
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
670,906 | docker compose not docker-compose | docker-compose กำลังจะถูก deprecate แล้วใช้ docker compose แทน มาดูว่าใช้ยังไงกัน สืบเนื่องมาจาก... | 0 | 2021-04-19T00:37:52 | https://dev.to/mrchoke/docker-compose-not-docker-compose-nph | composecli, ubuntu, dockercompose | ---
title: docker compose not docker-compose
published: true
date: 2021-04-19 00:33:40 UTC
tags: composecli,ubuntu,dockercompose
canonical_url:
---
docker-compose กำลังจะถูก deprecate แล้วใช้ docker compose แทน มาดูว่าใช้ยังไงกัน
สืบเนื่องมาจาก blog ของ **_คุณปุ๋ย_**
[https://www.somkiat.cc/docker-compose-to-docker-compose/](https://www.somkiat.cc/docker-compose-to-docker-compose/)
ทำให้เกิดอยากลองใช้บ้างซึ่งพบว่า
บน Docker Desktop macOS สามารถใช้คำสั่งนี้ได้เลย (ลองบน M1) เลยลองบน Ubuntu บ้างพบว่ายังใช้ไม่ได้ เลยตามไปสืบค้นดูพบว่า Project คือ
[docker/compose-cli](https://github.com/docker/compose-cli)
ทำมานานพอสมควรถ้าอ้างตามเอกสารนี้
[docker/compose-cli](https://github.com/docker/compose-cli/blob/main/INSTALL.md)
Docker Desktop macOS และ Windows จะถูก built-in ไปแล้วเลยใช้ได้ทันทีเหมือน buildx เลย
### Installation
ตาม link ด้านบนวิธีการติดตั้ง (ผมติดตั้งบน Ubuntu)
```
curl -L https://raw.githubusercontent.com/docker/compose-cli/main/scripts/install/install_linux.sh | sh
```
เมื่อติดตั้งสำเร็จจะมีคำสั่ง docker เพิ่มขึ้นมาใน path
```
/usr/local/bin/docker
```
ลองทดสอบดูว่าตอนนี้คำสั่ง docker ถูกเรียกจาก path ไหน
```
type docker
```
หรือ
```
which docker
```
ถ้ายังเรียกไปที่
```
/usr/bin/docker
```
ก็ให้ปิด shell แล้วเปิดใหม่ อ้อ!! ดูลำดับ path ของ PATH ด้วยนะครับว่า /usr/local/bin ต้องอยู่ก่อน /usr/bin
คราวนี้เราก็สามารถใช้คำสั่ง
```
docker compose
```
ได้แล้วจ้า….
<figcaption>docker compose</figcaption>
* * * | mrchoke |
671,101 | Quantum Computing | Quantum Computing Outline: Schrödinger's cat Quantum computer Basic operations Schrödinger's... | 0 | 2021-04-19T06:23:55 | https://dev.to/geehaad/quantum-computing-2a1h |
<body style="font-size:22px">
<h1>Quantum Computing</h1>
<div>
Outline:
<ul>
<li>Schrödinger's cat
</li>
<li>Quantum computer
</li>
<li>Basic operations
</li>
</ul>
<h1>Schrödinger's cat</h1>
</ul>
</div>
<div>
<br>
<p>
You probably heard before about the Schrödinger's cat, Schrödinger's cat is a thought experiment that asks a question, is the cat, which is inside a box, alive or dead?<br>
Let's imagine you opened the box at time x-1, and you found the cat is alive, now you think that the cat is always alive,<br>
but what if you opened the box at time x+1, and found that the cat is dead!!<br>
Now you know definitely that the cat is alive at time x-1 and dead at time x+1, but what is her situation at time x?<br>
In the thought experiment, a hypothetical cat may be considered simultaneously both alive and dead as a result of being linked to a random subatomic event that may or may not occur. <br>
</p><br>
<br><br>
</div>
<h1>Quantum computer</h1>
<p >
The experiment we viewed before is the main idea of the quantum computer.<br>
In normal computers, which we use nowadays, and are also known as classical computers, the data, or the bit, is either 0 or 1, on or off, and it cannot be both, <br>
that gives us one out of 2 to the power N possible permutations.<br>
But the quantum data, which is also known as a qubit, can be both 0 and 1 with All of 2 to the power N possible permutations.<br>
</p>
<h1>Basic operation</h1>
<p >
<div>
Now we will see some linear algebra operation in classical computer and quantum computer:<br>
</div>
<h1>Matrix multiplication</h1>
<h2 >Definition</h2>
<p >In mathematics, particularly in linear algebra, <span style="color:yellow">matrix multiplication</span> <br>
is a binary operation that produces a matrix from two matrices. <br>
For <span style="color:yellow">matrix multiplication</span>, the number of columns in the first matrix must be equal to the number of rows in the second matrix.<br>
The resulting matrix, known as the matrix product, has the number of rows of the first and the number of columns of the second matrix. <br>
The product of matrices A and B is denoted as AB. <br>
<div>From Wikipedia, the free encyclopedia</div></p>
<h2>How can we do this?</h2>
<p>Let's Define matrix A with size: m X k ,and matrix B with size: k X n <br></p>
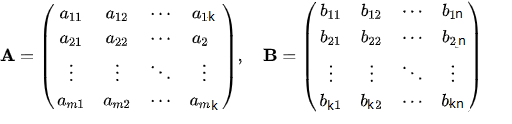
<br>
Then, as we saw in the definition, the number of columns in A is equal to the number of columns in B, then the multiplication, AB, can be done by the following approach:<br>
<br>
We consider multiplying the rows of the first matrix with the opposite columns of the second matrix.<br>
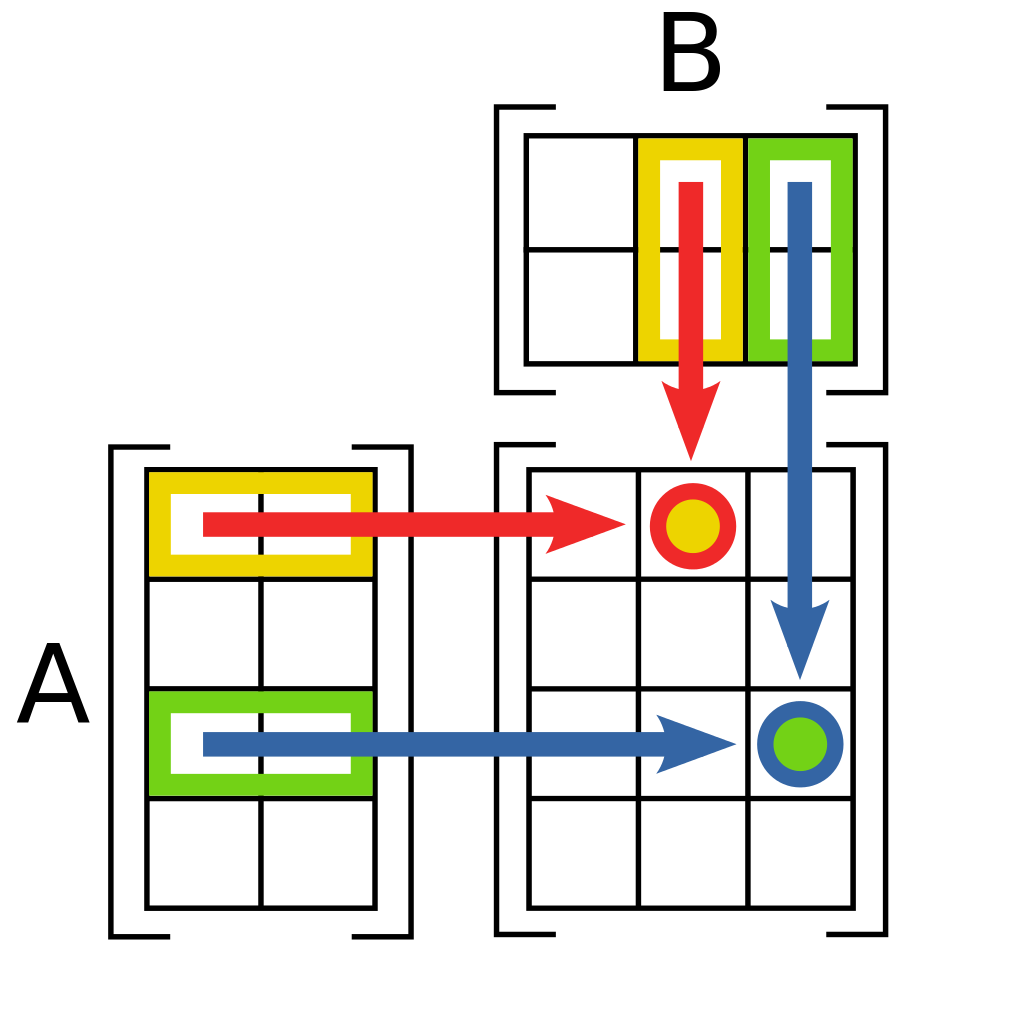
<h3>Steps: </h3>
We multiply the first element in the first row in the first matrix, A, with the first element of the first column in the second matrix, B, we also call this <span style="color:blue">dot notation</span><br>,<br>
we still in the same row of A, and the same column of B, we add the previous multiplication to the second multiplication, <br>
the second multiplication is multiplying the second element in the first row in the first matrix, A, with the second element of the first column in the second matrix, <br>
until the end of the row and the column <small>-remember that the number of columns of the first matrix is equal to the number of rows of the second matrix-</small> <br>
then we move to the second row of A and the second column of B and apply the same approach till the end of the two matrics.<br>
<div style=" text-align: center;">
<br>
</div>
Well, This is a lot of talking, let's write it in beautiful notations:<br>
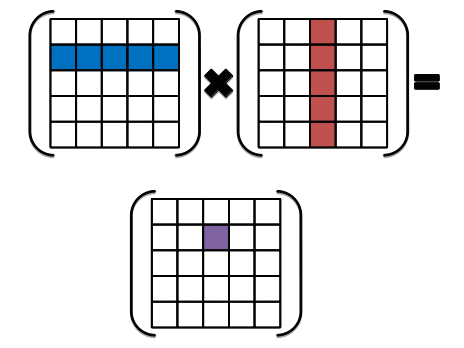
1- Let's consider the output matrix is C, we know that the first ever element:<br>
in A: A[0][0], and in B: B[0][0],<br>
we multiply them in put the answer in the first element in C:<br>
C[0][0] = A[0][0].B[0][0]<br>
2- The second element in the same row of A: a[0][1] and same column of B: b[1][0], <br>
as we still in the same row of A, we add this in the same element of C:<br>
C[0][0] += A[0][1].B[1][0],<br>
Do you get the equation? <br>
let's take another row of A:<br>
3- Consider we moved to the second row of A [1][0], and the second column of B[0][1]:<br>
remember the row of C is as the row of A, and the column of C is as B:<br>
C[1][0] = A[0][1].B[0][0]<br>
at the end C is looking like that:<br>
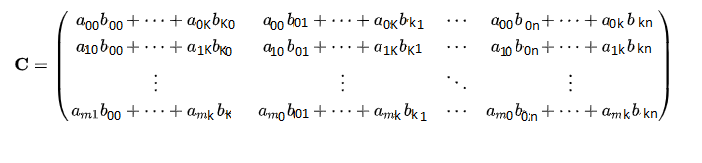<br>
Now we are ready to write the formal equation:<br>
C[i][j]= A[i][0].B[0][j]+ A[i][1].B[1][j]+ ... +A[i][n].B[n][j]<br>
<p>
<h1>Implement the outer product:</h1>
We Will see how to write the code in python:<br>
<ul>
<li>nested for loop <br>
With : O(n^3) <br>
</li>
<li><pre>for i in range(len(matrixA)): # iterat through rows of A
for j in range(len(matrixB[0])): # iterat through columns of B
for k in range(len(matrixB)): #iterate through raws of B
matrixC[i][j] += matrixA[i][k]*matrixB[k][j]</li>
</pre>
<p> The main idea here is to iterate over the rows of the first matrix and the columns of the second matrix,then apply the function we produce before.</p><br>
</ul>
</p>
<h2>Quantum computer</h2>
<p>
as we did before in classical linear algebra, the multiplication is the same, but it differes in that we get the transpose of the second matrix,<br>
we will use the vectore|matrix notation<br>
let's get the transpose of the matrix:<br>
<pre>
def trans(matrix):<br>
trans_matrix = [([0]*len(matrix)) for i in range(len(matrix[0]))]<br>
for i in range(len(matrix)):<br>
for j in range(len(matrix[0])):<br>
trans_matrix[j][i] = matrix[i][j]<br>
return trans_matrix<br>
</pre>
</p>
</p>
<div style=" text-align: center;"> </div>
</body> | geehaad | |
671,543 | Free desktop tool for insightful reporting. Let me know what you think😺 | Hey Dev.to community😸, I want to share the project my team and I are working on. We are developers... | 0 | 2021-04-19T11:51:31 | https://dev.to/juliianikitina/flexmonster-desktop-on-product-hunt-4mij | datascience, analytics, javascript, report | Hey Dev.to community😸,
I want to share the project my team and I are working on.
We are developers of JS data visualization library that is used by integrators as a powerful pivot table component for any web project.
Our team has decided to give **free access to the app to all people** using pivots in their everyday tasks.
We have embedded our pivot table into a simple desktop application on the base of our integration with Electron.js.
And now everyone can easily start working with it right after the download. This product is a convenient and simple solution for your fast reporting. And it doesn’t require any extra skills, knowledge or technical specialization.
**Flexmonster Pivot Table & Charts for desktop** is a lightweight reporting tool that provides a rich set of data analysis features: grouping, aggregating, filtering, sorting, pivot charts.
Once you build a pivot grid, emphasize important insights with formatting, customize your report or save results to any format, be it PDF, Excel, HTML, CSV, or PNG.
What makes Flexmonster Desktop an effective reporting tool for anyone is:
* a super quick start by loading data from desired sources,
* a lot of options to export your result to different formats,
* a simple way to change the view on your data: charts, compact or flat view,
* a convenient drag-and-drop and super friendly UI, that allow you to easily configure your report
& more.
You can just [download the app](https://desktop.flexmonster.com/?r=dt1), run it on your computer and quickly make a customized report to present it to your boss or colleagues in just a few minutes.
If you find it useful but need more custom scenarios for your own soft or website we have a [developer's version](https://www.flexmonster.com) of our component that can be embedded in your own project. It is powered by extended API calls and different customization options for any use case. You can also customize the app basing it on our Electron integration
😼 Today is a very important day for us - we are launching on ProductHunt: [https://www.producthunt.com/posts/flexmonster-desktop](https://www.producthunt.com/posts/flexmonster-desktop)
So we would greatly appreciate your feedback on the app and support on the platform😻.
If reporting is something you are familiar with - do give it a try!
| juliianikitina |
671,575 | Getting started with Jest in just 5 minutes | Testing with Jest, this may sound overwhelming but in fact getting started is very simple.... | 0 | 2021-04-19T13:00:40 | https://dev.to/ghana7989/getting-started-with-jest-in-just-minutes-297c | jest, testing, testdev, basictesting | Testing with Jest, this may sound overwhelming but in fact getting started is very simple.
## To get started let us test a simple function
```js
const celsiusToFahrenheit = (temp) => {
return (temp * 1.8) + 32
}
```
Here we declared a function named celsiusToFahrenheit which takes in a parameter temp which is temperature and is of type number. It returns the Fahrenheit value of celsius `temp`.
## Now let us test this!
Yeah, this our first test
First `npm i -D jest` here `-D` parameter to add it to dev dependency.
Next create a file name called anything.test.js, anything I mean literally anything.
```js
test('Should convert 0 C to 32 F', () => {
const temp = celsiusToFahrenheit(0)
if(temp!==32) throw new Error("This Test Failed")
})
```
Just paste this code and Voila! first test is done, Now let's dive into the code `test()` is a function that is made available globally by jest library when we installed. It takes two parameters, first one being simple the name of the test and second one being the testing function itself.
The testing function when finds an error then shows the output as failed this means a function with nothing inside still shows as a passed test
```js
test('Dummy', () => {})
```
The above test still passes.
But wait, what if there are many conditions to check or some asynchronous code?
Jest got our back
```js
test('Should convert 0 C to 32 F', () => {
const temp = celsiusToFahrenheit(0)
expect(temp).toBe(32)
})
```
Yes, expect is also a function provided in-built with jest package, now what that line means is - expect the temp variable to be a number 32 if not throw an error.
Now in terminal root project folder just run `jest` and see the passing test.
That's all and by the way this is my first blog post | ghana7989 |
671,952 | How to add unique meta tags in Django? | How to add unique meta tags in Django? | 0 | 2021-04-19T21:03:48 | http://makneta.herokuapp.com/post/how-to-add-unique-meta-tags-in-django/ | html, django | ---
title: How to add unique meta tags in Django?
published: true
description: How to add unique meta tags in Django?
tags: HTML, Django
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/hsb1pjqsq3qi95p3icwu.png
canonical_url: http://makneta.herokuapp.com/post/how-to-add-unique-meta-tags-in-django/
---
*Today I'm going to continue the subject of meta tags.* *I'll be talking about two things:*
*1. what meta tags we need to create Twitter Cards*
*2. how to make meta tags unique for each article in Django*
In my last article, I was writing about adding Open Graph to our meta tags to create Social Media Cards. http://makneta.herokuapp.com/post/what-are-metadata-and-meta-tags/ But to make sure that it will work on Twitter too, we should add a few more meta tags.
The tags that are required are **twitter:card** and **twitter:title** (or **og:title**).
If we want to display a big image with a title and description, we should set the content of **twitter:card** to **“summary_large_image”**
```
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:title" content="Your title" />
```
If we set content of twitter:card to “summary”, we will display the thumbnail image.
<meta name="twitter:card" content="summary" />
We can also add twitter:creator with our Twitter handle in content and twitter:site with the site’s Twitter handle
```
<meta name="twitter:creator" content="@your_handle" />
<meta name="twitter:site" content="@your_site_handle" />
```
Those two are not required but specific for Twitter cards.
If we have Open Graph tags such as og:description, og:title, og:image, og:url, we don’t have to add them separately for Twitter.
If we want to make our meta tags work for SEO purposes, each article on our website should have a unique title, description, image and URL.
Because I learn the best in practice (and because I had wanted to have nice Social Media cards for ages), now it’s time to add open graph tags and Twitter tags to my Django blog.
First, let’s look at my Post model
```
class Post(models.Model):
author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE)
title = models.CharField(max_length=250)
slug = models.SlugField(max_length=250, unique=True, default='', editable=False)
header_image = models.ImageField(upload_to='blog', blank=True, null=True)
image_alt = models.CharField(max_length=250, default="cover image", null=True)
text = RichTextUploadingField(max_length=50000, blank=True, null=True)
summary = models.TextField(blank=True, null=True)
created_on = models.DateTimeField(auto_now_add=True)
updated = models.DateTimeField(auto_now=True)
status = models.IntegerField(choices=STATUS, default=0)
```
I’m showing the Post model because in order to create unique cards for each blog post we need to use fields from the Post model.
In my meta tags, I’m using such fields as title, slug, header_image and summary. For most of them, it’s enough to use ```{{object.field_name}}```.
```
<title>{{object.title}}</title>
<meta property="og:title" content="{{object.title}}">
<meta property="og:url" content="http://yourwebsite.com/{{object.slug}}" >
```
Because my header_image field, as well as the summary field, are not mandatory, in order to avoid crashing the website I’m using some conditions.
If there is a summary, it should be used by meta tag description but if there isn’t a post summary (truncated to 160characters), it should take 160 characters from the blog article.
```
<meta property="og:description" content="{% if object.summary %}{{object.summary|striptags|truncatechars:160}}{% else %}
{{object.text|safe|striptags|truncatechars:160}}{% endif %}">
```
I don’t always add header images, sometimes I display my “universal” picture and I need to add the URL to an appropriate pic.
```
<meta property="og:image" content="{% if post.header_image %}http://yourwebsite.com{{ post.header_image.url }}
{% else %}http://yourwebsite.com{% static 'images/home-office.jpg' %}{% endif %}">
```
Now all those tags together
We can forget about twitter:card tag
```
<meta name="twitter:card" content="summary_large_image" />
<title>{{object.title}}</title>
<meta property="og:title" content="{{object.title}}">
<meta property="og:url" content="http://yourwebsite.com/{{object.slug}}" >
<meta property="og:description" content="{% if object.summary %}{{object.summary|striptags|truncatechars:160}}{% else %}
{{object.text|safe|striptags|truncatechars:160}}{% endif %}">
<meta property="og:image" content="{% if post.header_image %}http://yourwebsite.com{{ post.header_image.url }}
{% else %}http://yourwebsite.com{% static 'images/home-office.jpg' %}{% endif %}">
<meta name="twitter:card" content="summary_large_image" />
<title>{{object.title}}</title>
<meta name="twitter:creator" content="@your_handle" />
<meta name="twitter:site" content="@your_site_handle" />
```
One more thing. If we leave meta tags like here, the description, title and image won’t work on the home page or the about page.
That’s why we need to wrap it in a condition like this:
```
{% if object.slug in request.path %}
<meta property="og:title" content="{{object.title}}">
<meta property="og:url" content="http://yourwebsite.com/{{object.slug}}" >
<meta property="og:description" content="{% if object.summary %}{{object.summary|striptags|truncatechars:160}}{% else %}
{{object.text|safe|striptags|truncatechars:160}}{% endif %}">
<meta property="og:image" content="{% if post.header_image %}{{ post.header_image.url }}
{% else %}http://yourwebsite.com{% static 'images/home-office.jpg' %}{% endif %}">
<meta name="twitter:card" content="summary_large_image" />
<title>{{object.title}}</title>
{% else %}
<title>Your title</title>
<meta property="og:title" content="Your title">
<meta property="og:description" content="Description up to 160 characters">
<meta property="og:image" content="http://image-url.png">
<meta property="og:url" content="http://yourwebsite.com" >
<meta name="twitter:card" content="summary_large_image" />
{% endif %}
<meta name="twtter:site" content="@website_handle" />
<meta name="twtter:creator" content="@your_handle" />
```
This way my Twitter card from the previous post looks like that:

| makneta |
672,277 | Code Splitting in React using React.lazy and Loadable Components | When our project grows and we add more functionalities, we end up adding a lot of code and libraries,... | 0 | 2021-04-20T03:21:58 | https://www.codingdeft.com/posts/react-code-splitting/ | react, suspense | When our project grows and we add more functionalities, we end up adding a lot of code and libraries,
which result in a larger bundle size. A bundle size of a few hundred KBs might not feel a lot,
but in slower networks or in mobile networks it will take a longer time to load thus creating a bad user experience.
The solution to this problem is to reduce the bundle size.
But if we delete the large packages then our functionalities will be broken. So we will not be deleting the packages,
but we will only be loading the js code which is required for a particular page.
Whenever the user navigates or performs an action on the page, we will download the code on the fly,
thereby speeding up the initial page load.
When the Create React App builds the code for production, it generates only 2 main files:
1. A file having react library code and its dependencies.
2. A file having your app logic and its dependencies.
So to generate a separate file for each component or each route we can either make use of `React.lazy`,
which comes out of the box with react or any other third party library. In this tutorial, we will see both the ways.
{% youtube UbRdRRPbows%}
# Initial Project Setup
Create a react app using the following command:
```
npx create-react-app code-splitting-react
```
# Code splitting using React.lazy
Create a new component `Home` inside the file `Home.js` with the following code:
```jsx
import React, { useState } from "react"
const Home = () => {
const [showDetails, setShowDetails] = useState(false)
return (
<div>
<button
onClick={() => setShowDetails(true)}
style={{ marginBottom: "1rem" }}
>
Show Dog Image
</button>
</div>
)
}
export default Home
```
Here we have a button, which on clicked will set the value of `showDetails` state to `true`.
Now create `DogImage` component with the following code:
```jsx
import React, { useEffect, useState } from "react"
const DogImage = () => {
const [imageUrl, setImageUrl] = useState()
useEffect(() => {
fetch("https://dog.ceo/api/breeds/image/random")
.then(response => {
return response.json()
})
.then(data => {
setImageUrl(data.message)
})
}, [])
return (
<div>
{imageUrl && (
<img src={imageUrl} alt="Random Dog" style={{ width: "300px" }} />
)}
</div>
)
}
export default DogImage
```
In this component,
whenever the component gets mounted we are fetching random dog image from [Dog API](https://dog.ceo/dog-api/) using the `useEffect` hook.
When the URL of the image is available, we are displaying it.
Now let's include the `DogImage` component in our `Home` component, whenever `showDetails` is set to `true`:
```jsx
import React, { useState } from "react"
import DogImage from "./DogImage"
const Home = () => {
const [showDetails, setShowDetails] = useState(false)
return (
<div>
<button
onClick={() => setShowDetails(true)}
style={{ marginBottom: "1rem" }}
>
Show Dog Image
</button>
{showDetails && <DogImage />}
</div>
)
}
export default Home
```
Now include `Home` component inside `App` component:
```jsx
import React from "react"
import Home from "./Home"
function App() {
return (
<div className="App">
<Home />
</div>
)
}
export default App
```
Before we run the app, let's add few css to `index.css`:
```css
body {
margin: 1rem auto;
max-width: 900px;
}
```
Now if you run the app and click on the button, you will see a random dog image:
## Wrapping with Suspense
React introduced [Suspense](https://reactjs.org/docs/react-api.html#suspense) in version 16.6,
which lets you wait for something to happen before rendering a component.
Suspense can be used along with [React.lazy](https://reactjs.org/docs/react-api.html#reactlazy) for dynamically loading a component.
Since details of things being loaded or when the loading will complete is not known until it is loaded, it is called suspense.
Now we can load the `DogImage` component dynamically when the user clicks on the button.
Before that, let's create a `Loading` component that will be displayed when the component is being loaded.
```jsx
import React from "react"
const Loading = () => {
return <div>Loading...</div>
}
export default Loading
```
Now in `Home.js` let's dynamically import `DogImage` component using `React.lazy` and wrap the imported component with `Suspense`:
```jsx
import React, { Suspense, useState } from "react"
import Loading from "./Loading"
// Dynamically Import DogImage component
const DogImage = React.lazy(() => import("./DogImage"))
const Home = () => {
const [showDetails, setShowDetails] = useState(false)
return (
<div>
<button
onClick={() => setShowDetails(true)}
style={{ marginBottom: "1rem" }}
>
Show Dog Image
</button>
{showDetails && (
<Suspense fallback={<Loading />}>
<DogImage />
</Suspense>
)}
</div>
)
}
export default Home
```
`Suspense` accepts an optional parameter called `fallback`,
which will is used to render a intermediate screen when the components wrapped inside `Suspense` is being loaded.
We can use a loading indicator like spinner as a fallback component.
Here, we are using `Loading` component created earlier for the sake of simplicity.
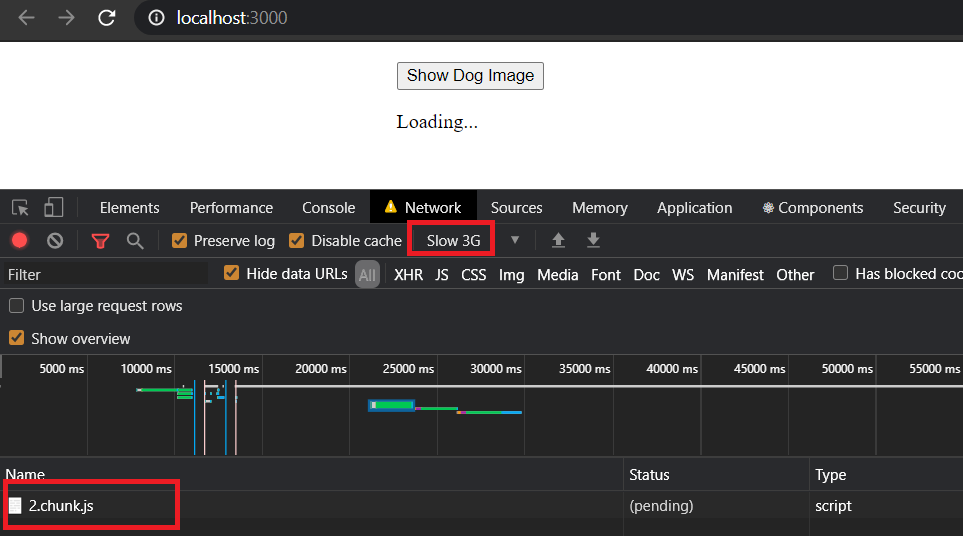
Now if you simulate a slow 3G network and click on the "Show Dog Image" button,
you will see a separate js code being downloaded and "Loading..." text being displayed during that time.
## Analyzing the bundles
To further confirm that the code split is successful, let's see the bundles created using `webpack-bundle-analyzer`
Install `webpack-bundle-analyzer` as a development dependency:
```bash
yarn add webpack-bundle-analyzer -D
```
Create a file named `analyze.js` in the root directory with the following content:
```js
// script to enable webpack-bundle-analyzer
process.env.NODE_ENV = "production"
const webpack = require("webpack")
const BundleAnalyzerPlugin = require("webpack-bundle-analyzer")
.BundleAnalyzerPlugin
const webpackConfigProd = require("react-scripts/config/webpack.config")(
"production"
)
webpackConfigProd.plugins.push(new BundleAnalyzerPlugin())
// actually running compilation and waiting for plugin to start explorer
webpack(webpackConfigProd, (err, stats) => {
if (err || stats.hasErrors()) {
console.error(err)
}
})
```
Run the following command in the terminal:
```bash
node analyze.js
```
Now a browser window will automatically open with the URL http://127.0.0.1:8888
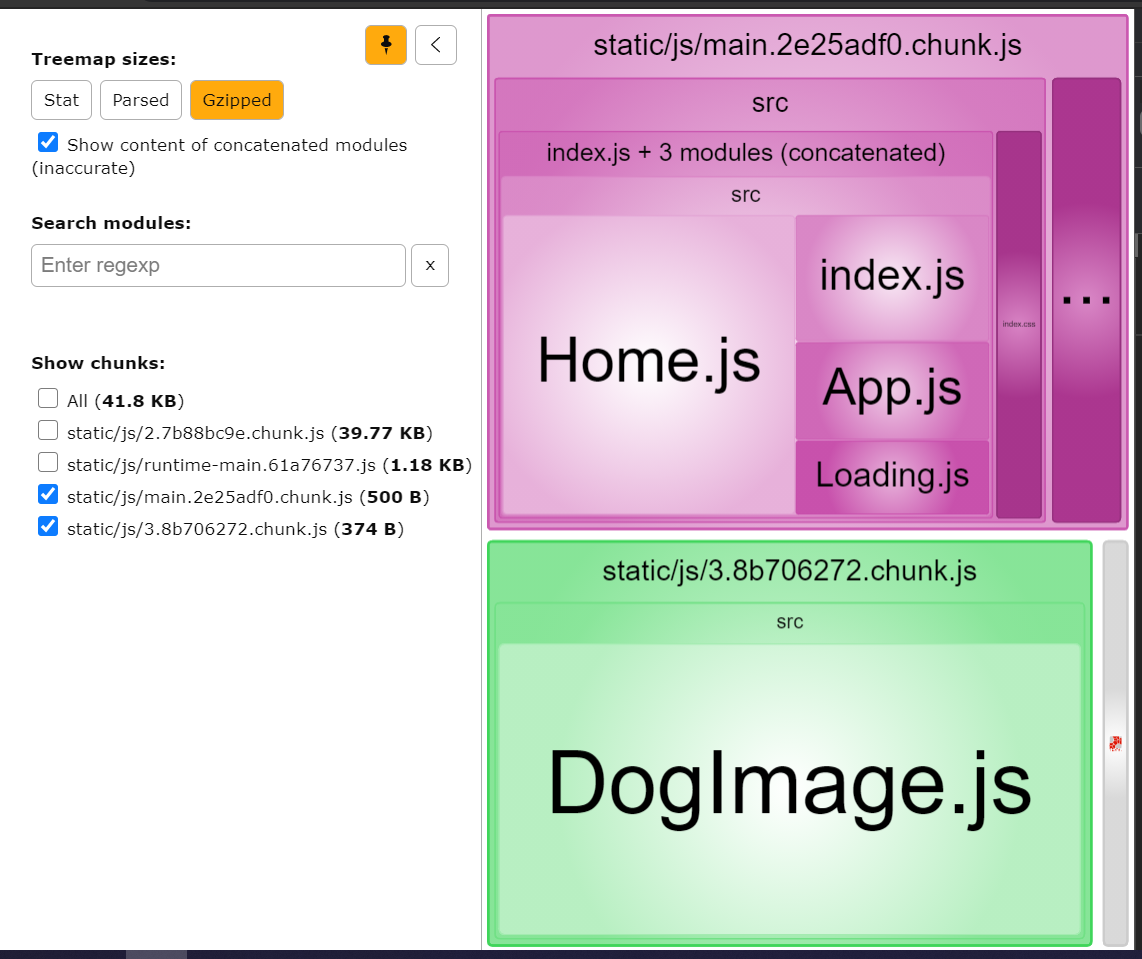
If you see the bundles, you will see that `DogImage.js` is stored in a different bundle than that of `Home.js`:
## Error Boundaries
Now if you try to click on "Show Dog Image" when you are offline,
you will see a blank screen and if your user encounters this, they will not know what to do.
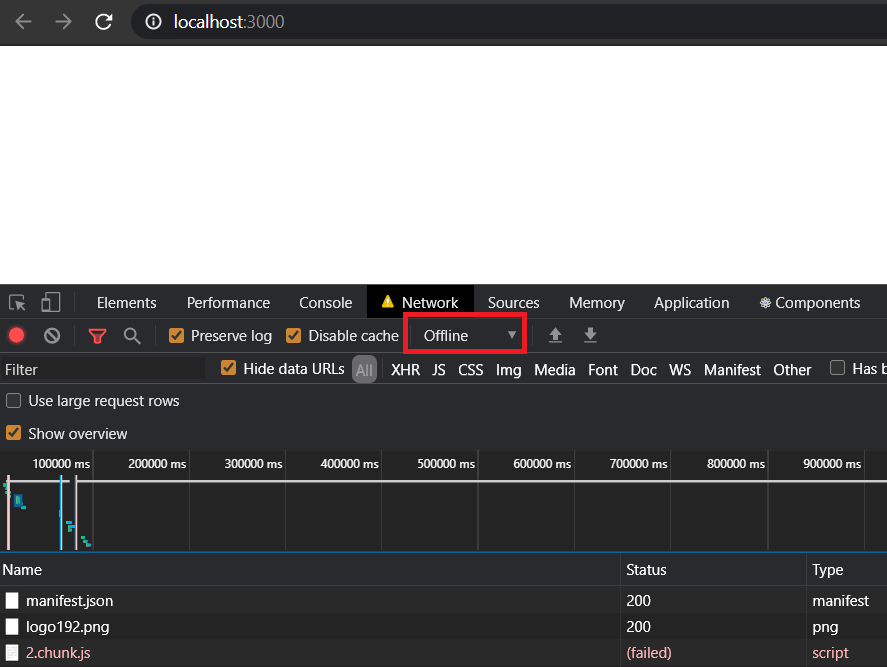
This will happen whenever there no network or the code failed to load due to any other reason.
If we check the console for errors, we will see that React telling us to add
[error boundaries](https://reactjs.org/docs/error-boundaries.html):
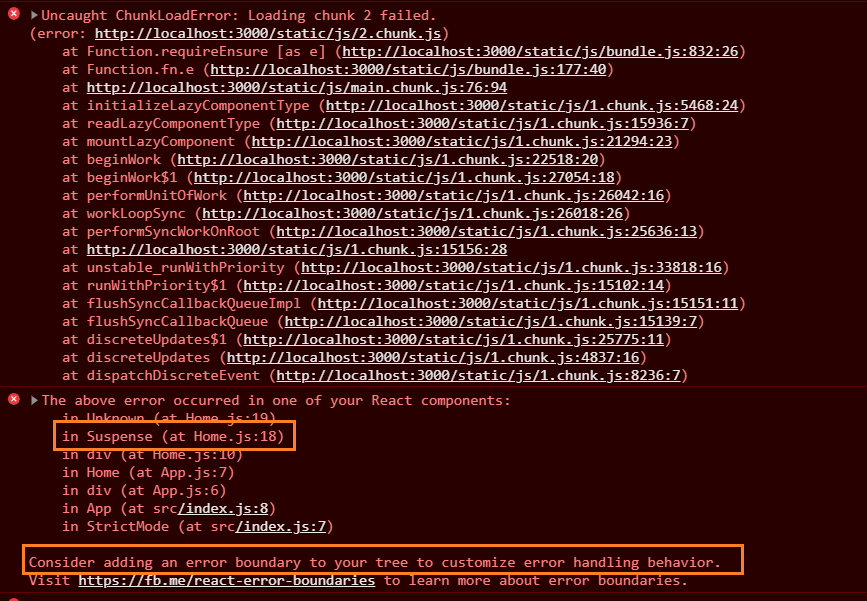
We can make use of error boundaries to handle any unexpected error that might occur during the run time of the application.
So let's add an error boundary to our application:
```jsx
import React from "react"
class ErrorBoundary extends React.Component {
constructor(props) {
super(props)
this.state = { hasError: false }
}
static getDerivedStateFromError(error) {
return { hasError: true }
}
render() {
if (this.state.hasError) {
return <p>Loading failed! Please reload.</p>
}
return this.props.children
}
}
export default ErrorBoundary
```
In the above class based component,
we are displaying a message to the user to reload the page whenever the local state `hasError` is set to `true`.
Whenever an error occurs inside the components wrapped within `ErrorBoundary`,
`getDerivedStateFromError` will be called and `hasError` will be set to `true`.
Now let's wrap our suspense component with error boundary:
```jsx
import React, { Suspense, useState } from "react"
import ErrorBoundary from "./ErrorBoundary"
import Loading from "./Loading"
// Dynamically Import DogImage component
const DogImage = React.lazy(() => import("./DogImage"))
const Home = () => {
const [showDetails, setShowDetails] = useState(false)
return (
<div>
<button
onClick={() => setShowDetails(true)}
style={{ marginBottom: "1rem" }}
>
Show Dog Image
</button>
{showDetails && (
<ErrorBoundary>
<Suspense fallback={<Loading />}>
<DogImage />
</Suspense>
</ErrorBoundary>
)}
</div>
)
}
export default Home
```
Now if our users click on "Load Dog Image" when they are offline, they will see an informative message:
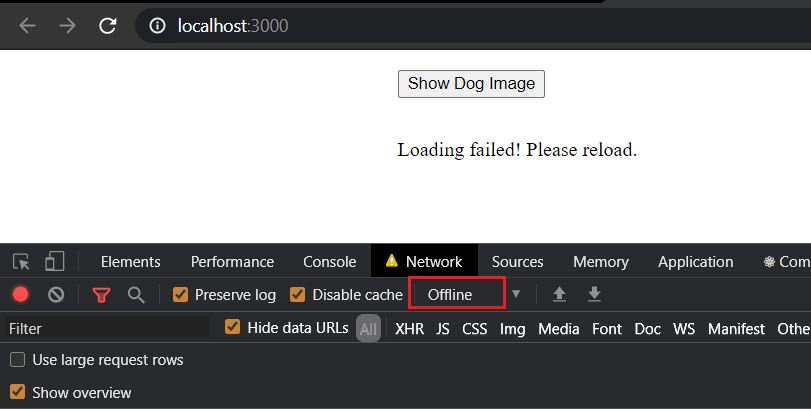
# Code Splitting Using Loadable Components
When you have multiple pages in your application and if you want to bundle code of each route a separate bundle.
We will make use of react router dom for routing in this app.
In my previous article, I have explained in [detail about React Router](https://www.codingdeft.com/posts/react-router-tutorial/).
Let's install `react-router-dom` and `history`:
```bash
yarn add react-router-dom@next history
```
Once installed, let's wrap `App` component with `BrowserRouter` inside `index.js`:
```jsx
import React from "react"
import ReactDOM from "react-dom"
import "./index.css"
import App from "./App"
import { BrowserRouter } from "react-router-dom"
ReactDOM.render(
<React.StrictMode>
<BrowserRouter>
<App />
</BrowserRouter>
</React.StrictMode>,
document.getElementById("root")
)
```
Let's add some Routes and Navigation links in `App.js`:
```jsx
import React from "react"
import { Link, Route, Routes } from "react-router-dom"
import CatImage from "./CatImage"
import Home from "./Home"
function App() {
return (
<div className="App">
<ul>
<li>
<Link to="/">Dog Image</Link>
</li>
<li>
<Link to="cat">Cat Image</Link>
</li>
</ul>
<Routes>
<Route path="/" element={<Home />}></Route>
<Route path="cat" element={<CatImage />}></Route>
</Routes>
</div>
)
}
export default App
```
Now let's create `CatImage` component similar to `DogImage` component:
```jsx
import React, { useEffect, useState } from "react"
const DogImage = () => {
const [imageUrl, setImageUrl] = useState()
useEffect(() => {
fetch("https://aws.random.cat/meow")
.then(response => {
return response.json()
})
.then(data => {
setImageUrl(data.file)
})
}, [])
return (
<div>
{imageUrl && (
<img src={imageUrl} alt="Random Cat" style={{ width: "300px" }} />
)}
</div>
)
}
export default DogImage
```
Let's add some css for the navigation links in `index.css`:
```css
body {
margin: 1rem auto;
max-width: 900px;
}
ul {
list-style-type: none;
display: flex;
padding-left: 0;
}
li {
padding-right: 1rem;
}
```
Now if you open the `/cat` route, you will see a beautiful cat image loaded:
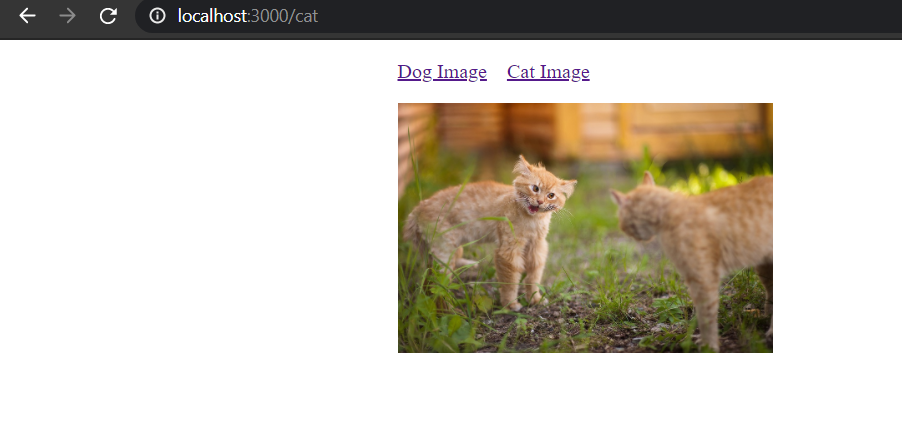
In order to load the `CatImage` component to a separate bundle, we can make use of [loadable components](https://loadable-components.com/).
Let's add `@loadable-component` to our package:
```bash
yarn add @loadable/component
```
In `App.js`, let's load the `CatImage` component dynamically using `loadable` function,
which is a default export of the loadable components we installed just now:
```jsx
import React from "react"
import { Link, Route, Routes } from "react-router-dom"
import Home from "./Home"
import loadable from "@loadable/component"
import Loading from "./Loading"
const CatImage = loadable(() => import("./CatImage.js"), {
fallback: <Loading />,
})
function App() {
return (
<div className="App">
<ul>
<li>
<Link to="/">Dog Image</Link>
</li>
<li>
<Link to="cat">Cat Image</Link>
</li>
</ul>
<Routes>
<Route path="/" element={<Home />}></Route>
<Route path="cat" element={<CatImage />}></Route>
</Routes>
</div>
)
}
export default App
```
You can see that even `loadable` function accepts a fallback component to display a loader/spinner.
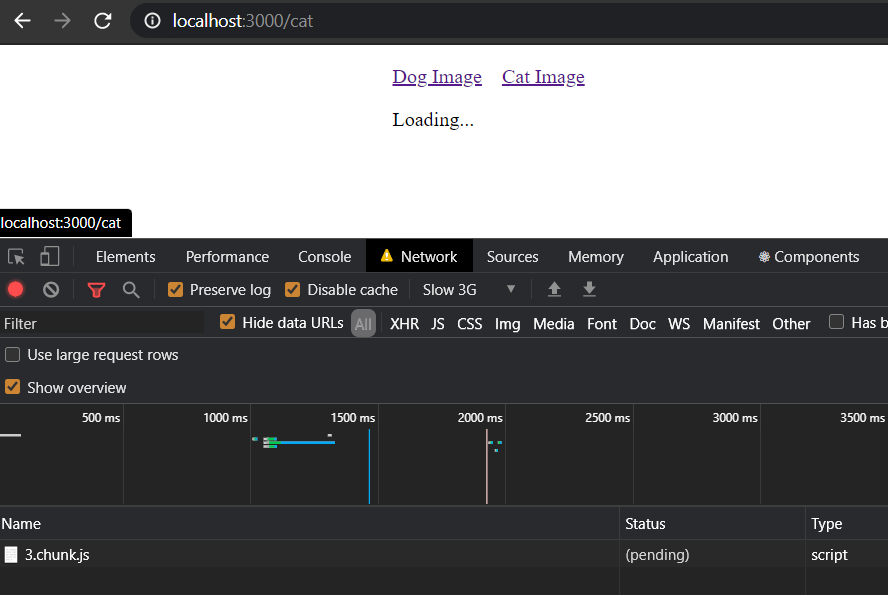
Now if you run the application in a slow 3G network,
you will see the loader and js bundle related to `CatImage` component being loaded:
Now if you run the bundle analyzer using the following command:
```bash
node analyze.js
```
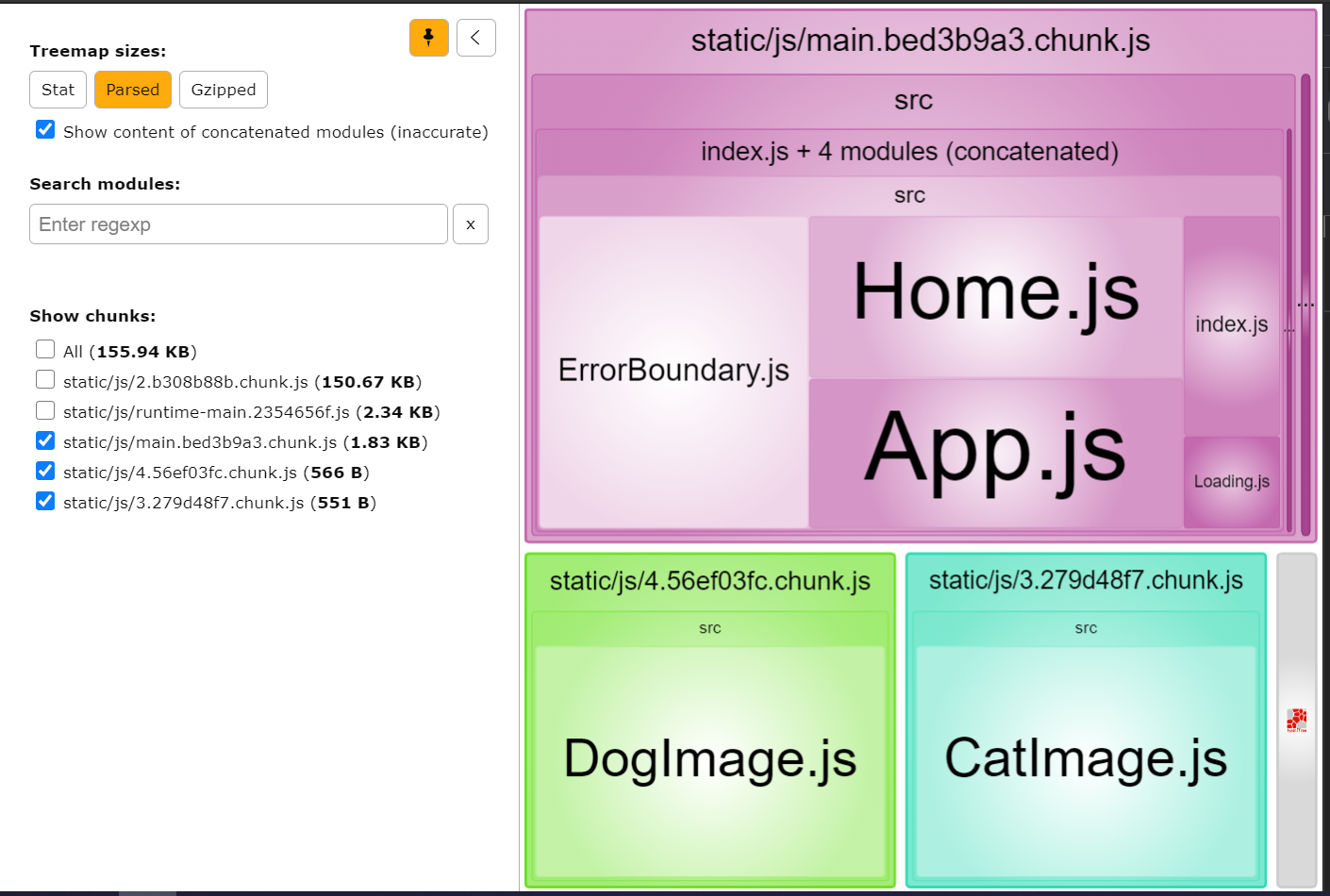
You will see that `CatImage` is located inside a separate bundle:
> You can use `React.lazy` for Route based code splitting as well.
# Source code and Demo
You can view the complete [source code here](https://github.com/collegewap/code-splitting-react) and a [demo here](https://code-splitting-react.vercel.app/).
| collegewap |
672,284 | Operating Systems in space! | NASA has just deployed Ingenuity, a lightweight helicopter sent with the payload of the most recent M... | 0 | 2021-04-20T04:05:57 | https://dev.to/arindavis/operating-systems-in-space-bie | [NASA](https://www.nytimes.com/2021/04/19/science/nasa-mars-helicopter.html#:~:text=At%203%3A34%20a.m.,crater%2C%20into%20the%20Martian%20sky.) has just deployed *Ingenuity*, a lightweight helicopter sent with the payload of the most recent Mars rover, *Perseverance*. At exactly 3:34 AM (ET) Ingenuity successfully executed the first powered flight on another planet.
That wasn't the only first in space history today, though. As it turns out, it was also the first time a linux process has ever been executed on another planet. Which got me wondering, what other operating systems have we as a species hurled into the cosmic abyss?
Let's get into it.
In the early days of spaceflight, when programs like Russia's [Sputnik](https://en.wikipedia.org/wiki/Sputnik_1) and the U.S's [Explorer](https://en.wikipedia.org/wiki/Explorer_1) were being rolled out, each new craft came with its own custom built OS. These were often tailored to those craft's specific needs, and extremely basic by modern standards.
Enter stage right: a man by the name of [J. Halcombe Laning](https://en.wikipedia.org/wiki/J._Halcombe_Laning). Laning was a pioneer of his time who worked with engineers at MIT to create the first ever real time computer in the early fifties, among many other notable accolades. By the time the [Apollo missions](https://www.nasa.gov/mission_pages/apollo/missions/index.html) were being conceived, NASA knew it would need a state of the art guidance system for it's new generation of space-craft, so they turned to Laning to help build out the software for it. Years later, the [Apollo Guidance Computer](https://en.wikipedia.org/wiki/Apollo_Guidance_Computer#cite_note-Hoag-17) was launched with Apollo I, which included the same basic real time operating system designed by Laning that would dominate most of the rest of the Apollo Program.
But, as with the early days, there was no real standardization during this period. That didn't come until 1987, when NASA adopted [VXworks](https://www.windriver.com/products/vxworks) as it's primary OS of choice.
Here's the crazy part: that standard hasn't changed in over thirty years, since it was originally adopted! Perseverance, the most recent rover that dropped off our little helicopter buddy from earlier, is running on the [same OS](https://blogs.windriver.com/wind_river_blog/2018/11/back-to-mars-with-vxworks/) that crafts in the late 80's and early 90's were.
Which, to be fair, is a bit of an oversimplification. While they haven't changed from VXworks in the last three decades, NASA *has* updated their proprietary version of it as time has gone on, so it's not like it is completely outdated.

VXworks itself was chosen because it was one of the leading OS's at the time, especially among government agencies and the military. According to [wikipedia](), VXworks is---
*"... designed for use in embedded systems requiring real-time, deterministic performance and, in many cases, safety and security certification, for industries, such as aerospace and defense, medical devices, industrial equipment, robotics, energy, transportation, network infrastructure, automotive, and consumer electronics."*
Which makes the choice of OS for Ingenuity even more interesting. It's packing a [Qualcomm Snapdragon 801 Processor](https://en.wikipedia.org/wiki/Qualcomm_Snapdragon), which is a CPU you'd usually find in a run of the mill laptop. Running the CPU is a relatively standard linux environment that is utilizing an open source framework called ["F Prime"](https://www.theverge.com/2021/2/19/22291324/linux-perseverance-mars-curiosity-ingenuity), that was specifically designed for powered flight using Ingenuity. This means that if you wanted to, you could go to [NASA's website](https://trs.jpl.nasa.gov/handle/2014/48425) and tinker with it yourself! How cool is that???

Now, I understand no conversation about modern space-tech would be complete without a mention of [Space-X](https://www.spacex.com/), the renegade hot-shot of the international aerospace community.
Unsurprisingly, their [engineers chose linux](https://thenewstack.io/the-hardware-and-software-used-in-space/#:~:text=But%20it's%20not%20necessarily%20a,its%20flightpath%2Ddirecting%20grid%20fins.) as their primary OS, which runs everything from their rockets to their onboard nav systems. Like the little mars helicopter who could, they are sporting modern x86 processors to run most of their processes. The interesting part to me, a web developer who is only just getting started in the field, is that they are using languages like Javascript, Python and C++ to execute the complex processes behind the scenes and tools like HTML and CSS to display information to their astronauts in the cockpit. Hell, they are using chromium and javascript for the touchscreen functionality on the main displays!

Which, in a weird way, makes me feel oddly closer to the cosmos at large. Like, one would assume that the kind of tech that helps put people into space is somewhat unknowable, left to only the smartest among us. But here we are, throwing CSS and HTML into the eternal nothing.
Of course these are all incredibly complex systems built by literally the smartest people in the world, but when it's all laid out into one brief overview you can notice that it's just one generation iterating into another, and is really no more unknowable than the first time you sat down to code javascript.
So raise a glass to the first linux process on the Red Planet. It will not be the last!
| arindavis | |
672,636 | Is SMS OTP authentication as safe as we believe? | Hi I'm Siddharth from SAWO Labs All of us who use banking or e-commerce applications are familiar... | 0 | 2021-04-20T12:23:06 | https://dev.to/sawolabs/sawo-one-stop-solution-for-your-authentication-needs-5dib | authentication, sawolabs, passwordless | 
Hi
I'm Siddharth from [SAWO Labs](https://sawolabs.com/)
- All of us who use banking or e-commerce applications are familiar with the authentication grind - enter your username and password and as additional security, enter the OTP sent to your registered phone number.
- Though we find it cumbersome and even downright annoying, especially when the phone is not by your side or has run out of charge, still, we go with the process simply because we believe it is necessary to protect our data and credentials. But is the SMS OTP authentication as safe as we believe?
- Before we jump into the answer, let's quickly look at the evolution of the practice of sending SMS OTPs to get an understanding of its advantages.
<b>Evolution of SMS OTP</b>
- With the growth of Internet applications and the availability of advanced tools for hackers, security became a concern, and the existing security mechanism of just a password became insufficient. So, a two-factor authentication became a preferred option as the identity of a user was verified at two levels.
- The first was the good old password, and this was followed by a code sent to a registered email ID or phone number. Since no downloads or physical tokens were required, this quickly became the de-facto way of authenticating users. But only until the downside was understood.
<b>Is SMS OTP safe?</b>
Though SMS OTP is touted to be safe and convenient, in reality, it is neither.
And why?
<u>SMS can be hacked</u>
- Don't be shocked at the heading! It is true.
- There have been many instances where the SMS codes have been hacked by leveraging the loopholes present in the telecom providers network.
- Take the case of a massive hack that happened in 2017. Fraudsters leveraged a loophole in Signaling System 7 (SS7), an internal telecommunications standard that defines how mobile phones must connect and exchange a number with each other. As a result, they intercepted the codes associated with the banking transactions of users to transfer funds to their own accounts.
- When this came to light, it caused a big uproar, but the practice of using SMS OTPs continued for a lack of other viable options.
<u>Greater acceptance for non-OTP options</u>
- Almost every major organization today is listening to the millennials, as they are the future users of existing systems.
- According to a survey conducted by Aite Group, more than 48% of millennials were open to the idea of switching authentication modes. In comparison, only 16% of seniors were open to this possibility.
- This goes to show that the next generation of users are more willing to explore authentication methods that go beyond just passwords and SMS codes. In fact, 85% of the respondents in this age group were open to fingerprints while 76% were willing to go with facial recognition. Since biometrics have a wider acceptance, many solutions have started embracing it, to not just meets the users' preferences, but also to improve the level of security and authentication.
- - -
<b>What is SAWO?</b>
- Secure Authentication Without OTP (SAWO) is the next-gen authentication system that moves away from passwords and OTPs, and at the same time, securely authenticates users.
- With SAWO, all that users have to do is enter their username and the associated email ID or phone number. That's it! No passwords and no OTPs at all. The system will trigger the phone lock and based on it, will automatically authenticate the user against the registered phone number or email ID to verify the credentials, and will accordingly, provide access.
- The best part is that SAWO stores no passwords, so there is no chance for hackers to access them. From an organization's standpoint, there are no hassles involved, and it is cost-effective as well because there is no dependence or financial payouts to third-party providers like cellular operators.
- For users, it is a safe and easy way to log in without having to remember complicated mashed-up passwords or waiting for the SMS code on their phones.
- In all, a win-win situation for everyone involved.
So, reach out to us right away to get started!
<b>Support & queries</b>
You can join our [Discord Server](https://discord.gg/TpnCfMUE5P) Community and interact with other developers and can ask for any support you require.
In case of any other query, feel free to reach out to us at community.sawolabs@gmail.com | sawolabs |
672,785 | Building a Daily Standup Application in 30 Minutes | by Kayode Alade The daily standup has become a norm in the schedule of most developers around the wo... | 0 | 2021-04-20T13:42:23 | https://dev.to/appsmith/building-a-daily-standup-application-in-30-minutes-9cb | opensource, javascript, firebase, lowcode | by **Kayode Alade**
The daily standup has become a norm in the schedule of most developers around the world. A [standup](https://www.atlassian.com/agile/scrum/standups) is a daily team meeting, at a specific time for a specific duration, that asks team members to answer three major questions:
1. What did I work on yesterday?
2. What am I working on today?
3. What issues are blocking me?
The daily standup answers these questions but does not resolve them. When put to good use, daily standups increase team productivity and also enhance cohesion between all the parties involved.
## Tutorial Overview with Appsmith
In this tutorial, you’ll learn how to build a daily standup application using [Appsmith](https://www.appsmith.com?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith), an open-source framework for building internal tools, admin panels, dashboards, and workflows. You’ll be using Appsmith to forward a summary of daily standups to [Slack](https://slack.com/ ). Using a web framework like Appsmith is a much quicker way to add this feature to your workspace than building a completely new internal tool.

Appsmith comes out-of-the-box with prebuilt widgets like forms, charts, and maps that you can easily configure to your team’s needs. It also supports APIs and different types of databases. For more details about its capability, visit their official [GitHub page](https://github.com/appsmithorg/appsmith?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith).
## Setting Up the Application and Data Model
First things first: head over to [Appsmith](https://www.appsmith.com?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith) to get a free account. After you sign up, it’s time to set up the user interface of your standup app.
- Click **Create New** on the dashboard to create a new app. You will be taken to an empty canvas as shown below where you can start creating your app. The explorer sidebar on the left is used to add widgets, create pages, and connect to APIs and data sources such as [Firestore](https://firebase.google.com/docs/firestore).

- To build all the features needed for this app, you’ll need to create two pages in Appsmith. Double-click **Page1** to rename it as _First Page_.
- On the Pages bar, click the **+** icon to add a page, then double-click to rename the new page as _Second Page_.
Now that you’ve created your two pages, it’s time to start adding widgets. Your app’s first page will contain:
* A personalized welcome message
* A paragraph showing yesterday's standup
* A text area where the user can enter what was done the previous day
* A text area to write out what they plan to do today
* An option field to show their blockers
* A table to show users who completed yesterday’s tasks
* Submit and reset buttons
Let’s create the custom welcome message next:
- Navigate to the **First Page** and click the **+** icon beside **Widgets** to add a new widget.
- Drag the text widget and drop it on the canvas.
- Type in a custom welcome message as shown below.

Next, let’s display yesterday’s standup to-do on top so that you can see at a glance what you planned to do yesterday and then make plans based on that for today.
1. Add two text widgets side by side on your canvas.
2. Label the first _Last Standup todo_. The second widget will hold the value, or what was on the last standup to-do list. This will eventually be drawn from the database, but for now, you can pre-populate it with filler text.
3. Style the widget’s text as you prefer via the Settings gear at the top right of each widget.

As mentioned earlier, the goal of a standup is to provide information about the previous day’s tasks, tasks that need to be done today, and anything standing in the way of accomplishing those tasks. Obviously, you’ll need a form to input all that information.
To create a form:
- Drag the form widget from the sidebar onto the canvas.
- Label the inputs or dropdowns appropriately (eg, _User_, _Yesterday’s todos_, _Yesterday completed_, and so on). Note that the form widget comes out-of-the-box with **Reset** and **Submit** buttons.

- Rename the form by double-clicking on the default name and editing it. Naming this particular form seemed unnecessary, so that the title widget in the form was deleted.
- To delete a widget, hover over it, then right-click the widget name at the top right corner. In the dropdown menu, you’ll see a Delete option. Click to delete the widget.
To finalize your first page’s UI, let’s add a table to display the users who’ve submitted their standup for the day:
- Drag the table widget onto the canvas. Note that the Table Data option in this widget already contains an array of objects. Later, you’ll change this to a query response from your database.

- Navigate to your **Second Page**, where you’ll add your table.
- Drag the table widget onto the canvas.
- Open the table options and add a new column called _Actions_.
- Click the Settings gear above the **Actions** column and set the following properties:
- Column Type: Button
- Label: Edit
- onClick: OpenModal
- Modal Name: New Modal

- In the **Actions** column you just created, click the button that now reads **Edit**. A new modal will popup, which you’ll use to edit the table’s data.
- Change the title text widget to _Edit Table_.
- Drag a text widget into the modal and set the following properties:
- Text value: Username
- Text align: Left
- Text style: Label
- Add a dropdown widget beside the label you just created. In the Settings for that widget, set **Selection type** to _Single Select_. This dropdown, which ought to display all users of your app, will read data from your database after connecting the database to Appsmith later in this tutorial.
- To add a field for blockers, drop in a text widget, name it _Blocker_, and add a dropdown widget as you’ve done previously.
- Add one field each for today’s to-do and yesterday’s to-do. These will take a text widget and an input widget each.
- Finally, add a field to confirm if yesterday’s to-do is complete. Drag over a text widget and a dropdown widget with the values _Yes_ or _No_.

## Connecting Your Database
Appsmith allows you to link data from several databases. For this tutorial, you’ll make use of [Firestore](https://firebase.google.com/products/firestore).
- In Appsmith, click **Second Page** on the sidebar, then click the **+** icon beside **DB Queries**.
- Select **Add a new data source**.
- Select **Firestore**.

- [Create a Firestore database](https://firebase.google.com/docs/firestore/quickstart) to get the project ID.
- From your Firebase console, click the Settings gear on the sidebar.
- Copy your project ID and paste it into Appsmith. Your database URL is `https://_your-project-id_.firebaseio.com`.

- Back in your Firebase console, click the **Service accounts** tab.
- Click **Create service account**. The JSON file containing your service account's credentials will download.
- Copy the contents of the file and paste it into the **Service Account Credentials** field.
- Click **Test** so that Appsmith can verify everything is correct, then click **Save**.
- Back in Firestore, click **Start Collection** to create a collection, or database table. Set the Collection ID to **User** and add fields for **name** and **email**, both as string type. Sample user values will work for each, eg _Chris_ for the name value and _chris@email.com_ for the email.

- To add a collection named _StandUps_, add fields for date ([in seconds](https://stackoverflow.com/questions/3830244/get-current-date-time-in-seconds)), today's to-dos, yesterday's to-dos, completed, and blocker in Firestore.
Note that since you’re building an internal app, you can create more users and standups in their respective collections.
## Creating Standup Queries
Mustache syntax (`{{...}}`) allows you to write JavaScript in Appsmith to read data from elements defined on a particular page. Let’s take advantage of this to pull information from queries or other widgets. First, let’s create the queries:
1. Click the **+** icon on the **DB Queries** menu. You should see your database as an option.
2. Click **New query** on the top right corner of your database option.
3. Rename it to _createStandUp_.
4. In the **Method** dropdown of the **createStandUp** window, select **Add Document to Collection**.
5. Set the database to the name of your database in Firestore. Fill in the body with the following code:
```
{
"yesterday": "{{Input3.value}}",
"user": "{{Input2.value}}",
"blocker": "{{Input5.value}}",
"todos": "{{Input4.value}}",
"prev_completed": "{{Dropdown2.value}}"
"date": {{Date.now()}}
}
```
Note that widgets in Appsmith are global objects, so you can access their values simply by calling `widget_name.value`.

Continue to round out your app’s queries:
- For **fetchUsers,** set the following properties:
- Method: Get Documents in Collection
- Document/Collection Path: users

- For **fetchStandUps**, set the following properties:
- Method: Get Documents in Collection
- Document/Collection Path: standUps
- Order By: `["date"]`

- For **updateStandUps**, set the following properties:
- Method: Update Document
- Document/Collection Path: `standUps/{{Table1.selectedRow._ref.id}}`
- Body: _paste in the following JSON_
```
{
"yesterday": "{{Input3.value}}",
"user": "{{Dropdown3.value}}",
"blocker": "{{Dropdown4.value}}",
"todos": "{{Input4.value}}",
"prev_completed": "{{Dropdown2.value}}"
}
```

Note that queries can only be referenced on the page where they’re defined. If you need the same query on another page, you need to copy and rename it on the other page.
## Connecting Widgets to Queries
Now let’s connect these queries to the widgets in your Appsmith app.
- On the **First Page** of your Appsmith app, replace the text in the widget next to **Last Standup todo** with:
```Javascript
{{fetchUserStandUps.data[0].todos}}
```
- For the **User** and **Blockers** dropdowns, replace the options with this:
```Javascript
{{fetchUsers.data.map((e,i) => {return {label: e.name, value: e.name}}) }}
```
- Fo the **Yesterday completed** dropdown, replace its options with this:
```JSON
[{"label": "Yes", "value": "true" }, { "label": "No", "value": "false" }]
```
- To configure the First Page’s Submit button, select **Execute DB query** under **onClick**, then select the **createStandUp** query.

- To configure the Second Page’s Refresh button, select **Execute DB query** under **onClick**, then select the **fetchStandUps** query.

- To configure the Second Page’s Search button, select **Execute DB query** under **onClick**, then select the **StandUpsByName** query. Set **onSucess** to store value, key to data, then set value to `{{StandUpsByName.data}}`.

## Integrating with Slack
To send the summary of your standup to Slack, integrate your Appsmith app with Slack using incoming webhooks.
> “Incoming Webhooks are a simple way to post messages from apps into Slack. Creating an Incoming Webhook gives you a unique URL to which you send a JSON payload with the message text and some options. You can use all the usual formatting and layout blocks with Incoming Webhooks to make the messages stand out.” - [Slack](https://api.slack.com/messaging/webhooks)
Let’s dive in with the integration:
- Head to [Slack](https://slack.com/) to create an account if you don’t have one.
- Open the [Create an App page](https://api.slack.com/apps?new_app=1). The **Create a Slack App** window appears automatically. If it doesn’t, click **Create New App*.
- Give your app a name and choose the Slack workspace you’re building it for. Click **Create App**. The **Building Apps for Slack** page opens.

- Click **Incoming Webhooks** to open the feature, and toggle the switch to **On** to activate it. Scroll to the bottom of the page to copy the webhook URL.

- Back in Appsmith, under **First Page**, click the **+** icon beside **APIs**, then select **Create new**.
- Paste the webhook in the first input field and change the request type to **POST**.
- Click the **Body** tab and fill in the message as a JSON object as shown:
```
{
"text": "New Standup added by {{Dropdown1.value}}, Yesterdays todo: {{Input1.value}}, Completed: {{Dropdown3.value}}, Todays todo: {{Input2.value}}, Blockers: {{Dropdown2.value}}, link: https://app.appsmith.com/applications/6043f3a5faf5de39951a897e/pages/6043f3a5faf5de39951a8980 "
}
```

Let’s go back to your **First Page** in your app and configure the **Submit** button so that it sends a Slack message on submit.
Click the Settings gear for the **Submit** button. Below **onClick**, find the **onSuccess** field and from the **Call An API** option, select your Slack API.

## Viewing the Completed Daily Standup Application
At this point, your Appsmith app should look like this:

And as a result, your Slack channel should look like this:

You can check out [this tutorial’s completed app on Appsmith](https://app.appsmith.com/applications/6043f3a5faf5de39951a897e/pages/6043f3a5faf5de39951a8980?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith).
## Summary
In this tutorial, you learned how to build a daily standup app using [Appsmith](https://www.appsmith.com?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith), including widgets that enable users to detail their accomplished tasks, their daily to-do lists, and any blockers keeping them from their goals. You then integrated your app with Slack, so you can send summarized standup reports to a specific Slack channel via incoming webhooks.
Have an idea for another app you’d like to build without reinventing the wheel? Check out Appsmith’s Getting Started [documentation](http://docs.appsmith.com?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith), or jump right in by [signing up for a free account](https://app.appsmith.com/user/signup?utm_source=devto&utm_medium=blog&utm_content=standup_appsmith_tutorial&utm_campaign=weeklyblog&utm_term=standup_appsmith).
----
Author Bio: Kayode is a tech enthusiast specializing in embedded systems and system design and modelling. His programming languages of choice include C, C++, JavaScript, and Python. In his free time, he loves adding value to people's lives with technology.
| vihar |
672,790 | Learn JavaScript's for...of and for...in - in 2 minutes | The for...in loop We use for...in when we want to use the keys of an Object. const myOb... | 0 | 2021-04-20T14:01:55 | https://jordienric.com/blog/for-in-for-of-javascript | javascript, webdev, beginners, codenewbie |
## The `for...in` loop
We use `for...in` when we want to use the **keys** of an Object.
```js
const myObject = {
keyOne: 'valueOne',
keyTwo: 'valueTwo',
keyThree: 'valueThree'
}
for (const propertyKey in myObject) {
console.log(propertyKey)
}
// Will result in:
> 'keyOne'
> 'keyTwo'
> 'keyThree'
```
As we can see in the example `propertyKey` will be the key of the object.
> You should know
> 💡 `for...in` will ignore any [Symbol](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Symbol)s in your Object
If we want to access the value we can still do it like this
```js
for (const propertyKey in myObject) {
console.log(myObject[propertyKey])
}
```
But instead of doing this we could use a `for...of` loop.
## The `for...of` loop
The `for...of` loop will iterate over the values of the Iterable Object.
Here's an example with an Array
```js
const myIterableObject = [
'valueOne', 'valueTwo', 'valueThree'
]
for (const myValue of myIterableObject) {
console.log(myValue)
}
// Will result in
> 'valueOne'
> 'valueTwo'
> 'valueThree'
```
This is a good alternative to the `forEach` method
This was a quick introduction to these two syntaxes of the for loop in Javascript. I recommend you play around with them. These two are really useful to know when you want to write short for loops.
## 🚀 Follow me on [twitter](https://twitter.com/jordienr) for more
| jordienr |
672,805 | 7 Tips For Clean Code | It's all about maintaining clean and readable code(which works of course). So, I wanted to share a... | 0 | 2021-07-26T09:33:47 | https://dev.to/akashshyam/7-tips-for-clean-code-3nk1 | discuss, codequality | It's all about maintaining clean and readable code(which works of course). So, I wanted to share a few tips with you guys. Feel free to correct me or share more tips of your own in the comments to create a learning experience for all of us. Let's get to it then:
### 1. Comments, Comments and More Comments
I'm not the ideal developer whose code is understood by everyone and I'm betting you aren't either. Instead of explaining what exactly to do, I'm going to tell you what not to do. Let's look at some sample code:
```js
// Created a constant variable "foo" and assigned a value of "bar"
const foo = "bar";
```
### 2. Meaningful Names
You want to use those kinds of names where the reader goes, "Yes! I know exactly what this does".
```js
// NEVER DO THIS
const abc = validateEmail('writecleancode@gmail.com')
// Good Job!
const isEmailValidated = validateEmail('writecleancode@gmail.com');
```
### 3. Console Warns/Errors
This is a huge problem, so many times I've seen developers commit code with eslint warnings. Infact, a couple of months ago, I started working on an existing project. When I compiled the frontend, there were over 100 warnings by jsx-ally, eslint etc.
We can use [husky] (https://www.npmjs.com/package/husky) along with [lint-staged] (https://www.npmjs.com/package/lint-staged) which will not let you commit code until you clear all the warnings and errors.
### 4. `as unknown` in Typescript
Typescript is smart, but sometimes, it just isn't smart enough! I've seen a lot of `// @ts-ignore`s or `as unknown`s in typescript code. So instead of doing this:
```
const user = dog as unknown;
```
do this:
```
const user dog as IUser
```
Even though doing this is not advisable, at least you get some type safety.
### 5. Use Babel Instead of tsc
From version 7, Babel added support for TypeScript, which means you no longer need to use the TypeScript compiler i.e. `tsc` to build your project, but instead can just use Babel which simply strips your types from all TypeScript files and then emits the result as JavaScript.
This is not only much faster than tsc, especially in bigger projects, but also allows you to use the whole Babel ecosystem within your project. For example, it's great when you want to use react or javascript features which are still in stage 3.
For back-end projects, this means you can simplify your clunky file-watching scripts and just use babel-node to watch for changes.
### 6. Use SonarJS and Eslint
Eslint has many rules that enforce best practises and conventions and will also help to prevent bugs.
(TSLint is being deprecated in favor of typescript-eslint; the TSLint plugin SonarTS has been adopted and is now part of SonarJS).
In addition to ESLint’s features, SonarJS adds some complexity checks to your code, which are helpful to just code away and then break your methods into smaller pieces.
### 7. Opaque Types
I'm not going to explain, I'll just demonstrate this to you.
Imagine we are building a banking API.
```typescript
// Account.ts
export type PaymentAmt = number;
export type Balance = number;
export type AccountNumberType = number;
function spend(accountNo: AccountNumberType, amount: PaymentAmt) {
const account = getAccount(accountNo);
account.balance -= amount;
}
```
```typescript
// controller.ts
import {spend} from "./accounting";
type Request = {
body: {
accountNumber: number,
amount: number
}
};
export function withdrawAmt(req: Request) {
const {accountNumber, amount} = req.body;
spend(amount, accountNumber);
}
```
Did you spot the bug? If you didn't, look at the place where we are calling the `spend()` function. I've (intentionally) passed the amount before the accountNumber but typescript does not complain.
If you are wondering why this happens, this is because `AccountNumberType` and `PaymentAmt` are assignable to each other because both of them are of type `number`.
There is a long standing issue in the typescript repo about this. Until the typescript team does something about this, we can use the following hack
```
// Can be used with any type
type Opaque<K, T> = T & { __TYPE__: K };
type Uuid = Opaque<"Uuid", string>;
```
The utility function Opaque<K, T> simply defines a new type that, aside from a variable’s value, also stores a (unique) key, such as Uuid.
###Conclusion
Thanks for reading! Check out my [twitter] (https://twitter.com/AkashShyam11) where I (try) to post tips & tricks daily. Bye 🤟
| akashshyam |
672,810 | Challenge: Create a `pad` function without using loops! | Create a function that takes some configuration and a value and returns the value with conditional amount of padding | 0 | 2021-04-20T14:28:32 | https://dev.to/_gdelgado/challenge-create-a-pad-function-without-using-loops-2id5 | challenge, functional | ---
title: Challenge: Create a `pad` function without using loops!
published: true
description: Create a function that takes some configuration and a value and returns the value with conditional amount of padding
tags: challenge, fp
cover_image: https://images.unsplash.com/photo-1574642860096-d04d5d385d86?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1350&q=80
---
> Photo Credit: Kylie Fitts / www.kyliefitts.com & https://unsplash.com
In any language, implement a function `pad` that takes a value and conditionally pads it with `n` number of `padding`:
```javascript
const padded = pad({
value: '👋',
padding: '*',
requiredLength: 4,
})
console.log(padded) // --> ***👋
//////////
// Case 2: do not pad a value whose length is equal to `requiredLength`
//
const padded = pad({
value: '👋👋👋👋',
padding: '*',
requiredLength: 4,
})
console.log(padded) // --> 👋👋👋👋
//////////
// Case 3: do not overwrite a value that is longer than `requiredLength`
//
const padded = pad({
value: '👋👋👋👋👋👋',
padding: '*',
requiredLength: 4,
})
console.log(padded) // --> 👋👋👋👋👋👋
```
#### Submit your solutions down below! 👇👇👇
Remember, your solution cannot use any sort of loop construct such as `while`, `do`, or `for`!
**WARNING**: Here is [my solution](https://gist.github.com/supermacro/1cdb1dbc40d3a5efa05ccd164162cc9f) in typescript.
| _gdelgado |
672,878 | Kotlin Multiplatform vs Flutter: Which One to Choose for Your Apps | Kotlin Multiplatform and Flutter are two of the hottest multi/cross-platform app frameworks and are... | 0 | 2021-04-20T15:40:49 | https://dev.to/tgloureiro/kotlin-multiplatform-vs-flutter-which-one-to-choose-for-your-apps-51oj | kotlinmultiplatform, flutter, kotlin, kmm | Kotlin Multiplatform and Flutter are two of the hottest multi/cross-platform app frameworks and are maturing quite fast. Both help you to reuse code when developing apps for Android and iOS. However, these platforms are very different and serve distinct purposes. Having worked with both, I'm going to share what I consider to be each one's strengths and weaknesses.
## Kotlin Multiplatform Mobile (KMM)
Kotlin is a great choice for developing mobile apps. Its conciseness, simplicity, and expressivity allow you to write correct and readable code effortlessly. Kotlin is the suggested language if you are starting a new native Android Project. Hence, if you have to target Android devices, you will probably end with the Android business logic written in Kotlin. Now, imagine being able to put your Android's business logic code, almost untouched, inside your iOS project as an iOS Framework. KMM is the best tool to do this right now and is being used by companies like VMware, Philips, and Netflix.

In KMM, you have a shared folder that is completely reused between platforms. Most of the business logic will be platform-independent. But, when you need to write code that depends on native/system libraries, you can count with KMM's **expect/actual** keywords.
> With this mechanism, a common source set defines an expected declaration, and platform source sets must provide the actual declaration that corresponds to the expected declaration. This works for most Kotlin declarations, such as functions, classes, interfaces, enumerations, properties, and annotations.
Curious for how it works? Look at this code:
```
// Shared (Common)
expect fun randomUUID(): String
```
```
// Android
import java.util.*
actual fun randomUUID() = UUID.randomUUID().toString()
```
```
// iOS
import platform.Foundation.NSUUID
actual fun randomUUID(): String = NSUUID().UUIDString()
```
(Available in [kotlinlang.org/docs](https://kotlinlang.org/docs/mpp-connect-to-apis.html))
Very straightforward, right? This way, the randomUUID() function can be used from reused code (common code), with the correct implementation being provided for each platform during compilation. Then, common code is provided for each platform as an Android module or iOS Framework.
## Flutter
Flutter is a cross-platform framework to target iOS and Android with a single codebase. Google calls it a "UI toolkit for building beautiful, natively compiled applications for mobile, web, and desktop". One of the superpowers of Flutter is that you can design almost any interaction or animation and have it running the same way in Android and iOS. No need to make special adjustments or to recreate the designed user interface using native platforms. For those who are looking to innovate in UI space or don't need to make strong use of native features, Flutter is a strong choice.

To write Flutter apps, you need to program in Dart. Dart is a C/Javascript/Java-like programming language, that may be very familiar if you have previous contact with some of these languages. New features like sound null safety makes Dart even closer to Kotlin and Swift. But make no mistake: to have modern language features like sealed classes, inline classes you may need to use code generators (Take a look at Remi Rousselet's [Freezed](https://pub.dev/packages/freezed) as an example of generated code in Flutter).
Flutter is very easy to use and has a really fast hot reload. It is nice to see your mobile UI rendered in almost real-time in an emulator/simulator as you code. It's not the best choice if you depend heavily on native features that don't have an existing library, because otherwise you may have to spend a lot of time making plumbing code for Flutter's platform channel. Another weakness is that the native UI components are recreated in Flutter's engine. This means that if a new OS version is released with new UI components, you will have to wait until Flutter catches up to use the newest resources.
# My experience with KMM and Flutter in a real world project
Yes, you're reading right. I worked with KMM for shared business logic between iOS and Android + Flutter for UI in a real-world app, that is yet to be launched. That way, we unified our low-level network code and business logic between platforms with KMM, leaving Flutter with only the UI layer of the app. I will detail the design decisions and how everything went in a next post.
## Which one should I choose? Summary:
### Kotlin Multiplatform Mobile may be a good choice if...
- Already have existing native-specific code to be reused.
- You care about having the most updated native components and want to have a 100% native look and feel on every new OS version.
- You want to incrementally share code between platforms on an existing codebase.
- You don't need to publish a desktop or web version of your app.
- You don't want to depend on Flutter engine's implementation on each platform.
- Your project isn't going to be released very soon, or you don't mind about KMM being in alpha status right now.
- Your app is strongly tied to multi-thread or it has background processing needs.
**Beware: KMM is currently in alpha and the APIs may change until it hits stable. Kotlin native memory management is being replaced (important for iOS). You will need to study how it handles memory management, concurrency and immutability to correctly implement multiplatform code for now. Check: https://kotlinlang.org/docs/native-concurrency.html#global-variables-and-singletons**
### Flutter may be a good choice if...
- You are in a small team and don't have resources for two native UI codebases.
- Your app depends mostly on simple API and database calls, a common use case in mobile apps. In this scenario, you can avoid writing Flutter's Platform Channel code as you won't need to interact with native code.
- Your app has a custom UI or you are innovating in UI space.
- You target Web and Desktop besides Mobile and want to have a working solution for these platforms right now. | tgloureiro |
673,065 | tmux: 13 Cool Tweaks to Make It Personal and Powerful | Intended Audience: tmux users (beginner) or who read the part one of my "Command Line Happiness" post... | 12,381 | 2021-04-20T18:07:20 | https://dev.to/krishnam/tmux-13-cool-tweaks-to-make-it-personal-and-powerful-487p | linux, productivity, tmux, developer | **Intended Audience:** tmux users (beginner) or who read [the part one](https://dev.to/krishnam/dev-productivity-command-line-happiness-with-terminal-multiplexing-5067) of my "Command Line Happiness" post or looking for best tips & tricks.
**Why do you want to tweak the default setup ?**
1. Keyboard shortcuts in tmux are a bit of **a stretch, both physically and sometimes mentally**
2. tmux has a lot of **less-than-stellar default** setting
3. Moreover, the configuration is fun, especially when you personalize it to **suit your needs**; after all, that's what it's for!
In general, I prefer using the default setting with any tech/tools that I use as long as it serves its purpose well. However, tmux is different. It is designed to be customizable. On top of that, these are my reasons why you should tweak it.
Follow along, and let's make your tmux friendly. Along the way, do not forget to put more comments in your configuration file; they'll jog your memory later. Treat your tmux config as a living document; Learn, practice, and update.
Here is your ready-to-use valuable tmux tips-&-tweaks. Try these to improve your day-to-day development while using tmux. Let's start with the biggie ! [prefix]
#### 1. Prefix Should be Simple
By default, all key bindings will demand a "prefix" key before they are active. It is similar to a [leader] key in vim. The default is `Ctrl-b`.
The default is a little hard to trigger as the keyboard button is pretty far. Most prefer the `Ctrl-a` as prefix key:
- It puts your prefix in the home row.
- CapsLock can be remapped with a Ctr key, and A sits just next to it.
- If you have already used the GNU screen, `Ctrl-a` is already the standard key for you.
```
unbind-key C-b # free the original bind-key key
set-option -g prefix C-a # setting the prefix from C-b to C-a
bind-key C-a send-prefix # ensure that we can send Ctrl-A to other apps or the shell that your interacting
```
#### 2. Just Reload the Config
Considering you will be doing config tweaks and testing often, it is good to introduce the shortcut here.
By default, there are two ways of reloading
1. shutting down all tmux sessions and start them
2. executing 'source-file ~/.tmux.conf' on all the sessions
Who on earth want to follow the above approaches all the time! let's create the shortcut - `Ctr+r`
```
bind-key C-r source-file ~/.tmux.conf \; display "Config Reloaded !"
```
#### 3. This is How I Want to Start
If you do not want to use your default shell and prefer something else, it is easy to set in tmux.
Let me set my default to my fav shell - zsh. Macs now use zsh as the default login shell across the operating system. It is for a reason. Give it a try if you don't already use zsh as your default shell.
```
set-option -g default-shell /usr/bin/zsh # login shell for new windows/pane
```
#### 4. I Can't See Enough !
- By default, the message that comes in the status bar disappears in the blink of an eye and the pane number display time also too short to notice. Tweak the time as you wish.
- If you feel your default history limit is not good enough for your case, crank that up too.
- Lock the session after x mins of inactivity. Sometimes, it is good to protect your screen to make sure other's should not see enough.
- Default names given to the window are based on what runs in the pane. Hi tmux, let me name it.
```
set-option -g display-time 2000 # By default, status msg disappears in the blink of an eye (750ms)
set-option -g display-panes-time 2000 # By default, pane number disappears in 1 s
set-option -g history-limit 50000 # maximum number of lines held in window history - crank it up from 2k default
set-option -g lock-after-time 3600 # lock the session after 60 mins of inactivity. Sometimes, it is good to protect your screen to make sure other's can't see enough.
set-option -wg automatic-rename off # default names are too vague to see. Let me name it.
```
#### 5. Count like Human
- By default, the windows or panes start with index 0 (silly programmers!). Though tmux is one of those "created by and for programmers", this indexing makes it challenging to do switching windows; window 0 will be all the way to left in the status bar and the 0 in keyboard is all way to the right, then 1 key comes in the left...it messes with you.
- Let's imagine you have three windows. If we removed the second window, the default result would be two remaining windows, numbered 1 and 3. but, tmux could automatically renumber the windows to 1 and 2 with the right setting.
Ok, Let's make tmux a human for a bit,
```
set-option -g base-index 1 # window index will start with 1
set-window-option -g pane-base-index 1 # pane index will start with 1
set-option -g renumber-windows on
```
#### 6. Kill it with X-Force !
By default, if you press <prefix> x, tmux will ask if you're sure you want to kill a pane before it does it. That's nice and all, but what if you'd rather just kill it? Let's do that. And, while we’re at it, let’s create a custom key combo for killing the entire session too.
```
unbind-key x # unbind-key “x” from it’s current job of “ask and then close”
bind-key x kill-pane # rebind-key it to just “close”
bind-key X kill-session # key combo for killing the entire session - <prefix> + shift + x
```
#### 7. Make Splitting Panes Intuitive
Splitting a window in panes are currently bound to <prefix> % and <prefix> ”>, which are hard to remember. It is much easier to remember if you use `|` for vertical splits and `_` for horizontal splits. For now, I will leave the default binding as it is since I don’t have any other use for these weird key commands.
Additionally, you could also mention the directory to open in the new pane when you split.
```
bind-key | split-window -h -c "#{pane_current_path}" # let's open pane with current directory with -c option
bind-key _ split-window -v -c "#{pane_current_path}"
```
#### 8. Make Movements Quick
One of the main reasons for using tmux is because it’s keyboard-centric and plays well with Vim, another my favourite keyboard-centric tool. If you use Vim, you’re probably familiar with its use of h, j, k, and l for movement keys. This way, you do not have to take your fingers off the home row to move to anywhere else.
Let's make movements in pane, window, & command prompt much familiar and faster,
```
# Pane: Vim Style Movements
bind-key -r h select-pane -L # go left
bind-key -r j select-pane -D # go down
bind-key -r l select-pane -R # go right
bind-key -r k select-pane -U # go up
# Pane: Arrow Movements
bind-key Up select-pane -U
bind-key Down select-pane -D
bind-key Left select-pane -L
bind-key Right select-pane -R
# Window: Movements
bind-key L last-window
bind-key -r C-h select-window -t :- # cycle through the windows for quick window selection
bind-key -r C-l select-window -t :+
# word separators for automatic word selection
set-window-option -g word-separators ' @"=()[]' # default => ‘ -_@’.
# tmux adds a short, almost imperceptible delay between the commands that can cause funny behavior when running vim inside tmux.
set-option -s escape-time 0
# Command Prompt Movements: within the tmux command prompt and the command prompt is accessed using <P>: (in the status line)
set-option -g status-keys vi
```
#### 9. Resizing Panes
The default key binding are `Ctr+ Up/Down/Left/Right` for one row movements , `Alt + Up/Down/Left/Right` for five row movements.
Let's add one more to the set (Vim way)
```
# Vim Style
bind-key -r H resize-pane -L 2 # resize a pane two rows at a time.
bind-key -r J resize-pane -D 2
bind-key -r K resize-pane -U 2
bind-key -r L resize-pane -R 2
```
#### 10. Copying and Pasting Text
We will do multiple custom setting here. This tweak can be a real productivity boost if you happen to do a lot of copying and pasting between windows.
We will do these;
- Navigating through output in a quick way like vi
- Vim Style in Copy-Mode
- Setup keys (install xclip if you don't already have it)
- To copy from the current buffer to the sys clipboard `Alt+c`
- To paste text from sys clipboard into current buffer `Alt+v`
- To copy to the sys clipboard directly from the selection `Ctr+c`
- To paste text from sys clipboard into the view `Ctr+v`
- Take a screenshot of the pane and store it with timestamp `Alt+s`
```
# To navigating through output in quick way, enable vim navigation keys
set-window-option -g mode-keys vi
# Vim Style in Copy-Mode "<prefix> ["
# Interacting with Paste Buffer
bind-key Escape copy-mode
bind-key -T copy-mode-vi 'v' send-keys -X begin-selection -N "start visual mode for selection"
bind-key -T copy-mode-vi 'y' send-keys -X copy-selection-and-cancel -N "yank text into the buffer"
bind-key C-b choose-buffer # view the buffer stack
unbind-key p
bind-key p paste-buffer # default "<prefix> ]"
# Alt+C: To copy from the current buffer to the sys clipboard .
bind-key M-c run "tmux save-buffer - | xclip -i -sel clipboard"
# Alt+V: To paste text from sys clipboard into current buffer
bind-key M-v run "tmux set-buffer \"$(xclip -o -sel clipboard)\""
# Ctr+C: Make it even better -just one step to move from sys->buffer->editor vice versa
bind-key -Tcopy-mode-vi C-c send -X copy-pipe "xclip -i -sel p -f | xclip -i -sel c" \; display-message "copied to system clipboard"
# Ctr+V: To paste text from sys clipboard into the view
bind-key C-v run "tmux set-buffer \"$(xclip -o -sel clipboard)\";tmux paste-buffer"
# To take ASCII screenshots (tmux-resurrect uses C-s for saving, here binding to Alt-s ) .
# create the dir for storing screenshots
bind-key M-s run "tmux capture-pane; tmux save-buffer ~/.mytmux/pane_screenshots/\"$(date +%FT%T)\".screenshots"
```
#### 11. Visual Styling: Configuring Colors
Once the proper colour mode is set, you'll find it much easier to use Vim, Emacs, and other full-colour programs from within tmux, especially when you are using more complex colour schemes shell or syntax highlighting.
What you can do here is up to your preference. It goes beyond just colour to your eyes. Let me demo with a few of my tricks;
- Let's dim out any pane that's not active. It is a lot easier to see the active pane this way than looking for * in the status bar.
- Customize pane divider to make it subtle but distinct.
- Make the message colour not harmful to your eyes
```
# Set the default terminal mode to 256color mode
set -g default-terminal "screen-256color"
# Pane divider
set-window-option -g pane-border-style fg=colour11,bg=colour234
set-window-option -g pane-active-border-style fg=colour118,bg=colour234
# Cool trick: Let's dim out any pane that's not active.
set-window-option -g window-style fg=white,bg=colour236
set-window-option -g window-active-style fg=white,bg=colour235
# Command / Message line
set-window-option -g message-style fg=black,bold,bg=colour11
```
#### 12. Dress Up the Status Line
This is how you tailor up the dress for your status line
- Update Status bar colour and window indicator colour
- Update What do you want to see on the left side & right side of the status line
- Setup soft activity alerts
Instead of going fancy here, I just focused on what can help me during my work and less resource-intensive operation. Below is my status bar config;
```
# Status Bar
set-option -g status-style fg=white,bg=colour04
set-option -g status-justify centre
set-window-option -g window-status-style fg=colour118,bg=colour04
set-window-option -g window-status-current-style fg=black,bold,bg=colour011
set-window-option -g window-status-last-style fg=black,bold,bg=colour011
set-window-option -g window-status-separator |
# Left Side
# Show my active session, window, pane name or id
set-option -g status-left-length 50 # default 10
set-option -g status-left "[#[fg=white]S: #S, #[fg=colour11]W #I-#W, #[fg=colour3]P: #P #[fg=white]]"
# set-option -g status-left-style
# Right Side
set-option -g status-right-length 50 # default 50
set-option -g status-right "#[fg=grey,dim,bg=default] uptime: #(uptime | cut -f 4-5 -d\" \" | cut -f 1 -d\",\")"
# Enable Activity Alerts
set-option -g status-interval 60 # Update the status line every 60 seconds (15 is default)
set-window-option -g monitor-activity on # highlights the window name in the status line
```
#### 13. Extending tmux with Plugins
There are many tmux [plugins](https://github.com/tmux-plugins?q=&type=&language=&sort=stargazers) available. If I have to choose one, that would be 'tmux-resurrect'.
- This plugin restores the tmux environment after system restart. This plugin goes to great lengths to save and restore all the details from your tmux environment. See [doc](https://github.com/tmux-plugins/tmux-resurrect)
- If you setup resurrect, then the next logical thing to do is set up 'continuum' to make the saving and restoring as an automatic step
Here is the step to setup tmux plugin management;
```
# List of plugins
set -g @plugin 'tmux-plugins/tpm'
set -g @plugin 'tmux-plugins/tmux-resurrect'
set -g @plugin 'tmux-plugins/tmux-continuum'
# Last saved environment is automatically restored when tmux is started.
set -g @continuum-boot 'on'
# terminal window will go fullscreen
set -g @continuum-boot-options 'fullscreen'
# Initialize TMUX plugin manager (keep this line at the very bottom of tmux.conf)
# run-shell "mkdir -p ~/.tmux/plugins/"
# run-shell "git clone https://github.com/tmux-plugins/tpm ~/.tmux/plugins/tpm"
run '~/.tmux/plugins/tpm/tpm'
# Hit prefix + I to install plugins for the first time.
# It takes few seconds. So, wait before panic.
#
# resurrect key bindings:
# prefix + Ctrl-s - save
# prefix + Ctrl-r - restore
#
```
_Note: All of these tweaks are tested and working in Ubuntu.20.10 and tmux3.1b_
You could access my tmux config [here](https://github.com/krishnam-eng/ohmy-linux/tree/main/tmux) | krishnam |
673,122 | Should I use a library for that? | Libraries and frameworks are here to ease our lives. They bundle up tons of logic and present us a re... | 0 | 2021-04-20T19:21:28 | https://dev.to/netikras/should-i-use-a-library-for-that-16bm | dependencies, design, hell, security |
Libraries and frameworks are here to ease our lives. They bundle up tons of logic and present us a remote control with very few buttons and knobs. A button says "blowItUp" and it blows the whole thing up. A button says "get500BitCoin" and it gets you 500 bitcoins. Well not exactly like that, but the point still stands. Libraries and frameworks know how to do THIS or THAT and they do their jobs well. So you don't have to worry about all the nuts and bolts that you may need to get the job done. Libraries and frameworks have thought of all of that for you. Just use them!
## Libraries and frameworks are great!
I must admit, the idea of libraries is brilliant: someone had a problem,figured out a way to solve it and shared the solution for others to reuse to solve the same (or similar) problems. Let's see what we love them for.
### Quick & easy solution
If you have a problem you have to solve, it might take hours, days or even weeks to solve it yourself. Ever looked at the implementation of the TCP library? There's a lot going on. Imagine if you needed to implement it yourself. That would take several months and still the implementation would be buggy.
What you can do instead, is to look for a library that solves that particular solution and add it to your project in minutes. And that's it - your problem is solved. In minutes, rather than hours, days, weeks or months.
Now off to the other problem (i.e. library lookup)
### Less boilerplate
... and less code to support. This means you are not responsible for the code in the libraries and you don't have to support it. If something doesn't work - just report it as a bug and let maintainers to worry about how to solve it. If you feel like it, you can probably propose your own solution and earn some karma points (and the great feeling of knowing that other projects will be running your solution). With libraries, you go fast. The TTM is short. And you develop less silly bugs. Not to mention you have to write less :)
### Not reinventing the wheel
Most of the problems you're running into have been already solved by someone else. Probably many, many times. If these folks solved those problems, then why should you repeat what they did? You can simply take their solution and use it in your project. There's also a good chance that by reinventing the wheel you'll introduce bugs you haven't thought of, and your solution will be less efficient. Let's not waste our time and use what's already out there.
### They are professionals - they can do it better than I can
Libraries and frameworks are often times developed by experienced professionals. If the maintainer is a professional, we expect him/her to know a great deal about the topic and only use the best practices in the solution of the problem. We want to learn from the best, we want to use what's the best, so we simply like to use what these PROs decided is the best. In many cases it's a no-brainer.
### Standartized usage
This is one of the key aspects that people like libraries for. If I use a library for the job that is popular in the industry, whoever comes after me will most likely know what we're talking about. They will know how to use it, they will know the caveats and possible points for improvements. This is the benefit of using any popular tool, not just libraries, not just frameworks, not just... software. It's easier to maintain the project as a whole when features follow some well-known standards or even are publicly documented and used by others elsewhere.
## However...
This blog post wouldn't exist if there wasn't the "however" part. While it seems that libraries solve all your problems and might even be solid building blocks to the complete application you're after (you only need to arrange them properly _et voila_ - the project is done), there are things to consider before diving into the dependency world (or hell).
### Foreign code
Any code you take in as a part of your project should be considered potentially harmful. It's very easy to modify your `pom.xml` or `gradle.properties` and add that one line adding a library that solves the problem for you! However, your build tools are downloading that library from external sources which you have no control over. Who wrote that library? Did they inject a backdoor in it? Will the authors hack my application if I use their library? I don't know - the library code is far too complex for me to digest and catch all the possible trojans (if any). And it's a tremendous waste of time! It would take weeks or even months... Do I want to spend this much time on that?
Do you think I'm overly paranoid? Sure you do! Have you seen how many attempts there were to inject backdoors into the Linux kernel? :) If you had, you would be too. And the Linux kernel is no different than any other open-source project in this sense!
Even if the maintainers/authors of the library had no intentions to harm you, they might be installing backdoor without their own knowledge. Have you heard of the very recent SolarWinds hack? Boy did that cause a mess... EVERYWHERE! Government, Homeland Security, treasury, energetics, corporations (think: Microsoft),... everywhere! This hack started a long time ago - someone injected a backdoor in the codebase - and all these companies used the affected SolarWinds tools. As a results, all these companies willingly (though unknowingly) installed a backdoor in their systems, granting an attacker a wide spectrum of accesses to huge amounts of services and data. Which could have been exploited for further hacking... SolarWinds is just an example, illustrating that things like this are happening at various scales. If Ubuntu maintainers managed to expose their repository passwords, who says your library maintainers haven't shared them somewhere by accident?
Even if the vendors manage to protect their codebase, they usually distribute their products as compiled bundles. For convenience. And that's all fine. What should trigger your red flags is that you almost never download those bundles from the vendor. You download them from another 3rd-party, which specializes in storing those bundles, e.g. Maven repository, Artifactory, DockerHub, etc. That's another segment in the chain that can be potentially accessed illegally and tinkered with. Should any unauthorized party get access to such hubs, they could replace those bundles with their own versions of the library (most likely a modified original library with a backdoor injected). Checksums make that a tad more difficult, but it's not impossible to bypass them too. So that's one more attack vector where somebody could be spinning up a backdoor in your application without you or vendor or maintainers having a clue. If you once again think I'm too paranoid, you should know that these things happen. Repositories get hacked and binaries get replaced.
I cannot find a reference now, but I recall reading in one blog about a guy who carried out an experiment: he added a potential backdoor (a stub of a backdoor - it will only call-home instead of connecting to CnC for further instructions) in his open-source node library. It sat there for months (or years?) and no one ever noticed it. He collected statistics after a while and summarized that he could have easily leveraged that backdoor for his own benefit to exploit millions (or was it billions?) of different projects. How many companies is that? :)
Whenever you are adding a 3rd-party library, consider it as a potential threat. It most likely is harmless, but there are ways it could become your and your employer's worst nightmare.
### Version upgrade
You probably have plenty of libraries in your project. As time goes (and your library versions don't change), it's very likely your project will have more **known** library-related bugs:
- security
- functionality
- performance
Naturally, you'd like to upgrade your library to a newer version,hoping those bugs have been resolved. It's easy - just update the version number in the pom.xml and reload the project! Or is it...
Most likely the library will have its contracts changed. Now your code doesn't compile, because some library classes got moved/renamed, others have methods with different signatures, some others got deprecated and removed or their fields/methods deprecated and removed! Not to mention cases where the general usage changes. It's hell! Now you have to scan your WHOLE code and look for spots where the usage of the library no longer compiles. Or even worse - it compiles, but it's used wrong in the context of this new version! You have to **adapt your code to the new version of the library**. So... you wanted to resolve a single issue (or at lease see whether it was resolved in this new version), but now your code no longer compiles, not to mention the correctness of its work. This is often the case with large frameworks, like Liferay or Spring or Hibernate (in Java's terms). How long will it take you to test if that bug was fixed? If it wasn't, you'll have wasted all this time for nothing. Does that sound right to you?
### Deprecated
If you think version upgrade causes a mess, I've got a better treat for you! Suppose there is a zero-day security vulnerability revealed in a library you are using, but that library is not maintained for the last... 8 years. Noone has forked it, no one has owned it - it's simply dead. Now you either have to live with that 0-day vulnerability (unacceptable), or patch the library code (have fun!), or replace the deprecated library with an alternative.
Patching is tedious, because it is not your code, you don't know it well and you are likely to introduce other bugs with your patch (assuming your patch fixed the 0-day properly in the first place!). Patching also means, that you will keep on living with a severely outdated and dead code, that no one looks after any more - no one but you. So instead of developing one project you now have two. One patch after another and eventually you'll have rewritten large portions of the foreign code. You might even say you have recreated that library anew. Which is more expensive than creating a new library, because (a) you had to learn the foreign code and (b) you had to fix it iteratively, i.e. not damaging the rest of the code.
Replacing the library is also not the most tempting idea, because an alternative library will have different contract, different classes, different methods, and, most likely, different behaviour. If you could use your old library by invoking a single static method, now you might have temporal coupling in place, requiring you to prep the library, initiate something, persist something and then call something on something. This, like a library version upgrade, introduces a massive scan of the code and lots of code replacements, sometimes even refactoring or change of flows. Might also require new infrastructure units. Now, once again, you have to **adapt your code to the library**.
### It no longer fits my needs perfectly
You have adopted some framework because it promised to tick all the checkboxes in the project requirements' sheet. And it offered an amazingly fast TTM (TimeToMarket) by covering most of the code you'd need to write! Amazing!
2 years later you find yourself in a position with dozens of framework entities/services extended and overridden, plenty of nasty hacks to keep all the overrides in order. Adding a new feature probably introduces yet another hack to **adapt your code to the framework**. The problem with hacks is that they have a tendency to introduce unexpected bugs, which are a pain to debug. Another problem is that the project becomes barely maintainable: estimates are loo-ooo-ooong (and yet many of them are too short), and more often than before you close the feature requests with "Won't do: not possible" closure code. You may even have introduced a dedicated Jira label: "Not Possible"!
A sane thing to do would be to eradicate the framework (or parts of the framework that are riddled with hacks), but that means you will have to invest lots of time to reinvent the wheel - it's still going to be round, but it will fit your carriage better than the wheel you have now. Who's going to pay for such a months-worth investment? Only once in a blue moon, a client cares for those details and understandingly agrees to pay for such maintenance.
On the other hand, would it perhaps be cheaper and faster to rewrite the whole project? And quite often people do choose this option. The framework is rooted SO deeply in the project, that it seems faster to rewrite the whole thing than to sort out all the hacks and remove the framework. Boy is that expensive..
### I need one more feature
You have adopted some library to do the job for you. And it works miracles! However, months later, another business request comes in - make a feature [that uses _THAT_ library] also do _THIS_. Uh-oh... But that library doesn't do that. You browse all the docs, forums, blog posts looking for instructions that would tell you how to do something at least close to what you need -- nil. You get nothing. Now you either have to extend that library and implement the feature you want, or you have to find another tool for the job. A good recent example I came across is caching. The project used EHCache for in-memory caching. The application needed plenty of data cached, but it only needed it for short periods of time - several seconds. After that, the data is no longer useful. Even worse - the expired data used up memory that was needed for other jobs. So you either boost your RAM by several gigs because you'll need them for cached objects for several seconds per hour (because expired TTL does not mean data is removed from RAM immediately), OR you limit your cache size risking many of the objects won't fit in it, causing slow response times. You would think EHCache has some way to enable a cleaning job that scans the cache periodically and evicts expired entries... But it doesn't (there are projects that extend EHCache and introduce that feature, but that's yet another library!).
What are your options now? Either augment the library or replace it with a more feature-rich library that covers your requirements... until next time. And switching libraries, as you have already read, is not always that easy!
### There is a bug! But how do I smash it?
Suppose you have a large framework (e.g. Liferay) you are building your app on. It's great, it works as expected, or even better! Time for a security audit! Auditors scan your application and find severe security problems. You fix most of them, but you struggle with the rest because they are the framework's bugs. You fix whatever can be fixed by summoning the power of manuals, blogs and forums, or even support (if you have a subscription). But what about the rest - the ones, where the support says "you'll need to upgrade the framework to a newer major version to have this fixed"? To those who have used Liferay, this option is a clear no-go, because it's easier to rewrite the whole thing than to upgrade the Liferay's version. You're stuck. It's probably time to introduce some kind of reflection-based hack that patches the security bug, hoping it doesn't open another one.
And if you report the bug to the vendor and the vendor says: "thank you, this will be fixed in the next release... in the next 8 months". What do you do all those months? Sit ducks and hope no one finds that flaw in the exploit-db and doesn't exploit it in your system? Here come the hacky patches! And the poor maintainability that comes with them! Even if you managed to live long enough without getting hacked with your patch and the new version got released, now you either forgot that you wanted to upgrade it (the client definitely has! He won't want to bring this back up as a possible expense), or you're now in the library upgrade hell.
### Code I don't need
If you're into embedded or mobile development, you might be familiar with the problem of too many classes. You don't even need libraries to run into this problem - just use Dagger2 extensively, and it will generate you loooots of classes - more than you'd like. Which causes compilation/packaging or deployment problems.
But even if you don't use Dagger2, or don't develop for Android, bear in mind, that you usually invite a foreign library to your codebase to help you out with problem P, while the library is designed to solve problems E, R, G, Y, O, J, B, B1, B2, B6, M, etc. Naturally, you bring far more code into your project than you actually need. Alternatives don't solve your problem completely, so you prefer this 120MB library for a solution, that actually is no more than 5MB. This is a great way to explode your PermGen (or MetaSpace) with stuff you don't need and have more OutOfMemoryErrors. It's also a nice way to bloat your application with excessive dependencies, excessive code. And make your deployments (and applications) slower.
When it comes to security, the rule of thumb is: "don't have stuff you don't need". This situation clearly violates the rule. Now you have a lot more moving (and potentially harmful) parts in your code. Even worse, if you had to make changes to **adapt your code to run well with the library code you don't use** (might be the case with Spring's beans).
### Indirect libraries
Even if you are using libraries from trusted sources and only libraries you truly need, bear in mind, that these libraries/frameworks most likely depend on some libraries themselves. As a result, your innocently looking library introduces even more code in your code than you thought. Definitely the case in npm-related development. The dependency graphs are enormous!
Not only the indirect libraries are a potential threat to your project, but they might also introduce compatibility issues: if the framework only works with an older version of some utility library AND you want to use a newer version of that utility library, in the end (at least in java's jars) only one version will be used. Which one? Noone knows. Something is definitely going to break.
## Should I use a library then?
### KISS
The right answer is **it depends**. Don't be a library whore (like [here](https://www.npmjs.com/package/is-even)). Also, it doesn't pay enough to spend nights reinventing the wheel on and on. Find the middle ground. If possible, set some guidelines in the project: when are you going to introduce a library, and when are you going to implement the thing yourself. I hear you gasping at "implement yourself" :) But that is a legitimate approach to consider. If you need an in-memory caching with an active TTL, after which entries are removed from the memory - it takes up to an hour to decorate a `HashMap` with synchronized `put()` methods and a thread that scans the map every minute and removes all the entries that have their TTL expired. You don't need a fancy library for that. And your custom implementation is no worse than any in-memory caching implementation out there. Remember: **KISS**!
I like to live by this rule: "_If it takes me up to 2 hours to implement the solution, I'll implement it myself rather than use a library_". The reasoning is simple: if I have to adopt some library, it will take me far more than 2 hours to
- carry out the market analysis (what libraries are out there? Which one fits my case best?)
- add the library to my code
- configure and use it right (means reading the docs)
- suffer from all of the points (and work around them) in the "However" section above.
If I eventually need the library, I can turn my solution into an adapter (see: _Adapter pattern_) for that library, without changing the signatures of my methods - a perfect decorator (see: _Decorator pattern_), which means I don't really need to change anything else in my code.
### Native abstraction of foreign code
And the above brings me to the practice that I've come to like the most. This practice solves many of the problems, regardless of whether I write my own solution or use a library. And while it doesn't solve the rest of the problems, it makes their mitigation easier and very non-invasive to the project.
Whenever you are introducing a library to your code, write an abstraction for it. If you want to introduce iText (a PDF generation utility), write an interface that has a `PdfFile toPdf(DocumentToConvert doc);` method. Implement both the data structures and implement that method - make it use the iText library for the job. And your code should NOT be using iText directly. Another example is JSON serialization. There are 2 major players out there (with others not far behind): Jackson and GSON. Instead of calling them directly, hide them behind an interface (contract layer)
```
public interface JSONSerializer {
T fromJson(String json, Class<T> type) throws SerializationException;
String toJson(Object pojo) throws SerializationException;
}
```
and write an implementation that uses either Jackson or GSON (or any other library).
This way you decouple foreign code from your product code. As a result, your code becomes
- more testable
- less dependent on the actual libraries
- less fragile (doesn't use library features you can live without)
- easier to maintain (extendable)
- more up-to-date, because you can upgrade/swap any library without a sweat (assuming you have created SOLID abstractions)
What I like the most about it, I can swap out libraries as often as I like, or even depend on multiple libraries (or custom implementations) of the feature, without the rest of the code ever needing to know about any of this.
This approach always pans out if you're unsure what library to choose for the job. You might need to try out multiple libraries before you find the one that works best for you. Or, perhaps, you might not be satisfied with any of them and write your own implementation. Or a hybrid implementation... doesn't really matter as long as the rest of the code doesn't need to know about any of this. Just swap the implementations and try them out easily. You won't need to adapt your application code for the change.
This is more difficult when it comes to frameworks because they are more integrated into your code. However, you can achieve a good enough setup with such abstractions that even make frameworks look like one of the features your code has.
Notice the highlighted parts of the blog saying that you have to **adapt your code for xxx**. You should not adapt your code for libraries. If anything, you should write your code assuming there is a simple utility that does the job. This way you write a library to enrich your application code rather than writing your code to be able to use that library you want. Libraries are tools. They should serve YOU, not the other way around.
### _Divide et impera_
Some libraries and frameworks are huge and do many things. Especially frameworks. They tend to cover lots of areas, solve lots of problems. Hiding a framework behind an interface would most likely be silly. The interface would have dozens or hundreds of methods and maintaining such a contract would be cumbersome. Here comes the interface segregation principle (SOL**I**D). Although, instead of splitting that enormous interface, you might want to first split the framework logically. What domains does it cover? Suppose it's some e-commerce framework. Can I extract an interface dealing with carts? Can I extract one for orders? For products' listings? For promotions? For anything else? The more fine-grained interfaces you extract, the easier it will be to maintain the abstraction. Noone says you have to write different implementations for all the interfaces - in Java a class can implement multiple interfaces. You can also use the Singleton pattern to back all implementations by the same instance of your e-commerce framework.
This approach applies to any _Jack-of-spades_ library/framework. Divide its responsibilities into smaller sets of features and implement them using the same library if you want. Or your own implementation. Or whatever fits your bill. This segregation gives you the freedom you'll eventually want.
Don't think of a framework as of an almighty know-it-all. Think of it as a collection of features bundled into one. And you can use those features separately if you like.
### Cut the losses - let your profits run
If you are a long-time framework user in some particular project and you notice that you spend more time **adapting your code** for that framework than working out the actual solution, perhaps it's time to leave that framework behind? It's always a choice on the table. If you've introduced that framework in your codebase as suggested above (nicely segregated abstractions), you can get rid of this bottleneck of a framework in no time. Just write your own implementations of those interfaces, write them iteratively if you like to. And eventually, you'll have eradicated that framework completely. And, once done, you are relieved of your duty to keep on adapting your code for the framework. You're now free to use that framework for the interfaces that you wouldn't benefit from rewriting and use your own implementations where you used to experience most of the maintenance bottlenecks.
## Summary
So should I use a library for that? The answer is: what do your project guidelines say about it? Do the pros of the newly introduced foreign code outweigh potential hazards and maintenance hell? Will it be easier to maintain the code with the library or with a custom implementation? Is it reasonable to write a custom implementation in the first place?
Define that in your project guidelines. If you want to, you can define your project to be one huge dependency graph with your code as the glue holding the parts together. However, such a project will most likely be unmaintainable (pretty good for PoC though). If you like to, you can write all the features yourself without any libraries. It will burn a lot of time, will create a lot of bugs and you will reinvent a wheel; but you'll have a complete control on all the aspects of the code. Or don't be a radical and choose what model suits best for you. If you asked me, I'd say use a library if it would take you >2 hours to write your own implementation to solve that problem; but regardless of whether you're using a library or a custom implementation, write an abstraction for it and only use abstraction in your code.
I find frameworks very useful to start a project with - later on I might phase them out of the codebase. Libraries are great for PoC and similar code writeups requiring extremely short TTM - I tend to reevaluate a need for them soon after.
## References
- https://sandofsky.com/architecture/third-party-libraries/
> Written with [StackEdit](https://stackedit.io/). | netikras |
673,154 | Object-Oriented Design Patterns | The longer I write programs the more I realize that the same problems keep showing up over and over... | 0 | 2021-04-20T22:17:02 | https://dev.to/markm208/object-oriented-design-patterns-4013 | designpatterns, tutorial, java, oop | The longer I write programs the more I realize that the same problems keep showing up over and over again. For example, in a spreadsheet application when one cell is updated often other cells need to be notified of the change. Similarly, in a social network application when someone adds a post their friends need to be notified. Both of these problems are the same, "how does one notify other objects when one is changed?"
A design pattern is a solution to a common problem. These patterns are collected by the software development community to capture their experiences so that they can be shared with others. Knowing the most common design patterns will make you a better OO programmer.
A design pattern is not code. In the example above, the spreadsheet app and the social network app share a problem, and it turns out that they share a solution (see the Observer pattern below), but it is not likely that they will share any code. A design pattern might be used in 100 different programs but share none of the same code.
This post describes some of the most common object-oriented design patterns and it includes fully worked out programs that implement them. You will be asked to follow along with the programs below. I am using Java but I believe you can understand the code even if you use a different OO language.
Just click on the links and a code playback page will load (you might want to open each one in a new tab). Then click on the comments on the left hand side of the playback screen or hit the play button to drive the development of the code. You can download the code at any point and run it on your machine. There are some controls in the top right hand side of the screen to make the text bigger or to switch to blog mode (which is good for small screens).
####Strategy
The Strategy pattern describes how to plug in different algorithms to a class while the program is running.
* [Strategy Pattern: Adjusting Grades in a Course](https://markm208.github.io/patternbook/chapter1/01/index.html)
####Singleton
The singleton pattern describes how to ensure that only a single instance of a class is created.
* [Singleton Pattern: A Testable Random Number Class](https://markm208.github.io/patternbook/chapter1/02/index.html)
####Composite
The Composite pattern describes how to compose whole/part relationships between similar elements.
* [Composite Pattern: Displaying a Hierarchical File System](https://markm208.github.io/patternbook/chapter1/03/index.html)
####Decorator
The Decorator pattern describes how to add new functionality to a class by wrapping it in another.
* [Decorator Pattern: Logging with Decorators](https://markm208.github.io/patternbook/chapter1/04/index.html)
####State
The State pattern describes how to react to a set of events depending on the state of the system.
* [State Pattern: String Splitting for Search Bars](https://markm208.github.io/patternbook/chapter1/05/index.html)
####Observer
The Observer pattern describes how to notify a group of objects when one changes.
* [Observer Pattern: Observing the Time Change](https://markm208.github.io/patternbook/chapter1/06/index.html)
####Proxy
The Proxy pattern describes how to add functionality in between objects that have a client/server relationship.
* [Proxy Pattern: Dealing Cards from a Remote Deck](https://markm208.github.io/patternbook/chapter1/07/index.html)
####Factory
The Factory pattern describes how to create families of objects together.
* [Factory Pattern: Getting Help in Mac and Windows](https://markm208.github.io/patternbook/chapter1/08/index.html)
####Visitor
The Visitor pattern describes how to add functionality to a hierarchy of classes without changing their interface.
* [Visitor Pattern: Adding Functionality to a Hierarchy of Classes (File and Directory)](https://markm208.github.io/patternbook/chapter1/09/index.html)
###Comments and Feedback
You can find all of these code playbacks in my free 'book', [OO Design Patterns with Java](https://markm208.github.io/patternbook/). I am always looking for feedback so please feel free to comment here or to send me a message. You can follow me on twitter [@markm208](https://twitter.com/markm208). | markm208 |
673,155 | All-in-one JavaScript SDK to make web apps passwordless | Hey guys! I built Passwordless Platform, and am looking for honest feedback to make the product use... | 0 | 2021-04-20T21:10:22 | https://dev.to/idemeum/all-in-one-javascript-sdk-to-make-web-apps-passwordless-37p | showdev, javascript, webdev, security | Hey guys!
I built **Passwordless Platform**, and am *looking for honest feedback to make the product useful*.
I embraced on a journey to combine passwordless authentication with the power of Single Sing-On across apps:
* I took what **Auth0** is doing (set of SDKs and tools to outsource auth e2e)
* Combined it with what **social login** is doing (SSO across domains and apps)
* Added privacy so that only users have access to identity data
* ...and created **idemeum**.
Today I have JavaScript SDK that can integrate into your SPA app and enable 3 types of auth flows:
1. Login with one-click
2. Login with biometrics
3. Login with mobile app
Let me know what you think. I will be happy to share working code examples of how to use JS SDK to go passwordless.
Live demo so you can play with auth experience.
https://jsdemo.idemeum.com | munkey |
673,297 | EC2インスタンス作成時にホスト名変更&AD参加する(RunCommand編) | 前回のUserData編に続き、達成したい目的は同じく下記のままで、 ①(AWS Managed ADではない)ADに参加 ②ホスト名を、自分がつけたNameタグの値に揃える やり方をUserD... | 0 | 2021-04-21T02:03:30 | https://dev.to/ryanch79/ec2-ad-runcommand-1b70 | aws, windows, ec2, activedirectory | 前回の[UserData編](https://dev.to/ryanch79/ec2-ad-userdata-19k6)に続き、達成したい目的は同じく下記のままで、
> ①(AWS Managed ADではない)ADに参加
> ②ホスト名を、自分がつけたNameタグの値に揃える
やり方をUserDataではなくもうちょっと柔軟なSystems Manager RunCommandを利用する方法を試していこうと思う。
Systems Managerを利用すると、もちろんできることの幅は非常に広がるのだが、その代わりSSMエージェントのインストールとインスタンスプロファイルの設定等、必要条件を満たす必要はある(Amazon提供のAMIならエージェントは最初から入っているので楽)。
<br>
インスタンスプロファイルに必要なIAM権限と、シークレットマネージャーへのADユーザー認証情報の登録等は前回同様なので省略する。
<br>
Systems Managerの「ドキュメント」を開き、「Create Document」から`Command or session`タイプを選択する。
<br>
ドキュメントの詳細はこんな感じで作成する。
ドキュメントタイプは`コマンドドキュメント`になる。
<br>
肝心なコマンドのコンテンツだが、前回のPowerShellスクリプトをそのまま流用して、大事そうなパラメータが指定できるようにだけ少し手を入れてYAML形式にしてみた。
```
---
schemaVersion: "2.2"
description: "Join AD and rename host with instance tag"
parameters:
DomainName:
type: "String"
description: "参加するADドメインのDNS名"
UserCredentialSecretID:
type: "String"
description: "AD参加に利用するユーザー認証情報を保持するSecrets ManagerシークレットID"
HostnameTag:
type: "String"
description: "ホスト名を定義するタグ名(デフォルトはName)"
default: "Name"
mainSteps:
- action: "aws:runPowerShellScript"
name: "example"
inputs:
runCommand:
- $secretManager = Get-SECSecretValue -SecretId {{UserCredentialSecretID}}
- $secret = $secretManager.SecretString | ConvertFrom-Json
- $username = $domainName + "\" + $secret.Account
- $password = $secret.Password | ConvertTo-SecureString -AsPlainText -Force
- $credential = New-Object System.Management.Automation.PSCredential($username,$password)
- $instanceID = Get-EC2InstanceMetadata -Category InstanceId
- $nameTag = Get-EC2Tag -Filter @{Name="resource-id";Value="$instanceID"},@{Name="key";Value="{{HostnameTag}}"}
- $newName = $nameTag.Value
- Add-Computer -DomainName "{{DomainName}}" -NewName "$newName" -Credential $credential -Passthru -Force -Restart
```
(パラメータ値は`{{}}`で囲む)
<br>
これで実際にRun Commandで実行する際には、こんな感じでパラメータを指定できるしEC2インスタンスの初回起動時じゃなくてもいつでも実行でき、たくさんのインスタンスに対しても一気に実行できるので一気に柔軟性が増す。
一々パラメータ設定が面倒であれば、デフォルト値をセットしてしまえば良し。
<br>
実際にやってみたが問題なく動作した。
今回は以上。次Chef好き向けにOpsWorksでやってみようかと思う。
<br>
※イラストはこちらからご提供いただきました:
<a href="https://www.freepik.com/vectors/computer">Computer vector created by macrovector - www.freepik.com</a> | ryanch79 |
673,531 | How to configure services in Squadcast: Best practices to reduce MTTR | With a rise in digital platforms, IT infrastructure has grown exponentially complex to a level where... | 0 | 2021-04-21T12:04:09 | https://www.squadcast.com/blog/how-to-configure-services-in-squadcast-best-practices-to-reduce-mttr | bestpractices, incidentmanagement | _With a rise in digital platforms, IT infrastructure has grown exponentially complex to a level where multiple application interdependencies coexist with varied architecture & oncall team types. This blog looks at how you can model your infrastructure in Squadcast to reduce your time to respond & resolve incidents._
As an SRE of an organization with a rapidly growing infrastructure with several interdependencies, you may have struggled with configuring things on an incident management platform. If you have a smaller team with a monolithic architecture in place it is still relatively easier to connect the infrastructure to your incident management platform and create rules for escalations and alerting. But what happens if you have a large on-call team spread across time zones looking after the infrastructure that has hundreds of microservices running concurrently? How do you configure it all in your incident management platform while keeping in mind the load your on-call team will be under?
Since most platforms let you create services that accept alerts from monitoring tools, should you create 100 such services for every component of your infrastructure?
We will be tackling similar questions in this blog. But before we dive deeper, here are few things to be aware of.
**Q:** What are the key aspects this article would be addressing?
**A:** In this blog, we look at ways your team can configure incident management platform, in particular Squadcast, to ensure that you don’t waste precious time responding to incidents.
**Q:** What this article won’t cover?
**A:** Unfortunately, we cannot have a single solution that will work for every type of situation. This post seeks to provide some clarity to this problem. We have put together a set of best practices that should cover most production systems out there.
Some of the concerns you may have while modelling your services are
- Will I be alerted on time?
- How to avoid irrelevant alerts?
- Is the alert getting routed to the right person?
- Am I getting alerts for the most critical pieces of my infrastructure?
As a modern incident management platform, [Squadcast](https://www.squadcast.com/) aggregates and routes alerts from [monitoring tools](https://www.squadcast.com/integrations) and provides a centralised dashboard for tracking and prioritising alerts along with taking action and ultimately resolving the incident (the latter part will be covered in our blog titled “Intelligent Incident Response Plan”). Owing to its flexible configuration capabilities, there are many ways you can set-up alerting for services within Squadcast.
This blog takes into account the different kinds of infrastructure (monolithic/microservices or distributed) and types of on-call teams that are present.
Before we get started with the best practices, here are some Squadcast specific features that you need to know while configuring the platform.
- **Squads:** These are groups of on-call engineers and non-technical users that can be organized by business function or technology.
- **Services:** Services are a logical group of alert sources that can be tagged, deduplicated or routed to the right person/team. They are most commonly used to represent individual parts of your infrastructure. Please note that services can receive alerts from more than one monitoring tool.
- **Tags:** Tags in Squadcast can be auto-created to include context rich information with alerts. You can create your own rules for tagging alerts.
- **Routing:** Routing in Squadcast is used when you want alerts to be sent to someone who is not the default recipient. This is helpful when a specific part of your infrastructure is facing issues that require more specialised knowledge.
- **Escalation Policies:** These policies see to it that a critical alert is never missed. You can configure them to ensure that the right users and squads are alerted at the right time.
- **On-call Rotations:** On-call schedules are used to determine who will be notified when an incident is triggered. This helps you build a balanced on-call culture and ensures that no critical alerts are missed.
These features provide the backbone for the best practices in alerting for your organisation. While the solutions described in this blog are generic, with a little tweaking, chances are they will work for you. We have tried to be as inclusive as possible while creating these best practices. Before we get started on modelling your system in Squadcast, here are the assumptions we are making about the alerting systems you have in place.
**Monitoring:** We are assuming that you are already monitoring all the important aspects of your infrastructure. This includes alerting, metric collection, log aggregation and tracing/instrumentation practices. We are also assuming that you have a good mix of [proactive, reactive and investigative alerts](https://www.oreilly.com/content/reduce-toil-through-better-alerting/) in place. Further, you have also categorised the alerts based on whether they are related to the infrastructure or to the application side(business dependent).
**Relevant Alerting:** The alerts you have in place are linked to important parts of your infrastructure and are already optimised. This includes alerts that are actionable and not over sensitive (the right threshold). This also includes having the right [deduplication rules](https://www.squadcast.com/blog/reducing-on-call-alert-fatigue-with-deduplication) in place to mitigate alert noise. We are also assuming that you can add identifying information to your alert payloads.
Our recommendations assume that the alerting system you have in place presently is well suited to the type of business and tech stack that you are using.
The way you model your system will depend on several factors. First we will be looking at the kind of architecture you have in place.
###**Architecture**
For the purpose of this blog post, we will consider the following as different types of architecture that you may be using:
- **Monolithic Architecture:** All of your core functionality is concentrated to a single executable application with related infrastructure dependencies like app server, databases, load balancers etc. Your SRE team is responsible for maintenance of this part of the infrastructure.
- **Distributed:** A distributed architecture has multiple interdependent executable applications that intercommunicate with their related infrastructure dependencies. These may or may not be replicated. We will assume that the number of internal units is low enough, that they can be committed to memory.
- **Microservices:** A distributed architecture with a very large number of components. Due to the sheer number of these services, it is not feasible to create individual Squadcast services for each component.
- **Multiple Unrelated Applications:** Though less commonly found, these can be treated as a special case of the types of architecture mentioned above. This scenario may come into being when you need an incident management system with a proprietary application framework that doesn’t fit into any of the above. This kind of architecture may be seen in organisations that require compartmentalised applications for security or compliance reasons.
- **Kubernetes based architecture:** Some types of alerts from this kind of infrastructure are eliminated or automatically resolved by Kubernetes itself. Other than this, there is no significant difference from a common microservice architecture.
###**Response Team Organisation**
- **All-in-One Incident Response Team:** In this type of setup, all responders are organised into one team. Due to the nature of this setup it is possible to have lesser or negligible routing for alerts in your incident management platform.
- **Service based:** For larger organisations with more complex infrastructure, each application may have a dedicated team. Each team maintains their application and the infrastructure it depends on. Some examples are: Public API Team, Inventory Service Team.
- **Infrastructure Layer based:** This type of team organisation can be found in larger companies. In addition to application teams, there are teams that specialise in managing certain kinds of technology. Examples include: Inventory System Team, Database Team, Load balancer Team, Networking Team.
- **L1/L2/L3 Teams:** In this system, teams are organised into first responders and escalation teams. This type or team organisation can be considered a special case of the types mentioned above and for the sake of simplicity, we will not be discussing these separately.
###**Recommendations for Configuring Services**
In order to see the best recommendation for your on-call team type and architecture, please follow this [link](https://www.squadcast.com/blog/how-to-configure-services-in-squadcast-best-practices-to-reduce-mttr).
**Conclusion:** Depending on the nature of your infrastructure as well as the size and composition of your on-call staff, combinations of the above guidelines would be ideal for your organization. Initially, you may need to do several tests to determine the best way to model services in Squadcast depending on your specific needs. If you are a large organization with multiple interconnected services, our recommendations will assist you in implementing a framework that will optimize your alerting processes and help reduce your MTTR (Mean Time To Resolve).
Our next blog in this series titled “Intelligent Incident Response”, will help you understand what needs to be done to mitigate impact or fix the issue with help of Squadcast and all the while ensuring that you learn from every incident, which should be the biggest takeaway from your Incident Response process.
_[Squadcast](https://www.squadcast.com/) is an incident management tool that’s purpose-built for SRE. Your team can get rid of unwanted alerts, receive relevant notifications, work in collaboration using the virtual incident war rooms, and use automated tools like runbooks to eliminate toil._
[](https://app.squadcast.com/register/) | squadcasthq |
673,657 | Gitlab Certification offer - due to the success of the offer, it takes end before 30th April | What is Gitlab? GitLab is a web-based Git repository that provides free open and private r... | 0 | 2021-04-21T09:11:43 | https://dev.to/gecikadm/gitlab-certification-offer-1p7o | beginners, devops, career, gitlab | # What is Gitlab?
GitLab is a web-based Git repository that provides free open and private repositories, issue-following capabilities, and wikis. It is a complete DevOps platform that enables professionals to perform all the tasks in a project—from project planning and source code management to monitoring and security.
# Deal => course and certification!
Gitlab is offering the opportunity to self-study and to pass the certification online
# how to proceed to get that offer ?
1. Go on gitlab
[Link](https://gitlab.edcast.com/log_in)
2. create an account
3. looking for the course
[Link](https://gitlab.edcast.com/pathways/cy-test-pathway-associate-study-exam/cards/1286380)
4. Enroll
5. When the course is in your basket you can proceed and use the code to get the content free
6. No need to enter any payment information as far as you enter the code, just billing information
Here is the code = E6B8A234458AE3D795
The offer end at the end of the month and you will have a year to do the course and pass the certification.
Enjoy learning ! | gecikadm |
673,660 | What is "White Screen of Death 💀" (WSoD), and how do you detect it in time? | ⚠️ NOTE: This article and its solution are based on our own product - Alertdesk, which is a paid prod... | 0 | 2021-04-21T09:27:52 | https://www.alertdesk.com/what-is-white-screen-of-death/ | webdev, wordpress, frontend, tutorial | **⚠️ NOTE: This article and its solution are based on our own product - Alertdesk, which is a paid product. If you have an alternative solution to the problem, feel free to post it in the comment below.**
Website errors. They come in all shades and are every website owner's fear.
What if I told you that there was an error so cunning that it was named after Death itself? Then you would be scared. Very scared 😱
{% youtube BkchoMJYKvU %}
If we turn down the drama a bit, then "White Screen of Death" (WSoD) is an extremely irritating error. Why?
* It makes your page inaccessible to visitors.
* It can shut you out of your backend (e.g., the WordPress admin area).
* It can occur suddenly and without you making any changes yourself.
* Most "Uptime Monitoring" services will not necessarily catch the error.
To put it mildly, it's annoying as hell.
But what exactly is the "White Screen of Death," and how does it occur?
##What is White Screen of Death?
"White Screen of Death" is an error that gives the visitor a white/blank screen. There is often no information about the error, just the color white as far as the eye can see.
It may occur as a result of a PHP and database error. Therefore, it also affects many CMS', including Magento and PrestaShop.
But where the error is most prevalent is probably at the world's most popular CMS, WordPress, where it has even found a place in the [official documentation](https://wordpress.org/support/article/common-wordpress-errors/#the-white-screen-of-death). Therefore, this article will also be based on WordPress.
The most common cause of a WSoD-error is a faulty plugin or theme. Other reasons can be:
* A syntax error in the code - e.g., if you have made edits yourself.
* The Memory Limit is set to low in either your wp-config.php file, .htaccess file, or php.ini file.
* A failed auto-update of WordPress - e.g., due to a server timeout.
* Problems with your [File Permissions](https://wordpress.org/support/article/changing-file-permissions/).
##How do you fix it?
You start by finding out what is causing the error. It may sound easier said than done when all you have to work with is a blank screen. But fear not.
WordPress has a built-in [debugging mode](https://wordpress.org/support/article/debugging-in-wordpress/) that makes errors visible on your page.
To enable it, open your [wp-config.php file](https://wordpress.org/support/article/editing-wp-config-php/) and find the following line:
```
define( 'WP_DEBUG', false);
```
Then change **false** to **true**, so it looks like this:
```
define( 'WP_DEBUG', true);
```
Error messages will now be visible on your page.
**💡 Tip:** If you are not that much into messing with files, then the [WP Debugging plugin](https://wordpress.org/plugins/wp-debugging/) does the same (obviously requires you to be able to get into the WordPress admin area). However, this is Dev.to so this properly isn't the case.
In the vast majority of cases, it will be a plugin that is causing the error. You will be able to see the name of the plugin in the error message.
If you have access to your WordPress admin area, simply deactivate the plugin on the "Installed plugins"-page.
If you can't access the admin area, you can deactivate the plugin manually via an FTP program or your web host's "File Manager"-tool.
Go to your plugin folder (wp-content -> plugins) and find the plugin that throws the error. Then rename the folder to something else, e.g., from "hello-dolly" to "hello-dolly-1". The plugin will now be disabled.
**💡 Tip:** Plugins can also be disabled via phpMyAdmin and WP-CLI - I just find this solution the easiest.
Reload your page and see if the issue is resolved.
##What can be done to detect it in time?
One of the most annoying things about the WSoD error is that it can occur suddenly - even without you actively changing anything on your website.
What's worse, if you have traditional "uptime monitoring" enabled, it will not necessarily catch the error.

Yes, you read that right. Most services, including Alertdesk, look at your site’s [HTTP status code](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes). If the page gives a status code 2XX or 3XX, it gets interpreted as up, where status code 4XX and 5XX gets interpreted as down.
"[There's got to be a better way!](https://www.youtube.com/watch?v=8uYuxd3c7ns)" you may think - and for fear of sounding like a classic American infomercial: Yes, there is.

When you set up an Uptime-check in Alertdesk, you have the option to set up specific "rules" for that check. We call this [Assertions](https://help.alertdesk.com/docs/uptime-check/#5-assertions-rules).
One of the rules you can set up is that a piece of text must be present on the page in order for it to be "up".
This is a super powerful tool when it comes to checking for WSoD errors.
If the text is not visible (which it won't be in the event of a WSoD error), your check will get marked as "down". You will then get notified immediately by E-mail, Push, Slack, or the channel you have selected.
###How to set up an Uptime-check with Assertions in Alertdesk
Start by creating an account on Alertdesk. Go to Monitoring, click the **"Add check"**-button and choose **"Uptime check"**. Enter your URL and click the *"Advanced settings"*-toggle in the right corner.
Scroll down to **Assertions** and select **"Text body"** under "Source", **Contains** under "Comparison," and then paste the piece of text that should be present on your page under "Target" (is case sensitive). Then click the **Add**-button.
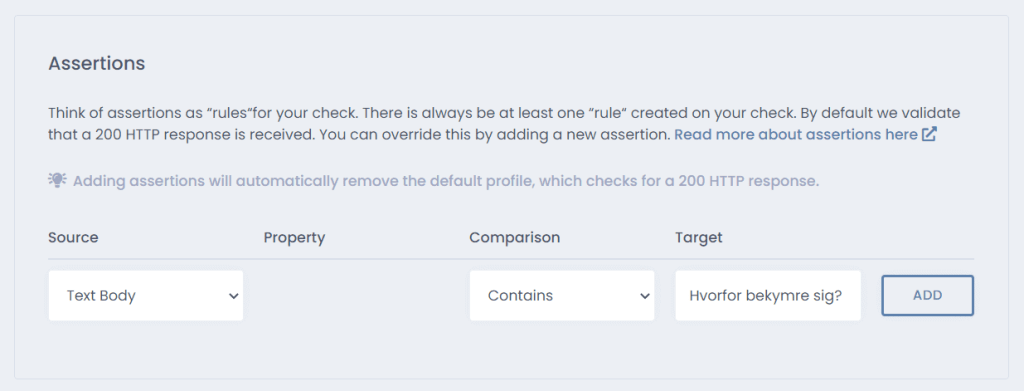
⚠️ **NOTE:** There may be issues with special characters, as they may be converted to HTML characters instead, which will not match. Therefore use text without special characters.
Then click the **Next**-button. Select who to notify and then click the **Next**-button again. Give your check a name and make sure everything looks fine. Finally, click **Save check**, and you are done.
Easy peasy lemon squeezy 🍋
You will now get notified immediately if your website should get a “White Screen of Death” error. | kaspera |
673,884 | Tech stack and initial project setup | Week one down! How exciting! This week was all about coming up with an idea and configuring the new... | 12,346 | 2021-04-21T13:36:54 | https://jonmeyers.io/build-a-saas-platform-with-stripe/tech-stack-and-initial-project-setup | webdev, javascript, nextjs | ---
title: Tech stack and initial project setup
published: true
date: 2021-04-21 13:32:11 UTC
tags: [webdev, javascript, nextjs]
canonical_url: https://jonmeyers.io/build-a-saas-platform-with-stripe/tech-stack-and-initial-project-setup
series: Build a SaaS Platform with Stripe
---
Week one down! How exciting! This week was all about coming up with an idea and configuring the new project. I will be keeping the [GitHub repo](https://github.com/dijonmusters/courses) up to date as I build out this project so make sure you check that out!
## Idea
I will be building a video tutorial/course platform that contains a collection of free and paid courses. You will be able to watch any of the free courses once you create an account. For the premium content, you can choose to purchase a single course to own forever, or subscribe on a monthly or yearly basis to access all the premium courses.
## Readme Driven Development (RDD)
I will be following Tom Preston-Werner's [Readme Driven Development](https://tom.preston-werner.com/2010/08/23/readme-driven-development.html) methodology, whereby the first thing you create is a readme describing your project. My key takeaways from Tom's article were:
- Making a product for users is a waste of time if it doesn't provide value
- Thinking about how your software will be used gives you a pathway with achievable milestones
- Helps inform tech decisions
- Creates a shared language and understanding across other devs and stakeholders.
You can checkout my [readme](https://github.com/dijonmusters/courses/blob/master/README.md) to see what I am planning to build.
## Stack
As the majority of this project can be statically generated ahead of time I will be building a Jamstack app. This will help keep the loading speed fast for users and keep the hosting costs ~~down~~ free!
### Next.js
Since most of the content can be generated at build time I was keen to use something that makes this process simple - Next.js or Gatsby. I went with Next.js as it gives me all that SSG (Static Site Generation) magic I am after, but also offers SSR (Server Side Rendering) if my application does require it in the future!
Additionally, I really like Next's API for generating static content. You just declare a getStaticProps function, co-located with the page component that uses the data. Next.js will iterate over any components that declare this function and make these requests at build time. I find this workflow to be a little more convenient than Gatsby, and requires less context switching than jumping out of the component and implementing some data fetching in gatsby-node.js.
That is just personal preference though. Both of these frameworks are absolutely awesome and are perfectly capable of building what we need!
Setting up Next.js was super simple. Just create a new folder and initialise it as an NPM project. My project will be called "courses".
```
mkdir courses && cd courses && npm init -y
```
Now to install Next.js and its dependencies.
```
npm i next react react-dom
```
Let's add some scripts to build and run our application. In the package.json file, replace the test script (that no-one uses in a side project) with the following.
```
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"export": "next export"
},
```
Next.js uses file-based routing so we can create pages simply by putting React components in the pages directory.
```
mkdir pages
```
Now create an index.js file and add the following code to create a welcoming home page.
```
// pages/index.js
const HomePage = () => <h1>Welcome to Courses!</h1>
export default HomePage
```
We now have a fully functioning Next.js application. Run the following command and go and visit it at [http://localhost:3000](http://localhost3000).
```
npm run dev
```
### API routes
We will need some serverside code in order to process payments with Stripe and interact with the database. These chunks of serverside code will be quite isolated and single purpose. This is a perfect usecase for serverless functions and Next.js makes this super simple!
Just create an API folder in the pages directory!
```
mkdir pages/api
```
And add a test.js file with the following content.
```
// pages/api/test.js
module.exports = async (req, res) => {
res.send('it works!')
}
```
That's it! It's done! To run this serverless function just go to [http://localhost:3000/api/test](http://localhost:3000/api/test).
> Next.js will pick up any .js files in this api folder and automatically turn them into serverless functions!
Super cool!
### SQL vs Document DB
We are going to need a database to store information about our users, and remember which courses they have purchased. There are a huge number of options here, but first we need to decide whether we want to use an SQL db - such as PostgreSQL - or a document db - such as MongoDB.
The biggest factor to consider between these two options is how you want to model relationships between different bits of data. An SQL db can stitch together data from different tables using one complex query, whereas you may need to do multiple queries in a document db, and stitch it together yourself.
Our application is going to be hosted on a different server to our db - potentially in a different continent - so making a single request, letting the db do some of the hard work and sending back a smaller dataset is likely going to be much more performant.
Again, the scope of this application is quite small so this is probably not going to be a problem, but since we know we will need at least a relationship between our user and the courses they have purchased, I am going to go with an SQL solution.
Additionally, the methodology of the Jamstack is all about being able to scale up easily and I think SQL gives us more options than a document db as things get more complex!
### Supabase
Again, there are a million options for a hosted SQL database. I have used Heroku extensively in the past and would highly recommend, however, I have been looking for an excuse to try Supabase and I think this is it!
Supabase is an open source competitor to Firebase. They offer a whole bunch of services - db hosting, query builder language, auth etc - however, we are just going to use it as a free db host.
Head on over to [their website](https://app.supabase.io) and create an account.
Once you're at the dashboard click "create a new project" - make sure to use a strong password (and copy it somewhere as we will need it again soon!) and pick a region that is geographically close to you!
Once it is finished creating a DB, head over to Settings > Database and copy the Connection String. We are going to need this in the next step!
### Prisma
Now we need to decide how we want to interact with our database. We could just send across big SQL query strings, but we're not living in the dark ages anymore!
I have a background in Rails and really like the ORM (object relational mapping) style of interacting with databases so I am going to choose Prisma!
Prisma is a query builder. It basically abstracts away complex SQL queries and allows you to write JavaScript code to talk to the DB. It's awesome! You'll see!
Let's set it up! First we need to install it as a dev dependency
```
npm i -D prisma
```
Now we initialise Prisma in our project.
```
npx prisma init
```
Next we need to create our models - how we want to represent our data.
```
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model Course {
id Int @id @default(autoincrement())
title String @unique
createdAt DateTime @default(now())
lessons Lesson[]
}
model Lesson {
id Int @id @default(autoincrement())
title String @unique
courseId Int
createdAt DateTime @default(now())
course Course @relation(fields: [courseId], references: [id])
}
```
Here we are creating a course which has a collection of lessons. A lesson belongs to a course.
We are just going to focus on our courses for now - users can come later!
Now we want to update the DATABASE\_URL in our .env with that connection string from Supabase.
```
// .env
DATABASE_URL="your connecting string"
```
Make sure you replace the password in the connection string with the password you used to create the Supabase project!
Now we need to make sure we add this .env file to our .gitignore so as to never commit our secrets to GitHub.
```
// .gitignore
node_modules/
.next/
.DS_Store
out/
.env
```
Okay, now that we have this hooked up to an actual database, we want to tell it to match our schema.prisma file. We do this by pushing the changes.
```
npx prisma db push --preview-feature
```
We need to pass the --preview-feature flag as this is an experimental feature, and may change in the future.
Now we want to install the Prisma client, which we will use to send queries to our database.
```
npm i @prisma/client
```
And generate our client based on the schema.
```
npx prisma generate
```
Lastly, let's create a serverless function to create some data in our database, and confirm everything is wired up correctly!
```
// pages/api/create-course
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
module.exports = async (req, res) => {
await prisma.course.create({
data: {
title: 'Learning to code!',
lessons: {
create: { title: 'Learn the terminal' },
},
},
})
// TODO: send a response
}
```
This will create a new course with the title "Learning to code!", but it will also create the first lesson "Learn the terminal".
This is the power of using a query builder like Prisma! Queries that would be quite complex in SQL are super easy to write and reason about!
Let's add another prisma query to select the data we have written to the DB and send it back as the response.
```
// pages/api/create-course.js
module.exports = async (req, res) => {
// write to db
const courses = await prisma.course.findMany({
include: {
lessons: true,
},
})
res.send(courses)
}
```
Our entire function should look like this.
```
// pages/api/create-course.js
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
module.exports = async (req, res) => {
await prisma.course.create({
data: {
title: 'Learning to code!',
lessons: {
create: { title: 'Learn the terminal' },
},
},
})
const courses = await prisma.course.findMany({
include: {
lessons: true,
},
})
res.send(courses)
}
```
Excellent! Now we can run this serverless function by navigating to [http://localhost:3000/api/create-course](http://localhost:3000/api/create-course).
You should get back the newly created course and lesson. We can also see this has actually been written to the DB by inspecting our data in the Supabase dashboard.
I recommend deleting this serverless function to avoid accidentally running it later and adding unnecessary courses! If you want to keep it as a reference, just comment out the code that creates the course.
```
// api/create-course.js
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
module.exports = async (req, res) => {
// await prisma.course.create({
// data: {
// title: 'Learning to code!',
// lessons: {
// create: { title: 'Learn the terminal' },
// },
// },
// })
// const courses = await prisma.course.findMany({
// include: {
// lessons: true,
// },
// })
// res.send(courses)
res.send('This is only here as a guide!')
}
```
Okay! Let's wire this up to Next!
## SSG
Back in our pages/index.js component we want to query our DB for all courses and display them in a list. We could make this request when a user visits our site, but since this data is not going to change very often this will mean a huge number of unnecessary requests to our API and a lot of users waiting for the same data over and over again!
What if we just requested this data when we build a new version of our application and bake the result into a simple HTML page. That would speed things up significantly and keep our users happy! A happy user is a user who wants to buy courses!
Next.js makes this super simple with a function called getStaticProps. Lets extend our index.js file to export this function.
```
export const getStaticProps = async () => {
const data = await getSomeData()
return {
props: {
data, // this will be passed to our Component as a prop
},
}
}
```
Since this is going to be run when Next.js is building our application, it will be run in a node process, rather than in a browser. This might seem confusing since it is being exported from a component that will be running in the user's browser, but at build time there is no user - there is no browser!
Therefore, we will need a way to make a request to our API from node. I am going to use Axios because I really like the API, but any HTTP request library will do!
```
npm i axios
// pages/index.js
import axios from 'axios'
// component declaration
export const getStaticProps = async () => {
const { data } = await axios.get('http://localhost:3000/api/get-courses')
return {
props: {
courses: data,
},
}
}
// component export
```
Whatever we return from getStaticProps will be passed into our component, so let's display that JSON blob in our component.
```
// pages/index.js
const Homepage = ({ courses }) => {
return (
<div>
<h1>Courses</h1>
<pre>
{JSON.stringify(courses, null, 2)}
</pre>
</div>
)
}
export default Homepage
```
> We can pass JSON.stringify additional arguments (null and 2) in order to pretty print our data.
Our whole component should look like this.
```
// pages/index.js
import axios from 'axios'
const Homepage = ({ courses }) => {
return (
<div>
<h1>Courses</h1>
<pre>
{JSON.stringify(courses, null, 2)}
</pre>
</div>
)
}
export const getStaticProps = async () => {
const { data } = await axios.get('http://localhost:3000/api/get-courses')
return {
props: {
courses: data,
},
}
}
export default Homepage
```
Now we just need to create that get-courses serverless function.
```
// pages/api/get-courses.js
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
module.exports = async (req, res) => {
const courses = await prisma.course.findMany({
include: {
lessons: true,
},
})
res.send(courses)
}
```
That's it! We should now have an entire system wired up end-to-end!
- Next.js is requesting our courses from the serverless function at build time
- Our serverless function is using Prisma to query the Supabase DB for the courses
- The results are piping through from Supabase -> Serverless function -> Next.js, which is baking them into a static page
- The user requests this page and can see the courses
## Tailwind
I also decided to challenge my opinion that Tailwind is just ugly inline styles, and actually give it a try! You will be hearing from me often if I do not like it!
Let's install it!
```
npm i -D tailwindcss@latest postcss@latest autoprefixer@latest
```
Next let's initialise some configuration.
```
npx tailwindcss init -p
```
We can also tell Tailwind to remove any unused styles in prod.
```
// tailwind.config.js
module.exports = {
purge: ['./pages/ **/*.{js,ts,jsx,tsx}', './components/** /*.{js,ts,jsx,tsx}'],
darkMode: false, // or 'media' or 'class'
theme: {
extend: {},
},
variants: {
extend: {},
},
plugins: [],
}
```
We are going to want to import Tailwind's CSS on every page, so will create an \_app.js file, which automatically wraps every page component.
```
import 'tailwindcss/tailwind.css'
import '../styles/globals.css'
const MyApp = ({ Component, pageProps }) => <Component {...pageProps} />
export default MyApp
```
Lastly, create a styles/globals.css file to import the Tailwind bits.
```
// styles/globals.css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
Awesome, now we have Tailwind configured. Check out [their docs](https://tailwindcss.com/docs) for great examples!
I will not be focusing on the styling aspect of this project throughout the blog series, but feel free to check out [the repo](https://github.com/dijonmusters/courses) for pretty examples.
## Great resources
- [Readme Driven Development](https://tom.preston-werner.com/2010/08/23/readme-driven-development.html)
- [Next.js docs](https://nextjs.org/docs/getting-started)
- [Prisma in Next.js app](https://www.prisma.io/docs/getting-started/setup-prisma/add-to-existing-project-typescript-postgres)
- [Supabase docs](https://supabase.io/docs/guides/platform)
## Next week
[Hosting on Vercel, automatic deploys with GitHub and configuring custom domains](https://jonmeyers.io/blog/build-a-saas-platform-with-stripe/hosting-on-vercel-automatic-deploys-with-github-and-configuring-custom-domains) | jonmeyers_io |
674,028 | To Jigsaw or not to Jigsaw? | I have been making interactive media since 1995... I have always avoided making jigsaw puzzles as the... | 0 | 2021-04-21T16:45:37 | https://dev.to/zimlearn/to-jigsaw-or-not-to-jigsaw-5c94 | jigsaw, puzzle, canvas, zimjs | I have been making interactive media since 1995... I have always avoided making jigsaw puzzles as they are the classic example and quite overdone. I would encourage my students to go beyond and at least make the pieces moving video parts or something different.
Well, on Discord https://zimjs.com/discord, someone was posting problems using code with a blog post from a while back - https://www.emanueleferonato.com/2018/03/13/build-a-html5-jigsaw-puzzle-game-with-zim-framework/ - I started to help but then felt it would be better to update the code as the blog post was quite popular. The result is found on CodePen at - come give it a fork and heart!
https://codepen.io/danzen/pen/rNjQWRY
It is fairly tricky to do a jigsaw puzzle. We have an alternative in ZIM called the Scrambler() which is just a few lines of code to implement. See https://zimjs.com/cat/scrambler.html. But in doing the Jigsaw, we really had to use many parts of interactive media.

The puzzle parts themselves are drawn with a Shape. We figured it would be good use a class here and make it so we can pass the format of the piece as an array of four sides with 1 being a bump out, 0 being no bump and -1 being a bump in:
```javascript
// ~~~~~~~~~~~~~~~~~~~~~
// CLASS to make JigSaw piece with bumps out or in or no bump on any four edges
class Piece extends Shape {
// format is 1 for bump out, -1 for bump in and 0 for no bump
constructor(w=100,h=100,format=[1,1,1,1],s=black,ss=4,f=white) {
super(w,h);
const p = Piece.part; // static property - defined below class
const g = Piece.gap;
// s() stroke, ss() strokeStyle, f() fill
// mt() moveTo, lt() lineTo, ct() curveTo()
this.s(s).ss(ss).f(f).mt(0,0);
if (format[0]==0) this.lt(w,0); // top left-right
else {
this.lt(w*p,0);
let s = format[0]==1?-1:1; // sign
this.ct(w*(p-g/2), s*w*g, w/2, s*w*g); // curve left to middle
this.ct(w*(p+g+g/2), s*w*g, w*(1-p), 0); // curve middle to right
this.lt(w,0)
}
if (format[1]==0) this.lt(w,h); // right top-bottom
else {
this.lt(w,h*p);
let s = format[1]==1?1:-1;
this.ct(w+s*w*g, h*(p-g/2), w+s*w*g, h/2);
this.ct(w+s*w*g, h*(p+g+g/2), w, h*(1-p));
this.lt(w,h)
}
if (format[2]==0) this.lt(0,h); // bottom right-left
else {
this.lt(w*(1-p),h);
let s = format[2]==1?1:-1;
this.ct(w*(p+g+g/2), h+s*w*g, w/2, h+s*w*g);
this.ct(w*(p-g/2), h+s*w*g, w*p, h+0);
this.lt(0,h)
}
if (format[3]==0) this.lt(0,0); // left bottom-top
else {
this.lt(0,h*(1-p));
let s = format[3]==1?-1:1;
this.ct(s*w*g, h*(p+g+g/2), s*w*g, h/2);
this.ct(s*w*g, h*(p-g/2), 0, h*p);
this.lt(0,0)
}
this.cp(); // close path
}
}
Piece.part = .37; // part of the edge with no gap ratio
Piece.gap = 1-Piece.part*2; // gap ratio of edge
```
As you can see, it is tricky to do the four sides using absolute positioning. Would have perhaps been better to use ZIM Generator() which does relative position - so we could use the same code for each side and rotate 90 before going to the next side. Anyway - it was not that bad, just a bit of mental twisting.

We wanted to have a version of the puzzle without the images that we could use as a hint. So the puzzle piece class did not use images - but rather just the shape.
Placing the shapes in position was also a challenge. We do not want bumps on the edges and the bumps have to align going from one piece to the next. We put a system in place inside the loop to handle the opposite of the last bump. Then we made sure there were no bumps for the edges.
```javascript
// ~~~~~~~~~~~~~~~~~~~~~
// PIECES
// makePieces gets called from Tile - for each piece
let count=0;
let lastX = rand()>.5?1:-1; // 1 or -1 for out or in horizontally
let lastYs = []; // 1 or -1 vertically - remember with array and modulus
loop(numX, i=>{lastYs.push(rand()>.5?1:-1);});
function makePiece() {
// prepare format for jigsaw piece [1,0,-1,0]
// 1 bump out, 0 no bump, -1 bump in, etc.
let currentX = lastX*-1; // opposite of last x
let currentY = lastYs[count%numX]*-1; // opposite of last y
let nextX = rand()>.5?1:-1; // randomize the next 1 or -1 for out or in horizontally
let nextY = rand()>.5?1:-1; // and vertically
// top, right, bottom, left
let format = [currentY, nextX, nextY, currentX];
lastX = nextX;
lastYs[count%numX] = nextY;
// override edges to 0
if (count < numX) format[0] = 0;
else if (count >= numX*numY-numX) format[2] = 0;
if (count%numX==0) format[3] = 0;
else if ((count-numX+1)%numX==0) format[1] = 0;
// make a container to hold jigsaw shape and later picture part
let piece = new Container(w,h).centerReg({add:false});
piece.puzzle = new Piece(w, h, format).addTo(piece);
piece.mouseChildren = false;
count++;
return piece;
}
const pieces = new Tile({
obj:makePiece,
cols:numX,
rows:numY,
clone:false // otherwise makes clone of piece
})
.center()
.drag(stage).animate({
props:{alpha:1},
time:.1,
sequence:.05
});
```
ZIM has dynamic parameters (called ZIM VEE values - with Pick() https://zimjs.com/docs.html?item=Pick). That means we can pass a function into the obj parameter of the Tile and each time it goes to make an item it will take the return value of the function. This is one of the formats of a dynamic parameter in ZIM. You can also pass in an array which it will randomly pick from or a series that it pics from in order, or a {min, max} object or a combination of these. Very powerful!
For figuring if the puzzle piece is in the right place we made little hit boxes and added them to the hint version of the puzzle which always stays in the right place. We could have used hitTestGrid() to calculate the right place but the hit boxes is easier to visualize and work with.
```javascript
// ~~~~~~~~~~~~~~~~~~~~~
// HINT AND SNAP HIT BOX
const hint = pieces.clone(true) // exact
.center()
.ord(-1) // under pieces
.cache(-5,-5,pic.width+10,pic.height+10) // cache by default does not include outside border
.alp(.2)
.vis(0); // checkbox below to show
// make a little box to do hit test to see if in right place
const snap = 50; // pixel distance considered correct
loop(hint, h=>{
h.box = new Rectangle(snap,snap).centerReg(h).vis(0); // do not use alpha=0 as that will make it not hittable
});
```
We then want to scramble the pieces both in position and rotation and add events to test if the piece is in the right place and if the whole puzzle is done. This is tricky as a single tap should rotate the piece but this should not happen if the piece is dragged. ZIM has tap() built in to handle a quick tap at one location. We are also animating rotation and do not want that process interrupted as that might leave us with a partially rotated piece.
```javascript
// ~~~~~~~~~~~~~~~~~~~~~
// ADD PICTURE TO PIECES, ADD EVENTS, ROTATE AND SCRAMBLE
const padding = 50;
const rotate = true;
loop(pieces, (piece,i)=>{
piece.alp(0); // sequence animation above will animate in alpha
pics[i].addTo(piece).setMask(piece.puzzle);
// test on mobile and see if you need to cache...
// usually this is just cache() but the bumps are outside the piece
// and the cache size really does not make a difference if rest is background transparent
if (mob) piece.cache(-100,-100,piece.width+200,piece.width+200);
if (rotate) {
piece.rotation = shuffle([0,90,180,270])[0];
piece.tap({
time:.5, // within .5 seconds
call:() => {
pieces.noMouse(); // do not let anything happen while animating until done
piece.animate({
props:{rotation:String(frame.shiftKey?-90:90)}, // string makes relative
time:.2,
call:() => {
pieces.mouse();
test(piece);
}
});
stage.update();
},
call2:() => { // if no tap
test(piece);
}
});
} else {
piece.on("pressup", () => {
test(piece);
});
}
piece.on("pressdown", () => {
// shadows are expensive on mobile
// could add it to container so shadow inside container
// then cache the container but might not be worth it
if (!mob) piece.sha("rgba(0,0,0,.4)",5,5,5);
});
// scramble location
piece.loc(padding+w/2+rand(stageW-w-padding*2)-pieces.x, padding+h/2+rand(stageH-h-padding*2)-pieces.y);
});
```
There are several places where we want to test the piece so we have put this functionality in a... function! We also quickly made an emitter for a reward here is the emitter code, followed by the test.
```javascript
// EMITTER
const emitter = new Emitter({
obj:new Poly({min:40, max:70}, [5,6], .5, [orange, blue, green]),
num:2,
force:6,
startPaused:true
});
```
```javascript
// TEST FOR PIECE IN RIGHT PLACE AND END
function test(piece) {
piece.sha(-1);
let box = hint.items[piece.tileNum].box;
if (piece.rotation%360==0 && box.hitTestReg(piece)) {
piece.loc(box).bot().noMouse();
emitter.loc(box).spurt(30);
placed++;
if (placed==num) {
stats.text = `Congratulations all ${num} pieces placed!`;
timeout(1, function () {
emitter.emitterForce = 8;
emitter.center().mov(0,-170).spurt(100)
})
timeout(2, function () {
hintCheck.removeFrom();
picCheck.removeFrom();
picCheck.checked = true;
pieces.animate({alpha:0}, .7);
outline.animate({alpha:0}, .7);
hint.animate({alpha:0}, .7);
pic.alp(0).animate({alpha:1}, .7);
new Button({
label:"AGAIN",
color:white,
corner:[60,0,60,0],
backgroundColor:blue.darken(.3),
rollBackgroundColor:blue
})
.sca(.5)
.pos(150,30,LEFT,BOTTOM)
.alp(0)
.animate({alpha:1})
.tap(()=>{zgo("index.html")})
});
} else stats.text = `Placed ${placed} piece${placed==1?"":"s"} of ${num}`;
} else stage.update();
}
```
To see the full code please fork and heart the CodePen page at
https://codepen.io/danzen/pen/rNjQWRY
All the best,
Dr Abstract - finally, a maker of a Jigsaw Puzzle.
| zimlearn |
674,072 | Kotlin Spring Boot + Angular 6 CRUD + PostgreSQL example | Spring Data JPA + REST APIs example | https://grokonez.com/spring-framework/spring-boot/kotlin-spring-boot/kotlin-spring-boot-angular-6-cru... | 0 | 2021-04-21T16:26:57 | https://dev.to/loizenai/kotlin-spring-boot-angular-6-crud-postgresql-example-spring-data-jpa-rest-apis-example-4lb7 | angular6, postgres, springdata | https://grokonez.com/spring-framework/spring-boot/kotlin-spring-boot/kotlin-spring-boot-angular-6-crud-postgresql-example-spring-data-jpa-rest-apis-example
Kotlin Spring Boot + Angular 6 CRUD + PostgreSQL example | Spring Data JPA + REST APIs example
In this tutorial, we show you Angular 6 Http Client & Spring Boot Server example that uses Spring JPA to do CRUD with PostgreSQL and Angular 6 as a front-end technology to make request and receive response.
Related Posts:
- <a href="https://grokonez.com/spring-framework/spring-boot/use-spring-jpa-postgresql-spring-boot">How to use Spring JPA with PostgreSQL | Spring Boot</a>
- <a href="https://grokonez.com/spring-framework/spring-boot/spring-jpa-postgresql-angularjs-example-spring-boot">Spring JPA + PostgreSQL + AngularJS example | Spring Boot</a>
- <a href="https://grokonez.com/spring-framework/spring-boot/kotlin-spring-jpa-postgresql-spring-boot-example">Kotlin Spring JPA + Postgresql | Spring Boot Example</a>
- <a href="https://grokonez.com/spring-framework/spring-boot/kotlin-spring-mvc-requestmapping-restful-apis-getmapping-postmapping-putmapping-deletemapping-springboot-example">Kotlin RequestMapping RESTful APIs with @GetMapping, @PostMapping, @PutMapping, @DeleteMapping</a>
- <a href="https://grokonez.com/spring-framework/spring-data/kotlin-springjpa-hibernate-one-many-relationship">Kotlin SpringJPA Hibernate One-To-Many relationship</a>
Related Pages:
<ul>
<li><strong><a href="https://grokonez.com/kotlin-tutorial">Kotlin</a></strong></li>
<li><a href="https://grokonez.com/angular-tutorial">Angular</a></li>
<li><a href="https://grokonez.com/angular-tutorial">SpringBoot</a></li>
</ul>
<!--more-->
<h2>I. Technologies</h2>
– Java 1.8
– Maven 3.3.9
– Spring Tool Suite – Version 3.8.4.RELEASE
– Spring Boot: 2.0.3.RELEASE
– Angular 6
- RxJS 6
<h2>II. Overview</h2>
<img src="https://grokonez.com/wp-content/uploads/2018/08/kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database-angular-http-service-architecture.png" alt="kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database + angular-http-service-architecture" width="570" height="542" class="alignnone size-full wp-image-14237" />
<h3>1. Spring Boot Server</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/08/kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database-spring-server-architecture.png" alt="kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database + spring-server-architecture" width="699" height="325" class="alignnone size-full wp-image-14238" />
<h3>2. Angular 6 Client</h3>
<img src="https://grokonez.com/wp-content/uploads/2018/08/kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-angular-client-architecture.png" alt="kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql + angular-client-architecture" width="696" height="462" class="alignnone size-full wp-image-14239" />
<h2>III. Practice</h2>
<h3>1. Project Structure</h3>
<h4>1.1 Spring Boot Server</h4>
<img src="https://grokonez.com/wp-content/uploads/2018/08/Angular-6-HttpClient-Kotlin-SpringBoot-PostgreSQLKotlin-SpringBoot-project.png" alt="Angular-6-HttpClient-Kotlin-SpringBoot-PostgreSQL+Kotlin-SpringBoot-project" width="352" height="363" class="alignnone size-full wp-image-14240" />
- <strong>Customer</strong> class corresponds to entity and table <strong>customer</strong>.
- <strong>CustomerRepository</strong> is an interface extends <strong>CrudRepository</strong>, will be autowired in <strong>CustomerController</strong> for implementing repository methods and custom finder methods.
- <strong>CustomerController</strong> is a REST Controller which has request mapping methods for RESTful requests such as: <code>getAllCustomers</code>, <code>postCustomer</code>, <code>deleteCustomer</code>, <code>deleteAllCustomers</code>, <code>findByAge</code>, <code>updateCustomer</code>.
- Configuration for Spring Datasource and Spring JPA properties in <strong>application.properties</strong>
- <strong>Dependencies</strong> for <strong>Spring Boot</strong> and <strong>PostgreSQL</strong> in <strong>pom.xml</strong>
<h4>1.2 Angular 6 Client</h4>
<img src="https://grokonez.com/wp-content/uploads/2018/08/kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database-angular-client-structure.png" alt="kotlin-spring-boot-angular-6-httpclient-spring-rest-api-data-postgresql-database + angular-client-structure" width="251" height="547" class="alignnone size-full wp-image-14241" />
In this example, we focus on:
- 4 components: <strong><em>customers-list</em></strong>, <strong><em>customer-details</em></strong>, <strong><em>create-customer</em></strong>, <strong><em>search-customer</em></strong>.
- 3 modules: <strong><em>FormsModule</em></strong>, <strong><em>HttpClientModule</em></strong>, <strong><em>AppRoutingModule</em></strong>.
- <strong><em>customer.ts</em></strong>: class Customer (id, firstName, lastName)
- <strong><em>customer.service.ts</em></strong>: Service for Http Client methods
<h3>2. How to do</h3>
<h4>2.1 Kotlin Spring Boot Server</h4>
<h5>2.1.1 Dependency</h5>
<pre><code class="language-html"><dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-stdlib-jdk8</artifactId>
</dependency>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-reflect</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency></code></pre>
<h5>2.1.2 Customer - Data Model</h5>
<em>model/Customer.java</em>
https://grokonez.com/spring-framework/spring-boot/kotlin-spring-boot/kotlin-spring-boot-angular-6-crud-postgresql-example-spring-data-jpa-rest-apis-example
Kotlin Spring Boot + Angular 6 CRUD + PostgreSQL example | Spring Data JPA + REST APIs example | loizenai |
674,690 | Day 39 of 100 Days Of SwiftUI | I just completed day 39 of 100 days of SwiftUI. Today I learnt about navigation links and also how to... | 0 | 2021-04-22T05:35:37 | https://dev.to/sanmiade/day-39-of-100-days-of-swiftui-2m4l | swift, 100daysofcode | I just completed day 39 of 100 days of SwiftUI. Today I learnt about navigation links and also how to parse JSON using hierarchical `Codables`.
Navigation links are used in Swift to show new screens. You can also use the sheet modifier to show a new screen but the sheet modifier is more suited to showing unrelated content like settings while navigation links should be used for showing details about a user's selection.
The `Codable` protocol is used to turn JSON into Swift objects. It works fine for simple JSON structures. But for more complicated ones you will have to help Swift out.
```swift
let input = """
{
"name": "Sanmi",
"about": {
"level": "9001",
"occupation": "Android Developer"
}
}
"""
struct User: Codable {
var name: String
var about: About
}
struct About: Codable {
var level: String
var occupation: String
}
let data = Data(input.utf8)
let decoder = JSONDecoder()
if let user = try? decoder.decode(User.self, from: data) {
print(user)
}
```
This code converts a JSON string to a Swift object. It's actually pretty simple. All you have to do is create structs that match the JSON | sanmiade |
678,139 | Understanding Compiler Design | Every one of us has used a compiler once in our programming journey or must have read about it. Ever... | 0 | 2021-04-25T16:52:03 | https://dev.to/sakshamak/understanding-compiler-design-lcd | Every one of us has used a compiler once in our programming journey or must have read about it. Ever thought about how a compiler works?
Today I will be discussing the design structure of a compiler.
A code basically has to pass through a different number of levels to get itself converted from high-level language to assembly language, and these are all hidden in a compiler.
Here is a basic diagram of a compiler :
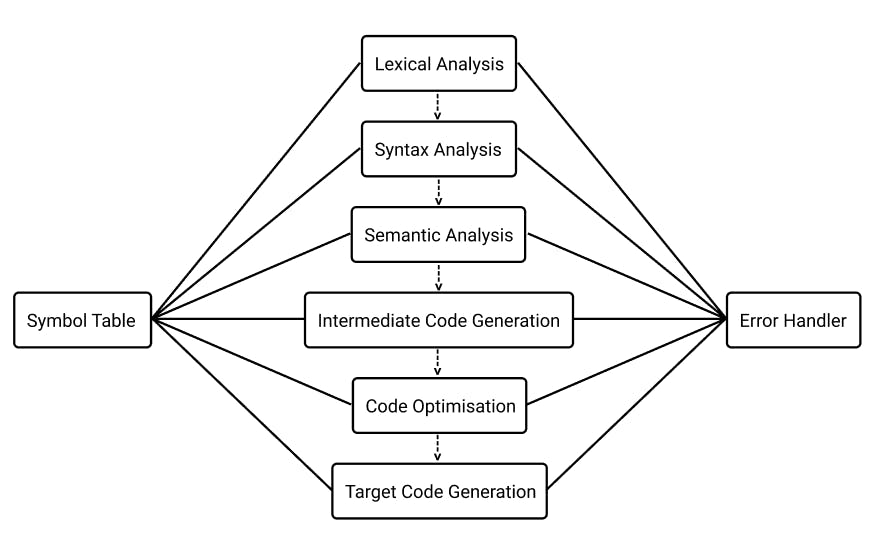
As we can see a compiler consists of a total of 6 different levels, where the first four are grouped together and are called frontend, and the bottom two are grouped and called backend.
The frontend part checks for any kind of errors in the code like syntax, grammar, or lexical errors whereas the backend part simplifies and generates the program by grouping the code snippets.
## The Internal Processes in brief.
When we write a code in any language and compiles it, the first thing a compiler does is to check for any kind of errors in the code for which it passes through the frontend or analytic part.
### Lexical Analysis
When a high-level language code is passed through lexical analysis it generates a stream of tokens, but before that, we should talk about preprocessors, the task of a preprocessor is to filter out a stream of characters by removing the header files and then passing it to the lexical analysis. (A stream of characters is nothing but just the keyboard characters we type in the code: int a = 23; or printf(" Hello World! ");)
but what is a token?
let's take a small code ```a = 10;```
Here a, =, 10, ; are all tokens. So total number of tokens here is 5.
So basically a token is the important part of a code. Why I said important? Because comments and characters such as white space or newline or tabs are not considered as tokens. And then these tokens are passed in the symbol table. The role of the symbol table is to get the record of the properties of tokens or variables such as type, size, scope, etc. The symbol table is connected to all the stages in the compiler as we can see in the diagram for future use.
After converting all the code to tokens, it is sent to the syntax analysis department.
### Syntax Analysis
When the code comes here, it is checked that if a code is syntactically correct or not. A parser is used here and the output that comes is called a parse tree as it comes in the form of a tree as shown:
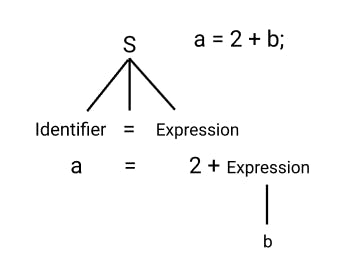
If there is a syntax error then an error is produced at this stage.
### Semantic Analysis
Here the analyzer checks the parse tree and finds semantic errors. Note that this part doesn't care about the syntax but checks whether the value of the variable is as per the type declared or the limit of a particular data type is not exceeded or whether variables are declared properly or not
### Intermediate Code Generator
This part is the middle man between frontend and backend, it generates a code that can be understood by the backend i.e. a machine-independent code (independent of OS). It creates a 3-address code which means that the code is divided into 3 variable statement which means that maximum of 3 addresses can be there in one statement if there is 4 or 5 then it is divided into 2 3 lines of code.
```
a = b + c * d;
// this is converted as
x = c * d;
a = b + x;
```
This 3-addressed code is sent to the next level i.e. optimization of code
### Code Optimisation
From here the backend part begins and code optimization is the first stage of the backend. As the name suggests, this part optimizes the code. There is not much to say about it as you all know what is optimisation. + sign is much easier to process than * hence a code like:
```
x = 4 * y
// can be converted to
x = y + y + y + y
// or
z = y + y;
x = z + z;
```
### Code generation
Here the code generator takes an optimized version of the intermediate code and links it with the target machine language. It translates the intermediate code into a sequence of re-locatable machine code. The machine code generated works the same way the intermediate code would do.
Like the Symbol Table, there is an error handler that is linked to all the phases which is responsible for handling the errors detected by the frontend
And at last, the code is converted to the assembly code or machine code. | sakshamak | |
680,127 | Weekly Challenge 110 | Challenge, My solutions TASK #1 › Valid Phone Numbers Task You are given a tex... | 0 | 2021-04-27T12:37:04 | https://dev.to/simongreennet/weekly-challenge-110-22ao | perl, perlweeklychallenge | [Challenge](https://perlweeklychallenge.org/blog/perl-weekly-challenge-110/), [My solutions](https://github.com/manwar/perlweeklychallenge-club/tree/master/challenge-110/sgreen)
# TASK #1 › Valid Phone Numbers
## Task
You are given a text file. Write a script to display all valid phone numbers in the given text file.
## My solution
Let's start with what is a valid phone number. I can tell you only the phone number starting with + would actually work from where I am. But for the task I guess this isn't really important.
If I was doing this outside the task, I would have used [Path::Tiny](https://metacpan.org/pod/Path::Tiny) to read the file. As regular readers would know, I prefer not to use modules that aren't part of core Perl in these challenges.
For this task, I simply read the file line-by-line and output a line if it matches the regular expression `/^(?:\+[0-9]{2}|\([0-9]{2}\)|[0-9]{4}) [0-9]{10}$/`. I use `0-9` as `\d` includes [digits in other languages](https://www.effectiveperlprogramming.com/2011/01/know-your-character-classes/).
## Example
```
» ./ch-1.pl input1.txt
0044 1148820341
+44 1148820341
(44) 1148820341
```
# TASK #2 › Transpose File
## Task
You are given a text file. Write a script to transpose the contents of the given file.
## My solution
This task didn't mention the format is CSV, although the example would indicate the input is a CSV file. Outside the challenge I would probably use [Text::CSV](https://metacpan.org/pod/Text::CSV) as this correctly handles escaping of values with commas in them.
For this task I read the input file and create an array of arrays with the values found called `@lines`. I then loop through each column and use `map { $_->[$col] // '' } @lines` and the `join` method to display each row of the output.
The logical-defined-or `//` is used in case some rows do not have the same number of columns and will prevent undef warnings in the output (albeit it to STDERR).
## Examples
```
» ./ch-2.pl input2.txt
name,Mohammad,Joe,Julie,Cristina
age,45,20,35,10
sex,m,m,f,f
``` | simongreennet |
685,598 | Golang Data Connector Part 2 | Intro Last time we started our small data collector. The idea is we want to move data fr... | 0 | 2021-05-02T17:42:48 | https://shindakun.dev/golang-data-connector-part-2/ | go | ---
title: Golang Data Connector Part 2
published: true
date: 2021-05-02 17:39:54 UTC
tags: go
canonical_url: https://shindakun.dev/golang-data-connector-part-2/
---
### Intro

[Last time](https://dev.to/shindakun/golang-data-connector-part-1-5a5f) we started our small data collector. The idea is we want to move data from a Ghost blog over to _something else_. This time we're going to extend our starting point to actually make use of the data that comes back from the API call. That means we need to take a closer look at the incoming data... and with that in mind let's get started.
### Adding Struct-ure
Currently, we are receiving our data and converting it from `[]byte` to `string` so we can print it to the screen. That's cool and all but not very useful. Instead, we need to see if we can parse the data and make it usable for the next stage of this project.
To do this we'll need to convert the JSON into a `struct`. OK, so how do we do that? There are a couple of different ways but the easiest I've found is to use the site [JSON to Go](https://mholt.github.io/json-to-go/). This site converts a JSON object into what is a matching Golang `struct`.

We can simply paste the raw output from the call to `https://demo.ghost.io/ghost/api/v4/content/posts/?key=22444f78447824223cefc48062` into the form. It will spit out the exact `struct` we need:
```go
type AutoGenerated struct {
Posts []struct {
ID string `json:"id"`
UUID string `json:"uuid"`
Title string `json:"title"`
Slug string `json:"slug"`
HTML string `json:"html"`
CommentID string `json:"comment_id"`
FeatureImage string `json:"feature_image"`
Featured bool `json:"featured"`
Visibility string `json:"visibility"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
PublishedAt time.Time `json:"published_at"`
CustomExcerpt string `json:"custom_excerpt"`
CodeinjectionHead interface{} `json:"codeinjection_head"`
CodeinjectionFoot interface{} `json:"codeinjection_foot"`
CustomTemplate interface{} `json:"custom_template"`
CanonicalURL interface{} `json:"canonical_url"`
EmailRecipientFilter string `json:"email_recipient_filter"`
URL string `json:"url"`
Excerpt string `json:"excerpt"`
ReadingTime int `json:"reading_time"`
Access bool `json:"access"`
OgImage interface{} `json:"og_image"`
OgTitle interface{} `json:"og_title"`
OgDescription interface{} `json:"og_description"`
TwitterImage interface{} `json:"twitter_image"`
TwitterTitle interface{} `json:"twitter_title"`
TwitterDescription interface{} `json:"twitter_description"`
MetaTitle interface{} `json:"meta_title"`
MetaDescription interface{} `json:"meta_description"`
EmailSubject interface{} `json:"email_subject"`
Frontmatter interface{} `json:"frontmatter"`
Plaintext string `json:"plaintext,omitempty"`
} `json:"posts"`
Meta struct {
Pagination struct {
Page int `json:"page"`
Limit int `json:"limit"`
Pages int `json:"pages"`
Total int `json:"total"`
Next interface{} `json:"next"`
Prev interface{} `json:"prev"`
} `json:"pagination"`
} `json:"meta"`
}
```
Let's start by updating `AutoGenerated` to say `Ghost`. From there we can add the entire `struct` to the top of our previous code - right above `main()`. That is if we want to just added. In our imagined receiving system the entire `struct` isn't necessary so I've left out a bit. I've also updated several of the `interface{}` entries to be strings since that's what we'll actually be getting if the value is set.
```go
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"time"
)
type Ghost struct {
Posts []struct {
ID string `json:"id"`
UUID string `json:"uuid"`
Title string `json:"title"`
Slug string `json:"slug"`
HTML string `json:"html"`
FeatureImage string `json:"feature_image"`
Featured bool `json:"featured"`
Visibility string `json:"visibility"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
PublishedAt time.Time `json:"published_at"`
CustomExcerpt string `json:"custom_excerpt"`
URL string `json:"url"`
Excerpt string `json:"excerpt"`
ReadingTime int `json:"reading_time"`
Access bool `json:"access"`
OgImage string `json:"og_image"`
OgTitle string `json:"og_title"`
OgDescription string `json:"og_description"`
TwitterImage string `json:"twitter_image"`
TwitterTitle string `json:"twitter_title"`
TwitterDescription string `json:"twitter_description"`
MetaTitle string `json:"meta_title"`
MetaDescription string `json:"meta_description"`
Plaintext string `json:"plaintext,omitempty"`
} `json:"posts"`
Meta struct {
Pagination struct {
Page int `json:"page"`
Limit int `json:"limit"`
Pages int `json:"pages"`
Total int `json:"total"`
Next interface{} `json:"next"`
Prev interface{} `json:"prev"`
} `json:"pagination"`
} `json:"meta"`
}
func main() {
...snip...
```
* * *
<!--kg-card-begin: html-->
| Enjoy this post? |
| --- |
| [How about buying me a coffee?](https://ko-fi.com/shindakun) |
<!--kg-card-end: html-->
* * *
### More Printing
Alright, we're slowly getting somewhere! Now, we are going to replace our `fmt.Println()` with code to actually use our `struct`. We'll read the body in using the same manner as last time.
```go
body, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
```
But this time instead of printing we'll create a variable `p` of the type `Ghost`. Using `p` we then `json.Unmarshal` our received body.
```go
var p Ghost
err = json.Unmarshal(body, &p)
if err != nil {
log.Fatal(err)
}
```
From here we now have access to `range` over the entirety of `p.Posts` and once again we print them out to the screen.
```go
for i := range p.Posts {
fmt.Printf("%v", p.Posts[i])
}
```
### Next Time
That's all for this quick post, you can see the full code listing below. Next time we'll be taking one more step forward and actually use the `http` package to send our posts to another service.
### Code Listing
```go
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"time"
)
type Ghost struct {
Posts []struct {
ID string `json:"id"`
UUID string `json:"uuid"`
Title string `json:"title"`
Slug string `json:"slug"`
HTML string `json:"html"`
FeatureImage string `json:"feature_image"`
Featured bool `json:"featured"`
Visibility string `json:"visibility"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
PublishedAt time.Time `json:"published_at"`
CustomExcerpt string `json:"custom_excerpt"`
URL string `json:"url"`
Excerpt string `json:"excerpt"`
ReadingTime int `json:"reading_time"`
Access bool `json:"access"`
OgImage string `json:"og_image"`
OgTitle string `json:"og_title"`
OgDescription string `json:"og_description"`
TwitterImage string `json:"twitter_image"`
TwitterTitle string `json:"twitter_title"`
TwitterDescription string `json:"twitter_description"`
MetaTitle string `json:"meta_title"`
MetaDescription string `json:"meta_description"`
Plaintext string `json:"plaintext,omitempty"`
} `json:"posts"`
Meta struct {
Pagination struct {
Page int `json:"page"`
Limit int `json:"limit"`
Pages int `json:"pages"`
Total int `json:"total"`
Next interface{} `json:"next"`
Prev interface{} `json:"prev"`
} `json:"pagination"`
} `json:"meta"`
}
func main() {
req, err := http.NewRequest(http.MethodGet, "https://demo.ghost.io/ghost/api/v4/content/posts/?key=22444f78447824223cefc48062", nil)
if err != nil {
log.Fatal(err)
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
var p Ghost
err = json.Unmarshal(body, &p)
if err != nil {
log.Fatal(err)
}
for i := range p.Posts {
fmt.Printf("%v", p.Posts[i])
}
}
``` | shindakun |
687,255 | Painless UI & e2e Testing with Cypress.io* | Free online meetup Thursday May 6th | 0 | 2021-05-04T10:28:49 | https://dev.to/d17e/painless-ui-e2e-testing-with-cypress-io-4ah | cypress, testing, e2e, javascript | ---
title: Painless UI & e2e Testing with Cypress.io*
published: true
description: Free online meetup Thursday May 6th
tags: cypress, testing, e2e, javascript
//cover_image: https://direct_url_to_image.jpg
---
**Free virtual meetup on Thursday May 6th, 5:30pm (CET)**
▶️ This is a remote event and the link to join the streaming is https://www.youtube.com/watch?v=ZGCF-cT8cmQ◀️
RSVP over at https://www.meetup.com/Software-Development-adesso-NL/events/277711454/
All times are in CET (GMT+1)
05:30pm start stream
05:35pm talk + Q&A
06:35pm wrap-up
🔌 **Painless UI & e2e testing with Cypress (*inc. automated user documentation)**
Ever wanted to write End-To-End Tests with surprising levity?
Having a test environment that is optimized for progress, rather than one that needs to be taken care of, often remains an elusive dream for many organizations.
In his talk, Tobias Struckmeier gives an overview of how you can achieve this dream with the help of cypress and sheds light on some of the strategies that maximize stability in your test suites with minimal effort.
As a big bonus he will present a way of leveraging this to keep your user documentation in sync with your application UI at all times.
👨💻 **Speaker's Bio: Tobias Struckmeier**
Tobias Struckmeier has been working in software development for over 20 years. He has been involved in numerous projects as a full-stack developer throughout the years working with a plethora of tools and technologies giving him substantial experience in fields ranging from UX/UI design, over extended CSS knowledge up to CI/CD pipelines and helping teams adapting software quality methodologies. However it was his passion for JavaScript and front-end technologies that earned him his current role of Principal JavaScript Engineer at adesso's HQ in Dortmund.
Next to that, Tobias is also quite active in the community and is running the German Cypress meetup community (https://www.meetup.com/de-DE/cypress-de-community/), is a Cypress ambassador and co-organizes the NgNiederrhein Angular meetups (https://www.meetup.com/de-DE/NgNiederrhein/) and JSUnconf (http://jsunconf.eu), so make sure to go check those out as well!
And if all that was not enough, he's also an amazing guy!
So make sure not to miss it!
**Free virtual meetup on Thursday May 6th, 5:30pm (CET)**
▶️ This is a remote event and the link to join the streaming is https://www.youtube.com/watch?v=ZGCF-cT8cmQ◀️
| d17e |
686,257 | Making a Copy-wrong right Web Component | One small Web Component to always keep the Copyright year right | 0 | 2021-05-03T12:43:18 | https://dev.to/dannyengelman/making-a-copy-wrong-right-web-component-m6a | webcomponents, unlist | ---
title: Making a Copy-wrong right Web Component
published: true
description: One small Web Component to always keep the Copyright year right
tags: webcomponents,unlist
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/2gj3o2d5ccocfnvfrag7.jpg
---
I might be a bit harsh, but I always judge a book by its cover.
And websites by the _copyright_ notations:
It is 2021, if I see:

I also wonder if your business processes are up to date
One Web Component is _forever_ enough:
```js
customElements.define("copy-right", class extends HTMLElement{
connectedCallback(){
this.innerHTML = "Copyright " + new Date().getFullYear()
}
});
```
Now all HTML required is:
```html
<copy-right></copy-right>
```
<br>
<hr>
<br>
{% jsfiddle https://jsfiddle.net/WebComponents/62f1eLay result,html,js %}
| dannyengelman |
686,593 | React authentication, simplified | A different approach to authentication in React applications. | 0 | 2021-05-03T17:46:23 | https://userfront.com/tutorials/react-authentication.html | react, javascript, tutorial, webdev | ---
title: React authentication, simplified
published: true
description: A different approach to authentication in React applications.
tags: react, javascript, tutorial, webdev
cover_image: https://res.cloudinary.com/component/image/upload/v1620063737/permanent/react-auth.png
---
Authentication is one of those things that just always seems to take a lot more effort than we want it to.
To set up auth, you have to re-research topics you haven’t thought about since the last time you did authentication, and the fast-paced nature of the space means things have often changed in the meantime. New threats, new options, and new updates may have kept you guessing and digging through docs in your past projects.
In this article, we lay out a different approach to authentication (plus access control & SSO) in React applications. Rather than add a static library that you have to keep up to date or re-research each time you want to implement auth, we’ll use a service that stays up to date automatically and is a much simpler alternative to Auth0, Okta, and others.
## React authentication
We typically use a similar approach when writing authentication in React: our React app makes a request to our authentication server, which then returns an access token. That token is saved in the browser and can be used in subsequent requests to your server (or other servers, if needed). Whether writing standard email & password authentication or using magic links or single sign on (SSO) logins like Google, Azure, or Facebook, we want our React app to send an initial request to an authentication server and have that server handle all the complexity of generating a token.
So React’s responsibility in authentication is to:
1. Send the initial request to the authentication server
2. Receive and store the access token
3. Send the access token to your server with each subsequent request
## JWT access tokens
JSON Web Tokens (JWTs) are compact, URL-safe tokens that can be used for authentication and access control in React applications. Each JWT has a simple JSON-object as its “payload” and is signed such that your server can verify that the payload is authentic. An example JWT would look like:
```
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VySWQiOjEsImF1dGhvcml6YXRpb24iOiJhZG1pbiJ9.f7iKN-xi24qrQ5NQtOe0jiriotT-rve3ru6sskbQXnA
```
The payload for this token is the middle section (separated by periods):
```
eyJ1c2VySWQiOjEsImF1dGhvcml6YXRpb24iOiJhZG1pbiJ9
```
The JWT payload can be decoded from base64 to yield the JSON object:
```js
JSON.parse(atob("eyJ1c2VySWQiOjEsImF1dGhvcml6YXRpb24iOiJhZG1pbiJ9"));
// =>
{
“userId”: 1,
“authorization”: “admin”
}
```
It’s important to note that this payload is readable by anyone with the JWT, including your React application or a third party.
Anyone that has the JWT can read its contents. However, only the authentication server can generate valid JWTs -- your React application, your application server, or a malicious third party cannot generate valid JWTs. So in addition to reading the JWT, your server also needs to verify the JWT as authentic by checking it against a public key. This allows your application server to verify incoming JWTs and reject any tokens that were not created by the authentication server or that have expired.
The flow for using a JWT in a React application looks like this:
1. Your React app requests a JWT whenever the user wants to sign on.
2. The authentication server generates a JWT using a private key and then sends the JWT back to your React app.
3. Your React app stores this JWT and sends it to your application server whenever your user needs to make a request.
4. Your application server verifies the JWT using a public key and then read the payload to determine which user is making the request.
Each of these steps is simple to write down, but each step has its own pitfalls when you actually want to implement it and keep it secure. Especially over time, as new threat vectors emerge and new platforms need to be patched or supported, the security overhead can add up quickly.
## Userfront removes auth complexity in React apps
Userfront is a framework that abstracts away auth complexity. This makes it much easier for you to work with authentication in a React application and, perhaps most importantly, keeps all the auth protocols updated for you automatically over time.
The underlying philosophy with Userfront is that world-class auth should not take effort – it should be easy to set up, and security updates should happen for you automatically. Userfront has all the bells and whistles of authentication, Single Sign On (SSO), access control, and multi-tenancy, with a production-ready free tier up to 10,000 monthly active users. For most modern React applications, it’s a great solution.
### Setting up authentication in React
Now we will go through building all the main aspects of authentication in a React application. The final code for this example is available [here](https://github.com/tyrw/david-walsh-blog-react-auth).
Use your favorite boilerplate to set up your React application and get your build pipeline in order. In this article, we’ll use [Create React App](https://reactjs.org/docs/create-a-new-react-app.html), which does a lot of the setup work for us, and we’ll also add [React Router](https://reactrouter.com/web/guides/quick-start) for our client-side routing. Start by installing Create React App and React Router:
```js
npx create-react-app my-app
cd my-app
npm install react-router-dom --save
npm start
```
Now our React application is available at http://localhost:3000

Just like it says, we can now edit the `src/App.js` file to start working.
Replace the contents of `src/App.js` with the following, based on the React Router quickstart:
```jsx
// src/App.js
import React from "react";
import { BrowserRouter as Router, Switch, Route, Link } from "react-router-dom";
export default function App() {
return (
<Router>
<div>
<nav>
<ul>
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/login">Login</Link>
</li>
<li>
<Link to="/reset">Reset</Link>
</li>
<li>
<Link to="/dashboard">Dashboard</Link>
</li>
</ul>
</nav>
<Switch>
<Route path="/login">
<Login />
</Route>
<Route path="/reset">
<PasswordReset />
</Route>
<Route path="/dashboard">
<Dashboard />
</Route>
<Route path="/">
<Home />
</Route>
</Switch>
</div>
</Router>
);
}
function Home() {
return <h2>Home</h2>;
}
function Login() {
return <h2>Login</h2>;
}
function PasswordReset() {
return <h2>Password Reset</h2>;
}
function Dashboard() {
return <h2>Dashboard</h2>;
}
```
Now we have a very simple app with routing:
| Route | Description |
| :----------- | :--------------------------------------- |
| `/` | Home page |
| `/login` | Login page |
| `/reset` | Password reset page |
| `/dashboard` | User dashboard, for logged in users only |
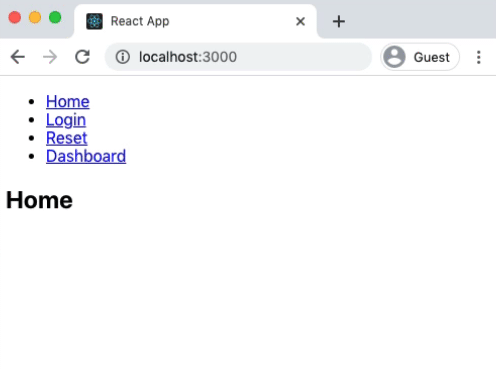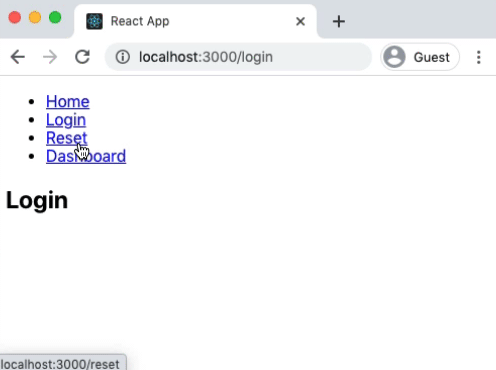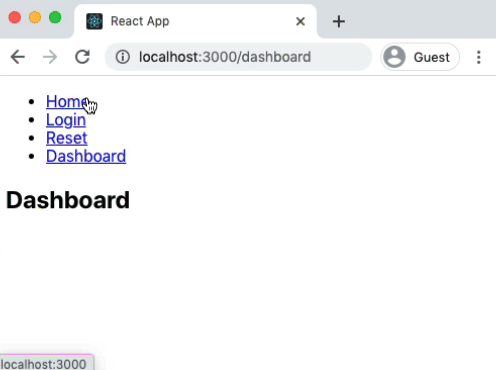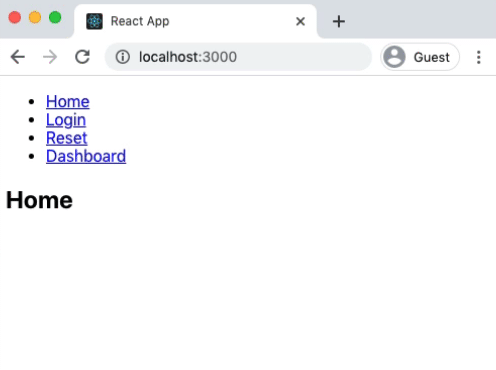
This is all the structure we need to start adding authentication.
### Signup, login, and password reset with Userfront
First, create a Userfront account at https://userfront.com. This will give you a signup form, login form, and password reset form you can use for the next steps.
In the Toolkit section of your Userfront dashboard, you can find the instructions for installing your signup form:
Follow the instructions by installing the Userfront react package with:
```js
npm install @userfront/react --save
npm start
```
Then add the form to your home page by importing and initializing Userfront, and then updating the `Home()` function to render the form.
```js
// src/App.js
import React from "react";
import { BrowserRouter as Router, Switch, Route, Link } from "react-router-dom";
import Userfront from "@userfront/react";
Userfront.init("demo1234");
const SignupForm = Userfront.build({
toolId: "nkmbbm",
});
export default function App() {
return (
<Router>
<div>
<nav>
<ul>
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/login">Login</Link>
</li>
<li>
<Link to="/reset">Reset</Link>
</li>
<li>
<Link to="/dashboard">Dashboard</Link>
</li>
</ul>
</nav>
<Switch>
<Route path="/login">
<Login />
</Route>
<Route path="/reset">
<PasswordReset />
</Route>
<Route path="/dashboard">
<Dashboard />
</Route>
<Route path="/">
<Home />
</Route>
</Switch>
</div>
</Router>
);
}
function Home() {
return (
<div>
<h2>Home</h2>
<SignupForm />
</div>
);
}
function Login() {
return <h2>Login</h2>;
}
function PasswordReset() {
return <h2>Password Reset</h2>;
}
function Dashboard() {
return <h2>Dashboard</h2>;
}
```
Now the home page has your signup form. Try signing up a user:
The form is in "Test mode" by default, which will create user records in a test environment you can view separately in your Userfront dashboard:
Continue by adding your login and password reset forms in the same way that you added your signup form:
```js
// src/App.js
import React from "react";
import { BrowserRouter as Router, Switch, Route, Link } from "react-router-dom";
import Userfront from "@userfront/react";
Userfront.init("demo1234");
const SignupForm = Userfront.build({
toolId: "nkmbbm",
});
const LoginForm = Userfront.build({
toolId: "alnkkd",
});
const PasswordResetForm = Userfront.build({
toolId: "dkbmmo",
});
export default function App() {
return (
<Router>
<div>
<nav>
<ul>
<li>
<Link to="/">Home</Link>
</li>
<li>
<Link to="/login">Login</Link>
</li>
<li>
<Link to="/reset">Reset</Link>
</li>
<li>
<Link to="/dashboard">Dashboard</Link>
</li>
</ul>
</nav>
<Switch>
<Route path="/login">
<Login />
</Route>
<Route path="/reset">
<PasswordReset />
</Route>
<Route path="/dashboard">
<Dashboard />
</Route>
<Route path="/">
<Home />
</Route>
</Switch>
</div>
</Router>
);
}
function Home() {
return (
<div>
<h2>Home</h2>
<SignupForm />
</div>
);
}
function Login() {
return (
<div>
<h2>Login</h2>
<LoginForm />
</div>
);
}
function PasswordReset() {
return (
<div>
<h2>Password Reset</h2>
<PasswordResetForm />
</div>
);
}
function Dashboard() {
return <h2>Dashboard</h2>;
}
```
At this point, your signup, login, and password reset should all be functional.
Your users can sign up, log in, and reset their password.
## Protected route in React
Usually, we don't want users to be able to view the dashboard unless they are logged in. This is known as protecting a route.
Whenever a user is not logged in but tries to visit `/dashboard`, we can redirect them to the login screen.
We can accomplish this by updating the `Dashboard` component in `src/App.js` to handle the conditional logic.
When a user is logged in with Userfront, they will have an access token available as `Userfront.accessToken()`. We can check for this token to determine if the user is logged in.
Add the `Redirect` component to the `import` statement for React Router, and then update the `Dashboard` component to redirect if no access token is present.
```js
// src/App.js
import React from "react";
import {
BrowserRouter as Router,
Switch,
Route,
Link,
Redirect, // Be sure to add this import
} from "react-router-dom";
// ...
function Dashboard() {
function renderFn({ location }) {
// If the user is not logged in, redirect to login
if (!Userfront.accessToken()) {
return (
<Redirect
to={{
pathname: "/login",
state: { from: location },
}}
/>
);
}
// If the user is logged in, show the dashboard
const userData = JSON.stringify(Userfront.user, null, 2);
return (
<div>
<h2>Dashboard</h2>
<pre>{userData}</pre>
<button onClick={Userfront.logout}>Logout</button>
</div>
);
}
return <Route render={renderFn} />;
}
```
Notice also that we've added a logout button by calling `Userfront.logout()` directly:
```js
<button onClick={Userfront.logout}>Logout</button>
```
Now, when a user is logged in, they can view the dashboard. If the user is not logged in, they will be redirected to the login page.
## React authentication with an API
You will probably want to retrieve user-specific information from your backend. In order to protect these API endpoints, your server should check that incoming JWTs are valid.
There are many libraries to read and verify JWTs across various languages; here are a few popular libraries for handling JWTs:
| | | | |
| ----------------------------------------------------- | ----------------------------------------- | -------------------------------------------- | ----------------------------------------- |
| [Node.js](https://github.com/auth0/node-jsonwebtoken) | [.NET](https://github.com/jwt-dotnet/jwt) | [Python](https://github.com/jpadilla/pyjwt/) | [Java](https://github.com/auth0/java-jwt) |
For Userfront, the access token is available in your React application as `Userfront.accessToken()`.
Your React application can send this as a `Bearer` token inside the `Authorization` header. For example:
```js
// Example of calling an endpoint with a JWT
async function getInfo() {
const res = await window.fetch("/your-endpoint", {
method: "GET",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${Userfront.accessToken()}`,
},
});
console.log(res);
}
getInfo();
```
To handle a request like this, your backend should read the JWT from the `Authorization` header and verify that it is valid using the public key found in your Userfront dashboard.
Here is an example of Node.js middleware to read and verify the JWT:
```js
// Node.js example (Express.js)
const jwt = require("jsonwebtoken");
function authenticateToken(req, res, next) {
// Read the JWT access token from the request header
const authHeader = req.headers["authorization"];
const token = authHeader && authHeader.split(" ")[1];
if (token == null) return res.sendStatus(401); // Return 401 if no token
// Verify the token using the Userfront public key
jwt.verify(token, process.env.USERFRONT_PUBLIC_KEY, (err, auth) => {
if (err) return res.sendStatus(403); // Return 403 if there is an error verifying
req.auth = auth;
next();
});
}
```
Using this approach, any invalid or missing tokens would be rejected by your server. You can also reference the contents of the token later in the route handlers using the `req.auth` object:
```js
console.log(req.auth);
// =>
{
mode: 'test',
tenantId: 'demo1234',
userId: 1,
userUuid: 'ab53dbdc-bb1a-4d4d-9edf-683a6ca3f609',
isConfirmed: false,
authorization: {
demo1234: {
tenantId: 'demo1234',
name: 'Demo project',
roles: ["admin"],
permissions: []
},
},
sessionId: '35d0bf4a-912c-4429-9886-cd65a4844a4f',
iat: 1614114057,
exp: 1616706057
}
```
With this information, you can perform further checks as desired, or use the `userId` or `userUuid` to look up user information to return.
For example, if you wanted to limit a route to admin users, you could check against the `authorization` object from the verified access token:
```js
// Node.js example (Express.js)
app.get("/users", (req, res) => {
const authorization = req.auth.authorization["demo1234"] || {};
if (authorization.roles.includes("admin")) {
// Allow access
} else {
// Deny access
}
});
```
## React SSO (Single Sign On)
From here, you can add social identity providers like Google, Facebook, and LinkedIn to your React application, or business identity providers like Azure AD, Office365, and more.
You do this by creating an application with the identity provider (e.g. Google), and then adding that application's credentials to the Userfront dashboard. The result is a modified sign on experience:
No additional code is needed to implement Single Sign On using this approach: you can add and remove providers without updating your forms or the way you handle JWTs.
## Final notes
Adding authentication and access control to your React application doesn't have to be a hassle. Both the setup step and, more importantly, the maintenance over time, are handled with modern platforms like [Userfront](https://userfront.com).
JSON Web Tokens allow you to cleanly separate your auth token generation layer from the rest of your application, making it easier to reason about and more modular for future needs. This architecture also allows you to focus your efforts on your core application, where you are likely to create much more value for yourself or your clients.
For more details on adding auth to your React application, visit the [Userfront guide](https://userfront.com/guide), which covers everything from setting up your auth forms to API documentation, example repositories, working with different languages and frameworks, and more.
[Create a free Userfront project](https://userfront.com)
| tyrw |
686,791 | Flutter: Interactive User Guidance or how to make a hole in the layout | Hi folks! I wanna show you an interesting Flutter feature. We can build interactive user guidance usi... | 0 | 2021-05-03T21:15:19 | https://medium.com/litslink/flutter-interactive-user-guidanc-e-or-how-to-make-a-hole-in-layout-d72bf6eb27f9 | flutter, tutorial, dart | Hi folks! I wanna show you an interesting Flutter feature. We can build interactive user guidance using blending colors in Flutter.
This simple trick allows you to build interesting user guidance in the app more than just a picture. It could be really interactive with animation etc.
## Layout
First of all, to build the overlay, you need to wrap the Scaffold widget of the target page in a Stack widget and left the Scaffold widget as a first item.
For the second place, create an overlay that covers the whole Scaffold with a bit transparent dark/light background. The root ColorFiltered has blend mode “source out” and the inner Container has “destination out” in the background, which allows us to clip widgets to clip them in the root ColorFiltered widget.
For example, in this case, we have a Container with size 150x150 and the color white, the color needed for blending and should not be transparent fully otherwise, you will not see it. So color is needed for blending to understand what area to clip out.
Keep in mind that the Stack widget out of Scaffold and doesn’t have any Material support, so wrap it with a Material widget that will be enough.
## Animation & Steps
I’ve prepared a simple example of switching guidance from one to another with animating clip area from the rectangle to a circle and moving. Just check my repository and get this experience.
The full project source code available on GitHub.
## Demo
There is a light demo that I’ve recorded on the Android Emulator to show you how it works.
YouTube: {% youtube qownBzacasY %}
# Code Samples
**See the original article with code samples by the canonical link.** | alexmelnyk |
686,842 | Use AWS to Start Sneakerbotting! | Whatcha talkin bout Willis! The internet has changed sneaker culture so drastically that y... | 0 | 2021-05-04T00:33:14 | https://dev.to/itsmenilik/use-aws-to-start-sneakerbotting-3dcl | aws, discuss, cloud, virtualmachines | # Whatcha talkin bout Willis!
The internet has changed sneaker culture so drastically that you used to have to visit Footlocker, Mom & Pop shops, and check Eastbay for the latest releases or just show up and find something super dope to wear. Now all information regarding sneakers is one click away. No more waking up early in the morning and waiting in line just to get a chance to purchase the most popular sneaker out there.
# Now What?
Well now, it's a lot more difficult to obtain limited sneakers because of this ease of access. Now a days people are using sophisticated computer programs to obtain sneakers within seconds during the checkout process. This is much faster than what any human could do manually. These programs are more commonly referred to as bots. Bots have become essential to obtaining limited sneakers online.
When it comes to sneaker botting, there is a lot to it. There are proxies, tasks, internet speed, server type, and the actual program/application. They all determine how well you can obtain a limited sneaker.
#
In this blog post, we are going to specifically talk about servers and their purpose in sneaker botting.
When it comes to getting a limited sneaker, speed is the name of the game. So in order to achieve better speeds, you can set up a separate computer for faster speeds. You just use your computer to connect to it. By doing this you get faster internet speeds, better pc specs (such as ram or cpu power), the ability to run more tasks, and have a better botting experience.
You might be asking yourself, "Why wouldn't I run a sneaker bot on my home computer"? Well, you run into the possibility of your computer crashing or slowing down because of its limited capabilities.
On the other hand, if you run your bot in a server provider such as AWS, then you are getting their speed and their connection. Which is generally better.
# OKAY ... I'm Listening
Now, this where I'll show you how to set up an EC2 instance. EC2 provides scalable computing capacity in the AWS Cloud. Think of it as a virtual machine in the cloud.
First you will want to sign up for a free account:

Once you are all signed in and ready to go, you will want to get into the AWS management console select EC2:
From there you will want to select Launch Instances:
Then you will want to select the Amazon Machine Image. In this example, we will select Microsoft 2016 BASE since it is eligible for the free tier account:

Next we will want to select the instance type. This is where you can increase the compute specs such as cpu and memory:

Now this is an important step. This is where you will create your key pair. A key pair consists or a public and private key that allow you to connect to your EC2 instance securely. This will get downloaded on your computer and you will want to make sure not one else has access this key pair:
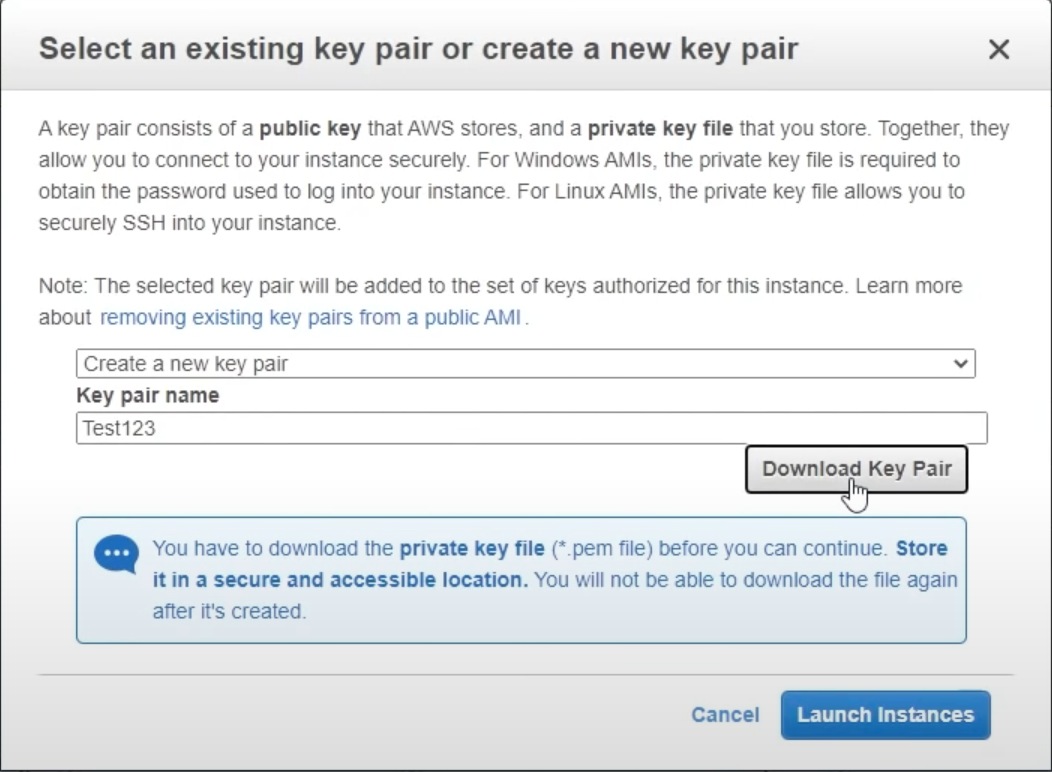
Once you have downloaded your key pair, you can now launch your EC2 instance and then begin to connect to it by right clink on your instance:
Next, you will want to select RDP client, hit Get Password, upload your key pair file, and then download the remote desktop file to your desktop:
Next you will want to connect to the remote desktop file, connect, and enter the password from you client:
The last step you have to do is just wait for your computer to connect to the EC2 instance and then install the bot application on it. In the picture below, you can see that I have download the [nikeshoebot](https://www.nikeshoebot.com/) on my EC2 instance:
Happy Botting! | itsmenilik |
687,055 | hey, it's Neph here! After 3years being in the game I now got a dev account! It was about time... | A post by Neph-dev | 0 | 2021-05-04T05:13:52 | https://dev.to/neph/hey-it-s-neph-here-after-3years-being-in-the-game-i-now-got-a-dev-account-it-was-about-time-2ok5 | productivity, ai, devops | neph | |
687,723 | Hello Dev | Just Setting Up My Devv!!!! | 0 | 2021-05-04T17:02:01 | https://dev.to/duskylantern/hello-dev-2114 | Just Setting Up My Devv!!!! | duskylantern | |
687,777 | Positive And Negative Lookahead | Lookaheads are patterns that tell JavaScript to look-ahead in your string to check for patterns fur... | 0 | 2021-05-04T18:33:30 | https://dev.to/rthefounding/positive-and-negative-lookahead-2hej | javascript, devops, tutorial, beginners | * *Lookaheads* are patterns that tell JavaScript to look-ahead in your string to check for patterns further along. This can be useful when you want to search for multiple patterns over the same string.
* There are two kinds of lookaheads: positive lookahead and negative lookahead.
* A positive lookahead will look to make sure the element in the search pattern is there, but won't actually match it. A positive lookahead is used as `(?=...)` where the `...` is the required part that is not matched.
* A negative lookahead will look to make sure the element in the search pattern is not there. A negative lookahead is used as `(?!...)` where the `...` is the pattern that you do not want to be there. The rest of the pattern is returned if the negative lookahead part is not present.
* Lookaheads are a bit confusing but let me show you an example:
A more practical use of lookaheads is to check two or more patterns in one string. Here we changed the pwRegex to match passwords that are greater than 5 characters long, and have two consecutive digits. ```
let sampleWord = "astronaut";
let pwRegex = /(?=\w{6,})(?=\D+\d\d)/;
let result = pwRegex.test(sampleWord);
```
```
console.log(result); will display false
```
```
let sampleWord = "bana12";
console.log(result); here it will display true
``` | rthefounding |
687,991 | Observations and Experiences Earning Money Through Codementor | Some observations about people learning to code on codementor.io platform and experiences earning some side money mentoring people on it. | 0 | 2021-05-04T22:05:29 | https://arihantverma.com/posts/2021/05/04/experiencing-earning-money-through-codementor/ | secondincome, mentoring, foundation, tech | ---
title: Observations and Experiences Earning Money Through Codementor
published: true
description: Some observations about people learning to code on codementor.io platform and experiences earning some side money mentoring people on it.
tags:
[
"secondincome",
"mentoring",
"foundation",
"tech",
]
cover_image: https://images.unsplash.com/photo-1522881193457-37ae97c905bf?ixid=MnwxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=1650&q=80
canonical_url: https://arihantverma.com/posts/2021/05/04/experiencing-earning-money-through-codementor/
---
I don't remember when I started following [Sunil](https://twitter.com/sunilc_) on Twitter. He's a developer who — apart from his day job — invests a lot of time in curating development resources in Twitter threads. He has a significantly large Twitter following. He spends a lot of free time freelancing. He also writes ebooks about developer platforms, passive income generation, freelancing, his developer experiences, how to become a better developer, [which he sells](https://gumroad.com/l/joCkt). Once, I saw him tweet about a platform called [codementor.io](https://codementor.io). After that tweet I repeatedly saw him tweet about how easy it was and how nice it felt to just help someone out with their doubts or help debug somebody's code and make easy money out of it.
So I decided to try it out. And he was right. It really is easy pocket money coming in on the side. I earned a little over my rent's money in about a month, helping people with their doubts about JavaScript, React, Redux, Typescript and CSS styling in my free time.
I got to talk to a lot of people, ranging from different behaviours, cultures, hailing from different countries, with varied experience levels.
1. A couple of super humble and eager to learn university students. What I learnt observing how they learnt was how aggresive they were towards getting their code working, not minding if they were doing things properly, or if they were handling edge cases or doing error handling upfront.
2. A person who had taken a project from someone and was seeking out help on it. Kinda like subletting.
3. A person in his mid 30s or early 40s. A mobile app developer, who had just inherited a React Redux web app code in a Create React App setup. He took notes by hand old school. I was able to help him get a general understanding of React and JavaScript ecosystem at large, and give him detailed suggestions as we walked through the codebase – surprisingly well written and commented. The amount of research, learning and follow up that he conveyed through chat messages afterwards was inspiring. He came up with smart doubts and questions and I loved resolving them.
4. A bootcamp student, a woman, who was doing her last project assignment. React on frontend with a Ruby on Rails backend. She had trouble making sense of React state across components and React Router usage. She sounded polite but panicked. She had a southern US accent. It was the first time I'd talked and listened to someone with one, outside of Hollywood movies. It was inspiring that she was seeking help. But by the sound of her voice I sensed that nobody until then had been able to explain to her some of the concepts that I did. When I asked her if I could help her run VS Code live share session because zoom's remote control was excruciatingly slow, she got worried that the live session will be live for anybody to see, which was sweet. But by the amount of tension she seemed to be was evident, even though she did a good job to cover it up with her naturally calming and polite voice. She asked me if I'd be willing to help her learn JavaScript in a better way, since things got rushed, as they often do, in the bootcamp.
5. A machine learning veteran. Having sold a couple of technology companies in the US, he had decided to not start a new one and instead work with an existing company. Hailing from Malleshwaram in Bangalore, we bonded over having lived in the same city. He told me that he had gone to Kendra Vidyalaya there. He then went onto study in the US and eventually settled there. He was trying UI development with React for the first time, working on a personal project. Being the experienced person he is, he had already found a couple of hackish solutions, albeit wrong, to the problem he had approached on the platform for. When I helped him learn to resolve the problem in the most correct 'React-y' way, he was elated. He gave me his number and email id and asked me to talk with him in case I'd need a job in Bangalore anytime, with possibly the double income that I'd have in mind. I was humbled and felt a little shy. I told him, I'd definitely let him know when need be. I helped him once again with some layouting.
From this experience I observed a very alarming fact – I had come across with all the people who had either started themselves out, or somebody else had started them out to learn web development in a way that might be misleading. I say that because I was started with learning web development the same way — through focussing too much on frameworks and not stressing more on the underlying foundations.
The coming of a new bare bones React framework called [Remix](https://www.youtube.com/watch?v=4dOAFJUOi-s&ab_channel=Remix) felt surprisingly liberating, because using it, one would actually be forced to code in a way that takes care of progressive enhancement (an app would work fine end to end even without JavaScript with all the forms and things and what have you). Inspired by remix and Sarah Drasner's Github tagline
> Comprehension Over Configuration
Over the next several weeks I'm going to embark on the journey to read through the [web.dev](https://github.com/GoogleChrome/web.dev) codebase and share my learnings from there.
Stay tuned!
| arihantverma |
688,079 | ", hopefully" - An Intro to Git Hooks | Learn the absolute basics of a git commit hook. Minimal shell experience required. | 0 | 2021-05-06T19:43:27 | https://dev.to/brodan/hopefully-an-intro-to-git-hooks-507c | git, shell | ---
title: ", hopefully" - An Intro to Git Hooks
published: true
description: Learn the absolute basics of a git commit hook. Minimal shell experience required.
tags: git, shell
//cover_image: https://direct_url_to_image.jpg
---
In yet another instance of a blog post inspired by a single tweet, this post will offer a _very_ basic introduction to git hooks (commit hooks, to be specific).

# The Tweet
{% twitter 1389708730086957061 %}
I saw this on my timeline earlier today, had a good chuckle, and then realized that despite knowing _about_ git hooks for a long time, I've never actually written one. I decided to fix that by writing a dead simple hook that would recreate the aforementioned Tweet.
# The Code
Start by initializing a new git repo as such:
```shell
cd /tmp && mkdir hook-testing
cd hook-testing
git init
```
git actually generates a number of sample hooks when you initialize a repo. You can see them all by running `ls .git/hooks/`.
If you look closely, there's a hook named `prepare-commit-msg.sample`. How convenient! This hook, once enabled, will run every time a `git commit` command is run when working in this repo.
You can read more about this hook in the [githooks Documentation](https://git-scm.com/docs/githooks#_prepare_commit_msg).
In order for git to actually pick up and run a hook, the `.sample` extension must be removed:
```shell
mv .git/hooks/prepare-commit-msg.sample .git/hooks/prepare-commit-msg
```
Open `.git/hooks/prepare-commit-msg` in an editor and feel free to look at the examples. Then replace it all with the following:
```shell
#!/bin/sh
COMMIT_MSG_FILE=$1
COMMIT_SOURCE=$2
DREAM=", hopefully"
if [[ "$COMMIT_SOURCE" == "message" ]]
then
echo `cat $COMMIT_MSG_FILE`$DREAM > $COMMIT_MSG_FILE
fi
```
I kept this hook pretty simple since my shell-scripting abilities are lackluster.
git passes three arguments into the `prepare-commit-msg` hook, but we only care about the first two:
- `$1` is the name of the file that contains the commit log message. We will append our optimistic message to this file.
- `$2` is the source of the commit message and is set according to how the commit is being generated (such as in a `merge`, `squash`, etc, or just a regular old `commit`).
In this case, the hook is only going to run if the commit source is `"message"`, meaning that the commit was made using the `-m` flag. Feel free to modify this to your liking.
In order to see it in action, we need to commit something:
```shell
git commit --allow-empty -m "adding an empty commit"
[master 1031a40] adding an empty commit, hopefully
```
As you can see above, the commit message was updated to include the `", hopefully"` message. You can run `git log` to see it again if you want to double-check.
# The Conclusion
I hope you found this post informative and entertaining. The hook itself is very simple but I actually learned a log about git internals while working on it.
If you'd like to see the other posts I've written that were inspired entirely by Tweets, consider these:
- [Build John Mayer's Customer Service Line with Twilio Voice and Python](https://www.twilio.com/blog/john-mayer-customer-service-line-twilio-voice-python)
- [Waifu MMS Bot - Send a Selfie, Receive a Waifu ](https://dev.to/brodan/waifu-mms-bot-send-a-selfie-receive-a-waifu-4617)
Thanks for reading! | brodan |
688,136 | What I've learned today - 3 - Elixir add color to console | Coloring your console prints Since Elixir 1.4.0 we have ANSI color printing option. Ir... | 0 | 2021-05-05T03:04:52 | https://dev.to/lgdev07/what-i-ve-learned-today-3-elixir-add-color-to-console-592p | elixir, programming | ## Coloring your console prints
Since Elixir 1.4.0 we have ANSI color printing option.
Ir supports also background colors.
For more information, see: [https://hexdocs.pm/elixir/IO.ANSI.html](https://hexdocs.pm/elixir/IO.ANSI.html)
## Examples
```elixir
import IO.ANSI
IO.puts red <> "red" <> green <> " green" <> yellow <> " yellow" <> reset <> " normal"
IO.puts Enum.join [red, "red", green, " green", yellow, " yellow", reset, " normal"]
IO.puts IO.ANSI.format([:blue_background, "Example"])
IO.puts IO.ANSI.format([:green_background, "Example"])
```
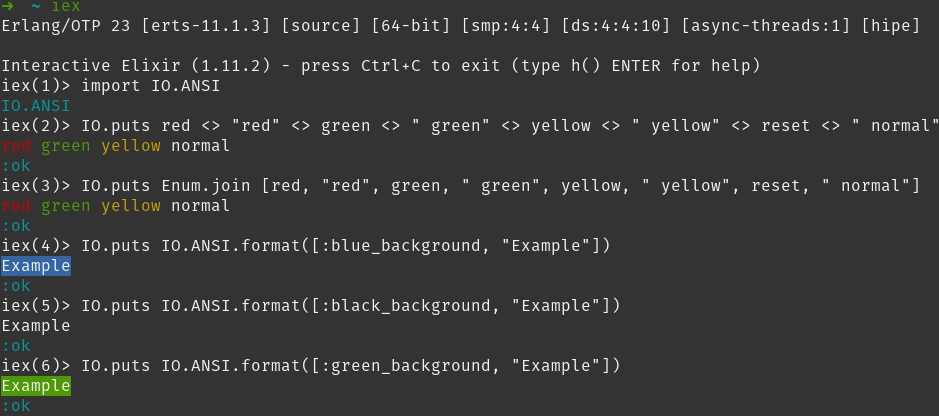
I appreciate everyone who has read through here, if you guys have anything to add, please leave a comment. | lgdev07 |
688,350 | Handling multiple checkboxes in react | Let's say we want to have input for our favorite foods and we want to show it on the page. First, we... | 0 | 2021-05-05T08:47:29 | https://dev.to/mhmmdysf/handling-multiple-checkboxes-in-react-3efe | react | Let's say we want to have input for our favorite foods and we want to show it on the page.
First, we should prepare two variables, one for the food list, and another for a list of the selected food which is empty by default.
```js
this.state = {
foods: [
{
id: 1,
name: '🍕'
},
{
id: 2,
name: '🍙'
},
{
id: 3,
name: '🍰'
},
],
selected: [],
}
```
Now we make the form and show the `selected` state.
```html
<form>
<p>
{ JSON.stringify(this.state.selected) }
</p>
<p>Foods</p>
{
this.state.foods.map(item => {
return (
<label key={ item.id }>
<input type="checkbox"></input>
<span>{ item.name }</span>
</label>
)
})
}
</form>
```
For checkbox input, we need to add `selected` and the usual `onChange` attributes.
```html
<input type="checkbox"
onChange={ () => this.onChange(item.id) }
selected={ this.state.selected.includes(item.id) }
></input>
```
The `selected` attribute accepts a boolean value that specifies if the input should be 'pre-selected' (checked) or not. And the `onChange` attribute will be triggered each time the input is checked and unchecked.
So because of this behavior, we have to put a function on the `onChange` attribute.
```js
onChange(id) {
let selected = this.state.selected
let find = selected.indexOf(id)
if(find > -1) {
selected.splice(find, 1)
} else {
selected.push(id)
}
this.setState({ selected })
}
```
`find` is a variable that checks whether the checked item is in the `selected` array or not. find > -1 means that the item exists in the selected variable and it is checked so we want to remove it from the selected list while find == -1 means the opposite. The item doesn't exist in the selected array so we want to add it to the array.
Now it should look like this

## Beyond IDs
If you want to keep the whole object (not only the id), we can change the way we find the index and push the item to the selected array
```js
onChange(id) {
let selected = this.state.selected
// instead of using indexOf, we can use findIndex to look through array of objects
let find = selected.findIndex(item => item.id === id)
if(find > -1) {
selected.splice(find, 1)
} else {
// We can use find to get the item based on its id
selected.push(this.state.foods.find(item => item.id === id))
}
this.setState({ selected })
}
```
Now it should look like this

## Sorting
And finally, basically the selected array has no specific order so if you want to keep the order you can add some sorting method before we use the `setState`.
```js
// sort by id in ascending order
selected.sort((a, b) => a.id - b.id)
``` | mhmmdysf |
688,365 | Unique SVG Shape Generators You Should Know About | Here I list a few CSS shape generators, which can be included in your project, these generators produ... | 0 | 2021-05-05T09:20:58 | https://dev.to/nillwebdev/unique-svg-shape-generators-you-should-know-about-3dgc | webdev, productivity, beginners, css | Here I list a few CSS shape generators, which can be included in your project, these generators produce svg codes, which can be copy-pasted into your project directly.
###[Blob Maker](https://www.blobmaker.app/)

###[Squircley](https://squircley.app/)

###[Blobs](https://blobs.app/?e=6&gw=6&se=21224&c=d1d8e0&o=0)

###[Chartgen](https://chartgen.frederickallen.co/)

###[Wavelry](https://wavelry.vercel.app/)

Thank you for reading! I hope this [SVG Shape Generators](https://exceed-team.com/tech/unique-SVG-shape-generators-you-should-know-about?s=de&a=a) were useful for you, good luck and have a nice day)
| nillwebdev |
688,458 | Fix keyboard is freezed by Xfce4 screensaver and LightDM light-locker | Background I use Artix Linux as my workstation. It is based on Arch Linux and adopts Syste... | 0 | 2021-05-05T14:56:18 | https://dev.to/nabbisen/keyboard-is-freezed-by-xfce4-screensaver-and-light-locker-f3n | xfce, screensaver, lightdm, lightlocker | ## Background
I use [Artix Linux](https://artixlinux.org/) as my workstation. It is based on [Arch Linux](https://archlinux.org/) and adopts [Systemd](https://www.freedesktop.org/wiki/Software/systemd/)-free approach.
I chose [Xfce4](https://www.xfce.org/) as lightweight desktop environment with [LightDM](https://wiki.archlinux.org/title/LightDM) as login manager and [OpenRC](https://wiki.gentoo.org/wiki/OpenRC) as init system.
I like it🙂
## Problem
Well, I had had a small but inconvenient problem.
Keyboard didn't work after the session was locked due to a certain time passed without any operation.
I logged in again then to restore the session. Then I hit some keys in application which had been the primary before locked. Nothing worked.
I had to activate another application once. So I could use the primary application as I had.
It was actually some sort of solution but inconvenient, unpleasant and uncomfortable.
## Cause and reason
I found it was because __both__ [Xfce4 screensaver](https://git.xfce.org/apps/xfce4-screensaver/about/) ( [`xfce4-screensaver`](https://git.xfce.org/apps/xfce4-screensaver) ) and [Light Locker](https://wiki.archlinux.org/title/LightDM#Lock_the_screen_using_light-locker) ( [`light-locker`](https://github.com/the-cavalry/light-locker) ) locked the session.
## Solution
### Summary
To disable either `xfce4-screensaver` or `light-locker`.
### Case 1: Use `light-locker` (= disable `xfce4-screensaver`)
Uninstall `xfce4-screensaver` if you don't use it:
```console
# pacman -Rs xfce4-screensaver
```
It was my option.
As another option, you may disable it with Xfce4 "Settings" menus. Go to "Settings" > "Session and Startup", select "Application Autostart" and uncheck "Screensaver". Make only "Screen Locker" checked:
Then log out and log in again.
You will see Light Locker screen when the session is locked:

### Case 2: Use `xfce4-screensaver` (= disable `light-locker`)
Go to "Settings" > "Session and Startup", select "Application Autostart" and uncheck "Screen Locker". Make only "Screensaver" checked:
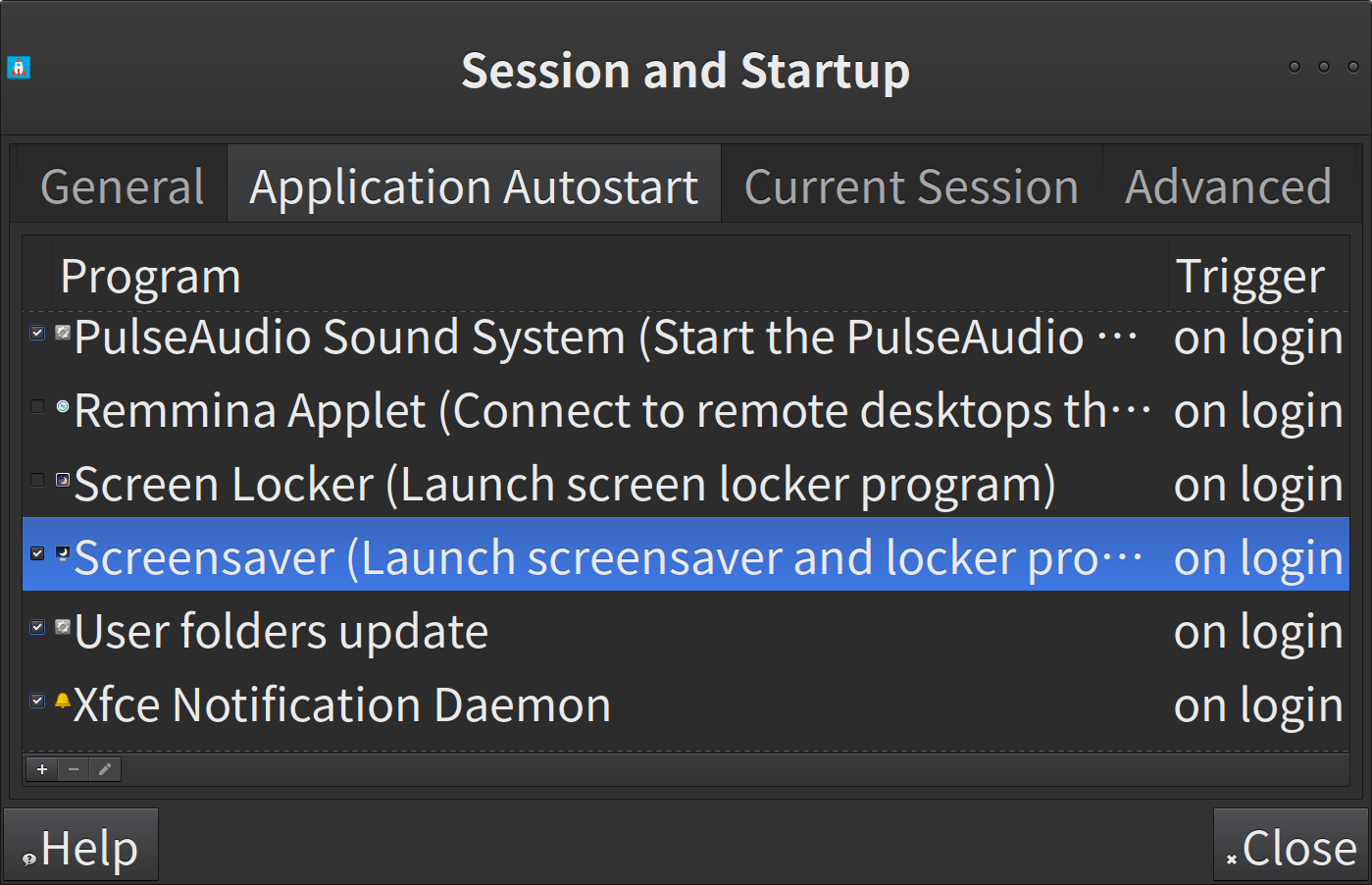
Then log out and log in again.
You will see Xfce4 Screensaver lock screen when the session is locked:
| nabbisen |
688,601 | A Note On Relational Databases | A Note on Relational Database Good day guys, in today's aricle i want to share with you so... | 0 | 2021-05-05T16:34:58 | https://dev.to/kalashin1/a-note-on-relational-databases-42hj | mysql, database, programming | # A Note on Relational Database
Good day guys, in today's aricle i want to share with you some few things i have learned from using a relational database management system (RDBMS). Earlier on when i was moving from frontend to backend i had to make a choice of which database to learn, i was interested in php then so i went with relational databases. I have to say that relational databases are quite robust database solutions for your business, they are easy to setup, learn and use, most of the time it requires zero configurations to start using relational databases even on a server. Relational databases also have a powerful tool, the manner in which they are queried. Enter SQL (Structural Query Language) a language that reads like plain English and was designed for relational databases, it provides a simple yet powerful declarative language for accessing and managing data in relational databases.
## RDBMS
A Relational database is database that operates with the relational model (RM). The RM is a way we store data by organizing and representing the data in such a way that such that we can relate one section, group or block of the data to another. The data is grouped into tables each table in turn has a row which represents an individual record in the data. Then there's columns, they describes an attribute of a particular record in the database. A row is also called a tuple. Each table usually have primary key. This primary key is an attribute of each record that will allow us to link to another record on another table. For us to link to another table, that table must specify on it it's column a field that will hold the equivalent value of the primary key of another table, once this is achieved we can link one or more tables together. we can also describe the type of relationship that exists among tuples. Examples of relational databases includes; MySQL, Microsoft SQL, Oracle DB amongst others. You can head [here](https://www.codecademy.com/articles/what-is-rdbms-sql) for more detailed explanation on relational databases
## Advantages of Relational Model
#### SQL
This is arguably the best advantage of using RDBMS. For you to Manage and access the data stored in an RDBMS you use SQL which stands for structural query language. It is a computer language for storing, accessing and updating data stored in a relational database. SQL reads much like plain english, it is very easy to learn. It can be simple enough for a beginner and when you mature enough and want to perform more complex operations on your data. SQL allows you to write complex queries for accessing and updating your data, you can even write a query within another query, all other advantages of relational databases is made possible because of SQL.
### Relationships
Relational database are very good at expressing relationships, you can have a one to one relationship where one table shares a relationship with only a single relationship, or you can have a many to one relationship with one table and other tables, or a many to many relationship between other different table, two or more tables could be linked to 4 or more tables.
### Normalization
If you follow standard practice and you like sticking to the book, you will probably normalize your data at some point, normalization gives you the ability to properly define your data and abstract the relationship that exists between different groups of data, it will ensure that you devise the best possible schema for your data to avoid redundancy and inefficiency.
### Standardization
The SQL language is standardized language hence all database that says it is an SQL database must be SQL compliant, thus enabling you to write queries that you can run across multiple relational database and you don't need to have mad coding skills to learn SQL, so i would advice you to get familiar with it, you can visit this [page](https://www.tutorialspoint.com/sql/index.htm) to learn more about SQL.
## Why Pick a Relational Database
Here are some of the reasons why you should pick a relational database;
### Hosting Service
There are lot's of web hosting companies that provide relational database service already so you will find that your basic plan should come with a free relational database. MySQL is often the most used in this case, but we have others too. But often they come at a price so you should definitely look at your budget.
### ACID compliant
Relational databases are ACID compliant and by that we mean that they conform to the following principles;
* Atomicity - Each operation is treated as a single transaction, it either succeeds completely or fails completely.
* Consistency - Each transaction can only bring the database from one valid state to another, only data that passes the rules is written to the database.
* Isolation - Each transaction is treated as a single unit and is run concurrently in isolation with other transactions thus ensuring that the database is finally arrives at the same state it would have if the transactions were run sequentially.
* Durability - This ensures that our data remains committed once it has been committed in case of system failures.
These are some bunch of principles that helps relational database to securely store, retrieve and update data in a reliable and consistent manner, you can head over [here](https://en.wikipedia.org/wiki/ACID) to read up more about ACID.
### Security of Data/Protection of sensitive data
In a Relational database the user is only able to manage and access the databases and tables that they have access to, this ensures that people working with the database cannot manipulate or make operations on objects in the database that they have given access to and none than that. Another thing i like about relational databases is that with the primary key you can get only the attribute of the record that you need, this ensures that you only request for what you need while leaving out what's meant to be hidden.
### Flexibility
Relational databases are often easy to install into any platform and you can access your database in any manner you see fit, either from a terminal or you could query the database using a programming language, php and MySQL are often the normal combination. It is also very easy to integrate relational databases with other systems and we can provision and expand it's capabilities by building tools on top of it.
### Data can be easily extended
If your data is properly structured then you will find that you can easily modify/extend your data, you can change the information on one table and be sure of the integrity of the data in other tables because we did not modify them, then we would just modify our queries to reflect the change.
I hope you learned something today, You can visit [EDUCBA](https://www.educba.com/relational-database-advantages/) for a free relational database tutorial, however if you prefer watching than reading, you can visit [this tutorial on youtube](https://youtube.com/playlist?list=PLV8vIYTIdSnaLvx1qGjOnYOb989ThPdU0). Please leave a comment and don't forget to hit the like button.
| kalashin1 |
688,635 | Top 5 plataformas LMS de e-learning para la formación en empresas | Las plataformas de e-learning ya no son un privilegio exclusivo de las grandes empresas, debido a que... | 0 | 2021-05-05T15:00:03 | https://dev.to/feygele/top-5-plataformas-lms-de-e-learning-para-la-formacion-en-empresas-l70 | elearning | Las plataformas de e-learning ya no son un privilegio exclusivo de las grandes empresas, debido a que hay muchos servicios accesibles e incluso gratuitos que pueden ser usados para la formación de los empleados. Sin embargo, aunque existen soluciones alternativas gratuitas, las empresas pequeñas están dispuestas a invertir en plataformas LMS o programas de gestión de formación que aseguren una implementación rápida, la mejor calidad en la entrega de dicha formación, soporte, y facilidad de uso.
En este artículo, hemos revisado cinco sistemas populares para la <a href="https://www.ispring.es/blog/formacion-continua">formación</a> online de empleados.
## Las mejores plataformas LMS de gestión y seguimiento de la formación
* iSpring Learn
* Docebo
* LearnUpon
* Litmos
* TalentLMS
Las cinco plataformas de e-learning presentadas en esta reseña son soluciones de “computación en la nube” o cloud-computing. “Cloud-computing” significa que el sistema funciona en línea y no necesita ser configurado. Normalmente, las soluciones en la nube son preferibles para los que quieren empezar a trabajar de inmediato y evitar implementaciones largas.
En esta reseña, hemos omitido intencionalmente las características que las plataformas tienen en común, ya que todas son muy intuitivas, pueden ser usadas en dispositivos móviles, y tienen funciones geniales como gamificación. En cambio, nos hemos centrado en las características que las hacen destacar y hemos definido ejemplos de usos para cada una.
## 1. iSpring Learn
Calificación: 4,7 / 5 – 87 reseñas (/<a href="https://www.capterra.com/p/144871/iSpring-Learn">Capterra</a>)
> Promesa del vendedor: “LMS rápido para tu proyecto esencial para la misión.”
<a href="https://www.ispring.es/ispring-learn">iSpring Learn</a>
es una plataforma LMS de computación en la nube fácil de usar para enseñar y evaluar empleados online.
Lo que diferencia iSpring Learn de sus competidores es iSpring Suite, un poderoso <a href="https://www.ispring.es/blog/mejores-herramientas-de-autor-de-elearning-para-usar">kit de herramientas de autor</a> integrado con el LMS. A diferencia de los programas incorporados para la creación de cursos que tienen algunos LMS, <a href="https://www.ispring.es/ispring-suite">iSpring Suite</a> ofrece funciones que van mucho más allá de añadir videos de YouTube y crear cursos simples de texto. Con su ayuda, puedes crear e-learning interactivo de alta calidad con evaluaciones avanzadas, videoconferencias, y simuladores de comunicaciones o diálogos.

Ejemplo de contenido de formación que puede crearse fácilmente con iSpring Suite
El archivo resultante puede subirse al sistema directamente desde el editor con 2 clics. Y dado que la plataforma LMS y el kit de herramientas de autor fueron desarrollados inicialmente para complementarse de forma natural, puedes obtener informes ampliados sobre el contenido y los usuarios.
### Precio
iSpring utiliza un modelo de precios basado en los usuarios activos. Esto significa que puedes registrar cualquier número de usuarios, pero un usuario se considera activo si él o ella ha iniciado sesión al menos una vez durante el período de facturación. El precio de los planes de iSpring Learn oscilan entre los 3,39 € por usuario activo al mes para 100 usuarios y 2,64 €/usuario/mes para 500 usuarios. Si el número de usuarios excede los 500, ofrecen un plan personalizado.
Con cualquier plan, obtienes todas las funciones del LMS. Además, el precio incluye al menos una licencia para iSpring Suite, una poderosa herramienta de autor para crear cursos, cuestionarios, simulaciones de diálogos, y videos.
### ¿Qué dicen los clientes?
Reseñas reales de los usuarios de iSpring Learn LMS. Fuente: <a href="https://www.capterra.es/software/144871/ispring-learn
">Capterra</a>
### Resumen
iSpring Learn es la solución que buscas si necesitas implementar formación corporativa fácilmente y en tan solo un día.
Gracias a su simplicidad y a que tendrás que pagar solamente por los usuarios activos, el LMS es perfecto tanto para los que lo usan siempre como para los que lo usan de forma esporádica. Junto con la poderosa herramienta de autor (además de una app móvil para estudiantes y el excelente soporte técnico), iSpring Learn es una plataforma de e-learning completa para tus empleados, socios, y clientes.
## 2. Docebo
Calificación: 4,2 / 5 — 108 reseñas (<a href="https://www.capterra.com/p/127213/Docebo/">Capterra</a>)
> Promesa del vendedor: “Alinea las necesidades de formación de tu organización con las de tus estudiantes con un LMS que utiliza algoritmos de inteligencia artificial específicos para producir experiencias de aprendizaje más profundas y efectivas.”
<a href="https://www.docebo.com/es/">Docebo</a> es una plataforma LMS flexible y escalable que ofrece una solución de aprendizaje empresarial completa.
Dos de las características de Docebo que llaman la atención al registrarse, son sus opciones de etiqueta blanca y marca. En la mayoría de las plataformas de e-learning, tener numerosas opciones de personalización de páginas es un privilegio. En Docebo, puedes personalizar literalmente todo: desde el fondo de la página de registro hasta el aspecto del catálogo de cursos; incluso puedes añadir tu logo y elegir los colores para la aplicación móvil.
Además de la personalización visual, Docebo también ofrece localización extensiva. Disponible en 40 idiomas, es una buena opción para empresas y compañías internacionales que necesitan ofrecer formación a empleados de todo el mundo. Hemos observado que algunas de las localizaciones parecen traducidas automáticamente. Sin embargo, una vez que tengas la traducción básica, puedes descargar una plantilla de tu idioma y mejorarla.
Otro aspecto interesante de Docebo es Capacita y Comparte (Coach and Share), una solución para aprendizaje social informal que promueve crear contenido generado por los usuarios. Los empleados pueden compartir sus ideas y mejores prácticas contribuyendo con presentaciones, guías, o videotutoriales en canales. Los estudiantes también pueden hacer preguntas y obtener respuestas de otros usuarios o expertos internos en el tema de una manera similar a un helpdesk: los expertos pueden ver la lista de preguntas pendientes y responderlas.
### Precio
Los planes de precios de Docebo varían dependiendo del número de estudiantes, las características requeridas, y los servicios prestados. Según FindTheLMS, el coste anual mínimo es de 2000 $ y puede llegar a los 500.000 $. El precio exacto solamente se puede saber contactando al proveedor.
### ¿Qué dicen los clientes?
Reseñas reales de los usuarios de Docebo. Fuente: <a href="https://www.capterra.es/software/127213/docebo">Capterra</a>
### Resumen
Gracias a las capacidades de su plataforma, Docebo merece estar en tu lista al seleccionar programas de gestión de formación para tu compañía. Al mismo tiempo, la sofisticación técnica también trae complejidad. Mientras algunos clientes de Docebo están satisfechos con sus numerosas características, a otros les decepciona el soporte ofrecido por el proveedor. Así que, si estás considerando Docebo, lo más probable es que necesites tiempo adicional para aprender a usarlo.
## 3. LearnUpon
Calificación: 4,9 /5 — 69 reseñas (Capterra)
> Promesa del vendedor: “Aprendizaje como debería ser. Capacita a tus empleados, socios, y clientes con el LMS de LearnUpon. Gestiona, monitoriza, y alcanza tus objetivos de aprendizaje usando una sola y poderosa solución.”

<a href="https://www.learnupon.com/">LearnUpon</a> es una plataforma LMS versátil que puede ser usada tanto para la formación de empleados internos como de socios externos.
Los diseñadores de LearnUpon hicieron un gran trabajo ya que la interfaz de la plataforma LMS parece estar ordenada y es fácil de usar, así que lo más probable es que sepas usar la mayoría de las funciones de la plataforma sin ningún entrenamiento. Al mismo tiempo, cada cliente tiene un gerente personal que le ayudará con cualquier posible problema.
Aunque la compañía ofrece a sus clientes soporte de primera categoría para todos los planes de precios, las funciones de la plataforma LMS sí dependen del plan de precios elegido. Si empiezas con el plan Básico, cuyo precio es de 599 € (~ 663 $) al mes, no tendrás ciertas funciones como gamificación, tareas, y facilidades para aprendizaje combinado, que están disponibles en los planes más caros.
Otra característica implementada sin problemas en LearnUpon (pero que depende del plan que elijas) es la facilidad de cambiar entre portales de aprendizaje. Esto te permite crear y personalizar ambientes de aprendizaje individuales para diferentes tipos de estudiantes, empleados o socios, u organizaciones.
### Precio
Un plan básico de LearnUpon te costará 699 € al mes con un máximo de 50 usuarios activos. Al elegir un plan más caso, el número de usuarios y características disponibles incrementará. Así que por 1,249 € al mes, puedes crear dos portales de aprendizaje, incorporar aprendizaje combinado, usar gamificación, tareas, y funciones para ventas online o eCommerce, y tener hasta 250 usuarios. Por 1,999 €, tendrás algunas integraciones adicionales, SSO, y más usuarios permitidos.
### ¿Qué dicen los clientes?
### Resumen
LearnUpon tiene reseñas muy amables de sus clientes, y casi todos hablan sobre lo fácil que es usar la interfaz fácil de la plataforma LMS, el diseño elegante, y la excelente atención al cliente.
Para algunas compañías más pequeñas, los planes de precios pueden ser demasiado caros, y quizás no puedan permitírselo. Sin embargo, es una solución muy buena para la formación de empleados, socios, y en empresas extendidas; muy bien pensada, fácil de entender, y usar tanto para administradores como para usuarios.
## 4. Litmos
Calificación: 4,2 /5 — 238 reseñas (<a href="https://www.capterra.com/p/133660/Litmos-LMS/#reviews">Capterra</a>)
> Promesa del vendedor: “Formación en el AHORA. La mejor plataforma de formación para empresas orientadas al cliente.”
(<a href="https://www.litmos.com/es-LA/">SAP Litmos</a>) es una plataforma LMS en la nube diseñada para publicar, proporcionar, y monitorizar rápidamente formación bajo demanda para miles de estudiantes. Es también un sistema fácil de usar tanto por el administrador como por el estudiante, ya que tiene un diseño agradable, y la interfaz es intuitiva.
SAP Litmos creó Litmos Heroes, un mercado gigante donde puedes tener acceso a más de 15.000 recursos de aprendizaje ya listos para usar. Los cursos están en formato video y son cortos (5 a 20 minutos de duración), por lo que mantendrán atento al estudiante.
Junto a un editor incorporado que te permite crear contenido de e-learning sencillo, esta plataforma es una buena opción para las compañías que no tienen actualmente un diseñador instruccional o que quieren ahorrar tiempo y dinero a la hora de producir sus propios contenidos de formación.
### Precio
SAP Litmos ofrece dos planes de precios. Uno es para el LMS y es facturado por usuario al mes, y el otro incluye acceso a la colección de cursos Litmos Heroes.
Para aquellos que solo buscan un LMS, serán 6 $ o 4 $ por usuario si la compañía entra en la categoría de 150-500 o 500-1,000 respectivamente. Si tienes menos de 150 usuarios al mes, solo puedes elegir el plan que incluye su librería de cursos (15 $ por usuario). Y, por supuesto, hay planes personalizados para aquellos con más de 1,000 estudiantes al mes.
### ¿Qué dicen los clientes?
Reseñas reales de los usuarios de SAP Litmos. Fuente: <a href="https://www.capterra.es/software/133660/litmos-lms">Capterra</a>
### Resumen
Aunque a algunos clientes no les gusta la asistencia ofrecida por el equipo de SAP Litmos, a otros la plataforma les parece intuitiva y muy fácil de usar, así que quizás no sea necesario ponerse en contacto con el servicio al cliente. De hecho, para esta reseña, hicimos una pequeña prueba y descubrimos cómo usarla en poco tiempo.
Por supuesto, algunos problemas solo se descubren después de usar la plataforma un cierto tiempo, por lo que una regla general al elegir un LMS es intentar contactar a los clientes existentes y preguntarles sobre su experiencia.
## 5. TalentLMS
Calificación: 4,6/5 – 317 reseñas (<a href="https://www.capterra.com/p/132935/TalentLMS/">Capterra</a>)
> Promesa del vendedor: “El camino más rápido hacia una mejor formación. Un programa en la nube muy fácil de usar para la formación de empleados, socios, y clientes.”
Aunque todas las plataformas LMS de esta lista son fáciles de usar (menos Docebo, quizás), <a href="https://es.talentlms.com//">TalentLMS</a> parece ser todavía más fácil. Después de registrarte para la versión de prueba, verás un tour del producto discreto, pero bien pensado que te muestra los primeros pasos y te ayuda a familiarizarte con las principales características que ofrece la plataforma.
Esta plataforma de e-learning destaca también por sus ajustes flexibles para la gamificación. El programa de gamificación de TalentLMS te permite añadir juegos y elementos de competición en los lugares adecuados, y configurarlos para casos de usos particulares. Por ejemplo, puedes crear contenido adicional oculto que solo estará disponible para los estudiantes que hayan alcanzado cierto nivel.
Los desarrolladores de TalentLMS también han trabajado en integraciones con muchas herramientas útiles. Hay más de 200 integraciones con servicios de terceros: Zapier, Shopify, Salesforce, WordPress, Slack, Zendesk, GoToMeeting, Trello, PayPal, Stripe, y más. Es perfecto para aquellos que usan diferentes servicios, ya que no tendrás que pagar extra para conectarlos todos.
### Precio
Para empezar, TalentLMS te permite elegir si quieres pagar por el número total de usuarios registrados o por usuarios activos al mes. Después puedes elegir pagar una tarifa mensual o anual (la tarifa anual es más barata).
El precio de los planes oscila entre los 59 $/mes por 40 usuarios registrados y los 429 $/mes por 1.000 usuarios. Para comparar, por 40 usuarios activos pagarás 129 $ al mes, mientras que para 100 pagarás 479 $/mes (casi no hay diferencia).
Además, si quieres empezar poco a poco, puedes usar la versión de prueba gratuita. Con esta versión puedes tener solamente 5 usuarios registrados y 10 cursos en el portal de aprendizaje, lo cual es poco incluso para el negocio más pequeño, pero es suficiente para empezar.
### ¿Qué dicen los clientes?
### Resumen
Las funcionalidades de TalentLMS no dependen del plan de precios, ya que todos los planes incluyen las características principales. Esto significa que las empresas más pequeñas disfrutarán de las mismas funciones que los clientes de empresas más grandes.
Gracias a su facilidad de uso que te permite empezar rápidamente, sin tener que pedir ayuda al servicio de atención al cliente y sin formación previa, TalentLMS es una buena opción si buscas un programa de formación y monitorización para empleados.
## Conclusión
Esta es nuestra conclusión cuando se trata de elegir plataformas LMS de formación y monitorización. Como probablemente ya habrás notado, a pesar de tener muchas cosas en común como ser servicios en la nube fáciles de usar, cada uno de estos es un paquete de características, servicios y precios únicos.
Nosotros te aconsejamos que uses las versiones de prueba gratuitas para ver cómo se adapta cada LMS a tus necesidades específicas y así encontrar la solución que mejor las satisfaga.
<a href="https://www.ispring.es/blog/5-plataformas-lms-de-lanzamiento-rapido-para-la-gestion-y-seguimiento-de-capacitacion ">Original source</a>
<a href="https://list.ly/list/5c6g-consejos-tips-y-trucos-en-e-learning">Más articulos sobre e-learning</a>
<a href="https://www.scoop.it/topic/e-learning-consejos-tips-y-trucos">Más</a>
<a href="https://sites.google.com/ispring.com/elearning-morning">Mi sitio web</a>
<a href="https://www.expoelearning.com/empresas-elearning">eLearning empresas</a>
<a href="https://www.expoelearning.com/plataformas-elearning">plataformas eLearning</a>
<a href="https://www.expoelearning.com/ispring-suite-max">iSpring Suite</a> | feygele |
688,756 | JavaScript Labels and Returning Early | Every once in a while, you find a feature of JavaScript you never knew about that has always been... | 0 | 2021-05-05T15:43:53 | https://alex.party/posts/2021-04-02-java-script-labels-and-returning-early/ | javascript, labels, loops | ---
title: JavaScript Labels and Returning Early
published: true
date: 2021-04-02 13:00:00 UTC
tags: [javascript,labels,loops]
canonical_url: https://alex.party/posts/2021-04-02-java-script-labels-and-returning-early/
---
Every once in a while, you find a feature of JavaScript you never knew about that has always been there. Labels are one of those odd vestigial bits of the language that make you go "But why?"
I have previously read about and experimented with labels on for loops in JavaScript and after seeing [Brendan Eich tweet about it](https://twitter.com/BrendanEich/status/1376912996748783616), I decided to experiment on if statements as well. I threw together a little [demo codepen](https://codepen.io/fimion/pen/NWddamo) and thought about why we don't use this style of syntax.
In a way, JavaScript labels are a callback to older languages and the GOTO command. Well, sort of. Traditionally, labels are used with the GOTO command to denote a place in the code to jump to. While you can still do this in C, it has fallen out of favor over the years as it is less readable and generally can be implemented with either a loop or an `if` statement. JavaScript does not have a GOTO command, but we do have labels. And they are rarely used because typically, there is another way to write your code.
### Label Use Case
The ideal use case for a label is typically with a nested loop or conditional.
{% codepen https://codepen.io/fimion/pen/WNRpaaK default-tab=js,result %}
In the above example, we can break out of the outer loop early by calling `break outer;` and it will immediately stop the outer loop. Brilliant! Similarly, you can do the same thing with `if` or `switch` statements, and leave those blocks early.
You can also label just a plain block of code. This is terribly out of fashion and will only work in non strict mode. More importantly, since ES6 modules are strict mode by default, using a label on a code block will cause your code to break. Generally speaking, I don't recommend doing this.
```javascript
// You can do this.
// But you really shouldn't.
label: {
console.log('this will run');
break label;
console.log('this will not');
};
```
### Returning Early
I mentioned earlier that the label pattern typically isn't seen in use because there are other ways of achieving the same functionality. A good example of this is to use functions to have the same outcome. This also allows the resulting code to be more testable and portable.
{% codepen https://codepen.io/fimion/pen/gOgmQzQ default-tab=js,result %}
In the above code we've broken the logic for both loops out into their own functions. The `outerLoop` function will call whatever callback we give it and the `innerLoop` function receives the value of `x` as an argument. We then call `outerLoop(innerLoop);` to kick off the whole thing. Both loops can escape early by returning before the loop is completed.
Code being broken into smaller pieces like this is why you do not see as much use of JavaScript labels. I love labels and the power they have, but I don't know that I'd want them in my code.
Originally Posted as [JavaScript Labels and Returning Early](https://alex.party/posts/2021-04-02-java-script-labels-and-returning-early/) at alex.party | fimion |
688,978 | CGN4 - Cloud Gaming Notes Episode 4 - Cross-platform social Sudoku with Azure PlayFab | Ever thought about what it takes to host a game in the Cloud? Well, this is the series for you! On... | 12,471 | 2021-05-05T18:23:12 | https://www.cloudwithchris.com/episode/sudoku-social | architecture, gamedev, gaming, azure | 
Ever thought about what it takes to host a game in the Cloud? Well, this is the series for you! On the first Wednesday of every month, we explore Cloud Concepts that impact your journey to a connected multiplayer gaming experience! In this session, Chris is joined by Dominic who has recently been through the process of building his own game, Sudoku Social! Take the classic puzzle game and adding a cross-platform social twist with the cloud. Sudoku Social has been a passion project to learn game development and bring players together to answer the ultimate question. Who is the fastest Sudoku player?
{% youtube GfOlIrflFq0 %} | reddobowen |
689,019 | SwiftUI: a new way to build views | One of the best announcement in 2019 was SwiftUI a complete different way to build visual interfaces... | 0 | 2021-05-19T13:03:04 | https://dev.to/cloudx/swiftui-a-new-way-to-build-views-3a82 | mobile, swift, ux, ios | One of the best announcement in 2019 was [SwiftUI](https://developer.apple.com/xcode/swiftui/) a complete different way to build visual interfaces more declarative and intuitive. Following Android with [Jetpack Compose](https://developer.android.com/jetpack/compose?hl=es-419) (both inspired by React Native ) Apple launched into the task of changing the old way that him have for make views.
##A Little history
Formerly for make apps in Apple environment we have to familiarizing with Storyboard this is a little difficult if you are a front-end developer used to web programming, concepts like a constraints, xibs and the way to connect the components with the view was something tedious, archaic and unintuitive. Also StoryBoards were difficult to merge, they almost always gave merge conflicts if 2 developers were working on the same StoryBoard even if they had not touched the same view, and they were difficult to undock.
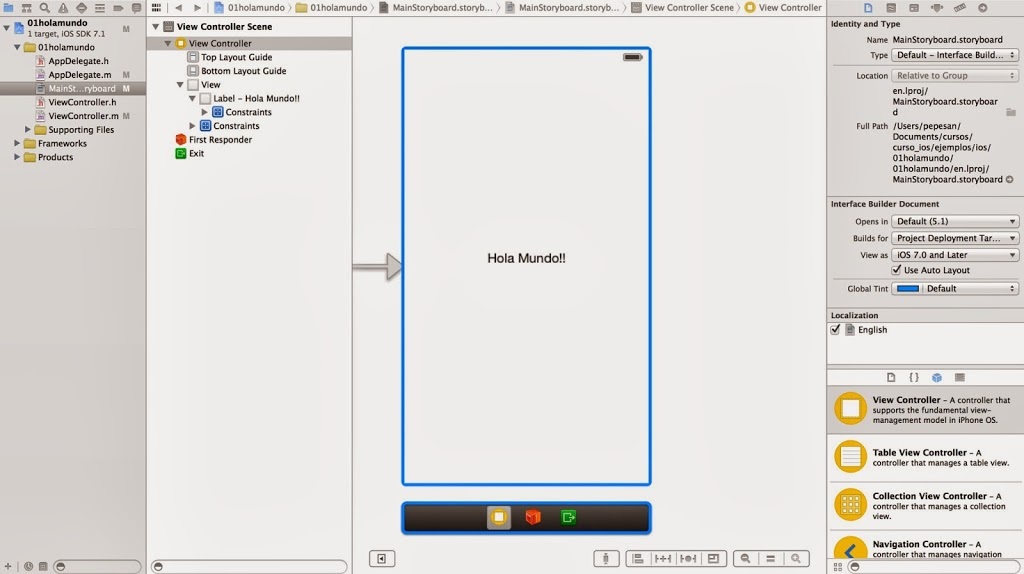
##SwiftUI and iOS 13
SwiftUI work with iOS13+ and this is for a simple reason and it have to do binary stability of the OS. Before iOS13 each app loaded in the SO have the specific resources library for the specific version of the code. Now iOS13 bring the resource library preloaded and can be understood with any app from iOS13, fir this reason the apps building for iOS13+ will weight less.
##How work SwiftUI
Those who have worked with React Native will found it very similar in the way to work, basically we have a view that return a body in where we have all the container at first level, just we can have one, and in that we can put anything you want, for example we can put a toolbar, like a first level, and nested containers inside.
What about the data?, we can pass data between different views that we use, use data enumerations within the structure itself, or create synchronous data sources that provide us with objects as dynamic data. Even asynchronous data that once retrieved causes events in the interface to be displayed. We can also give status to a property and each time it changes(DataBinding), the view on the screen will be redrawn. In the next example we have a NavigationView like a first container, so in the inside, we have a List with nested element like stacks and labels.
##Conclusion
SwiftUI is a new tools than allow create views that a way more intuitive, simple and declarative. After having working with React Native i realized of the archaic that Storyboard was. For that i loveled it SwiftUI. What do you think?
| ezequielmonteleone |
689,396 | Site to Site VPN for Google Kubernetes Engine | In this tutorial I will try to explain you briefly and concisely how you can set up a site-to-site... | 0 | 2021-05-06T06:37:08 | https://dev.to/alexohneander/site-to-site-vpn-for-google-kubernetes-engine-3ign | kubernetes, openvpn, google | ---
title: Site to Site VPN for Google Kubernetes Engine
published: true
description:
tags: kubernetes, openvpn, google
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/f2mzy51l9yawuu4hzu0w.jpg
---
In this tutorial I will try to explain you briefly and concisely how you can set up a site-to-site VPN for the Google Cloud Network.
### Prerequisites
We need 2 virtual machines. The first one on the side of our office and the other one on the side of Google.
#### Setup OpenVPN Clients
##### Site-to-Site Client Office Side
We need to install OpenVPN, we do it as follows:
```bash
apt install openvpn -y
```
After that we add our OpenVPN configuration under this path `/etc/openvpn/s2s.conf`.
*s2s.conf*
```
# Use a dynamic tun device.
# For Linux 2.2 or non-Linux OSes,
# you may want to use an explicit
# unit number such as "tun1".
# OpenVPN also supports virtual
# ethernet "tap" devices.
dev tun
# Our OpenVPN peer is the Google gateway.
remote IP_GOOGLE_VPN_CLIENT
ifconfig 4.1.0.2 4.1.0.1
route 10.156.0.0 255.255.240.0 # Google Cloud VM Network
route 10.24.0.0 255.252.0.0 # Google Kubernetes Pod Network
push "route 192.168.10.0 255.255.255.0" # Office Network
# Our pre-shared static key
#secret static.key
# Cipher to use
cipher AES-256-CBC
port 1195
user nobody
group nogroup
# Uncomment this section for a more reliable detection when a system
# loses its connection. For example, dial-ups or laptops that
# travel to other locations.
ping 15
ping-restart 45
ping-timer-rem
persist-tun
persist-key
# Verbosity level.
# 0 -- quiet except for fatal errors.
# 1 -- mostly quiet, but display non-fatal network errors.
# 3 -- medium output, good for normal operation.
# 9 -- verbose, good for troubleshooting
verb 3
log /etc/openvpn/s2s.log
```
We also have to enable the IPv4 forward function in the kernel, so we go to `/etc/sysctl.conf` and comment out the following line:
```
net.ipv4.ip_forward=1
```
We can then start our OpenVPN client with this command:
```bash
systemctl start openvpn@s2s
```
On the Office side we have to open the port for the OpenVPN client that the other side can connect.
##### Site-to-Site Client Google Side
When setting up the OpenVPN client on Google's site, we need to consider the following settings when creating it. When we create the machine, we need to enable this option in the network settings:

Also on this side we have to install the OpenVPN client again and then add this config under the path `/etc/openvpn/s2s.conf`:
```
# Use a dynamic tun device.
# For Linux 2.2 or non-Linux OSes,
# you may want to use an explicit
# unit number such as "tun1".
# OpenVPN also supports virtual
# ethernet "tap" devices.
dev tun
# Our OpenVPN peer is the Office gateway.
remote IP_OFFICE_VPN_CLIENT
ifconfig 4.1.0.2 4.1.0.1
route 192.168.10.0 255.255.255.0 # Office Network
push "route 10.156.0.0 255.255.240.0" # Google Cloud VM Network
push "route 10.24.0.0 255.252.0.0" # Google Kubernetes Pod Network
# Our pre-shared static key
#secret static.key
# Cipher to use
cipher AES-256-CBC
port 1195
user nobody
group nogroup
# Uncomment this section for a more reliable detection when a system
# loses its connection. For example, dial-ups or laptops that
# travel to other locations.
ping 15
ping-restart 45
ping-timer-rem
persist-tun
persist-key
# Verbosity level.
# 0 -- quiet except for fatal errors.
# 1 -- mostly quiet, but display non-fatal network errors.
# 3 -- medium output, good for normal operation.
# 9 -- verbose, good for troubleshooting
verb 3
log /etc/openvpn/s2s.log
```
We also have to enable the IPv4 forward function in the kernel, so we go to `/etc/sysctl.conf` and comment out the following line:
```
net.ipv4.ip_forward=1
```
##### Connection test
Now that both clients are basically configured we can test the connection. Both clients have to be started with systemctl. After that we look at the logs with `tail -f /etc/openvpn/s2s-log` and wait for this message:
```
Wed May 5 08:28:01 2021 /sbin/ip route add 10.28.0.0/20 via 4.1.0.1
Wed May 5 08:28:01 2021 TCP/UDP: Preserving recently used remote address: [AF_INET]0.0.0.0:1195
Wed May 5 08:28:01 2021 Socket Buffers: R=[212992->212992] S=[212992->212992]
Wed May 5 08:28:01 2021 UDP link local (bound): [AF_INET][undef]:1195
Wed May 5 08:28:01 2021 UDP link remote: [AF_INET]0.0.0.0:1195
Wed May 5 08:28:01 2021 GID set to nogroup
Wed May 5 08:28:01 2021 UID set to nobody
Wed May 5 08:28:11 2021 Peer Connection Initiated with [AF_INET]0.0.0.0:1195
Wed May 5 08:28:12 2021 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this
Wed May 5 08:28:12 2021 Initialization Sequence Completed
```
If we can't establish a connection, we need to check if the ports are opened on both sides.
#### Routing Google Cloud Network
After our clients have finished installing and configuring, we need to set the routes on Google. I will not map the Office side, as this is always different. But you have to route the networks for the Google network there as well.
To set the route on Google we go to the network settings and then to Routes. Here you have to specify your office network so that the clients in the Google network know what to do.

#### IP-Masquerade-Agent
IP masquerading is a form of network address translation (NAT) used to perform many-to-one IP address translations, which allows multiple clients to access a destination using a single IP address. A GKE cluster uses IP masquerading so that destinations outside of the cluster only receive packets from node IP addresses instead of Pod IP addresses. This is useful in environments that expect to only receive packets from node IP addresses.
You have to edit the ip-masq-agent and this configuration is responsible for letting the pods inside the nodes, reach other parts of the GCP VPC Network, more specifically the VPN. So, it allows pods to communicate with the devices that are accessible through the VPN.
First of all we're gonna be working inside the kube-system namespace, and we're gonna put the configmap that configures our ip-masq-agent, put this in a config file:
```yaml
nonMasqueradeCIDRs:
- 10.24.0.0/14 # The IPv4 CIDR the cluster is using for Pods (required)
- 10.156.0.0/20 # The IPv4 CIDR of the subnetwork the cluster is using for Nodes (optional, works without but I guess its better with it)
masqLinkLocal: false
resyncInterval: 60s
```
and run `kubectl create configmap ip-masq-agent --from-file config --namespace kube-system`
afterwards, configure the ip-masq-agent, put this in a `ip-masq-agent.yml` file:
```yaml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: ip-masq-agent
namespace: kube-system
spec:
template:
metadata:
labels:
k8s-app: ip-masq-agent
spec:
hostNetwork: true
containers:
- name: ip-masq-agent
image: gcr.io/google-containers/ip-masq-agent-amd64:v2.4.1
args:
- --masq-chain=IP-MASQ
# To non-masquerade reserved IP ranges by default, uncomment the line below.
# - --nomasq-all-reserved-ranges
securityContext:
privileged: true
volumeMounts:
- name: config
mountPath: /etc/config
volumes:
- name: config
configMap:
# Note this ConfigMap must be created in the same namespace as the daemon pods - this spec uses kube-system
name: ip-masq-agent
optional: true
items:
# The daemon looks for its config in a YAML file at /etc/config/ip-masq-agent
- key: config
path: ip-masq-agent
tolerations:
- effect: NoSchedule
operator: Exists
- effect: NoExecute
operator: Exists
- key: "CriticalAddonsOnly"
operator: "Exists"
```
and run `kubectl -n kube-system apply -f ip-masq-agent.yml`.
Now our site-to-site VPN should be set up. You should now test if you can ping the pods and if all other services work as you expect them to. | alexohneander |
689,590 | 💥ES6 ARRAYS 101 #1💥 | CREATE AN ARRAY IN ES5 In the ES5 specification, we mainly had two ways to create arrays:... | 0 | 2021-05-06T10:42:51 | https://dev.to/michalpzarzycki/es6-arrays-101-1-4ijo | programming, javascript, webdev | # CREATE AN ARRAY IN ES5
In the ES5 specification, we mainly had two ways to create arrays: array literal syntax and the `Array` constructor. Both ways only required listing the array elements one by one, which seems to be an easy task. But if we wanted to do something more like converting an array-like object (eg `arguments` in a function) to an array, we had some limitations and a lot of code to write.
# CREATE AN ARRAY IN ES6
To understand the problem of creating arrays with the Array constructor, it's worth seeing its unpredictability in action:
```js
let myArray = new Array(3);
console.log(myArray.length); //3
console.log(myArray[0]); //undefined
console.log(myArray[1]); //undefined
console.log(myArray[2]); //undefined
myArray = new Array("3")
console.log(myArray.length); //1
console.log(myArray[0]); //3
console.log(myArray[1]); //undefined
console.log(myArray[2]); //undefined
myArray = new Array(1,2,"3")
console.log(myArray.length); //3
console.log(myArray[0]); //1
console.log(myArray[1]); //2
console.log(myArray[2]); //3
```
When we passed a number in the form of `Number` to the constructor, it was assigned to the length property of the array, and whenever we changed the number to a `String`, it becomes the first element in the array. When we pass multiple values, they automatically become elements of the array. This behavior can confuse someone and cause many bugs, hence ES6 has a new option to create an array. In the form of the `Array.of()` method:
```js
let myArray = Array.of(3);
console.log(myArray.length); //1
console.log(myArray[0]); //3
myArray = Array.of(1, 2, "3")
console.log(myArray.length); //3
console.log(myArray[0]); //1
console.log(myArray[1]); //2
console.log(myArray[2]); //3
myArray = Array.of("3")
console.log(myArray.length); //1
console.log(myArray[0]); //3
```
To create an array, pass its values to `Array.of()`.
In most cases you don't need to use `Array.of()`, you just need to use plain array literal (`[]`), however when you need to pass the array constructor in a function, you'd better use `Array.of()`:
```js
function arrayCreator(creator, value) {
return creator(value)
}
let myArray = arrayCreator(Array.of, 69)
console.log(myArray) // [ 69 ]
```
Now let's move on to the problem I mentioned at the beginning, converting a non-array object to an array. This is what it looked like in ES5:
```js
function createArrayFrom(iWantToBeArray) {
var array = [];
for(var i=0; i<iWantToBeArray.length; i++) {
array.push(iWantToBeArray[i])
}
return array;
}
```
There is another way, to use the `slice()` method. You only need to define the this value for the slice method that acts on an array-like object. A little less code, but still not the best solution:
```js
function createArrayFrom(iWantToBeArray) {
return Array.prototype.slice.call(iWantToBeArray)
}
```
This moves to a new method in ES6 - `Array.from()`. When we give it, as the first argument, an element to be enumerated, or an array-like object, it will return an array:
```js
function createArrayFrom(iWantToBeArray) {
return Array.from(iWantToBeArray)
}
```
But it is not everything. If you want, you can add a mapping function as a second argument, with which you can change the values obtained during the conversion:
```js
function addOne() {
return Array.from(arguments, x=>x+1)
}
let myArray = addOne(1,2,3)
console.log(myArray) // [ 2, 3, 4 ]
```
Finally, you can use the `Array.from()` method on the iterating elements (any element containing `Symbol.iterator`):
```js
let sayHello = {
*[Symbol.iterator]() {
yield "Hello";
yield "World";
yield "!"
}
}
let LOUD_HELLO = Array.from(sayHello, x => x.toLocaleUpperCase())
console.log(LOUD_HELLO) // [ 'HELLO', 'WORLD', '!' ]
```
End of Part One.
💥Thanks for reading!💥
| michalpzarzycki |
689,688 | Why you should code in Rust in 2021 | Rust is one of the most loved languages by developers for 5 years - writing code in Rust will push y... | 0 | 2021-05-06T12:49:36 | https://www.heapstack.sh/why-you-should-code-in-rust-in-2021 | rust | Rust is one of the [most loved languages](https://stackoverflow.blog/2020/06/05/why-the-developers-who-use-rust-love-it-so-much/) by developers for 5 years - writing code in Rust will push you to be a better developer even if you will never use it in your daily job. In this article, I explain why you should learn to write code in Rust. Let's go.
# Better understanding of memory management
I remember the time I used to learn to program in Python. Memory was managed by the language, and I didn't need to understand how things work. Grasping algorithmic and all basic concepts when you are a beginner takes time. So spending time thinking about how to manage memory allocation is meaningless. But once you are fluent in programming and it is now so easy that you can focus on business value, it is maybe time to dig into how to build more efficient programs.
> For a long time, the efficiency of a program was about lower cost and performance. But in 2021, we can add a third dimension - power efficiency 🌎.
## Heap vs Stack
Java, Python, Javascript, Typescript, Go, Haskell, C# are managed programming languages. You don't need to think about memory allocation - does this variable `x` is allocated on the *heap* or on the *stack*? (*read more about [Heap vs Stack](https://www.guru99.com/stack-vs-heap.html)*). On the other hand, programming languages like C, C++, and Rust forced you to think about how you want to memory allocate your variable `x`.
```python
# Python - Stack x memory allocation
x = "hello world"
```
```rust
// Rust - Stack x memory allocation
let x: &str = "hello world";
```
Those two var assignations look similar, right? They are! They are allocated on the Stack. The difference is that with Rust, we have more fine-grained control on the memory allocation. For instance, to allocate "hello world" on the Heap:
```rust
// Rust - Heap x memory allocation
let x: String = String::from("hello world");
```
Heap allocation is not explicitly possible with Python - The interpreter manages it for you.
To summarize: Stack is used for static memory allocation and Heap for dynamic memory allocation, both stored in the computer's RAM. Variables allocated on the stack are stored directly to the memory, and access to this memory is very fast. The Heap memory allocation is slower than the Stack memory allocation.
## Reference vs Value
In Python, you don't even need to think about whether your function variables are passed by reference or value.
```python
# declare a function "sum"
def sum(a, b):
return a + b
sum(2, 1) # the result is 3
```
In this situation, values 2 and 1 are **passed** to the function `sum` **by value**.
```python
# declare a function "sum" accepting a list object
def sum(elements):
accumulator = 0
for e in elements:
accumulator += e
sum([2, 1]) # the result is 3
```
And in this situation, the list with values 2 and 1 inside is **passed** to the function `sum` **by reference**. 🙄
> It is not exactly true. In Python, "object references are passed by value" and not by reference. But I will not go into details here.
In Rust, you have to be specific if you want to pass a variable by reference or value.
```rust
// pass by value
fn sum(a: u16, b: u16) -> u16 {
a + b
}
sum(2, 1) // the result is 3
```
Values 2 and 1 are **passed** to the function **by value**. To pass by reference, you have to use `&` explicitly.
```rust
// pass by reference
fn sum(elements: &Vec<u16>) -> u16 {
let mut accumulator = 0;
for e in elements {
accumulator += e
}
accumulator
}
let values = vec![2, 1];
sum(&values) // the result is 3
```
We pass a list of values by reference to the function `sum`. And we can do the same by passing the value of the list by removing `&`
```rust
// pass by reference
fn sum(elements: Vec<u16>) -> u16 {
let mut accumulator = 0;
for e in elements {
accumulator += e
}
accumulator
}
let values = vec![2, 1];
sum(values) // the result is 3
```
The difference is that Rust will consume the list and will remove it from memory. This is a specific behavior of Rust (read [ownership](https://doc.rust-lang.org/book/ch04-01-what-is-ownership.html) ).
Passing variable by reference or value look anecdotal, but they are not when you need to build highly performant system like databases, embedded devices, and many others.
# Build safer programs
As a programmer, when you start to build concurrent programs, you don't really realize how hard it is to write safe concurrent code. This is so abstracted and easy to write unsafe code that we all fall into the trap at least once, and even when we are more experienced. Let me show one unsafe Golang code that I saw one time from an experienced developer:
```go
// golang example
m := make(map[string]string)
go func(m map[string]string) {
m["gender"] = "male"
}(m)
go func(m map[string]string) {
m["gender"] = "female"
}(m)
fmt.Println(m) // m["gender"] is male or female?
```
*this is not the exact code, but the idea of concurrently modifying a hashmap was the same*
So, the value of `m["gender"]` is `male` or `female`? 🤔
We can't know. This code is not deterministic due to concurrent writes. If you run this code multiple times, you will sometimes have `male`, sometimes `female`, and even sometimes `fatal concurrent write errors` 😨 To concurrently edit the hashmap `m` you have to make it *thread safe*. This kind of error happens all the time, even to experienced developers in more complex situations. This is where Rust helps developers to prevent this kind of mistake. Here is the equivalent in Rust:
```rust
let mut m: HashMap<&str, &str> = HashMap::new();
thread::spawn(move || {
m["gender"] = "male";
});
thread::spawn(move || {
m["gender"] = "female";
});
println!("{:?}", m);
```
And the compiler prevents you from doing nasty stuff.
```bash
error[E0382]: use of moved value: `m`
--> src/main.rs:11:19
|
5 | let mut m: HashMap<&str, &str> = HashMap::new();
| ----- move occurs because `m` has type `HashMap<&str, &str>`, which does not implement the `Copy` trait
6 |
7 | thread::spawn(move || {
| ------- value moved into closure here
8 | m["gender"] = "male";
| - variable moved due to use in closure
...
11 | thread::spawn(move || {
| ^^^^^^^ value used here after move
12 | m["gender"] = "female";
| - use occurs due to use in closure
```
Rust compiler is super smart, it prevents you from doing race condition, and there is no way to compile this kind of code because it is simply wrong. That's why so many developers said that [Rust is frustrating](https://vorner.github.io/difficult.html). The Rust compiler is just honest with you and tells you the truth about your code. You were probably writing wrong code for long time, and you didn't know until now. I know, it's hard to change habits, and that's why in this kind of situation Rust is your best friend. It will always tell you the truth, even if it is not pleasant :)
A thread-safe code in Rust looks like this (don't use it in production - using `.unwrap()` here can block threads):
```rust
let mut m: Arc<Mutex<HashMap<&str, &str>>> = Arc::new(Mutex::new(HashMap::new()));
thread::spawn(move || {
m.lock().unwrap()["gender"] = "male";
});
thread::spawn(move || {
m.lock().unwrap()["gender"] = "female";
});
println!("{:?}", m);
```
# Conclusion
I hope you liked this article, and it gives you the appetite to try out Rust. If you have no idea how to start learning it, I would recommend reading [the official free ebook](https://doc.rust-lang.org/book/). Then, trying to reimplement some good old academic (or not) algorithms and data structures in Rust. If you want to put your hands into dirty stuff, I can recommend contributing to my project [Qovery Engine](https://github.com/Qovery/engine) and [RedisLess](https://github.com/Qovery/redisless) as well.
Here is a shortlist of Rust projects that I recommend to read:
- [Meilisearch](https://github.com/meilisearch/MeiliSearch) : Algolia and Elasticsearch search engine alternative.
- [Sonic](https://github.com/valeriansaliou/sonic) : Lightweight Elasticsearch alternative.
- [Sled](https://github.com/spacejam/sled) : Storage engine written in Rust - alternative to RocksDB.
- [IsomorphicDB](https://github.com/alex-dukhno/isomorphicdb) : PostgreSQL clone - it is a good experimental project written in Rust.
- [Raft-rs](https://github.com/tikv/raft-rs) : Raft consensus protocol implemented in Rust by PingCap.
- [RedisLess](https://github.com/Qovery/redisless): RedisLess is a fast, lightweight, embedded, and scalable in-memory Key/Value store library compatible with the Redis API.
- [Qovery Engine](https://github.com/Qovery/engine): Qovery Engine is an open-source abstraction layer library that turns easy apps deployment on AWS, GCP, Azure, and other Cloud providers in just a few minutes.
==========
[I am hiring Rust developers](https://jobs.qovery.com) for my wonderful [company](https://www.qovery.com). | rophilogene |
689,837 | The Best Keyboards For Programming👨💻 in 2024✨ | Are you looking for a keyboard that can help you to work with ease and comfort? Then here is the best... | 0 | 2021-05-11T07:44:37 | https://dev.to/themeselection/the-best-keyboards-for-programming-in-2021-2f44 | programming, webdev, beginners | Are you looking for a keyboard that can help you to work with ease and comfort? Then here is the best collection of the best keyboards for programmers in 2024.

### Why Selection of a keyboard is important?
Well, we the programmers spend most of their days on a computer designing, writing, and testing code. That's what makes the keyboard one of the most important tools in our day-to-day job. A coder cannot just simply pick any random keyboard and hope it does the job.
We need to choose a keyboard that makes our work easy, stress-free, and fast. A keyboard that they can type on the whole day without straining and also reprogram it to access the most frequented applications on their computers easily. A great keyboard should minimize how often you use the mouse and consequently boost your productivity.
So, in order to provide you some of the best keyboards for programmers, we have made this collection of The Best Keyboards for programmers 2024. In this collection, we are going to discuss keyboards that you would love as a developer. The list I present is in no particular order, and I’m giving you my personal opinion on the keyboards and some facts.
### Which factors to consider while selecting the keyboard?
Well, the keyboard is not merely an input device for _hammering_ out lines of code. Programmers spend the majority of their time typing, therefore, a good keyboard must exhibit the following qualities:
1. **Comfort:** one programmer might be comfortable with a high-profile mechanical keyboard, while others might prefer a low-profile, membrane keyboard.
2. **Reliability:** a programmer can spend hours typing on their keyboard, and we’d want the keyboard to last for years. So reliability and build quality are very important.
3. **Responsiveness:** different keyboards can provide a different level of feedback depending on their switches, keycaps, and other factors. Good feedback is very important so we can spend less time making mistakes in our typing.
### Other Things to Consider When Buying a Keyboard
**Mechanical vs. Membrane**
Basically, There are two basic types of keyboards available: Membrane or Mechanical. The primary difference is based on how the keyboard actuates its input.
Now, a membrane keyboard utilizes a thin, commonly polyurethane film (the membrane) to press on a circuit layer when registering a pressed key. This design allows the keycaps to be much thinner than a mechanical keyboard, so the keyboard is typically more portable.
Besides, the membrane is also much cheaper to manufacture than the parts of a mechanical keyboard, so a membrane keyboard is typically much more affordable.
However, a membrane keyboard produces a mushy feel and less overall responsiveness. It is also much more difficult to clean and has a shorter lifespan.
While, a mechanical keyboard, utilizes mechanical parts, typically spring-loaded switches to actuate the pressed keys. This method offers a distinct response, the ‘click’ that is unique to mechanical keyboards, giving it a much better response than a membrane keyboard.
Well, a mechanical keyboard won’t directly help improve your programming skills, but it does offer a much more comfortable typing experience, which will indirectly help to make the coding experience more enjoyable.
As we know, improving our moods and comfort can significantly improve our productivity, and this is where a good mechanical keyboard comes in.
**Key Switch**
In a mechanical keyboard, the key switches will dictate the character of the keyboard itself. Also, Different switches will produce different feels and sounds to each keypress and will suit different people. This kind of affects the mood of the programmer.
**Ergonomics**
Well, Keyboards are built in many different designs, including products like the Microsoft Sculpt and Kinesis Advantage2 that provide unique ergonomic designs for additional comfort.
There are also some keyboards that offer unique shapes of keycaps, like the Spherical-All (SA) profile keycaps for different typing experiences. Some also offer features like wrist rests and other features to help with ergonomics.
Since coders can spend a lot of their time typing on the keyboard, it’s very important to choose the right shape/profile that will be comfortable for you.
**Form Factor**
Keyboards nowadays come in three main form factors (in a nutshell, sizes): full-sized, tenkeyless (TKL), and compact/mini.
- **Compact:** This form factor eliminates F1-F12 and the arrow keys, and to access these buttons we should use the function (Fn) keys. There are also other variations like the 65% layout that still includes the arrow keys and navigation cluster (Pg Up, Pg Dn, etc.).
- **Tenkeyless:** There are several different variations to the tenkeyless (TKL) form factor but in general you’ll have all the keys as you would in a standard keyboard _except_ the numeric pad (the numeric keypad is also known as _tenkey_, hence the name).
- **Full-sized:** They feature 104 keys in total including F1 to F12 and a full numeric pad. However, obviously, they are also the largest of the bunch and not very portable.
### Which one is a better keyboard type? Prograaming or Gaming?
Well, both offer some amazing features. For example, gaming keyboard offers
- **Precision** with anti-ghosting and other technologies to ensure you are getting exactly what you press. In long hours of programming, this can be very useful and improves efficiency.
- **Extra buttons**. Some gaming keyboards offer extra buttons like media playback, volume up/down, and so on. These can be useful to help in aiding your productivity.
- **Durable**. They are designed for long-term aggressive use, and typically also easier to clean.
- **Lighting** If you happen to like the colorful RGB lighting, then it can improve your mood. Obviously, lighting would also help when you work at night or in darker conditions.
- **Macros**. The ability to program certain keys. This can be useful, for example, in cases where you’ll need to repeatedly use a certain string. You can easily macro this string on a key.
- **Extra buttons**. Some gaming keyboards offer extra buttons like media playback, volume up/down, and so on. These can be useful to help in aiding your productivity.
Now, let's start the collection.

#### 1. [Das Keyboard 4 Professional Soft Tactile](https://www.daskeyboard.com/daskeyboard-4-professional/)

DAS is another most used keyboard for programmers as it gives easiness and comfort. Das mechanical keyboard for programming has moved from the usual Cherry MX switches we are used to and is instead using gamma Zulu switches. They claim that these switches can last for about 100 million keypresses. That is about 2x the MX. Das Keyboard 4 supports full NKRO over USB. No need to use a PS2 adapter anymore. Just press shift + mute to toggle to NKRO (works with both Windows and Linux).
**Product Details**
- Connectivity Technology: USB, USB 3.0, USB 2.0
- Brand: Das Keyboard
- Number of Buttons: 104
- Keyboard Description: Mechanical
- Number of Keys: 104
- Layout: ANSI, QWERTY
**About this product**
- Cherry MX switches with Gold contacts for reliability and quality
- Rugged construction with an aluminum top panel, built to handle 50+ million keystrokes (20-30 years on average)
- Two USB 3.0 Superhub
- Volume knob (oversized) and dedicated media controls with the instant sleep button
- Laser-etched key inscriptions with Bumps on the F and J keys for touch-typing aid.
- Updatable firmware
- Elevated height at 1.2 inches (3.1 cm)
- N-key rollover with full anti-ghosting
- Magnetically detachable footboard to raise the keyboard, can also function as a rule
**Advantages:**
- Sturdy build, as expected from DAS’s German engineering
- Cherry MX switch, long-lasting with great typing experience
- Dedicated media keys and a great, functional volume knob
- IFTTT protocol support for integration
**Disadvantages:**
- The volume knob is rather hard to rotate it
- It is not the cheapest
#### 2. [Keychron K2 Wireless Mechanical Keyboard](https://www.keychron.com/products/keychron-k2-wireless-mechanical-keyboard)

The keyboard is high quality, feels very robust, and it’s very comfortable, it is a bit high, and we recommend using a palm rest. It has support for multiple Bluetooth devices. Also. it t has a massive battery of 4000mAh, which translates in a lot of time without charging, though I usually have it plugged in, just for convenience. It has support for Windows, Linux, and Mac, and it even provides a different set of keys for Mac and windows so that you can customize it to your liking.
We at [Themeselection](themeselection.com), personally use this keyboard and we find it super smooth and amazing while working on it. We recommend this keyboard as it offers both comfort and speed together. We provide high-quality and easy-to-use [bootstrap admin templates](https://themeselection.com/products/category/bootstrap-admin-templates/), UI Kits, and Admin Dashboard Template.
#### 3. [Microsoft 5KV-00001 Sculpt Ergonomic Wireless Keyboard for Business](https://www.microsoft.com/accessories/en-ww/business/sculpt-ergonomic-keyboard-for-business/5kv-00001)

This is one of the most preferable keyboards for programmers. It is surprisingly comfortable. Furthermore, it is reinforced by a padded wrist rest that makes sure that you do not bend your wrist too much. Besides, the palm rest attaches to the keyboard by a magnet, and you can remove it if you prefer typing on your lap. And what's better is that the tilt is adjustable. You can experiment on different heights to find one that is most comfortable for you.
**Product Detail**
- Connectivity Technology: Wireless
- Brand: Microsoft
- Number of Buttons: 107
- Keyboard Description: Ergonomic
- Number of Keys: 107
**About this item**
- Split keyset design helps to position wrists and forearms in a natural, relaxed position
- Cushioned palm rest provides support and promotes a neutral wrist position
- Domed keyboard design positions wrists at a natural, relaxed angle
- Separate number pad provides greater flexibility for workspace setup
- Natural arc key layout mimics the curved shape of the fingertips
- Cushioned palm rest provides support and promotes a neutral wrist position
- Reverse tilt angles of the keyboard to promote a straight neutral wrist position
**Advantages:**
- Comfortable ergonomic design
- Separate num pad
- Wireless
- Detachable palm rest
- Adjustable tilt
#### 4. [Logitech MX Keys Advanced Illuminated Wireless Keyboard](https://www.logitech.com/en-in/products/keyboards/mx-keys-wireless-keyboard.920-009418.html)

The **MX Keys** from **Logitech** is an advanced wireless illuminated keyboard crafted for efficiency, stability, and precision. It comes packed with features like Perfect Stroke keys shaped for your fingertips, smart illumination, and a remarkably solid build. This keyboard also supports flow cross-computer typing across multiple screens.
**Product Details**
- Connectivity Technology: USB, USB 3.0
- Brand: Logitech
- Number of Buttons: 108
- Number of Keys: 108
**About the product:**
- Bundle includes: Logitech MX Keys Advanced Wireless Illuminated Keyboard and Knox Gear 4-Port USB 3.0 Hub
- Perfect stroke keys: Perfect Stroke keys are shaped for your fingertips and increased key stability reduces noise while optimizing responsiveness
- Comfortable design: Tactile reference for hand positioning makes it easy to stay oriented and in your flow
- Backlit Keys: The backlit keys light up the moment your hands approach, and automatically adjust to suit changing lighting condition
---
Apart from this, we recommend you check our latest [React Admin Dashboard](https://themeselection.com/item/category/react-admin-templates/) to create responsive web apps.
[](https://themeselection.com/item/materio-mui-react-nextjs-admin-template/)
---
#### 5. [NPET K10 Gaming Keyboard USB Wired Floating Keyboard](https://www.amazon.com/NPET-Floating-Keyboard-Mechanical-Illuminated/dp/B01ALLT2W4/)

2-in-1 NPET K10 keyboards have two different usage scenarios - office working and gaming. Fantastic mechanical feeling gaming keyboard, perfect for whatever battles you might face. Besides, it offers high performance as this keyboard adopts liquid silicone conductive film which has good resilience.
**Product Detail:**
- Connectivity Technology: Wired
- Brand: NPET
- Number of Buttons: 104
- Keyboard Description: Gaming
- Number of Keys: 104
**About this product:**
- Professional Gaming Keyboard. UV coated keycaps and injection laser carving ABS keycaps design, the letter of characters never fade. Anti-sweat, prevents keycap damage, enhanced durability, and tactile feedback.
- Thick and firm stainless steel base plate, long service life, and never deforms. Metal and ABS construction make it more solid and reliable.
- The NPET K10 gaming keyboard is more durable than the plastic keyboard, your best keyboard choice
- Colorful Illuminated Keyboard. 4 LED lighting backlit modes, breathing(7-color alternate).
- 3 Adjustable permanent mixed backlit modes, changeable breathing, or permanent lighting modes.
- 104 Keys Standard Keyboard. 13 multi-media key combinations, 26 keys non-conflict, strengthened space key.
**Advantages:**
- NPET LED backlit gaming keyboard, your best gaming teammate
- Strong durability, ultra-thin floating keycap design
- Non-slip ergonomic and spill-resistant design
- 26 anti-ghosting keys, never miss a keystroke during the game
- 4 LED lighting backlit modes, breathing
- Plug and play, easy to operate with the USB braided cable, no driver needed
- 13 multimedia key combinations
- Compatible with Windows 95/98/XP/2000/ME/VISTA/7/8/10 and Mac OS
#### 6. [Dell Multi-Device Wireless Keyboard](https://www.dell.com/en-us/shop/dell-multi-device-wireless-keyboard-and-mouse-combo-km7120w/apd/580-aisy/pc-accessories)

Dell Premier Multi-Device Wireless Keyboard and Mouse - KM7321W is engineered with full-sized yet slim, this quiet keyboard keeps you efficient with all the keys you need. Tilt legs give you the flexibility to adjust to your preferred typing position while the sculpted mouse is designed to fit perfectly in your hand. The native 1600 DPI mouse offers preset DPIs of up to 4000, adjustable via the Dell Peripheral Manager.
**Product Detail:**
- Connectivity Technology: Wireless, USB
- Brand: Dell
- Number of Buttons: 108
- Number of Keys: 108
**About this product:**
- Ultimate Productivity: Wireless - 2.4GHz or Bluetooth 5.0. Seamlessly connect and pair up to 3 devices with this premium combo via RF or Bluetooth connectivity.
- Stylish and sleek with a premium finish, this combo lets you work comfortably in style.
- 12 programmable keys and 5 shortcut mouse buttons let you customize to frequently used applications or functions.
**Advantages:**
- Flexible multi-tasking
- Well-crafted design
- Durable and secure
#### 7. [SteelSeries Apex 5 Hybrid Mechanical Gaming Keyboard](https://steelseries.com/gaming-keyboards/apex-5)

The Apex 5 combines the high performance and click tactile feel of a mechanical keyboard with the extreme durability and convenience of ip32 water resistance. Built from the ground up for gaming, it also includes a premium magnetic wrist rest, OLED smart display, and per-key RGB. The Apex 5 is the perfect hybrid between gaming and real life.
**Product Detail:**
- Connectivity Technology: USB
- Brand: SteelSeries
- Number of Buttons: 104
- Number of Keys: 104
**About this product:**
- Hybrid mechanical gaming switches – The tactile click of a blue mechanical switch plus a smooth membrane
- OLED smart display – Customize with gifs, game info, discord messages, and more.
- Aircraft-grade aluminum alloy frame – Manufactured for unbreakable durability and sturdiness
- Dynamic per-key RGB illumination – Gorgeous color schemes and reactive effects for every key
- Premium magnetic wrist rest – Provides full palm support and comfort
- 900 x 300 x 4 millimeter / 35.43 inches x 11.81 inches
**Advantages:**
- Hybrid mechanical switches
- Dedicated multimedia control
#### 8. [Razer Huntsman V2 Analog Gaming Keyboard](https://www.razer.com/gaming-keyboards/razer-huntsman-v2-analog/RZ03-03610200-R3U1)

If you’ve ever used a thumbstick or joystick, you’ll know how intuitive in-game movement feels with that type of control—the more the stick is pushed, the faster you go, and vice versa. With scaling inputs based on how far a key is pressed, Razer Analog Optical Switches work in a similar way and are ideal for racing games, flight sims, and the like
**Product Detail:**
- Connectivity Technology: USB
- Brand: Razer
- Number of Buttons: 104
- Number of Keys: 104
**About the product:**
- Ergonomic, Magnetic Wrist Rest: Made of plush leatherette to maximize comfort over extended gaming sessions (with built-in under glow lighting)
- Multi-function Digital Dial and 4 Media Keys: Configure them to pause, play, skip, and tweak everything from brightness to volume—the ultimate convenience as you enjoy your entertainment
- USB 3.0 passthrough: Instead of reaching over to your rig to plug in a device, you can connect it conveniently to your PC via a USB port in the Razer Huntsman V2 Analog
- Razer Analog Optical Switches: Set the desired actuation point to suit your playstyle, or use analog input for smoother, more nuanced control—doing away with rigid 8-way WASD movement for true 360-degree motion
**Advantages:**
- High-end design with high-quality RGB backlight, great if you prefer a gaming-oriented design
- Very stable on your table with rubber pads and various designs
- Reliable and high-performance Razer switches, some might prefer Razer switches over Cherry MX switches
- Great magnetically attachable wrist rests for comfortable typing
- Highly programmable, integration with Razer Synapse software
#### 9. [HyperX Alloy HX-KB1SS2-US FPS RGB](https://www.amazon.com/HyperX-HX-KB1SS2-US-Mechanical-Gaming-Keyboard/dp/B07G2PY7KH/)

HyperX alloy FPS RGB is a high-performance mechanical computer gaming Keyboard designed to enhance your gaming performance and keep your desktop layout colorful with customizable RGB LED lighting effects. The HyperX Alloy FPS RGB can be customized with easy-to-use HyperX Ingenuity software to help make your keys pop and stand out. Save up to three profiles and switch easily by pressing the F1, F2, and F3 keys to toggle between your different customization profiles.
**Product Detail:**
- Connectivity Technology: USB 2.0
- Brand: HyperX
- Number of Buttons: 104
- Number of Keys: 104
**About the product:**
- RGB backlit keys with dynamic lighting effects
- Advanced customization with HyperX Ingenuity software (available via download)
- Compact, ultra-portable design with detachable cable
- Solid steel frame
- Silver speed mechanical key switches
#### 10. [Logitech G213 Gaming Keyboard](https://www.amazon.com/Logitech-G213-Prodigy-Gaming-Keyboard/dp/B07QGHK6Q8/)

G213 Prodigy is a performance-driven wired Logitech keyboard designed for gamers of all levels. Slim, durable, precise, and spill-resistant, G213 Prodigy is designed for the way you play. Personalize brilliant Logitech RGB color lighting and lighting patterns to match your style from a spectrum of 16. 8 million colors. Customize all 12 Function keys to quickly and accurately execute complex maneuvers. With performance-tuned keys, G213 Prodigy brings together the best in tactile feedback you can feel and gaming-grade performance. Keys are tuned to deliver ultra-quick, responsive feedback that is up to 4 times faster than the keys on standard keyboards, while the anti-ghosting gaming matrix prevents response delays even when you press multiple keys simultaneously. With dedicated media controls, you can play, pause, and mute music and videos instantly right from the keyboard.
**Product Detail:**
- Connectivity Technology: Wired
- Brand: Logitech
- Number of Buttons: 104
- Number of Keys: 104
- Keyboard Description: AWERTY
**About this item**
- Prodigy Series Logitech G keyboard for advanced gaming-grade performance up to 4x faster than standard keyboards so every keypress is near instantaneous from fingers to screen
- Brilliant Color Spectrum Illumination lets you easily personalize up to 5 lighting zones from over 16.8 million colors to match your style and gaming gear
- Tactile performance keys tuned for gaming with responsiveness and more. LCD Display: No
- Dedicated media control let you quickly play, pause, skip and adjust the volume of music right from the keyboard
- Easily customize key lighting, 12 Function keys with custom commands, and more with free Logitech Gaming Software
#### 11. [Apple Magic Keyboard](https://www.apple.com/in/shop/product/MRMH2HN/A/magic-keyboard-with-numeric-keypad-space-grey?)

Magic Keyboard with Numeric Keypad features an extended layout, with document navigation controls for quick scrolling and full-size arrow keys for gaming. A scissor mechanism beneath each key allows for increased stability, while optimized key travel and a low profile provide a comfortable and precise typing experience. The numeric keypad is also great for spreadsheets and finance applications. And the built-in, rechargeable battery is incredibly long-lasting, powering your keyboard for about a month or more between charges
**Product Details:**
- Connectivity: Bluetooth, Wireless
- Keyboard Description: QWERTY
**About the product:**
- Magic Keyboard combines a sleek design with a built-in rechargeable battery and enhanced key features.
- With a stable scissor mechanism beneath each key, as well as optimized key travel and a low profile, Magic Keyboard provides a remarkably comfortable and precise typing experience.
- It pairs automatically with your Mac, so you can get to work right away.
#### 12. [Logitech G915 Wireless Mechanical Gaming Keyboard](https://www.amazon.com/gp/product/B07NY9ZT92/)

G915 is a new class of Wireless mechanical gaming Keyboard with 3 selections of low-profile GL switches and pro-grade 1 ms LIGHTSPEED Wireless. Capable of delivering 30 hours of non-stop gaming on a full charge. Fully customizable per-key, LIGHTSYNC RGB technology also reacts to in-game action, audio, and screen color as you choose. With a sleek, impossibly thin yet durable, and sturdy design, the G915 brings gamers to a Higher Dimension of play. Programmable G-keys let you create and execute complex actions simply and intuitively and the volume wheel and media keys give you fast, easy control over video, audio, and streaming.
Product Details:
- Connectivity Technology: Wireless
- Brand: Logitech
- Number of Buttons: 104
- Number of Keys: 104
**About the product:**
- Worlds NO. 1 Best Selling Wireless Gaming Gear Brand - Based on independent aggregated sales data (FEB ‘19 - FEB’20) of Wireless Gaming Keyboard, Mice, & PC Headset in units from US, CA, CN, JP, KR, TW, TH, ID, DE, FR, RU, UK, SE, TR
- LIGHTSPEED wireless delivers pro-grade performance with flexibility and freedom from cords. Creates clean aesthetics for Battlestations. Delivers 30 hours on a single full charge.
- LIGHTSYNC technology provides next-gen RGB lighting that synchronizes lighting with any content. Personalize each key or create custom animations from ~16. 8M colors with Logitech G HUB software.
- Low-profile mechanical switches offer the speed, accuracy, and performance of a mechanical switch at half the height. The GL Clicky switch features a distinctive sound and tactile feedback. Comes in 3 options: GL Tactile, GL Linear, or GL Clicky.
**Advantages:**
- Low-profile design with ultra-thin body
- Great Logitech key switches with reliable performance, a lot of people prefer Logitech switches to Cherry MX
- Great LIGHTSPEED wireless connectivity, very low latency
- RGB backlighting with Logitech LIGHTSYNC
**Disadvantages:**
- Expensive
- Skeletal design can trap dust
---
### Conclusion:
So, this was the collection of the best keyboards for programming in 2024. Here we have gathered some of the best programming keyboards that can help you work comfortably and smoothly.
As you can see, getting the right keyboard is a combination of several factors. Besides, there are also some technical aspects to it that an average user will find hard to understand. We have discussed those factors at the beginning of the collection in detail.
We hope this collection helps you pick the best one by considering each factor independently. Do tell us which one is your favorite keyboard in the comment section below. **Do share your keyboard pics as well..!!**

---
## About us
We at [ThemeSelection](https://themeselection.com/) provide Selected high-quality, modern design, professional, and easy-to-use Free and Premium [Bootstrap Admin Templates](https://themeselection.com/item/category/bootstrap-admin-templates/), [Asp NET Dashboard](https://themeselection.com/item/category/asp-net-dashboard/), [Vue JS Admin Template](https://themeselection.com/item/category/vuejs-admin-templates/), [Laravel Admin Panel](https://themeselection.com/item/category/laravel-admin-templates/), [Nuxt Dashboard](https://themeselection.com/item/category/nuxt-admin-template/),
[Django Admin Template](https://themeselection.com/item/category/django-admin-template/), [NextJS Admin Template](https://themeselection.com/item/category/next-js-admin-template/), HTML Themes, and [Free UI Kits](https://themeselection.com/item/category/free-ui-kits/) to create your applications faster!
If you want to [Free Admin Templates](https://themeselection.com/item/category/free-admin-templates/) then do visit [ThemeSelection](https://themeselection.com/).
--- | theme_selection |
689,989 | Curtidos Menacho | En Curtidos Menacho, queremos como mayorista de piel, que obtengas cueros de gran calidad. Somos expe... | 0 | 2021-05-06T17:23:25 | https://dev.to/mafer49822656/curtidos-menacho-3ni2 | cuero | En Curtidos Menacho, queremos como mayorista de piel, que obtengas cueros de gran calidad. Somos expertos en el curtido de trozos de piel y tenemos una gran experiencia en todo lo relacionado, con la piel y el curtido artesanal.
<a href="https://curtidosmenacho.com/es/">Curtidos Menacho</a>
| mafer49822656 |
690,348 | Fiscal Management/ Budgeting | Fiscal management is how an organization obtains and uses their funds in order to operate. One... | 11,710 | 2021-05-07T02:49:39 | https://dev.to/diyawi/fiscal-management-budgeting-46mg | lis55, learningdiary | Fiscal management is how an organization obtains and uses their funds in order to operate. One major part of this is creating a budget. A budget is an expenditure plan that involves using available funds over a given period of time, usually one fiscal year. For libraries, the main components of the budget are the operational budget, what is needed to run the library building, the personnel budget, what is needed to pay the library staff, and the materials or acquisitions budget, what is needed to grow the library collection. Major components of the materials budget include equipment, technological infrastructure, conservation and preservation expenses, vendor service charges, catalog cards (if the library still uses card catalogs), shipping and handling fees, institutional membership fees and shared digital repository fees.
In libraries, budgeting may be done in a variety of ways. Some of these are the zero-based budget, program or performance-based budget, the formula-based budget, the historical budget and the line-item budget.
The zero-based budget literally means starting from zero every year and calculating a new budget from scratch.
The program or performance-based budget is based on the plans and objectives set by the library each year as well as current ongoing library programs.
Formula-based budgets are calculated based off of a formula provided by an accrediting body or professional standards. It is not widely used because the inflexible nature of plugging values into a formula means that if some variable changes then the formula must be reworked.
Historical budgets start with the previous year's budget and determines which expenditure category needs to be incremented or decremented. For this type of budget it is of the utmost importance to provide accurate estimates for budget requests, which is done using funding projections for current levels of purchasing.
Line-item budgets are simply based on the calculated spending in each category of expenditure. It may be combined with historical budgets in order to have a basis for calculating spending in each category.
Sources of library funding may come from library fees, or come from an organization or from endowments or donations. However, one problem that libraries encounter with funds coming from outside sources is difficulty establishing credibility with possible outside sources of funding. These sources of funding do not realize that Consumer Price Index numbers do not apply to library materials. In essence, sources of funding may not realize that "cheaper alternatives" to some library materials do not exist. Competition between similar products does not happen, as different library collection materials contain different information and thus all have their own unique value. As a result producers are not motivated to keep their prices competitive and as such are above the CPI rate.
Instead of the CPI, the ALA's Library Materials Price Index (LMPI) Editorial Board of the Association for Library Collections and Technical Services division has created the "Prices of U.S. and Foreign Published Materials". The difficulty with these indexes lies in finding up to date information.
For publications from foreign libraries must also take into account shipping prices and unpredictable exchange rates that can greatly change from the time between proposing a budget, receiving the funding and being able to purchase the foreign materials. Another difficulty lies in comparing the different methods of procuring foreign items and choosing the best one. These difficulties are often felt in Philippine libraries, especially those whose collections consist mainly of books in English.
It is most common to allocate the budget funds into different categories based on the priorities of the library or its governing organization. Other ways of allocating funds include based on supply and demand factors, or formula allocation; based on previous fund allocation schemes, or historical allocation; based on format of library material, the format allocation method; based on expenditure category, category allocation method; and based on impulse, the impulse allocation method.
In general the largest amount, around half, of the libraries budget goes towards paying it's employees. The rest of the budget goes towards collections, operations and contingencies for the future. Fund allocation for the collection portion is usually based on past practices, changes in publication rates, unit cost and inflation rates, levels of demand and usage of materials.
One fiscal management activity that is unique to libraries is encumbering. Encumbering involves noting the price of individual library materials to be acquired and setting aside the necessary funds for it. Encumbering is different from simply noting down the cost of the library material since when the acquisition team picks out the material there is no way for them to know either the discounts the library may get from the publisher, or the shipping and handling fees that may be associated with getting that library material. Since multiple orders stack up daily and funds only become unencumbered once all the materials arrive and are actually paid for, the end result is that neither the acquisitions department nor the selectors know the precise balance except on the first and last day of the fiscal year. It is the job of the bookkeeper or accounting manager of the library to have some rough idea of the state of the library's funds.
Fiscal management and budgeting is essential for libraries because for libraries to operate they need money. These funds must be allocated in alignment with the principles of the library and its governing body, otherwise they could get taken away. In order to prove that these funds were used for their intended purpose the financial records of the library must be kept organized. To this extent, and audit is performed by an organization outside of the library.
An audit is the process of checking that financial records are accurate and follow accounting practices. It usually involves checking whether purchases were authorized, received properly and paid for appropriately and also making recommendations for how the process can be improved.
Types of audit include financial records audits, which are performed annually; operational audits, which check that the organization's procedures are being followed; performance audits, which check that the employees are doing their jobs correctly; and compliance audits, which check that the organization is complying with standards set by a higher body -- usually to continue being able to use funding granted by that body.
| diyawi |
690,611 | How to Add a Popup to WordPress Websites Freely and Quickly | When visiting a website, have you ever seen an image or message suddenly shown on the screen? That’s... | 0 | 2021-05-07T07:31:25 | https://gretathemes.com/add-popup-wordpress-website/ | wordpress, popup, wensite | When visiting a website, have you ever seen an image or message suddenly shown on the screen? That’s the popup or the notification window of the website.
Popup is a popular and effective marketing strategy, used by a lot of business runners and website owners. To add a popup like that to WordPress, you can use a free plugin to make it quick and simple. Even if you’re not an expert, it takes only 10 minutes to follow our instruction.
<!--more-->
<h2>Why Should You Use a Popup on a Business Website?</h2>
The image below is an example for the popup of a business website. It looks great, isn’t it?
<img class="aligncenter" src="https://i.imgur.com/74o9fr1.gif" alt="Install and activate the plugin in the Dashboard." width="1907" height="939" />
Popup is not only stunning (if you manage to design a well-matching and attractive one) but also have many other benefits like:
<ul>
<li>Promote important information, sale and marketing campaigns,...</li>
<li>Call to action, increase conversion rate</li>
<li>Generate lead</li>
</ul>
<h2>Add a Popup to WordPress with Popup Builder plugin</h2>
To add a popup to your WordPress website, you can hire a credible <a href="https://elightup.com/" rel="follow">web design company</a> or a coder. However, to save time and money, plugin is the best option. Among a plenty of popup plugins out there, Popup Builder may be the most easy-to-use and effective.
It is a free plugin and available on <a href="https://wordpress.org/plugins/popup-builder/">wordpress.org</a>, so you just need to i<a href="https://gretathemes.com/install-wordpress-plugin/">nstall and activate the plugin</a> right in the Dashboard.
<img class="aligncenter" src="https://i.imgur.com/vv5EQuH.png" alt="Install and activate the plugin in Dashboard." width="772" height="611" />
Upon finishing, follow these steps below.
<h3>Step 1: Choose the Popup’s Type</h3>
Now the <strong>Popup Builder</strong> submenu will show up on the Dashboard. Go there, click <strong>Add News</strong> and choose one of the 4 provided popup’s types.
<img class="aligncenter" src="https://i.imgur.com/vch1rPU.png" alt="Click Add News on Popup Builder submenu and choose 1 of 4 popup's style." width="1902" height="933" />
For better illustration, the image below is how the 4 types of popup provided by this plugin display on the front end.
<img class="aligncenter" src="https://i.imgur.com/0c2dHJs.png" alt="There are 4 types of popup." width="1000" height="800" />
After choosing the type you want, go to the next step.
<h3>Step 2: Add Content to the Popup</h3>
First, give the popup a name to manage it more easily.
<img class="aligncenter" src="https://i.imgur.com/ygjpy9L.png" alt="Name the popup." width="1624" height="905" />
Different types of popup need different contents. Let’s dig in each type.
<h4>Add Content to Facebook Popups</h4>
On the interface to create Facebook popups, you need to fill in these information:
<ol>
<li>The message that shows up in the popup. You should use a call-to-action sentence to encourage readers to interact. Also, you should add images, banners so that it will be more stunning.</li>
<li>Insert Facebook URL.</li>
<li>Choose a layout for the popup on a whim. Basically, these layouts are not so different. Thus, you can try them out and choose your favorite one.</li>
<li>Click here to hide the share button if you want.</li>
</ol>
<img class="aligncenter" src="https://i.imgur.com/iaL0NpM.png" alt="Fill in the popup's information." width="1920" height="933" />
And this is what I’ve got:
<img class="alignnone" src="https://i.imgur.com/43N3TJj.png" alt="Result of the Facebook popup." width="1920" height="931" />
<h4>Add Content to Image Popups</h4>
Here you just need to upload the image or insert the image’s link. This plugin supports JPG, PNG and GIF.
<img class="aligncenter" src="https://i.imgur.com/eSkpPma.png" alt="You need to upload the image or insert the image's link." width="1900" height="932" />
This is a beautiful banner that I made by myself for the Black Friday campaign of my website:
<img class="aligncenter" src="https://i.imgur.com/7Ha32Aj.png" alt="Example of the Black Friday image popup." width="1920" height="937" />
<h4>Add Content to HTML Popups</h4>
Adding content to HTML popup is just like writing a post in WordPress Gutenberg editor. You can insert images, videos, tables, buttons, quotes, … or any other content that WordPress editor supports. The interface is kinda similar to Gutenberg editor, so it’s quite friendly and native.
<img class="aligncenter" src="https://i.imgur.com/ewIjX3h.png" alt="Adding content to HTML popup is so easy like writing a post." width="1905" height="846" />
And this is my HTML popup on the front end:
<img class="aligncenter" src="https://i.imgur.com/KE1SGhB.png" alt="Here is HTML popup on the frontend." width="713" height="784" />
<h4>Add Content to Subscription Popups</h4>
Here we have quite a lot of content to fill in and customize for your subscription form. However, what you need to notice most is fields of the form, such as <strong>First name</strong>, <strong>Last name</strong>, <strong>Email</strong>, and customize their<strong> Placeholder</strong> and <strong>Required field</strong>.
<img class="aligncenter" src="https://i.imgur.com/70VWcX0.png" alt="You can fill many information in Subscription Popups." width="1920" height="937" />
After that, scroll down and customize the display of the form in terms of <strong>Form background options, Inputs’ style, Submit button styles</strong> to make it more stunning and matching to the website.
Notably, in the <strong>After successful subscription</strong> section, tactfully choose a suitable message, or information that you want to show to your users after they subscribe. For example, you can display thank-you notes, coupons, gifts, gift cards, … for these subscribers. By doing that, you can drag users’ impressions and improve their experience.
<img class="aligncenter" src="https://i.imgur.com/gPji94v.gif" alt="Choose a suitable message or information that you want to show to your users after they subcribe." width="1920" height="937" />
For example, this is my subscription email popup. Once they have submitted, I will show a notification about the Black Friday sale campaign, urging customers to go shopping.
<img class="aligncenter" src="https://i.imgur.com/859kNnD.gif" alt="Example of my content subscription popup." width="1920" height="937" />
Go to <strong>Popup Builder > All Subscribers</strong> to manage subscribers.
<img class="aligncenter" src="https://i.imgur.com/DElHVwd.png" alt="Go to Popup Builder > All Subscribers to manage subscribers." width="1920" height="937" />
You can even send emails to subscribers in the <strong>Newsletter</strong> tab.
<img class="aligncenter" src="https://i.imgur.com/sPByT88.png" alt="You can even send emails to subscribers in the Newsletter tab." width="1920" height="937" />
After adding content to it, scroll down. You will see many other setting options. Let’s dig in each option in the steps 4,5,6.
<h3>Step 3: Set up the Display Location and Condition of the Popup</h3>
<h4>Set up the Display Location</h4>
In the <strong>Popup Display Rules</strong> section, we need to adjust where the popup will/ will not show up.
You can choose <strong>Everywhere</strong> to show it on every page, post, tag, or customize, or show it in a certain place that you want. You can also click the (?) tooltip to get more details.
For example, I choose the location as a certain page, choose <strong>“is”</strong> to display it, and choose the display page as <strong>“Home”</strong>. In addition, you can add other locations by choosing <strong>Add</strong>.
<img class="aligncenter" src="https://i.imgur.com/3zNSk3t.gif" alt="In the Popup Display Rules section, we need to adjust where the popup will / will not show up." width="1449" height="673" />
<h4>Set up the Display Condition</h4>
In the <strong>Popup Events</strong> section, choose the time when the popup shows up (when the website has loaded for a few seconds, when users click somewhere, etc). This plugin support these following display conditions:
<ul>
<li><strong>On load</strong>: The popup will automatically show up after a few seconds (you can add the number of seconds in the <strong>Delay</strong> tab) from when the site finished loading.</li>
</ul>
<img class="aligncenter" src="https://i.imgur.com/3gHYZb2.png" alt="The popup will automatically show up after a few seconds from when the site finished loading." width="1151" height="442" />
<ul>
<li><strong>Set by CC class</strong>: allows users to click some component to enable the popup. This component will be based on the ID of it. This part is kinda complicated so you had better read the <a href="https://help.popup-builder.com/en/category/events-3cslam/">documentation</a> carefully.</li>
</ul>
<img class="aligncenter" src="https://i.imgur.com/evgzxT2.png" alt="Set by CC class: allows users to click some component to enable the popup." width="1108" height="502" />
<ul>
<li><strong>On click</strong>: similar to<strong> Set by CSS class</strong> section but you don’t need to use the ID of the popup to install the “button” to enable it.</li>
</ul>
Instead, if you choose <strong>Default</strong> in the<strong> Options</strong> section, the plugin will create a default class for the popup in the <strong>Default Class</strong> section as below.
<img class="aligncenter" src="https://i.imgur.com/p8Z8R9g.png" alt="if you choose Default in the Options section, the plugin will create a default class for the popup in the Default Class section." width="1422" height="422" />
If you choose <strong>Custom CSS</strong>, fill in the class that you have created yourself in the <strong>Custom Class</strong> section.
<img class="aligncenter" src="https://i.imgur.com/kNvxaMS.png" alt="If you choose Custom CSS, fill in the class that you have created yourself in the Custom Class section." width="1402" height="486" />
After that, add the class of the popup into the CSS of the component that you want.
For example, in this post, I added a button and the class I want in the <strong>Additional CSS classes</strong> section.
<img class="aligncenter" src="https://i.imgur.com/L1c3AXy.png" alt="I added a button and the class of the popup I want in the Additional CSS classes section." width="1523" height="905" />
This is the result on the front end:
<img class="aligncenter" src="https://i.imgur.com/RwIXrgj.gif" alt="Here is the result of popup. " width="1920" height="937" />
<ul>
<li><strong>Hover Click</strong>: when hovering on a component, the popup will show up. You can do the same as in the <strong>On Click</strong> section.</li>
</ul>
<img class="aligncenter" src="https://i.imgur.com/95pM9r7.png" alt="Hover Click: when hovering on a component, the popup will show up. You can do the same as in the On Click section." width="1396" height="492" />
<h3>Step 4: Customize the Popup’s Display</h3>
After step 3, you have had a basic popup. But if you want it to be more stunning, scroll down to the <strong>Design</strong> section. Here you can customize some components like interface, overlay, background to make it perfect as your favorite.
<img class="aligncenter" src="https://i.imgur.com/vM0bqKU.png" alt="In the Design section, you can customize some components as you like." width="1580" height="515" />
More than that, in the <strong>Dimensions</strong> section, adjust the its width and length by choosing <strong>Custom mode</strong>, or choosing <strong>Responsive mode</strong> to make its size match its content automatically.
<img class="aligncenter" src="https://i.imgur.com/FzunhgL.png" alt="In the Dimensions section, you can customize width and length of the popup." width="1427" height="390" />
<h3>Step 5: Customize Other Advanced Settings</h3>
These advanced settings allow you to configure displaying and interacting with popup, … in a more detailed way.
For example, you can choose how to close the popup window in the <strong>Close Settings</strong> section. There are many ways to close it, such as press <strong>Esc</strong>, or add a close button, … Choose one or more, that’s up to you.
<img class="aligncenter" src="https://i.imgur.com/1p2a1ly.png" alt="You can choose how to close the popup window in the Close Settings section." width="1432" height="578" />
If you want to add effects of closing and opening popup, or adjust the times it is shown for one user, … scroll down to the <strong>Popup Options</strong> section. You just need to click on the option that you want, and there you’ve done.
Note that when using the free Popup Builder plugin, the sections named <strong>Unlock Option</strong> colored in yellow like the image below are pro version’s features. You have to buy more extensions of this plugin to use them.
<img class="aligncenter" src="https://i.imgur.com/svDUs8I.png" alt="There are some premium features of Popup Builder" width="1431" height="591" />
Finally, on the sidebar, there is a very interesting option: adding a fixed button on the website to show the popup when click on. This floating button is really convenient, allowing people to see it everytime and everywhere. Its design is also pleasant and not annoying.
<img class="aligncenter" src="https://i.imgur.com/zGe1W6j.png" alt="On the siderbar, you can add a fixed button on the website to show the popup when click on." width="1902" height="895" />
This is the floating button on the website:
<img class="aligncenter" src="https://i.imgur.com/LTtLXoz.gif" alt="his is the floating button on the website." width="1900" height="934" />
Or you can disable it by clicking <strong>Disable</strong>.
<img class="aligncenter" src="https://i.imgur.com/hWgzQRq.png" alt="You can disable the popup by clicking Disable." width="518" height="574" />
Finally, click <strong>Publish</strong> to get it done.
So you have completed your popup after 6 steps from basic to advanced settings. You have done a good job!
<h2>Last Words</h2>
As you can see, adding a popup to WordPress is not really complicated. You just have to be patient a little bit when customizing its display, that’s all of the hard work!
In addition, there are many things to increase conversion rate of the website. If you want to build an effective landing page, you had better read some more articles about <a href="https://gretathemes.com/create-landing-page-really-convert/">how to create a high-converting landing page</a>, or <a href="https://metabox.io/create-product-pages/" rel="follow">how to create a product page</a>.
Good luck! | gretathemes |
690,628 | How To Improve Your SEO Ranking | In this article, we'll be discussing how to optimize your website or brand to increase its visibility on Google and other search engines. | 0 | 2021-05-07T08:19:10 | https://blog.jemimaabu.com/how-to-improve-your-seo-ranking | seo, a11y, beginners, webdev | ---
title: How To Improve Your SEO Ranking
published: true
description: In this article, we'll be discussing how to optimize your website or brand to increase its visibility on Google and other search engines.
tags: SEO, accessibility, beginners, webdev
canonical_url: https://blog.jemimaabu.com/how-to-improve-your-seo-ranking
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6v4hslodxz7sltwpg2x3.png
---
Fun fact: if you Google "[front end developer Nigeria](https://www.google.com/search?q=front+end+developer+nigeria)", my portfolio website shows up on the first page. Why? SEO.
Search Engine Optimization (SEO) is how you make sure your website shows up in relevant search results. Ranking refers to a website's position in those search results.
In this article, we'll be discussing how to optimize your website or brand to help you get a high ranking on Google and other search engines. We'll also discuss how to improve the online presence for yourself or your brand.
I'd like to preface this by saying that I'm not an SEO expert so I'll just be sharing the tips that worked for me.
Here's what we'll be covering in this article:
1. [What is SEO?](#what-is-seo)
2. [Why is SEO important?](#importance-of-seo)
3. [How do I improve my website's SEO ranking?](#tips-for-improving-seo)
4. [How do I improve my personal/my brand's online presence?](#tips-for-creating-an-online-presence)
5. [How do I test the SEO of my websites?](#testing-for-seo)
## What is SEO
> Search engine optimization is the process of improving the quality and quantity of website traffic to a website or a web page from search engines.
Simply put, SEO is ensuring that your website receives relevant and continuous traffic through organic search results. Organic search results refer to results that show up in search terms due to relevancy as opposed to paid search results.
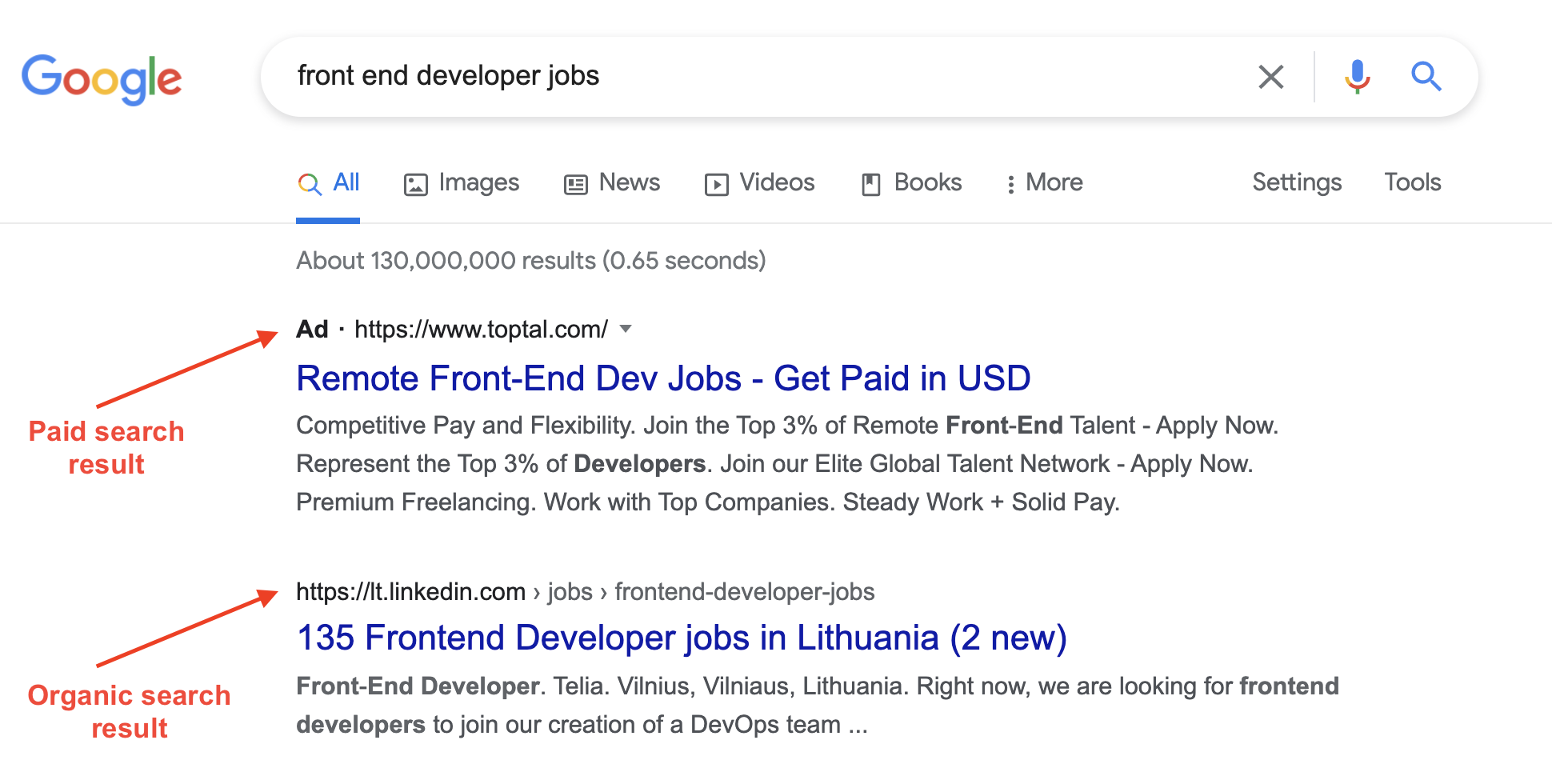
Studies have shown that people [tend to click more on organic search results than ads](https://www.oakcitytechnology.com/websites/do-people-actually-click-on-paid-ads-in-google/#:~:text=However%2C%20to%20answer%20this%20directly,organic%20results%20over%20paid%20ads.).
SEO doesn't just affect your websites; it affects the visibility of anything you post online such as articles, products or videos.
The world of Search Engine Optimization is so vast and complex that companies have dedicated [SEO managers](https://digitalmarketinginstitute.com/blog/what-does-an-seo-manager-do) just to ensure the visibility of their brand.
## Importance of SEO
The major importance of SEO is to increase the traffic and visibility of your website and content. High rankings are the best way to generate traffic to your site.
The above image is a screenshot of the traffic for [an article I wrote in 2017](https://jemimaabu.medium.com/how-to-write-a-cv-in-nigeria-d05d8981dbda). The article has had over 32,000 views since then and over 50% of that traffic was from organic search results on Google.
Having a high ranking means that you no longer have to constantly market your products and content and instead you attract your target audience naturally.
Think of it this way: when was the last time you went to the second page of Google? The higher your search engine ranking, the more visible your site is.
## Tips for Improving SEO
There are [multiple ranking factors](https://backlinko.com/google-ranking-factors) that can affect the SEO of your site but I'll be focusing on the factors I prioritized in order to optimize my website:
1. Accessibility
2. Metadata
3. Relevant content and links
4. Performance and page speed
5. Traffic and backlinks
6. Domain name and extensions
### Accessibility
Accessibility means creating websites that can be used by everyone. Ideally, you should build your websites to be as accessible as possible. Not only is it considered best practice but it also [directly affects your site SEO](https://www.dbswebsite.com/blog/accessibility-seo-a-perfect-fit/).
Accessibility also improves user experience which is another important contributor to SEO.
Here are some quick tips to focus on to ensure your personal website meets base accessibility needs:
- **Use the lang attribute in your HTML tag.** The lang attribute is what allows browsers to translate websites from one language to another so be sure to write your HTML tags appropriately e.g. `<html lang="en">`
- **Use alt tags for images that require description.** Alt tags describe the content of an image for screen readers and should be included as attributes in image tags `<img alt="" src="" />`. Alt tags are also [used by search engines](https://www.bigcommerce.com/ecommerce-answers/what-is-an-alt-tag-and-how-does-it-impact-seo/) to return relevant image results.
- **Use [semantic elements](https://www.w3schools.com/html/html5_semantic_elements.asp#:~:text=What%20are%20Semantic%20Elements%3F,%3E%20%2D%20Clearly%20defines%20its%20content.) for creating layouts in HTML.** Semantic elements such as `nav`, `footer` and `header` provide a description of the content to screenreaders.
- **Use heading tags in the appropriate order.** The rule of thumb is to have only one H1 tag on a page, serving as the title and let the headings follow in sequential order i.e. a `h4` tag shouldn't appear before a `h2` tag in the same section.
- **Ensure that the colors on your site have adequate contrast.** Adequate contrast between the colors of the text and the background allows for easily readable content.
- **Use descriptive links.** Links on your website should describe the page they lead to e.g. `Read More About Me` rather than generic statements like `Click Here`.
You can view my slides on [Getting Started With Web Accessibility](https://www.jemimaabu.com/talks/web-accessibility.html), watch my video on [Understanding Accessibility as A Concept](https://www.youtube.com/watch?v=QSXdTuD9Rak) or check out the [Accessibility Checklist by Jay Nemchik](https://romeo.elsevier.com/accessibility_checklist/downloads/developer_designer_checklist.pdf) for more information and resources.
### Metadata
Metadata is what provides information about your website to search engines.
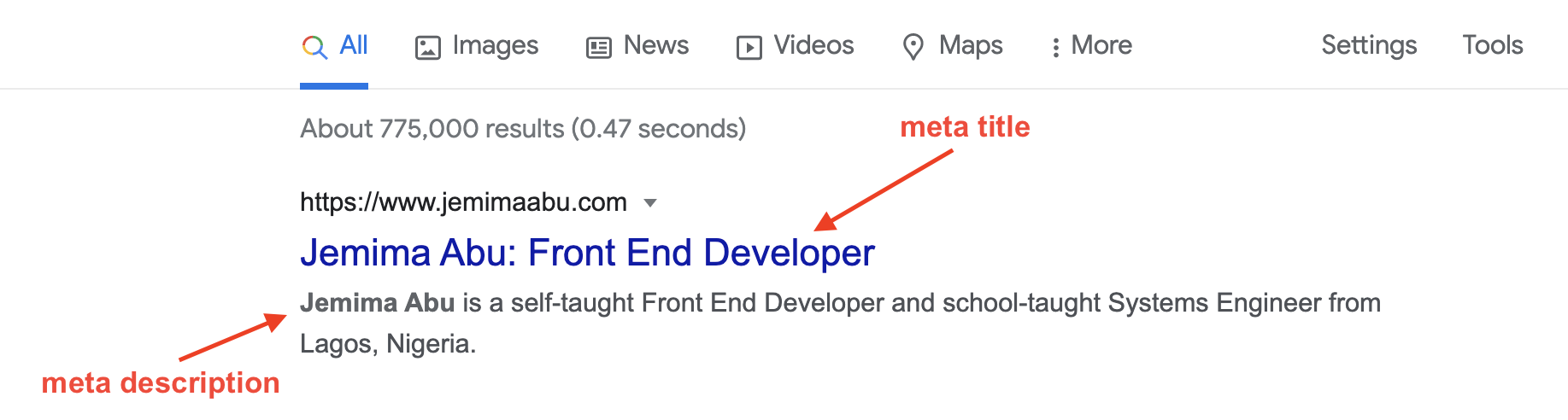
The two major tags for SEO are:
- **Title.** The `<title>` tag is included in HTML and it contains the name of your webpage. It's a good idea to include your main keyword in your title tag.
```html
<title>Jemima Abu: Front End Developer</title>
```
The title tag should be changed on each page to describe the content of the new page e.g. `<title>About Me | Jemima Abu</title>`. A descriptive title also improves the ranking for articles and videos. Your title should be between 50 to 60 characters to avoid search engines [truncating or ignoring it](https://unamo.com/blog/seo/title-tags-best-practices#:~:text=Length,cut%20off%20in%20the%20middle.).
- **Description.** The description tag describes the content of your webpage and it's also placed in the <head> tag of your HTML page. It should explain the main goal of your webpage and use more keywords related to the message you're trying to pass along.
```html
<html>
<head>
<meta name="description" content="Jemima Abu is a self-taught
Front End Developer and school-taught Systems Engineer
from Lagos, Nigeria.">
</head>
</html>
```
Another tag to mention is the **keywords** tag. It was previously used by search engines to match relevant keywords but most search engines have announced that [they no longer consider the meta keyword tag](https://www.reliablesoft.net/meta-keywords/#relevancy) in a site's ranking. Using too many keywords can also have a negative impact on your site's SEO as this could be seen as spam by some search engines.
### Relevant content and links
Providing relevant content on your website increases your website's SEO ranking. Here are some tips on increasing the relevancy of content for articles:
- **Use action words in your title** and words related to search terms. An article with a title like "Introduction to Web Accessibility" or "How to Make Your Website Accessible" would be placed higher than an article simply titled "Web Accessibility".
- **Use proper formatting** by separating sections with titles and emphasizing important content using bold text or italics.
- **Include links to related resources** in your article. [Using outbound links](https://blog.alexa.com/outbound-links-content-marketing/#:~:text=Linking%20to%20high%2Dquality%20external,SEO%20health%20of%20a%20page.) can lend to the credibility of your content.
- **Avoid plagiarism.** If Google detects the same content in two search results, they'll remove whichever they consider least relevant. If you're trying to upload your content to multiple sites, be sure to include a [canonical link](https://moz.com/learn/seo/canonicalization#:~:text=A%20canonical%20tag%20(aka%20%22rel,content%20appearing%20on%20multiple%20URLs.).
- **Provide a summary** of your content in list tags. Google tends to place summarized content at the top of search results.
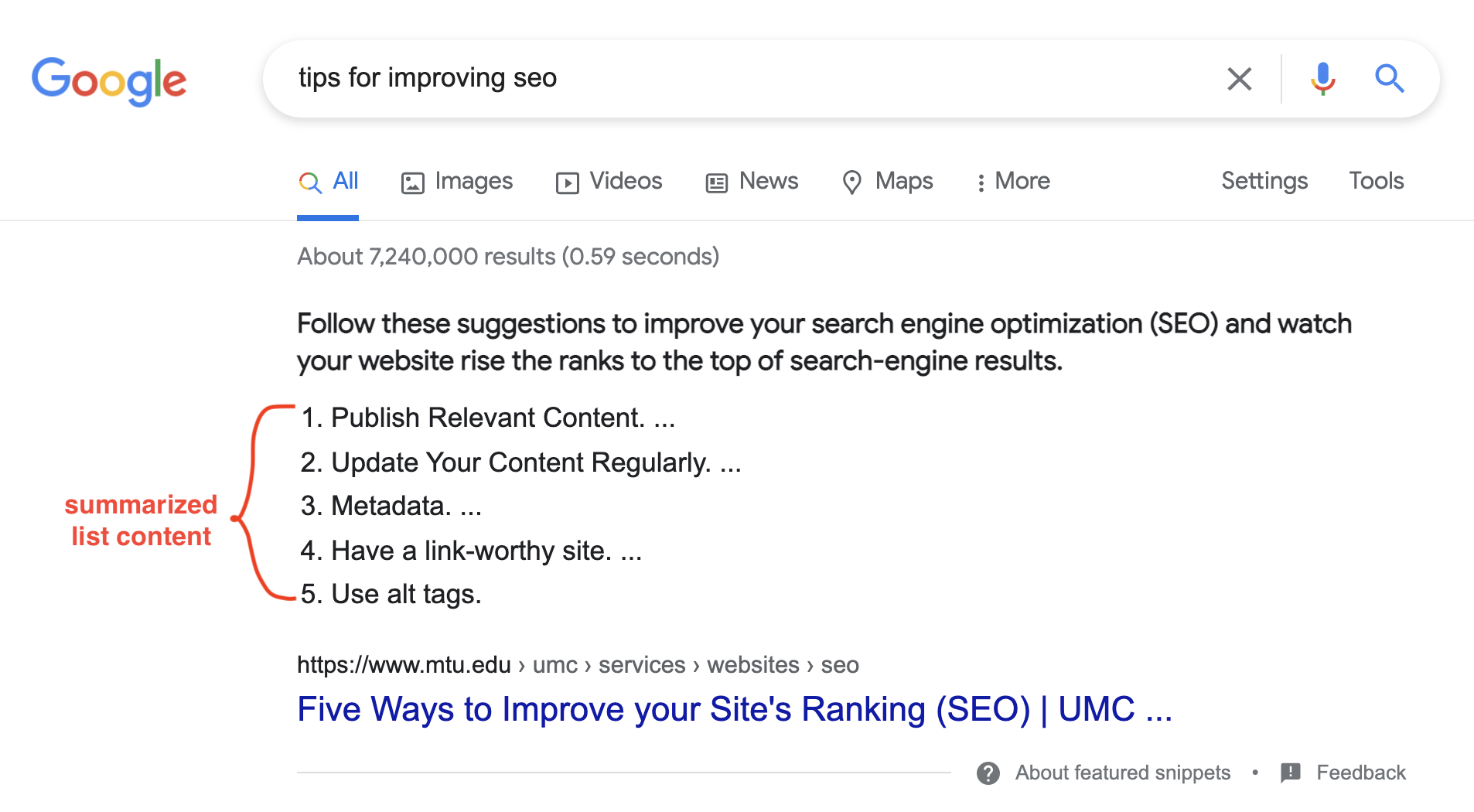
Using relevant keywords in the link of your article also helps with ranking. If I write an article titled "How To Make Your Website Accessible", a good link would be `myblog/make-your-website-accessible`.
### Performance and Page Speed
Performance and page speed are factors used by Google to determine a website's ranking. If your page loads slowly or has poor performance, it [directly affects your SEO](https://moz.com/learn/seo/page-speed).
Here are some tips on improving how fast your page loads:
- **Reduce images to the maximum rendered size.** If an image on a page only gets rendered at a maximum width of 450px then the width of the actual image shouldn't be more than 450px. You can also [optimize your images](https://kinsta.com/blog/optimize-images-for-web/) to reduce their data size.
- **Avoid using embeds.** When using embeds, the time it takes them to load is also calculated with your page speed. I was able to increase my page speed score from 63 to 91 by getting rid of the YouTube embeds on my landing page.
- **Reduce loading animation.** Google measures how long it takes for content to appear on your page so if you're animating content into the page, the time for animation might affect your score. Try to keep all loading animation under 1s.
- **Minify your files** You can reduce the size of your CSS and JavaScript files by minifying them. This means removing all spaces, new lines and other unnecessary characters. You can use the [Minifier tool](https://www.minifier.org/) to do this manually.
You can use [Page Speed Insights](https://developers.google.com/speed/pagespeed/insights/) on your website to get more information on how to improve the performance and decrease loading time.
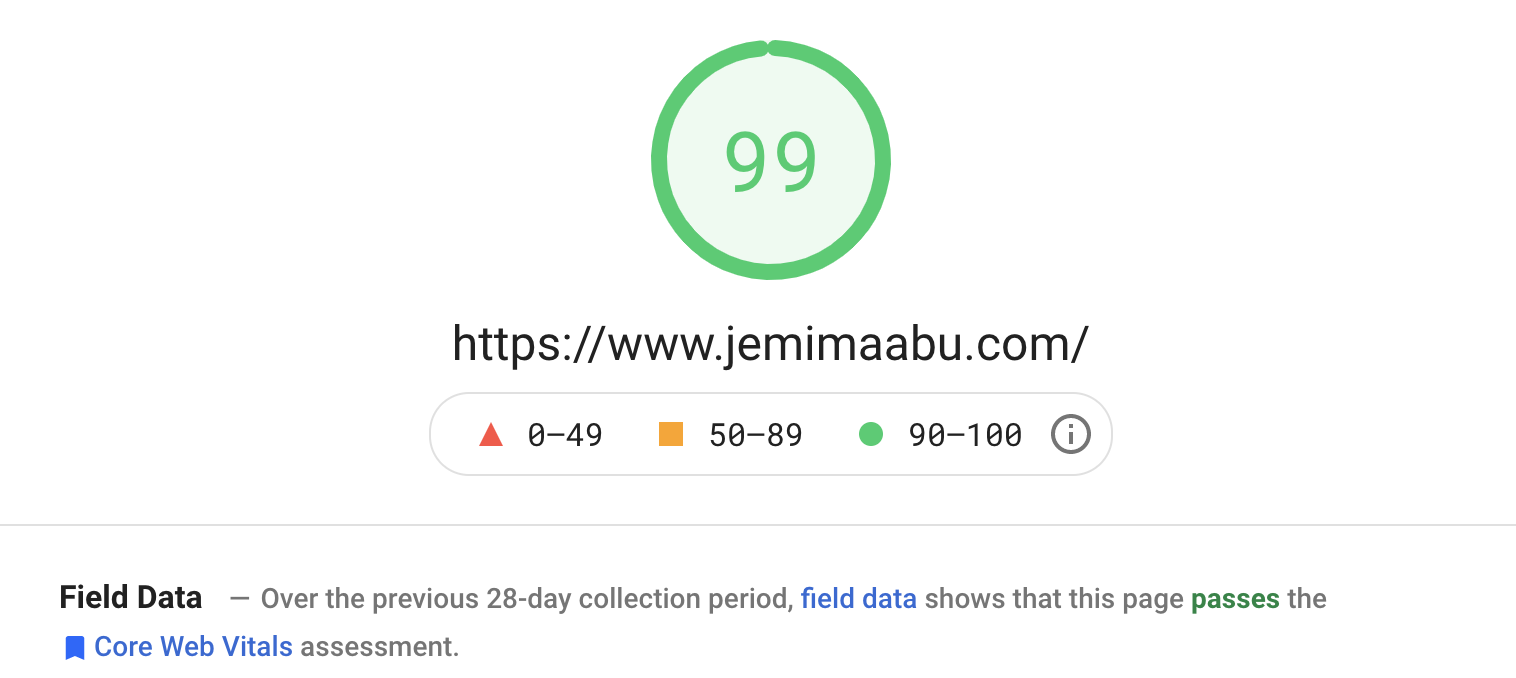
### Traffic and backlinks
If your site gets a lot of traffic from other sources, it increases its ranking as it seems more relevant. A good way of generating traffic and improving your SEO is using backlinks.
Backlinks are the inbound links for your site. They're created when other websites link to your site. Backlinks are basically votes from other sites vouching for the credibility of your site. A backlink from a highly ranked site also boosts your ranking.
Google uses backlinks as one of their [top three ranking factors](https://searchengineland.com/now-know-googles-top-three-search-ranking-factors-245882).
You can create backlinks by including a link to your site whenever you appear online. If you publish an article for an online magazine or you appear in an interview, including a link to your website on those sources create more backlinks for your site.
You can [read this article](https://backlinko.com/hub/seo/backlinks) to learn more about backlinks.
You can also use the [Google Analytics tool](https://www.freecodecamp.org/news/how-and-why-to-get-started-with-google-analytics-153dc35b7812/) to detect how much traffic your website generates and which sources you acquire traffic from.
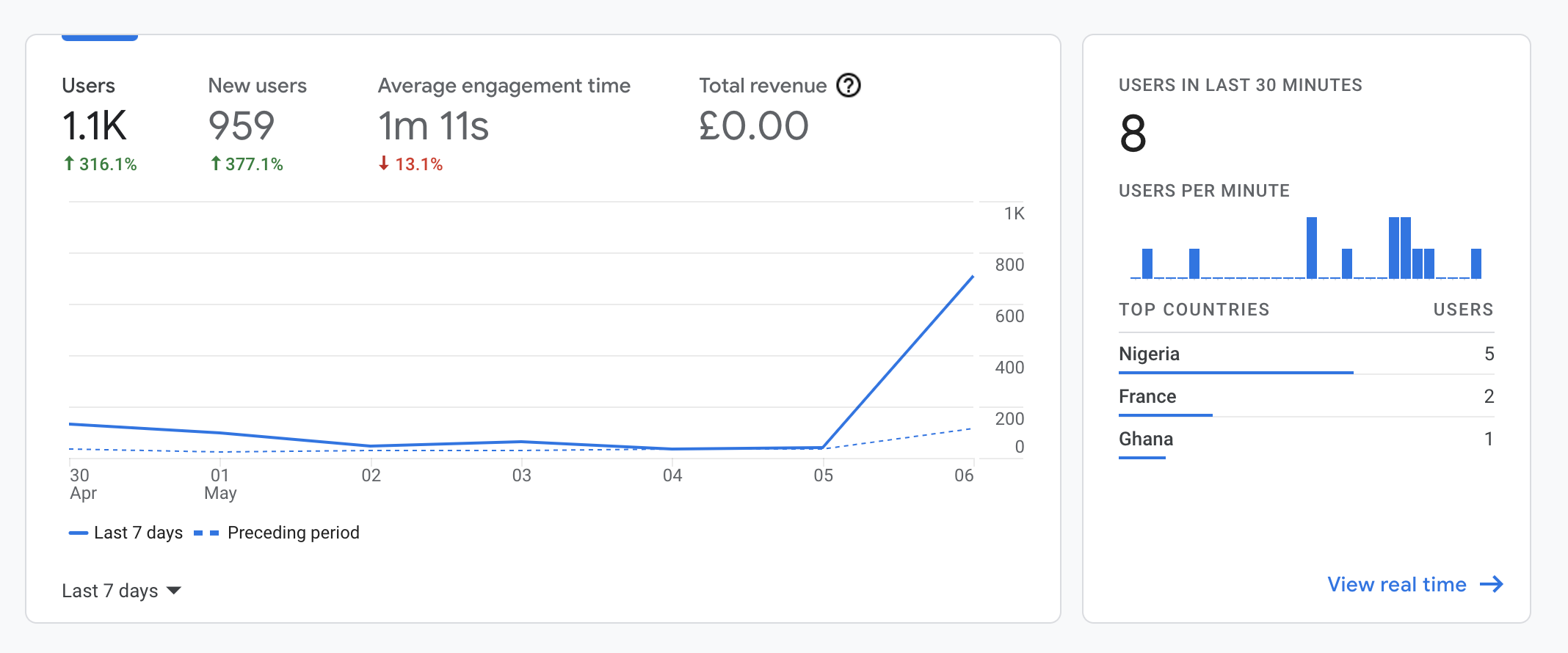
### Domain name and extensions
Having a domain name tailored to your website is a good way of increasing traffic to your site as it lends credibility. Your domain name should perfectly represent your website e.g. use your full name for a personal site or the main keyword for a business site.
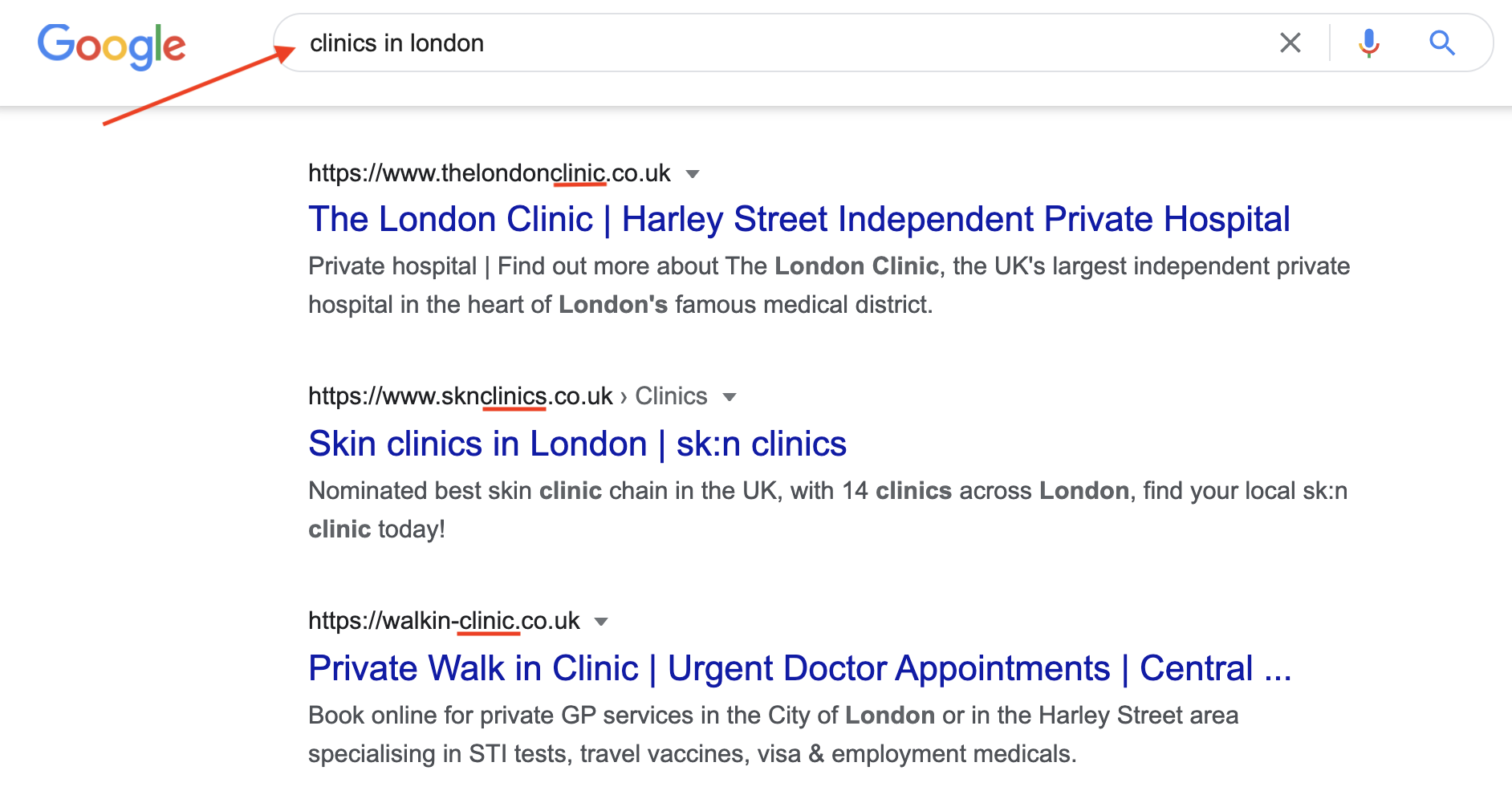
The domain extension also matters. `.com` domains are the most popular domain extension and [tend to have higher rankings](https://novanym.com/pages/why-com-is-the-best-domain-extension-for-seo#:~:text=with%20suffixes%20like%20.-,net%20and%20.,they%20have%20become%20more%20popular.). For location-targeted rankings, you can use country code domains e.g. `.co.uk` or `.eu`.
You can [buy a domain name on Namecheap](https://shrsl.com/2vhty) (this is an affiliate link so I get a commission if you decide to buy with this link).
## Tips for creating an online presence
Having an online presence refers to having all results related to you or your brand show up when you Google yourself.
While all the tips for improving SEO can also be applied to increasing your search results, here are some specific actions you can take to ensure a solid online presence:
- **Have a personal website.** If you're trying to secure your brand's online presence, invest in a [`.com` domain name](https://shrsl.com/2vhty) and make sure all your other online accounts (Twitter, Instagram, LinkedIn) point to that site.
You can read my article [How To Create a Portfolio Website](https://www.freecodecamp.org/news/beginners-guide-to-creating-a-portfolio-website/) for a step-by-step guide to creating your personal website.
- **Direct traffic to your site.** Aside from organic traffic, you can also take advantage of your social media presence to direct traffic to your personal site. If you have a viral tweet or video, be sure to include a link to your site somewhere.
- **Create accounts on larger platforms.** If you're going to create a personal blog, you might generate more traffic by creating it on a site like Hashnode, Medium or Dev.to than a lesser-known platform.
- **Use the same username across all accounts and URLs.** If you have a name you want to be known by online, make sure that's the name that you use for every account and in the same format.
- **Use common keywords on all your accounts.**
I use pretty much the same tagline for all my accounts (*"Self-taught Front End Developer, School Taught Systems Engineer"*) so this helps link them together.
## Testing for SEO
You can test your website's SEO by running the [Lighthouse audit tool](https://developers.google.com/web/tools/lighthouse) in Google Chrome. The audit returns a score based on how optimized your site is for search engines. The passed audits section contains the features of your website that improves SEO.
You can also use an [online SEO checker](https://www.seobility.net/en/seocheck/?px=2&a_aid=6094eba07a470) to get a more detailed report on the SEO of your website.
## Conclusion
And that's how you can get your website to the first page of search results for relevant keywords.
If you're interested in more in-depth research on the workings of SEO, you can check out these articles and tutorials:
1. [What is Search Engine Optimization?](https://searchengineland.com/guide/what-is-seo)
2. [10 Crucial SEO Ranking Factors You Need To Know](https://optinmonster.com/seo-ranking-factors/)
3. [SEO Specialization](https://click.linksynergy.com/deeplink?id=i1rVYzXnF5I&mid=40328&murl=https%3A%2F%2Fwww.coursera.org%2Fspecializations%2Fseo) - University of California, Coursera
You can also read my article on [How I Built My Perfect Portfolio Website](https://blog.jemimaabu.com/how-i-built-my-perfect-score-portfolio-website) for more insight into the process of creating my website.
If you found this article useful and you'd like to contribute to my content creation, feel free to [buy me a coffee](https://www.buymeacoffee.com/jemimaabu) 😊
If you have any questions or comments, leave a message below or reach out on [Twitter](https://twitter.com/jemimaabu). | jemimaabu |
690,644 | What is Pandoc? | Cover Image Credit: RFC: Designing Logo of Pandoc Introduction Most developers have... | 0 | 2021-05-07T11:04:16 | https://dev.to/killshot13/what-is-pandoc-1hbc | markdown, productivity, tutorial | >Cover Image Credit: _[RFC: Designing Logo of Pandoc](https://groups.google.com/g/pandoc-discuss/c/1bKIuyBnWaQ/discussion)_
## Introduction
Most developers have probably wondered or even asked the question at some point, "What exactly is [Pandoc](http://pandoc.org/installing.html)?" or "What do people use Pandoc for?"
I certainly did! So, I have written a short article to help answer that question. Much of the information in this article is sourced from [a gist I had put together](https://gist.github.com/killshot13/5b379355d275e79a5cb1f03c841c7d53) over the course of several months.
---
{% gist https://gist.github.com/killshot13/5b379355d275e79a5cb1f03c841c7d53 file=pandoc-install-intro.md %}
---
Defined as a universal [document converter](https://en.wikipedia.org/w/index.php?title=Pandoc&oldid=1018572588), Pandoc is an open-source software program for file conversion. Pandoc is not a markup language, nor is it a CLI, although it is used from one. 🙃
If you need to convert files from any conceivable format to another, Pandoc is your best friend. It has become popular across multiple industry and technology sectors.
The value of Pandoc shines brightest when used to transform file types like Markdown, Microsoft Word (.docx), and XML into more user-friendly documents and markup languages, including PDF and HTML.
---
## Installing Pandoc
I will assume at this point, if you are still reading, you likely want to try Pandoc out for yourself.
Listed below are the steps I took to install and configure Pandoc on Windows (10 Pro Edition) and Linux (Ubuntu 20.04 Focal) for Markdown to PDF document conversion.
Please note all disclaimers remain flapping in the breeze. Pandoc is open-source software that carries no warranty of any kind. Likewise, I make no guarantee that you will achieve a favorable result simply by following the steps below. 🙃
>_Your Mileage Might Vary_
### --> Pandoc on Windows
I have been using the [Chocolately](https://community.chocolatey.org/) package manager for Windows for several years now. So for me, the simplest way to get Pandoc up and running was first to install it with this command.
```bash
choco install pandoc
```
Then I grabbed the Windows installer for MikTex (one of many Pandoc engines) from the [official downloads page](https://miktex.org/download) and ran the `.exe` file to install.
---
 <figcaption>Before-and-after view when running the markdown-to-pdf command in Pandoc</figcaption>
No further configuration was necessary, at least not from a functional point of view. However, Pandoc will let you customize certain behaviors at quite a granular level.
There is a [configuration section](https://dev.to/killshot13/what-is-pandoc-1hbc#configuring-pandoc) toward the end of this article offers a good starting place for those wishing to take a deeper dive.
---
### --> Pandoc on Linux
Getting Pandoc setup with `.pdf` capabilities on Linux proved a bit more challenging.
After navigating a good deal of noise encountered while researching different packages, I found [the consensus](https://askubuntu.com/a/1219144/1153800) seemed to favor a Pandoc/TexLive setup.
Since I am running Ubuntu Linux on WSL2, I opted to build from scratch to avoid conflicts with my local Windows environment.
---
 <figcaption>Before-and-after view when running the markdown-to-html command in Pandoc</figcaption>
---
First, I pulled the latest tarball from the [release page](https://github.com/jgm/pandoc/releases/).
>There are multiple assets available with each release, so check your OS architecture first rather than blindly copying the snippets. This way, you can ensure you are requesting the correct package for your machine.
```bash
wget https://github.com/jgm/pandoc/releases/download/2.13/pandoc-2.13-linux-amd64.tar.gz
```
Then, without switching directories, I used a two-step installation process.
```bash
sudo tar xvzf $TGZ --strip-components 1 -C '/usr/local'
```
Note that $TGZ and the destination folder in the snippet above are generic, and substitutions must be made to reflect your home directory.
```bash
sudo apt-get install texlive texlive-latex-extra
```
And with that, Pandoc was installed on Linux to convert markdown files to PDF documents!
---
## Configuring Pandoc
These configuration options are just examples and may not apply in every situation.
One should always consult the [official Pandoc documentation](https://pandoc.org/MANUAL.html) for complete details and the latest changes.
```bash
--pdf-engine=PROGRAM
```
- Specifies which engine Pandoc should use when producing PDF output.
- Valid values are pdflatex, lualatex, xelatex, latexmk, tectonic, wkhtmltopdf, weasyprint, prince, context, and pdfroff.
- If the engine is not in your PATH, you can specify the full path of the engine here.
- If this option is not specified, pandoc uses the following defaults depending on the output format specified.
```bash
> -t latex or none
```
- defaults to pdflatex (other options: xelatex, lualatex, tectonic, latexmk)
```bash
> -t context:
```
- defaults to context
```bash
> -t html:
```
- defaults to wkhtmltopdf (other options: prince, weasyprint; visit [Print-CSS](https://print-css.rocks/) for a good introduction to PDF generation from HTML/CSS.)
```bash
> -t ms:
```
- defaults to pdfroff
---
 <figcaption>Pandoc can even apply custom styling when rendering HTML from Markdown</figcaption>
```bash
--pdf-engine-opt=STRING
```
- Use the given string as a command-line argument to the pdf-engine. For example, to use a persistent directory `foo` for [Latexmk](https://ctan.org/pkg/latexmk/)’s auxiliary files, use `--pdf-engine-opt=-outdir=foo`.
- Note that no check for duplicate options is done.
#### Credit: _[Pandoc User's Guide](https://pandoc.org/MANUAL.html)_
---
## Conclusion
On a related note, if you find yourself working with markdown, HTML, PDF, or XML files quite often, you should check out a little project of mine called mdEditor for VS Code.
The frameworks installed by mdEditor automate the configurations we just covered in such detail. Now you can generate file conversion with a simple key-binding or click in the command palette!
{% github killshot13/mdEditor no-readme %}
I hope you have found this tutorial useful, and thank you for taking the time to follow along!
Don't forget to 💖 this article and leave a 💭. If you're feeling extra generous, please click my name below to 🎆subscribe🎇!
-- killshot13
{% user killshot13 %}
---
**A Note on Pandoc**
>Copyright 2006–2021 [John MacFarlane](mailto:jgm@berkeley.edu). Released under the [GPL](https://www.gnu.org/copyleft/gpl.html), version 2 or greater. This software carries no warranty of any kind. (See COPYRIGHT for full copyright and warranty notices.) For a full list of contributors, see the file AUTHORS.md in the [Pandoc source code](https://github.com/jgm/pandoc).
| killshot13 |
690,726 | Performance🚀 hype🤓 | Ever since big G announced Page Experience metrics will become a part of its ranking algorithm, every... | 0 | 2021-05-07T10:09:49 | https://dev.to/cookieduster_n/performance-hype-4gef | performance, webdev, jamstack | Ever since big G announced [Page Experience](https://developers.google.com/search/docs/guides/page-experience) metrics will become a part of its ranking algorithm, every now and then, I do performance reviews of the cool and pretty websites. Sometimes just for the kicks, sometimes for our **account-based marketing** efforts, and sometimes provoked by clients when we talk about the benefits of better website performance.
While I can and do use Bejamas original case studies when talking with clients (like the last one, how we helped [Backlinko move to headless WordPress and Next.js](https://bejamas.io/blog/backlinko-case-study/) for better website performance), sometimes you do need to make a point on websites that are known to the clients.
Recently I came across Sumo’s [The Best Homepages Online](https://sumo.com/stories/best-homepages) post and wanted to check the performance and CWV of those together with some of the tools and their homepages I use in everyday work. So, this is just for kicks.😎
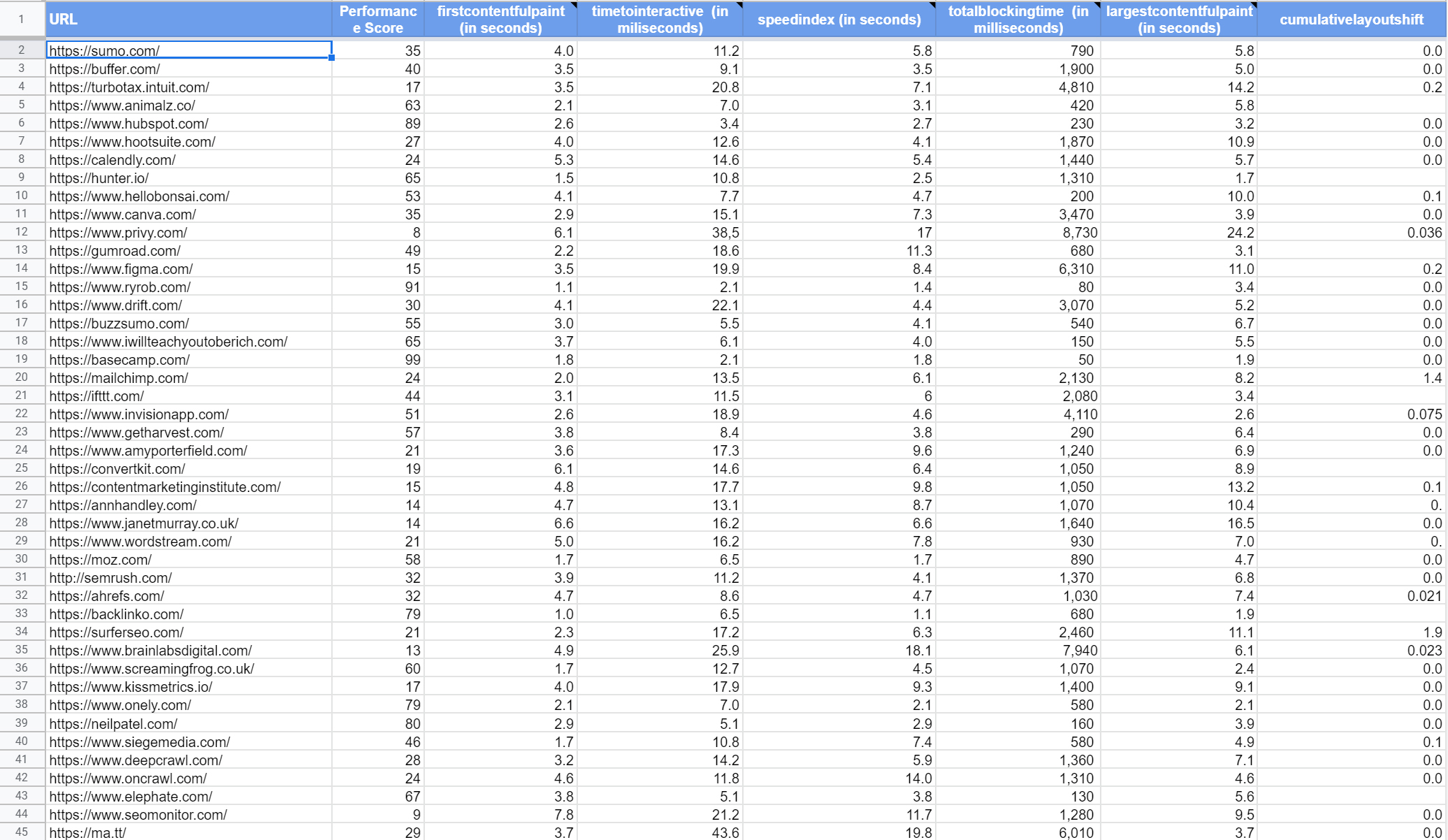
I’ve used the same approach measuring these previously explained in this post [here](https://dev.to/cookieduster_n/are-gatsby-websites-fast-47jn).
## Takeaway
Time and time again, we see brands fail when it comes to performance. That is if you stick to the numbers.
No doubt performance is hyped these days thanks to big G. While it is true that website speed/performance influences user experience, conversions, and, will soon, organic search ranking, it is also true you have to put your website performance in the context that matters.
That means in the context of the tech stacks you use, functionalities your website just has to have, the industry your business is in, audience expectations, and personal preferences, as I tried to explain in [the performance vs. functionalities](https://bejamas.io/blog/performance-vs-functionality/) post.
To give you an example, say you run a website in an industry (and keywords you’ll try to rank for) for which it is expected to have video or animation on a page. Most certainly, your performance won’t be that great. But it is also doubtful your text, and images-only page with excellent performance scores would rank well for industry-related keywords. On top of that, the page probably won’t convert the targeted audience well either because it did not deliver what is expected.
Performance, vital as it is, is just one piece of the puzzle that influences your potential buyers’ journey. It’s balancing all of them what matters and what brings the best business results. | cookieduster_n |
690,767 | How to install and set up Laravel's local development environment with Docker Compose | Introduction This article explains how to build a LEMP environment for PHP, nginx, and MyS... | 0 | 2021-05-07T11:19:25 | https://dev.to/ucan_lab/how-to-install-and-set-up-laravel-s-local-development-environment-with-docker-compose-5bcf | php, laravel, docker | ## Introduction
This article explains how to build a LEMP environment for PHP, nginx, and MySQL with Docker and Docker Compose.
## Prerequisites
- Docker
- Git
```
$ docker -v
Docker version 20.10.5, build 55c4c88
$ git --version
git version 2.31.1
```
### How to enable Docker Content Trust (DCT)
DCT is a security feature that protects your Docker image from spoofing and tampering.
It works automatically when the push, build, create, pull, or run command is executed.
```
$ echo export DOCKER_CONTENT_TRUST=1 >> ~/.zshrc
```
- https://docs.docker.com/engine/security/trust
## Repository
- https://github.com/ucan-lab/docker-laravel
## Container Structures
It has a three-tier structure consisting of an application server, a web server, and a database server.
```
├── app - service running php-fpm
├── web - service running nginx
└── db - service running mysql
```
## How to use a new project
### Step1. Create a new repository from template

Click `Use this template`.

Create a repository for `my-project`.

If you use the template repository, all commits will be combined into one.
### Step2. Clone your GitHub repository
```
$ git clone git@github.com:ucan-lab/my-project.git
$ cd my-project
```
### Step3. Create a Laravel Project
```
$ make create-project
```
### Step4. Show the Laravel Welcome page
http://localhost

### Step5. First commit and push
```
$ git add .
$ git commit -m "laravel install"
$ git push -u origin HEAD
```
## How to use an existing project
### (Optional) Delete the local repository
```
$ docker-compose down -v --rmi all
$ cd ..
$ rm -rf my-project
```
### Step1. Clone your GitHub repository
```
$ git clone git@github.com:ucan-lab/my-project.git
$ cd my-project
```
### Step2. Initialize your local environment
```
$ make init
```
### Step3. Show Laravel Welcome page
http://localhost

## If you want to specify the version of Laravel
Rewrite `Makefile` and execute.
```
laravel-install:
docker-compose exec app composer create-project --prefer-dist "laravel/laravel=6.*" .
```
## Remarks
### docker-compose.yml
```
version: "3.9"
volumes:
php-fpm-socket:
db-store:
services:
app:
build:
context: .
dockerfile: ./infra/docker/php/Dockerfile
volumes:
- type: volume
source: php-fpm-socket
target: /var/run/php-fpm
volume:
nocopy: true
- type: bind
source: ./backend
target: /work/backend
environment:
- DB_CONNECTION=mysql
- DB_HOST=db
- DB_PORT=3306
- DB_DATABASE=${DB_NAME:-laravel_local}
- DB_USERNAME=${DB_USER:-phper}
- DB_PASSWORD=${DB_PASS:-secret}
web:
build:
context: .
dockerfile: ./infra/docker/nginx/Dockerfile
ports:
- target: 80
published: ${WEB_PORT:-80}
protocol: tcp
mode: host
volumes:
- type: volume
source: php-fpm-socket
target: /var/run/php-fpm
volume:
nocopy: true
- type: bind
source: ./backend
target: /work/backend
db:
build:
context: .
dockerfile: ./infra/docker/mysql/Dockerfile
ports:
- target: 3306
published: ${DB_PORT:-3306}
protocol: tcp
mode: host
volumes:
- type: volume
source: db-store
target: /var/lib/mysql
volume:
nocopy: true
environment:
- MYSQL_DATABASE=${DB_NAME:-laravel_local}
- MYSQL_USER=${DB_USER:-phper}
- MYSQL_PASSWORD=${DB_PASS:-secret}
- MYSQL_ROOT_PASSWORD=${DB_PASS:-secret}
```
#### version
Docker Compose file version
- https://docs.docker.com/compose/compose-file
- https://docs.docker.com/compose/compose-file/compose-versioning/#version-3
> Note: When specifying the Compose file version to use, make sure to specify both the major and minor numbers. If no minor version is given, 0 is used by default and not the latest minor version. As a result, features added in later versions will not be supported. For example:
```
version: "3"
```
version: "3"
```
version: "3.0"
```
#### volumes
- https://docs.docker.com/compose/compose-file/compose-file-v3/#volumes
Define named volumes with the top-level `volumes` key to reuse volumes across multiple services.
#### services.*.build
- https://docs.docker.com/compose/compose-file/compose-file-v3/#build
#### services.*.ports
- https://docs.docker.com/compose/compose-file/compose-file-v3/#long-syntax-1
#### services.*.volumes
- https://docs.docker.com/compose/compose-file/compose-file-v3/#long-syntax-3
#### services.*.environment
- https://docs.docker.com/compose/compose-file/compose-file-v3/#environment
### app service
#### ./infra/docker/php/Dockerfile
```
FROM php:8.0-fpm-buster
LABEL maintainer="ucan-lab <yes@u-can.pro>"
SHELL ["/bin/bash", "-oeux", "pipefail", "-c"]
# timezone environment
ENV TZ=UTC \
# locale
LANG=en_US.UTF-8 \
LANGUAGE=en_US:en \
LC_ALL=en_US.UTF-8 \
# composer environment
COMPOSER_ALLOW_SUPERUSER=1 \
COMPOSER_HOME=/composer
COPY --from=composer:2.0 /usr/bin/composer /usr/bin/composer
RUN apt-get update && \
apt-get -y install git libicu-dev libonig-dev libzip-dev unzip locales && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* && \
locale-gen en_US.UTF-8 && \
localedef -f UTF-8 -i en_US en_US.UTF-8 && \
mkdir /var/run/php-fpm && \
docker-php-ext-install intl pdo_mysql zip bcmath && \
composer config -g process-timeout 3600 && \
composer config -g repos.packagist composer https://packagist.org
COPY ./infra/docker/php/php-fpm.d/zzz-www.conf /usr/local/etc/php-fpm.d/zzz-www.conf
COPY ./infra/docker/php/php.ini /usr/local/etc/php/php.ini
WORKDIR /work/backend
```
- https://hub.docker.com/_/php
- `FROM <image>:<verion>-<variant>-<os>`
- https://laravel.com/docs/8.x/deployment#server-requirements
- PHP >= 7.3
- BCMath PHP Extension
- Ctype PHP Extension
- Fileinfo PHP Extension
- JSON PHP Extension
- Mbstring PHP Extension
- OpenSSL PHP Extension
- PDO PHP Extension
- Tokenizer PHP Extension
- XML PHP Extension
#### ./infra/docker/php/php.ini
```
zend.exception_ignore_args = off
expose_php = on
max_execution_time = 30
max_input_vars = 1000
upload_max_filesize = 64M
post_max_size = 128M
memory_limit = 256M
error_reporting = E_ALL
display_errors = on
display_startup_errors = on
log_errors = on
error_log = /dev/stderr
default_charset = UTF-8
[Date]
date.timezone = ${TZ}
[mysqlnd]
mysqlnd.collect_memory_statistics = on
[Assertion]
zend.assertions = 1
[mbstring]
mbstring.language = Neutral
```
#### ./infra/docker/php/php-fpm.d/zzz-www.conf
```
[www]
listen = /var/run/php-fpm/php-fpm.sock
listen.owner = www-data
listen.group = www-data
listen.mode = 0666
access.log = /dev/stdout
```
### web service
#### ./infra/docker/nginx/Dockerfile
```
FROM node:16-alpine as node
FROM nginx:1.20-alpine
LABEL maintainer="ucan-lab <yes@u-can.pro>"
SHELL ["/bin/ash", "-oeux", "pipefail", "-c"]
ENV TZ=UTC
RUN apk update && \
apk add --update --no-cache --virtual=.build-dependencies g++
# node command
COPY --from=node /usr/local/bin /usr/local/bin
# npm command
COPY --from=node /usr/local/lib /usr/local/lib
# yarn command
COPY --from=node /opt /opt
# nginx config file
COPY ./infra/docker/nginx/*.conf /etc/nginx/conf.d/
WORKDIR /work/backend
```
- https://hub.docker.com/_/node
- https://hub.docker.com/_/nginx
#### ./infra/docker/nginx/default.conf
```
access_log /dev/stdout main;
error_log /dev/stderr warn;
server {
listen 80;
root /work/backend/public;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-XSS-Protection "1; mode=block";
add_header X-Content-Type-Options "nosniff";
index index.html index.htm index.php;
charset utf-8;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
location ~ \.php$ {
fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
include fastcgi_params;
}
location ~ /\.(?!well-known).* {
deny all;
}
}
```
- https://laravel.com/docs/8.x/deployment#nginx
### db service
#### ./infra/docker/mysql/Dockerfile
```
FROM mysql/mysql-server:8.0
LABEL maintainer="ucan-lab <yes@u-can.pro>"
ENV TZ=UTC
COPY ./infra/docker/mysql/my.cnf /etc/my.cnf
```
- https://hub.docker.com/r/mysql/mysql-server
#### ./infra/docker/mysql/my.cnf
```
[mysqld]
# default
skip-host-cache
skip-name-resolve
datadir = /var/lib/mysql
socket = /var/lib/mysql/mysql.sock
secure-file-priv = /var/lib/mysql-files
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
# character set / collation
character_set_server = utf8mb4
collation_server = utf8mb4_0900_ai_ci
# timezone
default-time-zone = SYSTEM
log_timestamps = SYSTEM
# Error Log
log-error = mysql-error.log
# Slow Query Log
slow_query_log = 1
slow_query_log_file = mysql-slow.log
long_query_time = 1.0
log_queries_not_using_indexes = 0
# General Log
general_log = 1
general_log_file = mysql-general.log
[mysql]
default-character-set = utf8mb4
[client]
default-character-set = utf8mb4
```
| ucan_lab |
690,869 | DISCUSS: The blurred line between front-end and fullstack | The meaning of a "front-end webdeveloper" has really shifted over the years as more technologies... | 17,289 | 2021-05-07T14:05:12 | https://dev.to/thalitadev/discuss-the-blurred-line-between-front-end-and-fullstack-20co | discuss, watercooler, webdev | The meaning of a "front-end webdeveloper" has really shifted over the years as more technologies started becoming the norm. Here are two of my favourite articles that talk about this:
- [**CSS Tricks**: ooooops I guess we’re* full-stack developers now](https://css-tricks.com/ooooops-i-guess-were-full-stack-developers-now/)
- [**Brad Frost**: front-of-the-front-end and back-of-the-front-end web development](https://bradfrost.com/blog/post/front-of-the-front-end-and-back-of-the-front-end-web-development/).
# Front-ends without frontiers
I've started off as a front-end webdeveloper myself. As I started learning more back-end technologies it was hard for me to tell when I could start considering myself a fullstack. Even today, I'm not actually sure where the front-end ends and where the back-end begins.
The front-end has become such a blurred subject that it made job hunting exceedingly slower. Now you have to carefully read every job description just to determine what kind of "front-end webdeveloper" they're talking about.
I've even seen job descriptions that use front-end and fullstack interchangeably. Yes. Not even sure if that's intentional or they're a little confused themselves. 😶
# ✍ Comment below answering the following questions
1. Do you consider yourself a fullstack webdeveloper? Why?
2. If you could make a clear definition of "front-end" and "fullstack", what would it be?
---

[Twitter](https://twitter.com/thalitadev) | [Website](https://thalita.dev) | thalitadev |
691,052 | How many hours should I work (as a programmer)? | Uncle Bob in his book "The clean coder" has a very clear answer to his question: "You should plan on... | 0 | 2021-05-07T14:44:03 | https://dev.to/codeandchaos/how-many-hours-should-i-work-as-a-programmer-500g | career, discuss, worklifebalance, healthyprogramming |
Uncle Bob in his book "The clean coder" has a very clear answer to his question:
"**You should plan on working 60 hours per week**. The first 40 hours are for your employer. The remaining 20 are for you. (...) Perhaps you do not want to make that kind of commitment. That's fine but you should not think of yourself as a professional. Professionals spend time caring for their profession."
This is a really bad answer and promotes very bad habits in the industry. If you look at how many hours a programmer works on average it will be in the range from 40-60+ hours a week. Very rarely you will find a part-time programmer.
Let's try to figure out what the correct number is.
## Is it harmful to work above 40 hours?
People that constantly working 60 hours are not professional and should consider this:
- Assuming you are employed for 40 hours and you work an additional 20 hours - If you would be a freelancer your salary would increase by +50% - however as an employee you will probably not be given a pay raise and you will not get any recognition because your extra work is just assumed as the new 'normal'
- You are putting your job as your only priority and will not have time for relationships, friends, family or your own personal interests.
- Additionally, you are harming other developers. Two developers working 60 hours a week do the same amount of hours as 3 developers working 40 hours a week. You effectively are eliminated a job opening making it more difficult for a junior developer to find a job.
I bet you are thinking right now: "_But there is so much to do, I cant work fewer hours. The project will fail if I do not get all the tasks done. My manager is pressuring me to work long hours_"
I am going to let you in on a couple of secrets:
- There is always a lot of work, the client will always want a new feature, bugfix, etc. that is the nature of developing software. In most cases, it is not the end of the world if a feature is delivered at a later point in time.
- Your manager's job is to get the most work out of you for the least cost. If you work more hours for free, hey that's quite a good deal for the manager in the short term. However great managers will realize that allowing programmers to go home and have a life outside of work will make them more effective at work thus actually improving the project's outcome in the long run.
- If you think the project will fail because you are not putting in extra hours, then the projects resources are being miss managed. Management is not aware of the state of the project - You pitching in and doing extra hours, makes the problem worse - as management just believes that the velocity of the project has not changed. You are not signaling to management that the project is not going well and the project cannot continue in this way - they do not know that they are allocating 150% of resources that are available to them. Everything seems to be fine - but in reality, management would have to take action to maintain the project's velocity they either have to hire additional people or adjust the deadlines to match the available resources.
- And finally, the deadline for the project is probably arbitrary. Any project manager knows that things go wrong in a software project. You can assume that there are multiple fallback deadlines. Even if there is the 'last' deadline - you are dealing with people and people can be flexible if you communicate with them - also if they already invested months of time and resources into a project, in most cases you do not throw that away immediately.
Overtime is sometimes unavoidable, but it always should be a temporary measure, never a permanent state.
It should not become a permanent state because studies have shown that most humans when working more hours just work less efficiently. So it is very likely that you can work fewer hours and achieve the exact same outcome because you are working more focused.
In short - you should only be working more than 40 hours for a good reason.
## Working for 40 hours is also bad
If you think you can clock in from 9-5 and just work on your tasks - you will burn out.
You have to stay up to date on what is going on in your field. You have to learn multiple programming languages. It is your responsibility as a professional developer.
Managers will not take care of this. Most times they will promise you 'trainings', while at the same time they will never have the budget for you to actually attend a training.
_"But learning a new technology that my employer does not need is just for me"_
Let's assume you learn an abstract programming language like [Piet](https://en.wikipedia.org/wiki/Esoteric_programming_language#Piet) - It seems useless for your employer at first, but maybe at your company for the problem that you have to solve this language may be the easiest solution. It also may be that this technology makes the problem harder and you should avoid using it.
No matter the outcome, you the developer will have sharpened your skills have a deeper understanding of the technologies being currently used by contrasting them with the newly learned technology. Additionally, you gain knowledge about technologies you might want to consider or avoid in the future. With the side benefit that you are less frustrated at your job because you know your skills are growing.
But without your effort in learning about the technology, your employer cannot make an educated decision and will just go with whatever they have always been using. The manager may not even be aware of this new technology. In the end, it is your job to explain to your employer if they should use technology or not - they rely on their employees to highlight the potential benefits/downsides of using any tech.
You have to plan this time, it's part of your self-management - just as you would plan time for your emails. It's just part of your job, your manager will not tell you to answer emails, it's just part of your job to do that, the manager assumes that you know that.
If you only dedicate 40 hours to complete the tasks that your employer gives you, you are neglecting your skills why your employer hired you in the first place - and risk to be replaced.
## Programming for 20 hours from 9-5
Now, let's take a look at my ideal view of how you should spend your 40 hours a week:
- 20 hours is for working on actual tasks
- 10 hours is for practicing skills and keeping up to date
- 10 hours is for meetings, email, and socializing
25% of your time spent on practicing seems excessive. Coding is equally craftsmanship and artistic expression. Consider other professions like a concert musician. A violinist would be practicing for months for a single concert - 99% training and 1% performance. Nobody would say that is excessive.
**Note**: Practicing skills means actively learning and solving problems it is **not** passively watching for hours YouTube talks or listening to podcasts
Meetings in an organization simply take time a lot of time that you are not spending programming, and many times you get the feeling you were in so many meetings you did not get anything done for the day and clock in an extra hour - however attending meetings is work. you did get something done - you are allowed to go home you may not have done fun things like coding - but you did work.
If you miss a deadline because of a meeting then you maybe should reconsider if you should've attended that meeting in the first place. nobody's forcing you to attend every meeting. If your manager complains that you're not going to attend a meeting then you can explain that you have a deadline to meet – The manager can then decide what is more important. You are the one that has to inform your manager about the conflicting responsibilities.
The remaining time you can spend working on tasks and that is if you are lucky around 20 hours.
## But I am passionate about programming
You can program as a hobby even while you're working in the field. But then you have to treat it as a hobby and you only should do it if you have the time and it gives you joy and satisfaction. - this also means working on your own project - not work-related and overall it should be relaxing.
## Quality over Quantity
It all comes down to quality over quantity. It is better to commit to fewer tasks and deliver them on time and in good quality than deliver many tasks with bugs. Because the bugs will drastically reduce your development velocity over a long period of time.
And in the end, your manager will also be happier because your work output becomes more predictable and reliable. As a bonus, the manager does not have to explain to people why the software was created with so many defects and then order overtime to fix them as fast as possible.
Working focused we get you much further than overworking and neglecting your life outside of work.
## There is no correct answer
You have to think about your personal situation and work the way it suits you.
Take your time to think about your current situation, your capabilities,
and set your priorities.
Take responsibility and control over how many hours you work. This is an active choice - do not passively just do that what everyone else is doing.
**What do you think? How many hours do you work?**
| codeandchaos |
691,159 | Transforming Media With Java Code | How to transform media on Cloudinary with Java code, e.g., crop images, apply a boomerang effect on videos, or concatenate or add a progress bar to videos. | 0 | 2021-05-07T16:45:38 | https://dev.to/rebeccapeltz/transforming-media-with-java-code-4863 | cloudinary, java, transformations | ---
title: Transforming Media With Java Code
published: true
description: How to transform media on Cloudinary with Java code, e.g., crop images, apply a boomerang effect on videos, or concatenate or add a progress bar to videos.
tags: Cloudinary, Java, transformations
cover_image: https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/java-cover.png
---
# Transforming Media With Java
Transforming media on Cloudinary in Java is fun because of the fluent interface. Cloudinary transformations are used to produce optimized media as well as aesthetic effects.
## Fluent Interface
In 2005, Martin Fowler created an API design pattern called the [fluent interface, which makes use of ](https://martinfowler.com/bliki/FluentInterface.html)method chaining and a domain-specific language and[ which has been adopted ](https://martinfowler.com/bliki/FluentInterface.html)in many popular APIs, such as .NET’s SQL API [Linq. ](https://docs.microsoft.com/en-us/dotnet/standard/linq/)With Linq, .NET programmers can write code that generates SQL.
Since then, Fowler has introduced many [design patterns](https://martinfowler.com/eaaCatalog/) for object-oriented programming that have been embraced by OO developers for building APIs.
### Method Chaining
Method chaining refers to a method that returns an instance of the object that encapsulates it, as in this example:
```
class Hello {
private string name;
Hello()
{
System.out.println("Calling The Constructor");
}
public Hello setName(String name)
{
this.name = name;
return this;
}
void say()
{
System.out.println("Hello " + name);
}
}
public class Hello {
public static void main(String[] args)
{
// "method chaining".
new Hello().setName("Martin").say();
}
}
```
**Fun fact:** The popular jQuery library, which leverages method chaining, was developed around the time Martin Fowler launched the fluent interface.
### Domain-Specific Language
Since the fluent interface comprises both object chaining and a domain-specific language, the code flows and is easy to read.
### Fluent Interface for Transformations
We're going to see here how to use the Cloudinary Java SDK's fluent interface to code fun and useful transformations.
## Cropping of Media
### Scale
Cloudinary performs simple cropping transformations with a fluent interface. An example is to apply a single dimension to an image or video and then scale the media item to maintain the aspect ratio, like this:
```
new Transformation().width(300).crop("scale")
```
Here’s an example of single-dimension scaling:
[https://res.cloudinary.com/cloudinary-training/image/upload/w_300,c_scale/dog.jpg](https://res.cloudinary.com/cloudinary-training/image/upload/w_300,c_scale/dog.jpg)
<table>
<tr>
<td>Original: 2519 x 2501
</td>
<td>Scaled: 300 x 298
</td>
</tr>
<tr>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog1.jpg" alt="dog original photo" title="dog original photo">
</td>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog2.jpg" alt="dog scaled photo" title="dog scaled photo">
</td>
</tr>
</table>
The transformed image adjusts the unspecified dimension (in this case, the height) so that the aspect ratio stays the same.
### Fit
To create a media item, say, an image, with a certain width and height, specify them and maintain the aspect ratio with the ``crop`` type ``fit``. Cloudinary then changes the dimensions and maintains aspect ration, but the image remains within the bounding box based on the two specified dimensions. See the example below.
dim
```
new Transformation().width(300).height(200).crop("fit")
```
<table>
<tr>
<td>
Fit: 201 x 200
</td>
</tr>
<tr>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog3.jpg" alt="resize with fit " title="resize with fit">
</td>
</tr>
</table>
The transformed image might not have the exact dimensions as specified but will not exceed them.
### Pad
You can set exact dimensions with the ``crop`` type ``pad``. To maintain the aspect ratio, ``pad`` scales the image to fit within the specified dimensions and creates a padding for any dimension that must be made smaller than the value specified. The color of the pad will default to white. For example:
```
new Transformation().width(300).height(200).crop("pad")
```
<table>
<tr>
<td>
Pad: 300 x 300
</td>
</tr>
<tr>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog4.jpg" alt="resize with pad" title="resize with pad">
</td>
</tr>
</table>
To change the color of the padding, just chain the ``background`` parameter to the code:
```
new Transformation().width(300).height(200).crop("pad").background("red")
```
<table>
<tr>
<td>
Red Padding: 300 x 200
</td>
</tr>
<tr>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog5.jpg" alt="resize with red padding" title="resize with red padding">
</td>
</tr>
</table>
To have Cloudinary determine the most used color in the media item and then apply that color to the padding, set ``background`` to ``auto``:
```
new Transformation().width(300).height(200).crop("pad").background("auto")
```
<table>
<tr>
<td>
Auto Padding: 300 x 200
</td>
</tr>
<tr>
<td>
<img src="https://res.cloudinary.com/cloudinary-training/image/upload/f_auto,q_auto/blog/java/dog6.jpg" alt="resize with auto pad" title="resize with auto pad">
</td>
</tr>
</table>
There are many more cropping transformations and you can learn about them [online](https://cloudinary.com/documentation/transformation_reference).
## Fun With Transformations
Once you have uploaded your media to Cloudinary, you can write Java code to create URLs, image tags, and video tags that contain transformation parameters. Below are a few fun video examples in which we create URLs with transformations.
### Boomerang Effect With Video
Consider a time-lapse video of an hourglass. How would the hourglass run if time moves backwards? To find out, apply the **boomerang** effect on the video as a transformation, like this:
```
cloudinary.url().transformation(new Transformation().effect("boomerang"))
.resourceType("video").generate("purple-hourglass.mp4")
```
Click this link to play the video in your browser:
[https://res.cloudinary.com/cloudinary-training/video/upload/e_boomerang/purple-hourglass.mp4](https://res.cloudinary.com/cloudinary-training/video/upload/e_boomerang/purple-hourglass.mp4)

### Concatenation of Videos
To play two videos in sequence, try this concatenation technique:
```
cloudinary.url().resourceType("video")
.transformation(new Transformation().width(300).height(200).crop("filt").chain()
.overlay(
new Layer().publicId("video:purple-hourglass"))
.flags("splice").width(300).height(200).crop("fit"))
.generate("3-o-clock.mp4")
```
Click this link to play the concatenated video in your browser:
[https://res.cloudinary.com/cloudinary-training/video/upload/c_fit,h_200,w_300/c_fit,fl_splice,h_200,l_video:purple-hourglass,w_300/3-o-clock.mp4](https://res.cloudinary.com/cloudinary-training/video/upload/c_fit,h_200,w_300/c_fit,fl_splice,h_200,l_video:purple-hourglass,w_300/3-o-clock.mp4)

### Progress Indicator
How about creating a visual indicator that shows how much time is left in your video? Simply add a progress bar, like this:
```
cloudinary.url().transformation(new Transformation().effect("progressbar:frame:FF0000:12")) .resourceType("video").generate("purple-hourglass.mp4")
```
Click this link to play the video with a progress bar:
[https://res.cloudinary.com/cloudinary-training/video/upload/e_progressbar:frame:FF0000:12/purple-hourglass.mp4](https://res.cloudinary.com/cloudinary-training/video/upload/e_progressbar:frame:FF0000:12/purple-hourglass.mp4)

## Summary
The design of the Cloudinary Java SDK makes it easy to code in Java. As you learn more about the many ways in which you can transform media with Cloudinary, you’ll become more creative and fluent with the process. Have fun!
## Credits
* Hourglass-timer video by [Samer Daboul](https://www.pexels.com/@samerdaboul?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels) from [Pexels](https://www.pexels.com/photo/close-up-view-of-a-sand-timer-1196530/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels)
* Clock video by [Jason H. Austin](https://www.pexels.com/@jason-h-austin-544053?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels) from [Pexels](https://www.pexels.com/photo/round-wall-clock-1509518/?utm_content=attributionCopyText&utm_medium=referral&utm_source=pexels)
* [Cloudinary Media Inspector Extension](https://chrome.google.com/webstore/detail/cloudinary-media-inspecto/ehnkhkglbafecknplfmjklnnjimokpkg) for insight on images | rebeccapeltz |
691,224 | A Complete Beginners Guide of Predis Package | Predis does not require any additional C extension by default, but it can be optionally paired with p... | 0 | 2021-05-07T17:45:20 | https://dev.to/techdurjoy/a-complete-beginners-guide-of-predis-package-26ok | predis | Predis does not require any additional C extension by default, but it can be optionally paired with phpiredis to lower the overhead of the serialization and parsing of the Redis RESP Protocol.
More details about this project can be found on the frequently asked questions.
#Main features
Support for Redis from 2.0 to 6.0.
Support for clustering using client-side sharding and pluggable keyspace distributors.
Support for redis-cluster (Redis >= 3.0).
Support for master-slave replication setups and redis-sentinel.
Transparent key prefixing of keys using a customizable prefix strategy.
Command pipelining on both single nodes and clusters (client-side sharding only).
Abstraction for Redis transactions (Redis >= 2.0) and CAS operations (Redis >= 2.2).
Abstraction for Lua scripting (Redis >= 2.6) and automatic switching between EVALSHA or EVAL.
Abstraction for SCAN, SSCAN, ZSCAN and HSCAN (Redis >= 2.8) based on PHP iterators.
Connections are established lazily by the client upon the first command and can be persisted.
Connections can be established via TCP/IP (also TLS/SSL-encrypted) or UNIX domain sockets.
Support for Webdis (requires both ext-curl and ext-phpiredis).
Support for custom connection classes for providing different network or protocol backends.
Flexible system for defining custom commands and override the default ones.
#How to install and use Predis
This library can be found on Packagist for an easier management of projects dependencies using Composer. Compressed archives of each release are available on GitHub.
#Loading the library
Predis relies on the autoloading features of PHP to load its files when needed and complies with the PSR-4 standard. Autoloading is handled automatically when dependencies are managed through Composer, but it is also possible to leverage its own autoloader in projects or scripts lacking any autoload facility:
[A Complete Beginners Guide of Predis Package](https://www.codecheef.org/article/a-complete-beginners-guide-of-predis-package)
[Laravel 8.x Cursor Based Pagination Example](https://www.codecheef.org/article/laravel-8-cursor-based-pagination-example) | techdurjoy |
691,250 | Run Batch Jobs with the Code Engine CLI | What is a batch job? A batch job is a scheduled program that is assigned to run on a compu... | 0 | 2021-05-07T18:36:56 | https://dev.to/jritten/run-batch-jobs-with-the-code-engine-cli-4m39 | ###What is a batch job?
A batch job is a scheduled program that is assigned to run on a computer without further user interaction. Batch jobs are often queued up during working hours, then executed during the evening or weekend when the computer is idle.
Once the batch job is submitted, the job enters into a queue where it waits until the system is ready to process the job. If the job queue contains many jobs waiting to be processed, the system processes the jobs either in chronological order or by priority.
Batch jobs are frequently used to automate tasks that need to be performed on a regular basis, like payroll, but don’t necessarily need to occur during the day or have an employee interacted with the system. Jobs that happen on a regular basis are incorporated into batch schedules.
A job runs one or more instances of your executable code. Unlike applications, which handle HTTP requests, jobs are designed to run one time and exit. When you create a job, you can specify workload configuration information that is used each time that the job is run.
The most valuable benefits of batch jobs include:
* Large programs can utilize more dedicated servers when the work processes are in night mode.
* With fewer users or employees online during off hours, the performance will be faster and more efficient at night. During the day it could be restricted to fewer servers and numbers needed.
* Employees are freed up to focus on less repeatable, more creative tasks.
The following guide will walk you through creating a Code Engine project and application using [sample code](https://github.com/IBM/CodeEngine), and then you will create batch jobs and run them. The following steps can also be followed to deploy an application to Code Engine from source code after following the setup instructions in Next Steps.
Happy Hacking!
#Let's Build Something
###Steps
1. Sign Up for a Free [IBM Cloud Account](https://ibm.biz/cloud-sign-up)
2. Install the [IBM Cloud Developer Tools CLI](https://cloud.ibm.com/docs/cli?topic=cli-getting-started) (command line interface, the commands you type into your Terminal)
3. Install the [IBM Cloud Code Engine Plugin](https://cloud.ibm.com/docs/codeengine?topic=codeengine-install-cli)
4. Login to Your IBM Cloud Account via the CLI
5. [Create a Code Engine Application](https://cloud.ibm.com/docs/codeengine?topic=codeengine-application-workloads#deploy-app-source-code)
6. [Create a Job from a Public Repo](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
7. Run a Batch Job
8. NEXT STEPS! [Build a Container Image from Source Code to Deploy to Code Engine](https://cloud.ibm.com/docs/codeengine?topic=codeengine-build-image) and [Run Batch Jobs](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
## Setup & Installation
###2. Install the IBM Cloud Developer Tools CLI
* For Mac and Linux, run the following command in Terminal:
```
curl -sL https://raw.githubusercontent.com/IBM-Cloud/ibm-cloud-developer-tools/master/linux-installer/idt-installer | bash
```
* Verify the IBM Cloud Developer Tools CLI is installed
```
ibmcloud dev help
```
* For Windows 10 Pro, run the following command as an administrator in Powershell:
```
[Net.ServicePointManager]::SecurityProtocol = "Tls12, Tls11, Tls, Ssl3"; iex(New-Object Net.WebClient).DownloadString('https://raw.githubusercontent.com/IBM-Cloud/ibm-cloud-developer-tools/master/windows-installer/idt-win-installer.ps1')
```
**Note For Windows Users: If you encounter a Git error similar to the one below, you will need to install Git in the correct path.**
```
bash: git: command not found
```
**Follow the Windows Guide [HERE](https://www.jcchouinard.com/install-git)**
###3. Install the IBM Cloud Code Engine Plugin
* For Mac, Linux, and Windows 10 Pro, run the following command:
```
ibmcloud plugin install code-engine
```
* Verify the IBM Cloud Code Engine Plugin is installed
```
ibmcloud ce help
```
###4. Login to Your IBM Cloud Account via the CLI
* For Mac, Linux, and Windows 10 Pro, run the following command:
```
ibmcloud login
```
* Enter email and password
* View available resource groups
```
ibmcloud resource groups
```
* Assign a target resource group (default to your "Default")
```
ibmcloud target -g Default
```
## Deploy to Code Engine & Run Batch Jobs
###5. Create a Code Engine Application
* Create a new Code Engine project and give it a name
```
ibmcloud ce project create --name PROJECT_NAME
```
```
ibmcloud ce project create --name sandbox
```
* Create a new app from a sample Container Image
```
ibmcloud ce application create --name APP_NAME --image IMAGE
```
```
ibmcloud ce application create --name myapp --image docker.io/ibmcom/hello
```
* Check the application status
```
ibmcloud ce application get -n APP_NAME
```
```
ibmcloud ce application get -n myapp
```
* Get the live application URL
```
ibmcloud ce application get -n APP_NAME -output url
```
```
ibmcloud ce application get -n myapp -output url
```
* View the live application at the URL in your browser
###6. [Create a Job from a Public Repo](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
* Create a job configuration that is named **myjob** and uses the container image **docker.io/ibmcom/firstjob**
```
ibmcloud ce job create --name JOB_NAME --image IMAGE
```
```
ibmcloud ce job create --name myjob --image ibmcom/firstjob
```
**Note: the format for creating a new job from an image is ibmcom/firstjob from the image docker.io/ibmcom/firstjob.**
###7. Run a Batch Job
* Run a job
```
ibmcloud ce jobrun submit --name testjobrun --job myjob --array-indices "1 - 5"
```
**Note: the following jobrun submit command creates five new instances to run the container image that is specified in the myjob job. the resource limits and requests are applied per instance, so each instance gets 4 G memory and 1 vCPU. This job allocates 5 * 4 G = 20 G memory and 5 * 1 vCPU = 5 vCPUs.**
* Resubmit a job run based the configuration of a previous job run, use the jobrun resubmit command
```
ibmcloud ce jobrun resubmit --jobrun testjobrun
```
* Access the Job Details, including the status of your instances, configuration details, and environment variables of your job
```
ibmcloud ce job get --name myjob
```
**[Options for Creating and Running Jobs](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)**
##CONGRATULATIONS!
If you've made it this far, then Kudos to you! The example commands given can be followed to create an application from a container image and deploy it to Code Engine with your own images. You can also follow the example commands given to create and run batch jobs with your own public images and repositories. For more information to get started with your own container images and/or source code, check out the [Tutorial Tuesday Code Engine Guide](https://dev.to/ibmdeveloper/deploy-a-cloud-native-application-to-code-engine-in-5-easy-steps-4bcg) along with the [Code Engine Documentation](https://cloud.ibm.com/docs/codeengine?topic=codeengine-learning-paths).
###8. Next Steps
####1. [Build a Container Image from Source Code](https://cloud.ibm.com/docs/codeengine?topic=codeengine-build-image)
####2. [Plan a Container Image for Code Engine Jobs](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
####3. [Create a Job from a Public Repository](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
####4. [Run a Batch Job!](https://cloud.ibm.com/docs/codeengine?topic=codeengine-job-deploy)
| jritten | |
691,266 | My [Automated] Trello Movie Organizer | I use Trello for everything. It only made sense (back when I did this) to put and track my movie... | 0 | 2021-10-20T17:44:02 | https://dev.to/fischgeek/my-automated-trello-movie-organizer-3774 | trello, aws, lambda, fsharp | I use Trello for [everything](https://dev.to/fischgeek/why-i-moved-my-notes-to-trello-po9). It only made sense (back when I did this) to put and track my movie collection into Trello.
It all started as an Excel file that I used to keep track of what movies I owned, where they were, who had them and what-not. As my development skills grew, the more I played with the movie list.
I always felt like I was in between technologies and didn't possess the necessary skills to pull off what I wanted to achieve. I used [AutoHotkey](https://autohotkey.com), C# with WinForms, WPF, I even went the painful route of vanilla HTML. Ultimately, these projects all failed.
I finally got an ASP.NET project working running on a Virtual Server on my home computer. You can see the issues with this setup, right? And, running a Windows server on Azure or AWS is only free for a limited time. This was not going to make me money so those options were out.
Recently, I learned about AWS Lambda. No, I haven't been living under a rock. I just simply didn't know about it, not to mention how to hold it.
At any rate, I finally figured it out and I gotta say I'm very happy with it!
In a nutshell, here's what I did...
1. Created an FSharp Lambda project in Visual Studio
1. Wrote the logic for handling the events I was interested in
1. Hooked up the Lambda with an AWS API Gateway
1. Registered a Webhook event in Trello's API
The result:
* A new movie (Card) is added
* Trello fires a Webhook event to my Lambda function's URL
* The Lambda function
* grabs the name of the new Card
* asks The Internet Movie Database (not IMDB) for a match
* selects the best match
* updates the Card Title with the proper movie title
* updates the Card Description with the movie's synopsis
* updates the Card's Cover with the movie's poster
See it in action:
{% youtube -q42-L8C1N8 %}
| fischgeek |
691,368 | What Financial Softwares, Martin Fowler, Uncle Bob and Alexander Hamilton have in common? | As Martin Fowler said in his article about Patterns of Enterprise Application Architecture... | 0 | 2021-05-24T12:57:12 | https://dev.to/lepsistemas/what-financial-softwares-martin-fowler-uncle-bob-and-alexander-hamilton-have-in-common-2o21 | As Martin Fowler said in his article about _Patterns of Enterprise Application Architecture_ (https://martinfowler.com/eaaCatalog/money.html):
> "A large proportion of the computers in this world manipulate money, so it's always puzzled me that money isn't actually a first class data type in any mainstream programming language."

Well, I didn't read the book _Patterns of Enterprise Application Architecture_, but I do know that he suggests the implementation of a class _Money_, with the attributes _currency_ and _amount_, as well as a method called **allocate** that receives a list of proportions and **distributes that money without leaking values with rounding**. In this article I'll show how we've implemented our _Money_ to solve a real problem of losing cents in apportionments, and also solve the mystery of this article's title.
We already had a _Money_ class, which made it really easier to write the _Money Pattern_. So, if I am to give you a first hint, it is: **DO NOT use _Double_ or _Big Decimal_ to financial values**. Build your "Value Object". After having financial values spread all over your system, it's gonna be harder - but not impossible - to refactor.
Our _Money_ class doesn't have the attribute _currency_ because we don't have the need for a internationalization, at least not yet. And we are not going to implement _currency_ until we actually need it. Just like we didn't have the _allocate_ method. Until we needed it. So, our _Money_ was like this:
```Java
public class Money implements Serializable {
private final BigDecimal amount;
private Money(BigDecimal amount) {
if (amount == null) {
throw new AmountCantBeEmptyException();
}
this.amount = amount;
}
public static Money of(BigDecimal amount) {
return new Money(amount);
}
public Money plus(Money addition) {
return Money.of(this.amount.add(addition.amount));
}
public Money minus(Money discount) {
return Money.of(this.amount.subtract(discount.amount));
}
public Money times(BigDecimal factor) {
return Money.of(this.amount.multiply(factor));
}
public BigDecimal getAmount() {
return amount;
}
@Override
public boolean equals(Object obj) {
if (obj == null || !(obj instanceof Money)) {
return false;
}
return this.amount.compareTo(((Money) obj).amount) == 0;
}
@Override
public int hashCode() {
return this.amount.hashCode();
}
}
```
This used to solve most of our financial problems. Until the day we needed the **allocate** method. A **debit worth of $ 1000.20 should be apportioned between several accounts** with the following rules:
| # | Proportion | Gross Value | Rounded Down | Rounded Up | Rounded Half Even |
|:-----:|-----------:|------------:|-------------:|-----------:|------------------:|
| 1 | 22,9% | 229.0458 | 229.04 | 229.05 | 229.05 |
| 2 | 27.7% | 277.0554 | 277.05 | 277.06 | 277.06 |
| 3 | 7.8% | 78.0156 | 78.01 | 78.02 | 78.02 |
| 4 | 22.6% | 226.0452 | 226.04 | 226.05 | 226.05 |
| 5 | 19% | 190.038 | 190.03 | 190.04 | 190.04 |
| Total | 100% | 1000.20 | 1000.17 | 1000.22 | 1000.22 |
As you can see, applying the apportionment percentage on every item, we'll never get to **1000.20** - this happens because **cents** are an indivisible unit, so the financial value represented by Money can't be 229.0458, for example. If we round down, 3 cents are lost in the end. If we round up, we get 2 extra cents. Even using Round Half Even will have precision loss.
And guess who faced a problem like this? George Washington himself and one of the proposed solutions came from Alexander Hamilton, one of the Founding Fathers, and first United States Secretary of the Treasury, using his Largest Remainder Method.
The problem faced at that time, described in [U.S. Census Bureau](https://www.census.gov/history/www/reference/apportionment/methods_of_apportionment.html), was shortly:
A country with 4 states, each one with its own population, and 20 Seats at the House of Representatives. How many senators each state should have so they are represented proportionally? A senator, just like a penny, can't be divided in pieces. Right? Just double checking...
| State | Population | Seats by State | Seats by State before Hamilton's method | Seats by State after Hamilton's method |
|-------|-----------:|---------------:|----------------------------------------:|---------------------------------------:|
| 1 | 2560 | 4.31 | 4 | 4 |
| 2 | 3315 | 5.**58** | 5 | 6 |
| 3 | 995 | 1.**67** | 1 | 2 |
| 4 | 5012 | 8.44 | 8 | 8 |
| Total | 11882 | 20 | 18 | 20 |
Hamilton's method consists in calculating the proportion between the population of **11882** and the number of **20** seats, resulting in the quota of **594.1**. Now, for each state, divide its population for the quota. For example in the state **1**, **2560/594.1** getting a quotient of **4.31**.
As we have agreed, **we can't have 4 senators and 0.31 of a senator** for a state. So the number of senators for the state 1 is 4, which is the **whole part** of the result. That happens for every state. In the end, because of the rounding, the **number of senators allocated in the states is 18**. Which states should the other **2 senators** go to? That's when **Hamilton** comes with a possible solution. His idea is that we distribute these 2 seats to the states that had the **largest decimal part before the rounding**.
I'll explain. If we suppress the whole part of the **Seats by State** column and desc order by the decimal part, we get:
1. 1,**67**
2. 5,**58**
3. 8,**44**
4. 4,**31**
Since we have a total of **2 seats to redistribute**, the states that will receive these senators are the **first 2 of the list**. Resulting in the column **Seats by State after Hamilton's method**.
There's a paradox to be noticed that was discovered by applying Hamilton's method in the population of Alabama, reason it is called the [Alabama Paradox](https://en.wikipedia.org/wiki/Apportionment_paradox#Alabama_paradox). That will not be covered here. But this is when **Uncle Bob** comes in the article.
Amongst his **countless contributions** to the software development community, Uncle Bob spread the **SOLID principles**. They were relevant in the 90's, they are relevant now. The principle we are focusing now is the Open-Closed Principle.
We need to change our **Money** class to implement the **allocate** method to distribute its values in ratios without losing any cents. So we created it like:
```Java
public class Money implements Serializable {
private static final BigDecimal ONE_HUNDRED = new BigDecimal(100);
public List<Money> allocate(List<BigDecimal> ratios, RemainderDistribution distribution) {
long amountInCents = toCents();
List<Quota> quotas = new ArrayList<>();
for (BigDecimal ratio: ratios) {
quotas.add(new Quota(amountInCents, ratio));
}
distribution.distribute(quotas, amountInCents);
return quotas.stream().map(Quota::toMoney).collect(Collectors.toList());
}
public long toCents() {
return this.amount.multiply(ONE_HUNDRED).longValue();
}
}
```
```Java
public class Quota {
private static final BigDecimal ONE_HUNDRED = new BigDecimal(100);
private long amount;
private long total;
private BigDecimal ratio;
public Quota(long total, BigDecimal ratio) {
this.total = total;
this.ratio = ratio;
this.amount = ratio.multiply(BigDecimal.valueOf(total)).longValue();
}
}
```
```Java
public interface RemainderDistribution {
void distribute(List<Quota> quotas, long total);
}
```
Remember the Alabama Paradox? Even having validated with our Product Manager that we would adopt Hamilton's method we still have some doubts about how this will behave in the user's hands. So we didn't want to have this hard-coded in **Money** class. We wanted to have it changeable whenever needed. We wanted to make our **Value Object** Opened for extension but Closed for modification. That's why **RemainderDistribution** is an interface. One of its possible implementations, the one we used, is **HamiltonApportionmentDistribution**:
```Java
public class HamiltonApportionmentDistribution implements RemainderDistribution {
@Override
public void distribute(List<Quota> quotas, long total) {
long remain = total;
for (Quota quota : quotas) {
remain = remain - quota.getAmount();
}
List<Quota> sortedQuotas = quotas.stream().sorted(Comparator.comparing(Quota::getFractionalPart).reversed()).collect(Collectors.toList());
Iterator<Quota> iterator = sortedQuotas.iterator();
while(remain > 0) {
remain = remain - 1;
iterator.next().addRemain(1);
}
}
}
```
This way we **solved** that initial problem. where **rounding down we lost 3 cents** (remember that rounding down is due to the cents, similar to when we round a senator down). **The calculation must be done using the smallest unit, in this case, cents**. And we got this result:
| # | Proportion | Gross Value | Gross Value in Cents | Final Value |
|:-----:|-----------:|------------:|---------------------:|------------:|
| 1 | 22.9% | 229.0458 | 22904.**58** | **229.05** |
| 2 | 27.7% | 277.0554 | 27705.54 | 277.05 |
| 3 | 7.8% | 78.0156 | 7801.**56** | **78.02** |
| 4 | 22.6% | 226.0452 | 22604.52 | 226.04 |
| 5 | 19% | 190.038 | 19003.**80** | **190.04** |
| Total | 100% | 1000.20 | 100020 | 1000.20 |
At this point I hope I have demystified the intersection between **Alexander Hamilton**, **Martin Fowler** and **Uncle Bob** with the **Financial Systems**. And, as bonus, you get some code to apply in your favorite language. Ah, all this **code was covered with Unit Tests**.
**Bonus**: if you don't know who **Alexander Hamilton** was, there is a musical movie available in Disney+, called Hamilton. It tells the story of this who was the **American First Secretary of Treasury** recorded with rap, hip hop and jazz, directly from the Broadway in 2016. Here's the trailer of this amazing film:
{% youtube DSCKfXpAGHc %} | lepsistemas | |
691,407 | How to uppercase the first letter of a string in JavaScript | JavaScript offers many ways to capitalize a string to make the first character uppercase. Learn the v... | 0 | 2021-05-07T22:50:24 | https://dev.to/codingcodax/how-to-uppercase-the-first-letter-of-a-string-in-javascript-5bi9 | javascript, beginners, string | JavaScript offers many ways to capitalize a string to make the first character uppercase. Learn the various ways, and also find out which one you should use, using plain JavaScript.
## 1. chartAt + slice
The first way to do this is through a combination of `cartAt()` and `slice()`. With `chartAt()` uppercases the first letter, and with `slice()` slices the string and returns it starting from the second character:
```javascript
const name = 'codax';
const nameCapitalized = name.charAt(0).toUpperCase() + name.slice(1);
// expected output: "Codax"
```
You can create a function to do that:
```javascript
const capitalize = (s) => {
return s.charAt(0).toUpperCase() + s.slice(1)
}
capitalize('codax'); // "Codax"
```
## 2. Replace function
My favorite is with `replace()` because I love regex (even if I'm not an expert) and regex is more customizable in general.
```javascript
const name = 'codax';
const nameCapitalized = name.replace(/^\w/, (c) => c.toUpperCase()));
// expected output: "Codax"
```
You can also make it a function:
```javascript
const capitalize = (s) =>
return s.replace(/^\w/, (c) => c.toUpperCase()));
}
capitalize('codax'); // "Codax"
```
### Conclusion
For readability, I recommend the first option (`chartAt` + `slice`), and for speed, I recommend the second option (`replace`).
If you know other/better ways please leave below in the comments, or how to improve on the ones mentioned here.
Thanks.
| codingcodax |
691,630 | Let's Build ML Application using Streamlit and Azure in 5mins!! | Cognitive Services brings AI within reach of every developer—without requiring machine-learning exper... | 0 | 2021-05-10T04:12:24 | https://dev.to/rajeshsilvoj/let-s-build-ml-application-using-streamlit-and-azure-in-5mins-477p | azure, nlp, machinelearning, microsoft | **Cognitive Services brings AI within reach of every developer—without requiring machine-learning expertise. All it takes is an API call to embed the ability to see, hear, speak, search, understand and accelerate decision-making into your apps. Enable developers of all skill levels to easily add AI capabilities to their apps**-Microsoft.
Microsoft has become a cloud-based provider of AI capabilities, machine learning capabilities and sentimental analysis.
we can use the azure cognitive services to build intelligent applications
Step-1: Create a [Microsoft Azure Account](//portal.azure.com).
Step-2:Create a new resource

Step-3: Search for Translator in resources
->Give resource name
->Select region as eastus
->Select free subscription in the pricing tier
Then you can see your API keys for the translator app.
Step-4: Let's set up Streamlit.
Step-5:Open your command line install them

Step-6: There is a good *[Streamlit course](https://www.udemy.com/course/python-streamlit-for-making-web-applications/)* on Udemy. It is a free course for beginners.
Let's set up our application.
Explore the [quick start](https://docs.microsoft.com/en-us/azure/cognitive-services/translator/quickstart-translator?tabs=python) guide on the Azure page and get the code.

Step-7: let's change some of the parameters and then our code will be ready.
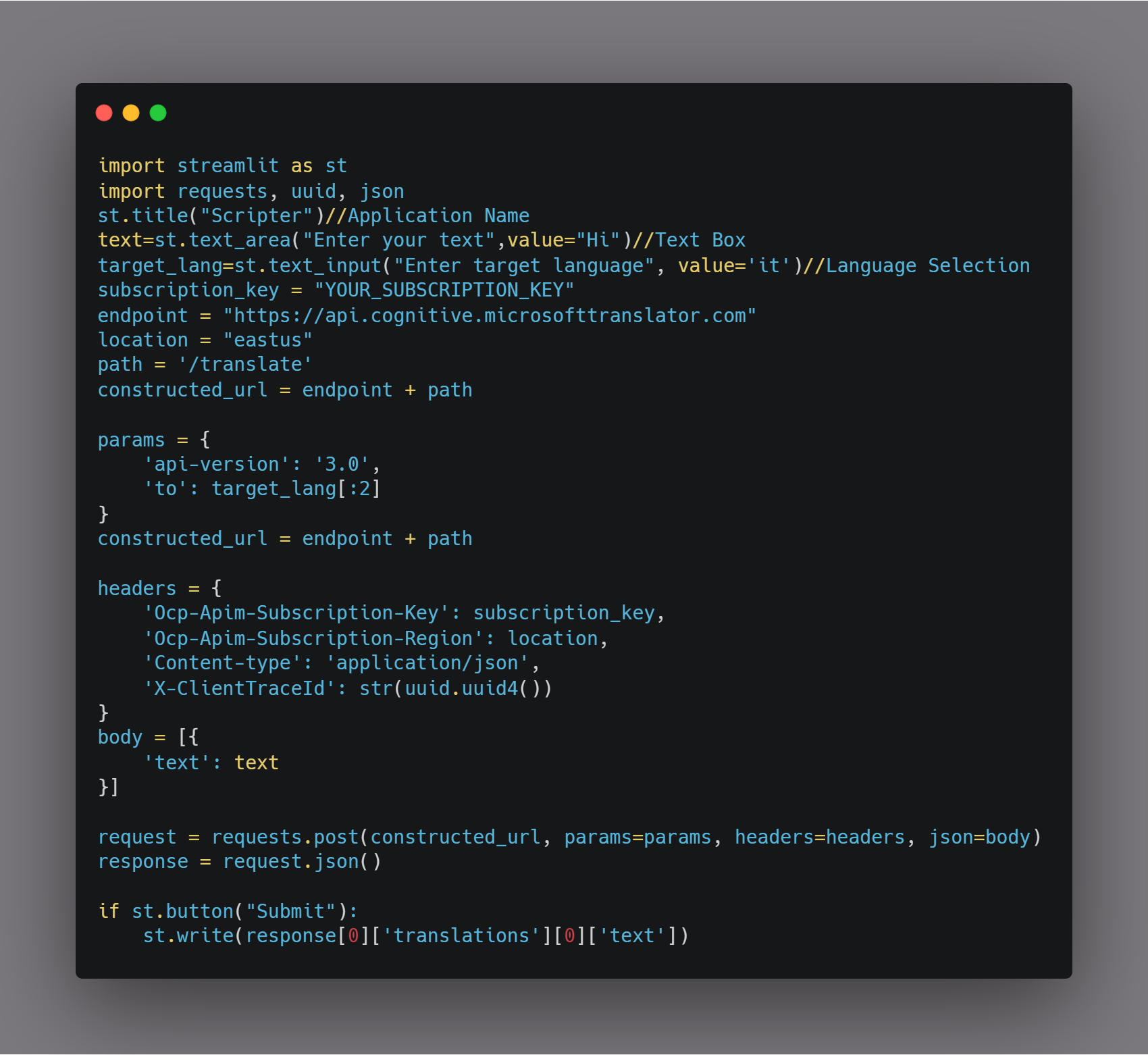
Step-8: Run application:- streamlit run <app-name>.py in command line.
####Try out a working application here: https://share.streamlit.io/rajeshsilvoj/scripter_app/main/app1.py
*Input*:"
The probosci's monkey (Nasalis larvatus) is endemic to the island of Borneo, where it is found predominantly in coastal areas, near rivers and in swamp forests. It is perhaps the most aquatic of the primates and is a fairly good swimmer, capable of swimming underwater; apart from this, it is largely arboreal. This photograph is a composite of three images and shows a probosci's monkey jumping between trees in Labuk Bay in the Malaysian state of Sabah."
**Translated to Italian**👇:

**Translated to Hindi**👇:
Github repo: https://github.com/rajeshsilvoj/Scripter-Article
Contact me :
[Linkedin](https://www.linkedin.com/in/silvoj-rajesh-kumar-ba655b1a7/), [Instagram](https://www.instagram.com/rajesh_silvoj/),[Github](https://github.com/rajeshsilvoj) | rajeshsilvoj |
691,897 | #30DaysOfAppwrite : Accounts & Users API | Intro #30DaysOfAppwrite is a month-long event focused on giving developers a walkthrough... | 0 | 2021-05-08T14:08:41 | https://dev.to/appwrite/30daysofappwrite-accounts-users-api-4592 | javascript, webdev, flutter, 30daysofappwrite | ## Intro
[#30DaysOfAppwrite](http://30days.appwrite.io/) is a month-long event focused on giving developers a walkthrough of all of Appwrite's features, starting from the basics to more advanced features like Cloud Functions! Alongside we will also be building a fully-featured Medium clone to demonstrate how these
concepts can be applied when building a real-world app. We also have some exciting prizes for developers who follow along with us!
## Accounts & Users API
Welcome to Day 8 👋. The Users and Accounts APIs seem to raise questions for newer Appwrite devs on our [Discord](https://appwrite.io/discord) server. Today, it's time to answer all of them. If you followed us yesterday, we reviewed the differences between the Client and Server Side SDKs and discussed the scopes accessible to each of them. So if you haven't already, we recommend you to read that first for some context.
## The Main Difference?
If you're looking for a TL;DR this table should help you.
| Users API | Accounts API |
|----------------------------------------------------|---------------------------------------------------------|
| Server Side API | Client Side API |
| Accessed using an API Key | Accessed using a Cookie (or JWT) |
| Operates in an Admin Scope | Operates in the scope of the currently logged in user |
| Perform CRUD operations on all of your app's users | Perform CRUD operations on the currently logged in user |
If you're on a quest for more information, read along 😊
The Users API is part of the **Server Side SDK** specification and operates in an **admin scope** (i.e. using an API key) with access to all your project users. The Users API allows you to perform actions like create, update, delete and list your app's users, create, update and delete their preferences, etc. The complete documentation for the Users API can be found [in our docs](https://appwrite.io/docs/server/users).
Alternatively, the Accounts API operates in the scope of the currently logged-in user (using a cookie or JWT) and usually used in a client-side integration. The Accounts API allows you to create an account, create user sessions using username and password as well as OAuth2, update your accounts' email and password, initiate password recoveries, initiate email verifications, etc. The complete documentation for the Accounts API can be found [here](https://appwrite.io/docs/client/account).
## Deep Dive into the Accounts API
Let's try to understand the Accounts API a little better. Some of the most notable methods of the Accounts API are the [`createSession()`](https://appwrite.io/docs/client/account?sdk=web#accountCreateSession) and the [`createOAuth2Session()`](https://appwrite.io/docs/client/account?sdk=web#accountCreateOAuth2Session) methods. If successful, their response contains a `set-cookie` header that tells the browser to save and include this cookie with every subsequent request. In our Flutter ( and upcoming Android ) SDKs, we make use of a [Cookie Jar / Cookie Store](https://developer.android.com/reference/java/net/CookieStore) to achieve similar functionality.
Appwrite supports a variety of authentication methods. Since 0.8, we've added support for **Anonymous Users**. When you develop an application, there might be times when you want to let a user interact with parts of your app before they're signed in. This also increases the conversion rate of your users, since the hurdle of registration is very high. If an anonymous user decides to sign up to your app, they can later convert their account using their email and password or the OAuth method.
You can enable and disable any authentication method under the **Settings** tab of the **Users** section of the console.
Let's make our first request using the **Accounts API**. To see this in action in a complete app, check out the source code of [our demo apps](https://github.com/appwrite?q=todo&type=&language=&sort=).
We'll be using a JavaScript example for this tutorial. Whether using a framework or vanilla JS, it's really easy to get started - our [Getting Started for Web](https://appwrite.io/docs/getting-started-for-web) tutorial explains how. Once you have installed and initialised your SDK, you can follow along.
### create()
This is the method to use if you want to implement **Sign Up** functionality in your app. Do note that this will only create a new user. You will **still need to call** the `createSession()` method using the same email and password to create a new session for this user. Make sure you've followed previous posts to initialize your Appwrite SDK with your Appwrite project's endpoint and project ID before proceeding to these steps.
```js
let promise = sdk.account.create("unique()", "email@example.com", "password", "name");
promise.then(
function (response) {
console.log(response); // Success
},
function (error) {
console.log(error); // Failure
}
);
```
### createSession()
If you want to achieve **Login** functionality in your app, this is the method you need. This method creates a session for an existing user, so make sure you've created the user by calling `create()`.
```js
// Using the promise syntax
let promise = sdk.account.createSession("email@example.com", "password");
promise.then(
function (response) {
console.log(response); // Success
},
function (error) {
console.log(error); // Failure
}
);
// Or using async/await
const login = async () => {
try {
let response = await sdk.account.createSession(
"email@example.com",
"password"
);
console.log(response);
} catch (e) {
console.log(e);
}
};
login();
```
If you inspect the response from `createSession()`, you'll find the following headers.
```
set-cookie:
a_session_6062f9c2c09ce_legacy=eyJpZCI6IjYwNmI3Y....NmVhMzQ2In0=; expires=Wed, 27-Apr-2022 14:17:29 GMT; path=/; domain=.demo.appwrite.io; secure; httponly
set-cookie:
a_session_6062f9c2c09ce=eyJpZCI6IjYwNmI3Y....NmVhMzQ2In0=; expires=Wed, 27-Apr-2022 14:17:29 GMT; path=/; domain=.demo.appwrite.io; secure; httponly; samesite=None
x-fallback-cookies
{"a_session_6062f9c2c09ce":"eyJpZCI6IjYwNmI3Y....NmVhMzQ2In0="}
```
An Appwrite session cookie uses the following syntax: `a_session_<PROJECT-ID>`, `a_session_<PROJECT-ID>_legacy`. Since many browsers disable 3rd party cookies, we use the `x-fallback-cookies` header to store the cookie in local storage and then use it in subsequent requests if the cookie has not already been set.
### deleteSession()
In order to implement **Logout** functionality, you will need to delete a session using a session ID. You can delete the current session by passing in `current` in place of the `SESSION_ID`.
```js
let promise = sdk.account.deleteSession("[SESSION_ID]");
promise.then(
function (response) {
console.log(response); // Success
},
function (error) {
console.log(error); // Failure
}
);
```
We've covered just a few essential methods to convey how the API works. The complete list of functionality can be found [here](https://appwrite.io/docs/client/account).
## Deep Dive into the Users API
We can achieve all the functionalities we discussed above with the Users API as well. However, you would be performing all the actions using an API key. If you're following along from yesterday, you would already have a project and API key set up. Otherwise, you can quickly get started [here](https://appwrite.io/docs/getting-started-for-server).
### create()
The create method can be used to create a new user. Do note that this is **not the same** as creating a session using the Accounts API. There is no cookie involved here. Think of this as an admin creating an account on behalf of one of their users. To create a session, the user will need to use these credentials to log in from a client-side app.
```js
let promise = users.create("email@example.com", "password");
promise.then(
function (response) {
console.log(response);
},
function (error) {
console.log(error);
}
);
```
### deleteSession()
Let's say that you have a Cloud Function that monitors account logins and alerts a user about a suspicious login from a different location or IP. In this case, as a preventive measure, you might want to delete the session or block the account altogether until the real user takes action. The `deleteSession()` method comes handy in this case.
```js
let promise = users.deleteSession("[USER_ID]", "[SESSION_ID]");
promise.then(
function (response) {
console.log(response);
},
function (error) {
console.log(error);
}
);
```
So for some closing remarks, use the **Accounts API** when building a client-side app and the **Users API** when building a server-side app.
In the next blog post, we will use the Accounts API to add some cool functionalities to our Medium clone 🤩.
## Credits
We hope you liked this write-up. You can follow [#30DaysOfAppwrite](https://twitter.com/search?q=%2330daysofappwrite) on Social Media to keep up with all of our posts. The complete event timeline can be found [here](http://30days.appwrite.io)
- [Discord Server](https://appwrite.io/discord)
- [Appwrite Homepage](https://appwrite.io/)
- [Appwrite's Github](https://github.com/appwrite)
Feel free to reach out to us on Discord if you would like to learn more about Appwrite, Aliens or Unicorns 🦄. Stay tuned for tomorrow's article! Until then 👋
| christyjacob4 |
692,099 | 5 Easy LeetCode questions to start competitive-coding | These are 5 LeetCode questions which boost my confidence to start competitive programming and there c... | 0 | 2021-05-08T16:46:17 | https://dev.to/nagasaisriya/5-easy-leetcode-questions-to-start-competitive-coding-48hn | _These are 5 LeetCode questions which boost my confidence to start competitive programming and there can be many easy ones out, but I started with these. I provided my Python solutions to the problems, these solutions can be optimized too, just sharing my approach :)_
## 1. [FizzBuzz](https://leetcode.com/problems/fizz-buzz/)
```python
class Solution:
def fizzBuzz(self, n: int) -> List[str]:
l=[]
for i in range(1,n+1):
if i%3==0 and i%5==0:
l.append("FizzBuzz")
elif i%3==0:
l.append("Fizz")
elif i%5==0:
l.append("Buzz")
else:
l.append(str(i))
return l
```
## 2. [Single Number](https://leetcode.com/problems/single-number/)
```python
class Solution:
def singleNumber(self, nums: List[int]) -> int:
return 2*sum(set(nums))-sum(nums)
```
## 3. [Intersection of two arrays](https://leetcode.com/problems/intersection-of-two-arrays/)
```python
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return set(nums1).intersection(set(nums2))
```
## 4. [Fibonacci Number](https://leetcode.com/problems/fibonacci-number/)
```python
class Solution:
def fib(self, n: int) -> int:
m=0
if n==0:
return 0
elif n==1:
return 1
else:
m=self.fib(n-1)+self.fib(n-2)
return m
```
## 5. [Array Partition-I](https://leetcode.com/problems/array-partition-i/)
```python
class Solution:
def arrayPairSum(self, nums: List[int]) -> int:
nums.sort()
return sum(nums[::2])
```
_Just make sure to start your journey no matter if you're a beginner or pro. I just started off and I can definitely feel the difference, be it in my problem-solving ways or maintaining consistency. Hope this article helps!!_ | nagasaisriya | |
692,347 | C# Basic Web Applications | HTTP CRUD Methods CRUD stands for **Create Read Update Delete. GET requests information f... | 0 | 2021-05-09T00:07:53 | https://dev.to/saoud/c-basic-web-applications-3n1e | csharp, beginners, codenewbie, webdev | ### HTTP CRUD Methods
**CRUD** stands for ***C**reate **R**ead **U**pdate **D**elete*.
**GET** requests information from the server, which is usually displayed to users. ASP.NET includes a `HttpGet()` method for GET requests.
**POST** alters information on the server. MVC has an `HttpPost()` method for POST requests.
**PATCH** updates *existing* information on the server.
**DELETE** removes data from the server.
We must use POST requests to update and delete records because HTML5 forms don't recognize PATCH AND DELETE.
### **Adding Delete to a Form Example**
```csharp
...
<form action="/items/delete" method="post">
<button type="submit" name="button">Clear All Items</button>
</form>
```
### **Adding Delete to a Controller Example**
```csharp
[HttpPost("/items/delete")]
public ActionResult DeleteAll()
{
// Code goes here.
}
```
Finding Objects with Unique IDs
Readonly property: a property that can be read but not overwritten.
## Introduction to RESTful Routing
### **Terminology**
- **REST**: Short for **Representational State Transfer**.
- **RESTful Routing**: A set of standards used in many different languages to create efficient, reusable routes.
### **REST Conventions**

- **Route Name** refers to the name of the route method in the controller.
- **URL Path** refers to the path listed above the route in a route decorator. This will also be the URL a user sees when navigating to this area of the site.
- **HTTP Method** refers to the HTTP method that route will respond to, or be invoked for.
- **Purpose** details what each route is responsible for.
- `:id` is a placeholder for where a specific object's unique ID will be placed.
## Applying RESTful Routing
### **Dynamic Routing**
**Dynamic Routing** refers to routes and their URL paths that can dynamically *change*. Here's an example of a dynamic route:
```
[HttpGet("/items/{id}")]
public ActionResult Show(int id)
{
Item foundItem = Item.Find(id);
return View(foundItem);
}
```
- The `{id}` portion of the path is a placeholder.
- The corresponding link in the view looks like this: `<a href='/items/@item.Id'>`.
## Objects Within Objects Interface Part 2
RESTful routing conventions for applications that use objects within objects look like the image below.
Following RESTful routing doesn't require we use all routes. It just requires that the routes we *do* need in our applications follow these conventions.

# **Using Static Content**
In order to add CSS or images to our application, we need to update the `Startup.cs` to `UseStaticFiles()`:
**Startup.cs**
```csharp
public void Configure(IApplicationBuilder app)
{
...
app.UseStaticFiles(); //THIS IS NEW
...
app.Run(async (context) =>
{
...
});
}
```
`img` and `css` directories need to be inside of `wwwroot`, which should be in the project's root directory.
```
└── wwwroot
└── img
└── css
└── styles.css
```
Now we can link to an image like this:
```
<img src='~/img/photo1.jpg'/>
```
## Layouts and Partials
**Layout view**: A view that allows us to reuse the same code and content on multiple pages.
**Partial view**: Reusable section of code that can be inserted into other views.
**Razor code block**: A way to indicate Razor code that looks like this:
```
@{
}
```
### **Using Layouts**
**Views/Shared/_Layout.cshtml**
```csharp
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>My To-Do List!</title>
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous">
<link rel="stylesheet" href="/css/styles.css">
</head>
<body>
@RenderBody()
</body>
</html>
```
Using the layout in a view:
**Views/Home/Index.cshtml**
```csharp
@{
Layout = "_Layout";
}
...
```
### **Using Partials**
A sample partial for a footer:
**Views/Shared/Footer.cshtml**
```csharp
<div id="footer">Bottom div content</div>
```
Adding the partial to another file:
**Views/Shared/_Layout.cshtml**
```csharp
<body>
@Html.Partial("Footer")
</body>
``` | saoud |
692,446 | CalmAPI - A Production ready REST API generator using NodeJS & MongoDB | Based on my previous NodeJS MongoDB starter package, Here is a Production ready Modular REST API Gene... | 0 | 2021-05-09T03:43:47 | https://dev.to/sunilksamanta/calmapi-a-production-ready-rest-api-generator-using-nodejs-mongodb-pd9 | node, mongodb, restapi, javascript | Based on my [previous](https://dev.to/sunilksamanta/rest-api-structure-using-nodejs-mongodb-mongoose-2hka) NodeJS MongoDB starter package, Here is a Production ready Modular REST API Generator using NodeJS & MongoDB.
[](https://badge.fury.io/js/calmapi)
### INSTALLATION
Install by running
```
npm i -g calmapi
```
Then run inside your workspace directory
```
calmapi
```
And follow the easy steps.
### FEATURES
* Production ready - Controller, Model & Service oriented architecture
* Modules with automated Routing (Nested Route support)
* Built-in Authentication Module with JWT & DB Store authentication
* Built-in User Module
* Build-in CRUD operations for modules with pagination, filters, sorters
* Sample Post Module (CRUD Operation Example)
* CRUD Module generation command line support.[Alpha]
* No Hidden sh*ts in your node_modules. Completely free to customize
* Prebuilt CRUD operation classes for Controller & Service
* DTO Support( Data transfer Object)
* Eslint rules enabled
* .env support
* And many more
Here is the [github repo](https://github.com/sunilksamanta/calmapi)
{% github sunilksamanta/calmapi %}
*We love your input! We want to make contributing to this project as easy and transparent as possible, whether it's: Reporting a bug, Documentation, Discussing the current state of the code, Submitting a fix or Proposing new features.* | sunilksamanta |
692,564 | GNU Hurd | GNU Hurd https://www.gnu.org/software/hurd/ The project homepage please see the above a... | 0 | 2021-05-09T08:34:35 | https://dev.to/aisuko/gnu-hurd-2j72 | gnuhurd | # GNU Hurd
> https://www.gnu.org/software/hurd/
The project homepage please see the above address. And I am the maintainer for this project but now only fixed the fewer issues. This is my first project on the GNU community. And we can see that the project no active status if you compare it to anyone of the cloud-native projects.
I can not talk too much, because I'm new to the project and need to read more and learn from the basics. As we know the way not similar to the modern open-source projects, nowadays project workflow may look like:
Github -> Slack(Discord) -> Zoom meeting
git.savannah.gnu.org -> IRC(freenode) meeting
And the most difference between GNU projects Github projects are you can only readonly on the source code. But as we know this is the GNU community's policy comes from https://www.gnu.org/philosophy/open-source-misses-the-point.html
*The terms “free software” and “open source” stand for almost the same range of programs. However, they say deeply different things about those programs, based on different values. The free software movement campaigns for freedom for the users of computing; it is a movement for freedom and justice. By contrast, the open source idea values mainly practical advantage and does not campaign for principles. This is why we do not agree with open source, and do not use that term.*
So, there are too many things that need to adapt. Let's get our hands dirty every day. I believe one day I can go easy.
There is the repo list of GNU Hurd:
http://git.savannah.gnu.org/cgit/hurd
And we do not need to follow the official document at Debian community to run GNU Hurdhttps://www.debian.org/ports/hurd/hurd-install, is too difficult for my personal.
I try this https://www.gnu.org/software/hurd/hurd/running/debian.html and it works well on my ubuntu 20.04 LTS with `qemu`.
and the latest pre-complied `gnu-hurd` address:
http://ftp.gnu.org/gnu/hurd/
If anyone interest in the project, please contact the community by using the ways below:
https://www.gnu.org/software/hurd/contact_us.html
And not only contributing code can be a contributing, any small case or spell-mistakes all can be contributing, more detail and ways:
https://www.gnu.org/software/hurd/contributing.html
# Finally
The cover photo was shot by myself fewer years ago's morning if I remember right. The camera capability of the iPhone 6's is amazing me until today.
I'd like to borrow little sentences from GNU document and send to myself.
*Final Words -- Difficulties*
*Please note that doing substantial contributions to a project as big and as encompassing as the GNU Hurd is not a trivial task. For working on the GNU Hurd's inner guts and getting useful work done, you have to plan for a many-months learning experience which will need sufficient self-motivation. Working on an advanced operating system kernel isn't something you can do in a few free minutes -- even less so without any previous kernel hacking experience.*
*Likewise, the Linux kernel maintainers are stating the exactly same difficulties, which is well presented by Jonathan Corbet in his 2010 Linux Kernel Summit report for the opening sessions about welcoming of newcomers.*
*But of course, none of this is meant to be dismissive, or to scare you away -- on the contrary: just start using the GNU Hurd, and either notice yourself what's not working as expected, or have a look at one of the Open Issues, and we shall see if you'll evolve to be the next core Hurd hacker! You'll just have to get excited about it!*
| aisuko |
692,651 | Data structure for react app | I have written in react tool for Satifactory game, which is just serverless one-page manager. The too... | 0 | 2021-05-09T10:20:38 | https://dev.to/jzechy/data-structure-for-react-app-2aln | react | I have written in react [tool for Satifactory game](https://zechy.cz/satisfactory/#/), which is just serverless one-page manager. The tool have something like "inner database", which is holding info about game objects, like buildings and recipes.
Now it is only a JSON files where is everything stored. But I am thinking...
If there some sort of database for react, where I could write these data? I would like something which will be a little more easier to maintain. | jzechy |
692,764 | My First Post | Hello there Hello there const x = 20; Enter fullscreen mode Exit... | 0 | 2021-05-09T14:15:18 | https://dev.to/ghostchaserr/my-first-post-5hci |
#Hello there
> Hello there
```javascript
const x = 20;
``` | ghostchaserr | |
692,892 | How I Got 4 Software Developer Job Offers In 4 Weeks | Despite not having worked as a formal software developer before | 0 | 2021-05-09T16:44:25 | https://bionicjulia.com/blog/how-i-got-4-software-developer-job-offers-in-4-weeks | career, reflections | ---
title: How I Got 4 Software Developer Job Offers In 4 Weeks
published: true
date: 2021-05-09 00:00:00 UTC
tags: career, reflections
canonical_url: https://bionicjulia.com/blog/how-i-got-4-software-developer-job-offers-in-4-weeks
description: Despite not having worked as a formal software developer before
---
I started my first formal software development role about 6 months ago, right in the middle of the pandemic. After taking some time to deliberate over whether software engineering was truly a career I wanted to pursue, I kicked off the process and managed to receive 4 jobs offers, just under a month after starting the application process. A few of my friends have asked how I managed to do this, so I thought I'd write a blog post about my process. I'm as surprised as anyone as to how this all worked out, so I've written this post for posterity - this is as much for me as for anyone else who's about to embark on their own software dev journey. 🤓
## Let's go back in time
For context, we need to rewind to around the start of September 2020. This may take a while, so feel free to skip to the next section if you just want to read about my job hunting process!
I had exited a tech startup I had co-founded at the start of 2020, and after a month's break, had decided to jump straight into starting another business with one of my co-founders, in a completely different industry. We gave it a good go, but decided to call it a day about 6 months in, after a lot of user and market testing.
Honestly, I was feeling extremely lost at this point and had no real plan of what to do next. I had effectively been running companies up to that point for the last 6 years, and whilst I had learnt a lot from being an entrepreneur, the skills I had painfully gained don't necessarily translate well to specific jobs in other companies which tend to ask for specialised skills and X years of professional experience, working in that role. So what to do?
I knew that of all the hats I had worn during my time as an entrepreneur, the one I enjoyed the most was software development. Prior to co-founding my first startup, I had actually left my finance job, to first go on a 6 month [solo travel adventure](https://solowayfarer.com), before returning to London to attend a full time, 3 month, intensive coding bootcamp. This was 100% one of the best decisions of my life as I discovered a real love of programming there and also ended up meeting 2 pivotal friends who would end up becoming my co-founders. Upon graduation, using our new-found programming powers, we built up our tech platform that would form the core of SaaS mar-tech business.
The first 2.5 years of my startup life was mostly spent building the product, using Ruby on Rails and Angular v1. As we started growing the business, raising more funding and growing the team however, I transitioned away from mostly writing software, to focus on running the operations and growth teams (HR, finance, legal, sales, marketing and customer success). There were more than enough things to keep my hands busy, and it made a lot more sense for the company to hire other engineers who could solely focus on building the product. It was a sad, sad day when I finally retired my code editor, but it was the right thing to do.
For the next 3 years, I didn't really write much code at all. I had my own personal website, written in Ruby, using Middleman, that I updated maybe 1-2 times a month, and that was pretty much it. Life as a startup founder was intense to say the least, and all of my waking moments were spent figuring out how we could take the company to the next level.
Fast forward to the final 3 months of the business however, as we were gearing up to sell and exit from the company, I started contributing to the code base again as the immediate focus at this time was to transition our assets (essentially our code IP), to our buyers. There was definitely a warming up period and a lot of re-learning to be done, considering how quickly programming languages and frameworks progress, but once I got into the flow of programming again, I knew that this was really what I wanted to be doing. It was also at this point when I was first introduced to React.
Fast forward a good few months when I was now working on the second startup. Entrepreneurship was something that I was still enjoying but I was also spending my evenings and weekends learning Javascript and React. Why? Because it was just something fun to do, and I really enjoyed the process of learning, writing code and actually building something anyone can interact with in real time. 👩🏻💻
By the time we decided to close down the second business, I had to make a choice on what to do next, having been out of "normal" employment for the last 6.5 years. Do I try to go back to finance? Try to find another co-founder to work with? Start another business idea? Try to find an operations role at another startup? None of these felt right to me... but **the clue was in what I was spending my leisure time doing - programming!** Now was the time to finally get that software development role I had been hankering for since signing up for that coding bootcamp all those years ago, before I was side-tracked into becoming a startup founder. 😆
Which finally brings me to the meat of this blog post - how I got multiple job offers in 4 weeks despite not having held a formal software engineering role before.
## TL;DR
- Formerly an investment banker, then graduated from a 3 month coding bootcamp and ran a couple of startups for over 6 years.
- Wrote production code for the first 2.5 years of my first startup. I then stopped completely for the next few years, before contributing to our code base again in the final 3 months of the business as we were preparing for an exit.
- After exiting the first startup, I started learning React during my leisure time, as a hobby, as I was working on my second startup.
## Preparation phase
### Step 1
I started by spending a good amount of time really thinking about whether software engineering was what I wanted to pursue. Things that helped:
- Writing a pros and cons list and giving myself the time to identify the downsides.
- Remembering all of the times I felt frustrated when programming hobby projects and how I would feel if that was my day job.
- Thinking through what I wanted my daily life to look like in 5 years, and asking myself if this next step as a software engineer would get me part of the way there.
### Step 2
The next step was to make a list of the industries and companies that I was interested in. Things that helped:
- Knowing that a massive criteria for me is personal passion and working for a mission-driven company, I wrote down all of the brands that I interact with and use on a daily basis.
- Listing all of the topics and industries I read about / listen to / watch content from, in my free time.
- Jotting down industries / companies that I thought could find relevant and value in the experience and skills I already have.
- Browsing through specific, curated job boards to see if any previously unconsidered industries or companies caught my fancy.
### Step 3
I then set up a way to track my progress. The tool I settled on was using a simple Notion table, where I listed out all the companies I was interested in. The column headers I tracked for each were:
- Interest level - how much did I want the role? Options:
- Low
- Medium
- High
- Status of my application - what action did I have to take next, if any? Options:
- To apply
- In progress
- Hiring process on hold
- Waiting to hear back
- No response - assume dead
- It's a No for now (aka "Rejected" - this was how I chose to spin it positively 😝)
- Offer received
- I turned down
- Application date - the date I applied
- Stages in the application process (I would continuously update this column as I progressed through each company's funnel, by filling in the date and the stage).
- e.g. 1st round - 20 Oct - Online coding test.
- Advertised salary
- Application deadline
- About - a brief description of the company
- Company website link
- Job description link
### Step 4
At this point, there was an element of research to be done to fill in my table of opportunities. Essentially, this step involved going through the career pages of each of the companies I was interested in and finding if there were open opportunities I could realistically apply for.
Knowing that I was particularly interested in working at a startup, I also perused startup job boards to identify companies with software engineering roles I may not have been aware about.
At this point, I now have a good long list of opportunities to go after.
### Step 5
Just one last thing, but probably the most important thing - making sure you've got your basic CV updated, along with your other social profiles you plan on going to market with. For me, this was [GitHub](https://github.com/juliatan), LinkedIn, Angel.co and my personal website. The thing I really focused on here was how I could stand out from the sea of other developers. For me, that meant **NOT focusing on my programming skills**, but the myriad of others skills I'd gained from my past lives in finance and as a start up founder. I think the most interesting thing about me is the fact that I'm a unique intersection of:
- Someone with investment banking skills;
- Someone with entrepreneurial skills in both marketing-technology and food waste / climate change;
- Someone with an executive coach diploma, who works with clients in my free time, and who's used these skills in my time as a manager of teams;
- Someone who's had a track record of trying new things and sometimes succeeding and sometimes failing;
- Someone who LOVES all things health and fitness, and has done things for the sheer fun of learning and pushing myself like running 8 international marathons, getting a holistic nutritionist certification etc etc. I think you get the gist - **what are the skills that only you have because of your unique experiences?**
## Execution phase
### Setting goals to optimise towards
Having come up with a long list of companies (I had about 10 to start with), it was then time to do the actual applications. The number one thing I had top of mind was how to maximise my chances of being able to dictate the role I wanted, rather than just accepting whatever was offered. The 2 goals I therefore tried to optimise for were:
1. **Giving myself adequate time to find a job I was truly excited and motivated by.** By this, I meant that I explicitly set myself a deadline of 4 months to find a job. Anything sooner would be a bonus. This allowed me to mentally prepare myself to be comfortable with rejecting job offers or opportunities that didn't feel right, or more like, to not freak out if I didn't have any offers before my 4 month deadline.
2. **Competitive tension.** How could I run the process in a way that meant I had multiple options to consider and pit against each other. It's a lot easier to negotiate when you've got fallback options. You'll also suddenly be a lot more in demand when a company finds out other companies are chasing after you as well.
To be clear, with both of the above, I had no idea starting off if I would even have any say or choice in the matter. Who knew? Maybe I'd find it hard to even get one job interview, let alone one offer, but I set out with those lofty goals anyway, because it's better to **shoot high and fail, rather than not trying in the first place**.
### Planning what a typical day looks like
I knew I'd go crazy if I just did applications all day. At the same time, I knew I'd also feel guilty if I didn't feel like I was spending every waking hour and more trying to get my dream role. To solve this, I set some ground rules for myself...because I'm the type of person that likes rules that reduces my need to make decisions.
My personal rules were:
1. To do a minimum of 2 job applications a day, and a maximum of 3. This perhaps took a maximum of 2 hours a day depending on how much of a tailored application I needed to do. It started off a lot longer, but the more applications I did, the faster it went as I started collating a good range of preset paragraphs I could copy & paste and quickly edit to match particular roles. After my daily applications were sent off in the morning, I would also do a quick scan through of new job openings on the various job boards I was watching and add any particularly interesting ones to my Notion table.
2. To spend at least 2 hours a day working on coding problems. I used [codewars](https://www.codewars.com/) for this.
3. To spend at least 2 hours a day working on my React side project (I was targeting front end engineering roles). I was building out a COVID tracking dashboard which was very topical for the time. This served as great conversation fodder in interviews.
4. To spend the rest of my free time doing interview specific preparation. This mostly meant:
(i) Watching a lot of YouTube videos and generally brushing up my knowledge on the fundamentals of front end development. i.e. HTML, CSS, Javascript.
(ii) Consuming as much content as I could around software engineering interviews - types of questions asked, how they are structured, what interviewers look out for etc.
(iii) Keeping up with the latest industry trends through blog posts, podcasts and industry leaders e.g. opinions on React hooks, Typescript, CSS utility classes etc.
(iv) Crafting my personal story and really nailing down how to sell myself when talking to anyone in the industry. Part of this was also figuring out how to communicate my wider set of skills beyond my limited programming-specific ones, since I knew I'd mostly be on the losing end if I made that the key focus of any job interview conversation.
5. Synthesising my daily learnings into cheat sheets centred around certain topics and / or interview stages. So for instance:
(i) Cheat sheet topic examples might be programming fundamentals (what is OOP, inheritance vs. composition, Javascript hoisting, etc.) or React (Redux vs. React context, lifecycle methods, hooks, CSS in JS etc.).
(ii) Cheat sheets oriented around the interview stages might be for e.g. myself (my personal story, skills, what I'm now looking for etc.), live coding challenge (most commonly used array and object methods, how recursion works etc.), architecture interviews (reminders to myself to start by restating the problem, talking out loud, typical things to look out for like scalability, accessibility, cost, tradeoffs and compromises etc.)... hopefully that gives you some ideas.
### Ordering my applications
The order in which I did my applications was extremely important. This is what I did, which I felt definitely led to the competitive tension I was aiming for in the end.
- The very first thing I did was to activate inbound requests on specific job market places. By that I mean setting up my job seeker profile on [Hired.com](http://hired.com) and [Cord](https://cord.co/), and enabling companies to contact me. I got a lot of conversations started with companies in this way.
- Applying for roles in companies that were not in my top tier first. This is somewhat obvious I think, because the main thing I first needed was a ton of interview practice after not having been in the game for the better part of half a decade. I obviously didn't want to be practicing on roles that I actually really _really_ wanted.
- One thing I found really tough was knowing how to benchmark my current programming skill level with the market's. Should I be going for junior roles or mid-level roles (I definitely wasn't a senior, that much I knew!). Speaking to some other engineers I knew, I ultimate set myself the goal of mid-level engineer...thought I actually thought it was completely ridiculous at the time, feeling like I knew nothing at all about programming. I therefore started by applying for junior roles, interspersed with mid-level roles, to get a sense of what the market was expecting. Read on to see how that turned out...
### Timeline of events
Alright, so all of this in place, I started making my first applications on the 18 September. The reality of what then happened took me by absolute surprise. Here's the gist.
- Applications for about 1.5 weeks, with first couple of responses coming in a day or so after applying for online tech tests.
- First interview was scheduled for the 28 September, for a mid-level full stack role.
- From the 28 September to 16 October, I was averaging 2 interviews every weekday, non-stop. The maximum I scheduled was 3 a day.
- It all got a little crazy at one point, where at the height, I had open conversations going with 16 companies. Each company's interview process tends to have a minimum of 3 and an average of 4 stages. The most I experienced for a single company was 8 stages. Talking to 16 companies was therefore getting seriously unmanageable, so I stopped making applications and accepting in-bound requests on 30 September.
- I received my first job offer on the 14th October. It was a great offer and one that was a genuine contender, so I used this to speed up the rest of my ongoing conversations, with the aim of gathering all job offers by 16 October, in order to make a decision over the weekend by 18 October. I was sleeping about 5 hours each night, barely stopping for breaks during the day in order to cram all the interviews AND interview prep in daily, so I was really ready at this point to take stock, make a decision and end my search process. 😪
- Also useful to note that once I felt I had gotten enough "interview practice", I really prioritised my top tier companies, by accepting their interview appointments faster, whilst taking longer to respond to companies where my interest level was a "medium". There's a fine balance to be had though, because there are different types of interviews and I needed practice with each different type, so I always tried to have at least one, say architecture-type interview with a medium tier company, so that I wasn't going in cold to my top-tier interviews once I reached that stage in the process with them.
## Conclusion
### Reflections on the overall process and what I learnt
- I'm really glad I applied to both junior and mid-level roles. Turns out that all of my offers were for mid-level roles, and I failed to pass the first filter for all the junior roles. 😂 If I had only applied for junior roles, I would've lost all hope and confidence very early on. I'm guessing the reason I failed was because I possibly had too much experience for a junior position, despite not having lots of formal software development experience. I would not have applied for mid-level roles if not for the encouragement of my friends, so I'm writing this as a reminder to myself to not let self-limiting beliefs dictate my actions in the future.
- I'm lucky enough to have had a lot of experience from my past lives, at playing the role of interviewer and having to hire for different positions. Traits that I really value in a candidate centre around how much I feel I can trust them, how they react to difficult questions / opposing viewpoints and their passion and love for continuous learning. I therefore tried to communicate all of these traits, as best as I could, in my conversations.
- Regarding trust, I think what worked really well for me was just being super honest about the level of software development experience I did actually have, whilst highlighting all of the areas that I still felt needed improvement. This saved the interviewers from having to probe and find out about my weaknesses themselves, and instead, allowed them to just quickly come to a decision on whether they could accept my current skill level as is and make a judgment on whether they felt I could make up my knowledge gaps in the amount of time they could allocate for this.
- The reason I felt comfortable doing this was because ultimately, I treated every interview I had as a 2-way appraisal. It wasn't just the company assessing whether I would be a good fit for them, but me also assessing whether the role / company was one that would be a good fit for me. I was lucky that I didn't have a looming deadline over my head (I had enough savings to see me through) so I appreciate that this is perhaps not easy for everyone to do, but I did find this extremely empowering. It really does shift the dynamic of the conversation when a company realises that you're not just a taker, but that they need to sell themselves to you as well. I did this by being forthright about what I was looking for in this next role and company, and knowing my limits. For example:
- Knowing I wanted to work for a mission-driven company;
- Wanting to understand the investment that company makes into continuous learning and development of its employees;
- Adoption of industry best practices like pair programming, code reviews and deployment processes;
- Company's approach to structuring teams and flexibility in allowing engineers to move across the code base / front and back end; etc.
- It's ultimately a numbers game. The more applications and open conversations you have with companies, the higher your chance of getting offers! My final stats were as follows (as you can see, there's a bunch of rejections too!):
- I applied to 10 companies and was approached by 9 companies. That's 19 companies in total.
- I turned down interview requests / declined to proceed with 7 companies.
- I got offers from 4 companies.
- I got rejections from 8 companies.
- I ran my process in a short and sharp way, basically trying to cram as much as I could into a very intense process. This meant applying, preparing for interviews and learning new things at the same time, which didn't leave a lot of time for proper rest, exercise or any kind of social life really. I was fairly stressed out over this period of time to say the least, but I prefer this way of working to having a more dragged out process. It's not sustainable long term though, so I'm really glad it worked out successfully within a month, but this may not be the best way of working for everyone (there are definitely healthier ways of doing this!).
### Final remarks
I've put all of the above in writing not because I think this is THE way to go about a job hunt, but just the way that I did it, based on what made sense to me. This won't work for everyone depending on your unique circumstances, but hopefully offers some snippets of useful ideas. 🤞🏻
To summarise:
- Be intentional about the role / company / industry you're looking to work in.
- Create a process and draw up ground rules that you can apply methodically.
- Treat interviews as a conversation - they need you as much as you need them.
- Be honest and communicate your weaknesses upfront so they don't need to probe you for them.
- Focus on your unique skills. This may not necessarily be programming-specific (in fact, having now been a software engineer for 6 months, I've realised a big part of the role has nothing to do with writing code).
- Allow your passion for the industry to shine through, be curious and communicate your love of learning and progression.
- Good luck, and keep persevering! It's not easy but keep going!
I'd love to hear what you think. Are you going through a job hunting process at the moment? Do you agree or disagree with anything I wrote? Let's chat on Twitter [@bionicjulia](https://twitter.com/bionicjulia).
| bionicjulia |
712,163 | Project Prioritize(Heap Practice) | https://github.com/TheHamhams/Project-Heap Hello, I am a stay at home dad who is working to become... | 0 | 2021-05-29T15:44:55 | https://dev.to/thehamhams/project-prioritize-heap-practice-3fn5 | python, beginners, bash, github | https://github.com/TheHamhams/Project-Heap
Hello,
I am a stay at home dad who is working to become a programmer. I am currently using Codeacademy to learn, but I am also starting to work on personal projects to practice my skills.
This project was meant to practice creating and utilizing a heap structure to prioritize personal projects. I know there is a heap library, but I wanted to implement my own as a way to understand it better. The program allows you to create a project list(house work, work projects, yard work, etc.) and add specific tasks with a prioritization level in order to sort them.
The max heap is standard save the ability to delete a project by name in addition to popping off the max. There is also a method that lets you print a sorted list of the desired project category. However, I am not very satisfied with how I accomplished it. I ended up creating a copy of the list, popping off the max values in order, adding them to another list, and then printing that list. I am sure there is a better way to accomplish this, but it was the solution I came up with.
One of my main focuses as I create my projects is to implement best practices with my code as much as possible. If anyone has any suggestions on how I can improve in this area I would love to hear it. I have a lot of practice getting feedback so I welcome hearing about areas I can improve.
| thehamhams |
712,327 | How to avoid frustration while learning something new | Cover Photo by Sebastian Knoll on Unsplash Daily we will face wars of ego, fr able, discouragement.... | 0 | 2021-05-29T19:24:25 | https://dev.to/daniloab/why-getting-frustrated-is-too-boring-578p | career, productivity, motivation, writing | _Cover Photo by [Sebastian Knoll](https://unsplash.com/@skenb?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on Unsplash_
Daily we will face wars of ego, fr able, discouragement. However, we cannot let that win us over. Close to bedtime, I was doing something when the frustration trigger suddenly went off. But, I remembered the very agreement I made with myself to go through moments like this.
To perhaps make you understand a little more about this agreement, let’s go back a few steps.
There are moments when life gives us the impression that we are stagnant and that we are unable to evolve. And, if we are not careful, it is at this moment that our mind begins to create nightmares in ourselves, blocks, etc. I found myself trapped in this type of situation every day. I didn’t feel complete in what to do, I wanted to look for more, I wanted to improve, but I didn’t know-how. I decided to sit down and understand what I could eliminate concerning what hindered me, before trying to add what could help. And because of this elimination, I ended up, on a shorter path, seeing what I needed most.
After that, seeking the common maximum of everything, what stood out among all was the practice. If I want to be more focused, I need to start creating ways to work on my focus. If I want to be smarter, I need to train my intelligence. If I want to drive better, soon I will need to train, improve.
Descending from the main idea to be the practice, we have to start thinking then about the ways that we can create to apply sustainably. If you have in mind that you need to be more focused, then you need to find a way to apply this. For example, whenever I am in the middle of an activity and I feel like doing anything else that is not related, I take a paper and write it down: check if that movie on Netflix is still available. So, in a free moment, I take and zero that list. Silly thing but that works for me.
However, it is important to stress that everything here needs to be built in a way that works for you and not for others. This is a pleasant way of working on my focus. But that may be for you it may not be.
Don’t skip steps, or take steps bigger than legs, grow evolutionary.
These were some of the ideas that I traced and woke up with myself to work on points in my person that I sought to improve. But all of them have a common goal: to share and help people who may be in the same limbo as I have been. That is, apply the golden rule (gold for me in this case), Learn in Public.
The focus is more technological, but I wanted to try to introduce the idea by clarifying that thought. If it was clear? I don’t know, I will change in the future too.
I have already prepared a text to follow this one, so click on the link up there. If you got here it costs nothing to read, but only if you want too =\] | daniloab |
712,512 | Test-Driven Development for Building User Interfaces | Test-driven development, or TDD, is a programming paradigm in which you write your tests first and yo... | 0 | 2021-05-31T15:26:02 | https://blog.testproject.io/2021/03/23/test-driven-development-for-building-user-interfaces/ | webdev, javascript, tdd, react | Test-driven development, or TDD, is a programming paradigm in which you write your tests first and your source code second. TDD is perfect when you’re writing code that has clear inputs and outputs, like pure functions or API endpoints.
But what about when building user interfaces? Can TDD be done for UI development?
You’re about to find out!
In this article we’ll explore a few questions:
* ***Can*** we use TDD to build UIs?
* If so, ***how*** do we do it?
* And finally, ***should*** we use TDD to build UIs?
---
## Background Motivation
When discussing test-driven development with frontend developers, the conversation usually goes something like this:
“Yeah TDD is great for simple functions or backend work, but it just doesn’t make sense for frontend work. When I’m building my UI, I don’t know what code I’ll end up writing. I have no idea if I’ll end up using a `div` or a `span` or a `p` element here. TDD for UIs just isn’t feasible.”
However, I’d like to argue that using TDD to build UIs isn’t as hard as we may think.
---
## Ideal Conditions for TDD
Ideally, we’d use TDD to write our code when the following two conditions are true:
1. We have clear project requirements
2. We have clear inputs and outputs
If those two requirements are not met, it’s difficult or nearly impossible to use TDD. So let’s examine those two requirements in the context of frontend development.
---
### Clear Project Requirements
When you’re developing a new feature, you’re typically given mockups by a UX designer. These mockups show you how the feature should look and how the feature should behave. For example, “when the user clicks this button, a dialog modal appears on the screen.”
Good mockups will clarify various details such as how inputs will look when in a hover or focus state, how empty states will look when content is missing, and how the page layout will change for desktop, laptop, and mobile screen sizes.
As you may have already guessed, the mockups provide the project requirements! We know exactly how our UI should look and behave. If there’s anything unclear in the mockups, engineers should ask clarifying questions with their UX designer or product manager so that the requirements are absolutely clear.
---
### Clear Inputs and Outputs
Now, what about clear inputs and outputs?
Most frontend engineers these days use a UI library or framework like React or Angular. A UI library like React allows you to build reusable components to create small building blocks of functionality that you can piece together to make an app.
Now, what is a component? Well, in React, it’s a function! Components are simply functions of props and state that return a piece of UI. So we have clear inputs and outputs!
Given the same props and state, a component will always render the same thing. Components are deterministic, and as long as they don’t kick off side effects like making an API request, they are pure functions.
---
## Practical Considerations
So, in theory, using TDD to build UIs *should work*. Both of our ideal conditions are met.
But what about the unknowns? As mentioned above, we still might not know a few things:
1. Component props and state we’ll use
2. Names we’ll give our methods and functions
3. HTML elements we’ll use
But we *do* know how the UI should look and behave. I’d argue that the unknown implementation details actually don’t matter.
This outdated way of thinking about testing implementation details largely stems from Airbnb’s testing library [Enzyme](https://enzymejs.github.io/enzyme/). Enzyme allowed you to dive into the internals of your React components, trigger class component methods, and manually update a component’s props and state.
However, none of those are things that a user can do. A user can only interact with your app through the interface that you provide. For example, the user might click on a button or fill out a form field.
[React Testing Library](https://testing-library.com/docs/react-testing-library/intro/)’s core philosophy is that we should write our tests in such a way that we simulate user behavior. By testing what the user can actually do, our tests focus less on implementation details and more on the actual user interface, which leads to less brittle tests and a more reliable test suite.
The key here is that React Testing Library actually facilitates using TDD to build UIs by taking the focus away from the implementation details.
Remember: the unknown implementation details don’t matter. What matters is how the UI looks and behaves.
---
## Want to Learn More?
If you'd like to see an in-depth real life demo for how we can use TDD to build UIs, [check out my followup article here](https://blog.testproject.io/2021/03/23/test-driven-development-for-building-user-interfaces/). We'll walk through how we can turn UX mockups into test cases, how we can adapt the "red, green, refactor" cycle for UI development, and see just how feasible using TDD to build UIs really is.
Happy coding! | thawkin3 |
712,609 | Video Games 📺🕹️ in Python | The first thing that made me attracted to computers 🖥️ was 8-bit video games. My father has presented... | 0 | 2021-06-04T05:19:03 | https://dev.to/bekbrace/video-games-in-python-1e4d | gamedev, python, programming | The first thing that made me attracted to computers 🖥️ was 8-bit video games.
My father has presented me an Atari 800 XL in 1990, I do not remember exactly how I felt at first, but before I knew it, I was sitting holding the joystick 🕹️ and pressing that orange button trying to hit the space invaders 📺 !
Then, after a month or so, Samuel - my father - asked me to join him in writing a small program using Basic language. Naturally, I didn't understand a word, but I followed him and somehow this seemed like a mission to do something important and that I was asked by the big guy to do it. I felt so important 😀 !
I wrote several programs using that silver book, and the result was a bouncing circle, a flower or a sun and I was very happy, I couldn't believe that I wrote some lines and created something on the TV screen - it felt kinda magical!
Years later, 25 years later to be precise, I discovered Python programming language and one of the first modules that I loved in Python was the "🐢 turtle module" , and if you have Python installed with a proper IDE, trying to hover over turtle module, this is what you will get :
> (module) turtle
Turtle graphics is a popular way for introducing programming to kids. It was part of the original Logo programming language developed by Wally Feurzig and Seymour Papert in 1966.
> Imagine a robotic turtle starting at (0, 0) in the x-y plane. After an import turtle, give it the command turtle.forward(15), and it moves (on-screen!) 15 pixels in the direction it is facing, drawing a line as it moves. Give it the command turtle.right(25), and it rotates in-place 25 degrees clockwise.
> By combining together these and similar commands, intricate shapes and pictures can easily be drawn.
Then I started to look up codes on the internet on how to recreate the classical games that I was playing when I was 7 or 8 y.o on Atari, like **Pong** , **Missile Command**, **Space Invaders**, **Pacman**, **Donkey Kong**, and many more like **Outlaw**, **basketball**, **Spy Hunter**, **Zorro**..etc , and the first four were on cartridges, the rest were on cassettes [ I did not own a Disk Drive, but a gray cassette recorder where the game can load for half an hour, and very often it crashes before the end of the loading time 😭!!
My programming journey started because I loved these 8-bit video games on Atari and got intrigued and curious on how to create such games, I had to understand that computers are really dumb and they only do what you asked them to do; I had to learn everything about hardware and software - at the time - so when I will sit and start coding a game, I can imagine how the hardware is receiving my instructions in the form of 0s and 1s then give me what I want to see on the screen.
| bekbrace |
712,728 | PouchDB.find is not a function | Debugging the Mango query Find for PouchDB Database for finding new documents. I am using... | 0 | 2021-05-30T10:21:00 | https://krishna404.com/pouchdb-find-is-not-a-function | devjournal, react, database | ##Debugging the Mango query Find for PouchDB Database for finding new documents.
I am using [CouchDB](https://couchdb.apache.org/) & [PouchDB](https://pouchdb.com/) for one of my projects.
Now CouchDB is an amazing database which is
- specifically designed for offline first applications.
- Has great replication support. So is insanely scalable.
- Gives user management out of the box.
- Individual database for each user.
- Manage roles & give access based to databases based on roles.
- Allow custom query-design documents, which pre-indexes the database & which leads to fast read/write times.
Due to above reasons for basic CRUD type apps, you don't even need a backend(with insane security), that is great for both development time & cost optimisation.
There are many more benefits to CouchDB, these are just at top of my mind. There are a few trade-offs too, so be mindful of those & see if this suites your needs. One of the major drawbacks is the community support lacking. Most of the articles are out-of-date & most of the links are stale, this is often frustrating when you need an answer. It took me about 4 months to find the slack channel where the community lives. I believe it will be smooth sail from here. 🤞
While CouchDB sits on the server, PouchDB is the database that sits on the client side. The app is supposed to talk to PouchDB & PouchDB then syncs with CouchDB behind the covers, so the app is not dependent on the server to be available. This neat structure is what allows CouchDB to be an awesome Offline First database. Do note, using PouchDB is not mandatory though.
####Note: If you plan to use this or any other similar offline first mechanisms for your app understand about the trade-offs of offline first structure (whether, couchDB or not). Some risks that you will have to plan for
- Possibility of data loss when offline.
- Data conflicts between the offline & online version.
There are more, do your research before so that you are not surprised later & see if you can incorporate a contingency plans for any issues. CouchDB has a really good conflict management structure though.
Now one of the most basics of using any database is querying. Other than the get method, CouchDB & PouchDB use [Mango queries](https://pouchdb.com/guides/mango-queries.html). Which is very similar to MongoDB queries(the wordplay!!!).
The most common query is `PouchDB.find` which is actually written like
```
var res = await this.pouchDB.find(
{selector:
selector
}
)
```
Now when I incorporated this in my solution, it kept throwing the error `PouchDB.find` is not a function. Here is more detail on this...
### Issue
Cant using the mango query find. Getting error
```PouchDB.find is not a function```
### Info
- Environment: Browser - Reactjs
- Platform: Chrome
- Adapter: IndexedDB
- Server: CouchDB
### Reproduce
Now as per the [docs here](https://pouchdb.com/guides/mango-queries.html) we need to use plugin `pouchdb-find` to be able to use Mango queries.
But as mentioned [here](https://github.com/nolanlawson/pouchdb-find) that pouchdb-find is now merged with pouchdb, so should not be needed at all.
So I tried using pouchdb-find plugin with both pouchdb & pouchdb-browser. It just didnt work.
####Options tried:
Option1
```
import PouchDB from 'pouchdb';
import pouchAuth from 'pouchdb-authentication';
PouchDB.plugin(pouchAuth);
PouchDB.plugin(require('pouchdb-find').default);
```
Option2
```
import PouchDB from 'pouchdb';
import pouchAuth from 'pouchdb-authentication';
import pouchFind from 'pouchdb-find';
PouchDB.plugin(pouchAuth);
PouchDB.plugin(pouchFind);
```
Option3
```
import PouchDB from 'pouchdb-browser';
import pouchAuth from 'pouchdb-authentication';
import pouchFind from 'pouchdb-find';
PouchDB.plugin(pouchAuth);
PouchDB.plugin(pouchFind);
```
Option4
```
import PouchDB from 'pouchdb';
import pouchAuth from 'pouchdb-authentication';
PouchDB.plugin(pouchAuth);
```
####Notes:
1. `pouchdb-authentication` is need to provide authentication if you are using CouchDBs inbuilt user managment.
Well the glitch wasn't in the plugin at all. It was about how the database was being called. So here is what I was doing
```
import PouchDB from 'pouchdb-browser';
import pouchAuth from 'pouchdb-authentication';
import pouchFind from 'pouchdb-find';
PouchDB.plugin(pouchAuth);
PouchDB.plugin(pouchFind);
...
const getDB = (dbName) => {
const localDB = new PouchDB(dbName, {auto_compaction: true});
return localDB;
}
const findDoc = async (input)=> {
let db = await getDB(dbName).find({
selector: {
type: { $eq: props[2]}
},
limit: 1
})
}
```
What worked for me was
```
... same as above
const findDoc = async (input)=> {
let db = await getDB(dbName)
db = await db.find({
selector: {
type: { $eq: props[2]}
},
limit: 1
})
}
```
Thankfully the community helped me figure this out. You can read about detail on the issue [here at github](https://github.com/pouchdb/pouchdb/issues/8303) .
I don't know what is wrong in the first option. If you know, please do let me know.
Caio till the next time.
Krishna.
Follow me at [https://krishna404.com](https://krishna404.com) for Tech Blogs & More. | krishna404 |
712,757 | Maintainer AMA : Liyas Thomas of Hoppscotch 🙏
| Community is at the heart of everything Open Source! *Post AMA Questions here * We’re... | 0 | 2021-05-30T15:54:43 | https://aviyel.com/post/91/ama-with-hoppscotch-maintainers-liyas-thomas-and-andrew-bastin | opensource, showdev, webdev, ama | 
Community is at the heart of everything Open Source!
[**Post AMA Questions here **](https://aviyel.com/post/91/announcing-ama-with-hoppscotch-maintainer-liyas-thomas)
We’re kick-starting our Maintainer AMA series, and we are thrilled to announce our first AMA with Liyas Thomas, the maintainer of [Hoppscotch](https://github.com/hoppscotch/hoppscotch) .One of the best ways we’ve discovered of gathering honest feedback and creating meaningful interactions is by hosting an ‘Ask Me Anything’ (AMA) session. Contributors and community members can submit their questions and the maintainer can directly respond to each one of them and interact with key participants.
Aviyel co-founders, [Jose](https://twitter.com/josekuttan) & Jacob will be curating the AMA session with other members to answer all the questions related to the Hoppscotch community.
Pushing our continuous efforts to reach out to the maximum number of audiences across the globe, we have always tried to get in touch with some of the best communities in the Open Source realm.
Speaker:🚩Liyas Thomas, Maintainer [Hoppscotch](https://github.com/hoppscotch/hoppscotch)
Save the date: 📆 Monday, May 31st, 2021
Time-7 PM IST (Asia) / 7 PM PST (North America)
Get ready with your questions!10 best questions get a chance to win exclusive merchandise & one on one time with the Maintainer.
The one caveat- this is an AMA about Hoppscotch and Open source! If you ask questions about plumbing or politics, you might not get an answer.
Catch you then,
Team Aviyel | aviyel4 |
712,858 | Create a Kubernetes NGINX controller with Dapr support | In this post, I will show how to create an NGINX controller that exposes the Dapr enabled applicati... | 0 | 2021-05-30T22:20:55 | https://dev.to/stevenjdh/create-a-kubernetes-nginx-controller-with-dapr-support-3e8n | kubernetes, nginx, dapr, helm | 
In this post, I will show how to create an NGINX controller that exposes the Dapr enabled applications in a Kubernetes cluster. Essentially, the NGINX controller will be configured with the same standard Dapr annotations to get injected with the daprd sidecar. By exposing this sidecar, it will allow external applications to communicate with the Dapr enabled applications in the cluster, see the [Dapr API reference](https://docs.dapr.io/reference/api/).
**Note:** There have been changes to what repo to use for the NGINX installation, the spec requirements for Kubernetes ingress resources, and the Dapr annotation names, so the information in this post is the updated version that should be followed.
## Prerequisites
* Kubernetes 1.19+ cluster with [Dapr](https://docs.dapr.io/operations/hosting/kubernetes/kubernetes-deploy/) configured.
* [Helm](https://github.com/helm/helm/releases) CLI 3x installed.
* [Kubectl](https://kubernetes.io/docs/tasks/tools/) CLI installed and configured to access the cluster.
* Optional: [OpenSSL](https://wiki.openssl.org/index.php/Binaries) for creating self-signed certificates.
## Prepare helm
Add the latest helm chart repo for the NGINX controller by running the following commands:
```bash
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
```
## Create an ingress namespace
Ensure that the current kubectl context is pointed to the correct Kubernetes cluster, and run the following command:
```bash
kubectl create namespace nginx
```
## Install NGINX controller with Dapr support
Create a file called `dapr-annotations.yaml` with the following content to set the annotations on the NGINX ingress controller pods:
```yaml
controller:
podAnnotations:
dapr.io/enabled: "true"
dapr.io/app-id: "nginx-ingress"
dapr.io/app-port: "80"
```
**Note:** The port above tells the daprd sidecar which port the NGINX controller is listening on. See [Dapr Kubernetes pod annotations spec](https://docs.dapr.io/operations/hosting/kubernetes/kubernetes-annotations/) for a complete list of supported annotations.
Run the following command, which references the file above:
```bash
helm install nginx-ingress ingress-nginx/ingress-nginx \
-f dapr-annotations.yaml \
--set controller.replicaCount=2 \
--namespace nginx
```
Add `--set controller.service.loadBalancerIP=0.0.0.0` to the above command if a static IP is needed, for example, the last IP from a peered subnet with on-premise.
## Create NGINX's daprd sidecar ingress resource
Create a file called `ingress-dapr.yaml` with the following content:
```yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-dapr
namespace: nginx
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
tls:
- hosts:
- api.example.com
secretName: tls-secret
rules:
- host: api.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-ingress-dapr
port:
number: 80
```
Dapr automatically creates the `nginx-ingress-dapr` service being referenced above. Make sure to modify the hostname placeholders.
Remove the `tls` section if TLS termination is not needed, otherwise, run the following commands to create a self-signed certificate for testing:
```bash
openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout tls.key -out tls.crt \
-subj "/CN=api.example.com/O=TLS Example"
kubectl create secret tls tls-secret \
--key tls.key --cert tls.cert -n nginx
```
Optionally, inspect the created certificate with the following command:
```bash
openssl x509 -in tls.crt -text -noout
```
It is recommended to use the FREE Let's Encrypt certificates that are globally recognized by following the steps defined in the [Securing NGINX-ingress](https://cert-manager.io/next-docs/tutorials/acme/ingress/) or [Encrypting the certificate for Kubernetes (Let’s Encrypt)](https://medium.com/avmconsulting-blog/encrypting-the-certificate-for-kubernetes-lets-encrypt-805d2bf88b2a) articles.
Now, run the following command to create the ingress resource:
```bash
kubectl create -f ingress-dapr.yaml
```
**Note:** This will target the sidecar's service, not the NGINX's service for the load balancer.
## Testing externally
If a static IP was not specified earlier, then get the external IP created as part of the NGINX controller setup running the following command:
```bash
kubectl get svc nginx-ingress-ingress-nginx-controller -n nginx
```
or,
```bash
kubectl get service --selector=app=nginx-ingress,component=controller \
-o jsonpath='{.items[*].status.loadBalancer.ingress[0].ip}' \
-n nginx
```
With the IP, run the follow test using cURL to see if the Dapr API for the cluster is reachable from outside the cluster:
```bash
curl http://<ingress ip>/v1.0/invoke/mathService/method/add \
-H "Content-Type: application/json"
-d '{ "arg1": 10, "arg2": 23}'
```
The above assumes that there is a microservice running using the Dapr app-id `mathService` that has a POST endpoint called `add`, which is an example taken from the [Service invocation API reference](https://docs.dapr.io/reference/api/service_invocation_api/).
To test without building an app, install redis, and use the redis state store building block following the [How-To: Configure state store and pub/sub message broker](https://docs.dapr.io/getting-started/configure-state-pubsub/) article. After, perform the curl commands in this [example](https://docs.dapr.io/reference/api/state_api/#example) to create and retrieve the key-value data in redis.
## Delete the NGINX controller
For convenience, here is the command to delete the NGINX controller:
```bash
helm delete nginx-ingress -n nginx
```
Don't forget to delete the ingress resources and the `nginx` namespace created earlier.
## Limiting access
If additional security is required around which Dapr APIs or services should be exposed, then the scope of this can be configured globally, or at a very granular level as needed. For more information, see the following articles:
* [Security](https://docs.dapr.io/concepts/security-concept/)
* [How-To: Selectively enable Dapr APIs on the Dapr sidecar](https://docs.dapr.io/operations/configuration/api-allowlist/)
* [How-To: Apply access control list configuration for service invocation](https://docs.dapr.io/operations/configuration/invoke-allowlist/)
* [Enable API token authentication in Dapr](https://docs.dapr.io/operations/security/api-token/) | stevenjdh |
712,868 | Staking Derivative Of Cosmos (rATOM) Is Live On Mainnet | The StaFi team has released the rATOM App on mainnet, after multy-party testing. It's a solution to u... | 0 | 2021-05-30T13:11:54 | https://dev.to/raphael91269290/staking-derivative-of-cosmos-ratom-is-live-on-mainnet-jmk | The StaFi team has released the rATOM App on mainnet, after multy-party testing. It's a solution to unlock the liquidty of Cosmos Staking Derivative.
ATOM holders can now stake ATOM tokens through the rATOM App. Not only can they obtain the maximized staking rewards, but also the rATOM tokens they get as the staking voucher can be freely transferred and traded on DEXes. Stakers can fully enjoy the real decentralized liquidity staking.
Introduction To rATOM
StaFi rATOM App is a decentralized DeFi product that unclocks the liquidity of the Cosmos token ATOM staking.
rATOM token is a staking derivative of ATOM issued by StaFi when users stake ATOM through StaFi rATOM App. rATOM tokens are anchored to the staked ATOM and the corresponding staking reward. rATOM will bring the flexibility to trade at any time while still receiving staking rewards. With rATOM App, ATOM stakers could enjoy efficient liquidity and maximized staking rewards at the same time.
Importance Of Using rATOM App to stake ATOM
rATOM App can help ATOM stakers to solve the following two problems:
1) There will be no need to wait for a long 21 day unbonding period to transfer or trade staked ATOM assets. rATOM App users can transfer and trade the staking voucher rATOM token at any time on Uniswap to enjoy liquidity and hedge price risks.
2) There is no need to learn the complicated Tendermint consensus mechanism of Cosmos and staking reward calculation rules any more. With rATOM App, users only need a few simple steps to deposit ATOM into the rATOM contract, which will automatically select the best validator by executing the Staking Reward Maximization strategy algorithm.
Staking Reward Maximization Strategy(SRMS Algorithm)
Now the estimated staking APY of ATOM staking on rATOM App is around 9.8% because of SRMS Algorithm:
1)Diversified delegation
The ATOM tokens deposited by the user will be distributed to several(N) mini staking pools. Parameter N will be set based on the scale of the total deposited funds. Each mini staking pool will then select several (M) best validators by executing the SRMS algorithm, so as to reduce the slashing occurrence probability from a single node.
2) Strictly select original validators candidates
In StaFi rATOM SRMS algorithm, it is very important to select the professional and high-quality validators to join as the Original Validators (OV), and ask them to set a reasonably low commission rate to provide higher APY for stakers. The rATOM App will monitor and evaluate the performance of original validator candidates from the metrics including active rate, slashing record, self-bond ratio, node identity, commission ratio, etc., to ensure that excellent validators with relatively low commission are selected.
3) Automatically delegate to the OVs with highest staking APY
The solution monitors OV’s on-chain data in real-time, such as commission ratio changes, commission volume ranking, slashing, off-line rate, and other indicators. This ensures that in each Era, the system selects the best OVs for delegation while simultaneously reinvesting profits.
4) Minimizes the potential loss when the OVs get slashed
When the system detects that the node is slashed or the online rate is lower than the standard, the rATOM staking contract will automatically initiate the redelegate operation and re-select other qualified validators for delegation.
Commission and Fees
The relevant commission and fee parameters in rATOM App are following:
1) Stake ATOM: There is no commission but a service fee, called Relay Fee. The Relay fee is paid in StaFi mainnet FIS token(1.5 FIS for now) and for the related gas fee cost from the cross-chain bridge’s contract interaction between StaFi and Cosmos .
2) Unbond ATOM: Users need to pay a 0.2% redemption fee(based on how much rATOM tokens s/he wants to unbond) and 3 FIS for the Relay Fee.
3) Staking Reward Commission: 10% of your net staking reward( your total staking reward minus validator commission).
The Circulation of rATOM tokens
rATOM tokens can be freely transferred and traded. So users can swap rATOM tokens into ERC-20 format at 1:1 ratio through rAsset App at any time, and then freely trade it on Uniswap.
About StaFi Protocol
StaFi is the first DeFi protocol unlocking liquidity of staked assets. Users can stake PoS tokens through StaFi and receive rTokens in return, which are available for trading, while still earning staking rewards. FIS is the native token on StaFi Chain. FIS is required to provide security to the network by staking, pay for transaction fees on the StaFi chain, and mint & redeem rTokens.
Website: www.stafi.io
rFIS Product: https://rtoken.stafi.io/rfis
rETH Product: https://rtoken.stafi.io/reth
Twitter:@Stafi_Protocol
Telegram Chat: https://t.me/stafi_protocol
Telegram Announcements: https://t.me/stafi_ann
Discord: https://discord.com/invite/jB77etn
Forum: https://commonwealth.im/stafi | raphael91269290 | |
712,883 | Making Sense Of Blockchain And CryptoCurrency | This article is my attempt to make sense of blockchain and cyptocurrency. I will be demystifying... | 12,993 | 2021-05-31T16:54:52 | https://medium.com/@rukyelebs/explaining-blockchain-and-cryptocurrency-to-myself-67bf9c3dff29 | blockchain | This article is my attempt to make sense of blockchain and cyptocurrency. I will be demystifying blockchain technology and explaining various cryptocurrency lingua franca.
###WHAT IS BLOCKCHAIN?
A blockchain is an auditable database. A database in which data can only be added but not removed or changed. Data can be periodically added to the database in things called blocks. As the name implies, a series of these blocks chained together is called a Blockchain.
###WHAT IS CRYPTOCURRENCY?
This is a digital currency in which transactions are verified and records maintained by a decentralized system using cryptography. Combining blockchain and cryptocurrency together. A blockchain is a network of computers (nodes) that run software to confirm the security and validity of (digital currency)on the network. Blockchain is the network and cryptocurrency is what is being spent on the network. Bitcoin is currently the most popular Blockchain and cryptocurrency but other blockchains exist like Etherum with (ether)as the currency being spent on the network.
###DECENTRALIZED VS CENTRALIZED
Most legacy financial institutions use a centralized system wherein user data is stored and managed by a private entity or group of entities. All users connect to a single source of data in that sense. This sort of relationship is called a centralized network, a major downside to this is that it provides a single point of failure. If the centralized database is wiped out all the data is lost and because a single entity(central bank)has power over the system they can make changes as they please. On the other hand in a decentralized network, data is stored on different nodes(computers)in the network and none of the nodes is managed by a central authority, all of the nodes have to somewhat agree to trust each other, the participating nodes have the exact copy of the database. If one node is down other nodes can provide the data. This provides a redundant and resilient network that ensures high reliability.
##How does the blockchain work?

<figcaption>Centralized Vs Decentralized</figcaption>
###HOW DOES THE BLOCKCHAIN WORK?
Imagine a large hall with briefcases on one end and glass on the other end, each briefcase has a lock and a chain that connects it to the next briefcase. Everyone can see the briefcases through the glass. But only the person who has the key to a briefcase can open it. Supposing I want to transfer money(currency) from my briefcase to yours I will need my key(crypto) to open and sign the transaction. Everyone looking through the glass will see that the transaction belongs to me along with the details of the transaction; as soon as it gets to you, you broadcast to everyone that you have received your money so everyone takes a note of it. After a period of time, someone gathers all these mini transactions and collates them into blocks which are then added to the chain; at a simplistic level, this is how a blockchain works. It is a series of these blocks chained together; It consists essentially of two parts: A Block and a chain. I refer to a block as a collection of transactions and a chain as the linking mechanism which checks if the block's signatures are valid.
_We define a bitcoin as a chain of digital signatures. Each owner transfers bitcoin to the next by digitally signing a hash of the previous transaction and the public key of the next owner and adding these to the end of the coin. A payee can verify the signatures to verify the chain of ownership._
-Satoshi Nakamoto, Bitcoin Whitepaper
The blockchain is downloaded by all the nodes in the network; when a new block is added to the chain, verification is done to check if the block is valid. If valid, it makes a copy of that block and forwards it to the other nodes in the network till all nodes have that block added to their chain.
##How does the blockchain work?

<figcaption>How does the blockchain work</figcaption>
###WHAT IS CRYPTO MINING?
This process of verifying if a block is valid is done by nodes called miners. Cryptocurrency mining is a term that refers to the process of gathering cryptocurrency as a reward for work that you complete. (This is known as Bitcoin mining when talking about mining Bitcoins specifically.) Whenever transactions are made, all network nodes receive them and verify their validity. Miner nodes go to collect all these transactions from the memory pool and attempts to organize them into blocks. The nodes perform a series of hashing functions (hard mathematical problems)according to preset protocols by that crypto network until it finds a valid hash. When a valid hash is found, the node that finds the hash will broadcast the block to the network. All other nodes will check if the hash is valid and, if so, add the block into their copy of the blockchain. This process of hashing the transactions to form blocks requires a lot of computational power therefore the nodes that perform these hashes are rewarded for their efforts. Nodes can combine together to pool resources so the currency reward is shared amongst them.

<figcaption>Mining Farm</figcaption>
##CONSENSUS ALGORITHM
###Proof Of Work
One of the challenges with distributed systems is ensuring honesty. How do we ensure that each node in the network is honest and the miners of these blocks do not just bring an invalid block without doing the proper work?. The answer can be found in a consensus algorithm. These are a series of algorithm mechanisms that govern miners in a blockchain, all the nodes know this algorithm so they can check for its validity. It is sorta like a lie detector in the chain. It verifies that the hashed block the miner is proposing is valid. If a miner brings forth an invalid hashed block. It would have wasted its computational time, resources, and reputation. If it brings a valid block it gets rewarded in the native coin. This type of consensus algorithm is called proof of work because miners have to prove that they have done the work.
###Proof Of Stake
In proof of stake instead of sacrificing computation resources nodes sacrifice crypto coins in a process known as staking. A pseudo-random node is selected based on some conditions to forge a new block. The node then stakes a percentage of its coin as a down payment that it's going to forge the block correctly. When the node completes the block It gets rewarded with transaction fees for its work. If it tries to cheat by not forging the block correctly. It loses both its stake and its reputation.
_HALVING_ is a process where by the reward miners get for mining is reduced. This is done to reduce the total value of its crypto coins in circulation.
###A PRACTICAL EXAMPLE
Gbenga and Ada are on the ecoin network. Gbenga wants to send 3 ecoins to Ada. Let's walk through the process.
Address- Both Gbenga and Ada need an address. The first time Gbenga issues a transaction. A private and a public key is generated, the private key for Gbenga to sign the transaction, and a public key for other people to verify Gbengas signature. Ada will also need all these at her end. After solving the address problem Gbenga then issues a statement saying "I Gbenga belonging to this address(123) is sending 3 ecoins to Ada in this address (1234)". He issues this statement with a hash of his public key and his signature (private key).When the coin gets to Ada she can verify it is his signature because of his public key. Ada then signals to the rest of the network that she has gotten her coins. As other people on the network hear that message, each adds it to a queue of pending transactions that they've been told about, but which haven't yet been approved by the network. David "a miner" checks his copy of the blockchain, and can see that each transaction is valid. He would like to help out by broadcasting news of that validity to the entire network so it can be added as a block. However, before doing that, as part of the validation protocol David is required to solve a hard computational puzzle - the proof-of-work. Without the solution to that puzzle, the rest of the network won't accept his validation of the transaction.
Once David solves this problem he is rewarded with a crypto coin and the block of transactions is added to the network.
Head to this site bitcoin explorer. -> Latest Blocks -> View All ->Select a Block that has been mined. You can see all the transactions associated with that block. You can hover on each column to get the information on the transaction.
###WHAT IF I WANT TO EXCHANGE CRYPTOCURRENCIES?
I understand how the exchange is done within a blockchain. But what if I want to exchange an ecoin for a gcoin?. There are two main ways to do this Centralized Exchanges vs Decentralized.
###Centralized Exchanges
In this type of exchange, a centralized body helps you swap coins. It manages your blockchain's private keys and handles the responsibility involved in managing transactions. (It's funny having a centralized body manage a decentralized system🤔). Supposing I want to swap x amounts of coin A for y amounts of coin B. The exchange removes x amounts of coins A value from my coin A crypto wallet and records it on its ledger. It then creates a crypto B wallet (if I have none )to store coin B and purchase coin B on my behalf. After which it gives my coin A to other people willing to buy coin A. The more people that want to buy coin A the more coin As the value goes up. Popular examples of centralized exchanges are Binance and CoinBase.
###Decentralized Exchanges
In a way, these work similarly to the centralized exchanges except that you have the responsibility of storing your own private keys. Your keys are not managed by a "central entity". This essentially allows peer-to-peer (P2P) trading, enabling you to directly transfer funds to the interested buyer/seller, without having to go through middlemen.
Decentralized exchanges work on agreements(smart contracts). The seller raises an order to sell and after filling in the necessary transaction details an advert is placed on a marketplace. Once a buyer agrees on terms with the seller a smart contract is created which cannot be changed until the payment is confirmed and both parties are settled.
###SMART CONTRACTS
A contract is an agreement between two parties what makes this one "smart" is that the third party(Lawyer, Bank) is replaced by a computer program that both parties understand. Why are smart contracts needed?. They can be used for a variety of reasons one of which is that they allow more systems to utilize an existing blockchains network. Supposing I want to create an app that can use blockchain technology to help me transfer music across a network in a secure way. I can go two ways
Create my own blockchain network(Very stressful)
Utilize an existing blockchains network(Less stressful)
The blockchain owners give me a smart contract guideline to follow in my app. With this smart contract, I can create my own token and peg it to the blockchain's native currency I then give my users my own token to use on the platform. An example will be:
Let's imagine I have a token called etoken. I want to use an existing blockchains network in our case let's say the Binance smart chain for my new project. To use it I need the blockchains native coins(BNBs). I decided that 5000 etoken is going to be worth 1BNB.I need 10,000 of these BNB tokens which will cost me 100,000 dollars. But there is a problem I cannot afford the BNB tokens. To raise money I go through a process known as an INITIAL COIN OFFERING.
Basically, I tell people to give me their money for my huge project coming up, I then reward the people with my etoken which they can use on my app. People will need to trust my project to give me their cash. After I get the cash I buy the BNB tokens which I can then use on the blockchains network.
Imagine Samuel a user on my app wants to buy music from Alice another user. An agreement is formed on the blockchain using a smart contract. This smart contract contains an agreement between Alice and Samuel. In the simplest terms, the agreement will look like this: "WHEN Samuel pays Alice 20 etokens, THEN Samuel will receive the music ". The blockchain checks if the smart contract is valid and then fulfills the transaction.
###AUTOMATED MARKET MAKERS
Automated market makers are like robots that give you the price of a currency using a formula. In traditional order books, let's say I have Ether and I want to trade it for Bitcoin. I will need to put out an advert that I am selling ETH for BTC. If I get a buyer we will then have to go through the hassle of negotiating till we come to a common agreement and the swap happens. But AMMs cut out this hassle process. It uses a formula to calculate the price of each asset automatically, allowing for a very fast and seamless swap between assets. People often refer to it as P2C(Peer to Computer) as against P2P(Peer to Peer). The exact technicalities of how it does this are beyond the scope of this reading but in summary.
-People submit their cryptocurrencies into a pool called a Liquidity pool. Anytime there is going to be a transaction with that cryptocurrency. The robots interact with that pool to get the currency to exchange.
-The people that submit their cryptocurrencies into the pool are rewarded a percentage of each transaction that happens with that currency.
-What price you get for an asset you want to buy or sell is determined by a formula. This formula can vary with each protocol.
###COINS VS TOKENS
With respect to my example on smart contracts, coins are native to their own blockchain. Whilst tokens have been built on top of another blockchain.
###FORKING
In the cryptocurrency world, a fork is when there is a change in the rules of the blockchain that the coin operates on or the nodes disagree on a historic transaction(s). Supposing you can your group of friends have been taking left on every turn and then you get to a particular turn and someone takes right. If no one joins him then he is left alone and excluded from the network. But if a minority of people go along he has created a new rule which can be said he has forked out of the original group. In cryptocurrency, if a lot of nodes agree with each other they can decide to fork out of the original network and create their own rules. A popular example is Bitcoin Cash which was forked out of the original Bitcoin.
###NON FUNGIBLE TOKENS
NFTS are unique digital assets. They are different from other cryptocurrencies because of one major reason. There are non-fungible. A fungible asset is one that is indistinguishable from one another. 1000 naira in your hand is the same value as it is in mine. With NFTS that is not the case. Its value is unique based on the NFT. I could digitize my painting into an NFT and then issue it out. People that purchase my NFTS now have a digital version of my painting. NFTS can be traded like other cryptocurrencies. But how do I assign value to my NFTS? As with all things in life, a value of a thing is determined by how much people deem it valuable.
###STORE OF VALUE
Some cryptocurrencies like Bitcoin are often referred to as digital gold due to their anti-inflationary nature. A pound of gold today is worth more than it was in 1970 which cannot be said about any other currency. Bitcoin bears similarities to gold in this regard. The value of 1BTC in 2021 is 1000 percent more than it was in 2011. Some may argue that the price of Bitcoin tends to crash from time to time. As with gold, the value is determined by how much people are willing to purchase it at that time.
Blockchain technology has the potential to impact several domains- from voting to healthcare, social media, finance it comes with a lot of promises, some of which include transaction automation as in the case of smart contracts which can function without the need of middlemen. Solving the trust problem, the lack of trust is the reason why a lot of organizations spend a lot on security and data protection. Blockchain helps to increase trust within parties that do not currently trust one another. Transparency due to the open and immutable state of the blockchain. They are publicly viewable and can be audited. Blockchain technology allows users to share data, openly and securely having confidence that the data is protected and both parties can be trusted to deliver.
###Conclusion
In this article, I have explained some concepts in the blockchain and cryptocurrency sphere and I do hope I have provided some useful information as you continue in your Blockchain journey.
###REFERENCES AND FURTHER READING
-[How CryptoCurrency Works](https://www.youtube.com/watch?v=0B3sccDYwuI&t=133s)
-[What is Block Chain](https://lifehacker.com/what-is-blockchain-1822094625)
-[What is Bitcoin ?](https://academy.binance.com/en/articles/what-is-bitcoin#chapter-4-the-bitcoin-halving)
-[how-the-bitcoin-protocol-actually-works](https://michaelnielsen.org/ddi/how-the-bitcoin-protocol-actually-works/)
-[what-is-ethereum](https://academy.binance.com/en/articles/what-is-ethereum)
-[What Is a Smart Contract and How Does it Work?](https://www.bitdegree.org/crypto/tutorials/what-is-a-smart-contract)
-[How-do-smart-contracts-work](https://www.quora.com/How-do-smart-contracts-work)
-[what-is-cryptocurrency-mining](https://academy.binance.com/en/articles/what-is-cryptocurrency-mining)
-[ERC-20 Token Standards](https://academy.binance.com/en/glossary/erc-20)
-[a-guide-to-crypto-collectibles-and-non-fungible-tokens-nfts
what-is-cryptocurrency#centralized-exchanges-cex](https://academy.binance.com/en/articles/what-is-cryptocurrency#centralized-exchanges-cex)
-[How does a decentralized exchange work and what are the most promising decentralized exchanges?](https://qr.ae/pGTYqR)
-[Binance Exchange](https://www.investopedia.com/terms/b/binance-exchange.asp#:~:text=Binance%20is%20an%20exchange%20where,own%20token%20currency%2C%20Binance%20Coin.)
-[So what problems does block chain actually solve?](https://medium.com/coinmonks/so-what-problems-does-blockchain-actually-solve-dc4446a550f6)
-[what-is-crypto-mining-how-does-cryptocurrency-mining-works](https://sectigostore.com/blog/what-is-crypto-mining-how-cryptocurrency-mining-works/)
-[What is an Automated Market Maker](https://academy.binance.com/en/articles/what-is-an-automated-market-maker-amm)
Follow me here and across my social media for more content like this [Twitter](https://twitter.com/ElegberunDaniel?s=09) [Linkedin](https://www.linkedin.com/in/olugbenga-elegberun/) | gbengelebs |
712,886 | Getting Started with Minikube Kubernetes | How to run local Kubernetes clusters? What is Minkube? Minikube is local Kubernetes, conc... | 0 | 2021-05-30T14:00:17 | https://dev.to/ssukhpinder/getting-started-with-minikube-kubernetes-556g | kubernetes, todayilearned, beginners, microservices | How to run local Kubernetes clusters?
### What is Minkube?
Minikube is local Kubernetes, concentrating on delivering an easy to learn and develop the infrastructure for Kubernetes.
It runs a single node cluster on your local computer.
### Before getting started
Check the system virtualization configuration. To validate virtualization support on Windows 8 and above, run the subsequent command on your Windows terminal or command prompt.
systeminfo
If you recognize the following output, virtualization is supported on Windows.
Hyper-V Requirements: VM Monitor Mode Extensions: Yes
Virtualization Enabled In Firmware: Yes
Second Level Address Translation: Yes
Data Execution Prevention Available: Yes
If you recognize the following output, the system already has a Hypervisor established.
Hyper-V Requirements: A hypervisor has been detected. Features required for Hyper-V will not be displayed.
### Prerequisites
* Install kubectl if not installed already. [Link](https://storage.googleapis.com/kubernetes-release/release/v1.19.0/bin/windows/amd64/kubectl.exe)
* Install a hypervisor if not installed already. [Hyper-V](https://msdn.microsoft.com/en-us/virtualization/hyperv_on_windows/quick_start/walkthrough_install) or [VirtualBox](https://www.virtualbox.org/wiki/Downloads)
### Minimum System specifications
<iframe src="https://medium.com/media/b440f0bf955a5a173288660949dda6bb" frameborder=0></iframe>
### Start Minikube
After completion of the required prerequisites, kindly run the below command to start Minikube on a single node cluster locally.
**NOTE: Run Command Prompt in Administrator Mode.**
minikube start --driver=<DriverName>
Example
minikube start --driver=hyperv
The above command will need some time to finish all the necessary configurations.
### Verify Minikube
Once minikube start ends, run the command below to check the status of the cluster. Refer below the screenshot to check the output.
minikube status
### Stop Minikube
To stop the local Minikube Kubernetes cluster, run:
minikube stop

Notice the above command outputs “1 node stopped” it confirms that Minkube runs on a single-node Kubernetes cluster.
### Troubleshoot
If minikube start throws an error means may be local state cleanup is required. Run the following command to clean the state:
minikube delete
After this try minikube start.
> # Let’s understand how to deploy an image on a local Kubernetes cluster using kubectl & minikube.
### Deploy an image on Kubernetes
Using an existing image named echoserver using kubectl command to deploy an existing image on the local cluster:
kubectl create deployment hello-minikube --image=k8s.gcr.io/echoserver:1.10
The console output is similar to this:
deployment.apps/hello-minikube created
### Access Minikube Deployment
Expose it as a Service:
kubectl expose deployment hello-minikube --type=NodePort --port=8080
The option --type=NodePort specifies the type of Service.
The console output is similar to this:
service/hello-minikube exposed
### Check container status
As we have just created the Service, need to wait until the Pod is up and running:
kubectl get pod
If the output shows the STATUS as ContainerCreating, it’s being created. The result is similar to this:
NAME READY STATUS RESTARTS AGE
hello-minikube 0/1 ContainerCreating 0 3s
If the output shows the STATUS as Running, it's now up and running. The product is identical to this:
NAME READY STATUS RESTARTS AGE
hello-minikube 1/1 Running 0 11m
### Get URL
To get the URL of the exposed Service to view its details, run the following command to
minikube service hello-minikube --url
The console output is similar to this:
[http://172.24.160.91:30599](http://172.24.160.91:30599)
### Browse the URL
To view the details, copy and paste the URL into your browser.
The output in the browser is similar to this:
Hostname: hello-minikube
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=172.17.0.1
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://172.24.160.91:8080/
Request Headers:
accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-encoding=gzip, deflate
accept-language=en-US,en;q=0.9
cache-control=max-age=0
connection=keep-alive
host=172.24.160.91:30599
upgrade-insecure-requests=1
user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36
Request Body:
-no body in request-
Congratulations..!! You have successfully deployed a basic application on Local Kubernetes Cluster.
Thank you for reading. Keep visiting and share this in your network. Please put your thoughts and feedback in the comments section.
Follow on following channels to stay tuned on upcoming stories on C#
[C# Publication](https://medium.com/c-sharp-progarmming), [LinkedIn](https://www.linkedin.com/in/sukhpinder-singh-532284a2/), [Instagram](https://www.instagram.com/sukhpindersukh/), [Twitter](https://twitter.com/sukhsukhpinder), [Dev.to](https://dev.to/ssukhpinder), [Pinterest](https://in.pinterest.com/ssukhpinder/_created/), [Substack](https://sukhpinder.substack.com/), [Wix](https://www.csharp-dotnet.com/)
<a href="https://www.buymeacoffee.com/sukhpindersingh" target="_blank"><img src="https://www.buymeacoffee.com/assets/img/custom_images/orange_img.png" alt="Buy Me A Coffee" style="height: 41px !important;width: 174px !important;box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;-webkit-box-shadow: 0px 3px 2px 0px rgba(190, 190, 190, 0.5) !important;" ></a>
| ssukhpinder |
713,063 | Why is my gitignore not ignoring? | Well. {ಠʖಠ}. I wrote: touch gitignore Enter fullscreen mode Exit fullscreen mode... | 0 | 2021-05-30T19:21:54 | https://dev.to/byibrahimali/why-is-my-gitignore-not-ignoring-48bj | github, whoopsies, blog | Well. {ಠʖಠ}. I wrote:
```bash
touch gitignore
```
Then wondered why the files that were supposed to be ignored somehow weren't being ignored... 🤦
IT IS 👇
```bash
touch .gitignore
```
{% youtube VZX0uBm5Dgk %}
⚠️ This is LOUD!
Originally written on [byIbrahimAli.com](https://www.notion.so/byibrahimali/It-s-not-gitignore-it-s-gitignore-e0c3d3cdd35247e1907ca8e746e606ce) 💛 | byibrahimali |
713,372 | My first look at Vuetify | I enjoy the UI-elements that are created to the specification outlined as part of Google's Material D... | 0 | 2021-06-11T05:42:44 | https://dev.to/rjzauner/my-first-look-at-vuetify-42hb | vue, vuetify, tutorial, uxengineering | I enjoy the UI-elements that are created to the specification outlined as part of [Google's Material Design](https://material.io/design). I had used [Material UI](https://material-ui.com) for React in the past, so when I started using Vue more intensely, I found myself looking for a similar framework. The answer to my quest came in the form of [Vuetify](https://vuetifyjs.com/en/).
I will be sharing my experience in getting to know what this framework is all about.
#Summary
* Project Setup
* App Layout
* UI-Elements
* Final Thoughts
#Project Setup
As of time of writing, Vuetify only supports Vue 2.x, which is what I will be using for this tutorial.
Let us first create a vue project using the [vue-cli](https://cli.vuejs.org):
`vue create vuetify-test`
I know, not the most original name, but it is a name.
I am setting this project up with Vue 2.x, as the latest stable release of Vuetify currently does not support Vue 3.x yet.
I am using TypeScript for this project, but you can use whatever you like. Alongside TypeScript, I am also going to be using the class-based syntax for my components.
After the installation has completed, we can cd into the vuetify-test directory and with `npm run serve` to check that everything went according to plan.

After completing the project setup it is time to add Vuetify to our freshly installed project:
`vue add vuetify`
This will use the vue-cli-vuetify-plugin to get us up-and-running.
I will be using the default setup:
That's it!
Very simple installation using the vue-cli.
Now use `npm run serve` to check and you should see a big difference:
Our setup is done - we can now have a play around with our code.
#App Layout
For the layout I would like to have a side-navigation with links to the different pages.
First, I am going to get rid of all the boilerplate code that comes with installing Vuetify.
##Navigation
Using the `<v-navigation-drawer app>` we can tell vuetify that we would like a navigation bar on the side. The attribute `app` tells Vuetify that this element is part of our layout.
Here is what my App.vue looks like:
```vue
<template>
<v-app>
<v-navigation-drawer app>
<v-divider></v-divider>
</v-navigation-drawer>
</v-app>
</template>
<script lang="ts">
import { Component, Vue } from "vue-property-decorator";
@Component
export default class App extends Vue {}
</script>
```
The `@Component` may look a little unfamiliar. This is the class-based syntax that Vue optionally allows through the vue-property-decorator package.
Now I am going to add an avatar and a few links to justify the existence of our navigation.
```vue
<template>
<v-app>
<v-navigation-drawer app>
<v-list>
<v-list-item class="d-flex justify-center">
<v-list-item-avatar
color="primary"
class="white--text"
>
UXE
</v-list-item-avatar>
</v-list-item>
</v-list>
<v-divider></v-divider>
<v-list>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-email-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Messages</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-file-sync-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Shared Files</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-account-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Contact List</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-archive-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>
Archived Messages
</v-list-item-title>
</v-list-item>
</v-list>
</v-navigation-drawer>
</v-app>
</template>
```
I was certainly a little overwhelmed when I first saw all of the v-this and v-that. So let us break this down a bit.
The [v-list](https://vuetifyjs.com/en/components/lists/) is the first new component we are using in this. We are using this component to display our avatar at the top and then again further down to display our links underneath each other.
The `v-list-item` specifies exactly what it says - an item of our list.
On our `v-list-item-avatar` we use the color-attribute to specify our background colour of avatar and the class of `white--text` tells with what colour we want our text to be.
Between the avatar at the top and the links we have this `<v-divider>` which separates them through a horizontal rule.
Each `v-list-item` here has a link-attribute - giving them that nice ripple effect when clicking on them.
The `v-list-item` also is made up of an icon and a label. The framework makes use of this huge [Material Design Icons Library](https://materialdesignicons.com/) for icons. You will find an icon for every occasion here.
We end up with something like this:

That is our navigation done. Let us separate this into its own component.
For that we can create a new file in the src directory and name it whatever you like - I am going to go with SideNavigation.vue and add in the markup:
```vue
<template>
<v-navigation-drawer app>
<v-list>
<v-list-item class="d-flex justify-center">
<v-list-item-avatar color="primary" class="white--text"
>UXE</v-list-item-avatar
>
</v-list-item>
</v-list>
<v-divider></v-divider>
<v-list>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-email-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Messages</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-file-sync-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Shared Files</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-account-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Contact List</v-list-item-title>
</v-list-item>
<v-list-item link>
<v-list-item-icon>
<v-icon>mdi-archive-outline</v-icon>
</v-list-item-icon>
<v-list-item-title>Archived Messages</v-list-item-title>
</v-list-item>
</v-list>
</v-navigation-drawer>
</template>
<script lang="ts">
import { Component, Vue } from "vue-property-decorator";
@Component
export default class SideNavigation extends Vue {}
</script>
```
Now we can add this component in our App.vue.
First import the component at the top, then register it:
```vue
<script lang="ts">
import { Component, Vue } from "vue-property-decorator";
import SideNavigation from "@/components/SideNavigation.vue";
@Component({
components: {
SideNavigation,
},
})
export default class App extends Vue {}
</script>
```
Finally, you can use it within your template:
```vue
<template>
<v-app>
<side-navigation></side-navigation>
</v-app>
</template>
```
This component does seem rather lonely - let's add some more.
#UI-Elements
The Vuetify-team have done a great job in documenting the different ways you can use the beautifully crafted components they have made. I definitely encourage you to have a play around with the different components and see what you can come up with.
## Basic Material Design Form
I found the way they make forms very helpful and interesting - therefore I am going to use this as my example for UI-Elements.
[Here](https://vuetifyjs.com/en/components/forms/) are docs for forms for those of you who are curious.
Let us create a new file for our signup form - SignUpForm.vue.
The template I will be using will look like this:
```vue
<template>
<v-form>
<v-container>
<v-row>
<v-col cols="12" md="6">
<v-text-field
v-model="user.firstName"
:rules="nameRules"
:counter="10"
label="First name"
required
></v-text-field>
</v-col>
<v-col cols="12" md="6">
<v-text-field
v-model="user.lastName"
:rules="nameRules"
:counter="10"
label="Last name"
required
></v-text-field>
</v-col>
<v-col cols="10" md="8">
<v-text-field
v-model="user.email"
:rules="emailRules"
label="E-mail"
required
></v-text-field>
</v-col>
</v-row>
<v-row>
<v-col cols="12" md="12">
<v-btn block color="green darken-2" class="white--text"
>Submit My Data</v-btn
>
</v-col>
</v-row>
</v-container>
</v-form>
</template>
```
Which yields the following form:
The `v-form` specifies our form container - within that we use the `v-container` to add padding on either side.
Inside our `v-container` we have our `v-rows` and `v-cols`. These control how our elements are placed in rows and columns.
If you are familiar with Bootstrap then these concepts shouldn't be totally new to you. The Vuetify Docs themselves state that the framework has been heavily influenced by Bootstrap.
The width of the `v-cols` can be controlled by using the `cols` and by using `md` in this case.
The `v-model` will look familiar to you, if you have used Vue before. This is how Vue allows us to manage our data - so handling user input or the data that gets sent from an API and many more.
Our two input fields for the first and last name have two props - `:rules` and `:counter`.
The `:rules` prop checks if an error has occurred and displays the correct error message:
```ts
private nameRules = [
(value: string) => !!value || "Field ist required",
(value: string) =>
value.length <= 10 || "Maxmimum of 10 Characters allowed",
];
```
The `:counter` prop, well, counts the number of characters and displays this to the user:

The error states will look like this:

We have 14 instead of the allowed 10 characters in the name.
And if we leave the field blank, we also get an error, because in this case, the field is required:

The full validation rules in my script-tag looks like this:
```vue
<script lang="ts">
import { Component, Vue } from "vue-property-decorator";
@Component
export default class SignUpForm extends Vue {
private user = {
firstName: "",
lastName: "",
email: "",
};
private nameRules = [
(value: string) => !!value || "Field ist required",
(value: string) =>
value.length <= 10 || "Maxmimum of 10 Characters allowed",
];
private emailRules = [
(value: string) => !!value || "Field is required",
(value: string) => /.+@.+/.test(value) || "E-Mail must be valid",
];
}
</script>
```
We also have validation rules for our E-Mail-Input - it is a regular expressions that checks if an @-symbol is in the string. If not, it again will display the error message.
#Final Thoughts
That is it for this article.
This was a small subsection of what Vuetify has to offer, I can wholeheartedly recommend the [documentation]() if you are interested in using Vuetify in your next project.
The documentation is great because they have different options for you to try out. They have done some really awesome work in making the documentation more interactive and interesting.
You can literally build out a version of your button in the browser, then transfer that into your code:
And then copy the button-markup straight into your project.
If you have used Vuetify or any other Material Design Framework before (does not have to be a Vue-related one) then leave a comment telling me what your experience was.
I'd love to hear from you.
| rjzauner |
713,437 | Forecast for the development of fintech trends: banking applications will be replaced by embedded finance
| Despite strong turbulence, global trends in the financial sector remain the same: increased inclusion... | 0 | 2021-05-31T07:38:46 | https://dev.to/ardasgroup/forecast-for-the-development-of-fintech-trends-banking-applications-will-be-replaced-by-embedded-finance-14fe | saas, development, software, dedicated | Despite strong turbulence, global trends in the financial sector remain the same: increased inclusion, improved customer experience, and the development of the digital economy. Consumer demands determine the vector of changes in the industry.
Read more https://ardas-it.com/forecast-for-the-development-of-fintech-trends-banking-applications-will-be-replaced-by-embedded-finance | ardasgroup |
713,468 | Why I don't like the "Tech Lead" role | I was recently discussing Team Leads and Tech Leads (and if they are different) on technical/software... | 0 | 2021-06-04T13:06:44 | https://jhall.io/archive/2021/05/31/why-i-dont-like-the-tech-lead-role/ | team, techlead, management, leadership | ---
title: Why I don't like the "Tech Lead" role
published: true
date: 2021-05-31 00:00:00 UTC
tags: team,techlead,management,leadership
canonical_url: https://jhall.io/archive/2021/05/31/why-i-dont-like-the-tech-lead-role/
---
I was recently discussing Team Leads and Tech Leads (and if they are different) on technical/software teams. Here I decided to share my thoughts on Tech Leads (maybe I’ll do Team Leads another day).
To clarify what I’m talking about, here’s what I mean when I say “Tech Lead”:
> _A “tech lead” makes technical decisions. I.e. they choose tools, frameworks, etc. Probably on the career track toward “systems architecture”._
In my personal opinion, the “Tech Lead” role is an anti-pattern, because it’s usually a title conferred in lieu of an actually meaningful recognition of someone’s contribution. That is to say, thet title is a form of what Erik Dietrich calls [Carnival Cash](https://daedtech.com/carnival-cash-the-cult-of-seniority/).
Further, even when technical leadership is actually needed, that role doesn’t really make sense on a per-team level. It usually makes sense on an organizational level. Giving that title out on a team is again, usually a form of carnie cash, and is often (ab)used as a way to “lord it over” people who are “less technically capable”.
If your organization has a “Tech Lead” title, I encourage you to do your best to only offer it to people when it is needed by the organization (i.e. the organization is lacking in recognized technical leadership), and also attach it to a meaningful salary increase (2% doesn’t cut it), so that it becomes actually meaningful. In particular, don’t start handing out the title like candy on every team, unless every team actually needs that role, and every team actually has someone qualified (and humble) enough to handle the role responsibly.
* * *
_If you enjoyed this message, [subscribe](https://jhall.io/daily) to <u>The Daily Commit</u> to get future messages to your inbox._ | jhall |
713,621 | Adding a loading state to fullCalendar | So last week I wrote my first "blog" and it was about the month change event. This week I tackled a... | 0 | 2021-05-31T11:59:29 | https://dev.to/bradisrad83/adding-a-loading-state-to-fullcalendar-4c56 | javascript, vue, tailwindcss, devjournal | So last week I wrote my first "blog" and it was about the month change event. This week I tackled a simple yet effective project which was to add a loading state to calendar whenever an async call is made. Why is this important? Well the overall call to get all events for a certain date range takes roughly 200miliseconds, which I know doesn't seem like but the idea is (since we are using this on mobile) is to make sure you don't have the ability to click on dates twice before an event is created and just to give a sense of hey something is happening here.
Ideally when a single date is click if we could add a loading wheel to that particular date, well that would be rad, and that would be more work that I really want to deal with. So in this project fullCalendar is being loaded through a Vue component and we are using Tailwind css. Little side note at first I thought tailwind was tailwind was stupid and way to verbose in the html, not I love it and will use it everywhere in the future. If you haven't given it a spin do yourself a favor and check it out.
So my idea for a loading state is to basically make a super quick change to the overall style of the calendar and make it un-clickable while that style is present. I know what an amazing loading state, right?!?!?!?!?!?!? Well working on small team we have limited bandwidth and this seemed like the easiest win. Since we are using Vue / tailwind seems like I could create a simple v-if for a div and that div would be an overlay of the calendar with an opacity and z-index.
```
data() {
return {
selectedCharter: null,
availableCharters: [],
isLoading: false,
calendarStart: "",
calendarEnd: "",
calendarOptions: {
timeZone: "UTC",
nextDayThreshold: "00:00:00",
plugins: [dayGridPlugin, interactionPlugin, timeGridPlugin],
events: [],
editable: true,
eventDurationEditable: false,
eventDrop: this.handleEventDrop,
dateClick: this.handleDateClick,
eventResize: this.handleEventResize,
datesSet: this.handleMonthChange,
headerToolbar: {
right: "today,prev,next",
left: "title",
},
},
};
},
```
So that's my data return object on the component and as you can see I added the isLoading property and set it to false to being with.
```
<div class="relative">
<div>
<FullCalendar ref="fullCalendar" :options="calendarOptions">
<template v-slot:eventContent="event">
<RangeEvent :event="event" @eventDeleted="handleEventDeleted" />
</template>
</FullCalendar>
</div>
<div
v-if="isLoading"
class="absolute top-0 right-0 h-full w-full bg-white opacity-50 z-50"
></div>
</div>
```
And here is what I did in the template of the Vue file added a wrapper div that has a position relative class and then below the `FullCalendar` component I have my loading state div. Super simple conditional that makes and "overlay" on the calendar. Super simple yet super effective.
So in my code there are 2 places I need set isLoading to true. Whenever the month is changed, and whenever a new event is added to the calendar. Then to make sure that the loading state is not on there forever whenever I fetchEvents (which is called at both places where I set isLoading to true), I set it to false at the end of the async call.
So there you have it a super effective yet simple loading state. This calendar has kind of been my project now for the past few weeks and I must say the other day we got some unsolicited feedback from a few users saying they really like these new upgrades and that it's more intuitive than our main competitors. Funny how a few simple non super devy things can make the difference. | bradisrad83 |
713,627 | GitOps for Confluent Schema Registry | If you are like me, you love version control. Not so much the CLI interface (git isn't very beginner-... | 0 | 2021-06-01T12:28:42 | https://dev.to/domnikl/gitops-for-confluent-schema-registry-n9h | kafka, schemaregistry, gitops | If you are like me, you love version control. Not so much the CLI interface (git isn't very beginner-friendly after all), but the concept of having a changelog of what has been done and - if you use meaningful commit messages - also the reasons behind a change.
Another thing that I love is Apache Kafka and that it is serialization-format agnostic. However most of the time, I use Avro-serialization because having a schema does bring a lot of pros to the table: it provides a safe way to change the contracts producers and consumers share and we all know:
> Change is inevitable in life. - Jack Canfield
## Schema evolutions and registry
[Confluent's Schema Registry](https://docs.confluent.io/platform/current/schema-registry/index.html) provides a central storage and retrieval API for schemas to be used by Kafka consumers and procuders. It also checks compatibility for schema evolutions to enable changes be backward- and/or forward-compatible.
Schema evolutions are often performed automatically when producers change the schema they use to write. This may be fine for prototyping but can lead to serious issues in production: in case of an error in the schema a rollback might not be as easy as going back to the previous version as eg. a newly-introduced field cannot be removed as easily and might need a lot of manual intervention to get back to the previous state. Also if the schema evolution fails because of compatibility issues, it will fail only when the changes are deployed and the new code runs for the first time. This one can be mitigated by testing on another environment first (which you should do regardless of this problem), but still.
## Open Source ftw!
Now I wanted to combine both technologies and open sourced [schema-registry-gitops](https://github.com/domnikl/schema-registry-gitops) to prevent from the above issues: having a version-controlled history of schema changes and push them to the registry only when ready and reviewed in QA. It can be used in CI/CD pipelines to ensure that schema changes are compatible with previous versions and can be part of your code review process.
My team at [FLYERALARM](https://www.flyeralarm.com/) uses it in our Atlassian Bamboo Pipelines to ensure that no bad schema evolutions make it into production and we've had no issues since! It's written in Kotlin using the APIs that Confluent provides for Schema Registry and Avro-serialization.
| domnikl |
713,968 | Creative Tips And Techniques For The Creative Photographer ORBIT GRAPHICS | https://www.orbitgraphics.com/ There are many tips and tricks to help even first-time photographers p... | 0 | 2021-05-31T13:32:09 | https://dev.to/rakibakandfamily/creative-tips-and-techniques-for-the-creative-photographer-orbit-graphics-39p | https://www.orbitgraphics.com/
There are many tips and tricks to help even first-time photographers produce eye-catching and beautiful photographs with a minimum of effort. The collection of tips compiled in this article can help an eager novice transform into a professional photographer.
Use a tripod for maximum camera stability. For random shots of your kids or buildings, a bit of camera shake isn't a big deal, but for once-in-a-lifetime shots that really matter, a bit of camera shake can ruin a perfect memory. If a tripod is not available, try setting the camera on a flat surface.
Pay attention to your light. The lighting in a photograph can bring a subject into better focus or change the mood of the picture. Different lighting setups will result in very different photographs. Avoid harsh direct lighting on your subject's face, as this will generally cause them to squint.
A good photography tip that can help you is to not be afraid of getting your work critiqued by other people. Putting your work out there can leave you feeling vulnerable, but it's very valuable to know how other people perceive your work. It can help you improve a lot.
When showing off your photographs, make sure to keep your less than perfect pictures at home. You do not want people to see your sub-par work; you only want them to see your best work. Delete any pictures on your camera that you do not want anyone else to see.
When taking a picture outside, try to do so either in the morning or before the sun sets. This is because the sky is not as high in the sky during these times, so the subject of your picture will not have as much of a shadow as it would during the midday hours.
An important photography tip to keep in mind is to always make sure there's a clear focal point in your photograph. Without a focal point, there won't be much there to keep the viewer's interest. Their eyes will just wander and they'll quickly move on to the next photograph.
Pay attention to your background. Your main focus should be on your object, but you should use the background to support it. Avoid any unnecessary distractions and clean your background to report the attention on your object. Play with lines and perspective in your background to compliment the shape of your object.
Learn how to use aperture on your camera. It indicates how much of the stuff that is seen in your view finder will be in focus. Low aperture means that only the foreground will be in focus and the background will be more blurred. High aperture means that everything will equally be in focus.
Start shooting pictures right away when you leave for your trip. A good shooting location doesn't necessarily have to be a beach or a famous landmark; you may find your best shots are ones in a car or rest stop. Pictures can memorialize the journey itself/ You can, for example, find fascinating photography subjects at an airport.
Do not try to be unique all the time. You will not lose your status as a good photographer if you take some classic looking shots. Learn to make the difference between what is art and what is not. Do not edit your basic pictures of your friends to make them look artsy.
Photo Editing
Try to do all your photo editing yourself. The amount of software available on the market for photo editing is truly astounding. Choose a program that is packed with features and allows you a great deal of freedom in editing and enhancing your photographs. Use one that you may use easily too!
Filters that you should consider investing in include; the polarizing filter to decrease the amount of reflections, the colorizing filters for an added richness in different colors, and the IR filter to shoot in the dark. Many filtering effects can now be added after the photo is taken with photo editing software.
Get different photo editing programs and experiment with them. Amateurs and pros alike can benefit from photo editing software's tools to improve the quality of their photos. It's possible to take an ordinary photograph and make it stellar with only a few simple touch-ups.
With a little luck, the ideas here will help you start to take better quality pictures. This series of tips was put together as a guide of features and methods to help you express yourself in your pictures. | rakibakandfamily | |
714,007 | Debugging PHP with XDebug and VsCode | https://www.youtube.com/watch?v=LNIvugvmCyQ http://xdebug.org/wizard At .bash_profile add export XDE... | 0 | 2021-05-31T14:24:45 | https://dev.to/rochapablo/debugging-php-with-xdebug-and-vscode-45i6 | <https://www.youtube.com/watch?v=LNIvugvmCyQ>
<http://xdebug.org/wizard>
At .bash_profile add `export XDEBUG_CONFIG="idekey=VSCODE"`
.vscode/launch.json
```
"configurations": [
{
"name": "Listen for Xdebug",
"type": "php",
"request": "launch",
"port": 9000
},
{
"name": "Launch currently open script",
"type": "php",
"request": "launch",
"program": "${file}",
"cwd": "${fileDirname}",
"port": 9000,
"runtimeExecutable": "/Applications/MAMP/bin/php/php8.0.0/bin/php"
}
]
```
/Applications/MAMP/bin/php/php8.0.0/conf/php.ini
```
[xdebug]
zend_extension = /Applications/MAMP/bin/php/php8.0.0/lib/php/extensions/no-debug-non-zts-20200930/xdebug.so
xdebug.mode=debug
xdebug.start_with_request=yes
xdebug.remote_enable=1
xdebug.remote_autostart=1
xdebug.client_port = 9000
xdebug.client_host = "127.0.0.1"
xdebug.idekey = VSCODE
``` | rochapablo | |
714,010 | Multi-CPU architecture container images. How to build and push them on Docker Hub (or any other registry) | This is the second post in the series on how we prepared our application to run on M1 (Apple... | 12,946 | 2021-06-02T12:09:09 | https://tidalmigrations.com/blog/tidal-tools-on-m1/#multi-cpu-architecture-container-images-how-to-build-and-push-them-on-docker-hub-or-any-other-registry | docker, multiarch, containers | This is the second post in the series on how we prepared our application to run on M1 (Apple Silicon).
In the previous part we were talking about Go programming language and its ability to easily [cross-compile applications](https://dev.to/tidalmigrations/how-to-cross-compile-go-app-for-apple-silicon-m1-27l6) for different operating systems and CPU architectures using just a developer's laptop.
With this post, I'm going to describe some other aspects of modern cross-platform applications development.
## Our application
It's worth repeating that at [Tidal Migrations](https://tidalmigrations.com/) we build our CLI application — [Tidal Tools](https://tidalmigrations.com/tidal-tools/) — to make it easier for our customers to deal with all sorts of data necessary on their way towards the clouds. Tidal Migrations' [May 2021 Newsletter](https://tidalmigrations.com/2021-may-newsletter/#product-highlight) describes Tidal Tools as the
> meat-and-potatoes of how you’ll start your cloud journey.
The CLI app could be run anywhere:
Locally
* on Microsoft Windows
* on Apple macOS (Intel or M1)
* on GNU/Linux
Or preinstalled on a free cloud VM in:
* [AWS](https://aws.amazon.com/marketplace/pp/prodview-uicif637zwja2)
* [Azure](https://azuremarketplace.microsoft.com/en-us/marketplace/apps/tidal-migrations.tidal_tools)
* [Google Cloud Platform](https://console.cloud.google.com/marketplace/product/tidal-migrations-public/tidal-tools)
## Tidal Tools architecture in brief
Tidal Tools is a Go command-line interface (CLI) application. It mostly acts as a [Tidal Migrations API](https://guides.tidalmg.com/api-getting-started.html) client accompanying our [web application](https://get.tidalmg.com/). It also has some additional features like [source code](https://guides.tidalmg.com/analyze-source-code.html) and [database analysis](https://guides.tidalmg.com/analyze-database.html).
Those two extra functionalities are implemented by [our technological partners](https://tidalmigrations.com/technology-partners/) in other programming languages.
We build Docker container images for such 3rd-party solutions and our application (Tidal Tools) runs containers under the hood using the awesome [Docker Go SDK](https://pkg.go.dev/github.com/docker/docker/client).
## Problems with container images
While preparing a new release of Tidal Tools for M1 Macs we discovered that our existing Docker container images won't work on the new Apple Silicon architecture. After some investigation we figured out that we build our container images for `amd64` architecture, while M1 Macs expect images for `arm64` CPU architecture.
Docker images can support multiple architectures, which means that a single image may contain variants for different architectures, and sometimes for different operating systems, such as Windows.
When running an image with multi-architecture support, `docker` automatically selects the image variant that matches your OS and architecture.
After some trial and error with our Docker images we are now finally confident in our happy path on how to build multi-CPU architecture Docker container images. In other words, we now know how to build container images for different architectures and push such images to container registries (e.g. Docker Hub) to be used on machines with different OSes and architectures. In short, build on (for example) Debian GNU/Linux — run on (for example) macOS for M1!
So, without further delay, let's jump straight to the topic!
## How to build multi-arch container images with `docker buildx`
**CAUTION!** To build container images with multi-CPU architecture support, you need to use [parent image](https://docs.docker.com/glossary/#parent-image) which supports multiple CPU architectures. Most of the official images on Docker Hub provide a [variety of architectures](https://github.com/docker-library/official-images#architectures-other-than-amd64). For example, the `openjdk` image variants (which we're going to use later) support `arm64v8` and `amd64`.
For this example, we're going to use “Hello world” application written in Java:
```java
// HelloWorld.java
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello world!");
}
}
```
Let's start with a `Dockerfile`:
```Dockerfile
# Dockerfile
FROM openjdk:8-jdk-slim AS builder
COPY HelloWorld.java /app/
WORKDIR /app
RUN javac HelloWorld.java
FROM openjdk:8-jre-slim
COPY --from=builder /app/HelloWorld.class /app/
WORKDIR /app
CMD ["java", "HelloWorld"]
```
To make it possible to build multi-CPU architecture container images we need to install [Docker Buildx](https://github.com/docker/buildx/). Docker Buildx is a CLI plugin that extends the `docker` command with some additional features, and multi-arch builds is one of those. If you're using recent Docker Desktop or Docker for Linux packages chances are high that Buildx is already available for you. If not, check the [installation instructions](https://github.com/docker/buildx/#installing).
Create and switch to using a new builder which gives access to the new multi-architecture features:
```
docker buildx create --name mybuilder --use
```
Log in to a Docker registry:
```
docker login
```
Build and push multi-arch container image for x86-64 (`amd64`) and AArch64 (`arm64`) CPU platforms (replace `your-username` with the actual Docker registry user name):
```
docker buildx build . \
--platform linux/arm64,linux/amd64 \
--tag your-username/hello-world:latest \
--push
```
Running the above commands would build and push multi-arch container images to your Docker Hub profile:

When running such image with multi-architecture support, `docker` automatically selects the image variant that matches the running OS and architecture.
That's it! With this simple trick you can build Docker container images for different operating systems and architectures and host such images on Docker Hub.
I hope you enjoyed this post! Stay tuned to learn more about how we prepared our application to run on M1 (Apple Silicon)! | rzmv |
714,046 | Angular Composition API | ⚠️ This article is based on an early version of the library. Click here for the most recent... | 0 | 2021-05-31T16:10:06 | https://dev.to/antischematic/angular-composition-api-93m | > ⚠️ This article is based on an early version of the library. [Click here](https://mmuscat.github.io/angular-composition-api/docs/intro) for the most recent version.
---
[Angular Composition API](https://github.com/mmuscat/angular-composition-api) is a lightweight (3kb), **experimental** library for writing functional Angular applications.
```ts
function State(props: Props) {
Subscribe(() => {
console.log("Hello World!")
})
}
```
# Concepts
This library introduces an **execution context** that removes a lot of the ceremony needed to wire and orchestrate Angular components. It provides a layer of abstraction on top of existing Angular constructs, such as lifecycle hooks, change detection, queries, host bindings and host listeners. It embraces the power of RxJS with composable subscriptions. Angular Composition API is designed to feel native to the Angular developer.
There are two core APIs: `View` and `Service`.
## View
The `View` API is a mixin that extends an Angular component or directive. It takes a `State` factory function and optional `Props` argument. The function will run in an execution context that allows other context-dependant APIs to be called.
## Service
The `Service` API is a mixin that creates a tree-shakable service from a factory function. The function will run in an execution context that allows other context-dependant APIs to be called.
## Definitions
When this library refers to `Value`, it means `BehaviorSubject`, and when it refers to an `Emitter`, it means `EventEmitter`.
# Example
To give you an idea of what application development with this library looks like, let's write a component to display some todos from a service.
First define the props interface. The component will inherit its metadata.
```ts
@Directive()
class Props {
@Input() userId: string
}
```
Next define a state function. It will receive props and return an object containing the todos `Value`.
```ts
function State(props: Props) {
const userId = DoCheck(() => props.userId) // <1>
const [todos, loadTodosByUserId] = Inject(LoadTodosByUserId) // <2>
Subscribe(userId, loadTodosByUserId) // <3>
return {
todos // <4>
}
}
```
A few things to observe:
1. We create a `userId` value that will update when the `userId` prop changes.
2. We `Inject` the `LoadTodosByUserId` token, which returns an array containing a `Value` and an `Emitter`.
3. We set up todos to be loaded whenever a new `userId` is emitted.
4. We return the todos `Value`, which will be automatically subscribed in the template. Change detection is scheduled whenever a returned `Value` changes.
```ts
@Component({
selector: "todo-list",
template: `
<todo *ngFor="let todo of todos"></todo>
`
})
export class TodoList extends View(Props, State) {}
```
Lastly connect the `Props` and `State` to the component with the `View` mixin.
# Service
What about `LoadTodosByUserId`? This is implemented using a `Service`. The example below is provided without comment.
```ts
function loadTodosByUserId() {
const http = Inject(HttpClient)
const emitter = Emitter()
const value = Value()
Subscribe(emitter, (userId) => {
const source = http.get(`//example.com/api/v1/todo?userId=${userId}`)
Subscribe(source, set(value))
})
return [value, emitter]
}
export const LoadTodosByUserId = Service(loadTodosByUserId, {
providedIn: "root"
})
```
# Subscribe
Effects are performed using `Subscribe`. It is similar to the subscribe method in `RxJS`, except you can return teardown logic from the observer. The teardown logic will be executed each time a new value is received by the observer, or when the context is destroyed. It can also be called with just an observer, which is called once when the view is mounted.
```ts
function State(props: Props) {
Subscribe(() => {
console.log("Hello World! I am only called once")
return () => console.log("Goodbye World!")
})
}
```
`Subscribe` can be used in both `View` and `Service` contexts.
# A Prelude
Perhaps when `NgModule` and `NgZone` opt out arrives from the [Angular roadmap](https://angular.io/guide/roadmap), we will gain access to more ergonomic, functional and type safe component APIs. Angular Composition API is a step in that direction.
That's it! Thanks for reading.
---
{% github mmuscat/angular-composition-api no-readme %}
| antischematic | |
714,537 | Our Top 10 Visual Studio Code Extensions | Visual Studio Code is one of the most popular code editors and a general favourite among developers.... | 0 | 2021-05-31T23:42:32 | https://dev.to/codecast/our-top-10-visual-studio-code-extensions-1lbl | visualstudiocode, webdev, extensions, tips | Visual Studio Code is one of the most popular code editors and a general favourite among developers. It’s definitely our editor of choice here at CodeCast. Through our never-ending pursuit of making our daily workflow easier, we have accumulated some Visual Studio Code extensions that we absolutely love. Without further ado, here are our top ten extensions:
**Bracket Pair Colorizer 2**: This is one of the simplest yet most helpful extensions I have added, and massively helped when I was learning JavaScript. The entire focus of this extension is to assign colours to bracket pairs so that you can easily match the opening and closing brackets to one another. Each new layer of nested brackets will be assigned a different colour. This saves a lot of time in trying to assess which bracket belongs to which when writing your code.
**EsLint**: This is one of the most popular extensions available, and for good reason. If you’re not familiar with EsLint it helps you "to find and fix problems in your JavaScript code". This is incredibly valuable if you work with JavaScript (or a JavaScript framework), and I would highly recommend it.
**Language Snippets**: This one is more of a category of extensions, where you would install the applicable ones for the languages you work in. Currently, on my machine, I have some snippets like EJS Snippets, React/Redux Snippets, and Ruby Snippets. They help add-in integrated language support like auto-closing tags, syntax highlighting and suggestions, and other features depending on the specific extension. This is very helpful when working with templating languages (like EJS) that don’t have auto-closing tags built into the editor.
**Prettier +**: This is a popular extension that auto-formats your code for you on save. It doesn’t work with all languages but works with a large number of the more commonly used ones. I personally really love this auto-formatter, but I will caution you that if you're a student, only download it once you’re comfortable with the language you’re working in because it will make you lazy about adding things like semicolons, and help structure your code automatically with proper indentation.
**Git Lens**: This is another very popular extension and is a fantastic tool if you work with a team of developers. This extension provides information about the code such as who wrote it and when it was changed directly within the editor, as opposed to needing to search for this information on GitHub. It makes it much easier for teams to discuss code and possible problems as the details of the code changes are directly available.
**Live Server**: This was another extension I relied on heavily when learning to code. It starts a live server so you can see how your code will appear in the browser. This was extremely helpful when learning HTML and DOM Manipulation. It starts with a simple click and updates the changes on every refresh of the browser window.
**Footsteps**: Footsteps is an extension that helps you keep track of where you were just working within a file. If you are working with hundreds of lines of code, and are scrolling back and forth between sections, this could be an incredibly helpful way to help you quickly find your place. It highlights the area or line of code you were just working on, slowly fading the line as you move away and write more code.
**Peacock**: This is an extension I just discovered, and I am honestly very excited about it. I am someone who likes having multiple instances of VSCode open at once, but it can become confusing about which window is which after working on them for a while. Peacock assigns a unique border colour to each of the instances, so you will be able to distinguish between them a lot easier. It’s a minor change, but can be incredibly helpful!
**Icon Packs**: What first seemed to be a purely aesthetic extension actually proved more valuable than I initially expected. It adds a substantial amount of unique icons for a large variety of different file types you find within languages. This makes it easy to quickly spot the file type you’re looking for. I currently use Material Icons, but there are a large number of them available and you just have to find which one is right for you!
**Themes**: As per most popular applications, you can customize your theme. However, VSCode takes it a step further and the customization capabilities are incredible. There are a ton of ready-made and available themes for download on VSCode that make reading your code a lot easier. Some of the popular themes are Dracula, Atom One, and the one I am currently using, Andromeda. The main draw of adding an additional theme instead of the default one is how much it colorizes or textually changes different parts of your code, so you easily understand exactly what you’re looking at.
There is no shortage of extremely valuable extensions available on Visual Studio Code. You can easily search to find exactly what you’re looking for, or for extensions that help make writing in your preferred language easier. But if you’re new to extensions, hopefully some of our faves will help get you started and make your coding that much easier!
Originally published at [codecast.io](codecast.io/blog) by [Amy Oulton](https://info.codecast.io/author/amy-oulton) | codecast |
714,542 | OWASP Top 10 for Developers: Using Components with Known Vulnerabilities | The OWASP Top 10 is an open-source project that lists the ten most critical security risks to web... | 11,706 | 2021-09-15T05:40:31 | https://dev.to/leading-edje/owasp-top-10-for-developers-using-components-with-known-vulnerabilities-13j1 | security | The OWASP Top 10 is an open-source project that lists the ten most critical security risks to web applications. By addressing these issues, an organization can greatly improve the security of their software applications. Unfortunately, many developers aren't familiar with the list, or don't have a thorough understanding of the vulnerabilities and how to prevent them. In this series, I'm going to break down each of the vulnerabilities on the list, explain what each one is, how to identify it in your projects, and how to prevent it.
## [Using Components with Known Vulnerabilities](https://owasp.org/www-project-top-ten/2017/A9_2017-Using_Components_with_Known_Vulnerabilities)
### What is it?
This is one of the most prevalent issues among the OWASP Top 10. The growing reliance on third-party components creates a risk if dependencies aren't kept up to date. There are numerous tools, such as the [Metasploit Framework](https://www.metasploit.com/), available to attackers, that allow them to easily identify and exploit known vulnerabilities in applications and operating systems. In many cases, a patch has been released for these vulnerable applications, but the victim organization has been slow to update their dependencies. Additionally, developers may not thoroughly understand the nested dependencies of all of the libraries that are being used in an application.
### How can you identify it?
Identifying this type of vulnerability requires a thorough review of all frameworks and dependencies used in an application to check for known vulnerabilities listed in the [CVE database](https://cve.mitre.org/). Additionally, applications need to be continuously monitored for newly reported vulnerabilities. This can be an extremely time consuming process, so it's safe to assume that, if your organization doesn't have a defined process for regularly updating your dependencies, then you probably have at least some vulnerabilities in your application.
### How can you prevent it?
In order to prevent this issue, your organization needs to implement regular checks of your dependencies against the CVE database for known vulnerabilities, as well as establishing a process for keeping all dependencies up-to-date. Fortunately, much of this can be automated using vulnerability scanning tools, such as the [OWASP Dependency Check](https://owasp.org/www-project-dependency-check/), [RetireJS](https://retirejs.github.io/retire.js/), or [Brakeman](https://brakemanscanner.org/). Additional tools, such as [WhiteSource's Renovate](https://www.whitesourcesoftware.com/free-developer-tools/renovate/), provide a complete dependency management solution by automatically updating any found vulnerabilities. In addition to keeping dependencies updated, it's important to remove any dependencies that are no longer being used.
### References
[OWASP Top 10 Project: 9. Using Components with Known Vulnerabilities](https://owasp.org/www-project-top-ten/2017/A9_2017-Using_Components_with_Known_Vulnerabilities)
[OWASP Dependency Check Project](https://owasp.org/www-project-dependency-check/)
[RetireJS](https://retirejs.github.io/retire.js/)
[Brakeman](https://brakemanscanner.org/)
[WhiteSource Renovate](https://www.whitesourcesoftware.com/free-developer-tools/renovate/)
[CVE Database](https://cve.mitre.org/)
<a href="https://dev.to/leading-edje">

<a/> | akofod |
714,546 | Happy LGBTQIA+ Pride Month! ❤️ | Join us in collecting stories of LGBTQIA+ pride — and amplifying organizations doing important work in this space. | 0 | 2021-06-01T15:56:55 | https://dev.to/devteam/happy-lgbtqia-pride-month-1j7b | devpride | ---
title: Happy LGBTQIA+ Pride Month! ❤️
published: true
description: Join us in collecting stories of LGBTQIA+ pride — and amplifying organizations doing important work in this space.
tags: devpride
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/tvesygxqhasx3l5e4wcf.png
---
## It's finally one of our favorite times of the year — Pride Month! 🌈
As many of you know, every year in June*, many countries around the world celebrate the diverse spectrum of LGBTQIA+ individuals and the great strides and sacrifices they have made throughout history to be seen, heard, respected, and safe to live life authentically. Many of our friends, family members, mentors, colleagues, and role models are members of the LGBTQIA+ community — many of you here on DEV are as well!
This month and always, we honor and celebrate alongside you.
You also might remember that in previous years, we have celebrated Pride Month by collecting stories from our LGBTQIA+ community members. We're continuing this tradition in 2021 with an added focus on amplifying organizations already doing important work with and for LGBTQIA+ individuals. Read on to find out how you can celebrate Pride Month with us...
## Pride Month at DEV
### 1. Share Your Story & Hear From Others
If you identify as an LGBTQIA+ individual and you'd like to share your experience as a person in software development, we'd love to hear from you. [This template](https://dev.to/new/devpride) is here to use as a jumping-off point, but please feel free to start from scratch if you prefer! Just remember to use the tag [#devpride](dev.to/t/devpride) so we can find (and share!) your post easily. When you're done, we'd love if you could drop the link to your post in the comments below (hint: use the DEV post liquid tag to embed your work) ❤️
If you are an ally, we encourage you to keep an eye on this tag throughout the month and learn more about the experiences of the LGBTQIA+ community members here on DEV.
### 2. Learn About LGBTQIA+ Organizations Doing Amazing Work
We also wanted to make some space in this year's Pride Month celebration to recognize several organizations doing fantastic work with and for LGBTQIA+ folks in tech.
_Here is a list of tech-focused LGBTQIA+ organizations we respect — and a bit about how they are celebrating Pride Month._
#### [Out in Tech](https://outintech.com/)
is a nonprofit organization dedicated to uniting the LGBTQIA+ tech community by creating opportunities for members to advance their careers, grow their networks, and use technology for good. They place a unique emphasis on kindness, knowledge, belonging, and joy.
In honor of Pride Month, Out in Tech is hosting "Out in Tech Pride" — an event focused on building equity in tech through courage and conviction. They will be celebrating some of their favorite LGBTQIA+ and allied tech leaders across streaming, retail, fintech, and other industries.
[>>Learn more about Out in Tech's Pride celebration here](http://outintech.com/pride)
#### [Lesbians Who Tech & Allies](https://lesbianswhotech.org/)
is a community of LGBTQIA+ women, non-binary, and trans individuals in technology. Their goals are to become more visible to and connected with one another and encourage more women, queer folks, trans individuals, and Black and Brown people to join the tech field. Lesbians Who Tech welcomes allies to join and support their organization, too!
In celebration of Pride Month, Lesbians Who Tech & Allies is hosting "(Not IRL) Pride Summit" — a 5-day virtual event focused on enhancing their leadership and technical skills and discussing ways we can do better as global citizens fighting oppression.
[>>Learn more about Lesbians Who Tech & Allies' Pride Summit here](https://lesbianswhotech.org/pridesummit2021/)
#### Start Out
is a nonprofit dedicated to growing the number of LGBTQIA+ entrepreneurs in tech and other fields, while increasing their diversity, impact, and empowerment.
Start Out has many events throughout the year. For Pride Month, the organization is hosting a "Wine Down Wednesday'' event on June 30th — a Pride-themed virtual networking opportunity for LGBTQIA+ founders and innovators.
[>>Learn more about Start Out's “Wine Down Wednesday (Pride-Edition)” Event here](https://www.eventbrite.com/e/networking-community-presents-wine-down-wednesday-tickets-152441758403)
#### Trans Tech Social Enterprises
is an incubator for LGBTQIA+ talent. TransTech's work is dedicated to empowering trans, lesbian, gay, bisexual, and queer people and allies with practical, career-ready skills and economic empowerment. Its members have access to a vibrant digital community, training series, and co-working spaces in Chicago, Illinois.
[>>In honor of Pride Month, we invite you to explore TTSE’s on-demand training options](https://www.transtechsocial.org/training/)
**Feel free to comment with any other meetups, groups, networks, and/or organizations focused on making technology more friendly and accessible for LGBTQIA+ folks.** You can also create a [DEV Listing](dev.to/listings) to broadcast any events that you or your company/organization are hosting and embed them in this thread.
---
## **A very happy Pride Month to all!** In the comments below, we'd love if you shared...
- Links to your [Pride stories](https://dev.to/new/devpride) (– don’t forget to use the DEV post liquid tag!)
- Any other LGBTQIA+ organizations we should know about
- Links to Pride Month/LGBTQIA+ DEV Listings for events/initiatives you or your company/organization are hosting
- Any other thoughts you have about this important global celebration
_*We would also like to acknowledge that while Pride Month does take place in June for a host of countries, many celebrate it during other months of the year. We learned so much about when and how different countries and regions celebrate Pride from [this calendar](https://www.iglta.org/Events/Gay-Pride-Calendar). Check it out!_
Here's to LGBTQIA+ Pride 💜
| thepracticaldev |
714,568 | A Developer's Guide to Productivity | How to improve your decision making | 0 | 2021-06-01T03:26:42 | https://arbaaz.io/posts/a-developers-guide-to-productivity | productivity, planning, selfdevelopment, decisionmaking | ---
title: A Developer's Guide to Productivity
published: true
description: How to improve your decision making
tags: productivity, planning, selfdevelopment, decisionmaking
//cover_image: https://direct_url_to_image.jpg
canonical_url: https://arbaaz.io/posts/a-developers-guide-to-productivity
---
We all know how vital **'Decision Making'** is for success, yet we make wrong decisions often. While it's easier to make the big decisions, it's harder to make the smaller ones. What we don't realize is the total of tiny choices that determine our success in life.
We know how to think, plan, and execute big decisions like choosing a career path or marrying or living. We prepare, set aside time and space for it.
But when it comes to the tiny ones, like when to sleep or that one glass of cold lemonade on a summer night, that might give you a sore throat. It's harder for you to plan like you would for the big ones. You do it and face the unintended consequences.
Today, we have more 'choices' than we can count for any given thing. Psychologist Barry Schwartz says in ["Paradox of Choice"](https://www.ted.com/talks/barry_schwartz_the_paradox_of_choice?language=en#t-470586) that while more choices allow us to achieve better results, they also lead to greater anxiety, indecision, and dissatisfaction.
With freedom of choice comes the responsibility to make the right ones.
Failing to know these ** 'tiny' dos and don'ts** might affect our **momentum** in essential tasks.
Let's see how can we fix them
## Make it Clear

According to [some sources](https://psychology.stackexchange.com/questions/17182/basis-for-we-make-35-000-decisions-a-day-statistic/17184#17184?newreg=6c5ad36acbcc463daefdc4d90304c492), we make thousands of decisions every day.
We can't make decisions upon decisions without paying a biological cost. Decisions have an unseen biological cost that we can't see and neglect.
> "There is nothing to writing. All you do is sit down at a typewriter and bleed." ― Ernest Hemingway.
Just knowing 'clearly' what you need to do or not is half the battle won. Write down activities that you need to do, as well as avoid them to be more productive. Things like - what to eat, what to wear, when to shop, how to use your apps, morning routines, sleep routines, etc.
## Cut it Out

When we make too many decisions, we suffer from **[Decision Fatigue](https://en.wikipedia.org/wiki/Decision_fatigue)**. It leaves us with less energy for mentally demanding tasks, [killing creativity](https://www.scientificamerican.com/article/don-t-overthink-it-less-is-more-when-it-comes-to-creativity/), drive and, in turn, affects happiness.
> The essence of strategy is choosing what not to do ― Michael Porter
Cutting out every unnecessary or unmade decision makes room and energy for productive ones. According to a [University of California Irvine study](https://www.ics.uci.edu/~gmark/chi08-mark.pdf), it takes an average of 23 minutes to get back to a task after an interruption.
**Try to estimate your focused time in a day as well as the cost of time breaks or energy leaks.**
To build momentum and maintain it. Simplify your day and daily routine with habits.
## Time It, Space It

Mornings are the natural way to start life. It's no wonder [most successful people start super early](https://youtu.be/qszsMyrChnE). After a good night's sleep, our body and brain are charged up for best performance.
Make a list of priorities - starting with the most challenging task because your brain is fresh and ready to handle it earlier in the day. [Studies](https://www.pnas.org/content/pnas/108/17/6889.full.pdf) have shown how the time of day affects good decision making and productivity.
> "In preparing for battle, I have always found that plans are useless, but planning is indispensable." ― Dwight D. Eisenhower
As there's no such thing as 'stability' in life, make mental and practical space to account for new or unexpected situations. Take breaks or a quick nap to recharge during the day. Intentionally STOP making decisions.
Leave room for new beginnings which usually take time and space, and let your brain sort things at its own pace.
## Make it Right

Identify your purpose – and make sure it's right. Please write down your goals and objectives to achieve them, and review them. Everything you do during the day, week, and year must align with this purpose, getting more efficient with time. Build habits around your goals.
Get a second opinion or some sound advice on your ideas to avoid your own cognitive biases. And be ready to iterate on your decisions based on outcomes. Iterative decision-making is faster, efficient, and leads to better results.
It doesn't matter how 'right' our choice is, but how motivated and committed we are to make it right. Having an actionable plan with the best decision is what leads to a success story.
## Do It
No amount of thinking or planning can take you closer to your goals. You have to give it a try and get started. Take action and be ready to fail. But pick yourself up and try again. Or change the course.

>"Unless commitment is made, there are only promises and hopes; but no plans." ― Peter F. Drucker
In summary, decision-making is more exhausting than any other mental activity.It's a lot of tiny things that make you or break you. So be mindful of how you regard them. Understand the proven and sustainable methods that seem dull or straightforward, but work.
Tweak them to suit your purpose. Avoid all sorts of distractions as much as possible. Respect your mind and body.
Believe in yourself, work hard and stay healthy!
| arbaaz |
714,719 | Clifford Agius is a developer flying a Boeing 787 for fun, and other things I learned recording his DevJourney (#153) | Clifford Agius is a developer flying a Boeing 787 for fun. After interviewing him for the DevJourney podcast, here are the key takeaways I took out of the discussion. | 0 | 2021-06-01T06:20:29 | https://timbourguignon.fr/devjourney153 | devjourney, career, learning, flying | ---
title: Clifford Agius is a developer flying a Boeing 787 for fun, and other things I learned recording his DevJourney (#153)
published: true
description: Clifford Agius is a developer flying a Boeing 787 for fun. After interviewing him for the DevJourney podcast, here are the key takeaways I took out of the discussion.
tags: DevJourney, Career, Learning, Flying
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/obsjhzyqwblei3r0sash.png
canonical_url: https://timbourguignon.fr/devjourney153
---
This week, I published Clifford Agius's #DevJourney story on my eponym Podcast: [Software developer's Journey](https://devjourney.info). Among many other things, here are my main _personal_ takeaways:
* Cliff grew up in east London, nose up, looking at planes taking off. Even though he aced Maths and Science, he had trouble getting through school and ended up joining a new electro-mechanical engineering apprenticeship with Ford Motor Company. Looking back, Cliff regards his apprenticeship at Ford very highly. He thinks it was the best for him, and he would encourage anyone on this path. There, he discovered PLCs (Programmable Logic Components) programming. But during all this time, he was looking up.
* He then got his private pilot license and learned what he needed to do to become a professional pilot. 2 years and ~90K£ later, he got his "wings"... right after September 11. It was hard to find a job. He continued contracting for his former company during this time, which is an excellent example of why you should NEVER burn bridges! Later on, he finally got a job as a pilot, worked his way up, and joined British Airways to fly a Boeing 787 Dreamliner.
* I asked Cliff why he wanted to become a developer while he was living his dream? His answer was clear. Due to JetLag, he was often awake when everyone was at work. So he started doing websites for friends, and one thing leading to the next, he woke up having a side business he loved as well!
* Doing client projects, he stumbled upon ASP, .NET, C#, and finally Xamarin. Being an electrical engineer, IoT also became an ideal subject. He found his sweet spot at the junction of those two and even contributed to the Xamarin codebase.
* One of Cliff's main side projects is building on the Open-Bionics source code to 3D-print prosthetics. He now managed to bring down the price of such prosthetics to less than 500£. His goal (before COVID) was to pack a few 3D printers, filaments, and gear and fly them to hospitals in India and Pakistan, where Cliff has contacts. Hopefully, this will restart as soon as COVID cools off. Follow [his account on Twitter](https://twitter.com/CliffordAgius) for more information about this.
* Many skills cross over from one domain to the other. One example Cliff gave is [decision making](https://www.youtube.com/watch?v=QsZWye0G9hI): _"in aviation, we make decisions very early, and review it regularly, and revise if needed."_
Advice:
* _"Always be learning"_
Quotes:
* Me: _"Do you sleep?"_ Cliff: _"yes, I sleep on the plane!"_ 😁
* _"When you remove yourself from an office, and stick yourself in a hotel room in Seattle at 4:00 and turn off your phone, there is no distraction, so you can crush out so much work"_
* _"I love flying, this is my passion, I get paid to do my hobby"_
Thanks, Clifford, for sharing your story with us!
You can find the entire episode and the show notes on [devjourney.info](https://devjourney.info/Guests/153-CliffordAgius.html) or directly [here on DEV](https://dev.to/devjourneyfm)
Did you listen to his story?
* What did you learn?
* What are your takeaways?
* What did you find particularly interesting? | timothep |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.