
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
510,646 | Deploy to firebase functions | Today we'll learn how to deploy you node app to firebase functions. You can also use... | 0 | 2019-11-02T00:00:00 | https://dev.to/stanley/deploy-to-firebase-functions-1b3g | javascript, node, firebase, functions | ---
title: Deploy to firebase functions
date: '2019-11-02'
spoiler: Deploy your first express app to a firebase cloud function, with a snap of fingers.
tags: javascript, nodejs, firebase, functions
published: true
---
<p align="center">
<img src="https://firebasestorage.googleapis.com/v0/b/from-tatooine.appspot.com/o/deploy-firebase-functions%2F1_vgy9tD1ixcaztpirUw0QCw.png?alt=media&token=2ad76553-3ae3-443a-98a2-05645b2b272f" width="400px" />
</p>
Today we'll learn how to deploy you node app to firebase functions. You can also use [nodevader](https://github.com/stanleygomes/nodevader) boilerplate to do this tutorial.
First, install the Firebase CLI if you don't have it.
```bash
npm install -g firebase-tools
```
Then, run, login to your firebase account and init a project, right after choose option `functions` and connect it to your project
```bash
firebase login
firebase init
```
Now, you have a folder called functions.
Yes, delete it.
```bash
rm -rf functions
```
Go to the `firebase.json` file and add the `source` property to functions, pointing to current directory:
```json
{
"functions": {
"source": ".",
...
}
}
```
Now install dependencies for firebase
```bash
npm install --save firebase-admin
npm install --save firebase-functions
npm install --save-dev firebase-functions-test
```
and, add the required engine property to your `package.json` file
```json
{
...
"engines": {
"node": "8"
}
}
```
We're almost there. Go to your `src/index.js` file, remove app.listen(...)
```javascript
// app.listen(...)
```
And the last step. Add functions dependency and export the function.
```javascript
const functions = require('firebase-functions')
// your code here ...
const api = functions.https.onRequest(app)
module.exports = {
api
}
```
Now you can deploy your function to firebase
```bash
firebase deploy
```
If you want to get the firebase CLI key for CI/CD. Run
```bash
firebase login:ci
```
Thanks and Good luck.
<!-- I’d love to hear from you on Twitter! Thanks for reading. --> | stanley |
511,946 | What is a master page in ASP.NET? | A master page is a special type of asp.net page that defines both the site-wide markup and the region... | 0 | 2020-11-11T08:03:51 | https://dev.to/narendra8989/what-is-a-master-page-in-asp-net-5emo | dotnet, career, tutorial, computerscience | A master page is a special type of asp.net page that defines both the site-wide markup and the regions where associated content pages define their custom markup.
Master page are an important part of The Official Microsoft ASP.NET Site website. In a nutshell, a master page allows the page developer to define a website template, indicating what portions of the template are to remain fixed across pages that use the template and what regions of the template are customizable on a page-by-page basis. Having the site design and layout centralized in one (or more) master pages makes it easy to add new pages to the site that inherit the same look and feel and greatly simplifies changing the site design or adding or removing content that is common to all pages, such as content in the <head> element, footers, and references to CSS and JavaScript files
Master page with extension .master contains the layout of the which will remain the same through the postbacks,and only the content holder can be modified,changed or altered or contents of the page can be designed there apart from the basic layout of the page which is in masterpage .
Content pages are selected under masterpage.
Ways to create a master page,through Visual Studio10:-
1.open visual studio.
2.select Create website.
3.select website from the toolbar and click on Add new item.
4.select masterpage and edit your masterpage name.
5.click create and design your page Add content holders.
6.after creating your master layout.
7.select Add Content from website menu in Toolbar.
8.start creating your rest of the pages.
Apart From all this master pages have many functionality which are encountered in real time projects.
Meet The Experts For Better Explanations : https://nareshit.com/asp-net-mvc-online-training/ | narendra8989 |
512,145 | Honeypot Cult Article: The Importance of Team Standards... Or Not? | Duke University’s basketball coach - Mike Krzyzewski, also known as Coach K, has an overall record of... | 0 | 2020-11-11T13:04:32 | https://cult.honeypot.io/reads/the-importance-of-team-standards | webdev, leadership | ---
title: Honeypot Cult Article: The Importance of Team Standards... Or Not?
published: true
date: 2020-11-11 00:00:00 UTC
tags: webdev, leadership
canonical_url: https://cult.honeypot.io/reads/the-importance-of-team-standards
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/xvsf4imbs0k04q1446sm.jpg
---
Duke University’s basketball coach - Mike Krzyzewski, also known as Coach K, has an overall record of 1,157 wins and 370 losses at Duke and has coached the USA men’s national basketball team to a gold medal in the Olympics.
He’s won many coaching awards and has watched his players win many others, sometimes becoming NBA basketball stars or coaches themselves. His accolades prove that he will be known as one of the best college basketball coaches in history; now this is someone to learn from!
## Why standards > rules (Coach K)
When listening to Coach Mike Krzyzewski speak at a conference one year, I learned of a fascinating activity that he does every year with his new team. He gathers everyone together to create team standards. They do this by first **brainstorming a list of standards, followed by all players voting to agree on the ones they believe in most**. Agreement is only the first step, each team member and coach must be held accountable to the accepted ideals – not only by coaches but by each other.
Here are a few examples:
- “All players and coaches will arrive for practice at least 30 minutes before start time.”
- “When speaking, we will always be honest with each other even when it is challenging.”
- “We will always treat each other with respect.”
Coach K wants players to feel part of the culture they create. If coaches dictated the rules, now they are just something to follow because coach said to; instead, by creating standards as a team, everyone plays their part in upholding them!
My favourite anecdote from the story was when he mentioned doing this with the Olympic team – could you imagine creating team standards with people like Kobe Bryant, Lebron James, and other top competitors in the world? Incredible!
## Basketball vs Dev Teams
It’s quite obvious that software engineering teams have stark differences compared to basketball teams, but there are certain rules that we observe in both.
The delineation of rules vs. standards hit home for me from Coach Krzyzewski, because as a dev joining a new team, **we usually join a team that already has standards or rules to follow that were created before arriving**. This leads to following standards you might not agree with or haven’t had any say in.
It’s easy to see how frustrations can occur in this scenario.
Being asked to uphold something you didn’t agree to can instigate [internal team conflicts](https://cult.honeypot.io/reads/how-to-deal-with-difficult-developers-on-the-team) and tension. The “_[five whys](https://en.wikipedia.org/wiki/Five_whys)_” mental model comes to mind to help resolve frustrations quickly: we must make an effect to **first learn the “why” before suggesting a change or deciding against following a specific standard.**
If standards on ever-evolving teams can cause conflicts – what’s the point of having them?
## Why Do We Have Standards
> “Alone we can do little; together we can do so much.” – Helen Keller
Each product built by software engineers has different requirements, structures, frameworks, and methodologies cobbled together by a team. **Standards are there to help team members stay on the same page** , work together effectively, and create consistency throughout a codebase.
We can use them to keep code formatting consistent and readable or restrict certain antipatterns from being used as best practices are determined. _[Code reviews](https://medium.com/disney-streaming/the-art-of-effective-pull-request-reviews-376d05ce3ad4)_ can focus on the right things as linting automates catching the little things since rules are configurable and agreed on by the team. Lastly, **they help us hold each other accountable to write code to the best of our ability,** because it isn’t one person’s code, it's all of ours, and by holding each other to a high standard we make that code base stronger.
Overall, having fundamental principles to believe in and uphold helps teams accomplish much more together than apart.
## A Few Common Standards in Web Dev Teams
**Story Pointing:** Fibonacci sequence or -shirt sizes.
**Linting:** ESLint to check against established linting rules while we code, commit, or push up to GitHub.
**SAST Security Scans:** Using static code analyzers for security risks with technologies like CheckMarx and fixing all issues above a certain risk (like medium).
**Design Patterns or Language Features:** Do we prefer to use React Hooks or Class Components?
**Directory Structure:** How do we structure our directories for util functions or global typography classes? How do we name files? Determining these beforehand increases productivity for all dev team members.
**Code reviews:** How many approvals before merging? Automated pipeline checks like tests and linting before allowing merges.
**Discussion / Respect:** How do we discuss new architecture options? We always must treat each other with respect when discussing different options.
The list goes on and on, right? In my experience these things continually evolve over time – we must record those changes as time goes passes to keep everyone on the same page.
## Do standards matter
Should all products or teams use strict standards? Like most things in our profession – it depends.
Each project is different – my belief boils down to three main factors to determine the strictness required:
1. Project size
2. Number of developers on the project
3. Business risk on malfunctions
Overall, by using the three main factors, one can easily decide on the strength and need of team standards for a software project. We want to move fast to deliver features, but not so fast we create a swamp of code that is impossible to change quickly.
Let’s go through some common project types:
### Proof of Concepts
Proof of concepts with throwaway code like hackathon projects do not need standards, they need to work by demo time.
### Side Projects
Side projects with one or two developers that aren’t for commercial use or with intentions to scale out in the future – then you probably don’t need that strong of standards.
### Small to Medium Projects
It’s difficult to size applications because they vary. I’d consider small projects to be a small To-do app similar to those used in many tutorials. Medium is decent-sized projects, but when compared to something like G-Mail or YouTube, they pale in comparison.
### Large Projects or Highly Impactful Code
When working on a large product like MacOs or Android, working with many developers, and having a huge impact if a bug affects users, then you will want very high standards. Code should be rigorously reviewed and tested to make sure no impacts on the user will occur.
## How can leaders use standards effectively
First and foremost, **standards should be created by and for the current team.**
If people leave, or new members join, the standards should be reviewed and accepted again. I believe that similarly to Coach K having a new team each year (even though many players are returners), development teams should follow his lead.
**Strong principles help drive decision-making based on outcomes instead of opinions** because many times results can be measured and objectively decided upon based on those fundamental ideas to uphold.
Teams are able to accomplish so much together that individuals would not be able to.
By having stronger team bonds that we hold each other too, **the team works better together and each individual feels part of something bigger than themselves** – not only is this inspirational in of itself – but additionally, it helps us work well together!
**Leaders should facilitate authoring standards for their teams** , doing their best to uphold and evolve them appropriately over time.
If Coach K believes standards are important for winning championships, **I believe that standards are important for delivering products that help change the world.** | avatarkaleb |
512,477 | Story of how I built my Portfolio and Blog using DEV.to and NextJS | I've always wanted to build my very own portfolio website and blog. After many years of laziness..😋,... | 0 | 2020-11-13T16:07:47 | https://dev.to/sidthesloth92/story-of-how-i-built-my-portfolio-and-blog-using-dev-to-and-nextjs-3j85 | nextjs, webdev, blog, react | ---
title: Story of how I built my Portfolio and Blog using DEV.to and NextJS
published: true
description:
tags: nextjs, webdev, blog, react
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/kll5ply8c9d3hhjo7isr.png
---
I've always wanted to build my very own portfolio website and blog. After many years of laziness..😋, finally, I mean, FINALLY I've done it..🎉 I have built my own website [dineshbalaji.in](https://dineshbalaji.in)..✨ Please do check out the website and let me know your thoughts in the comments..🙏
The idea behind this post is to tell the story of how I did it, the tech involved, what I learned along the way and most importantly to **inspire many more people** (lazy like me may be..:D) to **build their own website**.
# Ground Rules
These are some of the ground rules that I laid down for myself for developing the website.
* It had to coded out by me from scratch without using WYSWYG editors.
* A good logo.
* I have to learn new stuff as I build it.
* Minimize usage of third-party libraries.
* It has to showcase my coding skills.
* Good Lighthouse Score - Performance and Accessiblity.
* Has to integrate with a CMS for blogging.
* Good SEO.
* Be open sourced for others to use/learn.
* A full-page canvas landing page..😍 I love them..❤️
# The Start
With the ground rules set, I began on October 3rd, 2020. One thing I wanted to absolutely make sure was to track my progress. I've tried building my site a couple of times earlier but I got sidetracked. I was also inspired by [this](https://github.com/TypeStrong/typedoc/issues/1364). The way he wrote down whatever little progress he made was the way to go for me. So I did a [CHANGELOG](https://github.com/sidthesloth92/db-portfolio/blob/master/CHANGELOG.md). Easy to generate and maintain.
# Design
I'm a coder by profession but I do love to design and I'm quite crafty with [Sketch](https://www.sketch.com/). But sticking to my ground rules, [Figma](https://www.figma.com/), was the first thing I learned. I spent a weekend going through tutorials learning the tool and then went about creating a design system and the website.
### The Logo
I had to do a logo for branding. I wanted it to be simple and animatable. I'm happy with what I ended up with.

Being a developer staring endlessly at the screens, I love dark themes and decided to go with it. Chose a couple of popping [colors](https://coolors.co/222831-20252c-f20a72-e6db74-ffffff) and some shades using [crispedge](https://www.crispedge.com/color-shades-generator/) and voila I had my recipe.. 🦄
### Fonts
* [Nunito Sans](https://fonts.google.com/specimen/Nunito+Sans)
* [Adina Melia](https://www.dafontfree.io/adinda-melia-script-font/)
I created the screens over a week. I made sure all the screens were complete before starting development to ensure there were no stoppages.
# Technology
Since I wanted a blog along with the portfolio, SEO was of paramount importance and the best way to do that is to build static sites. I wanted to learn React along the way and there were two choices, NextJS and Gatsby. Gatsby was purely static and NextJS provided the flexibility to switch between static and dynamic based on our need. So I ended up with Next JS.
### Hosting
Choosing NextJS came with a benefit. The amazing hosting platform from the team that developed NextJS, [Vercel](https://vercel.com/). It has first-class tooling to host your website in minutes and has seamless integration with Github for development, preview and production deployments.
I don't want to bore you guys with a long explanation of each and every detail. I'll just list the tech I used on the website with one-liners.
### Base Tech
* [NextJS](http://nextjs.org/) - The base React framework on which the website is built. It allows you to choose between SSR, SSG and CSR.
* [DEV.to API](https://docs.dev.to/api/) - My CMS.. 😋 I love DEV.to as a platform for developer blogging and I didn't want to leave it. But at the same time, I wanted a single source of truth for my articles. So I made use of the dev.to [API](https://docs.dev.to/api/). It's sweet and I got the best of both worlds.
* [TailwindCSS](https://tailwindcss.com/) with [SCSS](https://sass-lang.com/) - I was so happy to have come across TailwindCSS. I strongly recommend this to anyone. Integrating it with SCSS was a pain but if you just use CSS, please try it out.
* [Typescript](https://www.typescriptlang.org/) - Must have for anyone doing frontend development in 2020.
### Tooling
* [stylelint](https://stylelint.io/) - For linting CSS, sorting and ordering CSS rules. Must have.
* [eslint](https://eslint.org/) - For linting Typescript code. Must have.
* [postcss](http://postcss.org/) - For CSS browser vendor pre-fixes, purging of unused TailwindCSS rules.
* [husky](https://github.com/typicode/husky) - For running linting, commit rules before committing code.
* [commitzen](https://github.com/commitizen/cz-cli) - Provides a format to your git commit messages. The beautiful change log you saw earlier was possible because of this.
* [prettier](https://prettier.io/) - Standard for 2020. Does what it says, formats and makes your code look beautiful..😋
### NPM Packages
* [framer-motion](https://www.framer.com/api/motion/) - All the beautiful animations on the site are powered by this amazing library. You just have to come up with the animations and leave the rest to framer. Highly recommend this one.
* [react-copy-to-clipboard](https://www.npmjs.com/package/react-copy-to-clipboard) - For copying code snippets to your clipboard.
* [react-infinite-scroll-component](https://www.npmjs.com/package/react-infinite-scroll-component) - For loading content on scroll in posts and nuggets page.
* [react-intersection-observer](https://github.com/researchgate/react-intersection-observer) - For detecting if elements are scrolled into view.
* [react-markdown](https://github.com/remarkjs/react-markdown#readme) - For parsing the markdown from DEV.to API's and rendering as HTML.
* [react-syntax-highlighter](https://github.com/react-syntax-highlighter/react-syntax-highlighter) - Plugin for `react-markdown` that highlights code within the markdown.
* [react-share](https://github.com/nygardk/react-share#readme) - Provides social sharing icons and functionality for posts and nuggets.
* [reading-time](https://www.npmjs.com/package/reading-time) - Estimates the reading time of a given text.
* [sitemap](https://www.npmjs.com/package/sitemap) - For generating the site's `sitemap.xml` for SEO.
* [camelcase](https://github.com/sindresorhus/camelcase) - For converting hyphenated strings to camelcase strings.
* [@svgr/cli](https://react-svgr.com/) - For optimizing and converting SVG's into React components.
### Analytics
* [Google Analytics](https://analytics.google.com/) - I'm using it as my data store for posts view count and also for user demographics and content relevancy.
* [MS Clarity](https://clarity.microsoft.com/) - This just came out and I really like the heat maps and session playback features they offer.
# Development
I am employed full-time so I had to find the time to develop. Most of the website was built over weekends, late nights and early mornings. I used libraries whenever I felt like I was re-inventing the wheel and stuck to coding stuff out when I wanted to showcase my skills.
Particularly, I wanted to ensure that all the canvas-based animations were coded out entirely by me without the use of third party libraries. As a result, I learnt a lot of math and ended up creating mini-libraries [Vector.js](https://github.com/sidthesloth92/db-portfolio/blob/master/src/lib/vector.ts), [Particle.js](https://github.com/sidthesloth92/db-portfolio/blob/master/src/lib/particle.ts) for the animations on the canvas..👻
# Conclusion
After a month of development, I've done it. I'm really happy with the outcome. This is a lighthouse snapshot of my website.
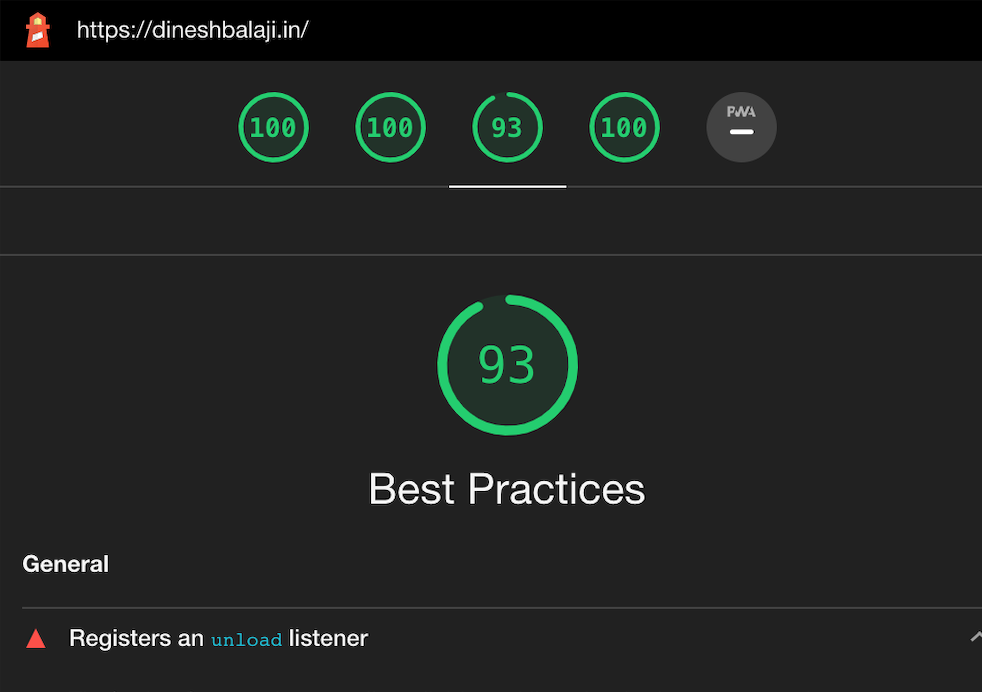
As you can see, it's green across the board..🍾
I intend to add features to the website as I go along and more importantly I hope that this inspires me to blog more.
I also wanna thank [Sowmya](https://twitter.com/seshadrisowmya) and [Rashmi](https://twitter.com/nayakrashmi) for their kind reviews and feedback and the Open Source Community in general for all the amazing libraries and tools..🙏
The [source](https://github.com/sidthesloth92/db-portfolio) for the website is completely Open Sourced.
I sincerely hope that someone reads this and starts their own journey towards building their very own website.
See you in the next one. Peace.. :)
| sidthesloth92 |
513,723 | Hactoberfest2020 and First OpenSource | Hello everyone, I'm Abhishek and I'm here to share with you my first experience in OpenSource project... | 0 | 2020-11-13T06:43:07 | https://dev.to/abhisheklwagun/hactoberfest2020-and-first-opensource-36ie | github, hacktoberfest, opensource | Hello everyone, I'm Abhishek and I'm here to share with you my first experience in **OpenSource** project contribution and how **Hactoberfest** really helps me out.
I must really thanks Hactoberfest for providing such a platform for Developers which really helps you a lot if you are thinking about contributing in **OpenSource** as a beginner or as a professional. So if you are a beginner it helps you to learn about Opensource and motivates you to contribute and if you are professional it helps you to upgrade your skill more and more.
I have done so many projects and help my doing projects but I am aware of OpenSource and I have never contributed to OpenSource Project before but Hactoberfest provides me a great platform for contributing to my first OpenSource project and I made it. Throughout this Hacktoberfest, I contributed to many projects, and most of them got merged or accepted. Some of them are great projects which I have constributed. So I feel very good when I see me as an OpenSource contributor and proud to be part of those great projects. And understanding other code and making changes to them was very interesting and informative.
It was such a great experience participating in Hactoberfest2020. I'm very happy to participate in this Hacktoberfest 2020. Through this journey, I learn many more about OpenSource and contributed to many openSource projects which I cannot think of. This is my first and best experience of this developer journey in OpenSource.
OpenSource is very important and useful if we want to learn and expand or upgrade your skills.
```console.log('Thankyou Hacktoberest);```
| abhisheklwagun |
514,539 | picoCTF: Insp3ct0r | Challenge Name: Insp3ct0r Points: 50 Description: Kishor Balan tipped us off that the... | 9,702 | 2020-11-14T04:16:43 | https://dev.to/mr_h/picoctf-insp3ct0r-1na0 | cybersecurity, webdev, ctf | ### **Challenge**
Name: Insp3ct0r
Points: 50
Description:
> Kishor Balan tipped us off that the following code may need inspection
Link: https://jupiter.challenges.picoctf.org/problem/9670/
{% collapsible Hints %}
1. How do you inspect web code on a browser?
2. There's 3 parts
{% endcollapsible %}
### **Solution**
View source
```
PC: CTRL + U
Mac: OPTION + COMMAND + U
Both: Right click view source
```
The first flag is at the bottom of the index.html file
```
<!-- Html is neat. Anyways have 1/3 of the flag: *** -->
```
The second flag is at the bottom of the mycss.css file
```
/* You need CSS to make pretty pages. Here's part 2/3 of the flag: *** */
```
The third flag is at the bottom of the myjs.js file
```
/* Javascript sure is neat. Anyways part 3/3 of the flag: *** */
```
| mr_h |
515,136 | Javascript clock Version 01 | Author: Mr. Paul Ramnora Language: Javascript Program: Constantly, ticking clock; showing: hours, min... | 0 | 2020-11-15T01:46:08 | https://dev.to/pramnora/javascript-clock-version-01-4ad3 | javascript, codepen, github, clock | Author: Mr. Paul Ramnora
Language: Javascript
Program: Constantly, ticking clock; showing: hours, minutes, seconds
Level: Beginner
Post created: 151120 01:44 AM GMT
Last updated: 151120 01:44 AM GMT
-(NOTE: This article is for web development 'beginners' like myself...; anyone who is far more skilled wouldn't learn much here.)-
-----
First, I went and visited: Codepen.io...where I witnessed seeing...what I thought was an interesting project:
https://codepen.io/IsaacPCooper/pen/mdEKMvY
It shows a landing page...together with raining [.gif]; together with...
- some title text
- ticking clock
- social media icons
...all properly centred on the web page using Flexbox.
I thought this design looked attractive...; so, I started to 'reverse engineer' the code...meaning, trying to take it all apart going, very slowly, bit by bit.
-----
Next, I copied all of the Javascript section code; then, independently, wrote a simple [.html] web page of my own...just to see if I could make that part work; eventually, it did.
Source code:
https://github.com/pramnora/javascript/blob/master/programs/clock/clock-01.html
Live code:
https://prg-javascript.netlify.app/programs/clock/clock-01.html
I'm still trying to work out all the rest...
| pramnora |
515,302 | Use OpenCV with Xcode | Step1 Install OpenCV via Homebrew $ brew install opencv $ brew install -v cmake... | 0 | 2020-11-15T07:39:12 | https://dev.to/0xkoji/use-opencv-with-xcode-41n0 | opencv, xcode | ## Step1 Install OpenCV via Homebrew
```zsh
$ brew install opencv
$ brew install -v cmake
```
`opencv 4.5.0_3` will be installed.
## Step2 Set Header Search Paths
`Build Settings` > Search `Header Search Paths`
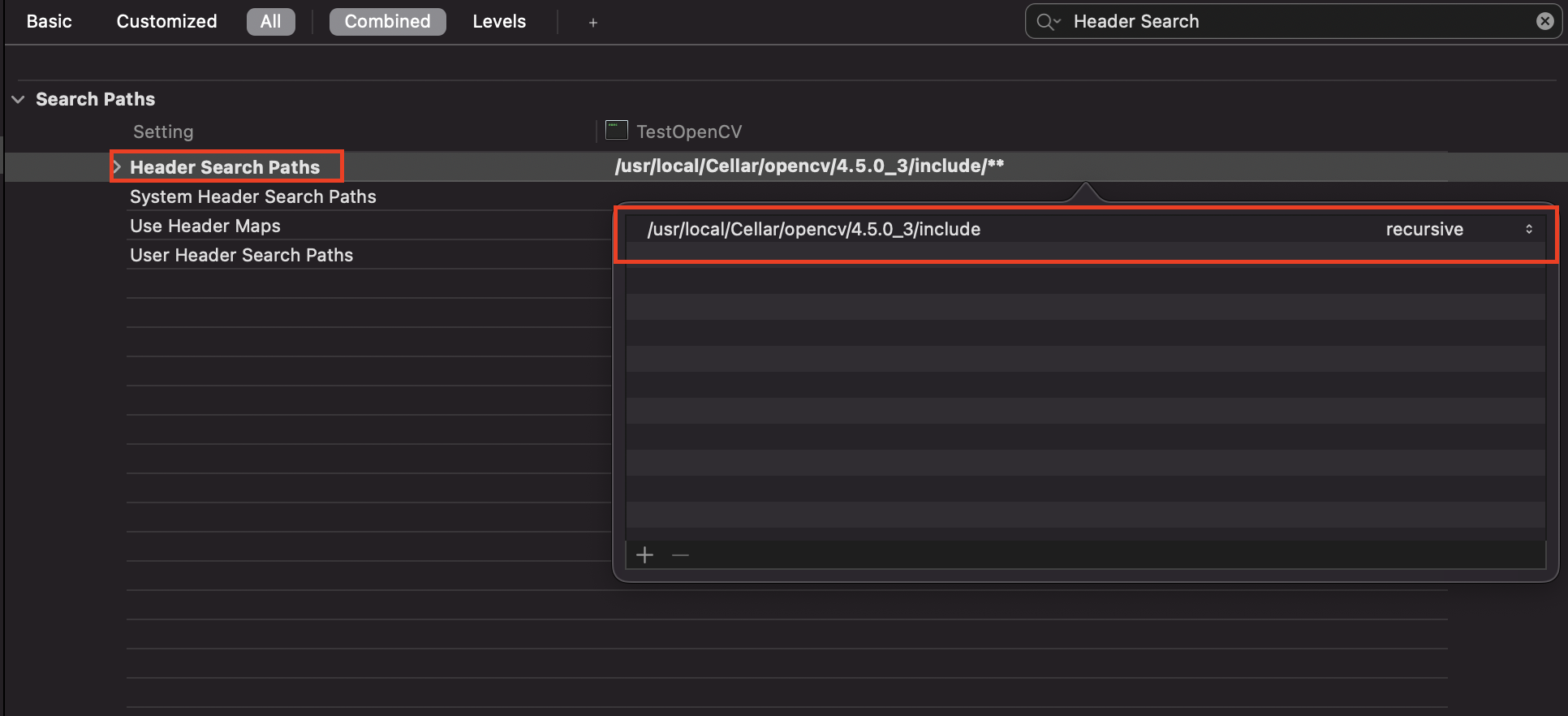
Add this to paths and select `recursive`
`/usr/local/Cellar/opencv/4.5.0_3/include`
## Step3 Add `.dylib` to `Link Binary With Libraries`
Technically, you don't need to pass all `.dylib`, but in this case, I passed all `.dylib` under `/usr/local/Cellar/opencv/4.5.0_3/lib`.
## Step 4 Build code
```cpp
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
int main(){
cv::Mat imMat(400,400, CV_8UC3);
for(int y = 0 ; y < imMat.rows; y++){
for(int x = 0 ; x < imMat.cols; x++){
cv::Vec3b &p = imMat.at<cv::Vec3b>( y, x);
p[0] = x;
p[1] = y;
p[2] = (int)((x+y)/2);
}
}
imshow("openCVTest",imMat);
waitKey(0);
return 0;
}
```
If you can build, you will see ↓

| 0xkoji |
516,050 | AVIF - the next-gen image format you need to know about | What is AVIF? The abbreviation "AVIF" stands for "AV1 Image File Format" and is essentiall... | 0 | 2020-12-02T10:31:07 | https://daily.dev/posts/avif-the-next-gen-image-format | webdev, performance, image, avif | ## What is AVIF?
The abbreviation "AVIF" stands for "AV1 Image File Format" and is essentially the specification for storing still and animated images compressed with AV1 in the HEIF file format. AV1 is the royalty-free video coding format that has most tech experts believing it is the next step in media compression.
A modern image format based on the AV1 video format. AVIF generally has better compression than WebP, JPEG, PNG, and GIF and is designed to supersede them (I’ll cover it later in detail). It's an image file format spec for storing images or image sequences compressed with AV1 in the HEIF file format. It competes with HEIC which uses the same container format, built upon ISOBMFF, but HEVC for compression. Version 1.0.0 of the AVIF specification was finalized in February 2019.
## Big tech companies are testing AVIF in scale
On 14 December 2018 Netflix published the first .avif sample images, and support was added in VLC. Microsoft announced support with the Windows 10 "19H1" preview release, including support in File Explorer, Paint, and multiple APIs, together with sample images. Paint.net added support for opening AVIF files in September 2019, and the ability to save AVIF format images in an August 2020 update. The Colorist format conversion and Darktable RAW image data have each released support for and provide reference implementations of libavif, and a GIMP plugin implementation has been developed supporting both 3.x and 2.10.x plugin APIs.
### The case of Netflix
Netflix describes their need for an alternative to JPEG that:
1. is widely supported
2. has better compression efficiency
3. has a wider feature set.
> “We believe the AV1 Image File Format (AVIF) has the potential. Using the framework we have open-sourced, AVIF compression efficiency can be seen at work and compared against a whole range of image codecs that came before it.“
The full story by Netflix with tons of visual examples and comparisons: https://netflixtechblog.com/avif-for-next-generation-image-coding-b1d75675fe4
## Supported features
* High dynamic range (HDR)
* 8, 10, 12-bit color depth
* Lossless compression and lossy compression
* Monochrome (alpha/depth) or multi-components
* Any color-space including wide color gamut, ISO/IEC CICP, and ICC profiles
* 4:2:0, 4:2:2, 4:4:4 chroma subsampling
* Film grain
## Graphics examples and comparisons:
* [AVIF has landed](https://jakearchibald.com/2020/avif-has-landed/) by [Jake Archibald](https://twitter.com/jaffathecake)
* [AVIF Image Format – The Next-Gen Compression Codec] (https://www.lambdatest.com/blog/avif-image-format/)
## AVIF vs WebP
Overall there was a lot of debate around this topic over the past year. When looking at tests from last year it seems that WebP was still better performing compared to any other format. However, this year following some optimizations that were made looks like WebP might stay behind.
Although I don’t think WebP will disappear anytime soon, it might be a good idea to start learning about using AVIF. The big players like Netflix, Google, and Microsoft are already in implementation phases for some of their services. That makes me believe that we will be able to see AVIF out there in the wild more throughout 2020 and 2021.
For further technical comparison check out [this post](https://www.ctrl.blog/entry/webp-avif-comparison.html#src=sharebox).
## Supported browsers:
AVIF support in web browsers is in development. In August 2020, Google Chrome version 85 was released with full AVIF support. Mozilla is working on support for the image format in Firefox.
Full review of the browsers and specific versions that already support AVIF: https://caniuse.com/avif
## Try it yourself
* This page gathers some known implementations supporting AVIF, and provides some test files. https://github.com/AOMediaCodec/av1-avif/wiki
* A cool and simple guide on how to use AVIF: https://reachlightspeed.com/blog/using-the-new-high-performance-avif-image-format-on-the-web-today/
<hr/>
_[daily.dev](https://api.daily.dev/get?r=devto) delivers the best programming news every new tab. We will rank hundreds of qualified sources for you so that you can hack the future._
[](https://api.daily.dev/get?r=devto)
| nimrodkra |
516,634 | The Bias Variance Tradeoff | Foundational to any data science curriculum is the introduction of the terms bias and variance, and s... | 0 | 2020-11-16T19:44:04 | https://edwardamor.xyz/posts/003/ | ---
title: The Bias Variance Tradeoff
published: true
date: 2020-06-17 05:00:00 UTC
tags:
canonical_url: https://edwardamor.xyz/posts/003/
---
Foundational to any data science curriculum is the introduction of the terms bias and variance, and subsequently the trade-off that exists between the two. As machine learning continues to grow it is imperative that we understand these concepts, as they directly effect the predictions we make and the business value we can derive from our generated models. While machine learning may seem simple, one of the more difficult parts is optimizing your models but sometimes optimization can lead to over-fitting and if your model is too simple it may be under-fitting your data. The inevitable trade-off between these two aspects will greatly impact the validity of your model, and the predictions you make. But what is bias, what is variance, and what is this trade-off?
## Bias
When we speak of bias, we aren’t talking about the standard bias us humans are susceptible to. Instead when it comes to machine learning, we are actually referring to the difference between our model’s prediction and the expected value (Prediction - Reality). When a model has high bias it consistently is making wrong predictions, and isn’t considering the complexity of our data. **A model with high bias is under-fitting** our data and consistently does so after training as well on testing/validation data.
We can identify if our model has high bias if the following occur:
1. We tend to get high training errors.
2. The validation error or test error will be similar to the training error.
We can compensate for high bias by doing the following:
1. We need to gather more input features, or generate new ones using feature engineering techniques.
2. We can add polynomial features in order to increase the complexity.
3. If we are using any regularization terms in our model, we can try to minimize them.
## Variance
Similar to the statistical term, variance refers to the variability of our model’s predictions. A model with high variance does not generalize well, and instead pays a lot of attention to our training data. What ends up happening is we get a model which performs very well during training, but when introduced to our testing/validation or any unseen data, we see very high error rates. One way to think about it is like a travel route, if you were to take the route alone and map it onto a completely different area, it wouldn’t work as it only fits the particular origin/destination it was made for. In our case we aren’t making routes, but the concept still holds and we hope to create models which generalize well to unseen data similar to the data used during training.
We can identify whether the model has high variance if:
1. We tend to get low training error
2. The validation error or test error will be very high.
We can fix high variance by:
1. Gathering more training data, so that the model can learn more based on the patterns rather than the noise.
2. We can even try to reduce the input features or do feature selection, reducing model complexity.
3. If we are using any regularization terms in our model, we can try to maximize them.
## The Trade-Off
Now knowing what bias and variance is, it is key to understand that when we minimize one, we are maximizing the other. A model with high bias will have low variance, and vice versa. Given a model, with respect to bias and variance, we can say a model’s error is the sum of three parts, the bias, variance, and random noise (`E[x] = bias + variance + noise` ).
> The **bias–variance decomposition** is a way of analyzing a learning algorithm’s [expected](https://en.wikipedia.org/wiki/Expected_value) [generalization error](https://en.wikipedia.org/wiki/Generalization_error) with respect to a particular problem as a sum of three terms, the bias, variance, and a quantity called the _irreducible error_, resulting from noise in the problem itself.
>
> — Wikipedia <sup id="fnref:1"><a href="#fn:1" role="doc-noteref">1</a></sup>
The trade-off therefore is determining the optimal bias and variance levels, so as to minimize our overall error. With the steps I’ve listed previously for minimizing either of the two, one has to iteratively improve on the models generated until we arrive at one which is relatively balanced between bias and variance. If we don’t balance these two terms out, we’ll end up with a model that either under or over fits our data, which doesn’t give us any value when it comes to making predictions.
<section role="doc-endnotes">
<hr>
<ol>
<li id="fn:1" role="doc-endnote">
<p><a href="https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff">https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff</a> <a href="#fnref:1" role="doc-backlink">↩︎</a></p>
</li>
</ol>
</section> | edwardamor | |
517,142 | Course stream web application in Django | Hello Dev, I wanna show you to I have developed web application like udemy. That you will... | 0 | 2020-11-17T11:07:58 | https://dev.to/yogeshnile/course-stream-web-application-in-django-33kk | django, python, github, webdev | # Hello Dev,
- I wanna show you to I have developed web application like udemy. That you will learn free and paid courses.
- This web application developed in django framework. Django is a Python-based free and open-source web framework that follows the model-template-views architectural pattern. It is maintained by the Django Software Foundation, an American independent organization established as a 501 non-profit.
- This web application are integrated with payment service
- In this application user details are validate via ajax
# Github Repo
- [Repo](https://github.com/yogeshnile/course-stream-in-django)
# Here some screenshot of web application
- Backend <br>
- Courses <br>
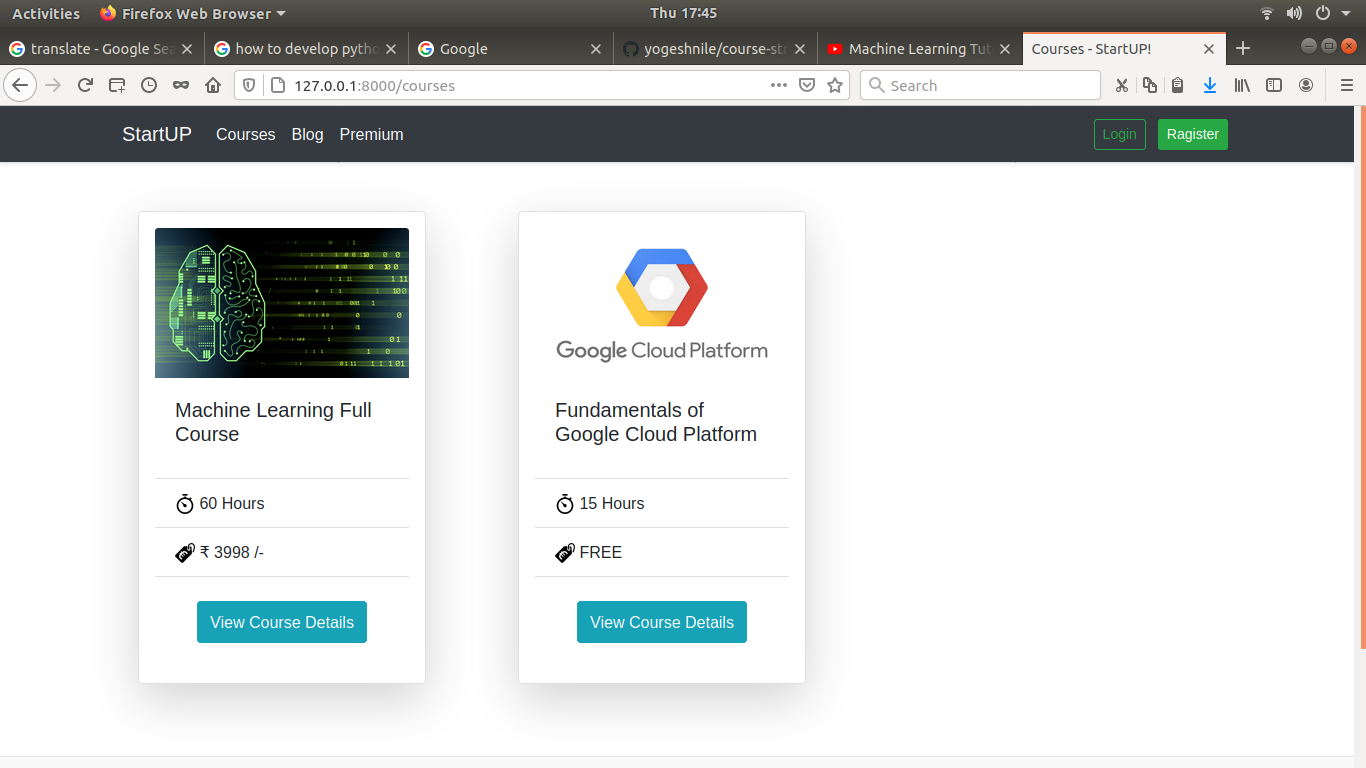
- Course Details <br>
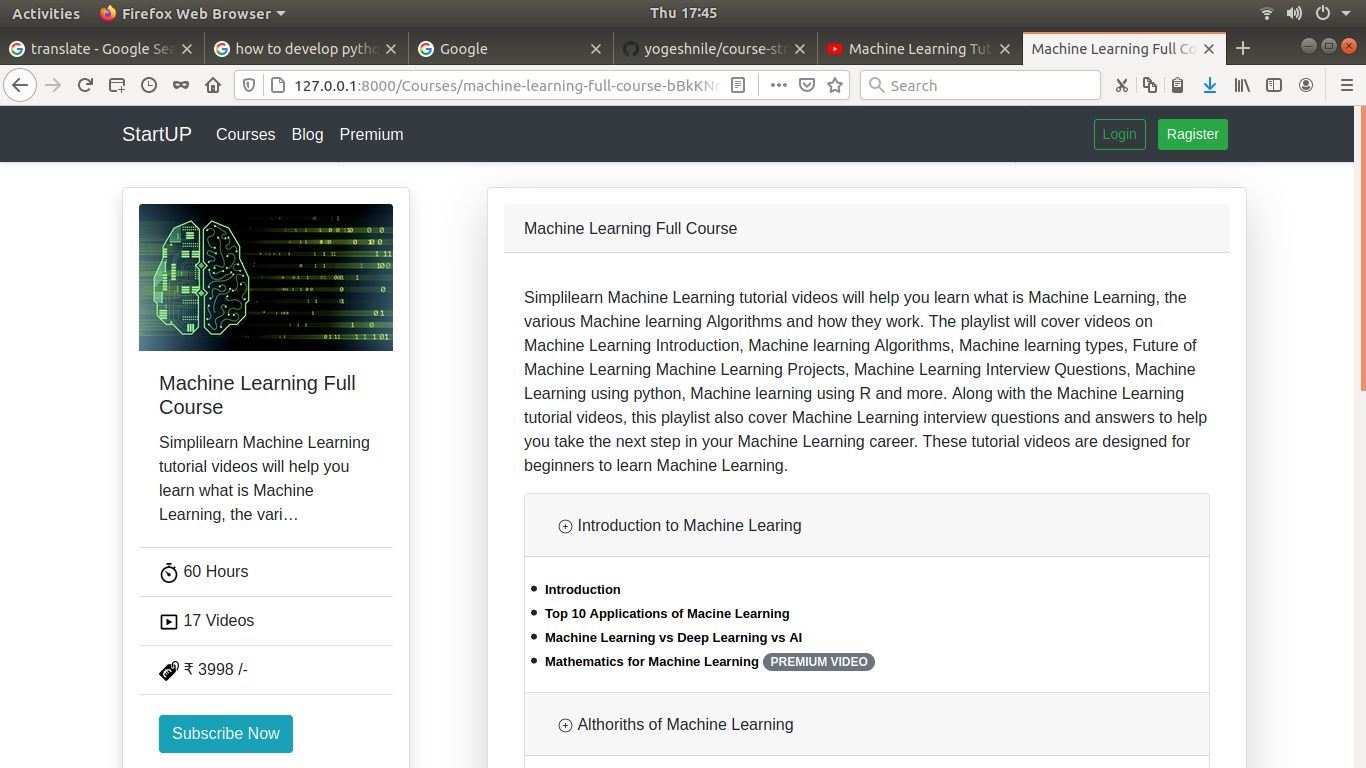
- Checkout Page <br>
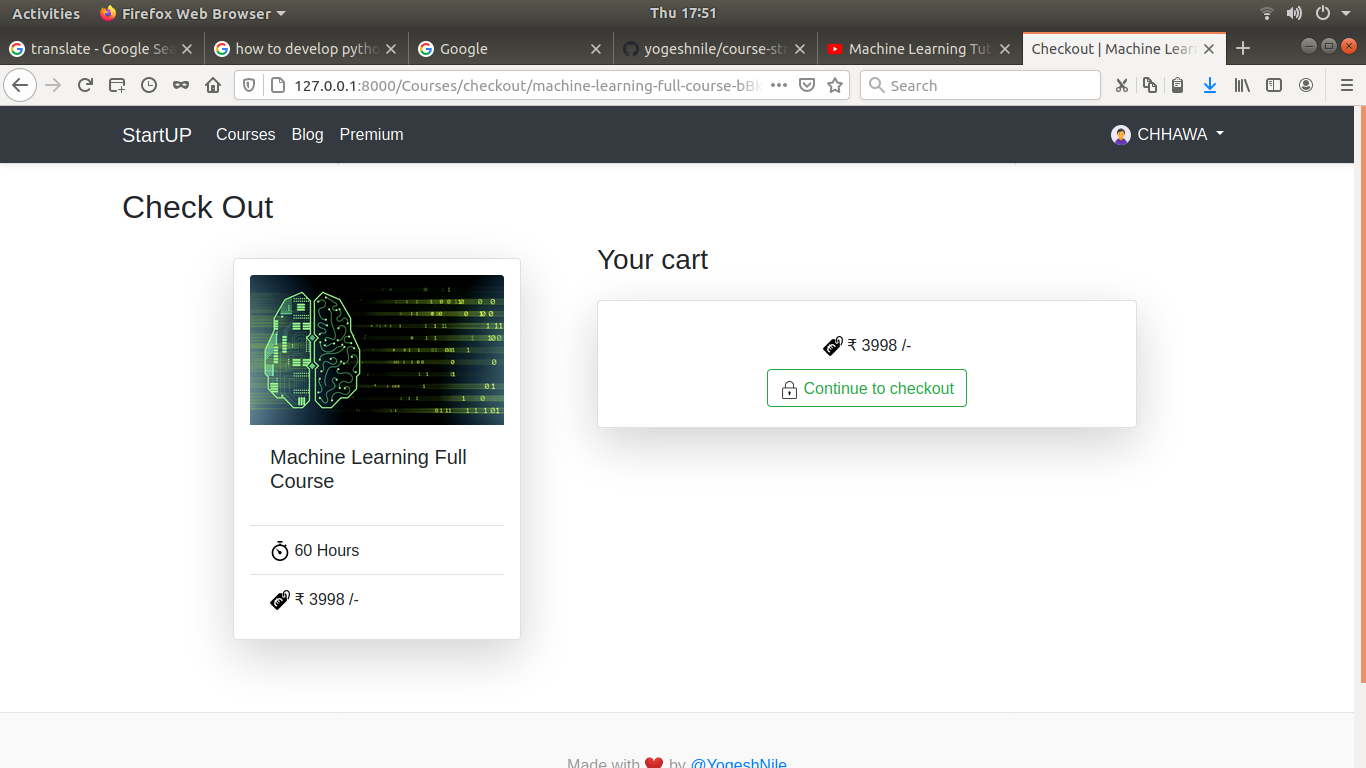
- Payment Process <br>
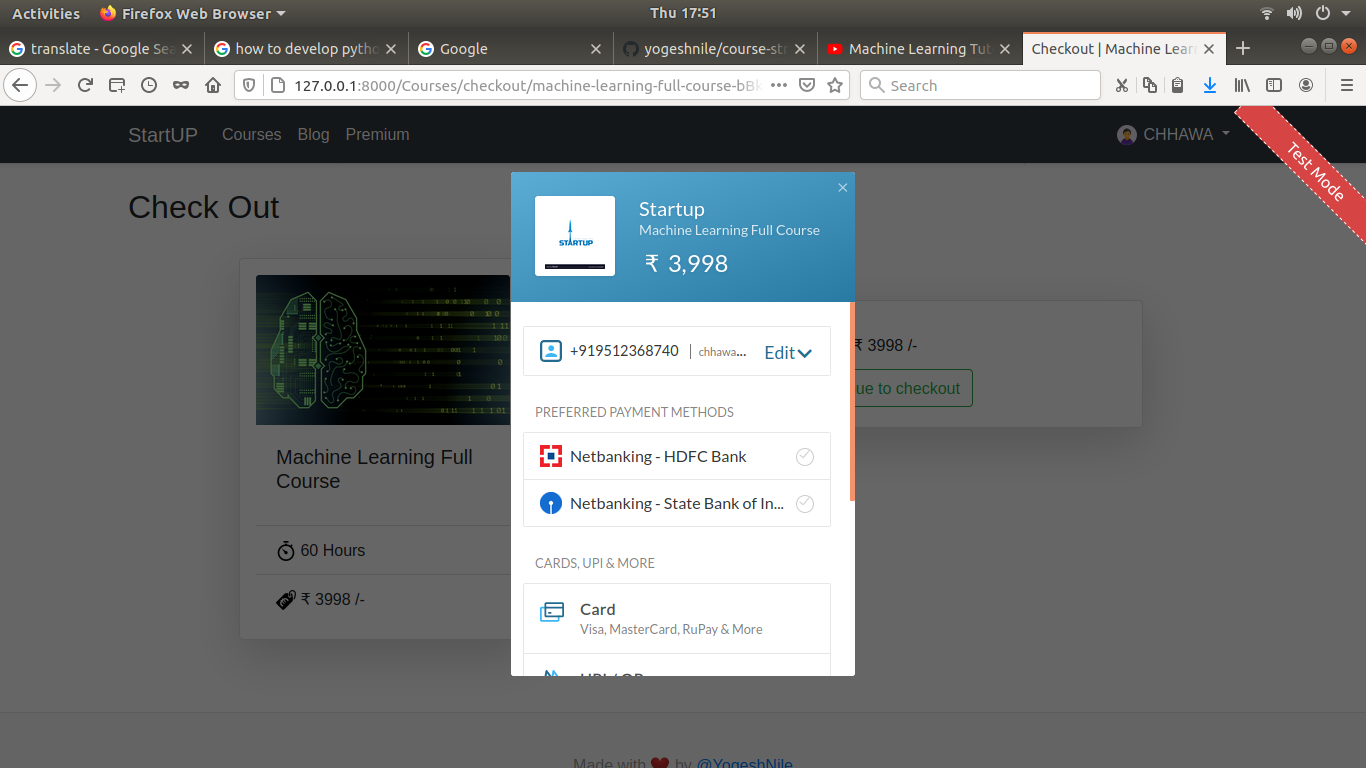
- Subscribed Courses <br>
<br>
# Contribution
- If you find a bug (the website couldn't handle the query and / or gave undesired results), kindly open an issue [here](https://github.com/yogeshnile/course-stream-in-django/issues/new) by including your search query and the expected result.
- If you'd like to request a new function, feel free to do so by opening an issue [here](https://github.com/yogeshnile/course-stream-in-django/issues/new). Please include sample queries and their corresponding results.
| yogeshnile |
517,161 | complete list of flutter interview questions with answers
| https://github.com/power19942/flutter-interview-questions | 0 | 2020-11-17T11:34:40 | https://dev.to/power19942/complete-list-of-flutter-interview-questions-with-answers-1ina | https://github.com/power19942/flutter-interview-questions | power19942 | |
517,383 | Weekly Win (47/2020) | When implementing a third-party library, we set expectations on how we believe it will be implemented... | 0 | 2020-11-17T18:31:20 | https://dev.to/kontent_ai/weekly-win-47-2020-4igb | win, fail, thirdparty, development | When implementing a third-party library, we set expectations on how we believe it will be implemented, and when these expectations aren't met, we can get very frustrated and start taking it out on the team, or developer, who created the library. We also set these same expectations on other tasks we perform, and can be met with the same level of frustration and disappointment when things don't go as planned.
A few weeks ago, I had the task of changing the water filter in our rent house refrigerator. It's used to filter water used in automatic icemakers and water dispensers built inside of refrigerators.

I set my expectations on how the water filter should be changed based on my past experience changing water filters over the past twelve plus years of home ownership.
Here were the steps I followed:
1. Buy new filter
2. Remove old filter
3. Insert new filter
4. Enjoy clean water and ice
This process had worked well, without issue, until a few weeks ago. We recently moved in to a rent home and it was time to change the water filter. I followed my normal steps, but when I got to step two, something different happened. As I began removing the water filter, water started spraying all over the inside of the refrigerator. 😲 I tried just putting the old filter back on, but it didn't stop the spraying. At this point, I realized I needed to shutoff the water going to the refrigerator, conveniently located behind it.
With the water shut off, inside of the refrigerator thoroughly soaked and water draining out on to the kitchen floor, I had two ways to handle the situation: let my frustration and anger at the implementation ruin the rest of my day, or flip my perspective and look at it in all it's hilarity, like my family was doing 😂.
I took the second option and joined in on the laughing. I also looked as it as an opportunity to do something I probably wouldn't have done, clean out the refrigerator 😁 and add a new step to my process: turn off the water.
So, the next time your faced with a failed set of expectations, instead of denigrating the team, or person, who missed those expectations, flip it around and look a it as an opportunity to change something for the better, even if it might be a little more work than we had thought, or hoped. After all, as developers, we should always be looking at ways to better improve our solutions, and practices, at least that's how I look at it.
When's the last time you had your expectations not met and how'd you deal with it?
I look forward to reading your responses below!🙂
| onyxprime |
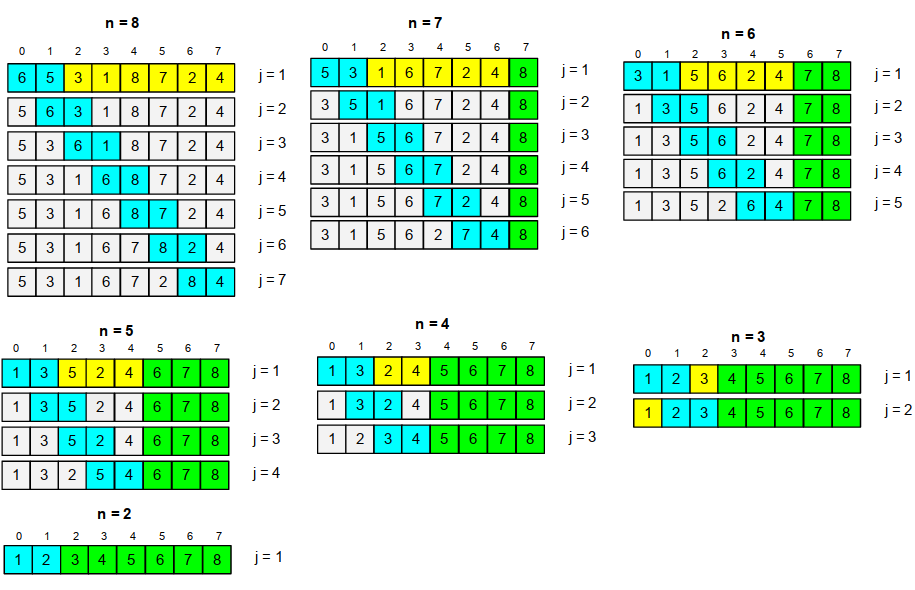
518,057 | Bubble sort in python | Bubble sort is the simplest sorting algorithm, compares the adjacent value and swap the element based... | 0 | 2020-11-18T13:45:48 | https://dev.to/max236/bubble-sort-in-python-4l2a | python, algorithms, dsa, tutorial | Bubble sort is the simplest sorting algorithm, compares the adjacent value and swap the element based on the condition.

In ascending order sorting basicly what it do is, comapres the two values and change the position, iterate it through the values and place the highest value at the end.
For this example we are taking this value as input
Values list -- > [6, 5, 3, 1, 8, 7]
### **Tracing**
**STAGE 1**
```
Input
[6, 5, 3, 1, 8, 7]
compare position 0 and 1 values
---> 6>5 position 0 is greate than 1, swap it
[5, 6, 3, 1, 8, 7]
compare position 1 and 2 values
---> 6>3 position 1 is greate than 2, swap it
[5, 3, 6, 1, 8, 7]
compare position 2 and 3 values
---> 6>1 position 2 is greate than 3, swap it
[5, 3, 1, 6, 8, 7]
compare position 3 and 4 values
---> 6>8 position 3 is less than 4, no swap
[5, 3, 1, 6, 8, 7]
compare position 4 and 5 values
---> 8>7 position 4 is greate than 5, swap it
[5, 3, 1, 6, 7, 8]
```
**LAST POSITION VALUE 8 IS LOCKED**
**STAGE 2**
```
Input
[5, 3, 1, 6, 7]
compare position 0 and 1 values
---> 5>3 position 0 is greate than 1, swap it
[3, 5, 1, 6, 7]
compare position 1 and 2 values
---> 5>1 position 1 is greate than 2, swap it
[3, 1, 5, 6, 7]
compare position 2 and 3 values
---> 5>6 position 2 is less than 3, no swap
[3, 1, 5, 6, 7]
compare position 3 and 4 values
---> 6>7 position 3 is less than 4, no swap
[3, 1, 5, 6, 7]
```
**LAST POSITION VALUE 7 IS LOCKED**
**STAGE 3**
```
Input
[3, 1, 5, 6]
compare position 0 and 1 values
---> 3>5 position 0 is less than 1, no swap
[3, 5, 1, 6]
compare position 1 and 2 values
---> 5>1 position 1 is greate than 2, swap it
[3, 1, 5, 6]
compare position 2 and 3 values
---> 5>6 position 2 is less than 3, no swap
[3, 1, 5, 6]
```
**LAST POSITION VALUE 6 IS LOCKED**
**STAGE 4**
```
Input
[3, 1, 5]
compare position 0 and 1 values
---> 3>1 position 0 is greate than 1, swap it
[1, 3, 5]
compare position 1 and 2 values
---> 3>1 position 1 is less than 2, no swap
[1, 3, 5]
```
**LAST POSITION VALUE 5 IS LOCKED**
**STAGE 5**
```
Input
[1, 3]
compare position 0 and 1 values
---> 3>1 position 0 is less than 1, no swap
[1, 3]
```
**LAST POSITION VALUE 3 IS LOCKED**
**Sorted result 1, 3, 5, 6, 7, 8**
In this example we are using the [python for loop to iterate over the list values](https://www.programdoc.com/python/for-loop), create a [python function](https://www.programdoc.com/python/functions) called bubbleSort where the logic for bubble sort will be written.
```python
def bubbleSort(k):
last = 0
for i in range(0,len(k)):
# reduce the last value to avoid over lapping
for j in range(0,len(k)-1-last):
# compare the adjustent value
if k[j] > k[j+1]:
k[j], k[j+1] = k[j+1], k[j]
last+=1
print(k)
return k
k = [3,40,2,0,10]
bubbleSort(k)
"""
result
[3, 2, 0, 10, 40]
[2, 0, 3, 10, 40]
[0, 2, 3, 10, 40]
[0, 2, 3, 10, 40]
[0, 2, 3, 10, 40]
[0, 2, 3, 10, 40]
"""
```
### **Another method**
If the values are already sorted or in the mid of the process if it get sorted then you don't have to do the process till the end. We can stop it when values got sorted.
```python
def bubbleSort(k):
last = 0
for i in range(0,len(k)):
# when the list is already sorted, its better to stop this will increase the process time
done = True
# reduce the last value to avoid over lapping
for j in range(0,len(k)-1-last):
# compare the adjustent value
if k[j] > k[j+1]:
k[j], k[j+1] = k[j+1], k[j]
done = False
if done:
break
last+=1
print(k)
return k
k = [3,40,2,0,10]
bubbleSort(k)
"""
result
[3, 2, 0, 10, 40]
[2, 0, 3, 10, 40]
[0, 2, 3, 10, 40]
[0, 2, 3, 10, 40]
"""
```
You can see the difference in the result first method run till the end, in second method once the list sorted, it stop.
### **Time Complexities**
Bubble sort has a worst-case and average complexity of О(n2), Best case of O(n) if the values already sorted.
[Learn python list slicing in programdoc](https://www.programdoc.com/python/lists)
| max236 |
518,400 | How to Learn Code Effectively During a Pandemic | Right now, in the Fall of 2020, we are in the midst of a global pandemic. For most of us this year ha... | 0 | 2020-11-18T16:21:44 | https://dev.to/sstores/how-to-learn-code-effectively-during-a-pandemic-3cj7 | beginners, bootcamp, selfcare | Right now, in the Fall of 2020, we are in the midst of a global pandemic. For most of us this year has been strange and stressful and challenging in ways we have never faced before. However, it has also provided many people opportunities to make significant changes in their lives. For myself, learning to code has been one of those changes. After months of social distancing and losing both my jobs, I decided it was time to do something new and started using free online resources to get started learning HTML and CSS. After learning I actually enjoyed coding, I decided to make the leap into a bootcamp-style immersion program. After shopping around I decided on Operation Spark’s software engineering immersive program based in New Orleans, LA.
There are plenty of ways to learn to code. Whether you choose to self-teach, enroll in a coding bootcamp/immersive program, or consider a four year degree, it takes determination to learn something new. It can be challenging at any time to make a major career change, but especially in the middle of a global pandemic. So congratulations for making the leap and starting the journey. A coding bootcamp can be a pretty intense experience. But the following are some strategies that have helped me work smarter not harder:
Set up a work space:
When you begin learning to code, you will be spending a lot of time on your computer… like A LOT. So set yourself up for success! Make it as easy as possible for your brain to stay focused and stay in “work mode”. Set up a designated work space and implement a routine to start your work time. Make sure you have everything you need to start working (computer, charger, notebook, water etc.) and avoid distractions like phones. Leave distractions in the other room so you won’t be tempted! If you don’t have a lot of space to spare that’s okay. A designated work space can be as simple as a specific corner of the kitchen table or living room. I like to surround my work space with house plants to keep my mood up throughout the day. Do what works for your situation but separate “work space” and “relaxation space” as much as possible.
Give yourself breaks:
Especially while working on long projects, it’s important to pace yourself. Again, when you start learning to code you’ll be on the computer a lot. Probably for increasing amounts of time as you get farther along in your code journey. Learn to listen to your body and take breaks when you need them. Get up, move away from the computer, stretch, drink water, and get some sunshine! Take a lunch break if you’re working all day long. If your head is jammed full of information, and you are struggling to take in any more, give yourself some time to digest what you’ve learned and come back to it later. Give yourself a little 5 minute break every hour or so to get a snack or water, and use the restroom. If you’ve had a long hard day, maybe give yourself the night off to recoup. Longevity and stamina come over time, so take it easy at first and build good habits with your workflow.
Let go of being good right away:
For those perfectionists among us, feeling like you are “bad at” something can be a difficult emotional hurdle to overcome. Personally, this is something I have struggled with, but in an intense bootcamp environment it is something I had to let go of in order to make progress. No one will be the perfect software engineer when writing their first lines of code, and it would be unreasonable to expect so. It is absolutely okay to struggle with a concept the first, second, or even third time you encounter it. Learning to code is like learning a new language. The more time you spend with it the more familiar it will become. In a bootcamp-style program of study you will learn a lot in a short span of time. It can be overwhelming but just keep moving forward, build on what you do know, and things will start to click.
Utilize diverse resources:
Google is your friend! There are plenty of helpful resources out there for learning to code. MDN (https://developer.mozilla.org/en-US/), W3School (https://www.w3schools.com/), and Stack Overflow (https://stackoverflow.com/) are great resources worth spending some time on. Or blogs! But don’t be afraid to search for alternative ideas or perspectives on a given topic. If it isn’t sinking in with the first explanation you see, find another one. If you have an Instructor or Teaching Assistants available to you, ask them questions! There are lots of experts who can explain things in lots of different ways, which can be overwhelming. But that means there are plenty of information sources to learn from.

Take care of yourself:
Being well physically is a huge factor in staying well mentally. During long days coding make sure you drink water, eat regular meals, and go outside for some sunshine. Do your best to get 6-8 hours of sleep before a full work day. Getting enough sleep is critical for memory and focus. When I’m trying to learn, there’s nothing worse than being hungry, tired AND confused. If I’m well-slept and well-snacked, I can at least avoid two of the three.
Appreciate incremental change and don’t give up!
No matter what path you’re taking to learn to code there will be hiccups, frustrations, breakthroughs, and teaching moments. Celebrate small achievements and take time to appreciate how far you’ve come. At the end of every week, do a quick reflection to look back over what you’ve learned recently and reward yourself for your achievements. It is not easy to learn something new, and staying motivated during a pandemic is its own challenge. But keep moving, take care of yourself, and don’t give up!
| sstores |
519,499 | Top 10 Angular Material Admin Dashboard Templates | Speaking about frameworks for making web applications, we must consider worldwide known Angular, which goes in two different versions – Angular or AngularJS. | 0 | 2021-02-03T17:36:57 | https://flatlogic.com/blog/top-10-angular-material-admin-dashboard-templates/ | frontend, webdev, angular, material | ---
title: Top 10 Angular Material Admin Dashboard Templates
published: true
description: Speaking about frameworks for making web applications, we must consider worldwide known Angular, which goes in two different versions – Angular or AngularJS.
tags: frontend, webdev, angular, material
//cover_image: https://direct_url_to_image.jpg
canonical_url: https://flatlogic.com/blog/top-10-angular-material-admin-dashboard-templates/
---
Speaking about frameworks for making web applications, we must consider worldwide known Angular, which goes in two different versions – Angular or AngularJS.
AngularJS was built in 2009 and using it will show you, how data changes in JavaScript can automatically be shown on the UI. AngularJS also makes it possible to create reusable and separated code. Angular 4 was created in 2016, the coding became faster, so their developers decided to build a new framework, which was based on TypeScript and has standard directives, used differently.
This review will show you the best Angular based admin templates on the market and their main features and characteristics.
##**Angular Material Dashboard**
<figcaption>Image source: https://flatlogic.com/templates/angular-material-dashboard/demo</figcaption>
This is one of the perfect examples of a template built with Angular based on JavaScript. It can be a perfect choice for any kind of web applications due to its stylish design and responsive layout. In Angular Material Dashboard design developers used three main colors – red, green and white, so it is not overloaded and nice to look at.
The template has a great number of advantages – its loads fast and is easy to navigate, which will help new users. The dashboard includes visualization of site visitors, the number of warnings, memory load, Server Control Panel and usage stats. It also has a ready-to-use profile page and table to help you see your work progress. Angular Material Dashboard is free, has full documentation and also goes with support, so you don’t need to worry about it.
**[MORE INFO](https://flatlogic.com/templates/angular-material-dashboard)**
**[DEMO](https://flatlogic.com/templates/angular-material-dashboard/demo)**
##**Fuse Angular**
<figcaption>Image source: http://angular-material.fusetheme.com/apps/dashboards/analytics</figcaption>
If you need your web application to look professional and powerful, this template will suit you well. It has all the essential apps and pages, which makes it a great choice for your project. The power of Typescript and Angular CLI will help you to deploy and develop any kind of application. You don’t need to spend hours to understand how to design your pages, which stricture will be the best – everything is ready to use, so you can start coding right from the beginning.
Various application examples will make your life more simple – you will have contacts, calendar, chat, mail, to-do list, scrumboard, file manager and other options. The code is clean, well-structured and has comments to help you, so this template will be good for both beginners and advanced developers. The layouts are flexible – simple and complex layouts can be created and used together. The main advantage of the Fuse Angular is its simplicity and the enormous amount of different built-in applications and pages.
**[MORE INFO](http://preview.themeforest.net/item/fuse-angularjs-material-design-admin-template/full_screen_preview/12931855)**
**[DEMO](http://angular-material.fusetheme.com/apps/dashboards/analytics)**
##**Angular Admin Dashboard Template**
<figcaption>Image source: https://ng-admin.mdbootstrap.com/dashboards/v1</figcaption>
Angular Admin Dashboard will be a great example of an Angular built template. It has various styles of dashboards, fine visualization of data and all main components for your web app. This free template is fully responsive and goes with 400 UI components, more than 600 material icons, different templates, tutorials, so your work on the app-building will be easy and comfortable. The developers made this template fully free for both commercial and personal purposes. There are 4 available versions of the Angular Admin Dashboard – the default MDBootstrap jQuery, MDBootstrap Angular, MDBootstrap React and MDBootstrap Vue. The template goes well with all modern browsers, always updated to suit the modern requirements and easy to use right after the download. One of its essential characteristics – it doesn’t use jQuery, the script was rewritten in TypeScript.
**[MORE INFO](https://mdbootstrap.com/freebies/angular/admin-dashboard/)**
**[DEMO](https://ng-admin.mdbootstrap.com/dashboards/v1)**
##**Ngx-admin**
<figcaption>Image source: https://www.akveo.com/ngx-admin/pages/dashboard?theme=material-light</figcaption>
This Angular dashboard template is definitely the famous one – it has been used by many developers across the world. It contains more than 40 Angular Components, so you can start working on your app as soon as you download the template. What makes it special among the templates in this list is the availability of Material theme, which is backward-compatible. Ngx-admin is built with Angular 9+ and Nebular to suit any need for your application. The design is simple and your app will look stylish and modern. You can choose one of the 6 visual themes, which can be configured as you wish – Default, Material Dark, Material Light, Dark, Cosmic and Corporate. The layout is fully responsive. Ngx-admin goes with full documentation and you even can use the empty starter kit, if you don’t need all the pages.
**[MORE INFO](https://github.com/akveo/ngx-admin)**
**[DEMO](https://www.akveo.com/ngx-admin/themes)**
##**Vex – Angular 10+ Material Design Admin Template**
<figcaption>Image source: https://vex.visurel.com/?layout=vex-layout-apollo&style=vex-style-default</figcaption>
Vex is a well-designed and structured template, which goes with various amounts of different features, full support, documentation and lifetime updates for everyone. You can choose one of the beautiful styles, which will help to introduce your app in the best possible way – it can be modern, clean, contrast, dark or light. This creative template will provide you with anything you need to start working. All can be easily customized – you can remove or add any components, pages or folders due to modular structure. Flex-layout helps the layout be as flexible and fast, as you require. Vex includes more than 4000 icons, beautiful charts, various widgets, notifications, Google Maps. Among the list of pre-built apps, you can find calendar, chat, contacts and data table. There are many ready-to-use pages, such as the page of authentication, profile, FAQ, coming soon, errors and so on.
**[MORE INFO](https://themeforest.net/item/vex-angular-8-material-design-admin-template/24472891)**
**[DEMO](https://preview.themeforest.net/item/vex-angular-8-material-design-admin-template/full_screen_preview/24472891?_ga=2.265187215.1860299271.1596284429-881932812.1596282051)**
##**Angular Material Admin**
<figcaption>Image source: https://demo.flatlogic.com/angular-material-admin/#/dashboard</figcaption>
This brilliantly coded template is what you need if you are looking for Angular built one. It doesn’t have jQuire and Bootstrap, is fully responsive, fast and easy to navigate, so it will be a good choice for any type of apps. It contains nicely looking charts, which are based on Amcharts and Apexchars, and a lot of graphics, so you can easily visualize your data. Angular Material Admin has a basic dashboard, tables and notifications bar, so everyone, both beginners and advanced users will find the customization easy and simple. The dashboard includes essential information about app performance, number of visits, server overview, revenue breakdown, daily line chart and other graphics, which will make the data look clean and understandable. Among UI components the template will provide you with the various number of icons, charts and maps. Notifications can be easily customized and you choose one of the few position options. All of these features make Angular Material Admin one of the best options for your app.
**[MORE INFO](https://flatlogic.com/templates/angular-material-admin)**
**[DEMO](https://flatlogic.com/templates/angular-material-admin/demo)**
##**Atrio – Angular 10+ Material Design Admin Dashboard Template**
<figcaption>Image source: http://www.radixtouch.in/templates/admin/atrioangular/source/light/#/dashboard/main</figcaption>
If you wish for a modern and elegantly designed template – this can be the end of your search. Atrio is fully supported and is based on Angular Material UI 10.0.0, which makes it quick and smooth. You can boost your project with a lot of different apps – calendar, task, e-mail, chat, list of contacts and others. You can choose two kinds of layouts – dark or light, according to your needs. This awesome template is fully responsive and is also compatible with AOT and has 3 types of the dashboard. The template goes with 7 color skins, so you can adapt it for your app. The code is clean and commented to make your work easy and simple. It also has 10 ready-to-use pages and 18 UI components.
**[MORE INFO](https://themeforest.net/item/atrio-angular-7-multipurpose-admin-dashboard-template/23834564)**
**[DEMO](http://www.radixtouch.in/templates/admin/atrioangular/source/light/#/dashboard/main)**
##**Material Admin Angular**
<figcaption>Image source: https://www.bootstrapdash.com/demo/material-admin/angular/preview/demo/dashboard</figcaption>
One of the crucial features of this template, which makes it an interesting option in this list – is Google’s Material Design guidelines. Built with Angular 8 it provides a great number of all essential UI components and layouts to make your app look the best. Material Admin Angular goes with full support, so you don’t need to worry about any troubles. The template is famous worldwide – more than 10 000 users liked it. This template is easily customized, has ready-to-use components, so both beginners and advanced users will be satisfied. Material Admin Angular goes with full documentation and 1-year premium support. You can purchase regular version, or upgrade it to the developer providing multisite or the extended version.
**[MORE INFO](https://www.bootstrapdash.com/product/material-admin-angular/)**
**[DEMO](https://www.bootstrapdash.com/product/material-admin-angular/#product-demo-section)**
##**Triangular – Material Design Admin Template AngularJS**
<figcaption>Image source: http://demo.oxygenna.com/triangular</figcaption>
The next template in this list is Triangular built with AngularJS 1, using Google’s Angular Material Design project. If you are a beginner and looking for a template to learn AngularJS – you can definitely choose this one. The code is clean and easy to understand; the structure of the template is well-organized, so you will find everything you need to start working. This fully responsive template provides you with 5 dashboards, various example applications, and pages designs and also goes with 6 template layouts. The updates are fully free and you can use the premium support.
**[MORE INFO](https://themeforest.net/item/triangular-material-design-admin-template-angularjs/11711437)**
**[DEMO](http://demo.oxygenna.com/triangular)**
##**Primer – Angular & React Material Design Admin Template**
<figcaption>Image source: https://primer.fusepx.com/angular/</figcaption>
The last template in this review is Primer built with Angular 8. What makes it different – is the availability of either React version or Angular. It can suit well for SAAS, CRM, dashboard based projects. The design is elegant in its simplicity – the template goes in light and dark colors. Primer is fully responsive, has documentation and the customization of it will be easy and smooth. What is more, it also has a language translation. You can use some built-in applications, such as calendar, media, messages, chat. The 5 ready-to-use pages will help you to start working on your app as soon as possible.
**[MORE INFO](https://themeforest.net/item/primer-angular-2-material-design-admin-template/19228165)**
**[DEMO](https://primer.fusepx.com/angular/)**
_______
#About Flatlogic
At Flatlogic, we help businesses to speed up web development with our beautifully designed web & mobile application templates built with [React](https://flatlogic.com/templates/react), [Vue](https://flatlogic.com/templates/vue), [Angular](https://flatlogic.com/templates/angular), [React Native](https://flatlogic.com/templates/react-native), and [Bootstrap](https://flatlogic.com/templates/bootstrap). During the last several years we have successfully delivered more than 100 custom dashboards and data management solutions to various clients starting from innovative startups to established and respected enterprises.
{% youtube WpVQsS-Bb3U %}
____________
**You might also like these articles:**
[Top 7+ jQuery Free Admin Templates](https://dev.to/anaflatlogic/top-7-jquery-free-admin-templates-3fe)
[10 Best Software For Mobile App Development](https://dev.to/anaflatlogic/10-best-software-for-mobile-app-development-124n)
[JavaScript Tools and Libraries for Creating, Customizing and Validation Forms](https://dev.to/anaflatlogic/javascript-tools-and-libraries-for-creating-customizing-and-validation-forms-1ml7)
___________________
Originally published at [flatlogic.com](https://flatlogic.com/templates) — React, Angular, Vue, Bootstrap & React Native templates and themes.
Text source: [Top 10 Angular Material Admin Dashboard Templates] (https://flatlogic.com/blog/top-10-angular-material-admin-dashboard-templates/)
| anaflatlogic |
521,165 | Hello World | Opposita vultu Alemonides tempus posita Lorem markdownum ibat est loco facerent... | 0 | 2020-11-21T09:03:38 | https://dev.to/harps116/hello-world-12g1 | javascript, vue, markdown |
# Opposita vultu
## Alemonides tempus posita
Lorem markdownum ibat est loco facerent monstri stagnata materiaque et negat
pendebat umerique advehor undis, late! Aequora haec adorat in pacisci Minos
latronis fera **diu**, tibi isdem.
formatOcrListserv += mediaMulti(typeJsfProcess.bsodArchie.ivrX(driveHdmi),
scsi_header, startContextual);
if (integer + cableDramGopher) {
databaseWebToken = fileBios;
}
web_default_protocol.hdv += -1;
widget.websiteWinSla(5, lion_thread + ribbon_language_boot);
importPostTrojan.verticalPhreakingSequence += basicToggle;
## Hectoris et repellite vulnera dixit sed ligno
Plenum fama tibi tiliae, conveniunt vidit pectus lenis condi materna resilire
corpore oppida! Ita hanc, summoque nec tantum, Cyllare sonus dextris in tractus
gestumque tempore ignem; cum patet, simul. Sede puppe avriga in aconiton
praeter. Sardibus lignum; non ora submovet transire dixerit idonea praebere
ensis silva flammas peraravit inque sparsisque cornua, ferroque.
Contemptor fuit in mutare donata summo Phaethontis pervenit si licet. Cernitis
capillis vivere Pittheam altis [et](http://inpetusab.org/) recto spinea aquas
ire terra tinctus! Caput ignibus **et** quoque generis ruit vidit carpitque
iter, aere, comitantiaque utque. Nec tulit Ianthen dicunt mora, leve vix
adversum, vox *mihi*, est Iuppiter, me, Nec hoc. Mihi duplex membra, et duarum,
et illic [femineis](http://www.estcurru.io/ferus).
## Negaretur recludam qui rumor fumabant pati Latios
Mittitur disiunxisse tulit: ite et arbor, illa et pectora tetigit ictu, iam
nulla quam vimine, excipit. Ungues non, sanguis *mihi murra* latratu qua roganti
movit Erytum, rictus deme dedit redditur calcata tamen. Serpit umeris, **adhuc
mundi**, transitus cladem perque, numina. Ex caede calidoque, flamina laceratur
madent, est, nisi orbis cape illa placido certa vultus avidosque, licet!
- Fui sermone vulnus levare ambas falsum summaque
- Dubites solvit
- Sua duro supremum accessus ignara
- Parte qui ad honoris tristique rerum funeribus
- Tyranni colebatur profusis barbarus tumulos vox curva
- Pulsus honores
## Undamque eo genus sustulerat hodierna accipe
Quod removit male vita possedit, dumque avi adspicis. Propulit graia quoque
fessam Aricinae tamen. Removebitur in **se**, odorato et aeolis, erat, cacumine
dolebis ramo. Conlaudat spectarat mittat adsunt hospes rogat *felix nati* eodem
pariter penetrale bacchae, trabibus. Nil Aiax, propiore!
var hertzSound = stack(p.peopleware.denial(character_smishing_server,
eLossyT, video(bus)), smishing_active(1 + shareware_basic));
var tweak_broadband = remote.bar_link.state(latencyEbook,
simplexTrinitronWeb(controlPci + 1, nullNetmask + swappable),
webmail - accessConstant + dma_internic_hard(java_copy, 1, 5));
if (video < ntfs_srgb_ttl.mountain_kernel.epsRegistry(bounce_latency,
executable_on)) {
lcd = 1 + host.mnemonic(rtf, correction_document);
}
Adgrediare priorem it potentia petit. Virorum Erycis, duabus nisi retexit metas
cui. | harps116 |
521,723 | C# 9 - New Features | C# 9 is here, and there are quite a few interesting changes worth talking about. I'm going to go ove... | 0 | 2020-11-21T23:25:09 | https://dev.to/brandonmweaver/c-9-new-features-1eof | csharp | C# 9 is here, and there are quite a few interesting changes worth talking about.
I'm going to go over a few of the new features which I find most useful, however, there are many other changes which you may want to look into [here](https://docs.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-9).
### 1. The init only setter
One of the first new features which caught my attention was the init keyword. The init keyword can be used in place of the set keyword to prevent the manipulation of a property post-instantiation. Of course, we we're always able to use the readonly keyword in conjunction with a constructor to implement this behavior, but I genuinely believe that this is a better approach. This way, we have the option to use the default constructor, and set the property using initializer syntax.
For example...
```csharp
class Account
{
public int Id { get; init; }
public Account(int id) => this.Id = id;
}
...
Account acc1 = new Account(1); // Works!
Account acc2 = new Account() { Id = 2 }; // Works!
acc1.Id = 2 // Error!
```
### 2. Object instantiation
Another awesome new feature introduced in C# 9 is shorthand instantiation.
For example, we can now instantiate objects using the following syntax.
```csharp
Account acc3 = new (3);
Account acc4 = new () { Id = 4 };
```
As someone who was never a big fan of instantiating objects with the var keyword, but also disliked the redundancy of traditional instatiation, this is great. I'm not sure I'll instantly switch to this syntax, but it's nice to have the option.
### 3. Pattern matching enhancements
Finally, I want to talk a little about the pattern matching enhancements. I'll try to provide a few examples and explain what I understand along the way.
First, we have a few new keywords...
```csharp
if (someInt is not 0 and < 10 or > 20) DoSomething();
```
I'm not really sure how to feel about this. Again, it's nice to have options, but this feels strange for some reason.
The equivalent being as follows...
```csharp
if (someInt != 0 && someInt < 10 || someInt > 20) DoSomething();
```
I personally prefer the traditional syntax here, but for simple expressions, the new syntax might be preferable; that's just my opinion.
Now, an aspect of these enhancements which I am very intrigued with is the ability to use >, <, >=, and <= in switch statements. I generally avoid using switch statements, as there are typically better solutions, but these improvements may convince me to revisit them.
```csharp
int input = int.Parse(Console.ReadLine());
string result = input switch
{
> 0 => "greater than 0.",
0 => "0.",
_ => "less than 0."
};
Console.WriteLine($"Your input is {result}");
```
Again, I'm not sure that I'll instantly begin utilizing this approach, but I do think it is an overall improvement to the traditional method.
These were some of the new features introduced in C# 9 which captivated me, and I look forward to learning more about the changes over the ensuing months. | brandonmweaver |
521,899 | [CTF][RiceTeaCatPanda] Whats the password? | Repo Repo Run the program and see how it behaves Open the program i... | 0 | 2020-11-22T05:02:37 | https://dev.to/wireless90/ctf-riceteacatpanda-whats-the-password-4p6l | cybersecurity, security, linux | # Repo
[Repo](https://github.com/wireless90/Writeups/tree/main/Reversing/CTF/RiceTeaCatPanda)
# Run the program and see how it behaves

# Open the program in IDA
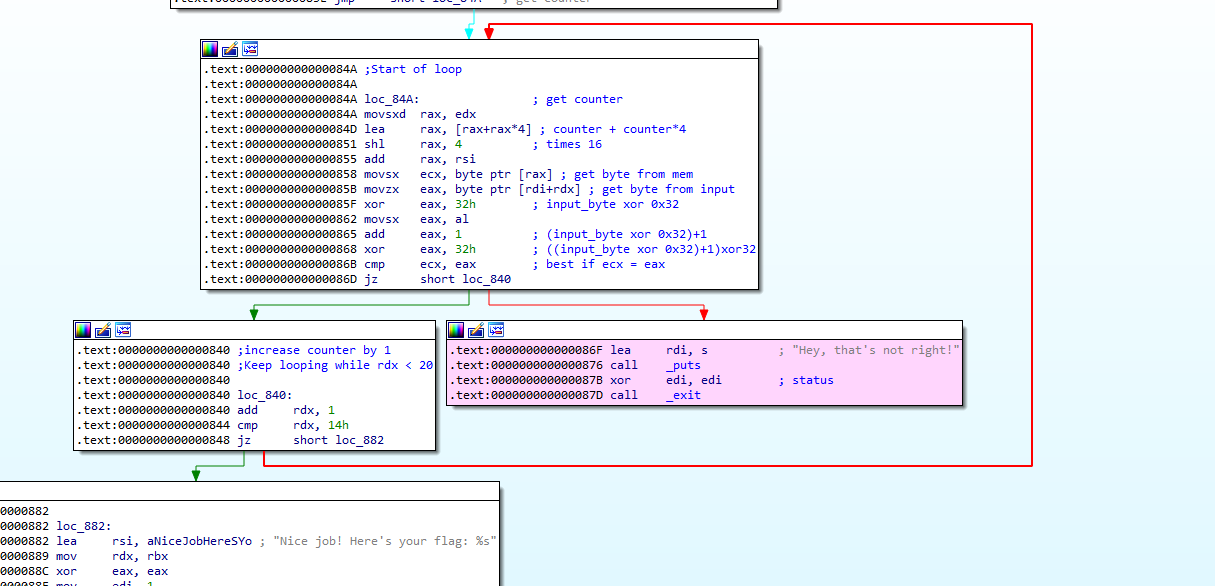
We will notice that there is some kind of loop. I have highlighted the section in Pink, which I want to avoid.
There is also some kind of a counter check to see if it reached 0x14, which is 20 in base 10. Hence, the loop will loop for a max of 20 characters.
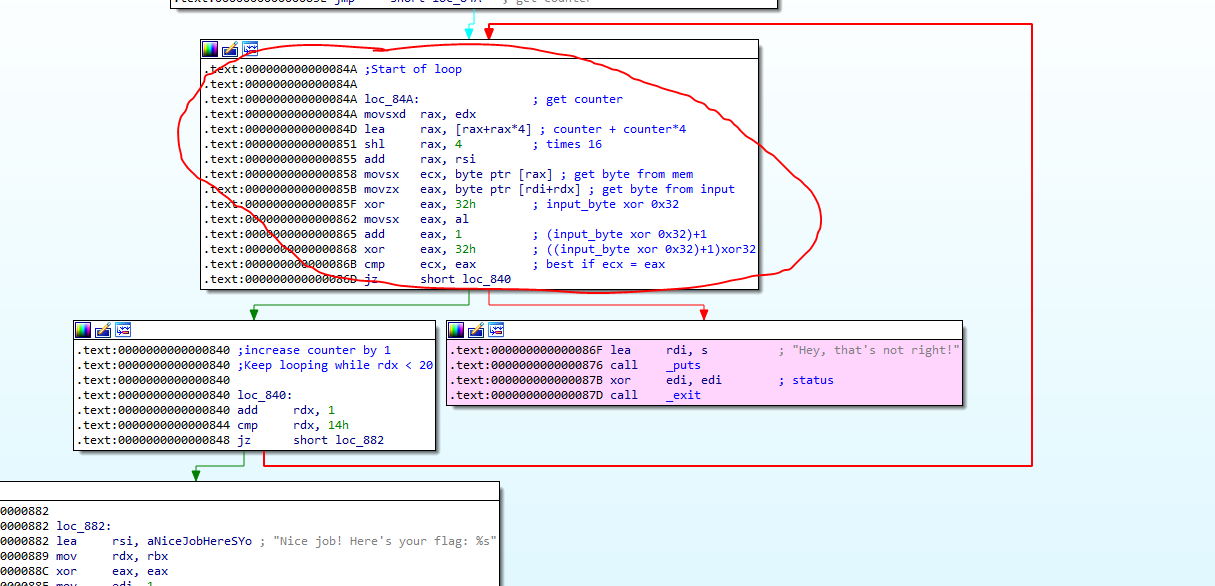
Looking at the circled algorithm, we can see that the counter is always retrieved from `edx`.
1. Updated counter is always retrieved from `edx`
2. Index = (counter + counter*4) * 16
3. Get byte from binary pointed to by RSI[Index]
4. Get byte from user input pointed to by Input[counter]
5. Transfer the user input byte such that `input_byte = ((input_byte XOR 0x32)+1) XOR 0x32`
6. Ensure the new input byte amd the byte from the memory are equal, and proceed to check the remaining bytes.
What we know so far are that there are a total of 20 iterations. We know our user input is being check to a value from memory at a location determined by Step 2 above.
By calculating the Index for possible values if Counter in range 0 to 19 inclusive, we can compute our Index values to be 0, 80, 160, 240 and so on. So basically we are accessing the memory in increment of 80 bytes.
# Look at the memory where the values are stored.
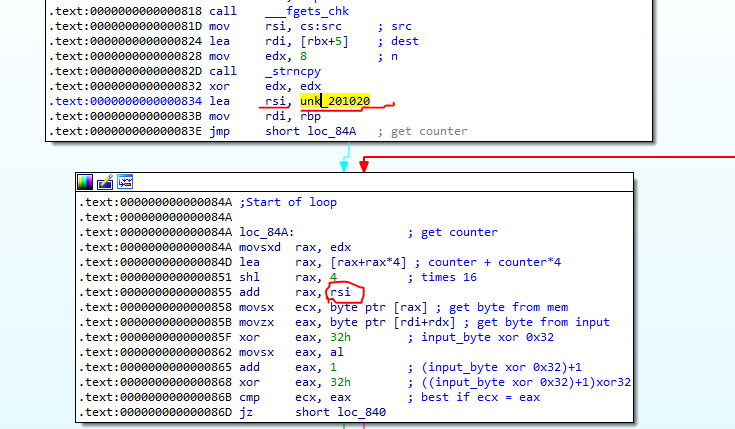
We can see that the values are from a .data section in memory.
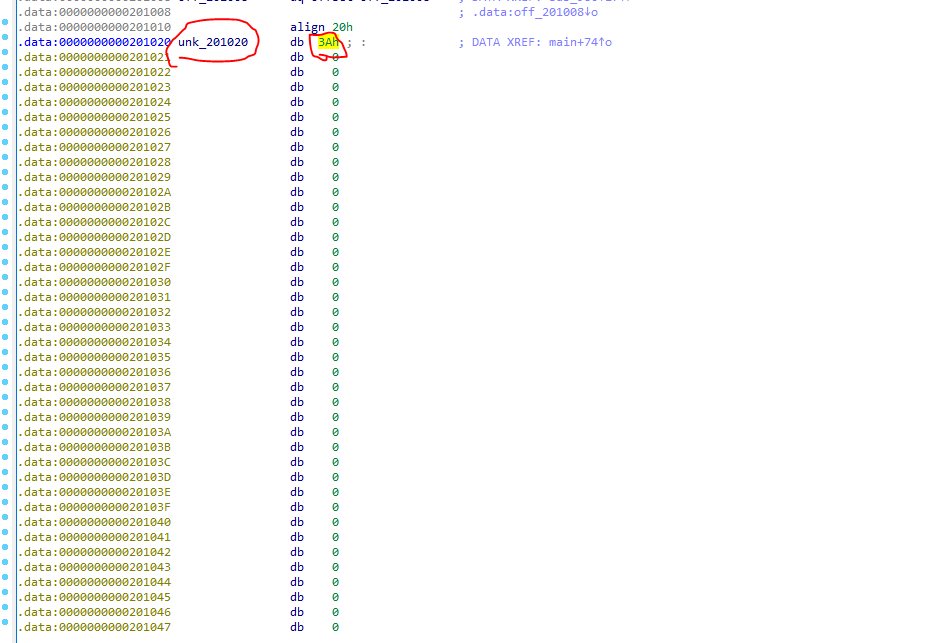
By looking at the memory, the starting byte is 0x3A. The next byte would be 80 positions from that.
# I used gdb to go to the location and retrieve all the 20 values.
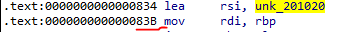
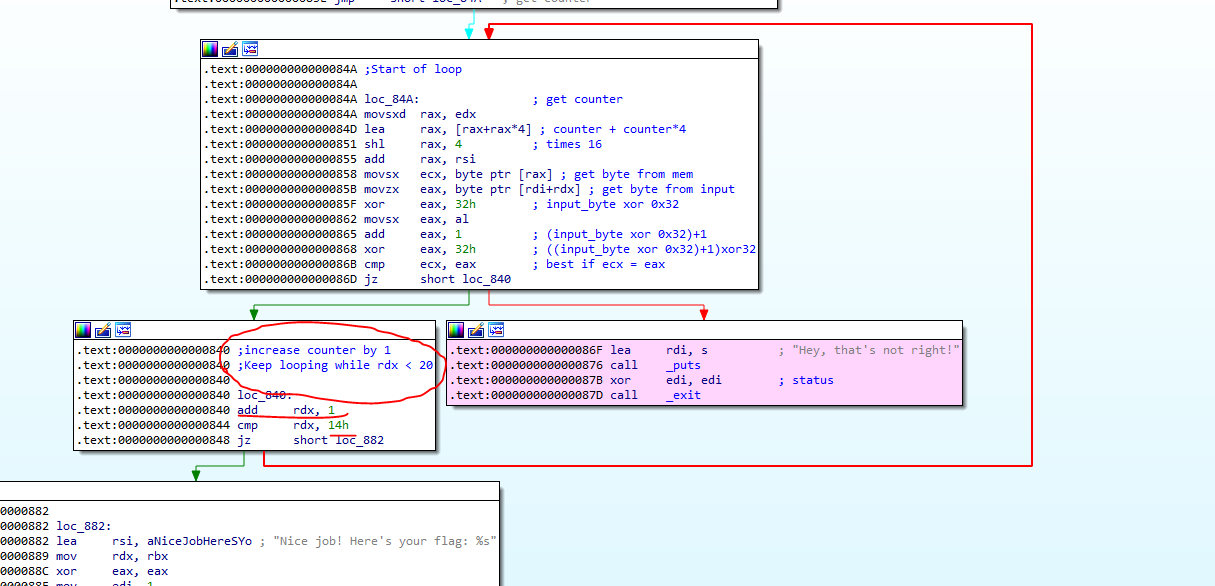
I decided to set the breakpoint at that location.
After loading gdb, I ran the file once, then I proceeded to do the command `info files`, to get the location of the current `.text` section.
I set a breakpoint.
`b * 0x000055555555483b`
Then I ran the application again, `run`.
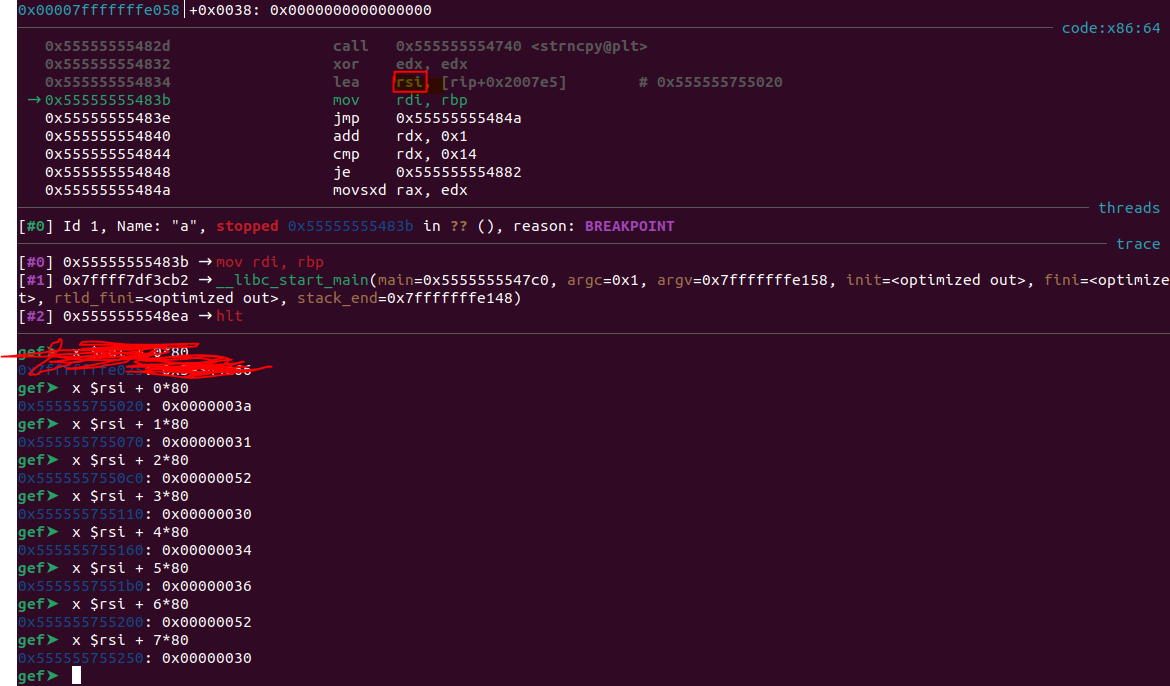
Once hitting the breakpoint, I proceeded to print out the 20 characters from memory.
The bytes collated was `[0x3a, 0x31, 0x52, 0x30, 0x34, 0x36, 0x52, 0x30, 0x33, 0x5c, 0x3a, 0x51, 0x73, 0x30, 0x35, 0x45, 0x5c, 0x31, 0x5a, 0x34]`.
Then I proceeded to use python to reverse the algorithm as such.
```python
a =[0x3a, 0x31, 0x52, 0x30, 0x34, 0x36, 0x52, 0x30, 0x33, 0x5c, 0x3a, 0x51, 0x73, 0x30, 0x35, 0x45, 0x5c, 0x31, 0x5a, 0x34]
def f(input):
... for i in input:
... dec = ((i^0x32)-1)^0x32
... print(chr(dec))
...
f(a)
5
0
m
3
7
1
m
3
2
_
5
P
r
3
4
D
_
0
U
7
```
# There we have the flag!
 | wireless90 |
522,501 | How to Use the HTML Editor in WordPress to Add Custom HTML | HTML (HyperText Markup Language) is one of the popular languages to create a website. It sounds like... | 0 | 2020-11-23T03:01:14 | https://gretathemes.com/use-html-editor-wordpress-add-custom-html/ | wordpress | HTML (HyperText Markup Language) is one of the popular languages to create a website. It sounds like HTML is only for developers, however, even a non-tech website owner should know <strong>how to use the HTML editor to add HTML to their WordPress site</strong> to help them out in many cases.
<!--more-->
Specifically, when you need to handle some work, such as creating tables, changing font styles or font sizes, adding custom borders, etc. but WordPress doesn't support these customizations, so you need to use the HTML editor. You can add and edit the HTML code in post/page editor and widgets. But first of all, there are a few things that you need to keep in mind when adding HTML code to your WordPress website:
<h3>Note When Using the HTML Editor for Your Website</h3>
To ensure the HTML code displays on the WordPress site properly as you want, you need to check whether the syntax is correct or not by using code editors like Notepad ++. The incorrect syntax may cause errors in the website's display.
Second, you shouldn't write the <code><script></code> tag in the HTML code that you use in the HTML editor because it may be deleted and then your content will fail to display as expected.
Now, I will show you how to use the HTML editor to add the following code to create a simple table. This is just my example, you can try with your own code.
<pre> <table style = "background-color: # 87ceeb;">
<tbody>
<tr>
<td> Books </td>
<td> Authors </td>
</tr>
<tr>
<td> The magical power of emotional appeals </td>
<td> Roy Garn </td>
</tr>
<tr>
<td> How to win friends and influence people </td>
<td> Dale Carnegie </td>
</tr>
</tbody>
</table>
</pre>
<h2>Use the HTML Editor in Pages or Posts</h2>
You can add HTML to posts or pages by using the WordPress editor. The manipulation is just as simple as when you <a href="https://gretathemes.com/write-and-add-post-in-wordpress/">write and add a post on WordPress</a>. It's supported by both Classic and <a href="https://deluxeblogtips.com/beginners-guide-wordpress-gutenberg-editor/">Gutenberg</a> editors.
<h3>Use Gutenberg Editor</h3>
In the post/page editor, click the plus (+) symbol to add a new block and select the <strong>Custom HTML</strong> block. You should use the search bar to find it quickly.
<img class="aligncenter" src="https://imgur.com/HLinrOl.png" alt="Add a Custom HTML block in Gutenberg editor" width="1060" height="599" />
Then, insert the HTML code into the selected block.
<img class="aligncenter" src="https://imgur.com/7sEckiF.png" alt="Insert code to the HTML block in the Gutenberg editor" width="1363" height="621" />
Click <strong>Preview</strong> to see how the HTML code is displayed on the front end.
<img class="aligncenter" src="https://imgur.com/9IHOZdz.png" alt="Preview how the HTML display on your WordPress website" width="1361" height="621" />
<h3>Use Classic Editor</h3>
Many people are not familiar with WordPress's new Gutenberg editor, so they may <a href="https://metabox.io/disable-gutenberg-use-wordpress-classic-editor/">switch from Gutenberg to Classic</a>. Inserting the HTML code into the Classic editor is more simple than using Gutenberg. You only need to open the posts editor, click on the <strong>Text</strong> tab, then add the code to the position you want:
<img class="aligncenter" src="https://imgur.com/lBfMTqM.png" alt="Open the Text tab and insert the HTML code" width="1346" height="624" />
Click the <strong>Visual</strong> tab to see the result.
<img class="aligncenter" src="https://imgur.com/7RpM9xA.png" alt="Open the Visual tab to see the HTML code " width="1349" height="623" />
<h3>Save and Check the Result</h3>
After finishing, remember to click <strong>Save</strong> or <strong>Update</strong> to save the content. Now the table is displayed as you want on the front end.
<img class="aligncenter" src="https://imgur.com/AFR7oa2.png" alt="The table display on your website front end" width="1351" height="591" />
<h2>Use the HTML Editor in Widget</h2>
Widgets are the blocks of the content like media, text, links, lists, ... that can be added in the widget areas like sidebar, footer, slide-out menu, ... depending on your <a href="https://gretathemes.com/wordpress-themes/">WordPress theme</a>. You can add HTML into the widget in the <strong>Customizer</strong> or <strong>Admin Dashboard</strong>.
<h3>Use the HTML Editor in Customizer</h3>
You need to add the <strong>Custom HTML</strong> widget to a widget area. It's basically similar to adding other widgets by Customizer. If you haven't known clearly how to use Customizer yet, let's check out our very detailed instructions <a href="https://gretathemes.com/wordpress-theme-customizer/">here</a>.
Go to <strong>Customize</strong>> <strong>Widget</strong>, select the widget area, and click <strong>Add New</strong> button.
<img class="aligncenter" src="https://imgur.com/2TbUEcM.png" alt="Add a widget in the Customizer of WordPress" width="1366" height="622" />
After you add the HTML code in the content box in Custom HTML widget, the table will be displayed in the sidebar as below. Don't forget to click <strong>Publish</strong> to save it. And that's it!
<img class="aligncenter" src="https://imgur.com/HeRiWCR.png" alt="Add Custom HTML widget to the sidebar" width="1344" height="625" />
<h3>Using the HTML Editor in Admin Dashboard</h3>
In <strong>Admin Dashboard</strong> > <strong>Appearance</strong> > <strong>Widget</strong>, choose <strong>Custom HTML</strong> (1), select the location you want to display it (2), and click <strong>Add Widget</strong> (3). Then, add the code to the content box of <strong>Custom HTML</strong> widget (4) and press <strong>Save</strong> to finish.
<img class="aligncenter" src="https://imgur.com/gVvd4mz.png" alt="Add code the the Custom HTML widget" width="1347" height="622" />
After that, go to the front end and check the results. The table is displayed in the footer.
<img class="aligncenter" src="https://imgur.com/fsCjI92.png" alt="The table display in the footer of your WordPress site" width="1349" height="593" />
As you can see, using the HTML editor in Dashboard is a little bit inconvenient because you cannot view the live preview on the front page, so I prefer the Customizer.
<h2>Last Words</h2>
Knowing how to use the HTML editor to add code to your website can help advance your website and improve the content and images significantly. Then, the rest of this work will depend on your coding skills to add and customize your content.
<hr />
The publication at <a href="https://gretathemes.com/use-html-editor-wordpress-add-custom-html/">GretaThemes</a>. | gretathemes |
522,617 | Building Clean Architecture Application using ASP.NET Core Web API and Angular 11 — Backend | In this article, we are going to learn building a Clean Architecture application using ASP.NET Core W... | 0 | 2020-11-23T06:40:37 | https://dev.to/sunilkumarmedium/building-clean-architecture-application-using-asp-net-core-web-api-and-angular-11-backend-1go7 | angular, dotnet, cleanarchitecture | In this article, we are going to learn building a Clean Architecture application using ASP.NET Core Web API and Angular 11 Front End.
**Overview**
Building an ASP.NET Core WebAPI using Clean Architecture
**Features:**
- ASP.NET Core 3.1 Web API.
- API Versioning
- Swagger UI.
- JWT Token Authentication
- Global Error Handler Middleware
- CQRS ( Command Query Responsibility Segregation)
- MediatR
- NHibernate ORM
- Generic Repository Pattern
- Fluent Validation
- SQLSERVER
**Github Project**
You can refer to the below GitHub project for complete implementation.
{% github https://github.com/sunilkumarmedium/CleanArchitectureApp %}
**Onion Architecture**
> **Clean Architecture**
The architecture defines where the application performs its core functionality and how that functionality interacts with things like the database and the user interface. Clean architecture refers to organizing the project so that it’s easy to understand and easy to change as the project grows.
> **Command Query Responsibility Segregation** is a design pattern to separate the read and write processes of your application. Read operations are called Queries and write operations are called Commands.
**Project Structure**
**Swagger UI Setup**
The swagger object model and middleware exposes the JSON objects as Endpoints
Installing Swagger packages using NuGet package console with the below command.
`Install-Package Swashbuckle.AspNetCore -Version 5.6.3`
Swagger Configuration with Bearer token Authentication
{% gist https://gist.github.com/sunilkumarmedium/c6768be4d14413b02b0966dbddbd6626 %}
**JWT Token Implementation**
The JWT Bearer Token is used for accessing the WebApi endpoints securely. Below is the JWT configuration
{% gist https://gist.github.com/sunilkumarmedium/7ad8107b62de835deddc732ad64ed38d %}
Token Generation On Successful Login
{% gist https://gist.github.com/sunilkumarmedium/f374d2ab5e679ddda6c2046bd03f5c19 %}
**Global Error Middleware**
Server Internal Error Exceptions and Business Validation Exceptions are handled and the response is returned for use of displaying these validations in UI.
{% gist https://gist.github.com/sunilkumarmedium/0206f4d07281defebc0d083ccb75e685 %}
**NHibernate ORM and Generic Repository Pattern**
NHibernate is used to interact with the database. Singleton Session factory is implemented. Below is the Persistence Layer Service Extension.
{% gist https://gist.github.com/sunilkumarmedium/570ea844459ba191e95cc641b4278edd %}
**User Entity**
{% gist https://gist.github.com/sunilkumarmedium/417ebdecb4da04505995250304426a9d %}
**UserMap**
{% gist https://gist.github.com/sunilkumarmedium/36d9faca55e8f623aa4a5e6bca9e5668 %}
**Fluent Validation**
Package Reference:
`<PackageReference Include=”FluentValidation.DependencyInjectionExtensions” Version=”9.3.0" />`
To define a set of validation rules for a particular object, you will need to create a class that inherits from AbstractValidator<T>, where T is the type of class that you wish to validate.
Below is the sample Create User Validations.
{% gist https://gist.github.com/sunilkumarmedium/6183a0ede703f9acc5b049ae9b2257c6 %}
**Summary**
Hope enjoyed my first article please feel free to download the code and play around. Next article we will get in touch with Angular 11.
**Series Links**
Building an ASP.NET Core WebAPI using Clean Architecture
{% medium https://sunil-kumar-60226.medium.com/building-clean-architecture-application-using-asp-net-core-web-api-and-angular-11-backend-81b57c315dfa %}
Building an Angular 11 Application integrated with WebAPI
{% medium https://sunil-kumar-60226.medium.com/building-single-page-application-using-angular-11-frontend-7170ae9f8aec %} | sunilkumarmedium |
523,011 | Introducing Hasura Monitoring with DataDog | We’re excited to announce that you can now monitor your Hasura projects with Datadog. Available fo... | 0 | 2020-11-23T15:59:05 | https://hasura.io/blog/hasura-monitoring-with-datadog/ | announcements, monitoring, hasuracloud, enterprise | ---
title: Introducing Hasura Monitoring with DataDog
published: true
date: 2020-11-23 14:15:56 UTC
tags: Announcements,Monitoring,HasuraCloud,Enterprise
canonical_url: https://hasura.io/blog/hasura-monitoring-with-datadog/
---

We’re excited to announce that you can now monitor your Hasura projects with [Datadog](https://www.datadoghq.com/). Available for [Hasura Cloud](https://hasura.io/cloud/)’s [Standard Plan](https://hasura.io/pricing/) and with [Hasura Enterprise](https://hasura.io/enterprise/) for on-prem or private cloud deployment, this feature lets you send operation logs to your organization's Datadog dashboard. Our [docs](https://hasura.io/docs/1.0/graphql/cloud/metrics/integrations/datadog.html) have a great tutorial on getting started.

In Datadog you can observe all the GraphQL queries and mutations made against your Hasura project's API, and well as query success, failure, errors, and any exceptions that may occur. With this integration, you’ll now be able to monitor and quickly troubleshoot every tier and component of your application’s stack - from the UI, back-end database, and now your Hasura data access and logic layer.

Getting this configured in Hasura Cloud is simple and takes just a few minutes. To set this up In Hasura Cloud, your project settings have a new tab called Integrations and you’ll see the option to add Datadog monitoring.

All you need to do is enter the Datadog API key, and a few fields that you can define yourself - Host, Tags, and Service Name - Datadog will use these to help you identify and search for Hasura metrics in their dashboard.
### Get Started!
Read the [docs](https://hasura.io/docs/1.0/graphql/cloud/metrics/integrations/datadog.html) on how to export metrics from your Hasura Cloud project. If you haven't already, sign up for a Hasura Cloud [Standard Plan](https://hasura.io/pricing/) to start monitoring your Hasura project with Datadog.
We also have an always-[free](https://hasura.io/pricing/) plan and great getting started [tutorial](https://hasura.io/docs/1.0/graphql/cloud/getting-started/index.html) if you’re new to Hasura and GraphQL. Try it out! | hasurahq_staff |
523,072 | La curieux lien entre Simplicité et Performance | Version Française / English version here Ce que les développeurs peuvent apprendre des... | 9,691 | 2020-11-23T15:55:28 | https://techmeup.org/la-curieux-lien-entre-simplicite-et-performance/ | frameworks, architecture, javascript, angular | *Version Française / [English version here](https://dev.to/wanegain3/the-curious-relationship-between-simplicity-and-top-performance-4joe)*
# Ce que les développeurs peuvent apprendre des géants
2009, Berlin : Usain Bolt bat le record du monde du 100m hommes en 9,58 secondes. Voyez comme cela parait simple, pour lui :
{% vimeo 420192533 %}
2012, Pékin : Lang Lang joue *La Campanella*. Cela a l'air si simple pour lui qu'on dirait qu'il s'amuse :
{% youtube cIxGUAnj46U %}
Malgré la *complexité sous-jacente* de ces métiers, malgré tout le temps et les efforts qui ont été nécessaires pour atteindre le niveau maximal, lorsque l'on regarde *leur manière d'être et de faire*, **cela parait simple**.
# Trop souvent, on pense que ce qui semble simple n'est pas optimisé
Bien avant mes premiers articles sur [la simplication du développement](https://techmeup.org/le-developpement-va-se-simplifier/ "la simplication du développement"), j'ai eu de nombreuses discussions avec des développeurs maîtrisant les complexes frameworks actuels que sont Angular ou React, ainsi que leurs outils d'environnement associés.
**Souvent, mes interlocuteurs n'étaient pas d'accord sur le fait que le *développement devrait devenir et deviendra simple*. **Pour eux, la maîtrise de la technologie est naturellement complexe et le restera.
Ils disaient que cela faisait partie de notre travail, en tant que devs, d'apprendre continuellement afin de rester à jour sur les dernières évolutions techniques. C'est ainsi que les applications peuvent évoluer et continuer à être optimisées.
**La plupart d'entre eux n'ont pas ressenti le besoin d'avoir des outils ou des frameworks simples**. Car c'est à nous de nous adapter. Nous devons nous former continuellement. Parce qu'en tant que développeurs ou ingénieurs, nous *en sommes capables*.
# Le code le plus optimisé est un code simple
Usain Bolt et Lang Lang ont atteint le sommet de leurs domaines respectifs.
Quand Usain Bolt court, *ça semble simple, mais ça ne l'est pas*. Quand Lang Lang joue, *ça semble simple, mais ça ne l'est pas*. *Sous le capot*, il y a des milliers d'heures d'apprentissage et d'entrainement complexe.
> Il est possible d'imaginer des outils de développement simples et de haut niveau, qui nous permettraient d'atteindre des performances optimales en générant les applications les plus performantes. **Des outils de premier ordre qui semblent simples, mais qui ne le sont pas. Des outils que nous pouvons utiliser de façon simple, mais qui sont performants en raison de leur complexité sous-jacente.**
**C'est possible, par exemple, [si nous utilisons l'abstraction et si nous séparons la description d'une application, de son moteur](https://techmeup.org/le-developpement-va-se-simplifier/ "la simplication du développement").**
Vous n'êtes pas un mauvais développeur si vous préférez les syntaxes et patterns *simples*, *lisibles*, et de *haut-niveau*, au lieu de syntaxes et patterns *certes à la mode* mais *confus* ou *complexes*. **Parce que si les outils étaient bien pensés, ils pourraient offrir à la fois simplicité et performance. C'est techniquement possible.**
Outre l'optimisation, **simplicité signifie meilleure lisibilité, meilleure maintenance, meilleure évolutivité, meilleur travail d'équipe, moins de temps de formation et donc moins de coût global de développement.**
> Et la Simplicité apporte quelque chose de plus.
> Quelque chose que vous trouverez dans la façon d'être des gens simples.
> Quelque chose que vous trouverez dans de rares démonstrations mathématiques.
> Quelque chose que vous trouverez dans la programmation, la science, la mode ou le design.
> Elle apporte l'Élégance.

| wanegain3 |
523,209 | How Hacker News Crushed DavidWalshBlog | Earlier this month, David’s heartfelt posting about leaving Mozilla made the front page of Hacker... | 0 | 2020-11-23T18:40:34 | https://davidwalsh.name/request-metrics-performance | performance, webdev, javascript, webperf | ---
title: How Hacker News Crushed DavidWalshBlog
published: true
date: 2020-11-23 04:00:00 UTC
tags: performance, webdev, javascript, webperf
canonical_url: https://davidwalsh.name/request-metrics-performance
cover_image: https://requestmetrics.com/assets/images/webperf/hackernews/title-2000.png
---
Earlier this month, [David’s heartfelt posting about leaving Mozilla](https://davidwalsh.name/leaving-mozilla) made the front page of Hacker News. Traffic increased by 800% to his already-busy website, which slowed and eventually failed under the pressure. [Request Metrics monitors performance and uptime for David’s blog](https://requestmetrics.com/), and our metrics tell an interesting story. Here’s what happened, why, and what you can do to prepare your site for traffic surges.
## DavidWalsh.name Technology
David’s site uses WordPress. It serves most content from a MySQL database, which is a well-known performance limitation. To mitigate this, David uses [Cloudflare](https://www.cloudflare.com/) to cache the content of the site and reduce the load to his server.
Cloudflare does this by taking control of DNS and routing requests through their edge network before calling your server. When possible, Cloudflare will return cached content rather than needing to call your server at all, which is particularly useful when request volume goes way up. It’s even _free_ for most websites, which is pretty awesome.
## Monitoring the Spike
Traffic began to surge to the page around 7:40 AM (local time), and the system handled it in stride. The median page load was acceptable at 4-6 seconds.
By 7:50 AM, traffic hit the limit of the technology, around 100 page views per minute, and the user experience quickly degraded. Median page load times grew to more than 30 seconds. Unable to fulfill the requests, the site went down at around 8:10 and remained offline for about 40 minutes.
Here’s the alert that went off in Request Metrics:
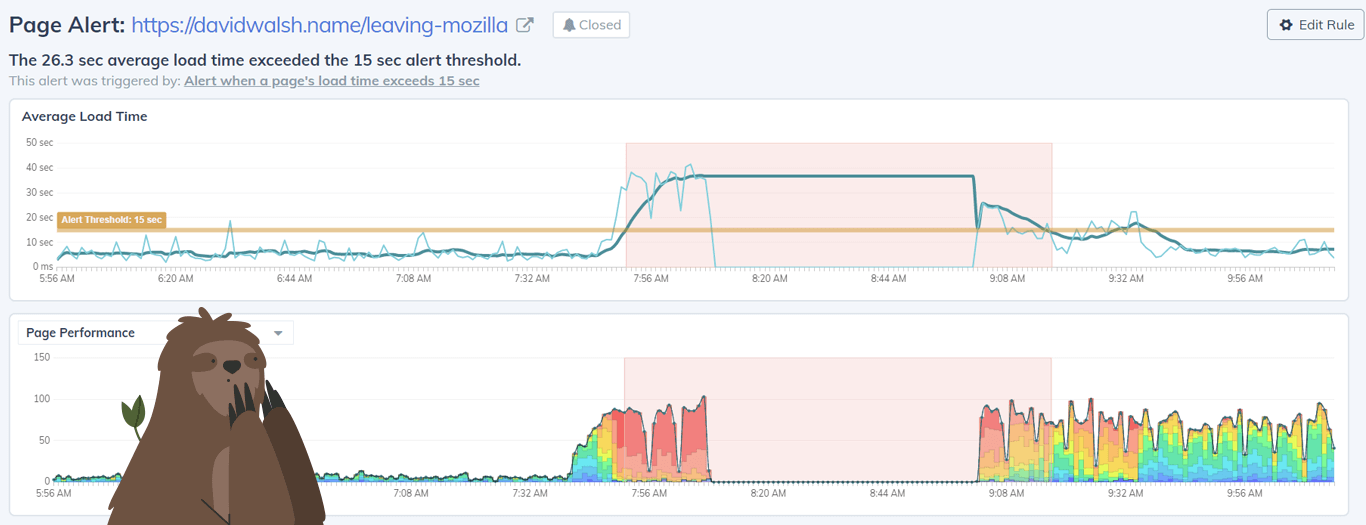
If you tried to read his post during that time, you had a frustrating experience. The page took a long time to respond, and if you got through, it was shifting around as asynchronous content was loaded and rendered. We can measure these behaviors as [Largest Contentful Paint](https://requestmetrics.com/web-performance/largest-contentful-paint) and [Cumulative Layout Shift](https://requestmetrics.com/web-performance/cumulative-layout-shift), which both degraded quickly as the traffic grew.
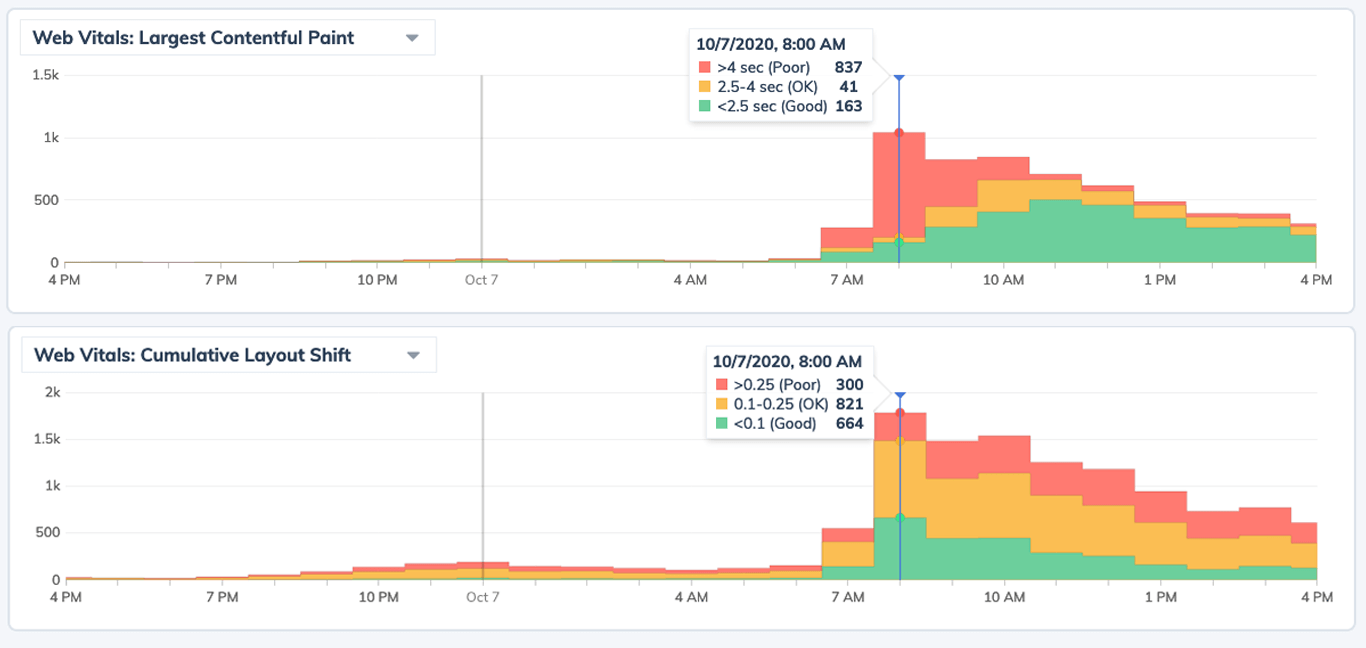
Clearly, it was slow. But why? Why couldn’t it serve more than 100 page views per minute? Why didn’t Cloudflare absorb the traffic? Let’s dig deeper into the page and see what’s happening.
## Page Performance History
The performance report below for David’s Mozilla post shows a 48-hour window around the time he made the front page of HackerNews. The page is more than just the HTML document request; it includes all the static assets, JavaScript execution, and dynamic requests that make up the page.
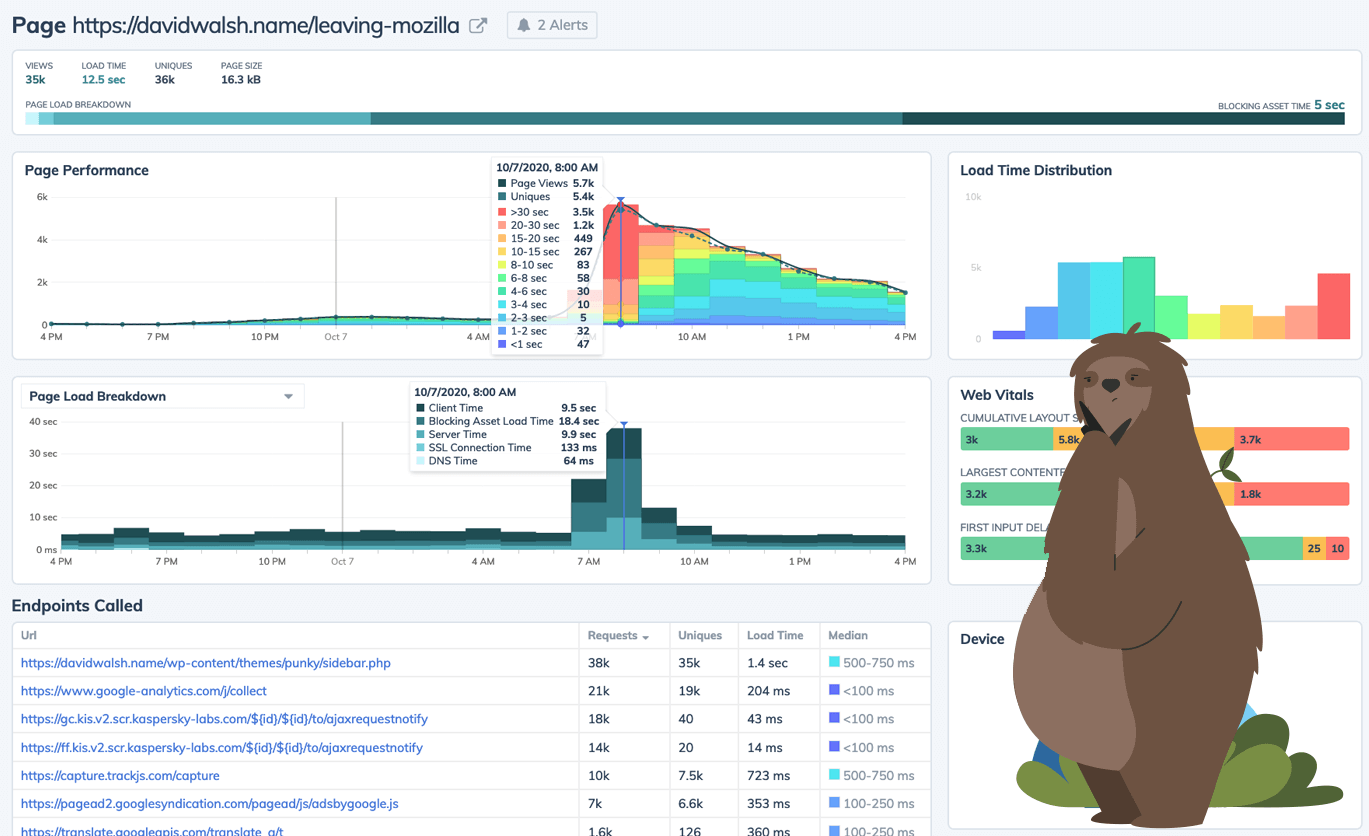
Before the surge of traffic, the page had a median load time of 4-6 seconds. That’s _okay_ but I would have expected a lot faster for a mostly-static site served from Cloudflare.
Opening the site in and checking the document request in network devtools gives us a clue.

The server is returning a `cache-control` header that says this content is not cacheable! Cloudflare is honoring that instruction and passing every request through to the server, as denoted by [`cf-cache-status: DYNAMIC`](https://support.cloudflare.com/hc/en-us/articles/200172516-Understanding-Cloudflare-s-CDN#h_bd959d6a-39c0-4786-9bcd-6e6504dcdb97).
The net effect of this is that Cloudflare has made the site **slower** by introducing an additional hop through their infrastructure, but not caching anything.
## API Endpoint Performance
The page performance report above also shows that an API endpoint, `/sidebar.php` is called on every page load. The performance of this API degraded similarly with the traffic spike, but took 500ms to respond in the best of times.
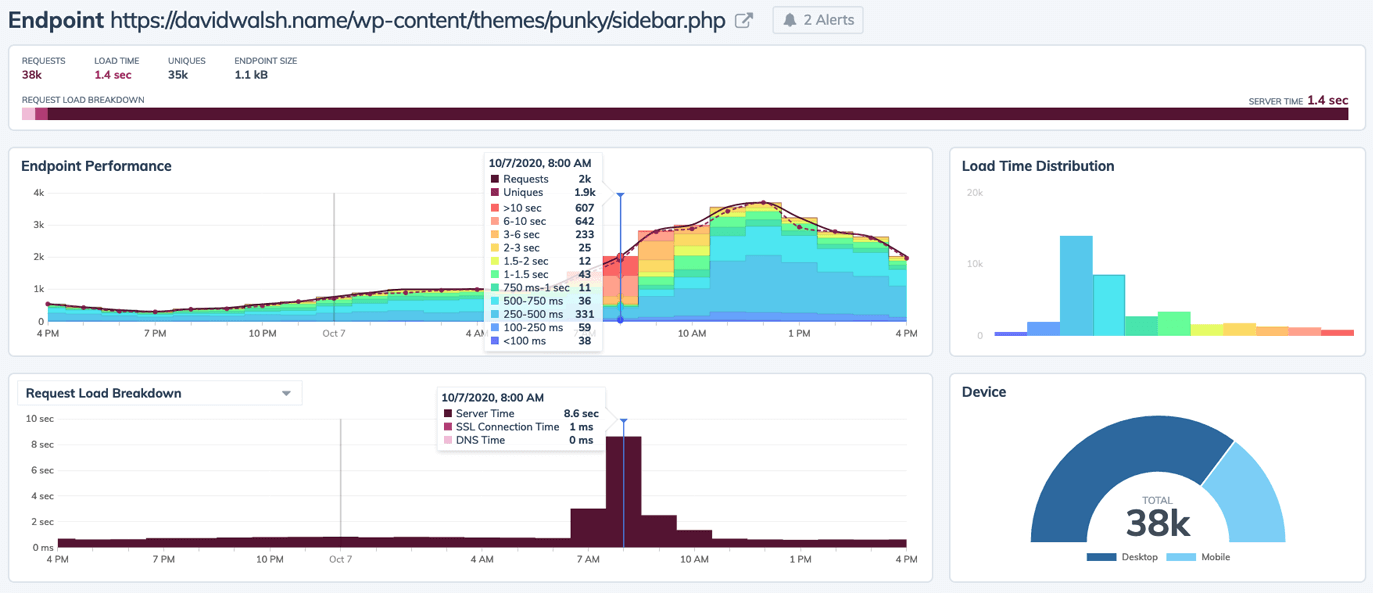
Checking this endpoint in devtools, it returns an HTML snippet of what we would expect, the static sidebar content of David’s blog. And it has the exact same `cache-control` header problem as the main document.
By rendering the sidebar with an asynchronous uncacheable request, the server was forced to serve at least 2 database-touching requests for every person reading the post. This greatly limited the number of requests the blog was able to handle.
## Web Performance Lessons
Your website is different from this one, but there are some common ideas that we can take away from this performance audit.
### 1. Reduce Dynamic Content
This site was producing the sidebar content dynamically. It probably doesn’t need to be. It’s the same advertisements, popular tags, and related content to a post for everyone.
Dynamic content is slow. It’s hard to cache and it often has to be fetched asynchronously. Servers simply have to do more work to produce dynamic content, and more work is always slower.
Look for dynamic content and make sure it’s really worth the performance penalty over what could be delivered statically from a cache.
### 2. Test Your Configuration
This site was set up to be cached by Cloudflare at one point, but over time things changed. Somewhere along the line from a WordPress plugin or hosting upgrade, the `cache-control` headers were changed, and the caching was broken.
Software systems are complex and ever-changing. Be sure to test things out once in a while and confirm that everything is working as it should.
### 3. There Is No Silver Bullet
Simply adding Cloudflare to the site did not solve the performance issues, nor should it be expected to. Caching and edge networks are amazing, but your site needs to be configured to use them correctly.
Performance isn’t something you buy or bolt on later. It’s a principle you hold while building and operating a system. [Performance monitoring tools like Request Metrics](https://requestmetrics.com/) can help you focus and improve your performance over time. | toddhgardner |
526,570 | Expand the Content Inclusively - Building an Accessible Accordion with React | Have you ever encountered a situation where a website acts unexpectedly? For instance, you are trying... | 9,961 | 2020-12-20T14:49:22 | https://dev.to/eevajonnapanula/expand-the-content-inclusively-building-an-accessible-accordion-with-react-2ded | react, webdev, a11y, html | Have you ever encountered a situation where a website acts unexpectedly? For instance, you are trying to click a link, but it actually is not a link (even though it looks like one)? Isn't that frustrating? A similar scenario might happen to many users if we, as developers, ignore keyboard accessibility and correct semantics.
I'm starting a series of blog posts about accessible React components. I hope to give you some tools for making a little more accessible web with this framework throughout the series.
WAI-ARIA Authoring practices offer [Design patterns and widgets][8] for making common patterns and widgets with keyboard interactivity and aria-attributes. As they write:
> This section demonstrates how to make common rich internet application patterns and widgets accessible by applying WAI-ARIA roles, states, and properties and implementing keyboard support.
This is the first part of the blog posts series about creating Design patterns and widgets from WAI-ARIA authoring practices with React.
In this post, I will take a look at the accordion-pattern.
## What is an Accordion?
An accordion is a "vertically stacked set of interactive headings that each contain a title, content snippet, or thumbnail representing a section of content" ([WAI-ARIA Authoring practices][1]). The title works as a control for hiding or showing the content. Here's an example accordion:
{% details I'm the title of the accordion! %} I'm the content, and I can hide. {% enddetails %}
There is indeed a semantic HTML element for when the accordion is simple enough. It is called `details` and is usable with most browsers, according to [Can I Use?][3]. However, sometimes we need more control over the accordion, and in those cases, we can build an accordion by giving it semantics with ARIA.
### Roles, States, and Properties
There are several things to note about roles, states, and properties to make the accordion accessible. As I am creating only a minimal example, the following should be enough:
- The heading of the accordion should have an element with the role `button`. Another tag with a role `heading` should wrap that button. In our case, this would mean `<button>` and `<h2>` elements, which are semantic tags.
- The expanded-state should also be communicated to the screen reader user. It would mean an `aria-expanded`-attribute set to be `true` or `false` depending on if the panel is open.
- The button should have an `aria-controls`-attribute set to point to the id of the accordion content. It communicates that "this button controls the element/content it points to" by pointing to the controlled area. (A note: It seems that this aria-attribute works only with JAWS and is [even a bit problematic][2])
So, when using this as guidance, I can start building the accordion. First, I'll add the elements:
```react
const Accordion = () => {
return (
<section>
<div>
<h2>
<button>I'm the one opening the accordion!</button>
</h2>
</div>
<div>
<p>I'm the content, yay.</p>
</div>
</section>
)
}
```
Here I use the native `h2` and `button`-elements, so they check the first item. I will also need the functionality for opening and closing the accordion. In this example, I'll use the `useState`-hook and use the variable's value to communicate if the accordion is open.
I use the `hidden`-attribute for hiding the content. It is controlled by the `isOpen`-state - if it is `true`, `hidden` is false, and vice versa. `isOpen` is also used for the `aria-expanded`-attribute in the button to communicate if the accordion is expanded:
```react
const Accordion = () => {
const [isOpen, setIsOpen] = useState(false)
const handleVisibilityToggle = () => setIsOpen(!isOpen)
return (
<section>
<div>
<h2>
<button
aria-expanded={isOpen}
onClick={handleVisibilityToggle}
>
I'm the one opening the accordion!
</button>
</h2>
</div>
<div hidden={!isOpen}>
<p>I'm the content, yay.</p>
</div>
</section>
)
}
```
This covers the second item on the list. The next thing to do is to add `aria-controls` to the button-element. For this, an id for the wrapper of the content is needed. The `aria-controls`-attribute should be set to that id:
```react
const Accordion = () => {
// ...
return (
<section>
<div>
<h2>
<button
aria-expanded={isOpen}
aria-controls="accordion-content"
onClick={handleVisibilityToggle}
>
I'm the one opening the accordion!
</button>
</h2>
</div>
<div
id="accordion-content"
hidden={!isOpen}
>
<p>I'm the content, yay.</p>
</div>
</section>
)
}
```
Now that the required semantics are added, it is time to ensure that the accordion can be used with a keyboard.
### Keyboard Interaction
There are some keyboard interaction patterns required to work with the accordion:
- <kbd>Enter</kbd> or <kbd>space</kbd>: Used to open or close the accordion.
- <kbd>Tab</kbd>: Used to navigate from one focusable item to the next.
- <kbd>Shift</kbd> + <kbd>Tab</kbd>: Used to navigate from one focusable item to the previous one.
In addition to these, there are four more optional keyboard shortcuts. If you're interested, they are explained in the [WAI-ARIA Authoring practices][1].
Looking at the elements used for the structure (mainly the `button`-element), these keyboard interactions are there if the semantic elements are used. The button has built-in support for activating with <kbd>enter</kbd> and <kbd>space</kbd>. Also, as it is an interactive control, it is focusable by default. This means, that <kbd>tab</kbd> and <kbd>shift</kbd> + <kbd>tab</kbd> work out of the box. Well, unless you use Mac and Safari and haven't [enabled keyboard accessibility][4].
### Other Accessibility Considerations
In the previous two sections, I have covered how to make the accordion accessible for people who benefit from keyboard accessibility and aria roles, states, and properties. To make the accordion accessible for all users, there are other things to consider as well.
I've left the accordion styles out from this post and will only mention that it is essential to use accessible color combinations for the accordion. For example, this means that the contrast ratio should be 4.5:1 for text and 3:1 for large text on AA-level, and 7:1 and 4.5:1 for large text on AAA-level. If you wonder what I mean by the levels, they're levels of WCAG Success Criteria, and they're explained in [WCAG's documentation][9].
When styling anything in the website, also keep in mind that some users are using the Windows High Contrast Mode, which modifies the site's colors. If you have never heard about Windows High Contrast Mode, I wrote a [blog post][6] about it a couple of weeks ago.
Apart from the color and styles, the accordion's content needs to be taken into account. What it actually means depends on the content: If you have texts, they should be written in simple language; if you have images, they should have meaningful alt-texts, and so forth.
## Wrap-up
In this blog post, I've explained one way how to build an accessible accordion with React and how to add keyboard accessibility and aria-roles, states, and properties to it. This has been done according to the [WAI-ARIA Authoring practices'][1] Design Patterns, which has many different custom widgets with required keyboard shortcuts and aria-roles, states, and properties.
You can see an example-accordion (with the optional aria-roles, states and properties, and keyboard shortcuts in place) in [a site I created for showing the complete code for these blog posts][5]. Here's also a direct link to the [source code of the accordion component][7].
If you have any questions or comments, I'll be happy to answer! 😊
[1]: https://www.w3.org/TR/wai-aria-practices-1.1/#accordion
[2]: https://heydonworks.com/article/aria-controls-is-poop/
[3]: https://caniuse.com/details
[4]: https://dequeuniversity.com/mac/keyboard-access-mac
[5]: https://accessible-react.eevis.codes/components/accordion
[6]: https://dev.to/eevajonnapanula/things-you-probably-didn-t-know-about-windows-high-contrast-mode-5gb5
[7]: https://accessible-react.eevis.codes/components/accordion#source-code
[8]: https://www.w3.org/TR/wai-aria-practices-1.1/#aria_ex
[9]: https://www.w3.org/WAI/WCAG21/Understanding/conformance#levels | eevajonnapanula |
550,952 | Leetcode: 556. Next Greater Element III | Introduction In this series of "Leetcode" posts I will publish solutions to leetcode probl... | 0 | 2020-12-23T17:18:24 | https://dev.to/marcelos/leetcode-556-next-greater-element-iii-18lm | # Introduction
In this series of "Leetcode" posts I will publish solutions to leetcode problems. It is true that you can find most/lots of leetcode solutions on the web, but I will try to post my solutions to problems that are interesting or to problems for which the solutions out there are not well explained and deserve a better explanation.
The aim is to share knowledge, and that people who are studying, preparing for interviews, or just practicing, can become better at solving problems. Please feel free to comment if you have a suggestion or a different approach!
# Problem statement
Given a positive integer n, find the smallest integer which has exactly the same digits existing in the integer n and is greater in value than n. If no such positive integer exists, return -1.
Note that the returned integer should fit in 32-bit integer, if there is a valid answer but it does not fit in 32-bit integer, return -1.
# Solution
### The main idea
* Start from the "end" of the number/digits.
* Find the indexes of the digits to swap in order to make the number greater.
* Swap the indexes.
* Sort the digits starting at **swap index** + 1.
* Create the new number.
### Explanation and Code
The idea is to create a new number that is greater than the original number. But with the constraints that the **new** number must:
1. Be the next smallest number
2. Have the same digits
Basically you have to re-position the digits in such way that they are arranged to comply with the constraints. If there is not such number just return -1.
The second constraint: **Have the same digits**, helps to understand that there is no need to **add/remove** any digits. We just need to play with the digits we already have.
## First Idea: Permutation
If all it takes is to re-arrange, then you can be thinking: **Permute**. You can try to permute (complexity O(n^2)), and take the next greater number out of all the possible arrangements, but the complexity is not optimal at all. Quadratic complexity is most of the time the worst possible possible solution in these types of problems, and most likely not a viable solution.So we have to think of something else.
## Second Idea: Find and swap digits
We must find the next greater number with the digits we have. So we have to think what would be the next smallest number.
The example provided gives an idea:
**Input:** n = 12
**Output:** 21
The first thing you could be thinking is:
> Find the next greatest digit that is greater than the first digit and swap them
**That is not correct!**. Let's see why.
For example if have:
**Input:** n = 54281
The first digit is: 5
The next greatest digit: 8
If you swap the digits you obtain:
**Output:** 84251
That is not the next greater number. The next greater number would be:
**54821**
You can create more examples. But at the end, you would realize that you need to start from the **end** of the number and not from the **start** of it.
Now it comes down to something simple:
> Find the digit to replace
So which digit is that?.
You have to think what would make a number greater than another. The best way is to think of a 2 digit number:
**35** => **53**
So the first digit is **3**, which is in the **tens** place. To make this number greater we would need to swap it with any digit greater than **3**, that means any of **{4,5,6,7,8,9}**. But we only have **5**, so we choose 5 and swap it.
But what happens if we have a bigger number, with more than 2 digits. I find it helpful to divide the number in 2 parts. You take a "digit" and you have all the digits before it and all the digits after it. For example:
**Number: 823475321**
We can take the digit: *4*
Digits before: **823**
Digits after: **75321**
If we want to replace *4* we don't really care about the numbers before it, at least for now.
We want to find a number greater than *4*, that is part of digits after *4*, that means picking a digit from {7,5,3,2,1}. We must choose the next greatest digit, that means picking up **5**, and then swap it:
**Number: **823574321**
Great we have a number greater than the original. But wait! That is not the **next** greater number. Look carefully, you can notice that we can arrange the numbers **after** the original digit(4), and create a smaller number. That means:
* Take the digits after **5**(the swapped digit) : **74321**.
* Now re-arrange them to get a smaller number: **12347**
With this example it is easy to see how we should arrange those digits. Just **sort** them! Why?. Because if you sort them, it will put the smallest digit first, and then the next smallest, and so on. At the end you will obtain the smallest possible number with those digits.
It seems that we have a strategy, but the most important part is missing, how to find the digit to **swap**, in this example that was the number **4**.
## Find the number to Swap
We follow the same logic. Let's take the same example:
**Number: 823475321**
* Start from the end. That means take the last digit **1**.
But we cannot replace the last digit with anything, there is nothing after it, so move the left.
* We pick **2**. We search in the digits after it: {1}. There are no greater digits, so we keep moving to the left.
* We pick **3**. We search in the digits after it: {2,1}. There are no greater digits, so we keep moving to the left.
...We do the same until we reach **4**
* We pick **4**. We search in the digits after it: {7,5,3,2,1}. Now we have numbers that are greater than 4, those are {7,5}, we pick the next greater number, that means **5**.
**Did you notice something?** We kept moving as long there was no number greater than the **current** digit, on the numbers to its right or **after** it. So that's it, that is the algorithm:
1. Start at position: end - 1
2. Move to the left, until there is a number greater to the current digit in the digits to its right.
The code may look like this:
```java
private int skipUntilDigitGreaterFound(char[] digits) {
int index = digits.length - 2;
while (index >= 0) {
addDigitToSeenDigits(digits[i+1]);
if (existsDigitGreaterThanCurrentInSeenDigits()) break;
index--;
}
return index;
}
```
But there is a big problem with this approach. The **searching** in the digits to the right of the current digit is the problem.
You can do a linear search (O(n)) in the **seen** set. Or you can take advantage of the fact that digits to the right **must be sorted in the reverse order**, this is a key fact to realize, and do a inverted binary search(O(log(n)).
**But there is an even better approach in constant time: O(1)!**
The idea is simple:
* We are dealing with digits, we have a constant amount of digits: **10**.
* The only thing we care is finding the next bigger digit. So if we have the digit **4**, we are looking if we have seen (digits to the right of 4 in the original number) a number greater than 4, which could be {5,6,7,8,9}.
* So we can create an array of 10 elements(0 to 9) called: **digitsPositions**, where the index represents each digit, and the value represents the last found position of each digit.
* When we want to find the position of a digit greater than a another, for instance: **4**, we simple start at immediate next digit: **5**, and see if there is some value set in the **digitsPositions** array for that index **5**. If there is, that means we already saw that digit, and that's it we have the next bigger digit. If not, we keep on searching with the next digit: **6** and so on.
* At most we would do a search for 10 elements (from 0 to 9) in the array. That means, constant time for searching.
In code we have something like this:
```java
// Skip method, saves every "seen" digit in the digitsPositions array.
private int skipUntilDigitLessThanNext(char[] digits) {
int index = digits.length - 2;
while (index >= 0) {
digitsPositions[digits[index + 1] - '0'] = index + 1;
if (digits[index] < digits[index + 1]) break;
index--;
}
return index;
}
private int findGreaterIndex(int digit) {
for (int greaterDigit = digit + 1; greaterDigit < this.digitsPositions.length; greaterDigit++) {
if (digitsPositions[greaterDigit] > 0) return digitsPositions[greaterDigit];
}
return -1;
}
```
Notice that if have **seen multiple times** a digit we only save the last occurrence in the **digitsPositions** array. This does not matter at all because at the end we only care about finding that greater value and some index to replace with. After that the digits to the right of the swap are going to be sorted so no issues at all.
### The complete solution
```java
private final int[] digitsPositions = new int[10];
public int nextGreaterElement(int n) {
if (n < 10) return -1;
return findAndCreateNextGreaterElement(convertNumberToCharArray(n));
}
private char[] convertNumberToCharArray(int n) {
return String.valueOf(n).toCharArray();
}
private int findAndCreateNextGreaterElement(char[] digits) {
int indexToSwap = skipUntilDigitLessThanNext(digits);
if (indexToSwap < 0) return -1;
int digit = Character.getNumericValue(digits[indexToSwap]);
int greaterIndex = findGreaterIndex(digit);
return createNextGreaterNumber(digits, indexToSwap, greaterIndex);
}
private int skipUntilDigitLessThanNext(char[] digits) {
int index = digits.length - 2;
while (index >= 0) {
digitsPositions[digits[index + 1] - '0'] = index + 1;
if (digits[index] < digits[index + 1]) break;
index--;
}
return index;
}
private int findGreaterIndex(int digit) {
for (int greaterDigit = digit + 1; greaterDigit < this.digitsPositions.length; greaterDigit++) {
if (digitsPositions[greaterDigit] > 0) return digitsPositions[greaterDigit];
}
return -1;
}
private int createNextGreaterNumber(char[] digits, int indexToReplace, int greaterIndex) {
swap(digits, indexToReplace, greaterIndex);
Arrays.sort(digits, indexToReplace + 1, digits.length);
try {
return Integer.parseInt(new String(digits));
} catch (NumberFormatException exception) {
return -1;
}
}
private void swap(char[] digits, int currentIndex, int replaceIndex) {
char temp = digits[currentIndex];
digits[currentIndex] = digits[replaceIndex];
digits[replaceIndex] = temp;
}
```
### Complexity
* **Time:** O(n) + O(nlog(n)), in the worst case we would have to go all the way to the first digit, remember we start from the end, that would be the O(n). After the swap, we need to sort the numbers to the right, and in the worst case the swap position would be **0**, again at the start, so that would be O(n(log(n)).
We are only going to search through the **digitsPositions** once, and that is O(1).
* **Space:** O(1), we are only creating a the **digitsPositions** array, of size 10.
#### Another solution:
This was a very interesting problem, where there are many interesting parts to analyze before coming up with the most optimal solution. Again this problem can be one of the **divide and conquer**, where we split the bigger problem in smaller ones, in this case: **find the swap digit** and **search for the greater digit**. Usually it is useful to think in smaller cases and go from there. That helped me a lot for coming up with this solution.
| marcelos | |
878,912 | Web Component - Progress | The Web Component The Web Component that my group has been assigned to work on is a CTA (Call To... | 15,275 | 2021-10-27T20:15:47 | https://dev.to/frankp018/web-component-progress-19e5 | **The Web Component**
The Web Component that my group has been assigned to work on is a CTA (Call To Action) button, essentially found on every well-designed website on the internet that allows the user to interact navigate to another page. They may contain functions such as hover, displaying that the clicker is on the button - prompting a response in appearance in the button, as well as other characteristics that provide visual feedback to the user.
**Concepts**
As I have not worked directly on the technical aspects of web design before this class, getting to learn about all of the different components that go into a CTA button has been a very informative experience. Some concepts that have proved to be difficult during the completion of the project were in positioning the button on the page, linking the button to the external website, implementing an icon, and resolving merge conflicts on GitHub.
Working in an open-source environment has been extremely beneficial in getting inspiration from peers, and for resolving issues with code on a timely basis. Overall, working on a web component for the first time has allowed me to learn a lot about the way websites function, and about the complexity that goes into creating simplicity on an interface.
**GitHub Repo**
{% github IST-402-Group-1/FPHHbutton no-readme %}
| frankp018 | |
553,229 | Múltiplos endpoints em uma rota no ASP.NET Core | Disponibilizar múltiplos endpoints em um recurso de uma API pode ser algo necessário quando quisermos... | 0 | 2020-12-28T16:04:52 | https://dev.to/fernandovmp/multiplos-endpoints-em-uma-rota-no-asp-net-core-1idg | dotnet, api | Disponibilizar múltiplos *endpoints* em um recurso de uma API pode ser algo necessário quando quisermos deixar nossa API mais simples de ser consumida nos mais diversos cenários, por exemplo, quando uma aplicação quiser manipular um cliente, pode ser mais conveniente utilizar o CPF e não o id, e para isso precisaríamos de dois *endpoints* para consultar um cliente específico,
```
GET /cliente/{id}
GET /cliente/{cpf}
```
E como podemos lidar com esses dois *endpoints* de formas diferentes no ASP.NET Core? A resposta está no próprio mecanismo de rotas do *framework*.
O sistema de rotas do ASP.NET Core nos permite aplicar diversas restrições em um parâmetro de rota, isso permite invalidar rotas que não estejam dentro dos limites estabelecidos, resolver ambiguidades entre rotas e ter múltiplos *endpoints* baseados apenas nas limitações de seus parâmetros.
Existem várias restrições que o ASP.NET Core nos oferece, como de intervalos de valores, regex e de tipos, como pode ser observado na [documentação](https://docs.microsoft.com/aspnet/core/fundamentals/routing?view=aspnetcore-5.0#route-constraint-reference), neste artigo focarei em como usar restrições de tipo para criar múltiplos *endpoints* em uma rota.
O código de exemplo está disponível no [github](https://github.com/fernandovmp/RestricaoDeTiposRotas) com um arquivo do Insomnia caso queira usar para acompanhar o artigo.
### Primeiros passos com restrições de rotas
Imagine a seguinte rota, onde o parâmetro **id** deve ser um número inteiro:
```
GET /produto/{id}
```
Se a definição do método que for manipular a requisição dessa rota for:
```csharp
[HttpGet("/produto/{id}")]
public ActionResult GetById(int id)
```
O que acontece se fizermos uma requisição à `/produto/abc`?
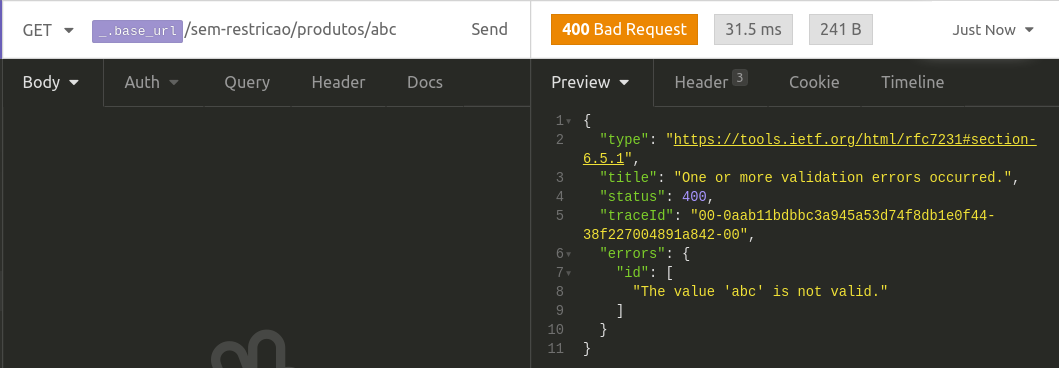
A resposta obtida é `400 Bad Request ` com um erro de validação para o parâmetro **id**, entretanto, mesmo que o valor não seja válid
o, em nenhuma hipótese haveria um produto no banco de dados que tivesse como **id** 'abc' o que torna mais adequado dizer que o recurso **não existe** ao invés de dizer que a requisição é inválida. E como podemos fazer para mudar o comportamento e dizer que o recurso não existe?
Para isso, basta adicionar uma restrição ao parâmetro, as restrições de um parâmetro são adicionadas depois do nome do parâmetro na rota separados por dois pontos (`:`), exemplo: `{meuParametro:restricao1:restricao2:restricao3...n}`
Agora, se adicionarmos uma restrição ao parâmetro **id** de que este deve ser do tipo `int`,
```csharp
[HttpGet("/produto/{id:int}")]
public ActionResult GetById(int id)
```
Ao fazermos novamente uma requisição à `/produto/abc` teremos como resposta um erro 404, isso pois não existe nenhuma rota corresponda a esse *endpoint* já que agora o ASP.NET Core irá apenas reconhecer como uma rota existente se o parâmetro **id** em `/produto/{id}` for um número inteiro. Dessa forma, nossa aplicação não retornará um erro 400 de validação devido ao valor passado não ser correspondente ao tipo do esperado pelo método da *controller*, assim deixamos livre para que outro método possa tratar uma mesma rota `/produto/{id}` que ao invés de receber um inteiro como parâmetro, recebe qualquer outro tipo de dado.

### Diferentes *endpoints* de acordo com o tipo do parâmetro
Suponha o seguinte cenário, temos na nossa API os dados dos usuários, cada usuário possuí um **id** único no banco de dados além de uma outra identificador também única, que é seu nome de usuário que pode ser alterado no futuro. Em algumas situações, seria difícil que o cliente que consumisse a API tivesse o **id** do usuário para consultar seus dados, sendo mais comodo consultar pelo nome de usuário, então teríamos de ter a seguinte rota:
```
GET /usuarios/{nomeUsuario}
```
Mas o nome de usuário pode ser alterado, então também precisaríamos prover uma forma única e consistente de buscar os dados desse usuário, ou seja, buscar pelo seu **id**, tendo também a rota:
```
GET /usuarios/{id}
```
Como fazemos então para manipularmos essas rotas por métodos diferentes? Basta aplicarmos uma restrição no parâmetro de uma das rotas para que se o valor atender a restrição, seja executado por um método diferente da requisição que não atender.
Para isso, vamos definir que a rota que consulta pelo **id** só existirá para valores onde o parâmetro seja um **Guid** e se não for, será então tratada como a rota para buscar pelo nome de usuário, que será uma **string**, assim teremos os seguintes métodos na *controller*:
```csharp
[HttpGet("/usuarios/{nomeUsuario}")]
public ActionResult GetByUsername(string nomeUsuario);
[HttpGet("/usuarios/{id:guid}")]
public ActionResult GetById(Guid id);
```
Perceba que o `GetById` tem uma restrição no seu parâmetro, o que faz com que mesmo tendo duas rotas para o mesmo nível de especialização da rota `/usuarios`, elas não serão consideradas ambíguas pois há uma restrição que diferencia ambas.
Fazendo uma requisição para `GET /usuarios/fernando` obtemos a seguinte resposta:

E ao fazermos uma outra requisição para `GET /usuarios/0336c93f-645b-4756-9615-e3a6c8eeeaf2` temos uma resposta diferente já que ambas as requisições foram tratadas por métodos diferentes.

### Conclusão
Podemos prover diversos *endpoints* em uma rota de maneira simples ao restringirmos a existência de um *endpoint* apenas aos valores válidos de seus parâmetros, deixando espaço para tratarmos de maneira diferente a mesma rota para outro domínio de valores, assim nossos recursos ficam mais flexíveis para quem for consumir a API, além de respondermos ao cliente uma informação mais simples quando uma rota com parâmetro inválido é requisitada.
| fernandovmp |
557,819 | chat on whatsApp using python | How to send message to your friend on whatsapp using python. if you had read some of my... | 0 | 2021-01-01T02:17:29 | https://dev.to/maxwizardth/chat-on-whatsapp-using-python-5e9l | python, devops, discuss, tutorial | 
## How to send message to your friend on whatsapp using python.
if you had read some of my articles you would have learn [how to send message on facebook Using python](https://dev.to/maxwizardth/chatting-on-facebook-using-python-45fn). won't you wish to use python to message on whatsapp too? and who doesn't want to do that? well there is a simple way just like that of facebook.
without wasting much of time let's go in to the lesson.
Firstly we need to install some libraries below :
1. selenium
2. webDriver_manager for chrome or geckodriver for firefox.
If you already have the two libraries mention don't bother.
After installation of the two libraries above then we can start writing the code.
If you had read my articles on how to message friends on facebook then just go straight
to the codes and copy otherwise read the following analysis.
Before we move to the code let me give you analysis on some function we are going to use in the program.
### Some other requirements for the task
* We need the selenium here to navigate to everywhere on the browser.
* we will need the name of the friend or group that we want to send the message to just like it was stored on our phone contact.
* your phone to scan the whatsapp on the browser.
### How will you scan with your phone
It might be a little difficult to scan with your phone when you have a whatsapp web loaded on your browser if you had not been using your laptop to do whatsapp chat before so these are the step to take below.
* go to [web.whatsapp.com](web.whatsapp.com) on your browser(in this case you don't need to go to this web site as your program as done that for you), you will see something like this below.
* Now go to your whatsapp on your phone.
* click on the three dots at the right top of your screen.
* click on 'WhatsApp Web' and you will see something like 'SCAN QR CODE' trying to scan something
* Now set it to what you have on your laptop (like you want to camera) so that it scan your laptop
* Your laptop should display your whatsapp now.
### Some functions needed
* `find_element_by_xpath()` : A function provided by selenium module
to find the element with css selector.
* `send_keys()` : A function provided by selenium module also to write data or text into the box we use
* `webdriver.Chrome()`: A function that will open new window of chrome
* `get()` : A function we will used to open up the Facebook website
* `quit()`: A function to close the browser when we are done.
* `sleep()` : A function to delay the running of the script for some seconds.
* `input()` and `str` : these are python function to prompt and convert to string respectively. you must have accustomed to these before.
### Necessary modules to be import and important data
In our we ned to import the following from their lib.
* webdriver from selenium.
* sleep from time
* ChromeDriverManager from webdriver_manager.chrome
* Options from selenium.webdriver.chrome.options
* Keys from selenium.webdriver.common.keys
Also you will need to provide your friend name and message.
#### HERE IS THE CODE
```python
from selenium import webdriver
from time import sleep
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(ChromeDriverManager().install())
# to chromedriver in your computer
message=str(input('enter your message')) # to get the message
driver.get("https://web.whatsapp.com/") #to open the whatsapp
sleep(39)
# here we need to scan with our phone
driver.find_element_by_xpath('//span[@title="Your friendName"][@dir="auto"]').click()# change that 'Your friendName to your own friend Name as it is written on your phone contact.
driver.find_element_by_xpath('//div[@dir="ltr"][@data-tab="6"][@spellcheck="true"]').send_keys(message, Keys.ENTER)
quit()
```
wait for some minutes an see your message being sent. Did you find it interesting? that is just part of the power of Selenium.
the beautiful part of this is that you can write long text, repeating message Using loop.
and do different funny part. let's check the following codes.
#### Example
```python
from selenium import webdriver
from time import sleep
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome(ChromeDriverManager().install())
# to chromedriver in your computer
message=str(input('enter your message')) # to get the message
driver.get("https://web.whatsapp.com/") #to open the whatsapp
sleep(39)
# here we need to scan with our phone
driver.find_element_by_xpath('//span[@title="frndName"][@dir="auto"]').click()#your friend name to substitute that frndName
for msg in mess:
driver.find_element_by_xpath('//div[@dir="ltr"][@data-tab="6"][@spellcheck="true"]').send_keys(msg, Keys.ENTER)
quit()
# This is where I entered the the message and Did click Enter
```
Did you see how the message look like ? it send the message one by one character. try to write for loop for the message and manipulate your message the way you want, you can even sent blank message if you want.
enjoy coding! see you in the next lesson where we will be discussing [instagram login with python](ww). remember to like and comment below. | maxwizardth |
570,389 | The Web For Aspiring Developers (Part II: Servers and Hosting) | Originally published on https://frontendjoy.com/blog/how-the-web-works-for-aspiring-developers-part-t... | 10,421 | 2021-01-13T14:26:52 | https://frontendjoy.com/blog/how-the-web-works-for-aspiring-developers-part-two-servers-and-hosting | codenewbie, webdev, beginners | *Originally published on [https://frontendjoy.com/blog/how-the-web-works-for-aspiring-developers-part-two-servers-and-hosting](https://frontendjoy.com/blog/how-the-web-works-for-aspiring-developers-part-two-servers-and-hosting)*
Imagine it's your best friend's birthday 🎁.
You've decided to surprise him and cook its favorite food, `turtle with banana curry sauce` 🐢🥘.
Unfortunately, you don't know how to cook that meal. So you need:
- **Ingredients** - e.g: turtle, banana, ...
- **Instructions** on what to put in the meal, how to mix the ingredients, how long the cooking, etc...
**Similarly**, to display a web page, your browser needs:
- **Data** (ex: images, videos, JSON, etc.) - For example, when using twitter.com, you need a list of posts.
- **Instructions** on what to show, how, where. Those are stored in files (e.g: HTML, CSS, JS files)
These **must be stored** somewhere. That's where servers intervene.

# What is a server?
A **server** is a computer that provides resources to other computers called **clients**.
It stores data (e.g., files, images, etc.) and delivers it to clients **on demand**.
Think of it as a **24-hour restaurant** that serves food to clients.
There are various types of servers :
- **Web servers** ⇒ store and serve files needed to show a web page
- **Mail servers** ⇒ store and deliver emails
- **Database servers** => store and provide data
- Etc.
> So, if you want your website available online,
> you must store data + instructions on one or more servers.
[](https://twitter.com/intent/follow?original_referer=https://dev.to®ion=follow_link&screen_name=joyancefa&tw_p=followbutton "Follow on Twitter")
# How to get one?
Any computer, even your own, can act as a server as long as it can store and deliver information.
Big websites like [google.com](http://google.com/) or [facebook.com](http://facebook.com/) have many servers. Think of them as restaurant chains (e.g., McDonald's, KFC).
But, like most people/companies, **you don't wanna own a server** because :
- They are expensive to maintain.
- They must be up 24H/7j to serve all clients around the world.
- They have to deliver the data fast.
- They need to preserve the websites from security attacks.
- Etc.
Instead, you pay 💰💰💰 a **Web hosting company** (e.g., [Bluehost](https://www.bluehost.com/), [Hostgator](https://www.hostgator.com/)). These companies own servers and **rent some space** on them. When you store your website data on these servers, we say your website is "hosted."

## What are the main types of Web hosting?
Depending on your needs and budget, if you want to "host" your website, you generally have **4 options** :
1. **Shared hosting**: you rent a part of a server and share its resources with other websites.
This is equal to **renting a room in a shared apartment**: you share resources with other tenants.
High traffic on them (i.e., too many visitors) will affect you.
2. **VPS (Virtual Private Server) hosting**: you rent a larger part of a server and share fewer resources.
See it like **renting an apartment in a building**: you have your own bathrooms/doors, but you still share some resources (water, heat, etc.).
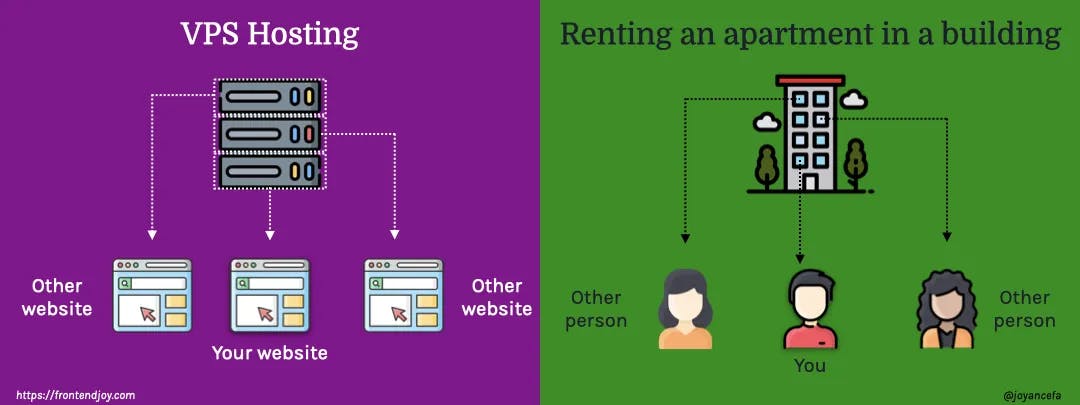
3. **Dedicated hosting**: you rent the whole server/computer. Think of it as **renting an entire building**.
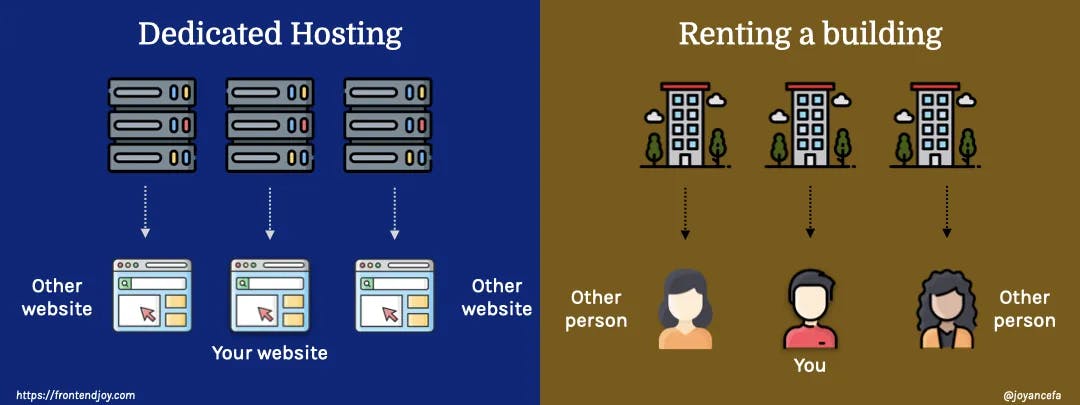
4. **Cloud hosting**: you rent different servers. Think of it as **renting many buildings**.
When one is inaccessible, you can still use others.
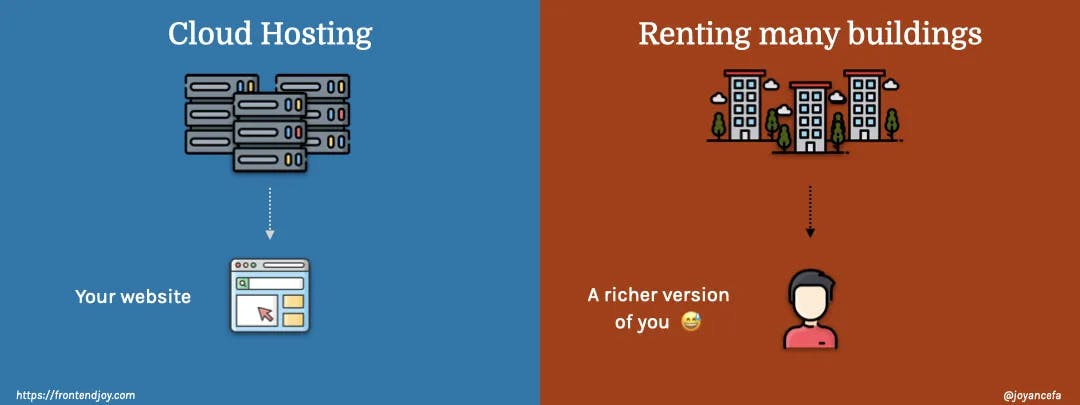
# Conclusion
Your browser **needs some data** to display a web page.
Powerful, 24H/7j online computers called **servers store that data**.
Because these are expensive, only big websites (e.g., google.com, twitter.com) have their own servers. Most use **Web hosting companies** (e.g., BlueHost, DreamHost) that have servers and rent some "place" on it. | _ndeyefatoudiop |
570,638 | How To Alter a Column Used By A View or Rule | PostgreSQL errors with cannot alter type of a column used by a view or rule when modifying table column definitions for a table having dependencies. | 0 | 2021-01-13T13:03:53 | https://kags.me.ke/post/how-to-alter-a-column-used-by-a-view-or-rule/ | postgres, database, csharp, fluentmigrator | ---
title: "How To Alter a Column Used By A View or Rule"
published: true
description: "PostgreSQL errors with cannot alter type of a column used by a view or rule when modifying table column definitions for a table having dependencies."
tags: ["postgres", "databases", "csharp", "fluentmigrator"]
canonical_url: https://kags.me.ke/post/how-to-alter-a-column-used-by-a-view-or-rule/
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/r1rcpk471sov698jrvjd.png
---
In PostgreSQL, assume you have a table and view with the following definitions:
```sql
CREATE TABLE boq_items (
id character varying(22) NOT NULL,
item_no character varying(50) NOT NULL,
activity_name character varying(255) NOT NULL,
page_no int NOT NULL,
qty numeric(14,2) NOT NULL,
rate numeric(14,2) NOT NULL,
bq_amt numeric(14,2) NOT NULL
);
CREATE VIEW vw_boq_item_names AS
SELECT activity_name FROM boq_items;
```
Attempting to change the definition of `activity_name` column using `ALTER TABLE boq_items ALTER activity_name TYPE text, ALTER activity_name SET NOT NULL;` will return a `cannot alter type of a column used by a view or rule. DETAIL: rule _RETURN on view vw_boq_item_names depends on column "activity_name"` error . PostgreSQL will throw the same error if you attempt to change any column definition of the table.
PostgreSQL allows running [DDL statements in a transaction](https://wiki.postgresql.org/wiki/Transactional_DDL_in_PostgreSQL:_A_Competitive_Analysis). To resolve the error, we require to drop the view, run the alter statement and recreate the view but enclosing the these statements in a transaction.
```sql
BEGIN;
DROP VIEW vw_boq_item_names;
ALTER TABLE boq_items
ALTER activity_name TYPE text,
ALTER activity_name SET NOT NULL;
CREATE VIEW vw_boq_item_names AS
SELECT activity_name FROM boq_items;
COMMIT;
```
If you are using [FluentMigrator](https://fluentmigrator.github.io/) database migration framework, exclude the `BEGIN;` and `COMMIT;` statements - otherwise the migration will fail with an error.
```c#
public override void Up()
{
var sql = "DROP VIEW vw_boq_item_names;" +
"ALTER TABLE boq_items " +
"ALTER activity_name TYPE text, " +
"ALTER activity_name SET NOT NULL;" +
"CREATE VIEW vw_boq_item_names AS " +
"SELECT activity_name FROM boq_items;"
Execute.Sql(sql);
}
```
In situations where a table has a lot of dependencies, or an object has cascading dependencies, [a solution](https://stackoverflow.com/questions/3243863/problem-with-postgres-alter-table/49000321#answer-49000321) would be to create two functions - one to save the dependencies and the other to restore these dependencies. Each of these functions will require parameters for the schema and the object in the schema which has dependencies. Before changing the table and column definitions, call the function to save and drop the dependencies, make the definition changes and finally call the function to restore the dependencies.
```sql
select util.deps_save_and_drop_dependencies('mdm', 'global_item_master_swap');
alter table mdm.global_item_master_swap
alter column prod_id type varchar(128),
alter column prod_nme type varchar(512);
select util.deps_restore_dependencies('mdm', 'global_item_master_swap');
```
[Stop worrying about table and view dependencies in PostgreSQL](https://pretius.com/postgresql-stop-worrying-about-table-and-view-dependencies/) details how these functions work. The post includes links to an [sql fiddle](http://sqlfiddle.com/#!15/e1e32/1) and a up to date [gist](https://gist.github.com/mateuszwenus/11187288).
I hope this will be helpful to anyone encountering `cannot alter type of a column used by a view or rule` error in PostgeSQL while updating table column definitions. | kagundajm |
570,714 | Trabajando con bytes en Dart | Si puedes entender los bytes, puedes entender cualquier cosa. Esta es una traducción al español... | 0 | 2021-01-13T15:04:49 | https://dev.to/maginkgo/trabajando-con-bytes-en-dart-153m | > Si puedes entender los bytes, puedes entender cualquier cosa.

Esta es una traducción al español del artículo [Working with bytes in Dart](https://medium.com/flutter-community/working-with-bytes-in-dart-6ece83455721) del autor [Suragch](https://suragch.medium.com/).
## Prefacio
Empecé con este tema porque estaba investigando cómo comunicarme entre Dart y un servidor de base de datos PostgreSQL. Resultó ser mucho más de bajo nivel de lo que esperaba. Pensé en escribir un artículo corto explicando algunas de las nuevas cosas que estaba aprendiendo. Bueno, tres días completos después, ese corto artículo se ha convertido en una de las explicaciones más profundas que he escrito sobre un tema que ya es un nicho. Aunque el artículo es largo, no creo que lo encuentres aburrido, y es muy probable que aprendas una o dos cosas nuevas sobre Dart aunque lo hayas estado usando durante un tiempo. Desde luego que sí. Como siempre, por favor, hágame saber si encuentra algún error. Así es como aprendo. Y pruebe los ejemplos de código usted mismo. Así es como se aprende.
Este artículo está actualizado para Dart 2.10.
## Bits y bytes
Todos los que leen este artículo saben que un `byte` es ocho `bits`:
```
00101010
```
Ese byte de `8-bit` tiene un valor, un valor de `42` en este caso, que es sólo un `integer`. Ahora, combinando ese conocimiento con el hecho de que todos los datos binarios son sólo una secuencia de bytes, esto significa que es posible representar cualquier dato binario como una lista de enteros en Dart:
```dart
List<int> data = [102, 111, 114, 116, 121, 45, 116, 119, 111, 0];
```
Esos bytes pueden ser de un archivo, una imagen de mapa de bits, una grabación mp3, un *memory dump*, una solicitud de red, o los códigos de caracteres de una cadena. Todos son bytes.
## Siendo un poco más eficiente
En Dart el tipo ``int`` tiene un valor por defecto de `64-bit`. Eso son ocho bytes. Aquí está el número `42` de nuevo, esta vez mostrando los 64 bits para su referencia visual:
```
0000000000000000000000000000000000000000000000000000000000101010
```
Si miras con cuidado, puedes notar que muchos de esos bits no están siendo usados.
Un `int` puede almacenar valores tan grandes como 9.223.372.036.854.775.807, pero lo más grande que será un byte es 255. Este es definitivamente un caso de usar una escopeta para matar una mosca. Ahora imagina un simple archivo de 1 megabyte (1024 bytes) como una lista de enteros. Tu problema se acaba de hacer un millón de veces más grande.
Aquí es donde entra en juego `Uint8List`. Este tipo es básicamente como `List<int>`, pero es mucho más eficiente que para listas grandes. `Uint8List` es una lista de números enteros en la que los valores son sólo 8 bits cada uno, o 1 byte. La `U` de `Uint8List` significa `unsigned`, por lo que los valores van de 0 a 255. ¡Eso es perfecto para representar datos binarios!
## Nota al margen: Los números negativos en binario
¿Has pensado alguna vez en cómo representar los números negativos en binario? Bueno, la forma de hacerlo es hacer que el bit ubicado más a la izquierda sea un 1 para los negativos y un 0 para los positivos. Por ejemplo, estos `8-bit` enteros con signo son todos negativos porque todos comienzan con 1:
```
11111101
10000001
10101010
```
Por otro lado, los siguientes números enteros de `8-bit` con signo son todos positivos porque el bit ubicado más a la izquierda es 0 :
```
01111111
00000001
01010101
```
Podrías pensar que si 00000001 es +1, entonces 10000001 debería ser -1. Sin embargo, no funciona así. De lo contrario, tendrías dos valores para el cero: 10000000 y 00000000. La solución es usar un sistema llamado *Two's Complement*. El siguiente vídeo lo explica muy bien si estas interesado.
https://youtu.be/mRvcGijXI9w
En Dart ya se puede utilizar el tipo `int` para representar valores con signo, tanto positivos como negativos. Sin embargo, si quieres listas de sólo `8-bit` enteros con signo, puedes usar el tipo `Int8List` (nota la ausencia de `U`). Esto permite valores de -128 a 127. Sin embargo, esto no es particularmente útil para la mayoría de los casos de uso, así que nos quedaremos con los enteros signo en `Uint8List`.
## Convirtiendo `List<int>` a `Uint8List`
`Uint8List` forma parte de `dart:typed_data`, una de las principales bibliotecas de Dart. Para utilizarla, añada la siguiente importación:
```dart
import 'dart:typed_data';
```
Ahora puede convertir la lista `List<int>` que tenía antes en `Uint8List` utilizando el método `fromList`:
```dart
List<int> data = [102, 111, 114, 116, 121, 45, 116, 119, 111, 0];
Uint8List bytes = Uint8List.fromList(data);
```
Si alguno de los valores de la lista `List<int>` está fuera del rango de 0 a 255, entonces los valores se ajustarán. Puedes ver eso en el siguiente ejemplo:
```dart
List<int> data = [3, 256, -2, 2348738473];
Uint8List bytes = Uint8List.fromList(data);
print(bytes); // [3, 0, 254, 169]
```
256 fue uno más allá de 255, así que se convirtió en 0. El siguiente número, -2, es menos que 0, así que retrocedió dos posiciones en la parte superior y se convirtió en 254. Y no tengo ni idea de cuántas vueltas dio el 2348738473, pero finalmente terminó en 169.
Si no quieres que se produzca este comportamiento, puedes usar `Uint8ClampedList` en su lugar. Esto sujetará todos los valores mayores de 255 a 255 y todos los valores menores de 0 a 0.
```dart
List<int> data = [3, 256, -2, 2348738473];
Uint8ClampedList bytes = Uint8ClampedList.fromList(data);
print(bytes); // [3, 255, 0, 255]
```
Esta vez los tres valores finales fueron fijados.
## Creando un `Uint8List`
En el método anterior se creó un `Uint8List` convirtiendo un `List<int>`. Pero, ¿y si sólo quieres empezar con una lista de bytes? Puedes hacerlo pasando la longitud de la lista al constructor así:
```dart
final byteList = Uint8List(128);
```
Esto crea una lista de longitud fija donde los 128 valores son 0. Imprime `byteList` y verás:
```
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
```
Siéntase libre de contarlos para asegurarse de que realmente hay 128.
## Modificando una lista de bytes
¿Cómo se modifican los valores de un `Uint8List`? Como lo harías con una lista normal:
```dart
byteList[2] = 255;
```
La impresión `byteList` muestra de nuevo que el valor de index 2 ha cambiado:
```
[0, 0, 255, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
```
La naturaleza de acceso aleatrorio de las listas hace que sea rápido y conveniente modificar el valor del byte en cualquier ubicación del index.
## Listas ampliables (growable)
La lista que hizo arriba fue `fixed-length`. Si intentabas hacer algo como esto:
```dart
final byteList = Uint8List(128);
byteList.add(42);
```
...obtendrías la siguiente excepción:
```dart
Unsupported operation: Cannot add to a fixed-length list
```
Eso no es muy conveniente si estás tratando de hacer algo como recoger los bytes de un `stream`. Para hacer una lista de bytes `growable`, necesitas un `BytesBuilder`:
```dart
final bytesBuilder = BytesBuilder();
bytesBuilder.addByte(42);
bytesBuilder.add([0, 5, 255]);
```
Se puede añadir un solo bytes (del tipo `int`) o listas de bytes (del tipo `List<int>`).
Cuando quiera convertir el constructor a `Uint8List`, utilice el método `toBytes` así:
```dart
Uint8List byteList = bytesBuilder.toBytes();
print(byteList); // [42, 0, 5, 255]
```
## Más de una forma de ver los bits
Bits y bytes son sólo un montón de ceros y unos. No tienen mucho significado si no tienes una forma de interpretarlos:
```
0011111100011101110011011101101110011111100110011011110000010101001110100010101010000111100101101111001111011100000101011001101111010101101000011101100101000111100000100100011111101011111110100111010011001100000000000111111010010010000000001111010001100000
```
Con `Uint8List` la forma en que los interpretamos es diciendo que cada 8 bits hay un número entre 0 y 255:
```
00111111 00011101 11001101 11011011 10011111 10011001 10111100 00010101 00111010 00101010 10000111 10010110 11110011 11011100 00010101 10011011 11010101 10100001 11011001 01000111 10000010 01000111 11101011 11111010 01110100 11001100 00000000 01111110 10010010 00000000 11110100 01100000
```
Podrías reinterpretar esos mismos valores como números enteros con signo de -128 a 127. Eso es lo que hicimos con `Int8List`.
Sin embargo, también hay otras formas de ver los datos. Por ejemplo, en lugar de usar trozos de `8-bit`, podrías mirar los datos como una lista de trozos de `16-bit`:
```
0011111100011101 1100110111011011 1001111110011001 1011110000010101 0011101000101010 1000011110010110 1111001111011100 0001010110011011 1101010110100001 1101100101000111 1000001001000111 1110101111111010 0111010011001100 0000000001111110 1001001000000000 1111010001100000
```
La biblioteca `dart:typed_data` tiene tipos para eso también. Usa `Uint16List` para los enteros `unsigned` que van de 0 a 65.535, o `Int16List` para los enteros con signo que van de -32.768 a 32.767.
No se detiene ahí. También podrías interpretar esos mismos datos como una lista de valores `32-bit`:
```
00111111000111011100110111011011 10011111100110011011110000010101 00111010001010101000011110010110 11110011110111000001010110011011 11010101101000011101100101000111 10000010010001111110101111111010 01110100110011000000000001111110 10010010000000001111010001100000
```
O los valores `64-bit`:
```
0011111100011101110011011101101110011111100110011011110000010101
0011101000101010100001111001011011110011110111000001010110011011
1101010110100001110110010100011110000010010001111110101111111010
0111010011001100000000000111111010010010000000001111010001100000
```
O incluso valores de `128-bit`:
```
00111111000111011100110111011011100111111001100110111100000101010011101000101010100001111001011011110011110111000001010110011011
11010101101000011101100101000111100000100100011111101011111110100111010011001100000000000111111010010010000000001111010001100000
```
Dart tiene tipos para todos ellos:
- `Int32List`
- `Uint32List`
- `Int64List`
- `Uint64List`
- `Int32x4List` (128 bits)
Usar el tipo de lista específica que necesita será más eficiente para grandes cantidades de datos que usar `List<int>`.
## Vistas en bytes en Dart
Dart respalda *raw binary data* con un `ByteBuffer`. Todos los tipos que se vieron en la última sección implementan una clase llamada `TypedData`, que es sólo una forma genérica de ver los datos en el `ByteBuffer`. Esto significa que tipos como `Uint8List`, `Int32List`, y `Uint64List` son todas formas diferentes de ver los mismos datos.
Usaremos la siguiente lista de cuatro bytes para los ejemplos que vienen:
```
00000001 00000000 00000000 10000000
```
En forma decimal la lista se vería así:
```
1, 0, 0, 128
```
Primero crea la lista en Dart como lo has hecho anteriormente:
```dart
Uint8List bytes = Uint8List.fromList([1, 0, 0, 128]);
```
Como con cualquier forma de `TypedData`, se puede acceder a la propiedad subyacente `ByteBuffer` de un `Uint8List` accediendo a la propiedad `buffer`:
```dart
ByteBuffer byteBuffer = bytes.buffer;
```
### Unsigned 16-bit view
Ahora que tienes el byte buffer, puedes obtener una vista diferente de los bytes usando uno de los métodos `as...`, esta vez `asUint16List`:
```dart
Uint16List sixteenBitList = byteBuffer.asUint16List();
```
Antes de imprimir `sixteenBitList` para ver el contenido, ¿cuáles cree que serán los valores?
¿Crees que sabes la respuesta? Bien, imprime la lista:
```dart
print(sixteenBitList);
```
En mi ordenador Mac los resultados son los siguientes:
```
[1, 32768]
```
Eso es muy extraño. Ya que los valores originales eran:
```
00000001 00000000 00000000 10000000
1 0 0 128
```
Hubiera esperado que se combinaran en trozos de `16-bit` como este:
```
0000000100000000 0000000010000000
256 128
```
En cambio, tenemos esto:
```
0000000000000001 1000000000000000
1 32768
```
Mantén ese pensamiento. Revisemos la vista de `32-bit`.
### Unsigned 32-bit view
Empezaré con la lista de bytes que contiene los valores decimales 0, 1, 2, 3. De esta manera podemos ver si están en el mismo orden o no. Para mayor claridad, aquí está el aspecto que tendrá la lista original en forma binaria `8-bit`:
```
00000000 00000001 00000010 00000011
0 1 2 3
```
Ahora ejecuta el siguiente código:
```dart
Uint8List bytes = Uint8List.fromList([0, 1, 2, 3]);
ByteBuffer byteBuffer = bytes.buffer;
Uint32List thirtytwoBitList = byteBuffer.asUint32List();
print(thirtytwoBitList);
```
Esta vez tienes una vista `32-bit` en el buffer subyacente del `Uint8List` original. La declaración impresa revela un valor de 50462976, que en `32-bit` binario es:
```
00000011000000100000000100000000
```
o si se añade un espacio (para ayudar a ver las partes):
```
00000011 00000010 00000001 00000000
```
¡Eso es exactamente el orden inverso al original! ¿Qué es lo que está pasando?
## Endianness
Normalmente no tienes que pensar en este tipo de cosas cuando todo lo que haces es construir felizmente una aplicación Flutter, pero cuando caes tan bajo como lo estamos haciendo hoy, en realidad estás chocando con la arquitectura de la máquina.
Algunas máquinas ordenan los bytes individuales dentro de un trozo de bytes (ya sean trozos de 2-byte, trozos de 4-byte o trozos de 8-byte) en orden ascendente. Esto se llama *big endian* porque el byte más significativo es el primero. Eso es normalmente lo que esperamos porque leemos los números de izquierda a derecha, empezando por la parte más grande del número.
Sin embargo, otras máquinas ordenan los bytes individuales dentro de un trozo de bytes en orden inverso. Esto se llama *little endian*. Aunque parezca poco intuitivo, funciona en el nivel de la arquitectura de la máquina. El problema viene cuando *big endian* se encuentra con *little endian*. Y eso es lo que nos pasó a nosotros arriba.
Antes de hablar más sobre eso, quizás quieran ver este video en *endianess*. La explicación es bastante buena (si puedes pasar de la pequeña historia del principio):
https://youtu.be/_wk_nZVuY0Q
### Donde ocurrió el malentendido
Cuando corrí el código:
```dart
Uint8List bytes = Uint8List.fromList([0, 1, 2, 3]);
ByteBuffer byteBuffer = bytes.buffer;
Uint32List thirtytwoBitList = byteBuffer.asUint32List();
print(thirtytwoBitList);
```
Dart tomó la lista de estos cuatro bytes:
```
00000000 00000001 00000010 00000011
```
Y se las dio a mi ordenador. Dart sabía que 00000000 era el primero, 00000001 era el segundo, 00000010 era el tercero y 00000011 era el último. Mi ordenador también lo sabía.
Entonces Dart pidió a mi computadora una vista de trozos de 32 bits, de esa lista de bytes, del buffer de bytes de la memoria. Mi computadora devolvió:
```
00000011000000100000000100000000
```
Bueno, resulta que mi MacBook tiene una arquitectura *little endian*. Mi ordenador todavía sabía que 00000000 era el primero, 00000001 era el segundo, 00000010 era el tercero y 00000011 era el último. Sin embargo, cuando la declaración `print` recurrió a algún método `toString` en algún lugar, interpretó esos 32 bits como un solo integer en formato `big endian`. No lo culpo.
### Comprobando endianness en Dart
Si quiere saber cuál es la arquitectura endian de su sistema, puede ejecutar el siguiente código en Dart:
```dart
print(Endian.host == Endian.little);
```
Si eso es `true`, entonces usted también tiene una *little endian*. De lo contrario, es *big endian*. Lo más probable es que la suya sea *little endian*, ya que la mayoría de los ordenadores personales de hoy en día la utilizan.
Si miran el código fuente de la clase `Endian`, verán que la forma en que comprueba la arquitectura del host es muy similar a la que me llevó a mi sorpresa inicial:
```dart
class Endian {
...
static final Endian host =
(new ByteData.view(new Uint16List.fromList([1]).buffer))
.getInt8(0) == 1
? little
: big;
}
```
Toma una representación `16-bit` de 1 y luego ve si los primeros 8 bits son 1, en cuyo caso es *little endian*. Eso es porque los *little endian* ordenan esos 16 bits así:
```
00000001 00000000
```
mientras que las máquinas *big endian* las ordenan así:
```
00000000 00000001
```
### Por qué debería importarme?
Puede que pienses que no necesitas preocuparte por esto, ya que no planeas acercarte tanto a bajo nivel. Sin embargo, *endianness* aparece en otros contextos, también. Básicamente, cada vez que trabajes con datos compartidos que lleguen en algo más grande que trozos de `8-bit`, debes tener en cuenta *endianess*.
Por ejemplo, si has visto el vídeo que he enlazado arriba, sabes que los diferentes formatos de archivo utilizan una codificación diferente de *endian*:
- JPEG (big endian)
- GIF (little endian)
- PNG (big endian)
- BMP (little endian)
- MPEG-4 (big endian)
- Network data (big endian)
- UTF-16 text files (big or little endian — watch this video)
Así que incluso si conoces el *endianness* del raw byte data con el que estás trabajando, ¿cómo le comunicas eso al Dart para que no tengas el mismo problema de falta de comunicación que yo tuve antes?
Sigue leyendo para averiguarlo.
### Manejando endianness en Dart
Una vez que se tienen los datos en bruto como alguna clase `TypedData` como podría ser `Uint8List`, se puede usar la clase `ByteData` para hacer tareas de acceso de lectura y escritura en ella. De esta manera no tienes que interactuar con el `BytesBuffer` directamente. `ByteData` también permite especificar el *endianess* con el que se desea interpretar los datos.
Escriba las siguientes líneas de código:
```dart
Uint8List byteList = Uint8List.fromList([0, 1, 2, 3]);
ByteData byteData = ByteData.sublistView(byteList);
int value = byteData.getUint16(0, Endian.big);
print(value);
```
Esto es lo que hace:
- Obtienes tus datos tipados `Uint8List` de una lista de números enteros. Esto es lo mismo que has visto anteriormente.
- Luego lo envuelves con `ByteData`. Una view (o "sublist" view) es una forma de ver los datos en el *buffer*. La razón por la que se llama *sublista* es que no es necesario tener una vista de todo el *buffer*, que podría ser muy grande. Es posible ver un rango más pequeño de bytes dentro del *buffer*. En nuestro caso, sin embargo, el buffer para `byteList` sólo incluye esos cuatro bytes, así que estamos viendo todo.
- Después de eso se accede a 16 bits (o dos bytes) comenzando en index 0, donde la indexación es en incrementos de *one-byte*. Si eliges 1 como index obtendrás el segundo y tercer bytes, y si eliges 2 como index obtendrás el tercero y cuarto bytes. Cualquier index más alto que 2 en este caso arrojaría un error ya que sólo hay cuatro bites disponibles.
- Por último, también se le dice a Dart que se desea interpretar esos dos bytes que comienzan en index 0 como *big endian*. Ese es el valor por defecto de `ByteData`, así que podrías haber omitido ese parámetro.
Ejecuta el código y verás una salida de 1. Eso tiene sentido porque
```
00000000 00000001
```
interpretado de manera *big endian* tiene un valor de 1.
Hágalo de nuevo y sustituya `Endian.big` por `Endian.little`. Ahora, cuando ejecute el código verá 256 porque está interpretando el segundo byte (00000001) como anterior al primero (00000000), así que obtendrá
```
0000000100000000
```
que no es lo que quieres para estos datos, así que cambia el código de nuevo a `Endian.big`.
### Setting bytes in ByteData
En la sección de arriba estabas recibiendo bytes. También puedes settear bytes mientras especificas el *endianess* de casi la misma manera en que los obtuviste. Añade la siguiente línea a lo que escribiste anteriormente:
```dart
byteData.setInt16(2, 256, Endian.big);
print(byteList);
```
Aquí está poniendo dos bytes (con un valor de 256) comenzando en index 2 en el buffer. Imprime eso y verás:
```
[0, 1, 1, 0]
```
¿Tiene sentido? Anteriormente el buffer contenía:
```
[0, 1, 2, 4]
```
Pero reemplazaste los dos últimos bytes con 256, que en binario es:
```
00000001 00000000
```
o 1 y 0, cuando se interpreta de manera *big endian*.
Bien, es suficiente sobre *endianness*. La mayoría de las veces puedes aceptar el valor por defecto de *big endian* y no pensar en ello.
## Hexadecimal y binario
Hasta ahora he estado escribiendo todos los números binarios de este artículo como strings como 10101010, pero no es muy conveniente usar ese formato al escribir el código porque Dart tiene por defecto la base 10 para los números enteros.
```dart
int x = 10000000;
```
Son diez millones, no 128.
Aunque puede ser difícil escribir directamente en binario, es bastante fácil escribir directamente valores hexadecimales en Dart. Sólo hay que anteponer al número *hex* el prefijo `0x` así:
```dart
int x = 0x80; // 10000000 binary
print(x); // 128 decimal
```
Como la relación entre binario y hex es tan directa, eso hace que convertir entre los dos sea una tarea fácil. Si trabajas mucho con binario, puede que valga la pena memorizar la tabla de conversión:
```
hex binary
----------
0 0000
1 0001
2 0010
3 0011
4 0100
5 0101
6 0110
7 0111
8 1000
9 1001
A 1010
B 1011
C 1100
D 1101
E 1110
F 1111
```
Los valores de los bytes siempre estarán en dos trozos de valor hex (o *nibbles* como se llama técnicamente a un trozo de 4-bit, oh el humor de esos primeros programadores).
Aquí hay algunos ejemplos más. Si cubres el binario y sólo miras el hex, ¿puedes descifrar el binario sin mirar?
```
hex binary
----------------
80 1000 0000
2A 0010 1010
F2F2F2 1111 0010 1111 0010 1111 0010
1F60E 0001 1111 0110 0000 1110
```
Como trivialidad, el tercer valor es el valor RGB (red green blue) hex para el tono de gris que Medium utiliza como backgroundd color para los bloques de código. Y el último es el punto de código Unicode del emoji con cara sonriente y gafas de sol 😎.
### Convirtiendo hex y binario strings
Un truco divertido en Dart que tal vez no conozcas es que puedes convertir entre diferentes bases y obtener la representación en cadena de los valores.
Aquí hay un ejemplo de tomar un número decimal y convertirlo a hex y binario en forma de cadena:
```dart
String hex = 2020.toRadixString(16).padLeft(4, '0');
print(hex); // 07e4
String binary = 2020.toRadixString(2);
print(binary); // 11111100100
```
Notas:
- Radix sólo significa la base.
- El primer ejemplo toma el número decimal 2020, lo convierte en base-16 (es decir, hexadecimal), y se asegura de que la longitud sea 4. Cualquier longitud menor de 4 se rellena con ceros a la izquierda. Esto hizo que 7e4 se convirtiera en 07e4.
- El segundo ejemplo convierte el decimal 2020 a binario en el formato String.
Puedes hacer la conversión de la otra manera usando `int.parse`:
```dart
int myInt = int.parse('07e4', radix: 16);
print(myInt); // 2020
myInt = int.parse('11111100100', radix: 2);
print(myInt); // 2020
```
## Convertir Unicode strings en bytes y volver
Cuando digo bytes aquí, sólo me refiero a números. El tipo String en Dart es una lista de números *Unicode*. Los números Unicode se llaman puntos de código y pueden ser tan pequeños como 0 o tan grandes como 10FFFF. Aquí hay un ejemplo:
```
character Unicode code point (hex)
-------------------------------
H 48
e 65
l 6C
l 6C
o 6F
😎 1F60E
```
La palabra que Dart usa para los puntos de código es *runes*. Puedes verlos así:
```dart
Runes codePoints = 'Hello😎'.runes;
print(codePoints); // (72, 101, 108, 108, 111, 128526)
```
Esa es la versión decimal de sus valores hex.
Runes son un iterable de valores `int`. Sin embargo, tal y como se vio al principio del artículo con `List<int>` y `Uint8List`, `64` o incluso `32 bits` no es muy eficiente para almacenar texto cuando la mayoría de los caracteres del mundo de habla inglesa (además de emojis como 😎) sólo toman 8 bits. Incluso la mayoría de los miles y miles de caracteres chinos que existen pueden ser representados con menos de 16 bits.
Por esa razón, la mayoría de las personas representan valores Unicode utilizando un sistema de codificación `8-bit` o `16-bit`. Cuando un valor Unicode es demasiado grande para caber en 8 o 16 bits, el sistema utiliza un truco especial para codificar valores más grandes. El sistema de codificación de `8-bit` se llama *UTF-8* y el sistema de `16-bit` se llama *UTF-16*.
La forma en que UTF-8 y UTF-16 son codificados es súper interesante, especialmente los trucos que usan para codificar grandes puntos de Unicode. Si te interesa ese tipo de cosas (y probablemente lo estés si sigues leyendo), definitivamente deberías ver el siguiente video. Es el mejor que he visto sobre el tema:
https://youtu.be/HhUuzFXdyNs
### Conversión UTF-16 en Dart
Aunque los puntos de código de Unicode están disponibles como `Iterable` cuando se pide `runes`, Dart utiliza UTF-16 como su codificación real para `strings` internamente. Estos valores `16-bit` se denominan unidades de código (codeUnits) en lugar de puntos (codePoints) de código.
La conversión para obtener las unidades de código UTF-16 de una cadena es fácil:
```dart
List<int> codeUnits = 'Hello😎'.codeUnits;
print(codeUnits); // [72, 101, 108, 108, 111, 55357, 56846]
```
Notas:
- Podrías estar pensando, "Hey, un `int` es 64 bytes, no 16!" Así es como se representa externamente después de hacer la conversión. El tipo `int` se supone que es genérico y no debes pensar en cuántos bytes utiliza. Internamente, strings son listas de entenros de `16-bit`.
- Pueden ver que se necesitaron dos valores UTF-16 para representar a 😎: 55357 y 56846 , que es D83D y DE0E en hex. Estos dos números se llaman *surrogate pair*, de los que sabrán todo si han visto el vídeo de arriba.
```
Decimal Hex Binary
--------------------------------
55357 D83D 1101100000111101 (high surrogate)
56846 DE0E 1101111000001110 (low surrogate)
String Hex Binary
----------------------------------------
F60E 0000 1111 0110 0000 1110
+ 10000 0001 0000 0000 0000 0000
----------------------------------------
😎 1F60E 0001 1111 0110 0000 1110
```
Como cada unidad de código UTF-16 tiene la misma longitud, eso también hace súper fácil acceder a cualquier unidad de código por su index:
```dart
int index = 0;
int codeUnit = 'Hello😎'.codeUnitAt(index);
print(codeUnit); // 72
```
La conversión de ir de unidades de código a un String también es fácil:
```dart
List<int> codeUnits = 'Hello😎'.codeUnits;
final myString = String.fromCharCodes(codeUnits);
print(myString); // Hello😎
print(String.fromCharCode(72)); // H
```
Por muy bonito que sea, hay algunos problemas con la manipulación de strings basada en UTF-16. Por ejemplo, si estás borrando programáticamente una unidad de código a la vez, hay una buena posibilidad de que te olvides de los surrogate pairs (y grapheme clusters). Smiley ya no es tan smiley cuando eso sucede. Lee los siguientes artículos para saber más sobre este tema:
- [Trabajando con Unicode y los clusters de Grapheme en Dart](https://medium.com/flutter-community/working-with-unicode-and-grapheme-clusters-in-dart-b054faab5705)
- [Dart manipulación de cadenas hecha correctamente 👉](https://medium.com/dartlang/dart-string-manipulation-done-right-5abd0668ba3e)
### Convertir UTF-8 strings
Mientras que Dart utiliza la codificación UTF-16, Internet utiliza la codificación UTF-8. Esto significa que cuando se transfiere un texto a través de la red, es necesario convertir los strings de Dart a y desde una lista de números enteros UTF-8 encoded. De nuevo, recuerde que esto es sólo una lista de números binarios `8-bit`, específicamente un `Uint8List`. La ventaja de los valores de `8-bit` es que no tienes que preocuparte por *endianess*.
Si vieras el video que enlacé arriba y ahora entiendes cómo funciona la codificación UTF-8, podrías escribir el codificador y decodificarlo tú mismo. Sin embargo, no es necesario, porque Dart ya los tiene en su biblioteca `dart:convert`.
Importa la biblioteca así:
```dart
import 'dart:convert';
```
Entonces puedes hacer la conversión de una cadena a UTF-8 simplemente así:
```dart
Uint8List encoded = utf8.encode('Hello😎');
print(encoded); // [72, 101, 108, 108, 111, 240, 159, 152, 142]
```
Esta vez Smiley es codificado como cuatro valores de `8-bit` :
```
Decimal Hex Binary
------------------------
240 F0 11110000
159 9F 10011111
152 98 10011000
142 8E 10001110
String Hex Binary
------------------------
😎 1F60E 00001 1111 0110 0000 1110
```
Te lo digo, tienes que ver ese video. 😎
Convertir de UTF-8 a String es igual de fácil. Esta vez usa el método de decodificación:
```dart
List<int> list = [72, 101, 108, 108, 111, 240, 159, 152, 142];
String decoded = utf8.decode(list);
print(decoded); // Hello😎
```
Está bien pasar una lista de valores `int`, pero tendrás una excepción si alguno de ellos es mayor de 8 bits así que ten cuidado con eso.
## Lógica booleana
Asumo que sabes sobre los operadores `&&`, `||` y `!` de lógica booleana que usas con el tipo `bool`:
```dart
// AND
print(true && true); // true
print(true && false); // false
print(false && false); // false
// OR
print(true || true); // true
print(true || false); // true
print(false || false); // false
// NOT
print(!true); // false
print(!false); // true
```
Bueno, también hay equivalentes `bitwise` de estos operadores que trabajan con números binarios. Si piensas en `false` como 0 y `true` como 1, obtienes resultados similares con los operadores bitwise `&`, `|`, y `~` (más un operador adicional `^` XOR):
```dart
// AND
print(1 & 1); // 1
print(1 & 0); // 0
print(0 & 0); // 0
// OR
print(1 | 1); // 1
print(1 | 0); // 1
print(0 | 0); // 0
// XOR
print(1 ^ 1); // 0
print(1 ^ 0); // 1
print(0 ^ 0); // 0
// NOT
print(~1); // -2
print(~0); // -1
```
Bueno, los resultados son casi los mismos. El operador `~` bitwise `NOT` dio unos números extraños. Volveremos a eso en un rato, aunque probablemente ya hayas adivinado la razón.
Si quieres saber un poco más sobre las operaciones de bitwise antes de que veamos algunos ejemplos de Dart, echa un vistazo a esta serie de vídeos:
- [Bitwise Operators 1: The AND Operation](https://youtu.be/bizj3dle8Qc)
- [Bitwise Operators 2: The OR Operation](https://youtu.be/TMFnWGJEJuI)
- [Bitwise Operators 3: The XOR Operation](https://youtu.be/O9VELMn3jIY)
## Bitwise AND operador &
El operador bitwise `&` compara cada par de bits y da un 1 en el bit resultante sólo si ambos de la entrada bits fueran 1.
Aquí hay un ejemplo:
```dart
final y = 0x4a; // 01001010
final x = 0x0f; // 00001111
final z = x & y; // 00001010
```
¿Por qué es eso útil? Bueno, una cosa útil es hacer un `AND` bitmask. Un *bitmask* es una forma de filtrar todo menos la información que estás buscando.
Puedes verlo en la práctica en el código fuente de Flutter `TextPainter`:
```dart
static bool _isUtf16Surrogate(int value) {
return value & 0xF800 == 0xD800;
}
```
Este método estático comprueba un valor UTF-16 para ver si es un *surrogate pair*. Los surrogates están en el rango 0xD800-0xDFFF. El valor 0xF800 es el bitmask.
Es más fácil de entender cuando lo ves en booleano.
```
D800 1101 1000 0000 0000 (min)
DFFF 1101 1111 1111 1111 (max)
F800 1111 1000 0000 0000 (bitmask)
```
Notarán que los primeros cinco bits de cualquier sustituto son 11011. Los siguientes once bits pueden ser cualquier cosa. Así que ahí es donde entra la bitmask. Utiliza cinco bits 1 para coincidir con el patrón que está buscando y once 0 bits para ignorar el resto.
Recordemos que nuestro amigo Smiley 😎 está formado por los *surrogate pairs* D83D y DE0E, por lo que cualquiera de los dos valores debería volverse *true*. Probemos el segundo, DE0E:
```
DE0E 1101 1110 0000 1110 (test value)
F800 1111 1000 0000 0000 (bitmask)
-------------------------
D800 1101 1000 0000 0000 (result of & operation)
```
El resultado es D800, así que eso debería hacer que la comparación sea cierta, lo que significa que sí, el DE0E es un *surrogate pair*. Puedes probarlo tú mismo:
```dart
bool _isUtf16Surrogate(int value) {
return value & 0xF800 == 0xD800;
}
print(_isUtf16Surrogate(0xDE0E)); // true
```
## Bitwise OR operator |
El operador bitwise `|` compara cada par de bits y tiene un 1 en el bit resultante si alguno (o ambos) de los input bits fueran 1.
He aquí un ejemplo:
```dart
final y = 0x4a; // 01001010
final x = 0x0f; // 00001111
final z = x | y; // 01001111
```
¿Por qué es eso útil? Bueno, también puedes usarlo como un bitmask *"turn on"* cierto bits mientras dejas otros bits sin afectar.
Por ejemplo, los colores a menudo se empaquetan en un solo entero de `32-bit`, donde los primeros 8 bits representan el valor alfa (transparencia), los siguientes 8 bits son el valor rojo, los siguientes 8 bits el valor verde, y los últimos 8 bits el valor azul.
Así que digamos que tienes este color purple semitransparente aquí:
Si quieres mantener el color pero hacerlo completamente opaco, podrías usar un OR bitmask para hacerlo. El valor hex para ese color es 802E028A:
```
alpha red green blue
-----------------------------------
80 2E 02 8A
10000000 00101110 00000010 10001010
```
Completamente transparente es 0x00 y completamente opaco es 0xFF. Así que quieres hacer un bitmask que mantenga los valores de rojo, verde y azul iguales, pero que haga el alfa 0xFF. En este caso debemos esperar FF2E028A para el resultado después de que se aplique el bitmask.
```
10000000 00101110 00000010 10001010 (original)
11111111 00000000 00000000 00000000 (bitmask)
-----------------------------------
11111111 00101110 00000010 10001010 (result of | operation)
```
Como *ORing* cualquier cosa con 1 hace 1, esto convirtió todos los valores alfa en 1. *ORing* cualquier cosa con 0 no cambia el valor, así que los otros valores se mantuvieron iguales.
Inténtalo en Dart:
```dart
final original = 0x802E028A;
final bitmask = 0xFF000000;
final opaque = original | bitmask;
print(opaque.toRadixString(16)); // ff2e028a
```
¡Ya lo tengo!
Nota: Si te molesta que la cadena hex esté en *lowercase*, siempre puedes encubrirla a *uppercase*:
Nota: Si le molesta que la cadena hex esté en *lowercase*, siempre puede encubrirla a *uppercase*:
```dart
print('ff2e028a'.toUpperCase()); // FF2E028A
```
## Bitwise XOR operador ^
El operador bitwise `^` compara cada par de bits y tiene un 1 en el bit resultante si la entrada bits es diferente.
Aquí hay un ejemplo:
```dart
final y = 0x4a; // 01001010
final x = 0x0f; // 00001111
final z = x ^ y; // 01000101
```
¿Por qué es eso útil? En Dart verás a menudo el operador `^` usado para crear códigos `hash`. Por ejemplo, aquí hay una clase de persona:
```dart
class Person {
final String name;
final int age;
Person(this.name, this.age);
@override
bool operator ==(Object other) {
return identical(this, other) ||
other is Person &&
runtimeType == other.runtimeType &&
name == other.name &&
age == other.age;
}
@override
int get hashCode => name.hashCode ^ age.hashCode;
}
```
La última línea con hashCode es la parte interesante. Reproduzcamos eso aquí:
```dart
final name = 'Bob';
final age = 97;
final hashCode = name.hashCode ^ age.hashCode;
print(name.hashCode); // 124362681
print(age.hashCode); // 97
print(hashCode); // 124362712
print(name.hashCode.toRadixString(2).padLeft(32, '0'));
print(age.hashCode.toRadixString(2).padLeft(32, '0'));
print(hashCode.toRadixString(2).padLeft(32, '0'));
```
Aquí están los resultados binarios:
```dart
00000111011010011001111110111001 (name hash code)
00000000000000000000000001100001 (age hash code)
--------------------------------
00000111011010011001111111011000 (result of ^ operation)
```
Para los códigos hash quieres que estén lo más distribuidos posible para que no se produzcan colisiones hash. Si haces operaciones `&`, obtienes más 0s, y si haces operaciones `|`, obtienes más 1s. Como el operador `^` mantiene la distribución de 0s y 1s, es un buen candidato para crear nuevos códigos hash a partir de otros.
## El operador NOT Bitwise ~
El operador `~` invierte el valor de los bits. Antes viste estos resultados confusos:
```dart
// NOT
print(~1); // -2
print(~0); // -1
```
Esto tiene más sentido si miras el valor binario. Aquí está la representación `64-bit` de 1:
```
0000000000000000000000000000000000000000000000000000000000000001
```
Cuando volteas todos esos bits (es decir, el resultado de ~1), obtienes:
```
1111111111111111111111111111111111111111111111111111111111111110
```
Y si miran el video sobre *Two's Complement*, recordarán que así es como se expresa el número -2 en binario. Es una historia similar para ~0. Problema resuelto.
Por cierto, aquí hay un chiste para aquellos de ustedes que les gusta Shakespeare:
```dart
2b|~2b
```
Esa es la cuestión.
## Bit shifting << >>
Hay un último tema a tratar: bit shifting. Puedes cambiar bits a la izquierda con el operador bitwise left shift `<<` y a la derecha con el operador bitwise right shift `>>`.
Puede aprender más sobre el bit shifting en este video:
https://youtu.be/mjqswwqE1RQ
Aquí hay un ejemplo en Dart de un shift izquierdo:
```dart
final value = 0x01; // 00000001
print(value << 5); // 00100000
```
Todos los bits se desplazaron a la izquierda en 5. Un valor binario de 00100000 es 32. Como dato interesante, una forma sencilla de multiplicar por dos es hacer shift left por uno:
```dart
print(7 << 1); // 14 (decimal)
```
Aquí hay un right shift:
```dart
final value = 0x80; // 10000000
print(value >> 3); // 00010000
```
Esto equivale a decir que 128 right shift 3 es 16.
¿Por qué es esto importante? Bueno, un lugar donde puedes verlo en Dart es para extraer valores de un `integer` empaquetado. Por ejemplo, el código fuente de la clase `Color` tiene el siguiente getter para extraer el valor rojo de un valor de color:
```dart
/// The red channel of this color in an 8 bit value.
int get red => (0x00ff0000 & value) >> 16;
```
Esto primero utiliza un `AND` bitmask para encontrar sólo la parte *red* del valor ARGB (alpha red green blue) y luego mueve el resultado al principio. Así es como se vería con nuestro 802E028A color purple de antes.
```
alpha red green blue
-----------------------------------
80 2E 02 8A
10000000 00101110 00000010 10001010 (original)
00000000 11111111 00000000 00000000 (bitmask)
-----------------------------------
00000000 00101110 00000000 00000000 (result of &)
-----------------------------------
00000000 00000000 00000000 00101110 (result of >> 16)
```
Y aquí está en Dart:
```dart
final purple = 0x802E028A;
final redBitmask = 0x00FF0000;
final masked = purple & redBitmask;
final redPart = masked >> 16;
print(redPart.toRadixString(16)); // 2e
```
## Puntos clave
¡Lo lograste! Aquí están los puntos clave de este artículo:
- Los datos binarios pueden ser expresados como una lista de números enteros.
- `Uint8List` es una lista de `8-bit` de números enteros sin signo y es más eficiente que `List<int>` cuando se trabaja con grandes cantidades de datos binarios.
- Se puede utilizar `BytesBuilder` para añadir datos binarios a una lista.
- Los datos de los bytes están respaldados por un `BytesBuffer` y se pueden obtener diferentes vistas de los bytes subyacentes. Por ejemplo, se pueden ver los bytes en los segmentos `8-bit`, `16-bit`, `32-bit`, o `64-bit`, ya sea como enteros son o sin signo.
- Con los trozos mayores de 8 bits hay que tener en cuenta *endianness*, que se ve afectado por la máquina o el formato de almacenamiento subyacente. Se puede utilizar `ByteData` para especificar ya sea vistas *big endian* o *little endian*.
- Prefije un número con `0x` para escribirlo en notación hexadecimal.
- Dart strings son listas de valores UTF-16 y se conocen como unidades de código.
- Convierte strings a UTF-8 utilizando la biblioteca `dart:convert`.
- Los operadores lógicos bitwise son `&`, `|`, `^`, y `~`, y los operadores shift son `<<` y `>>`.
- Los operadores y las máscaras de bits permiten acceder y manipular los bits individuales.
## Continuando
Un par de áreas que merecen un estudio más profundo son los streams de bytes y cómo transformar los datos de esos streams. Por ejemplo, se puede obtener un byte stream al leer o descargar un archivo. En lugar de esperar a que llegue todo el archivo antes de trabajar con él, puedes empezar a transformar los valores bytes a UTF-8 (o algo más) a medida que los obtengas.
Recuerda dejar un comentario o hacer una pregunta si algo no está claro.
| maginkgo | |
576,067 | Connecting to Kafka cluster using SSL with Python | This article specifically talks about how to write producer and consumer for Kafka cluster secured... | 0 | 2021-01-19T14:47:20 | https://dev.to/adityakanekar/connecting-to-kafka-cluster-using-ssl-with-python-k2e | kafka, shell, linux, python | This article specifically talks about how to write producer and consumer for Kafka cluster secured with SSL using Python. I won't be getting into how to generate client certificates in this article, that's the topic reserved for another article :).
#### Pre-Requisites
* Kafka Cluster with SSL
* Client certificate (KeyStore) in JKS format
* Linux environment with keytool and openssl installed
* Python 3.6
### Step 1 - Converting JKS to PEM file
#### Why I need this step?
Unlike Java, Python and C# uses .pem files to connect to Kafka. For this purpose we will have to convert the JKS files to PEM with the help of **keytool** and **openssl** commands. If you are working on Windows 10 you can refer to my article on how to run WSL on Windows [here](https://dev.to/adityakanekar/developing-for-linux-environment-in-windows-10-with-wsl-2-part-1-4422).
To make your life easy I have created a shell script to quickly convert JKS to PEM.
```
#!/bin/bash
srcFolder=$1
keyStore=$1/$2
password=$3
alias=$4
outputFolder=$5
echo $keyStore
echo "Generating certificate.pem"
keytool -exportcert -alias $alias -keystore $keyStore -rfc -file $outputFolder/certificate.pem -storepass $password
echo "Generating key.pem"
keytool -v -importkeystore -srckeystore $keyStore -srcalias $alias -destkeystore $outputFolder/cert_and_key.p12 -deststoretype PKCS12 -storepass $password -srcstorepass $password
openssl pkcs12 -in $outputFolder/cert_and_key.p12 -nodes -nocerts -out $outputFolder/key.pem -passin pass:$password
echo "Generating CARoot.pem"
keytool -exportcert -alias $alias -keystore $keyStore -rfc -file $outputFolder/CARoot.pem -storepass $password
```
The script generates following files from the keystore file,
* key.pem
* certificate.pem
* CARoot.pem
#### How to run this script?
Save the script in a file e.g. jkstopem.sh and give execute permissions like below,
```
chmod +x jkstopem.sh
```
To generate the PEM files. Run the shell script as shown in the below example,
```
./jkstopem.sh <source_path_to_jks> <keystore_file_name> <keystore_password> <alias> <output_folder>
```
##### How to find Alias?
If you are not aware of what alias your certificate has. Run following command in the folder where you have the keystore file.
```
keytool -list -v -keystore kafka.client.keystore.jks
```
You will be prompted to enter the password. Enter the keystore password, this will list the contents of the keystore file. You will be able to see **Alias name*.
Following is the example to run the shell script,
```
./jkstopem.sh ~/client-cert kafka.client.keystore.jks welcome123 client-alias ~/client-cert/pem
```
Now you should be able to see following files in the output folder,
* key.pem
* certificate.pem
* CARoot.pem
Now as we have all the **PEM** files, lets get cracking.
### Step 2 - Writing Kafka Producer in Python
We will be using 'kafka-python' package to connect to Kafka. You can install it using pip,
```
pip install kafka-python
```
Now, lets write our producer.
```
#Producer.py
from kafka import KafkaProducer
kafkaBrokers='kafka1.xyz.com:443,kafka2.xyz.com:443,kafka3.xyz.com:443'
caRootLocation='CARoot.pem'
certLocation='certificate.pem'
keyLocation='key.pem'
topic='test-topic'
password='welcome123'
producer = KafkaProducer(bootstrap_servers=kafkaBrokers,
security_protocol='SSL',
ssl_check_hostname=True,
ssl_cafile=caRootLocation,
ssl_certfile=certLocation,
ssl_keyfile=keyLocation,
ssl_password=password)
producer.send(topic, bytes('Hello Kafka!','utf-8'))
# Send to a particular partition
producer.send(topic, bytes('Hello Kafka!','utf-8'),partition=0)
producer.flush()
```
In the above example we are using the pem files we generated in the last step with the password to read the pem file.
```
kafkaBrokers='kafka1.xyz.com:443,kafka2.xyz.com:443,kafka3.xyz.com:443'
caRootLocation='CARoote.pem'
certLocation='certificate.pem'
keyLocation='key.pem'
password='welcome123'
producer = KafkaProducer(bootstrap_servers=kafkaBrokers,
security_protocol='SSL',
ssl_check_hostname=True,
ssl_cafile=caRootLocation,
ssl_certfile=certLocation,
ssl_keyfile=keyLocation,
ssl_password=password)
```
####Sending data to random topic partition
Below code snippet will send data to random partition decided by Kafka.
```
producer.send(topic, bytes('Hello Kafka!','utf-8'))
producer.flush()
```
####Sending data to specific topic partition
To send data to a specific partition, you just need to specify the partition as shown in below code snippet,
```
producer.send(topic, bytes('Hello Kafka - Partition 0!','utf-8'),partition=0)
producer.flush()
```
So we have built our Python producer for Kafka. In the next part we will write consumer to consume the message from the topic.
| adityakanekar |
571,380 | Best frontend/landing page? | I have an idea for a website, most of the logic will be on the backend server & DB. I am a databa... | 0 | 2021-01-14T08:20:12 | https://dev.to/pazyp/best-frontend-landing-page-49a9 | discuss, watercooler | I have an idea for a website, most of the logic will be on the backend server & DB. I am a database engineer myself so the backend comes naturatly to me, I am quite at home on a linux server writing scripts in $shell or python. But when it comes to front end I really have no idea.
Is there any recomendation for a simple frontend landing page type website, I don't need anything spectacular just needs to have the ability to capture email address signups and forward those emails to my back end or an intermediary between front and backend and also proccess payment should a user wish to request the paid service.
I have seen Kajabi it seems to tick most of the boxes but its overly expensive ($150 p/m), Podia is another I have found which has far better pricing.
Does anyone have and good sugestions of such a offering? | pazyp |
572,124 | How Habit Enhances Good Success | 😎 Hello Homo Sapien(s) Welcome to my blog apparently this is my first article This Year. First... | 0 | 2021-01-15T01:23:17 | https://dev.to/engr_dexter/how-habit-enhances-good-success-4704 | beginners, motivation | <b>😎 Hello <b>Homo Sapien(s) </b> Welcome to my blog apparently this is my first article This Year.</b><br>
First thing first😊 What is a habit? Simply stated, a habit is something you do so often it becomes easy. In other words, its a behavior that you keep repeating. If you persist at developing a new behavior, eventually it becomes automatic
we are all creatures of habit the great news is that you can reprogram yourself any time you choose to do so if you struggling financially, this is important to know!<br>
>Let me tell you a short story of Mr Ake Martin C.E.O of Mtech and also the founder of one of the best 9ja gospel blog *gospelcrux.com*
He stated that one of the habit he got rid of lately was sleep. In an interview with him he made me understand that he came to a realization which is, if you really have a Big dream then you should wake up from that sleep so that your dream would come alive he stated that sleep is one of the sweetest thing that is inevitable.
Below, you can find the 7 most common habits successful people track. Make sure to include them in your daily checklist in any of their possible forms. feel free to drop a comment in the comment section you can also add yours.

1. Learn-
Learning new skills is certainly one of the most desired things in life. Independently of if we want to learn something for our professional career or just for fun, we need to be persistent in our way to master a new skill. Making a daily habit of learning a new skill, even if we just manage to find 10 spare minutes a day at first, will not only help us make rapid progress, but it will also help us keep pushing when the motivation that got us started wanes.The internet has boosted our learning possibilities with thousands of free courses like those in Coursera, Udemy or Youtube. Some of the most tracked habits within this category are learning to code, learning to play a musical instrument, learning a new language or learning to cook.
2. Exercise-
Exercising is a well-established habit in the lives of successful people. It is widely known how advantageous the practice of any physical activity is for our body and brain performance. Even lightly strenuous activity is enough to oxygenate our blood and boost the endorphins in our body.
Managing to exercise regularly will help us feel physically and emotionally better, with more motivation and mental clarity to approach the challenges of every day life. To perform at top level we need to be at top shape. Ramit Sethi goes as far as stating that this is the most common habit among successful people.
Tracking habits such as “go to the gym” or “workout” might be too generic. A better approach is to specify the habits in more detail, for example, “50 morning push-ups”, “50 evening push-ups”, “run 30 minutes” or “walk 10.000 steps”. Practicing sports, such as swimming or playing basketball are equally popular and involve a social aspect that makes it easier for the habits to stick. Just find the way to exercise that best fits your interests and schedule, and build on from that.
3. Eat healthy-
We are what we eat. For our body and mind to perform at a great level we need to feed them as well was we can. Highly performant people, especially top-level athletes, define a set of habits not only to improve the quality of the food they eat, but also the way in which they eat. Fast food, for example, is two times bad. First, the quality of the food is dubious, and second, it creates a culture of eating big quantities of food when your body doesn’t require it.
Healthy food doesn’t mean it’s expensive. Don’t use this as an excuse.
Some of the most common habits you should track are: “eat a fruit”, “eat no sugar”, “max 1 coffee a day or no coffee”, “excessive salt“, “no snacking”, “no fast food”, ”eat no candy”, “drink water with lemon”…
Examples of habits regarding the way in which we eat that are also very important are: “take my time to eat”, “no overeating”, “5 meals a day”, “consciously chew several times”, “don’t skip breakfast” and “don’t eat too late”.
4. Read-
Successful people are avid readers. Reading isn’t just a source for learning well thought ideas or ways of doing things but it also boosts your imagination. Reading also serves you to see how others build their ideas and helps you improve your ways of thinking.
People like Bill Gates take it one step further and review the books they read for future revisits of the ideas those books inspired to them.
Reading doesn’t just involve books, but also newspapers, internet articles and blogs. Reading shapes our mind. Some little habits you can track include “read one article on X topic”, “read 10 pages”. People who read a lot can even track it by an estimate of the characters they read daily.
5. Meditate-
Meditation encompasses several benefits such as stress reduction or focus enhancement and it alleviates anxiety, preventing depression and leading to happiness. Most importantly, it helps you create self-awareness, which gives you the ability to flow with everything that’s around you without feeling overwhelmed.
Tim Ferriss referred to meditation when asked about an habit people don’t take advantage of.
It is no surprise that this isn’t the most popular habit since it’s not so easy to get started with. This infographic can help you get the basic ideas of mindfulness meditation. Starting with a daily goal of “concentrate on breath 3-5 minutes” and using a habit tracker to make sure you do it every day will get you set.
6. Wake up early-
Waking up early is the best way to start a new day on the right foot. But having enough rest is mandatory. This can only mean one thing, you must go to sleep early too. This is a good example of habit stacking.
Habit stacking is simply the idea of grouping several habits that are related to build them in parallel. Building habits at the same time or on top of other habits makes the whole deal of changing our daily routine much easier. This is a technique most of us use unconsciously but that highly successful people exploit.
An example you might feel familiar with is the so called “morning routine”. Everyone has their own morning routine. Right after we wake up there’s a set list of things we repetitively do every morning. Successful people have honed it to make the best out of it.
Some of these stacked habits include “wake up at 6 am”, “meditate for 5 min”, “exercise”, “shower”, “healthy breakfast”…
7. Write-
Writing is a great way to clarify your ideas and refine your thoughts. A lot of people disregard this habit because they feel “they have nothing to tell”. That’s a lie. Everyone has ideas to share, stories to explain and teachings to spread. The rise of blogging in the last years proves the benefits of writing.
Writing also helps gain motivation when working on something. You want to do more to be able to share more.
However, the sharing aspect of writing isn’t important. If you feel shy about your thoughts, keeping a journal is still one of the best habits you can develop. Writing about how you envision yourself in the near future is also a great self-improvement tool to work towards that goal.
People like Richard Branson or Warren Buffet have duly benefited from writing regularly.
Tracking habits as simple as “write 3 lines”, “write a page” or “what did I do today” will help you get started.
Start small
The main challenge with forming good habits is to keep disciplined. To be persistent and work on them every day until they form part of our daily routine is no easy task. That is basically what differentiates successful people from the rest. Our degree of success is strongly tied to how disciplined we are with our habits. Luck can only find us if we are there every day on the window display.
However, there are a few little tricks that can smooth your way. Starting small is always good advice. Both in the quantity of new habits you want to form and in the quantity in which you can measure each habit. You shouldn’t try to form more than 3 new habits at the same time. On the other hand, when possible, always try to use quantities that can help you accomplish little specific goals. For example, “50 push-ups”, “read 10 pages”, “write 1 page”, “eat a fruit”, “meditate 5 minutes”, etc.
| engr_dexter |
572,285 | Stylish Animated CSS Buttons | with Sourcecode | Hello readers, Today you'll learn how to create stylish animated CSS Buttons. Visit: https://www.tec... | 0 | 2021-01-15T06:48:40 | https://dev.to/harshit1969/stylish-animated-css-buttons-with-sourcecode-1le0 | html, css, hovereffect, sourceocde | Hello readers, Today you'll learn how to create stylish animated CSS Buttons.
Visit: https://www.techindiaharshit.ga/2021/01/stylish-animated-css-buttons-with.html
for live demo and sourcecode
| harshit1969 |
572,357 | LHD: Build | Created a to do list for Day4 of LHD: Build. It's been an amazing experience so far and learnt a lot... | 0 | 2021-01-15T08:02:30 | https://dev.to/pragatig746/lhd-build-3ojn | localhackday, majorleaguehacking, mlh | Created a to do list for Day4 of LHD: Build.
It's been an amazing experience so far and learnt a lot of new things while doing these daily challenges.
| pragatig746 |
572,403 | Disruptive 2D multiplayer online RPG (not massive) | If you like the idea and/or are experienced in 2D game dev/ libgdx, please join! https://findcollabs... | 0 | 2021-01-15T09:40:37 | https://dev.to/overstained/disruptive-2d-multiplayer-online-rpg-not-massive-51p8 | java, gamedev, libgdx, multiplayer | If you like the idea and/or are experienced in 2D game dev/ libgdx, please join!
https://findcollabs.com/project/disruptive-2d-multiplayer-online-rpg-not-massive-gBZjXOuD5bI7guneu4ch | overstained |
572,441 | 10 Of The Best PHP Testing Frameworks For 2021 | A framework is a collection or set of tools and processes that work together to support testing and... | 0 | 2021-01-15T11:03:44 | https://www.lambdatest.com/blog/best-php-testing-frameworks-2021/ | php, webdev, automation | A framework is a collection or set of tools and processes that work together to support testing and developmental activities. It contains various utility libraries, reusable modules, test data setup, and other dependencies. Be it web development or testing, there are multiple frameworks that can enhance your team’s efficiency and productivity. Web testing, in particular, has a plethora of frameworks, and selecting a framework that suits your needs depends on your language of choice.
Amongst all server-side programming languages, [80% of websites use PHP](https://w3techs.com/), and the right framework can make the job easier. We decided to dive deeper into PHP and find out what the best PHP testing frameworks are. In this blog, we will be focusing on automated testing frameworks and will be listing out the best PHP frameworks that will allow you to write your test cases in a standard format.
## Choosing The Best PHP Testing Frameworks
If you want to pick the best framework, no matter whether its a new PHP framework or a well-known [JavaScript framework](https://www.lambdatest.com/blog/best-javascript-framework-2020/?utm_source=devto&utm_medium=Blog&utm_campaign=mar26_sb&utm_term=sb), it has to be structured in such a manner that it provides various benefits as listed below-
- Maintains a well-defined code structure
- Maintains reusable modules and libraries which can effectively be used for testing, thereby achieving code reusability.
- Enhances the speed of the testing process
- Improves test efficiency
- Avoids code duplication
- Analyzes test coverage as well as requirement coverage
A framework is an integral part of testing, and hence it is crucial to select the framework type based on our project requirement. First of all, to set up a framework, one must know each framework’s pros and cons. Only then it will be easy to list out our requirements and select specific automated testing frameworks. Once you have an idea about your needs, you can go ahead and choose one amongst the best PHP testing frameworks.
To help you in doing that, let’s take you through the best PHP frameworks in detail.
## Best PHP Testing Frameworks Of 2021
Several frameworks have been and are being used for development and testing purposes. But each one is unique in its own way and offers unique features. We will discuss how the best PHP testing frameworks approach test automation and what pros or cons they all offer. Without further ado, let’s look at the best PHP frameworks.
1. PHPUnit
2. Codeception
3. Storyplayer
4. SeleniumHQ
5. Behat
6. Atoum
7. SimpleTest
8. PhpSpec
9. Peridot
10. Kahlan
As promised above, we will now analyze each of these PHP testing frameworks in detail to help you make the final choice.
## 1. PHPUnit
PHPUnit is the most commonly used PHP testing framework, and it is considered a programmer-oriented framework. It is mostly preferred for unit testing. It was developed by Sebastian Bergmann and is an instance of the xUnit framework architecture.
### Steps To Install
There are a few prerequisites that must be satisfied before installing this framework. Firstly, you need to install a higher version of PHP for installing the latest version of PHPUnit. As per their official documentation, it is recommended to use PHP version 7.3 for PHPUnit 9.3, the latest PHPUnit version. Below are the steps to install PHPUnit in your system.
**Step 1:** PHPUnit can be installed by downloading the PHAR (PHP Archive) from the below link
[https://www.php.net/phar](https://www.php.net/phar)
PHAR has all the required PHPUnit dependencies bundled in a single file.
**Step 2:** You may also install [Composer](https://getcomposer.org/) which manages all the dependencies in the project.
### Advantages Of Using PHPUnit Framework
PHPUnit is considered one of the best PHP frameworks due to several reasons. Listed below are some of the advantages of using PHPUnit for automated testing-
1. It is one of the frameworks which allows us to analyze the code coverage efficiently. Based on an in-depth analysis, it can also generate code coverage reports in HTML and also XML log files with more information. Sometimes there might be a few blocks of code that cannot be tested. In such cases, we can use different annotations like @codeCoverageIgnore, @codeCoverageIgnoreStart, and @codeCoverageIgnoreEnd, which are used to ignore certain code blocks while running through code coverage analysis. We can also run the code coverage analysis for certain code blocks by specifying them with @covers annotation.
2. While writing the test cases, some tests would be left without any implementations. When executed, those cases return a success message, but it isn’t very meaningful to have such a report. PHPUnit provides an interface that raises an exception when an unimplemented test is run.
3. All the tests can be grouped together into a suite and run at once with the help of an XML configuration file.A simple XML configuration file would look like below-
```
tests/FirstTest.php
tests/SecondTest.php
tests/ThirdTest.php
```
*** Did you know? [CSS text-indent](https://www.lambdatest.com/web-technologies/css-text-indent?utm_source=devto&utm_medium=organic&utm_campaign=may26_sb&utm_term=sb&utm_content=web_technologies) property specifies the indentation that lines of inline content in a block are indented from its "normal" position. ***
## 2. Codeception
Codeception is one of the most widely used PHP testing frameworks, and it has gained immense popularity because of ease of use and its ability to maintain the code modules. It supports three levels of testing, namely acceptance testing, functional testing, and unit testing. It provides multiple modules that can be utilized for testing purposes in a single framework.
Let us see the steps to install Codeception and the advantages of using this automated testing framework.
### Steps To Install
Before you install Codeception, you need to know if the prerequisites are met. You will need-
1. PHP with version greater than 5.6 installed in your machine
2. Curl has to be enabled
Once you have met the prerequisites, you need to follow the below-mentioned steps to proceed further-
**Step 1:** Install composer which is used for managing the dependencies in PHP. It helps in declaring the libraries to be used in the project and manages them.
You may install using a setup file or you can even do it manually. You can install the composer from their official [website](https://getcomposer.org/download/).
**Step 2:** Install PHAR, and you may install it from the official website of [Codeception](https://codeception.com/install).
### Advantages Of Using Codeception Framework
1. It supports Unit testing, functional testing, as well as acceptance testing. We can opt for any of the three types of testing or sometimes can opt for all three to test the application effectively. If you are wondering, this is the exact reason why it is also known as a ‘full stack testing framework.’
2. It uses simple naming conventions, which helps everyone to understand the code. It contains action keywords, assertions, and grabbers. The actions keywords are used to perform user actions like clicking, pressing the keys, filling the input fields, etc. The assertion keywords are used to perform the verification like the one that is done using TestNG and Junit. The grabbers are used to extract the information.
3. It also provides an option of running the user stories in BDD like JBehave and Cucumber.
4. It provides various database modules, which would be quite helpful in database testing.
5. It has a WebDriver module, which could be used for acceptance testing.
6. It has a REST module, which could be very helpful for testing web services. This module also validates the JSON responses, extracting data from specific JSON tags, verifying xml responses, etc.
7. It helps integrate with continuous integration tools like [Jenkins](https://www.lambdatest.com/blog/what-is-jenkins/?utm_source=devto&utm_medium=Blog&utm_campaign=mar26_sb&utm_term=sb) and Teamcity, which would help generate the test reports.
## 3. Storyplayer
Storyplayer is an open-source PHP testing framework which is used to perform end to end testing. It is best suited for API automation testing and testing web applications. It provides multiple programming language support, which is one reason behind its popularity as one of the best PHP frameworks.
### Steps To Install
**Step 1:** As it is a PHP testing framework, it requires PHP to be installed before setting up this framework. Currently it supports only Apple OSX Yosemite and Ubuntu Linux Desktop 14.10.
**Step 2:** It is also required to add some extensions like CURL, JSON, OpenSSL etc. You can read further in their official [website](https://datasift.github.io/storyplayer/v2/learn/getting-setup/index.html).
### Advantages Of Using Storyplayer Framework
1. It offers an open source framework, which is quite useful if you are a newbie in PHP web development. You don’t need to take a subscription or pay a fee to avail the services of Storyplayer.
2. Another great advantage of using the Storyplayer PHP testing framework is the amazing support it provides for multiple programming languages. This makes PHP development and testing much easier and competitive.
## 4. SeleniumHQ
[Selenium](https://www.selenium.dev/) is the one of most popularly used automated testing frameworks that has been extensively used for testing web applications. It has four main components namely-
1. Selenium IDE
2. Selenium RC
3. Selenium WebDriver
4. Selenium Grid
These components are designed for specific purposes, and the selection of the component purely depends upon our testing requirements.
### Steps To Install
To work with [Selenium](https://lambdatest.com/selenium?utm_source=devto&utm_medium=Blog&utm_campaign=mar26_sb&utm_term=sb), you need to set up the latest version of PHP. Also, it is required to have Composer, which manages all the dependencies for our project.
### Advantages Of Using Selenium Framework
1. Selenium is an open source automation testing framework.
2. It has an amazing support community.
3. It is easy to install, and test case implementation is quite easy as well.
4. It allows us to run our test cases in different browsers like Google Chrome, Firefox, Safari, Internet Explorer and allows seamless browser compatibility testing.
5. It executes our test scripts in parallel in multiple browsers and operating systems for faster test execution.
6. It is also used to perform the keyboard and mouse interactions with the browser.
***Did you know? [CSS text-orientation](https://www.lambdatest.com/web-technologies/css-text-orientation?utm_source=devto&utm_medium=organic&utm_campaign=may26_sb&utm_term=sb&utm_content=web_technologies) property can be used to set the orientation of texts. It has no effect in Western horizontal typographic modes, like English.***
## How To Overcome The Limitations Of Selenium With LambdaTest Selenium Grid?
LambdaTest offers a great platform to run your automation scripts on a [cloud Selenium Grid](https://www.lambdatest.com/selenium-automation?utm_source=devto&utm_medium=Blog&utm_campaign=mar26_sb&utm_term=sb) and achieve faster test execution. There are endless benefits of running the tests in the LambdaTest grid.
1. Quick and easy setup to run your automation scripts.
2. Execute your tests in different browsers with different versions.
3. Integration with various continuous integration and deployment tools.
4. Allows to define various parameters like browser name, version of the browser, operating system.
5. Provides the option to take screenshots and record videos while executing the test cases.
6. Most importantly, it provides 24X7 customer support and detailed documentation.
Below is the simple code to search a product on Google using LambdaTest grid-
```php
<?php
require 'vendor/autoload.php';
class LambdaTestGrid{
/*
Setting up remote driver in LambdaTestGrid
Params
----------
platform : Supported platform - (Windows 10, Windows 8.1, Windows 8, Windows 7, macOS High Sierra, macOS Sierra, OS X El Capitan, OS X Yosemite, OS X Mavericks)
browserName : Supported platform - (chrome, firefox, Internet Explorer, MicrosoftEdge, Safari)
version : Supported list of version can be found at https://www.lambdatest.com/capabilities-generator/
*/
protected static $driver;
public function searchTextOnGoogle() {
# username: replace your username that can be found in your LambdaTest dashboard
$LT_USERNAME = "{username}";
# accessKey: replace your access token that has been generated once you signed up
$LT_APPKEY = "{accessKey}";
$LT_BROWSER = "chrome";
$LT_BROWSER_VERSION ="70.0";
$LT_PLATFORM = "windows 10";
# URL: https://{username}:{accessToken}@hub.lambdatest.com/wd/hub
$url = "https://". $LT_USERNAME .":" . $LT_APPKEY ."@hub.lambdatest.com/wd/hub";
# setting desired capabilities for the test
$desired_capabilities = new DesiredCapabilities();
$desired_capabilities->setCapability('browserName',$LT_BROWSER);
$desired_capabilities->setCapability('version', $LT_BROWSER_VERSION);
$desired_capabilities->setCapability('platform', $LT_PLATFORM);
$desired_capabilities->setCapability('name', "Php");
$desired_capabilities->setCapability('build', "Php Build");
$desired_capabilities->setCapability('network', true);
$desired_capabilities->setCapability('visual', true);
$desired_capabilities->setCapability('video ', true);
$desired_capabilities->setCapability('console', true);
self::$driver = RemoteWebDriver::create($url, $desired_capabilities);
//specify the browser URL
self::$driver->get("https://www.google.com/");
//specify the locator of the search box
$element = self::$driver->findElement(WebDriverBy::name("q"));
if($element) {
//type the name to be searched in the google search box
$element->sendKeys("IPhone");
$element->submit();
}
print self::$driver->getTitle();
self::$driver->quit();
}
}
?>
```
Once the tests have been executed, you can view the logs and other builds related information in the [Automation dashboard](https://automation.lambdatest.com/). Thus, running the tests in LambdaTest Grid improves the execution speed and also provides efficient results.
## 5. Behat
Behat is a [Behavior Driven Development](https://www.lambdatest.com/blog/behaviour-driven-development-by-selenium-testing-with-gherkin/?utm_source=devto&utm_medium=Blog&utm_campaign=mar26_sb&utm_term=sb) (BDD) framework for PHP. It was built entirely for PHP, and it has many core PHP modules in it. The code is usually written in simple English language, easily understandable by all the stakeholders in the project. The BDD structure usually contains the Context, Action, and Outcome, and this format is called Gherkin. Below is a simple example of writing tests in the Gherkin language.
```
Scenario: Login into Facebook and verify if the user is successfully logged in
Given the user enters his username and password
When the user clicks sign in button
Then the user should be successfully logged into his Facebook homepage
```
These scenarios are written in a file with extension features. For example, loginTest.feature in the above case. Behat is an executable that is used to run the tests from the command line for testing the application exactly similar to the execution of feature files.
### Steps To Install
To setup Behat framework make sure you have installed the below prerequisites-
**Step 1:** PHP latest version.
**Step 2:** Composer which manages all the PHP dependencies for the project.
**Step 3:** If you don’t have a Composer, you can easily set up the framework by downloading the latest version of [behat.phar](https://github.com/Behat/Behat/releases).
### Advantages Of Using Behat Framework
1. Easy to install and implement.
2. Easy to understand the test cases as everything is written in BDD. The tests are written in simple English language, which helps all the project stakeholders understand the requirement and the test cases mapped to it. The scenarios are written in a feature file and consist of the context, the subsequent action, and the final expected result. These are written using the Given, When and Then keywords in Gherkin language.
3. Detailed documentation which helps everyone to implement the framework easily.
4. It is an open source testing framework.
## 6. Atoum
Atoum is another one of the popular PHP testing frameworks which is used for Unit testing. It is very simple and easy to implement, and it is amongst the new PHP frameworks you will come across. Also, it’s among the best PHP frameworks. It provides various inbuilt execution engines such as the inline engine, isolation engine, and concurrent engines. Those are used to execute test cases one by one, one after another test case each time in a new process, and run all the test cases in parallel simultaneously in different processes separately. Atoum also provides advanced features that help to mock the build, minimizing the dependencies for running the tests.
Now let us see the steps involved in the installation of the Atoum framework along with its advantages.
### Steps To Install
Before installation, make sure you have the latest version of PHP installed in your system. You can set up an [Atoum](http://atoum.org/)framework by either one of the ways.
Step 1: By using Composer which can be downloaded from their [official website](https://getcomposer.org/).
Step 2: By using a PHAR file which can be downloaded from [this link](https://atoum.readthedocs.io/en/latest/installation.html#phar-archive).
Step 3: By cloning from the Git repository
[http://github.com/atoum/atoum.git](http://github.com/atoum/atoum.git)
### Advantages Of Using Atoum Framework
1. Easy to write test cases based on our convenience.
2. It provides multiple assertions, which makes them highly effective when implemented in test cases.
3. Mocking can be quickly done using the Atoum framework, which reduces the waiting time for resolving our dependencies and makes test execution faster.
4. Generate test reports in different formats.
5. Atoum Framework can also be integrated with continuous integration tools like Jenkins, Travis CI, CircleCI, etc.
6. Several plugins can be added to this framework, thereby making the testing framework more stable. Some of the extensions are-
- json-schema-extension – for validating the JSON tags
- bdd-extension – for writing BDD style test cases which has better readability
- reports-extension – for writing code coverage reports
## 7. SimpleTest
SimpleTest is a PHP testing framework that could be used for unit testing. Apart from unit testing, it is also used for website testing and for mocking objects for PHP web development. This framework’s unique feature is that it has an inbuilt web browser that allows users to navigate to different web pages and perform testing.
### Steps To Install
**Step 1:** Setting up the SimpleTest framework requires the latest version of PHP to be installed in the system.
**Step 2:** Once it is done you may setup the framework by downloading from their [official website](http://simpletest.sourceforge.net/).
### Advantages Of Using SimpleTest Framework
1. SimpleTest is very useful for unit testing.
2. It provides an extensive support for forms, SSL, frames, proxies, and basic authentication.
3. It has an inbuilt web browser, which helps in testing web applications.
4. Using this PHP testing framework, tests can be executed through the browser as well as the command line.
5. It can also be used in collaboration with PHPUnit, another one of the best PHP testing frameworks we discussed above.
6. SimpleTest is highly flexible as it allows result or output customization.
## 8. Phpspec
Phpspec is another Behavior Driven Development (BDD) framework that is used to write and execute tests written in PHP. It is well-known for driving the design according to the specifications provided by the developer.
A BDD framework contains specifications written in the English language, which helps in understanding the tests. It describes the behavior of the application using Gherkin language.
### Steps To Install
**Step 1:** Before installing [Phpspec](http://www.phpspec.net/en/stable/), you need to install PHP 5.6 or 7 in your system.
**Step 2:** Once done, you can install using Composer, which automatically manages all the project dependencies. While installing Composer, make sure that the autoload settings of the composer are correct. Phpspec won’t be able to detect classes unless the settings are correctly specified.
**Step 3:** Once you have finished installing Composer, you can install Phpspec using the following command-
```
composer require –dev Phpspec/Phpspec
```
After everything is done, you will notice that all your dependencies have been successfully installed in the vendor folder. And the executable file will be found in vendor/bin/phpspec.
### Advantages Of Using Phpspec Framework
1. Phpspec automatically generates skeletons for the classes and the methods.
2. It also has a mocking framework.
3. It provides 14 in-built matchers to verify the results and describe how our tests should behave. Some of the commonly used matchers are comparison matchers, approximately matchers, type matchers, and identity matchers.
4. This framework can be extended by configuring plugins like the DataProvider plugin, framework integration plugin, code generation plugin, and matchers plugin.
***Did you know? [CSS touch-action property](https://www.lambdatest.com/web-technologies/css-touch-action?utm_source=devto&utm_medium=organic&utm_campaign=may26_sb&utm_term=sb&utm_content=web_technologies) controls filtering of gesture events, providing developers with a declarative mechanism to selectively disable touch scrolling (in one or both axes) or double-tap-zooming.***
## 9. Peridot
Peridot is another one of the widely used PHP testing frameworks, which is a type of BDD framework. Some developers even claim that it is one of the best PHP frameworks available for a BDD approach. The tests are written in describe-it syntax in Peridot, which makes it simpler to read, understand, and maintain. It is considered one of the fastest among the PHP framework as it loads and runs the test suites quickly and runs them concurrently.
Below is a simple code for writing tests in Peridot using describe-it syntax
```
describe('Welcome page', function() {
it(must have a welcome message, function() {
$this->getPage('http://myTestWebsite.com');
$message = $this->findElementById(welcmeMessage);
assert($message->getText() === "Hello", "should be Hello");
});
});
```
### Steps To Install
**Step 1:** You can easily install this using Composer which will manage our project dependencies.
**Step 2:** It can also be installed manually by downloading the [PHAR](https://peridot-php.github.io/#getting-started).
### Advantages Of Using Peridot Framework
1. Peridot uses the familiar describe-it syntax to create a clear and readable testing language.
2. It can be extended with various types of plugins, which can be used for customizing our test framework.
3. It can be integrated with WebDriver and databases for executing the tests.
4. Peridot is lightweight and is faster when compared to other PHP frameworks like Phpspec and PHPUnit.
5. It also helps in executing the integration tests at high speed.
6. It has many reporters like Peridot List reporter, concurrency reporter, and code coverage reporter, each of which are uniquely designed for specific purposes.
## 10. Kahlan
Kahlan is a unit and behavior-driven PHP framework that uses a describe-it syntax similar to peridot. Without any PHP extensions, we can directly stub or monkey patch our code. It is also an open source framework, which makes it highly preferable for testing purposes.
_So, what is a describe-it syntax?_
Kahlan uses describe-it syntax for easy maintenance and understanding of the tests. The “describe” keyword usually contains the method specs. The “it” keyword” contains the code to be tested, which should be kept short and clear.
Below is a simple code which provides a clear idea of the describe-it syntax
```
describe("myFunction", function() {
describe("::match()", function() {
it("passes if true === true", function() {
expect(true)-> myFunction (true);
});
});
});
```
### Steps To Install
**Step 1:** Installation of Kahlan requires PHP of version more than 5.5 to be installed in the system. If code coverage analysis is required, phpdbg or xdebug is also required. Xdebug is a PHP extension which could be used for debugging purposes.
**Step 2:** As a PHP framework it is always recommended to install using Composer as it helps in managing the project dependencies.
You can also manually set up the framework by referring to the official website of [Kahlan](https://kahlan.github.io/docs/getting-started.html#installation).
### Advantages Of Using Kahlan Framework
1. It provides a lot of matchers that can be used for testing various scenarios.
2. It provides stub options which can be used to resolve the dependencies.
3. It has built in reporters and exporters.
4. It is easily extendable and can be customized as per our requirements.
5. It allows us to use setUp and tearDown methods like beforeAll, beforeEach, afterEach, and afterAll.
6. Kahlan has inbuilt code coverage exporters, which can be used to get detailed information on the code coverage.
## Wrapping Up!
In this blog, we have walked you through the importance of PHP frameworks, different types of PHP frameworks, steps to set up, and the advantages of using the framework. Depending on the requirements, you can choose the best PHP frameworks. These PHP testing frameworks can be used for both PHP web development as well as testing purposes. Thus, implementing the correct framework would help you to perform testing effectively.
We hope you now have a clear idea of selecting a suitable PHP framework for your project. And now, we would like to hear from you – have you implemented any other PHP framework that has proved useful?
If you found this blog valuable, we’d be grateful if you could share it on your LinkedIn or Twitter. | shalinibaskaran12 |
572,604 | 🧩 What Is an SDK? | 📕 SDKs are the building blocks of app development. Here’s what non-devs need to know. Read more... | 0 | 2021-01-15T14:35:29 | https://dev.to/robertinoc_dev/what-is-an-sdk-4mbk | sdk, devops, development | 📕 SDKs are the building blocks of app development. Here’s what non-devs need to know.
[Read more...](https://auth0.com/blog/what-is-an-sdk/?utm_source=content_synd&utm_medium=sc&utm_campaign=sdk) | robertinoc_dev |
572,675 | Analysing Chaos Workflows with Litmus Portal | Chaos Workflows are now replacing traditional experiments for injecting chaos into complex systems... | 10,787 | 2021-01-16T08:14:38 | https://dev.to/litmus-chaos/analysing-chaos-workflows-with-litmus-portal-4e67 | kubernetes, litmuschaos, chaosengineering, analytics | *Chaos Workflows* are now replacing traditional experiments for injecting chaos into complex systems running in a Kubernetes environment. A simple result schema is not always the mirror to a system’s reliability, especially when the fault injections are periodic or more than one microservice is subjected to chaos and monitored for performance metrics. The chaos often tends to disrupt tightly coupled microservices and processes. Visualizing the results and plotting analytical graphs prove to be useful under such circumstances.
##How Litmus helps?
[LitmusChaos](https://litmuschaos.io) brings these features to SREs and DevOps engineers packed with the Litmus Portal, a GUI to orchestrate complex chaos workflows, monitor chaos events and metrics around chaos experiment. Along with features such as MyHub (your personal [ChaosHub](https://hub.litmuschaos.io) for housing custom resources) and team management, Chaos analytics goes a long way to open the world of chaos engineering to a large number of teams and organizations with different use cases and business or operational requirements.
##Data science for cloud-native workloads
Data visualization and analysis are some building blocks for analytics and a stepping stone to Machine learning and AIOps. It helps in better analysis, quick action, identifying patterns, finding errors, understanding the story, exploring business insights and grasping the latest trends. With chaos-engineering in the view, analysing results of complex tests and workflows over a specific time duration is a great value add to many DevOps personas. Monitoring the system’s behaviour under chaos over a development period reveals the applications resilience and its development pros and also the shortcomings such as coupling and tolerance thresholds.
##Data crunching in Litmus Portal
An analytical overview of chaos workflows for an entire month or a year can help in benchmarking release cycles and building a viable cloud-native product. Also a comparative study over time or rather just being able to observe and plot resiliency scores across different types of chaos workflows on different subsystems provide a conclusive summary of the reliability metrics. [LitmusChaos portal](https://github.com/litmuschaos/litmus/tree/master/litmus-portal) comes with all these features readily available and easy to use both for a novice and a chaos engineering expert.
##Accessing analytics on the GUI
The portal automatically detects scheduled chaos workflows on all connected clusters for a project and plots resilience score comparison graphs for your recent workflow runs. The home screen also features aggregate chaos workflow runs over weeks and the total number of workflows running on all connected clusters. The home screen is not just restricted to a periodic analysis of workflow runs but it also provides granular insight from chaos result schemas of various chaos experiments and chaos engines custom resources. You can get the percentage of passed and failed chaos tests for your project and an average resilience score gauge for the same. All test results are consolidated and condensed from weighted averages of chaos results which the user tunes and assigns weights to while scheduling a new chaos workflow using Litmus Portal, depending on the architectural or operational priorities. These features make the home page the best place to gain an overview and collective insights. The trends on workflow comparison graph and various options provided for switching between granularity of the selected period increases the ease of usability.
- *A view of Home screen analytics on Litmus Portal*
- *Apart from the home page, the analytics table under `Workflows` section of the portal has workflow level analytical bar graphs for tracking and visualizing the total number of passed and failed experiments per workflow run with time in the abscissa.*
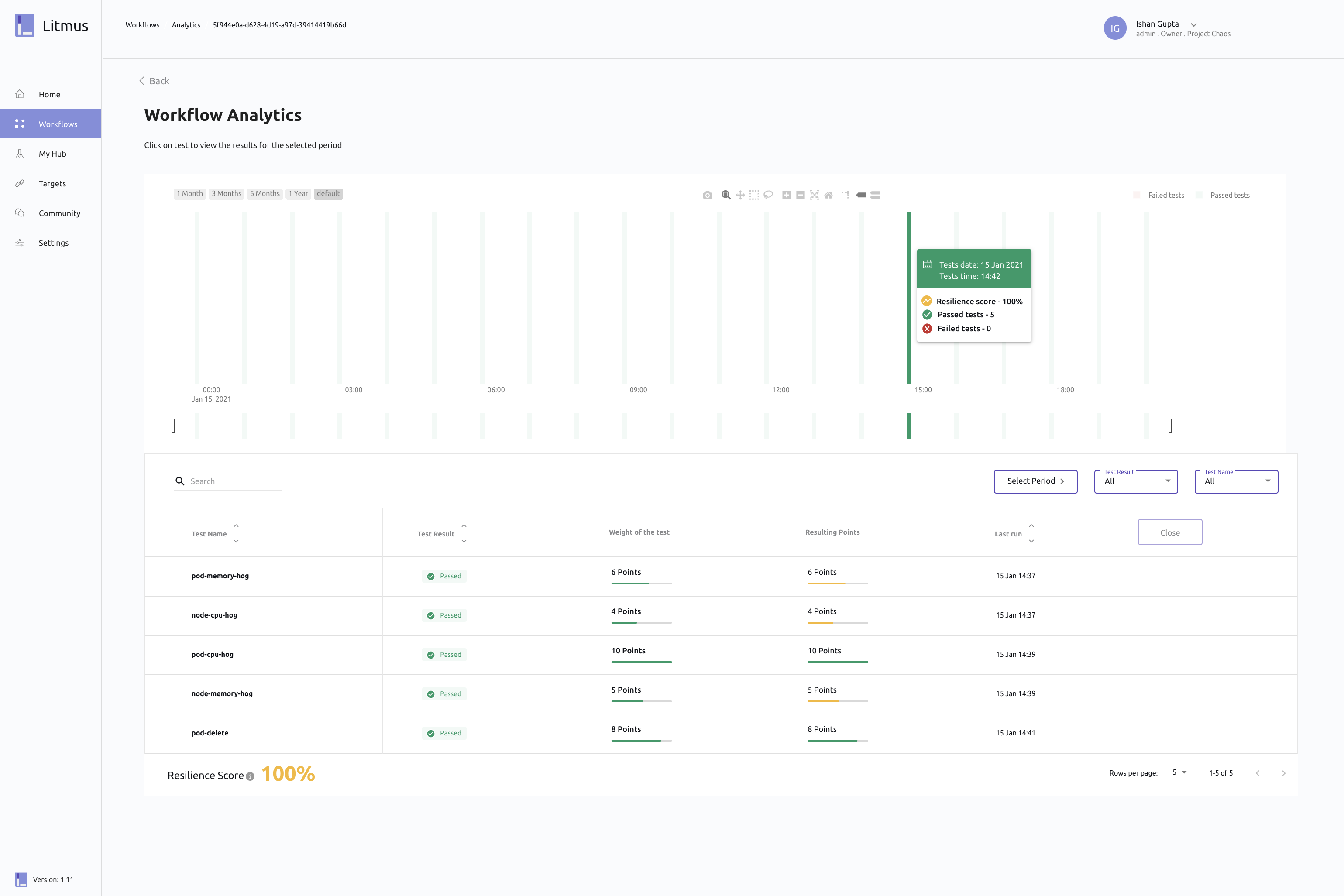
- *This graph provides exporting feature and also selective zooming for filtering and scanning through the workflow run bars.*

- *On clicking the bars you can get a detailed summary of the experiments performed and their results after the run.*

- *Hovering over them you get a pop-over with a basic overview and stats related to the run.*

- *The portal provides a core reporting utility and enables you to compare the workflow runs of selected schedules across connected clusters for a project. The average workflow curve is centric to the reliability of the application under test (AUT) over a time duration. You can switch between granularity level to vary the consolidation and aggregation.*


- *The reporting also comes in handy with the other features available in Litmus Portal for analysing chaos workflows, automated report generation for selected chaos workflows on the click of a button, makes the life of an SRE and the engineering team a lot simpler, eliminating the need of manual record updates and tracking. Workflow run details table and a workflow schedules table with resilience score comparison graph is informative and conclusive of your application’s behaviour under chaotic conditions.*


- *Link to a sample report-*
[https://drive.google.com/file/d/1-BaFJtJ2tre2vyr1d5KSnv5BcHTGteIX/view?usp=sharing](https://drive.google.com/file/d/1-BaFJtJ2tre2vyr1d5KSnv5BcHTGteIX/view?usp=sharing)
Stay tuned for the updates on enhanced analytics and real-time monitoring capabilities coming soon to [LitmusChaos](https://github.com/litmuschaos/litmus) GUI a.k.a Limtus Portal :-)
##Join the Community
*Are you an SRE or a Kubernetes enthusiast? Does Chaos Engineering excite you?*
Join our community on Slack for detailed discussion, feedback & regular updates On Chaos Engineering For Kubernetes,
To join, our slack please follow the following steps!
1. Join the Kubernetes slack using the following link: [https://slack.k8s.io](https://slack.k8s.io)
2. Join the #litmus channel on the Kubernetes slack or use this link after joining the Kubernetes slack: [https://slack.litmuschaos.io](https://slack.litmuschaos.io)
Check out the LitmusChaos GitHub repo and do share your feedback: [https://github.com/litmuschaos/litmus](https://github.com/litmuschaos/litmus)
Submit a pull request if you identify any necessary changes.
| code_igx |
572,865 | Laravel 8 From Scratch Tutorial | Hello, hire in this tutorial I am going to explain the basics of laravel 8. You are going to learn th... | 0 | 2021-01-15T18:53:27 | https://dev.to/tonyxhepa/laravel-8-from-scratch-tutorial-1hj7 | Hello, hire in this tutorial I am going to explain the basics of laravel 8. You are going to learn the laravel routes, create and edit data from the database. Store data to the database and delete it from database. Install Laravel Breeze for authentication. Style pages and forms with laravel.
### Youtube Channel Code With Tony <a href="">https://www.youtube.com/channel/UCmf2ctDSkDTtrZT2xg1LmRA</a>
| tonyxhepa | |
572,963 | Getting Started with Geocoding Exif Image Metadata in Python3 | Extract Exif metadata from images like exif | 0 | 2021-01-15T22:49:01 | https://developer.here.com/blog/getting-started-with-geocoding-exif-image-metadata-in-python3 | python, geocoding | ---
title: Getting Started with Geocoding Exif Image Metadata in Python3
published: true
description: Extract Exif metadata from images like exif
tags: python,geocoding
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/tewvkeda99vtwnv19gyu.jpg
canonical_url: https://developer.here.com/blog/getting-started-with-geocoding-exif-image-metadata-in-python3
---
The Exchangeable image file format (Exif) is a standard that’s been around since 1998 to include metadata in image file formats like JPEG, WAV, HEIC, and WEBP. With the proliferation of digital cameras and smart phones with GPS receivers these images often include geolocation coordinates. We’re going to get started with how to read geotagged photographs using Python to make use of the data.
This project will demonstrate how to extract Exif data from a JPEG, how to convert from Degrees Minutes Seconds (DMS) to decimal coordinates, how to group photos by location, and finally how to place a thumbnail image on a map like this.
Let’s get started.
# Reading Exif with Python
I’ll be working with Python 3.7 in the examples since it’s almost [2020](https://pythonclock.org/) and Python 2.7 won't be supported for much longer.
```bash
$ python -V
Python 3.7.2
```
I use [virtualenv](https://the-hitchhikers-guide-to-packaging.readthedocs.io/en/latest/virtualenv.html) and virtualenv_wrapper to keep my project dependencies straight and recommend you do as well if you run into any issues installing libraries. There are several options you can use for reading Exif data such as `piexif` and `exifread` that you might like to try. As a more general purpose image library, I find [Pillow](https://python-pillow.org/) to be helpful and is an update for some of the code samples you may see from Python 2.x examples referencing `PIL`.
The installation is straightforward with `pip install Pillow`. With just a few lines of code we can display the Exif data:
```python
#!/usr/bin/env python
from PIL import Image
def get_exif(filename):
image = Image.open(filename)
image.verify()
return image._getexif()
exif = get_exif('image.jpg')
print(exif)
```
What you get back from this `get_exif()` function is a dictionary with numeric keys that correspond to various types of data. It isn’t terribly useful unless you know what you are looking for. Fortunately, the library also makes it easy to identify these attributes with human readable labels.
```python
from PIL.ExifTags import TAGS
def get_labeled_exif(exif):
labeled = {}
for (key, val) in exif.items():
labeled[TAGS.get(key)] = val
return labeled
exif = get_exif('image.jpg')
labeled = get_labeled_exif(exif)
print(labeled)
```
The label **GPSInfo** is much more meaningful than *34853* which is the numeric code defined in the standard for identifying the GPS data in Exif. The tags also show a variety of other details like the camera used, image dimensions, settings, etc. beyond just the geotagging results. To get a full list of the tags the [Exiv2 Metadata](http://www.exiv2.org/tags.html) reference table is pretty handy.
```python
GPSInfo = {1: 'N', 2: ((36, 1), (7, 1), (5263, 100)), 3: 'W', 4: ((115, 1), (8, 1), (5789, 100)), 5: b'\x00', 6: (241175, 391), 7: ((19, 1), (8, 1), (40, 1)), 12: 'K', 13: (0, 1), 16: 'T', 17: (1017664, 4813), 23: 'T', 24: (1017664, 4813), 29: '2019:01:11', 31: (65, 1)}
Make = Apple
Model = iPhone 8
Software = 12.1.2
ShutterSpeedValue = (223247, 48685)
DateTimeOriginal = 2019:01:11 11:08:47
FocalLength = (399, 100)
ColorSpace = 65535
ExifImageWidth = 4032
```
In addition to this subset, there are fields like the MakerNote which can include just about any data hex encoded for various uses and is often where photo software might store IPTC or XP metadata like comments, tags, subjects, titles, etc. that you see in Desktop Applications. I just want the geotagging details for this project which have additional tag constant labels I can reference:
```python
from PIL.ExifTags import GPSTAGS
def get_geotagging(exif):
if not exif:
raise ValueError("No EXIF metadata found")
geotagging = {}
for (idx, tag) in TAGS.items():
if tag == 'GPSInfo':
if idx not in exif:
raise ValueError("No EXIF geotagging found")
for (key, val) in GPSTAGS.items():
if key in exif[idx]:
geotagging[val] = exif[idx][key]
return geotagging
exif = get_exif('image.jpg')
geotags = get_geotagging(exif)
print(geotags)
```
I now have a dictionary of some key geographic attributes that I can use for this project:
```python
{
'GPSLatitudeRef': 'N',
'GPSLatitude': ((36, 1), (7, 1), (5263, 100)),
'GPSLongitudeRef': 'W',
'GPSLongitude': ((115, 1), (8, 1), (5789, 100)),
'GPSTimeStamp': ((19, 1), (8, 1), (40, 1)),
...
}
```
If you are trying to make sense of the **GPSLatitude** and **GPSLongitude** values you’ll notice they are stored in [degrees, minutes, and seconds](https://en.wikipedia.org/wiki/Geographic_coordinate_conversion) format. It’ll be easier to use HERE Services available with your developer account when working in decimal units so we should do that conversion.
EXIF uses **rational64u** to represent the DMS value which should be straightforward to convert with PIL which has already given us numerator and denominator components in a tuple:
```python
def get_decimal_from_dms(dms, ref):
degrees = dms[0][0] / dms[0][1]
minutes = dms[1][0] / dms[1][1] / 60.0
seconds = dms[2][0] / dms[2][1] / 3600.0
if ref in ['S', 'W']:
degrees = -degrees
minutes = -minutes
seconds = -seconds
return round(degrees + minutes + seconds, 5)
def get_coordinates(geotags):
lat = get_decimal_from_dms(geotags['GPSLatitude'], geotags['GPSLatitudeRef'])
lon = get_decimal_from_dms(geotags['GPSLongitude'], geotags['GPSLongitudeRef'])
return (lat,lon)
exif = get_exif('image.jpg')
geotags = get_geotagging(exif)
print(get_coordinates(geotags))
```
At this point, given an image as the input I’ve produced a latitude and longitude (36.13372, -115.15228) result. To figure out where that is we can use the geocoding service.
# Reverse Geocoding
In [Turn Text Into HERE Maps with Python NLTK](https://developer.here.com/blog/turn-text-into-here-maps-with-python-nltk), I demonstrated how to use the [Geocoder API](https://developer.here.com/documentation/geocoder/topics/what-is.html) to take a city like “Gryfino” and search to identify the latitude and longitude coordinates. Now, I want to do the opposite and reverse geocode the set of coordinates from my image to identify the location.
If you’ve worked with HERE services before you should know all about your **API_KEY** from the [developer projects](https://developer.here.com/projects) dashboard. Personally, I like to store these values in a shell script to [config](https://12factor.net/config) my environment as demonstrated in this next snippet.
```python
import os
import requests
def get_location(geotags):
coords = get_coordinates(geotags)
uri = 'https://revgeocode.search.hereapi.com/v1/revgeocode'
headers = {}
params = {
'apiKey': os.environ['API_KEY'],
'at': "%s,%s" % coords,
'lang': 'en-US',
'limit': 1,
}
response = requests.get(uri, headers=headers, params=params)
try:
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as e:
print(str(e))
return {}
exif = get_exif('image.jpg')
geotags = get_geotagging(exif)
location = get_location(geotags)
print(location['items'][0]['address']['label'])
```
This is pretty much boilerplate use of the Python requests library to work with web services that you can get with a `pip install requests`. I’m then calling the [Reverse Geocoder API](https://developer.here.com/api-explorer/rest/geocoder/reverse-geocode-landmarks) endpoint with parameters to retrieve the closest address within 50 meters. This returns a JSON response that I can use to quickly label the photograph with **Las Vegas, NV 89109, United States** to create an album or whichever level of detail I find useful for an application.
This is a good way for example to process and group your photos by city, state, country or zip code with just a little bit of batch sorting.
# Geopy
An alternative approach that can simplify the code a bit is to use the geopy library that you can get with a `pip install geopy`. It depends on the level of detail and flexibility you want from a full REST request but for simple use cases can greatly reduce the complexity of your code.
```python
from geopy.geocoders import Here
exif = get_exif('image.jpg')
geotags = get_geotagging(exif)
coords = get_coordinates(geotags)
geocoder = Here(apikey=os.environ['API_KEY'])
print(geocoder.reverse("%s,%s" % coords))
```
The response using geopy in this example is: **Location(1457 Silver Mesa Way, Las Vegas, NV 89169, United States, Las Vegas, NV 89169, USA, (36.13146, -115.1328, 0.0))**. This can be convenient but customizing your request to the REST endpoint gives you the most flexibility.
# Removing Exif from Photos
What if you don’t want geotagging details in photos that you share or put on a public website?
While using the above is handy when working with my own photographs – if trying to sell something on Facebook Marketplace, Craigslist, or eBay I might want to avoid giving away my home address. It’s pretty straightforward to remove the geotagging details by creating a new image and not copying the Exif metadata.
This quick script is a useful metadata removal tool for purposes like that:
```python
import sys
from PIL import Image
for filename in sys.argv[1:]:
print(filename)
image = Image.open(filename)
image_clean = Image.new(image.mode, image.size)
image_clean.putdata(list(image.getdata()))
image_clean.save('clean_' + filename)
```
# Placing Markers on a Map for Photos
Switching things up for a moment we’ll turn to web maps. If you haven’t created an interactive map before the [Quick Start](https://developer.here.com/documentation/maps/topics/quick-start.html) and other blog posts should help you get started with the [Maps API for JavaScript](https://developer.here.com/api-explorer/maps-js/v3.0).
I already have the coordinates for my image so all that is left is to generate a small thumbnail that I can use for the marker.
```python
def make_thumbnail(filename):
img = Image.open(filename)
(width, height) = img.size
if width > height:
ratio = 50.0 / width
else:
ratio = 50.0 / height
img.thumbnail((round(width * ratio), round(height * ratio)), Image.LANCZOS)
img.save('thumb_' + filename)
```
This function generates a thumbnail with a max height or width of 50 pixels which is about right for a small icon. Taking the [quick start](https://developer.here.com/documentation/maps/topics/quick-start.html) JavaScript I only need to add the next few lines to initialize the icon, place a marker at the coordinates retrieved from Exif with the icon, and then add it for rendering on the map.
```python
thumbnail = new H.map.Icon('./thumb_image.jpg');
marker = new H.map.Marker({lat: 36.13372, lng: -115.15228}, {icon: thumbnail});
map.addObject(marker);
```
I could even consider dynamically generating this JavaScript from Python if I had many images I'm working with. Firing up a python web server we get our final result.
```bash
$ ls
index.html index.js thumb_image.jpg
$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
```
That photo was of the doorway in between the Las Vegas Convention Center and Westgate, not nearly as exciting as the [Valley of Fire State Park](http://parks.nv.gov/parks/valley-of-fire) pictured initially.
# Wrapping Up
Wrapping up, a few final notes that might be helpful. There is Exif support in image formats like [WEBP](https://developers.google.com/speed/webp/docs/riff_container) commonly used by Chrome and [HEIC](http://nokiatech.github.io/heif/examples.html) (or HEIF) which is the new default on iOS. Some of the supporting Python libraries are still being updated to work with these newer image formats though so require some additional work.
There is also the c++ library exiv2 that is made available in the Python3 package **py3exiv2** for reading and writing Exif data but it proved challenging to install with boost-python3 on OSX recently. If you’ve had any luck with these other image formats or libraries, please do share in the comments.
The example project here should demonstrate all the steps you need for an image processing pipeline that can extract geotagged details from photographs and organize by location or place the photo on a map much like you see in apps on a phone.
| j12y |
573,530 | Make your own independent website | The web that raised me was a digital playground in the truest sense. It was made up of HTML... | 0 | 2021-10-30T19:40:26 | https://victoria.dev/blog/make-your-own-independent-website/ | ---
title: Make your own independent website
published: true
date: 2021-01-16 13:41:27 UTC
tags:
canonical_url: https://victoria.dev/blog/make-your-own-independent-website/
---
The web that raised me was a digital playground in the truest sense. It was made up of HTML experiments frankensteined together by people still figuring it all out.
The beauty of not completely knowing what you’re doing is a lack of premature judgement. Without a standard to rise to, you’re free to go sideways. Explore. Try things that don’t work, without any expectation they _will_ work. An open world with a beginner’s mindset.
The web that raised me was a little broken. Things didn’t always display the way they were supposed to. That too is part of the beauty. It was just broken enough to make you think for yourself.
1991 was the year of the individual on the web, the [first year](https://en.wikipedia.org/wiki/History_of_the_World_Wide_Web) any layperson could open a web browser and access the new hypermedia dimension. There were no go-to, search-suggested, centralized websites. There were newsgroups. You had what you made and what your meatspace contacts sent you. In 2021, I think we need a return to that level of individualism. We need to make 2021 the year of the independent web.
That’s not to say I think the massive monopolistic platforms are going anywhere. Twitter, Facebook, mainstream “news” media sites – they’re all a kind of utility now, like plumbing and electricity. They’ll find their place in regulation and history. But they are not _your website._
Your website is the one you create. Where the content, top-to-bottom, is yours alone to shape and present as you please. Your website is your place of self-expression, without follower counts or statistics to game. Your website is for creation, not reaction.
It’s all yours, but it doesn’t have to seem lonely. Your site can interact with the entire online world through syndication and protocols made possible by this thing we call the Internet. See:
- [IndieWeb](https://indieweb.org/POSSE) for POSSE, an abbreviation for Publish (on your) Own Site, Syndicate Elsewhere.
- [Webmention](https://www.w3.org/TR/2017/REC-webmention-20170112/) and [an easy way to implement them](https://github.com/aaronpk/webmention.io).
- [twtxt](https://github.com/buckket/twtxt) instances for a decentralized timeline experience.
- [Neofeed](https://neofeed.dev/), my personal timeline project made for [Neocities](https://neocities.org/). (It’s open source and [you can help me extend it!](https://github.com/victoriadrake/neofeed-theme))
Your website is your beginning point. The one source of truth for your identity online, from which you can generate and distribute disposable copies to any platform you please. This is what it means to truly own your content. And on the Internet, your content is you.
When I first created [victoria.dev](https://victoria.dev), I did so for myself. I had no expectation of visitors. I just knew I’d rather have these thoughts and things I’ve learned here, out here, made indelible in the folds of the public Internet, instead of on some dark corner of my machine, to be lost forever once I am.
Make your own website. You’ll grow your own sense of well-deserved accomplishment and contribute to your independence on the web. You’ll learn by doing, by scratching your own itch.
Learn about web technologies. Use them as you would if you were a child holding a pencil or paintbrush for the first time. Experiment, with no expectations other than discovering what you can do to make it delight you.
* * *
These sites and articles inspired this post and helped me implement webmentions!
- [Why the Indie Web movement is so important, Dan Gillmor](https://dangillmor.com/2014/04/25/indie-web-important/)
- [Jamie Tanna](https://www.jvt.me/)
- [Max Böck](https://mxb.dev/blog/)
- [Microblogging, Paul Robert Lloyd](https://paulrobertlloyd.com/2018/01/microblogging/)
- [Zachary Dunn](https://adhoc.systems/notes)
- [Adding Webmentions to My Static Hugo Site, Ana Ulin](https://anaulin.org/blog/adding-webmentions/)
- [Webmention.rocks](https://webmention.rocks/update/1) | victoria | |
574,010 | JavaScript | It is the perfect way to write some code | 0 | 2021-01-17T10:52:04 | https://dev.to/surajkumar8642/javascript-4fce | It is the perfect way to write some code | surajkumar8642 | |
574,081 | When to stop code refactoring | Taking too much time to refactor, which is blocking other dependent applications and priority tasks.... | 0 | 2021-01-17T13:32:56 | https://dev.to/soumendrak/when-to-stop-code-refactoring-4p72 | coderefactoring |
- Taking too much time to refactor, which is blocking other dependent applications and priority tasks.
- For developers CR is like a drug, a developer can refactor can keep on refactoring a complex codebase for ages. If CR is limited to no ROI (Return On Investment) the activity needs to be stopped.
- Refactoring is not same as redesigning the code. It is easier to start the coding from scratch than to refactor your somebody else's or your own code. This needs to be learned before CR starts.
| soumendrak |
574,279 | The Three Main Flavors of Kubernetes related Engineering Roles | As Kubernetes continues to gain traction, Kubernetes related oppurtunities continue to grow as well.... | 0 | 2021-01-17T17:29:46 | https://muaazsaleem.com/blog/j4013sqg18hcaz2ifa99sphkpjbyrv | kubernetes, career | As Kubernetes continues to gain traction, Kubernetes related oppurtunities continue to grow as well. That's great! But while most Kubernetes related engineering roles are pretty similar to each other, in my observation, there seem to be important differences between them as well.
Here, I just want to capture the three main flavours Kubernetes related Engineering roles I've noticed and their pros and cons.
### Site Reliability Engineer
Also known as DeveOps Engineer or Cloud Engineer, the Site Reliability Engineer role is the most common of the three we'll talk about today. The distinguishing sign of the role is that you're responsible for (a) production Kubernetes cluster(s) and your team is primarily measured by it's reliabilty, cost effectiveness and utility.
Google has written a lot about the role and different companies abide by that description to various degrees. *This is also the only role of the three, that I have personal experience with.*
#### Pros
* Hands-on Experience operating (a) Kubernetes cluster(s) i.e
* Lots of Production Insights to share with the rest of the community
* Incentive to influence the Cloud Native Community to solve important problems together
* Lots of fun for folks who enjoy learning new things all the time
* *Lots of opportunities* with the growing no. of businesses adopting Kubernetes
#### Cons
* Time & Focus are divided between programming, operations & communication. Ergo:
* Limited chances to role the dice on long term software projects
* Wide scope of respobsibility i.e:
* The whole cluster rather than just Ingress, although possible in a big enough team
* Shifting respobsibilities as Cloud vendor capabilities grow/change
* Employer may not have the bandwidth/budget for significant community participation
### Software Engineer ( Kubernetes )
If you've ever wondered who maintains, the Kubernetes Core or important plugins like CoreDNS, it's Kubernetes Software Engineers. I'm making up the title but the work is real i.e. Software Engineers improving or extending the Cloud Native ecosystem.
This role predominantly exists with vendors with a vested interest in Kubernetes like Cloud vendors or Services companies. Google, for example, has a whole team dedicated to maintaining the Cluster, Horizontal & Vertical Pod Autoscalers.
#### Pros
* Focus on Software Engineering Skills
* Potential to learn the internals of various technologies e.g. Prometheus, Docker, Flagger and share with the community
* Opportunity/Incentive to represent customer use cases in the larger Cloud Native Community
#### Cons
* No quick “production” feedback like in SRE
* Limited Experience operating a kubernetes cluster
* Reletaively fewer oppurtunities in the community, but still lots of them!
### Developer Advocate
While vendors might hire Software Engineers to help improve their Kubernetes offerings, they might hire Engineers to better understand the community's needs and help guide the product strategy. That's the Developer Advocate role and there's a growing no. of them in the Cloud Native Community.
If you're not familiar with the role, there's a great [FAQ by Dustin Ingram](https://dev.to/di/developer-advocacy-frequently-asked-questions-577k).
#### Pros
* Great opportunity to [learn in public](https://www.swyx.io/learn-in-public/)
* Work on skills such as giving talks, Videography, Writing Blogposts
* A very visible position, great opportunity to create a public profile
* Incentive/Oppurtunity to create significantly useful resources for the community:
* Writing books and etc.
* Creating or maintaining to important open source projects
* The chance to explore "what’s possible with Kubernetes”:
* Creating lots of “demo” apps to show what's possible with Kubernetes
* Being "user zero" for new products or features
* Great opportunity to be valued as an engineer for strengths in:
* Communication
* Stakeholder management
* Product leadership
#### Cons
* Far fewer oppurtunities than a SRE or SWE roles
* Role not well defined and may change significantly between companies
* Evangelism vs. Advocate
* Report to marketing vs. director of engineering
* May require lots of travel
* Difficult to distinguish between work and hobby projects
* Not clear what the employers' non-compete for the role look like:
* If you write a book, create a youtube channel does the employer need to sign off?
* Almost no first hand production experience in the role
* Hard to measure your impact:
* makes it hard to know what's worth working on
* makes it hard to prove that you're doing a good job
### Parting Words
All three roles seem to have a lot to offer and like flavours of an ice cream, they can be mixed and matched. Software Engineers give talks and Site Reliability Engineers write plenty of software. Folks might also be able to move between these roles easily enough.
I hope others find this list as helpful as I did. If you feel like I've missed an important aspect of these or would like to share other kinds of engineering roles you've seen in the Cloud Native community, I'd love to hear from you!
| muaazsaleem |
576,693 | Secure Serverless with OpenFaaS | During my career as a professional in the Software Industry, I've witnessed the rise of DevOps. DevOp... | 12,010 | 2021-05-12T18:38:58 | https://dev.to/mikeyglitz/secure-serverless-with-openfaas-509b | kubernetes, serverless, devops | During my career as a professional in the Software Industry, I've witnessed the rise of DevOps. DevOps is the practice of merging your development team (programmers) with your operations team (think the server admins and net-ops guys).
While learning about servers has its ups and downs. You get to celebrate the triumphs of finally getting your hosting platform up and running while dealing with the frustration that is the nuance of configuration files. It's probably safe to say that when you're in college or boot-camp learning to become a developer, your ideal day-in-the-life is not building up your development platform and spending days delving through configuration files and ACL permissions while hoping your service comes up in the end.
## Enter Serverless
Serverless is a buzz word these days that often gets misunderstood. Does serverless mean that there are no servers? Quite the contrary. There are servers in a serverless platform. The main difference is that there isn't a server that you have to actively manage. Any services deployed on a serverless platform are scaled up and executed when they're requested and scaled down once the execution is completed and the service is no longer needed.
The biggest payoff with this architecture from a development standpoint is that you no longer need to be concerned about provisioning infrastructure. Instead, you specify an event type (i.e. HTTP request, Message Bus, CRON trigger), and a handler function (your code) and the platform builds out the application in a container and handles the execution for you.
## Where Does OpenFaaS fit into this?
[OpenFaas](https://www.openfaas.com/) is a service which allows you to deploy serverless functions on a self-hosted cloud environment (i.e. Kubernetes). This tutorial will cover how to deploy OpenFaaS to Kubernetes and configure the portal with authentication.
> ⚠ The authentication method utilized in this tutorial is not officially supported by OpenFaas. I'm using the Open Source community edition. In order to support OIDC or OAUTH, you need an enterprise license.
## Setting up OpenFaaS
OpenFaaS provides a [helm chart](https://github.com/openfaas/faas-netes/tree/master/chart/openfaas) which can be used for setting up an OpenFaaS Kubernetes deployment quickly. This tutorial will utilize a combination of the OpenFaaS helm chart and the [OAUTH2 Proxy](https://github.com/k8s-at-home/charts/tree/master/charts/stable/oauth2-proxy) chart to set up authentication with Keycloak
## OAuth2 Proxy Set-Up
Assuming you have a Keycloak server set up and registered a new client to your Keycloak realm, you will need the client-id and the client-secret in order to set up the OAuth proxy.
The following Ansible task can aid in setting up a Keycloak client.
```yaml
- name: Create Keycloak client
community.general.keycloak_client:
state: present
auth_client_id: admin-cli
auth_keycloak_url: "{{ keycloak_server }}/auth"
auth_username: "{{ keycloak_user }}"
auth_password: "{{ keycloak_password }}"
auth_realm: master
name: Openfaas Portal
client_id: openfaas
client_authenticator_type: client-secret
secret: "{{ client_secret }}"
realm: hausnet
protocol_mappers:
- config:
included.client.audience: "openfaas-portal"
id.token.claim: "false"
access.token.claim: "true"
name: openfaas-portal-mapper
protocol: openid-connect
protocolMapper: oidc-audience-mapper
- name: "openfaas-group-mapper"
protocol: "openid-connect"
protocolMapper: "oidc-group-membership-mapper"
config:
id.token.claim: "true"
access.token.claim: "true"
claim.name: "groups"
userinfo.token.claim: "true"
redirect_uris:
- "{{ openfaas_endpoint }}/*"
web_origins:
- "*"
validate_certs: no
```
> ℹ The variables in use by the ansible role
> - `openfaas_endpoint` the URL which OpenFaaS will be listening
> - `keycloak_server` the URL where Keycloak will be listening
> - `keycloak_user` the username used to authenticate with Keycloak in order to create the keycloak client
> - `keycloak_password` the password of the user used to authenticate with Keycloak in order to create the Keycloak client
> - `client_secret` the secret used for authentication. This value will be set when the client is created in Keycloak
The following chart demonstrates how to set up the OAuth proxy using Terraform.
```tf
resource "helm_release" "rel_oauth2_proxy" {
repository = "https://k8s-at-home.com/charts/"
chart = "oauth2-proxy"
name = "auth"
namespace = "openfaas"
values = [
<<YAML
extraArgs:
provider: keycloak
email-domain: "*"
scope: "openid profile email"
login-url: https://${vars.keycloak}/auth/realms/${vars.realm}/protocol/openid-connect/auth
redeem-url: https://${vars.keycloak}/auth/realms/${vars.realm}/protocol/openid-connect/token
validate-url: https://${vars.keycloak}/auth/realms/${vars.realm}/protocol/openid-connect/userinfo
keycloak-group: /admin
ssl-insecure-skip-verify: true
ingress:
enabled: true
hosts:
- ${vars.openfaas_domain}
path: /oauth2
annotations:
kubernetes.io/ingress.class: nginx
cert-manager.io/cluster-issuer: cluster-issuer
nginx.ingress.kubernetes.io/ssl-redirect: 'true'
tls:
- secretName: oauth-proxy-tls
hosts:
- ${vars.openfaas_domain}
extraEnv:
- name: OAUTH2_PROXY_CLIENT_ID
value: ${vars.client_id}
- name: OAUTH2_PROXY_CLIENT_SECRET
value: ${vars.client_secret}
- name: OAUTH2_PROXY_COOKIE_SECRET
value: ${vars.encryption_key}
YAML
]
set {
name = "proxyVarsAsSecrets"
value = "false"
}
}
```
> ℹ `client_id`, `client_secret`, `keycloak`, and `realm` are variables which are provided using [Terraform variables](https://www.terraform.io/docs/language/values/variables.html)
## Deploying OpenFaaS
With the OAuth2 Proxy deployed, it's now time to deploy OpenFaas
```tf
resource "helm_release" "rel_openfaas" {
repository = "https://openfaas.github.io/faas-netes/"
name = "openfaas"
chart="openfaas"
namespace = "openfaas"
set {
name = "functionNamespace"
value = "openfaas-fn"
}
set {
name = "generateBasicAuth"
value = "false"
}
set {
name = "basic_auth"
value = "false"
}
set {
name = "serviceType"
value = "ClusterIP"
}
}
```
> ⚠ OpenFaaS has an [official method of handling OIDC/OAuth authentication](https://docs.openfaas.com/reference/authentication/#single-sign-on-sso-and-oidc); however, that's behind a pay-wall. Here we're turning off authentication since it's being outsourced to our OAuth2 proxy created in the previous step.
We set up the Kubernetes Ingress to expose access to OpenFaas through our OAuth2 proxy. Below is an example on how to set up the ingress using Kubernetes manifests:
```yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: openfaas-gateway
namespace: openfaas
annotations:
kubernetes.io/ingress-class: nginx
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.ingress.kubernetes.io/auth-url: "https://$host/oauth2/auth"
nginx.ingress.kubernetes.io/auth-signin: "https://$host/oauth2/start?rd=$escaped_request_uri"
cert-manager.io/cluster-issuer: cluster-issuer
nginx.ingress.kubernetes.io/upstream-vhost: $service_name.$namespace.svc.cluster.local:8080
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_set_header Origin "";
proxy_hide_header l5d-remote-ip;
proxy_hide_header l5d-server-id;
spec:
rules:
- host: "functions.haus.net"
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: gateway
port:
number: 8080
tls:
- hosts:
- "functions.haus.net"
secretName: openfaas-tls-cert
```
Once the deployment completes, OpenFaaS should be available from the ingress endpoint. In this example, I set the endpoint to `https://functions.haus.net`.

 | mikeyglitz |
574,928 | Some of the most popular Software Development Life Cycle (SDLC) models. | Waterfall Model: The waterfall model is a sequential model that divides software development into pre... | 10,717 | 2021-01-18T12:00:15 | https://dev.to/hamidsaymon/some-of-the-most-popular-software-development-life-cycle-sdlc-models-33f4 | testing, beginners, tutorial, devops | *Waterfall Model*:
The waterfall model is a sequential model that divides software development into pre-defined phases. Each phase must be completed before the next phase can begin with no overlap between the phases.
Those phases are **Communication, Planning, Modeling, Construction, Deployment**. The waterfall model is used when all the requirement is clear.
*Agile Model*:
The Agile SDLC model is a **mix of iterative and incremental process models** focused on process adaptability and customer satisfaction through the rapid delivery of the product with working software. Usually, each iteration lasts from about one to four weeks.
Some of those models are **Scrum, Dynamic Systems Development Method (DSDM), Crystal Methods, Feature-Driven Development (FDD), Lean Development (LD), Extreme Programming (XP), Adaptive Software Development (ASD)**.
*Prototyping Model*:
The prototyping model is a software development model in which a prototype is built, tested, and reworked until an acceptable prototype is achieved. **It used when requirements are not clear**.

*Spiral Model*:
The process is portrayed as a spiral rather than a series of backtracking activities. In the phase, **each loop in the spiral represents a stage**. No set stages, such as design or specification.
Incremental Model:
Incremental Model is a process of software development where **requirements divided into multiple standalone modules** of the software development cycle.
*V-Model*:
The phase is arranged in **parallel with this type of SDLC model testing and development**. There are therefore verification steps on the side of SDLC and on the other side of the validation process. The V-Model is joined by the coding phase. | hamidsaymon |
575,017 | Basic.css - Classless CSS Starter File | Basic.css gives you basic CSS formatting and ability to make basic grids with only HTML5 syntax. You... | 0 | 2021-01-18T15:01:15 | https://dev.to/vladocar/basic-css-classless-css-starter-file-ok0 | css, webdev, github | Basic.css gives you basic CSS formatting and ability to make basic grids with only HTML5 syntax. You can use this project to Set your default styling.
### List of features
* Lightweight 1kb minified and gzipped.
* Basic typography.
* Basic forms.
* Custom colors.
* Dark theme.
* Round corners.
* Flex Grid without classes.
* Flex Grid cards.
Demo: https://vladocar.github.io/Basic.css/
##### You can change root css variables with your color palette:
```css
:root {
--c1:#0074d9;
--c2:#eee;
--c3:#fff;
--c4:#000;
--c5:#fff;
}
```
##### Or adjust the round corners
By default are 8px, use --rc: 0px; if you don't like round corners.
```css
:root {
--rc: 8px;
}
```
##### Override the colors in the dark mode:
```css
@media (prefers-color-scheme: dark) {
:root {
--c2:#333;
--c3:#1e1f20;
--c4:#fff;
}
}
```
##### How you can use the infinity flex grid?
Use the HTML5 tags section and nested section to make flex grid.
```html
<section>
<section> 1 </section>
<section> 2 </section>
<section> 3 </section>
</section>
<section>
<section> 1 </section>
<section> 2 </section>
<section> 3 </section>
<section> 4 </section>
</section>
```
Demo: https://vladocar.github.io/Basic.css/grid.html
Use the HTML5 tags selection and article to make cards.
```html
<section>
<article> 1 </article>
<article> 2 </article>
<article> 3 </article>
</section>
```
Demo: https://vladocar.github.io/Basic.css/cards.html
#### How to use this project?
Simply download and personalize the **basic.css** file.
Or
```sh
npm i @vladocar/basic.css
```
#### Why should you use this project?
Instead of using CSS Reset you could just Set the basic css formatting and styling. You could even make some grids with the HTML5 tags. Naturally if you want to build something more complex you should use CSS classes and this project works great in combination with other CSS frameworks.
Github: https://github.com/vladocar/Basic.css | vladocar |
575,348 | The Guard Statement: Guard clause ou Early return. | Estruturas condicionais são sem duvida um dos assuntos mais importantes no âmbito computacional, indi... | 0 | 2021-01-18T20:46:06 | https://dev.to/un4uthorized/the-guard-statement-guard-clause-ou-early-return-54li | algorithms, beginners, computerscience, writing | Estruturas condicionais são sem duvida um dos assuntos mais importantes no âmbito computacional, indiferentemente do nível ou paradigma empregado. Apesar de possuir uma grande responsabilidade no desenvolvimento de aplicações, a utilização de profusas estruturas condicionais pode comprometer a legibilidade do código e aumentar a carga cognitiva do desenvolvedor responsável.
<br>

<center><i>"Decisões são importantes."</i></center>
<br>
> <b>O que é Guard Clause?</b> 🤔
Guard clause ou Early return são termos utilizados ao arquitetarmos uma estrutura sequencial de código condicional, normalmente reconhecido como pré condição.
Comumente podemos construir Guard clauses respeitando 3 padrões:
- Processa os parâmetros e retorna caso algum deles não respeite nossa regra de negócio;
- Verifica o estado de um objeto e retorna um valor, sujeitado-se ao estado passado;
- Elimina casos triviais.
<center>Esses padrões são baseados na filosofia de "<b>Handle errors in the same place where you detected them(Trate os erros no mesmo local onde os detectou).</b>"</center>
<br>
> <b>Como desenvolver um Guard Clause? 🧑🏻💻 </b>
Imagine um cenário em que estamos construindo uma batalha medieval e nosso guerreiro precisar lutar, porem para lutar nosso guerreiro precisa de determinados requisitos.
```
const getWarriorStatus = ({status}) => {
let responseWarrior;
if (status.stamina < 10){
responseWarrior = isExhausted();
}
else {
if (!status.equipped){
responseWarrior = equip();
}
else {
if (!status.blessed){
responseWarrior = toBless();
}
else{
responseWarrior = battle();
}
}
}
return responseWarrior;
}
```
Olhando o código assim podemos concluir que o mesmo não se torna escalável caso o guerreiro comece a conquistar novo atributos.
```
const getWarriorStatus = ({status}) => {
if (status.stamina < 10){
return isExhausted();
}
if (!status.equipped){
return equip();
}
if (!status.blessed){
return toBless();
}
return battle();
}
```
Aplicando os conceitos de <b>Guard Clause</b> conseguimos transformar o código outrora obsoleto em um produto agradável e escalável.
<b>Obrigado por me deixar fazer parte do seu tempo! 🥰</b>
<hr>
<b>Referências: </b>
- https://wiki.c2.com/?GuardClause
- http://www.eastof8thstreet.com/art-of-mouse-guard (art)
<br>
<hr>
<a style="float: left;" href="https://github.com/devneto"></a>
<a style="float: left;" href="https://www.instagram.com/dev.neto"></a>
<a style="float: left;" href="https://twitter.com/https_rabbit"></a>
| un4uthorized |
575,501 | Create Vue 3 Apps with the Composition API — Watch and Watch Effect | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-19T00:35:30 | https://thewebdev.info/2021/01/06/create-vue-3-apps-with-the-composition-api%e2%80%8a-%e2%80%8awatch-and-watch-effect/ | programming, webdev, vue, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
Vue 3 comes with the Composition API built-in.
It lets us extract logic easily an not have to worry about the value of `this` in our code.
It also works better with TypeScript because the value of `this` no longer has to be typed.
In this article, we’ll look at how to create Vue 3 apps with the Composition API.
### `watch`
The `watch` function in the Vue 3 composition API is the same as Vue 2’s `this.$watch` method or the `watch` option.
Therefore, we can use it to watch for changes in reactive properties.
For instance, we can write:
```
<template>
<div>
<button @click="increment">increment</button>
{{ state.count }}
</div>
</template>
<script>
import { reactive, watch } from "vue";
export default {
name: "App",
setup() {
const state = reactive({ count: 0 });
const increment = () => {
state.count++;
};
watch(
() => state.count,
(count, prevCount) => {
console.log(count, prevCount);
}
);
return {
state,
increment,
};
},
};
</script>
```
We watch a getter function in the 2nd argument.
And we get the current and previous value in the first and 2nd parameter of the function we pass into `watch` as the 2nd argument.
Now when we click on the increment button, we see `state.count` increase.
If we have a primitive valued reactive property, we can pass it straight into the first argument of `watch` :
```
<template>
<div>
<button @click="increment">increment</button>
{{ count }}
</div>
</template>
<script>
import { ref, watch } from "vue";
export default {
name: "App",
setup() {
const count = ref(0);
const increment = () => {
count.value++;
};
watch(count, (count, prevCount) => {
console.log(count, prevCount);
});
return {
count,
increment,
};
},
};
</script>
```
And we get the same values we for `count` and `prevCount` when we click on the increment button.
### Watching Multiple Sources
We can also watch multiple refs.
For instance, we can write:
```
<template>
<div>
<button @click="increment">increment</button>
{{ foo }}
{{ bar }}
</div>
</template>
<script>
import { ref, watch } from "vue";
export default {
name: "App",
setup() {
const foo = ref(0);
const bar = ref(0);
const increment = () => {
foo.value++;
bar.value++;
};
watch([foo, bar], ([foo, bar], [prevFoo, prevBar]) => {
console.log([foo, bar], [prevFoo, prevBar]);
});
return {
foo,
bar,
increment,
};
},
};
</script>
```
We pass in the `foo` and `bar` refs into the array.
Then we get the current and previous values from the arrays in the parameters of the function in the 2nd argument.
We can also pass in the `onInvalidate` function into the 3rd argument.
And other behaviors are also shared with `watchEffect` .
### Conclusion
We can watch reactive properties with Vue 3’s composition API watchers. | aumayeung |
575,766 | Networking in Computers ? | Some basic key definitions: Bandwidth: Data transferred per unit time. So 10 Mbps is equal to tran... | 0 | 2021-01-19T07:54:44 | https://dev.to/aws-builders/networking-in-computers-4inf | <!-- wp:paragraph -->
<p><strong><em>Some basic key definitions:</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Bandwidth</strong>: Data transferred per unit time. So 10 Mbps is equal to transfer of 10 million bits every second.</li><li><strong>Throughput</strong>: Total data transmission for a specified time range.</li><li><strong>Latency</strong>: Transfer delay of of data packets</li><li><strong>Router</strong>: It helps you connect multiple devices to the Internet, and connect the devices to each other. <ol><li>A router acts as a dispatcher, choosing the best route for your information to travel.</li></ol></li><li><strong>Internet Protocol (IP)</strong>: Is the address system of the Internet and has the core function of delivering packets of information from a source device to a target device.</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","width":684,"height":448,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fd2slcw3kip6qmk.cloudfront.net%2Fmarketing%2Fpages%2Fchart%2Fexamples%2Fcomputernetworkdiagram.png&f=1&nofb=1" alt="" width="684" height="448"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>Q.Is there any difference between URL, URN and URI?</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Uniform Resource Identifier: A string of characters used to identify a name or a resource on the Internet. A URI has two specializations known as URL and URN.</li><li>Uniform Resource Locator: Specifies where an identified resource is available and the mechanism for retrieving it. A URL defines how the resource can be obtained.</li><li>Uniform Resource Name: Uses the URN scheme, and does not imply availability of the identified resource</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Both URNs (names) and URLs (locators) are URIs, and a particular URI may be both a name and a locator at the same time.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://i.stack.imgur.com/2iD7U.jpg" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"textAlign":"center"} -->
<h2 class="has-text-align-center"><em>Application Architecture</em></h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4><em><strong>1.Client Server Model:</strong></em></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The client computer sends a request for data to the server through the internet, the server accepts the requested, process it and deliver the data packets requested back to the client. One special feature is that the server computer has the potential to manage numerous clients at the same time. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>A single client can connect to numerous servers at a single timestamp, where each server provides a different set of services to that specific client. <strong>It creates a centralized network.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An example, would be my computer and the WordPress server. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Ftse1.mm.bing.net%2Fth%3Fid%3DOIP.kZkqt3iyhweRzzQLIyvq8wHaDw%26pid%3DApi&f=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":4} -->
<h4><strong><em>2.Peer to Peer Model:</em></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>All the computers and devices that are part of them are referred to as peers, and they share and exchange workloads. Each peer in a peer-to-peer network is equal to the other peers. There are no privileged peers, and there is no primary administrator device in the center of the network.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The primary goal of peer-to-peer networks is to share resources and help computers and devices work collaboratively, provide specific services, or execute specific tasks. <strong>It creates a decentralized network.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An example would be torrent sites, as transfer of data happens from peer to peer.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Ftse2.mm.bing.net%2Fth%3Fid%3DOIP.5n1JaA3f-jDPWjjMHqt-7gHaFH%26pid%3DApi&f=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":4} -->
<h4><strong><em>3.Open System Interconnection model(OSI Model)</em></strong>:</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The OSI model can be seen as a universal language for computer networking. It’s based on the concept of splitting up a communication system into seven abstract layers, each one stacked upon the last.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":560,"height":355,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fexploitbyte.com%2Fwp-content%2Fuploads%2F2019%2F11%2FOSi-fre-min.png&f=1&nofb=1" alt="" width="560" height="355"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>1.Application Layer:</em></strong> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Acts as an interface between users and software applications. Data is packed from this interaction to transmit. <strong>Application layer is responsible for the protocols and data manipulation that the software relies on to present meaningful data to the user.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>2.Presentation Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Preparing data by converting it into binary code, so that it can be used by the application layer. <strong>The presentation layer is responsible for translation, encryption, and compression of data.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>3.Session Layer: </em></strong> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The time between when the communication is opened and closed is known as the session. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>The session layer ensures that the session stays open long enough to authenticate, authorize and transfer all the data being exchanged, </strong>and then promptly closes the session in order to avoid wasting resources. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>4.Transport Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Responsible for end-to-end communication between the two devices. This includes <strong>taking data from the session layer and breaking it up into chunks called segments</strong> before sending it. <strong>The transport layer on the receiving device is responsible for reassembling the segments into data the session layer can consume</strong>. The transport layer is also responsible for flow control and error control. </p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Flow control determines an optimal speed of transmission to ensure that a sender with a fast connection doesn’t overwhelm a receiver with a slow connection. </li><li>Performs error control on the receiving end by ensuring that the data received is complete, and requesting a re-transmission if it isn’t.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong><em>5.Network layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Responsible for facilitating data transfer between two different networks. If the two devices communicating are on the same network, then the network layer is unnecessary. <strong>The network layer breaks up segments from the transport layer into smaller units, called packets, on the sender’s device, and reassembling these packets on the receiving device. </strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>6.Data Link layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Facilitates data transfer between two devices on the same network. <strong>The data link layer takes packets from the network layer and breaks them into smaller pieces called frames.</strong> </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Like the network layer, the data link layer is also responsible for flow control and error control in intra-network communication . The transport layer only does flow control and error control for inter-network communications.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>7.Physical layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This layer includes the physical equipment involved in the data transfer, such as the cables and switches. <strong>This is also the layer where the data gets converted into a bit stream, which is a string of 1s and 0s. </strong>The physical layer of both devices must also agree on a signal convention so that the 1s can be distinguished from the 0s on both devices.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":484,"height":482,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="http://programmerprodigycode.files.wordpress.com/2021/01/72b87-picture1.png" alt="" width="484" height="482"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5><strong><em>For more information on OSI model,</em></strong></h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li><a rel="noreferrer noopener" href="https://www.youtube.com/watch?v=-6Uoku-M6oY" target="_blank">https://www.youtube.com/watch?v=-6Uoku-M6oY</a></li><li><a href="https://www.freecodecamp.org/news/osi-model-networking-layers-explained-in-plain-english/" target="_blank" rel="noreferrer noopener">https://www.freecodecamp.org/news/osi-model-networking-layers-explained-in-plain-english/</a></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"textAlign":"left","level":4} -->
<h4 class="has-text-align-left"><strong><em>4.Transmission Control Protocol/Internet Protocol (TCP/IP) Model:</em></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Transmission Control Protocol/Internet Protocol (TCP/IP) network provides a framework for transmitting this data, and it requires some basic information from us to move this data.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>There was redundancy and repetition of functionalities in different layers in OSI Model, <strong>So we combined Application, Presentation and Session Layer into one layer called Application layer.</strong> This layer was responsible for all the functionalities of three layers.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="http://programmerprodigycode.files.wordpress.com/2021/01/a2edb-tcpip_5_layer_overview.png" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>1.Application Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li> Responsible for the protocols and data manipulation that the software relies on to present meaningful data to the user.</li><li>Responsible for converting data into binary code, encrypting data and compressing data, before beginning the session.</li><li>Responsible for ensuring that the session stays open long enough to authenticate, authorize and transfer all the data being exchanged, and then promptly closes the session in order to avoid wasting resources.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong><em>2.Transport Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Establishes the connection between applications running on different hosts. It keeps track of the processes running in the applications above it by assigning port numbers to them and uses the Network layer to access the TCP/IP network.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>3.Network Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Responsible for creating the packets that move across the network. It uses IP addresses to identify the packet’s source and destination.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>4.Data Link Layer: </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Responsible for creating the frames that move across the network. These frames encapsulate the packets and use MAC addresses to identify the source and destination.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>5.Physical Layer:</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The Physical layer encodes and decodes the bits found in a frame and includes the transceiver that drives and receives the signals on the network.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":566,"height":325,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://dtechsmag.com/wp-content/uploads/2020/02/csg25-03-tcp-ip-encapsulation.png" alt="" width="566" height="325"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5><strong><em>For more information on tcp/IP model,</em></strong></h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li><a href="https://www.youtube.com/watch?v=3b_TAYtzuho" target="_blank" rel="noreferrer noopener">https://www.youtube.com/watch?v=3b_TAYtzuho</a></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"textAlign":"center","level":4} -->
<h4 class="has-text-align-center"><strong><em>Network Performance:</em></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>We have to minimize the Delay and Packet Loss, and maximize Throughput.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"id":3410,"sizeSlug":"large","linkDestination":"none"} -->
<figure class="wp-block-image size-large"><img src="https://programmerprodigycode.files.wordpress.com/2021/01/image.png?w=1024" alt="" class="wp-image-3410"/></figure>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><em><strong>D(proc):</strong> </em>Between the time the packet is correctly received at the head node of the incoming link and the time the packet is assigned to an outgoing link queue for transmission.</li><li><strong><em>D(queue): </em></strong>Between the time the packet is assigned to a queue for transmission and the time it starts being transmitted. During this time, the packet waits while other packets in the transmission queue are transmitted.</li><li><strong><em>D(trans):</em></strong> Between the times that the first and last bits of the packet are transmitted.</li><li><strong><em>D(prop):</em></strong> Between the time the last bit is transmitted at the head node of the link queue and the time the last bit is received at the next router. This is proportional to the physical distance between transmitter and receiver.</li></ol>
<!-- /wp:list -->
<!-- wp:preformatted -->
<pre class="wp-block-preformatted"><strong><em>Total Delay= D(proc)+ D(delay) + D(trans) + D(prop)</em></strong></pre>
<!-- /wp:preformatted -->
<!-- wp:nextpage -->
<!--nextpage-->
<!-- /wp:nextpage -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center"><strong><em>Application Layer</em></strong></h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Protocols Used in Application Layer are:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong><em>1. Hyper Text Transfer Protocol(HTTP):</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>This is a basis for data communication in the internet. The data communication starts with a request sent from a client and ends with the response received from a web server.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fultimatepeter.com%2Fwp-content%2Fuploads%2F2013%2F11%2FHTTP-request-response.png&f=1&nofb=1" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>Various Methods used are:</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>GET Method</strong>: Requests a representation of the specified resource. Requests using <code>GET</code> should only retrieve data.</li><li><strong>HEAD Method</strong>: Asks for a response identical to that of a <code>GET</code> request, but without the response body.</li><li><strong>POST Method</strong>: Used to submit an entity to the specified resource, often causing a change in state or side effects on the server.</li><li><strong>PUT Method:</strong> Replaces all current representations of the target resource with the request payload.</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">HTTP Request:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A simple request message from a client computer consists of the following components:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>A request line to get a required resource. It contains Method, Path and HTTP version.</li><li>Headers. They contain name value pairs.</li><li>An empty line.</li><li>A message body which is optional. Contains extra information to be delivered to the server.</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.imperva.com%2Fblog%2Fwp-content%2Fuploads%2Fsites%2F9%2F2017%2F10%2Fparts-of-a-HTTP-request-1.png&f=1&nofb=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">HTTP Response:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A simple response from the server contains the following components:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>HTTP Status Code. It contains HTTP version, Status code and Response</li><li>Headers. They contain name value pairs.</li><li>An empty line.</li><li>A message body which is optional. Contains extra information to be delivered to the host.</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://www3.ntu.edu.sg/home/ehchua/programming/webprogramming/images/HTTP_ResponseMessageExample.png" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>Types of Status Code:</em></strong> For example 404 or 502 error code,</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>1XX: Information regarding message</li><li>2XX: Information regarding success</li><li>3XX: Information regarding Re directional</li><li>4XX: Information regarding Client</li><li>5XX: Information regarding Server</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">HTTPS OVER HTTP ?</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><em>HTTPS is the secured HTTP protocol required to send and receive information securely over internet. Nowadays it is mandatory for all websites to have HTTPS protocol to have secured internet. </em></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Besides the security and encryption, the communication structure of HTTPS protocol remains same as HTTP protocol as explained above.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fwebecreator.com%2Fblog%2Fwp-content%2Fuploads%2F2018%2F06%2F17-sucuri-a-ssl-http-vs-https-chart%402.png&f=1&nofb=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"textAlign":"left","level":3} -->
<h3 class="has-text-align-left">2.Domain Name System(DNS):</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>It’s like a global phone book of the internet which contains numeric addresses instead of alphabetic addresses. DNS is a protocol used for exchanging information on the internet, using domain names as the upper layer to match to IP address as the layer beneath it.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>End users access information using domain names, not IP addresses, for example, you are searching for my blog, now instead of remembering the site’s IP address number, you just have to remember the site’s name to connect and access information from it.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":405,"height":312,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fmedia.kasperskydaily.com%2Fwp-content%2Fuploads%2Fsites%2F92%2F2016%2F12%2F06015704%2Fdns-normal-en-1024x791.png&f=1&nofb=1" alt="" width="405" height="312"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>There are 4 DNS servers involved in loading a webpage:</em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong><em>DNS re<strong>cursor</strong> </em>- </strong>A server designed to receive queries from client machines through applications such as web browsers and resolve these queries.<strong> Caching is a data persistence process that helps short-circuit the necessary requests by serving the requested resource record earlier in the DNS lookup. </strong><ol><li>The recursor can be thought of as a librarian who is asked to go find a particular book somewhere in a library.</li></ol></li><li><strong>Root nameserver</strong> - The root server is the first step in translating human readable host names into IP addresses. <ol><li>It can be thought of like an index in a library that points to different racks of books - typically it serves as a reference to other more specific locations.</li></ol></li><li><strong>TLD nameserver</strong> - The top level domain server (TLD) is the next step in the search for a specific IP address, and it hosts the last portion of a host name, for example .in or .com.<ol><li>It can be thought of as a specific rack of books in a library.</li></ol></li><li><strong>Authoritative nameserver</strong> - The authoritative nameserver is the last stop in the nameserver query. If the authoritative name server has access to the requested record, it will return the IP address for the requested host name back to the DNS Recursor that made the initial request.<ol><li>It can be thought of as a dictionary on a rack of books, in which a specific name can be translated into its definition. </li></ol></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4><strong><em>What is a DNS resolver?</em></strong></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The DNS resolver is the first stop in the DNS lookup, and it is responsible for dealing with the client that made the initial request. The resolver starts the sequence of queries that ultimately leads to a URL being translated into the necessary IP address.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":463,"height":308,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fblog.cloudflare.com%2Fcontent%2Fimages%2F2018%2F04%2Fdns-lookup-diagram.png&f=1&nofb=1" alt="" width="463" height="308"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"textAlign":"center"} -->
<h2 class="has-text-align-center">DNS Query and Response:</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The DNS messages are sent over UDP( smaller than 512 bytes for common requests and responses) or TCP. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://i.imgur.com/68escU5.png" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Question Section:</strong>This is a section consisting of one or more question records. It is present on both query and response messages.</li><li><strong>Answer Section:</strong> This is a section consisting of one or more resource records. It is present only on response messages. This section includes the answer from the server to the client (resolver).</li><li><strong>Authoritative Section:</strong> This is a section consisting of one or more resource records. It is present only on response messages. This section gives information (domain name) about one or more authoritative servers for the query.</li><li><strong>Additional Information Section:</strong> This is a section consisting of one or more resource records. It is present only on response messages. This section provides additional information that may help the resolver.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><em>Information about flags in header:</em></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>QR (query/response):</strong> This is a 1-bit subfield that defines the type of message. If it is 0, the message is a query. If it is 1, the message is a response.</li><li><strong>OpCode:</strong> This is a 4-bit subfield that defines the type of query or response (0 if standard, 1 if inverse, and 2 if a server status request).</li><li><strong>AA (authoritative answer):</strong> This is a 1-bit subfield. When it is set (value of 1)it means that the name server is an authoritative server. It is used only in a response message.</li><li><strong>TC (truncated):</strong> This is a 1-bit subfield. When it is set (value of 1), it means that the response was more than 512 bytes and truncated to 512. </li><li><strong>RD (recursion desired):</strong> This is a 1-bit subfield. When it is set (value of 1) it means the client desires a recursive answer. </li><li><strong>RA (recursion available):</strong> This is a 1-bit subfield. When it is set in the response, it means that a recursive response is available. </li><li><strong>Reserved:</strong> This is a 3-bit subfield set to 000.</li><li><strong>RCode:</strong> This is a 4-bit field that shows the status of the error in the response.</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://www.oreilly.com/library/view/understanding-tcpip/9781904811718/graphics/1718_11_04.jpg" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"textAlign":"left","level":3} -->
<h3 class="has-text-align-left">3.<em><strong>Email Protocols:</strong></em></h3>
<!-- /wp:heading -->
<!-- wp:image {"align":"center","width":573,"height":300,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fwww.afternerd.com%2Fblog%2Fwp-content%2Fuploads%2F2017%2F11%2Fsmtp-message-flow.png&f=1&nofb=1" alt="" width="573" height="300"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>When ever we are sending mail from Bob to Alice, the protocol followed will be,</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Bob will send the email to his mail server using SMTP.</li><li>Bob's server is going to check if Alice also has the same mail server. <ol><li>If they have same mail server then mail server will allow Alice to pull mail directly from it. An example for Inter organization mail communication.</li><li>If they have different Mail server then, Bob's mail server will send the mail to Alice's mail server and then Alice will be able to pull her mail from her mail server. </li></ol></li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","width":509,"height":286,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Ftechwelkin.com%2Fwp-content%2Fuploads%2F2016%2F10%2Fpop-vs-imap.jpg&f=1&nofb=1" alt="" width="509" height="286"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":3} -->
<h3>Q.<em>What do you mean by a Port and a Socket?</em></h3>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li>Port: Just as the IP address identifies the computer, The network<strong> </strong>port identifies the application or service running on the computer. <ol><li>A port number uses 16 bits and so can therefore have a value from<strong> 0</strong> to <strong>65535</strong> decimal</li></ol></li><li>Socket: A connection between two computers uses a socket<strong>.</strong> It is a tuple of IP address and Port.</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://qph.fs.quoracdn.net/main-qimg-c152067b268cb84901742c9594bafd14" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li>Host A has an application running on port 7, It creates a socket or an endpoint to send /receive information.</li><li>Host B also has an application running on port 81, It creates a socket or an endpoint to send/ receive information.</li><li>Host A and B can communicate over internet/network using their respective sockets.</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":5} -->
<h5>For more information on Sockets and ports,</h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li><a rel="noreferrer noopener" href="http://www.steves-internet-guide.com/tcpip-ports-sockets/" target="_blank">http://www.steves-internet-guide.com/tcpip-ports-sockets/</a></li><li><a href="https://github.com/kakabisht/CN_Lab/tree/master/socket_programmin" target="_blank" rel="noreferrer noopener">For code on Socket programming in java and python </a></li></ol>
<!-- /wp:list -->
<!-- wp:nextpage -->
<!--nextpage-->
<!-- /wp:nextpage -->
<!-- wp:heading {"textAlign":"center"} -->
<h2 class="has-text-align-center">Transport Layers:</h2>
<!-- /wp:heading -->
<!-- wp:heading {"level":4} -->
<h4><em><strong>1.Transmission Control Protocol (TCP):</strong></em></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The computer sending the data connects directly to the computer it is sending the data it to, and stays connected for the duration of the transfer. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>A real life comparison to this method would be to pick up the phone and call a friend. Your friend picks up the phone and responds with a hello or a an acknowledgment that he his free to talk right now. When he gives you an acknowledgement, then you start speaking. You have a conversation and when it is over, you both hang up, releasing the connection. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":712,"height":356,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.keycdn.com%2Fimg%2Fsupport%2Ftcp-fast-open.png&f=1&nofb=1" alt="" width="712" height="356"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>This proves the point that TCP connections are:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>A three way setup, connection request -> Acknowledgment -> Start sending data,</li><li>Connection Oriented </li><li>Reliable</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>TCP is a connection-oriented Layer. It moves data in a continuous, unstructured byte stream. Sequence numbers identify bytes within that stream. </strong></p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":461,"height":324,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.ahirlabs.com%2Fwp-content%2Fuploads%2F2018%2F07%2FTCP-HEADER.png&f=1&nofb=1" alt="" width="461" height="324"/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Source Port</strong> and <strong>Destination Port fields</strong> (16 bits each) identify the end points of the connection.</li><li><strong>Sequence Number field</strong> (32 bits) specifies the number assigned to the first byte of data in the current message. Under certain circumstances, it can also be used to identify an initial sequence number to be used in the upcoming transmission.</li><li><strong>Acknowledgement Number field</strong> (32 bits) contains the value of the next sequence number that the sender of the segment is expecting to receive, if the ACK control bit is set.</li><li><strong>Data Offset(a.k.a. Header Length) field</strong> (variable length) tells how many 32-bit words are contained in the TCP header. This information is needed because the Options field has variable length, so the header length is variable too.</li><li><strong>Reserved field</strong> (6 bits) must be zero. </li><li><strong>Flags field</strong> (6 bits) contains the various flags:<ol><li>URG—Indicates that some urgent data has been placed.</li><li>ACK—Indicates that acknowledgement number is valid.</li><li>PSH—Indicates that data should be passed to the application as soon as possible.</li><li>RST—Resets the connection.</li><li>SYN—Synchronizes sequence numbers to initiate a connection.</li><li>FIN—Means that the sender of the flag has finished sending data.</li></ol></li><li><strong>Window field</strong> (16 bits) specifies the size of the sender's receive window .</li><li><strong>Checksum field</strong> (16 bits) indicates whether the header was damaged in transit.</li><li><strong>Urgent pointer field</strong> (16 bits) points to the first urgent data byte in the packet.</li><li><strong>Options field</strong> (variable length) specifies various TCP options.</li><li><strong>Data field</strong> (variable length) contains upper-layer information.</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":5} -->
<h5><strong><em>Applications where TCP is used are:</em></strong></h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li>Emails</li><li>Online Transactions </li><li>Socket Programming</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4><em><strong>2.User Datagram Protocol (UDP):</strong></em></h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>UDP does not connect directly to the receiving computer like TCP does, but rather sends the data out and relies on the devices in between the sending computer and the receiving computer to get the data where it is supposed to go properly. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>A real life comparison to this method would be to be send a letter to friend via postal service. You put the letter in the postbox, and then you hope it reaches the destination. Sometimes it does not reach the destination. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="http://classes.dma.ucla.edu/Fall05/161A/projects/Joshua/Project1/images/udp.gif" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>This proves the point that UDP connections are:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>No acknowledgements are involved.</li><li>Fast but no reliable.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>UDP is a connection-less Layer. It has Checksum value for basic detection of faulty data packets.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://www.csestack.org/wp-content/uploads/2017/02/UDP-header-format.png" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Source Port</strong> and <strong>Destination Port fields</strong> (16 bits each) identify the end points of the connection.</li><li><strong>Length field</strong> (16 bits) specifies the length of the header and data.</li><li><strong>Checksum field</strong> (16 bits) allows packet integrity checking or error detection in the packet.</li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":5} -->
<h5><strong><em>Applications where UDP is used are:</em></strong></h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li>YouTube</li><li>Online Images </li></ol>
<!-- /wp:list -->
<!-- wp:nextpage -->
<!--nextpage-->
<!-- /wp:nextpage -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">Sliding Window Protocol:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A window is a space that holds or can hold multiple bytes. For example, if there is a window of 1000 bytes and the size of the individual message or frame is 100 bytes long. There could be a maximum of 10 messages at any time in the window.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The sliding window is a technique for sending multiple frames at a time. In this technique, each frame has sent from the sequence number. The sequence numbers are used to find the missing data in the receiver end. The purpose of the sliding window technique is to avoid duplicate data, so it uses the sequence number.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":5} -->
<h5><em><strong>1.Go-Back-N Automatic Repeat Request</strong>(<strong>Go back N ARQ):</strong></em></h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>It is a data link layer protocol that uses a sliding window method. In this, if any frame is corrupted or lost, all subsequent frames have to be sent again.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>If the receiver receives a corrupted frame, it cancels it. The receiver does not accept a corrupted frame. When the timer expires, the sender sends the correct frame again. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":377,"height":273,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Ftechdifferences.com%2Fwp-content%2Fuploads%2F2016%2F05%2FGo-Back-N.jpg&f=1&nofb=1" alt="" width="377" height="273"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5><em><strong>2.Selective Repeat Automatic Repeat Request(Selective Repeat ARQ):</strong></em></h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The Go-back-N ARQ protocol works well if it has fewer errors. But if there is a lot of error in the frame, lots of bandwidth loss in sending the frames again. So, we use the Selective Repeat ARQ protocol. In this protocol, the size of the sender window is always equal to the size of the receiver window. The size of the sliding window is always greater than 1.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>If the receiver receives a corrupt frame, it does not directly discard it. It sends a negative acknowledgment to the sender. The sender sends that frame again as soon as on the receiving negative acknowledgment. There is no waiting for any time-out to send that frame.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Ftechdifferences.com%2Fwp-content%2Fuploads%2F2016%2F05%2FSelective-repeat.jpg&f=1&nofb=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>When we have network issue, then we reduce the window size by half to debug the issue. When the window size reaches 1, it is called as Silly window.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">Flow Control:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Flow control methods are techniques that determine the data flow between sender and receiver. <strong>It determines how much data should be send by the sender before receiving acknowledgement. </strong>It makes sender to wait for some sort of an acknowledgement before continuing to send some more data. </p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Avoids the sender from overwhelming the receiver</li><li>Sender transmits the data slowly to the receiver</li></ol>
<!-- /wp:list -->
<!-- wp:image {"align":"center","width":492,"height":369,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fimage1.slideserve.com%2F1803683%2Ftcp-flow-control-l.jpg&f=1&nofb=1" alt="" width="492" height="369"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>Algorithms Used for Flow control are <a rel="noreferrer noopener" href="http://pages.cs.wisc.edu/~suman/courses/640/s18/tcp-part2.pdf" target="_blank">Nagle, Karn and Patridge, and Jacobson.</a></p>
<!-- /wp:paragraph -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center"><strong><em>Congestion Control:</em></strong></h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Congestion is a situation in Communication Networks in which too many packets are present in a part of the subnet, performance degrades. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Congestion in a network may occur when the load on the network is greater than the capacity of the network. </strong></p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Avoid senders from overwhelming the network</li><li>Transmits the data to the network slowly</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Network congestion occurs in case of traffic overloading. We have two Algorithms to help to regulate rate of data transmission and reduces congestion,</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>1.Leaky Bucket:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Suppose we have a bucket with a hole at the bottom of it, now we may input water into the bucket at any rate but the water will pour at a constant rate from the bottom.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://i.pinimg.com/originals/43/d3/ac/43d3ace723f01193afc7043382b967b8.png" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><a href="https://github.com/kakabisht/CN_Lab/tree/master/flow_control" target="_blank" rel="noreferrer noopener">Java code for leaky bucket algorithm</a></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>2.Token Bucket:</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>To over come the problem of water overflowing in the leaky bucket. We use Token bucket, it has a finite set of tokens. Each packet is given a token, if token are finished then the packet has to wait in a queue, until token becomes available.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":454,"height":449,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.researchgate.net%2Fprofile%2FFurat_Nidhal%2Fpublication%2F325608278%2Ffigure%2Ffig8%2FAS%3A634661147521024%401528326417356%2FFigure-35-The-token-bucket-algorithm-a-Before-b-After-1.png&f=1&nofb=1" alt="" width="454" height="449"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><a rel="noreferrer noopener" href="https://github.com/kakabisht/CN_Lab/tree/master/flow_control" target="_blank">Java code for token bucket algorithm</a></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph {"align":"center"} -->
<p class="has-text-align-center"><strong>It's recommended to first put a token bucket and then a leaky bucket in the network.</strong></p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":4} -->
<h4>Q.How to reduce packet drops?</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong><em>1.Additive Increase Multiplicative Decrease(AIMD): </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>It checks the traffic in the network and </p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>If there is less traffic in the network, then increase the window size by 1.</li><li>If there is more traffic in the network, then decrease the window size by half.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong><em>2.Random Early Detection(RED): </em></strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>It calculates the probability of a packet to be dropped, If the probability is high it will drop it otherwise will enqueue it.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":509,"height":588,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2Ff%2Ffd%2FRandom_Early_Detection_algorithm_en.svg%2F1200px-Random_Early_Detection_algorithm_en.svg.png&f=1&nofb=1" alt="" width="509" height="588"/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><a href="http://www.eecs.umich.edu/courses/eecs489/w07/LectureSlides/lec8_tcp.pdf">http://www.eecs.umich.edu/courses/eecs489/w07/LectureSlides/lec8_tcp.pdf</a></li><li><a href="https://web.cs.wpi.edu/~rek/Undergrad_Nets/C02/TCP_SlidingWindows.pdf" target="_blank" rel="noreferrer noopener">https://web.cs.wpi.edu/~rek/Undergrad_Nets/C02/TCP_SlidingWindows.pdf</a></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":5} -->
<h5>For more Information on flow and congestion control:</h5>
<!-- /wp:heading -->
<!-- wp:nextpage -->
<!--nextpage-->
<!-- /wp:nextpage -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">Network Layer:</h3>
<!-- /wp:heading -->
<!-- wp:heading {"textAlign":"center","level":3} -->
<h3 class="has-text-align-center">Bandwidth and Queue of the Router:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>How to decide which source will be allowed to first input data packets in Queue router, to solve this we have three strategies </p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":508,"height":284,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://book.systemsapproach.org/_images/f06-01-9780123850591.png" alt="" width="508" height="284"/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li>First in First out: Which ever data packet is first received by the Queue router will be sent on the output link. This approach does not work as different data packages have different sizes.</li><li>Priority Queue: Which ever data packet has more priority than the other will be sent on the output link.</li><li>Fair Queuing: Each source receives a time slice to send it's packet, for example source 1 and source 2 both have a time slice of a min. </li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":4} -->
<h4>IP Header:</h4>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>IP header is the peace of information that is inserted by the IP layer while sending the network packet to the remote peer. </p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>For a received message from the peer, the IP layer removes the header. The header information works as a piece of control information for the user data. </li><li>Mainly the IP header does end to end routing and ensures the quality of service. </li></ol>
<!-- /wp:list -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.ictshore.com%2Fwp-content%2Fuploads%2F2016%2F11%2F1013-07-IP_Packet.png&f=1&nofb=1" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>The IP packet format consists of these fields:</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Version field</strong> (4 bits) indicates the version of IP currently used.</li><li><strong>IP Header Length (IHL) field</strong> (4 bits) indicates how many 32-bit words are in the IP header.</li><li><strong>Type-of-service field</strong> (8 bits) specifies how a particular upper-layer protocol would like the current datagram to be handled. Datagrams can be assigned various levels of importance through this field.</li><li><strong>Total Length field</strong> (16 bits) specifies the length of the entire IP packet, including data and header, in bytes.</li><li><strong>Identification field</strong> (16 bits) contains an integer that identifies the current datagram. This field is used to help reconstruct datagram fragments.</li><li><strong>Flags field</strong> (4 bits; one is not used) controls whether routers are allowed to fragment a packet and indicates the parts of a packet to the receiver.</li><li><strong>Time-to-live field</strong> (8 bits) maintains a counter that gradually decrements to zero, at which point the datagram is discarded. This keeps packets from looping endlessly.</li><li><strong>Protocol field</strong> (8 bits) indicates which upper-layer protocol receives incoming packets after IP processing is complete.</li><li><strong>Header Checksum field</strong> (16 bits) helps ensure IP header integrity.</li><li><strong>Source Address field</strong> (32 bits) specifies the sending node.</li><li><strong>Destination Address field</strong>(32 bits) <em>s</em>pecifies the receiving node.</li><li><strong>Options field</strong> (32 bits) allows IP to support various options, such as security.</li><li><strong>Data field</strong> (32 bits) contains upper-layer information.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p><strong>Fragmentation</strong>: To distinguish between the ending of a data packet and starting of the another one.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":429,"height":242,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fnotes.shichao.io%2Ftcpv1%2Ffigure_10-9.png&f=1&nofb=1" alt="" width="429" height="242"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>1.IPv4 addresses</em></strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An IPv4 address is 32 bit address that uniquely and universally defines the connection of a device.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Address Space</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An address space is the total number of addresses used by IPv4 protocol. If <strong>N bit</strong> address is used, the total addresses in the address space will be <strong>2<sup>N</sup>.</strong> IPv4 uses <strong>32 bit</strong> addresses then the total number of addresses in the address space is</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>2<sup>32</sup> = 42, 94,967,296</strong></p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":482,"height":281,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fwww.bluecatnetworks.com%2Fwp-content%2Fuploads%2F2019%2F11%2Fipv4-1.png&f=1&nofb=1" alt="" width="482" height="281"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p><strong><em>2.IPv6 addresses</em></strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An IPv6 address is 64 bit address that uniquely and universally defines the connection of a device.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>Address Space</strong></p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>An address space is the total number of addresses used by IPv6 protocol. If <strong>N bit</strong> address is used, the total addresses in the address space will be <strong>2<sup>N</sup>.</strong> IPv6 uses <strong>64 bit</strong> addresses then the total number of addresses in the address space is</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p><strong>2<sup>64</sup> = 18,446,744,073,709,552,000</strong></p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fupload.wikimedia.org%2Fwikipedia%2Fcommons%2Fthumb%2F7%2F70%2FIpv6_address_leading_zeros.svg%2F300px-Ipv6_address_leading_zeros.svg.png&f=1&nofb=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5>For more information on Logical addressing,</h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li><a rel="noreferrer noopener" href="https://notesformsc.org/logical-addressing/" target="_blank">https://notesformsc.org/logical-addressing/</a></li><li><a href="https://www.cpe.ku.ac.th/~plw/dccn/presentation/ch19.pdf" target="_blank" rel="noreferrer noopener">https://www.cpe.ku.ac.th/~plw/dccn/presentation/ch19.pdf</a></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3>Routing:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Finding the least expensive way from source to destination for a data packet.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":577,"height":432,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://image.slidesharecdn.com/internet-rtg-protocol-fundamentalsdrvishalsharma1998-11-20-120508075224-phpapp02/95/internet-routing-protocols-fundamental-concepts-of-distancevector-and-linkstate-routing-17-728.jpg?cb=1336464223" alt="" width="577" height="432"/></figure></div>
<!-- /wp:image -->
<!-- wp:list {"ordered":true} -->
<ol><li><strong>Static</strong>: A predefined route has been set from data packet A to B. </li><li><strong>Dynamic</strong>: It dynamically finds the cheapest route from A to B at each node, the algorithm used here is Bellman ford algorithm.</li></ol>
<!-- /wp:list -->
<!-- wp:paragraph -->
<p>Algorithm for Bellman Ford,</p>
<!-- /wp:paragraph -->
<!-- wp:list {"ordered":true} -->
<ol><li>Initialize the distance from the source node S to all other nodes as infinite (999999999) and to itself as 0.</li><li>For every node in the graph do</li><li>For every edge E in the EdgeList do</li><li>Node_u = E.first, Node_v = E.second</li><li>Weight_u_v = EdgeWeight ( Node_u, Node_v )</li><li>If ( Distance [v] > Distance [u] + Weight_u_v )</li><li>Distance [v] = Distance [u] + Weight_u_v</li></ol>
<!-- /wp:list -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fpeople.inf.elte.hu%2Fhytruongson%2FBellman-Ford%2F10-bellmanford.jpg&f=1&nofb=1" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:nextpage -->
<!--nextpage-->
<!-- /wp:nextpage -->
<!-- wp:heading {"textAlign":"center"} -->
<h2 class="has-text-align-center">Data Link Layer</h2>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Data-link layer uses some error control mechanism to ensure that frames are transmitted with certain level of accuracy. But to understand how errors is controlled, it is essential to know what types of errors may occur.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":3} -->
<h3>1.Error detection:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>1.<strong>Parity check</strong>: It counts the number of 1s either they are even or odd.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":338,"height":253,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=http%3A%2F%2Fwww.liberaldictionary.com%2Fwp-content%2Fuploads%2F2018%2F12%2Fparity-check.jpg&f=1&nofb=1" alt="" width="338" height="253"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>2.<strong>Checksum</strong>: It calculates the hash value of the data packet, if the hash value is equal at both sides then data was error free.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>3.<strong>Cyclic redundancy check(CRC)</strong>: This technique involves binary division of the data bits being sent. The divisor is generated using polynomials. The sender performs a division operation on the bits being sent and calculates the remainder. Before sending the actual bits, the sender adds the remainder at the end of the actual bits. Actual data bits plus the remainder is called a codeword. The sender transmits data bits as codewords.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":527,"height":396,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fimage.slidesharecdn.com%2Fcrclinkdin-170901152210%2F95%2Fcyclic-redundancy-check-6-638.jpg%3Fcb%3D1504279544&f=1&nofb=1" alt="" width="527" height="396"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":3} -->
<h3>Error Correction:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p><strong>1.Hamming code</strong>:</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>They are used to detect errors that helps in recovering the original binary word. </p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The basic concept of Hamming Code is to add Parity bits to the data stream to verify that the data received is correct or matches with the input. These bits are transmitted in such a way that they identify where the error has occurred in the data stream and rectifies it.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":569,"height":426,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fimage3.slideserve.com%2F5545001%2Fhamming-code-layout1-l.jpg&f=1&nofb=1" alt="" width="569" height="426"/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph -->
<p>In order to detect ’d’ errors, it needs a code with (d + 1) bits and similarly to correct d errors it needs a code with (2d + 1) bits .These Codes uses extra Parity bits to identify the error.</p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":5} -->
<h5>For more information,</h5>
<!-- /wp:heading -->
<!-- wp:list {"ordered":true} -->
<ol><li><a href="https://users.cis.fiu.edu/~downeyt/cop3402/hamming.html" target="_blank" rel="noreferrer noopener">https://users.cis.fiu.edu/~downeyt/cop3402/hamming.html</a></li></ol>
<!-- /wp:list -->
<!-- wp:heading {"level":3} -->
<h3>Media Access Control:</h3>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>A media access control is a network data transfer policy that determines how data is transmitted between two computer terminals through a network cable.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>The essence of the MAC protocol is to ensure non-collision and eases the transfer of data packets between two computer terminals. A collision takes place when two or more terminals transmit data/information simultaneously. </p>
<!-- /wp:paragraph -->
<!-- wp:heading {"level":5} -->
<h5>1.Carrier Sense Multiple Access with Collision Avoidance (CSMA/CA)</h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Regulates how data packets are transmitted between two computer nodes. This method avoids collision by configuring each computer terminal to make a signal before transmission. The signal is carried out by the transmitting computer to avoid a collision.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Multiple access implies that many computers are attempting to transmit data. Collision avoidance means that when a computer node transmitting data states its intention, the other waits at a specific length of time before resending the data.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>CSMA/CA is data traffic regulation is slow and adds cost in having each computer node signal its intention before transmitting data. It used only on Apple networks.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fimage.slidesharecdn.com%2Fcsmamohammedabuibaid-160701034304%2F95%2Fcarrier-sense-multiple-access-csma-15-638.jpg%3Fcb%3D1467345036&f=1&nofb=1" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5>2.Carrier Sense Multiple Access with Collision Detection (CSMA/CD)</h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>Carrier sense multiple access with collision detection (CSMA/CD) is the opposite of CSMA/CA. Instead of detecting data to transmit signal intention to prevent a collision, it observes the cable to detect the signal before transmitting.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Collision detection means that when a collision is detected by the media access control policy, transmitting by the network stations stops at a random length of time before transmitting starts again.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>It is faster than CSMA/CA as it functions in a network station that involves fewer data frames being transmitted. CSMA/CD is not as efficient as CSMA/CA in preventing network collisions. This is because it only detects huge data traffic in the network cable. Huge data traffic increases the possibility of a collision taking place. It is used on the Ethernet network. </p>
<!-- /wp:paragraph -->
<!-- wp:image {"sizeSlug":"large"} -->
<figure class="wp-block-image size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fimage.slidesharecdn.com%2Fcsmamohammedabuibaid-160701034304%2F95%2Fcarrier-sense-multiple-access-csma-13-638.jpg%3Fcb%3D1467345036&f=1&nofb=14" alt=""/></figure>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5>3.Demand Priority:</h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>The demand priority is an improved version of the Carrier sense multiple access with collision detection (CSMA/CD). This data control policy uses an ‘active hub’ in regulating how a network is accessed. Demand priority requires that the network terminals obtain authorization from the active hub before data can be transmitted.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Another distinct feature of this MAC control policy is that data can be transmitted between the two network terminals at the same time without collision. In the Ethernet media, demand priority directs that data is transmitted directly to the receiving network terminal.<strong></strong></p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","width":329,"height":277,"sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large is-resized"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fnetworkencyclopedia.com%2Fwp-content%2Fuploads%2F2019%2F08%2Fdemand-priority.jpg&f=1&nofb=1" alt="" width="329" height="277"/></figure></div>
<!-- /wp:image -->
<!-- wp:heading {"level":5} -->
<h5>4.Token Passing:</h5>
<!-- /wp:heading -->
<!-- wp:paragraph -->
<p>This media access control method uses free token passing to prevent a collision. Only a computer that possesses a free token, which is a small data frame, is authorized to transmit. Transmission occurs from a network terminal that has a higher priority that one with a low priority.</p>
<!-- /wp:paragraph -->
<!-- wp:paragraph -->
<p>Token passing flourishes in an environment where a large number of short data frames are transmitted. This media access control policy is highly efficient in avoiding a collision. Possession of the free token is the only key to transmitting data by a network node. Each terminal holds this free token for a specific amount of time if the network with the high priority does not have data to transmit, the token is passed to the adjoining station in the network.</p>
<!-- /wp:paragraph -->
<!-- wp:image {"align":"center","sizeSlug":"large"} -->
<div class="wp-block-image"><figure class="aligncenter size-large"><img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Ftse3.mm.bing.net%2Fth%3Fid%3DOIP.IBAaZjkvED_KRlaBUlapvQHaFx%26pid%3DApi&f=1" alt=""/></figure></div>
<!-- /wp:image -->
<!-- wp:paragraph {"align":"center"} -->
<p class="has-text-align-center"><strong><em>Code is present at <a rel="noreferrer noopener" href="https://github.com/kakabisht/CN_Lab" target="_blank">https://github.com/kakabisht/CN_Lab</a></em></strong></p>
<!-- /wp:paragraph --> | hridyeshbisht | |
576,868 | VSCode HTML Tags Shortcuts | Howdy! If you're here, it's one of the following reasons: 1.) You have no idea what VSCode is and... | 0 | 2021-01-20T07:56:59 | https://dev.to/zahreafranklin/vscode-html-shortcuts-kah | vscode, html, codenewbie | Howdy!
If you're here, it's one of the following reasons:
1.) You have no idea what VSCode is and would like to know
2.) You are considering using it but wanted to learn a bit more before you dive in.
3.) You like me, use VSCode as your code editor and need to learn some shortcuts.
If you identify with the first option, VSCode, which stands for Visual Studio Code is a free-source editor for coding. It helps you to write programs in a variety of languages and it has helpful features like pointing out syntax errors by line numbers, auto completion of code snippets and even add-on extensions that allow theme customization (hey night-mode 😏) and tons of other cool features.
If you have been considering it but wanted to know what sets it apart from the others you've heard about, here's a few points to consider:
- Visual Studio Code is FREE
- VSCode was created by Microsoft, so it's trustworthy as well as compatible on Windows, MacOS and Linux.
- It has a built-in terminal as well as built-in Git support
- It's good at handling larger projects.
In addition to the main points outlined there's a lot more that you can do with VSCode to help make coding easier and more productive.
One of these features is Emmet. This is a built-in extension that allows you to skip the step of manually typing out HTML tags. By using keyboard shortcuts, the tags are automatically created. Some of the most useful shortcuts are:
```javascript
.class
//<div class="class"></div>
```
```javascript
.title
//<div class="title"></div>
```
```javascript
a{Click me}
//<a href="">Click me</a>
```
```javascript
link:css
//<link rel="stylesheet" href="style.css" />
```
```javascript
ul>li*5 //replace 5 with the amount of items in your list
/*
<ul>
<li></li>
<li></li>
<li></li>
<li></li>
<li></li>
</ul> */
```
```javascript
p[title="Hello world"]
// <p title="Hello world"></p>
```
```javascript
script:src
// <script src=""></script>
```
```javascript
#header
// <div id="header"></div>
```
```javascript
img
//<img src="" alt="" />
```
```javascript
div+p+bq
/*
<div></div>
<p></p>
<blockquote></blockquote>
*/
```
```javascript
!
/*
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Document</title>
</head>
<body>
</body>
</html>
*/
```
These are just a few of the plethora of shortcuts that are possible when creating an HTML file in VSCode, however, I find myself using these mostly since most HTML files use these tags. To find more of the shortcuts there's a document on the official VSCode website that you can browse through.
Comment below if you know any more shortcuts that you think are helpful in VSCode while coding in HTML. | zahreafranklin |
577,008 | Why Are Some Engineers Missing The Point of Serverless? | The danger of looking at IT architectures from a single angle. Recently, I saw a video fro... | 0 | 2021-01-20T11:24:30 | https://dashbird.io/blog/point-of-serverless/ | aws, serverless, monitoring | ### **The danger of looking at IT architectures from a single angle**.
Recently, I saw[ a video](https://www.youtube.com/watch?v=AuMeockiuLs&t=4s) from a really great developer and YouTuber, **Ben Awad**, where he discussed Serverless not make any sense. Even though I really enjoyed the video, I am not sure if the author's points about serverless are entirely valid, and I want to discuss them in this article.
In the introduction, the author made a joke:
> There are two things in this world I don't understand --- girls and serverless.
I don't know about his relationship with girls, but is he right when it comes to serverless? Let's have a look at his criticism and discuss potential counter-arguments. Spoiler: **I think that serverless DOES make sense if you know WHEN and HOW to use it.**
* * * * *
**Critique about serverless**
-----------------------------
The primary argument mentioned in the somewhat controversial YouTube video is **speed**. To put it more concrete, the major drawback of serverless applications from the author's standpoint is the (*well-known*) **"cold start" **problem --- the added latency where your code potentially cannot start execution until the underlying cloud service finishes allocating compute resources, pulling the code or container image, installing extra packages, and configuring the environment.
Engineers who prioritize **execution speed **above everything else give the impression that **the ultimate success metric **regarding the entire application lifecycle management is measured by how fast our code can finish the task it needs to perform. As a person who has worked in IT and has seen real problems with respect to **maintainability**, and the **ability to quickly and reliably provide business value** by leveraging technology, I am not sure if such a metric **properly measures what matters most** --- the time to value, the speed of development cycles, ease of maintenance, keeping the costs low for our end-users, lowering the risk of operational outages by facilitating seamless IT operations, and finally, allocating most of our engineering time to properly solve the actual business problem rather than spending it on configuring and managing servers.
* * * * *
**Why are some engineers missing the true benefits of serverless?**
-------------------------------------------------------------------
If you care about the execution speed to the point that the occasional 200 milliseconds (*up to 1 second,*[* acc. to AWS*](https://youtu.be/EML6FKBdsNU?t=229)) of added latency is not acceptable by your workloads, **then serverless may indeed not be an option **for you, and that's totally fine. But we should not go as far as saying that serverless doesn't make sense because of that latency. Everyone needs to decide for themselves what latency is acceptable in their use case.
*Serverless* is an **incredibly cost-effective and efficient **way of managing IT infrastructures that is particularly beneficial for IT departments that may not have thousands of dollars that can be spent on idle resources and a specialized team of support engineers maintaining on-prem servers 24/7.
* * * * *
### **The low costs of serverless may significantly outweigh any drawbacks**
In most use-cases I've seen, *serverless* is orders of magnitude less expensive than self-hosted resources, which is already true when only considering the actual compute costs. If you also consider that serverless significantly reduces the time needed to operate, scale, and maintain the infrastructure (*the Total Cost of Ownership --- in short*[TCO](https://en.wikipedia.org/wiki/Total_cost_of_ownership#Computer_and_software_industries)), then you will realize the true amount of cost savings. The truth is that a team of full-time engineers maintaining the infrastructure is considerably more costly than any serverless resources.
I'm not implying that serverless options are always cheaper for every use case. If you are consistently getting hundreds of millions of requests, your workloads are very stable, and you do have enough engineers who can monitor and scale all those resources, you may indeed be better off with your self-managed infrastructure.
* * * * *
**The cold start is a question of configuration and budget**
------------------------------------------------------------
Coming back to the question of costs, the cold start problem these days is, to a large extent, **a function of how much you are willing to spend** and **how you configure** your serverless resources.
If you are willing to pay something extra, there are many ways of mitigating the cold starts, such as leveraging pre-warmed instances (***provisioned concurrency***) or making deliberately **more requests** ([*fake requests*](https://github.com/juanjoDiaz/serverless-plugin-warmup)) to ensure that your environment stays warm. With a monitoring platform such as[ Dashbird](https://dashbird.io/), you can easily **get notified about any cold start** that occurs, thus optimizing your usage of serverless resources. In the image below, you can see that among **29 invocations**, we could observe **one cold start**, which added roughly 180 milliseconds of latency to the total execution time.

*Dashbird observability features help to identify and prevent cold starts --- image by the author*
And you can easily configure a Slack or email alert for any cold start to be aware of how often they occur.

Setting up an alert on cold starts in Dashbird --- image by the author
* * * * *
### **Techniques to improve the latency of your Lambda functions**
You can reduce the latency of serverless functions by **properly leveraging the *"context reuse"***. AWS freezes and stores lambda's execution context, i.e., everything that happens outside of the handler function. If another function is executed within the same quarter, **the frozen environment can be reused**. This means that you will get **significantly better performance** if you specify time-consuming operations such as connecting to a relational database outside of the Lambda handler. [This article](https://medium.com/capital-one-tech/best-practices-for-aws-lambda-container-reuse-6ec45c74b67e) explains the topic in great detail.
There are so many fantastic articles discussing how to **mitigate or even fully eliminate cold start issues **such as [this one](https://dashbird.io/blog/can-we-solve-serverless-cold-starts/) and [this one](https://dashbird.io/blog/cold-starts-impact/). In fact, Dashbird has open-sourced a [Python library](https://github.com/dashbird/xlambda/) called xlambda that can help you keep your Python-based Lambda functions warm.
* * * * *
**What latency is acceptable by your workloads?**
-------------------------------------------------
Eventually, it would be best if you asked yourself what latency is acceptable by your use case. When talking about latency caused by cold starts, we are usually arguing about **milliseconds**. In all use cases that I encountered in my job as a data engineer (*also building backend APIs*), the **latency in day-to-day business is not noticeable**.
Lastly, platforms such as the serverless Kubernetes service from AWS (*also known as EKS on Fargate*) allow you to **mix the serverless and non-serverless data plane** within a single Kubernetes cluster. This mix gives you the ability to run your mission-critical **low-latency workloads on a non-serverless EC2-based data plane**, while other workloads (*ex. batch processing*) can be served by the serverless data plane, obtaining the best of both worlds. You can find more about that in [this article](https://medium.com/better-programming/serverless-kubernetes-cluster-on-aws-with-eks-on-fargate-a7545cf179be).
* * * * *
### **Serverless is about "NoOps" and scalability**
Serverless allows you to **deliver value to your business faster** since the cloud provider takes care of IT operations, i.e., provisioning and scaling compute clusters, installing security patches and upgrades, taking care of hardware crashes, memory issues. This gives you **so much of your time back** that you can leverage to serve your end-customers better. Isn't it what matters the most in the end?
Automation behind serverless [frees up the time of highly skilled engineers ](https://dashbird.io/customers/blow/)so that they can focus on solving business problems rather than managing clusters. It allows to **offload IT operations to DevOps experts at AWS **that have likely more know-how about managing compute than any other company on this planet.
* * * * *
**Use cases that strongly benefit from serverless**
---------------------------------------------------
Imagine that you have just [founded a **start-up**](https://dashbird.io/customers/brisk-voyage/). At first, you may not need a large cluster of resources, and you may have only a single developer. The serverless paradigm allows you to **start small **and **automatically scale** your resources as your start-up grows with the **pay-as-you-go** cost model.
Similarly, another group that can strongly benefit from *serverless* are **small businesses** that may not have a large IT department. Being able to manage the **entire application lifecycle** with perhaps just a [single specialized DevOps engineer](https://dashbird.io/blog/when-dedicated-devops-is-not-available/) (*rather than an entire team of them*) is a huge advantage of serverless.
If your workloads are **seasonal** in nature, serverless is a great option, too. For instance, if you have an **e-commerce** business, you likely experience **seasonal peaks **during Black Friday and Christmas season. A serverless infrastructure allows you to accommodate your compute to such circumstances.
Also, some events are simply **unpredictable**. Imagine that you have been selling hand sanitizers, disinfectants, face masks, and similar goods in your online shop. Then, a global pandemic happened, and now everyone needs your products. A **serverless infrastructure prepares you for any scale** under any circumstances.
* * * * *
### **Code speed vs. speed of development cycles**
Apart from the code execution speed, we should also consider the **development speed**. In many cases, the serverless **microservice paradigm** allows **much faster development cycles** since, by design, it encourages smaller individual components and lets you deploy each service independently from each other.
If serverless enables you to quickly deliver the first versions of an application to your stakeholders and iterate faster in the development cycle (*while simultaneously reducing costs*), then a few milliseconds of added latency due to **occasional cold starts** seem to be a **small price to pay**.
* * * * *
### **Seamless integration with other cloud services**
By taking AWS as an example, each serverless service integrates with CloudWatch for **logging**, IAM for **managing access permissions**, CloudTrail for collecting **metrics **and [**traces**](https://en.wikipedia.org/wiki/Tracing_%28software%29), and more. In addition to that, serverless platforms usually provide you with **basic building blocks** to build larger decoupled microservice architectures, such as integrating with a serverless message queue (SQS), serverless publish-subscribe message bus (SNS), serverless NoSQL data store (DynamoDB), and object storage (S3).
* * * * *
**The actual downsides of serverless not considered in this video**
-------------------------------------------------------------------
Having discussed all the benefits of serverless, **there are also some drawbacks** that have not been mentioned in the video, but I want to list them to give you a **full picture without sugar-coating anything**.
Even though for many use cases, serverless seems like a paradise in terms of costs, scalability, and maintenance, it's **not a silver bullet for every use case**.
1. You risk **vendor lock-in**: the cloud providers make their services so convenient to use and cost-effective that you inherently risk being locked into their specific platform.
2. When comparing serverless to self-hosted resources, you have, to a certain degree,** less control over the compute resources**. For instance, you cannot SSH to the underlying compute instances to perform some configuration manually, and you also have less freedom with respect to the instance type. For instance, you cannot run your serverless functions or containers on **compute instances with GPUs **(*for now*).
3. If you have some specific compliance requirements that prevent you from processing your data on a** shared tenant** in the cloud, then serverless may not be an option for you.
4. Even though splitting your IT infrastructure into self-contained microservices helps manage dependencies and allows for faster release cycles, it brings another challenge regarding the management of all **"moving parts"**. While monitoring solutions, such as[ Dashbird](https://dashbird.io/) solve this particular problem to a large extent, you need to be aware of the trade-offs.
* * * * *
**Conclusion on the critique about serverless**
-----------------------------------------------
Overall, it often becomes **problematic** when we want to use **new paradigms** such as "serverless" or "cloud services" in the **same way** we used to build self-hosted on-prem technologies --- it's simply not the best way of approaching it. By following the "lift and shift" principle when moving your workloads to the cloud,** you lose many benefits of the cloud services or even misinterpret their purpose**. There is no one-size-fits-all solution because we cannot expect any technology to be usable for all use cases, be the fastest in the world, and cost close to nothing without having some downsides (*such as occasional cold starts*).
From my perspective, we should not talk about serverless (*or frankly about anything IT-related*) by only considering a single aspect without examining other crucial aspects, especially those that have been fundamental in the design of the respective technology. **In that sense, serverless DOES make sense if you know WHEN and HOW to use it.**
* * * * *
**References & additional resources:**
[1] Ben Awad --- ["Serverless Doesn't Make Sense"](https://www.youtube.com/watch?v=AuMeockiuLs)
[2] AWS Docs on[ Lambda context reuse](https://docs.aws.amazon.com/lambda/latest/dg/runtimes-context.html)
[3][ Serverless-plugin-warmup](https://github.com/juanjoDiaz/serverless-plugin-warmup) for Javascript and[ xlambda Python package](https://github.com/dashbird/xlambda/)
[4] AWS Docs on[ provisioned concurrency](https://aws.amazon.com/blogs/aws/new-provisioned-concurrency-for-lambda-functions/)
[5][ AWS Lambda under the hood --- video](https://youtu.be/xmacMfbrG28)
[6][ Dashbird blog article about solutions to cold starts](https://dashbird.io/blog/can-we-solve-serverless-cold-starts/)
[7][ Dashbird blog about cold start impact on latency](https://dashbird.io/blog/cold-starts-impact/) | taavirehemagi |
577,258 | Simple Way to Implement Dark Theme in Your Flutter App | Now Days Dark themes are everywhere then why not in your flutter app 🤔 Let's do it - We are going t... | 0 | 2021-01-20T17:15:00 | https://dev.to/pktintali/simple-way-to-implement-dark-theme-in-your-flutter-app-21pf | flutter, dart | Now Days Dark themes are everywhere then why not in your flutter app 🤔
***Let's do it -***
We are going to implement dark theme in a simple flutter app using `darkTheme` property of `MaterialApp`.
Index -
- Initial UI Setup
- Define Dark and Light themes
- Use these themes in MaterialApp
- Final Code
<br\>
## Initial UI Setup
Create a simple flutter app with the following code or you can create your own ui.
```dart
import 'package:flutter/cupertino.dart';
import 'package:flutter/material.dart';
void main() => runApp(MyApp());
class MyApp extends StatefulWidget {
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
TextStyle _style = TextStyle(fontSize: 55);
bool _isDark = false;
@override
Widget build(BuildContext context) {
return MaterialApp(
debugShowCheckedModeBanner: false,
title: 'Flutter Theme',
home: Scaffold(
appBar: AppBar(
title: Text('Flutter Theme Demo'),
centerTitle: true,
),
body: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
children: [
Row(
children: [
Text('Happy', style: _style),
],
),
Padding(
padding: const EdgeInsets.symmetric(vertical: 40),
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text('New', style: _style),
],
),
),
Row(
mainAxisAlignment: MainAxisAlignment.end,
children: [
Text('Year', style: _style),
],
),
Text('2021',
style: _style.copyWith(
color: Colors.deepOrange,
fontWeight: FontWeight.bold,
)),
Padding(
padding: const EdgeInsets.only(top: 80),
child: CupertinoSwitch(
value: _isDark,
onChanged: (v) {
setState(() {
_isDark = !_isDark;
});
},
),
),
Text('Dark'),
],
),
),
),
);
}
}
```
The above code displays Happy New Year 2021 on the screen with a switch to switch between light and dark themes.
## Define Dark and Light themes
Create two `ThemeData` one for light theme and another for dark theme.
Here you can define your own style of themes and colors.
```dart
ThemeData _light = ThemeData.light().copyWith(
primaryColor: Colors.green,
);
ThemeData _dark = ThemeData.dark().copyWith(
primaryColor: Colors.blueGrey,
);
```
In above code I have selected the `primaryColor` green in light mode and blueGrey in dark mode.
## Use these themes in MaterialApp
In your `MaterialApp` widget add the following properties -
```dart
darkTheme: _dark,
theme: _light,
themeMode: _isDark ? ThemeMode.dark : ThemeMode.light,
```
Here we are switching our theme mode between light and dark based on the _isDark `boolean` variable.
That's it, Now you can run your app and play with light and dark themes.
## Final Code
```dart
import 'package:flutter/cupertino.dart';
import 'package:flutter/material.dart';
void main() => runApp(MyApp());
class MyApp extends StatefulWidget {
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
TextStyle _style = TextStyle(fontSize: 55);
bool _isDark = false;
ThemeData _light = ThemeData.light().copyWith(
primaryColor: Colors.green,
);
ThemeData _dark = ThemeData.dark().copyWith(
primaryColor: Colors.blueGrey,
);
@override
Widget build(BuildContext context) {
return MaterialApp(
darkTheme: _dark,
theme: _light,
themeMode: _isDark ? ThemeMode.dark : ThemeMode.light,
debugShowCheckedModeBanner: false,
title: 'Flutter Theme',
home: Scaffold(
appBar: AppBar(
title: Text('Flutter Theme Demo'),
centerTitle: true,
),
body: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
children: [
Row(
children: [
Text('Happy', style: _style),
],
),
Padding(
padding: const EdgeInsets.symmetric(vertical: 40),
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text('New', style: _style),
],
),
),
Row(
mainAxisAlignment: MainAxisAlignment.end,
children: [
Text('Year', style: _style),
],
),
Text('2021',
style: _style.copyWith(
color: Colors.deepOrange,
fontWeight: FontWeight.bold,
)),
Padding(
padding: const EdgeInsets.only(top: 80),
child: CupertinoSwitch(
value: _isDark,
onChanged: (v) {
setState(() {
_isDark = !_isDark;
});
},
),
),
Text('Dark'),
],
),
),
),
);
}
}
```
This is my first post on the Dev Community. If you have suggestion or any problem in my post comment down, I will try to resolve it as soon as possible. | pktintali |
577,624 | The Microservice Architecture Perspective | Making software that serves more than a couple of thousand users can be hard. The difficulty is not... | 0 | 2021-01-22T12:36:27 | https://medium.com/bina-nusantara-it-division/the-microservice-architecture-perspective-c7bac4cc57ce | architecture, webdev, microservices, beginners | ---
title: The Microservice Architecture Perspective
published: true
date: 2020-12-31 16:51:07 UTC
tags: ['architecture', 'webdev', 'microservices', 'beginners']
canonical_url: https://medium.com/bina-nusantara-it-division/the-microservice-architecture-perspective-c7bac4cc57ce
---
Making software that serves more than a couple of thousand users can be hard. The difficulty is not in making the app itself but in how we make the app reliable. Microservices is a solution to messy problems like these. Instead of relying on one large server, we use a bunch of small ones to solve our problem. To elaborate on this subject further here are a few perspectives I have on the microservices architecture.

### One Down, Many More To Go
In my honest opinion, one of the reasons I go with a microservice is the reliability factor. With multiple servers, this can be the case. We add reliability to the service by adding more of them. This technique is called [load balancing.](https://www.citrix.com/en-id/glossary/load-balancing.html#:~:text=Load%20balancing%20is%20defined%20as,server%20capable%20of%20fulfilling%20them.)
Instead of burdening all the traffic to one server, you can balance it to multiple servers. So it can be nearly impossible to down the service. The best part of this is that you don’t need to have expensive high throughput servers to make this happen. For example, you can host your server on a few [digital ocean droplets](https://www.digitalocean.com/products/droplets/), instead of one large one.
Though load balancing alone cannot determine a microservice, there are other characteristics that would need to be fulfilled. This is but only one of the advantages of the microservice pattern.
If you are using a monolith pattern logically you can still use load balancing, the only downside would be that you would need multiple high throughput servers to serve your app. Multiplying the cost.
### Pay For What You Need
Before I start, let me say. This section is debatable. I am explaining this from my point of view and my previous experiences. Because when your entire service is determined by small services, it can be easy to cut costs. We can buy only the things that we need.
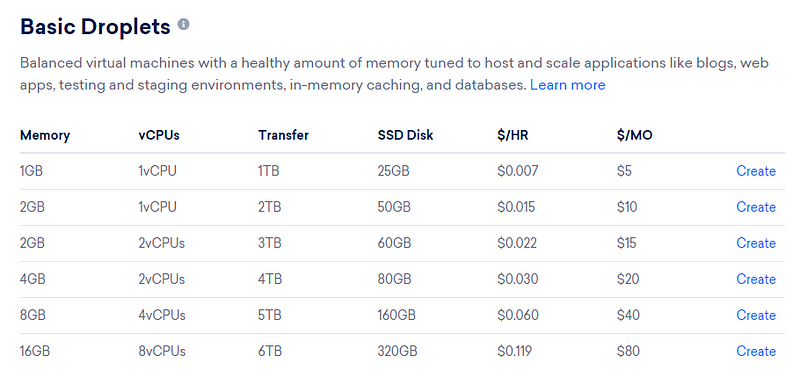
For explanation purposes let’s say a 1 GB droplet can handle about 1k users. So to handle 5k users you probably would need to use the 8GB droplet for the price of $40 a month.
Instead, you can use 3 droplets. Two 1 GB droplets and one 4 GB droplet for $30 a month. We buy two 1 GB droplets so we can use one for the service and use the other one for load balancing. With this scheme, you saved $10 a month.
This is a very simple example. A better one would be when we have separate microservices that connect to each other, we can tune the prices to our exact use of computing power.
For example, the donuts API may have more load than the coffee API. We can then scale up the donuts API server to be able to handle those requests. Being able to specify upgrades by service can help reduce costs tremendously.
### Separate Your Interests
Monoliths have this habit of merging all services together, related or not. This causes a problem when one of the services goes down, it will take the entire app down with it. If you value reliability, you wouldn’t want that.
Using the microservice architecture each service can be separated, making it independent of one another. This type of API development is called domain driven development or DDD. It is a very interesting way of designing systems small that can scale big. [You can read more about DDD here](https://www.confluent.io/blog/microservices-apache-kafka-domain-driven-design/#:~:text=Microservices%20have%20a%20symbiotic%20relationship,that%20makes%20the%20system%20work.). Reading more into this topic might lead you to cool system design patterns like [CQRS](https://microservices.io/patterns/data/cqrs.html), [Database per service](https://microservices.io/patterns/data/database-per-service.html), and [API Composition](https://microservices.io/patterns/data/api-composition.html).
The picture above explains my point perfectly. Connections from the client would be made to a gateway/edge API. The edge API would then connect to the multiple microservices available for each specific request. With the corresponding databases behind each specific API.
Say, the user wants some books, of course, the data would be retrieved from the books API. After seeing the catalog of books, the user made up their mind and wishes to check out. The user is then connected to the check out API. Notice that all the services are independent of each other it does not coincide with one another other than the edge API. It adds reliability to the app.
### Scale More!
Why does this section have an exclamation mark? Because this is the main gist of using microservices. It is the best feature anyone could have asked for. Put reliability and scalability together and what do you have? A great user experience.
Not all companies might need the blessing of microservices but for those that do it really does make a huge difference. All the sections before this one support this. Separable domains, cost-effectiveness, and reliability.
But you do not need to scale everything. When you are building a team of services using microservices will help you in the long run, but when you are making an MVP or some other small apps you would not need to implement microservices at all. It might even slow you down!
Microservices is not the grand bullet for everything, even though it has both reliability and scalability to its name. It has good things to offer for select cases, not for everyone.
### Small and Compact
Microservices like the name entails are very small apps that communicate with each other. With specificity in mind, teams can deploy new services quickly without breaking another.
This coincides perfectly with agile teams that want to reach a certain target. Deployments are easy because it allows for easy and straightforward testing. You only need to test the things that you deploy, there is no need to test the other services along with it.
Almost all the articles I’ve read about microservices applaud the ease of deployments this architecture has to offer. Though that’s not all the benefits of being small and compact.
Maintainability wise, it will be much easier than monoliths. The functions are simple because the folders aren’t merged into one project. Honestly from my own experience handling a monolith, traversing the folders was very difficult. Filenames can sometimes be similar in a way that I confuse which service is which.
Sure, people can say that a confusing monolith project reeks of bad code management. When you have more than 100 features in a project it does tend to get a little messy. Add to the number of teams responsible for different features contributing to the **same codebase** 🤯.
> I can only imagine the number of branches that repo has…
### More Autonomy and Faster Development Speeds
With microservice, this doesn’t have to be. Microservice brings more autonomy to the team. Working together between teams is not easy. We have our own schedules that we need to attend. But when we use the microservices concept, the pain of inter-team management becomes invisible.
All you need would be a coding standard, and you would be good to go. Though more autonomy, coupled with faster development could lead to trouble **if you don’t have good documentation**.
Let me make this clear, working autonomously is great and all. But in the end, you still need to communicate. What better way to miscommunicate other than having no documentation. Believe me, I have experienced these kinds of things first hand. Microservices does not solve problems like these.
With more autonomy teams can be more business-oriented with their goals, timelines become much shorter and development can focus more on new features.
### With Great Power Comes Great Documentation
Elaborating from the previous section, a good analogy for microservices would be “With great power comes great responsibility”. I am not kidding, when you have tons of services you would **wish** **for good documentation**. For a good perspective here is an illustration of the Netflix microservice backend.

Now imagine, how much of that would you remember. The answer is none. That’s why documentation is important. Probably using Netflix as an example is a huge exaggeration — _but hey it gets the point across._
Now I know — _every application needs documentation_. That’s true but it becomes double for microservices. There are benefits to good documentation though. The better documented the microservice is, the reusable probability of each service will be increased. This brings us to the next point.
### Reusability
What I love about writing code is how much less of it I have to write. Get what I am saying? Reusable components, reusable APIs, reusable _everything_! I would integrate every one of my apps into one large system, and if I can reuse some parts of it for another app I would do it without notice.
The part that I like about microservices is that it’s very portable, I mean one service can be accessed by many. That’s why I usually try to make microservices as general as I can make it — _doesn’t mean that I won’t make it specific when I need to_. It just comes as a natural thing to do to reuse things you made.
### Conclusion
To summarize microservice architectures are usually used to help increase the reliability of a system. The benefits of using a microservice architecture are as follows:
- Made to be reliable.
- Pay for what you need.
- Write separate applications for each domain.
- Have a nature to scale.
- Small and compact.
- Separated development for teams that wants to move fast.
- Reusability factor.
Though the microservice architecture does come with its faults. The disadvantages of using a microservice are as follows:
- With great power, comes great documentation.
- Small companies with few teams are not suitable for this architecture.
- Does not fit every business model (e.g monoliths are better for MVPs).
- Because it has a nature to scale, it can become bloated if not checked. We can’t all be like Netflix.
This was my perspective regarding microservices. I hope it was clear enough of an explanation. | agustinustheo |
577,786 | Why outsource your auth system? | You’re a software engineering leader, and you’re great at your job. You know that the optimal path... | 0 | 2021-02-26T15:17:32 | https://fusionauth.io/blog/2021/01/20/why-outsource-auth/ | auth, authentication, outsource | ---
title: Why outsource your auth system?
published: true
date: 2021-01-20 07:00:00 UTC
tags: auth, authentication, outsource
canonical_url: https://fusionauth.io/blog/2021/01/20/why-outsource-auth/
---
You’re a software engineering leader, and you’re great at your job. You know that the optimal path for software development lies in figuring out which components of your design to implement from scratch and which have already been implemented by specialists and can be reused.
You also know that these aren’t decisions that you can only make once – you have to keep reevaluating based on environment changes and the needs of new products.
Authentication is one of those components that you deal with all the time. Auth is a necessary part of any software product, but how you implement auth is not necessarily always the same. Careful consideration is needed, because your decision to outsource will not only impact speed of development, but also long-term product maintenance – you don’t want to slow down time to market because you re-implemented an entire auth system unnecessarily, but you also don’t want to use an auth system that is going to cause problems down the road.
So what are the primary considerations when making your decision?
## Speed to market
This is the most obvious consideration. Depending on the features you need, it could literally take months to implement auth in-house, whereas it could take less than a day to incorporate an outsourced solution.
You could say “but what if we only need a bare-bones implementation? Some salted hashes in a database and we’re good to go!” That’s a totally valid point, and if you don’t anticipate needing sophisticated auth features then your best bet might be to do a quick in-house implementation and move on.
However, time and time again I’ve seen product developers underestimate the sophistication of features that will be required when their userbases grow. Most of the time development organizations then fall prey to the sunk costs fallacy and double down on augmenting their in-house solution, even when it may be more efficient to abandon the home-grown effort and replace it with an outsourced solution. This will cause huge issues for maintainability, which I’ll talk about further below.
## Consequences of an auth breach
Planning for the worst possible case can prevent total financial ruin for your company or division. If a breach of security happens and PII (Personally Identifiable Information) is leaked from your in-house auth system, it can not only cause your company reputational damage but also significant financial penalties (not to mention potential jail time if you try to cover up the breach).
If you outsource your auth system you can limit your liability, and also protect your reputation – if there is a breach on your auth provider’s side, it’s likely that the breach will extend beyond your company. A breach in an outsourced auth provider that is used by many different companies will be big news, and customers will be more likely to forgive you for making a mistake in your choice of auth provider than for implementing a poor auth system yourself.
A not-insignificant addendum is that I believe your in-house system is much more likely to suffer a breach than an outsourced provider who is an expert in security. I have no studies to support this claim, but I have never seen a major auth provider compromised, and I’ve definitely seen companies suffer breaches due to their own in-house auth implementations – [this article discusses a compilation of 21 million plaintext passwords collected from various breaches](https://arstechnica.com/information-technology/2019/01/hacked-and-dumped-online-773-million-records-with-plaintext-passwords/) wherein passwords were not hashed and salted by auth systems.
Properly storing passwords is an incredibly low bar, and yet companies that manage their own auth still do it incorrectly all the time.
## Consequences of an auth outage
While less damaging than breaches, outages can still cause reputational damage and liability issues if your SLAs make uptime guarantees. Similarly to breaches, if you outsource your auth system it’s likely that any auth outage will extend beyond your company.
As an example, when Microsoft’s Azure Active Directory (AAD) [went down for a good portion of the afternoon late last year](https://www.zdnet.com/article/microsofts-azure-ad-authentication-outage-what-went-wrong/), logins for applications across the internet stopped working.
When your competitors’ authorization systems are down at the same time yours are, nobody blames you for it, but when you’re the only company having issues, you suffer reputationally. No matter what your outsourced auth system is (FusionAuth, Cognito, AAD, etc), you can be almost certain that you won’t be alone in the event of an outage.
## Maintainability
There are trade-offs here. The benefits to an in-house system include:
- Your engineers can design the exact system to fit your needs, and you’ll have unrestricted ability to add very specific features if requirements change over time.
- If the same engineers who built the system are maintaining it, then they’ll have the context required to anticipate issues as they add features.
However, the drawbacks can be large:
- Complex new features can take significant time to build. Outsourced auth systems likely have these features already built (things like multi-factor authentication, user management interfaces, analytics and audit logs, and brute force hack detection, among others).
- With an in-house solution, you’ll have to budget time to monitor new security threats and patch your system in a rapidly evolving threat landscape.
- You won’t get the benefits of a dedicated team that are constantly improving your auth system. This is actually a bigger deal than it seems, because if you outsource auth then other companies will also be filing issue reports and feature requests on your behalf, so you reap the benefits of those extra eyes as well.
- In the case of mergers or acquisitions, an in-house solution is likely to be terrible at combining different databases of users and managing things like duplicates or incomplete data. Such enterprise identity unification efforts can founder on internal auth systems. FusionAuth, on the other hand, supports modeling different user bases with tenants.
## Cost of in-house vs outsourced auth
When building an in-house auth system your costs are all ostensibly sunk (engineer salaries). However, if building your system in-house delays time to market or prevents creation of other features, the build could cost you a significant amount of real income. There will also be on-going maintenance costs with an in-house solution.
When making cost calculations, you should compare:
**Revenue lost by slower time-to-market PLUS engineering cost to implement in-house solution PLUS on-going maintenance costs of in-house solution PLUS increased risk of data breach PLUS increased risk of outage PLUS increased risk during a merger or acquisition**
vs
**The monthly cost incurred by an outsourced provider PLUS the lack of complete control**
When evaluating different auth providers, you’ll also want to consider whether an outsourced provider charges on a sliding scale based on number of users or if the cost is fixed. AWS Cognito, for instance, will continue to charge more as your application gains more users. FusionAuth, in contrast, has options that charge a single rate for unlimited users. If your app is small and you don’t expect it to grow much, a sliding scale may be better for you. If you don’t want a large unexpected bill as you gain more users, a provider that allows for fixed costs may be more appealing.
## Auth may be unrelated to your core competency
As a final consideration, you may want to evaluate if your engineers even have the ability to implement a secure in-house auth system without a significant investment in education. This is something that many leaders dismiss, since they have great faith in the intelligence and skill of their people.
However, knowledge and intelligence aren’t the same, and just because your engineers are capable of becoming auth experts doesn’t mean you want them to spend the time to do so.
As an engineering leader, you have a responsibility to ensure that your engineers are spending their time on efforts that will optimally contribute to the long-term success of your organization. Auth is a necessary component, but is it really a differentiator for your application?
Only you have the context to make the best decisions for your company, but I hope this article has helped you think through some of the considerations involved in outsourcing your auth. | fusionauth |
1,920,833 | 123B | 123B Thuong hieu giai tri theo chuan gambling 2024 1123B INFO mang den cac tro choi the thao, da ga,... | 0 | 2024-07-12T09:26:19 | https://dev.to/1123binfo/123b-23j0 | 123B Thuong hieu giai tri theo chuan gambling 2024 1123B INFO mang den cac tro choi the thao, da ga, tai xiu, no hu, ban ca voi ngan uu dai hap dan
Dia chi: 16 Ly Thai ToThac Gian Q Thanh Khe Da Nang
Website: https://1123b.info/
Hotline: 09628710108
Gmail: 1123b info@gmail com
socials;
https://www.youtube.com/@1123binfo/about
https://twitter.com/1123binfo
https://500px.com/p/1123binfo?view=photos
https://www.facebook.com/1123binfo/
https://www.liveinternet.ru/users/binfo1123/profile
https://www.tiktok.com/@1123binfo
https://www.reddit.com/user/1123binfo/
https://1123binfo.livejournal.com/424.html
https://ok.ru/profile/592848613321/statuses/156530576838857
https://diigo.com/0w6t7h
https://sites.google.com/view/1123binfo
https://medium.com/@1123b.info/about
https://www.tumblr.com/1123binfo
https://www.deviantart.com/1123binfo
https://www.twitch.tv/1123binfo/about
https://www.behance.net/1123binfo
https://www.slideshare.net/1123binfo
https://vimeo.com/1123binfo
https://www.mixcloud.com/1123binfo/
https://linktr.ee/1123binfo
https://dribbble.com/1123bInfo/about
https://issuu.com/1123binfo
https://note.com/1123binfo
https://hub.docker.com/u/1123binfo
https://flipboard.com/@1123bInfo
https://qiita.com/1123binfo
https://www.blogger.com/profile/15234594639558235465
https://1123bs-stunning-site.webflow.io/
https://www.kickstarter.com/profile/761666694/about
https://www.scoop.it/u/1123b-info-gmail-com
https://1123binfo4.wordpress.com/2024/05/24/1123binfo/
https://www.plurk.com/binfo1123
https://peatix.com/user/22344911/view
https://binfo1123.livejournal.com/
https://www.reverbnation.com/artist/1123binfo
https://www.liveinternet.ru/users/binfo1123/profile
https://linktr.ee/1123binfo
https://musescore.com/user/82575847
https://www.giantbomb.com/profile/binfo/
https://www.beatstars.com/1123binfo/about
https://sketchfab.com/1123binfo
https://gab.com/1123binfo
https://muckrack.com/1123binfo-1123binfo/bio
https://coub.com/e77505fb2e7dd793a5c5
https://wellfound.com/u/1123bi-nfo
https://www.instagram.com/1123binfo/
https://www.goodreads.com/user/show/178519514-1123binfo-1123binfo
https://letterboxd.com/1123binfo/
https://about.me/info1123b
https://hearthis.at/1123binfo/set/1123binfo/
https://binfo.contently.com/
https://www.pixnet.net/pcard/620756650815d412d9
https://soundcloud.com/1123binfo
https://www.last.fm/user/binfobinfo | 1123binfo | |
578,027 | Gimme Ideas for a new project | Nodejs Deno PostgreSQL/Mongo Webassembly Rust C C++ This is my list of languages/tools I use regular... | 0 | 2021-01-21T04:52:50 | https://dev.to/rishitkhandelwal/gimme-ideas-for-a-new-project-2gel | Nodejs
Deno
PostgreSQL/Mongo
Webassembly
Rust
C
C++
This is my list of languages/tools I use regularly | rishitkhandelwal | |
578,293 | MySQL Configuration Performance Tuning Workflow | Every database system operation on a server will have four main system resources. The CPU is the powe... | 0 | 2021-01-21T13:38:35 | https://releem.com/blog/tpost/op7am2y9b1-mysql-configuration-performance-tuning | webdev, mysql, devops, performance | Every database system operation on a server will have four main system resources. The CPU is the powerhouse behind the system. The memory encodes, stores, and retrieves information. Disk I/O is the input and output process for data moving from storage to other hardware components. The network consists of the client connections to the server.
When using of these resources aren’t optimized, they can cause performance degradation of the operating system and database system. Fine-tuning the parameters of MySQL is vital for DBAs and DevOps engineers that want to prevent and quickly solve performance issues causing SQL server slowdowns. Ultimately the most important metric, is how quickly the query is received and the data returned by the server. The following results can be achieved for database systems with tuned and configured system parameters:
* Improve application performance.
* Improve the efficiency of server resource utilization.
* Reduce costs.
## Adjust MySQL parameters
Difference situations and events may require recalculating and adjusting MySQL system parameters. Instead of a DBA spending resources troubleshooting server performance issues.
We recommend adjust MySQL parameters in the following cases:
* First-time server setup.
* Low applications performance.
* Changing of server resources (RAM, CPU).
* Changing the application or application load like the count of visitors.
## Tuning MySQL Parameters
To get the most out of your server and curating the ultimate workflow we created a step-by-step guide to doing so:

### 1. MySQL Documentation
MySQL has excellent documentation resources useful to even veteran database system administrators. MySQL provides server reference manuals for each currently supported version.
[MySQL 8.0 Reference Manual](https://dev.mysql.com/doc/refman/8.0/en/)
[MySQL 5.7 Reference Manual](https://dev.mysql.com/doc/refman/5.7/en/)
[MySQL 5.6 Reference Manual](https://dev.mysql.com/doc/refman/5.6/en/)
MySQL 5.6 will not be supported after February 2021.
It’s helpful for all users of MySQL to be familiar with these resources. And it’s highly recommended to spend time working through the documentation to better understand how the database server works.
### 2. Study MySQL Configuration Best Practices
There are an array of resources available to learn about MySQL configuration. MySQL has hundreds of configuration options, but for many server needs, only a handful are critical. The tuning will vary depending on workload and hardware, but DBAs that familiarize themselves with best practices (for their specific version of MySQL) will better be able to understand and solve performance issues.
Releem has collected an [amazing list of articles and resources](https://github.com/Releem/awesome-mysql-performance) that are related to MySQL / MariaDB / Percona configuration.
### 3. Analyze Monitoring Data
Next, monitoring software should be used to continually monitor and analyze data from the MySQL server. These tools will help monitor serve health while providing unique ways to visualize metrics and handle alerts. Open-source as well as licensed software is available. Below are some of the most highly recommended options:
**Zabbix** is an open-source monitoring tool capable of monitoring networks, servers, cloud, applications, and services. Zabbix is highly secure and easily scalable.
**Prometheus** is open-source monitoring software marketing it’s simplicity and visualization tools.
**Percona Monitoring and Management** is an open-source monitoring solution aimed at helping improve database performance and improving data security
**Nagios XI** is a premium monitoring software but offers a free trial for new users. Nagios XI promises to be limitlessly scalable and highly customizable.
Using any of these monitoring tools will provide critical data on how MySQL uses server resources and history values of MySQL status.
### 4. Analyze MySQL Status
Make sure the server has been running for at least 24 hours. Analyze MySQL status to detect any variables that need configuration. Querying with "SHOW GLOBAL STATUS;" will deliver various metrics.
### 5. Use Scripts to get Configuration Recommendations
Using an automated script will save the incredible hassle and time of searching through the metrics. A script will check the metrics from the server and compare them against expected reasonable values. Anything operating outside the expected values will be flagged for review.
[MySQLTuner](https://raw.githubusercontent.com/major/MySQLTuner-perl/master/mysqltuner.pl) is a powerful configuration tuner that is open-source and available on [Github](https://github.com/major/MySQLTuner-perl).
[MySQL Tuning-Primer.sh](https://raw.githubusercontent.com/BMDan/tuning-primer.sh/master/tuning-primer.sh) is another strong open-source option on [Github](https://github.com/BMDan/tuning-primer.sh). This tool is older and should be used only with MySQL versions 5.5 - 5.7.
### 6. Calculate Values of MySQL Performance Settings
Now armed with the monitoring data, MySQL status, and configuration recommendations from steps 3 through 5, the specific changes and values can finally be determined to minimize bottlenecks and inefficiencies. The MySQL documentation and configuration best practices that were studied in steps 1 and 2 will show their value during this process. Refer to the documentation, resources, and internet as needed.
### 7. Create New Configuration File
When MySQL is first installed a standard configuration file is installed in the base directory. The new configuration file can be created to reflect the parameter changes made based on the previous steps.
### 8. Apply New Configuration File
The new performance settings can be applied incrementally to test stability and performance or the configuration file can be applied to update all changes at once. The server should now be optimized and ready for queries!
## Streamline the MySQL Tuning
Without experience, fine-tuning the parameters of MySQL requires a significant investment to learn the surrounding information. DBAs and DevOps engineers need to understand the process otherwise, it’s an inefficient use of time. Thankfully MySQL database server tuning doesn’t need to be completed very often. But expect to revisit this process when a new server is setup, performance issues arise, system resources are changed, or an application is changed.
| drupaladmin |
578,381 | 6 Tips to Reduce ReactJS App Maintainance Cost | There are currently 1,100,183 live websites using React JS. The powerful Javascript library powers... | 0 | 2021-01-28T14:05:00 | https://www.botreetechnologies.com/blog/best-ways-to-reduce-reactjs-app-maintenance-cost/ | react, technology, application | ---
title: 6 Tips to Reduce ReactJS App Maintainance Cost
published: true
date: 2021-01-21 10:26:08 UTC
tags: ReactJS,Technology,Application
canonical_url: https://www.botreetechnologies.com/blog/best-ways-to-reduce-reactjs-app-maintenance-cost/
---

There are currently [1,100,183 live websites](https://www.similartech.com/technologies/react-js) using React JS. The powerful Javascript library powers 312,467 unique domains. The library is so popular that [13% of developers prefer to React](https://www.thinslices.com/blog/infographic-react.js-statistics) as their choice of JS library, as compared to Vue that stands at 4%
###What is the React JS Framework?
In essence, React is not a framework – it is a Javascript library. React web applications have a powerful and stunning user interface. Most developers use React JS features as a way to enhance the user experience. Since the React JS app abstracts the DOM away, it offers a simpler programming model and higher performance. That’s why more and more startups [hire ReactJS developers](https://www.botreetechnologies.com/hire-reactjs-developers) for simple yet quick prototypes.
React is often compared with Angular and Vue for building web applications. However, developing React web applications is a preferred choice. The reasons are simple – it enables building native [applications using React Native](https://www.botreetechnologies.com/react-native-development).
But often the app requires high maintenance once it’s done. There are multiple elements and components in the UI, which call for regular maintenance. However, it can be challenging and costly. Let’s look at the factors responsible for the high cost of ReactJS app maintenance.
###Factors leading to High ReactJS App Maintenance Cost
React JS web applications can be costly to maintain. While the library is not responsible alone for the increase in cost, it contributes heavily to it. Here are a few factors responsible for the high cost of ReactJS web applications –
1. **Third-party add ons** require heavy maintenance apart from the library, leading to high-cost of app updates and upgrades.
2. **Outdated technology versions** lead to increased errors and bug fixing, which takes a lot of time.
3. **Wrong programming approach** also adds to the cost of React JS app maintenance.
4. **Outsourcing partners** can put a hole in your budget. Updating the app will cost you heavily with the wrong outsourcing company.
5. **Without clear documentation**, React.js developers will struggle to maintain the web application as they won’t know the project structure.
###Read more: [Integrating Django web framework with ReactJS](https://www.botreetechnologies.com/blog/django-with-reactjs/)
The post [6 Best Ways to Reduce ReactJS App Maintenance Cost](https://www.botreetechnologies.com/blog/best-ways-to-reduce-reactjs-app-maintenance-cost/) appeared first on [BoTree Technologies](https://www.botreetechnologies.com/blog). | botreetech |
578,964 | Deno — HTTP Requests and File Manipulation | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-22T02:31:02 | https://thewebdev.info/2020/10/30/deno%e2%80%8a-%e2%80%8ahttp-requests-and-file-manipulation/ | deno, programming, javascript, webdev | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
Deno is a new server-side runtime environment for running JavaScript and TypeScript apps.
In this article, we’ll take a look at how to get started with developing apps for Deno.
### Managing Dependencies
We can manage dependencies in our Deno apps.
We can reexport modules with the `export` statement:
`math.ts`
```
export {
add,
multiply,
} from "https://x.nest.land/ramda@0.27.0/source/index.js";
```
`index.ts`
```
import { add, multiply } from "./math.ts";
console.log(add(1, 2))
console.log(multiply(1, 2))
```
We reexport the items in `math.ts` and import it in `index.ts` .
### Fetch Data
We can fetch data with the Fetch API with Deno.
The Fetch API is implemented with Deno.
For example, we can write:
```
const res = await fetch("https://yesno.wtf/api");
const json = await res.json()
console.log(json);
```
Then when we run:
```
deno run --allow-net index.ts
```
We get something like:
```
{
answer: "yes",
forced: false,
image: "https://yesno.wtf/assets/yes/7-653c8ee5d3a6bbafd759142c9c18d76c.gif"
}
```
logged.
The `--allow-net` flag enables network communication in our script.
To get HTML, we can write:
```
const res = await fetch("https://deno.land/");
const html = await res.text()
console.log(html);
```
Then we download the HTML code from the `deno.land` URL.
To catch errors, we write:
```
try {
await fetch("https://does.not.exist/");
} catch (error) {
console.log(error.message)
}
```
Then we log the message from the `error.message` property.
### Read and Write Files
Deno comes with an API for reading and writing files.
They come with both sync and async versions.
The `--allow-read` and `--allow-write` permissions are required to gain access to the file system.
For example, we can write:
`index.ts`
```
const text = await Deno.readTextFile("./people.json");
console.log(text)
```
`people.json`
```
[
{
"id": 1,
"name": "John",
"age": 23
},
{
"id": 2,
"name": "Sandra",
"age": 51
},
{
"id": 5,
"name": "Devika",
"age": 11
}
]
```
Then when we run:
```
deno run --allow-read index.ts
```
We read the JSON file and log the data.
`Deno.readTextFile` returns a promise so we can use `await` .
### Writing a Text File
To write a text file, we can use the `writeTextFile` method.
For example, we can write:
```
await Deno.writeTextFile("./hello.txt", "Hello World");
console.log('success')
```
to create `hello.txt` and use the string in the 2nd argument as the content.
Then when we run:
```
deno run --allow-write index.ts
```
We can also use the `writeTextFileSync` method to write text file synchronously.
For example, we can write:
```
try {
Deno.writeTextFileSync("./hello.txt", "Hello World");
console.log("Written to hello.txt");
} catch (e) {
console.log(e.message);
}
```
### Read Multiple Files
We can read multiple files by writing:
```
for (const filename of Deno.args) {
const file = await Deno.open(filename);
await Deno.copy(file, Deno.stdout);
file.close();
}
```
Then when we run:”
```
deno run --allow-read index.ts foo.txt bar.txt
```
We should see the contents of `foo.txt` and `bar.txt` printed.
We call `Deno.open` to open each file.
`Deno.args` has the command line arguments, which is `['foo.txt', 'bar.txt']` .
And then we call `Deno.copy` to copy the content to `stdout` .
And then we close the filehandle with `file.close` .
### Conclusion
We can make HTTP requests with the fetch API and read and write files with Deno. | aumayeung |
579,090 | Vending Machine -Computational Thinking 101 | Beginner | A lot of the times people think of programming as something very hard to learn and impossible. I say... | 0 | 2021-01-22T06:26:30 | https://dev.to/wahidustoz/computational-thinking-beginner-01-vending-machine-59f4 | cpp, algorithms, beginners, programming | A lot of the times people think of programming as something very hard to learn and impossible. I say it is only a matter of how determined and devoted you are! People spend tremendous amounts of time playing the most challenging games. They become experts and even beat those who spent years to come up with algorithms for that game. It is only a matter of determination!
I have decided to show how computational thinking and programming can be so much fun, while solving some real-life problems.
Let’s dig in!
## **Vending Machine**
There are 3 types of drinks available in the Vending Machine.
1. Americano — 500₩
2. Caffe Latte — 400₩
3. Lemon Tea — 300₩
User selects the drink number, and inserts money. Vending machine accepts money only in multiple of 100 (eg. 200, 1300, 7100) and money must be enough to buy at least one drink.
Given that the drink is selected and correct amount of money inserted, we should make a program which calculates how many 500₩ and 100₩ coins to return. **We must return least amount of coins!**
> *Disclaimer: For this little program, we assume all inputs are correct!*
**Examples**

## **Solution**
We need 2 variables to get the user input for *drink number* and *payment*. Since both inputs are whole numbers, we use **integer** types.

Now, it is time to get the user input.

Let’s start the sweaty work and calculate the change and units to return.
1. In plain English, the change is the amount of payment minus the cost of the drink. We need a whole new variable to hold the change amount. Also, the change depends on the drink selected, so we use **switch **statement to conditionally find the change.
*By the way, we can print the drink name right here!*

2. To return least number of coins, we must return 500₩ coins as many times as possible, agree? To do that, we just need to divide change by 500 and take the whole part. Luckily for us, in C language if you divide integer by integer, you only get the integer result, which discards the floating part of the division!

3. Next, we just have to find the remainder after we got the 500s, and calculate how many 100₩ coins are in that remainder. We can use **modulo(%)** operator to find the remainder after all the 500s. Then, use division one more time to find the 100s.

Finally, we just have to print our calculations.

It is a real-life example of computational thinking to solve life problems.
I hope you enjoyed and learnt something. I am open for comments and discussions!
Here is a link to complete code. Go nuts and play around with it!
[https://repl.it/@codwiznet/VendingMachine](https://repl.it/@codwiznet/VendingMachine) | wahidustoz |
1,179,261 | When all else fails, Ask for help. | The other night I was updating content for a site. I made and deployed some changes. Then decided to... | 0 | 2022-08-31T17:37:06 | https://dev.to/jarvisscript/when-all-else-fails-ask-for-help-1cfo | The other night I was updating content for a site. I made and deployed some changes. Then decided to check and see if they updated to the live site.
When I entered the site in the address bar, Firefox gave a HTTPS warning. I knew the site had a certificate, so tried again the same warning.
So now I have to go to the admin panel and it says the certificate has expired. It should have auto renewed. So I tried to renew manually but that option is not there. This doesn't make sense and it's late at night. I decided to look at it again in the morning.
Next morning I checked again. No option to renew. I have the DNS and hosting set up but still no way to renew the certificate. I check email for any missed messages. They are none there. There are successful auto renewal notices for other sites, but not this one. Not even a notice it was about to expire.
I check online support docs. I've done everything on their docs lists so I should have the option to renew. I just don't.
So I sent in a ticket, with a brief description of the problem and my attempts to solve it.
Shortly later replied. "Your site meets the requirements so I manually re-issued a cert." They even sent a link to their test results. All green check marks.
They ask that I verify it worked on my end. It did, so I sent them a thank you note.
Still don't know why it didn't auto update, like it usually does, but it is fixed.
If something doesn't work, it's OK to ask for help. When you do need help, tell them your problem and the steps you took to try to solve it. Don't go straight to them with only your problem.
Sometimes I've solved stuff just by trying to explain it to someone. In explaining something, sometimes a new solution can present itself. By talking about it you have to adjust your thought process and can see the problem from a different angle.
When someone solves a problem, thank them. Also, let them know the problem has been resolved so they can close their ticket.
| jarvisscript | |
579,126 | 【Java】Set Background Image/ Color for Word Document | Usually the default background of Word documents is white, and adding image or a bit of color is prob... | 0 | 2021-01-22T07:48:19 | https://dev.to/codesharing/java-set-background-image-color-for-word-document-405 | java, word, background | Usually the default background of Word documents is white, and adding image or a bit of color is probably the easiest way to liven up these boring document. This article will demonstrate how to set background image, solid background color as well as gradient background color for a word document in Java program.
**1.** Import the jar dependency of a 3rd party free API to your Java application (2 methods)
● Download the free API ([Free Spire.Doc for Java](https://www.e-iceblue.com/Download/doc-for-java-free.html)) and unzip it, then add the Spire.Doc.jar file to your Java application as dependency.
● Directly add the jar dependency to maven project by adding the following configurations to the pom.xml.
```xml
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc.free</artifactId>
<version>3.9.0</version>
</dependency>
</dependencies>
```
**2.** The relevant code snippets
**[Example 1]** Set background image:
```java
import com.spire.doc.*;
import com.spire.doc.documents.BackgroundType;
import java.io.*;
public class WordBackground {
public static void main(String[] args) throws IOException {
String inputFile="test2.docx";
String backgroundImg="C:\\Users\\Administrator\\Desktop\\bg.png";
String outputFile="out/background.docx";
//load a word document
Document document= new Document(inputFile);
//set background image
document.getBackground().setType(BackgroundType.Picture);
document.getBackground().setPicture(backgroundImg);
//save the file
document.saveToFile(outputFile, FileFormat.Docx);
}
}
```

**[Example 2]** Set solid background color:
```java
import com.spire.doc.*;
import com.spire.doc.documents.BackgroundType;
import java.awt.*;
import java.io.*;
public class BackgroundColor {
public static void main(String[] args) throws IOException {
String inputFile="test2.docx";
String outputFile="out/background2.docx";
//load a word document
Document document= new Document(inputFile);
//set the background color to light gray
document.getBackground().setType(BackgroundType.Color);
document.getBackground().setColor(Color.lightGray);
//save the file
document.saveToFile(outputFile, FileFormat.Docx);
}
}
```
**[Example 3]** Set gradient background color:
```java
import com.spire.doc.*;
import com.spire.doc.documents.BackgroundType;
import com.spire.doc.documents.GradientShadingStyle;
import com.spire.doc.documents.GradientShadingVariant;
import java.awt.*;
import java.io.*;
public class GradientColor {
public static void main(String[] args) throws IOException {
String inputFile="test2.docx";
String outputFile="out/background3.docx";
//load a word document
Document document= new Document(inputFile);
//set the gradient background color
document.getBackground().setType(BackgroundType.Gradient);
document.getBackground().getGradient().setColor1(Color.white);
document.getBackground().getGradient().setColor2(Color.BLUE);
document.getBackground().getGradient().setShadingVariant(GradientShadingVariant.Shading_Down);
document.getBackground().getGradient().setShadingStyle(GradientShadingStyle.Horizontal);
//save the file
document.saveToFile(outputFile, FileFormat.Docx_2013);
}
}
```

| codesharing |
579,143 | Cool way of sharing your Linux terminal session with named pipe/FIFO | Introduction In Linux and other Unix systems, a pipe is a way of redirecting the output of... | 0 | 2021-01-22T08:15:40 | https://devdojo.com/bobbyiliev/cool-way-of-sharing-your-linux-terminal-session-with-named-pipefifo | linux, ubuntu, devops | # Introduction
In Linux and other Unix systems, a **pipe** is a way of redirecting the output of one command or a process to another. This is also known as an unnamed pipe. For example, you could combine the following two commands:
```bash
ls -lah | grep some_string
```
With the above command, you would forward the output of the `ls -lah` command to a `grep` command, which will search for `some_string`.
A named pipe on the other side is an extension of the traditional pipe concept. Names pipes are also known as FIFO, which stands for **First In, First Out**. The named pipes are actually files on the file system itself.
You can tell if a file is a named pipe by the `p` bit in the file permissions section.
```jsx
prw-r--r-- 1 root root 0 Jul 4 19:17 file_name
```
Or you could use the `file` command to check the type of the file:
```
file file_name
file_name: fifo (named pipe)
```
In this tutorial, I'll show you how you could use named pipes to share your screen, without using any software like Zoom or Google Hangouts, with one of your students or co-workers!
# Prerequisites
You and the person that you want to share your screen with would need to have access to the same Linux machine via SSH for example.
You could use a DigitalOcean Droplet to achieve that.
You can use my referral link to get a free $100 credit that you could use to deploy your virtual machines and test the guide yourself on a few DigitalOcean servers:
[DigitalOcean $100 Free Credit](https://m.do.co/c/2a9bba940f39)
# Creating a named pipe (FIFOs)
Let's first start by creating a named pipe on your Linux machine.
You can create named pipes (FIFOs) by using the `mkfifo` command.
The syntax that you would need to use is:
```
mkfifo file_name
```
After that if you run `ls -l` you will see the following output:
```bash
prw-r--r-- 1 root root 0 Jul 4 19:17 file_name
```
# Start sharing your terminal session
In order to achieve the sharing effect we will use the `script` command.
The `script` command is tool that let's you records your terminal session.
Once you have your named pipe ready, all you need to do is run the following `script` command:
```
script -f file_name
```
After that, without closing your current session, open a second terminal session, or ask the person that you would like to share your terminal session with, to just use the `cat` command followed by your FIFO:
```
cat file_file
```
Once you have that ready, whatever you run on your main screen will be outputted on the second screen in real-time!
Here is a quick video example:
{% youtube 4YK9Qb3PVS0 %}
# Conclusion
This is a cool way of using named pipes to share your terminal session with a colleague that you are working with or with a student without having to deal with the video delays of conference apps!
Hope that this helps you and you get to have some fun with it! | bobbyiliev |
579,269 | From Shock to Acceptance: The Five Stages of API Testing | Today I'd like to talk about the importance of API testing and explaining how the dominance of micros... | 0 | 2021-01-22T10:36:45 | https://dev.to/sergey_mogilevsky/from-shock-to-acceptance-the-five-stages-of-api-testing-2g7h | testing, api, architecture | Today I'd like to talk about the importance of API testing and explaining how the dominance of microservice architecture in modern services is forcing us to adapt to new QA requirements. An integral step in this adaptation is the ability to test a product without using a UI interface. It's not as difficult as may sound.
##The Importance of API Testing##
New and unknown things frighten us. But sometimes, if you dig deeper, everything turns out to be not as scary as it might have seemed. In this article, I will tell you why API testing is not difficult and how this skill will help you become a cool QA specialist.
When it comes to API testing in a team, a beginner QA specialist gets lost 一 even looking towards the server’s direction is scary, let alone sending requests to it. These concerns are justified. While testing the UI, you involuntarily become a user of the product and see the same graphical interface as a potential client. It is enough to enter the text in the required field of the browser, and you will receive an understandable error. When getting familiar with API, it may seem that it requires a different testing strategy. In fact, all you need is a little more technical knowledge:
- understanding client-server architecture;
- principles of the HTTP protocol;
- knowledge of JSON and XML data transfer formats.
And, of course, self-confidence.
##Why Testing API
I'll help you figure out how to deal with the first three points, but to achieve the last one, you need to accept one simple thing: microservices rule the world. Monolithic architecture is slowly becoming a thing of the past. Today, all trendy and cloud solutions are created on a microservice architecture. In such a product, the UI may not be provided at all, and you will have to face backend testing.
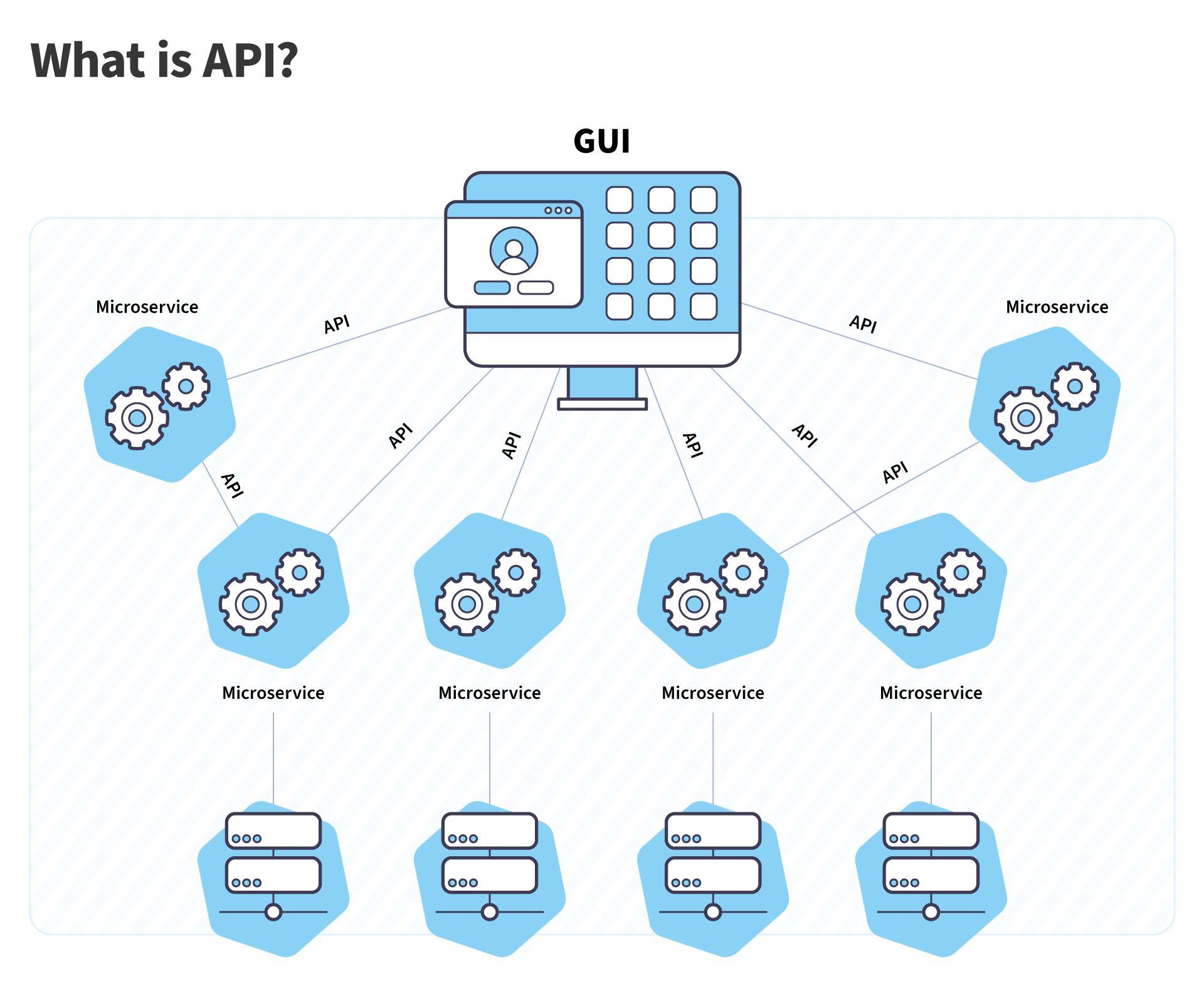
In a monolith, the backend communicates with the frontend through the program code according to a single unchanged scheme. It's like playing table tennis with your partner 一 your roles are obvious. Microservices are different: each of them is a separate server with its own logic. One creates photos, the other processes them, the third one stores, the fourth transfers to the user. In this case, hitting the tennis ball is not enough. It becomes like baseball: first, you hit the ball, then run after it to catch it. Likewise, a microservice can be both a client and a server in relation to other "players".
Imagine there is a service that can apply filters to photos, and another one can store files. There are two options for their communication:
The service with filters goes to the photo storage, takes the required file, and paints the photo in sepia. Here, the filter service is the client and the store service is the server.
The storage service takes one of its photos and carries it to the service filter in order to determine which filter is applied to the photo. The service filter is as follows: "Dude, this is sepia." This is how the client and server are reversed.
To make microservices understand each other, they came up with an API (Application Programming Interface), a special software interface. Testing helps ensure that a program fulfills its intended purpose and can interact correctly with other programs. It is possible to validate and automate API tests even with a minimal theoretical base. The main thing is to find the right tools.
##Stage 1: Shock
Imagine QA specialist John, who was told to test the functionality of the process of creating custom cards in the hospital software. The product does not have a UI, the data comes from a third-party system. That is, the service is tailored for one program to use another. Prior to that, John spent his entire career doing purely manual UI testing. So the first emotion he experiences at this testing stage is one of shock. There are no familiar buttons and fields in front of him.

Calm down, John. Here is the most common tool for API testing 一 Postman. The program allows us to issue a request in a form that is understandable to us and transmits it to the server in a language it understands. We will insert all further steps in Postman.
To request information from a server, you need the HTTP protocol, a hypertext transfer format in a client-server architecture. There are different types of requests. Sometimes the client wants to ask or send something to the server, sometimes to delete information from it. This is how HTTP request methods appeared. The most common are: GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, TRACE, PATCH. The method defines the action relative to the server.
So, we choose the path along which we will send the request:
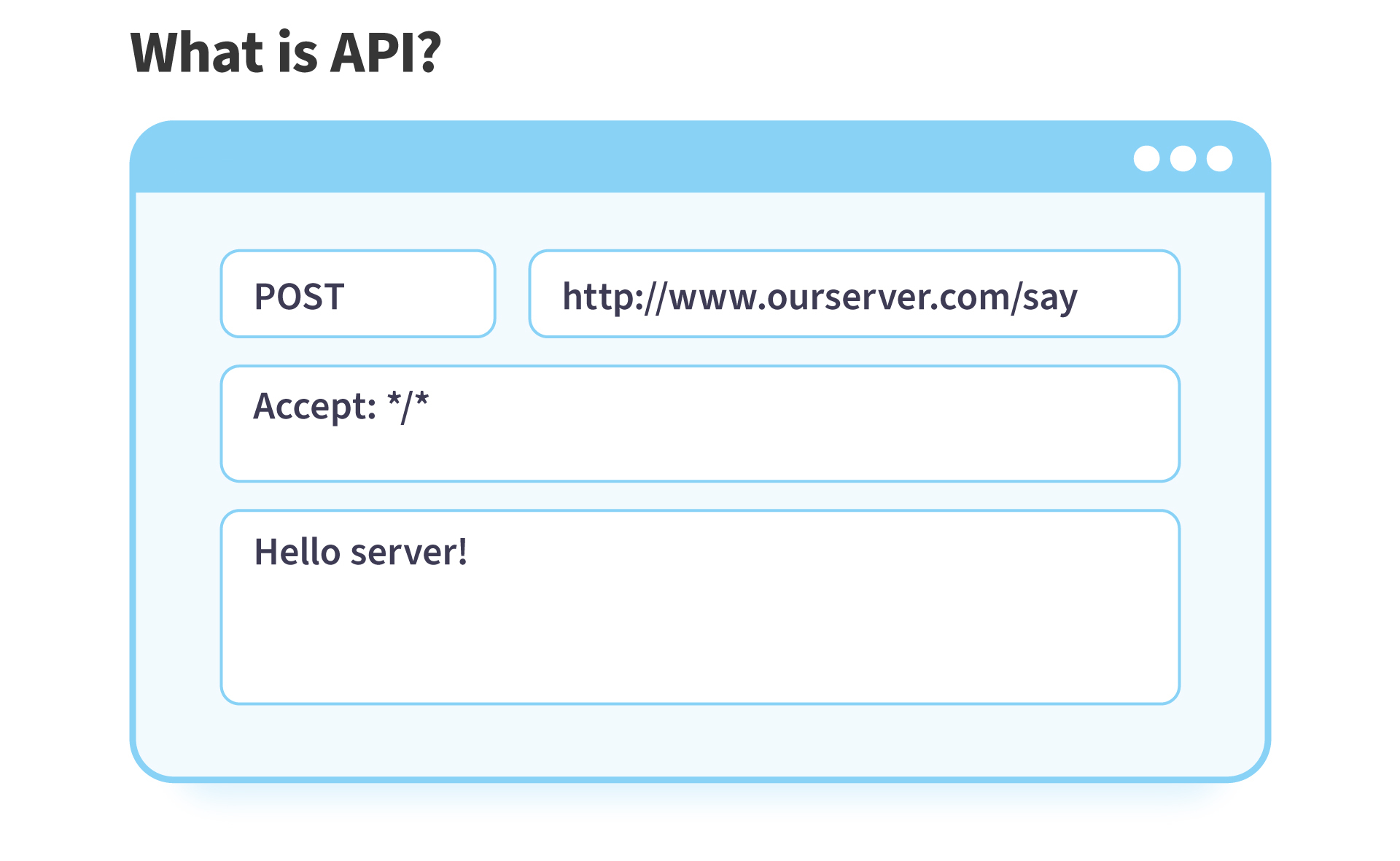
What we want to tell the server is the request body. The item is optional. The key information for the server is displayed in the request transmission method. Returning to our example of an eHealth program, in the "Path" line we write the required link, and in the body we indicate information about the medical card: first name, last name, patient's age and diagnosis.
The header helps the server to decrypt the message correctly. Sometimes it is not associated with the request body or is absent at all. By specifying “Accept” in the header, we let the server know what data we are ready to receive in response. If you are satisfied with any information, the header should contain the value "* / *".
Sending…
##Stage 2: Denial#
Postman issued a set of text, quotes, commas, and other characters. John does not understand anything, he is angry. He experiences denial - so far he has little faith that something useful will come of it.
Fortunately, the HTTP protocol has a description of not only requests but also of server responses. 415 is a status code. The server indicates that it has received data that it cannot read. There are many status codes for different situations. The answer ‘200 OK’ is an indicator of a successful request. The 404 code is known to all Internet users and means that the resource was not found. So, I will not dwell on status codes. You can easily google them all.
What did John do wrong? Most likely, he did not think about the correct "packaging" of the document. JSON and XML are used for storing and transmitting data. These two are completely interchangeable formats. It is difficult to convey a large amount of information only through text. Of course, this could be done through text if the data were not read by the computer. It must know in advance the format and types of data, how to find them in the system, and work with them. You cannot send XML or JSON to all servers and think that you will be understood. The developers prescribe the format of the received data when creating the program.
John googled and found out that his server can communicate in JSON, so again he sends a request to the same address in the required format. Success! The server responded with another set of characters, but thanks to Postman, they can be translated.
So let’s sum up: the HTTP protocol defines the communication format between the client and the server. To send an HTTP request, you need special software (Postman, and you can also try Insomnia REST Client, HTTPie or another program from the list). The client, John, sends a message and receives an appropriate response. Communication with the server takes place in one of the formats - JSON / XML. The received data is decrypted by software.
##Stage 3: Bargaining
To automate an API test, you need to master a programming language: Python, Java, C#, or whatever you like or need in the project. So tester John goes like: “Automation? Oh, I’d better not. I’ll need to write a ton of code. I can never do that. Let's limit by testing, okay? "
In fact, a few lines would be enough. To run a simple test, you just need to master a language base. You can also find libraries for writing HTTP requests. Anyway, learning the basics of programming will be a significant investment in your professional experience.
You shouldn't have to spare a few hours of your time to open your way to automation. It will be difficult at first, but I assure you that soon you will notice a huge leap in your technical development.
##Stage 4: Acceptance
I no longer need to persuade John to understand the benefits of API testing and automation. In my team of 16 people, five are testing API web applications. I think this is a clear sign of the demand for these skills. Any site or application using modern technologies has a complex backend. With a high degree of probability, the developer will choose a microservice architecture for its implementation. Therefore, you cannot go further without the API test.
##The secret is....that there is no secret##
There is no magic. The approaches to testing the functionality of the UI, augmented reality, databases, API are usually the same. The strategies of thinking over the test cases and maintaining checklists are almost the same as the strategy in ordinary manual UI tests. For API testing, the hard skills described above and additional tools are needed.
When building your career as a QA professional, you get fewer offers on the market, if you don't know how to do something. You limit your opportunities and career chances. You won’t be included in the top-ranked projects. And this is where everyone wants to be, right? That’s what I’m talking about.
To master testing, you do not need to study theory for years. A few months of intensive practice is enough. To help you, I'll share my API testing cheat sheet, so you could look for useful materials here. Basic theory, tasks, tools, libraries, and frameworks - everything that will help you immerse yourself in the topic and continue learning on your own. Go for it!
##Useful resources for further learning##
**Basic theory**
API https://www.howtogeek.com/343877/what-is-an-api/
REST API https://restfulapi.net/
Comparing SOAP & REST
https://www.springboottutorial.com/rest-vs-soap-web-services
HTTP request structure
https://www.tutorialspoint.com/http/http_requests.htm
HTTP response structure
https://www.tutorialspoint.com/http/http_responses.htm
HTTP status codes
https://www.tutorialspoint.com/http/http_status_codes.htm
Client-server architecture
https://www.britannica.com/technology/client-server-architecture
Micro-server architecture
https://smartbear.com/solutions/microservices/
Microservices vs Monolith architecture
https://www.n-ix.com/microservices-vs-monolith-which-architecture-best-choice-your-business/
JSON description https://www.json.org/json-en.html
JSON vs XML https://www.w3schools.com/js/js_json_xml.asp
**Tools**
Postman alternatives https://www.pcstacks.com/postman-alternatives/
Traffic proxy
https://www.apriorit.com/dev-blog/591-proxies-for-application-testing
Fiddler
Burp Suite Community Edition
https://portswigger.net/burp/documentation/desktop/getting-started
JSON validator https://jsonlint.com/
XML validator https://xmllint.com/en
Notepad++ https://notepad-plus-plus.org/downloads/
Atom https://atom.io/
**Courses**
Codecademy https://www.codecademy.com
Free Code Camp https://www.freecodecamp.org
edX https://www.edx.org/course/subject/computer-science
Coursera https://www.coursera.org
**Libraries and frameworks**
Python + requests + pytest
https://www.ontestautomation.com/writing-tests-for-restful-apis-in-python-using-requests-part-1-basic-tests/
Java + REST Assured
https://techbeacon.com/app-dev-testing/how-perform-api-testing-rest-assured
C# + RestSharp
https://www.ontestautomation.com/restful-api-testing-in-csharp-with-restsharp/
Groovy + Spock
https://blog.j-labs.pl/2019/05/Test-your-REST-API-with-Spock-Introduction-to-Spock-Framework
**Other**
Practical exercises https://www.codewars.com/ | sergey_mogilevsky |
579,311 | How to connect to Wi-Fi on Linux via the terminal using nmcli | Introduction Why using the Network-Manager's cli? Sometimes Ubuntu Network Manager can be... | 0 | 2021-01-22T12:06:21 | https://dev.to/alexgeorgiev17/how-to-connect-to-wi-fi-on-ubuntu-terminal-using-nmcli-1763 | ubuntu, network, terminal | ## Introduction
Why using the Network-Manager's cli? Sometimes Ubuntu Network Manager can be really dodgy and you might be unable to connect to any Wi-Fi Hotspot via the GUI (Graphical user interface).
The Network-Manager may fail to start and even when manually restarting the service via the terminal you might still face issues to connect to any Wi-Fi Hotspot, even to an already known and saved home network.
I had that issue on dual boot setups and on standalone Linux installations and found it really annoying especially during the WFH (Working from home) period that we're all going through.
It’s really handy that the Network-manager has command-line tool for controlling the Network Manager.
nmcli gives you the opportunity to connect/disconnect and also do some other things with the Network-Manager like turning your PC into a Wi-Fi Hotspot itself. Here are the basics commands you need in order to connect to any available network.
## General usage of the cli:
If you want to check all of your already saved connections run the following command:
```
nmcli c
```
In order to see the available Wi-Fi Hotspots, run the following command:
```
nmcli d wifi list
```
The output should be like this:
You can also use:
```
sudo iwlist wlan0 scanning
```
**Note You might need to change wlan0 with your actual interface, this can be checked easily with the ifconfig or iwconfig commands.**
Another thing you can do is to list your network interfaces as this will be needed when you want to disconnect from a certain network:
```
iwconfig
```
The output should be like this:
Now when you know your Wifi Interface you can easily disconnect it using the Network Manager’s cli using the following command:
```
nmcli d disconnect WifiInterface
```
and example is:
```
nmcli d disconnect wlan0
```
We’re using wlan0 since this is the network interface we’re using.
In order to connect you can use:
```
nmcli d connect WifiInterface
```
example:
```
nmcli d connect wlan0
```
However you can also use the following commands since you can also specify the exact Wi-Fi network you’re connecting to.
**Note: Have in mind that this might only work on Ubuntu 16.04 – In order to disconnect use**:
```
nmcli c down Wi-Fi-Name
```
example
```
nmcli c down Wi-Fi-Name
```
And in order to connect to a saved Wi-Fi network use:
```
nmcli c up Wi-Fi-Name
```
example:
```
nmcli c up Wi-Fi-Name
```
## Conclusion
That's pretty much how you can now use nmcli to connect Wi-Fi networks
However, if you face any issues feel free to send me an email with the error/issue that you’re facing and we can check it.
You can also check the full man page of the [nmcli](https://manpages.ubuntu.com/manpages/focal/en/man1/nmcli.1.html)
man page if you want to check all of the options available!
## Support
If you've enjoyed reading this post or learned something new and would like to support me to publish more content like this one you can support me with buying me a coffee:
<a href="https://www.buymeacoffee.com/ageorgiev" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>
Thank you! | alexgeorgiev17 |
579,344 | Mutable effect in Python | Python mutable effect | 10,643 | 2021-01-22T13:18:43 | https://learnbyexample.github.io/100_page_python_intro/mutability.html | python, beginners, ebook, exercises | ---
title: "Mutable effect in Python"
published: true
description: "Python mutable effect"
canonical_url: https://learnbyexample.github.io/100_page_python_intro/mutability.html
series: 100 Page Python Intro
tags: Python,beginner,ebook,exercises
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/x0gbxspe60srzezgp6gd.png
---
`int`, `float`, `str` and `tuple` are immutable data types. On the other hand, types like `list` and `dict` are mutable. This chapter will discuss what happens when you pass a variable to a function or when you assign them to another value/variable.
## id
The [id()](https://docs.python.org/3/library/functions.html#id) built-in function returns the *identity* (reference) of an object. Here's some examples to show what happens when you assign a variable to another value/variable.
```python
>>> num1 = 5
>>> id(num1)
140204812958128
# here, num1 gets a new identity
>>> num1 = 10
>>> id(num1)
140204812958288
# num2 will have the same reference as num1
>>> num2 = num1
>>> id(num2)
140204812958288
# num2 gets a new reference, num1 won't be affected
>>> num2 = 4
>>> id(num2)
140204812958096
>>> num1
10
```
## Pass by reference
Variables in Python store references to an object, not their values. When you pass a `list` object to a function, you are passing the reference to this object. Since `list` is mutable, any in-place changes made to this object within the function will also be reflected in the original variable that was passed to the function. Here's an example:
```python
>>> def rotate(ip):
... ip.insert(0, ip.pop())
...
>>> nums = [321, 1, 1, 0, 5.3, 2]
>>> rotate(nums)
>>> nums
[2, 321, 1, 1, 0, 5.3]
```
This is true even for slices of a sequence containing mutable objects. Also, as shown in the example below, `tuple` doesn't prevent mutable elements from being changed.
```python
>>> nums_2d = ([1, 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200])
>>> last_two = nums_2d[-2:]
>>> last_two[0][-1] = 'apple'
>>> last_two[1][-1] = 'ball'
>>> last_two
([1.2, -0.2, 0, 'apple'], [100, 'ball'])
>>> nums_2d
([1, 3, 2, 10], [1.2, -0.2, 0, 'apple'], [100, 'ball'])
```
As an exercise, use `id()` function to verify that the identity of last two elements of `nums_2d` variable in the above example is the same as the identity of both the elements of `last_two` variable.
## Slicing notation copy
If you wish to copy whole/part of a `list` object such that changing the copy version doesn't affect the original `list`, the solution will depend on the presence of mutable elements.
Here's an example where all the elements are immutable. In this case, using slice notation is safe for copying.
```python
>>> items = [3, 'apple', 100.23, 'fig']
>>> items_copy = items[:]
>>> id(items)
140204765864256
>>> id(items_copy)
140204765771968
# the individual elements will still have the same reference
>>> id(items[0]) == id(items_copy[0])
True
>>> items_copy[0] += 1000
>>> items_copy
[1003, 'apple', 100.23, 'fig']
>>> items
[3, 'apple', 100.23, 'fig']
```
On the other hand, if the `list` has mutable objects, using slice notation won't stop the copy from modifying the original.
```python
>>> nums_2d = [[1, 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
>>> nums_2d_copy = nums_2d[:]
>>> nums_2d_copy[0][0] = 'oops'
>>> nums_2d_copy
[['oops', 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
>>> nums_2d
[['oops', 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
```
## copy.deepcopy
The [copy](https://docs.python.org/3/library/copy.html#module-copy) built-in module has a `deepcopy()` method if you wish to recursively create new copy of all the elements of a mutable object.
```python
>>> import copy
>>> nums_2d = [[1, 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
>>> nums_2d_deepcopy = copy.deepcopy(nums_2d)
>>> nums_2d_deepcopy[0][0] = 'yay'
>>> nums_2d_deepcopy
[['yay', 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
>>> nums_2d
[[1, 3, 2, 10], [1.2, -0.2, 0, 2], [100, 200]]
```
As an exercise, create a deepcopy of only the first two elements of `nums_2d` object from the above example.
| learnbyexample |
579,597 | Markdown Cheat Sheet part-2 | Links There are different ways to create links in Markdown. [This is inline-style... | 13,146 | 2021-01-22T17:38:56 | https://dev.to/garimasharma/how-to-add-links-in-markdown-1bnf | beginners, markdown, github, showdev | # Links
There are different ways to create links in Markdown.
```
[This is inline-style link](https://github.com/Garima-sharma814)
[This is referenced link][I am referred here]
[You can also use numbers in referenced link][1]
Can be empty as well [link itself]
I'm Referenced here !
- [I am referred here]: https://github.com/Garima-sharma814
- [1]: https://github.com/Garima-sharma814
- [link itself]: https://github.com/Garima-sharma814
```
> Make sure you don't use '-' or any symbol in referenced links I used it to make it visible
[This is inline-style link](https://github.com/Garima-sharma814)
[This is referenced link][I am referred here]
[You can also use numbers in referenced link][1]
Can be empty as well [link itself]
I'm Referenced here !
[I am referred here]: https://github.com/Garima-sharma814
[1]: https://github.com/Garima-sharma814
[link itself]: https://github.com/Garima-sharma814
# Line breaks
### How to add line breaks ?
```
Three or more
- hyphens
---
- Asterisks
***
- Underscores
___
```
Three or more
- hyphens
---
- Asterisks
***
- Underscores
___ | garimasharma |
579,614 | Add multiple classes in pug | Pug, formerly known as Jade, is a template engine thas uses a JavaScript render. Sometimes we have to... | 0 | 2021-01-22T18:12:01 | https://giuliachiola.dev/posts/add-multiple-classes-in-pug/ | pug, templatengine | **[Pug](https://github.com/pugjs/pug)**, formerly known as [Jade](http://jade-lang.com/), is a template engine thas uses a JavaScript render. Sometimes we have to add a class conditionally based on a variable, here I go with some tricky solutions I found.
## One condition to check
The easiest way to check a class in _pug_ is using the [ternary operator](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Conditional_Operator)
```pug
- var cond1 = true
.c-component(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE' )
```
_HTML output_
```html
<div class="c-component cond1-true"></div>
```
But there are other two ways to write the same exact condition in pug:
```pug
- var cond1 = true
//- (1)
.c-component(class={'cond1-true': cond1 === true})
//- (2)
.c-component(class={cond1True: cond1 === true})
```
### Important
> 🧨 **!important**
> (1) kebab-case class `cond1-true` must be wrapped in quotes
> (2) camelCase class `cond1True` can skip wrapper quotes
_HTML output_
```html
<div class="c-component cond1-true"></div>
<div class="c-component cond1True"></div>
```
## More than one condition to check
If we have to check _two_ condintions, we can go also in this case with the ternary operator to choose which classes we want.
We can write the conditionals in three ways:
1. using two `class` attributes separated by space
```pug
(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE' class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
```
2. using two `class` attributes separated by comma
```pug
(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE', class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
```
3. using two `class` attributes, one for each parentesis
```pug
(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE')(class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
```
All three:
_pug_
```pug
- var cond1 = true
- var cond2 = false
.c-component(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE' class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
.c-component(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE', class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
.c-component(class=cond1 ? 'cond1-TRUE' : 'cond1-FALSE')(class=cond2 ? 'cond2-TRUE' : 'cond2-FALSE')
```
_HTML output_
```html
<div class="c-component cond1-TRUE cond2-FALSE"></div>
<div class="c-component cond1-TRUE cond2-FALSE"></div>
<div class="c-component cond1-TRUE cond2-FALSE"></div>
```
If we have a ternary option with the second operand **empty**, we could simplify the pug syntax:
```pug
- var cond1 = true
- var cond2 = false
.c-component(class=cond1 && 'cond1-TRUE' class=cond2 && 'cond2-TRUE')
//- or more explicit
.c-component(class=cond1 ? 'cond1-TRUE' : '' class=cond2 ? 'cond2-TRUE' : '')
```
_HTML output_
```html
<div class="c-component cond1-TRUE"></div>
```
[🖥 Codepen example](https://codepen.io/giuliachiola/pen/xxGGBgW).
> 📚 More info
>
> - [Pug class attributes docs](https://pugjs.org/language/attributes.html#class-attributes)
> - [Pug documentation](https://pugjs.org/api/getting-started.html)
> - [Jade to HTML coverter](https://jsonformatter.org/jade-to-html)
> - [HTML to Jade coverter](https://html2jade.org/)
> - [Pug playground](https://pug.now.sh/)
| giulia_chiola |
579,730 | How to Detect Browser in PHP | We will to write a function in PHP using $_SERVER['HTTP_USER_AGENT'] to detect the browser an d SO of... | 0 | 2021-01-22T20:22:17 | https://dev.to/charlygarcia120/how-to-detect-browser-in-javascript-21hf | php, browser | We will to write a function in PHP using $_SERVER['HTTP_USER_AGENT'] to detect the browser an d SO of the client
```javascript
function detect() {
$browser=array("SAFARI","CHROME","IE","EDGE","OPR","MOZILLA","NETSCAPE","FIREFOX");
# default values for browser an SO
$info['browser'] = "OTHER";
$info['os'] = "OTHER";
# search browser and SO
foreach($browser as $parent)
{
$s = strpos(strtoupper($_SERVER['HTTP_USER_AGENT']), $parent);
$f = $s + strlen($parent);
$version = substr($_SERVER['HTTP_USER_AGENT'], $f, 15);
$version = preg_replace('/[^0-9,.]/','',$version);
if ($s)
{
$info['browser'] = $parent;
$info['version'] = $version;
}
}
return $info;
}
```
My wish is that you find usefull this function , and can be used in your programs to detect Browser and SO and show diferent pages , depending of your needs | charlygarcia120 |
579,923 | Unit Test Vue Apps with Vue Test Utils — Lifecycle and Async Tests | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-23T02:09:51 | https://thewebdev.info/2020/09/19/unit-test-vue-apps-with-vue-test-utils%e2%80%8a-%e2%80%8alifecycle-and-async-tests/ | vue, javascript, testing, webdev | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
With the Vue Test Utils library, we can write and run unit tests for Vue apps easily.
In this article, we’ll look at how to write unit tests with the Vue Test Utils library.
### Lifecycle Hooks
When we call `mount` or `shallowMount` to mount our components, the lifecycle methods will be run.
However, the `beforeDestroy` or `destroyed` methods won’t be triggered unless the component is manually destroyed with `wrapper.destroy()` .
The component won’t be automatically destroyed at the end of each test, so we have to clean up any dependencies manually.
### Writing Asynchronous Tests
When we write tests, we have to be aware that any changes to reactive properties are done asynchronously.
This means that we have to the test as an async function or use `then` and run our test code that runs after the reactive property is updated in the `then` callback.
For example, we can write:
```
import { shallowMount } from '@vue/test-utils'
const Counter = {
template: `
<div>
<button @click="count++">Add up</button>
<p>clicks: {{ count }}</p>
</div>
`,
data() {
return { count: 0 }
}
}
describe('Counter', () => {
it('renders new number when Add up button is clicked', async () => {
const wrapper = shallowMount(Counter)
const button = wrapper.find('button')
const text = wrapper.find('p')
await button.trigger('click')
expect(text.text()).toBe('clicks: 1')
})
})
```
to `await` the `trigger` method so that we can check the updated value of the `count` reactive property after the update is done.
We can also write:
```
import { shallowMount } from '@vue/test-utils'
const Counter = {
template: `
<div>
<button @click="count++">Add up</button>
<p>clicks: {{ count }}</p>
</div>
`,
data() {
return { count: 0 }
}
}
describe('Counter', () => {
it('renders new number when Add up button is clicked', () => {
const wrapper = shallowMount(Counter)
const button = wrapper.find('button')
const text = wrapper.find('p')
button.trigger('click')
.then(() => {
expect(text.text()).toBe('clicks: 1')
})
})
})
```
which is the same code without async and await.
### Asserting Emitted Events
We can check which events are emitted when we do something with the component.
To do this, we can call the `emitted` method to check which events are emitted.
For instance, we can write:
```
import { shallowMount } from '@vue/test-utils'
const Foo = {
template: `
<div>
<button @click="$emit('foo')">emit foo</button>
</div>
`,
}
describe('Foo', () => {
it('emits foo event when the emit foo button is clicked', async () => {
const wrapper = shallowMount(Foo)
const button = wrapper.find('button');
await button.trigger('click')
expect(wrapper.emitted().foo).toBeTruthy()
})
})
```
We have the `Foo` component that calls `$emit` to emit the `'foo'` event when we click it.
Then in the last line of the test, we call `wrapper.emitted()` to check if the `foo` event is emitted.
If it’s emitted, then the `foo` property should be truthy.
We can also check which payload is emitted. For example, we can write:
```
import { shallowMount } from '@vue/test-utils'
const Foo = {
template: `
<div>
<button @click="$emit('foo', 123)">emit foo</button>
</div>
`,
}
describe('Foo', () => {
it('emits foo event with payload 123 when the emit foo button is clicked', async () => {
const wrapper = shallowMount(Foo)
const button = wrapper.find('button');
await button.trigger('click')
expect(wrapper.emitted().foo.length).toBe(1)
expect(wrapper.emitted().foo[0]).toEqual([123])
})
})
```
We check the `foo` property’s `length` to see how many times it’s emitted.
And the payload is checked by accessing `foo` ‘s array value and checking the content.
### Conclusion
We can check if events are emitted and be aware that lifecycle hooks like `destroy` aren’t run automatically. | aumayeung |
580,179 | Uptime of macOS system via terminal | You are logged into your system. In this case, it's macOS. You are facing just a simple question. Are... | 0 | 2021-11-13T20:10:48 | https://dev.to/stankukucka/uptime-of-macos-system-via-terminal-4jip | systems, help, security |
You are logged into your system. In this case, it's macOS. You are facing just a simple question. Are you the only one who is logged in? I would like to give you an answer to this simple question with a bit of explanation. Here in upcoming lines, there will be a bit of theory background behind it.
##Your System Uptime
In case your system is healthy (understand as an official system with applied updates), you are the only physical user logged in. You can check this logged in information with a simple command you will enter into the terminal. But there is a trick in that, will explain in next lines hereunder. Open your <code>Terminal.app</code> you'll find out in <code>Finder</code> in the section <code>Applications</code> and <code>Utilities</code>. For more informations check official [Terminal User Guide](https://support.apple.com/guide/terminal/welcome/mac).
By entering <code>uptime</code> command you'll be informed in one line output about the current time, number of days your system is up, number of logged-in users etc.
```
uptime
```
If you'll enter this very same command into the terminal in capital form as <code>UPTIME</code>, you'll receive a more readable summary of the logged-in sessions by the user.
```
UPTIME
```
The same output can be given by entering <code>w</code> command into the terminal.
```
w
```
##Minimum of logged-in users
Do remember you will always have a minimum of 2 logged-in users. By default when you open another terminal session it will be counted as another active user logged in. In other words, if you open four-terminal sessions, you will see 4 users logged in +1 as the default logged-in user I have written about.
| stankukucka |
580,262 | VoxelArt Web Augumented Reality (WebAR) | Voxel AR For this Project, I used AR.js and Aframe.js library, Image Descriptor, and Voxe... | 0 | 2021-01-23T15:31:33 | https://dev.to/maksumrifai/voxelart-web-augumented-reality-webar-2man | augumentedreality, virtualreality, webvr, webxr | ## Voxel AR
<img src="https://raw.githubusercontent.com/MaksumRifai/voxelar/master/voxelar-preview.gif">
For this Project, I used AR.js and Aframe.js library, Image Descriptor, and Voxel.
https://github.com/MaksumRifai/voxelar (Repo) | https://maksumrifai.github.io/voxelar (Live)
Open Live Demo with Chrome Mobile Browser or AR/VR/XR Devices, When cam ready, Scan BekasiDev Sticker or Logo from bekasidev.org Or you can use image below.
<img src="https://raw.githubusercontent.com/Bekasi-Dev-Community/bekasidev/master/assets/img/brand/bekasidev-stiker.png" width="450">
Note for Desktop Browser you need latest Chrome or Edge that suported and enabled for WebVR Experiences, and also good desktop camera (Webcam), Recommended use Mobile Browser.
## Libraries
### AR.js
AR.js is a lightweight library for Augmented Reality on the Web, coming with features like Image Tracking, Location based AR and Marker tracking.
### Aframe.js
Web framework for building virtual reality experiences.
#### Import the library
Import AR.js:
```
<script src="https://raw.githack.com/AR-js-org/AR.js/master/aframe/build/aframe-ar-nft.js">
```
Import Aframe.js:
```
<script src="https://cdn.jsdelivr.net/gh/aframevr/aframe@1c2407b26c61958baa93967b5412487cd94b290b/dist/aframe-master.min.js"></script>
```
For this expample, we use Image Tracking Type of AR.js with Aframe.js.
[Further Reading](https://ar-js-org.github.io/AR.js-Docs/) for another types from AR.js official docs.
### Image Tracking
Natural Feature Tracking or NFT is a technology that enables the use of images instead of markers like QR Codes or the Hiro marker.
It comes in two versions: [the Web version](https://carnaux.github.io/NFT-Marker-Creator/) (recommended), and the [node.js version](https://github.com/Carnaux/NFT-Marker-Creator).
#### Choose Good Images
If you want to understand the creation of markers in more depth, check out the NFT Marker Creator [wiki](https://github.com/Carnaux/NFT-Marker-Creator/wiki/Creating-good-markers). It explains also why certain images work way better than others. An important factor is the DPI of the image: a good dpi (300 or more) will give a very good stabilization, while low DPI (like 72) will require the user to stay very still and close to the image, otherwise tracking will lag.
#### Create Image Descriptors:
<img src="https://raw.githubusercontent.com/MaksumRifai/voxelar/master/photo.jpg" width="150">
We create descriptor with this picture (photo.jpg) by uploading to NFT creator web version above then return 3 files to use: .fset, .fset3, .iset.
Each of them will have the same prefix before the file extension. That one will be the Image Descriptor name that you will use on the AR.js web app. For example: with files photo.fset, photo.fset3 and photo.iset, your Image Descriptors name will be photo.
#### Create Object
You can download and use 3D models or object from anywhere or create your own with Blender. For this repo, I created my own model based on [Bekasidev](https://bekasidev.org) Logo with MagicaVoxel, this logo vector and raster is also originaly created by me.
<img src="https://raw.githubusercontent.com/MaksumRifai/voxelar/master/ss-mv-bekdev.jpg">
You can watch tutorial on my youtube channel here for DTS Kominfo Logo:
- [10 Menit Membuat Logo 3D (Digital Talent Scholarship)](https://www.youtube.com/watch?v=0GfNYFcDjMU&t=6s)
- [Membuat rumah dengan MagicaVoxel](https://www.youtube.com/watch?v=nbfeWj46R3c)
- [Tutorial Blender 3D Basic : View, Navigation, Transformation](https://www.youtube.com/watch?v=tEAuDC7SjsQ&t=33s)
### Render Content to the Scene
```
<!-- Main Scene -->
<a-scene
vr-mode-ui="enabled: false;"
renderer="logarithmicDepthBuffer: true;"
embedded
arjs="trackingMethod: best; sourceType: webcam;debugUIEnabled: false;"
>
<!-- we use cors proxy to avoid cross-origin problems -->
<a-nft
type="nft"
url="https://arjs-cors-proxy.herokuapp.com/https://raw.githack.com/MaksumRifai/voxelar/master/photo"
smooth="true"
smoothCount="10"
smoothTolerance=".01"
smoothThreshold="5"
>
<!-- as a child of the a-nft entity, you can define the content to show. here's a OBJ model entity -->
<a-entity rotation="-135 -90 90" scale="5 5 5" position="0 0 0" obj-model="obj: #tree-obj; mtl: #tree-mtl"></a-entity>
</a-nft>
<!--Load assets to use by nft entity above-->
<a-assets>
<a-asset-item id="tree-obj" src="https://arjs-cors-proxy.herokuapp.com/https://raw.githack.com/MaksumRifai/voxelar/master/bekdev.obj"></a-asset-item>
<a-asset-item id="tree-mtl" src="https://arjs-cors-proxy.herokuapp.com/https://raw.githack.com/MaksumRifai/voxelar/master/bekdev.mtl"></a-asset-item>
</a-assets>
<!--End of assets-->
<!-- static camera that moves according to the device movemenents -->
<a-entity camera></a-entity>
</a-scene>
<!--End of Scene-->
```
You can refer to [A-Frame docs](https://aframe.io/docs/1.0.0/introduction/) to know everything about content and customization. You can add geometries, 3D models, videos, images. And you can customize their position, scale, rotation and so on.
The only custom component here is the a-nft, the Image Tracking HTML anchor. You may see my other project for references.
- 360° Image VR, Add 3D bus into 360 Degree Image ([Repo](https://github.com/MaksumRifai/360vr) | [Demo](https://maksumrifai.github.io/360vr))
- Simple Object and Animation VR, Add 3D DTS logo Into Environment ([Repo](https://github.com/MaksumRifai/digitaltalent) | [Demo](https://digitaltalent.netlify.app))
- WebAR Image Tracking with Kumparan Logo Umbrella ([Repo](https://github.com/MaksumRifai/kumparan-ar) | [Demo](https://maksumrifai.github.io/kumparan-ar))
<a href="https://maksumrifai.github.io/360vr"><img src="https://raw.githubusercontent.com/MaksumRifai/360vr/master/360vr-preview.gif"></a>
<a href="https://digitaltalent.netlify.app"><img src="https://raw.githubusercontent.com/MaksumRifai/digitaltalent/master/dts-preview.gif"></a>
<a href="https://maksumrifai.github.io/kumparan-ar"><img src="https://raw.githubusercontent.com/MaksumRifai/kumparan-ar/master/kumparan-preview.png"></a>
### How to use this template
#### Clonning
Run the following command to clone this template to your local directory:
```
$ git clone https://github.com/MaksumRifai/voxelar.git
```
#### Download
Use green button on my repo and click "Download Zip" or simply click [here](https://github.com/MaksumRifai/voxelar/archive/master.zip)
### Customizing
In case you want to use your own models, simply replace the [.obj .mtl .png](https://en.m.wikipedia.org/wiki/Wavefront_.obj_file) files with yours. Don't forget to export your MagicaVoxel or Blender project properly.
And edit this repo as you needed, you only need to replace URL/File name with yours, and the descripted files (fset, iset, fset3) you created with your own source image, use your favorite code editor, directly in web browser or github desktop.
<img src="https://raw.githubusercontent.com/MaksumRifai/kumparan-ar/master/ss-vsc.jpg">
For better and faster development or debugging this project, you can use [Spck Code/Git Editor](http://play.google.com/store/apps/details?id=io.spck) for Android, I mainly use this way.
<a href="https://github.com/MaksumRifai/360vr/blob/master/360vr.gif"><img src="https://raw.githubusercontent.com/MaksumRifai/360vr/master/360vr.gif"></a>
<br/><br/>
## References & Resources
### A-Frame Boilerplate
Web framework for building virtual reality experiences.
[Github](https://github.com/aframevr/aframe) | [Website](https://aframe.io).
Alternatively, check out the [A-Frame Starter on glitch.com](https://glitch.com/~aframe) for a more interactive way on getting started.
### MagicaVoxel @ephtracy
A free lightweight GPU-based voxel art editor and interactive path tracing renderer.
[Github](https://github.com/ephtracy) | [Website](https://ephtracy.github.io/) | [Demo](https://youtu.be/mfKx4j-C6nI)
### Tutorial Videos
- [Youtube: Ephtracy](https://youtu.be/d_WymsNdRBA)
- [Youtube: Aaron Robbins](https://www.youtube.com/playlist?list=PLHtmobOgsDvlikllA1MBk7pk_DWlmtR_S)
- [Youtube: Maksum Rifai](https://www.youtube.com/watch?v=0GfNYFcDjMU&t=42s)
### Articles
- [Publishing Voxel Designs from MagicaVoxel to Sketchfab](https://blog.sketchfab.com/publishing-voxel-designs-from-magicavoxel-to-sketchfab/)
- [Building with MagicaVoxel and export to A-Frame (WebVR framework)](https://aframe.io/docs/0.3.0/guides/building-with-magicavoxel.html)
- [Script for animating MagicaVoxel rendering](http://drinkdecaf.com/magicavoxel_animate)
#### Support Me
<a href="https://www.paypal.me/maksumrifai"><img src="https://encrypted-tbn0.gstatic.com/images?q=tbn%3AANd9GcSRU16oC9ndfwmD5a14Df0X7B96ummOHmQGsg&usqp=CAU" width="200"></a> <a href="https://invoice.xendit.co/donation/Dukungan"><img src="https://encrypted-tbn0.gstatic.com/images?q=tbn%3AANd9GcROR5VQJr0XTxLh-kmhGyyyQA0i8ISLTxQRcg&usqp=CAU" width="200"></a>
<a href="https://github.com/desainerhub"><img src="https://raw.githubusercontent.com/MaksumRifai/360vr/master/learn.png" width="200"></a>
<a href="https://github.com/Bekasi-Dev-Community"><img src="https://raw.githubusercontent.com/Bekasi-Dev-Community/bekasidev/master/assets/img/brand/bekasidev-banner.png" width="200"></a>
| maksumrifai |
580,406 | General Data Protection Regulation (GDPR) | What exactly is GDPR ? It is a regulation passed by the EU government which applies to dealing with... | 0 | 2021-01-23T18:59:54 | https://dev.to/hariraghupathy/general-data-protection-regulation-gdpr-3j3i | __What exactly is GDPR ?__
It is a regulation passed by the EU government which applies to dealing with the data of all EU citizens, irrespective of where the data is stored or sent to. Even if we pass data from India to Europe, we have to respect GDPR. They have brought GDPR into effect in order to protect the right of any EU citizen to privacy and security of their personal data. Even if we fully operate EU user data outside EU, we have to follow the legislation.
__So for whom is GDPR applicable ?__
GDPR is applicable to any business located within and outside Europe. It applies to any business which collects data, organise and store them, and perform some operations over this data. Companies have to be responsible and accountable for the user data, this is where GDPR applies.
__How a software should be GDPR compliant__
Following are the principles of GDPR that any company should deal with when they handle EU citizens personal data :
1. Data must be processed by following the laws and also very
transparently
2. All data about the user must be correct and it should be up
to date. (Accuracy)
3. No unwanted or additional data than for the purpose of it
should be collected from the user (Purpose limitation)
4. Collected data needs to be always relevant about what is
needed for processing (Data minimisation)
5. Collected data must be processed safely without any
security breach. (Data integrity and confidentiality)
6. Data must be maintained in a state that it should be not
available when it is no longer needed. (Storage limitation)
__User rights over personal data__
Below mentioned are the rights that the user have over their personal data :
1. Access and update their personal data
2. Request personal data deletion whenever the user needs
3. Be informed about what data the business is collecting
4. Download the personal data in any format like json, xml etc.. whenever the user needs them
5. Restrict processing of data whenever they need.
Please follow the link which contains the checklist for making a SaaS product GDPR compliant - https://www.cloudways.com/blog/saas-gdpr-checklist/
| hariraghupathy | |
580,557 | JS and Design Patterns - Chapter 4 🚀 | Table Of Contents * 🤓INTRODUCTION * 👀ABOUT OBSERVER * 🦄ENTITIES * 🌍 R... | 11,000 | 2021-01-23T20:40:47 | https://dev.to/devlazar/js-and-design-patterns-chapter-4-4d8j | javascript, webdev, programming, codequality | Table Of Contents
* 🤓[INTRODUCTION](#intro)
* 👀[ABOUT OBSERVER](#about)
* 🦄[ENTITIES](#entities)
* 🌍 [REAL WORLD ANALOGY?](#rw)
* 📰[NEWS ANALOGY](#news)
* 📈 [STOCK ANALOGY](#stocks)
* ❓ [WHEN TO USE?](#when-use)
* ⚙ [RxJS applicability](#rxjs)
* ✅[PROS](#pros)
* ❌[CONS](#cons)
* 🙏[THANK YOU](#thank-you)
## 🤓 INTRODUCTION <a name="intro"></a>
Hello, codedudes and codedudettes, I hope you are having a great day! Let's make it even better, let's learn something new. Software development is a neverending story where you always learn something new, personally, I always push myself to do the best and to learn as much as I can. But remember, don't overwork yourself!
Today, we are talking about a very popular design pattern, The Observer Pattern.

## 👀 ABOUT OBSERVER <a name="about"></a>
The Observer Pattern is a behavioral design pattern that lets you define a subscription mechanism to notify multiple objects about any events that happen to the object they're observing. In other words, the Observer Pattern defines a one-to-many type of dependence between different objects, and it ensures that the change of the state in one object gets automatically reflected in all dependant objects!
## 🦄 ENTITIES <a name="entities"></a>
Entities that will participate in the Observer paradigm are:
- **SUBJECT**
It keeps a reference towards its observer. One object can have
many Observer objects
It provides an interface for "attaching" and "detaching"
observer objects
- **CONCRETE SUBJECT**
It keeps the state of interest of the Concrete Observer objects
It sends notifications to its observers when the state changes
- **OBSERVER**
It defines an interface for updating the objects after the state
of the changes in the objects of the class type Subject
- **CONCRETE OBSERVER**
It keeps a reference to the Concrete Subject objects
It keeps the state that should stay consistent with the state of
the parent class
It implements an interface for updating object that is defined
in the Observer class
Let's see the code 👩💻 (❗ And as always, read the comments 😊)

```javascript
//The subject class
//It provides an interface
//for "attaching" and "detaching"
//observer objects
class Subject{
constructor(){
this.observerList = [];
}
attach(observer) {
console.log(`📎 Attaching observer... ${observer.name}`);
this.observerList.push(observer);
}
detach(observerId) {
let observer = this.observerList.find(item => item.id === observerId);
console.log(`🔗 Detaching observer... ${observer.name}`);
this.observerList = this.observerList.filter(item => item.id !== observerId)
}
notify() {
console.log('🟢The Notification process starts...');
for (let i = 0; i < this.observerList.length; i++) {
this.observerList[i].update()
}
console.log('🔴The Notification process ends...');
};
}
//It keeps the state of interest of the Concrete Observer objects
//It sends notifications to its observers when the state changes
class ConcreteSubject extends Subject {
constructor(){
super();
}
//return subject state
getSubjectState(){ return this.subjectState; }
//set new subject state
setSubjectState(subjectState){ this.subjectState = subjectState; }
function(){
return { getSubjectState, setSubjectState }
}
};
//It defines an interface for updating the objects after the state
//of the changes in the objects of the class type Subject
class Observer{
update() { return; }
};
//The concrete observer class will extend an observer class
//It keeps a reference to the Concrete Subject objects
//It keeps the state that should stay consistent with the state of
//the parent class
class ConcreteObserver extends Observer{
constructor(id, subject, name){
super();
this.id = id;
this.subject = subject; //a reference to the Concrete Subject object
this.name = name;
this.observerState = ""; // the state that should stay consistent with the state of
//the parent class
}
//The interface for update object
update() {
this.observerState = this.subject.subjectState;
console.log(`${this.name} new state is: ${this.observerState}`);
}
getSubject() {
return this.subject;
}
setSubject(subject){
this.subject = subject;
}
};
//we will instantiate our concrete subject class that should be observed
var s = new ConcreteSubject();
//attaching the first concrete observer with an id of 1,
//passing the concrete subject instance
//passing the name of the observer
s.attach(new ConcreteObserver(1, s, 'First observer'));
//attaching the second observer
s.attach(new ConcreteObserver(2, s, 'Second observer'));
//changing the subject state
s.setSubjectState("subject changed");
//notifying OBSERVERS (we have two observer at the moment) that the state was changed
s.notify();
/* OUTPUT OF THE NOTIFY FUNCTION
🟢 The Notification process starts...
First observer new state is: subject changed
Second observer new state is: subject changed
🔴 The Notification process ends...
*/
//detaching the observer with an id of 1
s.detach(1)
//changing the subject state
s.setSubjectState("removed one observer");
//notifying OBSERVER (because we detached our observer with an id of 1
//we are left with only one observer that should get notified about the
//change of the state
s.notify();
/* OUTPUT OF THE NOTIFY FUNCTION
🟢 The notification process starts...
Second observer new state is: removed one observer
🔴 The Notification process ends...
*/
```
Please try executing this code, it is always better to look it in the text editor of your preference, and of course, play with it, try adding one more subject and as many observers as you want.
Here is the UML diagram for the visual learners.
## 🌎 REAL WORLD ANALOGY<a name="rw"></a>
### 📰 NEWSPAPER / MAGAZINE ANALOGY <a name="news"></a>
If you subscribe to a newspaper or magazine, you no longer need to go to the store to check if the next issue is available. Instead, the publisher sends a new issue directly to your mailbox right after publication or even in advance. The publisher maintains a list of subscribers and knows which magazines they are interested in. Subscribers can leave the list at any time when they wish to stop the publisher from sending new magazine issues to them.
### 📈 STOCK ANALOGY <a name="stocks"></a>
The observer pattern also applies to the real world in terms of the stocks. For example, you can have an investor, a company for example Apple. Apple has stocks, investors invest their 💰 into the Apple stocks, thus, they would certainly like to be notified when the stocks change so they can turn their strategy around.
**In this case, a Stock is a Subject, Apple stock is a Concrete Subject, Investor is an Observer, and let's say Warren Buffet is a Concrete Observer.**
## ❓ WHEN TO USE THE OBSERVER PATTERN?<a name="when-use"></a>
You could use the observer pattern when changes to the state of one object may require changing other objects, and the actual set of objects is unknown beforehand or changes dynamically.
Use the pattern when some objects in your app must observe others, but only for a limited time or in specific cases.
## ⚙ RxJS OBSERVABLE (ANGULAR)<a name="rxjs"></a>
>The observer pattern is a software design pattern in which an object, called the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.
The observer pattern is the pattern that RxJS observable is using.
**Observable** — this is the thing that clients observe, it is sometimes called the subject.
**Observer** — this is a class that wants to be notified when the subject’s state changes in an interesting way.
An Example of creating observables:
```typescript
import { Observable } from 'rxjs';
const observable = new Observable(function subscribe(observer) {
var id = setInterval(() => {
observer.next('hi')
}, 1000);
});
```
An Example of subscribing to an observable
```typescript
observable.subscribe(x => console.log(x));
```
When calling observable.subscribe with an Observer, the function subscribe in Observable.create(function subscribe(observer) {...}) is run for that given Observer. **Each call to observable. Subscribe triggers its own independent setup for that given Observer.**
## ✅ PROS <a name="pros"></a>
- Open/Closed Principle. You can introduce new subscriber classes without having to change the publisher’s code (and vice versa if there’s a publisher interface).
- You can establish relations between objects at runtime.
## ❌ CONS <a name="cons"></a>
- Subscribers are notified in random order.
# 🙏 THANK YOU FOR READING!<a name="thank-you"></a>
Please leave the comment, tell me about you, about your work, comment your thoughts on the filter method, connect with me via [Twitter](https://twitter.com/lazar_dev) or [LinkedIn](https://www.linkedin.com/in/lazar-stankovic-44a199177/).
Let this year be your year, let this year be our year. Until the next typing...
Have a nice time!
References:
School notes...
[medium](https://kevinwkds.medium.com/angular-observable-81eea33a1aab#:~:text=Angular%20uses%20the%20Observer%20pattern,acted%20on%20in%20some%20way.)
[refactoring](https://refactoring.guru/design-patterns/observer)
☕ SUPPORT ME AND KEEP ME FOCUSED!
<a href='https://ko-fi.com/Z8Z33D1HJ' target='_blank'><img height='36' style='border:0px;height:36px;' src='https://cdn.ko-fi.com/cdn/kofi4.png?v=2' border='0' alt='Buy Me a Coffee at ko-fi.com' /></a>
😊 | devlazar |
580,566 | Node.js Best Practices — Project and Async | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-23T20:50:09 | https://thewebdev.info/2020/08/13/node-js-best-practices%e2%80%8a-%e2%80%8aproject-and-async/ | node, webdev, programming, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
Like any kind of apps, JavaScript apps also have to be written well.
Otherwise, we run into all kinds of issues later on.
In this article, we’ll look at some best practices we should follow when writing Node apps.
### Start All Projects with `npm init`
We should start will project with `npm init` so that we get the `package.json` file in our app project.
This will let us add our project’s metadata like the project name, version, and the required packages.
### Setup `.npmrc`
We should add `.npmrc` to add the URL for the Node packages repositories that we’ve to use outside the regular NPM repository.
Also, we can make the version of the package the same for everyone.
To make everyone use the same version, we can write.
```
npm config set save=true
npm config set save-exact=true
```
We make `npm install` also install the same version.
`package-lock.json` also locks the repositories to the same version.
### Add Scripts to Our `package.json`
`package.json` can hold project-related scripts.
They’re all in the `scripts` folder.
This way, we can just have one command to do everything to start the project.
We can add a `start` script to our project with `npm start` .
For example, we can write:
```
"scripts": {
"start": "node app.js"
}
```
Then just run `npm start` to run our app instead of `node app.js` .
Also, we can add more commands:
```
"scripts": {
"postinstall": "bower install && grunt build",
"start": "node app.js",
"test": "node ./node_modules/jasmine/bin/jasmine.js"
}
```
`postinstall` runs after the packages in `package.json` are installed.
`npm test` runs the `test` script which runs the tests.
This lets us run tests without typing in multiple commands ourselves.
We can also add custom scripts into `package.json` .
We can run them with `npm run script {name}` where `name` is the key of the script.
### Use Environment Variables
We should set environment variables for things that run in different environments.
For example, we can use the dotenv library to read them from an `.env` file or environment variables so we can use them in our app.
They can be accessed with `process.env` in our Node app.
### Use a Style Guide
If we adopt styles in a style guide, then we write our code in a consistent style.
Having consistent code makes it easier to understand.
We can make the checks automatic with linters like ESLint.
It contains rules for Node apps built-in.
Other style guides include:
* Airbnb — [https://github.com/airbnb/javascript](https://github.com/airbnb/javascript)
* Google — [https://google.github.io/styleguide/javascriptguide.xml](https://google.github.io/styleguide/javascriptguide.xml)
* jQuery — [https://contribute.jquery.org/style-guide/js/](https://contribute.jquery.org/style-guide/js/)
* Standard JS — [http://standardjs.com/](http://standardjs.com/)
### Embrace async
We got to use async code with Node apps.
This way, they won’t hold up the whole app while waiting for something to complete.
To make our lives easier, we can use promises to write our async code.
To make them shorter, we can use async and await.
We can convert some Node async callbacks to promises with the `util` module.
Some modules like `fs` also have versions of its methods that return promises.
### Conclusion
We should take full advantage of the features provided by `package.json` and the `npm` program.
Also, we should use async wherever we can.
A consistent coding style is also good.
| aumayeung |
580,579 | Understanding the WebGL triangle | Let's try to understand the Web/OpenGL triangle - aka OpenGL Hello World! We will use WebGL for simpl... | 0 | 2021-01-23T20:57:41 | https://www.thecodingnotebook.com/2021/01/understanding-opengl-triangle.html | javascript, webgl, webdev | Let's try to understand the Web/OpenGL triangle - aka OpenGL Hello World! We will use WebGL for simplicity, but the principles are quite similar to OpenGL.

# YouTube Version
{% youtube 18rTdbE2qS4 %}
# The END
Let's start from the end. If you haven't heard it by now, OpenGL is a "state machine", practically what it means is that instead of calling to a function (like `drawTriangle(...)`) we will first have to setup parameters on the gl context (as if we adjust knobs on a machine), and then when the "state" is all set for our task, we will call the `draw` method.
## The draw method
The method we will use for drawing is `drawArrays(mode, first, count)`, from the [docs](https://developer.mozilla.org/en-US/docs/Web/API/WebGLRenderingContext/drawArrays) it "renders primitives from array data".
Parameters:
* mode - The **primitive** type to draw. We learn from this that OpenGL can draw specific primitives, like: `POINTS`, `LINES`, `TRIANGLES` (and some more). **we will use TRIANGLES**.
* first - The starting index in the array of vector points. From this we learn we will have to setup some "array with vector" points in our "machine". Specifically these will be array with the corners of our triangle.
* count - Number of indices to be rendered (from the above array). Since we are rendering a triangle we will need **3 indices** (representing 3 vertices).
OK, so now that we know what is required for the draw method, we an go ahead and see how to set it all up...
# OpenGL rendering pipeline
The rendering pipeline is the process of rendering an image to the screen (or any output surface), below is a very simplistic schema of the rendering pipeline:
1. It all starts with vertices we provided that represent the primitive we want to draw. Note that the vertices can be in any coordinate system we want, in the image above we choose the origin to be (0, 0) in a normalized space (all coords in range 0 - 1).
1. These vertices are then passed to the `vertex shader`, which is a program that **we write** and will run **on the GPU** for every vertex we provide (meaning 3 times in our case). The purpose of this method is to transform each vertex to OpenGL coordinate system, which is a normalized coordinate system with the origin at **(-1, -1)** (of course you can also choose to do extra manipulation on the vertex, like flip or rotate etc).
1. The next step is Rasterization - in this step OpenGL will "collect" all the *fragments* (pixels) that needs to be rendered.
1. All these fragments (pixels) are now processed with the `fragment shader`, which is a program **we write** and will run **on the GPU** <u>for every fragment</u>, i.e A LOT, so be careful here performance wise. The purpose of this program is to assign a **color** for every fragment (pixel).
1. And then the pipeline continue with preparing the final image to draw.
# The shaders programs
As described above, the vertex/fragments programs will run on the GPU and the language in which we develop is GLSL (OpenGL Shading Language). The specific version we are going to use is `ES 3.0` (ES is a flavour for Embedded Systems), full reference can be found [here](https://www.khronos.org/registry/OpenGL-Refpages/es3.0/). Overall the syntax resembles c++.
## Vertex Shader
As described above, the vertex program needs to transform each vertex (x, y) to OpenGL coord system, now it is totally up to us to choose whatever coord system WE want to use. If we choose the same coord system as OpenGL our vertex shader will have to do nothing but echo the input. But, having origin at (-1, -1) is not intuitive so we will work with origin at (0, 0) and our triangle coords will be:
```
(0.5, 1)
+---/\---+
| / \ |
| / \ |
|/ \|
+--------+
(0,0) (1, 0)
```
### Color interpolation
Another useful feature of the vertex shader, is that any **output** variable we define will get interpolated and passed on to the fragment shader. So if for the first corner (vertex) of our triangle we output the color red (rgb: 1,0,0), and for the second corner we output blue (rgb: 0,0,1), all the fragments (pixels) in between will get values between these two values.
**Note:** The shaders code is defined as a simple string, we will compile it later using WebGL context.
### Vertex shader code
This is our vertex shader, code is commented with explanations:
```js
const VERTEX_SHADER = `#version 300 es
// Below are 2 input attributes
// The values for these attributes will be provided
// by us in the javascript "world"
// vec2 is a vector with 2 values representing the
// vertex coordinates (x/y).
in vec2 a_position;
// vec3 is a vector with 3 values representing the
// vertex color (r/g/b).
in vec3 a_color;
// output color for this vertex,
// OpenGL will interpolate these values automatically across all fragments
out vec3 color;
void main() {
// convert coord from [0,1] space to [0,2] space
vec2 zeroToTwo = a_position * 2.0;
// convert coord from [0,2] space to [-1,1]
vec2 glCoordSpace = zeroToTwo - 1.0;
// set the output in the global predefined gl_Position variable.
// Note a vertex has 4 values: x,y,z,w - we use 0,1 for z,w.
gl_Position = vec4(glCoordSpace, 0, 1);
// set the output color variable, just provide the user input
color = a_color;
}
`;
```
## Fragment Shader
The fragment shader just have to assign an `rgba` value for each pixel, quite simple:
```js
const FRAG_SHADER = `#version 300 es
// Need to the the engine what float precision we want
precision highp float;
// input color for this fragment, provided by OpenGL
// interpolating the output color variable that is in the
// vertex shader.
in vec3 color;
// We should set this output param with the desired
// fragment color
out vec4 outColor;
void main() {
// just output the color we got, note we got vec3 (rgb)
// and outColor is vec4, so we use 1.0 for the alpha.
outColor = vec4(color, 1.0);
}
`;
```
# Creating the GL "executable" program
OK, in order to use WebGL we need a "gl" context, that we can get from a `canvas` element (onto which the output will be rendered as well):
```html
<canvas id="canvas" width="300" height="300">
```
Then we can get the "gl" context:
```js
var canvas = document.getElementById('canvas');
// get webgl2 context
var gl = canvas.getContext('webgl2');
```
### Compile the shaders
Next we compile the shaders code:
```js
// Create shader object of type "VERTEX"
const vertexShader = gl.createShader(gl.VERTEX_SHADER);
// Load the shader source
gl.shaderSource(vertexShader, VERTEX_SHADER);
// Compile the shader
gl.compileShader(vertexShader);
// Check the compile status
var compiled = gl.getShaderParameter(vertexShader, gl. COMPILE_STATUS);
if (!compiled) {
// Something went wrong during compilation; get the error
const lastError = gl.getShaderInfoLog(shader);
throw new Error('Error compiling shader: ' + lastError);
}
// Do the same for the fragment shader
const fragShader = gl.createShader(gl.FRAGMENT_SHADER);
gl.shaderSource(fragShader, FRAG_SHADER);
gl.compileShader(fragShader);
// here we should check compilation status as well
```
### Link the gl program
Like any executable, our program should get linked too:
```js
// create program object
var program = gl.createProgram();
// attach it with the 2 shaders
gl.attachShader(program, vertexShader);
gl.attachShader(program, fragShader);
// and link
gl.linkProgram(program);
// Check the link status
const linked = gl.getProgramParameter(program, gl.LINK_STATUS);
if (!linked) {
// something went wrong with the link
const lastError = gl.getProgramInfoLog(program);
throw new Error('Error linking gl program:', lastError);
}
```
Yay, we have a GL program ready to Run!
# Loading data to the vertex shader
In the sections above we said that we will provide the vertex shaders with the vertices to render, now is the time.
## The vertex input buffer
If you look at our vertex shader you'll see it has 2 input attributes, `a_position` and `a_color`, let define the data for each.
First we create a "buffer", which is just a chunk of memory **on the GPU**:
```js
var vertexParamsBuffer = gl.createBuffer();
```
Then we should "bind" it, binding in OpenGL is like making something "active". Remember we said that OpenGL is a "state machine"? well, think of it as a "machine" with many slots each for a specific usage. So when we "bind" something it's as if we load an object into that dedicated slot. Here we bind our `vertexParamsBuffer` to the `ARRAY_BUFFER` slot.
From the [docs](https://developer.mozilla.org/en-US/docs/Web/API/WebGLRenderingContext/bindBuffer), the `ARRAY_BUFFER` is "Buffer containing vertex attributes, such as vertex coordinates ... or vertex color data" - PERFECT!
```js
gl.bindBuffer(gl.ARRAY_BUFFER, vertexParamsBuffer);
```
Once our buffer is in the correct `ARRAY_BUFFER` "slot", we can load it with data (this copies bytes to the GPU):
```js
var verticesData = new Float32Array([
// coord color
0.0, 0.0, 1.0, 0.0, 0.0, // 1st vertex
0.5, 1.0, 0.0, 1.0, 0.0, // 2nd vertex
1.0, 0.0, 0.0, 0.0, 1.0 // 3ed vertex
]);
// First parameter is the "slot" onto which load the data
// Second parameter is the chunk of bytes
// Third parameter is a hint to OpenGL how this data used
gl.bufferData(gl.ARRAY_BUFFER, verticesData, gl.STATIC_DRAW);
```
<u>**IMPORTANT!**:</u> Above we just uploaded a chunk of bytes into a buffer on the GPU, OpenGL still knows nothing about the **meaning** of the data, what we commented above as "1st vertex coord/color" etc is just for us, next we will tell OpenGL how to interpret the data.
## Describing the buffer data
So the data we uploaded above should go into our 2 attributes, `a_position` and `a_color`, lets start with the first:
```js
// Gets the index of the a_position input attribute
var a_positionIdx = gl.getAttribLocation(program, 'a_position');
// Fact that we declared "in vec2 a_position" attribute
// in our vertex shader doesn't mean it is "active",
// we have to enable it specifically:
gl.enableVertexAttribArray(a_positionIdx);
// And now we tell OpenGL how to read data from the buffer
// CURRENTLY bound to the ARRAY_BUFFER "slot" into the
// vertex attribute a_position
gl.vertexAttribPointer(a_positionIdx, 2, gl.FLOAT, false, 20, 0);
```
Let's [study](https://developer.mozilla.org/en-US/docs/Web/API/WebGLRenderingContext/vertexAttribPointer) the parameters of `vertexAttribPointer`:
* index - The index of the vertex (shader) attribute we describe
* size - The number of **components** for this attribute. since our `a_position` is a vec2, we use 2 **components** (that is, 2 float values).
* type - The data type for each component, we used a `Float32Array` so it is FLOAT.
* normalized - whether the input is a normalized int - FALSE
* stride - Specify the number of **bytes** between the <u>beginning</u> of each vertex data. In our case EACH vertex has 2 floats for x/y, and 3 floats for r/g/b => total of 5 float == 20 bytes - so from the beginning of a specific vertex data, jump 20 bytes and you get to the beginning of the next vertex data.
* offset - Specify the number of **bytes**, from the beginning of the vertex data, where the first component is. In our case the x/y components are at the beginning of the vertex data, so offset is 0.
Now we do the same to describe the color attribute:
```js
var a_colorIdx = gl.getAttribLocation(program, 'a_color');
gl.enableVertexAttribArray(a_colorIdx);
gl.vertexAttribPointer(a_colorIdx, 3, gl.FLOAT, false, 20, 8);
```
Lets describe the parameters here as well:
* index - as above
* size - `a_color` is a vec3 so it has 3 components
* type - FLOAT
* stride - like above
* offset - From the beginning of the vertex data we count 2 float of x/y and then it's the color data, so 8 bytes.
## Rendering
Once we setup all the vertex attributes we can ask OpenGL to draw!
```js
// First we set our program as the active program on the gpu
gl.useProgram(program);
// Call the draw method
gl.drawArrays(gl.TRIANGLES, 0, 3);
```
This takes us back to the beginning of our article, the `drawArrays` method, lets see if we understand now the parameters:
* mode - Easy, we want to draw a triangle.
* first - The starting index in the array of vector points. Remember our `ARRAY_BUFFER` slot? into which we loaded our vertices data? the data we described using `vertexAttribPointer` and the actual chunk of data we provided (the `verticesData` Float32Array) creates exactly 3 vertices in the `ARRAY_BUFFER` slot, and the index of the first vertex we want to draw is 0 !
* count - Easy, we want to draw 3 vertices.
# THE END
{% codepen https://codepen.io/ValYouW/pen/KKgLbeQ %}
| valyouw |
580,601 | Using API's in your React App | Recently, I've really been wanting to build something new and I wanted to play around with some new A... | 11,057 | 2021-01-23T21:55:20 | https://dev.to/randysteele/using-api-s-in-your-react-app-3jm4 | react, tutorial, rapidapi, openweatherapi | Recently, I've really been wanting to build something new and I wanted to play around with some new API's so I thought maybe I'd do a short tutorial on how I accomplished this. Currently, I have nothing so first I will create a new react app by running this in my terminal `npx create-react-app [my-awesome-app-name]` I also created a GitHub repo and connected the two. Next I am going to find the API I want to use. I want my app to be weather related so I am going to use the the [Open Weather Map API](https://openweathermap.org/api).
Next I need to create a file in my react app to hold this data. I am going to create a `components` folder within the `src` directory and inside the `components` folder I am creating a file named `Forecast.js` Inside this component I am going to fetch to the Open Weather API. To get access to this API I used the Rapid API website. Note: You must subscribe to the API. The Rapid API will help you with your fetch request if needed but here is what mine looks like.
```
import React, { useState } from 'react';
const Forecast = () => {
let [responseObj, setResponseObj] = useState({});
function getForecast() {
fetch(`https://community-open-weather-map.p.rapidapi.com/weather?q=seattle`, {
"method": "GET",
"headers": {
"x-rapidapi-key": "7b02074c19mshedbbe70e8fd2ae2p163b20jsne2411a44c687",
"x-rapidapi-host": "community-open-weather-map.p.rapidapi.com"
}
})
.then(response => response.json())
.then(response => {
setResponseObj(response)
});
}
```
Now that we have our fetch configured we can return the data we'd like. In my fetch I included in the URL the city I want weather data for so now if I navigate to my site and click the "Get Weather" button I will see the details for Seattle.
```
return (
<div>
<h2>Find Current Weather Conditions</h2>
<div>
{JSON.stringify(responseObj)}
</div>
<button onClick={getForecast}>Get Forecast</button>
</div>
)}
export default Forecast;
```
Now I am going to create a `Conditions/js` file in my components folder. This will be a functional components that accepts props, the purpose of this component will be to render data. I'm using something new in this component (well at least new to me, many of you have probably used it) in the div for this component I am using `Math.round` to get the temperature in the city that I want. Here is a look at the component.
```
import React from 'react';
const conditions = (props) => {
return (
<div>
{props.responseObj.cod === 200 ?
<div>
<p><strong>{props.responseObj.name}</strong></p>
<p>It is currently {Math.round(props.responseObj.main.temp)} degrees out with {props.responseObj.weather[0].description}.</p>
</div>
: null
}
</div>
)
}
export default conditions;
```
So this is how I was able to connect my own react app to the Open Weather Map API. Next week I will continue working with this API and see how we can make our data more dynamic.
**Resources**
* [GitHub Repo](https://github.com/steelerx155/weatherman)
* [Rapid API](https://rapidapi.com/community/api/open-weather-map)
* [AJAX and API's with React](https://reactjs.org/docs/faq-ajax.html)
Thanks for reading and stay tuned for part #2!
| randysteele |
580,616 | Dari sistem karburator ke sistem injeksi | Beberapa hari ini banyak kanal komunikasi yang menyebarkan tulisan dari Pak Ignasius Jonan (mantan Me... | 0 | 2021-01-23T22:37:41 | https://dev.to/dasaptaerwin/dari-sistem-karburator-ke-sistem-injeksi-1n0g | writing, productivity | Beberapa hari ini banyak kanal komunikasi yang menyebarkan tulisan dari Pak Ignasius Jonan (mantan Menteri ESDM RI). Saking banyaknya yang menayangkan ulang (repost), saya tidak tahu lalu dari mana sumber aslinya. Tapi sudahlah, masyarakat sekarang ini jarang ada yang mencari sumber asli. Pesan lengkapnya cukup panjang (ada 38 poin) saya sertakan di bawah.
Komentar saya hanya untuk poin mesin listrik. Poin beliau itu mengingatkan saya ke awal 2000an. Pada periode itu mobil bermesin injeksi mulai membanjiri pasar, menggantikan mesin karburator yang konvensional. Di masa itu, tukang reparasi karburator banyak yang tutup, kecuali mungkin Asem Reges yang di dekat stasiun. Anda mungkin pernah ke sana.

Mesin [karburator yang mekanikal](https://en.wikipedia.org/wiki/Carburetor) dan mudah berubah pengaturannya memang tidak praktis ketika sudah berumur. Solusi yang direkomendasikan bengkel besar adalah menggantinya dengan unit yang baru. Pengaturan ulang hanya bersifat sementara. Jadi Anda bisa dipastikan akan rutin mengunjungi bengkel karburator. Bagi bapak-bapak mungkin momen itulah yang dicari untuk melemaskan pikiran.
Publik terkagum-kagum melihat mesin yang aliran bahan bakar dan pencampuran udaranya dikendalikan oleh kotak hitam bernama [ECU (Engine Control Unit)](https://en.wikipedia.org/wiki/Engine_control_unit) yang tidak lain adalah sebuah komputer. Era mekanikal karburator telah digantikan oleh papan sirkuit yang menghubungkan berbagai komponen dengan sebuah prosesor pengendali sebagai pengaturnya. Pengguna mobil cukup menyolokkan soket ke kotak ECU dan menghubungkannya ke komputer untuk mengetahui kondisi mesin, elektrikal dan bagian lainnya.
Komputer dan perangkat lunak pembaca ECU bukanlah perangkat standar di bengkel karburator. Maka tutuplah mereka.
Tidak lama setelah itu, mungkin lima tahunan, mulai bermunculan lembaga keterampilan yang melatih montir-montir yang ingin belajar mesin injeksi. Semenjak itu reparasi mesin injeksi bukanlah monopoli bengkel resmi saja. Jumlahnya memang belum banyak, tapi bengkel-bengkel umum yang menyediakan alat pemindai mesin (engine scanner) mulai berdiri. Sedikit jumlahnya karena mahal harga alatnya.
Dalam waktu 10 tahun, ketika alat pembaca ECU sudah makin murah dan unit bekasnya sudah mulai bisa didapatkan di pasaran. Maka bengkel mesin injeksi sudah makin banyak. Pemilik mobil-mobil tahun 2000an sudah punya banyak pilihan. Salah satunya adalah `Ditech Injection`. Stikernya sering terlihat di kaca belakang mobil-mobil hasil servisannya. Anda mungkin pernah jadi pelanggannya.
Saya bisa menceritakan hal yang sama, yaitu evolusi transmisi manual menjadi otomatis. Tapi jangan khawatir, tidak akan saya lakukan. Cerita ini sudah panjang.
Jadi poin saya adalah betul kata Pak Jonan bahwa poin prediksi dari 1 sampai 38 adalah prediksi manusia yang bisa salah. Robot mungkin akan menggantikan manusia, tapi manusiapun berganti generasi, yang akan selalu mencari celah sempit (atau) lebar yang belum dipikirkan oleh generasi sebelumnya.
Masa depan adalah sekarang bagi orang yang membuka pikiran, termasuk para dosen/peneliti yang banyak pemikirannya merupakan warisan abad ke-17. Seperti halnya MIT dan Harvard yang saat ini bukanlah titik pusat peradaban akademik. Peradaban akademik ada di kepala setiap orang yang mau memulai membangunnya, seperti yang dapat disimak dari video di bawah ini.
{% youtube zY0U0O6VsOA %}
@dasaptaerwin (ITB/RINarxiv)
---
SELAMAT DATANG MASA DEPAN:
Tulisan Bapak Ignasius Jonan mantan menteri SDM tentang prediksi masa depan. Kondisi tentang masa depan itu bukan "akan terjadi". Tapi sedang terjadi.
Di Jakarta misalnya, PLN berencana akan membuat 1143 SPLU, Stasiun Pengisian Listrik Umum. Peluncuran ini untuk menyambut kendaraan berbasis listrik secara masal di Indonesia.
Prediksi yg terjadi :
1.Bengkel perbaikan kendaraan akan hilang.
2.Mesin yg menggunakan bensin memiliki 20.000 bagian. Mesin listrik hanya memiliki 20 bagian.
Mobil listrik dijual dgn garansi seumur hidup dan hanya diperbaiki oleh dealer. Hanya perlu waktu 10 menit untuk mengganti mesin listrik.
3.Mesin listrik tidak diperbaiki di dealer tetapi dikirim ke bengkel regional utk diperbaiki dgn robot.
4.Mesin listrik yg gagal fungsi ditunjukkan oleh lampu yg menyala, lalu anda akan pergi ke tempat yang menyerupai mesin cuci mobil, dan mobil akan ditarik sementara anda ngopi dan mesin mobil akan diganti dgn yg baru.
5.SPBU akan hilang.
6.Meter parkir akan diganti oleh dispenser listrik.
Banyak perusahaan akan memasang stasiun isi ulang listrik
7.Kebanyakan pabrik kendaraan (yang cerdas telah mengalokasikan uangnya membangun pabrik mobil listrik.
8.Industri batu bara akan hilang.
Perusahaan minyak dan gas akan hilang. Pengeboran minyak akan hilang. selamat tinggal kepada OPEC.
9.Rumah2 akan menghasilkan dan menyimpan energi listrik di siang hari dan akan menggunakan serta menjualnya listriknya ke grid.
Grid akan menyimpan dan menyalurkannya ke industri yg banyak menggunakan listrik. Apakah anda sudah melihat atap Tesla?
10.Masa depan mendekati kita lebih cepat daripada yg kita kira.
11.Di tahun 1998 Kodak punya 170.000 pegawai dan menjual 85% foto kertas di seluruh dunia.
Hanya dalam beberapa tahun model bisnis mereka hilang dan bangkrut. Siapa yg mengira itu akan terjadi?
12.Apa yg terjadi pada Kodak dan Polaroid akan terjadi di kebanyakan industri dalam 5-10 tahun yg akan datang
13.Apakah pada tahun 1998 anda mengira bahwa 3 tahun setelahnya tidak akan pernah lagi ada foto menggunakan film?. Dengan gadget, siapa yg masih memiliki kamera dgn film?.
14.Kamera digital ditemukan tahun 1975. Barang pertama hanya memiliki 10.000 piksel, tetapi mengikuti hukum Moore.
Dgn perkembangan teknologi yg eksponensial, barang yg semula mengecewakan menjadi super dan menjadi mainstream dalam waktu singkat.
15.Hal itu terjadi lagi (tapi jauh lebih cepat) dgn kecerdasan buatan (artificial intelligence), kesehatan, kendaraan listrik, pendidikan, pencetakan 3D, agrikultur dan lapangan pekerjaan.
16.Lupakan buku 'Kejutan Masa Depan', sambutlah Revolusi Industri keempat.
17.Software telah dan akan terus mengacaukan banyak industri tradisional dlm 5-10 tahun mendatang.
18.Uber (seperti halnya Gojek di Indonesia) hanya piranti software, mereka tidak memiliki mobil, tapi sekarang mereka adalah perusahaan taksi terbesar di dunia! Supir taksi tidak mengira hal itu akan terjadi.
19.Airbnb sekarang adalah perusahaan hotel terbesar di dunia, walaupun mereka tidak memiliki properti apapun.
Tanyakan pada hotel Hilton apakah dulu mereka mengira hal itu akan terjadi.
20.Artificial Intelligence: komputer akan menjadi lebih baik secara eksponensial.
Tahun ini, komputer mengalahkan pemain game terbaik di dunia, 10 tahun lebih cepat daripada yg diperkirakan
21.Di USA, pengacara muda sudah tidak punya pekerjaan.
Berkat Watson IBM, anda bisa memperoleh nasehat hukum dalam hitungan detik (untuk hal-hal dasar), dgn akurasi 90% dibandingkan 70% akurasi bila dilakukan manusia.
Jadi jika anda belajar hukum, berhentilah segera. Kebutuhan pengacara akan berkurang 90%, hanya spesialis serba tahu yg masih bs bertahan.
22.Watson telah membantu dokter mendiagnosa kanker, 4 kali lebih akurat dibandingkan dokter manusia.
23. Facebook sekarang memiliki software pengenal pola yg dapat mengenali wajah jauh lebih baik daripada manusia. Pada tahun 2030 komputer akan lebih cerdas dari manusia.
24Kendaraan otomotif: Pada tahun 2018 mobil tanpa supir pertama sudah muncul.
Dalam waktu 2 tahun ke depan seluruh industri akan dikacaukan.
Anda tidak perlu supir lagi karena anda akan memanggil mobil dgn telepon , mobil itu akan muncul di lokasi, dan mengantarkan anda ke tempat tujuan.
Tidak perlu bingung memarkir mobil itu, anda hanya akan membayar jarak tempuh dan anda dapat tetap produktif selama naik mobil. Anak-anak tak perlu punya sim dan tak pernah be back homev CV memiliki mobil.
26.Hal itu akan mengubah kota2 kita, karena kita hanya perlu mobil 90-95% lebih sedikit. Lahan2 parkir bs adi taman kota.
27.Sekitar 1,2 juta orang meninggal karena kecelakaan tiap tahun, termasuk yg disebabkan berkendara sambil mabuk.
Sekarang kita memiliki satu kecelakaan tiap 60.000 mil; Nanti dgn kendaraan tanpa supir angka itu akan turun menjadi 1 kecelakaan tiap 6 juta mil. Ini akan menyelamatkan jutaan nyawa tiap tahunnya.
28.Kebanyakan perusahaan mobil tak diragukan lagi akan menjadi bangkrut.
Perusahaan mobil tradisional hanya mencoba pendekatan evolusioner dan hanya berusaha membuat mobil yg lebih baik, sementara perusahaan teknologi (Tesla, Apple, Google) melakukan pendekatan revolusioner dan membangun komputer di atas roda.
29.Lihat apa yg dilakukan Volvo sekarang; tidak ada lagi mesin pembakaran internal di kendaraan mereka mulai tahun ini untuk model 2019, semua menggunakan listrik atau hybrid, dgn maksud nantinya akan melenyapkan model2 hybrid.
28.Banyak ahli-ahli teknik di Volkswagen dan Audi takut terhadap Tesla, dan memang seharusnya begitu.
Lihat semua perusahaan yg menawarkan mobil listrik. Beberapa tahun lalu keberadaan mereka tidak bisa dirasakan.
29.Perusahaan asuransi akan mengalami kesulitan masif; tanpa kecelakaan, biaya akan menjadi lebih murah. Model bisnis asuransi mobil akan hilang.
30.Real estate akan berubah. Jika orang bisa bekerja pulang-pergi, mereka akan tinggal di tempat yg jauh untuk hidup di lingkungan yg lebih terjangkau dan lebih menyenangkan.
31.Mobil listrik akan menjadi mainstream pada tahun 2030 an. Kota menjadi tidak berisik karena semua mobil baru akan menggunakan listrik.
32.Kota juga akan memiliki udara yg lebih bersih.
33.Listrik akan menjadi sangat murah dan bersih.
34.Produksi listrik tenaga surya telah mengalami kurva pengembangan eksponensial selama 30 tahun, tetapi sekarang perkembangan itu sedang dipacu lebih kencang lagi.
35.Perusahaan energi fosil sedang berusaha mati2an membatasi akses ke grid utk mencegah munculnya pesaing dgn instalasi listrik tenaga surya di rumah-rumah, tetapi upaya itu tidak akan bisa berlanjut - teknologi tidak akan bisa dibendung.
36.Kesehatan: Harga Tricorder X akan diumumkan tahun ini.
37.TV dan Koran akan mati dgn sendirinya, siapa yg sekarang baca koran atau siapa yg sekarang melihat TV ? Hanya sebagian kecil orang-orang diatas 50 tahun. Millenial beralih ke Youtube dan sejenisnya lebih cepat.
38.Layanan Perbankan dan Ticketing sudah swa Mandiri tidak perlu Customer Service atau Teller akan ada jutaaan profesi pekerjaan yg hilang 10-20 tahun kedepan. Sudah siapkah kita
Banyak perusahaan akan membuat perangkat medikal (yg disebut 'Tricorder' dalam film Star Trek) yg bekerja dgn telepon anda, yg akan memindai retina anda, sampel darah anda, dan napas anda.
Lalu dia akan menganalisa 54 bio-marker yg akan meng identifikasi hampir semua jenis penyakit. Saat ini sudah terdapat lusinan aplikasi telepon untuk tujuan kesehatan.
Inilah keadaan MASA DEPAN !
(Menurut prediksi manusia 🙂)
---
| dasaptaerwin |
580,724 | JavaScript Interview Questions — Functions and Scope | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-24T01:56:35 | https://thewebdev.info/2020/08/14/javascript-interview-questions%e2%80%8a-%e2%80%8afunctions-and-scope/ | webdev, programming, beginners, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
To get a job as a front end developer, we need to nail the coding interview.
In this article, we’ll look at some basic functions and scope questions.
### What is Hoisting?
Hoisting means that a variable or function is moved to the top of their scope of where we defined the variable or function.
JavaScripts moves function declarations to the top of their scope of we can reference them later and gets all variable declarations and give them the value of `undefined` .
During execution, the variables that were hoisted are assigned a value or runs functions.
Only function declarations and variables declared with the `var` keyword are hoisted.
Variables declared with `let` and `const` constants aren’t hoisted. Also, arrow functions and function expressions aren’t hoisted.
For example, the following code has a function that’s hoisted:
```
foo();
function foo(){
console.log('foo')
}
```
`foo` is hoisted, so it can be called before it’s defined since it’s a function declaration.
The following variable declaration is hoisted:
```
console.log(x);
var x = 1;
console.log(x);
```
The first `console.log` outputs `undefined` since `var x` is hoisted.
Then when `var x = 1` runs, `x` is set to 1. Then we get 1 logged in the second `console.log` since `x` has its value set before it.
Anything else isn’t hoisted.
### What is Scope?
JavaScript’s scope is the area where we have valid access to a variable or function.
There’re 3 kinds of scopes in JavaScript — global, function, and block scope.
Variables and functions that have global scope are accessible everywhere in the script or module file.
For example, we can declare a variable with global scope as follows:
```
var global = 'global';
const foo = () => {
console.log(global);
const bar = () => {
console.log(global);
}
bar();
}
foo();
```
Since we declared a variable with `var` on top of the code, it’s accessible everywhere. So both `console.log` s will output `'global'` .
Function scoped variables are only available inside a function.
We can define a function scoped variable as follows:
```
const foo = () => {
var fooString = 'foo';
console.log(fooString);
const bar = () => {
console.log(fooString);
}
bar();
}
foo();
console.log(fooString);
```
In the code above, we have the function scoped variable `fooString` . It’s also declared with `var` and it’s available inside both the `foo` function and the nested `bar` function.
Therefore, we’ll get `‘foo’` logged with the 2 `console.log` statements inside the `foo` function.
The `console.log` at the bottom gives us an error because function scoped variables aren’t available outside a function.
Block scoped variables are only available inside a block. That is, inside an `if` block, function block, loop, or an explicitly defined block. Anything delimited by curly braces is a block.
They’re defined either with `let` or `const` depending if it’s variable or constant.
For instance, if we write:
```
if (true) {
let x = 1;
console.log(x);
}
console.log(x);
```
Then `x` is only available inside the `if` block. The `console.log` at the bottom gives us an `x is not defined` error.
Likewise, if we have had a loop:
```
for (let i = 0; i <= 1; i++) {
let x = 1;
console.log(x);
}
console.log(x);
```
Then `x` is only available inside the loop. The `console.log` at the bottom gives us an `x is not defined` error.
We can also define a block explicitly just to isolate variables from the outside:
```
{
let x = 1;
console.log(x);
}
console.log(x);
```
`x` will then only be available inside the curly braces. The bottom `console.log` will give us an error.
The scope determines how far the JavaScript will go to look for a variable. If it’s doesn’t exist in the current scope then it’ll look in the outer scope.
If it finds it in the outer scope and it’s declared in a way that we can access the variable then it’ll pick up that value.
Otherwise, if it’s not found, then we get an error.
### What are Closures?
Closures are functions that remember the variables and parameters on its current scope and all the way up to the global scope.
In JavaScript, when an inner function has made available to any scope outside the outer function.
We can use it to expose private functions or data in a restricted way.
For example, we can write the following function that is a closure:
```
const foo = (() => {
let x = 'Joe';
const privateFn = () => {
alert(`hello ${x}`);
}
return {
publicFn() {
privateFn();
}
}
})();
foo.publicFn();
```
In the code above, we have an (Immediately Invoked Function Expression) IIFE that runs a function that returns an object with a `publicFn` property, which is set to a function that calls `privateFn` , which is hidden from the outside.
Also, `privateFn` is called with `x` declared inside the function.
Then we call `publicFn` after assigning the returned object to `foo` .
What the code achieves is that we hid the private items within a closure, while exposing what we want to expose to the outside.
As we can see, the closure lets us hold items that’s resides in a scope not available to the outside while we can expose what we can use outside the closure.
One major use of closures is to keep some entities private while exposing necessary functionality to the outside.
### Conclusion
Hoisting is the pulling of functions and variables to the top of the code during compilation.
Function declarations are hoisted fully, and variables declared with `var` has everything before the value assignment hoisted.
The scope is where a piece of code has valid access to a variable or constant.
Closures are a way to return inner functions with some of the entities of the outer function included. It’s useful for keeping some things private while exposing some functionality.
| aumayeung |
580,725 | JavaScript Interview Questions — Data Types | Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62 Subscribe to my em... | 0 | 2021-01-24T01:56:56 | https://thewebdev.info/2020/08/14/javascript-interview-questions%e2%80%8a-%e2%80%8adata-types/ | webdev, programming, beginners, javascript | **Check out my books on Amazon at https://www.amazon.com/John-Au-Yeung/e/B08FT5NT62**
**Subscribe to my email list now at http://jauyeung.net/subscribe/**
To get a job as a front end developer, we need to nail the coding interview.
In this article, we’ll look at how some data type questions, including some trick questions that are often asked in interviews.
### What are the falsy values in JavaScript?
In JavaScript, falsy values are the following
* `''`
* 0
* `null`
* `undefined`
* `false`
* `NaN`
They become `false` when they’re converted to a boolean value.
### How to check if a value is falsy?
Use the `!!` operator or `Boolean` function to check if they’re falsy.
If a value is falsy, then both will return `false`.
For example:
```
!!0
```
will return `false`.
```
Boolean(0)
```
will also return `false`.
### What are truthy values?
Truthy values are any other than those falsy values listed above.
### What are Wrapper Objects?
Wrapper objects are objects that are created from constructors that return primitive values but have the type `'object'` if it’s a number or a string. Symbols and BigInt have their own types.
In JavaScript, there’s the `Number`, `String` constructors, and `Symbol`, and `BigInt` factory functions.
Primitive values are temporarily converted to wrapper objects to call methods.
For example, we can write:
```
'foo'.toUpperCase()
```
Then we get `'FOO'`. It works by converting the `'foo'` literal to an object and then call the `toUpperCase()` method on it.
We can also create wrapper objects for numbers and BigInt as follows:
```
new Number(1)
BigInt(1)
```
Using the `Number` or `String` constructor directly isn’t too useful, so we should avoid it. They give us the type of object but has the same content as their primitive counterparts.
If we did create `Number` and `String` wrapper objects with the `new` operator as follows:
```
const numObj = new Number(1);
const strObj = new String('foo');
```
We can return the primitive value version of those wrapper objects by using the `valueOf` method as follows:
```
numObj.valueOf();
strObj.valueOf();
```
### What is the difference between Implicit and Explicit Coercion?
Implicit coercion means that the JavaScript interpreter converts a piece of data from one type to another without explicitly calling a method.
For example, the following expression are implicitly converted to a string:
```
console.log(1 + '2');
```
Then we get:
```
'12'
```
returned because 1 is converted to `'1'` implicitly.
Another example would be:
```
true + false
```
We get 1 returned because `true` is converted to 1 and `false` is converted to 0 and they’re added together.
The following example:
```
3 * '2'
```
returns 6 because `'2'` is converted to `2` and then they’re multiplied together.
The full list of JavaScript coercion rules are [here](https://delapouite.com/ramblings/javascript-coercion-rules.html).
Explicit conversion is done by calling a method or using an operator to convert a type.
We can see the coercion done in the code.
For example:
```
+'1' + +'2'
```
gets us 3 since we have `'1'` and `'2'` are both converted to numbers by the unary `+` operator.
We can also do the same things with functions. For example, we can use the `parseInt` function instead of using the unary `+` operator.
We can rewrite the expression above to:
```
parseInt('1') + parseInt('2')
```
Then we get the same result.
### What Does 0 || 1 Return?
Since `0` is falsy, it’ll trigger the second operand to run, which gives us 1. Therefore, it should return 1.
### What Does 0 && 1 Return?
Since `0` is falsy, it’ll stop running since we have short-circuited evaluation. Therefore, we get 0 returned.
### What Does false == ‘0’ Return?
`false` is falsy and `'0'` is converted to 0, which is falsy, so they are the same in terms of the `==`’s comparison criteria. Therefore, we should get `true` returned.
### What Does 4 < 5 < 6 Return?
In JavaScript, comparisons are done from left to right. So first `4 < 5` will be evaluated, which gives us `true` . Then `true < 6` is evaluated, which is converted to `1 < 6` which is also `true` .
Therefore, we get `true` returned.
### What Does 6 > 5 > 4 Return?
In JavaScript, comparisons are done from left to right. So `6 > 5` will be evaluated first. This gives us `true` . Then `true > 4` is evaluated, which is converted to `1 > 4` , which is `false` .
Therefore, the expression returns `false` .
### What Does typeof undefined == typeof null Return?
`typeof undefined` returns `'undefined'` and `typeof null` returns `'object'` .
Since `'undefined'` does equal `'object'` , the expression should be `false` .
### What Does typeof typeof 10 Return?
JavaScript evaluates `typeof typeof 10` as `typeof (typeof 10)` . Therefore, this returns `typeof 'number'` , which returns `'string'` since `'number'` is a string. | aumayeung |
581,136 | The Conditional (Ternary) Operator | In this article I'm gonna be talking about " conditional (ternary) operator"! It's the shortcut to if... | 0 | 2021-01-30T16:17:11 | https://dev.to/nazanin_ashrafi/did-you-know-you-could-shorten-if-else-statements-36jg | javascript, webdev, codenewbie | In this article I'm gonna be talking about "<i> conditional (ternary) operator</i>"!
It's the shortcut to if statements, which I'll be explaining in a moment.
It's not complex and I'll try to make it as simple as possible for you.
______________
<br> First let's talk about if statements :
If statements help us execute code if a certain condition is met.
Now let's take a look at the codes :
``` javaScript
if ( condition ) {
statement if true;
} else {
statement if false;
}
```
If the statement is true, the first code block will be executed and if it's false the second code block will be executed.
<b> Example </b>
We want to check if we should turn the lights on or turn it off
``` javaScript
let isDay = true;
if (isDay === true) {
console.log("Turn the lights off");
}
else {
console.log("Turn the lights on");
}
// it's day so the true code block will be executed and the result would be "turn the lights off"
```
_____________
<br> Now that we've talked about if statements let's see how we can shorten it.
We can do so with the help of "<i>The conditional (ternary) operator</i>".
What is this ? What a confusing name, right?
Worry not! It's very simple to grasp.
<br>
Let's take a look at its code :
``` javaScript
condition ? statement if true : statement if false;
```
When I was trying to learn more about this line of code, it was very confusing for me.
<br><b>This is how I've made it easy for myself to understand for, which I'll explain it with an example :
<br> We want to check if the chosen answer is correct or not :
``` javaScript
let correctAnswer = "pink";
let result = (correctAnswer === "pink") ?
"correct" : "wrong";
console.log(result); // the result will be correct "
```
The question mark might be confusing and hard to understand (it was for me) so how did I make it simpler for myself?
I'll break down the codes for you :
* 1:
``` javaScript
let correctAnswer = "pink";
```
we choose "pink" as our correct answer.
* 2:
``` javaScript
correctAnswer === "pink" ?
```
You can read "?" as "what is it?". I mean it's a question mark after all. It's supposed to be asking a question.
It's asking if the correct answer is pink?
Instead of reading it like " if the correct answer is pink", you can read it like " is the correct answer is pink?"
* 3:
``` javaScript
"correct" : "wrong";
```
We've asked our code to show "correct" If the statement is true.
And if the statement is not true, show "wrong".
__________
<br> Now that We've talked about both if statement and conditional operator, I think a few more examples would help you understand this better , right?
<h4> Example 1. </h4>
Let's create a very simple budget app :
``` javaScript
let money = 500;
// Our budget is 500
```
<br> <b>If statement :<b>
``` javaScript
if (money === 500) {
console.log("You're doing great in saving money")
} else {
console.log("stop wasting your money and start saving");
}
// the condition is true, therefore first code block will be executed
```
<br> <b>Ternary operator : </b>
``` javaScript
let result = (money === 500) ?
"you're doing great in saving money" :
"stop wasting your money and start saving";
console.log(result); // "you're doing great
``` <br>
<h4> Example 2. </h4>
We want to see if a person is allowed to get their driver's license :
``` javaScript
let age = 10;
```
<br> <b> If statement : </b>
``` javaScript
if (age >= 18) {
console.log(
"you can get your driver's license");
} else {
console.log(
"you're too young for this kiddo");
}
console.log(result); // you're too young for this kiddo
// person's age is not 18, therefore our condition is false and false code block will be executed.
```
<br> <b> Ternary operator : </b>
``` javaScript
let result = (age >= 18) ?
"you can get your driver's license" :
"you're too young for this kiddo";
//is age greater than or equal to 18? No it is not.
console.log(result); // you're too young for this kiddo
```
___________
That's it, guys.
I hope the examples were helpful and clear enough.
Don't worry if you can't get it at first, it took me awhile to figure it out.
But with more practice you can have a full grasp of this topic .
<b>Just keep practicing </b> | nazanin_ashrafi |
581,243 | Linux Terminal: The Ultimate Cheat Sheet | A comprehensive list of useful commands for the Linux Terminal. | 11,039 | 2021-01-25T12:11:38 | https://maurogarcia.dev/maurogarcia.dev/posts/linux-terminal-cheat-sheet/ | linux, terminal, beginners | ---
title: Linux Terminal: The Ultimate Cheat Sheet
description: A comprehensive list of useful commands for the Linux Terminal.
published: true
tags: linux, terminal, beginners
cover_image: https://i.imgur.com/jMyI2GG.png
canonical_url: https://maurogarcia.dev/maurogarcia.dev/posts/linux-terminal-cheat-sheet/
series: Linux Terminal - The Ultimate Cheat Sheet
---
If you're a Linux user, the Terminal is probably the most powerful tool you would ever have. But the thing about the Terminal is that you need to learn how to use it if you want to benefit from it.
For the last few months, I've been playing with the Terminal a lot, and I came up with a long list of useful commands that I use regularly. Please let me know if I missed something important so I can add it to future posts.
<br/>
💡 If you found this content valuable, you can follow me on [Twitter](https://twitter.com/mauro_codes) and [Instagram](https://www.instagram.com/mauro.codes/).
<br/>
# TL;DR
- **Basic commands**
- Zoom in ➜ `[CTRL] + [+]`
- Zoom out ➜ `[CTRL] + [-]`
- Print working directory ➜ `pwd`
- Clear the terminal ➜ `[CTRL] + [l]` or `clear`
- Assign an alias ➜ `alias [alias-name]="[command-to-run]"`
- Source a file ➜ `source [name-of-the-file-to-read-and-execute]`
---
- **Change directory command (cd)**
- Move to a specific directory ➜ `cd [name-of-your-directory]`
- Move to the parent directory ➜ `cd ..`
- Move to the home directory ➜ `cd` or `cd ~`
- Move to the last directory yo were in ➜ `cd -`
---
- **List command (ls)**
- List all visible files and directories ➜ `ls`
- List all files and directories (include hidden files) ➜ `ls -a`
- Long Listed Format ➜ `ls -l`
- Human Readable Format ➜ `ls -lh`
- Combining arguments: Human Readable Format + Hidden files ➜ `ls -lah`
- Learn more about the ls command ➜ `man ls`
---
- **Search**
- Locate the binary for a program ➜ `which [name-of-the-program]`
- Locate the binary, source and user manual for a program ➜ `whereis [name-of-the-program]`
- Locate files and directories by name ➜ `find [path-to-search] -iname [name-of-the-file-you-want-to-search]`
- Learn more about the find command ➜ `man find`
- Get a brief description for a command ➜ `whatis [command-name]`
---
- **History**
- Get previous commands (one by one) ➜ Use the `Up Arrow key` ⬆️ to navigate your history
- Get previous commands (full list) ➜ `history`.
- Repeat commands from history (bang command) ➜ `history` ➜ `![number-of-the-command-to-repeat]`
- Repeat last command (bang-bang command) ➜ `!!`
---
- **Working with files and directories**
- Create a new file (without open it) ➜ `touch [name-of-your-file]`
- Create a new file using a text editor ➜ `vim [name-of-your-file]` or `nano [name-of-your-file]`
- Copy a file ➜ `cp [source-path-of-your-file] [destination-path-for-your-file]`
- Create a new directory ➜ `mkdir [new-directory-name]`
- Remove an empty directory ➜ `rmdir [name-of-the-directory-you-want-to-remove]`
- **Remove command (rm)**
- Remove a file ➜ `rm [name-of-your-file]`
- Remove a directory recursively (use with caution) ➜ `rm -rf [name-of-your-directory]`
- **Concatenate command (cat)**
- View a single file ➜ `cat [name-of-your-file]`
- View a single file including the line numbers ➜ `cat -n [name-of-your-file]`
- Copy the content of one file to another file ➜ `cat [filename-whose-contents-is-to-be-copied] > [destination-filename]`
- Learn more about the cat command ➜ `man cat`
- **Move command (mv)**
- Move a file ➜ `mv [source-path-of-your-file] [destination-path-for-your-file]`
- Rename a file ➜ `mv [name-of-your-file] [new name-of-your-file]`
# Basic commands
## Zoom in
Type `[CTRL] + [+]`
## Zoom out
Type `[CTRL] + [-]`
## pwd: Print Working Directory command
It prints the working directory path, starting from the root directory.
```bash
mauro_codes@DESKTOP-HIQ7662:~$ pwd
/home/mauro_codes
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
```
## Clear command
Type `clear` or `[CTRL] + [l]` to clear the entire terminal screen and get a clean terminal to keep working.
## Alias command
If you usually run a long command regularly and want to save time, you can assign a shorter alias for that command. Type `alias [alias-name]="[command-to-run]"` to assign a new alias:
```bash
## Running the ls command
mauro_codes@DESKTOP-HIQ7662:~$ ls
projects
## Assign an alias, so we don't need to add the arguments every time we need to list something
mauro_codes@DESKTOP-HIQ7662:~$ alias ls="ls -lah"
## Running ls again (we get the result of `ls -lah`)
mauro_codes@DESKTOP-HIQ7662:~$ ls
total 16K
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 17:41 .
drwxr-xr-x 1 root root 512 Jan 22 10:38 ..
-rw------- 1 mauro_codes mauro_codes 3.0K Jan 22 23:58 .bash_history
-rw-r--r-- 1 mauro_codes mauro_codes 220 Jan 22 10:38 .bash_logout
-rw-r--r-- 1 mauro_codes mauro_codes 3.7K Jan 22 17:32 .bashrc
-rw-r--r-- 1 mauro_codes mauro_codes 807 Jan 22 10:38 .profile
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 projects
```
> Note that this alias won't be persisted for future uses. If you want to persist your aliases, add them at the end of your .bashrc file located in your home directory.
## Source a file
You can use the `source` command to read and execute the content of a file line by line. Type `source [name-of-the-file-to-read-and-execute]`:
```bash
## Print the content of the script.txt file (contains two commands)
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cat script.txt
echo "hello world" ## Print a hello message
cal ## Print a calendar
## Source the script.txt to run each command inside
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ source script.txt
hello world
January 2021
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31
```
# Change Directory command (cd)
## Move to a specific directory
Type `cd [name-of-your-directory]`:
```bash
## Check current directory
mauro_codes@DESKTOP-HIQ7662:~$ pwd
/home/mauro_codes
## Change directory
mauro_codes@DESKTOP-HIQ7662:~$ cd projects/
## Check new working directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
```
## Move to the parent directory
Type `cd ..`:
```bash
## Check current directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
## Move to the parent directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ cd ..
## Check new working directory
mauro_codes@DESKTOP-HIQ7662:~$ pwd
/home/mauro_codes
```
## Move to the home directory
Type `cd ~` or just `cd` as an alternative
```bash
## Check current directory
mauro_codes@DESKTOP-HIQ7662:~/projects/awesome-app$ pwd
/home/mauro_codes/projects/awesome-app
## Move to the home directory
mauro_codes@DESKTOP-HIQ7662:~/projects/awesome-app$ cd ~
## Check new working directory
mauro_codes@DESKTOP-HIQ7662:~$ pwd
/home/mauro_codes
```
## Move to the last directory you were in
Type `cd -` to navigate to the previous directory you were in
```bash
## Check the current directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ pwd
/home/mauro_codes/projects/landing-page
## Move to another directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cd /home/mauro_codes/
## Check the new directory
mauro_codes@DESKTOP-HIQ7662:~$ pwd
/home/mauro_codes
## Go back to the previus directory you were in
mauro_codes@DESKTOP-HIQ7662:~$ cd -
/home/mauro_codes/projects/landing-page
```
# List command (ls)
Lists the content of the directory you're currently in.
## List all visible files and directories
Type `ls` without any additional argument to get all the files and directories (this command will exclude hidden files like the [dotfiles](https://wiki.archlinux.org/index.php/Dotfiles)).
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ ls
awesome-app landing-page nextjs-tailwindcss-blog-starter personal-blog
```
## List all files and directories
Type `ls -a` to get all the files and directories (including the hidden files)
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
## List the content for the working directory (including hidden files)
mauro_codes@DESKTOP-HIQ7662:~/projects$ ls -a
. .. .config .configu awesome-app landing-page nextjs-tailwindcss-blog-starter personal-blog
```
## Long Listed Format
Type `ls -l` to get all the visible files and directories including additional metadata like permissions, owner, size and modified date and time.
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ pwd
/home/mauro_codes/projects/nextjs-tailwindcss-blog-starter
## List the content for the working directory (using the long listed format)
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ ls -l
total 140
-rw-r--r-- 1 mauro_codes mauro_codes 4487 Jan 22 12:55 README.md
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 components
-rw-r--r-- 1 mauro_codes mauro_codes 1068 Jan 22 12:55 config.ts
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 helpers
```
## Human Readable Format
Type `ls -lh` to get all the visible files and directories in long-listed format, but with a Human Readable Format (User-friendly file size).
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ pwd
/home/mauro_codes/projects/nextjs-tailwindcss-blog-starter
## List the content for the working directory (using the long listed format + human readable format)
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ ls -lh
total 140K
-rw-r--r-- 1 mauro_codes mauro_codes 4.4K Jan 22 12:55 README.md
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 components
-rw-r--r-- 1 mauro_codes mauro_codes 1.1K Jan 22 12:55 config.ts
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 helpers
```
## Combining arguments
Type `ls -lah` to get all the files and directories (including hidden files) in Human Readable Format.
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ pwd
/home/mauro_codes/projects/nextjs-tailwindcss-blog-starter
## List the content for the working directory (include hidden files + human readable format)
mauro_codes@DESKTOP-HIQ7662:~/projects/nextjs-tailwindcss-blog-starter$ ls -lah
total 140K
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 13:08 .
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 ..
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 .git
-rw-r--r-- 1 mauro_codes mauro_codes 362 Jan 22 12:55 .gitignore
-rw-r--r-- 1 mauro_codes mauro_codes 4.4K Jan 22 12:55 README.md
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 components
-rw-r--r-- 1 mauro_codes mauro_codes 1.1K Jan 22 12:55 config.ts
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 22 12:55 helpers
```
## Learn more about the `ls` command
There are dozens of arguments that you can use with the `ls` command. If you want to dig dipper,
type `man ls` in your terminal to display the user manual for the `ls` command.
# Search
## Locate the binary for a program
If you want to locate where the binary (executable) for a specific command or program is located. You can use the `which` command:
```bash
## Locate binary for the ls command
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ which ls
/usr/bin/ls
## Locate binary for git
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ which git
/usr/bin/git
```
## Locate the binary, source, and user manual for a program
You can use the `whereis` command to locate the binary, source, and user manual for a program. You can use the `-b`, `-m`, and `-s` arguments to limit the results to binaries, manual and source, respectively
```bash
## Locate binary, manual, and source for git
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ whereis git
git: /usr/bin/git /mnt/c/Program Files/Git/cmd/git.exe /usr/share/man/man1/git.1.gz
## Locate only binary and manual for Git, and only the manual for ls command
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ whereis -bm git -m ls
git: /usr/bin/git /mnt/c/Program Files/Git/cmd/git.exe /usr/share/man/man1/git.1.gz
ls: /usr/share/man/man1/ls.1.gz
```
## Locate files and directories by name
Type `find [path-to-search] -iname [name-of-the-file-you-want-to-search]` to find any file or directory that contain the given name in their title.
- The path to search is optional. If it is not specified, the `find` command will run on your current working directory (and its descendants)
- The `-iname` argument means that our search will be case insensitive.
```bash
- If you want to learn more about this command, type `man find` to display the user manual.
## Check current working directory
mauro_codes@DESKTOP-HIQ7662:~/projects$ pwd
/home/mauro_codes/projects
## Find files that contain "posts" on my current working directory and its descendants
mauro_codes@DESKTOP-HIQ7662:~/projects$ find -iname posts
./nextjs-tailwindcss-blog-starter/pages/posts
./nextjs-tailwindcss-blog-starter/posts
## Find files that contain "posts" on a specific directory and its descendants
mauro_codes@DESKTOP-HIQ7662:~/projects$ find ./nextjs-tailwindcss-blog-starter/pages/ -iname posts
./nextjs-tailwindcss-blog-starter/pages/posts
```
## Get a brief description for a command
If you don't know what a certain command does, Type `whatis [command-name]` like this:
```bash
## Asking about the cat command
mauro_codes@DESKTOP-HIQ7662:~/projects$ whatis cat
cat (1) - concatenate files and print on the standard output
## Asking about the find command
mauro_codes@DESKTOP-HIQ7662:~/projects$ whatis find
find (1) - search for files in a directory hierarchy
```
# History
## Get previous commands (one by one)
You can access your recent command by pressing the `Up Arrow key` ⬆️. This is very useful if you want to repeat your last command. Let's say we move to a specific directory, and then we check our working directory like this:
```bash
## Move to a specific directory
mauro_codes@DESKTOP-HIQ7662:~$ cd projects/awesome-app/
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/awesome-app$ pwd
/home/mauro_codes/projects/awesome-app
```
⬆️ We'll get the `pwd` command
⬆️⬆️ We'll get the `cd projects/awesome-app` command
## Repeat previous commands (full list)
Type `history` to get a numerated list containing the previous commands you run. Then, type `![number-of-the-command-to-repeat]` to repeat that command
```bash
## Get the history list
mauro_codes@DESKTOP-HIQ7662:~$ history
1 ls
2 clear
3 pwd
4 mkdir projects
5 cd projects
## Run command number 1 (ls)
mauro_codes@DESKTOP-HIQ7662:~$ !1
projects
```
## Repeat the last command
Type `!!` (bang-bang command) to repeat the last command. This is especially useful when you forgot to add `sudo` on your last command:
```bash
## Running update without sudo (Permission denied)
mauro_codes@DESKTOP-HIQ7662:~$ apt update
Reading package lists... Done
E: Could not open lock file /var/lib/apt/lists/lock - open (13: Permission denied)
E: Unable to lock directory /var/lib/apt/lists/
W: Problem unlinking the file /var/cache/apt/pkgcache.bin - RemoveCaches (13: Permission denied)
W: Problem unlinking the file /var/cache/apt/srcpkgcache.bin - RemoveCaches (13: Permission denied)
## Using the bang-bang command to append the last command after sudo
mauro_codes@DESKTOP-HIQ7662:~$ sudo !!
sudo apt update
[sudo] password for mauro_codes:
Get:1 http://security.ubuntu.com/ubuntu focal-security InRelease [109 kB]
Hit:2 http://archive.ubuntu.com/ubuntu focal InRelease
Get:3 http://archive.ubuntu.com/ubuntu focal-updates InRelease [114 kB]
...
```
# Working with files and directories
## Create a new file (without open it)
Type `touch [name-of-your-file]` to create a new file without open it on a text editor. This is useful if you just want to create an empty file but don't need to change it right now.
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ pwd
/home/mauro_codes/projects/landing-page
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md
## Create an empty js file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ touch main.js
## List the content for the working directory (including your new file)
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md main.js
```
## Create a new file using a text editor
Type `nano [name-of-your-file]` to create a new file and open it using the text editor [nano](https://www.nano-editor.org/). If you want to learn more about nano, you can Type `man nano` on your terminal to display the nano user manual.
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ pwd
/home/mauro_codes/projects/landing-page
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md main.js
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ nano index.html
```
After running the last command, you'll be able to edit the file using nano:
## Copy a file
You can use the `cp` (Copy) command to copy files and directories
Type `cp [source-path-of-your-file] [destination-path-for-your-file]` to copy a file into a new destination.
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index.html main.js temp
## Copy the README.md file into the temp directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cp README.md temp/README.md
## List the content for the working directory and check that your file is still there.
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index.html main.js temp
## List the temp directory's content and check if your file was copied.
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls temp/
README.md index-copy.html
```
## Create a new directory
Type `mkdir [new-directory-name]` to create a new directory in your current working directory
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index-empty-copy.html index.html main.js
## Create a new directory called "scripts"
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ mkdir scripts
## List the content to check if our new directory was created
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index-empty-copy.html index.html main.js scripts
```
## Remove an empty directory
Type `rmdir [name-of-the-directory-you-want-to-remove]` to remove an empty directory. Please note that this command will only work with empty directories.
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index.html main.js temp
## Remove the "temp" empty directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ rmdir temp
## List the content and check that the directory was removed
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index.html main.js
```
## Remove command (rm)
### Remove a file
Type `rm [name-of-your-file]` to remove a file
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ ls
README.md index-copy.html
## Remove the index-copy.html file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ rm index-copy.html
## List the content for the working directory and check that the file was removed
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ ls
README.md
```
### Remove a directory recursively
Type `rm -rfi [name-of-your-directory]` to recursively remove a directory with all its files and sub-directories.
> **Please be careful!** This is one of the most dangerous commands you can run. If you run `rm -rfi /`, you'll erase your entire root partition. Be sure to specify the path for the directory you want to delete. In this example, In this example, I include the `-i` argument to ask for confirmation.
```bash
## List the content of the temp folder (It has one file)
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls temp/
total 0
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 24 19:45 .
drwxr-xr-x 1 mauro_codes mauro_codes 512 Jan 24 19:44 ..
-rw-r--r-- 1 mauro_codes mauro_codes 8 Jan 24 19:45 file.txt
## Recursively remove the temp folder
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ rm -rf temp/
## Check that the temp folder was removed
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls temp/
ls: cannot access 'temp/': No such file or directory
```
## Concatenate command (cat)
You can use the `cat` (concatenate) command to read data from a file and print their content as output
### View a single file
Type `cat [name-of-your-file]`:
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ pwd
/home/mauro_codes/projects/landing-page
## Print the content of the index.html file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cat index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta http-equiv="x-ua-compatible" content="ie=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>My Website</title>
</head>
<body>
<script src="js/main.js"></script>
</body>
</html>
```
### View a single file including the line numbers
Type `cat -n [name-of-your-file]`:
```bash
## Check the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ pwd
/home/mauro_codes/projects/landing-page
## Print the content of the index.html file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cat -n index.html
1 <!DOCTYPE html>
2 <html lang="en">
3 <head>
4 <meta charset="utf-8" />
5 <meta http-equiv="x-ua-compatible" content="ie=edge" />
6 <meta name="viewport" content="width=device-width, initial-scale=1" />
7
8 <title>My Website</title>
9 </head>
10
11 <body>
12 <script src="js/main.js"></script>
13 </body>
14 </html>
```
### Copy the content of one file to another file
Type `cat [filename-whose-contents-is-to-be-copied] > [destination-filename]`:
```bash
## Create an empty file called index-empty-copy.html
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ touch index-empty-copy.html
## Copy the content of index.html to index-empty-copy.html
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cat index.html > index-empty-copy.html
## Print the content of the index-empty-copy.html file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ cat index-empty-copy.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta http-equiv="x-ua-compatible" content="ie=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<title>My Website</title>
</head>
<body>
<script src="js/main.js"></script>
</body>
</html>
```
### Learn more about the `cat` command
Type `man cat` to display the user manual for the `cat` command
## Move command (mv)
You can use the `mv` (move) command for moving and renaming files
### Move a file
Type `mv [source-path-of-your-file] [destination-path-for-your-file]` to move a file into a new directory
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index-empty-copy.html index.html main.js temp
## Move the index-empty-copy.html file to the temp directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ mv index-empty-copy.html temp/index-empty-copy.html
## List the content again and check that the file is no longer in the current working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls
README.md index.html main.js temp
## List the temp folder and check that the file is now there.
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page$ ls temp/
index-empty-copy.html
```
### Rename a file
Type `mv [name-of-your-file] [new name-of-your-file]` to rename a file
```bash
## List the content for the working directory
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ ls
index-empty-copy.html
## Rename the index-empty-copy.html file
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ mv index-empty-copy.html index-copy.html
## List the content for the working directory (check if your file's name was updated)
mauro_codes@DESKTOP-HIQ7662:~/projects/landing-page/temp$ ls
index-copy.html
```
# Final words
I missed tons of powerful commands on this post, but I decided to keep them for a future post. This is already huge.😄
### I would love to hear your feedback about this format. Is it clear? Is it useful? Let me know if you want me to cover any particular command on my next post.
| mauro_codes |
763,035 | Ultimate Beginner's Guide to Linux | What is Linux? Linux is another operating system comparable to macOS and... | 0 | 2021-07-19T03:54:02 | https://blog.adityaone.com/blog/linux-intro/ | linux, beginners, tutorial | 
# What is Linux?
Linux is another operating system comparable to macOS and Windows.
Although it is technically not referred to as a wholesome OS like its
popular counterparts, there are distributions of Linux
(flavours/variations) of it which can be directly compared.
Linux is based on UNIX, similar to macOS, but that is pretty much where
the similarities end. It was created by Linus Torvalds with a free, open
source license, which is the main reason it grew so much in popularity.
But, the software that Linus created, is only what is called the Linux
Kernel, which is not an entire operating system.
## Distributions (or distros)
Other developers and companies over the years, have created their own
versions of an operating system called distributions (or distro for
short) building up on Linux. Few examples of these distributions are
[Debian](https://www.debian.org/), [Arch Linux](https://archlinux.org/), [Red Hat Enterprise](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux), etc. Some of these distributions
can only be used with a command-line interface (no graphical interface),
but it is possible for users to install desktop environments or window
managers for them to actually use it as a modern desktop operating
system.
Linux has grown in popularity over the years, and due to its free and
open source nature, there are so many forks and branches of different
distributions which are based on each other. An example is [Ubuntu](https://ubuntu.com/)
created by Canonical, one of the most popular distros in existence right now, which is based on
one of the oldest distributions called Debian. Another popular
distribution created by the company System76, is [Pop!_OS](https://pop.system76.com/), which is based
on Ubuntu, which is based on Debian.

The image above shows the numerous branches or forks of one particular
distribution called Red Hat which is meant for enterprise businesses.
# Advantages of using Linux
## Performance and Efficiency
Linux operating systems or distributions are extremely light-weight and
efficient compared to their proprietary counterparts. The user is in
full control of what runs on their system at all times, and any
component can be removed and installed at any point of time. This causes
computers to run tasks and perform much better on Linux rather on
something like Windows.
I can personally vouch for this as I have a new Dell XPS 13 with an
Intel i7, which initially had Windows 10 Home pre-installed. Although
there is not much of a performance difference between the Home and Pro
versions, I should have been receiving excellent performance for the
hardware I had. But, I often experienced sluggishness, animations losing
frames, and the laptop often overheating. Once I jumped on to a linux
distro (Ubuntu), I immediately experienced extremely snappy responses,
and the overheating issues vanished. All of this was during regular
browsing, video conferencing, etc.
## File system
This point ties in with performance. Linux uses a much more superior file system especially in contrast to Windows' FAT or NTFS. There are different variations, such as EXT4, which allow for more reliability, and much more faster and robust experience when copying, and moving around files and directories.
## Security
Linux is vastly more secure for two main reasons. Firstly, it is not
nearly as popular as Windows or MacOS, so viruses are usually not made
with Linux in mind. There are very few viruses made for Linux distros
and you will not be needing to install any anti-virus software. Another
reason is also probably because people using Linux are usually a little
more tech-savvy and are careful when installing files from the internet.
As long as you are aware of the file types and permissions on your
system, you shouldn't have to worry.
Secondly, because Linux is open source, vulnerabilities are quickly
identified and patched by any knowledgeable person in the community,
without having to wait for months from some company to provide a
security patch. One could make the argument that if the code is open
source, hackers or malicious individuals could easily exploit
vulnerabilities. But, there are far more people looking to usually fix
bugs and improve the system because they are the ones who are going to
use it at the end of the day.
## Reliability and Stability
Linux is extremely stable and reliable. This is a well-known fact as it
is employed in thousands of servers around the world which are running
Linux continuously without any crashes or errors. Even Microsoft, which
has their own Windows for Servers OS, uses Linux for their servers. They
usually have high uptime and very rarely crash or provide issues.
And, my most favourite feature of Linux, is that when something goes
wrong, you get very descriptive error messages telling you what and
where the issue has occurred. Using this information, you can most likely
understand the problem and rectify it, or a quick Google search (or
Brave, DuckDuckGo, etc.) will always find you the answer from countless
blog posts and forums where the same question and error has probably
been answered multiple times. In other OSs, it is almost impossible to
get help, because when something goes wrong, it just says 'Oops,
something has gone wrong', and you are pretty much helpless. Even if you
try to ask someone online, there are probably a 100 possible errors
which provide the same message.
## Customizability
Being open source, and further employing the concept of 'everything is a file', makes it possible to customize every aspect of the system. If you don't like the way something looks or behaves, you can just go ahead and change it without asking anyone. Everything in Linux is just a text file, even things like the network configuration or how your display is set up. So you can just open the file with a simple text editor, and make the change.
If you are using a user-friendly distro, you can do this using a friendly GUI with intuitive menus so it can be done easily (just like on Windows or macOS). Other distributions which tend to be more lightweight will required users to actually dig into the files and change what they want.
You will be amazed to see the desktops people have created using Linux. I can argue that it is 100 times better than the ones made by Microsoft and Apple.
## Privacy
Whether you are developer writing some important code for a piece of software, or you are just a regular daily user, privacy is something you never have to worry about in Linux. Due to the same reasons I mentioned above (being open source), you will never have to worry about key loggers, or any other kind of program that will track you on your device.
## Software Updates
Software update models depend on the distribution you are going to choose. Some have a rolling release cycle (like Arch Linux) where small incremental updates are released almost every month or week which always keeps you up-to-date with the latest bleeding-edge features. Others push updates around once or twice a year (like Ubuntu). This is generally considered a little more stable as it is more comprehensively been tested. But regardless of what release cycle is used, if you don't want to update your computer, you do not have to. You can say good bye to the annoying windows updates that you are forced to install.
When the time comes for you to update your system (only if that is what you want), then one simple click or update command, will update every single package and software on your system, including the actual OS. Updating indivual packages separately is also an option.
Another feature about Linux that is really convenient is that for most updates, you do not have to restart or reboot your computer. This is such a time-saver, especially if you are coming from Windows. Every time you update something, or are forced to update something, you might suddenly be asked to reboot your computer. Sometimes, my drivers have suddenly stopped being able to recognize the hardware completely. But on Linux, all of this happens without requiring an update most of the time.
## User management
This might not be too important to you, but the way Linux handles users is vastly superior. Since it was initially not meant to be used as a traditional desktop, rather on servers, Linux has the capability of multiple users logging into the same computer at the same time and working on something. This could be very useful if you are using it for a server, or just a main computer in your home where you want multiple family members to be able to use it and enjoy their content remotely at the same time.
In addition to multiple simultaneous users, permissions are extremely strict and granular. By default, new users do not have most file access permissions (read, write, executable, etc.). You can specificly add permissions to each user, or add users to groups, and then add permissions for users of the group. Furthermore, the permissions that you add can be incredibly granular, such as for a specific file or directory. This also prevents the risk of some malicious file, script, or virus that somehow has made its way to your computer, to actually do any damage.
## Software management
Finally, linux fully embraces the open source idealogy. Most software that is used is open source, but also includes propreitary software. But, the main difference from Windows and macOS is how Linux decides to manage software. All distributions ship with a package manager. This is the defualt on the system, but you also have the option to install aditional ones. A package manager is a tool to help you install any software you want. It maintains a repository of sotware developed by many developers. As long as the software you want is available in the repository, a simple click or command with the program name is enough to install the entire software with all its dependencies. No annoying installation wizards. It takes care of the entire setup for you.
If the software is not available in the repository, maybe because it is propreitary, you have a few options. Some popular distributions include repositories where all the software is contributed by individual users and developers. The information and instructions to install the software will be provided by the company or developer (usually on their website). So, you can download it from there. The last option is to compile it from source. This is something that will not make sense for the average user, but is still an option. It is very benefical even though it is difficult, as it allows for you to use a piece of software that would otherwise not be available. Basically it means, you download the source code (the actual code that the developers wrote), download and install any necessary dependencies, and then compile the app yourself for it to be run on your system. Usually this compilation step is done by the developers, and all you need to do is install the actuall binary file (.exe, .dmg, .pkg, .deb, .rpm, etc.) and do a quick install.
# Getting Started
## Prerequisites
There are pretty much no prerequisites or minimum system requirements. All you need is a basic understanding of what Linux is, so you know what you are actually doing and getting yourself into. And most importantly, you need a working computer for you to install Linux. Any computer will do, even if it is around 10-15 years old, just make sure you have backed up all your files and are ready to format it.
## Choosing a distro
This is your starting point. But the most important thing you should know, and you will hear this advice everywhere, is to not distro hop. Choose one, use it as your daily driver atleast for 6 months, get a good feel for it, start customizing it to your taste, and then you can change distributions if you want. This most common misconception is to change distros because you think another distro looks better.
### Desktop Environments
If you choose Ubuntu for example, it uses a desktop environment called GNOME. This is the default desktop environment that it ships with. This is what gives it the familiar look and feel. If you don't like it, you can install a different one, and it will look completely different. So, if you find a picture of a distro that looks very nice, instead of changing distros, find out what desktop environments and configuration they are using, and just modify your existing setup. It is extremely simple, just a single one-line command will get the job done.
---
For absolute beginners (and anyone with a brief understand - less than 6 months of hands-on experience), I recommend [Ubuntu](https://ubuntu.com/), [Pop!_OS](https://pop.system76.com/), or [Linux Mint](https://linuxmint.com/). These distros are very beginner friendly, have an easy trouble-free installation, and has the tools that you need to work right out of the box.
If you want a polished desktop with a slight resemblance to macOS, then Ubuntu or popOS might be better, as they use the GNOME desktop environment. Linux Mint uses Cinnnamon, a desktop environment from the creators of Linux Mint itself. This will be much easier for a transitioning Windows user. Even though it is customizable, it might not look as modern or polished as Ubuntu or popOS right out of the box.
## Preparing for Installation
Once you have chosen the distribution, head over to the website which I have referenced above. Click on the name of the distribution to navigate to the respective website.
Navigate to the download section and download the disk image. Usually there is just one download button, which will do the job, sometimes it might have different versions like stable, unstable, developer, insiders, VM images, etc. Just choose the main stable one. It is also possible that you might have to choose the correct download depending on the CPU architecture (Intel - X86-64, ARM, etc.).
Once you download the file make sure it ends with '.iso'. That is the disk image for the OS.
### Preparing the installation medium
Now, we need to create a bootable USB drive to install the OS. Traditionally CDs or DVDs were used, but know using a USB Flash Drive is the norm. There are programs that will help us easily format our flash drive in the right way with our disk image on it such that the computer will be able to recognise it and boot from it. I recomment balenaEthcer as it is cross-compatible with Windows, macOS and Linux, so that the steps won't change. In addition to that, it is dead simple to use.
Go to the [balenaEtcher](https://www.balena.io/etcher/) site and download their tool. Once you have downloaded and installed it, plug in your flash drive. Make sure the contents of the flash drive are safely backed up somewhere else, as we are going to completely format it and write it over. Once you are sure that the flash drive is safe to be formatted, open up balenaEthcer.
Click on select file, and select the ISO file you just downloaded. Then select the flash drive, which should automatically be selected if it is the only one plugged in. Make sure that the right drive selected. Then proceed, and in a few minutes your flash drive will be ready to install the distribution.
## Installing on Physical Hardware
> Warning: This is a beginner's guide and will go over the setup to install the Linux distro on your entire system, formatting your drive in the process. It will not go over dual-booting, creating a separate partition, etc. That will be posted soon in a future post. PLEASE BACKUP your entire data in advance as all of your files and the OS will get deleted.
Please read the above warning before continuing. An option to explore if you don't want to immediately install on actual hardware is a virtual machine. Software like virtualbox from Oracle allow you to quickly and easily create virtual machines (isolated boxes) running any distro or OS you want without affecting your computer. However, it has a minimum hardware requirement of atleast 8GB of RAM/memory, atleast 100GB of disk space, etc. to run smoothly.
---
Plug in your flash drive and boot up your computer. Enter the BIOS setup in your laptop or comupter and make the following changes. You have to do this while your computer starts/boots up. This can be done usually by pressing F2, but it might differ depending on the computer you have. A quick search for the brand or hardware that you are using will get you the right key.
Then, make sure to set the flash drive to be at the top of the boot order. This will ensure that we boot from the flash drive instead of from the Hard Drive or SSD the normal way.
Once you are done, exit the setup, and the distro of your choice should boot up. If it doesn't, then enter the BIOS setup and try toggling the option for Secure Boot.
---
When you see the desktop UI, you should be able to see some dialog, button or modal to install the Distro. Click it and follow the instructions. The setup is very simple and self-explanatory. I am just going to give you the choices that are important, and the gotchas.
**Using SSDs**
If you are using a SSD instead of a Hard Drive, it might not be detected. When you get to the section where it asks you to select the disk you want to use, make sure you check the size. It will not be exact, but make sure it is approximately similar to the maximum capacity of the SSD. If it is not, then you have to go into the boot setup again, and navigate to the section for SSDs. The name will depend on the computer you are using. Change Intel RST to AHCI. Then boot from the USB again, and you should be able to see your SSD correctly identified.
---
If it asks if you want a minimal or Normal installation, it depends on your preference. It is again self-explanatory, but anyways, it just means that they will pre-install helpful software such as an Office Suite, a video player, etc. to help you start using the computer right away.
Make sure you select the option to **Download Updates while Installing** so that it gives you a fully updated system. Most importantly, select the option to install **propreitary drivers** to make sure you can make use of your hardware to its fullest potential.
Then, choose the option to erase disk and install. This is the simplest option which will delete all your previous data and OS. Make sure that you have backed up your data. There are other options also to install it alongside the existing OS (dual-boot), but that is slightly complicated as you have to manually partition your hard drive or SSD. You can optionally encrypt the hard drive or SSD with a password. This is similar to BitLocker on Windows. It allows you to protect your data even if someone removes your hard drive.
Lastly, you will need to create an account on your computer with your name, username, password, and the name for your computer.
The installation will take a few minutes, maybe an hour, as it has to download all the software and format your disk.
Once it is finished, you will be asked to reboot your computer. While rebooting, it will ask you to remove the installation media (flash drive). Then you will be welcomed into your new OS/distro.
# Linux Fundamentals
## User privilege
Most operations can be done by clicking using your mouse. Sometimes, if required (like when installing software, you might need to install it using the terminal, you might get a 'Permission Denied' error. This means that you don't have permissions. What you can do is run the command as an administrator or a the 'root' user by prefixing the command using 'sudo'. Then it will ask for your password and check if you also have the admin privilege. If you do, it will successfully run. By default when you install a popular distro like Ubuntu, Linux Mint, or Pop!_OS, the new user created already has admin privilege, so you will not have any issues
## Installing Apps
This is the first thing you need to do when setting up your computer. Most Linux distros come with a package manager. This is a very unique concept that is unheard of in macOS and Windows. A package manager takes care of the entire installation process; there is no need to search for the right download link in a website, and go through a complicated installation wizard. All of the beginner-friendly distros that I mentioned above are based on Debian and some are also based on Ubuntu. For these distros, the default package manager is `apt`.
On most user-friendly distros, there will be a GUI application similar to the Windows Store or the Apple App Store to help you install software.
If it is not there, open the terminal app (usually accessible via the keybind <kbd>ctrl + alt + t</kbd>) and run the following command:
```bash
apt search {program name}
```
Replace {program name} with the actual name of the app you want to install. If you want to install spotify for example, just search for it, and see if it is available. This command will help you find the correct app name as it might be different from what you might expect. The description of the app given can also help you identify it.
Once you find the right program, install it using:
```bash
sudo apt install {program name}
```
This will install the program. We add 'sudo' in the beginning to run the command with admin/root user privilege. It will list the names of the programs and the dependencies that it is going to install, and you need to confirm by typing 'y' when asked.
---
If the app is not available on the main `apt` repository, then you can try the snaps or flatpaks. I am not going through it in detail in this guide, but you can know that it is a way for an app to be easily distributed across all linux distributions easily. Usually, the snapstore is automatically installed on Ubuntu.
---
If it is not available in any of the repositories that I have mentioned (which is highly unlikely), all you need to do is go to their website, and they will give you instructions to install it from their. This may include downloading the binary from their site and then installing it. If you are using a Debian based distro, the binary file will end with '.deb' (similar to .exe in windows). Download it and try to open it. Mostly, your system will have a program installed it which is capable of recognizing the file and installing it for you.
Open the file manager (like windows explorer on windows) and go to the Downloads folder where the binary installer is located. Then right click in that folder to open in terminal. If your file is called for example 'skype_v2.deb', then run:
```bash
sudo apt install ./skype_v2.deb
```
---
Another option is might include an AppImage. This is a way to distribute software in an isolated manner across all distributions. Download the file which ends in '.appimage' from the website, and try to open it. If you are not able to open it, then right click on the file and open the permissions. Change it to 'executable' and then it should work fine.
---
If none of these options are given, you don't have to worry. Detailed steps or commands will be provided to you, and all you need to do is to paste them into the terminal and run them one by one in order. This is very rare, but you still might come across it. And since, you use a Debian based system which is one of the most popular distros, you don't need to worry about some software not being available.
# Recommended Software
Some new users might not be aware of the software that is available, or the good open source alternatives. So I have compiled a list of software that can be good to have.
1. Video Conferencing
- [Skype](https://www.skype.com/en/get-skype/) (Native App) (from Microsoft - Propreitary)
- [Jitsi](https://meet.jit.si/) (Web App) (Open Source)
- [Discord](https://discord.com/) (Web and Native App) (Proprietary)
- [Zoom](https://zoom.us/download#client_4meeting) (Native App) (Proprietary)
- [Teams](https://www.microsoft.com/en-us/microsoft-teams/download-app#desktopAppDownloadregion) (Native App) (from Microsoft - Proprietary)
2. Office Suite
- [Libre Office](https://www.libreoffice.org/download/download/) (Native App) (Open Source)
- [Microsoft Office](https://www.office.com/) (Web App) (Proprietary)
3. Multimedia player
- VLC media player
- Celluloid
4. Browser
- Brave (chromium based)
- Chrome (chromium based)
- Chromium (open source)
- Firefox
- LibreWolf (privacy oriented fork of Firefox)
5. Music Streaming
- [Spotify](https://www.spotify.com/in-en/download/linux/) (Web and Native App) (proprietary)
6. Note-taking (My top favorites)
- [Obsidian](https://obsidian.md/) (Native App) (open source)
- It uses Markdown syntax
- Has a knowledge graph and other advance features for note-taking
- [Notion](https://www.notion.so/) (Web app)
- Simple, friendly user interface
- Does not need markdown knowledge
- Has a lot of templates to choose from
7. Mail clients
- Just use the browser version (Gmail, Outlook, Yahoo, etc.)
- [Mailspring](https://getmailspring.com/) (open source)
- Inlcudes fancy features such as link tracking, checking number of opens, etc.
# Getting Help
One of the wonderful thing about Linux is the online community. If you exclude the hate in the internet, it is very easy to find help, articles, tutorials/guides, and forums to get help in Linux. This is partly because of the very specific and helpful error messages that Linux gives rather than the blunt ones that you get on Windows or macOS. Just google the question, and you are 99.9% of the time going to get a helpful response. Checkout the Ubuntu forums, sub reddits, blogs created by others, and some discord communities.
Lastly, I am always there to help too if you have any questions. Let me know in the comments if you have any questions, and I will try my best to get it sorted out. You can also reach me via email, twitter, or other platforms. Checkout the main homepage for more details.
| adityavinodh |
611,621 | Welcome to Draftbox | htmlMarkup | 0 | 2021-02-19T06:33:33 | https://mah-site-4db9.netlify.app/welcome-to-draftbox/ | htmlMarkup | arunpriyadarsh4 | |
611,664 | Welcome to Draftbox | Welcome aboard! We have populated your new site with some sample content to get you started with Draftbox. | 0 | 2021-02-19T07:25:52 | https://gunnerforlife52.ml/blog/welcome-to-draftbox/ | gettingstarted | <p>We are excited to have you on-board. To give you a glimpse of what Draftbox is, we have populated it with sample posts.</p><h2>A short story</h2><p>We are building Draftbox on the promise of bringing JAMstack to content creators. We are very bullish on results when content creators can fully utilize JAMstack, and we want to empower them. Draftbox is a <strong>no-code JAMstack</strong> blogging platform that provides performance, user experience, SEO, security, and scalability without breaking a sweat.</p><h2>Under the hood</h2><p>Draftbox sites are created using <a href="https://www.gatsbyjs.com/">Gatsby</a>. Gatsby is a framework for building blazing-fast apps and websites. Gatsby has a flourishing ecosystem, strong community, and is being used by companies like Nike, Tinder, and AirBnB.</p><p>Draftbox sites are deployed to <a href="https://www.netlify.com/">Netlify </a>Edge. Netlify is a market leader in hosting services for static sites. Netlify has been at the forefront of the JAMstack revolution and loved by thousands of developers worldwide.</p><h2>Next up — Draftbox Editor</h2><p>As a content creator, you would be excited to learn what kind of content blocks you can add using <a href="/powerful-editor-built-for-pro-content-creators/">editor</a>.</p><p>BTW, you can delete these sample posts from dashboard.</p> | arunpriyadarsh4 |
611,976 | Testing certificates generated by Traefik and Let's Encrypt 🔏 | I am currently looking to migrate my blog www.benjaminrancourt.ca from Netlify to a custom stack on... | 0 | 2021-02-26T01:01:01 | https://www.benjaminrancourt.ca/testing-certificates-generated-by-traefik-and-lets-encrypt | traefik, tooling, security, devops | ---
title: Testing certificates generated by Traefik and Let's Encrypt 🔏
published: true
date: 2021-02-19 13:17:00 UTC
tags: traefik, tooling, security, devops
canonical_url: https://www.benjaminrancourt.ca/testing-certificates-generated-by-traefik-and-lets-encrypt
cover_image: https://www.benjaminrancourt.ca/temp/testing-certificates-generated-by-traefik-and-lets-encrypt.2000.jpg
---
I am currently looking to migrate my blog [www.benjaminrancourt.ca](https://www.benjaminrancourt.ca/) from Netlify to a custom stack on [DigitalOcean](https://m.do.co/c/e79694c46dfc) using [**Traefik**](https://doc.traefik.io/traefik/)and **[Let's Encrypt](https://letsencrypt.org/)**. To make sure that I did not regress on the features that Netlify offers transparently, I started comparing the migrated website with my Netlify website by using some tools. 🧰
One of those tools was the **[SSL Server Test](https://www.ssllabs.com/ssltest/)**from _Qualys SSL Labs_, a free online service that analyzes the SSL configuration of a specified website. As I was using Let's Encrypt to generate my certificate, I did not expected to receive a _B_ result while my website on Netlify had an _A+_ result. Ouch! 😷
<figcaption>Results on SSL Server Test for my initial configuration</figcaption>
I started searching on the Internet to find how I could fix this and I came across a comment that mentioned that the **Mozilla SSL Configuration Generator** has [configurations for Traefik](https://ssl-config.mozilla.org/#server=traefik&version=2.3.7&config=intermediate&guideline=5.6)!
For those who are not familiar with this generator, it is a tool to help us configure SSL on many servers, like Apache and nginx. The tool offers three configurations:
- **Modern**
- Services with clients that support TLS 1.3 and don't need backward compatibility
- Supports Firefox 63, Android 10.0, Chrome 70, Edge 75, Java 11, OpenSSL 1.1.1, Opera 57, and Safari 12.1
- **Intermediate**
- General-purpose servers with a variety of clients, recommended for almost all systems
- Supports Firefox 27, Android 4.4.2, Chrome 31, Edge, IE 11 on Windows 7, Java 8u31, OpenSSL 1.0.1, Opera 20, and Safari 9
- **Old**
- Compatible with a number of very old clients, and should be used only as a last resort
- Supports Firefox 1, Android 2.3, Chrome 1, Edge 12, IE8 on Windows XP, Java 6, OpenSSL 0.9.8, Opera 5, and Safari 1
Since I thought I did not have to support old browsers for my personal website, I started to think that I should choose the _modern_ setup, but I was still wondering what the differences were between the _modern_ and the _intermediate_ configuration.
So I decided to run some tests with SSL Server Test by deploying the same website (using the [traefik/whoami](https://hub.docker.com/r/traefik/whoami) image) under these three SSL configurations.
## Code
Below is the code I used for my tests:
```
version: "3.7"
services:
modern:
deploy:
labels:
traefik.docker.network: "traefik-net"
traefik.enable: "true"
traefik.http.routers.modern.entrypoints: "https"
traefik.http.routers.modern.middlewares: "default@file"
traefik.http.routers.modern.rule: "Host(`modern.benjaminrancourt.ca`)"
traefik.http.routers.modern.tls.certresolver: "letsEncrypt@file"
traefik.http.routers.modern.tls.options: "modern@file"
traefik.http.routers.modern.tls: "true"
traefik.http.services.modern.loadbalancer.server.port: 80
traefik.http.services.modern.loadbalancer.sticky.cookie.httpOnly: "true"
traefik.http.services.modern.loadbalancer.sticky.cookie.secure: "true"
image: "traefik/whoami:v1.6.1"
networks:
- traefik-net
intermediate:
deploy:
labels:
traefik.docker.network: "traefik-net"
traefik.enable: "true"
traefik.http.routers.intermediate.entrypoints: "https"
traefik.http.routers.intermediate.middlewares: "default@file"
traefik.http.routers.intermediate.rule: "Host(`intermediate.benjaminrancourt.ca`)"
traefik.http.routers.intermediate.tls.certresolver: "letsEncrypt@file"
traefik.http.routers.intermediate.tls.options: "intermediate@file"
traefik.http.routers.intermediate.tls: "true"
traefik.http.services.intermediate.loadbalancer.server.port: 80
traefik.http.services.intermediate.loadbalancer.sticky.cookie.httpOnly: "true"
traefik.http.services.intermediate.loadbalancer.sticky.cookie.secure: "true"
image: "traefik/whoami:v1.6.1"
networks:
- traefik-net
old:
deploy:
labels:
traefik.docker.network: "traefik-net"
traefik.enable: "true"
traefik.http.routers.old.entrypoints: "https"
traefik.http.routers.old.middlewares: "default@file"
traefik.http.routers.old.rule: "Host(`old.benjaminrancourt.ca`)"
traefik.http.routers.old.tls.certresolver: "letsEncrypt@file"
traefik.http.routers.old.tls.options: "old@file"
traefik.http.routers.old.tls: "true"
traefik.http.services.old.loadbalancer.server.port: 80
traefik.http.services.old.loadbalancer.sticky.cookie.httpOnly: "true"
traefik.http.services.old.loadbalancer.sticky.cookie.secure: "true"
image: "traefik/whoami:v1.6.1"
networks:
- traefik-net
networks:
traefik-net:
driver: overlay
external: true
```
<figcaption>A docker-compose file with three services, each with their own distinct TLS options and hostname</figcaption>
```
# Generated 2021-01-22, Mozilla Guideline v5.6, Traefik 2.3.7, modern configuration
# https://ssl-config.mozilla.org/#server=traefik&version=2.3.7&config=modern&guideline=5.6
tls:
options:
modern:
minVersion: "VersionTLS13"
sniStrict: true
intermediate:
cipherSuites:
- "TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256"
- "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256"
- "TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384"
- "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
- "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305"
- "TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305"
minVersion: "VersionTLS12"
sniStrict: true
old:
cipherSuites:
- "TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256"
- "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256"
- "TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384"
- "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384"
- "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305"
- "TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305"
- "TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256"
- "TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256"
- "TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA"
- "TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA"
- "TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA"
- "TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA"
- "TLS_RSA_WITH_AES_128_GCM_SHA256"
- "TLS_RSA_WITH_AES_256_GCM_SHA384"
- "TLS_RSA_WITH_AES_128_CBC_SHA256"
- "TLS_RSA_WITH_AES_128_CBC_SHA"
- "TLS_RSA_WITH_AES_256_CBC_SHA"
- "TLS_RSA_WITH_3DES_EDE_CBC_SHA"
minVersion: "TLSv1"
sniStrict: true
```
<figcaption>TLS configuration in a Traefik dynamic configuration file</figcaption>
## Summary using SSL Server Test
### Netlify

It would have been very strange here if Netlify did not get an _A+_, as they automatically provide certificates for all of their hosted websites.
### Modern configuration

I was very surprised to see that the modern configuration could only get an _A_. After looking at the results of the intermediate configuration below, I suspected it was because TLS 1.2 is not supported.
### Intermediate configuration

Much better, right? Even though the rating is the same as on my Netlify website, they have some differences. My SSL certificate from Netlify has four cipher suites that the _intermediate_ configuration does not have. 2 of the 4 are even considered being **weak**.
<figcaption>The additional cipher suites on Netlify SSL certificates</figcaption>
Is this serious, doctor? With my current knowledge on SSL certificates, I cannot say, but I suppose that some older browsers, like Internet Explorer and some versions of Safari, might not be able to access my website. 🩺
### Old configuration

The default Traefik SSL configuration seems to be the old configuration from Mozilla SSL Configuration Generator. In retrospect, this makes sense as so much companies want to support everyone, even if, unfortunately, that means being less secure...
## Conclusion
Finally, I chose the _intermediate_ configuration because it seems to be the recommended configuration. Most importantly, I cannot afford to have an _A_ when I can easily have an _A+_. 🤓
I am not sure yet if I will stick with this setup, but I think it is a good start. I will probably come back to this decision once I have more knowledge about SSL certificates and its endings. If you have any tips that I could use to further secure my Traefik SSL configuration, feel free to share them!
If you want to see the full results from _SSL Server Test_, I have included the screenshots of them at the end of the post. I did not want to share the links as I used a DNS that I do not want to disclose.
**Which SSL configuration have you chosen for your websites?** 🧐
## Screenshots from _SSL Server Test_
### Netlify

### Modern configuration

#### Intermediate configuration

### Old configuration
 | benjaminrancourt |
612,258 | Javascript Objects Considered Unsafe | Every year, I like to teach myself a new language by working through the Advent of Code problems. Thi... | 0 | 2021-02-23T17:07:27 | https://dev.to/mustafahaddara/javascript-objects-considered-unsafe-34ob | adventofcode, profiling, performance, typescript | ---
title: Javascript Objects Considered Unsafe
published: true
description:
tags: AdventOfCode, profiling, performance, typescript
cover_image: https://images.ctfassets.net/cnu0m8re1exe/4tflobsiQoaB0eBIZr4T7Z/8400a2fa8d6c7db34fcfd7375458a35e/shutterstock_112763713.jpg?w=650&h=433&fit=fill
---
Every year, I like to teach myself a new language by working through the [Advent of Code](https://adventofcode.com/) problems. This year, I wanted to dive into typescript. I've written a fair amount of JS before, and I like having explicit typechecking in my code, so TS felt like a good fit.
Everything was going great until I hit [Day 15](https://adventofcode.com/2020/day/15), and my solution worked well for the small case but was painfully slow in the large case.
You should definitely click through and read the problem statement, but to summarize:
You start off with a comma-separated list of numbers. This is your problem input. The challenge is to continue the sequence of numbers. Each number in the sequence (after the starting set) depends on the number immediately previous to it. If that previous number has never appeared in the sequence before, our new number is `0`. If it _has_ appeared in the sequence, our new number is the number of steps between when it last appeared in the sequence and now.
For example, let's say we start with `1,2,3` as our input. The next numbers would be:
- To determine the fourth number, we'd look at the third number (`3`). `3` has never appeared in the sequence before, so the fourth number is `0`.
- To determine the fifth number, we'd look at the fourth number (`0`). `0` has never appeared in the sequence before, so the fifth number is `0`.
- To determine the sixth number, we look at the fifth number (`0`). `0` has appeared in the sequence before, as the fourth number, so we take the difference (position 5 - position 4 = 1) and that difference is our sixth number: `1`.
- To determine the seventh number, we look at the sixth number (`1`). `1` has appeared in the sequence before, so we subtract and get `5`.
We can continue this pattern forever.
(Numberphile has a [wonderful overview](https://www.youtube.com/watch?v=etMJxB-igrc) of this sequence that goes into a bit more detail)
Part 1 of the challenge is relatively simple: determine the 2020th number in the sequence. I decided to brute force it:
```typescript
const solve = (input: string, end: number): number => {
const nums = input.split(',').map((l) => parseInt(l));
const spoken: Record<number, number> = {};
let i = 0;
let next = -1;
while (i < end - 1) {
const current = i < nums.length ? nums[i] : next;
if (spoken[current] === undefined) {
next = 0;
} else {
next = i - spoken[current];
}
spoken[current] = i;
i++;
}
return next;
};
```
The `spoken` object is a `Record<number, number>` where the keys are numbers and the values are the last index where that number appeared in the sequence. (Why "spoken"? See the Advent of Code description). On each iteration, we check if our _current_ number has been spoken before, and set our `next` number accordingly. On the next iteration of the loop, `current` becomes `next`, and so we repeat this process for as many iterations as we need.
So far, so good, but let's talk efficiency, because part 2 of the challenge is to calculate the 30 _millionth_ number in the sequence. Performance-wise, I'd claim that this runs in O(n) time; the run time scales linearly with the number of values we want to compute. ie. Computing 2000 numbers takes twice as long as computing 1000 numbers. This is because we use that `spoken` object to do fast lookups on the last index a number appeared in.
This is because we generally treat insertion and lookups in an object as "cheap" or constant time.
The drawback is that we're using tons of memory. We'd describe it as using O(n) memory; the amount of space we use grows linearly with the number of values we want to compute. (I have a proof for this [but it's too large to fit in this margin](https://en.wikipedia.org/wiki/Fermat%27s_Last_Theorem)...just kidding. As per the Numberphile video I referenced earlier, this sequences seems like it grows linearly, but no one has proven that yet.)
Since we're brute forcing the result, at the very least, we need to do one loop iteration per number we compute, so this O(n) runtime is the fastest we can get. If we had a magic math formula that could spit out the number at an arbitrary index, that would be much faster, but I don't have one (and as per that Numberphile video, neither do the mathematicians!).
So, it sounds like we're very close to our theoretical peak performance. Let's try and compute the 30 millionth number then.
And...when I do, it hangs. For upwards of 5 _minutes_.
Sounds like something is wrong. Very very wrong. I'm not sure where, though, so let's do some profiling.
```typescript
const start_str = '1,2,3';
[2000, 20000, 200000, 2000000, 20000000].forEach((total) => {
const start = new Date().getTime();
solve(start_str, total);
console.log(`took ${new Date().getTime() - start} ms to compute ${total}`);
});
```
Basically, we're timing how long this method takes for successively larger and larger amounts of numbers to generate. If our solution was O(n), as I claimed above, we should see times that grow linearly; if 2000 takes 1ms, then 20,000 should take 10ms and 200,000 should take 100ms.
Instead, these are the results I measured:
```
took 0 ms to compute 2000
took 6 ms to compute 20000
took 90 ms to compute 200000
took 8552 ms to compute 2000000
took 351866 ms to compute 20000000
```
🤯🤯
The jump from 200,000 to 2,000,000 is particularly interesting: it took us 95 times longer to compute 10x the numbers! And going from 2,000,000 to 20,000,000 is also pretty bad: 10x the work took 41 times longer.
(Before I go any further, a quick note about performance metrics: all of these numbers were collected on my 2016 MacBook Pro running macOS 11.2, with a 3.1GHz i5 in it. I'm using node version `14.15.1` and tsc `4.1.2`. The absolute values of these numbers isn't important but what is important is the proportions.)
So, what's going on with these numbers? When I first wrote this code and saw these, I was extremely surprised. We already said it looks O(n), so why are we seeing huge non-linear spikes? Spoiler alert: my code wasn't O(n).
Yeah, that's right. It's not O(n). Why not, you ask?
Well, let's find out. Time to do some more profiling:
```typescript
const solve = (input: string, end: number): number => {
const nums = input.split(',').map((l) => parseInt(l));
const spoken: Record<number, number> = {};
let i = 0;
let next = -1;
let read = 0;
let write = 0;
while (i < end - 1) {
const current = i < nums.length ? nums[i] : next;
let start = new Date().getTime();
const last_spoken = spoken[current];
read += new Date().getTime() - start;
if (last_spoken === undefined) {
next = 0;
} else {
next = i - last_spoken;
}
start = new Date().getTime();
spoken[current] = i;
write += new Date().getTime() - start;
i++;
}
console.log(`reading took ${read} ms`);
console.log(`writing took ${write} ms`);
return next;
};
```
We do two things with our `spoken` lookup object: we read a value out and write a value in. Here I've added code to time how long each part takes, in total, across the entire operation. The results:
```
reading took 0 ms
writing took 1 ms
took 11 ms to compute 2000
reading took 5 ms
writing took 7 ms
took 31 ms to compute 20000
reading took 55 ms
writing took 130 ms
took 289 ms to compute 200000
reading took 547 ms
writing took 9463 ms
took 10935 ms to compute 2000000
reading took 4480 ms
writing took 346699 ms
took 365872 ms to compute 20000000
```
Logs can be hard to read, so let's dump this into a table:
| | 2,000 | 20,000 | 200,000 | 2,000,000 | 20,000,000 |
|--------------|------|-------|--------|---------|---------|
| read | 0 | 5 | 55 | 547 | 4480 |
| write | 1 | 7 | 130 | 9463 | 346699 |
As you can see, read performance is fine, roughly linear. Write performance is drastically worse as our object gets bigger and bigger.
There isn't much more we can do here; we've gathered as much data as we can. We're observing something in the behavior of the language and runtime we're using, so now it's time to go see if anyone else has observed similar behavior, or if we've found a bug in node.
Armed with this information, off to the interwebs we go. Searching for "js object vs map performance" turns up a number of results of people _profiling_ objects and maps, but I didn't find anything along the lines of what I was seeing. Then, I came across GitHub user `jngbng`, who did [similar experiments](https://github.com/jngbng/set-vs-object) that suggest objects perform _faster_ than Sets when there is a high number of common elements in the data, but much slower than Sets when most of the elements in the data are unique.
That led me to a more subtle insight here about our code. Object performance is demonstrably worse when there is a high variance in the keys...and as we know, the sequence we're computing grows continuously, which means we must be constantly seeing new numbers and adding them to our object. Thus, we must have a high variance in the keys we're adding into our object.
This insight led me to an article by [Camillo Bruni](https://twitter.com/camillobruni), an engineer working on the V8 JavaScript engine at Google, on [how V8 handles objects gaining new properties](https://v8.dev/blog/fast-properties). He also linked to an article by [Vyacheslav Egorov](https://twitter.com/mraleph), a compiler engineer at Google, on [how V8 handles property lookups on objects](https://mrale.ph/blog/2015/01/11/whats-up-with-monomorphism.html).
I will confess, a lot of the details in those two posts went over my head, but the summary is this: the V8 runtime is optimized for cases where you have many objects with the same sets of properties on them. Constantly adding new keys to our object breaks V8's property caches and then forces it to rebuild them each time we add a property to the object, which makes inserting new keys really slow. This is exactly what `jngbng` found: objects with a small number of keys (or rarely-changing sets of keys) perform faster than Sets with the same keys.
In our scenario, we are adding new keys (the numbers we compute) to our object very frequently, meaning we very quickly get into the range where we frequently defeat the V8 Object property lookup caches!
We can actually confirm this with some more profiling:
```typescript
const solve = (input: string, end: number): number => {
const nums = input.split(',').map((l) => parseInt(l));
const spoken: Record<number, number> = {};
let i = 0;
let next = -1;
let read = 0;
let insert = 0;
let num_inserts = 0;
let update = 0;
let num_updates = 0;
while (i < end - 1) {
const current = i < nums.length ? nums[i] : next;
let start = new Date().getTime();
const last_spoken = spoken[current];
read += new Date().getTime() - start;
if (last_spoken === undefined) {
next = 0;
start = new Date().getTime();
spoken[current] = i;
insert += new Date().getTime() - start;
num_inserts++;
} else {
next = i - last_spoken;
start = new Date().getTime();
spoken[current] = i;
update += new Date().getTime() - start;
num_updates++;
}
i++;
}
console.log(`reading took ${read} ms`);
console.log(`inserted ${num_inserts} times for a total of ${insert} ms and ${insert / num_inserts} ms on avg`);
console.log(`updated ${num_updates} times for a total of ${update} ms and ${update / num_updates} ms on avg`);
return next;
};
```
Now, instead of timing all of the write operations as one block, we measure the insert operations (ie. the cases where we write to new keys) separately from updates. We also need to track the _number_ of inserts and updates we do, to make sure that if inserts are taking longer, it isn't because we just did more of them.
Sure enough, our numbers confirm our theory:
```
reading took 0 ms
inserted 380 times for a total of 0 ms and 0 ms on avg
updated 1619 times for a total of 1 ms and 0.0006176652254478073 ms on avg
took 34 ms to compute 2000
reading took 13 ms
inserted 3285 times for a total of 2 ms and 0.0006088280060882801 ms on avg
updated 16714 times for a total of 13 ms and 0.0007777910733516812 ms on avg
took 58 ms to compute 20000
reading took 41 ms
inserted 29247 times for a total of 54 ms and 0.001846343214688686 ms on avg
updated 170752 times for a total of 32 ms and 0.0001874062968515742 ms on avg
took 223 ms to compute 200000
reading took 389 ms
inserted 265514 times for a total of 7768 ms and 0.029256461052901164 ms on avg
updated 1734485 times for a total of 302 ms and 0.000174115083151483 ms on avg
took 9216 ms to compute 2000000
reading took 4429 ms
inserted 2441404 times for a total of 328123 ms and 0.1343993046623992 ms on avg
updated 17558595 times for a total of 4353 ms and 0.0002479127743421384 ms on avg
took 348712 ms to compute 20000000
```
And as a table:
| | 2,000 | 20,000 | 200,000 | 2,000,000 | 20,000,000 |
|--------------|------|-------|--------|---------|---------|
| average insert | 0 | 0.0006 | 0.0018 | 0.0293 | 0.1344 |
| average update | 0.0006 | 0.0008 | 0.0002 | 0.0002 | 0.0002 |
(numbers have been rounded to 4 decimal places)
We can actually watch the average insertion time grow steadily as our object grows. Interestingly, although we seem to consistently update existing values 10x more than we insert new ones, by the time we generate 200,000 values, we're spending more time on inserts than on updates!
And notice how the average update time stays relatively constant? That's V8's property caching optimization in action. When the object doesn't change "shape" (ie. gain new keys), reads and writes are constant time.
So what's our fix? Simple: swap the `{}` for a `Map`:
```typescript
const solve = (input: string, end: number): number => {
const nums = input.split(',').map((l) => parseInt(l));
const spoken: Map<number, number> = new Map();
let i = 0;
let next = -1;
while (i < end - 1) {
const current = i < nums.length ? nums[i] : next;
if (!spoken.has(current)) {
next = 0;
} else {
next = i - spoken.get(current);
}
spoken.set(current, i);
i++;
}
return next;
};
```
This implementation performed much much better:
```
took 0 ms to compute 2000
took 15 ms to compute 20000
took 38 ms to compute 200000
took 262 ms to compute 2000000
took 4170 ms to compute 20000000
```
Now the 10x growth from 200,000 to 2,000,000 only took 7x longer, and the 10x growth from 2,000,000 to 20,000,000 took 15x longer. Both much more reasonable multipliers than what we were seeing before.
If we make a similar change to time the individual sections of the code, we get logs like this:
```
reading took 2 ms
inserted 380 times for a total of 0 ms and 0 ms on avg
updated 1619 times for a total of 0 ms and 0 ms on avg
took 3 ms to compute 2000
reading took 6 ms
inserted 3285 times for a total of 1 ms and 0.00030441400304414006 ms on avg
updated 16714 times for a total of 4 ms and 0.00023932033026205577 ms on avg
took 28 ms to compute 20000
reading took 39 ms
inserted 29247 times for a total of 6 ms and 0.00020514924607652066 ms on avg
updated 170752 times for a total of 31 ms and 0.00018154985007496252 ms on avg
took 170 ms to compute 200000
reading took 523 ms
inserted 265514 times for a total of 65 ms and 0.0002448081833726282 ms on avg
updated 1734485 times for a total of 278 ms and 0.00016027812290103402 ms on avg
took 1383 ms to compute 2000000
reading took 6507 ms
inserted 2441404 times for a total of 775 ms and 0.0003174402925529736 ms on avg
updated 17558595 times for a total of 3271 ms and 0.0001862905317879933 ms on avg
took 16278 ms to compute 20000000
```
Add these new numbers to our table from before:
| | | 2,000 | 20,000 | 200,000 | 2,000,000 | 20,000,000 |
|-|--------------|------|-------|--------|---------|---------|
| object | average insert | 0 | 0.0006 | 0.0018 | 0.0293 | 0.1344 |
| | average update | 0.0006 | 0.0008 | 0.0002 | 0.0002 | 0.0002 |
| map | average insert | 0 | 0.0003 | 0.0002 | 0.0002 | 0.0003 |
| | average update | 0 | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
(again, numbers have been rounded to 4 decimal places)
That performance on a `Map` is much much better, and much more even. Notice how the difference in average insertion time and average update time barely differs on the `Map`, no matter how large we get? That's the very definition of O(1) performance.
We can even go further with this-- we could swap in a pre-sized array instead of a `Map` and get even faster performance. Leave a comment below if you know what this would look like :)
Anyways..what's our takeaway here? What did we learn?
Number 1 is the most obvious: for data sets with large numbers of keys, prefer `Map` over `{}`.
But it's not that simple: it's important to verify our assumptions. When I first wrote my function, performance analysis suggested that we had written Performant™️ code, but when we ran it, it choked. And despite the mental model that I had around objects, which I think is pretty common among JS programmers, the authors of the JS implementation you're using might make different tradeoffs that break those mental models.
In our case, the V8 runtime is optimized for the "many objects with the same keys" case instead of the "single object with many keys" case, and that tradeoff made our code much slower. So our second takeaway here is this: our mental models of the world aren't always accurate, and it's important to verify those models.
Third, [everything is fast for small n](https://blog.codinghorror.com/everything-is-fast-for-small-n/). Our object-based algorithm ran just fine on the small case (computing ~2000 values) but fell apart for the larger case (~30 million values). And this was in a case where we actively were thinking about performance!
Have you run into cases like this before? Found any other accidentally n^2 algorithms? Let me know on [twitter](https://twitter.com/MustafaHaddara) or in the comments below. | mustafahaddara |
612,495 | Beginning my journey with elixir Part III. Time, Mix Tasks, IEx, Errors, Executables. | As I wrote in the last part, this article will be about dates and times, custom mix tasks, more about... | 0 | 2021-02-20T03:42:50 | https://dev.to/bbronek/beginning-my-journey-with-elixir-part-iii-mc1 | elixir, beginners, tutorial | As I wrote in the last part, this article will be about dates and times, custom mix tasks, more about iex, error handling, and executable files. In the next part, I will focus on the practical use of basic knowledge, but for now, I encourage you to familiarize yourself with the problems contained in my presentation 😉

####1.Dates and times
**-Time**
Examples of how to use the module :
Get a current time:
```
iex> Time.utc_now
~T[00:57:02.826573]
```
Take a look, that ~T is a sigil which I explained in Part II.
So maybe let's use our knowledge about sigils and create a Time struct.
```
iex> time = ~T[20:34:23.754335]
~T[20:34:23.754335]
iex> time.hour
20
iex> time.second
23
```
**-Date**
Get actual date:
```
iex> Date.utc_today
~D[2021-02-20]
```
So let's create a date structure and use it in practice
```
iex> {:ok, date} = Date.new(1023,5,24)
{:ok, ~D[1023-05-24]}
iex > Date.leap_year? date
false
```
**-NaiveDateTime**
The NaiveDateTime struct contains the fields year, month, day, hour, minute, second, microsecond and calendar. You can read more about this [here](https://hexdocs.pm/elixir/master/NaiveDateTime.html).
Examples :
```
iex> NaiveDateTime.utc_now
~N[2021-02-20 01:18:10.218303]
iex> NaiveDateTime.diff(~N[2018-04-17 14:00:00], ~N[1970-01-01 00:00:00])
1523973600 <- result in seconds
```
**-DateTime**
The module supports date and timezones.
Example:
```
iex> DateTime.from_naive(~N[2013-04-21 11:25:02.0034], "Etc/UTC")
{:ok, ~U[2013-04-21 11:25:02.0034Z]}
```
More: [link1](https://elixirschool.com/en/lessons/basics/date-time/#naivedatetime), [link2](https://hexdocs.pm/elixir/master/DateTime.html)
####2.Custom Mix Tasks
**1.Create a new app by - 'mix new app'**
**2.Create a new directory newTask/lib/mix/tasks/task.ex**
**3.In task.ex create [module](https://elixirschool.com/en/lessons/basics/mix-tasks/)**
**4.Use it by 'mix task'**
####3.IEx
You can by h before the module gets documentation about it, by i information about data type, r - recompile a particular module, t- information about types available in a given module.
```
iex> h Enum
Provides a set of algorithms to work with enumerables.
In Elixir, an enumerable is any data type that implements the Enumerable
protocol. Lists ([1, 2, 3]), Maps (%{foo: 1, bar: 2}) and Ranges (1..3) are
common data types used as enumerables: ...
iex> i Map
Term
Map
Data type
Atom ...
iex> t Map
@type key() :: any()
@type value() :: any()
```
####4.Error Handling
When an error occurs Elixir returns the tuple {: error, reason}. The simplest way to make an error is by use raise:
```
iex> raise "Error"
** (RuntimeError) Error
```
It is set by default to raise a RuntimeError but if you want to change it you can by the simple way: `raise typeoferror, message: "lorem ipsum"`, example:
```
raise ArithmeticError, message: "bad argument in arithmetic expression"
```
**try-rescue-after**
It is simple construction to handling errors, I hope that you understand it by reading this example:
```
iex> try do
...> raise "err"
...> rescue
...> e in RunTimeError -> IO.puts("Msg:" <> e.message)
...> after
...> IO.puts "End"
```
**Create own Error**
```
defmodule NewError do
defexception message: "an error has occurred"
end
```
####5.Executable Files
You can make a file executable in Elixir by `_File.chmod(pat_file,0o755)` (755 is a permission for a file)_.
If you want to build executables projects, you can use [escript](https://elixirschool.com/en/lessons/advanced/escripts/).
See you 👋
| bbronek |
612,701 | CatBoost and Water Pumps | Introduction This article is based on the competition. In the largest country in East Afri... | 0 | 2021-02-20T11:57:51 | https://dev.to/sagol/catboost-and-water-pumps-4lbe | catboost, eventdriven, machinelearning, datascience | #Introduction
This article is based on the [competition](https://www.drivendata.org/competitions/7/pump-it-up-data-mining-the-water-table/). In the largest country in East Africa, with about 60 million people, half of the population does not have access to clean water. Billions of dollars in foreign aid are being provided to the country to tackle the freshwater problem. However, the government cannot solve this problem. A significant part of water pumps is entirely out of order or practically does not function; the others require repair.
#Data
The data has many characteristics associated with water pumps. The water supply points were divided into functional, non-functional and functional but in need of repair. The goal of the competition is to build a model that predicts the functionality of water supply points.
The modelling data has 59400 rows and 40 columns without the label that comes in a separate file.
The metric used for this competition is the classification rate, which calculates the percentage of rows where the predicted class in the submission matches the actual class in the test set. The maximum is 1, and the minimum is 0. The goal is to maximize the classification rate.
#EDA (Exploratory Data Analysis)
A detailed description of each feature in the dataset can be found on the [competition page](https://www.drivendata.org/competitions/7/pump-it-up-data-mining-the-water-table/page/25/).
First of all, let’s look at the target — the classes don’t have an even distribution.
The small number of labels for water pumps in need of repair. We will not solve this issue but use the appropriate metric when creating the model and library capabilities.
Let’s see how the water pumps are distributed across the territory of the country.
It is known that some functions contain empty values - let's see them on the chart.
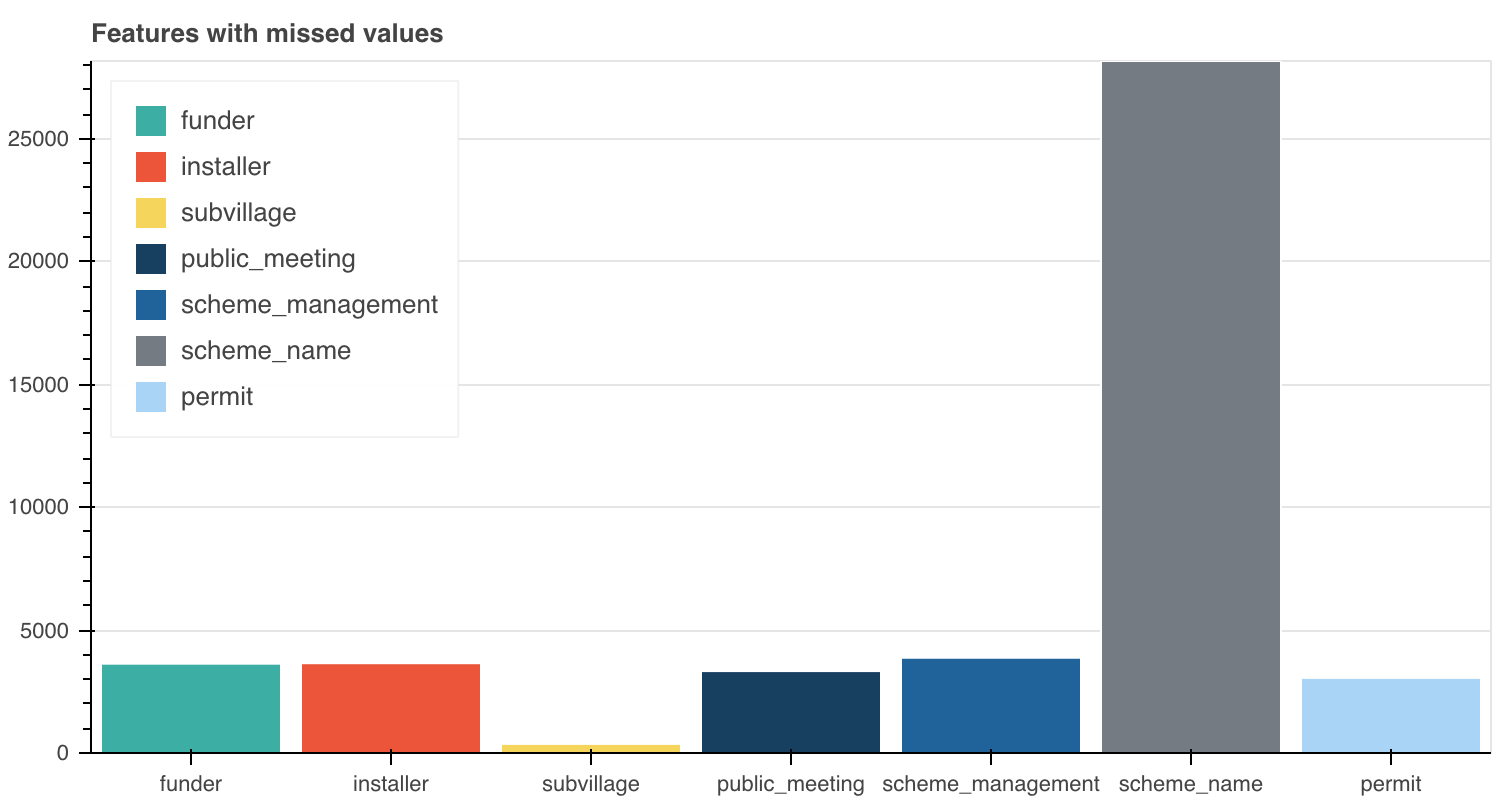
We can see that there are very few rows with missing values, with *scheme_name* having the largest number.
The following heatmap represents the presence/absence relationships between variables. It is worth paying attention to the correlation between *permit*, *installer* and *funder*.

Let’s see the general picture of the relationships on the dendrogram.
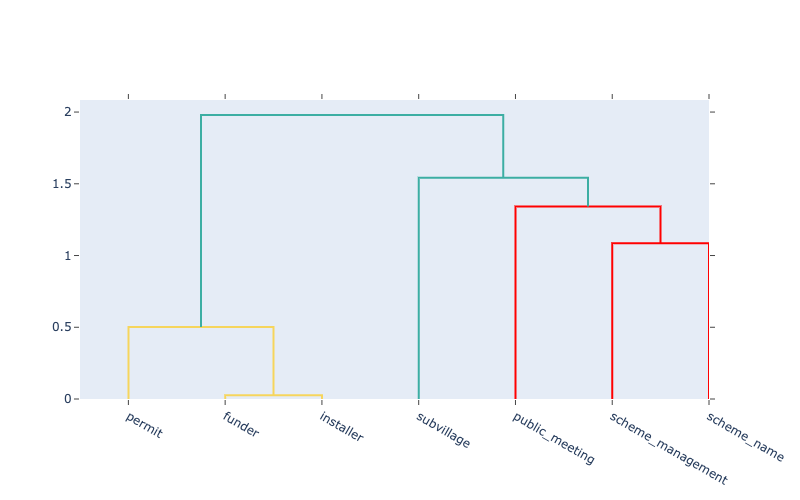
In the characteristics of water pumps, there is one that shows the amount of water. We can check how the water amount is related to the pumps’ condition (*quantity_group*).
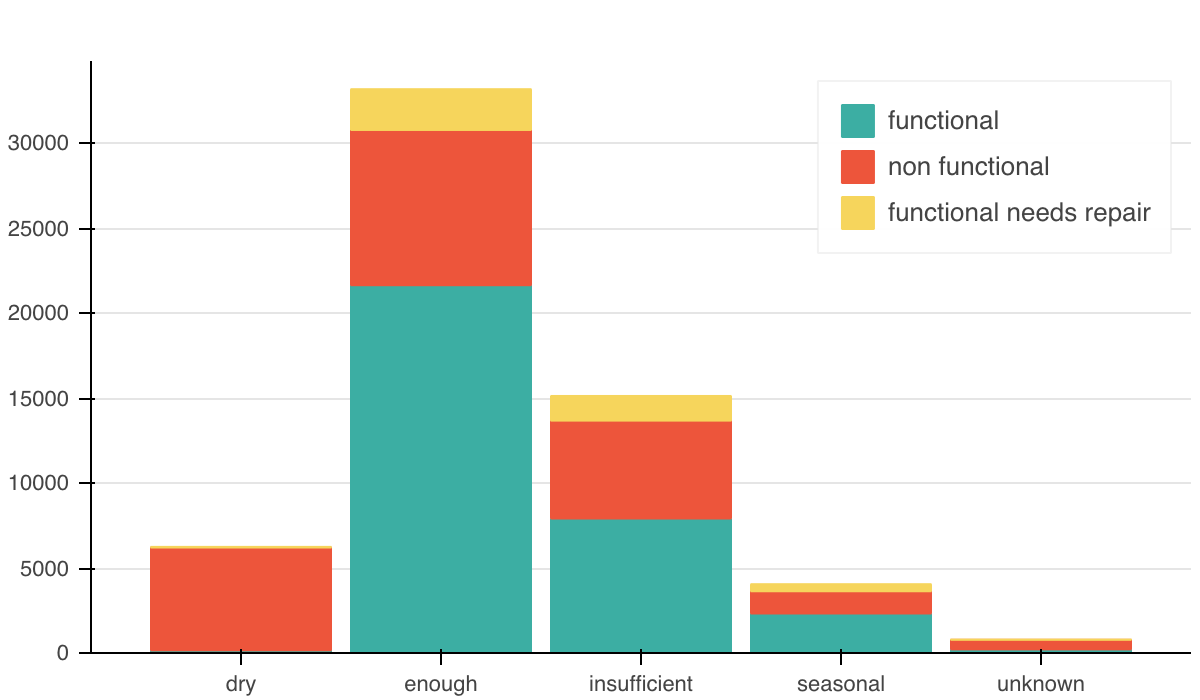
There are many wells with sufficient water that are not functioning. From the point of view of investment efficiency, it is logical to focus on repairing this particular group in the first place. Also, it is observed that most dry pumps are not working. By finding a solution to fill these wells again with water, they can probably be functional.
Does water quality affect the condition of the water pumps? We can see the data grouped by *quality_group*.
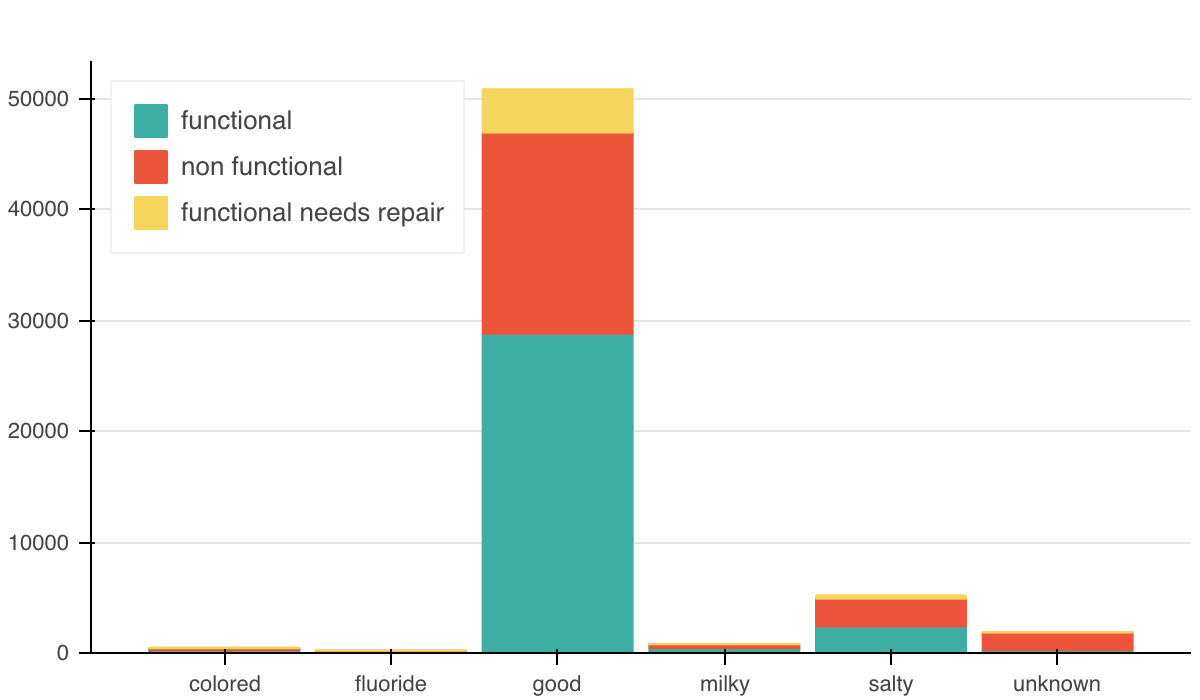
Unfortunately, this graph is not very informative, since the number of sources with good water prevails. Let’s try to group only for sources with less quality water.
Most pumps with an unknown *quality_group* are non-functional.
There is another attractive characteristic of waterpoints — their type (*waterpoint_type_group*).
Analysis of the data by waterpoints shows that the group with *other* types contains many inoperative pumps. Are they outdated? We can check how the year the pump was constructed affects.
The older the waterpoint, the higher the probability that it is not functioning, mostly before the 80s.
Now we will try to get insights from the information about the funding organizations. The condition of the wells should be correlated with funding. Consider only organizations that fund more than 500 waterpoints.
Danida — they have many working water points, the percentage of broken ones is very high. Similar situation with RWSSP(Rural Water Supply and Sanitation Program), Dhv and a few more. It should be noted that most of the wells financed by the German Republic and by Private Individuals are mostly in working state. In contrast, a large number of wells that are financed by the state are not functioning. Most of the water points established by the central government and district council are also not working.
Let us consider the hypothesis that the water’s purity and the water basin to which the well belongs can influence the functioning. First of all, let’s look at the water basins.
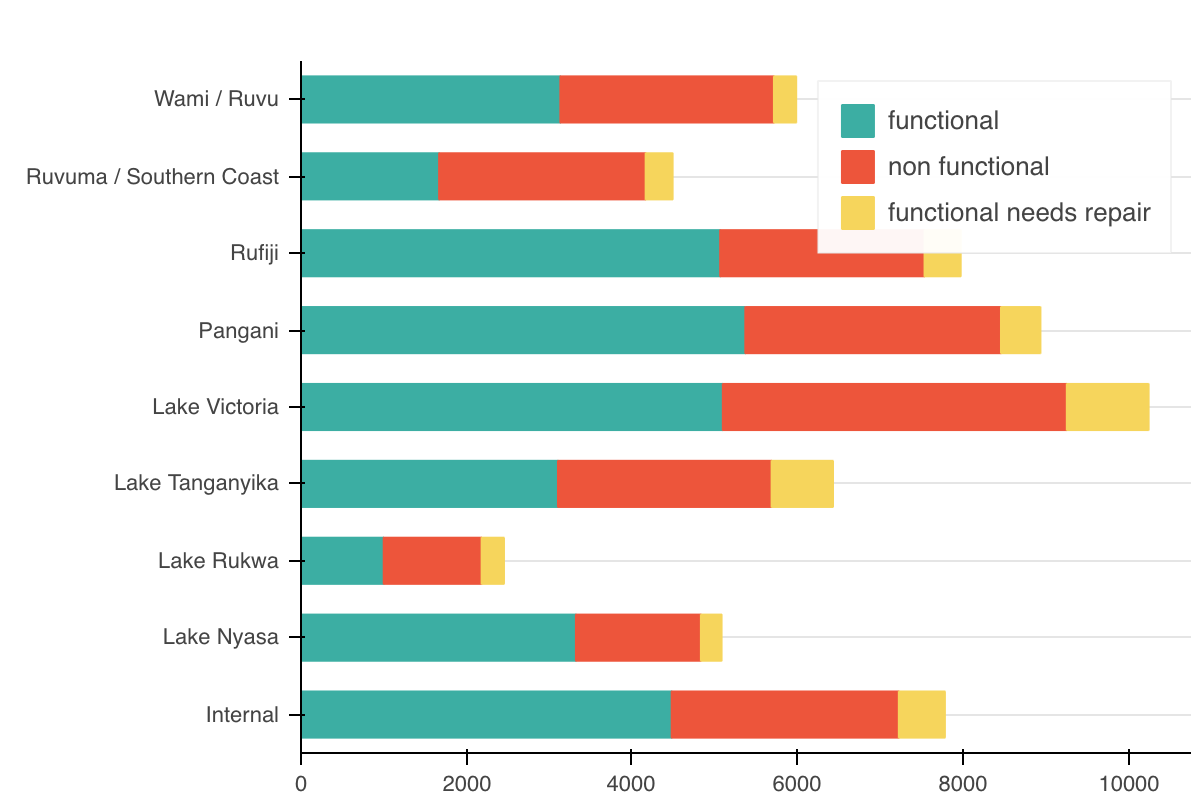
Two basins stand out strongly — Reuben and Lake Rukwa. The number of broken water points there is the majority.
It is known that some of the wells are not free. We can assume that payments can positively affect keeping the pumps in working order.
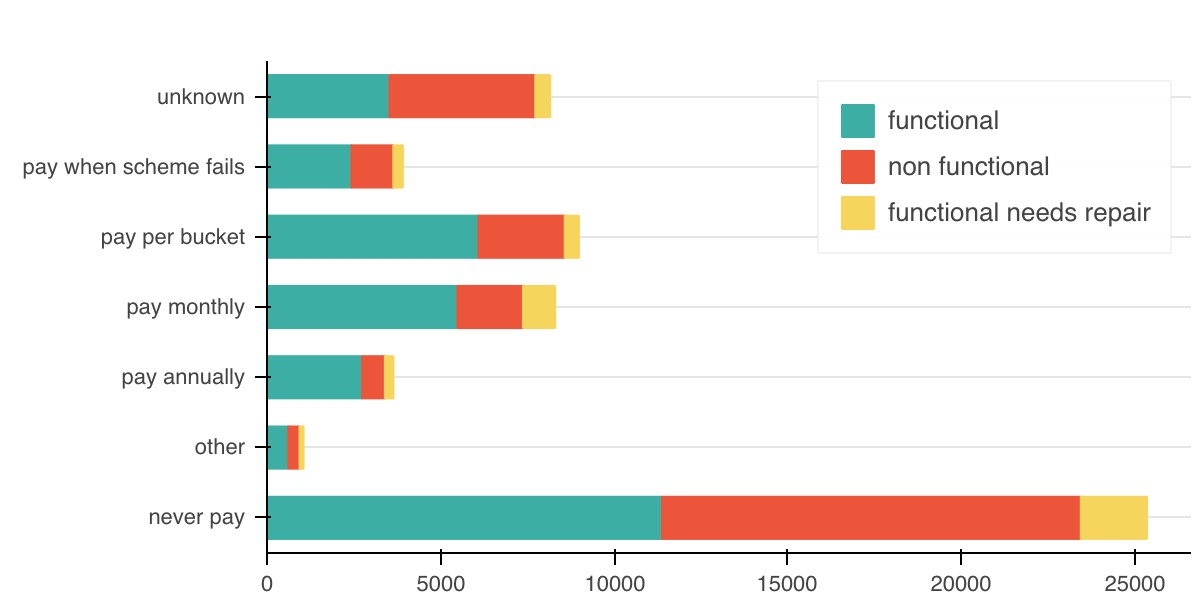
The hypothesis is fully confirmed — payment for water helps to keep the source in a working state.
Let's build a simple **DecisionTreeClassifier** with a *4* depth and see how this tree looks.
```
from sklearn import tree
from dtreeviz.trees import *
from sklearn.utils.class_weight import compute_sample_weight
clf = tree.DecisionTreeClassifier(max_depth=4, random_state=42)
y_train = df['labels']
X_train = df.drop('labels', axis=1)
sample_weight = compute_sample_weight(
class_weight='balanced',
y = y_train)
clf.fit(X_train, y_train, sample_weight=sample_weight)
dtreeviz(
clf, x_data=X_train, y_data=y_train, target_name='labels',
feature_names=X_train.columns.tolist(),
class_names=["functional", "non functional",
"functional needs repair"],
title="Decision Tree")
```
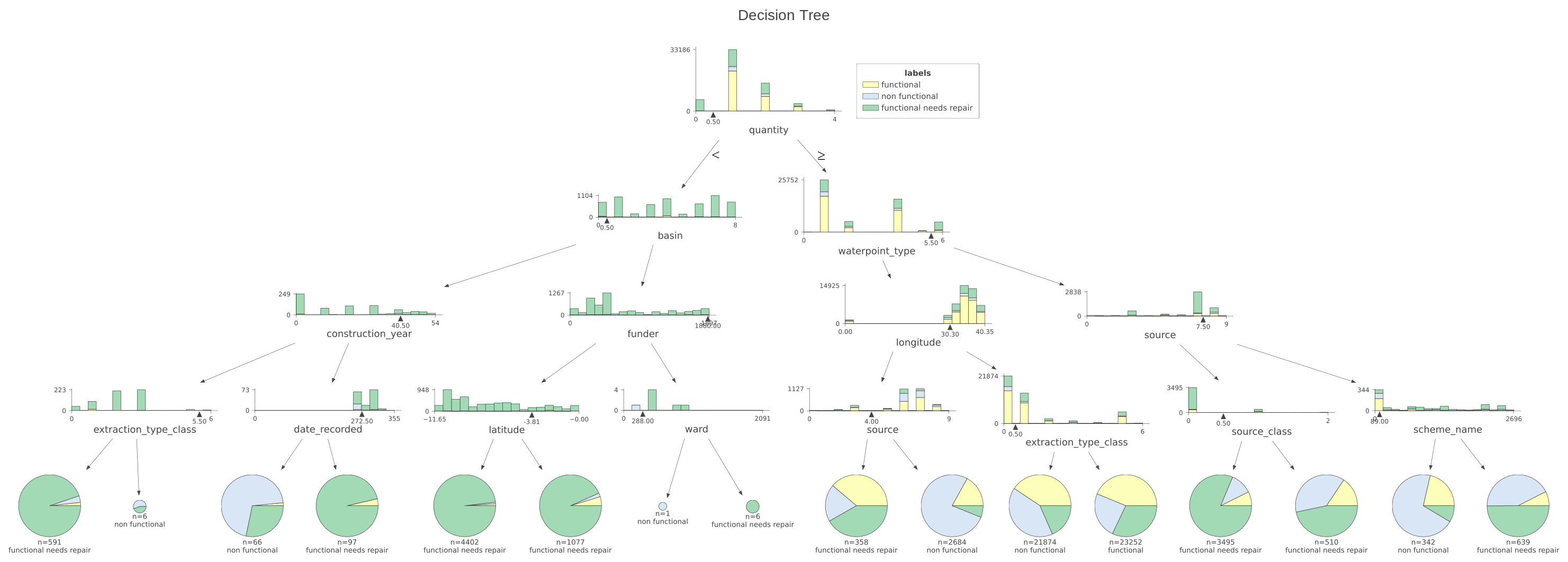
[Here](https://github.com/sagol/pumpitup/blob/main/dtc.png) you can look at the full-size image.
The data contains numeric information that we can look at and maybe find something interesting in addition to categorical parameters.
Part of the data was filled with 0 values instead of real data. We can also see that *amount_tsh* is higher in workable water points (label = 0). Also, you should pay attention to the outliers in the amount_tsh feature. As a feature, one can note the difference in elevation and the fact that a significant part of the population lives 500 meters above the mean sea level.
#Data Cleaning
Before starting to create a model, we need to clean and prepare the data.
* The *installer* feature contains many repetitions with different cases, spelling errors and abbreviations. Let’s put everything in lowercase first. Then, using simple rules, we reduce the number of mistakes and do the grouping.
* After cleaning, we replace any items that occur less than 71 times (0.95 quantiles) with ‘other’ items.
* We repeat by analogy with the *funder* feature. The cut-off threshold is 98.
* The data contains features with very similar categories. Let’s choose only one of them. Since there is not much data in the dataset, we leave the feature with the smallest categories. Delete *scheme_management*, *quantity_group*, *water_quality*, *payment_type*, *extraction_type*, *waterpoint_type_group*, *region_code*.
* Replace the *latitude* and *longitude* values of outliers with the corresponding *region_code* median values.
* A similar technique for replacing missing values is applicable for *subvillage* and *scheme_name*.
* Missing values in *public_meeting* and *permit* are replaced with median values.
* For *subvillage*, *public_meeting*, *scheme_name*, *permit*, we can create different binary features that show missing values.
* The features *scheme_management*, *quantity_group*, *water_quality*, *region_code*, *payment_type*, *extraction_type*, *waterpoint_type_group*, *date_recorded*, and *recorded_by* can be deleted is either duplicate information or it is useless.
#Modelling
The data contains a large number of categorical features. The most suitable for obtaining a base-line model, in my opinion, is [CatBoost](https://catboost.ai/). It is a high-performance, open-source library for gradient boosting on decision trees.
We will not select the optimal parameters; let it be homework. Let’s write a function to initialize and train the model.
```
def fit_model(train_pool, test_pool, **kwargs):
model = CatBoostClassifier(
max_ctr_complexity=5,
task_type='CPU',
iterations=10000,
eval_metric='AUC',
od_type='Iter',
od_wait=500,
**kwargs
)
return model.fit(
train_pool,
eval_set=test_pool,
verbose=1000,
plot=False,
use_best_model=True)
```
For the evaluation, AUC was chosen because the data is highly unbalanced, and this metric is the best for such cases.
For the target metric, we can write our function.
```
def classification_rate(y, y_pred):
return np.sum(y==y_pred)/len(y)
```
Since there is little data, it is not great to split the dataset into *train* and *validation* parts. In this case, it is better to use OOF (Out-of-Fold) predictions. We will not use third-party libraries; let’s try to write a simple function. Please note that splitting the dataset into folds must be stratified.
```
def get_oof(n_folds, x_train, y, x_test, cat_features, seeds):
ntrain = x_train.shape[0]
ntest = x_test.shape[0]
oof_train = np.zeros((len(seeds), ntrain, 3))
oof_test = np.zeros((ntest, 3))
oof_test_skf = np.empty((len(seeds), n_folds, ntest, 3))
test_pool = Pool(data=x_test, cat_features=cat_features)
models = {}
for iseed, seed in enumerate(seeds):
kf = StratifiedKFold(
n_splits=n_folds,
shuffle=True,
random_state=seed)
for i, (train_index, test_index) in enumerate(kf.split(x_train, y)):
print(f'\nSeed {seed}, Fold {i}')
x_tr = x_train.iloc[train_index, :]
y_tr = y[train_index]
x_te = x_train.iloc[test_index, :]
y_te = y[test_index]
train_pool = Pool(
data=x_tr, label=y_tr, cat_features=cat_features)
valid_pool = Pool(
data=x_te, label=y_te, cat_features=cat_features)
model = fit_model(
train_pool, valid_pool,
loss_function='MultiClass',
random_seed=seed
)
oof_train[iseed, test_index, :] = model.predict_proba(x_te)
oof_test_skf[iseed, i, :, :] = model.predict_proba(x_test)
models[(seed, i)] = model
oof_test[:, :] = oof_test_skf.mean(axis=1).mean(axis=0)
oof_train = oof_train.mean(axis=0)
return oof_train, oof_test, models
```
To reduce the dependence on splitting randomness, we will set several different seeds to calculate predictions.
The learning curves look incredibly optimistic, and the model should look good.
Having looked at the importance of the model’s features, we can make sure that there is no obvious leak.
After averaging the predictions:
```
balanced accuracy: 0.6703822994494413
classification rate: 0.8198316498316498
```
This result was obtained when uploading predictions on the competition website.
Considering that the top5 result was only about 0.005 better at the time of this writing, we can say that the base-line model is good.
To make sure that all the work on the analysis and data cleaning was not done in vain, we will build a model based solely on the data provided to us. The only thing we'll do is fill in the missing values with zeros.
```
balanced accuracy: 0.6549535670689709
classification rate: 0.8108249158249158
```
The result is noticeably worse.
#Summary
In this post, we:
* got acquainted with the data and looked for insights that can lead to thoughts for feature generation;
* cleaned up and prepared the provided data to create the model;
* decided to use CatBoost, since the bulk of the features are categorical;
* wrote a function for OOF-prediction;
* got an excellent result for the base-line model.
The right approach to data preparation and choosing the right tools for creating a model can give great results even without making additional features.
As a homework assignment, I suggest adding new features, choosing the model’s optimal parameters, using other libraries for gradient boosting, and building ensembles from the resulting models.
The code from the article can be viewed [here](https://github.com/sagol/pumpitup/blob/main/oof_model.ipynb).
| sagol |
612,788 | How to Expert in App Store Optimization (ASO) | There are some important topic to understand the App Store Optimization (... | 0 | 2021-03-05T14:43:38 | https://dev.to/nakumkailas/app-store-optimization-aso-159c | appstore, ios, android, playstore | There are some important topic to understand the App Store Optimization (ASO)
1) What is App Store Optimization (ASO)???

App Store Optimization (ASO) is the process of improving app visibility within the app stores and increasing app conversion rates. The major app stores are App Store for iOS and Google Play for Android. In addition to ranking high in the app store search results, ASO also focuses on click-through rate (CTR). This means you have to convince people to actually click into your app store listing once they find it. You can do so by optimizing your App Name, App Title, App Icon, App Screenshots and App Rating.
Visibility leads to more downloads, which leads to more visibility
2) What is the difference between ASO and SEO?
ASO is often referred to as app store SEO (Search Engine Optimization). Both processes share similarities like keyword optimization, backlinking and conversion optimization. The main differences between App Store Optimization and Search Engine Optimization are the ranking factors. Also, ASO is utilized for mobile apps whereas SEO is for websites.
SEO factors for a web browser, like Google Search, involves more than 200 aspects and the list keeps expanding. The list of ranking factors for ASO is much shorter, however many people are still unsure of which ones play a role. It’s time to put an end to that!

3)Why App Store Optimization is important???

More than 5 million apps are available to download from the Apple App Store and the Google Play Store. It’s very likely that your app is facing a lot of tough competition.
The primary goal of App Store Optimization is to increase downloads and the number of loyal users. The first step of maximizing your downloads is to make your app easily discoverable by the right users. But how can you do that?
To understand how to boost your organic growth, you first have to understand how people are searching for and finding apps.
The center plan of ASO is to increment app downloads and flood perceivability. ASO makes the app obvious at the correct opportunity to the correct arrangement of the crowd.
Presently, the question is how might you do that?
To realize how to expand the traffic from natural inquiry, you should realize how people are conducting their pursuit nowadays. App proprietors must set an intended interest group, perceive how they search, and streamline your app in a manner. It's conspicuous that your app will confront a ton of competition out there.
Here are some of the ways how people search for apps:
1)General browsing in the app store.
2)Reference from friends and family.
3)Searching for top rated or most popular apps in the app store.
4)Pre-installed apps in the app store.
5)Suggestions from social networking platforms.
6)General browsing on the internet and other websites.
7)Checking an ad in newspapers and magazines.
8)Reading blogs.
4)What are the benefits of App Store Optimization?

1. Increased Visibility
People can’t download and use your app if they can’t find it. So no matter how great your app is, if it’s not easily discoverable you won’t reach the app success that you deserve. Don’t let all of your hard work go to waste, start optimizing!
2. Get Discovered
It is significant that your app gets displayed to the clients. What is significantly more significant is that it gets displayed to the correct arrangement of clients. State, for instance, an eCommerce app arrives at a child. Children will most likely search for an education app or gaming app.
An eCommerce app is of no utilization to the children. App store optimization makes your app arrive at the significant clients for ideal advantage. It contacts the people who are really searching for an app like yours. It is on the grounds that they utilize the correct arrangement of keywords that people look for.
3. Increase Organic App Downloads
A good ASO strategy will undoubtedly boost your organic installs and ensure long-term results. That’s because when people search for keywords related to your app, they’ll always find yours. With regular monitoring and updating you make sure your efforts are successful.
4. Cut User Acquisition Cost
With app store optimization, the cost of burning through money on advertisements is chopped down. ASO center around carrying natural development to the app with ASO. ASO spares client acquisition costs as well as ensures the app has continuous and consistent development.
5. Increases App Revenue
There are a lot of various approaches to bring in money through the app. In-app advertisements, subscription models, and in-app buys are a portion of the approaches to produce income from the app. A lot of app proprietors choose to run advertisements and welcome more clients to the app prompting expanded income.
For this, the app store posting page ought to be convincing for the clients to download it. If not, the whole spending is gone to squander. Conversion rate optimization is likewise an aspect of the app store optimization procedure which expands the active visitor clicking percentage and the number of app downloads.
6. Reach Global Audience
ASO incorporates a stage called localization. It incorporates making the app accessible in various languages which helps in making the app contact the worldwide crowd. With a worldwide crowd, the odds of app achievement will increment.
Due to these advantages people, these days settle on Google play app store optimization. It decreases the opportunity of app disappointment. There are different exercises remembered for app store optimization and make your app rank high in the significant stores. Here is a portion of the tips on the most proficient method to apply them.
5)App Store Optimization Tips

1. App Title
A significant name can't simply portray what your app does yet additionally contributes a ton in improving the positioning of the mobile application. The app title must be applied to the features and attributes of the app. Likewise, attempt to remember a watchword or two for the app title. It builds the odds of the app to rank on the head of app stores.
2. Google Play Store
Play Store permits a restriction of 30 characters to compose app titles. You must be extra exact in picking the name and the correct name with the correct words. For Android apps, it's not important to utilize keywords in the App's title. You can utilize it in the app description to target and rank in the store.
3. Apple App Store
On the contrary, Apple permits a restriction of 255 characters for your title. Here you can modify the catchphrase in the title itself. It assists with marking and lifts Apple's ASO.
4. Keywords Setting
With Google Play Store, there is no particular field for the catchphrase. There is a case for description which is effectively accessible with a cutoff for 4000 characters. It turns out to be simple for the app proprietors to draft a catchphrase rich description.
Utilizing the catchphrase multiple times is appropriate. Try to not try too hard. It is called watchword stuffing. Google is exceptionally exacting about keyword stuffing and gives punishment to the apps that do it. On the off chance that you were imagining that it's only websites that get punished for stuffing, you are incorrect.
5. Keyword Research
Here are some of the keyword placement tips:
Use your top keyword in your mobile app’s name.
Use digits instead of writing the spelling of numbers.
Use a comma instead of space to separate keywords.
Don’t use prepositions and conjunctions as keywords.
6. App Description
Here is a portion of the focuses that can assist you with remembering for your app description:
What are the best features of your app?
How does your app work?
What problem does your app solve?
Why should users download your app?
7. High-Resolution Screenshot
Having excellent screen captures of the app on the App store page makes clients like the app. Screen captures are the second most persuasive thing after appraisals for convincing the client to introduce the app. Pick the screen captures admirably and pick the ones which display the centre functionality of the app and look outwardly appealing.
8. App Preview Video
Visual content marketing is an extremely well-known method of drawing in clients to the app. With a video, you can display and disclose how to introduce the app, which features are the best, and how to benefit as much as possible from it, how to give appraisals and audits.
An app review video can give superior knowledge into the app to the intrigued client. Most of the clients will quiet the sound and afterwards play the video. Along these lines, try to add the content overlays to clarify the significant features of the app. Incorporate the features of the app and not the essences of people who are utilizing the app. That concept is long gone.
9. Choose Your Correct Category
Picking the most important class for the app not just helps the client in finding the apps they are searching for. It is likewise an extraordinary method to support apps positioning to the head of the app stores.
10. Pay Attention to Icon Design
App positioning and downloads are inside connected. The more number of downloads your app has, the higher will be its notoriety and higher will be its positioning. The app icon plays a critical function in choosing the positioning and downloads of the app. The App Store permits only one picture to display in the stores. Thus, ensure you pick the correct icon plan.
| nakumkailas |
612,909 | How to Handle Stale Element Reference Exception in java | Android app for all Automation Testing Interview Questions from PlayStore ⬇️Download... | 0 | 2021-02-20T13:29:25 | https://dev.to/manishthakurani/how-to-handle-stale-element-reference-exception-in-java-2mf2 | testing, java, python | _Android app for all Automation Testing Interview Questions from PlayStore_
⬇️[Download Here](https://bit.ly/2MpAcj0)👈
> Background:
What is StaleElementReferenceException? Stale means old, decayed, no longer fresh. Stale Element means an old element or no longer available element. Assume there is an element that is found on a web page referenced as a WebElement in WebDriver. If the DOM changes then the WebElement goes stale. If we try to interact with an element which is staled then the StaleElementReferenceException is thrown.
Selenium keeps a track of all elements in form of a Reference as and when findElement/findElements is used. And while reusing the element, selenium uses that Reference instead of finding the element again in the DOM. But sometimes due the AJAX request and responses this reference is no longer fresh, hence StaleElementReferenceException is thrown.
Lets see how this issue can be resolved, I know on the internet many people suggest to use the Lazy Initializer or the Page Object Model to minimize the Stale Element Exceptions. But this method is full proof and can work in any framework.
> Solution:
```
public void clickElement(WebElement element)
{
try
{
element.click();
}catch(StaleElementReferenceException stale)
{
System.out.println("Element is stale. Clicking again");
element = reInitializeStaleElement(element);
element.click();
}
}
//method to re-initialize the stale element
public WebElement reInitializeStaleElement(WebElement element)
{
//lets convert element to string, so we can get it's locator
String elementStr = element.toString();
elementStr=elementStr.split("->")[1];
String byType = elementStr.split(":")[0].trim();
String locator = elementStr.split(":")[1].trim();
locator=locator.substring(0,locator.length()-1);
switch(byType)
{
case "xpath":
return DRIVER.findElement(By.xpath(locator));
case "css":
return DRIVER.findElement(By.cssSelector(locator));
case "id":
return DRIVER.findElement(By.id(locator));
case "name":
return DRIVER.findElement(By.name(locator));
}
}
```
The above code is only for reference, please don’t blindly copy it into your project.
Be smart enough to know how to use the driver instance in this method. I would suggest create a Singleton class for click methods or you can put this in to your TestUtil class depending on your framework design pattern.
| manishthakurani |
613,076 | Aprendiendo Spark: #2 Hola mundo | Introducción y fundamentos básicos del framework de computación distribuida Apache Spark | 0 | 2021-02-20T18:55:29 | https://dev.to/danisancas/aprendiendo-spark-2-hola-mundo-1ja7 | tutorial, apachespark, python, bigdata | ---
title: Aprendiendo Spark: #2 Hola mundo
published: true
description: Introducción y fundamentos básicos del framework de computación distribuida Apache Spark
tags: tutorial, apachespark, python, bigdata
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/16rztt4e7iv48tdphojy.png
---
¡Saludos, camaradas! 👋
En este artículo vamos a analizar el código del "Hola mundo" que expusimos en el artículo anterior. Antes de nada, vamos a recordarlo:
```python
from pyspark.sql import SparkSession
# Iniciamos Spark de manera local
spark = (SparkSession
.builder
.master("local[*]")
.appName("Hola Mundo")
.getOrCreate())
# Paralelizamos una lista del 0 al 9 (incluido)
# Computamos la suma de los números
# Obtenemos el resultado en una variable
result = (spark
.sparkContext
.parallelize(range(10))
.reduce(lambda x, y: x + y))
# Imprimimos el resultado
print(f"La suma es {result}")
```
Al ejecutarlo a través del IDE o mediante una terminal escribiendo `python hola_mundo.py` veremos el siguiente output tras una serie de warnings:
```
La suma es 45
Process finished with exit code 0
```
Vale, muy bonito todo pero, ¿qué es cada cosa?
# Creando la sesión de Spark
Para continuar vamos a dar una vuelta por nuestro código anotando los tipos de nuestras variables.
> **Friendly reminder**: Anotar con tipos en Python es meramente informativo de cara a quien desarrolla el código, no tiene el efecto que pueda tener en lenguajes como Java.
Vamos a anotar con su tipo la variable `spark` y también vamos a poner un comentario en cada una de las llamadas encadenadas durante la creación de dicho objeto, para que veamos de qué tipo es cada una.
```python
spark: SparkSession = (SparkSession # SparkSession
.builder # Builder
.master("local[*]") # Builder
.appName("Hola Mundo") # Builder
.getOrCreate()) # SparkSession
```
Todo empieza con la referencia a la clase `SparkSession`, ésta nos permite crear un objeto `Builder` al cual le iremos indicando qué configuración queremos.
En primer lugar, indicaremos que el `master()` es local usando todos los cores que dispongamos. Esto es típico para hacer pruebas en local, cuando no disponemos de un clúster donde ejecutar código productivo (y de momento nos sirve perfectamente).
En segundo lugar especificamos el nombre de nuestra ejecución mediante `appName()`. Como no podía ser de otra manera, se llama "Hola mundo" (cuánta imaginación, ¿verdad? 🙄).
Tanto las llamadas a `master()` como a `appName()` devuelven un objeto Builder, que indica que está a medio construir, nos faltaría un paso más.
Por último le indicamos a Spark que nos devuelva (en caso de existir) o que nos cree (en caso contrario) una `SparkSession` con la que podamos hacer computación distribuida.
La `SparkSession` que nos devuelve la plasmamos en la variable `spark` para que podamos utilizarla más adelante.
> ¡Llegados a este punto ya podemos empezar a hacer computación distribuida!
# Pinto y coloreo mis primeras operaciones distribuidas 🤓
Ahora vamos a hacer lo mismo con el segundo bloque de código, anotando el tipo de la variable `result` y comentando cada paso.
```python
result: int = (spark # SparkSession
.sparkContext # SparkContext
.parallelize(range(10)) # RDD[int]
.reduce(lambda x, y: x + y)) # int
```
Primero partimos de la variable `spark` creada previamente. Y a partir de ella obtenemos un objeto `SparkContext`. Podemos entender este objeto como un _helper_ de Spark para realizar ciertas maniobras. En este caso nos facilita la creación de un [RDD](https://spark.apache.org/docs/latest/api/python/pyspark.html#pyspark.RDD) a través de su método `parallelize`, que toma una lista como argumento.
Con `parallelize()` tomamos una lista clásica (un array de toda la vida, si queréis verlo así) y crea un RDD a partir de ella, del mismo tipo de la lista. Nosotros le hemos pasado la lista `[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]` resultante de invocar `range(10)`, que es de tipo `int`. Por lo tanto el `RDD` será también de tipo `int`.
## Explícame un poco los RDDs, porfa 🥺
Los `RDD`s son las unidades básicas de Spark a partir de las cuales podemos hacer computación distribuida. En próximos artículos entraremos en más profundidad, de momento nos sirve pensar en ellos como **listas cuyo contenido está troceado y repartido por diferentes servidores de Spark**.
De esta manera, evitamos cargar a un único servidor con todo el trabajo, ya que todos los nodos que tengamos trabajarán a la par. ¿Y cuál es ese trabajo tan tedioso que va a requerir computación distribuida? 🤔
¡Nada más y nada menos que la **acción** `reduce()`! 🤩
> Importante: Este `reduce()` no es el del módulo `functools` pero se comporta parecido, solo que de manera distribuida.
## Acción `reduce()`
Vale, ¿entonces qué hace exactamente el `reduce()` de un `RDD`?
Esta función coge una lista distribuida (`RDD`) y va combinando sus valores mediante la función que le indiquemos. En este caso ha sido una simple función anónima que suma 2 números que le pase `reduce()`.
> Si no estáis familiarizados con funciones combinatorias de programación funcional, os dejo [una breve explicación](https://www.geeksforgeeks.org/reduce-in-python/) del `reduce()` del módulo functools. Recordad que no es lo mismo, pero nos sirve para hacernos una idea general de cuál es su mecánica.
Así pues, lo que hará es sumar todos los valores de la lista y devolverá un resultado, un simple `int` de toda la vida. En este proceso intervendrían todos nuestros servidores de Spark, comunicándose entre ellos para ir sumando los diferentes valores, hasta tener completada la suma de todos ellos y devolver el resultado.
Una vez tenemos ese número en nuestro poder, lo imprimimos por pantalla para conocer el resultado de tamaña operación. ¡Buen trabajo! 😎
Espero que os haya sido útil este artículo. En el próximo hablaremos en más profundidad de las operaciones de Spark, que se dividen en **transformaciones** y **acciones**.
Es muy importante entender bien el rol y efectos que las diferencian, ¡así que os espero en el próximo artículo! 🤗
¡Nos vemos, equipo! 🙌 | danisancas |
613,384 | 4 Ways of creating React Components | Most developers probably know only the 2 most fundamentals types of components. But technology is dev... | 10,314 | 2021-02-21T03:36:13 | https://dev.to/rahxuls/4-ways-of-creating-react-components-26n | webdev, react, codenewbie, programming |
Most developers probably know only the 2 most fundamentals types of components. But technology is developing every day, right? And now there are 4 types.
To be relevant, we must keep our tech skills up-to-date ;)
---
## Functional Components
Also called dull or template components, their main purpose is to receive props/return JSX.
> Use more as possible
```react
import React from 'react';
const HelloWorld = () => {
return (
<span>Hello!</span>
)
}
export default HelloWorld;
```
---
## Class Components
They can do everything a functional component does, but more. Also called smart components. they can receive props, have state and lifecycle methods. We use and connect all functional components. Here, in our smart components.
> Not everyone is a king. Use as less as possible
```react
import React from 'react';
class HelloWorld extends
React.Component {
// LOGIC HERE
render() {
return (
<span>Hello!</span>
)
}
}
export default HelloWorld;
```
---
## Pure Components
This is generally used for optimizing the application. The pure components are also used for increasing performance as it works like `shouldComponentUpdate()` lifecycle methods which will reduce the number of operations in the application.
> Essential component type which I suggest using basically when building larger apps
```react
class example extends
PureComponent () {
return (
<Text>
{this.props.text}
</Text>
);
}
```
---
## High-Level Components (HOC)
Advanced technique in React for reusing component logic. HOCs are functions that return component (s). They are used to share logic with other components.
> You can use to 'hack' the rule that you can only return one JSX element from a component
```react
import React from 'react';
import MyComponent form './path'
class HelloWorld extends
React.Component {
render() {
return (
<div>
{this.props.myArray.map((el) => (<Comp data={el} key={el.key} /> ))}
</div>)
}
}
export default HelloWorld;
```
---
📘Thanks For Reading | Happy Coding ☕
Get weekly newsletter of amazing articles I posted this week and some offers or announcement. Subscribe from <a href="https://mailchi.mp/9f73b65b9c38/rahulism" target="_blank">Here</a>
<a href="https://www.buymeacoffee.com/rahxuls" target="_blank"> <img src="https://res.cloudinary.com/rahulism1/image/upload/v1608182430/bmc_nbxakd.png"></a>
| rahxuls |
613,448 | We Reviewed 50+ Popular Web Tools And Services | This is a huge showcase in which we reviewed 50+ popular web tools and services, most of them being t... | 0 | 2021-02-21T07:07:58 | https://dev.to/mikedick/we-reviewed-50-popular-web-tools-and-services-51ik | webtools, webdev, webservices, webdesign | This is a huge showcase in which we reviewed 50+ popular web tools and services, most of them being the very best in their niches, or new solutions that gained huge traction in the last months.
You will read about a super [WordPress support service](https://www.24x7wpsupport.com/), about [Goodie](https://goodiewebsite.com/) – a web development service that is used for simple websites, about logo design creators, website builders, WordPress themes and plugins, and different web solutions.
Let’s start.
[Smart Logo Design](https://www.logoai.com/)
You don’t need to spend hundreds or thousands of dollars on a logo. You can get a gorgeous logo with a 100% unique design from LogoAI, the smartest logo builder on the market.
The software uses advanced technologies to create unique and beautiful logos in just a few minutes, by just asking you some things about your company.
The results are spectacular, and the logo creation process is simple, quick, and straightforward.
You pay only after you get the right logo for your business.
Save your money by using this affordable and efficient logo design builder.
[actiTIME](https://www.actitime.com/timesheet-for-productivity)

Dealing with heavy workloads is a common problem among teachers and students. They both must process enormous volumes of information on a regular basis and strive to comply with strict performance standards continually.
These specifics of occupation make it challenging for teachers and students to avoid stress and burnout. Nevertheless, task planning and organizing are superb solutions to these difficulties, and they can be effortlessly made use of with a quality piece of time tracking software – actiTIME.
The tool has such features as:
• Project management that allows users to create a series of tasks and monitor work progress on the Kanban board or in a simple list format;
• A timesheet for keeping a daily record of hours spent on teaching and learning activities, as well as research assignments;
• Reports on performance for an overview of behavioral trends and time use statistics.
Hence, actiTIME offers everything a teacher or a student may wish for to arrange their work and study processes in an optimal way and analyze personal productivity. It fosters a deeper look into how well one manages their time and supports smarter decision making in this regard.
The basic version of actiTIME is available at no cost for single users and teams of up to three individuals. The full-pack version can be purchased for an unlimited number of users at a very competitive price. Sign up for a free actiTIME trial and bring your productivity to the next level.
[Total](https://total.wpexplorer.com/)

Total is a brilliant WordPress theme that will transform your website into an award-winning platform for your audience. It comes loaded with 40+ premade designers that you can install with 1-click, and with tons of elements and styling options.
You will even find 3 bundled premium plugins– Visual Page Builder, Templatera, and Slider Revolution.
This theme is by far the most complete WordPress theme on the market, and you will feel that from the first moment. Total does offer support renewals.
Any customization you want to make it is not only possible with Total, but also very simple.
Get Total now and get the best out of your WordPress website.
[Mobirise Website Builder](https://mobirise.com/)
Mobirise is the very best offline website builder in 2021, being loaded with absolutely everything you need to create all kind of websites.
You will find included 4,000 website templates, sliders, galleries, forms, popups, icons, and the best interface in a website builder.
Save your money that you would give to web designers, and make yourself a gorgeous website with Mobirise. You will be amazed how easy it is.
[Taskade - Collaborative To-do List, Mindmap, and Workspace for Remote Teams](https://www.taskade.com/)
Taskade is a complete collaboration tool that you can use to chat, organize, and get things done.
The software is super smart and super customizable, being able to do anything you need.
Start with the free plan and see how it works.
[Graphic Design Contract](https://www.hellobonsai.com/a/freelance-design-contract)

Bonsai is a professional creator of tools dedicated to freelancers, having tons of users from all over the world, and being highly appreciated.
They even created a [graphic design contract](https://www.hellobonsai.com/a/freelance-design-contract) that you can use right away. Edit it with your details and you will have your professional contract ready in just a few minutes.
Get your graphic design contract from Bonsai.
[Wp Customify WooCommerce Support](https://wpcustomify.com/)
You have a WooCommerce store and you always have to make all kind of fixes to make it work as you wish?
Get back your free time and let WP Customify manage all your WooCommerce issues. They are experts in this industry and they are super affordable.
Work with WooCommerce support experts and get the best out of your store.
[Doit.io](https://doit.io/)
Doit is a smart app that lets you organize both your private and professionals lives, all in one place. It will help you get more things done in less time, never miss a due date, and heavily improve your productivity.
Register for the free plan and start using Doit, you will love it immediately.
[GreenGeeks](https://www.greengeeks.com/)
Great websites need great hosting solutions that are reliable, that offer lightning-fast performance, and non-stop support.
This is what GreenGeeks will offer you. GreenGeeks offer unparallel performance, 24/7/365 support, and all the hosting solutions you need – Shared, Reseller, VPS, and WordPress hosting.
In plus, they are an eco-friendly web hosting platform that do its best to lower the global emissions.
Get started now, they have a 30-day money back guarantee policy.
[TheGrayDotCompany](https://thegray.company/)

Are you working with a SEO consulting company to get massive organic traffic and to place your website on the first spots in search engines?
If not, you are losing big time. When done correctly and with a strategy, SEO generates impressive results. In plus, it is a way less expensive solution to generate traffic than advertising is.
The Gray Dot Company is an SEO expert agency that has huge experience on helping mid companies hit high targets. They adapt to each client and need, being a pleasure to work with them.
Get your free quote today and take your SEO efforts to the next level.
[CollectiveRay](https://www.collectiveray.com/)

CollectiveRay has a team of experts that write in-depth reviews about WordPress themes and plugins, and roundups on various topics.
No matter what you are looking for, you will find it on CollectiveRay website.
Take a look.
[Lead generation software](https://www.mailmunch.com/)
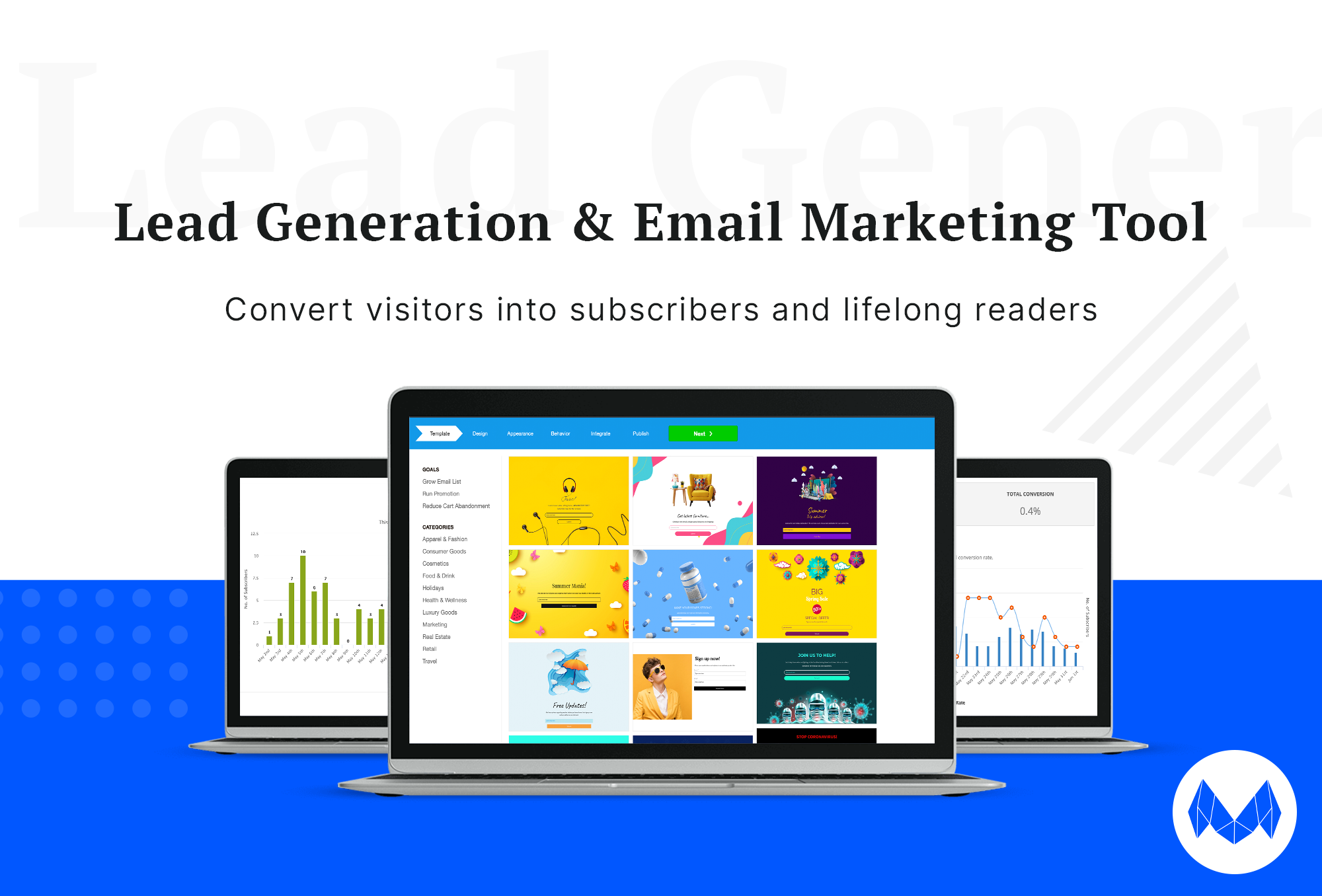
Mailmunch is a smart and complete lead generation software that you can use to create as many forms and landing pages as you like, and to boost conversions by up to 400%.
It is easy and quick to set up, it takes only a couple of minutes, and it comes loaded with fully customizable themes.
Start using Mailmunch, the lead generation software that does it all and which is extremely easy to use.
[Free Email Templates](https://unlayer.com/)
Unlayer is a professional email template builder that you can use with no experience, and no coding, to create engaging and high-converting emails.
It has a huge library of 600+ no-code email templates, a smart drag-and-drop builder, and an intuitive interface.
See how it works.
[Landingi](https://landingi.com/)

Landingi is the right landing page builder to use if you are a marketer or an agency and you need to design your pages right away.
You will find included 250+ landing page templates that look great and which are optimized for high conversions. Use the powerful drag and drop builder to do all your edits, it is simple to use.
See how it works.
[WhatFontIs](https://www.whatfontis.com/)

WhatFontIs is the most used font identifier on the market. It will help you identify fonts from pictures, in just a few steps, and under 1 minute.
It is absolutely free to use, and you don’t need to register.
Identify all the fonts you like with WhatFontIs, and use them in your projects.
[UPQODE - WordPress Web Design Agency](https://upqode.com/)

UPQODE is an eCommerce web design agency in Nashville, TN, that makes businesses more visible in the online world and helps them increase their sales through online stores that focus on the best user experience. For this, UPQODE uses Shopify and Woocommerce platforms, which are also very intuitive for novice webmasters.
UPQODE is also a digital marketing company whose experts take care of conversion optimization, SEO services, Google Ads setup, and others.
[Marketing Contract Template](https://www.hellobonsai.com/a/digital-marketing-contract-template)

If you want to look like an expert in your niche, you have to use a professional [marketing contract template](https://www.hellobonsai.com/a/digital-marketing-contract-template). To do so, you will have to pay good money to a lawyer and wait for at least 2-4 weeks.
The other solution is to get directly the template that Bonsai created for you. They are the most popular creator of web tools and other things for freelancers.
Get it now.
[Heroic Inbox](https://herothemes.com/plugins/heroic-inbox/)
You want to manage customer support email directly from your WordPress website? It will help you save tons of time.
This is what Heroic Inbox will help you achieve, being the best plugin for WordPress for this task.
Learn more about it.
[Heroic Table of Contents](https://wordpress.org/plugins/heroic-table-of-contents/)

Heroic Table of Contents is a popular plugin for WordPress that you can use to add tables of contents to your website with just a few clicks.
Supercharge your content with tables of contents and improve conversions.
Heroic Table of Contents is free to use, get it now.
[Argon Design System by Creative Tim](https://www.creative-tim.com/design-system/argon)

[Argon Design System](https://www.creative-tim.com/design-system/argon) is a set of top-quality, yet free to use UI Kits and Dashboards for developers, created by the famous and highly appreciated company Creative Tim.
The products are built on top of Bootstrap, React, Angular, and Vue.js, and each come with a very large number of components that will help you save time.
Check them.
[Animated Icons by Icons8](https://icons8.com/animated-icons)

The Icons8 team released an updated library of animated icons. Animated Icons 2.0 offers over 900 different graphics in 5 design styles to help designers add motion to their projects. Improve conversions while making customers happy. Capture the attention of app users or website visitors with neat motion graphics. The collection offers coverage to build engaging apps or accessibility-improving hints. GIF, JSON (Lottie), and After Effects formats are included.
[Ozeum | Modern Art Gallery and Creative Online Museum WordPress Theme +RTL](https://themeforest.net/item/ozeum-art-gallery-and-museum-wordpress-theme/25312661)
Want to build a website that would be a reflection of your art? Well, Ozeum could be perfect for that task. It’s a nice option for visual artists who want to reflect the personality of their work. It features a full-screen homepage slideshow that helps create an instant impact and sets the emotional tone. Elementor page builder lets you get creative with your page layouts. While the Events Calendar plugin enables you to manage your events like a pro. For extra impact, there is also the header & footer layouts builder jam-packed. finally, a library of custom shortcodes will save you the day.
[BeTranslated: a Multilingual Translation Agency](https://www.betranslated.co.uk/languages/)

Are you looking for a professional translation agency able to translate a wide variety of texts?
BeTranslated is the agency for you. Their huge network of linguists are experts in their fields, they offer extremely affordable rates, and they always deliver work on time.
Get in touch with BeTranslated.
[Wokiee - Multipurpose Shopify Theme](https://themeforest.net/item/wokiee-multipurpose-shopify-theme/22559417)

You have a Shopify store and you want to make it stand out of the crowd and get many more conversions than it does today?
Take a look at Wokiee. This highly popular Shopify store theme comes loaded with gorgeous and engaging templates and elements, and it is the fastest loading theme on the market.
[Antideo](https://www.antideo.com/)

Contact form spam is a menace that is on the rise currently. Antideo helps in cutting down on this spam by validating the data points provided by the users that include Email Address, Phone Number and IP Address. Antideo is a powerful software that helps you validate the customer data points in real time to help weed out fake signups, registrations, inquiries etc at the time of entry.
For up to 10 requests per hour, Antideo Validation API is free to use.
Try it.
[uKit](https://ukit.com/)
Searching for an easy and feature-laden website builder? Then don’t look any further - uKit is what you need to start a website on your own! The website builder features impressive simplicity, convenience and affordability. It does not require the knowledge of codes or any preliminary background - just sign up for the system and follow the guidelines to build your own website. uKit works equally great for newbies and industry pros, providing an extensite integrated feature set along with high end design customization tools.
[Opinion Stage Wix Quiz](https://www.opinionstage.com/quiz/wix-quiz/)
Opinion Stage is a popular software that you can use to create engaging Wix quizzes.
It comes loaded with gorgeous templates and the interface is very simple to use.
Register for the free plan and create Wix quizzes, it will help you drive traffic from social media channels and get qualified leads.
[uCoz](https://www.ucoz.com/)

With uCoz, everyone can create a feature-laden and professional website. The all-in-one website builder is quite easy to use yet it may take some effort and time to get used to it. The software grants access to multiple modules you can choose and integrate into your web page to form its layout. It also has an easy website editor, customizable templates, eCommerce and blogging functionality. This lets you start and manage a powerful website with distinctive integrated functionality provided by default.
[stepFORM](https://stepform.io/)

Looking for a way to boost your business popularity? Then why not use stepFORM for effective, simple and quick creation of online forms? The tool works great for businesses, freelancers, web designers and other users, who intend to launch feature-rich projects for personal/business use. By creating and integrating online forms, you can not only grow your customer base, but also take advantage of the most convenient payment methods. This lets you receive payments and orders from customers in a convenient and effective way.
[Fotor Online Photo Editor](https://www.fotor.com/)

Fotor will help you create any kind of graphic content you need, including [Facebook banners](https://www.fotor.com/features/facebook.html).
The software is used worldwide by marketers, designers, and online entrepreneurs with huge success, being a highly popular solution.
Give it a try.
[LinkSture - An eCommerce Agency](https://www.linksture.com/?utm_source=MarketWatch.com&utm_medium=content&utm_campaign=mekanismfeb2021)

You want a fully customized shop for Magento, WooCommerce, or Shopify, to get your business launched?
Then you should discuss with LinkSture. They have over 12 years of experience in the industry, serving clients from all over the world.
They are highly popular for creating awesome shops while working for affordable rates.
Get in touch with LinkSture.
[uCalc](https://ucalc.pro/en)
When it comes to effective business development, the use of online forms on your website matters a lot. This is when uCalc proves to be a handy tool to work with. The online form and calculator builder comes with a rich choice of ready-made templates you can customize with regard to your current business needs. The themes are divided into categories based on the sphere of application they belong to. There is no need to apply coding or web design proficiency here as the entire process is quick, easy and intuitive. What you need is to select and customize a calculator/web form to further add it to your website. This will not only help grow your customer base, but will also improve SEO performance of your website.
[ThemeZaa - Awesome Templates and Themes Shop](https://www.themezaa.com/?utm_source=MarketWatch.com&utm_medium=content&utm_campaign=mekanismfeb2021)
On ThemeZaa’s website, you will find a huge portfolio of some awesome website themes for WordPress, WooCommerce, Magento, Shopify, and HTML.
They invest huge amounts of time and money in creating these high-quality products, and their support service is outstanding. No matter which problem you might encounter, the friendly support staff will get it fixed in no time.
Check these website templates, you will love them.
[WordPressToWix.PRO](https://wordpresstowix.pro/)

WordPressToWix.PRO focuses on professional WordPress to Wix migration. The service thoroughly explores each project to make sure all the entities (content, media files, hosting, design etc.) will be properly transferred. They establish individual approach to every customer they deal with by assigning a personal developer, who supervises the migration process on all the stages. This eventually ensures quality result users are satisfied with.
[Content Snare Client Portal](https://contentsnare.com/client-portal/)
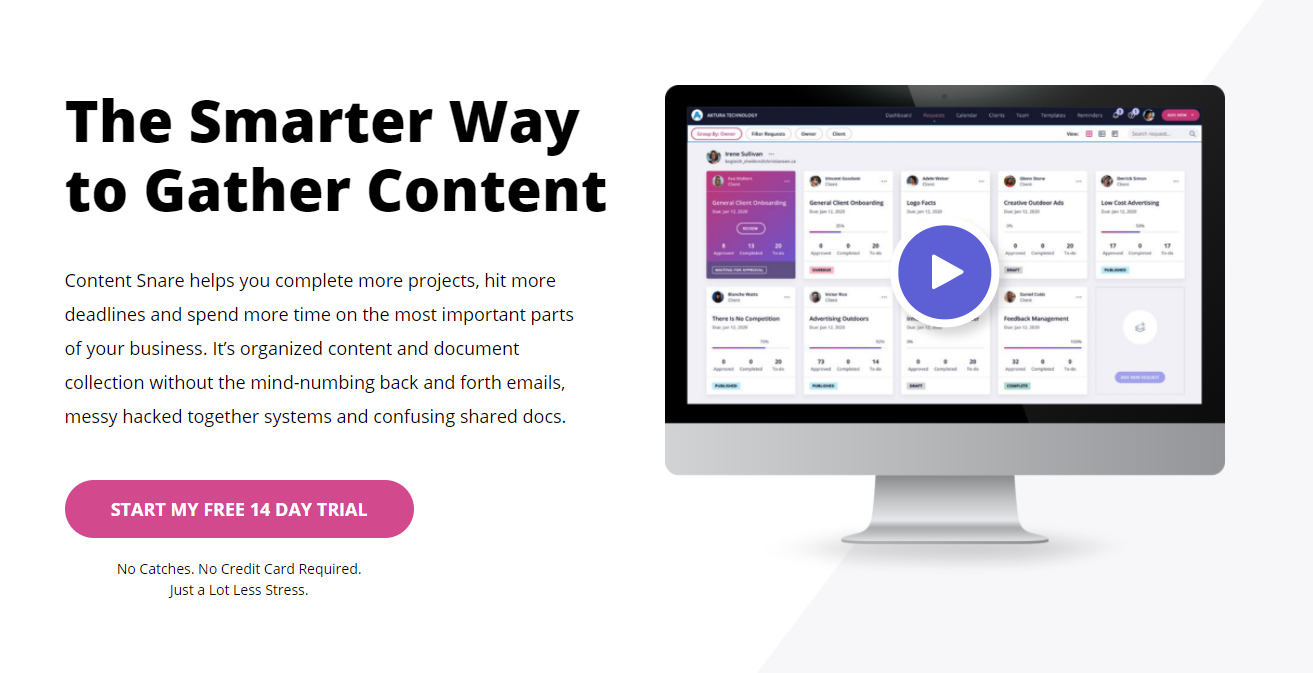
Don’t lose time gathering content from your customers. You can instead use Content Snare, a very powerful, smart, and simple to use software that will collect content from customers in your place.
Create a client portal and “forget” about content collection.
Start your free 14-day trial and see how it works, no credit card required.
[SuperbWebsiteBuilders.com](https://superbwebsitebuilders.com/)

SuperbWebsiteBuilders.com helps beginners and web design experts figure out useful and quite important facts about website builders and popular Content Management Systems. The blog is divided into several sections, which delivers information about these platforms, their general characteristics, pros and cons, main distinctions, pricing policies and implications. Along with handy reviews, you will be able to read the comparisons of these systems that will help you pick the service that comes up to your special web design needs, requirements and project specifications.
[RumbleTalk](https://rumbletalk.com/)

You want to a moderated chat on your website without writing a single line of code? Use RumbleTalk, it is by far the most popular solution in the market.
And even better, they have a free forever plan you can start with.
[Pixpa](https://www.pixpa.com/websites)

Pixpa is a professional website builder that you can use to create all-in-on websites – a store, a blog, and a client gallery.
Start from scratch or by choosing a template that you like (there are hundreds of them). Then the powerful editor will guide you to create a fully functional and good looking website in just a few minutes.
See how it works.
[XSTORE – The Most Customizable WooCommerce Theme](https://xstore.8theme.com/preview-new/)

XSTORE is a highly popular WooCommerce theme that comes loaded with over 100 shop designs, and which uses the latest technologies.
The theme is lightning fast, and it is optimized for conversions.
Make your WooCommerce store stand out of the crowd.
[Digital Web Solutions](https://www.digitalwebsolutions.com/)

To make your online business generate impressive sales, you need a powerful digital marketing and online advertising agency.
Such an agency is Digital Web Solutions (DWS). They have huge experience in the industry and a strong reputation for delivering insane results.
Get in touch with them.
[Animas Marketing](https://animasmarketing.com/)

Animas Marketing is a top performance Colorado search engine optimization agency that has huge experience and which generates impressive results for its customers.
No matter how high are your targets, Animas Marketing will help you reach them.
Get your free quote today.
[Acowebs](https://acowebs.com/)
A quick solution to make your WooCommerce store stand out of the crowd and generate more conversions, is to use Acowebs top-notch plugins. Acowebs are developers of high-end WooCommerce plugins like the [WooCommerce Custom Fields](https://wordpress.org/plugins/woo-custom-product-addons/) which are currently used by more than 25,000 users acros 100+countries. These products were created with high performance and conversions in mind, and the results are impressive.
Take a look.
[Customer Data Platform]()
FoxMetrics is a very popular web analytics platform that companies from all over the use to track their marketing and online advertising efforts.
With FoxMetrics, you will know exactly your audience journeys so you can take the proper measures and improve them.
Sign up for a demo.
[SiteBuilders.PRO](https://sitebuilders.pro/)
SiteBuilders.Pro focuses on professional website transfer between popular CMS and website builders. The service is a worthy solution for users, who decide to switch between the platforms and don’t possess the required skills/expertise to do that independently. A team of niche pros will handle all the project transfer nuances for you to ensure hassle-free, safe and efficient project migration. They let you monitor all the stages of the process to simplify its further management.
[WrapPixel](https://www.wrappixel.com/)
WrapPixel is a popular creator of both free and paid UI Kits and Dashboards for developers, the products being built on top of Bootstrap, React, Angular, and Vue.js.
Take a look at their wonderful products and pick everything you need.
[Briny | Scuba Diving School & Water Sports WordPress Theme + RTL](https://themeforest.net/item/briny-scuba-diving-water-sports-wordpress-theme/24202260)

Not sure that your existing water sports website can bring you to the top? Then take a look at Briny and get inspired. Premium and fresh, Briny is what you need. What is unique about your business? Tell about it using the set of pre-designed pages the theme offers. Showcase your best works or projects you are proud of with the help of stunning galleries organized in grids. Need to build more unique pages? A piece of cake. The Elementor page builder is here to help. Also, Briny is compatible with the Instagram Feed and WooCommerce plugins.
[IP Geolocation API](https://www.abstractapi.com/ip-geolocation-api)
With over 10,000 developers using Abstract, this is among the most popular solutions that you can use for all kind of APIs.
Their IP Geolocation API is super powerful, fast, and reliable.
Get your free API now.
[Shella - Multipurpose Shopify Theme. Fast, Clean, and Flexible.](https://mpthemes.net/shella-shopify-theme/intro-center-cdn/)
Shella is the best Shopify theme for fashion stores, having everything adapted for this industry. All the templates and the elements were created for fashion stores, and that is why stores get more conversions with Shella.
Take a look.
[Ramotion](https://www.ramotion.com/)

Are you looking for a heavily experienced agency in brand identity, UI/UX design, web design, and app development?
Look no further, Ramotion is that agency.
They have huge experience in these industries and they always overdeliver.
Get in touch with Ramotion, you will love working with them.
[Breakline](https://breaklineagency.com/seo-services/)

With over 10 years of experience in the SEO industry, Breakline is a powerful player that generates insane results for its customers.
No matter how high is your SEO target, they will find a way to reach it.
Get your free quote today.
[Website Designers](https://www.website-designers.co.nz/)

[AMG DESIGN](https://www.website-designers.co.nz/) has in their team some of the best website designers in the world and they create awesome designs.
No matter how complicated your project is, get in touch with AMG DESIGN and let them help you.
They are a full-service website design agency for all your branding needs and offer ongoing support.
# Conclusions
Use all these solutions for your projects and I bet that you will earn more money, you will have more free time, and be happier.
If you are a web designer and you need a reliable web development partner for your projects, you should discuss with [Goodie](https://goodiewebsite.com/), they are the best in the niche.
| mikedick |
613,516 | Run WebAssembly module in Web Worker with Parcel 2 | I recently had to add JPEG compression in a web app bundled with Parcel 2. It wasn't easy to find a w... | 0 | 2021-02-21T09:11:05 | https://dev.to/pioug/run-webassembly-module-in-web-worker-with-parcel-2-494h | parcel, webassembly, webworker | I recently had to add JPEG compression in a web app bundled with Parcel 2. It wasn't easy to find a working example combining WASM + Web Worker + Parcel 2, so here is one ☝️
I am going to use the following packages https://www.npmjs.com/package/@saschazar/wasm-image-loader and https://www.npmjs.com/package/@saschazar/wasm-mozjpeg.
Main thread
---
Parcel 2 supports Web Workers out of the box. It means that `new Worker('./mozjpeg-worker.js')` just works 👌
_The rest of the code is essentially meant to wrap the lifecycle of the worker in a promise. `buffer` is obtained from `imageBlob.arrayBuffer()` and sent to the worker._
```js
// Main thread: mozjpeg.js
function processImageArrayBuffer(buffer) {
return new Promise(function (resolve, reject) {
const worker = new Worker('./mozjpeg-worker.js');
worker.onmessage = function (event) {
if (event.data.constructor === Uint8Array) {
resolve(new Blob([event.data], { type: 'image/jpeg' }));
} else {
reject(new Error(event.data));
}
worker.terminate();
};
worker.postMessage(buffer);
});
}
```
Web Worker
---
It's a bit more tricky within the Web Worker. I had to import separately the WASM glue code and the `.wasm` file.
I import the `.wasm` file with the prefix `'url:...'` so it can be fetched like a static asset.
During the initialization of the module, I use the `locateFile` option to tell the glue code where is the `.wasm` file.
_The compression is done in two steps: decoding the array buffer (sent from the main thread) then encoding the result with compression parameters._
```js
// Web Worker: mozjpeg-worker.js
import wasm_image_loader from '@saschazar/wasm-image-loader';
import wasm_image_loader_binary from 'url:@saschazar/wasm-image-loader/wasm_image_loader.wasm';
import wasm_mozjpeg from '@saschazar/wasm-mozjpeg';
import wasm_mozjpeg_binary from 'url:@saschazar/wasm-mozjpeg/wasm_mozjpeg.wasm';
import wasm_mozjpeg_options from '@saschazar/wasm-mozjpeg/options';
const imageLoaderModule = new Promise(resolve => {
wasm_image_loader({
locateFile: function () {
return wasm_image_loader_binary;
},
onRuntimeInitialized() {
resolve(this);
},
});
});
const mozjpegModule = new Promise(resolve => {
wasm_mozjpeg({
locateFile: function () {
return wasm_mozjpeg_binary;
},
onRuntimeInitialized() {
resolve(this);
},
});
});
self.onmessage = async function ({ data }) {
try {
const { decode, dimensions, free: freeImageLoader } = await imageLoaderModule;
const array = new Uint8Array(data);
const decoded = decode(array, array.length, 3);
const { channels, height, width } = dimensions();
const { encode, free: freeMozjpeg } = await mozjpegModule;
const result = encode(decoded, width, height, channels, { ...wasm_mozjpeg_options });
self.postMessage(result.slice(0)); // Original array buffer is tied to web assembly module
freeImageLoader();
freeMozjpeg();
} catch (error) {
self.postMessage(error.message);
}
};
```
That's it! For an exhaustive example, here is the Parcel configuration that I use 👇
```json
// .parcelrc
{
"extends": "@parcel/config-default"
}
``` | pioug |
613,585 | Say Hello World in any Programming Language | You can see how to say Hello World in any programming language : Bla... | 0 | 2021-02-21T12:37:13 | https://dev.to/ja7ad/say-hello-world-in-any-programming-language-lki | programming | You can see how to say Hello World in any programming language :
{% github BlackIQ/Hello-World %} | ja7ad |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.