
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
613,638 | UI Trends: Center Column Squeezing | We've just opened our desktop browser to full screen and clicked on a link to one of the sites below... | 0 | 2021-02-21T15:05:50 | https://dev.to/jwp/ui-trends-wide-screen-and-high-resolution-monitors-24fm |
> We've just opened our desktop browser to full screen and clicked on a link to one of the sites below. Our browser zoom is 100%.
- Dev.To,
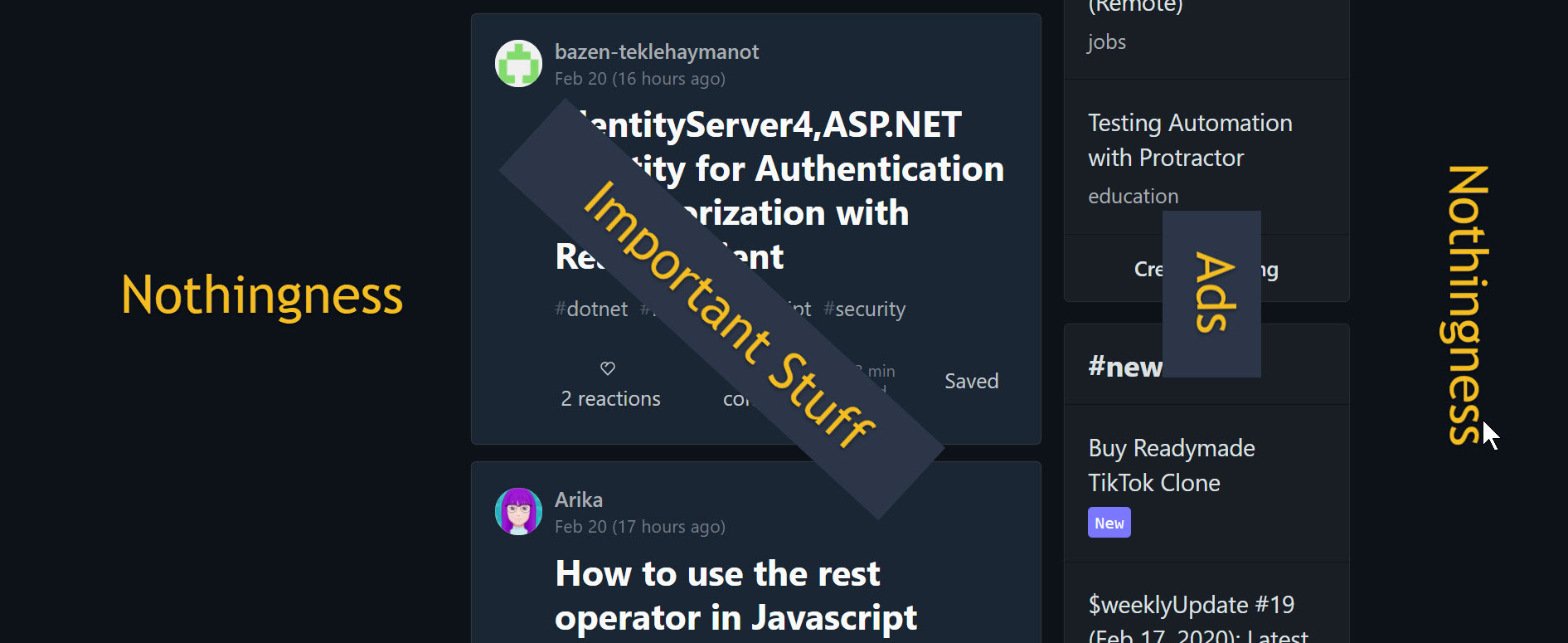
- FaceBook
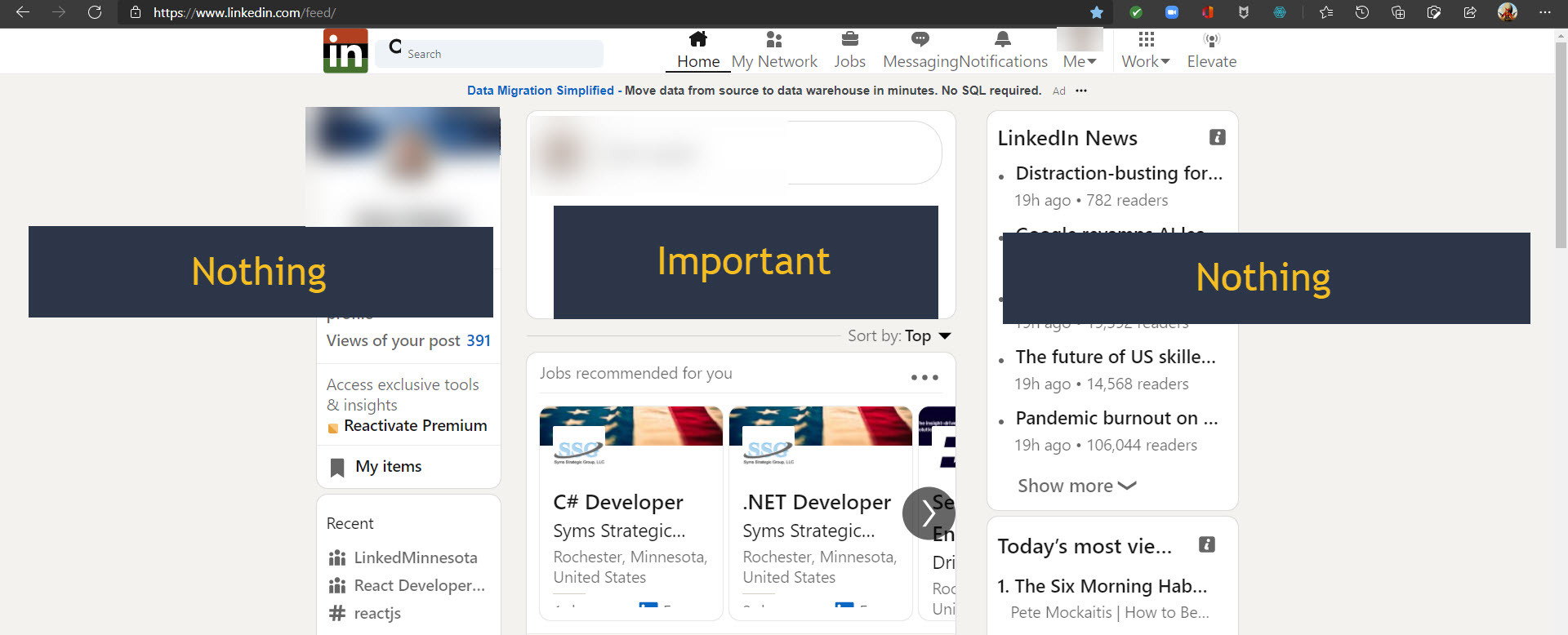
- LinkedIn,
- Git Api Docs
The important column; which is either column (two or three) in a four column layout is squeezed as shown below.
High Resolution and Wide Monitors show this:
Here's a random 'current' API doc on Git. In this one, the left hand menu item is not resizable.
**Facebook**
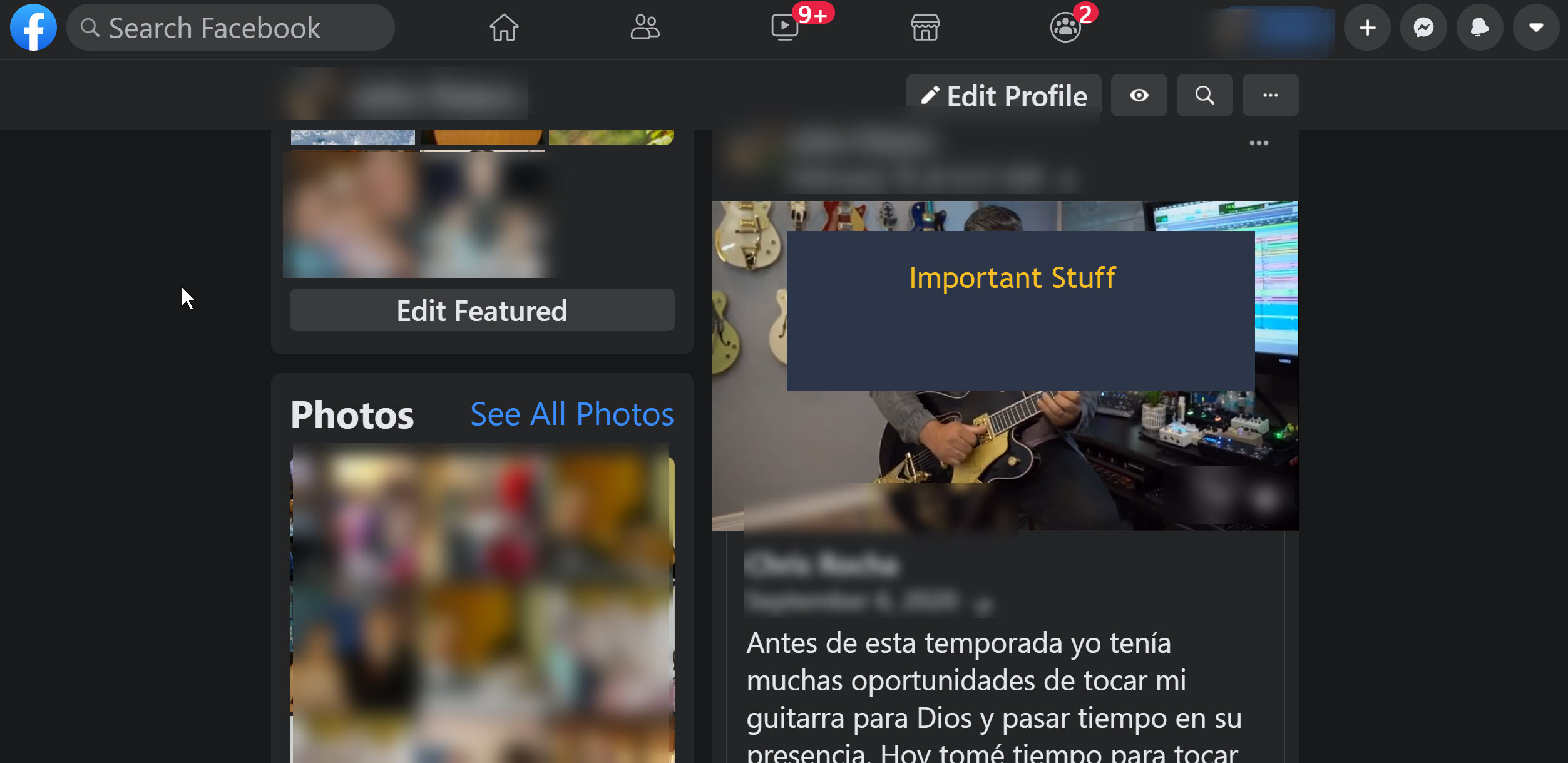
**LinkedIn**
Probably the most wasted space of all.
**Good Examples**
- StackOverFlow
Passable but just barely.
- Google Developer Docs
At first, it looks like too much space, but a browser resize will collapse both asides and just show important stuff, like this. Great example of responsive focusing on 'important stuff'.
- Amazon
At it for over 15 years now.
- Azure
Microsoft wakes up, in their new designs.
- .NET Core
- Gmail
KISS (Keep it stupid simple)
- MDN
KISS
Note: I don't claim to be an expert stylist; however, as a programmer; I read tons of material daily. I am a smart user of programming information. If I have to fuss with it too much to read it better, I'm apt to quit using that site altogether.
Sites I've quit over the years:
- Any Medium site
- Most sites that are not updated often.
- Secondary sites that do not have the Subject Matter Expertise I require.
- Any API or Training site which hides a table of content. This forces continual searches.
- Any site who has a built-in search that doesn't work well.
Smart Users know their stuff, as developers we owe a good experience to them.
**Take Away**
- The mobile first philosophy is good, but don't forget wide screen and high res desktop monitors
- Responsive sites, should always favor the stuff our users are there to read.
- Collapse asides when resizing width and focus only on the center column.
- Get rid of outdated layout styles and favor fully responsive sites that adapt to any width and resolution.
- Continuously improve.
| jwp | |
613,734 | Day 44,45,46:100DaysOfCode | not much within these days but ... studied spring boot further... continued with dp some good leetco... | 0 | 2021-02-21T16:09:57 | https://dev.to/taran17809555/day-44-45-46-100daysofcode-2p4j | 100daysofcode, programming, productivity | not much within these days but ...
studied spring boot further...
continued with dp
some good leetcode medium on dp, bst and array..
few past codeforces ques..
few past kickstart ques.....
completed binary search various ques from cp sheet.
You can Follow me->
https://github.com/singhtaran1005
https://www.linkedin.com/in/taranpreet-singh-chabbra-27517918a/ | taran17809555 |
613,750 | How to use 11ty with Headless WordPress | In this tutorial, we'll learn how to use 11ty with Headless WordPress, and then deploy it to Netlify.... | 0 | 2021-02-28T17:08:59 | https://davedavies.dev/post/how-to-use-11ty-with-headless-wordpress/ | wordpress, 11ty, headless | In this tutorial, we'll learn how to use 11ty with Headless WordPress, and then deploy it to Netlify.
You can see the final project hosted on Netlify at [headless-wordpress-11ty.netlify.app](https://headless-wordpress-11ty.netlify.app/), or skip the tutorial altogether and view the Git repo at [github.com/thedavedavies/Headless-WordPress-11ty](https://github.com/thedavedavies/Headless-WordPress-11ty). **Lets get started!**
##What is Eleventy?
Eleventy (or 11ty) is a Static Site Generator, which we can use to fetch our WordPress posts and pages, and then compile the data at build time. This allows us to use WordPress as a Headless CMS, and deploy an entirely static and lightweight site to [Netlify](https://www.netlify.com/). We can get this data from WordPress using either the WordPress REST API, or using a WPGraphQL endpoint. In this tutorial, we'll be using the WordPress REST API.
## Why use 11ty with Headless WordPress?
These days there are many great headless Content Management Systems (CMS) and Static Site Generators (SSG) to choose from, so why pick WordPress over any other? I've been working with WordPress for over 10 years, and had a load of established sites I wanted to be able to use the data on. Some of these sites didn't need any extra functionality and so entirely static HTML pages are a perfect solution.
WordPress also has an active and supportive community, with thousands of plugins to help you build any type of website. For sites which need extra functionality, you can use [NextJS with Headless WordPress](https://dev.to/thedavedavies/using-nextjs-with-headless-wordpress-44om) too.
## Using the WordPress fetch API
If you've never used Eleventy before, then there's loads of great resources at [https://www.11ty.dev](https://www.11ty.dev/). In the meantime, create a fresh project (we'll call ours **Headless-WordPress-11ty**) and open that new project in your code editor (I'm using VS Code).
Installing Eleventy into our project requires a `package.json` file. Let's create it with `npm init -y`. The `-y` parameter tells npm to skip all the questions and just use the defaults.
```
npm init -y
npm install --save-dev @11ty/eleventy node-fetch
```
In that code snippet above, the dependencies we're installing are:
- **Eleventy** -- The Static Site Generator
- [**node-fetch**](https://www.npmjs.com/package/node-fetch) -- We'll use this to fetch our data from the WordPress REST API.
## Preparing our 11ty project to fetch data from the WordPress REST API
After installing the **Eleventy** and **node-fetch** packages, create a new directory in the root of your project called **_data**, and inside that new **_data** folder create a file called **posts.js**. The **_data** directory is where all of our global data will be controlled. In our case, that means using the WordPress REST API to hit our endpoint and fetch our posts and pages.
Back in your root directory, create another new directory named **_layouts**, and inside **_layouts** create a new file called **layout.njk**.
> **What's with the .njk file extension?**
>
> The .njk file extension means that we're using Nunjucks as a templating language. You can easily use 10 different templating languages in 11ty (or a mixture of them all) so whilst we're using Nunjucks, if there's a different template language you're more comfortable using, then go ahead and use that.
Finally, back in your root directory again, create 2 new files called **index.njk** and **posts.njk**.
Having added these new directories and files, your project should be looking similar to this screenshot:
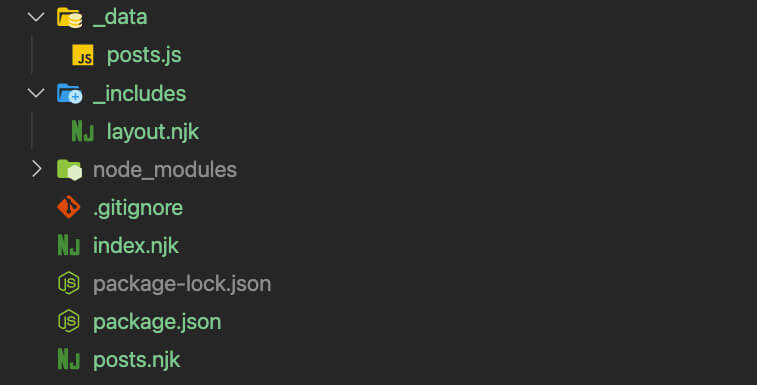
> **Creating a .gitignore file**
>
> While a **.gitignore** file isn't essential to testing out the WordPress REST API with 11ty, it's highly recommended for when you want to deploy your site. Here's the **.gitignore** settings I'm using for this project:
```
_site/
_tmp/
.DS_Store
node_modules/
package-lock.json
.env*
```
## Step 1: Fetching post data from the WordPress REST API
Now that we've prepared the foundations and set up our base project, let's get writing some code to fetch our posts from WordPress.
Head to your **_data/posts.js** file, and add the following code:
```
const fetch = require("node-fetch");
module.exports = async function () {
console.log("Fetching data...");
return fetch("https://fake-data.better-wordpress.dev/wp-json/wp/v2/posts")
.then((res) => res.json())
.then((json) => json);
};
```
**What does this code do?**
Exclusively a browser API, we can't use **fetch** in NodeJS. Using the **node-fetch** package brings the ability to use **fetch** into NodeJS. We're then setting up an **asynchronous function**, which expects a promise to be returned, which is exactly what's happening when we run `return fetch("https://fake-data.better-wordpress.dev/wp-json/wp/v2/posts")`.
## Step 1.5: Testing your fetch
Next, open your `package.json` file and in your scripts property add the following 2 scripts:
```
"scripts": {
"start": "npx @11ty/eleventy --serve",
"build": "npx @11ty/eleventy"
},
```
**What does this code do?**
The **scripts** property in your **package.json** file allows you to run predefined scripts. Once you've added the **start** and **build** scripts above, you'll be able to run `npm run start` to start up a hot-reloading local web server, and `npm run build` to compile any templates into the output folder (this defaults to **_site**).
**What do we get back from our fetch?**
The **async function** we wrote earlier in **_data/posts.js** returns to us a JSON object which we can then work with. To confirm that the data is coming back successfully from the WordPress REST API, you can change the final `.then` in your function to a `console.log()`:
```
return fetch("https://fake-data.better-wordpress.dev/wp-json/wp/v2/posts")
.then((res) => res.json())
.then((json) => console.log(json);
```
and run your `npm run start` script in your console. If all goes well with your fetch, then you should see an output similar to the screenshot below, with your JSON data logged out into the console:

## Step 2: Creating a layout template
Now that we're successfully fetching our posts from the WordPress REST API, we can start creating a template to show that data.
>If you changed your **fetch** function to `console.log(JSON)` the JSON data, then make sure you now return it to how it was in Step 1.
In your **_includes/layout.njk** file, paste in the following code:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>{{ posts.title.rendered }}</title>
</head>
<body>
{{ content | safe }}
</body>
</html>
```
**What does this code do?**
Very simply, the code above scaffolds out the HTML we'll use to display our data.
- `{{ posts.title.rendered }}` is the title object that we get back in our JSON object.
- Using `{{ content | safe }}` means that the layout template will populate the `content` data with the child template's content. Using the `safe` filter prevents double-escaping the output (this is built into Nunjucks).
## Step 3: Creating our index page
Now we get to start seeing content in our browser! In your **index.njk** file, paste the following code:
```
---
pagination:
data: posts
size: 2
layout: layout.njk
title: Latest Posts
---
<ol>
{%- for item in pagination.items %}
<li>
<a href="/posts/{{ item.title.rendered | slug }}">
{{ item.title.rendered }}</li>
</a>
{% endfor -%}
</ol>
<nav>
<ol>
<li>
{% if pagination.href.previous %}
<a href="{{ pagination.href.previous }}">Previous</a>
{% else %}Previous{% endif %}
</li>
{%- for pageEntry in pagination.pages %}
<li>
<a href="{{ pagination.hrefs[ loop.index0 ] }}" {% if page.url == pagination.hrefs[ loop.index0 ] %} aria-current="page" {% endif %}>Page
{{ loop.index }}</a>
</li>
{%- endfor %}
<li>
{% if pagination.href.next %}
<a href="{{ pagination.href.next }}">Next</a>
{% else %}Next{% endif %}
</li>
</ol>
</nav>
```
**What does this code do?**
Nunjucks uses **front matter**, which will be processed by our templates when we build our site. So what does this front matter do?
- **pagination** iterates over our data set and then creates pages for individual chunks of data.
- **data: posts** is taking our **_data/posts.js** as a data set. The front matter value for **data** needs to match up with our data file. So, if the file was called **_data/pages.js**, then our front matter would instead be: **data: pages**.
- **size: 2** is telling 11ty to list 2 of our posts before moving onto pagination
- **layout: layout.njk** is telling 11ty to use the layout that we built in Step 2.
With that saved, and `npm run start` running, you should now be able to see a paginated list of our pre-build posts from WordPress!

## Step 4: Creating a template for our single posts
The final task we have to do before launching our site is to create a template for our single posts. Paste the following code into **posts.njk**:
```
---
pagination:
data: posts
size: 1
alias: posts
permalink: "posts/{{ posts.title.rendered | slug }}/"
layout: layout.njk
---
<h1>{{ posts.title.rendered }}</h1>
<div class="mainContent">
{{posts.content.rendered | safe}}
</div>
```
**What does this code do?**
The front matter in our **posts.njk** file is similar to our **index.njk**, however this time our pagination size is just 1, and we're using an [alias](https://www.11ty.dev/docs/pagination/) in the slug.
11ty provides a number of filters which we can pass into our content. Here, we're using the **slug** filter to 'slugify' our URL, and the **safe** filter again to render out the HTML we get back from the WordPress REST API.
Finally we have a fully built (but very much unstyled) site which is populated from our existing WordPress website! Our last task is to deploy this site to Netlify.
## Step 5: Hosting our 11ty site with Netlify
Netlify is a powerful serverless hosting platform with an intuitive git-based workflow and a very generous free tier. This means we can deploy our static 11ty site to Netlify, and if you're using Git you can connect Netlify to your Git repo to trigger a rebuild every time you commit.
At this point, it's best practice to remove your API endpoint URLs from your code and use a **.env** file instead. So let's do that by installing the [**dotenv**](https://www.npmjs.com/package/dotenv) package: `npm i dotenv`. Next, create a **.env** file in the root of your project. This is where we'll add all of our secret endpoint URLs. If you created a **.gitignore** file earlier, make sure to have **.env*** in the file. This will tell git to ignore all .env files.
Open up your **.env** file, paste in your WordPress REST API endpoint along with a variable to link it to -- i.e.: `WORDPRESS_REST_API_URL=https://fake-data.better-wordpress.dev/wp-json/wp/v2/posts`
Next, we need to make sure that 11ty knows about our .env file, so create a **.eleventy.js** file (note the dot at the start of that filename), and paste the following code:
```
module.exports = function () {
require("dotenv").config();
};
```
**What does this code do?**
The **.eleventy.js** file holds all our custom site-wide configuration, but for now all we need to pass to it is our dotenv config. You can [read more about Eleventy configuration](https://www.11ty.dev/docs/config/).
Finally in our **_data/posts.js** file, we can replace our endpoint url with **process.env.WORDPRESS_REST_API_URL**. We can now safely commit our code to our Git repo without exposing our secret endpoint URLs, or any other API keys you need to keep secret.
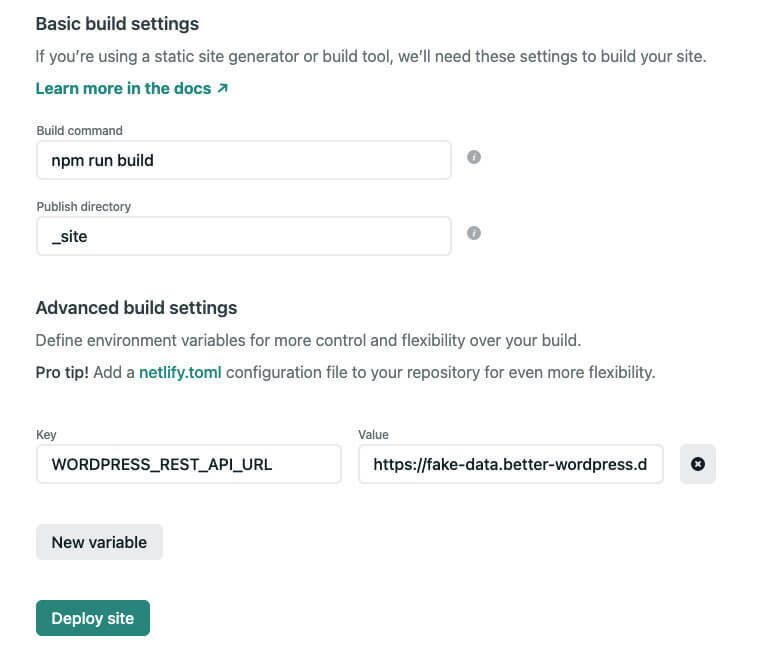
Netlify already has a super in-depth blog post on [deploying your site](https://www.netlify.com/blog/2016/09/29/a-step-by-step-guide-deploying-on-netlify/), so follow that to get your site up on Netlify. One addition we want to make though, is just before you Deploy your site - click **Advanced build settings** and add in your env key and value from your local .env file (which hopefully hasn't been committed to your repo).
## Finished!
And we're done! We now have a very high level proof-of-concept project to fetch our posts from the WordPress REST API, build them into a static site using Eleventy, then deploy that site to Netlify.
There's plenty more we can do, including styling the site and fetching various pages and other data that the WordPress REST API gives us. | thedavedavies |
614,026 | How to Build a Spoken Universal Translator with Node-RED and Watson AI services | What is Node-RED? Node-RED is a low-code programming environment for event-driven applicat... | 0 | 2021-02-22T01:43:26 | https://dev.to/ivanadokic/how-to-build-a-spoken-universal-translator-with-node-red-and-watson-ai-services-3pdb | cloud, javascript, node, ibmwatson | # What is Node-RED?
[Node-RED](https://nodered.org/) is a low-code programming environment for event-driven applications. It's a programming tool for wiring together hardware devices, APIs, and online services in new and interesting ways.
At the core of Node-RED is Node.js a JavaScript runtime environment built on Chrome's V8 JavaScript engine. Top 5 reasons to use Node-RED can be found [here](https://developer.ibm.com/blogs/top-5-reasons-to-use-node-red-right-now/).
## Let's build a spoken universal translator using Node-RED and Watson AI services
We will build a universal translator by using a Node-RED Starter application to connect with those Watson AI services:
- Speech to Text
- Language Translator
- Text to Speech

The [Node-RED Starter application](https://developer.ibm.com/tutorials/how-to-create-a-node-red-starter-application/) includes a Node-RED Node.js web server and a Cloudant database to store the Node-RED flows.
#### We will learn how to:
- Create a **Node-RED starter** app running in IBM Cloud. Create instances of the Watson services: Speech to Text, Text to Speech, and Language Translator and how to connect those services to your Node-Red app.
- Launch and configure the Node-RED visual programming editor.
- Install additional Node-RED nodes and create flows that use the Watson services to create the spoken universal translator.
## Prerequisites
This app can be completed using an IBM Cloud Lite account.
Create an [IBM Cloud account](https://cloud.ibm.com/registration?cm_sp=ibmdev-_-developer-tutorials-_-cloudreg)
Log into [IBM Cloud](https://cloud.ibm.com/login?cm_sp=ibmdev-_-developer-tutorials-_-cloudreg)
# Step 1 – Let's create a Node-RED Starter App
Follow these steps to create a Node-RED Starter application in IBM Cloud.
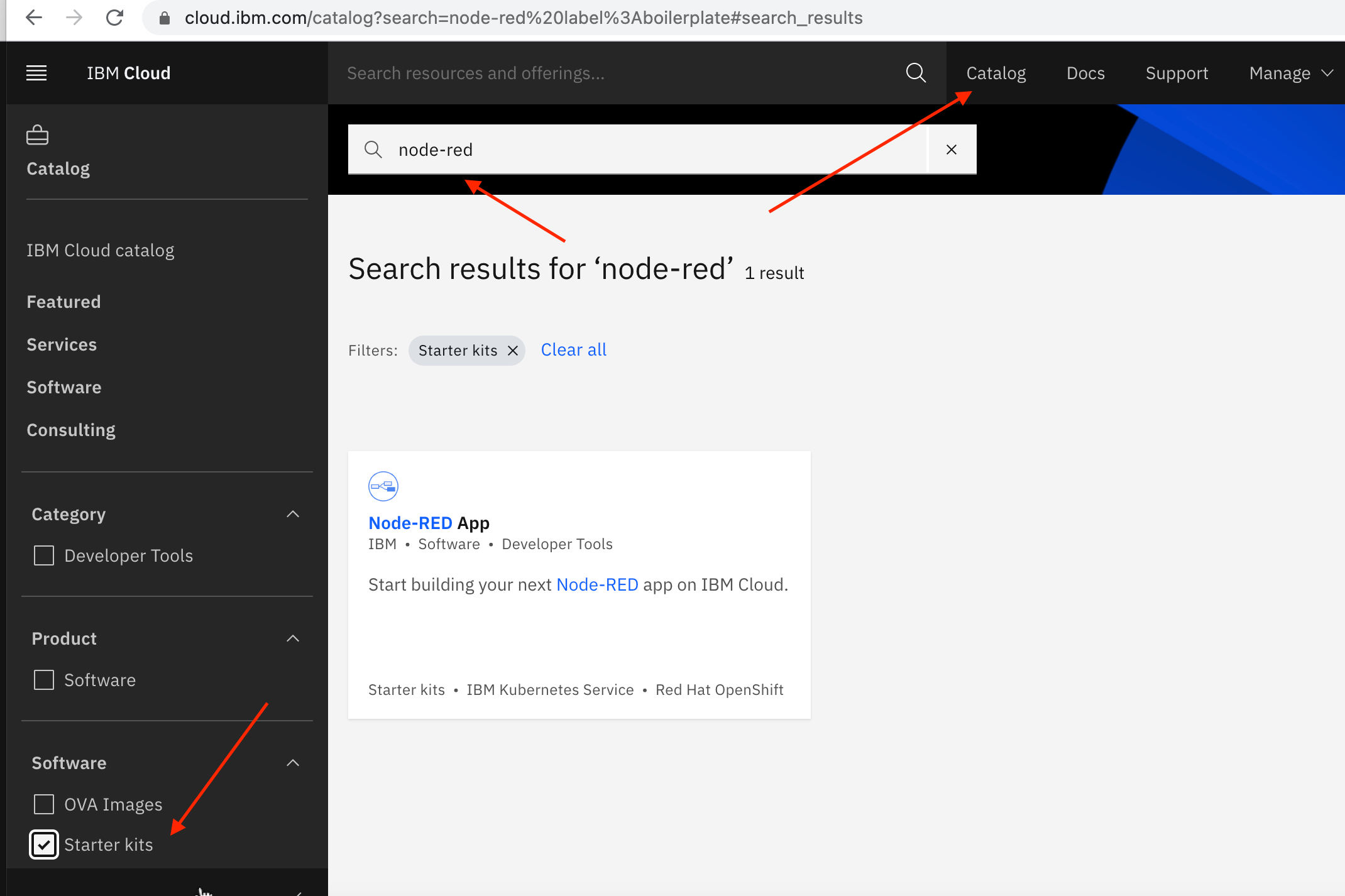
1. Log in to your IBM Cloud account.
2. Click on the Catalog
3. Search for node-red
4. Select the Starter Kits category, then select Node-RED Starter.
5. Enter a unique name for your application, it will be part of the application URL :
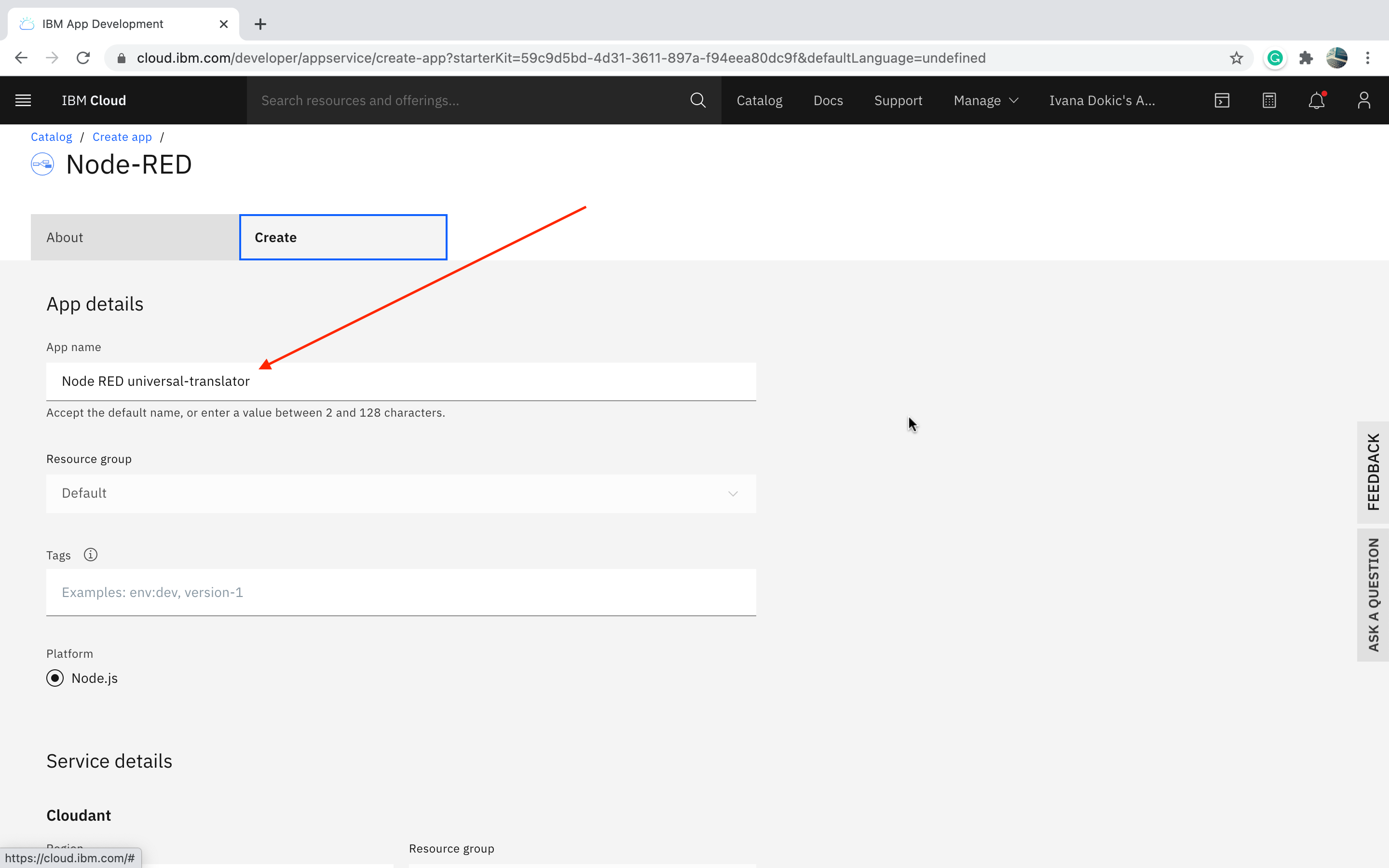
6. The Region, Organization, and Space fields will be pre-populated with valid options for your IBM Cloud account. I have a Lite account and I just accepted the defaults.
7. In the Selected Plan section, choose Lite.
8. Click the Create button.
The Node-RED Starter application will be provisioned in the IBM Cloud region that was specified. This process is called staging an application.
# Step 2 – Let's create the Watson AI service instances
You can add Watson AI microservices to your application as APIs, through instances that you can manage through credentials. We will create and bind these microservices to your Cloud Foundry application. There are three Watson AI services, all available in the *IBM Cloud Lite tier*, needed to build a universal translator:
- Watson Speech to Text
- Watson Text to Speech
- Watson Language Translator
In IBM Cloud Catalog search for speech and navigate to the AI category:
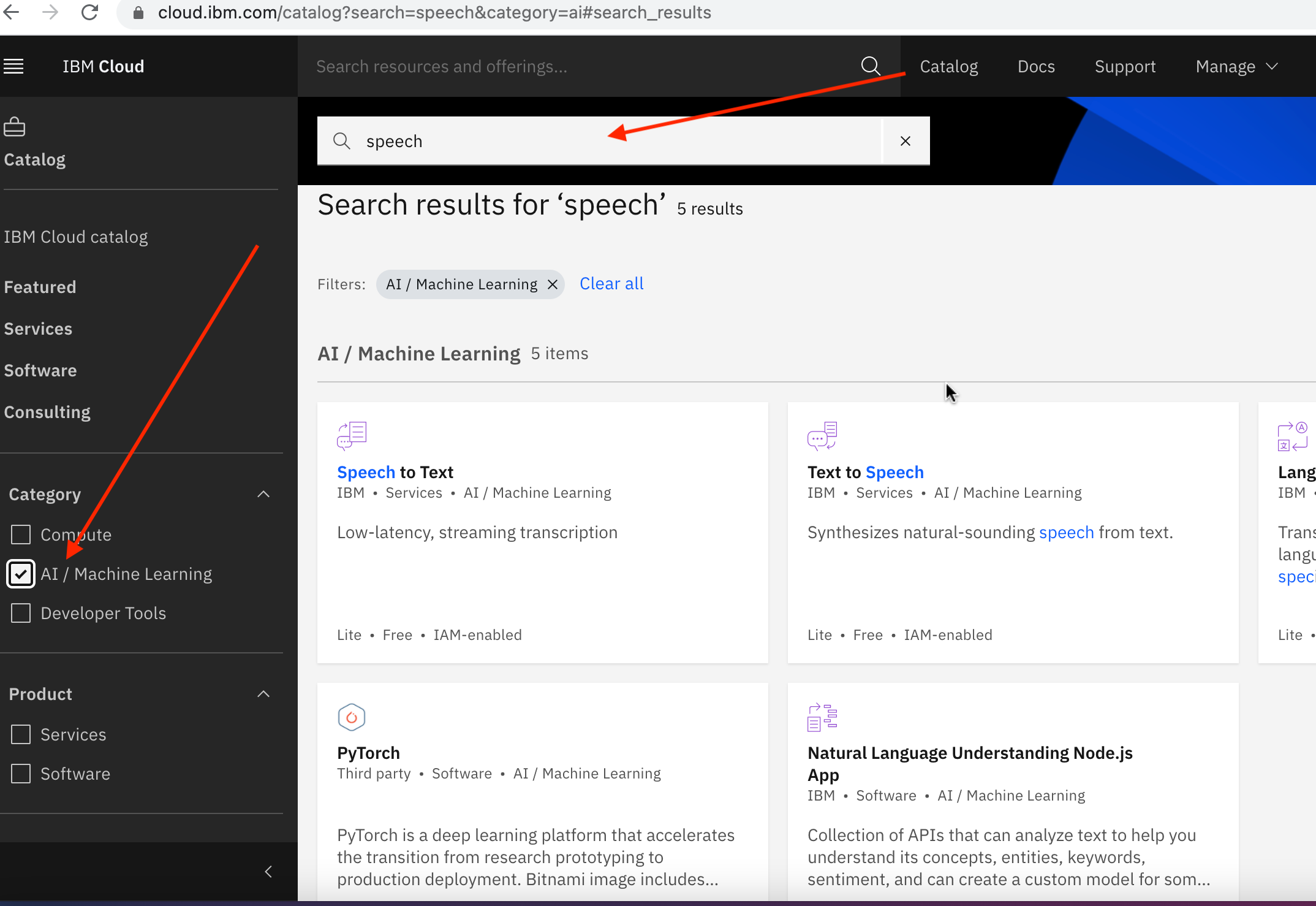
Select **Speech to Text**, and click the Create button.
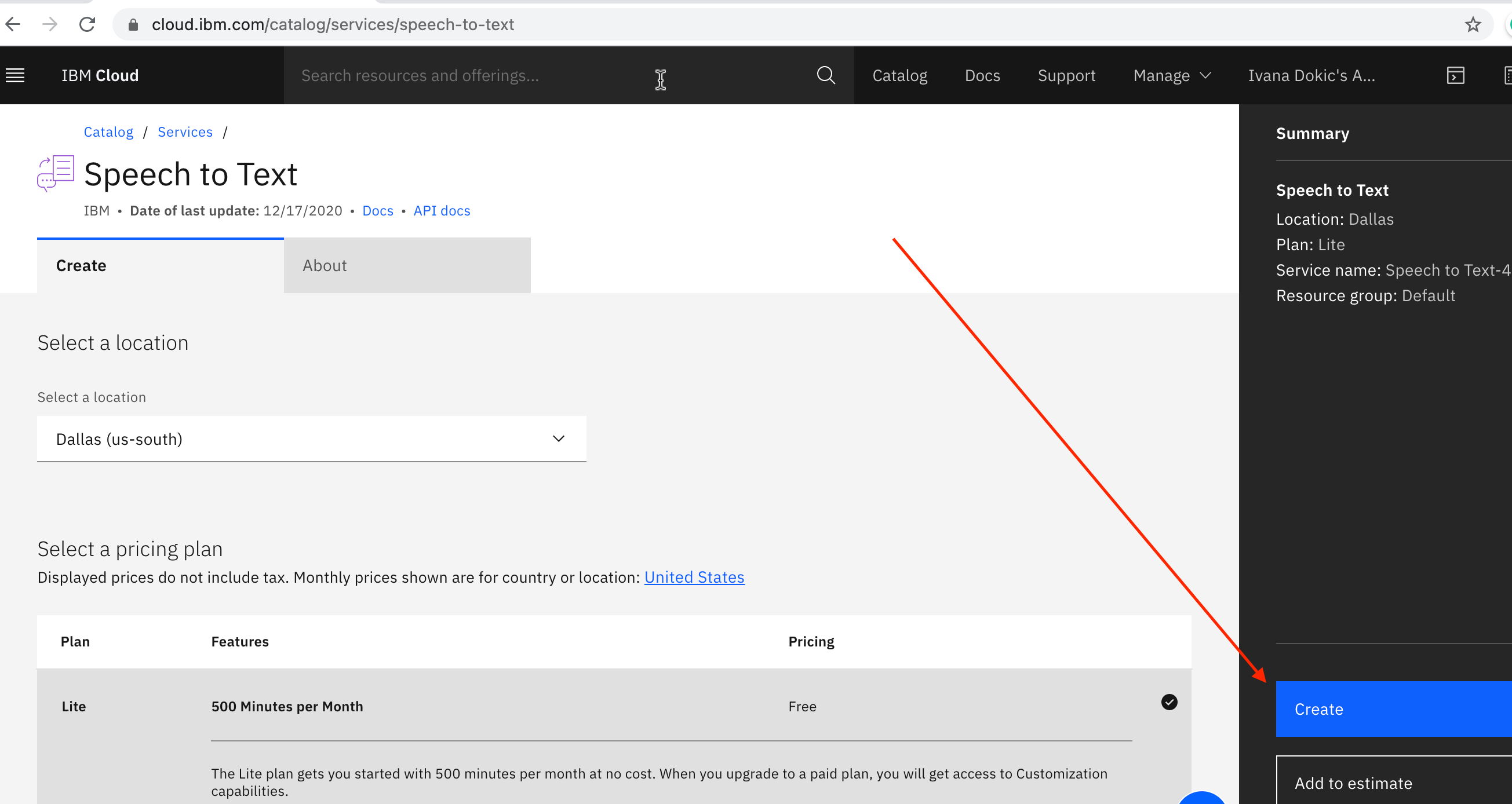
Return to the AI category in the IBM Cloud Catalog, and select **Text to Speech**, and click the Create button:
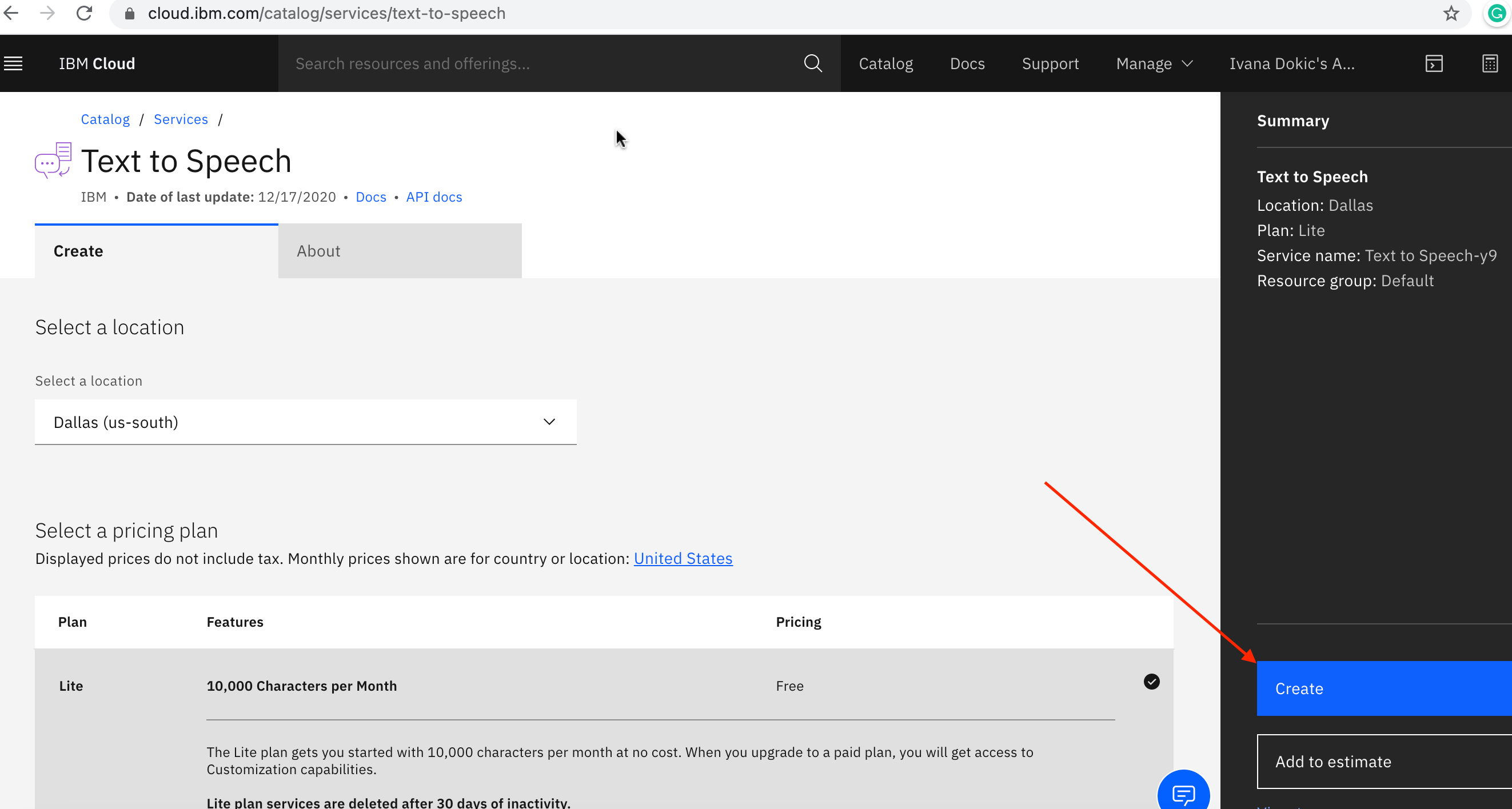
In IBM Cloud Catalog, search for a translator, navigate to the AI category, select **Language Translator**, and click the Create button, I already had the one:
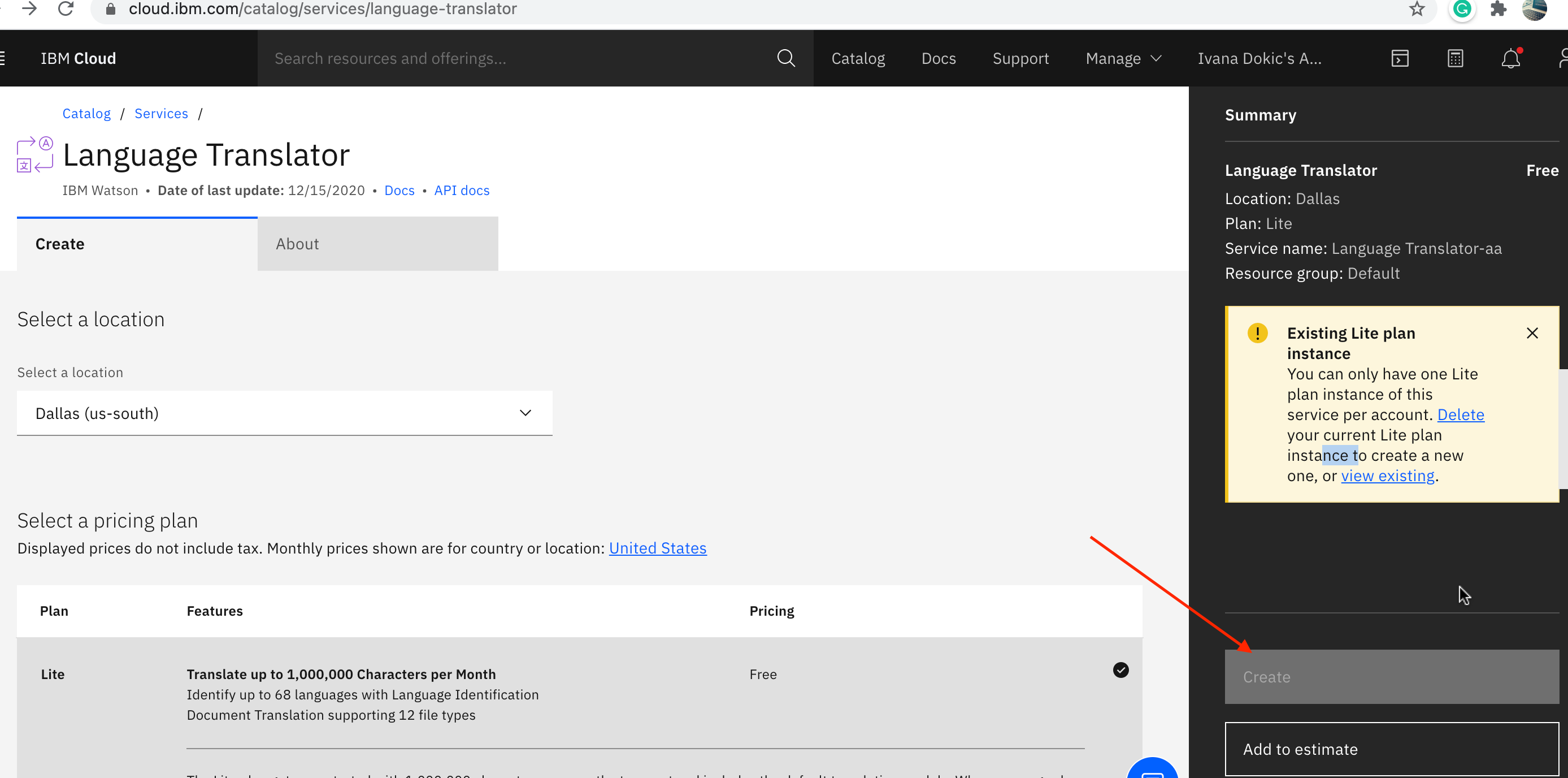
# Step 3 – Let's connect the Watson AI Services to the Node-RED Starter Application
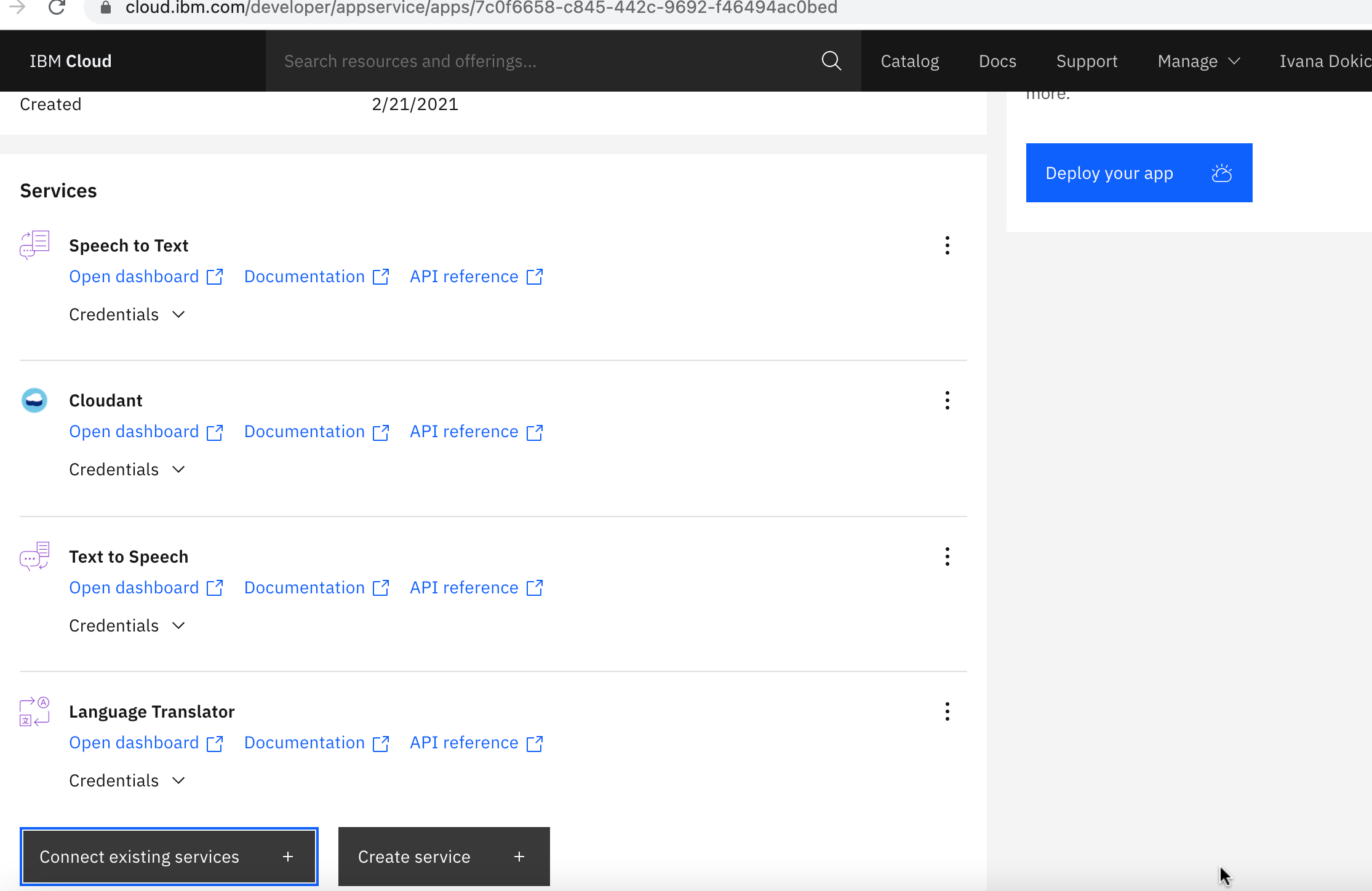
1. In [IBM Cloud Dashboard](https://cloud.ibm.com/resources?cm_sp=ibmdev-_-developer-tutorials-_-cloudreg) navigate to the Apps section and select Node-RED universal-translator (your apps unique name):
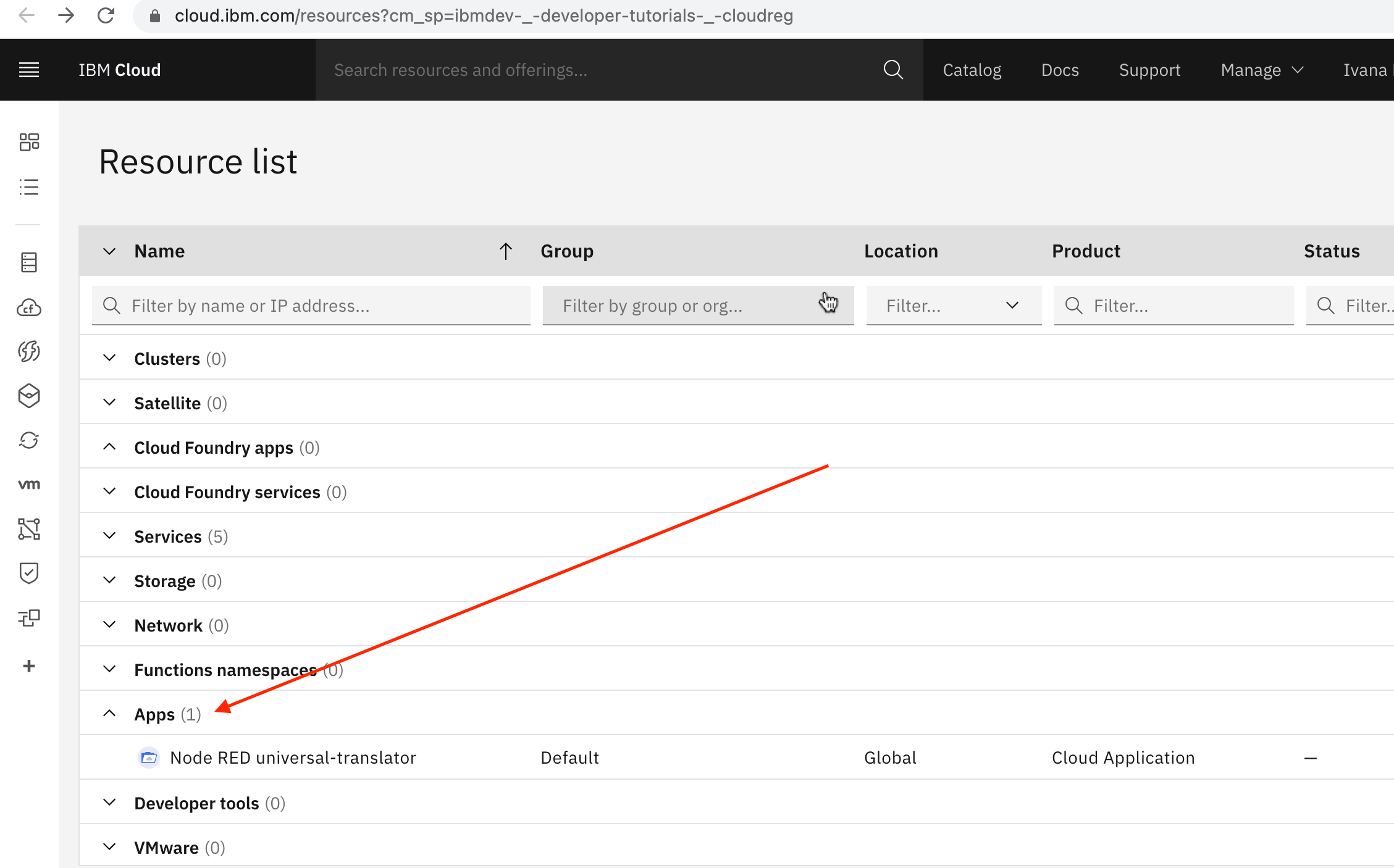
The Applications Details opens, search for the Watson services that you created in the previous step and press the Connect button. Once it's connected you will have those Services ( Speech to Text, Text to Speech, and Language Translator ) connected like this:
# Step 4 – Launch your Node-RED app and open the Node-RED visual programming editor
Node-RED is an open-source Node.js application that provides a visual programming editor that makes it easy to wire together flows.
The first time you start the Node-RED app, it will help you configure the visual programming editor. Once the Green Running icon appears, click the View App URL link, a new browser tab opens to the Node-RED start page:
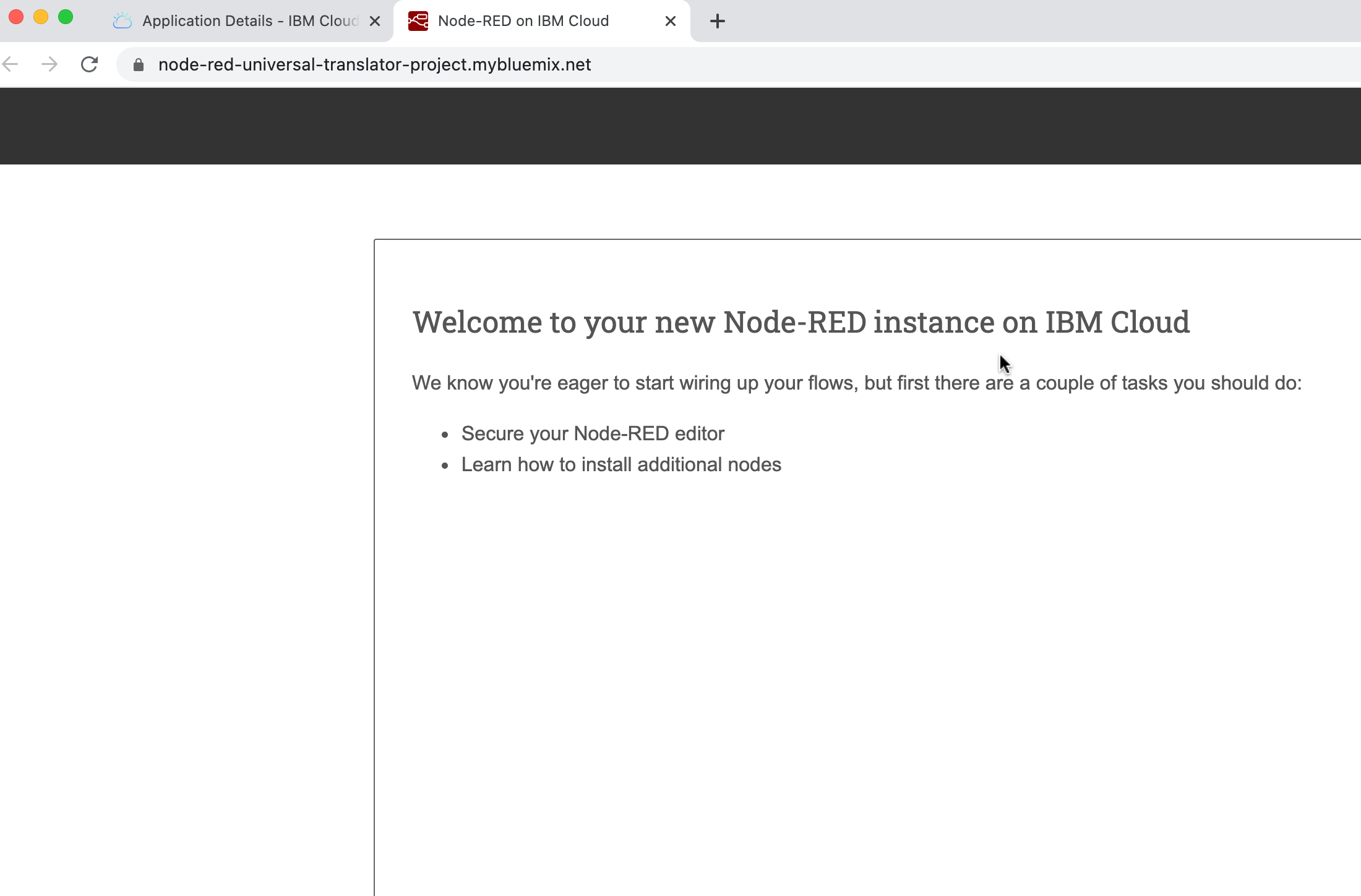
A new browser tab opens to the Node-RED start page.
Use the setup wizard to secure your editor with a user name and password and to browse and add more nodes. Click the Finish button to proceed:
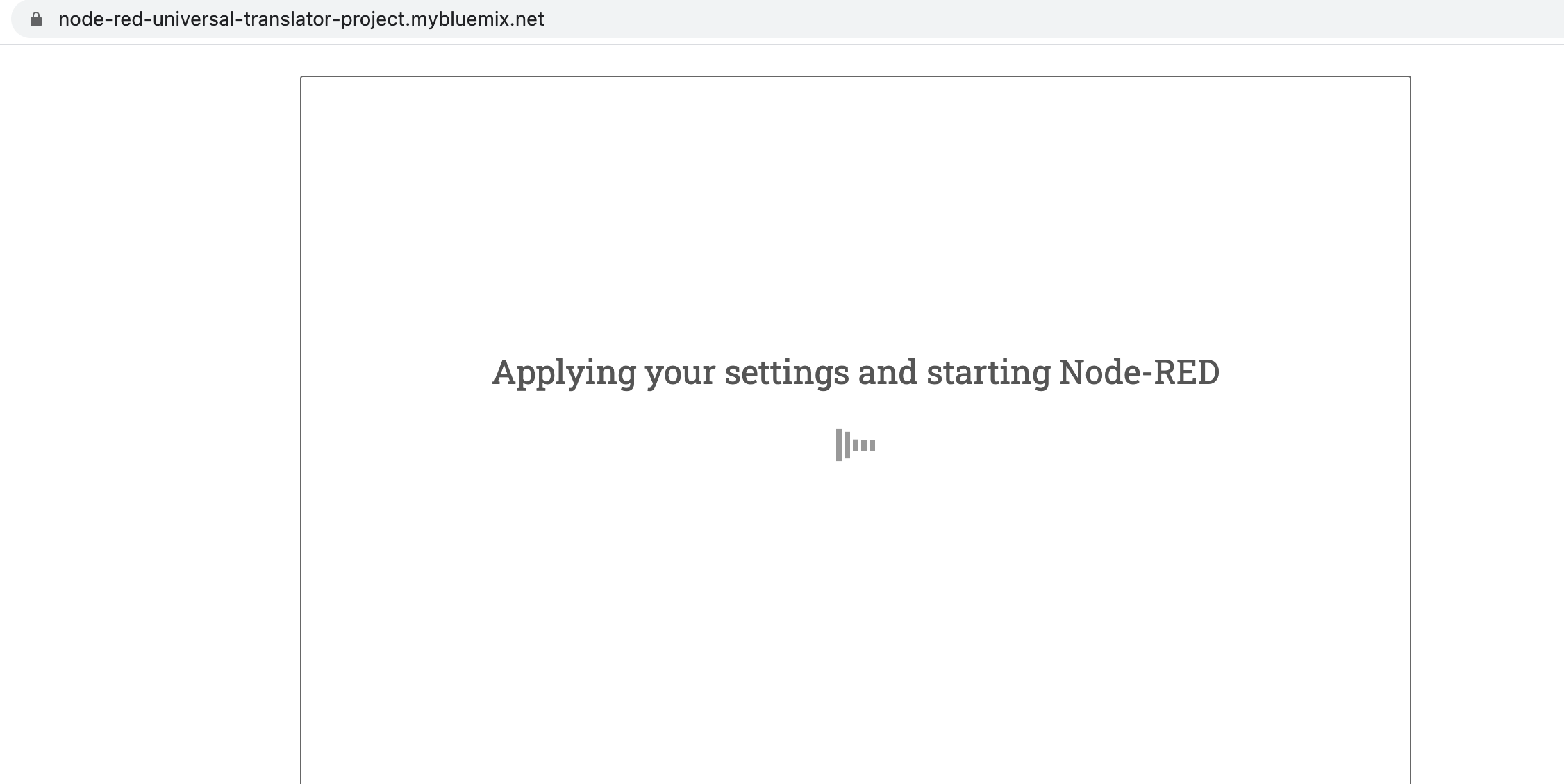
Click the Go to your Node-RED flow editor button to launch the Node-RED flow editor:
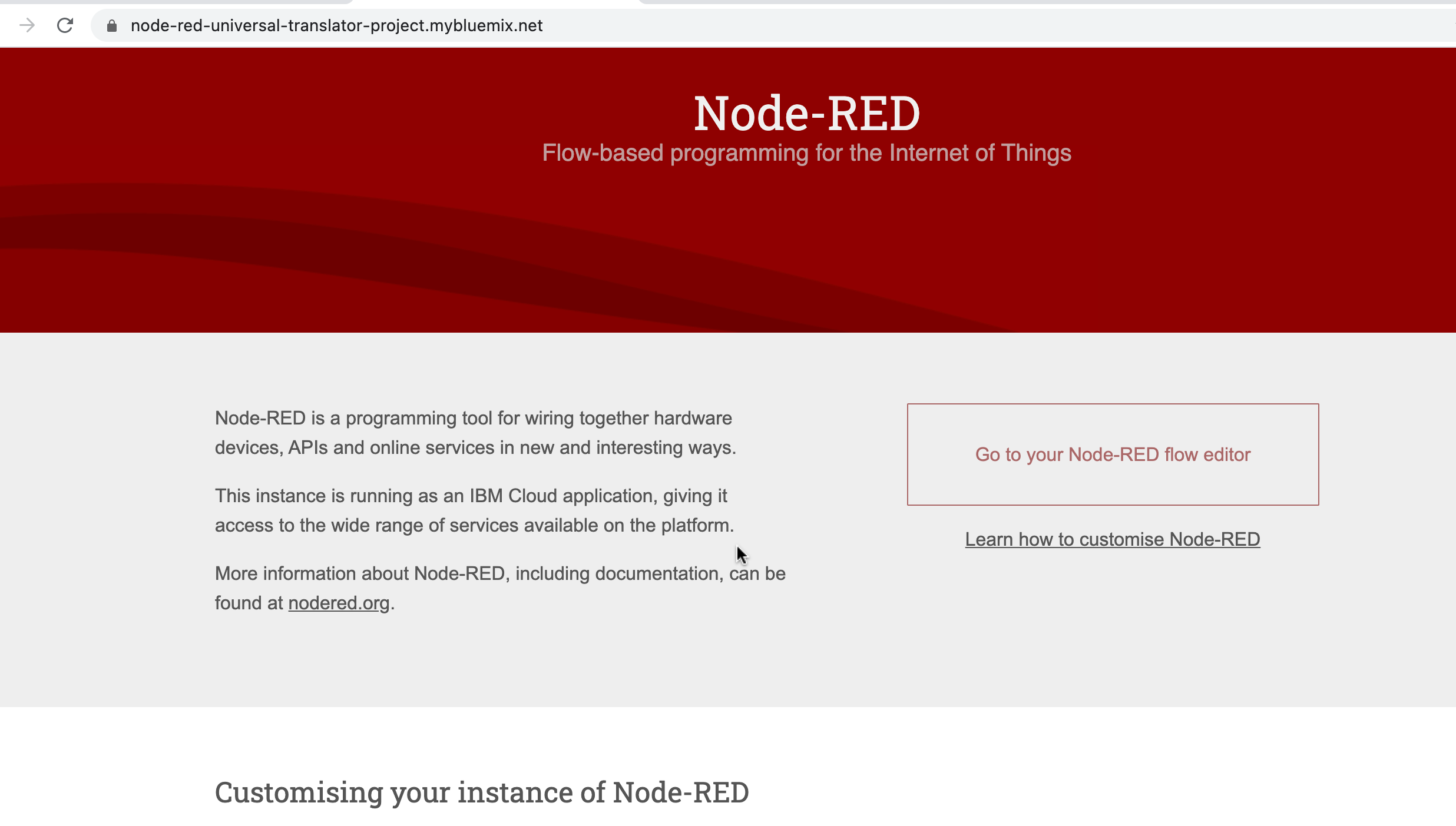
Click the Person icon in the upper right corner, and Sign in with your new username and password credentials and you will get a screen like this:
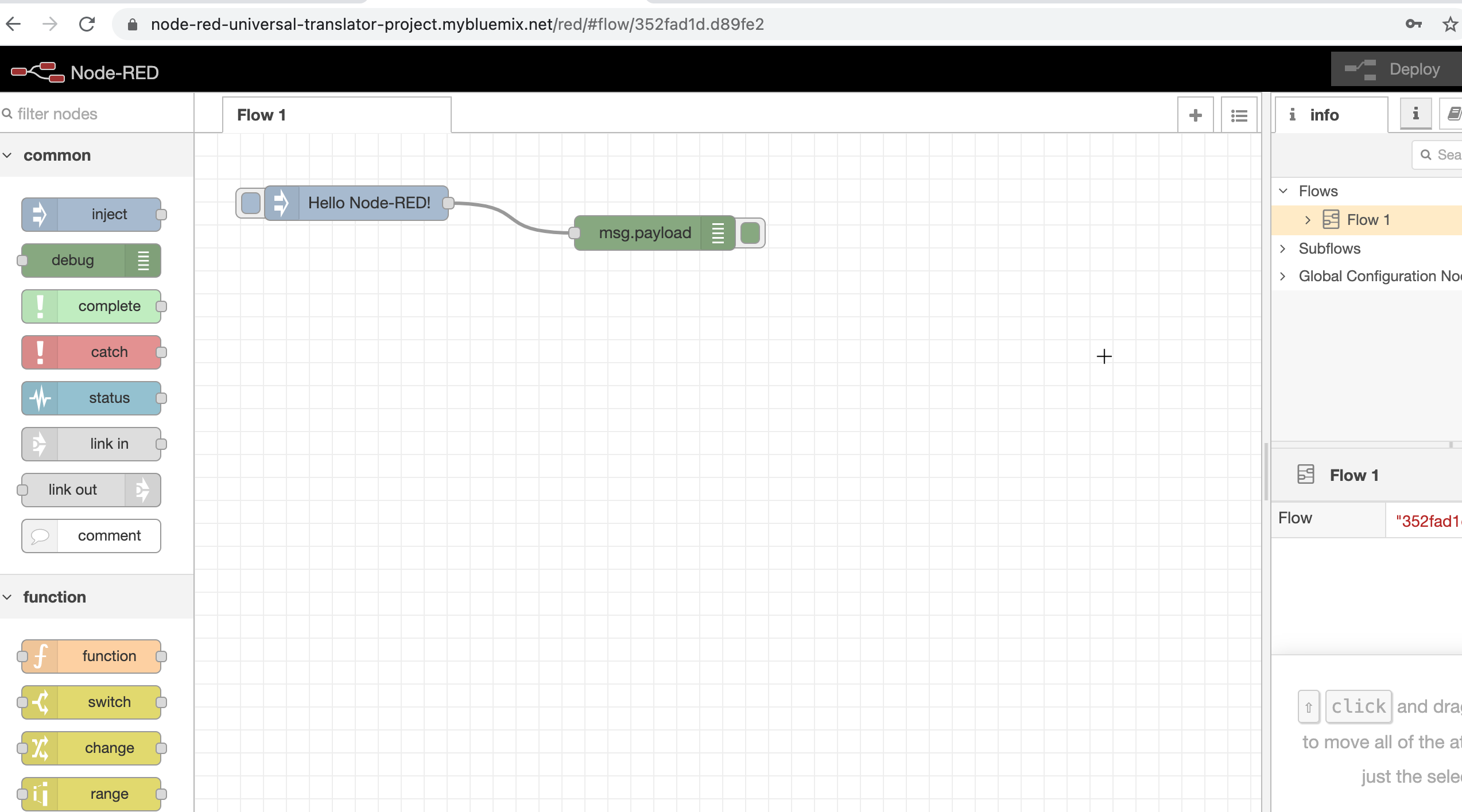
The Node-RED Visual Programming Editor has a left side with a palette of nodes that you can drag onto the flow and wire nodes together to create a program.
# Step 5 – Let's install Additional Node-RED Nodes
The universal translator that we are building needs a **microphone** to record your message and the ability to play the audio of the translation. We can add nodes to the Node-RED palette that add these capabilities, such a great thing!
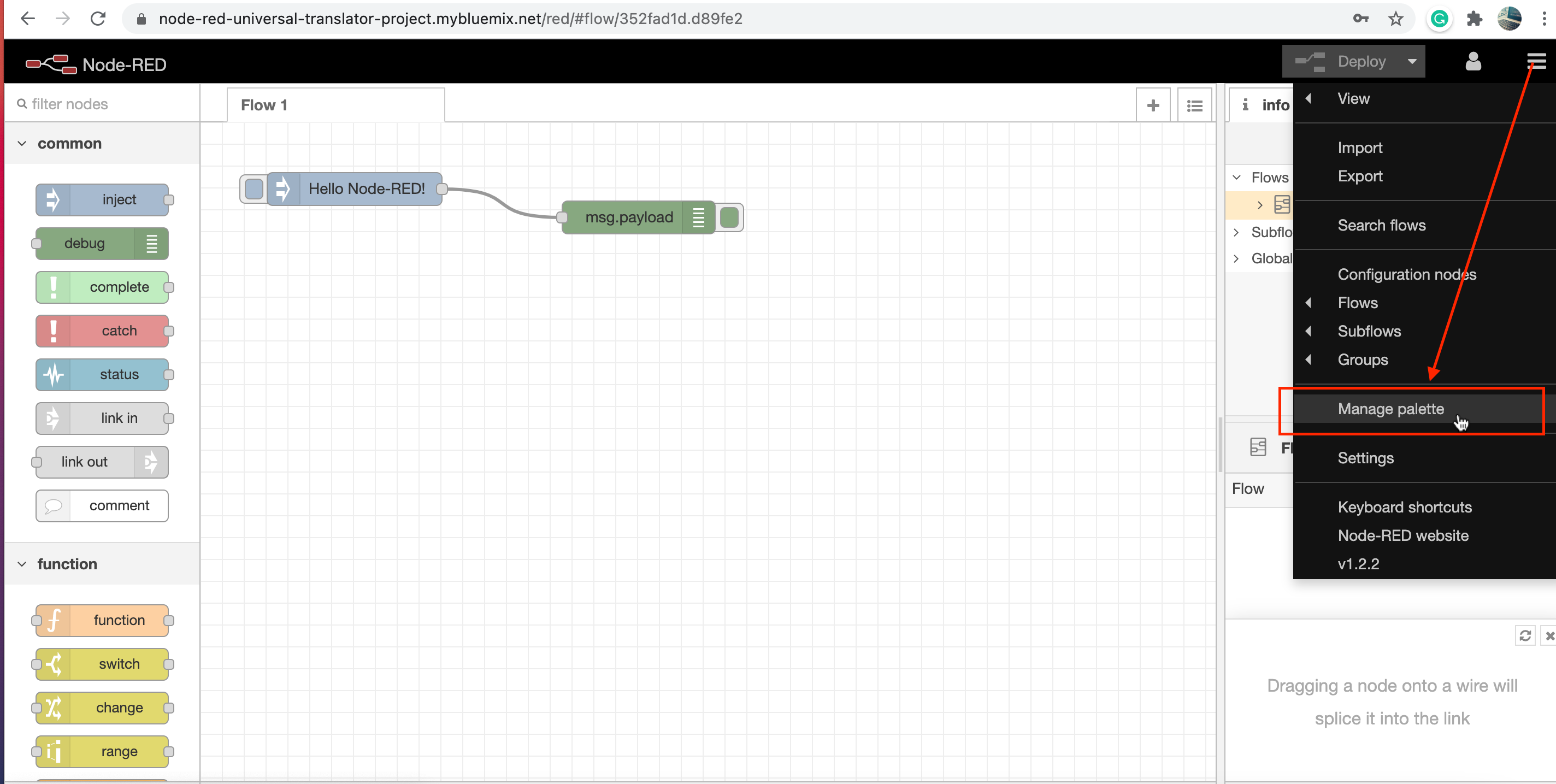
1. Click the Node-RED Menu, and select Manage palette
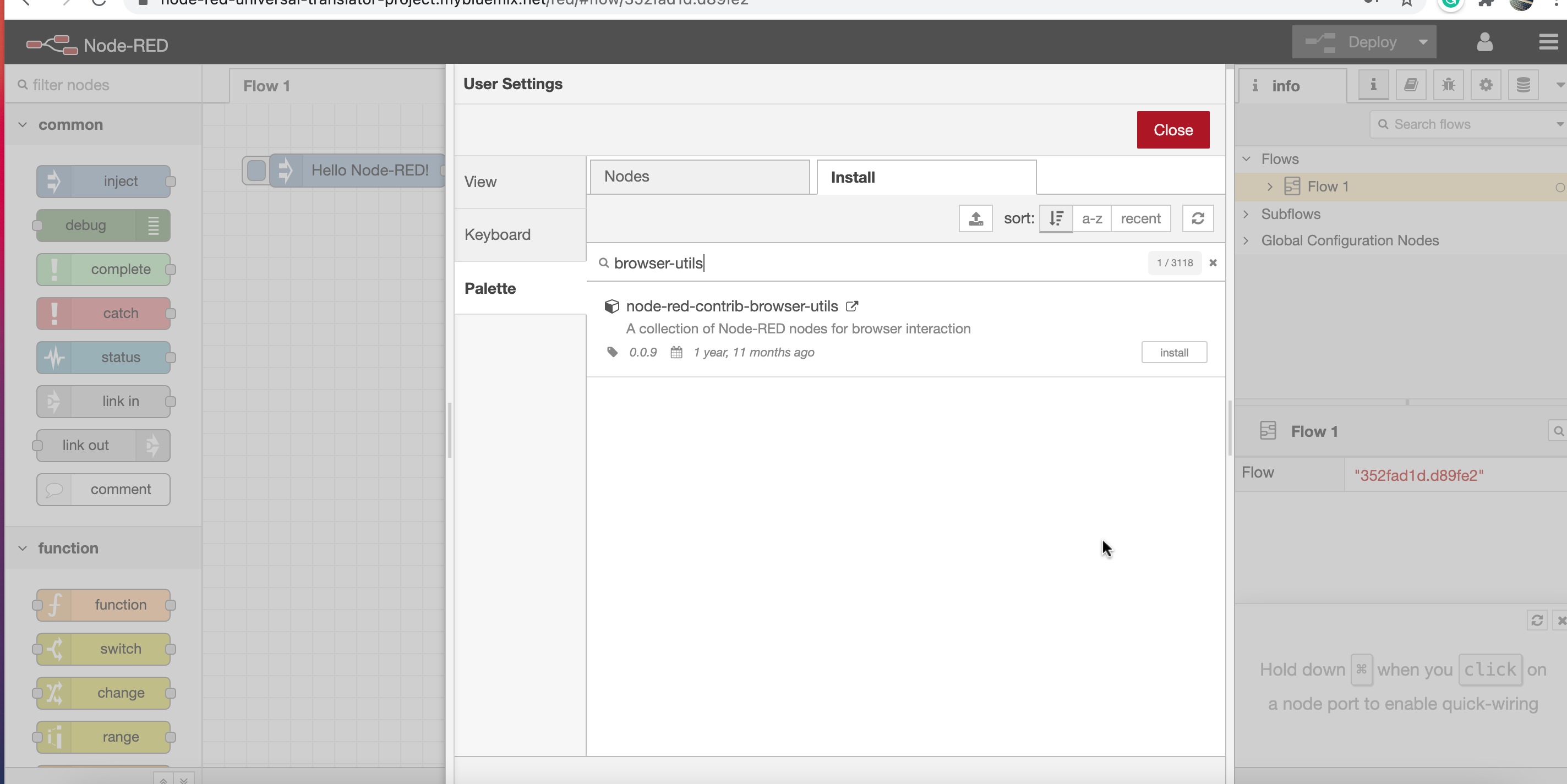
2. Select the Install tab, and search for *browser-utils* and Install the **node-red-contrib-browser-utils** node.
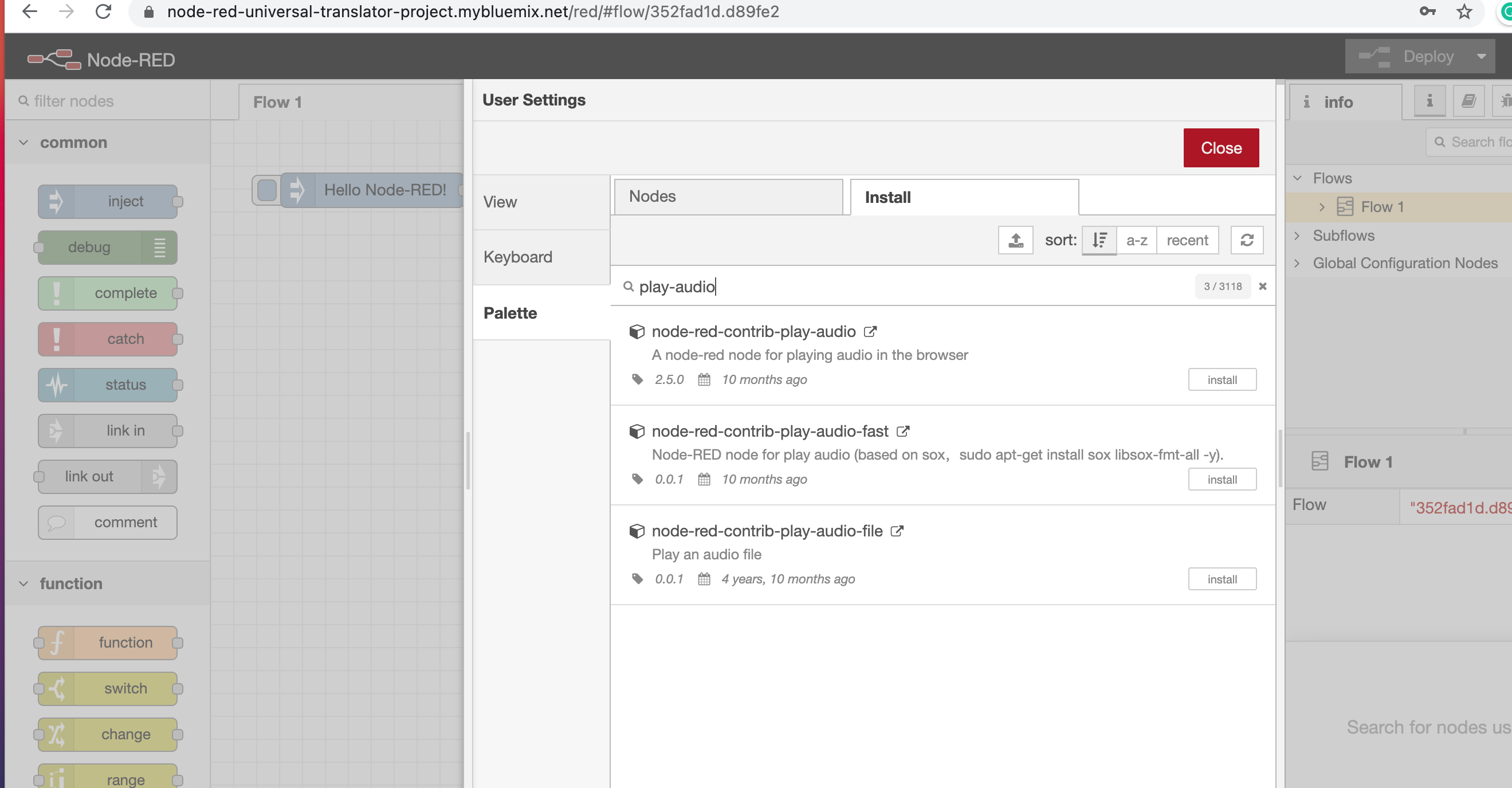
3. Search for *play-audio*, find the **node-red-contrib-play-audio** node, and click the Install button.
# Step 6 – Build the flows for the universal translator
Node-RED allows you to drag and drop Nodes from the left palette onto your flow canvas and wire them together to create programs.
### Speech-to-Text flow
Click and drag a microphone node to your flow.
Click and drag a Speech to Text node to your flow. Double-click it and select US English.
Click and drag a Debug node to your flow. Double-click it and have it output msg.transcription.
Wire the nodes together as shown in the screenshot below.
Click the red Deploy button.
Select the tab to the left of the microphone node and allow your browser access to the microphone on the laptop.
Record a message, like “wow this is so much fun!”
# Text-to-Speech flow
Now, let’s build the Text-to-Speech flow.
1. Click and drag an Inject node to your flow and double-click it and change the payload type to a string and type a message.
2. Click and drag a Text to Speech node to your flow, double-click it and select US English.
3. Click and drag a Change node to your flow, double-click the Change node and assign the msg.payload to msg.speech.
4. Click and drag a play-audio node to your flow.
5. Wire the nodes together as shown in the screenshot below:
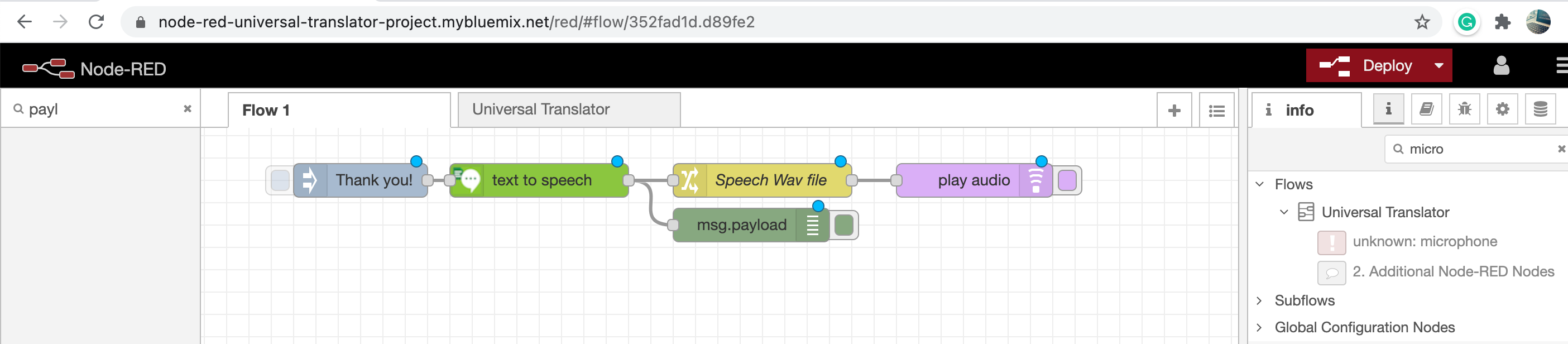
6. Press the Deploy button (the red one).
7. Select the tab to the left of the Inject node. The audio of the message will play.
# Language Translator flow
The universal translator will use the recorded transcript as the input to the language translator node, and send the foreign language to the Text to Speech node.
1. Click and drag another Change node to your flow, double-click it and assign msg.payload to msg.transcription like this:
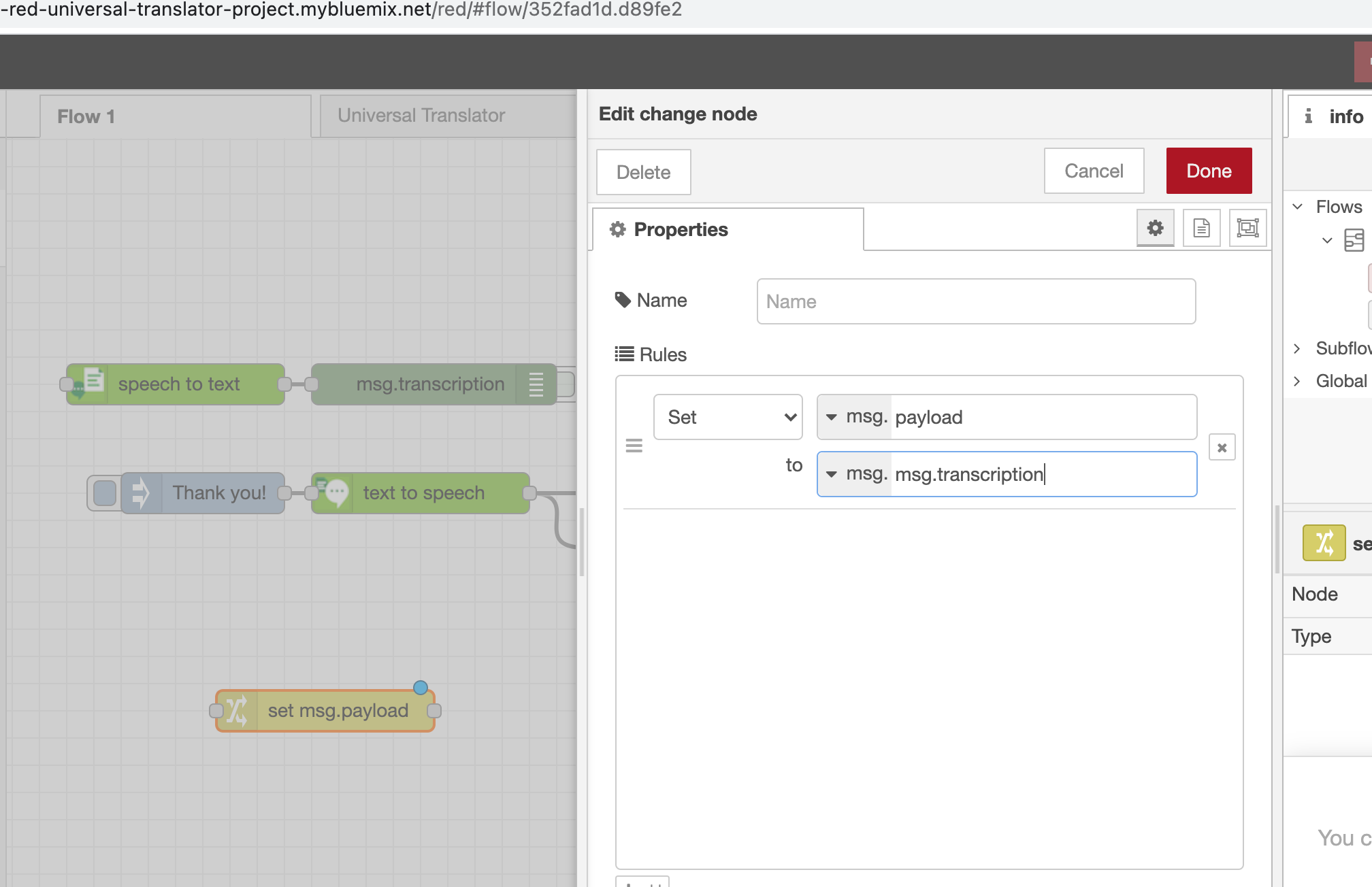
2. Click and drag a language translator node to your flow. Double-click it and select English as the Source and Croatian
as the Target.
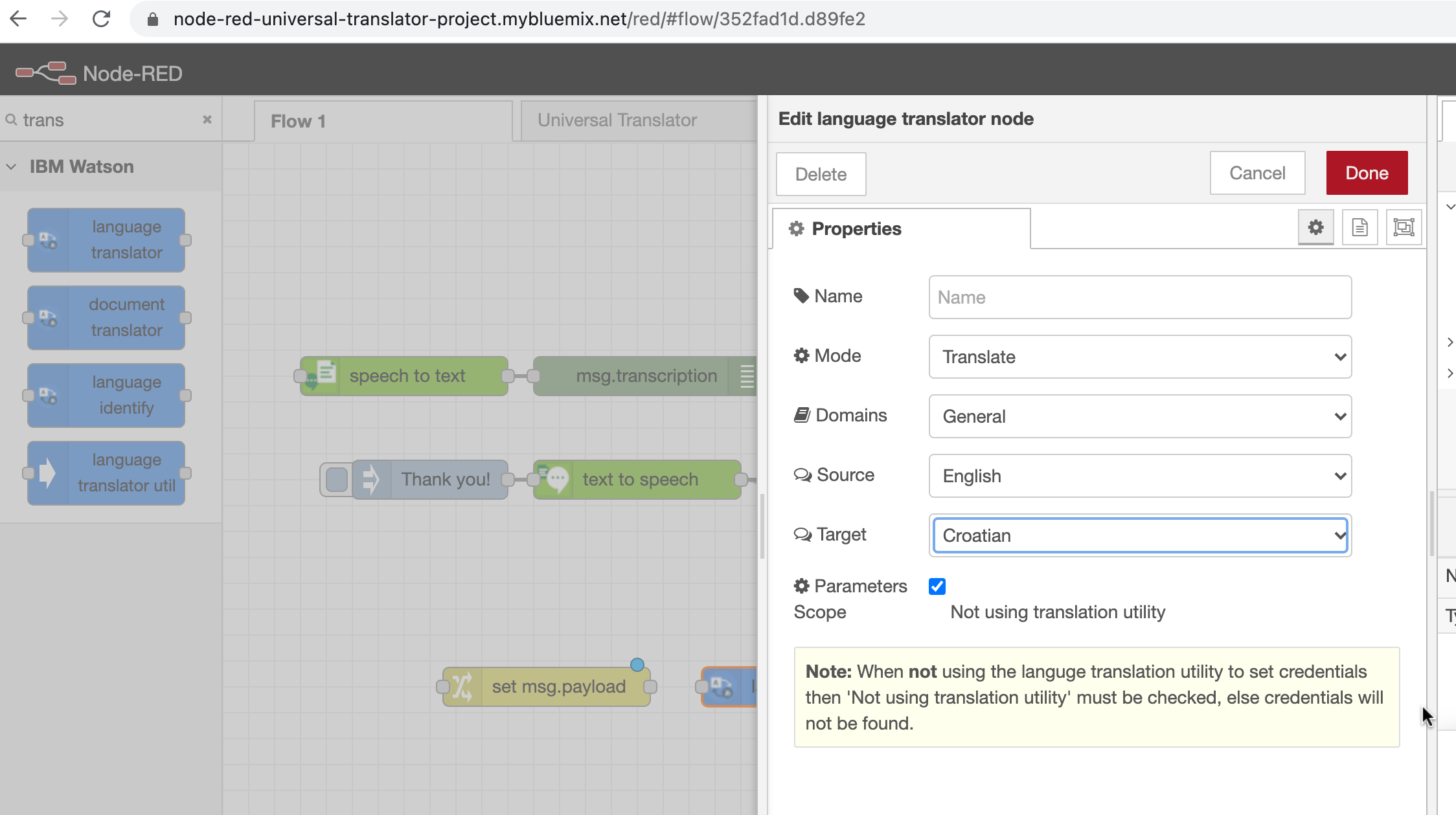
3. Click and drag a Debug node to your flow.
4. Double-click the Text to Speech node, and change the language to Spanish and select a voice (here I clicked and tried Croatian language but it was not available, doesn’t show it on the list and I'll stick with Spanish)
This is how your final flow should look like:
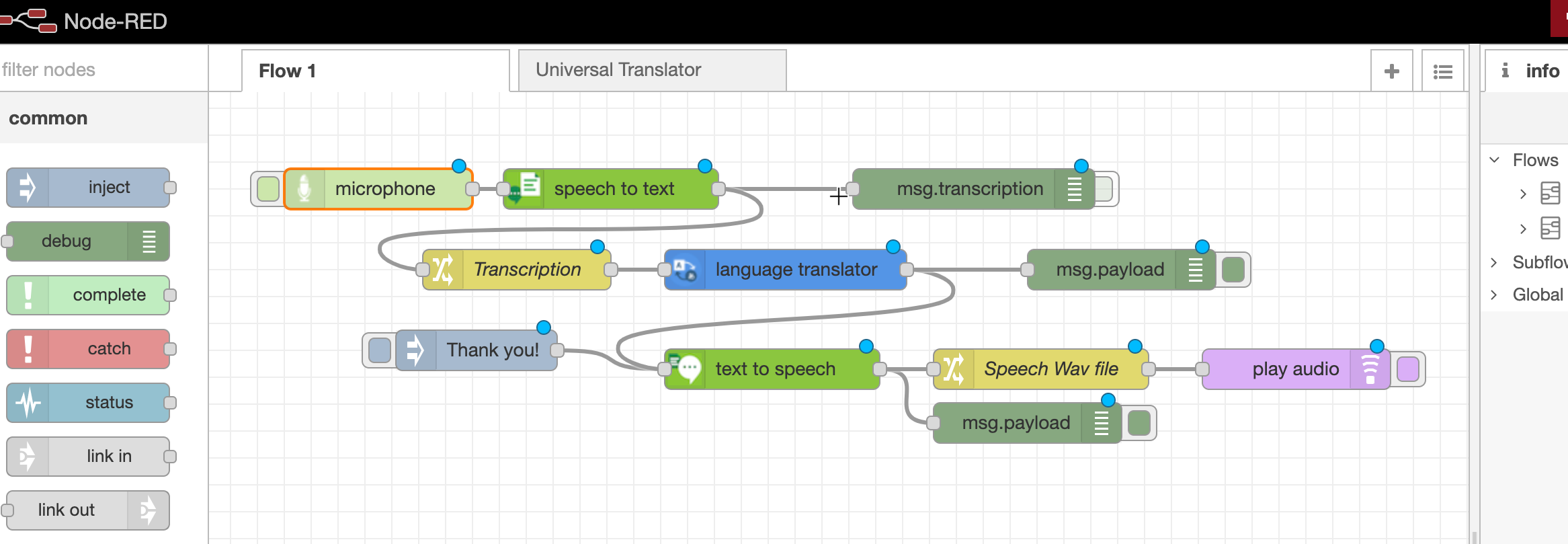
Finally, click the Deploy button (the red one) on the right top corner!
# Final Step – let's test universal translator
Select the tab to the left of the microphone node and allow your browser access to the microphone on the laptop and **record a message**.
You can follow the process and view the translations in the **Debug** tab of Node-RED:
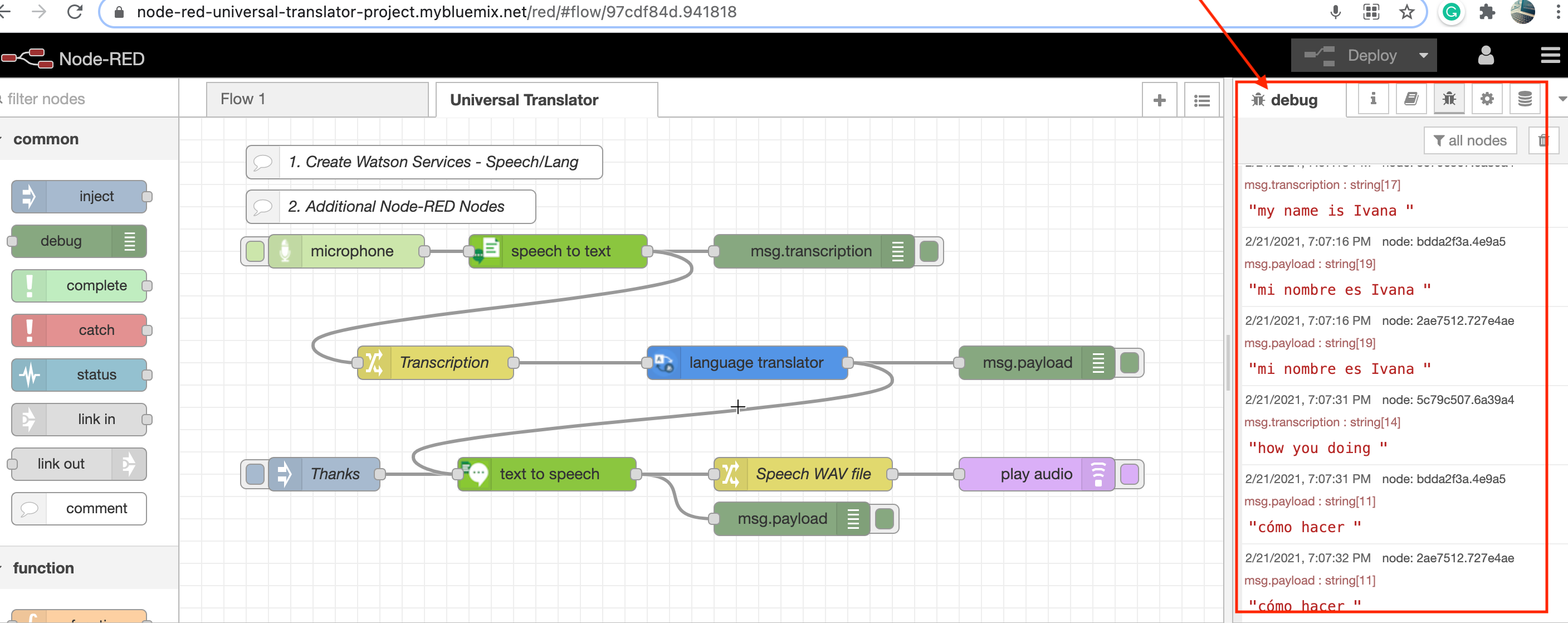
Full documentation and more details on how to build Node-RED starter application using Watson services in IBM Cloud can be found [here] (https://developer.ibm.com/technologies/iot/tutorials/build-universal-translator-nodered-watson-ai-services/)
To connect please check my [Github](https://github.com/ivanadokic), [LinkedIn](https://www.linkedin.com/in/ivana-dokic/) or [Twitter](https://twitter.com/LloydPile).
Thank you for reading!
| ivanadokic |
614,050 | How to use multiple GIT accounts per folder on Linux | Organize your repositories by GIT account without much stress | 0 | 2021-02-22T04:12:39 | https://dev.to/devatreides/how-to-use-multiple-git-accounts-per-folder-on-linux-1h50 | linux, webdev, git, howto | ---
title: How to use multiple GIT accounts per folder on Linux
published: true
description: Organize your repositories by GIT account without much stress
tags: linux, webdev, git, howto
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6a69aped9087gaq34sqd.png
---
Tipically, one of the first tools that a developer learns when starting the "dev journey" is **git**. For those who still don't know much about this little guy, it was created by *Linus Benedict Torvalds*, a Finnish software engineer, naturalized American, known as the creator of **linux kernel**. Torvald's idea was to have a simple versioning system that met three requirements that he himself considered indispensable (and that other software couldn't guarantee):
- It needed to be distributed;
- The performance had to be good;
- It needed to ensure that what was put in, was exactly what was obtained afterwards;
According to him, these three parameters were sufficient to discard virtually all versioning systems until then, so he decided to build his own system.
## A single git account on Linux: kid's stuff
Everyone who has ever set up a local git user knows that it have no secrets. You define the user name and email and... that's it.
>```bash
>git config --global user.name "Tom Benevides"
>git config --global user.email "tombenevides@mail.com"
>```
From now on, all the repositories you create will use these credentials.
>```bash
> mkdir new_repo && cd "$_"
> git init
> touch text.txt
> git add text.txt
> git commit -m "new file"
>```
And if I take a look at the *git log*, this will be the result:
>```bash
> commit 036573401e5788917383a27fb6c2acf607f5e441 (HEAD -> master)
> Author: Tom Benevides <tombenevides@mail.com>
> Date: Sun Feb 7 13:50:05 2021 -0400
>
> new file
>```
So, everything is fine with our configuration but... what if my project uses a different account?
## A git account per repository: still piece of cake, but it can be a little tricky
We'll now create another repository. This is going to be the *work_repo*. It actually uses a different email account because it's a company project and not a personal project like *new_repo*.
>```bash
> cd ~
> mkdir work_repo && cd "$_"
> git init
> touch text.txt
>```
If we commit the changes now, my personal account (system default) will be registered, but I need to use the work email, tombenevides@work.com. So, we need to configure the new credentials in the repository.
>```bash
> git config user.email "tombenevides@work.com"
> git add text.txt
> git commit -m "new file"
>```
Now, when committing, my registered email will be the work email.
>```bash
> commit f47e5c7140296c9fbe1f4fb001149b04b329b655 (HEAD -> master)
> Author: Tom Benevides <tombenevides@work.com>
> Date: Sun Feb 7 14:05:02 2021 -0400
>
> new file
>```
All right, happy ending? So-so. Now, imagine that you have several work repositories and several personal repositories. It will be a bit annoying that you have to configure the correct credential in each of the repositories. If your work account email changes or you have a new git account? You'll need to make the change in all repositories. Lot of job right? There're people who don't think so.
Personally, what I can do to make my life simpler, I’m doing and a nice idea would be to configure git so that every time I create a repository in a given folder, the credentials I want are automatically assigned to it. And look how cool; git does that!
## A git account per folder: the light at the end of the tunnel
The idea is pretty simple: we'll have two base folders (*Work* and *Personal*) where the repositories will be stored according to their respective origin. All repositories within each base folder will use the same credentials, different from the default and without configuration by repository. Structure proposal below.
>```bash
> Projects
> ├── Personal
> └── Work
>```
Now, we need to tell git that the *Personal* folder repositories will use the email "tombenevides@newmail.com" and not the default email we set up earlier. To do this, in your home (`cd ~`), create a file called `.gitconfig-personal` and as content, simply recipient of the email.
>```bash
> [user]
> email = tombenevides@newmail.com
>```
Once we set up the Personal folder credential, we will create a `.gitconfig-work` file to set up work credential.
>```bash
> [user]
> email = tombenevides@work.com
>```
With our config files created, we'll now edit the `.gitconfig` file found in the user home (`cd ~`) and let git know that whenever there is a repository inside the *Personal* folder, it must use the credential of the `.gitconfi-personal` file and every time there is a repository in the *Work* folder, git must use the credential of the `.gitconfig-work` file.
>```bash
> [user]
> name = Tom Benevides
> email = tombenevides@mail.com
> [includeIf "gitdir:Projects/Personal/**"]
> path = .gitconfig-personal
> [includeIf "gitdir:Projects/Work/**"]
> path = .gitconfig-work
>```
... and voilà! Now, the work repositories only need to be inside the `~/Projects/Work` directory and all commits will use the correct credentials, without any configurations by repository. The same goes to the *Personal* folder repositories. And if at any point, your work (or personal) git account email changes, just change the `.gitconfig-X` file corresponding to the folder and all repositories inside will use the new credential.
So... that's it! Try it and then tell me your experience in the comments, via [Twitter](https://twitter.com/tongedev) or [Instagram](https://www.instagram.com/tomb.dev)!
| devatreides |
614,230 | Animazioni con il Canvas di javascript: Come animare con gli sprite | Animazione gli sprites con il canvas | 0 | 2021-09-24T09:22:20 | https://dev.to/camizzilla/animazioni-con-il-canvas-di-javascript-come-animare-con-gli-sprite-3m2l | javascript, canvas, sprites, spritesheet | ---
title: Animazioni con il Canvas di javascript: Come animare con gli sprite
published: true
description: Animazione gli sprites con il canvas
tags: js, canvas, sprites, spritesheet
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/8m55nddwh0p5skfs34ie.jpg
---
Se volessimo creare una presentazioni animata o un videogioco con una grafica "non vettoriale" ma con una grafica raster (pixellosa) dovremmo __imparare a gestire gli sprites__.

Ma cosa sono gli sprites?
__Gli sprites sono delle immagini in sequenza__ che fatte scorrere ad una certa velocità ingannano l'occhio facendolo sembrare in movimento.

Per implementare gli sprite nel canvas abbiamo bisogno di uno spritesheet cioè __un immagine che contiene tutte le sequenze__ della nostra animazione. Come in questo esempio.

Se come me non siete dei grandi grafici, ci sono un sacco di risorse in internet. Li potete trovare tra gli archivi di immagini o in siti come
* https://itch.io/game-assets
* https://www.spriters-resource.com/ (quest'ultima è sotto copyright, quindi se li usate fatelo per uso personale)
* https://opengameart.org/
Io ho scelto di animare __questo cane che corre__, è __uno spritesheet semplice su una sola riga con 4 fasi dell'animazione__, più avanti vedremo sprite più complessi su più righe e che comanderemo con i tasti.
###INIZIALIZIAMO
Iniziamo inizializando un elemento _canvas_ grande 600x400, stampando, a video l'immagine (spritesheet) che contiente i 4 sprite una volta caricata.
* **HTML**
``` html
<canvas id="myCanvas"></canvas>
```
* **JS**
``` js
var canvas = document.getElementById("myCanvas");
var ctx = canvas.getContext("2d");
canvas.width = 600;
canvas.height = 400;
let img = new Image();
img.src = 'https://i.ibb.co/tmdzwtT/dog.jpg';
img.addEventListener('load', () => {
ctx.drawImage(img, 0, 0);
})
```
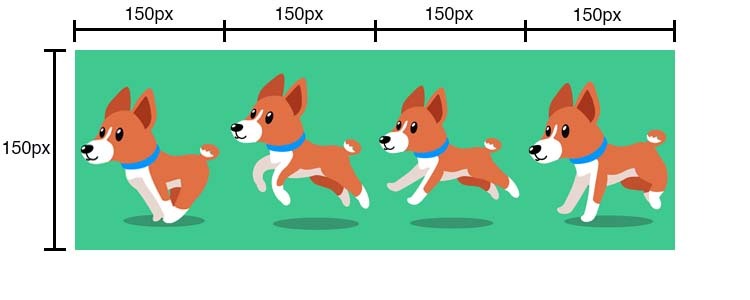
Una volta caricata, si vede __un'immagine 600 x 200 divisa in 4 frame della grandezza di 150 x 200 che comporranno la nostra animazione__.
Visto che a noi serve solo un frame alla volta dobbiamo __creare una maschera di 150 x 200 che mostra solo un frame alla volta__.
Questa operazione di ritaglio si può fare direttamente con il metodo ctx.drawImage che ha delle opzioni che ci premettono di visualizzare a video sono una pozione rettangolare di un immagine.
Avevo già trattato in questo post, ["Canvas Javascript: Come disegnare immagini"](https://dev.to/camizzilla/canvas-javascript-come-disegnare-immagini-54in), come fare, ma oggi andremo a vedere come si può __utilizzare questo metodo per creare del movimento__.
__Ritagliamo lo spritesheet in modo da visualizzare solo il primo frame__.
Partiamo dalla coordinata dell'immagine 0, 0 (rX, rY) e tagliamo una porzione larga 150px (rL) e lunga 200px (rA) ( il rettangolo che contiene il primo frame)
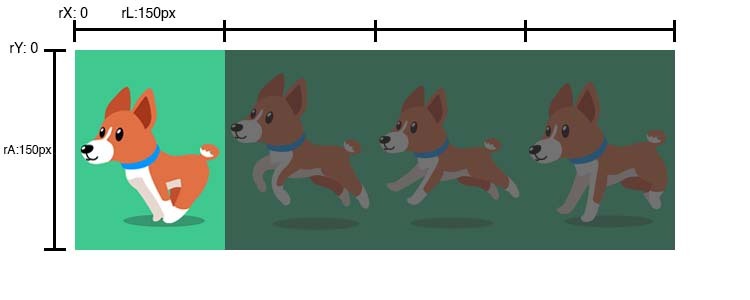
__Posizioniamo la maschera sul canvas__, circa al centro, alle coordinate 225, 100 (x,y) e lo visualizziamo con le stesse dimensioni del ritaglio, 150x200px (l, a)
``` js
img.addEventListener('load', () => {
//ctx.drawImage(img, rX, rY, rL, rA, x, y, l, a);
ctx.drawImage(img, 0, 0, 150, 200, 225, 100, 150, 200);
})
```
Adesso per creare l'effetto di movimento dobbiamo spostare la funzione _ctx.drawImage_ in un ciclo e far scorrere la maschera di ritaglio ad ogni frame e una volta finiti tornare al frame 0.

Creiamo una funzione loop che si chiamerà in modo ricorsivo grazie al metodo _requestAnimationFrame_ ad ogni fine ciclo.
_requestAnimationFrame_ è il metodo creato apposta per gestire i cicli nel canvas. Ne parlo in maniera più approfondita in questo post: ["Animazioni con il Canvas di javascript: Come cos'è e come implementarlo con un esempio base"](https://dev.to/camizzilla/animazioni-con-il-canvas-di-javascript-come-cos-e-e-come-implementarlo-con-un-esempio-base-gh)
``` js
let img = new Image();
img.src = 'https://i.ibb.co/d264Yhf/greeting.png';
img.addEventListener('load', () => {
requestAnimationFrame(loop)
})
let loop = () => {
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(img, 0, 0, 150, 200, 225, 100, 150, 200);
requestAnimationFrame(loop)
}
```
Al caricamento dell'immagine viene chiamata la funzione loop.
Che ha 3 metodi al suo interno: _clearRect_ che ripulisce il canvas, il metodo che stampa a video che abbiamo creato precedentemente e per ultimo _requestAnimationFrame(loop)_ che richiama se stessa.
Il prossimo passo è quello di aumentare il frame ad ogni ciclo.
Nel nostro caso sono 4 frames e vanno dal frame 0 al frame 3.

I frame si trovano ad una distanza di 150px, quindi il valore per rX sarà di:
* 0 per il frame 0
* 150px per il frame 1
* 300px per il frame 2
* 450px per il frame 3
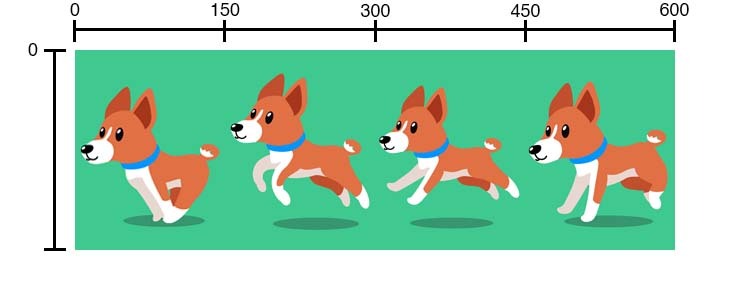
Da questo si può inturire che se moltiplichiamo il numero del frame con la larghezza (Lr) otterremo il valore rX.
rX = lr * frameCounter;
``` js
let lr= 150;
let frameCounter = 0;
let rX = 0
let loop = () => {
ctx.clearRect(0, 0, canvas.width, canvas.height);
rX = lr * frameCounter;
ctx.drawImage(img, rX, 0, lr, 200, 225, 100, 150, 200);
framecounter < 3 ? frameCounter++ : frameCounter = 0;
requestAnimationFrame(loop)
}
```
Nel primo ciclo il secondo argomento prende come risultato della moltiplicazione 150 * 0, quindi il ritaglio partirà dalla posizione 0, poi il framecounter aumenta di uno perchè il "frame" è minore di 3.
Nel secondo ciclo, il frame vale 1 che moltiplicato a 150 fa rX: 150... e cosi via 150 * 2 = 300, 150 * 3 = 450 e poi l'animazione ricomincia perchè il valore frame non è maggiore di 3 e il valore di framecounter tornerà a 0.
{% codepen https://codepen.io/camizzilla/pen/xxrjEjN %}
Se dovessimo lasciare il codice così, il nostro cane correrebbe troppo veloce, perchè gli fps, frame per secondo, sono troppo alti.
Gli fps sono dei valore che indicano quante volte il ciclo viene riprodotto in un secondo.
Niente paura, nel prossimo post, spegherò in maniera semplice cos'è l'fps e qual'è la tecnica per implementarlo al meglio.
Per adesso gli applicheremo un setTimeout che non è la miglior soluzione, ma sicuramente la più veloce
``` js
let lr= 150;
let frameCounter = 0;
let rX = 0
let framesPerSecond = 10;
let loop = () => {
setTimeout( () => {
ctx.clearRect(0, 0, canvas.width, canvas.height);
rX = lr * frameCounter;
ctx.drawImage(img, rX, 0, lr, 200, 225, 100, 150, 200);
frameCounter < 3 ? frameCounter++ : frameCounter = 0;
requestAnimationFrame(loop)
}, 1000 / framesPerSecond);
}
```
CONCLUSIONE
Abbiamo visto come gestire un animazione semplice con gli Sprites.
Successivamente vedremo gli fps per la gestire la velocità dei frame, come gestire SpriteSheet su più righe e come unire i comandi di tastiera con le animazioni.
Se avete dei consigli, suggerimenti o critiche costruttive lasciatemi un commento qui sotto oppure contattatemi trammite i miei social.
| camizzilla |
616,214 | Day.js with RelativeTime in Nuxt.js | This is a relatively short guide, and it's just to show how easy it is to implement day.js inside a... | 0 | 2021-02-23T23:21:42 | https://dev.to/seankerwin/day-js-with-relativetime-in-nuxt-js-3kk9 | dayjs, nuxt, vue | This is a relatively short guide, and it's just to show how easy it is to implement [day.js](https://day.js.org/) inside a Nuxt app.
I've always just used Moment.js for date formatting, but since Moment.js has now been abandoned and they're encouraging people to use alternatives, I needed to find a way to convert timestamps that are provided by the API's I consume. They usually return timestamps in the following format:
```
2020-10-08T07:51:58Z
```
Which to be honest, isn't really useful to anyone. That's where day.js comes in, it can convert the timestamp above into something like
```
Oct 8th 2020
```
It's pretty simple to do.
First we need to pull in the `@nuxtjs/dayjs` package with the following command.
```
yarn add @nuxtjs/dayjs
or
npm install @nuxtjs/dayjs
```
Once that is installed, open up your `nuxt.config.js` and add
`'@nuxtjs/dayjs'` to the `modules` section, and then outside of that, add the following `dayjs` object.
```js
modules: [
'@nuxtjs/dayjs',
...
],
dayjs: {
locales: ['en'],
defaultLocale: 'en',
plugins: ['relativeTime', 'advancedFormat'],
},
```
Set any *locales* you want, for me, being in the United Kingdom, I set my locale to `en` and then add any additional dayjs plugins you need. I'm using the [RelativeTime](https://day.js.org/docs/en/plugin/relative-time) and [AdvancedFormat](https://day.js.org/docs/en/plugin/advanced-format) plugins.
Once everything is installed, you from within any component you can do the following
```js
{{ $dayjs('2020-10-08T07:51:58Z').format('MMM Do YYYY') }}
```
Which will output this
```
Oct 8th 2020
```
You can also use the RelativeTime plugin to turn it into this:
```js
{{ $dayjs('2020-10-08T07:51:58Z').fromNow() }}
```
Which will return
`a year ago`
You can obviously, not use hard-coded dates and use props/variables such as
```js
{{ $dayjs(post.published_at).fromNow() }}
```
Day.js is a simple and ultra-lightweight replacement for Moment.js and is super easy to use.
| seankerwin |
614,394 | Free and open source Bootstrap 5 UI Kit | Hello devs 👋🏻 Today I want to show you a Bootstrap 5 UI Kit which we've been working on for about a... | 0 | 2021-02-22T10:10:20 | https://themesberg.com/product/ui-kit/pixel-free-bootstrap-5-ui-kit | opensource, bootstrap, css, javascript | Hello devs 👋🏻
Today I want to show you a Bootstrap 5 UI Kit which we've been working on for about a year with my friend. The first version one year ago was based on Bootstrap 4, but now that Bootstrap 5 has been updated to Beta we thought it was time to update the whole kit once again.
We used NPM, Gulp, and Sass to manage libraries, compile source files, and more easily change and update styles using the variables and mixins from Sass.

Pixel Bootstrap 5 UI Kit features over 80 UI components including date pickers, modals, pricing cards, profile cards, blog cards, and also 5 example pages.
## Workflow
* Most popular CSS Framework Bootstrap
* Productive workflow tool Gulp
* Awesome CSS preprocessor Sass
So without further ado, let me show you how you can install and use this Bootstrap 5 based UI Kit.
## Quick start
1. Download for free from [Themesberg](https://themesberg.com/product/ui-kits/pixel-lite-free-bootstrap-4-ui-kit?ref=github-pixel-lite-bootstrap) or [clone the repository on Github](https://github.com/themesberg/pixel-bootstrap-ui-kit)
2. Make sure you have Node and NPM installed on your machine
3. Download Gulp Command Line Interface to be able to use gulp in your Terminal:
```
npm install gulp-cli -g
```
4. After installing Gulp, run `npm install` in the main pixel/ folder to download all the project dependencies. You'll find them in the `node_modules/` folder.
5. Run `gulp` in the pixel/ folder to serve the project files using BrowserSync. Running gulp will compile the theme and open `/index.html` in your main browser.
While the gulp command is running, files in the `assets/scss/`, `assets/js/` and `components/` folders will be monitored for changes. Files from the `assets/scss/` folder will generate injected CSS.
Hit `CTRL+C` to terminate the gulp command. This will stop the local server from running.
## Theme without Sass, Gulp or Npm
If you'd like to get a version of our theme without Sass, Gulp or Npm, we've got you covered. Run the following command:
```
gulp build:dev
```
This will generate a folder `html&css` which will have unminified CSS, Html and Javascript.
## Minified version
If you'd like to compile the code and get a minified version of the HTML and CSS just run the following Gulp command:
```
gulp build:dist
```
This will generate a folder `dist` which will have minified CSS, Html and Javascript.
## Documentation
The documentation for Pixel Bootstrap UI Kit is hosted on our [website](https://themesberg.com/docs/pixel-bootstrap/getting-started/overview).
## File Structure
Within the download you'll find the following directories and files:
```
Pixel Bootstrap UI Kit
.
├── LICENSE
├── README.md
├── dist
│ ├── assets
│ ├── css
│ ├── html
│ ├── index.html
│ └── vendor
├── gulpfile.js
├── html&css
│ ├── assets
│ ├── css
│ ├── html
│ ├── index.html
│ └── vendor
├── package-lock.json
├── package.json
└── src
├── assets
├── html
├── index.html
├── partials
└── scss
```
## Resources
- Demo: <https://demo.themesberg.com/pixel-bootstrap-5-ui-kit/index.html>
- Download Page: <https://themesberg.com/product/ui-kits/pixel-lite-free-bootstrap-4-ui-kit?ref=github-pixel-lite-bootstrap>
- Documentation: <https://themesberg.com/docs/pixel-bootstrap/getting-started/overview?ref=github-pixel-lite-bootstrap>
- License Agreement: <https://themesberg.com/licensing?ref=github-pixel-lite-bootstrap>
- Support: <https://themesberg.com/contact?ref=github-pixel-lite-bootstrap>
- Issues: [Github Issues Page](https://github.com/themesberg/pixel-bootstrap-ui-kit/issues)
## Reporting Issues
We use GitHub Issues as the official bug tracker for Pixel Pro Bootstrap UI Kit. Here are some advices for our users that want to report an issue:
1. Make sure that you are using the latest version of Pixel Pro Bootstrap UI Kit. Check the CHANGELOG from your dashboard on our [website](https://themesberg.com?ref=github-pixel-lite-bootstrap).
2. Providing us reproducible steps for the issue will shorten the time it takes for it to be fixed.
3. Some issues may be browser specific, so specifying in what browser you encountered the issue might help.
## Technical Support or Questions
If you have questions or need help integrating the product please [contact us](https://themesberg.com/contact?ref=github-pixel-lite-bootstrap) instead of opening an issue.
## Licensing
- Copyright 2020 Themesberg (Crafty Dwarf LLC) (https://themesberg.com)
- Themesberg [license](https://themesberg.com/licensing#mit) (MIT License)
## Useful Links
- [More themes](https://themesberg.com/themes) from Themesberg
- [Free themes](https://themesberg.com/templates/free) from Themesberg
- [Bootstrap Themes, Templates & UI Kits](https://themesberg.com/templates/bootstrap) from Themesberg
- [Affiliate Program](https://themesberg.com/affiliate?ref=github-pixel-lite-bootstrap)
##### Social Media
Twitter: <https://twitter.com/themesberg>
Facebook: <https://www.facebook.com/themesberg/>
Dribbble: <https://dribbble.com/themesberg>
Instagram: <https://www.instagram.com/themesberg/>
| zoltanszogyenyi |
614,550 | Figuring it out no matter what ~ Leo Lima | Bringing you the next episode of Everyone Sucks, I (Kartik Budhiraja) had the honour to have... | 0 | 2021-02-22T13:41:56 | https://dev.to/kartikbudhiraja/figuring-it-out-no-matter-what-leo-lima-59hf | motivation, frontend, podcast, softwareengineering | ---
title: Figuring it out no matter what ~ Leo Lima
published: true
date: 2021-02-22 13:29:18 UTC
tags: motivation,frontenddevelopment,podcast,softwareengineering
canonical_url:
---

Bringing you the next episode of Everyone Sucks, I ([Kartik Budhiraja](https://medium.com/u/56d3cb6a43ed)) had the honour to have [Leonardo Lima](https://medium.com/u/5ad35097ded0) as the guest for this episode. Leo is from Brazil and is currently working as a Senior Software Engineer at a crypto marketplace company.
His story of being in development is really fascinating, as he studied journalism but pivoted into software development later. He talks about how many challenges he faced not being from a computer science background and how he was able to find what he loves and gets better at it.
Some key takeaways:
### Never complain
Leo provides us all with an example of making the best of our resources without complaining. For his very first internship interview (which he got by sending a cold-email to the founder of the company), he was given a coding assignment. Fortune playing its usual role, Leo was moving at that time and ended up being without an internet connection at his place with an assignment to do in a programming language he did not have experience in ( If you’re a developer, you can imagine how hard can that be). But instead of complaining, Leo actually spent his days at the public library as they had internet and finished the assessment on time.
Talk about finding a way out no matter what.
### Build and use the support network around you
When asked about his way of handling the pressure of moving into tech and dealing with the imposter syndrome, he talks about the importance of having a support network around oneself. He mentions how he used to talk with his best friend and other people around him openly about the challenges he’s facing and the doubts he has.
He puts it in a really impactful way by saying that “You do not have to fight alone. Help people around you and ask for help when you need it.”
### Transform self-doubt to fuel
At his first development job, Leo talks about how he always felt the pressure to prove himself. Not being from a computer science background, the self-doubt added additional pressure as one could imagine. Leo turned that self-doubt around and started using that as fuel for more focus. He talks about how he ended up taking his work with intense focus and putting in more hours just because he knew he had something to prove. It’s not to say that the pressure is good, it’s more to show that everyone feels that self-doubt, but the only thing we need to do with it eradicates it by focusing on what we can do i.e get after it and work with more focus.
### It’s always a people business
> “No matter what your role is, you have to remember it’s always a people business” ~ Leo
Leo tells how calling people as resources make him a bit uncomfortable as people are human, no matter what happens. He explains how important is it to remember this whether you’re a developer or in any other job. At the end of the day you are still working and communicating with people, so behave like one.
### Focus on what other person requires, not what you want to offer
When asked about his favourite failure, he talks about the importance of understanding other people’s needs. Through his own experience where he tried to help an intern by providing what he _thought_ would be the best for them. He explains how that backfired and reminded him that every person is different, just because you think that one thing would benefit that person, does not mean they would agree with you.
If you’re in a management role, take a step to figure out what your team wants first, and then work on providing them. Do not put the cart in front of the horse.
_Bonus Tip_: Coming from Journalism, writing is a major part of Leo’s life. He uses writing down the problem and its prospective solution to break it down into chunks and suggests everyone give it a shot.
Please feel free to reach out to Leo if anyone needs any guidance. You can find Leo online on Twitter at @leocavia.
We talked about a lot of other cool stuff, join us on youtube, Spotify, and every other place you get your podcast from. (Search for Everyone Sucks)
Spotify: [https://open.spotify.com/episode/6sm92aEs2vO8ES3KfegM3E?si=oHd4uv6qROKk5MBxH6pcdg](https://open.spotify.com/episode/6sm92aEs2vO8ES3KfegM3E?si=oHd4uv6qROKk5MBxH6pcdg)
{% youtube xbdXiHxth3w %}
* * * | kartikbudhiraja |
614,884 | The font-size trick in layouts | When you try to fit two 50% containers and they stack down | 0 | 2021-04-22T19:13:14 | https://dev.to/kenystev/the-font-size-trick-in-layouts-4joe | css, html, tips, webdev | ---
title: The font-size trick in layouts
published: true
description: When you try to fit two 50% containers and they stack down
tags: css, html, tips, webdev
//cover_image: https://direct_url_to_image.jpg
---
Have you ever faced the issue when 50% and 50% does not fit in 100%? 🤯 Where has the math gone?
I remember my first days learning CSS, putting markup tags here and there then styling them out! yeah! the least aesthetic page ever xD
Flexbox had just appeared and then barely used, we still fought aligning items with `float: left` and `float: right` and the famously used `clear: both`
Nothing worse than dealing with those properties and then boom! we played the fools trying to split a view evenly in two pieces 50/50 using `display: inline-block` and `width: 50%` ending with something like this:
### HTML
```html
<div class="container">
<div class="item">
item 1
</div>
<div class="item">
item 2
</div>
</div>
```
### CSS
```css3
.container {
width: 100%;
}
.item {
display: inline-block;
width: 50%;
}
```
# Fooling!
And you know the end, how 50% plus 50% is different than 100%? then more than one ended doing the weirdest thing ever done 50% and 49% 🤦🏻♂️ others tried to heal the wound a bit by evenly distributing the difference like 49.5% and 49.5%
But you know what? just to make it worse guess what? That's not gonna behave as well as expected if you're aiming for responsive views
# Problem solved!
Do you know what's the real issue here?
Well it's even simpler than you thought! The reason why 50/50 doesn't fit 100 is because of the `font-size` yeah!
Remember we're using `display: inline-block` right? to change the default `block` value of divs, and as fact in CSS all the inline elements by default share a property called `font-size`.
Wait! divs could have `font-size`? for sure they can once you change their display property from *block* to *inline*, even *inline-block*
## Conclusion
If you do not set a `font-size` property to your 50/50 elements they will inherit from their parent (which most of the time might not be zero)
All you have to do is set `font-size: 0;` to your items and boom! out of magic everything will work! Here's an example of the result so you could check it out:
{% codepen https://codepen.io/kenystev/pen/PoGMRNe %}
### Before you go!
Note: The example above it's working pretty well just because we don't have content inside those divs, once you have some content there by default most of the browsers set the property `box-sizing: content-box;` and I'd suggest you to set that property to `box-sizing: border-box;`.
Thanks for reading and see you soon... 🤗 | kenystev |
615,072 | Downloading and Displaying a file in React Native | React Native does not currently offer full support for downloading and showing a file. The approach i... | 0 | 2021-02-22T21:12:17 | https://dev.to/johannawad/how-to-download-and-display-a-file-in-react-native-26d8 | reactnative, firstpost, typescript, javascript | React Native does not currently offer full support for downloading and showing a file. The approach in this article shows you how to download and display a file using the [react-native-fs](https://github.com/itinance/react-native-fs) and [react-native-webview](https://github.com/react-native-webview/react-native-webview) libraries respectively.
In this example, the file is of a PDF format, however, the same approach can be used for images or other text file formats.
###Prerequisites:
A working React Native App. Not sure how to do this? Checkout the setup instructions on the [React Native Website](https://reactnative.dev/docs/getting-started).
##Downloading the file
###Install react-native-fs:
```
yarn add react-native-fs
```
or
```
npm install react-native-fs
```
If you're using React Native version 0.60.0 or higher, it a does auto-linking for you. If not, check the extra setup instructions on react-native-fs page.
Install the CocoaPods dependencies (iOS specific):
```
cd ios && pod install
```
###Using downloadFile function:
In this example, I will be retrieving a PDF file from an API endpoint using the downloadFile function from `react-native-fs`. This function has two required parameters - fromUrl and toFile , along with several other optional ones. I created an async function downloadPDF which requires a url and fileName. It also contains a basic header with an authorization token and content-type.
React-native-fs' DocumentDirectoryPath provides the Android or iOS where documents are stored. You can change this to your customised path if you wish.
```javascript
downloadPDF = async (url: string, fileName: string): Promise<any> =>{
//Define path to store file along with the extension
const path = `${DocumentDirectoryPath}/${fileName}.pdf`;
const headers = {
'Accept': 'application/pdf',
'Content-Type': 'application/pdf',
'Authorization': `Bearer [token]`
}
//Define options
const options: DownloadFileOptions = {
fromUrl: [baseUrl] + url,
toFile: path,
headers: headers
}
//Call downloadFile
const response = await downloadFile(options);
return response.promise.then(async res =>
//Transform response
if(res && res.statusCode === 200 && res.bytesWritten > 0 &&
res.path){
doSomething(res)
}else{
logError(res)
}};
```
The response from downloadFile contains `statusCode` , `jobId` and `bytesWritten` . To know if a request is successful, check whether the `statusCode` is `200` and the `bytesWritten` > `0`. It is important to check both values because, I found it returning 200 even when no files were written.
I saved the `path` in the Redux's `state` to later retrieve the file.
##Opening the saved file in a WebView
###Install react-native-webview:
```
yarn add react-native-webview
```
or
```
npm install react-native-webview
```
Again, install the CocoaPods dependencies (iOS specific):
```
cd ios && pod install
```
###Implementing the WebView:
Create a React Funcional Component containing a WebView .
```javascript
const WebViewComponent: React.FunctionComponent = ({ navigation, route}: any): JSX.Element => (
<WebView
source={{ uri: "file://"+ path}}
style={{ flex: 1 }}
originWhitelist={["*"]}
/>
)};
export default WebViewComponent;
```
The WebView source's URI should point to `file://` + `pathToFile` . Don't forget to include the `style` property and set `flex:1` as shown above. | johannawad |
615,080 | Easily embed React apps into WordPress with ReactPress plugin | Why React and WordPress WordPress and React are a killer combination to develop web apps. With Wo... | 0 | 2021-02-22T21:39:05 | https://rockiger.com/en/easily-embed-react-apps-into-wordpress-with-reactpress-plugin/ | react, wordpress, webdev | 
<!-- wp:heading -->
<h2>Why React and WordPress</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><a href="https://www.wordpress.org" target="_blank" aria-label="WordPress (opens in a new tab)" rel="noreferrer noopener" class="rank-math-link">WordPress</a> and <a href="https://reactjs.org" target="_blank" aria-label="React (opens in a new tab)" rel="noreferrer noopener" class="rank-math-link">React</a> are a killer combination to develop web apps.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>With WordPress you get:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>easy content management for help pages, your landing page, your blog, and your other marketing activities</li><li>secure and proven user management</li><li>over 100.000 plugins</li><li>a lot of flexibility over time to change the character of your site</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>React brings you the largest ecosystem to build great rich JavaScript apps that allow a simple data model, good performance and are easy to test.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>For example, if we want to write a new revolutionary email app, we can write the interface of the email client with React, but for everything else use WordPress. So while you're developing your app, you might want to:</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>choose and install a theme</li><li>create a landing page for your app</li><li>add a form to collect email addresses</li><li>create a blog and publish your posts on Twitter to promote your app</li><li>optimize your site for search engines</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Later it might be useful to</p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>offer a paid membership</li><li>create a forum or FAQ</li><li>create separate landing pages</li><li>all this can easily be done with WordPress, without writing a single line of code.</li></ul>
<!-- /wp:list -->
<!-- wp:heading -->
<h2>Embedding a React app into WordPress with ReactPress</h2>
<!-- /wp:heading -->
<!-- wp:image {"align":"left","id":1359,"width":256,"height":256,"sizeSlug":"large","linkDestination":"none"} -->
<div class="wp-block-image"><figure class="alignleft size-large is-resized"><img src="https://rockiger.com/wp-content/uploads/icon-256x256-1.png" alt="" class="wp-image-1359" width="256" height="256"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>While there are other ways to integrate React with WordPress, the <a aria-label="ReactPress (opens in a new tab)" href="https://wordpress.org/plugins/reactpress/" target="_blank" rel="noreferrer noopener" class="rank-math-link">ReactPress</a> plugin is the easiest to embed a React app into a WordPress page and lets you use <a aria-label="create-react-app (opens in a new tab)" href="https://reactjs.org/docs/create-a-new-react-app.html" target="_blank" rel="noreferrer noopener" class="rank-math-link">create-react-app</a> without any custom build configurations.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Not only does ReactPress automate the React integration for you, but it also ensures a seamless development experience, through running your local React dev server with the theme of your WordPress site.</p>
<!-- /wp:paragraph -->
<!-- wp:group {"backgroundColor":"light-background"} -->
<div class="wp-block-group has-light-background-background-color has-background"><div class="wp-block-group__inner-container"><!-- wp:heading {"level":3,"style":{"typography":{"fontSize":20}}} -->
<h3 style="font-size:20px">Why not just using headless WordPress with SSR</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>I know that headless WordPress with <a aria-label="Next.js (opens in a new tab)" href="https://nextjs.org" target="_blank" rel="noreferrer noopener" class="rank-math-link">Next.js</a>, <a aria-label="Gatsby (opens in a new tab)" href="https://www.gatsbyjs.com" target="_blank" rel="noreferrer noopener" class="rank-math-link">Gatsby</a>, or <a aria-label="Frontity (opens in a new tab)" href="https://frontity.org" target="_blank" rel="noreferrer noopener" class="rank-math-link">Frontity</a> is all the rage right now, but with these solutions, you add a layer of complexity to your app, and more importantly, you lose a lot of the benefits of the WordPress ecosystem (themes and plugins).</p>
<!-- /wp:paragraph --></div></div>
<!-- /wp:group -->
<!-- wp:paragraph -->
<p></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The steps from development to deployment are:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true,"start":0} -->
<ol start="0"><li>Setup your local dev environment.</li><li>Install ReactPress on your local WordPress installation</li><li>Create a new React app from your WP installation</li><li>Develop your React app</li><li>Build the app</li><li>Install ReactPress on live WordPress site</li><li>Create the same React app there</li><li>Upload the build of your React app to your live site to deploy it.</li></ol>
<!-- /wp:list -->
<!-- wp:embed {"url":"https://youtu.be/pVi07A_OZYA","type":"video","providerNameSlug":"youtube","responsive":true,"className":"wp-embed-aspect-16-9 wp-has-aspect-ratio"} -->
<figure class="wp-block-embed is-type-video is-provider-youtube wp-block-embed-youtube wp-embed-aspect-16-9 wp-has-aspect-ratio"><div class="wp-block-embed__wrapper">
https://youtu.be/pVi07A_OZYA
</div><figcaption>The video shows the process with the TwentyTwenty-theme.</figcaption></figure>
<!-- /wp:embed -->
<!-- wp:paragraph -->
<p>Repeat steps 3, 4 and 7 until your app is finished.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Setup your local dev environment.</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>To develop React apps your WordPress installations needs access to: </p>
<!-- /wp:paragraph -->
<!-- wp:list -->
<ul><li>the PHP function <code>shell_exec</code> and <code>exec</code>,</li><li>the <code>nodejs</code> package manager <code>npm</code> version 6 or higher</li><li>and a POSIX compatible system</li></ul>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>This means <a aria-label="Local by Flywheel (opens in a new tab)" href="https://localwp.com" target="_blank" rel="noreferrer noopener" class="rank-math-link">Local by Flywheel</a> won't work, because you don't have control over the node environment there. The easiest way to create a local WordPress installation that fits the requirements is using the <a aria-label="Bitnami-Installers (opens in a new tab)" href="https://bitnami.com/stack/wordpress/installer" target="_blank" rel="noreferrer noopener" class="rank-math-link">Bitnami-Installers</a>. They provide a self-contained installation that doesn't pollute your system. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>However you install your WordPress dev system, if it meets the requirements you should be fine.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Install ReactPress on your local WordPress installation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In your local WordPress go to plugin installation, search for <strong>ReactPress</strong>, install and activate the plugin.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Create a new React app from your local WP installation</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>In the admin of your WP installation, click on <strong>ReactPress</strong> in the sidebar. There you should see a form to create a new React app.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Enter a <strong>name</strong> (later you need to use the same name in the live system), enter a <strong>pageslug</strong>, choose the type "<strong>Develop a new app (Usually on a local machine).</strong>" and choose the <strong>create-react-app-template</strong> you would like to use and finally click the "<strong>Create React App</strong>" button.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>After a short while your app should be created and running at port: <strong>3000</strong>. If you click on the link you can see your local dev app running in the theme of your WP installation.</p>
<!-- /wp:paragraph -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://ps.w.org/reactpress/assets/screenshot-2.png?rev=2471443" alt=""/><figcaption>ReactPress with running React app <strong>reactino</strong>.</figcaption></figure>
<!-- /wp:image -->
<!-- wp:heading {"level":3} -->
<h3>Develop your React app</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Now you can develop your React app as you are used to. Use <a href="https://developer.wordpress.org/rest-api/" target="_blank" aria-label="WordPress's built-in REST-API (opens in a new tab)" rel="noreferrer noopener" class="rank-math-link">WordPress's built-in REST-API</a> to get data or use the <a href="https://www.wpgraphql.com" target="_blank" aria-label="WPGraphQL plugin (opens in a new tab)" rel="noreferrer noopener" class="rank-math-link">WPGraphQL plugin</a> if you prefer <a href="https://graphql.org" target="_blank" aria-label="GraphQL (opens in a new tab)" rel="noreferrer noopener" class="rank-math-link">GraphQL</a>.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Build the app</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>If you want to deploy to your live site, build your app through the WP admin. Don't use the CRA command line for this!</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Install ReactPress on live WordPress site</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Before you upload your React app, install ReactPress on your live site the same way you did on your local installation.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Create the same React app there</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Create the same React app on your live system, that you created on your local system. <em>Important!</em> Use the <em>exact same name</em> and this time choose "<strong>Deploy an already build app (Usually on a server).</strong>" as the type.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>Upload the build of your React app to your live site to deploy it.</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Finally, upload the build of your React app. Upload the build folder of your local React app to the app on your live system. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The ReactPress admin shows where your apps are located. It will be something like this: <code>.../htdocs/wp-content/plugins/reactpress/apps/[your-appname]</code>.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>If you click on the URL slug of your React app in ReactPress you should see your React app on your live system.</p>
<!-- /wp:paragraph -->
<!-- wp:image -->
<figure class="wp-block-image"><img src="https://ps.w.org/reactpress/assets/screenshot-6.png?rev=2471443" alt=""/><figcaption>Deployed React app embedded into live WordPress site with TwentyTwenty-theme.</figcaption></figure>
<!-- /wp:image -->
<!-- wp:heading -->
<h2>Where to go from here?</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>You should be able to create React app embedded in WordPress now. If you have the next big app idea you are ready to start. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>If you have any questions, let me know in the comments.</p>
<!-- /wp:paragraph --> | rockiger |
616,265 | How to Add Your Recently Published Medium Articles to Your GitHub Readme | Show off your latest Medium work on GitHub Photo by Christin Hume on Unsplash. GitHub recently... | 0 | 2021-03-22T06:26:02 | https://betterprogramming.pub/add-your-recent-published-mediums-article-on-github-readme-9ffaf3ad1606 | softwaredevelopment, opensource, medium, github | ---
title: How to Add Your Recently Published Medium Articles to Your GitHub Readme
published: true
date: 2020-08-16 16:32:37 UTC
tags: softwaredevelopment,opensource,medium,github
canonical_url: https://betterprogramming.pub/add-your-recent-published-mediums-article-on-github-readme-9ffaf3ad1606
---
> Show off your latest Medium work on GitHub
<figcaption>Photo by <a href="https://unsplash.com/@christinhumephoto?utm_source=medium&utm_medium=referral">Christin Hume</a> on <a href="https://unsplash.com?utm_source=medium&utm_medium=referral">Unsplash</a>.</figcaption>
GitHub recently released a new feature that allows you to create a Readme profile, so you can now customize your GitHub profile page.
You can see an example on [my GitHub profile](https://github.com/bxcodec):
<figcaption>My GitHub profile.</figcaption>
This feature is really nice. It makes your GitHub profile look more professional and content-rich. In the future, I expect GitHub to look like LinkedIn for developers.
### Introducing GitHub Readme — Recent Medium Articles
I’ve seen a lot of plug-ins that people have made, like the GitHub stats card, programming language stats, and even games (e.g. this [online chess game](https://github.com/timburgan/timburgan) or even [tic-tac-toe](https://github.com/alfari16/alfari16)).
In [this readme](https://github.com/alfari16/alfari16), the user has included a list of their recently published Medium articles. But it’s only available on their profile. To achieve the same results, I need to copy their code, which takes time.
That’s the original idea behind this plug-in. I created a separate repository with a customized function. I then made the function more generic so everyone can add their recently published Medium articles to their GitHub readme.
{% youtube hk6MoV-qWW8 %}
### Steps
To use this plug-in, you only need to add this script to your GitHub readme:
<iframe src="" width="0" height="0" frameborder="0" scrolling="no"><a href="https://medium.com/media/60fa24f400869923cd2f970850db9bf1/href">https://medium.com/media/60fa24f400869923cd2f970850db9bf1/href</a></iframe>
So the format is:
```
https://github-readme-medium-recent-article.vercel.app/medium/<medium-username>/<article-index>
```
- medium-username: Your medium username/profile
- article-index : Your recent article index (e.g. 0 means your latest article)
The full steps can be seen in [my repository](https://github.com/bxcodec/github-readme-medium-recent-article). Also if you’ve found any issues, just open an issue or create a PR directly on that repository.
### More About This Plug-In
- I’m using [Vercel](https://vercel.com/) for the static hosting and the serverless function to retrieve the recent articles. I might be able to add a custom domain, but that’s for later.
- I’m using an RSS feed from Medium. You can get your RSS feed from Medium by entering this URL: [https://medium.com/feed/@](https://medium.com/feed/@imantumorang)yourMediumUsername.
- Then convert it to JSON using API RSS to JSON:
```
[https://api.rss2json.com/v1/api.json?rss\_url=https://medium.com/feed/@imantumorang](https://api.rss2json.com/v1/api.json?rss_url=https://medium.com/feed/@imantumorang)
```
- Make it generic so everyone is able to use it.
To make it generic so people can directly pass their Medium username to the serverless function:
```
https://github-readme-medium-recent-article.vercel.app/medium/@imantumorang
```
I need to make the folder of my serverless function as follows:
```
└── medium
└── [user]
└── [index].ts
```
The [user] directory is required so I can make the username dynamic. I was stuck on this problem when I was making the plug-in. Actually, I can create it using query-param like ?username=@imantumorang, but from my experience and keeping REST in mind, making it path-param is the proper way to tell that the param is required. Also, I want to keep the experience the same as when you’re visiting your Medium profile (e.g. medium.com/@imantumorang).
I knew that comments in the Medium articles would be added automatically to the RSS. To only display the article, I added a filter function on the function:
```
if (thumbnail.includes("cdn")) {
fixItem.push(element)
}
```
So I only enabled articles that have a thumbnail. I’m still looking for a workaround for this because if the article doesn’t have any thumbnail, it will be skipped. At least for now, if your article has a thumbnail, it will be displayed when we import it to your GitHub readme.
It may take time to be able to get your recent article to be listed (for a new article) since the API RSS to JSON is cached. Please wait around 1-3 hours after the article has been published on Medium.
### Conclusion
Well, I think that’s all for now. If you find any issues, you can directly open an issue on GitHub. I’ll try to help as much as I can.
* * * | bxcodec |
615,361 | Project 50 of 100 - Firebase Sign Up and Login with React Router | Hey! I'm on a mission to make 100 React.js projects ending March 31st. Please follow my dev.to profil... | 0 | 2021-02-23T06:15:36 | https://dev.to/jameshubert_com/project-50-of-100-firebase-sign-up-and-login-with-react-router-5fbn | react, javascript, 100daysofcode | *Hey! I'm on a mission to make 100 React.js projects ending March 31st. Please follow my dev.to profile or my [twitter](https://www.twitter.com/jwhubert91) for updates and feel free to reach out if you have questions. Thanks for your support!*
Link to the deployed project: [Link](https://100-react-projects-day-50-compras-auth.netlify.app/)
Link to the repo: [github](https://github.com/jwhubert91/100daysofreact/tree/master/day-50-react-router-firebase-auth)
Today I made an authentication flow using React, React Router, and Firebase. I adapted the structure [from an earlier project]() for something new with a new UI here, but the main principles are the same. This will just be a short post highlighting the main functionalities here and how they're implemented.
We just have four components- the `App` component, `SignUp`, `Login` and `GlobalNavbar`. I have other components in the repo but they're not being used so feel free to ignore them. All of the magic happens in the App component where we import `react-router-dom` for our routing functionality.
```
# App.js
import React,{useState} from 'react';
import {auth} from './firebase';
import {
BrowserRouter as Router,
Route,
Switch,
Link
} from 'react-router-dom';
import SignUp from './pages/SignUp';
import SignIn from './pages/SignIn';
import GlobalNavbar from './components/GlobalNavbar';
```
As you can see we also import a custom {auth} object that we created in a local `firebase` file. That's just a js file we store in the src folder that imports the relevant firebase node modules and initializes them, and their connection to Firebase:
```
# firebase.js
import firebase from "firebase/app";
import "firebase/analytics";
import "firebase/auth";
import "firebase/firestore";
const firebaseConfig = {
apiKey: process.env.REACT_APP_FIREBASE_API_KEY,
authDomain: process.env.REACT_APP_FIREBASE_AUTH_DOMAIN,
projectId: process.env.REACT_APP_FIREBASE_PROJECT_ID,
storageBucket: process.env.REACT_APP_FIREBASE_STORAGE_BUCKET,
messagingSenderId: process.env.REACT_APP_FIREBASE_MESSAGING_SENDER_ID,
appId: process.env.REACT_APP_FIREBASE_APP_ID,
measurementId: process.env.REACT_APP_FIREBASE_MEASUREMENT_ID
};
// Initialize Firebase
firebase.initializeApp(firebaseConfig);
firebase.analytics();
export const auth = firebase.auth();
export default firebase;
```
As you can see I am storing that sensitive Firebase API information in environment variables. The node package `nodenv` allows us to create environment variables that can easily be left out of git commits by creating a .env file in the root of the project folder and putting our React App variables there with the following format:
```
REACT_APP_API_KEY=123123123123
```
You can then access those variables (after a server restart) by calling process.env.REACT_APP_API_KEY in your src folder files. Make sure those variables start with REACT_APP_ or CRA won't pick them up.
Anyway, the firebase.js file above initializes the connection to Firebase and imports the relevant methods for Firebase auth, analytics, and firestore. We export firebase.auth() just for convenience and brevity.
I trust you know how to make a form in React using text inputs- so I won't go over those. You just need an email and password text inputs plus a button to make this work. I'll just go over the Firebase methods used here:
To sign up a user with an email simply use `firebase.auth().createUserWithEmailAndPassword(email,password)` where email and password are text strings. I do this in the following function (after some basic validation):
```
const handleSignUp = () => {
if (handleConfirmPassword()) {
// password and confirm password match!
auth.createUserWithEmailAndPassword(email,password)
.then(result => {
alert(email+' signed in successfully',clearFields());
})
.catch(function(error) {
// Handle Errors here.
const errorCode = error.code;
const errorMessage = error.message;
if (errorCode === 'auth/weak-password') {
alert('The password is too weak.');
} else {
alert(errorMessage);
}
console.log(error);
});
clearFields()
}
}
```
This function will alert the user whether or not the submission was successful and tell the user why if there was an error.
In the SignIn page we have a similar setup. A simple form that takes an email and password. For that the functionality is very similar and we use the `firebase.auth().ignInWithEmailAndPassword(email, password)` method like so:
```
const logUserIn = () => {
auth.signInWithEmailAndPassword(email, password)
.then(result => {
alert(email+' signed in successfully',clearFields());
})
.catch(function(error) {
// Handle Errors here.
const errorCode = error.code;
const errorMessage = error.message;
if (errorCode === 'auth/weak-password') {
alert('The password is too weak.');
} else {
alert(errorMessage);
}
console.log(error);
})
}
```
These two methods are the heart are sign in and sign up with Firebase, which takes a lot of pain out of your authentication flow.
After we've imported the pages into App.js we put them into a React Router Switch like so (with the `GlobalNavbar` component on top of everything so it is present regardless of the page we're on):
```
return (
<div className="App">
<Router>
<GlobalNavbar />
<Switch>
<Route path='/login'>
<SignIn />
</Route>
<Route>
<SignUp path='/' />
</Route>
</Switch>
</Router>
</div>
);
```
I haven't done anything with it yet in this application, but the Firebase method to check if there is a logged in user or not is the following:
```
const [userExists,setUserExists] = useState(false);
auth.onAuthStateChanged((user) => {
if (user) {
setUserExists(true);
console.log('Signed in as '+user.email);
} else {
setUserExists(false);
}
});
```
If you get creative you can imagine using that piece of `userExists` state to automatically route a user to a main dashboard or other authenticated page if they're logged in.
Lastly, I just want to tell you about what you need to do to make an app like this work on Netlify. This app really relies on React Router working, but React Router and Netlify don't necessarily play well together. In fact, if you just upload a project with React Router to Netlify it won't work, and when you try to follow a redirect Netlify will show you a "Page does not exist" error.
So, to deal with this, before we build the project we've got to add a file called _redirects to the public folder. This tells Netlify that any redirects will come back to the index.html page that is the root of your project.
I followed [this](https://community.netlify.com/t/netlify-page-not-found-when-sharing-react-router-dom-based-links/11744/6) and [this](https://dev.to/rajeshroyal/page-not-found-error-on-netlify-reactjs-react-router-solved-43oa) to get it going. Ultimately- it's just a matter of putting the following single line of code into that _redirects file:
```
/* /index.html 200
```
That's it! Sorry it's not as detailed today- but check the code in the repo and I'm sure you can follow along. As usual if you get stuck don't be afraid to ping me in the comments :) | jameshubert_com |
615,393 | An better way to map over components in React | So earlier this week, I found out about an interesting way to map components in react. Here's an exam... | 0 | 2021-02-23T06:48:27 | https://dev.to/rushi444/an-alternative-way-to-map-components-in-react-35ik | react, javascript, webdev, tutorial | So earlier this week, I found out about an interesting way to map components in react. Here's an example of what I most commonly see.
A Todos component then returns a list of TodoCard:
```javascript
export const Todos = () => {
return (
<div>
{todos.map(todo => (
<TodoCard key={todo.id} todo={todo} />
))}
</div>
)
}
```
Here we have to explicitly give react the key, or your console will be filled with a nasty error 🤮. Turns out we can let react handle the key with React.Children.toArray(). Lets refactor the above component:
```javascript
export const Todos = () => {
return (
<div>
{React.Children.toArray(todos.map(todo => <TodoCard todo={todo} />))}
</div>
)
}
```
And tada 🎉, we no longer have to handle keys! | rushi444 |
615,536 | Looking for vscode and git coconut oil for complete novices | Hi, I'm coming from an nvim poweruser and linux background. I haven't used windows outside of work... | 0 | 2021-02-23T10:21:35 | https://dev.to/boydkelly/lookinf-for-vscode-and-git-coconut-oil-for-complete-novices-3j7 | vscode, windows, git | Hi, I'm coming from an nvim poweruser and linux background. I haven't used windows outside of work for 20 years. That said I need to get someone with very basic office computer skills set up with vscode and git. Any suggestions on what extensions would be best? Here are a couple of examples of initial issues/observations. (and there are problably a lot more!)
1) Vscode asks if you want to fetch periodically. I answered NO! Because I only want to merge. There is very low probablitly of any conflicts and if there are we can deal with it. The user doesn't even have to know what merge and fetch are. The file is 'synced' to the cloud. Period. Can't vscode ask me if I want to merge periodically? That would be ideal. Maybe there is a setting for that.
2) After initial install (with no extensions) the user has edited a file then (it seems to me) they must save it with a ctrl-s, then it appears under changed files in the navigator.
The user has to then stage and commit the changes, and *then* click on the minucule sync icon on the bar at the bottom of the screen. This is ok, (we *can* deal with it),but is there an extension that would allow the user to click on something and have it stage, commit and push no questions asked?
3) NEW FILES: If the user creates a new file there is a U showing it as untracked. But it seems really convoluted (for this type of user) to go to the command pallet and add this. It seems to me that out of the box, vscode would have an icon or at worst a right click button for this??? Similar to the tiny icon to stage changes???
OK, I think you get the point, we need this to be as easy and transparent as possible. Any suggestions appreciated!
| boydkelly |
615,617 | This Is How I Would Explain The Front-End, Back-End, And Apis To A Four-Year-Old Child | Recently, I told a friend of mine that I am a back-end developer. He asked me what the meaning of “ba... | 11,448 | 2021-02-23T11:38:09 | https://www.moremehub.com/15/this-is-how-i-would-explain-the-front-end-back-end-and-apis-to-a-four-year-old-child/ | beginners, javascript | Recently, I told a friend of mine that I am a back-end developer. He asked me what the meaning of “back-end” web development was. It took me lots of explanation and illustration to explain what back-end means in web development. I understand, he is not a techy guy. I noticed that not just non-techy are finding it hard to understand the terms, a lot of coding newbies can’t decipher the meaning. While some who think they “understand” probably misunderstood.
Just like I explained to my friend, this article is aimed at explaining various aspects (“ends”) of web development to newbies as I would explain to a 4-year-old. Don’t be offended when I say ‘like a four-year-old’, the phrase is to tell how simple and explicit the explanation would be.
I would represent the world of web development with a medium-sized restaurant. In a restaurant, you enter and give your order, the waiter brings the order to your table.
Basically, you are the user of the restaurant(website). You are less concerned with the processes of making the food. You just want your food and make payment.
The Front-end Aspect Of The Restaurant.
The front end is everything you can see in the restaurant. The HTML is synonymous with the structure of the restaurant, the tables, chairs, and other things. The CSS is the arrangement of things, the restaurant’s painting, the styles and every other thing put in place. The JavaScript handles how you are attended to. When you walk into the restaurant, the waiter gives you the menu, you check your favourite and make a request.
Then the waiter knows what to do with your request. The waiter can also help you with other things in the restaurant.
Therefore, everything happening right there is the front-end aspect of the restaurant.
The Back-end Aspect Of The Restaurants.
After making your request, you are less concerned with the cook or the ingredients the restaurant’s cook is using. You are there enjoying the serene environment and expecting the waiter to deliver your food.
You can think of the back-end as the cooks working tirelessly to prepare the food you ordered. The waiter hands over the menu, then the cook prepares the food and give it to the waiter.
You can think of everything happening in the kitchen as the back-end. The management of the restaurant, which includes decisions on pricing, payment of staff salaries, is done behind. This is the back-end!
The APIs Aspect Of The Restaurant.
You can think of the APIs as the waiters. They serve as a medium between the user and the cook/management.
Just like the way mini restaurants can do without waiters (case of a user requesting the cooks directly), websites can also do without APIs.
The API makes it possible to communicate with other mediums.
For example, if you own a blog app, you can get data across to a mobile app via the API.
APIs also makes it possible to deliver foods outside the restaurant. You can think of the delivery men as the APIS. | darphiz |
615,684 | [PHP] How to easily get video information from YouTube | If you want to get the video information of a specific channel or the playlist list, I think you will... | 0 | 2021-02-23T13:52:07 | https://dev.to/ichii731/php-how-to-easily-get-video-information-from-youtube-1683 | php, linux, webdev | If you want to get the video information of a specific channel or the playlist list, I think you will use YouTube API v3.
With PHP, it's good to use the official Google library with Composer, but for certain videos **you can get the video information more easily.**
Specifically, the JSON that stores the video information is called from the API.
that's all!
# JSON request parameter structure
`https://www.googleapis.com/youtube/v3/videos?id=[videoID]&key=[APIKey]&part=snippet,contentDetails,statistics,status`
[TIPS]The video ID is the character string following "watch? V = ~" in the URL.
Enter the API key obtained from Google API in [API Key].
# Sample code
Try to get the title of a specific video from YouTube API v3.
``` php
$api_key = "API Key"
$video_id = "Video ID"
$url = "https://www.googleapis.com/youtube/v3/videos?id=" . $video_id . "&key=" . $api_key . "&part=snippet,contentDetails,statistics,status";
$json = file_get_contents($url);
$getData = json_decode( $json , true);
foreach((array)$getData['items'] as $key => $gDat){
$title = $gDat['snippet']['title'];
}
// Output title
echo $title;
``` | ichii731 |
615,694 | Six things you should consider while designing a test architecture | The beginning of automated tests in a project is easy and difficult at the same time. You can start s... | 0 | 2021-02-23T14:20:55 | https://dev.to/kodziak/six-things-you-should-consider-while-designing-a-test-architecture-35k3 | testing, architecture | The beginning of automated tests in a project is easy and difficult at the same time. You can start smoothly, using base architecture, simple tests, etc - and it's gonna work! But... With growing architecture, solutions you'll take could be very hard to develop in the future.
That's why, you should consider a few things, before the start. I want to show you the problems and solutions do they solve.
## Page Object Model
POM - Page Object Model is a design pattern that is commonly used in test automation for avoiding code duplication and improve test maintenance.
This model contains classes that represent web pages. You break down each page into a corresponded page class. This class contains locators (selectors) to web page elements and methods that perform actions on them.
This fills the most common actions you'll be doing in test automation - find the element, fill the value, click the button. For small scripts, you can store selectors in the tests, but with growing suites, you'll face many duplications - that's bad, you don't want them. If one of the used selectors gonna change, you'll need to update every place, you've used it.
And... POM is the solution. You'll create a separate class that all of the tests gonna use. Then, if any of the selectors change, you'll only have to update one place. It's faster for the person which updates it.
But... There is another model of creating an architecture for automation tests. It's called App Actions. I've never tested it, so I can't recommend it, but here's a nice article about it - [click!](https://www.cypress.io/blog/2019/01/03/stop-using-page-objects-and-start-using-app-actions/)
## Logging
You should use a logging system to give the user (developer, or tester) enough information about what's happened in the tests while executing in a relatively short time. It's most possible, that you'll run your tests through a remote machine. If they fail, you need to know fast what's happened. Troubleshoot or reproduce failed tests with a stack trace and the latest assertion message only will be very hard.
That's why you should design a logging system.
A well-designed strategy will show the user step by step, what's happened in the test. In the project that I've worked on, we created a three-step strategy:
- begin,
- info,
- end,
To do this quickly, we've used decorators (TypeScript only).
For example (code base on puppeteer):
```tsx
@logger
function getText(selector) {
return page.$eval(selector, (el) => el.textContent);
}
```
Result with:
```
[BEGIN] - getText from: #email
[INFO] - getText result: sampleemail@gmail.com
[END] - getText from: #email
```
The assumption was simple. We want to know when the method starts, what's the result and when ends. We've used a method name and parameters as a recognizer. That comes out with well-structured logs, which helps us to know exactly what happened in test execution.
Also, you can use these logs in your reporting system, which is described below.
Another good idea to mention is to write custom, detailed assertion messages. For example,
```
Expect: 5, Received: 8
```
It's saying not much. Without the context and knowledge of what the test is checking, it's hard to assume what's happened. You'll need to check it manually. But...
```
We expect 5 elements on the listing, got 8.
```
It's easy to read and clearly saying what's happened. From the message, you can easily assume where's the problem.
Also, there are two more areas, where detailed messages could be helpful:
- timeout exceptions - ex. internet connections problem,
- architecture exceptions - ex. DB connection, auth connection problem.
I believe, that having a proper logging system could make your work easier and speed up the troubleshooting process.
## Test Data
Most common action in your tests gonna be to fill the value within the data. But... You need to have, or generate it. It's one of the most time-consuming actions, but necessary.
Let's split the data into two types:
- static data - the one you store in database/repository/somewhere,
- dynamic data - the one you generate using tools like a faker, etc.
Using class patterns you can design a system that handles the data for you. Connections to a database or dynamically creating sensitive data (ex. from `faker.js`).
## Parallel Executions
Parallelization is an automated process that automatically launches your actions simultaneously. The goal is to save execution time by distributing tests across available resources.
Consider a situation. You have a big database. Execution time takes 50 minutes to complete. You have 50 tests, where one approximately takes 1 minute. Tests are isolated (if not, you need to work on them). Using 5 parallel executions, you can reduce the total testing time to 10 minutes.
Fast, reliable tests are key to a stable product.
One, the interesting out-of-the-box solution is [Knapsack Pro](https://knapsackpro.com/). It helps run your tests in a parallel efficient way.
## Deployment Pipeline
A deployment pipeline is a process, where you take the code from version control and make it available for the users in an automated way. The team, which works on a project, needs an efficient way to build, test, and deploy their work to the production environment. In old fashion way, this was a manual process, where there were few deployments per week, now it's a few per day/hour. A set of automated tools doing it for us.
Imagine a problem. You have 50 tests and execution takes 50 minutes (without parallel executions). To test the fresh version of the code, the developers need to build an application locally and run the tests against it. And okay, the tests found an issue, so the user fixes the code and does it again. Hours and nervousness growing. I'm pretty sure, that after a few rounds they're not gonna use the tests. You don't want this.
The solution is to use an automated deployment pipeline. It's designed especially for cases like this.
Combining it with parallel executions, you will create an efficient, fast strategy, which gonna defend your production with the tests. Even better, if failed tests block the deployment. You'll never push broken code to the real users. 🥳
## Reports
Reporting is about documenting the process of test execution. They should combine a summary for the management and stakeholders. Also, should be detailed to give the developers feedback. Especially, when something fails.
Consider a failed execution. Tests are running on a remote machine, and somehow, you need to know what exactly happened. Why they failed and what's broken. Access to plain logs could be painful in searching this one failed test. A well-created report should cover that.
Each report could be different, but in my opinion, there are a few must-have metrics:
- machine/environment name,
- total number of running tests,
- duration,
- list of all test cases with logs (steps from logging system) in toggle,
- test result (for every test case).
Have I mentioned failed test executions and it's crucial to know what happened? 🥳 Constantly looking at a deployment pipeline dashboard or searching in logs isn't that efficient. A well-written report, mixed with the slack notification can speed up this process much.
## Conclusion
I've described six topics, which are really nice to consider in every mature test automation project. They solve problems, which you'll encounter on daily basis. By doing some coding and research, you'll easier your work and make the architecture expandable. Using a few hacks, you'll speed up your troubleshooting process and with automatically generated reports - you'll be as transparent as possible with your tests.
I believe, that this knowledge will help you at the beginning of your journey.
What's also good to consider:
- base architecture - pattern to re-use base methods, create browsers,
- video recordings - record whole test session,
Have a nice day! 🥳 | kodziak |
615,705 | 8 Resources To Learn Web Development | The tech industry has exploded with possibilities since the hit of the pandemic, which seems to be he... | 0 | 2021-02-23T14:36:57 | https://dev.to/debrakayeelliott/8-resources-to-learn-web-development-48fj | beginners, codenewbie, learning, webdev | The tech industry has exploded with possibilities since the hit of the pandemic, which seems to be here for the foreseeable future. In adjusting to this new normal, opportunities to learn new skills have rushed to the surface. Maybe they were always there, but a lot has changed and for many people it's now about survival and changing careers to create a better life.
If that's you, here are a few resources (in no particular order) to help you learn to code:
* [freeCodeCamp] (https://www.freecodecamp.org/)
* [Traversy Media YouTube channel] (https://www.youtube.com/c/TraversyMedia)
* [Internet Fundamentals] (https://internetfundamentals.com/)
* [Frontend Masters Web Development Bootcamp] (https://frontendmasters.com/bootcamp/)
* [Interneting is Hard] (https://www.internetingishard.com/)
* [MDN Web Docs] (https://developer.mozilla.org/en-US/)
* [The Web Developer Bootcamp 2021] (https://www.udemy.com/course/the-web-developer-bootcamp/)
* [Learn With Leon Web Development Bootcamp] (https://www.youtube.com/channel/UCGiRSHBdWuCgjgmPPz_13xw/featured)
But wait! Before you go diving head first into every resource to learn "all the things", check out my article [Examine How You Learn] (https://dev.to/debrakayeelliott/examine-how-you-learn-195o) so you don't get lost in numerous resources with no progress. Shiny Object Syndrome is real and it's easy to get caught up in what everyone says you should learn. This quickly leads to information overwhelm and frustration if you don't grasp technical concepts as fast as you see the developers you admire do.
Now don't let the hype on the interwebs fool you, learning to code is not easy. It will take a lot of time and you will get frustrated. There will be times you'll lose motivation and feel like giving up because it's not clicking the way people who are already successful developers talk about. Trust me.
Finding a supportive community that meets you where you are in your journey, helps you through your struggles and encourages you to keep going is also essential. *Trust me.*
I hope you found this helpful 🙂.
Until next time 👋🏾
| debrakayeelliott |
615,767 | How to start a WordPress blog? | Be it a blog for your small business or a brand blog to make money, it is easier to build one with a... | 0 | 2021-02-23T16:11:16 | https://dev.to/mudassir9s/how-to-start-a-wordpress-blog-4f6f | Be it a blog for your small business or a brand blog to make money, it is easier to build one with a CMS like WordPress.org.
It usually involves 4 steps:
1) Picking a niche to blog
2) Registering your website URL and web hosting
3) Installing blog on WordPress.org
4) Initial settings and the design
See, how easy-peasy it is!!
Being a blogger for more than 5 years, I have compiled a detailed guide on starting a blog to help aspirants and beginners to get started with blogging. I'm sure it helps, please check out it here - <a href="https://www.bloggingexplained.com/how-to-start-a-blog/">How to start a blog</a>
| mudassir9s | |
616,007 | How to Build a Video Streaming Service Like Netflix | If you want to build a website like Netflix, start with this guide from our expert team. | 0 | 2021-02-23T19:07:04 | https://www.codica.com/blog/how-to-make-website-like-netflix/ | webdev | ---
title: How to Build a Video Streaming Service Like Netflix
published: true
description: If you want to build a website like Netflix, start with this guide from our expert team.
canonical_url: https://www.codica.com/blog/how-to-make-website-like-netflix/
tags: webdev
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/kq28zfcl9mi35vxaapuz.jpg
---
In 2021, video streaming services are booming. Moreover, the global streaming market is expected to expand at a compound annual growth rate of 21.0% from 2021 to 2028.
To ride that wave, entrepreneurs need to know how to create a video streaming service like Netflix that people will love to use. These services represent [SaaS solutions](https://www.codica.com/services/saas-development/) that are very popular nowadays.
In this article, we’ll discuss the main steps and tools needed to build a Netflix clone.
# Step 1. Define your niche
When thinking through this topic, do not aim at every man, but find your specific target audience. The thing is, you need to offer the content that viewers will be binge-watching.
Let’s go through the video streaming market niches you can occupy.
**Entertainment**
Examples: Netflix, Amazon Prime, Hulu, HBO.
Content: Entertaining feature films and series.
**Infotainment**
Examples: Discovery+, Magic Stream, CuriosityStream.
Content: Skill-sharing videos, documentaries.
**Health & fitness**
Examples: Obe, NEOU, AKT.
Content: Fitness and dance workouts.
**Sports & cybersport**
Examples: Twitch, fuboTV, Dazn, ESPN+.
Content: Sports events.
To sum up this section, we must admit that the competition between video streaming services is quite tough. That is where some novelty could help. You can concentrate not only on the movies and series. You might look towards education, cybersport, or fitness themes. Also, these are combinable.
# Step 2. Set your content strategy
How can you find the content for your streaming platform? You can choose one of the three ways:
* Rent movies from the authorized distributor;
* Purchase permission from the copyright holder;
* Create your own video streaming content.
Mind that some films or shows can be subject to exclusive distribution rights, meaning you cannot buy a lifetime license for that content. Besides that, owners may state geolocation restrictions and sell the licenses for certain markets.
Such an option minimizes the risks and expenses for both owners and customers. And here is why. The content owners will not need to care about the technical side of the distribution, and customers will get skinny bundles.
These bundles provide more diverse and cheap viewing options, that is why customers find them cost-efficient.
The third option is not for beginners but rather for established video streaming platforms. In 2013, Netflix released its first in-house produced series House of Cards. Since then, many companies like Amazon have started creating original content.

[Source](https://sites.psu.edu/purcelleportfolio/wp-content/uploads/sites/15687/2014/12/BiooSTSCEAASZLq.jpg)
#Step 3. Choose your monetization model
Speaking of monetization, how are you going to capitalize your platform? You can begin with creating subscription plans for users. For example, the Hulu platform offers the following plans:

Let’s discuss the most common revenue generation models.
* **SVoD (subscription video on demand)**. This option is highly popular in video streaming as it’s well-suited for this domain. Viewers can stream video content without limitations by purchasing monthly or yearly subscriptions.
* **AVoD (advertising-based video on demand)**. It implies that you generate profit by embedding advertisements into the video content, and users won’t need to pay anything. With the growth of the audience, such an option gets especially beneficial.
* **Hybrid**. Within this model, viewers can use a streaming service before paying and get some advanced features on a subscription basis. This model is becoming more common among streaming platforms. And rightly so, as combining more than one revenue-generating model, you are more likely to boost your ROI, or return on investment.
# Step 4. Decide on the feature set
The functionality sets commonly used for building a website like Netflix don’t differ drastically. However, the implementation of specific features can vary on different platforms. When defining the functionality for your service, give primary consideration to the pain points of your audience.
What features to implement on your video streaming website in the first place?
* User registration and profiles;
* Search;
* Admin panel;
* Reviews/rating;
* Push notifications;
* Subscription and payout;
* Playback settings.
The list above contains a must-have functionality for a video-sharing service. We suggest that you implement these features in your MVP, or minimum viable product. You can discover more in our thorough article about the [MVP approach and reasons to opt for it](https://www.codica.com/blog/5-reasons-why-you-need-an-MVP-before-engaging-in-custom-software-development/).
# Step 5. Find the right tech stack
What are the programming languages and tools that will fuel your video streaming service? Why cannot you use any specific programming language or tool to handle the tech stack issue?
Note that you’ll save a lot if you consider technologies that are well-suited for your domain and project. So, let’s talk about the main parts of the technology stack that will help you create a website like Netflix that your users will love to use.
**Server-side**
Let’s begin with the back-end for a streaming website that builds the core functionality. Back-end part takes small chunks of video content and converts them into a suitable casting format.
You will need a powerful framework to fuel your platform. Consider Ruby on Rails, Node.js, C++, or Python.
For example, [Hulu](https://stackshare.io/hulu/hulu) and [Twitch](https://stackshare.io/twitch/twitch) are built with the use of Ruby on Rails. It proves the effectiveness of this framework in video streaming platform development.
**Client-side**
Front-end is in charge of the delivery of streaming content from the server to the user’s device.
React and Vue.js frameworks will work fine when you need to build a client-side part of a website like Netflix.
# Summing up
We hope that our guide helps you discover the video streaming basics. If you want to know how much a video-sharing website will cost you, read our thorough article about the creation of a video streaming service: [How Much Does it Cost to Make a Video Streaming Website Like Netflix](https://www.codica.com/blog/how-to-make-website-like-netflix/). | codicacom |
616,106 | Did "Clubhouse" ruined Clubhouse? | EDIT: clubhouse forced to changed their name! Because of this Introduction A but a... | 0 | 2021-03-03T19:40:39 | https://dev.to/zippytyro/did-clubhouse-ruined-clubhouse-2323 | android, discuss, business, webdev | EDIT: [clubhouse forced to changed their name! Because of this](https://thehardcopy.co/clubhouse-forced-to-change-name/)
##Introduction
A but a behavior I've noticed relating to fear of missing out (FOMO) and why this might be the best example.
You might be knowing about the voice-audio chat app called "Clubhouse", there's a lot of hype created around it, and evidently, it has a standout in the market even though a lot of the apps/websites with the same concept exist eg. discord.
People like Elon Musk, Joe Rogan, Naval Ravikant, etc tweeted about this app since then it has garnered a lot of traction. This is what Zero dollar marketing looks like. The screenshot says it all.

Why as a developer I'm talking about this? the answer is pretty simple we are creators; As creators, we must study the market and behavior of people reacting to it so that we learn from other's experiences.
------------------
##FOMO
There already existed an app, with the same name *clubhouse* due to this they are now having a hard time. Android users flooded the app with negative reviews. FOMO comes into play, all the android users downloaded the app having the same name *clubhouse*. Since the one on the play store is a project management platform. The users are thrashing the app thinking that is the **Social app Clubhouse.**

While we download/install most of the app from Google Playstore (android) and quite frequently install the wrong application. In seconds people rate it down, as same in the case with project *management tool Clubhouse*.
Android has a large user base in contrast to iOS. Google related searches -

Having a good rating earlier, we can see the rise in the number of 1-star ratings below.

-------
Without even reading about what it does people installed it and now rating it down. Some screenshots to prove this -


------
##Rescue
However, some people came for rescue.

#####Nonetheless, it is not going to having a huge impact. They need to take some steps in order to stop this.
-----
##Conclusion
EDIT: [clubhouse forced to changed their name!](https://thehardcopy.co/clubhouse-forced-to-change-name/)
I think now they have inhibited users from registration, as they are looking for something else, this proves people are oblivion. This app's rating is ruined because of this until they ask Google to withdraw these reviews nothing good can happen.
I think the social media app clubhouse should release notice regarding this, as it is harming/deteriorating someone else's business. What's your take on this? What would you do if you were in the position where *Clubhouse* management tool stands?
[Follow me on Twitter](https://twitter.com/zippytyro)
Shashwat
| zippytyro |
616,484 | XS-Leaks: Is Your Website Exposing Sensitive Data? | Are you exposing your users to malicious websites? Learn how xs-leaks are used to exfiltrate data fro... | 11,358 | 2021-02-24T07:07:22 | https://www.appsecmonkey.com/blog/xs-leaks/ |
Are you exposing your users to malicious websites? Learn how xs-leaks are used to exfiltrate data from a web application and how to prevent it in 7 steps.
The original and most up-to-date post can be read [here](https://www.appsecmonkey.com/blog/xs-leaks/).
## What are XS-leaks?
XS-Leaks (or Cross-Site Leaks) are a [set of browser side-channel attacks](https://xsleaks.dev/). They enable malicious websites to infer data from the users of other web applications.
The [Twitter silhouette attack](https://blog.twitter.com/engineering/en_us/topics/insights/2018/twitter_silhouette.html) was a superb example.
## Same Origin Policy
Before we get started, it's helpful to understand SOP ([Same Origin Policy](https://developer.mozilla.org/en-US/docs/Web/Security/Same-origin_policy)), which is the heart and soul of the web browser security model. It is a rule that more or less says:
1. Two URLs are of the same *origin* if their protocol, port (if specified), and host are the same.
2. A website from *any* origin can freely send `GET`, `POST`, `HEAD`, and `OPTIONS` requests to *any other* origin. Furthermore, the request *will* include the user's cookies (including the session ID) to that origin.
3. While sending requests is possible, a website from one origin cannot directly *read* the responses from another origin.
4. A website can still *consume* resources from those HTTP responses, such as by executing scripts, using fonts/styles, or displaying images. The [JSONP](https://www.w3schools.com/js/js_json_jsonp.asp) hack takes advantage of this fourth rule (don't use JSONP).
For example, this website's origin is `https://www.appsecmonkey.com/` where the `protocol` is `https`. The host is `www.appsecmonkey.com`, and the port is not specified (which is implicit `443` because of the `https` protocol).
Alrighty, that's the gist of it. Let's get to the attacks.
## XS-leaks through timing attacks
Browsers make it easy to time cross-domain requests.
```js
var start = performance.now()
fetch('https://example.com', {
mode: 'no-cors',
credentials: 'include'
}).then(() => {
var time = performance.now() - start;
console.log("The request took %d ms.", time);
});
```
```
The request took 129 ms.
```
This makes it possible for a malicious website to differentiate between responses. Suppose that there is a search API for patients to find their own records. If the patient has diabetes and searches for "diabetes", the server returns data.
`GET /api/v1/records/search?query=diabetes`
```yaml
{"records": [{"id": 1, ...}]}
```
And if the patient doesn't have diabetes, the API returns an empty JSON.
`GET /api/v1/records/search?query=diabetes`
```yaml
{"records": []}
```
Generally, the former request would take a longer time. An attacker could then create a malicious website that clocks requests to the "diabetes" URL and determines whether or not the user has diabetes.
You can expand the attack and search for a... b... c... d... yes. da.. db... di... yes. This sort of attack is known as [XS-search](https://xsleaks.dev/docs/attacks/xs-search/).
See all of the timing attacks on [xsleaks.dev](https://xsleaks.dev/).
## XS-leaks through error-based attacks
The next side-channel on our list is strategically catching error messages with JavaScript. Suppose that a page returns either `200 OK` or `404 not found`, depending on some sensitive user data.
An attacker could then create a page like the following, which queries the application and determines whether the endpoint returns an error for the browser user or not.
```js
function checkError(url) {
let script = document.createElement('script');
script.src = url;
script.onload = () => console.log(`[+] GET ${url} succeeded.`);
script.onerror = () => console.log(`[-] GET ${url} returned error.`);
document.head.appendChild(script);
}
checkError('https://www.example.com/');
checkError('https://www.example.com/this-does-not-exist');
```
```
[-] GET https://www.example.com/ succeeded.
[+] GET https://www.example.com/this-does-not-exist returned error.
```
## XS-leaks through frame counting
By obtaining a handle to a frame, it is possible to access the frame's [window.length](https://developer.mozilla.org/en-US/docs/Web/API/Window/length) property which is used to retrieve the number of frames (IFRAME or FRAME) in the window.
This knowledge can sometimes have security/privacy implications. For example, a website may render a profile page differently with a varying number of frames based on some user data.
There are a couple of ways to obtain a window handle. The first is to call [window.open](https://developer.mozilla.org/en-US/docs/Web/API/Window/open), which returns the handle.
```js
var win = window.open('https://example.com');
console.log("Waiting 3 seconds for page to load...");
setTimeout(() => {
console.log("%d FRAME/IFRAME elements detected.", win.length);
}, 3000);
```
Another is to frame the target website and get the handle of the frame.
```html
<iframe name="framecounter" src="https://www.example.com"></iframe>
<script>
var win = window.frames.framecounter;
console.log("Waiting 3 seconds for page to load...");
setTimeout(() => {
console.log("%d FRAME/IFRAME elements detected.", win.length);
}, 3000);
</script>
```
Those two are arguably the most important. There are others, such as `window.opener` and `window.parent`. See [this article](https://bluepnume.medium.com/every-known-way-to-get-references-to-windows-in-javascript-223778bede2d) for a more comprehensive list.
Read more about frame counting on [xsleaks.dev](https://xsleaks.dev/docs/attacks/frame-counting/).
## XS-leaks through detecting navigations
Knowing whether or not the browser navigated (e.g., redirected) somewhere, it is often possible to infer data about the user. For example, authenticated portions of websites tend to redirect the user to the login page. Unless, of course, the user is logged in already.
Observing navigations gives malicious websites the power to see which websites the browser user is logged in to, which is a huge privacy concern.
There are multiple ways by which malicious websites can detect redirects. These include:
- Creating a frame and counting how many times `onload` is called.
- Retrieving the `history.length` from a window handle.
- Creating a Content Security Policy (CSP) on the malicious website triggers exceptions when specific URL addresses are requested.
See them all here: [https://xsleaks.dev/docs/attacks/navigations/](https://xsleaks.dev/docs/attacks/navigations/)
# XS-leaks through browser cache
When users visit websites, the resources from those sites are usually cached and stored on the user's disk so they won't have to be downloaded again. This saves bandwidth, lowers server load, and improves user experience.
Unfortunately, the timing- and error-based xsleak variations can take advantage of this and determine whether a user has visited a website before.
The cache timing variation is simple, time the request, and if it's instantaneous, then the resource was cached.
The error-based version is slightly more involved. It's taking advantage of the fact that cached resources are never actually requested from the server. As such, an invalid HTTP request for a cached resource does not raise an exception (because the web server never gets a chance to reject it).
Read about both of them on xsleaks: [https://xsleaks.dev/docs/attacks/cache-probing/](https://xsleaks.dev/docs/attacks/cache-probing/).
# XS-leaks through ID-fields in frames
This one takes advantage of the fact that the [https://developer.mozilla.org/en-US/docs/Web/API/Element/focus_event](focus) event gets fired when a frame with an url like `https://www.example.com/#example` jumps to the element `example`.
If there is no `example` on the page, the event doesn't fire.
Read more about this variation on xsleaks: [https://xsleaks.dev/docs/attacks/id-attribute/](https://xsleaks.dev/docs/attacks/id-attribute/)
## XS-leaks through many other things
The variations mentioned thus far should give you the idea, but there are others. You can go to [xsleaks.dev](https://xsleaks.dev) for more attacks and details.
## How to prevent XS-leaks?
You won't be able to completely prevent *all* xsleaks in *all* browsers. The world isn't ready for that yet. But you can be pretty safe, especially for Chrome or Edge, which have all the bleeding edge security features under their belts. Here's how:
1. Protect your cookies with the SameSite attribute.
2. Use Content-Security-Policy and X-Frame-Options to prevent framing.
3. Consider using Cache-Control to disable caching.
4. Use the fetch metadata headers and the Vary header to prevent cache probes.
5. Implement a Cross-Origin Opening Policy.
6. Implement a Cross-Origin Resource Policy.
7. Implement an isolation policy.
## Protect your cookies with the SameSite attribute
All major browsers support a cool feature called [SameSite cookies](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Set-Cookie/SameSite). When you set a cookie with `SameSite=Lax`, browsers will not include it in cross-origin POST requests, which works nicely against [CSRF](https://www.appsecmonkey.com/blog/csrf-attack-and-prevention/) attacks.
Crucially for our xsleaks use case here, it also blocks GET requests that are not *top-level navigation*, which is to say, that script-tags, fetch-requests, image tags, etc., will not send the cookie anymore.
```yaml
Set-Cookie: SessionId=123; ...other options... SameSite=Lax
```
## Use Content-Security-Policy and X-Frame-Options to prevent framing
Another beautiful browser feature is the [Content Security Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/CSP), or CSP for short. CSP can be incredibly effective against [XSS](https://www.appsecmonkey.com/blog/xss-attack-and-prevention/) attacks. But in this case, we are interested in blocking framing, and the CSP recipe for that is:
```yaml
Content-Security-Policy: frame-ancestors 'none';
```
This CSP policy will prevent all modern browsers from letting any other website frame your application. If you want to support Internet Explorer as well, then also send [X-Frame-Options](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-Frame-Options).
```yaml
X-Frame-Options: DENY
```
## Consider using Cache-Control to disable caching
Disabling the cache is not for everyone. I, for example, couldn't possibly do it for this blog. But arguably, the most effective way to prevent caching-related xsleaks vectors is to disable caching for your website altogether. You can do this by returning the following [Cache-Control](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cache-Control) header in all your responses:
```yaml
Cache-Control: no-store, max-age=0
```
## Use the fetch metadata headers and the Vary header to prevent cache probes.
This approach is much more feasible but not supported by all browsers yet. The idea is to [Vary](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Vary) the cache based on the [fetch metadata request headers](https://www.w3.org/TR/fetch-metadata/).
The [Sec-Fetch-Site](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Sec-Fetch-Site) request header will contain the value `cross-site` if a malicious website attempts to make requests to your application. And because of the `Vary` header, that malicious website will sort-of have a cache of its own. It will not be able to deduce what the browser user has cached on the website.
```yaml
Vary: Sec-Fetch-Site
```
## Implement a Cross-Origin Opener Policy
The [Cross-Origin-Opener-Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Opener-Policy) is an HTTP response header that restricts malicious websites from obtaining a window handle to your website. You can set it like so:
```yaml
Cross-Origin-Opener-Policy: same-origin
```
It is [already fully supported](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Opener-Policy#browser_compatibility) in Chrome, Edge, and Firefox.
## Implement a Cross-Origin Resource Policy
The [Cross-Origin-Resource-Policy](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Cross-Origin-Resource-Policy) is an HTTP response header that restricts malicious websites from reading/embedding/rendering resources from your domain. Read more about it [here](https://resourcepolicy.fyi/). You can set it like so:
```yaml
Cross-Origin-Resource-Policy: same-origin
```
## Implement an isolation policy
It is possible to block cross-origin requests on the server-side as well. However, this is the bleeding edge, so you will probably have to write your middleware to do it.
One solution [proposed by xsleaks.dev](https://xsleaks.dev/docs/defenses/isolation-policies/strict-isolation/#implementation-with-fetch-metadata) is to take advantage of the new [fetch metadata request headers](https://www.w3.org/TR/fetch-metadata/), and block *any* requests with the `Sec-Fetch-Site` value of `cross-origin`. This radical approach will doubtless improve your security. But it will also affect your UX because hyperlinks to your application will cease to work.
They also propose more targeted isolation policies that help against some attacks but don't necessarily affect usability so much. Read more about them [here](https://xsleaks.dev/docs/defenses/isolation-policies/).
## Conclusion
There are quite a few XS-leaks, and browser vendors are coming up with tools to beat them as we speak.
Preventing all of them is not easy, if even possible. But by following the guidelines in this article and on [https://xsleaks.dev/](https://xsleaks.dev/), you should be fine.
## Get the web security checklist spreadsheet!
[](https://eepurl.com/hqAGt5)
☝️ [Subscribe](https://eepurl.com/hqAGt5) to AppSec Monkey's email list, get our best content delivered straight to your inbox, and <b>get our 2021 Web Application Security Checklist Spreadsheet for FREE</b> as a welcome gift!
## Don't stop here
If you like this article, check out the other application security guides we have on [AppSec Monkey](https://www.appsecmonkey.com/) as well.
Thanks for reading. | appsecmonkey | |
616,547 | How To Upgrade From Selenium 3 To Selenium 4? | This article is a part of our Content Hub. For more in-depth resources, check out our content hub on... | 0 | 2021-02-24T08:16:00 | https://www.lambdatest.com/blog/upgrade-from-selenium3-to-selenium4/ | java, selenium, automation, testing | This article is a part of our Content Hub. For more in-depth resources, check out our content hub on [Selenium 4](https://www.lambdatest.com/learning-hub/selenium-4?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu).
Selenium 4, the latest version of the Selenium framework, has become the talk of the town since its announcement in 2018. The excitement around Selenium 4 is evident since it is packed with a host of new features and enhancements than its predecessor. Though there is no official announcement on the ‘final’ release of Selenium 4, Selenium users and test automation enthusiasts have already started exploring and experimenting by downloading the [Alpha version of Selenium 4](https://www.selenium.dev/downloads/).

If you are thinking of upgrading from Selenium 3 to Selenium 4, this Selenium 4 tutorial will help you take the version leap! For folks waiting on the sidelines to try Selenium 4, the comparison between Selenium 3 vs. Selenium 4 could excite you to try Selenium 4 much sooner than you ever expected☺.
Though Selenium has various language bindings like Java, C#, Python, JavaScript, Ruby, and PHP, this Selenium 4 tutorial would focus on installing Java bindings.
## Selenium 3 vs. Selenium 4
Wondering ‘What uniqueness does Selenium 4 have compared to Selenium 3?’ Well, to answer that question, we’ll do a quick walk-through of the newness offered by Selenium 4 in this section of Selenium 3 vs. Selenium 4 tutorial:
**Selenium WebDriver W3C Standardization**
In Selenium 3, the JSON Wire Protocol was the primary communication mode between the test code and web browser. Major browser drivers like ChromeDriver, GeckoDriver, etc., follow the W3C standard. This resulted in the encoding and decoding of requests as per the W3C protocol.
Under the hood, Selenium 4 uses the WebDriver W3C protocol. This eliminates the overhead of encoding and decoding that was necessary with JSON Wire Protocol in Selenium 3. This major architectural change will result in less flaky and more stable cross browser tests (i.e., tests across different versions and types of browsers) with Selenium 4. You can refer to our detailed coverage on Selenium W3C WebDriver in Selenium 4 to gain more insights.
**Selenium 4 IDE**
The IDE in Selenium 4 is much more than a rudimentary playback and record testing tool. Along with Firefox, it is available for the Chrome browser (as a Chrome extension).
The SIDE Runner tool in Selenium 4 IDE lets you run Selenium tests parallel on local Selenium Grid and cloud-based Selenium Grid. The ‘export’ feature enables you to export the recorded tests in Selenium supported languages like Python, C#, Java, and more. [Selenium 4 IDE](https://www.lambdatest.com/blog/run-selenium-ide-test-on-online-selenium-grid/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu) is a renewed and super-useful offering available only in Selenium 4.
**Optimized Selenium Grid**
If you’re a Selenium 3 user, you must be aware of how painful it’s to start the Hub and Node jars each time you want to perform automation testing on the Grid. Distributed test execution is all set to change with the optimized Selenium Grid in Selenium 4.
In Selenium Grid 4, Hub and Node are packed in a single jar file. Selenium Grid 4 has a more scalable and traceable infrastructure that supports four processes – Router, Session Map, Distributor, and Node. Improved GUI and built-in support for Docker are some of the additional perks you get in [Selenium Grid 4](https://www.lambdatest.com/blog/selenium-grid-4-tutorial-for-distributed-testing/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu).
**Chrome DevTools**
In Selenium 4, there is native support for Chrome DevTools Protocol (CDP) through the DevTools interface. The Chrome DevTools interface’s APIs would make issue diagnosis and on-the-fly editing of pages much easier.
The native support of CDP will help emulate geolocation and network conditions in Selenium 4 with more ease. With Selenium 4, you could test the web product built for a global audience by emulating geolocation in the code. At the same time, you could also check how the product performs against varying network conditions (e.g., 3G, 4G, etc.).
**Relative Locators**
In Selenium 3, you have to use a series of findelement commands on the appropriate WebElement to locate its vicinity elements. There was no shortcut to finding an element that is above/below/right to/etc. of a particular WebElement.
Relative Locators (above, below, toRightOf, toLeftOf, and near) that are newly introduced in Selenium 4 Alpha help locate web elements’ relative’ to a particular element in the DOM. Our detailed coverage of [relative locators in Selenium 4](https://www.lambdatest.com/blog/selenium-4-relative-locator/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu) could help you get started with this feature exclusively available in Selenium 4.
Apart from these big enhancements in Selenium 4, it is packed with other new features:
- _TakeElementScreensho_t API lets you capture a screenshot of a particular WebElement on the page.
- Introduction of newWindow API helps in the simplified creation of a new Window (_WindowType.WINDOW_) or Tab (_WindowType.TAB_).
- Optimized and accelerated debugging process.
As far as Selenium 3 vs. Selenium 4 comparison is concerned, the overall experience with Selenium 4 (Alpha) is much more superior to Selenium 3. This is one of the primary motivating factors to download Selenium 4 (Alpha) and get your hands on the awesome features offered by Selenium 4.
## Upgrade from Selenium 3 to Selenium 4
As of writing this article, [Selenium 4.0.0-alpha-7](https://selenium-release.storage.googleapis.com/4.0-alpha-7/selenium-java-4.0.0-alpha-7.zip) was the latest Selenium 4 (Alpha) version available for download on the Selenium website. Selenium 4 for different language bindings is shown below:
| LANG | Download Link |
| ------------ | ----------------------------------- |
| Java | [https://selenium-release.storage.googleapis.com/4.0-alpha-7/selenium-java-4.0.0-alpha-7.zip](https://selenium-release.storage.googleapis.com/4.0-alpha-7/selenium-java-4.0.0-alpha-7.zip) |
| Python | [https://pypi.org/project/selenium/4.0.0.a7/](https://pypi.org/project/selenium/4.0.0.a7/) |
| C# | [https://www.nuget.org/api/v2/package/Selenium.WebDriver/4.0.0-alpha07](https://www.nuget.org/api/v2/package/Selenium.WebDriver/4.0.0-alpha07) |
| Ruby | [https://rubygems.org/gems/selenium-webdriver/versions/4.0.0.alpha7](https://rubygems.org/gems/selenium-webdriver/versions/4.0.0.alpha7) |
### Selenium with Maven – Upgrade from Selenium 3 to Selenium 4
If you are using Selenium with Java, you will likely use [Selenium with Maven](https://www.lambdatest.com/blog/getting-started-with-maven-for-selenium-testing/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu) to manage the dependencies associated with your Selenium project. For Selenium with Maven users, changing the Selenium version to 4 in pom.xml is all you need to upgrade from Selenium 3 to Selenium 4.
```
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.demo</groupId>
<artifactId>TestProject</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.9.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.28</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-remote-driver</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
</dependencies>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
```
[Maven Central repository](https://mvnrepository.com/) is the ideal location to look for dependencies or libraries for all the versions. As shown above, we downloaded the [Maven Dependency for Selenium 4 Java](https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java) and added the same in pom.xml
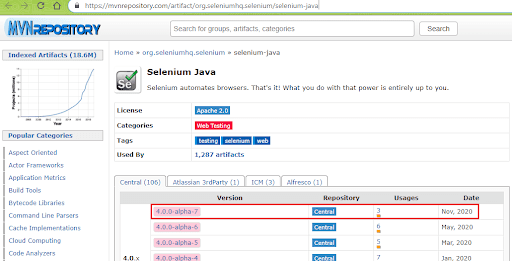
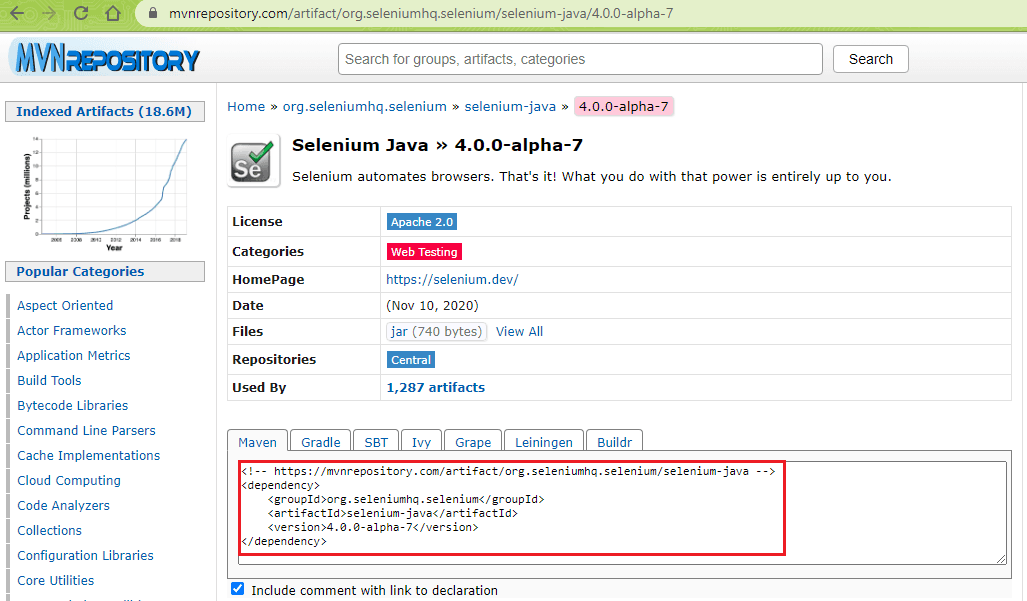
Along with Selenium 4 Java, we also added the Selenium 4 packages for selenium-chrome-driver and selenium-remote-driver in the POM file (pom.xml).
### Selenium with Gradle – Upgrade from Selenium 3 to Selenium 4
Gradle is a popular build tool that is used for Java-based applications. The build scripts in Gradle are written in Groovy or Kotlin DSL. If you are using Gradle for your Selenium Java project, the necessary dependencies must be configured in the build.gradle file, which is placed at the root level (of the project).
The necessary dependencies to be downloaded have to be added in build.gradle. Like Maven, the Maven Central Repository should be used for finding the required dependencies for the project.
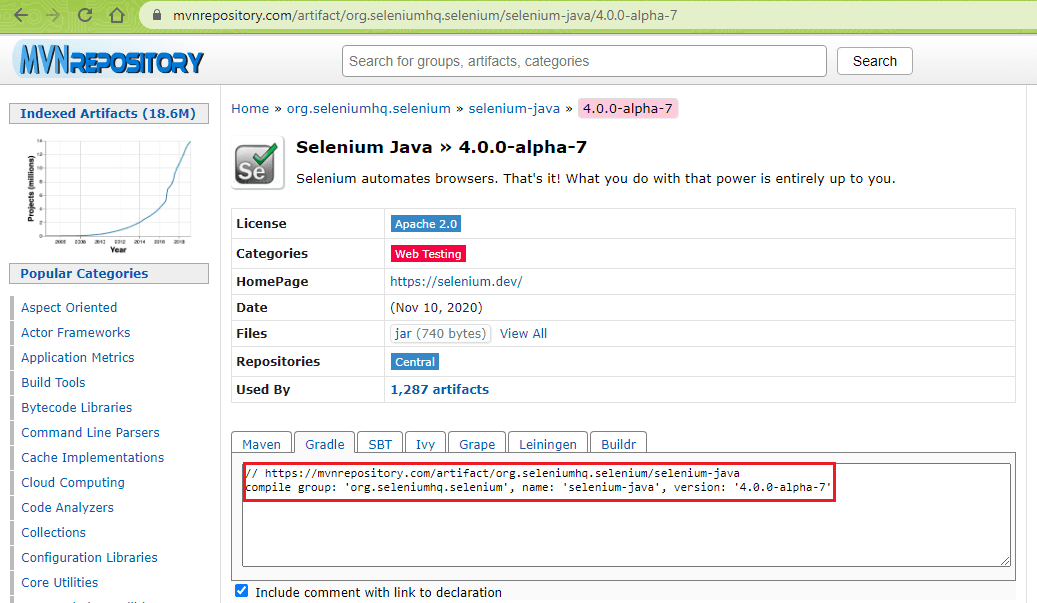
Here is the build file (build.gradle) for a Gradle project where we have used the 4.0.0-alpha-7 version of the Selenium Java binding. Since we are using the [TestNG framework](https://www.lambdatest.com/learning-hub/testng?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu) in the implementation, we have added the other dependencies in the build.gradle.
```
plugins {
id 'java'
}
group 'org.demo'
version '1.0-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
compile group: 'org.seleniumhq.selenium', name: 'selenium-java',
version: '4.0.0-alpha-7'
compile group: 'org.seleniumhq.selenium', name: 'selenium-chrome-driver',
version: '4.0.0-alpha-7'
compile group: 'org.seleniumhq.selenium', name: 'selenium-remote-driver',
version: '4.0.0-alpha-7'
compile group: 'org.testng', name: 'testng',
version: '6.14.3'
}
test {
useTestNG()
}
```
### Test Setup – Demonstration of upgrading from Selenium 3 to Selenium 4
To demonstrate how to upgrade from Selenium 3 to Selenium 4, we take a cross browser testing example where the search for “LambdaTest” is performed on Google. The test is performed on the Chrome browser.
**Test Scenario**
1. Go to Google
2. Search for LambdaTest
3. Click on the first search result
4. Assert if the page title does not match the expected page title
**Implementation**
Here is the overall project structure in [IntelliJ IDEA](https://www.lambdatest.com/blog/setup-junit-environment/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu):
**Downloading Selenium 4 using Maven**
In a Maven project, the pom.xml file consists of the required details about the configuration, dependencies, and more. Along with Selenium 4 Java, we have also added the Selenium 4 Chrome Driver and Selenium 4 remote Driver dependencies in pom.xml.
```
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.demo</groupId>
<artifactId>TestProject</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>6.9.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.28</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-remote-driver</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>4.0.0-alpha-7</version>
</dependency>
</dependencies>
<build>
<defaultGoal>install</defaultGoal>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
```
As we are using the TestNG framework, the details of the test scenarios are added in testng.xml.
```
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE suite SYSTEM "http://testng.org/testng-1.0.dtd">
<suite name="Demo Project">
<test verbose="2" preserve-order="true" name="Demo Project">
<classes>
<class name="Demo.DemoTest">
<methods>
<include name="test_search_demo"/>
</methods>
</class>
</classes>
</test>
</suite>
```
```
package Demo;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
import java.net.MalformedURLException;
import java.net.URL;
import static org.testng.AssertJUnit.assertEquals;
public class DemoTest
{
ChromeDriver web_driver = null;
@BeforeTest
public void testSetUp()
{
web_driver = new ChromeDriver();
web_driver.get("https://www.google.com");
web_driver.manage().window().maximize();
}
@Test
public void test_search_demo() throws InterruptedException
{
WebElement elem_search = web_driver.findElement(By.name("q"));
elem_search.sendKeys("LambdaTest" + Keys.ENTER);
Thread.sleep(3000);
WebElement elem_search_result = web_driver.findElement(By.xpath("//h3[.='LambdaTest: Most Powerful Cross Browser Testing Tool Online']"));
elem_search_result.click();
assertEquals(web_driver.getTitle(), "Most Powerful Cross Browser Testing Tool Online | LambdaTest");
}
@AfterTest
public void tearDown()
{
if (web_driver != null)
{
System.out.println("Demo Test is Completed");
web_driver.quit();
}
}
}
```
**Setting up Gradle**
The same project is used for demonstrating upgrading from Selenium 3 to Selenium 4 using Gradle. Dependencies, plugins, and the build scripts should be available in the build.gradle file, which is placed at the root level of the project.
For a quick recap on Gradle, you can refer to the detailed coverage of Gradle (with JUnit) in our earlier blog [here](https://www.lambdatest.com/blog/run-junit-from-command-line/). The dependencies of Selenium 4 Java, Selenium Chrome Driver (4.0.0-alpha-7), Selenium Remote Driver (4.0.0-alpha-7), and TestNG (6.14.3) are added in the build.gradle.
```
plugins {
id 'java'
}
group 'org.demo'
version '1.0-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
}
dependencies {
compile group: 'org.seleniumhq.selenium', name: 'selenium-java',
version: '4.0.0-alpha-7'
compile group: 'org.seleniumhq.selenium', name: 'selenium-chrome-driver',
version: '4.0.0-alpha-7'
compile group: 'org.seleniumhq.selenium', name: 'selenium-remote-driver',
version: '4.0.0-alpha-7'
compile group: 'org.testng', name: 'testng',
version: '6.14.3'
}
test {
useTestNG()
}
```
**Execution**
To execute the test scenario, right-click on testng.xml and select “run …\testng.xml”.
The execution snapshot below shows that the Chrome WebDriver was instantiated, and the test scenario was executed successfully.
For Gradle, we use the command line option (gradle test) to trigger the test in the project. As the test scenario (test\_search\_demo) is located in the class file DemoTest, we run the test using the following command (after navigating to the root folder of the project):
```
gradle test --tests DemoTest.test_search_demo
```
As seen in the execution snapshot, the test was executed successfully.
## Upgrade From Selenium 3 To Selenium 4 Using The cloud-based Selenium Grid
The advantages offered by Selenium 4 can be best exploited on a Selenium Grid where tests can execute in parallel on the appropriate nodes. The [Selenium 4 Grid](https://www.lambdatest.com/blog/selenium-grid-4-tutorial-for-distributed-testing) provides a host of new features that ease and accelerate Selenium web automation testing.
A cloud-based Selenium Grid like LambdaTest offers much-needed scalability, reliability, and security, difficult to attain with a local Selenium Grid. [Selenium testing on the cloud](https://www.lambdatest.com/blog/cloud-selenium-testing/?utm_source=dev&utm_medium=Blog&utm_campaign=Himanshu-24022021&utm_term=Himanshu) helps achieve better browser coverage, test coverage, and test coverage, as a number of tests can be executed in parallel on the cloud-based Selenium Grid.
We port the test demonstrated earlier so that it executes on LambdaTest’s Selenium 4 Grid. To get started, we generate the desired capabilities for Java language binding using LambdaTest Capabilities Generator.
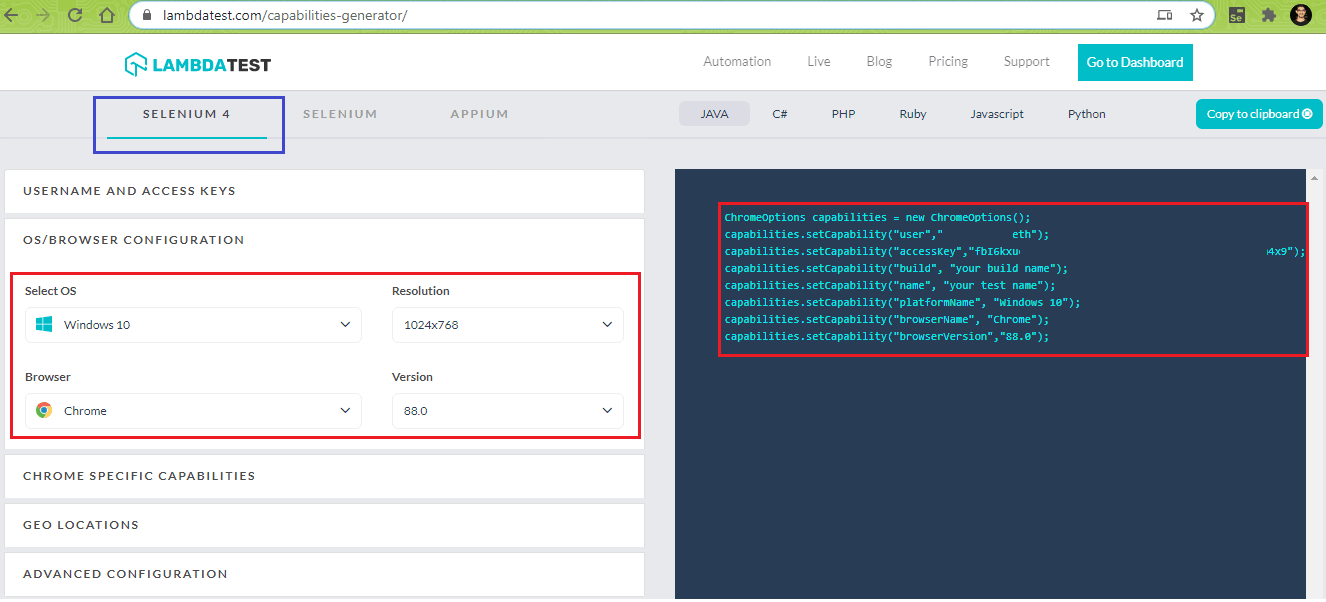
As a part of the setup, the method implemented under the @BeforeTest annotation will use the RemoteWebDriver instead of the local Chrome Driver. Shown below is the updated DemoTest.java where we use the LambdaTest Selenium Grid for running the test:
```java
package Demo;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.testng.annotations.AfterTest;
import org.testng.annotations.BeforeTest;
import org.testng.annotations.Test;
import java.net.MalformedURLException;
import java.net.URL;
import static org.testng.AssertJUnit.assertEquals;
public class DemoTest
{
/* ChromeDriver web_driver = null; */
public WebDriver web_driver;
public static String username = "user-name";
public static String access_key = "access-key";
@BeforeTest
public void testSetUp() throws MalformedURLException {
/* web_driver = new ChromeDriver(); */
DesiredCapabilities capabilities = new DesiredCapabilities();
capabilities.setCapability("build", "Testing on the LambdaTest Grid");
capabilities.setCapability("name", "Testing on the LambdaTest Grid");
capabilities.setCapability("platform", "Windows 10");
capabilities.setCapability("browserName", "Chrome");
capabilities.setCapability("version","88.0");
web_driver = new RemoteWebDriver(new URL("http://" + username + ":" + access_key + "@hub.lambdatest.com/wd/hub"), capabilities);
web_driver.get("https://www.google.com");
web_driver.manage().window().maximize();
}
@Test
public void test_search_demo() throws InterruptedException
{
WebElement elem_search = web_driver.findElement(By.name("q"));
elem_search.sendKeys("LambdaTest" + Keys.ENTER);
Thread.sleep(3000);
WebElement elem_search_result = web_driver.findElement(By.xpath("//h3[.='LambdaTest: Most Powerful Cross Browser Testing Tool Online']"));
elem_search_result.click();
assertEquals(web_driver.getTitle(), "Most Powerful Cross Browser Testing Tool Online | LambdaTest");
}
@AfterTest
public void tearDown()
{
if (web_driver != null)
{
System.out.println("Demo Test is Completed");
web_driver.quit();
}
}
}
```
The execution information is available in the [Automation Dashboard](https://automation.lambdatest.com/) of LambdaTest. As seen below, the test was executed successfully on the LambdaTest Selenium Grid:
## That’s All Folks

Selenium 4 offers several new features like relative locators, Chrome DevTools, improved Selenium Grid, and more, making it a worthy upgrade over Selenium 3. In this Selenium 4 tutorial, we had a detailed look at how to upgrade from Selenium 3 to Selenium 4 for Java language bindings. If you are using Maven for the project, upgrading to Selenium 4 is about fetching the Selenium 4 from the Maven Repository and adding the same in pom.xml.
Apart from Java, it is easy to upgrade to Selenium 4 for Selenium supported languages like Python, C#, PHP, Ruby, and JavaScript. As far as Selenium 3 vs. Selenium 4 is concerned, Selenium 4 (which is still in the Alpha stage) has a huge upper-edge over its predecessor.
If you are using Selenium 4, have you tried Selenium with Maven? Do share your experience in the comments section. Also, let us know which is your ‘go-to feature’ in Selenium 4.
Happy Automation Testing.☺ | himanshusheth004 |
616,604 | Splat Operator in PHP | ...$str is called a splat operator in PHP (other languages, including Ruby.) This feature allows you... | 0 | 2021-02-24T10:02:48 | https://dev.to/kiranparajuli589/splat-operator-in-php-3ija | php, operator, magic | `...$str` is called a splat operator in PHP (other languages, including Ruby.)
This feature allows you to capture a variable number of arguments to a function, combined with "normal" arguments passed in if you like. It's easiest to see with an example:
```php
<?php
function concatenate($transform, ...$strings) {
$string = '';
foreach($strings as $piece) {
$string .= $piece;
}
return($transform($string));
}
echo concatenate("strtoupper", "I'm ", 20 + 2, " years", " old.");
```
Output
```
I'M 22 YEARS OLD.
```
### Latest feature
After PHP 5.5.x, arrays and traversable objects can be unpacked into argument lists when calling functions by using the `...` operator.
```php
<?php
function add($a, $b, $c) {
return $a + $b + $c;
}
$operators = [2, 3];
echo add(1, ...$operators);
?>
```
Output
```
6
```
That's cool. 😎 | kiranparajuli589 |
616,619 | The Difference Between i++ and ++i (Postfix vs. Prefix) | This post was originally published at kais.blog. Let's move your learning forward together! Follow m... | 0 | 2021-02-24T14:37:35 | https://kais.blog/p/the-difference-between-i-and-i-postfix-vs-prefix | javascript, tutorial, beginners, programming | *This post was originally published at [kais.blog](https://kais.blog/p/the-difference-between-i-and-i-postfix-vs-prefix).*
**Let's move your learning forward together!** [Follow me on Twitter](https://twitter.com/intent/follow?screen_name=kais_blog) for your daily dose of developer tips. Thanks for reading my content!
---
JavaScript (and many other languages) support the *postfix* and the *prefix increment operator* (`++`). You have probably seen and used it before.
Often it's used like this:
```js
i++;
```
In this case it's almost equivalent to:
```js
i = i + 1;
```
But, what do you think? Is there a difference between
```js
let i = 3;
const j = i++;
```
and
```js
let i = 3;
const j = ++i;
```
...
Well, yes. The first example uses the *postfix increment operator* (`i++`). The second example uses the *prefix increment operator* (`++i`). At first, it seems like there's no difference. However, it's important to understand what is going on here:
The *postfix increment operator* increments the value and returns the value **before** the increment.
The *prefix increment operator* increments the value and returns the value **after** the increment.
Let's take a look at our two examples again:
```js
// postfix increment
let i = 3;
const j = i++;
console.log({ i, j }); // { i: 4, j: 3 }
```
```js
// prefix increment
let i = 3;
const j = ++i;
console.log({ i, j }); // { i: 4, j: 4 }
```
Spotted the difference? The value of `j` differs. Therefore, it is important to know this small difference between *postfix* and *prefix*.
By the way, the same applies to the *postfix decrement* and *prefix decrement operator* (`--`). The only difference is, that instead of *incrementing* we are *decrementing* the value.
That's all there is to say. I hope I made the difference a bit clearer. See you soon!
---
**Let's move your learning forward together!** [Follow me on Twitter](https://twitter.com/intent/follow?screen_name=kais_blog) for your daily dose of developer tips. Thanks for reading my content!
*This post was originally published at [kais.blog](https://kais.blog/p/the-difference-between-i-and-i-postfix-vs-prefix).* | kais_blog |
616,659 | Wednesday Links - Edition 2021-02-24 | Optional.stream() (2 min read) 🏞️ https://blog.frankel.ch/optional-stream Distributed Application Ru... | 6,965 | 2021-02-24T11:12:55 | https://dev.to/0xkkocel/wednesday-links-edition-2021-02-24-4cbn | java, kotlin, microservices, jvm | Optional.stream() (2 min read) 🏞️
https://blog.frankel.ch/optional-stream
Distributed Application Runtime (Dapr) v1.0 Announced (2 min read) 🏃
https://www.infoq.com/news/2021/02/dapr-production-ready
JEP draft: Frozen Arrays Preview (15 min read) 🥶
https://openjdk.java.net/jeps/8261007
unmodifiableCollection wrapping (30 sec read) 🌯
https://twitter.com/tagir_valeev/status/1363446543169257473
javadoc tag to avoid duplication of return information (1 min read) 🕳️
https://bugs.openjdk.java.net/browse/JDK-8075778
Writing Meaningful Commit Messages (8 min read) 📜
https://reflectoring.io/meaningful-commit-messages
ARCHITECTURE.md (2 min read) 📝
https://matklad.github.io//2021/02/06/ARCHITECTURE.md.html
Spring's JdbcTemplate + Java 15 Multiline Strings (30 sec read) 📃
https://twitter.com/helpermethod/status/1364511256154169344
JDoctor, a Java library for good error messages (2 min read) 🧑⚕️
https://github.com/melix/jdoctor
Multik: Multidimensional Arrays in Kotlin (2 min read) 🕯️
https://blog.jetbrains.com/kotlin/2021/02/multik-multidimensional-arrays-in-kotlin
Simulating Latency with SQL / JDBC (4 min read) 🐢
https://blog.jooq.org/2021/02/15/simulating-latency-with-sql-jdbc/ | 0xkkocel |
630,509 | 你好呀 | 你好呀DEV | 0 | 2021-03-10T02:50:57 | https://dev.to/lostkun/-6pl | 你好呀DEV | lostkun | |
621,945 | Download view-only shared Google Drive video | Download view-only shared Google Drive video Last week, I got a Google Drive recording... | 0 | 2021-03-07T15:10:43 | https://medium.com/@victorleungtw/download-view-only-shared-goo-9226ac5d9f44 | download, shared, googledrive, googleworkspace | ---
title: Download view-only shared Google Drive video
published: true
date: 2021-03-01 16:02:56 UTC
tags: download,shared,googledrive,googleworkspace
canonical_url: https://medium.com/@victorleungtw/download-view-only-shared-goo-9226ac5d9f44
---
### Download view-only shared Google Drive video
Last week, I got a Google Drive recording video and it was shared with me with View-Only access. The video was further shared with my team but they are getting access denied on the link. Here are the steps on how to download the video:
1. In Chrome, open developer tools and select the “ **Network** ” tab.
2. Reload the page that plays the video and filter by type “ **videoplayback** ”.
3. Right-click on this link and select “ **open in new tab** ”.
4. Right-click on the video and select “ **save video as** ”.
That is. No external plugin required. And you can upload your video to the shared drive for your teams, or upload it to youtube depending on your use case.
Written by **Victor Leung** who is a keen traveller to see every country in the world, passionate about cutting edge technologies.
[Get in touch](mailto:hello@victorleungtw.com) | [View my porfolio](https://victorleungtw.com/portfolio)
_Originally published at_ [_https://victorleungtw.com_](https://victorleungtw.com/download-view-only-shared-google-drive-video)_._ | victorleungtw |
629,651 | Top 10 Date Pickers in React | Never bend your head. Always hold it high. Look the world straight in the eye. - Helen Keller ... | 0 | 2021-03-10T12:13:05 | https://thecodeangle.com/top-10-date-pickers-in-react/ | react, javascript, webdev, tutorial | ---
title: Top 10 Date Pickers in React
canonical_url: https://thecodeangle.com/top-10-date-pickers-in-react/
published: true
description:
tags: react, javascript, webdev, tutorial
cover_image: https://res.cloudinary.com/dz4tt9omp/image/upload/v1615341416/picker-3.jpg
---
>_Never bend your head. Always hold it high. Look the world straight in the eye._
*\- Helen Keller*
## Table of Content
- <a href="#Introduction">**Introduction**</a>
- <a href="#y0c/react-datepicker">**10). @ y0c/react-datepicker**</a>
- <a href="#materialui-daterange-picker">**9). materialui-daterange-picker**</a>
- <a href="#React-DateTime-Picker">**8). React-DateTime-Picker**</a>
- <a href="#react-date-range">**7). react-date-range**</a>
- <a href="#react-date-picker">**6). react-date-picker**</a>
- <a href="#react-big-calendar">**5). react-big-calendar**</a>
- <a href="#react-datetime">**4). react-datetime**</a>
- <a href="#react-day-picker">**3). react-day-picker**</a>
- <a href="#material-ui/pickers">**2). @material-ui/pickers**</a>
- <a href="#reactdatepicker">**1). React Date Picker**</a>
- <a href="#conclusion">**Conclusion**</a>
<a name="Introduction"></a>
# Introduction
A Date Picker is a form of graphical user interface that allows users to select a date from a calendar and/or time from a time range. The common practice in which a date picker is implemented is by providing a text-box field, which when clicked upon to enter a date, displays a pop-up calendar, such that when one of the characters on the calendar is selected, it displays the value inside the text input field.
Some of the advantages of using a date picker include:
- Entering dates becomes easier for the user and you can control the format of the data you receive.
- Only valid dates can be entered.
- Dates are properly formated to avoid confusion.
- Date Pickers can help users out by including common holidays, for instance depending on the country chosen and integration of their own calendar.
- Making the user enter a date by merely clicking on a date in the pop-up calendar as opposed to having to take their hand off the mouse to type in a date, reducing the chances of error in the process.
In this tutorial, we will take a look at the top ten date pickers in react, using the estimated weekly downloads from the least number to the most on [NPM](https://www.npmjs.com/).
<a name="y0c/react-datepicker"></a>
## 10). @ y0c/react-datepicker
This date picker is a flexible, reusable, mobile-friendly DatePicker component for React. Its previous versions rely on **moment.js,** but now it is changed to **Day.js** because of bundle size issues.
### Brief Overview:
###### **Version **
1.0.4
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
677
###### **Unpacked-size**
154kb
###### Link To Repository
[@yoc/react-](https://github.com/y0c/react-datepicker)date picker
### Code Demo / Example
In this short tutorial, I'll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i @y0c/react-datepicker
```
#### Step 2
> ### app.js
```javascript
import React from "react";
import { DatePicker, RangeDatePicker } from "@y0c/react-datepicker";
import "@y0c/react-datepicker/assets/styles/calendar.scss";
const YocReactDatePicker = () => {
const onChangeValue = (date) => {
const dateValue = date.toDate();
console.log(dateValue);
};
const onChangeRangeValue = (title) => (...date) => console.log(date);
return (
<div>
<h1>YOC DatePicker Example</h1>
<DatePicker onChange={onChangeValue} />
<br />
<br />
<h1>YOC Date Range Picker Example</h1>
<RangeDatePicker onChange={onChangeRangeValue("date")} />
</div>
);
};
export default YocReactDatePicker;
```
What we did here was to create a new file. After this, we had to import **React**, **DatePicker**, **RangeDatePicker** as well as the assets for the **CSS.**
Next, we created a functional component that has two variables. The first one is called **onChangeValue** which takes in an argument, while the second one is called **onChangeRangeValue. **These variables allow us to log the data for the date in the console.
Finally in our code, we display the date pickers by calling both the ***<DatePicker onChange={onChangeValue} />*** and the **<RangeDatePicker onChange={onChangeRangeValue("date")} />** that was imported earlier.
Each one has an **onChange** prop that takes in the variables that we created earlier.
#### Result

#### Possible Errors
There is a chance you may get an error that says, ***ERROR Cannot find module 'node-sass'.*** All you have to do when you get this error message is to run the command `npm install node-sass` in your terminal or command line.
<a name="materialui-daterange-picker"></a>
## 9). materialui-daterange-picker
This is a react date range picker that makes use of @material-ui. Material-UI is the most popular React component library, with millions of users worldwide.
### Brief Overview:
###### **Version **
1.1.92
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
5,135
###### **Unpacked-size**
1.12 MB
###### Link To Repository
[materialui-daterange-picker](https://github.com/jungsoft/materialui-daterange-picker#readme)
### Code Demo / Example
In this short tutorial, I'll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i materialui-daterange-picker
```
#### Step 2
> ### *app.js*
```javascript
import React from "react";
import { DateRangePicker } from "materialui-daterange-picker";
const MaterialUiDateRange = () => {
const [open, setOpen] = React.useState(true);
const toggle = () => {
setOpen(open);
};
const setDateRange = (date) => {
console.log(date.startDate, date.endDate);
alert(date.startDate, date.endDate);
};
return (
<div>
<h1>Material UI Date Range</h1>
<DateRangePicker
open={open}
toggle={toggle}
onChange={(date) => setDateRange(date)}
/>
</div>
);
};
export default MaterialUiDateRange;
```
Here we import **React** and the **DateRangePicker** as expected. Then we created a functional component. In this component, we declared a React hook called **useState** that takes in a variable(open) and a function(setOpen).
We state the **useState** to **true** by default because that is how our date picker will get displayed on the page.
Next up, we assigned an anonymous function to a variable called toggle. This makes sure that our date picker is always open no matter the state.
We then create another variable called **setDateRange.** This variable takes in an anonymous function that logs and alert the value of the date selected. We get the value for both the start date and the end date.
Finally in our return, we assign each props in the <**DateRangePicker** /> component to each of the variables.
#### Result

<a name="React-DateTime-Picker"></a>
## 8). React-DateTime-Picker
This is a fast, lightweight and easy to style date picker that only provides support for modern browsers. It is only compatible with 16.3 or later. If you use an older version of React, please refer to the table below to find a suitable React-DateTime-Picker version.
| React version | Newest compatible React-DateTime-Picker version |
| --- | --- |
| ≥16.3 | latest |
| ≥16.0 | 2.x |
### Brief Overview:
###### **Version **
3.1.0
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
20,973
###### **Unpacked-size**
193 kB
###### Link To Repository
[react-datetime-picker](https://github.com/wojtekmaj/react-datetime-picker#readme)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-datetime-picker
```
#### Step 2
> ### *app.js*
```javascript
import React, { useState } from 'react';
import DateTimePicker from 'react-datetime-picker';
const ReactDateTimePicker = () => {
const [value, onChange] = useState(new Date());
const getDateValue = (value) => {
onChange(value)
console.log(value)
alert(value)
}
return (
<div>
<h2>React Date Time Picker</h2>
<DateTimePicker
onChange={getDateValue}
value={value}
/>
</div>
)
}
export default ReactDateTimePicker
```
From the above, we import **React**, **useState** and **DateTimePicker**, then we created a functional component. Then we declared a React hook called **useState** that takes in a variable(value) and a function(onChange).
The value takes in the value of the current date which will be displayed by default in the input field.
Next up we created a variable called **getDateValue**. This variable takes in an anonymous function that enables us to log and alert the value of the selected date. Also, the **onChange** function is called inside the anonymous function, this makes the date values in the input field change based on the date that was selected.
Lastly, in our return, we pass in the variables to the props inside the **<DateTimePicker />** component.
#### Result

<a name="react-date-range"></a>
## 7). react-date-range
This is a React Date Picker component for choosing dates and date ranges. It makes use of date-fns for date operations. Some of the qualities of this date picker include:
- Stateless date operations
- Highly configurable
- Multiple range selection
- Based on native js dates
- Drag n Drop selection
- Keyboard friendly
### Brief Overview:
###### **Version **
1.1.3
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
63,883
###### **Unpacked-size**
1.92 MB
###### Link To Repository
[react-date-range](https://github.com/hypeserver/react-date-range#readme)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-date-range
```
#### Step 2
> ### *app.js*
```javascript
import React, { useState } from "react";
import "react-date-range/dist/styles.css"; // main style file
import "react-date-range/dist/theme/default.css"; // theme css file
import { Calendar } from "react-date-range";
const ReactDateRange = () => {
const handleSelect = (date) => {
console.log(date);
alert(date);
};
return (
<div>
<h2>React Date Range</h2>
<Calendar date={new Date()} onChange={handleSelect} />
</div>
);
};
export default ReactDateRange;
```
The first thing we did was import **React**, the CSS files for the theme and also the necessary component from **react-date-range.**
Next, we created a function called **handleSelect**, that helps log the date values to the console.
Finally, in our return, our first component called **<Calendar />** we declared some props and assigned some variables to it. The first is the date prop that takes in a new Date value, second is the **onChange** prop that takes in the **handleSelect** variable that logs out the date values to the console.
#### Result

<a name="react-date-picker"></a>
## 6). react-date-picker
This is a fast, lightweight and easy to style date picker that only provides support for modern browsers. With this date picker you can pick days, months, years, or even decades.
It is only compatible with 16.3 or later. If you use an older version of React, please refer to the table below to find a suitable React-DateTime-Picker version.
| React version | Newest compatible React-Date-Picker version |
| --- | --- |
| ≥16.3 | latest |
| ≥16.0 | 7.x |
### Brief Overview:
###### **Version **
8.0.7
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
78,779
###### **Unpacked-size**
209 kB
###### Link To Repository
[react-date-picker ](https://github.com/wojtekmaj/react-date-picker#readme)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-date-picker
```
#### Step 2
> ### *app.js*
```javascript
import React, { useState } from "react";
import DatePicker from "react-date-picker";
const ReactDatePicker = () => {
const [value, onChange] = useState(new Date());
const dateValue = (range) => {
onChange(range)
console.log(range);
alert(value);
};
return (
<div>
<h2>React Date Picker</h2>
<DatePicker onChange={dateValue} value={value} />
</div>
);
};
export default ReactDatePicker;
```
From the above, we import **React**, **useState** and **DatePicker**, then we created a functional component. Next, we declared a React hook called **useState** that takes in a variable(value) and a function(onChange).
The value takes in the result of the current date which will be displayed by default in the input field.
Next up we created a variable called **dateValue** . This variable takes in an anonymous function that enables us to log and alert the value of the selected date. Also, the **onChange** function is called inside the anonymous function, this makes the date values in the input field change based on the date that was selected.
Lastly, in our return, we pass in the variables to the props inside the <**DatePicker** /> component.
#### Result

<a name="react-big-calendar"></a>
## 5). react-big-calendar
This is an events calendar component built for React and made for modern browsers (read: IE10+) and uses flexbox over the classic tables-based approach.
**react-big-calendar** makes use of three options for handling the date formatting and culture localization, depending on your preference of **DateTime** libraries. You can use either the [Moment.js](https://momentjs.com/), [Globalize.js](https://github.com/jquery/globalize) or [date-fns](https://date-fns.org/) localizers.
### Brief Overview:
###### **Version **
0.32.0
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
126,292
###### **Unpacked-size**
1.13 MB
###### Link To Repository
[react-date-calendar](https://github.com/jquense/react-big-calendar#readme)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-big-calendar
```
#### Step 2
> ### *app.js*
```javascript
import React from "react";
import { Calendar, momentLocalizer } from "react-big-calendar";
import moment from "moment";
import "react-big-calendar/lib/css/react-big-calendar.css";
const ReactBigCalendar = () => {
moment.locale("en-GB");
const localizer = momentLocalizer(moment);
const myEventsList = [
{
start: moment().toDate(),
end: moment().add(1, "days").toDate(),
title: "Play Nintendo Switch",
}
];
return (
<div>
<h2>React Big Calendar</h2>
<Calendar
localizer={localizer}
events={myEventsList}
/>
</div>
);
};
export default ReactBigCalendar;
```
From the above, we import **React**, the necessary dependencies from **react-big-calendar**, **moment.js** as well as the needed **CSS** assets.
Next up we set the structure for **moment.js**, after which we declare a variable called **myEventsList**. This variable contains an array of objects that sets a start-date, end-date as well as the title of the event to take place on those days.
Finally, we return our <**Calendar** /> component which contains the props in which we passed the date and also the list of events.
#### Results

<a name="react-datetime"></a>
## 4). react-datetime
This Date-Picker can be used as a date picker, time picker or both at the same time. It is **highly customizable** and it even allows to edit date's milliseconds.
### Brief Overview:
###### **Version **
3.0.4
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
207,604
###### **Unpacked-size**
296 kB
###### Link To Repository
[react-datetime](https://www.npmjs.com/package/react-datetime)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-datetime
```
#### Step 2
> ### *app.js*
```javascript
import React from "react";
import "react-datetime/css/react-datetime.css";
import Datetime from "react-datetime";
const ReactDateTime = () => {
let setDateTime = (e) => {
const dateValue = e.toDate();
console.log(dateValue);
alert(dateValue)
};
return (
<div>
<h2>React Date Time</h2>
<Datetime value={setDateTime} input={false} onChange={setDateTime} />
</div>
);
};
export default ReactDateTime;
```
Here we import **React**, the **CSS** assets and **Datetime** from the **react-datetime** library.
Inside our functional component, we created a variable called **setDateTime**. This variable takes in an anonymous function that will display the values of the date both inside the browser console and the alert box.
Finally, in our return, we create our <**Datetime** /> component and assign the necessary props to it, which makes our date-picker functional.
#### Results

<a name="react-day-picker"></a>
## 3). react-day-picker
This is a date-picker that is highly customizable, localizable, with ARIA support, no external dependencies.
### Brief Overview:
###### **Version **
7.4.8
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
454,148
###### **Unpacked-size**
686 kB
###### Link To Repository
[react-day-picker](https://github.com/gpbl/react-day-picker)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-day-picker
```
#### Step 2
> ### *app.js*
```javascript
import React from "react";
import DayPickerInput from "react-day-picker/DayPickerInput";
import "react-day-picker/lib/style.css";
const ReactDayPicker = () => {
const onDayChangeInput = (day) => {
console.log(day);
alert(day)
};
return (
<div>
<h3>DayPickerInput</h3>
<DayPickerInput
placeholder="DD/MM/YYYY"
format="DD/MM/YYYY"
onDayChange={onDayChangeInput}
/>
</div>
);
};
export default ReactDayPicker;
```
From the above code, we import **React**, the **DayPickerInput** and the **CSS** assets.
In our functional component, we created a variable called **onDayChangeInput**. Inside this variable is an anonymous function that logs the date valued to the console as well as showing an alert box.
Then finally, in our return, we include the props in our <**DayPickerInput** /> component.
#### Result

<a name="material-ui/pickers"></a>
## 2). @material-ui/pickers
This date-picker is an accessible, customizable, delightful date & time pickers for React. It is one of the most high-quality date-picker out there.
It is based on Material-UI, the world’s most popular React component library.
### Brief Overview:
###### **Version **
3.2.10
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
608,421
###### **Unpacked-size**
1.49 MB
###### Link To Repository
[material-ui pickers](https://github.com/mui-org/material-ui-pickers)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i @material-ui/pickers
```
#### Step 2
> ### *app.js*
```javascript
import React, { useState } from "react";
import DateFnsUtils from "@date-io/date-fns"; // choose your lib
import {
DatePicker,
TimePicker,
DateTimePicker,
MuiPickersUtilsProvider,
} from "@material-ui/pickers";
const MaterialUiPickers = () => {
const [selectedDate, handleDateChange] = useState(new Date());
const dateChangeValue = (date) => {
handleDateChange(date);
const dateValue = date;
console.log(dateValue);
alert(dateValue);
};
return (
<div>
<h2>Material UI Pickers</h2>
<MuiPickersUtilsProvider utils={DateFnsUtils}>
<DatePicker
variant="static"
value={selectedDate}
onChange={dateChangeValue}
/>
{/\* <br /> \*/}
<TimePicker value={selectedDate} onChange={dateChangeValue} />
<DateTimePicker value={selectedDate} onChange={dateChangeValue} />
</MuiPickersUtilsProvider>
</div>
);
};
export default MaterialUiPickers;
```
The code above shows how we import the necessary dependencies to run the project.
Then in our functional component, we created a **useState** hook that has a variable and a function called **selectedDate** and **handleDateChange** respectively.
Next, we created a variable called **dateChangeValue** that holds an anonymous function. Inside this function we do three things:
- We call the **handleDateChange** function from our **useSate**, this helps us update the change event on the date-picker, shown on the page.
- Next up we log and alert the value of the date that is clicked on the date-picker.
Finally. in our return, we have a <**DatePicker** />,<**TimePicker** /> and a <**DateTimePicker** />. Each of these components takes in props like **value** and **onChange** that have the appropriate variables assigned to them.
#### Result

#### Possible Errors
There is a possibility you run into this error: **Module not found: Can't resolve '@date-io/date-fns'**
When that happens, you can run the following commands to solve the issue:
```
$ npm i --save date-fns@next @date-io/date-fns@1.x
```
<a name="reactdatepicker"></a>
## 1). React Date Picker
This is a simple and reusable Datepicker component made for React. It is one of the most popular packages around the web, with hundreds of thousands of weekly downloads.
This date picker relies on [date-fns internationalization](https://date-fns.org/v2.0.0-alpha.18/docs/I18n) to localize its display components. By default, the date picker will use the locale globally set, which is English.
### Brief Overview:
###### **Version **
3.6.0
###### **License **
MIT
###### **Estimated-Weekly -Downloads **
835,537
###### **Unpacked-size**
509 kB
###### Link To Repository
[react-datepicker](https://github.com/Hacker0x01/react-datepicker)
### Code Demo / Example
In this short tutorial, I’ll be showing us how we can install, display and get the values of the date that is selected in the DatePicker.
#### Step 1
We will need to install React, this can be done trough Create-React-App. I wrote an article on how to install it [here](https://thecodeangle.com/angular-vs-react-vs-vue-getting-started/#reactinstallation).
Once that is done, we will need to navigate into the path of our folder in our terminal and run the npm command to install our Date-Picker package:
```
npm i react-datepicker
```
#### Step 2
> ### *app.js*
```javascript
import React, {useState} from "react";
import DatePicker from "react-datepicker";
import "react-datepicker/dist/react-datepicker.css";
const ReactDatePicker = () => {
const [startDate, setStartDate] = useState(new Date());
const getDateValue = (date) => {
setStartDate(date);
console.log(date)
alert(date)
}
return (
<div>
<h2>React Date Picker</h2>
<DatePicker
selected={startDate}
onChange={getDateValue}
/>
</div>
);
};
export default ReactDatePicker;
```
Above we import all the necessary dependencies. Then in the functional component, we create a **useState** hook. This hook takes in a variable and a function called **startDate** and **setStartDate** respectively.
Next, we create a variable with an anonymous function called **getDateValue.**
In this variable, the **setStartDate** function from the **useState** is updated with the value of the current date as they change on the page. We also log and alert the date values on the console.
Finally in our return, we declare our <**DatePicker** /> component and assign the necessary props to it.
#### Result

<a name="conclusion"></a>
## Conclusion
So that is it for the top Date pickers in React. Date pickers are very popular and important components in the Frontend Development world. It is really great that we have so many Date Pickers out there, and we can easily implement anyone that seems like the right fit for our project.
If you have any difficulties in implementing any of the Date Picker discussed above, feel free to drop your issue in the comment section.
Also if you are looking for an open-source project to contribute to, a lot of the above Date Pickers provide an excellent opportunity for you to do so.
Also, [here](https://github.com/desoga10/date-pickers) is the GitHub link to the code examples used in the article.
*Subscribe to my* [*Youtube Channel*](https://www.youtube.com/channel/UChi_aILZkMMx8_KlVAsbI7g) *for more tutorials on web development content.* | desoga |
629,755 | KotlinJS and State Hooks | At sKalable we are Kotlin Obsessed! Making the environment better is part of our daily mission. We wa... | 0 | 2021-03-09T15:31:00 | https://dev.to/skalabledev/kotlinjs-and-state-hooks-2426 | kotlin, react, codequality, webdev | At sKalable we are Kotlin Obsessed! Making the environment better is part of our daily mission. We want to make all things KotlinJS amazingly easy to work with too.
As part of our pursuit to clean up code, we will be delving into state management in this two part tutorial. :sunglasses:
`useState` part of React Hooks for `state` management is something that even [`Javascript`](https://www.javascript.com/) and [`Typescript`](https://www.typescriptlang.org/) engineers struggle with from time to time. We are going to reduce this struggle within the React ecosystem using KotlinJS and the ever incredible [Kotlin-React](https://github.com/JetBrains/kotlin-wrappers/blob/master/kotlin-react/README.md) library.
## Understanding state
To get an idea of what we are trying to do we need to grasp what `state` is in [react](https://reactjs.org/) programming.
**_So lets start!_**
### What is state
The React library provides components with a built-in `state` management object. In this `state` object we can store and manipulate the state of the React component on the fly. If the state object changes, then the component will re-render with the updated state and any UI changes will be reflected.
### How does it work

### Keeping things reactive
We can describe `state` as being reactive since it stores dynamic data for the component. The `state` object itself allows the component to keep track of changes and updates to the data and render views accordingly. It works similarly to the [Observer Pattern](https://www.tutorialspoint.com/design_pattern/observer_pattern.htm) given that it defines a subscription mechanism to notify observers of the data about any events that happen to the payload they are observing.
_Moving on we will cover `state` in both Class and Functional components._
### State in Class Components
A Stateful Class component is [lifecycle aware](https://reactjs.org/docs/state-and-lifecycle.html#converting-a-function-to-a-class) and has its `state` defined in an `external interface`. They can also initialise `state` as a class property _(which we will cover later in [The `useState` Hook](#the-usestate-hook))_ or in a constructor function — both approaches achieve the same result.
When we first initialise our custom `state`, it creates a `getter` and `setter` for the value of the property we want to have state aware. The getter is named similarly to a property variable in Kotlin [(see naming properties in Kotlin)](https://kotlinlang.org/docs/coding-conventions.html#property-names) such as `count` or `word`, i.e. descriptive of the data it holds.
To update the data in this `getter` we use the function defined as `setState`. Inside the Lambda block from this function we have access the variable we want to update.
```kotlin
/**
* A class component extends from [RComponent]. There is no requirement for
* an external prop or state. The values of [RProps] and / or [RState]
* can be provided without the need to declare external interfaces reflecting these.
*/
private class IndentWithDot : RComponent<RProps, IndentState>() {
/**
* To initialise the `state` when the class component is created we
* must override the `RState.init()` function corresponding to the external
* interface we provided to the component. In our case its `IndentState.init()`
*
* @see RComponent<IndentProps, IndentState> — (We're interested in IndentState)
* @see IndentState
*/
override fun IndentState.init() {
indentAmount = 1
indentationValue = "."
}
/**
* The render function gets called when the component mounts or is updated.
* Code inside the render function gets rendered when called.
*
* In our render function we have a single [button] that updates
* the [indent] each time its pressed and displays the current update to the user.
*
* In order to read the `indentationValue` and `indentAmount` we need to reference the `state` from our class
* and get the `indent` values from it.
* @see IndentState
*
*/
override fun RBuilder.render() {
div {
button {
// Update the string using the values from state.indentationValue and state.ident
+"press me to add another dot indent ${state.indentationValue} ${state.indentAmount}"
attrs {
onClickFunction = {
setState {
/**
* Reference the value of the `state.indent` and add 1.
* This will become the new value of `indent`.
*/
indentAmount = state.indentAmount + 1
indentationValue = ".".repeat(indentAmount)
}
}
}
}
}
}
}
/**
* ReactBuilder function used to construct the React Component IndentWithDot.
*/
fun RBuilder.indentByDots() = child(IndentWithDot::class) {}
```
Let's see the code in action!

Even though there is nothing wrong with class components, they can be quite verbose and heavyweight so let's compare how this code looks when optimised with the `useState` hook and Functional Components!
### The useState Hook!
Prior to [React 16.8](https://reactjs.org/blog/2019/02/06/react-v16.8.0.html), functional components could not hold a `state`. Luckily, this is no longer the case as we can now use [React Hooks](https://reactjs.org/docs/hooks-state.html) that include the power of `useState`!
Before this, one of the key differences between them was that functional components lacked the capability to hold an abstracted `state` property. With the introduction of the `useState` hook there is now an alternative to this. :)
```kotlin
val (word, setWord) = useState("")
```
The example above shows a simple `useState` variable of type `String`. The default value is initialised in the parameters of the `useState` function — i.e `useState("hello")`, this would declare the `getter` value as `"hello"`. To update the value of the `word` we use the function `setWord("World")`. Essentially, `word` is the getter and `setWord` is the setter.
We can actually tidy up this logic further with delegation using the [by](https://kotlinlang.org/docs/delegated-properties.html) keyword to delegate the `get` and `set` of `useState`.
```kotlin
var wordState by useState("")
```
To benefit from delegation, we need to convert the way we instantiate the state variable. To have `state` capability, the type of the property needs to become mutable — i.e. `val` to `var`. There is also no need to keep two properties for `get` and `set` either. Renaming the variable is important as it has a hidden superpower.
Here @sKalable our preference is to give it a suffix named `State` for more clarity around our code and hidden functionality.
### State in Functional Components
_lets refactor our Class Component to a Functional Component!_
```kotlin
/**
* [indentWithDot] is a react [functionalComponent]. This type of component is not
* lifecycle aware and is more lightweight than a class component [RComponent].
*/
private val indentWithDot = functionalComponent<RProps> {
/**
* To initialise the state within the function component we need to
* declare the [useState]s as the first variables in the function. Doing
* so ensures the variables are available for the rest of the code within
* the function.
*
* Using the `by` keyword allows for delegation of the get and set of [useState]
* into the indentState var.
*
* @see IndentState for state values
*/
var indentState by useState<IndentState>(object : IndentState {
override var indentAmount = 1
override var indentationValue = "."
})
/**
* In a [functionalComponent] (FC) the last code block should always be the HTML to
* render. Compared to a class component, there is no RBuilder.render() as the HTML
* at the end of the function is what gets rendered. A FCs first param is a lambda extending
* from [RBuilder] itself so RBuilder.render() is not required.
*
* As we can see, the [button] we render within [div] has an [onClickFunction] attribute that
* handles click events.
*
* Here, when handled, we update the [IndentState.indentAmount] by adding one.
* [IndentState.indentationValue] is then updated by adding a number of "."s equal
* to the amount of [IndentState.indentAmount].
*
* This value is then reflected in the text of the button.
*/
div {
button {
/**
* Update the string using the values from [IndentState.indentationValue] and [IndentState.indentAmount]
*/
+"press me to add another dot indent from FC ${indentState.indentationValue} ${indentState.indentAmount}"
attrs {
onClickFunction = {
indentState = object : IndentState {
/**
* reference the value of the [IndentState.indentAmount] and increment by one.
* The value of [IndentState.indentationValue] is then updated with a number of "."s
* equal to the new amount of [IndentState.indentAmount]
*/
override var indentAmount = indentState.indentAmount + 1
override var indentationValue = ".".repeat(indentAmount)
}
}
}
}
}
}
/**
* ReactBuilder function used to construct the React Component IndentWithDot.
*/
fun RBuilder.indentByDotsFC() = child(indentWithDot) {}
```
Running the code again we can see it works exactly the same as before, except with much less boilerplate.

There we have it, two approaches to using state in both a Class and Functional Component!
## To Summarise
Effective code is clean and readable code. Also, you might be wondering how to handle multiple states? We cover this in Part 2 of KotlinJS and State Hooks!
As always, you can find the sample project for the above [here](https://github.com/skalable-samples/KotlinJS-and-React-State)
Thank you for taking your time to learn with us! Feel free to reach out and say hello.
@sKalable we are a Kotlin-centric agency that builds code to ensure it is _Maintainable_, _Flexible_ and of course, _sKalable_.
Follow us on [Twitter](https://twitter.com/skalable_dev) and [Dev.to](https://dev.to/skalabledev) and [LinkedIn](https://www.linkedin.com/company/skalable-dev/) to get the latest on Kotlin Multiplatform for your business or personal needs.
| skalabledev |
629,884 | You Can Have It Fast Or You Can Have It Right - The Software Dilemma | When working with software, you often get told "faster, faster, faster!" But faster tends to lead to poor quality. What can you do? | 0 | 2021-03-09T13:49:28 | https://www.readysetcloud.io/blog/allen.helton/you-can-have-it-fast-or-you-can-have-it-right/ | career, tech | ---
title: You Can Have It Fast Or You Can Have It Right - The Software Dilemma
published: true
description: When working with software, you often get told "faster, faster, faster!" But faster tends to lead to poor quality. What can you do?
tags:
- career
- tech
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xotooo9hd46b88f7mcvl.jpg
canonical_url: https://www.readysetcloud.io/blog/allen.helton/you-can-have-it-fast-or-you-can-have-it-right/
---
I was sitting on a call the other day.
We were going through a list of requirements for a project my team has been working on. I had called the meeting to let stakeholders know development was going to slow down.
The senior architect on my team had left in the middle of the project. So I, of course, had to inform the people that care that the date was going to slip.
The answer I received was "that is a hard deadline, we still need all the work by that date."
So I still had to get the same amount of work done with 1 less person.
Great.
In some cases, this would actually be a good thing. I'm sure we've all seen this saying:
{% tweet 837435854591242240 %}
In my situation, the team was already running a little thin, so I had to remind all the stakeholders that *you can have software fast or you can have it right, but you can't have both*.
This refers to the timeless battle of quality over speed.
How do you balance it? What can you do to deliver **more** software **faster**?
## Finding a Balance
If you left it up to developers, software would never ship. They'd always want to add "one more feature" or tighten up some css on a webpage.
SPOILER ALERT:
> There is no such thing as perfect software.
Think about that from any lens. There is no software without bugs. You will not have 100% satisfaction across all your customers. There won't be a time when developers do not want to refactor something.
Software is constantly evolving. You must get it to your customers at some point.
On the other side, if it was up to the sales department, the software would have been done yesterday.
"Does it solve the business problem?"
"Kind of, yes."
"Ship it."

Unfortunately, the quality vs speed graph isn't linear. One would hope that for each week you move up a deadline, the quality just gets a little worse.
**Nope.**
Moving up dates means taking shortcuts when it comes to building software. If you start adding shortcuts on top of shortcuts, you are going to get exponentially worse results.
The software will appear unstable. It won't look as nice. You'll get intermittent behavior.
If you don't want to dig yourself into a hole, err on the side of quality.
## Be Consistent
One of the biggest principles I follow when building new software is [iteration](https://www.readysetcloud.io/blog/allen.helton/itturat-ituratte-iterat-iterate-iterate-65199c4d5d53).
Get through the business process end to end via the happy path. Then make another pass and improve everything just a little bit. Then do it again. And again.
This is going to provide you with a consistent feel throughout your app and also maintain the highest quality possible if you're asked to go fast.
I often see teams that build one section of their app completely before moving onto the next. By the time they reach the end, it either took too much time or they were asked to speed up a bit, leaving the results....somewhat to be desired.

*What happens when you focus on one area before you move onto the next*
This doesn't always happen but it doesn't mean it can't happen to you. Be sure you are [generous with your estimates](https://www.readysetcloud.io/blog/allen.helton/the-beginners-guide-to-software-estimation) and give yourself some padding on the timeline.
> It is always harder than you think.
## Do's and Don'ts
When it comes to speed vs quality in software, there are a few things you *should* do and a few you *should definitely not* do.
#### DO: Have a Plan
When people inevitably ask you how quickly you can do a project, be sure to have your trusty development plan handy.
Reference all the pieces of the plan and be ready to identify the areas that can and can't be shortcutted.
#### DON'T: Throw More Resources at a Problem
There's a saying that *9 women can't make a baby in one month.* Some jobs are meant to be done by the resources you already have.
Adding more developers to a team oftentimes will slow the team down at the beginning as they bring the new hires up to speed. Be intentional about the people you add to a project.
#### DO: The Minimum
The middle of a big push is not the time to start "gold-plating" features. Start tossing out features you were planning that aren't part of the requirements.
You can and should come back to those after you get your initial release to the customer.
#### DON'T: Work Without a Timeline
On the opposite end of the spectrum, don't do work without a set date in mind. People need deadlines.
When I was in college, I would get a project at the beginning of the semester that was due at the very end. I had the entire semester to work on it.
Every single time, I would ignore the project and start it a few days before it was due. I would do a mad scramble at the end and get it in last minute.
Don't let this happen to your software. With no deadline, you'll be lazy and have no reason to finish it. *Always work toward a goal*
#### DO: Be Intentional
You're going to cut things that shouldn't be cut. Quality is going to suffer because of a ridiculous date. These things we know.
There's no avoiding them, but you can mitigate some of the risk to your future self by being intentional about how you cut scope and feature sets.
At my job **configuration** is a bad word. It takes extra development and adds complexity for the customer. It frequently isn't even needed. If you [intentionally hardcode](https://www.readysetcloud.io/blog/allen.helton/new-project-just-hardcode-it-bac72e1a231e) areas of your app, you speed up development while avoiding the complexities of configuration (for now).
Maybe that piece of config wasn't needed after all?
Thinking with intentionality will open up ideas to powerful shortcuts that [maybe should have been the solution after all](https://www.readysetcloud.io/blog/allen.helton/think-unique-build-the-right-software-not-the-easy-software).
#### DON'T: Give Up
It can be hard to stay motivated when you're asked to do "unforgivable things" to your software. You feel a sense of pride and ownership in the software you build and somebody is asking you to cut corners.
There's a point on the fast vs right scale that you cannot go past. Things won't work, your app simply won't be your app.
**Push back.**
You're in the position you're in for a reason. There's trust in your decision making and reasoning. If you're asked to do too much, tell them it won't work.
As with everything in life, software is about compromise. Negotiate some give and take. People are almost always willing to work with you.
## Conclusion
Software is a delicate balance of too much/just right/not enough.
It really depends on where you are in the lifecycle of a product. Startups should do as little as possible as fast as possible to get their product out on the market. They are highly iterative and responsive to the feedback of their customers.
Other companies who have made their way with [waterfall development](https://www.readysetcloud.io/blog/allen.helton/will-waterfall-development-ever-die-probably-not-6ab4589e061) tend to be on the opposite side of the scale. They hone and build until it's done before sending it out.
There is no right or wrong way to all of this. But what you need to remember is the more shortcuts you take, the more quality will suffer.
So which report do you want to see yourself in? The report saying your company missed a date but delivered solid software or the one saying you hit the date but delivered an unstable product?
The choice is yours. | allenheltondev |
629,920 | To all developers out there | In recent times, in the galaxy near, nearby... There has been released an order in which nearly all... | 0 | 2021-03-09T15:00:20 | https://dev.to/camvanzek/to-all-developers-out-there-2mej | survey, webdev, coding, ux | In recent times, in the galaxy near, nearby...
There has been released an order in which nearly all of the developers are declared the enemies of the Great Emperor and convicted to be neutralised. Though the situation is drastic, there is a way to prevent the extermination from happening. We, a group of rebel designers, located in the Otasoft system, can stop the Emperor's plans, but to do that we need to understand how the developers think.
We send this cryptic message to all developers out here, looking for the answers only you can provide. This link will explain you everything...
https://docs.google.com/forms/d/e/1FAIpQLSdRu1xmA_n5s14l9x7g3oGyVVZz5539F86PGdqZrTK0F9_MzA/viewform
The fate of the galaxy is in your hands!
// end of message
| camvanzek |
630,123 | Open File Explorer and Browser from ZSH | Have you noticed that we can open a folder inside VSCode with code . command? Will it be cool if we... | 11,407 | 2021-03-09T17:15:21 | https://dev.to/equiman/open-file-explorer-and-browser-mbb | productivity, zsh, tutorial, terminal | Have you noticed that we can open a folder inside VSCode with `code .` command?
Will it be cool if we could do the same to open the file manager on the current folder or open the browser on a specific path from the terminal (or from VSCode)?
Well, it can be done by creating some functions and aliases 😎.
---
# Prerequisites
We need to install the [clipboard-cli](https://github.com/sindresorhus/clipboard-cli) package in order to use the `clipboard` no matter the OS we are using.
# Project
First of all, we need to create a folder to save our helper functions. I used to name it `.helpers` inside the home directory.
`take` command on zsh automatically creates folders and changes to the directory.
```
take .helpers/open
```
## Open
Now we are going to make a script to open folder/paths in File Explorer. Create a file called `open_path` inside the `open` folder and put this code.
```bash
#!/bin/bash
while getopts ":p:" opt; do
case $opt in
p) path="${OPTARG}"
;;
\?) echo "Invalid option -${OPTARG}" >&2
exit 1
;;
esac
done
case $path in
build)
path="./build"
;;
coverage)
path="./coverage"
;;
esac
isWSL=$(uname -a | grep WSL)
if [[ -n "${isWSL}" ]]; then
path=$(wslpath -w ${path})
fi
${OPEN} "${path}"
```
## Browser
Now we are going to make a script to open URLs or files in Browser. Create a file called `open_browser` inside the `open` folder and put this code.
```bash
#!/bin/bash
while getopts ":f:u:p:" opt; do
case $opt in
f) file="${OPTARG}"
;;
u) url="${OPTARG}"
;;
p) port="${OPTARG}"
;;
\?) echo "Invalid option -${OPTARG}" >&2
exit 1
;;
esac
done
address=""
if [ -n "${file}" ]; then
case $file in
coverage)
launcher=${BROWSER}
file="./coverage/lcov-report/index.html"
;;
esac
isWSL=$(uname -a | grep WSL)
if [[ -n "${isWSL}" ]]; then
file=$(wslpath -w ${file})
fi
address="${file}"
fi
if [ -n "${port}" ]; then
pattern="^([0-9]{1,4}|[1-5][0-9]{4}|6[0-4][0-9]{3}|65[0-4][0-9]{2}|655[0-2][0-9]|6553[0-5])$"
if [[ ${port} =~ ${pattern} ]]; then
url="${url}:${port}"
fi
fi
if [ -n "${url}" ]; then
pattern="^(http|https)://"
if (! [[ "${url}" =~ ${pattern} ]]); then
url="https://${url}"
fi
address="${url}"
fi
${BROWSER} "${address}"
```
### GitHub
Now we are going to make a script to get the git repo URL. Create a file called `get_repo_url` inside the `open` folder and put this code.
```bash
#!/bin/bash
url="$( git config remote.origin.url | sed -e "s/git@github.com:/https:\/\/github.com\//g" )"
if [ "${url:(-4)}" == ".git" ]; then
url="$( echo "${url}" | rev | cut -f 2- -d '.' | rev )"
fi
echo "$url"
```
Now we are going to make a script to browse the GitHub repository. Create a file called `open_git_repo` inside the `open` folder and put this code.
```bash
#!/bin/bash
url="$( get_repo_url )"
${BROWSER} ${url}
```
Now we are going to make a script to browse the GitHub repository on current branch. Create a file called `open_git_branch` inside the `open` folder and put this code.
```bash
#!/bin/bash
url="$( get_repo_url )"
current="$( git branch --show-current )"
${BROWSER} "${url}/tree/${current}"
```
Now we are going to make a script to browse the GitHub repository pull requests section. Create a file called `open_git_pull` inside the `open` folder and put this code.
```bash
#!/bin/bash
url="$( get_repo_url )"
${BROWSER} "${url}/pulls"
```
Now we are going to make a script to browse the GitHub repository comparing current branch with another branch (`dev` as default). Create a file called `open_git_compare` inside the `open` folder and put this code.
```bash
#!/bin/bash
base="dev" #default base branch
if [[ ! -z $1 ]]; then
base="$1"
fi
url="$( get_repo_url )"
current="$( git branch --show-current )"
if [ "$current" != "${base}" ]; then
url="${url}/compare/${base}...${current}"
else
url="${url}/compare/${base}..."
fi
${BROWSER} ${url}
```
## npm
Now we are going to make a script to browse the npm package project. Create a file called `open_npm_package` inside the `open` folder and put this code.
```bash
#!/bin/bash
package="$(node -p "require('./package.json').name")"
if [[ -z "$package" ]]; then
echo "No package.json found"
exit 1
fi
${BROWSER} "https://www.npmjs.com/package/${package}"
```
Now we are going to make a script to browse the an npm package searching by the name on `clipboard`. Create a file called `open_npm_clipboard` inside the `open` folder and put this code.
```bash
#!/bin/bash
# Requires:
# https://github.com/sindresorhus/clipboard-cli
# npm install -g clipboard-cli
url="https://www.npmjs.com/package"
value="$( clipboard )"
if [[ -n $value ]]; then
url="$url/$value"
fi
${BROWSER} ${url}
```
---
# Permissions
Add execution permissions to those files with:
```bash
chmod +x ~/.helpers/**/*
```
---
# Path and Alias
It's not good idea navigate to `.helpers/open` folder each time we want to use those commands.
In order to make it globally available need to add this `PATH` and aliases to `.zshrc`.
```bash
export OPEN="explorer.exe" #wsl2
export BROWSER="${OPEN}" #wsl2
export PATH="$HOME/.helpers/open/:$PATH"
# Open
alias o="open_path -p ." # open current folder
alias op="open_path -p" # +path
alias opb="open_path -p build" # open build path
alias opc="open_path -p coverage" # open coverage path
# Browse
alias b="open_browser -f ./index.html" # browse index.html
alias bu="open_browser -u" # +url
alias blh="open_browser -u http://localhost"
alias blhp="open_browser -u http://localhost -p" # +port
alias bcr="open_browser -f coverage" # browse coverage
alias bgr="open_git_repo" # browse git repo
alias bgb="open_git_branch" # browse git repo on current branch
alias bgp="open_git_pull" # browse git repo pulls
alias bgc="open_git_compare" # +base branch
alias bnp="open_npm_package" #browse npm package
alias bnc="open_npm_clipboard" #browse npm package from clipboard
```
> `OPEN` and `BROWSE` constants need to be configured according yor OS. Windows (WSL2) and macOS use the same command to open the file explorer or the default web browser, on Ubuntu (Linux) need to be specified each one.
|SO|`OPEN`|`BROWSER`|
|---|---|---|
|Windows (WSL2)|`"explorer.exe"`|`"${OPEN}"`|
|macOS|`"open"`|`"${OPEN}"`|
|Ubuntu|`"xdg-open"`, `"gnome-open"`, `"nautilus"` ...|`"googlechrome"`, `"firefox"` ...|
Once finish, reopen all terminals or update his source running source ~/.zshrc command and now you can use the new commands.
---
# Usage
Navigate to the path where you want to use the commands or aliases.
## File Explorer
|Alias|Command|Description|
|---|---|---|
|`o`|`open_p -p .`|Open current path on file explorer or finder|
|`o <path>`|`open_p -p <path>`|Open a relative or absolute path on file explorer or finder|
## Browser
|Alias|Command|Description|
|---|---|---|
|`b`|`open_browser -f ./index.htm`|Open a browser with `index.html` on current path|
|`bu <url>`|`open_browser -u <url>`|Open a browser with specified URL|
## React/Web
|Alias|Command|Description|
|---|---|---|
|`obf`|`open_path -p build`|Open `.\build` folder inside current path on file explorer or finder|
|`obc`|`open_path -p coverage`|Open `.\coverage` folder inside current path on file explorer or finder|
|`bcr`|`open_browser -f coverage`|Open coverage `.\coverage\lcov-report\index.html` report on Browser|
|`blh`|`open_browser -u http://localhost`|Open a browser as `localhost`|
|`blhp <port>`|`open_browser -u http://localhost -p <port>`|Open a browser as `localhost` on specific `port`|
## GitHub
|Alias|Command|Description|
|---|---|---|
|`bgr`|`open_git_repo`|Browse the current GitHub repo url|
|`bgb`|`open_git_branch`|Browse the current GitHub current Branch url|
|`bgp`|`open_git_pull`|Browse the current GitHub Pull Request url|
|`bgc [<branch>]`|`open_git_compare [<branch>]`|Browse the compare current branch with another base branch [`dev` by default] |
> Works with repositories cloned with HTTP or SSH
## NPM
|Alias|Command|Description|
|---|---|---|
|`bnp`|`open_npm_package`| Browse the NPM package on `package.json`|
|`bnc`|`open_npm_clipboard`|Browse the NPM package on browser searching by name on clipboard|
---
You can download or clone this code and other ZSH utilities from GitHub: [dot Files](https://github.com/deinsoftware/dot-files) repository.
---
**That’s All Folks!**
**Happy Coding** 🖖
[](https://github.com/sponsors/deinsoftware) | equiman |
630,161 | For Developers looking for profitable Micro-SaaS : Building $1K-$10K MRR Marketplaces - various domains and niches | Micro SaaS Ideas grew to 3000+ subscribers community and is one of the fastest growing newsletters. T... | 0 | 2021-03-09T18:20:22 | https://dev.to/upen946/for-developers-looking-for-profitable-micro-saas-building-1k-10k-mrr-marketplaces-various-domains-and-niches-49ae | saas, microsaas, microideas, developers | [Micro SaaS Ideas](https://microsaasidea.com) grew to 3000+ subscribers community and is one of the fastest growing newsletters. There is a lot coming up - perks, community, emerging trends for Pro subscribers. . If you haven’t seen, we also recently got onto [#1 on Product Hunt last month](https://www.producthunt.com/posts/micro-saas-idea)
No fluffy content. If your goal is to build a $100m ARR business, this is not the right post. If your goal is to make a $1K to $10K MRR, continue reading.
This post will cover one SAAS area and talk about multiple niches in this space. This post also explains more on how to do tech implementation, do market analysis, how the current players are doing, and also ends with a cost analysis to understand the overall cost for 100 users. (Some are available only in Pro version)
**Online marketplaces** existed for a long time in the form of Fiverr & Upwork for freelancers. There are a lot of marketplaces for selling/buying digital assets as well. But this concept can be extended to pretty much every niche.
**Current players**
[MentorCruise](https://mentorcruise.com) : Work with leading tech mentors and gain access to personalized guidance to reach your potential. Ongoing sessions and expert advice, on your terms, all for a flat monthly price. This is a true MRR model where the buyer side is paying a monthly fee. Making $6K MRR. Launched in September, 2017.
[MicroAqcuire](https://microacquire.com): Startup acquisition marketplace. Free. Private. No middlemen. Start the right acquisition conversations at your own pace. Get free and instant access to 30,000+ trusted buyers with total anonymity. Making $20K MRR, Launched in Feb, 2020
[IndieMaker](https://indiemaker.co): Buy & Sell Side-Projects, SaaS, Domains and Social Media Accounts IndieMaker is a community marketplace with 14,224+ members where makers sell their side-projects, unused domains and online businesses.
[Flexiple](https://flexiple.com): Hire Pre-Screened Freelance Developers & Designers Flexiple is a network of top freelance developers and designers with hourly rates ranging from $30 to $100. Making $1 million/year in revenue.
[GrowthMentor](https://www.growthmentor.com): Have 1-on-1 conversations about growth, marketing, and everything in between with the world's top 3% of startup and marketing mentors. Making $5K as of March 2020. Launched in August 2017.
[MoonlightWork](https://moonlightwork.com): Match with experienced developers to get work done quickly. Hire vetted developers to work with as contractors and employees. Making $80K/month and acquired.
[BuySellAds](https://www.buysellads.com): Diversify your advertising strategy using one platform. Reach technical audiences, explore unique ad placements, and run multi-channel campaigns all in one place. Making $5 million in revenue/year.
[CarbonAds](https://www.carbonads.net): Reach developers and designers effortlessly. Carbon is the best way to reach designers and developers at scale. Founded in 2010, highly profitable.
[UnicornFactory](https://www.unicornfactory.nz): Hire New Zealand's best freelancers. UnicornFactory helps connect you to Kiwi freelancers who are really really good at what they do to help you take the next step in reaching your business goals.
[Toptal](https://www.toptal.com): Toptal is an exclusive network of the top freelance software developers, designers, finance experts, product managers, and project managers in the world. Top companies hire Toptal freelancers for their most important projects. Making $100 million/year. Founded in 2010.
[PurpleAds](https://purpleads.io): With PurpleAds, get better results and reach different audiences through an exclusive network of websites with simple and effective native placements that don’t distract users.
[FreeUp](https://freeup.net): Hire pre-vetted freelancers. Get more done faster.
[ByeByeDomain](https://byebyedomain.com): Marketplace for buying and selling domains before they expire.
[Stackraft](https://stackraft.com): StackRaft is not a typical hiring platform — that’s a talent community.
[GumAffiliates](https://gumaffiliates.best): Gumaffiliates makes it easy for Gumroad creators and affiliates to find each other.
[GetCredo](https://www.getcredo.com): Top companies meet the best pre-vetted digital marketing providers through Credo in under 48 hours.
[SponsorGap](https://sponsorgap.com): SponsorGap is where newsletter and website creators find their next sponsor, post their open ad slots and brands publish their open sponsorships.
[TaskRabbit](https://www.taskrabbit.com): With TaskRabbit get help from thousands of trusted Taskers for everything from errands to contactless deliveries.
[BlenderMarket](https://blendermarket.com): The indie market for Blender creators. Making $60K/month.
**Negative Nancy**
Negative Nancy says - Marketplaces are tough to build and often take time to be profitable.
Me - Yes. That is correct but once it picks up and gains enough traction, it grows exponentially.
Negative Nancy says - It needs a lot of tech expertise to build a marketplace
Me - Disagree. Building a marketplace needs zero tech knowledge. You can just start with a simple Google sheets/Airtable sheet to start with. On top of that, once the product establishes and needs a full-blown site, there are a lot of ways to build marketplaces without investing heavily in tech. See the rest of the sections for a more detailed explanation.
Negative Nancy says - Marketplace comes with the inherent “chicken and egg” problem
Me - Yes. But that can be solved in most cases by picking one side or going in parallel. It's not going to easy but it is not impossible either. See the rest of the sections for a more detailed explanation.
**Deep-dive**
Ever heard of something as below?
Uber - The world’s largest taxi company owns no vehicles.
Airbnb - The largest accommodation providers own no real estate.
Alibaba - The most valuable retailer has no inventory/manufacturing units.
What is common from the above? All of these are curated lists of something and are often called ‘Marketplaces’. That is the advantage that the marketplace brings in. You are only connecting both parties (supply-side and demand-side) without actually maintaining any inventory and thereby keeping the actual costs low.
Another advantage of the marketplace is that you don’t need a lot of tech knowledge to build a marketplace. There is a lot of software for creating simple marketplaces. The core success of a marketplace lies in building the actual supply-side and
Still wondering if you should consider building a marketplace. See the latest update about Linked in reportedly building a freelance marketplace to beat Upwork and Fiverr.
All marketplaces typically have the “chicken and egg problem”. It is often tough to decide whether you should onboard the sellers/vendors or buyers. Which side should you concentrate on? We refer to sellers/vendors/service providers as “supply-side” and buyers/consumers as “demand-side”.
Typically for most cases, you should concentrate on the seller/vendors side by setting up a good expectation that it may take time to generate revenue. Once you have enough people on the ‘supply side’ (sellers/vendors) and confident that the ‘supply side’ got the momentum, start talking to the people on the demand side’ or both the activities can go in parallel as well. For example, if you are building a Freelance marketplace, it doesn’t make sense to reach out to companies when you have no freelancers (supply side) with you. So, in this case, ideally, you should be talking to at least 50-100 freelancers and onboard them on the marketplace. Pick and drill down a niche as much as you can.
One time vs Recurring revenue model - There are multiple models typically in a marketplace model. Some models, let buyers pay per use of seller service - as a one-time charge. But some marketplace chargers buy a flat monthly fee to access the seller services and keep certain limits. Another model is where buyers are charged an “access-fee” to access the ‘seller side’ and then pay an extra fee for the actual service. This access-fee could be a monthly or quarterly recurring fee as well.
**Some niches (This section includes profitable niches from existing players and a few new niches as well)**
- **Marketplace for Freelancers/Vetted Freelancers**: Normal freelancer marketplaces like Fiverr and Upwork are meant for general freelancers and caters to a much bigger market. A vetted freelance marketplace is meant for vetted freelancers. There is a lot of demand for freelance and vetted marketplace. A vetted marketplace is a premium version of a normal freelance market. This can be extended and drilled down to specific niches as well. While there a lot of marketplace products for freelancers in general, you could start A must-read story from Moonlight Developers if you want to build something around this space. See the story of Flexiple and how they just operate with Google sheets and still making one million dollars in revenue with now complex tools. Niche down your marketplace as narrow as you can. Start with any specific niche - for example - a vetted marketplace only for designers or only for react developers or only for frontend developers. You can drill down to a location as well. For example, UnicornFactory is meant for freelancers from New Zealand.
- **Marketplace for Mentors/Mentees**: Everyone needs a mentor at some point. This could be for mentoring related to job improvement, interview coaching, or technical coaching specific to “Engineering”, “Product Management” etc. This could be extended to life coaches, CEO coaches. Build an entire marketplace around the mentor/mentee model. A few startups are working in this niche but still, there is a huge market for something like this as people are spending more on quality content/guidance. But note that - unlike other models - a mentor/mentee model needs a lot of trust from both parties. So, this would relatively take more time to establish. For example, MentorCrusie took a couple of years before making profitable revenues. The same is the case with GrowthMentor that took its own sweet time before the platform is opened for everyone. On top of that, this model involves a lot of payment to mentors and the profit margin could be thin. But it works at scale.
- …. get another 10+ additional niches from Pro version of [Micro SaaS Ideas](https://microsaasidea.com)
[Get Pro version](https://gumroad.com/l/micro-saas-idea-pro)
✅ Another 10+ niches around Marketplaces
✅ Technical chops
✅ Marketing chops
✅ Cost Analysis for 100 customers
✅ Access to all previous issues.
👉👉 Perks (Coming up)
👉👉 Access to private community (Coming up)
👉👉 Emerging trends around Mirco-SaaS (Coming up)
Originally posted at https://microsaasidea.substack.com/p/micro-saas-products-around-marketplaces | upen946 |
630,209 | Minidoro Clock - React Native Project with FCC Background | This time it won't be a technical explanation, but rather a personal story with a few tips about the... | 0 | 2021-03-09T20:31:07 | https://dev.to/pawel/minidoro-clock-react-native-project-with-fcc-background-mfm | productivity, reactnative, android | This time it won't be a technical explanation, but rather a personal story with a few tips about the differences between React and React Native.
#Pomodoro Technique 🍅
Let's be honest, most of us have heard of Pomodoro Technique, I bet that most of you readers also use it on a daily basis and probably a huge part of you made your own version as a project. So what is the matter? Those familiar with FCC curriculum know that project where you have to build your own version of a 25 + 5 clock, and it is where this whole story started.
#The Beginning
It took me months, to finally get to that section. Each time when in vanilla JS things were starting to make sense, in React everything looked so complicated. Despite the obvious fact of React advantages, there was also React Native. A legendary framework, based on JS that lets you write mobile applications using native modules. Written once in JavaScript and compiled at the same time to both Android and iOS, sounds cool? There are of course some drawbacks, but I will not discuss them here.
After finishing FCC projects, I was thinking how can I rebuild one of the projects from scratch, add some simple features and also make it at least partly meaningful for other people. Rebuilding something in your own way lets you also revise all of the things you have learned up to a certain point. The best part of building projects from scratch is that you often find yourself coming up with very interesting solutions, different from what you learned during the tutorials. It is the essence of programming, one problem - countless solutions, and one of them can be yours. This is of course positive approach, and all of you who have some experience with these kinds of projects, know how frustrating it can be sometimes. Especially when you make something that supposed to be simple, but you still struggle with a simple piece of code.
#All right, so what is Minidoro Clock?
Most of us care a lot about money, we are afraid of losing it and always think how to spend it or invest it right, but what about our time? There are millions of time-consuming, entertainment apps, but not as many for organizing our time. In a world full of distractions I believe that minimalism and organizing our time well should be on the top of our priority list. This is how Mindoro Clock came to my mind. Minidoro is an application where minimalism meets the Pomodoro Technique. Super simple UI and just necessary options, help us organize our time more productively.
Minidoro is a simple application written in React Native, it is free and there are no advertisements. It is also open-source, so everyone can give their feedback and suggestions, or even contribute to the code of the application.
#React + React Native
Most probably, you can guess that the project React app, became a product landing website, to later evolve to a React Native application. The project is very simple, it barely touches some more advanced sides of React, but thanks to its simplicity it really helped me to revisit all of the core ideas behind React. Another thing is deployment, during tutorials we very rarely touch this topic, but how will other people reach your websites and applications?
The first step was to make a fully functional web version of the app, commit the code to GitHub and deploy it to Netlify. Up to this point, everything went quite smooth. It was time to convert the React app to its React Native equivalent.
#Silence before the storm
Nothing could go wrong, overall I already had some experience with React, web development, and even some Java experience. Unfortunately, if you think that knowing all of the things above, will make your way to writing or let's say converting React apps to React Native super easy, you may be surprised. Let's make things clear, React and React Native are very similar but not the same since React mainly is meant to run in web browsers, it is just a library that runs in a Java Script environment, where React Native is a hybrid framework for running JavaScript code as a layer on a different language.
#JSX is not the same anymore
One of the first and main differences between React and React Native is that HTML like tags that we know from React JSX won't work with React Native. Instead, you should think of each component in JSX as a native module. Also, events are not the same, for example, there is no such thing as `onClick` but `onPress` instead, which indeed has a bit different behaviour. The same goes for modules, and even though some of the React modules are compatible with React Native, most of the time you will find yourself looking for a corresponding library. Because of the different behaviour of mobile devices, many modules use a lot of asynchronous functions, so if you feel rusty in this topic I recommend you to revise it before putting your hands on React Native. In the end, the environment in which we build our React Native applications is not that obvious choice, as it used to be with regular React. At this point, I can only say that if you do not have any experience with Xcode or Android Studio - Expo may be the best decision.
#What next?
In conclusion, redesigning React applications for React Native may not be as easy and obvious as you may think. There are a lot of things to consider, which were done somehow behind the scenes for us in the web browsers. In my case, I used Expo and haven't even touched code in Java. However, it doesn't mean that when you write React Native applications you never have to think about native code. There are many cases where React Native code, will be just a part and touch the native code may still be a must. If you want the check out my application - Minidoro Clock you can find it [here](https://minidoroclock.netlify.app/)
Please let me know if you have any questions, suggestions or found some bugs.
| pawel |
630,374 | How to Deploy Laravel Project to China? | What is Laravel? Laravel is a modern web application framework developed written in PHP.... | 0 | 2021-03-09T23:07:08 | https://www.21cloudbox.com/solutions/how-to-deploy-laravel-project-in-production-server.html | laravel, php, webdev, china | ---
canonical_url: https://www.21cloudbox.com/solutions/how-to-deploy-laravel-project-in-production-server.html
---
# What is Laravel?
Laravel is a modern web application framework developed written in PHP. Their is a very active community that supports Laravel, resulting in large plug-in library to choose from.
[21YunBox](https://launch-in-china.21yunbox.com/) provides a very simple Laravel deployment method. You can quickly and easily deploy with 21YunBox in a **static webpage** environment.
# How to Deploy PHP Laravel in China?
1. Register as a [21YunBox member](https://www.21cloudbox.com/u/signup/)
2. Create a [PostgreSQL database](https://launch-in-china.21yunbox.com/solutions/how-to-create-a-postgresql-database.html)
3. Fork [Laravel example](https://gitee.com/eryiyunbox-examples/hello-laravel) on Gitee
4. Create a **Cloud Service** on the 21YunBox, and allow the 21YunBox to access your code base
5. Configure the following settings
**Environment**
```bash
PHP 7.2
```
**Build command**:
```bash
./build.sh
```
**Start command**:
```bash
php artisan serve --host=0.0.0.0 --port 10000
```
Click Advanced Configuration to configure environment variables:
| KEY | VALUE |
| :--------------: | :-------------: |
| **APP_ENV** | **`production`** |
| **DB_CONNECTION** | **`pgsql`** |
| **DATABASE_URL** | In the first step to create a cloud database<br> midpoint **Database URL** get |
| **APP_KEY** | Paste the key generated by `php artisan key:generate --show` |
If you'd like a step by step example, please refer to the video below:
[How to deploy the Laravel project to the server](https://www.bilibili.com/video/BV1ef4y1v7rK)
# Why Choose 21YunBox?
> 21YunBox is a Cloud Service Platform based out of Beijing, China. Our services provides you with an easy and budget friendly, end-to-end web platform deployment service for all applications and stacks. No matter your need, we have a flexible solution to assist.
>
> If needed, we also offer [full support in obtaining your ICP license](https://launch-in-china.21yunbox.com/solutions/how-to-get-an-ICP-license-for-china.html) which allows you to legally host online content within Mainland China.
To learn about the differences between 21YunBox and these foreign (outside of China) cloud service platforms, please refer to:
* [21YunBox vs Heroku](https://launch-in-china.21yunbox.com/solutions/how-to-speed-up-heroku-in-china.html)
* [21YunBox vs Netlify](https://launch-in-china.21yunbox.com/blog/solutions/alternatives-to-netlify-in-china.html)
* [21YunBox vs Vercel](https://launch-in-china.21yunbox.com/solutions/how-to-speed-up-vercel-in-china.html)
* [21YunBox vs Gatsby Cloud](https://launch-in-china.21yunbox.com/solutions/how-to-speed-up-gatsby-cloud-in-china.html)
* [21YunBox vs Github Pages](https://launch-in-china.21yunbox.com/solutions/how-to-speed-up-github-pages-in-china.html)
* [21YunBox vs Surge.sh](https://launch-in-china.21yunbox.com/solutions/how-to-speed-up-surgesh-in-china.html)
* [Compare in terms of function and price: 21YunBox vs Heroku, Netlify, Vercel](https://www.21yunbox.com/compare-others/)
<br>
*This article's content originated [here](https://launch-in-china.21yunbox.com/solutions/how-to-deploy-laravel-project-in-production-server.html)*
*For additional detail and future modifications, refer the original post.*
| 21yunbox |
630,500 | Technical Documentation Page | A post by Destiny Matthews | 0 | 2021-03-10T02:15:16 | https://dev.to/destiny_matthews_52022b29/technical-documentation-page-37g6 | codepen | {% codepen https://codepen.io/destinymatthews/pen/abBKoMR %} | destiny_matthews_52022b29 |
630,729 | Hire Laravel Developer for developing a unique and efficient website
| Most of the businesses have their website but not get outcomes as they want because of their website... | 0 | 2021-03-10T09:30:39 | https://laravelwebdevelopment.wordpress.com/2021/03/10/hire-laravel-developer-for-developing-a-unique-and-efficient-website/ | laravel, php, hirelaraveldeveloper | Most of the businesses have their website but not get outcomes as they want because of their website structure and development method. Business success obeys on staying one step ahead of their competitors. A unique business method will create value for their targeted audiences. Successful businesses do not compromise the quality of the product. Reach out to targeted audiences is not an easy task for businesses. For reaching out to those targeted customers, you have to strong online presence on the web. And the main method of making an online presence over the internet is a Website.
A website is a replica of your business on the internet. People judge your business through your website. So, developing a better website is a necessity. For any quality task, we find out an expert or experienced person to complete their task. Same in website development you should hire an expert web developer.
Laravel is a famous PHP website development framework. Laravel helps in building a unique and functionally rich website for your business. And developing a website with Laravel framework you should hire larvael developers or laravel development company.
Laravel developers have a high demand on the market because of their comparatively low cost and high efficiency as well as speedy work. Most businesses or company outsourced their website development task. And companies looking for web developers on market. Most businesses hire a Laravel developer for their business because this is a cost-effective and efficient way to develop a website.
Laravel lions is a Laravel Web Development company with hands-on experience in Laravel Development. Provide unique and Spontaneous solutions for your business. Also, a company offers custom Laravel development at an affordable rate. Being a reputed company, we take care of your Intellectual Property security, and we provide a signed Document for Intellectual Property Protection and also a Non-Disclosure Agreement at the beginning of any project.
So, [hire a dedicated laravel developer](https://www.laravellions.com/hire-laravel-developers/) from Laravel Lions and empower your web Identity.
| laravellions |
630,910 | Backend developers' help needed in research 💡 | Hi! We at UI Bakery, a low-code tool for building internal apps, are searching for the ways to impro... | 0 | 2021-03-10T13:36:23 | https://dev.to/ev_jennie/backend-developers-help-needed-in-research-39o1 | webdev, backend, frontend, ui | Hi!
We at UI Bakery, a low-code tool for building internal apps, are searching for the ways to improve the interface creation mechanism. We’re running user tests on different apps to find the best approach in visual building. If you have some free time and a desire to have your hands in a low-code tool development, feel free to contact me via [v.romanovskaya@akveo.com](v.romanovskaya@akveo.com), or just [send me a direct message in LinkedIn](https://www.linkedin.com/in/viktoria-romanovskaya-647607102/).
I’m looking for:
– Backend developers
– Those somehow related to backend development
– Developers with not much expertise with frontend
I’ll ask you to do a small task in several similar systems. It will not take a lot of time. :) | ev_jennie |
630,922 | Introducing an innovative New Model File System | MODLR, an innovative leader in Corporate Performance Management software, will be introducing a serie... | 0 | 2021-03-10T13:56:03 | https://modlr.co/au/news/new-model-file-system | javascript, programming, computerscience, cloud | [MODLR](https://modlr.co/), an innovative leader in Corporate Performance Management software, will be introducing a series of updates to its Cloud Platform for release in 2021’s Q1. These updates were showcased this month during the live MODLR user group, watch it here.
Included in the updates, is the New Model File System, which provides MODLR’s users with greater flexibility to organise their models and store third-party files within the Corporate Performance Cloud itself.
The Model File System’s features include:
* PDF, MS Excel and MS Word Uploads — The MODLR Model File System will provide users with the ability to upload PDFs and Microsoft Excel and Word Documents to a Model folder.
* Create shortcuts to various model components — Speed up your planning processes further through creating your own shortcuts to model components; optimising your workflow.
* Model File System available in MODLR’s Excel Add-in — The Model File System is accessible through MODLR’s Excel Add-In, allowing users to upload reports from MS Excel to store reports in MODLR.
* Cloud View of MS Excel Reports — In the MODLR Gateway, the Model File System will enable users to open Excel Reports, giving users a web view of Excel Reports within the MODLR Cloud.
* Publish an Excel Folder in MODLR — Users will have the ability to publish Excel folders to their MODLR application, enabling access to an Excel Folder’s processes, variables and more within MODLR.
<img width="100%" style="width:100%" src="https://cdn.modlr.co/288/art_MODLR_model_file_system_05.gif">
To see more of the features in store for the MODLR Cloud’s 2021 Q1 update, you can watch MODLR’s Roadmap for 2021 [here](https://www.youtube.com/watch?v=WWGW3lHY4xw). | adithyasrinivasan |
630,986 | Top 10 Video On Demand Companies To Build a VOD Platform in 2021 | Think about your day-to-day life: how many video on demand platforms do you subscribe to, and how man... | 0 | 2021-03-10T15:57:56 | https://dev.to/anthonynokws/top-10-video-on-demand-companies-to-build-a-vod-platform-in-2021-25pp | vodplatform, videostreaming, ott, vod | Think about your day-to-day life: how many video on demand platforms do you subscribe to, and how many more can you name?
The real-time streaming of video and audio content, combined with the entrance of big players into countries all around the world, has made the market value for video on demand solutions shoot through the roof.
The size of the market come 2026 is projected to be USD 175 Billion; North America alone will account for USD 19.7 Billion in 2027.
#Video on demand?
Video on Demand (VOD) is an immersive TV technology that enables viewers to access their choice of content and watch it in real-time or download it for later streaming.
VOD streaming helps them to access the video that is made available via Internet Protocol TV, at the consumer level.
These videos are part of a prepared catalogue that’s plugged into the VOD platform and enable users to browse through the selection, find videos they want to watch right now, or create playlists to watch at a later stage.
#Choose the right OTT platform
For starters, one must consider how well the video on demand solution provider supports streaming across devices. If it supports all the popular devices used to stream content today, then it is a surefire winner in that category.
You must also look for customization options, to ensure that you’re able to personalize the VOD solution to match your brand colors and identifiers. If this is of the highest priority for you, it is recommended that you choose a white label video streaming platform.
Video rights and distribution, monetization models and possibilities, and access to marketing analytics are other critical factors to consider.
#Benefits of using the best OTT Solutions
Firstly, VOD streaming platforms are the most convenient ways to watch videos at any time, anywhere. All you need is a stable internet connection and a device, such as a laptop, smartphone, or tablet, to watch shows.
They are also quite affordable compared to the fees to be paid to traditional TV or cable subscriptions. The variety of content is also unmatchable;
some platforms may choose to have niche content while yet others host content from all niches and genres.
As a result, video on demand services are where to go should you need to watch the latest show.
#Top 10 VOD Companies to launch your own VOD Streaming App
##1. [Vixy Video](https://www.vixyvideo.com/) - Video on Demand Platform
To allow your users quick access to your premium video content, VIXY offers a Whitelabel VOD platform with support for subscriptions (SVOD), pay-per-view (TVOD) & ads (AVOD).
**Highlighted Features**
• White label Platform
• Secure hosting
• Payment integration
• On demand & Live
• Multi-screen
##2. [Teyuto](https://teyuto.com) - Best White label Video Solution
Teyuto is a custom enterprise video streaming platform adjustable end-to-end with futuristic features backed by secure technologies.
When it comes to streaming video and audio content without a hitch across multi-device channels, it is the first choice of many across industries.
**Highlighted Features**
• Fully Customizable
• Inbuilt Video CMS
• On Premise/On Cloud
• Live Streaming
• Multi DRM Platform
• Video Monetization (SVOD, TVOD, AVOD, Gift Card, Trial Days, Coupons)
• All Device Player
##3. [Contus VPlay](https://www.contus.com) - Video on Demand Platform
Contus VPlay is a leading video streaming solution provider that is 100% customizable.
Through it, you can lay the groundwork for multi-facet live video streaming capabilities on multiple networks, websites, and devices.
**Highlighted Features**
• Multiple Video Monetization Options
• inbuilt Video Marketing Tools
• Video Hosting & Management
• Digital Rights Management
• HLS Player
• 100% Customizable Solution
##4. [Vimeo](https://www.vimeo.com/ott) - Video on Demand/OTT Service
Easily distribute from Vimeo On Demand your films, TV episodes, and movies worldwide. Many of the world's highest-selling films, including Oscar-nominated and Academy-winning ones, are available to watch on Vimeo. The best thing is that after processing costs, you retain 90 percent of the income as a creator.
**Highlighted Features**
• High-quality player
• Video Analytics
• Secured Privacy Options
• Monetization Models
##5. [Kaltura](https://www.kaltura.com) - VOD Streaming APP
Video-on-demand and live interactions of virtual classes, lecture capture, and secure webinar hosting capabilities can be powered by Kaltura Video Cloud for Education. It ties in seamlessly with existing CMS and is great to have for e-learning courses, seminars, and webinars.
**Highlighted Features**
• Searchable & Accessible Videos
• Integrated into Your Existing Platforms
• Real-time, Live, VOD
• video cloud platform
##6. [Panopto](https://www.panopto.com/) - Vod and CMS Services
Panopto is yet another one of the popular VOD platform companies out there, for its stable VOD viewing experience that will revolutionize the way in which you exchange knowledge and information.
Centralize and stream the videos safely, build playlists, optimize replay, and evaluate the interest of the viewer through in-built analytics. With one-click, professional-grade live streaming, you can even broadcast to ten viewers or ten thousand without a hitch.
**Highlighted Features**
• Optimal playback on every device
• Intelligent video content delivery
• Support for RTMP encoders
• Flexible video streaming options
##7. [Uscreen](https://www.uscreen.com/) - Vod Streaming Platform
Uscreen is said to be one of the top video on demand platforms in terms of monetization. With it, you can customize the appearance of your platform storefront, launch videos on OTT apps, select from myriad monetization models to drive revenue, track subscriber analytics, and stream onto any device in real-time, among other benefits.
**Highlighted Features**
• Multiple Monetization Formats (Buy, Rent, Sell)
• Scheduled Content Delivery
• Video Progress Tracking
• Customizable Themes
• SEO Friendly
##8. [Brightcove](https://www.brightcove.com/) - Video On Demand Solution
This video distribution platform has the capacity to deliver hosted video across multiple users and screens without a hitch and all at once.
Their Media Cloud provides you what you need on a centralized video network with applications for monetization, marketing, live streaming, encoding, analytics, and more available to leverage for success.
**Highlighted Features**
• Video & Ad Monetization
• Live Video Streaming
• Analytic Reports
• High-end Security
• Social Media Integration
##9. [Vidyard](https://www.vidyard.com/) - Video on Demand Platform
Vidyard is an on demand video service provider that helps with online video hosting on a large scale.
It is said that it is the best way online to host and manage videos. The features, the player connectivity, the customer service are all unmatched.
**Highlighted Features**
• Video Hosting and Video Management
• Personalized Video Experience
• Video Analytics
• Marketing Integrations
##10. [Vidizmo](https://www.vidizmo.com/) - Video on Demand Platform
It's an all-in-one multimedia system that covers all equipment, deployment, servicing, and upgrades to set up the video or VOD network.
**Highlighted Features**
• Multi Distribution
• On Premise/On Cloud
• Video Monetization
• High-Quality Video Player
##Conclusion
Today, the market is overflowing with video on demand companies, each better than the last. Therefore, there’s a hard choice to make, and understanding the right platform to choose towards reaching your business goals is the first step in the process.
| anthonynokws |
631,187 | Full background-color that will take the full width on hover | How can I style my hoverable background color to take full width in a display:flex styling? I have a... | 0 | 2021-03-10T16:54:48 | https://dev.to/dnjosh10/full-background-color-that-will-take-the-full-width-on-hover-3bkc | html, css, nav, hover | How can I style my hoverable background color to take full width in a display:flex styling?
I have a navigation link nested in a div class, on hover, the background-color is only around the text content. I want it to take the full width since the display is given a flex-direction of column | dnjosh10 |
631,467 | Raspberry Pi Weather Station with Secure Scuttlebutt | A Secure Scuttlebutt Weather Station Secure Scuttlebutt is a replicating, peer-to-peer log... | 0 | 2021-03-10T23:39:24 | https://dev.to/rickcarlino/raspberry-pi-weather-station-with-secure-scuttlebutt-39f3 | ---
title: Raspberry Pi Weather Station with Secure Scuttlebutt
published: true
date: 2019-04-06 14:33:00 UTC
tags:
canonical_url:
---
# A Secure Scuttlebutt Weather Station
[Secure Scuttlebutt](https://scuttlebot.io/more/protocols/secure-scuttlebutt.html) is a replicating, peer-to-peer log database.
It is unique because it is theoretically possible to create a mesh of replicating nodes that do not have internet access. Information is “gossiped” over local WiFi. When users move between wifi networks, the “gossip” moves with them, enabling friends (and friends-of-friends) to pass data along the social mesh. (See: [SSB Protocol Guide](https://ssbc.github.io/scuttlebutt-protocol-guide/))
Currently, SSB is used for social apps that revolve around chat, microblogging and file sharing. The most popular apps are [Patchwork](https://github.com/ssbc/patchwork) (desktop) and [Manyverse](https://www.manyver.se/) (mobile), which can be thought of as peer-to-peer Twitter-analogs. SSB’s gossip makes it well suited for these types of apps.
I have not yet seen SSB used for remote sensor networks, and I think it is a good use case for it, given the protocol’s delay tolerance and ability to store immutable log data.
This month’s project creates a weather station that uses SSB as a replacement for internet connectivity. Weather logs are transmitted via data mule until they eventually find their way to a peer with internet connectivity, at which point the weather data reaches the global mesh of SSB users on the internet.
To put that in more practical terms:
1. An always-offline box in a remote location collects data.
2. A data mule connects to the weather station’s internal wifi network while Manyverse (mobile SSB client) is open on the data mule’s mobile phone. The network is only a LAN- there is no internet access at the remote site.
3. Within a few seconds, the weather station perform UDP peer discovery and exchange gossip.
4. The data mule goes home.
5. When the data mule connects to an internet-enabled wifi network at home, the data is gossiped to the wider SSB community (known as the “Scuttleverse”).
# See It in Action
If you want to see the weather logs for yourself, you can follow its identity on the Scuttlverse:
```
@siAx0bQUNVIS3IH2d++o44atOzn8h7BuoULySDiKrHc=.ed25519
```


# How We Built It
It’s a [custom NodeJS application](https://github.com/FoxDotBuild/WeatherStation) with a few dependencies:
- `node-dht-sensor`: For reading an attached temperature sensor.
- `ssb-client`: For writing to an append-only SSB feed.
The application reads the temperature once per day as well as at startup time. The reading is written to the machine’s SSB log so that it can be gossiped and replicated later.
### Parts List
- Wooden case (custom built)
- DHT-22
- Realtime Clock
- Raspberry Pi 3 (the pi0 was too slow)
- [RaspAP-GUI](https://github.com/billz/raspap-webgui) (to create a WiFi LAN for UDP peer discovery)
- USB battery pack
### Operation
At startup, `systemd` initiates two services:
- `ssb-server`, which provides an HTTP-based API for reading and writing to SSB feeds.
- The custom Node app detailed in the section above.
The services run in the background and poll for temperature updates at startup and once per 24 hour period.
The full source code can be found [on Github](https://github.com/FoxDotBuild/WeatherStation).
### Improvements
This was a hobby project. Like all hobby projects, it is neither perfect nor optimized for real world conditions. If we were to spend more time on this project (we probably won’t), I would:
- Use deep sleep to conserve battery
- Add a solar cell for better off-grid support (we placed it in a spot that had grid power)
- Automate the build process (currently, setup is a manual process)
- Build a viewer app instead of publishing messages as `"type": "post"`. Some users view the weather reports as “noise” on Patchwork. | rickcarlino | |
631,715 | How to create an awesome product card with HTML & CSS only | Hello Everyone, In this post, we are gone be discussing, How to create an awesome product card using... | 0 | 2021-03-11T05:46:39 | https://dev.to/ananiket/how-to-create-an-awesome-product-card-with-html-css-only-35m3 | Hello Everyone,
In this post, we are gone be discussing, **How to create an awesome product card using HTML & CSS** which includes some Fancy **CSS Transitions & little animations** as well.
Important ⚠️
For Icons, I have used the heroicons
First of all starting with the HTML, as we know it very well HTML is used for creating the markups for a minimal webpage it is must be included.
####HTML Markup
````
<div class="container">
<div class="card">
<div class="imgBx">
<img src="./nike-main.png" alt="nike_main">
</div>
<div class="contentBx">
<h2>Nike Air</h2>
<p>Air Jordan 1 Mid</p>
<!-- Stars -->
<div class="stars">
<ul>
<li>
<svg fill="currentColor" viewBox="0 0 20 20" xmlns="http://www.w3.org/2000/svg"><path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.07 3.292a1 1 0 00.95.69h3.462c.969 0 1.371 1.24.588 1.81l-2.8 2.034a1 1 0 00-.364 1.118l1.07 3.292c.3.921-.755 1.688-1.54 1.118l-2.8-2.034a1 1 0 00-1.175 0l-2.8 2.034c-.784.57-1.838-.197-1.539-1.118l1.07-3.292a1 1 0 00-.364-1.118L2.98 8.72c-.783-.57-.38-1.81.588-1.81h3.461a1 1 0 00.951-.69l1.07-3.292z"></path></svg>
</li>
<li>
<svg fill="currentColor" viewBox="0 0 20 20" xmlns="http://www.w3.org/2000/svg"><path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.07 3.292a1 1 0 00.95.69h3.462c.969 0 1.371 1.24.588 1.81l-2.8 2.034a1 1 0 00-.364 1.118l1.07 3.292c.3.921-.755 1.688-1.54 1.118l-2.8-2.034a1 1 0 00-1.175 0l-2.8 2.034c-.784.57-1.838-.197-1.539-1.118l1.07-3.292a1 1 0 00-.364-1.118L2.98 8.72c-.783-.57-.38-1.81.588-1.81h3.461a1 1 0 00.951-.69l1.07-3.292z"></path></svg>
</li>
<li>
<svg fill="currentColor" viewBox="0 0 20 20" xmlns="http://www.w3.org/2000/svg"><path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.07 3.292a1 1 0 00.95.69h3.462c.969 0 1.371 1.24.588 1.81l-2.8 2.034a1 1 0 00-.364 1.118l1.07 3.292c.3.921-.755 1.688-1.54 1.118l-2.8-2.034a1 1 0 00-1.175 0l-2.8 2.034c-.784.57-1.838-.197-1.539-1.118l1.07-3.292a1 1 0 00-.364-1.118L2.98 8.72c-.783-.57-.38-1.81.588-1.81h3.461a1 1 0 00.951-.69l1.07-3.292z"></path></svg>
</li>
<li>
<svg fill="currentColor" viewBox="0 0 20 20" xmlns="http://www.w3.org/2000/svg"><path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.07 3.292a1 1 0 00.95.69h3.462c.969 0 1.371 1.24.588 1.81l-2.8 2.034a1 1 0 00-.364 1.118l1.07 3.292c.3.921-.755 1.688-1.54 1.118l-2.8-2.034a1 1 0 00-1.175 0l-2.8 2.034c-.784.57-1.838-.197-1.539-1.118l1.07-3.292a1 1 0 00-.364-1.118L2.98 8.72c-.783-.57-.38-1.81.588-1.81h3.461a1 1 0 00.951-.69l1.07-3.292z"></path></svg>
</li>
<li>
<svg fill="currentColor" viewBox="0 0 20 20" xmlns="http://www.w3.org/2000/svg"><path d="M9.049 2.927c.3-.921 1.603-.921 1.902 0l1.07 3.292a1 1 0 00.95.69h3.462c.969 0 1.371 1.24.588 1.81l-2.8 2.034a1 1 0 00-.364 1.118l1.07 3.292c.3.921-.755 1.688-1.54 1.118l-2.8-2.034a1 1 0 00-1.175 0l-2.8 2.034c-.784.57-1.838-.197-1.539-1.118l1.07-3.292a1 1 0 00-.364-1.118L2.98 8.72c-.783-.57-.38-1.81.588-1.81h3.461a1 1 0 00.951-.69l1.07-3.292z"></path></svg>
</li>
</ul>
</div>
<div class="size">
<h3>Size : </h3>
<div class="sizes_">
<ul>
<li class="active">7</li>
<li>8</li>
<li>9</li>
<li>10</li>
</ul>
</div>
</div>
<div class="color">
<div>
<h3>Color : </h3>
<div class="colors_">
<ul>
<li class="active"></li>
<li></li>
<li></li>
</ul>
</div>
</div>
<div class="price">
<h5>$100.20</h5>
</div>
</div>
<div class="buy_btn">
<a href="javascript:void(0)">BUY</button>
</div>
</div>
</div>
</div>
```
Here we are ended with HTML Markup, Now **Styling this markup**
####CSS
```
/* Imported Font Family from google fonts => Oswald */
@import url('https://fonts.googleapis.com/css2?family=Oswald&display=swap');
/* Root */
*{
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: 'Oswald', sans-serif;
overflow: hidden !important;
}
/* Body */
body{
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
background-color: #131313;
}
/* CONTAINER */
.container{
position: relative;
animation: fadeIn 1.5s;
}
/* CONTAINER - ANIMATION */
@keyframes fadeIn {
0%{
opacity: 0;
}
100%{
opacity: 100;
}
}
/* CARD */
.container .card{
position: relative;
width: 320px;
height: 555px;
background-color: #232323;
border-radius: 20px;
overflow: hidden;
}
/* BEFORE */
.container .card::before{
content: '';
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
background-color: #ffbe00;
clip-path: circle(222px at 90% 17%);
transition: 0.5s ease-in-out;
}
.container .card:hover:before{
clip-path: circle(222px at 50% 0%);
}
.container .card:after{
content: 'Nike Air';
position: absolute;
top: 30%;
left: 9%;
font-size: 5rem;
font-weight: normal;
text-transform: uppercase;
color: white;
transition: 0.5s;
}
/* IMGBOX */
.container .card .imgBx{
position: absolute;
top: 45%;
transform: translateY(-50%);
width: 100%;
z-index: 1000;
height: 220px;
transition: 0.5s;
}
.container .card:hover .imgBx{
top: 5%;
transform: translateY(0%);
}
.container .card:hover::after{
top: 5%;
transform: translateY(0%);
}
/* IMAGE */
.container .card .imgBx img{
position: absolute;
top: 48%;
left: 48%;
transform: translate(-60%, -60%) rotate(-25deg);
width: 300px;
filter: drop-shadow(0 4px 4px rgba(39,39,39,0.8));
}
/* CONTENTBOX */
.container .card .contentBx{
position: absolute;
bottom: 2.5%;
width: 100%;
height: 100px;
z-index: 10;
padding: 1.2rem;
transition: 0.5s;
}
.container .card .contentBx:hover{
height: 290px;
}
.container .card .contentBx h2{
font-size: 15px;
color: #ffff;
text-transform: uppercase;
font-weight: 500;
letter-spacing: 1px;
}
.container .card .contentBx p{
font-size: 22px;
text-transform: capitalize;
font-weight: 500;
letter-spacing: 1px;
color: #ffffffe8;
}
/* STARS */
.container .card .contentBx .stars ul {
display: flex;
align-items: center;
margin: 2px;
}
.container .card .contentBx .stars ul li svg{
width: 15px;
color: #ffbe00;
}
.container .card .contentBx .stars ul li:nth-child(5) svg{
width: 15px;
color: rgb(223, 223, 223);
}
/* SIZE */
.container .card .contentBx .size h3, .container .card .contentBx .color h3{
font-size: 15px;
color: #dfdfdf;
font-weight: normal;
text-transform: uppercase;
margin-top: 10px;
}
.container .card .contentBx .size span {
width: 12px;
height: 12px;
border-radius: 7px;
background-color: #dfdfdf;
}
.container .card .contentBx .size .sizes_ ul{
display: flex;
align-items: center;
}
.container .card .contentBx .size .sizes_ ul li.active{
background-color: #ffbe00;
}
.container .card .contentBx .size .sizes_ ul li{
font-size: 15px;
width: 20px;
height: 19px;
border-radius: 3px;
background-color: #e6e6e6;
display: flex;
align-items: center;
justify-content: center;
margin: 8.5px;
}
/* COLOR */
.container .card .contentBx .color{
display: flex;
justify-content: space-between;
}
.container .card .contentBx .color .price{
float: right;
margin-top: 10px;
}
.container .card .contentBx .color .price h5{
color: #dfdfdf;
font-size: 17px;
font-weight: normal;
}
.container .card .contentBx .color .colors_ ul{
display: flex;
align-items: center;
}
.container .card .contentBx .color .colors_ ul li{
width: 15px;
height: 15px;
border-radius: 25px;
margin: 6px;
}
.container .card .contentBx .color .colors_ ul li.active{
background-color: #ffbe00;
}
.container .card .contentBx .color .colors_ ul li:nth-child(2){
background-color: #e6e6e6;
}
.container .card .contentBx .color .colors_ ul li:nth-child(3){
background-color: #0d7f7f;
}
/* BUY BUTTON */
.container .card .contentBx .buy_btn{
width: 100%;
height: fit-content;
background-color: #ffbe00;
text-align: center;
border-radius: 7px;
padding: 7px;
margin-top: 1rem;
}
.container .card .contentBx .buy_btn a {
text-decoration: none;
color: black;
font-size: 18px;
}
```
If you think is this so much to watch & read, check out this full step by step tutorial
[Click to watch](https://youtu.be/s6VN1BpPErU)
Thanks for watching & Happy Coding !!
| ananiket | |
631,840 | Ceph data durability, redundancy, and how to use Ceph | This blog post is the second in a series concerning Ceph. Creating data redundancy One of... | 11,576 | 2021-03-12T11:35:55 | https://dev.to/itminds/ceph-data-durability-redundancy-and-how-to-use-ceph-2ml0 | kubernetes, ceph | *This blog post is the second in a series concerning Ceph.*
# Creating data redundancy
One of the main concerns when dealing with large sets of data is data durability. We do not want a cluster in which a simple disk failure will introduce a loss in data. What Ceph aims for instead is fast recovery from any type of failure occurring on a specific failure domain.
Ceph is able to ensure data durability by using either replication or erasure coding.
## Replication
For those of you who are familiar with RAID, you can think of Ceph's replication as RAID 1 but with subtle differences.
The data is replicated onto a number of different OSDs, nodes, or racks depending on your cluster configuration. The original data and the replicas are split into many small chunks and evenly distributed across your cluster using the CRUSH-algorithm. If you have chosen to have three replicas on a 6-node cluster, these three replicas will be spread out onto all six nodes, not just three nodes containing the full replicas.
It is important to choose the right level of data replication. If you are running a single-node cluster, replication on the node level would be impossible and your cluster would lose data in the event of a single OSD failure. In this case, you would choose to replicate data across the OSDs you have available on the node.
On a multi-node cluster, your replication factor decides how many OSDs or nodes you can afford to lose in case of disk or node failure, without data loss. Of course, the replication of data introduces the problem of lowering your total amount of space available in your cluster. If you choose a replication factor of 3 on the node level, you will only have 1/3 of your total storage available in your cluster for you to use.
Replication in Ceph is fast and only limited by the read/write operations of the OSDs. However, some people are not content with "only" being able to use a small amount of their total space. Therefore, Ceph also introduced erasure coding.
## Erasure Coding
Erasure coding encodes your original data in a way so that when you need to retrieve the data again, you only need a subset of the data to recreate the original information. It splits objects into *k* data fragments and then computes *m* parity fragments. I will provide an example.
Let us say that the value of our data is 52. We could split it into:
`x = 5`
`y = 2`
The encoding process will then compute a number of parity fragments. In this example, these will be equations:
`x + y = 7`
`x - y = 3`
`2x + y = 12`
Here, we have a *k = 2* and *m = 3*. *k* is the number of data fragments and *m* is the number of parity fragments. In case of a disk or node failure and the data needs to be recovered, out of the 5 elements we will be storing (the two data fragments and the three parity fragments) we only require two of these five to recover. This is what ensures data durability when using erasure coding.
Now, why does this matter? It matters because these parity fragments take up significantly less space when compared to replicating the data. Here is a table that shows how much overhead there is on different erasure coding schemes. The overhead is calculated with *m / k*.
| Erasure coding scheme *(k+m)* | Minimum number of nodes | Storage overhead |
|:---------------------------:|:-----------------------:|:----------------:|
| 4+2 | 6 | 50% |
| 6+2 | 8 | 33% |
| 8+2 | 10 | 25% |
| 6+3 | 9 | 50% |
As we can see in the table, you can use the *(8+2)* scheme to make sure you can lose two of your nodes without losing any data, and this with only a 25% storage overhead.
If you look at this from a storage space optimization standpoint, this is a much better use of the storage. However, it is not without certain downsides. The parity fragments take time for the cluster to calculate and read/write operations are therefore slower than with replication. Therefore, erasure coding is usually recommended on clusters that deal with large amounts of [cold data](https://www.komprise.com/glossary_terms/cold-data/).
# Using Ceph
A natural part of deployments on Kubernetes is to create persistent volume claims (PVCs). PVCs can claim a volume and use that as storage for data in the pod. In order to create a PVC you first need to define a StorageClass in Kubernetes.
```
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
spec:
failureDomain: host
replicated:
size: 3
requireSafeReplicaSize: true
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph # namespace:cluster
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/fstype: ext4
allowVolumeExpansion: true
reclaimPolicy: Delete
```
In this StorageClass file, you can see that we first create a replica pool that creates 3 replicas in total and uses `host` as the failure domain. After that, we define whether or not we should allow volume expansion after a volume is created and what the reclaim policy should be. Reclaim policy determines whether the data that is stored in the volume should be deleted or retained when a pod ceases to exist. In this case, I have chosen delete.
```
# kubectl get storageclass -n rook-ceph
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 10m
```
Now that the StorageClass has been created, we can now create a PVC:
```
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: rook-ceph-block
```
This creates a PVC that is now running on our Kubernetes cluster:
```
# kubectl get pvc -n rook-ceph
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
rbd-pvc Bound pvc-56c45f01-562f-4222-8199-43abb856ca94 1Gi RWO rook-ceph-block 37s
```
We will now deploy a pod that uses this PVC:
```
---
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: web-server
image: nginx
volumeMounts:
- name: mypvc
mountPath: /var/lib/www/html
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: pvc
readOnly: false
```
After deploying this pod, you can see it in the pod list:
```
# kubectl get pods -n rook-ceph
NAME READY STATUS RESTARTS AGE
demo-pod 1/1 Running 0 118s
```
That is how you deploy pods that create persistent volume claims on your Ceph cluster!
| jaxels10 |
632,032 | React 101 - part 6: Function Components | After my Javascript series:... | 11,583 | 2021-03-11T19:55:00 | https://dev.to/ericchapman/react-101-part-6-function-components-2ia5 | javascript, react, beginners, tutorial | ---
title: React 101 - part 6: Function Components
published: true
description:
tags: javascript, react, beginner, tutorial
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/r3ui703pme0meo82pu5o.png
series: React 101
---
After my Javascript series: https://dev.to/rickavmaniac/javascript-my-learning-journey-part-1-what-is-javascript-role-and-use-case-49a3
I am now ready to begin my React learning journey :)
Click follow if you want to miss nothing. I will publish here on Dev.to what I learn from my React course the day before.
Without further ado here is a summary of my notes for day 6.
<h2>Function component</h2>
The first and recommended component type in React is functional components. A functional component is basically a JavaScript function that returns React JSX.
A valid React function component:
- Is a JavaScript function
- Must return a React element (JSX)
- Always starts with a capital letter (naming convention)
- Takes props as a parameter if necessary
According to React's official docs, the example below is a valid functional component:
```jsx
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
```
Alternatively, you can also create a functional component with the arrow function:
```jsx
const Welcome = (props) => {
return <h1>Hello, {props.name}</h1>;
}
```
We can create function component in a separate file and export it so you can import it somewhere else
```jsx
function Welcome(props) {
return <h1>Hello, {props.name}</h1>;
}
export default Welcome;
```
import example:
```jsx
import Welcome from './Welcome';
function App() {
return (
<div className="App">
<Welcome />
</div>
);
}
```
<h2>Hook</h2>
Hooks are the new feature introduced in the React 16.8 version. It allows you to use state and other React features in a function component (without writing a class).
Hooks are the functions which "hook into" React state and lifecycle features from function components. It does not work inside classes.
Hooks are backward-compatible, which means it does not contain any breaking changes. Also, it does not replace your knowledge of React concepts.
If you write a function component, and then you want to add some state to it, previously you do this by converting it to a class. But, now you can do it by using a Hook inside the existing function component.
<h2>useState hook</h2>
useState hook is the new way of declaring a state in React app. Hook uses useState() functional component for setting and retrieving state. Let us understand useState with the following example.
Counter component:
We will start simple by creating a Counter.jsx file with this content
```jsx
import React from 'react'
export function Counter() {
return <div>
Counter Component
</div>
}
```
To display this component we need to import and call it in our index.js file
```jsx
import ReactDOM from 'react-dom';
import { Counter } from './Counter'
ReactDOM.render(
<Counter/>,
document.getElementById('root')
);
```
Now let import useState and add a state to our Counter.jsx component
```jsx
import React, { useState } from 'react'
export function Counter() {
const count = useState(0)
console.log(counter)
return <div>
<h1>Counter Component</h1>
</div>
}
```
The useState(0) is a React Hook that will set the state default value to zero and return an array of 2 entry:
- count(0) hold the actual state value
- count(1) hold the function to modify the state
A better way to set the useState is to use deconstructing:
```js
const [count, setCount] = useState(0)
```
Thats exactly the same but a lot easier to read. So we still have our two entry:
- count variable hold the actual state
- setCount variable hold the function to set the state.
Note that those variables names could have been anything. We choose count and setCount for clarity purpose.
Now that we have set our state we can use it inside our component
```jsx
import React, { useState } from 'react'
export function Counter() {
const [count, setCount] = useState(0)
const handleClick = () => setCount(count+1)
console.log(count)
return <div>
<h1>Counter Component</h1>
<p>{count}</p>
<button onClick={handleClick}>+</button>
</div>
}
```
We create a button name + Each time we click on + we call the handleClick function. The function then set the state by using our SetCount function.
It is possible to have more than one useState per component
```jsx
import React, { useState } from 'react'
export function Counter() {
const [count, setCount] = useState(0)
const [count2, setCount2] = useState(0)
const handleClick = () => setCount(count+1)
const handleClick2 = () => setCount2(count2+1)
console.log(count)
return <div>
<h1>Counter Component</h1>
<p>{count}</p>
<button onClick={handleClick}>+</button>
<h1>Counter Component 2</h1>
<p>{count2}</p>
<button onClick={handleClick2}>+</button>
</div>
}
```
<h2>Conclusion</h2>
That's it for today. tomorrow the journey continue... If you want to be sure to miss nothing click follow me!
Follow me on Twitter: <a href="https://twitter.com/justericchapman?ref_src=twsrc%5Etfw" class="twitter-follow-button" data-show-count="false">Follow @justericchapman</a><script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> | ericchapman |
632,326 | Conversão de Tipos de Dados | Chegamos a mais um post da minha saga de estudos em JavaScript. No post de hoje irei falar sobre con... | 0 | 2021-03-11T23:31:45 | https://dev.to/nandobfr/conversao-de-tipos-de-dados-4eb6 | Chegamos a mais um post da minha [saga de estudos](https://dev.to/inando85/bem-vindo-de-novo-javascript-1b48) em JavaScript.
No post de hoje irei falar sobre conversão de tipos.
Significa dizer que é possível converter um tipo de dado para outro, e mais, terão momentos em que fazer isso será necessário para obter determinado resultado na aplicação.
No exemplo abaixo, eu irei criar uma variável `score` e irei atribuir uma `string` para ela. E no console.log irei realizar soma de + 1 ao valor dela, e como já falamos anteriormente, quando uma `string` é somada a um `number`, ocorre a concatenação, logo, não teremos o resultado esperado.
E iremos verificar o tipo do dado da variável utilizando o `typeof`, que irá nos retornar o tipo do dado atribuído a variável.
```js
let score = '100'
console.log(score + 1) // 1001
console.log(typeof score) // string
```
Eu irei utilizar funções construtoras para realizar a conversão de tipos, não se atenham muito a elas ainda, irei falar de funções mais a frente. Mas é importante saber que converter tipos é perfeitamente possível.
```js
let score = '100'
score = Number(score)
console.log(score + 1) // 101
console.log(typeof score) // number
```
Porém a conversão de strings leva em consideração que se a `string `a ser convertida para `number` não fizer sentido (matematicamente falando), o Not a Number `NaN` será retornado.
```js
const crazyConversion = Number('Maça')
console.log(crazyConversion) // NaN
console.log(typeof crazyConversion) // number
```
Também é possível converter `number` para `string`, utilizando a função construtora `String()`.
```js
const convertedNumber = String(97)
console.log(convertedNumber) // 97
console.log(typeof convertedNumber) // string
```
E ainda existe a possibilidade de conversão para o tipo de dado `boolean`.
Mas para isso, é importante frisar que no JavaScript, alguns valores são considerados verdadeiros `truthy` e outros falsos `falsy`.
Valores considerados falsy = [0, "", '', ``, null, undefined, NaN]
Valores considerados truthy = Todos os valores que não são falsy.
Sabendo dessa informação, ficará claro o exemplo abaixo:
```js
const booleanConversionTruthy = Boolean('Dominic')
const booleanConversionFalsy = Boolean('null')
console.log(booleanConversionTruthy) // true
console.log(booleanConversionFalsy) // false
```
Deixo aqui o link para a documentação da MDN sobre [conversão de tipos](https://developer.mozilla.org/en-US/docs/Glossary/Type_Conversion).
________________________________________________________________
Esse foi mais um post da minha saga de estudos em JavaScript Vanilla. Espero que estejam gostando!
Qualquer dúvida ou sugestão, vocês me encontram nas minhas redes sociais:
[LinkedIn](https://linkedin.com/in/inando85)
[GIthub](https://github.com/inando85)
[Twitter](https://twitter.com/inando85)
| nandobfr | |
632,362 | Supprimer un billet de blog, ça tourne mal | J'ai supprimé par inadvertance mon fichier markdown sur l'article CUL 0b11 avec un bon rm cul-3.md.... | 0 | 2021-06-16T10:56:30 | https://blog.lyokolux.space/supprimer-son-article-%C3%A7a-tourne-mal.html | python, blogging | J'ai supprimé par inadvertance mon fichier markdown sur l'article _CUL 0b11_ avec un bon `rm cul-3.md`. Le fail, j'ai validé la commande plus vite que mon ombre _facepalm_.

Comment s'en sortir et le retrouver, sans backup ?
Heureusement Python est mon ami. L'idée est simple : récupérer le code source de l'article, directement depuis le site. Je prends la partie qui m'intéresse.
Puis avec une recherche internet, je tombe sur _html2text_. Un coup de `pip3 install` et hop je suis parti pour un one-liner dégueulasse :
```
import html2text
open('cul-3.md', 'w').write(html2text.html2text(open('article-en-html').read()))
```
Et voilà, je retrouve mon article correctement nommé. Plus qu`à retrouver les metadonnées de l'article en 30 secondes et c'est bon. Boulette réparée.
Après test sur un serveur en local (merci `python -m http.server`), il est de nouveau là. J'aime l'informatique. | lyokolux |
632,366 | What is Randomness? Is it Predictable? | Since ancient times, people have wondered about the uncertainty in the consequences of events. From t... | 0 | 2021-03-11T19:20:44 | https://dev.to/alicanakca/what-is-randomness-is-it-predictable-108j | machinelearning, python, computerscience, math | Since ancient times, people have wondered about the uncertainty in the consequences of events. From the rolling of a dice, to the rotation of a card between two consoles, the concept of chance has developed. Randomness, as a definition, is not well founded, but we can simply call it the unpredictable state of a pile of events. For example, when a dice is rolled, its outcome cannot be predicted; the probability of coming double is 2 times more than coming 1.
In this article, we will examine the uncertainty starting from the recent past. Finally, we will consider the case of estimation with some regression models. Before we get started, let's examine our article in short headlines:
1. **Summary**
2. **What is Randomness?**
3. **Is it Predictable?**
4. **Application**
5. **Result**
# Summary
Randomness is not an outcome in itself. The result of the heads and tails is chaotic, not random. (See: Chaos Theory) It is an indication that we do not have instruments that can measure its randomness. The center of gravity of a metal coin is not clear due to the patterns on it. This money affects the result of situations such as being thrown from any side, shooting angle. The presence of too many variables on the result does not make it possible to estimate it completely in practice. I would like to underline that it is not impossible in theory.
# What is Randomness?
The concept of randomness is a measure of uncertainty. It is not possible to catch randomness, except in the quantum state, which I will mention shortly. I mentioned the reason for this. It is practically impossible to find all the variables separately and calculate the result. To give an example, let's want to choose between objects with the same properties; we cannot seek pure randomness in this choice. Because we interpret within a stack of probabilities, more simply, we can predict the result with some accuracy.
You are familiar that in the microuniverse we call the subatomic level, we cannot apply a number of laws. The reason is the uncertainty, that is, the quantum state. Radioactive materials are made up of atoms that decay over time. The atoms that decay break down into smaller atoms. Scientifically, the probability of the atom to decay in a certain time interval can be calculated, but it is not possible to predict which atom is the next one to decay. "God doesn't roll dice!" he said. In reference to this statement, he mentioned that although the methods used are of great benefit in theory, they are not a good option to bring him closer to his secret. Said god is a philosophical god defined by Einstein himself.
# Is it Predictable?
If you have managed to come up to this section, you can interpret the answer to the question yourself. Except for the quantum state, which we call a special case, predictions can be made about the distribution of results within the frame of probability. For the predictable situation, I would like to point out that it can be predicted in a very unrealistic way when the variables in the chaotic situation I mentioned earlier are ignored.
We gave our examples physically, but can random numbers be generated in computer environment? The short answer is that random generation cannot be made. It can be determined as a result of complex algorithms. I want to emphasize that it has been determined; The algorithms used work deterministically. Whatever the output is, it is certain.
# Application
We will construct the pseudo-randomness case with the Python language and discuss its predictability. Since this part is for the fancier, you can skip to the conclusion part. Let's get to know the data set:

We have 5 'independent' variables: gender, age, number of monthly entries to the application, the number of monthly purchases, the averages of these purchases, and finally the conclusion part that we expect to stop applying. However, in our experiment; We have a total of 11 'independent' variables to make the entry, number of purchases and the average 3 each. The value we predict will leave is the dependent variable.
```
import random
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import confusion_matrix
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LinearRegression
def jsonToCSV(numberOfDatas):
name = ["data" + str(numberOfDatas[i]) for i in range(len(numberOfDatas))] #filenames = data + numberofdata's items
fig, axs = plt.subplots(len(numberOfDatas)) #row numbers
fig.suptitle('Epic Prediction')
plt.setp(axs, yticklabels = ['SVC','LR','KN',"GNB",'DT',"RF"]) #label names
y_pos = np.arange(len(['SVC','LR','KN',"GNB",'DT',"RF"])) #customizations
fig.tight_layout()#customizations
for i in range(len(name)): #We will generate random numbers as many as the element in the list numberOfDatas
axs[i].set_yticks(y_pos+1)
def gender():
genderBinary = random.randint(0,1)
return genderBinary
def age():
ageRandom = random.randint(18,65)
return ageRandom
def enteries():
enteriesRandom = random.randint(0,300)
return enteriesRandom
def purchases():
purchasesRandom = random.randint(1,100)
return purchasesRandom
def purchasesAv():
purchasesAvRandom = random.randint(10,1500)
return purchasesAvRandom
def isLeave():
isLeaveRandom = random.randint(0,1)
return isLeaveRandom
limit,index = 0,0
dicts = {}
while True:
dicts[str(index)] = [gender(),
age(),
enteries(),enteries(),enteries(),
purchases(),purchases(),purchases(),
purchasesAv(),purchasesAv(),purchasesAv(),
isLeave()]
index +=1
limit +=1
if limit == numberOfDatas[i]:
break
with open(f'{name[i]}.json', 'w') as outfile: #We saved it in document datax.json (x = numberofdata's items)
json.dump(dicts, outfile)
df = pd.read_json(rf'{name[i]}.json')
df.T.to_csv (rf'{name[i]}.csv', index = None) #We converted it to csv document. + transpose
dataset = pd.read_csv(f'{name[i]}.csv') #we separated it as dependent independent variable.
allOfThem= dataset.iloc[:,1:11].values
willPredict = dataset.iloc[:,11:12].values
X_train, X_test, y_train, y_test = train_test_split(allOfThem, willPredict, test_size = 0.25, random_state = 3)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
"""
confusion matrix results
[A B
C D]
Accuracy = (A+D/A+B+C+D ) * 100 => %bla bla
"""
classifier = SVC(kernel = 'sigmoid', random_state = 4)
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
cm_SVC = confusion_matrix(y_test, y_pred)
cm_SVC_C = (cm_SVC[0][0]+cm_SVC[1][1])/len(y_test)*100
#print("SVC: %",cm_SVC_C)
logr = LogisticRegression(random_state=3)
logr.fit(X_train,y_train)
y_pred = logr.predict(X_test)
cm_LR = confusion_matrix(y_test, y_pred)
cm_LR_C = (cm_LR[0][0]+cm_LR[1][1])/len(y_test)*100
#print("LR: %",cm_LR_C)
knn = KNeighborsClassifier(n_neighbors=11, metric='minkowski')
knn.fit(X_train,y_train)
y_pred = knn.predict(X_test)
cm_KNN = confusion_matrix(y_test,y_pred)
cm_KNN_C = (cm_KNN[0][0]+cm_KNN[1][1])/len(y_test)*100
#print("KN: %",cm_KNN_C)
gnb = GaussianNB()
gnb.fit(X_train, y_train)
y_pred = gnb.predict(X_test)
cm_GNB = confusion_matrix(y_test,y_pred)
cm_GNB_C = (cm_GNB[0][0]+cm_GNB[1][1])/len(y_test)*100
#print("GaussianNB: %",cm_GNB_C)
#print("Score:" , gnb.score(y_test, y_pred))
dtc = DecisionTreeClassifier(criterion = 'entropy')
dtc.fit(X_train,y_train)
y_pred = dtc.predict(X_test)
cm_DT = confusion_matrix(y_test,y_pred)
cm_DT_C = (cm_DT[0][0]+cm_DT[1][1])/len(y_test)*100
#print("DT: %",cm_DT_C)
rfc = RandomForestClassifier(n_estimators=10, criterion = 'entropy')
rfc.fit(X_train,y_train)
y_pred = rfc.predict(X_test)
cm_RF = confusion_matrix(y_test,y_pred)
cm_RF_C= (cm_RF[0][0]+cm_RF[1][1])/len(y_test)*100
#print("RF: %",cm_RF_C)
listOfResults_X = [round(cm_SVC_C,4),round(cm_LR_C,4),round(cm_KNN_C,4),round(cm_GNB_C,4),round(cm_DT_C,4),round(cm_RF_C,4)]#we rounded the numbers
listOfResults_Y = [1,2,3,4,5,6]
axs[i].barh(1,cm_SVC_C,height = 1,color = "darkcyan", label='SVC')
axs[i].barh(2,cm_LR_C,height = 1,color = "darkturquoise", label='LR')
axs[i].barh(3,cm_KNN_C,height = 1,color = "steelblue", label='KN')
axs[i].barh(4,cm_GNB_C, height = 1,color = "palevioletred", label='GNB')
axs[i].barh(5,cm_DT_C, height = 1,color = "darkmagenta", label='DT')
axs[i].barh(6,cm_RF_C,height = 1,color = "rosybrown", label='RF')
for x in range(6):
axs[i].text(x = listOfResults_X[x] , y = listOfResults_Y[x] - 0.25, s = listOfResults_X[x], size = 9)
axs[i].set_title("The Number Of Data : " + str(numberOfDatas[i]))
axs[i].set_xlabel('Prediction Rate')
axs[i].set_ylabel('Regression Models')
axs[-1].legend(loc=2)
plt.show()
jsonToCSV([100,1000,5000]) #If you want, you can change these items.
```
# Result
Since we entered the values of 100,1000 and 5000, we obtained 3 result graphs. In the case of low data numbers, the models are more predictable, while the higher this number, the lower the performance rate. First of all, we can make this comment. Next, we will focus on the fact that when the data increase, the rates of correct estimation decrease and the results of the regression models are close to each other. Why is it so low? Although it is low, how and why does it show results close to 50%?
In fact, we can interpret such low rates as the fact that there is no link between the data. Likewise, we can relate its convergence to 50% with the probability distributions I mentioned earlier. You can [click here](https://alicanakca.com/discrete-probability-distributions-with-python) for the article on this topic.
| alicanakca |
632,426 | NFTs beyond art — 3 uses with real utility | NFTs, Non-Fungible Tokens, have broken into the mainstream in the past few weeks. Nifties, as some... | 0 | 2021-03-15T16:16:33 | https://joeczubiak.com/nfts-beyond-art-3-uses-with-real-utility/ | nft, crypto | ---
title: NFTs beyond art — 3 uses with real utility
published: true
date: 2021-03-11 12:00:00 UTC
tags: nft,crypto
canonical_url: https://joeczubiak.com/nfts-beyond-art-3-uses-with-real-utility/
---

NFTs, Non-Fungible Tokens, have broken into the mainstream in the past few weeks.
Nifties, as some call them, are a way to prove ownership of a digital asset like a photo, illustration, or video using the blockchain. NFTs aren't a currency like BitCoin or Ethereum, they have no intrinsic value, the value of an NFT comes from the value of the actual asset that it represents.
The NFT markets have been skyrocketing and this excitement and energy is largely centered on NFT art. Digital art is being sold as NFTs. It usually comes in the form of a jpeg, gif, mp4, or other common image and video file formats. NFTs contain metadata and the metadata usually includes a link to the artwork, hosted elsewhere on the web. This means the artwork itself is not on the blockchain but the certificate of ownership, NFT, is on the blockchain or public ledger.
Because of this, if you want to use one of these pieces of art as your background image on your device, there's nothing in place to stop you. The file is public and anyone can right-click and download it just like any other image on the internet.
**So then why own NFT art?**
Nifty art has little utility beyond being able to display it in somewhat obscure virtual worlds. Some say to buy them for bragging rights, because owning things feels good, or to start a collection. Maybe that resonates with you, maybe, like me, it doesn't. I'd say a lot of people are buying NFT art because they don't understand the speculation trap they've fallen into.
NFTs today, feel a lot like the crypto craze of 2018. The difference is that NFTs have no inherent value, are not a store of value, and there's no way to get your money out besides finding a buyer for your specific token.
The nifty art market is based on artificial scarcity, hype, and speculation. Artificial scarcity isn't enough to drive lasting value. Almost every article about NFTs mentions Crypto Kitties as an example of the power of artificial scarcity but they overlook the fact that the cats offered utility in that you could breed them and sell the offspring to others, for a profit.
## Beyond art
While nifty art is getting all the attention, there are very practical use cases for NFTs that will outlast the art craze.
NFTs have two important traits that make them valuable tools. They are tradable on open markets and they prove ownership. Taking advantage of these traits to provide utility is where the real value of NFTs comes from. NFTs are not art. Art is just one type of asset that an NFT can represent and it's important to remember that.
These are a few of the real-world scenarios where NFTs could be game-changing.
### Tickets
Tickets are a great use case for NFTs. Tickets to concerts, games, conferences, or other events and shows — both in person and online. In this case, there are already markets set up to sell your tickets to another person but they're fraught with uncertainty and fraud. Oftentimes, all you need is a barcode printed out or on your phone to get into an event. If you bought the ticket second-hand, which has become increasingly the only way due to a proliferation of bots buying tickets as soon as they go on sale, how can you be certain that they didn't sell the same barcode to someone else or several others? First one to arrive gets in and everyone else got scammed. That's not a good system.
There have been attempts to make physical tickets have holographic or otherwise hard to counterfeit traits but to a one time buyer I wouldn't know how to know if what I'm looking at is real or an elaborate fake.
This is what provability of ownership solves. With the NFT, you can see that the ticket originated from the official organization in charge of the event and there is no way for someone else to use the ticket. You can be sure that you didn't buy a fraudulent ticket and be sure that it will work to get in.
### Movies
Movie ownership feels a little different than it used to. We used to own DVDs. They were ours and we could do what we wanted with them, permitting we weren't breaking laws. These days, if you click buy in iTunes, what do you get? You get the privilege to watch the movie from your account, in iTunes, and that's it. There's no transferability. You can't move that movie to Google Play or lend it to a friend because you didn't buy the movie. You bought a privilege to consume it through a service.
If digital movies instead used the NFT model, you would own a copy of the actual files and you could watch that movie through any service or player that you want. You could give it to a friend for the weekend. When you're tired of it, just like a good old-fashioned garage sale, you could sell it off.
I don't foresee large movie studios being at the forefront of this innovation, they are currently benefiting from this lopsided system. I would expect smaller studios and independents to be the driving force in this change.
## Game assets
Have you ever bought in-game items? If you have, you've given money to the makers of the game, and in return, you get to use the item with your account in their game and that's it. If instead, you bought an NFT that represents a digital asset in the game, doors start to open. You could exchange your items on a public marketplace. You could show off the items you own on your blog. If you no longer play this game, you can sell off all of your items.
At first, it feels like all of the power is being given back to the users and the game makers are losing if they adopt NFTs. But, they won't lose if they adapt. NFTs create more reason to buy items and an ability for users to show off items which drives demand for more limited-run items. The switch to an NFT model creates a more thriving market and the ability for the game makers to produce more items to sell.
There are so many more ways that NFTs can and are being used but just because they can be used, doesn't mean that you should. No article about crypto would be complete without including a mention of the environmental effects of using crypto, which is enormous. With such high environmental costs, NFTs should only be used when it offers real utility and value that is hard to obtain otherwise.
To understand the environmental costs, I'll send you to this article explaining them. [https://everestpipkin.medium.com/but-the-environmental-issues-with-cryptoart-1128ef72e6a3](https://everestpipkin.medium.com/but-the-environmental-issues-with-cryptoart-1128ef72e6a3) | joeczubiak |
632,505 | Learning Rails | So, I decided to write this article to share a few resources I have used over the last twenty months... | 0 | 2021-03-11T22:07:50 | https://dev.to/eclecticcoding/learning-rails-1k0l | ruby, rails, webdev | So, I decided to write this article to share a few resources I have used over the last twenty months of learning Ruby and Ruby on Rails in the hopes it may help others. Also, I am writing to share a little of my story.
I have always loved web technologies and am a self-taught developer, which started as a hobby. Initially, I build my first website with HTML 3.2 because my business needed a website. For fun, I eventually, I supported many area non-profits by building WordPress sites for many years. However, two years ago, something changes, I had a desire to learn more and transition to a professional career.
In August 2019, I started at [Flatiron School](https://flatironschool.com/) and fell in love with the entire Ruby eco-system: Ruby, Sinatra, and especially [Ruby on Rails](https://rubyonrails.org/). I have a thirst and drive to **be better tomorrow than I am today**, so these resources reflect that desire.
## Free Resources
[Gorails](https://gorails.com/start) - this course is by Chris Oliver of GoRails, creator of [JumpstartPro](https://jumpstartrails.com/?utm_source=gorails) and [Hatchbox](https://hatchbox.io). This is a new free course for beginners , and is a great place to begin, watch, and code along.
[Rails Code Along](https://www.railscodealong.com/) - Steve Polito's course is a little different. This course bridges the gap between building side-projects, to a full production application. It follows full Test Driven Development with a Continuous Integration workflow. If you have been coding Rails for a little while, this will really way to step up your game.
[Rails Guides](https://guides.rubyonrails.org/) - Yes, the Rails Guides. Rails documentation is actually quite good. Any sharp developer needs to learn to read the documentation.
**Other I have not used:**
[OdinProject](https://www.theodinproject.com/courses/ruby-on-rails) - a lot of Rails developers started with Odin Project, I just never have.
[Web-Crunch](https://web-crunch.com/) - Andy Leverenz has a multi-part Rails series that I understand is quite good.
## Commercial Resources
[Rails Tutorial](https://www.learnenough.com/) - the Rails Tutorial, by [Michael Hartl](https://twitter.com/mhartl), has been the definitive standard for learning Rails for years. It is on longer free, so it is listed in the Commercial section, but it is worth the cost of admission. Even if you only purchase the Book, it is a great resource. I finished this tutorial while learning Rails at Flatiron, and I am continually referencing the book, or the finished application. It covers User accounts (not Devise), relationship models, and all with TDD using minitest.
[Professional Rails Code Along](https://www.udemy.com/share/101EFgB0UTdV9TRnw=/) - this Udemy course takes a unique approach of mimicking a Professional Production application, designed to meet the clients' expectations. It includes an Administration Dashboard to manager users and resources, and full Test Driven Development. Now, the tutorials are dated as they are built with Rails 4.2.6. So, I decided to build with the latest Rails and Ruby versions. When I hit a roadblock, I stop, worked through the problems, and documented the results.
[Ruby on Rails 5 - BDD, RSpec and Capybara](https://www.udemy.com/course/ruby-rails-5-bdd-rspec-capybara/) - a full TDD course by Mashrur Hossain and Emmanuel Asante. Again, a little dated (Rails 5.1), so as before I decided to build with the latest Rails and Ruby versions.
[Andrea Fomera](https://store.afomera.dev/) - Andrea's courses are top notch. She has a Rails course that touches on User accounts, relationships, and Javascript reactive rendering, just to name a few topics. There is also a new pre-released course **Learn Hotwire by Building a Forum** that I am doing right now that covers reactivity of Hotwire and is excellent.
[Jason Charnes](https://courses.jasoncharnes.com/) - offers a great course called **Interactive Rails with StimulusReflex** which I highly recommend, which teaches Stimulus Reflex.
## Books
Books I have read and/or reading that I have found beneficial
- **Confident Ruby** by Avdi Grimm
- **Metaprogramming Ruby** by Paola Perrotta
- **Practical Object-Oriented Design** by Sandi Metz
## Communities
Being in a community of developers has been vital to my personal growth:
- [VirtualCoffee](https://virtualcoffee.io/) - Virtual Coffee is a laid-back conversation with developers twice a week. It's the conversation that keeps going in slack. It's the online events that support developers at all stages of the journey. It's the place you go to make friends.
- [GoRails](https://gorails.com/) - a community of Rails developers, learning Ruby on Rails to build their ideas, products, and businesses.
- Local and virtual Ruby Meetups
- Rails and StimulusReflex Discord
## Workflow
When I first graduated from Flatiron, in February 2020, I was pulled in
a lot of directions, mostly influenced by the amount of job posting I was
reading. I spent time learning more about Redux, a lot of time learning Vue,
which I loved, and time learning the basics of Python, which I have a
desire to fully learn. Eventually I spent some time considering exactly what I wanted to do with my development career - I LOVE RAILS, so I redoubled my efforts to just Rails.
It was important for me to develop a routine, a routine that was missing since Bootcamp.
My daily routine is the same each day:
- In my office at 6am everyday
- Catch up on emails, and follow up on potential Ruby/Rails job openings
- Network on Twitter, LinkedIn, and the Slack communities I am a member
- Then, pay attention to this part, **I code eight hours a day**, committing and pushing code to a repository, running continuous integration, and sometimes deploying.
That's right I work as if I already had the job I am searching. It is important to develop skills and the muscle memory of developing.
The second routine I have developed is to make notes. If I have worked through a problem, in a tutorial or side project, I document in a Notions workbook. There is no reason to do the same task of discovery all over again.
It is fine to study, learn, listen to others, follow tutorials, but you just have to build stuff. It is the task of build were you learn to work through problems, and solve tasks.
## So, What now.
I have been searching for my first full-time Rails position for thirteen months. During this time I have met a lot of wonderful developers, I have sharpened my skills, and with a strong passion and desire to **be better tomorrow than I am today**, I continue to code. Why?
I am a Rails Developer. Even though I am still searching for that first position, I am a Rails developer and therefore I code.
## Footnote
This has been fun. Leave a comment or send me a DM on [Twitter](http://twitter.com/EclecticCoding).
Shameless Plug: If you work at a great company, and you are in the market for a Software Developer with a varied skill set and life experiences, and strives to be *better tomorrow than I am today*, send me a message on [Twitter](http://twitter.com/EclecticCoding) and check out my [LinkedIn](http://www.linkedin.com/in/dev-chuck-smith).
Credit: [Localhost SSL](https://github.com/codica2/rails-puma-ssl)
| eclecticcoding |
633,138 | Angular 11 + SpringBoot Upload/Download MultipartFile | https://grokonez.com/angular-11-springboot-upload-download-multipartfile When uploading files to Ser... | 0 | 2021-03-12T15:31:38 | https://dev.to/loizenai/angular-11-springboot-upload-download-multipartfile-4bbe | angular11, springboot, uploadfile, downloadfile | https://grokonez.com/angular-11-springboot-upload-download-multipartfile
When uploading files to Servlet containers, application needs to register a <strong>MultipartConfigElement</strong> class. But <strong>Spring Boot</strong> makes thing more easy by configuring it automatically. In this tutorial, we're gonna look at way to build an Angular 11 App Client to upload/get MultipartFile to/from Spring Boot RestApi Server.
Related posts:
- <a href="https://grokonez.com/spring-framework/spring-boot/upload-multipartfile-spring-boot">How to upload MultipartFile with Spring Boot</a>
- <a href="https://grokonez.com/spring-framework/spring-boot/multipartfile-create-spring-ajax-multipartfile-application-downloadupload-files-springboot-jquery-ajax-bootstrap">MultipartFile - SpringBoot + JQuery Ajax + Bootstrap.</a>
- <a href="https://grokonez.com/spring-framework/spring-boot/multipartfile-create-spring-angularjs-multipartfile-application-downloadupload-files-springboot-angularjs-bootstrap">MultipartFile – SpringBoot + AngularJs + Bootstrap.</a>
<!--more-->
<h2>I. Technologies</h2>
- Angular 11
- Java 1.8
- Spring Boot 2.0.3.RELEASE
- Maven 3.3.9
- Spring Tool Suite 3.9.0.RELEASE
<h2>II. Overview</h2>
<h3>1. Spring Boot Server</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/06/angular-6-upload-multipart-files-spring-boot-server-project-structure-server.png" alt="angular-6-upload-multipart-files-spring-boot-server-project-structure-server" width="320" height="327" class="alignnone size-full wp-image-13335" />
- <code>StorageService</code> helps to init, delete all files, store file, load file
- <code>UploadController</code> uses <code>StorageService</code> to provide Rest API: POST a file, GET all files
- <strong>application.properties</strong> to configure parameters such as MultipartFile max size...
- Spring Boot Starter Web dependency in <strong>pom.xml</strong>
<h3>2. Angular 11 App Client</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/06/angular-6-upload-multipart-files-spring-boot-server-project-structure-client.png" alt="angular-6-upload-multipart-files-spring-boot-server-project-structure-client" width="263" height="421" class="alignnone size-full wp-image-13336" />
- <code>upload-file.service</code> provides methods: push File to Storage and get Files.
- <code>list-upload.component</code> gets and displays list of Files.
- <code>form-upload.component</code> helps upload File.
- <code>details-upload.component</code> is detail for each item in list of Files.
<img src="https://grokonez.com/wp-content/uploads/2018/06/angular-6-upload-multipart-file-spring-boot-angular-overview.png" alt="angular-6-upload-multipart-file-spring-boot-angular-overview" width="440" height="407" class="alignnone size-full wp-image-13337" />
<h2>III. Practice</h2>
<h3>1. Spring Boot Server</h3>
<h4>1.1 Create Spring Boot project</h4>
With Dependency:
<pre><code class="language-html"><dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency></code></pre>
<h4>1.2 Create Storage Service for File Systems</h4>
Create <strong>StorageService</strong> with 4 functions:
- public void store(MultipartFile file): save a file
- public Resource loadFile(String filename): load a file
- public void deleteAll(): remove all uploaded files
- public void init(): create <strong>upload directory</strong>
<em>storage/StorageService.java</em>
<pre><code class="language-java">
package com.javasampleapproach.spring.uploadfiles.storage;
import java.io.IOException;
import java.net.MalformedURLException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.core.io.Resource;
import org.springframework.core.io.UrlResource;
import org.springframework.stereotype.Service;
import org.springframework.util.FileSystemUtils;
import org.springframework.web.multipart.MultipartFile;
@Service
public class StorageService {
Logger log = LoggerFactory.getLogger(this.getClass().getName());
private final Path rootLocation = Paths.get("upload-dir");
public void store(MultipartFile file) {
try {
Files.copy(file.getInputStream(), this.rootLocation.resolve(file.getOriginalFilename()));
} catch (Exception e) {
throw new RuntimeException("FAIL!");
}
}
public Resource loadFile(String filename) {
try {
Path file = rootLocation.resolve(filename);
Resource resource = new UrlResource(file.toUri());
if (resource.exists() || resource.isReadable()) {
return resource;
} else {
throw new RuntimeException("FAIL!");
}
} catch (MalformedURLException e) {
throw new RuntimeException("FAIL!");
}
}
public void deleteAll() {
FileSystemUtils.deleteRecursively(rootLocation.toFile());
}
public void init() {
try {
Files.createDirectory(rootLocation);
} catch (IOException e) {
throw new RuntimeException("Could not initialize storage!");
}
}
}
</code></pre>
<h4>1.3 Create Upload Controller</h4>
<em>controller/UploadController.java</em>
<pre><code class="language-java">
package com.javasampleapproach.spring.uploadfiles.controller;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.Resource;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.web.servlet.mvc.method.annotation.MvcUriComponentsBuilder;
import com.javasampleapproach.spring.uploadfiles.storage.StorageService;
@Controller
public class UploadController {
@Autowired
StorageService storageService;
List<String> files = new ArrayList<String>();
@PostMapping("/post")
public ResponseEntity<String> handleFileUpload(@RequestParam("file") MultipartFile file) {
String message = "";
try {
storageService.store(file);
files.add(file.getOriginalFilename());
message = "You successfully uploaded " + file.getOriginalFilename() + "!";
return ResponseEntity.status(HttpStatus.OK).body(message);
} catch (Exception e) {
message = "FAIL to upload " + file.getOriginalFilename() + "!";
return ResponseEntity.status(HttpStatus.EXPECTATION_FAILED).body(message);
}
}
@GetMapping("/getallfiles")
public ResponseEntity<List<String>> getListFiles(Model model) {
List<String> fileNames = files
.stream().map(fileName -> MvcUriComponentsBuilder
.fromMethodName(UploadController.class, "getFile", fileName).build().toString())
.collect(Collectors.toList());
return ResponseEntity.ok().body(fileNames);
}
@GetMapping("/files/{filename:.+}")
@ResponseBody
public ResponseEntity<Resource> getFile(@PathVariable String filename) {
Resource file = storageService.loadFile(filename);
return ResponseEntity.ok()
.header(HttpHeaders.CONTENT_DISPOSITION, "attachment; filename=\"" + file.getFilename() + "\"")
.body(file);
}
}
</code></pre>
<h4>1.4 Config multipart</h4>
Open <strong>application.properties</strong>:
<pre><code class="language-javascript">
spring.servlet.multipart.max-file-size=500KB
spring.servlet.multipart.max-request-size=500KB
</code></pre>
- <code>spring.servlet.multipart.max-file-size</code>: limit total file size for each request.
- <code>spring.servlet.multipart.max-request-size</code>: limit total request size for a multipart/form-data.
<h4>1.5 Init Storage for File System</h4>
<em>SpringBootUploadFileApplication.java</em>
<pre><code class="language-java">
package com.javasampleapproach.spring.uploadfiles;
import javax.annotation.Resource;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import com.javasampleapproach.spring.uploadfiles.storage.StorageService;
@SpringBootApplication
public class SpringBootFileUploadApplication implements CommandLineRunner {
@Resource
StorageService storageService;
public static void main(String[] args) {
SpringApplication.run(SpringBootFileUploadApplication.class, args);
}
@Override
public void run(String... arg) throws Exception {
storageService.deleteAll();
storageService.init();
}
}
</code></pre>
<h3>2. Angular 11 App Client</h3>
<h4>2.0 Generate Service & Components</h4>
Run commands below:
- <code>ng g s upload/UploadFile</code>
- <code>ng g c upload/FormUpload</code>
- <code>ng g c upload/ListUpload</code>
- <code>ng g c upload/DetailsUpload</code>
On each Component selector, delete <code>app-</code> prefix, then change <strong>tslint.json</strong> <code>rules</code> - <code>"component-selector"</code> to <strong>false</strong>.
<h4>2.1 App Module</h4>
<em>app.module.ts</em>
<pre><code class="language-java">
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import { HttpClientModule } from '@angular/common/http';
import { AppComponent } from './app.component';
import { DetailsUploadComponent } from './upload/details-upload/details-upload.component';
import { FormUploadComponent } from './upload/form-upload/form-upload.component';
import { ListUploadComponent } from './upload/list-upload/list-upload.component';
@NgModule({
declarations: [
AppComponent,
DetailsUploadComponent,
FormUploadComponent,
ListUploadComponent
],
imports: [
BrowserModule,
HttpClientModule
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
</code></pre>
<h4>2.2 Upload File Service</h4>
<em>upload/upload-file.service.ts</em>
<pre><code class="language-java">
import { Injectable } from '@angular/core';
import { HttpClient, HttpEvent, HttpRequest } from '@angular/common/http';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class UploadFileService {
constructor(private http: HttpClient) { }
pushFileToStorage(file: File): Observable<HttpEvent<{}>> {
const formdata: FormData = new FormData();
formdata.append('file', file);
const req = new HttpRequest('POST', '/post', formdata, {
reportProgress: true,
responseType: 'text'
});
return this.http.request(req);
}
getFiles(): Observable<any> {
return this.http.get('/getallfiles');
}
}
</code></pre>
https://grokonez.com/angular-11-springboot-upload-download-multipartfile | loizenai |
633,149 | Build a Scalable Video Chat App with Agora in Flask | Introduction Flask is a micro web framework written in Python. It is mostly used to build... | 0 | 2021-04-13T14:56:46 | https://www.agora.io/en/blog/build-a-scalable-video-chat-app-with-agora-in-flask/ | flask, python, agora, videocall |
#Introduction
Flask is a micro web framework written in Python. It is mostly used to build API endpoints but can be extended to build fully-fledged applications. We are going to build a one-on-one video call application with Flask on the hassle-free Real-Time Engagement platform; Agora.
Previously, I built a video chat app with WebRTC and Laravel and wrote about it here: {% link https://dev.to/mupati/adding-video-chat-to-your-laravel-app-5ak7 %}
WebRTC is only one of the ways that people can implement video chat features. Companies like <a href="https://www.agora.io/en/" target="_blank">Agora</a> also provide a fully packaged video chat SDK to provide a high-quality Real-Time Engagement video chat experience. As someone who has WebRTC development experience, I can tell you there are some limitations with WebRTC, such as:
<ol>
<li><strong>Quality of experience:</strong> Since WebRTC is transmitted over the Internet, which is a public domain, the quality of experience is hard to guarantee.</li>
<li><strong>Scalability:</strong> Scalability is fairly limited on group video calls due to the peer-to-peer nature of WebRTC.</li>
</ol>
After my experience with the Agora platform, I concluded it was not worthwhile for a company to invest a lot of development hours into building a video call feature as part of their main application with WebRTC. Agora is here to save you in that light. Through this article, I'm going to show you how to achieve that in your application you built with Flask.
# Why Agora Is the Preferred Solution
After building a video chat app with Agora, I want to highlight some of the advantages:
<ol>
<li>There's one SDK for everything - voice, video, live streaming, screen sharing, and so on.</li>
</li>
<li>I didn't have to set up a turn server with <a href="https://github.com/coturn/coturn" target="_blank">coturn</a> on Amazon EC2 as I did in the other implementation to relay traffic between peers on different networks.</li>
<li>You get <a href="https://www.agora.io/en/pricing/" target="_blank">10,000 minutes every month </a>free, and this gives you the flexibility to develop your solution prototype for free.</li>
<li>You don't have the challenge of managing the underlying infrastructure supporting the video call functionality.</li>
<li>Intuitive API documentation is available.</li>
</ol>
# Prerequisites
<ul>
<li>Python 3.8.5</li>
<li>A Flask application with authentication. Download the following starter project to get started: <a href="https://github.com/Mupati/agora-flask-starter" target="_blank">Flask Auth Starter Project</a>. We are going to build on top of this starter project.</li>
<li>A fair understanding of the factory and blueprint pattern in Flask. The starter project has been structured that way.</li>
<li>A free pusher account on <a href="https://pusher.com/" target="_blank">pusher.com</a></li>
<li>An understanding of <a href="https://pusher.com/docs/channels/using_channels/presence-channels" target="_blank">pusher presence channels</a> and the <a href="https://github.com/pusher/pusher-http-python#installation" target="_blank">python server library</a>.</li>
<li>Agora Developer Account: (See <a href="https://www.agora.io/en/blog/how-to-get-started-with-agora" target="_blank">How to get started with Agora</a>)</li>
</ul>
# Project Setup
1. Create and activate a python3 virtual environment for this project.
2. Open your terminal or command prompt and navigate to the starter project you downloaded as part of the prerequisites. The folder is named <strong>agora-flask-starter</strong>.
3. Follow the instructions in the README.md file in the agora-flask starter to set up the application.
4. Install additional dependencies from your terminal or command prompt.
```
pip install pusher
```
5. Download the AgoraDynamicKey Python3 code from the Agora repository: <a href="https://github.com/AgoraIO/Tools/tree/master/DynamicKey/AgoraDynamicKey/python3" target="_blank">AgoraDynamicKey</a>
Keep the downloaded folder in a location outside the project folder. Some of these files from the folder will be copied into our project when we're configuring the back end.
# Configuring the Backend
We are going to create the views for the agora blueprint and import the classes needed to generate the Agora token to establish a call. We will set up Pusher at the server-side as well.
### 1. Add the downloaded AgoraDynamicKey generator files
* Open your terminal or command prompt and navigate into the agora blueprint directory.
```
cd app/agora
```
* Create a subdirectory named <strong>agora_key</strong>.
```
mkdir agora_key
```
* Copy <strong>AccessToken.py</strong> and <strong>RtcTokenBuilder.py</strong> from the <strong>src</strong> directory in the downloaded files and add them to the <strong>agora_key</strong> directory.
### 2. Create the agora view
Add the following code to the <strong>views.py</strong> file in the <strong>app/agora</strong> directory.
{% gist https://gist.github.com/Mupati/27221a76bcd33d9989934313e96db418 %}
#### Breakdown of Methods in agora/views.py
<ul>
<li><strong>index:</strong> To view the video call page. Only authenticated users can view the page but non-authenticated users are redirected to the login page. We return a list of all the registered users.</li>
<li><strong>pusher_auth:</strong> It serves as the endpoint for authenticating the logged-in user as they join the pusher's presence channel. The ID and name of the user are returned after successful authentication with the pusher.</li>
<li><strong>generate_agora_token:</strong> To generate the Agora dynamic token. The token is used to authenticate app users when they join the agora channel to establish a call.</li>
<li><strong>call_user:</strong> This triggers a <strong>make-agora-call</strong> event on the <strong>presence-online-channel</strong> to which all logged-in users are subscribed.</li>
</ul>
The data broadcast with the <strong>make-agora-call</strong> event across the <strong>presence-online-channel</strong> contains the following:
<ul>
<li><strong>userToCall:</strong> This is the ID of the user who is supposed to receive a call from a caller.</li>
<li><strong>channelName:</strong> This is the call channel that the caller has already joined on the front end. This is a channel created with the Agora SDK on the client-side. It is the room the caller has already joined, waiting for the callee to also join to establish a call connection.</li>
<li><strong>from:</strong> The ID of the caller.</li>
</ul>
From the <strong>make-agora-call</strong> event, a user can determine whether they are being called if the userToCall value matches their ID. We show an incoming call notification with a button to accept the call. They know who the caller is by the value of from.
# Configuring the Front End
We are going to create the user interface for making and receiving the video call with the ability to toggle the on and off states of the camera and the microphone.
### 1. Update the HTML file for the index view.
The HTML file will contain the links to the CDN for Agora SDK, Vue.js, Pusher, Bootstrap for styling, and our custom CSS and Javascript.
The index.html file will also inherit a base template which is used to render the view.
<ul>
<li>Open the <strong>index.html</strong> file in the agora subdirectory in the templates directory. The location is <strong>app/templates/agora</strong><br/>
Currently, it only displays a welcome message for an authenticated user</li>
<li>Update the index.html file with the following code.
{% gist https://gist.github.com/Mupati/7e9ddc307f2ec4437c0e2ca67550a9f3 %}
</li>
</ul>
We use Flask's templating language to help with code reuse. As indicated early on, we inherit a base template named base.html. It has the following blocks:
<ul>
<li><strong>head_scripts:</strong> This is the block where we place the link to the Agora SDK and our index.css for styling the video call page.</li>
<li><strong>content:</strong> The content block contains the user interface for rendering the video stream with its control buttons.</li>
<li><strong>bottom_scripts:</strong> This block contains the links to the Pusher SDK, an instance of the Pusher Class with the presence channel authentication, Axios for sending AJAX requests, and Vuejs for writing the client-side logic for our video chat application.</li>
</ul>
### 2. Create the static files
We have index.css for custom styling and index.js; our script for handling the call logic.
Run the following command to create the files from your terminal or command prompt.
```bash
cd static/agora/
touch index.css index.js
```
Add the following to <strong>index.js</strong>
{% gist https://gist.github.com/Mupati/d82046799825bd4f37c69a578fbec9ba %}
Add the following to <strong>index.css</strong>
#### Breakdown of the Agora Call Page
On the video call page, i.e <strong>app/templates/agora/index.html</strong>, we display buttons that bear the name of each registered user and whether they are online or offline at the moment.
To place a call, we click the button of a user with online status. An online user indicates one who is available to receive a call. For our demo, we see a list of users. The user named <strong>Bar</strong> is indicated as being online. The caller named <strong>Foo</strong> can call <strong>Bar</strong> by clicking the button.

<strong>Bar</strong> gets an incoming call notification with Accept and Decline buttons and the name of the caller.
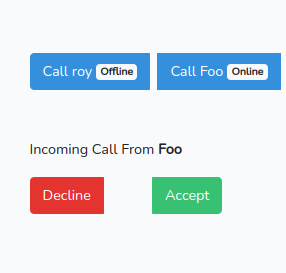
From the call notification image above, we see that the caller's name is <strong>Foo</strong>. <strong>Bar</strong> can then accept the call for a connection to be established.
The following diagram explains the call logic in terms of the code:

### 3. Update flaskenv variables with Pusher and Agora keys
The <strong>.flaskenv</strong> file is located at the root of your project folder. Add the credentials you got from Agora and Pusher. Add the secret key too if you didn't add it during the project setup.
{% gist https://gist.github.com/Mupati/0c42768dd83d6b7d184dd5c459b21349 %}
# Testing
1. Start the Flask development server from your terminal.
```bash
flask run
```
2. Open two different browsers or two instances of the same browser, with one instance in incognito mode, and navigate to the registration page.<br/>
<a href="http://127.0.0.1:5000/register
target="_blank">http://127.0.0.1:5000/register</a>
3. In one of the browsers create about 4 users by registering 4 times.
4. Login with the account details you just created on each of the browsers from the login page: <a href="http://127.0.0.1:5000/login
target="_blank">http://127.0.0.1:5000/login</a>
5. In each of the browsers you opened, the other users registered on the application are displayed.
6. In one browser, you can call the user who is logged in and on the other browser by clicking the button that bears their name.
7. The other user is prompted to click the Accept button to fully establish the call.
# Video Demonstration of the Video Call
To confirm that your demo is functioning properly, see my demo video as an example of how the finished project should look and function:
{% youtube aEPQlOMCTnQ %}
# Conclusion
You have now implemented the video call feature in your Flask application! It's not that hard, right?
To include video calling functionality in your web app, you don't have to build it from scratch.
Agora provides a lot of great features out of the box. It also helps businesses save development hours when implementing video chat into existing projects. The only thing a developer has to do is build a compelling front end - Agora handles the video chat back end.
Online Demo link: [https://watermark-remover.herokuapp.com/auth/login?next=%2Fagora](https://watermark-remover.herokuapp.com/auth/login?next=%2Fagora)
Completed Project Repository (it is located on the branch named completed in the starter kit):
https://github.com/Mupati/agora-flask-starter/tree/completed
Make sure the demo link or production version is served on HTTPS.
Test accounts:<br/>
foo@example.com: DY6m7feJtbnx3ud<br/>
bar@example.com: Me3tm5reQpWcn3Q<br/>
# Other Resources
<ul>
<li><a href="https://docs.agora.io/en/Video/API%20Reference/web/interfaces/agorartc.client.html#agorartc.client.html%23on" target="_blank">Available events on the Agora Client</a></li>
<li>For more information about Agora.io applications, take a look at the: <a href="https://docs.agora.io/en/Video/run_demo_video_call_web?platform=Web" target="_blank">Agora Quickstart Guides</a></li>
<li>Take a look at the complete documentation for the functions discussed above and many more: <a href="https://docs.agora.io/en/Video/API%20Reference/web/index.html" target="_blank">Agora Web SDK API</a></li>
</ul>
I also invite you to <a href="https://app.slack.com/client/T265K8ZT9/C263V5MFV/thread/CPQP4GMJ9-1585749906.115600" target="_blank">join the Agora.io Developer Slack community</a>.
| mupati |
1,637,831 | Supabase | Supabase is an open-source Backend-as-a-Service (BaaS) platform that combines the benefits of a... | 0 | 2023-10-17T19:30:13 | https://dev.to/madzimai/supabase-4ocb | react, api | Supabase is an open-source Backend-as-a-Service (BaaS) platform that combines the benefits of a real-time database and an instant API. It provides developers with a set of tools and services to build scalable and feature-rich applications rapidly.
Supabase is built on top of PostgreSQL, a powerful and reliable open-source relational database. It leverages the capabilities of PostgreSQL to provide real-time updates using websockets, authentication and authorization services, and a RESTful API layer for easy data access.
Key features of Supabase include:
1. Real-time updates: Supabase offers real-time data synchronization using websockets. This means that any changes made to the database are instantly pushed to connected clients, enabling real-time collaboration and dynamic user experiences.
2. Authentication and authorization: Supabase provides authentication services out of the box, including password-based authentication, social login (e.g., Google, GitHub), and third-party providers (OAuth). It also supports fine-grained access control with row-level security, allowing you to define specific permissions for different users or roles.
3. Database functionality: Supabase is built on PostgreSQL, which means it inherits the powerful querying capabilities and support for complex data structures offered by PostgreSQL. You can perform advanced queries, create complex relationships between tables, and leverage the full potential of SQL.
4. Serverless functions: Supabase allows you to write serverless functions using the popular JavaScript runtime, Node.js. This enables you to execute custom business logic on the server-side, interact with external APIs, and perform complex operations.
5. Storage and file handling: Supabase provides an easy-to-use file storage system, allowing you to upload, manage, and serve files. It supports both public and private file storage, making it convenient for handling user uploads or static assets.
6. Scalability and extensibility: Supabase is designed to scale with your application's needs. As it is built on PostgreSQL, you can leverage the scalability and performance optimizations provided by PostgreSQL. Additionally, you have the flexibility to extend Supabase by running custom code and leveraging the ecosystem of PostgreSQL extensions.
Supabase aims to provide developers with a complete backend solution that is easy to set up, highly scalable, and offers real-time capabilities. It is a popular choice for developers looking for a self-hosted alternative to traditional BaaS platforms.
I can provide you with an example of how you can create a POST request to a Supabase endpoint using a popular HTTP client library like Axios in JavaScript.
Assuming you have the necessary credentials and endpoint URL for your Supabase project, here's an example of creating a POST request:
```javascript
const axios = require('axios');
const supabaseUrl = 'https://your-supabase-url.com';
const supabaseKey = 'your-supabase-key';
async function createPost(title, content) {
try {
const response = await axios.post(`${supabaseUrl}/your-table-name`, {
title: title,
content: content,
}, {
headers: {
'Content-Type': 'application/json',
'apikey': supabaseKey,
},
});
console.log('Post created successfully:', response.data);
} catch (error) {
console.error('Error creating post:', error);
}
}
```
In this example, you need to replace `'https://your-supabase-url.com'` with your actual Supabase URL and `'your-supabase-key'` with your Supabase API key. Additionally, replace `'your-table-name'` with the name of the table you want to create the post in.
The `createPost` function takes `title` and `content` as parameters and sends a POST request to the Supabase endpoint using Axios. The Supabase API key is included in the request headers for authentication. The response is logged to the console.
Enjoy reading | madzimai |
633,349 | Titanium News #1 | Since there is currently no TiWeekly or tidev (https://www.tidev.io/ - perhaps soon again?) I thought... | 0 | 2021-03-12T20:09:06 | https://dev.to/miga/titanium-news-1-1fn8 | appcelerator, titanium, mobile, news | Since there is _currently_ no TiWeekly or tidev (https://www.tidev.io/ - perhaps soon again?) I thought it would be nice to make a Titanium News post here since there was a lot happening in the last weeks.
## Axway announced End-of-Support for Titanium
Perhaps the biggest new at the moment that is floating around:
https://devblog.axway.com/featured/product-update-changes-to-application-development-services-appcelerator/
At March 1, 2022 Axway won't officially support Titanium any longer and will hand it over to the community (most parts of the SDK are already open-source!).
Same for the back-end services (Sept 1, 2022). Have a look at the blog post above for more details.
While this was a shock for the community at first it turns out that there is already a nonprofit corporation "TiDev, Inc" that will drive the future development of Titanium! Big :clap: for the community members that basically started it a day after the announcement and already had their first board meeting :thumbsup:
Besides that there is still a lot of activity in the official Appcelerator Titanium repo and the developers continue to submit PRs and features!
Checkout the #tidev channel at TiSlack.org for more infos!
## Repo talk
It is still some time before the switch but Axway is already opening more repos to be available for the community:
Liveview: https://github.com/appcelerator/liveview
Hyperloop: https://github.com/appcelerator/hyperloop.next
both compile fine, so we can start working on PRs ;-)
Hopefully they will release some of the premium modules too, like encrypted databases (implemented my own version on Android) or the bluetooth module (already other modules available).
## SDK
The next SDK 10.x is packed with a lot of new features and bug fixes.
#### Material
There was a lot of Material work on the Android side and even the <a href="https://github.com/appcelerator/kitchensink-v2/pull/56">KitchenSink app will get a big update</a>.
The Day/Night mode got an update as well: you can now switch and the app will automatically reopen the current window in the background and reflect the changes.
#### OptionBar
A new component called `Ti.UI.OptionBar` was added
```
const optionBar1 = Ti.UI.createOptionBar({
labels: ["One", "Two", "Three"]
});
```
#### So much more
There are still many <a href="https://github.com/appcelerator/titanium_mobile/pulls?q=is%3Aopen+is%3Apr">open PRs</a> in line and many bugfixes that will be included in 10.x
## New discussion page
Next to <a href="tislack.org/">TiSlack</a> - the Titanium Slack channel there is now a Github discussion forum:
https://github.com/appcelerator/titanium_mobile/discussions
So for the quick chat and "I need to get this sorted right away" you can now post your questions, bugs or information to the Github discussion forum!
Very nice addition to the Slack and better for bigger questions!
## Video tutorials
A while ago I've started <a href="fromzerotoapp.com/">from zero to app</a> with some written tutorials with basic topics to get started with Titanium and master everyday tasks like "Push notifications", "Maps" or just different "app layouts". More guides will be added all the time but I finally found some time to record my first video tutorials:
<ul>
<li><a href="https://www.youtube.com/watch?v=keAzBXvQAYk">How to install Appcelerator Titanium on Linux</a></li>
<li><a href="https://www.youtube.com/watch?v=C75vifuaAPA">Create a new app</a></li>
</ul>
Very basic at the moment but for a new user you have to start at zero :smile:
The next video is already recorded but I'll need to record the audio and cut it.
## Modules
At the end some interesting modules I would like to point out:
<a href="https://github.com/hansemannn">@hansemannn</a> released many new modules:
* https://github.com/hansemannn/titanium-intercom: Use the native iOS / Android Intercom SDK's in Appcelerator Titanium.
* https://github.com/hansemannn/titanium-huawei-analytics: Huawei Analytics Android SDK
* https://github.com/hansemannn/titanium-huawei-messaging: Huawei Messaging Android SDK
TiGL - an OpenGL 2D scenegraph for Android: https://github.com/DzzD/TIGLDemo/ by <a href="https://github.com/DzzD/">@DzzD</a>
And an Android live blur view for Android by me: https://github.com/m1ga/ti.blurview
<hr/>
That's it ;-) If you have some nice app or module you want to see in the next article feel free to send me a note!
Michael
_header background created with https://app.haikei.app/_ | miga |
633,375 | Six Secret Easter Eggs in GitHub | GitHub has quite a few Easter eggs hidden deep in the code. This post highlights a few of them - well... | 0 | 2021-03-12T22:07:14 | https://dev.to/github/six-secret-easter-eggs-in-github-2j17 | github | GitHub has quite a few Easter eggs hidden deep in the code. This post highlights a few of them - well, 6 to be exact!
**Did you know:** The phrase "_Easter egg_" was first coined in 1979 by Steve Wright, Director of Software Development at Atari. If you saw the movie Ready Player One, you'll know exactly what I'm talking about. Here's the scene where they uncover the world's first Easter egg in the classic game 'Adventure':
{% youtube kSzRvnby7mg %}
## 1. Easy as pi
I don't think there's a language that _doesn't_ have the value for pi in it's standard/math library. But if Google is down, and you forget your high school math, you can always point your browser to a https://github.com/π.
There you'll get an ASCII art representation of Pi correct to 336 decimal places! Handy huh?
```
3.141592653589793238462643383279
5028841971693993751058209749445923
07816406286208998628034825342117067
9821 48086 5132
823 06647 09384
46 09550 58223
17 25359 4081
2848 1117
4502 8410
2701 9385
21105 55964
46229 48954
9303 81964
4288 10975
66593 34461
284756 48233
78678 31652 71
2019091 456485 66
9234603 48610454326648
2133936 0726024914127
3724587 00660631558
817488 152092096
Via https://github.com/Legend-of-iPhoenix/ascii-pi
```
I believe you'll also get other representations to π by adding file extensions like [`.json`](https://github.com/π.json) or [`jpeg`](https://github.com/π.jpeg). Mmmm... pie.

## 2. Octocats in the system
Speaking of ASCII art, did you know there's an API endpoint for Mona, GitHub's Octocat mascot? Curl or visit `https://api.github.com/octocat` in a browser:
```
curl https://api.github.com/octocat
MMM. .MMM
MMMMMMMMMMMMMMMMMMM
MMMMMMMMMMMMMMMMMMM ____________________________
MMMMMMMMMMMMMMMMMMMMM | |
MMMMMMMMMMMMMMMMMMMMMMM | Keep it logically awesome. |
MMMMMMMMMMMMMMMMMMMMMMMM |_ ________________________|
MMMM::- -:::::::- -::MMMM |/
MM~:~ 00~:::::~ 00~:~MM
.. MMMMM::.00:::+:::.00::MMMMM ..
.MM::::: ._. :::::MM.
MMMM;:::::;MMMM
-MM MMMMMMM
^ M+ MMMMMMMMM
MMMMMMM MM MM MM
MM MM MM MM
MM MM MM MM
.~~MM~MM~MM~MM~~.
~~~~MM:~MM~~~MM~:MM~~~~
~~~~~~==~==~~~==~==~~~~~~
~~~~~~==~==~==~==~~~~~~
:~==~==~==~==~~
```
That speech bubble contains a little bit of GitHub Zen that my buddy [@benbalter](https://github.com/benbalter) explains in this [blog post](https://ben.balter.com/2015/08/12/the-zen-of-github/).
🚨 **WARNING:** Be careful if you `curl` ASCII art (or anything for that matter) off of the internet. Turns out that [some ASCII art is executable](https://github.com/xyzzy/smile)! 🤯
## 3. Everything zen
After a long day staring at a dark terminal, [GitHub CLI](https://cli.github.com/) users can take a deep breath, and take a walk through their repository's roguelike garden with `gh repo garden`. You can even navigate with `vi` keys!

Each flower is represented by the first letter of the committer's GitHub username, and the color of each flower is the first 6 characters of the commit's SHA interpreted as a hex code.
Eg. commit `b6b3d26ee50fc6540e1796d8bdc563d22da44ba5` would be `#b6b3d2` ([a nice lilac color](https://www.color-hex.com/color/b6b3d2)). Thistle do nicely :ok_hand:
## 4. Spruced-up user profiles
It's not exactly a _secret_ secret, but you you can customize your user profile by adding a special repo named after your username:
With a little a bit of Markdown and an image or two, it's a great way to tell people about yourself, show what you're working on, etc.
If you're looking for some inspiration, check out this post featuring [ten standout profile READMEs](https://dev.to/github/10-standout-github-profile-readmes-h2o).
## 5. Spooktacular contributions
Once every year your contributions graph will look even _more_ spooktacular as those lovely shades of green turn... halloweeny (_is that a word?_).

## 6. Viewing your contributions... 80s style
If you haven't stumbled upon it yet, [GitHub Skyline](https://skyline.github.com/) is a cool little visualization of your contributions for a given year. Look at [mine from 2020](https://skyline.github.com/leereilly/2020) for example. You can download those Skylines as `.stl` files to print, purchase physical copies of them, and/or explore them in virtual reality.
To activate the Easter egg, enter the [Konami Code](https://en.wikipedia.org/wiki/Konami_Code) once a Skyline has loaded and you'll be transported back even _further_ in time...
<kbd>↑</kbd> <kbd>↑</kbd> <kbd>↓</kbd> <kbd>↓</kbd> <kbd>←</kbd> <kbd>→</kbd> <kbd>←</kbd><kbd>→</kbd> <kbd>B</kbd> <kbd>A</kbd>
Kudos to [@carlesnunez](https://github.com/carlesnunez) for discovering it:
{% twitter 1362159214479761415 %}
End of line | leereilly |
633,445 | Day 39: Blackjack Checker | def read_player_hands(): player_hands = [] lines = open('input').readlines() for line in... | 11,086 | 2021-03-12T22:48:37 | https://dev.to/mattryanmtl/day-39-blackjack-checker-35a6 | 100daysofcode, python | ```python
def read_player_hands():
player_hands = []
lines = open('input').readlines()
for line in lines:
tokens = line.split(": ")
name = tokens[0]
cards = map(lambda s : s.split(" ")[0], tokens[1].split(", "))
player_hands.append((name, cards))
return player_hands
def eval_hand(hand):
card_values = {
'Two' : 2,
'Three' : 3,
'Four' : 4,
'Five' : 5,
'Six' : 6,
'Seven' : 7,
'Eight' : 8,
'Nine' : 9,
'Ten' : 10,
'Jack' : 10,
'Queen' : 10,
'King' : 10 }
val = 0
aces = 0
for card in hand:
if card == 'Ace':
aces += 1
else:
val += card_values[card]
if aces > 0:
aces -= 1
val += aces
if aces > 0:
if val + 11 <= 21:
val += 11
else:
val += 1
if val <= 21 and len(hand) >= 5:
return 22
elif val > 21:
return 0
else:
return val
def get_winner(hand_values):
winning_val = max(map(lambda v : v[2], hand_values))
if winning_val == 0:
print("Everyone busts.")
else:
winners = [hand_val for hand_val in hand_values if hand_val[2] == winning_val]
if len(winners) == 1:
if winning_val == 22:
print("%s wins with the 5 card trick." % winners[0][0])
else:
print("%s wins." % winners[0][0])
else:
print("Draw between %s." % " and ".join(map(lambda v : v[0], winners)))
def play():
hand_values = []
for hand in read_player_hands():
hand_values.append((hand[0], hand[1], eval_hand(hand[1])))
get_winner(hand_values)
play()
``` | mattryanmtl |
633,523 | A tip on how to stay motivated and not give up when learning to code | Remind yourself why you started learning to code In this Facebook community Sunjay A. shar... | 0 | 2021-03-13T00:39:30 | https://dev.to/patricktunez123/a-tip-on-how-to-stay-motivated-and-not-give-up-when-learning-to-code-49h2 | coding, javascript, motivation, learntocode | ### Remind yourself why you started learning to code
In this [Facebook community](https://www.facebook.com/groups/codecademy.community/) Sunjay A. shared the following advice:
> “In those days you feel without motivation, take a deep breath and find ways to rest. Next… try to remember the goal you had when you first began this journey. What motivated you then? If you had no specific goal, set one today and work toward that.”
Well, I agree with Sunjay because I believe that remembering why you started can be a nice way to rediscover what inspired you in the first place, reinvigorate your desire to learn, and help you find the motivation to keep going.
Thank you for reading!
You can follow/connect me on:
* [Linkedin](https://www.linkedin.com/in/patrick-tunezerwane-0a901ba8/)
* [GitHub](https://github.com/patricktunez123)
* [Twitter](https://twitter.com/tunezpatrick) | patricktunez123 |
633,740 | Create a Azure bot in Python | This article shows you how to build a bot by using the Python Echo Bot template, and then how to test... | 0 | 2021-03-15T16:12:49 | https://dev.to/prabhumanoharaa/create-a-azure-bot-in-python-4aa9 | azure, python | This article shows you how to build a bot by using the Python Echo Bot template, and then how to test it with the Bot Framework Emulator.
Creating a bot with Azure Bot Service and creating a bot locally are independent, parallel ways to create a bot.
**Prerequisites**
* Python 3
* Bot Framework Emulator
* Knowledge of asynchronous programming in Python
**Templates**
1. Install the necessary packages by running the following commands:
```python
pip install botbuilder-core
pip install asyncio
pip install aiohttp
pip install cookiecutter
```
The last package, cookiecutter, will be used to generate your bot. Verify that cookiecutter was installed correctly by running `cookiecutter --help`.
2. To create your bot run:
```python
cookiecutter https://github.com/microsoft/BotBuilder-Samples/releases/download/Templates/echo.zip
```
This command creates an Echo Bot based on the Python echo template
**Create a bot**
You will be prompted for the name of the bot and a description. Name your bot `echo-bot` and set the description to `A bot that echoes back user response`. as shown below:

**Start your bot**
1. From a terminal navigate to the `echo-bot` folder where you saved your bot. Run `pip3 install -r requirements.txt` to install any required packages to run your bot.
2. Once the packages are installed run `python3 app` to start your bot. You will know your bot is ready to test when you see the last line shown in the screenshot below:

Copy the last for digits in the address on the last line (usually 3978) since you will be using them in the next step. You are now ready to start the Emulator.
**Start the Emulator and connect your bot**
1. Start the Bot Framework Emulator.
2. Select Open Bot on the Emulator's Welcome tab.
3. Enter your bot's URL, which is the URL of the local port, with /api/messages added to the path, typically http://localhost:3978/api/messages.
4. Then select Connect.
Send a message to your bot, and the bot will respond back. | prabhumanoharaa |
633,906 | Managing Cluster Membership with Etcd | In this post we want to take a look at how we can utilize etcd to manage cluster membership in a distributed application. | 0 | 2021-03-31T08:17:16 | https://dev.to/frosnerd/managing-cluster-membership-with-etcd-l0k | java, distributedsystems, cluster, etcd | ---
title: Managing Cluster Membership with Etcd
published: true
description: In this post we want to take a look at how we can utilize etcd to manage cluster membership in a distributed application.
tags: java, distributedsystems, cluster, etcd
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/zw2jhpftbtkf77mitdb1.png
---
# Introduction
In the era of global internet services, distributed systems have become ubiquitous. To harness the power of distributed computation and storage however, coordination of the involved parties is required. Distributed algorithms combine multiple physical components into a single logical component. When a user sends a request to a load balancing cluster or distributed database, the fact that there are multiple processes involved should be transparent.
A cluster is a collection of nodes which are connected through a network. Most distributed algorithms require a consistent (or at least eventually consistent) view of all nodes that are members of the cluster. In a distributed data processing engine for example, we use the cluster view to determine how to partition and distribute the data. How can we maintain a consistent view of the cluster inside each member?
Our goal is to maintain an in-memory membership list in each node. When a node joins or leaves the cluster, we need to update the membership lists in all nodes. Ideally, we also want to detect nodes that are down, since they might not be able to send a leave request in case of a hardware fault, out of memory error, or a similar problem.
Generally there are two types of distributed communication paradigms that can be used to share membership updates across a cluster: Decentralized and centralized approaches. Decentralized approaches include epidemic, or gossip-style protocols that distribute information among peers without a central coordinator / single source of truth. Centralized approaches rely on some sort of coordinator that acts as the single source of truth and distributes updates to all interested parties.
Gossip-style protocols became popular because of their scalability and the lack of a single point of failure. Since all members are equal, they can be replaced easily. In the face of concurrent modifications, however, resolving conflicts and reaching consensus can be challenging. This is why many applications rely on an external application to manage and track membership information consistently. Popular examples of such coordination services are [Apache Zookeeper](https://zookeeper.apache.org/), [Consul](https://www.consul.io/), or [etcd](https://etcd.io/).
In this post we want to take a look at how we can utilize etcd to manage cluster membership in a distributed application. We will combine different etcd APIs, such as the key value store, watchers and leases to build and maintain an in-memory membership list in our nodes. The application is written in Java and the [source code](https://github.com/FRosner/etcd-playground) is available on GitHub. The remainder of the post is structured as follows.
First, we will give an overview of the target architecture, introducing the different etcd functionality needed on a conceptual level. Afterwards, we will implement the design step by step. We are closing the post by summarizing the main findings and discuss potential improvements. The [source code](https://github.com/FRosner/etcd-playground) is available on GitHub.
# Design
The target architecture consists of a set of application nodes forming a cluster, and etcd. Each node stores its metadata in the etcd key-value (KV) store when joining the cluster. We can identify a node by a randomly generated UUID.
Every node subscribes to membership updates through the etcd watch API, in order to update its local state. Failure detection is implemented by connecting the metadata of a node to a lease. If the node fails to keep the lease alive because it crashed, it will be removed from the cluster automatically.
For more information about the etcd APIs, you can check ["Interacting with etcd"](https://etcd.io/docs/next/dev-guide/interacting_v3/). The following diagram illustrates the setup of a four-node cluster.
In the next section we will implement this functionality step by step.
# Implementation
## Foundations
As a first step we will implement a class encapsulating all functionality of a single node. Each node needs a connection to etcd and a membership list. Let's look at the entire file first and then go through it step by step.
```java
package de.frosner.server;
import ...
public class Node implements AutoCloseable {
private final NodeData nodeData;
private final Client etcdClient;
private final ConcurrentHashMap<UUID, NodeData> clusterMembers =
new ConcurrentHashMap<>();
public Node(List<URI> endpoints) {
nodeData = new NodeData(UUID.randomUUID());
etcdClient = Client.builder().endpoints(endpoints).build();
}
public void join() throws JoinFailedException {
// TODO
}
public void leave() throws LeaveFailedException {
// TODO
}
public Set<NodeData> getClusterMembers() {
return ImmutableSet.copyOf(clusterMembers.values());
}
public NodeData getNodeData() {
return nodeData;
}
@Override
public void close() {
leave();
etcdClient.close();
}
}
```
We want to associate metadata with each node. The `NodeData` class stores this information. Metadata could be system specific, such as the time the node joined the cluster, or application specific, such as the partitions the node is responsible for in case of a distributed database. For the sake of simplicity, we will only have a UUID inside `NodeData`.
To communicate with etcd, we will use [jetcd](https://github.com/etcd-io/jetcd). Each node has an etcd client that connects to our central etcd cluster. The membership list will be represented as a `ConcurrentHashMap<UUID, NodeData>` to ensure that we can safely interact with it from different threads later on.
We also created stubs for the `join()` and `leave()` methods, and implemented `AutoCloseable` so we can use the `Node` inside a try-with-resources statement. The `JoinFailedException` and `LeaveFailedException` are custom exceptions we created to indicate that something went wrong during joining or leaving the cluster.
Next, we will create a test skeleton, so we can check our implementation through automated tests. Thanks to the amazing [Testcontainers](https://www.testcontainers.org/) library it is very easy to create an etcd server as part of the test lifecycle. Here goes the test class:
```java
package de.frosner.server;
import ...
@Testcontainers
class NodeTest {
private static final Network network = Network.newNetwork();
private static final int ETCD_PORT = 2379;
private ToxiproxyContainer.ContainerProxy etcdProxy;
@AfterAll
private static void afterAll() {
network.close();
}
@Container
private static final GenericContainer<?> etcd =
new GenericContainer<>(EtcdContainer.ETCD_DOCKER_IMAGE_NAME)
.withCommand("etcd",
"-listen-client-urls", "http://0.0.0.0:" + ETCD_PORT,
"--advertise-client-urls", "http://0.0.0.0:" + ETCD_PORT,
"--name", NodeTest.class.getSimpleName())
.withExposedPorts(ETCD_PORT)
.withNetwork(network);
@Container
public static final ToxiproxyContainer toxiproxy =
new ToxiproxyContainer("shopify/toxiproxy:2.1.0")
.withNetwork(network)
.withNetworkAliases("toxiproxy");
@BeforeEach
public void beforeEach() {
etcdProxy = toxiproxy.getProxy(etcd, ETCD_PORT);
}
private List<URI> getClientEndpoints() {
return List.of(URI.create(
"https://" + etcd.getContainerIpAddress() +
":" + etcd.getMappedPort(ETCD_PORT)
));
}
private List<URI> getProxiedClientEndpoints() {
return List.of(URI.create(
"https://" + etcdProxy.getContainerIpAddress() +
":" + etcdProxy.getProxyPort()
));
}
@Test
public void testNodeJoin() throws Exception {
try (Node node = new Node(getClientEndpoints())) {
node.join();
}
}
}
```
The skeleton contains a single test that makes a node join the cluster and then closes it, causing it to leave again. Since we did not implement any functionality, yet, we do not expect anything to happen.
Note that we are creating a custom docker network and a [Toxiproxy](https://github.com/Shopify/toxiproxy) container. For the initial tests this is not required, but we need it later on when we want to simulate network failures. For the sake of simplicity we will only use a single etcd node. In a production scenario you should have an etcd cluster of at least three nodes.
Let's implement a basic join algorithm next.
## Joining a Cluster
When joining the cluster, a node puts its metadata to etcd. We are storing all node metadata under `NODES_PREFIX = "/nodes/"`, which enables us to watch for membership changes based on this prefix later on.
```java
public void join() throws JoinFailedException {
try {
putMetadata();
} catch (Exception e) {
throw new JoinFailedException(nodeData, e);
}
}
private void putMetadata() throws Exception {
etcdClient.getKVClient().put(
ByteSequence.from(
NODES_PREFIX + nodeData.getUuid(),
StandardCharsets.UTF_8
),
ByteSequence.from(
JsonObjectMapper.INSTANCE.writeValueAsString(nodeData),
StandardCharsets.UTF_8
)
).get(OPERATION_TIMEOUT, TimeUnit.SECONDS);
}
```
Given this implementation, we can modify the existing test case to query etcd for the node metadata.
```java
@Test
public void testNodeJoin() throws Exception {
try (Node node = new Node(getClientEndpoints())) {
node.join();
assertThat(getRemoteState(node.getNodeData()))
.isEqualTo(node.getNodeData());
}
}
private NodeData getRemoteState(NodeData node) throws Exception {
String nodeDataJson = etcdClient.getKVClient()
.get(ByteSequence.from(Node.NODES_PREFIX + node.getUuid(),
StandardCharsets.UTF_8))
.get(Node.OPERATION_TIMEOUT, TimeUnit.SECONDS)
.getKvs()
.get(0)
.getValue()
.toString(StandardCharsets.UTF_8);
return JsonObjectMapper.INSTANCE
.readValue(nodeDataJson, NodeData.class);
}
```
Now a node can join the cluster but it will not notice when other nodes join as well. So let's implement that functionality next.
## Updating Cluster Membership
When constructing a new node object, we want to keep the membership list up-to-date. To accomplish this, we first load an existing snapshot of the cluster metadata and then watch for changes starting from the last seen revision. The updated constructor looks like this:
```java
public Node(List<URI> endpoints, long leaseTtl) throws Exception {
nodeData = new NodeData(UUID.randomUUID());
etcdClient = Client.builder().endpoints(endpoints).build();
long maxModRevision = loadMembershipSnapshot();
watchMembershipChanges(maxModRevision + 1);
}
```
Loading the snapshot is done using the key value API by providing a prefix as an additional `GetOption`. We then populate `clusterMembers` based on the returned values and calculate the maximum data revision.
```java
private long loadMembershipSnapshot() throws Exception {
GetResponse response = etcdClient.getKVClient().get(
ByteSequence.from(NODES_PREFIX, StandardCharsets.UTF_8),
GetOption.newBuilder()
.withPrefix(ByteSequence.from(NODES_PREFIX, StandardCharsets.UTF_8))
.build()
).get(OPERATION_TIMEOUT, TimeUnit.SECONDS);
for (KeyValue kv : response.getKvs()) {
NodeData nodeData = JsonObjectMapper.INSTANCE.readValue(
kv.getValue().toString(StandardCharsets.UTF_8),
NodeData.class
);
clusterMembers.put(nodeData.getUuid(), nodeData);
}
return response.getKvs().stream()
.mapToLong(KeyValue::getModRevision).max().orElse(0);
}
```
Using the watch API we can create a watch for the same prefix, starting from the next revision, so we do not lose any membership changes that might happen between the snapshot and the watch query. We handle the incoming watch events in a separate function `handleWatchEvent`.
```java
private void watchMembershipChanges(long fromRevision) {
logger.info("Watching membership changes from revision {}", fromRevision);
watcher = etcdClient.getWatchClient().watch(
ByteSequence.from(NODES_PREFIX, StandardCharsets.UTF_8),
WatchOption.newBuilder()
.withPrefix(ByteSequence.from(NODES_PREFIX, StandardCharsets.UTF_8))
.withRevision(fromRevision)
.build(),
watchResponse -> {
watchResponse.getEvents().forEach(this::handleWatchEvent);
},
error -> logger.error("Watcher broke", error),
() -> logger.info("Watcher completed")
);
}
```
The watch response might contain `PUT` or `DELETE` events, depending on whether nodes join or leave the cluster. `PUT` events contain the updated node metadata which we can add to `clusterMembers`. `DELETE` events contain the key that has been deleted, from which we can extract the node UUID to update `clusterMembers` accordingly. Note that in production you might want to handle events on a separate thread to not block the gRPC executor thread.
```java
private void handleWatchEvent(WatchEvent watchEvent) {
try {
switch (watchEvent.getEventType()) {
case PUT:
NodeData nodeData = JsonObjectMapper.INSTANCE.readValue(
watchEvent.getKeyValue().getValue().toString(StandardCharsets.UTF_8),
NodeData.class
);
clusterMembers.put(nodeData.getUuid(), nodeData);
break;
case DELETE:
String etcdKey = watchEvent.getKeyValue().getKey()
.toString(StandardCharsets.UTF_8);
UUID nodeUuid = UUID.fromString(extractNodeUuid(etcdKey));
clusterMembers.remove(nodeUuid);
break;
default:
logger.warn("Unrecognized event: {}", watchEvent.getEventType());
}
} catch (Exception e) {
throw new RuntimeException("Failed to handle watch event", e);
}
}
private String extractNodeUuid(String etcdKey) {
return etcdKey.replaceAll(Pattern.quote(NODES_PREFIX), "");
}
```
Given our new functionality to update the membership list, we can create a new test case where two nodes join the cluster and expect that to be reflected in the local state of each node eventually. Thanks to the [Awaitility](https://github.com/awaitility/awaitility) DSL we can conveniently wait for the eventual update to happen.
```java
@Test
public void testTwoNodesJoin() throws Exception {
try (Node node1 = new Node(getClientEndpoints())) {
node1.join();
try (Node node2 = new Node(getClientEndpoints())) {
node2.join();
Awaitility.await("Node 1 to see all nodes")
.until(() -> node1.getClusterMembers()
.containsAll(List.of(node1.getNodeData(), node2.getNodeData())));
Awaitility.await("Node 2 to see all nodes")
.until(() -> node2.getClusterMembers()
.containsAll(List.of(node1.getNodeData(), node2.getNodeData())));
}
}
}
```
Next, let's see how we can detect failed nodes and remove them from the cluster automatically.
## Failure Detection
Failure detection will be performed by a simple centralized heartbeat failure detector. Etcd provides a lease API for that purpose. Leases expire after a configurable amount of time unless they are kept alive. We will store the lease ID and the keep alive client in new fields in order to clean up the lease when leaving later on.
```java
private volatile long leaseId;
private volatile CloseableClient keepAliveClient;
```
Now we modify the `join` method to first request a lease grant before putting the metadata.
```java
public void join() throws JoinFailedException {
try {
grantLease();
putMetadata();
} catch (Exception e) {
throw new JoinFailedException(nodeData, e);
}
}
```
Granting the lease is done using the lease API. When the lease is granted, we have to keep it alive. We can provide a `StreamObserver` that reacts to successful, failed, or completed keep-alive operations, as shown in the following code.
```java
private void grantLease() throws Exception {
Lease leaseClient = etcdClient.getLeaseClient();
leaseClient.grant(5) // 5 sec TTL
.thenAccept((leaseGrantResponse -> {
leaseId = leaseGrantResponse.getID();
logger.info("Lease {} granted", leaseId);
keepAliveClient = leaseClient.keepAlive(leaseId,
new StreamObserver<>() {
@Override
public void onNext(LeaseKeepAliveResponse leaseKeepAliveResponse) {
// you can increment some metric counter here
}
@Override
public void onError(Throwable throwable) {
// log and handle error
}
@Override
public void onCompleted() {
// we're done, nothing to do
}
});
})).get(OPERATION_TIMEOUT, TimeUnit.SECONDS);
}
```
The node metadata is attached to the newly acquired lease, so it gets deleted automatically when the lease expires or is removed.
```java
private void putMetadata() throws Exception {
etcdClient.getKVClient().put(
ByteSequence.from(
NODES_PREFIX + nodeData.getUuid(),
StandardCharsets.UTF_8
),
ByteSequence.from(
JsonObjectMapper.INSTANCE.writeValueAsString(nodeData),
StandardCharsets.UTF_8
),
PutOption.newBuilder().withLeaseId(leaseId).build()
).get(OPERATION_TIMEOUT, TimeUnit.SECONDS);
}
```
To test the lease functionality, we make use of the [Toxiproxy Testcontainers module](https://www.testcontainers.org/modules/toxiproxy/) to introduce network delay that exceeds the lease TTL, triggering the removal of the failed node.
```java
@Test
public void testTwoNodesLeaseExpires() throws Exception {
try (Node node1 = new Node(getClientEndpoints())) {
node1.join();
try (Node node2 = new Node(getProxiedClientEndpoints())) {
node2.join();
Awaitility.await("Node 1 to see all nodes")
.until(() -> node1.getClusterMembers()
.containsAll(List.of(node1.getNodeData(), node2.getNodeData())));
etcdProxy.toxics()
.latency("latency", ToxicDirection.UPSTREAM, 6000);
Awaitility.await("Node 1 to see that node 2 is gone")
.until(() -> node1.getClusterMembers()
.equals(Set.of(node1.getNodeData())));
}
}
}
```
Note that additional actions can be added as a reaction to a lease which failed to be kept-alive. Nodes could attempt to rejoin the cluster, for example. The concrete actions depend on the application, obviously. Last but not least, let's implement a graceful leave operation.
## Leaving a Cluster
Leaving a cluster is as simple as revoking the lease. Etcd will automatically remove all keys associated with the lease, essentially removing the node metadata.
```java
public void leave() throws LeaveFailedException {
try {
logger.info("Leaving the cluster");
if (keepAliveClient != null) {
keepAliveClient.close();
}
etcdClient.getLeaseClient().revoke(leaseId)
.get(OPERATION_TIMEOUT, TimeUnit.SECONDS);
} catch (Exception e) {
throw new LeaveFailedException(nodeData, e);
}
}
```
We extend the test suite by adding a test case where a node joins and leaves, and the remaining nodes should observe the membership changes.
```java
@Test
public void testTwoNodesJoinLeave() throws Exception {
try (Node node1 = new Node(getClientEndpoints())) {
node1.join();
try (Node node2 = new Node(getClientEndpoints())) {
node2.join();
Awaitility.await("Node 1 to see all nodes")
.until(() -> node1.getClusterMembers()
.containsAll(List.of(node1.getNodeData(), node2.getNodeData())));
Awaitility.await("Node 2 to see all nodes")
.until(() -> node2.getClusterMembers()
.containsAll(List.of(node1.getNodeData(), node2.getNodeData())));
}
Awaitility.await("Node 1 to see that node 2 is gone")
.until(() -> node1.getClusterMembers()
.equals(Set.of(node1.getNodeData())));
}
}
```
That's it! We have a working implementation of a node that can join and leave a cluster and manages membership through etcd!
# Summary and Discussion
In this post we have implemented a very basic distributed application. Etcd manages and propagates the cluster membership through its key-value API and watch API, but also acts as a failure detector thanks to its lease API. Implementing automated tests was easy thanks to Testcontainers. The Toxiproxy module provides a convenient way to simulate faults during test execution.
Note that the Java code we wrote is only a foundation. Depending on the tasks your distributed application is supposed to perform, you will have to add functionality to the join and leave algorithm, for example. Etcd also provides a lock API, which you can use to add additional coordination.
| frosnerd |
634,002 | Hoisting in JavaScript | Hoisting is a concept of JavaScript in which JavaScript host all function expression and variables at... | 0 | 2021-03-13T15:43:38 | https://dev.to/miniscript/hoisting-in-javascript-4m0k | javascript, shopify, ui, frontend | Hoisting is a concept of JavaScript in which JavaScript host all function expression and variables at top of the environment and because of that we can use a variable or function before declaring it.
In Simple layman language -
Hoisting in JavaScript is accessing the variables and functions even before declaring or initialising them without any error.
| miniscript |
634,076 | The Variable | I was going to call this "The Constant Variable", just for the oxymoron. | 0 | 2021-03-13T18:41:03 | https://dev.to/dwd/the-variable-9l5 | javascript, beginners | ---
title: The Variable
published: true
description: I was going to call this "The Constant Variable", just for the oxymoron.
tags: javascript,beginner
//cover_image: https://direct_url_to_image.jpg
---
## A Rose By Any Other Name
```javascript
let a = 1 + 1;
```
There's some code. It's JavaScript, but it might as well be any of a dozen (or more) other languages. Your challenge? Point to the variable.
It seems easy, except that just because I've asked you, you're thinking this might be a trick question. And it sort of is.
Let's start with the things that are not the variable for certain.
`let` is a form of declaration. It's definitely not a variable, but it does cause a new variable to be created.
`=` is an operator, in this case it might be the assignment operator - but might also be an initialization operator, or even a match operator, in other languages. It's causing the variable, newly declared by `let`, to be created with a particular value.
`1 + 1` is an expression, providing that value.
`a` is what we generally call a variable. But really, it's a name. In some languages (notably C) a variable name always points to a unique value - you cannot have one variable with two names for it - and this is still technically true in C++, which really tries very hard to muddy the waters. In others, including Javascript and Python, many names can point to the same value. In most languages (possibly all) you can have values with no names at all - and if you think this is esoteric, just link of an array: one name covering lots of values.
So in some senses the variable doesn't exist in the source code at all. It is a value, held somewhere in the computer's memory, and the name merely references it - together, they make up the variable.
"Memory" here is a nebulous term. It might be that this is an actual memory location, but it could also be a CPU register. Either way, the value might change over time, and the location might move, but the identity of the value never does.
## By thy name I bind thee ...
```javascript
let a = {phrase: 'Hello!'};
let b = a;
b.phrase = 'Goodbye!';
console.log(a.phrase);
// Prints "Goodbye!"
```
What we've actually done in the first code is create a variable, initialize it with a value, and finally bind it to a name.
Javascript allows us to later bind the variable to a new name. In this little snippet, we've bound the variable to `b` as well. Changing the variable's value does just that - the change is visible through both bound names.
We could also do other things, like rebinding the name to a different variable. Somewhat confusingly, Javascript does this using the same assignment operator:
```javascript
let a = {phrase: 'Hello!'};
let b = {phrase: 'Goodbye!'};
let c = a;
a.phrase = 'What?';
a = {phrase: 'This one.'}; // <--
console.log(c.phrase);
// Prints "What?"
```
In the line marked with an arrow, we're not changing the variable (like we do in the line above), we're rebinding `a`. This doesn't occur with, say, a number:
```javascript
let a = 0;
let b = a;
a += 1;
console.log(a, b);
// Prints 1 0
```
This is so confusing that Javascript provides an alternate declaration keyword, `const`, which prevents rebinding. In Java, this would be `final`. It also makes numbers and other "primitive types" constant, like the `const` keyword in C or C++.
It's as if the designers of Javascript, faced with a confusing capability, decided to make it more confusing.
## ... to my service unto death
Values have a lifetime, whereas names have a scope. These two are often (but not always) interlinked.
While the value exists, it takes up a chunk of the memory for the program (whereas names need not). The program can, if it has a reference to the value, read and change it.
While the name is "in scope", the program source can use that name - once it's "out of scope" it will cause a syntax error.
Javascript is, once more, odd here - so let's ignore it and pick the (surprisingly) simpler C.
```C
{
int i = 0;
/* Some stuff here */
}
```
In C, a variable name exists from the point of its declaration until the end of the block (the brace-enclosed statements). In earlier versions of C, variables had to be defined at the top of the block, but that was easy to work around since a block can be used anywhere a single statement can be (it's how `if` statements work, for example), so if you needed to, you could nest a block. Modern C allows you to declare the variable anywhere.
When the block is exited, the name falls out of scope and cannot be used anymore, and the value is instantly destroyed, its memory freed for use by something else.
C++ makes this a bit more explicit, since if the value is an object, special methods are called when the value is created (the "constructor") and when it is destroyed (the "destructor"). This means you can trivially see when an object is destroyed, and actually do something.
These values and variables - called "automatic variables" in C - are created on the program stack. You can create values with a different lifetime by creating them on the heap, but if you do this, you take responsibility for their lifetime entirely - the program will never destroy them unless you specifically ask it to. Equally, you don't create these values with a name - you'll instead get the memory location back (a kind of number, at least usually), and have to store that in turn as a more traditional variable somewhere.
Many languages prefer not to make the destruction explicit in the same way - these are known as "garbage collection" languages. Java, Python, and Javascript are all like this - objects are created by the programmer explicitly, as normal, but the language itself decides when you're no longer using them. This usually happens automatically for the programmer (which is nice) but can occasionally be confused by circular references and other problems.
```javascript
const a = {friend: null};
const b = {friend: a};
a.friend = b;
b = a;
a = b.friend;
// Which cup is the ball under?
```
In the code above, `a` references a value which references another value which references itself. Deciding when these values can be discarded is tricky.
But for the most part, this usually "just works".
In the vast majority of languages, scope works in the same way - "local" variable names created within a function are visible from the point of declaration through to the end of the function. C's nested blocks mean that some names have a reduced sub-scope of that function. Calling another function creates a new, empty scope - the variable names from the caller's scope are not visible to the callee.
Global variables - names created outside of a function - are "in scope" to everything, and since anything might change them unexpectedly, it's best to avoid these. Many languages have a module scope as well which behaves similarly.
Member variables - more properly called "object fields" - are only in scope inside the methods for that object.
Javascript is complex here, since the scope depends on how they're declared.
```javascript
a = 'Implicit declaration';
var b = 'Explicit declaration';
let c = 'Let';
const d = 'Const';
```
`let` and `const` both operate the same way for scope, which is largely the same way as C as described above.
A minor difference here is that Javascript "hoists" the name creation (but not the value creation) to the beginning of the block. This is primarily of importance for the interview question, "What is Javascript variable hoisting?", and is otherwise pointless and confusing.
`var`, though, creates a new variable name - which is dutifully hoisted to the beginning of the scope - but which is visible through the entire function. This is pretty weird.
```javascript
function call_me() {
// aa actually created here.
console.log('Caller start:', aa);
var aa = 0;
if (aa === 0) {
var aa = 1; // <--
}
console.log('Caller end:', aa);
}
call_me();
```
You might think that the line marked with an arrow declares a new variable - but it doesn't, it just assigns the existing one a new value.
This behaviour is vital for, again, interview questions. Just use `let` or `const`.
You can also define a variable implicitly, by just assigning a value to the name. What this actually does, though, is define a new global variable (or module/file scope variable, strictly) - even if you're in a function. This is probably not what you expected to happen. Try this:
```javascript
function call_me_too() {
console.log(typeof bb);
bb = 'Weird, huh?'
console.log(bb);
}
console.log(typeof bb);
call_me_too();
console.log(bb);
```
## A summary
The moral of the story is:
* Use `const` - if you can - or `let` - if you can't.
* Thank ESLint for finding this kind of stuff for you.
* Anything else is for answering interview questions.
| dwd |
634,162 | Workstation 2.0 | A post by Hans | 0 | 2021-03-13T20:15:14 | https://dev.to/codehrafn/workstation-2-0-256k | 
| codehrafn | |
634,426 | Understanding Kubernetes in a visual way (in 🎥 video): part 6 – CronJobs | Serie of videos about Kubernetes. Explaining in a visual way Kubernetes principles. | 11,186 | 2021-03-14T09:11:49 | https://dev.to/aurelievache/understanding-kubernetes-in-a-visual-way-in-video-part-6-cronjobs-28a5 | kubernetes, devops, docker, beginners | ---
title: Understanding Kubernetes in a visual way (in 🎥 video): part 6 – CronJobs
published: true
description: Serie of videos about Kubernetes. Explaining in a visual way Kubernetes principles.
tags: Kubernetes, DevOps, Docker, beginners
series: Understanding Kubernetes in a visual way - (in video) in video
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/a3y5shgfne3jojlk7smv.jpg)
---
Understanding Kubernetes can be difficult or time-consuming. In order to spread knowledges about Cloud technologies I started to create sketchnotes about Kubernetes, then I've auto-published a book and since now I've started a new serie of video! :-)
I imagined a serie of short videos with a mix of sketchnotes and speech.
I think it could be a good way, more visual, with audio & video to explain Kubernetes (and others technologies).
The sixth episode is focused on a very important Kubernetes object: CronJobs.
{% youtube UMJg_JasNXw %}
The video is in French BUT I done the subtitles in english (and french too).
If you liked the video and are interested to watch another ones, please give me some feedbacks (and you can also subscribe to [my Youtube channel](https://www.youtube.com/channel/UCrRk0kOP58lBMl9B8ZS8Vlg), if you want to ❤️).
If you are interested, I published all the sketchnotes on Kubernetes (and new ones!) to make a "book" of 120 pages: ["Understanding Kubernetes in a visual way"](https://gumroad.com/aurelievache#uCxcr).
If you like theses sketchnotes, you can follow me, I will publish others sketchs shortly :-). | aurelievache |
634,939 | Answer: Using Firebase in React Native shows a timer warning | answer re: Using Firebase in React Na... | 0 | 2021-03-15T00:59:03 | https://dev.to/harri_jefria_6eeedca586ba/answer-using-firebase-in-react-native-shows-a-timer-warning-11k0 | {% stackoverflow 46678121 %} | harri_jefria_6eeedca586ba | |
634,944 | Develop Frontend Apps Faster with OpenAPI 3.0 and Prism Mock Server | One aspect of dev work that usually has friction is between API engineers and frontend developers. Th... | 11,685 | 2021-03-24T16:21:47 | https://dev.to/raphael_jambalos/develop-frontend-w-o-an-api-backend-with-openapi-3-0-and-prism-mock-server-3n3n | devops, webdev, aws, api | <!--
# Title Studies
Decouple your dev team with OpenAPI Specs
Allow your devs to work independently with OpenAPI specs
Develop w/o an API Backend with OpenAPI and Prism Mock Server
-->
One aspect of dev work that usually has friction is between API engineers and frontend developers. The frontend developer usually has to wait for an API endpoint to be finished before he can integrate it into his work. Even after he has done so, the API engineer might change the endpoint and the frontend developer has to revisit the integration. This leads to wasted time re-coding and more frustrated frontend developers.
## Recap
In the [previous post](https://dev.to/raphael_jambalos/develop-web-apps-faster-with-api-first-design-97e), we looked at the API-First Design process and applied the concepts that we learned to our simple loyalty application. We also produced an API sketch that listed each endpoint and top-level details about them.
## This Post
In this post, we take our API sketch and turn it into an OpenAPI 3.0 definition. This document describes in finer detail how each of our endpoints operates: what the properties should be in the requestBody/responseBody, should there be query or path parameters, etc.
By having both API engineers and frontend developers start with planning the API, a lot of thought about the frontend-backend interaction has been done upfront. The API definition serves as a "contract" between both developers on how the API should operate. By working on this "contract" before any development, we minimize changes to the API and it guides how both developers implement their projects.
## [1] Let's dive right in! 🌊
Before we get bogged down in too much concept, let's get our hands dirty writing OpenAPI definitions. On a separate tab, open up the [Swagger editor](https://editor.swagger.io/) in your browser. The swagger editor allows you to conveniently create OpenAPI definitions using your browser.
### (1.1)
Empty the default contents of the left side of the Swagger editor and place this snippet instead:
```yml
openapi: 3.0.0
info:
title: Loyalty Card API
version: "0.1"
paths: {}
```
The snippet declares the version of the OpenAPI definition and some top-level information about your API. We intentionally left the `paths` key to have an empty value so we don't have an error.
As you type the visual documentation on the right updates. It also informs you of syntax errors in your API definition. Right now, it should look like this:

### (1.2)
Next, let's define schemas for our API. As we learned in the [previous post](https://dev.to/raphael_jambalos/develop-web-apps-faster-with-api-first-design-97e), standard endpoints define a consistent interface centered around resources in your API (i.e Create a Transaction, Read one transaction, Read all transactions, Edit transaction, etc).
In the schema section, we define how these resources look like: what properties it has and what data type each property is. At this point, it might be tempting to say that the resource should look identical to the database schema. It is not. We can omit some attributes (i.e we opt not to show each transaction's `approval_code`) or even have the transaction resource not represented by a transaction table altogether.
While at the start the transaction API and the transaction database table might be similar, over time the divergence between them can be quite huge.
```yml
components:
schemas:
Transaction:
type: object
properties:
id:
type: string
amount:
type: number
equivalent_points:
type: number
card_id:
type: string
partner_id:
type: string
```
Your API should now look like this:
### (1.3)
Now, let's get to the meat 🥩 of the API definitions: `paths`. Paths define the URL paths of our API endpoints. Let's replace the line `paths: {}` with the code snippet below.
```yml
# remember to replace paths: {}
paths:
/transactions:
post:
summary: create transaction
tags:
- Transactions
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/Transaction'
responses:
'201':
description: Created user
headers:
Location:
schema:
type: string
```
In the code snippet, we defined a path: `POST /transactions` to create a transaction.
- `summary` - A short info about the endpoint
- `tags` - The documentation of the right-side side
- `requestBody` - For each type of content, we can define a different schema. In this example, we have the application/json content
- `responses` - For each type of response type (HTTP 201 is "object created", HTTP 500 is "internal server error", and so on), we can define different response formats. In this example, if the requests results in HTTP 201, we return an empty response with the header "Location"
### (1.4)
Next, we define the `GET /transactions` path. Make sure to add this snippet right below the code snippet in 1.3.
```yml
# add this under paths
# add this under /transactions
get:
summary: get all transactions
tags:
- Transactions
parameters:
- name: "partner_id"
in: "query"
description: ""
required: false
schema:
type: integer
responses:
'200':
description: OK
content:
application/json:
schema:
type: object
properties:
items:
type: array
items:
$ref: '#/components/schemas/Transaction'
```
This code snippet is a bit different. Instead of defining a request body, we defined a query parameter instead: `/transactions?partner_id=10`. The query parameter allows your frontend to get all transactions posted by a specific partner.
Since this is a GET request, we expect to *get* something in return. In the responses, we see that if the request is successful (HTTP 200), we return an array of transaction objects.
### (1.5)
Once we can create transactions (1.3) and view all transactions (1.4), we need to have a way to view individual transactions. In the code snippet below, that's exactly what we are doing:
```yml
# add this under paths
/transactions/{id}:
parameters:
- schema:
type: integer
name: id
in: path
required: true
get:
summary: View Transaction
tags:
- Transactions
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/Transaction'
```
In this snippet, we used a path parameter instead to define the id of the transaction we are viewing. The response is similar to 1.4 except that it instead returns a single object instead of an array of objects.
The right side of our editor should now look like this:
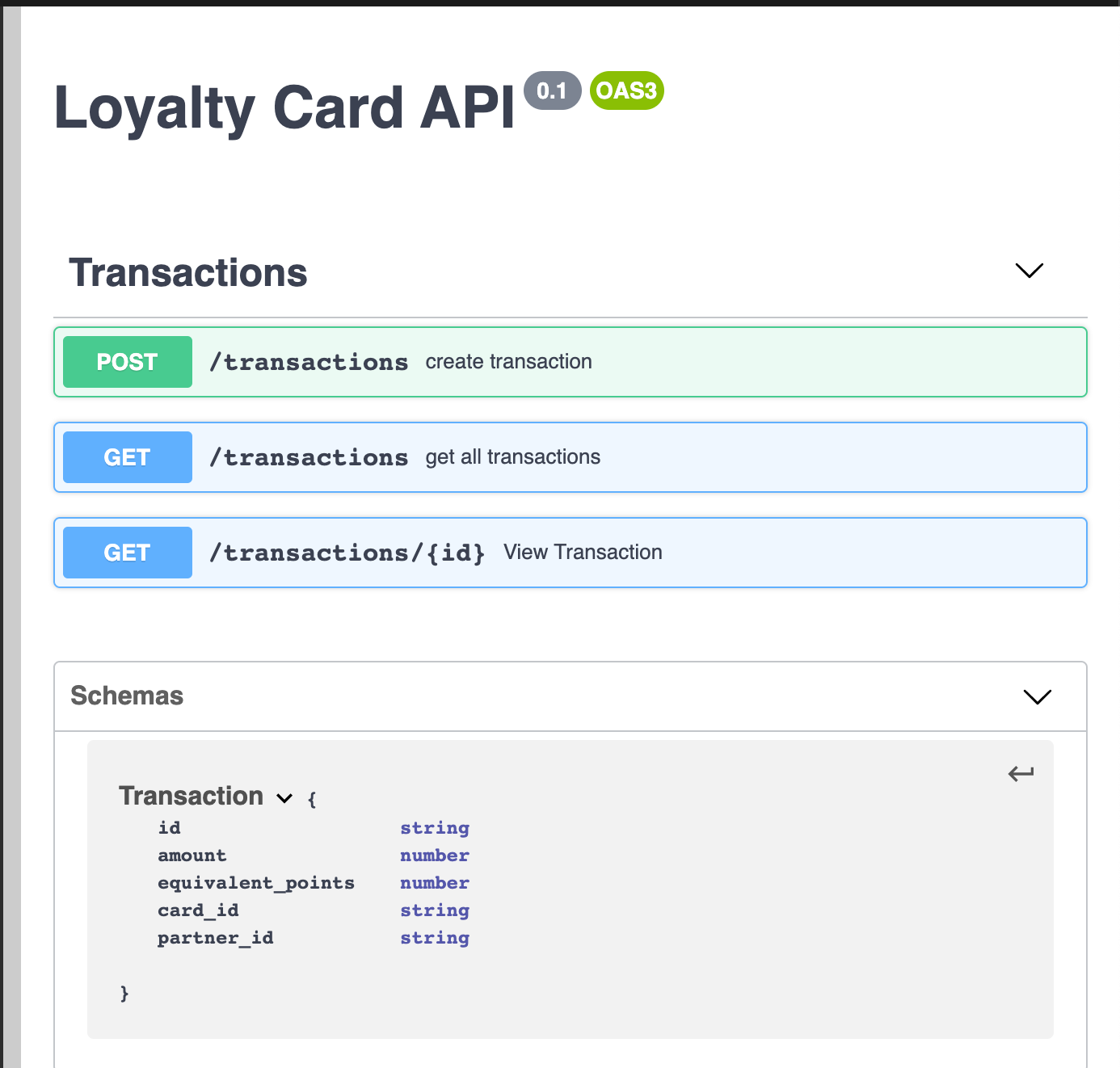
At this point, you might be wondering why I didn't include all the other resources in the API sketch. That would make the blog post very large. I chose to instead focus on the transaction resource. I leave creating the API definition for the other resources as a homework for you. If you get stuck or just want a quick reference, the full Open API 3.0 definition for the simple loyalty application is found [at this Github Gist](https://gist.github.com/jamby1100/66ae6b19cb5e9642d92a7e29cbf4bcb3)
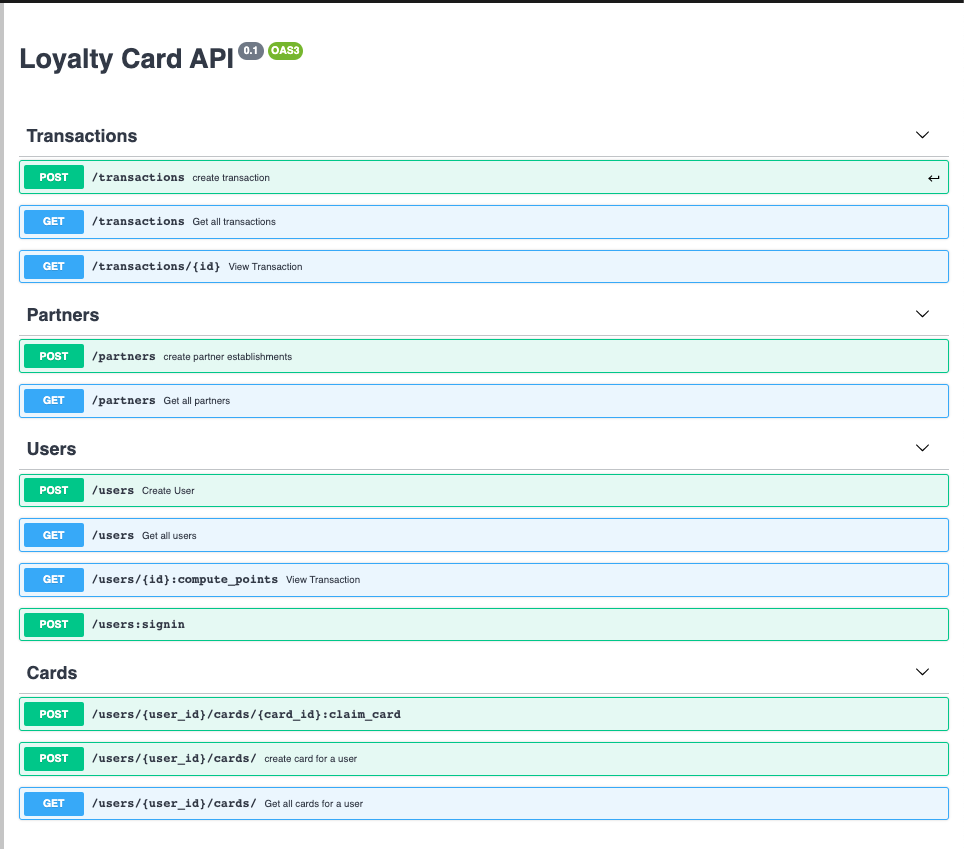
## [2] Mock Server with Prism
In this step, we will use the API definition we created in step 1 to run a mock server locally. For this, we will use Prism, a NodeJS CLI utility to run mock servers.
### (2.1)
First, install prism.
```sh
npm install --global @stoplight/prism-cli
```
### (2.2)
Save the file locally as "blog_api.oas.yml" and `cd` to that directory in your command line. We added the .oas extension to signify that it is a YAML file in the OpenAPI format.
### (2.3)
Now, let's run the Prism mock server:
```sh
prism mock -p 8080 ./blog_api.oas.yml
```
Your CLI should look like this:

Now, trying typing this on your browser: `http://127.0.0.1:8080/transactions/495`. You should see a very basic response:

You now have a fully operational mock server at your disposal. No need to wait for the API engineer to develop the business logic: your frontend developer can get started coding the frontend right away!
## [3] Additional Perks
If that wasn't enough to convince you to do API-First Design, here are a few more perks. These perks are features of the [Swagger editor](https://editor.swagger.io/) that we used in the first 2 steps.
#### [1] Pre-generate your backend
API engineers can pre-generate their whole API backend system using just the API definition. This saves a lot of time setting up paths and routing for the application.
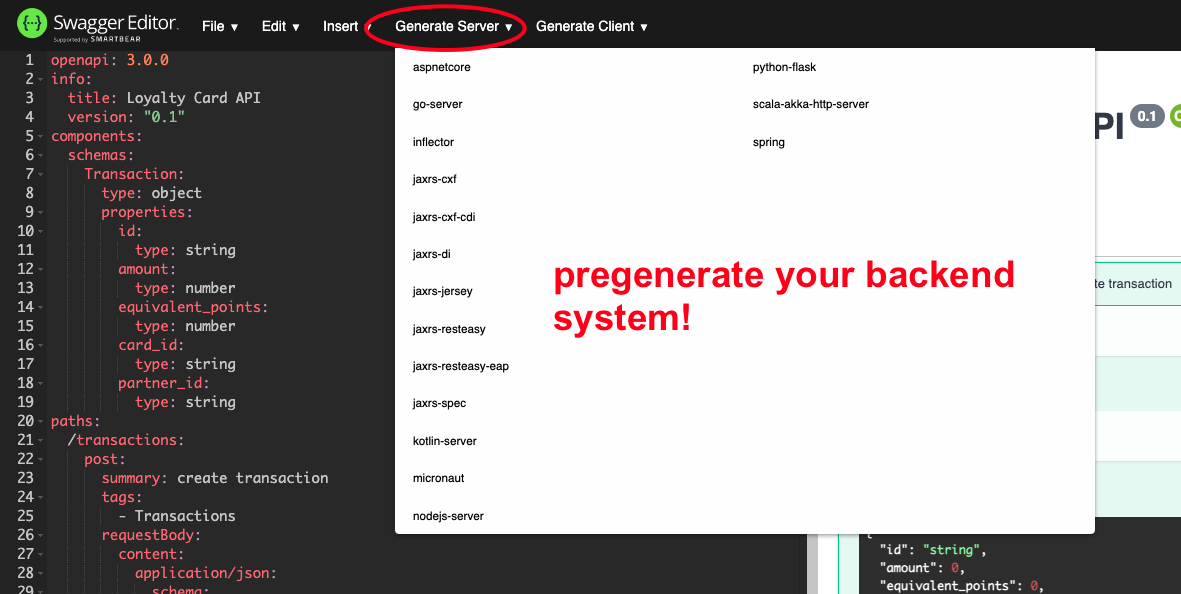
The generated application does not come with business logic. It is composed of stubbed routes that return sample responses. But this scaffolding goes a long way in getting you up and running quickly
#### [2] Pre-generate an SDK
Your API engineers can also pre-generate an SDK (Software Development Kit). SDKs help your end-users interact with your system by providing a software package instead of directly calling your API endpoints. This saves them the boilerplate work of validating request/responses, handling error codes, etc.
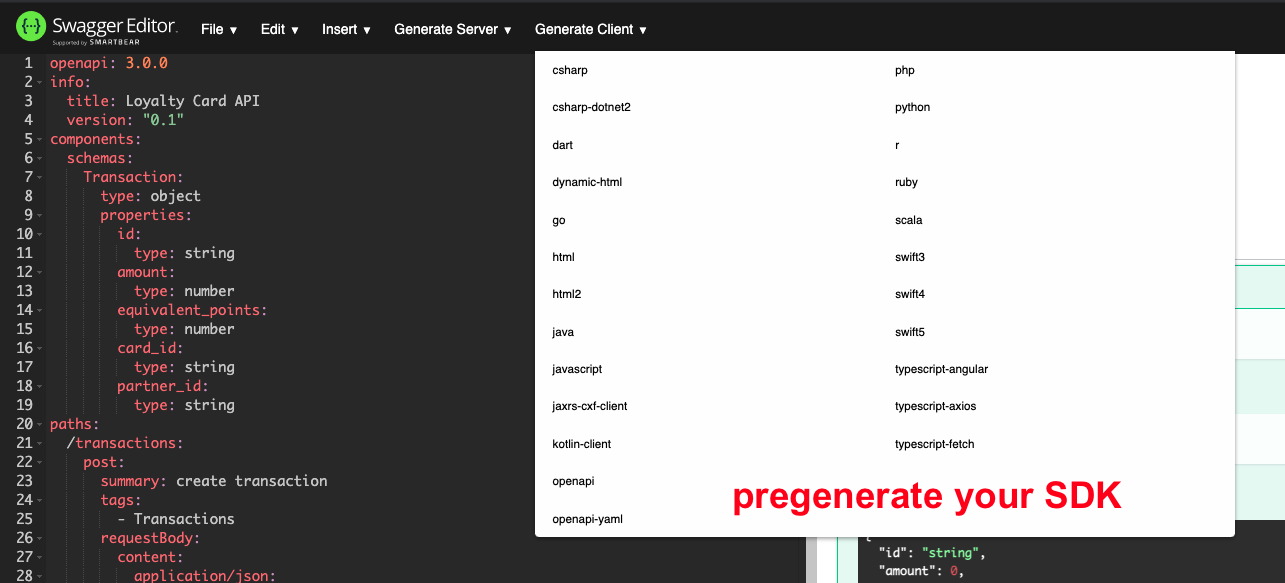
The SDK package generated will not be ready for use by your end-users. You will still have to do some more coding. But at least it gets you halfway there already.
## Finish!
With our OpenAPI 3.0 Definition, we have created a mock server that allows our frontend developer to integrate API endpoints without waiting for the API engineer to finish the business logic. The dependency between them is minimized and harmony is restored with the team!
We also looked at code pre-generation as a way to help the API engineers create the API backend and SDK faster.
## Special Thanks
Special thanks to Allen for making my posts more coherent. This blog post is also made possible by the authors below who have made learning APIs a joy.
- [API Design Patterns](https://www.manning.com/books/api-design-patterns) by JJ Geewax
- [Designing APIs with Swagger and OpenAPI](https://www.manning.com/books/designing-apis-with-swagger-and-openapi) by Joshua S. Ponelat and Lukas L. Rosenstock
- [Design and Build Great Web APIs](https://pragprog.com/titles/maapis/design-and-build-great-web-apis/) by Mike Amundsen
Photo by <a href="https://unsplash.com/@shots_of_aspartame?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Julia Joppien</a> on <a href="/s/photos/faster?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a> | raphael_jambalos |
634,992 | How to deploy Blazor WebAssembly to Cloudflare Pages | With ASP.NET Blazor WebAssembly (WASM) you can create .NET web applications that run completely... | 0 | 2021-03-20T04:06:57 | https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-cloudflare-pages | dotnet, blazor, cloudflare | ---
title: How to deploy Blazor WebAssembly to Cloudflare Pages
published: true
date: 2021-03-14 00:00:00 UTC
tags: dotnet, blazor, cloudflare
canonical_url: https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-cloudflare-pages
cover_image: https://swimburger.net/media/jvhfzhwh/blazor-cloudflare-pages-social.png?anchor=center&mode=crop&width=1000&height=420
---
With ASP.NET Blazor WebAssembly (WASM) you can create .NET web applications that run completely inside of the browser sandbox. The published output of a Blazor WASM project are **static files**. Now that you can run .NET web applications without server-side code, you can deploy these applications to various **static site hosts, such as the brand-new [Cloudflare Pages](https://pages.cloudflare.com/)**.
Here are some other tutorials if you're interested in hosting Blazor WASM on other static site hosts:
- [Azure Static Web Apps](https://swimburger.net/blog/dotnet/how-to-deploy-aspnet-blazor-webassembly-to-azure-static-web-apps)
- [GitHub Pages](https://swimburger.net/blog/dotnet/how-to-deploy-aspnet-blazor-webassembly-to-github-pages)
- [AWS Amplify](https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-aws-amplify "How to deploy Blazor WebAssembly to AWS Amplify")
- [Firebase Hosting](https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-firebase-hosting)
- [Netlify](https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-netlify "How to deploy Blazor WebAssembly to Netlify")
- [Heroku](https://swimburger.net/blog/dotnet/how-to-deploy-blazor-webassembly-to-heroku "How to deploy Blazor WebAssembly to Heroku")
This walkthrough will show you how to deploy Blazor WASM to Cloudflare Pages. Cloudflare Pages is a brand-new service by Cloudflare to host static websites. Cloudflare Pages integrates with GitHub to pull down your code from your repositories, then builds your website on their build platform, and uploads the resulting static files to their static hosting service. **The biggest benefit of using Cloudflare is that your site will be backed by their global CDN, and Cloudflare is outstanding at speed and scale.**
This guide will walk you through these high-level steps:
1. Create Blazor WebAssembly project
2. Commit the project to a Git repository
3. Create a new GitHub project and push the Git repository to GitHub
4. Create a new Cloudflare Pages website
**Prerequisites** :
- .NET CLI
- Git
- GitHub account
- Cloudflare account (free tier is sufficient)
**You can find the [source code for this guide on GitHub](https://github.com/Swimburger/BlazorWasmCloudflarePages).**
## Create Blazor WebAssembly project
Run the following commands to create a new Blazor WASM project:
```powershell
mkdir BlazorWasmCloudflarePages
cd BlazorWasmCloudflarePages
dotnet new blazorwasm
```
To give your application a try, execute `dotnet run` and browse to the URL in the output (probably https://localhost:5001):
```powershell
dotnet run
# Building...
# info: Microsoft.Hosting.Lifetime[0]
# Now listening on: https://localhost:5001
# info: Microsoft.Hosting.Lifetime[0]
# Now listening on: http://localhost:5000
# info: Microsoft.Hosting.Lifetime[0]
# Application started. Press Ctrl+C to shut down.
# info: Microsoft.Hosting.Lifetime[0]
# Hosting environment: Development
# info: Microsoft.Hosting.Lifetime[0]
# Content root path: C:\Users\niels\source\repos\BlazorWasmCloudflarePages
# info: Microsoft.Hosting.Lifetime[0]
# Application is shutting down...
```
Optional: You can use the `dotnet publish` command to publish the project and verify the output:
```powershell
dotnet publish
# Microsoft (R) Build Engine version 16.8.0+126527ff1 for .NET
# Copyright (C) Microsoft Corporation. All rights reserved.
#
# Determining projects to restore...
# All projects are up-to-date for restore.
# BlazorWasmCloudflarePages -> C:\Users\niels\source\repos\BlazorWasmCloudflarePages\bin\Debug\net5.0\BlazorWasmCloudflarePages.dll
# BlazorWasmCloudflarePages (Blazor output) -> C:\Users\niels\source\repos\BlazorWasmCloudflarePages\bin\Debug\net5.0\wwwroot Optimizing assemblies for size, which may change the behavior of the app. Be sure to test after publishing. See: https://aka.ms/dotnet-illink
# Compressing Blazor WebAssembly publish artifacts. This may take a while...
# BlazorWasmCloudflarePages -> C:\Users\niels\source\repos\BlazorWasmCloudflarePages\bin\Debug\net5.0\publish\
```
In the publish directory, you will find a web.config file and a wwwroot folder. The config file helps you host your application in IIS, but you don't need that file for static site hosts. **Everything you need will be inside of the wwwroot folder. The wwwroot folder contains the index.html, CSS, JS, and DLL files necessary to run the Blazor application**.
## Push Blazor project to GitHub
For this walkthrough, your application source code must be inside of a GitHub repository.
First, you need to create a local Git repository and commit your source code to the repository using these commands:
```powershell
# add the gitignore file tailored for dotnet applications, this will ignore bin/obj and many other non-source code files
dotnet new gitignore
# create the git repository
git init
# track all files that are not ignore by .gitignore
git add --all
# commit all changes to the repository
git commit -m "Initial commit"
```
Create a new GitHub repository ([instructions](https://docs.github.com/en/github/getting-started-with-github/create-a-repo)) and copy the commands to "push an existing repository from the command line" from the empty GitHub repository page, here's what it should look like but with a different URL:
```powershell
git remote add origin https://github.com/Swimburger/BlazorWasmCloudflarePages.git
git push -u origin main
```
## Create the Cloudflare Pages website
Log in to Cloudflare and click on the Pages-link on the right side:
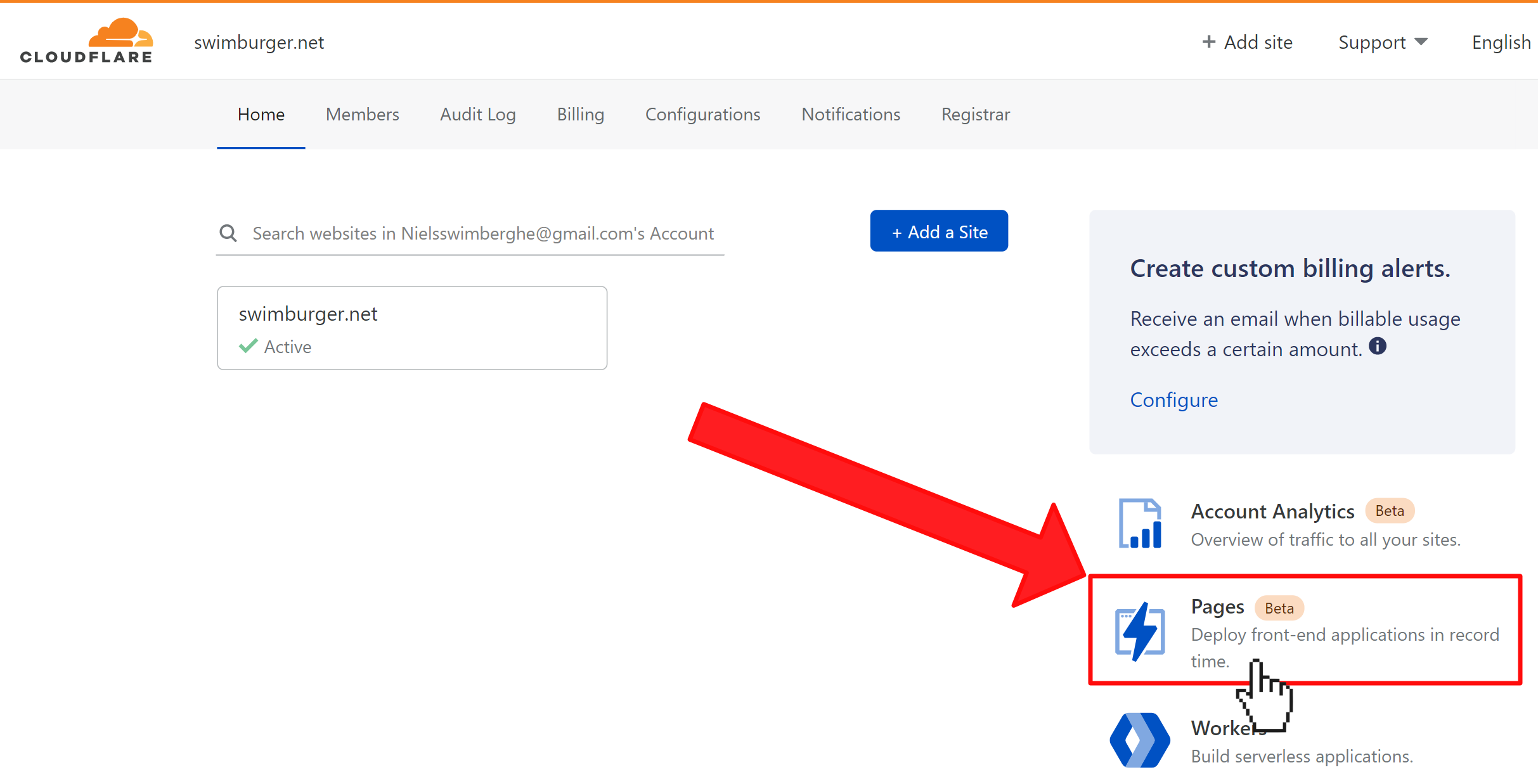
On the next screen click on the "Create a project" button:
You will need to give Cloudflare access to your GitHub repositories if this is your first time setting up a Cloudflare Pages website. Click on the "Connect GitHub account" button and give Cloudflare access to your GitHub repositories. At a minimum, you need to give Cloudflare access to the repository you want to deploy.
After giving Cloudflare access to your GitHub account, Cloudflare will prompt you to select the repository you want to deploy.
Select the GitHub repository you created earlier and click on the "Begin setup" button:
The next screen prompts you for a bunch of information:
- **Project name** : this name will be used to generate the subdomain under the pages.dev domain
- **Production branch** : this is the branch that will be used to build the production website. This should be "main", "master", or whatever your main branch name is.
- **Framework preset** : Cloudflare Pages has a lot of presets to make the setup easier. There's no official support for .NET and also no framework preset. You can leave this to none.
- **Build command** : This is the most important setting. In this setting, you can tell Cloudflare Pages which commands to run to build your static website. Since .NET isn't installed on the build environment, you'll first need to install .NET and then publish your Blazor WASM project. Unfortunately, this is a single-line text field, but you can enter multiple commands separated by ";".
Copy/paste the following commands into the "Build command" field:
```bash
curl -sSL https://dot.net/v1/dotnet-install.sh > dotnet-install.sh;
chmod +x dotnet-install.sh;
./dotnet-install.sh -c 5.0 -InstallDir ./dotnet5;
./dotnet5/dotnet --version;
./dotnet5/dotnet publish -c Release -o output;
```
This script does the following:
-
The **curl** command downloads a shell script to install the .NET SDK provided by Microsoft.
-
The **chmod** command changes the permission of the shell script to allow execution of the script.
-
The ' **dotnet-install.sh**' script installs the .NET SDK:
-
The **-c** argument tells the install script to install .NET **version 5.0** which is the version I am using. Change 5.0 to your version if you're using a different version.
-
The **-InstallDir** argument will instruct the script to install the SDK in a specific directory. In this case it will create a directory called 'dotnet5' and put the SDK there.
- The `dotnet --version` command will print the version of the .NET SDK to verify the successful installation of the .NET SDK. Note how it is invoking the dotnet CLI from the 'dotnet5' folder where the .NET 5 SDK was installed by the 'dotnet-install.sh' script.
- The `dotnet publish` builds & publishes the Blazor WASM project:
- The **-c** argument tells the CLI to build in Release configuration.
- The **-o** argument tells the CLI to put the output in the '_output_' folder.
- **Build output directory** : Using this setting you can specify which folder should be deployed to Cloudflare Pages. Set this to ' **_output/wwwroot_**' because that's where the Blazor WASM project will be published to.
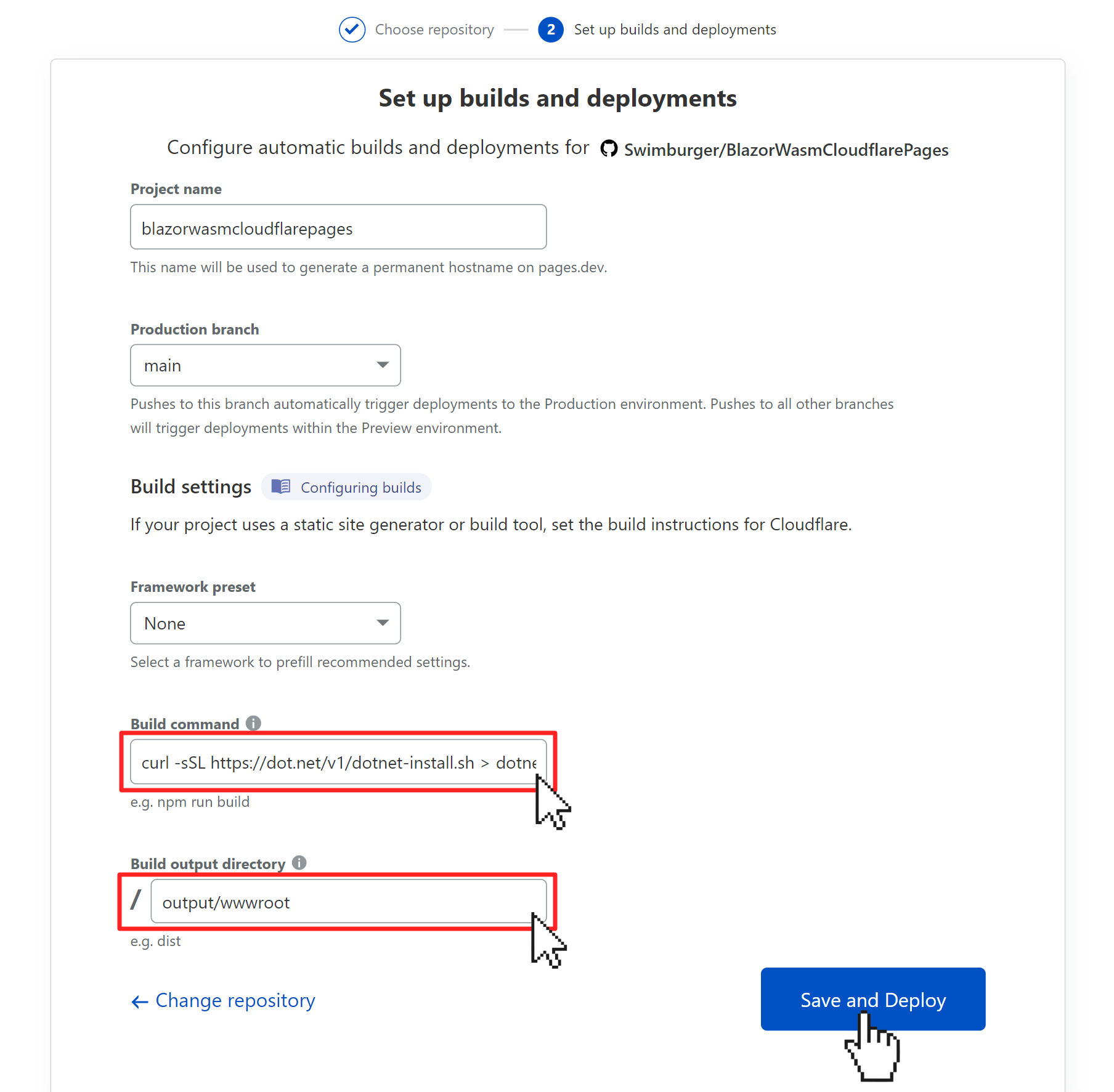
Note: There are some more settings that have been omitted from the above list and screenshot to keep things shorter.
Fill out the form as specified in the above screenshot and list. Click on the "Save and Deploy" button.
Cloudflare Pages will now build and deploy your Blazor WASM application. The output of this process will be shown in real-time.
Once the build & deploy process is completed, the URL of your website will be shown at the top right:
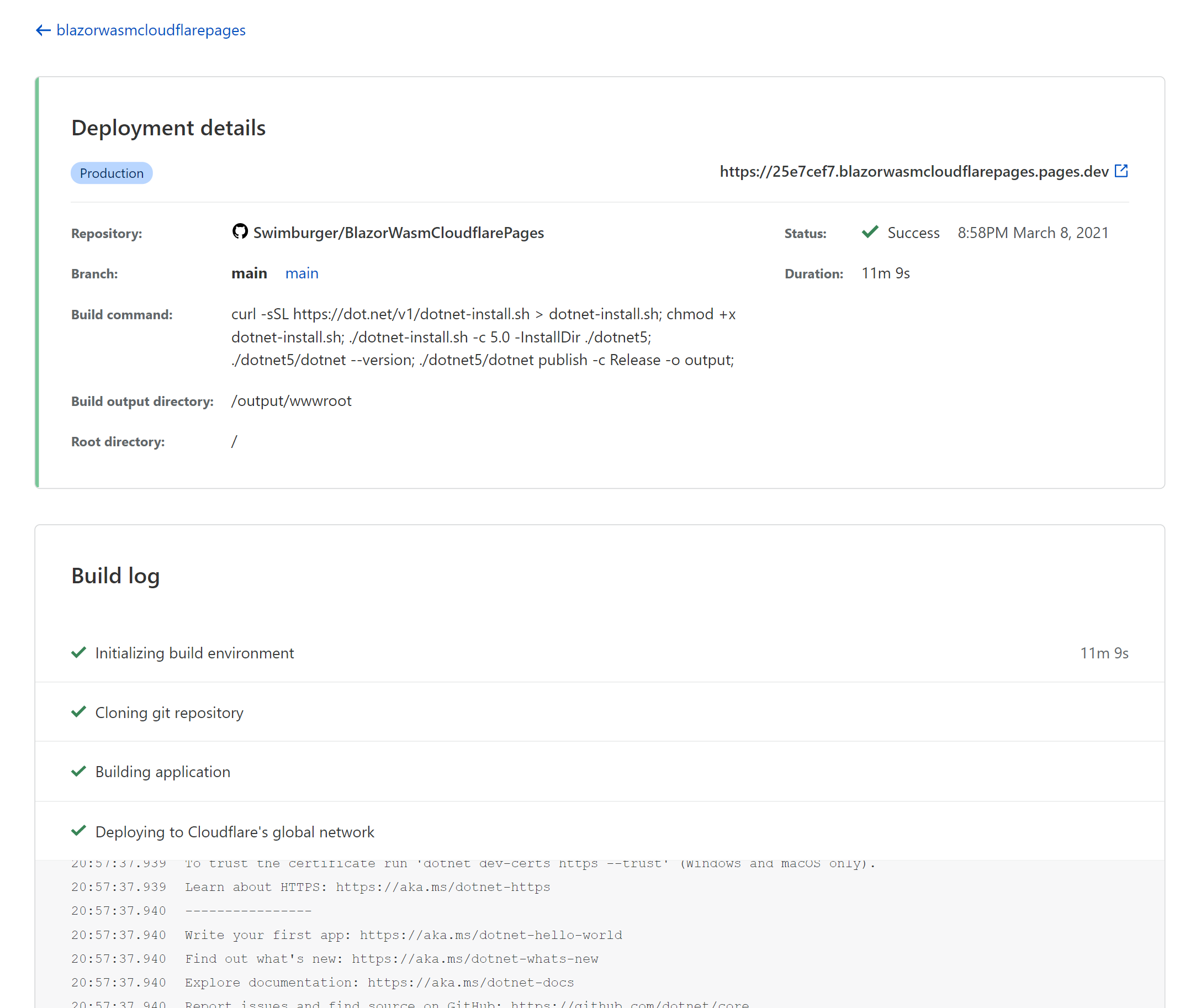
Click on the link of your website and verify whether your Blazor WASM application is working as expected. It should.
Unlike many other static site hosts, there's no need for any additional configuration changes because of [the sensible defaults](https://developers.cloudflare.com/pages/platform/serving-pages) chosen by Cloudflare.
Out of the box, Cloudflare Pages will provide SPA rewrite functionality:
> If your project doesn't include a top-level `404.html` file, Pages assumes that you're deploying a single-page application. This includes frameworks like React, Vue, and Angular. **Pages' default single-page application behavior matches all incoming paths to the root (****`/`), allowing you to capture URLs like `/about` or `/help` **** and respond to them from within your SPA.**
> Source: [Serving Pages by Cloudflare](https://developers.cloudflare.com/pages/platform/serving-pages)
Unfortunately, Cloudflare Pages does not come with .NET support out of the box. As a result, you have to install .NET as part of the build process which slows down the build & deployment.
## Bonus: Pull Request Previews
Cloudflare Pages has built-in support for creating preview environments for your pull requests. When you create a Pull Request on GitHub, you will see Cloudflare Pages building right from the pull request.
When the build & deploy has completed, Cloudflare Pages will add a comment on your Pull Request with the status and URL to your preview environment:
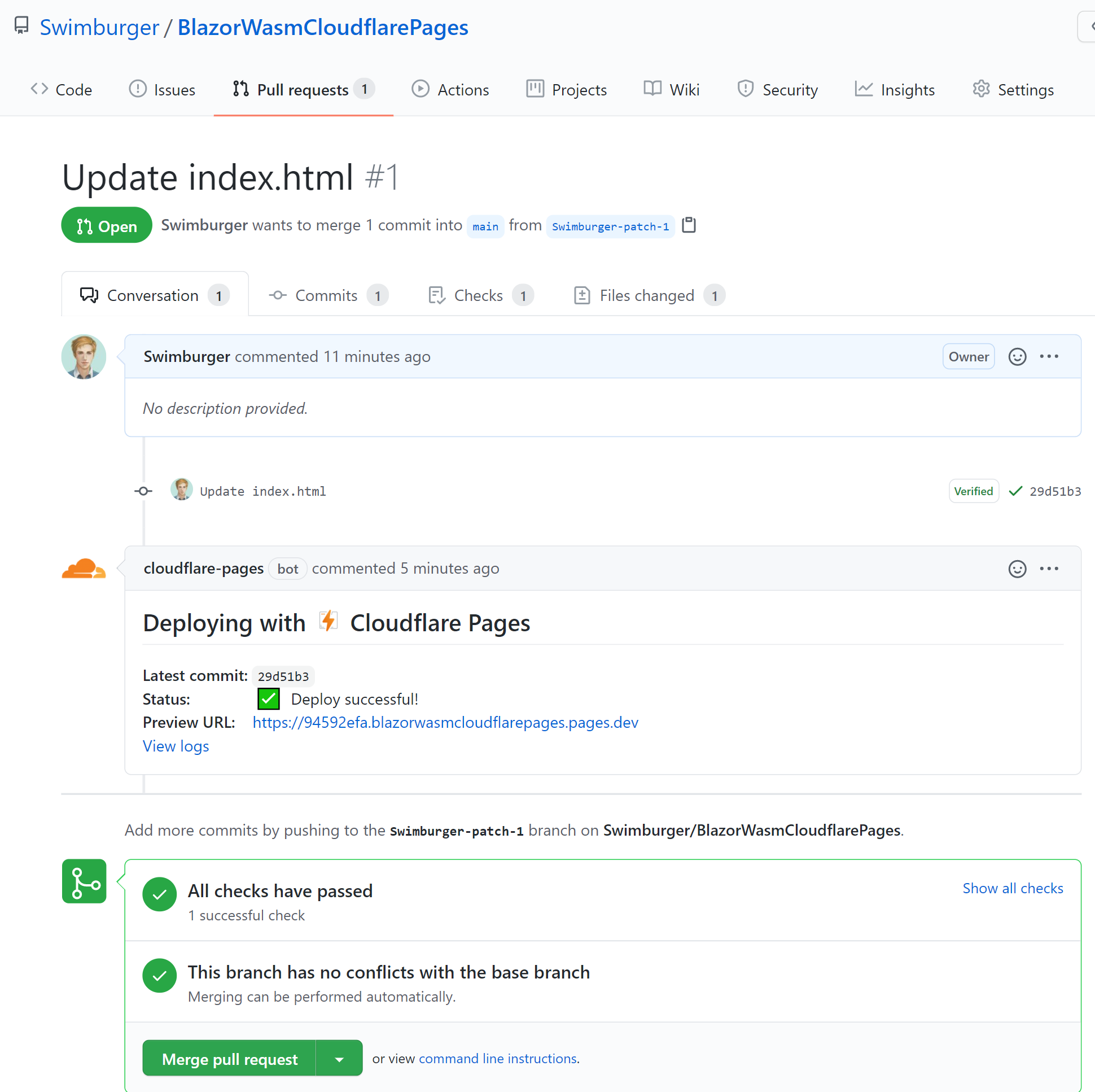
You can also find the preview build & deploy on your Cloudflare Pages website dashboard with the label "Preview":
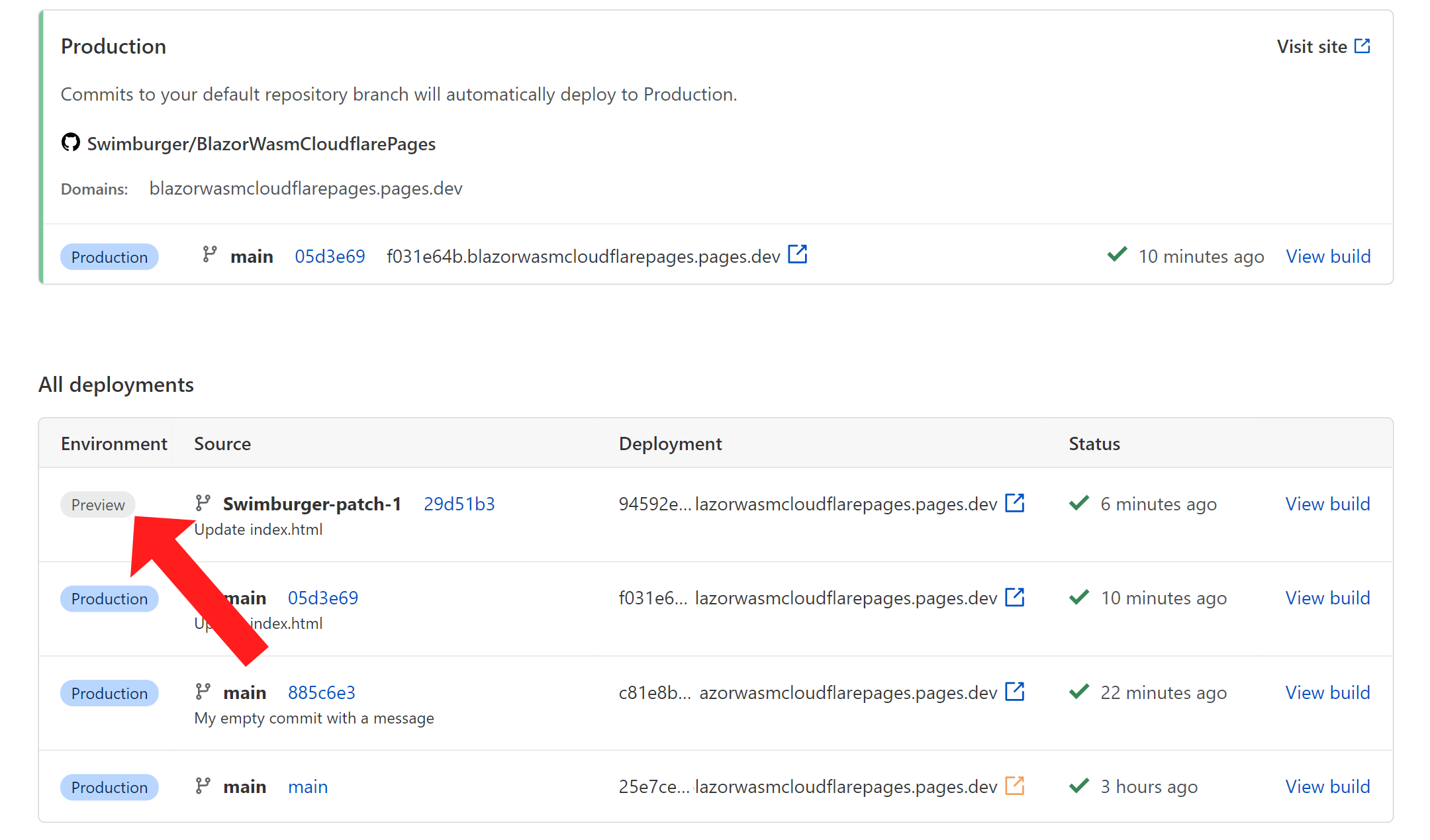
## Summary
Blazor WebAssembly can be served as static files. These files can be hosted in static hosting services such as Cloudflare Pages. You can create a new Cloudflare Pages application using GitHub as the source code provider. Cloudflare Pages's does not contain .NET build tooling so you have to install them yourself during the build process. Once installed, you can run the publish command to build & publish your Blazor WASM application and tell Cloudflare Pages to deploy the resulting static assets. | swimburger |
635,218 | GYRO-WEB: ACCESSING THE DEVICE ORIENTATION IN JAVASCRIPT | This article has interactive version. You may open it to play around with the device orientation rig... | 0 | 2021-03-15T13:18:18 | https://dev.to/trekhleb/gyro-web-accessing-the-device-orientation-in-javascript-2492 | javascript, webdev, beginners, react | > This article has [interactive version](https://trekhleb.dev/blog/2021/gyro-web/). You may open it to play around with the device orientation right from your mobile device.
## Accessing device orientation in pure JavaScript
In Javascript, you may access your device orientation data by listening to the [deviceorientation](https://developer.mozilla.org/en-US/docs/Web/API/Detecting_device_orientation) event. It is as easy as the following:
```javascript
window.addEventListener('deviceorientation', handleOrientation);
function handleOrientation(event) {
const alpha = event.alpha;
const beta = event.beta;
const gamma = event.gamma;
// Do stuff...
}
```
Here is the meaning of the `alpha`, `beta` and `gama` angles:
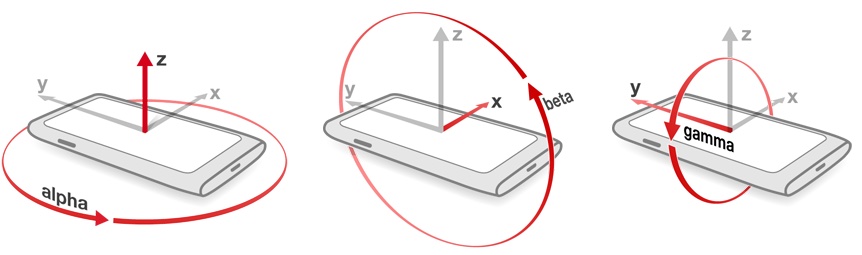
_Image source: [newnow.co](https://newnow.co/me-myself-and-i/)_
**But!** Not every browser allows you to access the orientation data without user's permission. For example, in iOS 13 Apple has introduced the [requestPermission](https://www.w3.org/TR/orientation-event/#dom-deviceorientationevent-requestpermission) method. It must be triggered on user action (click, tap or equivalent).
The example of accessing the device orientation becomes a bit more complicated:
```javascript
function onClick() {
if (typeof DeviceMotionEvent.requestPermission === 'function') {
// Handle iOS 13+ devices.
DeviceMotionEvent.requestPermission()
.then((state) => {
if (state === 'granted') {
window.addEventListener('devicemotion', handleOrientation);
} else {
console.error('Request to access the orientation was rejected');
}
})
.catch(console.error);
} else {
// Handle regular non iOS 13+ devices.
window.addEventListener('devicemotion', handleOrientation);
}
}
```
If you would turn the device orientation toggle on in the [interactive version of this post](https://trekhleb.dev/blog/2021/gyro-web/) you should see what angles your device is reporting.

## Debugging the orientation access in the browser
In case if you're using the desktop device you may imitate the device rotation from the "Sensors" tab in dev-tools:
Cool! So now we have the access to device orientation, and we can even test it in the browser!
## React hook for accessing the device orientation
The last step I would like to take is to come up with the [React hook](https://reactjs.org/docs/hooks-intro.html), that will encapsulate the orientation fetching for me, and make it easier to use it in the React components (like the one that displayed the angles to you above).
Here is an example of the `useDeviceOrientation.ts` hook, that is written in TypeScript:
```typescript
import { useCallback, useEffect, useState } from 'react';
type DeviceOrientation = {
alpha: number | null,
beta: number | null,
gamma: number | null,
}
type UseDeviceOrientationData = {
orientation: DeviceOrientation | null,
error: Error | null,
requestAccess: () => Promise<boolean>,
revokeAccess: () => Promise<void>,
};
export const useDeviceOrientation = (): UseDeviceOrientationData => {
const [error, setError] = useState<Error | null>(null);
const [orientation, setOrientation] = useState<DeviceOrientation | null>(null);
const onDeviceOrientation = (event: DeviceOrientationEvent): void => {
setOrientation({
alpha: event.alpha,
beta: event.beta,
gamma: event.gamma,
});
};
const revokeAccessAsync = async (): Promise<void> => {
window.removeEventListener('deviceorientation', onDeviceOrientation);
setOrientation(null);
};
const requestAccessAsync = async (): Promise<boolean> => {
if (!DeviceOrientationEvent) {
setError(new Error('Device orientation event is not supported by your browser'));
return false;
}
if (
DeviceOrientationEvent.requestPermission
&& typeof DeviceMotionEvent.requestPermission === 'function'
) {
let permission: PermissionState;
try {
permission = await DeviceOrientationEvent.requestPermission();
} catch (err) {
setError(err);
return false;
}
if (permission !== 'granted') {
setError(new Error('Request to access the device orientation was rejected'));
return false;
}
}
window.addEventListener('deviceorientation', onDeviceOrientation);
return true;
};
const requestAccess = useCallback(requestAccessAsync, []);
const revokeAccess = useCallback(revokeAccessAsync, []);
useEffect(() => {
return (): void => {
revokeAccess();
};
}, [revokeAccess]);
return {
orientation,
error,
requestAccess,
revokeAccess,
};
};
```
The hook might be used as follows:
```tsx
import React from 'react';
import Toggle from './Toggle';
import { useDeviceOrientation } from './useDeviceOrientation';
const OrientationInfo = (): React.ReactElement => {
const { orientation, requestAccess, revokeAccess, error } = useDeviceOrientation();
const onToggle = (toggleState: boolean): void => {
const result = toggleState ? requestAccess() : revokeAccess();
};
const orientationInfo = orientation && (
<ul>
<li>ɑ: <code>{orientation.alpha}</code></li>
<li>β: <code>{orientation.beta}</code></li>
<li>γ: <code>{orientation.gamma}</code></li>
</ul>
);
const errorElement = error ? (
<div className="error">{error.message}</div>
) : null;
return (
<>
<Toggle onToggle={onToggle} />
{orientationInfo}
{errorElement}
</>
);
};
export default OrientationInfo;
```
## Demo
Finally, having the access to the device orientation, let's imitate a 3D space, and a possibility to look at the object from a 3D perspective by rotating your mobile device. Imagine you have a virtual shopping item, and you want to see it from different angles and sides before putting it into your basket.
We will use a simple 3D cube which is made with pure CSS by using the [perspective](https://css-tricks.com/almanac/properties/p/perspective/), [perspective-origin](https://css-tricks.com/almanac/properties/p/perspective-origin/) and [transform](https://css-tricks.com/almanac/properties/t/transform/) properties (you may find the full example with styles [on css-tricks.com](https://css-tricks.com/how-css-perspective-works/)).
Here we go, here is our Gyro-Cube that you should be able to see from the different angles depending on your device orientation!
In case if you're reading the article from the laptop, here's how the demo should work on mobile devices if you would launch the [interactive version of this post](https://trekhleb.dev/blog/2021/gyro-web/):

You may find all the code examples from this article (including the Gyro-cube styles) in [trekhleb.github.io](https://github.com/trekhleb/trekhleb.github.io/tree/master/src/posts/2021/gyro-web/components/) repo.
I hope this example was useful for you! I also hope that you will come up with much more interesting and realistic use-case for the device orientation than the Gyro-Cube above 😄 Happy coding!
| trekhleb |
635,340 | Fully typed API responses using GraphQL | At my workplace, we were setting up the environment for a brand-new app and decided to go with typesc... | 0 | 2021-03-16T17:23:58 | https://dev.to/santosh898/typesafe-api-calls-using-graphql-2dmj | react, graphql, typescript, vscode | At my workplace, we were setting up the environment for a brand-new app and decided to go with typescript to get the most out of the static analysis it provides. We have a standard architecture, a REST API, and react/react-native frontend.
Furthermore, we were able to make sure that the whole app is type-safe except for the part where we consume the API responses. I had to manually write the types for the API responses. The biggest problem with this approach is there is no way we can ensure the responses are type-safe because we are just "assuming" their types.
Then I wondered what would happen if we have [GraphQL](https://graphql.org/) in the picture and set out on a journey. If you don't know what GraphQL is, it's a Query language for your API, where you define what your API can provide as strictly typed schema and clients will consume a subset of it.
I decided to build a POC using GraphQL with a complete type-safe frontend. You can access the full code(server and client) [here](https://github.com/santosh898/typesafe-graphql).
## Server-side
I won't be dealing with the server-side aspect of this, and I won't go deep into GraphQL as well. The following is the schema of my API.
> the server is written using node+typescript+apollo-sever
### Schema
```
type Book {
id: Float!
title: String!
subtitle: String!
author: String!
published: String
publisher: String
pages: Int!
description: String!
website: String!
}
type Query {
getBooks(limit: Int): [Book]
getBookDetails(id: Float): Book
}
```
In the above schema, `type Book` is a resource, and `type Query` is where we define what kind of queries are supported.`getBooks` will respond with an array of `Books` and `getBookDetails` will respond with a `Book` for the given `ID`.
## Client-side
So we have the following problems to crack.
* Connect front-end to GraphQL.
* Get Fully typed responses automatically.
* IntelliSense when writing the queries.
### Connect the front-end to GraphQL
I created a GraphQL powered react-app using [Create Apollo app](https://apolloapp.org/) by running
```
yarn create apollo-app client
```
It has out-of-the-box support for `.graphql` files and the boilerplate code to connect to the backend.
> See client/src/index.tsx
But later I found that the template is pretty old and upgraded `graphql` and migrated from `react-apollo` to `@apollo-client`.
> I used the create-apollo-app for generating the server codebase as well.
We can consume data by using the `useQuery` hook from `@apollo/client` like this.
> client/src/queries/getBooks.ts
```
import { gql } from "@apollo/client";
export const GET_BOOKS = gql`
query getBooks($limit: Int) {
getBooks(limit: $limit) {
id
title
subtitle
author
}
}
`
```
> client/src/ListBooks.tsx
```
import { useQuery } from "@apollo/client";
import { GET_BOOKS } from './queries/getBooks.ts'
const ListBooks: React.FC<{}> = () => {
const { loading, error, data } = useQuery(GET_BOOKS,{
variables: {
limit: 5,
},
});
...render data
}
```
It works but the data isn't fully typed yet.
### Get Strongly typed responses automatically
To avoid writing the types for the responses manually we are going to use [GraphQL Code Generator](https://graphql-code-generator.com/docs/getting-started/index).
graphql-codegen is a CLI tool that generates types automatically from the provided GraphQL Schema. They have a lot of plugins and options for generating the types for both frontend and backend.
**By using this we can have the server-side written GraphQL schema as a single source of truth for the whole application.**
The setup is pretty straightforward. Refer to the [Installation page](https://graphql-code-generator.com/docs/getting-started/installation):
```
# install the cli as a dev-dependency
yarn add -D @graphql-codegen/cli
# Step by step walkthrough initialization
yarn graphql-codegen init
```
The above code adds relevant dev-dependencies based on our selection and creates a `codegen.yml` file at the project root. My `codegen.yml` file looks like this.
```
overwrite: true
schema: "http://localhost:8080/graphql"
documents: "src/**/*.ts"
generates:
src/queries/typedQueries.ts:
plugins:
- "typescript"
- "typescript-operations"
- "typescript-react-apollo"
```
I'll walk you through the options.
- **schema** - the URL for the schema. Can be a file, function, string as well. See the documentation.
- **documents** - where to search for the GraphQL queries and fragments. I asked it to search in the `.ts` files
- **generates** - the target file path.
- **plugins** - automatically added based on the options selected in the `init`
- **typescript** - bare minimum plugin to generate types.
- **typescript-operations** - to generate types for the [GraphQL Operations](https://graphql.org/learn/queries/)
- **typescript-react-apollo** - to generate typed hooks for the queries written and other support for the @apollo/client.
Now after running `yarn generate` it'll generate the file `typedQueries.ts`. And I updated my component to use the generated `hook`.
```
import React from "react";
import { useGetBooksQuery } from "./queries/typedQueries.ts";
const ListBooks: React.FC<{}> = () => {
const { loading, error, data } = useGetBooksQuery({
variables: {
limit: 5,
},
});
...render data
}
```
What changed here? we are not importing the query anymore, the generated types will do that for us. and guess what? the `data` is fully typed.:confetti_ball:
Instead of having to run `yarn generate` every time we change a query, we can run the codegen-cli in watch mode as well.See [Documentation](https://graphql-code-generator.com/docs/getting-started/development-workflow).
> **Note**: If you are going to use node for the backend, codegen-cli will be helpful for generating types from Schema so that you don't need to define the types two times. Refer to server code in my codebase for reference.
### IntelliSense when writing the queries (in vscode)
The [Apollo VS Code extension](https://marketplace.visualstudio.com/items?itemName=apollographql.vscode-apollo) provides an all-in-one tooling experience for developing apps with Apollo.
We will get the syntax highlighting by just installing the extension. But to have IntelliSense we have to add a config file to the project.
> client/apollo-config.js
```
module.exports = {
client: {
service: {
name: "my-graphql-app",
url: "http://localhost:8080/graphql",
},
excludes: ["**/src/queries/typedQueries.ts"],
},
};
```
after adding this config, the extension downloads the schema from the URL and provides the IntelliSense when you write the queries.
One last thing! when I updated the schema, the extension didn't pick that up, so I had to run `reload schema` manually. (`ctrl+shift+p` to open command palette)
I don't know if there's an option for this to happen automatically. I didn't go deep into the extension [documentation](https://www.apollographql.com/docs/devtools/editor-plugins/).
That's it. Now I have a strong type system for API calls plus added benefits of GraphQL.
This is my first ever post. If you are still here, thank you for having the patience to stay this long. | santosh898 |
635,430 | Prismjs + Nuxtjs -Easy set up | This website is an ongoing project. It's not perfect, and it never will be; in fact, as you search th... | 11,795 | 2021-03-15T11:43:33 | https://www.ricardomoreira.io/coding/highlight-syntax-with-prismjs-on-a-nuxt-wesbite-and-netlify-cms/ | prismjs, nuxt | This website is an ongoing project. It's not perfect, and it never will be; in fact, as you search the website you will see many things that you might see me [advocate](https://twitter.com/mugas11/status/1367772956533915648?s=20) that I am not doing on the website.
I know it might seem an easy way out, but the fact is that I want to upgrade the website as I upgrade myself, so I want to share when I update the website with something new. Like that, I learn better, get documented and hopefully, it helps someone in the future.
So expect many posts about things I did on this website.
Today it will be about code snippets and their highlight while writing for example a code post.
When I created this website and started to write code posts I realize that the code was not highlighted and would not look good.
The best solution was adding [Prismjs](https://prismjs.com/) and after some fast search was easy to implement.
So let's do it:
First, we install Prismjs:
```js
npm install --save prismjs clipboard
```
Then in the file `nuxt.config.js` add the plugin:
```js
plugins: [{ src: '~/plugins/prism' }]
```
After that go to your plugin folder in Nuxt and create a file named `prism.js`. Open it and write this code:
```js
import Prism from 'prismjs'
import 'prismjs/themes/prism-tomorrow.css' // You can add other themes if you want
export default Prism
```
There are many options besides the ones above, but there are the basics to make it work.
So now Prism is installed and we informed Nuxt about it we just need to add it to the page we need, normally `_slug.vue`
```js
<script>
import Prism from '~/plugins/prism'
mounted() {
Prism.highlightAll()
}
```
And that is all. With a few steps, you have nice highlights on your blog page.
If you like this post, feel free to follow me on [Twitter](https://twitter.com/mugas11/) and send me a message in case you have any doubt about this post 😊 | mugas |
635,651 | Crashtest Security Suite - Vulnerability scanner | My name is Santhosh and I am a Senior Growth Hacker at Crashtest Security GmbH. I support organizati... | 0 | 2021-03-15T16:23:52 | https://dev.to/santhosh_crashtest_security/crashtest-security-suite-vulnerability-scanner-1l4c | My name is Santhosh and I am a Senior Growth Hacker at Crashtest Security GmbH. I support organizations to detect and fix vulnerabilities within their Single, multipage, JavaScript application and API.
| santhosh_crashtest_security | |
635,802 | C : Loops and Control Statements | What are loops? Types (entry and exit controlled loop) What is infinite/endless loop? Types of loop... | 0 | 2021-03-15T17:53:17 | https://dev.to/supriya2371997/c-loops-aob | 1. What are loops?
2. Types (entry and exit controlled loop)
3. What is infinite/endless loop?
4. Types of loop constructs (while, do...while, for)
5. For loop in more detail
6. Nested loop
7. What are Loop Control Statements
8. Types (break, continue, goto)
****
1.**Loops :** Loop executes the sequence of statements many times until the stated condition becomes false. A loop consists of two parts, a body of a loop and a control statement. The control statement is a combination of some conditions that direct the body of the loop to execute until the specified condition becomes false. The purpose of the loop is to repeat the same code a number of times.
2.**Types:** Depending upon the position of a control statement in a program, looping in C is classified into two types:
2.1 **Entry controlled loop :** also called as pre-checking loop. A condition is checked before executing the body of a loop.
2.2 **Exit controlled loop :** also called as post-checking loop. A condition is checked after executing the body of a loop.
**3. what is infinite/endless loop?**
->The loop that does not stop executing and processes the statements number of times is called as an **"infinite loop"**. An infinite loop is also called as an **"Endless loop"**.
->some characteristics of an infinite loop:
** No termination condition is specified. **
** The specified conditions never meet. **
->Thus, to avoid this situation the control conditions must be well defined and specified otherwise the loop will execute an infinite number of times.
->The for loop is traditionally used for this purpose. Since none of the three expressions that form the 'for' loop is required, you can make an endless loop by leaving the conditional expression empty.
```
#include <stdio.h>
int main ()
{
for( ; ; )
{
printf("This loop will run forever.\n");
}
return 0;
}
```
**4. Types of loop constructs:-**
4.1 **while:**
->It is an entry-controlled loop. In while loop, a condition is evaluated before processing a body of the loop. If a condition is true then and only then the body of a loop is executed. After the body of a loop is executed then control again goes back at the beginning, and the condition is checked if it is true, the same process is executed until the condition becomes false. Once the condition becomes false, the control goes out of the loop.
->In while loop, if the condition is not true, then the body of a loop will not be executed, not even once.
```
while (testExpression)
{
// the body of the loop
}
```
```
/*Example: */
#include <stdio.h>
int main()
{
int i = 1;
while (i <= 5)
{
printf("%d\n", i);
++i;
}
return 0;
}
```
4.2 **Do while:**
->It is more like a while statement, except that it tests the condition at the end of the loop body.
->it terminates with a semi-colon (;)
->The body of do...while loop is executed at least once.
->After the body is executed, then it checks the condition. If the condition is true, then it will again execute the body of a loop otherwise control is transferred out of the loop.
```
do
{
// the body of the loop
}
while (testExpression);
```
```
/*Example: */
#include<stdio.h>
#include<conio.h>
int main()
{
int num=1;
do
{
printf("%d\n",2*num);
num++;
}while(num<=10);
return 0;
}
```
4.3 **For:**
->step1: In this initialization, statement is executed only once.
->step2: The condition is a Boolean expression that tests and compares the counter to a fixed value after each iteration, stopping the for loop when false is returned.
->step3: The incrementation/decrementation increases (or decreases) the counter by a set value and again the test expression is evaluated.
->step4: This process goes on until the test expression is false. When the test expression is false, the loop terminates.
```
for (initial value; condition; incrementation or decrementation )
{
statements;
}
```
```
/*Example:*/
#include<stdio.h>
int main()
{
int number;
for(number=1;number<=10;number++)
{
printf("%d\n",number);
}
return 0;
}
```
5.**For loop in more detail:**
->for loop can have multiple expressions separated by commas in each part.
```
for (x = 0, y = num; x < y; i++, y--) {
statements;
}
```
->we can skip the initial value expression, condition and/or increment by adding a semicolon.
```
int i=0;
int max = 10;
for (; i < max; i++) {
printf("%d\n", i);
}
```
6.**Nested Loop:-**using one loop inside another loop.
->**nested for loop:**
```
for ( init; condition; increment ) {
for ( init; condition; increment ) {
statement(s);
}
statement(s);
}
```
->**nested while loop:**
```
while(condition) {
while(condition) {
statement(s);
}
statement(s);
}
```
->**nested do while loop:**
```
do {
statement(s);
do {
statement(s);
}while( condition );
}while( condition );
```
->you can put any type of loop inside any other type of loop. For example, a 'while' loop can be inside a 'for' loop or vice versa.
```
#include <stdio.h>
int main() {
int i, j;
int table = 2;
int max = 5;
for (i = 1; i <= table; i++)
{
for (j = 0; j <= max; j++)
{
printf("%d x %d = %d\n", i, j, i*j);
}
printf("\n");
}
}//main end
```
**NOTE :** In some versions of 'C,' the nesting is limited up to 15 loops, but some provide more.
7.**Loop Control Statements :**change execution from its normal sequence. When execution leaves a scope, all automatic objects that were created in that scope are destroyed.
8.1 **Break :**
->Terminates the loop or switch statement and transfers execution to the statement immediately following the loop or switch.
```
break;
```
->The break statement is almost always used with if...else statement inside the loop.
```
#include <stdio.h>
int main()
{
int num = 5;
while (num > 0)
{
if (num == 3)
break;
printf("%d\n", num);
num--;
}
}
```
8.2 **Continue :** The continue statement skips the current iteration of the loop and continues with the next iteration. Its syntax is:
```
continue;
```
->The continue statement is almost always used with the if...else statement.
```
#include <stdio.h>
int main()
{
int nb = 7;
while (nb > 0)
{
nb--;
if (nb == 5)
continue;
printf("%d\n", nb);
}
}
```
8.3 **Go to:**
->Transfers control to the labeled statement.
->The label is an identifier. When the goto statement is encountered, the control of the program jumps to label: and starts executing the code.
->Here label can be any plain text except C keyword and it can be set anywhere in the C program above or below to goto statement.
```
goto label;
... .. ...
... .. ...
label:
statement;
```
```
/*Example:*/
#include <stdio.h>
int main () {
int a = 10;
LOOP:do
{
if( a == 15)
{
a = a + 1;
goto LOOP;
}
printf("value of a: %d\n", a);
a++;
}while( a < 20 );
return 0;
}
```
**NOTE :** Use of the goto statement is highly discouraged in any programming language because it makes it difficult to trace the control flow of a program, making the program hard to understand and hard to modify. Any program that uses a goto can be rewritten to avoid them.
| supriya2371997 | |
636,315 | Azure Functions and .NET 5: Dependency Injection | .NET 5 support for Azure Functions is announced as GA in this blog article! We can find developer gu... | 0 | 2021-03-16T10:04:59 | https://dev.to/kenakamu/azure-functions-and-net-5-dependency-injection-5ed4 | azurefunctions, dotnet, di | .NET 5 support for Azure Functions is announced as GA in [this blog article](https://techcommunity.microsoft.com/t5/apps-on-azure/net-on-azure-functions-roadmap/ba-p/2197916)!
We can find developer guide at [Guide for running functions on .NET 5.0 in Azure](https://docs.microsoft.com/en-us/azure/azure-functions/dotnet-isolated-process-guide) and [Develop and publish .NET 5 functions using Azure Functions](https://docs.microsoft.com/en-us/azure/azure-functions/dotnet-isolated-process-developer-howtos?pivots=development-environment-vscode&tabs=browser)
Today, I want to share how to use DI (Dependency Injection) in this "isolated process" when we use .NET 5.
[Reference: Start-up and configuration](https://docs.microsoft.com/en-us/azure/azure-functions/dotnet-isolated-process-guide#start-up-and-configuration)
# Create project
First thing first! We need to create function project by using new template.
1\. Install the latest version of Azure Function Core Tools v3. See [here](https://docs.microsoft.com/en-us/azure/azure-functions/functions-run-local?tabs=windows%2Ccsharp%2Cbash#v2) for more detail.
2\. Once you install the tool, make sure to check the version. It should be higher than 3.0.3381.
```shell
func --version
```
3\. Create new folder and initialize the function.
```shell
mkdir dotnet5func
cd dotnet5func
func init
```
4\. Now, we can see new option available. Select "dotnet (isolated process".
5\. Then, create new function project. Select any trigger as you want. I selected HttpTrigger this time.
```shell
func new
```
6\. Enter function name to complete, then run the function and confirm it works as expected.
```shell
func start
```
7\. Stop the function and open the project by using Visual Studio Code or Visual Studio.
```shell
code .
```
# Configure Dependency Injection
The most important thing to know when use DI is, that we don't need Startup.cs!! We can directly change code in Program.cs to configure DI now.
1.\ Program.cs should looks like below when we scaffold the project.
```csharp
using System.Threading.Tasks;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Hosting;
using Microsoft.Azure.Functions.Worker.Configuration;
namespace dotnet5func
{
public class Program
{
public static void Main()
{
var host = new HostBuilder()
.ConfigureFunctionsWorkerDefaults()
.Build();
host.Run();
}
}
}
```
2.\ To use DI, we simply modify HostBuilder. Let's add HttpClient factory. We can simply use ConfigureServices method and use **AddHttpClient()** which is exactly same as ASP.NET project.
```csharp
using System.Threading.Tasks;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.DependencyInjection;
namespace dotnet5func
{
public class Program
{
public static void Main()
{
var host = new HostBuilder()
.ConfigureFunctionsWorkerDefaults()
.ConfigureServices(s => {
s.AddHttpClient();
})
.Build();
host.Run();
}
}
}
```
3\. Open function code and accept IHttpClientFactory via DI. We need to change several places.
- Remove **static** keywords so that we can instantiate class
- Add private IHttpClientFactory and receive it via constructor
- Change signature of **Run** method to make it asynchronous call
I use swapi.dev this time. swapi is a cool api if you love Star Wars. Check out [swapi.dev](https://swapi.dev/) for more detail.
```shell
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Http;
using Microsoft.Extensions.Logging;
namespace dotnet5func
{
public class dotnet5func
{
private readonly IHttpClientFactory clientFactory;
public dotnet5func(IHttpClientFactory clientFactory)
{
this.clientFactory = clientFactory;
}
[Function("dotnet5func")]
public async Task<HttpResponseData> Run([HttpTrigger(AuthorizationLevel.Function, "get", "post")] HttpRequestData req,
FunctionContext executionContext)
{
var logger = executionContext.GetLogger("dotnet5func");
logger.LogInformation("C# HTTP trigger function processed a request.");
var client = clientFactory.CreateClient();
var swapires = await client.GetStringAsync("https://swapi.dev/api/people/1/");
var response = req.CreateResponse(HttpStatusCode.OK);
response.Headers.Add("Content-Type", "text/plain; charset=utf-8");
response.WriteString(swapires);
return response;
}
}
}
```
4\. Run the function again and call the endpoint.
```shell
func start
```

# Summary
Even though there are still slight differences between Azure Functions and Web API when we writing code, I can easily and effectively reusing my knowledge once I fill the gap!
I cannot wait .NET 6 release which is LTS next year!
| kenakamu |
636,511 | webMethods 10.7 Release Announcement | Software AG delivers latest Release of webMethods is geared towards helping business achieve Digital... | 0 | 2021-04-07T08:56:44 | https://tech.forums.softwareag.com/t/webmethods-10-7-release-announcement/239520 | webmethods, release, announcement, integration | ---
title: webMethods 10.7 Release Announcement
published: true
date: 2021-03-11 10:05:55 UTC
tags: #webmethods, #release, #announcement, #integration
canonical_url: https://tech.forums.softwareag.com/t/webmethods-10-7-release-announcement/239520
---
**Software AG delivers latest Release of webMethods is geared towards helping business achieve Digital Transformtion faster and drive innovation by removing complexity of managing APIs, microservices and integration and giving business-level control of applications.**
Software AG’s webMethods products empower you to build solutions on the top-rated hybrid integration platform and integrate cloud-based apps and on-premises systems without coding, simplify with one toolset for on-premises and cloud integrations and use microservices-style architecture to deliver and scale new integrations faster.
The webMethods Microservices Runtime brings all of the power of their Integration Platform, including the power to connect to any application or API, free your data for use in new applications, and quickly configure new business logic, eliminating the complexity of recreating services from scratch and building new silos of data.
Software AG has now introduced a new graphical flow editor that brings the full power of their Eclipse-based IDE to the browser. Users can now speed through building integrations with user interfaces tailored to their developers, whether integration power users, ad hoc integrators or citizen developers.
And with integrations increasingly spanning cloud and on premises IT environments, Software AG also added the ability to gain visibility across hybrid landscapes with full hybrid end-to-end monitoring across Integraiton, API, and B2B integrations.
## Some of the key highlights of this release are:
### Integration and Microservices
- Support for an OpenAPI v3.0-based REST API provider. The REST provider can now be developed using the OpenAPI-first approach.
- Support for a REST-based Administrator API which allows developers to automate deployment and support continuous integration and deployment scripts.
- Integration Server Administrator provides access to all administrative tasks through a brand new, simplified, graphically rich, tab-based interface with improved accessibility, simpler debugging tools, and server controls.
- Microservices Runtime now provides support to inject new configuration assets into an existing Microservices Runtime Docker image, which will be updated every three months on Docker Hub.
- Microservices Runtime is now certified to work with Istio Service Mesh. The Microservices hosted on the Microservices Runtime can be managed by the Istio Service Mesh control plane and can work with Istio components such as Envoy.
- webMethods Service Development plugin can now work with Cloud Container, allowing developers to browse Integration Server packages, services, and APIs hosted in Cloud Container.
- The Trading Networks built-In services guide is now integrated with Software AG Designer in service development mode to help you create custom flows for business use cases.
- Universal Messaging now provides liveness/readiness probes that can be leveraged by Kubernetes to determine the state of the software and native Prometheus support with additional new metrics.
- Fixes can now be applied on an Active/Active UM cluster without cluster shutdown, with the intention of providing zero-downtime updates of the servers. Functionality is available also in 10.3 after fix 16.
- CloudStreams Server now supports additional options for replaying Salesforce streaming events, such as a CloudStreams connector listener for Salesforce Streaming API can replay events from the last received event, and a CloudStreams connector listener can now attempt recovery for errors configured as recoverable in the associated CloudStreams Connector.
- CloudStreams Server now supports the ability to create a connector by consuming an OpenAPI 3.0 definition of a webservice.
- CloudStreams Server can now configure JWT or Service Account Authentication with Adobe Experience Platform.
- Software AG’s latest release adds support for many new applications including Adobe AEP and Magento Commerce; Microsoft Dynamics 365 and ADLS Gen2; SAP S/4HANA Cloud, C/4HANA Commerce; Ariba Cloud, PO, and CPI; Salesforce CPQ; and Google Cloud Spanner.
- The new runtime UI is enabled by default now for all new tenants that are created in the AgileApps Cloud platform.
- Customers can now leverage the new automatic creation of stacks to build a view of their environments in the Stacks view of the Command Central web user interface. They can then manage their landscape using the entire set of functions supported by the stacks.
- Command Central now provides the ability to upgrade a set of installations grouped as a stack through the web user interface. This will enable customers to easily upgrade to a major version, for example, from 10.3 to 10.5. After upgrading a stack, the stack has the same name and configurations, but an upgraded release version and applied fixes (if available).
### API Management
With this release, Software AG’s webMethods AppMesh ties together their API Management and Microservices platforms to bring application-level visibility and control, while taking the complexity out of managing business applications. webMethods Microgateway, works with webMethods API Gateway or as a standalone solution to control API access to microservices in a distributed environment. It supports service mesh architectures offering independent and sidecar deployments.
- API Management in the Software AG hosted cloud now offers an Azure hosting option in addition to AWS, and allows switching between tenants used as different development stages.
- API Gateway now supports OpenShift and in addition to standard swagger descriptors, users can get Postman collection documentation with examples on how public APIs of the API Gateway can be used.
- API Gateway now provides support for AppMesh, in which API Gateway acts as the controlling and monitoring body. Microgateway acts as the body enforcing policies defined in API Gateway, acting as a sidecar to microservices. Users can now configure connection to Kubernetes clusters where service mesh resides. API Gateway also supports Istio-enabled service meshes as well as plain Kubernetes.
- API Gateway now features a user interface for users with accessibility needs. This UI has been simplified and caters only to a small subset of API Gateway functionality such as searching and browsing APIs.
- API Gateway now displays all the subscriptions made (along with plans and packages) and their status which includes data on package, plan, the current usage, and the percentage of time and quota used.
- API Gateway captures all the data flowing through it with API calls. Additionally, it captures “design-time” events data about things done by users or happening any other way.
- API Portal deployment now allows for using Postgres as external database.
- API Portal has been certified to run on Azure cloud platform.
- API Gateway is now able to handle streaming (responses sent as stream and byte) in API responses.
- This release of Microgateway provides support for AppMesh, in which Microgateway acts as the body enforcing policies defined in API Gateway, acting as a sidecar to microservices.
- CentraSite users can now import APIs from OpenAPI 3 compliant descriptors. It is also possible to create OpenAPI Specification (OAS3) compliant APIs from scratch.
### Suite
- Customers can now leverage the new automatic creation of stacks to build a view of their environments in the Stacks view of the Command Central web user interface. They can then manage their landscape using the entire set of functions supported by the stacks.
- Command Central now provides the ability to upgrade a set of installations grouped as a stack through the web user interface. This will enable customers to easily upgrade to a major version, for example, from 10.3 to 10.5. After upgrading a stack, the stack has the same name and configurations, but an upgraded release version and applied fixes (if available).
- Enhanced Command Central templates and documentation are available on GitHub for better on-premise infrastructure automation.
- A REST based adapter available for OpenText Document Management System and a Sharepoint Adapter is available for various platforms.
- You can now use the Software AG Installer to install your products and the latest or selected updates. You can use this feature when installing the 10.7 or 10.5 release.
- Using the Software AG Installer command line interface, you can now build Docker images for the combination of Microservices Runtime, layered products such as API webMethods Product Suite 10.7 Release Notes 5 Gateway, and Universal Messaging. One use of such images is to aid in the move from on-premises to private cloud.
webMethods 10.7 GA release will be available for download on April 15th 2021.
For further details, please refer to the webMethods 10.7 Release Notes at
[webMethods 10.7 Release Notes](https://documentation.softwareag.com/webmethods/wmsuites/wmsuite10-7/relnotes/10-7_webMethods_Release_Notes.pdf)
[Read full topic](https://tech.forums.softwareag.com/t/webmethods-10-7-release-announcement/239520) | mariela |
636,916 | Mis primeros 6 años después de la universidad | Hola soy Miguel, vivo en México, y estudié la licenciatura en Informática en la universidad. En dicie... | 0 | 2021-04-06T05:54:19 | https://dev.to/miguelvillegasr/mis-primeros-6-anos-despues-de-la-universidad-21oh | Hola soy Miguel, vivo en México, y estudié la licenciatura en Informática en la universidad. En diciembre de 2014 terminé el último semestre de la carrera y decidí buscar trabajo de programador, aún no sabía en que especialidad quería trabajar, solo que me urgía trabajar.
Después de 2 meses de entrevistas y exámenes en diferentes empresas, fui a una entrevista en dónde buscaban un programador web. Tuve suerte en que el examen que me pusieron era sencillo (crear un login en php y enviar los datos a una base de datos), pues ya me habían tocado exámenes muy difíciles para mi grado de dominio de los lenguajes de programación que conocía (c, c++ y php).
Obtuve el trabajo y hoy llevo 6 años en esa empresa, a continuación, describo lo que hice en cada año y lo que aprendí en base a mis errores:
###Primer Año
Mi prueba de fuego fue realizar un memorama en html5 puro, la empresa se dedica a crear cursos elearning con actividades en html5, no sabia usar para nada jquery, lo aprendí a usar, no sabia de librerías de javascript, asi que tuve que ingeniármelas haciendo código para resolver el random de la tarjetas, el girado de la tarjeta del memorama, el detectar dispositivos moviles o resoluciones distintas, etc.
Después aprendí a usar una herremienta de Adobe que se llamaba adobe edge animation (creo), creabas paginas html5 a apartir de un programa de diseño, insertaba código, creaba frames de animación y el proyecto en dónde utilice ese conocimiento fue para convertir de flash (action script) a html5 unos cursos que ya se habían hechos anteriormente. Ese fue mi trabajo durante ese año, convertir actividades diseñadas en flash a html5 y llegue hasta programar actividades en action script.
### Segundo año
Comencé a incursionar en el mundo de javascript en código nativo, empecé a usar las nuevas características de html5, como la geolocalización, local storage e indexedDB. Realicé una calculadoras de ingresos y gastos, que se guardan en local storage e indexedDB, pues estas calculadoras solo tenían un espacio designado en la pagina del cliente, sin acceso a lenguajes backend.
También comencé a conocer el estándar SCORM y a crear pequeñas funciones para guardar el avance de los cursos elearning en el LMS. Comencé a conocer Moodle en sus tripas, me encargaron realizar una suite de reporteo de las actividades del SCORM dentro de moodle y obtener un reporte mas gráfico del avance de los usuarios a través de las diferentes actividades del curso - simulador que había realizado la empresa. Aquí fueron mis primeros dolores de cabeza y sensación de arrepentimiento por haber elegido querer ser programador. Las bases de datos no eran mi fuerte, me costaba la lógica en php para tratar la información obtenida de la base de datos; hacia y des hacia los cambios no conocía git, perdía código que resolvían algunas cosas, y decidí hacer respaldos de cada cambio que realizaba, tenía una versión estable y varias versiones de prueba. Restauraba la base de datos en mi ambiente de prueba constantemente por que el cliente tenia en producción el sistema y los reportes no arrojaban la información necesaria, fueron meses de mucho estrés y desaliento en algunas ocasiones.
### Tercer año
Comencé con las instalaciones y configuraciones de moodle en servidores linux, no sabía nada de administración de sistemas, aunque usaba ubuntu en mi computadora personal, el primer contacto con un cliente que necesitaba que le instaláramos un moodle en su servidor centos fue algo muy difícil, gracias a un programador avanzado y con conocimientos bastante sólidos en administración de sistemas pude realizar la tarea. Me costaba saber por que no salia a internet mi yum install, ja ja ja ahora me da risa, por que no se veía mi pagina en el navegador, pues solo se veía welcome to apache, je je je y así muchas cosas por el estilo que los administradores de servidores conocen a la perfección. Practiqué bastante las instalaciones de Moodle en servidores virtualizados hasta que el proceso lo hice sin problemas, pero eso no bastó, pues en años adelante me tope con configuraciones mas complicadas.
Realicé una plantilla de curso elearning en html5, donde solo se debía colocar la etiqueta de la imagen y esta se animaba mediante jquery y greensock; había un código heredado de otras plantillas que re-dimensionaba el contenido, basado en la resolución de la pantalla. Ademas de crear varias funciones para cambiar de pantalla, guardar el avance, resetear el curso, obtener información del usuario desde el LMS, etc. Funcionó bastante esa plantilla para mi gusto, tal vez para el de mi jefe no, je je je, pero era funcional.
### Cuarto año
Se comenzó con la expansión de la empresa, abarcar mas productos, crear software, ofrecer mas servicios, etc. Se contrató a un nuevo programador, con bastantes habilidades técnicas y muy dedicado. A mi me dejaron para atender a clientes, instalaciones de Moodle, deje de programar y me dedique al trato con el cliente, con algunas incursiones en revisión de servidores para checar configuraciones de moodle, hasta el momento en que llegó un cliente que nos pidió un LMS de videos y evaluaciones, le dijimos que si lo podíamos hacer pero en php, lo acepto y se realizó, gracias al otro programador logramos concluir el proyecto con éxito, yo solo le ayude en las cuestiones del frontend, mientras que el hizo todo el backend y sección administrativa. Después regreso el mismo cliente con el mismo proyecto pero en C#, ¡¿WHAT?!, lo conocíamos, pero no lo practicábamos ni lo dominábamos, pero bueno, se acepto ese proyecto y el colmo: el proyecto se debía terminar en 3 meses, con una sección de CMS; para quedar claros ¡¡¡era un LMS y CMS juntos en tres meses!!!. Fallamos, no teníamos la experiencia, ni la capacidad técnica, solo eramos dos programadores, aunque entraron varias personas a auxiliar, la mayoría solo sabia lenguajes frontend, nadie conocía cómo trabajar en un ambiente de c#, sql server, y demás chunches que tiene el desarrollo sobre tecnologías microsoft. Nos penalizaron por todo el tiempo que tardamos y no lo entregamos completo, nos quedamos como al 70 u 80 %. Se desesperó el cliente y metió programadores de su equipo para solventar el problema. Aprendizaje: nunca aceptes proyectos de tecnologías que no conoces. Hasta el momento veo vacantes de trabajo que solicitan programador web en c# y me viene a la mente ese proyecto en el que fallamos.
###Quinto año
Comenzamos el desarrollo de plugins de reportes e información analítica para Moodle. Eso si lo sabíamos hacer, tal vez la estructura de los plugins no tanto, pero sacar información de la base de datos de moodle y presentarla en una tabla o en gráficas no sonaba tan difícil de hacer, y en efecto no era difícil. Lo difícil fue la interacción con el cliente, cambiaba de opinión de lo que necesitaba, pedía algo básico primero y después lo complicaba, no terminábamos nada, por que siempre había algo que añadir o algo que no hacía. Tuvimos muchas juntas para convencer al cliente de que eso era lo que había solicitado al principio, hasta que decidimos hacer documentación de entrega de proyecto parcial, con esto logramos que lo que se le entregara fuera incrementando el avance de proyecto por que ya habíamos cumplido requerimientos solicitados y documentados. Puedo decir que esto nos ayudo en organización y administración.
Entró un nuevo programador novato, se le enseño lo mas posible pero se fue el primer programador.
###Sexto año
Moodle se hizo famoso por la pandemia, pero no nos buscaban tantos clientes como lo habíamos pensado, así que se nos enfocamos en proyectos internos, en tecnologías como vuejs, rethinkdb, meteorjs. Aprendí mucho de administración de sistemas, aunque aún falta mucho más. Aprendimos muchas cosas sobre cómo funcionan las apis de moodle y la forma de estructurar plugins en moodle.
| miguelvillegasr | |
637,017 | How to Make Background Image Fit to Screen in CSS | Create a Responsive CSS Background Image | How to Make CSS Background Image Fit to Screen, | Create a Responsive CSS Background Image, how to to... | 0 | 2021-03-17T02:08:33 | https://dev.to/hmawebdesign/how-to-make-background-image-fit-to-screen-in-css-create-a-responsive-css-background-image-4h54 | webdev, design, css, html | How to Make CSS Background Image Fit to Screen, | Create a Responsive CSS Background Image, how to to make background image responsive css.
In this tutorial, we’ll go over the simplest technique for making a background image fully stretch out to cover the entire browser viewport. We’ll use the CSS background-size property to make it happen; no JavaScript needed.
# Watch Full Video:
{% youtube Asoth7MIggM %}
Setting background-size to fit screen — Using CSS, you can set the background-size property for the image to fit the screen (viewport). The background-size property has a value of cover. It instructs browsers to automatically scale the width and height of a responsive background image to be the same or bigger than the viewport. Use the background-size property to cover the entire viewport The CSS background-size property can have the value of cover. The cover value tells the browser to automatically and proportionally scale the background image's width and height so that they are always equal to, or greater than, the viewport's width/height.
responsive background image css tricks,
css background image size to fit screen,
CSS background image responsive,
css background image size to fit screen mobile,
how to create responsive image height css,
html background image size to fit,
background image height: 100,
------------------------------------------------------------------
Please have a look at my website for more details!
https://hmawebdesign.com
------------------------------------------------------------------
Suggested Videos:
How to Send Email to Client Using PHP Mail Function | Sending Email in PHP 2021 Tutorial
https://youtu.be/DeqOVJ-aXkg
$_POST | What is the Post Variable in PHP | How to Use Post Variables in PHP 2021
https://youtu.be/HO-TrXY4a1A
How to Define Variables in PHP | How to Create PHP Variables | (PHP tutorial-3) - 2021
https://youtu.be/bfqAa0Gm3YY
How to Start First PHP Web Project on Local Server/Localhost PHP Tutorial-2
https://youtu.be/18I7U4-nJb0
How to Start Web Project with Microsoft Visual Studio 2021 | Visual Studio Project
https://youtu.be/MLzuQ_pH9Ew
How to Get Start PHP Hello World Page on Live Web Server | PHP Tutorial - 1
https://youtu.be/Uc7uLD7Ur6M
-------------------------------------------------------------------------------------------------
Contact me through social media for web development work:
- Fiverr https://www.fiverr.com/haaddison1?up_rollout=true
- witter: https://twitter.com/HmaWebdesign
- Facebook: https://web.facebook.com/HmaWebdesign
- LinkedIn: https://www.linkedin.com/in/engrmianayub/
- Instagram https://www.instagram.com/hmawebdesign/ | hmawebdesign |
637,172 | Staging vs. Committing: an explanation for Git beginners | I get these questions quite often: "What is the difference between staging and committing?" "Why i... | 0 | 2021-03-17T12:00:24 | https://practicalgit.com/blog/staging-vs-commit.html | git, beginners | I get these questions quite often:
> "What is the difference between staging and committing?"
> "Why is there a `git add` and a `git commit`? What's the difference?"
## What is the difference?
Imagine you are doing online shopping. You browse through the pages of your favorite online store and add some products to your shopping cart. The shopping cart is like **staging**. Things are there ready to be paid for. You can keep adding stuff to it or remove some from it.
When you are done shopping, you go and pay for the things in your shopping cart. That can be compared to making a **commit**. Now there is a record somewhere of what you have bought and when. There is a history.
Notice that you can easily change your mind when things are in staging, but once you have made a commit things are hard to change (although not impossible!).
## Why are they separated?
The fact that you need to stage and commit separately in Git has many benefits. Generally it is a good idea to make your commits small. And to make sure that all the changes that are included in one commit are related to each other.
For example a commit that fixes a bug in Feature A should not also include an improvement you made to Feature B. If you have been productive 😎 and have done those two things at once, you should not commit everything at once. You should separate them by staging the bug fixes and committing those first and then staging the improvements to Feature B and making a second commit.
That way, if someone looks at the Git history of your project, they are not confused by one giant commit that did a lot of things. They can see clearly that you performed two different tasks: one bug fix in Feature A and one improvement to Feature B.
## How to stage and commit
Ok so now that you know the difference between **staging** and **committing**, let's see how to do these things in Git:
To **add** the changes you made to a file to staging, use this command
```bash
$ git add <path-to-file>
```
If you want to add all the files at once, put a dot instead of path to each file, like this:
```bash
$ git add .
```
All the changes will be staged, ready to be committed.
To commit use the command:
```bash
$ git commit -m "some descriptive message"
```
I have created a Git cheat sheet for beginners to make it easier to look up these basic commands. You can grab a free copy from [here](https://chipper-musician-9131.ck.page/fc2d4720ba). | foadlind |
637,293 | DIY: Building a busy light to show your Slack presence | Going back a year in time, I created a post about building my Busy Light, which I connected to the Mi... | 0 | 2021-03-17T08:47:46 | https://dev.to/estruyf/diy-building-a-busy-light-to-show-your-slack-presence-2k0g | slack, wfh, homebridge, meetings | Going back a year in time, I created a post about building my Busy Light, which I connected to the Microsoft Graph. Homebridge is used to control the busy light, its colors, and statuses.

> **Info**: The related article: [Building a busy light to show your Microsoft Teams presence](https://www.eliostruyf.com/diy-building-busy-light-show-microsoft-teams-presence/)
The busy light has been running without issues since I hang it at my office until earlier this week. It did not break. It was because I stopped using Microsoft Teams and switched to Slack.
> Reason: I moved to another company.
## Getting my busy light working again
To be sure that my wife and kids know I am in a meeting. I had to dive into the Slack APIs to understand how presence works in Slack.
Slack and Microsoft Teams' significant difference in your presence is that Slack only has two presence states: `online` and `away`, where Microsoft Teams supports many more.
I was checking at my new colleagues and reading some articles. Slack uses a combination of the presence and the user's status.
Like the Google Calendar app, some apps can automatically change your status when jumping into a meeting.
To make Slack's presence work with my busy light. I started by creating a fork of the [Homebridge Presence switch connected to Microsoft Graph](https://github.com/estruyf/homebridge-presence-switch-msgraph) and removed all the authentication and Microsoft Graph logic.
> **Info**: [Homebridge presence switch connected to Slack](https://github.com/estruyf/homebridge-presence-switch-slack)
The logic of calling the Microsoft Graph got replaced by calling the profile-, presence-, and dnd-API from Slack.
By calling these three APIs, the Homebridge plugin can provide you the following busy light states:
- Available
- Away
- DnD
- Offline
- `<Slack status>`: This is a state you control yourself. You can add all your status texts and their corresponding colors.
You can find more information about the plugin and the installation process on the [Homebridge presence switch connected to Slack](https://github.com/estruyf/homebridge-presence-switch-slack) repository.
> **Important**: The Homebridge plugin also creates additional switches for each of the presence states. These switches allow you to automate your home even more. Like for instance, when I go to a meeting, my speaker will automatically stop playing.
## The hardware
The hardware is still the same as the one I used for the Microsoft Teams Busy Light: [busy light hardware](https://www.eliostruyf.com/diy-building-busy-light-show-microsoft-teams-presence/#the-hardware).
## The server
To control the LED HAT on the Raspberry Pi, I use a service I wrote in `Python`: [the busy light service](https://www.eliostruyf.com/diy-building-busy-light-show-microsoft-teams-presence/#the-busy-light-service).
## The Slack permission scope
The `Homebridge Presence` Slack App I have created will ask you to consent to the following permissions to get the information it requires to control the lights correctly.
You can find more information about the Homebridge plugin installation process on the repo its readme: [plugin installation](https://github.com/estruyf/homebridge-presence-switch-slack#installation);
*Article originally published to [eliostruyf.com](https://www.eliostruyf.com/diy-building-busy-light-show-slack-presence/)* | estruyf |
637,347 | TypeORM - Query Builder with Subquery | The article demonstrates how complex subquery should be created with TypeORM in Node.js, TypeScript. | 13,156 | 2021-03-18T04:17:56 | https://dev.to/yoshi_yoshi/typeorm-query-builder-with-subquery-490c | node, sql, typescript, database | ---
title:TypeORM - Query Builder with Subquery
description: The article demonstrates how complex subquery should be created with TypeORM in Node.js, TypeScript.
series: TypeORM
tags: node, sql, typescript, database
---
##Introduction
I was a .Net developer and am a Node.js/Typescript developer at the moment. Of course, I used to write SQL and use [LINQ](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/concepts/linq/) which supports the code-base SQL execution. This describes how I convert from SQL to TypeScript coding with [TypeORM](https://typeorm.io/#/).
##Basic Query
####Entity model of TypeORM
```TypeScript
import {Entity, PrimaryGeneratedColumn, Column} from "typeorm";
@Entity()
export class Student {
@PrimaryGeneratedColumn()
id: number;
@Column()
firstName: string;
@Column()
lastName: string;
@Column()
isActive: boolean;
}
```
#####TypeScript with TypeORM
```TypeScript
const student = await connection
.getRepository(Student)
.createQueryBuilder("stu")
.where("stu.firstName = :name", { name: "Sam" })
.getOne();
```
#####Actual SQL of the above code
```SQL
SELECT *
FROM Student as stu
WHERE stu.firstName = 'Sam'
LIMIT 1;
```
##Query with Subqueries
Building a simple SELECT query with entities is easy. However, this is not enough for creating graphs or displaying calculated results on the tables. This is the main part to demonstrate how we should build complex queries with [TypeORM](https://typeorm.io/#/).
#####Target SQL converted to TypeScript with TypeORM
```SQL
SELECT
cs.course_id as course_id,
DATE_FORMAT(
asses.created_datetime, '%Y-%m-%d'
) AS submitted_date,
IFNULL(count(cs.courseId), 0) as correct_submission_number,
IFNULL(total_exam.number, 0) as total_number
FROM
assessment as asses
INNER JOIN submission as sub ON asses.submission_id = sub.id
INNER JOIN subject_exam as se ON se.exam_id = sub.exam_id
INNER JOIN course_subject as cs ON cs.subject_id = se.subject_id
LEFT OUTER JOIN (
SELECT
cs.course_id as course_id,
IFNULL(COUNT(cs.course_id), 0) as number
FROM
course_subject as cs
LEFT OUTER JOIN subject_exam as se ON cs.subject_id = se.subject_id
WHERE
cs.dept_id = 'abcdefg'
GROUP BY
cs.course_id
) as total_exam ON total_exam.course_id = cs.course_id
WHERE
asses.result = '2' -- = pass
AND asses.status = '2' -- = submitted
AND cs.dept_id = 'abcdefg'
GROUP BY
cs.course_id,
DATE_FORMAT(
asses.created_datetime, '%Y-%m-%d'
)
ORDER BY
DATE_FORMAT(
asses.created_datetime, '%Y-%m-%d'
) asc,
cs.course_id asc;
```
#####TypeScript with TypeORM
```TypeScript
import {getManager} from "typeorm";
// in class 'GetDailyStats'
//Build a subquery to get the total number of exams
const totalExamNumbers: any = getManager().createQueryBuilder()
.select("cs.courseId", "course_id")
.addSelect("IFNULL(COUNT(*), 0)", "number")
.from(CourseSubject, "cs")
.leftJoin(SubjectExam, "se", "cs.subject_id = se.subject_id")
.andWhere("cs.dept_id = :deptId", {
deptId: deptId
})
.groupBy("cs.course_id");
//Build a main query with the subquery for stats
const dailyStatsQuery: any = getManager().createQueryBuilder()
.select("cs.courseId", "courseId")
.addSelect("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "submitted_date")
.addSelect("IFNULL(COUNT(cs.courseId), 0)", "correct_submission_number")
.addSelect("IFNULL(total_exam.number, 0)", "total_number")
.from(Assessment, "asses")
.innerJoin(Submission, "sub", "asses.submission_id = sub.id")
.innerJoin(SubjectExam, "se", "se.exam_id = sub.exam_id")
.innerJoin(CourseSubject, "cs", "cs.subject_id = se.subject_id")
.leftJoin("(" + totalExamNumbers.getQuery() + ")", "total_exam", "total_exam.course_id = cs.course_id")
.where("asses.result = :result", {
result: AssessmentResult.PASS
})
.andWhere("asses.status = :status", {
status: AssessmentStatus.SUBMITTED
})
.andWhere("cs.dept_id = :deptId", {
deptId: deptId
})
.groupBy("cs.course_id")
.addGroupBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')")
.orderBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "ASC")
.addOrderBy("cs.course_id", "ASC")
.setParameters(totalExamNumbers.getParameters())
// Execute the generated query
const dailyStatsRaws = await dailyStatsQuery.getRawMany();
//Convert raws to our appropriate objects
const dailyStats = dailyStatsRaws.map((s: any) => {
const item: DailyStatsItem = {
courseId: s.courseId,
submittedDate: s.submittedDate,
correctSubmissions: s.correctSubmissions,
totalSubmissions: s.totalSubmissions
};
return item;
});
return dailyStats;
```
You can consolidate the main query and subquery if you want but I prefer the divided ones because of the readability and the possibility of sharing the subqueries with the other classes.
>**IMPORTANT**: What is `setParameters()`?
When you set some parameters on a subquery, setting values is not ready to execute with the main query. You explicitly need to set them on your main query before calling `getRawMany()`.
>Do we need to call `setParameters()` for parameters on the main query? No, you do not need it. It is just for separated queries.
>**HINT**: What is `IFNULL` in MySQL?
The `IFNULL()` function returns a specified value if the expression is `NULL`.
>**HINT**: Grouping by `DATETIME`?
>If you want to change the grouping rules by `DATETIME` columns, please change the `DATE_FORMAT` parts.
>Hourly base: `DATE_FORMAT(asses.created_datetime, '%Y-%m-%d %H:00:00')`
>Daily base: `DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')`
>Monthly base: `DATE_FORMAT(asses.created_datetime, '%Y-%m')`
>Yearly base: `DATE_FORMAT(asses.created_datetime, '%Y')`
##Subqueries with Optional Parameters
How should we create a query with optional values? No worries, this is easy with [TypeORM](https://typeorm.io/#/).
#####in class 'SubQueryBuilder'
```TypeScript
import {getManager} from "typeorm";
public getTotalNumberExams(deptId? : string | undefined) {
const subquery: any = getManager().createQueryBuilder()
.select("cs.courseId", "course_id")
.addSelect("IFNULL(COUNT(cs.courseId), 0)", "umber")
.from(CourseSubject, "cs")
.leftJoin(SubjectExam, "se", "cs.subject_id = se.subject_id")
.groupBy("cs.course_id");
//Filter the list if a deptId is not undefined
if (deptId !== undefined) {
subquery.where("cs.deptId = :deptId", {
deptId: deptId
});
return subquery;
}
}
```
#####in class 'GetDailyStats'
```TypeScript
import {getManager} from "typeorm";
import {getTotalNumberExams} from "SubQueryBuilder";
// in class 'GetDailyStats'
const totalNumberExams = getTotalNumberExams(deptId);
//Build a main query with the subquery for stats
const dailyStatsQuery: any = getManager().createQueryBuilder()
.select("cs.courseId", "courseId")
.addSelect("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "submitted_date")
.addSelect("IFNULL(COUNT(cs.courseId), 0)", "correct_submission_number")
.addSelect("IFNULL(total_exam.number, 0)", "total_number")
.from(Assessment, "asses")
.innerJoin(Submission, "sub", "asses.submission_id = sub.id")
.innerJoin(SubjectExam, "se", "se.exam_id = sub.exam_id")
.innerJoin(CourseSubject, "cs", "cs.subject_id = se.subject_id")
.leftJoin("(" + totalNumberExams.getQuery() + ")", "total_exam", "total_exam.course_id = cs.course_id")
.where("asses.result = :result", {
result: AssessmentResult.PASS
})
.andWhere("asses.status = :status", {
status: AssessmentStatus.SUBMITTED
})
.groupBy("cs.course_id")
.addGroupBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')")
.orderBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "ASC")
.addOrderBy("cs.course_id", "ASC")
.setParameters(totalNumberExams.getParameters())
//Filter the list if a deptId is not undefined
if (deptId !== undefined) {
dailyStatsQuery.andWhere("cs.deptId = :deptId", {
deptId: deptId
});
// Execute the generated query
const dailyStatsRaws = await dailyStatsQuery.getRawMany();
//Convert raws to our appropriate objects
const dailyStats = dailyStatsRaws.map((s: any) => {
const item: DailyStatsItem = {
courseId: s.courseId,
submittedDate: s.submittedDate,
correctSubmissions: s.correctSubmissions,
totalSubmissions: s.totalSubmissions
};
return item;
});
return dailyStats;
```
##Subquery's Performance
Some experienced developers mention you should not use subqueries often because inside subqueries might execute without the index's or DB optimization's benefits.
Please check an article, [TypeORM - Multiple DB Calls vs Single DB Call](https://dev.to/yoshi_yoshi/typeorm-multiple-db-calls-vs-single-db-call-178). It might be helpful for you.
##Check Generated SQL
[TypeORM](https://typeorm.io/#/) supports checking the generated SQL syntaxes. Please simplely replace from `getRawMany()` to `getQuery()`.
#####in class 'GetDailyStats'
```TypeScript
import {getManager} from "typeorm";
import {getTotalNumberExams} from "SubQueryBuilder";
// in class 'GetDailyStats'
const totalNumberExams = getTotalNumberExams(deptId);
//Build a main query with the subquery for stats
const dailyStatsQuery: any = getManager().createQueryBuilder()
.select("cs.courseId", "courseId")
.addSelect("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "submitted_date")
.addSelect("IFNULL(COUNT(cs.courseId), 0)", "correct_submission_number")
.addSelect("IFNULL(total_exam.number, 0)", "total_number")
.from(Assessment, "asses")
.innerJoin(Submission, "sub", "asses.submission_id = sub.id")
.innerJoin(SubjectExam, "se", "se.exam_id = sub.exam_id")
.innerJoin(CourseSubject, "cs", "cs.subject_id = se.subject_id")
.leftJoin("(" + totalNumberExams.getQuery() + ")", "total_exam", "total_exam.course_id = cs.course_id")
.where("asses.result = :result", {
result: AssessmentResult.PASS
})
.andWhere("asses.status = :status", {
status: AssessmentStatus.SUBMITTED
})
.groupBy("cs.course_id")
.addGroupBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')")
.orderBy("DATE_FORMAT(asses.created_datetime, '%Y-%m-%d')", "ASC")
.addOrderBy("cs.course_id", "ASC")
.setParameters(totalNumberExams.getParameters())
//Filter the list if a deptId is not undefined
if (deptId !== undefined) {
dailyStatsQuery.andWhere("cs.deptId = :deptId", {
deptId: deptId
});
// Generate an actual SQL query
const actualSqlQuery = await dailyStatsQuery.getQuery();
console.log(actualSqlQuery);
```
##Conclusion
[TypeORM](https://typeorm.io/#/) is a powerful tool to implement the Code-First approach. I am going to share useful information if I find it.
##Bio
When I was 30 years old, I went to Australia for changing my career on a Working Holiday visa. I graduated from University of Sydney with a Bachelor of Computer Science and Technology. During the period, I also worked as a Fraud Prevention Analyst at Amex in Sydney, Australia (yes, it was super busy. I went to my uni during the day and worked at night...)
After graduation, I worked as a C#/.Net developer for an Australian small business for 5 years. Now, I came back to Japan and work as a TypeScript/Go/React developer for a Japanese security start-up company.
I love learning new fields which is a big challenge. I am happy if you support me to accelerate the improvement of my skill/knowledge. Please feel free to contact me if you are interested in my unique career.
Thanks,
| yoshi_yoshi |
637,706 | 🔪 The Ultimate Knife Block | We’ve all been there, chopping vegetables with a knife so blunt it would be more effective to use a t... | 0 | 2021-03-17T17:59:40 | https://dev.to/t3chflicks/the-ultimate-knife-block-3g42 | We’ve all been there, chopping vegetables with a knife so blunt it would be more effective to use a teaspoon. In that moment, you reflect on how you got there: your knives were sharp as razors when you bought them but now, three years down the line, they’re thoroughly inadequate. “I should’ve sharpened my knives” you think to yourself. Shoulda, coulda, woulda but I didn’t.
Most of us don’t bother to sharpen our knives. It’s an extra bit of effort and when you’re just trying to make dinner, faffing around with a sharpener is the last thing you want to do. But what if it wasn’t..?
We decided to make a knife block which incorporates a mechanical knife sharpener. A sharpener right next to your knives — and solar powered so you don’t even need to bother charging it! This build is super straightforward and you end up with a great final product which would be a helpful addition to any kitchen!

## Supplies
* Rechargeable 18650 battery — [https://amzn.to/2XF7cno](https://amzn.to/2XF7cno)
* Charge controller TP4056- [https://amzn.to/2XF7cno](https://amzn.to/2L6MU4Y)
* Push button — [https://amzn.to/2XF7cno](https://amzn.to/2GKp5eZ)
* Small motor — [https://amzn.to/2XF7cno](https://amzn.to/2GN44k1)
* Battery Holder — [https://amzn.to/2XF7cno](https://amzn.to/2vwHNAx)
* Glue Gun — [https://amzn.to/2XF7cno](https://amzn.to/2UDKcDz)
* Soldering Iron — [https://amzn.to/2XF7cno](https://amzn.to/2GJ4XtR)
* Wire — [https://amzn.to/2XF7cno](https://amzn.to/2GIzGa9)
* Sharpening stone — [https://amzn.to/2XF7cno](https://amzn.to/2vlYheF)
* 3 packets of spaghetti — [https://amzn.to/2XF7cno](https://amzn.to/2UHnavm)
* Red PLA — [https://amzn.to/2XF7cno](https://amzn.to/2XKszDV)
* Grinding stone — [https://amzn.to/2XF7cno](https://amzn.to/2vlYheF)
* 3X Screws 12mm m3 — [https://amzn.to/2XF7cno](https://amzn.to/2VsZL5g)
> # [🔗 Get The Ultimate Knife Block Files On Github 📔](https://github.com/sk-t3ch/ultimate-knife-block)
## Tutorial 🤖
### Knife Block Design

The basic knife block design is a curvy cuboid with a detachable lid and a space for a solar panel in the front. The lid has slots for the knives. To figure out how big the block needed to be and how wide the knife slots would be, we measured the knives we wanted to put in and designed accordingly.
To power the rotating sharpener, we decided to use a solar panel to keep the design cordless (you don’t want to plug *another* thing in the kitchen) and remove the hassle of recharging batteries. Also, chances are that unless you’re a serial knife sharpener, a solar panel will provide plenty power.
The electronics are pretty simple to put together. For power, you need one rechargeable battery — preferably 18650 lithium ion. To charge it, you’ll need a solar panel — we used 5V, 500mA because we had one spare, but a smaller one would be perfectly fine. You’ll also need a battery protection circuit and something to put the battery in.
The whole thing will be controlled by a simple button which sits in the top of the knife block. To operate the sharpener, the button needs to be depressed. This is actually a pretty good safety mechanism because it means the sharpener will stop turning as soon as you let go of the button. On the end of the motor, there’s a small grinding stone which I found online.
### Print the 3D Case
Firstly, 3D print your knife block shell.
We made the 3D design using Fusion360. To be honest, it was quite a fiddly and time consuming process. If you’d like a tutorial on how to do this, please let us know in the comments below. We’re still learning, too, so if anyone has any tips on the design or good places to learn more about 3D design, please share.
### Electronics
We are going to put together following circuit:
### Solder Wires Onto the Solar Panel
Take two wires about 10cm long and solder one onto the positive and one onto the negative tab on the solar panel.

## Connect the Battery
Put the battery into the holder and solder the positive and negative wires to the B+ and B- inputs on the charge controller.

## Connect the Switch and Motor
From the push button terminals, solder one wire from the positive output of the charge controller to the input of the push button. Solder another wire from the output of the push button to the positive of the motor. Solder a wire from the negative output of the charge controller to the negative of the battery.
Check the connections work and note which way the motor turns — you want to put it in the case so it will rotate away from you.


## Put in the Motor
Slot the motor into the hole in the knife block. To reduce vibration and help keep the motor in place, you could glue it using a glue gun — this is optional, though, as it fits snugly.
Push the grinding stone onto the end of the motor.


## Put on Push Button
Put the push button through the hole in the lid and glue in place.

## Put on the Solar Panel
Solder the positive wire from the solar panel to the positive input on the charge controller. Solder the negative wire from the solar panel to the negative input on the charge controller.
Glue around the perimeter of the case and push on the solar panel.


## Fill Up With Spaghetti
Fill the large internal cavity with spaghetti. This might sound random, but it gives the block some weight so it doesn’t move around when sharpening and it also helps keep the knives in place.
We used about 3 packs of spaghetti to fill the space. It was a bit long so we trimmed the ends so the lid would fit.

## Put on Lid
Screw the lid in place to close the knife block.

## Put in Knives
Put your knives into your block and swirl it round in the sun.
We did think that adding little rubber feet would be a good way to reduce vibration, noise and slipperiness, but we didn’t quite get round to that. We also thought that we could add a bottle opener or an electric can opener to make this the ultimate kitchen gadget!
If you have any suggestions for improvements or additions, please let us know in the comments below!

## Thanks for reading
I hope you have enjoyed this article. If you like the style, check out [T3chFlicks.org](https://t3chflicks.org/) for more tech focused educational content ([YouTube](https://www.youtube.com/channel/UC0eSD-tdiJMI5GQTkMmZ-6w), [Instagram](https://www.instagram.com/t3chflicks/), [Facebook](https://www.facebook.com/t3chflicks), [Twitter](https://twitter.com/t3chflicks)). | t3chflicks | |
637,896 | Quarkus - Reactive programming without callback headache | The world of asyncronous and reactive programming is a matter that the JavaScript developers know wel... | 0 | 2021-03-29T21:20:14 | https://dev.to/davide_d_cube/quarkus-reactive-programming-without-callback-headache-5goo | quarkus, performance, kotlin, coroutines | The world of asyncronous and reactive programming is a matter that the JavaScript developers know well. In the world of the "ancient" stacks is an approach that only on the last years is becoming a thing that seams to be look with a certain interest.
Especially in Java world there are years that there is support for multi threading computation, but this is an approach that is requested to parallelize long time consuming blocking situations, what the asyncronous and reactive programming try to resolve is to use better the resources that modern processors offer to the computational world.
## Start from the basics: kotlin
Kotlin is a programming language that takes advantages, in terms of echosystem, from the JVM world infact it is a language that is part of the family of JVM languages.
Kotlin allows developers to develop their structures under different approaches such as functional programming, object oriented programming.
It is a modern language born with simplicity in mind, it is proposed as official programming language for Android applications development and allows to develop **crossplatform code** between iOS, Android, Web and Desktop.
This elasticity is not gifted by "some ghost behind the scenes" that works heavily to guarantee a limping compatibility with the supported platform, but simply the compiler behind the kotlin language knows how to translate and optimize the kotlin code into the different platforms to be compatible with.
## A step forward: Quarkus
Quarkus is a mordern full stack framework that permits to develop backend applications with minimum effort and with maximum performance and specially allow Spring users to recycle theire knowledge to write applications that are scalable, require minimum memory footprint and are performant under the cloud world.
Quarkus can be used also as traditional framework for developing traditional monolitic backend services, but developer can do this with some advantages offered by the **Event bus**, **Reactive programming**, **Many plugins ready to use** and so on.
## Asyncronous and Reactive programming
The scope of this article is not to dive into the techical differences and similarities between asyncronous and reactive programming, but what is matter to know is that the *reactive programming* is an approach to *asyncronous programming*.
## Put all togheter
The reactive programming, as JavaScript developers know, requires that the result of an asyncronous action can be used into a function called **callback** that is passed as argument to the method that is computing the asyncronous result or, in other cases, the callback is hooked as a ring of a chain that forms a pipeline of computation.
This is a typical use of reactive programming applied to Quarkus framework.
```java
public static Uni<Fruit> findById(PgPool client, Long id) {
return client.preparedQuery("SELECT id, name FROM fruits WHERE id = $1").execute(Tuple.of(id))
.onItem().transform(RowSet::iterator)
.onItem().transform(iterator -> iterator.hasNext() ? from(iterator.next()) : null);
}
```
Without entering in the specifications, what you can see is the fact that developer that needs to process a response of a certaing http call, needs to concatenate some methods for controlling the process of the information.
This is a behavior that the JavaScript and NodeJS worlds has resolved with the keywordss **async** and **await**, these keywords allow developer to describe the implementation without callbacks and reconduct all the implementation to the classic imperative code style delegating the compiler to resolve correctly the callbacks. Behind the scenes these two keywords are difficult to implement in a good way and this should have as final goal to use better the performance of the CPU.
In Java world the async and await is not implemented officialy, there is the **project loom** that in a near future will enable to write some code that look like this, but for now, if you want a clean and non blocking code, you need to write code with callbacks.
Kotlin, in the other hand, has the concept of **coroutine** that is very similar to the concept of async and await, but has more features and allow to control also the threads and process management. In this first approach lets say that we are happy if we can write performant code in a simple way.
Quarkus uses **SmallRye Mutiny** as library to perform all asyncronous operations, this library is very similar to the other libraries such as RXJava, RXJavascript, Reactor and so on, but has the advantage to be very simple and to have a limited family of operators that can be empowered by using in smart way the common Java functionalities.
With the version *0.13.0* Mutiny has accepted the Pull Request of a contrubutor that has implemented the coroutines as extended methods of Mutiny's main classes (Uni<T> and Multi<T>).
Now let's see the code reported before with kotlin language
```kotlin
fun findById(client: PgPool, id: Long?): Uni<Fruit?> {
return client.preparedQuery("SELECT id, name FROM fruits WHERE id = $1").execute(Tuple.of(id))
.onItem().transform(RowSet::iterator)
.onItem().transform { iterator -> if (iterator.hasNext()) from(iterator.next()) else null }
}
```
Now let's see the same code writen with assistance of the new library
```kotlin
suspend fun findById(client: PgPool, id: Long): Fruit? {
val rowset = client.preparedQuery("SELECT id, name FROM fruits WHERE id = $1")
.execute(Tuple.of(id))
.awaitSuspending()
val rowIterator = rowset.iterator()
return if (rowIterator.hasNext()) {
from(rowIterator.next())
} else {
null
}
}
```
As you can see the callbacks are disappeared and the basic things such as flow control or exception management is a little bit easy do manage.
Obviously is possible also to reconvert a coroutine to a publisher object that is recognized as Mutiny's object:
```kotlin
fun mutinyService(id: Long): Uni<Fruit?> {
GlobalScope.async {
findById(id)
}.asUni()
}
```
Refer to Mutiny's documentation for more informations about coroutines support: [Offial documentation](https://smallrye.io/smallrye-mutiny/guides/kotlin)
Here there is a complete project that uses eavily the stack described in this article: [Smart-home backend services](https://github.com/iot-tetracube-red/smart-hub) | davide_d_cube |
638,058 | Difference between functions and methods in Golang | Difference between functions and methods in Golang The words function and method are used... | 0 | 2021-03-18T03:43:28 | https://penthaa.medium.com/difference-between-functions-and-methods-in-golang-54db90fb92c9 | go | # Difference between functions and methods in Golang
The words function and method are used almost interchangeably, but there are subtle differences in their implementation and usage when used in Golang. Let's see what the difference is and how its used.
### Function
Functions accept a set of input **parameters**, perform some operations on the input and produce an output with a specific **return type.** Functions are independent that is they are **not attached to any user defined type**.
***Syntax:***
```go
func FunctionName(Parameters...) ReturnTypes...
```
There cannot exist two different functions with the same name in the same package.
```go
type Rectangle struct {
Width float64
Height float64
}
type Circle struct {
Radius float64
}
func Area(r Rectangle) float64 {
return 2 * r.Height * r.Width
}
func Area(c Circle) float64 {
return math.Pi * c.Radius * c.Radius
}
```
[Run above code in The Go Playground](https://play.golang.org/p/LQNBLtOfhFi)
The above code throws an error : `Area redeclared in this block`
### Method
A method is effectively a function attached to a user defined type like a **struct**. This user defined type is called a **receiver**.
***Syntax:***
```go
func (t ReceiverType) FunctionName(Parameters...) ReturnTypes...
```
There can exist different methods with the same name with a different receiver.
```go
type Rectangle struct {
Width float64
Height float64
}
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
type Circle struct {
Radius float64
}
func (c Circle) Area() float64 {
return math.Pi * c.Radius * c.Radius
}
type Triangle struct {
Base float64
Height float64
}
func (t Triangle) Area() float64 {
return 0.5 * t.Base * t.Height
}
```
[Run above code in The Go Playground](https://play.golang.org/p/ASQP_J_RUSU)
| penthaapatel |
669,135 | Understanding the React useState() Hook | Introduction Hooks were introduced in React v16.8.0. Prior to that, if we had written a fu... | 0 | 2021-04-17T07:22:43 | https://raunaqchawhan.hashnode.dev/understanding-the-react-usestate-hook | react, programming, javascript, webdev | ## Introduction
[Hooks](https://reactjs.org/docs/hooks-intro.html) were introduced in React **v16.8.0**. Prior to that, if we had written a functional component and wanted to add `state` or make use of `lifecycle` methods to perform operations such as data fetching and manual DOM manipulation, the functional component had to be converted into class based component.
However, introduction of Hooks made adding state and performing those operations in functional component possible. It also helped in keeping the mutually related code together rather than splitting the code based on lifecycle methods. Hooks don't work inside classes rather they let us work with React without the need for class.
In this post, we will learn about the built-in **useState()** Hook and how to use it in a functional component. We will also understand the difference in initializing, updating and accessing the state in class component as compared to functional component.
## Rules of Hooks
Following are the two rules of Hooks that needs to be followed:
- Hooks should always be called at the top level of the React function which means it shouldn't be called inside loops, conditionals or nested functions. This is done to ensure that Hooks are called in the same order each time a component renders.
- Never call Hooks from regular JavaScript functions. Instead, call it from React function components or [custom Hooks](https://reactjs.org/docs/hooks-custom.html).
## useState() Hook
As the name suggests, `useState` Hook is used to add state to function components.
The syntax for useState is as below:
```javascript
const [state, setState] = useState(initialState);
// assigns initialState to state
// setState function is used to update the state
```
useState() returns an `array` with exact two values. Array destructuring can be used to store these values in different variables.
The first value returned represents the state and the second value returned is a function that can be used to update the state. You can give any name to these two variables. For our understanding, we'll name the state variable as `state` and the function that updates it as `setState`. You can follow this convention of assigning any name to state variable and then prefixing it with 'set' to form the function name.
The 'initialState' argument passed to useState sets the initial state. On subsequent re-renders, state is updated through the `setState` function returned from the `useState` Hook.
Now, let's take a look at the following code block which represents a **class component** with state
```javascript
import React, { Component } from "react";
export default class App extends Component {
constructor(props) {
super(props);
this.state = {
weather: 'hot',
disabled: false
}
}
render() {
return (
<div>
<p>The weather is {this.state.weather}</p>
<button
onClick={() => this.setState({weather: 'cloudy', disabled: !this.state.disabled})}
disabled={this.state.disabled}>
Change weather
</button>
</div>
);
}
}
```
When the above class component gets rendered to the screen, you get a paragraph `The weather is hot` with a 'Change weather' button below it.
On clicking the button, the component re-renders and output changes to `The weather is cloudy` with the button getting disabled.
In a class component, you can initialize state in the constructor by using `this.state`. In the above example, it is initialized to `{weather: 'hot', disabled: false}`. Any update to state is done through `this.setState` and respective values can be accessed using `this.state.weather` and `this.state.disabled`.
The state is defined as an object and all the state updates done through `this.setState` is merged into that object as class component can have a single state object only. Therefore, `{weather: 'cloudy', disabled: !this.state.disabled}` gets merged with the previous value and state is updated.
*In order to initialize, update or access any value from state in a class component, you always need to use `this` keyword.*
Now, let's take a look at the following **functional component** using the **State Hook** that works the same way as the earlier class component
```javascript
// import useState Hook from "react" package
import React, { useState } from "react";
export default function App() {
const [weather, setWeather] = useState('hot'); // "weather" value initialized to "hot"
const [disabled, setDisabled] = useState(false); // "disabled" value initialized to "false"
return (
<div>
<p>The weather is {weather}</p>
<button onClick={() => {
setWeather('cloudy'); // setWeather('cloudy') updates the "weather" to "cloudy"
setDisabled(!disabled); // setDisabled(!disabled) updates the "disabled" to "true"
}} disabled={disabled}>Change weather</button>
</div>
);
}
```
- In order to use state in functional component, you first need to import `useState` Hook from React.
- Unlike class component where you can have a single state object only, functional component allows you to have multiple state variables. Here, `weather` and `disabled` state variables are initialized to the argument passed to `useState` Hook.
- This argument can be of any type such as number, string, array or object unlike class component where state is initialized to object only.
- On clicking the button, `setWeather` and `setDisabled` functions are called with new state values passed to it. React will then re-render the component by passing the new `weather` and `disabled` values to it.
- In a functional component, updating a state value always replaces the previous value unlike class component where state updates are merged.
In the above example, new state values are not dependent on previous state values. Therefore, we directly pass new value to state update function. In scenarios where new state value depends on previous state value, you can use the following functional update format to update the state.
```javascript
setState(previousStateValue => {
// newStateValue determined using previousStateValue
return newStateValue;
})
```
This functional update format is used to update the state depending on the previous state value.
## Conclusion
In this post, you learnt about the **useState()** Hook that makes it possible to use state in a functional component without transforming it into a class component. You learnt how to initialize, update and access the state variables in a functional component using Hooks.
___
Thank you for taking the time to read this post 😊
Hope this post helped you!! **Please share** if you liked it.
I would love to connect with you on [Twitter](https://twitter.com/_raunaq_).
Do share your valuable feedback and suggestions you have for me 👋 | raunaqchawhan |
669,283 | hay | A post by notanneso | 0 | 2021-04-17T11:27:15 | https://dev.to/notanneso/hay-2996 | codepen | {% codepen https://codepen.io/notanneso/pen/LYxBzqY %} | notanneso |
669,297 | Laravel Livewire Fullcalendar Integration Example | Today, I will learn you how to use fullcalendar with livewire example. We will explain step-by-step l... | 0 | 2021-04-17T12:03:04 | https://dev.to/dharmik_tank/laravel-livewire-fullcalendar-integration-example-26ah | laravel, livewire, php | Today, I will learn you how to use fullcalendar with livewire example. We will explain step-by-step laravel livewire fullcalendar integration. you can easily make livewire fullcalendar integration in laravel.
more
https://itwebtuts.blogspot.com/2021/04/laravel-livewire-fullcalendar.html | dharmik_tank |
669,495 | Angular 6 Search Box example with Youtube API & RxJS 6 | https://grokonez.com/frontend/angular/angular-6/angular-6-search-box-example-with-youtube-api-angular... | 0 | 2021-04-17T15:24:23 | https://dev.to/loizenai/angular-6-search-box-example-with-youtube-api-rxjs-6-42ap | angular6, rxjs, youtube | https://grokonez.com/frontend/angular/angular-6/angular-6-search-box-example-with-youtube-api-angular-rxjs-6-tutorial
Angular 6 Search Box example with Youtube API & RxJS 6
In this tutorial, we’re gonna build an Angular Application that helps us to search YouTube when typing. The result is a list of video thumbnails, along with a description and link to each YouTube video. We'll use RxJS 6 for processing data and <code>EventEmitter</code> for interaction between Components.
<!--more-->
<h2>Angular 6 Search Box example with Youtube API overview</h2>
<h3>Goal</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/11/angular-search-box-example-youtube-api.gif" alt="angular-search-box-example-youtube-api" width="764" height="676" class="alignnone size-full wp-image-15785" />
<h3>Technology</h3>
- Angular 6
- RxJS 6
- YouTube v3 search API
<h3>Project Structure</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/11/angular-search-box-example-youtube-api-angular-tutorial-project-structure.png" alt="angular-search-box-example-youtube-api-angular-tutorial-project-structure" width="267" height="487" class="alignnone size-full wp-image-15786" />
- <code>VideoDetail</code> object (<em>video-detail.model</em>) holds the data we want from each result.
- <code>YouTubeSearchService</code> (<em>youtube-search.service</em>) manages the API request to YouTube and convert the results into a stream of <code>VideoDetail[]</code>.
- <code>SearchBoxComponent</code> (<em>search-box.component</em>) calls YouTube service when the user types.
- <code>SearchResultComponent</code> (<em>search-result.component</em>) renders a specific <code>VideoDetail</code>.
- <code>AppComponent</code> (<em>app.component</em>) encapsulates our whole YouTube searching app and
render the list of results.
<h2>Practice</h2>
<h3>Setup Project</h3>
<h4>Create Service & Components</h4>
Run commands:
- <code>ng g s services/youtube-search</code>
- <code>ng g c youtube/search-box</code>
- <code>ng g c youtube/search-result</code>
<h4>Add HttpClient module</h4>
Open <em>app.module.ts</em>, add <code>HttpClientModule</code>:
<pre><code class="language-java">
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import { HttpClientModule } from '@angular/common/http';
import { AppComponent } from './app.component';
import { SearchBoxComponent } from './youtube/search-box/search-box.component';
import { SearchResultComponent } from './youtube/search-result/search-result.component';
@NgModule({
declarations: [
AppComponent,
SearchBoxComponent,
SearchResultComponent
],
imports: [
BrowserModule,
HttpClientModule
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
</code></pre>
<h3>Result DataModel</h3>
More at:
https://grokonez.com/frontend/angular/angular-6/angular-6-search-box-example-with-youtube-api-angular-rxjs-6-tutorial
Angular 6 Search Box example with Youtube API & RxJS 6
| loizenai |
669,513 | Satanic Text Generator Tool | Relatively few content generators can transform the textual styles and messages into some sort of unu... | 0 | 2021-04-17T16:17:06 | https://dev.to/limmedia/satanic-text-generator-tool-1mi5 | satanictext | Relatively few content generators can transform the textual styles and messages into some sort of unusual characters that are regularly extremely hard look and perused. They are called evil images which are written in a type of animal structure or brutal structure. There is a motivation behind why you can utilize them as inverse to the mirror where a few group likes to utilize basic and cool content, where others likes to go past the cutoff points and pick distinctive heading to astound their companions and pull tricks on them.
Utilizing every one of these wicked images would permit you to utilize them for some, different purposes like structure your online media accounts with images and furthermore produce the writings for utilizing numerous different things by composing, informing, sending logo, making startling images and some more. This is a serious fun and agreeable book generator. With this content scrambler you will actually want to make proper textual styles and convert them into more appalling to panic others.
cap makes evil spirit name generator not the same as any remaining content generators?
This <a href="https://textandfonts.com/satanic-text-generator/">satanic text generator</a> is explicitly made to change over any composed messages or letters into evil spirit text where a portion of individuals will not comprehend and that makes you a virtuoso in your own specific manner to join and send them to anybody you need. This one is such a lot of various and interesting to command notice who frequently prefers to utilize face book, twitter, and numerous other social stages. Likewise you will be capable compose remarks in a language that no one but you can comprehend and interpret.
What number of highlights evil content generator offers?
This one has astonishing number of highlights that makes it an extraordinary one. How frequently you have seen programming that gives you various alternatives of changing over your writings into a logo and create. Presently you get your total opportunity to unnerve your dear companions and partners in new type of writings. Here are a portion of the mind boggling highlights you should consider such to be,
How you can utilize devil name generator?
You will be glad to realize that, you don't have to join or make any record. All you need is to just visit the site and duplicate glue to transform your writings into <a href="https://en.wikipedia.org/wiki/Bad_Words_(film)">evil words</a>. Likewise quite possibly you can handle the peculiarity of the subsequent box to roll out certain improvements to your content, making it convoluted for anybody to see the distinction. You will get stunning textual style logo you can utilize.
Devilish content generator is without a doubt extraordinary compared to other with regards to assist you with excursion producing textual styles, letters effortlessly. You can turn into your own master and pick them to execute for any reasons. Simply attempt it once and you will see the amount it is worth in any case.
Evil Text Generator tends to transform the typical content into such strange shape that it turns out to be difficult to peruse and look. You may have seen these sorts of text in Human Verification while making a record on Gmail, Yahoo or BING.
Every one of the strange writings which are hard to peruse or look are perused are known as Satanic Text since they are written in such vague content animals and peculiar structure. Producing text from Satanic Text Generator can be utilized anyplace on friendly records or blog entry however the greater part of individuals utilize such a content inverse to mirror to stand out enough to be noticed.
You can play a riddle game with your companions by sending them and requesting that they judge. By utilizing every one of the satanic images, you can change your online media accounts names and can produce other emblematic textual styles for your content for composing messages, making logos, startling images and some more. With text scrambler, Satanic Text Generator can make alarming writings which can panic others.
Evil Text Generator is the lone present content generator in the market which explicitly changes over the content into devil text. You can command the notice of your online media mates then Satanic Text Generators may be your best accomplice. And furthermore you can remark on your companion's photos or situations with a language which could just interpret and describe it.
Sinister Symbol has a few quantities of highlights that can change your content in uniqueness. There are just not many programming that gives you numerous choices to changing over your content into a large number of various Fonts and Satanic Text Generator is one of them. We should head towards the highlights of Satanic Text Generator, so here we go!
It offers you unique Font Size
The User Interface is simple
It has diverse composing style for example Shadow, Gold, White and Glowing Effects.
instructions to utilize evil content generator
enter your content or social name in the content box of sinister content generator , at that point click on the believer button , it will returns you evil style text. That is about sinister content, on the off chance that you folks have any inquiry with respect to this you can ping us. | limmedia |
669,540 | Import a File as a Raw String in Gatsby or React | ...and how to create advanced code snippets with Gatsby or React! | 0 | 2021-04-17T17:08:34 | https://dev.to/fullstackchris/import-a-file-as-a-raw-string-in-gatsby-or-react-10ad | gatsby, react, webpack, typescript | ---
title: Import a File as a Raw String in Gatsby or React
published: true
description: ...and how to create advanced code snippets with Gatsby or React!
tags: Gatsby,React,Webpack,TypeScript
cover_image: https://images.pexels.com/photos/4164418/pexels-photo-4164418.jpeg
---
# Right to the Example
The [fully working CodeSandbox is here](https://codesandbox.io/s/boring-surf-tqtkc). Later on in this post, you'll see step-by-step how it's possible to build such a component for your own blog posts or site!
# Why Did I Need to Import Files as a Raw String?
Some readers have may have already explored [my blog's snippets page](https://chrisfrew.in/snippets), where I've collected key snippets from across all my blog posts in the cleanest form possible. This was heavily inspired by [the snippets page on Josh Comeau's blog](https://www.joshwcomeau.com/snippets/).
I've added my own flair to my snippets page: I have snippets from all around the stack, including snippets from languages like C#, Python, and Node.js
I think the TypeScript / JavaScript toggler I built is particularly cool! Later in this post, we'll go through a tutorial on how you can implement your own language toggler.
If you check out [the repo for my blog](https://github.com/princefishthrower/chrisfrew.in), you'll see that I have a folder with each snippet actually as a normal code file in it's own language (`.py` for python, `.cs` for C#, `.ts` for TypeScript, and so on). As we'll see by the end of this post, I actually import each of these files as a raw string and then syntax highlight them using the [`prism-react-renderer`](https://github.com/FormidableLabs/prism-react-renderer) library.
# Walkthrough of My First (Failed) Attempt
As a walkthrough, let's assume we want to just render a single snippet, which will be a React hook, just a normal ol' TypeScript file (`.ts` extension), `useDidMount.ts`. The actual code of the hook itself is the following:
```ts
import { useState, useEffect } from 'react'
export const useDidMount = (): boolean => {
const [didMount, setDidMount] = useState<boolean>(false)
useEffect(() => {
setDidMount(true)
}, [])
return didMount
}
```
To try to render this file on my blog here, I tried first naïvely to import the file directly and just calling `toString()` on it. 😂 Observe this example component which does that:
```tsx
import * as React from "react"
import { useDidMount } from '../snippets/useDidMount';
const ExampleComponent = () => {
return (
<>
<p>useDidMount()</p>
<pre>{useDidMount.toString()}</pre>
</>
)
}
export default ExampleComponent
```
The result of this component ends up looking like this if you were actually to see this in browser:

Yeah... the original source code of the snippet has been transformed and become all Webpack-y. Not useful at all for the developer visiting the site who wants the clean snippet code!
So it's clear that we can't use the standard `import` method to import our code snippets for rendering.
**We need to import them as raw strings.**
# The Solution
The solution was more challenging to find than I thought. There _is_ a package, [gatsby-remark-embed-snippet](https://www.gatsbyjs.com/plugins/gatsby-remark-embed-snippet/), which helps you embed code snippets from a file in Gatsby, but that is a remark plugin intended only for use in markdown (or MDX) files, and anyway as of writing this, that package's dependencies were not yet upgraded to be compatible with Gatsby V3, which my blog is using. My snippets page is _not_ an `.md` or `.mdx` file; it's a typescript react component, in a `.tsx` file, and I didn't want to refactor the entire page to `.md` or `.mdx`.
So, with some searching, I first found [this Stackoverflow post about importing a CSS file in a raw fashion](https://stackoverflow.com/questions/55205774/how-to-import-a-css-file-in-a-react-component-as-raw-text), as the original poster was creating a WYSIWYG editor, and wanted to render the CSS exactly as it was written in the editor. In that post, I found the answer:
**You need to use `require` with Webpack's `raw-loader` to import files as a raw string!**
Following the `useDidMount` example we've been using, that would be:
```typescript
const useDidMount = require("!!raw-loader!./useDidMount");
```
We can then render this variable using `useDidMount.default.toString()`, for example in a `<pre>` tag:
```tsx
<p>useDidMount()</p>
<pre>{useDidMount.default.toString()}</pre>
```
This will render the snippet's source code in the browser exactly as it appears in its source file, looking like this:

Perfect! That's exactly what we want! Now it's just a matter of syntax highlighting the actual code string, and we're off!
I created [a Stack Overflow question for this, which I answered myself](https://stackoverflow.com/a/66832315/2805387), but it was downvoted for some reason. 😞 I'm not sure why - I think my solution is the only one that works if you want to import files as raw strings into a Gatsby project into a non-markdown or MDX file!
## The Fun Part: How I make those fancy TypeScript / JavaScript Togglers on the Snippets Page!
So, with the knowledge we've learned so far in this post, I'll now provide a tutorial of how I actually build those snippet togglers on my [snippets page](https://chrisfrew.in/snippets).
The name I chose for my snippet toggler component was... `SnippetToggler`! Essentially, we will need a label for what we want to call our snippet, the two file labels (one for javascript and one for TypeScript) and then the actual two code sources - which will come from the headache that was the whole `raw-loader` issue.
So, let's start with a skeleton of our component, setting up the interface contract for the props we will need:
```tsx
export interface ISnippetTogglerProps {
snippetLabel: string
fileLabels: Array<string>
typeScriptCode: string
javaScriptCode: string
}
export function SnippetToggler(props: ISnippetTogglerProps) {
return <></>
}
```
So far so good. The first thing we'll need to do is to pull off all the props:
```tsx
export interface ISnippetTogglerProps {
snippetLabel: string
fileLabels: Array<string>
typeScriptCode: string
javaScriptCode: string
}
export function SnippetToggler(props: ISnippetTogglerProps) {
const {
snippetLabel,
fileLabels,
typeScriptCode,
javaScriptCode
} = props
return <></>
}
```
Then let's think about the state we will need. We'll need a `boolean` state variable to let us know which of the two snippets to actually render. I called it `showJavaScript`. We'll then make use of an `activeModeText` and `className` which will help us change styles and the label when we toggle the snippet:
```tsx
export interface ISnippetTogglerProps {
snippetLabel: string
fileLabels: Array<string>
typeScriptCode: string
javaScriptCode: string
}
export function SnippetToggler(props: ISnippetTogglerProps) {
const {
snippetLabel,
fileLabels,
typeScriptCode,
javaScriptCode
} = props
const [showJavaScript, setShowJavaScript] = useState<boolean>(false)
const activeModeText = showJavaScript ? "JavaScript" : "TypeScript"
const className = activeModeText.toLowerCase()
return <></>
}
```
Let's then start to think about render markup. I save the TypeScript and JavaScript version of the code block as two seperate `const` variables respectively:
```tsx
export interface ISnippetTogglerProps {
snippetLabel: string
fileLabels: Array<string>
typeScriptCode: string
javaScriptCode: string
}
export function SnippetToggler(props: ISnippetTogglerProps) {
const {
snippetLabel,
fileLabels,
typeScriptCode,
javaScriptCode
} = props
const [showJavaScript, setShowJavaScript] = useState<boolean>(false)
const activeModeText = showJavaScript ? "JavaScript" : "TypeScript"
const className = activeModeText.toLowerCase()
const typeScriptBlock = (
<>
<code className={className}>{fileLabels[0]}</code>
<Pre
codeString={typeScriptCode}
language="typescript"
/>
</>
)
const javaScriptBlock = (
<>
<code className={className}>{fileLabels[1]}</code>
<Pre
codeString={javaScriptCode}
language="javascript"
/>
</>
)
return <></>
}
```
where the `<Pre/>` component is yet another react component (it's rather involved due to the fact that we need javascript based, not markdown based syntax highlighting - here I've left out various parts of my own `<Pre/>` component, like a copy button and showing confetti when it is clicked. I've also fixed the syntax highlighting theme as `github`, but there are many other themes to choose from. See [my `<Pre/>` component on the repository to explore the full one](https://github.com/princefishthrower/chrisfrew.in/blob/master/src/components/CodeCopyButton/Pre.tsx).
```tsx
import React from "react";
import Highlight, { defaultProps, Language } from "prism-react-renderer";
import github from "prism-react-renderer/themes/github";
export interface IPreProps {
codeString: string;
language: Language;
}
export const Pre = (props: IPreProps) => {
const { codeString, language } = props;
return (
<Highlight
{...defaultProps}
code={codeString}
language={language}
theme={github}
>
{({ className, style, tokens, getLineProps, getTokenProps }) => (
<pre
className={className}
style={{
...style,
padding: "2rem",
position: "relative",
overflowX: "scroll"
}}
>
{tokens.map((line, i) => (
<div {...getLineProps({ line, key: i })} style={style}>
{line.map((token, key) => (
<span {...getTokenProps({ token, key })} />
))}
</div>
))}
</pre>
)}
</Highlight>
);
};
```
Returning to our `<SnippetToggler/>` component, we can get to the `return` statement, adding in the actual switch component, and use the state variable `showJavaScript` to determine which of those `const` variables to render.
**We've arrived at the final version of our SnippetToggler component:**
```tsx
import * as React from "react";
import { useState } from "react";
import { Pre } from "./Pre";
export interface ISnippetTogglerProps {
snippetLabel: string;
fileLabels: Array<string>;
typeScriptCode: string;
javaScriptCode: string;
}
export function SnippetToggler(props: ISnippetTogglerProps) {
const { snippetLabel, fileLabels, typeScriptCode, javaScriptCode } = props;
const [showJavaScript, setShowJavaScript] = useState<boolean>(false);
const activeModeText = showJavaScript ? "JavaScript" : "TypeScript";
const className = activeModeText.toLowerCase();
const typeScriptBlock = (
<>
<code className={className}>{fileLabels[0]}</code>
<Pre codeString={typeScriptCode} language="typescript" />
</>
);
const javaScriptBlock = (
<>
<code className={className}>{fileLabels[1]}</code>
<Pre codeString={javaScriptCode} language="javascript" />
</>
);
return (
<>
<h3 className={className}>{snippetLabel}</h3>
<div>
<label className={`switch ${className}`}>
<input
type="checkbox"
onChange={() => setShowJavaScript(!showJavaScript)}
checked={showJavaScript}
/>
<span className="slider round" />
<span className="switch-text snippet">
{activeModeText} Mode Active
</span>
</label>
</div>
{showJavaScript ? javaScriptBlock : typeScriptBlock}
</>
);
}
```
**Nice, we're done! 🎉**
Here's the SCSS I have for the colors and switch used in our `<SnippetToggler/>`, if you're interested:
```scss
$typeScriptBlue: #2f74c0;
$javaScriptYellow: #efd81c;
$width: 50px;
$height: 27px;
$lightColor: #ffffff;
$darkColor: #191919;
.switch {
position: relative;
text-align: center;
display: inline-block;
height: $height;
& .switch-text {
margin-top: 1rem;
display: block;
}
& input {
opacity: 0;
width: 0;
height: 0;
}
& .slider {
width: $width;
position: absolute;
cursor: pointer;
top: 0;
left: 0;
right: 0;
bottom: 0;
background-color: $lightColor;
-webkit-transition: 0.4s;
transition: 0.4s;
margin: 0 auto;
}
& .slider:before {
position: absolute;
content: "";
height: 19px;
width: 20px;
left: 4px;
bottom: 4px;
background-color: $darkColor;
-webkit-transition: 0.4s;
transition: 0.4s;
}
& input:checked + .slider {
background-color: $darkColor;
}
& input:checked + .slider:before {
background-color: $lightColor;
}
& input:focus + .slider {
box-shadow: 0 0 1px $darkColor;
}
& input:checked + .slider:before {
-webkit-transform: translateX(22px);
-ms-transform: translateX(22px);
transform: translateX(22px);
}
/* Rounded sliders */
& .slider.round {
border-radius: $height;
}
& .slider.round:before {
border-radius: 50%;
}
}
.switch.typescript {
& .switch-text {
color: $typeScriptBlue;
}
& .slider {
background-color: $typeScriptBlue;
}
}
.switch.javascript {
& .switch-text {
color: $javaScriptYellow;
}
& input:checked + .slider {
background-color: $javaScriptYellow;
}
}
```
# Working Example
I've put up [a CodeSandbox](https://codesandbox.io/s/boring-surf-tqtkc) with the full code referenced in this blog post if you'd like to take a look and fool around with it yourself. The SCSS is the minimum working example, so of course it won't look _exactly_ like the togglers you see on my blog, but it's pretty close!
I still have future work planned for this component. Some ideas:
- `context` prop, where I can reference what blog post or posts that I've used or shown the snippet
- `description` prop that gives a brief overview of what the snippet does
- `usage` prop that shows the function being called in some realistic looking context
- `id` prop, so I can link to specific snippets, as I expect [the snippets page](https://chrisfrew.in/snippets) to get quite long
# Thanks!
As always, thanks for reading and I hope this post was useful to you! You now know how to import files as raw strings and do whatever you want with them in Gatsby and / or React!
Cheers! 🍻
-Chris
| fullstackchris |
669,689 | Flutter Provider Journey with Today App | Part 1 Use Provider to get data across the app 1 - Install Provider in .yaml fi... | 0 | 2021-04-17T20:27:41 | https://dev.to/valerianagit_83/flutter-provider-journey-with-today-app-i46 |
##Part 1
###Use Provider to get data across the app
1 - Install Provider in .yaml file and get packages
2 - Build mindmap of a simple Provider implementation
3 - Build mindmap for Todoey app and Provider implementation
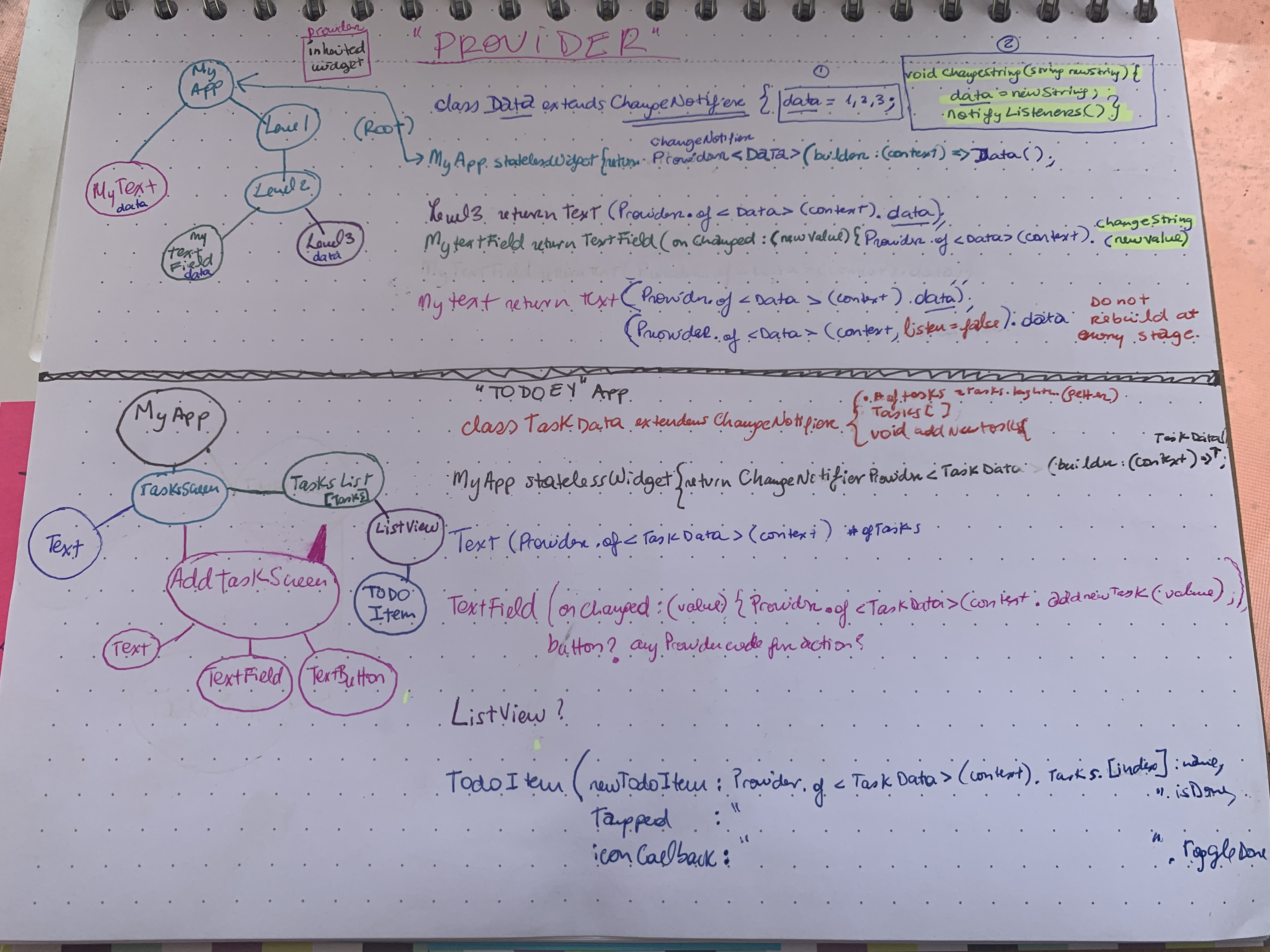
First areas of struggle -
* How to use Provider with ListView and its tiles(parts 3 and 4)
* Buttons updating state (part 2)
4 - Start writing code
###Create TaskData class
Properties tasks = []; (lift from tasks list)
Getter for taskCount
`int get taskCount {
return tasks.length;
}`
Void addNewTasks() { // addTask to list ; notifyListeners(); }
`void addNewTasks(String newTaskTitle) {
final task = Task(name: newTaskTitle);
tasks.add(task);
notifyListeners();
}`
###Update root to access data at highest level
Got an error The argument type 'Widget Function(BuildContext)' can't be assigned to the parameter type 'Widget Function(BuildContext, Widget).
Turns out using builder is deprecated and we must use create instead. (April 16/ 2021).
###Tasks Screen
Update Text widget to provide number of tasks
`'${Provider.of<TaskData>(context).tasks.length}',`
Comment out SetState in AddTaskScreen
Convert to stateless widget since we are no longer using `setState`
Update TaskListobject to not need any property constructors
###Tasks List
Import provider and task_data
Delete tasks property, won’t be needed anymore, the constructor is not needed either
Replace ToDoItem constructor data, depending on which property you are trying to access
`Provider.of<TaskData>(context).tasks[index].name`
Also comment out `setState`
Convert to stateless widget since we are no longer using setState
###The Consumer Widget from Provider
To not have to repeat all the places where `Provider.of<TaskData>(context).tasks[index].name` is going to be accessed.
Wrap highest level widget where these will be used
In our case in Tasks List is the List View widget
End up with this
`return Consumer<TaskData>(
builder: (context, taskData, child) {
Return ListView….;
},
child: ListView.builder(`
Now taskData can replace `Provider.of<TaskData>(context)`
##Part 2
Add Tasks to list functionality
###AddTasks Screen
Button
`onPressed: () {
//newValue comes from textfield input
Provider.of<TaskData>(context, listen: false)
.addNewTasks(newTaskTitle);
Navigator.pop(context);
},`
##Part 3
Functionality for tile’s state
###Task Data
`void updateTask(Task task) {
task.toggleDone();
}`
###Task Tile
Tasks List (nothing specific to Provider, except for the use of updateTask)
`final task = taskData.tasks[index];
return TodoItem(
newTodoItem: task.name,
tapped: task.isDone,
iconCallBack: (bool checkBoxState) {
TaskData().updateTask(task);
});`
With current setup, it should work, but Tasks Screen only updated when the button is pressed in the Add Tasks Screen. I think it is related to changes / updates in Provider. Related to that I had to set the listen: false . .. Maybe it is because we are using Consumer
SUCCESS! Because of changes made to the newer versions of Provider package, where we need to set the listen property to false. Even though we are inside Consumer, we still need to access updateTask calling through explicitly calling Provider to be able to set the listen property to false. This way the widget can rerender.
`final task = taskData.tasks[index];
return TodoItem(
newTodoItem: task.name,
tapped: task.isDone,
iconCallBack: (checkBoxState) {
Provider.of<TaskData>(context, listen: false)
.updateTask(task);
});`
##Part 4
###Delete Tasks
1 create new method in TaskData model to delete the task
`void deleteTask(Task task) {
_tasks.remove(task);
notifyListeners();
}`
2 - create a new callback in the TodoItem constructor
`final Function longPressCallBack;
TodoItem({this.newTodoItem, this.tapped, this.iconCallBack, this.longPressCallBack});`
3 - ListTile has a property - onLongPress, which is where we’ll call the new property in the constructor
`return ListTile(
onLongPress: longPressCallBack,`
4 - Update TodoItem constructor in the TasksList Widget
`longPressCallBack: () {
Provider.of<TaskData>(context, listen: false)
.deleteTask(task);
},);`
5 - The TaskScreen creates a new TasksList Widget as a child, so it should get all this information and update. DONE!
| valerianagit_83 | |
669,720 | FREE Magic Popup To Increase Signups By 50% ( Proven Working ) | A popup like this has helped Josh ( https://twitter.com/JoshWComeau ) to increase his email subscribe... | 0 | 2021-04-17T22:45:01 | https://dev.to/frontendor/free-magic-popup-to-increase-signups-by-50-proven-working-2bc6 | A popup like this has helped Josh ( https://twitter.com/JoshWComeau ) to increase his email subscribers, so he jumped **from 1,000 to 28,000 subscribers** in 1 year only. 😻
This popup is new and people are not used to seeing it! that's why it grabs and forces your visitors to pay attention to your offer.
👉 **HOW IT WORKS** 👈
While your visitor is scrolling down, your picture or illustration will show up suddenly so it grabs the attention immediately, and after 1 second it says:
" Hi, there! Can I share a cool thing I’m working on with you? ".
This question makes your visitor curious and will lead him to click on Yess.
You can use the Yess as a redirect to another page, on the same page, or to open your email form.
👉 **FEATURES** 👈
✅ It's FREE.
✅ **Simple Tool For Quick Customization.**
✅ Lightweight (Won't Make Your Website Slow).
✅ Developers-friendly (Clean Code).
✅ Suitable For Non-tech People (#NoCode).
✅ Use illustrations To Attract More Users Attention.
👉 Get it now for Free: https://frontendor.com/magic-popup/ | frontendor | |
688,776 | Why Vue is Better than React | Podcast | What is HTML All The Things HTML All The Things is a web development podcast and disco... | 0 | 2021-05-05T15:44:57 | https://dev.to/mikehtmlallthethings/why-vue-is-better-than-react-podcast-4e1g | vue, react, webdev, podcast | {% spotify spotify:episode:1mBcmfFFt9B5PgJMVBRqic %}
## What is HTML All The Things
HTML All The Things is a [web development podcast](https://podcast.htmlallthethings.com/) and [discord community](https://discord.com/invite/jweMCx9) which was started by Matt and Mike, developers based in Ontario, Canada.
The podcast speaks to web development topics as well as running a small business, self employment and time management. You can join them for both their successes and their struggles as they try to manage expanding their Web Development business without stretching themselves too thin.
## What's This One About?
In this episode Matt and Mike discuss Vue and React, two major web development tools that promise to improve UI development in their own unique ways. However, as a bit of a twist, the duo won't just be discussing these two JavaScript frameworks/libraries, instead Mike has taken the stance that Vue is better than React and will be presenting his case throughout the episode. Let the React versus Vue wars begin!
## Show Notes
5:20 - What is a reactive framework?
8:15 - Why Vue is better than React?
8:40 - Easier to get started with
22:28 - Better first party plugins
29:54 - Vue is more popular with developers
33:25 - Common counter points for React
34:30 - Larger talent pool for React
35:40 - React is built to scale
38:55 - More plugins/tools available
##Key Takeaways
* Vue is an easier framework to get started with and has the same if not better utility/functionality to React.
##Resources
[https://brainhub.eu/library/vue-vs-react/](https://brainhub.eu/library/vue-vs-react/)
##Social Links
You can find us on all the podcast platforms out there as well as
[Instagram (@htmlallthethings)](https://www.instagram.com/htmlallthethings/)
[Twitter (@htmleverything)](https://twitter.com/htmleverything)
[Facebook (Html All The Things)](https://www.facebook.com/htmlallthethings)
[Tiktok (htmlallthethings)](https://www.tiktok.com/@htmlallthethings?lang=en) | mikehtmlallthethings |
669,905 | How to Fix instanceof Not Working For Custom Errors in TypeScript | In JavaScript, you can create custom errors by extending the built-in Error object (ever since ES 201... | 0 | 2021-05-12T13:42:07 | https://www.dannyguo.com/blog/how-to-fix-instanceof-not-working-for-custom-errors-in-typescript | typescript | ---
title: How to Fix instanceof Not Working For Custom Errors in TypeScript
published: true
date: 2021-04-17 00:00:00 UTC
tags: typescript
canonical_url: https://www.dannyguo.com/blog/how-to-fix-instanceof-not-working-for-custom-errors-in-typescript
---
In JavaScript, you can create custom errors by extending the built-in [Error object](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Error) (ever since [ES 2015](https://en.wikipedia.org/wiki/ECMAScript#6th_Edition_%E2%80%93_ECMAScript_2015)).
```javascript
class DatabaseError extends Error {}
```
You can do the same thing in [TypeScript](https://www.typescriptlang.org/), but there is an important caveat if your `tsconfig.json` has a compilation [target](https://www.typescriptlang.org/tsconfig#target) of ES3 or ES5. In that case, `instanceof` doesn’t work, which breaks any logic that is based on whether or not an error is a case of the custom error.
```typescript
class DatabaseError extends Error {}
const error = new DatabaseError("Unique constraint violation");
// prints "true"
console.log(error instanceof Error);
// incorrectly prints "false"
console.log(error instanceof DatabaseError);
```
You can try [this out yourself](https://www.typescriptlang.org/play?target=1&ts=4.2.3#code/MYGwhgzhAEAiYBcwCNIFMCiAnLB7L0aAHgmgHYAmM2eBA3gL4BQTwuZEChO+0AvNDJoA7nEQp0NfAAoARAFUyASwCOAVzTQ2HBFjBKyXAG5Lc4BKbKyAlAG4WAegfQADlgMIYs3Rtmt2EGZoAHQguADm0mg8BAacYGTAaLgAZtBSWHZMTtAGbDhowAggAJ6u7oZeKWAgEGh+2oEgIWGR0bS5OglJqWJIqHUZdkA) in the TypeScript playground. This is a [known issue](https://github.com/microsoft/TypeScript/issues/13965) that started with [TypeScript version 2.1](https://github.com/Microsoft/TypeScript/wiki/Breaking-Changes#extending-built-ins-like-error-array-and-map-may-no-longer-work). The recommended fix is to manually set the prototype in the constructor.
```typescript
class DatabaseError extends Error {
constructor(message: string) {
super(message);
Object.setPrototypeOf(this, DatabaseError.prototype);
}
}
const error = new DatabaseError("Unique constraint violation");
// both print "true" now
console.log(error instanceof Error);
console.log(error instanceof DatabaseError);
```
Any custom errors which further extend `DatabaseError` still need the same adjustment.
```typescript
class DatabaseError extends Error {
constructor(message: string) {
super(message);
Object.setPrototypeOf(this, DatabaseError.prototype);
}
}
class DatabaseConnectionError extends DatabaseError {
constructor(message: string) {
super(message);
Object.setPrototypeOf(this, DatabaseConnectionError.prototype);
}
}
const error = new DatabaseConnectionError("Invalid credentials");
// all print "true"
console.log(error instanceof Error);
console.log(error instanceof DatabaseError);
console.log(error instanceof DatabaseConnectionError);
```
## Upgrade the Compilation Target
Remember that this is only an issue if your compilation target is ES3 or ES5. Instead of having to remember to set the prototype, you could consider upgrading your target to ES 2015 or even later. ES 2015 has [over 97% browser support](https://caniuse.com/es6), so it may be a reasonable choice for you, especially if you are okay with dropping support for Internet Explorer. | dguo |
670,484 | How to render conditionals to action view with application helpers in Ruby on Rails | PROBLEM: Writing if-else statements in your rails action view template does not look good or professi... | 0 | 2021-04-18T13:37:03 | https://dev.to/ashakae/how-to-render-conditionals-to-action-view-with-application-helpers-in-ruby-on-rails-4oj9 | ruby, rails, webdev | **PROBLEM**: Writing if-else statements in your rails action view template does not look good or professional. You can use partials but they are still __html.erb__ which still is an action view. Take a look at the code below;
##### menu.html.erb
```ERB
<% if controller_name == 'groups' && action_name == 'show' %>
<p class="font-bold mr-3 text-md"> <small class="font-medium mr-1">created by </small> <%= project.user.name %></p>
<% end %>
```
```ERB
<% 1.upto(20) do |i| %>
<li class="p-4 m-1">
<%= f.radio_button :icon, @icons[i]['link'], class: "focus:ring-secondary h-4 w-4 text-secondary border-gray-300" %>
<%= f.label :icon, value: @icons[i]['link'], class: "w-2 h-2 py-4" do %>
<img src="<%= @icons[i]['link']%>" alt="" class="w-14 h-14">
<% end %>
</li>
<% end %>
```
and
##### _partial.html.erb
```ERB
<% if logged_in? %>
<a href="/users/<%= current_user.id %>">
<% else %>
<a href="/">
<% end %>
```
A much cleaner solution would be to use the helper methods inside __application_helper.rb__ to render these conditionals.
Inside the helper file, create a method, set an empty string to a variable, and write your conditional statement like you would write it in ruby. Remove the erb tags and wrap HTML code in strings. Now push the string with your code into the variable and set it to _variable.html_safe_. example;
##### application_helper.rb
```Ruby
def show_proj_name(project)
content = ''
if controller_name == 'groups' && action_name == 'show'
content << "<p class='font-bold mr-3 text-md'>
<small class='font-medium mr-1'>
created by </small> #{project.user.name} </p>"
end
content.html_safe
end
def show_icons(ico)
content = ''
1.upto(20) do |i|
content << "<li class='p-4 m-1'>
#{ico.radio_button :icon, @icons[i]['link'], class: 'focus:ring-secondary h-4 w-4 text-secondary border-gray-300'}"
content << "#{ico.label :icon, value: @icons[i]['link'], class: 'w-2 h-2 py-4' do
image_tag(@icons[i]['link'], class: 'w-14 h-14')
end}"
content << '</li>'
end
content.html_safe
end
end
def navlink(*)
content = ''
content << if logged_in?
"<a href='/users/ #{current_user.id}'>"
else
"<a href='/'>"
end
content.html_safe
end
```
Because they're functions that need to be run, you call them directly in the action view with the erb tags that executes ruby code __<%= %>__. see the finished result;
##### menu.html.erb
```ERB
<%= show_proj_name(project) %>
```
<small>
<strong>N.B. </strong> *f is passed as an argument because, in the action view, the form was built with that variable.*
</small>
```ERB
<%= show_icons(f) %>
```
##### _partial.erb
```ERB
<%= navlink(logged_in?) %>
```
**Conclusion**
You can now see less bulky and much cleaner code in your action views and, focus on writing more HTML code.
Thanks for reading. | ashakae |
670,495 | Appliquez des filtres sur vos vidéos avec Javascript | Appliquez des filtres sur vos vidéos avec Javascript Que ce soit pour améliorer la netteté... | 0 | 2021-05-11T16:54:20 | https://www.qphi.dev/posts/appliquez-des-filtres-videos-avec-javascript | javascript, tutorial, french, imageprocessing | ---
canonical_url: https://www.qphi.dev/posts/appliquez-des-filtres-videos-avec-javascript
---
# Appliquez des filtres sur vos vidéos avec Javascript
Que ce soit pour améliorer la netteté d'une image, rehausser sa luminosité, modifier la répartition des couleurs, ou pour des centaines de raisons toutes aussi fondées, la plupart des images affichées par nos écrans subissent de nombreux traitements.
En règle générale, ces corrections s'appliquent avant l'enregistrement des images sous forme de fichier (pour des raisons d'optimisations évidentes). Cela dit, il est parfois nécessaire d'appliquer des filtres sur un contenu vidéo en temps réel.
## Comment retoucher des images à la volée ?
Je vous propose une solution très simple permettant d'effectuer ces traitements directement depuis notre navigateur.
Cette méthode peut se résumer ainsi :
- Intégrer une vidéo la page, grâce à la balise `<video>` (idéalement en caché)
- Récupérer son flux vidéo dans un objet `ImageData`
- Effectuer le traitement de l'image dessus
- Afficher le résultat dans une balise `<canvas>`.
### Intégrer une vidéo à la page
```html
<video
id="tuto-video"
src="your-video-url"
width="300"
height="300"
controls
></video>
```
### Récupération du flux vidéo en JS
Si vous vous êtes déjà intéressés à l'**encodage des vidéos**, vous savez qu'obtenir un flux de pixels à partir d'un fichier est une tâche complexe. Pour parser les fichiers vidéos, maîtriser les différents formats est un indispensable.
*« - Alors, nous allons devoir apprendre tous les formats vidéos pour continuer ? »* 😨
Non, revenez ! Le navigateur s'occupe de tout !
Avec la balise `<video>`, extraire les pixels d'une vidéo se fait en seulement quelques lignes :
```js
const video = document.getElementById('tuto-video');
// Create canvas for video's pixel extraction
const extractPixelCanvas = document.createElement('canvas');
const extractPixelContext = extractPixelCanvas.getContext('2d');
/**
* @param {HTMLVideoElement} video
* @param {Number} width
* @param {Number} height
* @return {ImageData} the pixel matrix
*/
function extractVideoImageData(video, width, height) {
// avoid unnecessary resize as much as possible (optimization)
if (extractPixelCanvas.width !== width) {
extractPixelCanvas.width = width;
}
if (extractPixelCanvas.height !== height) {
extractPixelCanvas.height = height;
}
extractPixelContext.drawImage(video, 0, 0, extractPixelCanvas.width, extractPixelCanvas.height);
return extractPixelContext.getImageData(0, 0, extractPixelCanvas.width, extractPixelCanvas.height);
}
```
### Manipuler ses pixels avec `ImageData`
Pour afficher le contenu d'une matrice de pixel sur un écran, il suffit de l'injecter dans un contexte canvas :
```js
canvasContext2D.putImageData(instanceOfImageData, 0, 0);
```
#### Quelques explications sur la classe `ImageData`
La structure de l'objet est relativement simple :
* une instance possède les propriétés `width` et `height`correspondant à la résolution de l'image.
* Les pixels sont stockés dans la propriété `data`, une matrice de type `Uint8ClampedArray`.
* Les pixels sont encodés sous forme `RGBA`. L'*alpha* est compris entre 0 et 255.
Pour modifier une image à la volée, on modifiera les pixels contenus dans `data`.
Un exemple tiré de [la documentation](https://developer.mozilla.org/en-US/docs/Web/API/ImageData/ImageData).
```js
// Iterate through every pixel
for (let i = 0; i < imageData.data; i += 4) {
imageData.data[i + 0] = 0; // R value
imageData.data = 190; // G value
imageData.data = 0; // B value
imageData.data // A value
}
```
### Afficher une image retouchée dans un `<canvas>`
```html
<!--html-->
<canvas id="tuto-canvas"></canvas>
```
```js
//js
const canvas = document.getElementById('tuto-canvas');
canvasContext2D = canvas.getContext('2d');
const instanceOfImageData = applyYourAmazingFilter(/* ... */);
canvasContext2D.putImageData(instanceOfImageData, 0, 0);
```
## Un filtre, oui ; mais aussi une animation !
L'utilisation d'un filtre sur un flux vidéo est considérée (ici) comme une **animation**.
L'implémentation du filtre et la modification des pixels font office de **méthode de rendu**, tandis que la synchronisation entre le canvas et le lecteur vidéo déterminera le comportement de la **boucle de rendu**.
Ces termes vous paraissent abstraits ? J'ai écrit un tutoriel sur ce sujet : [Faîtes vos propres animations en JS](https://dev.to/qphilippot/faites-vos-propres-animations-en-js-34ok).
### Synchroniser l'animation avec le lecteur vidéo - Définir la boucle de rendu
L'animation doit se lancer lorsqu'on clique sur play, s'arrêter à la fin de la vidéo ou quand appuie sur pause (pour ne pas rafraîchir une image qui ne change pas, ce serait dommage de gâcher des ressources CPU pour rien).
En d'autres termes, la boucle de rendu doit être pilotée par le lecteur vidéo.
Pour rappel, la **boucle de rendu** s'occupe de rafraîchir automatiquement notre canvas.
```js
const animation = new Animation({ /* … */ });
video.addEventListener('play', () => {
animation.play();
});
video.addEventListener('pause', () => {
animation.pause();
});
video.addEventListener('end', () => {
animation.pause();
});
// render animation once when we click on timeline
video.addEventListener('timeupdate', () => {
animation.askRendering()
});
```
### Implémentation d'un filtre - Définir une méthode de rendu
Nous savons désormais comment extraire les pixels d'une vidéo et configurer la boucle de rendu. Il ne reste plus qu'à définir la méthode de rendu.
```js
const animation = new Animation({
canvas: document.getElementById('tuto-canvas'),
// rendering method is here
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
// apply filter over imageData here;
animation.clear();
context.putImageData(imageData, 0, 0);
}
}
);
```
Ce tutoriel s'appuie sur une connaissance rudimentaire des `canvas`. Besoin d'une piqûre de rappel ? Cet [article](https://developer.mozilla.org/en-US/docs/Web/API/Canvas_API/Tutorial/Pixel_manipulation_with_canvas) est un classique, de plus, il montre comment appliquer des filtres sur des images. Il constitue un excellent complément à ce tuto. N'hésitez pas à y jeter un œil ! 👍
## Résumé
```js
import Animation from '../../shared/animation.model';
document.addEventListener('DOMContentLoaded', () => {
// Create canvas for video's pixel extraction
const extractPixelCanvas = document.createElement('canvas');
const extractPixelContext = extractPixelCanvas.getContext('2d');
function extractVideoImageData(video, width, height) {
// avoid unnecessary resize as much as possible (optimization)
if (extractPixelCanvas.width !== width) {
extractPixelCanvas.width = width;
}
if (extractPixelCanvas.height !== height) {
extractPixelCanvas.height = height;
}
extractPixelContext.drawImage(video, 0, 0, extractPixelCanvas.width, extractPixelCanvas.height);
return extractPixelContext.getImageData(0, 0, extractPixelCanvas.width, extractPixelCanvas.height);
}
const video = document.getElementById('tuto-video');
const animation = new Animation({
canvas: document.getElementById('tuto-canvas'),
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
// apply filter over imageData here;
animation.clear();
context.putImageData(imageData, 0, 0);
}
});
video.addEventListener('play', () => {
animation.play();
});
video.addEventListener('pause', () => {
animation.pause();
});
video.addEventListener('end', () => {
animation.pause();
});
video.addEventListener('timeupdate', () => {
animation.askRendering()
})
});
```
## Résultat préliminaire

*« - Hein ? Je ne vois aucune différence… »* 🙈
Précisément ! Nous n'avons encore appliqué aucun filtre. Toutefois, on constate que notre flux vidéo est bel et bien répliqué sans déformation ni latence.
Pour appliquer un filtre sur l'image, il suffira d'**appliquer un traitement sur l'`ImageData`** extraite dans la méthode de rendu.
Ce tutoriel pourrait s'arrêter là ; le mécanisme n'est guère plus compliqué. Toutefois, cela commence à peine à devenir cool, ne nous arrêtons pas en si bon chemin !
# Exemple d'implémentation de filtres en JS
## Grayscale
Nous allons simplement transformer les pixels `RGB` en niveau de gris.
```js
// get grayscale value for a pixel in buffer
function rgbToGrayscale(buffer, offset) {
return Math.ceil((
0.30 * buffer[offset] +
0.59 * buffer[offset + 1] +
0.11 * buffer[offset + 2]
) * (buffer[offset + 4] / 255.0));
}
/**
* @param {Uint8Array} pixelBuffer
*/
function applyGrayscaleFilter(pixelBuffer) {
for (let offset = 0; offset <pixelBuffer.length; offset += 4) {
const grayscale = rgbToGrayscale(pixelBuffer, offset);
pixelBuffer[offset] = grayscale;
pixelBuffer[offset + 1] = grayscale;
pixelBuffer[offset + 2] = grayscale;
pixelBuffer[offset + 3] = 255;
}
}
const animation = new Animation({
canvas: document.getElementById('tuto-canvas'),
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
applyGrayscaleFilter(imageData.data);
animation.clear();
context.putImageData(imageData, 0, 0);
}
});
```
Nous remplaçons les canaux RGB de chaque pixel par leur niveau de gris.
Intuitivement, il serait tentant de calculer une moyenne des composantes `R`, `G` et `B` et d'utiliser cette valeur comme niveau de gris. Toutefois, l'œil humain ne perçoit pas toutes les couleurs avec la même sensibilité. Et puisque nous sommes plus sensibles à certaines couleurs, il est tout naturel de donner plus d'importances à celles-ci lors du calcul du niveau de gris.
Cela explique la présence des constantes `0.30`, `0.59` et `0.11` dans la méthode `rgbToGrayscale`. L'intensité obtenue par cette méthode est appelée la **luminance** du pixel.

## Supporter les interactions souris
Une animation, c'est bien. Mais une animation qui interagit avec la souris, c'est mieux ! Transformons le code afin d'invoquer `applyGrayscaleFilter` seulement quand le pointeur se trouve au dessus du canvas.
```js
const animation = new Animation({
canvas: document.getElementById('tuto-canvas'),
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
// compute isPointerHoverCanvas ...
if (isPointerHoverCanvas === false) {
applyGrayscaleFilter(imageData.data);
}
animation.clear();
context.putImageData(imageData, 0, 0);
}
});
```
### Déterminer la position de la souris par rapport au canvas
Il existe plusieurs façons de déterminer si le curseur est au-dessus d'un canvas. Selon l'approche, certaines sont plus appropriées que d'autres.
Dans cette situation, la plus simple consiste à :
* Récupérer les coordonnées du canvas.
* Calculer sa **boîte englobante** (ou **hitbox**)
* Vérifier si les coordonnées du pointeur se trouvent dans la boîte englobante ([collision AABB](https://developer.mozilla.org/en-US/docs/Games/Techniques/3D_collision_detection#point_vs._aabb)).
```js
const pointerCoords = {x: 0, y: 0};
document.addEventListener('pointermove', event => {
pointerCoords.x = event.clientX;
pointerCoords.y = event.clientY;
});
const animation = new Animation({
canvas: document.getElementById('tuto-canvas'),
render: (context, canvas) => {
// …
const boundingBox = canvas.getBoundingClientRect();
const isPointerHoverCanvas = (
pointerCoords.x >= boundingBox.left &&
pointerCoords.y >= boundingBox.top &&
pointerCoords.x < boundingBox.right &&
pointerCoords.y < boundingBox.bottom
);
if (isPointerHoverCanvas === false) {
applyGrayscaleFilter(imageData.data);
}
}
});
```

## On corse le jeu ! 🚀
On va appliquer le filtre grayscale sur toute l'image et ne faire apparaître les couleurs que sur les pixels autour de notre curseur.
Petite subtilité : pour créer un effet plus lisse, on déterminera un cercle à l'intérieur duquel les pixels seront colorés, mais avec une intensité inversement proportionnelle à la distance au centre…
### Rappel géométrique
Un cercle peut être défini par un point (son centre), et un rayon. Dans notre cas, le centre du cercle correspond à la position du pointeur. Quant au rayon, nous prendrons une valeur arbitraire.
Déterminer si un point est dans un cercle revient à calculer la **collision entre un point et un cercle**.
Pour en savoir plus sur les méthodes de collision : http://www.jeffreythompson.org/collision-detection/point-circle.php
### Approche générale
Pour chaque pixel, vérifions s'il est à l'intérieur du cercle autour du pointeur. Afin de faciliter le calcul, nous allons nous placer dans le *repère géométrique de notre canvas*. Les coordonnées ne seront plus exprimées en fonction de la page, mais de l'élément `<canvas>`.
```js
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
const coordsRelativeToCanvas = PointerCoordsHelper.getCoordsRelativeToElement(
canvas,
pointerCoords.x,
pointerCoords.y
);
const buffer = imageData.data;
// apply to the whole buffer, execept a circle defined by pointer position
for (let offset = 0; offset < buffer.length; offset += 4) {
const pixelOffset = (offset / 4); // pixels have 4 channel in ImageData
const pixelX = pixelOffset % canvas.width;
const pixelY = pixelOffset / canvas.width;
// arbitrary radius
const radius = 50;
const isInCircle = CollisionHelper.isPointInCircle(
pixelX, pixelY,
coordsRelativeToCanvas.x, coordsRelativeToCanvas.y,
radius
);
const grayscale = rgbToGrayscale(buffer, offset);
if (isInCircle === false) {
buffer[offset] = grayscale;
buffer[offset + 1] = grayscale;
buffer[offset + 2] = grayscale;
buffer[offset + 3] = 255;
} else {
const distance = GeometryHelper.getDistanceBetween2DPoints(
pixelX, pixelY,
coordsRelativeToCanvas.x, coordsRelativeToCanvas.y
);
const weight = distance / radius;
// apply a weight in order to let color intensity increase from the outside to the center
buffer[offset] = weight * grayscale + (1 - weight) * buffer[offset];
buffer[offset + 1] = weight * grayscale + (1 - weight) * buffer[offset + 1];
buffer[offset + 2] = weight * grayscale + (1 - weight) * buffer[offset + 2];
buffer[offset + 3] = 255;
}
}
animation.clear();
context.putImageData(imageData, 0, 0);
}
```

<details>
<summary>⚠️ Remarque sur le calcul de coordonnées (Niveau avancé) ⚠️</summary>
La position du curseur est exprimée relativement à notre canvas (l'origine du repère mathématique est le coin supérieur gauche du canvas).
On aurait pu implémenter le filtre en utilisant directement les coordonnées du pointeur dans la fenêtre (repère standard), mais les équations auraient étés plus compliquées.
De plus, la résolution du canvas (*pixel théorique*) et sa taille (*pixel physique*) peuvent parfois varier. Puisque l'algorithme itère sur les pixels théoriques du canvas (`animation.context.width` ou `animation.canvas.width`), pour supporter correctement ce type de situation, il faudra modifier les équations pour prendre en compte ce changement de repère supplémentaire…
</details>
## Sa vision est basée sur le mouvement ! 🦖
Le filtre implémenté dans cet exemple n'affichera que les mouvements perceptibles entre deux frames.
*« - Calculer les mouvements ? Ça à l'air difficile, non ? »*
Tout dépend ce que l'on appelle *mouvement*. Pour notre exemple, calculer la différence deux pixels entre deux frame est largement suffisant !
Le principe pour calculer le mouvement entre deux frame N-1 et N :
* Calculer le niveau de gris de la frame N-1
* Calculer le niveau de gris de la frame N
* Créer une image en niveau de gris correspondant à la valeur absolue de la différence des niveaux de gris des frame N et N - 1
Parce qu'un code vaut mieux que mille mots :
```js
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
const buffer = imageData.data;
applyGrayscaleFilter(buffer);
// first rendering
if (lastBuffer === null) {
lastBuffer = buffer.slice(0);
window.lastBuffer = lastBuffer;
return;
}
// compute movement
const diffBuffer = new Uint8Array(buffer.length);
for (let offset = 0; offset < buffer.length; offset += 4) {
diffBuffer[offset] = Math.abs(buffer[offset] - window.lastBuffer[offset]);
diffBuffer[offset + 1] = Math.abs(buffer[offset + 1] - window.lastBuffer[offset + 1]);
diffBuffer[offset + 2] = Math.abs(buffer[offset + 2] - window.lastBuffer[offset + 2]);
diffBuffer[offset + 3] = 255;
}
// update "last" buffer
window.lastBuffer = buffer.slice(0);
// overwrite image data in order to browse only the differences between the two frames
diffBuffer.forEach((value, index) => {
imageData.data[index] = value;
});
animation.clear();
context.putImageData(imageData, 0, 0);
}
```

*« - Mouais, avouons que c'est pas terrible... »* 😞
En effet, on peut mieux faire ! Néanmoins, concentrons-nous sur le positif : nous avons un début de quelque chose !
Nous parvenons à déceler les **contours** du perroquet lorsqu'il effectue un mouvement. Mais ses déplacements sont lents, peu perceptibles d'une frame sur l'autre.
De plus, le **taux de rafraichissement** étant relativement élevé (60 fps), nous effectuons un rendu approximativement toutes les 16ms. Les mouvements ne sont donc perceptibles que durant ce laps et temps et sont oubliés au rendu suivant.
Sachant que la **persistance rétinienne** est de l'ordre de 1/25 de secondes (40 ms), pour avoir un rendu plus fidèle, il faudrait garder en mémoire l'image des 40 dernières ms, et les prendre en compte dans notre calcul du mouvement.
### Amélioration simple
Plutôt que de se lancer dans un calcul périlleux sur le taux de rafraîchissement optimal, nous allons opter pour une solution bête et méchante : calculer le mouvement en prenant en compte, non pas la dernière frame, mais les X dernières frames.
```js
function computeMovement(target, newFrame, oldFrame) {
let offset = 0;
const length = newFrame.length;
// another version of for-loop to compute movement
while (offset < length) {
target[offset] = Math.abs(newFrame[offset] - oldFrame[offset]);
target[offset + 1] = Math.abs(newFrame[offset + 1] - oldFrame[offset + 1]);
target[offset + 2] = Math.abs(newFrame[offset + 2] - oldFrame[offset + 2]);
offset += 4;
}
}
/**
* check previous frame difference and apply a weight
* @return Uint8Array buffer with some extra movement pixel to add
*/
function computePersistance(buffer) {
/*** @var {Number} historyLength is a global var, it's the number of frame to consider ***/
let indexedHistoryBuffer = Array(historyLength);
let weights = Array(historyLength);
for (let k = 0; k < historyLength; k++) {
indexedHistoryBuffer[k] = getHistoryBuffer(k);
weights[k] = state.persistanceFactor * (k / historyLength);
}
const length = buffer.length;
let pixelOffset = 0;
let historyBufferOffset, historyBuffer;
let c1, c2, c3, c4;
while (pixelOffset < length) {
c1 = pixelOffset;
c2 = c1 + 1;
c3 = c2 + 1;
c4 = c3 + 1;
buffer[pixelOffset] = 0;
buffer[c2] = 0;
buffer[c3] = 0;
buffer[c4] = 255;
historyBufferOffset = historyLength - 1;
while (historyBufferOffset >= 0) {
historyBuffer = indexedHistoryBuffer[historyBufferOffset];
buffer[pixelOffset] += weights[historyBufferOffset] * historyBuffer[pixelOffset];
buffer[c2] += weights[historyBufferOffset] * historyBuffer[c2];
buffer[c3] += weights[historyBufferOffset] * historyBuffer[c3];
historyBufferOffset--
}
pixelOffset++;
}
}
```
**Remarques :**
* Afin d'appliquer notre *facteur de persistance* on se base directement sur les différences calculées lors des rendus précédents.
* Pour éviter d'instancier une trop grande quantité de buffers, nous utilisons un pool d'instances que nous gérons grâce à `getHistoryBuffer`
```js
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
const buffer = imageData.data;
applyGrayscaleFilter(buffer);
// first rendering
if (lastBuffer === null) {
lastBuffer = buffer.slice(0);
window.lastBuffer = lastBuffer;
return;
}
const diffBuffer = new Uint8Array(buffer.length);
const persistanceBuffer = new Uint8Array(buffer.length);
computeMovement(diffBuffer, buffer, window.lastBuffer);
computePersistance(persistanceBuffer);
shallowCopy(lastBuffer, buffer);
// clamp sum of diffs
for (let offset = 0; offset < buffer.length; offset += 4) {
buffer[offset] = Math.ceil(Math.min(255, diffBuffer[offset] + persistanceBuffer[offset]));
buffer[offset + 1] = Math.ceil(Math.min(255, diffBuffer[offset + 1] + persistanceBuffer[offset + 1]));
buffer[offset + 2] = Math.ceil(Math.min(255, diffBuffer[offset + 2] + persistanceBuffer[offset + 2]));
buffer[offset + 3] = 255;
}
let currentHistoryBuffer = diffHistory[state.currentOffset];
shallowCopy(currentHistoryBuffer, diffBuffer);
state.currentOffset = nbFrameRendered % historyLength;
animation.clear();
context.putImageData(imageData, 0, 0);
}
```
**Remarques :**
* Lorsqu'on additionne des buffers, ne pas oublier d'effectuer un **clamp** afin de s'assurer que les valeurs additionnées restent dans l'intervalle des valeurs autorisées par la structure de donnée (entre 0 et 255).
* La méthode `shallowCopy` se contente d'effectuer une **copie superficielle** d'un tableau dans un autre tableau. Le but est de réutiliser les instances existantes et d'éviter la répétition de code. Son implémentation est triviale et disponible sur le [git](https://github.com/qphilippot/tuto/blob/master/apply-filter-on-video/).

Voici une tentative se basant sur les 5 dernières frames, avec coefficient équivalent à 15. Si les mouvements sont davantages perceptibles, le coût en calcul lui est nettement plus élevé. On passe de 60 fps à un peu plus de 20 fps. Rien de plus normal, on a presque triplé la charge de travail.
Il existe des méthodes permettant d'obtenir un résultat plus propre et moins gourmant en calcul, mais également moins simple à expliquer 😁.
Puisque le but de cet article est de présenter des filtres simples, je les passe sous silence. Cela fera peut-être l'objet d'un prochain tutoriel.
## La vie en bleu 🦜
Dans ce dernier exemple, je propose de teindre ce cher perroquet en bleu.
Pour atteindre notre objectif, considérons la couleur de son plumage d'origine. Il n'est pas simplement rouge, mais couvre une nuance de rouge. Le filtre devra prendre en compte toutes ces nuances, pour proposer un rendu réaliste prenant en compte la pigmentation naturelle des plumes ainsi que les variations de luminosité.
### Rappel sur la représentation de la couleur
La représentation des couleurs dans les `ImageData` est en `RGBA`. En d'autres termes, la couleur finale est obtenue à partir d'un mélange des quatre composantes.
Une solution naïve consisterait à supprimer la dimension rouge (mettre toutes les intensités à 0). Le défaut de cette représentation (`RGBA`), toutes les couleurs ont une part contiennent une part de rouge. Autrement dit, si l'on modifie la composante `R`, quasiment toutes les couleurs seront impactées.
Bonne nouvelle : il existe énormément d'espaces couleurs et dont la plupart ne sont pas couplés à la couleur rouge ! Des formules mathématiques permettent de changer facilement de représentation, il n'y a donc aucune raison de se borner à ce bon vieux `RGB`.
Selon le cas d'usage, certains espaces couleurs sont plus pratiques que d'autres (`YCrCb` pour la compression, `CMJN` pour l'impression, etc).
Dans le cas présent, l'ensemble `HSL` *Hue Saturation Lightness*, ou `TSV` en français semble le plus approprié. Dans cet espace, la **teinte** des couleurs est définie via un cercle colorimétrique.
Pour transformer du "rouge" en "bleu", il suffit de déterminer une section du cercle que l'on souhaite remplacer et d'y coller la section par laquelle on souhaite le remplacer.

### Principe du filtre
* Récupérer la couleur des pixels `RGBA`.
* Les convertir en `HSL`.
* Manipuler les teintes *rouges* et les remplacer par des *bleues*.
* Reconvertir en `RGBA`.
* Remplir l'instance `ImageData` avec les pixels modifiés.
### Implémentation
Concernant les fonctions de transformations `HSL` vers `RGBA` et réciproquement, je vous laisse checker le [git](https://github.com/qphilippot/tuto/blob/master/apply-filter-on-vide).
Pour des raisons de performances, nous allons implémenter une **Look Up Table (*LUT*)**, c'est-à-dire une table de correspondance pour toutes nos couleurs. L'enjeu est de ne pas calculer toutes les correspondances de couleurs à la volée (pixels par pixels à chaque rendu), mais de les calculer une bonne fois pour toutes au lancement de la page.
La méthode de rendu n'aura qu'à lire dans cette LUT pour y lire les résultats et gagner un temps précieux (et un meilleur frame rate).
#### Calcul de la LUT
```js
function generateRedToBlueLUT() {
const size = 16777216; // 256 * 256 * 256
const lut = new Array(size);
// initialize all colors to black
for (let i = 0; i < size; i++) {
lut[i] = [0, 0, 0];
}
// iterate through RGB combinaisons
for (let redOffset = 0; redOffset < 256; redOffset++) {
for (let greenOffset = 0; greenOffset < 256; greenOffset++) {
for (let blueOffset = 0; blueOffset < 256; blueOffset++) {
// Use a pool design pattern
// If you want to implements it without object pool, juste replace it by [0, 0, 0]
const rgb = vec3Pool.getOne();
const hsl = vec3Pool.getOne();
rgb[0] = redOffset;
rgb[1] = greenOffset;
rgb[2] = blueOffset;
// color conversion, check sources for detailled implementation
rgbToHSL(rgb, hsl);
// Clamp saturation and lightness
hsl[1] = Math.max(0, Math.min(hsl[1], 1));
hsl[2] = Math.max(0, Math.min(hsl[2], 1));
// Here is the trick: hue is represented by a degree angle
// We want : 0 <= hue < 360
if (hsl[0] < 0) {
hsl[0] += 360;
}
hsl[0] = hsl[0] % 360;
// Assume that :
// - "red" hues are between 340° and 20°
// - "blue" are between 140° and 220°
// replace hue
if (hsl[0] > 340 && hsl[2] < 0.85) {
hsl[0] -= 120;
}
else if (hsl[0] < 20 && hsl[2] < 0.85) {
hsl[0] += 240;
}
// sanitize angle : 0 <= hue < 360
if (hsl[0] < 0) {
hsl[0] += 360;
}
hsl[0] = hsl[0] % 360;
hslToRGB(hsl, rgb);
// store RGBA converted into lut
lut[redOffset * 65536 + greenOffset * 256 + blueOffset] = Array.from(rgb);
// recycle instance, only for object pool implementation
vec3Pool.recycle(rgb);
vec3Pool.recycle(hsl);
}
}
}
return lut;
}
window.lut = generateRedToBlueLUT();
```
Plusieurs remarques sur cette implémentation :
* Notre LUT est un tableau. On calcule l'index de chaque couleur par la formule `R * 255 * 255 + G * 255 + B`
* Pour des raisons de performances, on utilise un object pool design pattern. Le calcul d'une LUT demande d'instancier pas mal de petits tableaux, cela peut surcharger inutilement la mémoire du navigateur. Pour en savoir plus sur l'implémentation de l'object pool design pattern en JS, lisez l'article suivant : [Optimisez vos applications JS avec l'Object Pool Design Pattern !](https://dev.to/qphilippot/optimisez-vos-applications-js-avec-l-object-pool-design-pattern-3g8)
* Les calculs d'angles sont empiriques, à partir du cercle colorimétrique. D'ailleurs, en regardant attentivement le rendu, on peut s'apercevoir que la "teinture" n'est pas parfaite et que quelques pointes de rouges se promènent ça et là 😉
#### Coup d'oeil sur la méthode de rendu
```js
render: (context, canvas) => {
const imageData = extractVideoImageData(video, canvas.width, canvas.height);
const buffer = imageData.data;
for (let offset = 0; offset < buffer.length; offset += 4) {
const r = buffer[offset];
const g = buffer[offset + 1];
const b = buffer[offset + 2];
// 65536 = 256 * 256
const lutIndex = r * 65536 + g * 256 + b;
// just replace color by pre-computed value
const color = window.lut[lutIndex];
buffer[offset] = color[0];
buffer[offset + 1] = color[1];
buffer[offset + 2] = color[2];
buffer[offset + 3] = 255;
}
animation.clear();
context.putImageData(imageData, 0, 0);
}
```
Et voici un beau perroquet haut en couleur ! :D

## Conclusion
J'espère sincèrement que ce tutoriel vous a plu. Le principe derrière l'utilisation de filtres en live est assez simple à implémenter, mais nécessitait bien selon moi quelques exemples pour comprendre son utilisation. Je suis passé assez rapidement sur certains points pour éviter de dévier du sujet principal : ~~torturer ce pauvre oiseau~~ utiliser une boucle de rendu pour appliquer des filtres en temps réels.
N'hésitez pas à me faire part de vos commentaires ou de vos remarques, c'est toujours un plaisir 😉
*Photo de couverture créée par* [Anthony](https://www.pexels.com/@inspiredimages) | qphilippot |
670,537 | # The Great Merge Hexagram 44 | A precautionary tale that many of you may experience(d). A project manager with more money than se... | 0 | 2021-04-18T14:58:19 | https://dev.to/nigel447/the-great-merge-hexagram-44-4bb2 | microservices, management, consutlant, psychology |
A precautionary tale that many of you may experience(d).
- A project manager with more money than sense and no technical expertise.
- A distributed development team with little in common in terms of language and communication.
- Teams trapped in DSL, obsessed with micro goals and oblivious to the wider picture.
You have been invited in to help move the project forward and introduced to the type of code so common to this dysfunctional environment. Countless feature branches with nothing merged.
Working with the teams, pruning branches merging and setting clear well defined goals. Trying to communicate between the developers and the project manager.
I had a bad feeling, so I asked the oracle and received [44](https://www.iching-hexagrams.com/summer-light/hexagram-44/hexagram-44-text/).
This was good advice. I had become infected by the chaos, I was to controlling, trying to channel the whirlwind of commits. I stopped, stood back, put myself in the place of the devs, "What good is strength if no one cares?", "After breathing in, one pauses for a moment.", "Amidst the hustle and bustle sensitivity emerges."
I focused on sensitivity and the devs started to respond, a shared sense of ownership began to emerge, spontaneous merge policies and the code begins to build correctly.
I am left to consider this most important question "You may be driving the chariot, But who or what drives you?" | nigel447 |
670,542 | BMI Calculator [Version - 1.0] | So basically this is my project named BMI calculator with some useful features in version 1.0... I m... | 12,366 | 2021-04-18T15:47:59 | https://dev.to/yuvraj101/bmi-calculator-version-1-0-48gd | html, javascript, css, webdev | So basically this is my project named BMI calculator with some useful features in version 1.0... I m also upgrading to second version with some advance features ...🙏🏻🔥
⚡You can check the code here - https://github.com/yuvraj-07/Web-Projects/blob/d68c99dc92d2f499b887f9425a0ed99857115929/BMI.html
---------------------------------------
Guys pls show me some support and please help me to enhance my skills ❤️❤️❤️
----------------------------------------
-
📢 Facebook handle - https://www.facebook.com/profile.php?id=100010656091936
-
📢 GitHub handle - https://github.com/yuvraj-07
| yuvraj101 |
670,685 | Desempenho - Economizando memória em Structs com StructLayout | Olá, este é um artigo da seção Desempenho e, desta vez, vamos falar sobre StructLayout, uma forma de... | 0 | 2021-04-18T18:20:31 | https://dev.to/wsantosdev/desempenho-economizando-memoria-em-structs-com-struclayout-345p | csharp, dotnet, performance, braziliandevs | Olá, este é um artigo da seção **Desempenho** e, desta vez, vamos falar sobre StructLayout, uma forma de organização dos campos de uma struct que permite economizar memória.
Antes de começarmos, vale lembrar a razão pela qual utilizamos structs. Structs, de forma resumida, são *value types*, que são alocados em um espaço de memória não monitorado pelo Garbage Collector chamado *stack*, e tem um ciclo de vida restrito ao método onde foram declarados ou recebidos como argumentos.
Portanto, utilizar structs representa uma economia de memória do ponto de vista da aplicação, e de processamento do ponto de vista do *runtime*, já que o Garbage Collector não sofrerá pressão por elas e, consequentemente, será menos acionado.
Isto dito, vamos entender como structs são alinhadas na memória.
## Alinhamento em Memória
O que é alinhamento em memória? É a forma como o compilador distribui os bytes que serão alocados para a sua struct na memória. Por padrão, strcuts são alinhadas em pacotes cujo tamaho é dado de acordo com o tamanho do maior campo presente. Ou seja, se o maior campo de uma struct for um inteiro de 64bit, que tem 8 bytes, os campos de sua struct serão alinhados em blocos de 8 bytes.
Imagine a seguinte struct:
```c#
namespace Lab.Desempenho.StructLayout
{
public struct Struct1
{
public byte Byte;
public int Int;
public long Long;
}
}
```
Seu alinhamento em memória seria o seguinte:
```c#
Size: 16 bytes. Paddings: 3 bytes (%18 of empty space)
|===============================|
| 0: Byte Byte (1 byte) |
|-------------------------------|
| 1-3: padding (3 bytes) |
|-------------------------------|
| 4-7: Int32 Int (4 bytes) |
|-------------------------------|
| 8-15: Int64 Long (8 bytes) |
|===============================|
```
Repare no seguinte: lendo do final do para o começo da tabela acima, temos nesta struct um campo `long` (inteiro de 64 bits, com 8 bytes), e ele determina o tamanho dos blocos de alinhamento em memória da struct por padrão por ser o maior campo. Acima dele, temos 4 bytes de nosso campo `int` (4 bytes), um `padding` (3 bytes) e nosso campo `byte` (1 byte).
Agora, você pode estar se perguntando, o que é esse `padding`? Ele é o responsável por garantir que nossa struct será alinhada em blocos de 8 bytes. Ou seja, caso em vez de um `int` e um `byte` tivéssemos dois `byte`, esse `padding` seria de 6 bytes em vez de 3, pois 6 bytes seria a diferença do tamanho do bloco, 8 bytes, para os 2 bytes dos campos `byte` declarados.
Um detalhe muito interessante aqui é que a ordem dos campos importa, já que o alinhamento também é dado por ele. Então, veja este outro exemplo com a mesma struct, mas trocando a ordem de nosso campo `long` com nosso campo `int`:
```c#
namespace Lab.Desempenho.StructLayout
{
public struct Struct1
{
public byte Byte;
public long Long;
public int Int;
}
}
```
Seu alinhamento passaria a ser o seguinte:
```c#
Size: 24 bytes. Paddings: 11 bytes (%45 of empty space)
|=============================|
| 0: Byte Byte (1 byte) |
|-----------------------------|
| 1-7: padding (7 bytes) |
|-----------------------------|
| 8-15: Int64 Long (8 bytes) |
|-----------------------------|
| 16-19: Int32 Int (4 bytes) |
|-----------------------------|
| 20-23: padding (4 bytes) |
|=============================|
```
Repare em um detalhe fundamental: não apenas a organização dos blocos mudou, como o tamanho da struct aumentou em 8 bytes!
Isso aconteceu porque, como o alinhamento é dado pelo campo de maior tamanho e pela ordem de declaração, foi necessário aumentar o primeiro `padding` de 3 para 7 bytes, para acompanhar o tamanho do campo `long` e, para que o campo `int` também o acompanhasse, foi necessário criar um novo `padding` com 4 bytes.
Ou seja, apenas por força da ordem de declaração de seus campos, sua struct ficou 11 bytes maior!
## StructLayout: lidando com o alinhamento
Agora que entendemos como nossas structs são alinhadas na memória, a pergunta que fica é: como lidamos com isso e evitamos os `paddings`?
Existem duas formas de resolver este problema. Um deles, que você já deve ter imaginado, é organizar os campos em uma sequência que resulte na menor quantidade e tamanho possível de `paddings`. Mas há uma outra forma, fornecida pelo próprio .Net que nos ajuda com essa tarefa ingrata, o atributo `StructLayout`.
Com este atributo, podemos não apenas definir a ordem pela qual nossos campos serão distribuídos pelo compilador como, também, informar o tamanho do bloco de alinhamento, de modo a controlar a ocorrência de paddings.
Vejamos um exemplo com uma nova versão da mesma struct:
```c#
using System.Runtime.InteropServices;
namespace Lab.Desempenho.StructLayout
{
[StructLayout(LayoutKind.Auto)]
public struct Struct2
{
public byte Byte;
public long Long;
public int Int;
}
}
```
O resultado será o seguinte:
```c#
Size: 16 bytes. Paddings: 3 bytes (%18 of empty space)
|=============================|
| 0-7: Int64 Long (8 bytes) |
|-----------------------------|
| 8-11: Int32 Int (4 bytes) |
|-----------------------------|
| 12: Byte Byte (1 byte) |
|-----------------------------|
| 13-15: padding (3 bytes) |
|=============================|
```
Repare que, neste caso, usando o atributo `StructLayout` e informando o `LayoutKind` como `Auto`, o compilador se encarregou de organizar nossos campos do maior para o menor, utilizando o `padding` de 3 bytes apenas para compensar o restante para completar os 8 bytes de nosso `long`.
Ou seja, utilizando o atributo com esta configuração, nos livramos do trabalho para organizar nossos campos.
Legal. Né? Mas tem mais!
É possível não apenas determinar a ordem de alinhamento dos campos como, também, definir o tamanho do pacote de alinhamento.
Vejamos um novo exemplo:
```c#
using System.Runtime.InteropServices;
namespace Lab.Desempenho.StructLayout
{
[StructLayout(LayoutKind.Sequential, Pack = 4)]
public struct Struct3
{
public int Int;
public long Long;
public int Int2;
}
}
```
Repare que, aqui, temos o `LayoutKind.Sequential`, que significa que o alinhamento vai seguir a mesma ordem definida no código (que é a opção padrão). Além disso, introduzimos uma propriedade chamada `Pack`, que é o tamanho do pacote de alinhamento dos bytes de nossos campos, com o valor 4. Isso significa que serão criados blocos com 4 bytes para alinhar nossos campos, e não mais 8 como seria o padrão dado pelo campo de maior tamanho (nosso, `long`).
Portanto, o resultado será o seguinte:
```c#
Size: 16 bytes. Paddings: 0 bytes (%0 of empty space)
|=============================|
| 0-3: Int32 Int (4 bytes) |
|-----------------------------|
| 4-11: Int64 Long (8 bytes) |
|-----------------------------|
| 12-15: Int32 Int2 (4 bytes) |
|=============================|
```
E voi lá! Temos apenas os 16 bytes de nossos campos sendo alinhados. Nosso `long` é entendido como uma sequência com dois blocos com 4 bytes cada, e isso permite que nossa struct evite dos dois paddings com 4 bytes que seriam criados caso a propriedade `Pack` não tivesse sido definida.
Vamos colocar a afirmação acima a prova?
A struct abaixo tem a mesma distribuição de campos do exemplo acima, mas dispensa o atributo `StructLayout` e, por consequência, a propriedade `Pack` (lembrando que a ausência do atributo tem o mesmo efeito de declarar seu `LayoutKind` como `Sequential`):
```c#
namespace Lab.Desempenho.StructLayout
{
public struct Struct4
{
public int Int;
public long Long;
public int Int2;
}
}
```
Veja o resultado abaixo: temos agora não mais 16 bytes, mas 24. Isso porque a ausência da propriedade `Pack` de `StructLayout` fez retornar o comportamento padrão, que é definir o tamanho do pacote a partir do campo de maior tamanho.
```c#
Size: 24 bytes. Paddings: 8 bytes (%33 of empty space)
|=============================|
| 0-3: Int32 Int (4 bytes) |
|-----------------------------|
| 4-7: padding (4 bytes) |
|-----------------------------|
| 8-15: Int64 Long (8 bytes) |
|-----------------------------|
| 16-19: Int32 Int2 (4 bytes) |
|-----------------------------|
| 20-23: padding (4 bytes) |
|=============================|
```
## Conclusão:
Pudemos observar como um detalhe simples, como a forma como distribuímos os campos em nossas structs pode afetar seu tamanho final e, por consequência, o desempenho de nossa aplicação. Sem dúvida uma questão tão interessante quanto pouco conhecida.
Mas tão interessante quando conhecer este comportamento do alinhamento das structs, é compreender os comportamentos do compilador do C#. Conhecer a maneira como ele traduz nosso código nos dá uma visão de como promover otimizações em nosso código com um mínimo de esforço.
Em fututos posts da seção **Desempenho** traremos mais detalhes sobre como podemos extrair maior velocidade de execução e maior economia de recursos utilizando pequenos truques, sejam eles a partir de ferramentas do próprio .Net como neste caso, ou através de simples mudanças na escrita de nosso código.
Como de costume, segue um projeto de exemplo no [Github](https://github.com/wsantosdev/lab-desempenho-structlayout) para verificar os resultados obtidos no post. Para a geração destes relatórios é utilizado um componente muito interessante, o [ObjectLayoutInspector](https://github.com/SergeyTeplyakov/ObjectLayoutInspector).
Gostou? Me deixe saber pelos indicadores. Tem dúvidas ou sugestões? Deixe um comentário ou me procure pelas redes sociais.
Até a próxima! | wsantosdev |
670,739 | Is Redux DEAD? Try Zustand! | Quick tutorial on zustand and how it compares to other state management solutions in React | 0 | 2021-04-18T19:10:33 | https://dev.to/marius/is-redux-dead-try-zustand-9g8 | react, showdev, javascript, beginners | ---
title: Is Redux DEAD? Try Zustand!
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hd3x7ei3hkyoq2u8hh3v.jpg
published: true
description: Quick tutorial on zustand and how it compares to other state management solutions in React
tags: react, showdev, javascript, beginners
---
With the advent of hooks a lot of ReactJS developers have moved away from Redux as the default state management of choice.
However is simply using useState, useReducer, and the context API good enough? I highly recommend checking out Zustand! Dead simple and unopinionated state management!
> **Zustand is a small, fast and scaleable bearbones state-management solution. Has a comfy api based on hooks, isn't boilerplatey or opinionated, but still just enough to be explicit and flux-like.**
[In this video](https://youtu.be/UcHkC5sJPWw) we're going to walk through the basics of using Zustand. We'll also discuss the pros and cons of this approach compared to reducer-based and context-based solutions like the useReducer hook and Redux.
Let me know what you think of Zustand!
{% youtube UcHkC5sJPWw %}
| marius |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.