
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
404,332 | How do you stay motivated with your side projects? | Tips and tricks for helping stay motivated on side projects. | 0 | 2020-07-19T23:16:15 | https://dev.to/jonoyeong/how-do-you-stay-motivated-with-your-side-projects-4e59 | discuss, productivity, beginners | ---
title: How do you stay motivated with your side projects?
published: true
description: Tips and tricks for helping stay motivated on side projects.
tags: discuss, productivity, beginners
//cover_image: https://direct_url_to_image.jpg
---
For me, it's staying organized. I'm tracking my feature list on my Github project. Keeping the features relevant and up to date has helped me stay on track. Here's what my [Github project](https://github.com/jonathanyeong/phoenix_blog/projects/1) looks like:
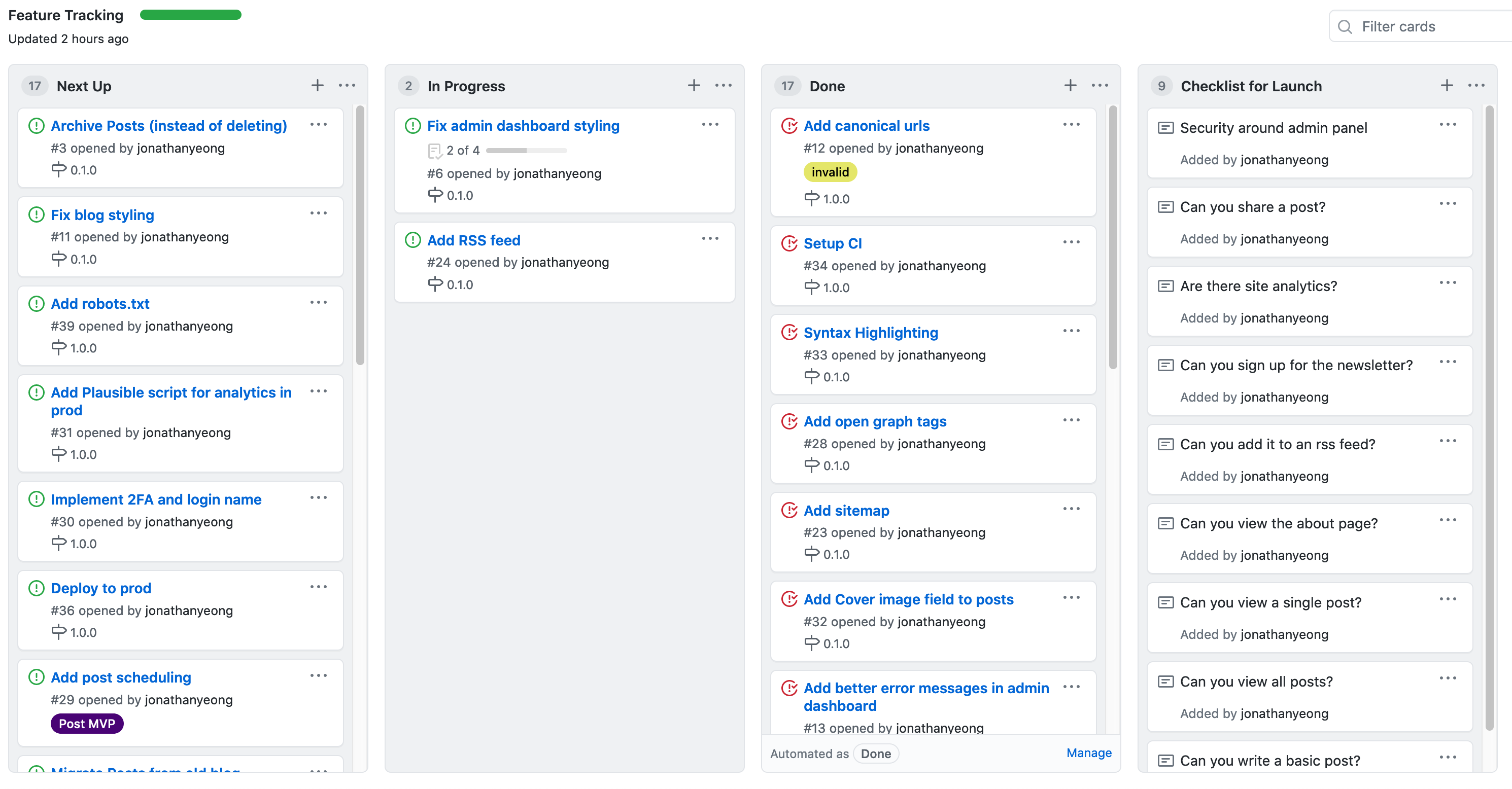
What helps keep you motivated with your side projects? I'd love to hear some of your tips and tricks! | jonoyeong |
404,432 | When to use OOP in Python if you are not developing large applications | It is not a matter of how, but why. | 0 | 2020-07-20T02:50:56 | https://dev.to/pedrohasantiago/when-to-use-oop-in-python-if-you-are-not-developing-large-applications-2h2k | python, beginners, oop, datatypes | ---
title: When to use OOP in Python if you are not developing large applications
published: true
description: It is not a matter of how, but why.
tags: python, beginners, oop, datatypes
cover_image: https://images.unsplash.com/photo-1588591795084-1770cb3be374?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1500&q=80
---
Having started studying programming from a data science perspective, I had a lot of trouble understanding not exactly *what* object-oriented programming (OOP) was, but *why* should I use it. After all, the code I wrote seemed to do just well without custom classes and objects.
Inspired by [an introduction on OOP in Python I watched in a recent online conference (in Brazilian Portuguese)](https://youtu.be/QBmEvGMZG6A) – *congrats on the talk, Maria Clara!* –, I decided to write an introduction to OOP that will not focus on syntax or Python perks (I will assume you already know fairly well how to declare classes in Python), but will actually focus on when OOP should be used. I will present: (1) to what kind of code and issues OOP was created, (2) whether it has a place in non-complex applications and (3) what features Python has that can be used besides ordinary class declarations for most of the projects.
## Why OOP in the first place?
OOP was developed as a strategy to organize code in large and complex applications.
Let's say we are making an application in a bank that will read the balance of an account from a database and decrease it under request of a user, if there are enough funds. It could follow this very simplified layout:
```python
from db_connection import db_connection
def get_balance(db_connection, account_no):
...
return balance
def withdraw(balance, amount):
if amount <= balance:
return balance - amount
else:
raise Exception('Insufficient funds')
def update_balance(db_connection, account_no, new_balance):
...
if __name__ == '__main__':
account_no = input('Type account number: ')
to_withdraw = float(input('Type amount to be withdrawn: '))
old_balance = get_balance(db_connection, account_no)
new_balance = withdraw(old_balance, to_withdraw)
update_balance(db_connection, account_no, new_balance)
```
What if we want to allow a certain category of bank accounts to withdraw more money than available in the balance under a certain interest rate, as a loan? Our code quickly becomes way more complex:
```python
from db_connection import db_connection
ACCOUNT_CATEGORIES_ALLOWED_TO_LOAN = set(...)
def get_balance(db_connection, account_no):
...
return balance
def get_account_category(db_connection, account_no):
...
return account_category
def withdraw(balance, amount, is_allowed_to_loan):
if not is_allowed_to_loan and amount > balance:
raise Exception('Insufficient funds')
else:
return balance - amount
def update_balance(db_connection, account_no, new_balance):
...
def register_loan(db_connection, account_no, amount_loaned):
...
if __name__ == '__main__':
# Get account info
account_no = input('Type account number: ')
to_withdraw = float(input('Type amount to be withdrawn: '))
acct_category = get_account_category(db_connection, account_no)
# Withdrawal operation
old_balance = get_balance(db_connection, account_no)
is_allowed_to_loan = acct_category in ACCOUNT_CATEGORIES_ALLOWED_TO_LOAN
new_balance = withdraw(old_balance, to_withdraw, is_allowed_to_loan)
# Updates
update_balance(db_connection, account_no, new_balance)
if new_balance < 0:
register_loan(db_connection, account_no, new_balance)
```
Now imagine that there could be many different bank account categories, each of them with different consequences for different operations and available funds. The code base would quickly become spaghetti code: a bunch of different functions and flow control statements that is difficult to understand and to maintain.
That is where OOP steps in. It associates a specific set of data with specific functions to act on them, in a way that the relation between the information your code is dealing with and what it is able to do with it is very clear. Let's check how this is done.
### Abstraction
Code in OOP is organized through abstractions of real-life objects. In this sense, the bank account in our application example would be a class, a "thing" with its own characteristics (the data, called "attributes" in OOP) and actions (the "methods"), just like it is in the real world:
```python
class Account:
def __init__(self, balance):
self.balance = balance
def withdraw(self, amount):
if amount <= self.balance:
self.balance -= amount
else:
raise Exception('Insufficient funds')
```
Just from taking a quick look at the snippet above, you can know that (1) every account has a certain balance (2) every account can receive a "withdraw" action. This is different from what we had in our previous spaghetti application: if we were to change anything regarding bank accounts in our system, we would have to search through all the code to find where the changes should be made – and we would have to hope that we were making the change in all the necessary places. Classes help everything be more concentrated.
Our application could now be simplified to this:
```python
from db_connection import db_connection
from classes.accounts import Account
def get_account(db_connection, account_no) -> Account:
...
return Account(balance)
def update_database(db_connection, account_obj: Account):
...
if __name__ == '__main__':
account_no = input('Type account number: ')
to_withdraw = float(input('Type amount to be withdrawn: '))
account = get_account(db_connection, account_no)
account.withdraw(to_withdraw)
update_database(db_connection, account)
```
Notice that all the actions related to changing the data related to the account (ie, the account's *state*) is not present in this script anymore. The act of withdrawing money can now be all in a separate script where the definition of the `Account` class is - a package called "classes", with a script called "accounts.py", for example. Any change related to what happens when money is withdrawn from an account should be made in that separate script; any change related to how a user withdraws money (what information is requested, for example), should be made in our main script.
If you paid attention to the type annotations, you may have noticed that the database-related functions now deal with `Account` objects directly. This makes it easier if, in addition to withdrawing money, we also want the user to be able to call other methods from the `Account` class - that would just require the addition of some more lines, with no need to instantiate new objects.
### Encapsulation
Our `Account` class can have its balance easily edited during runtime. If we do `account.balance = 0.0005`, the balance would change, even though that would be a strange amount for an ordinary account in dollars.
That is why it is recommended that the attributes of a class be encapsulated, ie, hidden from the outside world (the rest of the code). In Python, this can be done with the help of the `@property` decorator (or, alternatively, with the convention of naming attributes with leading underscores[^1]):
[^1]: Check the use of single and double leading underscores here: https://dbader.org/blog/meaning-of-underscores-in-python. This is a convention adopted in PEP8, the style guide of the Python language: https://www.python.org/dev/peps/pep-0008/.
```python
class Account:
def __init__(self, balance):
self.balance = balance
def withdraw(self, amount):
if amount <= self.balance:
self.balance -= amount
else:
raise Exception('Insufficient funds')
@property
def balance(self):
# Nothing special about getting the balance;
# we will just return it.
return self._balance
@balance.setter
def balance(self, new_value):
# When changing the balance, however,
# we want to enforce certain rules
if (new_value * 100) % 1 > 0:
raise Exception('Balance can only have up to two decimal houses')
else:
self._balance = new_value
```
Now, any time that the `balance` attribute of the `Account` class is set up with no respect to the rules defined in the `Account` class itself, an exception is raised:
```python
>>> acct = Account(55.663)
...
Exception: Balance can only have up to two decimal houses
```
Encapsulation allows the implementation of the attributes to be reserved to the code of the class itself. Instead of checking in our main script if the new balance is a valid value, this action is reserved to the class declaration. Again, this results in a more organized code.
### Inheritance
Inheritance is a nice feature of OOP that allows classes to be related to each other. When one class inherits another, all the attributes and the methods of the class it is inheriting from are automatically attached to it, with no code repetition being necessary. In our bank application, this allows different `Account` types to be easily implemented, as a different `HighIncomeAccount` type, for example:
```python
class HighIncomeAccount(Account):
pass
```
Just the lines of code above are enough to create a different data structure that has the same attributes and methods of the main `Account` class (and is recognized as an instance of it, although "indirectly", in practice), at the same time it can be recognized as an object of a different type:
```python
>>> simple_account = Account(55)
>>> high_income_account = HighIncomeAccount(99955)
>>> all(hasattr(acct, 'withdraw')
... for acct in (simple_account, high_income_account))
True
>>> isinstance(high_income_account, Account)
True
>>> type(simple_account) is type(high_income_account)
False
```
In our application, we would have to change our `get_account` function to create either an `Account` or a `HighIncomeAccount` object depending on the case. However, besides that change, the rest of the code would be able to continue calling `account.withdraw` in the same way as before. **This is how OOP programs are seen to work: as "messages" (such as the `withdraw` order) being transmitted from one part of the code to another.**
### Polymorphism
Inheritance can be better used in our application by taking advantage of polymorphism: the same method can produce different results depending on which object it is called. We can, for example, change how `withdraw` works for a `HighIncomeAccount`:
```python
class HighIncomeAccount(Account):
def withdraw(self, amount):
diff = self.balance - amount
if diff >= 0:
super().withdraw(amount)
else:
self.amount_loaned = diff
self.balance = diff
```
That way, the exception regarding insufficient funds is raised only on `Account` objects, but not on `HighIncomeAccount` objects:
```python
>>> simple_account = Account(55)
>>> high_income_account = HighIncomeAccount(99955)
>>> simple_account.withdraw(99999999)
...
Exception: Insufficient funds
>>> high_income_account.withdraw(99999999)
>>> high_income_account.balance
-99900044
```
And, once again, our main script representing the user interaction can remain unchanged (besides the database interactions, which should be updated to consider the new `amount_loaned` attribute). All the logic regarding the bank accounts is concentrated in the classes definition. The code base as a whole is, therefore, much easier to read and maintain.
## Using OOP in simpler applications
All the above makes a lot of sense if you are dealing with code for complex systems. It is a different reality, however, if you write code for exploratory data analysis, for example, which is much more objective: given a certain dataset, tasks are executed one after another in order to provide certain insights (results). In this case, classes may not be necessary, as your code may not have to deal with different data structures. If everything is a DataFrame and all your functions can act on any DataFrame, there is not much reason to waste your time creating classes and declaring different methods. Much of the features of OOP, such as inheritance and polymorphism, in fact, would just not be useful at all.
As a rule of thumb, **creating custom classes is useful when you have the need to associate specific data and actions**. That was the case in the application example above: we needed a way to associate a "balance" with a certain "withdraw" action. As a different example, it can also be useful if we are building a scraper that collects information from different sources or in different ways, as the scraper of a hospitals database that also looks for the distance between one hospital and another and checks a different database for the number of beds in the hospital:
```python
class Hospital():
def __init__(self, address):
self.address = address
self.beds_no = self.get_number_of_beds()
def get_number_of_beds(self):
...
return beds_no
def get_distance(self, to: 'Hospital'):
...
return distance
```
Using such a class in your program can make information be transmitted much more easily between different parts of your code. It is clearer and shorter to call `Hospital.get_distance(to=another_hospital)` when necessary than to retrieve an address, call a separate function like `get_distance(from=one_address, to=another_address)` and deal with scattered information.
Another good application of data and actions being put together is when you need a different custom data type. In Python, data types such as `list` and `dict` can be seen as classes with special methods - as any other class, you can inherit from them and change their behavior. Let's say you need a `list` that only accepts instances of a `dict`, and you need to be sure of that, for any obscure reason. Then you can be creative and do:
```python
class ListOfDicts(list):
def __init__(self):
# We will not accept iterables as an argument to the constructor,
# or else ListOfDicts({'a': 'dict'}) will result in ['a'].
super()
def append(self, item):
self._execute_if_is_dict(super().append, item)
def insert(self, idx, obj):
self._execute_if_is_dict(super().insert, idx, obj)
def __setitem__(self, item):
self._execute_if_is_dict(super().__setitem__, item)
def _execute_if_is_dict(self, action, *args):
if not isinstance(args[-1], dict):
raise Exception('Only dicts are accepted as items')
else:
action(*args)
```
This approach should only be used if you are really sure of which methods you need to override. It shows, however, how Python can be flexible. If you ever catch yourself asking what if a certain data type could behave in a specific way, do some research: it is probable that someone has already written a custom class that does exactly what you need.
## Beyond classes: useful data structures
You may be tempted to create a class to encapsulate a simple set of information, for example:
```python
>>> class Person:
... def __init__(self, name, age, address):
... self.name = name
... self.age = age
... self.address = address
>>> holmes = Person('Sherlock Holmes', 60, '221B Baker Street')
```
Do not do it this way for simple data structures like this one. You can aggregate data like that in a simple `dict`, and that will not raise questions regarding the possibility of any special method being attached to your `Person` class – which is, actually, very simple:
```python
>>> holmes = {
... 'name': 'Sherlock Holmes',
... 'age': 60,
... 'address': '221B Baker Street'
... }
```
This will equally allow you to retrieve information from the "holmes" object in a very direct way. It is true, however, that you may need a template, ie, a way of ensuring that every possible `Person` have three different attributes associated with it: a name, an age, and an address. That is the use case of a `NamedTuple`.
### Named tuples
A [named tuple](https://docs.python.org/3/library/collections.html#namedtuple-factory-function-for-tuples-with-named-fields) is, like a `tuple`, an immutable ordered collection. However, its items can be retrieved based on a named index, just like in a `dict`. In the end, they are like an immutable `dict` that must be created from a specific template:
```python
>>> from collections import namedtuple
>>> Person = namedtuple('Person', ['name', 'age', 'address'])
>>> holmes = Person('Sherlock Holmes', 60, '221B Baker Street')
```
Instantiating an object from a named tuple is very similar to instantiating an object from a custom class. Accessing the attributes is also done with dot notation and, besides all that, printing the object will exhibit a user-friendly representation:
```python
>>> holmes.age
60
>>> print(holmes)
Person(name='Sherlock Holmes', age=60, address='221B Baker Street')
```
### Data classes
Named tuples may present issues in some applications:
- A named tuple can be compared as equal to another that carries the same fields. The `holmes` object we created could be considered equal to a named tuple `Character(name='Sherlock Holmes', age=60, address='221B Baker Street')`, for example;
- In the same way, a named tuple is also considered equal to a tuple carrying the same fields: `holmes == ('Sherlock Holmes', 60, '221B Baker Street')` returns `True`.
- Named tuples are iterable. Part of your code may iterate on a `Person` named tuple and expect it to return a name, an age and then an address; if you add a different field to the named tuple definition (a `country` attribute, for example), you may break this other part unwillingly.
- You may want to change the values of an attribute in the named tuple. However, as tuples are immutable, that is not possible.
- You may want more complexity. Maybe you want to query Wikipedia before creating your `holmes` object, and then save the resulting link to the named tuple itself. This is not possible, as you cannot change the methods underlying the named tuple (unless you create a new custom class yourself).
- Composing the attributes in a named tuple based on other named tuples (as if doing class inheritance) is complicated and may result in obscure code.
These issues require a complex data structure - which is solved with the use of classes. However, much of the work related to the creation of a class to hold different attributes was made easier in Python 3.7 with the addition of the `@dataclass` decorator (see the [documentation](https://docs.python.org/3/library/dataclasses.html) and the discussion reported in [PEP 557](https://www.python.org/dev/peps/pep-0557/#python-ideas-discussion)). Its basic use eliminates some of the boilerplate necessary when creating a class, at the same time it adds a lot of advanced functionality for when you need something more complex than both a `dict` and a named tuple:
```python
from dataclasses import dataclass, field
@dataclass
class Person:
name: str
age: int
address: str
wikipedia_page: str = field(init=False, repr=False)
def __post_init__(self):
self.wikipedia_page = get_wikipedia_page(self.name)
def get_wikipedia_page(query):
...
return page_address
```
The code above is equivalent to this one:
```python
class Person:
def __init__(self, name: str, age: int, address: str):
self.name = name
self.age = age
self.address = address
self.wikipedia_page: str = get_wikipedia_page(self.name)
def __repr__(self):
attrs_dict = vars(self)
attrs_dict.pop('wikipedia_page')
attrs_as_str = ', '.join(f'{k}={v.__repr__()}' for k, v in attrs_dict.items())
return f'{type(self).__name__}({attrs_as_str})'
def get_wikipedia_page(query):
...
return page_address
```
What the `@dataclass` decorator does is to look for the class variables that contain a type annotation and make both a `__init__` constructor and a `__repr__` method with them. There is also extra functionality: the `field` function, for example, is telling the decorator that this field should be taken care of by the `__post_init__` function and that it should not show up in the `__repr__` result. The `dataclass` class also contains extra functionality that allows for a finer control of how the object will be instantiated (see the options of the class constructor and the field function), compared to others (see `eq` and `order` parameters of the constructor) and transformed into different data types (`asdict` and `astuple` methods) or in just a different object with different fields (`replace` method). This is a good amount of fine tuning in a much simpler code structure, as seen from the reduction of lines above.
## Conclusion
OOP does not have much space in simple, procedural programs. When necessary, however, they can add a lot of functionality to your data structures at the same time they can make code that is easier to scale and maintain. For everyday scripting (as in much of data science tasks), a `dict`, a named tuple or the simplification provided by the `@dataclass` decorator are all good alternatives to the creation of a custom class if there is no necessity of putting together specific data and functions.
---
Let me know your thoughts and comments. This is my first article on programming and any criticism is very appreciated :smile:
What do you think about OOP when not building complex applications? Do you think functional programming or other programming styles can scale just as well?
Cover image by [Ross Sneddon](https://unsplash.com/@rosssneddon?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText). | pedrohasantiago |
404,467 | Show * Database MySQL | A brief overview of Database Management Systems (DBMS) and proper syntax while interacting with MySQL... | 0 | 2020-07-20T05:07:51 | https://dev.to/jamesfthomas/show-database-mysql-4cfh | *A brief overview of Database Management Systems (DBMS) and proper syntax while interacting with MySQL.*
Before we can get into the specific meat and bones of interacting with the MySQL database, we must first do a little bit of explaining what a database is and why you would ever need to use one. Once we have established our base understanding of what and why the specific ways to interact with the MySQL database will be far more relevant to the future success of your web design projects. So without any more waisted whitespace let’s `describe * databases`.
### What is a database && why use one?
A database is simply a specifically organized assemblage of correlated electronic information that can range from a simple list of items, groups of photos, or even massive anthologies of customer-related information from a large corporation. Typically, the data or information housed within these electronic storage containers is arranged into tables, that then displayed in a column x row format, which makes interaction with these stored values far more economical. A Database is usually employed when multiple processes are accessing and altering data concurrently. The database serves to ensure that these simultaneous inquiries, do not overwrite the changes being performed on either the user or server-side. In the case of someone interacting with database information, this task is called performing a “query” and will require you to use particular verbiage to be successful in the appending or retrieving of desired data.

### Are all databases the same?
There are serval different types of databases available for use in your next project, but which one you employ is dependent upon not only some personal choices but also upon the project itself. Some considerations to help guide your database management system (DBMS) choice is:
* Data structure (how it looks and is to be presented)
* Data consistency (usability of stored data)
* Data protection (access and encryption of stored data)
* Accessibility/integration (the ability of multiple parties to
access and utilize data)
* Interaction efficiency/ scalability (response time to
interactions and ability to change data)
* Usability (regards how easy it is to work with DBMS)
* Service/implementation costs.
Once you have considered the factors that will guide your choice you can sit down and choose your DBMS type. Here is a list of some of the types of DBMS:
* Centralized – database information is stored at a centralized
location
* Distributed – database information is stored across varies sites
* Personal – data collected and stored on personal computers
* End-user – shared data designed for end-users (i.e. different
department managers)
* Commercial – for huge data sets, subject-specific, paid access
through commercial links
* NoSQL – for large sets of unstructured data
* Operational – information related to company operations
* Relational – data organized by tables (rows x columns),
predefined category
* Cloud – database built for a virtual environment
* Object-oriented – a mixture of object-oriented programing and
relations database structures.
* Graph – a type of NoSQL database that uses graph theory to store,
map, and query data relationships
With all these factors to consider and types of databases to choose from you can see just how complex this decision of which database to use in your next project can be. So, in that light, I have included links to this very influential information below in my sources section in the hope that you can utilize it to make the most appropriate choice for your project shortly. As for this blog project we will choose the relational database management system specifically MySQL and highlight how to interact with the tabled values stored within this database.
###How do I interact with relationally stored data?
Remember earlier we stated that the interaction with stored information was done via something called a query. Well that query, is simply a statement to the DBMS containing keywords along with instructions of how the program should alter data you want to target. Unlike other programing interaction verbiage, you may have encountered in the world of code, I find MySQL syntax extremely readable and more closely resembling human speech than JavaScript or syntax.
Keywords such as `SHOW`, `USE`, `CREATE`, `SELECT`, `DELETE`, `DESCRIBE`, `INSERT`, `LOAD DATA`, `FROM`, `WHERE`, `IN`, & `ORDER BY` are just some of the words and or terms used to interact in specific ways with stored data. Since this is our first encounter with MySQL syntax lets stick with some basic queries and get more advanced in the blogs to come.
**Create a new database on server**
```
mysql> CREATE DATABASE test;
```
**View existing databases on the server:**
```
mysql> SHOW DATABASES;
+----------+
| Database |
+----------+
| mysql |
| test |
| tmp |
+----------+
```
**Create a new table**
```
mysql> CREATE TABLE animal (name VARCHAR(20), owner VARCHAR(20),
species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
```
**Display the new table you just made**
```
mysql> DESCRIBE animal;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
```
**Add a value to the table you just made**
```
mysql> INSERT INTO pet
VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
```
These simple queries will get you started arranging information in your database by creating a place for and adding more values to your relational tables. We have only scratched the surface of our journey into databases, so I do hope these 4 examples show just how simple yet readable the MySQL query syntax is to understand and if you choose, put to use.
####Topic Recap:
* a database is an organized collection of electronic information
* many factors influence the type of database you will employ in
your project
* interaction with stored data is called a query, queries are
strings
* MySQL query syntax is very human-readable
##### Conclusion:
The modern database has evolved into many different choices that will be affected by a multitude of different factors that should be considered before your project beginning. I suggest a little bit of research into some queries into the syntax used in each one before you make your choice. While your free to choose anyone you want, I like the syntax utilized in the RDBMS MySQL for its human readability and structured displays. These may change with greater experience but for now, MySQL is the base I am banking on. With the information highlighted in this blog, I hope to have armed you with all you need to choose the best DBMS for your next project no matter it is big or small.
Happy Coding!!!
Sources:
* MySQL Docs (https://dev.mysql.com/doc/refman/8.0/en/what-is-
mysql.html)
* Oracle Docs (https://www.oracle.com/database/what-is-
database.html)
* “8 Key Considerations When Choosing a DBMS”
(https://blog.paessler.com/key-considerations-when-choosing-a-
dbms)
* “Types of Databases” (https://www.tutorialspoint.com/Types-of-
databases)
| jamesfthomas | |
404,559 | Javascript Promises | A promise is an object that can potentially turn into a value in the future. The value will either be... | 0 | 2020-07-20T04:11:24 | https://dev.to/jcorley44/javascript-promises-357d | A *promise* is an object that can potentially turn into a value in the future. The value will either be resolved or unresolved and if it does resolve it will be either resolved, rejected or pending. A better example of this would be to conceptually think of a promise in javascript just like a promise you might make to someone in real life. When you make that promise it will either be unresolved or resolved. While waiting for the promise to be fulfilled it has three stages of existence as mentioned previously: resolved, rejected or pending.
###**Stages of a Promise**
**Resolve**: the promise will have a value
**Reject**: the promise has failed
**Pending**: the stasis period of waiting for the promise to receive either of the two previously mentioned states.
###**Example of a Promise**
````javascript
let firstPromise = new Promise(function(resolve, reject) {
setTimeout(function() {
resolve('I will only eat one cookie');
}, 2000);
});
firstPromise.then(function(data) {
console.log(data); //will log 'I will only eat one cookie' after two seconds
});
```
Promises have become the standard way to deal with asynchronous code. Asynchronous coding models let multiple code blocks execute at the same time. It allows for new actions to start while the program is being ran. In the example the *firstPromise* is using *resolve* to fulfill the promise. After we use the *then* function to bind a callback so we can use the data from the resolve function. It is possible to bind multiple callbacks too!
````javascript
var indecisivePromise = new Promise(function(resolve, reject) {
setTimeout(function() {
resolve('I will only eat one cookie');
}, 2000);
});
indecisivePromise.then(function(data) {
console.log(data + ' hopefully.');
});
indecisivePromise.then(function(data) {
console.log(data + ' maybe.');
});
indecisivePromise.then(function(data) {
console.log(data + ' I make no promises.');
});
```
Promises can only be resolved once. The method *then* can be chained but there can only be one resolve. Just like in real life once a promise has been fulfilled you can not fulfill the same promise for a second time unless you have another condition to the promise. That's why the *then* method is useful. IT
````javascript
let multiResolvePromise = new
Promise(function(resolve, reject) {
setTimeout(function() {
//only this will revolve
resolve('first resolve');
//the promise ends after the first resolve
resolve('second resolve');
resolve('third resolve');
resolve('fourth resolve');
}, 1000);
});
multiResolvePromise.then(function success(data) {
console.log(data); //will print 'first resolve'
});
```
What happens if the promise is not fulfilled? The *catch* method allows us to have an output if the promise fails.
```javascript
const failedPromise = new Promise((resolve, reject) => {
let numberOfCookies = 1000000;
if (numberOfCookies < 1) {
resolve('Good job you only at one cookie!')
} else {
reject('I knew you would eat more than one, but one million that is madness.')
}
});
failedPromise.then((resolveData) => {
console.log(resolveData)
}).catch((rejectData) => {
console.log(rejectData)
});
```
Since the conditional statement above is false the promise fails so the *resolve* method will not trigger thus leaving the promise unfulfilled.
###Conclusion
Promises allow for coding asynchronously to be easier to understand and avoid using more complicated programming strategies. Promises will either resolve or reject depending on the criteria of the promise object. Once the promise is pending we can then chain then and catch to implement more intuitive asynchronous code instead of venturing into a "callback hell". If we were to use a lot of callbacks the code would be extremely hard to follow and become unruly making errors and debugging much harder to do. | jcorley44 | |
404,641 | Iterators in Java | The iterator pattern is one of approaches to access elements of a collection, alongside with streams.... | 0 | 2020-07-20T06:38:44 | https://www.mednikov.tech/how-to-use-iterators-in-java/ | java, tutorial | ---
title: Iterators in Java
published: true
description:
tags: java, tutorial
cover_image: https://www.mednikov.tech/wp-content/uploads/2020/07/unrecognizable-indian-man-using-laptop-while-working-at-home-4307853-1260x709.jpg
---
The iterator pattern is one of approaches to access elements of a collection, alongside with streams. From a technical point of view, the iterator traverses elements in a sequential and predictable order. In Java the behaviour of iterators is defined in _java.util.Iterator_ contract, which is a member of Java Collections Framework.
Iterators are similar to enumerators, but there are differences between these concepts too. The enumerator provides inderect and iterative access to each element of a data structure exactly once. From the other side, iterators does the same task, but the traversal order is _predictable_. With this abstraction a caller can work with collection elements, without a direct access to them. Also, iterators allow to delete values from a collection during the iteration.
## Access elements of a collection
As it was mentioned before, the order of accessing elements is predictable, which means that the iterator traverses elements sequentialy. Therefore, the general Java contract does not allow to access _the particular element_ (however, that is possible using Commons Collections, even this violates the idea). In order to access the next element, use _next()_ method. It returns an element or throws _NoSuchElementException_, when the iterator does not contain more elements.
In order to prevent this unchecked exception, you should call the _hasNext()_ method prior to accessing an element.
```java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
int x = iterator.next() * 2;
System.out.println(x);
}
```
This code snippet demonstrates the usage of the iterator for sequential retrieving of elements and the printing of double value of each element.

The important thing to note here, is that once elements are consumed, the iterator can not be used. That means, that calling the iterator after traversing will lead to an exception:
```java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
int x = iterator.next() * 2;
System.out.println(x);
}
int value = iterator.next();
```
The execution of the above code snippet will lead to the following result:

I already mentioned Apache Commons Collections. This library contains a helper class _IteratorUtils_, which has a number of static utility methods to work with iterators. While some of them violate the core pattern, they can be useful. So, alongside with a sequential access, it possible to access a particular element by its index, as well there is a wrapper method to get the first element.
```java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = numbers.iterator();
int first = IteratorUtils.first(iterator);
Assertions.assertThat(first).isEqualTo(1);
```
## Consuming an element
Since Java 8 iterators permit also to specify a consumer function, which can be performed on each element. This is a shortcut of what we can do using a while block. Let consider the first example implemented with the _forEachRemaining()_ method. Take a look on the code snippet below:
```java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = numbers.iterator();
iterator.forEachRemaining(number -> System.out.printf("This is a consumer. Value: %d \n", number*2));
```
This program listing produces the following result:

It is possible to perform such behavior with IteratorUtils. It has two static methods:
* _forEach()_ = applies the function to each element of the provided iterator.
* _forEachButLast()_ = executes the defined function on each but the last element in the iterator
Both methods accept two arguments: an iterator instance and a [closure](http://commons.apache.org/proper/commons-collections/apidocs/org/apache/commons/collections4/Closure.html) function. The second concept defines a block of code which is executed from inside some block, function or iteration. Technically, it is a same thing as a consumer functional interface. The example of using this helper method is below:
```java
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6);
Iterator<Integer> iterator = numbers.iterator();
IteratorUtils.forEach(iterator, number -> System.out.printf("This is a closure. Value: %d \n", number*2));
```
The output of this snippet is:

## Remove elements
Finally, we need to observe how to use an iterator to delete elements. The _java.util.Iterator_ interface defines the _remove()_ method. It deletes from the underlying collection the last element returned by the iterator. This method can be called only once per call of the _next()_ function. Note, that this operation is optional.
```java
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
numbers.add(4);
numbers.add(5);
System.out.println("Initial list: ");
numbers.stream().forEach(System.out::println);
Iterator<Integer> iterator = numbers.iterator();
while(iterator.hasNext()) {
iterator.next();
iterator.remove();
}
System.out.println("Modified list: ");
numbers.stream().forEach(System.out::println);
```
This code snippet executes and prints elements of the array list before and after removing elements, like it is snown on the screenshot below:

There are things to remember, when you use _iterator.remove()_:
* As this operation is optional, it can throw the _UnsupportedOperationException_, if a collection does not have an implementation of this method (that is why I used an array [list](https://www.mednikov.tech/how-to-check-if-a-list-contains-a-value-in-clojure/) and not a generic list)
* You must call the _next()_ method BEFORE calling the _remove()_ method, otherwise it will lead to the _IllegalStateException_ to be thrown
That is how you can utilize an iterator in order to access elements of a collection, to perform an action on each element or to remove elements from a collection. These are general considerations. If you want to learn how to use iterators with concrete types of collections (lists, sets, queues) and to learn more advanced iterator patterns - check my [book on Java Collections Framework](https://www.smashwords.com/books/view/1029860).
| iuriimednikov |
404,820 | Scalar Type Declaration | Today, I like to share some of the key features provided in PHP. The PHP community has introduced som... | 0 | 2020-07-20T16:16:12 | https://dev.to/ashish11/scalar-type-declaration-a28 | php | Today, I like to share some of the key features provided in PHP. The PHP community has introduced some good features like Scalar type declaration, Return type declarations, etc.., which add some extra features to the PHP development, and provides flexibility in the development lifecycle. In this blog, I would like to explain the Scalar type declaration feature, I hope this will help you to improve your knowledge and help you somehow in the future.
# Scalar Type Declaration
Type declaration is also known as Type Hinting, allows a function to accept a parameter of a certain type if the given value is not of the correct type (Integer, Float, Boolean, string) PHP will return a fatal error. The older version of PHP (PHP 5) gives a recoverable error while the new release (PHP 7) returns a throwable error.
PHP 7 has introduced the following Scalar type declarations.
1.Boolean
2.String
3.Float
4.Integer
5.Iterable
Scalar Type Declaration comes in two types Coercive(i.e. default), and another one is Strict, if we want to enforce PHP to use a strict type declaration then, we should set the strict value to 1 using a declare directive, please check the example below.
`declare(strict_types=1);`
Please check the example below for Coercive and Strict type declarations.
# Coercive Scalar Type Declaration
```
try{
function sum(int …$ints)
{
return array_sum($ints);
}
}catch(Exception $ex)
{
echo $ex->getMessage();
}
print(sum(2, ‘3’, 4.1));
```
In the above example just want to highlight one thing i.e. we are not using a strict value for parameter type like 2 of Integer type, 3 of String type 4.1 of Float type. The above code will output the value int(9).
# Strict Scalar Type Declaration
```
declare(strict_types=1);
try {
function sum(int …$ints)
{
return array_sum($ints);
}
} catch (Exception $ex)
{
echo $ex->gt;
getMessage();
}
print(sum(2, ‘3’, 4.1));
```
Note that, if we declare the `strict_type` value to 1, the above code will output “Fatal error: Uncaught TypeError: Argument 2 passed to sum() must be of the type integer, string is given”.
The above code will help us to enforce the other developer to use a variable of strict type i.e. Integer, Float, etc.
# Use of Scalar Type Declaration
The scalar type declaration can be used in different areas of development, like, defining strict values in an interface, so that, the child class which is overriding the interface must follow the strict type.
I hope that will help you somehow. Feel free to leave a comment below. Let me know what you think about this | ashish11 |
404,938 | How can I update a JSON file using fetch? | Fetch I just started using fetch to make requests over http. I used to use axios, but I do... | 0 | 2020-07-20T13:06:38 | https://dev.to/seanolad/how-can-i-update-a-json-file-using-fetch-5ag7 | explainlikeimfive, help | #Fetch
I just started using `fetch` to make requests over http. I used to use axios, but I don't any more. I need to make changes to the json file using fetch, but I don't know how. What can I do? | seanolad |
405,095 | Basic explanation – Lean Web Test Automation Architecture | This article belongs to a How to create Lean Test Automation Architecture for Web using Java librarie... | 0 | 2020-07-20T14:51:44 | https://dev.to/eliasnogueira/basic-explanation-lean-web-test-automation-architecture-3dek | java, testing, architecture | This article belongs to a How to create [Lean Test Automation Architecture for Web using Java libraries](http://www.eliasnogueira.com/how-to-create-lean-test-automation-architecture-for-web-using-java-libraries/) series
# Introduction
This is a series of articles showing how to create lean test automation architecture for web test automation using Java libraries.
**Lean** means that we will have less code as possible to create realize, maintainable and useful architecture.
**Architecture** means the organization, features, and configurations that should be present to enable you to create the automated scripts.
This first article will show to you the basic explanation about the necessary elements to create lean architecture.
# Basic Architecture
## Clean architecture
Architecture is the overall design of the project. It organizes the code into different layers and defines how they will interact with each other.
In Clean architecture, you will organize the project to make it easy to understand and change as the project evolves.
There’s an excellent post by Uncle Bob about [The Clean Architecture](https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html) that will show you a proposed organization based on an application (not a test framework/architecture).
## Design Patterns
You can use any design pattern to help you to better organize and maintain your code. There are some you can always use to achieve those benefits for a specific task.
### Factory Method
You can use the [Factory Method](https://en.wikipedia.org/wiki/Factory_method_pattern) pattern to create **browser instances** because a better test architecture for web test automation should provide an easy mechanism to create them.
You can also use this design pattern to create a Data Factory.
### Builder
You can use the [Builder](https://en.wikipedia.org/wiki/Builder_pattern) pattern to create simplify the creation of the complex objects you have in your code, like:
* in the model classes, you will create to reuse the concrete entities
* in the page object, to make it easier to consume
* in the test data builder, to make the data creation easier
### Singleton
You can use the [Singleton](https://en.wikipedia.org/wiki/Singleton_pattern) pattern reuse the same object instance among your tests, like:
* have shared access to the data of your configuration files
* share the same database connection (if you need)
## Testing Patters
As the Design Pattern, you can use some Testing Patterns that will show the same benefits.
### Base Test
You can use the Base Test to reuse the same behavior in all your tests avoiding code duplication. The best example for the web test automation is the pre and post condition you will always have: create the browser instance opening it, and close it when the test finishes.
### Test Data Factory
It combines the [Object Mother](https://martinfowler.com/bliki/ObjectMother.html) and the Fluent Builder into a class to create data for your models. Imagine you have a Payment model wherein your test you will use it to approve or reject depending. The Test Data Factory will create differents Payment objects based on the data, so you can have an amount that won’t be accepted on the approval process, and another that will be accepted.
### Page Object
You can use the [Page Object](https://www.selenium.dev/documentation/en/guidelines_and_recommendations/page_object_models/) pattern to enhancing test maintenance and reducing code duplication modeling your pages into classes that will be the interface between the code and the UI.
## Logs and Reports
Test code needs to be handled like your production code. You might face problems during the testing execution like:
* assertion errors
* elements not present in the UI
* timeout exceptions
* architecture-specific exceptions
You can add a **logging strategy** in your test architecture to easily, analyze, and understand the errors, so you can take action or have historical information about the problems.
You might need to inform your stakeholders about how reliable your application is, showing a user-friendly report that can show all the important metrics, as well as the testing evidence (like screenshots).
The **report strategy** is required even for you to quickly analyze the test results.
## Data Generation
Generate data for the test is one of the most time-consuming actions, even for automated tests, but it is necessary.
We can apply, at least, three different approaches:
* **Fake generation**: is the way we can generate non-sensitive data
* **Static generation**: is the way we can control the data through a data pool, like files (csv, yaml, txt, json, etc…)
* **Dynamic generation**: is the way we can generate sensitive data using an approach without any changes in our scripts
## Parallel Execution
This is the most needed feature in a web test architecture today, We need to execute the test as fastest as we can, and to speed up all the test execution, thought a test suite, we need to use a grid infrastructure.
The first step is to either create a parallelization solution or use an existent one present in the testing library (like JUnit or TestNG).
The second step is to define the environment solution. It can be either:
local solution using bare metal that might not scale
local solution using containers and auto-scale up and down it
cloud solution to auto-scale up and down
## Pipeline
The last item we need to create is the strategy to execute all the scripts. It will require first the definition of your **regression testing execution** where you will create est suites. Defining this strategy you can control when and where executing the test scripts.
The second part is the **pipeline script** that you should create dividing into stages to sequentially execute your test suites to get faster feedback on your application reliability. | eliasnogueira |
405,126 | Make a Ruby gem configurable | In the Ruby ecosystem, a well established way of customizing gem behavior is by using configuration... | 0 | 2020-07-21T13:32:50 | https://dev.to/vinistock/make-a-ruby-gem-configurable-228d | ruby, rails, tutorial, webdev | In the Ruby ecosystem, a well established way of customizing gem behavior is by using configuration blocks. Most likely, you came across code that looked like this.
```ruby
MyGem.configure do |config|
config.some_config = true
config.some_class = MyApp
config.some_lambda = ->(variable) { do_important_stuff(variable) }
end
```
This standard way of configuring gems runs once, usually when starting an application, and allows developers to tailor the gem's functionality to their needs.
# Adding the configuration block to a gem
Let's take a look at how this style of configuration can be implemented. We'll divide our implementation in two steps: writing a configuration class and exposing it to users.
## Writing the configuration class
The configuration class is responsible for keeping all the available options and their defaults. It is composed of two things: an initialize method where defaults are set and attribute readers/writers.
Let's take a look at an example, where we can configure an animal and the sound that it makes. If the sound does not match the expected, we want to raise an error while configuring our gem. We'll then access what is configured for animal and sound and use it in our logic.
```ruby
# lib/my_gem/configuration.rb
module MyGem
class Configuration
# Custom error class for sounds that don't
# match the expected animal
class AnimalSoundMismatch < StandardError; end
# Animal sound map
ANIMAL_SOUND_MAP = {
"Dog" => "Barks",
"Cat" => "Meows"
}
# Writer + reader for the animal instance variable. No fancy logic
attr_accessor :animal
# Reader only for the sound instance variable.
# The writer contains custom logic
attr_reader :sound
# Initialize every configuration with a default.
# Users of the gem will override these with their
# desired values
def initialize
@animal = "Dog"
@sound = "Barks"
end
# Custom writer for sound.
# If the sound variable is not exactly what is
# mapped in our hash, raise the custom error
def sound=(sound)
raise AnimalSoundMismatch, "A #{@animal} can't #{sound}" if SOUND_MAP[@animal] != sound
@sound = sound
end
end
end
```
## Exposing the configuration
To expose the configuration means both letting users configure it and allowing the gem itself to read the value of each option.
This is done with a singleton of our Configuration class and a few utility methods.
```ruby
# lib/my_gem.rb
module MyGem
class << self
# Instantiate the Configuration singleton
# or return it. Remember that the instance
# has attribute readers so that we can access
# the configured values
def configuration
@configuration ||= Configuration.new
end
# This is the configure block definition.
# The configuration method will return the
# Configuration singleton, which is then yielded
# to the configure block. Then it's just a matter
# of using the attribute accessors we previously defined
def configure
yield(configuration)
end
end
end
```
The gem is now set to be configured by the applications that use it.
```ruby
MyGem.configure do |config|
# Notice that the config block argument
# is the yielded singleton of Configuration.
# In essence, all we're doing is using the
# accessors we defined in the Configuration class
config.animal = "Cat"
config.sound = "Meows"
end
```
# Using the configuration in the gem
Now that we have the customizable Configuration singleton, we can read the values to change behavior based on it.
```ruby
# lib/my_gem/make_sound.rb
module MyGem
class AnimalSound
def initialize
@animal = MyGem.configuration.animal
@sound = MyGem.configuration.sound
end
def make_sound
"The #{@animal} #{@sound}"
end
end
end
```
# Using lambdas for configuration
In specific scenarios, there may be a need for a configuration to not have a predetermined value, but rather to evaluate some logic as the application is running.
For these cases, it is typical to define a lambda for the configuration value. Let's go through an example. The configuration class is similar to our previous case.
```ruby
# lib/my_gem/configuration.rb
module MyGem
class Configuration
attr_reader :key_name
# Define no lambda as the default
def initialize
@key_name = nil
end
# Raise an error if trying to set the key_name
# to something other than a lambda
def key_name=(lambda)
raise ArgumentError, "The key_name must be a lambda" unless lambda.is_a?(Proc)
@key_name = lambda
end
end
end
```
Now we can configure the lambda to whatever we need. You could even query the database if desired inside the lambda and return values from the app's models.
```ruby
MyGem.configure do |config|
config.lambda_config = ->(model_name) { model_name == "Post" ? :posts : :articles }
end
```
Finally, the gem can use the lambda and get different results as the app is running.
```ruby
MyGem.configuration.key_name&.call("Article")
=> :articles
MyGem.configuration.key_name&.call("Post")
=> :posts
```
That's about it for configuration blocks. Have you used this before to make your code/gems customizable? Do you know other strategies for configuring third party libraries? Let me know in the comments! | vinistock |
405,283 | Ultimate PROBLEM SOLVING GUIDE for Acing Programming Interviews | Advice like "clarify the question" and "write pseudocode" is a good place to start, but it's not wher... | 0 | 2020-07-21T16:58:40 | https://dev.to/candidateplanet/problem-solving-guide-for-acing-faang-coding-interviews-4nof | career, interview, beginners, computerscience | Advice like "clarify the question" and "write pseudocode" is a good place to start, but it's not where you want to end if you're trying to impress an interviewer with your problem solving skills. How do you actually SOLVE the problem?
In this video I dive deep into all of the steps -- and problem solving strategies -- you need in order to ace a high-bar coding interview. Watch this video if the feedback(lol) you're getting from rejections isn't helpful, and/or you want an honest explanation of what your interviewer is looking for.
In addition to challenging one-size-fits-all advice, I address the crux of the problem solving coding interview: coming up with a solution while managing risk and limited time.
For timestamp links see video description in YouTube: {% youtube -UhBywlBvw8 %}
CANDIDATE PLANET:
Empowering candidates to ace interviews, negotiate offers and advocate for themselves at work. Leave a comment or email Lusen@CandidatePlanet.com with questions you want me to answer.
PLEASE SUBSCRIBE \o/:
☆ Youtube ☆ https://youtube.com/CandidatePlanet
☆ Newsletter ☆ http://newsletter.candidateplanet.com
☆ LinkedIn ☆ https://linkedin.com/in/lus
ONE-ON-ONE COACHING:
Schedule a one-on-one coaching session with me: https://lusen.youcanbook.me
SALARY NEGOTIATION PLAYLIST:
☆ https://www.youtube.com/playlist?list=PLY0uEDNh-Haqes9eEvyGtzrUWOHv-c1op
ACE YOUR INTERVIEWS PLAYLIST:
☆ https://www.youtube.com/playlist?list=PLY0uEDNh-HarP6UtKFYRJZnkXzz4ICi73
Dubstep bee and Kipo art inspired by Kipo and the Age of Wonderbeasts. | candidateplanet |
405,393 | Gooey SVG Effects, Game UI, and Meetups - Frontend Horse #7 | This is an issue from the newsletter Frontend Horse. This was originally published on July 16th, 2020... | 7,253 | 2020-07-20T19:31:13 | https://frontend.horse/issues/7/ | webdev, css, html, javascript | _This is an issue from the newsletter Frontend Horse. This was originally published on July 16th, 2020. Visit [Frontend.Horse](https://frontend.horse) to subscribe and find more issues._
---
Helloooo, and welcome to _the Seabiscuit of frontend newsletters_!
We’ve got a coffee cup, a Zelda UI tutorial, and a meetup I'm hosting all ready for race day. I hope you're wearing [some ridiculous clothing and your fanciest hat](https://www.thetrendspotter.net/what-to-wear-to-the-races/).
So place your bets, find your seats, and let’s get started!
---
### CODEPEN
## Coffee For You

I’m amazed by the level of detail and care that’s gone into [Vadim Bauer](https://twitter.com/BauerVadim)’s gorgeous [cup of coffee](https://codepen.io/v_Bauer/pen/zYrBoJa). It's a great piece and _I just had to know how he made it._
{% codepen https://codepen.io/v_Bauer/pen/zYrBoJa %}
The detailed CSS drawing is stunning in its own right. However, the part that dropped my jaw was the animation on the bubbles. They drift from the center of the cup towards the edge to join the other foam there. When they get close, the edge foam moves outward like real form on liquid would!
How the heck is he achieving this effect?
His answer? **SVG Filters**
Welp, it’s official: I’m crushing _hard_ on SVG filters. They’re just so dang versatile! In previous issues we’ve seen them used to make water and lightning effects. Now you’re telling me that they can make stuff goop together? So rad.
Vadim breaks down the effect:
> It’s an SVG filter that basically applies a huge blur to the elements and then increases the contrast for the alpha channel, so that the now bigger shape doesn’t look blurred anymore. The result is the elements merging when they get close to each other.
> It’s known as the gooey effect. You can find a pretty good post about it on [CSS-Tricks: Gooey Effect](https://css-tricks.com/gooey-effect/)
This is an awesome tutorial and you can see how it’s similar to Vadim’s effect.

The other thing I loved about “Coffee for you” was the subtle steam that drifted by. Guess how he made it?
> That’s also an SVG filter. This time with feTurbulence for the texture and feDisplacementMap to distort it. The rest was pure trial and error to get it to look like some real steam.
To learn, Vadim recommends digging into the CodePens you admire and playing with them.
> Changing things and seeing what happens is always a great way to learn about code.
Vadim, I couldn’t agree more.
[Check it out ->](https://codepen.io/v_Bauer/pen/zYrBoJa)
---
### TUTORIAL
## Building a Zelda UI
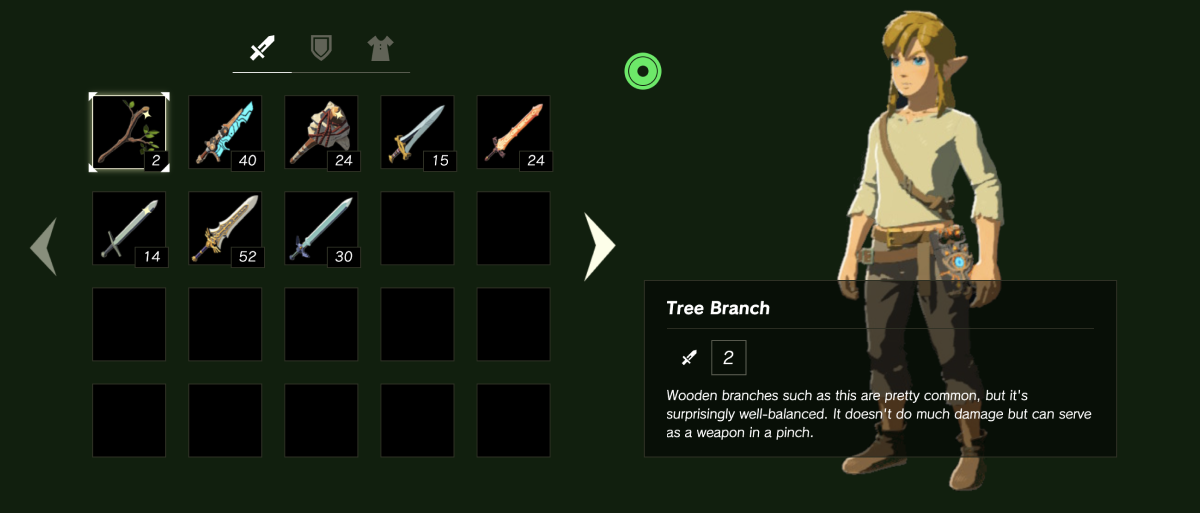
I’ve always been a fan of video games, and the Zelda series is by far my favorite franchise. So when my friend Tim sent me a [a Zelda UI tutorial](https://dev.to/flagrede/how-to-replicate-the-zelda-botw-interface-with-react-tailwind-and-framer-motion-part-1-298g), how could I not dig into it?
At first I thought it was just a cool idea, maybe a fun gimmick for a tutorial. But it’s much more than that. The author, [Florent Lagrede](https://twitter.com/flagrede), shows you how to build out a quality UI using React, TailwindCSS, and Framer-Motion.
This is the gummy-vitamin of tutorials. Zelda is the hook, but there’s great stuff here, too.
So much of teaching is packaging the content in ways that the learner enjoys. That’s why people like Bill Nye the Science Guy was able to sneak so much education into our brains.
Throughout both articles, Florent decomposes the interface down to small parts, and concretely talks about how he plans to implement it. Turning a design spec into a web layout is such an important skill to develop, and it’s always helpful for me to see how other people approach it.
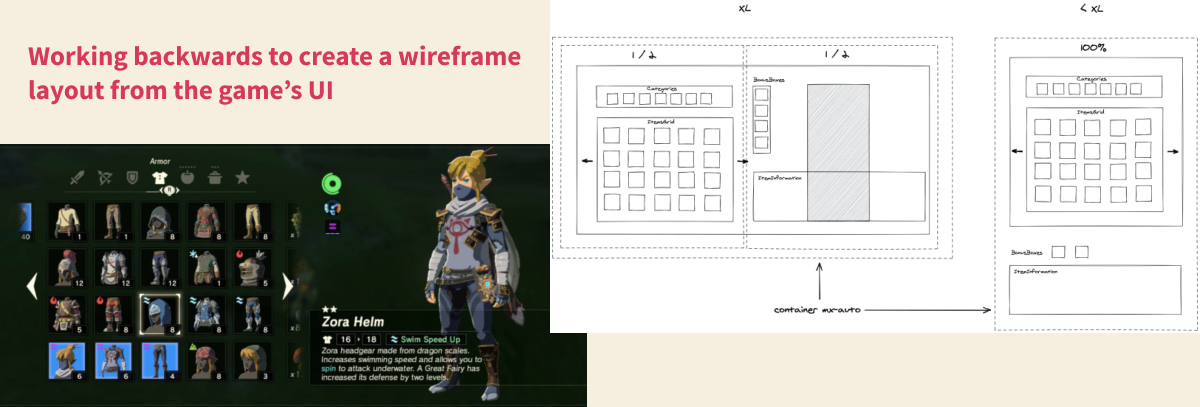
[The result](https://www.gameuionweb.com/zelda-botw/inventory) is just awesome. Not only can you navigate with your keyboard the way you’d expect to in the game, but it even accurately combines character buffs you get from wearing certain parts of clothing.
The tutorials are a part of something larger: Florent’s project, [Game UI on Web](https://www.gameuionweb.com/). It’s Florent’s site where he’s recreating video game UIs and creating tutorials on his process. To start he’s recreated menus from Hollow Knight and Zelda. It started when Florent was looking through the UI resource [Interface In Game](https://www.interfaceingame.com), which has hundreds of stills and videos from all kinds of video games. He wondered _why can’t we do this on the web_?
So he built out the [Hollow Knight demo](https://www.gameuionweb.com/hollow-knight) as a challenge, and had so much fun he got hooked on making game UIs.

> Then I came up with the idea to make tutorials that would focus on _doing_ instead of only _reading_. As developers, I think we learn best by doing. However, it can be difficult to get started. I find that having a motivating goal can help you begin. Having fun while learning makes the process even easier.
I asked Florent what he thought web developers could learn from building these game interfaces? He said:
• How to make interactions more enjoyable, visible and understandable
• Small details that add to the experience
• Using sounds in an interface
While web dev has a lot of ‘sameness’ right now, Florent’s projects and tutorials on GameUIonWeb feel unique. Creating game UIs with web technology is such a great concept. So many UX design principles carry over.
Picking apart a well designed game UI will deepen your understanding of web and user experience design. Plus, as the [web becomes more whimsical](https://whimsical.club/), some of these game dev skills are going to come in handy!
**What’s to Come**
Florent has big plans for Game UI on Web. He wants to build more game UIs that go beyond the ‘inventory menu’ type that he’s done already. He also wants to write tutorials that teach web developers the tricks that bring delight and joy to games.
I think it’s safe to say that Florent wants to make the web a lot more fun.
Check out [Part 1](https://dev.to/flagrede/how-to-replicate-the-zelda-botw-interface-with-react-tailwind-and-framer-motion-part-1-298g) and [Part 2](https://dev.to/flagrede/how-to-replicate-the-zelda-botw-interface-with-react-tailwind-and-framer-motion-part-2-3nd4) of his Zelda Breath of the Wild tutorial. Then check out [Game UI on Web](https://www.gameuionweb.com/) to see the demos of what he’s built so far.
### Resources
This [Interface In Game](https://interfaceingame.com/) site is such a fantastic resource. For example, check out this huge collection of [Animal Crossing screenshots and videos](https://interfaceingame.com/games/animal-crossing-new-horizons/)!
Florent created his excellent wireframes in [Excalidraw](https://excalidraw.com/), a free web-based drawing tool.
---
### EVENT
## Codefwd: Design Patterns
If you’re reading this as it comes out, then I have some exciting news! I’m going to be hosting a meetup with a wonderful round of talks and I’d LOVE to see you there!
We’ll be streaming over on the [Codefwd Twitch channel](https://www.twitch.tv/codefwd) starting at 6PM EST. Please ride through and throw some horse puns into the chat! It’s my first time hosting a remote conference, so I’m pretty excited.
Here’s the lineup:
* Responsive Design in 2020 - Kilian Valkhof
* Event Driven Serverless Microservices - Gareth Mc Cumskey
* Simple Rules for Complex Systems - Jake Burden
* MongoDB Schema Design Best Practices - Joe Karlsson
I hope to see you there!
---
## So Long, Partner
And it's a photo finish! What a race, I don't care who won, I'm just glad you were here for it!
Follow [@FrontendHorse on Twitter](https://twitter.com/frontendhorse). If you enjoyed this I’d be over the moon if you share it with a friend or tweet about it.
Special thanks to Vadim Bauer and Florent Lagrede for speaking with me about their work.
Now let's get out of here before the next race starts. You take care.
Your Neigh-bor,
Alex
---
If you liked this post, head to [Frontend.Horse](https://www.frontend.horse) to subscribe! You'll get the next issue before it's posted here on Dev. | trostcodes |
405,537 | Resource recommendations | I am currently teaching myself web development through online courses and other means. I work four 12... | 0 | 2020-07-20T23:12:45 | https://dev.to/kessinger_c/resource-recommendations-e6n | discuss | I am currently teaching myself web development through online courses and other means. I work four 12 hour shifts each week, during those times I am not around a computer so coding isn’t possible. Does anyone have any recommendations for books, blogs, or any other source that I could read on web dev while I am at work? | kessinger_c |
405,565 | Kinx Library - Isolate (Multi Thread without GIL) | Hello, everybody! The script language Kinx is published with the concept of Looks like JavaScript, F... | 0 | 2020-07-29T21:49:18 | https://dev.to/krayg/kinx-library-isolate-multi-thread-without-gil-1m5e | kinx, ruby, javascript, thread | Hello, everybody!
The script language [Kinx](https://github.com/Kray-G/kinx) is published with the concept of **Looks like JavaScript, Feels like Ruby, Stable like AC/DC(?)**.
This time it is an Isolate, which is a native thread library without **GIL**.
* Reference
* First motivation ... [The post of introduction](https://dev.to/krayg/kinx-as-a-script-language-4iko)
* Kinx, I wanted a scripting language with a syntax of C family.
* Repository ... https://github.com/Kray-G/kinx
* I am waiting for pull requests.
As you can see from the name Isolate, as a thread model, each thread operates independently and does not share the memory. This is chosen to increase safety.
## Isolate
### Model of multi threading
The memory sharing model of threads like C/C++ is too dangerous and difficult. You have to pay attention much to the race condition trap and ensure deadlock control, but you will still get deadlock easily. The battle between multithreading and safety is still ongoing.
The threading model of Ruby and Python is safe, but its weakness is that GIL (Global Interpreter Lock) gives many limitations for parallelism.
* [GIL (Global Interpreter Lock)](https://en.wikipedia.org/wiki/Global_interpreter_lock)
Let's challenge this wall also at **Kinx**. Ruby hasn't been freed from GIL due to past concerns, but it's likely to move on to the next stage.
So Kinx prepared the mechanism named as **Isolate**. It's a completely independent **native thread**. The exchange of information is limited to Integer, Double and String. Therefore, if you want to send an object, you need to prepare the mechanism of serializing and deserializing it. The most easy way is to make it a string and just execute it because the source code of Isolate is given as a string.
But note that only the compile phase is not reentrant. So the compilation phase will be locked and processed in sequence.
### Isolate Object
Roughly, the Isolate object is used as follows.
* Create an Isolate object by `new Isolate(src)`. Not executed yet at this point. `src` is just a string.
* Compile & execute with `Isolate#run()`. The return value is `this` of the Isolate object.
* By `Isolate#join()`, wait for the thread to finish.
* When the main thread ends, all threads will end **with nothing to be cared**.
* Therefore, when controlling the end, synchronize by using a method such as data transfer described later, and correctly `join` in the main thread.
### Example
#### Creating a new thread
Look at the example first. What is passed to the constructor of Isolate is just a **string**. It feels good to looks like a program code when write it as a raw string style, but there is a trap on it.
* A `%{...}` in a raw string has been recognized as an inner-expression for the raw string itself.
So, you had better avoid to use `%{...}` inside a raw string.
For example below, using `%1%` for that purpose and applying the value directly into a string. It is like a little JIT.
```javascript
var fibcode = %{
function fib(n) {
return n < 3 ? n : fib(n-2) + fib(n-1);
}
v = fib(%1%);
var mutex = new Isolate.Mutex();
mutex.lock(&() => System.println("fib(%1%) = ", v));
};
34.downto(1, &(i, index) => new Isolate(fibcode % i).run())
.each(&(thread, i) => { thread.join(); });
```
Locking for printing has been used to avoid to a strange output.
```
fib(15) = 987
fib(10) = 89
fib(20) = 10946
fib(3) = 3
fib(11) = 144
fib(21) = 17711
fib(4) = 5
fib(9) = 55
fib(23) = 46368
fib(16) = 1597
fib(14) = 610
fib(8) = 34
fib(2) = 2
fib(24) = 75025
fib(26) = 196418
fib(28) = 514229
fib(29) = 832040
fib(7) = 21
fib(30) = 1346269
fib(25) = 121393
fib(5) = 8
fib(13) = 377
fib(12) = 233
fib(19) = 6765
fib(22) = 28657
fib(18) = 4181
fib(17) = 2584
fib(6) = 13
fib(27) = 317811
fib(31) = 2178309
fib(1) = 1
fib(32) = 3524578
fib(33) = 5702887
fib(34) = 9227465
```
The order might be changed because of a multi thread.
```
fib(10) = 89
fib(19) = 6765
fib(14) = 610
fib(11) = 144
fib(26) = 196418
fib(17) = 2584
fib(21) = 17711
fib(20) = 10946
fib(9) = 55
fib(13) = 377
fib(28) = 514229
fib(18) = 4181
fib(30) = 1346269
fib(31) = 2178309
fib(7) = 21
fib(3) = 3
fib(8) = 34
fib(4) = 5
fib(25) = 121393
fib(16) = 1597
fib(22) = 28657
fib(23) = 46368
fib(12) = 233
fib(27) = 317811
fib(29) = 832040
fib(15) = 987
fib(2) = 2
fib(5) = 8
fib(1) = 1
fib(6) = 13
fib(32) = 3524578
fib(24) = 75025
fib(33) = 5702887
fib(34) = 9227465
```
#### End of thread
The thread will be finished when the `Isolate` code has been reached at the end.
The returned status code from the thread will be returned as a return code of `join`.
```javascript
var r = new Isolate(%{ return 100; }).run().join();
System.println("r = %d" % r);
```
```
r = 100
```
#### Transfer data - Isolate.send/receive/clear
For simple data transfer you can use `Isolate.send(name, data)` and `Isolate.receive(name)`. The buffer is distingished by `name`, the threads are send/receive data by the `name`.
* `name` can be omitted. When it is omitted, it is same as specifying `"_main"`.
* As `data`, only Integer, Double, and String is supported.
* That is why for an object, you should stringify it and it should be reconstructed by receiver.
* To clear the buffer by `Isolate.clear(name)`.
* If you do not clear the buffer by `Isolate.clear(name)`, the buffer data will be remaining. It means the same data can be got by `Isolate.receive(name)` many times.
#### Mutex
Mutex object is constructed by `Isolate.Mutex`. By the way, the mutex is distinguished by the name even if it is in the same process.
```javascript
var m = new Isolate.Mutex('mtx');
```
By using the same name, the same mutex will be constructed. If you omit the name, the name will be the same as `"_main"`.
Mutex object is used with `Mutex#lock(func)` method. The callback function of `func` is called with a locked mutex.
```javascript
var m = new Isolate.Mutex('mtx');
m.lock(&() => {
// locked
...
});
```
#### Condition
You can use a condition variable. That is used with a mutex object together. When passing a locked mutex to `Condition#wait()`, it waits after mutex is unlocked. In that status, when another thread do the `Condition#notifyAll()` and the thread can get the lock, to come back from the waiting status.
`Condition#notifyOne()` is not supported because everybody says 'nobody should use it!'.
```javascript
var cond = %{
var m = new Isolate.Mutex('mtx');
var c = new Isolate.Condition('cond');
m.lock(&() => {
var i = 0;
while (i < 10) {
System.println("Wait %1%");
c.wait(m);
System.println("Received %1%");
++i;
}
System.println("Ended %1%");
});
};
var ths = 34.downto(1, &(i, index) => new Isolate(cond % i).run());
System.sleep(1000);
var c = new Isolate.Condition('cond');
16.times(&(i) => {
System.println("\nNotify ", i);
c.notifyAll();
System.sleep(500);
});
ths.each(&(thread) => {
thread.join();
});
```
#### NamedMutex
It is a mutex object with using between processes. To construct it, use `Isolate.NamedMutex`, but the usage is same as a normal mutex object.
But I do not know if it is good that the name should be `Isolate.NamedMutex`, because it role is over the `Isolate`. If you have any idea of that, please let me know. For example, `Process.NamedMutex`, or `System.NamedMutex`, or something.
```javascript
var mtx = Isolate.NamedMutex('ApplicationX');
mtx.lock(&() => {
...
});
```
It is used when you want to exclusive it with other processes.
### Data serialization and deserialization
So far, there is no feature of serializing and deserializing data. You do it yuorself. In fact, I hope I want to add some features for that, so I am now thinking about the functionality of that.
Now what you can do is to stringify it and reconstruct it to the object. When it is the JSON object as a simple structure, you can realize it by `JSON.stringify` and `JSON.parse`. As an another simple way, you can also put it directly with `toJsonString()`.
```javascript
var t = %{
var o = %1%;
System.println(["Name = ", o.name, ", age = ", o.age].join(''));
};
var o = {
name: "John",
age: 29,
};
new Isolate(t % o.toJsonString()).run().join();
```
```
Name = John, age = 29
```
You want to pass data dynamically, you need the code to deserialize it.
```javascript
var t = %{
var o;
do {
o = Isolate.receive();
} while (!o);
System.println("Received message.");
o = JSON.parse(o);
System.println(["Name = ", o.name, ", age = ", o.age].join(''));
};
var o = {
name: "John",
age: 29,
};
var th = new Isolate(t).run();
Isolate.send(o.toJsonString());
th.join();
```
```
Received message.
Name = John, age = 29
```
## Conclusion
To realize a native thread without GIL, I did a lot of things depended on the runtime context and I designed the C function of Kinx should be reentrant. I believe it is really unnecessary to lock by GIL, if there is no mistake and bug...
To tell the truth, I ca not promise I haven't made a mistake. I believe you understand it if you were a developper. But I don't face any problem so far. Of course I will fix it if you report the bug.
Anyway, this is a challenge!
As I wanted to add the functionality of Isolate as a multi-threading for the multi-core, I did it. But it is still on the early stage. Challenge anything!
See you next time.
| krayg |
405,578 | Kubernetes Services | In this tutorial post, we will see why we need service and then see what is a service and the types o... | 7,787 | 2020-07-21T02:50:44 | https://dev.to/preethamsathyamurthy/kubernetes-services-4f44 | tutorial, kubernetes, devops | ---
series: 'Kubernetes in Private Cloud'
---
In this tutorial post, we will see why we need service and then see what is a service and the types of services in Kubernetes.
Let us take our scenario where we have a WordPress and MySQL deployments.
Now, if we want to establish connectivity from a Wordpress pod to another MySQL pod, the MySQL pod does not know which pod to connect to. As a hypothetical scenario, we have to establish a connection via IPs and when we establish a connection by hardcoding IPs, we keep giving work to the same MySQL pod and the other pods are not utilized.
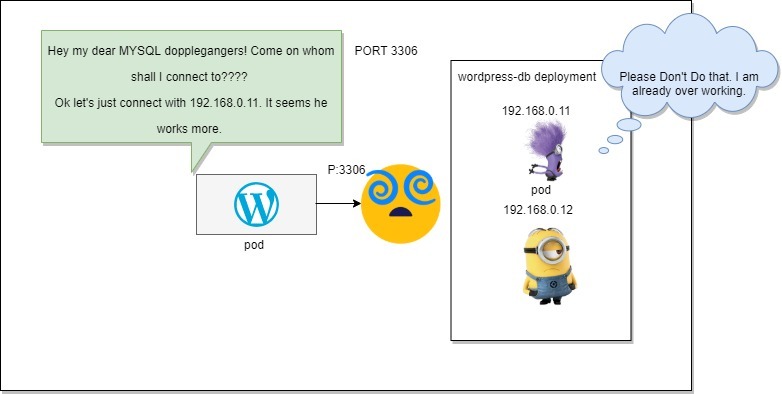
Now that takes away the very benefit that deployments give and the pods become mortal again. Let's say a pod with x IP is deleted, the deployment controller will create another pod with y IP. Now, WordPress pod doesn't know which MySQL pod it should connect to as it only knew pod with x IP.
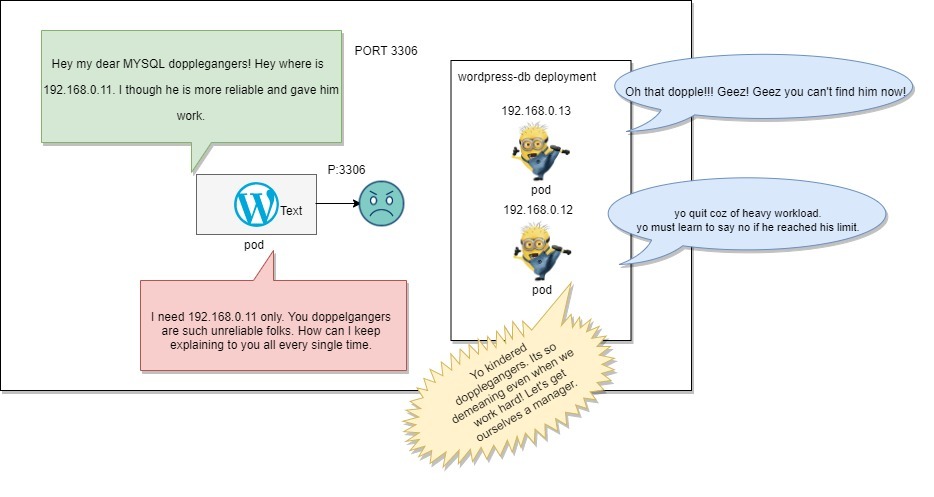
Its a pandemonium. Now the MySQL pods decide that they will get themselves a manager which will be discovered easily by the WordPress Pod and to others if needed by a single static name and load balance the work among them.
> Thus services are born. A Kubernetes Service is an abstract way to expose an application running on a set of Pods as a network service. With Kubernetes, you don't need to modify your application to use an unfamiliar service discovery mechanism.
Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods and can load-balance across them.
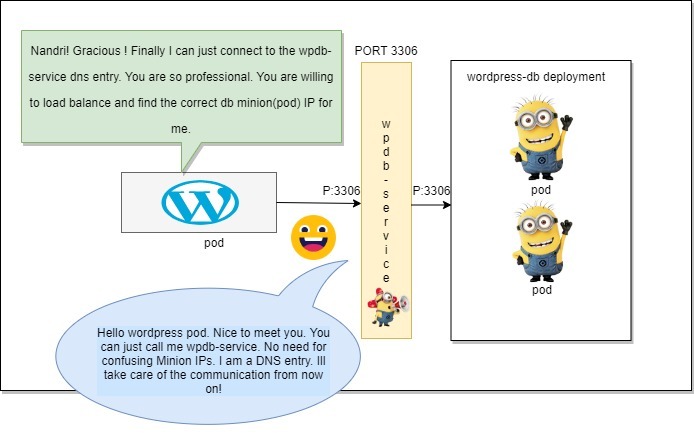
Now the WordPress pod doesn't need to know about MySQL pod or its IPs. It only needs to know about the name of the service that front-ends the MySQL pods.
> You can have many services within the cluster. Kubernetes services can efficiently power a microservice architecture.
Services provide features that are standardized across the cluster(irrespective of the nodes on which the service and pods are running on):
<ul>
<li>Load balancing
<li>Service discovery between applications (DNS,port-mapping).
<li>Features to support zero-downtime application deployments (on combination with rollingUpdates of deployments).
</ul>
There are 3 different types of services.
<ul>
<li>ClusterIP
<li>NodePort
<li>LoadBalancer
</ul>
####ClusterIP
This is the default Service type. It exposes the service on a cluster internal IP. Choosing this type makes the service reachable only from within the cluster.
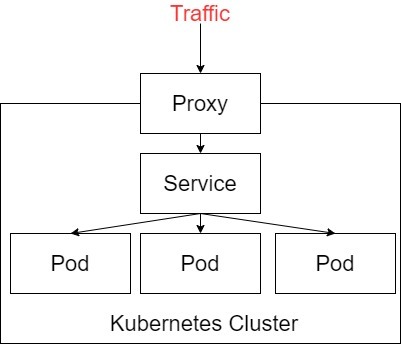
So except the web or app service, all other services which should not be accessed from the outside like DB use ClusterIP service.
####NodePort
A NodePort is a very basic way to get external traffic directly to your service.
NodePort opens a specific port on your node/VM and when that port gets traffic, that traffic is forwarded directly to the service. The service is applied to all nodes in the cluster(master and workers) and hence can be accessed by http://anyNodeName:port.
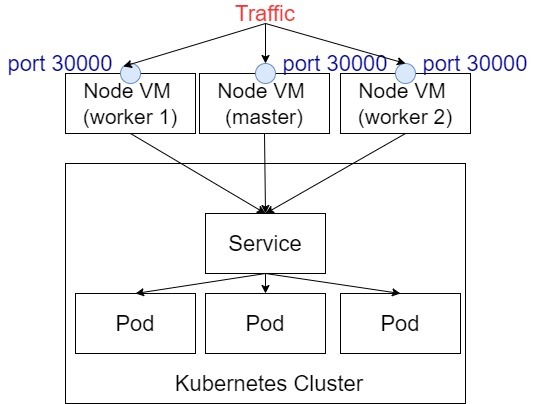
For a NodePort service, Kubernetes allocates a port from a configured range ( default is 30000 - 32767). We cannot use standard ports like port 80 or 8080. It is possible to define a specific port number(in the range), but you should take care to avoid potential port conflicts.
There are a few limitations like
<ul>
<li> Only one service per port
<li> You can only use ports 30000-32767.
<li> Dealing with dynamic or changing node/VM IP is difficult.
</ul>
####LoadBalancer
A LoadBalancer is the standard way to expose a service to the internet.
> `Only in case of public cloud providers like Azure, GCP, AWS, etc, on creating a service of type LoadBalancer, an external LoadBalancer in that public cloud would be created.`
In the case of a private cloud, by default, a service of type LoadBalancer would behave like a service of type NodePort. A custom load balancer like NGINX or load balancers applications like DevCental F5 will use the IP and port of the nodes on which the service is running to load balance it.
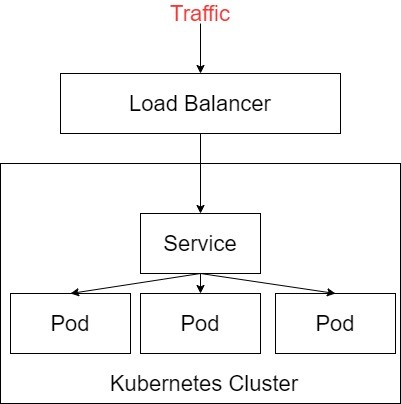
A service manifest like other kubernetes object manifests have
<ul>
<li> apiVersion
<li> kind
<li> metadata
<li> spec - selector and ports
</ul>
###.spec
####.spec.type
`.spec.type` specifies the type of service we need to create.
Default is ClusterIP and other acceptable values are NodePort and LoadBalancer.
####.spec.selector
Like we have seen in a deployment manifest, `.spec.selector` must match the `.metadata.labels` of the pods which have to be load-balanced and catered by this service. This is the link between the service and the pods in the deployment.
The difference between deployment manifest and service manifest selectors is that deployment manifest selector will have `.spec.selector.matchLabels` and service manifest will have `.spec.selector`
####.spec.ports
Below, ports[i..n] represents the index of the port object
<ul>
<li> .spec.ports[i..n].port represents the port on which the service is listening to.
<li> .spec.ports[i..n].targetPort represents the port of the pods to connect to.
<li> .spec.ports[i..n].protocol is the protocol to use - default is tcp
<li> .spec.ports[i..n].name is the name of the virtual server (each port)
</ul>
.spec.ports is an array and we can define multiple ports here.
```yaml
---
apiVersion: v1
kind: Service
metadata:
name: app-service
labels:
app: wordpress
type: app-service
spec:
selector:
app: wordpress
type: app
type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 80
name: wordpress
```
In the above example, we created a service of type LoadBalncer and the values in .spec.selector should match with the label of the pod to connect to and port 80 represents that the service is listening to requests on port 80 and targetPort 80 represents that the service is sending traffic to the nodes on port 80.
| preethamsathyamurthy |
405,628 | Hosting your WordPress Site on Microsoft Azure: Pros and Cons, and How to Use | Azure is a top cloud vendor offering a wide range of cloud storage services, which you can use to hos... | 0 | 2020-07-21T01:54:06 | https://metabox.io/hosting-wordpress-site-microsofm-azure/ | wordpress | Azure is a top cloud vendor offering a wide range of cloud storage services, which you can use to host your WordPress site. This article examines key pros and cons of hosting WordPress on Azure, explains the installation process, and explores four pro tips you can use to optimize your Azure-based WordPress site.
### What Is Azure?
Azure is a platform for cloud computing that is available in software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS) formats. You can use Azure to gain access to storage, computing, or networking resources as well as pre-built services like backends for web apps or machine learning tools.
Some of the most valuable features of Azure cloud services include:
- **Scalability** --- you can manually or automatically scale resources to meet traffic demands and optimize resource use.
- **Flexibility** --- you can deploy Azure resources with most operating systems, frameworks, and tools. You can also deploy fully in the cloud or in hybrid configurations.
- **Reliability** --- Azure resources are provided with service level agreement (SLA) ensuring 99.5% availability.
- **Global** --- Azure provides access to globally distributed resources with data centers available in all regions of the world.
- **Cost-effective** --- you can use resources and pay-as-you-go, avoiding upfront costs or fees for unused services.
### Hosting Your WordPress Site on Microsoft Azure: Pros and Cons
When deciding which provider to host your site with, there are several pros and cons about Azure that you should consider.
### Pros of Azure
The benefits of hosting on Azure resources include:
- **Better user experience** --- Azure enables you to distribute traffic workloads across multiple resources with low latency. This can help ensure that content loading happens smoothly for all users regardless of how many active requests you have.
- **Autoscaling** --- your resources can scale up or down as needed. This can help ensure that your services remain available with consistent performance. It can also help you save costs by scaling down when traffic demands decrease.
- **Integrated** [**content delivery network (CDN)**](https://gretathemes.com/speed-up-website-using-cdn/) --- Azure offers a built-in CDN that you can use to cache static, high-bandwidth content. It also includes functionality that enables you to use edge computing for faster delivery of dynamic content.
- **Reliability** --- any data stored in Azure is automatically replicated across resources to ensure availability and protect you from single points of failure. You can also easily backup data via Azure Backup.
### Cons of Azure
The downsides of hosting on Azure include:
- **Price** --- Azure works well for enterprise-level sites that require significant resources or bandwidth. However, for smaller sites, the cost is often too high because you cannot benefit from purchasing resources in bulk.
- **Database speed** --- if you try to host WordPress with the free database option you may not have enough connections or storage. You can upgrade your database and optimize it with plugins but this costs extra. If you do want to go this route, you can use plugins like WP-Optimize which enables you to clear irrelevant data.
- **Migration** --- if you are currently hosted on-premises or in another cloud, you should keep in mind the complexity of [migrating your database to Azure](https://cloud.netapp.com/blog/anf-cloud-migration-moving-oracle-databases-azure-deployment). [Migration](https://metabox.io/wordpress-migration-plugins/) requires some extra effort but can be made easier with the use of Azure's Data Migration Service.
### How to Install WordPress on Microsoft Azure
Once you've decided that Azure is right for your site, or if you want to see what setup in Azure is like, you can take the following steps.
### 1\. Sign up for Azure
If you are new to Azure you can [create a free, trial account](https://azure.microsoft.com/en-us/free/) to get started. This trial provides **12 months** of access to Windows and Linux machines and up to **750 hours of compute time**. This is roughly equal to a month of hosting. The trial also grants access to 5Gb of storage, 250GB of SQL database, and 15GB of bandwidth.
After your account is created and verified, you can sign into the Azure Portal. If you already have an Azure account, you can sign in directly.

### 2\. Create a New Resource
In the portal, from the main **Dashboard**, select the + button and choose to create a new resource. You should see a prompt allowing you to search the Azure Marketplace. There you can find pre-built WordPress configurations.

Select the setup you want and click **Create**.
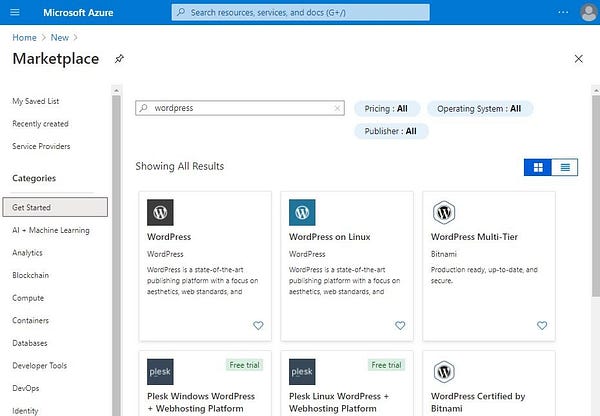
*Select the setup you want*

*Click Create*
### 3\. Resource Configuration
Once your resource is selected you can define your desired configuration. After you are finished, select **Create**. Options to configure include:
- **App name** --- a unique name to help you identify your WordPress installation.
- **Subscription** --- defaults to the account you are currently signed in under.
- **Resource group** --- defaults to the app name you define.
- **Database provider** --- should default to Azure Database for MySQL.
- **App service plan/location** --- select the data center nearest to the majority of your site users.
- **Database** --- define unique database credentials. It's a good idea to make a note of these in case you need to directly access your database later.
- **Application insights** --- leave the default value.
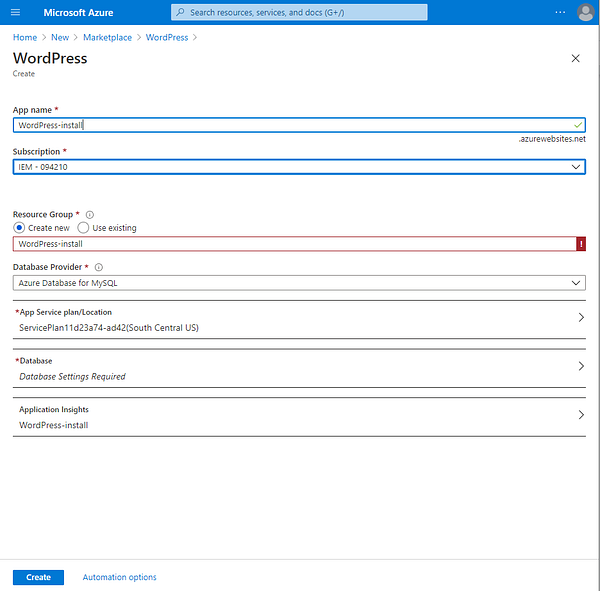
### 4\. WordPress Install Wizard
From the Azure dashboard, you should be able to select your resource. You'll then see a temporary URL of your WordPress site. Select the URL link to run the WordPress wizard.
Follow the wizard prompts, entering information as necessary. Once you're finished, you can open your site to verify that it's active.

### How to Optimize WordPress On Microsoft Azure
Once your site is operational there are a few practices you can apply to optimize your performance.
- **Compress images** --- large images consume more bandwidth and can significantly slow your site loading times. Rather than delivering images as is, consider using Azure blob storage to store multiple versions of each file. You can then deliver the [optimal image](https://gretathemes.com/image-optimization/) to each device, for example, high-resolution images for users with large screens, and smaller images for smartphones.
- **Reduce dependency requests** --- reducing your CSS and JavaScript to single files can help you reduce the number of requests for dependencies. You can use plugins like [Better WordPress Minify](https://wordpress.org/plugins/bwp-minify/) to combine style sheets. You should also try to store all files in your site storage rather than relying on third-party libraries.
- **Azure Redis Cache for object caching** --- you can use object caching to store query results from your site or web applications. This can help speed your site performance and makes it easier to scale since objects can be delivered from the cache rather than requiring more database traffic. Learn more in the [documentation](https://docs.microsoft.com/en-us/azure/azure-cache-for-redis/).
- **Use Azure CDN** --- you can use [Azure CDN](https://azure.microsoft.com/en-us/services/cdn/) to automatically check where users are and serve content from the nearest server to them. You can also use the CDN to deliver optimized images or other media. If you're not familiar with CDNs, learn more about [how CDNs work](https://www.imperva.com/learn/performance/what-is-cdn-how-it-works/).
### Conclusion
When hosting your WordPress site on Azure, you gain fast loading speed, autoscaling according to traffic demands, built-in content delivery network (CDN), and high reliability. However, Azure pricing is often too high for users unable to purchase resources in bulk.
Additionally, the free database storage is typically not enough for [good speed loads](https://gretathemes.com/speed-up-wordpress-website/), and upgrading your database will cost you extra funds. To save on bandwidth costs, you can compress images. You can also reduce deployment requests to improve performance, and Azure CDN can automatically ensure users are served [optimized content](https://gretathemes.com/10-tools-and-services-wordpress-content-optimization/).
--- --- ---
The publication at [Meta Box](https://metabox.io/hosting-wordpress-site-microsofm-azure/). | wpmetabox |
405,632 | My Flatiron School Rails App | project code • project demonstration Overview I have created a web app that b... | 0 | 2020-07-21T02:33:31 | https://dev.to/colerau/my-flatiron-school-rails-app-47hh | flatiron, rails, flatironschool, ruby | # [project code](https://github.com/colerau/appt_booker) • [project demonstration](https://www.youtube.com/watch?v=p2O7vWri394)
# Overview
I have created a web app that books appointments for the Parvenu hair salon. To book an appointment, a user chooses a stylist (employee) and an appointment time. If the appointment details pass validations, the user can then edit or delete their appointment. The URL to see which user has the most appointments is `http://localhost:3000/users/most_appointments`.
The app was built with Ruby on Rails. A user can sign up and log in via Facebook so they don’t have to remember a new password. [OmniAuth](https://github.com/omniauth/omniauth) was used to create this feature. My application follows REST, MVC, and persists data with a SQLite database.
# Model Associations
* A User has many Appointments
* A User has many Employees through Appointments
* An Appointment belongs to a User
* An Appointment belongs to an Employee
* An Employee has many Appointments
* An Employee has many Users through Appointments
The consequence of these associations are that Users and Employees have a many-to-many relationship, the join table being Appointments.
# Model Attributes
**User:**
* id
* name
* email
* password_digest
* password_confirmation
* uid (user_id for Facebook)
* image (user's Facebook profile picture)
**Appointment:**
* id
* user_id
* employee_id
* time
**Employee:**
* id
* name
# Project Process
The hardest part of making this project was figuring out how a user would choose an appointment time.
I first thought of creating another model called EmployeeTimes, which would belong to an Employee (an Employee would have many EmployeeTimes). However, if I chose this solution, I wouldn’t have known how to make the `appointments#new` form. I would have needed to alter what the form displays based on which employee the user chose. It seemed like I needed to know some JavaScript in order to make this functionality.
Ultimately, I decided on incorporating time as an attribute of the Appointment model. Time would be a DateTime data type. Before the appointment's time would be saved to the database, a number of validations would be performed, such as: is the time between 9:00am and 5:00pm? (to coincide with salon hours); is the time’s hour an odd number and the time’s minute zero? (to make sure appointments are spaced at least two hours apart); and, is the time unique and in the future?
As an aside, I was lucky to find out that Rails handles mass assignment with DateTime very well, so it was easy to create/edit an appointment with the `params` hash.
---
I’ve heard of software developers fearing time zones, and I got a taste of that with this project. After some googling, I figured out I needed to put the time zone I wanted (GMT-7) into config/application.rb with the line `config.time_zone = "Pacific Time (US & Canada)"`. This would prevent the appointment time from being off by seven hours.
One thing I feared implementing in this project were nested routes, but they turned out to be my best friend. Nesting my appointment's resources under `users` gave me routes like `/users/:id/appointments/:id/edit`, which let me easily use Rails `_path` helper methods. I figured out that the `_path` methods can accept two ids, the first argument being the user’s id, and the second argument being the appointment’s id.
Rails' `form_for` made CRUD a blast to implement. `form_for` knew implicitly whether a user was editing or creating a new appointment. Rails was definitely a welcome change from Sinatra, though the convention over configuration philosophy was frustrating at times if I didn’t know the exact Rails convention. | colerau |
866,155 | Malware /virus creation | how can I get a malware that can extract files when clicked on the link ? | 0 | 2021-10-16T21:52:29 | https://dev.to/gjeotech/malware-virus-creation-1hm8 | how can I get a malware that can extract files when clicked on the link ? | gjeotech | |
405,695 | 🔒 How do you admin your Tokens on Github? | I'm using some APIs on my first web projects. I know isn't safe to let tokens visible on the repos, a... | 0 | 2020-07-21T04:13:01 | https://dev.to/bocanegradev/how-do-you-admin-your-tokens-on-github-em2 | discuss, beginners, github, git | I'm using some APIs on my first web projects. I know isn't safe to let tokens visible on the repos, and I can use an .env file.
The thing is that, if I delete the project on my pc, will I lose the token info?
How do you admin your own tokens? I would like to read you.
Thanks! 🙌 | bocanegradev |
405,788 | A New Video Series: The Maintainers | I know you've heard this before, but I'm starting yet another video series Don't worry the Rants are... | 0 | 2020-07-26T05:39:47 | http://wildermuth.com/2020/07/21/A-New-Video-Series-The-Maintainers | videos, opensource | ---
title: A New Video Series: The Maintainers
published: true
date: 2020-07-21 01:20:56 UTC
tags: Videos,OpenSource
canonical_url: http://wildermuth.com/2020/07/21/A-New-Video-Series-The-Maintainers
---
[](https://youtube.com/watch?v=dZ_ZVZS-FNc) I know you've heard this before, but I'm starting yet another video series Don't worry the Rants are continuing soon, just didn't feel right to complain during COVID-19 too much.
This new series is all about the open source projects you use every day. I am interviewing people who maintain those projects. I hope to get your favorite developers to talk about why Open Source is so important to them.
In this first episode, I talk with [Jimmy Bogard](https://twitter.com/jbogard) about AutoMapper and how he built it so many years ago. I hope you like it!
<iframe src="https://www.youtube.com/embed/dZ_ZVZS-FNc" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen=""></iframe>
If you did enjoy the video, please like and subscribe to my channel. Every subscription helps!
Do you have any of your favorite open source projects you'd like me to highlight? If so, just leave a comment and I'll see if I can shine a light on the maintainers!
[](http://creativecommons.org/licenses/by-nc-nd/3.0/)
This work by [Shawn Wildermuth](http://wildermuth.com) is licensed under a [Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License](http://creativecommons.org/licenses/by-nc-nd/3.0/).
Based on a work at [wildermuth.com](http://wildermuth.com).
* * *
If you liked this article, see Shawn's courses on [Pluralsight](http://shawnw.me/pscourses).
 | shawnwildermuth |
405,859 | 5 practical ways for web developers to stay updated in the latest tech news | The tech world moves forward at a staggering pace. Every day that passes it becomes increasingly hard... | 0 | 2020-07-21T08:53:10 | https://daily.dev/posts/5-practical-ways-for-web-developers-to-stay-updated-in-the-latest-tech-news | webdev, codenewbie, productivity, news | The tech world moves forward at a staggering pace. Every day that passes it becomes increasingly hard to stay updated in the latest web development news. For many web developers, it is an essential part of our job. We either stay updated or stay behind. That is why we made this quick guide, especially for you! Hope you’d find it useful ❤️
# Subscribe to development newsletters
Starting from the most traditional method - newsletters! There are tons of them out there so if you feel this method is the right one for you make sure to check our previous post: [10 useful web development newsletters](https://r.daily.dev/10-useful-web-development-newsletters)
**Pros**: Carefully curated content. Bitesize articles.
**Cons**: Frequency is a bit low (once a week usually). Narrow to a specific tech.
# Join a developers community
The beautiful thing about us developers is that we live online. That is the reason why many amazing communities were formed along the years to serve our need to socialize and improve our professional skills. Developers’ communities are great because they give you a good sense of what really matters at the moment for other people like you. [DEV](https://dev.to) and [Reddit/webdev](https://www.reddit.com/r/webdev/) are a good way to start (we are sure there are many other good communities worth mentioning).
**Pros**: it has a very clear context. You can interact with other devs around the news and posts.
**Cons**: Requires active involvement. Will probably consume much of your time.
# Explore development news discovery platforms
For busy developers who really don’t want to spend much time, we recommend using development news platforms. It is usually a website or an app that aggregates articles from many different parts of the web. Some popular platforms are [Hacker News](https://news.ycombinator.com/) and [EchoJS](https://echojs.com/).
**Pros**: a lot of content is being streamed over there so you can discover the good stuff.
**Cons**: content overload which makes it hard to find the good stuff. No filtering features.
# Follow exceptional developers on Twitter
Many of the most brilliant and influential web developers are living and breathing on Twitter. If you want to get the sense of the web development world it is a good idea to find a few influencers that you appreciate and follow them.
As we don’t want to promote any specific individual in this post, we will leave it to you to find the ones you appreciate. I’m sure that in a simple search on Google you will be able to find them.
**Pros**: real humans with real thoughts. Highly interactive and fun (a bit addictive so be careful).
**Cons**: very opinionated. Not all tweets will be technical, some of them are personal thoughts.
# Bookmark and read later
You probably had this moment that you found a good article or that a friend sent you one. In order to keep track try to make a habit for reading them later. First, find a bookmarking app that you like. We love [Pocket](https://getpocket.com/) and [Raindrop](https://app.raindrop.io/) but there are many other great ones in the market. Then, every time you find a good postת save it there for later reading. However, it is easy to never come back and read what you saved so make sure you fix time on your schedule to read it at least once a week!
**Pros**: highly focused only on things you found interesting.
**Cons**: easy to save but difficult to find time to read later.
## More posts that might be interesting as well
* [How to write viral stories for developers](https://dev.to/dailydotdev/how-to-write-viral-stories-for-developers-fho)
* [7 productivity best practices for remote working developers](https://dev.to/dailydotdev/7-productivity-best-practices-for-remote-working-developers-1c3i)
* [How to gain experience as a web developer? Powerful ideas for code newbies](https://dev.to/dailydotdev/how-to-gain-experience-as-a-web-developer-powerful-ideas-for-junior-developers-2p44)
* [5 useful DevOps newsletters that will blow your mind 🤯
](https://dev.to/dailydotdev/5-useful-devops-newsletters-that-will-blow-your-mind-1dh4)
* [10 useful web development newsletters](https://dev.to/dailydotdev/10-useful-web-development-newsletters-37nf)
<hr/>
_[daily.dev](https://r.daily.dev/get?r=devto) delivers the best programming news every new tab. We will rank hundreds of qualified sources for you so that you can hack the future._
[](https://r.daily.dev/get?r=devto)
| nimrodkra |
405,924 | Oauth 1.0 access token issue | I was trying to get access token with oauth 1.0 but getting Invalid signature for signature method HM... | 0 | 2020-07-21T10:11:06 | https://dev.to/vikaschandel/oauth-1-0-access-token-issue-1ajb | I was trying to get access token with oauth 1.0 but getting Invalid signature for signature method HMAC-SHA1. I have the request token and verifier.
Api i want to integrate:
https://api.immobilienscout24.de/api-docs/authentication/three-legged/
$consumerKey = "myrealapiKey";
$consumerSecret = "wEBxKUuQWYqRQ0Kb";
| vikaschandel | |
416,145 | Splunk: AWS CloudWatch Log Ingestion - Part 1 - Introduction & Setup | Introduction The advent of the cloud has transformed centralized log management into an es... | 8,126 | 2020-08-02T18:38:29 | https://dev.to/armandoinfosec/splunk-aws-cloudwatch-log-ingestion-part-1-introduction-setup-1kml | aws, security, splunk | # Introduction
The advent of the cloud has transformed centralized log management into an essential component of an organization's security program. While it is true that cloud service providers often offer native logging mechanisms with their solutions, said features may not be robust enough to satisfy the needs of certain organizations – particularly those with both on-premises and cloud environments. Similarly, entities with mature security programs may already possess a fine-tuned centralized logging platform such as Splunk or Elastic Stack.
The aim of this series is to provide meaningful insights for feeding AWS CloudWatch logs to Splunk. These articles will cover the following ingest mechanisms: the [Splunk Add-On for AWS] (https://docs.splunk.com/Documentation/AddOns/released/AWS/Description), [AWS Lambda] (https://dev.splunk.com/enterprise/docs/devtools/httpeventcollector/useawshttpcollector/) functions using the [“splunk-cloudwatch-logs-processor”] ( https://console.aws.amazon.com/lambda/home?#/create/configure-triggers?bp=splunk-cloudwatch-logs-processor) blueprint, and [Kinesis Data Firehose] (https://docs.aws.amazon.com/firehose/latest/dev/vpc-splunk-tutorial.html). I will attempt to be as clear and detailed as practically possible. However, please note that this is neither a comprehensive nor exhaustive guide for Splunk or AWS. A degree or familiarity with each of these platforms is assumed and links to relevant resources will be included for further reading.
## Initial Considerations & Testing Environment
First and foremost, I strongly advise against using a production environment for testing purposes. The entirety of my research was conducted using a VM for my Splunk single instance deployment and a “non-prod” AWS VPC. The daily indexing capacity (1GB) provided by Splunk Enterprise trial license is more than sufficient for the scope of this exercise.
### Considerations
* Respect all applicable EULAs.
* Exercise caution when creating and/or updating firewall policies. Keep in mind that certain firewalls and ACLs may not be stateful and use the defense in depth principle whenever possible.
* Be mindful when creating new users, roles, and/or access policies. Use the least privilege principle whenever possible.
### Testing Environment
* An AWS account dedicated for testing our configurations. Please note that you will need root or near root-level privileges to the AWS account in order to crate: new IAM users, roles, and policies, EC2 instances, Lambda functions, Kinesis Firehose delivery streams, CloudWatch log groups, CloudWatch log group subscriptions, VPCs, and any other necessary components.
* A VM for our single instance Splunk deployment using a [Splunk Enterprise free trial license] (https://www.splunk.com/view/SP-CAAAAEQ). Two CPU cores, 4 GB of memory, and 30 GB of storage should provide an adequate performance baseline. You may want to consider allocating more system resources to your Splunk VM if you intend to use it in future projects. In a nutshell, additional CPU cores allow for greater search concurrency, more system memory improves the performance of large and complex searches, and extra storage provides for longer retention periods.
## Homework
Part 2 of this guide should be coming out soon. In the meantime, please ensure that you have completed the tasks below so that you will be able to follow along.
* [Install Splunk Enterprise in your testing environment.] (https://docs.splunk.com/Documentation/Splunk/8.0.5/SearchTutorial/InstallSplunk) I opted for an on-prem Splunk instance to mimic the use case of an organization which already has an existing Splunk deployment. You can choose to setup your Splunk instance in a cloud environment, but I will not be providing any considerations for that type of setup at this time.
* [Create an AWS account to use throughout our project.] (https://aws.amazon.com/premiumsupport/knowledge-center/create-and-activate-aws-account/) | armandoinfosec |
405,951 | Crie seu próprio sistema de migrations em PHP! Parte 2 — Final | Bem, no último post vimos a respeito das migrations e como fazemos para criar no Laravel. E, como eu... | 0 | 2020-07-21T10:59:40 | https://dev.to/tadeubdev/crie-seu-proprio-sistema-de-migrations-em-php-parte-2-final-h7l | php, migrations, programacao, portugues | Bem, no último post vimos a respeito das migrations e como fazemos para criar no Laravel. E, como eu disse, existem bibliotecas disponíveis para o uso das migrations e você pode utilizar em seus projetos. Mas se tem uma coisa que gosto é saber como as coisas funcionam, como eu faço a mesma coisa ou parecida, que aquele framework fez e não simplesmente adicionar trocentas linhas de código via composer e encher o meu diretório vendor.
Ok, vamos combinar que nem sempre a gente vai criar as coisas ao invés de usar bibliotecas. E eu as utilizo! Há projetos que desenvolvo e crio em Laravel, Vuejs etc. A questão aqui não é “reinventar a roda”, mas entender como as coisas funcionam! Combinado?! ;)
### Mundo open source

Bem, há um motivo pelo qual me aventurei a criar tal sistema de migrations. O [Zig Money](https://github.com/valdiney/zig). Um sistema em PHP criado por um cara firmeza, o [Valdiney](https://github.com/valdiney), que está sempre envolvido com o mundo open source. Como lemos no próprio repositório:
O ZigMoney é um projeto que visa ajudar pequenos
comércios e comerciantes que precisam registrar suas
vendas diárias de forma simples e organizada.
Trata-se de um sistema web escrito em PHP e Mysql.
O intuito é disponibilizar uma plataforma
com módulos que facilite e potencialize o controle
de informações de vendas totalmente online.
A proposta, além da descrita acima, é desenvolver um sistema sem utilizar muitas bibliotecas, assim crescemos junto com o projeto. Confira e envie uma contribuição, por mais que represente pouco para você, representará muito para nós e para quem usufrui da ferramenta! :D
---
A ideia foi criarmos as migrations via linha de comando, adaptando um sistema de linha de comando que já existia na ferramenta. O primeiro passo foi criar a parte da linha de comando, para que ao digitar o seguinte comando: `php comando.php create migration lorem ipsum dolor`, fosse gerado um *arquivo.sql* dentro de um diretório específico. Para isso você pode criar um arquivo *comando.php* na raiz do projeto com o seguinte conteúdo:
```php
<?php
$parametros = array_slice($argv, 1);
$comando = "{$parametros[0]} {$parametros[1]}";
$migrationNome = array_slice($argv, 3);
$migrationNome = str_replace(" ", "_", $migrationNome);
$pathname = "migrations/{$migrationNome}.sql";
if ($comando == "create migration") {
file_put_contents("", $pathname);
echo "Migration criada em: {$pathname}";
}
```
Claro, tentei simplificar aqui, mas você pode melhorar bastante esse sistema!
Após criar o arquivo, basta colocarmos dentro do arquivo sql gerado, o conteúdo que gostaríamos, suponhamos que digitei: `php comando.php create migration cria tabela de usuarios, o arquivo de cima irá gerar o arquivo *migrations/cria_tabela_de_usuarios.sql*. Dentro desse arquivo iremos colocar:
```
CREATE TABLE usuarios IF NOT EXISTS (
id int NOT NULL AUTO_INCREMENT,
nome varchar(60) NOT NULL,
email varchar(60) NOT NULL,
password varchar(60) NOT NULL,
PRIMARY KEY (id)
);
```
Lembra do nosso *comando.php*? Vamos alterar algumas coisas:
```php
<?php
$parametros = array_slice($argv, 1);
if (count($parametros) > 2) {
$comando = "{$parametros[0]} {$parametros[1]}";
$migrationNome = array_slice($argv, 3);
$migrationNome = str_replace(" ", "_", $migrationNome);
$pathname = "migrations/{$migrationNome}.sql";
//
if ($comando == "create migration") {
file_put_contents("", $pathname);
echo "Migration criada em: {$pathname}";
}
exit;
}
if ($parametros[0] == "migrate") {
$files = glob("migrations/*.sql", GLOB_BRACE);
foreach ($files as $file) {
$content = file_get_contents($file);
// executa o comando sql da migration
DB::execute($content);
}
}
```
Pronto! Com algumas adaptações o seu *comando.php* estará pronto para criar e executar as suas **migrations** ;)
---
Espero que tenham gostado e que de alguma maneira isso possa adicionar algo a sua carreira. Não deixem de conferir o ZigMoney e deixarem uma contribuição. Até a próxima!
*Imagem: [Tammy Duggan-Herd por Pixabay](https://pixabay.com/pt/users/Campaign_Creators-9720680/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=3582975)* | tadeubdev |
405,971 | 5 ways to make HTTP requests in Java | [header image credit: Iron in the Butterfly Nebula, NASA Astronomy Picture of the Day July 21 2020... | 0 | 2020-07-23T11:28:15 | https://www.twilio.com/blog/5-ways-to-make-http-requests-in-java | java, web, http | ---
title: 5 ways to make HTTP requests in Java
published: true
date:
tags:
- java
- web
- http
canonical_url: https://www.twilio.com/blog/5-ways-to-make-http-requests-in-java
---

_[header image credit: Iron in the Butterfly Nebula, [NASA Astronomy Picture of the Day July 21 2020](https://apod.nasa.gov/apod/ap200721.html) (modified)]_
Making HTTP requests is a core feature of modern programming, and is often one of the first things you want to do when learning a new programming language. For Java programmers there are many ways to do it - core libraries in the JDK and third-party libraries. This post will introduce you to the Java HTTP clients that I reach for. If you use other ones, that’s great! Let me know about it. In this post I’ll cover:
##### Core Java:
- HttpURLConnection
- HttpClient
##### Popular Libraries:
- ApacheHttpClient
- OkHttp
- Retrofit
I’ll use the [Astronomy Picture of the Day](https://apod.nasa.gov/apod/astropix.html) API from the [NASA APIs](https://api.nasa.gov/) for the code samples, and the code is all [on GitHub](https://github.com/mjg123/java-http-clients) in a project based on Java 11.
## Core Java APIs for making Java http requests
Since Java 1.1 there has been an HTTP client in the core libraries provided with the JDK. With Java 11 a new client was added. One of these might be a good choice if you are sensitive about adding extra dependencies to your project.
### Java 1.1 HttpURLConnection
First of all, do we capitalize acronyms in class names or not? Make your mind up. Anyway, close your eyes and center yourself in 1997. Titanic was rocking the box office and inspiring a thousand memes, Spice Girls had a best-selling album, but the biggest news of the year was surely [HttpURLConnection](https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/net/HttpURLConnection.html) being added to Java 1.1. Here’s how you would use it to make a `GET` request to get the APOD data:
```java
// Create a neat value object to hold the URL
URL url = new URL("https://api.nasa.gov/planetary/apod?api_key=DEMO_KEY");
// Open a connection(?) on the URL(??) and cast the response(???)
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// Now it's "open", we can set the request method, headers etc.
connection.setRequestProperty("accept", "application/json");
// This line makes the request
InputStream responseStream = connection.getInputStream();
// Manually converting the response body InputStream to APOD using Jackson
ObjectMapper mapper = new ObjectMapper();
APOD apod = mapper.readValue(responseStream, APOD.class);
// Finally we have the response
System.out.println(apod.title);
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/JavaHttpURLConnectionDemo.java)]
This seems quite verbose, and I find the order that we have to do things is confusing (why do we set headers _after_ opening the URL?). If you need to make more complex requests with `POST` bodies, or custom timeouts etc then it’s all possible but I never found this API intuitive at all.
When would you use `HTTPUrlConnection`, then? If you are supporting clients who are using older versions of Java, **and** you can’t add a dependency then this might be for you. I suspect that’s only a small minority of developers, but you might see it in older codebases - for more modern approaches, read on.
### Java 11 HttpClient
More than twenty years after `HttpURLConnection` we had Black Panther in the cinemas and a new HTTP client added to Java 11: [`java.net.http.HttpClient`](https://docs.oracle.com/en/java/javase/11/docs/api/java.net.http/java/net/http/HttpClient.html). This has a much more logical API and can handle HTTP/2, and Websockets. It also has the option to make requests synchronously or asynchronously by using the `CompletableFuture` API.
99 times out of 100 when I make an HTTP request I want to read the response body into my code. Libraries that make this difficult will not spark joy in me. HttpClient accepts a `BodyHandler` which can convert an HTTP response into a class of your choosing. There are some built-in handlers: `String`, `byte[]` for binary data, `Stream<String>` which splits by lines, and a few others. You can also define your own, which might be helpful as there isn’t a built-in `BodyHandler` for parsing JSON. I’ve written one ([here](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/JsonBodyHandler.java)) based on [Jackson](https://www.twilio.com/blog/java-json-with-jackson) following [an example from Java Docs](https://docs.oracle.com/en/java/javase/13/docs/api/java.net.http/java/net/http/HttpResponse.BodySubscribers.html#mapping(java.net.http.HttpResponse.BodySubscriber,java.util.function.Function)). It returns a `Supplier` for [the APOD class](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/APOD.java), so we call `.get()` when we need the result.
This is a synchronous request:
```java
// create a client
var client = HttpClient.newHttpClient();
// create a request
var request = HttpRequest
.newBuilder(URI.create("https://api.nasa.gov/planetary/apod?api_key=DEMO_KEY"))
.header("accept", "application/json")
.build();
// use the client to send the request
var response = client.send(request, new JsonBodyHandler<>(APOD.class));
// the response:
System.out.println(response.body().get().title);
```
For an asynchronous request the `client` and `request` are made in the same way, then call `.sendAsync` instead of `.send`:
```java
// use the client to send the request
var responseFuture = client.sendAsync(request, new JsonBodyHandler<>(APOD.class));
// We can do other things here while the request is in-flight
// This blocks until the request is complete
var response = responseFuture.get();
// the response:
System.out.println(response.body().get().title);
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/JavaHttpClientDemo.java)]
## Third-party Java HTTP client libraries
If the built-in clients don’t work for you, don’t worry! There are plenty of libraries you can bring into your project which will do the job.
### Apache HttpClient
The [Apache Software Foundation’s](https://www.apache.org/) [HTTP clients](https://hc.apache.org/httpcomponents-client-ga/) have been around for a long time. They’re widely-used and are the foundation for a lot of higher-level libraries. The history is a little confusing. The old [Commons HttpClient](https://hc.apache.org/httpclient-3.x/) is no longer being developed, and the new version (_also_ called HttpClient), is under the [HttpComponents](https://hc.apache.org/httpcomponents-client-5.0.x/index.html) project. Version 5.0 was released in early 2020, adding HTTP/2 support. The library also supports synchronous and asynchronous requests.
Overall the API is rather low-level - you are left to implement a lot for yourself. The following code calls the NASA API. It doesn’t look too hard to use but I have skipped a lot of the error handling which you would want in production code and again I had to add [Jackson](https://www.twilio.com/blog/java-json-with-jackson) code to parse the JSON response. You might also want to configure a logging framework to avoid warnings on stdout (no big deal, but it does irk me a bit). Anyway here’s the code:
```java
ObjectMapper mapper = new ObjectMapper();
try (CloseableHttpClient client = HttpClients.createDefault()) {
HttpGet request = new HttpGet("https://api.nasa.gov/planetary/apod?api_key=DEMO_KEY");
APOD response = client.execute(request, httpResponse ->
mapper.readValue(httpResponse.getEntity().getContent(), APOD.class));
System.out.println(response.title);
}
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/ApacheHttpClientDemo.java)]
Apache provides several more examples for [sync](https://hc.apache.org/httpcomponents-client-5.0.x/examples.html) and [async](https://hc.apache.org/httpcomponents-client-5.0.x/examples-async.html) requests.
### OkHttp
[OkHttp](https://square.github.io/okhttp/) is an HTTP client from [Square](https://squareup.com/gb/en) with a lot of helpful built-in features, like automatic handling of GZIP, response caching and retries or fallback to other hosts in case of network errors as well as HTTP/2 and WebSocket support. The API is clean although there is no built-in parsing of JSON responses so again I added code to parse the JSON with Jackson:
```java
ObjectMapper mapper = new ObjectMapper();
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url("https://api.nasa.gov/planetary/apod?api_key=DEMO_KEY")
.build(); // defaults to GET
Response response = client.newCall(request).execute();
APOD apod = mapper.readValue(response.body().byteStream(), APOD.class);
System.out.println(apod.title);
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/OkHttpDemo.java)]
This is fine, but the real power of OkHttp is clear when you add Retrofit over the top.
### Retrofit
[Retrofit](https://square.github.io/retrofit/) is another library from Square, built on top of OkHttp. Along with all the low-level features of OkHttp it adds a way to build Java classes which abstract the HTTP details and present a nice Java-friendly API.
First, we need to create an interface which declares the methods we want to call against the APOD API, with annotations defining how those correspond to HTTP requests:
```java
public interface APODClient {
@GET("/planetary/apod")
@Headers("accept: application/json")
CompletableFuture<APOD> getApod(@Query("api_key") String apiKey);
}
```
The return type of `CompletableFuture<APOD>` makes this an asynchronous client. Square provide [other adapters](https://github.com/square/retrofit/tree/master/retrofit-adapters) or you could write your own. Having an interface like this helps with mocking the client for tests, which I appreciate.
After declaring the interface we ask Retrofit to create an implementation which we can use to make requests against a given base URL. It’s also helpful for integration testing to be able to switch the base URL. To generate the client, the code looks like this:
```java
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.nasa.gov")
.addConverterFactory(JacksonConverterFactory.create())
.build();
APODClient apodClient = retrofit.create(APODClient.class);
CompletableFuture<APOD> response = apodClient.getApod("DEMO_KEY");
// do other stuff here while the request is in-flight
APOD apod = response.get();System.out.println(apod.title);
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/RetrofitDemo.java)]
#### API Authentication
If there are multiple methods in our interface which all need an API key it is possible to configure that by adding an `HttpInterceptor` to the base `OkHttpClient`. The custom client can be added to the `Retrofit.Builder`. The code needed to create the custom client is:
```java
private OkHttpClient clientWithApiKey(String apiKey) {
return new OkHttpClient.Builder()
.addInterceptor(chain -> {
Request originalRequest = chain.request();
HttpUrl newUrl = originalRequest.url().newBuilder()
.addQueryParameter("api_key", apiKey)
.build();
Request request = originalRequest.newBuilder()
.url(newUrl)
.build();
return chain.proceed(request);
})
.build();
}
```
[[full code on GitHub](https://github.com/mjg123/java-http-clients/blob/master/src/main/java/com/twilio/RetrofitCustomClientDemo.java)]
I like this kind of Java API for all but the simplest cases. Building classes to represent remote APIs is a nice abstraction that plays well with dependency injection, and having Retrofit create them for you based on a customizable OkHttp client is great.
## Other HTTP clients for Java
Since posting this article [on Twitter](https://twitter.com/MaximumGilliard/status/1285933743518212096) I have been delighted to see people discussing which HTTP clients they use. If none of the above is quite what you want, have a look at these suggestions:
- [REST Assured](http://rest-assured.io/) - an HTTP client designed for testing your REST services. Offers a fluent interface for making requests and helpful methods for making assertions about responses.
- [cvurl](https://corese4rch.github.io/cvurl/) - a wrapper for the Java 11 HttpClient which rounds off some of the sharp edges you might encounter making complex requests.
- [Feign](https://github.com/OpenFeign/feign) - Similar to Retrofit, Feign can build classes from annotated interfaces. Feign is highly flexible with multiple options for making and reading requests, metrics, retries and more.
- Spring [RestTemplate](https://spring.io/guides/gs/consuming-rest/) (synchronous) and [WebClient](https://docs.spring.io/spring-boot/docs/2.0.3.RELEASE/reference/html/boot-features-webclient.html) (asynchronous) clients - if you’ve used Spring for everything else in your project it could be a good idea to stick with that ecosystem. Baeldung has [an article comparing them](https://www.baeldung.com/spring-webclient-resttemplate).
## Summary
There are a lot of choices for HTTP clients in Java - for simple cases I would recommend the built-in `java.net.http.HttpClient`. For more complex use-cases or if you want to have your HTTP APIs abstracted as Java classes as part of a larger application look at Retrofit or Feign. Happy hacking, I can’t wait to see what you build!
📧 [mgilliard@twilio.com](mailto:mgilliard@twilio.com)
🐦 [@MaximumGilliard](https://twitter.com/maximumgilliard?lang=en) | mjg123 |
406,430 | Converting Multiple Images to WebP | This is how to convert your multiple any images from .png or .jpeg to .webp format with storage... | 0 | 2020-07-22T13:52:24 | https://www.raufsamestone.com/converting-multiple-images-to-webp/ | seo, webp, image, optimization | ---
title: Converting Multiple Images to WebP
published: true
date: 22/07/2020
tags: SEO, WebP, image, optimization
canonical_url: https://www.raufsamestone.com/converting-multiple-images-to-webp/
---
This is how to convert your multiple any images from **.png** or **.jpeg** to **.webp** format with storage (Cloud) and optimization features.
**WebP** is so fast image format for your web app. [WebP](https://web.dev/serve-images-webp/ "Google Web Dev") is also developed and recommended by **Google**. It is also extremely important for **SEO** and web performance with image contents. Normally, you can use Google's native [WebP Converter](https://developers.google.com/speed/webp/). But this is not capable of web storage and other image optimization.
We use [Cloudinary](https://cloudinary.com/ "Cloudinary") image storage for this converting solutions.There are **two** simple solutions to converting multiple images.
## Solution 1
You can set up the pre-transformation Upload settings on Cloudinary.
Go to **Settings** and **Add Upload Preset** :

Click to **Upload Manipulations** :

And then click to **Add Eager Transformation:**

Set your pre upload.
- Choose the format as **WebP**
- You don't have to set the image resolution to **1080** , but most screen device is smaller than 2K or 4K for web image contents.
- You can check for other useful flags like adding **unique ID** of _filename_.
Here is the final settings should look like:

Thus, every image you upload will be automatically optimized to **webp** using both Media library UI or CLI.
## Solution 2
But what if we want to change the images we uploaded before? In this case, we have to use [Cloudinary CLI](https://cloudinary.com/documentation/cloudinary_cli "Cloudinary CLI").
You can transform your all images using URL [reference](https://cloudinary.com/documentation/image_transformation_reference) adding variables after **/upload/** path like **/c_scale,f_auto,h_517,w_1080/**.
But you have to list all URL of your images.
### Listing URLs
Firstly, we must install the CLI with [Python PIP](https://pypi.org/project/pip/ "Python PIP").
```
pip3 install cloudinary-cli
```
Configure your CLI with your **Cloudinary API KEY**
```
export CLOUDINARY_URL=cloudinary://123456789012345:abcdefghijklmnopqrstuvwxyzA@cloud_name
```
- You can find your API key on dashboard.
And, we should list all images info with [Search API](https://cloudinary.com/documentation/search_api).
You can search any variable like that, but we have to add **output** option for listing items to _JSON_ file.
```
cld search "cat" -f context -f tags -n 10 output.json
```
The output should be like that:
```json
"public_id": "5953361",
"filename": "sasdasd-01_ek7rzs",
"format": "webp",
"version": 1595336182,
"resource_type": "image",
"type": "upload",
"created_at": "2020-07-21T12:56:22+00:00",
"uploaded_at": "2020-07-21T12:56:22+00:00",
"bytes": 47488,
"backup_bytes": 0,
"width": 1080,
"height": 796,
"aspect_ratio": 1.35678,
"pixels": 859680,
"pages": 1,
"url": "http://res.cloudinary.com/raufsamestone/image/upload/v1595336182/sdasdasd.ek7rzs.webp",
"secure_url": "https://res.cloudinary.com/raufsamestone/image/upload/v1595336182/asdasd.webp",
"status": "active",
"access_mode": "public",
"access_control": null,
"etag": "581034c158165f6f9c9c872f03618a6c",
"created_by": {
"access_key": "126251566858748",
"custom_id": "asdasdfas12ff",
"external_id": "61c057372fa8c45e60a23fa51aebf1"
},
"uploaded_by": {
"access_key": "126251566858748",
"custom_id": "asdasdasdasd",
"external_id": "61c057372fa8c45e60a23fa51aebf1"
}
},
```
And we can map the specify "URL" from **JSON** with **Node JS** for listing all URLs.
```javascript
const data = require('./output.json');
const output = data.map(url => url.url);
console.log(output);
```
and then you can replace and modify your all URL with any IDE.
## What about JAMstack?
If you are interesting in adding Cloudinary to your **JAMstack** project, you can check [Gatsby's](https://gatsbyjs.org/) image optimization plugin called **gatsby-transformer-cloudinary** and you can connect with [Netlify CMS](https://www.netlifycms.org/docs/cloudinary/) to your Clodinary API.
[@raufsamestone](https://twitter.com/raufsamestone) | raufsamestone |
409,188 | Best of Modern JavaScript — Prototypes and Function Names | Since 2015, JavaScript has improved immensely. It’s much more pleasant to use it now than ever. In... | 0 | 2020-07-30T00:08:12 | https://thewebdev.info/2020/07/25/best-of-modern-javascript%e2%80%8a-%e2%80%8aprototypes-and-function-names/?utm_source=rss&utm_medium=rss&utm_campaign=best-of-modern-javascript%25e2%2580%258a-%25e2%2580%258aprototypes-and-function-names | javascript, webdev | ---
title: Best of Modern JavaScript — Prototypes and Function Names
published: true
date: 2020-07-25 00:36:27 UTC
tags: javascript,webdev
canonical_url: https://thewebdev.info/2020/07/25/best-of-modern-javascript%e2%80%8a-%e2%80%8aprototypes-and-function-names/?utm_source=rss&utm_medium=rss&utm_campaign=best-of-modern-javascript%25e2%2580%258a-%25e2%2580%258aprototypes-and-function-names
---
Since 2015, JavaScript has improved immensely.
It’s much more pleasant to use it now than ever.
In this article, we’ll look at properties in JavaScript.
### Using call and apply to Call `hasOwnProperty()` Safely
`hasOwnProperty` is a method of an object’s prototype.
Therefore, it can easily be overridden with an object’s own methods.
To call `hasOwnProperty` safety, we can call it with `call` .
So instead of writing:
```
obj.hasOwnProperty('prop')
```
We write:
```
Object.prototype.hasOwnProperty.call(obj, 'prop')
```
The 2nd way is safer because `hasOwnProperty` is always part of the `Object.prototype` .
We can’t guarantee that `hasOwnProperty` isn’t overridden with the first way.
With ES6, we can use the `Map` constructor to store key-value pairs, so that we don’t need to create objects to store them.
Therefore, we won’t need `hasOwnProperty` as much.
### Abbreviations for `Object.prototype` and `Array.prototype`
Using `Object.prototype` and `Array.prototype` are long.
But we can shorten `Object.prototype` to an empty object literal.
We can shorten `Array.prototype` to an empty array literal.
So instead of writing:
```
Object.prototype.hasOwnProperty.call(obj, 'prop')
```
We can write:
```
({}).hasOwnProperty.call(obj, 'prop')
```
With arrays, we can write:
```
[].slice.call(1)
```
### The `name` Property of Functions
The `name` property of the function contains the function’s name.
For example, we can write:
```
function foo() {}
```
Then `foo.name` returns `'foo'` .
Arrow functions also has the `name` property.
For instance, if we write:
```
`const` bar `=` `()` `=>` `{};`
```
Then `bar.name` returns `'bar'` .
### Default Values
If we use a function as a default value, then it gets its name from its variable or parameter.
For example, if we have:
```
`let` `[foo =` `function` `()` `{}]` `=` `[]`
```
Then `foo.name` is `'foo'` .
Likewise,
```
`let` `{` bar`:` foo `=` `function` `()` `{}` `}` `=` `{};`
```
and
```
`function` `g(foo =` `function` `()` `{})` `{`
`return` `foo.name;`
`}`
```
all get the same result.
### Named Function Definitions
If we have function declarations, then the `name` property of the function will have the name:
```
function foo() {}
console.log(foo.name);
```
`foo.name` would be `'foo'` .
For function expressions, we get the same thing:
```
const bar = function baz() {};
console.log(bar.name);
```
so `bar.name` is `'bar'` .
However, if we assigned a named function to a variable, then the function’s name would be the function’s name.
For example, if we write:
```
const bar = function baz() {
console.log(baz.name);
};
bar()
```
Then we call it with `bar` and `baz.name` would be `baz` .
But we can’t write `baz()` to call it, we’ll see the ‘Uncaught ReferenceError: baz is not defined’ error.
### Methods in Object Literals
Methods in object literals can be defined with fixed and computed property names.
For instance, we can write:
```
function qux() {}
let obj = {
foo() {},
bar: function() {},
['ba' + 'z']: function() {},
qux,
};
```
`foo` is defined with the object method shorthand.
`bar` is defined as a traditional method.
`baz` is defined with the computed key.
And `qux` is passed in from the outside.
If we get the `name` property of each method:
```
console.log(obj.foo.name);
console.log(obj.bar.name);
console.log(obj.baz.name);
console.log(obj.qux.name);
```
We get:
```
foo
bar
baz
qux
```
### Conclusion
We can use the `name` property to get the property name of a function.
Also, we can call a constructor instance’s method in shorter ways in some situations.
The post [Best of Modern JavaScript — Prototypes and Function Names](https://thewebdev.info/2020/07/25/best-of-modern-javascript%e2%80%8a-%e2%80%8aprototypes-and-function-names/) appeared first on [The Web Dev](https://thewebdev.info). | aumayeung |
410,034 | Distributed Tracing with Spring Cloud Sleuth and Zipkin - AQAP Series | There's a lot going on related to cloud services, libraries, providers etc. In fact, everything cloud... | 4,393 | 2020-07-26T14:11:39 | https://dev.to/brunodrugowick/distributed-tracing-with-spring-cloud-sleuth-and-zipkin-3moo | spring, cloud, sleuth, zipkin | There's a lot going on related to cloud services, libraries, providers etc. In fact, everything cloud-related gets a lot of attention right now.
One thing I wanted to try was distribute tracing. Spring has a very interesting project under the [Spring Cloud umbrella](https://spring.io/projects/spring-cloud), called [Spring Cloud Sleuth](https://spring.io/projects/spring-cloud-sleuth), that auto-configures your app to work with distributed tracing tools.
Together with this project you have Spring Cloud Zipkin Client that takes your instrumented log information and sends it to a Zipkin server. The server provides a clean and easy to use interface to understand the relationships between your services.
# The Demo
## Description
To explore the projects I developed 3 "layers" of services that talk to each other. The first layer contain only one service (service-one) and requests data from the second layer, comprised of two services (service-two, service-three).
At this point we can talk about Spring Cloud Load Balancer. This project is used to configure client-side load-balancing on the service-one for the second layer of services. The picture below shows how the services relate to each other.
Any service of the second layer then calls the service from the third layer (service-four). The list of services the request went through is put together and returned to the client by service-one.
The two possible responses to a call to `service-one/info` are:
```json
//Using service-two on the second layer
{
"info": {
"Service 4": "Wow, request arrived this far!",
"Service 2": "ok",
"Service 1": "ok"
}
}
```
```json
//Using service-three on the second layer
{
"info": {
"Service 4": "Wow, request arrived this far!",
"Service 3": "ok",
"Service 1": "ok"
}
}
```
Service-one will unevenly load-balance between service-two and service-three because there's a `Thread.sleep(200)` on service-three.
## Running
To make it easy to run your own tests and see the distributed tracing in action, I've prepared a repository with the four services described above and a `.jar` for the Zipkin server.
{% github brunodrugowick/distributed-tracing-demo no-readme %}
Clone it and just run `/scripts/start-all.sh`. If you have Java 11 and Apache Bench (and a GNU/Linux operating system), everything runs and perform 10 thousand requests to fill your Zipkin server with some data.
## The trace
After waiting for a couple of minutes for the tests to run, the script instructs you to go to `http://localhost:9411`. Let's explore it a bit...
### Zipkin server
After searching for traces by clicking on the search icon, that's what the homepage looks like:
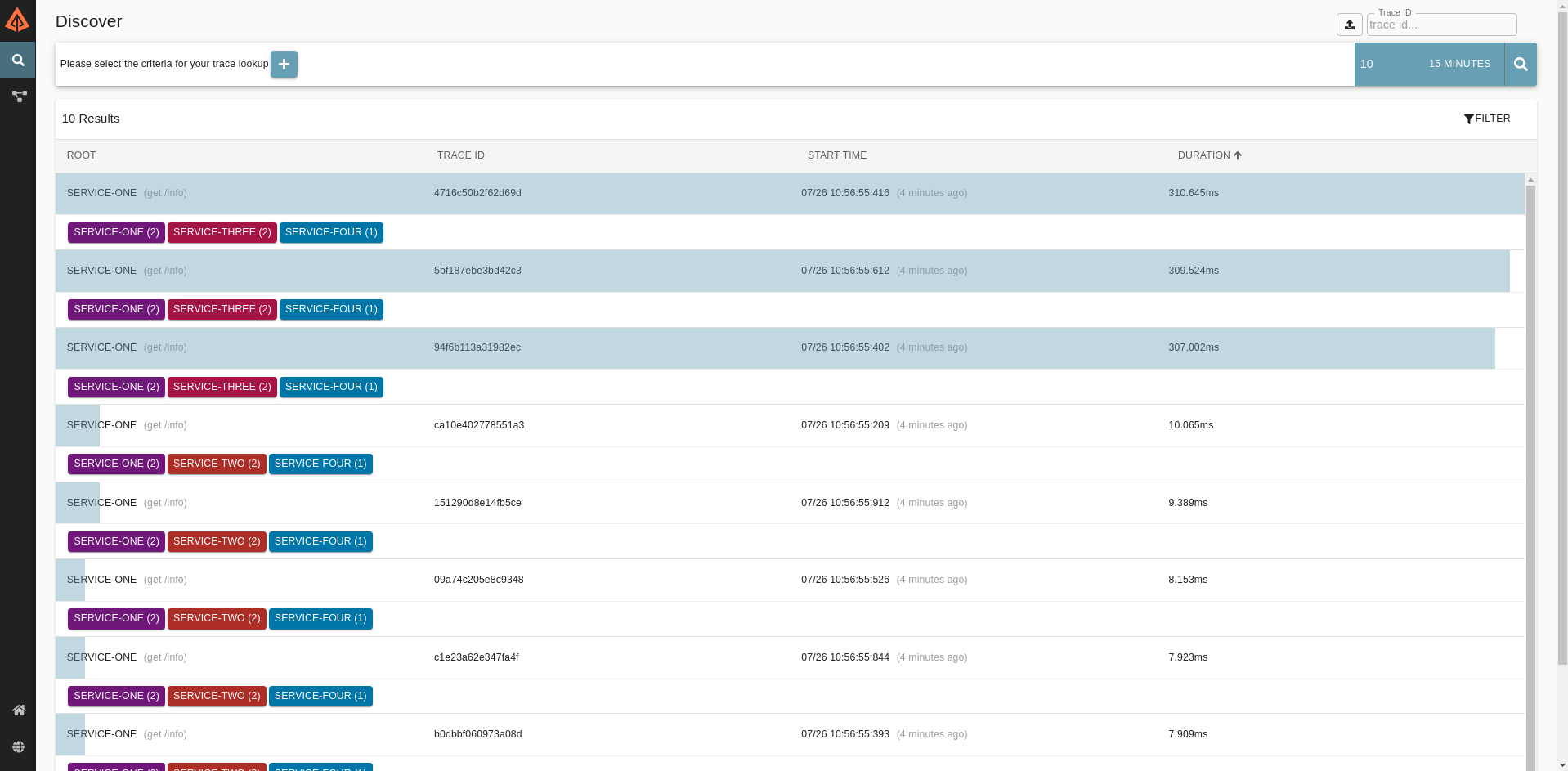
A very useful feature is the ability to filter traces based on the service name:
Inspecting a trace gives you this view, where you can easily see how long the request took in every service:
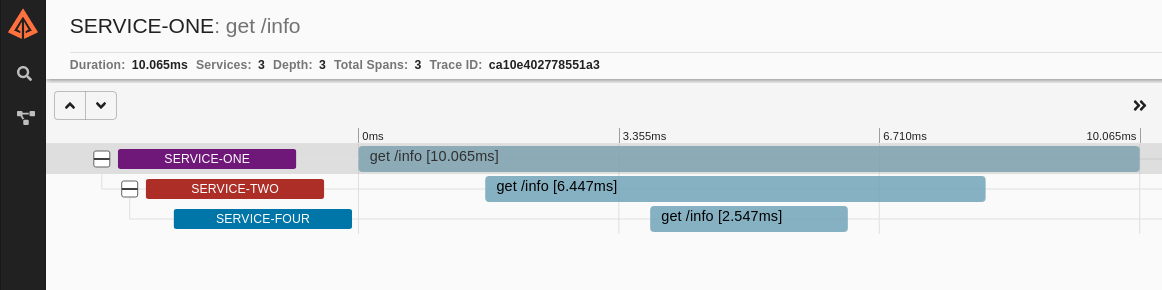
Finally, a very useful feature is understand your services dependencies using the Dependencies Page. Make sure you select a Start and End time and click the magnifier glass icon:
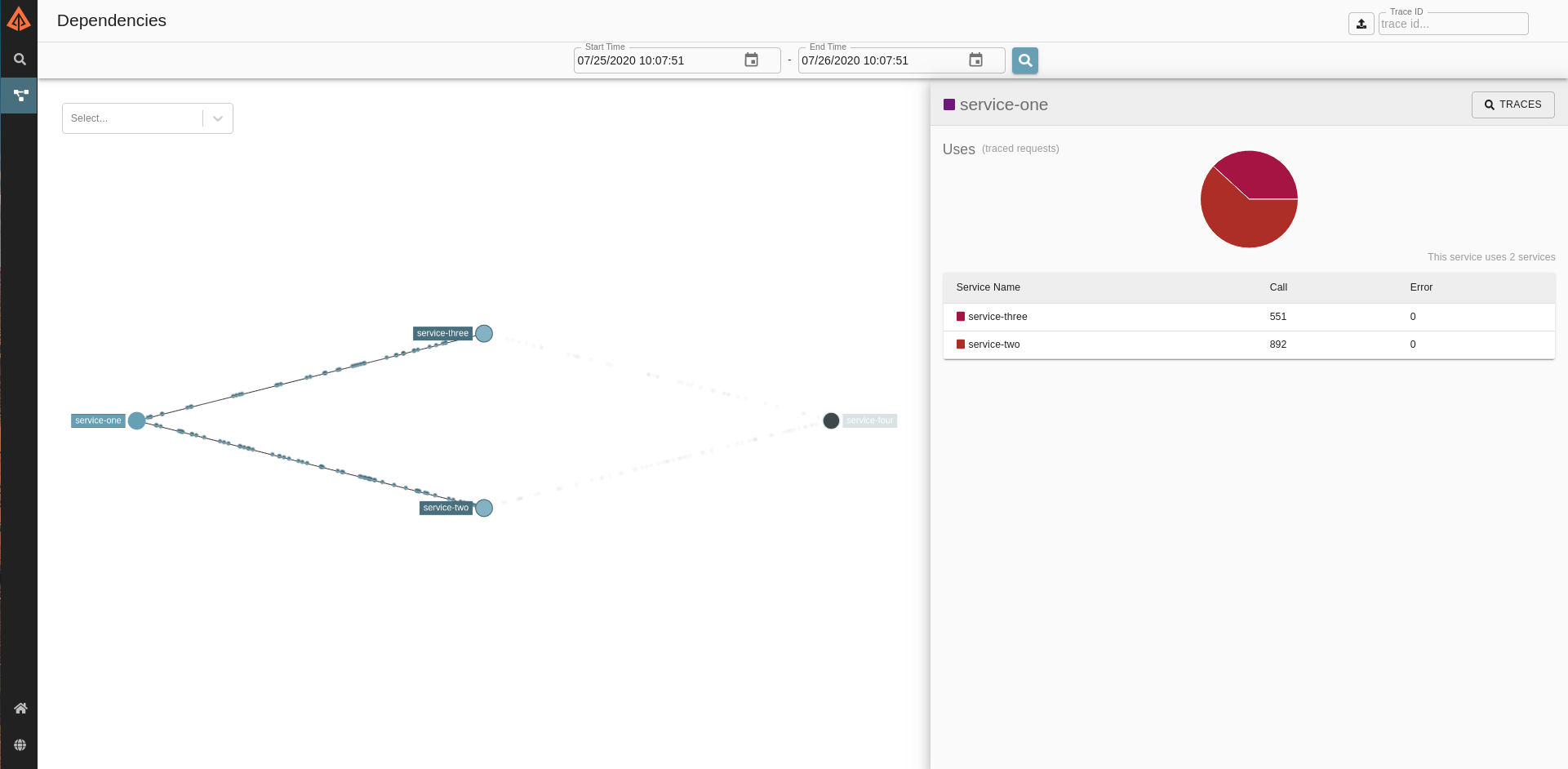
# AQAP Series
As Quickly As Possible (AQAP) is a series of quick posts on something I find interesting. I encourage (and take part on) the discussions on the comments to further explore the technology, library or code quickly explained here.
---
Image by <a href="https://pixabay.com/pt/users/jaykingsta14-4885997/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=2358636">Jason King</a> por <a href="https://pixabay.com/pt/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=2358636">Pixabay</a> | brunodrugowick |
410,070 | Frontend Development Trainers | We are looking for Front-End Development trainers who can build video courses. Get in touch if you en... | 0 | 2020-07-26T07:52:16 | https://dev.to/rahulvenati/frontend-development-trainers-5g10 | html, css, career, webdev | We are looking for Front-End Development trainers who can build video courses. Get in touch if you enjoy teaching and have industry experience. We have a part-time role that we promise would be a good fit for you. People who have already created video tutorials or screencasts will be preferred. Please Comment or DM to discuss more. | rahulvenati |
415,366 | Give some ideas | Can you guys give me ideas to design the skill page for my personal portfolio website 🤔? Here is the... | 0 | 2020-08-01T11:38:09 | https://dev.to/touhidulshawan/give-some-ideas-18gd | portfolio | Can you guys give me ideas to design the skill page for my personal portfolio website 🤔?
Here is the link for my [website](https://touhidulshawan.github.io/touhidulshawan/#/)
| touhidulshawan |
415,492 | Navigating through the Adventure | Hey there, Here is the summary of my last 2 weeks in JULY. Goal: The goal for this week was to add t... | 6,952 | 2020-08-01T16:08:47 | https://dev.to/theshubham99/navigating-through-the-adventure-4a74 | Hey there,
Here is the summary of my last 2 weeks in JULY.
Goal:
The goal for this week was to add the dynamic URI's to the app and add some roles to the system. Along with that to add small features like `back` navigation.
Brief:
Initially, I updated the structure of the project according to community inputs. Later, Some UI animations were fixed/removed.
Some features added during this period are -
✔️ URI based rendering.
✔️ Navigational buttons and permalink button.
✔️ Jump feature to switch stages dynamically.
✔️ External links handling.
✔️ pathMap roles and paths:
* Player Role.
* Artist Role.
* Basic contribution path.
* Documentation and i18 Role.
Links:
Pull Requests -
https://github.com/MovingBlocks/AdventureSite/pull/10
https://github.com/MovingBlocks/AdventureSite/pull/11
https://github.com/MovingBlocks/AdventureSite/pull/12
https://github.com/MovingBlocks/AdventureSite/pull/13
https://github.com/MovingBlocks/AdventureSite/pull/14
https://github.com/MovingBlocks/AdventureSite/pull/15
https://github.com/MovingBlocks/AdventureSite/pull/16
Post Type: Update.
Regards,
Prathamesh (TheShubham99)
$ Ctrl+z
program exited with exit code 0 (0x0) | theshubham99 | |
415,649 | Making Our ⚛ Components Reusable♻️ | React’s value add for frontend developers is that it makes single page web app development much easie... | 7,861 | 2020-08-01T20:30:54 | https://dev.to/speratus/making-our-components-reusable-4451 | react, javascript, reusable, components | React’s value add for frontend developers is that it makes single page web app development much easier by combining the well understood syntax of HTML with the scripting capabilities of JavaScript in an intuitive and convenient way.
One of React’s *most important* features that is easy for new developers to overlook is component reusability. We need to be building React components that are designed to be reused throughout the UI.
I get it though, it can be hard to see how a component can be reused. I hope to be able to pass on some tips that I’ve learned during my journey into React to help keep components reusable.
# Start with the planning stage
In the last post in the series, I broke down a series of wireframes into a component hierarchy. Detailed planning is the first step to identifying reusable components.
When looking at a mockup or a wireframe, it’s critical to identify parts of the UI which are identical to other parts of the UI or are extremely similar but with minor variations.
## Aristotle and UI
The Greek philosopher Aristotle formalized thought regarding an object’s essence. According to Aristotle, an object’s essence is the set of characteristics that make the object what it is and without which it would not be what it is.
For example, we could say that the essence of a button is its clickability. All buttons are clickable and perform some action when clicked. Similarly, if a part of a UI is never clickable, then we can say that it is not a button.
In contrast to an object’s essence, Aristotle held that objects also have “accidental” characteristics. Basically what Aristotle meant by the term “accidental” is “not essential”. That is, an accidental characteristic is something which can be removed from an object without making the object something other than what it is.
In our example, a button’s color, shape, or text would all be accidental characteristics because they can all be changed without making the button not a button. A red button is still a button.
> In Aristotle’s thought, an “accidental” characteristic is not one which occurs by chance, but rather a characteristic which can be altered without changing the object into a different kind of object.
## How does all this relate to reusability ♻️?
When identifying reusable components, first look for all the parts of the UI which share essential characteristics. Identify UI elements which are accidental characteristics of the components to which they belong, so that you can see all the features that it shares in common with similar components.
Reusable components share the same set of essential characteristics in **every** part of the UI, even though some of their accidental characteristics might change between parts of the UI.
# Building Reusable components
If you haven’t already, create a new react app for our forum project.
```bash
npx create-react-app
```
When it’s finished, navigate to the new project and install missing dependencies:
```bash
yarn add @mdi/js @mdi/react bulma rbx \
react-router react-router-dom \
graphql-request redux react-redux \
immer easy-redux-reducers
```
Here’s a brief explanation of the dependencies
* [Bulma][bulma], [rbx][rbx]: npm packages to use the bulma framework with react
* `@mdi/js`, `@mdi/react`: packages to use the material design icon font with react
* `react-router`, `react-router-dom`: allows us to have multiple pages in one react app.
* `graphql-request`: allows us to easily query our GraphQL backend.
* [redux][redux], `react-redux`: helps us manage complex application state
* [immer][immer]: allows us to maintain immutability but also to modify state objects directly.
* [easy-redux-reducers][reducers]: a tiny package to eliminate the need for writing switch statements in redux reducers.
Once those are finished installing, we’re ready to begin building reusable components
# Delete unnecessary files
Remove the files `index.css`, `app.css`, `logo.svg`, `favicon.ico` and all the references to those files. We won’t need them and they’ll just get in the way.
# Creating our first reusable component
Let’s tackle the most reused component in our component hierarchy: `Field`. If you look back at the last post, you’ll see that this field is probably the most reused component in the whole hierarchy.
For clarity, I’m calling `Field` `FormField` in the actual code to reduce ambiguity since there is a `field` component in Bulma.
Here’s my code for `FormField`:
```jsx
// src/components/FormField.js
import React from 'react';
import {Field, Label, Control, Input} from 'rbx';
const FormField = props => {
return <Field>
<Label>{props.name}:</Label>
<Control>
<Input
type="text"
placeholder={props.name}
value={props.value}
onChange={props.onChange}
/>
</Control>
</Field>
};
export default FormField;
```
The `Field`, `Label`, `Control`, and `Input` components are all components from `rbx` required to use Bulma styles and make sure that they stay consistent.
Notice that I have not actually passed any values (other than the “text” property) to any of the components. This is key to keeping a component reusable. We need to make sure it behaves predictably in whatever context we use it.
`FormField` does not maintain any state, but rather expects an `onChange` prop so that it’s parent component can keep track of state management. Since `FormField` is a functional component, getting the value of the `Input` component would have been challenging.
## The `TopicTitle` component
Let’s look at another example. Here’s my code for the `TopicTitle` component:
```jsx
import React from 'react';
import { withRouter } from 'react-router-dom';
import { Box, Title } from 'rbx';
const TopicTitle = props => {
return <Box onClick={()=> props.history.push({pathname: props.to})}>
<Title>{ props.text }</Title>
</Box>
}
export default withRouter(TopicTitle);
```
This component displays the title of a topic and also acts as a link to the topic itself. Again, by using props, I can make this component highly reusable with minimal effort. I wrapped the whole component in `react-router`’s `withRouter()` function to enable it to properly integrate with the browser’s history API.
# Go build some reusable♻️ components
I hope I have been able to give you some tips regarding how to make React components reusable. As always, feel free to ask me questions in the comments.
The code for this part of the series is available on [GitHub][repo]
{% github speratus/miniforum-frontend %}
[bulma]: https://bulma.io
[rbx]: https://github.com/dfee/rbx
[redux]: https://redux.js.org
[immer]: https://immerjs.github.io/immer/docs/introduction
[reducers]: https://github.com/speratus/easy-redux-reducers
[repo]: https://github.com/speratus/miniforum-frontend/tree/part1-reusability
| speratus |
415,674 | Day 16: One line | Only one line made it to Github today. A media query to handle responsiveness. I'm obsessed with the... | 0 | 2020-08-01T20:29:26 | https://dev.to/mtee/day-16-one-line-3j8k | 100daysofcode, javascript | Only one line made it to Github today. A media query to handle responsiveness. I'm obsessed with the green dots on github 😅 so i had to salvage the 16 day streak.😎 Meanwhile, I've been reading on saving form data, the implementation has hit a dead end though but I'll figure it out soon enough.
_Day 16_ | mtee |
415,727 | Lessons learned as a software intern during a pandemic | Interning is tough enough even when there isn’t a pandemic. I feel for every person who has had to st... | 0 | 2020-08-01T21:53:35 | https://dev.to/compscilauren/lessons-learned-as-a-software-intern-during-a-pandemic-1dj9 | career, internship | Interning is tough enough even when there isn’t a pandemic. I feel for every person who has had to stress over the well-being of their loved ones or worry a lot for their own health and safety. I’ve been extremely fortunate in that my level of pandemic-related stress has probably been average, or maybe even below-average.
I just want to say that for anyone who has had to deal with a high amount of stress because of this pandemic, or any reason really, you’re not alone and it’s okay if you feel like you aren’t excelling as much as you would under regular circumstances. I’ve dealt with stressful situations and I know that sometimes just getting through the work day or school day is an accomplishment in itself. It’s hard to give it your all when you’re already dealing with so much as it is.
I've been lucky to be able to spend time this summer focusing a lot on my internship, and what I want in my career. I'm lucky to have had a strong support system to help me as I navigated my virtual internship too.
Everyone who helps run the summer internship program at Cerner has been absolutely amazing and gone out of their way to help everyone succeed. They provided guidance and helped us all navigate our virtual internships.
I also had a ton of support from my team, other associates at Cerner, and some wonderful friends. They know who they are and I will be forever grateful to each of them.
At the end of the day, I think having a strong support system and others who can help guide you is one of the best things for your career or any other major endeavor.
Being an intern in a virtual setting has really made it clear to me that my career is truly in my own hands. Even from the first day of work, it was clear.
It was up to me to login and figure out how to set everything up so that I could make it to that first day of training. Once I had my first real task to do, it was on me to get it done.
That’s true even under regular circumstances. But when you’re alone in a room all day, it feels more apparent. There was no one to physically stop by my desk and check in with me.
If anything, I think working remotely made me even more determined to do well. The last thing I wanted was for anyone to think that I wasn’t giving it my best effort.
If people couldn’t physically observe me working, then I needed to make sure that they saw it in the work I was pushing out.
I think success is something that looks different for everyone. What you want to prioritize is up to you and can change over time, and that’s the real beauty of it. For me, I’ve been studying for years to become a software engineer and I’m beyond excited to be so close to reaching that goal. With this being my final internship and only one more semester to go, I’ve felt easily motivated and eager to make as much progress as I reasonably can.
For me, my focus is currently on my career. And I've been lucky to have a ton of inspirational people to learn from at this internship, including other interns. I’ve seen people accomplish some amazing things this summer, and it has definitely inspired me.
Being committed to doing good work and finding ways to make valuable contributions helps everyone, including yourself.
Everyone make mistakes sometimes. I know I did. But I think at the end of the day, if you're putting in effort, have a positive attitude, and can learn from those mistakes, you'll do great.
All that said, it was also critical to know when to take a break and prevent burnout. It’s easy to lose track of time when there’s no physical disconnect between work and personal life. Living in a small apartment also meant that I couldn’t have a whole room dedicated to doing just work.
I also learned that I actually feel better when I can move around occasionally. Whether it was doing some work on the couch or sitting outside when the weather was nice, sometimes a change of scenery was surprisingly helpful.
Working remotely has its perks. There’s no commute. That’s the best perk in my mind. I’ve saved an impressive amount of time and money by not having to drive to and from work each day.
It also has some pitfalls to avoid. Like making sure you aren’t all alone when you’re working. It’s easy to just spend the day doing work and going to meetings, but not talking to anyone outside of that.
Normally you could walk down a hallway or step into the break room and talk with people. Or stop by someone’s desk to have a quick chat. That just isn’t a thing in remote work.
It was also important to keep in mind that this was not the typical situation for remote work.
Working remotely during a pandemic is not going to feel the same as it would under regular circumstances. So keeping an eye on how I was feeling and making sure I was doing okay was crucial.
I learned how to reach out to people. Whether it was a teammate, a fellow intern friend, or someone else I’d met virtually. It could be about work, or maybe we would just catch up for a bit. It was nice to just chat occasionally, like you would if you were working in the same building.
One of the best things the summer internship program involved was the Friday “lunch roulettes”. Every Friday we were assigned a new group and we could meet up to get virtual lunch together.
I was able to meet lots and lots of other interns this way, and it was a blast. I even met with a few interns on other days of the week to do our own lunch get-togethers, and it was awesome.
I also met a lot of people just through virtual chatting and through special events, like at the ShipIt hackathon and the DevCon conference.
I wasn’t sure if I would make any friends in a remote setting like this, but I was pleasantly surprised to meet a lot of great people who I hope to stay in touch with even after the internship is over.
I'm grateful to have had an internship at all this summer, and I'm especially glad that it was with Cerner. Making healthcare better is something that I find extremely meaningful, and I'm proud to have made some contributions to that through this virtual internship.
Tomorrow is my last day, and even though everyone warned me it would go by fast, I’m still shocked. It may have gone by fast, but I’ve learned a great deal. I don’t know exactly what my final semester of classes will look like, or how long I’ll continue to do work remotely. But I know that this internship has made me more than prepared to adapt and take on whatever comes next.
This article was originally published on my personal website's blog, [Joy Bytes](https://www.compscilauren.com/blog/lessons-learned-as-a-software-intern-during-a-pandemic). | compscilauren |
415,789 | Quick go-to Angular API service setup | I've been playing around with the Deezer API and have found that when working with APIs I tend to use... | 0 | 2020-08-02T02:19:19 | https://dev.to/lornasw93/quick-go-to-angular-api-service-setup-39k7 | angular, webdev, womenintech | I've been playing around with the [Deezer API](https://rapidapi.com/deezerdevs/api/deezer-1) and have found that when working with APIs I tend to use the same layout in terms of project structure.
I always have a pretty simple and generic abstract base service class where contains just 3 methods, purposes being to return individually a item, count and list.
## Base API Service
```
import { Injectable } from '@angular/core';
import { HttpClient } from '@angular/common/http';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export abstract class BaseApiService<T> {
baseUrl = 'https://localhost:44331';
abstract resourceUrl: string;
constructor(protected httpClient: HttpClient) { }
getList(url): Observable<T[]> {
var to = `${this.baseUrl}/${this.resourceUrl}?${url}`;
console.log(`GET LIST: ${to}`);
return this.httpClient.get<T[]>(`${to}`);
}
get(url): Observable<T> {
var to = `${this.baseUrl}/${this.resourceUrl}?${url}`;
console.log(`GET: ${to}`);
return this.httpClient.get<T>(`${to}`);
}
count(url): Observable<T> {
var to = `${this.baseUrl}/${this.resourceUrl}?${url}`;
console.log(`COUNT: ${to}`);
return this.httpClient.get<T>(`${to}`);
}
}
```
## Deezer Service
I create service classes that extend from my base abstract, again, keeping it simple.
```
import { Injectable } from '@angular/core';
import { HttpClient } from '@angular/common/http';
import { BaseApiService } from "./base.api.service";
import { Deezer } from "../models/deezer.model";
@Injectable({
providedIn: 'root'
})
export class DeezerService extends BaseApiService<Deezer> {
resourceUrl = 'api/Deezer?searchTerm=';
constructor(http: HttpClient) {
super(http);
}
getSearchResults(query) {
return this.getList(query);
}
}
```
## Component
At component level, I pass in an data if required and call the method from the service.
```
import { Component, OnInit } from '@angular/core';
import { FormBuilder, FormGroup, Validators } from '@angular/forms';
import { DeezerService } from "../../core/services/deezer.service";
@Component({
selector: 'app-deezer-search',
templateUrl: './deezer-search.component.html'
})
export class DeezerSearchComponent implements OnInit {
searchResults: any;
searchForm: FormGroup;
constructor(private readonly deezerService: DeezerService,
private formBuilder: FormBuilder) {
}
ngOnInit() {
this.searchForm = this.formBuilder.group({
query: ['', Validators.required]
});
}
onSearchSubmit() {
const query = this.searchForm.value.query;
this.deezerService.getSearchResults(query).subscribe((data: any) => {
this.searchResults = data;
},
(err) => {
// handle errors here
});
}
}
```
To note I've omitted irrelevant bits. | lornasw93 |
415,819 | Hello world | This is a test hello world post. Originally Posted on Aug 2, 2020 | 0 | 2020-08-02T03:27:44 | https://dev.to/srikant_code/hello-world-1bhg | This is a test hello world post.
Originally Posted on Aug 2, 2020 | srikant_code | |
415,832 | Is a big layoff in tech coming? | Layoff at Dell, über, Airbnb, Groupon, etc. Who is next? | 0 | 2020-08-02T04:26:04 | https://dev.to/pandaquests/is-a-big-layoff-in-tech-coming-1l0c | discuss, career | Layoff at Dell, über, Airbnb, Groupon, etc. Who is next? | pandaquests |
415,925 | React Image Navigation | Am New to React Please Hoe Can i Create Image Header Navigation And Pass It Please | 0 | 2020-08-02T06:59:49 | https://dev.to/stephenlove003/react-image-navigation-36o0 | Am New to React
Please Hoe Can i Create Image Header Navigation And Pass It
Please | stephenlove003 | |
416,188 | Opt out of extension updates for VS Code | If you do not want extensions to automatically update, you can clear the Extensions: Auto Update chec... | 0 | 2020-08-02T16:39:16 | https://dev.to/taoliu12/opt-out-of-extension-updates-for-vs-code-5d1i | If you do not want extensions to automatically update, you can clear the `Extensions: Auto Update` check box in the Settings editor (Ctrl+,).
>or
If you use the JSON editor to modify your settings, add the following line:
`"extensions.autoUpdate": false` | taoliu12 | |
415,937 | My first blog post about middleware in .Net Core | Hello everybody I wrote a blog post about middleware in .Net core in Medium yesterday. I just want t... | 0 | 2020-08-02T07:50:46 | https://dev.to/muhammedalibalci/my-first-blog-post-about-middelware-in-net-core-3i8k | csharp, dotnet | Hello everybody
I wrote a blog post about middleware in .Net core in Medium yesterday. I just want to share with you this.
https://medium.com/@muhammedalibalci/middleware-in-net-core-a4448e74af17
| muhammedalibalci |
416,008 | Docker File & Semantics | Hey, I have share my short note on DockerFile and semantics. check it out.... | 0 | 2020-08-02T10:52:56 | https://dev.to/shailbhatt/docker-file-semantics-4bgk | docker, codenewbie, tutorial, todayilearned | Hey, I have share my short note on DockerFile and semantics. check it out.
{% twitter 1289872049783967745 %}
You will get next notes on What are underlying technology docker use? Stay tune!! | shailbhatt |
416,117 | How to Build & Test Twitch Chat Bot Commands with Next.js | Intro I recently worked on a side project that involved building custom chat commands for... | 0 | 2020-08-02T14:53:41 | https://dev.to/wescopeland/how-to-build-test-twitch-chat-bot-commands-with-next-js-4j1g | javascript, node, serverless, typescript | ## Intro
I recently worked on a side project that involved building custom chat commands for a bot on Twitch.tv. The commands themselves required a lot of heavy lifting with the Google Sheets API - something that was the perfect candidate for a Node.js server.
This wasn't the first time I've done custom bot work on Twitch or Discord. For previous projects, I've always spun up a custom server to manage the bot that was then deployed (at cost) to Heroku. However, after a few hours of initial work on this new project, I discovered it would be much easier to tackle the bot commands using modern serverless technologies. After all, each bot command is just a function.
In theory, this could be done using anything that lets you easily host an API endpoint without a server. I chose Next.js because a lot of similar non-bot-related feature work lived in the same Next.js project.
---
## How it works

- 🤖 Your Twitch channel is running [Nightbot](https://nightbot.tv/), which supports [custom API-based "UrlFetch" commands](https://docs.nightbot.tv/commands/variables/urlfetch). Nightbot is free to use and takes less than 20 seconds to set up on your channel.
- 👨💻 You use [Next.js's API routes support](https://nextjs.org/docs/api-routes/introduction) to build serverless backend microservice functions.
- 😎 You deploy your project to [Vercel](https://vercel.com) or [Netlify](https://netlify.com) for free.
- 📡 You [create a custom command with Nightbot](https://docs.nightbot.tv/commands/commands) leveraging UrlFetch and your newly-deployed API route.
---
## 🔧 Let's build it
### Set up a fresh Next.js project
Let's create a new Next.js project. I'll be using TypeScript for this project, but this can easily be adapted to work with JavaScript instead.
In your terminal in the directory you'd like to create the project, run:
```
npx create-next-app --example with-typescript
OR
yarn create next-app --example with-typescript
```
After a few minutes, your project should be ready to go, and a dev server can be started with `npm run dev` or `yarn dev`.
### Add a new API route
Creating serverless functions in Next.js is so easy it feels like cheating. You should have a _pages_ folder in your project. Create an _api_ folder inside _pages_ and within it create a new file: _ping.ts_. Your file structure should look something like this (I have not modified the TypeScript example project):

With your dev server running at `yarn dev`, http://localhost:3000/api/ping now automagically maps to your _ping.ts_ file! But it isn't doing anything yet.
### Make the API route useful for Nightbot
Our custom chat command will be very simple. There will be no heavy lifting involved. For this article, we want the command to say hello, print the initiator's username, and print the current channel. Like so:
Let's get coding. Open up _ping.ts_ and paste this content in:
```typescript
// ping.ts
import { NextApiRequest, NextApiResponse } from 'next';
export default async function (req: NextApiRequest, res: NextApiResponse) {
res.status(200).send('Hello!');
}
```
With your local dev server running (`npm run dev` or `yarn dev`), if you visit localhost:3000/api/ping, you should see "Hello!" printed to the screen. Cool!
Some things to note if this is your first Next.js rodeo:
- `req` and `res` may look like conventional Express.js request and response arguments, but _they are not_. `NextApiRequest` and `NextApiResponse` are Express-like. Docs [here](https://nextjs.org/docs/api-routes/response-helpers) on response helpers might be useful.
- If _all_ of this looks like moon language, the [Next.js API routes documentation](https://nextjs.org/docs/api-routes/introduction) is a pretty good first start.
- By default, **Nightbot expects a plain-text response.** [JSON is supported](https://docs.nightbot.tv/commands/variables/urlfetch), but beyond the scope of this article.
Alright, we're printing "Hello" to the screen, but what about the username and the current channel? When Nightbot sends an API request, it sends along headers with all that metadata too! Info on these headers can be found [on the UrlFetch docs page](https://docs.nightbot.tv/commands/variables/urlfetch):

We're specifically interested in `Nightbot-User` and `Nightbot-Channel`. Nightbot sends data in these headers along as query strings, like this:
```typescript
req.headers['nightbot-channel'] =
'name=kongleague&displayName=KongLeague&provider=twitch&providerId=454709668';
req.headers['nightbot-user'] =
'name=wescopeland&displayName=WesCopeland&provider=twitch&providerId=52223868&userLevel=moderator'
```
We can use JavaScript's built-in `URLSearchParams` constructor to parse these pretty easily. Add these functions to your _ping.ts_ file:
```typescript
// somewhere in ping.ts
const parseNightbotChannel = (channelParams: string) => {
const params = new URLSearchParams(channelParams);
return {
name: params.get('name'),
displayName: params.get('displayName'),
provider: params.get('provider'),
providerId: params.get('providerId')
};
};
const parseNightbotUser = (userParams: string) => {
const params = new URLSearchParams(userParams);
return {
name: params.get('name'),
displayName: params.get('displayName'),
provider: params.get('provider'),
providerId: params.get('providerId'),
userLevel: params.get('userLevel')
};
};
```
Updating the _ping.ts_ API function to display the username and channel is now relatively straightforward!
```typescript
// ping.ts
export default async function (req: NextApiRequest, res: NextApiResponse) {
const channel = parseNightbotChannel(
req.headers['nightbot-channel'] as string
);
const user = parseNightbotUser(req.headers['nightbot-user'] as string);
res
.status(200)
.send(
`Hello! Your username is ${user.displayName} and the current channel is ${channel.displayName}.`
);
}
```
---
## ✅ Let's test it
Our endpoint is built, but how would we go about building a unit test for it? You'll see below this is not too difficult. Note that Jest does not ship with new Next.js projects by default, [but it is simple to set up](https://github.com/arcatdmz/nextjs-with-jest-typescript).
### Add a testing dev dependency
To make life less painful, I recommend installing the `node-mocks-http` library:
```
npm i node-mocks-http --save-dev
OR
yarn add -D node-mocks-http
```
If you're a regular Express.js user, you may be familiar with testing API endpoints using `supertest`. Unfortunately, `supertest` cannot help us with Next.js serverless API routes.
### Create the test file
Your natural inclination might be to put a _ping.test.ts_ file in the same directory as _ping.ts_. This is a good pattern to follow, but due to how Next.js's folder-based routing works it isn't a great idea because Vercel will then try to deploy your tests 😱
I recommend creating a `__tests__` folder at the root of your project where tests for anything inside of _pages_ can live. Inside of `__tests__`, create an _api_ folder that contains _ping.test.ts_.
### Write the tests
Building the test code from here is pretty straightforward:
```typescript
import { createMocks } from 'node-mocks-http';
import ping from '../../pages/api/ping';
describe('Api Endpoint: ping', () => {
it('exists', () => {
// Assert
expect(ping).toBeDefined();
});
it('responds with details about the user and channel', async () => {
// Arrange
const { req, res } = createMocks({
method: 'GET',
headers: {
'nightbot-channel':
'name=kongleague&displayName=KongLeague&provider=twitch&providerId=454709668',
'nightbot-user':
'name=wescopeland&displayName=WesCopeland&provider=twitch&providerId=52223868&userLevel=moderator'
}
});
// Act
await ping(req, res);
const resData = res._getData();
// Assert
expect(resData).toContain('Your username is WesCopeland');
expect(resData).toContain('the current channel is KongLeague');
});
});
```
---
## 🤖 Finally, set up Nightbot
Go to [the Nightbot website](https://nightbot.tv/), sign up, and click the "Join Channel" button in your Nightbot dashboard. Nightbot will now be on your Twitch (or YouTube!) channel.
**I am assuming you've deployed your Next.js project somewhere.** You should be able to hit your newly created `ping` route inside your browser. If you're new to this, deploying to Vercel is probably easiest for Next.js projects. It should just be a matter of signing up, pointing to your GitHub repo, and clicking Deploy.
Now that Nightbot is in your Twitch channel, go to your chat on Twitch. Create a new Nightbot command by entering in the chat:
```
!commands add !ping $(urlfetch https://YOUR_URL/api/ping)
```
After this is done, Nightbot should respond saying the command has been added. You should now be able to type "!ping" in the chat and see your API response! You're all set!
---
## 🔒 Don't forget security
Anyone can access Nightbot's list of commands for your Twitch channel just by using "!commands". Nightbot hides API route addresses, treating them like secrets or environment variables, **but anyone who knows the address to one of your endpoints can mock headers and pretend to be someone they're not in Postman or Insomnia.**
In other words, you need another layer of security if you want to treat the initiator of the chat command as being "authenticated".
If this is important to you (typical in advanced use cases involving things like channel points or user roles), I recommend adding code to your endpoint that ensures the API call actually came from Twitch or Nightbot itself. It's possible to check for this in the request headers of the API call.
---
## 👋 That's all!
Thanks for reading, hopefully this was helpful to someone out there! If you're interested in any of my future content, be sure to follow me here on dev.to. | wescopeland |
416,123 | Plataforma de reconhecimento de áudio | Vou compartilhar uma plataforma de reconhecimento de áudio que encontrei essa semana. Achei muito i... | 0 | 2020-08-02T14:59:51 | https://dev.to/alexandrefreire/plataforma-de-reconhecimento-de-audio-5a89 | Vou compartilhar uma plataforma de reconhecimento de áudio que encontrei essa semana. Achei muito interessante e vi que é utilizada por grandes empresas como "Deezer, Alibaba Group...". Ainda não implementei em nenhum projeto meu, porém tem um período gratuito para testes além de possuir muitos recursos legais, se você conhecer alguma outra plataforma desse tipo compartilha com agente nos comentários.
## Sobre
### Integração Fácil
Conjunto completo de API e SDK para permitir integrações sólidas, ajustáveis e flexíveis. Você pode usar o kit de desenvolvimento de software e a interface de programação de aplicação não só para receber resultados de reconhecimento, mas também para controlar tudo na plataforma através da API RESTful.
### Reconhecimento De Música
O novo padrão para reconhecimento de música.
Oferecemos um dos maiores bancos de dados de impressões digitais de música do mundo, com mais de 72 milhões de faixas, sendo constantemente atualizado.
Os Serviços de Reconhecimento Musical do ACRCloud permitem que os desenvolvedores equiparem diretamente aos serviços de música online (Spotify, Deezer, Youtube etc.) e códigos padrão, como ISRC e UPC. Ele permite que os clientes ofereçam links diretos aos seus usuários, permitindo que eles reproduzam ou comprem faixas instantaneamente em seus respectivos serviços de música.
### broadcast monitoring
Monitoramento De Transmissão
Os primeiros serviços com API de monitoramento de transmissão para seu negócio.
Monitore a transmissão de músicas de estações de rádio ou monitore músicas de fundo de estações de TV com um dos maiores bancos de dados do mundo de impressões digitais musicais. Obtenha o ISRC e o UPC nos resultados, permitindo que o ACRCloud detecte músicas mesmo dos canais de TV com dublagens.
Carregue seus próprios anúncios ou conteúdo personalizado em seu banco de dados privado, permitindo que o ACRCloud comece a rastrear automaticamente o conteúdo nos canais de TV e estações de rádio.
### Live Channel Detection
Detecção De Canal Ao Vivo
Detectar canais ao vivo e canais com função Timeshift em escala.
Descubra Quais Canais Que o Público Está Assistindo Ou Ouvindo.
O ACRCloud armazena o conteúdo com alteração de horário automaticamente. Portanto, quando o público assiste ao conteúdo com alteração de horário, você sabe exatamente o que eles assistiram.
### Second screen sync
Sincronização De Segunda Tela
Detectar conteúdo pré-gravado em escala e interagir com transmissões de televisão selecionadas.
Ao identificar o conteúdo gravado reproduzido na TV, rádio ou qualquer outra tela interativa ou não interativa, transformamos a experiência de visualização/escuta passiva e reclinada em um ponto focal de engajamento e interatividade do público.
Utiliza as ferramentas fornecidas pelo ACRCloud para gerar impressões digitais no servidor local e enviá-las em massa com metadados personalizados via API.
### copyright compliance
Conformidade Com Direitos Autorais
Proteger direitos autorais de música.
Permite a ação de plataformas com conteúdo de áudio ou vídeo gerado pelo usuário, que são necessárias para censurar ou exibir conteúdo musical não licenciado, além de rastrear e gerenciar conteúdos para fins monetização e relatórios.
### Data deduplication
Deduplicação De Dados
Refinar o banco de dados da mídia.
Permite a ação de plataformas com conteúdo de áudio ou vídeo gerado pelo usuário, que são necessárias para censurar ou exibir conteúdo musical não licenciado, além de rastrear e gerenciar conteúdos para fins monetização e relatórios.
### audience measurement
Medição De Audiência
Mais preciso e convincente.
Detecta canais ao vivo em tempo real para descobrir quais canais o público está assistindo ou ouvindo.
Detecta conteúdo pré-gravado, como anúncios ou filmes, para determinar o conteúdo que o público está assistindo.
### humming recognition
Reconhecimento De Cantarolado
Descubra o nome de uma música apenas cantarolando a canção em seu dispositivo.
A ACRCloud indexou mais de 1 milhão de músicas na sua base de dados de canto. Isso inclui músicas em inglês, chinês, japonês, francês, espanhol e português.
De forma similar à busca textual e reconhecimento de voz, o reconhecimento de canto é uma nova forma de identificar canções.
### offline recognition
Reconhecimento Off-Line
Detectar conteúdo personalizado em dispositivos sem conexão de rede.
A solução para identificação de áudio offline do ACRCloud permite que as impressões digitais do conteúdo de pós-produção e a metodologia de acionamento sejam armazenadas em um aplicativo com antecedência. Isso permite a identificação e o acionamento de informações sem qualquer utilização da Internet, o que é crítico para eventos sem acesso à rede ou utilização extensiva da Internet por longos períodos de tempo.
### Algoritmos De Alto Nível
Os serviços contam com excelentes algoritmos de impressão digital e consulta de áudio para cantarolados.
https://www.acrcloud.com/pt-br/ | alexandrefreire | |
416,127 | Build an app using the Disaster Resiliency Starter Kit | I have published a blog on Medium sharing my experience of conducting a webinar with Here Technologie... | 0 | 2020-08-02T15:58:42 | https://dev.to/mridulrb/build-an-app-using-the-disaster-resiliency-starter-kit-2c0f | android, ios, reactnative, tutorial | I have published a blog on Medium sharing my experience of conducting a webinar with Here Technologies. Link: https://link.medium.com/dWMAtvD8e8 <a href=https://www.medium.com/@mridulrb target="blank"><img src=https://cdn.jsdelivr.net/npm/simple-icons@3.0.1/icons/medium.svg alt="mridulrb" height="20" width="20" /></a> | mridulrb |
416,282 | Shared folder, permission denied issue in Virtual box Guest OS | Simple technique to get rid of Permission denied issue in Virtualbox Guest when accessing Shared fold... | 0 | 2020-08-02T19:25:43 | https://dev.to/gchandra/shared-folder-permission-denied-issue-in-virtual-box-guest-os-10en | virtualbox, linux, ubuntu, oracle | Simple technique to get rid of Permission denied issue in Virtualbox Guest when accessing Shared folder.
Run this command from Virtual Box GUEST OS
$ sudo adduser $USER vboxsf
REBOOT the Guest OS. | gchandra |
416,304 | SQL Injection!!! | Hi guys . How to protect yourself from SQL Injection? Specially Inputs??? I know i can google it but... | 0 | 2020-08-02T20:17:46 | https://dev.to/amirdev/sql-injection-3gjj | Hi guys . How to protect yourself from SQL Injection?
Specially Inputs???
I know i can google it but i think experiences are more useful. | amirdev | |
416,896 | 👩💻 Learning Ruby: first impressions from a JavaScript developer | I have just finished the last class of the "Le Wagon - Programming for Everybody" online learning ser... | 0 | 2020-08-04T14:53:07 | https://dev.to/rossellafer/learning-ruby-first-impressions-from-a-javascript-developer-1d11 | ruby, beginners | I have just finished the last class of the ["Le Wagon - Programming for Everybody"](https://info.lewagon.com/programming-for-everybody-tokyo) online learning series. This was my very first dip into the world of Ruby... and I must admit, I was surprised to discover how developer friendly and humanly readable this language is.
###Why Ruby
You might be wondering, why did a professional developer decide to join a beginner course about Ruby? First of all, a little bit about myself. I am a self-taught developer and I got a job as a front end developer after learning how to code on Freecodecamp, Codecademy and just building projects.
I wanted to experience a structured learning course with a real instructor, where I could ask questions not only about the syntax, but also about best practices and why Ruby does things the way it does. By the end of the course, I also realised that learning a language like Ruby can make me a better JavaScript developer.
###Ruby and JavaScript: some observations
####Object Oriented Programming
Ruby is an **Object Oriented Language**, which means it manipulates programming constructs called objects. If you type `"Ruby"`, you are creating an instance of the class String. As a class instance, your string will inherit methods like `.length`, `.capitalize` etc., that you can use to manipulate your string.
JavaScript, on the other hand, is not a class-based Object Oriented language, but with prototype based inheritance and constructor functions, it has ways of using Object Oriented Programming (OOP).
####Data types
To determine what type of value something is (a number, a string, an array), in Ruby you append `.class` at the end of the object, since you want to find out the class of the object it's called on. There are classes like Integer, Float, String, Array, Hash... even True and False are their own class!
```
true.class
# TrueClass
false.class
# FalseClass
```
In JavaScript, you use `typeof` before your data, and this will return whether that element is a string, a number, a boolean, an object etc.
```
typeof true
# boolean
typeof false
# boolean
```
####Method naming conventions
In Ruby, I saw for the first time methods ending with "?", a naming convention used to indicate that a specific method will return either true or false. For example, if you have a hash (a key value pair data structure) with tv show titles and ratings, you can use the simple method `.key?` to check if the hash contains a certain key.
```
tv_shows = {
"Friends" => 10,
"Community" => 10,
"The Witcher" => 9
}
puts tv_shows.key?("Friends")
```
In JavaScript, functions can't end with punctuation but can be named semantically so that their name will describe well what they do. If you are curious to know how you can check if an object has a specific key in JavaScript, this is how you do it:
```
const tv_shows = {
"Friends": 10,
"Community": 10,
"The Witcher": 9
}
tv_shows.hasOwnProperty("Friends")
```
####There is more than one way to do something
Ruby is built for usability. I was surprised to discover that for example the methods `.map` and `.collect` do exactly the same thing and that collect was just created in order to make Ruby feel more intuitive.
###Where to go from here?
I plan on continuing learning Ruby until I am able to contribute to my company's projects that use this language. That's how I would like to reinforce this initial knowledge and put it into practice:
1. Codewars kata
2. Build a scraper - apparently this can be done only with a few lines of code in Ruby
3. [The Odin Project learning track](https://www.theodinproject.com/courses/ruby-programming)
| rossellafer |
416,903 | @Azure Mini Fun Bytes: How to create a static web site using blob storage | I take you through a few real-world problems and find some solutions. Today, we answer: How do I cr... | 0 | 2020-08-03T14:35:25 | https://dev.to/azure/azure-mini-fun-bytes-how-to-create-a-static-web-site-using-blob-storage-pd1 | azure, storage, beginners | I take you through a few real-world problems and find some solutions. Today, we answer:
**How do I create a static web site using blob storage?**
Simple websites sometimes need simple solutions to host them. If you have a static website and just need to host some HTML and images, Azure blob storage allows you to easily [enable static web hosting](https://docs.microsoft.com/azure/storage/blobs/storage-blob-static-website-how-to?tabs=azure-portal&WT.mc_id=devto-blog-jagord). You can keep costs low, [customize your URL](https://docs.microsoft.com/azure/storage/blobs/storage-custom-domain-name?tabs=azure-portal&WT.mc_id=devto-blog-jagord), [integrate a Content Delivery Network](https://docs.microsoft.com/azure/storage/blobs/static-website-content-delivery-network?WT.mc_id=devto-blog-jagord) to serve quickly and do so all while ensuring developers can deploy easily.
{% youtube XZXZPdMfcWw %}
I take questions and give you a start with code and procedure to deploy it.
Follow AzureFunBytes on [Twitter](https://twitter.com/azurefunbytes) and [Twitch](https://www.twitch.tv/azurefunbytes) for updates on future episodes.
Links for you!
[Introduction to the core Azure Storage services](https://docs.microsoft.com/azure/storage/common/storage-introduction?WT.mc_id=devto-blog-jagord)
[What is Azure Blob storage?](https://docs.microsoft.com/azure/storage/blobs/storage-blobs-overview?WT.mc_id=devto-blog-jagord)
[Introduction to Azure managed disks](https://docs.microsoft.com/azure/virtual-machines/windows/managed-disks-overview?WT.mc_id=devto-blog-jagord)
[Use the portal to attach a data disk to a Linux VM](https://docs.microsoft.com/azure/virtual-machines/linux/attach-disk-portal?WT.mc_id=devto-blog-jagord)
Microsoft Learn: [Core Cloud Services - Azure data storage options](https://docs.microsoft.com/en-us/learn/modules/intro-to-data-in-azure/?WT.mc_id=devto-blog-jagord)
Microsoft Learn: [Azure Fundamentals](https://docs.microsoft.com/learn/paths/azure-fundamentals/?WT.mc_id=devto-blog-jagord)
[Microsoft LearnTV](https://docs.microsoft.com/learn/tv/?WT.mc_id=devto-blog-jagord) 24*7 streaming Azure content
[Get $200 in free Azure credit along with 12 months of free services](https://azure.microsoft.com/en-us/free/?WT.mc_id=devto-blog-jagord)
| jaydestro |
416,997 | How to scrape the web with Playwright | Playwright is a browser automation library very similar to Puppeteer. Both allow you to control a web... | 0 | 2020-08-03T16:30:54 | https://blog.apify.com/how-to-scrape-the-web-with-playwright-ece1ced75f73 | tutorial, playwright, automation, javascript | [Playwright](https://github.com/microsoft/playwright) is a browser automation library very similar to [Puppeteer](https://github.com/puppeteer/puppeteer). Both allow you to control a web browser with only a few lines of code. The possibilities are endless. From automating mundane tasks and testing web applications to data mining.
With Playwright you can run Firefox and Safari (WebKit), not only Chromium based browsers. It will also save you time, because Playwright automates away repetitive code, such as waiting for buttons to appear in the page.
> You don’t need to be familiar with Playwright, Puppeteer or web scraping to enjoy this tutorial, but knowledge of HTML, CSS and JavaScript is expected.
In this tutorial you’ll learn how to:
1. **Start a browser with Playwright**
2. **Click buttons and wait for actions**
3. **Extract data from a website**
## The Project
To showcase the basics of Playwright, we will create a simple scraper that extracts data about [GitHub Topics](https://github.com/topics). You’ll be able to select a topic and the scraper will return information about repositories tagged with this topic.

We will use Playwright to start a browser, open the GitHub topic page, click the *Load more* button to display more repositories, and then extract the following information:
* Owner
* Name
* URL
* Number of stars
* Description
* List of repository topics
## Installation
To use Playwright you’ll need [Node.js](https://nodejs.org/) version higher than 10 and a package manager. We’ll use `npm`, which comes preinstalled with Node.js. You can confirm their existence on your machine by running:
node -v && npm -v
If you’re missing either Node.js or NPM, visit the [](https://docs.npmjs.com/downloading-and-installing-node-js-and-npm) to get started.
Now that we know our environment checks out, let’s create a new project and install Playwright.
mkdir playwright-scraper && cd playwright-scraper
npm init -y
npm i playwright
> The first time you install Playwright, it will download browser binaries, so the installation may take a bit longer.
## Building a scraper
Creating a scraper with Playwright is surprisingly easy, even if you have no previous scraping experience. If you understand JavaScript and CSS, it will be a piece of cake.
In your project folder, create a file called `scraper.js` (or choose any other name) and open it in your favorite code editor. First, we will confirm that Playwright is correctly installed and working by running a simple script.
{% gist https://gist.github.com/mnmkng/b517605fe5b4d4982cc5f1a52f56bd56 %}
Now run it using your code editor or by executing the following command in your project folder.
node scraper.js
If you saw a Chromium window open and the GitHub Topics page successfully loaded, congratulations, you just robotized your web browser with Playwright!
### Loading more repositories
When you first open the topic page, the number of displayed repositories is limited to 30. You can load more by clicking the *Load more…* button at the bottom of the page.
There are two things we need to tell Playwright to load more repositories:
1. **Click** the *Load more…* button.
1. **Wait** for the repositories to load.
Clicking buttons is extremely easy with Playwright. By prefixing `text=` to a string you’re looking for, Playwright will find the element that includes this string and click it. It will also wait for the element to appear if it’s not rendered on the page yet.
```js
await page.click('text=Load more');
```
This is a huge improvement over Puppeteer and it makes Playwright lovely to work with.
After clicking, we need to wait for the repositories to load. If we didn’t, the scraper could finish before the new repositories show up on the page and we would miss that data. [`page.waitForFunction()`](https://playwright.dev/#version=v1.2.1&path=docs%2Fapi.md&q=pagewaitforfunctionpagefunction-arg-options) allows you to execute a function inside the browser and wait until the function returns `true`.
```js
await page.waitForFunction(() => {
const repoCards = document.querySelectorAll('article.border');
return repoCards.length > 30;
});
```
To find that `article.border` selector, we used browser Dev Tools, which you can open in most browsers by right-clicking anywhere on the page and selecting **Inspect**. It means: Select the `<article>` tag with the `border` class.

Let’s plug this into our code and do a test run.
{% gist https://gist.github.com/mnmkng/0ace1f4e1035f92d8da4f4ae1080f026 %}
If you watch the run, you’ll see that the browser first scrolls down and clicks the *Load more…* button, which changes the text into *Loading more*. After a second or two, you’ll see the next batch of 30 repositories appear. Great job!
### Extracting data
Now that we know how to load more repositories, we will extract the data we want. To do this, we’ll use the [`page.$$eval`](https://playwright.dev/#version=v1.2.1&path=docs%2Fapi.md&q=pageevalselector-pagefunction-arg-1) function. It tells the browser to find certain elements and then execute a JavaScript function with those elements.

It works like this: `page.$$eval` finds our repositories and executes the provided function in the browser. We get `repoCards` which is an `Array` of all the repo elements. The return value of the function becomes the return value of the
`page.$$eval` call. Thanks to Playwright, you can pull data out of the browser and save them to a variable in Node.js. Magic!
If you’re struggling to understand the extraction code itself, be sure to check out [this guide on working with CSS selectors](https://developer.mozilla.org/en-US/docs/Learn/CSS/Building_blocks/Selectors) and [this tutorial on using those selectors to find HTML elements](https://javascript.info/searching-elements-dom#querySelectorAll).
And here’s the code with extraction included. When you run it, you’ll see 60 repositories with their information printed to the console.
{% gist https://gist.github.com/mnmkng/3390066cd11c68a35d8998d2e4497c1c %}
## Conclusion
In this tutorial we learned how to start a browser with [Playwright](https://playwright.dev/), and control its actions with some of Playwright’s most useful functions: `page.click()` to emulate mouse clicks, `page.waitForFunction()` to wait for things to happen and `page.$$eval()` to extract data from a browser page.
But we’ve only scratched the surface of what’s possible with Playwright. You can log into websites, fill forms, intercept network communication, and most importantly, use almost any browser in existence. Where will you take this project next? How about turning it into a command-line interface (CLI) tool that takes a topic and number of repositories on input and outputs a file with the repositories? You can do it now. Happy scraping! | mnmkng |
417,348 | Day 64 : #100DaysofCode - Still Playing Around With OmniAuth | Today I learned more about OmniAuth. I mostly played around with it to see if I can use it for variou... | 7,070 | 2020-08-04T02:27:53 | https://dev.to/sincerelybrittany/day-64-100daysofcode-still-playing-around-with-omniauth-48gb | Today I learned more about OmniAuth. I mostly played around with it to see if I can use it for various different login techniques. I want to allow the users in future applications that I build to have the ability to log in using Google, Github, or Twitter. I am trying to see if I can master it so it will become second nature when building an application.
Wish me luck!
Sincerely,
Brittany | sincerelybrittany | |
417,387 | LeetCode:125. Valid Palindrome | https://leetcode.com/problems/valid-palindrome/ Solutions step1: apply .isalnum() on each... | 0 | 2020-08-07T12:53:34 | https://dev.to/effylh/leetcode-125-valid-palindrome-1292 | leetcode, algorithms, python | ERROR: type should be string, got "\n\nhttps://leetcode.com/problems/valid-palindrome/\n## Solutions\n**step1:** apply .isalnum() on each character for filtering out all the alphanumeric characters in the given string .\n**step2:** compare filtered list with the one in reversed order, if they're identical with each other, we got the string with pattern of palindrome\n\n## Submissions\n* faster than 98.95%\n```\nclass Solution:\n def isPalindrome(self, s: str) -> bool:\n result=''\n for i in s:\n if i.isalnum():\n result+=i.lower()\n if result==result[::-1]:\n return True\n return False\n```\n\n" | effylh |
417,509 | What is functional programming for you? | A post by pandaquests | 0 | 2020-08-04T07:25:47 | https://dev.to/pandaquests/what-is-functional-programming-for-you-25ik | computerscience, discuss, codenewbie | pandaquests | |
417,690 | Getting started with tailwindcss | tailwind is a utility based framework with minimal code which let you focus on the main instead of wa... | 0 | 2020-08-04T13:16:47 | https://dev.to/kabcoder/getting-started-with-tailwindcss-1ng0 | css, codenewbie, productivity, webdev | tailwind is a utility based framework with minimal code which let you focus on the main instead of wasting time on utilities to help your design.
Today i will be talking about tailwind CSS and how you can use it, grab your coffee, hoop on and let's ride.
Tailwind CSS have been around for quit sometimes now and since it's launch it has been gaining popularity more and more, i personally use this for my personal project i work on.
##**Before**
before the launch of tailwindcss many CSS frameworks like **Bootstrap** and **Material UI** have been using predefined component.
In which this libraries reduce the stress of designing all UI from the start and most of this libraries enable users to add their own feature and customize this to their own thirst.
However, this customization most of the time involves overwriting. For example, creating new classes to overwrite the existing styles provided by the library.
this is where tailwindcss comes in
##**Tailwindcss**
Tailwind is utility based CSS framework which focus on utility and it take a lot of work off your head.
with this utility frame work you can build anything in matter of minutes this has utilities like, color, background, margin, padding and so on.
So lets div into examples to see what am talking about.
here is a link to [tailwindcss](https://tailwindcss.com/ "A utility-first CSS framework for rapidly building custom designs")
##**Installation**
unfortunately tailwindcss is not hosted online in which you can just link to your html file but that's where the Syntactic sugar comes in.
all you have to do is to install it via npm in your project then configure the package which tailwindcss has already done for you.
**process**
using `` npm install tailwind.css``
this will automatically install tailwind in your project then you now go to your project folder the create a file ``input.css`` and the other folder ``output.css`` then open ``input.css`` and put the following code
``@tailwind base;
@tailwind components;
@tailwind utilities;``
now go to your ``package.json`` file and the following code on your script ``input.css -o public/style.css`` that's it welcome to the world of tailwindcss.
## **examples of tailwind utility classes**
| Tailwind class | Css |
| ----------- | ----------- |
| ``.w-1/2`` | `width: 50%` |
|.w-0 |width: 0;
you can browse through their website to know more about this utilities
# Conculsion
so far so good we've seen how we can install and work with tailwindcss feel free to checkout my github which can also help you in your way of becoming a good developer.
check it out now !! ***[@binismail](https://github.com/binismail "A design minded software engineer")***
have a lovely day.
| kabcoder |
417,825 | Using Defer to improve performance | In my last post, Exploring the benefits of HTTP2, I wrote about removing jQuery and my global.min.j... | 0 | 2020-09-05T08:02:52 | https://www.juanfernandes.uk/blog/using-defer-to-improve-performance/ | defer, javascript | ---
title: Using Defer to improve performance
published: true
date: 2020-08-03 23:00:00 UTC
tags: defer, javascript
canonical_url: https://www.juanfernandes.uk/blog/using-defer-to-improve-performance/
---

In my last post, [Exploring the benefits of HTTP2](https://www.juanfernandes.uk/blog/exploring-the-benefits-of-http-2/ "Exploring the benefits of HTTP2"), I wrote about removing jQuery and my `global.min.js` files in favour of loading JavaScript on a per component or partial basis, so only when that component is included on a page it then loads the needed JavaScript code and library.
Which lead me to look into Defer in JavaScript as another way to improve performance.
"This Boolean attribute is set to indicate to a browser that the script is meant to be executed after the document has been parsed, but before firing DOMContentLoaded.
Scripts with the defer attribute will prevent the DOMContentLoaded event from firing until the script has loaded and finished evaluating." - [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script "MDN Web Docs")
Since the testimonials slider on my homepage is near the end of the page, I don't need to load the JavaScript right away and since it's not used on every page, it makes sense to only load it where the slider is being used.
I read a few articles on Async and Defer to try and understand the difference between both and which was the correct one to use for the testimonials slider.
So I figured I would just need to add the defer attribute to the `<script>` tag for the TinySlider JavaScript and that would be it...
But I found that doing this, it stopped the slider from working - I'm still learning JavaScript, so you will have to forgive me. I looked at the TinySlider example code I used and realised it was written so it would run as soon as the browser loads that part of the code.
What I needed to do was change the code to only run when the DOM had finished loading and this meant that the HTML code for the slider would have been loaded too.
```
<link rel="stylesheet" href="/assets/css/components/slider.css">
<script src='/assets/js/tiny-slider.js' defer></script>
<script>
document.addEventListener("DOMContentLoaded", () => {
let slider = tns({
container: '.testimonials__slider',
items: 1,
autoHeight: true,
speed: 400,
loop: true,
autoplay: true,
autoplayButtonOutput: false,
controls: false,
autoplayHoverPause: true,
nav: true,
navPosition: "bottom",
});
});
</script>
```
*** | juanfernandes |
417,866 | Schedule Netlify Builds with GitHub Actions | I use a custom static site generator to publish my blog. It automatically deploys to Netlify when I m... | 0 | 2020-08-05T19:45:31 | https://dancroak.com/schedule-netlify-builds-with-github-actions | netlify, static, github, actions | I use a [custom static site generator](https://github.com/croaky/blog) to publish my blog. It automatically deploys to Netlify when I merge new articles into my Git repository's `main` branch.
To support a "scheduled article" feature, I have configured a [GitHub Actions scheduled workflow](https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#onschedule):
```yaml
name: daily publish
on:
schedule:
- cron: "0 0 * * *" # every day at midnight UTC
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Trigger Netlify build
shell: bash
env:
NETLIFY_BUILD_HOOK: ${{ secrets.NETLIFY_BUILD_HOOK }}
run: curl -X POST -d {} "$NETLIFY_BUILD_HOOK"
```
Every day at midnight UTC, GitHub runs the workflow, deploying the site using a [Netlify build hook](https://docs.netlify.com/configure-builds/build-hooks/). The build hook is a URL which I've stored as a [GitHub encrypted secret](https://help.github.com/en/actions/configuring-and-managing-workflows/creating-and-storing-encrypted-secrets#using-encrypted-secrets-in-a-workflow).
When there are articles whose scheduled date matches the new UTC date, they are automatically published by this workflow. | croaky |
417,943 | Creating a Testimonials Section with a Slideshow Using Pure HTML, CSS and JavaScript (video tutorial) | Testimonials are a great way of building trust to your potential clients. Adding them to your website... | 7,953 | 2020-08-04T17:56:35 | https://dev.to/chaoocharles/creating-a-testimonials-section-with-a-slideshow-using-pure-html-css-and-javascript-4447 | html, css, javascript, webdev | Testimonials are a great way of building trust to your potential clients. Adding them to your website can drastically improve your products sales or receive more gigs. In the following video tutorial I will show you how you can create a cool testimonials section with a slideshow for your website from scratch.
Starter Files and Source Code: https://github.com/chaoocharles/testimonials-with-slideshow
I'm on twitter: https://twitter.com/ChaooCharles
{% youtube tVDzUskKcSA %}
| chaoocharles |
418,112 | Resilience and rest | Hoje é o Dia 006, mas também vou falar do dia 005, calma gente. Dia 005 Ontem eu decidi não postar n... | 0 | 2020-08-04T23:28:43 | https://dev.to/olarsarah/resilience-and-rest-1c2j | html, webdev, womenintech, 100daysofcode | Hoje é o Dia 006, mas também vou falar do dia 005, calma gente.
**Dia 005**
Ontem eu decidi não postar nada porque eu estava **extremamente** cansada, muito mais do que no outro dia que eu reclamei de cansaço.
Eu mal prestei atenção nas aulas que eu estava assistindo e foi basicamente só isso que eu fiz ontem. Eu assisti algumas aulas e acertei a edentação do meu código até aqui, além disso só consegui estudar meia hora, então não achei que valia a pena postar sobre, porém tem algo que vale a pena sobre isso e é o que eu vou falar agora.
**Resiliência**
Gente, eu levo extremamente a sério tudo que eu faço e ainda assim, pra mim, é difícil me manter resiliente em vários aspectos. Estudar, embora eu goste bastante, acaba sendo um dele.
Uma das grandes coisas do desafio de **100 dias de código** é justamente você conseguir manter a frequência dos dias enquanto a vida está acontecendo. Então mesmo estando **super** cansada e não tendo conseguido prestar atenção direito no que eu estava vendo, eu estou feliz porque o desafio está me ajudando a ser mais constante nessa área.
É claro gente que **NÃO EXISTE FORMULA MÁGICA**, mas cada passinho em direção a melhora é sempre bem vindo.
Acredito que até o final do desafio, não devo mais ser tão inconstante com os meus estudos e devo conseguir metrificar melhor o tempo que eu tomo com as minhas atividades, já que é outra coisa que o desafio tem me mostrado que eu ainda sou bem ruim em metrificar.
**Dia 006**
Hoje eu tirei boa parte do dia para descansar, quase como um dia de "folga", mas mantive meu compromisso com o estudo.
Por estar mais descansada hoje as coisas fluíram melhor e pra compensar só ter estudado meia hora ontem, hoje eu estudei uma hora e meia.
Oficialmente minhas aulas de HTML puro acabaram hoje e agora eu estou entrando na parte de CSS. Aqui está a listinha das coisas que eu fiz hoje:
*Atualizei o título do meu site (Portfolio aparecendo no navegador estava estranho)
*Atribuí um título as imagens dos ícones (Embora não apareça visualmente no site, isso faz com que em pesquisa aquela imagem seja assimilada ao meu nome/site)
*Fiz os links indicarem para páginas externamente (Caso vocês tenham visto, antes o meu site só trocava você de página para a página que você clicou para ir, agora ele abre uma nova página sem te tirar do site)
*Criei uma folha de estilo vazia (Como o meu próximo passo nessa empreitada é adicionar "estilo" ao meu site, achei melhor deixar a folha criada para só precisar fazer alterações)
*Atualizei tudo no github ( Ou seja o meu site já foi atualizado também)
É engraçado que enquanto estamos produzindo não parece ser tanta coisa, mas escrevendo a gente acaba tendo uma noção melhor que até aqui e só com pequenas alterações muita coisa já mudou.
Bom gente, obrigada a quem está acompanhando meu progresso.
Amanhã tem mais! **<3** | olarsarah |
418,314 | PHP is still in the game | We have so many options to choose from when it comes to choosing right technology stack for our appli... | 0 | 2020-08-05T04:51:31 | https://dev.to/asdflkjh/php-is-not-dead-5hej | We have so many options to choose from when it comes to choosing right technology stack for our application. There are even more frameworks and libraries supporting **amazingly fast** development. So you might be thinking that php is dead and it cannot compete with this fast development than hold on please.
There are many well known companies who are using php and its framework for tech stack. **9GAG & BBC** still have php in their current tech stack.
Still people choose **WordPress** for to go solution for blog and simple websites. Taking about WordPress reminds me of famous tech blog [Tech Crunch](https://techcrunch.com/) is still using WordPress.
Php have super powerful [Laravel](https://laravel.com/) framework. And yes php also have package manager like [npm](https://www.npmjs.com/) which is [composer](https://getcomposer.org/).
If you or your server are looking for alternative of Laravel then my friends php has everything. My next php framework is [CodeIgniter](https://codeigniter.com/).
It is super easy to setup and I'll be writing one more DEV post on how to setup CodeIgniter in few simple steps. | asdflkjh | |
418,394 | #100DaysOfCode | Day 10, 11 | ▄█ █▀█ █▀█ █▀▄ ▄▀█ █▄█ █▀ █▀█ █▀▀ █▀▀ █▀█ █▀▄ █▀▀ ░█ █▄█ █▄█ █▄▀ █▀█ ░█░ ▄█ █▄█ █▀░ █▄▄ █▄█ █▄▀ ██▄ H... | 8,256 | 2020-08-05T07:21:33 | https://dev.to/banji220/100daysofcode-day-10-11-jkf | challenge, 100daysofcode, python, codenewbie | ▄█ █▀█ █▀█ █▀▄ ▄▀█ █▄█ █▀ █▀█ █▀▀ █▀▀ █▀█ █▀▄ █▀▀
░█ █▄█ █▄█ █▄▀ █▀█ ░█░ ▄█ █▄█ █▀░ █▄▄ █▄█ █▄▀ ██▄
Hey everyone, wassup?
I just wanna write about my day 10 and 11 of **#100DaysOfCode Challenge!**
I have good news for myself!
I mad a simple twitter bot with Tweepy ;)
It was not so hard for me but I got confused about some of the concepts and methods in that library, and I know that's actually normal.
It was my first time that I used a framework to make something, and to be honest that was so __COOL!__
In the next post I'm gonna share my codes and the way I created a __twitter-bot__ with __Tweepy__, so if you are a beginner like me you can take advantage of it and automate some of your task!
Keep Moving Forward __ツ__
Enjoy Your Journey 👊
Code with __💛__
__🅑🅐🅝🅙🅘__
| banji220 |
577,897 | Selecting in Pandas using where and mask | This is the fifth post in a series on indexing and selecting in pandas. If you are jumping in the mid... | 0 | 2021-01-21T01:21:45 | https://www.wrighters.io/selecting-in-pandas-using-where-and-mask/ | python, pandas | ---
title: Selecting in Pandas using where and mask
published: true
date: 2021-01-21 01:16:17 UTC
tags: Python, pandas
canonical_url: https://www.wrighters.io/selecting-in-pandas-using-where-and-mask/
---
This is the fifth post in a series on indexing and selecting in pandas. If you are jumping in the middle and want to get caught up, here’s what has been discussed so far:
- [Basic indexing, selecting by label and location](https://www.wrighters.io/indexing-and-selecting-in-pandas-part-1/)
- [Slicing in pandas](https://www.wrighters.io/indexing-and-selecting-in-pandas-slicing/)
- [Selecting by boolean indexing](https://www.wrighters.io/boolean-indexing-in-pandas/)
- [Selecting by callable](https://www.wrighters.io/indexing-and-selecting-in-pandas-by-callable/)
Once the basics were covered in the first three posts we were able to move onto more detailed topics on how to select and update data. In this post, we’ll look at selecting using `where` and `mask`.
In the third post of this series, we covered the concept of boolean indexing. If you remember, boolean indexing allows us to essentially query our data (either a `DataFrame` or a `Series`) and return only the data that matches the boolean vector we use as our indexer. For example, to select odd values in a `Series` like this:
```
>>> import pandas as pd
>>> import numpy as np
>>>
>>> s = pd.Series(np.arange(10))
>>> s[s % 2 != 0]
1 1
3 3
5 5
7 7
9 9
dtype: int64
```
## Where?
You’ll notice that our result here is only 5 elements even though the original `Series` contains 10 elements. This is the whole point of indexing, selecting the values you want. But what happens if you want the shape of your result to match your original data? In this case, you use `where`. The values that are selected by the where condition are returned, the values that are not selected are set to `NaN`. This way, the value you select has the same shape as your original data.
```
>>> s.where(s % 2 != 0)
0 NaN
1 1.0
2 NaN
3 3.0
4 NaN
5 5.0
6 NaN
7 7.0
8 NaN
9 9.0
dtype: float64
```
`where` also accepts an optional argument for what you want the other values to be, if `NaN` is not what you want, with some flexibility. For starters, it can be a scalar or `Series`/`DataFrame`.
```
>>> s.where(s % 2 != 0, -1) # set the non-matching elements to one value
0 -1
1 1
2 -1
3 3
4 -1
5 5
6 -1
7 7
8 -1
9 9
dtype: int64
>>> s.where(s % 2 != 0, -s) # set the non-matching elements to the negative value of the original series
0 0
1 1
2 -2
3 3
4 -4
5 5
6 -6
7 7
8 -8
9 9
dtype: int64
```
Both the first `condition` argument and the `other` can be a callable that accepts the `Series` or `DataFrame` and returns either a scalar or a `Series`/`DataFrame`. The condition callable should return boolean, the other can return whatever value you want for non selected values. So the above could be expressed (more verbosely) as
```
s.where(lambda x: x % 2 != 0, lambda x: x * -1)
```
Using `where` will always return a copy of the existing data. But if you want to modify the original, you can by using the `inplace` argument, similar to many other functions in pandas (like `fillna` or `ffill` and others).
```
>>> s.where(s % 2 != 0, -s, inplace=True)
>>> s
>>> s
0 0
1 1
2 -2
3 3
4 -4
5 5
6 -6
7 7
8 -8
9 9
dtype: int64
```
The `.mask` method is just the inverse of `where`. Instead of selecting values based on the condition, it selects values where the condition is `False`. Everthing else is the same as above.
```
>>> s.mask(s % 2 != 0, 99)
0 0
1 99
2 -2
3 99
4 -4
5 99
6 -6
7 99
8 -8
9 99
dtype: int64
```
## Updating data
One thing that I noticed in writing this that I had missed before is that `where` is the underlying implementation for boolean indexing with the array indexing operator, i.e. `[]` on a `DataFrame`. So you’ve already been using `where` even if you didn’t know it.
This has implications for updating data. So with a `DataFrame` of random floats around 0,
```
>>> df = pd.DataFrame(np.random.random_sample((5, 5)) - .5)
>>> df
0 1 2 3 4
0 -0.326058 -0.205408 -0.394306 0.365862 0.141009
1 0.394965 0.283149 -0.014750 0.279396 -0.172909
2 -0.141023 -0.297178 -0.247611 -0.170736 0.229474
3 -0.276158 -0.438667 -0.290731 0.317484 -0.378233
4 -0.018927 0.354160 -0.254558 -0.056842 -0.245184
>>> df.where(df < 0) # these two are equivalent
>>> df[df < 0]
0 1 2 3 4
0 -0.326058 -0.205408 -0.394306 NaN NaN
1 NaN NaN -0.014750 NaN -0.172909
2 -0.141023 -0.297178 -0.247611 -0.170736 NaN
3 -0.276158 -0.438667 -0.290731 NaN -0.378233
4 -0.018927 NaN -0.254558 -0.056842 -0.245184
```
You can also do updates. This is not necessarily that practical for most `DataFrame`s I work with though, because you I rarely have a `DataFrame` where I want to update across all the columns like this. But for some instances that might be useful, so here’s an example. We could force all the values to be positive by inverting only the negative values.
```
>>> df[df < 0] = -df
>>> df
0 1 2 3 4
0 0.326058 0.205408 0.394306 0.365862 0.141009
1 0.394965 0.283149 0.014750 0.279396 0.172909
2 0.141023 0.297178 0.247611 0.170736 0.229474
3 0.276158 0.438667 0.290731 0.317484 0.378233
4 0.018927 0.354160 0.254558 0.056842 0.245184
```
## NumPy `.where`
If you’re a NumPy user, you are probably familiar with `np.where`. To use it, you supply a condition and optional `x` and `y` values for `True` and `False` results in the condition. This is a bit different than using `where` in pandas, where the object itself provides data for the `True` result, with an optional `False` result (which defaults to `NaN` if not supplied). So here’s how you’d use it to select odd values in our `Series`, and set the even values to `99`.
```
>>> np.where(s % 2 != 0, s, 99)
array([99, 1, 99, 3, 99, 5, 99, 7, 99, 9])
```
Another way to think about this is that the pandas implementation can be used like the NumPy version, just think of the `self` argument of the `DataFrame` as the `x` argument in NumPy.
```
>>> pd.Series.where(cond=s % 2 != 0, self=s, other=99)
0 99
1 1
2 99
3 3
4 99
5 5
6 99
7 7
8 99
9 9
dtype: int64
```
## More examples
Let’s go back to a data set [from a previous post](https://www.wrighters.io/indexing-and-selecting-in-pandas-by-callable/). This is salary info for City of Chicago employees for both hourly and salaried employees.
One thing I noticed about this data set last time was that there were a lot of `NaN` values because of the different treatment of salaried and hourly employees. As a result, there’s a column for annual salary, and separate columns for typical hours and hourly rates. What if we just want to know what a typical full salary would be for any employee, regardless of their category?
Using `where` is one way we could address this if we wanted a uniform data set. Now we won’t apply it to the entire `DataFrame` as the update example above, we’ll use it to create one column.
```
>>> # you should be able to grab this dataset as an unauthenticated user, but you can be rate limited
>>> # it also only returns 1000 rows (or at least it did for me without an API key)
>>> sal = pd.read_json("https://data.cityofchicago.org/resource/xzkq-xp2w.json")
>>> sal = sal.drop('name', axis=1) # remove personal info
>>> sal = sal.drop('name', axis=1) # remove personal info
>>> sal['total_pay'] = sal['annual_salary'].where(sal['salary_or_hourly'] == 'Salary',
sal['typical_hours'] * sal['hourly_rate'] * 52)
```
Another way to do this, would be to selectively update only rows for hourly workers. But to do this, you end up needing to apply a mask multiple times.
```
>>> sal['total_pay2'] = sal['annual_salary']
>>> mask = sal['salary_or_hourly'] != 'Salary'
>>> sal.loc[mask, 'total_pay2'] = sal.loc[mask, 'typical_hours'] * sal.loc[mask, 'hourly_rate'] * 52
```
So using `where` can result in a slightly more simple expression, even if it’s a little long.
## NumPy `where` and `select` for more complicated updates
There are times where you want to create new columns with some sort of complicated condition on a dataframe that might need to be applied across multiple columns. Using NumPy `where` can be helpful for these situations. For example, we can creating an hourly rate column that calculates an hourly equivalent for the salried employees, but use the existing hourly rate.
```
>>> sal['hourly_rate_all'] = np.where(sal['salary_or_hourly'] == 'Salary',
sal['annual_salary'] / (52 * 40),
sal['hourly_rate'])
```
If you have a much more complex scenario, you can use `np.select`. Think of `np.select` as a where with multiple conditions and multiple choices, as opposed to just one condition with two choices. For example, let’s say that the hourly rate for employees in the police and fire departments was slightly different because of their shift schedule, so their calculation was different. We could do the calculation in one pass. Note that I chose to use the hourly rate as the default (using the last parameter), but could have just as easily made it a third condition.
```
>>> conditions = [
... (sal['salary_or_hourly'] == 'Salary') & (sal['department'].isin(['POLICE', 'FIRE'])),
... (sal['salary_or_hourly'] == 'Salary') & (~sal['department'].isin(['POLICE', 'FIRE'])),
... ]
>>> choices = [
... sal['annual_salary'] / (26 * 75),
... sal['annual_salary'] / (52 * 40)
... ]
>>> sal['hourly_rate_all2'] = np.select(conditions, choices, sal['hourly_rate'])
>>> sal.head()[['department', 'hourly_rate_all', 'hourly_rate_all2']]
department hourly_rate_all hourly_rate_all2
0 POLICE 53.578846 57.150769
1 POLICE 45.250962 48.267692
2 DAIS 57.023077 57.023077
3 WATER MGMNT 56.284615 56.284615
4 TRANSPORTN 44.400000 44.400000
```
In summary, using pandas’ `where` and `mask` methods can be useful ways to select and update data in the same shape as your original data. Using NumPy’s `where` and `select` can also be very useful for more complicated scenarios.
Stay tuned for the next post in this series where I’ll look at the `query` method.
The post [Selecting in Pandas using where and mask](https://www.wrighters.io/selecting-in-pandas-using-where-and-mask/) appeared first on [wrighters.io](https://www.wrighters.io). | wrighter |
419,281 | Benefits of Hiring Magento Developers | It has become a compulsion for every big or small business company to establish its online presence i... | 0 | 2020-08-05T10:30:18 | https://dev.to/priyank15056440/benefits-of-hiring-magento-developers-46e | magento2upgradeservices, hiremagentodevelopers, laraveldevelopmentservices | It has become a compulsion for every big or small business company to establish its online presence in today's competitive world. Because it attracts great advantages, such as the low cost of investment firms, it can extend the scope of its customers and business audiences. Companies in many Pan Asian developing countries like India have already begun moving into online eCommerce business by introducing an online eCommerce store based on various CMS available on the market. Selection of perfect CMS for e-commerce website is always a bit confusing and a challenge because of the easy availability of many platforms on the market. But out of them all Magento platform has demonstrated its credibility in boosting the company's e-commerce business in every conceivable way. It has proven to be a profitable option for many of our customers hiring Magento developers as it is effective, inexpensive and almost entirely customisable.
Read More:- https://rocktechnolabs.com/benefits-of-hiring-magento-developers/ | priyank15056440 |
419,382 | Color & Shape Changer Javascript | Random Color & Shape Changer Using Javascript | 0 | 2020-08-05T11:57:09 | https://dev.to/isurojit/color-shape-changer-javascript-490l | codepen | <p>Random Color & Shape Changer Using Javascript</p>
{% codepen https://codepen.io/isurojit/pen/LYGJbjw %} | isurojit |
419,410 | JavaScript Katas: Every possible sum of two digits | We learn how to use String, split, map, for | 7,718 | 2020-08-05T12:50:19 | https://dev.to/miku86/javascript-katas-every-possible-sum-of-two-digits-12p9 | javascript, beginners, webdev, codenewbie | ---
title: "JavaScript Katas: Every possible sum of two digits"
description: "We learn how to use String, split, map, for"
published: true
tags: ["JavaScript", "Beginners", "Webdev", "Codenewbie"]
series: JavaScript Katas with miku86
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jfyzv0grswtx1mlo17m.jpg
---
## Intro 🌐
Problem solving is an important skill, for your career and your life in general.
That's why I take interesting katas of all levels, customize them and explain how to solve them.
---
## Understanding the Exercise❗
First, we need to understand the exercise!
If you don't understand it, you can't solve it!.
My personal method:
1. Input: What do I put in?
2. Output: What do I want to get out?
---
### Today's exercise
Today, we'll have a look at our first `7 kyu` kata,
meaning we slightly increase the difficulty.
Source: [Codewars](https://www.codewars.com/kata/5b4e474305f04bea11000148)
Write a function `everyPossibleSum`, that accepts one parameter: `myNumber`.
Given a number, e.g. `1234`,
return every possible sum of two digits, e.g. `[ 3, 4, 5, 5, 6, 7 ]`.
For this example, we calculate:
`[ 1 + 2, 1 + 3, 1 + 4, 2 + 3, 2 + 4, 3 + 4 ]`
---
Input: a number.
Output: an array of numbers.
---
## Thinking about the Solution 💭
I think I understand the exercise (= what I put into the function and what I want to get out of it).
Now, I need the specific steps to get from input to output.
I try to do this in small baby steps:
1. Get the single digits of the input number
1. Go to the first digit and find all sums with each next digit, starting from the second
1. Go to the second digit and find all sums with each next digit, starting from the third
1. Do this for every digit
1. Return the array with each sum in it
---
Example:
- Input: `1234`
- Go to the first digit and find all sums with each next digit, starting from the second: `1 + 2`, `1 + 3`, `1 + 4`
- Go to the second digit and find all sums with each next digit, starting from the third: `2 + 3`, `2 + 4`
- Do this for every digit: `3 + 4`
- Return the array with each sum in it: `[ 3, 4, 5, 5, 6, 7 ]`
- Output: `[ 3, 4, 5, 5, 6, 7 ]` ✅
---
## Implementation ⛑
```js
function everyPossibleSum(myNumber) {
// split up number into its digits
const split = String(myNumber) // make it a string
.split("") // split it
.map((digit) => Number(digit)); // convert each split char to a number
const sums = [];
// first number: iterate from the first to the last number
for (let first = 0; first < split.length; first++) {
// second number: iterate from the next number after the current first number to the last number
for (let second = first + 1; second < split.length; second++) {
// save the sum in the sums array
sums.push(split[first] + split[second]);
}
}
return sums;
}
```
### Result
```js
console.log(everyPossibleSum(1234));
// [ 3, 4, 5, 5, 6, 7 ] ✅
console.log(everyPossibleSum(81596));
// [ 9, 13, 17, 14, 6, 10, 7, 14, 11, 15 ] ✅
```
---
## Playground ⚽
You can play around with the code [here](https://repl.it/@miku86/js-katas-every-possible-sum-of-two-digits)
---
## Next Part ➡️
Great work!
We learned how to use `String`, `split`, `map`, `for`.
I hope you can use your new learnings to solve problems more easily!
Next time, we'll solve another interesting kata. Stay tuned!
---
If I should solve a specific kata, shoot me a message [here](https://forms.gle/RmQLq7CLDiD2Ptmw5).
If you want to read my latest stuff, [get in touch with me!](https://miku86.com/newsletter)
---
## Further Reading 📖
- [String](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/String)
- [split](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/split)
- [map](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/map)
- [for](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for)
---
## Questions ❔
- How often do you do katas?
- Which implementation do you like more? Why?
- Any alternative solution? | miku86 |
419,473 | HOW TO PUT A ANGULAR APPLICATION TO A DOCKER CONTAINER | I have read quite complicated articles on how to deploy an Angular application to a docker container... | 0 | 2020-08-05T14:03:25 | https://dev.to/kalikimanzi/how-to-put-a-angular-application-to-a-docker-container-496j | angular, docker | I have read quite complicated articles on how to deploy an Angular application to a docker container that is why I am motivated to write this simplest step by step guide to putting your angular app to docker container
1 Assuming you have already created your app and now you want to dockerize it. run the code below to create a dist folder in your application folder
`ng build`
2 create a file called Dockerfile under root of your application as illustrated below
3 copy following code to your Dockerfile
```
FROM node:alpine AS my-app-build
WORKDIR /app
COPY . .
RUN npm install && npm run build
FROM nginx:alpine
COPY --from=my-app-build /app/dist/{name-of-your-application} /usr/share/nginx/html
EXPOSE 80
```
4 Now your application is ready to be put in a docker container. this tutorial assumes you have downloaded docker and a copy is running locally on your machine. if you have not downloaded the docker application visit the Docker website to download the version suitable for your machine . when all that has been set up use the code below to build image for your application.
```
// docker build -t name-of-container:tag-of-image .
docker build -t my-application-container:latest .
```
5 To start your application locally and test it on a browser run
`docker run --publish 80:80 --detach --name bb bulletinboard:lastest`
I hope you enjoyed this tutorial. i will write more tutorials on how to deploy your Docker container on Azure.
| kalikimanzi |
419,553 | Improving Postmortems from Chores to Masterclass with Paul Osman | Originally published on Failure is Inevitable. In our 2019 Blameless Summit, Paul Osman spoke abo... | 0 | 2020-08-05T15:24:07 | https://dev.to/blameless/improving-postmortems-from-chores-to-masterclass-with-paul-osman-45gb | devops, sre, techtalks | Originally published on [Failure is Inevitable](https://www.blameless.com/blog).
{% youtube AoWWZxrjPb8 %}
In our 2019 Blameless Summit, Paul Osman spoke about how to take postmortems or incident retrospectives to a new level.
The following transcript has been lightly edited for clarity. Slides from this talk are available here.
Paul Osman: I lead the SRE team at Under Armour. Who here knows about Under Armour as a tech company? Does anybody think about Under Armour as a tech company? Under Armour makes athletic attire, shirts and shoes. We are also the company that owns MapMyFitness, MyFitnessPal and Endomondo, which are all fitness trackers that our customers use to either keep track of nutrition goals or fitness goals. That's Under Armour, and specifically that's actually my team. We work on the reliability of those consumer applications.
I'm going to be talking today about postmortems and the postmortem process. First, I'm going to zoom out a little bit and talk about incident analysis, which is actually a much bigger field. Incident analysis is the study of how to actually analyze what happened during events that we can learn from. I'm going to try to give some lessons that we've learned doing incident analysis.
Let's talk about postmortems. The term comes from medicine and the actual definition is an examination of a dead body to determine the cause of death. That was the first thing that came up when I Googled it. That's awful. I'm really glad that's not what I do. I have a huge amount of respect for doctors. I don't have the stomach for it, and I'm really glad that nobody tends to die when our systems go down. I'm sure there are maybe some people in this room for whom that's true, but that's certainly not true for us.
The reason I'm bringing this up is, I hate the term. I hate that we've all decided that postmortem is the term for what we do. I don't think it is, but I'm probably not going to change the vernacular of our industry, so we'll go with it.
Postmortems have to do with incidents, accidents that happen in production systems usually in this context. John Allspaw, who's the former CTO of Etsy, has described incidents this way: “Incidents are unplanned investments.” There's two things that I really like about that. One is the emphasis on the fact that incidents are unplanned. They're surprises. The other thing is that they're investments. Incidents take time. They add stress to people's lives, not just customers, but internally to engineers, people who are working customer support cues, and other stakeholders.
These are all people that we're paying. If we're making that investment, then what we talk about when we discuss postmortems and the postmortem process is opportunities to try to get some return from those investments. I've always thought of incident analysis or postmortems as opportunities for trying to recoup some return on that investment of that incident. What are those returns going to look like?
Action items are one way that we can recoup some return on those investments. Increasingly, I'm becoming convinced, however, that the real return is actually in learning. If we can figure out ways to improve how learning happens internally after an incident, then we improve lives for our customers and for our engineers, and we generally get better as an organization.
Increasingly, I'm becoming convinced, however, that the real return is actually in learning. If we can figure out ways to improve how learning happens internally after an incident, then we improve lives for our customers and for our engineers, and we generally get better as an organization.
In practice, this is roughly what that process might look like: you construct a timeline of events that took place during an incident, you get a big group of people together—it can vary in size from the people who are directly involved in an incident to being an open invitation to everyone in the company—and you discuss that timeline. You go over the causal chain of events and then you talk about what went well. What are the things that we should preserve? You talk about what went wrong. And, depending on the group, this can get to be a very interesting discussion. Out of that, there will be a bunch of action items and that's the real value that you get.
This is definitely how I used to think about incidents. This was my primary mental model and it served me for a while. It definitely resonated with teams I was on and there is some use to it. But what are the problems here? I think there are a few.
One of the things that I found is that I've been a part of many postmortem review meetings where attendance was really poor. That's awful. This is an opportunity to learn from things that happened and to get better, so it shouldn't be like that. That seems like we might be doing something wrong. I've also heard people discuss these as theater, and I've certainly described them as theater in the past, meaning there's a trap you can fall into where you go through this review process, you generate a bunch of action items at the end and you're done, and then those action items sit in a backlog forever. That can really detract from morale and contributes to the first problem which is people not being excited to go to these things.
The other thing is that the timeline can be just pre-agreed upon. In this model, you've already assembled the timeline. You've come up with what happened by the time you get a group of people together to discuss it. That can be limiting.
One of the problems that I started to think about is that big meetings aren't the best place to talk about that timeline. If you are getting a big group of people together and you're asking them about this incredibly stressful, sometimes traumatic event, then having a big group of people isn't going to encourage people to get back into that mindset where they were responding to an incident. Maybe it was 2:00 in the morning, maybe they were under a lot of stress. I don't know about you, but a big group is not the place where I necessarily want to go through that again.
One of the problems that I started to think about is that big meetings aren't the best place to talk about that timeline. If you are getting a big group of people together and you're asking them about this incredibly stressful, sometimes traumatic event, then having a big group of people isn't going to encourage people to get back into that mindset where they were responding to an incident.
Try this instead. This is something that we've started experimenting with, which is having one-on-one interviews as part of your review process. Actually, Amy Tobey has a great talk called One-on-One SRE. Amy talks about her experiences conducting these interviews as part of the postmortem review process. We've started doing this internally at Under Armour and it has dramatically improved the experience.
One of the things that I found in conducting these interviews is that you can do things that you can't do in big meetings, which is like establish rapport, relate experiences, get people talking about what mindframe they were in, and what context they had during the response. Funnily enough, I've had people give me feedback that when we go through the process like this where someone interviews them and then we get together as a big group and we read back what we've been told, people felt more heard than if they were actually just given the floor during a postmortem review process. That was a really interesting takeaway for me.
But more than anything else, some of the gems that have come out of these interviews have been amazing. People talking about the ergonomics of tools that they're using, talking about some dashboard where they know is not right. There are all sorts of things that can come up in that one-on-one context that might not necessarily get surfaced otherwise. This emphasizes something I wanted to bring up. I've experienced this a lot and I've heard this repeated a lot: blamelessness is not the same as psychological safety.
Psychological safety is super important, and I think it's a great thing, but it's not blamelessness. What I mean by that is you can have a group of people who are super psychologically safe or comfortable with being vulnerable in front of each other, who are really close and work as a team effectively, and they will still not come up with this info. If you're doing things in a certain way, they will still be susceptible to falling into traps.
Psychological safety is super important, and I think it's a great thing, but it's not blamelessness.
Blamelessness is not being safe to say, "I fucked up," because that's still centering you as the person who made a bad decision, which is actually inherently blameful even though it's an example of psychological safety. This tends to tease out some of these subtle nuances in the way that we use some of the vernacular.
Another problem that I've certainly experienced is that action items never get done. You have these postmortem review processes and these action items just sit at the bottom, which really makes me question if they're the key value that comes out of these things. If action items aren't getting done, are they that important or was the process geared to generate action items and that's why you did them?
Another thing that I've noticed here is that action items get done and you didn't know about it. You had the meeting, you went through what went well, what didn't go well, and you generated a list of action items. It turns out there's a whole bunch of stuff that engineers actually already did. Well, how could they know? You hadn't had the meeting yet, you hadn't come up with a list of action items, but it's because they had the context right after the incident.
If you have that engineer who's like, "You know what? I've been meaning to fix that thing. I knew it was wrong. We just had an incident; I'm going to schedule like five hours and just fix this thing,” that's not going to come up in one of these meetings necessarily, but you still want to capture that. This can be more effectively done through one-on-one interviews.
Something I've tried is shifting this focus towards stories, not action items. Action items are valuable, but stories I think are where the real value from incidents can be captured. I say stories because it enforces two things in my mind. Humans learn through storytelling. We relate experiences through storytelling. I think that just seems natural, and it really makes me think as somebody who does incident analysis, when I'm writing up a document or an artifact about an incident, I'm going to write it to be read because this is a story I'm telling. It's a narrative I'm forming. And if I do my job well, then this is going to be something that people refer to, that people enjoy reading, that they tell other engineers, "Oh, you're new on the team, you should read about this thing that happened." It just becomes part of the lore of a team, it becomes part of your organization.
We relate experiences through storytelling. I think that just seems natural, and it really makes me think as somebody who does incident analysis, when I'm writing up a document or an artifact about an incident, I'm going to write it to be read because this is a story I'm telling. It's a narrative I'm forming.
These are the things that I think can really impact teams and organizations.They're gems that we can uncover. What this really stresses for me is this shift in thinking. Engineers love technical systems because technical systems can be reasoned about. We can think about them in certain ways, but the sources of resilience in our systems are not actually the technical systems but the humans who operate them. If we focus our processes on giving value to those humans, then we can really tap into the sources of resilience. Your systems are never going to be completely functioning, they're never going to be completely up to date, but what you can do is you can empower the people who have adaptive capacity to actually respond to those systems.
Engineers love technical systems because technical systems can be reasoned about. We can think about them in certain ways, but the sources of resilience in our systems are not actually the technical systems but the humans who operate them.
There are incidents I've been a part of and done the analysis of where engineers will say things like, "Oh, we always know that that dashboard isn't right." Well, then why don't you fix it? Well, maybe there's a bunch of reasons. Maybe they don't have time, maybe they don't have enough people on their team, maybe they don't have anybody who knows about that system right now. But if they know that, if they've internalized that, then they have the ability to say, "Double check those metrics. Don't rely on those.”
These are the types of things that can give you surprising adaptive capacity. Even in that example, it could be something that's more nefarious, more subtle and nuanced. It's not as easy to fix, but if people are learning and people are repeating stories about incidents, then they're going to have the ability to respond to incidents much more effectively.
This is also instructed on another shift of thinking which is uncomfortable to me as an engineer, or at least it was. It's coming to the conclusion that our goal in doing these postmortems is not actually to understand what happened. It's not to understand a clear causal chain of events that led to an incident. It's actually to understand the context that people were operating within when responding to an incident that either helped or hindered their ability to make decisions. That's something that you can only get by conducting one-on-one interviews, by focusing on storytelling, not action items. What was going through somebody's head? What kind of circumstances were they dealing with at the time?The things that helped you are your sources of resilience. The things that hindered you are the things that you can attack as an organization. Try to figure out what you can do to limit those things that hindered people's ability to make decisions during an incident.
It's coming to the conclusion that our goal in doing these postmortems is not actually to understand what happened. It's not to understand a clear causal chain of events that led to an incident. It's actually to understand the context that people were operating within when responding to an incident that either helped or hindered their ability to make decisions.
This has been the evolution of how we've thought about incident analysis. It's gone from this very linear way of looking at things. When I first started, we were using a system called the 5 Whys. It's not without its uses. Something I always repeat when I'm talking about this stuff is all mental models are wrong, some are useful. This is wrong, but it is useful. I'm not going to completely trash it. What I am going to say is that the 5 Whys can really limit your analysis.
When we started, for anybody who's unfamiliar with the 5 Whys, it's the basic idea that you start with an incident and you work your way backwards by asking why did X happen? Well, because of X or Y. Why did Y happen? Because of Z. After five whys, you'll arrive at this root cause. What's interesting about that is it trains you to think about causal chains of events.
There's been a lot of work done in this area. There's a woman named Nancy Leveson who's a giant in the area of accident analysis. She's written tons about this and practiced accident analysis at scales that I can't even fathom, and she observed that different groups using the 5 Whys will arrive at different root causes. That immediately makes you suspicious of the method. What it's doing is, at every stage, you're actually limiting discussion to one causal chain of events and eliminating a whole bunch of other possibilities that are actually rich sources of information from your incident.
If you get different groups of people looking at the same accident or incident using a technique like this and they're arriving at different conclusions, that also leads to another thing which is this idea of a singular root cause. If you can get five groups of people applying the 5 Whys to the same event and they're coming up with five different root causes, is it possible that there isn't such a thing as a root cause? That there are multiple contributing factors to any particular incident? If we focus on one root cause, we're making arbitrary decisions about where we stop our analysis, which means that we are also limiting what we can learn from this incident. Instead of root cause analysis, we tend to think about contributing factors.
If you can get five groups of people applying the 5 Whys to the same event and they're coming up with five different root causes, is it possible that there isn't such a thing as a root cause? That there are multiple contributing factors to any particular incident?
When I first joined Under Armour, we were doing root cause analyses, we were doing 5 Whys, and we actually did weekly root cause analysis meetings. The idea was, if we could find all the broken things and fix all the broken things, then we'd be in a better world. I think that went on for about a year and we saw zero improvement. We saw dwindling interest in these retrospectives, and we started asking, "How's this working for us?" The answer was, it wasn't.
This is what our adjusted process looks like now having gone through some of these shifts and incorporating these practices that try to bring out some pretty nuanced concepts. We now analyze data and what that means is an incident will happen and somebody is given the responsibility of shepherding the incident analysis process. They're going to go through what data we captured during that incident. It could be chat transcripts, could be video conferences, could be some recorded bridge or something like that. They're going to identify people who were playing a key role in incidents and select those people as interesting people to interview and then schedule times to interview those participants and get their perspectives and collect information.
We actually ask people if they mind if we record those for our own purposes as the incident analyst. I'm surprised at how many people are like, "Yes, please. I have no problem whatsoever." It's really useful for me when I'm going through that information afterwards and collecting notes to have a recording of that conversation. It also allows me during the actual one-on-one to focus myself completely on asking questions of that person and not sitting there with a laptop having to take notes, which can be alienating.
Out of that interview process, we go back and analyze. Sometimes we pick new people to interview. This can go back and forth a few times and eventually we write a draft analysis. This is structured to be read, not something that we want customers to get. It's something that we want people to be excited to read. We try to approach it as though we're writing a narrative. When we meet with a group, we make the invites open at Under Armour. That's really useful because it can get more people excited about learning from these things. We've actually found a surprising number of people wanting to show up to certain postmortem reviews.
During those reviews, the person who's tasked with doing this analysis, actually reads back the information. Like I said earlier, I've had people say that they've really felt like their point of view was represented even more so than if we just gave them a floor. This is an opportunity to say, "Hey, did I miss anything? Is there anything misrepresented here? Is this wrong?" Some really interesting discussions can come out of this because for the first time, you're taking all these one-on-one narratives and you're combining them and you're seeing what the group thinks is important or thinks is not important.
That can go back and forth too. You can have a meeting and go back to revise your draft. You can incorporate feedback from the group of people who were involved in the incident and then produce something new and then meet with people again and say, "Hey, how does this look? Am I getting this right? Does this accurately represent how it felt to be part of this incident and does this capture a lot of the learnings that we had from this incident?" Eventually you’ll publish with revisions.
One of the things that I try to be careful to do is document the action items as things that happened along the way because, like I said, the action items don't necessarily have to fall out at the end of the incident. It's not like a function that you input an incident, you get action items out. Action items can be stuff that engineers did in the moments after an incident. They can be stuff that happened in the next sprint after an incident if that amount of time has passed. It's good to document those things. I like to keep track of those things because it gives us a certain amount of confidence. We can look back and say, "Look at all the things that people have self-organized to do in response to these incidents."
The action items don't necessarily have to fall out at the end of the incident. It's not like a function that you input an incident, you get action items out. Action items can be stuff that engineers did in the moments after an incident. They can be stuff that happened in the next sprint after an incident if that amount of time has passed.
As far as publishing, this is something that we're still tackling. We don't have a perfect solution for this, but make these things accessible. I have a future vision in my head where we have some internal tool that makes these things searchable by tags where a new engineer can just come on board and just say, "Show me everything that's ever happened to this system or everything that's involved this service that I work on.”
Some concrete takeaways that I would encourage is, if any of this resonated with you, practice interviewing responders as part of your postmortem process. It's been a really interesting experience for me. I would definitely encourage it. It also helps you connect with a lot of people on different teams in ways that you weren't maybe previously able to do. Focus on stories instead of action items. Think about incidents as opportunities for storytelling and for things that you can learn and internalize in your organization.
Practice interviewing responders as part of your postmortem process. It's been a really interesting experience for me. I would definitely encourage it. It also helps you connect with a lot of people on different teams in ways that you weren't maybe previously able to do. Focus on stories instead of action items. Think about incidents as opportunities for storytelling and for things that you can learn and internalize in your organization.
Understand that I'm not going to try to convince you all to change your process completely, but at least understand that 5 Whys and root cause analysis can limit our investigations. They can focus on one thing instead of a plethora of opportunities. Write incident reports to be read. Practice writing as a skill. If you're involved in the SRE world, then you're communicating and it's a really important skill I think to try to improve.
Focus on humans more, software less. Humans are a huge part of your system. They are there to protect when things go bad and they're there to make sure that the systems are always improving. Give them knowledge, give them opportunities to tell their stories and to surface what they go through operating the systems that we build. This is one of the areas where I think as software people, we have a lot to learn from people in other industries about how they do this stuff.
If you enjoyed this, check out these resources:
* [Resilience in Action, Episode 1: Narratives in Incidents with Lorin Hochstein](https://www.blameless.com/blog/resilience-in-action-episode-1-narratives-in-incidents-with-lorin-hochstein)
* [Improving Postmortem Practices with Veteran Google SRE, Steve McGhee](https://www.blameless.com/blog/improve-postmortem-with-sre-steve-mcghee)
* [5 Best Practices on Nailing Postmortems](https://www.blameless.com/blog/5-best-practices-nailing-postmortems)
| kludyhannah |
419,799 | Creating a Teams presence publisher with Azure Functions, local and cloud | Want to go straight to the code? Here it is Teams Presence Presence info has been around... | 0 | 2020-08-05T21:13:17 | https://jpda.dev/teams-presence-publisher | azure, teams, presence, graph | ---
title: Creating a Teams presence publisher with Azure Functions, local and cloud
published: true
date: 2020-03-24 15:04:11 UTC
tags: azure, teams, presence, graph
canonical_url: https://jpda.dev/teams-presence-publisher
---
_Want to go straight to the code? [Here it is](https://github.com/jpda/i-come-bearing-presence)_
## Teams Presence
Presence info has been around a long time - we had it in Skype for Business and its predecessors - Lync, OCS, LCS, etc. There were even devices you could buy with lights indicating presence - super useful, especially in more ‘open’ offices to achieve some focus.

The Embrava lights were popular, I had one on my desk, in fact - but they don’t seem to work with Teams presence. Combine that with more recent news:
- [Presence is now in Microsoft Graph](https://developer.microsoft.com/en-us/graph/blogs/microsoft-graph-presence-apis-are-now-available-in-public-preview/)
- [Working from home is a new reality for many people](https://news.microsoft.com/covid-19-response/)
- [Working from home with an entire family](https://ed.sc.gov/districts-schools/schools/district-and-school-closures/)
And since I have little ones at home, it got me thinking about ways to let them know if I’m on the phone or not. I wanted something multitenant that could publish presence for anyone, not just me. In that spirit - any solution worth a solution is worth an over-engineered solution, right? _Right?!_ Click the video to see it in action.
[](https://www.youtube.com/watch?v=ujDyD63KdbA)
At home I’ve got a few bulbs, in my office but also upstairs so my family can see if I’m on the phone or not.

Same for the office - rather than a small light, I felt the size of this lamp really reinforced the message.

## Let’s build!
Here’s what we’re going to build:
A presence-poller running in Azure Functions, which…
- logs in a user and stores a `refresh_token`,
- polls the Graph for Presence updates,
- stores the update (if any) in Azure Table Storage, and
- notifies subscribers over a Service Bus topic.
Plus, we have a local Azure Function, which…
- runs in a container on a raspberry pi,
- creates a subscription to the Service Bus topic, and
- interacts with the local Philips Hue Hub over HTTP
There is no webhook or push support yet for Presence updates, so until then, we need to poll for it ourselves. Rather than having multiple devices poll for the same data, I thought it prudent to poll from one component, then push to as many subscribers as are interested. The local Function acts as a shim for interacting with whatever local devices are interested in presence updates. In my case, two Philips Hue Hubs - one in the office, one at home. This also helps with firewall silliness - since the poller runs cloud side but publishes changes to a topic, our local function only needs outbound internet access - no inbound access required.
## Presence updater job
The [`presence-refresh`](https://github.com/jpda/i-come-bearing-presence/blob/2d633408772be906a9c1423eef31e8ec6a4447c2/ComeBearingPresence.Func/PresencePublisher.cs#L103) function calls `CheckAndUpdatePresence`, which does the bulk of the heavy lifting. This timer job is responsible for actually pinging the Graph to fetch a user’s current presence, check it against the last known presence, and, if different, publish it to subscribers. I’m using the user’s ID as the service bus topic name - this way we have enough information at runtime to know which topic to use for sending updates.
First, we need to know which user for which we want presence data. This is driven by a store of accounts in Table storage. The key here is _how_ the accounts get into the list in the first place - and how we get access tokens for querying the graph.
## Authenticating users and asking for consent
Of course, being the Graph, everything here is authenticated via Azure AD. We need the `Presence.Read` permission, which (as of March 2020) is an admin-consentable permission _only._ This means that only an administrator of an Azure AD tenant can consent to apps using this permission. There are some reasons we can infer from that - a malicious app that knows your presence could risk far more information exposure than your organization (or you) would be comfortable with. Once we have an app with that consent, we still need to capture individual user consent (you can, of course, consent tenant-wide as an administrator) and record that this user would like to get their presence info published to them.
To configure this, first we need to register an app. The app itself needs `Presence.Read` but little else. We’ll also need certain reply URLs registered. You can read more about this process [here](https://docs.microsoft.com/en-us/azure/active-directory/develop/quickstart-register-app). You’ll get a client ID (application ID) and secret (a random string, or a certificate). Save them off, we’ll need them in a little bit. Note I’m using a certificate here for authentication, since this `Presence.Read` is a sensitive scope. We also need a way to securely share that secret (be it a string or a certificate) with our Function.
We’ll use KeyVault and Managed Identity for accessing the secret. This way, our Function will have an identity usable only by itself - we’ll assign this identity permissions in KeyVault to pull the secrets, so we don’t keep any secrets in code. Alternatively, you can assign the Presence.Read permission directly to your Managed Identity, removing the need for KeyVault entirely. Read on [here](https://docs.microsoft.com/en-us/azure/key-vault/managed-identity) for more info on using KeyVault with Managed Identities.
Alternatively, if using certificate authentication to Azure AD, you can store the certificate in App Service directly, then reference it using normal Windows certificate store semantics (e.g., CurrentUser/My, etc). In fact, I had to switch to this for testing, as I was having issues getting connected to KeyVault reliably.
Next, let’s get into the `auth-start` and `auth-end` functions, which actually authenticate our users.
### `auth-start`
This function is responsible for two things - authenticating a user to capture `access_` and `refresh_token`s, in addition to storing the user in the PresenceRequests table (e.g., please start polling for presence updates). We need the `Presence.Read` and `offline_access` scopes so we get a refresh token. Auth start doesn’t do a whole lot except redirect the user over to Azure AD to authenticate. We’re going to use the `authorization_code` flow here to keep any tokens out of the user’s browser. After the user signs in, we’ll ask Azure AD to do an HTTP POST back to us with the authorization code in tow. While we could generate that URL ourselves, we can hand it off to MSAL here using `ConfidentialClientApplication.GetAuthorizationRequestUrl`, making sure to also include `response_mode=form_post` to ensure we’re keeping the code out of the URL.
### `auth-end`
This function handles the return trip from Azure AD. Notably, it receives the `authorization_code` Azure AD generates after a successful sign-in and authorization, sends that _back_ to Azure AD to receive an access\_token & refresh\_token for the requested scopes. We could, again, handle this ourselves, but better to let a library do the heavy lifting - MSAL’s `AcquireTokenByAuthorizationCode` handles the interaction with Azure AD, then caches the tokens for us.
Next we store the fact that a user authorized us in tables - this is what the timer job uses to determine which presences to request.
## Token caching & MSAL
Rather than reimplement an entire token cache, since we’re only interested in changing the _persistence_ of the cache and not the mechanisms of how the cache is serialized, MSAL provides us some delegates we can set - namely, `BeforeAccess` and `AfterAccess`. Set these delegates to your own methods to handle the last-step persistence (and rehydration) of your preferred storage medium. I’m using table storage here again, so my Before and After access delegates are only concerned with writing and reading the bytes to and from table storage.
Now - [if you read through the guidance from the MSAL team in the wiki & in the docs](https://github.com/AzureAD/microsoft-authentication-library-for-dotnet/wiki/token-cache-serialization#token-cache-for-a-web-app-confidential-client-application) - you’ll notice this:
> A very important thing to remember is that for Web Apps and Web APIs, there should be one token cache per user (per account). You need to serialize the token cache for each account.
In web apps, this is fairly straightforward to accomplish - a user is signed in, so we usually have some bit of identifying information about them to use as a cache key. This way we can query _something_ like Redis, Cosmos, SQL, etc to fetch our MSAL cache. In our case, however, we don’t have an interactive user except for the first time. In fact, we want to keep a very Microsoft-Flow-esque user experience: sign in, store off tokens, do background work as necessary. This means that when we run our timer job without any sort of user context available, it gets dicey trying to figure out which token cache to use.
`TokenCacheNotificationArgs` (what your BeforeAccess and AfterAccess delegates will receive) don’t have enough user data for us to determine which cache to use, because we don’t have an `Account` object yet - at timer job runtime, we literally have an empty MSAL object - configured, but no accounts or data yet. That MSAL’s main entry point objects are called ‘Applications’ (`PublicClientApplication` and `ConfidentialClientApplication`) is a bit misleading. In reality, the uniqueness per application object is really the token cache itself. What I learned here was that, in fact, we don’t want to use a singleton ConfidentialClientApplication, instead we want a `ConfidentialClientApplication` _per unique token cache_ which, per the guidance, is per-user. Beyond that, a singleton `ConfidentialClientApplication` would cause problems with cache serialization - as all accounts within the object at the time are serialized instead of a notion of a ‘swappable’ cache in the same object. Needless to say, I spent a ton of time trying to figure out the best way to go forward.
What I ended up with is an MSAL client factory. Not a big fan of it, but it lets me request an MSAL ConfidentialClientApplication configured with the right caches per user, sent in at runtime. Find it [here](https://github.com/jpda/i-come-bearing-presence/tree/master/ComeBearingPresence.Func/TokenCache).
You may also notice a transfer between transient & actual keys. The reason for this is that during the `auth-end` callback, we have no context to know who the user is - so when we create our CCA to consume the code (`AcquireTokenByAuthorizationCode`), if we don’t set the cache delegates upfront, they don’t get persisted. This sets the cache before with a random identifier, which is then renamed in storage to the user’s actual identifier once we know who the user is.
Rube Goldberg would be proud.
Once we’ve plowed through this circus, we have a reliable way to get access\_tokens for calling the graph. At this point, we’re publishing presence changes from the graph to a topic! Our cloud-side work is done.
## Publishing to subscribers
The Service Bus topics are created per user ID, each subscriber should have its own topic subscription (unless they are competing, in that they are doing the same work). I have two locations, Home & Office, so I have two subscriptions, one for each. If I had multiple _instances_ of a subscriber working on a common goal (e.g., updating the lights at my home), those instances would share the same subscription.
## Subscribing to updates and manipulating our Philips Hue Hub

OK! Now we’ve gotten our access token and we’re polling the graph. Great! Now we need something to listen for those status changes. This could be anything you want - a light, a sign, or even a puff of smoke (like when they pick a new pope). I’m using Philips Hue bulbs, but my colleague [Matthijs](https://twitter.com/mahoekst/status/1215179713888391168?s=20) built some wild stuff with his presence and a bunch of boards and hundreds of LEDs, plus a really cool MSAL Device Code flow.
Talking to the Hue Hub means creating the equivalent of an API key on the local Hub, then using that in subsequent requests. I looked at Philips’ online stuff, but you can only have one Hue hub per account? Seems like a strange limitation, but since I have one at home and at work, I figured that wasn’t going to work out. Instead, I’ll just talk to them locally.
Creating an api key to talk to the hub locally is a pretty quick one-time procedure. You can do it manually or automate it - but you’ll need to press the button on your Hub, then run your code within a window of time. See more about creating Hue keys [here](https://developers.meethue.com/develop/get-started-2/).
Now on to our [LocalHueHubSubscriber](https://github.com/jpda/i-come-bearing-presence/tree/master/LocalHueHubSubscriber.Func) function. This function is what runs locally, with a network path to your Hue Hub. There is a dockerfile to build targeting `dotnet2.0-arm32v7`, which runs on a raspberry pi. This function is what’s going to ping our Hue Hub with new colors depending on status. I have a crude status-to-color map (find that [here](https://github.com/jpda/i-come-bearing-presence/blob/2d633408772be906a9c1423eef31e8ec6a4447c2/LocalHueHubSubscriber.Func/Function1.cs#L25)) - it uses a Service Bus trigger and when it fires, makes an HTTP call to the hub with the desired color.
On your raspberry pi, all you need is docker. Use the `.env.local` file to store configuration and push it into the container at runtime. You’ll need your SB topic subscription’s connection string, plus your local Hue Hub’s IP and path to your light group.
## todo
- UI for adding user endpoints
- ARM template for Azure resources
- finish code for creating SB topics when new user onboards
:bowtie:
Find me at [@AzureAndChill](https://twitter.com/AzureAndChill) with any questions or concerns! | jpda |
420,216 | Reddit for programmers | Reddit is an amazing resource for beginner programmers. It's a goldmine of references to valuable mat... | 0 | 2020-08-06T08:14:16 | https://dev.to/blorente/reddit-for-programmers-4ejk | beginners, codenewbie, programming, tips |
Reddit is an amazing resource for beginner programmers. It's a goldmine of references to valuable materials and a place where a lot of great folks gather to give each other feedback.
It has helped me throughout my career and, in this post, I want to explain how you could be engaging with Reddit's communities to skyrocket your engineering skills.
{% youtube tlI022aUWQQ %}
# Why Reddit?
At its core, Reddit is a place where communities live. These communities, or _subreddits_ revolve around a particular concept. For instance, [r/cpp](https://www.reddit.com/r/cpp/) is a community of people that know about the C++ language, [r/gamedev](https://www.reddit.com/r/gamedev/) is about developing videogames, and [r/learnprogramming](https://www.reddit.com/r/learnprogramming/) is about... well... learning how to program.
There is probably a subreddit for everything you can think of, no matter how big or small.
The key concept here is **community**. A community is a place where like-minded people get together to talk about something that interests them.
Communities are incredibly valuable when developing your skills. They can give you direction, encouragement, and great advice!
Unfortunately, communities are sometimes hard to come by, or difficult to get into.
This is what makes Reddit such a good resource. The communities are already there, ready to help! It's the perfect place to ask questions and find people who have walked the same path as you.
# How Reddit?
Hopefully, I've convinced you that Reddit is a valuable asset to have for your career.
Now, how can you leverage the power of these great communities? I've found that there are three main ways of benefitting from a community:
- Reading their curated resource lists.
- Seeking feedback from the community.
- Giving feedback to other members.
Let's go one by one.
# The sidebars and FAQs are golden fountains of knowledge. Use them!

Most subreddits get a lot of beginner questions. Eventually, most of these questions start repeating over time. To help with that, most subreddits have compiled answers and resources in their "about" or "FAQ" pages. The size of the "about" page depends on the size of the subreddit, with the largest subreddits having fully-fledged wikis! (like this one, from [r/fitness](https://thefitness.wiki/getting-started-with-fitness/))
> Whenever I want to learn something new, like a new tool or a new language, **my first instinct is to check the sidebar of that subreddit**.
These "about" pages (also called _sidebar_) have one advantage over Googling things:
**All of these resources have been useful to real humans** with the same problems as you're likely to face.
Plus, **nobody makes any money** with these resource lists, so there's no incentive to advertise products that are not genuinely useful.
These lists are pure gold. When a new hobby piques my interest, the first thing I do is to check the sidebar for that hobby's subreddit.
It's the same with programming. Whenever I want to learn something new, like a new tool or a new language, **my first instinct is to check the sidebar of that subreddit**.
I don't know how else to put it. Go check the sidebars!
# Seek feedback from the amazing community
> We all need people who will give us feedback. That’s how we improve.
>
> -- **Bill Gates**
Good feedback is the cornerstone of learning. However, good feedback is hard to come by, because it requires someone to give you their thought, attention, and careful consideration. The good news is, most subreddits are full of people eager to help!
**Subreddits** are amazing to get some expert eyes on your work. There are only two rules that ensure that you have a good interaction with a subreddit:
- **Read the subreddit's rules**. When you post a question or a request for feedback, you are essentially asking for people's time. Treat that time with respect by reading the rules and doing your best to fulfil them.
- **Write thoughtful questions** to get thoughtful answers. If someone wants to help you, you need to give them as many details as possible. Make questions **concrete**, and give enough context so that the reader can immediately understand where you're coming from. This is easier than it seems since most subreddits have very good guides on asking good questions, like [r/learnprogramming](https://www.reddit.com/r/learnprogramming/comments/61oly8/new_read_me_first/).
> Most subreddits are full of knowledgeable people willing to help. As long as you are respectful of their time, don't be afraid to ask them for answers or feedback!
Note that there was no rule about how experienced you need to be to post a question. Even if it can feel intimidating to post a question and look dumb, it helps to keep in mind that **a moment of looking dumb now can save you months of struggling**. From this perspective, **not posting is much worse** than posting a "dumb question".
That said, most subreddits have a mindset of "no question is too dumb", as long as you follow the second rule and put some real effort into asking the question properly. So **ask without fear**!
Now, there is another great kind of feedback you can get from a subreddit: **Code review**.
If you're working on a personal project, chances are you're not too sure of what the right way to do something is. **Showing your work** to a subreddit is a great way of getting the feedback you need to ensure you're on the right track.
Here's an example:
When I was in college, I wanted to learn the C++ language. I was able to write some code that worked, but I didn't know if what I was writing was "the right way" of writing C++ code (also called "the **idiomatic** way").
I posted my code in [r/cpp_questions](https://www.reddit.com/r/cpp_questions/), asking specifically for that kind of advice. The response was amazing!
I got lots of great advice **that it would have taken me months to figure out** on my own:
[Reddit post: So I made a CHIP-8 Interpreter as my first production-level C++ project, any advice?](https://www.reddit.com/r/cpp_questions/comments/46kfn6/so_i_made_a_chip8_interpreter_as_my_first/)
**One more time**: Most subreddits are full of knowledgeable people willing to help. As long as you are respectful of their time, don't be afraid to ask them for answers or feedback!
# Help people in the subreddit to develop your code reading and communication skills

I hope this doesn't come as a surprise, but these two skills are the mark of a senior engineer:
- Senior engineers can **navigate a codebase** they've never seen before efficiently without much direction.
- Senior engineers can **communicate technical concepts** effectively to other engineers of any level.
If someone is seeking people to review their project on Reddit, this is a great opportunity to develop both of those skills!
- Reviewing someone's project forces you to tackle a codebase you've never seen before, so you train your code navigation muscles.
- If you get stuck, you can always go back to the post and ask the author questions or clarification! Chances are they are delighted to answer them. After all, that's why they posted in the first place!
- Reviewing that code may expose you to techniques and technologies you've never seen before.
- After reviewing someone's code, you need to formulate your feedback in a way that's useful for them. This will train your communication muscles.
Don't be afraid to give your feedback, **especially if you're still starting out**. We all want to write readable code, and your feedback and questions can help the author realize where the author could make their code more approachable!
Sidenote: There is not a lot of good material on learning to approach new codebases, but I'm working on a manual to help with that. If you're interested, subscribe below so that you don't miss out when I announce it.
On top of it all, you're contributing to the well-being of the community and helping another fellow programmer, which is always awesome.
# Recap
I hope I've convinced you that Reddit is a good place to find growth as a programmer, and give you some useful pointers to use it effectively.
What are your experiences with Reddit?
I'd love to read your comments here, in my Twitter account [@BeyondLoop](https://twitter.com/BeyondLoop) or in the place this was originally posted: [Beyond The Loop](https://beyondtheloop.dev/how-to-use-reddit-to-skyrocket-your-improvement/). | blorente |
420,480 | Building my first E-commerce Website | https://medium.com/@bipinthecoder/building-my-first-online-food-ordering-platform-f2027457c681 | 0 | 2020-08-06T13:47:45 | https://dev.to/bipinthecoder/building-my-first-e-commerce-website-1lo0 | javascript, beginners, react, redux | https://medium.com/@bipinthecoder/building-my-first-online-food-ordering-platform-f2027457c681 | bipinthecoder |
420,813 | Flutter vs React Native: What to Choose in 2020 | The year 2020 has come with its ups and downs. One industry that has seen a huge growth in revenue is... | 0 | 2020-08-06T21:00:25 | https://dev.to/aeimenb/flutter-vs-react-native-what-to-choose-in-2020-4h72 | react, reactnative | The year 2020 has come with its ups and downs. One industry that has seen a huge growth in revenue is the mobile application industry. According to a study, worldwide consumer spending on mobile apps is projected to reach $171 billion by 2024, which is more than double the $85 billion from 2019. With demand on the rise, the industry is looking towards a huge influx of new and upcoming mobile applications. While there are heaps of frameworks to choose from, Flutter and React Native are the front runners in 2020. Before you choose either one you need to know our thoughts on [Flutter vs React Native](https://novateus.com/flutter-vs-react-native-2020).
Before moving on to the comparison let’s first go through a brief introduction of both.
##Flutter
Flutter has caused a storm in the mobile app development world. Google released Flutter in May 2017. Similar solutions have been offered for native iOS and Android mobile app development but Flutter is an independent SDK. It is not a framework for development to be exact. Flutter is a newer option in competition with technologies like React Native and Xamarin.
To read further on Flutter specifically you can read a few of our previous articles.
##React Native
On the other hand, React Native is an open-sourced platform that uses JavaScript. It offers cross-platform development for mobile apps. Facebook launched React Native at the end of 2015 and it quickly gained wide community support and is one of the most popular Android development platforms today. It was built on top of React JS which is comparable to Google’s release of Angular JS.
This was just a brief introduction of both these technologies. Now we will get into the pros and cons of each so we can help you make an informed decision.
##[Flutter vs React Native](https://novateus.com/flutter-vs-react-native-2020)
###Performance
App performance is one of the main concerns that customers are looking for. When it comes to who takes the lead here, we would say Flutter.
Flutter comes compiled with ARM x86 native libraries, which make it really fast. When Flutter came to be these libraries were starting to build up and people have very little hope for it packing a performance punch in the upcoming years. Additionally, it uses Dart and C++ as its major programming languages. The use of these languages makes Flutter robust and boosts the performance of its apps.
On the other hand, while React Native packs a powerful performance punch but it is not nearly as powerful as Flutter. React Native uses JavaScript and Native languages which makes it less performant than Flutter. To give it a boost in performance developers then have to combine their applications with additional native features like notifications, gestures, etc.
A test performed on a simple timer app at Thoughtbot reveals the following performance percentages in Flutter vs React Native applications on the same device.
###flutter vs react native performance
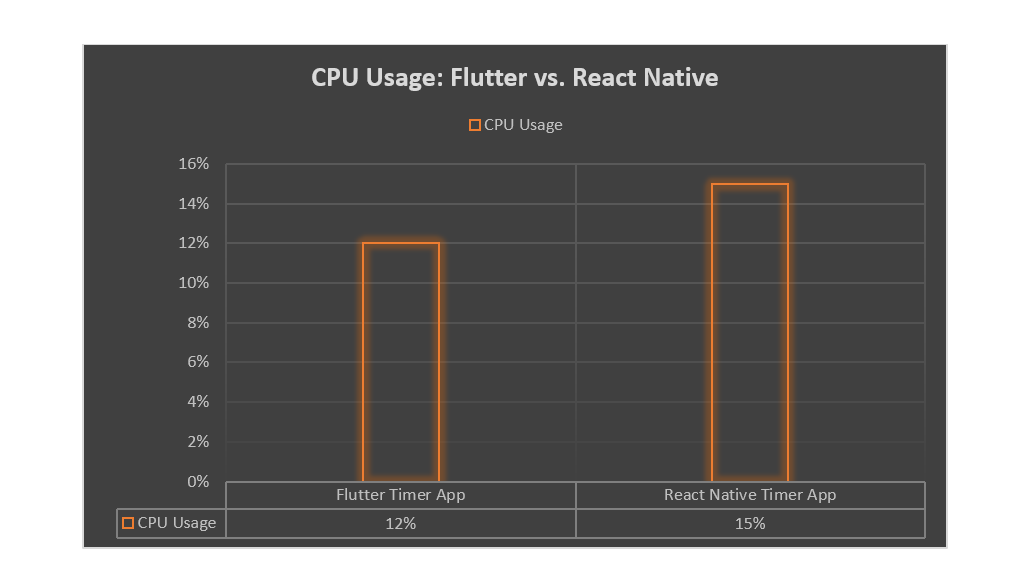
Source: https://thoughtbot.com/blog/examining-performance-differences-between-native-flutter-and-react-native-mobile-development
###Programming Language
Flutter uses Dart as its primary programming language. It matches the way they wanted to have their UI developed. Dart is an Object-Oriented language that is Ahead Of Time (AOT), its compiles faster and is predictable. The flexibility for Just in Time (JIT) compilation of code is also offered in Dart. Moreover, it is very much similar to most languages out there.
However, React Native on the other hand uses JavaScript as its primary language. Because of this factor, it is still preferred by many developers who have been working with it for years. Statically-typed programming languages have been included as well, you can even use TypeScript – a JavaScript subset.
That being said, Flutter is quickly gaining popularity and many developers are turning to Flutter. Additionally, Flutter introduced documentation for React Native developers so they can easily transition. With the audience slowly growing this takes us to our next point of discussion: Community.
###Flutter vs React Native: The Developer Community
React Native without a doubt takes the lead here. Let us break it down for you.
Recall us saying while Dart is a robust programming language it is still new as compared to Java Script. As compared to Flutter, React Native has a vast, established, and experienced community all over the world. To add to that, Dart is not as popular a programming option as Java Script, given that it has been around for more than a decade.
Flutter has a lot of room to cover when it comes to having community-wide support. Essentially, it is not that big of a disadvantage. Flutter is growing exponentially and so is the audience. Google Stats revealed percentages of the distribution of developers working at different levels to develop mobile applications using Flutter.
###flutter vs react native developers
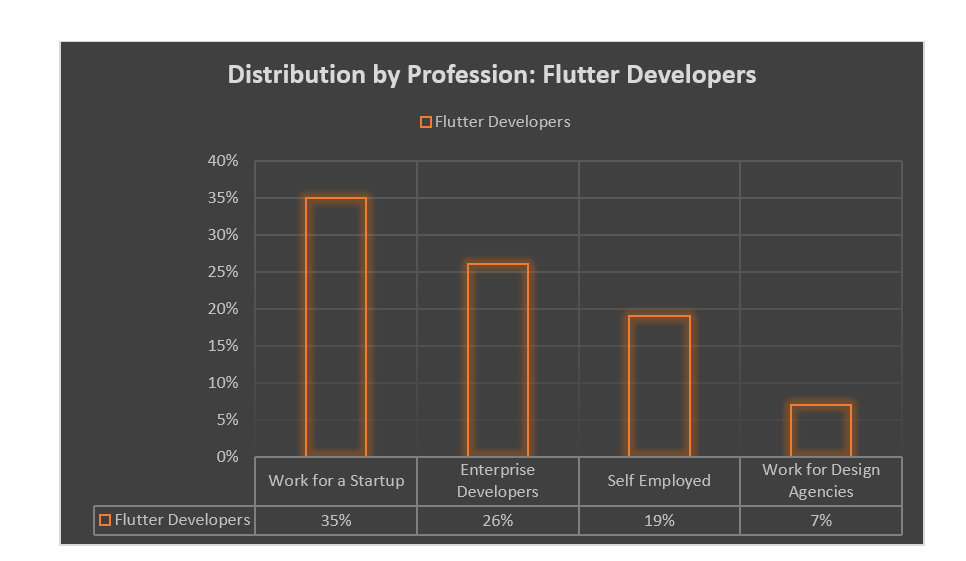
Source: https://venturebeat.com/2020/04/22/google-500000-developers-flutter-release-process-versioning-changes/
These numbers are very promising when we look at the fact that Flutter only launched about two and a half years ago.
###UI Stability
Coming to the general look and feel of the App Flutter steals the show here. Flutter doesn’t rely on Native system components rather; it has its own set of custom widgets. These widgets are maintained and updated by the Flutter’s very own graphic engine. Additionally, Flutter applications have a very user-friendly UI thus backing the reason Flutter was created: the ability to create your very own widgets or customize the existing ones offered.
Bonus fact: All designs look almost the same on all old and new android and iOS devices so you don’t have to worry about support/updates for new/old devices.
On the contrary, React Native Apps have a comparatively fragile UI. You must know by now that React uses native UI elements in development so all systems due for an update, will automatically have updated widgets. But, sometimes this is not what the application needs. These updates can sometimes break the applications UI. It happens very rarely, but sometimes potential changes in the native UI components API can be very dangerous.
The possibility of this happening is pretty rare but with Flutter the UI is a lot more stable.
###Learning Curve
Dart is an easy to understand Language. Flutter being Google’s creation, comprehensive documentation is a big focus. People with mediocre knowledge of programming are developing apps and prototyping on Flutter. That said, Flutter’s learning curve is steep for beginners. While it may be difficult at first, once you do learn to code in Flutter things will get easier.
React Native was built on the foundation principles of React. Many web developers working with React who want to shift to mobile development will find the learning curve easy. This is the developer community’s unified perspective. But me, being a young developer and having only worked on React Native for a year: The learning curve for React Native was off the charts. To be able to code using React Native, I had to master HTML and CSS, had to learn to properly use them.
That being said, Flutter vs React Native, when it comes to learning curve React Native is comparatively easier to learn because it uses JavaScript, which has been around for years.

##MVP (Minimum Viable Product) Apps
Flutter and Minimum Viable Application development strategies are coming up in discussion frequently nowadays. MVP apps are some of the most successful strategies for new and upcoming startups to test out their ideas in front of potential investors. These apps are like a prototype to gather user input and then develop a proper app based on these responses.
flutter used to develop mvp apps
The biggest hindrance in any startups progress is the limited funding sources. Flutter being a cross development platform reduces the development costs significantly. How you might ask? The lower the time and cost resources the lesser a mobile app development company will charge. Additionally, the hot reload function enables developers to code even faster to deliver MVP apps within short deadlines.
Also, Flutter helps deliver intricately designed solutions because of its stable UI.
##Conclusion
Flutter continues to attract more and more companies as Google continues to push in powerful updates. Monthly updates are refining Flutter to be one of the top development options in the community. Huge companies like Ali Baba are already using Flutter, which goes on to prove that it has a bright future. According to Google’s trends, the top five territories for Flutter are India, China, the United States, the EU, and Brazil. If you’ve been in the tech industry long enough you’ll know these are the primary regions for development hubs and such promising numbers mean that the toolkit has a promising future.
That said, with popular apps like Instagram running successfully, React Native is still the most popular mobile development platform. Flutter is definitely making changes but side by side Facebook is currently focusing on a large-scale re-architecture of the technology. Given the continuous growth of the platform, it is unlikely that we will see this toolkit in the dust anytime soon.
All things said, Flutter is definitely emerging as a powerful competitor to React Native and is certainly a good choice to choose as a development option in 2020. | aeimenb |
420,839 | Rust 1 - Basic syntax | Installation Getting started official guide cargo new my-project # create new project ca... | 8,165 | 2020-08-06T21:44:58 | https://dev.to/petr7555/rust-1-basic-syntax-4cng | rust | ## Installation
[Getting started official guide](https://www.rust-lang.org/learn/get-started)
```bash
cargo new my-project # create new project
cargo build # build the project
cargo run # run main()
```
```bash
rustup --version
rustup check # checks if newer version is available
rustup update
```
```bash
cargo fmt # runs rustfmt formatter
cargo clippy # detects and fixes problems in code
```
## Hello World!
```rust
fn main() {
println!("Hello, world!"); // '!' means this is a macro
// strings are enclosed in double quotes
}
```
## Binding
```rust
fn main() {
let x = 5; // this is binding, in other languages know as definition
// x is immutable (constant)
println!("Value of x is: {}", x);
// x += 5 would throw an error
// x = 10 also throws an error
let y: u32 = 6;
println!("Value of y is: {}", y);
}
```
## Shadowing
```rust
fn main() {
let x = 5;
println!("Value of x is: {}", x);
let x = x + 5;
println!("Value of x is: {}", x);
}
```
## Mut binding
```rust
fn main() {
let mut x = 5; // mutable binding, uses keyword 'mut'
println!("Value of x is: {}", x);
x = 10;
println!("Value of x is: {}", x);
x += 1; // Rust does not support neither x++ nor ++x
println!("Value of x is: {}", x);
}
```
## Data types
| Number of bits | Signed | Unsigned |
|----------------|--------|----------|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
## Numeric literals
| Type | Example |
|-----------|-------------|
| Decimal | 98_222 |
| Hexa | 0xff |
| Octal | 0o77 |
| Binary | 0b1111_0000 |
| Byte (u8) | b'A' |
## Constants
```rust
const MAX_POINTS: u32 = 100_000;
```
## Floating point numbers
```rust
fn main() {
let x = 2.0; // f64
println!("Value of x is: {}", x);
let x: f32 = 10;
println!("Value of x is: {}", x);
}
```
## Type conversion
```rust
fn main() {
let x = 2;
let y: f64 = x as f64;
let z: i32 = y as i32;
let pi: f32 = 3.14;
let u: f32 = pi.trunc();
let v: f32 = pi.ceil();
let w: f32 = pi.floor();
println!("Value of u is: {}", u); // 3
println!("Value of v is: {}", v); // 4
println!("Value of w is: {}", w); // 3
}
```
## Booleans
```rust
fn main() {
let t = true;
let f: bool = false; // explicit type
let value: i32 = f as i32; // bool is in Rust always either 0 or 1. Nothing else.
}
```
## Characters
```rust
fn main() {
let c = 'z'; // 'char'
let z = 'ℤ'; // 'char'
let heart_eyed_cat = '😻'; // 'char'; character is utf-8,
// therefore it is not compatible with byte, i. e. u8
}
```
## Tuples
```rust
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {}", y);
let five_hundred = tup.0;
let six_point_four = tup.1;
let one = tup.2;
}
```
## Arrays
```rust
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
let b = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
let index = 2;
let element = a[index];
println!("The value of element is: {}", element);
let months = ["January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November",
"December"];
}
```
## Functions
```rust
fn main() {
another_function(5, 6);
}
fn another_function(x: i32, y: i32) {
println!("The value of x is: {}", x);
println!("The value of y is: {}", y);
}
```
## Conditions
```rust
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
let condition = true;
let number2 = if condition { 5 } else { 6 };
println!("The value of number is: {}", number2) // 5
}
```
## Loop
```rust
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {}", result); // 20
}
```
## While
```rust
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("The value is: {}", a[index]);
index += 1;
}
}
```
## Handling input
```rust
use std::io;
fn main() {
loop {
println!("Please enter some number.");
let mut number = String::new();
io::stdin()
.read_line(&mut number)
.expect("Failed to read line");
let number: u32 = match number.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("Your number: {}", number);
break;
}
}
```
# Exercise
## Task
User enters 3 numbers, which correspond to the sizes of triangle sides. The programm computes circumference, area, whether the triangle is equilateral, isosceles or right.
## Solution
[Triangle](https://github.com/petr7555/Learning-Rust/tree/master/01/triangle)
---
Check out my learning Rust repo on GitHub!
{% github petr7555/Learning-Rust/ no-readme %} | petr7555 |
421,084 | Using Google Analytics without that annoying consent popup | Note: I have written this article on my linkedIn as well.GDPR has been the talking point for a while.... | 0 | 2021-07-04T11:30:55 | https://kambanthemaker.com/using-google-analytics-without-that-annoying-consent-popup-ckdjrnhl10230z2s10qkkavxa | googleanalytics, gdpr, cookiepopup, consentpopup | ---
title: Using Google Analytics without that annoying consent popup
published: true
date: 2020-08-07 05:01:37 UTC
tags: GoogleAnalytics,GDPR,cookiepopup,consentpopup
canonical_url: https://kambanthemaker.com/using-google-analytics-without-that-annoying-consent-popup-ckdjrnhl10230z2s10qkkavxa
---
Note: I have written this article on my linkedIn as well.GDPR has been the talking point for a while. Google Analytics is having enough trouble since users need to show cookie consent popup even when users don’t need the private information in ques... | kambanthemaker |
421,244 | Game Dev Digest — Issue #56 - Level Design, UI, VFX and more | Issue #56 - Level Design, UI, VFX and more Tons of Unite Now videos to get through this... | 4,330 | 2020-08-07T10:34:22 | https://gamedevdigest.com/digests/issue-56-level-design-ui-vfx-and-more.html | gamedev, unity3d, csharp, news | ---
title: Game Dev Digest — Issue #56 - Level Design, UI, VFX and more
published: true
date: 2020-08-07 10:34:22 UTC
tags: gamedev,unity,csharp,news
canonical_url: https://gamedevdigest.com/digests/issue-56-level-design-ui-vfx-and-more.html
series: Game Dev Digest - The Newsletter About Unity Game Dev
---
###Issue #56 - Level Design, UI, VFX and more

Tons of Unite Now videos to get through this week, all very useful. Check out the Probuilder/Progrids/Polybrush series if you want tips on faster level design iteration. There is also 2D content, UI, Shader Graph galore, and much more. Dig in as usual and enjoy!
---
[**Using Meshroom to Insert Real Life Objects in Unity**](https://www.raywenderlich.com/9559662-using-meshroom-to-insert-real-life-objects-in-unity) - In this article you’ll learn how to use Photogrammetry to photoscan and insert real life objects into your Unity projects with Meshroom.
[_raywenderlich.com_](https://www.raywenderlich.com/9559662-using-meshroom-to-insert-real-life-objects-in-unity)
[**Practical Tips: Maximizing Your Unity Game's Performance [Part-2]**](https://www.gamasutra.com/blogs/MaheshAthirala/20200803/367474/Practical_Tips_Maximizing_Your_Unity_Games_Performance_Part2.php) - This is the final and Continuation of Game Optimization tips.
[_Mahesh Athirala_](https://www.gamasutra.com/blogs/MaheshAthirala/20200803/367474/Practical_Tips_Maximizing_Your_Unity_Games_Performance_Part2.php)
[**Unity: Optimized Frame Pacing for Smooth Gameplay**](https://thegamedev.guru/unity-performance/optimized-frame-pacing-smooth-gameplay/) - Let's talk about the concept of frame pacing to learn how to reduce the performance stutters that your game suffers. If you want smoother gameplay in your Android games, then this post is for you.
[_The Gamedev Guru_](https://thegamedev.guru/unity-performance/optimized-frame-pacing-smooth-gameplay/)
[**Advanced scenes management in Unity**](https://dev.to/flatmango/advanced-scene-management-in-unity-14k2) - I would like to show you the approach that I've been using for years. It makes things easier to debug, more transparent and understandable what's going on with all that scenes' transitions.
[_Oleh Zahorodnii_](https://dev.to/flatmango/advanced-scene-management-in-unity-14k2)
[**Unity Shader Graph *Important Resources***](https://timcoster.com/2020/08/04/unity-shader-graph-important-resources/) - For the sake of not having to scour the internet over and over again🙄, here are links to my most used resources for creating node based shaders with Unity Shader Graph.
[_Tim Coster_](https://timcoster.com/2020/08/04/unity-shader-graph-important-resources/)
[**Fire Shader Breakdown**](https://cyangamedev.wordpress.com/2020/08/04/fire-shader-breakdown/) - A fairly common method of creating fire is to use a particle system, however many transparent quads produces overdraw which can affect performance, especially for VR and mobile platforms. Rather than using a particle system, a different approach to fire is a quad which faces the camera, where a noise texture is used to warp the UVs for sampling another texture (or generated ellipse / teardrop-like shape).
[_Cyan_](https://cyangamedev.wordpress.com/2020/08/04/fire-shader-breakdown/)
[**Particle Trail Sim - A Detailed How-To**](https://sbatman.blog/2020/08/04/particle-trail-sim-a-detailed-how-to/) - The core of the simulation is a two-dimensional grid of floats representing the signal (or “energy”) that the particles use to determine their route of travel.
[_SBATMAN.BLOG_](https://sbatman.blog/2020/08/04/particle-trail-sim-a-detailed-how-to/)
[**Procedural VFX: Artwork by John Parsaie**](https://80.lv/articles/procedural-vfx-artwork-by-john-parsaie) - Check out an awesome VFX artwork he made in Unity and Houdini by John Parsaie.
[_80 Level_](https://80.lv/articles/procedural-vfx-artwork-by-john-parsaie)
[**Case Study: Vector Displacement Mapping in Real-Time**](https://80.lv/articles/case-study-vector-displacement-mapping-in-real-time) - Amplify Creations team shared an extensive write-up on Vector Displacement Mapping and their experiments with VDMs and Amplify Shader Editor as well as explained step by step how to create VDM in Mudbox and use it in Unity.
[_80 Level_](https://80.lv/articles/case-study-vector-displacement-mapping-in-real-time)
[**Unity Tip: Improved UI Scaling**](https://www.thesleepyorder.com/post/unity-tip-improved-ui-scaling) - Something I see all too often in Unity games by small devs is poorly scaled UI, especially for border/background images
[_The Sleepy Order_](https://www.thesleepyorder.com/post/unity-tip-improved-ui-scaling)
[**A Guide to Making Damage Text Popups in Unity**](https://wintermutedigital.com/post/damage-text-unity/) - Making damage numbers or damage text popups appear above a sprite in Unity, at first glance, seems like a simple one. There are definitely many approaches to this, but one must beware of inefficient, resource intensive or bug-prone solutions.
[_Wintermute Digital_](https://wintermutedigital.com/post/damage-text-unity/)
[**ICYMI: Pixelblog 8 - Intro To Animation**](https://www.slynyrd.com/blog/2018/8/19/pixelblog-8-intro-to-animation) - Ultimately, the most effective way to learn is by going through the motions.
_[Also check out [Motion Cycles](https://www.slynyrd.com/blog/2020/1/23/pixelblog-25-motion-cycles)]_
[_Raymond Schlitter_](https://www.slynyrd.com/blog/2018/8/19/pixelblog-8-intro-to-animation)
[**Community Component: 10 Unity creators to watch**](https://blogs.unity3d.com/2020/08/03/community-component-10-unity-creators-to-watch/) - Welcome to another episode of the Community Component! Whether you are a seasoned developer or just starting out with Unity, these incredible community contributors will make your life with Unity both easier and more fun. Check out these inspiring community creators!
[_Unity_](https://blogs.unity3d.com/2020/08/03/community-component-10-unity-creators-to-watch/)
## Videos
[](https://www.youtube.com/watch?v=GioRYdZbGGk)
[**Faster level design iteration with ProBuilder and Polybrush | Unite Now 2020**](https://www.youtube.com/watch?v=GioRYdZbGGk) - If you’re a 3D modeler, environment artist or level designer, watcht this video to learn how to use Unity’s proven tools for designing, prototyping, and artistically finishing a scene.
_[Also check out [Asset Management with FBX Exporter, ProBuilder, and PolyBrush | Unite Now 2020](https://www.youtube.com/watch?v=7LHiye0OsBw), and @BinaryImpactG's tip on [tidying up your UVs](https://twitter.com/BinaryImpactG/status/1290595959949406208)]_
[_Unity_](https://www.youtube.com/watch?v=GioRYdZbGGk)
[**Creating a UI Line Renderer in Unity**](https://www.youtube.com/watch?v=--LB7URk60A) - Unity's Line Renderer Component doesn't work in the UI system... So, let's create one that does...
[_Game Dev Guide_](https://www.youtube.com/watch?v=--LB7URk60A)
[**Physics and Slow Motion in Unity | Beginner Prototype Series**](https://www.youtube.com/watch?v=F0kezWUqytM) - Physics is fun to play with in Unity, but what about Physics AND Slow Motion?! Having the power to slow down time in a sandbox game is magnificent. In this particular video, we showcase how we can manipulate time in Unity using timeScale and how to modify it via code!
[_Unity_](https://www.youtube.com/watch?v=F0kezWUqytM)
[**More Holograms in Unity Shader Graph and URP**](https://www.youtube.com/watch?v=wVmhqzzkFYE&feature=emb_title) - In the last video, we created holograms in Shader Graph. This time, we're adding distortion and noise effects to add a bit of imperfection - it's like making the effect look worse, in a good way!
[_Daniel Ilett_](https://www.youtube.com/watch?v=wVmhqzzkFYE&feature=emb_title)
[**Creating Customizations with Shader Graph in Unity! (Tutorial)**](https://www.youtube.com/watch?v=zlg3lP7F9Rg) - In this video, we're going to take a look at how we can use Shader Graph with the Universal Render Pipeline, URP for short, to create customizations, custom liveries and skins for our vehicles!
[_Unity_](https://www.youtube.com/watch?v=zlg3lP7F9Rg)
[**Unity animated character controller with root motion**](https://www.youtube.com/watch?v=4y4QXEPnkgY) - This video demonstrates how to convert from a rigid body to a character controller to be able to walk up and down stairs and slopes. A character controller is always very specific to the game you're making, I've had to make some tweaks for it to play nice with animation rigging. I hope this gives you inspiration to customise it further for your needs.
[_TheKiwiCoder_](https://www.youtube.com/watch?v=4y4QXEPnkgY)
[**Mobile Joystick with NEW Input System and Cinemachine - Unity 2020 Tutorial**](https://www.youtube.com/watch?v=YV5KOZHsIz4&feature=emb_title) - Learn how to make a third person controller for mobile using the new input system and cinemachine. Works for Unity 2019.3 and up and am currently using version 2020.1.
[_samyam_](https://www.youtube.com/watch?v=YV5KOZHsIz4&feature=emb_title)
[**Simulate your Game with Device Simulator in Unity! (Tutorial)**](https://www.youtube.com/watch?v=uokF9CmUs9c) - Using the Device Simulator in Unity, you can now view, simulate and change the behavior of your game in various mobile devices! Device Simulator aims to give an accurate image of how an app will look on a device.
[_Unity_](https://www.youtube.com/watch?v=uokF9CmUs9c)
[**Unity + Amazon GameLift Series**](https://www.youtube.com/playlist?list=PLOtt3_R1rR9VMkqZvMF-39TeKrbpKZocW) - Unity + Amazon GameLift series which covers how to integrate GameLift SDKs into your Unity project and how to communicate between GameLift servers and the client game sessions.
[_Battery Acid_](https://www.youtube.com/playlist?list=PLOtt3_R1rR9VMkqZvMF-39TeKrbpKZocW)
[**Easy Trajectory Line in Unity 2D**](https://www.youtube.com/watch?v=igeHa5y8eio) - Learn how to create an easy 2D Trajectory line in the unity engine. We use physics including, gravity and drag to create an accurate 2D Trajectory Prediction line in Unity. A Beginner Friendly 2D Game Development Tutorial.
[_Tyler Potts_](https://www.youtube.com/watch?v=igeHa5y8eio)
[**Super Units! Visual Scripting in Unity! (Bolt)**](https://www.youtube.com/watch?v=o3GTDHBbUuQ) - Let's build some Super Units with Bolt Visual Scripting in Unity!
[_Code Monkey_](https://www.youtube.com/watch?v=o3GTDHBbUuQ)
[**Unity 2020.1 Released | Visual Scripting, Graphics, 2D & MORE!**](https://www.youtube.com/watch?v=WNRQayqiFNs) - Unity 2020.1 is now available and it comes with updates, new features, and a whole lot more to offer in Graphics, 2D, Visual Scripting, AR and VR, and more!
[_Sykoo_](https://www.youtube.com/watch?v=WNRQayqiFNs)
[**Introducing the Terrain Editor | Unite Now 2020**](https://www.youtube.com/watch?v=PDKZXjyhwh0) - Learn the basics of Unity’s features for terrain. We show you how to set up the Terrain Tool, build a custom terrain, adjust topography, paint textures, add foliage, and more.
[_Unity_](https://www.youtube.com/watch?v=PDKZXjyhwh0)
## Assets
[](https://www.humblebundle.com/books/game-design-animation-packt-books?partner=unity3dreport)
[**HUMBLE BOOK BUNDLE: GAME DESIGN & ANIMATION BY PACKT**](https://www.humblebundle.com/books/game-design-animation-packt-books?partner=unity3dreport) - We've teamed up with Packt for our newest bundle! Get ebooks like Unreal Engine 4 Virtual Reality Projects, Learn Clip Studio Paint, Create a Game Character: Blender, Substance Painter, and Unity, Game Design with Unity 2019, Learn the Foundations of Blender, and Practical Game Design. Plus, your purchase will support the Arthritis Foundation!
$1,190 WORTH OF AWESOME STUFF
PAY $1 OR MORE
DRM-FREE
[_Humble Bundle_](https://www.humblebundle.com/books/game-design-animation-packt-books?partner=unity3dreport) **Affiliate**
[**Advanced Character Movement 2D**](https://assetstore.unity.com/packages/tools/physics/advanced-character-movement-2d-147191?aid=1011l8NVc) - The Advanced Character Controller 2D (ACC2D) package will give you advanced control of movement of a 2D character. It was developed to work in a 2d platform game in Unity. Main features:
- Easy to use without coding via the Unity editor
- Horizontal movement, adjustable speed and friction
- Jump, long jump, double jump, wall jump
- Configurable controls
- Crouch, run, walk, wall surfing
- Just in time jump to allow to jump à short time after falling à ledge
- Different dust effects for jump, double jump, walk, land …
- Gizmos shows the ground detection position and trigger
- Character state parameters can be sent to multiple animators
- Demo samples and à tutorial on how to install and use in this document
[_Pixel Crown_](https://assetstore.unity.com/packages/tools/physics/advanced-character-movement-2d-147191?aid=1011l8NVc) **Affiliate**
[**Localization**](https://github.com/antonsem/Localization) - A simple way to translate strings in a project A more detailed description can be found on [my blog](https://www.anton.website/a-simple-localization-system/). I have updated my localization system. Now it is more scalable!
[_Anton Semchenko_](https://twitter.com/TheAntonSem/status/1290633585662230528) *Open Source*
[**generate-upm-changelog**](https://github.com/neogeek/generate-upm-changelog) - Generate a CHANGELOG for Unity Package Manager repositories that use the UPM branch.
[_Scott Doxey_](https://github.com/neogeek/generate-upm-changelog) *Open Source*
[**MultiScreenshotCapture.cs**](https://gist.github.com/yasirkula/fba5c7b5280aa90cdb66a68c4005b52d) - Capture multiple screenshots with different resolutions simultaneously in Unity 3D
[_Süleyman Yasir KULA_](https://gist.github.com/yasirkula/fba5c7b5280aa90cdb66a68c4005b52d) *Open Source*
[**UnityLighsaber**](https://github.com/Tvtig/UnityLightsaber) - A Lighsaber brought to life in unity. I decided to learn how to slice meshes in unity. Going through Unity's documentation I learnt that you can cut meshes by iterating the triangles in the mesh object and create new ones based on the intersections of a plane.
_[watch the [video](https://www.youtube.com/watch?v=BVCNDUcnE1o&feature=youtu.be)]_
[_Tvtig_](https://github.com/Tvtig/UnityLightsaber) *Open Source*
[**Cool Visual Effects - Part 1**](https://thedevelopers.tech/cool_visual_effects.html) - Cool Visual Effects Part 1 is a FREE Unity Asset. It contains 10 unique & cool effects made with VFX Graph.
[_The Developer_](https://twitter.com/the_developer10/status/1290311505209171971)
## Spotlight
[](https://www.youtube.com/watch?v=WbDI2K0H920)
[**RPG Devlog part 6 - DESTRUCTION - Explode Barrels & More - Will Unity break? | Make a RPG in Unity |**](https://www.youtube.com/watch?v=WbDI2K0H920) - My name is Leon and I'm a german indie gamedev working on a RPG.
Something about my game: The RPG is based on the book I'm writing and will lead you through the story in a different way the book does but not only because of the general differences between games and books. In the game you'll have the opportunity to make decisions, which can not only cause little, but also dramatically changes in the story, while the story of the book is already written. For more informations about the game mechanics, features and stuff like this watch the upcoming devlogs. So stay tuned and maybe if you like what I'm creating you'll write your own story when i published the game.
[_LFStudio_](https://www.youtube.com/watch?v=WbDI2K0H920)
---
You can subscribe to the free weekly newsletter on [GameDevDigest.com](https://gamedevdigest.com)
This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article. | gamedevdigest |
421,375 | Creating a web server using Express | "Express is a minimal and flexible Node.js web application framework that provides a robust set of... | 0 | 2020-08-07T13:07:25 | https://www.90-10.dev/js-express-web-server/ | javascript, tutorial | ---
title: Creating a web server using Express
published: true
date: 2022-12-08 09:29:23 UTC
tags: JavaScript, tutorial
canonical_url: https://www.90-10.dev/js-express-web-server/
---
"Express is a minimal and flexible Node.js web application framework that provides a robust set of features for web and mobile applications."
# Installation
In the terminal, we'll create and navigate to a folder that will host our server - we're using a folder named `my_server` located in the home directory:
```shell
mkdir ~/my_server
cd ~/my_server
```
Next step is to initialise your application:
```shell
npm init -y
```
We'll also create the file that will act as the entry point:
```shell
touch index.js
```
To add `Express` to our app, we'll run the following in the terminal:
```shell
npm install express --save
```
# A Simple Server
We'll add a single endpoint that will display a simple "90-10.dev" message. Update `index.js` as follows:
```javascript
const express = require('express');
const app = express();
const port = 9010;
app.get('/', (req, res) => {
res.send('Welcome to 90-10.dev');
});
app.listen(port, () => {
console.log(`Server started at http://localhost:${port}`);
});
```
# Run
Assuming an `index.js` file in your current path:
```shell
node index.js
```
Now, if you point our browsers to http://localhost:9010, we'll see a webpage containing the 'Welcome to 90-10.dev' message.
## Avoid relaunch
One of the limitations we're going to encounter, is the need to relauch it if changes are afflicted to the source file.
A great utility to overcome this limitation is `nodemon`. To install it please run the following:
```shell
npm install -g nodemon
```
Launching the server will now be done by replacing `node` with `nodemon`:
```shell
nodemon index.js
```
# Templating engines
Express supports a lot of templating engines - we're going to use one called `pug`. To add it to our app:
```shell
npm install pug --save
```
## Integrate
Next, we'll integrate it into our app inside `index.js` - here is the top of it:
```javascript
const express = require('express');
const app = express();
const port = 9010;
app.set('view engine', 'pug');
app.set('views','./views');
...
```
## Views
You'll notice above that we're going to use a folder named `views` to store our `pug` templates. Let's create it together with a `index.pug` file inside:
```shell
mkdir views
touch views/index.pug
```
## First template
Let's add our first view - update `views/index.pug`:
```javascript
doctype html
html
head
title = "90-10.dev"
body
p Welcome to 90-10.dev
```
## Using the template
Back in `index.js`, let's make use of the new template - the file is listed in its entirety below:
```javascript
const express = require('express');
const app = express();
const port = 9010;
app.set('view engine', 'pug');
app.set('views','./views');
app.get('/', (req, res) => {
res.render('index');
});
app.listen(port, () => {
console.log(`Server started at http://localhost:${port}`);
});
```
## Relaunch the server
```shell
nodemon index.js
```
The reloaded webpage, http://localhost:9010, will now contain HTML as per the template - the noticeable difference is the browser window title now showing: '90-10.dev'.
# What next?
The Express website has lots of good resources, amonst them the API reference. | 90_10_dev |
421,525 | Answer: Using Power BI Desktop, how can I present Time Duration in a matrix that converts it to decimal? | answer re: Using Power BI Desktop, ho... | 0 | 2020-08-07T16:34:54 | https://dev.to/nilotpalc/answer-using-power-bi-desktop-how-can-i-present-time-duration-in-a-matrix-that-converts-it-to-decimal-il1 | timeduration | {% stackoverflow 61681518 %} | nilotpalc |
421,894 | Row-Echelon Form & Reduced Row-Echelon Form - [Linear Algebra #2] | Some learning points from making the visualization Develop with the principle of Mobile F... | 8,162 | 2020-08-10T11:24:35 | https://dev.to/tlylt/row-echelon-form-reduced-row-echelon-form-linear-algebra-2-1ldh | computerscience, codepen | #### Some learning points from making the visualization
* Develop with the principle of Mobile First, even if it is less intuitive. This will greatly reduce work on responsiveness of the website later on.
* Use setInterval and setTimeout to create simple animation/stop motion effects.
#### A demo of Row-Echelon Form & Reduced Row-Echelon Form
{% codepen https://codepen.io/tlylt/pen/MWyYxEG %} | tlylt |
422,217 | What does community mean to you? | I asked the above question to my local tech community. The following is a curated list of their answe... | 0 | 2020-08-08T17:53:24 | https://dev.to/jcsmileyjr/what-does-community-mean-to-you-4ejm | motivation, developer, community | I asked the above question to my local tech community. The following is a curated list of their answers:
[George Spake](https://www.linkedin.com/in/georgespake/)
Community, for me, has just been about getting to share my journey with a bunch of different people. Everybody's coming from a different place and doing their own thing but we're all moving towards the same kind of goals so it's great to be able to motivate and support and learn from each other along the way.
[Corey McCarty](https://www.linkedin.com/in/coreydmccarty/)
Community means involvement and relationship. In dog/wolf packs each member needs to know it's place in the 'pecking order'. This means that there are special responsibilities and everyone is placed into the hierarchy above some and below others. This means that you have an identity within that community.
[Agrit Tiwari](https://www.linkedin.com/in/agrit-tiwari-69171715b/)
Community means a source of inspiration to me. A group of people that will help you till a point. where I can also help newbie to programming like me. It's a cycle of support and involvement. I feel real free to ask basic questions, Like how do guys manage to keep coming back after an unproductive day?
[Dennis Kennetz](https://www.linkedin.com/in/dennis-kennetz-377448142/)
Community is awesome! The different perspectives and paths that people bring to a conversation really fill me up and ultimately enable to enjoy the world more. Thankful for you guys!
[Dinesh Sharma](https://www.linkedin.com/in/dinesh14sharma/)
Community is being in touch with like minded people and having a group which you can look up to, may be for bouncing ideas, seeking help or just knowing the world better.
[JC Smiley](https://www.linkedin.com/in/jcsmileyjr/)
You can't choose what family you are born in. You normally can't choose what neighborhood you are raise in. But at some point you can choose a community to inspire and help you to do great things. I have seen others make the biggest leaps in their career by being in a community. It is a fact, you are the product of the 5 people you associate with.
Community means being in a relative safe place where everyone wants me to succeed and pushes me safely past my perceived limits.
#Recap
**A good community is about:**
1. identity and belonging somewhere
2. not being alone
3. helping one another,
4. each person has the ability to ask questions
5. moving as a collective toward a goal.
**To be an active member of a good community is to be:**
1. Involved
2. Share your journey with others
3. Having a responsibility.
> A great community is where everyone comes from different places with different perspectives.
[Code Connector](https://codeconnector.io/) is a non-profit that's organized tech meetups to help people start their journey into tech. You can join our daily conversations by clicking this link: [Code Connector slack channel](https://bit.ly/2Ywnzqc).
| jcsmileyjr |
422,336 | MLH Fellowship: Getting in and experience | In early May 2020, halfway through my exchange program and at the peak of the COVID-19 crisis, I didn... | 0 | 2020-08-10T19:12:01 | https://dev.to/gmelodie/mlh-fellowship-getting-in-and-experience-5hdc | mlhgrad, python, go, career | In early May 2020, halfway through my exchange program and at the peak of the COVID-19 crisis, I didn't have any idea what I was going to do next.
One day a friend sent me a link for the MLH Fellowship program. I applied.
## Motivation
I have always been super interested in Open Source development, ever since I got into college and started coding 5 years ago. However, I never really got into it, either because (1) I didn't have enough time, (2) had other priorities or (3) got discouraged by toxic people.
Being paid to do this kind of work, alongside other super impressive students and experienced maintainers and mentors, was definitely a one-in-a-lifetime experience.
If you like software development, enjoy contributing to Open Source or would like to start (even though you don't know much about it yet) [apply](https://fellowship.mlh.io/). Just do it. It takes 10 minutes tops. Do it, I'll wait.
## Application Process
The overall application schedule is:
1. **Online application**: you fill a form and answer questions like "why do you want to be a fellow" and "what are your preferred programming languages".
2. **General interview**: a 10-minute interview where you explain where you come from and what are you interested in.
3. **Technical interview**: you choose a piece of code you wrote and think it's representative of your abilities, and explain it to your interviewer.
### The general interview (1 of 2)
A couple days after I applied I got an email to participate on the first, non-technical, interview. It was super casual and it took at best 10 minutes.
My interviewer had a lot of background noise and his microphone wasn't the best so I had to ask him to repeat a lot of the questions. He even typed some of them on the chat. I was worried that he would think I didn't speak English very well or that I didn't have a good connection (which wasn't the case, but in a 10-minute interview you never know, so it's also a bit of luck).
I was super relieved when I got the news that I had passed to the next phase.
### The technical interview (2 of 2)
Later that day I received an invitation to the technical interview. I scheduled it to about a week after the first one.
Here your task is to share your screen and show your interviewer one piece of code you wrote that you find interesting. I didn't have many amazing side projects, so I chose a queue handling app I was doing for an internship selection process. It wasn't impressive at all.
But then how did I get selected among these other super impressive fellows (some of which had worked as interns at companies like Twitter and Google)? Well, good thing about getting into the program is that you can actually message the person that interviewed you.
**Gabriel:**
> I wanted to know what was your impression of me, what you thought were my strengths and weaknesses, and what made you recommend me for the program at the end of the day
> I don't even know if you are allowed to give me this information, so I do apologize if you are not
**My interviewer:**
> I remember I liked seeing your advanced vim usage (which indicates you taught yourself)
> And that you setup Docker on your project, which is good follow through into a totally separate world of devops
> And you could tell me what a PATH variable is. Most cannot. This was big
So I guess one could say the code you choose doesn't matter. My tips are:
- Are you passionate about code? Yes? Can you prove it? Did you build any projects with that passion?
- Do you like vim? Neat! Can you show me something cool about it?
- Have you been using Linux exclusively for almost 5 years now? That's impressive! What are some hacks you've done with it or learned along the way?
I would've *never* guessed that [Vim](https://www.vim.org/) (I actually use [Neovim](https://neovim.io/)) would get me into a program like this but, when you stop to think about it, it makes sense. I've learned Vim and [touch typing](https://www.typingclub.com/) all by myself and today I'm practically fluent on vim (meaning I can do my day-to-day stuff, not that I'm one of those vim magicians).
**Bottom line**: it's not about how big your project is. It's about how it demonstrates a valuable piece of your personality.
## The Program
### Pods
Your pod is the group of people (~10 fellows + 1 mentor) you'll be spending most of your time with. You work on the same set of projects, pair program, review each others' codes and play games together.
MLH will try to group you with people that are more or less in your timezone, but in my case we were probably the most spread out group of people in the fellowship (from Canada and US all the way to Europe and Africa).
### The Work
You don't necessarily work on one sole project the entire program. In fact, that's very unlikely. My pod had about 10 different Open Source projects: FastAPI, Typer, Howdoi, HTTPie, Beego, and the Pallets projects (such as Flask, Werkzeug and Click).
What's interesting about contributing to Open Source is that you start with [very small contributions](https://github.com/gleitz/howdoi/pull/273) and quickly find yourself doing [much bigger ones](https://github.com/jakubroztocil/httpie/pull/932). After a while you get comfortable with the general workflow and even those who seemed super challenging end up being only a [very small and specific commit](https://github.com/astaxie/beego/pull/4051).
Another great thing about the MLH Fellowship is that you get direct contact with maintainers on the Discord server. They're there! Feel free to message them anytime.
### Talks
MLH knows a lot of people, so you'll get a lot of interesting talks throughout the program from all sorts of different people. Can't attend a talk live? No problems! Most talks are recorded and released on [Youtube](https://www.youtube.com/playlist?list=PLPDgudJ_VDUeBNIwQ9vMzQ3TIANCTIcG1).
### Other Events
Other than the talks and workshops, MLH is really into promoting hackathons, so you bet they have fellowship hackathons as well! There are two hackathons during the fellowship. In the first week of the program there's the kickoff hackathon, where [me and my pod mates did a home task management app](https://devpost.com/software/taskapp-cdbe62). In the in the middle of the program there's the halfway hackathon where me and my team of fellows got first place for Best Showcase / Portfolio Project with the [Fellowship Wrapped app](https://devpost.com/software/fellowbookwrapped).
Also, fellows can organize their own events, and they are strongly encouraged to do so. As I'm into security stuff, [I put together a CTF (Capture The Flag) competition for the fellows](https://fellowship-ctf.tech/). MLH is even giving some prizes for the top teams!
## The stuff people don't say
Getting a fellowship is not easy. I've been into Computer Science for 5 years now, I've applied to hundreds of programs and either got rejected or didn't even get a reply.
If you don't get in, that doesn't mean you're not good enough. It just means that you didn't get in. Nothing more than that.
Go work on what you like to work. Go build the skills you think are important. Go interact with other people.
People hate to say this, but a *big* part of life is luck. If you try more times, you're more likely to land a job or internship. Once you do, it gets easier to land the second one, and so on and so forth.
You just need one "yes". Don't stop trying.
## Special Thanks
I can say from the bottom of my heart that this fellowship was by far the best professional experience I've had, and I am super thankful to all the friends I've made on the way and to all the MLH crew for putting so much effort into it <3
| gmelodie |
422,418 | World of WoqlCraft - Ep.19 making of the Smart Query? | This time we are doing something different, looking at the idea of creating a wrapper of the WOQL.py to create a smooth passing of the Python object to the WOQLQuery. We will also explore the possibility of using a metaclass in Python. | 0 | 2020-08-08T22:57:00 | https://dev.to/terminusdb/world-of-woqlcraft-ep-19-making-of-the-smart-query-4ej | python, database, query, metaclass | ---
title: World of WoqlCraft - Ep.19 making of the Smart Query?
published: true
description: This time we are doing something different, looking at the idea of creating a wrapper of the WOQL.py to create a smooth passing of the Python object to the WOQLQuery. We will also explore the possibility of using a metaclass in Python.
tags: Python, database, query, metaclass
---
This time we are doing something different, looking at the idea of creating a wrapper of the WOQL.py to create a smooth passing of the Python object to the WOQLQuery. We will also explore the possibility of using a metaclass in Python.
Find the source code from our [tutorial repo](https://github.com/terminusdb/terminus-tutorials).
Join the TerminusDB community at [Discord](https://discord.gg/Gvdqw97)
| cheukting_ho |
422,668 | My learning development progress💻💪🤯 | posts about my learning development progress | 0 | 2020-08-09T08:55:26 | https://dev.to/dmitryvdovichencko/my-learning-development-progress-df7 | javascript, postgres, react | ---
title: My learning development progress💻💪🤯
published: true
description: posts about my learning development progress
tags: javascript, postgresql, react
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/ybe3dlomz0it9uv4ayvt.jpg
---
Hi, my name is Dmitry and I'm fullstack NodeJS developer from Russia 🥶.
Here is some posts 👇 about my development learning progress📈.
At the end of the week, I'll write one post 📇 about my progress, and another - about my goals 💪 for next week.
So, this is the first post about my goals for next week.
Also, to each point, I'll attach 📎 some links to learning resources. Some of them written in russian 🇷🇺, because it's my native language.
## Javascript 🤓 🎓
1. Working with theory: This&Objects
[YDKJS: this & Object Prototypes](https://github.com/getify/You-Dont-Know-JS/tree/1st-ed/this%20%26%20object%20prototypes)
[Object basics from learn.javascript.ru](https://learn.javascript.ru/object-basics)
## Postgresql🤯
1. Isolation in Postgresql
[MVCC - isolation from habr](https://habr.com/ru/company/postgrespro/blog/442804/)
## Algorithms🧠
1. Binary search from [Grokking Algorithms](https://www.amazon.com/Grokking-Algorithms-illustrated-programmers-curious/dp/1617292230)
| dmitryvdovichencko |
423,554 | How to Add Bootstrap to your Nodejs Project | This article was originally published here in my blog. If you're building apps with Nodejs and feel... | 0 | 2020-08-10T09:42:34 | https://dev.to/bam92/how-to-add-bootstrap-to-your-nodejs-project-ngc | tutorial, node, bootstrap, codenewbie | *This article was originally published [here](https://www.abelmbula.com/blog/bootstrap-node/) in my blog*.
If you're building apps with Nodejs and feel like you need a tool to help you enhance the UI, this article is for you. It will guide you step by step on how you can add `Bootstrap` to your `Nodejs`.
Let's create a simple app that contains the text `Hello the World` in a Bootstrap `jumbotron`.
## The Initial Project
Create a simple Node project like the one below.
Nothing tricky here. Create a folder for your project and initialize it as Node project, `npm init -y`. Create the server file, `app.js` (`touch app.js`), and other directories (`mkdir views`).
Let's install `express` to configure a lightweight Node server.
`npm i express` or `yarn add express`.
We can now create our basic server.
```js
const express = require("express")
const path = require('path')
const app = express();
app.get("/", (req, res) => {
res.sendFile(path.join(__dirname, 'views/index.html'))
});
app.listen(5000, () => {
console.log('Listening on port ' + 5000);
});
```
We are listening on port `5000` and serving up `index.html` file. Make sure you have it created already and add some `html` contents in it.
Start your server (`node app.js`) and see if everything is OK. If so, let's move to the next session.
## Adding Bootstrap CSS
The first solution I'd suggest here is to use a CDN. Here's how you can do it.
Go [here](https://getbootstrap.com/docs/4.5/getting-started/introduction/#quick-start) to copy Bootstrap CSS and eventually additional JS and paste them in your index file.
### Using a CDN
Now is the time to modify our `index.html` so that we can add Bootstrap CSS.
```html
<!doctype html>
<html lang="en">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous">
<title>Hello, the world!</title>
</head>
<body>
<div class="jumbotron">
<div class="container"><h1>Hello, the world!</h1></div>
</div>
<!-- Optional JavaScript -->
<!-- jQuery first, then Popper.js, then Bootstrap JS -->
<script src="https://code.jquery.com/jquery-3.5.1.slim.min.js" integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script>
<script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/js/bootstrap.min.js" integrity="sha384-OgVRvuATP1z7JjHLkuOU7Xw704+h835Lr+6QL9UvYjZE3Ipu6Tp75j7Bh/kR0JKI" crossorigin="anonymous"></script>
</body>
</html>
```
I added two Bootstrap classes: `container` and `jumbotron`.
Restart your server and go check if `Bootstrap` is on the page (just see if a fluid jumbotron is there).
This solution is good, but when working offline, you'll be limited. That's why I want you to test the next solution.
### Using `npm`
The first thing you have to do here is to install packages, which are `bootstrap` and optionally `jquery`.
`npm i bootstrap jquery --save`
To make use of these files we have to modify our `app.js` so that it will serve them to us.
```js
// app.js
const express = require("express")
const path = require('path')
const app = express();
app.use('/css', express.static(path.join(_dirname, 'node_modules/bootstrap/dist/css')))
app.use('/js', express.static(path.join(_dirname, 'node_modules/bootstrap/dist/js')))
app.use('/js', express.static(path.join(_dirname, 'node_modules/jquery/dist')))
app.get("/", (req, res) => {
res.sendFile(path.join(__dirname, 'views/index.html'))
});
app.listen(5000, () => {
console.log('Listening on port ' + 5000);
});
```
Thanks to `express.static()` we are able to serve up `Bootstrap` without any difficulty.
Now we can make use of `Bootstrap` in our `HTML` pages by just linking to it as `<link rel="stylesheet" href="./css/bootstrap.min.css">`.
## Conclusion
In this article, we learned how to integrate `Bootstrap` in our `Nodejs` project in two different ways. The first way is to use official `CDN` and the last one to use `npm`. This last solution is suitable if you're working locally (and offline).
Do you have another way to work with Bootstrap in a Node project? Share with us!
<hr>
In case you like this post, consider hitting love and unicorn buttons or follow me on [Twitter](https://twitter.com/abelmbula) or read more post on my blog.
| bam92 |
422,937 | pfsense OPT port | I am slowly trying to build up to having a tiny cluster Raspberry Pi 4s at home. I have 2 of them (so... | 0 | 2020-08-09T18:03:09 | https://dev.to/tonetheman/pfsense-opt-port-1f34 | ---
title: pfsense OPT port
published: true
description:
tags:
//cover_image: https://direct_url_to_image.jpg
---
I am slowly trying to build up to having a tiny cluster Raspberry Pi 4s at home. I have 2 of them (so far) connected to a small switch. I needed internet connectivity and I use this little tiny pfsense box at home https://www.netgate.com/solutions/pfsense/sg-1100.html
It is lovely and works wonderfully.
Just due to where everything is located I did not have any open ports physically near where I was at so I wanted to use the OPT port on the Netgear. Almost all things network are somewhat challenging and there are tons of misinformation on how to use the OPT port on the web.
I ended up using this guide.
https://www.cyberciti.biz/faq/how-to-pfsense-configure-network-interface-as-a-bridge-network-switch/
In short, you have to enable the OPT interface and do not assign it an IP.
Then create a bridge between LAN and OPT.
Then finally add a firewall rule on LAN but select the OPT interface. The rule I added there was basically allow everything just to verify things were working.
Once that is done plugin and use ping to verify it works.
One thing to note the IP address you get on the OPT port come from the DHCP so you are not on a separate LAN. In my case that is what I wanted.
| tonetheman | |
423,182 | Spring JPA: Under the covers | Spring Data JPA In the early days, the DAO layer used to consist or still has a lot of b... | 0 | 2020-08-10T03:29:20 | https://dev.to/ashwani1218/spring-jpa-under-the-covers-11hi | java, springboot2, springdatajpa, database | 
#Spring Data JPA
In the early days, the DAO layer used to consist or still has a lot of boilerplate code which makes it cumbersome to implement. Spring Data JPA, part of the spring-data framework, helps to reduce this boilerplate code and makes it easy for a developer to focus on what's really important.
Reduced boilerplate means reduced code and artifacts to define and maintain. Spring JPA takes this to another level wherein you can replace the DAO layer with a configuration in a property file. The level of abstractions JPA provides helps the developer to only have an interface artifact to maintain.
To start working with Spring JPA a DAO interface must extend JPARepository. Just my extending this interface the developer has tons of methods already implemented and ready to use.
```
public interface FooRepository extends JpaRepository<Foo, Long> {
}
```
#### But how does Spring JPA work!
There are many ways you can leverage the power of Spring JPA, We will discuss Query creation here.
#####There are two ways to implement query creation:
1. Automatic Custom Queries
2. Manual Custom Queries
#### 1. Automatic Custom Queries:
When we extend the JPARepository Spring scans every method in the interface and tries to parse it to generate queries. It stripes the prefixes such as **find...By**, **read...By**, **count...By**, **query...By**, **get...By**, from the method, and starts parsing the rest of it.
```
public interface FooRepository extends JpaRepository<Foo, Long> {
public Optional<Foo> findByName(String name);
}
```
The first **'By'** acts as a delimiter to indicate the start of the query. We can add conditions on the entity properties and concatenate them with **'And'** or **'Or'**. we can also add a Distinct clause to set a distinct flag.
```
public interface FooRepository extends JpaRepository<Foo, Long> {
public Optional<Foo> findByFirstnameAndLastname(String firstname, String lastname);
public List<Foo> findByFirstnameOrLastname(String firstname, String lastname);
public List<Foo> findDistinctByLastname(String lastname);
}
```
**_" Expressions are usually property traversal combined with operators that can be concatenated. We can combine properties expression with 'And' and 'Or'. There are other operators such as 'Between', 'LessThan', 'GreaterThan', 'Like' for property expression." :- Spring Docs_**
The above line defines the automatic query creation perfectly.
##### Property Expression
Property expression can only refer to a direct property of the managed entity. At query creation time, you already make sure that the parsed property is a property of managed domain class
#### 2. Manual custom Queries
If we still wish to write some custom query to refine our result and to achieve the desired set of records which cannot be done using the Automatic query creation we are free to write custom JPQL queries.
We can define the custom queries using the **@Query** annotation.
```
public interface FooRepository extends JpaRepository<Foo, Long> {
@Query("SELECT f FROM Foo f WHERE LOWER(f.name) = LOWER(:name)")
Foo retrieveByName(@Param("name") String name);
}
```
Once we use the **@Query** annotation the method name doesn't
matter as the method name won't be parsed.
#### Conclusion
Thanks to the Spring Data JPA team we can implement the DAO layer effortlessly and focus on what matters. This blog is just a gist of what Spring Data JPA has to offer, there is a lot more we can do with the JPA implementation
| ashwani1218 |
423,264 | Moderating Online Events | So you’ve decided to jump into the world of running online tech conferences! It may not be what... | 0 | 2020-10-05T03:31:43 | https://aisha.codes/moderating-online-events/ | ---
title: Moderating Online Events
published: true
date: 2020-06-22 00:00:00 UTC
tags:
canonical_url: https://aisha.codes/moderating-online-events/
---
So you’ve decided to jump into the world of [running online tech conferences](https://dev.to/aishablake/running-online-tech-conferences-1013)! It may not be what you’re used to, but there are tons of resources available to learn from. Most of my participation in online events up to this point has involved training and leading moderation teams, so I’d like to do my part and share what I know.
## Online event safety
The first thing you need to understand is that your community’s safety is as important now as it’s ever been. Just because you’re not meeting in meat space doesn’t mean your attendees are now magically safe from harm. You need to take steps to reduce harm _before_ it happens. That means having a comprehensive, enforceable code of conduct and a well-trained, properly supported moderation team.
### Writing a code of conduct
A code of conduct lays out the expectations for anyone involved in your event, clarifying the kinds of behavior that are or are not acceptable. The more detailed and thoughtful you are in crafting this document, the less confusion your attendees will need to deal with. Everyone who attends your event needs to agree to the code of conduct, which should include clear instructions for reporting violations.
There’s no need to reinvent the wheel. Start with the [Conference Code of Conduct template](https://confcodeofconduct.com/) and build from there. Get as specific as you can. If you have policies you want people to adhere to, spell them out. Now is not the time to rely on vague phrases like “Be kind.” Feel free to check out [Women of React’s code of conduct](https://womenofreact.com/code-of-conduct) for an example in the wild.
In addition to outlining proper _conduct_, a code of conduct should do the following:
- Explain exactly how participants should report violations (including an option to do so anonymously)
- Tell participants how they’ll be able to recognize event team members
- Hold team members to at least the same level of accountability as everyone else
### Choosing your moderators
Your mods are your enforcers. The organizer(s) of an event can’t be everywhere at once. Delegate! Find trustworthy community members willing to pitch in. You may be accustomed to providing tickets and/or hotel rooms in exchange for “volunteer” work at in-person conferences. Especially if you’re making money, consider paying your moderators.
> Want to hire me to train/lead your moderation team? [Reach out via Twitter!](https://twitter.com/AishaBlake)
Reach out to your community for volunteers but try to go beyond your own social circles and recruit a diverse team to minimize bias. You need to be able to trust your moderation team to uphold the safety of your online event. Ask for recommendations from other organizers. If you open an application process, ask for references.
Recruit more mods than you think you need. Especially since this is an online event, some percentage of your volunteers will probably drop out at the last minute. Don’t take it personally if that happens, just prepare for the possibility. The number you actually need depends on the number of people chatting, the number of separate channels you set up, and the amount of time your event will be live.
## Training moderators
I love a good onboarding process! You could have 20 enthusiastic mods ready and rarin’ to go on the day of your online conference but… they won’t be very effective if they don’t know what tools they have available to them or how you’d like them to respond when issues arise.
Prep your moderators and let them ask questions ahead of time. You may find that doing this exposes holes in your carefully laid plans. That’s great! Now you’ve got more time to fill them in.
### Writing a mod manual
Writing a [moderator manual](https://dev.to/aishablake/the-moderator-manual-ijh) for your mod team not only gives _them_ a reliable point of reference but it also forces _you_ to articulate how you want them to take care of your community.
This can be a living document! Just make sure you’re proactive in communicating with your mods as you make changes.
### Live moderator training
Sharing your plans is important but getting the moderators together to talk and ask questions and even to practice exercising their mod powers..? Next level. Hop on a video call and give a brief demo showing how to use the platform. Walk through everything the mods might have to do, let them practice muting, locking down channels, whatever you’ve given them access to.
Walk your mods through a few different scenarios. What should they do if you get a report about someone who’s threatened a community member in the past? What’s the procedure if someone drops the n-word in chat? Figure that stuff out now while everyone is relatively calm.
Provide your mods with some canned replies that they can use if a community member confronts them about an action they’ve taken. (You can also include this in your moderator manual!)
## Selecting a community forum
You’ll need to weigh your own priorities and skills against the various offerings out there. Each has its own set of baked in (and sometimes third-party, supplemental) moderation tools. No matter what you choose, you always have the option of incorporating Discord as a space for rich, ongoing communication while relying on a separate platform for broadcasting.
### Discord
[Women of React](https://womenofreact.com) used YouTube to stream the entire conference. However, the organizers disabled comments in YouTube and focused all the discussion in Discord. Since invitation to the Discord server was restricted, this kept the content widely accessible while increasing attendees’ safety. You can also [stream directly to your Discord server](https://www.youtube.com/watch?v=r26XzJ6fpaI).
See my post on [moderating Discord servers](https://dev.to/aishablake/moderating-discord-servers-1i0f) for a detailed guide on setting your moderators up for success with [Discord](https://discord.com/new) and [Dyno Bot](https://dyno.gg/).
### YouTube
You can also opt to keep both the stream and the conversation in one place using YouTube’s live chat feature, assigning moderators at the channel level. This means that moderators have permission to moderate all of your live streams, not just a particular event, so make sure you remove mod permissions as needed when your event is finished! Moderators can remove comments as well as flag, hide, and mute participants.
For more information, see [Google’s docs on moderating live chat](https://support.google.com/youtube/answer/9826490?hl=en&ref_topic=9257984).
### Twitch
The team behind the [BlackGirlGamers Summit](https://www.twitch.tv/collections/HZM7vo80GBb0NA) relied on Twitch to broadcast the even, which made sense given the organization’s focus on gaming and large existing audience on that platform. Moderators are an essential part of Twitch culture and they have some basic capabilities at their disposal out of the box. (Twitch has more info on [managing roles for your channel](https://help.twitch.tv/s/article/Managing-Roles-for-your-Channel?language=en_US).) By default, your moderator(s) can change the chat mode as well as ban or timeout participants.
That said, regular streamers tends to use bots to augment the basic moderation tools. ([Nightbot](https://nightbot.tv/) is one very popular example.) You can apply more nuanced permissions to different members of your community, set up custom commands, even set messages to post at specific intervals. This kind of setup makes more sense if you’re building a community over time versus planning for a one-time event.
Twitch has a number of [articles on channel moderation](https://help.twitch.tv/s/topic/0TO3a000000Yu88GAC/channel-moderation?language=en_US) to help you consider all your options.
### Vito
Vito is a brand new broadcasting tool developed by the folks behind the ticketing service [Tito](https://ti.to/home). I was first introduced to the platform while leading the moderation team for Kim Crayton’s [Introduction to Being an Antiracist](https://ti.to/kim.crayton.llc/introduction-to-being-an-antiracist/en) workshop. The team has been super responsive to feedback so far, even adding moderation features in the week leading up the event.
### Self-hosted
[JuneteenthConf](https://juneteenthconf.com/) and several other events have hosted their live streams on their own sites. You have complete control in this case. Mix and match whatever tools you’d like. Include a chat option or not. You can [watch the recordings on YouTube](https://www.youtube.com/channel/UCbbgMoZpzSPu6nv1yysylHw/videos).
## Next steps
Check out [Moderating Discord Servers](https://dev.to/aishablake/moderating-discord-servers-1i0f) for a more detailed look at that workflow. You can also [reach out via Twitter](https://twitter.com/AishaBlake) for help training your mod team. | aishablake | |
423,301 | Tank Off | Hi there. Well I'm excited to say I've been the game dev efforts of Martian Games since 2011 and Tank... | 0 | 2020-08-10T06:40:49 | https://dev.to/jenninexus/tank-off-1pib | Hi there. Well I'm excited to say I've been the game dev efforts of Martian Games since 2011 and Tank Off is now Coming Soon on Steam.
https://store.steampowered.com/app/1391380/Tank_Off
I assisted with the site [Tank-Off.com](https://tank-off.com), setting up the Steamworks page, and got to help with the official Tank Off box art on [Giant Bomb](https://www.giantbomb.com/tank-off/3030-79589). Here's a link to the [teaser trailer](https://youtu.be/wAnJiM3_6G0) on YouTube.
Hope you like it! More updates to come. :-)
~ Jenni
[jenninexus.com](https://jenninexus.com) | jenninexus | |
423,331 | Sharing is caring | Quick tip to add awesome sharing to your app | 0 | 2020-08-10T07:06:02 | https://gregbenner.life/sharing-is-caring/ | frontend, webshare, javascript, pwa | ---
title: "Sharing is caring"
published: true
description: "Quick tip to add awesome sharing to your app"
tags: ['frontend', 'webshare', 'javascript', 'pwa']
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/7b6ld2c3bl65co0l6d5t.png
canonical_url: "https://gregbenner.life/sharing-is-caring/"
---
Wouldn't it be grand to click a button and have your mobile's native share dialog come up?
This used to take funky third party js widgets, or registering for all the various site api's individual; I remember it could take a week to get it right with SEO back in the golden days.
Well friends fear no more check out the <a href="https://developer.mozilla.org/en-US/docs/Web/API/Navigator/share">webshare</a> api
Now hypothetically say you have a fullscreened progressive web app, looks slick don't it? The problem though is the missing url bar.
Example:
Here's your solution in the form of a method. One caveat is this must be called on a user action like click.
```js
share() {
if (navigator.share) {
navigator
.share({
title: 'title',
text: 'description',
url: `url`
})
.catch(err => {
console.log(`Couldn't share because of`, err.message);
});
} else {
console.log("web share not supported");
}
}
```
```html
<a class="show-mobile" href="#" @click.prevent="share">🔗 share</a>
```
Oh one more thing, this is only supported on mobile devices. I find this solution better than the user agent sniffing dark arts.
```css
.show-mobile {
display: none;
}
@media (pointer: coarse) {
.show-mobile {
display: inline-block;
}
}
```
Why not fire up your cellular device and give it a try with this article, how meta would that be?
| jswhisperer |
424,189 | tsParticles with customizable and switchable themes | A post by Matteo Bruni | 0 | 2020-08-11T00:21:00 | https://dev.to/tsparticles/tsparticles-with-customizable-and-switchable-themes-1idp | codepen | {% codepen https://codepen.io/matteobruni/pen/rNeOaWP %} | matteobruni |
424,553 | An open-source CI/CD tool flow.ci | About flow.ci flow.ci is a powerful and user-friendly CI/CD tool to level up your DevOps e... | 0 | 2020-08-11T12:44:11 | https://dev.to/gy2006/open-source-ci-cd-tool-flow-ci-5cg9 | devops, github | # About flow.ci
flow.ci is a powerful and user-friendly CI/CD tool to level up your DevOps experience.
> GitHub: https://github.com/flowci
> Website: https://flowci.github.io
# Key Features
- Zero configuration, start the first build within a minute
- Simple YAML configuration and template
- Elastic agents to speed up your build
- Web terminal to debug the job in time
- Flexible plugins
- Scaleable on server-side to improve availability
- Run steps either on any docker images or native os
# Preview


---
for more info please refer to [doc](https://github.com/FlowCI/docs)
Need help? submit issue from [here](https://github.com/flowci/docs/issues)
Happy build :)
| gy2006 |
424,663 | How to Prepare for a Technical Interview | Technical Interview preparation is hard, and that's why sites like AlgoDaily exist. However, it's important to know exactly _how_ to prepare. We're talking about the schedule to set, the cadence, what problems and concepts to focus on, and exactly how to actually study. | 0 | 2020-08-11T13:12:55 | https://algodaily.com/lessons/how-to-prepare-for-a-technical-interview | webdev, career, productivity, beginners | ---
title: How to Prepare for a Technical Interview
published: true
description: Technical Interview preparation is hard, and that's why sites like AlgoDaily exist. However, it's important to know exactly _how_ to prepare. We're talking about the schedule to set, the cadence, what problems and concepts to focus on, and exactly how to actually study.
tags: webdev, career, productivity, beginners
canonical_url: https://algodaily.com/lessons/how-to-prepare-for-a-technical-interview
cover_image: https://images.pexels.com/photos/1569076/pexels-photo-1569076.jpeg
---
## How to Prepare for a Technical Interview
Technical Interview preparation is hard, and that's why [AlgoDaily](https://algodaily.com) exists. However, it's important to know exactly _how_ to prepare. We're talking about the schedule to set, the cadence, what problems and concepts to focus on, and exactly how to actually study.
Most people waste time in their efforts. This tutorial will go through everything you need to read, observe, and do in order to go into your interview with confidence.
This guide also assumes that you've already landed the interview and are preparing for on-sites, though the advice here is definitely applicable for technical phone screens as well.
So first, a word on timing.
<div class="col-lg-6 col-sm-12 m-auto">
<img src="https://storage.googleapis.com/algodailyrandomassets/curriculum/misc/how-to-prepare-for-a-technical-interview.svg" />
</div>
## How Long Do I Need?
If given a choice, I’d obviously advocate long-term technical preparation— the longer the better. As a general recommendation, roughly **2-3 months** to get fully prepared. This lets you get in around **60-120 challenges**, which seems to be the amount you need to do to build the algorithmic intuition.
Obviously this depends on work experience, familiarity with computer science fundamentals, and proximity to interviews themselves.
It may take 3-6 months for a new bootcamp grad with zero exposure to data structures and algorithms to get fully ramped. On the other hand, it could take take **1-2 weeks** for a low-level Senior Systems Engineer.
Could you pass a whiteboard technical interview from absolute scratch with a month’s prep? Depends on you, but it's certainly doable-- just be sure you’re applying the 80/20 principle and hitting the major themes.
If there’s only a month left, the recommendation would be to do 1-2 problems a day _the right way_, and perhaps include some light reading. We'll get to that in how to study individual coding problems.
## Best Materials to Prep
I think it goes without saying that [I'd recommend AlgoDaily](https://algodaily.com), so let's get that out of the way.
Many people swear by our daily newsletter and premium challenges to do well in interviews. I'd recommend trying a problem today and seeing if our walkthroughs, code visualizations, and newsletter are helpful in understanding the more complex algorithms.
For those looking for a little less-hand holding, here's a list of coding interview sites with tons of sample problems:
- https://leetcode.com - You've probably heard of these guys. Tons of questions, community-driven. Decent IDE, well known.
- https://hackerrank.com - More for recruiting purposes nowadays, but same idea.
- https://topcoder.com - Known for competitive programming, but same idea as well.
- https://geeksforgeeks.org - Tons of questions, explanations are hit or miss though.
There's some great Youtube Channels that do a wonderful job of explaining concepts and walking through problems:
- [Tushar Roy's Youtube Channel](https://www.youtube.com/channel/UCZLJf_R2sWyUtXSKiKlyvAw)
- [MyCodeSchool Channel](https://www.youtube.com/user/mycodeschool)
- [The CS Dojo Channel](https://www.youtube.com/channel/UCxX9wt5FWQUAAz4UrysqK9A)
Then there are people who will recommend textbooks. I personally think most people struggle with reading huge, academic algorithms textbooks, but the following method has helped in the past:
0. Set aside a "reading time" every day -- this is important to help make it a habit. Perhaps right before or after work/school.
1. Decide on a cadence. Similar to how AlgoDaily shines with one problem a day, 10-15 pages per day of the textbook is a good goal.
2. Scan the headings and summary first, and then read the chapters. This will allow you to have something to hang your knowledge on.
3. Take light notes in outline form. This could be part of your portfolio or be useful as references for later. More importantly, taking notes encourages active reading.*
With that said, here are some books that have been helpful to myself and others in the past:
- [Cracking the Coding Interview by Gayle Laakmann McDowell](https://www.amazon.com/gp/product/0984782850/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=0984782850&linkId=2b33994731da7a50ddab24d06342a923) - this is the O.G. of technical interview prep books. Extremely comprehensive, highly recommended.
- [Grokking Algorithms](https://www.amazon.com/gp/product/1617292230/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=1617292230&linkId=1c8a77a507eee9070e3a3593c1fd6eba) - good basic primer and introduction. Great graphs.
- [Introduction to Algorithms by Cormen, Leiserson, Rivest, Stein](https://www.amazon.com/gp/product/0262033844/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=0262033844&linkId=4728084ad37c1daa97f94951b5e4c64f) - another classic in academia.
- [Elements of Programming Interviews](https://www.amazon.com/gp/product/1537713949/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=1537713949&linkId=82b0d4d56d0bb6050f3cc1a74885c64d) - harder problems than CTCI.
- [Programming Interviews Exposed: Secrets to Landing Your Next Job](https://www.amazon.com/gp/product/111941847X/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=111941847X&linkId=b33a8eb59c404a346f6f3541fe5de267)
## What Should I Know? Give Me a Checklist!
The biggest challenge with technical interviews is that almost anything under the sun can fall under the term "technical". If we're specifically talking about software engineering jobs, then the scope shrinks considerably, but it's still not that great. Here's _an attempt_ at all the topics to cover for technical interviews. Be sure to go to the previous section for a guide on *how* to study these topics.
<div class="col-lg-6 col-sm-12 m-auto">
<img src="https://images.pexels.com/photos/4316/technology-computer-chips-gigabyte.jpg" class="img-fluid" />
</div>
These lists are prioritized from most important to least important. Ultimately, it's a pretty minor subset of all the algorithms and data structures we know of. The great thing is that this is pretty fixed over time, as the academic underpinnings of Computer Science don't change too much.
**Big O notation**
You _must_ get this part, as it forms the foundation for understanding algorithmic performance and how to choose a data structure.
At least the very least, know the underlying theory and why it's important (hint: scaling, good decision making, trade-offs, etc.). The point here of this is that interviewers want to know you can avoid poor-performing code. Imagine if Facebook took an hour to find your friends, or if Google took a day to display search results.
Refer to [the Big O cheatsheet](http://bigocheatsheet.com/) for more.
**Data structures**
- **Hashtables** - Arguably the single most important `data structure` known to mankind. [Make sure you can implement one from scratch](https://www.algodaily.com/challenges/implement-a-hash-map).
- **Stacks/Queues** are essential, know what FILO and FIFO are.
- **Linked Lists** - Know about singly linked lists, doubly linked lists, circular.
- **Trees** - Get to know basic tree/node construction, traversal and manipulation algorithms. Learn about the subsets-- binary trees, n-ary trees, and trie-trees. Lower-level or senior programmers should know about balanced binary trees and their implementation.
- **Graphs** - Get to know all implementations (objects and pointers, matrix, and adjacency list) and their pros and cons.
**Algorithms**
- **Sorting** - get to know the details of at least two n*log(n) sorting algorithm, I recommend Quicksort and Mergesort.
- **Binary Search**
- **Tree/Graph traversal algorithms**: Breadth-first Search and Depth-first Search are _musts_. Also know inorder, postorder, preorder.
- **Advanced** - for the most part optional, but if you wanted to go beyond the basics, I'd recommend Dijkstra, A*, Traveling Salesman, Knapsack Problem.
**Math (rare)**
- Basic discrete math (logic, set theory, etc.)
- Counting problems
- Probability (permutations vs. combinations)
**Programming Languages**
- Know the ins-and-outs of your language (I'm fond of JS). The language you choose should be one that you have mastered, or know best. The interview is not the time to be figuring out how to write a for-loop or what is truthy.
- Don't worry about choice of language. There is some controversy around this point-- if you're going for a Frontend role, perhaps `Javascript` is a better language than `Python` (and vice-versa for a backend role). But for the most part, the interviewer is conducting the interview because they are looking for your algorithmic reasoning skills and thought process. I've had interviewers not know the ins-and-outs of ES6 JS, and I just kindly explained parts that were unintuitive to them (like why you don't need return statements in certain arrow functions).
- Helps a lot to know one of Python, C++, Java
**OOP Design**
- Polymorphism
- Abstraction
- Encapsulation/Inheritance
**Systems Design**
- Scoping/User Cases/Constraints
- Component Design
- OOP Design
- Database Schema Design
- Vertical Scaling
- Horizontal Scaling
- Caching
- Load Balancing
- Database Replication
- Database Partitioning
- Map-Reduce
- Microservices
- Concurrency
- Networking
- Abstraction
- Estimation
_Note: Systems Design is a huge interview topic in itself._ I highly recommend the [System Design Cheatsheet](https://gist.github.com/vasanthk/485d1c25737e8e72759f) and reading [Designing Data-Intensive Applications](https://www.amazon.com/gp/product/1449373321/ref=as_li_qf_asin_il_tl?ie=UTF8&tag=algodaily03-20&creative=9325&linkCode=as2&creativeASIN=1449373321&linkId=a3df75216423bba9fccb08b81ccf5e2d). You may [also enjoy this guide](https://algodaily.com/lessons/a-systems-design-primer-for-new-engineers?view=article).
## How to Use Sample Coding Problems
The way most people study/prepare with coding problems isn't conducive. The average person will go on a site like AlgoDaily or Leetcode, and will look at a problem for 30 seconds to a few minutes.
Often they'll then jump to the solution after getting stuck, read the solution, and call it a day. If this sounds familiar, don't sweat it.
Trying to memorize the solution doesn't really work. Here's a more effective way, and it's why AlgoDaily was designed the way it was:
<strong>0. First, choose a cadence. One interview challenge a day seems to be the ideal amount. If you do `2` or `3` a day in the manner described, you'll be spending 3-4 hours doing it, which is quite ambitious unless you have all day to spend.
It's also mentally tiring, and you likely won't derive a whole lot of marginal benefits from the 3rd or 4th problem. At a certain point, you'll probably begin to eagerly jump towards obvious solutions, which causes you not to understand where your strengths and weaknesses are. The below process nudges your thought process towards retaining the patterns, and eventually will help you solve problems you've never seen prior.</strong>
1. Commit to about 20-30 minutes of trying to solve it by yourself before going to the solution. Really try to get some semblance of a correct output. Brute force it if you have to - just try to reason about any kind of working solution, no matter how slow. It will help you understand the necessities to optimize later.
2. If you get stuck, start by look at a hint. Then keep trying to solve it. Repeat until there are no more hints.
3. No hints? Start going through the walkthrough or solution _very slowly_. As soon as you get unstuck, STOP READING.
4. Use the bit of insight to start trying to code again again.
Anytime you get stuck again, repeat step 1. Even though you’ve read a part of the solution, the vast majority of learning comes from the struggle of thinking it through yourself. That is what will help you retain it for next time.
Here's some additional steps that really made the difference in my prep:
5. Write the solution again **in another programming language**. This forces you to think through the abstractions again, and helps with retention.
6. Save the problem, **and revisit in increasingly long spurts**. So you might do it again in 2 days, then revisit in a week, then a month.
Some questions to ask at each step:
- What have I learned thus far? Is there anything I should know for next time?
- What pattern or technique did the solution derive from?
- What hint did I need? How far was I from solving it myself?
- If asked this same question tomorrow, can I readily solve it without any assistance?
<img src="https://images.pexels.com/photos/1569076/pexels-photo-1569076.jpeg" class="img-fluid" />
## More Advanced Prep and Materials
At startups and smaller companies, or for specialized roles or research positions,you may get more specific questions. As an example, for a `Javascript` Engineer role, you may be asked: `What is hoisting in Javascript?`
Questions like that rely heavily on experience, and are often harder to `hack` or learn in a short period of time. For these, `google.com` is key -- it's pretty easy to find a quick and dirty list of `Must Know Data Engineering Interview Questions` and to do a few quick passes.
For these lists of questions, since the answers are pretty short, the best way to study might be flash-card style. There are tons of flash-card applications online. Or you could pull in a friend to conduct a mock interview. Speaking of which:
## Mock Interviews Are Key
You must do some mock interviews before the actual interview. Ideally it would simulate as much of the real interview as possible. If it's a whiteboard interview, grab a whiteboard and a knowledgable friend, and force yourself to answer random algorithm/data structure questions from them.
If you don't have a friend available, [pramp.com](https://pramp.com) is a fantastic resource that I used quite heavily when preparing.
## How Do I Actually Approach the Problem?
You've made it all this way, and are now ready for the interview! Check out [AlgoDaily's guide to approaching the interview problem](https://algodaily.com/lessons/how-to-get-better-at-coding-interviews) for a great next step.
| jacobjzhang |
505,399 | Hacktoberfest 2020 Recap | Hacktoberfest is done and dusted and I wanted to do a quick recap on my experience. Reflecting on... | 0 | 2020-11-03T17:31:33 | https://www.jonathanyeong.com/posts/hacktoberfest-2020-recap/ | hacktoberfest | ---
title: Hacktoberfest 2020 Recap
published: true
date: 2020-11-03 08:00:00 UTC
tags: hacktoberfest
canonical_url: https://www.jonathanyeong.com/posts/hacktoberfest-2020-recap/
---
Hacktoberfest is done and dusted and I wanted to do a quick recap on my experience. Reflecting on this month has helped me appreciate the hard work maintainers put into their projects. I've also found myself surprised by the open source world, and I've learnt a big lesson along the way. In the end, I created five pull requests (PRs) over four projects. Only three of those PRs were counted towards Hacktoberfest. One was pending, and the other occurred during the opt-in transition. While I'm a little sad I didn't complete, I'm mostly happy that I was able to contribute at all. First off, I wanted to share what I appreciated the most when working on my open source contributions.
- **Detailed Contribution guides**. It was helpful knowing what the maintainers were expecting in terms of making a contribution. These guides also helped me understand the process of making PRs which can vary a lot between projects.
- **Getting started guides**. Bouncing around different projects meant that I was doing a lot of setup. Having an up-to-date getting started guide was an absolute lifesaver. When I was looking for projects to contribute to, this guide was definitely something I was looking for.
- **"Good first issue" labels.** These labels were a great way to provide visibility on what issues I could actually help with.
- **Active maintainers.** All of the projects I worked on had an active maintainer presence or a separate community for questions. These maintainers helped unblock me and kept me engaged in the project.
What surprised me most about open source was how much it felt like actual work. When contributing to a project you had to communicate with people, and create meaningful well tested PRs. This is something I do every day at work. Serious props to maintainers. I don't know how they maintain an open source project on top of their full time job. I felt drained after my five PRs. It ended up feeling like a second job. And working on that many projects was not sustainable. Again, I don't know how maintainers do it. Which leads me to my big realization.
**Have empathy for maintainers.** Over this month, I realized how much time and effort maintainers put into open source. I can't imagine what it would be like for them to have to sift through the many (sometimes spammy) PRs from Hacktoberfest. Ultimately, Github added a way for [maintainers to limit interactions](https://twitter.com/github/status/1311772722234560517?s=20). But there's still some serious sustainability issues with open source. For example, some maintainers spend their free time working on a tool for others without getting paid. I'd love to discuss ways to make open source more sustainable. But as a start, lets give maintainers as much empathy and compassion as we can.
Hacktoberfest for me was a jumping off point for contributing to open source. Moving forward I want to sustain these efforts. I'm setting a goal with myself to do 1-2 open source PRs a month. Don't let the end of October mean the end of contributing to open source. It feels damn good getting a PR merged! Especially, when you know it's going to help a project that you're passionate about. I've really enjoyed being a part of the open source world and I hope you have (or will) too!
## Good "new contributor" repositories [#](#good-%22new-contributor%22-repositories)
Here are a few projects which I thought had a great Contributing doc, Getting Started guide, and awesome maintainers. If you're new to contributing to open source I recommend taking a look at them.
- [Exercism/V3](https://github.com/exercism/v3)
- [Papercups-io/Papercups](https://github.com/papercups-io/papercups)
- [Forem/Forem](https://github.com/forem/forem) | jonoyeong |
506,021 | Setting up Virtual Host on Ubuntu 20
| What is Virtual Host: Virtual host is a mechanism to set up multiple hosts in a single sys... | 0 | 2020-11-04T11:45:03 | https://dev.to/shriaas2898/setting-up-virtual-host-on-ubuntu-20-joe | ## What is Virtual Host:
Virtual host is a mechanism to set up multiple hosts in a single system the user feels that they are getting redirected to different locations when in reality their requests are sent to the same IP, just on different directories. Every virtual host is identified by virtualname. Virtual are useful because you can utilize a single IP location and single machine to host multiple websites. Let’s see how we can setup virtual host on our own machine in few simple steps
## Pre-requisites:
In order to setup vhost you need to install and configure **apache 2** on your ubuntu system. You can refer to [this](https://www.linuxbabe.com/ubuntu/install-lamp-stack-ubuntu-20-04-server-desktop) link to setup apache.
### Step 1: Intitalizing and configuring directory
The first step is to create directory which contains the website i.e the document root of your site.
create the folder for your website in `var/www/html`:
```bash
sudo mkdir /var/www/mysite
```
You need to have root priviliges to create a folder in `var/www/html`
Now we need to change the permissions for `mysite` so that it can be accessed without root privilages. We will change the owner to current logged-in user to gain full access of `mysite` folder:
```bash
sudo chown $USER:$USER /var/www/mysite/
```
Where `$USER` contains name of current logged-in user.
Also we can ensure that `mysite` is readable by all the users:
```bash
sudo chmod 755 /var/www/mysite/
```
### Step 2: Creating demo page in `mysite`
Now that we are all done with setting up directory let's add some content to it.
**Note:** You can skip this step if you have website content ready with you.
Create a file in `mysite` using `nano
` or you can use any editor.
```bash
nano /var/www/mysite/index.html
```
Add some content like this:
```html
<html>
<title>My Site</title>
<body>
<h1>Hello and Welcome to My Site<h2>
This is where it all started......
</body>
</html>
```
Press `Ctrl+X` and save the file.
### Step 3: Creating configuration files for virtual host
We are all done with setting up content for our site. Let's move on to setup our virtual host file.
Apache provides a default file for virtual host called `000-default.conf` present in `/etc/apache2/sites-available/` which we can copy and modify a bit for our virtual host.
Let's copy the default file and open it in nano:
```bash
sudo cp /etc/apache2/sites-available/000-default.conf /etc/apache2/sites-available/mysite.local.conf
sudo nano /etc/apache2/sites-available/mysite.local.conf
```
You will see a bunch of parameters in this file. We will modify four of them for basic setup.
`SeverAdmin` -> the email of your website's admin
`Sever Name` -> the address of your website
`Document Root` -> the directory which contains the website.
`Server Alias` -> a sudo or virtual name that should be displayed on search bar while accessing the site.
```bash
<VirtualHost *:80>
ServerName 127.0.0.2
ServerAlias mysite.local
ServerAdmin admin@mysite.com
DocumentRoot /var/www/mysite
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
```
Save the file and exit.
### Step 4: Enabling newly added virtual host
After configuring the virtual host file we have to enable it using `a2ensite` command (which rougly translates to apache2 enable site)
Change the directory and enable the site:
```bash
cd /etc/apache2/sites-available/
sudo a2ensite mysite.com.conf
```
To make the changes restart the apache server
```bash
sudo systemctl restart apache2
```
### Step 5: Configuring hosts file
The last step is to configure `/etc/hosts` file which contains list of IP addresses and names. It acts like a local DNS file.
Let's open the file using `nano`:
```bash
sudo nano /etc/hosts
```
Now add the IP address and name of the site.
**Note:** the name should be same as the name of file for virtual host i.e `mysite.local.conf`
```bash
127.0.0.1 localhost
127.0.0.2 mysite.local
```
And that's it!!
Open browser and type `http://mysite.local` and you can access your site.
Congratulations! you just setup a virtual host.
### References:
https://www.digitalocean.com/community/tutorials/how-to-set-up-apache-virtual-hosts-on-ubuntu-18-04-quickstart
https://linuxhint.com/install_apache_web_server_ubuntu/ | shriaas2898 | |
575,995 | NetSuite Interview Questions | If you're looking for NetSuite Interview Questions for Experienced or Freshers, you are in right plac... | 0 | 2021-01-19T12:33:30 | https://dev.to/jessica40648132/netsuite-interview-questions-1c7k | netsuite, technical, functional | If you're looking for NetSuite Interview Questions for Experienced or Freshers, you are in right place. There are a lot of opportunities from many reputed companies in the world. According to research, NetSuite has a market share of about 8.2%. So, You still have the opportunity to move ahead in your career in NetSuite Development. Mindmajix offers Netsuite Training and Advanced NetSuite Interview Questions 2021 that helps you in cracking your interview & acquire a dream career as NetSuite Developer.
1) Explain what is a Lead and how Leads are captured in Netsuite?
Ans: In accounting terminology, a lead is classified as an individual who is interested in the product or service that is been offered and they are in a state to take a decision to purchase the product or service.
Within Netsuite, the term “Lead” is considered as a standard object where several other informational fields are captured while taking up Lead information.
2) Explain what is the Lead Generation Process?
Ans: The lead generation process actually starts after the fact, i.e. when a product is completely developed or the service is readily available for the consumers. A lead generation process is nothing but a marketing strategy where the products or services are presented to the consumers to try them out and further promote them to sign up for the regular usage of the product or the services that the company is offering.
Most of the time lead generation process is taken up by the sales team of an organization. One has to make sure that they have sound knowledge about the product or the service where they are going to promote.
3) Explain the lead conversion process in Netsuite?
Ans: The lead conversion process in NetSuite can be executed in two different methods:
>> Within the system, for an opportunity, if we have keyed in the estimates, sales transactions then the lead is automatically converted as per the default statues.
>> If you are explicitly using the lead conversion process then you can follow the below process:
1. Click on the convert button on the lead record
>> The above process is commonly used in sales organizations and business to consumer businesses
4) List out the process flow for procuring to pay process in Netsuite and let us know how it works?
Ans: The procure to pay process in Netsuite is as follows:
1. Purchase Order Entry
2. Purchase order Approval
3. Receiving
4. Matching
5. Bill Approval
For More Info Visit <a href="https://mindmajix.com/netsuite-interview-questions">Here</a>
Do You Want to become NetSuite Professional then get trained & Certified at Mindmajixs'<a href="https://mindmajix.com/netsuite-training"> NetSuite Online Certification Training</a> Institute | jessica40648132 |
506,126 | CSS GUIDE: The Art of Naming (Save hrs for debugging) | I have heard lots of developers say they hate CSS. In my experience, this comes as a result of not ta... | 0 | 2020-11-04T13:53:51 | https://dev.to/rahxuls/css-guide-the-art-of-naming-save-hrs-for-debugging-5j3 | css, design, webdev, codenewbie | I have heard lots of developers say they hate CSS. In my experience, this comes as a result of not taking the time to learn CSS. So here is my latest post, I'll tell you about a few naming conventions that will save you a bit of stress and countless hours down the line.
**Why only CSS**
CSS isn’t the prettiest ‘language,’ but it has successfully powered the styling of the web for over 20 years now.
However, as you write more CSS, you quickly see one big downside.
It is darn difficult to maintain CSS.
Poorly written CSS will quickly turn into a nightmare.
# Conventions To Use 👊
### Use hyphen Delimited strings
-> If you write a lot of JavaScript then writing variables in camel case is a common practice.
Eg:-
```Javascript
var blueBox = document.getElementById('......')
```
This is correct, right?
The problem is that this type of naming is **not **well-suited to CSS.
```css
.blueBox {
border: 3px solid blue;
}
/* Wrong way. Don't Do This */
```
```css
.blue-box{
border: 3px solid blue;
}
/* Do This. The correct way*/
```
This is a pretty standard CSS naming convention.
<hr>
Teams have different approaches to writing CSS selectors. Some teams use **hyphen delimiters**, while others prefer to use the more structured naming convention called BEM.
**There are 3 problems that CSS naming conventions try to solve**
- To know what selector does, just by looking at its name
- To have an idea where selector can be used by just looking at it
- To know the relationships between class names, just by looking at them
Have you ever seen class names written like this:
```css
.nav--secondary{
....
}
.nav__header{
....
}
/* This is called BEM naming convention. */
```
### Real life explanation 😅👊
Today is John's first day at work.
He is handed over an HTML code that looks like this.
```html
<div class="siteNavigation">
</div>
```
John realizes this may not be the best way to name things in CSS. So he goes ahead and refractors like the codebase like so.
```html
<div class="site-navigation">
</div>
```
Poor John, he is unknown that he had broken the codebase 😩😩.
Somewhere in JavaScript code, there was a relationship with the previous class name, **siteNavigation**:
```Javascript
const nav = document.querySelector('siteNavigation')
```
So the change in the class name the nav variable became **null**.
So SAD 😩
<hr>
To prevent cases like this Developer has come with some amazing and very different strategies.
## Use js-class names
One way to mitigate such bugs is to use a js-* class name to denote a relationship with the DOM element in question.
for example:-
```html
<div class="site-navigation js-site-navigation">
<div>
```
and in javascript code
```javascript
const nav = document.query.Selector('.js-site-navigation')
```
As a convention, anyone who sees the .js-site-navigation class name would understand that there is relationship with that **DOM** element in the JavaScript code.
Some developer use data attributes as JavaScript hooks. This isn't right.
By definition, data attributes are used to store custom data.
If people use the `rel` attribute, then it's perhaps okay to use data attributes in certain cases. It's your call after all.
<hr>
> This has nothing to do with name convention but will save your time too.
-> You don't need to write a comment to say `color: red;` will give the color as red. <br>
But, if you're using a CSS trick that is less obvious, feel free to write a comment.
<hr>
Don't forget to get [daily.dev](https://api.daily.dev/get?r=rahxuls) extension.
Thanks For Reading. <br>
Hope this article is helpful for you. 😁
| rahxuls |
506,715 | Great thought of life in hindi | Golden words in hindi image read and share with your friends thought of life | 0 | 2020-11-05T05:36:35 | https://dev.to/deepr0325/great-thought-of-life-in-hindi-4aip | greatthought, niceline, motivation, statusline | Golden words in hindi image read and share with your friends
<a href="https://www.motivateboost.com/2020/07/golden-words-in-hindi-with-images.html">thought of life</a> | deepr0325 |
506,829 | Elixir Mix project from scratch | Mix เป็น build tool ของ elixir และ เป็น dependencies manangement tool ด้วย (ถ้าใครใช้ Node.js มาก็คือ... | 0 | 2020-11-05T07:58:26 | https://dev.to/iporsut/elixir-mix-project-from-scratch-52le | elixir | [Mix](https://hexdocs.pm/mix/Mix.html) เป็น build tool ของ elixir และ เป็น dependencies manangement tool ด้วย (ถ้าใครใช้ Node.js มาก็คือเครื่องมือแบบเดียวกันกับ npm หรือ ถ้าใครใช้ Ruby มาก็คือแบบ bundler นั่นเอง)
จริงๆ mix ก็เป็น command line ที่มีคำสั่งย่อยให้เราสร้างโครงของ Elixir Project ได้แหละ แต่บทความนี้เราจะมาดูว่าจริงๆแล้วถ้าเราจะเขียน config file ต่างๆขึ้นมาเองเพื่อให้ mix เริ่มทำงานได้ ต้องทำยังไงบ้าง
## อย่างน้อยที่สุดคือมีไฟล์ mix.exs เพื่อ config Mix.Project
จริงๆแล้ว Mix Project ต้องการแค่ `mix.exs` ไฟล์เดียวนั่นเองซึ่งในนั้นจะต้องเป็น Module ที่ `use Mix.Project` เพื่อที่จะ register ตัวเองให้กับ mix ว่าที่คือ module สำหรับ config project และ ต้องมี function `project/0` เพื่อกำหนด config ของ project ที่ต้องมีอย่างน้อย 2 ค่าคือ `:app` กับ `:version` เช่น
```elixir
defmodule MixFromScratch.MixFile do
use Mix.Project
def project do
[
app: :mix_from_scratch,
version: "0.1.0"
]
end
end
```
ตอนนี้ใน directory ของ project เรามีแค่ไฟล์เดียวแบบนี้
```
mix-from-scratch
└── mix.exs
```
ให้เราสั่ง iex ขึ้นมาโดยโหลด project เราโดยสั่ง `iex -S mix` แล้วลองเช็ค project config ด้วยฟังก์ชัน `Mix.Project.config/0`
```
iex(1)> Mix.Project.config
[
aliases: [],
build_embedded: false,
build_per_environment: true,
build_scm: Mix.SCM.Path,
config_path: "config/config.exs",
consolidate_protocols: true,
default_task: "run",
deps: [],
deps_path: "deps",
elixirc_paths: ["lib"],
erlc_paths: ["src"],
erlc_include_path: "include",
erlc_options: [],
lockfile: "mix.lock",
preferred_cli_env: [],
start_permanent: false,
app: :mix_from_scratch,
version: "0.1.0"
]
```
เราจะเห็นค่า default config อื่นๆ ที่สำคัญคือ `elixirc_paths: ["lib"]` นั่นคือเราสามารถสร้าง lib directory แล้วเขียนโค้ด Elixir ในนี้เพื่อให้ mix คอมไพล์และโหลด module ของเราได้ เช่น ถ้าเรามีไฟล์ `lib/message.ex` แบบนี้
```
mix-from-scratch
├── lib
│ └── message.ex
└── mix.exs
```
```elixir
defmodule Message do
def hello do
IO.puts "Hello"
end
end
```
เมื่อเราสั่ง `iex -S mix` อีกรอบ mix จะ compile และ load module ให้เราแล้ว เราสามารถสั่งรัน `Message.hello/0` ได้เช่น
```
iex(1)> Message.hello
Hello
:ok
iex(2)
```
ถ้าเราอย่างเพิ่ม external dependencies ก็ให้แก้ config ที่ mix.exs เช่นจะเพิ่ม package `jason` มาใช้งานก็เพิ่มได้แบบนี้
```elixir
defmodule MixFromScratch.MixFile do
use Mix.Project
def project do
[
app: :mix_from_scratch,
version: "0.1.0",
deps: [
{:jason, "~> 1.2"}
]
]
end
end
```
แต่ตาม convention ที่เราได้เห็นจากเวลา mix generate ให้ มักจะ extract ส่วนของ deps ออกเป็นอีกฟังก์ชัน แบบนี้
```elixir
defmodule MixFromScratch.MixFile do
use Mix.Project
def project do
[
app: :mix_from_scratch,
version: "0.1.0",
deps: deps()
]
end
defp deps do
[
{:jason, "~> 1.2"}
]
end
end
```
แล้วสั่ง `mix deps.get` เพื่อให้โหลด dependencies ตามที่เรา config
จากนั้นลองสั่ง `iex -S mix` ซึ่งก็จะทำการ compile และ load dependencies module ให้เราแล้ว สามารถลองเล่น Jason ได้แบบนี้
```
iex(1)> Jason.encode(%{message: "Hello"})
{:ok, "{\"message\":\"Hello\"}"}
```
จากที่ลองเล่นก็ทำให้เราใจการทำงานของ Mix และเข้าใจ config ของ Mix.Project มากขึ้น ถ้าอยากรู้ config อื่นๆเอาไว้ทำอะไรบ้างดูต่อได้ที่ document ที่นี่ได้เลย https://hexdocs.pm/mix/Mix.Project.html
| iporsut |
506,875 | The Art of War - How to Beat the Bugs, Faster and Harder | Imagine how much time developers from all over the world spend on dealing with bugs and issues that a... | 0 | 2020-11-05T09:31:23 | https://dev.to/lxkuz/the-art-of-war-how-to-beat-the-bugs-faster-and-harder-2e4g | beginners, webdev, productivity, codenewbie | Imagine how much time developers from all over the world spend on dealing with bugs and issues that arise in code. In fact, it might feel like your abilities in this area can define how valuable you are as a professional developer.
Experienced developers usually end up helping juniors out in difficult code fixes. So, if you’re a junior developer and you feel like you’re always getting stuck and begging your seniors for help, you might be wondering - just how on earth do they do it?
### What’s The Answer?
The answer here isn’t totally straightforward. You might think that the reason your senior colleagues can help with all your queries is that they have more experience or better debugging skills. But I would say that’s only half the story. The other 50% is all about psychological advantage, for the following reasons:
You asked ‘em! You’ve shown that you believe in their professional abilities and this positive reinforcement is powerful. This can actually make a person smarter - that vote of confidence gives them a real life intelligence boost.
It’s not their problem, so they don’t have any fear of failure. Without this anxiety, it’s much easier to focus 100% of their brain capacity on finding the actual solution to the problem.
Even though they have nothing to lose, your colleague knows that if they solve the problem, it will give them an added psychological bonus, as you will be in awe of their superiority and high levels of professional skill.
You see, there’s no stick for them, just a big bunch of carrots.
Let’s think about some ways that you can grow your own skill set. I’ve tried to pull together here some useful thoughts and ideas that work for me. I believe that reading this list and applying the advice will push your skills forward, until you’re a fine match for those gurus who you usually turn to for help.
### Do Not Call for Help
This is an incredibly important point that will really help your development. You should ask for help only after you’ve methodically worked through all of the points explained below and you’re still well and truly stuck - and I mean banging your head against the wall kind of stuck. Some of the best growth I’ve ever experienced is when I’ve been in situations where nobody could really help me with my problem. I had no choice but to figure it out by myself.
### Don’t Give in to Hate
Getting emotional is never going to be helpful in resolving bugs. You shouldn’t have bugs you hate. It only makes them more difficult to solve. Every bug is a great opportunity to hone your skills, so it’s much better to try to learn to love them all.
### Do You Believe in Magic?
I believe that if you’re really stuck on a debugging problem for a long time, this is likely to be at least 50% for psychological reasons, or maybe even more.
A voice in your head says, “It can’t be like this! It must be black magic!” You feel as if the world has gone mad, and it can’t possibly be your fault. You feel like all you can do is run away from the problem.
Don’t listen to this voice! Everything in code always happens for a reason! There’s no black magic breaking your code, and I’m sorry to break it to you, dude, but there’s no magic wand to fix it either! You just need to find the specific line of code that’s working in the wrong way, and fix it. Simple.
### Read the Error
Please don’t just copy and paste the error into Google or Stack Overflow straight away. You should take the opportunity to learn something from every bug and develop your skills - this is particularly important when you’re stuck with a difficult bug to fix.
It’s best to carefully read the error and try to understand the process. Often the reason for the error is right there in front of you - you just need to look at it properly.
### Read the Code
Don’t panic. Usually, the code is already telling you what is wrong. What’s the worst thing that can happen? You waste a bit of time reviewing the code and you don’t find the answer.
But actually, that time won’t be wasted, because you will know more about the project. Until you are 100% familiar with it, there’s always work to be done. Plus, it’s always helpful to practice your code reading skills.
### The Army Rule
This simple rule was told to me by an air defense officer during military training. When you service a complex piece of machinery and something goes wrong, or is not functioning in the same way as it used to, you should focus your attention on the modules that you worked on in the latest fix or check.
This is 100% applicable to programming as well! So you need to look at any piece of code that was updated or fixed recently.
### Achieve Instant Bug Replay
When you realize that the issue is hard and you’re going to need to do a lot of tests, you should pause for a while in order to improve the testing process. In a perfect world, your bugfix checking process would be totally automated.
If you can figure out a way to recreate the error more quickly, then you can test multiple solutions much more efficiently. This will help you to concentrate on the problem and find a rapid fix. You can even temporarily simplify existing code logic to make every test much faster.
### Deductive Reasoning
I found out about this approach from a school physics tournament called SYPT. This method is used in scientific research and can also be used to resolve hard programming issues. So here is the science approach:
1) Inspect the process and observe what is happening.
2) Try to formulate a theoretical explanation for what’s going on. Define all the possible factors that could be causing the problem.
3) Then you should check these theories one by one, starting with the one that seems to be the most plausible. Make sure you are asking the right questions. Every check should encapsulate the essence of the problem. Do not test several theories at once. This will interfere with the full picture and won’t lead you to the right conclusions.
Every reason or theory should be either proved or rejected by the test results. These same principles can be applied to solving complex bug problems.
### Rubber Duck Debugging
This is a famous method, based on the story of a programmer who used to carry a rubber duck around and force himself to explain the coding problem to the duck. This would help him to unlock the problem.
Sometimes I find myself telling somebody about a bug, even though I know that they won’t be able to help me at all! But it’s useful, just the same. Often I discover the right solution while I’m talking. When you’re trying to talk someone through the issue, your mind is organizing it and putting it into the right order to be explained. Sometimes this can be just what you need to unlock the next logical steps that you need to take.
I know that this seems in conflict with the previous advice, Do Not Call for Help, but this is a fallacy. The Rubber Duck method makes you work harder to solve the problem yourself. It’s definitely not a sign of madness here to talk through the problem with people, animals, plants or even inanimate objects like the famous rubber duck.
### Code Bisect
This is the best rule! It works even if you don’t completely understand what is happening in a huge piece of code. I guess you might have got the point from the title already, but let me explain it in more detail anyway. Let's say to start off with that the code is falling, but the reason is unclear.
You can bisect the code by commenting out a section of it, then repeating the check. If the error has disappeared, then you know that it was in the part of the code that you commented out. If not, then you repeat the process with other sections of code.
The problem will be in one exact line, and you need to repeat the test until you isolate the piece of code where the problem is.
Of course, you have to inspect the whole code to fully understand it and make decisions to prevent the error, but it’s much faster if you don’t have to read all of the suspected code when you’re looking for the error itself.
### Error on PROD!
Ok, first thing’s first - don’t panic! Panicking won’t help to resolve the problem quickly. Here’s what you can do instead to handle production errors - ask yourself this question before doing anything else:
Can I reproduce the error on my local?
- YES? All good, let’s debug it and understand the reason for the problem. Fix, deploy, go home, kiss your wife (your own wife, please!)
- NO? You know, people tend to freak out when something is OK locally but fails on production. I would say, let’s try to see both the negatives and the positives in this situation.
This challenge already gives us some clues as to how to find a solution. What is the difference between the local and production environments? Possibly we have a different configuration or different web server settings, or some other issue that could be applicable to the problem. It’s mostly a matter of logic.
### Slow and Steady Wins the Race
Even if you need to fix something ASAP, it does not mean you should test your fix straightaway on production! I can’t tell you how many times I’ve seen double or even triple deployments having to take place, all because of some stupid typo during the hotfixing. Check local tests and try to keep high code quality. One gradual fix with one deploy is better than three hotfixes with three deployments.
### Carry Some Blue Duct Tape!
Imagine that you’re working on a particularly painful bug. The company is losing money right now because of this problem. You’ve discovered the reason for the bug, and realized that the fix would be a huge piece of work and would obviously require extra unit testing and so on. What should we do in situations like these?
Let’s work to provide some possible temporary hotfix. It’s ok if it’s not perfect, but it needs to be fast and to prevent the company from losing more money while you’re working on the definitive solution.
If some new feature that we’re trialling is buggy, we can roll it back first to protect the main process. So we can just apply the stable version of the code while we take our time in figuring out how to fix the bug properly.
### Flaky Tests
Sometimes your CI shows failing tests for no reason, even if they aren’t failing on your local interface. These kinds of test failings are a separate theme for a separate article… or even a book.
The reason for failing is definitely the order in which your tests are running. But even if you know the right order, that’s not necessarily the answer, as you can have thousands of tests running and it’s impossible to even identify which exact test is the reason for the failure.
Some testing tools (such as ruby rspec) have smart bisect functionality that helps to minimize the number of tests involved in the count. However, this can be a really slow process and will not necessarily give a definitive result.
So it’s better to read the issue and recognize what common resources have been touched before the test that has affected it. Then you can predict what tests are the reason for the failure. After that, all you need to do is run target tests in the right order to prove your theory.
Yeah, I know this sounds like a hard process, but the fixing of such tests always leads to an improvement in their structure.
### Bonus: How To Write Code Without Bugs?
I don't want to brag, but these days my code has a lot fewer bugs than it used to have. I learned to be more attentive and compose correct code structures with good architecture that will force bugs to surface. You most likely won’t face so many or such serious bugs if you understand the process at a very high level and in a lot of detail.
Your own brain can function in the same way as your programming code runner. Apart from that, I try to use TDD and end-to-end testing if there is enough time. It’s impossible to avoid 100% of bugs, but you can decrease the number of bugs significantly by working in this way.
### The Final Words
Try to enjoy your bug fixing! Maybe to start with, it feels less satisfying than writing new code, but it has its own advantages.
For instance, some hard bugs will turn you into a true detective and you will really enjoy the thrill of the chase when you’re on the right path.
So, the harder the bug, the more pleasure you will get when you win! Thank you for reading! And good luck beating those bugs!
PS: Big thanks for illustrations to my friends from [Pixel Point](https://pixelpoint.io)
| lxkuz |
507,127 | Daily Developer Jokes - Thursday, Nov 5, 2020 | Check out today's daily developer joke! (a project by Fred Adams at xtrp.io) | 4,070 | 2020-11-05T13:00:24 | https://dev.to/dailydeveloperjokes/daily-developer-jokes-thursday-nov-5-2020-1k98 | jokes, dailydeveloperjokes | ---
title: "Daily Developer Jokes - Thursday, Nov 5, 2020"
description: "Check out today's daily developer joke! (a project by Fred Adams at xtrp.io)"
series: "Daily Developer Jokes"
cover_image: "https://private.xtrp.io/projects/DailyDeveloperJokes/thumbnail_generator/?date=Thursday%2C%20Nov%205%2C%202020"
published: true
tags: #jokes, #dailydeveloperjokes
---
Generated by Daily Developer Jokes, a project by [Fred Adams](https://xtrp.io/) ([@xtrp](https://dev.to/xtrp) on DEV)
___Read about Daily Developer Jokes on [this blog post](https://xtrp.io/blog/2020/01/12/daily-jokes-bot-release/), and check out the [Daily Developer Jokes Website](https://dailydeveloperjokes.github.io/).___
### Today's Joke is...

---
*Have a joke idea for a future post? Email ___[xtrp@xtrp.io](mailto:xtrp@xtrp.io)___ with your suggestions!*
*This joke comes from [Dad-Jokes GitHub Repo by Wes Bos](https://github.com/wesbos/dad-jokes) (thank you!), whose owner has given me permission to use this joke with credit.*
<!--
Joke text:
___Q:___ What did the Class say in court when put on trial?
___A:___ I strongly object!
-->
| dailydeveloperjokes |
507,771 | I completed the Hacktoberfest Challenge! | [Intro Heading] Background Contributions Reflections | 0 | 2020-11-06T04:48:18 | https://dev.to/jameslwong/i-completed-the-hacktoberfest-challenge-m10 | hacktoberfest | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### [Intro Heading]
<!-- If you are new to the DEV community, introduce yourself and share a bit about why you joined DEV and decided to participate in Hacktoberfest this year. -->
### Background
<!-- Are you brand new to open source? What about coding in general? Tell us about how you got here →
### Progress
<!-- Share a bit about where you’re at in your Hacktoberfest journey. What stage are you at? How has the process been? -->
### Contributions
<!-- This is where you can list the contributions you made and explain why you chose the projects you did. Don’t forget to add links! -->
### Reflections
<!-- Overall, how has your Hacktoberfest 2020 experience been? If you’re a first-timer, will you participate again? What have you learned? Have you made any interesting connections? What is your next step in open source? --> | jameslwong |
508,104 | Tự học Dart - 002 | Biến (Variables) Khai báo biến bằng từ khóa var Dart sẽ ngầm hiểu kiểu dữ liệu của nó. Khi... | 0 | 2020-11-17T13:51:36 | https://dev.to/sonempty/dart-c-b-n-002-3g96 | dart, flutter | # Biến (Variables)
Khai báo biến bằng từ khóa `var` Dart sẽ ngầm hiểu kiểu dữ liệu của nó. Khi khai báo trong phạm vi local thì nên dùng `var` thay vì dùng kiểu khai báo tường minh như `String` `double` `int`....
```dart
String title = 'Đây là 1 ví dụ về biến';
main() {
var name = "Son Tran";
String s = "abcxyz";
double d = 1.1;
int num = 2;
print(title);
print("Variables are: $s $d $num $name");
}
```
Khi đã khai báo biến rồi, thì biến đó thuộc kiểu dữ liệu cố định. Nếu gán giá trị kiểu khác sẽ bị lỗi.
```dart
var i = 1;
i = 'somethings';
/*
Sẽ lỗi do biến `i` thuộc kiểu `int` mà giờ lại gán qua kiểu String
*/
```
Nếu muốn gán kiểu khác, hãy dùng `dynamic` hoặc khai báo kiểu `Object`
```dart
main() {
// Dùng dynamic
dynamic s = 1;
s = 'a cat';
/*
Dùng `Object` vì như đã nói mọi kiểu dữ liệu đều là một instance
của class Object trong Dart
*/
Object x = 99;
x = 'a dog';
print("Variables is: $s $x");
}
```
Ngoài ra còn có từ khóa khai báo kiểu hằng số là `const` và `final`. Chúng khác nhau ở chỗ là `const` khai báo hằng số ở complie-time còn `final` là run-time.
Và hằng số thì không thể gán giá trị sau khi khởi tạo.
```dart
main() {
const PI = 3.14;
final TODAY = DateTime.now();
print("Variable is: $PI $TODAY");
PI = 3.1416; //Lỗi
}
```
Ngoài ra với Dart 2.5 còn có thể dùng `is` `as` và Spread Operator (`...`)
```dart
main() {
const Object i = 3;
const list = [i as int]; // Sử dụng typecast.
const map = {if (i is String) i: "String" else "aaa": "Other"};
// Dùng `is` và lệnh `if else`.
const set = {if (list is List<int>) ...list};
// Dùng Spread Operator `...`
print("Variable is: $list $map $set");
}
```
# Kiểu dữ liệu trong Dart
Cơ bản có các kiểu sau:
- Kiểu numbers gồm: `num`, `int` và `double`
- Kiểu string
- Kiểu booleans
- lists (hay array - mãng)
- sets
- maps
- runes (chuỗi Unicode)
- symbols
### Kiểu numbers
Cũng dễ như bình thường thôi :D
```dart
main() {
//`num` có thể là kiểu số nguyên hoặc thập phân
num i = 100;
num d = 7.55;
/*
`int` là kiểu số nguyên, và `double` là kiểu số thập phân.
Hai kiểu này là sub-class của `num`
*/
int n = 999999;
double x = 68.25;
double y = 1; // ngầm hiểu `double y = 1.0`
//Ép kiểu
var one = int.parse('1');
//Một số cách biểu diễn số khác
var hex = 0xFF;
var exp = 1.42e5;
print("Variable is: $i $n $d $x $hex $exp");
}
```
| sonempty |
508,590 | Firebase: Deploying a single page application in React | Firebase is a company founded by James Tamplin and Andrew Lee in 2011 and then acquired by Google in... | 0 | 2020-11-07T04:38:52 | https://dev.to/josesrodriguez610/firebase-deploying-a-single-page-react-application-19lp | Firebase is a company founded by James Tamplin and Andrew Lee in 2011 and then acquired by Google in October 2014.
Firebase platform is used for creating mobile and web applications. Firebase gives developers many tools to develop quality apps. Firebase is a NOSQL database program.
Firebase supports: authentication, realtime database, hosting a Test lab and notifications.
Today I’m going to be focusing on how simple it is to deploy a website with Firebase.
First go to your terminal and create a folder
````javascript
mkdir deploy-test
```
then check that it is there with 'ls' and then access your file and open vs code with code.
Vs code is going to open and now let’s create a React application that we will call deploy. If you press command + J, your terminal will open and there type
````javascript
npx create-react-app deploy
```
This is going to take a second so let's go ahead and visit firebase.
When you get to firebase, there is a button that says get started and when you press it you will have to sign in with a google account.
Now here is where you see all your projects and if you want to add a new project you press on the Add project plus sign
Now you have to enter the name you want to give your project. I’m going to call it test-deploy and press continue
Then you will be asked about Google analytics and just press continue.
Then Configure Google Analytics which I always choose the default and I press Create project
It is going to start creating your project and while we wait for that to finish let’s go to our vs code.
Our react app has been created!
Let’s get into our app with:
````javascript
cd deploy
```
and then let’s run,
````javascript
npm start
```
to see our application

Great! Now we have our application running. Let’s do some clean up so we can create our own application.
Let’s go to our left side and delete a couple of files.
We are going to delete
-App.test.js
-logo.svg
-setupTests.js
Your app is going to freak out because it is looking for the logo so our next step is to go to App.js and clean that file.
````javascript
import logo from './logo.svg';
import './App.css';
function App() {
return (
<div className="App">
<header className="App-header">
<img src={logo} className="App-logo" alt="logo" />
<p>
Edit <code>src/App.js</code> and save to reload.
</p>
<a
className="App-link"
href="https://reactjs.org"
target="_blank"
rel="noopener noreferrer"
>
Learn React
</a>
</header>
</div>
);
}
export default App;
```
Here we are going to delete the import for the logo and we are going to delete in the return everything expect that first div and we are going to write and h1 that says hello world with a rocket.
````javascript
import './App.css';
function App() {
return (
<div className="App">
<h1>Hello World 🚀</h1>
</div>
);
}
export default App;
```
Now we are going to go to App.css
And delete everything. Then we are going to add
````javascript
* {
margin: 0;
}
```
Now let’s go back to firebase and it looks like our project is ready!
Press continue, now let’s click on web:
the next step is to give our app a nickname. I’m going to call it deploy and let’s create it
Then the next page press next and then you will see this right here!
npm install -g firebase-tools
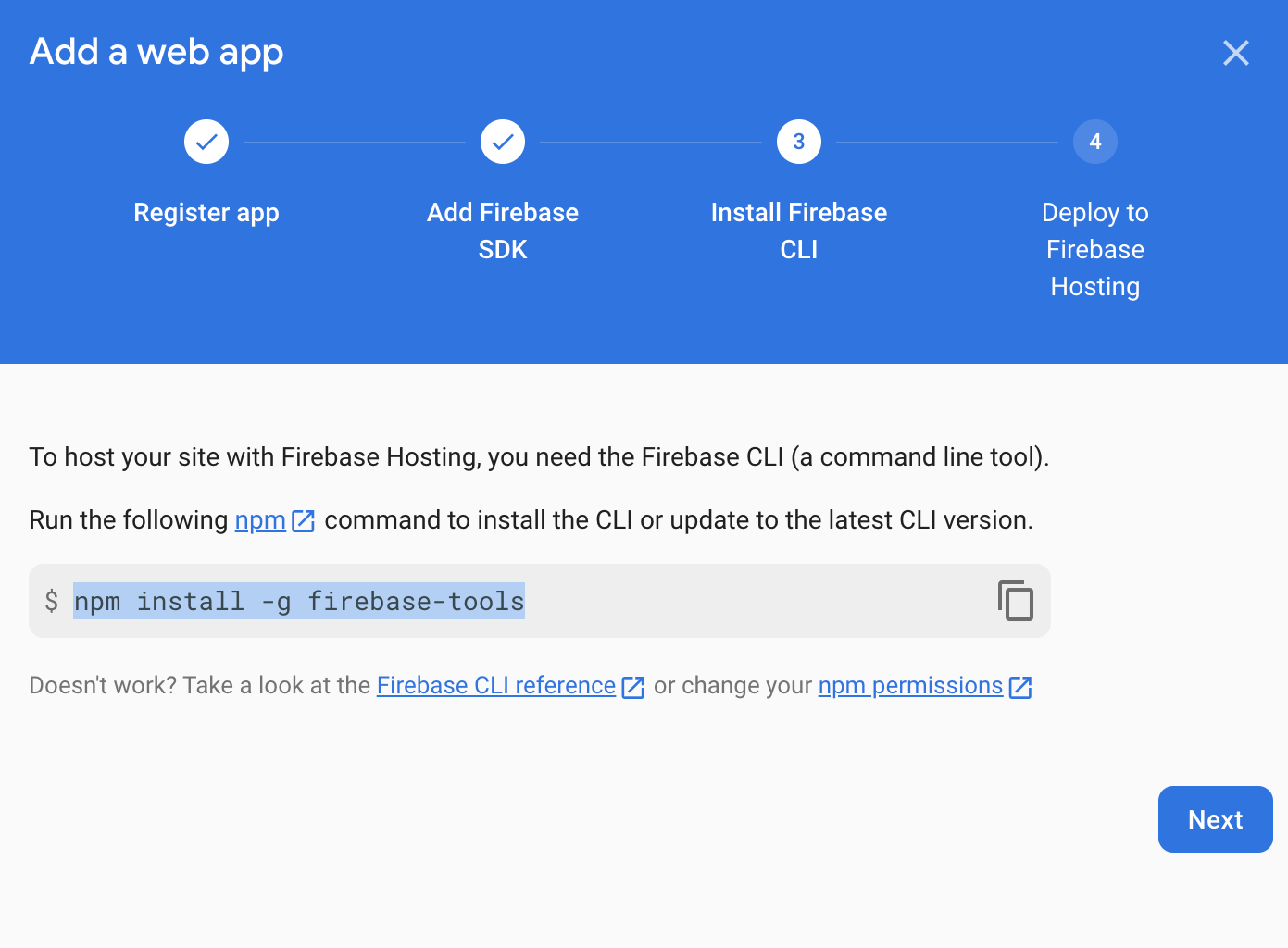
You have to install that in your terminal.
Then the next page is going to tell you how to deploy. First you do firebase login which is your login with google in your terminal then you will do firebase init and then firebase deploy then go to continue to console and let’s go back to our react app.
Now lets open another terminal and lets go into our app with 'cd deploy' and we are going to install:
````javascript
npm install -g firebase-tools
```
After that is installed you are going to sign in with google by putting
````javascript
Firebase login
```
After you put your password go ahead and type the command
````javascript
Firebase init
```
Here there are going to be a couple of options. Go all the way to Hosting and press space and it will get selected
Now you can press enter
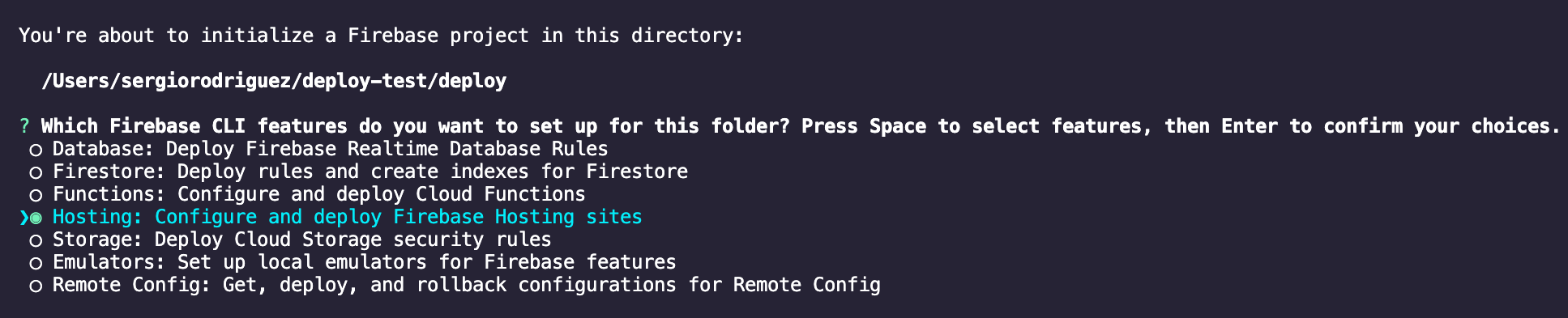
Now you are going to press
Use an existing project

And now you are going to pick your project and press enter
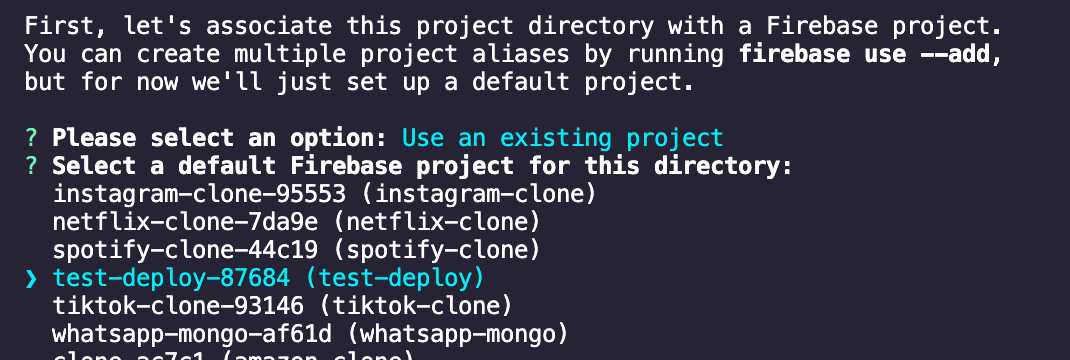
This part is very important. They are going to ask.
What do you want to use as your public directory?
You need to write 'build' and press enter
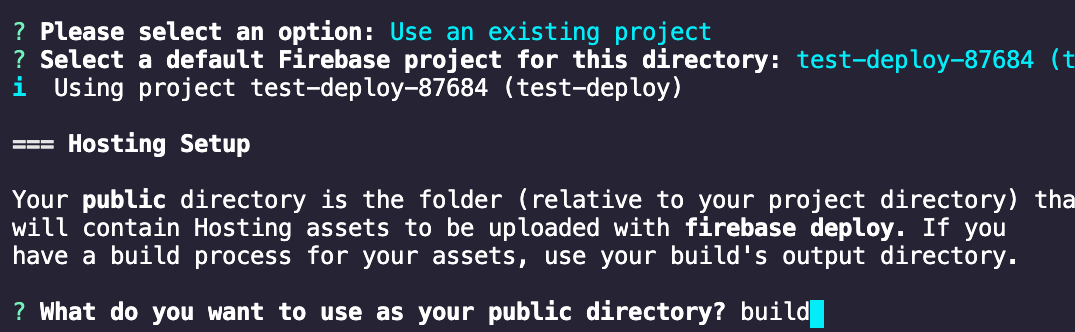
- Now they are going to ask if you want to configure as a single-page app and you put y
- then it will ask if you want to deploy with GitHub, say N
It is going to tell you that firebase initialization is complete.
Now run in your terminal
````javascript
npm run build
```
And now let’s type
````javascript
Firebase deploy
```
And That’s It!
There is going to be a hosting URL and it you click it you will see your application!
**Conclusion:**
Firebase is a powerful tool that lets you create big applications fast and easy.
| josesrodriguez610 | |
508,787 | Intersection Observer using React | Today we are gonna explore how to use the intersection observer API in React and see some useful exam... | 0 | 2021-02-15T07:57:50 | https://dev.to/producthackers/intersection-observer-using-react-49ko | react, webdev, javascript, html | Today we are gonna explore how to use the intersection observer API in React and see some useful examples, you can find the code in the following [repository](https://github.com/zygisS22/intersectionObserverApi), let's begin.
---
[Mozilla web documentation](https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API) describes the intersection observer API as:
> lets code register a callback function that is executed whenever an element they wish to monitor enters or exits another element (or the viewport), or when the amount by which the two intersect changes by a requested amount. This way, sites no longer need to do anything on the main thread to watch for this kind of element intersection, and the browser is free to optimize the management of intersections as it sees fit.
In plain english, it allows us to detect when certain elements are visible in our [viewport](https://developer.mozilla.org/en-US/docs/Web/CSS/Viewport_concepts), this only happens when the element meets your desired intersection ratio.
As you can see, if we scroll down the page the intersection ratio will be going up until it meets the designed threshold and that's when the callback function is executed.
---
## Initialization

The intersection observer object constructor requires two arguments:
1. Callback function
2. Options
Just like that we are ready to see some action but first we need to know what each option means, the options argument is an object with the following values:

- **root**: The element that is used as the viewport for checking visibility of the target. Must be the ancestor of the target. Defaults to the browser viewport if not specified or if null.
- **rootMargin**: This set of values serves to grow or shrink each side of the root element's bounding box before computing intersections, the options are similar to those of margin in CSS.
- **threshold**: Either a single number or an array of numbers which indicate at what percentage of the target's visibility the observer's callback should be executed, ranges from 0 to 1.0, where 1.0 means every pixel is visible in the viewport.
---
## Using React.js

Now let's see an implementation of the intersection observer API using react.
1. Start with a reference to the element we want to observe, use the react hook **useRef**.
2. Create a state variable <code>isVisible</code>, we are gonna use it to display a message whenever our box is in the viewport.
2. Declare a **callback** function that receives an array of IntersectionObserverEntries as a parameter, inside this function we take the first and only entry and check if is intersecting with the viewport and if it is then we call <code>setIsVisible</code> with the value of <code>entry.isIntersecting</code> (true/false).
3. Create the options object with the same values as the image.
4. Add the react hook **useEffect** and create an observer contructor using the callback function and the options we just created before, it's **optional** in our case but you can return a cleanup function to unobserve our target when the component **unmounts**.
5. Set the **useRef** variable on the element we want to observe.

6. Let's add a background and some properties to our HTML elements
7. It's done, simple and easy!
remember this is just a basic implementation and there are many different ways of doing it.
---
## Hooking it up

Let's now implement the same code we just did before but separating all the logic into a new hook called <code>useElementOnScreen</code>.
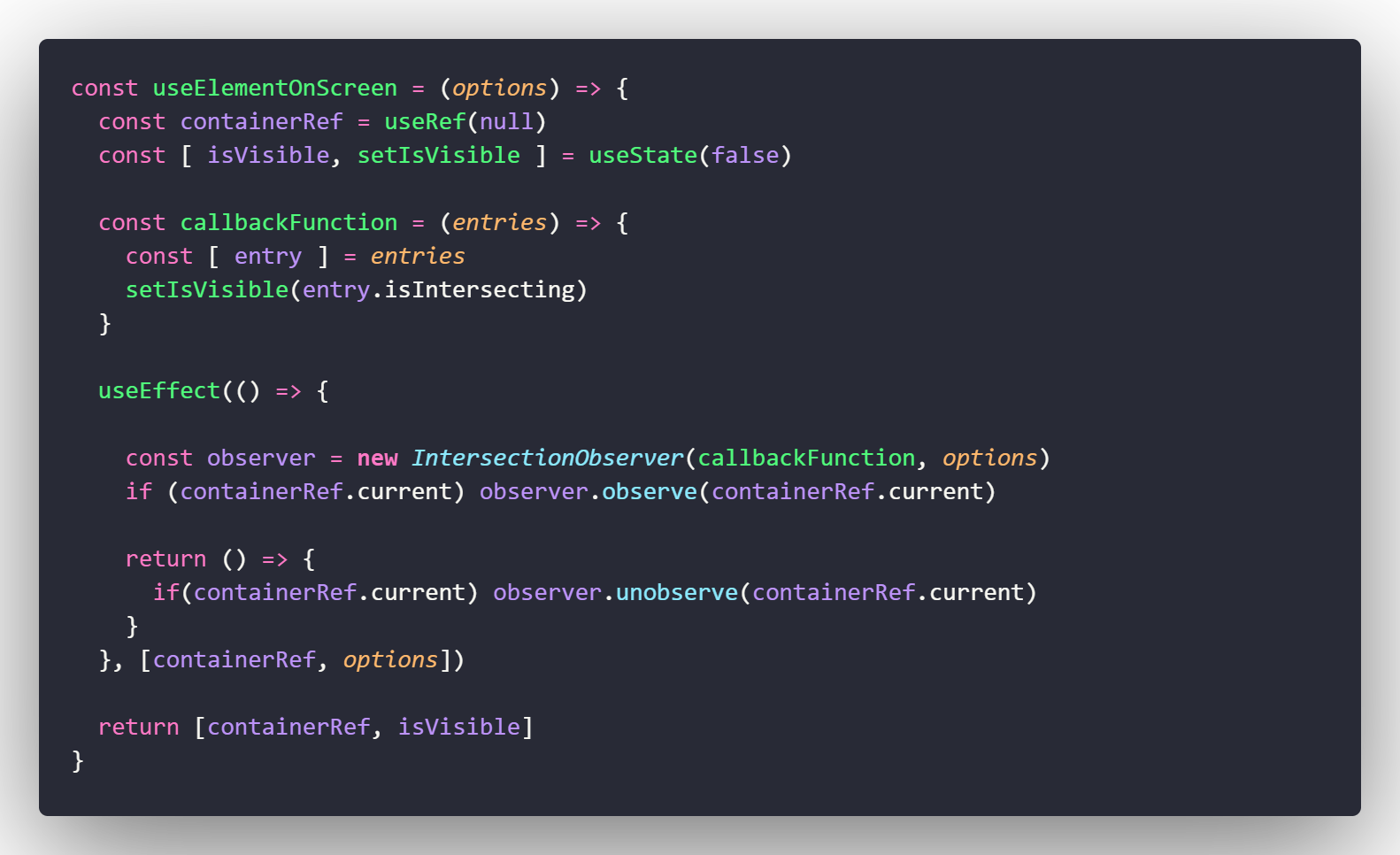
1. Create a new function called <code>useElementOnScreen</code> with the parameter **options**
2. Move **useRef**, **useState** and the entire **useEffect** inside our new shiny hook.
3. Now the only thing missing in our hook is the return statement, we pass <code>isVisible</code> and <code>containerRef</code> as an array.
4. okay, we are almost there, we just need to call it in our component and see if it works!
1. Import the recently created hook file into our component.
2. Initialize it with the options object.
3. Just like that we are done.
Congratulations we have successfully used the intersection observer API and we even made a hook for it!
---
## Final words
Thanks for reading this, Hopefully it helped someone getting started with the IO API using react, stay safe ❤️!

| zygiss22 |
510,455 | My picks for AllDayDevOps | 15 Talks to Tune In To at AlldayDevops 2020 | 0 | 2020-11-09T16:45:55 | https://dev.to/canarian/my-picks-for-alldaydevops-2fj4 | devops, conference | ---
title: My picks for AllDayDevOps
published: true
description: 15 Talks to Tune In To at AlldayDevops 2020
tags: devops, conference
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/udbclfbol2cetra6zwnw.png
---
[AllDayDevOps 2020](https://www.alldaydevops.com/) is happening in 24 hours from now!
It's packed with content and choosing the talks to attend isn't a trivial task.
That's why I decided to compile my own recommendations list.
So here they are - 14 talks to attend at AllDayDevops!
1.
SITE RELIABILITY ENGINEERING
**Managing Systems in an Age of Dynamic Complexity**
Laura Nolan, Slack
--
I like the title of this talk. And I believe folks at Slack know a thing or two about how we work and collaborate.
2.
CULTURAL TRANSFORMATION
**Bullet-Proof Coding : Adaptive Collaboration for Resilience**
Anton Weiss, Otomato Software
--
Regretfully my own talk occupies the same time slot as Laura's presentation. So you have to choose :)
3.SITE RELIABILITY ENGINEERING
**Site Reliability Engineering: Anti-patterns in Everyday Life and What They Teach Us**
Jennifer Petoff, Google
--
It's time we hear from Google about how not to SRE.
4.
MODERN INFRASTRUCTURE
**The Past, Present, and Future of Cloud Native API Gateways**
Daniel Bryant, Ambassador Labs
--
I love Daniel's presentation skills and API gateways/service meshes/smart proxies are all such exciting technologies!
5.
CULTURAL TRANSFORMATION
**Using DevOps Principles to Measure Value Flow**
Helen Beal, DevOps Institute
--
Helen is a great speaker and DevOps without measurements is like a fish without water.
6.
KEYNOTES
**Ask Me Anything Keynote: DevSecOps**
John Willis, Red Hat and Shannon Lietz, Intuit
--
John is one of the godfathers of the DevOps movement and a great speaker. Ask him anything about DevSecOps - do that!
7.
SITE RELIABILITY ENGINEERING
**The Unmonitored Failure Domain: Mental Health**
Jaime Woo, Incident Labs
--
If you don't monitor your team's mental health - little else matters.
8.
KEYNOTES
**Ask Me Anything Keynote: Chaos Engineering**
Casey Rosenthal, Verica / Nora Jones, Jeli
--
Chaos engineering is one of the more compelling topics in modern IT. Nora and Casey are both definitely the right people to ask anything about that.
9.
MODERN INFRASTRUCTURE
**Service Mesh Past, Present, and Future with Envoy Proxy and WebAssembly**
Idit Levine, Solo.io
--
Idit is my super-talented compatriot and the work solo.io have been doing with WebAssmebly and Envoy is pushing the industry forward!
10.
SITE RELIABILITY ENGINEERING
**Fast & Simple: Observing Code & Infra Deployments At Honeycomb**
Liz Fong-Jones, honeycomb.io
--
Honeycomb is one of the more interesting stars on the observability sky.
11.
CULTURAL TRANSFORMATION
**Doing DevOps With Deming**
Ken Muse, Wintellect
--
How does one do DevOps without Deming?!?!
12.
MODERN INFRASTRUCTURE
**Solving the Service Mesh Adopter’s Dilemma**
Lee Calcote, Layer5
--
Lee is a great presenter and knows service meshes like nobody else does. Layer5 ftw!
13.
SITE RELIABILITY ENGINEERING
**0 to SRE: Lessons from a First-Year SRE**
Reginald Davis, Elasticsearch
--
Getting started with SRE is definitely harder than it sounds.
14.
CULTURAL TRANSFORMATION
**Gatekeeping and the DevOps Revolution: We Haven't Always Known Everything**
Kat Cosgrove, JFrog
--
Gatekeepers - do we really need them? Kat is a great speaker and she'll provide the answers.
Those are my picks - and what are yours? | antweiss |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.