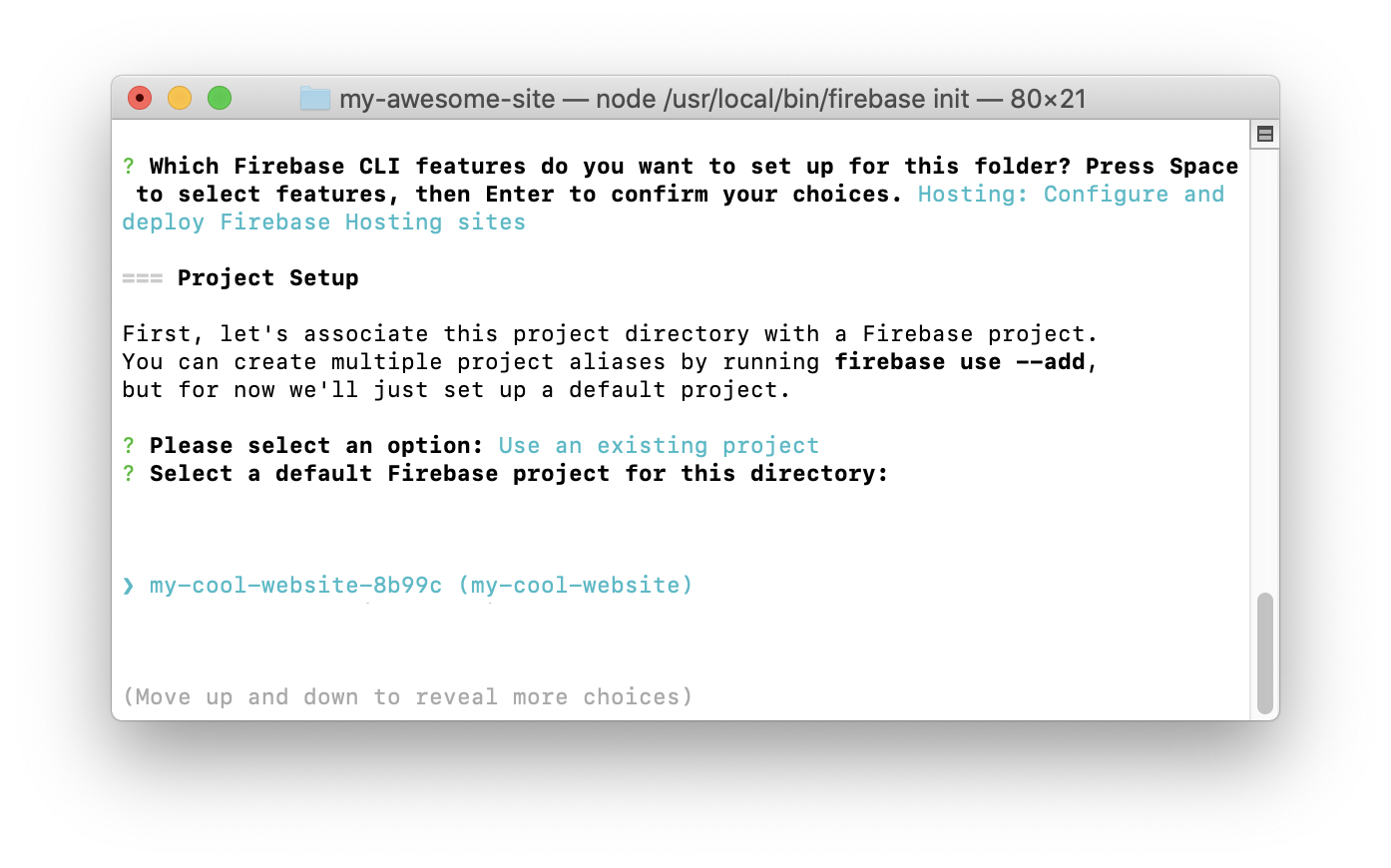
* Key in `_site` as your public directory, `Yes` to configure as single-page app and `No` to overwrite the index.html.
> :warning: These step will create two new files under root folder.
* `firebase.json` contains information about public folder and route.
* `.firebaserc` contains information about firebase project.
Step 4, (Optional) Deploy the site to Firebase.
```bat
firebase deploy
```
This will deploy to firebase hosting. When your command prompt / Terminal shows success, means your site is live!
This is cool **BUT** we don't want to do this everytime we add a new post, right? Ideally, when we write a post and it shall be show in the website without deploying manually.
<a name="chapter-4"></a>
##4. Github
Github is perfect for source control. And, there is some reason to consider,
* It won't loss, if you were to save in your hard disks, if they fail, it's all GONE!
* Rolling back to last successfully build if we messed up.
* Editing old files and republish them easily.
* FREE, so why not?
Step 1, Head over to [Github](www.github.com) and create a new repository.
> Public or private? Your choice!
Step 2, Now, Git everything in the folder!
```bat
git init
git add .
git commit -m "First commit"
git remote add origin [YOUR_GITHUB_URL]
git remote -v
git push origin master
```
_Replace `[YOUR_GITHUB_URL]` with your Github repository link._
> :bulb: Whenever you have done something (eg add a new post), just remember to `git add .` and `git push`.
<a name="chapter-5"></a>
##5. TravisCI to automatically update every new post
Last step! There's several CI tools out there, like CircleCI, TravisCI, etc. But, I gonna use TravisCI.
Step 1, Go to [TravisCI](https://travis-ci.com/). Create a new account and sync with your Github.
Step 2, Once done sync with your Github, go to your dashboard, choose the repository you created and click **Trigger Build** button.
Step 3, Configure Travis.
Travis uses YAML script, a very simple language and in order to let Travis know you have the script ready, save them as `.travis.yml` under the root folder. Use the script below. Travis is just like you doing the manual deploying, but automagically!
(a) Before configuring, you must need to have Firebase Token ready. In order to get the token, in your Terminal,
```bat
firebase login:ci
```
In your terminal, copy the token.
(b) Copy the following script and save as `.travis.yml` in root folder.
```yml
language: ruby
rvm: 2.4.1
branches:
only:
- master
notifications:
email:
on_success: always
on_failure : always
script:
- gem update --system
- gem install bundler
- bundler update --bundler
- gem install jekyll bundler
- bundle exec jekyll build
after_success:
- firebase deploy --token "[YOUR_FIREBASE_TOKEN]"
env:
global:
- NOKOGIRI_USE_SYSTEM_LIBRARIES=true # speeds up installation of html-proofer
sudo: false
```
_Replace `[YOUR_FIREBASE_TOKEN]` with your Firebase token obtained in step 3a._
> The script is simple. It basically lists down what we did earlier for manual deploying.
(c) Add the file to Github repo.
```bat
git add .
git commit -m "added travis.yml"
git push origin master
```
Step 4, Watch the build done automatically everytime there's update to your Github repo.
In your TravisCI dashboard, you will see something like
##5. What's next?
(a) Use Markdown editor to write new blog posts under `_posts ` folder. The documentation can be found [here](https://jekyllrb.com/docs/posts/).
(b) Add file and commit
(c) Repeat.

<a href="https://www.buymeacoffee.com/hongvin" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-blue.png" alt="Buy Me A Coffee" width = "140px" ></a>
| khvmaths |
312,730 | Porting Linux to Nabla Containers | This is an introduction of Linux Kernel Library ported to Nabla Containers. runnc is an OCI runtime... | 8,088 | 2020-04-18T08:20:05 | https://retrage.github.io/2020/04/18/lkl-nabla-en.html | docker, linux, unikernel, anykernel | This is an introduction of Linux Kernel Library ported to Nabla Containers.
[runnc](https://github.com/nabla-containers/runnc.git) is an OCI runtime that runs process-level isolated unikernels. It is built on the top of [Solo5](https://github.com/Solo5/solo5), a sandbox for unikernels, and several unikernels (MirageOS, IncludeOS, Rumprun) run on it. The original runnc uses Rumprun, a NetBSD based unikernel. However, as Docker is started from Linux, it is needed to have system call level compatibility with Linux. Therefore, I ported Linux Kernel Library (LKL) and musl libc to Solo5 and put together with runnc.
## frankenlibc on Solo5
frankenlibc is a set of tools to run Rump unikernels in various environments. It has a fork that ported LKL and some libraries. I used this frankenlibc fork and added Solo5 platform support.
* https://github.com/retrage/frankenlibc/tree/solo5
### Building frankenlibc
Clone the repository and checkout `solo5` branch.
```console
$ git clone https://github.com/retrage/frankenlibc.git
$ cd frankenlibc
$ git checkout solo5
```
Clone full Solo5 repository to avoid build failure and update submodules.
```console
$ git clone https://github.com/Solo5/solo5.git
$ git submodule update --init
```
Apply some patches.
```console
$ for file in `find patches/solo5/ -maxdepth 1 -type f` ; do patch -p1 < $file ; done
```
Finally, run the build script.
```console
$ ./build.sh -k linux notests solo5
```
You can find libraries and toolchain wrappers in `rump` directory after building successfully.
### Testing
Even if `notests` specified, `build.sh` builds simple tests to `rumpobj/tests`.
Create a `tap100` tap device.
```console
$ sudo ip tuntap add tap100 mode tap
$ sudo ip addr add 10.0.0.1/24 dev tap100
$ sudo ip link set dev tap100 up
```
Create `disk.img` disk image. As LKL/frankenlibc creates directories on initialization, some operations fail if read-only ISO image is used. To avoid this issue, we use the Ext4 file system image.
```console
$ dd if=/dev/zero of=disk.img bs=1024 count=20480
$ mkfs.ext4 -F disk.img
```
Note that Solo5 requires an application manifest on build time, which is embedded in a unikernel binary. In current frankenlibc Solo5 support, the manifest is common across binaries and specifies `rootfs` block device and `tap` network device. We have to provide these devices even not used in the applications.
* https://github.com/retrage/frankenlibc/blob/solo5/platform/solo5/manifest.json
Run `hello` test.
```console
$ RUMP_VERBOSE=1 ./rump/bin/rexec rumpobj/tests/hello rootfs:disk.img tap:tap100
```
In the Linux platform, `rexec` provides a sandbox environment for unikernels using seccomp like Solo5's tenders. In the Solo5 platform, it is just a shell script wrapper for `spt` tender.
## LKL Nabla Containers
Now, it's time to integrate with Nabla Containers. Since the original runnc imports older version of Solo5, I updated it and adapted the runnc code base.
* https://github.com/retrage/runnc/tree/lkl-musl
### Updating Supplied Arguments
Below is the original code that creates arguments for Solo5 tender.
```go
var args []string
if mac != "" {
args = []string{r.NablaRunBin,
"--x-exec-heap",
"--mem=" + strconv.FormatInt(r.Memory, 10),
"--net-mac=" + mac,
"--net=" + r.Tap,
"--disk=" + disk,
r.UniKernelBin,
unikernelArgs}
} else {
args = []string{r.NablaRunBin,
"--x-exec-heap",
"--mem=" + strconv.FormatInt(r.Memory, 10),
"--net=" + r.Tap,
"--disk=" + disk,
r.UniKernelBin,
unikernelArgs}
}
```
In the latest Solo5 (frankenlibc Solo5 platform uses), `--net-mac` option is removed and we can specify multiple block devices and network devices with `--block:` and `--net:` options. Ideally, it should support multiple devices. However, as described before, it can specify `rootfs` and `tap` only. So, the port ends up with the support of these devices like this.
```go
var args []string
args = []string{r.NablaRunBin,
"--mem=" + strconv.FormatInt(r.Memory, 10),
"--net:tap=" + r.Tap,
"--block:rootfs=" + disk,
r.UniKernelBin}
```
### Creating Disk Image
I added `CreateExt4()` function and `llmodules/fs/ext4_storage.go` to create Ext4 rootfs.
```go
// CreateExt4 creates ext4 raw disk image from the dir argument
func CreateExt4(dir string, target *string) (string, error) {
var fname string
if target == nil {
f, err := ioutil.TempFile("/tmp", "nabla")
if err != nil {
return "", err
}
fname = f.Name()
if err := f.Close(); err != nil {
return "", err
}
} else {
var err error
fname, err = filepath.Abs(*target)
if err != nil {
return "", errors.Wrap(err, "Unable to resolve abs target path")
}
}
absDir, err := filepath.Abs(dir)
if err != nil {
return "", errors.Wrap(err, "Unable to resolve abs dir path")
}
cmd := exec.Command("virt-make-fs", "-F", "raw", "-t", "ext4",
absDir, fname)
err = cmd.Run()
if err != nil {
return "", errors.Wrap(err, "Unable to run virt-make-fs command")
}
return fname, nil
}
```
`virt-make-fs`, a part of [libguestfs](http://libguestfs.org/) has similar interface with `genisoimage`.
It would be better to switch `NewISOFsHandler()` and `NewExt4FsHandler()` on run time.
### Building and Installing runnc
Same as original.
```console
$ git clone https://github.com/retrage/runnc.git
$ mkdir -p $GOPATH/github.com/retrage
$ ln -sf $PWD/runnc $GOPATH/github.com/retrage/runnc
$ cd runnc
$ git apply patches/0001-solo5-elf-segment-align-workaround.patch
$ make build
$ make install
```
### Testing with Docker Images
I provided a set of Makefiles build LKL Nabla Container base Docker images. It builds Solo5 and frankenlibc, and Docker images.
* https://github.com/retrage/lkl-nabla-base-build
I also pushed pre-built Docker images to Docker Hub.
* [retrage/lkl-nabla-hello-base](https://hub.docker.com/repository/docker/retrage/lkl-nabla-hello-base)
* [retrage/lkl-nabla-python3-base](https://hub.docker.com/repository/docker/retrage/lkl-nabla-python3-base)
You can use images like this.
```console
$ sudo docker run --rm --runtime=runnc retrage/lkl-nabla-python3-base:
latest -c "print(\'hello\')"
[sudo] password for akira:
nabla-run arg [/opt/runnc/bin/nabla-run --mem=512 --net:tap=tap28157ba5950e --bl
ock:rootfs=/var/run/docker/runtime-runnc/moby/28157ba5950e3e84824bd843fd1dafb06eccc7de2020a0619d6a5b463e5f2c2b/rootfs.img /var/lib/docker/overlay2/3d36c19950e53eefded8e1933f3d7e51990fc4c7b065be6c00776eeab8fb3136/merged/python3.nabla __RUMP_FDINFO_NET_tap=4 PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=28157ba5950e PYTHONHASHSEED=1 PYTHONHOME=/usr/local HOME=/ -- -c print(\'hello\')]
| ___|
__| _ \ | _ \ __ \
\__ \ ( | | ( | ) |
____/\___/ _|\___/____/
Solo5: Bindings version v0.6.4-6-g756accf-dirty
Solo5: Memory map: 512 MB addressable:
Solo5: reserved @ (0x0 - 0xfffff)
Solo5: text @ (0x100000 - 0x889fff)
Solo5: rodata @ (0x88a000 - 0xb4cfff)
Solo5: data @ (0xb4d000 - 0xe7dfff)
Solo5: heap >= 0xe7e000 < stack < 0x20000000
sleeping 50000 usec
hello
Solo5: solo5_exit(0) called
```
## Conclusion
In this post, I introduced a brief of LKL Nabla Containers. It is still in an early stage and has room for improvement, but already runs practical applications like Python. I would like to measure the performance and evaluate the pros/cons.
Below is the TODO list:
* Replace workaround for Solo5
* Flexible `manifest.json` handling on build time
* ~~Pass `lkl.json` through run time arguments~~
* Do not pass `__RUMP_FDINFO_NET_tap=4` environment variable on run time
## Update: May 1st, 2020
After wrote this post, I found that LKL must use network information created by the container runtime. Otherwise, the network does not work properly. I added the 3rd feature described in the above TODO list to frankenlibc and runnc.
* [add external lkl json config support](https://github.com/retrage/frankenlibc/commit/fb4fde66c73c8bec58d754249db77edb66537955)
* [Create lkl config json](https://github.com/retrage/runnc/commit/e73c1203e8a1b19d4813917d893aec6181432e01)
The OCI runtime builds and passes JSON config for LKL at startup. LKL parses it along with environment variables and arguments.
Now, popular network applications Nginx and redis work on LKL Nabla Containers. They are available as base Docker Images.
* [retrage/lkl-nabla-nginx-base](https://hub.docker.com/repository/docker/retrage/lkl-nabla-nginx-base)
* [retrage/lkl-nabla-redis-base](https://hub.docker.com/repository/docker/retrage/lkl-nabla-redis-base) | retrage |
312,755 | first time remote speaker? | Corona has moved our entire life online. Same is with confs and meetups. Hope the below points help s... | 0 | 2020-04-18T10:01:06 | https://dev.to/tanaypratap/first-time-remote-speaker-29pj | remote, speaker, live | Corona has moved our entire life online. Same is with confs and meetups. Hope the below points help someone.
These are running notes from 4 different conf/talk/meetup I attended. I am a [Youtuber](youtube.com/tanaypratap) myself so, I have put some tips from my experience.
1. **Private chats** are good. People can talk to each other. Otherwise they might move out of the conf.
1. Make speakers co-host. Elevate permissions.
1. Have speaker's name, twitter handle, and talk title on each slide. People join in between and **need context**.
1. You can do a Zoom meeting with few folks and then stream the entire thing on Youtube. This way you limit the people who can ask questions by interrupting the meeting but at the same time increase the reach of your talk.
- another benefit of this is that it doesn't need any sign up or install.
- folks are worried about **security and privacy** concerns.
1. One person needs to **moderate the Youtube chat** in that case. Take questions from there and also remove spammers.
1. It is a good idea to take best practices from conferences. Which means that attendees **ask their questions at end** on audio, chat is fine.
- what happens is that folks unknowingly switch ON/OFF their mic and the speaker gets disturbed
1. **Visibility** is extremely important. \#speakertips
- use bigger fonts on the slides.
- live streaming degrades quality.
- use colors of high contrast. know about the color wheel.
- use high resolution photos, otherwise it looks pixelated when streamed
1. Checklist:
- don't use a bluetooth mic
- use a mic if possible to avoid echo
- if you don't have a mic, don't close the room, **mitigate echo**
- be in line-of-sight of your wifi router. live streaming needs **bandwidth**
1. Use live slides. put link in chat or slide.
- See how live streamers take some screen to show static data.
- This way people can see your slides in a separate window as well.
- Helps in note taking too if they want you to go back.
1. Use shortened links everywhere. It's easier to read. Easier to note down.
- QR code is another good option
1. Use some storytelling and humor to your advantage. People are listening to it alone at home. Attention span runs short. \#speakertips
1. If you're a **first time speaker**, it could be tempting to write everything in the notes and read from there. But then your voice will sound robotic. So, avoid that. _Aaas_ and _ummms_ make you human and relatable. /#personaltip
1. If you are planning to share your screen/live code. Test it before starting the talk. Sometimes you just share the slide/window and not the desktop. Prepare a **check list for the talk**.
1. Biggest issue with zoom/skype is that these tools are for group meetings. Therefore it's hard to mute everyone. Someone will switch ON the mic and you'll get a lot of noise. Thus, Youtube Live helps but then takes away the audio interactivity.
- my tip: If you have a talk **with more than 20 folks, go for Youtube Live**.
1. Recently attended FreeCodeCamp Live conf. They had a paid entry to chatrooms. Good idea if you want to **monetise the conf**.
1. The FCC conf had full screen video of speakers. The ReactJS Meetup has only slides.
- a balance would be better. Have a **small video on the side**. Again, see some Twitch LiveStreams to get inspiration.
1. Having a private chat room shared before is good. What if your zoom is not running? or you get into any technical difficulty before starting your talk. Happened with [mentorship-karona](bit.ly/mentorship-karona) session.
- YT live link prepared before hand would give you a chat room ON. Which is pretty good as you can add moderators there as well.
- can do a telegram group. It will also serve as a place to hangout for interested people later.
1. Closing notes: Share a tip on how you're coping up with the lockdown. Add that **personal touch**. Maybe share a photo of your home setup. :)
1. Adding this just because I like prime numbers. The world needs more people to create content so that those who are stuck at home and can't do much to fight have at least something productive and positive to tune in to. More power to you my friend!
If you like this, and you don't know me, _consider following me on [Twitter](https://twitter.com/tanaypratap)_. I am dangerously active on social media btw. :) | tanaypratap |
312,762 | Quick way to implement darkmode in Nuxt.js & Tailwindcss — Corona Virus Tracker | Quick way to add darkmode in Nuxt.js & Tailwindcss project— Corona Virus Tracker Darkm... | 0 | 2020-04-18T14:13:16 | https://medium.com/@fayazara/quick-way-to-implement-darkmode-in-nuxt-js-tailwindcss-corona-virus-tracker-712d004a0846 | javascript, coronavirus, tailwindcss, vue | ---
title: Quick way to implement darkmode in Nuxt.js & Tailwindcss — Corona Virus Tracker
published: true
date: 2020-04-18 10:10:17 UTC
tags: javascript,coronavirus,tailwind-css,vuejs
canonical_url: https://medium.com/@fayazara/quick-way-to-implement-darkmode-in-nuxt-js-tailwindcss-corona-virus-tracker-712d004a0846
cover_image: https://cdn-images-1.medium.com/max/1013/1*9z3vKvVA9TCqv5ODedaARA.png
---
### Quick way to add darkmode in Nuxt.js & Tailwindcss project— Corona Virus Tracker
Darkmode is trending and being implemented almost everywhere on web and apps these days, so I thought of implementing it on one of my side projects [tvflix.co](https://tvflix.co/) v2 which is being built with tailwind & nuxt. Dark mode is a good experience for users who visit your webpages & a lot of users asked for & was a little difficult to build earlier, we wil make it in a easy and modular way.
Today we’ll make a small webpage and implement dark mode with the awesome Tailwindcss & Nuxtjs. I will explain a little about them. You can skip this part if you already are aware of them.
#### TLDR
We will use [nuxt-color-mode](https://github.com/nuxt-community/color-mode-module) module and [tailwindcss-dark-mode](https://github.com/ChanceArthur/tailwindcss-dark-mode) plugin, which will gives us access to `dark:` selector. Here’s the [github repo](https://github.com/fayazara/nuxt-tailwind-darkmode) if you just want to check the code directly & you can see the live [demo](http://covid19-nuxtjs.surge.sh/) here.
#### _What’s tailwindcss?_
The documentation says:
> Tailwind CSS is a highly customizable, low-level CSS framework that gives you all of the building blocks you need to build bespoke designs without any annoying opinionated styles you have to fight to override.
What it means is, tailwindcss will not provide you classes for opinionated frontend sections like cards, accordions, navbars etc, instead you them by yourself, and tailwind will provide classes at a granular level, making you code modular and you have more control over the frame and the end ui.
#### What’s Nuxt.js?
Nuxt is a framework for Vue.js which will handle a lot of practical use cases like routing, nested routing, prerendering, SSR out of the box, with vue would have to manually setup all these individually and have end up with a lot of boilerplate code.
1.Create a nuxt project by running `npx create-nuxt-app darkmode` in your terminal, make sure you select the **Tailwind CSS UI framework from the options** when prompted,which will save a lot of time, unless you want to add tailwindcss module seperately. I also selected axios to make a api call.
2. Let it finish initializing the project, once done open the project in vscode or whatever editor you prefer. Quick tip don’t close the terminal just type `code darkmode/` this will open the project in vscode.
3. We will need [nuxt-color-mode](https://github.com/nuxt-community/color-mode-module) module and [tailwindcss-dark-mode](https://github.com/ChanceArthur/tailwindcss-dark-mode) plugin to make it work, let’s install them by running command `npm i tailwindcss-dark-mode @nuxtjs/color-mode --save-dev`
Let’s make a small webpage which tracks Covid 19 Cases in India. I will be making use of api from [Covid19India](https://www.covid19india.org/), a community driven Corona virus tracker which has crowdsourced data, kudos to the team and the people helping. Here is the api endpoint [https://api.covid19india.org/data.json](https://api.covid19india.org/data.json).
Since I will be explaning only how to implement dark mode, I will skip explaining how I made the actual page, you can find the code for the project at the end of the article.
This is my page in Light mode.
<figcaption>Light Mode</figcaption>
Now setup the plugins we had installed earlier. You need to add the color-mode nuxt module in your nuxt.config.js inside the buildModules object.
```
{
buildModules: [
'@nuxtjs/color-mode'
]
}
```
Now open your tailwind.config.js file and add the below configuration.
{% gist https://gist.github.com/fayazara/5d95dda869423bc5603539380cb8ad48.js %}
Great, we have setup dark mode configuration on the site.
A brief idea on how the plugin works is, we have access to a special selector called `dark:` which we can add to our html elements like below
To give a better idea, this below example is using the default tailwind classes.
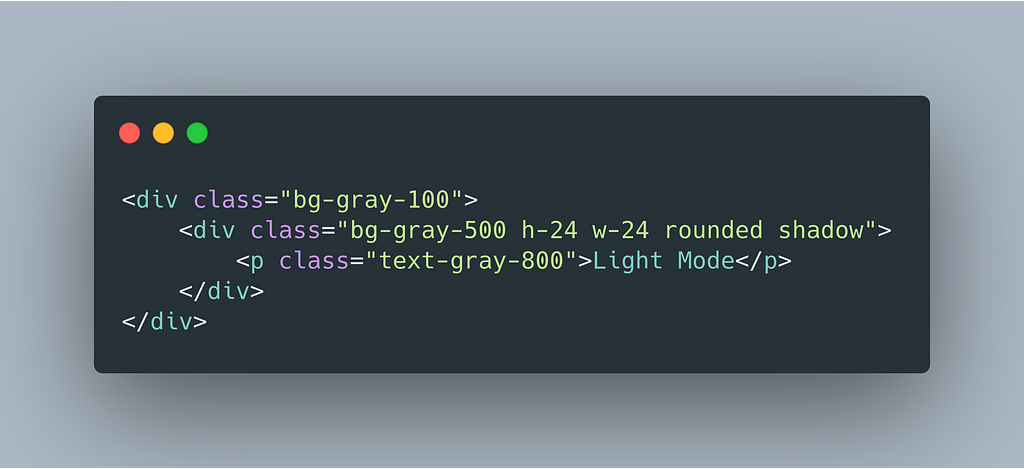<figcaption>Code without dark selector</figcaption>
If we want the dark selector added to it, we do it this way.
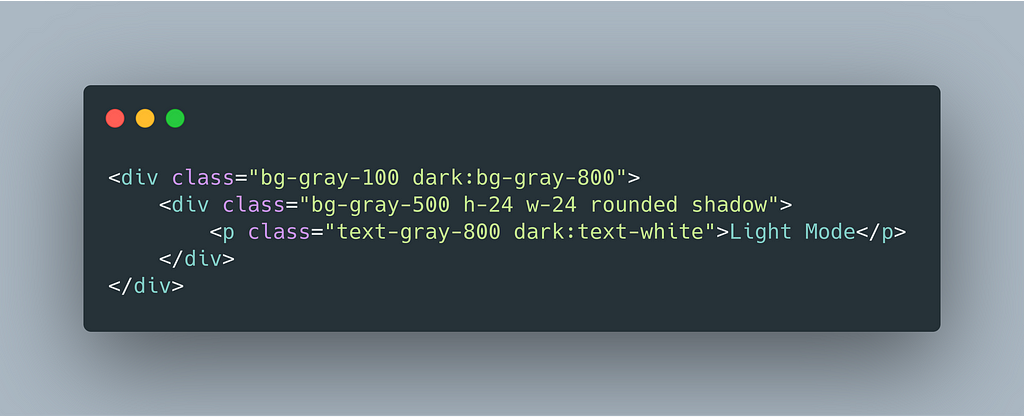<figcaption>Code with dark selector</figcaption>
Similarly you will also have access to `dark-hover` `dark-focus` `dark-active` and some other selectors too.
Let’s add the dark mode toggle button to our website. The nuxt color-mode module gives us access to `$colorMode` helper function globally in our project, we can set its preference value either dark or light `$colorMode.preference = 'dark'` (or anything if we want, say a sepia mode). I have written a small toggle method to switch between light and dark modes for the site.
{%gist https://gist.github.com/fayazara/374605faf20df74000db150a4ff4d529 %}
A small note, before making a production build. Nuxt also includes purgeCSS when we installed the TailwindCSS framework, which auto removes unused css, since we are adding dark selector classes manually, we need to whitelist them in our nuxt config like below
```
purgeCSS: {
whitelist: ['dark-mode'],
}
```
Here is how the site looks in dark mode
<figcaption>Dark Mode</figcaption>
You can see a demo of the final website [here](http://covid19-nuxtjs.surge.sh/), you can find the source code [here](https://github.com/fayazara/nuxt-tailwind-darkmode), just clone it and do a `npm install` and start the project with `npm run dev`.
This way of adding dark mode to tailwindcss is not just restricted to Nuxt, you can add it to almost any framework like React, jQuery or vanilla js, all you have to do is add adark-mode class to the html tag, the tailwind plugin will take care of the rest. | fayaz |
312,764 | REST API Testing with Cypress( Full CRUD Example) | In this video cypress tutorial for beginners, We are going to learn to perform REST API Testing with... | 0 | 2020-04-18T10:34:19 | https://dev.to/promode/rest-api-testing-with-cypress-full-crud-example-33c4 | cypress, testing, beginners, tutorial | In this video cypress tutorial for beginners, We are going to learn to perform REST API Testing with cypress.
[](https://youtu.be/3q4l3wzFiMI "Cypress API Testing")
👉 Learn Software Testing Concepts: https://scrolltest.com
🙏 Learn Cypress Tutorial: https://cypresstutorial.com.
👔 Learn API Testing: https://www.learnapitesting.com
👮🏻♀️ Automation Tester Training: https://thetestingacademy.com
--
Be sure to subscribe for more videos like this!
[](https://www.youtube.com/TheTestingAcademy?sub_confirmation=1 "TheTestingAcademy") | promode |
312,765 | I implemented a queue system in NodeJS | It's common for workloads that can be processed asynchronously to increase in your application flow.... | 0 | 2020-04-20T05:11:54 | https://dev.to/employremotely/implementing-a-queue-system-in-nodejs-2fg3 | node, javascript, tutorial | It's common for workloads that can be processed asynchronously to increase in your application flow. This is the situation I found myself in building [EmployRemotely.com](https://www.employremotely.com) (for context, this is a platform we created to help developers find remote jobs). Upon a user being registered or an advert being submitted I was performing various actions that didn't need to be performed immediately, such as:
* Sending a user email
* Distributing that advert to various channels (Twitter, Reddit etc)
* Sending data off internally (tracking systems, Slack channels etc)
All of this was being handled within the relevant APIs, and as this list of actions grew it became more obvious this wasn't the right approach to take. It was becoming more complex, error prone and potentially providing a bad experience for the users. So I decided to look for a better alternative.
**To avoid any confusion with the terminology used in this article here are the differences between the terms "adverts" and "jobs" mentioned throughout.**
* **Advert** - A job advertisement you would typically see published on the website to attract and inform candidates to apply for a specific position at a company
* **Job** - A task that gets pushed into a queue system to be processed at a later stage. This can be anything.
## Queues
A queue system is a way of storing enough information about a particular job for it to be carried out at a later stage. Usually the main app will store this information, and push it into a queue of jobs to be processed in the future.
Some of the benefits of a queue system include:
* Distribute the workload over time
* Decoupling work
* Retry logic
* Consistency between external system integration
In my case, if I wanted to distribute an advert to Twitter and/or Reddit I would add these to a queue, which would allow me to process them independently, in isolation which is decoupled from the original application flow.
## Bull
After some research I decided to reach for [Bull](https://github.com/OptimalBits/bull) for my queuing system. Bull is "the fastest, most reliable, Redis-based queue for Node".

Bull simply ticked some important boxes for me. It was feature rich, had a very simple interface and looked easy enough to get up and running with. Because [EmployRemotely.com](https://www.employremotely.com) is not full-time for me, time was definitely an important factor.
## Implementation
#### 1. Installation
a. Ensure you have [Redis](https://redis.io/topics/quickstart) installed on your local machine.
b. Install Bull into your project `npm install bull --save`
#### 2. Structure.
It always helps me to understand how things are tied together when I can see a directory structure. So, I created two new directories to separate queues and jobs.
#### 3. Create queues and processes.
Witin the `/queues/distributeAdvert.js` file create my queue and processing function for each job to be processed by. The `Queue` constructor creates a new queue that is persisted in Redis. Every time the same queue is instantiated. The first parameter of the queue is the queue name.
```js
// src/queues/distributeAdvert.js
const Queue = require('bull');
const sendTweet = require('../jobs/twitter');
const sendReddit = require('../jobs/reddit');
const distributeAdvert = new Queue('distributeAdvert', process.env.REDIS_URL);
distributeAdvert.process(async job => {
const { slug, service } = job.data;
try {
switch (service) {
case 'twitter': {
const response = await sendTweet(job);
return Promise.resolve({ sent: true, slug });
}
case 'reddit': {
const response = await sendReddit(job);
return Promise.resolve({ sent: true, slug });
}
default: {
return Promise.resolve({ sent: true, slug });
}
}
} catch (err) {
return Promise.reject(err);
}
});
module.exports = distributeAdvert;
```
#### 4. Adding jobs to the queue.
In my API where I would handle the advert submission and create a database entry for it. Its here I was also previously sending this off to Twitter and Reddit to be published also.
Now I can remove these requests to Twitter and Reddit and simply replace it with the queue system we've created by adding the necessary job information to the queue to be processed.
Here the job is added to the `distributeAdvert` queue. The job is nothing but an Object that contains the required data to process it.
```js
const express = require('express');
const { distributeAdvert } = require('../../queues/');
const router = express.Router();
router.post('/create', checkUser, async (req, res, next) => {
const {
...
slug,
} = req.body;
// ...code to insert advert into database
try {
distributeAdvert.add({ service: 'reddit', slug });
distributeAdvert.add({ service: 'twitter', slug });
return res.status(200).json({
message: 'Your advert has been submitted successfully, good luck in your candidate search!',
});
} catch (err) {
return res.status(422).json({
message: 'There was an unexpected error submitting your advert.',
});
}
});
module.exports = router;
```
And that's all that is needed.
* We've created our directory structure within the project
* We've created our `distributeAdvert` queue
* We've replaced requests to third parties (Twitter, Reddit etc) with code to add these jobs into our queue to be processed.
## Summary
So in summary, by implementing queues, I have now:
* Smoothed out my process
* Decoupled unnecessary tasks from important APIs
* Have a less complex and more readable process in place
* Have an approach that will scale better
* Made distributing an advert to third parties more consistent
Thanks for reading.
If you're interested in following our progress on [EmployRemotely.com](https://www.employremotely.com), including what works and what doesn't, head over to my Twitter [@codebytom](https://www.twitter.com/codebytom)
Sign up to our [newsletter](https://www.employremotely.com/#newsletter) to get relevant job opportunities emailed to you weekly | coding_tom |
312,805 | Automatic Versioning for React Native Apps | Don't do it manually. | 0 | 2020-04-18T12:27:42 | https://dev.to/osamaqarem/automatic-versioning-for-react-native-apps-2bf3 | react, reactnative, fastlane, version | ---
title: Automatic Versioning for React Native Apps
published: true
description: Don't do it manually.
tags: react,reactnative,fastlane,version
---
## Problem
You need to update your app's version to 1.0.0:
1\. You open up `android/app/build.gradle` to update the version and bump the build number.
2\. You do the same thing for iOS using Xcode because editing build configuration files directly is more error prone.
3\. You need to keep it all consistent, so you open up `package.json` and update the version so the reference to the version shown to the user from the JS side is correct.
```js
import { version } from "./package.json"
console.log(version)
// 1.0.0
```
_I feel so productive and happy!_
Said no developer ever after going through that.
## Solution
The ideal experience is to update only a single version number. Here's what we're going to do:
1\. Use `npm version [patch|minor|major]` to handle the JS package version (see [semantic versioning](https://docs.npmjs.com/about-semantic-versioning)).
The JS version is our **source of truth**. Therefore, the Android and iOS versions should match whatever the `package.json` version is set to.
2\. Use fastlane to handle the Android and iOS sides.
> [fastlane](https://fastlane.tools/) is an amazing open source tool focused at automating Android and iOS tasks. It has a wide library of community developed plugins that can help us handle things like, _versioning_.
3\. Combine the above 2 steps into a single npm script.
### Steps
We will use a fresh React Native project as a starting point:
```bash
npx react-native init MyApp
```
Install fastlane if you do not already have it:
```bash
# Install the latest Xcode command line tools
xcode-select --install
# Install fastlane using RubyGems
sudo gem install fastlane -NV
# Alternatively using Homebrew
brew install fastlane
```
Set up a fastlane directory and create an empty fastfile:
```bash
cd MyApp
mkdir fastlane && cd fastlane
touch Fastfile
```
We want to be able to run the `fastlane` command from the root of our React Native project. Therefore we will install our versioning plugins from the root directory:
```bash
cd ..
# Install plugins
fastlane add_plugin increment_version_name increment_version_code load_json
```
Say 'yes' if it asks about creating a gemfile.
The first two plugins are for handling the version, version code on android and the third one is for reading a JSON file (our `package.json`).
Next, we are going to add our fastlane scripts. Copy the following to the fastfile at `fastlane/Fastfile`.
```ruby
desc 'Android: Increment versionCode and set versionName to package.json version.'
package = load_json(json_path: "./package.json")
private_lane :inc_ver_and do
increment_version_code(
gradle_file_path: "./android/app/build.gradle",
)
increment_version_name(
gradle_file_path: "./android/app/build.gradle",
version_name: package['version']
)
end
desc 'iOS: Increment build number and set the version to package.json version.'
private_lane :inc_ver_ios do
package = load_json(json_path: "./package.json")
increment_build_number(
xcodeproj: './ios/' + package['name'] + '.xcodeproj'
)
increment_version_number(
xcodeproj: './ios/' + package['name'] + '.xcodeproj',
version_number: package['version']
)
end
desc 'Bump build numbers, and set the version to match the pacakage.json version.'
lane :bump do
inc_ver_ios
inc_ver_and
end
```
Next we are going to add the following scripts to our package.json for automatic patch, minor and major version bumps:
```json{11-13}
{
"name": "MyApp",
"version": "0.0.1",
"private": true,
"scripts": {
"android": "react-native run-android",
"ios": "react-native run-ios",
"start": "react-native start",
"test": "jest",
"lint": "eslint .",
"bump-patch": "npm version patch --no-git-tag-version && bundle exec fastlane bump",
"bump-minor": "npm version minor --no-git-tag-version && bundle exec fastlane bump",
"bump-major": "npm version major --no-git-tag-version && bundle exec fastlane bump",
},
```
The first part of the command will upate the JS package version without making a commit to the git repo. The second part will execute the fastlane bump command, which will automatically bump the android and iOS build numbers and update the version to match the JS side.
```bash
# npm
npm run bump-patch
# yarn
yarn bump-patch
```
--------------------
PS: I'm maintaining a React Native [template with a lot of goodies](https://github.com/osamaq/react-native-template/) like the one in the article. | osamaqarem |
312,822 | Efficient Software vs Software that just works | I landed on this post today. Link This is a post from 2018 and I landed on this looking for a good... | 0 | 2020-04-18T12:53:46 | https://dev.to/barelyhuman/efficient-software-vs-software-that-just-works-5kk | programming, coding, development, codequality | ---
title: Efficient Software vs Software that just works
published: true
description:
tags: programming, coding, development, codequality
---
I landed on this post today.
[Link](https://dev.to/tux0r/does-your-website-really-need-to-be-larger-than-windows-95-16mm)
This is a post from 2018 and I landed on this looking for a good way to build multi platform apps while maintaining a really small footprint. The arguments and discussions in its comments were hilarious and kinda pleasing it lead me to a rust based webview for pure web apps but on a desktop.
Anyway, was close to locking on programming the whole thing in C/C++ and use some abstractions to support all 3 platforms, and all this headache because, I realized that a lot of tools that I have installed are built with the chromium engine as a window layer with Electron on the top. A few to name would be VS Code, Postman, Spotify , WebTorrent which ended up taking a lot of space on my disk vs softwares like Sublime and Transmission that hardly take up any space and the only reason I don't use Sublime is because the packages I need are obsolete and need a little tweaking to get them to work. So I, just end up letting vscode eat my ram and battery.
For anyone else, the disk/ram/battery usage is important to me because I have a entry level Macbook Pro with just 121gb of user storage and that fills up quickly when you are a nodejs developer. Cause well, just 20 Repositories have over GB's worth of just node_modules and then I even decided to download XCode and Android Studio because someone wanted a Flutter and React Native application as well.
I agree with @tux0r and being a fellow minimalist it would be a nice if software was efficient and more focused on being performant while being small instead of
"Yeah, this library, that lib, add all of them up and ship it, if the user needs the software he'll download the 200GB installation candidate!"
Now, @tux0r's argument was specific to websites being a huge ram hog
but in the comments he ends up supporting desktop apps for heavier tasks and most of the people end up supporting electron and JS as a language.
Now I know its not going to be ideal for business as they want everything quick and not always *done right* but a lot of us do build projects for fun and we should actually try to build something that is a lot faster to use while not being a ram hogger. Cause , a lot of people don't upgrade for a long time and they can't really enjoy the software you built.
On a different note, I'm still unable to decide what I should be doing for that multi platform desktop app I wanted to build...
| barelyhuman |
314,626 | How to Make a Markdown Blog With Next.js | Create a markdown blog with Next.js and Tailwind.css. | 0 | 2020-04-20T06:37:19 | https://jfelix.info/blog/how-to-make-a-static-blog-with-next-js | react, programming, webdev | ---
cover_image: https://res.cloudinary.com/dmq9pzw0o/image/upload/v1587361417/how-to-make-static-blog/glenn-carstens-peters-npxXWgQ33ZQ-unsplash_1_1_i5sg7h.jpg
title: How to Make a Markdown Blog With Next.js
description: Create a markdown blog with Next.js and Tailwind.css.
updatedAt: "2020-04-20"
published: true
tags:
- Reactjs
- programming
- webdev
canonical_url: https://jfelix.info/blog/how-to-make-a-static-blog-with-next-js
---
*Don't want to code along? See this template on [Github](https://github.com/Jfelix61/nextjs-starter-blog) with even more features such as SEO, and deploy it instantly to Netlify or Zeit Now.*
Recently, I had to create a blog for my [Next.js personal website and portfolio](https://jfelix.info/). I looked online for any solution that could help me develop the blog, however, I could not find any simple solution like you would for [Gatsby.js](https://www.gatsbyjs.org/).
This post will try to create a blog similar to [Gatsby Starter Blog](https://github.com/gatsbyjs/gatsby-starter-blog) with Next.js and tailwind.css.
> There are many ways of parsing markdown such as using MDX. However, in this post, I'll focus on normal markdown with frontmatter so you can use a CMS like [Netlify CMS](https://www.netlifycms.org/) with it.
## Creating a Next.js project
We will create a Next.js app using its CLI. Run one of these commands. This will create an initial layout where we will start developing our blog.
```
npm init next-app
# or
yarn create next-app
```
Now run:
```
cd YOUR_PROJECT_NAME && yarn dev
```
Great! We have created our next app. You should be seeing this:

## Installing main dependencies
We will be using [gray-matter](https://www.npmjs.com/package/gray-matter) to parse our frontmatter and markdown, [react-markdown](https://www.npmjs.com/package/react-markdown) for converting it to HTML and displaying it, and [tailwind.css](https://www.npmjs.com/package/tailwindcss) to streamline styles quickly.
Let's add all necessary dependencies:
```
npm install --save-dev gray-matter react-markdown tailwindcss postcss-preset-env && npm install react-markdown
# or
yarn add -D gray-matter tailwindcss postcss-import autoprefixer && yarn add react-markdown
```
## Configure Tailwind.css
Thanks to this [tutorial](https://github.com/tailwindcss/setup-examples/tree/master/examples/nextjs), we can get started with Tailwind.css quickly. Initialize it with the next command; it will create our config:
```
npx tailwind init
```
Next, create a file called `postcss.config.js` to configure [Postcss](https://postcss.org/), and add this:
```js
module.exports = {
plugins: ["postcss-import", "tailwindcss", "autoprefixer"],
};
```
Then, let's create a CSS style sheet on `styles/tailwind.css`.
```css
@import "tailwindcss/base";
@import "tailwindcss/components";
@import "tailwindcss/utilities";
```
Finally, create `pages/_app.js` and import our newly created style sheet:
```js
// pages/_app.js
import "../styles/tailwind.css";
export default function MyApp({ Component, pageProps }) {
return <Component {...pageProps} />;
}
```
#### Great! now we can start working on our blog directly.
## Configure Purgecss for tailwind (optional)
Adding [Purgecss](https://purgecss.com/) is highly recommended when using tailwind.css or CSS. It automatically removes any unused CSS at build time, which can reduce our bundle size.
First, add the necessary dependency:
```
npm install --save-dev @fullhuman/postcss-purgecss
# or
yarn add -D @fullhuman/postcss-purgecss
```
Then, update our `postcss.config.js`
```js
const purgecss = [
"@fullhuman/postcss-purgecss",
{
content: ["./components/**/*.js", "./pages/**/*.js"],
defaultExtractor: (content) => content.match(/[\w-/:]+(?<!:)/g) || [],
},
];
module.exports = {
plugins: [
"postcss-import",
"tailwindcss",
"autoprefixer",
...(process.env.NODE_ENV === "production" ? [purgecss] : []),
],
};
```
## Creating Our Posts
We will be using markdown with [jekyll's frontmatter syntax](https://jekyllrb.com/docs/front-matter/) to write our posts. This will help us maintain our posts in a clean and easy to use format.
All our posts will be located in `content/posts`, so proceed to create this route and add our first post called `first-post.md`.
```markdown
---
title: First post
description: The first post is the most memorable one.
date: 2020-04-16
---
# h1
## h2
### h3
Normal text
```
Now let's create a second one called `second-post.md`.
```markdown
---
title: Second post
description: The second post is the least memorable.
updatedAt: 2020-04-16
---
# h1
## h2
### h3
Normal text
```
## Fetching our posts
Having our initial posts, we can begin to work on our index page. Let's delete whatever we had previously, and start with a clean component:
```jsx
export default function Home() {
return (
<div>
</div>
);
}
```
To get all posts we will use [getSaticProps](https://nextjs.org/docs/basic-features/data-fetching#getstaticprops-static-generation). This method will fetch all our posts and feed it as props to our page.
The main benefit of `getStaticProps` is its static generation which means the content will be generated at build time, and will not be fetched every time our user visits our blog.
```jsx
import fs from "fs";
import matter from "gray-matter";
export default function Home({ posts }) {
return (
<div>
{posts.map(({ frontmatter: { title, description, date } }) => (
<article key={title}>
<header>
<h3>{title}</h3>
<span>{date}</span>
</header>
<section>
<p>{description}</p>
</section>
</article>
))}
</div>
);
}
export async function getStaticProps() {
const files = fs.readdirSync(`${process.cwd()}/content/posts`);
const posts = files.map((filename) => {
const markdownWithMetadata = fs
.readFileSync(`content/posts/${filename}`)
.toString();
const { data } = matter(markdownWithMetadata);
// Convert post date to format: Month day, Year
const options = { year: "numeric", month: "long", day: "numeric" };
const formattedDate = data.date.toLocaleDateString("en-US", options);
const frontmatter = {
...data,
date: formattedDate,
};
return {
slug: filename.replace(".md", ""),
frontmatter,
};
});
return {
props: {
posts,
},
};
}
```
Now you should be seeing this:

Awesome! We can see all our posts.
## Adding Layout component
Before we start working on `index.js` styles. Let's first add a layout component that will wrap our pages. Create a `components/layout.js` and add this:
```jsx
import Link from "next/link";
import { useRouter } from "next/router";
export default function Layout({ children }) {
const { pathname } = useRouter();
const isRoot = pathname === "/";
const header = isRoot ? (
<h1 className="mb-8">
<Link href="/">
<a className="text-6xl font-black text-black no-underline">
Next.Js Starter Blog
</a>
</Link>
</h1>
) : (
<h1 className="mb-2">
<Link href="/">
<a className="text-2xl font-black text-black no-underline">
Next.Js Starter Blog
</a>
</Link>
</h1>
);
return (
<div className="max-w-screen-sm px-4 py-8 mx-auto">
<header>{header}</header>
<main>{children}</main>
<footer>
© {new Date().getFullYear()}, Built with{" "}
<a href="https://nextjs.org/">Next.js</a> 🔥
</footer>
</div>
);
}
```
It should look like this:

## Styling Our Blog's Index Page
Let's style our index page. We won't do anything fancy, but I welcome you to take your time and style is as best as you can.
So, lets start:
```jsx
// ...
export default function Home({ posts }) {
return (
<Layout>
{posts.map(({ frontmatter: { title, description, date } }) => (
<article key={title}>
<header>
<h3 className="mb-1 text-3xl font-semibold text-orange-600">
{title}
</h3>
<span className="mb-4 text-sm">{date}</span>
</header>
<section>
<p className="mb-8">{description}</p>
</section>
</article>
))}
</Layout>
);
}
// ...
```
## Creating Post Page
Right now we have something like this, pretty cool right?

However, what is the point of a blog if we can't read our posts. So let's get started at creating our post page. Go ahead and Create `pages/post/[slug].js`, and add this:
```jsx
import React from "react";
import fs from "fs";
import path from "path";
import matter from "gray-matter";
export default function Post({ content, frontmatter }) {
return (
<Layout>
<article></article>
</Layout>
);
}
export async function getStaticPaths() {
const files = fs.readdirSync("content/posts");
const paths = files.map((filename) => ({
params: {
slug: filename.replace(".md", ""),
},
}));
return {
paths,
fallback: false,
};
}
export async function getStaticProps({ params: { slug } }) {
const markdownWithMetadata = fs
.readFileSync(path.join("content/posts", slug + ".md"))
.toString();
const { data, content } = matter(markdownWithMetadata);
// Convert post date to format: Month day, Year
const options = { year: "numeric", month: "long", day: "numeric" };
const formattedDate = data.date.toLocaleDateString("en-US", options);
const frontmatter = {
...data,
date: formattedDate,
};
return {
props: {
content: `# ${data.title}\n${content}`,
frontmatter,
},
};
}
```
We created what is called a template, basically a blueprint of how our posts should look like. That `[slug].js` format indicates a dynamic route within Next.js, and based on the slug we will render the post we need. Read more on [dynamic routes](https://nextjs.org/docs/routing/dynamic-routes).
Here we used both `getStaticProps` and `getStaticPaths` to create our post's dynamic route. The method [getStaticPaths](https://nextjs.org/docs/basic-features/data-fetching#getstaticpaths-static-generation) allows us to render dynamic routes based on the parameters we provide, in this case, a slug. You may have noticed that we are receiving a `params.slug` parameter in `getStaticProps`. This is because `getStaticPaths` passes the current slug, for us to fetch the post we need.
We are providing our Post component both the content and frontmatter of our post. Now, all that is left is to render the markdown with React Markdown. React Markdown's job is to convert our markdown to HTML so we can display it on our site. Add the following to your `[slug].js`:
```jsx
// ...
import ReactMarkdown from "react-markdown/with-html";
// ...
export default function Post({ content, frontmatter }) {
return (
<Layout>
<article>
<ReactMarkdown escapeHtml={false} source={content} />
</article>
</Layout>
);
}
// ...
```
## Connecting Our Index with Post
Our post template is done, but we have to be able to access it through a link on our page. Let's wrap our post's title with a (Link)\[<https://nextjs.org/docs/api-reference/next/link>] component provided by Next.js on `index.js`.
```jsx
// ...
import Link from "next/link";
export default function Home({ posts }) {
return (
<Layout>
{posts.map(({ frontmatter: { title, description, date }, slug }) => (
<article key={slug}>
<header>
<h3 className="mb-2">
<Link href={"/post/[slug]"} as={`/post/${slug}`}>
<a className="text-3xl font-semibold text-orange-600 no-underline">
{title}
</a>
</Link>
</h3>
<span className="mb-4 text-xs">{date}</span>
</header>
<section>
<p className="mb-8">{description}</p>
</section>
</article>
))}
</Layout>
);
}
// ...
```
Click any of the posts and...

Isn't it beautiful? Well, not quite since our markdown is not being styled yet.
## Styling Our Markdown
We could start adding rule by rule in CSS to style all the post's headings and other elements, however, that would be a tedious task. To avoid this, I'll be using [Typography.js](https://kyleamathews.github.io/typography.js/) since it gives us access to more than 20 different themes, and add these styles automatically.
> Don't feel pressured to use this solution. There are many ways you achieve this, feel free to choose whatever works for you best.
First, let's add Typography.js to our dependencies:
```shell
npm install typography react-typography
# or
yarn add typography react-typography
```
I will be using Sutra theme since for me it looks really good and sleek. You can access [Typography.js main site](https://kyleamathews.github.io/typography.js/) and preview all the different themes. Without further ado, let's add it:
```shell
npm install typography-theme-sutro typeface-merriweather typeface-open-sans
# or
yarn add typography-theme-sutro typeface-merriweather typeface-open-sans
```
> You may notice I'm adding some packages which contain local fonts. Typography gives us the option to get our fonts through Google Fonts, nevertheless, I prefer having these fonts locally.
Now that we have the packages we need, create a `utils/typography.js` to create our main Typography.js configuration:
```javascript
import Typography from "typography";
import SutroTheme from "typography-theme-sutro";
delete SutroTheme.googleFonts;
SutroTheme.overrideThemeStyles = ({ rhythm }, options) => ({
"h1,h2,h3,h4,h5,h6": {
marginTop: rhythm(1 / 2),
},
h1: {
fontWeight: 900,
letterSpacing: "-1px",
},
});
SutroTheme.scaleRatio = 5 / 2;
const typography = new Typography(SutroTheme)
// Hot reload typography in development.
if (process.env.NODE_ENV !== `production`) {
typography.injectStyles();
}
export default typography;
```
Then, create `pages/_document.js` to inject our typography styles.
```jsx
import Document, { Head, Main, NextScript } from "next/document";
import { TypographyStyle } from "react-typography";
import typography from "../utils/typography";
export default class MyDocument extends Document {
render() {
return (
<html>
<Head>
<TypographyStyle typography={typography} />
</Head>
<body>
<Main />
<NextScript />
</body>
</html>
);
}
}
```
To import out typeface font go to `pages/_app.js` and add this line:
```javascript
// ...
import "typeface-open-sans";
import "typeface-merriweather";
// ...
```
Typography.js includes a CSS normalization that will collide with tailwind's. Therefore, let's disables tailwind's normalization in `tailwind.config.js`
```javascript
module.exports = {
theme: {
extend: {},
},
variants: {},
plugins: [],
corePlugins: {
preflight: false,
},
};
```
Now our blog's index page looks sleek:

## Working With Images
Adding images is very straightforward with our setup. We add our desired image to `public`. For the sake of this tutorial I'll add this cute cat picture to my `public` folder.

Then, in `content/posts/first-post`:
```markdown
---
title: First post
description: The first post is the most memorable one.
date: 2020-04-16
---
# h1
## h2
### h3
Normal text

```
Notice the forward-slash before `cat.jpg`. It indicates that it is located in the `public` folder.
We should have something like this:
### That's it!! We have successfully created our static blog. Feel free to take a break, and pat yourself in the back.
## (Bonus) Adding Code Blocks
Our current blog works perfectly for non-coding posts. However, if we were to add code blocks our users will not be able to see them as we expect them to with syntax highlighting.
To add syntax highlighting we will use [react-syntax-highlighter](https://www.npmjs.com/package/react-syntax-highlighter) and integrate it with `react-markdown` since the latter won't parse tokens for our code.
First, let's add a new post in `content/posts/coding-post`:
```markdown
---
title: Coding Post
description: Coding is such a blissful activity.
date: 2020-04-16
---
\`\`\`jsx
import React from "react";
const CoolComponent = () => <div>I'm a cool component!!</div>;
export default CoolComponent;
\`\`\`
```
> Remove the component's backslashes after you copy them, so it can be highlighted.
Then, add `react-syntax-highlighter`:
```shell
npm install react-syntax-highlighter
# or
yarn add react-syntax-highlighter
```
Finally, change `pages/post/[slug].js` to:
```jsx
import React from "react";
import fs from "fs";
import path from "path";
import matter from "gray-matter";
import ReactMarkdown from "react-markdown/with-html";
import { Prism as SyntaxHighlighter } from "react-syntax-highlighter";
import Layout from "../../components/Layout";
const CodeBlock = ({ language, value }) => {
return <SyntaxHighlighter language={language}>{value}</SyntaxHighlighter>;
};
export default function Post({ content, frontmatter }) {
return (
<Layout>
<article>
<ReactMarkdown
escapeHtml={false}
source={content}
renderers={{ code: CodeBlock }}
/>
</article>
</Layout>
);
}
// ...
```
Now if we open our coding post, we should see this:

## (Bonus) Optimize Our Images
Adding [next-optimized-images](https://github.com/cyrilwanner/next-optimized-images) in our blog will allow us to deliver optimized images in production which makes our site faster.
First, let's add `next-optimized-images` and `next-compose-plugins` to our packages:
```shell
npm install next-optimized-images next-compose-plugins
# or
yarn add next-optimized-images next-compose-plugins
```
Then, create `next.config.js` in the root of our project:
```javascript
const withPlugins = require("next-compose-plugins");
const optimizedImages = require("next-optimized-images");
module.exports = withPlugins([optimizedImages]);
```
Next Optimized Images uses external packages to optimize specific image formats, so we have to download whichever we need. In this case, I'll optimize JPG and PNG images, therefore I'll use the `imagemin-mozjpeg` and `imagemin-optipng` packages. Head to [next-optimized-images's github](https://github.com/cyrilwanner/next-optimized-images) to see which other packages are available.
Furthermore, we will also add `lqip-loader` to show a low-quality image preview before they load, just like Gatsby.js does.
```shell
npm install imagemin-mozjpeg imagemin-optipng lqip-loader
# or
yarn add imagemin-mozjpeg imagemin-optipng lqip-loader
```
Once added, `next-optimized-images` will automatically apply optimizations in production.
Now, let's head to `pages/post/[slug].js` and add the following:
```jsx
import React, { useState } from "react";
import Layout from "../../components/Layout";
// ...
const Image = ({ alt, src }) => {
const [imageLoaded, setImageLoaded] = useState(false);
const styles = {
lqip: {
filter: "blur(10px)",
},
};
// Hide preview when image has loaded.
if (imageLoaded) {
styles.lqip.opacity = 0;
}
return (
<div className="relative">
<img
className="absolute top-0 left-0 z-10 w-full transition-opacity duration-500 ease-in opacity-100"
src={require(`../../content/assets/${src}?lqip`)}
alt={alt}
style={styles.lqip}
/>
<img
className="w-full"
src={require(`../../content/assets/${src}`)}
alt={alt}
onLoad={() => setImageLoaded(true)}
/>
</div>
);
};
export default function Post({ content, frontmatter }) {
return (
<Layout>
<article>
<header>
<h1 className="my-0">{frontmatter.title}</h1>
<p className="text-xs">{frontmatter.date}</p>
</header>
<ReactMarkdown
escapeHtml={false}
source={content}
renderers={{ code: CodeBlock, image: Image }}
/>
</article>
</Layout>
);
}
// ...
```
Finally, change `content/posts/first-post.md` image route:
```markdown
---
title: First post
description: The first post is the most memorable one.
date: 2020-04-16
---
# h1
## h2
### h3
Normal text

```
With this, we have created a component that will render each time an image is found in our markdown. It will render the preview, and then hide it when our image has loaded.
## Conclusion
Next.js is a really powerful and flexible library. There are many alternatives on how to create a blog. Regardless, I hope this has helped you create your own and notice it is not as hard as it seems.
I created a template of this post (look at it here [next-starter-blog GitHub repository](https://github.com/Jfelix61/nextjs-starter-blog)), which will be updated soon with more features such as a sitemap, SEO and RSS feed. Stay tuned!
For more up-to-date web development content, follow me on [Twitter](https://twitter.com/Jose_R_Felix), and [Dev.to](https://dev.to/jfelx)! Thanks for reading! 😎
---
Did you know I have a newsletter? 📬
If you want to get notified when I publish new blog posts and receive an **awesome weekly resource** to stay ahead in web development, head over to [https://jfelix.info/newsletter](https://jfelix.info/newsletter). | joserfelix |
315,298 | How to create an Animated order button with just HTML and css | A post by Augustus Otu | 0 | 2020-04-20T21:10:33 | https://dev.to/augani/how-to-create-an-animated-order-button-with-just-html-and-css-15d5 | codepen | {% codepen https://codepen.io/augani/pen/JjPLMwR %} | augani |
318,501 | Can developers challenge product decision? | Continuous journey of working from home due to COVID-19 outbreak at the world. This is my journey, my challenges in trying to be productive and completely changing my work habits from office first to remote first. (Working from home Journey (Day 26/27)) | 5,674 | 2020-04-24T14:05:28 | https://dev.to/thatferit/can-developers-challenge-product-decision-4533 | remote, webdev, development, watercooler | ---
title: Can developers challenge product decision?
published: true
description: Continuous journey of working from home due to COVID-19 outbreak at the world. This is my journey, my challenges in trying to be productive and completely changing my work habits from office first to remote first. (Working from home Journey (Day 26/27))
tags: remote, webdev, development, watercooler
series: working from home
---
_Thanks for reading! I'm writing about my remote work journey thanks to covid-19 forced me to_ 😂 _I'm writing now almost a month now (Day 26 and 27)_
## Work-related
The beginning of this week is still mainly around tackling big pull-request and supporting our apps team.
I prepared my open questions about a 3K LoC AB-Test which seemed too big. Big in, it is not easy to answer what is tested.
Our open questions were:
* Do we want to test the value of our Outfits API?
* Do we want to test the value of the Outfits UI as entry point?
From my understanding, the test was about a), yet the solution seems to be about b). Therefore, we scheduled a meeting with the Product Manager.
At the end, she decides what to put in here, yet we raised our concerns in creating such big pull-requests and the team should have smaller work packages (slices).
One thing I will not easily forget is something she said, when she thought we were blocking this and we want less features:
> I'm surprised that developers are now challenging product managers. I thought you do what we need.

This hit me. I believe in any lean / agile environment giving feedback and asking questions is the whole idea of having such processes. Even when this person is not in your team.
So, shouldn't developers request changes to Features? **Yes you should**.
Our job is not about doing what business and product want without questioning anything. Even if you have a good relationship personally, this will end up in [Mini-Waterfall](https://www.projecttimes.com/articles/are-you-practicing-agile-or-mini-waterfalls.html).
When a feature is given to us frontend developers, there are multiple levels we need to evaluate:
* Is the given design consistent (challenge UX) ?
* What hypothesis do we want to answer ?
* Are we measuring the correct things to answer it?
* How many different slices (work packages) do I see?
* Is it involving some legacy codebase?
...
## Today I (re)learned (TIL)
Debugging can be a lot of fun!

What I learned were rather trivial things. Yet:
- Be careful when using custom `X-Custom-Headers`. Some weird bugs I discovered were related to our Frontend overwriting them, when WebViews were injecting them too.
- Scala Template engine (Twirl) is confusing. Nothing to add 😃
## Personal
This week is really intense. I have many topics and deadlines at the same week. Thanks to my wife, who took another leave from work, I can focus.
Yet, it's a lot of things and I will be happy when this whole week ends. Giving Feedback to 7 people, doing bug bashing for 2 weeks, fixing other stuff, questioning product designs etc..
I guess this is what happens the more experienced you get. You see more stuff. Otherwise I start enjoying working from home. It's stressful (the whole covid-19 situation) but I feel better. Not commuting means less time wasted in busses, trains. Less exposure to sickness.
Take care!
Cheers,
Ferit | thatferit |
319,288 | Py Project: Key Logger | Greetings, So I wanted to create a project within Python then break down the code to gain understand... | 0 | 2020-04-25T14:32:10 | https://dev.to/iamdesigniso/py-project-key-logger-7ek | Greetings,
So I wanted to create a project within Python then break down the code to gain understanding while doing. The goal is to become a great software engineer, but I don’t want to be caught in tutorial hell. Great advice from several of the developers were to break each line of code down. Then do some “googling” if you aren’t understanding what you see. It makes total sense and with that I went online to find a project .A great project that was showing a bit in forms to start with was a logger program. With the logger program, it will allow you to type some keys on your screen via keyboard. While pressing the keys, the program should log your keystrokes via a text file. The concept was easy to grasp however when doing projects you don’t want to just write the code, get the concept, and then move on. No… way Jose! lol. So instead I decided to come back this AM to review what the basic project was broken down to via comments. So heads up great people when seeing the projects posted going forward. It’s all about the learning and growth, not just a copy and paste scenario. I hope you enjoy and learn much!
Keep coding great devs!
Key Logger Program : https://github.com/DesignisOrion/Keylogger-Program/blob/master/main.py | iamdesigniso | |
318,550 | Awesome CSS frameworks (PART 2) | CSS frameworks are great tools for web development. I have compiled a list of some awesome framework... | 0 | 2020-04-24T14:47:20 | https://dev.to/totallymustafa/awesome-css-frameworks-part-2-2pdn | css, html, javascript, beginners | CSS frameworks are great tools for web development.
I have compiled a list of some awesome frameworks.
This is part 2 of that list.
PART 1 is available [here](https://dev.to/totallymustafa/awesome-css-frameworks-part-1-2ko2).
https://getbase.org/

https://get.foundation/

https://semantic-ui.com/

https://milligram.io/

https://materializecss.com/

https://picturepan2.github.io/spectre/
 | totallymustafa |
318,574 | Acing Remote Interviews | More and more people have to interview remotely. There are some interesting strategies you can use to make the interview go even more favorably than before. | 0 | 2020-04-24T15:30:58 | https://dev.to/recursivefaults/acing-remote-interviews-doi | career, interview | ---
title: Acing Remote Interviews
cover_image: https://source.unsplash.com/QrqeusbpFMM/900x500
description: More and more people have to interview remotely. There are some interesting strategies you can use to make the interview go even more favorably than before.
published: true
tags:
- career
- interview
---
There are lots of strategies you can employ when preparing for a job interview. There are a few more opportunities to pay attention to when you are interviewing remotely. So how can you set yourself up for even more success when you interview from afar?
One of my mentees has a wonderful story where they knew that they were going to be interviewing over video. As a part of her preparation, she took into account what was going to be in view on the camera and took a little extra time to stage that shot. She included items into the shot to make it look both attractive and to draw in the interviewers. The interviewers noted the musical instruments, and that started a conversation about music. That conversation left a positive impression on those interviewers, and that goes a long way.
# Set the Scene
Just like my brilliant mentee did when you are interviewing remotely, what are you putting into view? Will your shot be clean and organized, or will you have dishes, cups, and piles of paper everywhere. That last bit is how my desk is on any given day, but it wouldn’t be for an interview.
What else are they going to see about you when your interview starts? What do you surround yourself with? My mentee included musical instruments to draw in the interviewers. What other things would you be able to add to your shot to leave an impression? Here’s a list of ideas you can include:
- Books (Programming or fun)
- Items from hobbies
- Video games
- Memorabilia
- Artwork
- Certifications, awards, accolades
- Plants
While you may come up with all sorts of items you can include, think about what impression you would have of someone who saw you and your set stage. Set the scene you want them to see. Adjust the lighting and check the sound. Give a great first impression.
# Have a Backup
If you go into a video interview and expect the technology to work correctly, you should think again. Technology loves to betray us when we need it most.
When you’re planning your interview, have a backup method to interview on standby. For example, if your interviewers send you a Zoom link, have a Google Hangout on standby. Also, be prepared to move to a simple conference call.
When technology fails, and it will, you will show them how prepared you are when you seamlessly move the whole interview to a working state by having a backup.
# Have A Strategy For Media
This last bit is a bit more tricky to consider, but whatever you put in front of your interviewers needs to give you better odds of getting an offer. If that means video conferencing is your best option, push for it. If avoiding video conferencing is your best chance, create that reality.
I have gone so far as to ensure I’m interviewing in a specific location so that people hear the sounds of nature or water. This always leads to a conversation that is on my terms and focused on mutual interest. For example, I will take the call when I’m out on a porch. I have my full attention on the interview, but the sound of birds and occasional wind leads to a, “Where are you?” I can quickly use that to respond by talking about how I like to work outside and enjoy the fresh air, and then ask them about what they enjoy. The more I keep them engaged, the better my odds.
Maybe you want to have some small examples of work that you can screen share. If you are going to screen share, set the scene there too. Leave only the things open you want them to see. When you show them something on your screen, it’s a chance to engage them. Look for those opportunities and take them.
I was on a video call recently where someone was sharing their screen, and I saw they were playing a video game in the background. This observation led to a pretty funny and awkward conversation about the games we play. Our relationship is stronger because of that bond that started only because their screen share showed something they didn’t realize.
# Its Your Interview
When you interview in person, you are usually in their office on their terms. When you interview remotely, you have a lot more say in how that interview goes. Everything from the technology, what is seen and heard are all things you can nudge to be slightly in your favor. Next time you interview remotely, take some time and think about how you want your interviewers to experience you. Have a strategy to engage them on your terms. Leave the impression you want them to have. | recursivefaults |
318,620 | COVIDiary pt. 4.5 - Database Fixes | Welcome to Part 4.5 of the COVIDiary project! If you’re just joining us or missed a post, here’s... | 0 | 2020-04-24T16:31:08 | https://www.codewitch.dev/covidiary_pt_4_5_-_database_fixes | beginners, codenewbie, database | ---
title: COVIDiary pt. 4.5 - Database Fixes
published: true
date: 2020-04-24 16:21:20 UTC
tags: #beginners #codenewbies #database
canonical_url: https://www.codewitch.dev/covidiary_pt_4_5_-_database_fixes
---
<center>
<img alt="Cool Cats and Kittens" src="https://media.giphy.com/media/RGixkYkOKdWATSReHt/source.gif">
</center>
Welcome to Part 4.5 of the COVIDiary project! If you’re just joining us or missed a post, here’s what we’ve done so far:
- [Part 1: Project Introduction](https://dev.to/audthecodewitch/covidiary-a-rails-react-project-2gl6)
- [Part 2: Initial Setup](https://dev.to/audthecodewitch/covidiary-part-2-initial-setup-2g2d)
- [Part 3: Building the Database](https://dev.to/audthecodewitch/covidiary-pt-3-building-the-database-4o04)
- [Part 4: Frontend Setup](https://dev.to/audthecodewitch/covidiary-pt-4-frontend-setup-3cp1)
This week, we’re going to work on our PostgreSQL database in the `CD-api` directory. By the end of today, we will:
1. Fix improper boolean names
2. Add is\_public boolean to entries
3. Update seed file
4. Reset database
## Ch-ch-ch-CHANGES
I was reading up on naming conventions this week, and I came across [this article](https://dev.to/michi/tips-on-naming-boolean-variables-cleaner-code-35ig). I realized the boolean names in our tables did not follow best practices, and I set about changing them.
<center>
<img alt="Good Idea at the Time" src="https://media.giphy.com/media/gKGzjtXVrVPIsgbREz/source.gif">
</center>
I’m going to go into Part 3 and fix the mistakes I made. If you’ve been coding along with me, check out the video below to see how to make the changes yourself!
<center>
{% youtube MVqeF7RTjAk %}
</center>
## Coming Up
Next week, we’ll work on setting up our routes, serializers, and controllers so the front and back ends can talk to one another. Until then, stay well!
<center>
<img alt="Stay Home" src="https://media.giphy.com/media/lQ701BEcCllM2BOQpR/source.gif">
</center> | audthecodewitch |
318,732 | From Firewalls to Security Groups | Originally posted at https://cyral.com/blog/from-firewalls-security-groups Several large enterprises... | 0 | 2020-04-24T19:59:53 | https://cyral.com/blog/from-firewalls-security-groups | security, aws, devops, cloud | _Originally posted at_ [_https://cyral.com/blog/from-firewalls-security-groups_](https://cyral.com/blog/from-firewalls-security-groups)
Several large enterprises we work with at Cyral are working on shifting to a fully cloud-native architecture, and end up leaning on us as a partner to help them fully leverage all the tools at their disposal (one of our engineers recently shared this excellent [presentation](https://www.linkedin.com/feed/update/urn:li:activity:6658825750139019267/) he had made before a bank). One of the common themes we see is security teams worrying about firewalls becoming less effective in the cloud-native world, and we often find ourselves explaining how tools like AWS security groups are even more powerful and can be used instead. We thought it was worthwhile to write a blog post on this topic.
For decades, companies have only relied on physical network devices called firewalls to wall off and protect their digital footprint. With the meteoric rise and adoption of cloud computing, these devices have been replaced by software defined access controls that now protect increasingly complex cloud native infrastructure. In a traditional network environment, a firewall was placed at the perimeter of the trusted and untrusted zones of the network, monitoring and typically blocking most traffic. In a cloud-native world, modern applications scale up and down ephemeral resources in response to traffic. These ephemeral instances no longer solely exist in a trusted network on site at a corporate office or dedicated data center and require new controls to protect them.
Traditional firewalls were designed to parallel physical security controls. The term firewall was first used by T. Lightoler in 1764[1] in the design of buildings to separate rooms from others that would most likely have a fire such as a kitchen. Firewalls are still used in modern construction to this day. Depending on the type of construction, firewalls are used to slow the spread of a fire, between rooms in a single family home or between adjoining buildings such as in a row home or townhome in order for the occupants to be able to escape [[2](https://ncma.org/resource/detailing-concrete-masonry-fire-walls/)]. In the physical world, firewalls are rated on the length of time provided to slow down a fire [[3](https://en.wikipedia.org/wiki/Firewall_(construction)#Performance_based_design)]. In the digital world though, firewalls are often thought of as completely blocking outside threats and not merely as a temporary barrier that can eventually be breached.
Network device firewalls were implemented to function as the gate or physical walls of a castle as put forth in the [Castle Model of security](https://www.sciencedirect.com/science/article/abs/pii/S0740624X16300120). This methodology called for building walls which protected the barriers but left the inside of the castle unprotected. Home networks and many corporate offices are still designed this way and still have devices acting as firewalls. These networks are generally end user computers and do not serve content to any other users. Computer network firewalls have existed “since about 1987” as detailed in [_A History and Survey of Network Firewalls_](https://www.cs.unm.edu/~treport/tr/02-12/firewall.pdf) published in 2002 by Kenneth Ingham and Stephanie Forrest. Firewalls have long been promised as the panacea for completely blocking attacks, instead though, they should be viewed as most physical firewalls are: a temporary barrier. To that end, many companies are now moving to a zero trust model where a firewall is only the first barrier protecting the outside and the inside is no longer implicitly trusted [[4](https://www.usenix.org/system/files/login/articles/login_dec14_02_ward.pdf)].
The power of a virtual firewall is that it no longer needs to only have coarse grained filters at the edges of a network. Virtual firewalls can now be assigned to groups of instances and be referenced by others in their configuration. Virtual firewalls are not beholden to network segmentation or physical location they were first set up for. In the classic three tier model, you can now create three virtual firewalls to protect the individual tiers and reference those tiers specifically. In this model, you create individual firewalls for the frontend, application and data layers. In the frontend firewall configuration, you allow https access to only those instances that are responsible for serving frontend content. At the second tier, you reference the frontend firewall only allowing it to access the application layer and block broad access to your application. Finally, at the data layer, you reference the application firewall and allow it direct access to the data layer but block all other access.
In Amazon Web Services (AWS) these virtual firewalls are called security groups. One of the key differences between AWS security groups and classic firewalls is that you can only specify rules that allow traffic. All traffic is implicitly blocked except for the rules that you define to allow. The other key feature of security groups that may differ is that all rules are stateful. When you allow traffic in on a specific port, you do not need to specify allow rules for the return traffic. Security groups function similarly to the classic network firewall model, your allow rules specify a protocol (TCP or UDP) and a port. Security groups can not perform deep packet inspection based on the type of traffic that it evaluates.
In the example below, we look at how you would configure three security groups for the classic three tier architecture. In each example, we choose either a predefined Type which will automatically fill out the Protocol and Port range, or you can choose the Protocol and Port range yourself.
_Fig 1. MyWebServer security group allows access to HTTP and HTTPS from anywhere_
_Fig 2. MyApplicationServer security group only allows access to HTTPS directly from the MyWebServer security group. All other access is implicitly blocked_
_Fig 3. MyDatabaseServer security group only allows access from the MyApplicationServer security group. All other access is implicitly blocked_
AWS has now consolidated security group configuration at the VPC level. In the console, you can access their configuration from the EC2 page or via the VPC page. VPC’s can also implement [network access control lists](https://docs.aws.amazon.com/vpc/latest/userguide/vpc-network-acls.html) (ACL) that can provide yet another layer of security that is akin to a traditional firewall device. Network ACLs follow the standard firewall convention that you are familiar with including, inbound and outbound rules as well as applying rules in order. Network ACLs are best used as an enforcement of separation of duties, use Network ACLs to enforce minimum policy and security groups for fine grained control of instances. For example, a network ACL could be used to enforce SSH only from a bastion host preventing a security group opening up direct SSH. Security groups are much more flexible, whereas Network ACLs should be used as a backup mechanism.
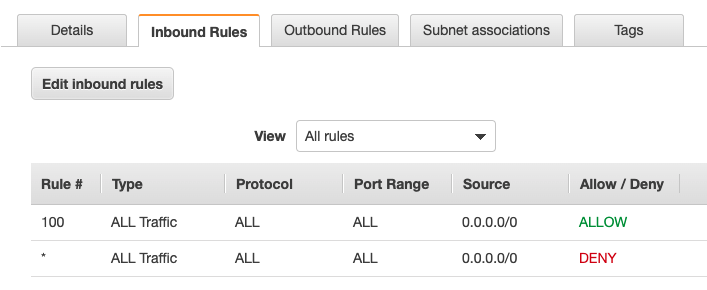
_Fig 4. Default Network ACL giving your instances network access_
As your footprint grows, your security groups can quickly grow out of hand. We’ve found that managing security groups as code with [Terraform](https://www.terraform.io/docs/providers/aws/r/security_group.html) or similar helps with this issue. You should also be mindful of security group quotas. The defaults are 2500 groups per region and 60 inbound and 60 outbound rules. Inbound and outbound rules are enforced separately for IPv4 vs IPv6. If enabled, Trusted Advisor will flag security groups that have more than 50 total rules for performance reasons.
AWS has recognized many of the pitfalls associated with managing security groups per VPC per account and announced their [AWS Firewall Manager](https://aws.amazon.com/firewall-manager/pricing/) service in 2018. This is an add on service to AWS Shield and AWS WAF. AWS Firewall Manager for security groups allows you to manage “security groups for your Amazon VPC across multiple AWS accounts and resources from a single place”. Read more on this service [here](https://docs.aws.amazon.com/waf/latest/developerguide/getting-started-fms-security-group.html) or watch this [tech talk](https://www.youtube.com/watch?v=w-zbsmpi7vw).
AWS security groups are an incredibly powerful tool when used in the context of a cloud-native environment. Their simplicity and focus on pure network traffic are a forcing function for clear separation of infrastructure tiers. Their simplicity also gives you the guarantee that they will not interfere with the speed with which you can scale your application. A cloud-native infrastructure provides you with the flexibility to leave the old guard behind and focus on what matters most.
[1] Lightoler, T. 1764. _The gentleman and farmer’s architect. A new work. Containing a great variety of ... designs. Being correct plans and elevations of parsonage and farm houses, lodges for parks, pinery, peach, hot and green houses, with the fire-wall, tan-pit, &c particularly described ..._ R. Sayer, London, UK
_Image by Elio Reichert via the OpenIDEO Cybersecurity Visuals Challenge under a Creative Commons Attribution 4.0 International License_ | dant24 |
318,739 | JavaScript: Execution Context and Lexical Scope | When I can't fully explain something I try to go back and understand it better and often create notes. These are my notes from trying to further explain both JavaScript's execution context and lexical scope. | 0 | 2020-04-24T20:50:45 | https://dev.to/coffeecraftcode/javascript-execution-context-and-lexical-scope-5h4m | javascript, beginners, webdev, learning | ---
title: JavaScript: Execution Context and Lexical Scope
published: true
description: When I can't fully explain something I try to go back and understand it better and often create notes. These are my notes from trying to further explain both JavaScript's execution context and lexical scope.
tags: #javascript #beginner #webdev #learning
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/fljet8d7uak9nq89kdhl.jpg
---
When I can't fully explain something I try to go back and understand it better and often create notes. These are my notes from trying to further explain both JavaScript's execution context and lexical scope.
## Global Execution Context
When your code initially runs, JavaScript creates what is called a Global Execution Context.
This context gives us access to two things right off the bat.
- First is the global `this`
- Second is a global object. In the browser this global object is the window.

In the above image I have opened a web page that only has html. There is a single paragraph element.
Yet, in the console I can type in both this and window and see that they are available to me.
The other thing to note is that currently they are the same thing.
`this === window`
### Global Variables
In JavaScript(JS), if we create a variable like `var aNewVariable = "Hello world"`
this variable will now be globally available.
Let's look at the variable in the console.
Inside my JS panel I add the new variable.

In the console I can call that variable by its name or with the global window object.
If we type in window and open that up we will also see our new variable.
{% codepen https://codepen.io/cgorton/pen/KKdWqQE default-tab=js,result %}
We are now getting in to what is referred as the Lexical Environment or Lexical Scope.
### Lexical Environment
Right now our variable is `scoped` to the global window object. If we created extra functions or variables those would also be `scoped` to our global object.
The lexical scope refers to where the code is written.
Let's look at an example of where a function would not be globally scoped.
I've created a silly function called `myName()` that returns another function called `firstName()`. If I were to go to the console and type firstName() what do you think would happen?

We get `undefined.`
This function is `scoped` to the `myName()` function and is not available on the global object.
`myName()` is available on the global window object and when we type in `myName()` we now can see our firstName function and what `myName` returns.

In this case `firstName` is executed inside our `myName` function and returns "Christina" .
{% codepen https://codepen.io/cgorton/pen/abvJGpw default-tab=js,result %}
More on `function execution context` in a bit.
### Hoisting
>"Hoisting is a JavaScript mechanism where variables and function declarations are moved to the top of their scope before code execution." - [Mabishi Wakio](https://scotch.io/tutorials/understanding-hoisting-in-javascript)
If you have a variable declared with `var` or a `function` declaration, JavaScript will `hoist` it or allocate memory for it after the first run through of your code.
So if your code looked something like this:
```jsx
console.log(perfectMatch)
austenCharacter();
var perfectMatch = "Willoughby"
function austenCharacter() {
console.log("Colonel Brandon")
}
```
What would you expect to see in the console?
In the console we get `undefined` and `Colonel Brandon`.
What is going on here?
When the JS engine had a first pass at our code it looked for all of the `var` variables and functions and allocated memory to them.
So in the case of `perfectMatch` when the code runs the first time it stores our variable `perfectMatch` as undefined. We do not actually define the variable until later on in the code but we do store the actual variable in memory.
Our function is also `hoisted` or stored in memory but because it is a complete function we can execute the code inside even if `austenCharacter();` is called before the function is defined in our code.
Because it has been `hoisted` JavaScript has kept this function in memory and wherever we then place the function call `austenCharacter();` no longer matters.
## Local execution context
Another type of execution context happens within functions.
When a function is called a new execution context is created.
Below is a common Javascript interview question surrounding local execution context.
After looking at scope and hoisting a bit what do you think will happen when this code is run?
```jsx
var perfectMatch = "Willoughby"
var newMatch = function () {
console.log(perfectMatch + " is the perfect match") // what do we expect?
var perfectMatch = "Colonel Brandon"
console.log(perfectMatch + " is the perfect match") // what do we expect?
};
newMatch()
```
You might expect the first console.log to be "Willoughby is the perfect match" and the second to be "Colonel Brandon is the perfect match".
What we actually get is similar to what happened in our previous example.
First we get undefined and then we get
`"Colonel Brandon is the perfect match".`
{% codepen https://codepen.io/cgorton/pen/OJypOoE default-tab=js,result %}
When our function is called it is looking inside itself for its variables.
A new execution context, in this case a function or local execution context, executed.
So within the function JavaScript looks for the `var` variables and then runs the console.logs.
It allocates perfectMatch to undefined initially so when we run the first
`console.log(perfectMatch + " is the perfect match")`
it returns `undefined`.
We then define it with `var perfectMatch = "Colonel Brandon"`
And can then see "Colonel Brandon is the perfect match" with the second console.log.
Our code:
```jsx
var newMatch = function () {
console.log(perfectMatch + " is the perfect match") // what do we expect?
var perfectMatch = "Colonel Brandon"
console.log(perfectMatch + " is the perfect match") // what do we expect?
};
```
A representation of our code after hoisting:
```jsx
var newMatch = function () {
var perfectMatch = undefined // our hoisted variable
console.log(perfectMatch + " is the perfect match") // So now this console.log is undefined
var perfectMatch = "Colonel Brandon" // we now define our variable as "Colonel Brandon"
console.log(perfectMatch + " is the perfect match")
// Now we can console.log our newly defined variable:
// "Colonel Brandon is the perfect match"
};
``` | coffeecraftcode |
318,819 | Creating a basic blog with Eleventy and Netlify CMS completely from scratch | New video version available! Eleventy is a powerful and wonderfully simple static site generator. Ne... | 0 | 2020-04-24T23:46:18 | https://dev.to/koabrook/creating-a-basic-blog-with-eleventy-and-netlify-cms-completely-from-scratch-197e | webdev, netlify, tutorial, beginners | [New video version available!](https://www.youtube.com/watch?v=WEApDhZMAL4)
[Eleventy](https://www.11ty.dev/) is a powerful and wonderfully simple static site generator. [Netlify CMS](https://www.netlifycms.org/) is a simple, open-source content management system that makes adding, editing and deleting posts and other content a breeze. Today I'm going to show you how to create a basic blog using eleventy and Netlify CMS, entirely from scratch- no boilerplates, no templates, no nothing. Be aware that this tutorial will create an absolute bare-bones text blog for you to build upon- I'm not even adding CSS! Let's get to it.
##Part 1: Setting up
###Requirements:
- Node.js and NPM installed
- Git installed
- A Git provider such as GitLab or GitHub
- A free Netlify account
First, there're some things we need to get set up before we begin coding. First, create a git repository on your preferred service (I use and recommend [GitLab](https://gitlab.com/)) and clone the empty repo to your computer.
Enter the project root with your terminal and install eleventy by typing `npm install @11ty/eleventy --save-dev`. Once that is done, install luxon by typing `npm install luxon`. Luxon is the only special addition here and will allow us to format readable dates in our posts.
Create a new folder in the project's root and name it `_includes`. This folder will contain templates that our blog will use to render pages. Create another new folder in the root directory called `images` and another inside of that called `uploads`. Netlify CMS will use this folder to store images uploaded to your site. Create *yet another folder* in the root of your project called `admin` and finally, a folder in the root named `posts`. Once that's done, we're ready to start coding!
Create a file in the root of the project named `.eleventy.js` and write this in:
```
module.exports = function(eleventyConfig) {
eleventyConfig.addPassthroughCopy('images')
eleventyConfig.addPassthroughCopy('admin')
const {
DateTime
} = require("luxon");
// https://html.spec.whatwg.org/multipage/common-microsyntaxes.html#valid-date-string
eleventyConfig.addFilter('htmlDateString', (dateObj) => {
return DateTime.fromJSDate(dateObj, {
zone: 'utc'
}).toFormat('yy-MM-dd');
});
eleventyConfig.addFilter("readableDate", dateObj => {
return DateTime.fromJSDate(dateObj, {
zone: 'utc'
}).toFormat("dd-MM-yy");
});
};
```
The `eleventy.js` file is a configuration file. The `addPassthroughCopy` lines tell Eleventy to include those folders and their contents in the generated site. The rest is just some JavaScript to make the dates in the postslist more readable.
Now create another folder within `_includes` named `layouts`. Within that folder we can create a new file called `base.njk`. The `base` file forms the basis of every page on our website. We'll add add `<head>` elements and a site header here. Any element that should appear on *every single page* should reside in `base.njk`. Let's add the following to the file:
```
<html>
<head>
<title>Eleventy + Netlify CMS from scratch</title>
</head>
<body>
<h1>
Eleventy + Netlify CMS from scratch
</h1>
{{ content | safe }}
</body>
</html>
```
Like I said: Bare bones. Note the line that says `{{ content | safe }}`: this is where page content for other pages will be rendered.
Now, create a file named `index.njk` at the **root of your project**. This will be your homepage. Add the following to `index.njk`:
```
---
layout: layouts/base.njk
permalink: /
---
Hello! Welcome to the Eleventy + Netlify from scratch homepage.
```
Our Nunjucks (`.njk`) files will accept html, markdown and more. Between the sets of hyphens lies our page's **frontmatter**. This data tells Eleventy how to handle our page and provides other information as we need it to. `layout` tells it which template to use, in this case `base.njk` whilst `permalink` tells it what the URL for this page will be (in this case, `/`, or the homepage). Anything under the hyphens will be used as the main content on the page. You can use text, markdown or html to create the body. In this case I simply use a line of text.
Now open your terminal back up and run this command:
`npx eleventy --serve`
If your website doesn't open automatically, browse to `localhost:8080` and you should see our homepage!
##Part 2: Blog posts
Let's add a page that will be used for blog posts next. In the `_includes/layouts` folder, add a new file called `post.njk`. We'll come back to this in a minute, but first let's create a basic blog post. In the `posts` folder, create a file called `posts.json` and add the following:
```
{
"tags": "posts"
}
```
This will ensure that every post in this folder has the correct tag attached. Now add a file in the `posts` folder named `my-first-post.md`. Even though this is a markdown file, we will still add some frontmatter here. Add the following code to `my-first-post.md`:
```
---
layout: layouts/post.njk
title: My first post
description: The first post on the Eleventy + Netlify CMS from scratch blog
date: 2020-04-18
featuredImage: /images/uploads/image1.jpeg
---
Hello, here is the body of the post.
```
Let's take a look at our frontmatter:
- `layout` tells this post which template to use, in this case `layouts/post.njk`
- `title` is the title of the post
- `description` is a short description of the post
- `date` is the date the post was written
- `featuredImage` is an image for the post. Drop any image you want into `images/uploads` and use its path- mine is `image1.jpeg`
Again, anything underneath the frontmatter will be the blog post content. Note that we won't be creating posts like this in future since the Netlify CMS will take care of it for us!
Now that our post is ready, lets render it. Add the following to `_includes/layouts/post.njk`:
```
---
layout: layouts/base.njk
---
<h2>{{ title }}</h2>
<h3>{{ date | readableDate }}</h3>
<img src="{{ featuredImage | url }}" alt="{{ featuredImage }}"></img>
<p>{{ content | safe }}</p>
```
Our post page uses the `layouts/base.njk` template and renders blog post data in its body. We use double brackets `{{ }}` to refer to data in the post's frontmatter. In the case of `my-first-post.md`, the `{{ title }}` will end up being `My first post`, which we provided in the markdown file. Eleventy will create a blog post page for every markdown file in the `posts` folder. Neat!
We now have a working blog, but no way to see the posts. Let's fix that by adding a new file in the `_includes` folder called `postslist.njk`. This file will use a `For Loop` to create a list of all of our posts. Add this to the file:
```
<ul>
{% for post in postslist %}
<li>
<strong>
<a href="{{ post.url | url }}">{{ post.data.title }}</a>
</strong>
-
<time datetime="{{ post.date | htmlDateString }}">{{ post.date | readableDate }}</time>
-
<span>{{ post.data.description }}</span>
</li>
{% endfor %}
</ul>
```
With the above code, Eleventy searches for every post in a variable called `postslist` and renders the title, date and description of each. To create the `postslist` variable, create a new file in the root of the project called `posts.njk`:
```
---
layout: layouts/base.njk
permalink: /posts/
---
{% set postslist = collections.posts %}
{% include "postslist.njk" %}
```
This file populates the `postslist` variable with every `post` that has the tag `posts`. Earlier we created `posts.json` to take care of the tagging for us! If all is well, you can now browse to `localhost:8080/posts/` to see your list of posts! Feel free to add a couple more posts as `.md` files in the `posts` folder to see how they show up.
The very last thing to do with the blog portion of our website is to go back to `index.njk` at the project root and add this line at the bottom:
```
{% set postslist = collections.posts %}
{% include "postslist.njk" %}
```
The `includes` keyword basically embeds the file into the current page- we're rendering `postslist.njk` inside the homepage, which now shows your post list as well!
Whew! We're done with this part. Go over to your terminal and push the changes to your Git repository.
##Part 3: Netlify CMS
Now it's time to set up the Netlify CMS. First we'll have to get our website hosted with Netlify. Login to Netlify and click `New site from Git`. Login with your Git provider (I use GitLab) and authorize Netlify to access your repositories. Select your repo from the list. Under `Basic build settings`, set the `Build command` to `npx eleventy` and the `Publish directory` to `_site`. Click `Deploy site`.
After your deploy completes, you will see a link (ending with `.app`) that will take you to your live blog.
In the menu above your site URL, click `Identity`.
On the Identity screen, click `Enable Identity`. After it's enabled, click `Settings and usage` and find `Services`. Click `Enable Git Gateway`. Sign in again if prompted.
In the above steps we have successfully created a live website with Netlify. We also enabled Netlify's Identity feature which will take care of authentication and accounts for us. Finally, we enabled Git Gateway, which is an API that will let the Netlify CMS commit changes to the git repository without needing to re-authenticate or give anybody access to it directly.
Back in your project, create `index.html` inside the `admin` folder. In this file we will add some basic HTML [provided by Netlify](https://www.netlifycms.org/docs/add-to-your-site/#app-file-structure) which loads the CMS UI and authorization widget:
```
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Content Manager</title>
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script>
</head>
<body>
<!-- Include the script that builds the page and powers Netlify CMS -->
<script src="https://unpkg.com/netlify-cms@^2.0.0/dist/netlify-cms.js"></script>
</body>
</html>
```
Create another file in the `admin` folder named `config.yml`. .YML files rely on accurate indentation. Be sure to use **spaces to indent, not tabs**! First, we will enable the Git Gateway API by adding the following:
```
backend:
name: git-gateway
branch: master # Branch to update
```
Now we'll point to our `images/uploads` folder, which is where pictures uploaded from the CMS will be stored, however since Eleventy stores our static site in the `_site` folder, we also need to add a public folder too. Add these lines underneath `branch: master`, making sure the lines are **not** indented:
```
media_folder: "_site/images/uploads"
public_folder: "/images/uploads"
```
The last thing to do is to create a **collection** for our posts. We'll use the `config.yml` file to create this collection, and **it will match the frontmatter we set in our post markdown files** earlier. Add this under the `media_folder:` line we just created:
```
collections:
- name: "posts" #The name of the collection and should match our posts.json file's tag
label: "Posts" #The name of the collection on the CMS itself
folder: "posts" #The folder that our blog posts will be loaded from and saved to
create: true #Tells the CMS that new posts can be created
slug: "{{year}}-{{month}}-{{day}}-{{slug}}" #this sets the URL for the post
fields:
- {label: "Layout", name: "layout", widget: "hidden", default: "layouts/post.njk"}
- {label: "Title", name: "title", widget: "string"}
- {label: "Description", name: "description", widget: "string"}
- {label: "Date", name: "date", widget: "date", default: ""}
- {label: "Post Body", name: "body", widget: "markdown"}
- {label: "Featured Image", name: "featuredImage", widget: "image"}
```
Let's explore the `fields` section. Notice that each field matches the frontmatter of our `my-first-post.md` file. Let's also explore each part of each line:
- `label` is the name of the field that will appear in the CMS
- `name` is the name of the field, it must match the frontmatter exactly
- `widget` tells the CMS which widget to display from a selection. `string` is a single line of text and others are available, listed [here](https://www.netlifycms.org/docs/widgets/). `markdown` is generally used for the post content.
- `default` sets a default value for the field
A full explanation of the collections section can be found [here](https://www.netlifycms.org/docs/add-to-your-site/#collections). A collection doesn't have to be for posts only- you can add one for individual pages or even individual datasets. That is beyond the scope of this article, however.
The last thing to do is to return to `layouts/base.njk` and add this line and add it before the closing `</head>` tag:
`<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script>`
In the same file, add this before your closing `</body>` tag:
```
<script>
if (window.netlifyIdentity) {
window.netlifyIdentity.on("init", user => {
if (!user) {
window.netlifyIdentity.on("login", () => {
document.location.href = "/admin/";
});
}
});
}
</script>
```
Great news: You're pretty much done! Save, commit your changes and push your project. Wait for the deploy to complete (make sure your commit says `Published` in Netlify under `Production deploys`) then go to your website's url. Add /admin to the url and you'll be transported to the login screen! Log in and you'll be taken to the Netlify CMS backend where you can create and edit posts and upload media! Please be aware that posts added via the CMS can take a few minutes to appear after you submit them. Netlify will re-deploy your site when a new post is added!
This tutorial was a very quick and crude integration of Eleventy and Netlify CMS, however it should help you to understand *how* the two connect, rather than using a boilerplate or template blog, which can easily be too cluttered from the get-go. I hope that this tutorial was helpful in showing you how you can build a simple blog with a back-end editor with very little time and effort. I encourage you to play around with frontmatter, different collections and pages. Please reach out to me on Twitter @KoaBrook with any questions or feedback, as well as to show you your attempts!
## Resources
- [11ty.dev](https://11ty.dev)
- [Netlify CMS](https://www.netlifycms.org/)
- [Eleventy Base Blog](https://www.netlifycms.org/): Provided the starting steps for my journey with Eleventy! | koabrook |
318,859 | Step Indicator in SwiftUI | This SwiftUI iOS cocoapods library is used for indicating step actions for series of steps involved f... | 0 | 2020-04-25T01:17:09 | https://dev.to/badrinathvm/step-indicator-in-swiftui-4n7e | swiftui, ios, stepindicator, swift | This SwiftUI iOS cocoapods library is used for indicating step actions for series of steps involved for any task. For eg: if you wanna illustrate the steps for collecting cash from an ATM , steps involved for any loan application. etc..
Here’s the library which does the work with just couple of lines which accepts below View Modifiers
```swift
.addSteps(_ steps: [View]) : array of views to be rendered closer to indicator
.alignments(_ alignments: [StepperAlignment]) : optional defaults to .center, available with custom options either .top, .center, .bottom sections
.indicatorTypes(_ indicators:[StepperIndicationType]): enum provides the options to use .circle(color, width) , .image(Image, width) , .custom(AnyView)
.lineOptions(_ options: StepperLineOptions): color, thickness line customization.
.spacing(_ value: CGFloat): spacing between each of the step views.
.stepIndicatorMode(_ mode: StepperMode): vertical, horizontal display modes.
```
```swift
var body: some View {
StepperView()
.addSteps([Text("Account"), Text("MemberShip"))
.indicators([.center,.center])
.stepIndicatorMode(StepperMode.horizontal)
.spacing(50)
.lineOptions(StepperLineOptions.custom(1,Colors.blue(.teal).rawValue))
}
```
__References__:
[Cocoapods](https://cocoapods.org/pods/StepperView)
[Github](https://github.com/badrinathvm/StepperView)
[More Documentation](https://badrinathvm.github.io/StepperView/)
Feel free to request any new features or create a pull request.
Happy Coding..!
| badrinathvm |
318,907 | *Intermediate Algorithm Scripting: Arguments Optional | /*Intermediate Algorithm Scripting: Arguments Optional Create a function that sums two arguments toge... | 0 | 2020-04-25T03:25:46 | https://dev.to/95freedom95/intermediate-algorithm-scripting-arguments-optional-48gh | replit, node | ---
title: *Intermediate Algorithm Scripting: Arguments Optional
published: true
tags: replit, nodejs
---
/*Intermediate Algorithm Scripting: Arguments Optional
Create a function that sums two arguments together. If only one argument is provided, then return a function that expects one argument and returns the sum.
For example, addTogether(2, 3) should return 5, and addTogether(2) should return a function.
Calling this returned function with a single argument will then return the sum:
var sumTwoAnd = addTogether(2);
sumTwoAnd(3) returns 5.
If either argument isn't a valid number, return undefined.
**/
function addTogether(a,b) {
if(typeof a === 'number' && typeof b === 'number' || !isNaN(b)){
a+=b;
}if(typeof a === 'number' && !isNaN(a) && typeof b === 'number' && !isNaN(b)){
return a;
}if(typeof a === 'number' && !isNaN(a)){
var sumTwoAnd = function arr(e){
if(typeof a === 'number' && !isNaN(a) &&typeof e === 'number'){
e+=a; console.log(e); return e
}
}
sumTwoAnd(3);
return sumTwoAnd ;
}
}
addTogether(2);
/*
addTogether(2, 3) should return 5.
Passed
addTogether(2)(3) should return 5.
Passed
addTogether("http://bit.ly/IqT6zt") should return undefined.
Passed
addTogether(2, "3") should return undefined.
Passed
addTogether(2)([3]) should return undefined.*/
/*https://www.freecodecamp.org/learn/javascript-algorithms-and-data-structures/intermediate-algorithm-scripting/make-a-person*/
{% replit @oscarhernandez6/Intermediate-Algorithm-Scripting-Arguments-Optional %} | 95freedom95 |
318,955 | Apache Kafka in a Nutshell | So, you’ve heard of this Kafka thing that’s popping up all over the shop. From green-sprout startups... | 0 | 2020-04-25T06:15:05 | https://medium.com/swlh/apache-kafka-in-a-nutshell-5782b01d9ffb | apachekafka, eventsourcing, eventstreaming, microservices | So, you’ve heard of this Kafka thing that’s popping up all over the shop. From green-sprout startups to greedy multi-nationals, in all sorts of weird and wonderful contexts. It appears that someone has figured out a Swiss Army knife piece of über-tech that works for microservices, event-streaming, CQRS, and just about anything else that makes the headlines.
As someone who’s been working with Apache Kafka since 2015, helping several clients build complex event-driven and microservices-style applications, I’ve heard my fair share of questions. First, it was I who was doing most of the asking. Then I found myself on the receiving end. At the time of writing, I’m trending among the [top-ten writers on Quora](https://www.quora.com/topic/Apache-Kafka/writers) — a feat I owe mostly to the mistakes I’ve made along the way, which have made me a little more aware. With the shameless chest-beating out of the way, I thought I’d put together an FAQ-style post that breaks Kafka down, focusing on the aspects that matter.
[Read the rest of the article on Medium](https://medium.com/swlh/apache-kafka-in-a-nutshell-5782b01d9ffb) | ekoutanov |
319,069 | Reading Snippets [55 => Scoping] | It is important to try and avoid scope pollution when using global variables in a program. Tightly sc... | 0 | 2020-04-25T08:51:09 | https://dev.to/calvinoea/reading-snippets-55-scoping-3h6k | codenewbie, beginners, javascript | It is important to try and avoid scope pollution when using global variables in a program. Tightly scoping variables using the block scope provides several advantages:
🙂 Makes code more legible as blocks organize code in discrete sections
🙂 Makes code easier to understand
🙂 Makes code easier to maintain
🙂 Saves memory in code
<kbd><small><a href="https://www.codecademy.com/courses/introduction-to-javascript/lessons/scope/exercises/block-scope-ii">Codecademy: JavaScript Course</a></small></kbd>
| calvinoea |
319,078 | Uploading a file - Svelte form and SpringBoot backend | Introduction Some web applications require files to be used for data entry or processing, and, typic... | 0 | 2020-04-25T16:10:26 | https://dev.to/brunooliveira/uploading-a-file-svelte-form-and-springboot-backend-18m6 | spring, svelte, files, api | **Introduction**
Some web applications require files to be used for data entry or processing, and, typically, they come in the form of a user uploaded file that gets sent to the back-end for further processing.
The file is uploaded through a form and sent to the back-end where the file can be processed and a response sent back to the UI. There are many ways to go about it, but, here, I will build a very simple Svelte upload form for the front-end that uses the fetch API to upload the file and SpringBoot to maintain the endpoint that will receive and process the file.
**The Svelte upload form**
A very simple, barebones upload component will look like:
It will contain a basic file input html component and will show the name of the file when the user selects it.
The code for the component is the following:
```svelte
<script>
let files;
let dataFile = null;
function upload() {
const formData = new FormData();
formData.append('damName', value);
formData.append('dataFile', files[0]);
const upload = fetch('http://localhost:8080/file', {
method: 'POST',
body: formData
}).then((response) => response.json()).then((result) => {
console.log('Success:', result);
})
.catch((error) => {
console.error('Error:', error);
});
}
</script>
<input id="fileUpload" type="file" bind:files>
{#if dataFile && files[0]}
<p>
{files[0].name}
</p>
{/if}
{#if value}
<button on:click={upload}>Submit</button>
{:else}
<button on:click={upload} disabled>Submit</button>
{/if}
```
In Svelte, a component is defined entirely in a single file, containing both styles and logic, embedded respectively, in the tags: `<style></style>` and `<script></script>`, just like in standard HTML files.
Below both of these tags (note, the styles are optional), you can define the standard HTML for the component, all bundled in a single file with the `.svelte` extension.
As we see, we have at our disposal a sort of templating engine that allows to define looping constructs, ifs, lifecycle constraints on the components, amongst many other things. Add to this the fact that all of it is bundled in a single source file, and it becomes very easy and intuitive to structure your Svelte applications in terms of components and data flow between them, and as I explore the framework more, I keep finding more interesting and powerful concepts, and I can at this point recommend everyone to try it!
**Svelte feels to me like writing applications in the plain old CSS,JS and HTML stack, but, with exactly the right level of encapsulation and abstraction added on top, that offers great component building blocks for designing apps in a much cleaner way.**
As per our component, we simply define a simple HTML file input field, and we **bind** the files variable to it. In Svelte, this means that when the value for that input field will change, it will be bound to the `files` variable.
On the submit button we add the logic to fill in and send the form to the backend using a POST request with the fetch API.
Note the `let` keyword to declare variables and also the if/else syntax, used to display the name of the file after the user uploaded it, and also to enable the submit button. This is a simple example of the Svelte template syntax.
With our front-end component written, we can now look at the backend code.
**The SpringBoot back-end endpoint to receive a file**
The fetch API shown above, will send a POST request to `http://localhost:8080/file` to send the file to the backend, that should be running. In our case, this will be a basic SpringBoot app, with a single endpoint listening on port 8080. Let's look at the code:
```java
@PostMapping(value = "/file",consumes = "multipart/form-data", produces = "application/json")
public ResponseEntity<List<PlotDataDTO>> uploadData(
@RequestPart("dataFile") @Valid @NotNull @NotBlank MultipartFile dataFile) throws IOException {
fileProcessingService.processDTO(new DamFileDTO(dataFile));
return fileProcessingService.getPlotData();
}
```
I will quickly highlight some useful things in this simple Spring endpoint that are important to get right:
- this is an endpoint that only accepts POST requests, as indicated by the `@PostMapping` annotation on its header. This is because we are *sending* data;
- the endpoint consumes data of type `"multipart/form-data"`, to tell Spring that we are receiving data which originated from a form, as opposed to simple request body;
- to keep in sync with the type of data that the endpoint consumes, in the method, we annotate our parameters as `@RequestPart`, to indicate that it's a part of the form we are receiving here. The name used here in the annotation needs to match the field in the form;
If we do this correctly, we will now have our uploaded file stored inside the `dataFile` variable. Then, we pass it to a `FileProcessingService` class, that can process it, encapsulating any logic within.
Our service can look like this, assuming we were reading a XLS file:
```java
@Service
public class FileProcessingService {
private final List<PlotDataDTO> dataToPlot = new ArrayList<>();
public FileProcessingService() {
}
public void processDTO(DamFileDTO file) throws IOException {
dataToPlot.clear();
MultipartFile f = file.getDataFile();
XSSFWorkbook workbook = new XSSFWorkbook(f.getInputStream());
XSSFSheet worksheet = workbook.getSheetAt(0);
for(int i=1;i<worksheet.getPhysicalNumberOfRows() ;i++) {
PlotDataDTO plotData = new PlotDataDTO();
XSSFRow row = worksheet.getRow(i);
plotData.setTime(row.getCell(0).getNumericCellValue());
plotData.setAcceleration(row.getCell(1).getNumericCellValue());
dataToPlot.add(plotData);
}
}
```
So, we can extract and read the data in our uploaded file easily from our service and do any business logic there to prepare a response.
This completes the entire flow of uploading a file and reading it in the backend.
**Conclusion**
We saw how we can integrate Svelte and SpringBoot to upload and process a file and how flexible Svelte can be! Any questions, suggestions, tips, are welcome! | brunooliveira |
319,176 | Let’s code a dribble design with Vue.js & Tailwindcss (Working demo) — Part 2 of 2 | Let’s code a dribble design with Vue.js & Tailwindcss (Working demo) — Part 2 of... | 0 | 2020-04-25T10:35:27 | https://medium.com/@fayazara/lets-code-a-dribble-design-with-vue-js-tailwindcss-working-demo-part-2-of-2-256799d40ee | code, javascript, vue, design | ---
title: Let’s code a dribble design with Vue.js & Tailwindcss (Working demo) — Part 2 of 2
published: true
date: 2020-04-25 09:50:58 UTC
tags: code,javascript,vue,design
canonical_url: https://medium.com/@fayazara/lets-code-a-dribble-design-with-vue-js-tailwindcss-working-demo-part-2-of-2-256799d40ee
cover_image: https://cdn-images-1.medium.com/max/1024/1*uXp7R4kZ4B9pssZy4xhdww.png
---
### Let’s code a dribble design with Vue.js & Tailwindcss (Working demo) — Part 2 of 2
> Article #6 of my “1 article a day till lockdown ends”
So in the [part 1](https://dev.to/fayazara/let-s-code-a-dribble-design-with-vue-js-tailwindcss-working-demo-part-1-of-2-3h9) of this article, we made a UI from the dribble design we picked and used tailwindcss to code it. Let’s add the behaviour & some code to actually make it work.
We have divided our input fields into seperate components and trying to get their value by clicking a button which is outside these components, due to which we need some logic to hear changes from these components to our parent component, i.e our index.vue file, it needs to listen to changes happening inside gender.vue.
Vue let’s you listen to child components using the [emit](https://vuejs.org/v2/guide/components.html#Listening-to-Child-Components-Events) property. So we need to “emit” a function in our child component and a listener in our parent component.
<figcaption>Child and parent component communication</figcaption>
In the above image, a child component has a button and we want to pass a value to our parent component, I will add a custom event listener in our parent component — <component @name-listenter="doSomethingWithName" /> the child component will be emitting a function like <button @click="$emit('name-listenter', 'Fayaz')"> , the name-listener is the key here and vue will listen to it whenever emitted.
Let’s do the same to our gender.vue file, where we will change the value on clicking the male/female card and emit the value to our index.vue file.
Here is how I did it.
{% gist https://gist.github.com/fayazara/032865c9deff1412f943bc500a7e9a97 %}
For the Height component I will use a watch proprty of vue, since the slider event is not explicitly triggering a manual event on value change, we will add a watch listerner and emit the value there.
{% gist https://gist.github.com/fayazara/d76676bbf1474352988038a471593960 %}
Similarly add emit events for our age and weight component. I have added a long press directive [plugin](https://github.com/ittus/vue-long-click) to the weight and age buttons, which let’s you update the value when you hold the buttons.
#### Calculating the BMI.
Now, that we have received all our value in our parent component. To calculate the BMI, the formula is weight(kg)/height\*height(m) , and we also find out that age and gender are not needed to calculate the BMI 😂.
I would suggest you add some sort of validation before showing the results, like handle the negative values and stuff.
#### Lets show the BMI in the result Page.
There are multiple ways we can pass the bmi to the next , we could use vuex, and store the value there, use localStorage or we could just pass the bmi value in the url, because the other two methods seem like a overkill. The below function is calculating the BMI and passing the value as a parameter in the url and redirecting to the result page.
{% gist https://gist.github.com/fayazara/ad021dd8b06dc3283324591d4e746215 %}
We can capture the bmi from the URL by using the route object of vue like $route.query.bmi . We now have the value, all we need to do is just show it in our result page, this was the design from the dribble page.
There’s also the BMI range classification, which I found in [Wikipedia](https://en.wikipedia.org/wiki/Classification_of_obesity). Let’s make use of this as well.
There’s a Re calculate button, lets just redirect them back to home and for the “Save Button” Let’s replace it with “Share” chrome’s [Web Share API](https://web.dev/web-share/).
Here is the boiler plate code you can use to build the UI
{% gist https://gist.github.com/fayazara/20e0b8b9feb52f87d48745fd26434ea3 %}
The Final result page will look this, I have also added a Webshare button which share’s your BMI with others, this works only on phones though.
So far, we have divided a design in to components, and made the UI, added functionality with vue and passed the value in the next page.
This concludes this small project hope you enjoyed.
You can find the live working demo [here](https://bmi-app.netlify.app/) and the complete project on [github here](https://github.com/fayazara/bmi-calculator-example).
Let me know if you need any help with this or if you are stuck somewhere while making it.
Make sure you follow me on [twitter](https://twitter.com/fayazara) and here as well, to get more articles and updates. | fayaz |
319,182 | Flutter Web and Machine Learning | In case it helped :) We will cover how to implement Machine Learning using TensorFlow.. Fea... | 0 | 2020-04-25T10:37:19 | https://dev.to/aseemwangoo/flutter-web-and-machine-learning-258a | javascript, flutter, machinelearning, tensorflow | *In case it helped :)*
<a href="https://www.buymeacoffee.com/aseemwangoo" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Pass Me A Coffee!!" style="height: 41px !important;width: 174px !important;box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;-webkit-box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;" ></a>
<!-- wp:paragraph -->
<p>We will cover how to implement</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Machine Learning using TensorFlow..</strong></li><li><strong>Feature Extraction from image…</strong></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4>Pre-Requisite :</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This article uses the concept of calling JavaScript functions from Flutter Web, which is explained <a rel="noreferrer noopener" href="https://medium.com/flutterpub/flutter-web-and-location-2be96d3ad3e" target="_blank"><strong>in de</strong></a><strong><a href="https://flatteredwithflutter.com/detect-user-location-in-flutter-web/" target="_blank" rel="noreferrer noopener" aria-label="tail here (opens in a new tab)">tail here</a></strong><a rel="noreferrer noopener" href="https://medium.com/flutterpub/flutter-web-and-location-2be96d3ad3e" target="_blank"><strong>.</strong></a></p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":4} -->
<h4>Machine Learning using TensorFlow in Flutter Web..</h4>
<!-- /wp:heading -->
####Article here: https://flatteredwithflutter.com/machine-learning-in-flutter-web/
<!-- wp:paragraph -->
<p>We will use <a rel="noreferrer noopener" href="https://www.tensorflow.org/js/tutorials" target="_blank"><strong>TensorFlow.js</strong></a>, which is a JavaScript Library for training and deploying machine learning models in the browser and in Node.js</p>
<!-- /wp:paragraph -->
{% youtube lYf5WwyzUHE %}
<!-- wp:paragraph -->
<p><strong>Setup :</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Using Script Tags</p>
<!-- /wp:paragraph -->
<!-- wp:code -->
<pre class="wp-block-code"><code>script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.0.0/dist/tf.min.js"></script></code></pre>
<!-- /wp:code -->
<!-- wp:paragraph -->
<p>Add the above script tag inside the head section of your index.html file</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>That’s it…..</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:heading {"level":4} -->
<h4>Implementing a Model in Flutter Web…</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>What will we do :</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Create a linear Model</li><li>Train the model</li><li>Enter a sample value to get the output…</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Explanation :</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>We will create the above linear model. This model follows the formula</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>(2x — 1)</strong>. For instance,</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>when x = -1, then y = -3</li><li>x = 0, y = -1 and so on…..</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>We will give a sample input as 12, and predict the value from this model..</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":4} -->
<h4>Create the model…</h4>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li>Create a js file (in our case ml.js)</li><li>Define a function (in our case learnLinear)</li></ol>
<!-- /wp:list -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">async function learnLinear(input) {}</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Initialize a sequential model, using <a href="https://js.tensorflow.org/api/0.6.1/#sequential" rel="noreferrer noopener" target="_blank"><strong>tf.sequential</strong></a><strong>.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">const model = tf.sequential();</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>A sequential model is any model where the outputs of one layer are the inputs to the next layer.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Lets add our input layer to this model, using <a rel="noreferrer noopener" href="https://js.tensorflow.org/api/0.6.1/#layers.dense" target="_blank">tf.layers.dense</a>.</p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">model.add(tf.layers.dense({ units: 1, inputShape: [1] }));</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Parameters :</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li><strong>units (number) </strong>: Size of the output space. We will output just a single number</li><li><strong>inputShape</strong> : Defines the shape of input. We will provide the input as an array of length 1.</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Finally, we add this layer to our sequential model, using <a href="https://js.tensorflow.org/api/0.6.1/#tf.Sequential.add" rel="noreferrer noopener" target="_blank">model.add</a></p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Next, we need to compile the model,</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">model.compile({<br> loss: 'meanSquaredError',<br> optimizer: 'sgd'<br>});</pre>
<!-- /wp:preformatted -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>We use <a href="https://js.tensorflow.org/api/0.6.1/#tf.Model.compile" rel="noreferrer noopener" target="_blank">model.compile</a> for compiling the model..</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Parameters :</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>loss</strong> : we seek to minimize the error. Cross-entropy and mean squared error are the two main <strong>types of loss</strong> functions to use when training neural network models.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>optimizer : string name for an Optimizer. In our case <strong>Stochastic Gradient Descent or sgd</strong></p>
<!-- /wp:paragraph -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Next, we need to train the model,</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">// INPUT -> [6, 1] 6rows 1 columns<br>const xs = tf.tensor2d([-1, 0, 1, 2, 3, 4], [6, 1]);<br>const ys = tf.tensor2d([-3, -1, 1, 3, 5, 7], [6, 1]);</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>We define the input for x-axis using <a href="https://js.tensorflow.org/api/0.6.1/#tensor2d" rel="noreferrer noopener" target="_blank">tf.tensor2d,</a> <strong>called as xs</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Parameters :</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>values :</strong> The values of the tensor. Can be nested array of numbers, or a flat array. In our case [-1, 0, 1, 2, 3, 4]</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>shape : </strong>The shape of the tensor. If not provided, it is inferred from <code>values</code>. In our case, its an array of 6 rows and 1 column, hence [6, 1]</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Similarly, we define the output for y-axis using <a rel="noreferrer noopener" href="https://js.tensorflow.org/api/0.6.1/#tensor2d" target="_blank">tf.tensor2d,</a> <strong>called as ys</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">// TRAIN MODEL -> EPOCHS (ITERATIONS)<br>await model.fit(xs, ys, { epochs: 250 });</pre>
<!-- /wp:preformatted -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Now, we train the model using <a href="https://js.tensorflow.org/api/0.6.1/#tensor2d" rel="noreferrer noopener" target="_blank">model.fit</a></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Parameters :</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li><strong>x</strong> : an input array of <a href="https://js.tensorflow.org/api/0.6.1/#class:Tensor" rel="noreferrer noopener" target="_blank">tf.Tensor</a>s, in our case xs</li><li><strong>y</strong>: an output array of <a href="https://js.tensorflow.org/api/0.6.1/#class:Tensor" rel="noreferrer noopener" target="_blank">tf.Tensor</a>s, in our case ys</li><li><strong>epochs</strong>: Times to iterate over the training data arrays.</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>As we trained our model now, lets test it…..Time to predict values using <a rel="noreferrer noopener" href="https://js.tensorflow.org/api/0.6.1/#tf.Sequential.predict" target="_blank">model.predict</a></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">// PREDICT THE VALUE NOW...
var predictions = model.predict(tf.tensor2d([input], [1, 1]));
let result = predictions.dataSync();
console.log('Res', result[0]); //number</pre>
<!-- /wp:preformatted -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Parameters :</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>x: I</strong>nput data, as an <code>Array</code> of <a href="https://js.tensorflow.org/api/0.6.1/#class:Tensor" rel="noreferrer noopener" target="_blank">tf.Tensor</a>s, in our case this value is an array of 1 element, passed from dart.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The result is stored in a <code>predictions</code> variable. In order to retrieve the data, we call</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><a href="https://js.tensorflow.org/api/0.6.1/#tf.Tensor.dataSync" rel="noreferrer noopener" target="_blank">dataSync</a> : Synchronously downloads the values from the <a href="https://js.tensorflow.org/api/0.6.1/#class:Tensor" rel="noreferrer noopener" target="_blank">tf.Tensor</a> as an array..</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":4} -->
<h4>Get Predicted Value in Flutter Web…</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In the above step, we created the TensorFlow model as a JS function which accepts a parameter..</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">async function learnLinear(input) {}</pre>
<!-- /wp:preformatted -->
<!-- wp:list {"ordered":true} -->
<ol><li>Import the package</li></ol>
<!-- /wp:list -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">import 'package:js/js_util.dart' as jsutil;</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>2. Create a dart file calling the JS function…</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">@JS()
library main;
import 'package:js/js.dart';
@JS('learnLinear')
external num linearModel(int number);</pre>
<!-- /wp:preformatted -->
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p>Note : <code><em>learnLinear</em></code> is the same JS function which we defined in the above section</p></blockquote>
<!-- /wp:quote -->
<!-- wp:paragraph -->
<p>3. As our function is an async function, we need to await the result from it..</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">await jsutil.promiseToFuture<num>(linearModel(12))</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>We will make use of <a href="https://api.dart.dev/stable/2.7.1/dart-js_util/promiseToFuture.html" rel="noreferrer noopener" target="_blank"><strong>promiseToFuture</strong></a><strong>. </strong>What this does is</p>
<!-- /wp:paragraph -->
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p>Converts a JavaScript Promise to a Dart <a href="https://api.dart.dev/stable/2.7.1/dart-async/Future-class.html" rel="noreferrer noopener" target="_blank">Future</a>.</p></blockquote>
<!-- /wp:quote -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Lets call this function from a button now,</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">OutlineButton(<br> onPressed: () async {<br> await jsutil.promiseToFuture<num>(linearModel(12));<br> },<br> child: const Text('Linear Model x=12'),<br>)</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>We have provided input value as <strong>12</strong>, and the output we get is :</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":4} -->
<h4>Feature Extraction From Image…</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>For the feature extraction, we use an existing model <strong>called MobileNet.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p>MobileNets are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection similar to how other popular large scale models, are used.</p></blockquote>
<!-- /wp:quote -->
<!-- wp:paragraph -->
<p>It takes any browser-based image elements (<code><img></code>, <code><video></code>, <code><canvas></code>) as inputs, and returns an array of most likely predictions and their confidences.</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Setup :</strong></li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Using Script Tags</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/mobilenet@1.0.0"> </script></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Add the above script tag inside the head section of your index.html file</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>2. <strong>Function in JS : </strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>We will define an image tag inside our body html as</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted"><img id="img" src="" hidden></img></pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Define a function in JS as :</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">async function classifyImage() {}</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Get the source of the image tag as</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">const img = document.getElementById('img');</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Load the mobilenet model and extract the features from the image selected as</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">// LOAD MOBILENET MODEL
const model = await mobilenet.load();
// CLASSIFY THE IMAGE
let predictions = await model.classify(img);
console.log('Pred >>>', predictions);
return predictions</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Predictions is an array which looks like this :</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">[{<br> className: "Egyptian cat",<br> probability: 0.8380282521247864<br>}, {<br> className: "tabby, tabby cat",<br> probability: 0.04644153267145157<br>}, {<br> className: "Siamese cat, Siamese",<br> probability: 0.024488523602485657<br>}]</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>Finally, return these predictions.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>3. <strong>Function in dart :</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">@JS()
library main;
import 'package:js/js.dart';
@JS('learnLinear')
external num linearModel(int number);
@JS('classifyImage')
external List<Object> imageClassifier();</pre>
<!-- /wp:preformatted -->
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p>Note : This file was already created in the above section, we just added the last 2 lines…The name classifyImage is same as the JS function created in step 1</p></blockquote>
<!-- /wp:quote -->
<!-- wp:paragraph -->
<p><strong>4. Call the function from button</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">OutlineButton(<br> onPressed: () async {<br> await jsutil.promiseToFuture<List<Object>>(imageClassifier());<br> },<br> child: const Text('Feature Extraction'),<br>)</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>The return type of the <code>imageClassifier()</code> is a <code>List<Object></code> . In order to extract the results, we need to convert this list into a custom Model class</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>5. Convert into Custom Model</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>We create a custom Class called <strong>ImageResults</strong> as</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">@JS()
@anonymous
class ImageResults {
external factory ImageResults({
String className,
num probability,
});
external String get className;
external num get probability;
Map<String, dynamic> toMap() {
final _map = <String, dynamic>{
'className': className,
'probability': probability,
};
return _map;
}
}</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>First, we will convert each <strong>Object into a String</strong>, and then the string into <strong>ImageResults model…</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">List<ImageResults> listOfImageResults(List<Object> _val) {
final _listOfMap = <ImageResults>[];
for (final item in _val) {
final _jsString = stringify(item);
_listOfMap.add(jsonObject(_jsString));
}
return _listOfMap;
}</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p><strong>stringify</strong> is a function, defined as </p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">@JS('JSON.stringify')<br>external String stringify(Object obj);</pre>
<!-- /wp:preformatted -->
<!-- wp:paragraph -->
<p>this string is converted to <strong>ImageResults</strong> model using <strong>jsonObject..</strong></p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">@JS('JSON.parse')<br>external ImageResults jsonObject(String str);</pre>
<!-- /wp:preformatted -->
<!-- wp:separator -->
<hr class="wp-block-separator"/>
<!-- /wp:separator -->
<!-- wp:paragraph -->
<p>Now, you can easily access the values in dart as :</p>
<!-- /wp:paragraph -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted">for (final ImageResults _item in _listOfMap) ...[<br> Text('ClassName : ${_item.className}'),<br> Text('Probability : ${_item.probability}\n'),<br>]</pre>
<!-- /wp:preformatted -->
*In case it helped :)*
<a href="https://www.buymeacoffee.com/aseemwangoo" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Pass Me A Coffee!!" style="height: 41px !important;width: 174px !important;box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;-webkit-box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;" ></a>
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p>Hosted URL : <a href="https://fir-signin-4477d.firebaseapp.com/#/" rel="noreferrer noopener" target="_blank">https://fir-signin-4477d.firebaseapp.com/#/</a></p></blockquote>
<!-- /wp:quote -->
<!-- wp:quote -->
<blockquote class="wp-block-quote"><p><a href="https://github.com/AseemWangoo/experiments_with_web" rel="noreferrer noopener" target="_blank">Source code for Flutter Web App..</a></p></blockquote>
<!-- /wp:quote -->
{% youtube lYf5WwyzUHE %} | aseemwangoo |
319,241 | Twiter | https://blog.twitter.com/developer/en_us.html,https://github.com/json-api/json-api.git,https://blog.t... | 0 | 2020-04-25T12:40:15 | https://dev.to/thassadar1387/twiter-fij | https://blog.twitter.com/developer/en_us.html,https://github.com/json-api/json-api.git,https://blog.twitter.com/engineering/en_us/topics/infrastructure/2019/bts-of-launching-the-new-twitter.html,https://blog.twitter.com/engineering/en_us/topics/insights/2018/twitter_silhouette.html | thassadar1387 | |
319,249 | Create a custom report for RCPTT | RCPTT (RCP Testing Tool) includes a functionality that allows to generate reports in multiple formats... | 0 | 2020-04-26T12:13:52 | https://dev.to/hiclab/create-a-custom-report-for-rcptt-m6g | rcptt, eclipse, custom, report | RCPTT [(RCP Testing Tool)]( https://www.eclipse.org/rcptt/) includes a functionality that allows to generate reports in multiple formats based on the results obtained from executing test cases. However, the default reports might be insufficient for our needs but fortunately; RCPTT is flexible because it supports generating custom reports.
In this post, we illustrate the basic steps needed to create a custom report renderer so it can be used in RCPTT whether IDE or Test Runner. We use Maven to configure and build the plugin and other related artifacts. By the way, we use a specific project to build an update site for our plugin.
The full code is available at the following repository [rcptt-reporting](https://github.com/hichlab/rcptt-reporting).
##Create a report renderer
RCPTT provides the interface <code> IReportRenderer</code> which is the entry point for report generation. Renderers implementing this interface receive a <code>Report</code> iterable object to iterate over all internal reports generated for a given test execution.
```java
public class XMLCustomReportRenderer implements IReportRenderer {
@Override
public IStatus generateReport(IContentFactory factory, String reportName, Iterable<Report> reports) {
// iterate over reports, process their information and create a file in your preferred format ...
return Status.OK_STATUS;
}
@Override
public String[] getGeneratedFileNames(String reportName) {
return new String[] { reportName };
}
}
```
To access to the results of executed tests, we have to iterate over a collection of <code>Report</code> objects and retrieve the information as follows:
```java
Iterator<Report> reportIterator = reports.iterator();
while (reportIterator.hasNext()) {
Report report = reportIterator.next();
Node item = report.getRoot();
Q7Info info = (Q7Info) item.getProperties().get(IQ7ReportConstants.ROOT);
// Q7Info object contains the information of an executed test case
}
```
##Add an extension
Once the report renderer is implemented, we have to add an extension for this plugin to be able to use it. The following entry must be added to plugin.xml.
```xml
<extension point="org.eclipse.rcptt.reporting.reportRenderer">
<reportRenderer
class="com.hiclab.rcptt.reporting.XMLCustomReportRenderer"
description="XML Custom Report Renderer"
extension="xml"
id="XmlReport"
name="Xml Custom Report">
</reportRenderer>
</extension>
```
The <code>id</code> is needed especially when using Test Runner. For more details, check the description of the argument *report* in [Test Runner documentation]( https://www.eclipse.org/rcptt/documentation/userguide/runner/arguments/). | hiclab |
319,294 | How does your company handle research and investigation work? | Tickets? Spikes? Nothing at all? | 0 | 2020-04-25T14:45:42 | https://dev.to/aleccool213/how-does-your-company-handle-research-and-investigation-work-1h2h | discuss, agile, estimation, planning | ---
title: How does your company handle research and investigation work?
published: true
description: Tickets? Spikes? Nothing at all?
tags: discuss, agile, estimation, planning
---
Software companies which follow agile usually do some sort of planning and estimation. It lets stakeholders know how long things will take to get done and can help with how a project plays out. To get better estimations, developers are usually tasked with doing some initial research to find out how difficult things will be, what unknowns exist.
How does your component do this from a process standpoint? Tickets? Spikes (a form of research ticket familiar to some)? Nothing at all?
| aleccool213 |
319,392 | Hackathon update #4 - Shoot into the wild blue | So this is it, my final update on the hackathon, it's kind of sad really but it's been pushed to a li... | 6,110 | 2020-04-25T18:24:21 | https://dev.to/joro550/hackathon-update-4-shoot-into-the-wild-blue-44bf | twiliohackathon, cloud, production | So this is it, my final update on the hackathon, it's kind of sad really but it's been pushed to a live server (azure to be specific) but I just wanted to let people have a sneak peak into how to get messages.
# Subscribing to an event:
When you are logged into the website these buttons will appear, these buttons allow you to subscribe to the updates on the event, once an update is published to the event a message will be sent to all of the subscribers of the event via twilios api.
_Note_ : Oh I should mention that these buttons only appear if you have a mobilenumber associated with your account.
And well.. that's all I have to say. This was a blast to work on
Checkout the website: https://artemiswebserver.azurewebsites.net
{% github joro550/artemis %} | joro550 |
319,413 | How to hide Ruby 2.7 deprecation warnings in docker | Tired of Ruby 2.7 alerts in your docker application? Put this key into your environment: RUBYOPT=-W... | 0 | 2020-04-25T19:09:25 | https://dev.to/marcelotoledo/how-to-hide-ruby-2-7-deprecation-warnings-in-docker-181g | docker, ruby, tutorial | Tired of Ruby 2.7 alerts in your docker application? Put this key into your environment: `RUBYOPT=-W0`. In your docker-compose.yml:
``` docker
# docker-compose.yml
version: '3.6'
services:
server:
image: "your_image"
container_name: "your_application_name"
ports:
- "3000:3000"
environment:
- BUNDLE_PATH=vendor/bundle
- BUNDLE_DISABLE_SHARED_GEMS=1
- RUBYOPT=-W0
```
Cheers :beers: | marcelotoledo |
319,421 | MySQLDump.js | MySQL comes with a built-in program called mysqldump to do logical backups. It generates a SQL script... | 0 | 2020-04-25T19:23:54 | https://dev.to/sirwanafifi/mysqldump-js-37p1 | mysql, backup, showdev, sql | MySQL comes with a built-in program called `mysqldump` to do logical backups. It generates a SQL script of the database so that you can transfer it to another database server.
I have written a tiny wrapper around `mysqldump` which can be used in Node.js applications:
https://github.com/SirwanAfifi/sqldumpjs
Please give it a try. I would be glad If you would like to contribute. | sirwanafifi |
319,454 | Forewords and domain model | This series is about sharing some of the challenges and lessons I learned during the development of... | 6,223 | 2020-05-08T11:16:27 | https://dev.to/vncz/forewords-and-domain-model-1p13 | javascript, typescript, functional | This series is about sharing some of the challenges and lessons I learned during the development of [Prism](https://github.com/stoplightio/prism) and how some functional concepts lead to a better product.
**Note:** As of January 2021, I no longer work at Stoplight and I have no control over the current status of the code. There is a [fork](https://github.com/XVincentX/prism) on my GitHub account that represents the state of the project when I left the company.
---
In this specific post, I will start explaining what Prism is, detail some of its key features and discuss a little bit about its domain and its intended audience.
This will hopefully help you understand the technical choices I made that I will cover in the next articles.
## What Is Prism
{% github stoplightio/prism no-readme %}
Prism is a mock server for [OpenAPI 2](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md) (from now on OAS2), [OpenAPI 3](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md) (from now on OAS3) and [Postman Collections](https://www.postman.com/collection) (from now on PC).
For those of you that aren't familiar with such, OAS2/3 and PC are essentially specifications defining a standard and language-agnostic interface to (possibly RESTful) APIs.
To be a little bit more pragmatic:
```yml
openapi: 3.0.0
paths:
/list:
get:
description: Returns a list of stuff
responses:
'200':
description: Successful response
```
This YAML file is an OpenAPI 3.0 document claiming that:
1. There's an API
2. It has a `/list` path
3. It has a `GET` method
4. When a `GET` request to the `/list` endpoint is made, `200` is one of the possible responses you _might_ get, whose details (such as payload shape, returned headers) haven't been specified.
We aren't going to go too much into detail about these formats; if you’re interested, you can go and read the official specifications:
* [OpenAPI 2.0](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/2.0.md)
* [OpenAPI 3.0](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.3.md)
* [Postman Collections](https://schema.getpostman.com/json/collection/v2.0.0/docs/index.html)
Despite this simple example, we can say that all the specifications allow (with some nuances) to specify pretty complicated scenarios, ranging from authentication, request and response validation, to web hooks, callbacks and example generation.
---
A mock server is nothing more than a little program that reads the description document and spins up a server that will behave in the way that the document mandates.
Here's an example of Prism starting up with a standard OAS3 document:

## Prism Peculiarities
Technical decisions and trade-offs were driven by features. Here are the most relevant ones regarding this series:
### 100% TypeScript
Prism is written entirely in [TypeScript](https://typescriptlang.org). Primarily because [Stoplight](https://stoplight.io)'s stack is largely based on NodeJS and TypeScript.
We are using the maximum level of strictness that TypeScript allows.
### A Lot Of Custom Software
Prism is not using any of the web frameworks you usually find on the market and employed for web applications, so you won't find Express, you won't find Hapi, nothing.
It was initially written using [Fastify](https://fastify.io); and at that time I was not working on the project. I ultimately [decided to remove it](https://github.com/stoplightio/prism/pull/927) in favour of a [tiny wrapper](https://github.com/turist-cloud/micri) on top of the regular `http` server that NodeJS offers.
In case you are asking, the main reason for this is because most of the frameworks focus on the 80% of the use cases, which is totally legit.
On the other hand, Prism aims for 100% compatibility with the document types it supports, and, for instance, some of them have some [very…creative parameters support](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md#encoding-object) that no parser on the market supports.
Another example? OpenAPI 2 and 3 are using path templating, but not the same as URI Templating specified in the [RFC6570](https://tools.ietf.org/html/rfc6570). For this reason, a custom parser and extractor had to be defined.
This specific case, together with other ones that required special code to be wrote, led us to gradually dismantle and neglect different Fastify features until I realised that we were not using it at all if not for listening on the TCP port; on the contrary, we were just fighting it because it was too opinionated on certain matters, such as errors.
You can find more about the motivations in the relative [GitHub issue](https://github.com/stoplightio/prism/issues/790)
### Custom Negotiator
Prism contains a custom made negotiator — which is that part of the software that taken an incoming HTTP Request, its validation results (headers, body, security) and the target API Specification document will return the most appropriate response definition that can then be used by the generator to return a response instance to the client.
The negotiator itself is kind of complicated, but I think we've done a good job in both documenting its decision process:
The diagram is also pretty much reflected in the code as functions division.
### Input, output and security validation
One of Prism's key features is the extensive validation.
Based on the provided API Description document, Prism will validate different parts of the incoming HTTP request, ranging from deserialising the body according to the `content-type` header and then checking the resulting object with the provided JSON Schema (if any).
The same goes for the query parameters (because yes, OpenAPI defines encoding for query parameters as well), the headers and ultimately the security requirements.
The input validation result will influence the behaviour of the negotiator as well as the proxy's one.
It turns out that validation is a very complicated part of Prism and, although [we](https://github.com/stoplightio/prism/pull/664) have [reworked](https://github.com/stoplightio/prism/pull/731) it [several times](https://github.com/stoplightio/prism/pull/862) we still [haven't got that right](https://github.com/stoplightio/prism/issues/1135).
## Prism Request Flow
The journey of an HTTP Request from hitting your application server to return a response to the client is articulated.
We often do not think about it because the web frameworks do usually a very good job in abstracting away all the complexity.
Since Prism is not using any frameworks, I fundamentally had the opportunity of reimplementing almost the whole pipeline — and I started to have observations.
Here's what Prism is doing when a request is coming in:
* Routing
- Path Match with templating support, where we also extract the variables from the path, returning `404` in case it fails
- Method Match, returning `405` in case it fails
- Server Validation, which is checking the `HOST` header of the request against the servers listed in the specification document, returning `404` in case it fails
* Input deserialisation/validation
- The path parameters get validated according to what is stated in the specification files (whether it's required, whether it's a number or a string) `422/400/default`
- The query string is deserialised following the rules stated in the specification file, returning `422/400/default` in case there is a deserialisation failure
- Headers get validated against the JSON-esque format that OAS2/3 defines; we convert them to a draft7 specification and run [ajv](https://github.com/ajv-validator/ajv) on it, returning `422/400/default` in case there is a validation failure.
- Body gets validated against the JSON-esque format that OAS2/3 defines; we convert it to a draft7 specification and run `ajv` on it, returning `422/400/default` in case there is a validation failure.
- Depending on the security requirements specified in the routed operation, Prism will check the presence of certain headers and when possible it will also try to validate that their content respects the general format required for such security requirements. Returns `401/400/default`
* Negotiator/Proxy
- The negotiator kicks in and looks for an appropriate response definition based on the validation result, the requested content type, the accepted media types and so on. It returns `2XX/406/500/User Defined Status code` depending on the found response definition.
- If the Proxy is on, Prism will skip the negotiator and send the result to the upstream server and take note of the returned response.
* Output violation and serialisation
- Response Headers, whether they're generated from a response definition, extracted from an `example` or returned from a Proxy request get validated agains the response definition, returning `500` (erroring the request or a violation header) in case they do not match
- Response Body, whether it's generated from a response definition, extracted from an `example` or returned from a Proxy request, gets validated agains the response definition, returning `500` (erroring the request or a violation header) in case they do not match.
---
Here comes the first key observation: almost _every_ step that Prism executes might fail, and each failure has a specific semantic meaning and precise status code is associated.
Last time that I checked, on over 32 "exit paths", 30 of these were errors and only two of them were a "successfully returned response". Doing some math:
{% katex inline %}
2/32 = 1/16 = 0,06
{% endkatex %}
This fundamentally says that, in case of evenly distributed exit paths occurrences, only 6% of the request will be successful.
Are the exit path occurrences evenly distributed? Although I do not have a specific answer to that (but hopefully we will, since we're gathering statistics in the hosted version of Prism) — we have some empirical evidence I’ll talk about in the next paragraph that we can keep in mind.
## Prism User
Prism is a developer tool and, although it can be used as a runtime component, it is primarily used by API designers and client developers during the development phase of the API.
This is a very important detail since the typical developer that is using Prism has totally different aims from a regular API developer. The following table summarised some the differences that I've identified with an Application Developer
| Client Application Developer | API Developer |
|---------------------------------|-------------------------------|
| Clear mission in mind | No idea of what they're doing |
| Probably read API documentation | Experimental phase |
| Likely sending valid data | Likely sending garbage |
| Aims for success | Changes code and spec every second |
When you're developing an application, you're likely striving for success — and so you're going to create all the requests you need with likely valid data, likely following the flow indicated in the documentation.
On the other hand, when mocking an API with Prism, you're deep in the design phase. You'll probably tweak the document multiple times per minute (and Prism will hot-reload the document). You'll likely send invalid data all the time because you just forgot what you wrote in the document. You'll try weird combinations of stuff that is never supposed to happen.
We stated some paragraphs before that in case of evenly distributed exit path occurrences, only 6% of the request will be successful.
Now that we have clarified a little bit the typical user of Prism, it's fair to say that the exit paths occurrences are clearly not evenly distributed and, although we can't give a precise number, we can claim that's heavily leaning towards the errors side.
Essentially, when you send a request to Prism, most likely you'll get an error as a response.
After thinking a lot about this, I wrote this sentence that was the key factor to radically change Prism's architecture.
**Prism's job is to return errors.**
In the next article we'll talk about the abstraction used to model such use cases correctly and how I found it _accidentally_.
| vncz |
319,580 | Is CSS a programming language? | A few hours ago I was talking with a friend and asked him this question. We're both working in our t... | 0 | 2020-04-25T23:48:25 | https://dev.to/parrol/is-css-a-programming-language-1okj | css | A few hours ago I was talking with a friend and asked him this question.
We're both working in our thesis for a software engineering title, but right know we're working on a web dev project, and having worked before with PROLOG I realized CSS is very similar in a sense.
The way I see it, with CSS you can define rules allowing computers to do some math and resolve a problem based on the previous rules. I know there's a lot of discussion in this topic, but I'm kinda new here and wanted to see on first-hand what people have to say about it.
| parrol |
319,645 | No I Don't Want To Look At Your Calculator App (Or: The Problem With Tutorials) | If you spend any time looking at one programming language, or all programming languages, as a "hobbyi... | 0 | 2020-04-26T01:05:29 | https://dev.to/chillhumanoid/no-i-don-t-want-to-look-at-your-calculator-app-or-the-problem-with-tutorials-23n9 | tutorial, beginners, produ | If you spend any time looking at one programming language, or all programming languages, as a "hobbyist" or "junior dev" ―however you see yourself or whatever your role is―you'll inevitably see the cacophony of "This is my first app" posts. They usually ask for advice, or pointers, and they're admirable. There is something really cool about seeing people learn something new.
But it has almost become a right of passage to post on the subreddit dedicated to that language or technology a link to your github page, or app url, and say "this is my first app, it is a calculator. Let me know what you think".
It is a calculator.
It is the thing that comes with the phone and there's really no need to flood the Google Play Store or the dev.to feed with yet another calculator app. I would give you feedback, but inevitably you copied the same exact tutorial code that everyone else used, and changed up some variable names and the color of the enter button. Unless you found a way to make the calculator do something unique, the tutorial only served one purpose and that was to teach you how to make something. Don't share that, we've all done the tutorial.
# It's Getting Worse
The tutorial culture has shifted and become older. I have seen a thousand posts on various sites and subreddits that say "how i made a coronavirus tracker in….". And while these are usually done by people who have more skill, and are not following tutorials, it still stems from the same underlying problem. Lack of creativity.
Some of my best learning has been done because I had a problem I needed to solve. We need to stop treating tutorials like they're solving a problem. We have coronavirus trackers, we're friends with them on Facebook. We have calculators, everywhere. There's no shortage of them.
But there ARE various problems we face in our day to day lives that we often think "man, if I was a better programmer, I'm sure I could solve this".
And that is how tutorials train us to think. If you only ever get so far as the calculator and think it is really cool that you are now published on the Google Play Store, you will never get to the point where you are ready to solve actual problems (unless they're math problems).
# Do Not Limit Yourself To What A Tutorial Wants You To Make
Tutorials are perfect for showing us how to implement principles. And that means that we need to know what principles we want to implement. Following a tutorial from front to back will only show you how to figure out what principles you need to know in that exact use case of not having a calculator but having a computer cable of compiling your code.
What I challenge us to start doing is to stop making applications for others. Don't go with market trends, don't go against market trends, don't look at market trends. We can see that a service or software is doing really well and want to emulate that but we can't because they had a problem they solved, and by solving it, we don't have the same problem to solve.
But we all know that there is no shortage of problems we face every day. And that problem can exist in something that was created to solve a different problem. If all the calculator apps did something different, than that would be amazing, and we'd be better for it.
# You Have The Skill, You Just Need A Reason To Learn It
Don't lament that you don't have a skill. Learn the skill. The calculator tutorials contain concepts, but implement them in a very linear way. I still need to look up tutorials for how to do simple concepts in python from time to time because I forgot what the exact syntax or keywords were. I'm thankful for the calculator app tutorial then.
The world would be a much better place if we stopped trying to solve the same problem and started solving our own.
# What Problems Have You Solved Mr. chillhumanoid?
My github page is a mess of different projects, some that have good reason for, and others that I started just because I wanted to (boredom is a problem).
* I have an android app that was created because I have ADHD and many Bibles, and a plan that requires keeping track of 10 different chapters.
* I have a discord bot for a server I run that has a fairly unique scenario that I decided to learn how to make a discord bot, and in 3 days made it into a really neat little bot that does some cool things that a few servers have found useful.
* I have some scripts that are solely for my church and their livestream in this season, since all our services are pre-recorded and it's up to me to make sure that we go live at the right times. I knew I'd mess up, so I made a little python script that handles everything for me.
* I have a Bible XML editor to make editing Bible XMLs easier.
* I started editing Bible XMLs because I needed a parsable version of the NIV 2011, but all I could find was the NIV 1984 translation.
* I have a python app that will keep track of Teen Bible Quiz scores throughout a whole season across multiple teams. I created this because I was tired of the excel spreadsheet with macros that didn't like it when you changed who was seated where, and only kept track for the given meet.
I do not have any calculators.
And I point that out calculators a lot because we need to move past the thing that everyone has already done. And if you learned it in a tutorial, it's definitely already been done by everybody.
We don't need another coronavirus tracker.
You would be amazed at how many people would feel that they need an application to solve the problem you have but you haven't done anything about.
So make that.
For the love of all that is Holy, please stop asking for people to review your calculator app. Does 2+ 2 = 4? Then you did great.
Good job.
#Final Note
Do not get me wrong. You should make things you want to make and give very little thought to if it has been done before. As long as you feel there is good reason to make what it is you are making.
These are never things that are covered in tutorials though. Those are things that everyone has made, and there is nothing you do by making it that solves any problem that hasn't been solved already outside of you didn't know concepts and now you do. Part of my point is that you should treat tutorials only in that way, to teach you concepts you didn't know before. The other part of my point is that you can learn the concepts without the calculator tutorials.
On that note.
```python
def goodbye():
print("Goodbye")
if __name__ == "__main__":
goodbye()
``` | chillhumanoid |
319,667 | Whatsupp SSH? - accessing SSH over WhatsApp | We all wanted to have this superpower of controlling anything from anywhere, but that's not possible... | 0 | 2020-04-26T18:43:34 | https://dev.to/manojnaidu619/whatsupp-ssh-accessing-ssh-over-whatsapp-2g3g | twiliohackathon, tutorial, node, javascript |
We all wanted to have this superpower of controlling anything from anywhere, but that's not possible yet! (maybe someday in the future...) But today I am joyful to showcase my first ever [dev.to](https://dev.to) hackathon project, which doesn't open the doors to rule every single thing, but certainly [SSH](https://en.wikipedia.org/wiki/Secure_Shell) / Remote Server over WhatsApp.
While I was doing my internship, I used to SSH into EC2 many times a week, and to do that I always needed to have my laptop handy. This is not a thing to be worried about. But... when you seriously need to access your remote server for some important update which cannot be postponed and you realize that your laptop is resting at your home. That "*oh No!*" moment hurts a lot...
So, then I started to look for alternatives for accessing my EC2 without leaning towards my laptop always. Then eventually, my internship came to an end, but that "*search for alternatives*" was still hanging in my mind.
Recently, I started learning [NodeJS](http://nodejs.org/) and this is when I also came across *#twiliohackathon* tag on dev. I had no idea about Twilio until I had a look at their [wide range of APIs](https://www.twilio.com/docs/all) and cool web services offered by them.
After digging deep into Twilio's services. Finally, that "*search for alternatives*" got a slight spark.
## So, What I built?
I built a Nodejs application integrated with [Twilio's API for WhatsApp](https://www.twilio.com/whatsapp), which could be installed and configured on any remote server(*dead simple to setup!, trust me* 🙌) or computer(with UNIX based OS), results in gaining access to it remotely and execute shell commands over WhatsApp.
## Category Submission
Exciting X-Factors
## Demo
✅ **Custom Authentication**
✅ **brew-update over Whatsapp**
✅ **Executing git commands**
✅ **mkdir over whatsapp**
✅ **executing Python script**
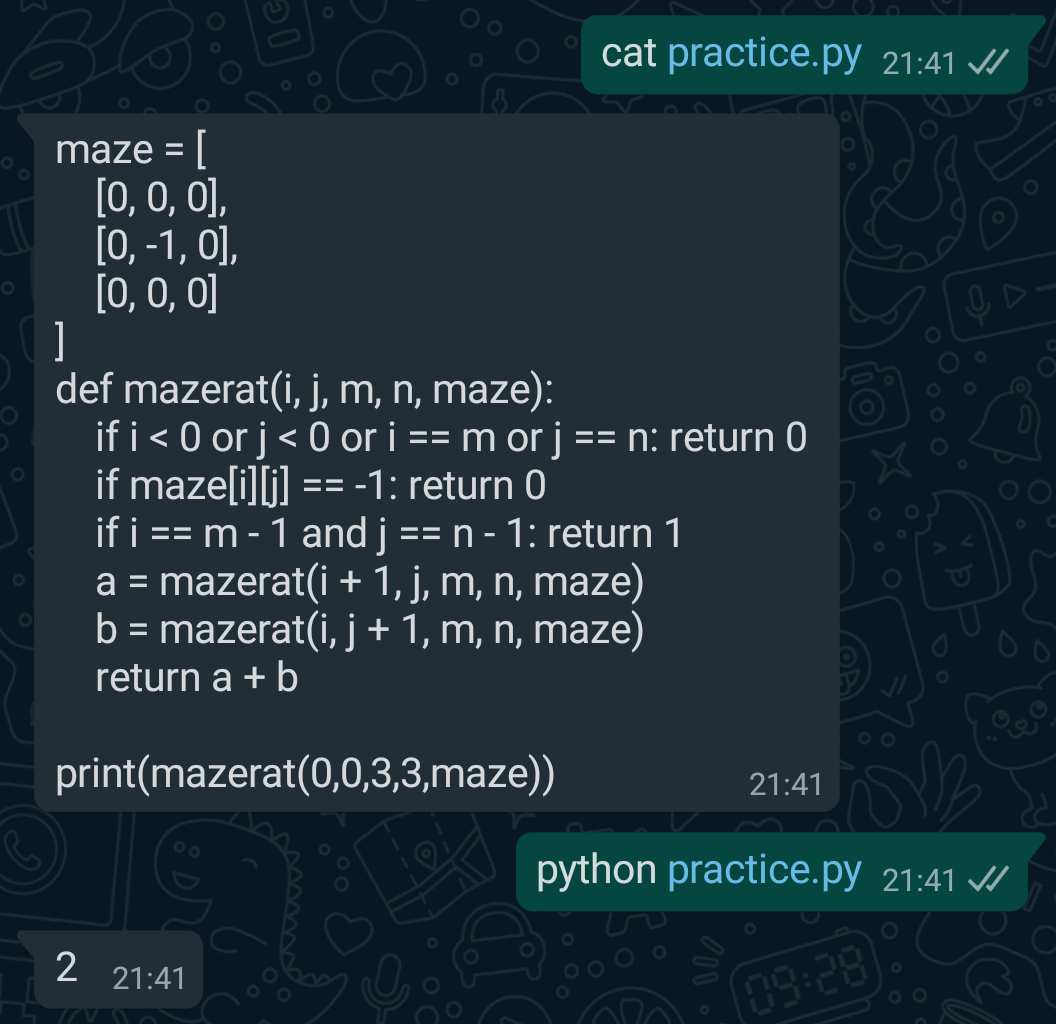
✅ Demonstrating custom command **ssh-help**

✅ Demonstrating custom command **ssh-reset** (to reset the working directory)
✅ Demonstrating custom command **ssh-status** (to retreive system status and extra info)
✅ Demonstrating custom command **ssh-history** (alias version of `history` bash command. But here it lists the commands executed over Whatsapp)
## How does it work?
**PHASE-1** ➜ The command which we need to execute on the server is sent to Twilio.
**PHASE-2** ➜ Twilio forwards the request to our app. For this particular action to work, we need to setup a webhook inside twilio console...(We will talk about this in *Setup* section of this post).
**PHASE-3** ➜ After receiving the request from Twilio, Our app first verifies that the request is actually being sent by Twilio. Otherwise, the request would be rejected. Then, it executes the command entered by the user and sends back the output/response in the format which is understood by Twilio ([Twilio Markup Language(TwiML)](https://www.twilio.com/docs/glossary/what-is-twilio-markup-language-twiml))
**PHASE-4** ➜ Once Twilio receives back the TwiML response from our app, it sends it back to the user.
## What's the Stack?
* Pure NodeJS
📍 But, to setup and get started we need...
* Valid Twilio account
* A remote server/ computer (on which we could execute shell commands, I am using AWS EC2)
## How to Setup?
The setup process is really simple, you just have to follow these four steps...
✏️ **STEP-1**. Signup for a Twilio Account and join the Twilio Whatsapp sandbox.
* Signup for an account [here](https://www.twilio.com/try-twilio)
* Now, login and join the [sandbox](https://www.twilio.com/console/sms/whatsapp/learn) by doing as directed on screen and complete all 3 steps. **Don't share your sandbox code with anyone** (*The red block covers my sandbox code*)
* One final thing needs to be added into Twilio. We will see that later...
----
✏️ **STEP-2** Configure port on the server/ computer.
* If you are setting up in the local computer, then you are free to skip to **STEP-3**.
* If setting up in a remote server, then you need to configure the instance/ droplet to open **port 3003** for incoming requests.
> 📌 port 3003 is where Twilio would be forwarding the requests to...
If using AWS EC2 then you need to add a new rule inside *Security Groups -> Inbound rules* of a particular instance.
* Then add a new rule like so...
> 📌 If using other than EC2, then refer to official docs.
----
✏️ **STEP-3** Let's move towards our computer/ server.
> 📌 All the actions from now are performed inside the terminal.
* `cd` into the directory where you want to clone the app.
* Now, clone the project repo.
{% github manojnaidu619/Whatsupp-SSH no-readme %}
```bash
$ sudo git clone https://github.com/manojnaidu619/Whatsupp-SSH.git
```
* `cd` into the project folder and run `sudo npm install`
```bash
$ cd Whatsupp-SSH/
$ sudo npm install
```
* As we are logging the requests into a log file, we need to give appropriate permissions to the app directory and the folders inside it.
(The path to project must be absolute)
```bash
$ sudo chmod -R a+rw ~/home/Whatsupp-SSH
```
* Now adding `env` variables, which our app relies on. *Make sure the key is same as mentioned below.*
> 📌 Here, I am considering Ubuntu as the OS.
```bash
$ sudo nano /etc/bash.bashrc
```
scroll down to the bottom of the file and add these lines by replacing the values.
```
export SSH_PSWD=YOUR_DESIRED_PASSWORD
export TWILIO_URL=http://PUBLIC_IP_OF_SERVER:3003/Whatsupp-SSH
export TWILIO_AUTH_TOKEN=YOUR_TWILIO_AUTH_TOKEN
```
then source the `bash.bashrc` file by typing.
```bash
$ source /etc/bash.bashrc
```
* Now, copy the same TWILIO_URL that was added to `bash.bashrc` file.
> 📌 Remember that we had one last thing to add to *Twilio sandbox configuration*... It's time to do that.
head to *twilio console -> programmable SMS -> Whatsapp -> Sandbox*
After adding that, scroll down and hit **Save**.
----
✏️ **STEP-4**. Head to your server/computer and run these final commands.
* install `pm2`.
```bash
$ sudo npm install pm2 --global
```
* Now, run `pm2 startup` to initialize startup scripts. So, whenever the server reboots/ crashes, our node app would also be picked up automatically.
```bash
$ pm2 startup
```

Now copy-paste the command given by pm2 (the one outlined by red border) and hit **enter**.
* Now, to save them all run `pm2 save`.
```bash
$ pm2 save
```
* just one final command left, you have successfully setup the app. Now let's start the `pm2` server.
```bash
$ pm2 start ABSOLUTE_PATH_TO_WHATSUPP-SSH/src/app.js
```
**Hurray! 🙌 your app is now up and running, get started by sending a simple command to your Twilio sandbox over Whatsapp**.
## What are all the Unique features?
Apart from executing traditional shell commands, our app supports and has cool features built-in. Here they are...
* **in-app user authentication**. Before executing any command, the user has to authenticate himself by entering the correct password. He can continue, only if the authentication is successful.
> 📌 The execution thread gets locked automatically every 5 minutes(once after the user is authenticated), even if no operations were performed.
The user has to re-enter the correct password to continue...This is to stay safe from non-auth users. *The lock interval could be modified in `src/utils/validators/authValidator.js`*
* **Helper commands**. `ssh-help` is the command to view the list of built-in helper commands.
* `ssh-history` gives the history of remotely executed commands. The log file is saved in logs/requestLogs.log
> ❗️ Make sure to frequently clear the file. (By setting a cronjob or by doing it manually).
* `sudo reboot` can also be executed, which reboots the system and our node server gets automatically picked up during bootup(as we are using pm2 to manage our node server).
> 📌 Our node app starts automatically, even if there was a sudden system crash/ Unexpected error occurs.
## How secure is it?
It could be explained in different layers...
* Layer-1
**Webhook Validation**. This is technically validating the incoming request and making sure it was sent by Twilio. It is done by verifying `x-twilio-signature` passed in request headers by Twilio and with different parameters like (*authToken*, *x-twilio-signature*, *webhookUrl*, *req.body*). More info on this could be found [here](https://www.twilio.com/blog/how-to-secure-twilio-webhook-urls-in-nodejs)
* Layer-2
**in-app authentication**. After the request is validated in layer-1, the user needs to enter the correct password to get authenticated and the user's authStatus would be reset every 5 minutes.
## Challenges came across
* **Managing change in directory state**. This was very challenging because once the command is executed by the child-process, it gets killed and the further executing process has no idea about the prior change in the working directory.
* **Custom Authentication**. I've talked about it earlier, it was hard to manage the state of the user and to validate each request by also keeping an eye on the last login time.
* **Error Handling**. Needed to take care of different scopes of errors and process/ child-process crashes.
* **Async code handling**. As `fs` and `childProcess` modules provide mostly async functions, these needed to be handled carefully.
## What I learned along the way?
The development process was just amazing, every day I got to try something new and different. I would say "*Learn and ~~Code~~ Explore*" had been my mantra throughout the flow. Learned a lot about spawning a new process and dealing with child processes. Got my hands on file-system, custom middlewares, startup scripts/ init.d scripts, systemctl, etc...
## Limitations
* Currently does **not** support multiple commands execution at once like... `cd Sample && touch hello.txt`
* Does **not** know how to react for interactions like when critical commands with `sudo` are executed.
## Link to Code
{% github manojnaidu619/Whatsupp-SSH no-readme %}
## Additional Resources/Info
* [NodeJS childProcess](https://nodejs.org/api/child_process.html)
* [NodeJS fileSystem](https://nodejs.org/api/fs.html)
* [Twilio WhatsApp API Docs](https://www.twilio.com/docs/whatsapp/api)
| manojnaidu619 |
319,670 | When should you use event.preventDefault() | All too often I see event.preventDefault() sprinkled through applications where it doesn't make a who... | 0 | 2020-04-26T03:09:50 | https://dev.to/scottstern06/when-should-you-use-event-preventdefault-d2i | beginners, webdev, javascript | All too often I see `event.preventDefault()` sprinkled through applications where it doesn't make a whole lot of sense.
You should be using this method to prevent the default action of an event....easy enough, right?. Well no.
The conversation should **NOT** go:
> Oh theres an `event` being handled, lets add an `event.preventDefault()`
If you take ANYTHING away from this article, please **ASK WHY** if you dont know why something is happening. You will learn and make a much more informed decision.
> Back to my soap box.....
The only examples I can think you would want to use this is during the following cases AND to prevent their default action (please comment below if you can think of any more):
- Checkbox
- Default action: input being checked
- Button with type submit
- Default action: Submitting the form data
- Input with an `onChange` handler
- Default Action: Adding the text to the input
- Link tag
- Default Action: Visiting the link
### Lets do an example
*What do I want to accomplish?* I want to click a link and do something instead of allow the user to go to the `href` specified in the tag.
*Lets Assume* I have an `a` tag that looks like this
```html
<a class="dev-test" href="https://example.com">Click Here</a>
```
```js
const el = document.getElementsByClassName('dev-test')[0];
el.addEventListener('click', e => {
e.preventDefault();
// Do something else.
});
```
[Here is a codepen to play around with this concept](https://codepen.io/sstern6/pen/RwWVaJN)
#### HOT TIP ALERT
1. Click the link and see what happens.
1. Comment out the `e.preventDefault()`, then click the link and see what happens.
What do all of these have in common? They all have a default action that can be prevented.
So, in s u m a t i o n, next time you come across a `preventDefault` in the wild, think, "what action am I preventing and why is this here?"
For more information on the official spec you can read more [here](https://developer.mozilla.org/en-US/docs/Web/API/Event/preventDefault).
Hope you enjoyed reading! If you have any comments, questions or topics you want me to go over please comment below!
| scottstern06 |
319,686 | JavaScript's ecosystem is uniquely paranoid | Why is NPM so full of one-liners and other seemingly-trivial packages? Paranoia. | 0 | 2020-04-26T04:22:47 | https://listed.to/@crabmusket/14061/javascript-s-ecosystem-is-uniquely-paranoid | javascript, node, npm, opinion | ---
title: JavaScript's ecosystem is uniquely paranoid
published: true
description: Why is NPM so full of one-liners and other seemingly-trivial packages? Paranoia.
tags: ['javascript', 'node', 'nodejs', 'npm', 'opinion']
canonical_url: https://listed.to/@crabmusket/14061/javascript-s-ecosystem-is-uniquely-paranoid
---
Another week, another [NPM-related snafu](https://github.com/then/is-promise/issues/13). Why does this keep happening to the JavaScript ecosystem? The answer is paranoia. 😱
---
Many are quick to assert that JavaScript just has a too-low barrier to entry and the n00bs are messing it up. Whenever anyone says "JavaScript is the new PHP!" this is probably what they mean. I don't feel the need to provide evidence against this claim; I think it comes from an understandable frustration, expressed through all-too-common tech elitism.
Others say we should blame resume-driven-development, and the ego boost of having published thousands of open-source modules. We must all suffer, the argument goes, because a few obsessive individuals want to be able to boast about how critical _they personally_ are to the JavaScript ecosystem. While this is probably a real trend, why isn't it more prevalent in other open-source ecosystems?
> **Disclaimer before proceeding**: I use JS every day, and I actually really like it. I'm not trying to criticise it, just to explore some unique problems it has. I hope this post doesn't come across as too harsh.
There are probably _many_ contributing factors that have shaped NPM into what it is today. However, I assert that the _underlying_ reason for the bizarre profusion of tiny, absurd-seeming one-liner packages on NPM is **paranoia**, caused by a _unique combination_ of factors.
## JavaScript makes you paranoid
Three factors have caused a widespread cultural paranoia among JavaScript developers. This has been inculcated over years. These factors are: JavaScript's weak dynamic type system; the diversity of runtimes JavaScript targets; and the fact of deploying software on the web.
### 1. Weak dynamic typing
It's well-known that JavaScript's "type system" leaves a lot to be desired. [This well-known talk](https://www.destroyallsoftware.com/talks/wat) is a humourous take on some of the many ways you can shoot yourself in the foot in JavaScript.
Unless your team (and every open-source package your team depends on) always uses `===`, knows _exactly_ when `typeof` is acceptable, is good at defensive programming, and designs APIs that have good type discipline*, you've probably been tripped up by a string that behaved like a number, a 0 that was skipped for being falsy, an `undefined` turning up somewhere surprising, `typeof null === 'object'`, etcetera.
This isn't _entirely_ unique to JavaScript - many languages have dynamic types, and many languages have weak types and implicit coercions. But I would argue JavaScript is quite a dire example. And this is still an important contributing factor, without which the second factor probably wouldn't be as significant.
\*Or, you are TypeScript users. See Appendix 3.
### 2. Browser runtimes
It's not just the case that "JavaScript is missing a standard library". For example, there is a really easy and straightforward "standard" way to check if an object is an array: `thing instanceof Array`.
But wait! Enter the `iframe`! If the array came from a different context, this check will fail, because the `iframe`'s `Array` constructor is a different object from the parent window's `Array`. Do you _really_ know where that value came from?
Enter `Array.isArray` to save the day! But wait! What if your code needs to run in an older browser which doesn't support `isArray`? Is your transpilation+polyfill pipeline reliable enough to handle this? What do you _mean_ you're not using `babel-env-preset` or whatever the package is called now? This is the downfall of many a well-intentioned addition to JavaScript's standard library (like `String.padStart`).
Having to deal with an extreme diversity of runtimes seems unique to JavaScript among mainstream languages. This could be my bias showing (I'm primarily a web developer), but it's certainly true of the difference between web frontend code and web backend code. You just _never know_ where your code is going to run - in Internet Explorer 8, on Opera for Android, or someone's old version of Safari on their iPhone 5 they're clinging to because it would be too expensive to upgrade.
This is bad enough for application developers, who can to _some_ extent draw a line and decide _not_ to support users in certain demographics. (Or, in Kogan's case, [charge those users more](https://www.kogan.com/au/blog/new-internet-explorer-7-tax/).) But it's a nightmare for library developers, who want to make their code usable by as many _other developers_ as possible.
### 3. Bundle size
Do you remember a few months ago when the internet joined in a collective hate-on for the `is-buffer` package? This package, as its name suggests, checks whether something is a Buffer.
Why would one need a package for that? Well, weak typing might make one want to check types like this; moving targets in the runtime might make one worry that one doesn't know _how_ to check the type reliably - but still, why doesn't one just depend on the buffer package?
Enter the final triumvir of this unholy alliance: _bundle size paranoia_, which was ostensibly [the reason](https://github.com/feross/is-buffer/blob/e5a3b31419315bf954f9a7fab2d0d2fceb818f21/README.md#why-not-use-bufferisbuffer) the `is-buffer` package was created. Because JavaScript programs have to be downloaded _frequently_ by users (even multiple times by the same user on the same day, if caching isn't used carefully), and because Google has convinced us that milliseconds of additional page load time will have _dire_ consequences for our users and consequently for our bank accounts, _and because_ bundlers and module systems have not provided adequate support for modularity, we web developers go to _extreme lengths_ to avoid shipping unnecessary bytes to our users.
When the unit of modularity is "NPM package", rather than "file" or even "function", some will go to great lengths to [split their code across NPM packages](https://www.npmjs.com/search?q=keywords:lodash-modularized). (For more on this, see Appendix 1.) This works with old bundlers that can't tree-shake, and it _can_ avoid reuse - though as noted by the [lodash project itself](https://lodash.com/per-method-packages), they are thankfully moving away from this pattern because it may introduce more opportunities to _duplicate_ code than to _deduplicate_ it!
A huge amount of effort has been poured into not just minifying a source bundle, but producing the best possible bundle in the first place. The NPM ecosystem as it stands today has been shaped in part by these efforts.
## Future proof
These three factors combine and interact in unexpected and awful ways.
Over the years there has been rapid evolution in both frontend frameworks and backend JavaScript, high turnover in bundlers and best-practises. This has metastasized into a culture of uncertainty, an air of paranoia, and an extreme profusion of small packages. Reinventing the wheel can sometimes be good - but would you really bother doing it if you had to learn all the arcane bullshit of browser evolution, IE8 compatibility, implementation bugs, etc. _ad infinitum_?
And it's not just that you don't understand how things work _now_, or how they _used_ to work - but that they'll change in the future!
Whenever NPM's package culture is discussed, one of the benefits touted is that if one of your dependencies is ever updated, your own code will now be updated "for free"! Your application will remain correct, because it depends on an abstraction that will remain correct. (Abstractions are good, but see Appendix 2.)
This is a very reasonable expectation, and an important piece of progress in software development. But I believe the paranoia created by the three factors I discussed above have led to the excesses we see in the current NPM ecosystem. This is why we have [is-even](https://www.npmjs.com/package/is-even) and its whole ludicrous web of dependencies, and why we don't have `is-even` in Python.
"Surely," the rational developer exclaims, "there could be no future changes to the `is-even` package. The definition of even numbers isn't going to change any time soon!"
No, the definition of even numbers won't ever change. But sadly, my friend, this is JavaScript - and you can _never really be sure._
---
### Appendix 1. In praise of modules
My thoughts on this issue have been brewing for a while, but [this comment by Sindre Sorhus](https://github.com/sindresorhus/ama/issues/10#issuecomment-117766328), noted small-package developer, really put it all in focus for me.
Sindre makes a very good argument in favour of modules:
> tl;dr You make small focused modules for reusability and to make it possible to build larger more advanced things that are easier to reason about.
However, this is not an argument in favour of _NPM packages_. All the benefits Sindre lists could be achieved by simply designing programs in a modular way. If another developer wants to avoid having to re-implement an interesting but not-entirely-trivial piece of functionality, they should be able to lift a well-defined module (ideally a [single file](https://github.com/kazzkiq/darkmode/blob/2312fdcf4ac49721a6ec0e4727106ba8d2e485f7/src/index.ts)) from one project to another.
A lot of the issues with NPM are caused by... well, NPM, not by some inherent property of small modules. This was the case for last week's `is-promise` debacle (which precipitated me actually writing this blog post). _Small NPM packages_ are the "problem", not small modules, and the problem, at its root, is caused by paranoia.
### Appendix 2. The meaning of abstractions
What's wrong with this code?
```javascript
const isPromise = require('is-promise');
if (isPromise(thing)) {
thing.then(successCallback).catch(failureCallback);
}
```
(It's from a real application that uses `is-promise`, but I won't name names.)
Did you spot it? `catch` might be undefined. Why? `is-promise` implements the [Promises/A+ spec](https://promisesaplus.com/), which only requires a `then` method. The specific meaning of "is `thing` a promise?" can actually change based on _how you want to use the answer_. The "promise" is not a reliable abstraction here, because JavaScript has so many versions of it, and because promises can be used in many ways.
This is slightly tangential to the paranoia discussed above, but is an outcome of a "don't ask" approach to packages ("don't ask" because the details will horrify you), and probably not unique to JavaScript.
> **UPDATE:** apparently even the package maintainer [failed to notice the distinction](https://github.com/then/is-promise/pull/40) between a `Promise` and something that has a `then` method. This stuff is not trivial.
The pattern of doing this kind of typecheck is all-too-prevalent in the JS ecosystem, which privileges APIs that seem "simple" because you can chuck anything you want into them, but pushes the burden of being compatible with every conceivable input onto the library. Which brings me to my next appendix...
### Appendix 3. TypeScript
Is there a solution to all this? How can we stop the madness?
I don't believe TypeScript is a _solution_. If anything, it's a clear _symptom_ of the problem. But I believe that TypeScript helps do something important: *it makes poorly-typed code annoying to write*.
Yes, you [can design](https://www.typescriptlang.org/docs/handbook/functions.html#overloads) a method that accepts anything from a `string` to a `then`able that will return an object containing a `Float64Array`, but writing the type of that method becomes _ugly_, and implementing it becomes a _pain_ because TypeScript forces you to demonstrate to its satisfaction that you've done it correctly.
Fewer APIs that take and return different types make it less necessary to implement code like `is-buffer`, `is-number`, etcetera. Of course, browser compatiblity and bundle size anxiety will still present problems. But maybe with an increase in JavaScript developers designing code with types, we'll see less demand for typecheck packages and the like.
### Appendix 4. Deno
One of the reasons I'm excited for [Deno](https://deno.land)'s upcoming stable release is that it builds on a philosophy of _fewer, better dependencies_. But even in cases where you need a specific dependency, Deno's URL-based imports make it trivial to:
- Import _just a single file_ without downloading a whole package plus its tests and everything else. Refer back to Appendix 1 for why this is cool.
- Pin each import _to a commit hash_ or other stable identifier.
Yes, many people are concerned about the idea of importing URLs for many legitimate reasons. NPM is a more trusted place to host packages than some random website. But not even NPM can be 100% reliable indefinitely. Deno at least makes you stop and think... _do I trust this source?_ | crabmusket |
319,693 | Sass Functions | Notes and reference on Sass | 6,230 | 2020-05-04T00:38:49 | https://dev.to/mikkel250/sass-functions-j6e | sass, beginners, css, stylesheets | ---
title: Sass Functions
published: true
description: Notes and reference on Sass
tags: sass, beginner, css, stylesheets
series: SASS basics
---
####Functions in Sass
The full list of functions is available in the Sass docs. Only the ones likely to be frequently used will be covered here.
The builtin functions are written in C, and so performance concerns are not a big factor when deciding whether to use them. Functions that are written by us as developers do not necessarily share this trait, so it's something to bear in mind when writing and using your own functions. More on functions:
https://sass-lang.com/documentation/at-rules/function
and the complete list of built-ins:
https://sass-lang.com/documentation/modules
Note that an entire series on just colors could be written, so use Google to find out more about colors if necessary. A good place to start would be https://developer.mozilla.org/en-US/docs/Web/HTML/Applying_color
#####Color functions
#####Creating color
```sass
rgb($red, $green, $blue);
rgba($red, $green, $blue, $alpha);
red($color);
green($color);
blue($color);
mix($color1, $color2, [$weight]);
```
The above are pretty self-explanatory given the function names and variable names, but research them if needed, to learn more. Some of the more complicated functions are outlined below to get an idea of how functions work.
#####adjust-hue
```sass
adjust-hue(#63f, 60deg)
```
adjust-hue takes the initial color as as the first argument, and the degrees of rotation (clockwise around the color wheel) as the second (the 'deg' is optional, but helpful for remembering later that this value is degrees on a circle).
#####darken and lighten
```sass
darken($color, $percent);
lighten($color, $percent);
```
Note that the percent value is not multiplicative. In other words, we are subtracting 20% from its brightness value. We are not decreasing its current brightness value by multiplying the current value by 20% and subtracting the product. It is a scale of 0-100.
#####saturate and desaturate
```sass
desaturate($color, $percent);
saturate($color, $percent);
```
Color saturation is essentially how much of a channel is mixed into a particular color. A color saturated to 100% is very vivid, whereas a color with 0% saturation would be grey scale.
| mikkel250 |
319,697 | The Visitation of Visitor Pattern: How it makes your software more useful | Original post here The visitor pattern is a behavior design pattern, which means it's a way for obje... | 0 | 2020-04-26T05:37:00 | https://dev.to/minhthanh3145/the-visitation-of-visitor-pattern-how-it-makes-your-software-more-useful-4flb | architecture, java, p | [Original post here](https://dafuqisthatblog.wordpress.com/2020/04/25/the-visitation-of-visitor-pattern/)
The visitor pattern is a behavior design pattern, which means it's a way for objects to interact in order to solve a problem. The problem for the visitor pattern is to add functionalities to a class hierarchy without having to modify every single class for every single functionality. This sounds abstract, but I will try to be more concrete as we proceed.
The constraint that you may not modify code of any class within the hierarchy, like the case of third-party library classes, yet still allow for additional functionalities that are relevant to the classes to be added, is actually a constraint frequently met by library designers.
In this post, my goal is to perhaps make sense of the
## The platitudinous Problem
The problem we will use for this post is, without a doubt, very platitudinous: How to design a hierarchy of objects to represent shapes with certain computable aspects like area and volume.

Did someone say my name ? Also, shapes ? Again ?
I often find such problems to be too simple and therefore delude the purpose of design patterns. However, a real world example would perhaps contain too many extra functional and non-functional requirements that would also delude the focus on design patterns. On rare occasions, platitudes may be re-interpreted in ways that are helpful and delightful. Not saying that this post is definitely either of these things, but hopefully it would be.
Let's start even smaller. On the computable aspects, let's say you're not mathematically gifted. You only know properties of individual shapes (rectangles, circles, etc) and the formula to calculate their area only if they are described in a requirement. Also, your team unfortunately works in a way that all relevant requirements don't come to you at the same time, but scattered through time and space and are influenced by multiple parties. Now that sounds more realistic.
So as you are looking melancholically at your female co-worker while leaning against something, the first requirements comes.

[https://undraw.co/thankful](https://undraw.co/thankful)
It is to calculate the area of the shapes using their respective attributes and formula.
## A solution Without visitor pattern
So a no-brainer solution is, well, a no-brainer. Ignore the `static`, I find them rather annoying, but for the sake of having a `main` function I will be tolerant.
The solution is just literally a hierarchy of shapes in the most obvious way imaginable, and the computations, which are represented by literal values (I aint mathematically gifted y'all), are put into the appropriate classes.
```java
public class WithoutVisitorPattern {
public abstract static class Shape {
public abstract int getArea();
}
public static class Rectangle extends Shape {
@Override
public int getArea() {
return 0;
}
}
public static class Circle extends Shape {
@Override
public int getArea() {
return 1;
}
}
public static class Shape1 extends Shape {
@Override
public int getArea() {
return 2;
}
}
public static class Shape2 extends Shape {
@Override
public int getArea() {
return 3;
}
}
public static void main(String\[\] args) {
List<Shape> shapes = new ArrayList<>();
shapes.add(new Rectangle());
shapes.add(new Circle());
shapes.add(new Shape1());
shapes.add(new Shape2());
System.out.println(calculateShapeArea(shapes));
}
public static int calculateShapeArea(List<Shape> shapes) {
int result = 0;
for(Shape shape : shapes) {
result += shape.getArea();
}
return result;
}
}
```
And frankly, it works well. With the current scope of requirements, any more complexity would be unnecessary. Minimalism is a respectable pursuit.
But life isn't that simple. After a while, your team decide to distribute the above code into production. This can either mean this code live in an official release of your application, or live inside a version of a library that your clients will use. Let's be dramatic and assume the second scenario. You distribute your library as a `JAR` file to your clients. Your clients use this library to calculate the area of the shapes to do some, uh, mathematical mission-critical stuffs.
But as they use it, their mathematics extend to well beyond area of shapes, and thus they demand that your library accommodates their new requirement - which is to calculate volume of the shapes. Okay, so with the above solution, in order to accommodate a new method called `getVolume` for every shape, you must add the signature to the base class, and then for every subclass, you also need to add the signature `getVolume`.
Because your team supports an extensive library for shapes, there are more than 23 shapes in the hierarchy. 23 is my current age by the way. Anyway, you would need to add 23 `getVolume` methods into each of these 23 classes. Did I mention 23 is my age ? Okay enough with these.
## Why the problem matters ?
You may be thinking: "I see that this is the problem that you mentioned earlier: To add additional functionalities relevant to the class hierarchy without modifying the class hierarchy. But hey, you have to add 23 different `getVolume` methods either way, because the formula for each of these 23 shapes is different from each other, so what's the harm in placing these methods in the class hierarchy itself, compared to an alternative. Sure, it'd be more elegant and also adhere to the so-called [Open-Closed Principle](https://en.wikipedia.org/wiki/Open%E2%80%93closed_principle). But, the first one is subjective, the second one sounds like [Authority Bias](https://en.wikipedia.org/wiki/Authority_bias) to me. "
Okay, maybe you won't be thinking exactly that, but something like that is a reasonable objection. However, one of the important characteristics of good software designs is to accommodate changes.
### Because other software depend on your software
Another software team is working on a different mathematics project and they found your software to be very useful, but lacking some shapes that are particular to their projects. So they use the `JAR` file you distribute, extend the subclass `Shape` and implement another 23 shapes that work for them.
Now the requirement for volume of shapes comes, among other requirements such as bug fixes and optimizations. You simply add 23 `getVolume` methods to each of the class in the hierarchy and release the new version of the library with attractive bug fixes and optimizations. However, because the software team above also extends from your base class, they would also need to add `getVolume` into their 23 shapes in order to use the new version. The risk tends to pose difficulty in justifying the library upgrade, so likely they won't use the new version(s). For you, this means that people are not receiving values from your new releases. What's the point of software if it's not to continue to provide values ?
This gets worse when it cascades to further software teams that depend on the software team above, and I think this is enough to tell you that your design, as it currently stands, does not accommodate changes very efficiently. This problem suggests that another solution is needed to keep the propagation of change to be minimal.
### Because software ceases to evolve
It is not an exception that software components cease to evolve. They may stop because the budget runs out so no one is maintaining the library anymore. They may stop because of a natural disaster that kills everyone who works on that library specifically. Whatever the cause is, a consequence is that you and your team, as the library developers, can no longer accommodate new changes to the library. That responsibility unfortunately will fall into other software teams who extend your library. However, just because your library is not maintained doesn't mean it is not useful anymore.
So when your project is no longer maintained, new functionalities can no longer be added into the hierarchy inside your library. The software team who decides to use your library to reap its existing benefits must create a new class hierarchy that use your class hierarchy to add functionalities. There is no other way. This, unfortunately, would mean that new functionalities would have to be used differently than old functionalities, which confuse new members of the team, which adds more to the cost. It's also annoying to explain that we have to code this way because of, quote, unquote, legacy code.
## A solution that solves the problem
So after we have seen that adding functionalities by directly modifying code of the hierarchy is not a design that would facilitate useful, long-lasting software libraries.
So what's the solution ? It is to do what future software teams would have to do if they no longer can modify your class hierarchy. Create another class hierarchy and make it do the computations, instead of having the computations inside the Shape hierarchy.
From the above solution without visitor pattern, if we go along with the idea of delegating the computations to another hierarchy, we would end up with something like this.
```java
public class EvolutionToVisitorPattern {
public abstract static class Shape {
public abstract int getArea(AreaCalculator areaCalculator);
}
public static class AreaCalculator {
public int getAreaOf(Rectangle shape) {
return 0;
}
public int getAreaOf(Circle shape) {
return 1;
}
public int getAreaOf(Shape1 shape) {
return 2;
}
public int getAreaOf(Shape2 shape) {
return 3;
}
}
public static class Rectangle extends Shape {
@Override
public int getArea(AreaCalculator areaCalculator) {
return areaCalculator.getAreaOf(this);
}
}
public static class Circle extends Shape {
@Override
public int getArea(AreaCalculator areaCalculator) {
return areaCalculator.getAreaOf(this);
}
}
public static class Shape1 extends Shape {
@Override
public int getArea(AreaCalculator areaCalculator) {
return areaCalculator.getAreaOf(this);
}
}
public static class Shape2 extends Shape {
@Override
public int getArea(AreaCalculator areaCalculator) {
return areaCalculator.getAreaOf(this);
}
}
public static void main(String\[\] args) {
List<Shape> shapes = new ArrayList<>();
shapes.add(new Rectangle());
shapes.add(new Circle());
shapes.add(new Shape1());
shapes.add(new Shape2());
System.out.println(calculateShapeAttribute(shapes));
}
public static int calculateShapeAttribute(List<Shape> shapes) {
AreaCalculator areaCalculator = new AreaCalculator();
int result = 0;
for(Shape shape : shapes) {
result += shape.getArea(areaCalculator);
}
return result;
}
}
```
This solution creates a class called `AreaCalculator` which implements the computation to get area of the shapes. Each call to `getArea` is now given an instance of `AreaCalculator` and simply delegate to `AreaCalculator` to compute and return the area.
At first glance, the obvious problem seems to be code duplication. If we look at the patterns of text in the child classes, it's not unreasonable to think they're duplication, and instead we can just modify the base class to:
```java
public abstract static class Shape {
public int getArea(AreaCalculator areaCalculator) {
return areaCalculator.getAreaOf(this);
}
}
```
However, that won't work, because `this` is of type `Shape` which the `AreaCalculator` does not have a method that accepts. To fix this, we may want to modify `AreaCalculator` to:
```java
public int getAreaOf(Shape shape) {
if(shape instanceof Rectangle) {
return aPrivateMethodToCalculatAreaForRectangle(shape);
}
if(shape instanceof Shape1) {
}
// 21 more to go :(
}
```
But this defeats the purpose. Suppose that another software team want to extend `AreaCalculator` into their own class because they want to optimize the current calculation of area for `Rectangle`. Too bad, they can't do it because finding the right shape and delegating to the right private method happens within the same function. Therefore doing it this way would prevent customization of existing functionalities.
So we want to maintain the solution as it is, because then another software team only need to extends `AreaCalculator` and override `public int getAreaOf(Rectangle shape)` to provide their own customized implementation.
The second aching problem is that, each method is receiving an `AreaCalculator` instance, this seems unnecessary, can we just inject the instance into the class constructor and then re-use it. So, start with the base class.
```java
public abstract static class Shape {
protected AreaCalculator calculator;
Shape(AreaCalculator calculator) {
this.calculator = calculator;
}
public abstract int getArea(AreaCalculator areaCalculator);
}
```
Wait a minute, there are red marks !

Turns out that, we have to add a constructor for all classes extending `Shape` in order to do it this way. Suddenly, it doesn't seem to worth the efforts anymore. With every instance of `AreaCalculator` you save from a method, the same instance must go into the constructor. However, saying that it takes the same efforts for both approaches does not give us information to choose one over another.
A practical reason would be that, if we decide to give an instance `AreaCalculator` to all shapes in the constructor, it implies that we **have to make an instance of `AreaCalculator`** before we can use any shape. The construction of an `AreaCalculator` instance that must do intense computations in an optimized way would be costly. When such an `AreaCalculator` instance is constructed, an implementation that maximizes optimization would have to read CPU resources, retrieving information from other parts of the application in order to determine the most efficient area computation strategy.
On the other hand, our `Shape` subclasses represent lightweight objects that contain information about the shapes at hand. We even delegate computations to another class. If we have to make an instance of `AreaCalculator` before every shape is created, it turns out to be sub-optimal, because we are creating a very costly object that we don't use yet. We can't make the assumption that the area computation would occur right after these shapes are created. Therefore, delaying the construction of `AreaCalculator` right to the moment when the shapes need it, is the optimal strategy. For this reason, we maintain our solution as it is.
## A solution with visitor pattern
With all that said, the visitor pattern is actually half-way achieved. In order to support a volume computation, we can just create the method `getVolume` for each of the class in the class hierarchy and delegate the logic to a `VolumeCalculator`. However, we can notice that `AreaCalculator` and `VolumeCalculator` actually shares the same signatures, and they are used in the same way by the subclasses of `Shape`, so they can be grouped together into a new inheritance hierarchy. This new hierarchy has the base class `Calculator` which has a method `calculate` that is used by `getArea` and `getVolume`.
So now, `getVolume` and `getArea` has the same signature and logic: Receiving a `Calculator` instance, call `Calculator.calculate(this)` and return the result, therefore they are practically just one method in the class `Shape` hierarchy. Let's this method be called `getComputedValueFrom(Calculator)`.
Now your `Shape` use `Calculator` as something that it merely passes `this` to and receive a value, it's not strictly just about computation anymore, because we can perform additional logic and algorithm inside `Calculator.calculate` as well. Whenever we see an abstraction that does multiple things, it's a good idea to name it something generic so that its subclass can take on concrete meanings. With this principle, we replace `Calculator` by `Visitor`, `getComputedValueFrom` with `accept`, and `calculate` method with `visit`. Voila. You end up with the visitor pattern.
```java
public class WithVisitorPattern {
public static abstract class ShapeVisitor {
public abstract int visit(Rectangle shape);
public abstract int visit(Circle shape);
public abstract int visit(Shape1 shape);
public abstract int visit(Shape2 shape);
}
public static class AreaShapeVisitor extends ShapeVisitor {
public int visit(Rectangle shape) { return 0;}
public int visit(Circle shape) { return 1;}
public int visit(Shape1 shape) { return 2;}
public int visit(Shape2 shape) { return 3;}
}
public static class VolumeShapeVisitor extends ShapeVisitor {
public int visit(Rectangle shape) { return -0;}
public int visit(Circle shape) { return -1;}
public int visit(Shape1 shape) { return -2;}
public int visit(Shape2 shape) { return -3;}
}
public abstract static class Shape {
public abstract int accept(ShapeVisitor visitor);
}
public static class Rectangle extends Shape {
@Override
public int accept(ShapeVisitor visitor) {
return visitor.visit(this);
}
}
public static class Circle extends Shape {
@Override
public int accept(ShapeVisitor visitor) {
return visitor.visit(this);
}
}
public static class Shape1 extends Shape {
@Override
public int accept(ShapeVisitor visitor) {
return visitor.visit(this);
}
}
public static class Shape2 extends Shape {
@Override
public int accept(ShapeVisitor visitor) {
return visitor.visit(this);
}
}
public static void main(String\[\] args) {
List<Shape> shapes = new ArrayList<>();
shapes.add(new Rectangle());
shapes.add(new Circle());
shapes.add(new Shape1());
shapes.add(new Shape2());
ShapeVisitor visitor = new VolumeShapeVisitor();
System.out.println(calculateShapeAttributes(visitor, shapes));
}
public static int calculateShapeAttributes(ShapeVisitor visitor, List<Shape> shapes) {
int result = 0;
for(Shape shape : shapes) {
result += shape.accept(visitor);
}
return result;
}
}
```
I am not gonna comment on why we name things like `Visitor` and `visit`, because to be honest I haven't thought of a reasonable explanation. But nevertheless, our derivation of this pattern so far has not touched upon such concepts, so I don't think these are necessary.
| minhthanh3145 |
319,742 | Callbacks | Callback Function | 0 | 2020-04-26T08:24:52 | https://dev.to/giandodev/callbacks-2bo9 | javascript, beginners | ---
title: Callbacks
published: true
description: Callback Function
tags: javascript, beginner
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/o2025yyq2yfansg2cd3u.jpg
---
The callback function is a simple function that we pass inside another function as an argument.

The Callback function allows us to write asyncronus code for example the code above is asyncronus code because javascript can wait for a click before running our callback function and move on with the execution of the code.
In synchronous code javascript executes the code from top to bottom, left to right. Without the callback function in the code above, javascript would freeze (blocked) until the user clicks the button.
Now is a good time to talk about event loops and since we are all sitting on the shoulders of the giants, no one better than [Philip Roberts](https://twitter.com/philip_roberts) explained events loops:
[Philip Roberts event loops video](https://www.youtube.com/watch?v=8aGhZQkoFbQ)
I hope you watched the video;
We may write our callback function also with the arrow function like this:
 | giandodev |
319,779 | Weekly report #3 | ✅ What we did this week The legacy app Release v0.15.3 Merged horizontal split... | 0 | 2020-04-26T10:51:09 | https://dev.to/rokt33r/weekly-report-3-2hig | boostnote, markdown, weeklyreport, noteapp | ---
title: Weekly report #3
published: true
description:
tags: boostnote, markdown, weeklyreport, noteapp
---
# ✅ What we did this week
## The legacy app
- Release v0.15.3
- Merged horizontal split mode (It will be shipped in v0.16)
https://github.com/BoostIO/Boostnote/pull/2936
## The new app
- Released v0.4.0 and v0.4.1 of the desktop app
- Rolled out v0.4.1 of the mobile app (In review now. It’ll be published in 3 days)
- Fixed Navigating UX (Shipped in v0.4.0)
- Fixed Emoji bug (Shipped in v0.4.1)
- Fixed app crash after editing (Shipped in v0.4.1)
- Refined UI coloring (This issue has been resolved partially in v0.4.0, but I still need to work more to completely finish it)
# 🏃 What we will do next week
## The legacy app
- Review and merge opening a note in a new window
https://github.com/BoostIO/Boostnote/pull/3110
Opening a note in a separate window is really awesome, but the pull request is affecting the electron main processor, so I need to check that the auto updater is compatible with this feature.
## The new app
- Improve cloud storage sync speed and authentication flow
- Re-implement Bookmark
- Support i18n completely
- Implement initial prototype of File System based storage.
The list isn’t changed from last week because I was working on fixing some critical bugs in both the mobile app and the desktop app. But this week, I think I can fully focus on these issues.
# 🆘 Featured issues
From this week, we want to introduce some issues and pull requests that anyone can tackle and review. If you would like to contribute to our project, please consider the list below.
## Issues to resolve
- Implement synced scrolling for split view
https://github.com/BoostIO/BoostNote.next/issues/247
- Implement PDF export
https://github.com/BoostIO/BoostNote.next/issues/243
- Improve default preview CSS style (Easy)
https://github.com/BoostIO/BoostNote.next/issues/435
- Improve storage deleting message (Easy)
https://github.com/BoostIO/BoostNote.next/issues/434
- Implement option to show notes only in a folder, not in its sub folders
https://github.com/BoostIO/BoostNote.next/issues/419
## Pull requests to review
- Introduce Italian locale https://github.com/BoostIO/BoostNote.next/pull/436 | rokt33r |
319,788 | tes | test | 0 | 2020-04-26T11:13:10 | https://dev.to/executedwell/tes-3p7n | test | executedwell | |
319,970 | What is IOTA Cryptocurrency? Explained For Beginners | In this article, we are going to talk about IOTA (Ticker: MIOTA). According to the whitepaper of IOTA... | 0 | 2020-04-26T14:14:38 | https://blog.coincodecap.com/iota-coin-explained-for-beginners/?utm_source=rss&utm_medium=rss&utm_campaign=iota-coin-explained-for-beginners | crypto, blockchain, iota | ---
title: What is IOTA Cryptocurrency? Explained For Beginners
published: true
date: 2020-04-26 13:48:22 UTC
tags: Crypto,blockchain,crypto,iota
canonical_url: https://blog.coincodecap.com/iota-coin-explained-for-beginners/?utm_source=rss&utm_medium=rss&utm_campaign=iota-coin-explained-for-beginners
---
In this article, we are going to talk about IOTA (Ticker: MIOTA). According to the whitepaper of IOTA, it is a cryptocurrency for the Internet-of-Things (IoT) industry. It provides a feeless platform with high scalability.
In [Bitcoin](https://blog.coincodecap.com/a-candid-explanation-of-bitcoin/), the major drawback was scalability. It can process seven transactions per second. The process of clubbing transactions into a block and solving the complex puzzle adds additional cost(called mining fees). It is unsuitable for micropayments as you may end up paying more. There can be a clash in the network because of distinguished designations like Miners and Nodes.
## **IOTA** **Architecture and Participants**
IOTA doesn’t use blockchain; instead, it uses a [Directed Acyclic Graph(DAG)](https://en.wikipedia.org/wiki/Directed_acyclic_graph) structure called **Tangle** for storing the transactions.
The Tangle consists of sites and edges. The participants in the IOTA are called **Nodes**. They are responsible for issuing and validating transactions.
**Sites** are individual transactions in the network, and **Edges** are the connection to the previous two sites.
**Tips** are transactions that are yet to be confirmed. To make sure the network is operational, the IOTA team has introduced a Coordinator, which is like a centralized protocol that performs the same task as individual users.
It is important to note that IOTA is an asynchronous network. This means different nodes may have different data.
## **IOTA** **Transaction Validation**
As mentioned earlier, IOTA is a feeless platform. So, the only way to do that is to get rid of miners.
You must be wondering how does the network operates without miners as they are responsible for verifying transactions.
IOTA came up with an innovative way to assure trust in the network as well as verify the transactions.
First of all, to issue a valid transaction, the node must solve a cryptographic puzzle. This is achieved by finding a nonce such that the hash of that nonce concatenated with some data from the approved transaction has a particular form.
Here the transaction and a nonce is converted to trits ( ternary numerical system), and it is then hashed using curl hash function.
For the transaction to be valid, the hash should end with the right number of zeros.Otherwise, the nonce is changed. It keeps going on until a hash is generated, which ends with the specified number of zeros.
Second, to include a transaction in the network, the node must approve any previous two tips. The tip selection is made through Markov Chain Monte Carlo (MCMC) algorithms.
The approval can direct or indirect. In the case of direct approval, there is a direct arrow between two transactions. For example, B approves the transaction A.
In the case of indirect approval, there is no direct arrow, but there is a path that has at least two transactions in it. For example, D approves transaction A through the path ABCD.
This feature makes IOTA highly scalable. As the flow of transaction increases in the network, so will be the approval of the transaction.
<figcaption>Direct Approval</figcaption>
<figcaption>Indirect Approval</figcaption>
As a reward, the node’s transaction will be included in the network, and in the future, the new transactions will verify it.
This will increase the confidence of the network in the transaction. If the node finds an invalid or conflicting transaction, the nodes need to decide which transactions will become orphaned. The orphaned transaction will fall into oblivion.
## **Concept of Weight and Cumulative Weight**
<figcaption>IOTA Cumulative Weight</figcaption>
The **weight** of a transaction is proportional to the amount of work that the issuing node invested into it.
It is attached to the transaction, and it acts as proof that the transaction is valid.
It shows that some work was done by the user to show that the transaction is a valid one.
Transactions with large weights are considered as more important than the one with a small weight.
**Cumulative Weight** is defined as the sum of its own weight of a particular transaction and the weights of all transactions that directly or indirectly approve this transaction.
Sites with high weight usually have a high cumulative weight.
In the above diagram, The small number denotes weight, and the numbers in the circle indicate cumulative weight. Transactions A,B,C,E directly or indirectly approves transaction F. The cumulative weight of F is 3 (own weight)+ 1(A) + 3(B) + 1(C) + 1(E) =9.
## IOTA’s Roadmap
**Qubic** : It is one of the promising features of IOTA. So, let us familiarize ourselves with some terms.
- Quorum is the minimum amount of vote needed to reach consensus in a distributed system.
- Oracle machines are external data providers to the Tangle.
- Sometimes, the computational processes are too intensive for a device to handle. In such cases, outsourced computation helps in distributing computational tasks.
- Smart contracts are deterministic programs that are executed when a specific condition is fulfilled.
According to the official definition,
**What is IOTA Qubic?**
Qubic is a protocol that specifies IOTA’s solution for quorum-based computations, including such constructs as oracle machines, outsourced computations, and smart contracts.
So, a Qubic is a manifestation of all of the above to make IOTA programmable, secure, trusted, incentivized, and, as said by founders, an IOTA-based world supercomputer.
- **Improved networking** : Research and development of a networking broker is on its way by IOTA that enables to switch between different networking protocols fluidly
- **Automated Snapshotting:** It will enable IoT devices to stay updated with the ledger without storing the whole ledger.
- **Identity of Things(IDoT)**: The underlying idea to give an identity to the IoT devices. It includes it’s manufacture details and functionalities.
- **Permandos** : Certain devices will need the whole ledger for their function. So, Permanode stores the entire Tangle history and data in it permanently and securely.
- **Masked Authenticated Messaging(MAM)**: MAM allows devices to encrypt entire data streams and securely anchor those into the Tangle in a quantum-proof fashion. Only authorized parties will be able to read and reconstruct the whole data stream. It is similar to how modern communication systems except that it will be between devices in a decentralized fashion.
#### Application of IOTA
1. Jaguar Landrover is using the IOTA Technology to pay drivers for car data.
2. IOTA, Dell Technologies, and The Linux Foundation come together to create a project that verifies the authenticity of data coming from sensors.
IOTA is still in its development phase. Currently, they are working on a protocol that will make IOTA quantum attack free. The team is aiming to make IOTA more mainstream, secure, and decentralized by getting rid of coordinators.
- [Shrimpy Review – Crypto Trading Bots for Social Portfolio Management](https://blog.coincodecap.com/shrimpy-crypto-trading-bot-review/)
- [Understanding Cryptocurrency Trading Bots [2020](Opens in a new browser tab)](https://blog.coincodecap.com/a-guide-to-cryptocurrency-trading-bots/)
- [Ethereum versus Bitcoin](https://blog.coincodecap.com/ethereum-versus-bitcoin/)
- [What are Dapps? (An ultimate guide)](https://blog.coincodecap.com/what-are-dapps-an-ultimate-guide/)
- [Proposing Future Ethereum Access Control](https://blog.coincodecap.com/proposing-future-ethereum-access-control/)
- [Building An Ethereum Simulation Game – Part 3 – The Front End](https://blog.coincodecap.com/building-an-ethereum-simulation-game-part-3-the-front-end/)
- [Bitcoin ATM – Pros & Cons](https://blog.coincodecap.com/bitcoin-atm-pros-and-cons/)
- [Commit Rank is now Activity Rank](https://blog.coincodecap.com/commit-rank-is-now-activity-rank/)
- [Cryptocurrency —Advantage, Disadvantage, and Risk](https://blog.coincodecap.com/cryptocurrency-advantage-disadvantage-risk/)
- [ChangeNOW review – A reliable way to exchange crypto](https://blog.coincodecap.com/changenow-review-a-secure-crypto-exchange/)
The post [What is IOTA Cryptocurrency? Explained For Beginners](https://blog.coincodecap.com/iota-coin-explained-for-beginners/) appeared first on [CoinCodeCap Blog](https://blog.coincodecap.com). | coinmonks |
319,983 | Node.js REST API with Docker, Redis and MongoDB | Hi guys, this is my first post and I want to share a simple Node.js REST API (Express) that includes... | 0 | 2020-04-26T14:51:50 | https://dev.to/renacargnelutti/node-js-rest-api-with-docker-redis-and-mongodb-3p7c | node, mongodb, redis, docker | Hi guys, this is my first post and I want to share a simple Node.js REST API (Express) that includes Docker, Redis and MongoDB.
You can run this project with docker-compose, we won't explain anything about it but you refer these links [Docker](https://docs.docker.com/install/) and [Docker Compose](https://docs.docker.com/compose/install/). Check the repo link at the end to be able to run the GitHub project.
In the file api.js, we use mongoose to connect to MongoDB server:
```javascript
mongoose.connect(`mongodb://${process.env.MONGO_INITDB_ROOT_USERNAME}:${process.env.MONGO_INITDB_ROOT_PASSWORD}@${process.env.MONGO_CONTAINER_NAME}/${process.env.MONGO_INITDB_DATABASE}?authMechanism=SCRAM-SHA-1&authSource=admin`,
{ useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true }
, (err) => {
if (err) {
console.log('could\'t connect to Mongo DB ', err);
}
});
```
Inside libs/redis-client.js you can see the Redis connection:
```javascript
const redis = require('redis');
const { promisify } = require('util');
const client = redis.createClient(process.env.REDIS_URL);
client.on("error", (error) => {
console.error(`Error to connect Redis: ${error}`);
});
```
Then let's use it:
mongoose -> api/routes/users.js. (Check User schema inside models/user)
```javascript
// retrieve users
let users = await User.find({}).lean().exec();
```
redis -> api/routes/users.js.
```javascript
// retrieve user
const rawData = await redisClient.getAsync(req.params.email);
// save user
await redisClient.setAsync(req.params.email, JSON.stringify(user));
```
The repo is available at: [https://github.com/renacargnelutti/express-mongo-redis](https://github.com/renacargnelutti/express-mongo-redis)
I hope you enjoy the post!
Let me know any question. | renacargnelutti |
320,048 | How to implement i18n in your WebApp? Part 1 | How to localize your Application from the Database point of view? | 0 | 2020-04-26T18:20:14 | https://dev.to/adancarrasco/localization-part-1-the-database-14o1 | webdev, design, database, showdev | ---
title: How to implement i18n in your WebApp? Part 1
published: true
description: How to localize your Application from the Database point of view?
tags: webdev, design, databases, showdev
---
One common denominator for Software is that it can scale, most of the time scaling comes with i18n (internationalization) and l10n (localization). This time, I'm going to show you a way on how you can implement those in your application. As i18n involves many layers I will split the posts in different parts. **This part will cover the database**.
## What is i18n and l10n?
Internationalization better known as i18n, and localization better known as (l10n), is the part of Software where you handle the representation of your data/content depending on where it's consumed. As we know there are a lot of languages, and even in languages there are many variations.
Depending on your region, you may write: Localization or localisation; and internationalization or internationalisation.
Let's see it in an example:
| Language | Region | Word | locale tag |
|----------|---------------|----------------------|------------|
| English | United States | Internationalization | en_us |
| English | England | Internationalisation | en_gb |
In the previous example, even tough the language is the same, depending on the region the writing might be different and in some cases the meaning will be different as well.
Or we can just simply support different languages:
| Language | Region | Word | locale tag |
|----------|---------------|--------|------------|
| English | United States | Hello | en_us |
| Spanish | Mexico | Hola | es_mx |
| German | Germany | Hallo | de_de |
Now that we know the difference let's see how that can apply to Software.
## Localizing Software
After reading and doing some research my personal conclusion is that there are two main areas in regards of localizing.
### 1. Your app's data
The first part is your data, and this is what you have in your database that can dynamically change, it can be the products you sell, the articles you have, jobs you offer, any description, etc.
**Before i18n**
| job | |
|-------------|--------------|
| id | uuid PK |
| posted_date | date |
| title | varchar(50) |
| description | varchar(250) |
If we had the necessity to add one more language, keeping this structure, all of our data would be duplicated. For this we can extract common fields and create a *translation_entity* table.
Where our fields that doesn't need localization are:
| job | |
|-------------|--------------|
| id | uuid PK |
| posted_date | date |
And our fields that need localization are:
| job_translation | |
|-------------|--------------|
| title | varchar(50) |
| description | varchar(250) |
Then we need to add a couple of columns to link the translations with the localization.
| job_translation | |
|-----------------|-----|
| job_id | uuid FK |
| locale_id | uuid FK |
**After i18n**
The final design for our localized database would be as follows:
*Entity*
| job | | sample data |
|-------------|---------|---------------------|
| id | uuid PK | 1111-2222-3333-4444 |
| posted_date | date | 2020-26-04 19:52:44 |
*Entity-Translation*
| job_translation | | sample data |
|-----------------|--------------|---------------------|
| job_id | uuid FK | 1111-2222-3333-4444 |
| locale_id | uuid FK | 4444-3333-2222-1111 |
| title | varchar(50) | English teacher |
| description | varchar(250) | Teach the english language |
*Locales*
| locale | | sample data |
|--------|------------|-------------|
| id | guid PK | 4444-3333-2222-1111 |
| ISO | varchar(5) | en-us |
With this we will have unique data for each language our application will support.
In this example the columns to be localized are only two but if we had 10, 50, we will be saving a lot of space as well as performance and scalability will be reflected.
### 2. Your app's presentation
In the other hand, there's the part that is not involved in our data. This comes from the presentation layer, such as labels, texts, alt for images, etc. That part can easily be put in a single table (it can get complex as well depending on the needs, for now, let's keep it simple).
| translation | | sample data |
|-------------|---------------|----------------------------|
| id | uuid PK | 3333-1111-2222-4444 |
| locale_id | varchar(5) FK | 4444-3333-2222-1111 |
| locale_key | varchar(100) | homePage.welcomeMessage.h1 |
| value | varchar(250) | Welcome to my awesome App |
### Ready to persist localized data
Separating your data in those two main layers will give you enough to have your App ready to scale in terms of different languages/regions.
This summarizes all regarding the database so you can translate your App. In the following posts I will be posting how to manage this data in the *Application Layer* as well as in the *Presentation Layer*.
How do you localize your apps? Do you know any other ways to do it? Feel free to share.
Thanks for reading! | adancarrasco |
320,069 | Short Circuit Evaluation with React | I've been playing with React for several months now. I love it. Reusable components makes front end d... | 0 | 2020-04-26T17:06:13 | https://dev.to/harlessmark/short-circuit-evaluation-with-react-3dn4 | react, javascript, beginners | I've been playing with React for several months now. I love it. Reusable components makes front end developing so much easier and enjoyable. Rendering these components using conditional rendering is something I enjoy coding, and I'm not sure why. It's not hard, it's sometimes not easy but I like it regardless. In this blog post, I'm going to show you how to render a component using the "logical `&&`" method.
Let's consider this code:
```js
import React, { useState } from 'react'
import Welcome from '../components/Welcome'
function About() {
const [showWelcome, setShowWelcome] = useState(false)
return (
<div>
{showWelcome ? <Welcome /> : null}
</div>
)
}
export default App
```
The code above is a crude illustration of a homepage. If a user is logged in, we want to greet them by rendering `<Welcome />`. If the user isn't logged in, we don't want to show anything.
So, in between the `div`s we have a ternary operator. A ternary operator is basically a shorthand for an `if... else` statement.
`if` `showWelcome` is `true` then render `<Welcome />` or `else` render nothing.
But there's a simpler way to do this using "logical `&&`". Using the same logic, we can code the following:
```js
{showWelcome && <Welcome />}
```
Wait a minute 🧐.
At first, it may not make sense. It didn't for me. Let's think about. The `&&` logical operator means that both conditions on either side of it have to be met in order for it to be `true`. Right now, as the code stands, `showWelcome` is `false` because that's what it's initially set at by `useState`. So nothing, or `null`, would be rendered. If it were set to `true`, however, both conditions would be successfully met and then render `<Welcome />`.
I thought this was a clever way of rendering a component if there wasn't a need for an `else` statement. If you do need to render one component or another, it's best to use a normal ternary operator as shown in the first code block! | harlessmark |
320,078 | Twilio Hackton: getting started late in the game | Happy Sunday!!! When I read about the twilio Hackton weeks ago I wanted to be part of it, but pandem... | 0 | 2020-04-26T17:15:18 | https://dev.to/pachicodes/twilio-hackton-getting-started-late-in-the-game-17md | twiliohackathon, wecoded | Happy Sunday!!!
When I read about the twilio Hackton weeks ago I wanted to be part of it, but pandemic life happened and I forgot about it.
Yesterday my dear friend Corbin mentioned that to be, and since I want to apply for the Twilio Hatch program, that would be a great experience and addition to my resume.
The challenge is, I have 4 days!
I enlisted my brothers to help me brainstorm.
I got a simple yet usefull idea.
Can I do it?
Maybe!
Let's see how it goes and wish me lucky! | pachicodes |
320,095 | Easily remove or extract the audio from a video with ffmpeg | It turns out removing the audio from a video is very easy with FFMPEG! To remove the audio from... | 6,271 | 2020-04-26T17:42:11 | https://donaldfeury.xyz/remove-or-extract-audio-from-a-video-with-ffmpeg/ | ffmpeg, productivity, video, linux | {% youtube FUqkMWDhWFk %}
It turns out removing the audio from a video is very easy with FFMPEG!
To remove the audio from a video:
```sh
ffmpeg -i video.mp4 -c:v copy -an out.mp4
```
The `-an` option will completely remove the audio from a video, and since we're just copying the video codec as is, this most likely will only takes seconds.
To extract the audio from a video:
```sh
ffmpeg -i video.mp4 -vn audio.wav
```
As you might have guessed, the `-vn` option will remove the video stream from the output, leaving only the audio. In this case, I'm re-encoding the audio as WAV, as that is a very good encoding to work with in terms of further processing. | dak425 |
320,108 | Send API response directly to a variable using hooks. | We will be cruising through the following topics What the heck is SWR? Usage of SWR What if there a... | 0 | 2020-04-26T18:11:06 | https://dev.to/gillarohith/send-api-response-directly-to-a-variable-using-hooks-fml | javascript, webdev, react, beginners | We will be cruising through the following topics
- What the heck is SWR?
- Usage of SWR
- What if there are multiple endpoints?
## What the heck is SWR
This is an awesome library for remote data fetching.
The name “SWR” is derived from `stale-while-revalidate`, an HTTP cache invalidation strategy popularized by RFC 5861.
SWR first returns the data from cache (stale), then sends the fetch request (revalidate), and finally comes with the up-to-date data again.
You can read more about SWR [here](https://swr.now.sh/).
## Usage of SWR
To demonstrate the usage, I will be taking an example which involves the use of the following [API](https://covid19.mathdro.id/api/)
For instance, let's assume we want to load [https://covid19.mathdro.id/api/](https://covid19.mathdro.id/api/) into a variable.
Usually, we use `axios` library inside `useEffect` hook and store the data using a state created by `useState` hook.
But now, SWR simplifies all your hard work into one command.
```js
const { data,error } = useSWR(
"https://covid19.mathdro.id/api/",
url => fetch(url).then(_ => _.json())
);
```
Now the `data` variable contains the response fetched from the API endpoint. The `console.log(data)` looks like this.

Wow, sounds perfect right 🙌🏻
## What if there are multiple endpoints?
Now you may be wondering 🤔 what if there are multiple endpoints you need to get data from, how to name the variables `data` and `error`.
We can name them in the way shown in the below snippet to overcome this problem.
```js
const { data: generalDetails, error: generalDetailsError} = useSWR(
"https://covid19.mathdro.id/api/",
url => fetch(url).then(_ => _.json())
);
const {data: dailyData, error:dailyDataError} = useSWR(
"https://covid19.mathdro.id/api/daily",
url => fetch(url).then(_ => _.json())
);
const {
data: covidCases,
error: covidCasesError,
} = useSWR("https://covid19.mathdro.id/api/confirmed", (url) =>
fetch(url).then((_) => _.json())
);
```
Now you can use them as different variables.
I am not inserting the images of the log statements in the console, because these responses are enormous.
Hope you enjoyed the article.
Peace ✌🏻,
Rohith Gilla | gillarohith |
320,145 | A cool new progress bar for python! | Hello! I'm the author of alive-progress, a new kind of Progress Bar for python like you've never see... | 0 | 2020-04-27T20:25:37 | https://dev.to/rsalmei/a-cool-new-progress-bar-for-python-1c0g | python, showdev, inthirtyseconds, sideprojects | Hello!
I'm the author of [alive-progress](https://github.com/rsalmei/alive-progress), a new kind of Progress Bar for python like you've never seen, with real time throughput, eta and very cool animations!
It's also very easy to use and feature-packed, take a look!

There's a plethora of builtin spinner styles to choose from!
And you can easily create your own, there's builtin support for several special effects like frames, scrolling, bouncing, delayed and compound spinners! Get creative!
Also bar styles!

To install, just:
```bash
$ pip install alive-progress
```
That's it, you're good to go!
More details in [alive-progress](https://github.com/rsalmei/alive-progress), enjoy!
Kind Regards,
Rogério. | rsalmei |
320,203 | Calculate the length of the opposite of a right triangle | Hiya, I am trying to solve something but it's driving me mad, please save me, no this is not math hom... | 0 | 2020-04-26T20:56:38 | https://dev.to/adam_cyclones/calculate-the-length-of-the-opposite-of-a-right-triangle-5enf | help | Hiya, I am trying to solve something but it's driving me mad, please save me, no this is not math homework I am 30 years old.
I have this triangle here:
Hypot = 60
Adjacent = 30
Opposite ??
lets give them nice names
Hypot = C
Adjacent = A
Opposite = B
I do not know the angles apart from that this is a right angle triangle.
What are the steps to solve this?
I am JavaScript centric so code in this language or explanations in code would be super! (math is not my strongest suit sometimes) | adam_cyclones |
320,207 | Sağ Tık Eklentisi(Yönetici olarak çalıştır, run as root) | Bazı durumlarda yetkiden dolayı dosya işlemleri yapamayız. Bunun için bazı işlemleri ya komut satırın... | 0 | 2020-04-28T17:19:42 | https://dev.to/aciklab/sag-tik-eklentisi-yonetici-olarak-calistir-run-as-root-7ha | Bazı durumlarda yetkiden dolayı dosya işlemleri yapamayız. Bunun için bazı işlemleri ya komut satırından yönetici olarak yapmamız gerekir ya da "sudo thunar" komutu ile pencereyi yönetici olarak çalıştırıp yapmamız gerekir. Aşağıda yapacağımız sağ tık eklenti ile komut satırı açmadan sağ tık ile yönetici yetkili pencere açabiliriz.
Bunun için;
Dosya Yöneticisini açtıktan sonra düzenle>Özelleştirilmiş eylemleri yapılandır'a tıklayınız.
Ve aşağıdaki bilgileri giriniz.


Ayarları yaptıktan sonra aşağıdaki gibi gözükmesi gerekmektedir.(Simge seçeneğinden istediğiniz simgeyi de seçebilirsiniz.)



Şifrenizi girdikten sonra thunar üzerinde işlemlerinizi yönetici(root) olarak yapabilirsiniz. | mertysr | |
320,210 | Iframes and communicating between applications | Introduction Iframes are awesome! They allow you to embed another HTML page inside the cur... | 0 | 2020-04-26T21:21:34 | https://dev.to/damcosset/iframes-and-communicating-between-applications-31k5 | iframes, html, javascript, css |
## Introduction
Iframes are awesome! They allow you to embed another HTML page inside the current one. The embedded page carries its own browsing context with it. So, if a HTML page creates an iframe with a remote application as its source, you'll have the first application _hosting_ that remote application with all its functionalities. It's a technique that's used by a lot of companies to allow developers to use their service easily ( Stripe and Yousign come to mind)
## The problem
The problem is this: I want an iframe to be added to the HTML DOM when the user interacts with an element, in my case, a click on a button. I want that iframe to take up the entire page. From the user perspective, it would look like you actually travelled to a new page, or that a full width modal just opened.
## Setting up
So, we need an 2 applications. One of them, when we click on a button, will open an iframe. Inside that iframe will be embedded the second application. I'll use React for both my applications, but the concepts work with any framework.
Let's create our two React application. I'll do that with _create-react-app_. So, I'll run `create-react-app main-app` and `create-react-app iframe-app`.
Go the to the _App.js_ file inside the _main-app_ React application and add a button to open an iframe:
```js
import React from "react";
import "./App.css";
function App() {
let openFrame = () => {
let iframe = document.createElement("iframe");
iframe.src = `http://localhost:3001`;
iframe.frameBorder = "0";
iframe.id = "iframe";
iframe.style.position = "absolute";
iframe.style.zIndex = "999";
iframe.style.height = "100%";
iframe.style.width = "100%";
iframe.style.top = "0";
iframe.style.backgroundColor = "white";
iframe.style.border = "none";
document.body.prepend(iframe);
document.body.style.overflow = "hidden";
};
return (
<div className="App">
<header className="App-header">
<p>This app opens an iframe and runs on port 3000</p>
<button onClick={() => openFrame()}>Open IFRAME</button>
</header>
</div>
);
}
export default App;
```
So, this application runs on port 3000 and open an iframe when the user clicks on the button. That will create an iframe with the _src_ attribute _http://localhost:3001_ where our second application will run.
Notice that I wrote that in vanilla javascript to show you how it could be used anywhere.
Then, we are adding some styles to make our iframe take up the whole page, just like if it was a different page. Notice that we also set _overflow: hidden_ on the body, to not be able to scroll the main page.
Now, go to the second application in _iframe-app_ and change the _App.js_ file:
```js
import React from "react";
import "./App.css";
function App() {
let closeIframe = () => {};
return (
<div className="App">
<button onClick={() => closeIframe()}>Close Iframe </button>
<p>This app runs on port 3001 and his embedded inside the iframe</p>
</div>
);
}
export default App;
```
This application will run on port 3001. When we click on the button, we will close the iframe.
Make sure your main application is running on port 3000, and your iframe application is running on port 3001. (by running `PORT=3001 yarn start`)
Ok, so if you now go to _http://localhost:3000_ in your browser, and click on the _Open IFRAME_ button. You will see the second React application take up the whole page inside its iframe. We're still on the port 3000 page. From the user, it doesn't look like an iframe at all though!


Awesome, now, our first app correctly opens an iframe. The functionality works as expected.
## Closing the iframe
Now, what we need to do next is allow the user to close the iframe. Since we want the user to experience our iframe opening as a modal or a new page, we need to give him a way to close/go back.
It does seem easy. Add a close button, click on it, then make the iframe disappear. Well, it's not that simple. The React application is on a different domain from the HTML page. The functionality to close the iframe will start on the React application. But we will try to manipulate the DOM of the first application. For security reasons, we can't manipulate the DOM from another domain (thankfully...). There are two ways we can solve this issue:
- Make the React applications communicate with one another.
- Create a header that would still be part of the first React application.
The second solution is the simplest one. Just style your DOM to show a button above the iframe content (maybe using some z-index styles), or show a header above the iframe (so the iframe would not take the whole height of the page, leaving some space for that header).
The second solution, for our purposes, doesn't suit me. So, to make both pages communicate with one another, we will use _window.postMessage()_
The _postMessage_ function allows to send messages between cross-origin domains. When we would want to close our iframe, we will use this function to tell the main HTML page that we need to make the iframe disappear.
### Adding the closing functionality

We need to call _postMessage_ on the _targetWindow_. The target window, in our case, is the window of the HTML page. We can get that window's reference with _window.parent_. Note that in the main HTML page, which does not have a parent, _window.parent_ is the main window.
The first argument that the postMessage function takes is a message. You could send an object if you wish, or a string. Here, we don't need to send anything special, so I'll just call it _close-iframe_. The second argument it takes is the url of the target window. That would be _http://localhost:3000_ in our case. But, we want to make that dynamic:
```js
let closeIframe = () => {
let url =
window.location != window.parent.location
? document.referrer
: document.location.href;
window.parent.postMessage("close-iframe", url);
};
```
Notice how we retrieve the parent's url. If the window's location is different from the parent's location, we'll get it through _document.referrer_, otherwise, for IE browsers, we'll get it with document.location.href.
### Get the message in the main application
Now that the iframe application sends a message, we need the main application to catch it. To do that, we can use the _addEventListener_ method. We will add this event listener inside a _useEffect_ hook.
```js
// Inside your App.js file
useEffect(() => {
window.addEventListener("message", function (event) {
let frameToRemove = document.getElementById("iframe");
if (frameToRemove) {
frameToRemove.parentNode.removeChild(frameToRemove);
document.body.style.overflow = "inherit";
}
});
});
```
The _postMessage_ function sends a _message_ event. Inside this _addEventListener_, we retrieve our iframe element and we remove it from the DOM. This is how it will looks like in your browser.
{% youtube EA_L9Pl3GaU %}
Congratulations! You can now make two applications communicate with one another through an iframe. Now, remember that the postMessage can work both ways. We made it from from child to parent, but parent to child is also valid!
Have fun :heart:
| damcosset |
320,870 | Running Folding@Home on AWS with AWS CDK | Folding@Home(aka FAH) is a distributed computing project. To quote from their website, FAH is a... | 0 | 2020-05-19T16:21:13 | https://sathyasays.com/2020/04/26/folding-at-home-aws-cdk/ | aws, tutorial, foldingathome, python | ---
title: Running Folding@Home on AWS with AWS CDK
published: true
date: 2020-04-26 06:16:24 UTC
tags: AWS, tutorial, foldingathome, Python
canonical_url: https://sathyasays.com/2020/04/26/folding-at-home-aws-cdk/
---
[Folding@Home](https://foldingathome.org/about/)(aka FAH) is a distributed computing project. To quote from their website,
> FAH is a distributed computing project for simulating protein dynamics, including the process of protein folding and the movements of proteins implicated in a variety of diseases. Folding@Home involves you donating your spare computing power by running a small client on your computer. The client then contacts the Folding@Home Work Assignment server, gets some workunits and runs them, You can choose to have it run when only when your system is idle, or have it run all the time.
While I used to run FAH long, long back - dating back to my [forum days](https://sathyasays.com/about/), I eventually stopped due to lack of proper computing equipment. Recent events with the COVID-19 situation and FAH's projects around it (see [Coronavirus - What we're doing](https://foldingathome.org/2020/03/15/coronavirus-what-were-doing-and-how-you-can-help-in-simple-terms/) and [COVID-19 Small Molecule Screening Simulation](https://foldingathome.org/2020/03/30/covid-19-free-energy-calculations) for details) and the relatively [powerful computer I built recently](https://sathyabh.at/2020/01/19/hellforge-remastered-home-desktop/) meant that I could run FAH on my desktop computer.
Now, I had some extra credits for AWS that were to expire soon and I figured instead of letting them go to waste, I thought to myself maybe I could spin up some EC2 instances and run Folding@Home on them. I started looking at the pricing of the GPU instances - and they were a bit pricier than what I could sustain. Considering this, I selected the c5n.large instance as I didn't need instance and EBS-backed disks would be handy in setting up aa Auto Scaling Group.
To reduce expenses further, I started looking at Spot prices and it turned out, the spot prices were about 68% cheaper as compared to the on-demand prices. Since we don't really care about what happens when the spot termination happens and the ASG will bring the instance count back up, I went with this option.

The spot pricing trend revealed that the prices had remained stable and just to ensure the spot bids would be fulfilled, I kept the max spot price couple of cents more than the maximum price going then. Initially, the instances were brought up by manually launching them from the AWS Console. Since long I'd been meaning to use [AWS CDK](https://aws.amazon.com/cdk/), this was the perfect opportunity to learn and try to use it.
The CDK code will bring up a new VPC, a couple of subnets, an ASG and attach a security group to allow for SSH into the instance. The code is not the best, there's a bunch of hard-coding of regions, AMIs, SSH key names, but pull requests to clean up and make it more generic is more than welcome! Check out the code on my [GitHub Repo](https://github.com/SathyaBhat/folding-aws)
{% github SathyaBhat/folding-aws %}
| sathyabhat |
320,246 | My WebDev Notes: A simple and accessible accordion | How to create a simple and accessible accordion | 5,123 | 2020-04-28T10:22:39 | https://dev.to/ziizium/my-webdev-notes-a-simple-and-accessible-accordion-4076 | html, css, javascript | ---
title: My WebDev Notes: A simple and accessible accordion
published: true
description: How to create a simple and accessible accordion
tags: html, css, javascript
series: My WebDev Notes
---
> <b>The design pattern for the accordion is inspired by the first example in [Sara Soueidan's article entitled: Accordion markup](https://www.sarasoueidan.com/blog/accordion-markup/) and the accordion keyboard navigation is based on code from [W3C accordion example](https://www.w3.org/TR/wai-aria-practices/examples/accordion/accordion.html)</b>.
> <b>Check the accordion online: https://ziizium.github.io/my-webdev-notes/accordion/</b>
##__Intoduction__
An accordion is a _graphical control element_ used for showing or hiding large amounts of content on a Web page. On a normal day, accordions are vertically stacked list of items that can be expanded or stretched to reveal the content associated with them.
Accordion gives control to people when it comes to reading a Web page content. The user can ignore the accordion or read its content by expanding it.
__This simple but detailed post is about creating a usable and accessible accordion__ using HTML, CSS, and a lot of JavaScript (considering how small the accordion is). As stated earlier the accordion has to be accessible, therefore, we have to satisfy the following requirements:
* The contents of the accordion must be readable without CSS.
* The contents of the accordion must be accessible without JavaScript.
* The user should be able to print the contents of the accordion.
In order to satisfy all three requirements mentioned above, we have to build the accordion with _accessibility_ in mind and before every coding decision. We have to keep our users in mind and approach the development in a _progressive enhancement_ manner.
This means we must start with _semantic_ HTML, then we add some CSS that will not render the content of the accordion useless without it and finally we add JavaScript for the _true_ accordion interactivity.
##__The HTML markup__
As stated at the beginning of this post the design pattern for the accordion is inspired by an example from [Sara Souiedan's post entitled: Accordion markup](https://www.sarasoueidan.com/blog/accordion-markup/). The markup is giving in the image below.

When we convert this to code, users with CSS or JavaScript can access the content, then with JavaScript, we can convert it to the following markup accessible to users with a JavaScript-enabled browser:
The markup is giving in the snippet below:
```html
<header>
<h1 id="h1" style="">Accordion</h1>
</header>
<main>
<article class="accordion">
<h2 class="accordion__title">First title</h2>
<div class="accordion__panel">
<p><!-- Put large text content here --></p>
</div>
</article>
<article class="accordion">
<h2 class="accordion__title">Second title</h2>
<div class="accordion__panel">
<p><!-- Put large text content here --></p>
</div>
</article>
<article class="accordion">
<h2 class="accordion__title">Third title</h2>
<div class="accordion__panel">
<p><!-- Put large text content here --></p>
</div>
</article>
</main>
```
When you load the file in your browser you'll get something similar to the image below:

This is our _baseline_ experience and browsers with no support for CSS or JavaScript will have access to the accordion content.
##__The CSS and JavaScript code__
Next, we need to add some basic styling to the elements on the page so that we have a better view of what we are working on.
```css
/* CSS reset */
* {
padding: 0;
margin: 0;
box-sizing: border-box;
}
/* End of CSS reset */
/**
* Cpsmetics styles just so you can see the
* accordion on screen properly
*/
body {
font-family: "Fira code", "Trebuchet Ms", Verdana, sans-serif;
}
header {
padding: 1em;
margin-bottom: 1em;
}
header > h1 {
text-align: center;
text-transform: uppercase;
letter-spacing: 0.05em;
}
main {
display: block;
width: 100%;
}
@media screen and (min-width: 48em) {
main {
width: 70%;
margin: 0 auto;
}
}
p {
font-family: Georgia, Helvetica, sans-serif;
font-size: 1.2em;
line-height: 1.618;
margin: 0.5em 0;
}
/* End of Cosmetic styles */
```
In its current state, the accordions are closer to each other and the contents are aligning with the _headers_, we need to change this. First, we apply some padding to push the content a little bit to the right, we change the background color and at the same time, we take care of _overflow_ so that the content of one accordion won't affect the content of the subsequent accordion.
In the end, we add a _margin_ between the edges of the accordions and some animation using CSS transitions so the accordion content can feel like _sliding_ in and out of view. The next snippet will take care of this.
```css
/**
* The accordion panel is shown by default
* and is hidden when the page loads the
* JavaScript code.
*/
.accordion__panel {
padding: 0 18px;
background-color: #ffffff;
overflow: hidden;
transition: 0.6s ease-in-out;
margin-bottom: 1em;
}
```
When you reload your browser you will notice minor changes. Let's proceed.
Due to the way accordions work we need to hide the accordion panels before the user can expand or ignore it. __We can not hide the panel by adding properties that will hide it directly__ to the `accordion__panel` class and later use JavaScript to remove these properties in order to show it because __if we do this__ any user with __JavaScript disabled in their browser will not be able to expand the panel and ultimately loose access to the accordion content__.
__The better approach is to write a CSS class that will hide the panel and then we can add this class to the accordion panel via JavaScript__. Doing this any user who has JavaScript disabled in their browser will have access to the accordion content because JavaScript was unable to hide.
There are several ways to hide stuff in CSS. In our approach, we set the _height_ and _opacity_ of the panel to _zero_.
```css
/* We hide it with JavaScript */
.accordion__panel.panel-js {
max-height: 0;
opacity: 0;
}
```
Then we'll have to add this to the panel via JavaScript.
I made the assumption that you will use the format of the accordion HTML markup and the resulting JavaScript code in your projects and you won't like the variable declarations to mess up your codebase, therefore, all the code for our accordion will be placed in an Immediately Invoked Function Expression (IIFE). Doing this all the variables will only live inside the IIFE and won't pollute the global scope.
Create a `script` tag or a JavaScript file to save the JavaScript code and create an IIFE syntax as shown below:
```js
(function () {
// All JavaScript for the accordion should be inside this IIFE
})();
```
Now, we can write code that will hide the panel. The approach is straight forward, we'll grab all the accordion panels and then add the `.panel-js` CSS code to each panel via the `classList` attribute.
```js
/**
* We hide the accordion panels with JavaScript
*/
let panels = document.getElementsByClassName('accordion__panel');
for (let i = 0; i < panels.length; i++) {
panels[i].classList.add('panel-js');
}
```
When you save your file and refresh your browser you will realize the panel is now hidden and all you'll see are the accordion titles.

That view is boring, let's change it.
The approach we'll take is similar to how we hid the panels. First, we will grab all the accordion titles and we loop through the resulting `NodeList` and then we'll transform the accordion title to a `button` which will have a `span` element within it that will be the new accordion title. All this is inspired from the example taken from Sara's blog post.
As a refresher and to prevent you from scrolling to the beginning of this blog post, here is the image that we'll implement:

First, we grab all the accordion titles using `document.getElementsByClassName`, then we'll loop through the result and perform the following steps:
* Create the `button` and `span` elements.
* Create a _text node_ from the accordion titles.
* Append the _text node_ to the newly created `span` elements.
* Append the `span` element to the newly created `button` element.
* Append the `button` to the accordion titles.
* Delete the text in the accordion title since we already appended it to the newly created `span` element.
* Set the `button` attributes.
* Set the accordion panel attributes.
In code:
```js
/**
* We grab the accordion title and create
* the button and span elements. The button
* will serve as the accordion trigger and the
* span element will contain the accordion title.
*
*/
let accordionTitle = document.getElementsByClassName('accordion__title');
for (let i = 0; i < accordionTitle.length; i++) {
// Create the button and span elements
let button = document.createElement('button');
let span = document.createElement('span');
// We create a text node from the accordion title
let textNode = document.createTextNode(accordionTitle[i].innerHTML);
// We append it to the newly created span element
span.appendChild(textNode);
// We append the span element to the newly created
// button element
button.appendChild(span);
// Then we append the button to the accordion title
accordionTitle[i].appendChild(button);
// We delete the text in the accordion title
// since we already grabbed it and appended it
// to the newly created span element.
button.previousSibling.remove();
// Set the button attributes
button.setAttribute('aria-controls', 'myID-' + i);
button.setAttribute('aria-expanded', 'false');
button.setAttribute('class', 'accordion__trigger');
button.setAttribute('id', 'accordion' + i + 'id')
// The next sibling of the accordion title
// is the accordion panel. We need to attach the
// corresponding attributes to it
let nextSibling = accordionTitle[i].nextElementSibling;
if (nextSibling.classList.contains('accordion__panel')) { // just to be sure
// set the attributes
nextSibling.setAttribute('id', 'myID-' + i);
nextSibling.setAttribute('aria-labelled-by', button.getAttribute('id'));
nextSibling.setAttribute('role', 'region');
}
} // End of for() loop
```
Save and refresh your browser. The titles are now HTML buttons and when you inspect a button with the Developer Tools you'll see the attributes we created.
The buttons are quite small because we have not styled them, let's change that!.
```css
/**
* This removes the inner border in Firefox
* browser when the button recieves focus.
* The selector is take from:
*
* https://snipplr.com/view/16931
*
*/
.accordion__title > button::-moz-focus-inner {
border: none;
}
.accordion__title > button {
color: #444444;
background-color: #dddddd;
padding: 18px;
text-align: left;
width: 100%;
border-style: none;
outline: none;
transition: 0.4s;
}
.accordion__title > button > span {
font-size: 1.5em;
}
/* The .active is dynamically added via JavaScript */
.accordion__title.active > button,
.accordion__title > button:hover {
background-color: #bbbbbb;
}
.accordion__title > button:after {
content: "\02795"; /* plus sign */
font-size: 13px;
color: #777777;
float: right;
margin-left: 5px;
}
/**
* When the accordion is active we change
* the plus sign to the minus sign.
*/
.accordion__title.active > button:after {
content: "\02796"; /* minus sign */
}
```
Save and refresh your browser. We have a better view!

There is a tiny little problem. __When you click the button nothing happens__, that is because we have not created two things:
* The CSS code that will allow show us the panel.
* The JavaScript code that will dynamically add and remove this CSS code.
Let's start with the CSS. If you remember from the `.panel-js` CSS code, we hid the panel by setting the `max_height` and `opacity` to zero. Now, we have to do the reverse to reveal the panel and its content.
```css
/**
* When the user toggle to show the accordion
* we increase its height and change the opacity.
*/
.accordion__panel.show {
opacity: 1;
max-height: 500px;
}
```
The JavaScript to reveal the panel is a little bit tricky. We'll attach an event listener to all accordion titles and perform the following steps:
* Add the `.active` CSS class that we declared earlier when styling the buttons.
* Grab the accordion panel.
* Hide or show the panel based on the user interaction.
* Count the accordion title child elements.
* We expect it to be a single button so we get the tag name via its _index_.
* If the child element is one and in fact a button, we perform the following
* Save the child element in a variable.
* We get its `aria-expanded` value.
* If the `aria-expanded` value is `false` we set it to `true` otherwise we set it to `false`.
The resulting JavaScript code:
```js
for (let i = 0; i < accordionTitle.length; i++) {
accordionTitle[i].addEventListener("click", function() {
// Add the active class to the accordion title
this.classList.toggle("active");
// grab the accordion panel
let accordionPanel = this.nextElementSibling;
// Hide or show the panel
accordionPanel.classList.toggle("show");
// Just to be safe, the accordion title
// must have a single child element which
// is the button element, therefore, we count
// the child element
let childElementCount = this.childElementCount;
// We get the tag name
let childTagName = this.children[0].tagName;
// Then we check its just a single element and
// it's in fact a button element
if (childElementCount === 1 && childTagName === "BUTTON") {
// If the check passed, then we grab the button
// element which is the only child of the accordion
// title using the childNodes attribute
let accordionButton = this.childNodes[0];
// Grab and switch its aria-expanded value
// based on user interaction
let accordionButtonAttr = accordionButton.getAttribute('aria-expanded');
if (accordionButtonAttr === "false") {
accordionButton.setAttribute('aria-expanded', 'true');
} else {
accordionButton.setAttribute('aria-expanded', 'false');
}
}
});
} // End of for() loop
```
Save your file and refresh your browser. Now, click the button to reveal or hide the accordion panel and its content.

There you go our accordion is complete! Or is it?
There are two problems in this completed accordion:
* The user can not navigate the accordion with their keyboard
* The user can not print the content of the accordion
The first point is evident when you hit the `Tab` key on your keyboard the accordion button does not receive focus.
For the second point, when the user prints the accordion they will only see the accordion title in the printed document. A print preview is shown below in Chrome:

This is quite easy to fix but to enable the keyboard navigation is not straight forward. Let's start with it then we'll fix the printing issue later.
If we want the user to navigate through the accordion with their keyboard we'll have to listen for events specifically on the accordion buttons which have a class titled `.accordion__trigger`. When we select all elements with this class name, we'll get a `NodeList` in return.
This `NodeList` has to be converted to an _array_. Why? Because when the user navigates through the accordion with their keyboard we must calculate the location of the next accordion using the index location of the current accordion and the number of accordions on the Web page. By this, you should know we are going to need the `indexOf` operator to get the location of the current accordion and the `length` property which will return the number of accordions on the Web page.
The `length` property is available to the `NodeList` but the `indexOf` is not. Hence, the conversion.
We'll use `Array.prototype.slice.call()` method to convert the `NodeList` to an array then we'll grab all accordions via their class name `.accordion` then loop through the result and perform the following steps:
* Add an event listener to all accordions and we listen for the `keydown` event.
* We get the `target` element which is the current element that has received the event.
* We get the corresponding key that the user pressed on their keyboard.
* We check if the user is using the `PgUp` or `PgDn` keys to navigate the accordion.
* To be safe we make sure that the button truly has the `.accordion__trigger` class name then we perform the following steps:
* We check if the user is using the arrow keys on their keyboard or if they are using it along with the `Ctrl` key then we perform the following steps:
* Get the index of the currently active accordion.
* Check the direction of the user arrow keys, if they are using the down key we set the value to `1` else we set it to `-1`.
* Get the length of the array of accordion triggers.
* Calculate the location of the next accordion.
* Add a `focus` class to this accordion.
* We prevent the default behavior of the buttons.
* Else if the user is using the `Home` and `End` keys on their keyboard we do the following:
* When the user presses the `Home` key we move focus to the first accordion.
* When they press the `End` key we move focus to the last accordion.
* We prevent the default behavior of the buttons.
All these steps converted to code is in the snippet below:
```js
/**
* The querySelectorAll method returns a NodeList
* but we will like to loop through the triggers
* at a later time so that we can add focus styles
* to the accordion title that's why we convert
* the resulting NodelIst into an array which will
* allow us too used Array methods on it.
*/
let accordionTriggers = Array.prototype.slice.call(document.querySelectorAll('.accordion__trigger'));
for (let i = 0; i < accordion.length; i++) {
accordion[i].addEventListener('keydown', function(event) {
let target = event.target;
let key = event.keyCode.toString();
// 33 = Page Up, 34 = Page Down
let ctrlModifier = (event.ctrlKey && key.match(/33|34/));
if (target.classList.contains('accordion__trigger')) {
// Up/ Down arrow and Control + Page Up/ Page Down keyboard operations
// 38 = Up, 40 = Down
if (key.match(/38|40/) || ctrlModifier) {
let index = accordionTriggers.indexOf(target);
let direction = (key.match(/34|40/)) ? 1 : -1;
let length = accordionTriggers.length;
let newIndex = (index + length + direction) % length;
accordionTriggers[newIndex].focus();
event.preventDefault();
}
else if (key.match(/35|36/)) {
// 35 = End, 36 = Home keyboard operations
switch (key) {
// Go to first accordion
case '36':
accordionTriggers[0].focus();
break;
// Go to last accordion
case '35':
accordionTriggers[accordionTriggers.length - 1].focus();
break;
}
event.preventDefault();
}
}
});
}
```
If you save your file and refresh your browser the keyboard navigation should work but you won't know the currently active accordion. The fix is simple, we have to add a focus style to the parent element of the currently active button (the accordion triggers) which is an`h2` element. We remove the focus styles when the accordion is not active.
The CSS focus styles:
```css
.accordion__title.focus {
outline: 2px solid #79adfb;
}
.accordion__title.focus > button {
background-color: #bbbbbb;
}
```
The resulting JavaScript code:
```js
// These are used to style the accordion when one of the buttons has focus
accordionTriggers.forEach(function (trigger) {
// we add and remove the focus styles from the
// h1 element via the parentElment attibuts
trigger.addEventListener('focus', function (event) {
trigger.parentElement.classList.add('focus');
});
trigger.addEventListener('blur', function (event) {
trigger.parentElement.classList.remove('focus');
});
});
```
To fix the print issue we have to __revert the styles for the accordion panels to its initial state before it was hidden with JavaScript__ and some few modifications.
The reverted styles have to be placed in a `media` query targeting _print_ media.
```css
/**
* Print styles (Just in case your users
* decide to print the accordions content)
*/
@media print {
.accordion__panel.panel-js {
opacity: 1;
max-height: 500px;
}
.accordion__title button {
font-size: 0.7em;
font-weight: bold;
background-color: #ffffff;
}
.accordion__title button:after {
content: ""; /* Delete the plus and minus signs */
}
}
```
The new print preview in Chrome:

With that, we are done with the accordion. The code is not perfect but it works and you can improve it.
The GitHub repo for this series:
{% github ziizium/my-webdev-notes %}
_Have fun!_
| ziizium |
320,307 | Essential Javascript for the React Developer | Pt. 1 of 4 Learning a front-end javaScript framework /library is essential for developers as it spee... | 6,248 | 2020-04-27T02:00:12 | https://dev.to/kevsage/essential-javascript-for-the-react-developer-57g9 | Pt. 1 of 4
Learning a front-end javaScript framework /library is essential for developers as it speeds up the production process while minimizing the lines of code. For JavaScript developers, the most common frameworks are React.js, Angular, and Vue.js. Today, we’re going to focus our attention on React.js.
Before jumping headfirst into React, it is important that you have a very solid foundation in JavaScript as there are several concepts that all burgeoning react developers must become familiar/comfortable with to get the most out of this useful tool.
Var vs. Let vs. Const
ECMA6 introduced a new way to declare variables that differs from the traditional way variables are declared using the “var” keyword, the previous js standard. It is highly advised that javascript developers use “let” and “const” keywords as opposed to using “var” when declaring variables.
The reasoning behind this is that ‘let’ utilizes “function” scope while ‘let’ and ‘const’ use “block” scope. This is an important distinction as block scoping is preferred because we don’t want to give access to our variables outside of a defined block.
function helloWorld() {
for (var i = 0; i < 5; i++) {
console.log(i)
}
console.log(i)
}
helloWorld()
In the previous example, we have a helloWorld function. Within that function is a for loop that increments by one as long as ‘i’ is less than 5. In this example, we have 2 console logs, one within the function scope and the other within the for loop block. Using var to declare our variable allows the 2nd console log to have access to the ‘i’ variable within the for loop, which as we described previously, is not ideal. Now, let’s take a look at the same example, but this time we’ll use the let keyword.
function helloWorld() {
for (let i = 0; i < 5; i++) {
console.log(i)
}
console.log(i)
}
helloWorld()
Using the let keyword, the 2nd console log should throw an error as the i variable will only be accessible within the for loop, as let is block scoped, not function scoped.
That leaves us with “let” and “const” as our preferred methods of declaring variables. “Const” is used when we have a variable that will not change and “let” if a variable will be reassigned at a later time, therefore, const would not be a good choice for an incrementing for loop.
Objects
Properties and Methods
In javascript, objects are collections of related data consisting of ‘key-value’ pairs in the for of variables, also known as properties, and functions which are referred to as methods.
Dot and Bracket Notation
When we know which particular property or method we’d like to access, dot notation works well.
let dog = {
name = "Fido",
age = 3,
color = "black",
owner = "Kevin"
}
dog.owner = "Richard"
On the other hand, we use bracket notation when we are unsure of the property or method we want to be able to access.
let dog = {
name = "Fido",
age = 3,
color = "black",
owner = "Kevin"
}
let newOwner = 'owner'
dog[newOwner.value] = "Richard"
In our next installment, we’ll be taking a look at the ‘this’ keyword. | kevsage | |
320,395 | Paid education: the seed for classism | I try, I swear it. But when I come across Coursera, Lynda, and other platforms of eLearning... oh, it... | 0 | 2020-04-27T03:24:02 | https://dev.to/allnulled/paid-education-the-seed-for-classism-52en | covid, education, coursera, university | I try, I swear it. But when I come across **Coursera**, **Lynda**, and other platforms of eLearning... oh, it pisses me off.
The best part comes when you talk to them about the Free Online University, and they say: *"there is a lot of information on the internet, you do not need to pay if you want!"*. Well, let me tell you, please, one thing:
- if you have time to put order to the chaos you ignored till yesterday, and...
- if you do not mind to study something that will not provide you with any official (by the State and the Law) homologation or accreditation...
...then yes, pick a course on Coursera and fill better with yourself.
But, honestly, I can see, with these little things, why universe is smaller than I used to think.
Is it so difficult to understand the relevance of sharing what we know, as a collective, to be trustable?
Ok, we conform with this situation, where each person uses the law that that bastards (sorry, politicians, but you have not yet solved free education, you are just bastards opportunists) created to take **profit** from and **advantage** of the rest of the society.
I feel sad to check that **unefficiency** and inoperance are key for capitalism to keep itself healthy with mediocre leaders, in the economical, educational, political.
People that need to exploit others ignorance to fit in society as they think they deserve.
Remember that, when I share an apple, I lose one apple. When I share a knowledge, I do not lose the knowledge.
Of course, elitism, classism, imposed ignorance or different ways of social supremacy, like the economy tries to, are too fashion to be overcome.
We are only at 2020. Covid-19 is not enough to see that we are already rich, that it is our poor mentality of life what makes extreme poverty and extreme wealth, dirty the natural identity of human beings. | allnulled |
320,447 | Day-15 Array Partition I | Background This problem statement was a part of LeetCode's learn card: Array and Strings.... | 0 | 2020-04-27T05:37:58 | https://dev.to/mridubhatnagar/day-15-array-partition-i-h8i | python, challenge | ##### Background
This problem statement was a part of LeetCode's learn card: Array and Strings. Under the sub-heading Two pointer technique.
##### Problem Statement
Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1, b1), (a2, b2), ..., (an, bn) which makes sum of min(ai, bi) for all i from 1 to n as large as possible.
##### Example 1
```
Input: [1,4,3,2]
Output: 4
Explanation: n is 2, and the maximum sum of pairs is 4 = min(1, 2) + min(3, 4).
```
Note:
1. n is a positive integer, which is in the range of [1, 10000].
2. All the integers in the array will be in the range of [-10000,
10000].
##### Solution Approach 1
1. Pick some random examples. And, try calculating the sum of pairs manually for different combination of integers to see if there is some pattern.
2. Based on step 1. One conclusion that can be drawn is pairing consecutive small numbers together, followed by pairing large numbers. Leads to maximum sum.
3. Now, 2 achieve step 2. We can sort the given array.
4. Once the array is sorted. We can have 2 variables. One variable points to the current element. Another element points to the next element.
5. The current element and the next element form a pair.
6. Size of array is 2n. Number of pairs are n is mentioned in the problem statement. Based on this we can break the loop.
```
class Solution:
def arrayPairSum(self, nums: List[int]) -> int:
current=0
next_element = current+1
total = 0
counter = 0
nums.sort()
while current < next_element:
total += min(nums[current], nums[next_element])
current = next_element + 1
next_element = current+ 1
counter += 1
if counter == int(len(nums)/2):
break
return total
```
##### Learnings and obervation from solution approach 1
1. Time complexity of list.sort() is O(nlogn). Then we are iterating over the list. And calling built-in method min. Min has its own complexity. This in turn would increase the overall time complexity.
2. We are already sorting the array. And then forming pairs. So, always the minimum element would be the current element. Hence, no need to again call built-in min method to find the minimum of the two numbers.
##### Updated code based on takeaways from solution approach 1
```
class Solution:
def arrayPairSum(self, nums: List[int]) -> int:
current=0
next_element = current+1
total = 0
counter = 0
nums.sort()
while current < next_element:
total += nums[current]
current = next_element + 1
next_element = current+ 1
counter += 1
if counter == int(len(nums)/2):
break
return total
```
In the above solution, we are breaking the loop when count of pairs is equal to half the length of the array. Another approach could be to scrap this whole part off. Instead, put this condition. The index of current element should always be less the length of array.
```
class Solution:
def arrayPairSum(self, nums: List[int]) -> int:
current=0
next_element = current+1
total = 0
nums.sort()
while current < next_element and current < len(nums)-1:
total += nums[current]
current = next_element + 1
next_element = current+ 1
return total
```
##### Learnings
1. Time complexity - O(nlogn).
2. Got rid of unnecessary min() built-in function.
3. Two pointer technique.
4. List.sort() method is an in-place sort. Using sorted() for sorting would have returned a new list. That, however, was not needed.
| mridubhatnagar |
320,489 | 5 AI Trends To Watch for in 2020!
| With the benefits of Artificial Intelligence plunging into major industry verticals, the AI industry... | 0 | 2020-04-27T07:00:38 | https://dev.to/ruchita_varma/5-ai-trends-to-watch-for-in-2020-20gm | aitrends, topaitrends, artificialintelligencetrends, aitrendsin2020 | With the benefits of Artificial Intelligence plunging into major industry verticals, <i>the AI industry is on the rise</i>. Businesses today are realizing the potential of this advanced technology and leveraging its benefits to boost business profits.
<b><i>According to the market research firm Tractica, in 2019, <a href=https://tractica.omdia.com/research/artificial-intelligence-market-forecasts/">the global AI software market</a> is expected to grow from $10.1 billion in 2018 to $126.0 billion by 2025.</i></b>
With increased popularity and usage, Artificial Intelligence trends are revolutionizing the business world these days. It is clearly evident that enterprises are leveraging this advanced technology to enhance business efficiency. AI techniques help in performing tasks that require human intelligence with greater speed and accuracy as compared to humans.
<b><i>A report by Accenture stated that the impact of <a href="https://www.accenture.com/in-en/insight-artificial-intelligence-future-growth">AI technologies</a> on the business is projected to increase labor productivity by up to 40 percent and enable people to make more efficient use of their time.</b></i>
<b><i>Top AI Trends that you need to Look at!</i></b>
Here in this blog, I have discussed some of the major AI trends that will rule the roost in the coming future. These trends predicted by the industry experts will determine the future of Artificial Intelligence.<i>Let's explore the top AI trends in 2020 that may turn into exciting developments in the future.</i> Read these in detail.
<b><i>Rise of Predictive Analytics!</b></i>
The magic of AI can help you know the future. One of the popular AI trends allows you to predict the future. Do you know which AI trend does so? Predictive Analytics it is. By using predictive analytics, enterprises can forecast results in advance. This AI trend utilizes a combination of machine learning algorithms, historical data and other processes to predict future outcomes. Build smart strategies using advanced AI techniques to <a href="https://www.resourcifi.com/resources/ebooks/startups/business-plan-template/">enhance your business growth </a>by selecting a team of AI developers.
By leveraging Predictive Analytics, a company can take advantage of the patterns and trends for designing better strategies right from advertising to security. AI trends such as Predictive Analytics are becoming popular not only for the benefits that they provide to scale business growth but also for letting businesses gain an advantage over their competitors.
<b><i>According to a <a href="https://www.globenewswire.com/news-release/2018/03/02/1414176/0/en/Trends-in-Predictive-Analytics-Market-Size-Share-will-Reach-10-95-Billion-by-2022.html">report</a>, the global predictive analytics market was valued at approximately USD 3.49 billion in 2016 and is expected to reach approximately USD 10.95 billion by 2022, growing at a CAGR of around 21% between 2016 and 2022.</i></b>
<b><i>Higher Use Of Anomaly Detection!</i></b>
Common flaws may occur at any time while doing a task. This may occur due to a human error or due to a machine failure. No matter, the error occurred due to a human fault or a technical one, in both the cases, the company has to bear great losses.
So, it's important for the companies to keep a check so as to detect problems before they actually happen. Here comes the role of Anomaly Detection. With its incredible ability to detect problems, <i>AI-driven Anomaly detection</i> has become one of the popular <a href="https://www.resourcifi.com/blog/advantages-of-ai-in-films/">AI trends</a> for detecting major problems before they cause serious losses to the company. This helps in increasing business efficiency too.
This is the reason why <i><b>31% of marketing, creative, and IT professionals worldwide plan to invest in AI technology in the next 12 months</b></i>, <a href="https://cmo.adobe.com/articles/2018/2/adobe-2018-digital-trends-report-findings.html#gs.4m7q3z">says</a> Adobe.
This AI-driven procedure compares current and historical data to find the datasets that stand out and are different from the norm. Enterprises can discover flaws in cybersecurity, marketing, advertising and any area of business. <i>All thanks to Predictive Analytics which is one of the most dominating AI trends in 2020.</i>
<b><i>[Good <a href="https://blogs.oracle.com/datascience/introduction-to-anomaly-detection">Read</a>:- Introduction to Anomaly Detection]</i></b>
<b><i><a href="https://blogs-images.forbes.com/louiscolumbus/files/2018/01/AI-for-enterprise-Apps.jpg">Source</a></i></b>
<b><i>ML-driven Cybersecurity will be on the rise!</i></b>
<i>Cybersecurity has become a growing concern globally</i> which results in the loss of data. Such security breaches can harm the reputation of a brand in the market. This is why companies these days are leveraging <i>Artificial Intelligence to enhance their security</i>.
<b><i>The number of attacks, including phishing, advanced malware, and ransomware attacks is rising - with <a href="https://www.securitymagazine.com/articles/89586-nearly-70-percent-of-smbs-experience-cyber-attacks">67 percent </a> of businesses experiencing a cyber-attack and 58 percent of them experiencing a data breach in the last 12 months.</i></b>
With its ability to sort through millions of files and identify potentially hazardous ones, Machine Learning algorithms are used for removing these. ML algorithms use Artificial Intelligence for detecting cyber-attacks thus enabling organizations to work smoothly.
<i>AI is a boon to Cybersecurity</i>. Clearly, the use of Machine Learning for Cybersecurity is one of the popular AI trends ruling the business space now.
<i>For instance, Microsoft’s Windows Defender Advanced Threat Protection is a great example that is built into Windows 10 devices. The software deploys cloud AI and machine learning algorithms to detect threats and misconfigurations that can cause harm.</i>
<b><i>Increased Adoption of AI Platforms!</i></b>
The availability of highly compatible and advanced AI platforms to perform multiple tasks help businesses in boosting their growth. It wouldn’t be wrong to say that it is one of the top AI trends that is dominating the business industry today.
<b><i>37% of businesses surveyed have implemented AI in their company, and this number is rising</b></i>, <a href="https://www.gartner.com/en/newsroom/press-releases/2019-01-21-gartner-survey-shows-37-percent-of-organizations-have">says</a> a Press Release by Gartner.
By leveraging one of these AI trends to create well-tailored apps, companies that help to boost business profits.
Artificial Intelligence allows marketing and sales teams to draw useful insights based on the analysis of customers’ behavioral patterns. AI-driven chatbots and virtual assistants help companies in increasing customer engagement.<i> Amazon’s Alexa </i> is a prime example of this. It is an AI-enabled virtual assistant that can control several smart devices in an automated system based on voice commands.
<b><i>Use of Artificial Intelligence to improve Productivity!</i></b>
<i>Capitalizing on these AI trends can help companies boost profits</i>. Leveraging advanced AI techniques allows businesses to improve their productivity. This is why enterprises these days are incorporating strategies driven by Artificial Intelligence trends.
<b><i>PwC <a href="https://www.pwc.com/gx/en/issues/data-and-analytics/publications/artificial-intelligence-study.html">estimates</a> that AI will contribute $15.7 trillion to the global economy by 2030</i></b>. It predicts that rendering an improved personalized experience, providing enhanced products and boosting labor productivity are some of the reasons responsible for the increase.
AI helps to improve work balance too. Let’s see how. The company VMware is a suitable example showing how AI improves work balance. Before using AI, VMware faced a lot of challenges in meeting targets and quality standards.
Later, the company looked for ways to integrate an AI-driven content solution. Finally ,after AI-integration, the company could automate menial tasks like editing and corrections. This helped in saving a lot of time that employees used for doing value-driven work such as training more writers, onboarding new members and creating better systems.
<b><i>The Bottomline</i></b>
So, these are some of the top AI trends that help businesses predict better solutions and decisions (predictive analytics), find opportunities and weak points in an organization to protect assets( anomaly detection) and to maintain work balance. Cybersecurity through advanced Machine Learning algorithms is of the AI trends being used for detecting cyber attacks.
AI trends have emerged as a game-changer in the industry. Businesses across the globe are adopting these AI trends for achieving better productivity. I am sure, after seeing the incredible benefits, you will incorporate techniques enabled by these AI trends in 2020 for scaling your business growth.
| ruchita_varma |
320,564 | Scheduling JAMstack builds in Netlify with Github actions | Introduction Netlify is a fantastic choice for hosting JAMstack websites as all sites on N... | 0 | 2020-04-27T09:46:54 | https://medium.com/@wearethreebears/scheduling-jamstack-builds-in-netlify-with-github-actions-509fcc87fa72 | jamstack, javascript, github, webdev | #Introduction
Netlify is a fantastic choice for hosting JAMstack websites as all sites on Netlify are prebuilt for performance and deployed directly to Netlify Edge, which works similarly to a CDN but with extra functionality. JAMstack websites are often misrepresented because it’s often claimed they are not dynamic, hard to update and cannot support a CMS but that’s simply not true.
# What is JAMstack?
JAMstack is a term coined by Mathias Biilmann (founder of Netlify), which stands for JavaScript, APIs, and Markup. JAMstack offers better performance, higher security and lower cost because the user is served static files. There are a number of familiar frameworks you can use to build JAMstack websites: Vue, Nuxt, Gridsome, React, Next, Gatsby and 11ty to name a few.
# What is Netlify?
Neflify offers a web hosting infrastructure and automation technology at an affordable price — In fact Netlify offers a free plan with 300 build minutes/month, perfect for hosting JAMstack websites.
# Getting started
NOTE: From this point onwards will I assume you have a JAMstack website in Github and will walk you through the transferable steps.
To get started with Netlify, we’re going to create a new site from Git:
In our case we’ll be creating a new site from Github. From here we’ll be able to pick our chosen Github repository:
Upon choosing a repo you will be able to configure your deployment settings. From the settings you can specify the build command that Netlify runs when the repo is updated, as well as the build output directory. For example, in a Nuxt project (assuming you have used the default settings), you would set the build command to: ```npm run generate``` and the publish directory to: `dist`
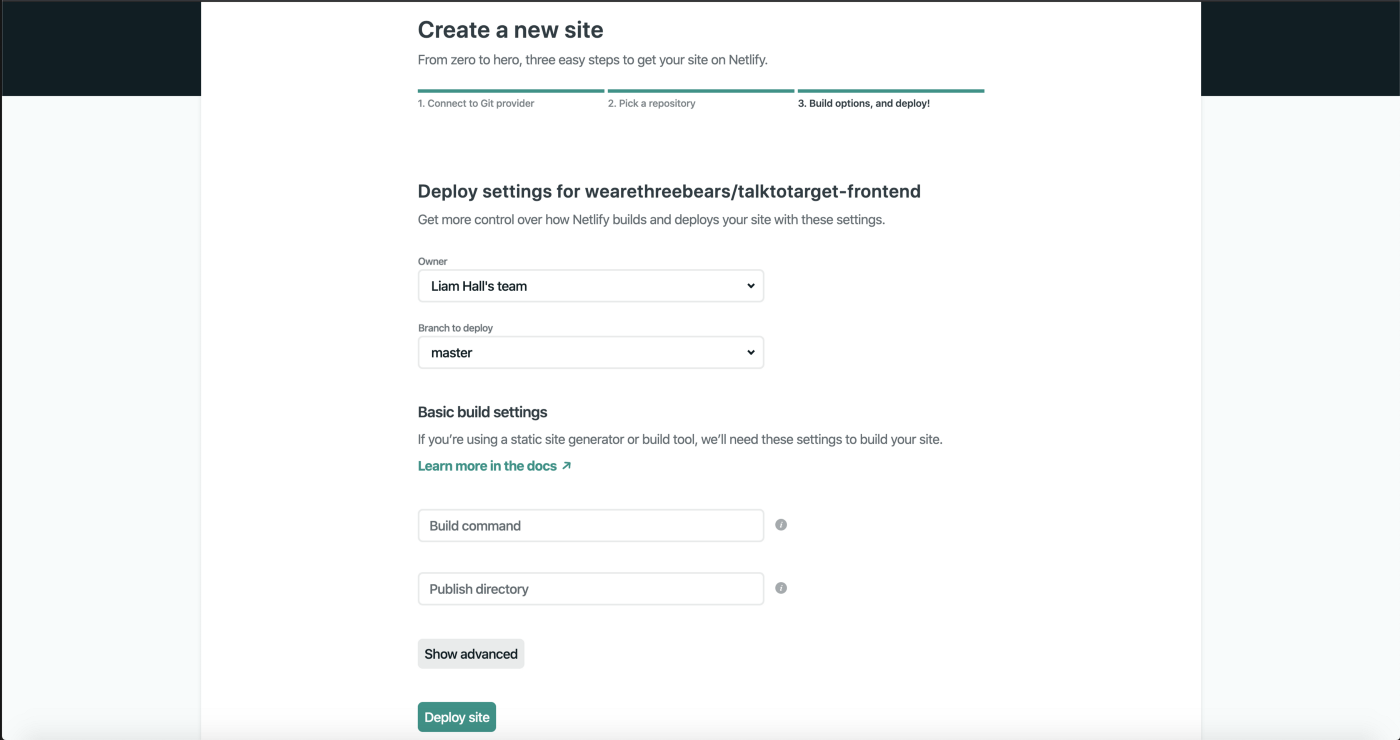
On clicking Deploy site, if your settings are correct, Netlify will build your site — Giving you a personal Neflify URL:
Netlify is now set up to build the website from your Git repository, every time you push to your chosen branch, Netlify will rebuild your JAMstack website.
So this is great — But what if we have a website driven via a CMS? It’s not practical to log into Netlify or to push a change to Git every time we want to rebuild with up to date content. Thankfully Netlify offers Build hooks.
# What are Build hooks?
Build hooks in Netlify allow us to set up an a unique end point to trigger a deployment build.
# Setting up a build hook
Setting up a build hook in Netlify is really simple — Begin by clicking Deploy Settings from the Deploys dashboard:
Scroll down to the Build hooks section:
Create a new build hook by giving it a name and select your chosen branch — Usually master.
Save the Build hook configuration and take note of the unique URL:
So now we have a build hook set up, what exactly do we do with it? One option would be to use Web hooks.
# What are Web hooks?
Web hooks are a means of delivering data to other applications as it happens, meaning you get data immediately. We could use Web hooks to perform a POST request to our Netlify every time some data is created, updated or deleted within our CMS.
The issue with Web hooks is that if data is changing all the time we are constantly hitting our build hook and racking up a lot of build time minutes which could take us beyond our threshold. This is where we can take advantage of Github actions to automate our JAMstack builds.
# What are Github actions?
GitHub Actions help you automate your software development workflows in the same place you store code.
To view Github actions from your repository click actions:
# Creating a Github action to Trigger Netlify builds
To create a Github action to trigger Netlify builds you’ll need to create a new file in your local directory: `.github/workflows/main.yml`
Within `main.yml` you’ll need to add the following code:
```
# .github/workflows/main.yml
name: Trigger Netlify Build
on:
schedule:
# Every 20 minutes
- cron: '0-59/20 * * * *'
jobs:
build:
name: Netlify build
runs-on: ubuntu-latest
steps:
- name: Curl request
run: curl -X POST -d {} NETLIFY_BUILD_HOOK_URL
```
To suit your needs you’ll need to replace `NETLIFY_BUILD_HOOK_URL` with your Netlify build hook URL that you generated earlier. The example will run every 20 minutes, if you’d like to run your build at shorter or longer intervals you’ll need to update the `- cron` value. A fantastic tool for cron schedule expressions is https://crontab.guru/.
Once you’ve configured your `main.yml` create a new commit and push to origin master. Your Github actions will now appear in the actions tab, triggering your Netlify build hooks at the configured intervals:
# Conclusion
I’m a big fan of the JAMstack and in my opinion Github actions are a great way to schedule builds at given intervals, reducing the demand for manual deployments and reducing the burden of web hook triggered builds.
If you’ve found this article useful, please follow me here, on [Medium](https://medium.com/@wearethreebears) and [Twitter](https://twitter.com/wearethreebears). | wearethreebears |
320,632 | Gabut Mode On: Bikin Aplikasi Inventaris Kosan (Bagian 2 - Analisa Tipe Data) | Halo lagi. Pada bagian sebelumnya, saya sudah sampai ke fitur apa saja yang akan masuk ke... | 6,284 | 2020-04-27T11:34:56 | https://dev.to/farishan/gabut-mode-on-bikin-aplikasi-inventaris-kosan-bagian-2-analisa-35di | webdev, javascript, beginners, bahasa | ## Halo lagi.
Pada bagian [sebelumnya](https://dev.to/farishan/gabut-mode-on-bikin-aplikasi-inventaris-kosan-bagian-1-rencana-591a), saya sudah sampai ke fitur apa saja yang akan masuk ke dalam MVP. Yaitu:
1. Mencatat barang-barang
2. Menampilkan daftarnya
3. Menghapus data barang
### TL;DR
Mau yang to the point? langsung scroll ke paling bawah aja.
---
Kata "barang" menjadi poin utama di aplikasi ini. Barang ini adalah data, yang tipe/bentuknya baru mau saya pikirkan. Yang paling sederhana itu _string_.
```javascript
let barang = 'meja'
```
Tapi untuk berjaga-jaga kalau user minta yang aneh-aneh, misalnya mau mencatat harga barang tersebut, masuk ke daftar barang kapan, dan informasi tambahan lainnya, aneh kan kalau masuk ke string yang sama?
```javascript
let barang = 'meja | 100 ribu'
// atau
let barang = 'meja, 100.000'
```
Selain aneh, malah ribet jadinya. Harus motong-motong string. Gimana kalau tipe data barang itu _array_?
```javascript
let barang = ['meja'] // gini?
// kalau pakai informasi tambahan gimana?
let barang = ['meja', 100000] // gitu?
```
Lumayan keren sih, tapi gimana developernya tau kalau 100000 itu harga barangnya? Lupakan array. Coba string aja semua, tapi jelas.
```javascript
let barang = 'meja'
let hargaBarang = 100000
```
Sejauh ini bentuk data di atas yang ternyaman untuk dipahami.
---
Bagaimana kalau masih ada bentuk data yang lebih nikmat?
Barang itu objek. Ada atributnya. Nama barangnya apa. Harganya berapa. Pasti lebih cocok kalau tipe datanya _object_ dong? Nih:
```javascript
let barang = {
nama: 'Meja',
harga: 100000
}
```
Lebih enak lagi kalau di-bahasa-inggris-in. Bener deh. Nih:
```javascript
let thing = {
name: 'Meja',
price: 100000
}
```
Kenapa 'Meja' ga jadi 'Table'?
Karena yang akan masukin namanya bukan saya sebagai developer (yang _keminggris_) ini, tapi user. Hak user mau masukin barang dengan bahasa apa kesitu. Tapi kalau object dan _attribute_/_properties_-nya, itu saya usahakan selalu bahasa inggris. Lebih cocok sama _syntax_ aja. Namanya juga selera. Maafkan ya. Hehe.
---
## Kesimpulan. Seadanya.
Sudah ditetapkan bahwa barang adalah sebuah _object_, dengan bentuk tunggal seperti ini:
```javascript
let thing = {
name: 'Meja',
price: 100000
}
```
Sedangkan untuk bentuk jamaknya, sudah pasti array. Jadinya _array of objects_.
```javascript
let thing = {
name: 'Meja',
price: 100000
}
let thing2 = {
name: 'Kursi',
price: 20000
}
let things = [thing1, thing2]
```
---
Demikian analisa yang seadanya ini. Jalan panjang di depan akan selalu beraroma array of objects. Jangan pusing dulu karena masih bagian 2, sampai jumpa di bagian [selanjutnya](https://dev.to/farishan/gabut-mode-on-bikin-aplikasi-inventaris-kosan-bagian-3-setup-2hek). Dadah. | farishan |
320,662 | Mithril : Hall of Fame | Here a simple example in Mithril that illustrates various concepts. let root = document.getElementB... | 0 | 2020-04-27T12:30:50 | https://dev.to/artydev/mithril-hall-of-lame-3f7g | mithri, component, closure, javascript | Here a simple example in Mithril that illustrates various concepts.
```js
let root = document.getElementById("root");
let globalCount = 0;
b.css(
"body",
b({
maxWidth: "80%",
margin: "0 auto",
})
);
let cardStyle =
"" +
b({
border: "1px solid black",
width: "250px",
height: "230px",
textAlign: "center",
paddingTop: "20px",
":hover": {
cursor: "pointer",
},
});
let layoutCards =
"" +
b({
display: "flex",
flexWrap: "wrap",
justifyContent: "space-around",
});
let buttonContainer =
"" +
b({
textAlign: "center",
border: "none",
marginTop: "10px",
marginBottom: "10px;",
});
let buttonStyle =
"button." +
b({
border: "none",
width: "250px",
":hover": {
cursor: "pointer",
},
});
let hrefStyle =
"a." +
b({
textDecoration: "none",
color: "#121212",
fontSize: "1.2rem",
});
let titleStyle =
"h1." +
b({
textAlign: "center",
fontSize: "2rem",
});
let creditStyle =
"p" +
b({
textAlign: "center",
});
let claimStyle =
"p" +
b({
textAlign: "left",
padding: "10px",
lineHeight: "1.5rem",
});
let unicode =
"" +
b({
fontSize: "1.0rem",
});
let statUser =
"" +
b({
fontSize: "1.0rem",
marginTop: "5px",
});
function Card() {
let clickCard = (link) => {
window.location.href = link;
};
let report = (count) =>
`like(s) : ${count} (${((100 * count) / globalCount).toFixed(2)} %)`;
return {
view: ({ attrs: { name, count, clickHandler } }) =>
m(
"",
m(cardStyle, { onclick: () => clickCard(Links[name]) }, [
m(hrefStyle, { href: Links[name] }, name),
Claims[name] && m(claimStyle, Claims[name]),
]),
m(
buttonContainer,
m(
buttonStyle,
{ onclick: clickHandler },
m("p", [
m(unicode, m("span", "Vote \u2192 \ud83d\udc4d")),
m(statUser, globalCount > 0 && report(count)),
])
)
)
),
};
}
function Lib() {
let count = 0;
let clickHandler = () => {
globalCount++;
count++;
};
let getPerCent = () => {
let percent = 0;
if (globalCount > 0) {
percent = (100 * count) / globalCount;
}
return `(${count}) / (${percent})`;
};
return {
view: (v) =>
m(Card, {
name: v.attrs.name,
clickHandler,
count: globalCount == 0 ? 0 : count,
getPerCent,
}),
};
}
// I could have done a Json object...this is easier to read
const Libs = ["Mithril", "AppRun", "HyperApp", "Svelte", "Stencil"];
const Links = {
Mithril: "https://mithril.js.org/",
AppRun: "https://github.com/yysun/apprun",
HyperApp: "https://github.com/jorgebucaran/hyperapp",
Svelte: "https://github.com/sveltejs/svelte",
Stencil: "https://stenciljs.com/",
};
const Claims = {
Mithril:
"Mithril is a modern client-side Javascript framework for building Single Page Applications. It's small (< 8kb gzip), fast and provides routing and XHR utilities out of the box",
AppRun:
"AppRun is a 3K library for building applications using the elm architecture and event publication and subscription.",
HyperApp:
"1 kB JavaScript micro-framework for building declarative web applications ",
Svelte:
"The magical disappearing UI framework The web's JavaScript bloat crisis, solved. Svelte turns your templates into tiny, framework-less vanilla JavaScript.",
Stencil: "The magical, reusable web component compiler",
};
let App = {
view: () => [
m(titleStyle, "Hall of Fame"),
m(
layoutCards,
Libs.map((item) => m(Lib, { name: item }))
),
m("h2", "Number of votes: " + globalCount),
m("button", { onclick: () => (globalCount = 0) }, "reset votes"),
m(creditStyle, "Made with the awesome and lightweight Mithril"),
],
};
m.mount(root, App);
```
You can test it here : [Hall of Fame](https://flems.io/#0=N4IgtglgJlA2CmIBcAWAbAOgJwA4A0IAxgPYB2AzsQskVbAIYAO58UIB5hATncgNoAGPAIC6BAGYQE5fqFL0wiJCAwALAC5hY7WqXXw9NADxQIANwAE0ALwAdED2Lr7APlukLF90YD0psy46LAiE6hBkMsoAjEgATCAAvnhyCkoqAFYyBCR6Buo0COoWjkXWFlDEhACuinoYAObw6gCiCLXqAEIAngCSUAAU9iX2AJTu7oUW9bDEAEb0sADCxFV6FmUC46SzGITk5P0A5LPEUF2HeBaz-cDunhZg9AAeAOrQ6qpIFoc4AgCkFzunkeXHqEFIX3sAgs9Cq6mI9nu7gSIzGpAmTQshHoXCgAGV1F0EOsvCBEQBqK43cbqE64+BcL6HKKMJ4WSiwaBXBiEADWgPR6gA7u9Pt9YgBWASsgW2D7wCD1DRM2IAZmlTwFnn0T3UAEFOfUIaTCHkGfY8EDGPQYOD6gAVYiMFUarXfJCqYhmBmHCxfW4ee7VLiURnfRjEcH6LiHIEJLykFFbSYMLordSLHFQcgk+wUqkBuWmciMVOQkDiBBPC00yvwV5cJjloWNxg1wXpKrkMLiLrLXJ6csl+imgC0OJWpCgecTaIxRVmcPhpH76no4IZubJIAslOuhfUOv1huN9lNuS4FoTcrpUAZ5dIZHg7blILBpEdztJUQ1L80OPfDonHhMByx-VkAG52wTJN0VISZF0PMgCSJeAt0Q5cMHzfcaVve9SUfUhn3YIERSgD5y0lX8SMFewPS9c1kAsA85WDUNywjKNGJpBJkTneDMVULh4HEFDiTKex6Cwnc92pQMjwAEXgEhGzCMgmUI+A3RIGYw3sABiKJYiMozoIscQyHUPEIAAL3gMCMFiYSwBnWD5wsMJ1AQMS0IkkBVCiaTdwLIEjwNRVTyIM1LxozwLL0ay7L9UknPgFyyVnZNMW4VgICswlxNJNsZJC+T62PCLy3PaNXP4yZCAYCAwB8rdiuCnCyt1cKjXLBBxGcWKLGtW1SHqJBmVdS1A05IiAAkFSVdQHIlZzaqyopVggEg7y3bC5LiyzEvs78MAEVaMrcgSim7eh1AAVRYLhdpKjqDoS2zjvsQKzrSsy33BT9ywlVk1o8dxxFWUJwg8TNcX6EZmKBerOT5WGoBJGbeXWFxmJFKdiCFDAZmxNTSDUYTxAx8FeV46bMWEiMuFKLFJ1KHGAANOV5eB+nIBGvgAEmAEhVnUeN+iF-of2hAAqFnRZ8aY5gWZZRZGDB4QAMQgJ5WH6WIRnjP4RnZmlhPUKouA8Fj1DMCB4CFL4blu9QQ39eRFEuEW9C9lHeVm+gpwQLgEhRbGaTlV9Bm3KbI+ceOwH6bFcR8y5gDIBqtt5J2EesHHM9RrN+gAGWp8g+A9+ARENy4+CBe4G4efohJE1PmJb8QvlL0heXLyuRCSCxK5GKbG8bxZGrAPvUhECwADI56bhr12agr4EuCeV+nxRq-rxvq9j+O48TjCyFXdciK4S497Hk+l2Qte04zv2vgL-3A7gBlB5vsem8ORgLgWDroGX+jdE6bW2uvJu9hhzonYKSAAak4NCthbBVGMlgWIXg0FQBwKqacODCAoGnCAVEo9QFgN5mue6j1Lj9CVvMJYrMLA42hAvYo8BGbqCTqzVEaIKEWGrvw3+c4j7qFEbTWm4NIakwsKXa4CMDz1WYRsGkyMs4ByDpuMo8NsaI1ouoBhKtWbknJBHdQ3t1CmJ4mozEjR1AAAUGSLDyCSXRed9Fx0mIwBk1USQCCggYiAlN6EzEYarNYrDFHmLlD4rgfiyjSwsHLSxFgfBTDCcY0W5ipHx3NpbDw7MJbC1ZmHdJxS4nVRRKbQUuT8lW08fHO2DsviWA8T-ROaM04xPjpXVpGAXYhgwJXQ+cdWJ+00Z-K+PTWKsy+EYphot1gbAsAAfgsNCV+rNRliPsU4rgLi9A9LcmLZEWwfDpJ6PLWA6NVD0G9OUJ8MILAAClKAeDmOkZS6gMC-I+BAHMAKLDwHoOQe2T14QcJtO4HI3Y5EQFmDmMofBDgAFk8pCSkIAw4epGCMAAEqrGxbNLocTcUAOviAPE3pYD6CvPYAkBhCBSHsCILYsKijd17iSAMFh0UfC4FIJkGh1DMCQBcyAAqpAYEyBgYgoIfBanJYS40hwRViouWCD4VQdgkDAD4LoXRyCrB8EwRgXAiWjxJWSvFwrDwasVhinVuxiD6vSPKxoi5k6Bx8KoUlDIzWALuNS+AtLjpqvteQcVjrtW6tdT4cgNL9CZATUmrSo9GWkGZbAO1oqo0XO7EyqQsq9WKpguyiIRRN5NSRfozw-LMU5tJA2wVsArA5noA8U4DIPCZzyKOMFO0Xn3NBdwCAjAijiEbIoIU8qsYWSeouKQphRoWGsqNYkDj6CNAsOSlGt1obkAwBYHo6hDg5nII8WAbb+hGAsDgXkswpg2XHSPcyoKigfyGjwO2d4cw8DhHaGEU4LAAA1Zr4osIBzkYR4A5nTBYYglN5RXGINWQayrVjlkwx4IFnbVQAGkLCclmI2LgXRzLyquFUZdQGzX7tJjmLsQGUOhrADCeJqg8rfMtmhL98BvRrEYDqhj0NgPo2NYisdE7obSXIdahk5KwIWF5B0V5I68TSaKJAbgxBRxTtSLOrg86qNLpuUBu8y9VLmDQkKeAT76NbQPREUk5CQ1hvLPaVQaFHhgmxG24sZqQWCtXXdK5BmZ1zosF52z9nz3qbMPQTTgqJ3cmILdLEgqwXkEuByb0UBj3uf0B5ApOY0yWw8mlUst04NWD0MQDy4IuiXAiw7Odo5pA5kS6QKQDAEtJa03JoEmbs2ee8w8bdTnYCXGEl2egsxiR2afXqiMRE1grakIxJEiZ1q7rxTymkzTHYWHcTjYBDdE6eW8o-UkAdr2IcpprVIoxLieHMYnVM6Y0Y5fhYijAjxGD9G4+xjxid5FpyHqkL4wOLAojIe9o4qhYjYoAHI1FmJuJDFgzDIKjd8YKCyIniJ2YnY499SCAPTlml+J3c440JyojZ38HBwcxDj-Q5AXt70TjlUw+VUKUtRTaWzGKPLjfoHZygihxPEcVBoOzcuigtpZaQmkbKdukDAP91m-QSiXHJSMHQG3g40HmBj7QHBQ3fMPTQAQSABCjiiCgCUSAog4ESMkEAlcaC7H2EbyyeQaCJDECATGkQ+ApEUDQSVjadCW20ModV+afCrEYLyeoLr9Ux9bQAAUCoFNAPhs-SsyDoQkPiaCcBS-kJIke0iIqyCAePNAk-RtT+nzPPgG954wBKRyXf9gysb+XtIVfx014HkAA) | artydev |
320,681 | Top 10 Web Development Frameworks of 2020
| As 2020 becomes three months older and new updates on the technologies keep coming in the market. Whi... | 0 | 2020-04-27T13:10:46 | https://dev.to/rlogical/top-10-web-development-frameworks-of-2020-5hai | angular, reactnative, laravel, python | As 2020 becomes three months older and new updates on the technologies keep coming in the market. Which is making the selection of the framework for web development pretty tough.
Here we are listing out the top 10 web development frameworks to choose and work in 2020.
1. Angular js
Angular js is an open source front-end web development framework. Google developed angular, and Google, Microsoft, and Paypal giants are using it. AngularJS lets developers write client side applications using JavaScript in a clean Model View Controller (MVC) way. Angular allows the developers to build large scale, high-performance, and easy to-maintain web applications.
2. React
React is not a framework, it’s a front-end library developed and maintained by Facebook. React is fast, secure, and scalable. Big companies such as Facebook, Instagram, Netflix and Apple use it. The main goals of this framework is to make front end development effortless.
3. Ruby on Rails
The most significant feature of RoR is that you can build a cloud-based application using this framework. Ruby on Rails has a vast number of libraries and tools. Ruby on Rails provides the Fast development, Automation and, Huge Community.
4. Laravel
Laravel is an open source php framework for building robust Web Services & Web Applications. Laravel is full of featured backend web development framework which Integrated with mail services. Laravel follows the model-view-controller (MVC) architectural pattern. Laravael development supports the Routing controllers.
5. Django – Python Framework
Django is a high level Python web framework.Django provides the easier way to build better Web apps more quickly, with less code.
Django is a Model-View-Template framework. Big giantess Google, Youtube, and Instagram use this framework. Such large websites built on Django Pinterest, Disqus, Mozilla, National Geographic. Django is highly supportive in protecting the user data from the website.
6. Vue.js Framework
Vue.js started as an individual project and quickly grew in the market becoming one of the most trending JS frameworks. Vue supports the progressive framework like if you have an existing project, you can still adopt Vue for one portion of the project, and everything would work just fine. Vue.js is very easy to maintain, and fast in Development.
7. Ember Javascript Framework
Ember javascript is considered the best framework used by professional developers to build front-end web applications.
Ember based on Model–view–viewmodel (MVVM) pattern. Tech giants such as LinkedIn, Heroku, Zendesk, Twitch, Microsoft, and others rely on this framework. Ember provides a built-in data layer, which leads to super simple UI sync with the backend.
8. Node.JS
Node.js is a web application development built on JavaScript runtime. It is fast and easy to use framework. Node.js supports various third party open-source frameworks. Express.js is the most popular framework for Node.js. Node.js acquire the rich library of various JavaScript modules which simplifies the development of web applications using Node.js to a great extent.
9. Spring
Spring is a very thin and lightweight framework. Spring framework is the collection of sub-frameworks such as Struts, Hibernate, Tapestry, EJB, JSF, etc.. Spring framework has templates for JDBC, Hibernate, JPA etc. technologies which reduces code size by hiding the basic steps of the technologies.
10. Backbone
Backbone.js communicates to the server entirely through a RESTful API and it has extremely lightweight file size. Backbone has an incredibly small library for functionality and structure. Backbone has only one dependency Underscore.js. It is amazingly supportive of the one page web application and the small application.
Reference url: https://www.rlogical.com/blog/top-10-web-development-frameworks-of-2020/ | rlogical |
320,728 | Using dotenv to manage environment variables in Nodejs | Have you ever faced any of these scenarios: You have some dynamic values in your code whi... | 0 | 2020-04-27T14:23:46 | https://dev.to/vyasriday/using-dotenv-to-manage-environment-variables-in-nodejs-3ja1 | node, webdev, javascript, codenewbie | #### Have you ever faced any of these scenarios:
1. You have some dynamic values in your code which you don't want to hardcode.
2. You have API Keys in your opensource project which you obviously don't want to push to GitHub
3. You have some values in your code that depend on what environment you are building your code for.
*If you fall into any of the above-mentioned scenarios I have a got a solution for you.* 😃
##### Node Environment Variables Using dotenv
In Node, there is something called environment variables which you can see by logging `process.env`.
For example, you can set a `NODE_ENV` variable which is basically used to define what environment you want to build your code for.
```javascript
process.env.NODE_ENV='dev'
```
Then further use this variable to generate different builds.
Instead of setting these environment variables ourselves, we will be using the `dotenv` package.
```bash
$ npm i --save dotenv
```
Once dotenv is installed let's create a `.env` file in the root of our project
and add the `PORT` variable into it.
`.env`
```
PORT=3000
```
Now let's see how we can use this `.env` file in our code. We will create a basic node server and use `PORT` defined in our `.env`.
NOTE: If you do not understand the server part, don't worry. It's not important to understand how to use `dotenv`.
`app.js`
```javascript
require('dotenv').config()
const http = require('http')
const server = http.createServer(callback)
server.listen(process.env.PORT || 4000)
```
### Let's see what we just did here.
We basically created a server in node and the server is listening on the port defined in our node environment variables. If it's not defined there we give it a fallback value.
Now the value of this `PORT` can be different depending upon where you deploy your server be it Heroku or something else.
dotenv is loaded first and it has a config function that basically reads our `.env` file and populates the environment variables.
You can use dotenv to store your server configuration or use it with webpack to define global variables using webpack's definePlugin.
PS:
1. You need to load your env config once in your webpack config or in your entry file and also never commit your `.env` files
2. In order to maintain multiple `env` files each for different environment you can use `dotenv-flow` package. You must set your `process.env.NODE_ENV` variable first as `dotenv-flow` uses that variable to decide which env file to pick. https://www.npmjs.com/package/dotenv-flow
If you face any problem in implementing this, let me know in the comments. I will be happy to resolve.
Thanks for reading 😀
| vyasriday |
320,775 | Money Is Not Everything | I am currently searching for new work. I tend to phrase it as "looking for new opportunities" or "ch... | 0 | 2020-04-27T14:46:44 | https://www.tegh.net/misc/money-is-not-everything/ | work, personal, money | I am currently searching for new work.
I tend to phrase it as "looking for new opportunities" or "challenges".
But let's call it as it is. **I am on a job hunt.**
## The money question
Quite often I find myself in an interview baffled by a question about my financial terms.
Some interviewers require a range, some a single number.
It is easier if the job ad has the offered range specified from the beginning, but only a little.
Having been a professional software developer for almost 15 years (i.e. since I started my [self-employment](https://www.infoza.pl) in 2006) I am not shy to ask for the top offered value.
Unfortunately there is a catch with this tactic.
I have found that MANY companies LIE about the actual salary range they are capable or willing to pay.
I have been turned down a few times because my salary expectations were said to be too high.
The recruiters wrote: "we value your expertise, and we would like to have you on board, but you a) have too much of experience and we would not be able to challenge you enough or b) we cannot meet financial expectations". WTF, I ask you?
I have since came to realise, that I do not want to work for a company that misleads its prospective employees.
Just do not waste time.
> I guess I needed to get this out of my chest and in the open.
In both of my previous jobs I got to enjoy the feeling of not having to work at all, because the people there and the things we got to do, made it seem like so much fun.
The most important thing is that we bonded and supported each other. This allowed everyone to grow. **No money can buy that!**
# Tell me what you think is fair
That is my default answer now.
Money is important. It is the means with which we can support our goals and dreams, but **it is not the deciding factor**.
As it turns out - it never has been!
I am sure we can come to a mutually beneficial arrangement if we just keep honest and open about our expectations and capabilities.
Now, Let's talk how we can work together!
> original post: https://www.tegh.net/misc/money-is-not-everything/ | pawzar |
349,833 | Answer: ERROR: unsatisfiable constraints using apk in dockerfile | answer re: ERROR: unsatisfiable const... | 0 | 2020-06-05T11:39:32 | https://dev.to/dvsingh9/answer-error-unsatisfiable-constraints-using-apk-in-dockerfile-1f7n | {% stackoverflow 62178736 %} | dvsingh9 | |
320,826 | Dark and light theme with switch for docsify sites (also supports docsify-themeable) | About me Hi imboopathikumar working as Full stack JavaScript developer also in AWS. I pers... | 6,297 | 2020-04-27T20:02:05 | https://dev.to/boopathikumar/dark-and-light-theme-with-switch-for-docsify-sites-4l57 | docsify, darkmode, plugin, javascript | # About me
Hi [imboopathikumar](https://boopathikumar.me) working as Full stack JavaScript developer also in AWS. I personally using docsify for generating documentation websites and I am big fan of dark mode. So I desided to create a plugin `docsify-darklight-theme` for docsify generated sites to switch between `dark-mode` and `light mode`. This is my first open source project and [npm package](https://www.npmjs.com/package/docsify-darklight-theme)
# What is docsify
[docsify.js](https://docsify.js.org) is static website generator using Markdown. It parses your Markdown files and displays them as a website less than a minute instead of generating static html files. Using various plugin support, You can create better looking website with docsify.
# docsify-darklight-theme *plugin*
[docsify-darklight-theme](https://docsify-darklight-theme.boopathikumar.me) which is a simple and highly customizable theme plugin for the documentation websites generated using [docsify.js](https://docsify.js.org/). Using this theme, documents will have a theme switcher to switch between <svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewBox="0 0 24 24" fill="#ffffff" stroke="#34495e" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="feather feather-moon"><path d="M21 12.79A9 9 0 1 1 11.21 3 7 7 0 0 0 21 12.79z"></path></svg> `dark-mode` and <svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" viewBox="0 0 24 24" fill="#ffffff" stroke="#34495e" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="feather feather-sun"><circle cx="12" cy="12" r="5"></circle><line x1="12" y1="1" x2="12" y2="3"></line><line x1="12" y1="21" x2="12" y2="23"></line><line x1="4.22" y1="4.22" x2="5.64" y2="5.64"></line><line x1="18.36" y1="18.36" x2="19.78" y2="19.78"></line><line x1="1" y1="12" x2="3" y2="12"></line><line x1="21" y1="12" x2="23" y2="12"></line><line x1="4.22" y1="19.78" x2="5.64" y2="18.36"></line><line x1="18.36" y1="5.64" x2="19.78" y2="4.22"></line></svg> `light-mode` also comes with starter kit. Now available through [npm & CDN](https://docsify-darklight-theme.boopathikumar.me/#/installation). Try now for your docsify websites. It also supports with [docsify-themeable](https://jhildenbiddle.github.io/docsify-themeable/#/)
**[docsify-themeable](https://jhildenbiddle.github.io/docsify-themeable/#/)** is a simple theme system for [docsify.js](https://docsify.js.org/). It have Legacy browser support (IE10+).
## #Features
- Default [theme mode detection](https://docsify-darklight-theme.boopathikumar.me/#/configuration?id=default-browser-theme-detection) in supported browser versions.
- Theme Switcher.
- Switcher support for [docsify-themeable](https://jhildenbiddle.github.io/docsify-themeable/#/). View [setup guide](https://docsify-darklight-theme.boopathikumar.me/#/docsifyThemeable) here.
- Tooltip view for long sidebar items.
- Themes are customizable based on your color preferences.
- Option for other plugins to support (Dark/Light) mode. View [setup guide](https://docsify-darklight-theme.boopathikumar.me/#/themeSupport) here.
- Preferences can be modified directly in `window.$docsify` [configuration object](https://docsify-darklight-theme.boopathikumar.me/#/configuration).
- Using [configuration object](https://docsify-darklight-theme.boopathikumar.me/#/configuration)toogle icons can be configured based on your preference.
- Default theme(Dark/Light) can be configured based on your needs.
- Themes are remembered and retrieved from local storage.
- Redesigned search box.
## #Installation
You can use `docsify-darklight-theme` in three ways
- [By starter template](https://docsify-darklight-theme.boopathikumar.me/#/installation?id=by-starter-template)
- [Using NPM](https://docsify-darklight-theme.boopathikumar.me/#/installation?id=using-npm) adding to your existing project
- [Using jsdelivr CDN](https://docsify-darklight-theme.boopathikumar.me/#/installation?id=using-jsdelivr-cdn) adding to your existing project
Also it provides [theme support for other plugins](https://docsify-darklight-theme.boopathikumar.me/#/themeSupport) which are developed for **docsify.js**
### #Finally
Try [docsify-darklight-theme](https://docsify-darklight-theme.boopathikumar.me) for your docsify generated websites and share your thoughts.
Thank you everyone for the support
Follow me on twitter [@imboopathikumar](https://twitter.com/imboopathikumar) and [@docsify-darklight-theme](https://twitter.com/docsifyDrkLtThm)
| boopathikumar |
320,829 | The difference between Medium and Dev.to in one title | A post by Evgenia Karunus | 0 | 2020-04-27T16:01:50 | https://dev.to/lakesare/the-difference-between-medium-and-dev-to-in-one-title-4538 | ---
title: The difference between Medium and Dev.to in one title
published: true
description:
tags:
---
 | lakesare | |
320,834 | How to launch your side project in less than a day | In this article I’m going to share my process for launching a side project fast. I'll show you how to go from idea to launch in less that a day without sacrificing the quality of the final product. | 0 | 2020-04-27T16:12:24 | https://www.mrmadhat.com/articles/launch-side-project-less-than-day | efficiency, beginners, webdev | ---
published: true
title: 'How to launch your side project in less than a day'
description: "In this article I’m going to share my process for launching a side project fast. I'll show you how to go from idea to launch in less that a day without sacrificing the quality of the final product."
tags: ['efficiency', 'beginner', 'webdev']
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/5l39tp1of8492fcbmill.png
canonical_url: https://www.mrmadhat.com/articles/launch-side-project-less-than-day
---
## Process overview
The process I follow includes many of the standard pillars of software
development and can be seen in both waterfall and agile methodologies. The basic outline of the process I follow is:
1. Plan
2. Reduce scope
3. Design
4. Build
5. Launch
6. Review
I’m going to take you through this process step-by-step using my latest project,[multiplayer hangman](https://hangman.mrmadhat.com) as an example.
## Planning
### Idea
The idea for my latest project came after playing _Cards Against Humanity_ with my family through a site called [allbad.cards](https://allbad.cards/). The site allows multiple people on different devices to play the popular game together from any location. I was interested in learning about how real-time communication works in web apps and wanted to build something that would help me learn. I decided to recreate the classic game of hangman but a multiplayer version that allows people to play together.
### Basic Requirements
Once I had the basic idea I then spent some time planning out how I wanted the game to work by writing a list of steps involved during a typical session:
- **Host creates a game session**
- Host provides username to be used during the session
- A unique link is generated for the session that can be shared with other players
- Players join using the link: Username required to join
- Host starts game once all players have entered
- player order is decided here and doesn't change throughout the session
- **Game**
- setup
- Word to guess is chosen at random
- The group of players (team) is assigned a number of lives
- The player to go first is randomly chosen
- Each player is shown n blank spaces representing the letters of the word
- Turn
- Player whose turn it is is shown a collection of letters to choose from
- 1 letter of the collection is in the word and the rest are not
- Player chooses a letter
- If correct the letter is revealed
- If not a life is deducted from the game
- Player attempts to guess the word
- If correct game ends and a new game starts
- If not two lives are deducted
I also drew some sketches to further clarify my thoughts about how I wanted the game to work.
## Reduce scope
Reducing the scope of work required is the most important part of my development process. It's at this point I ask myself “What can be removed that means I can launch by the end of the day?” this question is critical because it allows me to focus on the most important features whilst postponing the less critical.
> **“What can I removed that means I can launch by the end of the day?”**
I like to use a day as a timescale because it means that the risk of failure is reduced. As long as I've been realistic with what I think I can accomplish I should be able to build it in a day. Even when I've underestimated the work required the project generally overruns by days rather than months. The shorter development cycle also means I can get the product in front of users quicker and gain valuable feedback which can then direct further development.
### What I removed
In the case of the hangman project I removed the majority of the features and decided my first iteration would focus purely on the core game without
multiplayer functionality. Yes, the purpose of creating the game is to explore real-time communication but that can only happen once there is a game that can be played.
Plus, don't forget that we're talking in terms of days not months. Tomorrow I can work on adding multiplayer functionality if I want to and I can do so knowing that the core functionality of the game is taken care of and I don't need to worry about it.
I took my sketches and narrowed them down to just one main sketch with slight variations for user notification, such as when the user guesses wrong. I also rewrote my functionality tasks to narrow down the steps needed.
## Design
In previous side-projects I would skip the design initially and end up paying for it later. Completing the design first not only saves time but also removes headaches because design and development decisions aren't mixed. The less context switching the better.
I created a main design housing the major components then made some additional copies that included other essential features. Here’s the designs:
## Build
With the bulk of the thought process completed for the game and the design in hand the build is really straight forward. I took my reduced "steps of the game" that I wrote when I reduced the scope and began thinking about each item in more detail:
- Game
- Setup
- Word to guess chosen at random
- Initial number of lives given
- Player shown n blank spaces representing the letters of the word
- Turn
- If player has lives remaining
- Generate and display letters to choose from
- Player makes letter choice
- Correct: the letter is revealed
- Incorrect: a life is taken
- If player doesn't have lives remaining
- Show "Better luck next time" message and restart game button
- If all letters are known
- Show "Congratulations!" message and restart game button
I also sourced a list of [common english words](https://github.com/first20hours/google-10000-english) for use within the app and setup my project to use [husky](https://github.com/typicode/husky) to run tests and lint my code before being committed. Lastly, I built out the game in React using `create react app`, view the source [here](https://github.com/mrmadhat/hangman-game).
## Launch
In practically no time the game was ready to be deployed. I want the process of deployment to be automatic and I want to spend the least amount of time thinking about it as possible.
For this project I chose github pages for the deployment, whenever I want to deploy I just type `npm run deploy` and latest changes will automatically be published. One change I would like to make to this workflow is to setup a github action that will automatically deploy whenever there is a commit on the master branch. Another, arguably simpler option would be to move the hosting to netlify where deploys would automatically happen on push to the master branch.
## Review and feedback
Overall I’m happy with how the first iteration of the game turned out. I shared it with my friends and family to get some initial feedback, they said that the game is quite difficult and would be better if it was easier. Another piece of feedback I received was that the game should show the word when the player runs out of lives.
This feedback is invaluable, if I was building the game as something to generate profit then this initial feedback would allow me to quickly add improvements to the game that users actually want. This all comes back to the speed of delivery, you should constantly strive to strip anything that’s unnecessary and build the most important thing first then iterate quickly based on real-world feedback.
## Summary
Hopefully this article has been helpful, if it has and you'd like to hear read more stories from me please consider subscribing to my mailing list.
| mrmadhat |
320,835 | List of Github cli commands | Github cli commands A list of Github cli commands feel free to star this... | 0 | 2020-04-27T16:25:17 | https://dev.to/web/list-of-github-cli-commands-5516 | github, githubcli, git | Github cli commands
============
_A list of Github cli commands_
--
feel free to star [this](https://gist.github.com/vimalverma558/50d523bc3af426a3b51d59cabb49eeff)
___
___

### Repository
| Description | Command |
| ------- | ----------- |
| Initialize a Github repository [default private] | `gh repo create <name>` |
| Initialize a Github public repository | `gh repo create <name> --public` |
| Create a local copy of a remote repository | `gh repo clone <repository-name>` or <br> `gh repo clone https://github.com/<username>/<repository-name>` |
| Create a fork for the current repository | `gh repo fork` |
### Pull requests
| Description | Command |
| ------- | ----------- |
| Check status | `gh pr status` |
| Create a pull request | `gh pr create`|
| Quickly navigate to the pull request creation page | `gh pr create --web`|
| list of open pull requests | `gh pr list`|
| View a pull request | `gh pr view` |
### issue
| Description | Command |
| ------- | ----------- |
| Create a new issue | `gh issue create` |
| Create an issue using flags | `gh issue create --title "Issue title"` |
| list of open issues | `gh issue list` |
| list of closed issues | `gh issue list --state closed` |
| Show status of relevant issues | `gh issue status` |
| View an issue | `gh issue view {<number> / <url>}` |
[follow](https://github.com/vimalverma558) | vimal |
320,840 | Build ticTactoe game!! | PLSSS give your valuable feedback!! https://codepen.io/iamgs/full/jObMdGe | 0 | 2020-04-27T16:34:17 | https://dev.to/gauravsingh9356/build-tictactoe-game-1kch | javascript, css, webdev, devops | PLSSS give your valuable feedback!!
https://codepen.io/iamgs/full/jObMdGe | gauravsingh9356 |
320,902 | Build Your Team an Accessible, Shareable Component Library | Use React and TypeScript to build your team an accessible, shareable component library that can be included in as many projects as you can manage. | 0 | 2020-04-27T18:19:42 | https://dev.to/rpearce/build-your-team-an-accessible-shareable-component-library-53mj | react, typescript, javascript, library | ---
title: "Build Your Team an Accessible, Shareable Component Library"
published: true
description: "Use React and TypeScript to build your team an accessible, shareable component library that can be included in as many projects as you can manage."
tags: react, typescript, javascript, library
---
_Orginally posted on https://robertwpearce.com/build-your-team-an-accessible-shareable-component-library.html_
Today we're going to dive into building a frontend component library from start to finish that you can share privately with your team or publicly with everyone!
By the end of this post, you will be able to use [TypeScript](https://www.typescriptlang.org), [React](https://github.com/facebook/react), [Storybook](https://github.com/storybookjs/storybook), and more to provide a simple way to create accessible components that can be included in all of your projects.
If you'd like to skip to the code, here is the example component library we're going to make: https://github.com/rpearce/example-component-library.
## Overview
This is a big post that covers a lot of ground, so buckle up.
1. [When Should I Make a Component Library and Why?](#when-should-i-make-a-component-library-and-why)
1. [Project API (Usage)](#project-api-usage)
1. [Main Project Tools](#main-project-tools)
1. [Project Structure](#project-structure)
1. [Component Structure](#component-structure)
1. [Creating the Project](#creating-the-project)
1. [TypeScript Setup](#typescript-setup)
1. [Linting Setup](#linting-setup)
1. [Testing Setup](#testing-setup)
1. [Storybook Setup](#typescript-setup)
1. [An Example Component](#an-example-component)
1. [Building Our TypeScript](#building-our-typescript)
1. [Building Our CSS](#building-our-css)
1. [Building Our Stories](#building-our-stories)
1. [Continuous Integration Notes](#continuous-integration-notes)
1. [Publishing Notes](#publishing-notes)
## When Should I Make a Component Library and Why?
### Scenario 1: Component Entropy
Components make up large parts of our applications. As projects age, components can become increasingly coupled with other components, business logic, and application state management tools like [redux](https://github.com/reduxjs/redux).
These components usually start out small, focused, and pure. As time passes and the imperative of timely code delivery takes its toll, these components become harder to compose, harder to reason about, and cause us to yearn for simpler, less-involved times.
Instead of rewriting those components in place and repeating the same process, consider extracting and developing each one in isolation in a library. This will allow you to keep each one's surface area small and keep your business logic, state management, routing logic, etc., where it belongs: in your application.
With this scenario, a good intermediary step, before pulling components into their own project, would be to create a folder in your application for these components and set up a tool like storybook to house the individual examples and compositions of them.
### Scenario 2: Multiple Projects (or The Possibility of Multiple Projects)
Consider this exchange:
> **Them**: You know that spinner/widget/dropdown/search thing we have over here? It looks and works great! We want the same thing over here and over here. How difficult is that?
>
> **Me**: Those are different projects, and that is really more like 4 different components working together, so a) hard to do cleanly but good for the long-term or b) easy (for now) if I copy and paste.
>
> **Them**: We need to ship.
>
> **Me**: Okay, so copy and paste it is...
What's special about this exchange is that _both sets of concerns and perspectives are valid_. Software stakeholders typically want and need to ship features and fixes quickly, and they usually want to maintain brand consistency across their ecosystems. Software developers at those companies want to be able to ship features and fixes and maintain brand consistency, but they are also aware of the cost of short-term decision making (this is a way of accruing technical debt).
We know that even the best code is useless to a business if there are no customers around paying to use it, but we also know that suboptimal tech decision making can grind projects to a halt over time, averting the stakeholder's directive of shipping features and fixes quickly.
So what can we do to not only amend the scenario above but also make this undesired state unrepresentable in the future? We can start our projects with an accompanying component library! For existing projects, we can begin moving them in that direction.
## Project API (Usage)
Let's first define how we are going to include our components in our project.
### JS Imports
Component JavaScript can be imported in a few different ways:
```javascript
// import from the main (or module) specification in
// package.json, depending on your bundler and its version
import { Circle } from 'mylib'
// straight from the ESModule build
import Circle from 'mylib/dist/esm/Circle'
// straight from the CommonJS build
import Circle from 'mylib/dist/cjs/Circle'
// straight from the Universal Module Definition build
import Circle from 'mylib/dist/umd/Circle'
```
### CSS Imports
Component CSS can be imported like this:
```javascript
import 'mylib/dist/css/Circle/styles.css'
```
If you know you will use all of the components and wish to import all of their CSS at once:
```javascript
import 'mylib/dist/css/styles.css'
```
The JS import is simple enough, but you might be wondering, "What's the deal with importing CSS like this? I thought we were on to things like styled-components, emotion, CSS modules, etc?"
These tools are great if the consuming application can bundle up and inject the styles using the same instance of the tool, but can you guarantee each app will use these same styling tools? If so, by all means go that direction. However, if your library is injecting its own styles into the document at runtime, you will not only potentially run into style specificity / collision issues if you don't have the application styles load last, but strict content security policies will potentially disallow the dynamically added styles from even being applied!
The solution? Go with the lowest common denominator: regular, vanilla CSS (or something that outputs regular, vanilla CSS). We'll come back to this in [the example component section](#an-example-component).
## Main Project Tools
It's time to build the project! Here are the main tools we will use:
* [NodeJS](https://nodejs.org/en/) (version `13.13.0`)
* [TypeScript](https://www.typescriptlang.org)
* [React](https://github.com/facebook/react)
* [Storybook (UI examples)](https://github.com/storybookjs/storybook)
* [jest](https://github.com/facebook/jest) (testing)
* [axe-core](https://github.com/dequelabs/axe-core) (testing accessibility)
* linting
* [eslint](https://github.com/eslint/eslint) with [prettier](https://github.com/prettier/prettier)
* [husky](https://www.npmjs.com/package/husky) with [lint-staged](https://www.npmjs.com/package/lint-staged); only on `pre-push`
## Project Structure
```bash
.
├── .storybook (1)
│ └── ...
├── dist (2)
│ └── ...
├── docs (3)
│ └── ...
├── examples (4)
│ └── ...
├── scripts
│ └── buildCSS (5)
├── source (6)
│ └── ...
├── .eslintignore
├── .eslintrc.js
├── .gitignore
├── .prettierrc.js
├── CHANGELOG.md (7)
├── LICENSE (8)
├── README.md
├── husky.config.js
├── jest.config.js
├── lint-staged.config.js
├── package.json
├── testSetup.ts
├── tsconfig.base.json (9)
├── tsconfig.cjs.json
├── tsconfig.esm.json
├── tsconfig.json
└── tsconfig.umd.json
```
1. `.storybook/` – storybook examples configuration
1. `dist/` – compiled project output
1. `docs/` – compiled storybook examples output
1. `examples/` – add `create-react-app`, `gatsby`, and other example projects here
1. `scripts/buildCSS` – store build scripts here like this CSS-related one
1. `source/` – where your project lives; we'll dive into this in the next section
1. `CHANGELOG.md` – be a good teammate and document your library's changes; very useful for your teams and useful if you decide to open source the project
1. `LICENSE` – a good idea if you plan to open source; otherwise, put `UNLICENSED` in your `package.json` license field
1. `tsconfig.json`, et al – typescript build configs; we'll dive into this in [the project setup section](#project-setup)
## Component Structure
```bash
.
└── source
└── ComponentA
├── __snapshots__
│ └── test.tsx.snap
├── index.tsx
├── stories.tsx
├── styles.css
└── test.tsx
└── ComponentB
└── ...
└── ComponentC
└── ...
├── index.ts
└── test.tsx
```
The component and everything to do with it are co-located in the `source/ComponentA/` folder:
* `index.tsx` component file (and any additional component files)
* storybook stories
* CSS
* tests
This grouping of everything having to do with a component makes it very easy to find everything you need. If you would prefer a different setup, you can adjust the tool configurations however you like.
Each component is then exported from the main `index.ts` file.
It's now time to start the project from scratch and make this outline a reality!
## Creating the Project
To begin, let's create the project and a `package.json` file with some project-related information:
```bash
$ mkdir example-component-library && cd $_
$ touch package.json
```
And in `package.json`:
```javascript
{
"name": "@yournpm/example-component-library",
"version": "0.1.0",
"description": "Example repository for a shared React components library",
"main": "dist/cjs/index.js",
"module": "dist/esm/index.js",
"repository": {
"type": "git",
"url": "git@github.com:yourgithub/example-component-library.git"
},
"homepage": "https://github.com/yourgithub/example-component-library",
"bugs": "https://github.com/yourgithub/example-component-library",
"author": "Your Name <you@youremail.com>",
"license": "BSD-3",
"keywords": [],
"tags": [],
"sideEffects": ["dist/**/*.css"],
"files": ["LICENSE", "dist/"],
"scripts": {},
"devDependencies": {},
"peerDependencies": {
"react": "*",
"react-dom": "*"
},
"dependencies": {}
}
```
Once you save that, run your build tool to make sure everything is ok:
```bash
$ npm install
```
Notably, we've set our `main` field to `dist/cjs/index.js`, the CommonJS build, for compatibility with NodeJS environments because they don't yet work well with ESModules. We've set our `module` field to look at `dist/esm/index.js`, the ESModule build. If you want to make use of the Universal Module Definition build we'll create later on, you can use the `browser` field: `"browser": "dist/umd/index.js"`. Personally, if I build with webpack, I want webpack to select the `module` field over the `browser` one because it will always be of a smaller size, for the UMD builds are meant to be run in any of a few different environments.
Also of importance is the `sideEffects` field. If our library code was pure and didn't have side effects, we would set the value to `false`, and build tools like webpack would prune away all of the unused code. However, since we also are exporting CSS, we need to make sure that it doesn't get dropped by the build tool, so we do that with `"sideEffects": ["dist/**/*.css"]`.
Lastly, we know we're going to be using React, so we can go ahead and set that as a `peerDependency` (it's up to you to decide what versions of React you'll support).
## TypeScript Setup
We can now add TypeScript to our project with some compiler and project-related options. We'll also add some type definition libraries that we'll use later, as well as a dependency on [`tslib`](https://www.npmjs.com/package/tslib) to make compiling our code to ES5 seamless.
```bash
$ npm install --save-dev --save-exact \
@types/node \
@types/react \
@types/react-dom \
typescript
$ npm install --save --save-exact tslib
$ touch tsconfig.base.json tsconfig.json
```
We will place our `compilerOptions` in `tsconfig.base.json` so that they can be extended in all our different builds in the future:
```javascript
{
"compilerOptions": {
"allowJs": false,
"allowSyntheticDefaultImports": true,
"declaration": true,
"esModuleInterop": true,
"importHelpers": true,
"jsx": "react",
"lib": ["es2020", "dom"],
"moduleResolution": "node",
"noImplicitAny": true,
"outDir": "dist/",
"sourceMap": false,
"strict": true,
"target": "es5"
}
}
```
Note that the `importHelpers` flag tells `tslib` whether it should be enabled or not.
The `tsconfig.json` will be used as a default to include our future `source` directory:
```javascript
{
"extends": "./tsconfig.base.json",
"include": ["source/**/*"]
}
```
We'll add some more TypeScript-related packages when we get to the tools that need them, and we'll add more TypeScript build configurations in the section on [building our typescript](#building-our-typescript).
## Linting Setup
Linting is a great way to have everyone adhere to the same set of rules for code style. For our project, we're going to install a few tools to help us out.
```bash
$ npm install --save-dev --save-exact \
@typescript-eslint/eslint-plugin \
@typescript-eslint/parser \
eslint \
eslint-config-prettier \
eslint-plugin-jest \
eslint-plugin-jsx-a11y \
eslint-plugin-prettier \
eslint-plugin-react \
eslint-plugin-react-hooks \
husky \
lint-staged \
prettier
$ touch \
.eslintignore \
.eslintrc.js \
.prettierrc.js \
husky.config.js \
lint-staged.config.js
```
The `.eslintignore` file will make sure we include files and folders that are ignored by default (using the `!`) and exclude files and folders that we don't care about linting.
```bash
!.eslintrc.js
!.prettierrc.js
!.storybook/
dist/
docs/
examples/
```
The `.eslintrc.js` file is something you and your team will need to figure out for yourselves, but here's where I stand on the issues:
```javascript
module.exports = {
env: {
browser: true,
es6: true,
jest: true,
node: true,
},
extends: [
'plugin:react/recommended',
'plugin:@typescript-eslint/recommended',
'prettier/@typescript-eslint',
'plugin:prettier/recommended',
'plugin:jsx-a11y/recommended',
],
parserOptions: {
ecmaVersion: 2020,
sourceType: 'module',
},
parser: '@typescript-eslint/parser',
plugins: ['jsx-a11y', 'react', 'react-hooks', '@typescript-eslint'],
rules: {
'@typescript-eslint/no-unused-vars': 'error',
'jsx-quotes': ['error', 'prefer-double'],
'jsx-a11y/no-onchange': 'off', // https://github.com/evcohen/eslint-plugin-jsx-a11y/issues/398
'no-trailing-spaces': 'error',
'object-curly-spacing': ['error', 'always'],
quotes: ['error', 'single', { allowTemplateLiterals: true }],
'react-hooks/exhaustive-deps': 'error',
'react-hooks/rules-of-hooks': 'error',
'react/prop-types': 'off',
semi: ['error', 'never'],
},
settings: {
react: {
version: 'detect',
},
},
overrides: [
{
files: ['*.js', '*.jsx'],
rules: {
'@typescript-eslint/explicit-function-return-type': 'off',
'@typescript-eslint/no-var-requires': 'off',
},
},
],
}
```
The `.prettierrc.js` file defines your [prettier](https://github.com/prettier/prettier) configuration:
```javascript
module.exports = {
semi: false,
singleQuote: true,
}
```
We're almost done with the linting! There are two files left.
For our `husky.config.js` file, we'll set it up to run `lint-staged` before we push our code to our repository:
```javascript
module.exports = {
hooks: {
'pre-push': 'lint-staged',
},
}
```
And for `lint-staged.config.js`, we'll specify that we want to run `eslint --fix` on our staged files:
```javascript
module.exports = {
'*': ['eslint --fix'],
}
```
Now that we've got this all in place, we can update our `package.json`'s `script` object to include a `lint` command:
```javascript
"scripts": {
"lint": "eslint ."
},
```
You can test this by running:
```bash
$ npm run lint
```
## Testing Setup
We're going to use Jest and [`@testing-library/react`](https://testing-library.com/react) to handle running our tests and testing our component code, so let's install those tools and their companion TypeScript libraries. We'll also install axe-core to handle some automated accessibility testing.
```bash
$ npm install --save-dev --save-exact \
@testing-library/jest-dom \
@testing-library/react \
@types/jest \
axe-core \
jest \
ts-jest
$ touch jest.config.js testSetup.ts
```
Our `jest.config.js` collects coverage from the right places, ignores distribution and example directories, requires the `testSetup.ts` file, and sets us up to use TypeScript in our tests.
```javascript
module.exports = {
clearMocks: true,
collectCoverage: true,
collectCoverageFrom: ['<rootDir>/source/**/*.{ts,tsx}'],
coveragePathIgnorePatterns: [
'/node_modules/',
'<rootDir>/source/@types',
'stories',
],
moduleNameMapper: {},
preset: 'ts-jest',
setupFilesAfterEnv: ['<rootDir>/testSetup.ts'],
testPathIgnorePatterns: ['dist/', 'examples/'],
verbose: true,
}
```
And here is our `testSetup.ts` file that you can use to provide global testing tools, patch JSDOM, and more:
```javascript
import '@testing-library/jest-dom/extend-expect'
```
All we do in `testSetup.ts` is add a lot of custom matchers to the `expect` function from jest via [`@testing-library/jest-dom`](https://github.com/testing-library/jest-dom).
While we're on the testing subject, we should also update our `package.json`'s `scripts` object to include a `test` command:
```javascript
"scripts": {
// ...
"test": "jest"
},
```
We don't have any test files yet, but you can confirm everything is set up correctly by running
```bash
$ npm run test
```
## Storybook Setup
Storybook is a great way to not only share examples of your components but also get instant feedback while developing them, as well. It also comes with [a great set of official addons](https://storybook.js.org/addons/).
Let's install Storybook for React with TypeScript, and let's also add the addons for accessibility and knobs:
```bash
$ npm install --save-dev --save-exact \
@storybook/addon-a11y \
@storybook/addon-knobs \
@storybook/preset-typescript \
@storybook/react \
babel-loader \
ts-loader
$ mkdir .storybook
$ touch .storybook/main.js
```
The `.storybook/main.js` file is where we can specify our Storybook options:
```javascript
module.exports = {
addons: [
'@storybook/addon-a11y',
'@storybook/addon-knobs',
'@storybook/preset-typescript',
],
stories: ['../source/**/*/stories.tsx'],
}
```
## An Example Component
For our example component, we are going to make a circle with SVG. With only this simple component, we will cover the following aspects of component development:
* TypeScript interfaces for required and optional React props
* Component CSS
* Testing (regular, snapshot, and accessibility)
* Storybook examples
Let's create the files we know we're going to need:
```bash
$ mkdir source/Circle
$ touch source/Circle/index.tsx \
source/Circle/stories.tsx \
source/Circle/styles.css \
source/Circle/test.tsx
```
### Component File
```typescript
import React, { FC } from 'react'
// className, desc, and fill are optional,
// whereas title and size are required
interface Props {
className?: string
desc?: string
fill?: string
size: number
title: string
}
// we provide our Props interface to the
// function component type
const Circle: FC<Props> = ({
className = 'rl-circle',
desc,
fill,
size,
title,
}) => (
<svg
className={className}
height={size}
fill={fill}
role="img"
viewBox="0 0 100 100"
width={size}
xmlns="http://www.w3.org/2000/svg"
>
<title>{title}</title>
{desc && <desc>{desc}</desc>}
<circle cx="50" cy="50" r="50" />
</svg>
)
export default Circle
```
In this component file, we define the parameters that we're willing to work with, provide a fallback in the case of `className`, and make a regular old component.
This file should be pretty straightforward, so let's move on to the CSS!
### Component CSS
This is a real easy one.
```css
.rl-circle { margin: 1em; }
```
The `rl` is short for "react library", and I made it up. The CSS that we are creating needs to be made unique, and prefixing your classes is the simplest way of doing that.
### Component Tests
It's time to write some tests! We're going to make explicit expectations and do some snapshot tests so that everybody is happy.
```typescript
import React from 'react'
import { render } from '@testing-library/react'
import Circle from './index'
test('with all props', () => {
const { asFragment, container, getByText } = render(
<Circle
className="class-override"
desc="A blue circle"
fill="#30336b"
size={200}
title="Water planet"
/>
)
const svgEl = container.querySelector('svg')
const titleEl = getByText('Water planet')
const descEl = getByText('A blue circle')
expect(svgEl).toHaveAttribute('height', '200')
expect(svgEl).toHaveAttribute('width', '200')
expect(titleEl).toBeInTheDocument()
expect(descEl).toBeInTheDocument()
expect(asFragment()).toMatchSnapshot()
})
test('with only title & size', () => {
const { asFragment, container, getByText } = render(
<Circle title="Water planet" size={200} />
)
const svgEl = container.querySelector('svg')
const titleEl = getByText('Water planet')
const descEl = container.querySelector('desc')
expect(svgEl).toHaveAttribute('height', '200')
expect(svgEl).toHaveAttribute('width', '200')
expect(titleEl).toBeInTheDocument()
expect(descEl).not.toBeInTheDocument()
expect(asFragment()).toMatchSnapshot()
})
```
These first tests provide different sets of props and test various aspects of our component based on given props' inclusion.
Next, we can use the `axe-core` tool to try our hand at accessibility testing:
```typescript
import axe from 'axe-core'
// ...
test('is accessible with title, desc, size', (done) => {
const { container } = render(
<Circle desc="A blue circle" size={200} title="Water planet" />
)
axe.run(container, {}, (err, result) => {
expect(err).toEqual(null)
expect(result.violations.length).toEqual(0)
done()
})
})
test('is inaccessible without title', (done) => {
const { container } = render(
<Circle desc="A blue circle" title="Water circle" size={200} />
)
// do something very wrong to prove a11y testing works
container.querySelector('title')?.remove()
axe.run(container, {}, (err, result) => {
expect(err).toEqual(null)
expect(result.violations[0].id).toEqual('svg-img-alt')
done()
})
})
```
While the first test should be clear, the second test almost seems pointless (hint: it is). I am including it here to demonstrate what a failing accessibility scenario might look like. In reality, the first test in this group pointed out the error in the second test, for I was originally _not_ requiring `title`, but I was giving the SVG `role="img"`. This is a no-no if there is no `aria-label`, `aria-labelledby`, nor `<title>` to supply the SVG with any textual meaning.
Testing is easy if you keep things simple, and automated accessibility testing is even easier than that, for all you need to do is provide DOM elements.
### Component Stories
I find it very difficult to do test driven development when developing components, for it is an exploratory, creative experience for me. Instant feedback makes it easy to run through all my bad ideas (there are many!) and eventually land on some good ones. Storybook stories can help us do that, so let's make our first story in `source/Circle/stories.tsx`.
```typescript
import React from 'react'
import { storiesOf } from '@storybook/react'
import { withA11y } from '@storybook/addon-a11y'
import { color, number, text, withKnobs } from '@storybook/addon-knobs'
// import our component and styles from
// the distribution (build) output
import { Circle } from '../../dist/esm'
import '../../dist/css/Circle/styles.css'
// group our stories under "Circle"
const stories = storiesOf('Circle', module)
// enable the accessibility & knobs addons
stories.addDecorator(withA11y)
stories.addDecorator(withKnobs)
// add a new story and use the
// knobs tools to provide named
// defaults that you can alter
// in the Storybook interface
stories.add('default', () => (
<Circle
desc={text('desc', 'A blue circle')}
fill={color('fill', '#7ed6df')}
size={number('size', 200)}
title={text('title', 'Abstract water planet')}
/>
))
stories.add('another scenario...', () => (
<Circle {/* other example props here */} />
))
```
Each component gets its own `stories.tsx` file, so there's no need to worry about them getting out of hand with all the different components in your library. Add as many different stories for your components as you like! Our Storybook config will collect them all for you into a single place.
## Building Our TypeScript
We've already created a `tsconfig.base.json` and `tsconfig.json` file, and now it's time to add ones for CommonJS (CJS), ESModules (ESM), and Universal Module Definitions (UMD). We will then add some NPM scripts to build out TypeScript for us.
```bash
$ touch tsconfig.cjs.json tsconfig.esm.json tsconfig.umd.json
```
```javascript
// tsconfig.cjs.json
{
"extends": "./tsconfig.base.json",
"compilerOptions": {
"module": "commonjs",
"outDir": "dist/cjs/"
},
"include": ["source/index.ts"]
}
```
```javascript
// tsconfig.esm.json
{
"extends": "./tsconfig.base.json",
"compilerOptions": {
"module": "esNext",
"outDir": "dist/esm/"
},
"include": ["source/index.ts"]
}
```
```javascript
// tsconfig.umd.json
{
"extends": "./tsconfig.base.json",
"compilerOptions": {
"module": "umd",
"outDir": "dist/umd/"
},
"include": ["source/index.ts"]
}
```
Each of these specify where to find the source, what type of module to output, and where to put the resulting compiled code. If you want your code to be compiled to the output, make sure it is either included in the `include` field or is `require`d by something that is.
In our `package.json`, let's add some scripts that make use of these configs:
```javascript
"scripts": {
"build:js:cjs": "tsc -p tsconfig.cjs.json",
"build:js:esm": "tsc -p tsconfig.esm.json",
"build:js:umd": "tsc -p tsconfig.umd.json",
// ...
},
```
Easy! If you are guessing that we might want to run these all together in a `build:js` command, there are two ways to do that (one verbose and one less so).
Our first attempt:
```javascript
"scripts": {
"build:js": "npm run build:js:cjs && npm run build:js:esm && npm run build:js:umd",
// ...
},
```
Not bad, but we can use the [`npm-run-all`](https://www.npmjs.com/package/npm-run-all) tool to not only write a more succinct script but also run these in parallel!
```bash
$ npm install --save-dev --save-exact npm-run-all
```
```javascript
"scripts": {
"build:js": "run-p build:js:cjs build:js:esm build:js:umd",
// ...
},
```
The `npm-run-all` tool gives us `run-p` for running scripts in parallel and `run-s` for running them synchronously.
Watching for changes is also very simple:
```javascript
"scripts": {
// ...
"build:js:esm:watch": "tsc -p tsconfig.esm.json -w",
// ...
},
```
While we're here, let's go ahead and add a `clean`ing script for our `dist/` directory:
```javascript
"scripts": {
// ...
"clean": "clean:dist", // we'll add more here shortly
"clean:dist": "rm -rf dist",
// ...
},
```
Now that we can do some `clean`ing and `build`ing, let's create a single `build` script that we can continue adding build steps to as we go:
```javascript
"scripts": {
"build": "run-s clean build:js", // we'll add more here shortly
// ...
}
```
Give it all whirl, if you like:
```bash
$ npm run build
```
You should see the following tree structure for your `dist/` folder:
```bash
.
└── dist
└── cjs
└── Circle
├── index.d.js
└── index.js
├── index.d.js
└── index.js
└── esm
└── Circle
├── index.d.js
└── index.js
├── index.d.js
└── index.js
└── umd
└── Circle
├── index.d.js
└── index.js
├── index.d.js
└── index.js
```
We're getting places! We have JS, and now we need our CSS.
## Building Our CSS
For our styles, we have two goals:
1. output each component's styles in a component CSS folder like `dist/css/Circle/styles.css`
1. output a combination of each component's styles in a single file in `dist/css/styles.css`
To achieve this, we're going to write a short bash script, and we're going to place it in `scripts/buildCSS`.
```bash
$ mkdir scripts
$ touch scripts/buildCSS
$ chmod +x scripts/buildCSS
```
And in `scripts/buildCSS`:
```bash
#!/bin/bash
set -euo pipefail
function copy_css {
local dir=$(dirname $0)
local component=$(basename $dir)
local dist_css=$PWD/dist/css
# concatenate component CSS to main CSS file
mkdir -p $dist_css
cat $0 >> $dist_css/styles.css
# copy component CSS to component folder
mkdir -p $dist_css/$component/
cp $0 $dist_css/$component/
}
export -f copy_css
function build {
find $PWD/source \
-name '*.css' \
-exec /bin/bash -c 'copy_css $0' {} \;
}
build
```
We lean on some `coreutils` here to solve our problems for us. The last line of our script, `build`, calls the function of the same name that looks inside the `source` directory for all CSS files and tells the `bash` program to run `copy_css` with the path to the CSS file. There's a catch, though: `bash` is going to run in a subshell, so we need to make sure our `copy_css` function is exported and available by `export -f copy_css`.
For the `copy_css` function, it's much simpler than it looks! Here are the
steps:
1. `mkdir -p $dist_css` creates our output directory, `dist/css`.
1. `cat $0 >> $dist_css/styles.css` concatenates all the lines of our source CSS file and appends them to `dist/css/styles.css`.
1. `mkdir -p $dist_css/$component/` creates a component CSS folder like `dist/css/Circle/`. We derive the `$component` variable by getting the `basename` of the `dirname` of our full CSS file path. For example, `/Users/myuser/projects/example-component-library/source/Circle/styles.css` has a `dirname` of `/Users/rpearce/projects/example-component-library/source/Circle`, and that has a `basename` of `Circle`! Using that deduction, we can derive what component we're working with and create that output directory simply by finding a CSS file.
1. `cp $0 $dist_css/$component/` copies the source component CSS file to the output component directory; that's it!
If you have a different CSS setup, you'll need to adjust this build script accordingly.
Now that we have our `buildCSS` script, we can add an NPM `script` to handle building this for us and add that to our `build` script:
```javascript
"scripts": {
"build": "run-s clean build:js build:css",
"build:css": "./scripts/buildCSS",
// ...
},
```
Similarly to our `build:js:esm:watch` command, how might we watch for CSS changes and run our script in a `build:css:watch` command? Luckily, there's a tool that can help us with that: [`chokidar`](https://www.npmjs.com/package/chokidar).
```bash
$ npm install --save-dev --save-exact chokidar
```
```javascript
"scripts": {
// ...
"build:css:watch": "chokidar \"source/**/*.css\" -c \"./scripts/buildCSS\"",
// ...
},
```
## Building Our Stories
To develop our components and get instant feedback in our Storybook examples, we're going to need to run a few things at once to get it all to work together.
First, let's add a line to our `package.json`'s `scripts` object called
`storybook`:
```javascript
"scripts": {
// ...
"storybook": "start-storybook -p 6006"
},
```
Next, let's add a `start` command that, in this sequence,
1. cleans the `dist/` directory
1. builds only the ESModule JS output
1. builds the CSS
and then, in parallel,
1. watches the JS for changes and rebuilds the ESModule output
1. watches the CSS for changes and rebuilds the CSS
1. runs storybook, which watches for changes to the prior two items, for it will detect changes to its `import`s from the `dist/` folder
```javascript
"scripts": {
// ...
"start": "run-s clean:dist build:js:esm build:css && run-p build:js:esm:watch build:css:watch storybook",
// ...
},
```
If you want to break those up into different scripts to make it more legible, here's a way to do that:
```javascript
"scripts": {
// ...
"start": "run-s start:init start:run",
"start:init": "run-s clean:dist build:js:esm build:css",
"start:run": "run-p build:js:esm:watch build:css:watch storybook",
// ...
},
```
You can then run this from the command line, and it should automatically open your web browser and take you to http://localhost:6006.
```bash
$ npm run start
```
Your Storybook library should have your component, and you can adjust the component knobs in one of the sidebars, and you can also see the accessibility audit located in the tab next to the knobs. _Note: no amount of automated testing can guarantee accessibility, but it can help you catch silly mistakes._
With all these pieces in place, you can now develop your components and get instante feedback in the browser using the same code that you would provide to a consumer of your package!
Did you know that you can also build static HTML, CSS, and JavaScript files and serve that up through something like GitHub Pages? We can update our `package.json` `scripts` to include scripts for building our Storybook output to the `docs/` folder and for cleaning the `docs/` folder, as well.
```javascript
"scripts": {
// ...
"build:docs": "build-storybook -o docs",
"clean:docs": "rm -rf docs"
"storybook": "start-storybook -p 6006"
},
```
The `clean:docs` script, if ran first, will guarantee that we have fresh output in our `docs/` folder. Let's give it a go:
```bash
$ npm run clean:docs && npm run build:docs
```
Since we can now clean and build our Storybook folder, we can update our `build` and `clean` scripts accordingly:
```javascript
"scripts": {
"build": "run-s clean build:js build:css build:docs",
// ...
"clean": "run-p clean:dist clean:docs",
// ...
},
```
## Continuous Integration Notes
When you set up a continuous integration (CI) tool for this project, it will be tempting to tell it to simply run `$ npm run build`; however, this will not include your linting and testing scripts, and you could potentially have a green light from CI when really you have problems!
While you could always run your linting and testing scripts inside of `build` ( this can get tedious) or multiple scripts from your CI configuration, let's instead add another script named `ci` to handle this for us:
```javascript
"scripts": {
// ...
"ci": "run-p lint build test",
// ...
},
```
No worries! Now we can use `$ npm run ci` in our CI configuration.
## Publishing Notes
I recommend adding a `prepublishOnly` script that ensures your linter and tests pass before trying to build your component output:
```javascript
"scripts": {
// ...
"prepublishOnly": "run-p lint test && run-p build:js build:css",
// ...
},
```
Also, if you want this to be a private repository, make sure you add `"private": true` to your `package.json` before publishing.
## Wrapping Up
Thank you for reading this, and I hope this helps you create an awesome, accessible component library.
<br />
Robert
| rpearce |
320,917 | What's new in OAuth 2.1? | A draft of the OAuth 2.1 specification was recently released. What's coming down the pike? | 0 | 2020-04-27T18:48:24 | https://dev.to/fusionauth/what-s-new-in-oauth-2-1-154d | oauth, security, sso, standards | ---
title: What's new in OAuth 2.1?
published: true
description: A draft of the OAuth 2.1 specification was recently released. What's coming down the pike?
tags: oauth,security,sso,standards
---
Hey look! OAuth is getting spiffed up a bit. The original OAuth 2.0 specification was released in October 2012 as [RFC 6749](https://tools.ietf.org/html/rfc6749). It replaced OAuth 1.0, released in April 2010. There have been some extensions over the years. A new OAuth specification has been proposed and is currently under discussion. As of this blog post's writing, the specification was most recently updated on March 8, 2020. If approved, [OAuth 2.1](https://tools.ietf.org/html/draft-parecki-oauth-v2-1-01) will obsolete certain parts of Oauth 2.0 and mandate additional security best practices. The rest of the OAuth 2.0 specification will be retained.
This post assumes you are a developer or have similar technical experience. It also assumes you are familiar with OAuth and the terms used in the various RFCs. If you’d like an introduction to OAuth and why you’d consider using it, [Wikipedia is a good place to start](https://en.wikipedia.org/wiki/OAuth). This post discusses proposed changes to OAuth that might affect you if you are using OAuth in your application or if you implement the OAuth specification.
## Why OAuth 2.1?
It's been a long time since OAuth 2.0 was released. A consolidation point release was in order. As outlined in a [blog post](https://aaronparecki.com/2019/12/12/21/its-time-for-oauth-2-dot-1) by Aaron Parecki, one of the authors of the OAuth 2.1 draft specification:
> My main goal with OAuth 2.1 is to capture the current best practices in OAuth 2.0 as well as its well-established extensions under a single name. That also means specifically that this effort will not define any new behavior itself, it is just to capture behavior defined in other specs. It also won’t include anything considered experimental or still in progress.
So, this is not a scrape and rebuild of OAuth 2.0. Instead, OAuth 2.1 consolidates the changes and tweaks to OAuth 2.0 that have been made over the past eight years, with a focus on better default security. It establishes the best practices and will serve as a reference document. Here's a suggested description pulled from the [ongoing mailing list discussion](https://mailarchive.ietf.org/arch/msg/oauth/Ne4Q9erPP7SpC5051sSy6XnLDv0/): "By design, [OAuth 2.1] does not introduce any new features to what already exists in the OAuth 2.0 specifications being replaced." Many of the new draft specification details are drawn from the [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14) document. However, in the name of security best practices, some of the more problematic grants will be removed.
At the end of the day, the goal is to have a single document detailing how to best implement and use OAuth, as both a client and an implementor. No longer will developers have to hunt across multiple RFCs and standards documents to understand how a specified behavior should be implemented or used.
## I use OAuth in my application, what does OAuth 2.1 mean to me?
Don’t panic.
As mentioned above, the discussion process around this specification is ongoing. A draft RFC was posted to the IETF mailing list in mid-March. As of the time of writing, the revision and discussion are still actively occurring.
You may ask, when will it be available? The short answer is "no one knows".
The long answer is "truly, no one knows. It does seem like we’re early in the process, though."
Even after OAuth 2.1 is released, it will likely be some time before it is widely implemented. Omitted grants may be supported with warnings forever. The exact changes to the specification are still up in the air, the release of the RFC is even further in the future and when it is released, you can continue to use an OAuth 2.0 server if that serves your needs.
That said, when this is released the biggest impact on people who use OAuth for authentication or authorization in their applications will be planning on how to handle the removed grants: the Implicit grant or Resource Owner Password Credentials grant.
## What is changing?
The draft RFC has a [section](https://tools.ietf.org/html/draft-parecki-oauth-v2-1-01#section-12) outlining the major changes between OAuth 2.0 and OAuth 2.1. There may be other changes not captured there but the goal is to document all formal changes there. There are six such changes:
> The authorization code grant is extended with the functionality from PKCE ([RFC7636](https://tools.ietf.org/html/rfc7636)) such that the only method of using the authorization code grant according to this specification requires the addition of the PKCE mechanism
> Redirect URIs must be compared using exact string matching as per Section 4.1.3 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
> The Implicit grant ("response_type=token") is omitted from this specification as per Section 2.1.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
> The Resource Owner Password Credentials grant is omitted from this specification as per Section 2.4 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
> Bearer token usage omits the use of bearer tokens in the query string of URIs as per Section 4.3.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
> Refresh tokens must either be sender-constrained or one-time use as per Section 4.12.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
Whew, that's a lot of jargon. We'll examine each of these in turn. But before we do, let’s define a few terms that will be used in the rest of this post.
* A `client` is a piece of code that the user is interacting with; browsers, native apps or single-page applications are all clients.
* An `OAuth server` implements OAuth specifications and has or can obtain information about which resources are available to clients--in the RFCs this is called an Authorization Server, but this is also known as an Identity Provider. Most users call it "the place I log in".
* An `application server` doesn’t have any authentication functionality but knows how to delegate to an OAuth server. It has a client id which allows the OAuth server to identify it.
### The Authorization Code grant and PKCE
> The authorization code grant is extended with the functionality from PKCE ([RFC7636](https://tools.ietf.org/html/rfc7636)) such that the only method of using the authorization code grant according to this specification requires the addition of the PKCE mechanism
Wow, that's a mouthful. Let’s break that down. The Authorization Code grant is one of the most common OAuth grants and is the most secure. If flow charts are your jam, here’s [a post explaining the Authorization Code grant](https://fusionauth.io/learn/expert-advice/authentication/webapp/oauth-authorization-code-grant-sessions).
The [Proof Key for Code Exchange (PKCE) RFC](https://tools.ietf.org/html/rfc7636) was published in 2015 and extends the Authorization Code grant to protect from an attack if part of the authorization flow happens over a non TLS connection. For example, between components of a native application. This attack could also happen if TLS has a vulnerability or if router firmware has been compromised and is spoofing DNS or downgrading from TLS to HTTP. PKCE requires an additional one-time code to be sent to the OAuth server. This is used to validate the request has not been intercepted or modified.
The OAuth 2.1 draft specification requires that the PKCE challenge must be used with every Authorization Code grant, protecting against the authorization code being hijacked by an attacker.
### Redirect URIs must be compared using exact string matching
> Redirect URIs must be compared using exact string matching as per Section 4.1.3 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
Some OAuth grants, notably the Authorization Code grant, use a redirect URI to determine where to send the client after success. For example, here’s a FusionAuth screen where the allowed redirect URIs are configured (it is the "Authorized redirect URLs" setting):
In this case, the only allowed value is `http://localhost:3000/oauth-callback` but you can configure multiple values. The client specifies which one of these the user who is signing in should be redirected to.
Now, it would sure be convenient to support wildcards in this redirect URI list. At FusionAuth, we hear this request from folks who want to simplify their development or CI environments. Every time a new server is spun up, the redirect URI configuration must be updated to include the new URI.
For example, if a CI system builds an application for every feature branch, it might have the hostname `dans-sample-application-1551.herokuapp.com`, if the feature branch was a fix for bug #1551. If I wanted to login using the Authorization Code grant, I’d have to update the redirect URI settings for my OAuth server to include that specific redirect URI: `https://dans-sample-application-1551.herokuapp.com/oauth-callback`.
And then when the next feature branch build happened, say for bug #1552, I’d have to add `https://dans-sample-application-1552.herokuapp.com/oauth-callback` and so on. Obviously, it’d be easier to set the redirect URI to a wildcard value like `https://dans-sample-application-*.herokuapp.com/oauth-callback`; in an ideal world, any URL matching that pattern would be acceptable to the OAuth server. Of course, if you are using FusionAuth, you can [update your application configuration as part of the CI build process](https://fusionauth.io/docs/v1/tech/apis/applications#update-an-application) as an alternative.
An additional use case for a wild card redirect URI is when the redirect URI needs dynamic parameters useful to the final destination page, like `trackingparam=123&specialoffer=abc`. These may be appended to the redirect URL before the OAuth process began. A URL with dynamic parameters won't match any of the configured redirect URIs, and so the redirect fails.
However, allowing such wildcard matching for the redirect URI is a security risk. If the redirect URI matching is flexible, an attacker could redirect a user to an open redirect server controlled by them, and then on to a malicious destination; OWASP further discusses the [perils of such open redirect servers](https://cheatsheetseries.owasp.org/cheatsheets/Unvalidated_Redirects_and_Forwards_Cheat_Sheet.html#dangerous-url-redirects). While this would require compromising the request in some fashion, using exact matching for redirect URIs eliminates this risk because the redirect URI is always a known value.
### The Implicit grant is removed
> The Implicit grant ("response_type=token") is omitted from this specification as per Section 2.1.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
The Implicit grant is inherently insecure when used in a single-page application (SPA). If you use this grant, your access token is exposed. You’ll get an access token that is either in the URL fragment, and accessible to any JavaScript running on the page, or is stored in localstorage and is accessible to any JavaScript running on the page, or is in a non HttpOnly cookie, and accessible to any JavaScript running on the page. (Is there an echo in here?) In all cases, an attacker gaining an access token is allowed to, well, access resources as your end user. Bad.
Access tokens are not necessarily one-time use, and can live from minutes to days depending on your configuration. So if they are stolen, the resources they protect are no longer secure. You may think "well, I don’t have any malicious JavaScript on my site." Have you audited all your code, and its dependencies, and their dependencies, and their dependencies? (There’s that echo again.) Do you audit all your code automatically? Extensive dependency trees can lead to unforeseen security issues: someone took over an [open source node library](https://snyk.io/blog/malicious-code-found-in-npm-package-event-stream/) and added malicious code that was downloaded millions of times.
Here’s an [article about the least insecure way to use the Implicit grant for an SPA](https://fusionauth.io/learn/expert-advice/authentication/spa/oauth-implicit-grant-jwts-cookies). This redirects to the SPA after setting an HttpOnly cookie. In the end it basically recreates the Authorization Code grant, illustrating how the Implicit grant can't be made secure.
The OAuth 2.1 draft specification omits the Implicit grant. The "OAuth 2.0 Security Best Current Practices" document, however, stops short of prohibiting the Implicit grant, stating instead:
> In order to avoid these issues, clients SHOULD NOT use the implicit grant (response type "token") … unless the unless access token injection in the authorization response is prevented and the aforementioned token leakage vectors are [mitigated]
From my perspective, this means that the omission of this grant in the final RFC is still not a done deal. However, if the final version of the OAuth 2.1 spec omits the Implicit grant, a compliant OAuth 2.1 server will not support it. If you use this grant in your application, you’ll have to replace it with a different one if you want to be compliant with OAuth 2.1. May we suggest the Authorization Code grant?
### The Resource Owner Password Credentials grant is removed
> The Resource Owner Password Credentials grant is omitted from this specification as per Section 2.4 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
This grant was added to the OAuth 2.0 specification with an eye toward making migration to OAuth compliant servers easier. In this grant, the application server receives the username and password (or other credentials) and passes it on to the OAuth server. Here’s [an article breaking down each step of the Resource Owner Password Credentials grant](https://fusionauth.io/learn/expert-advice/authentication/webapp/oauth-resource-owner-password-credentials-grant-jwts-refresh-tokens-cookies). This grant is often used for mobile applications. While this grant made it easier to migrate OAuth with minimal application changes, it breaks the core delegation pattern and makes the OAuth flow less secure. No longer can you leave the work of securing your user’s credentials and data up to the OAuth server so you can focus on building your own app. Now you must ensure that your application backend is just as secure, since it will also be sent the username and passwords.
Unlike the Implicit grant, the "OAuth 2.0 Security Best Current Practices" document requires that this grant no longer be allowed:
> The resource owner password credentials grant MUST NOT be used.
So it’s a good bet that this grant is going to be omitted in the final RFC. If you have a mobile application using this grant, you can either update the client to use an Authorization Code grant using PKCE or keep using your OAuth 2.0 compliant system.
### No bearer tokens in the query string
> Bearer token usage omits the use of bearer tokens in the query string of URIs as per Section 4.3.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
Bearer tokens, also known as access tokens, allow access to protected resources and therefore must be secured. These days, most tokens are JWTs. Clients store them securely and then use them to make API calls back to the application server. The Application server then uses the token to identify the user calling the API. When first defined in [RFC 6750](https://tools.ietf.org/html/rfc6750), such tokens were allowed in headers, POST bodies or query strings. The draft OAuth 2.1 spec prohibits the bearer token from being sent in a query string. This is a particular issue with the Implicit grant (which is omitted from the OAuth 2.1 specification).
A query string and, more generally, any data in the URL, is never private. JavaScript executing on a page can access it. A URL or components thereof may be captured in server log files, caches, or browser history. In general, if you want to pass information privately over the internet, use TLS and put the sensitive information in a POST body or HTTP header.
### Limiting refresh tokens
> Refresh tokens must either be sender-constrained or one-time use as per Section 4.12.2 of [OAuth 2.0 Security Best Current Practices](https://tools.ietf.org/html/draft-ietf-oauth-security-topics-14)
[Refresh tokens](https://tools.ietf.org/html/rfc6749#section-6) allow a client to retrieve new access tokens without reauthentication. This is helpful if you need access to a resource for longer than an access token live, or if you need infrequent access (such as being logged into your email for months or years). As such, they are typically longer lived than access tokens. Therefore you should take twice as much care when it comes to securing a refresh token.
If they are acquired by an attacker, the attacker can create access tokens at will. Obviously at that point, the resource which the access tokens protect will no longer be secure. As an example of how to secure refresh tokens, here’s a [post using the Authorization Code grant](https://fusionauth.io/learn/expert-advice/authentication/spa/oauth-authorization-code-grant-jwts-refresh-tokens-cookies) which stores refresh tokens securely using HttpOnly cookies and a limited cookie domain. Incidentally, never share your refresh tokens between different devices.
The OAuth 2.1 draft specification provides two options for refresh tokens: they can be one-time use or tied to the sender with a cryptographic binding.
One time use means that after a refresh token (call it refresh token A) is used to retrieve an access token, it becomes invalid. Of course, the OAuth server can send a new refresh token (call it refresh token B) along with the requested access token. In this case, once the newly delivered access token expires, the client can request another access token using refresh token B, receive the new access token and a new refresh token C, and so on and so on. The change to one-time use refresh tokens may require changing client code to store the new refresh token on every refresh.
The other recommended option is to ensure the OAuth server cryptographically binds the refresh token to the client. The options mentioned in the "OAuth 2.0 Security Best Current Practices" document are [OAuth token binding](https://www.ietf.org/archive/id/draft-ietf-oauth-token-binding-08.txt) or Mutual TLS authentication [RFC 8705](https://tools.ietf.org/html/rfc8705). This binding ensures the request came from the client to which the refresh token was issued.
To sum up, the OAuth 2.1 spec requires an OAuth server protect refresh tokens by requiring them to either be one-time use or by using cryptographic proof of client association.
## What’s unchanged?
These are the major changes in the proposed OAuth 2.1 RFC. The OAuth 2.1 spec is built on the foundation of the OAuth 2.0 spec and inherits all behavior not explicitly omitted or changed. For example, the Client Credentials grant, often used for server to server authentication, continues to be available.
## Can you use OAuth 2.1 right now?
Well no. As of right now, there’s nothing stamped "OAuth 2.1". And the draft spec isn’t finalized. But if you follow best practices around security, you can reap the benefits of this consolidated draft, and prepare your applications for when it is released. FusionAuth has an eye toward the future and already has support for many of these changes.
When writing a client application, avoid the Implicit grant and the Resource Owner Password Credentials grant. However, as these are part of the OAuth 2.0 specification, they are currently supported by FusionAuth.
Make sure your OAuth server is doing to following:
* Using PKCE whenever you use the Authorization Code grant. ([FusionAuth highly recommends using PKCE.](https://fusionauth.io/docs/v1/tech/oauth/#example-authorization-code-grant))
* Make sure that your redirect URIs are compared using exact string matches, not wildcard or substring matching. (FusionAuth has you covered: ["URLs that are not authorized [configured in the application] may not be utilized in the redirect_uri"](https://fusionauth.io/docs/v1/tech/core-concepts/applications#oauth).)
* Make sure bearer tokens are never present in the query string. (FusionAuth doesn’t support access tokens in the query string other than in the Implicit Grant. But you shouldn’t be using that anyway.)
* Limit your refresh tokens to make sure they are not abused. (FusionAuth forces refresh tokens be tied to the client to which the refresh token was sent, but doesn’t, as of now, follow the cryptographic signing behavior outlined in the OAuth 2.1 draft.)
## Future directions
> It's tough to make predictions, especially about the future." - Yogi Berra
Please note that this specification is under active discussion on the OAuth mailing list. If you are interested in following or influencing this RFC, review the [discussion archives](https://mailarchive.ietf.org/arch/browse/oauth/) and/or [join the mailing list](https://www.ietf.org/mailman/listinfo/oauth).
Beyond this draft RFC, which is going to consolidate security best practices but leave most of OAuth 2.0 untouched, there’s also an OAuth3 working group, [reimagining the protocol from the ground up](https://oauth.net/3/). The OAuth3 specification is further from release than the OAuth 2.1 specification.
_This post originally published at [https://fusionauth.io/blog/2020/04/15/whats-new-in-oauth-2-1](https://fusionauth.io/blog/2020/04/15/whats-new-in-oauth-2-1?utm_source=devto&utm_medium=crosspost)_ | fusionauth |
320,926 | The Programming Puzzle That Landed Me a Job at Google | Back in 2011, as I was getting a bored with my job and I started looking for new options. During my s... | 0 | 2020-04-27T19:27:49 | https://www.abahgat.com/blog/the-programming-puzzle-that-got-me-my-job/ | java, programming, career | Back in 2011, as I was getting a bored with my job and I started looking for new options. During my search, my friend Daniele (with whom I had built [Novlet][novlet] and [Bitlet][bitlet] years before) forwarded me a link to the careers page of the company he was working for at the time, [ITA Software](https://en.wikipedia.org/wiki/ITA_Software).
While Google was in the process of acquiring ITA Software, ITA still had a number of open positions they were looking to hire for. Unlike Google, however, they required candidates to [solve a programming challenge][hiring-puzzles] before applying to engineering roles.
The problems to solve were surprisingly varied, ranging from purely algorithmic challenges to more broadly scoped problems that still required some deep technical insight. As I browsed through the options, I ended up settling on a problem that intrigued me because I thought it resembled a problem I might one day wanted to solve in the real world and seemed to try to test both the breadth of my knowledge (it required good full stack skills) as well as my understanding of deep technical details.
I have good memories of the time I spent investigating this problem and coming up with a solution. When I was done, I had learned about a new class of data structures (suffix trees), gained a deeper understanding of Java's internals. A year later, I got a job offer due in part to this puzzle.
<!--more-->
#### The Problem Statement
The brief for the challenge was the following:
> **Instant Search**
>
> Write a Java web application which provides "instant search" over properties listed in the National Register of Historic Places. Rather than waiting for the user to press a submit button, your application will dynamically update search results as input is typed. We provide the file `nrhp.xml.gz`, which contains selected information from the register's database.
>
> **Database** The key component of your server-side application is an efficient, in-memory data structure for looking up properties (written in pure Java). A good solution may take several minutes to load, but can answer a query in well under 0.1 ms on a modern PC. (Note that a sequential search of all properties is probably too slow!) An input matches a property if it is found at any position within that property's names, address, or city+state. Matches are case-insensitive, and consider only the characters A-Z and 0-9, e.g. the input "mainst" matches "200 S Main St" and "red" matches "Lakeshore Dr." Note that the server's JVM will be configured with 1024M maximum heap space. Please conform to the interfaces specified in `nrhp.jar` when creating your database.
>
> **Servlet** Your servlet should accept an input string as the request parameter to a GET request. Results should include the information for a pre-configured number of properties (e.g. 10), the total number of matches which exist in the database, and the time taken by your search algorithm. Your servlet should be stateless, ie. not depend on any per-user session information. Paginate your additional results as a bonus!
>
> **Client** Your web page should access the servlet using JavaScript's XMLHttpRequest object. As the user types, your interface should repeatedly refine the list of search results without refreshing the page. Your GUI does not have to be complicated, but should be polished and look good.
>
> Please submit a WAR file, configuration instructions, your source code, and any comments on your approach. Your application will be tested with Tomcat on Sun's 64-bit J2SE and a recent version of Firefox.

#### Client
I started building this from the UI down.
The puzzle brief mentioned using `XMLHttpRequest`, so I avoided using any client-side libraries (the functionality I was asked to build on the client was, after all, quite simple).
The screenshot included with the puzzle brief included just a text field for the search query and a list of results.
I wrote a function to listen for key presses, dispatch an asynchronous call to the server and render the response as soon as it came back. By 2011, I had been coding web applications for a while and I was able to implement that functionality in less than an hour of work.
#### Web application and Servlet code
The Servlet layer was also quite simple, since all it had to was handle an incoming XML request and dispatch it to what the brief called a *database*. Again, less than an hour of work here.
At this level, I also wrote code to parse the database of strings to index from an XML file containing data from the National Register of Historic Places. The Tomcat server would run this code when loading my web application and use the resulting data to construct a data structure to use as an index for power the fast search functionality I needed to build. I needed to figure that out next.
#### Finding a suitable data structure
This is, unsurprisingly, the most challenging part of the puzzle and where I focused my efforts the most. As pointed out in the problem description, looping sequentially through the list of landmarks would not work (it would take much longer than the target 0.1ms threshold). I needed to find data structure with good runtime complexity associated with lookup operations.
I spent some time thinking about how I would implement a data structure allowing the fast lookup times required in this case. The most common fast-lookup option I was familiar with, the *hash table*, would not work straight away with this problem because it would expect the search operation to have the full key string.
In this problem, however, I wanted to be able to look up entries in my index even when given an incomplete substring, which would have required me to store all possible substrings as keys in the table.
After doing some sketching on paper, it seemed reasonable to expect that [tries][tries] would work better here.
#### Suffix trees
As I was researching data structures providing fast lookup operations given partial strings, I stumbled upon a number of papers referencing suffix trees, commonly used in computational biology and text processing, offering lookup operations with linear runtime with respect to the length of the string to search *for* (as opposed to the length of the string to search *within*).
Plain suffix trees, however, are designed to find matches of a given candidate string sequence within a *single*, longer, string, while this puzzle revolved around a slightly different use case: instead of having a single long string to look up matches in, I needed to be able to find matches in multiple strings. Thankfully, I read some more and found a good number of papers documenting data structures called [*generalized* suffix trees][gst] that do exactly that.
Based on what I had learned so far, I was convinced this type of tree could fit my requirements but I had two likely challenges to overcome:
* Suffix trees tend to occupy much more space than the strings they are indexing and, based on the problem statement, "the server's JVM will be configured with 1024M maximum heap space" and that needed to accommodate the Tomcat server, my whole web application and the tree I was looking to build.
* Much of the complexity of working with suffix tree lies in *constructing* the trees themselves. While the puzzle brief was explicitly saying my solution could take "several minutes to load", I did not want the reviewer of my solution to have to wait several hours before they could test my submission.
#### Ukkonen's algorithm for linear runtime tree construction
Thankfully, had I found a popular algorithm for generating Suffix Trees in linear time (linear in the total length of the strings to be indexed), described by Ukkonen in a paper published in 1995 ([On–line construction of suffix trees](https://www.cs.helsinki.fi/u/ukkonen/SuffixT1withFigs.pdf)).
It took me a couple days of intermittent work (remember: I was working on this during nights and weekends -- I had another day job back then) to get my suffix tree to work as expected.
Interestingly, some of the challenges with this stage were revolving around a completely unexpected theme: Ukkonen's paper includes the full algorithm written in pseudo-code and good prose detailing the core steps. However, that same pseudo-code is written at such a high level of abstraction that it did take some work to reconduct it to fast and efficient Java code.

Also, the pseudo-code algorithm is written assuming we are working with a single string represented as a character array, so many of the operations outlined there deal with *indices* within that large array (e.g. *k* and *i* in the procedure above).
In my Java implementation, instead, I wanted to work with `String` objects as much as possible. I was driven by a few different reasons:
1. Java implements [string interning](https://en.wikipedia.org/wiki/String_interning) by default -- there is no memory benefit in representing substrings by manually manipulating indices within an array of characters representing the containing string: the JVM *already does that* transparently for us.
2. Working with `String` references led to code that was much more legible to me.
3. I knew my next step would be to generalize the algorithm to handle building an index on *multiple* strings and that was going to be much more difficult if I had to deal with low level specifics about which array of character represented which input string.
#### *Generalized* Suffix Trees
This last consideration proved to be critical: generalizing the suffix tree I had up to this point to work with multiple input strings was fairly straightforward. All I had to do was to make sure the nodes in my tree could carry some *payload* denoting which of the strings in the index would match a given query string. This stage amounted to a couple hours of work, but only because I had good unit tests.
At this point, things were looking great. I had spent maybe a couple days reading papers about suffix trees and another couple days writing all the code I had so far. I was ready to try out running my application with the input data provided with the puzzle brief: the entire National Register of Historic Places, an XML feed totaling a few hundred megabytes.
#### Trial by fire: `OutOfMemoryError`
The first run of my application was disappointing. I started up Tomcat and deployed my web application archive, which triggered parsing the XML database provided as input and started to build the generalized suffix tree to use as an index for fast search. Not even two minutes into the suffix tree construction, the server crashed with an `OutOfMemoryError`.
The 1024 megabytes I had were not enough.
Thankfully, a couple years earlier I had worked with a client that had a difficult time keeping their e-commerce site up during peak holiday shopping season. Their servers kept crashing because they were running out of memory. That in turn led me to learn how to read and make sense of JVM memory dumps.
I never thought I would make use of that skill for my own personal projects but this puzzle proved me wrong. I fired up [visualvm](https://visualvm.github.io) and started looking for the largest contributors to memory consumption.
It did not take long to find that there were a few memory allocation patterns that were not efficient. Many of these items would hardly be an issue for an average application, but they all ended up making a difference in this case because of the sheer size of the tree data structure being constructed.
#### Memory micro-optimizations
Analyzing a few heap dumps suggested me a series of possible changes that would lead to savings in memory, usually at the cost of additional complexity or switching from a general purpose data structure implementation (e.g. maps) to special purpose equivalent tailored to this use case and its constraints.
I ranked possible optimizations by their expected return on investment (i.e. comparing value of the memory savings to the additional implementation complexity, slower runtime and other factors) and implemented a few items at the top of the list.
The most impactful changes involved optimizing the memory footprint of the suffix tree *nodes*: considering my application required constructing a very large graph (featuring tens of thousands of nodes), any marginal savings coming from a more efficient node representation would end up making a meaningful difference.
A property of suffix tree nodes is that no outgoing edges can be labeled with strings sharing a prefix. In practice, this means that the data structure implementing a node must hold a reference to a set of outgoing edges keyed by the first character on the label.
The first version of my solution was using a `HashMap<Character,Edge>` to represent this. As soon as I looked at the heap dump, I noticed this representation was extremely inefficient for my use case.
Hash Maps in Java are initialized with a [load factor][load-factor] of 0.75 (meaning they generally reserve memory for at least 25% more key/value pairs than they hold at any given point) and, more importantly, with enough initial capacity to hold 16 elements.
The latter item was a particularly poor fit for my use case: since I was indexing strings using the English alphabet (26 distinct characters) a map of size 16 would be large enough to accommodate more than half the possible characters and would often be wasteful.
I could have mitigated this problem by tuning the sizing and load factor parameters but I thought I could save even more memory by switching to a specialized collection type.
The default map implementations included in the standard library require the key and value types to be reference types rather than native types (i.e. the map is keyed by `Character` instead of `char`) and reference types tend to be much less memory efficient (since their representation is more complex).
I wrote a special-purpose map implementation, called `EdgeBag`, which featured a few tweaks:
* stored keys and values and two parallel arrays,
* the arrays would start small gradually grew if more space if necessary,
* relied on a linear scan for lookup operation if the bag contained a small number of elements and switched to using binary search on a sorted key set if the bag had grown to contain more than a few units,
* used `byte[]` (instead of `char[]`) to represent the characters in the keys. Java's 16-bit `char` type takes twice as much space as a `byte`. I knew all my keys were ASCII characters, so I could forgo Unicode support here and could squeeze some more savings by casting to a more narrow value range.
Some more specific details on this and other changes to reduce the memory footprint of my suffix tree implementation are in the [Problem-specific optimizations](https://www.abahgat.com/project/suffix-tree#problem-specific-optimizations) section of the Suffix Tree project page.
#### Conclusion
When I tested out my program after the memory optimizations, I was delighted to see it met the problem requirements: lookups were lightning fast, well under 0.1ms using the machine I had back then (based on an Intel Q6600 2.4GHz CPU) and the unit tests I had written gave me good confidence that the program behaved as required.
I packaged up the solution as a WAR archive, wrote a brief README file outlining design considerations and instructions on how to run it (just deploy on a bare Tomcat 6 server) and sent it over email. Almost a year later, I was packing my bags and moving to Amsterdam to join Google (which had by then acquired ITA Software).
I owe it in no small part to the fun I had with this coding puzzle.
When I think of how much I enjoyed the time I spent building Instant Search, I think it must be because it required both breadth (to design a full stack application, albeit a simple one) and depth (to research the best data structure for the job and follow up with optimizations as required). It allowed me to combine my background as a generalist with my interest with the theoretical foundations of Computer Science.
The careful choice of specifying both memory and runtime constraints as part of the problem requirements made the challenge much more fun. When the first version I coded did not work, I was able to reuse my experience with memory profiling tools to identify which optimizations to follow up with. At the same time, I built a stronger understanding of Java's internals and learned a lot more about implementation details I had, until then, just given for granted.
When ITA retired Instant Search (and other programming puzzles[^puzzles]), I decided to [release the Java Generalized Suffix Tree as open source][gst] for others to use. Despite the many problem-specific optimizations I ended up making, it is generic enough that has been used in a few other applications since I built it, which gives me one more thing to be thankful for.
I write about programming, software engineering and technical leadership. You can [follow me on twitter](https://www.twitter.com/abahgat) for more posts like this.
*This post was originally published on [abahgat.com](https://www.abahgat.com/blog/the-programming-puzzle-that-got-me-my-job/) on Sep 30, 2019*
[^puzzles]: While the original page is no longer online, the Wayback Machine still has a snapshot of the original page with the original selection of [past programming puzzles][hiring-puzzles]. They are still a great way to test your programming skills.
[hiring-puzzles]: https://web.archive.org/web/20111012115624/http://itasoftware.com/careers/work-at-ita/hiring-puzzles.html
[bitlet]: https://www.abahgat.com/project/bitlet
[novlet]: https://www.abahgat.com/project/novlet
[gst]: https://www.abahgat.com/project/suffix-tree
[tries]: https://xlinux.nist.gov/dads/HTML/trie.html
[visualvm]: https://visualvm.github.io/
[load-factor]: https://en.wikipedia.org/wiki/Hash_table#Key_statistics | abahgat |
320,930 | migrating jenkins home directory in linux | I recently had an issue with my Jenkins server complaining of not enough space in the partition and d... | 0 | 2020-04-27T19:22:46 | https://dev.to/polroyal/migrating-jenkins-home-directory-in-linux-2ba5 | jenkins, linux, centos7 |
I recently had an issue with my Jenkins server complaining of not enough space in the partition and directory where it was installed on my Centos 7 OS. This obviously is the default ‘va/lib/jenkins directory.
A couple of tries and solutions seemed to work until Jenkins was spinning again and the problem seemed to persist. After some struggles I managed to make Jenkins happy and decided to put together what I believe would be the best solution to migrating the Jenkins default home directory to a new one with enough space.
The following command should quickly tell which partitions have enough space
[root@pol pol]# df -h
Remember to stop the jenkins service before starting the process.
[root@pol pol]# systemctl stop jenkins
We start by creating a new Jenkins directory within the /home/ directory
[root@pol pol]# mkdir /home/jenkins/
Copy all the contents of the old jenkins directory to the new one
[root@pol pol]# cp -rvf /var/lib/jenkins/* /home/jenkins/
Once the copy operation is completed, we need to update the environment variable for Jenkins home directory(JENKINS_HOME). This can be done with the following command
[root@pol pol]# export JENKINS_HOME=/home/jenkins
Jenkins home directory has now been changed but we need to make sure those changes hold even after a reboot. We navigate to the ‘bash_profile’ file located in the /home directory
root@pol home]# vim ~/.bash_profile
We then make the following entry at the bottom of the file
export JENKINS_HOME=/home/jenkins
We also should navigate to the jenkins config file and change the PATH to the new home directory.
[root@pol pol]# vim /etc/sysconfig/jenkins
Change from JENKINS_HOME="/var/lib/jenkins" to the following
JENKINS_HOME="/home/jenkins"
Before restarting the service we need to recursively take care of directory access rights for the jenkins user and group otherwise Jenkins will not be happy with our actions!
chown -R jenkins:jenkins $JENKINS_HOME
The last step would be to restart the jenkins service to implement the changes
[root@pol pol]# systemctl start jenkins
Now if you log back into the Jenkins GUI the home direction should not complain and should be changed! | polroyal |
321,009 | OWASP, DevSecOps, AppSec & Cloud Security Podcasts | OWASP, DevSecOps, AppSec & Cloud Security Podcasts I was recently asked which... | 0 | 2023-11-25T10:37:32 | https://dev.to/securestep9/owasp-devsecops-appsec-cloud-security-podcasts-3ilc | ---
title: OWASP, DevSecOps, AppSec & Cloud Security Podcasts
published: true
date: 2020-04-27 21:36:49 UTC
tags:
canonical_url:
---
### OWASP, DevSecOps, AppSec & Cloud Security Podcasts

I was recently asked which OWASP/DevSecOps/Application Security/Cloud Security-themed podcasts I listen to.
Here’s the list:
_(please note that these podcasts are available on all/most podcasts platforms, in this list I only provide the Google Podcasts links):_
**Application Security Podcast (produced by Chris Romeo/ Security Journey)**: [https://podcast.securityjourney.com/](https://podcast.securityjourney.com/application-security-podcast/episodes/)
**OWASP Podcast** (now known as **DevSecOps Podcast** Supported by OWASP — produced by Mark Miller — interview format): [https://soundcloud.com/owasp-podcast](https://soundcloud.com/owasp-podcast)
**BeerSecOps — ** Podcast About Dev, Sec, Ops, and Everything in Between (run be Steve Giguere/AquaSec - Interview format): [https://podcasts.google.com/?feed=aHR0cHM6Ly9hbmNob3IuZm0vcy9mMzg2Njg0L3BvZGNhc3QvcnNz](https://podcasts.google.com/?feed=aHR0cHM6Ly9hbmNob3IuZm0vcy9mMzg2Njg0L3BvZGNhc3QvcnNz)
**DevSecOps Overflow** (produced by Michael Man, interview format) **:** [https://podcasts.google.com/?feed=aHR0cHM6Ly9mZWVkcy5idXp6c3Byb3V0LmNvbS83MzMwNzAucnNz](https://podcasts.google.com/?feed=aHR0cHM6Ly9mZWVkcy5idXp6c3Byb3V0LmNvbS83MzMwNzAucnNz)
**Absolute AppSec(**produced by Ken Johnson and Seth Law, chat with guests) [https://podcasts.google.com/?feed=aHR0cHM6Ly9hYnNvbHV0ZWFwcHNlYy5jb20vcnNzLnhtbA](https://podcasts.google.com/?feed=aHR0cHM6Ly9hYnNvbHV0ZWFwcHNlYy5jb20vcnNzLnhtbA)
**Cloud Security Podcast** : [https://podcasts.google.com/?feed=aHR0cHM6Ly9hbmNob3IuZm0vcy8xMGZiOTkyOC9wb2RjYXN0L3Jzcw&ved=2ahUKEwiHte\_Uu4npAhUShhoKHcTBCLYQ4aUDegQIARAC](https://podcasts.google.com/?feed=aHR0cHM6Ly9hbmNob3IuZm0vcy8xMGZiOTkyOC9wb2RjYXN0L3Jzcw&ved=2ahUKEwiHte_Uu4npAhUShhoKHcTBCLYQ4aUDegQIARAC)
**The Secure Developer Podcast** (produced by Heavybit, interview format): [https://podcasts.google.com/?feed=aHR0cHM6Ly93d3cuaGVhdnliaXQuY29tL2NhdGVnb3J5L2xpYnJhcnkvcG9kY2FzdHMvdGhlLXNlY3VyZS1kZXZlbG9wZXIvZmVlZA&ved=0CB0Q27cFahcKEwi4kpi8uonpAhUAAAAAHQAAAAAQBw](https://podcasts.google.com/?feed=aHR0cHM6Ly93d3cuaGVhdnliaXQuY29tL2NhdGVnb3J5L2xpYnJhcnkvcG9kY2FzdHMvdGhlLXNlY3VyZS1kZXZlbG9wZXIvZmVlZA&ved=0CB0Q27cFahcKEwi4kpi8uonpAhUAAAAAHQAAAAAQBw)
**DevSecOps Talk Podcast** (Mattias Hemmingsson, Julien Bisconti and Andrey Devyatkin chat about latest stuff, and ideas): [https://podcasts.google.com/?feed=aHR0cHM6Ly9mZWVkLnBvZGJlYW4uY29tL2RldnNlY29wcy9mZWVkLnhtbA](https://podcasts.google.com/?feed=aHR0cHM6Ly9mZWVkLnBvZGJlYW4uY29tL2RldnNlY29wcy9mZWVkLnhtbA) | securestep9 | |
321,013 | BeTheHope - What did Data say? [3] | Hello again! In the past, there have been times when I had an idea, and I felt that this is it. This... | 6,170 | 2020-04-28T16:32:57 | https://dev.to/abhinavchawla13/bethehope-what-did-data-say-3-2970 | twiliohackathon, data, presentation, video | Hello again! In the past, there have been times when I had an idea, and I felt that this is it. This is my Eureka moment. In eagerness to start working on the project, I ended up forgetting to do some research to see if alternates exist or data supports my thesis. And well, I’ll just say that it ended up in a few disappointing endings.
Learning from these mistakes, over the past year, whenever I start a new project, I try to dig in some data to ensure that the idea brings something unique to the table, can be backed by data and it’s feasibility to reach the intended audience.
###I ask myself, is it worth pulling all-nighters?
And with BeTheHope, it was a definite ***yes***. First week, my brain was juggling around between a couple of ideas. Eventually, I let the data decide (so maybe I can call myself a data-driven person? 🤓). I had gathered enough data to convince myself to build a solution easing donations for everyone.
---
###How’s the progress been so far?
Luckily, I’m almost done with the development, ahead of my schedule, so I decided to work on a couple of cool things to show my passion for the project. Firstly, since I had done the heavy load of digging some valuable data in the first week, I decided to prepare a deck with some numbers to show the importance of this solution. For now, here’s a quick peek (I’ll share the complete deck in the submission post):

Secondly, I never thought I'd be doing this, but since I have some time on my hands, I decided to try getting my hands dirty trying to edit a walkthrough demo video for the entire platform. To be honest, I basically realized how hard it is to edit videos (Salute to YouTubers!). Nonetheless, I’m super excited to complete it. If done right, I’ll be putting it into my hall of fame 😎
![iMovie] (https://i.imgur.com/Ni46ve6.png)
---
Before I leave, a quick update on the donations page (shared in first [post](https://dev.to/abhinavchawla13/bethehope-first-glimpse-1-29ei)) for the donors: As it is a mobile-first page, I re-designed the page to provide desktop viewers a similar experience as they would get on their mobile devices. Here it is:
![Donation page] (https://i.imgur.com/mOFltSW.png)
I’m happy with the progress; hopefully I should be able to wrap things up soon and post my final submission by tomorrow 🤞. Until then, Happy Hackathon!
| abhinavchawla13 |
321,055 | GitHub, TDC Online e Azure DevOps | E aí, tudo certo? Os últimos dias foram bem agitados por aqui, e estou aqui para fazer um pequeno re... | 0 | 2020-04-27T23:08:00 | https://dev.to/julioarruda/github-tdc-online-e-azure-devops-mii | github, tdc, azuredevops | E aí, tudo certo?
Os últimos dias foram bem agitados por aqui, e estou aqui para fazer um pequeno resumo de tudo oque aconteceu aqui no canal.
20 de abril
**Oque mudou no GitHub**
Neste vídeo, eu falo um pouco sobre novidades que ocorreram em questão de precificação, entre outras coisas. Assista o vídeo para entender melhor.
{% youtube 22z-EsiMpPY %}
22 de Abril
**Realizando testes de Integração com PowerShell e Pester**
Esta foi uma live bem bacana, onde contamos com a presença do meu amigo, e também Microsoft MVP, [Guido Oliveira](https://mvp.microsoft.com/pt-br/PublicProfile/5001325?fullName=Guido%20Basilio%20Oliveira).
Guido é um especialista em PowerShell, e contribui muito com a comunidade neste tema. Ele participou dessa live, e trouxe um conteúdo muito bom, e quem esteve conosco, gostou bastante da apresentação. Quer saber mais? Assista o vídeo:
{% youtube LWdRS3TTIf8 %}
25 de Abril
**Tech Saturday #1 | O Inicio**
Esta foi a primeira edição do Tech Saturday, um meetup online realizado pelo .Net Vale em parceria com meu canal do YouTube, e nesta edição, contamos com presenças ilustres como [Claudenir Andrade](https://mvp.microsoft.com/pt-br/PublicProfile/7863?fullName=Claudenir%20Campos%20Andrade),[Douglas Romão](https://mvp.microsoft.com/pt-br/PublicProfile/5002850?fullName=Douglas%20Romão%20) e [Renato Groffe](https://mvp.microsoft.com/pt-br/PublicProfile/5002142?fullName=Renato%20José%20Groffe). Tivemos palestras ótimas sobre inovação, Power Plataform, .Net Core e GitHub.
Assista a gravação da Live
{% youtube Lx_Z1rlL770 %}
**TDC BH Online**
Nesse mesmo dia, aconteceu o TDC BH Online, onde fiz uma apresentação sobre novidades do GitHub desde sua compra pela Microsoft.

27 de Abril
**Utilizando Containers no seu CI com Azure DevOps**
Já neste dia, lancei um vídeo falando sobre como você pode utilizar containers para deixar seus agentes de CI mais genéricos e práticos de gerenciar. Assista o vídeo e entenda como isso pode te ajudar.
{% youtube 0MZlzjmo7xM %}
| julioarruda |
321,089 | What is Azure Data Science? | In this article, we have jotted down every single thing that you need to know about the role of Azure in Data Science. | 0 | 2020-04-28T00:25:10 | https://dev.to/sadiakhan3/what-is-azure-data-science-2e92 | datascience, azure | ---
title: What is Azure Data Science?
published: true
description: In this article, we have jotted down every single thing that you need to know about the role of Azure in Data Science.
tags: datascience, Azure
---
<p>In war technology, it is considered that Microsoft Azure's massive adoption is one of the reasons for this profound popularity globally. As a result, there is a growing demand for jobs in the role of data exploration. Data is the life force of all current businesses; in addition, the need for information based on data is not likely to pass away in a little while! More importantly, it is believed that Azure data scientists may easily play an important role in making important business decisions. However, IT professionals have many job opportunities in the line of Azure, specifically in data-processing. Thus, enduring capabilities on Azure Data-Scientist workstations are important recommendations to use.</p>
<p><h2>An Opportunity to Become an Azure Data-Scientist</h2></p>
<p>If a person is willing to be an Azure Data-Scientist, so no power will stop and nothing is unmanageable! However, one still has to initiate from the precise phase of training as well as keep an eye on the factual track to achieve the objectives. On the other hand, industries possibly will discover the sources they need to run cloud operations. As a result, investing in databases, servers, storage, and analytics would no longer burden businesses. Businesses of all sizes can use Microsoft Azure to avoid significant business support. The adoption rate of Microsoft Azure for Fortune 500 companies is almost 85.7%. This clearly demonstrates that the <a href="https://www.trendmut.com/data-science-tips-and-tricks"> roles of data scientist</a> Azure will have to dominate the new time market. This is why Azure definitely has the credibility to build a career as a data scientist.</p>
<p><h3>Azure Data Science Certification</p></h3>
<p>On the other hand, a career requires an Azure Data Scientist certification. However, it is perceived that certification can have significant career benefits as a data scientist. Though, it provides evidence of the Microsoft Azure application for science skills. Most importantly, by obtaining the <a href="https://www.datascienceacademy.io/training-library/microsoft-azure.html"> Microsoft Azure training</a> and gaining the credentials gives you the opportunity to find higher-paying jobs. In addition, this certification likewise delivers the necessary evidence of the assurance as well as loyalty to the continued practiced growth. All the same, this certification is considering as the accurate choice in order to step-in the successful line of business as Azure Data-Scientist. However, the name of the accreditation assessment is integrating as Microsoft Azure data technology solution design and implementation. </p>
<p><h2>Reasons to Chase Azure Data-Science Work</p></h2>
<p>The motivation for becoming a Microsoft Azure expert is likewise crucial to determine. Azure Data- Science uses about 120,550 customers per month. In addition, there is a great demand for Azure data scientists. After that, it is clear that growth from 2019 was 35.4%. Moreover, the regularity of work vacancies across various search forums is steadily growing in the information sciences. In addition, most IT professionals begin proper learning in relevant industry parts. Furthermore, a member of Azure Data Scientist possibly will have contact with a broad platform of Azure professionals as well as specialists.</p>
<p><h3>Core Skills Required- Azure Data Science<p></h3>
<p>The abilities required to obtain information about an Azure scientist are also very important when choosing a career in this field. To prepare, you need to know if the Azure area of knowledge and information matches your understanding. </p><p>Following are the core skills of it:</p>
• The core competency constraint for the job is apparent in diagnostic assistances. The best expertise of any pro is considering as the talent to analyze data.
• The essential condition for work is openness as well as originality.
• Communication helps as an essential factor for experts since they need to elucidate the facts
• Advanced mathematical knowledge plus basic programming is crucial
<p><h3>Microsoft Azure Data Science Professional Salary</p></h3>
<p>Azure certifications and professionals are very demanding. This means that the requirement of Azure data expert is also in great need these days. However, it is simply not a statement; some data facts regarding this report that over and above 65,550 jobs will be obtainable in the sector, which is more likely predictable to increase in the coming years. Furthermore, several studies have correspondingly indicated that the regular salary of an expert of Azure Data-Science is about 135,550 dollars. In addition, in a few years, Azure’s research salary will reach 160,550 dollars. In short, an Azure data-scientist is globally recognizing as the most up-to-date occupation in the current consequences. On the other hand, people are supposed to make sure that an individual is hard-working or else in need of a talent chain to stay in a highly competitive position.</p>
<p><h3>Azure Data Science – Guide for Job Opportunities</p></h3>
<p>The next most important factor in Azure’s discussions of data science policy is job openings. This employment guide exhibits you accurately anything one can assume in the upcoming line of business. Thus, the mission of Azure Data Scientist is to apply data mining and scientific hardness techniques to retrieve the statistics that can be used as the information. Additionally, individuals may catch the succeeding important elements in their job portrayal as an expert of Azure Data-Science.</p>
• Use methods based on machine learning to train, evaluate and use AI model development model to achieve business goals.
• Use applications for natural call processing, automatic recognition, along with computing perception
• Continue through a member of the multidisciplinary group and integrate moral, administrative as well as confidentiality into the solution.
• Excellent code for the production of transport models
• Work with statistics and tests
• Work with clients in a straight line or secondarily to solve technical problems
• Work on product characteristics
• Use a wide range of machine learning tools and diagnostics to solve various high impact businesses
<p><b>Final Thoughts</p></b>
<p>It is concluded that new openings in Azure data-science are very significant for all relevant industry professionals, particularly in the long run. More importantly, people need to acquire ways to understand the importance of it along with the directing power among several technologies that are emerging in 2020. After that, you will also need relevant training materials, advice, and assistance to pass the certification exams. Therefore, it is necessary to choose a suitable platform that will provide you with transparent support throughout your trip. Ultimately, you have to commit to becoming an expert and it can't be impossible for you!</p>
| sadiakhan3 |
321,107 | Accessing a composed params var with refs | How we can access refs of a composed params. Example : i m trying to access data-show of a modal PS... | 0 | 2020-04-28T01:46:15 | https://dev.to/saadela/accessing-a-composed-params-var-with-refs-50c8 | react, reactrefs | How we can access refs of a composed params.
Example : i m trying to access data-show of a modal
PS : the issue is not in accessing refs but in having access to a combined params as above | saadela |
321,109 | debugging the micronaut package and code smells in nix | I am the maintainer for NixOS's micronaut package. This package installs the micronaut cli which can... | 0 | 2020-04-28T02:27:03 | https://dev.to/moaxcp/debugging-the-micronaut-package-and-code-smells-in-nix-dhh | nixos, linux, micronaut | I am the maintainer for NixOS's micronaut package. This package installs the micronaut cli which can be used for creating projects and classes. The package is very simple. Here is the original.
```
{ stdenv, fetchzip, jdk, makeWrapper, installShellFiles }:
stdenv.mkDerivation rec {
pname = "micronaut";
version = "1.3.2";
src = fetchzip {
url = "https://github.com/micronaut-projects/micronaut-core/releases/download/v${version}/${pname}-${version}.zip";
sha256 = "0jwvbymwaz4whw08n9scz6vk57sx7l3qddh4m5dlv2cxishwf7n3";
};
nativeBuildInputs = [ makeWrapper installShellFiles ];
installPhase = ''
runHook preInstall
rm bin/mn.bat
cp -r . $out
wrapProgram $out/bin/mn \
--prefix JAVA_HOME : ${jdk}
installShellCompletion --bash --name mn.bash bin/mn_completion
runHook postInstall
'';
meta = ...;
}
```
This package copies the content into $out, wraps the `mn` command, and installs shell completion.
There are two problems with this script. First, `--prefix` is used for `JAVA_HOME` instead of `--set`. This causes two paths to be in the variable which can cause problems. Second, my user's `PATH` contains `jdk14` but the script should use the default `jdk`.
```
{ stdenv, fetchzip, jdk, makeWrapper, installShellFiles }:
stdenv.mkDerivation rec {
pname = "micronaut";
version = "1.3.2";
src = fetchzip {
url = "https://github.com/micronaut-projects/micronaut-core/releases/download/v${version}/${pname}-${version}.zip";
sha256 = "0jwvbymwaz4whw08n9scz6vk57sx7l3qddh4m5dlv2cxishwf7n3";
};
nativeBuildInputs = [ makeWrapper installShellFiles ];
installPhase = ''
runHook preInstall
rm bin/mn.bat
cp -r . $out
wrapProgram $out/bin/mn \
--prefix PATH : ${jdk}/bin
installShellCompletion --bash --name mn.bash bin/mn_completion
runHook postInstall
'';
meta = ...;
}
```
This still introduces the user's entire path into the script breaking purity of the install. One principle of NixOS is that the environment is pure. Every input for the application is declared and the ouput is deterministic. Even though at this point the package works on my computer it is incorrect. Since PATH can contain anything there could be missing input in the package. The package may work when run locally but it may not always work with every user's `PATH` variable. Using `--prefix` for PATH should be considered a code smell in nix. `--set` should be used instead.
```
{ stdenv, fetchzip, jdk, makeWrapper, installShellFiles }:
stdenv.mkDerivation rec {
pname = "micronaut";
version = "1.3.2";
src = fetchzip {
url = "https://github.com/micronaut-projects/micronaut-core/releases/download/v${version}/${pname}-${version}.zip";
sha256 = "0jwvbymwaz4whw08n9scz6vk57sx7l3qddh4m5dlv2cxishwf7n3";
};
nativeBuildInputs = [ makeWrapper installShellFiles ];
installPhase = ''
runHook preInstall
rm bin/mn.bat
cp -r . $out
wrapProgram $out/bin/mn \
--set PATH ${jdk}/bin
installShellCompletion --bash --name mn.bash bin/mn_completion
runHook postInstall
'';
meta = ...;
}
```
This results in an error because there is in fact a missing dependency for micronaut that was not accounted for.
```
Error: Could not find or load main class io.micronaut.cli.MicronautCli
```
This is an interesting problem. At this point I almost gave up. The script `mn` builds a variable `CLASSPATH` which is used by `java` to run the application. If the class cannot be found this means the classpath is incorrect. Something I learned about bash is that it can be debugged using `set -x`. This can be patched into the `mn` script using nix.
```
patchPhase = ''
sed -i '2iset -x' bin/mn
'';
```
Running `mn` again reveals some missing dependencies that result in classpath not being setup correctly.
```
...
++ dirname /nix/store/mhdwrfxd9dj0hipzygbdy4h70dhkq3yh-micronaut-1.3.4/bin/.mn-wrapped
/nix/store/mhdwrfxd9dj0hipzygbdy4h70dhkq3yh-micronaut-1.3.4/bin/.mn-wrapped: line 24: dirname: command not found
...
++ basename /nix/store/mhdwrfxd9dj0hipzygbdy4h70dhkq3yh-micronaut-1.3.4/bin/.mn-wrapped
/nix/store/mhdwrfxd9dj0hipzygbdy4h70dhkq3yh-micronaut-1.3.4/bin/.mn-wrapped: line 29: basename: command not found
...
/nix/store/mhdwrfxd9dj0hipzygbdy4h70dhkq3yh-micronaut-1.3.4/bin/.mn-wrapped: line 53: uname: command not found
+ CLASSPATH=//cli-1.3.4.jar
...
```
The missing dependencies are all located in the `coreutils` package. Its path can be added.
```
--set PATH ${coreutils}/bin:${jdk}/bin
```
Now when `mn` is run java appears to run and start the application but there is an exception.
```
Exception: java.lang.StackOverflowError thrown from the UncaughtExceptionHandler in thread "main"
```
The problem here is not obvious at all. It requires debugging the jvm. To do this from a nix expression options need to be added to the start the application with the debugger enabled. The `mn` script passes these options by setting `MN_OPTS`.
```
installPhase = ''
runHook preInstall
rm bin/mn.bat
cp -r . $out
wrapProgram $out/bin/mn \
--set MN_OPTS -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=8000 \
--set JAVA_HOME ${jdk} \
--set PATH ${coreutils}/bin:${jdk}/bin
installShellCompletion --bash --name mn.bash bin/mn_completion
runHook postInstall
'';
```
To debug and set breakpoints I needed to checkout [micronaut-core](https://github.com/micronaut-projects/micronaut-core/tree/v1.3.4) and open it in intellij. After a few hours I was able to narrow the problem down to the [jline](https://github.com/jline/jline2/blob/jline-2.12/src/main/java/jline/internal/TerminalLineSettings.java) dependency. This code calls `sh` which is not on `PATH`.
The final result:
```
{ stdenv, coreutils, fetchzip, jdk, makeWrapper, installShellFiles }:
stdenv.mkDerivation rec {
pname = "micronaut";
version = "1.3.4";
src = fetchzip {
url = "https://github.com/micronaut-projects/micronaut-core/releases/download/v${version}/${pname}-${version}.zip";
sha256 = "0mddr6jw7bl8k4iqfq3sfpxq8fffm2spi9xwdr4cskkw4qdgrrpz";
};
nativeBuildInputs = [ makeWrapper installShellFiles ];
installPhase = ''
runHook preInstall
rm bin/mn.bat
cp -r . $out
wrapProgram $out/bin/mn \
--set JAVA_HOME ${jdk} \
--set PATH /bin:${coreutils}/bin:${jdk}/bin
installShellCompletion --bash --name mn.bash bin/mn_completion
runHook postInstall
'';
meta = with stdenv.lib; {
description = "Modern, JVM-based, full-stack framework for building microservice applications";
longDescription = ''
Micronaut is a modern, JVM-based, full stack microservices framework
designed for building modular, easily testable microservice applications.
Reflection-based IoC frameworks load and cache reflection data for
every single field, method, and constructor in your code, whereas with
Micronaut, your application startup time and memory consumption are
not bound to the size of your codebase.
'';
homepage = "https://micronaut.io/";
license = licenses.asl20;
platforms = platforms.all;
maintainers = with maintainers; [ moaxcp ];
};
}
```
To recap the only changes made were to set `JAVA_HOME` instead of prefix it and to set `PATH` to all inputs into the application runtime. This problem was very easy to cause and difficult to debug. It is possible that it is in other packages in nix. Especially packages I wrote. | moaxcp |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.