
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
338,515 | Overwriting Shared Libraries in AWS Lambda | The latest Ruby runtime for AWS Lambda runs Ruby 2.7. Though this version of ruby is only 6 months ol... | 0 | 2020-05-18T23:26:39 | https://dev.to/nckslvrmn/overwriting-shared-libraries-in-aws-lambda-479h | aws, serverless, ruby | The latest Ruby runtime for AWS Lambda runs Ruby 2.7. Though this version of ruby is only 6 months old, the version of OpenSSL that Lambdas instance of Ruby was compiled with is over 3 years old. You can verify that by running the function below and seeing what it returns:
```
require 'openssl'
def lambda_handler(event:, context:)
return OpenSSL::OPENSSL_VERSION
end
# OpenSSL 1.0.2k 26 Jan 2017
```
That's Old! That means that Ruby's OpenSSL library is missing some key features like `SHA-3`, `TLS 1.3`, and the `scrypt` KDF.
I wanted to see if I could load in a newer version of the OpenSSL shared library ruby loads so I could leverage some of these shiny new features. Well, it turns out, [AWS Lambda Layers](https://docs.aws.amazon.com/lambda/latest/dg/configuration-layers.html) was a big part of the answer here. In the documentation, a Lambda Layer is available to your Lambda code via the `/opt` directory. Now anyone who uses a lot of gem dependencies might have already come across this feature as it's a great way to share gems across different functions while keeping the function size itself fairly small.
But interestingly enough, it's not just a place to load gems. Lambda also adds to the `RUBYLIB` environment variable with a path you can fill with a Lambda Layer (specifically `/opt/ruby/lib`). This path is also *prefixed* to the `LOAD_PATH` variable. This is where things get interesting.
Now that we know we can load up a Lambda Layer with a shared library that will be part of the auto searched `LOAD_PATH`, we can construct a Lambda Layer with the necessary files to load our own version of OpenSSL. To do this, we need a newer instance of `openssl.so` that was compiled with Ruby and we also need the `libssl.so.1.1` and `libcrypto.so.1.1` files to support the shared library.
I was able to extract a copy of these files by installing the latest version of OpenSSL from my package manager (pacman), and installing Ruby 2.7 from RVM so it re-compiled on my machine. In the end, I constructed a directory structure that looked like this:
```
.
├── lib
│ ├── libcrypto.so -> libcrypto.so.1.1
│ ├── libcrypto.so.1.1
│ ├── libssl.so -> libssl.so.1.1
│ └── libssl.so.1.1
└── ruby
└── lib
└── openssl.so
```
I then zipped that up and uploaded that zip to a new Lambda Layer destined for my function. Upon running the below function, we can see that my OpenSSL version is now nice and new and should include the features I want! Running the original function above, I now see `OpenSSL 1.1.1d 10 Sep 2019`. Excellent! Now I can go generate all the `scrypt` keys and initiate all the `TLS 1.3` connections I want right?
Not exactly. It turns out, Ruby has a fun little behavior when it sees it needs to load some files. when calling `require`, ruby will search through the `LOAD_PATH` for the code you are trying to load, but specifically with `require`, it will load .rb files **and** shared libraries with the `.so` extension. So When I tried to create a new `SHA-256` digest, I was met with an unexpected error:
```
require 'openssl'
def lambda_handler(event:, context:)
return OpenSSL::Digest::SHA256.new
end
# uninitialized constant OpenSSL::Digest::SHA256
```
What happened? Well it turns out, because my `openssl.so` file is now *ahead* of Ruby's built-in `openssl.rb` code, I am only loading the shared library which comes with some classes, but not all the classes I expect. To get around this, it's quite simple:
```
require 'openssl.rb'
def lambda_handler(event:, context:)
return OpenSSL::Digest::SHA256.new
end
# #<OpenSSL::Digest::SHA256: ...>
```
By specifying the `.rb` extension, I am now instructing Ruby to look through its `LOAD_PATH` until it finds the first instance of a file called `openssl.rb`. This is included with ruby and is the code that loads in all of the classes I expect to see, as well as an explicit call to load `openssl.so`. This now allows me to use all of the shiny new features that OpenSSL 1.1.1(x) provides without having to use a [Custom Runtime](https://docs.aws.amazon.com/lambda/latest/dg/runtimes-custom.html). | nckslvrmn |
338,527 | Using scispaCy for Named-Entity Recognition (Part 1) | A step-by-step tutorial for extracting data from biomedical literature Photo by Beatriz Pé... | 0 | 2020-05-18T23:32:37 | https://dev.to/akashkaul/using-scispacy-for-named-entity-recognition-5ddh | namedentityrecognition, tutorial, nlp, scispacy | ---
title: Using scispaCy for Named-Entity Recognition (Part 1)
published: true
date: 2020-05-18 03:13:23 UTC
tags: namedentityrecognition,tutorial,nlp,scispacy
canonical_url:
---
#### _A step-by-step tutorial for extracting data from biomedical literature_
<figcaption>Photo by <a href="https://unsplash.com/@beatriz_perez?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Beatriz Pérez Moya</a> on <a href="https://unsplash.com/backgrounds/art/paper?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a></figcaption>
In 2019, the Allen Institute for Artificial Intelligence (AI2) developed scispaCy, a full, open-source spaCy pipeline for Python designed for analyzing biomedical and scientific text using natural language processing (NLP). scispaCy is a powerful tool, especially for named entity recognition (NER), or identifying keywords (called entities) and ordering them into categories. I will be taking you through a basic introduction to using scispaCy for NER, and you will soon be on your way to becoming a master of NLP.
### **Agenda**
1. Set up Environment
2. Install pandas
3. Install scispaCy
4. Choose a Model
5. Import Packages
6. Import Data
7. Select Data
8. Implementing Named-Entity Recognition
9. Larger Data
### **Setting Up an Environment**
The first step is to choose an environment to work in. I used Google Colab, but Jupyter Notebook or simply working from the terminal are fine, too. If you do work from the terminal, just make sure to create a virtual environment to work in. If you are working in Google Colab, there is no need to do this. Easy-to-follow instructions on creating a virtual environment can be found [here](https://uoa-eresearch.github.io/eresearch-cookbook/recipe/2014/11/26/python-virtual-env/).
_Because I used Google Colab, the syntax used may be slightly different than that used for other environments._
The full code for this project can be found [here](https://github.com/akash-kaul/Using-scispaCy-for-Named-Entity-Recognition).
### **Installing pandas**
Pandas is a Python library used for data manipulation. This will help with importing and representing the data we will analyze (talked about in the next section). If you’re working from Google Colab, pandas comes pre-installed, so you can ignore this step. Otherwise, install pandas using either Conda or PyPI (whichever you prefer). You can view all the steps for the installation process [here](https://pandas.pydata.org/pandas-docs/stable/getting_started/install.html).
### **Installing scispaCy**
Installing scispaCy is pretty straight-forward. It is installed just like any other Python package.
```
!pip install -U spacy
!pip install scispacy
```
### **Picking a Pre-trained scispaCy Model**
After installing scispaCy, you next need to install one of their premade models. scispaCy models come in two flavors: Core and NER. The Core models come in three sizes (small, medium, large) based on the amount of vocabulary stored, and they identify entities but do not classify them. The NER models, on the other hand, identify and classify entities. There are 4 different NER models built on different entity categories. You may need to experiment with the different models to find which one works best for your needs. The full list of models and specifications can be found [here](https://allenai.github.io/scispacy/). Once you pick a model, install it using the model URL.
```
!pip install https://s3-us-west-2.amazonaws.com/ai2-s2-scispacy/releases/v0.2.4/en_core_sci_sm-0.2.4.tar.gz
```
_Example of installing the “en_core_sci_sm” model_
### **Import your packages**
Once you have installed all of your packages and a virtual environment is created, simply import the packages you just downloaded.
```
import scispacy
import spacy
import en_core_sci_sm
from spacy import display
import pandas as pd
```
You may notice we also import an additional package “displacy”. Displacy isn’t required to perform any of the NER actions, but it is a visualizer that helps us see what’s going on.
### **Importing Data**
For this example, we used the metadata from CORD-19, an open database of research papers about Covid-19. The metadata, as well as the full collection of articles, can be found [here](https://www.semanticscholar.org/cord19/download).
_The metadata file is a bit finicky, so if the file is doing what you want, just copy the contents to a new file. This should resolve any problems you encounter with the file._
To import the data, we use the pandas _read_csv()_ function.
```
df = pd.read_csv(“content/sample_data/metadata.csv”)
```
The function reads in the file path and stores the data as a DataFrame, the main Pandas data structure. For more information on how pandas stores and manipulates data, you can view the documentation [here](https://pandas.pydata.org/pandas-docs/stable/index.html).
_If you are using Colab, you can drag the file into the “Files” section, then right-click and choose “Copy Path” to easily access the path to the file you want._
### **Selecting the Relevant Data**
The metadata provides lots of useful information about the over 60,00 papers in CORD-19, including authors, reference numbers, etc. However, for our purposes, the data we care about is the abstracts. The full abstract of each paper is listed under the column named “abstract”. So, our next step is to choose this text. We will do this using the DataFrame _loc_ function. This function takes in the location of a cell in the DataFrame and returns the data present in that cell. To access a specific abstract, just type the specific row you want and the header of the column, and store as a string variable.
```
text = meta_df.loc[0, “abstract”]
```
This finds the abstract located in the first row of the table (remember, in Python indexing starts at 0). You can then print your newly created string to verify you have the data you want. It should look something like this:

### **Named- Entity Recognition**
Now that you have your text, you can get into the fun part. Thanks to scispaCy, entity extraction is relatively easy. We will be using a Core model and a NER model to highlight the differences between the two.
**Core model:**
```
nlp = en_core_sci_sm.load()
doc = nlp(text)
displacy_image = displacy,render(doc, jupyter = True, style = ‘ent’)
```
Your output should look like this:

**NER model:**
```
nlp = en_ner_jnlpba_md.load()
doc = nlp(text)
displacy_image = displacy,render(doc, jupyter = True, style = ‘ent’)
```
_Here we used a model designed to identify entities of the type DNA, Cell Type, RNA, Protein, Cell Line_
The output should look like this:

### **Expanding to Larger Data**
Just like that, you have successfully used NER on a sample text! But, that was only one abstract of the over 60,000 in the CORD-19 metadata. What if we wanted to use NER on 100 abstracts? What about 1,000? What about all of them? Well, the process, though requiring a little more finesse, is essentially the same as before.
I highly recommend following along with the [Google Colab project](https://github.com/akash-kaul/Using-scispaCy-for-Named-Entity-Recognition) as you read this section to fully understand what we are doing.
So, the first step is the same as before. We need to read in our data.
```
meta_df = pd. read_csv(“/content/metadata.csv”)
```
_Again use the specific path to the metadata file_
Next, we load in our models. For this example, we are going to use all 4 NER models, so you’ll need to install and import them if you haven’t already. Just follow the instructions as described earlier, then load them.
```
nlp_cr = en_ner_craft_md.load()
nlp_bc = en_ner_bc5cdr_md.load()
nlp_bi = en_ner_bionlp13cg_md.load()
nlp_jn = en_ner_jnlpba_md.load()
```
Next, we want to create an empty table that will store the entity and value pairs. The table will have 3 columns: “_doi”_, “_entity”_, and “_class”_. The table will be normalized so that the doi for every entity/class pair will be in the “_doi”_ column, even if that doi has already been listed. This is done so that there are no blank spaces in any of the columns, which helps if you want to use the data for other programs later. To create the table, you need to create a dictionary with 3 lists inside.
```
table= {“doi”:[], “Entity”:[], “Class”:[]}
```
Now is where things get a little complicated. We’ll start by looping over the entire file. To do this, we use the pandas _index_ function, which gives you the range of values (the number of rows. We then use the _itterrows()_ function to iterate over the entire file. So, your loop should look something like this.
```
meta_df.index
for index, row in meta_df.iterrows():
```
For each iteration of the loop, we want to extract the relevant abstract and doi. We also want to ignore any empty abstracts. The empty cells are stored as NaNs in Python, which have the type float.
```
text = meta_df.loc[index, “abstract”]
doi = meta_df.loc[index, “doi”]
if type(text) == float:
continue
```
_The continue statement ends the current iteration of the loop and moves on to the next one. This allows us to skip any rows with blank abstracts._
Now that we have our text, we need to use one of our models loaded earlier to extract the entities. If you view the code on Google Colab, this step is divided into several separate methods, but it can also be written without the use of any helper methods. Do note, however, that it is best to run the models one at a time, especially in Colab where reading and writing files take quite a long time. The aggregate code using one of the 4 NER models should look something like this:
```
doc = nlp_bc(text)
ent_bc = {}
for x in doc.ents:
ent_bc[x.text] = x.label_
for key in ent_bc:
table[“doi”].append(doi)
table[“Entity”].append(key)
table[“Class”].append(ent_bc[key])
```
_Remember that all of this code is inside the initial for loop_
This code might look scary, but in reality, it’s quite similar to what we’ve already practiced. We pass our text through a model, but this time instead of displaying the result using displacy, we store it in a dictionary. We then loop through the dictionary and append the results, along with the corresponding doi of the article we are looking at, to our table. We continue to do this, looping over every row in the file. Once the table is filled, and the for loop has ended, the last step is to create an output CSV file. Thanks to pandas, this is quite easy.
```
trans_df = pd.DataFrame(table)
trans_df.to_csv (“Entity.csv”, index=False)
```
You can choose any title for the output file, as long as it follows the format shown. Once your code is done running, the output file will show up in the “Files” section on Google Colab. You can then download the file and admire all of your hard work.
<figcaption>Example CSV output using the bc5cdr model(opened in Excel)</figcaption>
Alternatively, you can download all 4 output CSV files from [Gofile](https://gofile.io/d/mMh5zc).
### **Conclusion**
If you followed along with this post, Congratulations! You just made your first step in the world of scispaCy and NER for scientific documents; however, there’s so much more to explore. Within scispaCy alone, there are methods for abbreviation detection, dependency parsing, sentence detection, and much more. I hope you enjoyed learning a little about scispaCy and how it can be used for biomedical NLP, and I hope you all continue to play around, explore, and learn.
### **Resources:**
1. [https://uoa-eresearch.github.io/eresearch-cookbook/recipe/2014/11/26/python-virtual-env/](https://uoa-eresearch.github.io/eresearch-cookbook/recipe/2014/11/26/python-virtual-env/)
2. [https://github.com/akash-kaul/Using-scispaCy-for-Named-Entity-Recognition](https://github.com/akash-kaul/Using-scispaCy-for-Named-Entity-Recognition)
3. [https://pandas.pydata.org/pandas-docs/stable/getting\_started/install.html](https://pandas.pydata.org/pandas-docs/stable/getting_started/install.html)
4. [https://allenai.github.io/scispacy/](https://allenai.github.io/scispacy/)
5. [https://www.semanticscholar.org/cord19/download](https://www.semanticscholar.org/cord19/download)
6. [https://pandas.pydata.org/pandas-docs/stable/index.html](https://pandas.pydata.org/pandas-docs/stable/index.html)
* * * | akashkaul |
338,565 | Testes em Python - Parte 1: Introdução | Essa é a primeira parte da série de testes em Python. A primeira parte tem por objetivo fazer uma i... | 0 | 2020-05-19T01:22:52 | https://dev.to/womakerscode/testes-em-python-parte-1-introducao-43ei | python, testes, iniciante, womenintech |
Essa é a primeira parte da série de testes em Python.
A primeira parte tem por objetivo fazer uma introdução a testes automatizados utilizando o framework nativo do Python unnitest. Aqui, veremos alguns conceitos primordiais para escrever os primeiros casos de teste.
### Pré-requisito
- Conhecimento básico de Python
### Roteiro
1. O que são testes
2. Teste unitário (de unidade)
3. Conceitos
4. Exemplos
5. Considerações adicionais
6. Conclusão
---
## 1. O que são testes
### 1.1 Motivação
Ao escrever nossos programas, precisamos validar se o resultado que ele produz é o **correto**.
Se tratando dos primeiros programas que escrevemos, normalmente rodamos o nosso código e passamos diversos valores para verificar se o que ele retorna é o esperado. Quando isso não acontece, temos que fazer uma varredura pelo nosso código e tentar entender o que ocorreu. Pode ter sido exibido [algum erro ou exceção ao usuário](https://docs.python.org/3/tutorial/errors.html) ou o programa retornar o valor errado e não exibir erro nenhum (ocasionado por erro de lógica na maioria das vezes). Nos dois casos, podemos usar o [modo debug](https://docs.python.org/3/library/pdb.html) (que são facilitados por uma IDE¹) ou adicionar alguns *outputs* no terminal usando a função *print.* Com isso, podemos identificar o problema e corrigir nosso código para retornar o que é esperado. **Isso é um teste manual.**
> IDE¹ (Integrated Development Environment) do português ambiente integrado de desenvolvimento. É um ambiente que nos ajuda a desenvolver nossos códigos sendo possível não só utilizar como editor de texto, mas também facilitar execução, debbug e integração com outras ferramentas. Em Python, o [Pycharm](https://www.jetbrains.com/pt-br/pycharm/) é uma IDE muito utilizada e difundida.
Repare que isso se torna extremamente cansativo e está sujeito a falhas fazer validações dessa forma. Assim, não garantimos a qualidade do nosso programa de forma facilitada se mais funcionalidades forem adicionadas pois todas as vezes teríamos que executar nosso programa e verificar os cenários na mão.
### 1.2 Testes automatizados
Testes automatizados são cenários que escrevemos através de linha de código simulando os testes manuais que antes eram feitos. Poupando assim tempo e esforço nessas verificações.
Escrever testes automatizados vai muito além do que somente escrever cenários para validar que o código faça o que deveria fazer. O teste também nos ajuda a:
- Deixar o código mais limpo (ajuda na remoção de [code smell](https://www.quora.com/What-are-some-common-Python-code-smells-and-how-should-one-refactor-them))
- Garantir maior manutenção do código
- Servir como documentação: de forma visual conseguimos saber quais são os cenários esperados e os tratamentos em caso de erro olhando o arquivo de teste
- Evitar trabalho manual (um teste automatizado é muito melhor do que um teste manual com *print*)
- Evitar bug's
- Prover feedback para quem está desenvolvendo a aplicação: conseguimos saber se o programa está retornando o que é esperado mesmo alterando a lógica do programa principal.
## 2. Teste unitário
Um teste unitário é a maneira de você testar as pequenas unidades existentes em seu código. Também é chamado de teste de unidade.
Para nos ajudar com os testes, iremos utilizar o framework built-in (nativo) do Python chamado [unittest](https://docs.python.org/3/library/unittest.html).
**Exemplo 1:**
```python
from unittest import main, TestCase
def square(x):
return x ** 2
class TestSquare(TestCase):
def test_if_returns_square_of_2(self):
result = square(2)
expected = 4
self.assertEqual(result, expected)
if __name__ == '__main__':
main()
```
No exemplo acima, estamos testando uma pequena unidade do nosso código, estamos validando um cenário da função chamada **square**.
Repare que todo o contexto de teste está sendo utilizado dentro de uma [classe](https://docs.python.org/pt-br/3/tutorial/classes.html).
Mas, para entender melhor como funciona o exemplo acima, vamos primeiro entender alguns conceitos.
## 3. Conceitos
### 3.1 Preparação do teste
Nessa etapa é feita a preparação do ambiente para fazer o teste rodar. Essa preparação é chamada de **fixture** e consiste nos itens necessários para um ou mais testes serem executados.
- Exemplo: para conseguir testar uma função que lê um determinado arquivo precisamos de um arquivo no nosso ambiente de teste para ser possível fazer a validação
Pode conter o uso dos métodos [setUp() e tearDown()](https://riptutorial.com/python/example/13280/test-setup-and-teardown-within-a-unittest-testcase). Isso são ações que são executadas antes e depois, respectivamente, da execução de cada um dos cenários de teste.
### 3.2 Caso de teste
É o conjunto de cenários que queremos testar.
Em um caso de teste agrupamos todos os pequenos cenários que queremos validar de forma unitária que fazem parte do mesmo contexto.
Com o framework unittest, usamos uma classe base chamada **TestCase**.
### 3.3 Asserções
Asserções servem para validar que o cenário do seu código ocorreu como o esperado.
O **assert** é um comando built-in (nativo) do Python. E podemos usar da seguinte forma:
Repare que na primeira asserção é comparada se a soma de 1+1 é igual a 2. Como o resultado é verdadeiro, nada é exibido no console.
Já na asserção seguinte, há uma falha e um erro é levantado do tipo **AssertionError** (erro de asserção).
O framework **unittest** facilita nessas asserções que vamos precisar fazer. As asserções completas podem ser vistas em sua própria [documentação](https://docs.python.org/3/library/unittest.html#assert-methods).
### 3.4 Test Runner
Permite rodar a execução dos testes. O test runner orquestra a execução dos testes e exibe para o usuário os resultados.
Além de utilizar o [test runner do unittest](https://docs.python.org/3/library/unittest.html#command-line-interface) outros podem ser utilizados como o [pytest](https://docs.pytest.org/en/latest/usage.html).
### 3.5 Coverage
[Coverage](https://coverage.readthedocs.io/en/coverage-5.1/) remete a cobertura de testes, ou seja, o quanto o seu código está sendo testado.
Executando o coverage, conseguimos saber quais trechos de código foram testados e quais não foram.
**ATENÇÃO:** 100% de cobertura é diferente de ter todos os cenários testados! Além de testar o fluxo principal do programa também precisamos testar casos inesperados (veremos mais adiante na série "Testes em Python").
### 3.6 Mock
[Mock](https://docs.python.org/3/library/unittest.mock.html) é uma biblioteca utilizada em testes quando queremos simular um determinado comportamento. Mock em inglês é literalmente "imitar". Ele é bastante utilizado quando nosso código se comunica com elementos externos como por exemplo: conexão com o banco de dados e chamadas HTTP.
Se não for utilizado o mock, no momento que executarmos nosso código chamadas reais irão acontecer para a rede ou banco de dados, por exemplo (veremos mais adiante na série "Testes em Python").
## 4. Exemplos

Cat writing: show me the code!
### 4.1 Vamos entender o funcionamento do Exemplo 1
```python
from unittest import main, TestCase
def square(x):
return x ** 2
class TestSquare(TestCase):
def test_if_returns_square_of_2(self):
result = square(2)
expected = 4
self.assertEqual(result, expected)
if __name__ == '__main__':
main()
```
Na primeira linha importamos os itens necessários do framework unittest.
`main()` ⇒ chamamos o **Test Runner** da biblioteca para ao rodar nosso código Python (python meu_arquivo.py).
`TestCase` ⇒ fornece a estrutura necessária para montar o caso de teste.
```python
from unittest import main, TestCase
```
O próximo bloco se refere ao nosso código com o trecho que queremos validar
```python
def square(x):
return x ** 2
```
Criamos uma classe de teste herdando o `TestCase` do unittest e seus métodos são os **casos de teste**.
Repare que dentro da classe escrevemos de modo descritivo o cenário que está sendo testado (estamos testando se o nosso código retorna o quadrado de dois). Depois fazemos uma **asserção** usando `assertEqual` comparando se a chamada da função **square** retorna o esperado, que é 4.
```python
class TestSquare(TestCase):
def test_if_returns_square_of_2(self):
result = square(2)
expected = 4
self.assertEqual(result, expected)
```
**Nota:** Repare que o nome da classe e o cenário começam com a palavra "test". O nome "test" é obrigatório ser iniciado para as funções de teste, mas opcionais para a classe (no entanto é recomendado por questões de clareza).
Por fim, o último trecho chama o **main()** do unittest quando o arquivo python for executado.
```python
if __name__ == '__main__':
main()
```
Para rodar o exemplo basta rodar como um arquivo python normalmente (no meu caso eu salvei em um arquivo my_first_test.py)
```bash
python my_first_test.py
```
No console será exibido que 1 teste foi executado e ele está com o status OK, ou seja, o teste passou.

Vamos adicionar outro cenário de teste para simular um erro
```python
from unittest import main, TestCase
def square(x):
return x ** 2
class TestSquare(TestCase):
def test_if_returns_square_of_2(self):
result = square(2)
expected = 4
self.assertEqual(result, expected)
def test_if_returns_square_of_4(self):
result = square(4)
expected = 4
self.assertEqual(result, expected)
if __name__ == '__main__':
main()
```
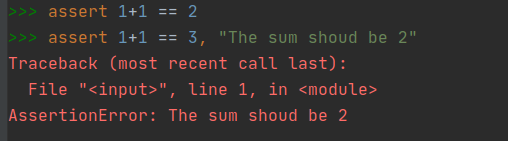
Executando novamente o código acima temos o seguinte retorno:
Repare que adicionando o cenário **test_if_returns_square_of_4** executamos no total 2 testes e justamente esse cenário falhou. Isso por que chamando a função **square** ela retorna 16 e estamos tentando validar que o esperado a ser retornado é 4.
Corrigindo o nosso código, ele deveria ficar da seguinte forma:
```python
from unittest import main, TestCase
def square(x):
return x ** 2
class TestSquare(TestCase):
def test_if_returns_square_of_2(self):
result = square(2)
expected = 4
self.assertEqual(result, expected)
def test_if_returns_square_of_4(self):
result = square(4)
expected = 16
self.assertEqual(result, expected)
if __name__ == '__main__':
main()
```
**Observação:** Os testes nos ajudam a identificar problemas no nosso código principal, mas o próprio cenário de teste também está suscetível a erros. Devemos sempre validar se o teste está bem escrito e se realmente testando o cenário esperado.
**Observação 2:** Note que existe outra forma de calcular o quadrado de um número. No exemplo acima calculamos como `x*x` mas perceba que se mudarmos a forma que é calculada para `x ** 2` o resultado retornado é o mesmo e isso não afeta os nossos testes. Se executarmos novamente veremos que os cenários continuarão passando.
Um teste não deve enviesar a forma como é implementado o código. Por isso se efetuarmos refatorações² no código, rodando os testes conseguimos garantir se o comportamento é o mesmo retornado pelo código anterior.
> Refatoração² é o efeito de você mudar a implementação do código sem afetar o seu retorno (comportamento externo). A implementação é mudada de forma que o código fique mais organizado, mais limpo e melhor estruturado.
**Nota:** É uma boa prática separar o código principal do código dos testes, veremos isso no próximo exemplo.
### 4.2 Detecção de divisão
O exemplo abaixo mostra uma função que detecta uma divisão. Se a divisão for possível deverá retornar **verdadeiro**, se não deverá retornar **falso**.
Essa função está armazenada dentro de um arquivo chamado **division_detect.py**
```python
def division_detect(numerator: int, denominator: int) -> bool:
if numerator / denominator:
return True
return False
```
*Código 4.2.1*
Vamos escrever um cenário de testes para essa função. Para isso, vamos criar um arquivo chamado **test_division_detect.py**
**Nota:** Apesar dos testes rodarem independente do nome do arquivo, é uma boa prática escrever o arquivo de teste começando com a palavra **"test"** assim como nossa classe.
O arquivo de teste possui o seguinte esqueleto:
```python
from unittest import TestCase
class TestDivisionDetect(TestCase):
def test_it_returns_true_if_division_by_number_is_successful(self):
pass
```
*Código 4.2.2*
Para escrever esse cenário de teste, queremos validar se a nossa função `division_detect` retorna `true` se a divisão for bem sucedida.
A questão é: qual número vamos usar para fazer esse teste? Poderíamos escolher dois números aleatórios como 10 para o numerador e 2 para o denominador. Importando a função e comparando se o resultado retornado é verdadeiro com a asserção `assertTrue` temos o seguinte cenário de teste:
```python
from unittest import TestCase
from division_detect import division_detect
class TestDivisionDetect(TestCase):
def test_it_returns_true_if_division_by_number_is_successful(self):
result = division_detect(
numerator=10, denominator=2
)
self.assertTrue(result)
```
*Código 4.2.3*
No teste acima, vamos validar se a divisão de `10/2` é considerada válida.
Vamos rodar o arquivo de teste com o comando abaixo:
```bash
python -m unittest test_division_detect.py
```
Como sabemos, o resultado da operação é 5 e `bool(5)` é verdadeiro
Veremos que um teste rodou e o resultado foi **OK** (o cenário de teste passou)

Mas, o que aconteceria se a gente mudasse o código principal no arquivo **division_detect.py** para esse código:
```python
def division_detect(numerator: int, denominator: int) -> bool:
if numerator == 10:
return True
return False
```
*Código 4.2.4*
Claro que aqui estamos forçando um pouco a barra e alterando completamente a lógica do código principal, mas se os testes forem executados novamente o teste vai passar.
Nesse caso o teste passou mas isso não é garantia que o cenário está sendo validado de fato. Para garantir que a divisão está sendo feita vamos gerar números aleatórios tanto para o numerador quanto para o denominador. Para isso vamos usar a função do python `randint`
```python
from random import randint
from unittest import TestCase
from division_detect import division_detect
class TestDivisionDetect(TestCase):
def test_it_returns_true_if_division_by_number_is_successful(self):
result = division_detect(
numerator=randint(0, 100000), denominator=randint(0, 100000)
)
self.assertTrue(result)
```
*Código 4.2.5*
Repare que tanto para o numerador como para o denominador está sendo gerado números aleatórios entre 0 e 100000 e se executarmos novamente o arquivo **division_detect.py** que foi escrito no **Código 4.2.4** vamos ver que o código não vai passar. Vamos voltar o código para que fique o mesmo do **Código 4.2.1**.
Olhando novamente para o cenário de teste, o que aconteceria se o denominador sorteado fosse 0?

É, aqui temos um problema. A divisão de qualquer número por zero é **indefinida**!*
> *[Divisão por zero é uma operação que tende ao infinito e portanto é dada como indefinida.](https://pt.khanacademy.org/math/algebra/introduction-to-algebra/division-by-zero/v/why-dividing-by-zero-is-undefined)
Vamos adicionar um novo cenário de teste para validar isso, dessa vez vamos forçar que o denominador seja zero.
```python
from random import randint
from unittest import TestCase
from division_detect import division_detect
class TestDivisionDetect(TestCase):
def test_it_returns_true_if_division_by_number_is_successful(self):
result = division_detect(
numerator=randint(0, 100000), denominator=randint(0, 100000)
)
self.assertTrue(result)
def test_it_returns_false_if_division_by_number_is_not_possible(self):
result = division_detect(numerator=randint(0, 100000), denominator=0)
self.assertFalse(result)
```
*Código 4.2.6*
Rodando novamente esse arquivo de testes, vamos receber o seguinte retorno
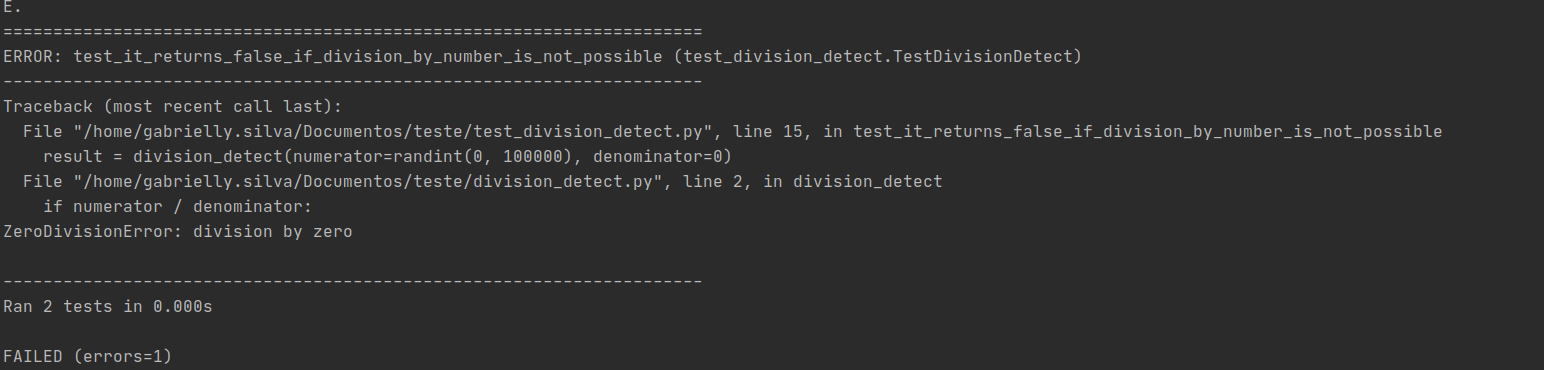
Repare que dois testes foram executados, o que é correto pois escrevemos dois cenários de teste. Mas um dos testes, o `test_it_returns_false_if_division_by_number_is_not_possible`, falhou. Isso pois aconteceu um erro chamado `ZeroDivisionError` (https://docs.python.org/3/library/exceptions.html#ZeroDivisionError).
Olhando nosso código principal, vemos que não está sendo feito nenhum tipo de tratamento para esse erro. Vamos refatorar então o nosso código para lidar com esse erro, para isso vamos usar o [statement try/except do Python](https://docs.python.org/3/tutorial/errors.html#handling-exceptions).
```python
def division_detect(numerator: int, denominator: int) -> bool:
try:
numerator / denominator
except ZeroDivisionError:
return False
else:
return True
```
*Código 4.2.7*
No código acima primeiro tentamos fazer a divisão entre os dois parâmetros recebidos, se a operação for bem sucedida irá retornar `True`, mas se acontecer uma exceção do tipo `ZeroDivisionError` irá retornar `Falso`.
Rodando novamente os testes com `python -m unittest test_division_detect.py` vamos ver que os dois cenários passaram.
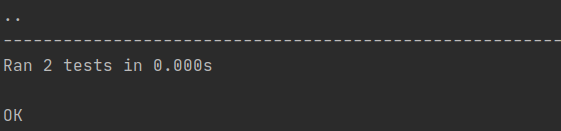
**Nota:** Repare que nosso código original não estava preparado para uma divisão por zero. Isso é chamado de corner case, ou seja, são cenários que podem acontecer fora do padrão esperado. Para tratar esse cenário tivemos que adicionar um tratamento com as exceções do Python.
No arquivo de teste, para os dois cenários que estamos testando, estamos repetindo `randint(0, 100000)` . Como queremos pegar sempre um numerador aleatório para todos os testes, podemos utilizar o `setUp()`(https://docs.python.org/3/library/unittest.html#unittest.TestCase.setUp) que é uma inicialização que é executada sempre no início de cada cenário de teste.
Por fim, chegaremos ao código abaixo:
```python
from random import randint
from unittest import TestCase
from division_detect import division_detect
class TestDivisionDetect(TestCase):
def setUp(self) -> None:
self.random_numerator = randint(0, 100000)
def test_it_returns_true_if_division_by_number_is_successful(self):
result = division_detect(
numerator=self.random_numerator, denominator=randint(1, 100000)
)
self.assertTrue(result)
def test_it_returns_false_if_division_by_number_is_not_possible(self):
result = division_detect(numerator=self.random_numerator, denominator=0)
self.assertFalse(result)
```
Repare que o denominador no primeiro cenário sorteia um número entre 1 e 100000, pois estamos querendo validar um cenário onde a divisão é bem sucedida.
## 5. Considerações adicionais
Aqui, listo alguns pontos que devem ser levados em consideração no momento de programar e testar seus códigos:
- Divida para conquistar: Mantenha a estrutura de arquivos organizadas. Se um projeto é grande, é sempre uma boa prática dividir em arquivos menores (isso facilita a manutenção e legibilidade)
- Um teste também deve ser limpo igual ao código principal (Clean Code - Robert C. Martin)
- Use nomes descritivos para as funções de teste, mesmo que seja um nome muito longo
- Pense em corner cases (cenários fora do padrão esperado), igual fizemos na divisão por zero no exemplo 2
- Um teste não deve engessar a implementação do seu código, igual vimos no exemplo 1 (o quadrado de um número pode ser feito de duas formas)
- Escrever em pequenas unidades ajudam a testar o código e a melhorar sua clareza
- Refatore: Sempre que puder melhorar seu código melhore! (Lema de escoteiro)
De acordo com a [PEP20](https://www.python.org/dev/peps/pep-0020/#id3)³:
> Errors should never pass silently
PEP³ (do inglês (Python Enhancement Proposals) se refere a propostas de como utilizar o Python da melhor forma: https://www.python.org/dev/peps/
## 6. Conclusão
Testes são uma maneira de garantir que o seu programa **retorna o** **resultado esperado.** Além disso, garante maior qualidade no produto que está sendo entregue. Os testes também ajudam que a equipe de desenvolvedores entendam os cenários que acontecem na aplicação e ajudam a identificar cenários fora do padrão. Testando nosso código, conseguimos encontrar também maneiras de deixar nosso código mais limpo e conciso, facilitando assim na manutenção futura e a evitar bugs que possam ocorrer. É melhor que um teste pegue o erro do que o cliente usando o seu produto :)
Essa foi a primeira série de Testes em Python, espero que tenha ficado claro o entendimento dessa introdução e em breve teremos mais publicações sobre esse assunto. Dúvidas podem ser colocadas no comentário e lembre-se que testar faz parte do processo de escrever um bom código, segundo o programador Pete Goodliffe
> "Um bom código não surge do nada. [...] Para ter um bom código é preciso trabalhar nele. Arduamente. E você só terá um código bom se realmente se importar com códigos bons."
Como Ser Um Programador Melhor: um Manual Para Programadores que se Importam com Código (Pete Goodliffe)
 | gabriellydeandrade |
338,601 | blah | A post by Tod Sacerdoti | 0 | 2020-05-19T03:16:05 | https://dev.to/tod/this-article-updates-itself-44ao | tod | ||
344,580 | Contact Tracing and Exposure Notification | When Google and Apple announced in April that they would be working together on a contract tracing AP... | 0 | 2020-05-27T00:58:36 | http://www.thagomizer.com/blog/2020/05/26/contact-tracing-and-exposure-notification.html | covid19 | ---
title: Contact Tracing and Exposure Notification
published: true
date: 2020-05-27 00:17:45 UTC
tags: COVID-19
canonical_url: http://www.thagomizer.com/blog/2020/05/26/contact-tracing-and-exposure-notification.html
---
When Google and Apple announced in April that they would be working together on a contract tracing API, a lot of people got concerned about privacy. Today, I’m going to try to explain how these apps work so that people can make an informed decision about the technology. Personally, if an app using this technology becomes available for my area, I’ll install it.
## Dispelling Misconceptions
First, Apple and Google aren’t making apps. Instead, they are working together to build core technology to make it easier for public health authorities to build apps for their local area. By working together, they can ensure that everyone can get important health information no matter what phone they have.
Second, the Google and Apple joint effort doesn’t use location data[1]. Some COVID related health apps use [location data](https://9to5mac.com/2020/05/13/utah-dismisses-covid-19-exposure-api-from-apple-and-google-opts-for-location-based-solution/), but this project does not. To understand why location data via GPS isn’t ideal, think about how often the GPS in your phone is off by a block. Also, location data can’t differentiate between someone on the 1st floor of a building and the 15th floor of a skyscraper. That difference could be relevant for COVID-19 exposure.
The Apple and Google effort uses Bluetooth. Bluetooth works well over the distances health experts say are relevant when determining COVID-19 exposure. Bluetooth also works in cell phone and GPS dead zones. Like subway stations, basements, parking garages, and offices and houses like mine that don’t have a strong cell or GPS signal. Also, the signal strength of the Bluetooth connection can be used to approximate the distance between two phones to determine if they are close enough that COVID transmission is likely.
Finally, you must actively consent to have your data shared. By default, all the data stays on your device. Data is only shared if you get sick and you tell the app to share your data, which it does anonymously.
If you are curious, here is [Google’s Explanation](https://blog.google/documents/66/Overview_of_COVID-19_Contact_Tracing_Using_BLE_1.pdf) of the API and [Apple’s FAQ](https://covid19-static.cdn-apple.com/applications/covid19/current/static/contact-tracing/pdf/ExposureNotification-FAQv1.1.pdf).
## So How Does It Work?
So if these apps don’t use location data, how do they work?
First, you have to install an app from your local health department. Your phone won’t get the exposure notification application automatically.
Once you install the app, your phone starts broadcasting a random code via Bluetooth to anyone nearby who also has the app installed. This code changes a couple of times an hour as an additional privacy measure. Your phone keeps track of which codes it has broadcast.

Your phone is also listening for any other phones nearby that are broadcasting codes. It records all the codes it “hears.”
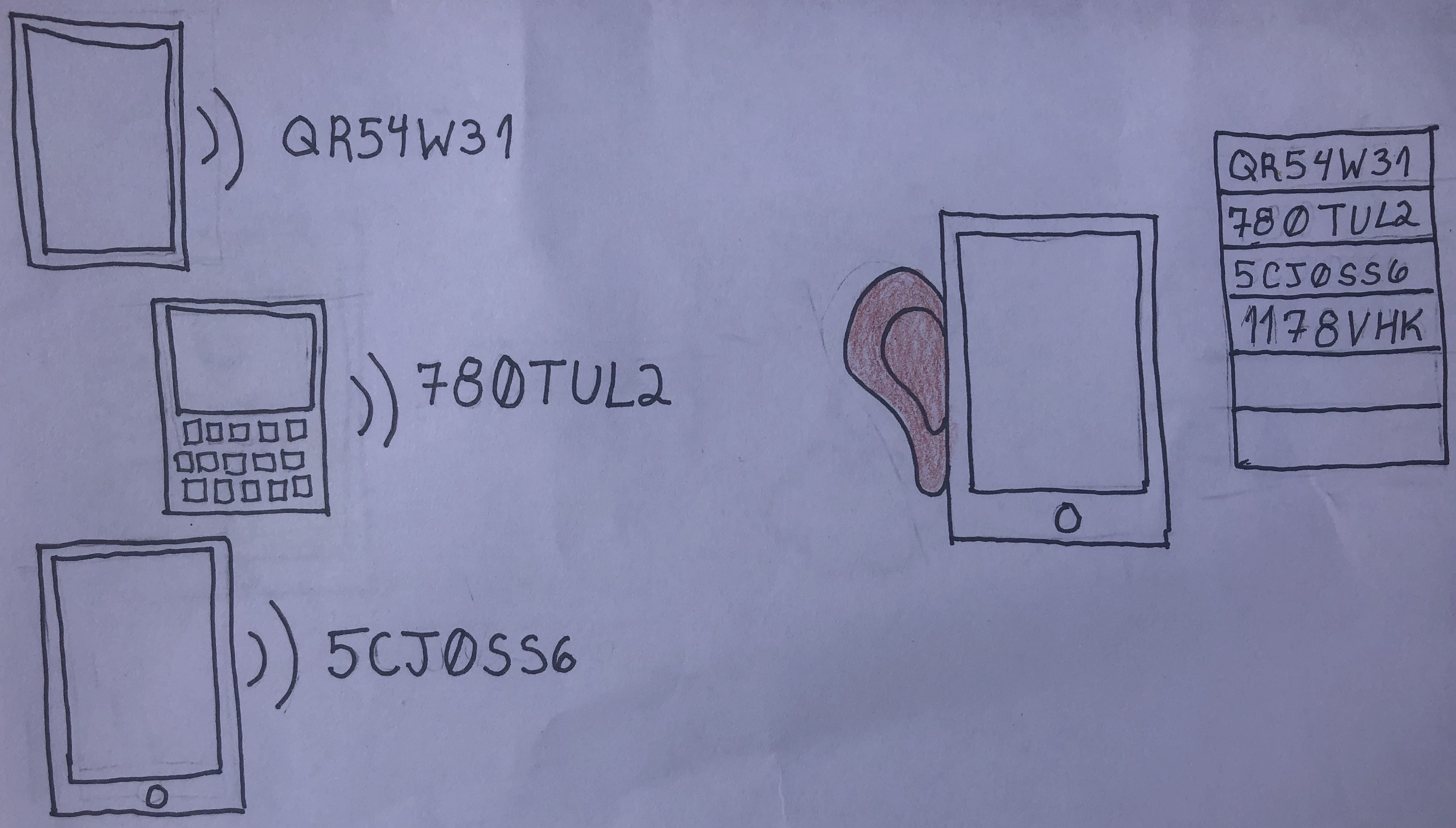
Once a day or so, the app on your phone contacts the cloud. It downloads a list of these random codes that were broadcast by the phones of people diagnosed with COVID-19. It compares that list to the list of codes it has “heard.” If there’s a match, the app shows you an alert saying you may have been exposed to COVID-19 and gives you instructions about how to proceed.

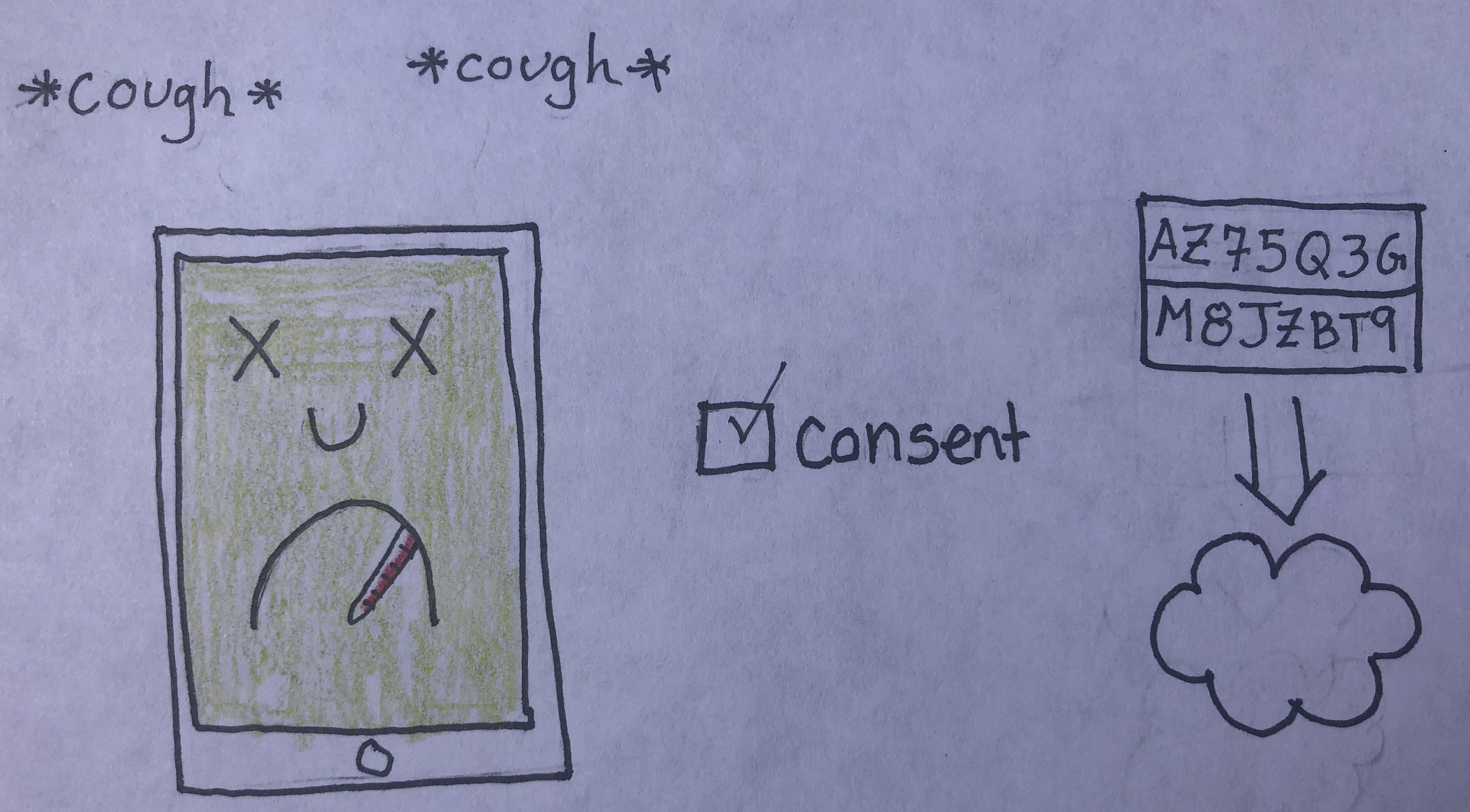
If you get diagnosed with COVID-19, you can open up the app and volunteer to share all the codes your phone has broadcast for the last 14 days. If you volunteer this info, the list of codes gets uploaded to servers in the cloud. None of your personally identifying information is shared, just the codes.
## Summary
To summarize the essential points:
- The exposure notification software Google and Apple are cooperating on does not use location data.
- No personally-identifying information is shared.
- No data leaves your phone without your consent.
- You choose whether or not to share your COVID-19 diagnosis, and if you do, it’s done so anonymously.
The main downside I see to these apps is that they need as many people as possible to install them to be effective. My goal for this blog post is to explain the technology so that people can make an informed decision about whether to install the app for their region. I’ll be installing it, and I hope many others do as well.
* * *
[1] The [terms of service](https://blog.google/documents/72/Exposure_Notifications_Service_Additional_Terms.pdf) for the Exposure Notification API explicitly prevent apps from using location data. Apps also must be endorsed by a government health authority. Apps will not be available in the relevant store if they don’t meet terms of service. | thagomizer |
344,653 | Timer - tjctf | This one is a cool blacklist bypass. It's pretty simple. You are presented a text interface asking yo... | 0 | 2020-05-27T03:48:40 | https://cheuksblog.ca/writeup/2020/05/26/timed-tjctf.html | security, ctf | This one is a cool blacklist bypass. It's pretty simple. You are presented a text interface asking you to enter a python command.
```console
Type a command to time it!
```
Trying some simple functions seem to work fine, but....
```console
Type a command to time it!
print(1)
Runtime: 1.09672546387e-05
Type a command to time it!
import os
Hey, no hacking!
```
...there seems to be a blacklist of characters that get screened before the command is run. We must obfuscate it somehow. By digging around, we can see exactly what is in the blacklist and what isn't in the blacklist. Most peculiarly, `timeit` is **NOT** in the blacklist.
> Sidenote: it is hinted that `timeit` could be a possibility because it is visible in the source whenever we provide invalid python code for the program to execute.
```console
Type a command to time it!
arst
Traceback (most recent call last):
File "/timed.py", line 36, in <module>
time1=t.timeit(1)
File "/usr/lib/python2.7/timeit.py", line 202, in timeit
timing = self.inner(it, self.timer)
File "<timeit-src>", line 6, in inner
arst
NameError: global name 'arst' is not defined
Runtime: 0
Type a command to time it!
12.,,
Traceback (most recent call last):
File "/timed.py", line 31, in <module>
t=timeit.Timer(res)
File "/usr/lib/python2.7/timeit.py", line 129, in __init__
compile(setup + '\n' + stmt, dummy_src_name, "exec")
File "<timeit-src>", line 2
12.,,
^
SyntaxError: invalid syntax
```
We can do something like the following in order to trick the program into executing blacklisted commands:
```python
# We want to execute the following python
want_exec = 'import pty;pty.spawn("/bin/bash")'
# So we obfuscate it a bit
obfuscated = [ord(x) for x in want_exec]
# and we can just reverse it using a join-map
assert want_exec == ''.join(map(chr, obfuscated))
# Payload:
timeit(''.join(map(chr, [105, ...])))
```
By pasting the payload into the program, we get a shell:
```console
Type a command to time it!
timeit(''.join(map(chr, [105, ...])))
bash: /root/.bashrc: Permission denied
nobody@c51f99923c23:/$ ls
ls
bin dev flag.txt lib media opt root sbin sys tmp var
boot etc home lib64 mnt proc run srv timed.py usr
nobody@c51f99923c23:/$ cat flag.txt
cat flag.txt
tjctf{iTs_T1m3_f0r_a_flaggg}
```
| csys |
344,658 | Makefile Application Presets | We saw in the last post how to use Makefile wildcards to write targets like this: migrate-to-%:... | 0 | 2020-05-27T04:08:23 | https://www.robg3d.com/2020/05/makefile-application-presets/ | make, programming, cli | ---
title: Makefile Application Presets
published: true
date: 2020-05-26 13:30:21 UTC
tags: make, programming, cli
canonical_url: https://www.robg3d.com/2020/05/makefile-application-presets/
---
We saw in the [last post](https://lithic.tech/blog/2020-05/makefile-wildcards) how to use Makefile wildcards to write targets like this:
```
migrate-to-%:
@bundle exec rake migrate[$(*)]
guard-%:
@if [-z '${${*}}']; then echo 'ERROR: variable $* not set' && exit 1; fi
logs: guard-STACK
@awslogs get -w /ecs/$(STACK)_MyService
```
So that we can build CLIs like this:
```
$ make migrate-to-50
Migrating to version 50...
$ make logs
ERROR: variable STACK not set
$ STACK=qa make logs
...
```
(Note the `@` prefix on commands in the Makefile, it avoids the line being echoed to stdout)
This is neat but it only works well for user-supplied values, like `"50"`.There are cases where we want the user to supply an **argument** , but not the **value**.Say, for example, users want to specify ‘production’ to ‘staging’but we don’t want them to remember the URL to the server.
We can use wildcards to dynamically select a Make variable:
```
staging_url:=https://staging-api.lithic.tech
production_url:=https://api.lithic.tech
ping-%:
curl "$($(*)_url)"
```
And we can use it as so:
```
$ make ping-staging
curl "https://staging-api.lithic.tech"
```
Okay, this example isn’t incredibly useful.But for some clients, we have multiple deployed versions of the same application,and we can use these variables to avoid having to remember where applications are deployed.
For example, let’s say we have 3 versions of a codebase deployed in Heroku: one staging and two production apps.In the Make snippet below, each `_app` variable refers to the name of a Heroku app.We can use that app name to get the database string using the Heroku CLI,and pass that to `psql` (Postgres CLI).
```
staging_app:=lithic-api-staging
production-pdx_app:=lithic-api-production
production-nyc_app:=lithic-api-production-nyc
psql-%:
psql `heroku config:get DATABASE_URL --app=$($(*)_app)`
```
Now to connect to staging, it’s as simple as:
```
$ make psql-staging
```
If we use Heroku’s Review Apps, we should also support an environment-variable version of these sorts of commands,since the app names are ephemeral. Instead of a wildcard, we’ll require the `APP` environment variable is set:
```
psql-app: guard-APP
psql `heroku config:get DATABASE_URL --app=${APP}`
```
## Putting It All Together
The example above has a couple small error cases that may confuse users:if `psql` or `heroku` are not on the `PATH`,the command will error with a sort of cryptic error:
```
$ make psql-staging
psql `heroku config:get DATABASE_URL --app=lithic-api-staging`
/bin/sh: heroku: command not found
could not connect to server: No such file or directory
```
Yuck! Can we use something like our lovely `guard-%` target to declare our executable dependencies?
**_You bet we can!_**
```
cmd-exists-%:
@hash $(*) > /dev/null 2>&1 || \
(echo "ERROR: '$(*)' must be installed and available on your PATH."; exit 1)
guard-%:
@if [-z '${${*}}']; then echo 'ERROR: environment variable $* not set' && exit 1; fi
psql-%: cmd-exists-heroku cmd-exists-psql
psql `heroku config:get DATABASE_URL --app=$($(*)_app)`
psql-app: guard-APP cmd-exists-heroku cmd-exists-psql
psql `heroku config:get DATABASE_URL --app=${APP}`
```
Now if you’re missing `heroku` or `psql`, you get a nice message:
```
$ make psql-staging
ERROR: 'heroku' must be installed and available on your PATH.
```
Who knew Make could be so _fun_ to use?
## Not done with Make yet
We’ll have one more blog post involving Make next week, along with a dump of a bunch of useful Makefile helpers.Stay tuned!
_This was originally posted on my consultancy’s blog, at [https://lithic.tech/blog/2020-05/makefile-apps](https://lithic.tech/blog/2020-05/makefile-apps). If you have any questions, please leave a comment here!_ | robgalanakis |
344,665 | Visualizing the power of CSS Filters using Picturesque.css | Hey folks! How you doing? I was quite busy recently focusing all my efforts into making this app wor... | 0 | 2020-05-27T05:16:53 | https://dev.to/thebuildguy/visualizing-the-power-of-css-filters-using-picturesque-css-o2 | showdev, css, javascript, codenewbie | Hey folks! How you doing?
I was quite busy recently focusing all my efforts into making this app work! I know the name sounds terrific, but that's actually what the app is all about.
{% twitter 1265332914125930497 %}
# 🤷♂️ What is Picturesque.css?
Picturesque is an online tool that provides a convenient interface to visualize your images with CSS filter effects and get the corresponding CSS styles after the filters have been applied. And that's it.

## 💁♂️ What it's built using?
Well, it's pretty much a beginner's stack, as I wanted to use what I learned, to build something from scratch. Yes, it's good old **HTML, CSS (Sass) and JS (jQuery)**.
## 🙌 Who does it help?
Almost about anyone, starting to learn the powers of CSS Filters and also people who used to spend a lot of time earlier getting the right %'s of `brightness` or `blur` to their images!

## 🤘 How can I access it?
It's proudly hosted on amazing **[Vercel](https://vercel.com/).** You can watch the live site, **[Picturesque](https://picturesque-css.now.sh/)**.
## ⭐ Is it Open Source?
Hell yeah, it's at the heart of every software. Here's a link to its source code, at GitHub. Make sure to give it a ⭐ if its something you liked!
{% github heytulsiprasad/picturesque.css %}
# 🎉 Contribute
If you are having any dope ideas to improve this *(even as little as changing the font-face)*, don't think twice, the repo is very **beginner-friendly. (**I'm too **😅)** Go ahead, create an issue, and start working or let me know at Twitter [@heytulsiprasad](https://twitter.com/heytulsiprasad). | thebuildguy |
344,727 | [Question] Dev API podcast URL | Hi everyone, Just a quick question regarding the DEV API. Is there any method to get the URL of a po... | 0 | 2020-05-27T07:53:30 | https://dev.to/cristianionut/question-dev-api-podcast-url-2g50 | Hi everyone,
Just a quick question regarding the DEV API.
Is there any method to get the URL of a podcast?
Based on the docs you can get the relative path of an episode, but I would also like to get the URL of the stream.
This is the model of a podcast episode that I can get right now from https://dev.to/api/podcast_episodes:
```json
{
"type_of": "podcast_episodes",
"id": 13894,
"path": "/codenewbie/s11-e7-why-site-reliability-is-so-important-molly-struve",
"image_url": "https://dev-to-uploads.s3.amazonaws.com/uploads/podcast/image/2/9f50a462-9152-429a-b15e-d024baaa8e01.png",
"title": "S11:E7 - Why site reliability is so important (Molly Struve)",
"podcast": {
"title": "CodeNewbie",
"slug": "codenewbie",
"image_url": "https://dev-to-uploads.s3.amazonaws.com/uploads/podcast/image/2/9f50a462-9152-429a-b15e-d024baaa8e01.png"
}
}
``` | cristianionut | |
344,845 | Top 6 Unique Reasons Why Need To Hire Android App Developer | Biggest and major companies in mobile industry and technology – Apple and Google are continuously int... | 0 | 2020-05-27T13:06:26 | https://dev.to/dannyroot/top-6-unique-reasons-why-need-to-hire-android-app-developer-d75 | Hokuapps | <p style="text-align: justify;">Biggest and major companies in mobile industry and technology – Apple and Google are continuously introducing new innovations and advancements to dominate the mobile industry. In this era, mobile application development (Android and iPhone apps) are emerging through different sectors especially in most businesses, brands, and other larger industry. Both of these major mobile platforms are competing with each other but only shares one goal – to contribute a more futuristic approach to every task of human life.</p>
<p style="text-align: justify;">According to data gathered from statistic reports, Android users are continuously increasing and contributing to the market for about 80% at a much higher rate compared to iOS which is only 17%. So, if you’re business doesn’t have an Android application yet, then now is time to consider hiring Android app developers.</p>
<p style="text-align: justify;">In this article, let’s tackle the top reasons that will prove how important and beneficial it is to hire android app programmers from an Android app development company.</p>
<p style="text-align: justify;">Let’s get started.</p>
<p style="text-align: justify;"><strong>#1: Customer convenience</strong></p>
<p style="text-align: justify;">It is true that having a mobile application for your business can contribute its overall success and increase in profitability. The fact that many people use their smartphones is to fulfill their general needs in terms of transactions and communications. With these benefits such as online shopping, location finding using Google Maps, or just searching solutions or knowledge, the need for Android OS devices is also increasing.</p>
<p style="text-align: justify;">Android application is a great way to communicate with other people for a different location, sharing contents such as images, videos, or documents, and so much more. So, if you’re planning to create successful Android applications, you should consider hiring an experienced Android app developer.</p>
<p style="text-align: justify;"><strong>#2: Revenue and Sales increase</strong></p>
<p style="text-align: justify;">Of course, the main and sole goal of building a business is to make more money. Taking advantage of the use of mobile applications could surely increase your business profitability in terms of sales and revenue. Creating a perfect business-centric and market-centric application can be quite difficult which is why it is beneficial for your business to hire Android app developers to achieve your goals.</p>
<p style="text-align: justify;">Aforementioned, having a mobile application for your business has now become mandatory. So, you’ll want to consider hiring an Android app developer to provide you a successful application. This could pave your way through a greater chance of sale and customer experience in your business as well.</p>
<p style="text-align: justify;"><strong>#3: Ease of Accessibility</strong></p>
<p style="text-align: justify;">Nowadays, more and more manufacturers are integrating the open-source platform ability of Android. Besides, there are also several mobile application stores that allow the users to purchase and download any Android apps for their devices that use the Android platform. Google play, for instance, is the counter-part of Apple’s app store, but this market is made available for other developers who can contribute to the improvement of the existing mobile app.</p>
<p style="text-align: justify;"><strong>#4: Multiple version and devices support</strong></p>
<p style="text-align: justify;">In the iOS platform, 5 main devices can support iOS applications. While Android applications can be compatible with over 170 types of devices. Which is why it is very important to choose and hire Android app developer that has the ability to develop an app that can be used on any devices regarding its version and screen sizes.</p>
<p style="text-align: justify;">It is also important to make a thorough research while selecting a certain version for the developed app. hiring a developer from trusted mobile application development companies like <a href="https://www.thedigitalenterprise.com/articles/ai-chatbots-machine-learning/5-ways-hokuapps-transforming-an-app-development-industry-with-ai/" target="_blank">HokuApps</a> can let you know if there any issues of the development of the Android application.</p>
<p style="text-align: justify;"><strong>#5: Great user experience</strong></p>
<p style="text-align: justify;">One of the major goals of having a mobile application whether it is an iOS or Android app is the user experience. In order to achieve this goal, it is very important to choose the right and suitable Android application developer that is aware of the user’s behavior and preferences as well. This will allow you to create a list of detailed information about the features of your app.</p>
<p style="text-align: justify;"><strong>#6: Concerns about Security</strong></p>
<p style="text-align: justify;">With the fact that the Android platform is an open source technology, more and more developers are continuously improving its security issues. Hiring Android app developers that have proper training, certifications, credibility, and skill can help you address these issues concerning your app’s security.</p>
<p style="text-align: justify;">There are many professionals out there that could help you in your next mobile app projects. HokuApps is a Singapore-based Android and iOS application development company that can transform your ideas into reality.</p>
<p style="text-align: justify;"><strong>Conclusion:</strong></p>
<p style="text-align: justify;">When it comes to hiring an Android application developer, it is important to make a thorough research and having a focus on the core area of your business in order to know what type of Android application should you develop. Leave it to the experts and professional developer from Techtechnology, Singapore.</p>
<p style="text-align: justify;">Are you ready for your first mobile application for your business? If yes, then contact Techtechnology, Singapore now.</p>
<p style="text-align: justify;"><strong>Related Links:</strong><br /><a href="https://www.einnews.com/pr_news/492207304/hokuapps-automation-platform-helps-improve-efficiency-for-the-field-service-industry" target="_blank">HokuApps Automation Platform helps Improve Efficiency for the Field Service Industry</a> <br /><a href="https://www.prnewswire.com/news-releases/hokuapps-redefines-enterprise-mobility-for-roofing-southwest-300658333.html" target="_blank">HokuApps Redefines Enterprise Mobility for Roofing Southwest</a> <br /><a href="https://www.prnewswire.com/news-releases/hokuapps-iphone-apps-development-services-promise-fastest-app-development-300622874.html" target="_blank">HokuApps iPhone Apps Development Services Promise Fastest App Development</a> <br /><a href="https://www.cloudexpoasia.com/exhibitors/hokuapps" target="_blank">HokuApps – Cloud Expo Asia Singapore 2019</a> </p>
<p style="text-align: justify;">Visit Hokuapps on <a href="https://twitter.com/HokuApps" target="_blank">Twitter</a> And Watch Video of <a href="https://youtu.be/h2TI4yGS_8A" target="_blank">Hokuapps</a></p> | dannyroot |
344,872 | Choose Distroless containers by default | I have been using Distroless containers for a little over a year now, and they're awesome! They're se... | 0 | 2020-05-29T13:59:30 | https://dev.to/jacobfrericks/choose-distroless-containers-by-default-19oi | containers, docker, devops, security | ---
title: Choose Distroless containers by default
published: true
description:
cover_image: https://tr1.cbsistatic.com/hub/i/r/2017/04/06/6f6fb9b1-b297-464d-a0e0-48b366745fe2/resize/770x/e75cd06318a179e5041993a6a8034df6/dockersechero.jpg
tags: containers, Docker, devops, security
---
I have been using Distroless containers for a little over a year now, and they're awesome! They're secure, easy to use, and smaller than your average container. So why don't I see them being used more often? Let's take a look!
# What is Distroless?
Distroless containers are based off of the Debian container, but they are very different from Ubuntu. First of all, Google manages these containers. That means you can rely on them to mow the lawn, pull the weeds, and remove newly discovered vulnerabilities.
Second difference is there are [specific containers for specific languages](https://console.cloud.google.com/gcr/images/distroless/GLOBAL). As of now, they have dotnet, java, node, rust, and golang (which just runs on the base distroless image). Why have specific containers for specific images? Why not install them all on one container? Besides the size problem, Google has removed 90% of the container and have kept only what is required to run the specific language. This greatly removes the amount of vulnerabilities that can be found in the container. For instance, let's say someone is able to exec into your container and they want to run a command. Guess what? There's no shell. Let's say a vulnerability has been found in a library in Debian. Chances are that the library doesn't exist in Distroless. It would be like if you only used your place of residence for sleeping. You don't need a kitchen, basement, living room, tv, etc. So why pay for a full house? This is how it is when you use a full container for simply running an app.
# Advantages of Distroless
As I already mentioned, someone the size of Google is maintaining these containers, so you can bet they are kept up to date. They have publicly said that they use them internally, and just expose them for everyone else. There is a team constantly updating them, so they're going to stick around.
I know some people got a bad taste when I said that these are Google containers. Let me help put your mind at ease.
1. Google doesn't install anything on these containers. There's no Google Play Services on these containers. It's open source, so if you want to verify for yourself, [have at it](https://github.com/GoogleContainerTools/distroless).
1. I know Google has a reputation of trying things for a while, then just dropping them. While I don't think this would happen (Google has taken security seriously in the past, and they want their own containers to be secure), it is a very easy migration to another container. I was able to just change the base image of my Java application to the OpenJDK image, and run a java command at the end, and it worked just fine. This can also be done if you simply don't want the weighted blanket of Distroless helping you sleep at night anymore. The migration process is very simple.
# Disadvantages of Distroless
That all sounds perfect... why aren't they used everywhere? There are some disadvantages.
1. You cannot install anything else with your app. You want to install something to assist with some metrics? Sorry, not in this container. Does your security want to install something on everyone's container? Sorry, not here! (is that a disadvantage?) Many of these things can be made up if you host on a PaaS, however.
1. One of my biggest issues with Distroless came when attempting to publish to AWS. AWS does not expect to not have a shell in a container, so it's health checks start failing. I'll go into how I fixed this in a future post (stay tuned!)
1. You can only use the versions of each language they provide. Do you want to use Java 6? They don't support that. What about Java 14? Sorry, only 8 and 11 [are supported right now](https://github.com/GoogleContainerTools/distroless/issues/459).
1. You can use one and only one language. I came across someone who wanted to use both python and java in the same container. That won't work with distroless!
# How to use Distroless?
Using a distroless image is very simple, but it might be a little confusing at first. How can I start a Java app (for example) if I can't run any java commands (it requires a shell to run "java -jar xxx.jar", remember?) Luckily, they have excellent documentation. Here's an example, as well as the links to other examples:
```
FROM gcr.io/distroless/java:11
COPY ./main.jar /app
WORKDIR /app
CMD ["main.jar"]
```
The container is set to run the equivalent of "java -jar" already, it just needs the path to your jar in a CMD. Here are the official examples:
* [dotnet](https://github.com/GoogleContainerTools/distroless/blob/master/examples/dotnet/Dockerfile)
* [golang](https://github.com/GoogleContainerTools/distroless/blob/master/examples/go/Dockerfile)
* [java](https://github.com/GoogleContainerTools/distroless/blob/master/examples/java/Dockerfile)
* [nodejs](https://github.com/GoogleContainerTools/distroless/blob/master/examples/python3/Dockerfile)
* [python](https://github.com/GoogleContainerTools/distroless/blob/master/examples/python3/Dockerfile)
* [rust](https://github.com/GoogleContainerTools/distroless/blob/master/examples/rust/Dockerfile)
Questions? Comments? Concerns? Let me know! | jacobfrericks |
344,873 | JAM Stack Conference is live! | Hi everyone, the JAM Stack Conf' is live right now. https://jamstackconf.com/ | 0 | 2020-05-27T13:55:32 | https://dev.to/bernardbaker/jam-stack-conference-is-live-5f1l | beginners | Hi everyone, the JAM Stack Conf' is live right now.
https://jamstackconf.com/ | bernardbaker |
344,897 | Get Chrome To Show The Full URL In The Address Bar | Hey Devs 👋, Has the address bar change been frustrating you because you can't see the full URL anym... | 0 | 2020-05-27T14:47:35 | https://dev.to/frontenddude/get-chrome-to-show-the-full-url-in-the-address-bar-ag9 | chrome, tutorial, browsers, tips | Hey Devs 👋,
Has the address bar change been frustrating you because you can't see the full URL anymore? Here is a handy tip to get it back, including the protocol.
1. Enable chrome://flags/#omnibox-context-menu-show-full-urls
2. Right click the address bar
3. Select 'Always show full URLs'
---
For more awesome tips about FrontEnd dev follow me:
💙[Twitter](https://www.twitter.com/frontenddude)
🖤[Dev.to](https://dev.to/frontenddude)
| frontenddude |
344,963 | 🛑🛑 Advice to Software Tester Before Starting API Testing 🛑🛑 | In this video of 30 Days of API Testing Challenge, I am going to discuss Advice to Software Tester Be... | 0 | 2020-05-27T16:48:40 | https://dev.to/promode/advice-to-software-tester-before-starting-api-testing-3o18 | testing, tutorial, webdev, beginners | In this video of 30 Days of API Testing Challenge, I am going to discuss Advice to Software Tester Before Starting API Testing.
> 🚀 Day 27 Task: Advice for someone looking to get started with API testing.
[](https://youtu.be/YJsNKmxCKaQ "30 Days of API Testing")
🚀 Thread: https://scrolltest.com/api/day27

🚀 All Task List: https://scrolltest.com/api/task
🚀 Watch Full Playlist: https://apitesting.co/30days
--
## 🚀 Mastering API Testing - https://www.learnapitesting.com
--
Be sure to subscribe for more videos like this!
[](https://www.youtube.com/TheTestingAcademy?sub_confirmation=1 "TheTestingAcademy")
| promode |
344,974 | Permissions Security For Deno | Today I released a new security module for Deno called permission-guard! This module is a zero-depen... | 0 | 2020-05-27T17:09:16 | https://dev.to/craigmorten/permissions-security-for-deno-2k8b | deno, javascript, typescript, security | Today I released a new security module for [Deno](https://deno.land/) called [permission-guard](https://github.com/asos-craigmorten/permission-guard)!
This module is a zero-dependency, minimal permission guard for Deno to prevent overly permissive execution of your applications.
```ts
import { guard } from "https://deno.land/x/permissionGuard@2.0.1/mod.ts";
await guard();
console.log("Execute my code...!");
```
If the application is run with permissions it doesn't need, or without permissions it does need, the guard will shield your application and prevent it from running.
For example, the `guard` in the above example would prevent
```bash
deno run --unstable -A ./index.ts
```
from executing any further. This extra protection means you are safer from potential malicious 3rd party code that could otherwise take advantage of overly permission application executions.
## Installation
This is a [Deno](https://deno.land/) module available to import direct from this repo and via the [Deno Registry](https://deno.land/x).
Before importing, [download and install Deno](https://deno.land/#installation).
You can then import `permission-guard` straight into your project:
```ts
import { guard } from "https://deno.land/x/permissionGuard@2.0.1/mod.ts";
```
> **Note:** `permission-guard` makes use of the unstable Deno Permissions API which requires `--unstable` to be passed in the Deno `run` command. You can use `permission-guard` in applications and not provide the `--unstable` flag, `permission-guard` will simply return as a no-op and not provide any defenses.
## Features
- Protection against unnecessary top-level permissions.
- Protection against missing required permissions.
- Recommendations where permissions could be better scoped (if `log: true` provided).
- Useful logs detailing the missing or insecure permissions (if `log: true` provided).
## Docs
- [Docs](https://asos-craigmorten.github.io/permission-guard/) - usually the best place when getting started ✨
- [Deno Docs](https://doc.deno.land/https/deno.land/x/permissionGuard/mod.ts)
## Examples
`permission-guard` has [all the examples you need](https://github.com/asos-craigmorten/permission-guard/tree/master/examples) to get started.
To run the [examples](./examples):
1. Clone the `permission-guard` repo locally:
```bash
git clone git://github.com/asos-craigmorten/permission-guard.git --depth 1
cd permission-guard
```
Then run the example you want:
```bash
deno run --unstable ./examples/defaults/index.ts
```
All the [examples](./examples) contain example commands in their READMEs to help get you started.
## More!
Want to know more? Head over to the [permission-guard GitHub](https://github.com/asos-craigmorten/permission-guard) page for full details.
Want to help, found a bug, or have a suggestion? Please reach out by commenting below or raising issues / PR on the repo! | craigmorten |
344,983 | PCA and UMAP with cocktail recipes 🥃🍸🍹 | Lately I’ve been publishing screencasts demonstrating how to use the tidymodels framework, from first... | 0 | 2020-05-27T17:29:51 | https://juliasilge.com/blog/cocktail-recipes-umap/ | machinelearning, datascience, tutorial, rstats | ---
title: PCA and UMAP with cocktail recipes 🥃🍸🍹
published: true
date: 2020-05-27 00:00:00 UTC
tags: machinelearning, datascience, tutorial, rstats
canonical_url: https://juliasilge.com/blog/cocktail-recipes-umap/
---
Lately I’ve been publishing [screencasts](https://juliasilge.com/category/tidymodels/) demonstrating how to use the [tidymodels](https://www.tidymodels.org/) framework, from first steps in modeling to how to evaluate complex models. Today’s screencast isn’t about predictive modeling, but about **unsupervised machine learning** using with this week’s [`#TidyTuesday` dataset](https://github.com/rfordatascience/tidytuesday) on cocktail recipes. 🍸
{% youtube _1msVvPE_KY %}
Here is the code I used in the video, for those who prefer reading instead of or in addition to video.
## Explore the data
Our modeling goal is to use unsupervised algorithms for dimensionality reduction with [cocktail recipes from this week’s #TidyTuesday dataset](https://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-05-26/readme.md). In my [earlier blog post](https://juliasilge.com/blog/tidylo-cran/) this week, I used one of the cocktail datasets included and here let’s use the other one.
```
boston_cocktails <- readr::read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-05-26/boston_cocktails.csv")
boston_cocktails %>%
count(ingredient, sort = TRUE)
## # A tibble: 569 x 2
## ingredient n
## <chr> <int>
## 1 Gin 176
## 2 Fresh lemon juice 138
## 3 Simple Syrup 115
## 4 Vodka 114
## 5 Light Rum 113
## 6 Dry Vermouth 107
## 7 Fresh Lime Juice 107
## 8 Triple Sec 107
## 9 Powdered Sugar 90
## 10 Grenadine 85
## # … with 559 more rows
```
There’s a bit of data cleaning to do to start, both for the `ingredient` column and the `measure` column.
```
cocktails_parsed <- boston_cocktails %>%
mutate(
ingredient = str_to_lower(ingredient),
ingredient = str_replace_all(ingredient, "-", " "),
ingredient = str_remove(ingredient, " liqueur$"),
ingredient = str_remove(ingredient, " (if desired)$"),
ingredient = case_when(
str_detect(ingredient, "bitters") ~ "bitters",
str_detect(ingredient, "lemon") ~ "lemon juice",
str_detect(ingredient, "lime") ~ "lime juice",
str_detect(ingredient, "grapefruit") ~ "grapefruit juice",
str_detect(ingredient, "orange") ~ "orange juice",
TRUE ~ ingredient
),
measure = case_when(
str_detect(ingredient, "bitters") ~ str_replace(measure, "oz$", "dash"),
TRUE ~ measure
),
measure = str_replace(measure, " ?1/2", ".5"),
measure = str_replace(measure, " ?3/4", ".75"),
measure = str_replace(measure, " ?1/4", ".25"),
measure_number = parse_number(measure),
measure_number = if_else(str_detect(measure, "dash$"),
measure_number / 50,
measure_number
)
) %>%
add_count(ingredient) %>%
filter(n > 15) %>%
select(-n) %>%
distinct(row_id, ingredient, .keep_all = TRUE) %>%
na.omit()
cocktails_parsed
## # A tibble: 2,542 x 7
## name category row_id ingredient_numb… ingredient measure measure_number
## <chr> <chr> <dbl> <dbl> <chr> <chr> <dbl>
## 1 Gauguin Cocktail … 1 1 light rum 2 oz 2
## 2 Gauguin Cocktail … 1 3 lemon jui… 1 oz 1
## 3 Gauguin Cocktail … 1 4 lime juice 1 oz 1
## 4 Fort La… Cocktail … 2 1 light rum 1.5 oz 1.5
## 5 Fort La… Cocktail … 2 2 sweet ver… .5 oz 0.5
## 6 Fort La… Cocktail … 2 3 orange ju… .25 oz 0.25
## 7 Fort La… Cocktail … 2 4 lime juice .25 oz 0.25
## 8 Cuban C… Cocktail … 4 1 lime juice .5 oz 0.5
## 9 Cuban C… Cocktail … 4 2 powdered … .5 oz 0.5
## 10 Cuban C… Cocktail … 4 3 light rum 2 oz 2
## # … with 2,532 more rows
```
I typically do my data cleaning with data in a tidy format, like `boston_cocktails` or `cocktails_parsed`. When it’s time for modeling, we usually need the data in a wider format, so let’s use `pivot_wider()` to reshape our data.
```
cocktails_df <- cocktails_parsed %>%
select(-ingredient_number, -row_id, -measure) %>%
pivot_wider(names_from = ingredient, values_from = measure_number, values_fill = 0) %>%
janitor::clean_names() %>%
na.omit()
cocktails_df
## # A tibble: 937 x 42
## name category light_rum lemon_juice lime_juice sweet_vermouth orange_juice
## <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Gaug… Cocktai… 2 1 1 0 0
## 2 Fort… Cocktai… 1.5 0 0.25 0.5 0.25
## 3 Cuba… Cocktai… 2 0 0.5 0 0
## 4 Cool… Cocktai… 0 0 0 0 1
## 5 John… Whiskies 0 1 0 0 0
## 6 Cher… Cocktai… 1.25 0 0 0 0
## 7 Casa… Cocktai… 2 0 1.5 0 0
## 8 Cari… Cocktai… 0.5 0 0 0 0
## 9 Ambe… Cordial… 0 0.25 0 0 0
## 10 The … Whiskies 0 0.5 0 0 0
## # … with 927 more rows, and 35 more variables: powdered_sugar <dbl>,
## # dark_rum <dbl>, cranberry_juice <dbl>, pineapple_juice <dbl>,
## # bourbon_whiskey <dbl>, simple_syrup <dbl>, cherry_flavored_brandy <dbl>,
## # light_cream <dbl>, triple_sec <dbl>, maraschino <dbl>, amaretto <dbl>,
## # grenadine <dbl>, apple_brandy <dbl>, brandy <dbl>, gin <dbl>,
## # anisette <dbl>, dry_vermouth <dbl>, apricot_flavored_brandy <dbl>,
## # bitters <dbl>, straight_rye_whiskey <dbl>, benedictine <dbl>,
## # egg_white <dbl>, half_and_half <dbl>, vodka <dbl>, grapefruit_juice <dbl>,
## # blended_scotch_whiskey <dbl>, port <dbl>, white_creme_de_cacao <dbl>,
## # citrus_flavored_vodka <dbl>, whole_egg <dbl>, egg_yolk <dbl>,
## # blended_whiskey <dbl>, dubonnet <dbl>, blanco_tequila <dbl>,
## # old_mr_boston_dry_gin <dbl>
```
There are lots more great examples of #TidyTuesday EDA out there to explore on [Twitter](https://twitter.com/hashtag/TidyTuesday)!
## Principal component analysis
This dataset is especially delightful because we get to use [recipes](https://recipes.tidymodels.org/) with **recipes**. 😍 Let’s load the tidymodels metapackage and implement principal component analysis with a recipe.
```
library(tidymodels)
pca_rec <- recipe(~., data = cocktails_df) %>%
update_role(name, category, new_role = "id") %>%
step_normalize(all_predictors()) %>%
step_pca(all_predictors())
pca_prep <- prep(pca_rec)
pca_prep
## Data Recipe
##
## Inputs:
##
## role #variables
## id 2
## predictor 40
##
## Training data contained 937 data points and no missing data.
##
## Operations:
##
## Centering and scaling for light_rum, lemon_juice, ... [trained]
## PCA extraction with light_rum, lemon_juice, ... [trained]
```
Let’s walk through the steps in this recipe.
- First, we must tell the `recipe()` what’s going on with our model (notice the formula with _no outcome_) and what data we are using.
- Next, we update the role for cocktail name and category, since these are variables we want to keep around for convenience as identifiers for rows but are not a predictor or outcome.
- We need to center and scale the numeric predictors, because we are about to implement PCA.
- Finally, we use `step_pca()` for the actual principal component analysis.
Before using `prep()` these steps have been defined but not actually run or implemented. The `prep()` function is where everything gets evaluated.
Once we have that done, we can both explore the results of the PCA. Let’s start with checking out how the PCA turned out. We can `tidy()` any of our recipe steps, including the PCA step, which is the second step. Then let’s make a visualization to see what the components look like.
```
tidied_pca <- tidy(pca_prep, 2)
tidied_pca %>%
filter(component %in% paste0("PC", 1:5)) %>%
mutate(component = fct_inorder(component)) %>%
ggplot(aes(value, terms, fill = terms)) +
geom_col(show.legend = FALSE) +
facet_wrap(~component, nrow = 1) +
labs(y = NULL)
```
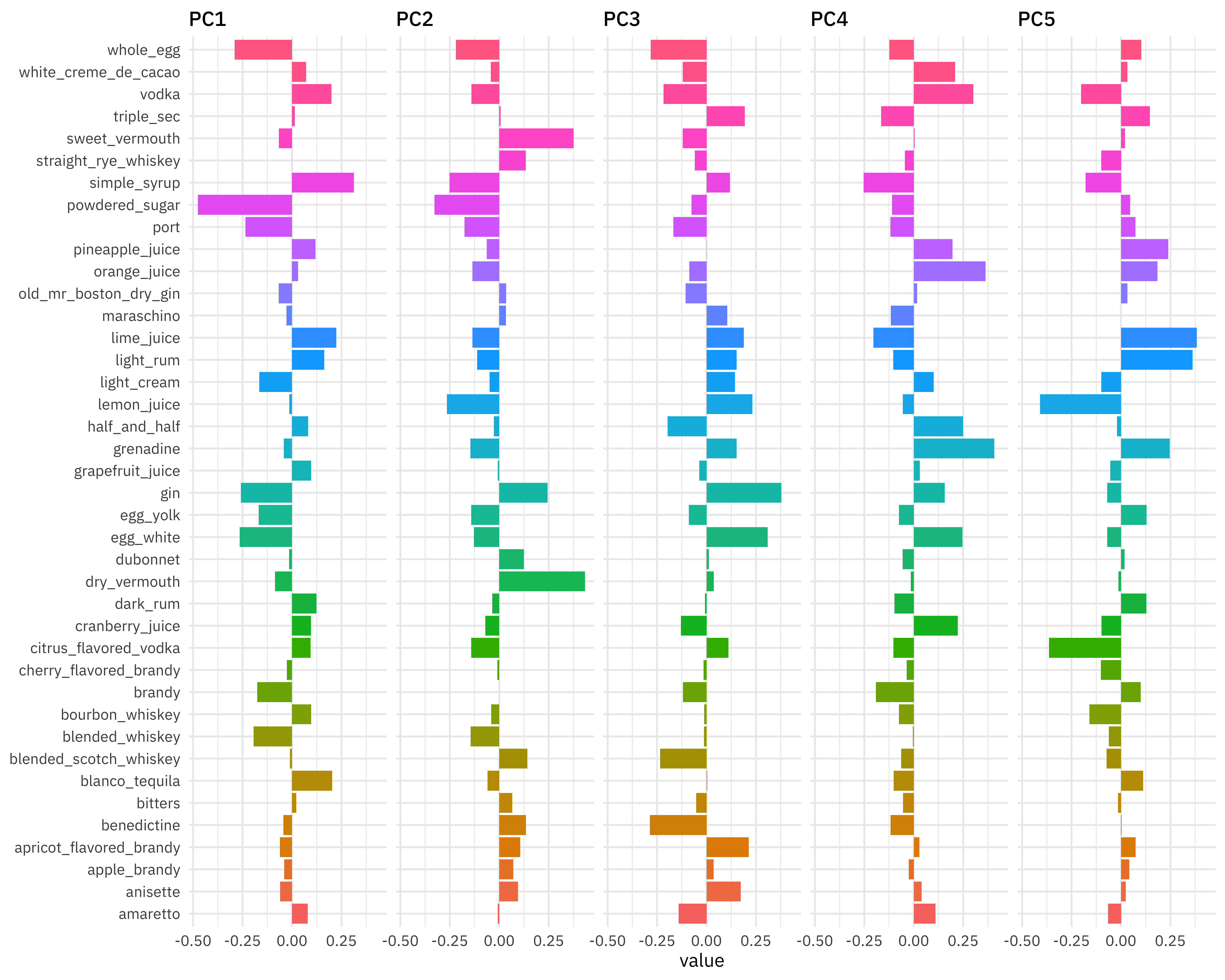
The biggest difference in PC1 is powdered sugar vs. simple syrup; recipes are not likely to have both, which makes sense! Let’s zoom in on the first four components, and understand which cocktail ingredients contribute in the positive and negative directions.
```
library(tidytext)
tidied_pca %>%
filter(component %in% paste0("PC", 1:4)) %>%
group_by(component) %>%
top_n(8, abs(value)) %>%
ungroup() %>%
mutate(terms = reorder_within(terms, abs(value), component)) %>%
ggplot(aes(abs(value), terms, fill = value > 0)) +
geom_col() +
facet_wrap(~component, scales = "free_y") +
scale_y_reordered() +
labs(
x = "Absolute value of contribution",
y = NULL, fill = "Positive?"
)
```
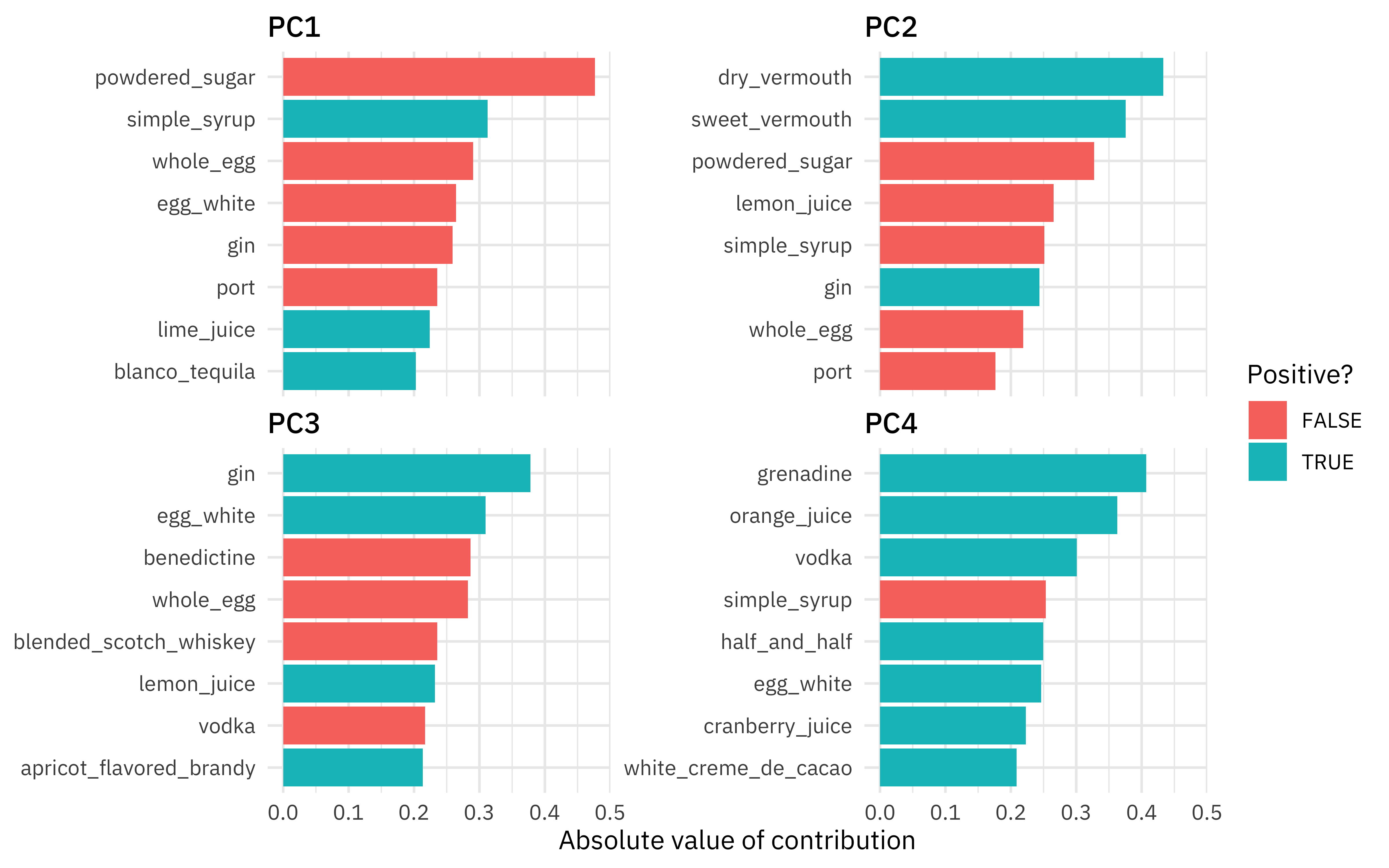
So PC1 is about powdered sugar + egg + gin drinks vs. simple syrup + lime + tequila drinks. This is the component that explains the most variation in drinks. PC2 is mostly about vermouth, both sweet and dry.
How are the cocktails distributed in the plane of the first two components?
```
juice(pca_prep) %>%
ggplot(aes(PC1, PC2, label = name)) +
geom_point(aes(color = category), alpha = 0.7, size = 2) +
geom_text(check_overlap = TRUE, hjust = "inward", family = "IBMPlexSans") +
labs(color = NULL)
```
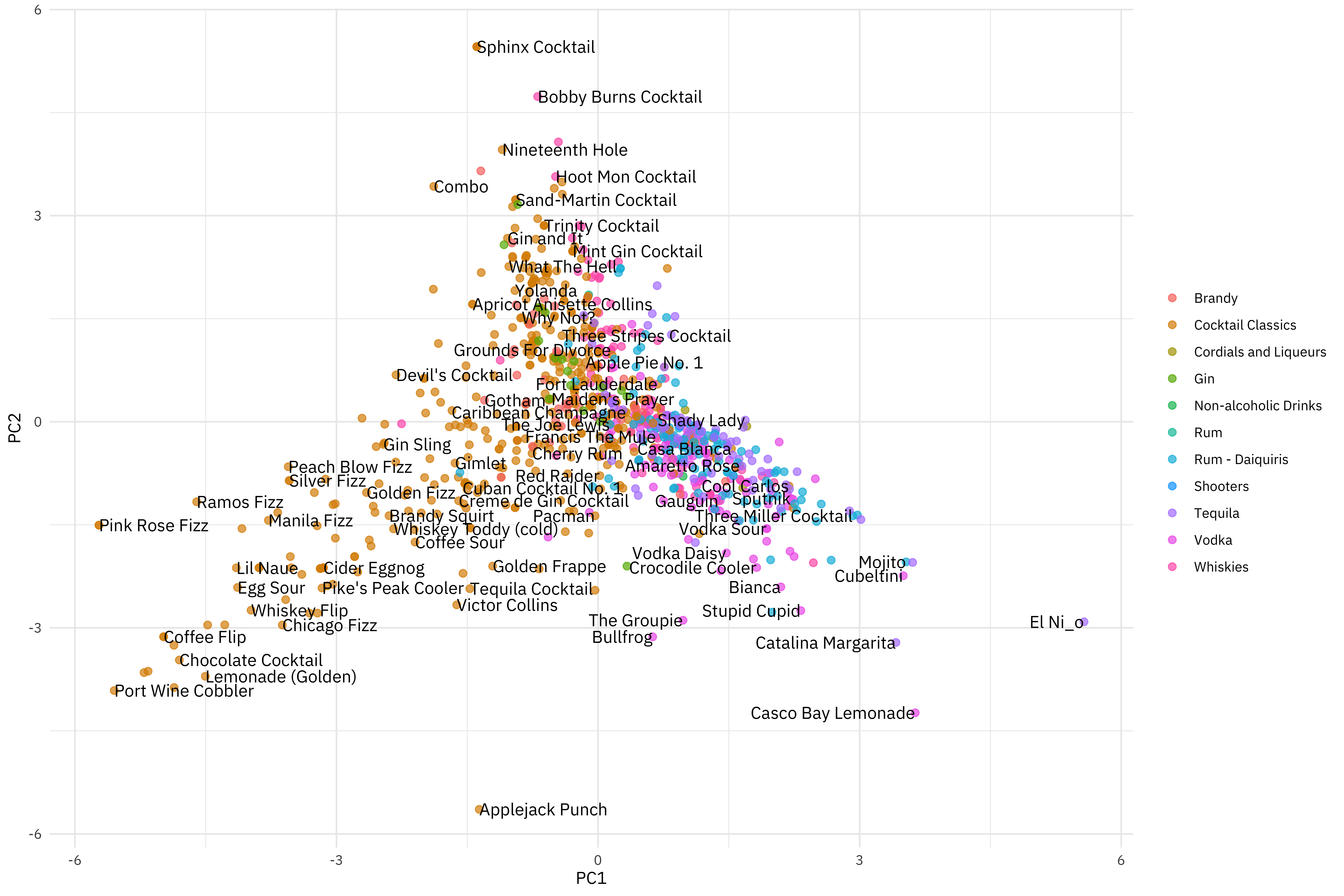
- Fizzy, egg, powdered sugar drinks are to the left.
- Simple syrup, lime, tequila drinks are to the right.
- Vermouth drinks are more to the top.
You can change out `PC2` for `PC4`, for example, to instead see where drinks with more grenadine are.
## UMAP
One of the benefits of the tidymodels ecosystem is the flexibility and ease of trying different approaches for the same kind of task. For example, we can switch out PCA for [UMAP](https://umap-learn.readthedocs.io/en/latest/how_umap_works.html), an entirely different algorithm for dimensionality reduction based on ideas from topological data analysis. The [embed](https://embed.tidymodels.org/) package provides recipe steps for ways to create embeddings including UMAP. Let’s switch out the PCA step for the UMAP step.
```
library(embed)
umap_rec <- recipe(~., data = cocktails_df) %>%
update_role(name, category, new_role = "id") %>%
step_normalize(all_predictors()) %>%
step_umap(all_predictors())
umap_prep <- prep(umap_rec)
umap_prep
## Data Recipe
##
## Inputs:
##
## role #variables
## id 2
## predictor 40
##
## Training data contained 937 data points and no missing data.
##
## Operations:
##
## Centering and scaling for light_rum, lemon_juice, ... [trained]
## UMAP embedding for light_rum, lemon_juice, ... [trained]
```
Now we can example how the cocktails are distributed in the plane of the first two UMAP components.
```
juice(umap_prep) %>%
ggplot(aes(umap_1, umap_2, label = name)) +
geom_point(aes(color = category), alpha = 0.7, size = 2) +
geom_text(check_overlap = TRUE, hjust = "inward", family = "IBMPlexSans") +
labs(color = NULL)
```
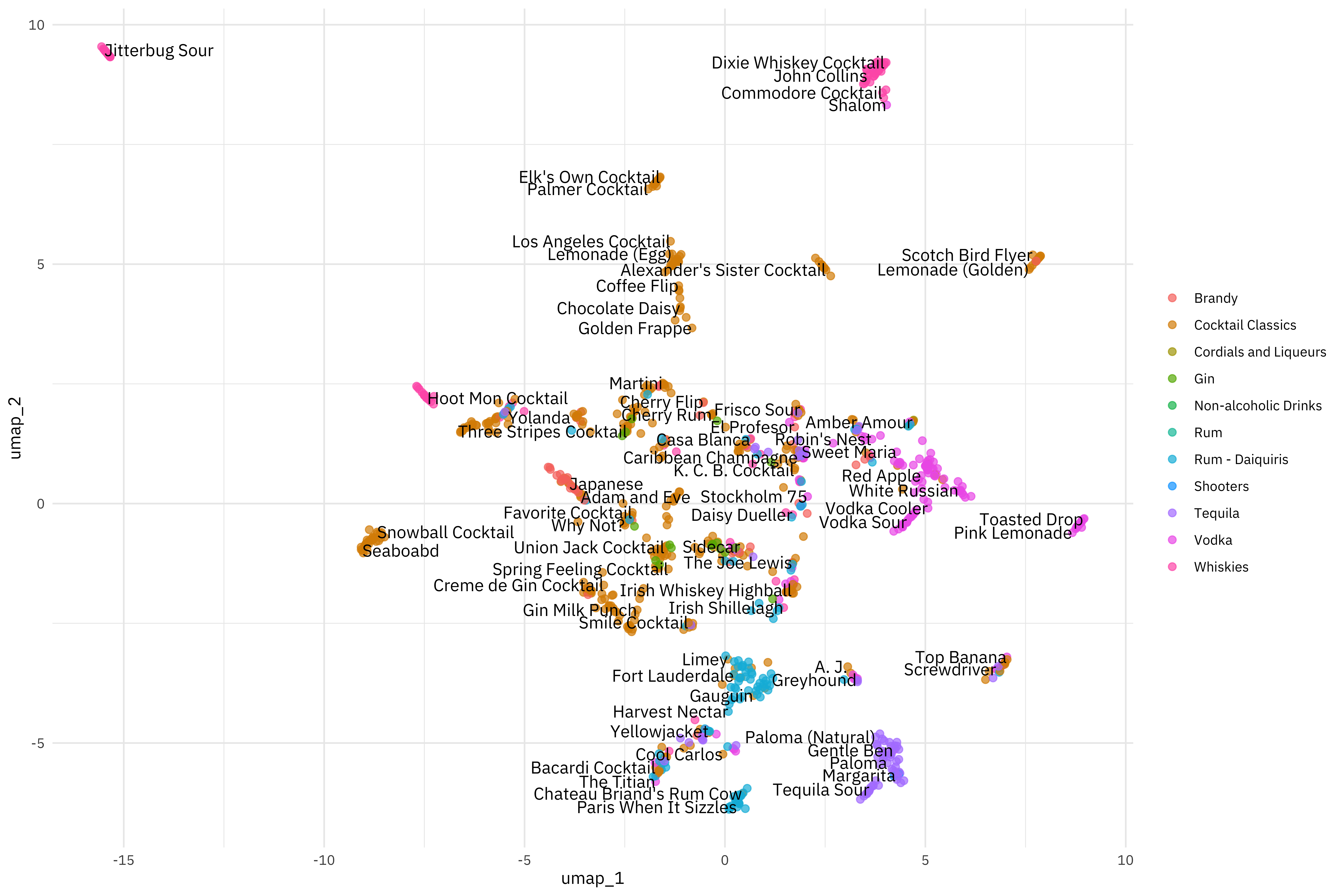
Really interesting, but also different! This is because UMAP is so different from PCA, although they are both approaching this question of how to project a set of features, like ingredients in cocktail recipes, into a smaller space. | juliasilge |
345,033 | Authentication in React App with Context | To be honest I avoided using Context for a long time. I easily began to use hooks, but I did not imme... | 0 | 2020-05-27T19:13:05 | https://dev.to/victormagarlamov/authentication-in-react-app-with-context-2plo | react, javascript, webdev | To be honest I avoided using Context for a long time. I easily began to use hooks, but I did not immediately understand Сontext. In this article I will show you one way to use Context.
```javascript
const App = () => {
<Switch>
<Route path=”/profile” component={ProfilePage} />
<Route path=”/login” component={LoginPage} />
<Redirect to=”/login” />
</Switch>
};
```
Let's restrict access to the `ProfilePage` - only authenticated users can access this page. If the user is a guest, we redirect him to the login page.
```javascript
const LoginPage = () => {
const [redirectTo, setRedirectTo] = useState(null);
const submitHandler = e => {
e.preventDefault();
const formData = new FormData(e.target);
authenticate(formData).then(user => {
if (user.authenticated) {
this.setState({ redirectTo: ‘/profile’ });
}
});
}
if (redirectTo) {
return (
<Redirect to={redirectTo} />
);
}
return (
<Form omSubmit={submitHandler}>
<Form.Input required type=”email” name=”email” label=”Email” />
<Form.Input required type=”password” name=”password” label=”Password” />
<Form.Button type=”submit” />
</Form>
);
};
```
The `authenticate` method sends user credentials to the API. When we get a response, we redirect the user to the `ProfilePage`. All is well, except for one trifle - everyone can access to the `ProfilePage` without authentication. To fix this, we need a flag - a global variable - to indicate whether the user is authenticated or not. Let's create Context that allows us to send a flag to components.
```javascript
import React, { useState } from ‘react’;
export const AuthContext = React.createContext();
export const AuthProvider = ({ children }) => {
const [authenticated, setAuthenticated] = useState(false);
return (
<AuthContext.Provider value={{authenticated, setAuthenticated}}>
{children}
</AuthContext.Provider>
);
};
export const AuthConsumer = AuthContext.Consumer;
```
Go to the `App.js` file and wrap the `Switch` into the `AuthProvider`. `AuthContext.Provider` allows us to pass the context value - the `authenticated` flag and the `setAuthenticated` method - to all child components.
```javascript
import { AuthProvider } from ‘./authContext’;
const App = () => {
<AuthProvider>
<Switch>
<Route path=”/profile” component={ProfilePage} />
<Route path=”/login” component={LoginPage} />
<Redirect to=”/login” />
</Switch>
<AuthProvider>
};
```
And make changes to the `LoginPage`.
```javascript
import React, { useState, useContext } from ‘react’;
import { AuthContext } from ‘./authContext’;
const LoginPage = () => {
const context = useContext(AuthContext);
const [redirectTo, setRedirectTo] = useState(null);
const submitHandler = e => {
e.preventDefault();
const formData = new FormData(e.target);
authenticate(formData).then(user => {
context.setAuthenticated(true);
```
Now we just have to subscribe to the changes and send off a guest.
```javascript
import { AuthConsumer } from ‘./authContext’;
const ProtectedRoute = ({ component: Component, ...rest }) => (
<Route {...rest} render={matchProps => (
<AuthConsumer>
{value => (
<Fragment>
{value.authenticated || (
<Redirect to=”/login” />
)}
<Component {...matchProps} />
</Fragment>
)}
</AuthConsumer>
)} />
);
```
Consumer is a React component, that subscribes to Context changes. It takes the function as a child and passes the current Context value to it.
Finishing touch.
```javascript
import { AuthProvider } from ‘./authContext’;
import { ProtectedRoute } from’./ProtectedRoute’;
const App = () => {
<AuthProvider>
<Switch>
<ProtectedRoute path=”/profile” component={ProfilePage} />
<Route path=”/login” component={LoginPage} />
<Redirect to=”/login” />
</Switch>
<AuthProvider>
};
``` | victormagarlamov |
345,044 | What's something you're currently learning? | I am seriously considering starting a tutorial on Vue.js. I've been working with React for half a yea... | 0 | 2020-05-27T19:39:31 | https://dev.to/arikaturika/what-s-something-you-re-currently-learning-4o1 | discuss, tutorial, javascript, beginners | I am seriously considering starting a tutorial on `Vue.js`. I've been working with `React` for half a year now, I'm by no means a pro at it but I was thinking that learning another Javascript framework would be a good idea.
What are you learning at the moment/ are you planning to explore in the near future and why would you like to do that?
*Image source: Negative Space/ @negativespace on Pexels* | arikaturika |
345,067 | Secure your Java Servlet Application with Keycloak | We'll see how to configure a Java Servlet based application so it can be secure with Keycloak. Keyc... | 0 | 2020-05-27T20:28:44 | https://dev.to/m4nu56/secure-your-java-servlet-application-with-keycloak-4826 | java, keycloak | We'll see how to configure a Java Servlet based application so it can be secure with Keycloak.
[Keycloak](https://www.keycloak.org/) is an Open Source Identity and Access Management that can be used to delegate entirely the security of an application.
## 1. Keycloak configuration
The Keycloak documentation is really easy to follow. You can see for yourself here the section about the configuration of your Keycloak instance: [https://www.keycloak.org/docs/latest/authorization_services/#_getting_started_hello_world_create_realm](https://www.keycloak.org/docs/latest/authorization_services/#_getting_started_hello_world_create_realm)
You need to configure:
- A realm
- A user with role `user`, we'll see later how it's used
- A Client. It's a representation of your Java application
- Client protocol: openid-connect
- Access Type: public
- Valid Redirect URIs: the url of your development environment or `*` for the time being
## 2. Tomcat security-constraint
We're using the Tomcat `security-constraint` that enable a security verification at the application level on Tomcat.
The Keycloak team developed a convenient Valve for the Tomcat Security system that handle the redirect to and from the Keycloak login page.
### 2.1. You need to add the following to the `context.xml` of your application:
```xml
<Context>
<Valve className="org.keycloak.adapters.tomcat.KeycloakAuthenticatorValve"/>
</Context>
```
### 2.2. Install the [Keycloak Valve libraries](https://mvnrepository.com/artifact/org.keycloak/keycloak-tomcat-adapter-dist) into the `${tomcat}/lib` directory on your Tomcat server
### 2.3. You need to copy the `keycloak.json` config file into `/WEB-INF/keycloak.json`
You can download the file in your Client installation tab:
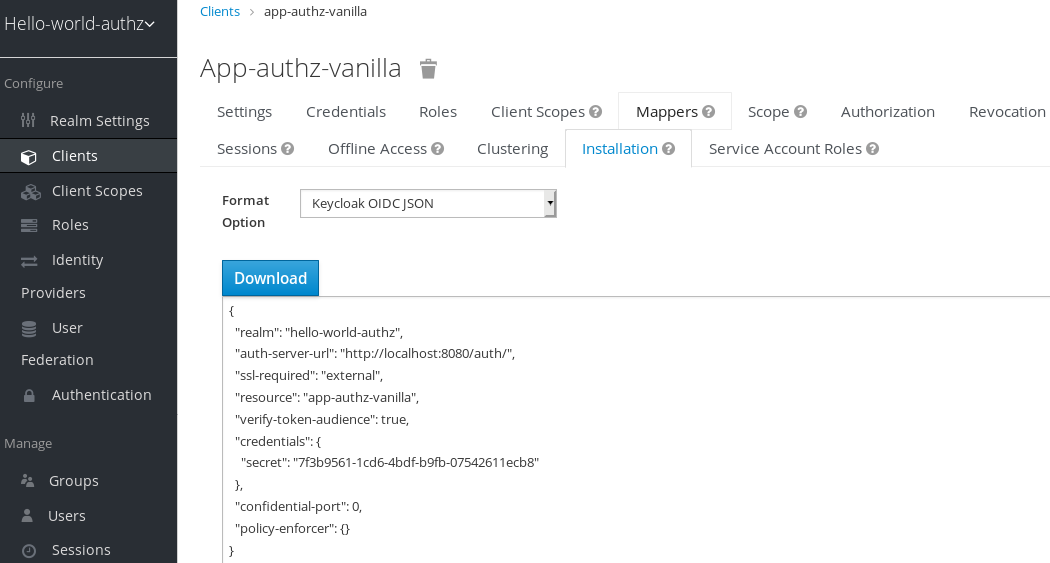
### 2.4. Add `security-constraint` in your `web.xml`
```xml
<security-constraint>
<web-resource-collection>
<web-resource-name>Private area</web-resource-name>
<url-pattern>/esp_privat/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>user</role-name>
</auth-constraint>
</security-constraint>
<security-constraint>
<web-resource-collection>
<web-resource-name>Public area</web-resource-name>
<url-pattern>/api/*</url-pattern>
</web-resource-collection>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>this is ignored currently</realm-name>
</login-config>
<security-role>
<role-name>user</role-name>
</security-role>
```
Here we defined 2 URL patterns:
- `/esp_privat/*` that require a user to be connected with a role `user`
- `/api/*` that require no authentification
### 2.5. Results
So when you try accessing any route under `/esp_privat/` in your application Keycloak valve now automatically redirect you to the login page in your Keycloak instance.
When successfuly logged in Keycloak redirects you to the asked page.
What we need to do now is to identify the user logged in thank's to the token Keycloak is adding to the cookies of the web navigator.
## 3. Intercept Keycloak access token to log the user into your app
### 3.1. Keycloak dependencies
Add the following to the `pom.xml` of your `webapp` application:
```xml
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-core</artifactId>
<version>9.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-adapter-core</artifactId>
<version>9.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.keycloak</groupId>
<artifactId>keycloak-adapter-spi</artifactId>
<version>9.0.2</version>
<scope>provided</scope>
</dependency>
```
Notice the scope = `provided` since we will be using the libraries added previously into the tomcat library folder. We don't want to override it with another version of the libraries.
### 3.2. Read the token
The following snippet will extract the token from the request and verify if it's lifetime is expired. It returns true in case the token is valid.
```java
import org.keycloak.KeycloakSecurityContext;
import org.keycloak.TokenVerifier;
import org.keycloak.common.VerificationException;
import org.keycloak.representations.AccessToken;
...
/**
* Verify if user is logged in keycloak by validating token in request
*/
public boolean isLoggedInKeycloak(HttpServletRequest request) throws VerificationException {
KeycloakSecurityContext keycloakSecurityContextToken = getKeycloakSecurityContextToken(request);
if (keycloakSecurityContextToken == null) {
return false;
}
return !isTokenExpired(keycloakSecurityContextToken);
}
private boolean isTokenExpired(KeycloakSecurityContext keycloakSecurityContextToken) throws VerificationException {
AccessToken token = TokenVerifier.create(keycloakSecurityContextToken.getTokenString(), AccessToken.class).getToken();
if (token.isExpired()) {
logger.warn("User token is expired..." + token);
return true;
}
return false;
}
```
In our case we also needed to verify if the user is a member of the correct group so we added the following method check:
```java
private void handleGroupMembership(@Nonnull KeycloakSecurityContext keycloakSecurityContext, String keycloakPreferredUsername) {
Object groups = keycloakSecurityContext.getToken().getOtherClaims().getOrDefault("groups", new ArrayList<>());
if (groups == null) {
throw new GenericRuntimeException("Fail to read groups from the token of the user " + keycloakPreferredUsername);
}
((List<String>) groups)
.stream()
.filter(s -> s.equalsIgnoreCase("/my-group"))
.findFirst()
.orElseThrow(() -> new GenericRuntimeException("User \"" + keycloakPreferredUsername + "\" is not a member of /my-group"));
}
```
We then called the previous method in a pre-action hook into all the call received by our servlets so that it can be catched by any servlet like so:
```java
boolean isUserLoggedIn = request.getSession().getAttribute(USER_SESSION) != null;
if (isLoggedInKeycloak(request) && !isUserLoggedIn) {
logger.info("User logged in Keycloak but not logged in the app. Logging in the user...");
new KeycloakLoginService().login(request, getKeycloakSecurityContextToken(request));
}
else if (!isLoggedInKeycloak(request) && isUserLoggedIn) {
logger.info("User not logged in Keycloak but logged in the app. Logging out the user...");
sessionLogout.logout(request, response);
return;
}
```
### 3.3. Logout
To logout a user from Keycloak you can use the `request.logout()` method. We use the following method:
```java
public void logout(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
HttpSession session = request.getSession(false);
if (session != null) {
session.invalidate();
}
request.logout();
request.getSession(true); // create a new session
response.sendRedirect(request.getContextPath());
}
```
## 4. Maven profiles to compile versions with and without keycloak login
In one of our project we needed to be able to deploy a version of the app that doesn't use the Keycloak login feature but our previous login mechanism.
Of course we wanted to keep a unique codebase with the less difference as possible.
We identify that the only thing preventing us from working as before was the `security-constraint` section in the `web.xml` config file.
We will be using the Maven filtering solution with a little hack we found on SO: [https://stackoverflow.com/questions/3298763/maven-customize-web-xml-of-web-app-project/8593041#8593041](https://stackoverflow.com/questions/3298763/maven-customize-web-xml-of-web-app-project/8593041#8593041)
It consists in adding 2 variables in your web.xml like so:
```xml
${enable.security.start}
<security-constraint>
...
// all of the XML that you need, in a completely readable format
...
</login-config>
${enable.security.end}
```
And have it replaced by comment block start `<!--` and end `->` in the profile where you don't want to use Keycloak.
So in our default `ci` profile we defined the following properties:
```xml
<enable.security.start></enable.security.start>
<enable.security.end></enable.security.end>
```
and in the `without-keycloak` profile:
```xml
<enable.security.start><!--</enable.security.start>
<enable.security.end>--></enable.security.end>
```
| m4nu56 |
345,080 | Blog Intent | As I am new to web development, I reached out for help in my journey yesterday to Sam Julien. The foc... | 0 | 2020-05-27T20:59:40 | https://dev.to/tsbarrett89/blog-intent-1m7a | As I am new to web development, I reached out for help in my journey yesterday to Sam Julien. The focus of the conversation was my [portfolio](https://thomasbarrett.dev), but in general I sought advice in my efforts to land that first tech job. During the conversation Sam suggested I start a blog. Nothing special, just a written record of my journey that I can share and reflect on. Today marks the beginning of that record.
My intent will be to write every other day, at least, about anything related to my journey. That may be about learning Pixijs, or how to improve my resume, or a new person I met and what I took from the interaction.
I imagine this will reach a rather small audience, initially, but I do ask anyone interested to help by holding me accountable. If I have not posted recently, please ask my why. Too often I convince myself that I am wasting time because I see no results. The problem is that often means I stop spending time on things that matter before the results are visible, but that does not mean they are not present.
-Thomas Barrett | tsbarrett89 | |
345,109 | Hey JVM! ¿What this tests actually mean? | Let's start by talking about unit-tests and their motif behind why we test. We can name a few known b... | 0 | 2020-05-31T00:26:27 | https://dev.to/yamilmedina/hey-jvm-what-this-tests-actually-mean-12pl | android, testing, java, kotlin | Let's start by talking about unit-tests and their motif behind why we test. We can name a few known by everyone that we continuously repeat time after time: "Assure the quality of our codebase", "Fault tolerant", "Enables posterior changes", but one goal behind tests we often underestimate or maybe we don't understand it at all, I'm talking about documentation, yes the good old RTFM of a codebase and a system itself.
Once upon a time I heard from a coworker — who recently was changing from project and also technologies, specifically from python to swift — who said to me:
> The first action I take when assessing a new codebase to understand the business, the technologies and frameworks involved, its architecture is...have a look at the tests
And it turns out that this quote, it has more sense today as I have been changing from project, my idea it's not diminished what a good onboarding process has to cover in terms of gaining business/project context. So we are going to focus this post in apply the good practices that enable better documentation/specification of an application and how we can use the concepts brought by other testing frameworks that changed the mindset around testing.
# Defining our goal
> Write better tests on the JVM that serve as a good documentation of your app and also that give us a comprehensible error feedback.
## Option 1: Just with JUnit.
Almost every Java project (also Kotlin) comes with JUnit configured as a Test engine. Sadly we don't have many tools to help us to achieve our goal (☝️👀). Let's see how we can improve the better understanding of our test purpose. Here an example:
### Let's take the next test as a starting point.
```Java
@Test
public void shouldAddMultipleNumbersAndProduceCorrectResult() {
//given
Calculator calculator = new Calculator();
//when
Integer total = calculator.sum(1, 2);
//then
assertEquals(3, total);
}
```
- 1.1. Name of the tests
A minor improvement towards our goal is, is writing a more intentional name that tell us right when you look what is it really doing this unit test:
```Java
@Test
public void addingTwoNumbersReturnsItsSum() {
//given...
//when...
//then...
assertEquals(3, total);
}
```
- 1.2. Better validations "asserts"
Using assert expression closer to our human language, with the help of _[Hamcrest][1]_. When you compare previous test presented here with the next one, we can tell a little improvement was made doing this kind of assertion.
[1]: http://hamcrest.org/JavaHamcrest/tutorial
```Java
import static org.hamcrest.CoreMatchers.is;
@Test
public void addingTwoNumbersReturnsItsSum() {
//given...
//when...
//then
assertThat(total, is(3));
}
```
## Option 2: The Kotlin "way"
Kotlin, we already know it came to make a revolution in many aspects in the way we write code on the JVM, it has several similarities in what groovy already tried (yes I know I'm old!)

Kotlin, has taken it further, thanks to the support given by Google and Android, this made Kotlin go to several levels above in a short period of time. Assuming the previous improvements already made, lets continue from there, but now focusing in what Kotlin offers us.
- 2.1. The "Backticks Hack"
Kotlin give us a simple way to write more readable tests out of the box, quoting its coding conventions:
> … In tests (and only in tests), it’s acceptable to use method names with spaces enclosed in backticks …
So, we can write our test with the following structure:
```Kotlin
@Test
fun `Adding TWO numbers in a Calculator should return their total`() {
//given...
//when...
//then...
}
```
Much more clear the real purpose behind this test, right? Maybe it's debatable, but I can assure you, that when the time to read this test in a log of a thousand tests, It will be easier for you, even when you have to read this as a code documentation for our calculator.
## Option 3: Introducing Specs and Spek
I know many of us are familiarized with concept "specification tests", is a technique for doing BDD, that lets test our code and also serve as documentation for the rest of our teammates. (I'm not talking about our inner demons 🙃). I'm talking about future developers or the product/business people.
This way of writing tests is very popular in other languages using frameworks like RSpec, Jasmine and several more. The important part of this towards our goal (☝️👀) is that in Kotlin exists a complementary framework called [Spek][2], developed by JetBrains itself. Lets see how this framework can help us with our goal.
[2]:https://spekframework.github.io/spek/docs/latest/#_what_is_spek
```Kotlin
import org.spekframework.spek2.style.specification.describe
import org.spekframework.spek2.Spek
object CalculatorSpec: Spek({
describe("A calculator") {
val calculator by memoized { Calculator() }
context("addition") {
it("returns the sum of its arguments") {
assertThat(calculator.sum(1, 2), is(3))
}
}
}
})
```
> *_Context/Describe:_* Here we define a group or context of execution, it's similar to a Suite, and help us in our case to group tests for the calculator, and the addition "context".
> *_It:_* used to make a specific and atomic assertion of our test, in other words is the specification for the correct addition of our calculator.
Now putting this into practice, we can imagine how we can approach adding a new feature to our calculator and at the same time having documented it. Let's do an exercise.
> We want to include the possibility to divide in our calculator, so we can see the description of this new feature and the use cases, we can describe it (describe) with a test in the same context (calculator).
```Kotlin
object CalculatorSpec: Spek({
context("A calculator") {
val calculator by memoized { Calculator() }
describe("addition") { /*..*/}
describe("division") {
it("returns the division of its arguments") {
assertThat(calculator.divide(10, 2), is(5))
}
it("throws an exception when divisor is zero") {
assertFailsWith(ArithmeticException::class) {
calculator.divide(1, 0)
}
}
}
}
})
```
---
Below is the required configurations to add Spek2 to your android project:
- App: build.gradle
```Groovy
android {
...
sourceSets.each {
// In case we have our tests under kotlin folder
it.java.srcDirs += "src/$it.name/kotlin"
}
testOptions {
junitPlatform {
filters {
engines {
include 'spek2'
}
}
}
...
}
}
dependencies {
testImplementation "org.junit.jupiter:junit-jupiter-api:5.5.1"
testImplementation "org.junit.platform:junit-platform-runner:1.5.1"
testImplementation "org.spekframework.spek2:spek-dsl-jvm:2.0.9"
testImplementation "org.spekframework.spek2:spek-runner-junit5:2.0.9"
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.5.1'
}
//Apply plugin that lets run junit5 on android modules
apply plugin: "de.mannodermaus.android-junit5"
```
- Root: build.gradle
```Groovy
buildscript {
dependencies {
classpath "de.mannodermaus.gradle.plugins:android-junit5:1.6.0.0"
}
}
```
----
To close this post looking beyond the techniques, patterns that we use to write tests in our applications, one important thing is to think in our future "Me" that would take this code to do a support task, or maybe this new person will be one without context of the product, or maybe playing with the words could be ourselves. So we should always write empathetic code with the mindset to help us in the future.
References:
[1][3] Spek: What is Spek?
[3]: https://spekframework.github.io/spek/docs/latest/#_what_is_spek | yamilmedina |
345,114 | The Importance Of The .Dockerfile File | Cross Post From Coding Zeal Blog For a while now, I have been using Docker for local devel... | 0 | 2020-05-28T21:06:43 | https://www.codingzeal.com/post/the-importance-of-the-dockerignore-file | docker, webdev | #### [Cross Post From Coding Zeal Blog](https://www.codingzeal.com/post/the-importance-of-the-dockerignore-file)
For a while now, I have been using Docker for local development on my Ruby on Rails applications. This has worked out great and I've spent plenty of time tweaking Docker to suit my needs, as things have changed. I recently started a new initiative to use Docker in a production environment, not just for local development. Unfortunately, I hit a little hiccup.
## Setting Up Docker: The Problem
If you are like me, the first time you configured your `Dockerfile` for Ruby on Rails, you found a guide to set up your `Dockerfile`. It was great for setting up a local development environment. It probably had you set up a `Dockerfile`, create a `docker-compose.yml file`, and set up a build and run process.
Here is a very abbreviated example of my Dockerfile
```bash
FROM ruby:2.5.3
###############################################################################
# Base Software Install
###############################################################################
RUN curl -sL https://deb.nodesource.com/setup_$RAILSDOCK_NODE_VERSION.x | bash -
RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \
echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list
.
.
.
###############################################################################
# Ruby, Rubygems, and Bundler Defaults
###############################################################################
ENV LANG C.UTF-8
.
.
.
ENV RAILS_ENV production
###############################################################################
# Final Touches
###############################################################################
.
.
.
RUN bundle config build.nokogiri --use-system-libraries
RUN bundle check || bundle install
# Copy for package.json and yarn.lock to do install to save layer size
COPY package.json yarn.lock ./
RUN yarn install --check-files --production=true
# Finally copy over rest of app
COPY . /app
# Precompile assets for production
RUN bundle exec rake assets:precompile
.
.
.
```
If you just do the standard tutorials, everything works great in development. But, most of these tutorials don't cover the .dockerignore file. This file is very important and not having one becomes a problem when Docker runs the following line in the above Dockerfile:
```bash
# Finally copy over rest of app
COPY . /app
```
## Locking Down Your Docker Image For Production or Sharing
By default, when you run a Docker build and copy your directory into the image, it will grab every single file in your directory: the `node_modules`, those weird `.DS_Store` files, and even your `.env` files that could contain sensitive information. Why is this a problem? If you happen to make your Docker image publicly available after it's built, people can look inside and see those extra files that were included inside. Most Dockerize your Rails app guides don't cover.
The solution is to use a `.dockerignore` file. It functions exactly like a `.gitignore` file. Put the files and folder paths that you don't want committed to your Docker image.
Here is an example of my .dockerignore file.
```bash
**/.classpath
**/.dockerignore
**/.env
**/.git
**/.gitignore
**/.project
**/.settings
**/.toolstarget
**/.vs
**/.vscode
**/*.*proj.user
**/*.dbmdl
**/*.jfm
**/azds.yaml
**/charts
**/docker-compose*
**/Dockerfile*
**/node_modules
**/npm-debug.log
**/obj
**/secrets.dev.yaml
**/values.dev.yaml
README.md
.DS_Store
.bin
.git
.gitignore
.bundleignore
.bundle
.byebug_history
.rspec
tmp
log
test
config/deploy
config/master.key
public/packs
public/packs-test
node_modules
yarn-error.log
coverage/
```
This keeps a lot of development cruft out of my Docker image. Reviewing it, I could probably update it again 😁. Once you add your `.dockerignore` file to your project, try to build things again.
Now, your Docker container should be leaner (no more extra files you don't need in there) and more secure! | talk2megooseman |
1,439,208 | My first bash script | I started learning how to code about a month and a half back. Joined a full-stack web development... | 0 | 2023-04-18T01:24:42 | https://dev.to/utsavaa/my-first-bash-script-15fm | I started learning how to code about a month and a half back. Joined a full-stack web development coding bootcamp. Got introduced to the basics of bash scripting. And was encouraged to learn more on my own. So I picked the following problem and wanted to write a bash script to solve it: Write a bash script to check and validate passwords. An acceptable password must be:
- No less than 8 and no more than 16 characters long
- Must have at least one lowercase and one uppercase characters
- Must have at least one numeric character
- Must contain one of "#,@,$,%,*,+,-,="
Now I've seen how the create and enter password sequence works on Linux-based systems. Typically, there's a text that prompts you to enter a password. So, that became the first line of my script (after shebang, of course):
echo "Enter new password:"
The user is required to enter their password after this line. And I had to recreate it. How? From NetworkChuck's YouTube videos, I knew that somehow the read command had to be used. But the user input can't be shown on the console. So, the read command had to be used with the '-s' flag. That gave me my second line:
read -s password
And when a user enters a password, the program should start validating the input against the minimum requirements.
First things first. If a user enters less than 8 characters, the program should tell them that they must do better. The conditional in which I understood the use case gave away what I should do to implement it in the script: an if-then statement:
if [ ${#password} -ge 8 ]; then
If the input matches the requirement, what must the program do? I must evaluate the input further, validating it against the rest of the requirements, one after another:
if [ ${#password} -ge 8 ]; then
if [ ${#password} -le 16 ]; then
if [[ ${password} =~ [a-z] ]]; then
if [[ ${password} =~ [A-Z] ]]; then
if [[ ${password} =~ [0-9] ]]; then
if [[ ${password} =~ [#,@,$,%,*,+,-,=] ]]; then
echo "Password created"
But what if doesn't meet one of these requirements. I had to throw in feedback to the user why it didn't work. And I had to account for all possible cases:
else echo "Must contain at least one of: #, @, $, %, *, +, -, ="
fi
else echo "Must contain at least one numeric char"
fi
else echo "Must contain at least one uppercase char"
fi
else echo "Must contain at least one lowercase char"
fi
else echo "Can't be longer than 16 chars"
fi
else echo "Must be at least 8 chars long"
fi
And there you go. I tasted success! Couldn't wait to try it out.
So, I saved my changes (I used the nano editor to author the script). Made the script an executable. And entered the command: bash password.sh
And there! My labor had already borne fruits. Never before did Enter a password on the screen look this beautiful!
I entered a password that wasn't 8 characters long and pressed Enter.
Wow! "Password must be at least 8 characters long" - Now I wasn't a mere consumer any longer. This was my first step as a producer. Soon I would be producing solutions to really complex prob...
My castle fell apart prematurely. The program exited immediately after providing feedback. I ran the program again and again to check whether it looks for all the specified conditions. And that it does. But that's not good enough. The program must not exit when a user input doesn't match a condition. It should inform the user and prompt them to enter a password again. Now, that's not how I visualized the problem at the outset. Also, even that's not enough. The script needs to be refactored to make sure that the user is consistently prompted to enter a password until all conditions match. This requires some sort of a looping mechanism. Which I've been trying to incorporate into my script but haven't been able to succeed yet. Here's what my script looks like now and I am looking for pointers: where did I go wrong?
#!/bin/bash
echo "Enter new password:"
read -s password
while [ ${password} != "" ]
do
if [ ${#password} -ge 8 ]; then
if [ ${#password} -le 16 ]; then
if [[ ${password} =~ [a-z] ]]; then
if [[ ${password} =~ [A-Z] ]]; then
if [[ ${password} =~ [0-9] ]]; then
if [[ ${password} =~ [#,@,$,%,*,+,-,=] ]]; then
echo "Password created"
else
while ! [[ ${password} =~ [#,@,$,%,*,+,-,=] ]]
do
{
echo "Must contain at least one of: #, @, $, %, *, +, -, =";
echo "Enter new password:";
read -s password;
}
done
fi
else
while ! [ ${password} =~ [0-9] ]
do
{
echo "Must contain at least one numeric char";
echo "Enter new password:";
read -s password;
}
done
fi
else
while ! [ ${password} =~ [#,@,$,%,*,+,-,=] ]
do
{
echo "Must contain at least one uppercase char";
echo "Enter password:";
read -s password;
}
done
fi
else
while ! [ ${passwoord} =~ [a-z] ]
do
{
echo "Must contain at least one lowercase char";
echo "Enter password:";
read -s password;
}
done
fi
else
while [ ${#password} -gt 16 ]
do
{
echo "Can't be longer than 16 chars";
echo "Enter password:";
read -s password;
}
done
fi
else
while [ ${#password} -lt 8 ]
do
{
echo "Must be at least 8 chars long";
echo "Enter password:";
read -s password;
}
done
fi
done
| utsavaa | |
345,138 | Twelve Do's of Consistency in Aerospike | For applications that demand absolute correctness of data, Aerospike offers the Strong Consistency (S... | 0 | 2020-05-28T00:29:26 | https://dev.to/aerospike/twelve-do-s-of-consistency-in-aerospike-30ac | consistency, aerospike, nosql, transactions | For applications that demand absolute correctness of data, Aerospike offers the Strong Consistency (SC) mode that guarantees no stale or dirty data is read and no committed data is lost. Aerospike's [strong consistency support](https://www.aerospike.com/lp/exploring-data-consistency-aerospike-enterprise-edition/) has been independently confirmed through [Jepsen testing](http://jepsen.io/analyses/aerospike-3-99-0-3).
Developers building such applications should follow the following Twelve Do's of Consistency.
---
###1. Model your data for single record atomicity.
The scope of a transaction in Aerospike is a single request and a single record. In other words, an atomic update can only be performed on a single record. Therefore model your data such that data that must be updated in a transaction (atomically) is kept in a single record. [Data modeling techniques](https://www.aerospike.com/blog/modeling-data-aerospike/) like embedding, linking, and denormalization can be used to achieve this goal.
---
###2. Configure the namespace in SC mode by setting strong-consistency to true.
Per the CAP theorem, the system must make a choice between Availability and Consistency if it continues to function during a network partition. Aerospike offers both choices. A namespace (equivalent to a database or schema) in a cluster can be configured in AP (choosing Availability over Consistency) or SC (Strong Consistency, choosing Consistency over Availability) mode. All writes in SC mode are serialized and synchronously replicated to all replicas. ensuring one version and immediate consistency.
---
###3. Use the Read-Modify-Write pattern for read-write transactions.
In this pattern, the generation comparison check is included in the write policy. A record's generation is its version, and this check preserves validity of a write that is dependent on a previous read. The "Check-And-Set" (CAS) equality check with read generation would fail raising generation-error if another write has incremented the generation in the meanwhile. In which case, the entire Read-Modify-Write pattern must be retried.
{% gist https://gist.github.com/neelp-git/401260631d9c0e5d1fe83c611cb6ea29 %} *Read-Modify-Write pattern for read-write transactions*
---
###4. Tag a write with a unique id to confirm if a transaction succeeded or failed.
Uncertainty about a transaction's outcome can arise due to client, connection, and server failures. System load can lead to incomplete replication sequence before the request times out with "in-doubt" status. There is no transaction handle for the application to use to probe the status in this case. It must therefore tag a record with a unique id as part of the transaction, which it can use later to check if the transaction succeeded or failed.
{% gist https://gist.github.com/neelp-git/0b462008fd01423de76ce4698d620808 %} *Tagging a write with a unique id*
---
###5. Achieve multi-operation atomicity and only-once effect through Operate, predicate expressions, and various policies.
The Aerospike operation [Operate](https://www.aerospike.com/docs/client/python/usage/kvs/write.html#multi-ops) allows multiple operations to be performed atomically on a single record. It can be combined with various policies that enable conditional execution to achieve only-once effect. Examples include [predicate expressions](https://www.aerospike.com/apidocs/python/predexp.html#module-aerospike.predexp) in [operate policy](https://www.aerospike.com/apidocs/python/client.html#operate-policies), insertion in map with [create-only write mode](https://www.aerospike.com/apidocs/python/client.html#map-policies), insertion in list with [add-unique write flag](https://www.aerospike.com/apidocs/python/aerospike.html#list-write-flags), and so on.
---
###6. Simplify write transactions by making write only-once (idempotent).
An only-once write (enabled by the mechanisms described in 5 above) becomes safe to just retry on failure. A prior success will result in an "already exists" failure which indicates prior successful execution of the transaction.
{% gist https://gist.github.com/neelp-git/edcdd0fc8acdae4de52dba633b8025cf %} *Safe retries with only-once write transactions*
---
###7. Record the details for subsequent handling in a batch or manual process if a write's outcome cannot be resolved.
During a long duration cluster split event, the client may be unable to resolve a transaction's outcome. The client can timeout after retries but should record the details needed for external resolution such as the record key, transaction id, and write details.
{% gist https://gist.github.com/neelp-git/dff1fd6fc2c562d07a23cb7395baf6e2 %} *Record transaction details for external resolution*
---
###8. Choose the optimal read mode.
There are four SC read modes to choose from: Linearizable, Session, Allow-replica, and Allow-unavailable. They all guarantee no data loss and no dirty reads, but differ in "no stale" guarantees as well as performance. A Linearizable read ensures the latest version across all clients, but it involves checking with all replicas and therefore is most expensive. Also, without additional external synchronization mechanism among clients, the version is not guaranteed to be the latest when it reaches the client. A Session read is faster as it directly reads from the master replica, and therefore recommended. In a multi-site cluster, local reads are much faster than remote reads. Since the master replica may reside at another site, the Allow-replica mode offers much better performance with no-stale guarantee practically equivalent to the Session mode, and therefore is recommended in multi-site clusters. There are no staleness guarantees with Allow-unavailable mode, but the application may judiciously leverage it when it is aware of stale data but can still derive positive value from it.
---
###9. Use the default value for max-retries (zero) in write-policy.
The max-retries value indicates the number of retries that the client library will perform automatically in case of a failure. Because the transaction logic is sensitive to the type of failure, a transaction failure must be handled in the application, not automatically by the client library. Therefore use the default value to turn off the automatic retries in the client library.
---
###10. For maximum durability, commit each write to the disk on a per-transaction basis using commit-to-device setting.
With this setting, a replica flushes the write buffer to disk before acknowledging back to the master. The application on a successful write operation is certain that the update is secure on the disk at each replica, thus achieving maximum possible durability. Be aware of the performance implications of flushing each write to disk (unless using data in PMEM), and balance it with the desired durability.
---
###11. For exactly-once multi-record (non-atomic) updates use the pattern: record atomically - post at-least-once - process only-once.
Aerospike does not support multi-record transactions. To implement exactly-once semantics for multi-record updates, record the event atomically in the first record as part of the update. Implement a process to collect the recorded event and post it for processing in the second record. At-least-once semantics can be achieved by removing the event only after successful hand-off to or execution of the subsequent step which would update another record with only-once semantics. This sequence achieves exactly-once execution of multi-record updates. The pattern is explored further in this [post](https://www.aerospike.com/blog/microservices-with-aerospike/).
---
###12. Resolve in-flight transactions during crash recovery by recording the transaction intent.
Before a write request is sent to the server, record the intent so that it can be read and retried if necessary during crash recovery. The intent is removed on successful execution as part of normal processing. During recovery, the intent list is read and retried.
--- | nphadnis |
345,145 | Set up Coil with Gridsome | Everybody hates ads and creators hate adblockers... There must be a middle grou... | 0 | 2020-05-28T01:19:41 | https://dev.to/gingerchew/set-up-coil-with-gridsome-56m0 | vue, javascript, webmonetization, gridsome | ## Everybody hates ads
### and creators hate adblockers...
There must be a middle ground to find. If you're like me, you're likely to lean towards a service like YouTube Red _or whatever they're calling it now_. You pay a monthly fee, no longer see advertisements, and that monthly fee is spread out evenly among the creators you watch based on view time.
I would argue that this is the most favorable solution out there for bloggers, for these reasons:
1. Seamless
2. Sleek
3. Simple
#### Seamless:
Why is it seamless? Well, I've already implemented it on my blog here, and you probably didn't know! Nothing has changed. With the Coil extension installed, you'll see it "saturate" and it will notify you that this content is "Web-Monetized". _[CSS-Tricks](https://css-tricks.com/site-monetization-with-coil-and-removing-ads-for-supporters/) is the website featured in the example_

This little green speech bubble let's you know your money is being put towards content you like.
#### Sleek:
I think sleek speaks for itself! I don't have to do anything! I don't have to give them an email, a password, a login, a social, nothing. It's already taken care of.
#### Simple:
I list simple because of how simple it is for bloggers and developers to implement. So let's go through that real quick here.
When you sign up as a creator with Coil, you have to choose a "Digital Wallet". I'm not a huge fan of online-crypto-whoozy-whatsits, so I signed up with [Stronghold](https://stronghold.co).
When you signup through the Coil creator portal, you are asked for the "payment pointer". Follow the instructions on Stronghold, or the digital wallet you signed up with, to get this before moving forward. Got it? Good!
Now its as simple as adding it to the head as a meta tag!
Bish! Bash! Bosh!
Here's mine if you want to confirm it's there: [https://frankie.tech/](https://frankie.tech/)
<pre><code><meta
name="monetization"
content="$pay.stronghold.co/1a19885d42feebf4dc0b9efac6fa2fb3318"
/>
</code></pre>
It's just that simple.
#### Gridsome
But we're developers. Sure we can just manually put things in the head of the `index.html`, but whats fun about that?! I agree, so here's how I did it with Gridsome. _I've followed the guide on the Gridsome website, so do that first then come back._
First, I went into my `gridsome.server.js`, and add to my `site` variable:
```js
const site = {
...
monetization: '$pay.stronghold.co/1a19885d42feebf4dc0b9efac6fa2fb3318',
};
```
Then I load all of that along with all of the other "metadata" site variables using this exported function:
```js
module.exports = function(api) {
api.loadSource(async (store) => {
for (let [key, value] of Object.entries(site)) {
store.addMetadata(key, value);
}
});
};
```
Next, I opened up `App.vue` and added a `static-query`:
```js
<static-query>
query {
metadata {
...
monetization
}
}
</static-query>
<script>
export default {
metaInfo() {
return {
meta: [
...
{
key: 'monetization',
name: 'monetization',
content: this.$static.metadata.monetization,
},
],
};
},
};
</script>
```
Now whenever Gridsome generates your site/blog/whatever, this monetization link will be automatically put in the head of your site.
Thats it! Seamless! Sleek! Simple! I hope more people will adopt technologies like Coil and that the [Web-Monetization API](https://webmonetization.org/) is adopted into the Web Standards.
Some other relevant links:
[CSS Tricks Article](https://css-tricks.com/site-monetization-with-coil-and-removing-ads-for-supporters/)
[Web Monetization in Vue App](https://dev.to/jasmin/web-monetization-in-vue-app-using-plugin-4092) by [Jasmin Virdi](https://twitter.com/JASMINVIRDI)
| gingerchew |
345,164 | Getting started with Deno (Spanish) | Este es el segundo post ya sobre Deno en español, la primera parte esta en este enlace: First look wi... | 0 | 2020-05-28T02:48:44 | https://dev.to/riviergrullon/getting-started-with-deno-spanish-27g0 | deno, javascript, typescript, node | Este es el segundo post ya sobre Deno en español, la primera parte esta en este enlace: [First look with deno(Spanish)](https://dev.to/buttercubz/first-look-with-deno-spanish-30dh).
## Configurando el entorno de trabajo.
Pasando a la instalación de Deno, abriendo la terminal digitan el siguiente comando:
**Shell (macOS, Linux):**
```curl -fsSL https://deno.land/x/install/install.sh | sh```
**PowerShell (Windows):**
```iwr https://deno.land/x/install/install.ps1 -useb | iex```
ya instalado Deno en el editor de código asumiendo que es Visual Studio Code pasamos a instalar la extensión que soporta a deno de ***justjack***
ya instalada, en la carpeta .vscode se crea el archivo settings.json. Dentro del archivo se pone
```javascript
//settings.json
{ "deno.enable": true, }
```
**Comencemos a construir la Rest API**
la estructura del proyecto será
```
.
├── mod.ts
├── controllers
│ └── handlers.ts
└── routes
└── routes.ts
```
usaremos el framework Oak.
Comencemos por crear el archivo mod.ts importando Application de https://deno.land/x/oak/mod.ts y el enrutador de './routes/routes.ts'
```javascript
import { Application } from 'https://deno.land/x/oak/mod.ts'
import router from './routes.ts'
```
despues se crea el setup del entorno ya sea para poner en deploy o hacerlo local
```javascript
const env = Deno.env.toObject();
const PORT = env.PORT || 3000;
const HOST = env.HOST || 'localhost';
```
Ahora creamos el archivo routes.ts:
```javascript
import { Router } from 'https://deno.land/x/oak@v4.0.0/mod.ts';
import { getDog,deleteDog,updateDog,addDog,getDogs } from '../controllers/handlers.ts';
const router = new Router()
router.get('/dogs', getDogs)
.get('/dogs/:id', getDog)
.post('/dogs', addDog)
.put('/dogs/:id', updateDog)
.delete('/dogs/:id', deleteDog)
export default router
```
(Las funciones implementadas en estas rutas se crean en el archivo handlers.ts)
ya con esto terminamos nuestro mod.ts
```javascript
const app = new Application();
console.log(`App is listening in ${HOST} in port ${PORT}`);
app.use(router.routes());
app.use(router.allowedMethods());
await app.listen(`${HOST}:${PORT}`);
```
Ahora creamos nuestro handlers.ts primero declarando la interfaz para el arreglo de perros
```javascript
interface Dogs {
id : string,
name: string,
age: number
};
let dogs:Array <Dogs> = [
{
id: "1",
name: 'Pepe',
age: 2
},
{
id: "2",
name: 'ajio',
age: 3
}
];
```
creamos el metodo getDogs:
```javascript
const getDogs = ({ response }: { response: any }) => {
response.body = dogs
}
```
getDog: retorna un solo perro
```javascript
const getDog = ({ params, response }: { params: { id: string }; response: any }) => {
const dog: Dogs | undefined = searchDogById(params.id)
if (dog) {
response.status = 200
response.body = dogs[0]
} else {
response.status = 404
response.body = { message: `dog not found.` }
}
}
```
addDog: crea un nuevo perro
```javascript
const addDog = async ({ request, response }: { request: any; response: any }) => {
const body = await request.body()
const dog: Dogs = body.value
dogs.push(dog);
response.body = { message: 'OK' }
response.status = 200
}
```
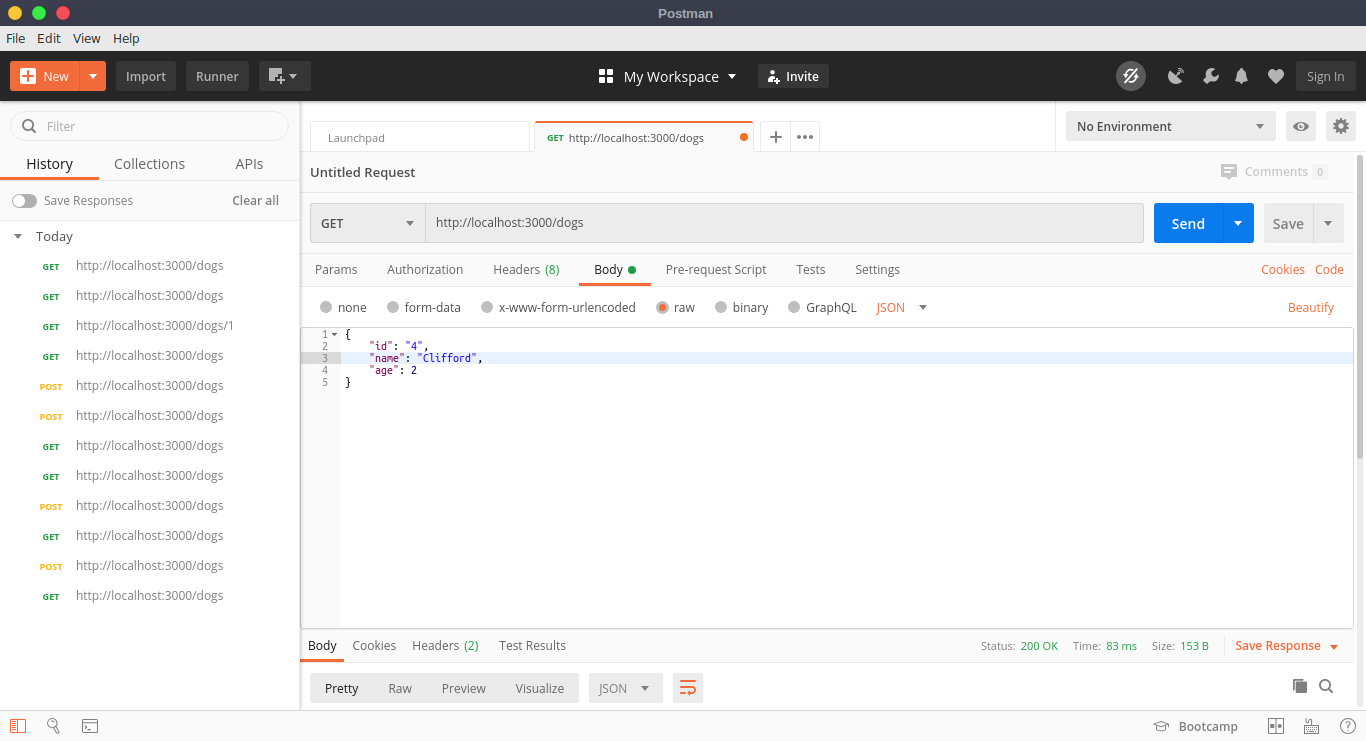
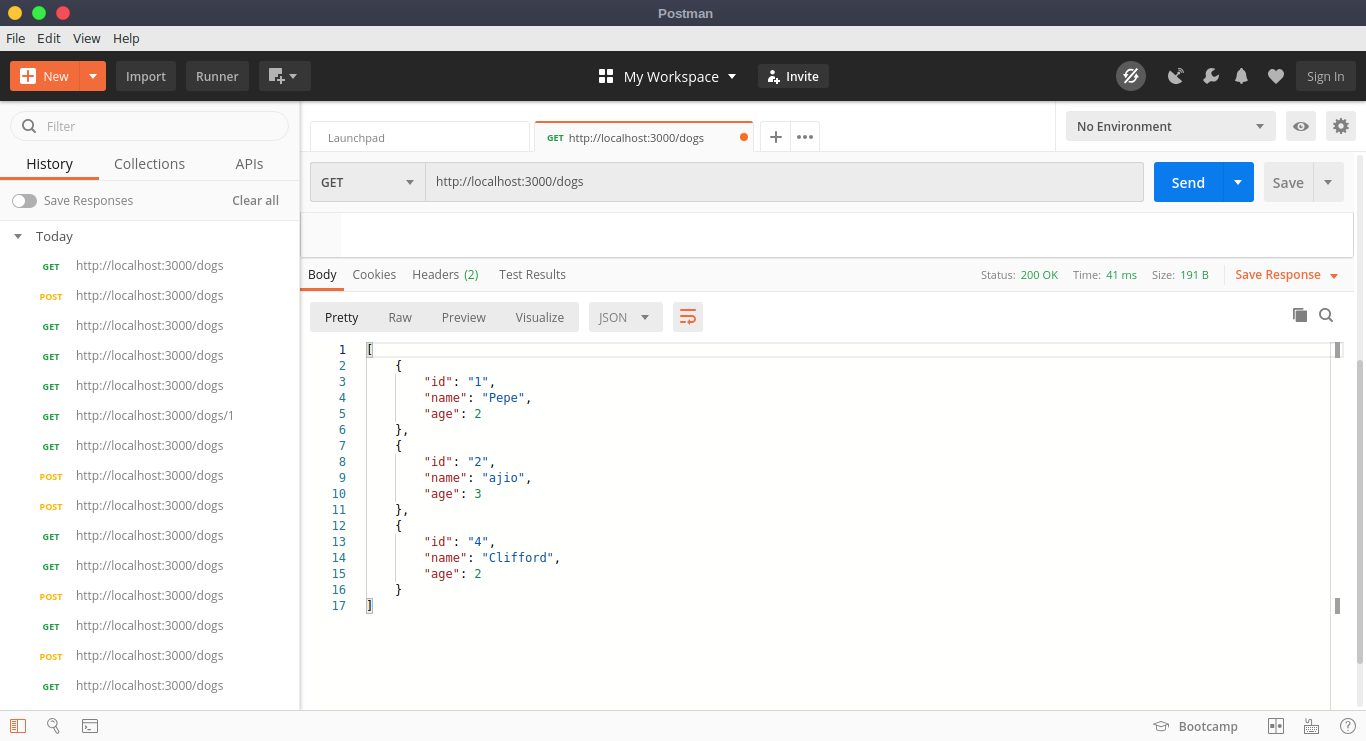
updateDog: actualizar algun dato del perro
```javascript
const updateDog = async ({ params, request, response }: { params: { id: string }; request: any; response: any }) => {
let dog: Dogs | undefined = searchDogById(params.id)
if (dog) {
const body = await request.body()
const updateInfos: { id?: string; name?: string; age?:number} = body.value
dog = { ...dog, ...updateInfos}
dogs = [...dogs.filter(dog => dog.id !== params.id), dog]
response.status = 200
response.body = { message: 'OK' }
} else {
response.status = 404
response.body = { message: `Dog not found` }
}
}
```
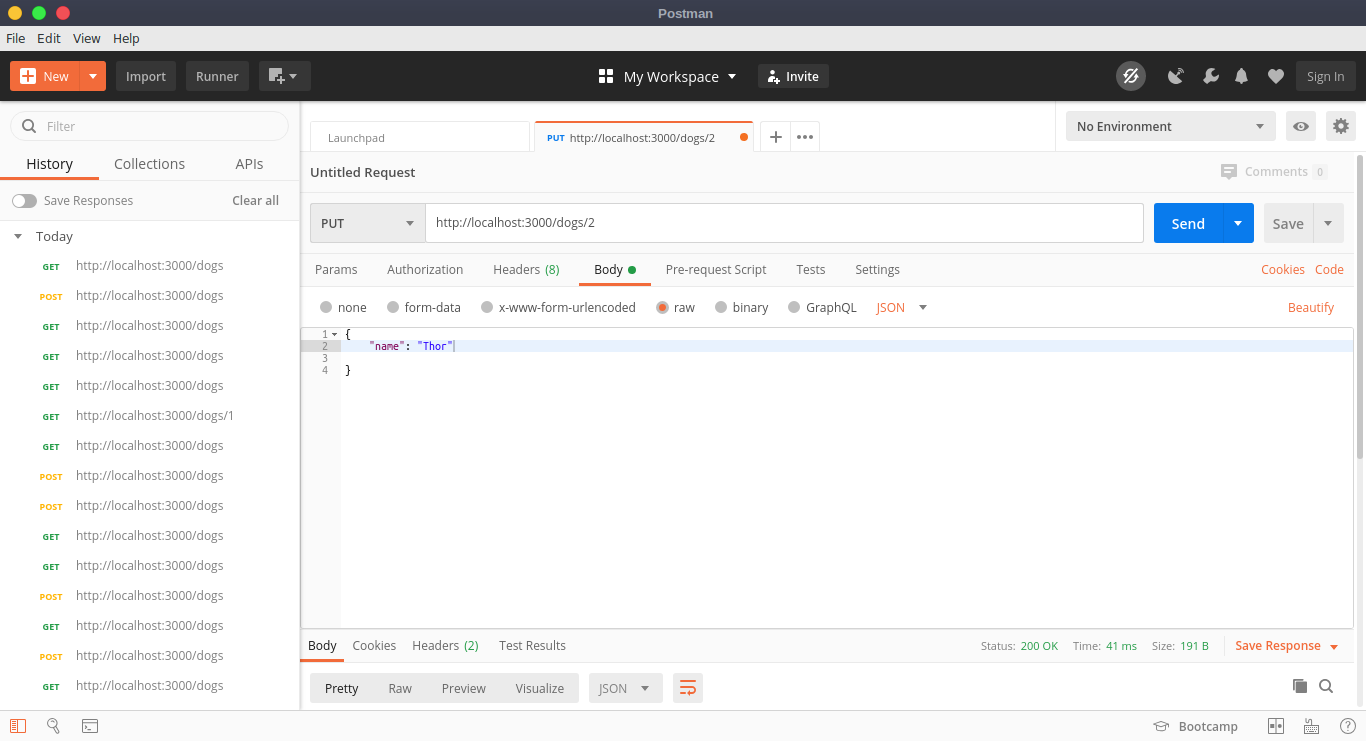
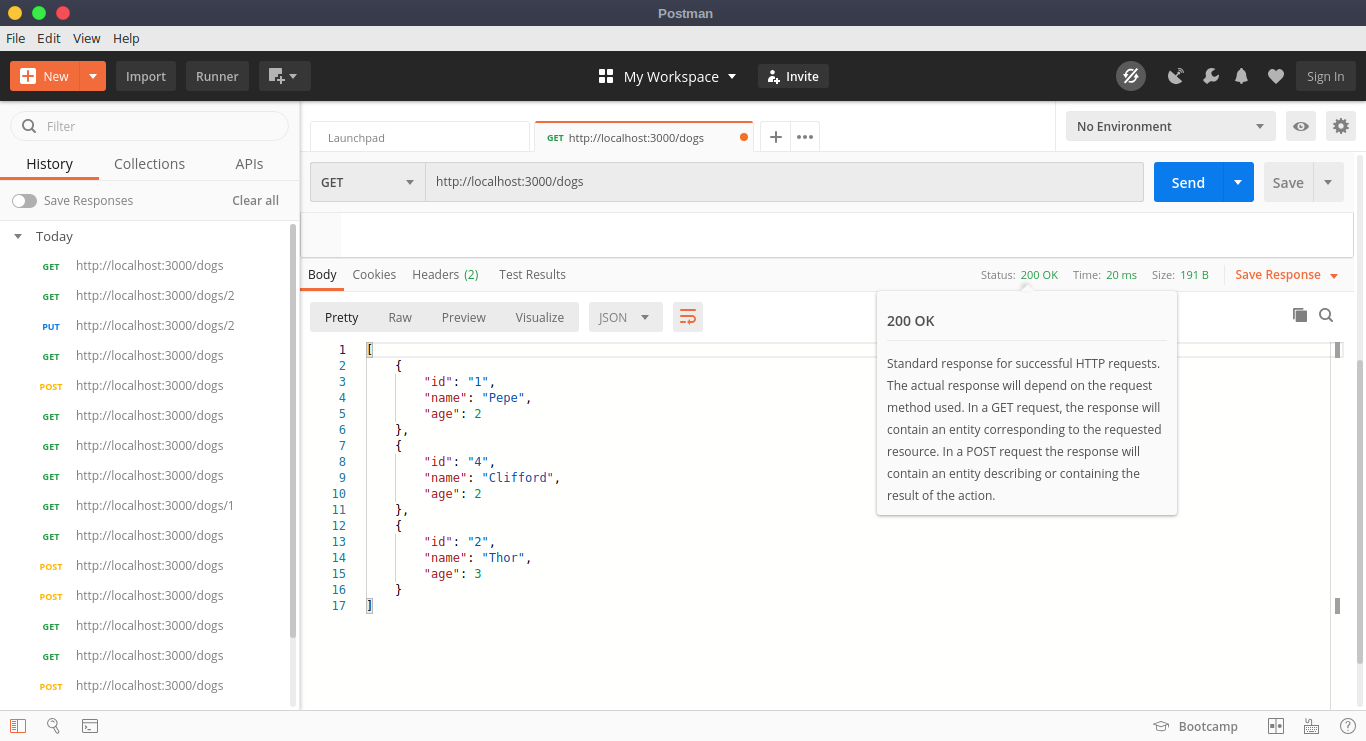
delete: para eliminar un perro especifico buscando por su id
```javascript
const deleteDog = ({ params, response }: { params: { id: string }; response: any }) => {
dogs = dogs.filter(dog => dog.id !== params.id)
response.body = { message: 'OK' }
response.status = 200
}
const searchDogById= (id: string): ( Dogs | undefined ) => dogs.filter(dog => dog.id === id )[0]
export{
getDogs,
getDog,
updateDog,
deleteDog,
addDog
}
```
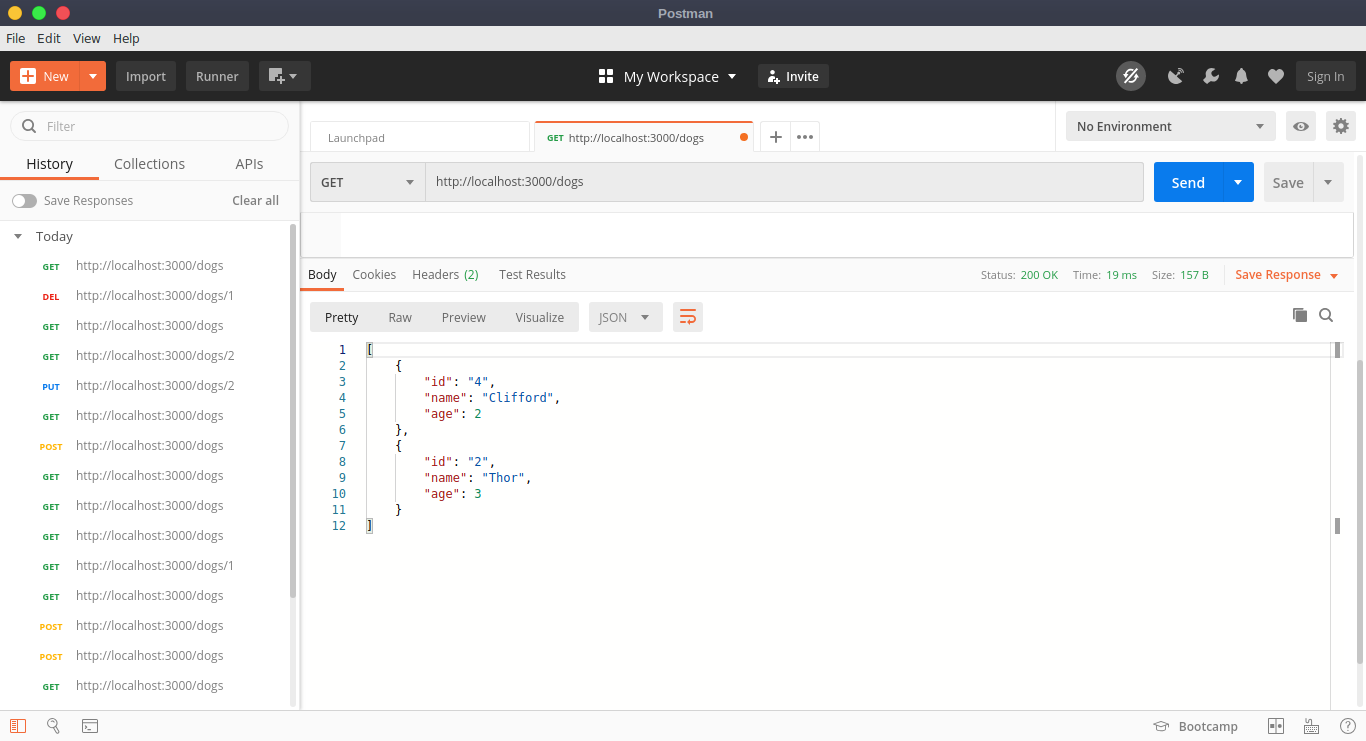
##Fin
| riviergrullon |
345,182 | Introducción sobre la librería Hybrids | ¿Qué es Hybrids? Hybrids es una librería de interfaz de usuario para crear componente... | 0 | 2020-05-28T03:49:10 | https://dev.to/corteshvictor/introduccion-sobre-la-libreria-hybridsjs-ld2 | hybrids, javascript, frontend, library | <h1 align="center">
<img alt="hybrids - the web components" src="https://raw.githubusercontent.com/hybridsjs/hybrids/master/docs/assets/hybrids-full-logo.svg?sanitize=true" width="500" align="center">
<br/>
</h1>
# ¿Qué es Hybrids?
Hybrids es una librería de interfaz de usuario para crear componentes web con un fuerte enfoque declarativo y funcional basado en objetos simples y funciones puras. Creada por Dominik Lubański en mayo de 2018. La librería hybrids proporciona una forma simple y declarativa para crear elementos personalizados.
Si estas más interesado en ver un video y la utilización de la librería con código, al final del articulo puedes ver dos enlaces a youtube donde puedes ver mi explicación de la librería como un tutorial y otro video donde hablamos de ella acompañado de otras personas.
## Competidores
Para entender en qué posición se encuentra esta librería, debemos saber quienes son sus competidores más cercados o mas populares.
| React | Stencil | Polymer | Slim | Skatejs |
| :---: | :---: | :---: | :---: | :---: |
| <img alt="React" src="https://cdn4.iconfinder.com/data/icons/logos-3/600/React.js_logo-512.png" width="80" /> | <img alt="Stencil" src="https://s3.amazonaws.com/media-p.slid.es/uploads/249891/images/6369783/Screen_Shot_2019-07-18_at_6.59.32_AM.png" width="80" /> | <img alt="Polymer" src="https://upload.wikimedia.org/wikipedia/commons/6/69/Polymer_Project_logo.png" width="80" /> | <img alt="Slim" src="https://avatars2.githubusercontent.com/u/39967650?s=200&v=4" width="80" /> | <img alt="Skatejs" src="https://avatars0.githubusercontent.com/u/7636121?s=280&v=4" width="80" /> |
## Concepto
Actualmente, de forma nativa, La única forma de crear un elemento personalizado es usar una clase, que extiende de HTMLElement y definirlo con Custom Elements API: [CustomElements.define()](https://developer.mozilla.org/es/docs/Web/API/CustomElementRegistry/define)
```js
class MyElement extends HTMLElement {
...
}
customElements.define('my-element', MyElement);
```
Con Hybrids, usted define sus elementos personalizados con la función **define** de la librería, en lugar de utilizar las funciones integradas del navegador:
```js
import { define, html } from 'hybrids';
const HelloWorld = {
name: 'Mundo',
render: ({ name }) => html`Hola ${name}!`;
};
define('hello-world', HelloWorld);
```
Es mucho mas legible y concisa que la versión vanilla
```js
class HelloWorld extends HTMLElement {
constructor() {
super();
this.name = 'Mundo';
this.attachShadow({mode: 'open'});
this.shadowRoot.appendChild(document.createTextNode(this.name));
}
}
customElements.define('hello-world', HelloWorld);
```
**Componente HelloWorld**
Entrando en detalle, importamos `define` y `html` de la librería hybrids.
```js
import { define, html } from 'hybrids';
```
- **html:** Es lo que envuelve o hace referencia a nuestras etiquetas propias de html, es decir, si tenemos un título y un párrafo en nuestro archivo html de esta forma:
``` html
<h1>Título</h1>
<p>Párrafo</p>
```
se puede utilizar `html` de hybrids para representar esas etiquetas de la siguiente manera:
```html
html`<h1>Título<h1>
<p>Párrafo</p>`
```
- **define:** como se mencionó anteriormente, `define` nos ayuda a definir los elementos personalizados o customElements que queremos crear o utilizar. Tiene algún parecido con el vue-custom-element del framework vue.js.
El objeto que vemos a continuación, es el que contiene la estructura del componente web con sus propiedades y también determina la interfaz con la que interactúa el usuario.
```js
const HelloWorld = {
name: 'Mundo',
render: ({ name }) => html`Hola ${name}!`;
};
```
- **render:** Una de las funciones principales que debería tener tu componente es la propiedad `render` que es una función que te permite crear o renderizar tu elemento para visualizarlo.
- **name (property):** Es la propiedad o el estado del componente, este nombre lo puedes definir como desees, no necesariamente se debe llamar `name`
**NOTA:** Las propiedades o estados utilizan la función de transformación (transform) para garantizar el tipo estricto del valor establecido por propiedad o atributo. Es decir, cuando agregas un valor por defecto, como el caso de `name: 'Mundo'`, estas definiendo que el valor es una cadena o string, por ende, el transform congela el tipo de valor para evitar la mutación de sus propiedades. Además, defaultValue se comparte entre instancias de elementos personalizados, por lo que ninguno de ellos debería cambiarlo. Para omitir la transformación, defaultValue debe establecerse en undefined.
*Transform Types*
- string -> String(value)
- number -> Number(value)
- boolean -> Boolean(value)
- function -> defaultValue(value)
- object -> Object.freeze(value)
- undefined -> value
## Uso
Puedes configurar webpack, rollup para empaquetar tu proyecto e instalando el paquete de hybrids.
```
npm i hybrids
```
Si se dirige a los navegadores modernos y no desea utilizar herramientas externas (como webpack, parcel, Rollup), puede usar ES modules:
```js
<script type="module">
// We can use "/src" here - browsers, which support modules also support ES2015
import { html, define } from 'https://unpkg.com/hybrids@[PUT_VERSION_HERE:x.x.x]/src';
...
</script>
```
## Ventajas y Desventajas
**Ventajas**
- Definición simple: objetos simples y funciones puras, nada de clase o el contexto del `this`
- Recálculo rápido: caché inteligente integrada y mecanismos de detección de cambios que permite activar la función de actualización `render` solo cuando cambia una de las propiedades del componente.
- Se puede integrar de forma fácil con otras librerías como Redux y React.
**Desventajas**
- Poca documentación: la página oficial tiene la documentación básica para entender la librería pero no profundiza.
- Baja comunidad: La comunidad es muy poca, casi nula, la que utiliza esta librería, por ende, no existe tanta documentación, artículos, ejemplos para apoyarte sobre ciertos conceptos que quieras aclarar y la documentación no lo brinda.
## Conclusión
Me parece que es una librería que tiene mucho potencial, su curva de aprendizaje no es baja pero tampoco tan compleja, pero sí dificulta buscar información. Para una persona que apenas esta iniciando en el desarrollo de componentes web, la documentación es simple comparada con React, Vue y Svelte, y como no tiene una comunidad grande se dificulta su aprendizaje. Cabe aclarar que, prácticamente, el único que la mantiene es el mismo creador hasta el momento.
Es posible utilizar Hybrids en un proyecto de producción, pero en lo personal, no lo utilizaría por el momento, para proyectos que impliquen varios desarrolladores. De pronto para un proyecto pequeño personal, sí la tendría presente pero en un proyecto empresarial no.
¿Por qué estas aprendiendo sobre la librería si no la piensas utilizar?, como desarrollador web, pienso que es bueno conocer que existen otras librerías y framework que te ayudan a solucionar o construir proyectos web, en algunos casos, dependiendo del proyecto tu decides que utilizar y entre mas conocimiento en general tengas, puedes decidir cual te conviene más.
Por obtener conocimientos generales de varias herramientas no te va a disminuir el rendimiento por la cual te has especializado, puede que en un futuro te encuentres con un proyecto hecho en esta librería y al menos cuentas con las bases de su mecanismo para utilizarla.
## Enlaces externos
comparto el enlace oficial de la librería hybrids por si quieres consultar y tener mayor información. También comparto un enlace donde coderos propuso un reto utilizando esta librería en la que participe con otras personas explicando el código de la solución y dando nuestros puntos de vista.
Doy gracias a Coderos, especialmente a Christopher Díaz por presentar el reto, hacer que indagará un poco sobre ella y así poder aprender de forma muy general su base y utilización para crear componentes web con hybrids.
- [Video tutorial sobre hybrids](https://youtu.be/CUQNJi4cB58)
{% youtube CUQNJi4cB58 %}
- [Hablando sobre hybrids - Coderos](https://www.youtube.com/watch?v=8M9PLG4SFrU)
{% youtube 8M9PLG4SFrU %}
- [Documentación oficial](https://hybrids.js.org/) | corteshvictor |
345,667 | Submit button | What I built A demo of a functionality that should be included in a web page that have a b... | 0 | 2020-05-28T20:25:53 | https://dev.to/gerardocrdena14/placeholder-title-3m7o | gftwhackathon | [Instructions]: # (To submit to the Grant For The Web x DEV Hackathon, please fill out all sections.)
## What I built
A demo of a functionality that should be included in a web page that have a button of submit. The submit button will only work if the browser supports Web Monetization.
### Submission Category:
[Note]: # (Foundational Technology, Creative Catalyst, or Exciting Experiments)
The category of this project is: Foundational Technology
## Demo
JUST COPY THE NEXT IN A FILE WITH .HTML EXTENSION.
<html>
<head><title>Submit only if it supports Web Monetization</title>
<SCRIPT LANGUAGE="JavaScript">
<SCRIPT LANGUAGE="JavaScript">
<!-- Oculto código a navegadores que no soportan JavaScript
function submitAllclearinFields(){
document.Datos.Vo.value="";
document.Datos.Vf.value="";
document.Datos.A.value="";
document.Datos.D.value="";
document.Datos.T.value="";
}
function resuelve(){
doc=open('','Processed',"width=350,height=400,resizable,scrollbars");
doc.document.write('<html><head> <meta name="monetization" content="$ilp.uphold.com/3L3ZYG97kmMk"><title>Submission</title></head><body>');
if (document.monetization) {
doc.document.write('<b>Your data was submitted.</b>');
submitAllclearinFields();
}//if (document.monetization) {
else {
doc.document.write('<b>Your data was NOT submitted.</b>');
doc.document.write('<b>Your browser should support web monetization.</b>');
}//else from if document.monetization
doc.document.write('</body></html>');
doc.document.close();
}
// Termino de ocultar código-->
</SCRIPT>
</SCRIPT>
</head>
<body bgcolor="#000000" leftmargin="50" topmargin="50" marginwidth="50" marginheight="50">
<form name="Datos">
<center>
<font color="yellow">
<h1>Your data:</h1>
</font>
<br />
<table>
<tr>
<td><font color="white"><b>FILL THE FIELDS:</b></font></td>
</tr>
<tr>
<td>
<font color="white">
</font>
</td></tr>
</table>
<br>
<TABLE BORDER="10" CELLPADDING="5" CELLSPACING="2" BORDERCOLOR="00FF00" bgcolor="ffffff">
<tr>
<td>
<b>TEMA:</b> Type anything that will be submitted.
</td>
</tr>
<tr>
<td>
</td>
</tr>
<tr>
<td>
Name:<input type="text" name="Vo" value=""><br>
Favorite food:<input type="text" name="Vf" value=""><br>
Favorite drink:<input type="text" name="A" value=""><br>
Favorite dessert<input type="text" name="D" value=""><br>
Hobby:<input type="text" name="T" value=""><br>
<center>
<input type="button" name="SUBMIT" value="SUBMIT" onClick="resuelve();">
</center>
</td>
</tr>
</table>
</center>
</form>
</body>
</noscript>
</html>
## Link to Code
[Note]: # (Our markdown editor supports pretty embeds. If you're sharing a GitHub repo, try this syntax: `{% github link_to_your_repo %}`)
## How I built it
In a notepad i created this web page to illustrate the functionality of the "SUBMIT" button. It will be nice to have a prebuilt button that only will works if the browser supports MONETIZATION. In other words, the function called when the button is pressed will be executed only if the browser supports WEB MONETIZATION.
[Note]: # (For example, what's the stack? did you run into issues or discover something new along the way? etc!)
## Additional Resources/Info
[Reminder]: # (We hope you consider expanding your submission into a full-on application for the Grant for the Web CFP, due on June 12.) | gerardocrdena14 |
346,239 | PostScript Documents | PS documents have mostly been replaced by other web page sketch file formats, such as. PDF. Even then... | 0 | 2020-05-29T20:50:13 | https://dev.to/aayush55575854/postscript-documents-1jf | anonymous | PS documents have mostly been replaced by other web page sketch file formats, such as. PDF. Even then, they are supported by a range of printers and programs.In general, any printer utility that supports PostScript can access it. We can convert PS archives to PDFs with Acrobat Distiller, a tool bundled with Adobe Acrobat, and Apple Preview, a tool bundled with macOS.We can also use conversion tools on websites like smallpdf, ilovepdf, i generally use [pdfdoctor](https://pdfdoctor.com/postscript-to-pdf) due to its speed and ad-free nature | aayush55575854 |
348,475 | Good Morning, Next time, I won't get 1,111 reactions and 5000 views in stats. | I used to check Dev.to with my mails and BBC news every morning before I walked out of bed. I recall... | 0 | 2020-06-03T03:13:20 | https://dev.to/manishfoodtechs/good-morning-next-time-i-won-t-get-1-111-reactions-and-5000-views-in-stats-5024 | showdev, jokes, beginners, startup | I used to check Dev.to with my mails and BBC news every morning before I walked out of bed.
I recall when I was a student of engineering (15 years ago) and whenever I saw my digital wrist watch / mobile phone: incidentally, much of the time was the same hour and minute (10:10, 16:16, 22:22) or the same number was repeated as time (11:11, 22:22).
Today, I saw two numbers of stats ...... exact at ... 1,111 (total reactions to my posts) :
and

5000 views (to one of my posts). If logged 5 minutes later, the stats numbers would have been different.
***"Absolute popular / repeatative numbers makes you happy without any reason"***
What you say?
| manishfoodtechs |
349,356 | Poll: Tailwind or Bootstrap? 👩💻👨💻 | About 3 months ago I wrote an article comparing Tailwind CSS with Bootstrap on Themesberg. Since then... | 0 | 2020-06-04T12:15:15 | https://dev.to/zoltanszogyenyi/poll-tailwind-or-bootstrap-1153 | tailwindcss, bootstrap, poll, community | About 3 months ago I wrote an [article comparing Tailwind CSS with Bootstrap](tailwind-css-vs-bootstrap) on Themesberg. Since then Tailwind became even more popular and there is an increasing amount of front-end web developers switching from the good old Bootstrap.
In the coming months it is expected that [Bootstrap 5 will be released removing jQuery and IE 10/11 support](https://themesberg.com/blog/design/bootstrap-5-release-date-and-whats-new).
With that being said, which CSS Framework do you prefer using?
<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Which do you prefer? <a href="https://twitter.com/tailwindcss?ref_src=twsrc%5Etfw">@tailwindcss</a> or <a href="https://twitter.com/getbootstrap?ref_src=twsrc%5Etfw">@getbootstrap</a>?<a href="https://t.co/KeGXQ5c6D0">https://t.co/KeGXQ5c6D0</a><a href="https://twitter.com/hashtag/tailwind?src=hash&ref_src=twsrc%5Etfw">#tailwind</a> <a href="https://twitter.com/hashtag/bootstrap?src=hash&ref_src=twsrc%5Etfw">#bootstrap</a> <a href="https://twitter.com/hashtag/web?src=hash&ref_src=twsrc%5Etfw">#web</a> <a href="https://twitter.com/hashtag/dev?src=hash&ref_src=twsrc%5Etfw">#dev</a></p>— Themesberg (@themesberg) <a href="https://twitter.com/themesberg/status/1268516333098086400?ref_src=twsrc%5Etfw">June 4, 2020</a></blockquote> <script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>
Feel free to share your thoughts and experience in the comments section! | zoltanszogyenyi |
349,633 | How to add some badges in your git readme (GitHub, Gitlab etc.) | While I published this repo I was looking for some badges to add in my readme. And found some interes... | 0 | 2020-06-04T21:34:22 | https://dev.to/ananto30/how-to-add-some-badges-in-your-git-readme-github-gitlab-etc-3ne9 | git | While I published [this](https://github.com/Ananto30/cap-em) repo I was looking for some badges to add in my readme. And found some interesting services worth sharing.
The most amazing place to make your badges is the https://shields.io. But I will explain each category to use them in the shield.
## Build
First, the badge you will look for is the build passing badge. You have written some amazing tests and you need to show that they are passing. There are several good services for that, I used **[Travis CI](https://travis-ci.com)**.
The integration is really easy. You need to add a `.travis.yml` file in your repo. Mine was pretty straight-forward -
```yml
language: python
python:
- "3.7"
install:
- pip install -r requirements.txt
script:
- python -m pytest --cov-report term --cov=app
after_success:
- codecov
```
I will talk about the `after_success` part next. Before that, you need the badge, right? You can get it by simply clicking the `build passing` button.
## Code Coverage
You have the tests passing, and the earned the badge. Now you need some coverage for your tests. You already know it by running tests with coverage option. For Python you may run this `python -m pytest --cov-report term --cov=app`. But how to get the badge?
You can use **[Codecov](https://codecov.io/)**. For Python you need to install the `codecov` package by `pip install codecov`. Then just add this line in your `.travis.yml` -
```yml
after_success:
- codecov
```
You can find the badge in the settings page.
You can also use **[Coveralls](https://coveralls.io/)** for the same purpose. In that case, you need to install `coveralls` package in Python. You can find the badge in the bottom of your repo page in coveralls.
## Dependency monitor
This is really useful, not only for the badge but you can also manage your dependencies with the coming updates.
For Python you can use **[requires.io](https://requires.io/)**. To get PR for new package changes you need to configure it by these steps: Hooks -> New pull request -> (configure as you like) -> save changes. And you can find the badge in specific repo page.
For Node.js **[Depfu](https://depfu.com/)** is a good service. You will get PR automatically, don't need to setup any hooks. You can find the badge in the settings of the specific repo page.
## Code Quality
There's a few services for that. I used both **[lgtm](https://lgtm.com)** and **[Code Climate](https://codeclimate.com)**. I won't comapre or judge them as they both marked my code A 😅
You can find lgtm badges in the specific repo's integration page and the codeclimate badges can be found in the repo settings page.
There are also other services specific to your needs. You can know about them from [shields](https://shields.io) actually. Making badge is really easy with them. Have a try!
| ananto30 |
349,661 | Passwordless Authentication for GraphQL APIs with Magic | I recently stumbled on the new Magic authentication service, which offers a straightforward solution... | 0 | 2020-06-09T16:52:38 | https://dev.to/mandiwise/passwordless-authentication-for-graphql-apis-with-magic-2chk | graphql, node, apollo, authentication | I recently stumbled on the new [Magic](https://magic.link/) authentication service, which offers a straightforward solution for handling passwordless authentication in web applications. Magic has [an example in its documentation](https://docs.magic.link/tutorials/full-stack-node-js) that demonstrates how to use it in a typical full-stack Node.js app with Express and Passport, but I wanted to see how easy it would be to use it to authenticate users with a GraphQL API backed by Apollo Server.
After some research and experimentation, I managed to get a basic working example up and running. In this post, I'll show you how to integrate Magic-based authentication with Apollo Server, as well as NeDB to store user data.
In this tutorial, we will:
- Create a Magic account and obtain API keys
- Set up Express, Apollo Server, and NeDB
- Use Magic's Node.js Admin SDK and its browser SDK to handle user authentication
- Create custom middleware to parse tokens from Magic and forward the information contained within to the Apollo Server context
- Add authorization to the API with GraphQL Shield
**TL;DR** You can find [the complete code in this repo](https://github.com/mandiwise/graphql-magic-auth-demo).
## Sign Up for Magic
Before we write any code, we'll need to create a Magic account to obtain API keys to use with our app. Magic has a free tier that allows up to 250 active users for your app and you don't need a credit card to sign up. You can create your new Magic account here: https://dashboard.magic.link/signup
The authentication flow you go through to create your Magic account will be exactly what users will experience when they authenticate with our demo app later on. In short, after entering your email into the sign-up form, you'll receive an email containing a link to log in. After you click the link, you can go back to the tab where you originally signed up and you'll see that you are now _magically_ (sorry, I couldn't resist 😉) authenticated and can view the dashboard:
You'll see that there's already an app created in your account called "First App." Click the "Get Started" button to get its API keys:
Tip! If you want to change the name of the app to something more relevant, then click on "Settings" in the lefthand menu and update the app name there:
It's important to pick a relevant app name because users will see this name in the email that they receive from Magic to log into the app.
Keep the test keys handy as we'll need to add them to a `.env` file shortly.
## Installfest
Now that we have a Magic account, we can set up our project. We'll begin by creating a new directory for it:
```sh
mkdir graphql-magic-auth-demo && cd graphql-magic-auth-demo
```
Next, we'll create a `package.json` file:
```sh
yarn init --yes
```
Now we can install some initial dependencies:
```sh
yarn add @magic-sdk/admin@1.1.0 apollo-server-express@2.14.2 dotenv@8.2.0 \
esm@3.2.25 express@4.17.1 graphql@15.0.0 nedb-promises@4.0.3
```
**Note:** I ran into node-gyp errors when I tried installing the `@magic-sdk/admin` package with npm initially, but had no issues when I used Yarn.
We'll also install Nodemon as a development dependency:
```sh
yarn add -D nodemon@2.0.4
```
Here's what all of these packages will be used for:
- `@magic-sdk/admin`: This is the library provided by Magic for Node.js that will allow us to leverage [Decentralized ID Tokens](https://docs.magic.link/tutorials/decentralized-id) to authenticate users with our GraphQL API. You can [read more about its API here](https://docs.magic.link/admin-sdk/node-js).
- `apollo-server-express`: To facilitate integrating Node.js middleware with our server, we'll use the Apollo/Express integration.
- `dotenv`: We'll use this package to load some Magic API keys as environment variables.
- `esm`: This package is a "babel-less, bundle-less ECMAScript module loader" that will allow us to use `import` and `export` in Node.js without any hassle.
- `express`: Again, we'll use Express to add some middleware to our server.
- `graphql`: Apollo requires this library as a peer dependency.
- `nedb-promises`: [NeDB](https://github.com/louischatriot/nedb) is a lightweight, MongoDB-like database that we'll use to store some metadata about users after they authenticate with Magic. The `nedb-promises` library provides a promise wrapper for NeDB's callback-based CRUD methods. You can [view the NeDB documentation here](https://github.com/louischatriot/nedb).
- `nodemon`: Nodemon will automatically reload our application when files change in the project directory.
Next, we'll create some subdirectories to organize our app's files:
```sh
mkdir config data graphql
```
We'll need files to create a new instance of `Magic` and a database store for our user metadata:
```sh
touch config/magic.js config/users.js
```
NeDB can be used as an in-memory or persisted database, but we'll opt for persisting the data in a `users.db` file in the `data` directory:
```sh
touch data/users.db
```
Next, we'll add some files to organize our API-related code:
```sh
touch graphql/resolvers.js graphql/typeDefs.js
```
And lastly, we'll need `.env` and `index.js` files in the root directory too:
```sh
touch .env index.js
```
The current directory structure will now look like this:
```text
graphql-magic-auth-demo
├── config /
| └── magic.js
| └── users.js
├── data /
| └── users.db
├── graphql /
| └── resolvers.js
| └── typeDefs.js
├── node_modules/
| └── ...
├── .env
├── package.json
├── yarn.lock
```
## Set Up Express and Apollo Server
With our Magic API keys and a scaffolded project directory ready to go, we can set up a basic GraphQL API using Apollo Server and Express and configure our database. Once these pieces are in place, we'll add a Magic-based authentication layer on top of them.
We'll begin by copying and pasting the secret key from the Magic dashboard into our `.env` file. We'll also set `NODE_ENV` and `PORT` variables:
```text
MAGIC_SECRET_KEY=sk_test_XXXXXXXXXXXXXXXX
NODE_ENV=development
PORT=4000
```
To use Magic with our API, we'll need to instantiate a new `Magic` object from the Node.js Admin SDK. We'll do that in `config/magic.js`, passing our secret key into the constructor:
```js
import { Magic } from "@magic-sdk/admin";
export default new Magic(process.env.MAGIC_SECRET_KEY);
```
Next, we'll create a `Datastore` to persist the user data in `config/users.js`:
```js
import Datastore from "nedb-promises";
import path from "path";
export default Datastore.create({
autoload: true,
filename: path.resolve(__dirname + "/../data/users.db")
});
```
If you're familiar with MongoDB, then you can think of a NeDB `Datastore` as the rough equivalent of a collection. The CRUD methods we'll use on the `Datastore` object will closely resemble MongoDB's as well. We set `autoload` to `true` here to automatically load the `users.db` datafile upon creation.
Next, we'll create the initial type definitions for our GraphQL API in `graphql/typeDefs.js`:
```js
import { gql } from "apollo-server-express";
const typeDefs = gql`
type User {
id: ID!
email: String!
lastLoginAt: String!
}
type Query {
user(id: ID!): User!
users: [User]
}
`;
export default typeDefs;
```
Above, we have an object type called `User` that will represent a user account. We also add `user` and `users` queries to the schema to query a single user by their `ID` (which will correspond to their Magic token's "issuer" value) or the full list of all users.
We'll also add the corresponding resolvers for the schema in `graphql/resolvers.js`:
```js
import { ApolloError, ForbiddenError } from "apollo-server-express";
import magic from "../config/magic";
import users from "../config/users";
const resolvers = {
Query: {
user(root, { id }, context, info) {
return users.findOne({ issuer: id });
},
users(root, args, context, info) {
return users.find({});
}
}
};
export default resolvers;
```
In this file, we import the `users` datastore object so we can call its `findOne` and `find` methods in our two query resolvers. Like MongoDB, the first argument to these methods is an object specifying the fields you wish to match on. An empty object will query all documents.
For the `user` query we search for a single user document using the `id` argument from the GraphQL query, which will correspond to the `issuer` field inside of the NeDB document.
Note that we also imported some predefined errors from Apollo Server and our `magic` object into this file to use in our resolvers later on.
With our type definitions and resolvers in place, we can scaffold our GraphQL API server with Apollo and Express in `index.js`:
```js
import { ApolloServer } from "apollo-server-express";
import express from "express";
import resolvers from "./graphql/resolvers";
import typeDefs from "./graphql/typeDefs";
/* Express */
const port = process.env.PORT;
const app = express();
/* Apollo Server */
const server = new ApolloServer({
typeDefs,
resolvers
});
server.applyMiddleware({ app });
/* Kick it off... */
app.listen({ port }, () =>
console.log(`Server ready at http://localhost:${port}${server.graphqlPath}`)
);
```
To start up the API, we'll update `package.json` by adding a `scripts` property with a `dev` script to start the application with Nodemon:
```json
{
// ...
"scripts": {
"dev": "nodemon -r esm -r dotenv/config index.js"
}
}
```
We use the `-r` (or `--require`) flag when running Node.js to preload the `esm` and `dotenv` modules (as is required by the esm package). Now we can run `yarn dev` and see GraphQL Playground running at `http://localhost:4000`.
## Get a Token from Magic
At this point, we've run into a bit of chicken-egg problem.
We can only obtain a DID token for a user from Magic using the `loginWithMagicLink` method from the auth module in their browser SDK. We'll need this token to send along with the `Authorization` header from GraphQL Playground (just as you would with a JSON web token).
However, we're only going to concern ourselves with building the back-end application in this tutorial and use GraphQL Playground as a client for testing purposes. But we can't obtain a DID token from Magic to test authenticating our API requests in GraphQL Playground unless we use their client-side library and go through their web/email authentication flow... 🤔
As a solution, we'll build a bare-bones login page that will allow us to sign up or login users through Magic. Once the new user is created in Magic, we'll render their DID token at this route so we can copy and paste it into GraphQL Playground. With this token in hand, we'll be able to create our own `login` mutation to handle the remainder of the sign-up and login process within the context of our application (i.e. add user-related data to NeDB).
We'll use [EJS](https://ejs.co/) to create a template to render a login page at the `/login` route in our Express app:
```sh
yarn add ejs@3.1.3
```
Next, we'll create `views` directory in our app:
```sh
mkdir views
```
And a `login.ejs` file inside of it:
```sh
touch views/login.ejs
```
Now we'll add the following code to `views/login.ejs`:
```html
<html>
<head>
<title>GraphQL + Magic Demo</title>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<script src="https://cdn.jsdelivr.net/npm/magic-sdk/dist/magic.js"></script>
<script>
const magic = new Magic("<%= MAGIC_PUBLISHABLE_KEY %>");
const render = async (token) => {
let html;
if (!token) {
html = `
<h1>Please sign up or login</h1>
<form onsubmit="handleLogin(event)">
<input type="email" name="email" required="required" placeholder="Enter your email" />
<button type="submit">Send</button>
</form>
`;
} else {
html = `
<h1>Token</h1>
<pre style="white-space: pre-wrap; word-wrap: break-word">${token}</pre>
<button onclick="handleLogout()">Logout</button>
`
}
document.getElementById("app").innerHTML = html;
};
const handleLogin = async event => {
event.preventDefault();
const email = new FormData(event.target).get("email");
if (email) {
const didToken = await magic.auth.loginWithMagicLink({ email });
render(didToken);
}
};
const handleLogout = async () => {
await magic.user.logout();
render();
};
</script>
</head>
<body onload="render()">
<div id="app">Loading...</div>
</body>
</html>
```
**Note:** I adapted the above code from the [Magic's full-stack Node.js reference example](https://docs.magic.link/tutorials/full-stack-node-js).
This template loads the [Magic Browser JS SDK](https://www.npmjs.com/package/magic-sdk) and then uses a `MAGIC_PUBLISHABLE_KEY` variable (which we will define shortly in our `.env` file) to instantiate a new `Magic` object. We can then call the `loginWithMagicLink` method exposed in the `magic` object's `auth` module to sign up or log in a user when they submit their email address through the form.
For convenience's sake during testing, you can also log a user out by clicking the "Logout" button here once they're authenticated, but we'll eventually add a `logout` mutation to our GraphQL API that will handle this action as well.
Next, we'll update the `.env` file by copying and pasting the publishable key for this app from the Magic dashboard as the `MAGIC_PUBLISHABLE_KEY` variable:
```text
MAGIC_PUBLISHABLE_KEY=pk_test_XXXXXXXXXXXXXXXX # NEW!
MAGIC_SECRET_KEY=sk_test_XXXXXXXXXXXXXXXX
NODE_ENV=development
PORT=4000
```
Now we can add the `/login` route to our Express app in `index.js`:
```js
// ...
/* Express */
const port = process.env.PORT;
const app = express();
app.set("views"); // NEW!
app.set("view engine", "ejs"); // NEW!
app.get("/login", function (req, res) {
res.render("login", {
MAGIC_PUBLISHABLE_KEY: process.env.MAGIC_PUBLISHABLE_KEY
});
}); // NEW!
// ...
```
We can now visit the login form at `http://localhost:4000/login`:
Enter your email into the form. You'll see that the authentication process for our app will work exactly like the one during our initial Magic account sign-up. After completing the Magic authentication process, we'll be able to see our token rendered at `http://localhost:4000/login` instead of the form:
Now we can copy and paste this token to use in the `Authorization` header in GraphQL Playground, prefixing the value with `Bearer` and a single space:
This token may remind you of a JWT. Like a JWT, it's a Base64-encoded. However, instead of containing period-delimited header, payload, and signature sections, it's a tuple representing a proof and a claim. (I encourage you to take a look at [the Magic docs](https://docs.magic.link/tutorials/decentralized-id) for more details on DID tokens.)
One more important note! Magic tokens are only valid for 15 minutes, so you'll need to obtain a new token for use in GraphQL Playground whenever it expires.
## Create Middleware to Process the Token and Add It to the Apollo Server Context
Now that we can obtain our new user's DID token from Magic and send it along with an API request, we need a way to handle the `Authorization` header once it reaches our server.
The Magic docs say that it's up to us to use the Admin SDK to validate the DID Token, so we'll create some custom Express middleware to do just that. Once we have validated the incoming token, we'll add the decoded user information to the `req` object on a `user` property. If you've ever used the [express-jwt](https://github.com/auth0/express-jwt) middleware, we're going to being coding something that roughly analogous to that for DID tokens.
First, we'll update our code in `index.js` with some new imports:
```js
import { ApolloServer } from "apollo-server-express";
import { SDKError as MagicSDKError } from "@magic-sdk/admin"; // NEW!
import express from "express";
import magic from "./config/magic"; // NEW!
import resolvers from "./graphql/resolvers";
import typeDefs from "./graphql/typeDefs";
// ...
```
Next, after we create our Express app we'll add a `didtCheck` function to `index.js` that will serve as our DID token-checking middleware:
```js
// ...
/* Express */
const port = process.env.PORT;
const app = express();
// ...
/* Magic Middleware */
const didtCheck = function (req, res, next) {
if (!!req.headers.authorization) {
try {
const didToken = magic.utils.parseAuthorizationHeader(
req.headers.authorization
);
magic.token.validate(didToken);
req.user = {
issuer: magic.token.getIssuer(didToken),
publicAddress: magic.token.getPublicAddress(didToken),
claim: magic.token.decode(didToken)[1]
};
} catch (error) {
res.status(401).send();
return error instanceof MagicSDKError
? next(error)
: next({ message: "Invalid DID token" });
}
}
}; // NEW!
app.use(didtCheck); // NEW!
// ...
```
In the code above, we wrap our DID token-checking code in a conditional to see if an authorization header was sent. We don't want to throw an error here if a DID token wasn't sent in the header because we want to provide some unauthenticated access to our app (specifically, to the `/login` route and GraphQL Playground at `/graphql`).
But fear not! We will later add middleware to our GraphQL API that will check if users are authenticated and protect our API and user data on a per-query and per-mutation basis.
Inside the `try`/`catch` block, we first confirm that the DID token header is in the correct shape and extract the token value from the header using the `parseAuthorizationHeader` method (this method will throw an error the `Authorization` header value is not in the `Bearer ${token}` format).
Next, we validate the token using the Magic's `validate` method (it will also throw an error if the token is not authentic or it has expired) and add the valid token's user details to the `req` object under a `user` property.
We'll need to make one more update to `index.js` here to attach the `req.user` object to the Apollo Server context so we can access this user information inside of our resolver functions:
```js
// ...
/* Apollo Server */
const server = new ApolloServer({
typeDefs,
resolvers,
context: ({ req }) => {
const user = req.user || null;
return { user };
} // NEW!
});
// ...
```
For reference, the `user` object we just attached to the context will have the following shape:
```js
{
issuer: 'did:ethr:0x56cc0c4eC95d...',
publicAddress: '0x56cc0c4eC95dc6...',
claim: {
iat: 1591302692,
ext: 1591303592,
iss: 'did:ethr:0x56cc...',
sub: 'ifKoHiIfQBv7L9l...',
aud: 'did:magic:382fd...',
nbf: 1591302692,
tid: '0fe7f5a4-14c0-4...',
add: '0x7e6636fabbf91...'
}
}
```
The `issuer` field will be particularly useful to uniquely identify each user in our application.
## Create Login and Logout Mutations
Our next step will be to create `login` and `logout` mutations. While we saw how to sign up and log in/out users using Magic's browser's SDK in `login.ejs` earlier, these mutations will handle authentication more generally in our application.
Specifically, when a user sends a `login` mutation with a valid DID token from Magic, we'll see if we can find a matching document in the database. If we can't, then we'll create a new document for the user in NeDB containing their issuer value, email address, and the time they last logged in. If the user already exists, we'll update their document with a current value for their last login time.
When logging out, we'll call the `logoutByIssuer` method provided by the Magic Admin SDK and return a boolean from the `logout` resolver.
First, we'll update our `graphql/typeDefs.js` file with the new mutations and a new `AuthPayload` type:
```js
import { gql } from "apollo-server-express";
const typeDefs = gql`
type AuthPayload {
user: User
} # NEW!
type User {
id: ID!
email: String!
lastLoginAt: String!
}
type Query {
user(id: ID!): User!
users: [User]
}
type Mutation {
login: AuthPayload
logout: Boolean
} # NEW!
`;
export default typeDefs;
```
Next, we'll add the `login` resolver to `graphql/resolvers.js`:
```js
// ...
const resolvers = {
// ...
Mutation: {
async login(root, args, { user }, info) {
const existingUser = await users.findOne({ issuer: user.issuer });
if (!existingUser) {
const userMetadata = await magic.users.getMetadataByIssuer(user.issuer);
const newUser = {
issuer: user.issuer,
email: userMetadata.email,
lastLoginAt: user.claim.iat
};
const doc = await users.insert(newUser);
return { user: doc };
} else {
if (user.claim.iat <= user.lastLoginAt) {
throw new ForbiddenError(
`Replay attack detected for user ${user.issuer}}.`
);
}
const doc = await users.update(
{ issuer: user.issuer },
{ $set: { lastLoginAt: user.claim.iat } },
{ returnUpdatedDocs: true }
);
return { user: doc };
}
}
} // NEW!
};
export default resolvers;
```
The `login` mutation above extracts the `user` from the context and uses its `issuer` value to query the database for an existing user. If it can't find one, then it creates a new user document and returns an object in the shape of the `AuthPayload` type.
If a matching user document does exist, then we first check to make sure the time the DID token was issued at (the claim's `iat` value) is greater than the value of the last recorded login time saved in the database (to protect against [replay attacks](https://go.magic.link/replay-attack)). If everything checks out, then we update the `lastLoginTime` in the user document to the claim's current `iat` value and return the document in the `AuthPayload`.
The `logout` mutation will be more straightforward to implement. We call Magic's `logoutByIssuer` method to do this and return `true` after its promise resolves:
```js
// ...
const resolvers = {
// ...
Mutation: {
// ...
async logout(root, args, { user }, info) {
try {
await magic.users.logoutByIssuer(user.issuer);
return true;
} catch (error) {
throw new ApolloError(error.data[0].message);
}
} // NEW!
}
};
export default resolvers;
```
As a final update to the resolvers, we'll need to map the `issuer` field in the user document to the `id` field of the `User` type:
```js
// ...
const resolvers = {
User: {
id(user, args, context, info) {
return user.issuer;
}
}, // NEW!
// ...
};
export default resolvers;
```
With this code in place, we can test our new mutations. First, we'll try testing `login` in GraphQL Playground. Be sure to obtain a fresh DID token from the `/login` route and add it to the "HTTP Headers" panel first:
```graphql
mutation {
login {
user {
id
email
lastLoginAt
}
}
}
```
Here's the mutation response:
```json
{
"data": {
"login": {
"user": {
"id": "did:ethr:0x56cc0c4eC95dc69dC98752141B96D9f7fcF21f92",
"email": "mandi@email.com",
"lastLoginAt": "1591306801"
}
}
}
}
```
In `data/users.db`, we should be able to see that a new user document was successfully added as well:
```json
{"issuer":"did:ethr:0x56cc0c4eC95dc69dC98752141B96D9f7fcF21f92","email":"mandi@email.com","lastLoginAt":1591306801,"_id":"FlkUvCgHadAfiy79"}
```
We can also try running the `logout` mutation now:
```graphql
mutation {
logout
}
```
That mutation will provide the following response:
```json
{
"data": {
"logout": true
}
}
```
Now that we have some data in our database, we can also test out the `users` query too:
```graphql
query {
users {
id
email
lastLoginAt
}
}
```
Here's the query response:
```json
{
"data": {
"users": [
{
"id": "did:ethr:0x56cc0c4eC95dc69dC98752141B96D9f7fcF21f92",
"email": "mandi@email.com",
"lastLoginAt": "1591306801"
}
]
}
}
```
Lastly, we can query a single user by the ID (i.e. their DID token's `issuer` value):
```graphql
query {
user(id: "did:ethr:0x56cc0c4eC95dc69dC98752141B96D9f7fcF21f92") {
id
email
lastLoginAt
}
}
```
And here's that query response:
```json
{
"data": {
"user": {
"id": "did:ethr:0x56cc0c4eC95dc69dC98752141B96D9f7fcF21f92",
"email": "mandi@email.com",
"lastLoginAt": "1591306801"
}
}
}
```
## Lock Down the GraphQL API
Now that we can authenticate users using Magic and log them in and out within the context of our application, we need to protect the queries and mutations in our API so that only authenticated users can send these requests.
There are different schools of thought on how to add a permissions layer to a GraphQL API, but my go-to option is usually [GraphQL Shield](https://github.com/maticzav/graphql-shield). I like this package because it offers an intuitive interface for adding authorization rules on a per-type or per-field basis and keeps these rules abstracted away from the type definitions and resolvers as a separate middleware layer.
We'll begin by installing that package along with graphql-middlware to our project:
```sh
yarn add graphql-middleware@4.0.2 graphql-shield@7.3.0
```
Next, we'll add a `permissions.js` file to the `graphql` directory:
```sh
touch graphql/permissions.js
```
In `graphql/permissions.js`, we'll add a rule to make sure that the authenticated user information has been successfully add to the Apollo Server context:
```js
import { rule, shield } from "graphql-shield";
const hasDidToken = rule()((parent, args, { user }, info) => {
return user !== null;
});
```
A GraphQL Shield `rule` has all of the same parameters as a resolver function, so we can destructure the `user` object from the `context` parameter as we would in a resolver, and then check that the user is not `null`, otherwise we will return `false` to throw an authorization error for this rule.
Next, we'll set the permissions for the types in our schema by calling the `shield` function in `graphql/permissions.js`:
```js
import { rule, shield } from "graphql-shield";
const hasDidToken = rule()((parent, args, { user }, info) => {
return user !== null;
});
const permissions = shield(
{
Query: {
users: hasDidToken,
user: hasDidToken
},
Mutation: {
login: hasDidToken,
logout: hasDidToken
}
},
{ debug: process.env.NODE_ENV === "development" }
); // NEW!
export default permissions; // NEW!
```
Alternatively, we could use a wildcard to set `Query: { "*": hasDidToken }` and `Mutation: { "*": hasDidToken }` inside the rules object passed into `shield`, but we may wish to set more nuanced rules for the various queries and mutations in the future so we'll opt for explicitly adding `hasDidToken` for each.
For our new permissions to have any effect, we'll need to add them as middleware to Apollo Server in `index.js`. Do that, we'll need to update the imports in that file as follows:
```js
import { ApolloServer, makeExecutableSchema } from "apollo-server-express"; // UPDATED!
import { applyMiddleware } from "graphql-middleware"; // NEW!
import { SDKError as MagicSDKError } from "@magic-sdk/admin";
import express from "express";
import magic from "./config/magic";
import permissions from "./graphql/permissions"; // NEW!
import resolvers from "./graphql/resolvers";
import typeDefs from "./graphql/typeDefs";
// ...
```
As a final step, we'll need to add the `permissions` as middleware to our GraphQL API. Do do that, we'll do some slight refactoring, passing our `typeDefs` and `resolvers` into the newly imported `makeExecutableSchema`. Then we'll the `schema` property in the `ApolloServer` constructor to the return value of calling `applyMiddleware` with the `schema` and `permissions` as arguments (rather than passing the `typeDefs` and `resolvers` into the constructor directly):
```js
// ...
/* Apollo Server */
const schema = makeExecutableSchema({ typeDefs, resolvers }); // NEW!
const server = new ApolloServer({
schema: applyMiddleware(schema, permissions), // UDPATED!
context: ({ req }) => {
const user = req.user || null;
return { user };
}
});
server.applyMiddleware({ app });
// ...
```
If we go back and test our queries and mutations in GraphQL Playground now, we'll see that we get a "Not Authorised!" error if we try running any of them without a valid DID token submitted in the `Authorization` header.
## Summary
In this tutorial, we built out a Node.js app using Express, Apollo Server, and NeDB. We also created a Magic account and used our API keys to add authentication to our GraphQL API.
To lock down our GraphQL API, we had to create some custom middleware to validate the DID token provided by Magic and then forward it on to the Apollo Server context. We also had to set up GraphQL Shield to add basic permissions-checking to our API using the decoded DID token.
You can find the [complete code for this tutorial on GitHub](https://github.com/mandiwise/graphql-magic-auth-demo).
As a final point to keep in mind, please note that I left out persisting any sessions on the server, which would likely be something you would want to consider in the context of a real app. Check out [express-session](https://github.com/expressjs/session) and/or [Passport](http://www.passportjs.org/) for more guidance on this.
While putting tougher this tutorial, I found these resources particularly helpful and I'd encourage you to take a look too if you'd like to learn more about Magic authentication in Node.js apps:
- [Magic Docs - Full Stack Node.js](https://docs.magic.link/tutorials/full-stack-node-js)
- [Magic Authentication For Passport JS](https://github.com/magiclabs/passport-magic)
- [Simple Auth Setup for Your React App](https://arunoda.me/blog/simple-auth-setup-for-your-react-app)
---
Photo credit: [Sharon McCutcheon](https://unsplash.com/photos/62vi3TG5EDg) | mandiwise |
349,672 | Benefits of a Throwaway Environment | The state of a developer's workstation can very easily be summarized as "works on my machine". Docker can be used to try new things without creating a mess. | 0 | 2020-06-05T13:40:47 | https://dev.to/dhandspikerwade/benefits-of-a-throwaway-environment-3i0p | docker, productivity, devops | ---
title: Benefits of a Throwaway Environment
published: true
description: The state of a developer's workstation can very easily be summarized as "works on my machine". Docker can be used to try new things without creating a mess.
tags: docker, productivity, devops
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/cx7ngkq0jo61ww0e7kic.jpg
---
The state of a developer's workstation can very easily be summarized as "works on my machine" - something different is installed or configured differently and I don't know what or how it got that way. Every machine is personal. Some try to minimize this by using Ansible or Chef to create the ability to spin up their environment cleanly. However at the end of the day, we're developers, sometimes we need to just try something and see what happens. Sometimes trying new things creates a mess that never really gets swept up.
This is where Docker comes in handy! For the same reason that it's great for immutable deployments, it's great for creating an environment to play in and then toss away once you're done - with very little overhead. A container will only leak the changes that you tell it to. Only changes to the files in a mounted volume will be preserved.
### CI/CD
If you are using a CI/CD system like GitLab CI, Bitbucket Pipelines, or CircleCI, you may already be using a throwaway environment without realizing it. Continuous integration relies on the ability to run multiple builds simultaneously that may have differing requirements and toolchains. Containers and virtual machines are often used to isolate those build processes while allowing the development team to install any needed tools without affecting another team's workflow. We wouldn't want a build to start failing randomly just because another team decided to try the newest NodeJS beta.
### Why would you use it?
This all sounds great right, but how do you use it in practice? You use it to experiment! Whether that is trying your app in the newest NodeJS beta, testing a script in a sandbox, or updating up an outdated library. All without affecting your workstation permanently; if anything goes wrong or not as you wanted to, delete the container and start again. No need to break your already working environment.
### Reusability
While it's great to have the ability to have a fresh sandbox each time you want to try something, sometimes you want some tools pre-installed. Using the same process that is used to create immutable deployments, we are able to create images that include tools you commonly use. For example, I personally have an image that is able to build different PHP versions so I that I can test different configs across versions. This can be done by finding a pre-made image on DockerHub or creating your own via a Dockerfile. If you are interested in creating your own, I'd recommend heading over to the [official documentation](https://docs.docker.com).
*Photo by [Ferenc Horvath](https://unsplash.com/photos/4gKHjKG7ty4) on [Unsplash](https://unsplash.com/)*
| dhandspikerwade |
349,681 | Learning react | I'm a react and react native beginner.I wanted to know what scenarios in creating e-commerce website... | 0 | 2020-06-05T02:21:50 | https://dev.to/kennymanman/learning-react-e6g | I'm a react and react native beginner.I wanted to know what scenarios in creating e-commerce website or regular website that i will have to use handlechange and onchange. How also can i learn to use handlechange as a beginner and also setstate. Thank you. | kennymanman | |
349,703 | The Industry Hates Me For Being Honest | Over the past 2 months I have interviewed with several companies and 2 of them stood out at rejecting... | 0 | 2020-06-05T03:59:53 | https://dev.to/bastianrob/the-industry-hates-me-for-being-honest-11pp | Over the past 2 months I have interviewed with several companies and 2 of them stood out at rejecting me. Let's call them Company A, and Company B!
> I know right? Developers are bad at naming!
I guess part of it is my fault too! I am old and slow. Doesn't like competitive programming and already forgot most of how to answer algorithm question. I can't even answer some of the algorithm question I've flawlessly answered back when I was fresh out of University.
## Company A
When I got chance to interview at Company A, they require me to answer HackerRank style interview. It's my first time in nearly a decade of working in the industry to feel like I'm in a classroom exam again. I hate it, and I deliberately voiced my distaste to the answers comment:
```go
// Paraphrasing
// I'm sorry, I'm dumb!
// I never faced anything like this in real world work...
// ......
```
But guess what? My answer still pass the score, have a call with their VP, which proceed to have another call with their Lead Engineer.
Talked about my experience with Event Driven System and CQRS+ES and they decided that I am:
- Arrogant
- Too RND in my tech stack
- And overkill in CQRS+ES
And decided they don't need me.
They hate me for having a headstrong personality which translates as Arrogance to the perceiving end.
## Company B
Another HackerRank style interview. Guess I passed their score this time without me typing some strong comment and proceed to have another test with their Lead Engineer.
This time they want 5 question answered in google docs within 60 minutes.
Two of them stood out to me for being impossible to work on 12 minutes (60 / 5 if you're wondering). Or maybe I'm just old and dumb?!
The others are just questions copied word for word from Geeks For Geeks.
One of the question requires me to write a password brute force attack to an imaginary API.
The other requires me to find a combination of math `+` or `-` operation from `a strings of numbers` that results in `a number`.
My `Arrogance` kicks in and I start typing a comment
```go
// Paraphrasing
// I am sorry but I feel this is impossible for me to think of in 12 minutes
// (60 / 5 if you're wondering)
// But I know you guys got this question from Rosseta Code!
// Here's the link, but I don't know the logic behind it
```
See? I've worked on this question back when I was still a University student and remember where to look at.
Unsurprisingly, I've heard the feedback that I was rejected although I've answered one of their question `FLAWLESSLY`. I know they are being sarcastic at this point. haha.
---
I was trying to be honest about what I can and can't do in the `N` minutes timeframe and the Industry hates me.
I guess The Industry love people who can grind `GFG` or other algorithm websites, remember the solutions out of their head, and quietly answer their `genuinely original question` without pointing the flaws back at them. | bastianrob | |
349,706 | Correctly ignoring .DS_Store files | Ignore .DS_Store files from all folders and subfolders in git repo | 0 | 2020-06-05T04:34:19 | https://dev.to/travelingwilbur/correctly-ignoring-dsstore-3hpm | ---
title: Correctly ignoring .DS_Store files
published: true
description: Ignore .DS_Store files from all folders and subfolders in git repo
tags:
//cover_image: https://direct_url_to_image.jpg
---
This is a simple trick, but I'm posting it here as reference.
When you do `git status` and find some `.DS_Store` files scattered through your app's folders there a simple line to add to your `.gitignore` to ignore them all for good:
```
**/.DS_store
```
However, if the `.DS_Store` files are already there type:
```
find . -name .DS_Store -print0 | xargs -0 git rm -f --ignore-unmatch
```
This will remove them from folders and subfolders. Then just commit and push to your repo.
```
git commit -m "remove .DS_Store files from everywhere"
git push
```
And that's it.
| travelingwilbur | |
349,723 | Performantly loading Google Fonts based on Data Saver | Efficiently and Asynchronously load Google Fonts based on Data Saver mode | 0 | 2020-06-05T05:42:51 | https://puruvj.dev/blog/google-fonts-prefetch | ---
title: Performantly loading Google Fonts based on Data Saver
description: Efficiently and Asynchronously load Google Fonts based on Data Saver mode
date_time: 05/06/2020
canonical_url: https://puruvj.dev/blog/google-fonts-prefetch
---
> *This article was originally posted at [puruvj.dev](https://puruvj.dev/blog). Check it out for more content Javascipt and Web development*
You. Yes you, who is loading a 50-100kbs of fonts on your site, drop them. Use Comic Sans instead.
Just Kidding. Use as many fonts as you need. I am myself loading 60kb of fonts on this very blog page, just a little more efficiently than the default approach.
## Problem
Using custom fonts isn't bad. They make a bold brand statement. Imagine Google's logo without its beautiful geometric font or Medium without its classic font.
Nowadays, advice like <mark>Don't use fonts</mark> is just impractical. Sure, <mark>Use less fonts</mark> is a good, but the prebuilt system fonts are just hideous(Looking at you, Ariel) and reading content in those is just not as appealing as it was a decade ago.
But, if you look at stats, the average website uses about <mark> 50 - 70 KiloBytes</mark> of fonts nowadays. For scale, this blog you're reading, without images, is a total of 78KB, out of which the fonts take up 60kb. We are using way too much fonts nowadays, but it can't really be helped.
So we have to figure out ways to not let the loading time of fonts get in the way of User experience, while at the same time, respecting the user's data plan. In US, 60KB is basically dust, whereas in countries like Nigeria and India, 60KB can be **real** money.
## Solution
We are going to use the amazing resource hint tag.
```html
<link rel="prefetch" href="URL" />
```
This tag simply loads the given URL and stores it in cache/memory until it is actually used. This loading happens asynchronously and doesn't delay the page's loading.
In simple terms adding this tag to a page will not make it any slower than before.
The important bit here:
> If the browser's data saver is on, this tag will be ignored, thus saving that additional request.
[Read more about Resource Hints](https://medium.com/reloading/preload-prefetch-and-priorities-in-chrome-776165961bbf)
Let's say that our fonts' URL is:
```html
https://fonts.googleapis.com/css?family=Comfortaa|Fira+Code|Quicksand&display=swap
```
Instead of loading them the standard way
```html
<link
rel="stylesheet"
href="https://fonts.googleapis.com/css?family=Comfortaa|Fira+Code|Quicksand&display=swap"
/>
```
We do it like this
```html
<link
rel="prefetch"
href="https://fonts.googleapis.com/css?family=Comfortaa|Fira+Code|Quicksand&display=swap"
as="style"
onload="this.onload=null;this.rel='stylesheet'"
onerror="this.onerror=null;this.rel='stylesheet'"
/>
```
This code above is doing multiple good things at once. The `onload` will fire when the resource has fully loaded, and replace the `rel=prefetch` with `rel=stylesheet`, making the effects of the fonts active.
But another thing is happening here.
> If somehow, due to poor connectivity, the request fails, the `onerror` will try **again** to load the resource. This solution kills 2 birds with one bullet(proverbially only, off course)
## Downsides
- Doesn't load the fonts if old browser or (at the time of writing) latest Safari.
- Slightly degrades the experience for data saver users, but honestly, people are on a site because of the content primarily. Besides, if they have data saver on, this means their data speeds are very slow and data plans quite expensive. They will thank you for making a fast loading site.
_That's it for today. Hope you liked the article. Ping me on Twitter if you have any problems or simply leave a review. Link is in the footer._
| puruvj | |
349,788 | XQuery negate regex | XQuery negate regex... | 0 | 2020-06-05T10:01:03 | https://dev.to/momo_6x/xquery-negate-regex-3f5i | {% stackoverflow 32993708 %} | momo_6x | |
349,798 | Answer: selenium count elements of xpath | answer re: selenium count elements of... | 0 | 2020-06-05T10:34:18 | https://dev.to/momo_6x/answer-selenium-count-elements-of-xpath-59do | {% stackoverflow 46192447 %} | momo_6x | |
349,888 | Post Makers - Week 12 | This week has been a first for me, I participated in my first Hackathon....and won! If you would hav... | 0 | 2020-06-05T12:38:50 | https://dev.to/davidpaps/post-makers-week-12-2g1p | hackathon, jobhunt, quarantine, reactnative | This week has been a first for me, I participated in my first Hackathon....and won!
If you would have asked me what a hackathon was 2 weeks ago, i'm not sure I would have known what to reply. Last week makers sent around an email detailing that they were organising a 'Hack for Heroes' event, detailed specifically to helping the heroes on the frontline.
As a big believer in the feat the front line are accomplishing, I was more than happy to oblige. It turns out that a hackathon is fundamentally a timed sprint to create the best app possible. The apps are then independently judged and the winner is announced based on set criteria - addressing the problem, solving the problem, and doing it in a cool way.
Monday morning I joined the zoom call and after basic orienteering started to discuss ideas with the 100 participants. Groups were then split based on interest/topic, and that was it - GO! We had 2.5 days to present the best app possible. This was then to be judged by top CTO's/Engineers from fantastic companies around the UK.
I was lucky enough to be joined by my old partners in crime Nic and Asia. Together with team members Bassel, Thomas, Lucian and Ben, we set apart formulating a plan. We decided that the biggest problem facing the frontline staff currently was the extreme mental health stresses they were under. This was unanimously agreed on and we set about brainstorming the idea. We decided on a React Native app (with no one previously using this tech..) so that is was accessible and available to everyone on the go. We decided to use a Node/Express/PostgreSQL backend (my suggestion as i have previously been working with this) and use Expo to run the app locally on our machines.
We ended up with a very nifty mental health tracking app. A user could log in, and then speak to a chatbot that would ask them how they were feeling. A value and comment on this value was logged in the database, and could then be tracked over time to identify trends and patterns. The chatbot would then take the user on a conversation, giving resources and suggestions based on user input.
We also identified the power of positive affirmation and Neural Linguistic Programming, and many group members said first hand how this had helped them. We therefore gave the app preset mantras that could push notifications to the users phone at selected intervals. The user could also add their own mantras.
Overall we worked amazingly well, always having 3 different zoom room open so that pairs could float between parts of the build and ask/contribute to the development. I started to build the RESTful API backend in Node/Express and connect it to the database, I then connected this to Heroku and deployed the PostgreSQL database. Other members built out the framework in the React/Native front end and we connected the two. I then got to work on the Chart.js data, and helped out with the push notifications. Everyone worked around the clock and contributed to all areas - I am genuinely prod of what we achieved. Day 1 we met out MVP and day 2 we finished all the features we set out to complete. Day 3 involved styling and writing and rehearing the presentation. We had a flawless presentation, with everyone being concise and coherent, coupled with a very slick demo of our app (we gave a barcode that could be scanned that allowed everyone watching to download the app and use it themselves.
We were lucky enough to be selected as winners, well done to the team! I learnt so much in a small space of time, and had such a blast collaborating with the team. The time frame/competition element really spurred us on, and collectively we united to give a product we are all proud of.
There are some ideas to enhance the app in the future involving adding a machine learning element to the chatbot, but for now its a beer and some rest!
As always stay safe,
David
| davidpaps |
349,963 | Hacky Friday Stuff #05.06.2020 | Photo by Martin Shreder on Unsplash. Links about web development, product engineering, tools and ser... | 0 | 2020-06-05T15:03:02 | https://dev.to/sunnymagadan/hacky-friday-stuff-05-06-2020-mp7 | ruby, rails, javascript, hackyfriday | Photo by [Martin Shreder](https://unsplash.com/@martinshreder) on [Unsplash](https://unsplash.com/@martinshreder).
*Links about web development, product engineering, tools and services from all over the internet.*
[The 2020 Developer Survey results](https://stackoverflow.blog/2020/05/27/2020-stack-overflow-developer-survey-results/)
65,000 developers shared their thoughts on the state of software today in the 10th annual developer survey conducted by Stack Overflow.
[GitHub Classroom](https://classroom.github.com/)
Managing and organizing your class is easy with GitHub Classroom. Track and manage assignments in your dashboard, grade work automatically, and help students when they get stuck— all while using GitHub, the industry-standard tool developers use.
[Marketing for Engineers](https://github.com/LisaDziuba/Marketing-for-Engineers)
A curated collection of marketing articles & tools to grow your product.
### Tutorials & articles
[List of top Open Source alternatives to popular products](https://dev.to/fayazara/top-open-source-alternatives-to-popular-products-stop-paying-16jn)
Great alternatives to some very popular products.
[Two Commonly Used Rails Upgrade Strategies](https://www.fastruby.io/blog/rails/upgrades/rails-upgrade-strategies.html)
Rails upgrades can be done in many different ways. Depending on the application that you want to upgrade, some ways make more sense than others. There are factors that determine which Rails upgrade strategy is the best for your case, like how big your application is, or how frequently changes are pushed to the master branch. This article will be covering two common Rails Upgrade strategies so you can decide which one is the best for your application.
[Writing better Stimulus controllers](https://boringrails.com/articles/better-stimulus-controllers/)
In early 2018, Basecamp released StimulusJS into the world. Stimulus closed the loop on the “Basecamp-style” of building Rails applications. This article is explicitly not an introduction to Stimulus. It explores common failure paths when people are getting started with Stimulus and how to fix that by writing better controllers.
[Rails 6.1 adds support for signed ids to Active Record](https://blog.saeloun.com/2020/05/20/rails-6-1-adds-support-for-signed-ids-to-active-record.html)
There are many ways of generating a signed link for implementing things like invitation email, unsubscribe link or password reset feature. You could add a token field on the model, use JWT tokens. But in the upcoming Rails versions, the functionality to generate tamper-proof and verifiable ids will be built into rails.
[Open source status update, May 2020](https://timriley.info/writing/2020/06/01/open-source-status-update-may-2020/)
May was a breakthrough month in terms of the integration of the standalone components into Hanami 2 for Tim Riley. Let’s dig right in.
### Tools & libraries
[Solid](https://github.com/ryansolid/solid)
Solid is a declarative Javascript library for creating user interfaces. It does not use a Virtual DOM. Instead it opts to compile its templates down to real DOM nodes and wrap updates in fine grained reactions. This way when your state updates only the code that depends on it runs.
[htmx](https://htmx.org/)
htmx allows you to access AJAX, WebSockets and Server Sent Events directly in HTML, using attributes, so you can build modern user interfaces with the simplicity and power of hypertext.
htmx is small (~7k min.gz'd), dependency-free, extendable & IE11 compatible.
[BackstopJS](https://garris.github.io/BackstopJS/)
Visual regression testing for web apps.
[Geared Pagination](https://github.com/basecamp/geared_pagination)
Most pagination schemes use a fixed page size. Page 1 returns as many elements as page 2. But that's frequently not the most sensible way to page through a large recordset when you care about serving the initial request as quickly as possible. This is particularly the case when using the pagination scheme in combination with an infinite scrolling UI.
Geared Pagination allows you to define different ratios. By default, we will return 15 elements on page 1, 30 on page 2, 50 on page 3, and 100 from page 4 and forward. This has proven to be a very sensible set of ratios for much of the Basecamp UIs.
[triki](https://github.com/josacar/triki)
You want to develop against real production data, but you don't want to violate your users' privacy. Enter Triki: standalone Crystal code for the selective rewriting of SQL dumps in order to protect user privacy. It supports MySQL, Postgres, and SQL Server.
[pghero](https://github.com/ankane/pghero)
A performance dashboard for Postgres. [See it in action.](https://pghero.dokkuapp.com/)
[PgTyped](https://github.com/adelsz/pgtyped)
PgTyped makes it possible to use raw SQL in TypeScript with guaranteed type-safety.
### Videos
[Hanami :: API by Luca Guidi](https://www.youtube.com/watch?v=tbyT-zhYMd4&feature=youtu.be)
Hanami is a full-stack web framework for Ruby. With Luca we will learn what will be the major changes for 2.0 release.
Luca is the creator of Hanami and author of redis-store. Also a dry_rb core team member.
### Podcasts
[Remote Ruby | 80. RailsBytes.com, AppLocale and more with Andrew Fomera](https://remoteruby.transistor.fm/80)
Today, our special guest is Andrew Fomera, from Podia, co-worker of Jason, and friend of Jason, Chris, and Andrew Mason. He’s got a course on “Learn Rails by Building Instagram,” he’s launched AppLocale, and launched a tool called RailsBytes with Chris. Chris and Andrew Fomera talk about what RailsBytes is and how they got into building it. Also, Andrew Fomera tells us more about AppLocale, how he got started on it, what it does, and why it will change the world. What is “Thor” and why doesn’t Andrew like it? And why has Jason hit some major “Stonks” as a developer?
| sunnymagadan |
349,975 | SignalR / WebSocket Concepts : in ASP.NET Core 3.1 | The WebSocket is its own Layer 7 protocol. It's not the HTTP protocol (also running in Layer 7) but... | 7,133 | 2020-06-05T16:25:45 | https://dev.to/jwp/asp-net-core-3-1-websocket-concepts-4018 | angular, websockets, aspnetcore | The [WebSocket](https://en.wikipedia.org/wiki/WebSocket) is its own [Layer 7](https://en.wikipedia.org/wiki/OSI_model) protocol.
It's not the HTTP protocol (also running in Layer 7) but it seems to be able to share port 80 and 443 with HTTP.
**SignalR**
A 'helper' library for WebSockets. The SignalR library introduced the "hub" concept. This allows both the server and client to call each other's methods.
>
<sub>You mean my server can invoke a method in my Typescript client and my Angular code can call a server method directly? Yes...</sub>
So what's so helpful with SignalR?
Similar to the DOM object where context is everything, SignalR provides contextual access to properties of the connection.
We have access to the SignalR wrappers' properties, such as user, userid, features, as well as its commands.
Clients can call methods on *all* connected clients, a single client, or specific client groups.
Sounds like an instant chat application doesn't it? Or perhaps a legitimate heartbeat application?
Everything is async by default with strong type support. Events are built-in as is Error Handling.
> <sup> Note: The Web Socket architecture is similar to FTP (full duplex). In FTP there are two ports; one is the command channel, the other is the data channel. Commands can be sent asynchronously with respect to the data flow. FTP is completely interrupt-able and has full-duplex ability.
</sup>
**Security**
CORS must be enabled for the Web Site Port. These are the configurations necessary in startup.cs.
```csharp
// In method ConfigureServices
// Only allow port 4200 to 'bypass' CORS
services.AddCors(options =>
{
options.AddPolicy("CorsPolicy",
builder => builder.WithOrigins("http://localhost:4200")
.AllowAnyMethod()
.AllowAnyHeader()
.AllowCredentials());
});
// And the 'strongly typed' endpoint added
// In method Configure
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
// This makes the HUB fly
endpoints.MapHub<AHubClass>("/hub");
});
```
**Angular Client**
The SignalR Typescript counterpart starts as a service.
It imports the @aspnet/signalar library and will define a signalr.HubConnection. This hubconnection is configured via a HubConnectionBuilder which will identify the url to connect.
The connection is then started which allows for adding eventhandlers. The handler names must match the server-side SendAsync's first string parameter which is the key of that message.
```typescript
import { Injectable } from '@angular/core';
import * as signalR from "@aspnet/signalr";
import { MyModel } from '../_interfaces/mymodel.model';
@Injectable({
providedIn: 'root'
})
export class SignalRService {
public data: MyModel[];
private hubConnection: signalR.HubConnection
public startConnection = () => {
this.hubConnection =
new
signalR.HubConnectionBuilder()
// This url must point to your back-end hub
.withUrl('https://localhost:8081/hub')
.build();
this.hubConnection
.start()
.then(() => console.log('Connection started'))
.catch(err => console.log('Error while starting connection: ' + err))
}
public addDataListener = () => {
this.hubConnection.on('specificMessageName', (data) => {
this.data = data;
console.log(data);
});
}
}
```
**Summary**
For those that use Signalr the name is synonymous with WebSockets. Signalr merely makes it easier to establish Websocket connections, and introduces the HUB type in C# and Typescript. This is great for intellisense and discovering the API...
**References**
[ASP.Net Core WebSocket support](https://docs.microsoft.com/en-us/aspnet/core/fundamentals/websockets?view=aspnetcore-3.1)
[ASP.NET SignalR](https://docs.microsoft.com/en-us/aspnet/core/signalr/introduction?view=aspnetcore-3.1)
[SignalR Hubs](https://docs.microsoft.com/en-us/aspnet/core/signalr/hubs?view=aspnetcore-3.1)
[Remote Procedure Calls](https://en.wikipedia.org/wiki/Remote_procedure_call)
[CodeMaze SignalR Chart](https://code-maze.com/netcore-signalr-angular/#angularchart)
**Interview Answers**
How would you create a chat client? Answer: I use ASP.NET Core's SignalR Websocket library. It allows for a centralized hub, and all connected clients to send messages back and forth. It also allows the server to control all connections as well as to message each client's functions! | jwp |
350,051 | Make an IoT Device for tracking vehicles | Learn how to build IoT devices easy and cheap (beginners guide) | 0 | 2020-06-15T03:03:41 | https://dev.to/satellitebots/make-an-iot-device-for-tracking-vehicles-1706 | iot, raspberrypi, sim7000, embedded | ---
title: Make an IoT Device for tracking vehicles
published: true
description: Learn how to build IoT devices easy and cheap (beginners guide)
tags: IoT, Raspberrypi, sim7000, embedded
//cover_image: https://direct_url_to_image.jpg
---
# Introduction
IoT (Information of Things) devices have become more and more prevalent in everyday life. From home assistants to smart toasters these devices are all over most households and offices. Most of the house appliances utilize WiFi module in order to communicate with the designated API. However, for IoT devices to be able to collect data at a remote location or on the go a SIM module would be needed. In this article we will explore implementing an IoT device to collect and send data on the go.
# BOM
Below are the parts that are required for the project. (Note: Though link provided, please purchase at your own risk)
- [Raspberry pi](https://www.microcenter.com/product/486575/Zero_W) (Zero W used for demo, but any model should work)
- [SIM7000 (A used for demo, but select based on location) breakout board (breakout boards simplify the circuit for easier development/testing)](https://www.aliexpress.com/item/32964568200.html)
- [Female-Female jumper wires](https://www.adafruit.com/product/1951)
- [Header pins](https://www.adafruit.com/product/3662) (for the Zero model this is needed)
- [GSM Antenna](https://www.adafruit.com/product/1991)
- [GPS Antenna](https://www.adafruit.com/product/2461)
# Schematic
The wiring is straight forward, breakout board needs 5V so, connect pin 2 (5V) from raspberry pi to the V pin then connect pin 6 (GND) from raspberry pi to G. For UART protocol, connect Receiver pin to Transmitter pin, so R pin connects with pin 8 (Tx), and T pin connects with pin 10 (Rx). Please refer to the below schematic for better guidance.
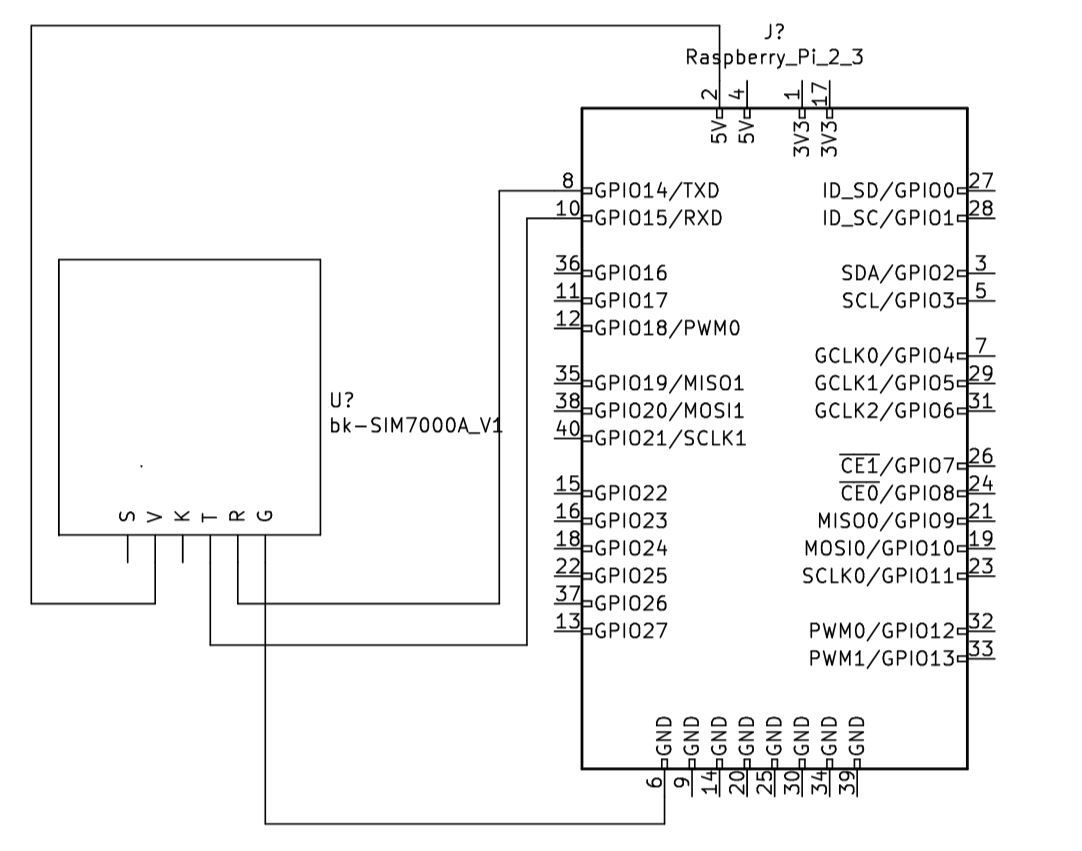
Fig 1.1: Raspberry pi and SIM7000 breakout board schematic
# Setting up Raspberry pi
The raspberry pi zero W has a WiFi module that allows setting up the device headless. To do this, please follow this wiki: http://wiki.lofarolabs.com/index.php/Install_Raspbian
Once the device is setup headless or with monitor, keyboard and mouse, please start off with making sure that everything is updated.
`sudo apt-get update`
`sudo apt-get install upgrade -Y`
Once everything is updated and the device is ready, please start validating that [UART is enabled](https://www.raspberrypi.org/documentation/configuration/uart.md).
- `sudo raspi-config`
- option 5 - interfacing options
- option P6 - serial
- `Would you like a login shell to be accessible over serial?` -> `No`
- `Would you like the serial port hardware to be enabled?` -> `Yes`
With UART configured please check whether or not you see the device we will be interfacing with `/dev/ttyS0` with command: `ls -l /dev | grep tty`.
This project utilizes the UART protocol for communicating with the SIM7000 module. In this case there is a python-serial library that will simplify the communication with the module. However, initially there is a possibility that the device might not respond to commands, this is mostly due to a power issue. This is why standard USB port on laptops/desktops might not be enough to power the device. The recommendation is to first give it 10-15 minutes and see if it responds, if not would recommend trying a different power source. The best result was achieved by using a power brick, but YMMV. During this testing phase it is not practical to run the actual python code as there are already tools for sending UART commands.
Please run the following to install minicom.
`sudo apt-get install minicom -Y`
Once minicom is installed please run it by specifying the device and baudrate you want to use as well.
`minicom -D /dev/ttyS0 -b 115200`
Once in, for first time usage please note that to exit press `[CTRL]+[A]` -> `[Z]` (*Note: not all three together, first two combo, then last key*). This is crucial because if the device is not working then screen will be blank and you will not be able to get out, this should save you from that panic attack. For better understanding of what is going on, please press `[CTRL]+[A]` -> `[E]` to enable echo and this should allow you to see that the commands are being sent, just no response. For basic tests to see that the device is at least responding, please try the command `AT` in the minicom window/terminal. This should return `OK`. Once this is verified we can move onto the next step: Running the Code.
# Running the Code
Please clone the [library here](https://github.com/AlwaysUP/iottracker). To verify this please ensure that the `python-serial` library is installed, as that is the only prerequisite for this script. Then run using `python tracker.py` and you should the commands and the output of the commands on the screen. Once done, please schedule it to run on boot by scheduling a cron job. Run `crontab -l` to check existing cron jobs, then run `crontab -e` to edit. Please add the following:
`@reboot python /full/path/to/tracker.py`
to the cron script. (Please comment if something is not working as expected)
# Logical Breakdown
The basic concept for the project is to upload data from a low power consuming device on the go using internet to an API then utilize those data points to show the travel history of the device. This was then broken down into three components to simplify the project. The components are API, UI, and the IoT device. The API supports GET and POST request for footprints (data points). The UI displays the footprints on a map, and allows user to get direction to the place where the last ping was received from. Though there are libraries for the SIM modules, the most reliable implementation is through serial library, as the user could follow the official documentation for the AT commands by device model.
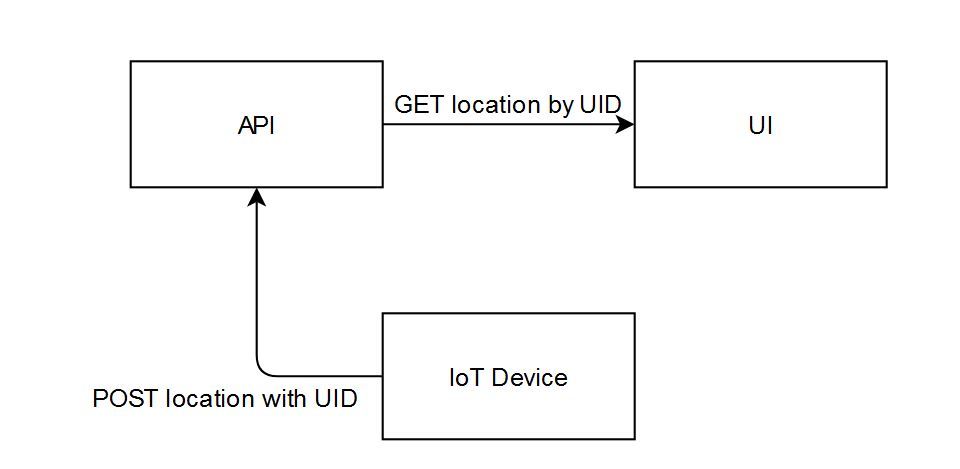
Fig 1.2: Diagram of the project design
# Conclusion
The possibilities with IoT devices are limitless, however, because we see them mostly utilizing WiFi for communication which might be discouraged when thinking of outdoor projects. Whether you are concerned about reliability, cost, or simplicity of implementing your ideas the road towards them have already been paved. [Hologram](hologram.io) provides free data for beginners, [SIMcom](simcom.com) provides affordable SIM modules with well documented guides, and [Heroku](heroku.com) provides free easy to host solution for deploying web apps.
All relevant code:
- [API](https://github.com/AlwaysUP/tracker-api)
- [UI](https://github.com/AlwaysUP/tracker-ui)
- [IoT Device](https://github.com/AlwaysUP/iottracker)
If you would like more information on the code, please let me know and I will create a second part.
If you would like to see a different kind of project please let me know, and I will do my best to implement it.
| satellitebots |
350,054 | Accessing sharepoint sites using rest api's | Hi, I am new to React development. Please help me understand if we can access sharepoint sites direct... | 0 | 2020-06-05T18:23:56 | https://dev.to/archananair/accessing-sharepoint-sites-using-rest-api-s-586b | Hi,
I am new to React development. Please help me understand if we can access sharepoint sites directly using rest api's. I have tried but getting 403 error. I read in few of the stack overflow sites where it was suggested to go with Microsoft SPFx solution. It has build-in httpclient for rest call, if so is there any link which I can refer of how to use Spfx with react js. Please advice. | archananair | |
350,358 | Structuring your asynchronous communication | “Open offices” became popular without really studying what affect they would have. Similarly there is... | 0 | 2020-06-06T14:39:03 | https://dev.to/uclusionhq/structuring-your-asynchronous-communication-4ln6 | productivity | “Open offices” became popular without really studying what affect they would have. Similarly there is a tendency to adopt communication tools without paying much attention to results. Promoting your digital collaboration to first class citizen is more involved than just taking the synchronous communication you were going to have, writing it down in a channel or card and waiting an indeterminate amount of time for a response. That’s because the idea behind most asynchronous productivity tools is too simple:
*It is better to concentrate on what you’re doing until you produce results, than to immediately respond to messages.*
**But what if you can’t make further progress without communication?**
In that case, in an asynchronous world, the following is needed:
1. A way to advertise you’re “blocked”
2. A mechanism to approve alternative tasks
3. The ability to quickly see if someone has alternate work they can be doing
In other words, you need [**structured communication](https://medium.com/@jchyip/logical-message-structure-underlies-all-effective-workplace-communication-d7f62d805826)**. Structured communication is about having a context for a conversation that can be quickly understood. Typically, the reason everyone wants a response in real time is not knowing or being able to reduce the cost of delayed response. Clearly you can’t say, “Hey don’t worry about responding quickly anymore.” as you’re still missing out on important information.
For instance if you have a process that gives out assignments every two weeks and try to go full asynchronous communication, then its only a matter of time before someone has nothing to do. After that happens a few times a “daily stand-up” is introduced. Synchronous communication isn’t the problem; its the attempted solution.
Whether or not you can take breaks during a long email thread is important but not sufficient. With two or three of those unstructured conversations going at once its more likely your actual work just becomes an interruption from your on going collaboration.
Nor can use one tool for things that need quick response and another for things that can wait. Unless your colleagues have amazing discipline, all things will need a quick response.
There are two realistic solutions to constantly devolving to synchronous methods:
1. Messages to be conveyed with context so that the reader can quickly decide what needs to be done and how soon.
1. Correctly assessing the costs of synchronous communication. Meetings cost time and money, and that cost should be weighed against the business benefit.
**Tips for practical implementation**
Any scheduled daily or weekly meeting should be seen as a signal that your asynchronous communication is not structured enough. If the task keeps coming up, it needs to part of the asynchronous process plan of record. Synchronous time (meetings) should be used when that plan fails. **The best approach is very planned, structured asynchronous communication backed up by ad hoc, unstructured synchronous communication; the opposite of what many teams are practicing.**
For example, take a support ticket, where the asynchronous collaboration is first class:
* It has a context at the top including resolved or not.
* It provides some built in workflow for ticket assignment that does not require synchronous communication.
* It usually employs smart notifications to make sure the ticket gets assigned and the right people are kept up to date.
* Synchronous communication, scheduling a quick call, only happens if the asynchronous communication wasn’t enough and even then everything established in structured communication keeps the call short.
Its great that we are now paying more attention to whether communication is synchronous or not but not if we use it as an excuse to over simplify. We invite you to check out [Uclusion](https://www.uclusion.com/?utm_source=devto&utm_medium=blog&utm_campaign=devstructured) for free to see a tool with structured asynchronous communication.
| uclusion |
350,069 | Notion + YouTube - A Powerful Combination for Productivity | I want to preface this article with the fact that this is not my standard article. I don't normally c... | 0 | 2020-06-05T18:58:46 | http://codestackr.com/blog/notion-youtube-a-powerful-combination-for-productivity/ | productivity, webdev, beginners, tutorial | I want to preface this article with the fact that this is not my standard article. I don't normally create blogs on Notion or how to use Notion. And this article isn't going to teach you how to use Notion. It's going to show you how I use Notion to create consumable content.
Also, this article is not sponsored in any way by Notion.
## I asked, you responded
I created a poll on Twitter asking if you'd like to see a video on how I use Notion to track my content creation process and here were the results.
So I'm going to show you what Notion is, how I use it, and I'm going to give you the template that I use. You'll find the link to that template in the description below.
{% youtube gZPxd2PXyII %}
> If you are interested in more content like this, feel free to [subscribe](https://www.youtube.com/codeSTACKr/?sub_confirmation=1) to my YouTube channel.
## What is Notion?
Let me quickly go over what Notion is and how it can help you track.. things.
Notion was built as an all-in-one workspace. It really defies traditional categorization. It's crazy how much you can do with Notion, how flexible it is, and how customizable it is.
You can use it as a note-taker. You can create Wikis. You can use it for project and task tracking, which is what I use it for. It has built-in Kanban functionality much like Trello. It has a crazy hybrid markdown system that I'll show you. You can also link within documents to other documents, you can create databases, you can create checklists. You can collaborate with others. So if you have a team, Notion is a collaborative workspace. There's just so much that it can do!
There are also a ton of templates that you can choose from, such as habit trackers, calendars, and to-do lists.
## Pricing
They very recently updated their pricing structure. It's now FREE for personal use. You get unlimited pages and blocks. You can share it with 5 guests. And you can sync across devices. If you do work with a team then you would want to upgrade your plan. But for the majority of content creators, I think that the personal plan will work just fine.
## Notion is worth it
Because Notion is so robust, many find it difficult to get started. It can be overwhelming and sometimes confusing, just because it is so customizable.
So we're going to go through how I use it and hopefully it will make sense to you.
Now, before I started using Notion I really didn't have a system at all. I used Google Docs and just randomly named folders and it was a mess.
## First look
Here's Notion.
I have my content planner and my courses planner. Then this video planner/tracker template. This template is what my other trackers are based on. It looks a lot like a spreadsheet. But this is basically a database. And unlike spreadsheets, this is much more flexible. You can actually look at them in different views, such as Kanban view and calendar view.
So, here we have columns with different types of information, but the cool thing about Notion is that a database here really is a database. It isn't just a spreadsheet of information. Every single row is actually its own page, and within these pages, you can put whatever you want including other databases. So this can get really, really powerful.

## Creating a project
So first, I'll just give you an overview of how this works. So when I think of a new content idea, I can just type here and say "New JavaScript Features".
But if I do this, I'm just going to end up with a blank page. And that's fine if I just wanted a blank page. But I want some templated information. So this template actually has another template built-in. Instead of clicking "new", we'll click the down arrow and select the project template.
We'll go through the rest of this in a minute, but I'm just going to fill in the title for now. By default, the template gives the video a number of 999. This is because I have this view setup to sort by the video number, descending. That way the new project will always be at the top. So everything that is active should be near the top.
## Views
Now I'm going to set the status of this project to "idea".
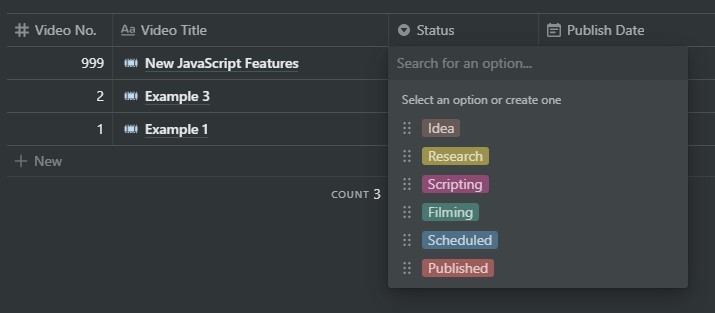
Notice that it disappeared. I have setup several views in this template. This view shows me all projects except ones with the status of "idea". I have an idea view specifically setup.
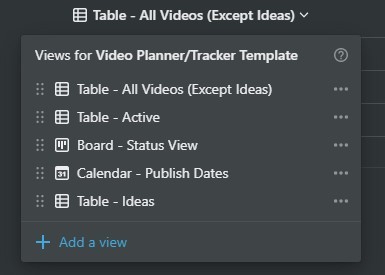
I don't want to clutter my other views with things that I'm not actively working on. So when I have a new idea for content, I just type in the title and set the status to "idea".
When it's time to take an idea and start working on it, I can either change the status, or I can switch to the "Board - Status View". This is like a Trello Kanban view. In here I can drag and drop projects into the appropriate status.
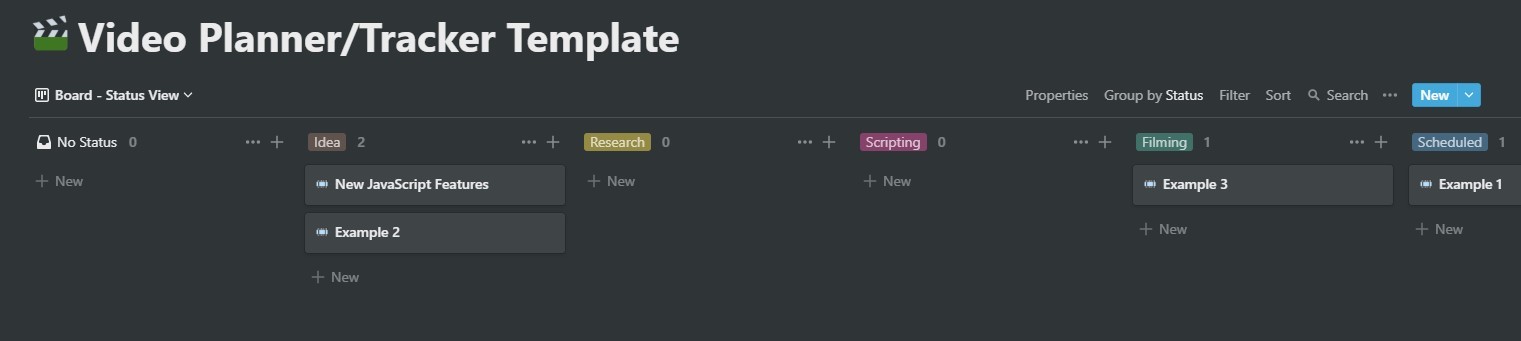
We can also look at the project with a calendar view. This will show us when the project was published or is scheduled to be published.
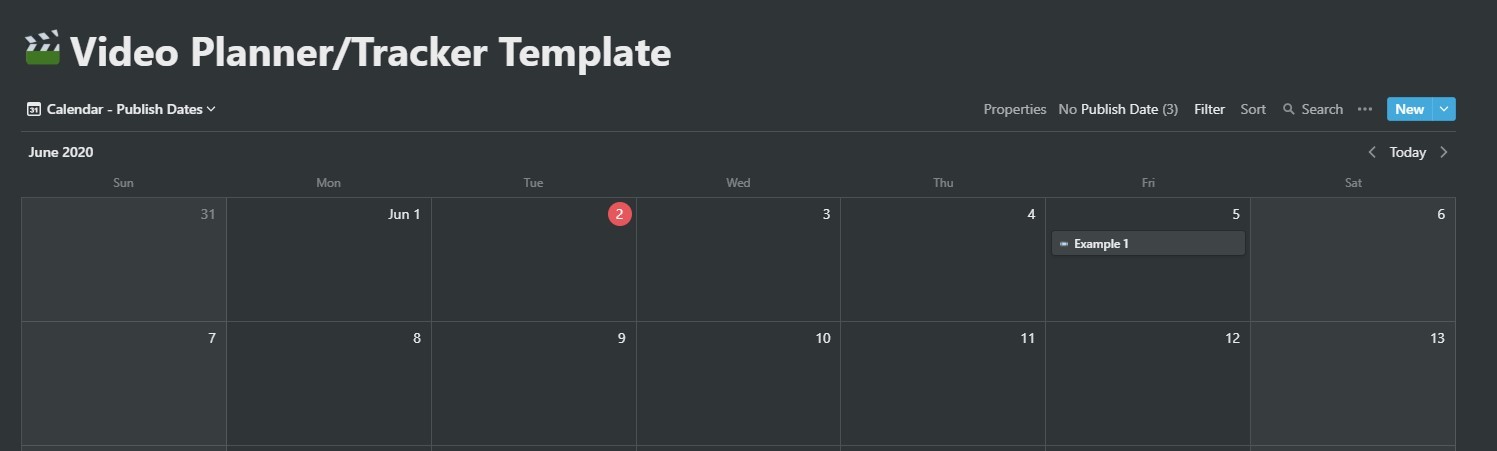
And the last view is my active view. This filters out the ideas and published projects to truly only show active projects.
All of these views can be customized to your liking. You can change these or create new views.
## Local file tracking
The video numbering is very important to my process. Like I was saying before, I used random folder names and had no system of keep track of my projects. Now I have a folder where I keep each project and it's numbered corresponding to the number in Notion. So it's very easy for me to find assets while I'm creating the content. I keep all of my images, thumbnails, screen recordings, code example, etc. in these folders.
## Project details
Let's open up this project and we can "open as page" to make it full screen. Here we have access to the same data that shows up in the table views along with some additional stuff.
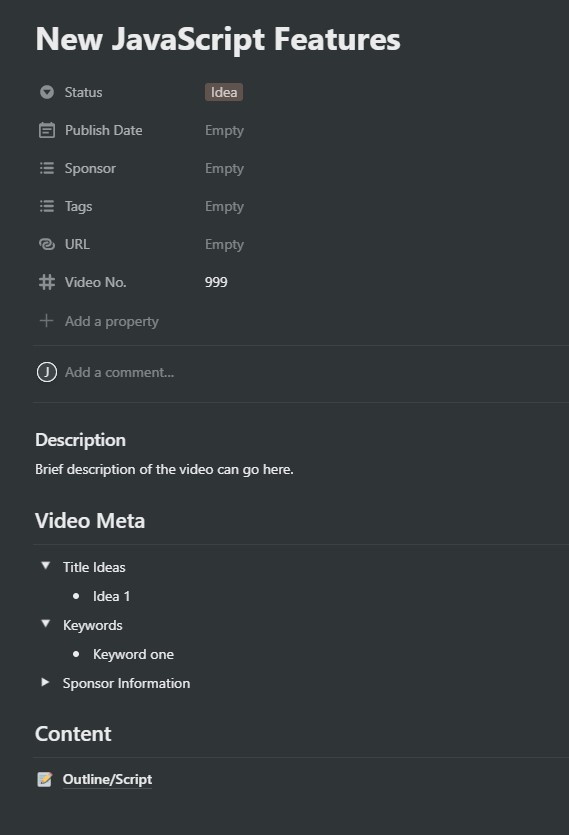
There is a URL field, which I use for the YouTube video URL. Then we have the description, which would be the YouTube description.
Then we have Title Ideas, which is a toggle. Within that we have bullets where we can list multiple title ideas. Then Keywords, same thing. And sponsor info.
## Outline / Script
Then we have the outline/script. So if you have noticed, I have been referring to content planning and not specifically video planning. This started out as a YouTube video planner. But recently I have started creating other content, such as blogs and Instagram posts. At first I only created an outline with the main points that I wanted to cover and some code examples. I realized that this was so close to being a blog post. I just needed to spend a little extra time to fill in the blanks and polish it up. So now, just about every one of my projects become a video, blog, and Instagram post with very little effort.
Let me step you through the script creation process. Notice that this opens a new page. So it's a page within a page. And we have some breadcrumbs here at the top.

Notion uses a hybrid markdown system. If I press forward slash `/`, you can see all of the options. Basic blocks, inline, database, media, embeds, etc. So I start out with my headings, just like creating an outline. So I'll type `/2` and that will create an H2 block. And I'll keep creating all of the basic headlines that I want to cover. Then I'll start filling them in. By default each line will be a text block but we can change it by pressing `/` and selecting the block we want.
I use code blocks often. It has syntax highlighting and you can pick the appropriate language.
Now the really cool thing about this is that it is basically markdown. I can highlight all of this and copy/paste it into any markdown editor, such as the editor on [dev.to](http://dev.to) and it will be properly formatted for me.
So now I'll record the video, post this on my personal blog and sometimes on other blogs such as [dev.to](http://dev.to), and create an Instagram post. All based off of the information in this project.
## Download the template
You will have to sign up for a Notion account, which again is FREE. When you click on the link, this is what you will see.
Just click "Duplicate" and it will copy the template into Notion and you can customize it and start using it however you would like.
- [Video Tracker Template](https://www.notion.so/04a2e20768af4208838989067d420b5e?v=0b0be78b301a4bcf975e325310622223)
## Conclusion
So Notion is in my opinion the best all-in-one workspace for planning and tracking projects. Let me know what you think. Do you use something different? Are you going to give Notion a try?
## **Thanks for reading!**
Say Hello! [Instagram](https://www.instagram.com/codeSTACKr) | [Twitter](https://twitter.com/codeSTACKr) | [YouTube](https://youtube.com/codeSTACKr) | codestackr |
350,092 | The stack | A stack is an abstract data structure which uses an order of operations called LIFO (Last In First Ou... | 7,135 | 2020-06-05T23:03:26 | https://dev.to/jamesrweb/the-stack-17hf | computerscience, typescript, data, beginners | A stack is an abstract data structure which uses an order of operations called LIFO (Last In First Out) which does as it says on the tin, the last element added to the stack will be the first one to be removed.
> You can think of this like a stack of plates, adding or removing plates is only possible from the top of the stack.
Thus, a stack controls elements held within via two principal operations:
1. The `push` operation adds an element to the collection
2. The `pop` operation removes the most recent element in the collection
There are a few other methods which we will implement but the ordering combined with these operations are the signature of a stack.
> Stacks are used in a variety of ways in the real world, for example the JavaScript [Call Stack](https://developer.mozilla.org/en-US/docs/Glossary/Call_Stack) is a stack which tracks function calls and allows the browser to track all the various things being executed as they run without conflicts between calls occurring.
In this article we will explore how I would implement a stack and I will also explain each method we implement in detail.
## Tests
For the tests of our stack I will be using the [Jest](https://jestjs.io/) test runner alongside [ts-jest](https://www.npmjs.com/package/ts-jest) which will support us to test our [TypeScript](https://www.typescriptlang.org/) implementation.
```ts
let stack: Stack<number>;
beforeEach(() => {
stack = new Stack<number>();
});
describe("Stack", () => {
it("Should have predictable defaults", () => {
expect(stack.count).toBe(0);
expect(stack.items).toEqual([]);
});
it("Should add an item to the stack", () => {
stack.push(1);
expect(stack.count).toBe(1);
});
it("Should return the index of the item added to the stack", () => {
expect(stack.push(1)).toBe(0);
});
it("Should remove an item from the stack", () => {
stack.push(1);
expect(stack.count).toBe(1);
expect(stack.items).toEqual([1]);
stack.pop();
expect(stack.count).toBe(0);
expect(stack.items).toEqual([]);
});
it("Should return the value of the item removed from the stack", () => {
stack.push(1);
expect(stack.pop()).toBe(1);
});
it("Should return undefined if no items exist in the stack when trying to pop the top value", () => {
expect(stack.pop()).toBe(undefined);
});
it("Should return undefined if the item being searched for doesn't exist", () => {
expect(stack.find(1)).toBe(undefined);
})
it("Should return the index of the value if it is found", () => {
stack.push(1);
expect(stack.find(1)).toBe(0);
});
it("Should allow us to peek at the item at the top of the stack", () => {
stack.push(1);
expect(stack.peek()).toBe(1);
});
it("Should return undefined if there is no item to peek at", () => {
expect(stack.peek()).toBe(undefined);
});
it("Should let us check if the stack is empty", () => {
expect(stack.empty()).toBe(true);
});
it("Should let us check how many items are in the stack", () => {
expect(stack.size()).toBe(0);
});
it("Should clear the stack", () => {
stack.push(1);
stack.push(1);
expect(stack.count).toBe(2);
expect(stack.items).toEqual([1, 1]);
stack.clear();
expect(stack.count).toBe(0);
expect(stack.items).toEqual([]);
});
});
```
For the tests I chose to use a `Stack` using `number` types for simplicity. If you want to explore and run the tests, you can use the repl below.
{% replit @jamesrweb/stacks %}
## Implementation
For this implementation we will be using [TypeScript](https://www.typescriptlang.org/).
```ts
class Stack<T> {
public items: T[] = [];
public count: number = 0;
push(item: T): number {
this.items[this.count] = item;
this.count++;
return this.count - 1;
}
pop(): T | undefined {
if(this.count === 0) return undefined;
this.count--;
const deletedItem = this.items[this.count];
this.items = this.items.slice(0, this.count);
return deletedItem;
}
find(value: T): number | undefined {
for(let index = 0; index < this.size(); index++) {
const item = this.items[index];
if(Object.is(item, value)) return index;
}
return undefined;
}
peek(): T | undefined {
return this.items[this.count - 1];
}
empty(): boolean {
return this.count === 0;
}
size(): number {
return this.count;
}
clear(): T[] {
this.items = [];
this.count = 0;
return this.items;
}
}
```
We are using [Generics](https://www.typescriptlang.org/docs/handbook/generics.html) as a part of the implementation to provide opt-in type strictness for our stack, this is represented by the type `T` in the implementation above. To see this in action we can do this for example:
```ts
const stack = new Stack<number>();
stack.push(1); // Works fine
stack.push("1"); // Throws a TypeError
```
If no type `T` is provided then anything can be added into the stack like so:
```ts
const stack = new Stack();
stack.push(1); // Works fine
stack.push("1"); // Also works fine
```
Personally though, I would recommend that if you don't want to lock the types of the items in your stack then add the explicit `any` type to the `T` type instead since being explicit is always better than being implicit with such things, for example:
```ts
const stack = new Stack<any>();
stack.push(1); // Works fine
stack.push("1"); // Also works fine
```
### Properties
Our `Stack` contains 2 properties, the `items` currently within the stack and the `count` of the items in the stack, we can access these like so:
```ts
const stack = new Stack();
console.log(stack.count); // 0
console.log(stack.items); // []
state.push(1);
console.log(stack.count); // 1
console.log(stack.items); // [1]
```
### Methods
Alongside the properties of the `Stack` are it's methods, let's explore these and what they do a bit more.
#### `push`
The `push` method adds an item to the stack and returns the index of that item once added, for example:
```ts
const stack = new Stack();
const idx = stack.push(1);
const idx2 = stack.push(2);
console.log(idx, idx2, stack.items); // 0, 1, [1, 2]
```
#### `pop`
The `pop` method removes an item from the stack and returns the value of the removed item, for example:
```ts
const stack = new Stack();
stack.push(1);
stack.push(2);
const item = stack.pop();
console.log(item, stack.items); // 2, [1]
```
#### `find`
The `find` method finds an item in the stack and returns its index if it is found or `undefined` if it isn't, for example:
```ts
const stack = new Stack();
console.log(stack.find(1)); // undefined
stack.push(1);
console.log(stack.find(1)); // 0
```
#### `peek`
The `peek` method lets us check what item is currently at the top of the stack, for example:
```ts
const stack = new Stack();
stack.push(1);
console.log(stack.peek()); // 1
```
#### `empty`
The `empty` method lets us check if the stack is empty or not, for example:
```ts
const stack = new Stack();
console.log(stack.empty()); // true
stack.push(1);
console.log(stack.empty()); // false
```
#### `size`
The `size` method lets us see how many items are in the stack currently, for exmaple:
```ts
const stack = new Stack();
console.log(stack.size()); // 0
stack.push(1);
console.log(stack.size()); // 1
```
#### `clear`
The `clear` method lets us remove all items from the stack, for example:
```ts
const stack = new Stack();
stack.push(1);
stack.push(1);
stack.push(1);
console.log(stack.count, stack.items); // 3, [1, 1, 1]
stack.clear();
console.log(stack.count, stack.items); // 0, []
```
## Conclusions
Stacks are really efficient data structures for setting, getting, deleting and finding a value, we can see that with the Big O of these operations coming in as follows:
| | Average | Worst |
|--------|---------|-------|
| Get | Θ(n) | Θ(n) |
| Set | Θ(1) | Θ(1) |
| Delete | Θ(1) | Θ(1) |
| Find | Θ(n) | Θ(n) |
This makes it one of the most efficient data structures that you can use and this is why it one of the most common data structures you will come across when developing software.
I hope this post brought you some value and feel free to leave a comment below! | jamesrweb |
350,098 | Try to write more advanced React | After learning React Hooks, useState, useEffect, useContext; redux and redux-thunk/redux-saga, mobx;... | 0 | 2020-06-05T20:06:06 | https://dev.to/so2liu/try-to-write-more-advanced-react-103d | react | After learning React Hooks, useState, useEffect, useContext; redux and redux-thunk/redux-saga, mobx; some UI Lib, you may feel losing direction, just like me.
This article is about what could be helpful for improving your react skill.
## Everything comes from indirection
> We can solve any problem by introducing an extra level of indirection.
React contains already a few directions somehow:
- `useState` is a simplify of `useReducer`
- `useMemo` and `useCallback` can be implemented by `useRef`
However, if we regard these hooks as a default base layer, the hooks can be divided to six directions:
1. base build-in layer from React official.
2. hooks to simplify the state update, like immer.js for immutability.
3. Use "state + behavior" concept, build a complex context by declaration.
4. Encapsulation of data structure, like manipulation of arrays.
5. Encapsulation of scene, like padination arrays, multiple checkbox.
6. Implement to real scene.
### Use immer.js to update state
**Problem**: Hard to update a state deep in a object when you want to keep the immutability.
```js
const newValue = {
...oldValue,
foo: {
...oldValue?.foo,
bar: {
...oldValue?.foo?.bar,
alice: newAlice
},
},
};
```
**Solution**: write hooks using immer.js (or use community version).
```js
const [state, setState] = useImmerState({foo: {bar: 1}});
setState(s => s.foo.bar++);
setState({foo: {bar: 2}});
const [state, dispatch] = useImmerReducer(
(state, action) => {
case 'ADD':
state.foo.bar += action.payload;
case 'SUBTRACT':
state.foo.bar -= action.payload;
default:
return;
},
{foo: {bar: 1}}
);
dispatch('ADD', {payload: 2});
```
### Encapsulation of state and behavior
Most development of components and feature implements belongs to the pattern "one state + a serious of behavior".
The state and the behaviors are strongly related.
This pattern is similar to class concept in OO.
In hooks, we write somehow like this:
```js
const [name, setName] = useState('');
const [age, SetAge] = useState(0);
const birthday = useCallback(
() => {
setAge(age => age + 1);
},
[age]
);
```
Problems:
1. Repeated `useState` and `useCallback` is bad for code reuse.
2. Hard to find the relationship between behavior and properties.
Solution: [`useMethods`](https://github.com/pelotom/use-methods/blob/master/README.md) is an encapsulation of one state and behaviors related to this state.
```js
const userMethods = {
birthday(user) {
user.age++; // with immer.js
},
};
const [user, methods, setUser] = useMethods(
userMethods,
{name: '', age: 0}
);
methods.birthday();
```
### Abstract of data structure
Problem:
1. Some data structure's immutable manipulation is complex, like `Array.splice`.
2. Semantic changes. For example, `setState` doesn't return a value, while `Array.pop` returns the popped element.
3. Some types like `Set` and `Map` are always mutable.
Solution: lots of hooks in community like `useNumber`, `useArray`, `useSet`, `useMap`, `useBoolean`, `useToggle`.
```ts
// A implement of useArray
const [list, methods, setList] = useArray([]);
interface ArrayMethods<T> {
push(item: T): void;
unshift(item: T): void;
pop(): void;
shift(): void;
slice(start?: number, end?: number): void;
splice(index: number, count: number, ...items: T[]): void;
remove(item: T): void;
removeAt(index: number): void;
insertAt(index: number, item: T): void;
concat(item: T | T[]): void;
replace(from: T, to: T): void;
replaceAll(from: T, to: T): void;
replaceAt(index: number, item: T): void;
filter(predicate: (item: T, index: number) => boolean): void;
union(array: T[]): void;
intersect(array: T[]): void;
difference(array: T[]): void;
reverse(): void;
sort(compare?: (x: T, y: T) => number): void;
clear(): void;
}
```
### Ecaplutaion of general scene
For example
- [Alibaba's umi.js](https://hooks.umijs.org/hooks/async)
These ecaplutations should not coupled with UI components.
They are able to apply on different UI components/lib.
## TBD...
| so2liu |
350,125 | HTML txt assignment | A post by E2017-erkan | 0 | 2020-06-05T21:12:40 | https://dev.to/e2017erkan/assignment-3mp0 | codepen | {% codepen https://codepen.io/E2017Erkan/pen/QWybLxz %} | e2017erkan |
350,131 | Day 148 : Needed | liner notes: Professional : Had another great day. It's not because of the work I did, that went we... | 0 | 2020-06-05T21:32:31 | https://dev.to/dwane/day-148-needed-28ho | hiphop, code, coding, lifelongdev | _liner notes_:
- Professional : Had another great day. It's not because of the work I did, that went well, but because I got to talk with my team about all types of things. Very much needed after what is happening. Shouts to them!
- Personal : Went through a few tracks for the radio show. Did a little bit of coding. Even tested the pomodoro timer on my side project during the day.
Going to do my laundry and finish up preparing for the radio show. Want to figure out how I want to implement the task list on my side project. Hopefully get it working this weekend.
Have a great night and weekend!
peace piece
Dwane / conshus
https://dwane.io / https://HIPHOPandCODE.com
{% youtube n8woH4GxUMk %} | dwane |
350,285 | Finest Software program Training Institute | So far as knowledge science is concerned, there's enormous scope on this business in India. By our In... | 0 | 2020-06-06T11:15:30 | https://dev.to/arohi00466286/finest-software-program-training-institute-ggc | So far as knowledge science is concerned, there's enormous scope on this business in India. By our Information Science Training In Hyderabad, we shape our students in direction of becoming complete Information Science trade prepared specialists by the point of their course completion. Data Science coaching online contains a lot of constituent elements, and the Intellipaat programs present the most comprehensive and in-depth learning expertise.
But information science also has some needed expertise that can make your working profession widespread. Attend one full batch of Python for Data Science coaching. The Certification Programme in Knowledge Science will empower you to scale profitable heights in your career. This 225+ hours of live instructor based mostly classroom program of Information Science Training In Hyderabad that covers complete breath of the ideas in Data Science.
Effectively laid out course content and professional faculty ensure a wonderful learning experience. The college right here for Knowledge Science is very a lot skilled & has mentioned a lot of actual-time concepts. To be a knowledge scientist one should have mathematical, programming and enterprise abilities. Non-technical or non-programmers might really feel little confused to move into Knowledge Science career.
Now I'm an expert in information science and may confidently make a career in it. This trend is additional boosted by MNCs equivalent to Wells Forgo, organising their strategy information science delivery center in the city of Hyderabad. Analytics Path is an academic, coaching and profession development organization delivering high-rated <a href="https://www.excelr.com/business-analytics-training-in-bangalore">Business Analytics course</a>.
Information Science, with its ability to generate transformative experiences with regards to the external and inner functioning of the business, has gained immense traction over the decade. As the demand for Large Data Analytics is rising beyond any leaps however in distinction there's a huge scarcity of expert Information Scientists. Make your dream job a reality and enroll today in 360DigiTMG - the perfect institute for data science in Bangalore.
We are located at :
Location :
ExcelR - Data Science, Data Analytics Course Training in Bangalore
49, 1st Cross, 27th Main BTM Layout stage 1 Behind Tata Motors Bengaluru, Karnataka 560068
Phone: 1800-212-2120/ 070224 51093
Hours: Sunday - Saturday 7AM - 11PM
| arohi00466286 | |
350,430 | Copying objects in JavaScript | Scenario: Whenever we pass objects between components as props or as arguments in function... | 0 | 2020-06-06T17:56:09 | https://dev.to/ip127001/copying-objects-in-javascript-440b | javascript, typescript, react, angular | #####Scenario:
Whenever we pass objects between components as props or as arguments in function, we need to copy that object to make sure that it doesn't affect the original one. Now we can easily make any changes to the copied object to our need.
So, following are the methods that we can use to do so:
- Spread operator
- Object.assign
- JSON.parse and JSON.stringify
Does using any of these methods entirely copy the object? Will it also copy a nested object?
Let's look at another example:
```javascript
let deepObj = {a: 4: b: {name: 'react'}, d: {name: 'angular'}};
```
So `deepObj` is a nested object and when it comes to copying nested objects i.e. objects with values as references, there comes the concept of shallow copy and deep copy.
- __Shallow copy__: Only copies one level meaning if any of the value is a reference type then copy the reference but the exact value is not copied in the new object.
- __Deep copy__: Copy every level of nested values even if it is a reference type like our example with `deepObj` object above.
*__Let's go one by to try copying the objects:__*
-------------------------------------------------------------
**1. Spread Operator & Object.assign():**
*Example 1:*
```javascript
let obj1 = {a: 3, b: 4, c: "react"}, copiedObj1 = {};
copiedObj1 = {...obj1};
copiedObj1.c = "angular";
console.log(copiedObj1, obj1);
{a: 3, b: 4, c: "angular"}
{a: 3, b: 4, c: "react"}
let obj2 = {a: 3, b: 4, c: "react"}, copiedObj2 = {};
copiedObj2 = Object.assign({}, obj2);
copiedObj2.c = "vue";
console.log(copiedObj2, obj2);
{a: 3, b: 4, c: "vue"}
{a: 3, b: 4, c: "react"}
```
Both will perfectly copy the object because there is no reference type in object values and if you try to change any property that will not have any effect on copied object.
*Example2:*
```javascript
let obj1 = {a: 3, c: [1,2]}, newObj1 = {};
newObj1 = {...obj1};
newObj1.c.push(5);
console.log(newobj1, obj1);
{a: 3, c: [1,2,5]}
{a: 3, c: [1,2,5]}
let obj2 = {a: 3, c: [1,2]}, newObj2 = {};
newObj2 = Object.assign({}, obj2);
newObj2.c.push(5);
console.log(newobj2, obj2);
{a: 3, c: [1,2,5]}
{a: 3, c: [1,2,5]}
```
Here property c value is changes to [1,2,5] in both objects, so this is not perfectly copied because of reference type i.e. array ([1,2]). It just copies the reference to the array. Hence `Spread operator and Object.assign() only does shallow copying not deep copying.`
**2. JSON.parse() and JSON.stringify():**
```javascript
var obj1 = {a: 3, b: 4, c: "react"};
var copiedObj1 = JSON.parse(JSON.stringify(obj1));
copiedObj1.c = "node";
console.log(copiedObj1, obj1);
{a: 3, b: 4, c: "node"}
{a: 3, b: 4, c: "react"}
var obj2 = {a: 3, c: [1,2]};
var copiedObj2 = JSON.parse(JSON.stringify(obj2));
copiedObj2.c.push(5);
console.log(copiedObj2 , obj2);
{a: 3, c: [1,2,5]}
{a: 3, c: [1,2]}
```
This perfectly copies the object as any change in copied object in both case doesn't have any effect in original object.
> But this works only in those cases where value is converted to string first and it gets parsed again.
Following are few of the cases where it fails to copy the object.
```javascript
let obj = {
name: 'laptop',
value: function () {
return 100000';
}
}
let copiedObj = JSON.parse(JSON.stringify(obj));
console.log(copiedObj);
{name: 'laptop'}
```
Failed -> It removed the value method from copied object.
```javascript
let obj = {a: undefined, b: new Date()}
let copiedObj = JSON.parse(JSON.stringify(obj));
console.log(copiedObj);
{b: "2020-06-06T16:23:43.910Z"}
```
Failed -> Removed the first property and converted the date value to string;
--------------------------------------------------------------------
###For Shallow copying use
1. Spread operator
2. Object.assign().
### For Deep copying
1. Use lodash library `cloneDeep` method (_.cloneDeep(any nested object))
2. Make a custom function which will handle reference types like in below example covering just one case.
```javascript
function deepCopy(obj) {
let copiedObj = {};
for(key in obj) {
if(Array.isArray(obj[key])) {
copiedObj[key] = [...obj[key]];
} else {
copiedObj[key] = obj[key]
}
}
return copiedObj;
}
var obj = {value1: 5, value2: [1,2,3]};
var copiedObj = deepCopy(obj);
copiedObj.value2.push(5);
console.log(copiedObj , obj);
{value1: 5, value2: [1,2,3,5]}
{value1: 5, value2: [1,2,3]}
```
> Better way will be to use recursion to handle reference type
So there are other libraries exists which provide good performance event to do deep cloning as you saw it need more cumputation or you can make a custom function and add more edge case.
Conclusion: Always watch for values if any is reference types in the object that is being passed around. And use shallow and deep copying better.
Thanks for reading! | ip127001 |
350,434 | Bulma Navbar Toogle with React Hooks | When starting a new project, the styling we use is often one of the first considerations. I generally prefer to code my own SCSS, but often there in not time, and I reach for a CSS framework of some kind. I tend to prefer the utility systems like Tailwind or Bulma. | 0 | 2020-06-06T17:43:34 | https://dev.to/eclecticcoding/bulma-navbar-toogle-with-react-hooks-18ek | react, bulma, webdev, beginners | ---
title: Bulma Navbar Toogle with React Hooks
published: true
tags: react, bulma, webdev, beginner
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/vzzvtarz2rcv09nylzmd.jpg
description: When starting a new project, the styling we use is often one of the first considerations. I generally prefer to code my own SCSS, but often there in not time, and I reach for a CSS framework of some kind. I tend to prefer the utility systems like Tailwind or Bulma.
---
When starting a new project, the styling we use is often one of the first considerations. I generally prefer to code my own SCSS, but often there in not time, and I reach for a CSS framework of some kind. I tend to prefer the utility systems like Tailwind or Bulma.
I enjoy using Bulma but it does not include JavaScript actions for menu toggle. So, the developer is left to find a solution. This article is an example of a simple way to use React hooks as an way to toggle a Navbar menu.
TLTR: Jump straight to the [code][REPO] and try it out, and you can take a look at the deployed [Demo][SITE].
## Setup
We are doing to set up a basic React App. My personal preference is to use my **React Parcel Boilerplate** using Parcel as a bundler. You can read the two part tutorial [ARTICLE](https://www.eclecticsaddlebag.com/react-boilerplate-part-1/) or view the Code of my [Parcel Boilerplate][BOILERPLATE].
{% link https://dev.to/eclecticcoding/react-boilerplate-15pk %}
However, in this tutorial, we will use [Create React App][CRA], so we all are in a familiar environment to begin.
To start a new project with CRA, install as shown:
```
yarn create react-app react-bulma-navbar
```
or
```
npx create-react-app react-bulma-navbar
```
**Clean up CRA**
Next we are going to clean up the default setup. Delete the header section,`<header> ... </header>` from `App.js`, and replace with the following just to give us some content:
```html
<h1>React Bulma Navbar Toggle</h1>
```
Delete the following files and their associated import statements:
1. Delete `logo.svg` and the import statement in `App.js`
2. Delete `App.css` and the import statement in `App.js`
3. Delete `index.css` and the import statement in `App.js`
Congratulations! You are the proud owner of an ugly site.

## Add Bulma for Styling
Add Bulma to our project with `yarn add bulma` or `npm install --save bulma`. We will also need `node-sass` as a Dev dependency: `yarn add -D node-sass` or `npm install --save-dev node-sass`.
Create in the src directory a file for our custom styles `touch main.scss`, and in the new file, import `bulma`: `@import "~bulma/bulma";`. In `App.js` add an import for our stylesheet: `import 'main.scss'`
## Add Navbar
We are going to create a new functional component for our menu. As seen below, I have imported the default example from the Bulma web site, and trimmed some of the navigation out so we have just enough as an example:
```jsx
import React from 'react'
export default function Navbar() {
return (
<nav className='navbar' role='navigation' aria-label='main navigation'>
<div className='navbar-brand'>
<a href='/' className='navbar-item'>
<img
src='https://bulma.io/images/bulma-logo.png'
alt='Logo'
width='112'
height='28'
/>
</a>
<a
role='button'
className={'navbar-burger burger'}
aria-label='menu'
aria-expanded='false'
data-target='navbarBasicExample'
>
<span aria-hidden='true'></span>
<span aria-hidden='true'></span>
<span aria-hidden='true'></span>
</a>
</div>
<div id='navbarBasicExample' className='navbar-menu'>
<div className='navbar-end'>
<div className='navbar-item'>
<a href='/' className='navbar-item'>
Home
</a>
<a href='/' className='navbar-item'>
Documentation
</a>
</div>
</div>
</div>
</nav>
)
}
```
Remember to add the import to `App.js`:
```javascript
import React from 'react'
import Navbar from './Navbar'
import './main.scss'
function App() {
return (
<div className='App'>
<Navbar />
<h1 className='container is-fluid'>React Bulma Navbar Toggle</h1>
</div>
)
}
export default App
```
If you start your development server it all will display nicely, but on the smaller screen sizes, the menu toggle does not work.
## Add Navbar Toggle
There are a few ways to handle an event to toggle the menu on a click event. In a plain HTML project we could us VanillaJS to create a click handler with `addEventListener()`, you can use JQuery, or you can use a pure CSS menu toggle.
In React there are a few options as well. You can create click handlers in a class Component. In our example, I have specifically chosen a functional component so we can utilize React Hooks.
So, first we need to create a custom Hook:
```javascript
export default function Navbar() {
const [isActive, setisActive] = React.useState(false)
return (
...
)
}
```
Then add a click event to the Burger button, and ternary expressions to make the classes used dynamic and affected by the state. The new functional component looks like this:
```javascript
export default function Navbar() {
const [isActive, setisActive] = React.useState(false)
return (
<nav className='navbar' role='navigation' aria-label='main navigation'>
<div className='navbar-brand'>
<a href='/' className='navbar-item'>
<img
src='https://bulma.io/images/bulma-logo.png'
alt='Logo'
width='112'
height='28'
/>
</a>
<a
onClick={() => {
setisActive(!isActive)
}}
role='button'
className={`navbar-burger burger ${isActive ? 'is-active' : ''}`}
aria-label='menu'
aria-expanded='false'
data-target='navbarBasicExample'
>
<span aria-hidden='true'></span>
<span aria-hidden='true'></span>
<span aria-hidden='true'></span>
</a>
</div>
<div id='navbarBasicExample' className={`navbar-menu ${isActive ? 'is-active' : ''}`}>
<div className='navbar-end'>
<div className='navbar-item'>
<a href='/' className='navbar-item'>
Home
</a>
<a href='/' className='navbar-item'>
Documentation
</a>
</div>
</div>
</div>
</nav>
)
}
```
What's next? Nothing you are done. When you click the menu toggle, the click handler, sets the state to the opposite of the current state. That is it.
Remember this is just the default example from Bulma. In a live site it would be helpful to use Link from React Router for the menu links, but this is a good basic start.
[REPO]: https://github.com/eclectic-coding/article_react-bulma-navbar
[SITE]: https://react-bulma-navbar.now.sh/
[BOILERPLATE]: https://github.com/eclectic-coding/react-parcel-boilerplate
[CRA]: https://reactjs.org/docs/create-a-new-react-app.html
| eclecticcoding |
350,470 | Data passing by props Object and function in OptionsAPI | Definition callback function by PropOptions on Child Component <template> <di... | 0 | 2020-06-06T19:17:34 | https://dev.to/adachi_koichi/data-passing-by-props-object-and-function-in-optionsapi-13of | nuxt, vue, optionsapi, props | # Definition callback function by PropOptions on Child Component
```vue
<template>
<div>
<h3>This is a OptionsAPI Component Callback Example</h3>
<v-btn @click="increment">increment</v-btn>
</div>
</template>
<script lang="ts">
import { Vue } from 'nuxt-property-decorator'
import { PropOptions } from 'vue'
export default Vue.extend({
name: 'CallbackChild',
props: {
obj: {
type: Object,
required: true
} as PropOptions<{ initialCount: number }>,
onClickIncrementButtonListener: {
type: Function,
required: true
} as PropOptions<(count: number) => {}>
},
data() {
return { count: this.obj.initialCount }
},
methods: {
increment() {
this.count++
this.onClickIncrementButtonListener(this.count)
}
}
})
</script>
<style scoped></style>
```
# Call from parent component
passing callback method
```vue
<template>
<div>
<CallbackChild
:on-click-increment-button-listener="onClick"
:obj="{ initialCount: 100 }"
></CallbackChild>
<p v-if="$data.count">{{ count }}</p>
</div>
</template>
<script lang="ts">
import { Vue } from 'nuxt-property-decorator'
import CallbackChild from '~/components/options/CallbackChild.vue'
export default Vue.extend({
name: 'CallbackParent',
components: {
CallbackChild
},
data() {
return { count: 0 }
},
methods: {
onClick(count: number) {
this.count = count
}
}
})
</script>
<style scoped></style>
```
| adachi_koichi |
350,498 | Projeto Ecoleta da NLW finalizado! | Dica do dia: concluir um projeto é bom para a autoestima. Consegui finalizar o projeto prá... | 0 | 2020-07-12T13:46:39 | https://dev.to/dauryellen/projeto-ecoleta-da-nlw-finalizado-5g16 | node, javascript, beginners | # Dica do dia: concluir um projeto é bom para a autoestima.
Consegui finalizar o projeto prático da NLW#1. O projeto é um aplicativo web que ajuda as pessoas a encontrarem pontos de coleta de resíduos de forma eficiente. Fiquei feliz porque compreendi a maior parte do conteúdo que foi passado. Estou aos poucos evoluindo e é muito bom perceber isso.
O projeto completo está no meu [Github](https://github.com/dauryellen/ecoleta-nlw-starter). Consegui ir além do que foi passado nas aulas e desenvolvi as funções de editar e excluir registros. :)
As principais tecnologias utilizadas foram:
- HTML,
- CSS,
- JavaScript,
- NodeJS,
- Nunjucks,
- Express e
- Sqlite3.
# A importância dos projetos pessoais
A frase "Feito é melhor que perfeito" faz muito sentido quando o assunto é fazer projetinhos. Deixar de produzir alguma coisa por medo de não sair do jeito que você quer ou com defeitos, vai fazer com que você nunca inicie nada. Todos nós sabemos que alguma coisa, o mínimo que seja, é maior do que nada. Isso não quer dizer que você vai fazer um código cheio de bugs e ficar por isso mesmo porque "é melhor do que nada". Isso significa que você vai estudar mais. Vai aprender a consertar seus próprios bugs. Assim, vai obter mais conhecimento e experiência que você nunca teria se não tivesse tentado construir algo em algum momento. Errar faz parte do processo de aprender.
| dauryellen |
350,695 | The Front End Podcast - Episode #9 | Hey you! Yes, you! It's that time again for another instalment of The Front End. In this ninth epis... | 0 | 2020-06-08T07:45:40 | https://dev.to/kendalmintcode/the-front-end-podcast-episode-8-2d1n | career, podcast, frontend | Hey you! Yes, you! It's that time again for another instalment of [The Front End](https://thefrontendpodcast.site).
In this ninth episode I thought I'd do something a little different and host a solo talk where I answer your most frequently asked questions.
I'll be answering golden questions such as:
- How do I get into front end development?
- Is HTML a programming language?
- How can I improve my design and CSS skills?
- What do I think about the term front end development in 2020?
- What skills should front end developers have?
- and many more!
Listen to episode 9 today on the following channels:
- Apple Podcasts > https://podcasts.apple.com/gb/podcast/the-front-end/id1499349107
- Pocket casts > https://pca.st/osul2zsa
- Spotify > https://open.spotify.com/show/4GuAxptrtY8Es5iHwp09dT
- Anchor > https://anchor.fm/the-front-end
## About episode 9
I'm a senior software engineer specialising in front end technologies and React. I hosted an [ask me anything](https://dev.to/kendalmintcode/senior-front-end-dev-here-ask-me-anything-i4m) style session on this very platform a few weeks ago and thought I'd turn the most popular questions into an episode so people can get their favourite questions answered straight from the horse's mouth.
If you have any unanswered questions then please leave me a comment and I'll be happy to answer them :D
## Listening direct
Want to listen directly from here?
{% spotify spotify:episode:25Yh6NEbvu3WcYVjSxGoIt%}
## Want to be a guest or sponsor the show?
I'm definitely looking for guests to talk about a range of different development topics from careers to origin stories, learning and professional growth, frameworks and more.
Similarly, we're looking for sponsors to fill promotional slots within the show.
You can find out more here:
- [Being a guest](https://thefrontendpodcast.site/guests)
- [Sponsorship information](https://thefrontendpodcast.site/sponsorship)
Thanks for listening! | kendalmintcode |
350,503 | Using EasyRandom with Spring Framework | Tired of creating objects in tests. Try using EasyRandom library. Here is how easily you can add it t... | 0 | 2020-06-06T20:52:08 | https://www.deskriders.dev/posts/029-easy-random-spring-boot/ | java, springframework | Tired of creating objects in tests. Try using EasyRandom library. Here is how easily you can add it to a Spring Java project
#### Step 1: Add gradle/maven dependency
https://mvnrepository.com/artifact/org.jeasy/easy-random
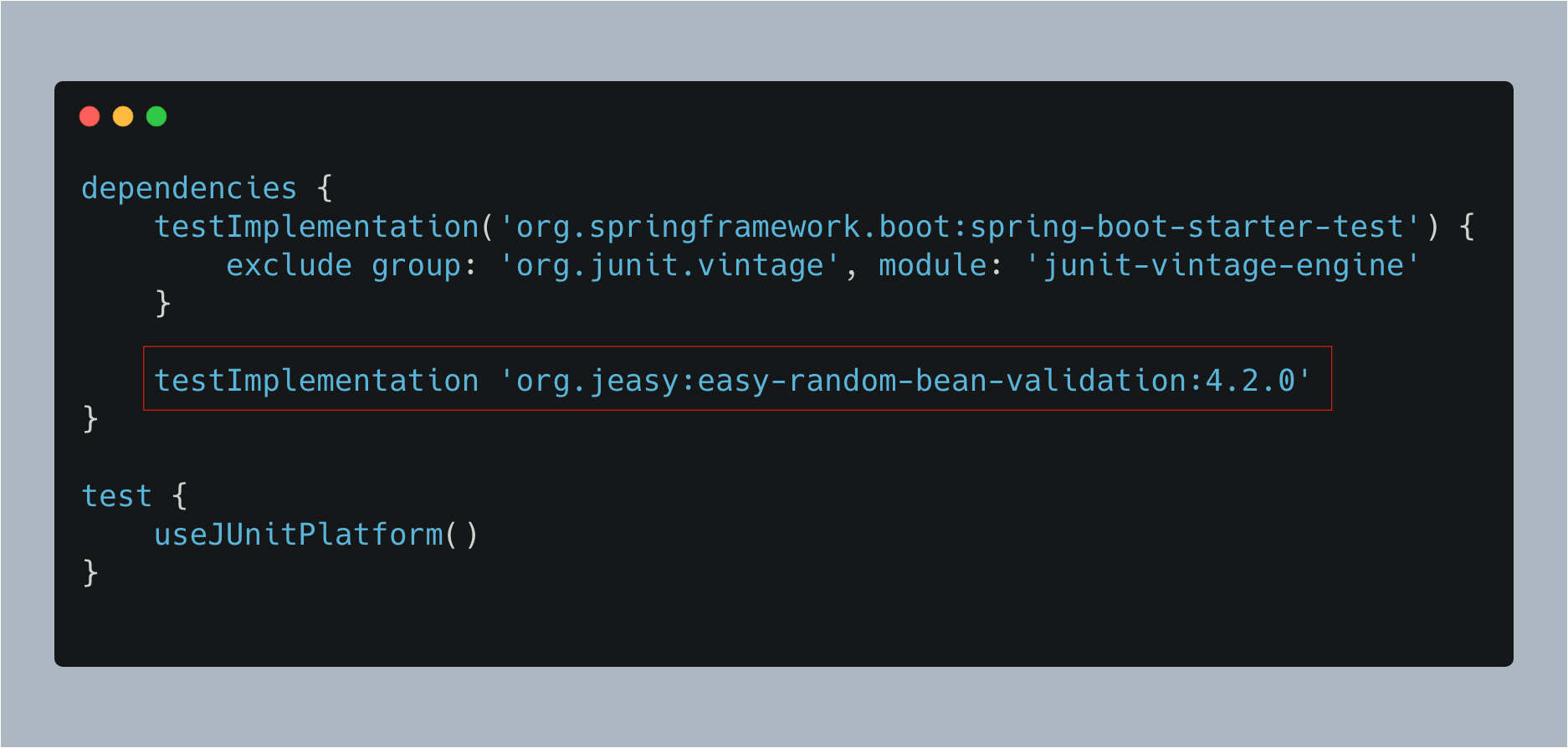
#### Step 2: Declare it in test
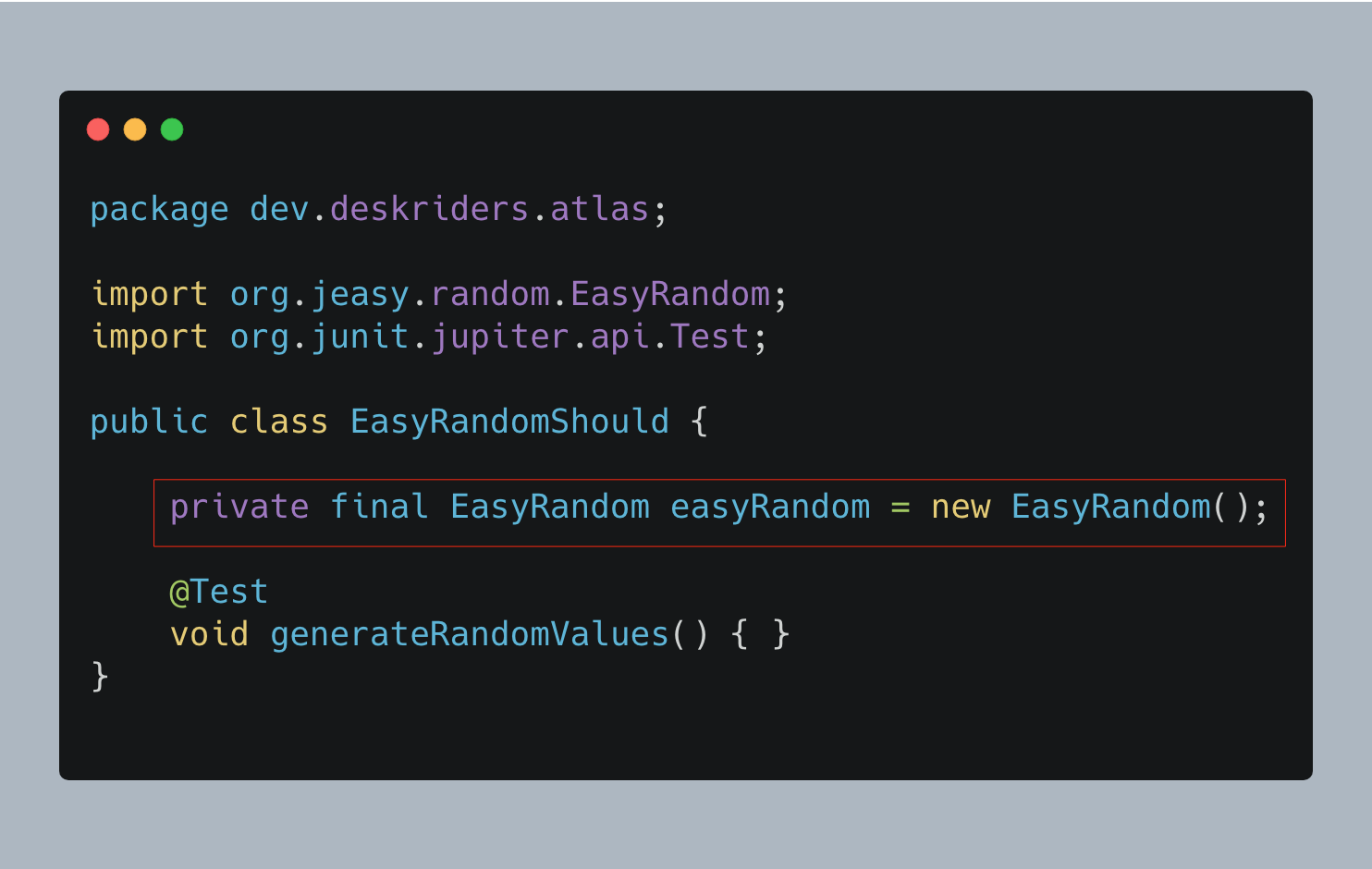
#### Step 3: Use it to generate random data objects
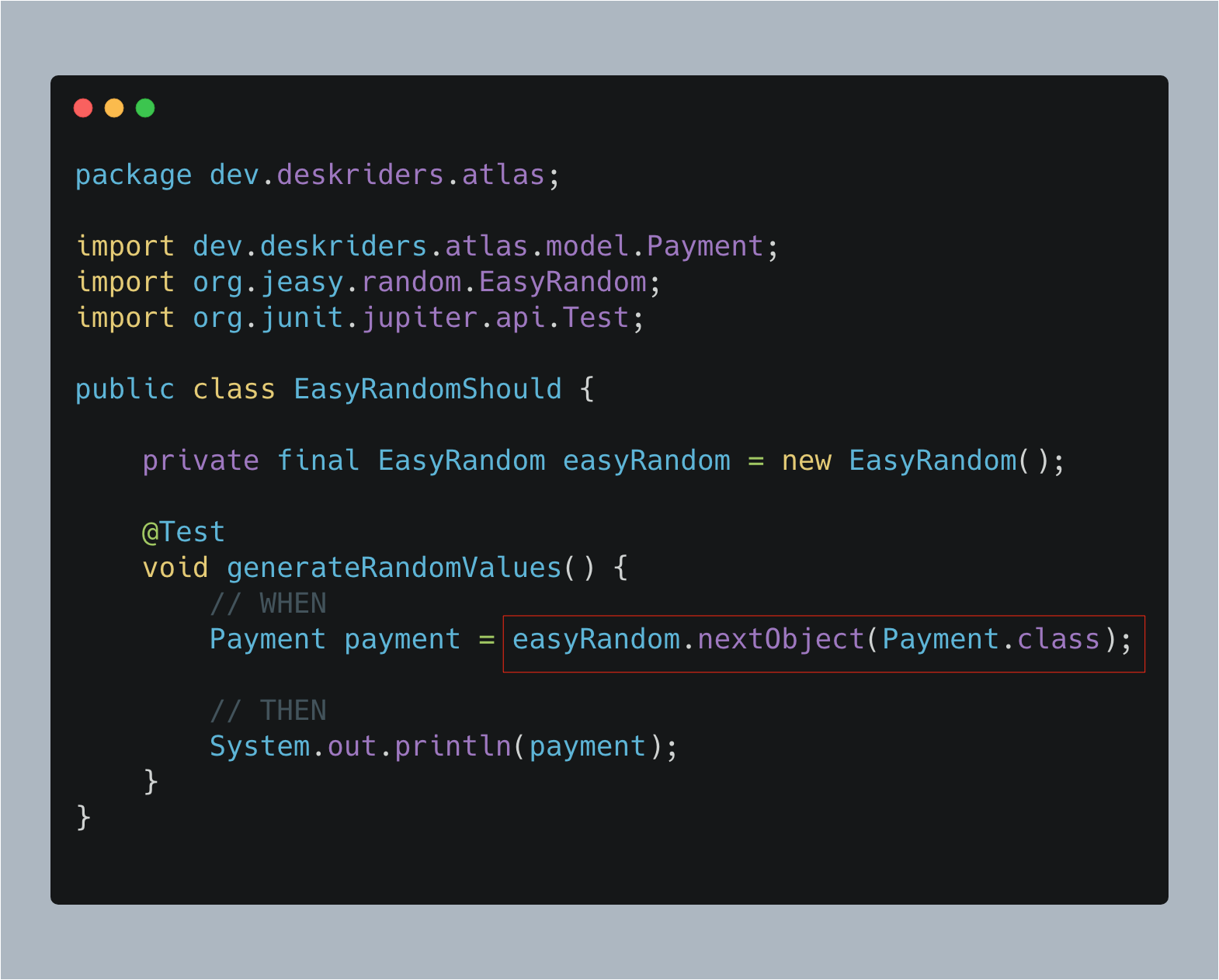
#### Step 4: 😍
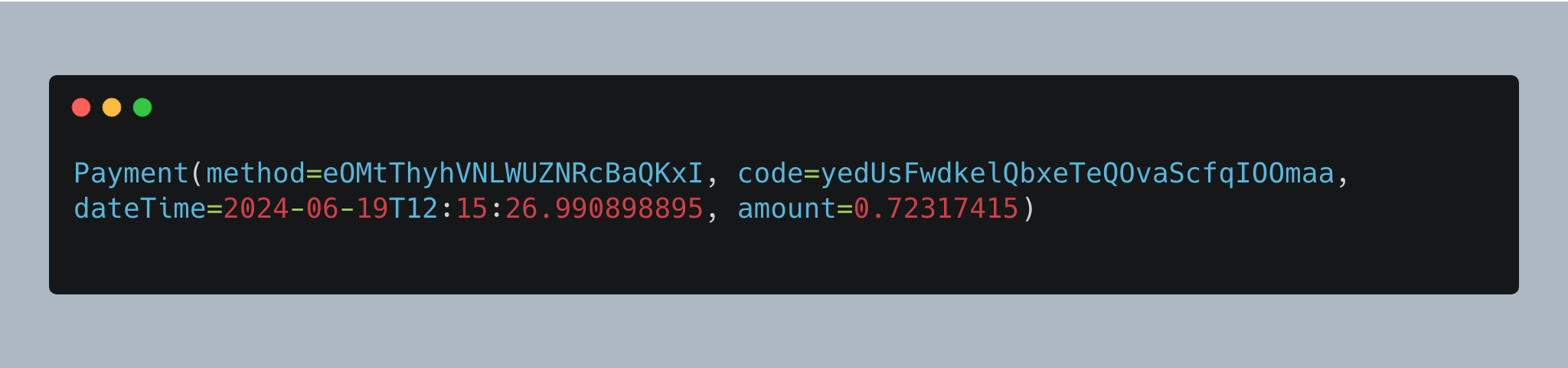
#### Tips:
#### Random initial seed
In the default setup, EasyRandom uses a default seed value to generate randam data.
Although it is quite simple to initiate EasyRandom with a random seed.
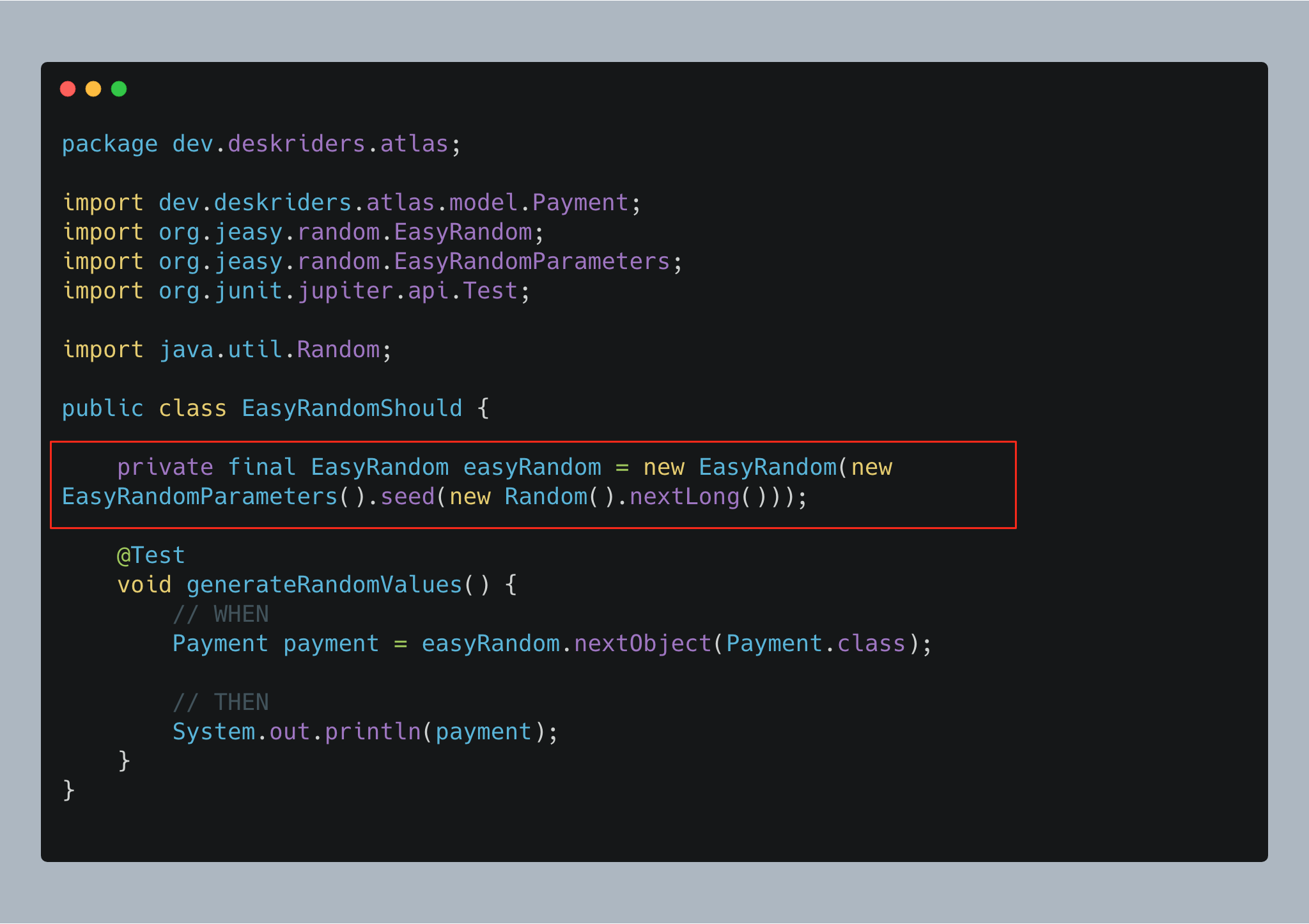
#### Enforcing javax.validation rules:
If an object is using javax.validation then there is an extension which enforces those rules when generating random objects.
Include https://github.com/j-easy/easy-random/wiki/bean-validation-support
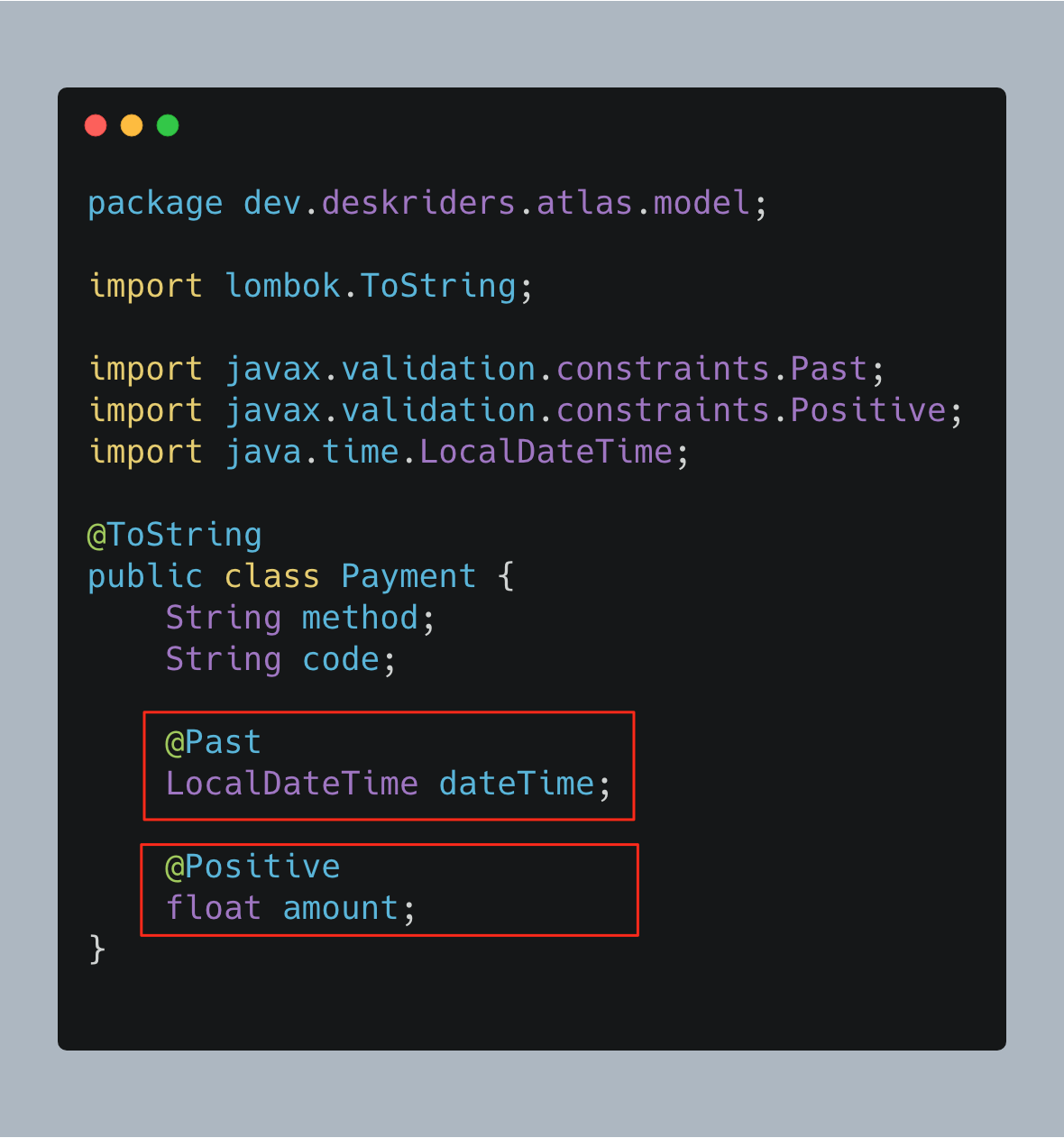
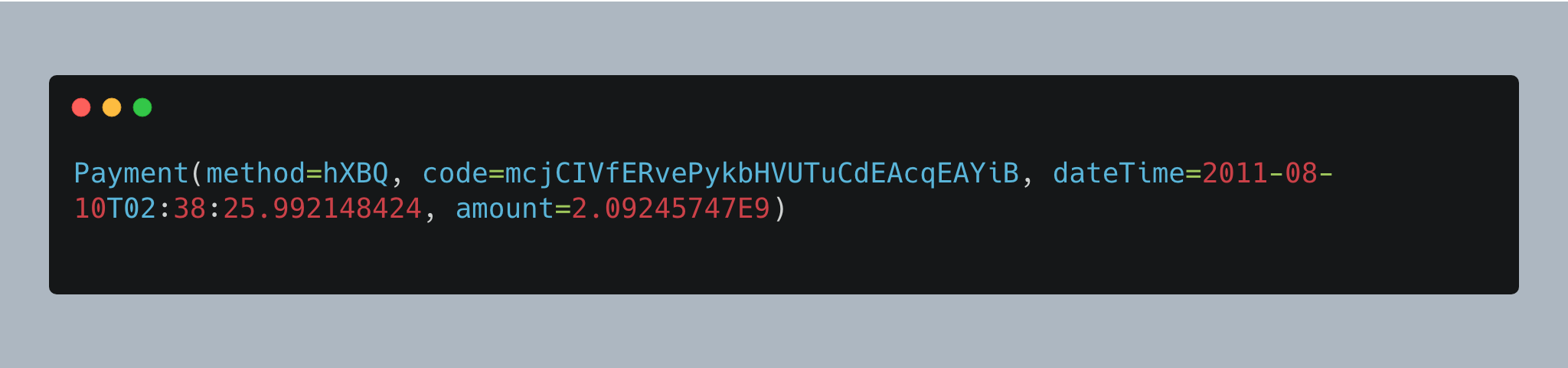
Github: https://github.com/namuan/dev-rider-codesnippets/tree/master/spring-boot-snippets | namuan |
350,550 | Let’s discover Ruby on Rails | Hello hello everyone ... I hope you are doing well despite this situation of global health crisis ..... | 7,231 | 2020-06-06T22:42:02 | https://dev.to/lionnelpat/let-s-discover-ruby-on-rails-4knl | ruby, rails, webdev, productivity |
Hello hello everyone ...
I hope you are doing well despite this situation of global health crisis ...
I want through this series of articles to invite you to discover the **Ruby on Rails** web framework. But first of all, I will introduce myself.
#What about me..
I am Patrick Lionnel. I live in Senegal (AFRICA) since 2013 where I did an engineering cycle in networks and telecoms. in 2016 after my diploma, I wanted to learn to code and this is how my professional adventure in the middle of the code started ... I thus started as a junior Android developer for 1 year. Then I started to do the web with PHP ... it was pretty cool.
After 2 and a half years, I went to a start-up where I did a little excessive Javascript and I improved my front-end knowledge with learning the JavaScript Angular2 framework for almost a year. and in January 2020, I was recruited by another start-up to work on a really exciting project ... Alas, the project had to be done on a technology that I had never used ... you can guess Ruby on Rails ....
So despite the hundreds of candidates who have applied, I knew how to stand out with what I already had as experience in the web and the challenge was to succeed in learning the language and to be productive in a stressful environment and a reduced time .... **_Nothing better than real challenges_** ...
#The Challenge...
This is how I dived into the marvelous universe of RoR (Ruby on Rails) and I would like through this series to present to you what I learned, why it’s good and especially why it is still a relevant choice today as well for start-ups who want to quickly prototype or have an app in a limited time, as for larger companies who want a robust platform.
As far as I'm concerned, I started this adventure in a team of 03 people including myself with the aim of producing a v0 of a SaaS web platform, responsive in two months. During these two months, we designed the platform with [Figma]( https://www.figma.com/), coded the application with Ruby on Rails, and deployed on [Clever-cloud](https://www.clever-cloud.com/).
#How did we achieve this feat...
How did we achieve this feat? With a dev who had never done Rails? How do I manage to learn so quickly and adapt to my new work environment? How did I fall in love with Ruby on Rails? What can this framework bring you as a Dev, CTO, or entrepreneur? more in my next article.
By the way, if you too have already had to work under pressure, share your experience with us in a comment. Are you a Ruby developer? Tell me in a comment why and what do you like in this Framework ... | lionnelpat |
350,617 | Mis primeros pasos en vim | Una guía para comenzar en Vim. Yo usare Neovim, que es un fork de vim. Para comenzar vamos a instal... | 0 | 2020-06-07T04:03:42 | https://dev.to/bawbam/mis-primeros-pasos-en-vim-1k06 | vim, beginners, productivity | Una guía para comenzar en Vim.
Yo usare Neovim, que es un fork de vim.
Para comenzar vamos a instalar neovim - [https://github.com/neovim/neovim/wiki/Installing-Neovim](https://github.com/neovim/neovim/wiki/Installing-Neovim)
Aquí pueden encontrar la instalación en su SO preferido.
Yo estoy en Debian, una distribución de Linux. Asi que estos son los comandos para instalar neovim:
```bash
sudo apt update
```
```bash
sudo apt-get install neovim
sudo apt-get install python3-neovim
```
Excelente, ahora ya tenemos [Neovim](https://neovim.io/) en nuestro sistema y para comprobar que es cierto, vamos a abrir nuestra terminal.
En la terminal escribimos el siguiente comando:
```bash
# Abrir neovim
nvim
# Abrir un archivo en neovim
nvim nombre_del_archivo.extension_del_archivo + enter
```
Se te mostrara una ventana de bienvenida de Neovim.
Si bien con estos pasos ya podemos empezar a utilizar neovim, pero en este punto aún le faltan super poderes a nuestro editor, así que para poder dotarlo de estos poderes, es necesario crear un archivo de configuración llamado **init.vim** , es en este archivo donde vamos agregarle los poderes, vamos a crear este archivo:
```bash
# primero ubicate en la terminal en la raiz de tu user
~
# entra a la carpeta .config
cd .config
# Crear la carpeta nvim
mkdir nvim
# Crea el archivo init.vim, dentro de la carpeta nvim
touch nvim/init.vim
# Abre el archivo init.vim y agrega la siguiente linea:
set number
# guarda los cambios y reinicia neovim para que los cambios tengan efecto
# Ahora se te mostraran las lineas del archivo
1 set number
```
**Comandos para salir de nvim:**
```bash
# presiona 2 veces ESC, para volver al modo normal
# Salir sin guardar
:q
# forzar la salida
:q!
# Salir y guardar cambios
:w
```
**Comandos básicos para navegar adentro del archivo:**
```bash
# mover a la derecha
h
# mover a la izquierda
l
# mover hacia abajo
j
# mover hacia arribba
k
# lleva al comienzo de una palabra avanzando para adelante
w
# lleva al comienzo de una palabra avanzando para atrás
b
# te lleva al final de cada palabra
e
```
**Comandos para guardar cambios:**
```bash
# Para guardar cambios sin salir del editor
:w
# guardar cambios y salir del editor
:wq
```
En el siguiente post, mostrare como instalar plugins en neovim. | bawbam |
350,639 | Dev.to 👩🏻💻 + Skynox 🚀 | A developer's humble journey into open source development and getting to work with the amazing DEV team. | 0 | 2020-06-30T13:22:33 | https://dev.to/xenoxdev/dev-to-skynox-65c | discuss, showdev, productivity, meta |
---
title: Dev.to 👩🏻💻 + Skynox 🚀
published: true
description: A developer's humble journey into open source development and getting to work with the amazing DEV team.
tags: discuss, showdev, productivity, meta
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/rsu0ldpw18escfcuxwwv.gif
---
This post is about the collaboration of my company, Skynox Tech, with DEV. Yes, this very platform you're reading this post on. This post is one I've been dying to write for months!
## A Serendipitous Discovery
It all started in 2016 while I was involved in my first venture. One of the developers in my team received a letter. As he opened it, I saw some stickers come out. I was instantly curious and asked him what it was all about.
"These are from Dev.to. They're sending stickers to everyone who signs up," he told us.
That was the first time I heard about DEV. Even though I didn't sign up right away, I remember thinking how cool it was. I really loved those stickers. 😍

Up until a few years ago, I used to write articles on Medium only. In mid-2018, however, I decided to contribute more to open source development and document my experience in the form of articles as well. Around the same time, one of my friends suggested that Dev.to is a much better platform than Medium if one wishes to write for developers. I recalled the stickers from 2016 and finally made an account on Dev.to in August 2018.
I soon published my [First post](https://dev.to/sarthology/a-repo-with-list-of--super-productive-movie-soundtracks--p).
But my first hit was:
{% link https://dev.to/teamxenox/best-open-source-tools-for-developers--300f %}
## First Interaction with the DEV Team
Till this date, I have written 50+ posts on Dev.to. I always felt a very special connection with this community, and I believe that's what the DEV team tries its best to make us feel. My first interaction with the team started when I wrote this post:
{% link https://dev.to/sarthology/why-devto-is-winning-over-hashnode-27nj %}
Folks from the DEV team commented on my post for the first time, and it was so special to me. 😅 From that very moment, I wanted to work with the DEV team and make this community better. So I started making small tools for the community. I made these two projects, which I think turned out pretty cool and were received very well by the community.
{% link https://dev.to/teamxenox/-dev10--a-christmas-gift-for-the-best-community-on--44bg %}
{% link https://dev.to/teamxenox/devto-cli-a-valentines-day-gift-to-my-favorite-people-56bd %}
I really enjoyed working on them so I decided to take my open source contribution to the next level. I publicly committed to making 12 products in 12 months in my new year resolution for 2019. Two of these products were, of course, [DEV10]() and [DEV-CLI](). In fact, the DEV team even helped us by hunting DEV10 on ProductHunt for us.
[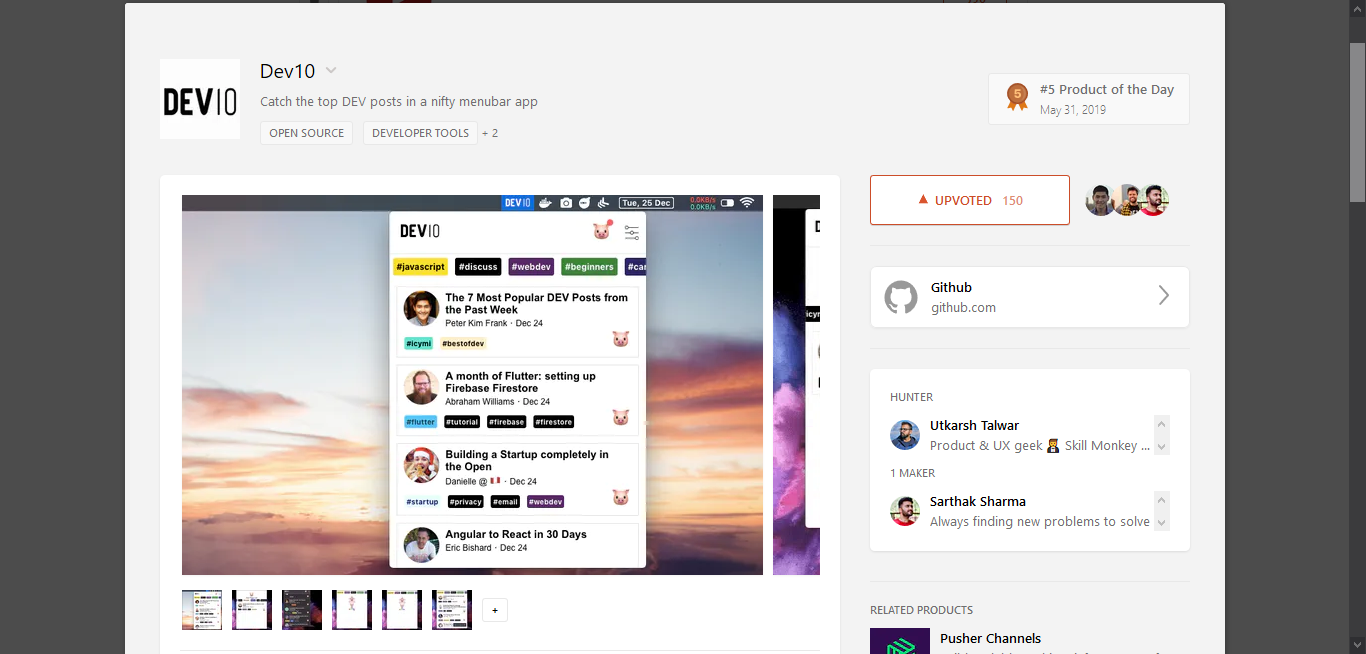](https://www.producthunt.com/posts/dev10)
[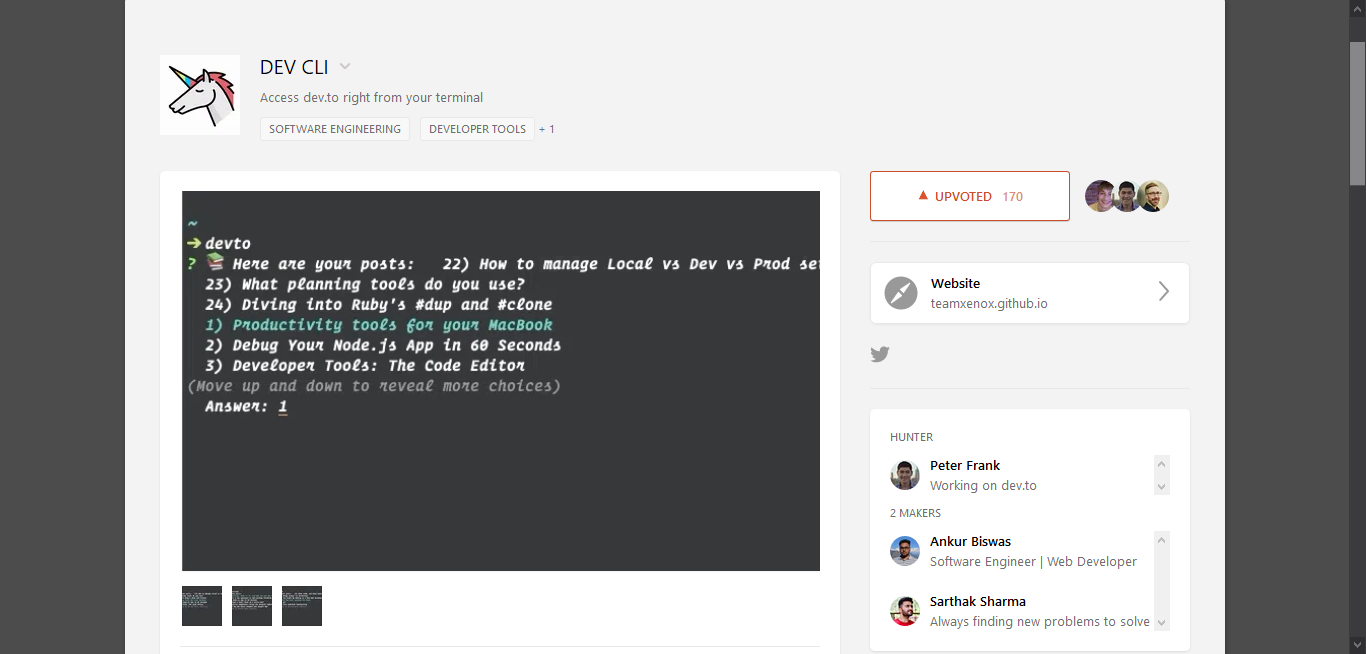](https://www.producthunt.com/posts/dev-cli)
## The Start of Something Great
On May 22nd 2020, I founded Skynox Tech, a company that helps startups get their MVPs out in the market fast. After years of working in the startup ecosystem, I realized that executing your vision accurately and testing your hypotheses quickly is extremely important, and that was the core belief of Skynox. We have helped a few startups launch their MVPs so far.
[WeCause](https://wecause.app/) is one of the oldest ones, based in Canada and the brainchild of my friend Pallavi Panigrahi. In a sentence, WeCause helps NGOs and causes connect with young volunteers. Volunteers sign up for various gigs and tasks put up on the platform by said NGOs and causes. The startup has been especially very helpful in the past few months with the COVID-19 pandemic looming over us.
Another one we worked on recently is Comicer, which is an Indian startup and currently in closed beta. Comicer is an end to end GRC (Governance, Risk & Compliance) tracking solution which aspires to bring change in large organizations by helping them easily deal with a large number of compliances. Not gonna bore you all with any more details but it was a really exciting and challenging project for us. First time for us working in the domain.
And over the last year, we've worked on a number of projects like this, each time getting better and delivering something greater.
But the biggest breakthrough for Skynox was this message sent to me by Jess:
> "On a totally separate note, we'll have contractor roles opening up soon. What would it look like to work with Team Xenox?"

That was the happiest day for Skynox ever since its inception, I'd say. I told Jess that we'd love to be involved with the DEV platform, and soon enough, we started discussing the legal terms. That didn't take too long, and on Monday, 18th November 2019, we started officially working with Dev.to. After a year of dreaming to work with this brilliant team, I finally wrote my first line of code for DEV.
## Our Work So Far
We started working on the DEV Connect module first thing, and I was actually quite thrilled to be the developer leading its development. DEV Connect has come far since then, and there are a bunch of really cool features (mentioning users via @handles, group chats for organizations, video chat, etc.) that we've worked hard to develop in the last few months. If you haven't given it a try, you definitely should right now!
Check out a couple of my favorite PRs so far!
{% github https://github.com/thepracticaldev/dev.to/pull/5460 %}
{% github https://github.com/thepracticaldev/dev.to/pull/7385 %}
After an initial period of about 3 months, both our teams decided we had good synergy and could take this partnership further. So I had a call with Ben and the team, and they shared their long-term vision for the platform with me. We decided to put more developers on this and officially sign a longer-term contract in March. I couldn't be happier about this turn of events. Suffice it to say, there are a lot of fantastic things planned for DEV that will blow your mind. 😉
## Expect More Great Things!
And Skynox Tech is going to stay right beside the DEV team, supporting them in this vision in every way possible. Watch out for this power-packed partnership as we bring more amazing features to you month after month. 💪💯

### P.S.
1. Leave a comment suggesting some cool features you want to see in DEV Connect!
2. Inspired by the DEV team, we've decided to start a podcast of our own very soon! If you were a fan of the [Ultra List](http://bit.ly/aug19ul) series and miss it, you will most definitely love the podcast, so look forward to it! Join us on the newly launched [Team Xenox subreddit](https://bit.ly/xenoxreddit) so you don't miss the announcement!
---
[](https://bit.ly/xenoxauthor)
---
[](https://bit.ly/joinxenox)
---
[](https://bit.ly/skynox-angel)
--- | sarthology |
350,644 | Survey site focus on HTML flow | Survey focus on css flow The default style for position is position: static and offset pr... | 0 | 2020-06-07T06:11:21 | https://dev.to/heggy231/survey-site-focus-on-html-flow-dbh | html, css | # [Survey](https://heggy231.github.io/chingu-webdev-speedrun-challenge/frontend/survey/) focus on css flow
- The default style for position is `position: static` and offset properties (`top`, `bottom` will not work)
- `Position: Relative` means relative to its default static position on the web page.
```css
.box-bottom {
background-color: DeepSkyBlue;
position: relative;
// offset properties top, left
top: 20px;
left: 50px;
}
```
- `position: fixed` will remove its element out of HTML flow. Therefore, it covers element following.
To fix, add `position: relative`, provide offset amount to the element that is currently covered by the `position: fixed` element.
```css
nav {
// nav element is removed from HTML flow
position: fixed
}
// element following `nav` is body
body {
// take the element out of html flow
position: relative;
// offset
top: 200px;
}
```
- When use display property: `inline-block`, element can be placed next to each other and have dimension. image element is good example of `inline-block`.
```html
<header>
<ul>
<li>Question 1</li>
<li>Question 2</li>
<li>Question 3</li>
<li>Question 4</li>
<li>Question 5</li>
</ul>
</header>
```
We then can set `li` to `display: inline-block;` to questions to show up side by side.

| heggy231 |
350,700 | Build your own Australian Address Search API | Code can be found here There are multiple services available that offer API's for Austrlian address... | 0 | 2020-06-07T10:06:52 | https://glenbray.com/australian-address-api | rails, elasticsearch, ruby | [Code can be found here](https://github.com/glenbray/australian_address_api)
There are multiple services available that offer API's for Austrlian address autocomplete that also have generous free daily limits. But, there may be times when those limits aren't enough and the costs of using the service may not be viable. An example of a time when this was useful for me can [viewed here](https://dev.to/glenbray/extracting-addresses-from-millions-of-pages-with-automl-and-ruby-3djd/).
Lets look at whats involved in creating our own Australian address search API using the [GNAF dataset](https://psma.com.au/product/gnaf).
We'll be doing the following:
1. Run the gnaf-loader to import address data into a separate postgres DB.
2. Setup a new rails api project.
3. Use the new multi-database feature to connect to the GNAF DB in our app.
4. Sync to Elasticsearch.
5. Create 2 endpoints for address autocomplete and reverse geolocation lookup.
<hr />
## Import Australian Addresses with the gnaf-loader
Clone the gnaf-loader project.
$ git clone git@github.com:minus34/gnaf-loader.git
The gnaf-loader has a [few options]https://github.com/minus34/gnaf-loader#process) to import the data. Choose whichever option you prefer to load the data into Postgres. This article will cover loading the data with docker.
1. From your terminal change directory to the repo you've just cloned `gnaf-loader`
2. Create a data directory in the root of the repo `mkdir data`.
3. Download the PSMA GNAF and ESRI shape file as mentioned from the readme of `gnaf-loader`.
4. Extract both and move directories into the `data` directory.
5. Before we build the address database let's update the dockerfile and open some ports.
The change made can be [viewed here](link-to-file).
6. Run `docker-compose up` to build and run the containers.
Once the containers start running, this will start the import process. This will take a while to run. While we wait, let's set up the API. Our API will use Elasticsearch so we'll set that up first. With mac and homebrew this can be done with:
```bash
$ brew install Elasticsearch
$ brew services start Elasticsearch
```
<hr />
## Create a new rails project
```bash
$ rails new australian_address_api --api --database=postgresql`
```
Configure your database.yml
```yaml
development:
primary:
<<: *default
database: australian_address_api_development
gnaf:
<<: *default
database: gnaf
```
This setup the DB.
$ rails db:setup
We'll use the searchkick gem to search and index records in Elasticsearch. So lets add that to the [gemfile](path/to/gemfile) and `bundle install`.
<hr />
## Prepare to sync to Elasticsearch
There are a few things we need to do before we start syncing records to Elasticsearch. Firstly, we'll create an Address model and have it connect to our GNAF DB. We'll use the new rails 6 multiple database feature to have this model connect to our GNAF DB. This will enable us to separate the GNAF database from our API DB. Here's the code to get that in place.
```ruby
class Address < ApplicationRecord
connects_to database: {reading: :gnaf, writing: :gnaf}
self.primary_key = "gid"
self.table_name = "gnaf_202005.addresses"
end
```
Now that we can connect to the GNAF DB, lets setup searchkick.
```ruby
class Address < ApplicationRecord
# ...
STREET_SYNONYMS = [
['street','st'],
['terrace','tce'],
['road','rd'],
['boulevard','bvd'],
['close','cl'],
['crest','crst'],
['drive','dr'],
['avenue',' av'],
['highway',' hwy']
]
searchkick default_fields: [:full_address],
word_start: [:full_address],
synonyms: STREET_SYNONYMS,
locations: [:location]
scope :search_import, -> { where("confidence > 0") }
def should_index?
confidence > 0
end
def full_address
[address.titlecase, locality_name.titlecase, state, postcode].join(' ')
end
def search_data
{
full_address: full_address.downcase,
suburb: locality_name.downcase,
state: state.downcase,
postcode: postcode,
location: {
lat: latitude.to_s,
lon: longitude.to_s
}
}
end
end
```
The `search_data` method is used to send the data for a record to Elasticsearch for what we'd like to make searchable. We'll only be using the `full_address` and `location` fields in this article.
The `search_import` and `should_index?` methods are used to only sync records matching the specified condition. More information on what the [confidence score means here](https://psma.com.au/product/gnaf/).
We'll want to handle abbreviations for certain words within the address e.g `street` -> `st`. I've created a synonyms constant for those mappings which are passed to searchkick.
<hr />
## Sync to elasticsearch
Now with that in place, let's start syncing records to Elasticsearch. You can do this with `Address.reindex` from the rails console. This will sync around 11 - 14 million records and will take a while to do. You can do this async to speed it up, but that is out of the scope of this article. See the searchkick [readme](https://github.com/ankane/searchkick#parallel-reindexing) for more info.
When syncing finishes, we can test search in the rails console:
```ruby
pry(main)> Address.search("38a wentworth rd vaucluse").first
Address Search (168.3ms) addresses_development/_search {"query":{"bool":{"should":[{"dis_max":{"queries":[{"match":{"full_address.analyzed":{"query":"38a Wentworth Road Vaucluse NSW 2030","boost":10,"operator":"and","analyzer":"searchkick_search"}}},{"match":{"full_address.analyzed":{"query":"38a Wentworth Road Vaucluse NSW 2030","boost":10,"operator":"and","analyzer":"searchkick_search2"}}},{"match":{"full_address.analyzed":{"query":"38a Wentworth Road Vaucluse NSW 2030","boost":1,"operator":"and","analyzer":"searchkick_search","fuzziness":1,"prefix_length":0,"max_expansions":3,"fuzzy_transpositions":true}}},{"match":{"full_address.analyzed":{"query":"38a Wentworth Road Vaucluse NSW 2030","boost":1,"operator":"and","analyzer":"searchkick_search2","fuzziness":1,"prefix_length":0,"max_expansions":3,"fuzzy_transpositions":true}}}]}}]}},"timeout":"11s","_source":false,"size":10000}
Address Load (1.8ms) SELECT "gnaf_202005"."addresses".* FROM "gnaf_202005"."addresses" WHERE "gnaf_202005"."addresses"."gid" = $1 [["gid", 12706313]]
=> #<Address:0x00007f827a068250
gid: 12706313,
gnaf_pid: "GANSW710434263",
street_locality_pid: "NSW2925230",
locality_pid: "NSW4107",
alias_principal: "P",
primary_secondary: nil,
building_name: nil,
lot_number: nil,
flat_number: nil,
level_number: nil,
number_first: "38A",
number_last: nil,
street_name: "WENTWORTH",
street_type: "ROAD",
street_suffix: nil,
address: "38A WENTWORTH ROAD",
locality_name: "VAUCLUSE",
postcode: "2030",
state: "NSW",
locality_postcode: "2030",
confidence: 2,
legal_parcel_id: "381//DP1061794",
mb_2011_code: 10892260000,
mb_2016_code: 10892260000,
latitude: -0.3385606636e2,
longitude: 0.15126996495e3,
geocode_type: "PROPERTY CENTROID",
reliability: 2,
geom: "0101000020BB1000001FEA888DA3E86240F0B31D9593ED40C0">
```
<hr />
## Address autocomplete
While we wait for the sync to finish let's implement autocomplete address endpoint.
```ruby
# app/controllers/address_autocomplete_controller.rb
Rails.application.routes.draw do
get "/address/autocomplete", controller: :address_autocomplete, action: :index
end
```
```ruby
# app/controllers/address_autocomplete_controller.rb
class AddressAutocompleteController < ActionController::API
def index
@addresses = Address.search(params[:q], match: :word_start)
end
end
```
With the jbuilder gem, we can create a few templates that will generate our JSON. When setting up a rails project this gem is included in the gemfile but commented out. Uncomment it and run `bundle install`.
```ruby
# app/views/addresses/_address.jbuilder
json.address address["address"]
json.lot_number address["lot_number"]
json.flat_number address["flat_number"]
json.level_number address["level_number"]
json.number_first address["number_first"]
json.number_last address["number_last"]
json.street_name address["street_name"]
json.street_type address["street_type"]
json.street_suffix address["street_suffix"]
json.suburb address["locality_name"]
json.postcode address["postcode"]
json.state address["state"]
json.longitude address["longitude"]
json.latitude address["latitude"]
```
The above is a shared partial that will be used by both autocomplete and reverse geolocation.
```ruby
# app/views/address_autocomplete/index.jbuilder
json.partial! 'addresses/address', collection: @addresses, as: :address
```
<hr />
## Reverse geolocation
Another feature that we'll implement is the ability to search for addresses near a given
longitude and latitude.
Let's update the address model to support reverse geocode searches.
```ruby
Address
# ...
def self.reverse_geocode(longitude, latitude, within)
within = 1 if within.blank? || within <= 0
Address.search(
where: {
location: {
near: {
lon: longitude.to_f,
lat: latitude.to_f
},
within: "#{within}m",
}
}
)
end
end
```
Finally, to finish this off - the route, controller and view.
```ruby
# app/controllers/address_autocomplete_controller.rb
Rails.application.routes.draw do
get "/coordinates/reversegeocode", controller: :reverse_geocode, action: :index
end
```
```ruby
class ReverseGeocodeController < ActionController::API
def index
@addresses = Address.reverse_geocode(params[:lng], params[:lat], params[:within])
end
end
```
Our API will accept the params `longitude`, `latitude` and `within`. The within params accepts an integer. It allows us to filter addresses within a distance in meters from the longitude and latitude.
```ruby
# app/views/reverse_geocode/index.jbuilder
json.partial! 'addresses/address', collection: @addresses, as: :address
```
<hr />
That completes our minimal Australian address API. As mentioned above, there are API's available that have a daily free limit and are fairly cheap. Depending on your situation it might be better to just use those to save time.
| glenbray |
350,713 | Creating Markdown powered blog with nuxt | Creating blog is a passion of lots of people; that includes me. But starting out with it is really re... | 0 | 2020-06-07T10:31:47 | https://santoshb.com.np/blog/creating-markdown-powered-blog-with-ease/ | vue, blog, markdown, nuxt | Creating blog is a passion of lots of people; that includes me. But starting out with it is really really hard. So I thought to share an easy way (If you are familiar with **Vue**) to create own blog. Technically there are various methods of doing this. But of the most impressive and famous way is Jamstack and the entire article is based upon it.
## About Jamstack
So if you are already wondering what is jamstack and why jamstack, then you should head over to the [jamstack website](https://jamstack.org/) to know more about it. Because if I started talking about it, the article can get really long 😜. Altough the below listed are very basic ones but here are some awesome feature you should know:
- No need of server to host website
- Higher security
- Cheaper
With that being said, JAMstack makes things only better!
## Prerequisites
To get started with buliding your own blog we need to install few things. _You need to have **Node.js** installed on your machine!_
#### Nuxt
It is the most essential stuff today. It is really easy if you know vue. Also it provides way more than just generating static sites. This is just one of its awesome features. With it you can try so many awesome things and it even makes so many complex stuffs really really easy. It also has an active community and really helpful developers and core team members. To know more about it you can have a look at the [official website](https://nuxtjs.org/)!
#### Nuxt content
Nuxt content is an official module by the nuxt team which aims to provide ease to use features while working with _markdown_, _JSON_, _YAML_ and _CSV files. Although it is a preety nuch module by the nuxt team, it already contains really amazing feature which makes our task easier. Also the dev team is working to add new features to the module. So you should keep track of the module to learn about the new amazing features that the module will be getting. More information about it can be found [here](https://content.nuxtjs.org/)!
Thats basically what we will need to start developing the blog. So lets dive deep into building the blog!
## Development
There are few phases of developing the blog. I will try to explain them with minimum words but with maximum meaning. I hope it helps you!
### Writing a blog article
With the `@nuxt/content` module activated you can start with ease to write blog articles. ALl you should be doing is create a **content** directory in the root of your project directory and create files inside it. Generally you can place your article files directly inside the content directory. But if you plan to host files other than blog articles with the content module, I would suggest to create your articles inside `/content/blog` or any subdirectory of your choice. **I strongly recommend to place the markdown articles into a subdirectory. You will understand the reason while reading through this article!**
```markdown
---
title: article1
---
## About this article
You can write any markdown content here and it can be easily displayed later!
```
As you see in the example above I have added YAML front matter block. All the items added will be injected into the article object and you will be able to see them when you fetch the article object. This can be really helpful if you want to add some properties to the article. You can even set the title, date, author details or anything else in the markdown file and later fetch, use them as you like.
All of your general content goes below the front matter block. You can do everything that you can do with a markdown file. On top of that you can even use html and vue components in the markdown file and with the magic of the module, it will be rendered properly. Which means you can customize your content in the markdown file completely! Also the content module provides syntax highlighting using [PrismJS](https://prismjs.com/). So you can even demonstrate codeblock examples!
There is a lot more to writing content though. You can definitely check it out [here](https://content.nuxtjs.org/writing/)!
### Fetching the blog article
Writing alone is not enough right? You would want to fetch the articles and display them. So why not look into fetching the articles next.
Fetching the contents is really really easy. The content module globally injects a **$content** instace, so you can access it anywhere within the project; either `this.$content` or `context.$content` based upon where you use it. That is really easy, isn't it?
Based upon the usage, I can think up of two specific ways you would want to fetch the content. We will look into both the usage methods below.
- Fetching all the articles to list them out
- Fetching a specific article to display it's content
The first use case for fetching the articles is to list them out. While fetching the article list you would either want to fetch all the articles or even filter the articles based upon some parameters. Here is how you would do that:
```js
// Fetching all the article list
const articles = await this.$content('blog').fetch();
// Fetching articles with filters
const articles = await this.$content('blog')
.search('title', 'welcome')
.fetch();
// Fetching specific article [1]
const article = await this.$content('blog', articleSlug).fetch();
// Fetching specific article [2]
const article = await this.$content('blog')
.where({ slug: articleSlug })
.fetch();
```
- The first method seen in the example above fetches all the articles inside the `/content/blog` directory.
- The second method also fetches all the articles inside the `/content/blog` but returns result matching the search criteria. _Useful when you are implement a search bar!_
- The third method fetches a specific article based upon the second parameter passed to it. **You get an object instead of array when fetching in this method!**
- The last method is just an alternative to the third method. **It returns an array instead of Object, so you might want to treat it as an array!** _Speaking from experience already..._
You might now always want all the properties of the content. For e.g. when listing title only, you can simply get only the title of the articles using the `.only()` method i.e. `.only(['title'])`. You can even limit the number of items in the result using the `.limit(n)` chainable method. Also you can skip number of results using the `.skip()` method.
I personally use the last method to fetch a specific article and I would even suggest you to do so. It is because it will work even if you decide to change the structure of your content directory and more stuffs here and there. _I personally do that a lot!_ But for the earlier method i.e. you will have to know the exact file location otherwise you will not be able to fetch it.
The content module provides way more control over how you fetch the articles. There is just too many possibilities how you can control fetching your content. It is as good as impossible to know about your specific use case. Thus to know how to customize your fetch request you can have a look [here](https://content.nuxtjs.org/fetching/)!
### Displaying the blog article
This has to be the most easiest task throughout this article. The content module provides a **use-and-enjoy** component which we will be simply using to display the content of our blog article.
```html
<template>
<div>
<nuxt-content :document="article">
</div>
</template>
```
The above example will simply display the content of the fetched article. How you customize the page is completely upto you yet again. The article passed into the `document` prop is the object that we obtained after fetching specific article after the dyanmic slug param. Theoritically that is all you should do to display the content of the article. But you would love to add more details right? You can simply modify the page template to show off your imagination!
Furthermore your page design will not be included into the markdown content. Thus if you want to customize the markdown with custom style you will have to do that like:
```css
/* Making the h2 component have red color. This is just me, you don't have be bad with examples! */
.nuxt-content h2 {
color: red;
}
```
A live example of the usage can be found [here](https://github.com/nuxt/content/blob/master/docs/pages/_slug.vue#L65-L191)! I too have used the same thing... _No copyright please!_
### Working with dynamic routes
The core concept of this article is working with static generate site. So we will have to specify all the routes (_the article list for us_) while generating the site. This too is really easy with the content module. With that simple addition of the code below to `nuxt.config.js` your site will be ready to handle the dyanmic article page.
```js
export default {
modules: [
'@nuxt/content'
],
generate: {
async routes() {
const { $content } = require('@nuxt/content');
const articles = await $content('blog').only(['slug']).fetch();
// Generating the routes for the unique page of each article...
return articles.map((article) => `/article/${article.slug}`);
}
}
}
```
**NOTE:** From 2.13+, `nuxt export` is said to have a crawler integrade to the core module. Which means the code above will not have to be injected into your config file!
That has to be all with the development of a basic markdown powered blog using `nuxt` and `nuxt-content`. If you did everything right then your blog should be working as well. If not just tell me in the comments below!
Also like any other module, content also provides customization options so that you can customize the behavious as you like. You can check about the customization options [here](https://content.nuxtjs.org/configuration)!
## Bonus
It was a really long article to write and I am preety sure it was hard to read it all as well. So I thought about sharing some interesting things with you guys. I actually wanted to list out points/stuffs which you might find interesting, and you can even integrate it with the blog you will be making with the awesome `content` module:
- [Netlify](https://www.netlify.com/): Host the blog you created right away!
- [Implement reading time](https://content.nuxtjs.org/advanced#contentfilebeforeinsert): You can implement reading time in your articles. _Details are from the official nuxt-content module!_
- [Sitemap](https://github.com/nuxt-community/sitemap-module): Let the web crawlers know each and every of your content!
- [Blog feeds](https://github.com/nuxt-community/feed-module): Let your community know when articles are out!
- [Nuxt color mode](https://github.com/nuxt-community/color-mode-module/): Which do you prefer, day or night ??
- [Nuxt components](https://github.com/nuxt/components): Get rid of those component imports that occur everywhere. _Comes with core nuxt 2.13+_
- [Disqus](https://disqus.com/): I love user engaged community!
- [vue-disqus](https://www.npmjs.com/package/vue-disqus) to make things easy.
- Optionally you can go for facebook comment plugin or other comment plugin provider!
- [**This site**](https://github.com/TheLearneer/santoshb.com.np) is a live example and demo of using this article! _Lots of changes will be made to the site and article itself to show what more you can do with it!_
---
<center>I am always open for feebacks :heart:</center>
---
<center>Originally posted on [my blog here](https://santoshb.com.np/blog/creating-markdown-powered-blog-with-ease/)</center>
--- | bsantosh909 |
350,722 | Créer des Snaps en pointant simplement un formulaire Web vers un dépôt Git avec Fabrica : application à MicroK8s … | Il existe de nombreuses façons de créer des snaps. Vous pouvez le faire sur votre système localemen... | 0 | 2020-06-07T10:59:27 | https://medium.com/@deep75/cr%C3%A9ez-des-snaps-en-pointant-simplement-un-formulaire-web-vers-un-d%C3%A9p%C3%B4t-git-avec-fabrica-986c2944fe9f | devops, cloud, containers, kubernetes | ---
title: Créer des Snaps en pointant simplement un formulaire Web vers un dépôt Git avec Fabrica : application à MicroK8s …
published: true
date: 2020-06-07 10:44:13 UTC
tags: devops,cloud,containers,kubernetes
canonical_url: https://medium.com/@deep75/cr%C3%A9ez-des-snaps-en-pointant-simplement-un-formulaire-web-vers-un-d%C3%A9p%C3%B4t-git-avec-fabrica-986c2944fe9f
---
Il existe de nombreuses façons de créer des snaps. Vous pouvez le faire sur votre système localement, en exécutant manuellement des commandes dans une fenêtre de terminal.
Si vous avez un compte développeur dans le Snap Store , vous pouvez utiliser la fonctionnalité de construction intégrée pour créer des snaps. Vous pouvez également utiliser Launchpad, Electron Builder ou une gamme de dispositifs de CI/CD.
Vous pouvez également gérer votre propre usine de construction de Snaps auto-hébergée comme cela va être le cas ici !

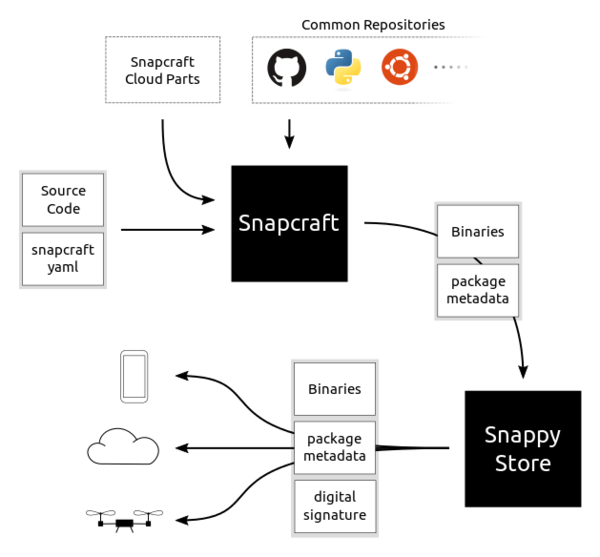
> Snap est un système open source de déploiement de logiciels et de gestion de packages développé par Canonical pour le système d’exploitation Linux. Les packages, appelés snaps, et l’outil pour les utiliser, snapd, fonctionnent sur une gamme de distributions Linux permettant un package logiciel en amont indépendant de la distribution. Les packages d’applications Snap sont autonomes et fonctionnent sur une large gamme de distributions Linux. Cela diffère des approches de gestion de packages Linux traditionnelles, comme APT ou YUM, qui nécessitent des packages spécifiquement adaptés pour chaque distribution Linux. Ce qui ajoute un délai entre le développement d’applications et son déploiement pour les utilisateurs finaux.
> Les snaps eux-mêmes ne dépendent d’aucun «app store» et peuvent être obtenus à partir de n’importe quelle source. Ils peuvent donc être utilisés pour le déploiement de logiciels en amont. Lorsque des snaps sont déployés sur Ubuntu et d’autres versions de Linux, le Snap Store peut être utilisé comme back-end …
[Getting started | Snapcraft documentation](https://snapcraft.io/docs/getting-started)

**Fabrica** est un tout nouveau service Web hébergé localement, conçu pour aider les développeurs à créer des snaps. L’idée derrière Fabrica est simple: obtenir un système automatisé qui peut connecter des référentiels distants et créer des snaps à chaque fois qu’il y a un changement dans l’arborescence source. De cette façon, vous pouvez gérer plusieurs projets et générer des versions à jour, avec peu ou pas d’interaction …
[Install fabrica - your own snap build factory for Linux using the Snap Store | Snapcraft](https://snapcraft.io/fabrica)
Fabrica se compose de deux couches:
- Une interface utilisateur Web simple qui vous permet d’ajouter un nombre illimité de dépôts Git clonables accessibles publiquement. Vous pouvez choisir des branches différentes (ou multiples) pour chaque dépôt.
- Fabrica exécute un service de conteneur via l’hyperviseur LXD, qui génère des instances à l’intérieur desquelles les arborescences Git sont clonées et qui vont procéder à la construction des snaps. Vous pourrez ensuite «télécharger» les snaps générés, les tester et les utiliser.
Je commence donc à lancer un droplet Ubuntu 20.04 LTS dans DigitalOcean :
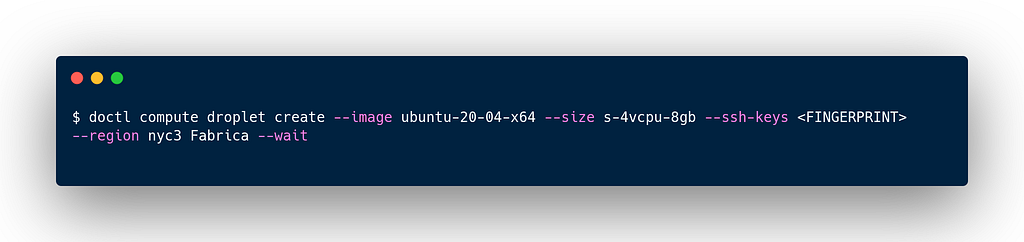

Et je procède à l’installation de Fabrica via l’installation de son snap :


> Les snaps sont conçus pour être des applications autonomes, avec une forte sécurité et une isolation du système sous-jacent et des autres logiciels qui y sont exécutés. Un accès granulaire aux ressources système est possible grâce à un mécanisme appelé interfaces.
> Certaines interfaces sont connectées automatiquement ; lorsque vous installez un composant logiciel enfichable, les ressources demandées sont provisionnées automatiquement. Certaines, pour des raisons de sécurité, ne le sont pas.

Dans ce cas particulier, j’accorde ici à Fabrica l’autorisation d’accéder au service LXD, ) monter / observer (lire la table de montage et les informations de quota) et à observer le système (lire le processus et les informations système) via ces commandes …
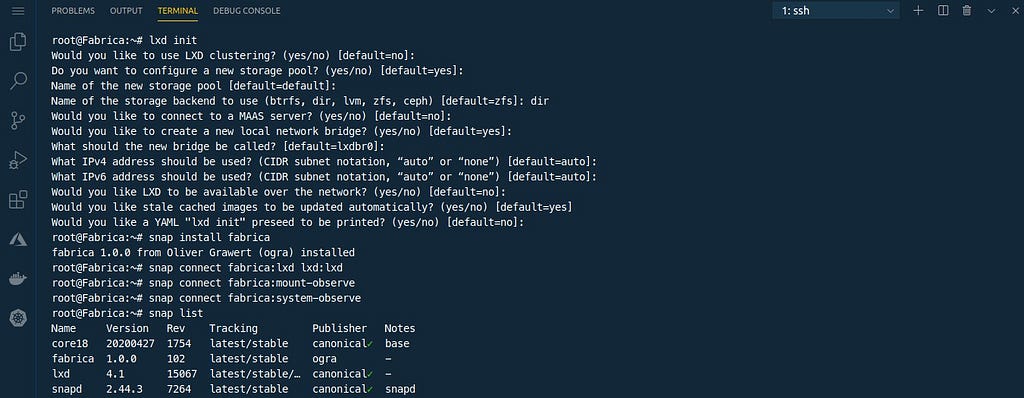
> Fabrica s’exécute et écoute alors sur le port TCP 8000. Pour le moment, la connexion est disponible via HTTP, et il n’y a pas de tunnel sécurisé ou d’authentification, ce qui signifie que vous devez tester et exécuter ce service uniquement sur des réseaux de confiance …
Dans un précédent article, j’avais illustré la mise en oeuvre de MicroK8s via son snap :
[Edge Computing : Aperçu de la fonction clustering dans MicroStack et MicroK8s …](https://medium.com/@deep75/edge-computing-aper%C3%A7u-de-la-fonction-clustering-dans-microstack-et-microk8s-fd89fd28204c)
Je vais donc pour cette expérience ajouter le dépôt Git de MicroK8s en le pointant sur sa branche Master :
[ubuntu/microk8s](https://github.com/ubuntu/microk8s)

[MicroK8s - Zero-ops Kubernetes for developers, edge and IoT | MicroK8s](https://microk8s.io/docs)
en renseignant le formulaire Web :

Une fois le dépôt Git ajouté, je peux déclencher manuellement une génération de snap ou attendre une opération planifiée sur le dépôt. Fabrica interroge les dépôts Git ajoutés pour suivre d’éventuelles modifications toutes les cinq minutes. Et déclenchera la génération de snap si nécessaire …
Lancement ici manuel du “Build” :

Je peux voir que Fabrica a généré localement un conteneur LXC pour la construction du snap :

Pendant qu’un build est en cours d’exécution, je peux inspecter ce qui se passe en cliquant sur l’icône «i» dans chaque ligne de build. Cela permet de dérouler le journal des logs et affichera les commandes en cours d’exécution à l’intérieur du conteneur lxc, comme l’extraction des données du dépôt Git, la mise à jour du système, la compilation ou d’autres commandes. Tout cela se produit indépendamment du système sous-jacent :
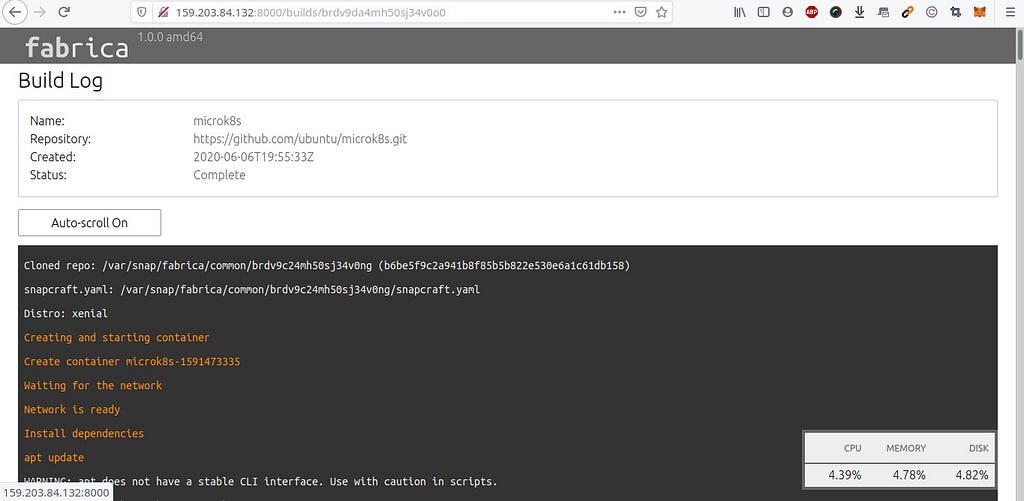
Je peux voir la génération du snap pour MicroK8s se terminer au bout d’une trentaine de minutes :

Une fois le paquet snap créé, on peut utiliser le bouton «Télécharger» pour le récupérer à l’intérieur de l’environnement de construction du conteneur et le placer quelque part sur le disque de son choix :


Je le place localement sur mon Instance Ubuntu 20.04 LTS en exécution sur DigitalOcean :

Et je le teste sur cette dernière (avec la branche Master, je me retrouve donc avec un snap de MicroK\_s correspondant à la version 1.18.3 de Kubernetes):
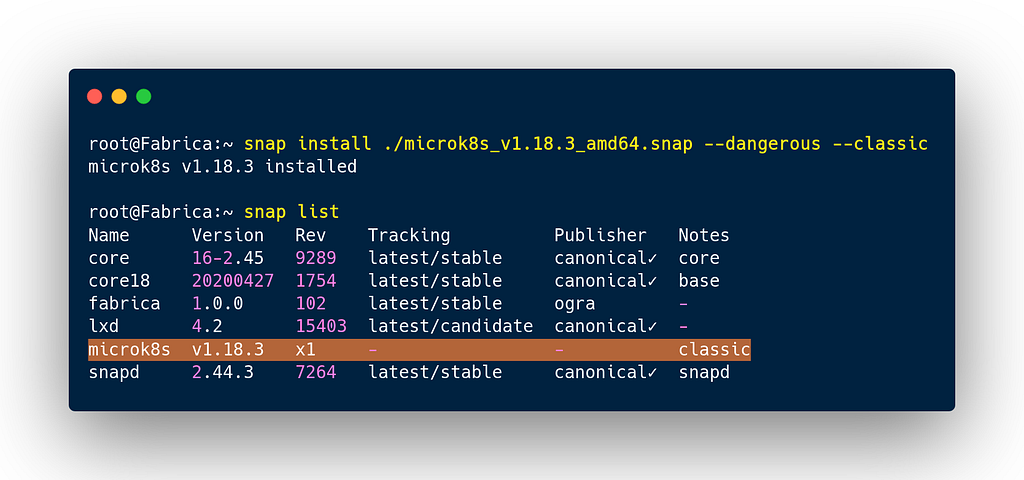
MicroK8s m’a généré un cluster K8s actif et opérationnel sur l’instance Ubuntu :

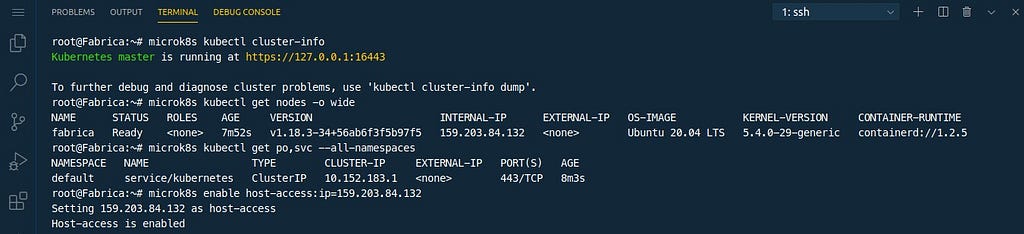
De cette manière, je peux éviter de passer par le Snap Store (qui propose les mêmes versions) 😋 :
Fabrica génère actuellement des builds uniquement pour l’architecture locale (comme AMD64) sur laquelle il va s’exécuter. Donc si vous voulez créer des builds pour d’autres architectures, vous devrez configurer Fabrica sur le matériel correspondant (comme une carte Raspberry Pi 4 pour ARMv8 par exemple) …
[Fabrica - Your self-hosted snap factory | Ubuntu](https://ubuntu.com/blog/fabrica-your-self-hosted-snap-factory)
On a vu que Fabrica propose une solution simple et pratique pour automatiser la construction de snaps en complètant les mécanismes de construction et d’intégration robustes déjà en place et en offrant une autre boîte à outils pratique aux développeurs. Certaines options et fonctionnalités sont actuellement indisponibles, comme l’authentification ou une période de déclenchement personnalisable mais elles arriveront probablement dans un futur proche …

À suivre ! | deep75 |
350,818 | Updating fish shell from source code | In this post I'll briefly talk about how to update fish from HEAD from linux (Mac OS is different, ch... | 0 | 2020-06-07T15:27:33 | https://dev.to/thefern/updating-fish-shell-from-source-code-4l6k | fish, shell, git | ---
title: Updating fish shell from source code
published: true
description:
tags: fish, shell, git
//cover_image: https://direct_url_to_image.jpg
---
In this post I'll briefly talk about how to update fish from HEAD from linux (Mac OS is different, check out https://github.com/fish-shell/fish-shell for specific build instructions). This means the latest commit in your default branch.
Why would you want to do this, and not wait for a release? Occasionally a feature you want has been fixed, but not released, and releases are quarterly or bi-yearly, etc. Though sometimes running unreleased code can mean untested bugs, and unknown territory. The steps here also work for most other programs provided they have clear build instructions like fish.
## Add an update-fish.sh
Let's create an update-fish.sh, usually I run personal scripts from `~/.local/bin/scripts` make sure that path is added to your PATH, or you could just drop the script into `~/.local/bin` if you prefer. Where you put the script is up to you, and a personal preference. You don't even need the script in path, if you are used to running scripts from a specific path all the time. If the script is in path, you can run it from anywhere.
> This assumes the fish-shell repo is already cloned to `~/git, change cd path accordingly if is different`
```shell
#!/usr/bin/env bash
cd ~/git/fish-shell
# check for upstream updates
git fetch origin
git merge origin/master
# build fish
sudo rm -r build
mkdir build; cd build
cmake ..
make
sudo make install
```
## Make script executable
```
sudo chmod +x fish-update.sh
```
## Build and Install
Run the script, and when asked for sudo enter your password. Make sure you have all build tools, and dependencies installed. Also listed in the repo. All and all it takes 2~min to build.
```
update-fish.sh
```
Lastly check your updated version
```
fish --version
```
| thefern |
350,881 | Are unit tests a waste of your time? | First published on techpilot.dev TL;DR In a perfect world, we would have automated tests for every... | 0 | 2020-06-07T22:36:00 | https://techpilot.dev/article/are-unit-tests-a-waste-of-time | testing, bestpractices, teamleading | > First published on [techpilot.dev](https://techpilot.dev/article/are-unit-tests-a-waste-of-time)
**TL;DR In a perfect world, we would have automated tests for everything, but in reality, there's always a compromise between code quality and costs.**
I've been lucky enough to start a fair amount of greenfield projects in the past years. Looking back, I feel like writing tests had always saved time in the long run but were rather cumbersome when working on UI and smaller projects.
It goes without saying that for some apps (i.e. life-critical, mission-critical) an unit test coverage of 80%+ should be required. But, despite what most of the literature says, in some cases, unit tests are actually slowing us down. In which case, how do we decide if it's worth the trouble and keep a balance between quality and costs?
Here are a couple of things to consider.
* **Debugging process** Remember when you had that one awkward bug, and it took days only to reliably reproduce it? Unit tests allow you to control the state of your components in great detail, making it easier to find and fix such issues.
* **Reusability and life span** If you wrapped up some code in a reusable library, chances are you'll improve it frequently in the beginning. Unit tests can help you ensure no breaking changes sneak through each iteration.
* **Complexity** When you can't reason about a system in the wild, it helps to frame it in isolation. Unit tests do just that.
* **Third-party dependencies** Software requires the perfect alignment of many moving parts, some of them not under your control. When third parties act unexpectedly, it becomes almost impossible to debug your system. Mocking dependencies in your unit tests solves this.
* **Costs** If you think you don't have enough time to write unit tests it automatically means you're ready to trade quality for it. This might work in some scenarios (e. g. proof of concepts), but you must be aware of the implications.
* **Team size** You'll find that as you make your code testable, you also increase its intrinsic quality. Also, unit tests are the closest thing to written specs, and while you can manage without any formal requirements while working on a part-time project by yourself, larger, heterogeneous teams would have a hard time doing so.
Unit testing is time-consuming, especially if you have a poorly designed codebase. You can decide to skip it, and it might be the right thing to do, depending on the context, but you'll have to trade code quality in return. | rad_val_ |
374,446 | Make useful JS/TS errors in AWS Lambda | I have been playing with custom errors and how it can help with monitoring AWS lambda based... | 8,062 | 2020-07-31T12:10:56 | https://dev.to/arijusg/make-useful-js-ts-errors-in-aws-lambda-313i | typescript, logs, lambda | ---
title: Make useful JS/TS errors in AWS Lambda
tags: typescript, logs, lambda
series: logging and monitoring
---
I have been playing with custom errors and how it can help with monitoring AWS lambda based APIs.
The native Error of JavaScript is kinda meh. You can only set a message, which, I find, is not enough to determine an issue in production, i.e. ‘http request failed’. What I would love to know is some context, at least: url, headers, payload, response.
I have tried to stringify error context and attach to an error message, but it was difficult to read the logs and therefore didn't spark joy.
Ultimately, I would prefer not to look at the logs at all, the monitoring tool should tell me what's wrong and maybe even give a solution. Got better things to do, than debugging logs :)))
## Error does not like serialisation.
```
try {
throw new Error("Something bad happened");
} catch (err) {
const serialised = JSON.stringify(err);
console.log(serialised);
}
```
outputs:
```
{}
```
## Let's serialise the Error
So what we could do is to create an BaseError, which has a property reason.
```
export class BaseError extends Error {
public readonly reason: string;
constructor(reason: string) {
super(reason);
this.name = BaseError.name;
Object.setPrototypeOf(this, new.target.prototype); // restore prototype chain
this.reason = reason;
}
}
```
now when we run this:
```
try {
throw new BaseError("Something bad happened");
} catch (err) {
let serialised = JSON.stringify(err);
console.log(serialised);
}
```
we get
```
{"name":"BaseError","reason":"Something bad happened"}
```
## Let's make a custom Error
So once we have a BaseError, we can create an purpose built error like that:
```
export class SuperHeroError extends BaseError {
public readonly superHeroName: string;
constructor(superHeroName: string) {
super(`superhero ${superHeroName} malfunctioned`);
this.name = SuperHeroError.name;
Object.setPrototypeOf(this, new.target.prototype); // restore prototype chain
this.superHeroName = superHeroName;
}
}
```
and when we run it:
```
try {
throw new SuperHeroError("Batman");
} catch (err) {
let serialised = JSON.stringify(err);
console.log(serialised);
}
```
we get this:
```
{"name":"SuperHeroError","reason":"superhero Batman malfunctioned","superHeroName":"Batman"}
```
## AWS CloudWatch LogInsights report
Once we have some failure logs, we can write a query like this:
```
fields @timestamp as timestamp, name, reason
| sort @timestamp desc
| limit 100
```
and the result will be:
-----------------------------------------------------------------------------
| timestamp | name | reason |
|-------------------------|----------------|--------------------------------|
| 2020-07-23 12:59:30.716 | SuperHeroError | superhero Batman malfunctioned |
-----------------------------------------------------------------------------
This is very basic error logging, in the real world you will need much more data in the logs, like sessionId, requestId etc. :)
| arijusg |
350,898 | I made a portfolio generator for developers - feedback appreciated! | Hi there, I've been working on this project for the past couple of months and decided to really make... | 0 | 2020-06-07T17:44:07 | https://dev.to/emilepw/i-made-a-portfolio-generator-for-developers-feedback-appreciated-49i5 | showdev, portfolio, career | Hi there,
I've been working on this project for the past couple of months and decided to really make a push to get it out after I recently got laid off due to the pandemic.
It's a portfolio generator that takes the info from your GitHub account and generates a portfolio website where you can edit the content/design and deploy to web in a few clicks: https://www.profiled.app
Would love any feedback on it from the community here and I hope it could be useful to some of you :) | emilepw |
350,942 | Why I (still) love Vaadin | It's funny how things come in sequences. Recently, on three separate occasions, I stumbled upon quest... | 0 | 2020-06-07T18:36:11 | https://blog.frankel.ch/why-love-vaadin/ | vaadin, productivity, gui, java | It's funny how things come in sequences. Recently, on three separate occasions, I stumbled upon questions asking what people used for front-end technologies. Every time, my answer was [Vaadin](https://vaadin.com/). Unfortunately, some places, _e.g._ Twitter, are too limiting to explain my answer in depth.
In this blog, I've no such limitations.
In one sentence, Vaadin is a framework to create <abbr title="Graphical User Interface">GUI</abbr> using plain Java, or any JVM-based language for that matter. One develop in Java, and the framework takes care of all the rest: this includes the generation of the client-side code, **and** the communication between the client-side code in the browser and the backend code on the server.
## Benefits of using Vaadin
This architecture provides the following benefits.
### Easy onboarding
The first and foremost characteristic of Vaadin is that there's no need to know _other_ technologies. Let's think what skills are required for a "standard" app that consists of a REST API and a JavaScript front-end:
. Java
. Jakarta EE API, _i.e._ Servlets and JAX-RS or the Spring framework
. <abbr title="REpresentational State Transfer">REST</abbr> principles
. <abbr title="Asynchronous JAvaScript + XML">AJAX</abbr> for browser-server inter-communication
. HTML
. <abbr title="Cascading Style Sheet">CSS</abbr>
. JavaScript (or TypeScript)
. A front-end framework: the most popular contenders are currently [Angular](https://angular.io/), [Vue.js](https://vuejs.org/) or [React](https://reactjs.org/).
That's no less than 8 completely unrelated technologies. And I'm particularly generous: I'll leave out any additional JavaScript libraries, as well as the build tool necessary to build the front-end artifact. Yet, the latter is required in order to transpile from TypeScript to JavaScript, or from the latest JS version to one that is supported by most browsers. With Vaadin, the list becomes limited to Java... and Vaadin.
If you read this, you might consider that it's not that a huge benefit, because you are surrounded by 10 times developers, [whatever that means](https://blog.frankel.ch/developers-productivity/)). My experience is quite different: I've worked more than 15 years as a contractor, for a lot of different customers. Most developers are regular people, happy to work from 9 to 5, and then go back home to live their lives. They have neither the will nor the time to learn yet-another-technology outside of office hours. With the premise that training needs to take place during office time, less technologies mean less training time, and more time dedicated to developing the app.
### No integration phase
The simplicity that Vaadin provides has an additional benefit. If one app's architecture is separated into a front-end and a back-end that communicate via a REST API, there are two strategies to organize one's team:
* Development per layer
This strategy is based on two specialized teams, the front-end team, and the back-end team. They are very good in their own stack. They both work in parallel, in their respective stack. After the slowest of them finishes, they integrate their respective work together.
My experience has shown me that in the parallel phase, the work is done (quite) quickly. On the opposite, the integration phase takes a lot of time. My experience is that it takes up to the time spent in the first phase - effectively doubling the development time. The worst is that this second phase is underestimated by most teams, including project managers.
* Development per use-case
This strategy is based on full-stack developers. This kind of developer is able to work on both ends, front and back. Each developer is assigned a use-case/user story, then needs to understand the business around it, and afterwards is able to develop the whole flow from the GUI to the database.
I personally believe that the full-stack developer is a concept which was invented by managers to make developers interchangeable. That way, task planning becomes so much easier for them. Anyway, let's admit that such unicorns do exist. If one is skilled in that many technologies, one should have had time to learn them. That brings me back to the point made above: most developers have a life beside their job. Of course, there are geeks, but in that case they must be paid accordingly. Unfortunately, regular companies don't have enough budget: they might afford one, but not a complete team of unicorns.
In that regard, Vaadin allows non-rockstar developers to develop the application using the 2nd strategy. It also allows them to spend more time on the business side of things, and less time on the technical issues.
### Parallelization between backend and front-end development
By default, Vaadin lets developers who don't double as graphic designers to develop acceptable-looking GUIs. However, it happens that the product owner has requirements - and sometimes even budget - to customize the design.
With the traditional approach, designers achieve that with HTML and CSS. They will design specific HTML templates and CSS classes. Then, developers will be asked to use them.
If requirements change mid-way, developers will need to stop their work to integrate the changes required by designers: there's a high dependency between the workflow of developers and the one of designers. Some technologies such as JSP, JSF and Thymeleaf allow designers' artifacts to be reused as-is by developers. In that case, both will need to work on the same artifacts. Git merge conflicts are always fun when one doesn't completely grasp upstream changes.
Vaadin introduces two abstractions that decouple the work of developers and designers: themes and components.
* A **theme** is a collection of CSS (and [Sass](https://sass-lang.com/)). Because Vaadin generates the HTML, designers know the structure to expect, and can design their CSS accordingly.
The _Lumo_ theme is applied by default. Another theme, _Material_ is provided out-of-the-box. The ecosystem offers additional themes, each being available as a JAR that only needs to be added to the classpath. It's also possible for a designer to create one's own.
Note that switching themes is possible through a simple method call.
* A **component** has both a HTML template, and a Java class that represents it on the server side.
Such a component may place other components in a layout. While the Java class manages them as attributes, the HTML template is responsible to the layout. This way, the developer's work on the Java class - or any other class that uses it - and the designer's work on the template are completely isolated from each other: they can be fully executed in parallel.
### Designed for "business" applications
Finally, Vaadin is designed at its core to develop business applications.
* On the UI side, components include widgets frequently used in such applications _e.g._ fields, combo boxes, forms, tables, etc.
* Most components display data. The design of those components introduce an abstraction between a component and its data. There are different concretions:
1. For scalar values _e.g._ an email displayed in a _field_
2. For collection values _e.g._ the list of countries displayed in a _combo-box_
3. For two-dimensional values _e.g._ tabular data displayed in a _table_
## Arguments I heard against using Vaadin
In all those years, I've heard quite a few arguments against using Vaadin.
They mostly all boil down to the following two.
### "But does it scale?"
You might be interested in knowing that this question is part of the 10 tricks to appear smart in meetings ([#6](https://thecooperreview.com/10-tricks-to-appear-smart-during-meetings/)).

On a more serious tone, scaling definitely deserves some digging in. Vaadin stores the state of components server-side. With a huge number of components, and with the increase of the number of clients, this leads to an exponential consumption of memory. In that regard, traditional applications don't differ that much from Vaadin applications.
First, we need to understand that there's the vast majority of applications are stateful. However, the differentiating factor between them lies in *where the state is stored*. As I mentioned, Vaadin stores it on the server. There are only two other alternatives:
1. Store it in the database. Do I need to detail why it's a bad idea?
2. Store it on the client. I makes a lot of sense to store UI-related data on the client. There's one not no minor caveat though: if more than one tab is opened, it needs to be handled server-side somehow.
Note that Vaadin manages multiple tabs by putting a hidden token when it renders the page initially. When the user interacts with the page, the token is checked, and then a new one is sent to the browser again.
While beyond ten thousands of **concurrent** users, I might start thinking about other alternatives than Vaadin, anything below that number is fair game. That's 99.99% of all applications.
### Not API-first
Another argument I've heard against Vaadin is that it's not API-first. Good software developers/architects alway develop an API in order to let different kind of clients to use: browsers, but also native clients, and other services - whether internal or third-party.
Unfortunately, I think this is herd mentality. API-first is desirable in the context of multiple clients. Most business applications I've worked on are just <abbr title="Create Read Update Delete">CRUD</abbr> applications with more or less business logic applied on top.
But what if additional clients become necessary in the future? [YAGNI](https://en.wikipedia.org/wiki/You_aren%27t_gonna_need_it)! If you do, remember that Twitter was able to rewrite its complete information system from Ruby on Rails to Java: migrating the GUI layer of an application is well within the bounds of the possible.
### Boring
Finally, while I never heard anything like that, I believe one of the reasons Vaadin is not that popular nor widespread is because it's so boring. It has been around since more than 15 years, it works as expected, and most challenges around it have already been solved. Unfortunately, this doesn't fit developers who practice [Résumé-/Hype-/Ego-Driven Development](https://blog.frankel.ch/ego-driven-architecture/).
## Conclusion
I discovered Vaadin a bit more than 10 years ago, and that was love at first sight. In fact, I immediately began to tinker with it, and tried to [integrate it with another of my crush, the Spring framework](https://blog.frankel.ch/vaadin-spring-integration/).
Version 10 saw a massive rewrite of the framework. Product management steered it toward more web-y features, such as web components, the introduction of routes, etc. I believe this move was done in order to appeal more to web developers. To be fair, I'm not very happy with those changes.
However, that doesn't change the fact I'm still a huge fan of the framework. I admit it's not as hype as JavaScript frameworks. On the other side, it's a massive productivity boost when developing business applications compared to any other hype alternative.
_Originally published at [A Java Geek](https://blog.frankel.ch/why-love-vaadin/) on June 7th, 2020._ | nfrankel |
350,979 | Quick Sort en Java / Python | 1) Defina una sintaxis para expresar en pseudocódigo las siguientes operaciones: -Asignac... | 0 | 2020-06-08T17:56:41 | https://dev.to/jeffpr11/quick-sort-en-java-python-1hhd | ####**1) Defina una sintaxis para expresar en pseudocódigo las siguientes operaciones:**
**-Asignación**
La manera simple será con ->, por ejemplo:
```C
x -> 1
```
En este caso se está asignando el valor entero 1 a la variable x.
La asignación múltiple se realizará de la siguiente forma:
```C
x, y -> 1, 3
```
Finalmente se asigna 1 a la variable x y 3 a la variable y.
**-Repetición mientras se cumple condición**
Similar a C, de la siguiente manera:
```C
while (condición de parada)
{
sentencias del ciclo
}
```
Por ejemplo:
```C
a -> 0 // definimos el contador en 0
while (a < 5) // la condición es hasta que a llegue a 5
{
a++ // aumenta el contador para que imprima desde 1
print("conteo: %d \n", a) // imprime el valor
}
```
**-Iteración sobre una secuencia**
Similar a C, de la siguiente manera:
```C
for (expresión de inicio, condición de parada, incremento)
{
sentencias del ciclo
}
```
Por ejemplo:
```C
for (a -> 1, a < 5, a++) // definimos el contador en 1, la condición es hasta que el
{ // valor a llegue a 5 y aumenta el contador en cada iteración
print("conteo: %d \n", a) // imprime el valor
}
```
####**2) Para el siguiente problema escriba una solución utilizando lenguaje de alto nivel, diagrama de flujo, pseudocódigo, Java y Python.**
Problema: Se tienen 2 listas ordenadas ascendentemente y se desea crear una nueva lista que contenga todos los valores de ambas listas y que también este ordenada. Por ejemplo: lista1=[2,8,12,20], lista2=[10,11,12,15,30,35], resultado=[2,8,10,11,12,12,15,20,30,35]
#####Palabras
En breves instrucciones, lo primero en hacer sería unir lista1 y lista2 en una lista final para luego proceder a ordenarla.
Dado que ya tenemos una sola lista, lo que haremos es seguir el algoritmo Quick Sort en dónde tomaremos un pivote(en Java son 2, el primer elemento y el úlitmo mientras que en Python sólo el primero) para a partir de este iterar la lista e ir comparando. Si el elemento sobre el que se itera es menor que el pivote, entonces se ubica a la izquierda. En cambio, si el elemento es mayor, se ubica a la derecha. Si tienen el mismo valor no importa en que lado se ubique aunque depende de la implementación.
Finalmente lo que vuelve óptimo este algoritmo es que se usa recursividad para ordenar de vuelta y asi lograr el objetivo.
#####Diagrama de flujo
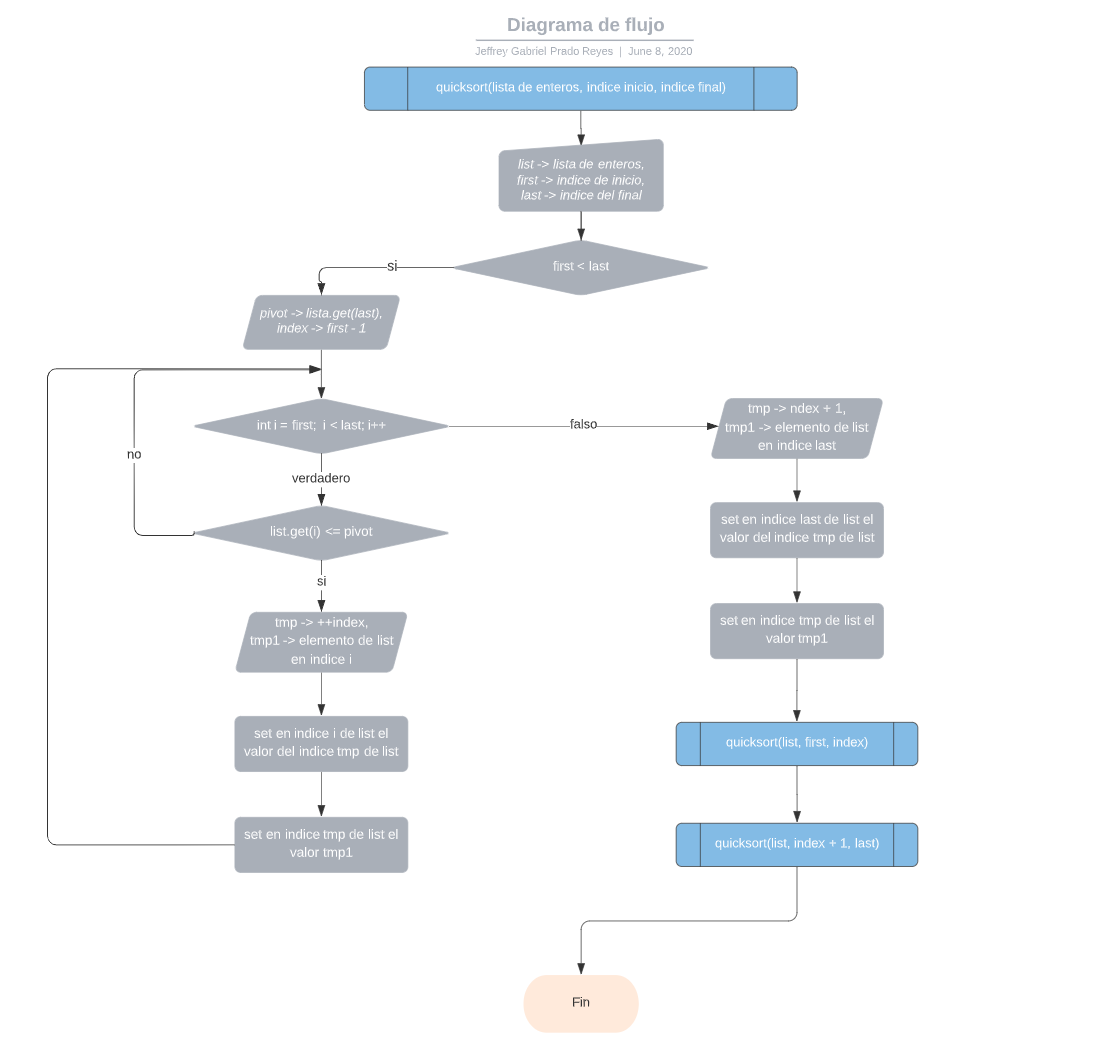
#####Pseudocódigo
```pseint
lista1 = [2,8,12,20]
lista2 = [10,11,12,15,30,35]
listaFinal = []
funcion merge(list1 -> lista de enteros 1, list2 -> lista de enteros 2,
tmp -> lista de enteros final) {
while (list1 & list2 no esten vacías) {
e1 -> extraer elemento de list1 //al extraer que sea con
e2 -> extraer elemento de list2 //pop, asi se limpian las listas
if (e1 > e2) {
agregar e2 a tmp
} else if(e1 == e2) {
agregar e1 a tmp
agregar e2 a tmp
} else {
agregar e1 a tmp
}
}
}
funcion makeList(lista de enteros 1, lista de enteros 2, lista de enteros final) {
for (i -> 0, i < tamaño de lista de enteros 1, i++) {
agregar elemento de la lista de enteros 1 en la lista de enteros final
}
for (i -> 0, i < tamaño de lista de enteros 2, i++) {
agregar elemento de la lista de enteros 2 en la lista de enteros final
}
}
funcion quickSort(lista de enteros, indice inicial, indice final) {
if (indice inicial < indice final) {
pivot -> elemento del indice final de la lista de enteros
index -> indice inicial - 1
for (i -> indice inicial, i < indice final, i++) {
if (elemento del indice inicial de la lista de enteros <= pivot) {
tmp -> ++index,
tmp1 -> elemento de list en indice i
set en indice i de list el valor del indice tmp de list
set en indice tmp de list el valor tmp1
}
}
tmp -> ndex + 1,
tmp1 -> elemento de list en indice last
set en indice last de list el valor del indice tmp de list
set en indice tmp de list el valor tmp1
quickSort(list, first, index)
quickSort(list, index + 1, last)
}
}
makeList(lista1, lista2, listaFinal)
quickSort(listaFinal, 0, tamaño de listaFinal - 1)
```
#####Java
```Java
public static void merge(ArrayList<Integer> listA, ArrayList<Integer> listB, ArrayList<Integer> finalList){
for (int i: listA) {
finalList.add(i);
}
for (int i: listB) {
finalList.add(i);
}
}
public static void sortT(ArrayList<Integer> list, int first, int last) {
if (first < last) {
int pivot = list.get(last);
int index = first - 1;
for (int i = first; i < last; i++) {
if (list.get(i) <= pivot) {
int tmp = ++index;
int tmp1 = list.get(i);
list.set(i, list.get(tmp));
list.set(tmp, tmp1);
}
}
int tmp = index + 1;
int tmp1 = list.get(last);
list.set(last, list.get(tmp));
list.set(tmp, tmp1);
sortT(list, first, index);
sortT(list, index + 1, last);
}
}
public static void main(String[] args) {
ArrayList<Integer> lista1 = new ArrayList<>();
ArrayList<Integer> lista2 = new ArrayList<>();
lista1.add(2);
lista1.add(8);
lista1.add(12);
lista1.add(20);
lista2.add(10);
lista2.add(11);
lista2.add(12);
lista2.add(15);
lista2.add(30);
lista2.add(35);
ArrayList<Integer> listaFinal = new ArrayList<>();
merge(lista1, lista2, listaFinal)
quickSort(listaFinal)
}
```
#####Python
```Python
def merge(listA, listB, list):
for i in listA:
list.append(i)
for i in listB:
list.append(i)
def quickSort(list):
size = len(list)
if size <= 1:
return list
else:
pivot = list[0]
lower = []
equal = []
greater = []
for i in list:
if i > pivot:
greater.append(i)
elif i == pivot:
equal.append(i)
else:
lower.append(i)
return quickSort(lower) + equal + quickSort(greater)
lista1 = [2,8,12,20]
lista2 = [10,11,12,15,30,35]
listaFinal = []
merge(lista1, lista2, listaFinal)
quickSort(listaFinal)
```
| jeffpr11 | |
351,001 | Test-With-Expect: A BDD-style Go naming pattern | This article has received minor edited since it was first released, see the full history on GitHub.... | 0 | 2020-06-10T07:36:35 | https://dev.to/smyrman/test-with-expect-a-bdd-style-go-naming-pattern-5eh5 | go, testing, bdd | **This article has received minor edited since it was first released, see the full [history](https://github.com/smyrman/blog/commits/master/2020-06-test-with-expect/blog_gwt.md) on GitHub.**
_TL;DR: This article demonstrate how to write GWT-inspired tests in plain Go, and how to name them. Skip to the Go TWE heading to see the result, or explore the [summary article](https://medium.com/@smyrman/test-with-expect-a-bdd-style-go-naming-pattern-1838f84a4128) on Medium_.
[GWT][gwt], or "Given-When-Then", is a great naming convention for tests that comes from the [BDD][bdd], or "Behavior-Driven-Development" paradigm. It makes it easy to _plan_ tests as well as the _behavior_ of your feature before you start the detailed implementation.
GWT is composed of three concepts or steps:
- Given: A precondition for the test (context)
- When: The action to perform (action)
- Then: A result to expect (check)
Each of these steps can be nested, or sometimes skipped.
The challenge of this article is not to write GWT or BDD style tests in Go, this has been [demonstrated][gwt-demo-1] many times [before][gwt-demo-2], but an exploration into how we can do this without a third-party test framework and DSL. There are also some benefits associated with relying on the the default test-runner as well as good-old (yes they are 4 years now!) [subtests][go-subtests] that we will look into.
## Code under test
In this article, we will imagine that we are going to write a generic `Sum` function. Generic is a loaded term in the programming world. In our case, we plan to write a function that accepts any slice or array of numeric values and returns the sum. Because _type parameterization_ is not (yet) possible in Go, we will allow the function to return an error when it receives invalid input.
Let's define the interface we want this function to have:
```go
package mypkg
import (
)
// Sum accepts any kind of slice or array holding only
// numeric values, and returns the sum.
func Sum(v interface{}) (float64, error) {
return -1, errors.New("NYI")
}
```
Following the sprit of BDD and TDD, we will wait with the actual implementation until _after_ we are done with the tests. In fact, since this article is about writing and naming tests, we will leave the _entire implementation_ as an exercise for the reader.
## Planning our tests
For the scope of this article, let's hash out how we want this function to behave for **integer slice** (`[]int`) input in particular. By the power of GWT, we plan our tests in plain text first:
```txt
TestSum:
Given a non-empty int slice S:
When calling Sum(S):
Then it should not fail
Then it should return the correct sum
Then S should be unchanged
Given an empty int slice S:
When calling Sum(S):
Then it should not fail
Then it should return zero
Then S should be unchanged
```
Great, we have specified our tests, but how does it look once we turn it into Go code? And what kind of output can we expect?
## Writing the tests in Go
Some popular BDD frameworks, such as [Ginko][ginko], define their own test runner and re-implement Go sub-tests (although it predates them, to be fair) by structuring their library to implement a form of DSL (Domain Specific Language). This framework can render pretty output for tests, especially if run in a a terminal that supports color. However, if you wish to focus on a failing sub-test, you can not rely on `go test -run` to do it; you need to do it the "Ginko way". Because of this, you can also not rely on editor or IDE integrations in the same way you can with other Go tests.
Contrary to popular belief however, it is actually possible to write GWT-style tests in Go _without_ using a BDD-style framework or DSL; GWT itself is just a naming convention, and we can use it with normal Go sub-tests. The most importantly benefit of doing this, is that your GWT-style tests will behave **consistently to other Go tests**, and can thus be **treated equally** by both humans and tools. This means you can spend less time in training humans, CIs, JUnit parsers, IDEs, etc., and more time _writing tests_. Especially so if your team is Go-centric anyways.
So let's write it!
```go
func TestSum(t *testing.T) {
t.Run("Given a non-empty int-slice S", func(t *testing.T) {
s := []int{1, 2, 3}
t.Run("When calling Sum(S)", func(t *testing.T) {
i, err := mypkg.Sum(s)
t.Run("Then it should not fail", subtest.Value(err).NoError())
t.Run("Then it should return the correct sum", subtest.Value(i).NumericEqual(6))
t.Run("Then S should be unchanged", subtest.Value(s).DeepEqual([]int{1, 2, 3}))
})
})
t.Run("Given an empty int-slice S", func(t *testing.T) {
s := []int{}
t.Run("When calling Sum(S)", func(t *testing.T) {
i, err := mypkg.Sum(s)
t.Run("Then it should not fail", subtest.Value(err).NoError())
t.Run("Then it should return zero", subtest.Value(i).NumericEqual(0))
t.Run("Then S should be unchanged", subtest.Value(s).DeepEqual([]int{}))
})
})
}
```
To shorten the implementation somewhat, we are using our own **experimental** matching library [searis/subtest][subtest]. Subtest works like other matcher libraries, but instead of taking `t *testing.T` as a parameter, like [testify/assert][testify-assert], or initialize a matcher instance, like [Gomega can do][gomega-xunit], it returns a test-function (a.k.a. sub-test) that we can pass directly to `t.Run`. A convenient side-effect of this is that `subtest` allows focus on _individual checks_ via `go test -run '^ParentTestName/SubTestName/CheckName$'`.
PS! I want to underline that I don't view a matcher library to be a test framework. `library != framework`. If you are not convinced, it is possible to write tests without a matcher library as well, and in fact, this what the Go team does. It's not _difficult_ to do the checks, and there are good arguments for doing the checks yourself, but it requires a very high discipline and use of boiler-plate to ensure consistently styled failure output.
But we are diverging... The code reads well now, but **there is a problem**!
## Long test-names and duplicated information
These are the full test names that was generated by our code above:
```txt
TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S)/Then_it_should_not_fail
TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S)/Then_it_should_return_the_correct_sum
TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S)/Then_S_should_be_unchanged
TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S)/Then_it_should_not_fail
TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S)/Then_it_should_return_zero
TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S)/Then_S_should_be_unchanged
```
Once you mange to grok them, they make sene, but they are _long_, and it _stutters_. If you find the names _themselves_ intimidating, try scanning them _quickly_ from the `go test` output:
```txt
$ go test github.com/smyrman/blog/2020-06-test-with-expect/mypkg -run ^(TestSum)$
--- FAIL: TestSum (0.00s)
--- FAIL: TestSum/Given_a_non-empty_int-slice_S (0.00s)
--- FAIL: TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S) (0.00s)
--- FAIL: TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S)/Then_it_should_not_fail (0.00s)
sum_gwt_test.go:16: error is not nil
got: *errors.errorString
NYI
--- FAIL: TestSum/Given_a_non-empty_int-slice_S/When_calling_Sum(S)/Then_it_should_return_the_correct_sum (0.00s)
sum_gwt_test.go:17: not numeric equal
got: float64
-1
want: float64
6
--- FAIL: TestSum/Given_an_empty_int-slice_S (0.00s)
--- FAIL: TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S) (0.00s)
--- FAIL: TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S)/Then_it_should_not_fail (0.00s)
sum_gwt_test.go:25: error is not nil
got: *errors.errorString
NYI
--- FAIL: TestSum/Given_an_empty_int-slice_S/When_calling_Sum(S)/Then_it_should_return_zero (0.00s)
sum_gwt_test.go:26: not numeric equal
got: float64
-1
want: float64
0
FAIL
FAIL github.com/smyrman/blog/2020-06-test-with-expect/mypkg 0.350s
FAIL
```
To me, one of the most obvious problem with the names is that space (` `) is replaced by underscore (`_`); this makes them hard to scan. The default go test runner also _repeats_ the parent names when printing the sub-test name, contributing to the problem. But perhaps the biggest problem, is actually that the names themselves are _too long_. In fact, the names themselves are duplicating information. In particular `"When_calling_Sum(S)"` is information that can already by understood by reading the top-level test-name `TestSum`. We are testing Sum -- how can we do that without calling it?
Naming a test after the type, function or method that is under test is a pretty common Go convention for unit-tests. And even we are writing this test as BDD, this particular test _is_ a unit-test. If we can keep following this convention, it does makes the test behave _more_ like other Go tests.
## Test-With-Expect
The fundamental concepts that GWT offers, are pretty cool, but the words themselves -- Given, When, Then -- is actually less important. We will look at an alternative wording that fit better for Go in particular, but it can of-course apply elsewhere.
Another aspect wi will attack, is that GWT names are written to be human readable, and as they form near complete "English-like" sentences using what BDD-guys call _natural language_, they are also _naturally_ long. If there is _one_ idiom that is important in Go though, it is that _names_ should be short and precise, rather then long-winded. That's not my words. Here is an extract from Rus Cox's porclaimed and well-worded [naming philosophy][rsc-quote]:
> A name's length should not exceed its information content. (...) Global names must convey relatively more information, because they appear in a larger variety of contexts. Even so, a short, precise name can say more than a long-winded one: compare acquire and take_ownership. Make every name tell.
Other advice and information that relate to Go names, include:
- Names in Go have [semantic effect](https://golang.org/doc/effective_go.html#names).
- One should avoid redundancy in names, E.g. package names + global names.
- Short and concise appear more important than grammatical correctness. E.g. a constant named `StatusFail` read just as well as `StatusFailure`.
The first restriction to note here, is that names have semantic effect. Relevant to our case, all test function names in Go _have_ to start with the word `Test`. Taking the consequence of this, we might as well include that as our first word. The next two words follow relatively naturally from that restriction:
- Test: Type or function to test (subject).
- With: Configuration or input that are some-how passed to subject (configuration)
- Expect: What to expect afterwards (check).
To sum it up (no pun intended), these are our new test-names:
```txt
TestSum/With_non-empty_int_slice/Expect_no_error
TestSum/With_non-empty_int_slice/Expect_correct_sum
TestSum/With_non-empty_int_slice/Expect_input_is_unchanged
TestSum/With_empty_int_slice/Expect_no_error
TestSum/With_empty_int_slice/Expect_zero
TestSum/With_empty_int_slice/Expect_input_is_unchanged
```
Notice that we write just `Expect_correct_sum` over the more _correct_ `Expect_the_correct_sum_to_be_returned`. or the previous `Then_it_should_return_the_correct_sum`. This is just an application of the Go naming philosophy to BDD-style _natural language_. Keep it Short, Precise, and Happily Sacrifice Some English Grammar -- or KISPAHSSEG to make an abbreviation that you wil defiantly remember!
PS! KISPAHSSEG, is a very inclusive version of English, especially for the non-native speaker.
## Go TWE
Finally, here is the code for our tests in Test-With-Expect format:
```go
package mypkg_test
import (
"github.com/smyrman/mypkg"
)
func TestSum(t *testing.T) {
t.Run("With non-empty int slice", func(t *testing.T) {
s := []int{1, 2, 3}
i, err := mypkg.Sum(s)
t.Run("Expect no error", subtest.Value(err).NoError())
t.Run("Expect correct sum", subtest.Value(i).NumericEqual(6))
t.Run("Expect input is unchanged", subtest.Value(s).DeepEqual([]int{1, 2, 3}))
}
t.Run("With empty int slice", func(t *testing.T) {
s := []int{}
i, err := mypkg.Sum(s)
t.Run("Expect no error", subtest.Value(err).NoError())
t.Run("Expect zero", subtest.Value(i).NumericEqual(0))
t.Run("Expect input is unchanged", subtest.Value(s).DeepEqual([]int{}))
}
}
```
And the co-responding test output:
```txt
$ go test github.com/smyrman/blog/2020-06-test-with-expect/mypkg -run ^(TestSum)$
--- FAIL: TestSum (0.00s)
--- FAIL: TestSum/With_non-empty_int_slice (0.00s)
--- FAIL: TestSum/With_non-empty_int_slice/Expect_no_error (0.00s)
sum_twe_test.go:14: error is not nil
got: *errors.errorString
NYI
--- FAIL: TestSum/With_non-empty_int_slice/Expect_correct_sum (0.00s)
sum_twe_test.go:15: not numeric equal
got: float64
-1
want: float64
6
--- FAIL: TestSum/With_empty_int_slice (0.00s)
--- FAIL: TestSum/With_empty_int_slice/Expect_no_error (0.00s)
sum_twe_test.go:21: error is not nil
got: *errors.errorString
NYI
--- FAIL: TestSum/With_empty_int_slice/Expect_zero (0.00s)
sum_twe_test.go:22: not numeric equal
got: float64
-1
want: float64
0
FAIL
FAIL github.com/smyrman/blog/2020-06-test-with-expect/mypkg 0.064s
FAIL
```
## Extensions
Test-With-Expect is our _base_, but these three words are not always enough. Maybe you need more words? One additional word I have used myself, is `After`. It is not useful in this example, but what if you are writing tests that utilize a for-loop and do a check for each iteration? Other starting words could be called for in specific contexts, but be sure to limit the number and usage to ensure consistency.
```txt
TestX/With_Y/After_N_repetitions/Expect_no_error
```
You can also include information for failing tests _without_ putting information in the name; just make a call to `t.Log`/`t.Logf`. By default, this output only appear if your (sub-)test actually fails.
The following code shows both a log statement and a useful setup/teardown pattern:
```go
func TestResourceFind(t *testing.T) {
setup := func(t *testing.T, cnt int) (r Resource, teardown func()) {
t.Logf("Resource R set-up with %d records", cnt)
// setup r with records ...
// setup teardown function ...
return
}
t.Run("With Query={Limit:5,Offset:32}", func(t *testing.T) {
r, teardown := setup(t, 1000)
defer teardown()
// test r.Find ...
})
// ...
}
```
## Improving test-runner output
So to the problems that we have not resolved. Can we print space instead of underscore? Can we avoid printing the parent names? Can we add color?
To answer all of those question at once, I would like to quote Bob the Builder:
> Can we fix it? Yes we can!
We can even fix it without writing or using a separate _test-runner_; All we need is a separate _test-formatter_ that can handle the output of `go test -json`. But this is an exercise for another blog post.
Besides, having the full test name printed in-tact _does_ hold value; it can be copy-pasted and inserted into `go test -run` to _focus_ on individual tests or groups of tests. Perhaps in the future our IDEs and editors can also insert links to re-run them?
## Conclusion
As for a final conclusion, I want to leave this up to the reader. Do _you_ think Test-With-Expect is a meaningful way to name sub-tests in Go? Would you prefer to use sub-tests, or would you prefer the DSL from one of the main frameworks?
[go-subtests]: https://blog.golang.org/subtests
[gwt]: https://www.agilealliance.org/glossary/gwt/
[bdd]: https://www.agilealliance.org/glossary/gwt/
[gomega]: http://onsi.github.io/gomega/
[gomega-xunit]: https://onsi.github.io/gomega/#using-gomega-with-golangs-xunit-style-tests
[ginko]: http://onsi.github.io/ginkgo/
[go-convey]: http://goconvey.co
[godog]: https://github.com/cucumber/godog
[gospec]: https://github.com/luontola/gospec
[testify-assert]: https://pkg.go.dev/github.com/stretchr/testify/assert?tab=doc
[go-names]: https://www.reddit.com/r/golang/comments/8wxwgv/why_does_go_encourage_short_variable_names/
[gwt-demo-1]: https://rollout.io/blog/implementing-a-bdd-workflow-in-go/
[gwt-demo-2]: https://semaphoreci.com/community/tutorials/how-to-use-godog-for-behavior-driven-development-in-go
[subtest]: https://github.com/searis/subtest
[rsc-quote]: https://research.swtch.com/names
| smyrman |
351,023 | Multi-Directional Navigation | tl;dr demo, repo In my previous job, I had the opportunity to work on a web application for a video... | 0 | 2020-06-08T20:21:26 | https://dev.to/sylvhama/multi-directional-navigation-31k2 | react, webdev, a11y, testing | tl;dr [demo](https://multi-directional-navigation.netlify.app/), [repo](https://github.com/sylvhama/multi-directional-navigation)
In my previous job, I had the opportunity to work on a web application for a video game company. This web app is embedded within AAA games on PlayStation 4, Xbox One and Nintendo Switch. I want to share what I've learned during this experience, especially how to manage the navigation.
## UI for a TV Screen 📺
Most web developers are now used to develop responsive user interfaces for mobile, tablet and desktop computers. Your webpage should provide a user experience for people using a touch screen, a mouse, a keyboard, a screen reader...
In our case however, the app gets rendered on television screens! or on the Switch screen when being used in portable mode.
Gaming systems, even those supporting 4K resolutions, will render our web app in a 1080p resolution (1920x1080 pixels viewport). Other might render it in 720p (1280x720 pixels viewport). Each has their specificity, for instance, the Nintendo Switch reserves an area at the bottom of the screen to display their own footer.
To handle all those resolutions, we better work on an **adaptive design**. The content (such as the system logo) and its size will adapt to each system and its resolution. There is no reason to worry about unsupported resolutions here, simply because the user can't resize their viewport.
People use a gamepad to navigate in the app. The goal is to provide them an User Experience that is similar to the one they see in-game. So we don't want to display a mouse cursor or scroll bars, this might break their momentum and create frustration.
Here's a list of tips:
- Display a legend somewhere to indicate which button can be pressed and what action do they trigger. For example, you want to tell them "by pressing this button you will go back".
- Look at existing game menus and dashboards. You want to use all the space available in the viewport and have some "fixed" content (e.g. a menu, header, footer...). [Viewport units](https://css-tricks.com/fun-viewport-units/), [REM](https://css-tricks.com/confused-rem-em/) and [CSS Grid](https://cssgrid.io/) help a lot! Some browsers might not support all those cool features, you can fallback to something else like [flexbox](https://flexboxfroggy.com/).
- *Highlight* which element is focused. If you use React in your project you might want to try [styled-components](https://styled-components.com/). It lets you create components that have a [dynamic style](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/components/shared/Base/Base.ts) based on their props in a very smooth way.
- The URL is your friend. You can tell the gaming system to hide it. So the user won't be able to modify its content. Use it to do conditional rendering and to pass information from the game to your app via query strings.
- You can also use Node environment variables to create different builds to support different systems.
- Not all your teammates have a dev kit to start a game and test your app. Deploying a private version usable from any computer via its keyboard and tools such as [Storybook](https://storybook.js.org/) helps a lot.
## Gamepad Navigation 🎮
The UI is made of **focusable elements** where the user can navigate in at least **four directions**: up, down, left and right.
<a href="https://multi-directional-navigation.netlify.app"><img alt="Preview" src="https://i.imgur.com/Y3r0vT7.gif" /></a>
Browsers don't support such navigation natively. You might have heard about web accessibility that lets you use `tab` and `shift`+`tab` to focus elements one by one. Accessibility best practices are a good source of inspiration. You might wonder, why not using the [gamepad api](https://www.voorhoede.nl/en/blog/navigating-the-web-with-a-gamepad/)? Fun fact, not all gaming system browsers support it. We instead ask the system to map each button as keyboard keys. The goal is to create a custom focus manager that will take care of:
- inserting/updating/removing elements in a list;
- programmatically focusing an element based on a direction.
In my [demo](https://github.com/sylvhama/multi-directional-navigation) which uses React, I opted for [useReducer](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/contexts/MultiDirection/reducer/reducer.ts) and the [Context API](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/contexts/MultiDirection/MultiDirection.tsx). But the logic can be reused with any other state management solution, such as Redux. I won't go into the implementation details, here are the main takeaways:
- Each focusable [element](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/contexts/MultiDirection/types.ts#L8) is represented by an object containing a *unique* id, its position (top, bottom, left, right) and its depth. We can use [Element.getBoundingClientRect()](https://developer.mozilla.org/en-US/docs/Web/API/Element/getBoundingClientRect) or pass our own custom values.
- Imagine the depth like an equivalent of the z-index in CSS. It let us handle different layers of focusable elements, such as a modal.
- We use a global event listener to listen to keyboard inputs. When matching one of the arrow keys we [find the closest neighbour](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/utils/findClosestNeighborId/findClosestNeighborId.ts) based on the current focused element and the current depth. My function to find the closest neighbour [can be overriden](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/hooks/multiDirection/useDirectionListener/useDirectionListener.ts#L18). We could imagine different algorithms to find the next focused element depending on the current page.
- Then it's up to you to create custom hooks and to have fun! E.g. in [my app](https://github.com/sylvhama/multi-directional-navigation/blob/master/src/components/App/App.tsx#L30) I am playing a "move" sound effect when the current focus id changes. Check this [article](https://joshwcomeau.com/react/announcing-use-sound-react-hook/) if you want to useSound too!
## Testing 🤖
Automated tests and continuous integration improve your confidence when shipping code.
It's very important to write unit tests for vital parts of your apps, like the pure functions that are used to find the closest neighbour. I like writing [snapshot tests](https://github.com/styled-components/jest-styled-components) for my Styled Components which have dynamic styles. I also have a few integration tests made with React Testing Library.
But I believe that end-to-end tests are the best here because they are very natural to write and will cover all your business logic without needing to mock everything. That's why most of my hooks have no dedicated tests. For example here is a test made with [Cypress](https://www.cypress.io/) that visits a page, opens a modal, navigates within it and then closes it.
<img alt="end to end test" src="https://i.imgur.com/KS5p21M.gif" />
Thanks for reading, let me know if you have questions!
- Check the [demo](https://multi-directional-navigation.netlify.app/);
- Browse the [repo](https://github.com/sylvhama/multi-directional-navigation).
Merci [Jean-Loup](https://twitter.com/jtrollia) for proofreading. He was also one of my teammates!
| sylvhama |
351,326 | ASP.NET Coreでwwwroot以下の特定のファイルを発行対象外にする | ASP.NET Coreでは以下のファイルは無条件で発行されるようです。 **\*.config **\*.json wwrwroot\* これらのファイルのうち、特定のファイルを発行対象外に設... | 0 | 2020-06-08T09:47:42 | https://dev.to/tackme31/asp-net-core-wwwroot-57m3 | dotnet, dotnetcore | ASP.NET Coreでは以下のファイルは無条件で発行されるようです。
- `**\*.config`
- `**\*.json`
- `wwrwroot\*`
これらのファイルのうち、特定のファイルを発行対象外に設定するには、csprojファイルに以下のように記述する必要があります。
```xml
<Project Sdk="Microsoft.NET.Sdk.Web">
...省略...
<ItemGroup>
<!-- wwwroot\log以下の全ファイルを発行対象外に設定 -->
<Content Update="wwwroot\log\*" CopyToPublishDirectory="Never" />
</ItemGroup>
...省略...
</Project>
```
## 参考
- [Visual Studio publish profiles (.pubxml) for ASP.NET Core app deployment | Microsoft Docs](https://docs.microsoft.com/en-us/aspnet/core/host-and-deploy/visual-studio-publish-profiles?view=aspnetcore-3.1#exclude-files) | tackme31 |
351,197 | 91/100 100daysofcode Flutter | day 91/100 of #100daysofcode #Flutter Learning Flutter , courses Udemy from @maxedapps Today learn t... | 7,120 | 2020-06-08T03:44:33 | https://dev.to/triyono777/91-100-100daysofcode-flutter-3bal | 100daysofcode | day 91/100 of #100daysofcode #Flutter
Learning Flutter , courses Udemy from
@maxedapps
Today learn to implements image picker,vidation file, some logic
https://github.com/triyono777/100-days-of-code/blob/master/log.md | triyono777 |
351,222 | Dev | A post by ADAM | 0 | 2020-06-08T05:28:06 | https://dev.to/iyalex250/dev-31fa | iyalex250 | ||
351,268 | Top 20 Fascinating IoT Projects | The Internet of Things (IoT) will transform the world in so many ways. Either you learn about it or g... | 0 | 2020-06-08T10:08:22 | https://dev.to/anujgupta/top-20-fascinating-iot-projects-4pdo | computerscience, python, productivity, machinelearning | <blockquote><strong><em>The Internet of Things (IoT) will transform the world in so many ways. Either you learn about it or get left behind.</em></strong></blockquote>
<p><strong>Internet of Things (IoT), a field that has magic and madness both intertwined.</strong> An absolutely astonishing field that connects smart devices across the globe digitally. IoT is no less than a wonderland that’s way better than Alice had been into.</p>
<p><strong>Here’s a complete series of projects ideas of all the Latest cutting-edge Technologies-</strong></p>
<ol>
<li><a href="https://dev.to/anujgupta/top-20-career-defining-python-projects-51d1"><strong><em>Python Projects</em></strong></a></li>
<li><a href="https://dev.to/anujgupta/top-20-exclusive-data-science-projects-48l1"><strong><em>Data Science Projects</strong></em></a></li>
<li><a href="https://dev.to/anujgupta/top-20-sparkling-machine-learning-projects-59i6"><strong><em>Machine Learning Projects</strong></em></a></li>
<li><a href="https://dev.to/anujgupta/twinkle-twinkle-little-star-have-you-tried-these-data-science-projects-with-r-1gma"><em><strong>R Programming Projects</strong></em></a></li>
<li><strong><a href="https://dev.to/anujgupta/top-10-unique-django-projects-31c5"><em>Django Projects</strong></em></a></li>
<li><a href="https://dev.to/anujgupta/top-20-thrilling-artificial-intelligence-projects-3eon"><strong><em>Artificial Intelligence Projects</strong></em></a></li>
<li><a href="https://dev.to/anujgupta/top-20-deep-learning-projects-189n"><strong><em>Deep Learning Projects</strong></em></a></li>
<li><a href="https://dev.to/anujgupta/top-20-scintillating-computer-vision-projects-389i"><strong><em>Computer Vision Projects</strong></em></a></li>
</ol>
<p><strong>So, if you got that madness to be a part of this fascinating field of IoT, here’s something specially meant to satiate your appetite for the same-</strong></p>
<ol>
<li style="font-weight: 400;"><span style="font-weight: 400;">Flood Detection and Avoidance System</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Smart Mirror</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Heart Rate Monitoring </span></li>
<li style="font-weight: 400;"><a href="https://bit.ly/3dUjyQY"><em><strong>Video Surveillance</strong></em></a></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Weather Reporting System</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Intelligent Traffic Management System</span></li>
<li style="font-weight: 400;"><a href="https://bit.ly/2XHqPhx"><em><strong>Traffic Signs Recognition</strong></em></a></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Smart Irrigation System</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Smart Parking System</span></li>
<li style="font-weight: 400;"><a href="https://bit.ly/2AcDrnY"><em><strong>Image Recognition and Classification</strong></em></a></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Smart Waste Management System</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Home Automation</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Gas Leakage Monitoring</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Soil Moisture Detection</span></li>
<li style="font-weight: 400;"><a href="https://bit.ly/2zdu8nj"><em><strong>Color Detection</strong></em></a></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Air Pollution Monitoring</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Self-Balancing Robot</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Automatic Coffee Maker</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Facial Recognition Door Unlock</span></li>
<li style="font-weight: 400;"><span style="font-weight: 400;">Night Patrolling Robot</span></li>
</ol>
<p><strong>Having a career in IoT means that you’re class apart from all the other professionals.</strong><span style="font-weight: 400;"> All these projects will ensure your smooth journey into the most fascinating field of this generation. </span></p>
<p><a href="https://dev.to/anujgupta/stay-ahead-of-your-friends-with-all-the-latest-technology-trends-43k3"><strong><em>Let your wisdom extend by having all the latest technology trends</em></strong></a></p>
<p><strong>Thanks for your time!! :-)</strong></p> | anujgupta |
351,319 | Complete Guide - How to find a job as a Software Engineer in Switzerland🇨🇭 | A detailed step by step guide for finding a job in the beautiful country of Switzerland | 0 | 2020-06-08T09:25:43 | https://dev.to/swissgreg/complete-guide-how-to-find-a-job-as-a-software-engineer-in-switzerland-5gl0 | career, showdev, tutorial | ---
title: Complete Guide - How to find a job as a Software Engineer in Switzerland🇨🇭
published: true
description: A detailed step by step guide for finding a job in the beautiful country of Switzerland
cover_image: https://thepracticaldev.s3.amazonaws.com/i/89f64eizfq9vatu9234n.jpg
---
> This guide is based on my personal experience of working as a Software Developer in Switzerland since 2017.
> It was first published on [swissdevjobs.ch](https://swissdevjobs.ch), a dedicated IT job board that I am building as an indie project.
#### **Content of the guide:**
1. [How difficult is to find a job as a Software Developer in Switzerland?](#how-difficult)
1. [Work experience and technologies](#work-experience)
2. [Being from Switzerland or EU](#being-switzerland)
3. [Language skills](#language-skills)
2. [Step by step process for finding a job as an EU citizen](#step-by-step)
1. [Apply to companies while staying in your country](#apply-in-your-country)
2. [Job interviews](#job-interviews)
3. [Moving to Switzerland](#moving-to-switzerland)
3. [Things to do after moving to Switzerland](#things-to-do-after)
1. [Formalities after arriving](#formalities)
2. [How much does living in Swizerland cost](#cost-of-living)
<a name="how-difficult"></a>

# 1. How difficult is to find a job as a Software Developer in Switzerland?
This is a commonly asked question.
Switzerland is one of the best countries to work in as a Software Engineer.
In terms of salary, you can easily **earn above 100,000 CHF** (note: 1 CHF is around 1 USD), add to that the European work-life balance and beautiful nature - lakes and mountains.
Because of that, and the fact that Switzerland is a rather small country with a population of just below 8.5 million, finding a job here isn’t particularly easy. The IT market in Switzerland is much smaller compared to Germany or France.
There are a few factors that you need to consider and might work either in your favor or against you:
<a name="work-experience"></a>
**1. Work experience and technologies** - while finding a job in Switzerland is not easy, good luck finding a job as a Junior Software Engineer, especially when you are a foreigner. Most of the companies are looking for Developers with 2+ years of experience (since they are going to pay them 100,000 per year, anyway).
Having said that, it is possible to find a job even as a Junior but you would be rather looking at internship/trainee offers.
The 2nd part is the technology that you specialize in. In the job data on
<a href="https://swissdevjobs.ch/" target="_blank">SwissDev Jobs</a> you can see that there are many offers with Java, [JavaScript](https://swissdevjobs.ch/jobs/JavaScript/All), or [Python jobs](https://swissdevjobs.ch/jobs/Python/All) but not as much for Mobile, Ruby or C++.
<a name="being-switzerland"></a>
**2. Being from Switzerland or EU** - if you are a citizen of one of the EU countries it will be pretty easy for you to obtain a work permit in Switzerland - it is a matter of filling the papers after you get the job.
However, if you are from a different region, say the United States or India, the process becomes more difficult. In such a case, the employer needs to offer you a visa sponsorship and prove to the government that it was not possible to find a qualified person in Switzerland for that position.
Again, if you are a great developer, you might get this chance, but in most of the cases, companies will restrict their potential candidates to just the **EU + Switzerland region**.
<a name="language-skills"></a>
**3. Language skills** - Switzerland has 4 official languages: German, French, Italian, and Romansh.
Speaking the main language of the part you would be in is definitely an advantage and many companies require it. However, you can still pretty easily find a job with English only.
<a name="step-by-step"></a>

# 2. Step by step process for finding a job as an EU citizen:
<a name="apply-in-your-country"></a>
**Step 1. Apply to companies while staying in your country:**
It has 2 big advantages: first, you don’t have to bear the high costs of living in Switzerland and second, you can focus on the important things - interviews.
In this step, you need to find the job offers. For that, you can use <a href="https://swissdevjobs.ch/" target="_blank">SwissDev Jobs</a> or any other job board. Alternatively, you might want to get in touch with a headhunter to help you.
From our experiences, it’s worth to work with headhunters if you are on Junior level (0-2 years of experience) because Swiss companies tend to be quite reluctant to hire graduate developers from abroad.
A headhunter might get you a couple of interviews which is really nice. You have to be cautious though - headhunters often work with a subset of firms and sometimes will not present you the big picture (or clearly show the downsides of the company). If you are working with a proven one you will be fine.
<a name="job-interviews"></a>
**Step 2. Job interviews:**
Normally the interview process has 2 or 3 steps.
It starts with an introduction call or/and a coding task - pretty standard.
Then, if you are not located in Switzerland, there might be a video call with live coding.
The last round will be an onsite interview where you come to Switzerland and visit the company office.
The practice of reimbursing travel and accommodation costs is not widely spread, though some companies may offer it. Therefore, it’s best to try to schedule a couple of onsite interviews on subsequent days to not have to fly back and forth
After the last interview, you should get a yes or no answer in the following days, max. 2 weeks.
If you have multiple offers, you might want to negotiate your package, though be careful to not give the impression that money is your main motivation - in Switzerland it’s rather a taboo topic.
<a name="moving-to-switzerland"></a>
**Step 3. Moving to Switzerland:**
Congratulations - you have found a job in Switzerland. That was the hard part, now the formalities.
After signing the contract you need to prepare to move. If the company doesn’t offer any relocation package or help you need to have between 2 and 4k CHF for the relocation.
What we recommend is to find a hostel or Airbnb room (Couchsurfing might also be a good option). For this, you will need around 1.5k CHF for the first month.
When you arrive you might start looking for long term accommodation.
There are 2 options:
1. **Rent a flat** - this is your choice if you bring your family
2. **Rent only a room** - it might be a good option if you come without family (in Switzerland it’s called living in a Wohngemeinschaft).
Please be aware that the deposit you need to make when renting a flat is 3x the monthly rent which means 3x 2,000 CHF or even more. Therefore if you are tight on budget you might want to wait for your first salary.
<a name="things-to-do-after"></a>

# 3. Things to do after moving to Switzerland:
<a name="formalities"></a>
With regards to the formalities, you need to take care of the following:
* **Get work permit** - most important. For that, you need to go with your work contract to the local public office (Gemeinde). Check the details on the [official government website](https://www.ch.ch/en/working-switzerland-eu-efta/).
* **Open a bank account** - you will finally have an account in one of those famous Swiss Banks™. They charge for pretty much everything, therefore make sure to compare the offers and pick the best for you. Revolut seems to be the best multi-currency card out there.
* **Choose health insurance (Krankenkasse)** - in Switzerland you have to pay your health insurance separately (it’s not deducted from your salary). You can use the [Comparis](https://en.comparis.ch/krankenkassen/default) website to compare the options. **You have 3 months to choose both the company and your franchise.** Franchise is the amount of money you maximally pay per year for medical services. After reaching this limit the insurance company comes in and takes 90% of your costs. The higher the franchise, the lower your monthly premium.
* **Other important things** - if you plan to use public transport, we recommend you to buy the [Half Fare card](https://www.sbb.ch/en/travelcards-and-tickets/railpasses/half-fare-travelcard.html). It gives you a 50% discount on most public transport in Switzerland (it costs 185 CHF per year). For the phone, you can either use a prepaid option or a subscription.
* **Integrate and have fun** - find local groups related to your hobbies and interests. There are also some general expat groups like [Zurich Together](https://www.facebook.com/groups/zurichtogether/)
<a name="cost-of-living"></a>
**Bonus question:**
### How much does living in Swizerland cost? 💰
Switzerland is one of the most expensive countries in the world, the top most expensive cities in the world are all in Switzerland, therefore prepare for a price shock.
Although the first month or two might be tough, after getting your 1st and 2nd salary you will quickly realize that the things are not that expensive when living here.
To be more detailed below is a breakdown income and costs for someone **earning 120k CHF and living in Zurich:**
120,000 CHF annually according to this calculator gets you **7,746.20 CHF** net per month. It assumes that you are single and have no children. (Switzerland offers some generous tax reduction when having children)
To simplify, let’s assume **7,700 CHF** monthly to spend.
Now let’s move to the costs:
* **Apartment: 2,000–3,000 CHF** (with 3k you can get a pretty but not the biggest one in the center) or if you share a flat in a Wohngemeinschaft: 700-1,200 CHF
* **Insurance: 280–500 CHF** (280 for the 2500 CHF franchise)
* **Food: 150 - 1,000 CHF** (150 if you are always cooking for yourself, 1,000 if you are a foodie and eat out every 2nd day)
* **Entertainment: 200–1,500 CHF** (a drink in a club costs ~20 CHF, monthly gym subscription 100 CHF, again, all depends on you, traveling to other countries is pretty cheap)
* **Other: 200–1,000 CHF** (phone, clothes, public transport or a car, etc)
To sum up, if you go the “live cool and don’t care about expenses” option you will spend monthly around **7,000 CHF** and still save some money.
If you, on the other hand, want to go the student-like route (living in Wohngemeinschaft, not eating out too much) and try to save, you can easily live on **1,500-2,000 CHF** per month and save the majority of your salary.
## Wrap up 🎉🎉🎉
I hope you liked the guide and that it answered your potential questions about finding a job in Switzerland as a Software Developer.
I can personally recommend living here :)
If you still have questions or would like to check the jobs from Swiss companies, feel free to visit: [swissdevjobs.ch](https://swissdevjobs.ch)
[](https://swissdevjobs.ch/subscribe-newsletter?utm_source=devto&utm_medium=article-cta-image&utm_campaign=article-cta-devto) | swissgreg |
351,324 | Kubernetes Dashboard WebUI | In this topic, we are going to consider the Kubernetes WebUI Dashboard. The Web User Interface allows... | 0 | 2020-06-15T16:19:27 | https://appfleet.com/blog/kubernetes-dashboard-webui/ | docker, kubernetes, devops | In this topic, we are going to consider the Kubernetes WebUI Dashboard. The Web User Interface allows us to browse our playground cluster and perform administrative tasks and things like that. It gives a good way to see what you have done on your playground without having to use the command line. So, let's get started!
#Setup
The first thing we do is to use `kubectl apply` command to apply configuration to a resource by a specified filename. The resource name must be specified and if the resource does not exist it will be created.
In our case the file is provided by Kubernetes repo:
```
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc2/aio/deploy/recommended.yaml
```
Once we apply the recommended file, it will create the namespace for Kubernetes Dashboard that includes the Metrics Scraper and Dashboard.
If you want to take a closer look on what that `yaml` file does, you need to get it to your local system:
```
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc2/aio/deploy/recommended.yaml
```
And then you can look at the content of Kubernetes Configuration through the sample of `recommended.yaml` file:
```
less recommended.yaml
```
We can see all of the seperate Kubernetes objects that have been created by `kubectl apply` command. The secrets, configutation map, role creation, the cluster role together with binding. By looking at this sample and the deployment itself you can learn a lot about the `yaml` format and you can see what it is actually doing to our playground cluster in order to install the Dashboard.
Moving forward to the next command
```
kubectl get pods --all-namespaces
```
We will see 2 pods are out there running - the Dashboard itself and the Scrapper. Another way to look at these would be:
```
kubectl --namespace=kubernetes-dashboard get pods
```
Here we need to specify the *namespace*.
Next, we need to create the `yaml` file in order to create admin user in the Kubernetes Dashboard. Please paste the following to the `admin.yaml` file:
```
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin
namespace: kubernetes-dashboard
```
This file will create a Service Account called `admin` in the namespace `kubernetes-dashboard`. Apply this file:
```
kubectl apply -f admin.yaml
```
Once we execute the file, it creates the Service Account `admin`. Next, we need to create the admin cluster role binding. Please paste the following to the `admin_cluster.yaml` file:
```
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin
namespace: kubernetes-dashboard
```
It takes the Service Account we have just created and it creates a cluster role called `admin_cluster`. Next, we need to apply that:
```
kubectl apply -f admin_cluster.yaml
```
The next command we are going to use is in the namespace `kubernetes-dashboard` where we will explore a secret. We have to do a trick here in order to get that secret:
```
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin | awk '{print $1}')
```
When we do that, we will see that we have the encrypted token. The point is to get the token for the `admin` user which we have created, copy it and save it to use if for logging to the Kubernetes WebUI Dashboard. Please copy the token in any text file you want and save it for future use.
Moving forward, we are going to start the proxy in order to expose the Dashboard on your localhost and run it on a background:
```
kubectl proxy &
```
Now, if you have started your dashboard not on a local machibe you need to turn on the tunnel to your Kubernetes Dashboard to make it reachable from your `localhost`. Please open a new terminal window and run the following command:
```
ssh -g -L 8001:localhost:8001 -f -N <username@kubernetes_dashboard_hostname>
```
Once you run the command you can then use the following [localhost:8001 Link](http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/.)
In order to token to the Dashboard, please copy token from your text file and paste it, and click `Sign in`.
If you are new to it, please spend some time looking around it to understand the menu and how it works. Here is an example of Kubernetes Dashboard:
#Possible problems and solutions
It might occur that your dashboard pods are in a *Pending* state. Usually, the reason is that Kubernetes Network is not configured. You may notice that `coredns` or `kube-dns` are stuck in *Pending* state. Don't worry, this is an expected part of the design. Kubernetes is network-provider agnostic, so you should install the pod network solution of your choice, for instance **Flannel** or **Calico**. You have to install a pod network solution before `coredns` or `kube-dns` may be fully deployed.
In this article we will use *Calico* as a pod network solution. So, please run following command in order to initialize the master:
```
kubeadm init --pod-network-cidr=192.168.0.0/16
```
Optional. If you haven't configured your `kubectl` yet, please execute the following commands:
```
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
```
Last step would be to install **Calico**:
```
kubectl apply -f https://docs.projectcalico.org/v3.9/manifests/calico.yaml
```
Now, confirm that all of the pods are up and running with the following command:
```
watch kubectl get pods --all-namespaces
```
That's it! Now you are ready to run `kubectl proxy` command and access your Dashboard running on a single-host Kubernetes cluster equipped with **Calico**.
For the record, it might be an option when you need to remove the taints on the master so that you can schedule your pods on it. In this case, please run the following command:
```
kubectl taint nodes --all node-role.kubernetes.io/master-
```
You will see the result that node was untained. Following that, confirm that you now have a node in your cluster with the following command:
```
kubectl get nodes -o wide
```
#Conclusion
As a result, we now have a running Kubernetes Dashboard, which is equipped with Calico virtual networking solution and we may conclude that the Kubernetes Dashboard is a really great way to understand and visualize what is going on in your cluster. | jimaek |
351,370 | My first app in React Native | Hello buddies, Not long ago (like 3 months) I started working on my side project called Rate Me. It'... | 0 | 2020-06-08T11:14:27 | https://dev.to/zabka229/my-first-app-in-react-native-1n5b | reactnative, node, javascript | Hello buddies,
Not long ago (like 3 months) I started working on my side project called Rate Me. It's a simple app where you can rate other people appearance, chat with each other and see some summaric score.
It's still just an MVP, because I don't know if the app has some potential.
https://play.google.com/store/apps/details?id=ovh.zaba.rateme
For now only available on android, but if it will have some good feedback from users I'll upload it for app store.
Technologies I have used:
- React native for mobile app
- NestJS for backend
What you think about that? | zabka229 |
351,395 | CI/CD for ETL/ELT pipelines | One of Dataform’s key motivations has been to bring software engineering best practices to teams buil... | 0 | 2020-06-08T12:14:52 | https://dataform.co/blog/ci-cd-for-etl-elt-pipelines?utm_source=dev_to&utm_campaign=ci_cd | cicd, etl, elt, dataengineering | One of Dataform’s key motivations has been to bring software engineering best practices to teams building ETL/ELT pipelines. To further that goal, we recently launched support for you to run Continuous Integration (CI) checks against your Dataform projects.
## What is CI/CD?
CI/CD is a set of processes which aim to help teams ship software quickly and reliably.
Continuous integration (CI) checks automatically verify that all changes to your code work as expected, and typically run before the change is merged into your Git master branch. This ensures that the version of the code on the master branch always works correctly.
Continuous deployment (CD) tools automatically (and frequently) deploy the latest version of your code to production. This is intended to minimize the time it takes for new features or bugfixes to be available in production.
## CI/CD for Dataform projects
Dataform already does most of the CD gruntwork for you. By default, all code committed to the master branch is automatically deployed. For more advanced use cases, you can configure exactly what you want to be deployed and when using [environments](https://docs.dataform.co/dataform-web/scheduling/environments?utm_source=dev_to&utm_campaign=ci_cd).
CI checks, however, are usually configured as part of your Git repository (usually hosted on GitHub, though Dataform supports other Git hosting providers).
## How to configure CI checks
Dataform distributes a [Docker image](https://hub.docker.com/r/dataformco/dataform) which can be used to run the equivalent of [Dataform CLI](https://docs.dataform.co/dataform-cli?utm_source=dev_to&utm_campaign=ci_cd) commands. For most CI tools, this Docker image is what you'll use to run your automated checks.
If you host your Dataform Git repository on GitHub, you can use [GitHub Actions](https://help.github.com/en/actions/configuring-and-managing-workflows/configuring-a-workflow) to run CI workflows. This post assumes you’re using GitHub Actions, but other CI tools are configured in a similar way.
Here’s a simple example of a GitHub Actions workflow for a Dataform project. Once you put this in a `.github/workflows/<some filename>.yaml` file, GitHub will run the workflow on each pull request and commit to your master branch.
```yaml
name: CI
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
compile:
runs-on: ubuntu-latest
steps:
- name: Checkout code into workspace directory
uses: actions/checkout@v2
- name: Install project dependencies
uses: docker://dataformco/dataform:1.6.11
with:
args: install
- name: Run dataform compile
uses: docker://dataformco/dataform:1.6.11
with:
args: compile
```
This workflow runs `dataform compile` - this means that if the project fails to compile, the workflow will fail, and this will be reflected in the GitHub UI.
Note that it’s possible to run any `dataform` CLI command in a CI workflow. However, some commands do need credentials in order to run queries against your data warehouse. In these circumstances, you should encrypt those credentials and commit the encrypted file to your Git repository. Then, in your CI workflow, you decrypt the credentials so that the Dataform CLI can use them.
For further details on configuring CI/CD for your Dataform projects, please see our [docs](https://docs.dataform.co/guides/ci-cd?utm_source=dev_to&utm_campaign=ci_cd). As always, if you have any questions, or would like to get in touch with us, please send us a message on [Slack](https://join.slack.com/t/dataform-users/shared_invite/zt-dark6b7k-r5~12LjYL1a17Vgma2ru2A)! | benbirt |
351,462 | A Guide to Promises in JavaScript | Table of Contents First Class Functions in JavaScript (Re)-Introducing Callbacks Ent... | 0 | 2020-06-09T19:11:40 | https://dev.to/rfaulhaber/a-guide-to-promises-in-javascript-42hf | javascript, beginners |
# Table of Contents
1. [First Class Functions in JavaScript](#first-class-functions-in-javascript)
2. [(Re)-Introducing Callbacks](#re-introducing-callbacks)
3. [Enter Promises](#enter-promises)
4. [Promisifying](#promisifying)
5. [`async` / `await`](#enter-async-await)
6. [Conclusion](#conclusion)
7. [Further reading](#further-reading)
Although the `async` and `await` keywords are now part of standard JavaScript, under the hood they ultimately use Promises. Here we’ll explore what Promises are, why they’re needed, and how you can “promisify” callbacks in JavaScript.
I find a lot of newcomers are often confused by terms like “callbacks”, “Promises”, and what exactly `async` and `await` do. I hope to clear that up with this article.
For the sake of clarity, this guide will use `function` syntax, and not arrow functions. If you know how to use arrow functions, you can replace much of this code with arrow functions and have it behave similarly. Also, some of these code samples are more verbose than they need to be. Methods like `Promise.resolve()` can cut down on boilerplate code.
<a id="first-class-functions-in-javascript"></a>
# First Class Functions in JavaScript
In JavaScript, functions can be used like any other variable. This makes them *first class*. For example:
```js
function callFunc(val, f) {
return f(val);
}
// a simple function that adds 10 to any number
function add10(x) {
return x + 10;
}
// here we're passing the `add10` function to another function
callFunc(3, add10); // => 13
```
Note that in the above example, `callFunc` is calling the function we pass it and passing in a value itself. Here `f` could be replaced with any function.
In JavaScript functions can be **anonymous**, simply meaning that they aren’t named<sup><a id="fnr.1" class="footref" href="#fn.1">1</a></sup>.
You can pass an anonymous function to another function directly if you so choose. We can rewrite the call to `callFunc` using an anonymous function in the following way:
```js
callFunc(3, function(x) {
return x.toString();
}); // => '3'
```
One interesting aspect of this feature is that it allows for a deferral of execution of sorts. The function we pass to `callFunc` doesn’t actually get called until the function itself calls it.
<a id="re-introducing-callbacks"></a>
# (Re)-Introducing Callbacks
A **callback** is an extension of this concept. Some definitions of callbacks make them sound just like first class functions, but a more specific definition would be: a function that is invoked at the end of an asynchronous operation.
A classic example is with JavaScript’s `setTimeout` function:
```js
setTimeout(function() {
console.log('hello world!');
}, 2000);
```
In the above example, “hello world!” will get printed after two seconds. You can think of `setTimeout` as performing an operation, in this case, waiting for two seconds, and then calling the anonymous function after that time has passed. We don’t have any control over what `setTimeout` is doing, but we know that it will wait for 2000 milliseconds, and are able to provide it a function to be executed once it’s done (of course we expect `setTimeout` to do this). This is generally what callbacks are.
Callbacks developed as a pattern in JavaScript because they were an easy way to know when some asynchronous actions ended. Fetching data from a server, for example, usually involved writing a callback to handle that resulting data.
Although callbacks do get the job done, they do lead to very confusing code, and this is perhaps the biggest problem with them. Consider the following example. Suppose we have a function called `getDataFromServer` that takes some data necessary for a database query and a callback, to be executed upon the completion of that callout:
```js
// `getDataFromServer` takes a callback and data and passes `data` and
// `error` to whatever callback we provide
getDataFromServer(someInitialData, function(data, error) {
if (data) {
// here we do our second query
getDataFromServer(data, function(nextData, error) {
// here we get our next result
if (nextData) {
doSomethingElse();
}
});
}
// ...
});
```
It’s possible to rewrite the above code using named functions but it doesn’t make it much less confusing.
```js
getDataFromServer(initialData, firstRetrieval);
function firstRetrieval(data, error) {
if (data) {
getDataFromServer(nextRetrieval, data);
}
// ...
}
function nextRetrieval(data, error) {
if (data) {
doSomethingElse();
}
// ...
}
```
This is referred to as “callback hell”, because, aside from *looking* like hell, it creates a maintenance issue: we’re left with a bunch of callbacks that may be difficult to read and mentally parse through.
Neither of these examples consider variables that live outside the context of these functions. Code like this used to be quite commonplace. Maybe you need to update something on the DOM once you get the first query. Very confusing!
<a id="enter-promises"></a>
# Enter Promises
A `Promise` in some sense is a glorified callback. They allow you to transform code that utilize callbacks into something that appears more synchronous.
A `Promise` is just an object. In its most common usage it can be constructed as such:
```js
const myPromise = new Promise(executor);
```
`executor` is a function that takes two arguments provided by the `Promise` object, `resolve` and `reject`, which are each functions themselves. `executor` usually contains some asynchronous code and is evaluated as soon as the `Promise` is constructed.
A trivial example of a `Promise` can be seen with `setTimeout`
```js
const myPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
const message = 'hello world';
console.log('message in promise: ', message);
resolve(message);
}, 2000);
});
```
This code is a little different than our original `setTimeout` code. In addition to printing “hello world” to the console, we’re passing that string to the `resolve` function. If you run this code, `message in promise: hello world` gets printed to the console after two seconds.
At this point, it may not be clear why Promises are useful. So far we’ve just added some more decorum around our callback code.
In order to make this code a little more useful, we’ll invoke the Promise’s `.then()` method:
```js
const myPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
resolve('hello world');
}, 2000);
}).then(function(message) {
console.log('message: ', message);
});
```
By calling `.then()` we can actually use the value passed to `resolve`. `.then()` takes a function itself, and that function’s arguments are whatever get passed into the `resolve` function. In the above code we’re passing `'hello world'` and we can expect it to be passed to whatever function we give `.then()`.
It’s important to note that `.then()` actually returns another `Promise`. This lets you chain `Promise` calls together. Whatever is returned in the function passed to a `.then()` is passed to the next `.then()`.
```js
const myPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
resolve('hello world');
}, 2000);
}).then(function(message) {
console.log('message: ', message); // logs "message: hello world"
return message.toUpperCase();
}).then(function(message) {
console.log('message: ', message); // logs "message: HELLO WORLD"
});
```
There is an additional method, `.catch()`, which is used for error handling. This is where the `reject` function comes into play. The `.catch()` callback will be called not only if the `reject` function is called, but if *any* of the `.then()` callbacks throw an error.
```js
const myPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
reject('hello world');
}, 2000);
}).then(function(message) {
console.log('message: ', message); // this will not get called
}).catch(function(err) {
console.log('error:', err); // this will log "error: hello world"
});
```
One last note on `.then()` methods, and this may be somewhat confusing: it actually takes two parameters. The first is the callback for when the `Promise` is fulfilled, and the second being for when the `Promise` is rejected.
The above code could just as well be written:
```js
const myPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
reject('hello world');
}, 2000);
}).then(function(message) {
console.log('message: ', message); // this will not get called
}, function(err) {
console.log('error:', err); // this will log "error: hello world"
});
```
Note that we’re passing two callbacks into the `.then()`. What distinguishes this from using a `.catch()` is that this form corresponds directly to a specific handler. This is useful if you need to handle the failure of one callback specifically.
<a id="promisifying"></a>
# Promisifying
Converting a function that uses callbacks into one that utilizes `Promise` objects is done in the following steps:
1. Wrap the code that uses a callback in a new `Promise`
2. In the success condition of your callback, pass whatever result you get into the `resolve` function, if applicable
3. In the error condition of your callback, pass whatever failure you get into the `reject` function, if applicable
We can make our `getDataFromServer` function asynchronous by wrapping it in a `Promise` as described:
```js
function getDataFromServerAsync(data) {
return new Promise(function(resolve, reject) {
getDataFromServer(data, function(result, error) {
// we'll assume that if error !== null,
// something went wrong
if (error) {
reject(error);
} else {
resolve(data);
}
});
});
}
```
This allows us to chain the `Promise` returned.
```js
getDataFromServerAsync(data)
.then(function(result) {
return getDataFromServerAsync(result);
}).then(function(result) {
// do something with the result of the second query
})
.catch(function(error) {
// do something with any rejected call
});
```
And this is the ultimate benefit of Promises: rather than getting lost in callback after callback, we can simply chain a series of functions together.
There is one noticeable problem with all that we’ve gone over, however. Despite the more logical structuring that is delivered by a `Promise`, having code that deals with values not directly inside the callback scope is still an issue.
For example, I’ve seen newcomers to `Promise` write code similar to the following:
```js
let resultVal;
new Promise(function(resolve) {
setTimeout(function() {
resolve('foo');
}, 1);
}).then(function(val) {
resultVal = val;
});
console.log('resultVal', resultVal);
```
If you run this code, `resultVal` will print `undefined`. This is because the `console.log` statement actually gets run before the code in the `.then()` callback. This *may* be desirable if you know `resultVal` wouldn’t be used after some time, but it leaves your program in (what I would consider) an invalid state: your code is waiting on something to be set that it has no direct control over.
There are ways around this, but there’s no easy, simple, or sure-fire way around it. Usually you just end up putting more code in the `.then()` callbacks and mutate some kind of state.
The most straightforward way around this, however, is to use a new feature…
<a id="enter-async-await"></a>
# `async` / `await`
A few years ago the latest JavaScript standards added `async` and `await` keywords. Now that we know how to use Promises, we can explore these keywords further.
`async` is a keyword used to designate a function that returns a `Promise`.
Consider a simple function:
```js
function foo() {
// note that there exists a function called `Promise.resolve`
// which, when used, is equivalent to the following code
return new Promise(function(resolve) {
resolve('hello world');
});
}
```
All this function does is just return `'hello world'` in a Promise.<sup><a id="fnr.2" class="footref" href="#fn.2">2</a></sup>
The equivalent code using `async` is:
```js
async function foo() {
return 'hello world';
}
```
You can then think of `async` as syntactic sugar that rewrites your function such that it returns a new `Promise`.
The `await` keyword is a little different though, and it’s where the magic happens. A few examples ago we saw how if we tried logging `resultVal` it would be `undefined` because logging it would happen before the value was set. `await` lets you get around that.
If we have a function that uses our `getDataFromServerAsync` function above, we can use it in an `async` function as such:
```js
async function doSomething() {
const data = await getDataFromServerAsync();
console.log('data', data);
}
```
`data` will be set to whatever `getDataFromServerAsync` passes to the `resolve` function.
On top of that, `await` will block, and the following `console.log` won’t be executed until `getDataFromServerAsync` is done.
But what if `getDataFromServerAsync` is rejected? It will throw an exception! We can, of course, handle this in a `try/catch` block:
```js
async function doSomething() {
try {
const data = await rejectMe();
console.log('data', data);
} catch(e) {
console.error('error thrown!', e); // => 'error thrown! rejected!' will print
}
}
function rejectMe() {
return new Promise(function(resolve, reject) {
reject('rejected!');
});
}
doSomething();
```
At this point you may find yourself thinking “Wow! This `async` stuff is great! Why would I ever want to write Promises again?” As I said it’s important to know that `async` and `await` are just syntactic sugar for Promises, and the `Promise` object has methods on it that can let you get more out of your `async` code, such as [`Promise.all`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise/all), which allows you to wait for an array of Promises to complete.
<a id="conclusion"></a>
# Conclusion
Promises are an important part of the JavaScript ecosystem. If you use libraries from NPM that do any kind of callouts to server, the odds are the API calls will return `Promise` objects (if it was written recently).
Even though the new versions of JavaScript provide keywords that allow you to get around writing Promises directly in simple cases, it’s hopefully obvious by now that knowing how they work under the hood is still important!
If you still feel confused about Promises after reading all this, I strongly recommend trying to write code that uses Promises. Experiment and see what you can do with them. Try using [fetch](https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API/Using_Fetch), for example, to get data from APIs. It’s something that may take some time to get down!
---
I’m a software developer based in Cleveland, OH and I’m trying to start writing more! Follow me on [dev.to](https://dev.to/rfaulhaber), [GitHub](https://github.com/rfaulhaber), and [Twitter](https://twitter.com/ryan_faulhaber)!
This is also my first dev.to post!
This article was written using [Org Mode](https://orgmode.org) for Emacs. If you would like the Org mode version of this article, see my [writings repo](https://github.com/rfaulhaber/writings), where the .org file will be published!
<a id="further-reading"></a>
# Further reading
- [Promises on MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise)
- [Async/Await on MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/async_function)
# Footnotes
<sup><a id="fn.1" href="#fnr.1">1</a></sup> A brief explanation of named and anonymous functions:
```js
// named, function declaration
function foo() {}
// named function expression
// this is "named" because of "function bar()",
// not because we're assigning it to a variable named "foo"
// doing this is optional and may make reading stack
// traces or writing a recursive function easier
const foo = function bar() {};
// the right hand side of this assignment is an
// anonymous function expression
const foo = function() {};
// arrow function, nearly equivalent to form above.
// arrow functions are always anonymous
const foo = () => {};
```
<sup><a id="fn.2" href="#fnr.2">2</a></sup> This function’s body can also be written as:
`return Promise.resolve('hello world');`
| rfaulhaber |
351,501 | How to show (Angular) components in specific order according to a backend configuration | How to show (Angular) components in specific order according to a backend configuration | 0 | 2020-06-08T15:23:36 | https://dev.to/jdavidhermoso/how-to-show-angular-components-in-specific-order-according-to-a-backend-configuration-498m | angular, sort, components, cms | ---
title: How to show (Angular) components in specific order according to a backend configuration
published: true
description: How to show (Angular) components in specific order according to a backend configuration
tags: #angular #sort #components #cms
cover_image: https://s3.eu-central-1.amazonaws.com/juandavidhermoso.es/web-design-2038872_1920.jpg
---
## UPDATE: ⚠️ This is an awful idea for accessibility.⚠️ 🤭
### It's a terrible solution for accessibility because things are being rendered in the screen in an absolutely different order as they're written in the HTML code.
### So screen readers, tab navigation, etc. is different to what users may be seeing in the screen.
So it's wrong.
In any CMS you can configure your content to appear in a specific order,
so you don't need to code in order to change how it's rendered.
Last week, I faced that issue in an app I'm working on: I had some Angular components and I wanted to be able to sort them in a different way, according to a BE configuration.
### Why you would do that?
Let's guess you are building a **Learning platform**. You have a results page with some filters.
So users can filter the courses to find the ones more interesting to them.
Basically, making the filters sortable is a business need:
Some specific reasons:
- A/B testing
- Same code, different brands, different kind of customers, and different configuration
- Different sorting configuration according to courses search result
- Highlight new filters at the top
### The requirements
- Configuration needs to be easy to understand just taking a look at it
- If there's no configuration in the BE, components must appear how they currently are (written in the HTML).
### The solution
If you want to avoid reading the whole post, that's the solution:
I used Flexbox `order` property.
The parent containing all the filters must be a flexbox element and flexbox direction must be column.
You can do that using the CSS properties:
```
display: flexbox;
flex-direction: column;
```
I get a configuration object from the backend side, containing the order of every component.
```
sortableFilters: {
price: 0,
language: 2
rating: 1,
duration: 3,
difficultLevel: 4
}
```
I apply a `style.order` in the template to every component:
`[style.order]="sortableElements.OrderId"`.
And that's it. But there's a bit more to tell, if you want to keep reading.
You can read more about Flexbox: https://css-tricks.com/snippets/css/a-guide-to-flexbox/
### The configuration: It needs to be easy to understand
The configuration needs to be easy to understand for a content manager that does not need to know how the frontend is done (that by the way, can be changing).
And the configuration needs to work for a web client, but it needs to do so for any other client (Android, iOs, etc).
In Flexbox order property, the bigger the number, the lower the element appears.
Guess We have the following configuration in the backend (coming from a CMS or whatever) side:
```
{
price: 0,
language: 1
rating: 2,
duration: 3,
difficultLevel: 4
}
```
Price filter would appear in first place, Language filter in second place, and so on.
I don't think it's an intuitive configuration.
If you don't know how the front-end side is built, it seems to say:
"More number, more priority. So it will appear closer to the top".
So... Why the person setting up it needs to know how the Frontend is built?
I don't think it's the way it should work.
#### I reversed the data, not the content.
So my solution was to reverse every configuration number to its negative if it's greater than 0.
I reversed them in the frontend side because it's done because of the style. It's not something to be done in the backend.
In Angular, I'm doing it in the service, before the component gets the data.
The observable of the filter order configuration will emit with the numbers already in negative.
**Note: In Angular, you should not manage data in components, but in services**.
```
public getFiltersOrderConfiguration(): Observable<FiltersOrderConfiguration> {
// In the real world this would be a HTTP call.
return this.demoService.filtersOrderConfigurationBehaviorSubject
.pipe(map(this.turnFiltersOrderConfigurationIntoNegative));
}
private turnFiltersOrderConfigurationIntoNegative(filtersOrderConfiguration: FiltersOrderConfiguration): FiltersOrderConfiguration {
for (const filterID in filtersOrderConfiguration) {
if (filtersOrderConfiguration[filterID] > DemoService.DEFAULT_FILTER_ORDER_CONFIGURATION) {
filtersOrderConfiguration[filterID] = filtersOrderConfiguration[filterID] * -1;
}
}
return filtersOrderConfiguration;
}
```
So, this way, the configuration in the backend can be:
```
{
price: 4, // More important / Closer to the top
language: 3
rating: 2,
duration: 1,
difficultLevel: 0 // Not configured, indeed.
}
```
And the frontend will have
```
{
price: -4, // More important / Closer to the top
language: -3
rating: -2,
duration: -1,
difficultLevel: 0 // Not configured.
}
```
This way, the filter components will be displayed in the following order:
1. Price
2. Language
3. Rating
4. Duration
5. Difficult
#### Why you turn into negative?
So every order number will be negative if it's been set up in the backend side.
I could avoid it to be turn into negative using `flex-direction: reverse-column;` instead of `flex-direction: column`.
It would show the filters reverse to how they are written in the HTML template.
Adding a component to the bottom of the template, would lead in a new component at the top.
And I think that's quite weird and not intuitive for the developers maintaining the code after me.
So that's basically why **I turn every configuration number into negative**.
### Conclusion
I wasn't sure about this solution, but I did not find any other working for my context.
I was trying with Angular *dynamic components*.
And they could have work, but they're not there for this use case.
And every filter emits its own *output event* , and gets its own *input properties*, of different types.
So using *dynamic components* led in a mess of code impossible to maintain and close to modifications.
Read more about Angular dynamic components here: https://angular.io/guide/dynamic-component-loader
I built a simplified example:
Demo: http://demo-angular-sort-components.s3-website.eu-west-3.amazonaws.com
GitHub repo: https://github.com/jdavidhermoso/show-angular-components-sort-configuration
NOTE: That was my solution. If you think there's a better solution and you want to discuss it, you can ping me at:
- https://twitter.com/jdavidhermoso
- https://www.linkedin.com/in/juan-david-hermoso-17746062/?locale=en_US
It'd help me.
| jdavidhermoso |
351,508 | Deploy a Gridsome App on Azure Static Web Apps | Microsoft Build happened a few weeks back, among the various exciting news, one of my favorite ones... | 0 | 2020-06-09T08:41:04 | https://www.giftegwuenu.com/deploy-a-gridsome-app-on-azure-static-web-apps | gridsome, jamstack, staticwebapps | ---
title: Deploy a Gridsome App on Azure Static Web Apps
published: true
date: 2020-06-08 15:10:12 UTC
tags: gridsome, jamstack
canonical_url: https://www.giftegwuenu.com/deploy-a-gridsome-app-on-azure-static-web-apps
---
[Microsoft Build](https://mybuild.microsoft.com/home) happened a few weeks back, among the various exciting news, one of my favorite ones was the newly unveiled [Azure Static Web Apps](https://azure.microsoft.com/en-us/services/app-service/static/). I'm excited to give it a try and show you how to deploy a Gridsome web application. There's already enough tutorials about this why write more? Well, because I couldn't find one with a Gridsome example and I decided to take on the opportunity, there's never enough written tutorials on a subject.
## What is Azure Static Web Apps?
Azure Static Web Apps is a service that automatically builds and deploys full-stack web apps to Azure from a GitHub repository.

These are some of the features it ships with out of the box:
* Free web hosting
* Free SSL Certificates
* Authentication Integrations
* Custom Domains
* Globally distributed
Here's a more detailed guide on how [Azure Static Web Apps Works](https://docs.microsoft.com/en-us/azure/static-web-apps/overview).
In this tutorial, We'll go over how to deploy a static website to Azure using the Static Web Apps service. For this example, I have a Gridsome app I'll like to deploy to this service, and I'll walk through how to set up and deploy my app.
## Prerequisites
To follow this guide, you need to have basic knowledge of Vue.js, have an Azure account, Node.js installed, and a GitHub account handy.
## Step 1:
Install Gridsome CLI tool:
```bash
npm install --global @gridsome/cli
```
## Step 2:
I’m using a starter project I created to get things moving fast here. Go ahead and run the command to create a new Gridsome project.
```
gridsome create my-blog https://github.com/lauragift21/gridsome-minimal-blog
```
Now run your app locally with the command.
```bash
npm run develop
```

## Step 3:
We have our [Gridsome](http://www.gridsome.org) application up and running, Let's push the app to GitHub we'll do so using the following commands:
```bash
git add.
git commit -m 'my new gridsome blog'
```
Next, create a repository on [GitHub](https://github.com/new) called my-fancy-blog or use any fancy name you want and run the following commands:
```bash
git remote add origin git@github.com:<YOUR-USER-NAME>/my-fancy-blog.git`
git push -u origin master
```
We've now added our application to GitHub successfully. Let's move on to the last step.
## Step 4:
This is where we deploy the web app on Azure Static Web Apps.
You need to have an active Azure account to follow these next steps.
* Login to your Azure account and navigate to Azure Portal
* Click on create a resource

* Search for Static Web Apps and click create

* Next, pick a subscription from the dropdown and pick a resource group in my case, I selected the default subscription and created a new resource group.
* Give your app a name and choose a region that’s closest to you.
* Click on the sign in with the GitHub button. It'll enable you to connect your repository to Azure Static Web Apps.

* Once you have GitHub connected, you can choose your GitHub repository and choose the branch you want to deploy.

* Specify a folder location to store static output in my case I’m using thedistdirectory.

In the last step, we can review our configuration to make sure we have everything set up correctly and click create to get the app deployed.

That's it! You'll get redirected to a page showing your app deployment is ongoing.


* To check how things are working under the hood, Log on to GitHub and check the actions tab on your repo.

You should see the actions running, and when that ends, your app should be live. Check back on the Azure portal you should see a browse button by clicking on it will take you to your deployed app🎉

## Conclusion
That was fun! I'm quite impressed with how straightforward it was to get this working. In just a few clicks, I deployed version of my site. If you're interested in learning more about how to deploy another kind of application, The Azure team has a [well-documented guide](https://docs.microsoft.com/en-us/azure/static-web-apps/) on how to do that. I hope this was helpful as much I enjoyed writing and trying out Azure Static Web Apps.
[Originally published on my blog](https://www.giftegwuenu.com/deploy-a-gridsome-app-on-azure-static-web-apps/) | lauragift21 |
351,538 | Imperative vs Declarative Programming | Let's compare and contrast what these concepts mean and where the approaches are most applicable. | 6,947 | 2020-06-08T16:41:25 | https://dev.to/ben/imperative-vs-declarative-programming-5fgi | healthydebate, codequality, discuss | Let's compare and contrast what these concepts mean and where the approaches are most applicable. | ben |
351,544 | Dependency Injection กับ Service Locator ต่างกันยังไงนะ? | ในโลกของ OOP เรามักจะสร้างคลาสต่างๆ ที่มีการเรียกใช้กันต่อเป็นทอดๆ มากมาย เช่นโค้ดข้างล่างนี่ clas... | 0 | 2020-06-09T15:44:57 | https://www.centrilliontech.co.th/blog/2805/dependency-injection-vs-service-locator/ | programming, learning, tips, oop | ในโลกของ OOP เรามักจะสร้างคลาสต่างๆ ที่มีการเรียกใช้กันต่อเป็นทอดๆ มากมาย
เช่นโค้ดข้างล่างนี่
```java
class Car {
private Engine engine;
public Car() {
this.engine = new Engine();
}
}
Car car = new Car();
```
เราสร้างคลาส `Car` และ `Engine` คือ**รถ**และ**เครื่องยนต์**ขึ้นมา โดยการจะสร้างรถได้ เราจะต้องสร้างเครื่องยนต์ขึ้นมาด้วย
ในกรณีแบบนี้เราเรียกว่าคลาส `Car` depend on `Engine` (Car ต้องการ Engine) หรือแปลว่า *เราไม่สามารถสร้างคลาส Car ได้ถ้าไม่มีคลาส Engine* หรือ *Engine นั้นเป็น "Dependency" ของคลาส Car* นั่นเอง
แต่ตามหลักการออกแบบ OOP แล้วเราไม่ควรเขียนแบบโค้ดด้านบน **คือไม่ควร `new` อ็อบเจคตรงๆ ในคลาสอื่น เพราะจะทำให้เราเปลี่ยนแปลงพฤติกรรมต่างๆ ของโค้ดทำได้ยาก**
เช่นถ้าเราต้องการจะเปลี่ยน Engine ไปเป็น EcoEngine เครื่องยนต์แบบอีโค่เราจะต้องแก้โค้ดในคลาส Car เท่านั้น
วิธีการแก้แบบมาตราฐานก็คือถ้าเราต้องการใช้อ็อบเจคจากคลาสอื่น อย่าnewเอง แต่ให้รับอ็อบเจคเข้ามาแทน อาจจะทาง constructure แบบนี้ก็ได้
```java
class Car {
private Engine engine;
public Car(Engine engine) {
this.engine = engine;
}
}
```
แต่สำหรับมือใหม่หัดเขียน OOP นั้นมักจะไม่เขียนโค้ดในแพทเทิร์นแบบนี้ ด้วยเหตุผลว่าเวลาเราจะสร้าง Car ขึ้นมาใช้นั้น จะต้องไปสร้าง Dependencies ทั้งหมดของ Car ขึ้นมาซะก่อน (คือ new ตรงๆ ทันทีไม่ได้นั่นแหละ)
```java
Engine engine = new Engine();
Car car = new Car();
```
ถ้ามี Dependencies ไม่เยอะก็ยังไม่เท่าไหร่ แต่ถ้าเยอะๆ นี่ก็มีความปวดหัวเหมือนกัน
เช่น ถ้าเราต้องการสร้างบ้านขึ้นมา แต่บ้านก็ต้องมี ประตู หน้าต่าง กำแพง บลาๆๆ
```java
Door door = new Door();
Window window = new Window();
Wall wall = new Wall();
Ceil ceil = new Ceil();
Floor floor = new Floor();
House house = new House(door, window, wall, ceil, floor);
```
ซึ่งถ้าเราย้ายโค้ดพวกนี้เข้าไปไว้ในคลาส การจะสร้าง `House` ขึ้นมาก็จะเหลือแค่นี้
```java
House house = new House();
```
## DI Service แบบคร่าวๆ
หลักการ DI (หรือ Dependency Injection) แบบคร่าวๆ คือเราจะไม่ new อ็อบเจคในคลาสแบบที่เล่าไปข้างต้น แต่เพราะวิธีการนี้มันยุ่งยากกว่า คนส่วนใหญ่เลยชอบสร้างคลาสกันแบบ new ตรงๆ ในคลาสเลย ไม่ทำการรับอ็อบเจคเข้ามาทาง Constructure
ดังนั้นเลยมีคนเห็นปัญหานี้ ในเมื่อ DI เป็นคอนเซ็ปที่ดี แต่เขียนยุ่งยากมาก ... จะดีกว่าถ้าเราสามารถสร้างอ็อบเจคที่มี dependencies เต็มไปหมดด้วยการสั่ง new ง่ายๆ
DI Service คือตัวช่วยที่ว่า ซึ่งเป็นเหมือนตัวที่จะคอยจัดการและสร้างอ็อบเจคให้เราแทน
ซึ่งการใช้งานส่วนใหญ่จะแบ่งออกเป็น 2 เฟส นั่นคือการกำหนดค่าว่า Dependencies แต่ละตัวมีวิธีสร้างยังไง หลังจากนั้นคือการสั่งให้มันสร้างอ็อบเจคกลับมาให้เรา
```java
// Setup
DIService di = ...
di.set<Engine>(new Engine());
// Create Object
Car car = di.newObject<Car>();
```
แต่เอาจริงๆ บางครั้ง ในบางภาษา การจะใช้งาน DI Service พวกนี้ก็ยุ่งยากกว่าการสร้างเองตรงๆ ซะดี (ฮา) ตัวอย่างเช่น **[Dagger2](https://dagger.dev/)** สำหรับภาษา Java
## แต่..เอ๊ะ! นี่มัน Service Locator ตั้งหาก
ในบางภาษา หากเราเสิร์จหา library เพื่อมาช่วยเราทำ DI Service เราอาจจะเจอตัวที่ใช้แพทเทิร์นแบบ Container
แบบนี้
```java
class Car {
private Engine engine;
public Car() {
this.engine = Container.get<Engine>();
}
}
```
นั่นคือ แทนที่จะรับอ็อบเจคเข้ามาผ่าน Constructure ตรงๆ แต่จะใช้วิธีการขอจากสิ่งที่เรียกว่า **Container** แทน (ไม่ได้ new เองนะ แต่ขออ็อบเจคมาจากคอนเทนเนอร์)
วิธีใช้งานก็คล้ายๆ กับ DI Service นั่นแหละ คือต้องทำการกำหนดค่า dependencies ซะก่อน แล้วถึงจะเรียกใช้งานได้
```java
// Setup
Container.set<Engine>(new Engine());
// Create Object
Car car = new Car();
```
เอาล่ะ! ถึงผลลัพธ์จะออกมาเหมือนกันเป๊ะ! แถมคนส่วนใหญ่ยังเรียกวิธีการทั้ง 2 ตัวนี้ว่า DI ทั้งคู่อีกตั้งหาก
แต่เนื่องจากโค้ดมันเขียนไม่เหมือนกัน ดังนั้นเขาเลยตั้งชื่อแยกมันออกเป็น 2 แพทเทิร์น นั่นคือ **"Dependency Injection"** และ **"Service Locator"**

### ข้อแตกต่างล่ะ?
#### Service Locator
- คอนเซ็ปคือคลาสเป้าหมาย ขออ็อบเจคจาก Service Locator ซึ่งจะไปตามหามาให้
- คลาสเป้าหมายเรียกใช้ Service Locator
- มีสิ่งที่เรียกว่า Container สำหรับเก็บอ็อบเจค
- คลาสจะขออ็อบเจคจาก Container แทนการ new ขึ้นมาเอง
- ใช้งานและเข้าใจได้ง่าย เพราะอยากได้อ็อบเจคอะไรก็ขอเอาจาก Container ตรงๆ ได้เลย (ส่วนใหญ่ Container จะเป็นแบบ static คือเรียกจากตรงไหนในโปรแกรมเราก็ได้)
- ปัญหาคือมันจะทำให้มี dependency เพิ่มขึ้นมาในระบบเราอีก 1 ตัวคือ Container นั่นแหละ แถมคลาสแทบทุกคลาสในระบบเรายัง depend on เจ้าคอนเทนเนอร์นี้ซะอีก
- ถ้าเกิดอยากเปลี่ยน library สำหรับทำ Service Locator จะต้องแก้โค้ดแทบจะทั้งโปรแกรม!
#### Dependency Injection
- คอนเซ็ปคือ DI Service จะเช็กดูว่าคลาสเป้าหมาย เวลาจะสร้างต้องการ dependencies อะไรไป ก็จะไปหามาให้ แล้วเอาไป new อ็อบเจคเป้าหมายขึ้นมา
- คลาสเป้าหมายไม่ได้เรียกใช้ DI Service, แต่ DI Service เป็นฝ่ายที่จะ new อ็อบเจคขึ้นมาเอง
- ใช้วิธี inject อ็อบเจคเข้าไปตรงๆ
- สำหรับคลาสเป้าหมายจะไม่ต้องเปลี่ยนอะไรมากนัก เพราะ dependencies ทั้งหมดถูกส่งเข้ามาทาง Constructure อยู่แล้ว
- เขียนเทสได้ง่ายโดยการสร้าง mock dependencies ขึ้นมาเองไม่ต้องผ่าน DI Service เลยก็ยังได้
## เขียนเทสยังไง?
จริงๆ เป้าหมายของการทำ DI ทั้งหมดคือเพื่อเอามาเขียนเทสหรือการทดสอบโปรแกรมได้ง่ายๆ นะ
```java
class Car {
private Engine engine;
public Car(Engine engine) {
this.engine = engine;
}
}
Car testCar = new Car(new TestEngine());
```
ซึ่งในเคสนี้ Service Locator จะ mock อ็อบเจคต่างๆ ได้ยากมากเพราะเป็นการเรียกใช้งานแบบ static คือเรียกตรงๆ ที่ Container ในคลาสเลย
ดังนั้นคำแนะนำสำหรับคนใช้แพทเทิร์น Service Locator คืออย่าเรียก Container ตรงๆ แต่ให้ inject Container นี้เข้าไปแทน
แบบนี้
```java
class Car {
private Engine engine;
public Car(Container container) {
this.engine = container.get<Engine>();
}
}
```
เพราะจะทำให้เราสร้าง container สำหรับเทสอ็อบเจคขึ้นมาได้
```java
// Develop
Container container = new Container();
container.set<Engine>(new Engine());
Car car = new Car(container);
// Testing
Container testContainer = new Container();
testContainer.set<Engine>(new TestEngine());
Car testCar = new Car(testContainer);
```
| nartra |
351,578 | What is Polymorphism? | This post is originally published at - https://www.asquero.com/vc/what-is-polymorphism | 0 | 2020-06-08T18:07:09 | https://dev.to/srajangupta__/what-is-polymorphism-5hk8 | java, python, cpp, asquero | This post is originally published at - https://www.asquero.com/vc/what-is-polymorphism | srajangupta__ |
351,593 | Self Learning: Why I Built A Meditation App | Learning anything new can be very difficult. Self-learning is difficult and quite frankly it is a pre... | 0 | 2020-07-01T16:20:40 | https://dev.to/dewudev/self-learning-why-i-built-a-meditation-app-10el | beginners, javascript, journey, developer | Learning anything new can be very difficult. Self-learning is difficult and quite frankly it is a pretty lonely path. We suffer things like impostor syndrome, inconsistency, tutorial hell, being overwhelmed e.t.c. For full disclosure, this is not focused on how I got into learning web development or picking up programming as a skill. It is advice and a niche I found that went a long way in my programming journey. I felt I could share with people that could relate or have thought about picking up programming as a skill in the nearest future.
If you are like me, you have probably heard that with no experience in the field you have to build real-world projects, and building these projects can show you can do the work. It accounts for that lack of experience before mentioned. Trust me, lack of experience is one of the issues self-taught developers have to face.
So I pick up the skills watching one tutorial video after another, and like everything in life that has its pros and cons. I build complex enough projects, maybe even scalable ones. But then that’s all the knowledge I have at that point. It ends in that project. Don’t get me wrong I am not saying you need to re-invent the wheel or anything but honestly building those cant be enough. I found that out the hard way.
I’m a front-end web developer. I have watched tons of tutorial videos and built quite a few complex and cozy projects. But until a buddy of mine told me to **focus on learning and building things that could improve my day-to-day life**, I honestly had no enthusiasm to keep going. That advice turned everything around for me.
I then found out that most tech companies have __in-house projects__ that they use to improve their productivity within. Learning this gave me a sense of direction. Coupled with the advice I got from my friend, I looked at my day-to-day lifestyle and tried to figure out how I could use the skills I had gotten from these tutorials to improve it. And from the go, the first thing I could think of was the meditation app on my phone with a monthly subscription.

I was not excited about that, so that was the first thing I had to improve.
One skill a good developer has to have is __problem-solving & researching__. I had a problem and I found a solution. Going back to what I said earlier about not re-inventing the wheel. The internet has so many resources and materials to make it so that you never have to build anything you want from scratch again. Knowing this should be all the inspiration you need to get going. I found so many ideas that were similar to what I had in mind and compiled all those and built upon them. I like to be in-depth so I tore it down and rebuilt it again and again(tweaking it over and over).
After building my meditation web-app, I realized I could also improve the skills I had learned by involving the people around me in this new process of mine. so I built a recipe book app for my best friend who is a chef. She always had to search for various recipes on different sites. The app made all the recipes she could think of be one click away.
Those two simple projects did a lot for me and improved my excitement towards not just the learning but the building projects process. You could call them side projects if you’d like. To me, they are my in-house projects. Doing this made me interested in building a lot more things and learning new technologies.
Teaching yourself anything can be difficult and draining but when you care about what you are learning it becomes part of your everyday life and it inspires and motivates you to do more.
Before I forget, here's the link you can use to check it out
[Meditation App Github link](https://github.com/Dewudev/Meditation-App)
You can see it live here [Netlify](https://meditation-zone.netlify.app/)
**P.S Don't load on phone screens:)**
Thank you for reading.
| dewudev |
351,636 | ClockWorks, Web Worker library | As a spin off from another simple static web page app that I made the other day using Alpine.js and T... | 0 | 2020-06-08T21:27:37 | https://dev.to/reecem/clockworks-web-worker-library-37l6 | javascript, webworker, library | As a spin off from another simple static web page app that I made the other day using Alpine.js and TailwindCSS I was in the need of pushing the `setInterval()` functions off to the Web Worker API.
The result is a naïve implementation of a stack system to manage a set if intervals and timeouts (`setTimeout()` isn't available as of v0.1.x).
The whole package is cool in that it is currently less than 1KB zipped as of version 0.1, which is quite neat.
The first implementation of the system was baked into the app, and gave me a place to test the base logic and ideas.
After an afternoon to stick the package together, the simple way to have a interval firing on the web worker is below:
{% jsitor https://jsitor.com/embed/ce0buTYXN?js&result %}
> **IMPORTANT** Please note that the first few versions are only pushing the timers into the web worker, the callback is still done in the main thread.
## Details
The idea was simple, and only after I added some tags to the repo did I find it's not the first but glad to know that I was on the right track before learning how others had done similar :D.
Usage is pretty simple, you can spin up the intervals/timers when you instantiate the class like so:
```javascript
/**
* Create a new instance of the class and then print the time to the console.
*
* We will also remove the clock after 5 seconds, by counting a variable.
*/
let triggers = 0;
let clockWorks = new ClockWorks([
{
name: 'clock',
time: 1000,
callback: () => {
console.log((new Date()).toLocaleString())
}
},
{
name: 'remove-clock',
time: 1000,
callback: () => {
if (++triggers >= 5) {
$clock.pull('clock')
$clock.pull('remove-clock')
}
}
}
])
```
Or during the process of running your app you can call the push or pull methods, these allow you to selectively add or remove a timer from the stack by using the name you defined in the object.
Example of adding one:
```javascript
clockWorks.push({
name: 'new-timer',
time: 5000,
callback: () => {
console.log('New interval has fired at [%s]', (new Date()).toLocaleString());
}
})
```
And to pull that same one later on would be:
```javascript
clockWorks.pull('new-timer');
```
## Web Worker
I got around having to send a separate web worker as the implementation shouldn't need to be edited by bundling in the package and then using the `Blob` technique to get it running.
This actually has a neat side effect in that because each web worker gets a new blob url, you can create multiple instances with their own worker each.
The code that makes it possible is from a bit of finding it isn't the first time people have tried this and also the classic SO questions that have been asked. From looking at a bunch, I decided that the best way would be to do the following when `installing` a new Web Worker:
```javascript
import workerFile from './worker';
// ... later on
// in the startWorker method, we use blob to make the url
// we convert the function into a string, and then wrap it in IIFE thingy so it runs and works correctly, that was a bit of fun.
var blob = new Blob([`(${workerFile.toString()})();`], { type: 'text/javascript' });
// then put it in a Worker thingy :)
this.worker = new Worker(window.URL.createObjectURL(blob));
```
The actual worker file is rather bland, but you can check it out here: [worker.js](https://github.com/ReeceM/clockworks/blob/master/src/worker.js)
This works pretty well as its able to have the script bundled and then add it dynamically.
## Microbundle
For this package I decided to use [microbundle](https://github.com/developit/microbundle) as I was not wanting a whole complex build system for something that was going to be slap stick.
It worked as advertised 🎉, LOL.
But it did to as it was labeled, straight forward and easy to get running bundler. Which is nice for this build as I was able to target different things.
### Planned features
A planned feature that I will implement is to be able to define just a straight forward callback, with an optional name. This would then be tracked internally and the user will get an id they can use to pull it from the stack of timers if it is an interval one.
This would give the user the ability to do this:
```javascript
let id = clockWorks.push(() => {
var element = document.querySelector('[worker-main]');
// select Alpine Element
element.__x.refreshGraphData();
})
```
### GitHub repo.
If you would like to see more details or how to make use of it you can check out the Git repo.
The library is currently in pre-release as there are still some features that can be added. PRs for any bugs are welcome too.
{% github reecem/clockworks no-readme %}
0_o | reecem |
351,644 | Zsh vs Bash | This article was originally posted on StackAbuse.com. Check it out for more articles, guides, and mo... | 0 | 2020-06-09T15:03:07 | https://stackabuse.com/zsh-vs-bash/ | bash, zsh | > This article was originally posted on [StackAbuse.com](https://stackabuse.com/). Check it out for more articles, guides, and more. 👍
When we talk about Unix-based programming, it's usually about the shells, terminals, and the command line interfaces. The most prevalent shell in this regard is [Bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) but there are other variants available and used widely as well, like Zsh, or the [Z shell](https://en.wikipedia.org/wiki/Z_shell).
In this article, we'll attempt to draw the line between the two shells and show the differences so you can get a sense of why you might use one or the other. But first, in the following sections we'll introduce both shells before we compare them together.
# Z Shell
Zsh, or Z shell, was first released by Paul Falstad back in 1990 when he was still a student at Princeton University. Z shell is included in many operating systems, including Mac OS (although it isn't the default that's actually used).
Much like Bash, Z shell can basically be seen as an extended version of the [Bourne shell](https://en.wikipedia.org/wiki/Bourne_shell), and does contain a lot of the same features as Bash, which you'll probably notice in the sections below. You may also notice that it pretty closely resembles the Korn shell as well. Some of the features that are worth mentioning include (but are not limited to):
- File [globbing](https://en.wikipedia.org/wiki/Glob_(programming))
- Spelling correction
- Directory aliases (much like `~` or `..`)
- Loadable modules, like socket controls or an FTP client
- Compatibility modes: e.g. You can use `/bin/bash` as a drop-in replacement for Bash
- Startup/shutdown scripts via `zshenv`, `zprofile`, `zshrc`, `zlogin`, and `zlogout`
- `git` command completion
- Path expansion: e.g. Enter `cd /u/lo/b`, press tab, and it will be completed to `cd /usr/local/bin` since it is the only matching pattern
There are _a lot_ more features than what we've shown here, but at least this gives you an idea as to how shells can be different.
# Bash
The Bash shell (also known as the "Bourne-again shell") was also released around the same period as the Z shell (in 1989) and Brian Fox is regarded as the creator behind it. It was initially written as a replacement for the Bourne shell. For many years it has shipped as the default shell for GNU, most Linux distributions, and Mac OS X (version 10.3+). Like a true replacement should, Bash is capable of executing all of the Bourne shell commands without a problem.
There are quite a few features that the Bash shell has and some of the lesser-known ones include:
- Insert the last parameter(s) of the preceding command in your current command using `Alt` + `.`
- You can keep a process running even after logging out. To do so, use the command `disown -h <pid>` where you will have to place the process ID (PID) of the program instead of `<pid>`
- Execute the previous command again, but this time running with `sudo` using the command `sudo !!` (`!!` is shorthand for 'the previous command')
- Perform a reverse incremental search using the `Ctrl` + `R` keys
- Press tab twice and you will see the list of completions for the word that you have just typed or are typing
- When executing a script with `bash`, use the `-x` option to output the script contents as it's being executed
If you want to learn more, you can see a much larger list of Bash-specific features [here](http://web.mit.edu/gnu/doc/html/features_4.html#SEC20).
# Comparing Z shell and Bash
Now that we've give you a brief introduction to both of the shells, let's see how they hold up when actually compared and contrasted together.
The first thing to look at (and one of the more significant aspects, in my opinion) is prevalence and popularity of the shell. While the Z shell has its fair share of users throughout the developer community, it's usually safer to write your scripts for Bash since there is a much larger group of people that will be able to run those scripts.
The importance of adoption holds true for the public resources and documentation as well. Thanks to its large community, Bash has quite a few more resources out there to help you learn how to use it.
So, if you are planning on writing a script that you want many developers to easily be able to run then I'd recommend that you go with Bash. However, this shouldn't stop you from using Z shell if your end goal is more suited to Z shell. Finding the right solution to a problem is much more important than just using what's popular, so keep that in mind as well.
Although Bash is much more popular, that doesn't mean Z shell is without any useful features of its own. It's actually heavily praised for its interactive use, because it's more customizable than Bash. For example, the prompts are more flexible. It can display a prompt on the left _and_ another on the right side of the screen, much like vim's split screen. The auto-completion is also more customizable and is actually faster than Bash's.
To give you a better sense of what kind of features Z shell has, here is a list of things that you will have access to when using Z shell over Bash:
- The built-in `zmv` command can help you do massive file/directory renames. e.g. to append '.txt' to every file name run `zmv –C '(*)(#q.)' '$1.txt'`
- The `zcalc` utility is a great command-line calculator which is a convenient way to do a quick calculation without leaving the terminal. Load it with `autoload -Uz zcalc` and run with `zcalc`
- The `zparseopts` command is a one-liner that lets you to parse complex options that are provided to your script
- The `autopushd` command helps you do `popd` after you use `cd` to go back to your previous directory
- Floating point support (which Bash suprisingly _does not_ have)
- Support for hash data structures
There are also a bunch of features that are present in the Bash terminal but are absent from almost all of the other shells. Here are a few of them as well:
- The `–norc` command-line option, which allows the user to proceed with the shell initialization _without_ reading the `bash.rc` file
- Using the option `–rcfile <filename>` with `bash` allows you to execute commands from the specified file
- Excellent [invocation features](https://www.gnu.org/software/bash/manual/html_node/Invoking-Bash.html)
- Can be invoked with the `sh` command
- Bash can be run in a specific POSIX mode. Use `set –o posix` to invoke the mode or `--posix` on startup
- You can control the look of the prompt in Bash. Setting the `PROMPT_COMMAND` variable to one or more of the [special characters](https://www.gnu.org/software/bash/manual/html_node/Controlling-the-Prompt.html) will customize it for you
- Bash can also be invoked as a [restricted shell](https://www.gnu.org/software/bash/manual/html_node/The-Restricted-Shell.html) (with `rbash` or `--restricted`), which means certain commands/actions are no longer allowed, such as:
- Setting or unsetting the values of the `SHELL`, `PATH`, `ENV`, or `BASH_ENV` variables
- Redirecting output using the `>`, `>|`, `<>`, `>&`, `&>`, and `>>` redirection operators
- Parsing the value of SHELLOPTS from the shell environment at startup
- Using the exec builtin to replace the shell with another command.
- And many more...
It's difficult to say which shell is actually better. It all really depends on your own preferences and what you actually want to do with the shell. In the case of Bash vs Z shell, neither is really better than the other.
There are quite a few fans of the Z shell throughout the developer community who advocate for it quite heavily thanks to the many useful features it provides. On the other side, there are even more fans of Bash who know that their biggest advantage is their far larger user base. It's easy to see why it is so difficult to get developers to switch from Z shell to Bash and vice versa.
---
Thanks for reading! Check us out over at [StackAbuse.com](https://stackabuse.com/) for more articles, guides, and other resources. You can also follow us [@StackAbuse](https://twitter.com/stackabuse) for new articles daily. | scottwrobinson |
351,649 | Maintaining and Governing Developer Accounts with AWS Control Tower, Part 2 | I work at a consulting company where there are numerous developers and consultants that require a san... | 7,186 | 2020-06-12T18:10:22 | https://dev.to/dereksedlmyer/maintaining-and-governing-developer-accounts-with-aws-control-tower-part-2-1bg6 | aws, controltower, governance | I work at a consulting company where there are numerous developers and consultants that require a sandbox environment in AWS. Developers may be working in isolation or they may be collaborating with other developers on a shared project.
At present, everyone shares a single AWS account and it becomes challenging to govern. We routinely have to prune resources no longer in use when our monthly bill becomes out of control. This requires an admin to look through the resources in numerous regions and reach out to developers to figure out who owns a resource.
To help manage and govern our AWS usage, I'm going to use AWS Control Tower to allow admins and developers to provision isolated accounts at the developer or project scope and to provide a set of guardrails to enforce AWS best practices.
In the second part of this series, I'm going to describe how the Landing Zone is configured for my team and the customizations added to support some of our policies.
# User Management
The first administrative task is to create User accounts in AWS Single Sign-On so that developers can access appropriate AWS accounts in the organization.
Control Tower configures an AWS Single Sign-On directory in the Master account. This directory can be configured to use a user identity store in Active Directory, an external identity provider, or through the built-in identity store in AWS SSO. For my team, we're going to use the built-in identity store.
The next step is to begin inviting the users into the Organization. The users will be added to the **AWSAccountFactory** group initially. This will give them permissions to use Account Factory to create new AWS accounts within the Organization. Upon create a new user, an invitation will be sent via email where the user can set their password and login.
> A recommended practice is to create groups that model your organization's roles and responsibilities. Since groups in AWS SSO can't be members of other groups, assign users to groups managed by your organization and the AWS-managed groups.
I'm going to create a **Developers** group within AWS SSO and assign the developer users to that group.
There are a few of us on the team that will be administrators on Control Tower and the Organization. These users will have administrator access to the Master account and full access to AWS Control Tower. For them, I'm going to create an **Admins** group and assign their user accounts to that group.
In AWS SSO, the current list of groups:
For my organization-managed **Admins** group, I'm going to assign it the **AWSAdministratorAccess** Permission Set to the Master, Log archive, and Audit AWS accounts.
> Permission Sets are backed by an IAM policy. Use Permission Sets to enforce permissions on a User or Group for an AWS Account.
# Landing Zone Configuration
A common issue with using a single-shared AWS account is that the account becomes like the wild west. Resources are created but never terminated, team members come and go, and it is tedious to determine who created a resource when it comes time to prune resources when the AWS bill comes due.
Another issue with the single-shared AWS account is the blast radius if the account were ever to become compromised. When an account is compromised AWS disables the account until all issues are resolved. This could have a wide impact on other developers and projects.
To improve management and governance, each developer will have a dedicated AWS account. Additionally, there are shared projects which numerous developers work and collaborate. Each shared project will so have a dedicated AWS account.
Each developer AWS account and project AWS account will be added to the Landing Zone configured by Control Tower. The account will inherit the guardrails assigned to the account's OU. All API activities and resource configurations will also be logged.
Two Organizational Units (OUs) will be added as well. One for **developers** and one for **projects**. Using separate OUs will allow us to manage and govern the accounts with different guardrails and policies.
This diagram illustrates the layout of the OUs within the Landing Zone.
When creating OUs for Control Tower, it is best practice to create them through Control Tower and not through AWS Organizations. Using Control Tower to add OUs to the Landing Zone will ensure that they display within Control Tower and have guardrails applied to them. Control Tower will manage the lifecycle of an OU within AWS Organizations.
> OUs within Control Tower should be parented to the Root OU and not nested in another OU. Nested OUs are not accessible to Control Tower as it only displays the top-level OUs.
After creating the **developers** and **projects** OUs within Control Tower, the Organizational Units page looks like this:
Examining the developers OU, it will show details on the OU including accounts assigned to the OU and guardrails.
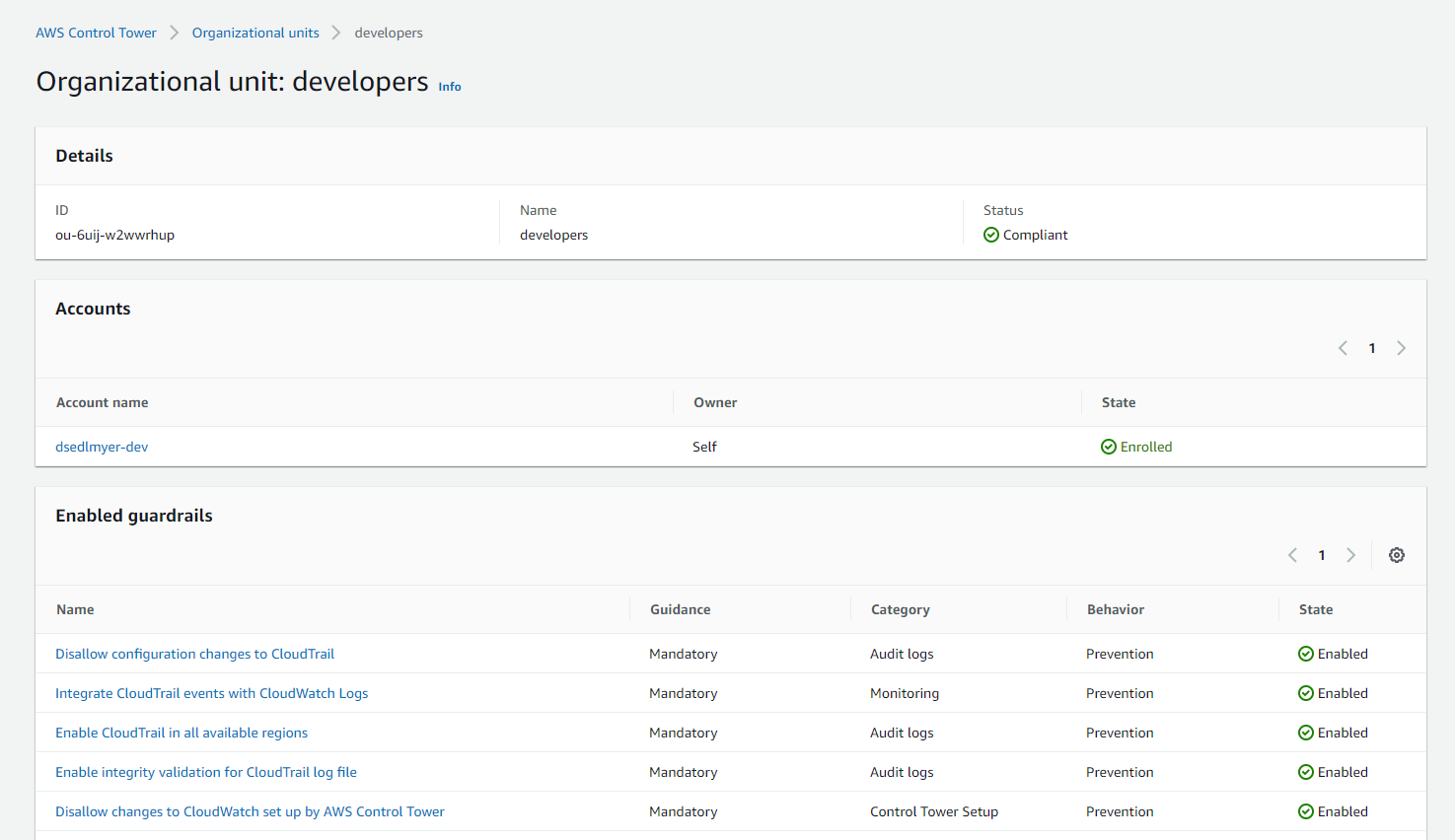
At this time, the OU is ready to be used and new accounts can be assigned to the OU. There are further customizations required to enforce some custom policies which will be covered next.
# Landing Zone Customizations
While AWS Control Tower provides a good base set of guardrails on member accounts, my team would like to add further policies. For instance for developer accounts, initially we would like to enforce these policies:
* Limit EC2 Instance Types to nano, micro, small, or medium instance types
* Limit RDS Instance Types to micro, small, or medium instance types
To enforce these policies, Service Control Policies (SCPs) can be configured within AWS Organizations and attached to an OU or an individual account.
Additionally, we would like to add a resource to each developer AWS account:
* Set up an initial budget of $25 per month and send notifications at configured thresholds
Resources can be added to AWS accounts using CloudFormation and by using StackSets to deploy to the member AWS accounts from the Master account.
Configuring Service Control Policies and CloudFormation stacks is straightforward, it can be difficult to do at scale. Managing SCPs at the OU level in AWS Organizations makes it easier to enforce policies, the same is not true for CloudFormation stack sets. After accounts are creating through the Account Factory, an admin will have to remember to set up the appropriate CloudFormation stacks on the new account. Also, if new resources and stacks need to be added to exist accounts, then an admin must manually configure the stacks on each AWS account. This can be very tedious and error prone.
AWS provides a custom solution named Customizations for AWS Control Tower.
From the Customizations for AWS Control Tower Deployment Guide:
> The Customizations for AWS Control Tower solution combines AWS Control Tower and other highly-available, trusted AWS services to help customers more quickly set up a secure, multi-account AWS environment using AWS best practices. Before deploying this solution, customers need to have an AWS Control Tower landing zone deployed in their account. This solution enables customers to easily add customizations to their AWS Control Tower landing zone using an AWS CloudFormation template and service control policies (SCPs). You can deploy the custom template and policies to individual accounts and organizational units (OUs) within your organization. This solution integrates with AWS Control Tower lifecycle events to ensure that resource deployments stay in sync with the customer's landing zone. For example, when a new account is created using the AWS Control Tower account factory, the solution ensures that all resources attached to the account's OUs will be automatically deployed.
Information on Customizations for AWS Control Tower can be found here: https://aws.amazon.com/solutions/implementations/customizations-for-aws-control-tower/.
Customizations for AWS Control Tower configures the following deployment architecture in the Master account to deploy SCPs and CloudFormation Stack Sets on existing member accounts and new member accounts.
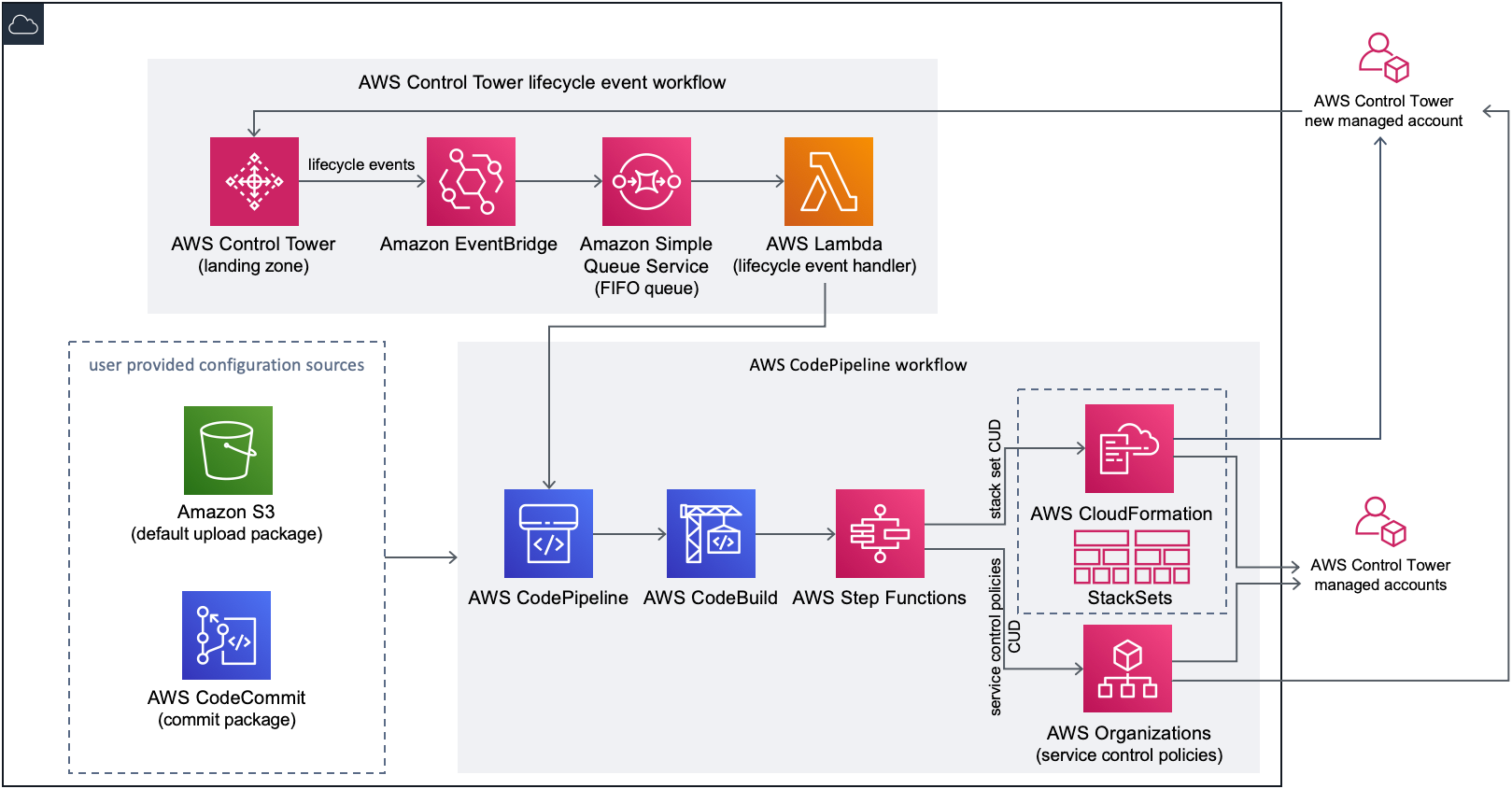
## Deploying the Customizations for AWS Control Tower Solution
To configure Customizations for AWS Control Tower in the Master account use the CloudFormation template that's included. It can be found at: https://s3.amazonaws.com/solutions-reference/customizations-for-aws-control-tower/latest/custom-control-tower-initiation.template.
There are 2 parameters for the CloudFormation stack -- PipelineApprovalEmail and PipelineApprovalStage.
Set *PipelineApprovalStage* to *Yes* if you would like to approve any changes to SCPs or CloudFormation StackSets before deployment. An email will be sent to email address set in the *PipelineApprovalEmail* parameter to notify when there is a pending approval.
## Setup Customization Configuration Package
The Customizations for AWS Control Tower will deploy SCPs and CloudFormation StackSets using policy files and templates contained in a Configuration Package. AWS CodePipeline in the Customizations for AWS Control Tower will create SCPs using the policy files and create CloudFormation StackSets from the templates and apply them to the appropriate accounts at the OU or account levels.
The developers guide for the Configuration Package and Customizations for AWS Control Tower can be found at: https://s3.amazonaws.com/solutions-reference/customizations-for-aws-control-tower/latest/customizations-for-aws-control-tower-developer-guide.pdf.
The Configuration Package is uploaded into an S3 bucket which will trigger the deployment process in AWS CodePipeline.
I created a GitHub repo with a sample Configuration Package that contains Service Control Policies for limiting instance types for EC2 and RDS and a CloudFormation template for configuring a Budget in each member account.
{%github DerekSedlmyer/aws-landing-zone-sample no-readme%}
The manifest file in the Configuration File controls the deployment of SCPs and CloudFormation templates. In the manifest file, the list of Organization Policies (SCPs) and CloudFormation Resources is configured to include the OUs or individual member accounts to target. The configuration of the manifest file will be described in the following sections.
## Configuring Service Control Policies
In our team's member accounts, we want to limit the size of the EC2 and RDS instances in order to save costs. This can be controlled via Service Control Policies (SCPs). SCPs are defined as IAM policies. The SCPs will be configured within AWS Organizations via the Customizations for AWS Control Tower solution.
> Service Control Policies (SCPs) offer central control over the maximum available permissions for all accounts in your organization. SCPs help you to ensure your accounts stay within your organization’s access control guidelines.
The following is a sample SCP for limiting EC2 instance types to only nano, small, micro, or medium. In this policy there is an explicit deny to Run EC2 Instances that don't match the pattern of *.nano, *.small, *.micro, or *.medium.
[custom-control-tower-configuration/policies/ec2-instance-types.json](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/policies/ec2-instance-types.json):
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LimitEC2InstanceType",
"Effect": "Deny",
"Action": "ec2:RunInstances",
"Resource": "arn:aws:ec2:*:*:instance/*",
"Condition": {
"ForAnyValue:StringNotLike": {
"ec2:InstanceType": [
"*.nano",
"*.small",
"*.micro",
"*.medium"
]
}
}
}
]
}
```
The following is a sample SCP for limiting RDS instance types to only small, micro, or medium. In this policy there is an explicit deny to Create or Start RDS databases that don't match the pattern of *.small, *.micro, or *.medium.
[custom-control-tower-configuration/policies/rds-instance-types.json](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/policies/rds-instance-types.json):
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LimitRDSInstanceType",
"Effect": "Deny",
"Action": [
"rds:CreateDBInstance",
"rds:StartDBInstance"
],
"Resource": "arn:aws:rds:*:*:*",
"Condition": {
"ForAnyValue:StringNotLike": {
"rds:DatabaseClass": [
"db.*.micro",
"db.*.small",
"db.*.medium"
]
}
}
}
]
}
```
With the SCPs defined in the two separate files, the next step is to configure them within the manifest so they are applied appropriately. It will apply the SCP to all current and future accounts within the **developers** OU.
This section of the manifest file will apply the SCPs to the appropriate member accounts in the landing zone.
[custom-control-tower-configuration/manifest.yaml](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/manifest.yaml):
```yaml
organization_policies:
- name: limit-ec2-instance-types
description: Limit EC2 instance type in member accounts
policy_file: policies/ec2-instance-types.json
apply_to_accounts_in_ou:
- developers
- name: limit-rds-instance-types
description: Limit RDS instance type in member accounts
policy_file: policies/rds-instance-types.json
apply_to_accounts_in_ou:
- developers
```
After deployment, we can see the SCP configured in AWS Organizations for the developers OU.
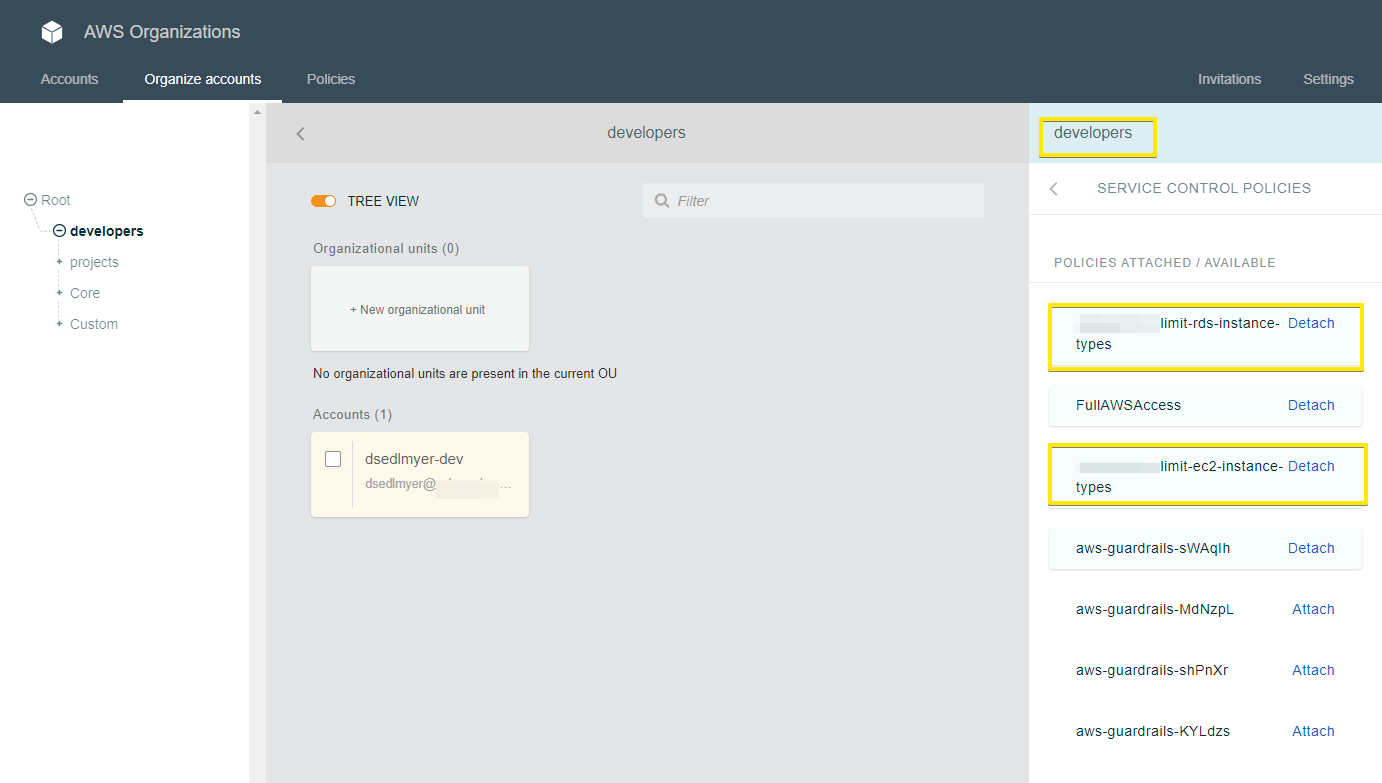
In any AWS account within the **developers** OU, the creation of EC2 or RDS instances outside of the policy will not be allowed.
## Configuring CloudFormation Resources
In our team's member accounts, we want to create a budget for $25 per month (for example) and then notify once budget thresholds of 75/90/100/110% thresholds. This will help us govern costs so that we can stop unused resources before the bill becomes out of control.
To set up the Budget, a CloudFormation template is needed. A CloudFormation StackSet will be created within the Master account using the template and will create individual CloudFormation stacks in the appropriate member AWS accounts.
> AWS CloudFormation StackSets extends the functionality of stacks by enabling you to create, update, or delete stacks across multiple accounts and regions with a single operation. Using an administrator account, you define and manage an AWS CloudFormation template, and use the template as the basis for provisioning stacks into selected target accounts across specified regions.
The CloudFormation template to define the Budget is shown here.
[custom-control-tower-configuration/templates/budget.template](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/templates/budget.template)
```yaml
AWSTemplateFormatVersion: 2010-09-09
Description: Configures Budget Notifications for member accounts at 75/90/100/110% thresholds
Parameters:
BudgetName:
Description: Name to assign budget
Type: String
BudgetAmount:
Description: Budget Limit for one month
Type: Number
Default: 25
NotificationEmailAddress:
Description: Email Address to notify when 75/90/100/110% thresholds are reached
Type: String
Resources:
AccountBudget:
Type: AWS::Budgets::Budget
Properties:
Budget:
BudgetName: !Ref BudgetName
BudgetLimit:
Amount: !Ref BudgetAmount
Unit: USD
TimeUnit: MONTHLY
BudgetType: COST
NotificationsWithSubscribers:
- Notification:
NotificationType: ACTUAL
ComparisonOperator: GREATER_THAN
Threshold: 75
ThresholdType: PERCENTAGE
Subscribers:
- SubscriptionType: EMAIL
Address: !Ref NotificationEmailAddress
- Notification:
NotificationType: ACTUAL
ComparisonOperator: GREATER_THAN
Threshold: 90
ThresholdType: PERCENTAGE
Subscribers:
- SubscriptionType: EMAIL
Address: !Ref NotificationEmailAddress
- Notification:
NotificationType: ACTUAL
ComparisonOperator: GREATER_THAN
Threshold: 100
ThresholdType: PERCENTAGE
Subscribers:
- SubscriptionType: EMAIL
Address: !Ref NotificationEmailAddress
- Notification:
NotificationType: ACTUAL
ComparisonOperator: GREATER_THAN
Threshold: 110
ThresholdType: PERCENTAGE
Subscribers:
- SubscriptionType: EMAIL
Address: !Ref NotificationEmailAddress
```
The next step is to configure the CloudFormation template within the manifest so the CloudFormation resources are created appropriately and targets the right accounts. The CloudFormation template to define a Budget will be configured to be created in all current and future AWS accounts in the **developers** OU.
This section of the manifest file will apply the CloudFormation resources to the appropriate member accounts in the landing zone.
[custom-control-tower-configuration/manifest.yaml](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/manifest.yaml)
```yaml
cloudformation_resources:
- name: budget-small
template_file: templates/budget.template
parameter_file: parameters/budget.small.json
deploy_method: stack_set
deploy_to_ou:
- developers
regions:
- us-east-1
```
The parameters file will define the parameter values to be used when creating the CloudFormation StackSets. In this case, the values for a small budget will be used. You will notice that `BudgetAmount` is $`25`
[custom-control-tower-configuration/parameters/budget.small.json](https://github.com/DerekSedlmyer/aws-landing-zone-sample/blob/master/custom-control-tower-configuration/parameters/budget.small.json)
```json
[
{
"ParameterKey": "BudgetName",
"ParameterValue": "budget-small"
},
{
"ParameterKey": "BudgetAmount",
"ParameterValue": "25"
},
{
"ParameterKey": "NotificationEmailAddress",
"ParameterValue": "name@email.com"
}
]
```
After deployment, we can see the CloudFormation StackSet created in the Master account in the landing zone with a few instances in the member accounts:
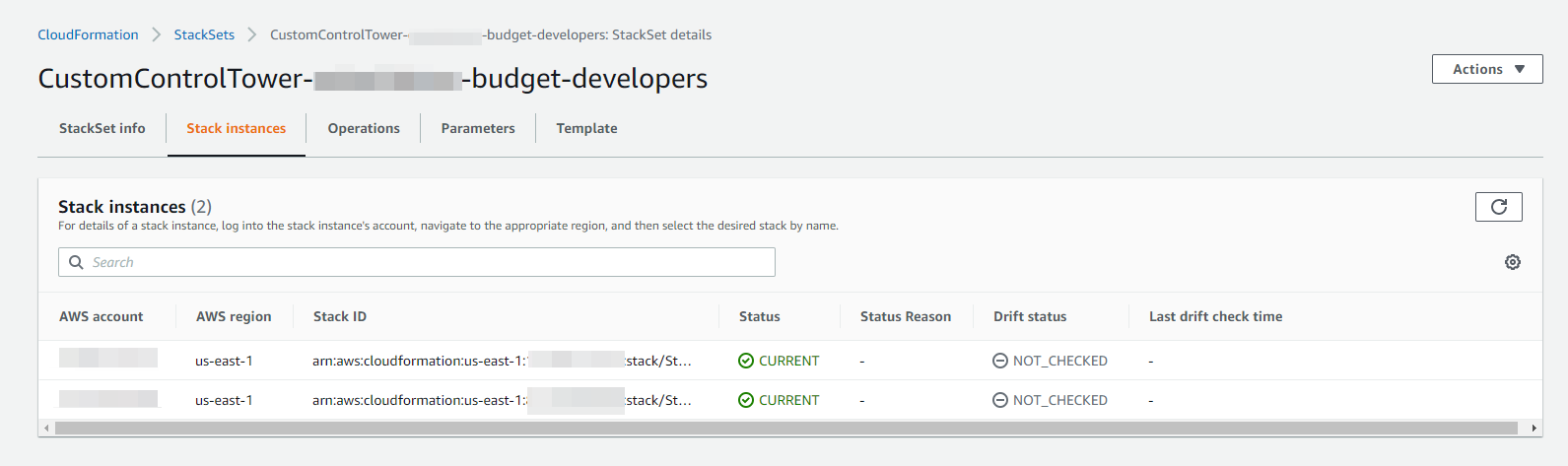
If we look in a member account, we can see the instance of the CloudFormation stack that was created from the StackSet in the Customizations for AWS Control Tower solution in the Master account.
# Conclusion
This post shows how to configure the Landing Zone created by AWS Control Tower and also how to deploy custom policies and resources to AWS accounts in the Landing Zone using the Customizations for AWS Control Tower.
Stay tuned for additional posts in this series on AWS Control Tower and governance.
| dereksedlmyer |
351,672 | Lessons Learnt: PHPUnit for Beginners | I took the course PHPUnit for Beginners by Laravel Daily. It is suitable for total testing beginners... | 0 | 2020-07-09T19:40:58 | https://martinbetz.eu/articles/lessons-learnt-phpunit-course | ---
title: Lessons Learnt: PHPUnit for Beginners
published: true
date: 2020-06-08 00:00:00 UTC
tags:
canonical_url: https://martinbetz.eu/articles/lessons-learnt-phpunit-course
---
I took the course [PHPUnit for Beginners by Laravel Daily](https://laraveldaily.teachable.com/p/laravel-phpunit-testing-for-beginners). It is suitable for total testing beginners and walks you through a simple CRUD application.
Here are my takeaways in the format of question and answer. They are sorted by occurence in the course but you can use whatever you need for your application and testing – not everything is related to testing:
## Why choose `@forelse … @empty … @endforelse` for loops?
It covers the case where there is no data
```
@forelse ($users as $user)
<li>{{ $user->name }}</li>
@empty
<p>No users</p>
@endforelse
```
## How to create content with custom values with Eloquent
```
$product = Product:create([
'name' => 'Product 1',
'price' => 99.99
]);
// in your test
$response->assertSee($product->name);
```
## How to setup test database?
- `phpunit.xml` overwrites `.env.testing`
- Edit `DB_CONNECTION` for `MySQL/sqlite`
- Change value of `DB_DATABASE` into `value=":memory:"` to get fast in memory store
## What does `RefreshDatabase` trait do?
- It Runs migrations
- Creates a fresh database
- Usage
- `use Illuminate\Foundation\Testing\RefreshDatabase;` above class
- `use RefreshDatabase;` in class, not single test
## When should you use a MySQL test database?
- When you use raw MySQL statements for the following features:
- Date formatting
- String functions
- Date differences
- Geospatial features
## How to set up a MySQL test database in `phpunit.xml`?
- `<server name="DB_CONNECTION" value="MySQL"/>`
- `<server name="DB_DATABASE" value="name_of_db"/>`
## Why to test data and not visuals (assertSee)?
- To avoid false positives because of incomplete results
- Example
- Blade: show product name `{{ $product->name }}`
- Data: `['name' => 'Product 1000]`
- Visual test: `$response->assertSee('Product 1')` would turn green and create a false positive
## How to get view data of e.g. $products to test?
```
$view = $response->viewData('products') // was passed to view in controller
$this->assertEquals($product->name, $view->first()->name);
```
## What do unit tests capture?
- Internal logic
- No Endpoint
- Data processing
## How to create a Laravel service to translate currency
- Create service in `app\services` -> `CurrencyService.php`
- Import using `use App\Services\CurrencyService`
- Call `new CurrencyService()->convert();`
- No changes in database needed
## How to create temporary database/accessor field (e.g. dynamic price in another currency)?
- This is also called accessor
- On model `Product.php`
```
public function getPriceEurAttribute() {
return $this->price*0.8;
}
```
## How to create an unit test?
- `art make:test NAME --unit`
## How to paginate in controller and view?
- (In Controller): `$products = Product::paginate(10);`
- In View: `{{ $products->links() }}`
## How to call factories?
- `factory(Product::class, 10)->create();`
## How to echo variable result into log?
- Call `info($var)` in your code
## How to test if login works?
- Create user
- Post login data and set response
```
$response = $this->post('login', [
'email' => 'EMAIL',
'password' => 'PW'
]);
// assert where you expect to be redirected to, e.g. home
$response->assertRedirect('/home');
```
## How to quickly log in for tests?
- `$this->actingAs($user)->get('/')`
## How to protect a route via auth?
- `Route::get('/')->middleware('auth')`
## Easiest way to add admin?
- Add field to user model: `is_admin`
- Add to fillable in model
- Create middleware `app\Http\Middleware\IsAdmin` (see following snippet)
- Add middleware to `App\Kernel`
- Add middleware to your route `Route::middleware('auth', 'is_admin')`
```
public function handle($request, Closure $next)
{
if (! auth()->user()->is_admin)
{
abort(403);
}
return $next($request);
}
```
## Which visual assertions are usual?
- `$response->assertSee()`
- `$response->assertDontSee()`
## How to create simple factory states?
- Example: `is_admin`, yes/no
- Create private function with factory and optional parameter in it
```
private function create_user(is_admin = 0)
{
$this->user = factory(User::class)->create([
'is_admin' => $is_admin,
]);
}
```
### How to store everything you get via form?
```
// Controller
public function store(Request $request)
{
Product::create($request->all());
return redirect()->route('home');
}
```
## How to test a POST request with parameter `name = 'Test 1'`?
- `$this->post('products', ['name' => 'Test 1', 'price' => 99.99]);`
## How to assert that something is in the database? (db side)
- `$this->assertDatabaseHas('products', ['name' => 'Test 1', 'price' => 99.99]);`
## How to test whether saved data gets returned?
- `$product = Product::orderBy('id', 'desc')->first();`
- `$this->assertEquals('String', $product->name);`
- `$this->assertEquals('price', $product->price);`
## How to check whether data for edit is available in view?
- `$product = Product::first();`
- `$response->assertSee('value="' . $product->price . '"');`
## How to update all data from a request?
```
public function update(Product $product, UpdateProductRequest $request)
{
$product->update($request->all());
return redirect()->route('products.index');
}
```
## Where and how to create a form request?
- `app/Http/Requests/UpdateProductRequest.php`
```
public rules() {
return [
'name' => 'required',
'price' => 'required',
];
}
```
## How to test an update request?
`$response = $this->put('/products/' . $product->id, ['name' => 'Test']);`
## How to test for session error on 'name'?
`$response->assertSessionHasErrors(['name']);`
## How to update as json API call?
```
$response = $this->actingAs($this->user)
->put('/products/' . $product->id,
[
'name' => 'Test',
'price' => 99.99,
],
[
'Accept' => 'Application/json',
]);
```
## How to create a delete item view?
```
<form action={{ route('products.destroy' . $product->id) }} method="POST" onsubmit="confirm('Sure?')">
<input type="hidden" name="_method" value="DELETE">
<input type="hidden" name="_token" value="{{ csrf_token() }}">
```
## How to delete item in controller?
```
public function destroy(Product $product) {
$product->delete();
return redirect()->route('products.index');
}
```
## How to assert that data gets deleted?
1. Create product with factory
2. `$this->assertEquals(1, Product::all())`
3. `$response = $this->actingAs($this->user)->delete('products/' . $product->id);` (Route missing?)
4. `$response->assertStatus(302)`
5. `$this->assertEquals(0, Product::count());` | martin_betz | |
351,687 | The Dos und Don’ts of containers | So I got a very nice question from a community member here, which I would like to pick up in this ser... | 7,196 | 2020-06-10T07:17:08 | https://dev.to/habereder/the-dos-und-don-ts-of-containers-5en | containers, docker, cloud, automation | So I got a very nice question from a community member here, which I would like to pick up in this series.
It was as follows:
*I’m going from being a low-code developer to full-stack.
I’m building my first web app and wondering how I go from ‘it runs on my machine’ to ‘ive got a multi-environment, self-healing, auto-scaling, well-oiled internet machine’.
What would you say are the key tasks to achieve with containers and when should they be done in the project?*
That is a fantastic question which merits a whole series of posts to be perfectly honest. The topic of containers might seem intimidating at first.
Containers, Images, Operators, Orchestration-Tools, Ingresses, Observability, Monitoring, PaaS, CaaS, SaaS and many more buzzwords await you in the world of containers.
But fear not, there are many essentials you can always keep in mind, that I will try to cover as much as possible in this series.
These tasks/tips will get you into a great starting position, once you start tackling the topic of containers.
Let's split that question up into smaller chunks first.
We have the following three topics to talk about here:
- The key tasks to achieve with containers
- When they should be done
- The actual transition from bare-metal/manual deployment to containers
## 1) The key tasks to achieve with containers
There are many benefits to containers, here is a small list of things my customers have said in the past, that were of "special importance to them".
- Save money by using hardware as optimally as possible
- Have software be more portable
- Improve speed and quality of development
I think these reasons don't sound too bad. A lot can be already done, even without containers, but here is my take on it:
*Save money by using hardware as optimally as possible*
Containers require less overhead than the typical VM-Landscape many companies have today. By removing the hypervisor and sharing the same kernel between all containers, you suddenly get a lot more containers onto your hardware than VMs.
Not only do you save overhead, you also gain in speed. While VMs are just as scalable as containers, horizontally scaling a simple apache2 container is quite a bit faster than spinning up preimaged VMs.
*Have software be more portable*
**Damn it, I forgot to install a JDK on Server X, now the microservice won't even start!**
This won't happen with a container, since you package everything you need with your deliverable, the service.
If your container runs locally, it will run on Azure, GCS, Amazon ECS, or an on-premise PaaS (except if something is majorly borked).
*Improve speed and quality of development*
If you correctly set up your environments, a deployment to a different cluster/location/stage might just be a simple additional line:
```
kubectl config use-context aws
kubectl apply -f awesomeapp-deployment.yaml
```
Want to deploy on azure instead?
```
kubectl config use-context azure
kubectl apply -f awesomeapp-deployment.yaml
```
In my opinion, it doesn't really get easier or faster than that.
Quality, as always, is (probably) not to blame on the technology.
## 2) When they should be done
This can be answered pretty quick, I would say **as early as possible**. What I have learnt in many years of non-stop containerization is, "do it correct and right at the beginning". Go the extra mile, make your containers and surrounding infrastructure as seamless as possible. Don't skimp on things you think "might be overkill".
Automation/Optimization is boring, sometimes ugly and very cumbersome. But try to do it anyways, so you can reap the rewards as early as possible. You can easily strip out functionality you may not need afterwards. But adding onto a pipeline at the end almost always ends up in chaos.
## 3) The actual transition
What we want to achieve is, as was perfectly described before, "a well-oiled internet machine". So let's get started with the do's and don't's of containers with practical Dockerfiles.
### Tip 1) Control
Have a single base-image, all your other images derive from. If you need something on top of it, make another base-image that derives from that. Put your actual stuff another layer down in final Images.
It could look like that:
```
minimal-baseimage (for example ubuntu, alpine, centos)
|__ nginx-baseimage
| |__ awesome-website-container
|__ quarkus-baseimage
| |__ awesome-java-microservice
|__ python-baseimage
|__ awesome-flask-webapp
```
Why would you do that?
It's simple really, you need to update your images because of CVE's, patches or need something else in all your images? Update your top minimal-baseimage, kick off your CI and watch all your images getting updated to the same basic state.
Let's take a look at the path minimal -> nginx -> awesome-website.
This could be your Dockerfile for your minimal-baseimage:
```dockerfile
FROM ubuntu:18.04
RUN apt-get -y update && \
apt-get -y upgrade && \
apt-get autoclean && \
apt-get clean
WORKDIR /opt
RUN chown nobody. /opt
USER nobody
```
This could be an image that installs nginx to host your webpage for example:
```dockerfile
FROM my-ubuntu-base:18.04-somebuildnumber
USER root
RUN apt-get install -y nginx && \
apt-get clean && \
chown nobody. /usr/share/nginx/html
USER nobody
EXPOSE 80
STOPSIGNAL SIGTERM
CMD ["nginx", "-g", "daemon off;"]
```
And finally, this would be the actual container you deploy your website with:
```dockerfile
FROM my-ubuntu-nginx-base:1.18.0-stable
COPY awesomefiles/index.html /usr/share/nginx/html/index.html
```
This might look overkill, if you could replace the whole chain by doing something like this:
```dockerfile
FROM nginx
COPY static-html-directory /usr/share/nginx/html
```
But what is the difference, except copious amounts of effort for a single nginx-image with an awesome html-file?
Many things, but here are four important examples
- You know and control what is inside your container
- You can make sure it is updated and control the update process yourself
- You already got the prerequisites to fix anything when it's broken, or your security scanner complains about "outdated packages" (Which in a commercial environment will happen a lot)
- You control the security context inside your container, by example with using nobody instead of root in the official nginx image
### Tip 2) Simplicity
As a rule of thumb, always keep in mind: "one function per container".
While multiple processes in a single container are possible and in some edge-cases may be perfectly reasonable, it will increase dramatically in difficulty to manage the whole thing.
Imagine the following processtree:
```bash
root@cc726267a502:/# pstree -ca
bash
|-bash springboot.sh
| `-sleep 6000
|-bash prometheus.sh
| `-sleep 6000
|-bash grafana.sh
| `-sleep 6000
|-bash h2.sh
| `-sleep 6000
`-pstree -ca
```
What would happen if prometheus died? Nothing really, and you wouldn't even know or get informed by docker. The main process, in this case some kind of bash wrapperscript, would still run. So Docker would have no reason to restart the container or identify it as broken.
This would be the result:
```bash
root@cc726267a502:/# kill 347
root@cc726267a502:/# pstree -ca
bash
|-bash springboot.sh
| `-sleep 6000
|-bash grafana.sh
| `-sleep 6000
|-bash h2.sh
| `-sleep 6000
|-pstree -ca
`-sleep 6000
[2] Terminated bash prometheus.sh
```
If you split all these processes into their own containers, your orchestration would notice if they died and spin them back up again. More on orchestration in another part, promised :)
There are also other very practical reasons as for why you should limit yourself to a single process:
- Scaling containers is much easier if the container is stripped down into a single function. You need another container with your app in it? Spin one up somewhere else. If your container contains all the other apps, this complicates things and maybe you don't even want a second grafana or prometheus
- Having a single function per container allows the container to be re-used for other projects or purposes
- Debugging a simple container locally is way easier than pulling a gigantic god-container that was blown way out of proportions
- Patching. Update your base-image, kick off your CI and you are good to go. Having to test for side-effects in other processes isn't fun
- Above also holds true for rollbacks of changes. The update bricked your app? No problem, change the tag in your deployment descriptor back to the old one, and you are finished.
I could go on about security, too, but let's leave it at that, you probably get the point.
**Important: I am not saying that multi-process containers are inherently bad. They can work and have their uses. As a beginner into containerization, I am just recommending you to keep it as simple as possible"**
This tip won't come with a Dockerfile of the bad example really, since I don't want to encourage you starting the wrong way. Maybe later down the series we will tackle that process.
### Tip 3) Updates
As hinted towards in Tip 1) already, keep your containers updated. Always, regularly, automatically. Modern CI-Tools can help with that, most of them have webhook integrations for Git that can trigger your build-jobs. Or if you don't want to implement too much infrastructure at the start, build a cronjob or something.
Just keep it automated. You should never have to patch a container yourself, because that increases the chance to just forget it.
### Tip 4) Automation
Automate as much as possible. You don't want to fumble around in a live container. Update the source, build, push, run your CI. Never touch a running container afterwards, or you are in for a world of pain if a live-container behaves different from a freshly built one and you don't know why.
If you followed Tip 3), you already have a patch-pipeline in place, make use of that.
### Tip 5) Safety
Keep your container safe. The saying goes "nobody is perfect", which fits right into containers. User root is bad news.
Your software should run as nobody, so a breach will get the intruder exactly nowhere, even if you forget to remap your usernamespace ids.
Use base images with slimmed down containers. Your containers should contain no curl, no compilers, no ping or nslookup. Nothing that can result in changes or load to your or other peoples infrastructure if someone breaks in.
Harden your runtime with best practices, remap your user namespace ids, scan your images regularly for vulnerabilities and keep privilege escalations like `USER root` to a minimum. You know, the things you would do with a good server too. Containers should be treated like a possible Botnet member just as well.
### Tip 6) Reliability
This tip contains two things. Choose your base system wisely and stick to it as much as possible. For example **alpine**. While alpine has drawbacks, and sometimes doesn't work with what you have planned to run on it, it does provide the following advantages:
- super small footprint (6MB vs. Ubuntus 74MB or CentOS whopping 237MB)
- minimal attack surface from the outside, since alpine was designed with security in mind
- Alpine Linux is simple. It brings it's own package manager and works with the OpenRC init system and script driven set-ups. It just tries to stay out of your way as much as possible
Build your container yourself. While there might be 100 containers that already do what you want to get done, you have no idea how frequently they are patched, or what else is in them. So build the container of your dreams yourself. It helps you to get into the routine of hardening, patching and optimizing them. You can never get enough experience in that regard. Always keep in mind, "you build it, you run it, you are liable for it".
## Congrats you made it this far
I believe these few simple tips will get you a good headstart in developing healthy containers. Next time, we will take a look at how a CI for your containers could look like, by using Jenkins or Tekton.
If I left you with questions, as always, don't shy away from asking. There are no stupid questions, only stupid answers! | habereder |
351,746 | What is Positive & Negative Infinity in JavaScript? | This post is originally published at - https://www.asquero.com/vc/what-is-positive-negative-infinity-... | 0 | 2020-06-09T03:11:02 | https://dev.to/srajangupta__/what-is-positive-negative-infinity-in-javascript-4097 | javascript, webdev, node, asquero | This post is originally published at - https://www.asquero.com/vc/what-is-positive-negative-infinity-in-javascript | srajangupta__ |
377,733 | How I became a programmer | I started learning programming on FreeCodeCamp on January 2019, and on July, I became a back-end deve... | 0 | 2020-07-01T17:50:03 | https://dev.to/aldora/how-i-became-a-programmer-51h3 | newbie | I started learning programming on FreeCodeCamp on January 2019, and on July, I became a back-end developer. This maybe seems kind fast, but actually it’s just because I skipped during the course and some luck.
When I was in the middle of Data Visualization Course in FreeCodeCamp, I stopped it, and built my first [static website](https://shakalakab.github.io/ontology/) work by mimic for job interview. The website gave me the best opportunity to learn at a very fast speed. Once I finished it, I began to look for a job, within one week, I got the back-end job offer.
So, why back-end, not front-end?
Well, it’s an coincidence. I always hope to have full-stack capability, and this is the answer I gave in every job interview when asked about career plan. And I also told them my shortcoming is that I would lose patience quickly when things get iterated. Luckily, one manager just get interested by my character and learning speed, so he seriously asked me: you don’t need to wait, I can give you the offer as back-end developer now, but you only have three months to prove to us that this is a right choice for both of us, do you want to take this? I took it. Then I’m a back-end developer now.
Don’t let the better be the enemy of good. The thing I learned from this experience is: I shouldn’t wait for the perfect moment to act, I don’t need to start next step only when I get everything prepared. When I learned programming on FCC, I always thought it as a step-by-step path, I can only start next course after I get this certificate, I can only start to build my first website when I finished the whole course, I can only start when I seem perfect. No, don’t let this be a reason to postpone to act, don’t let this learning, preparing process be the reason..
If you feel struggling, it's ok. When learning programming, I found learning isn’t a linear line, it’s a spiral process. First, you got a problem, search it and get a strange word, struggle through complicated articles, you remember its name. Later, you encounter it again, not afraid this time, and read articles patiently, basically know the how. Then, it pops up again, maybe with some delicate make up, show you the point you miss. You study it one more time. Then it’s not a problem anymore but a toy. Seem like walking with same problem, but every time the known cycle get bigger. This is a typical pattern for me to learn programming.
I found building the website really helps me grow, it mixes css, js and so much problem I never expects. If we focus too much on the FCC tasks, and geting higher score, then we kind of learn things by memory, not exposed to the real battleground. Then it's natural to forget what we have memorized.
The thing they really value is your learning speed and your potential, not how good you are now, for them, no matter how much you have learned on FCC, you are just a newbie who never have real experience. Compared with knowing all answers for every question during interview, it's more important to show: 'I don't know the answer, but it doesn't matter, I can learn fast, it's not a problem". Your confidence would add the chance that they bet on you. | aldora |
351,767 | Effective Project Management - Casestudy | Overview Practically, most construction companies would want their projects to be completed and deli... | 0 | 2020-06-09T05:12:24 | https://dev.to/optisolb/effective-project-management-casestudy-23ba | machinelearning, projectmanagement, facarecognition | Overview
Practically, most construction companies would want their projects to be completed and delivered on time without any delay. It is the duty of a project manager to take proactive steps in order to avoid any hold ups.
But how can the manager get a hold of what is happening without getting an in-depth knowledge on the progress of work?
With the help of the project management tool, one can monitor the physical progress, manpower, labor productivity engineering, design status and direct cost. It assists the project team to monitor the
physical progress through Daily Progress Reports and financial progress through Cost Register Reports.
The tool identifies and assesses critical areas of each project and based on its inbuilt alert system, slippages are monitored and hierarchically escalated to various stakeholders for effective decision making and taking necessary actions.
User can download the jobs that are related to them and update their progress both online and offline.
With the help of Machine Learning, attendance can be marked by the facial recognition of employees.
The facial feature matching technology helps the application user to match the faces of the employee with the database and provide exact match.
While marking attendance, with the help of facial recognition using Machine Learning, the system will be able identify and recognize any new faces and prompts the user to create a profile for them and add it to the existing labor list.
With the assistance of AI&ML, the system will be able to identify the faces of individual laborers and match it with the database, even if it has to run a facial recognition on a group picture.
Approvals
Superiors can approve a work progress entry in a particular location by just tapping on the pin location and the list of jobs that needs approval will be listed.
Tech Stack
Xamarin Forms: Xamarin.Forms is an open source cross-platform framework from Microsoft, that extends the .NET developer platform with tools and libraries for building mobile apps.
Zetetic-SQLITE: SQLCipher is a security extension to the SQLite database platform that facilitates the creation of encrypted databases.
OpenCV: OpenCV (Open Source Computer Vision) is a library of programming function mainly aimed at real-time computer vision. It is a library that is mainly used to do all the operation related to Image processing and Video analysis, as in the case of facial recognition and detection.
Cosine Similarity: Cosine similarity is a Similarity Function that is often used in Information Retrieval. It measures the angle between two vectors and in this case, used for facial feature matching.
TensorFlow: It is a framework developed and written in Python, C++ and Cuda. TensorFlow provides multiple API’s in Python, C++, Java etc. CNN architecture with TensorFlow backend has been used to extract vector facial features, which is the architecture behind computer vision applications.
Conclusion:
With the help of this management tool, delivering a project on time can be achieved by identifying and highlighting activities that are likely to cause delay and address the issues on time.
This tool also facilitates forecasting the manpower requirement based on quantum of works planned with respect to actual productivity reflected in Productivity Register Report.
| optisolb |
351,782 | Normal people exists in tech roles? | Hello, everyone! Programing and related areas are surrounded by "gods" and "monsters" that started p... | 0 | 2020-06-09T16:08:33 | https://dev.to/andrelfa/normal-people-exists-in-tech-roles-28mp | discuss, debate | Hello, everyone!
Programing and related areas are surrounded by "gods" and "monsters" that started programing with 15 years old or maybe less and today have a startup or work on big tech companies like Facebook or Google?
Everytime I speak with them, I usually hear a history about how this person always loved technology and started in development with eleven or something, so I would like to know the life history of regular people who today work with tech, people that have interesteded for tech with 40 or that get a role in a tech position after years working in another profession. So, please, share this experiences with me :)
By the way, what is your opinion about this? Do you think that technology is surrounded by geniuses or it's just impression? | andrelfa |
351,787 | How you can host websites from home | Have an old PC or laptop that you are not using anymore? Well, guess what? You can turn it into a web... | 6,418 | 2020-06-09T07:06:05 | https://dev.to/lloyds-digital/how-you-can-host-websites-from-home-4pke | apache, server, ubuntu, website | Have an old PC or laptop that you are not using anymore? Well, guess what? You can turn it into a web server and host your website from your home network to the whole world! If you happen to have a Raspberry Pi, that’s even better because Pi is silent and very low on power consumption.
However, any computer that can run Ubuntu or similar OS will do just fine!
We will talk about network setup, firewall, Apache, virtual hosts, dynamic IP problem and more. Go make yourself a cup of coffee and dive into building your own web server at home!
___
Requirements:
* PC/Laptop/Raspberry Pi with [Ubuntu](https://ubuntu.com/download)/[Ubuntu Server](https://ubuntu.com/download/server) OS installed
* Username and password for accessing router settings
We’ll talk about:
* [Port forwarding](#portFrowarding)
* [Initial server and firewall configuration](#serverConf)
* [Installing Apache web server on Ubuntu](#installApache)
* [Setting up Apache virtual hosts](#virtualHosts)
* [Useful commands](#commands)
* [Dynamic IP problem](#dyndns)
* [Conclusion](#conclusion)
For setting up web server I will use Raspberry Pi 3 with Ubuntu 18.04 LTS installed. Always look for LTS (Long Term Support) version of Ubuntu when downloading it from the official website. If you are confident with terminal, you can also use [Ubuntu Server](https://ubuntu.com/download/server). At the time of writing this blog, the latest Ubuntu LTS version is 20.04 and is supported until April 2025.
### Port forwarding <a name="portFrowarding"></a>
Once you have your Ubuntu up and running, the first thing I recommend doing is to configure port forwarding on your home network. We are doing this to enable access to our web server over the internet. You can do this using any computer that is connected to your home network.
To access your router settings, you need default gateway IP address. To get it use Command Prompt/Terminal and enter one of three commands, depending on which OS you are currently using. Default gateway IP address is usually 192.168.1.1 or similar.
```
ipconfig | findstr /i "Gateway" // Windows - Command Prompt
ip r | grep default // Ubuntu - Terminal
route get default | grep gateway // Mac OS
```
Once you find your default gateway IP address, enter it in your web browser. You will need to enter the username and password to log in and get access to router settings. Those credentials could often be found at the bottom of a router, usually on a small sticker. If not, you can look online to find out the default credentials for your router model.
When you successfully log in, look for “Port forwarding” or “Virtual Servers Setup”. Different routers can name the same settings differently. You need to add two new entries to allow traffic through ports 22 for SSH and 80 for web server.
To do that correctly, you need the local IP address of the computer which will be used as a web server. In my case it’s Raspberry Pi which is on Ubuntu so to get Raspberry Pi local IP address all I have to do is open Terminal and enter this command:
```
hostname -I
// 192.168.1.22
```
Raspberry Pi local IP address is similar but for sure different from default gateway IP address. We need to point incoming requests to our local server address and we’ll do that through ports 22 and 80, that’s why we need our local server IP address.
So, in your router settings, you need to add those two ports to allow traffic through them to your local server IP address. When adding port 22 you can name it “SSH”, under “Server IP Address” enter your local server IP (in my case it’s 192.168.1.22) and under “External/Internal Port Start/End” enter “22”. Use TCP protocol. Do the same for port 80 and name it “Apache”.
Ok, now you have these ports configured on the router side. Go to [canyouseeme.org](https://canyouseeme.org/) and check if ports 22 and 80 are opened. There are two fields, “Your IP” which shows you your public IP address and “Port to check”. Simply enter port number 22 or 80 and click “Check Port”.
Don’t worry if you get an “Error: I could not see your service on your_ip on your_port”, that’s perfectly fine. That’s because the firewall on your server is doing a good job blocking all disallowed connections. We will get to that.
### Initial server and firewall configuration <a name="serverConf"></a>
On a freshly installed Ubuntu, it’s a good idea to do some basic server configuration so the server is ready for future use. To start configuring, open Terminal on your server (in my case Raspberry Pi) and follow along.
First of all, we'll create a new user which we’ll use to log in into the server over SSH, both inside and outside of our home network (local and external). Also, we will set a new user as “superuser” which means it will have root privileges.
This allows our new user to run commands with administrative privileges by putting the word “sudo” before each command. When creating a new user you will have to enter a password and some basic user info.
```
sudo adduser john // create new user john
sudo usermod -aG sudo john // add user john to sudo group
```
Our new Ubuntu user should now be ready, but before we can log in over SSH, we need to configure a firewall. We need to allow port 22 through the firewall so we can log in with our new user over SSH, both locally and externally.
```
sudo ufw status numbered // check current firewall status
sudo ufw allow OpenSSH // allow port 22 through firewall
sudo ufw enable // enable firewall
```
By enabling firewall and allowing port 22 through, now it’s possible to connect to our server using SSH. You should be able to connect to the server from any computer connected to your local network, and also if you have done port forwarding right you should be able to connect from anywhere in the world.
To connect to your server simply use Command Prompt or Terminal and enter the command:
```
ssh john@192.168.1.22 // local connection - use your local server IP
ssh john@xxx.xxx.xxx.xxx // external connection - use your public IP
```
If you want to connect externally, outside your local network, you can find your public IP at [canyouseeme.org](https://canyouseeme.org/) and also if you now check if port 22 is opened, you should get “Success: I can see your service on your_ip on port 22”. That means port forwarding and initial server setup are properly done. Good job!
### Install Apache web server on Ubuntu <a name="installApache"></a>
Apache web server is one of the most popular web servers and it’s fairly simple to install.
```
sudo apt-get update // update available software list
sudo apt install apache2 // install apache2 package
```
Apache is now installed and to make it work it’s necessary to modify firewall settings to allow external access to Apache web server.
Earlier we opened port 22 for connecting over SSH, now we need to open port 80 for Apache. If you are planning to install an SSL certificate on your website I recommend using the “Apache Full” profile which opens both 80 and 443. For non-SSL website “Apache” profile which opens only port 80 will do just fine.
```
sudo ufw app list // list ufw application profiles
// Available applications:
// Apache
// Apache Full
// Apache Secure
// OpenSSH
sudo ufw allow 'Apache' // opens port 80
sudo ufw allow 'Apache Full' // opens port 80 and 443
sudo ufw allow 'Apache Secure' // opens port 443
```
If you check your current firewall status, you should get a similar output. A firewall is now allowing traffic through port 80 if you used the “Apache" profile, and also through port 443 if you used the “Apache Full” profile.
```
sudo ufw status // current firewall status
// Status: active
// To Action From
// -- ------ ----
// Apache Full ALLOW Anywhere
// OpenSSH ALLOW Anywhere
// Apache Full (v6) ALLOW Anywhere (v6)
// OpenSSH (v6) ALLOW Anywhere (v6)
```
Go on [canyouseeme.org](https://canyouseeme.org/) and check if port 80 is opened. If you get “Success: I can see your service on your_ip on port 80” that means your server is accessible from the internet. Awesome!
### Setting up Apache virtual hosts <a name="virtualHosts"></a>
Before configuring Apache to serve your own website, if you check Apache status you should get “active (running)”. To check if your website works locally enter local IP server address in your internet browser (in my case that’s 192.168.1.22).
For checking if your website is available on the internet I suggest using your smartphone. Turn off your Wi-Fi and use the mobile internet (3G/4G). Open your internet browser and enter the public IP address of your home network. If you get to default Apache landing page you can be sure your server is up and running!
```
sudo systemctl status apache2 // check apache status
hostname -I // get local server IP address like 192.168.1.22
curl -4 icanhazip.com // get public IP address of your home network
```
Apache by default serves documents from the */var/www/html* directory. We’ll leave this directory as is and create our new directory which we’ll use to serve our website from.
```
sudo mkdir /var/www/mywebsite
sudo nano /var/www/mywebsite/index.html
```
Inside “mywebsite” directory, we’ll create an “index.html” file and paste some basic HTML markup, save and close the file.
```html
<html>
<head>
<title>Hello World!</title>
</head>
<body>
<h1>My website is live!</h1>
</body>
</html>
```
In order for Apache to serve this website, it’s necessary to create a new virtual host (*.conf*) file. The default configuration file is located at */etc/apache2/sites-available/000-default.conf* and we’ll also leave this file as is and create our new *mywebsite.conf* file.
```
sudo nano /etc/apache2/sites-available/mywebsite.conf
```
Inside *mywebsite.conf* file paste following configuration which is similar to the default one, but updated with your ServerAdmin, ServerName and DocumentRoot.
```
<VirtualHost *:80>
ServerAdmin your@email.com // your email
ServerName xxx.xxx.xxx.xxx // your public IP address
DocumentRoot /var/www/mywebsite // document root of your website
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
```
At this point, we need to enable created website using *a2ensite* command.
```
sudo a2ensite mywebsite.conf // enable mywebsite
```
Don’t forget to disable Apache default website using *a2dissite*.
```
sudo a2dissite 000-default.conf // disable default Apache website
```
Run test for configuration errors. You should get a “Syntax OK” message.
```
sudo apache2ctl configtest
// Syntax OK
```
Finally, restart the Apache server for the changes to take effect.
```
sudo systemctl restart apache2
```
On your smartphone, open your web browser and type in your public IP address and hit enter. If you see “My website is live!” text, you have successfully configured your Apache web server, congratulations!
### Useful commands <a name="commands"></a>
Here are some commands that you might find useful while configuring your server.
```
// UFW Firewall commands
sudo ufw allow OpenSSH
sudo ufw allow Apache
sudo ufw status numbered
sudo ufw delete X
// SSH server commands
sudo systemctl status ssh
sudo systemctl stop ssh
sudo systemctl start ssh
sudo systemctl disable ssh
sudo systemctl enable ssh
// Apache server commands
sudo systemctl start apache2
sudo systemctl stop apache2
sudo systemctl restart apache2
sudo systemctl reload apache2
sudo systemctl disable apache2
sudo systemctl enable apache2
```
### Dynamic IP problem <a name="dyndns"></a>
In most cases for home networks, the public IP address changes every 24 hours. Also if your router gets disconnected from the internet you will automatically get a new IP address when reconnected.
That’s a problem because every time your IP changes, to access your website you need to use the current public IP address of your network and also you need to update Apache config file. If you have a static public IP address then you are fine. Usually, ISP charges extra for static IPs.
There is a solution for this without having to pay for static IP. You can use free dynamic DNS service like [no-ip.com](http://no-ip.com/) where you can choose a free domain name and point it to your public IP address. You also need to add that domain name and your no-ip.com account credentials in your dynamic DNS router settings.
After you do that, your router and dynamic DNS service will work together and update your public IP address as it changes. This way, to access your website, you can always use the same domain name chosen on your dynamic DNS service as it always points to your current, up to date public IP address.
### Conclusion <a name="conclusion"></a>
You should now have a basic understanding of how the web server works. Setting up your own web server at home is a good way to train your server administration skills. Having knowledge of setting up a server at home, you shouldn’t have problems administrating one on AWS, DigitalOcean or similar services.
Where to go from here? Well, you could buy your own domain name like *mydomain.com* and point it to your server IP address. After that, you can create any number of subdomains like *subdomain.mydomain.com* and host multiple different sites, all from one Apache instance. Also, it’s a good idea to install an SSL certificate on your website. But more on that later, I need to leave some content for my next blog. 😉
| drusac |
351,801 | Understand React Redux - Introduction | This month, I started to learn more about Redux, so I decided to write a basic post with my knowledge... | 0 | 2020-06-09T06:30:44 | https://dev.to/ebraimcarvalho/understand-react-redux-introduction-5chn | react, redux, frontend, javascript | This month, I started to learn more about Redux, so I decided to write a basic post with my knowledge of Redux with React. I am also learning, so correct me if there is an error.
For Redux, you need some things:
- Reducer: A function that manages your actions and return a new state;
- Actions: A function that tells your reducer what it needs to do;
- Store: A state that will pass to our application;
There is a recomendation to focus our variables that define our actions, defining a string to a constant.
Let's look at an example, first our Reducer and Actions:
```js
// our constant with a string type
const ADD = 'ADD';
// our action creator, needs to be a pure function
const addMessage = (message) => {
return {
type: ADD,
message: message
}
}
// our reducer, also needs to be a pure function
const messageReducer = (state = [], action) => {
switch(action.type) {
case ADD :
// join the new message with the others
return [...state, action.message]
default :
return state
}
}
// need to import {createStore} from 'redux'
const store = createStore(messageReducer)
```
That's it, our state are ready. Now we need to call it on our component to read the state or send an action. Let's see how we can do that:
``` js
import {useState} from 'react';
import { Provider, connect } from "react-redux";
const Presentational = (props) => {
const [input, setInput] = useState('')
const handleChange = (e) => {
setInput(e.target.value)
}
const handleSubmit = () => {
// we can call through the props because we use mapDispatchToProps below
props.submitNewMessage(input)
setInput('')
}
return (
<div>
<h2>Type a new message:</h2>
<input type="text" value={input} onChange={handleChange} />
<button onClick={handleSubmit}>Submit new message</button>
<ul>
// we can read through the props because we use mapStateToProps below
{props.messages.map((message, index) => (
<li key={index}>{message}</li>
))}
</ul>
</div>
)
}
const mapStateToProps = (state) => {
return {messages: state}
};
const mapDispatchToProps = (dispatch) => {
// if we has another action, we will pass in this object
return {
submitNewMessage: (message) => {
dispatch(addMessage(message))
}
}
}
// connect all of this things in a Container wrapper
const Container = connect(mapStateToProps, mapDispatchToProps)(Presentational);
const App = () => {
return (
// here the magic happens
<Provider store={store}>
<Container />
</Provider>
)
}
```
That's it, I'm learning and that's what I understood so far, what did you think of redux? | ebraimcarvalho |
360,256 | Compilers - One of the more intimidating projects | The terms “compiler” and “Intermediate language” used to be somewhat intimidating to me; that is unti... | 0 | 2020-06-21T15:18:16 | https://dev.to/atleastitry/compilers-one-of-the-more-intimidating-projects-4fc9 | The terms “compiler” and “Intermediate language” used to be somewhat intimidating to me; that is until I decided to take on the challenge of building my very own compiler. Better yet, to make it a little bit more interesting, I also went ahead and developed it in Java, which is an unusual choice considering I primarily work in C#. Now, this challenge wasn’t so much a quick “look on Stack Overflow and get it done”. It required a lot of reading and research into just how compilers work. Most of my time was spent reading the “Dragon Book”, which, even though might be a bit outdated for the more modern compilers of today, possessed core concepts that are still very much relevant.
Before we dive into the nitty-gritty of my journey, it is important to understand the basic structure of a compiler. I won’t go into full detail as we can save that for another time but the following are the core steps of a simple compiler:
1. Lexical analysis - the compiler processes the source code and outputs a stream of tokens.
2. Parser - the compiler processes the stream of characters and outputs a syntax tree.
3. Intermediate code generator - the compiler processes the syntax tree and outputs some IL.
## How it was built
After installing a useful “compiler-builder” framework called “ANTLR”, the first step was to generate my grammar. This grammar would define exactly how my custom language behaves. I decided to take a strongly typed approach to my language design much like C# as it provides a bit more security against those easy semantical bugs. We all know how confusing enterprise JavaScript projects can get. The full grammar can be found [here](https://github.com/AtLeastITry/antlr-python-compiler/tree/master/src/main/antlr4).
The language I proposed looks a little something like this:
```
int b;
b = factorial(8);
int factorial(int n) {
int val;
int counter;
val = 1;
counter = 1;
while(counter <= n) {
val = val * counter;
counter = counter + 1;
};
return val;
};
print(b);
```
Once the grammar was complete, it was then time to use ANTLR to parse my source code using the grammar and generate an expression tree I could convert into my own AST (abstract syntax tree). Now, this wasn’t the most simple process but I followed the “visitor” pattern to walk through the expression tree one node at a time and then translated those nodes into my own AST. The code for the translation can be found [here](https://github.com/AtLeastITry/antlr-python-compiler/blob/master/src/main/java/compiler/implementation/visitors/ParseVisitor.java).
Now having generated my own AST, the next logical step was to run a semantic analysis to check if there were any errors in the program code I was compiling. This might include errors such as attempting to set a string value to an integer or use a variable before it is declared. The code for the semantic analyzer can be found [here](https://github.com/AtLeastITry/antlr-python-compiler/blob/master/src/main/java/compiler/implementation/visitors/SemanticAnalyser.java).
A little extra challenge I set myself was to allow the compiler to handle unbound declarations, meaning you can call a function before it is declared. Now, this required a bit more research but, in the end, I decided to tackle this problem with a simple dependency graph. My compiler generates the dependency graph after semantic analysis has occurred and then reorders the AST based on the dependencies it has graphed out. To reorder the AST, two pass-throughs must occur. In the first pass-through, the dependency graph is bound to the AST to ensure that all of the variable and function declarations are found. The dependency graph is then re-bound to the AST for the second pass-through to build up the dependencies to the variables and functions discovered in the first pass-through. The code for the dependency graph can be found [here](https://github.com/AtLeastITry/antlr-python-compiler/blob/master/src/main/java/compiler/implementation/visitors/ASTDependencyRetriever.java).
At this point, we’re at the final (and probably easiest) step of my journey - walking the AST to generate something useful. Now, this was as simple as recursively walking each of the nodes using the visitor pattern I mentioned earlier. I generated a number of “AST visitors”; the most interesting of those being a “Python visitor” which outputted the AST in executable Python code and a “DOT visitor” which outputted the AST in a DOT graph.
The entire repo of the compiler can be found [here](https://github.com/AtLeastITry/antlr-python-compiler)
## What I learned
Building this compiler was no easy task but it gave me a much deeper understanding of the high-level languages we all take for granted. I, personally, had never seen myself having to worry about symbol tables and dependencies on a low language level. It makes you take a step back and appreciate the work done from some of the clever minds out there behind the popular compilers like Rosyln and Javac. It's an incredible rollercoaster of knowledge getting to understand exactly how the code we write daily gets compiled into machine code and executed. If I could have done anything differently, I would have avoided using ANTLR and, instead, created my own lexer and grammar parser. While ANTLR was great and helped me on this journey, I feel like I skipped some of the learning experiences that I could have gained. I also would have stuck with C#, as it is within my comfort zone. Java was fine but I just had a few minor issues with it, one being the lack of dynamic method overloading as it would have simplified the implementation of the AST Visitors.
| atleastitry |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.